
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
13,099 | Arch Linux 的 pacman 命令入门 | https://itsfoss.com/pacman-command/ | 2021-02-09T11:14:00 | [
"pacman"
] | https://linux.cn/article-13099-1.html |
>
> 这本初学者指南向你展示了在 Linux 中可以使用 pacman 命令做什么,如何使用它们来查找新的软件包,安装和升级新的软件包,以及清理你的系统。
>
>
>

[pacman](https://www.archlinux.org/pacman/) 包管理器是 [Arch Linux](https://www.archlinux.org/) 和其他主要发行版如 Red Hat 和 Ubuntu/Debian 之间的主要区别之一。它结合了简单的二进制包格式和易于使用的 [构建系统](https://wiki.archlinux.org/index.php/Arch_Build_System)。`pacman` 的目标是方便地管理软件包,无论它是来自 [官方库](https://wiki.archlinux.org/index.php/Official_repositories) 还是用户自己构建的软件库。
如果你曾经使用过 Ubuntu 或基于 debian 的发行版,那么你可能使用过 `apt-get` 或 `apt` 命令。`pacman` 在 Arch Linux 中是同样的命令。如果你 [刚刚安装了 Arch Linux](https://itsfoss.com/install-arch-linux/),在安装 Arch Linux 后,首先要做的 [几件事](https://itsfoss.com/things-to-do-after-installing-arch-linux/) 之一就是学习使用 `pacman` 命令。
在这个初学者指南中,我将解释一些基本的 `pacman` 命令的用法,你应该知道如何用这些命令来管理你的基于 Archlinux 的系统。
### Arch Linux 用户应该知道的几个重要的 pacman 命令
与其他包管理器一样,`pacman` 可以将包列表与软件库同步,它能够自动解决所有所需的依赖项,以使得用户可以通过一个简单的命令下载和安装软件。
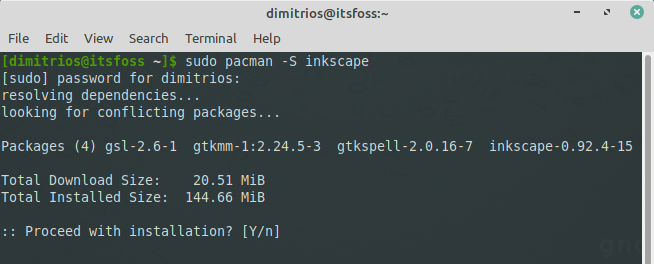
#### 通过 pacman 安装软件
你可以用以下形式的代码来安装一个或者多个软件包:
```
pacman -S 软件包名1 软件包名2 ...
```

`-S` 选项的意思是<ruby> 同步 <rt> synchronization </rt></ruby>,它的意思是 `pacman` 在安装之前先与软件库进行同步。
`pacman` 数据库根据安装的原因将安装的包分为两组:
* **显式安装**:由 `pacman -S` 或 `-U` 命令直接安装的包
* **依赖安装**:由于被其他显式安装的包所 [依赖](https://wiki.archlinux.org/index.php/Dependency),而被自动安装的包。
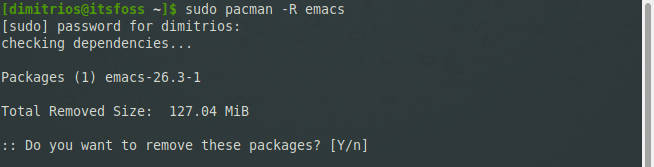
#### 卸载已安装的软件包
卸载一个包,并且删除它的所有依赖。
```
pacman -R 软件包名
```

删除一个包,以及其不被其他包所需要的依赖项:
```
pacman -Rs 软件包名
```
如果需要这个依赖的包已经被删除了,这条命令可以删除所有不再需要的依赖项:
```
pacman -Qdtq | pacman -Rs -
```
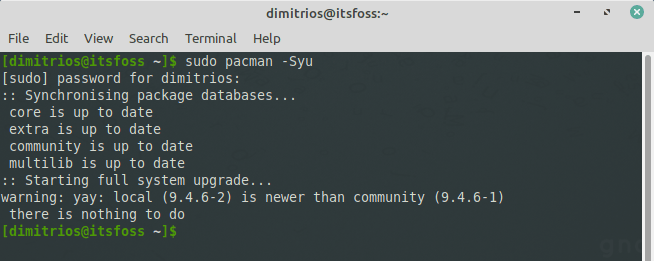
#### 升级软件包
`pacman` 提供了一个简单的办法来 [升级 Arch Linux](https://itsfoss.com/update-arch-linux/)。你只需要一条命令就可以升级所有已安装的软件包。这可能需要一段时间,这取决于系统的新旧程度。
以下命令可以同步存储库数据库,*并且* 更新系统的所有软件包,但不包括不在软件库中的“本地安装的”包:
```
pacman -Syu
```
* `S` 代表同步
* `y` 代表更新本地存储库
* `u` 代表系统更新
也就是说,同步到中央软件库(主程序包数据库),刷新主程序包数据库的本地副本,然后执行系统更新(通过更新所有有更新版本可用的程序包)。

>
> 注意!
>
>
> 对于 Arch Linux 用户,在系统升级前,建议你访问 [Arch-Linux 主页](https://www.archlinux.org/) 查看最新消息,以了解异常更新的情况。如果系统更新需要人工干预,主页上将发布相关的新闻。你也可以订阅 [RSS 源](https://www.archlinux.org/feeds/news/) 或 [Arch 的声明邮件](https://mailman.archlinux.org/mailman/listinfo/arch-announce/)。
>
>
> 在升级基础软件(如 kernel、xorg、systemd 或 glibc) 之前,请注意查看相应的 [论坛](https://bbs.archlinux.org/),以了解大家报告的各种问题。
>
>
> 在 Arch 和 Manjaro 等滚动发行版中不支持**部分升级**。这意味着,当新的库版本被推送到软件库时,软件库中的所有包都需要根据库版本进行升级。例如,如果两个包依赖于同一个库,则仅升级一个包可能会破坏依赖于该库的旧版本的另一个包。
>
>
>
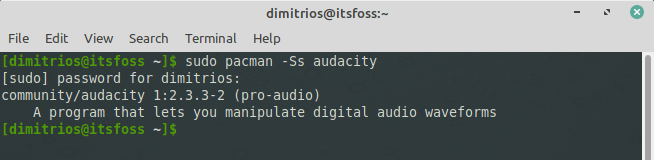
#### 用 Pacman 查找包
`pacman` 使用 `-Q` 选项查询本地包数据库,使用 `-S` 选项查询同步数据库,使用 `-F` 选项查询文件数据库。
`pacman` 可以在数据库中搜索包,包括包的名称和描述:
```
pacman -Ss 字符串1 字符串2 ...
```

查找已经被安装的包:
```
pacman -Qs 字符串1 字符串2 ...
```
根据文件名在远程软包中查找它所属的包:
```
pacman -F 字符串1 字符串2 ...
```
查看一个包的依赖树:
```
pactree 软件包名
```
#### 清除包缓存
`pacman` 将其下载的包存储在 `/var/cache/Pacman/pkg/` 中,并且不会自动删除旧版本或卸载的版本。这有一些优点:
1. 它允许 [降级](https://wiki.archlinux.org/index.php/Downgrade) 一个包,而不需要通过其他来源检索以前的版本。
2. 已卸载的软件包可以轻松地直接从缓存文件夹重新安装。
但是,有必要定期清理缓存以防止文件夹增大。
[pacman contrib](https://www.archlinux.org/packages/?name=pacman-contrib) 包中提供的 [paccache(8)](https://jlk.fjfi.cvut.cz/arch/manpages/man/paccache.8) 脚本默认情况下会删除已安装和未安装包的所有缓存版本,但最近 3 个版本除外:
```
paccache -r
```

要删除当前未安装的所有缓存包和未使用的同步数据库,请执行:
```
pacman -Sc
```
要从缓存中删除所有文件,请使用清除选项两次,这是最激进的方法,不会在缓存文件夹中留下任何内容:
```
pacman -Scc
```
#### 安装本地或者第三方的包
安装不是来自远程存储库的“本地”包:
```
pacman -U 本地软件包路径.pkg.tar.xz
```
安装官方存储库中未包含的“远程”软件包:
```
pacman -U http://www.example.com/repo/example.pkg.tar.xz
```
### 额外内容:用 pacman 排除常见错误
下面是使用 `pacman` 管理包时可能遇到的一些常见错误。
#### 提交事务失败(文件冲突)
如果你看到以下报错:
```
error: could not prepare transaction
error: failed to commit transaction (conflicting files)
package: /path/to/file exists in filesystem
Errors occurred, no packages were upgraded.
```
这是因为 `pacman` 检测到文件冲突,不会为你覆盖文件。
解决这个问题的一个安全方法是首先检查另一个包是否拥有这个文件(`pacman-Qo 文件路径`)。如果该文件属于另一个包,请提交错误报告。如果文件不属于另一个包,请重命名“存在于文件系统中”的文件,然后重新发出更新命令。如果一切顺利,文件可能会被删除。
你可以显式地运行 `pacman -S –overwrite 要覆盖的文件模式**,强制`pacman` 覆盖与 给模式匹配的文件,而不是手动重命名并在以后删除属于该包的所有文件。
#### 提交事务失败(包无效或损坏)
在 `/var/cache/pacman/pkg/` 中查找 `.part` 文件(部分下载的包),并将其删除。这通常是由在 `pacman.conf` 文件中使用自定义 `XferCommand` 引起的。
#### 初始化事务失败(无法锁定数据库)
当 `pacman` 要修改包数据库时,例如安装包时,它会在 `/var/lib/pacman/db.lck` 处创建一个锁文件。这可以防止 `pacman` 的另一个实例同时尝试更改包数据库。
如果 `pacman` 在更改数据库时被中断,这个过时的锁文件可能仍然保留。如果你确定没有 `pacman` 实例正在运行,那么请删除锁文件。
检查进程是否持有锁定文件:
```
lsof /var/lib/pacman/db.lck
```
如果上述命令未返回任何内容,则可以删除锁文件:
```
rm /var/lib/pacman/db.lck
```
如果你发现 `lsof` 命令输出了使用锁文件的进程的 PID,请先杀死这个进程,然后删除锁文件。
我希望你喜欢我对 `pacman` 基础命令的介绍。
---
via: <https://itsfoss.com/pacman-command/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The [pacman](https://www.archlinux.org/pacman/?ref=itsfoss.com) package manager is one of the main difference between [Arch Linux](https://www.archlinux.org/?ref=itsfoss.com) and other major distributions like Red Hat and Ubuntu/Debian. It combines a simple binary package format with an easy-to-use [build system](https://wiki.archlinux.org/index.php/Arch_Build_System?ref=itsfoss.com). The aim of pacman is to easily manage packages, either from the [official repositories](https://wiki.archlinux.org/index.php/Official_repositories?ref=itsfoss.com) or the user’s own builds.
If you ever used Ubuntu or Debian-based distributions, you might have used the apt-get or apt commands. Pacman is the equivalent in Arch Linux. If you [just installed Arch Linux](https://itsfoss.com/install-arch-linux/), one of the first few [things to do after installing Arch Linux](https://itsfoss.com/things-to-do-after-installing-arch-linux/) is to learn to use pacman commands.
In this beginner’s guide, I’ll explain some of the essential usage of the pacmand command that you should know for managing your Arch-based system.
## Essential pacman commands Arch Linux users should know
Like other package managers, pacman can synchronize package lists with the software repositories to allow the user to download and install packages with a simple command by solving all required dependencies.
### Install packages with pacman
You can install a single package or multiple packages using pacman command in this fashion:
`pacman -S _package_name1_ _package_name2_ ...`
The -S stands for synchronization. It means that pacman first synchronizes
The pacman database categorises the installed packages in two groups according to the reason why they were installed:
**explicitly-installed**: the packages that were installed by a generic pacman -S or -U command**dependencies**: the packages that were implicitly installed because[required](https://wiki.archlinux.org/index.php/Dependency?ref=itsfoss.com)by another package that was explicitly installed.
### Remove an installed package
To remove a single package, leaving all of its dependencies installed:
`pacman -R package_name_`
To remove a package and its dependencies which are not required by any other installed package:
`pacman -Rs _package_name_`
To remove dependencies that are no longer needed. For example, the package which needed the dependencies was removed.
`pacman -Qdtq | pacman -Rs -`
### Upgrading packages
Pacman provides an easy way to [update Arch Linux](https://itsfoss.com/update-arch-linux/). You can update all installed packages with just one command. This could take a while depending on how up-to-date the system is.
The following command synchronizes the repository databases * and* updates the system’s packages, excluding “local” packages that are not in the configured repositories:
`pacman -Syu`
- S stands for sync
- y is for refresh (local cache)
- u is for system update
Basically it is saying that sync to central repository (master package database), refresh the local copy of the master package database and then perform the system update (by updating all packages that have a newer version available).
#### Attention! Read this before you update
If you are an Arch Linux user before upgrading, it is advised to visit the [Arch Linux home page](https://www.archlinux.org/?ref=itsfoss.com) to check the latest news for out-of-the-ordinary updates. If manual intervention is needed an appropriate news post will be made. Alternatively, you can subscribe to the [RSS feed](https://www.archlinux.org/feeds/news/?ref=itsfoss.com) or the [arch-announce mailing list](https://mailman.archlinux.org/mailman/listinfo/arch-announce/?ref=itsfoss.com).
Be also mindful to look over the appropriate [forum](https://bbs.archlinux.org/?ref=itsfoss.com) before upgrading fundamental software (such as the kernel, xorg, systemd, or glibc), for any reported problems.
**Partial upgrades are unsupported** at a rolling release distribution such as Arch and Manjaro. That means when new library versions are pushed to the repositories, all the packages in the repositories need to be rebuilt against the libraries. For example, if two packages depend on the same library, upgrading only one package, might break the other package which depends on an older version of the library.
### Use pacman to search for packages
Pacman queries the local package database with the -Q flag, the sync database with the -S flag and the files database with the -F flag.
Pacman can search for packages in the database, both in packages’ names and descriptions:
`pacman -Ss _string1_ _string2_ ...`
To search for already installed packages:
`pacman -Qs _string1_ _string2_ ...`
To search for package file names in remote packages:
`pacman -F _string1_ _string2_ ...`
To view the dependency tree of a package:
`pactree _package_naenter code hereme_`
### Cleaning the package cache
Pacman stores its downloaded packages in /var/cache/pacman/pkg/ and does not remove the old or uninstalled versions automatically. This has some advantages:
- It allows to
[downgrade](https://wiki.archlinux.org/index.php/Downgrade?ref=itsfoss.com)a package without the need to retrieve the previous version through other sources. - A package that has been uninstalled can easily be reinstalled directly from the cache folder.
However, it is necessary to clean up the cache periodically to prevent the folder to grow in size.
The [paccache(8)](https://jlk.fjfi.cvut.cz/arch/manpages/man/paccache.8?ref=itsfoss.com) script, provided within the [pacman-contrib](https://www.archlinux.org/packages/?name=pacman-contrib&ref=itsfoss.com) package, deletes all cached versions of installed and uninstalled packages, except for the most recent 3, by default:
`paccache -r`
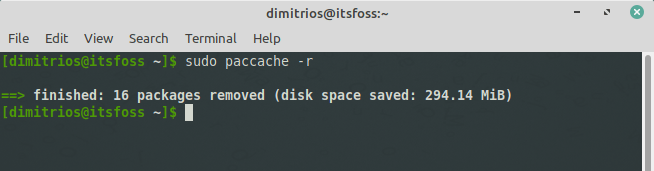
To remove all the cached packages that are not currently installed, and the unused sync database, execute:
`pacman -Sc`
To remove all files from the cache, use the clean switch twice, this is the most aggressive approach and will leave nothing in the cache folder:
`pacman -Scc`
### Installing local or third-party packages
Install a ‘local’ package that is not from a remote repository:
`pacman -U _/path/to/package/package_name-version.pkg.tar.xz_`
Install a ‘remote’ package, not contained in an official repository:
`pacman -U http://www.example.com/repo/example.pkg.tar.xz`
## Bonus: Troubleshooting common errors with pacman
Here are some common errors you may encounter while managing packages with pacman.
### Failed to commit transaction (conflicting files)
If you see the following error:
```
error: could not prepare transaction
error: failed to commit transaction (conflicting files)
package: /path/to/file exists in filesystem
Errors occurred, no packages were upgraded.
```
This is happening because pacman has detected a file conflict and will not overwrite files for you.
A safe way to solve this is to first check if another package owns the file (pacman -Qo * /path/to/file*). If the file is owned by another package, file a bug report. If the file is not owned by another package, rename the file which ‘exists in filesystem’ and re-issue the update command. If all goes well, the file may then be removed.
Instead of manually renaming and later removing all the files that belong to the package in question, you may explicitly run **pacman -S –overwrite glob package** to force pacman to overwrite files that match
*.*
*glob*### Failed to commit transaction (invalid or corrupted package)
Look for .part files (partially downloaded packages) in /var/cache/pacman/pkg/ and remove them. It is often caused by usage of a custom XferCommand in pacman.conf.
### Failed to init transaction (unable to lock database)
When pacman is about to alter the package database, for example installing a package, it creates a lock file at /var/lib/pacman/db.lck. This prevents another instance of pacman from trying to alter the package database at the same time.
If pacman is interrupted while changing the database, this stale lock file can remain. If you are certain that no instances of pacman are running then delete the lock file.
Check if a process is holding the lock file:
`lsof /var/lib/pacman/db.lck`
If the above command doesn’t return anything, you can remove the lock file:
`rm /var/lib/pacman/db.lck`
If you find the PID of the process holding the lock file with lsof command output, kill it first and then remove the lock file.
I hope you like my humble effort in explaining the basic pacman commands. Please leave your comments below and don’t forget to subscribe on our social media. Stay safe! |
13,100 | 我为什么要用 D 语言写脚本? | https://opensource.com/article/21/1/d-scripting | 2021-02-09T13:44:46 | [
"D语言"
] | https://linux.cn/article-13100-1.html |
>
> D 语言以系统编程语言而闻名,但它也是编写脚本的一个很好的选择。
>
>
>

D 语言由于其静态类型和元编程能力,经常被宣传为系统编程语言。然而,它也是一种非常高效的脚本语言。
由于 Python 在自动化任务和快速实现原型想法方面的灵活性,它通常被选为脚本语言。这使得 Python 对系统管理员、[管理者](https://opensource.com/article/20/3/automating-community-management-python)和一般的开发人员非常有吸引力,因为它可以自动完成他们可能需要手动完成的重复性任务。
我们自然也可以期待任何其他的脚本编写语言具有 Python 的这些特性和能力。以下是我认为 D 是一个不错的选择的两个原因。
### 1、D 很容易读和写
作为一种类似于 C 的语言,D 应该是大多数程序员所熟悉的。任何使用 JavaScript、Java、PHP 或 Python 的人对 D 语言都很容易上手。
如果你还没有安装 D,请[安装 D 编译器](https://tour.dlang.org/tour/en/welcome/install-d-locally),这样你就可以[运行本文中的 D 代码](https://tour.dlang.org/tour/en/welcome/run-d-program-locally)。你也可以使用[在线 D 编辑器](https://run.dlang.io/)。
下面是一个 D 代码的例子,它从一个名为 `words.txt` 的文件中读取单词,并在命令行中打印出来:
```
open
source
is
cool
```
用 D 语言写脚本:
```
#!/usr/bin/env rdmd
// file print_words.d
// import the D standard library
import std;
void main(){
// open the file
File("./words.txt")
//iterate by line
.byLine
// print each number
.each!writeln;
}
```
这段代码以 [释伴](https://en.wikipedia.org/wiki/Shebang_(Unix)) 开头,它将使用 [rdmd](https://dlang.org/rdmd.html) 来运行这段代码,`rdmd` 是 D 编译器自带的编译和运行代码的工具。假设你运行的是 Unix 或 Linux,在运行这个脚本之前,你必须使用`chmod` 命令使其可执行:
```
chmod u+x print_words.d
```
现在脚本是可执行的,你可以运行它:
```
./print_words.d
```
这将在你的命令行中打印以下内容:
```
open
source
is
cool
```
恭喜你,你写了第一个 D 语言脚本。你可以看到 D 是如何让你按顺序链式调用函数,这让阅读代码的感觉很自然,类似于你在头脑中思考问题的方式。这个[功能让 D 成为我最喜欢的编程语言](https://opensource.com/article/20/7/d-programming)。
试着再写一个脚本:一个非营利组织的管理员有一个捐款的文本文件,每笔金额都是单独的一行。管理员想把前 10 笔捐款相加,然后打印出金额:
```
#!/usr/bin/env rdmd
// file sum_donations.d
import std;
void main()
{
double total = 0;
// open the file
File("monies.txt")
// iterate by line
.byLine
// pick first 10 lines
.take(10)
// remove new line characters (\n)
.map!(strip)
// convert each to double
.map!(to!double)
// add element to total
.tee!((x) { total += x; })
// print each number
.each!writeln;
// print total
writeln("total: ", total);
}
```
与 `each` 一起使用的 `!` 操作符是[模板参数](http://ddili.org/ders/d.en/templates.html)的语法。
### 2、D 是快速原型设计的好帮手
D 是灵活的,它可以快速地将代码敲打在一起,并使其发挥作用。它的标准库中包含了丰富的实用函数,用于执行常见的任务,如操作数据(JSON、CSV、文本等)。它还带有一套丰富的通用算法,用于迭代、搜索、比较和 mutate 数据。这些巧妙的算法通过定义通用的 [基于范围的接口](http://ddili.org/ders/d.en/ranges.html) 而按照序列进行处理。
上面的脚本显示了 D 中的链式调用函数如何提供顺序处理和操作数据的要领。D 的另一个吸引人的地方是它不断增长的用于执行普通任务的第三方包的生态系统。一个例子是,使用 [Vibe.d](https://vibed.org) web 框架构建一个简单的 web 服务器很容易。下面是一个例子:
```
#!/usr/bin/env dub
/+ dub.sdl:
dependency "vibe-d" version="~>0.8.0"
+/
void main()
{
import vibe.d;
listenHTTP(":8080", (req, res) {
res.writeBody("Hello, World: " ~ req.path);
});
runApplication();
}
```
它使用官方的 D 软件包管理器 [Dub](https://dub.pm/getting_started),从 [D 软件包仓库](https://code.dlang.org)中获取 vibe.d Web 框架。Dub 负责下载 Vibe.d 包,然后在本地主机 8080 端口上编译并启动一个 web 服务器。
### 尝试一下 D 语言
这些只是你可能想用 D 来写脚本的几个原因。
D 是一种非常适合开发的语言。你可以很容易从 D 下载页面安装,因此下载编译器,看看例子,并亲自体验 D 语言。
---
via: <https://opensource.com/article/21/1/d-scripting>
作者:[Lawrence Aberba](https://opensource.com/users/aberba) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The D programming language is often advertised as a system programming language due to its static typing and metaprogramming capabilities. However, it's also a very productive scripting language.
Python is commonly chosen for scripting due to its flexibility for automating tasks and quickly prototyping ideas. This makes Python very appealing to sysadmins, [managers](https://opensource.com/article/20/3/automating-community-management-python), and developers in general for automating recurring tasks that they might otherwise have to do manually.
It is reasonable to expect any other script-writing language to have these Python traits and capabilities. Here are two reasons why I believe D is a good option.
## 1. D is easy to read and write
As a C-like language, D should be familiar to most programmers. Anyone who uses JavaScript, Java, PHP, or Python will know their way around D.
If you don't already have D installed, [install a D compiler](https://tour.dlang.org/tour/en/welcome/install-d-locally) so that you can [run the D code](https://tour.dlang.org/tour/en/welcome/run-d-program-locally) in this article. You may also use the [online D editor](https://run.dlang.io/).
Here is an example of D code that reads words from a file named `words.txt`
and prints them on the command line:
```
open
source
is
cool
```
Write the script in D:
```
#!/usr/bin/env rdmd
// file print_words.d
// import the D standard library
import std;
void main(){
// open the file
File("./words.txt")
//iterate by line
.byLine
// print each number
.each!writeln;
}
```
This code is prefixed with a [shebang](https://en.wikipedia.org/wiki/Shebang_(Unix)) that will run the code using [rdmd](https://dlang.org/rdmd.html), a tool that comes with the D compiler to compile and run code. Assuming you are running Unix or Linux, before you can run this script, you must make it executable by using the `chmod`
command:
`chmod u+x print_words.d`
Now that the script is executable, you can run it:
`./print_words.d`
This should print the following on your command line:
```
open
source
is
cool
```
Congratulations! You've written your first D script. You can see how D enables you to chain functions in sequence to make reading the code feel natural, similar to how you think about problems in your mind. This [feature makes D my favorite programming language](https://opensource.com/article/20/7/d-programming).
Try writing another script: A nonprofit manager has a text file of donations with each amount on separate lines. The manager wants to sum the first 10 donations and print the amounts:
```
#!/usr/bin/env rdmd
// file sum_donations.d
import std;
void main()
{
double total = 0;
// open the file
File("monies.txt")
// iterate by line
.byLine
// pick first 10 lines
.take(10)
// remove new line characters (\n)
.map!(strip)
// convert each to double
.map!(to!double)
// add element to total
.tee!((x) { total += x; })
// print each number
.each!writeln;
// print total
writeln("total: ", total);
}
```
The `!`
operator used with `each`
is the syntax of a [template argument](http://ddili.org/ders/d.en/templates.html).
## 2. D is great for quick prototyping
D is flexible for hammering code together really quickly and making it work. Its standard library is rich with utility functions for performing common tasks, such as manipulating data (JSON, CSV, text, etc.). It also comes with a rich set of generic algorithms for iterating, searching, comparing, and mutating data. These cleverly crafted algorithms are oriented towards processing sequences by defining generic [range-based interfaces](http://ddili.org/ders/d.en/ranges.html).
The script above shows how chaining functions in D provides a gist of sequential processing and manipulating data. Another appeal of D is its growing ecosystem of third-party packages for performing common tasks. An example is how easy it is to build a simple web server using the [Vibe.d](https://vibed.org) web framework. Here's an example:
```
#!/usr/bin/env dub
/+ dub.sdl:
dependency "vibe-d" version="~>0.8.0"
+/
void main()
{
import vibe.d;
listenHTTP(":8080", (req, res) {
res.writeBody("Hello, World: " ~ req.path);
});
runApplication();
}
```
This uses the official D package manager, [Dub](https://dub.pm/getting_started), to fetch the vibe.d web framework from the [D package repository](https://code.dlang.org). Dub takes care of downloading the Vibe.d package, then compiling and spinning up a web server on localhost port 8080.
## Give D a try
These are only a couple of reasons why you might want to use D for writing scripts.
D is a great language for development. It's easy to install from the D download page, so download the compiler, take a look at the examples, and experience D for yourself.
## Comments are closed. |
13,103 | Python 之禅:时机最重要 | https://opensource.com/article/19/12/zen-python-timeliness | 2021-02-09T23:17:15 | [
"Python"
] | https://linux.cn/article-13103-1.html |
>
> 这是 Python 之禅特别系列的一部分,重点是第十五和第十六条原则:现在与将来。
>
>
>

Python 一直在不断发展。Python 社区对特性请求的渴求是无止境的,对现状也总是不满意的。随着 Python 越来越流行,这门语言的变化会影响到更多的人。
确定什么时候该进行变化往往很难,但 [Python 之禅](https://www.python.org/dev/peps/pep-0020/) 给你提供了指导。
### <ruby> 现在有总比永远没有好 <rt> Now is better than never </rt></ruby>
总有一种诱惑,就是要等到事情完美才去做,虽然,它们永远没有完美的一天。当它们看起来已经“准备”得足够好了,那就大胆采取行动吧,去做出改变吧。无论如何,变化总是发生在*某个*现在:拖延的唯一作用就是把它移到未来的“现在”。
### <ruby> 虽然将来总比现在好 <rt> Although never is often better than right now </rt></ruby>
然而,这并不意味着应该急于求成。从测试、文档、用户反馈等方面决定发布的标准。在变化就绪之前的“现在”,并不是一个好时机。
这不仅对 Python 这样的流行语言是个很好的经验,对你个人的小开源项目也是如此。
---
via: <https://opensource.com/article/19/12/zen-python-timeliness>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is always evolving. The Python community has an unending appetite for feature requests but also an unending bias toward the status quo. As Python gets more popular, changes to the language affect more people.
The exact timing for when a change happens is often hard, but the [Zen of Python](https://www.python.org/dev/peps/pep-0020/) offers guidance.
## Now is better than never.
There is always the temptation to delay things until they are perfect. They will never be perfect, though. When they look "ready" enough, that is when it is time to take the plunge and put them out there. Ultimately, a change always happens at *some* now: the only thing that delaying does is move it to a future person's "now."
## Although never is often better than *right now*.
This, however, does not mean things should be rushed. Decide the criteria for release in terms of testing, documentation, user feedback, and so on. "Right now," as in before the change is ready, is not a good time.
This is a good lesson not just for popular languages like Python, but also for your personal little open source project.
## Comments are closed. |
13,104 | 9 个易用的基于 Arch 的用户友好型 Linux 发行版 | https://itsfoss.com/arch-based-linux-distros/ | 2021-02-10T11:28:59 | [
"Arch"
] | https://linux.cn/article-13104-1.html | 在 Linux 社区中,[Arch Linux](https://www.archlinux.org/) 有一群狂热的追随者。这个轻量级的发行版以 DIY 的态度提供了最前沿的更新。
但是,Arch 的目标用户是那些更有经验的用户。因此,它通常被认为是那些技术不够(或耐心不够)的人所无法触及的。
事实上,只是最开始的步骤,[安装 Arch Linux 就足以把很多人吓跑](https://itsfoss.com/install-arch-linux/)。与大多数其他发行版不同,Arch Linux 没有一个易于使用的图形安装程序。安装过程中涉及到的磁盘分区,连接到互联网,挂载驱动器和创建文件系统等只用命令行工具来操作。
对于那些不想经历复杂的安装和设置的人来说,有许多用户友好的基于 Arch 的发行版。
在本文中,我将向你展示一些 Arch 替代发行版。这些发行版附带了图形安装程序、图形包管理器和其他工具,比它们的命令行版本更容易使用。
### 更容易设置和使用的基于 Arch 的 Linux 发行版

请注意,这不是一个排名列表。这些数字只是为了计数的目的。排第二的发行版不应该被认为比排第七的发行版好。
#### 1、Manjaro Linux

[Manjaro](https://manjaro.org/) 不需要任何介绍。它是几年来最流行的 Linux 发行版之一,它值得拥有。
Manjaro 提供了 Arch Linux 的所有优点,同时注重用户友好性和可访问性。Manjaro 既适合新手,也适合有经验的 Linux 用户。
**对于新手**,它提供了一个用户友好的安装程序,系统本身也设计成可以在你[最喜爱的桌面环境](https://itsfoss.com/best-linux-desktop-environments/) (DE)或窗口管理器中直接“开箱即用”。
**对于更有经验的用户**,Manjaro 还提供多种功能,以满足每个个人的口味和喜好。[Manjaro Architect](https://itsfoss.com/manjaro-architect-review/) 提供了安装各种 Manjaro 风格的选项,并为那些想要完全自由地塑造系统的人提供了各种桌面环境、文件系统([最近推出的 ZFS](https://itsfoss.com/manjaro-20-release/)) 和引导程序的选择。
Manjaro 也是一个滚动发布的前沿发行版。然而,与 Arch 不同的是,Manjaro 首先测试更新,然后将其提供给用户。稳定在这里也很重要。
#### 2、ArcoLinux

[ArcoLinux](https://arcolinux.com/)(以前称为 ArchMerge)是一个基于 Arch Linux 的发行版。开发团队提供了三种变体。ArcoLinux、ArcoLinuxD 和 ArcoLinuxB。
ArcoLinux 是一个功能齐全的发行版,附带有 [Xfce 桌面](https://www.xfce.org/)、[Openbox](http://openbox.org/wiki/Main_Page) 和 [i3 窗口管理器](https://i3wm.org/)。
**ArcoLinuxD** 是一个精简的发行版,它包含了一些脚本,可以让高级用户安装任何桌面和应用程序。
**ArcoLinuxB** 是一个让用户能够构建自定义发行版的项目,同时还开发了几个带有预配置桌面的社区版本,如 Awesome、bspwm、Budgie、Cinnamon、Deepin、GNOME、MATE 和 KDE Plasma。
ArcoLinux 还提供了各种视频教程,因为它非常注重学习和获取 Linux 技能。
#### 3、Archlabs Linux

[ArchLabs Linux](https://itsfoss.com/archlabs-review/) 是一个轻量级的滚动版 Linux 发行版,基于最精简的 Arch Linux,带有 [Openbox](https://en.wikipedia.org/wiki/Openbox) 窗口管理器。[ArchLabs](https://archlabslinux.com/) 在观感设计中受到 [BunsenLabs](https://www.bunsenlabs.org/) 的影响和启发,主要考虑到中级到高级用户的需求。
#### 4、Archman Linux

[Archman](https://archman.org/en/) 是一个独立的项目。Arch Linux 发行版对于没有多少 Linux 经验的用户来说通常不是理想的操作系统。要想在最小的挫折感下让事情变得更有意义,必须要有相当的背景知识。Archman Linux 的开发人员正试图改变这种评价。
Archman 的开发是基于对开发的理解,包括用户反馈和体验组件。根据团队过去的经验,将用户的反馈和要求融合在一起,确定路线图并完成构建工作。
#### 5、EndeavourOS

当流行的基于 Arch 的发行版 [Antergos 在 2019 结束](https://itsfoss.com/antergos-linux-discontinued/) 时,它留下了一个友好且非常有用的社区。Antergos 项目结束的原因是因为该系统对于开发人员来说太难维护了。
在宣布结束后的几天内,一些有经验的用户通过创建一个新的发行版来填补 Antergos 留下的空白,从而维护了以前的社区。这就是 [EndeavourOS](https://itsfoss.com/endeavouros/) 的诞生。
[EndeavourOS](https://endeavouros.com/) 是轻量级的,并且附带了最少数量的预装应用程序。一块近乎空白的画布,随时可以个性化。
#### 6、RebornOS

[RebornOS](https://rebornos.org/) 开发人员的目标是将 Linux 的真正威力带给每个人,一个 ISO 提供了 15 个桌面环境可供选择,并提供无限的定制机会。
RebornOS 还声称支持 [Anbox](https://anbox.io/),它可以在桌面 Linux 上运行 Android 应用程序。它还提供了一个简单的内核管理器 GUI 工具。
再加上 [Pacman](https://itsfoss.com/pacman-command/)、[AUR](https://itsfoss.com/aur-arch-linux/),以及定制版本的 Cnchi 图形安装程序,Arch Linux 终于可以让最没有经验的用户也能够使用了。
#### 7、Chakra Linux

一个社区开发的 GNU/Linux 发行版,它的亮点在 KDE 和 Qt 技术。[Chakra Linux](https://www.chakralinux.org/) 不在特定日期安排发布,而是使用“半滚动发布”系统。
这意味着 Chakra Linux 的核心包被冻结,只在修复安全问题时才会更新。这些软件包是在最新版本经过彻底测试后更新的,然后再转移到永久软件库(大约每六个月更新一次)。
除官方软件库外,用户还可以安装 Chakra 社区软件库 (CCR) 的软件包,该库为官方存储库中未包含的软件提供用户制作的 PKGINFOs 和 [PKGBUILD](https://wiki.archlinux.org/index.php/PKGBUILD) 脚本,其灵感来自于 Arch 用户软件库(AUR)。
#### 8、Artix Linux

[Artix Linux](https://artixlinux.org/) 也是一个基于 Arch Linux 的滚动发行版,它使用 [OpenRC](https://en.wikipedia.org/wiki/OpenRC)、[runit](https://en.wikipedia.org/wiki/Runit) 或 [s6](https://en.wikipedia.org/wiki/S6_(software)) 作为初始化工具而不是 [systemd](https://en.wikipedia.org/wiki/Systemd)。
Artix Linux 有自己的软件库,但作为一个基于 `pacman` 的发行版,它可以使用 Arch Linux 软件库或任何其他衍生发行版的软件包,甚至可以使用明确依赖于 systemd 的软件包。也可以使用 [Arch 用户软件库](https://itsfoss.com/aur-arch-linux/)(AUR)。
#### 9、BlackArch Linux

BlackArch 是一个基于 Arch Linux 的 [渗透测试发行版](https://itsfoss.com/linux-hacking-penetration-testing/),它提供了大量的网络安全工具。它是专门为渗透测试人员和安全研究人员创建的。该软件库包含 2400 多个[黑客和渗透测试工具](https://itsfoss.com/best-kali-linux-tools/) ,可以单独安装,也可以分组安装。BlackArch Linux 兼容现有的 Arch Linux 包。
### 想要真正的原版 Arch Linux 吗?可以使用图形化 Arch 安装程序简化安装
如果你想使用原版的 Arch Linux,但又被它困难的安装所难倒。幸运的是,你可以下载一个带有图形安装程序的 Arch Linux ISO。
Arch 安装程序基本上是 Arch Linux ISO 的一个相对容易使用的基于文本的安装程序。它比裸奔的 Arch 安装容易得多。
#### Anarchy Installer

[Anarchy installer](https://anarchyinstaller.org/) 打算为新手和有经验的 Linux 用户提供一种简单而无痛苦的方式来安装 ArchLinux。在需要的时候安装,在需要的地方安装,并且以你想要的方式安装。这就是 Anarchy 的哲学。
启动安装程序后,将显示一个简单的 [TUI 菜单](https://en.wikipedia.org/wiki/Text-based_user_interface),列出所有可用的安装程序选项。
#### Zen Installer

[Zen Installer](https://sourceforge.net/projects/revenge-installer/) 为安装 Arch Linux 提供了一个完整的图形(点击式)环境。它支持安装多个桌面环境 、AUR 以及 Arch Linux 的所有功能和灵活性,并且易于图形化安装。
ISO 将引导一个临场环境,然后在你连接到互联网后下载最新稳定版本的安装程序。因此,你将始终获得最新的安装程序和更新的功能。
### 总结
对于许多用户来说,基于 Arch 的发行版会是一个很好的无忧选择,而像 Anarchy 这样的图形化安装程序至少离原版的 Arch Linux 更近了一步。
在我看来,[Arch Linux 的真正魅力在于它的安装过程](https://itsfoss.com/install-arch-linux/),对于 Linux 爱好者来说,这是一个学习的机会,而不是麻烦。Arch Linux 及其衍生产品有很多东西需要你去折腾,但是在折腾的过程中你就会进入到开源软件的世界,这里是神奇的新世界。下次再见!
---
via: <https://itsfoss.com/arch-based-linux-distros/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In the Linux community, [Arch Linux has a cult following](https://itsfoss.com/why-arch-linux/). This lightweight distribution provides bleeding-edge updates with a DIY (do it yourself) attitude.
However, [Arch Linux](https://www.archlinux.org/?ref=its-foss) is also aimed at more experienced users. As such, it is generally considered to be beyond the reach of those who need more technical expertise (or persistence) to use it.
Things like [installing Arch Linux](https://itsfoss.com/install-arch-linux/) are paint points for new users as it does not feature an easy-to-understand graphical installer like Ubuntu. The process is getting easier at the time of updating this article.
Here, I will list some of these Arch alternative distributions that are easier to set up and use. These distributions come with a graphical installer, graphical package manager, and other tools that are easier to use than their command-line alternatives.
## 1. Manjaro Linux
[Manjaro](https://manjaro.org/?ref=itsfoss.com) doesn’t need any introduction. It is one of the most popular Linux distributions for several years and deserves it.
Manjaro provides all the benefits of Arch Linux combined with a focus on user-friendliness and accessibility. Manjaro is suitable for both newcomers and experienced Linux users alike.
For newcomers, a user-friendly installer is provided, and the system is designed to work fully ‘straight out of the box’ with your [favourite desktop environment](https://itsfoss.com/best-linux-desktop-environments/) (DE) or window manager.
Manjaro is also a rolling release cutting-edge distribution. However, unlike Arch, Manjaro tests the updates first and then provides them to its users. Stability is better there.
[Long-Term Support versions](https://itsfoss.com/long-term-support-lts/)instead of Arch-based rolling releases.
## 2. ArcoLinux
[ArcoLinux](https://arcolinux.com/?ref=itsfoss.com) (previously known as ArchMerge) is a distribution based on Arch Linux. The development team offers three variations. ArcoLinux, ArcoLinuxD and ArcoLinuxB.
ArcoLinux is a full-featured distribution that ships with the [Xfce desktop](https://www.xfce.org/?ref=itsfoss.com), [Openbox](http://openbox.org/wiki/Main_Page?ref=itsfoss.com), and [i3 window managers](https://i3wm.org/?ref=itsfoss.com) by default.
**ArcoLinuxD** is a minimal distribution that includes scripts that enable power users to install any desktop and application.
**ArcoLinuxB** is a project that gives users the power to build custom distributions, while also developing several community editions with pre-configured desktops, such as Awesome, bspwm, Budgie, Cinnamon, Deepin, GNOME, MATE and KDE Plasma.
ArcoLinux also provides various video tutorials as it places a strong focus on learning and acquiring Linux skills.
## 3. Archlabs Linux

[Distrowatch](https://distrowatch.com/table.php?distribution=archlabs)
[ArchLabs Linux](https://itsfoss.com/archlabs-review/) is a lightweight rolling release Linux distribution based on a minimal Arch Linux base with the [Openbox](https://en.wikipedia.org/wiki/Openbox?ref=itsfoss.com) window manager. [ArchLabs](https://archlabslinux.com/?ref=itsfoss.com) is influenced and inspired by the look and feel of [BunsenLabs](https://www.bunsenlabs.org/?ref=itsfoss.com) with the intermediate to advanced user in mind.
It comes with a live session of the dk window manager, based on dwm and bspwm. Other desktops like i3WM, Openbox etc are available to install through the installer.
## 4. Archman Linux
[Archman](https://archman.org/en/?ref=itsfoss.com), a name derived from a combination of **Arch** Linux and Pac**man** package management, is an independent project based on Arch Linux. Arch Linux distros, in general, are not ideal operating systems for users with little Linux experience.
Considerable background reading is necessary for things to make sense with minimal frustration. Developers of Archman Linux are trying to change that reputation.
Archman’s development is based on an understanding of development that includes user feedback and experience components. With past experience, the feedback and requests from the users are blended, and the road maps are determined, and the build works are done.
They ship Xfce, KDE Plasma, Mate, Deepin, Gnome, Lxde, and Lxqt versions, while XFCE remains the main version.
## 5. EndeavourOS
When the popular Arch-based distribution [Antergos was discontinued in 2019](https://itsfoss.com/antergos-linux-discontinued/), it left a friendly and extremely helpful community behind. The Antergos project ended because the system was too hard to maintain for the developers.
Within days after the announcement, a few experienced users planned on maintaining the former community by creating a new distribution to fill the void left by Antergos. That’s how [EndeavourOS](https://itsfoss.com/endeavouros/) was born.
[EndeavourOS](https://endeavouros.com/?ref=itsfoss.com) is lightweight and ships with a minimum amount of preinstalled apps. An almost blank canvas ready to personalize.
Later in 2022, [it added ARM installation support](https://news.itsfoss.com/endeavouros-artemis-release/) too. XFCE is their default desktop, offering several others through the online installer.
## 6. RebornOS
[RebornOS](https://rebornos.org/?ref=itsfoss.com) developers’ goal is to bring the true power of Linux to everyone, with one ISO for 15 desktop environments and full of unlimited opportunities for customization.
RebornOS also claims to have support for [Anbox](https://anbox.io/?ref=itsfoss.com) for running Android applications on desktop Linux. It also offers a simple kernel manager GUI tool.
Coupled with [Pacman](https://itsfoss.com/pacman-command/), the [AUR](https://itsfoss.com/aur-arch-linux/), and a customized version of Calamares graphical installer, Arch Linux is finally available for even the least inexperienced users.
## 7. Garuda Linux
Garuda Linux is an easy-to-install Linux distribution based on Arch Linux. It is known for its heavily customized desktops and availability of GUI tools to carry out complex operations.
It uses the BTRFS file system, with automatic system snapshots before each upgrade, accessible from the GRUB menu.
Another exciting feature is its Chaotic-AUR as a repository featuring one of the biggest precompiled software choices out of the box. Currently, there are around 2400 packages.
It offers several desktop environments, and users can download them individually.
## 8. Artix Linux
[Distrowatch](https://distrowatch.com/table.php?distribution=artix)
[Artix Linux](https://artixlinux.org/?ref=itsfoss.com) is a rolling-release distribution based on Arch Linux that uses [OpenRC](https://en.wikipedia.org/wiki/OpenRC?ref=itsfoss.com), [runit](https://en.wikipedia.org/wiki/Runit?ref=itsfoss.com) or [s6](https://en.wikipedia.org/wiki/S6_(software)?ref=itsfoss.com) init instead of [systemd](https://en.wikipedia.org/wiki/Systemd?ref=itsfoss.com).
Artix Linux has its own package repositories but as a pacman-based distribution, it can use packages from Arch Linux repositories or any other derivative distribution, even packages explicitly depending on systemd. The [Arch User Repository](https://itsfoss.com/aur-arch-linux/) (AUR) can also be used.
## 9. BlackArch Linux

[BlackArch](https://blackarch.org/) is a [penetration testing distribution](https://itsfoss.com/linux-hacking-penetration-testing/) based on Arch Linux that provides many cyber security tools. It is specially created for penetration testers and security researchers. The repository contains more than 2800+ [hacking and pen-testing tools](https://itsfoss.com/best-kali-linux-tools/) that can be installed individually or in groups. BlackArch Linux is compatible with existing Arch Linux packages.
BlackArch is a relatively new project that offers a Full ISO containing multiple window managers and a slim ISO featuring the XFCE Desktop Environment.
## 10. Archcraft
Archcraft is a very minimal and lightweight distribution that can run under 500Mb of memory, thanks to the lightweight applications.
It provides bspwm, LXDE, Openbox, and Xfce as desktops and also features built-in support for AUR.
## Want Real Arch Linux? Try The Installer Tool
The recent releases of Arch Linux have an installer tool called `archinstall`
, which is available along with the ISO. You can [use this tool to install Arch Linux](https://itsfoss.com/install-arch-linux-virtualbox/) easily. It is still a text-based installer but easier to understand.
In either case, you can try graphical installers like [Zen Installer](https://sourceforge.net/projects/revenge-installer/?ref=itsfoss.com) to make things easy.
These Arch-based distributions allow Linux newbies to experience Arch by eliminating some of the hassles. You can try them if you want to try something new for a change!
*💬 What is your favorite Arch-based distribution?* |
13,106 | 基础:如何在 Linux 中运行一个 Shell 脚本 | https://itsfoss.com/run-shell-script-linux/ | 2021-02-10T23:53:00 | [
"脚本",
"shell"
] | https://linux.cn/article-13106-1.html | 
在 Linux 中有两种运行 shell 脚本的方法。你可以使用:
```
bash script.sh
```
或者,你可以像这样执行 shell 脚本:
```
./script.sh
```
这可能很简单,但没太多解释。不要担心,我将使用示例来进行必要的解释,以便你能理解为什么在运行一个 shell 脚本时要使用给定的特定语法格式。
我将使用这一行 shell 脚本来使需要解释的事情变地尽可能简单:
```
abhishek@itsfoss:~/Scripts$ cat hello.sh
echo "Hello World!"
```
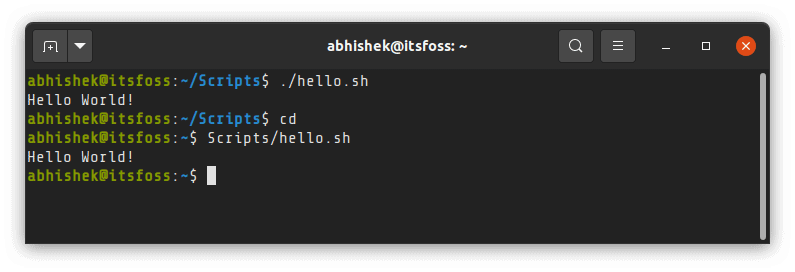
### 方法 1:通过将文件作为参数传递给 shell 以运行 shell 脚本
第一种方法涉及将脚本文件的名称作为参数传递给 shell 。
考虑到 bash 是默认 shell,你可以像这样运行一个脚本:
```
bash hello.sh
```
你知道这种方法的优点吗?**你的脚本不需要执行权限**。对于简单的任务非常方便快速。

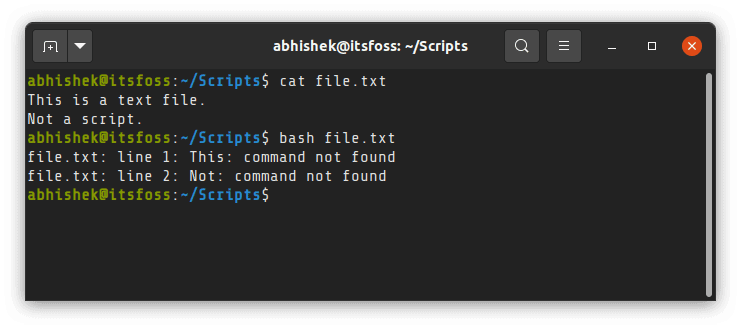
如果你还不熟悉,我建议你 [阅读我的 Linux 文件权限详细指南](https://linuxhandbook.com/linux-file-permissions/) 。
记住,将其作为参数传递的需要是一个 shell 脚本。一个 shell 脚本是由命令组成的。如果你使用一个普通的文本文件,它将会抱怨错误的命令。

在这种方法中,**你要明确地具体指定你想使用 bash 作为脚本的解释器** 。
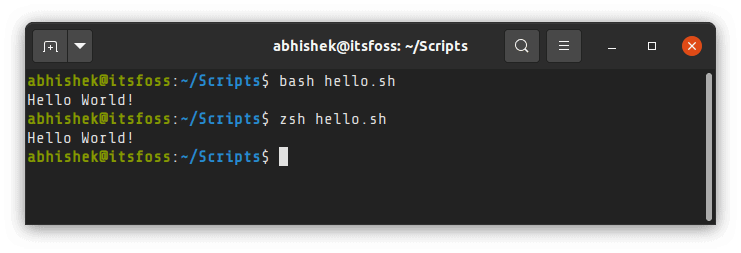
shell 只是一个程序,并且 bash 只是 Shell 的一种实现。还有其它的 shell 程序,像 ksh 、[zsh](https://www.zsh.org) 等等。如果你安装有其它的 shell ,你也可以使用它们来代替 bash 。
例如,我已安装了 zsh ,并使用它来运行相同的脚本:

### 方法 2:通过具体指定 shell 脚本的路径来执行脚本
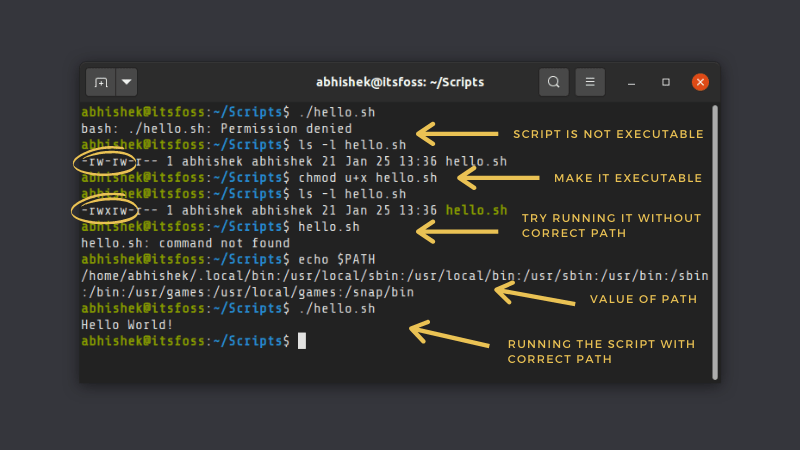
另外一种运行一个 shell 脚本的方法是通过提供它的路径。但是要这样做之前,你的文件必须是可执行的。否则,当你尝试执行脚本时,你将会得到 “权限被拒绝” 的错误。
因此,你首先需要确保你的脚本有可执行权限。你可以 [使用 chmod 命令](https://linuxhandbook.com/chmod-command/) 来给予你自己脚本的这种权限,像这样:
```
chmod u+x script.sh
```
使你的脚本是可执行之后,你只需输入文件的名称及其绝对路径或相对路径。大多数情况下,你都在同一个目录中,因此你可以像这样使用它:
```
./script.sh
```
如果你与你的脚本不在同一个目录中,你可以具体指定脚本的绝对路径或相对路径:

在脚本前的这个 `./` 是非常重要的(当你与脚本在同一个目录中)。

为什么当你在同一个目录下,却不能使用脚本名称?这是因为你的 Linux 系统会在 `PATH` 环境变量中指定的几个目录中查找可执行的文件来运行。
这里是我的系统的 `PATH` 环境变量的值:
```
abhishek@itsfoss:~$ echo $PATH
/home/abhishek/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
```
这意味着在下面目录中具有可执行权限的任意文件都可以在系统的任何位置运行:
* `/home/abhishek/.local/bin`
* `/usr/local/sbin`
* `/usr/local/bin`
* `/usr/sbin`
* `/usr/bin`
* `/sbin`
* `/bin`
* `/usr/games`
* `/usr/local/games`
* `/snap/bin`
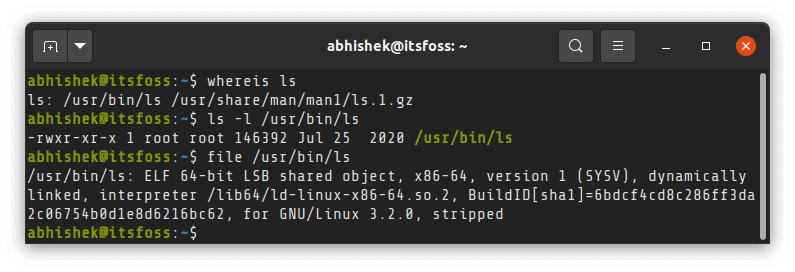
Linux 命令(像 `ls`、`cat` 等)的二进制文件或可执行文件都位于这些目录中的其中一个。这就是为什么你可以在你系统的任何位置通过使用命令的名称来运作这些命令的原因。看看,`ls` 命令就是位于 `/usr/bin` 目录中。

当你使用脚本而不具体指定其绝对路径或相对路径时,系统将不能在 `PATH` 环境变量中找到提及的脚本。
>
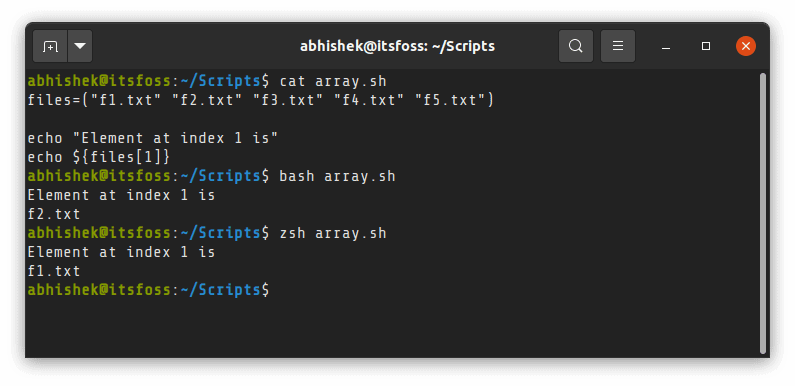
> 为什么大多数 shell 脚本在其头部包含 #! /bin/bash ?
>
>
> 记得我提过 shell 只是一个程序,并且有 shell 程序的不同实现。
>
>
> 当你使用 `#! /bin/bash` 时,你是具体指定 bash 作为解释器来运行脚本。如果你不这样做,并且以 `./script.sh` 的方式运行一个脚本,它通常会在你正在运行的 shell 中运行。
>
>
> 有问题吗?可能会有。看看,大多数的 shell 语法是大多数种类的 shell 中通用的,但是有一些语法可能会有所不同。
>
>
> 例如,在 bash 和 zsh 中数组的行为是不同的。在 zsh 中,数组索引是从 1 开始的,而不是从 0 开始。
>
>
> 
>
>
> 使用 `#! /bin/bash` 来标识该脚本是 bash 脚本,并且应该使用 bash 作为脚本的解释器来运行,而不受在系统上正在使用的 shell 的影响。如果你使用 zsh 的特殊语法,你可以通过在脚本的第一行添加 `#! /bin/zsh` 的方式来标识其是 zsh 脚本。
>
>
> 在 `#!` 和 `/bin/bash` 之间的空格是没有影响的。你也可以使用 `#!/bin/bash` 。
>
>
>
### 它有帮助吗?
我希望这篇文章能够增加你的 Linux 知识。如果你还有问题或建议,请留下评论。
专家用户可能依然会挑出我遗漏的东西。但这种初级题材的问题是,要找到信息的平衡点,避免细节过多或过少,并不容易。
如果你对学习 bash 脚本感兴趣,在我们专注于系统管理的网站 [Linux Handbook](https://linuxhandbook.com) 上,我们有一个 [完整的 Bash 初学者系列](https://linuxhandbook.com/tag/bash-beginner/) 。如果你想要,你也可以 [购买带有附加练习的电子书](https://www.buymeacoffee.com/linuxhandbook) ,以支持 Linux Handbook。
---
via: <https://itsfoss.com/run-shell-script-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There are two ways to run a shell script in Linux. You can use:
`bash script.sh`
Or you can execute the shell script like this:
`./script.sh`
That maybe simple, but it doesn’t explain a lot. Don’t worry, I’ll do the necessary explaining with examples so that you understand why a particular syntax is used in the given format while running a shell script.
I am going to use this one line shell script to make things as uncomplicated as possible:
```
abhishek@itsfoss:~/Scripts$ cat hello.sh
echo "Hello World!"
```
## Method 1: Running a shell script by passing the file as argument to shell
The first method involves passing the script file name as an argument to the shell.
Considering that bash is the default shell, you can run a script like this:
`bash hello.sh`
Do you know the advantage of this approach? **Your script doesn’t need to have the execute permission**. Pretty handy for quick and simple tasks.
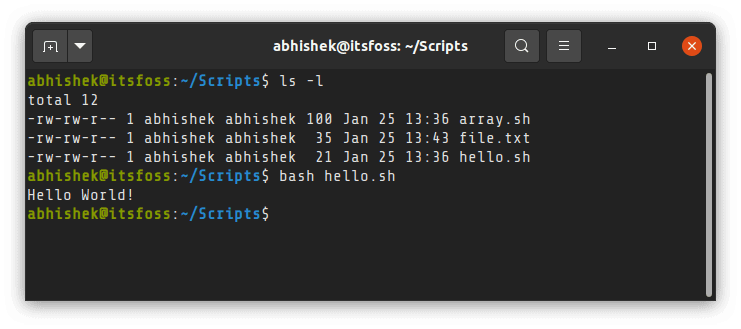
If you are not familiar already, I advise you to [read my detailed guide on file permission in Linux](https://linuxhandbook.com/linux-file-permissions/?ref=itsfoss.com).
Keep in mind that it needs to be a shell script that you pass as argument. A shell script is composed of commands. If you use a normal text file, it will complain about incorrect commands.
In this approach, **you explicitly specified that you want to use bash as the interpreter** for the script.
Shell is just a program and bash is an implementation of that. There are other such shells program like ksh, [zsh](https://www.zsh.org/?ref=itsfoss.com), etc. If you have other shells installed, you can use that as well instead of bash.
For example, I installed zsh and used it to run the same script:
## Method 2: Execute shell script by specifying its path
The other method to run a shell script is by providing its path. But for that to be possible, your file must be executable. Otherwise, you’ll have “permission denied” error when you try to execute the script.
So first you need to make sure that your script has the execute permission. You can [use the chmod command](https://linuxhandbook.com/chmod-command/?ref=itsfoss.com) to give yourself this permission like this:
`chmod u+x script.sh`
Once your script is executable, all you need to do is to type the file name along with its [absolute or relative path](https://linuxhandbook.com/absolute-vs-relative-path/?ref=itsfoss.com). Most often you are in the same directory so you just use it like this:
`./script.sh`
If you are not in the same directory as your script, you can specify it the absolute or relative path to the script:
### That ./ before the script is important (when you are in the same directory as the script)
Why can you not use the script name when you are in the same directory? That is because your Linux systems looks for the executables to run in a few selected directories that are specified in the PATH variable.
Here’s the value of PATH variable for my system:
```
abhishek@itsfoss:~$ echo $PATH
/home/abhishek/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
```
This means that any file with execute permissions in one of the following directories can be executed from anywhere in the system:
- /home/abhishek/.local/bin
- /usr/local/sbin
- /usr/local/bin
- /usr/sbin
- /usr/bin
- /sbin
- /bin
- /usr/games
- /usr/local/games
- /snap/bin
The binaries or executable files for Linux commands like ls, cat etc are located in one of those directories. This is why you are able to run these commands from anywhere on your system just by using their names. See, the ls command is located in /usr/bin directory.
When you specify the script WITHOUT the absolute or relative path, it cannot find it in the directories mentioned in the PATH variable.
### Why most shell scripts contain #! /bin/bash at the beginning of the shell scripts?
Remember how I mentioned that shell is just a program and there are different implementations of shells.
When you use the #! /bin/bash, you are specifying that the script is to run with bash as interpreter. If you don’t do that and run a script in ./script.sh manner, it is usually run with whatever shell you are running.
Does it matter? It could. See, most of the shell syntax is common in all kind of shell but some might differ.
For example, the array behavior is different in bash and zsh shells. In zsh, the array index starts at 1 instead of 0.
Using #! /bin/bash indicates that the script is bash shell script and should be run with bash as interpreter irrespective of the shell which is being used on the system. If you are using zsh specific syntax, you can indicate that it is zsh script by adding #! /bin/zsh as the first line of the script.
The space between #! /bin/bash doesn’t matter. You can also use #!/bin/bash.
## Was it helpful?
I hope this article added to your Linux knowledge. If you still have questions or suggestions, please leave a comment.
Expert users can still nitpick this article about things I missed out. But the problem with such beginner topics is that it is not easy to find the right balance of information and avoid having too much or too few details.
If you are interested in learning bash script, we have an [entire Bash Beginner Series](https://linuxhandbook.com/tag/bash-beginner/?ref=itsfoss.com) on our sysadmin focused website [Linux Handbook](https://linuxhandbook.com/?ref=itsfoss.com).
[Bash Tutorial Series for Beginners: Start Learning Bash ScriptingThe 10 chapter series will teach the bash scripting essentials.](https://linuxhandbook.com/tag/bash-beginner/)

If you want, you may also purchase the ebook with additional exercises to support Linux Handbook.
[Learn Bash Quickly - Bash Beginner Book for Linux UsersThis book is available for FREE to Linux Handbook members.Learn Bash Quickly will teach you everything you need to get started with bash scripting. Each bash concept is explained with easy to understand examples. You’ll learn to:Create and run a bash scriptUse variables and pass arguments to scriptU…](https://linuxhandbook.gumroad.com/l/ejfGu) |
13,107 | 基于 Tmux 的多会话终端管理示例 | https://www.ostechnix.com/tmux-command-examples-to-manage-multiple-terminal-sessions/ | 2021-02-11T10:10:00 | [
"Tmux"
] | https://linux.cn/article-13107-1.html | 
我们已经了解到如何通过 [GNU Screen](https://www.ostechnix.com/screen-command-examples-to-manage-multiple-terminal-sessions/) 进行多会话管理。今天,我们将要领略另一个著名的管理会话的命令行实用工具 **Tmux**。类似 GNU Screen,Tmux 是一个帮助我们在单一终端窗口中创建多个会话,同一时间内同时运行多个应用程序或进程的终端复用工具。Tmux 自由、开源并且跨平台,支持 Linux、OpenBSD、FreeBSD、NetBSD 以及 Mac OS X。本文将讨论 Tmux 在 Linux 系统下的高频用法。
### Linux 下安装 tmux
Tmux 可以在绝大多数的 Linux 官方仓库下获取。
在 Arch Linux 或它的变种系统下,执行下列命令来安装:
```
$ sudo pacman -S tmux
```
Debian、Ubuntu 或 Linux Mint:
```
$ sudo apt-get install tmux
```
Fedora:
```
$ sudo dnf install tmux
```
RHEL 和 CentOS:
```
$ sudo yum install tmux
```
SUSE/openSUSE:
```
$ sudo zypper install tmux
```
以上,我们已经完成 Tmux 的安装。之后我们继续看看一些 Tmux 示例。
### Tmux 命令示例: 多会话管理
Tmux 默认所有命令的前置命令都是 `Ctrl+b`,使用前牢记这个快捷键即可。
>
> **注意**:**Screen** 的前置命令都是 `Ctrl+a`.
>
>
>
#### 创建 Tmux 会话
在终端中运行如下命令创建 Tmux 会话并附着进入:
```
tmux
```
抑或,
```
tmux new
```
一旦进入 Tmux 会话,你将看到一个 **沉在底部的绿色的边栏**,如下图所示。

*创建 Tmux 会话*
这个绿色的边栏能很容易提示你当前是否身处 Tmux 会话当中。
#### 退出 Tmux 会话
退出当前 Tmux 会话仅需要使用 `Ctrl+b` 和 `d`。无需同时触发这两个快捷键,依次按下 `Ctrl+b` 和 `d` 即可。
退出当前会话后,你将能看到如下输出:
```
[detached (from session 0)]
```
#### 创建有名会话
如果使用多个会话,你很可能会混淆运行在多个会话中的应用程序。这种情况下,我们需要会话并赋予名称。譬如需要 web 相关服务的会话,就创建一个名称为 “webserver”(或任意一个其他名称) 的 Tmux 会话。
```
tmux new -s webserver
```
这里是新的 Tmux 有名会话:

*拥有自定义名称的 Tmux 会话*
如你所见上述截图,这个 Tmux 会话的名称已经被标注为 “webserver”。如此,你可以在多个会话中,轻易的区分应用程序的所在。
退出会话,轻按 `Ctrl+b` 和 `d`。
#### 查看 Tmux 会话清单
查看 Tmux 会话清单,执行:
```
tmux ls
```
示例输出:

*列出 Tmux 会话*
如你所见,我们开启了两个 Tmux 会话。
#### 创建非附着会话
有时候,你可能想要简单创建会话,但是并不想自动切入该会话。
创建一个非附着会话,并赋予名称 “ostechnix”,运行:
```
tmux new -s ostechnix -d
```
上述命令将会创建一个名为 “ostechnix” 的会话,但是并不会附着进入。
你可以通过使用 `tmux ls` 命令验证:

*创建非附着会话*
#### 附着进入 Tmux 会话
通过如下命令,你可以附着进入最后一个被创建的会话:
```
tmux attach
```
抑或,
```
tmux a
```
如果你想附着进入任意一个指定的有名会话,譬如 “ostechnix”,运行:
```
tmux attach -t ostechnix
```
或者,简写为:
```
tmux a -t ostechnix
```
#### 关闭 Tmux 会话
当你完成或者不再需要 Tmux 会话,你可以通过如下命令关闭:
```
tmux kill-session -t ostechnix
```
当身处该会话时,使用 `Ctrl+b` 以及 `x`。点击 `y` 来关闭会话。
可以通过 `tmux ls` 命令验证。
关闭所有 Tmux 服务下的所有会话,运行:
```
tmux kill-server
```
谨慎!这将终止所有 Tmux 会话,并不会产生任何警告,即便会话存在运行中的任务。
如果不存在活跃的 Tmux 会话,将看到如下输出:
```
$ tmux ls
no server running on /tmp/tmux-1000/default
```
#### 切割 Tmux 窗口
切割窗口成多个小窗口,在 Tmux 中,这个叫做 “Tmux 窗格”。每个窗格中可以同时运行不同的程序,并同时与所有的窗格进行交互。每个窗格可以在不影响其他窗格的前提下可以调整大小、移动位置和控制关闭。我们可以以水平、垂直或者二者混合的方式切割屏幕。
##### 水平切割窗格
欲水平切割窗格,使用 `Ctrl+b` 和 `"`(半个双引号)。

*水平切割 Tmux 窗格*
可以使用组合键进一步切割面板。
##### 垂直切割窗格
垂直切割面板,使用 `Ctrl+b` 和 `%`。

*垂直切割 Tmux 窗格*
##### 水平、垂直混合切割窗格
我们也可以同时采用水平和垂直的方案切割窗格。看看如下截图:

*切割 Tmux 窗格*
首先,我通过 `Ctrl+b` `"` 水平切割,之后通过 `Ctrl+b` `%` 垂直切割下方的窗格。
如你所见,每个窗格下我运行了不同的程序。
##### 切换窗格
通过 `Ctrl+b` 和方向键(上下左右)切换窗格。
##### 发送命令给所有窗格
之前的案例中,我们在每个窗格中运行了三个不同命令。其实,也可以发送相同的命令给所有窗格。
为此,使用 `Ctrl+b` 然后键入如下命令,之后按下回车:
```
:setw synchronize-panes
```
现在在任意窗格中键入任何命令。你将看到相同命令影响了所有窗格。
##### 交换窗格
使用 `Ctrl+b` 和 `o` 交换窗格。
##### 展示窗格号
使用 `Ctrl+b` 和 `q` 展示窗格号。
##### 终止窗格
要关闭窗格,直接键入 `exit` 并且按下回车键。或者,按下 `Ctrl+b` 和 `x`。你会看到确认信息。按下 `y` 关闭窗格。

*关闭窗格*
##### 放大和缩小 Tmux 窗格
我们可以将 Tmux 窗格放大到当前终端窗口的全尺寸,以获得更好的文本可视性,并查看更多的内容。当你需要更多的空间或专注于某个特定的任务时,这很有用。在完成该任务后,你可以将 Tmux 窗格缩小(取消放大)到其正常位置。更多详情请看以下链接。
* [如何缩放 Tmux 窗格以提高文本可见度?](https://ostechnix.com/how-to-zoom-tmux-panes-for-better-text-visibility/)
#### 自动启动 Tmux 会话
当通过 SSH 与远程系统工作时,在 Tmux 会话中运行一个长期运行的进程总是一个好的做法。因为,它可以防止你在网络连接突然中断时失去对运行进程的控制。避免这个问题的一个方法是自动启动 Tmux 会话。更多详情,请参考以下链接。
* [通过 SSH 登录远程系统时自动启动 Tmux 会话](https://ostechnix.com/autostart-tmux-session-on-remote-system-when-logging-in-via-ssh/)
### 总结
这个阶段下,你已经获得了基本的 Tmux 技能来进行多会话管理,更多细节,参阅 man 页面。
```
$ man tmux
```
GNU Screen 和 Tmux 工具都能透过 SSH 很好的管理远程服务器。学习 Screen 和 Tmux 命令,像个行家一样,彻底通过这些工具管理远程服务器。
---
via: <https://www.ostechnix.com/tmux-command-examples-to-manage-multiple-terminal-sessions/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chensanle](https://github.com/chensanle) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
13,109 | 英特尔 Optane:用于数据中心内存缓存 | https://www.networkworld.com/article/3387117/intel-formally-launches-optane-for-data-center-memory-caching.html#tk.rss_all | 2021-02-12T11:17:46 | [
"内存"
] | https://linux.cn/article-13109-1.html |
>
> 英特尔推出了包含 3D Xpoint 内存技术的 Optane 持久内存产品线。英特尔的这个解决方案介乎于 DRAM 和 NAND 中间,以此来提升性能。
>
>
>


英特尔在 2019 年 4 月的[大规模数据中心活动](https://www.networkworld.com/article/3386142/intel-unveils-an-epic-response-to-amds-server-push.html)中正式推出 Optane 持久内存产品线。它已经问世了一段时间,但是目前的 Xeon 服务器处理器还不能充分利用它。而新的 Xeon8200 和 9200 系列可以充分利用 Optane 持久内存的优势。
由于 Optane 是英特尔的产品(与美光合作开发),所以意味着 AMD 和 ARM 的服务器处理器不能够支持它。
正如[我之前所说的](https://www.networkworld.com/article/3279271/intel-launches-optane-the-go-between-for-memory-and-storage.html),OptaneDC 持久内存采用与美光合作研发的 3D Xpoint 内存技术。3D Xpoint 是一种比 SSD 更快的非易失性内存,速度几乎与 DRAM 相近,而且它具有 NAND 闪存的持久性。
第一个 3D Xpoint 产品是被称为英特尔“尺子”的 SSD,因为它们被设计成细长的样子,很像尺子的形状。它们被设计这样是为了适合 1u 的服务器机架。在发布的公告中,英特尔推出了新的利用四芯或者 QLC 3D NAND 内存的英特尔 SSD D5-P4325 [尺子](https://www.theregister.co.uk/2018/02/02/ruler_and_miniruler_ssd_formats_look_to_banish_diskstyle_drives/) SSD,可以在 1U 的服务器机架上放 1PB 的存储。
OptaneDC 持久内存的可用容量最初可以通过使用 128GB 的 DIMM 达到 512GB。英特尔数据中心集团执行副总裁及总经理 Navin Shenoy 说:“OptaneDC 持久内存可达到的容量是 DRAM 的 2 到 4 倍。”
他说:“我们希望服务器系统的容量可以扩展到每个插槽 4.5TB 或者 8 个插槽 36TB,这是我们第一代 Xeon 可扩展芯片的 3 倍。”
### 英特尔Optane内存的使用和速度
Optane 有两种不同的运行模式:内存模式和应用直连模式。内存模式是将 DRAM 放在 Optane 内存之上,将 DRAM 作为 Optane 内存的缓存。应用直连模式是将 DRAM 和 OptaneDC 持久内存一起作为内存来最大化总容量。并不是每个工作负载都适合这种配置,所以应该在对延迟不敏感的应用程序中使用。正如英特尔推广的那样,Optane 的主要使用情景是内存模式。
几年前,当 3D Xpoint 最初发布时,英特尔宣称 Optane 的速度是 NAND 的 1000 倍,耐用是 NAND 的 1000 倍,密度潜力是 DRAM 的 10 倍。这虽然有点夸张,但这些因素确实很令人着迷。
在 256B 的连续 4 个缓存行中使用 Optane 内存可以达到 8.3GB/秒的读速度和 3.0GB/秒的写速度。与 SATA SSD 的 500MB/秒左右的读/写速度相比,可以看到性能有很大提升。请记住,Optane 充当内存,所以它会缓存被频繁访问的 SSD 中的内容。
这是了解 OptaneDC 的关键。它能将非常大的数据集存储在离内存非常近的位置,因此具有很低延迟的 CPU 可以最小化访问较慢的存储子系统的访问延迟,无论存储是 SSD 还是 HDD。现在,它提供了一种可能性,即把多个 TB 的数据放在非常接近 CPU 的地方,以实现更快的访问。
### Optane 内存的一个挑战
唯一真正的挑战是 Optane 插进内存所在的 DIMM 插槽。现在有些主板的每个 CPU 有多达 16 个 DIMM 插槽,但是这仍然是客户和设备制造商之间需要平衡的电路板空间:Optane 还是内存。有一些 Optane 驱动采用了 PCIe 接口进行连接,可以减轻主板上内存的拥挤。
3D Xpoint 由于它写数据的方式,提供了比传统的 NAND 闪存更高的耐用性。英特尔承诺 Optane 提供 5 年保修期,而很多 SSD 只提供 3 年保修期。
---
via: <https://www.networkworld.com/article/3387117/intel-formally-launches-optane-for-data-center-memory-caching.html>
作者:[Andy Patrizio](https://www.networkworld.com/author/Andy-Patrizio/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[RiaXu](https://github.com/ShuyRoy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
13,110 | 使用 Material Shell 扩展将你的 GNOME 桌面打造成平铺式风格 | https://itsfoss.com/material-shell/ | 2021-02-12T16:23:05 | [
"平铺"
] | https://linux.cn/article-13110-1.html | 平铺式窗口的特性吸引了很多人的追捧。也许是因为它很好看,也许是因为它能提高 [Linux 快捷键](https://itsfoss.com/ubuntu-shortcuts/) 玩家的效率。又或者是因为使用不同寻常的平铺式窗口是一种新奇的挑战。

从 i3 到 [Sway](https://itsfoss.com/sway-window-manager/),Linux 桌面拥有各种各样的平铺式窗口管理器。配置一个平铺式窗口管理器需要一个陡峭的学习曲线。
这就是为什么像 [Regolith 桌面](https://itsfoss.com/regolith-linux-desktop/) 这样的项目会存在,给你预先配置好的平铺桌面,让你可以更轻松地开始使用平铺窗口。
让我给你介绍一个类似的项目 —— Material Shell。它可以让你用上平铺式桌面,甚至比 [Regolith](https://regolith-linux.org/) 还简单。
### Material Shell 扩展:将 GNOME 桌面转变成平铺式窗口管理器
[Material Shell](https://material-shell.com) 是一个 GNOME 扩展,这就是它最好的地方。这意味着你不需要注销并登录其他桌面环境。你只需要启用或关闭这个扩展就可以自如的切换你的工作环境。
我会列出 Material Shell 的各种特性,但是也许视频更容易让你理解:
这个项目叫做 Material Shell 是因为它遵循 [Material Design](https://material.io/) 原则。因此这个应用拥有一个美观的界面。这就是它最重要的一个特性。
#### 直观的界面
Material Shell 添加了一个左侧面板,以便快速访问。在此面板上,你可以在底部找到系统托盘,在顶部找到搜索和工作区。
所有新打开的应用都会添加到当前工作区中。你也可以创建新的工作区并切换到该工作区,以将正在运行的应用分类。其实这就是工作区最初的意义。
在 Material Shell 中,每个工作区都可以显示为具有多个应用程序的行列,而不是包含多个应用程序的程序框。
#### 平铺式窗口
在工作区中,你可以一直在顶部看到所有打开的应用程序。默认情况下,应用程序会像在 GNOME 桌面中那样铺满整个屏幕。你可以使用右上角的布局改变器来改变布局,将其分成两半、多列或多个应用网格。
这段视频一目了然的显示了以上所有功能:
#### 固定布局和工作区
Material Shell 会记住你打开的工作区和窗口,这样你就不必重新组织你的布局。这是一个很好的特性,因为如果你对应用程序的位置有要求的话,它可以节省时间。
#### 热建/快捷键
像任何平铺窗口管理器一样,你可以使用键盘快捷键在应用程序和工作区之间切换。
* `Super+W` 切换到上个工作区;
* `Super+S` 切换到下个工作区;
* `Super+A` 切换到左边的窗口;
* `Super+D` 切换到右边的窗口;
* `Super+1`、`Super+2` … `Super+0` 切换到某个指定的工作区;
* `Super+Q` 关闭当前窗口;
* `Super+[鼠标拖动]` 移动窗口;
* `Super+Shift+A` 将当前窗口左移;
* `Super+Shift+D` 将当前窗口右移;
* `Super+Shift+W` 将当前窗口移到上个工作区;
* `Super+Shift+S` 将当前窗口移到下个工作区。
### 安装 Material Shell
>
> 警告!
>
>
> 对于大多数用户来说,平铺式窗口可能会导致混乱。你最好先熟悉如何使用 GNOME 扩展。如果你是 Linux 新手或者你害怕你的系统发生翻天覆地的变化,你应当避免使用这个扩展。
>
>
>
Material Shell 是一个 GNOME 扩展。所以,请 [检查你的桌面环境](https://itsfoss.com/find-desktop-environment/),确保你运行的是 GNOME 3.34 或者更高的版本。
除此之外,我注意到在禁用 Material Shell 之后,它会导致 Firefox 的顶栏和 Ubuntu 的坞站消失。你可以在 GNOME 的“扩展”应用程序中禁用/启用 Ubuntu 的坞站扩展来使其变回原来的样子。我想这些问题也应该在系统重启后消失,虽然我没试过。
我希望你知道 [如何使用 GNOME 扩展](https://itsfoss.com/gnome-shell-extensions/)。最简单的办法就是 [在浏览器中打开这个链接](https://extensions.gnome.org/extension/3357/material-shell/),安装 GNOME 扩展浏览器插件,然后启用 Material Shell 扩展即可。

如果你不喜欢这个扩展,你也可以在同样的链接中禁用它。或者在 GNOME 的“扩展”应用程序中禁用它。

### 用不用平铺式?
我使用多个电脑屏幕,我发现 Material Shell 不适用于多个屏幕的情况。这是开发者将来可以改进的地方。
除了这个毛病以外,Material Shell 是个让你开始使用平铺式窗口的好东西。如果你尝试了 Material Shell 并且喜欢它,请 [在 GitHub 上给它一个星标或赞助它](https://github.com/material-shell/material-shell) 来鼓励这个项目。
由于某些原因,平铺窗户越来越受欢迎。最近发布的 [Pop OS 20.04](https://itsfoss.com/pop-os-20-04-review/) 也增加了平铺窗口的功能。有一个类似的项目叫 PaperWM,也是这样做的。
但正如我前面提到的,平铺布局并不适合所有人,它可能会让很多人感到困惑。
你呢?你是喜欢平铺窗口还是喜欢经典的桌面布局?
---
via: <https://itsfoss.com/material-shell/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There is something about tiling windows that attracts many people. Perhaps it looks good or perhaps it is time-saving if you are a fan of [keyboard shortcuts in Linux](https://itsfoss.com/ubuntu-shortcuts/). Or maybe it’s the challenge of using the uncommon tiling windows.
[Image Source](https://imgur.com/gallery/wxBZFN5)
From i3 to [Sway](https://itsfoss.com/sway-window-manager/), there are so many tiling window managers available for Linux desktop. Configuring a tiling window manager itself requires a steep learning curve.
This is why projects like [Regolith desktop](https://itsfoss.com/regolith-linux-desktop/) exist to give you preconfigured tiling desktop so that you can get started with tiling windows with less effort.
Let me introduce you to a similar project named Material Shell that makes using tiling feature even easier than [Regolith](https://regolith-linux.org/).
## Material Shell GNOME Extension: Convert GNOME desktop into a tiling window manager
[Material Shell](https://material-shell.com) is a GNOME extension and that’s the best thing about it. This means that you don’t have to log out and log in to another [desktop environment](https://itsfoss.com/what-is-desktop-environment/) or window manager. You can enable or disable it from within your current session.
I’ll list the features of Material Shell but it will be easier to see it in action:
The project is called Material Shell because it follows the [Material Design](https://material.io/) guideline and thus gives the applications an aesthetically pleasing interface. Here are its main features:
### Intuitive interface
Material Shell adds a left panel for quick access. On this panel, you can find the system tray at the bottom and the search and workspaces on the top.
All the new apps are added to the current workspace. You can create new workspace and switch to it for organizing your running apps into categories. This is the essential concept of workspace anyway.
In Material Shell, every workspace can be visualized as a row with several apps rather than a box with several apps in it.
### Tiling windows
In a workspace, you can see all your opened applications on the top all the time. By default, the applications are opened to take the entire screen like you do in GNOME desktop. You can change the layout to split it in half or multiple columns or a grid of apps using the layout changer in the top right corner.
This video shows all the above features at a glance:
### Persistent layout and workspaces
That’s not it. Material Shell also remembers the workspaces and windows you open so that you don’t have to reorganize your layout again. This is a good feature to have as it saves time if you are particular about which application goes where.
### Hotkeys/Keyboard shortcut
Like any tiling windows manager, you can use keyboard shortcuts to navigate between applications and workspaces.
`Super+W`
Navigate to the upper workspace.`Super+S`
Navigate to the lower workspace.`Super+A`
Focus the window at the left of the current window.`Super+D`
Focus the window at the right of the current window.`Super+1`
,`Super+2`
…`Super+0`
Navigate to specific workspace`Super+Q`
Kill the current window focused.`Super+[MouseDrag]`
Move window around.`Super+Shift+A`
Move the current window to the left.`Super+Shift+D`
Move the current window to the right.`Super+Shift+W`
Move the current window to the upper workspace.`Super+Shift+S`
Move the current window to the lower workspace.
## Installing Material Shell
Warning!
Tiling windows could be confusing for many users. You should be familiar with GNOME Extensions to use it. Avoid trying it if you are absolutely new to Linux or if you are easily panicked if anything changes in your system.
Material Shell is a GNOME extension. So, please [check your desktop environment](https://itsfoss.com/find-desktop-environment/) to make sure you are running ** GNOME 3.34 or higher version**.
I would also like to add that tiling windows could be confusing for many users.
Apart from that, I noticed that after disabling Material Shell it removes the top bar from Firefox and the Ubuntu dock. You can get the dock back by disabling/enabling Ubuntu dock extension from the Extensions app in GNOME. I haven’t tried but I guess these problems should also go away after a system reboot.
I hope you know [how to use GNOME extensions](https://itsfoss.com/gnome-shell-extensions/). The easiest way is to just [open this link in the browser](https://extensions.gnome.org/extension/3357/material-shell/), install GNOME extension plugin and then enable the Material Shell extension.
If you don’t like it, you can disable it from the same extension link you used earlier or use the GNOME Extensions app:
**To tile or not?**
I use multiple screens and I found that Material Shell doesn’t work well with multiple monitors. This is something the developer(s) can improve in the future.
Apart from that, it’s a really easy to get started with tiling windows with Material Shell. If you try Material Shell and like it, appreciate the project by [giving it a star or sponsoring it on GitHub](https://github.com/material-shell/material-shell).
For some reasons, tiling windows are getting popular. Recently released [Pop OS 20.04](https://itsfoss.com/pop-os-20-04-review/) also added tiling window features. There is a similar project called [PaperWM](https://itsfoss.com/paperwm/) which does the same.
But as I mentioned previously, tiling layouts are not for everyone and it could confuse many people.
How about you? Do you prefer tiling windows or you prefer the classic desktop layout? |
13,112 | LaTeX 排版(1):列表 | https://fedoramagazine.org/latex-typesetting-part-1/ | 2021-02-13T09:41:11 | [
"LaTex"
] | https://linux.cn/article-13112-1.html | 
本系列基于前文《[在 Fedora 上用 LaTex 和 TeXstudio 排版你的文档](https://fedoramagazine.org/typeset-latex-texstudio-fedora)》和《[LaTeX 基础](https://fedoramagazine.org/fedora-classroom-latex-101-beginners)》,本文即系列的第一部分,是关于 LaTeX 列表的。
### 列表类型
LaTeX 中的列表是封闭的环境,列表中的每个项目可以取一行文字到一个完整的段落。在 LaTeX 中有三种列表类型:
* `itemize`:<ruby> 无序列表 <rt> unordered list </rt></ruby>/<ruby> 项目符号列表 <rt> bullet list </rt></ruby>
* `enumerate`:<ruby> 有序列表 <rt> ordered list </rt></ruby>
* `description`:<ruby> 描述列表 <rt> descriptive list </rt></ruby>
### 创建列表
要创建一个列表,需要在每个项目前加上控制序列 `\item`,并在项目清单前后分别加上控制序列 `\begin{<类型>}` 和 `\end`{<类型>}`(将其中的`<类型>` 替换为将要使用的列表类型),如下例:
#### itemize(无序列表)
```
\begin{itemize}
\item Fedora
\item Fedora Spin
\item Fedora Silverblue
\end{itemize}
```

#### enumerate(有序列表)
```
\begin{enumerate}
\item Fedora CoreOS
\item Fedora Silverblue
\item Fedora Spin
\end{enumerate}
```

#### description(描述列表)
```
\begin{description}
\item[Fedora 6] Code name Zod
\item[Fedora 8] Code name Werewolf
\end{description}
```

### 列表项目间距
可以通过在导言区加入 `\usepackage{enumitem}` 来自定义默认的间距,宏包 `enumitem` 启用了选项 `noitemsep` 和控制序列 `\itemsep`,可以在列表中使用它们,如下例所示:
#### 使用选项 noitemsep
将选项 `noitemsep` 封闭在方括号内,并同下文所示放在控制序列 `\begin` 之后,该选项将移除默认的间距。
```
\begin{itemize}[noitemsep]
\item Fedora
\item Fedora Spin
\item Fedora Silverblue
\end{itemize}
```

#### 使用控制序列 \itemsep
控制序列 `\itemsep` 必须以一个数字作为后缀,用以表示列表项目之间应该有多少空间。
```
\begin{itemize} \itemsep0.75pt
\item Fedora Silverblue
\item Fedora CoreOS
\end{itemize}
```

### 嵌套列表
LaTeX 最多最多支持四层嵌套列表,如下例:
#### 嵌套无序列表
```
\begin{itemize}[noitemsep]
\item Fedora Versions
\begin{itemize}
\item Fedora 8
\item Fedora 9
\begin{itemize}
\item Werewolf
\item Sulphur
\begin{itemize}
\item 2007-05-31
\item 2008-05-13
\end{itemize}
\end{itemize}
\end{itemize}
\item Fedora Spin
\item Fedora Silverblue
\end{itemize}
```

#### 嵌套有序列表
```
\begin{enumerate}[noitemsep]
\item Fedora Versions
\begin{enumerate}
\item Fedora 8
\item Fedora 9
\begin{enumerate}
\item Werewolf
\item Sulphur
\begin{enumerate}
\item 2007-05-31
\item 2008-05-13
\end{enumerate}
\end{enumerate}
\end{enumerate}
\item Fedora Spin
\item Fedora Silverblue
\end{enumerate}
```

### 每种列表类型的列表样式名称
| **enumerate(有序列表)** | **itemize(无序列表)** |
| --- | --- |
| `\alph*` (小写字母) | `$\bullet$` (●) |
| `\Alph*` (大写字母) | `$\cdot$` (•) |
| `\arabic*` (阿拉伯数字) | `$\diamond$` (◇) |
| `\roman*` (小写罗马数字) | `$\ast$` (✲) |
| `\Roman*` (大写罗马数字) | `$\circ$` (○) |
| | `$-$` (-) |
### 按嵌套深度划分的默认样式
| **嵌套深度** | **enumerate(有序列表)** | **itemize(无序列表)** |
| --- | --- | --- |
| 1 | 阿拉伯数字 | (●) |
| 2 | 小写字母 | (-) |
| 3 | 小写罗马数字 | (✲) |
| 4 | 大写字母 | (•) |
### 设置列表样式
下面的例子列举了无序列表的不同样式。
```
% 无序列表样式
\begin{itemize}
\item[$\ast$] Asterisk
\item[$\diamond$] Diamond
\item[$\circ$] Circle
\item[$\cdot$] Period
\item[$\bullet$] Bullet (default)
\item[--] Dash
\item[$-$] Another dash
\end{itemize}
```

有三种设置列表样式的方式,下面将按照优先级从高到低的顺序分别举例。
#### 方式一:为各项目单独设置
将需要的样式名称封闭在方括号内,并放在控制序列 `\item` 之后,如下例:
```
% 方式一
\begin{itemize}
\item[$\ast$] Asterisk
\item[$\diamond$] Diamond
\item[$\circ$] Circle
\item[$\cdot$] period
\item[$\bullet$] Bullet (default)
\item[--] Dash
\item[$-$] Another dash
\end{itemize}
```
#### 方式二:为整个列表设置
将需要的样式名称以 `label=` 前缀并封闭在方括号内,放在控制序列 `\begin` 之后,如下例:
```
% 方式二
\begin{enumerate}[label=\Alph*.]
\item Fedora 32
\item Fedora 31
\item Fedora 30
\end{enumerate}
```
#### 方式三:为整个文档设置
该方式将改变整个文档的默认样式。使用 `\renewcommand` 来设置项目标签的值,下例分别为四个嵌套深度的项目标签设置了不同的样式。
```
% 方式三
\renewcommand{\labelitemi}{$\ast$}
\renewcommand{\labelitemii}{$\diamond$}
\renewcommand{\labelitemiii}{$\bullet$}
\renewcommand{\labelitemiv}{$-$}
```
### 总结
LaTeX 支持三种列表,而每种列表的风格和间距都是可以自定义的。在以后的文章中,我们将解释更多的 LaTeX 元素。
关于 LaTeX 列表的延伸阅读可以在这里找到:[LaTeX List Structures](https://en.wikibooks.org/wiki/LaTeX/List_Structures)
---
via: <https://fedoramagazine.org/latex-typesetting-part-1/>
作者:[Earl Ramirez](https://fedoramagazine.org/author/earlramirez/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rakino](https://github.com/rakino) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This series builds on the previous articles: [Typeset your docs with LaTex and TeXstudio on Fedora](https://fedoramagazine.org/typeset-latex-texstudio-fedora) and [LaTeX 101 for beginners](https://fedoramagazine.org/fedora-classroom-latex-101-beginners). This first part of the series is about LaTeX lists.
## Types of lists
LaTeX lists are enclosed environments, and each item in the list can take a line of text to a full paragraph. There are three types of lists available in LaTeX. They are:
**Itemized**: unordered or bullet**Enumerated**: ordered**Description**: descriptive
## Creating lists
To create a list, prefix each list item with the \*item* command. Precede and follow the list of items with the \*begin*{<type>} and \*end*{<type>} commands respectively where <type> is substituted with the type of the list as illustrated in the following examples.
### Itemized list
\begin{itemize} \item Fedora \item Fedora Spin \item Fedora Silverblue \end{itemize}

### Enumerated list
\begin{enumerate} \item Fedora CoreOS \item Fedora Silverblue \item Fedora Spin \end{enumerate}

### Descriptive list
\begin{description} \item[Fedora 6] Code name Zod \item[Fedora 8] Code name Werewolf \end{description}

## Spacing list items
The default spacing can be customized by adding \*usepackage{enumitem}* to the preamble. The *enumitem* package enables the *noitemsep* option and the \*itemsep* command which you can use on your lists as illustrated below.
### Using the noitemsep option
Enclose the *noitemsep* option in square brackets and place it on the \*begin* command as shown below. This option removes the default spacing.
\begin{itemize}[noitemsep] \item Fedora \item Fedora Spin \item Fedora Silverblue \end{itemize}
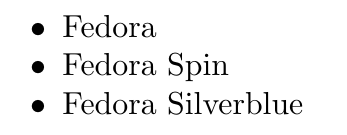
### Using the \itemsep command
The \*itemsep* command must be suffixed with a number to indicate how much space there should be between the list items.
\begin{itemize} \itemsep0.75pt \item Fedora Silverblue \item Fedora CoreOS \end{itemize}

## Nesting lists
LaTeX supports nested lists up to four levels deep as illustrated below.
### Nested itemized lists
\begin{itemize}[noitemsep] \item Fedora Versions \begin{itemize} \item Fedora 8 \item Fedora 9 \begin{itemize} \item Werewolf \item Sulphur \begin{itemize} \item 2007-05-31 \item 2008-05-13 \end{itemize} \end{itemize} \end{itemize} \item Fedora Spin \item Fedora Silverblue \end{itemize}

### Nested enumerated lists
\begin{enumerate}[noitemsep] \item Fedora Versions \begin{enumerate} \item Fedora 8 \item Fedora 9 \begin{enumerate} \item Werewolf \item Sulphur \begin{enumerate} \item 2007-05-31 \item 2008-05-13 \end{enumerate} \end{enumerate} \end{enumerate} \item Fedora Spin \item Fedora Silverblue \end{enumerate}

## List style names for each list type
Enumerated | Itemized |
\alph* | $\bullet$ |
\Alph* | $\cdot$ |
\arabic* | $\diamond$ |
\roman* | $\ast$ |
\Roman* | $\circ$ |
$-$ |
## Default style by list depth
Level | Enumerated | Itemized |
1 | Number | Bullet |
2 | Lowercase alphabet | Dash |
3 | Roman numerals | Asterisk |
4 | Uppercase alphabet | Period |
## Setting list styles
The below example illustrates each of the different itemiszed list styles.
% Itemize style \begin{itemize} \item[$\ast$] Asterisk \item[$\diamond$] Diamond \item[$\circ$] Circle \item[$\cdot$] Period \item[$\bullet$] Bullet (default) \item[--] Dash \item[$-$] Another dash \end{itemize}

There are three methods of setting list styles. They are illustrated below. These methods are listed by priority; highest priority first. A higher priority will override a lower priority if more than one is defined for a list item.
### List styling method 1 – per item
Enclose the name of the desired style in square brackets and place it on the \*item* command as demonstrated below.
% First method \begin{itemize} \item[$\ast$] Asterisk \item[$\diamond$] Diamond \item[$\circ$] Circle \item[$\cdot$] period \item[$\bullet$] Bullet (default) \item[--] Dash \item[$-$] Another dash \end{itemize}
### List styling method 2 – on the list
Prefix the name of the desired style with *label=*. Place the parameter, including the *label=* prefix, in square brackets on the \*begin* command as demonstrated below.
% Second method \begin{enumerate}[label=\Alph*.] \item Fedora 32 \item Fedora 31 \item Fedora 30 \end{enumerate}
### List styling method 3 – on the document
This method changes the default style for the entire document. Use the \*renewcommand* to set the values for the labelitems. There is a different labelitem for each of the four label depths as demonstrated below.
% Third method \renewcommand{\labelitemi}{$\ast$} \renewcommand{\labelitemii}{$\diamond$} \renewcommand{\labelitemiii}{$\bullet$} \renewcommand{\labelitemiv}{$-$}
## Summary
LaTeX supports three types of lists. The style and spacing of each of the list types can be customized. More LaTeX elements will be explained in future posts.
Additional reading about LaTeX lists can be found here: [LaTeX List Structures](https://en.wikibooks.org/wiki/LaTeX/List_Structures)
## kd
Helpful, thanks
## Earl Ramirez
Glad that is was helpful
## Jorge Dominguez
Thanks for the tips, I’m starting out with LaTeX, so this was indeed helpful
## Earl Ramirez
LaTeX is great, I first starting using LaTeX after I saw the article “Typeset your docs with LaTex and TeXstudio on Fedora.”
## Julio Gonzalez
Love it!
I use vim+latex and I find it very fun, cause you merged the vim power with LaTeX style.
## James Aker
Great Scott! It’s back to future. I remember doing college assignments using LaTeX. Anymore I use Emacs+LaTex to create PDF’s on my fedora workstation.
Thanks for the article
## ddd
why deleting my post?
???
## Stephen Snow
I can’t seem to find a previous post from you. Would you mind commenting again?
## Leslie Satenstein
Gee, It seems to make asciidoc a dog of a format program, when compared to Latex.
Why do we need both? is there a way to merge the two format languages?
## Earl Ramirez
I believe that asciidoc does support LaTeX backend, but I have never used it or asciidoc. |
13,113 | 2021 年开源生产力的 3 个愿望 | https://opensource.com/article/21/1/productivity-wishlist | 2021-02-13T10:34:00 | [
"生产力"
] | https://linux.cn/article-13113-1.html |
>
> 2021年,开源世界可以拓展的有很多。这是我特别感兴趣的三个领域。
>
>
>

在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的最后一天。
我们已经到了又一个系列的结尾处。因此,让我们谈谈我希望在 2021 年看到的更多事情。
### 断网

*我在假期期间制作的(Kevin Sonney, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
对*许多、许多的*人来说,2020 年是非常困难的一年。疫情大流行、各种政治事件、24 小时的新闻轰炸等等,都对我们的精神健康造成了伤害。虽然我确实谈到了 [抽出时间进行自我护理](https://opensource.com/article/21/1/self-care),但我只是想断网:也就是关闭提醒、手机、平板等,暂时无视这个世界。我公司的一位经理实际上告诉我们,如果放假或休息一天,就把所有与工作有关的东西都关掉(除非我们在值班)。我最喜欢的“断网”活动之一就是听音乐和搭建大而复杂的乐高。
### 可访问性
尽管我谈论的许多技术都是任何人都可以做的,但是软件方面的可访问性都有一定难度。相对于自由软件运动之初,Linux 和开源世界在辅助技术方面已经有了长足发展。但是,仍然有太多的应用和系统不会考虑有些用户没有与设计者相同的能力。我一直在关注这一领域的发展,因为每个人都应该能够访问事物。
### 更多的一体化选择

*JPilot(Kevin Sonney, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
在 FOSS 世界中,一体化的个人信息管理解决方案远没有商业软件世界中那么多。总体趋势是使用单独的应用,它们必须通过配置来相互通信或通过中介服务(如 CalDAV 服务器)。移动市场在很大程度上推动了这一趋势,但我仍然向往像 [JPilot](http://www.jpilot.org/) 这样无需额外插件或服务就能完成几乎所有我需要的事情的日子。
非常感谢大家阅读这个年度系列。如果你认为我错过了什么,或者明年需要注意什么,请在下方评论。
就像我在 [生产力炼金术](https://productivityalchemy.com) 上说的那样,尽最大努力保持生产力!
---
via: <https://opensource.com/article/21/1/productivity-wishlist>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In prior years, this annual series covered individual apps. This year, we are looking at all-in-one solutions in addition to strategies to help in 2021. Welcome to the final day of 21 Days of Productivity in 2021.
Here we are, at the end of another series. So let's talk about the things I want to see more of in 2021.
### Disconnecting

I built this over the holidays
For many, many, *many* people, 2020 was a very difficult year. The pandemic, the various political events, the 24-hour news cycle, and so on took a toll on our mental well-being. And while I did talk about [making time for self-care](https://opensource.com/article/21/1/self-care), I only touched on disconnecting—that is, turning off alerts, phones, tablets, etc., and just ignoring the world for a bit. One of the managers in my company actually told us to turn off all our work-related stuff if we had a holiday or a day off (unless we were on call). One of my favorite "disconnect" activities is just listening to music and building big, complex Lego sets.
### Accessibility
While many of the techniques I talked about are something anyone can do, the software aspects all have some difficulty with accessibility. Linux and the open source world have come a long way when it comes to assistive technologies since the early days of the movement. However, there are still far too many applications and systems that do not consider that the user may not have the same abilities as the person who designed them. I am keeping an eye on developments in this area because everyone should be able to access things.
### More all-in-one options
JPilot
There are nowhere near as many all-in-one Personal Information Manager solutions in the FOSS world as there are in the commercial software world. The overall trend has been to use individual apps that must be configured to talk to each other or through an intermediary service (like a CalDAV server). The mobile market largely drives this trend, but I still yearn for the days when something like [JPilot](http://www.jpilot.org/) could do almost everything I needed without extra plugins or services.
Thank you all very much for reading the series year. Please comment with what you think I missed or need to look at for next year.
And as I say on [Productivity Alchemy](https://productivityalchemy.com), do your best to Stay Productive!
## Comments are closed. |
13,115 | 物联网专家都从何而来? | https://www.networkworld.com/article/3404489/where-are-all-the-iot-experts-going-to-come-from.html | 2021-02-14T10:29:20 | [
"IoT"
] | https://linux.cn/article-13115-1.html |
>
> 物联网(IoT)的快速发展催生了对跨职能专家进行培养的需求,这些专家可以将传统的网络和基础设施专业知识与数据库和报告技能相结合。
>
>
>

如果物联网(IoT)要实现其宏伟的诺言,它将需要大量聪明、熟练、**训练有素**的工人军团来实现这一切。而现在,这些人将从何而来尚不清楚。
这就是我为什么有兴趣同资产优化软件公司 [AspenTech](https://www.aspentech.com/) 的产品管理、研发高级总监 Keith Flynn 通邮件的原因,他说,当处理大量属于物联网范畴的新技术时,你需要能够理解如何配置技术和解释数据的人。Flynn 认为,现有的教育机构对物联网特定课程的需求越来越大,这同时也给了以物联网为重点,提供了完善课程的新私立学院机会。
Flynn 跟我说,“在未来,物联网项目将与如今普遍的数据管理和自动化项目有着巨大的不同……未来需要更全面的技能和交叉交易能力,这样我们才会说同一种语言。”
Flynn 补充说,随着物联网每年增长 30%,将不再依赖于几个特定的技能,“从传统的部署技能(如网络和基础设施)到数据库和报告技能,坦白说,甚至是基础数据科学,都将需要一起理解和使用。”
### 召集所有物联网顾问
Flynn 预测,“受过物联网教育的人的第一个大机会将会是在咨询领域,随着咨询公司对行业趋势的适应或淘汰……有受过物联网培训的员工将有助于他们在物联网项目中的定位,并在新的业务线中提出要求——物联网咨询。”
对初创企业和小型公司而言,这个问题尤为严重。“组织越大,他们越有可能雇佣到不同技术类别的人”Flynn 这样说到,“但对于较小的组织和较小的物联网项目来说,你则需要一个能同时兼顾的人。”
两者兼而有之?还是\*\*一应俱全?\*\*物联网“需要将所有知识和技能组合在一起”,Flynn 说到,“并不是所有技能都是全新的,只是在此之前从来没有被归纳在一起或放在一起教授过。”
### 未来的物联网专家
Flynn 表示,真正的物联网专业技术是从基础的仪器仪表和电气技能开始的,这能帮助工人发明新的无线发射器或提升技术,以提高电池寿命和功耗。
“IT 技能,如网络、IP 寻址、子网掩码、蜂窝和卫星也是物联网的关键需求”,Flynn 说。他还认为物联网需要数据库管理技能和云管理和安全专业知识,“特别是当高级过程控制(APC)将传感器数据直接发送到数据库和数据湖等事情成为常态时。”
### 物联网专家又从何而来?
Flynn 说,标准化的正规教育课程将是确保毕业生或证书持有者掌握一套正确技能的最佳途径。他甚至还列出了一个样本课程。“按时间顺序开始,从基础知识开始,比如 [电气仪表] 和测量。然后讲授网络知识,数据库管理和云计算课程都应在此之后开展。这个学位甚至可以循序渐进至现有的工程课程中,这可能需要两年时间……来完成物联网部分的学业。”
虽然企业培训也能发挥作用,但实际上却是“说起来容易做起来难”,Flynn 这样警告,“这些培训需要针对组织的具体努力而推动。”
当然,现在市面上已经有了 [大量的在线物联网培训课程和证书课程](https://www.google.com/search?client=firefox-b-1-d&q=iot+training)。但追根到底,这一工作全都依赖于工人自身的推断。
“在这个世界上,随着科技不断改变行业,提升技能是非常重要的”,Flynn 说,“如果这种提升技能的推动力并不是来源于你的雇主,那么在线课程和认证将会是提升你自己很好的一个方式。我们只需要创建这些课程……我甚至可以预见组织将与提供这些课程的高等教育机构合作,让他们的员工更好地开始。当然,物联网课程的挑战在于它需要不断发展以跟上科技的发展。”
---
via: <https://www.networkworld.com/article/3404489/where-are-all-the-iot-experts-going-to-come-from.html>
作者:[Fredric Paul](https://www.networkworld.com/author/Fredric-Paul/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Percy (@scvoet)](https://github.com/scvoet) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
13,116 | 如何判断你的 Python 代码实现是否合适? | https://opensource.com/article/19/12/zen-python-implementation | 2021-02-14T12:05:26 | [
"Python"
] | /article-13116-1.html |
>
> 这是 Python 之禅特别系列的一部分,重点介绍第十七和十八条原则:困难和容易。
>
>
>

一门语言并不是抽象存在的。每一个语言功能都必须用代码来实现。承诺一些功能是很容易的,但实现起来就会很麻烦。复杂的实现意味着更多潜在的 bug,甚至更糟糕的是,会带来日复一日的维护负担。
对于这个难题,[Python 之禅](https://www.python.org/dev/peps/pep-0020/) 中有答案。
### <ruby> 如果一个实现难以解释,那就是个坏思路 <rt> If the implementation is hard to explain, it's a bad idea </rt></ruby>
编程语言最重要的是可预测性。有时我们用抽象的编程模型来解释某个结构的语义,而这些模型与实现并不完全对应。然而,最好的释义就是*解释该实现*。
如果该实现很难解释,那就意味着这条路行不通。
### <ruby> 如果一个实现易于解释,那它可能是一个好思路 <rt> If the implementation is easy to explain, it may be a good idea </rt></ruby>
仅仅因为某事容易,并不意味着它值得。然而,一旦解释清楚,判断它是否是一个好思路就容易得多。
这也是为什么这个原则的后半部分故意含糊其辞的原因:没有什么可以肯定一定是好的,但总是可以讨论一下。
---
via: <https://opensource.com/article/19/12/zen-python-implementation>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,117 | SQLite3 实践教程 | https://opensource.com/article/21/2/sqlite3-cheat-sheet | 2021-02-14T13:12:13 | [
"SQLite3"
] | https://linux.cn/article-13117-1.html |
>
> 开始使用这个功能强大且通用的数据库吧。
>
>
>

应用程序经常需要保存数据。无论你的用户是创建简单的文本文档、复杂的图形布局、游戏进度还是错综复杂的客户和订单号列表,软件通常都意味着生成数据。有很多方法可以存储数据以供重复使用。你可以将文本转储为 INI、[YAML](https://www.redhat.com/sysadmin/yaml-beginners)、XML 或 JSON 等配置格式,可以输出原始的二进制数据,也可以将数据存储在结构化数据库中。SQLite 是一个自包含的、轻量级数据库,可轻松创建、解析、查询、修改和传输数据。
* 下载 [SQLite3 备忘录](https://opensource.com/downloads/sqlite-cheat-sheet)
SQLite 专用于 [公共领域](https://sqlite.org/copyright.html),[从技术上讲,这意味着它没有版权,因此不需要许可证](https://directory.fsf.org/wiki/License:PublicDomain)。如果你需要许可证,则可以 [购买所有权担保](https://www.sqlite.org/purchase/license?)。SQLite 非常常见,大约有 1 万亿个 SQLite 数据库正在使用中。在每个基于 Webkit 的 Web 浏览器,现代电视机,汽车多媒体系统以及无数其他软件应用程序中,Android 和 iOS 设备, macOS 和 Windows 10 计算机,大多数 Linux 系统上都包含多个这种数据库。
总而言之,它是用于存储和组织数据的一个可靠而简单的系统。
### 安装
你的系统上可能已经有 SQLite 库,但是你需要安装其命令行工具才能直接使用它。在 Linux上,你可能已经安装了这些工具。该工具提供的命令是 `sqlite3` (而不仅仅是 sqlite)。
如果没有在你的 Linux 或 BSD 上安装 SQLite,你则可以从软件仓库中或 ports 树中安装 SQLite,也可以从源代码或已编译的二进制文件进行[下载并安装](https://www.sqlite.org/download.html)。
在 macOS 或 Windows 上,你可以从 [sqlite.org](https://www.sqlite.org/download.html) 下载并安装 SQLite 工具。
### 使用 SQLite
通过编程语言与数据库进行交互是很常见的。因此,像 Java、Python、Lua、PHP、Ruby、C++ 以及其他编程语言都提供了 SQLite 的接口(或“绑定”)。但是,在使用这些库之前,了解数据库引擎的实际情况以及为什么你对数据库的选择很重要是有帮助的。本文向你介绍 SQLite 和 `sqlite3` 命令,以便你熟悉该数据库如何处理数据的基础知识。
### 与 SQLite 交互
你可以使用 `sqlite3` 命令与 SQLite 进行交互。 该命令提供了一个交互式的 shell 程序,以便你可以查看和更新数据库。
```
$ sqlite3
SQLite version 3.34.0 2020-12-01 16:14:00
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite>
```
该命令将你使你处于 SQLite 的子 shell 中,因此现在的提示符是 SQLite 的提示符。你以前使用的 Bash 命令在这里将不再适用。你必须使用 SQLite 命令。要查看 SQLite 命令列表,请输入 `.help`:
```
sqlite> .help
.archive ... Manage SQL archives
.auth ON|OFF SHOW authorizer callbacks
.backup ?DB? FILE Backup DB (DEFAULT "main") TO FILE
.bail ON|off Stop after hitting an error. DEFAULT OFF
.binary ON|off Turn BINARY output ON OR off. DEFAULT OFF
.cd DIRECTORY CHANGE the working directory TO DIRECTORY
[...]
```
这些命令中的其中一些是二进制的,而其他一些则需要唯一的参数(如文件名、路径等)。这些是 SQLite Shell 的管理命令,不是用于数据库查询。数据库以结构化查询语言(SQL)进行查询,许多 SQLite 查询与你从 [MySQL](https://www.mysql.com/) 和 [MariaDB](https://mariadb.org/) 数据库中已经知道的查询相同。但是,数据类型和函数有所不同,因此,如果你熟悉另一个数据库,请特别注意细微的差异。
### 创建数据库
启动 SQLite 时,可以打开内存数据库,也可以选择要打开的数据库:
```
$ sqlite3 mydatabase.db
```
如果还没有数据库,则可以在 SQLite 提示符下创建一个数据库:
```
sqlite> .open mydatabase.db
```
现在,你的硬盘驱动器上有一个空文件,可以用作 SQLite 数据库。 文件扩展名 `.db` 是任意的。你也可以使用 `.sqlite` 或任何你想要的后缀。
### 创建一个表
数据库包含一些<ruby> 表 <rt> table </rt></ruby>,可以将其可视化为电子表格。有许多的行(在数据库中称为<ruby> 记录 <rt> record </rt></ruby>)和列。行和列的交集称为<ruby> 字段 <rt> field </rt></ruby>。
结构化查询语言(SQL)以其提供的内容而命名:一种以可预测且一致的语法查询数据库内容以接收有用的结果的方法。SQL 读起来很像普通的英语句子,即使有点机械化。当前,你的数据库是一个没有任何表的空数据库。
你可以使用 `CREATE` 来创建一个新表,你可以和 `IF NOT EXISTS` 结合使用。以便不会破坏现在已有的同名的表。
你无法在 SQLite 中创建一个没有任何字段的空表,因此在尝试 `CREATE` 语句之前,必须考虑预期表将存储的数据类型。在此示例中,我将使用以下列创建一个名为 `member` 的表:
* 唯一标识符
* 人名
* 记录创建的时间和日期
#### 唯一标识符
最好用唯一的编号来引用记录,幸运的是,SQLite 认识到这一点,创建一个名叫 `rowid` 的列来为你自动实现这一点。
无需 SQL 语句即可创建此字段。
#### 数据类型
对于我的示例表中,我正在创建一个 `name` 列来保存 `TEXT` 类型的数据。为了防止在没有指定字段数据的情况下创建记录,可以添加 `NOT NULL` 指令。
用 `name TEXT NOT NULL` 语句来创建。
SQLite 中有五种数据类型(实际上是 *储存类别*):
* `TEXT`:文本字符串
* `INTEGER`:一个数字
* `REAL`:一个浮点数(小数位数无限制)
* `BLOB`:二进制数据(例如,.jpeg 或 .webp 图像)
* `NULL`:空值
#### 日期和时间戳
SQLite 有一个方便的日期和时间戳功能。它本身不是数据类型,而是 SQLite 中的一个函数,它根据所需的格式生成字符串或整数。 在此示例中,我将其保留为默认值。
创建此字段的 SQL 语句是:`datestamp DATETIME DEFAULT CURRENT_TIMESTAMP`。
### 创建表的语句
在 SQLite 中创建此示例表的完整 SQL:
```
sqlite> CREATE TABLE
...> IF NOT EXISTS
...> member (name TEXT NOT NULL,
...> datestamp DATETIME DEFAULT CURRENT_TIMESTAMP);
```
在此代码示例中,我在语句的分句后按了回车键。以使其更易于阅读。除非以分号(`;`)终止,否则 SQLite 不会运行你的 SQL 语句。
你可以使用 SQLite 命令 `.tables` 验证表是否已创建:
```
sqlite> .tables
member
```
### 查看表中的所有列
你可以使用 `PRAGMA` 语句验证表包含哪些列和行:
```
sqlite> PRAGMA table_info(member);
0|name|TEXT|1||0
1|datestamp|DATETIME|0|CURRENT_TIMESTAMP|0
```
### 数据输入
你可以使用 `INSERT` 语句将一些示例数据填充到表中:
```
> INSERT INTO member (name) VALUES ('Alice');
> INSERT INTO member (name) VALUES ('Bob');
> INSERT INTO member (name) VALUES ('Carol');
> INSERT INTO member (name) VALUES ('David');
```
查看表中的数据:
```
> SELECT * FROM member;
Alice|2020-12-15 22:39:00
Bob|2020-12-15 22:39:02
Carol|2020-12-15 22:39:05
David|2020-12-15 22:39:07
```
#### 添加多行数据
现在创建第二个表:
```
> CREATE TABLE IF NOT EXISTS linux (
...> distro TEXT NOT NULL);
```
填充一些示例数据,这一次使用小的 `VALUES` 快捷方式,因此你可以在一个命令中添加多行。关键字 `VALUES` 期望以括号形式列出列表,而用多个逗号分隔多个列表:
```
> INSERT INTO linux (distro)
...> VALUES ('Slackware'), ('RHEL'),
...> ('Fedora'),('Debian');
```
### 修改表结构
你现在有两个表,但是到目前为止,两者之间没有任何关系。它们每个都包含独立的数据,但是可能你可能需要将第一个表的成员与第二个表中列出的特定项相关联。
为此,你可以为第一个表创建一个新列,该列对应于第二个表。由于两个表都设计有唯一标识符(这要归功于 SQLite 的自动创建),所以连接它们的最简单方法是将其中一个的 `rowid` 字段用作另一个的选择器。
在第一个表中创建一个新列,以存储第二个表中的值:
```
> ALTER TABLE member ADD os INT;
```
使用 `linux` 表中的唯一标识符作为 `member` 表中每一条记录中 `os` 字段的值。因为记录已经存在。因此你可以使用 `UPDATE` 语句而不是使用 `INSERT` 语句来更新数据。需要特别注意的是,你首先需要选中特定的一行来然后才能更新其中的某个字段。从句法上讲,这有点相反,更新首先发生,选择匹配最后发生:
```
> UPDATE member SET os=1 WHERE name='Alice';
```
对 `member` 表中的其他行重复相同的过程。更新 `os` 字段,为了数据多样性,在四行记录上分配三种不同的发行版(其中一种加倍)。
### 联接表
现在,这两个表相互关联,你可以使用 SQL 显示关联的数据。数据库中有多种 *联接方式*,但是一旦掌握了基础知识,就可以尝试所有的联接形式。这是一个基本联接,用于将 `member` 表的 `os` 字段中的值与 linux 表的 `rowid` 字段相关联:
```
> SELECT * FROM member INNER JOIN linux ON member.os=linux.rowid;
Alice|2020-12-15 22:39:00|1|Slackware
Bob|2020-12-15 22:39:02|3|Fedora
Carol|2020-12-15 22:39:05|3|Fedora
David|2020-12-15 22:39:07|4|Debian
```
`os` 和 `rowid` 字段形成了关联。
在一个图形应用程序中,你可以想象 `os` 字段是一个下拉选项菜单,其中的值是 `linux` 表中 `distro` 字段中的数据。将相关的数据集通过唯一的字段相关联,可以确保数据的一致性和有效性,并且借助 SQL,你可以在以后动态地关联它们。
### 了解更多
SQLite 是一个非常有用的自包含的、可移植的开源数据库。学习以交互方式使用它是迈向针对 Web 应用程序进行管理或通过编程语言库使用它的重要的第一步。
如果你喜欢 SQLite,也可以尝试由同一位作者 Richard Hipp 博士的 [Fossil](https://opensource.com/article/20/11/fossil)。
在学习和使用 SQLite 时,有一些常用命令可能会有所帮助,所以请立即下载我们的 [SQLite3 备忘单](https://opensource.com/downloads/sqlite-cheat-sheet)!
---
via: <https://opensource.com/article/21/2/sqlite3-cheat-sheet>
作者:[Klaatu](https://opensource.com/users/klaatu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Applications very often save data. Whether your users create simple text documents, complex graphic layouts, game progress, or an intricate list of customers and order numbers, software usually implies that data is being generated. There are many ways to store data for repeated use. You can dump text to configuration formats such as INI, [YAML](https://www.redhat.com/sysadmin/yaml-beginners), XML, or JSON, you can write out raw binary data, or you can store data in a structured database. SQLite is a self-contained, lightweight database that makes it easy to create, parse, query, modify, and transport data.
**[Download our SQLite3 cheat sheet]**
SQLite has been dedicated to the [public domain](https://sqlite.org/copyright.html), which [technically means it is not copyrighted and therefore requires no license](https://directory.fsf.org/wiki/License:PublicDomain). Should you require a license, you can [purchase a Warranty of Title](https://www.sqlite.org/purchase/license?). SQLite is immensely common, with an estimated 1 *trillion* SQLite databases in active use. That's counting multiple databases on every Android and iOS device, every macOS and Windows 10 computer, most Linux systems, within every Webkit-based web browser, modern TV sets, automotive multimedia systems, and countless other software applications.
In summary, it's a reliable and simple system to use for storing and organizing data.
## Installing
You probably already have SQLite libraries on your system, but you need its command-line tools installed to use it directly. On Linux, you probably already have these tools installed. The command provided by the tools is **sqlite3** (not just **sqlite**).
If you don't have SQLite installed on Linux or BSD, you can install it from your software repository or ports tree, or [download and install it](https://www.sqlite.org/download.html) from source code or as a compiled binary.
On macOS or Windows, you can download and install SQLite tools from [sqlite.org](https://www.sqlite.org/download.html).
## Using SQLite
It's common to interact with a database through a programming language. For this reason, there are SQLite interfaces (or "bindings") for Java, Python, Lua, PHP, Ruby, C++, and many many others. However, before using these libraries, it helps to understand what's actually happening with the database engine and why your choice of a database is significant. This article introduces you to SQLite and the **sqlite3** command so you can get familiar with the basics of how this database handles data.
## Interacting with SQLite
You can interact with SQLite using the **sqlite3** command. This command provides an interactive shell so you can view and update your databases.
```
$ sqlite3
SQLite version 3.34.0 2020-12-01 16:14:00
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite>
```
The command places you in an SQLite subshell, and so your prompt is now an SQLite prompt. Your usual Bash commands don't work here. You must use SQLite commands. To see a list of SQLite commands, type **.help**:
```
sqlite> .help
.archive ... Manage SQL archives
.auth ON|OFF Show authorizer callbacks
.backup ?DB? FILE Backup DB (default "main") to FILE
.bail on|off Stop after hitting an error. Default OFF
.binary on|off Turn binary output on or off. Default OFF
.cd DIRECTORY Change the working directory to DIRECTORY
[...]
```
Some of these commands are binary, while others require unique arguments (like filenames, paths, etc.). These are administrative commands for your SQLite shell and are not database queries. Databases take queries in Structured Query Language (SQL), and many SQLite queries are the same as what you may already know from the [MySQL](https://www.mysql.com/) and [MariaDB](https://mariadb.org/) databases. However, data types and functions differ, so pay close attention to minor differences if you're familiar with another database.
## Creating a database
When launching SQLite, you can either open a prompt in memory, or you can select a database to open:
`$ sqlite3 mydatabase.db`
If you have no database yet, you can create one at the SQLite prompt:
`sqlite> .open mydatabase.db`
You now have an empty file on your hard drive, ready to be used as an SQLite database. The file extension **.db** is arbitrary. You can also use **.sqlite**, or whatever you want.
## Creating a table
Databases contain *tables*, which can be visualized as a spreadsheet. There's a series of rows (called *records* in a database) and columns. The intersection of a row and a column is called a *field*.
The Structured Query Language (SQL) is named after what it provides: A method to inquire about the contents of a database in a predictable and consistent syntax to receive useful results. SQL reads a lot like an ordinary English sentence, if a little robotic. Currently, your database is empty, devoid of any tables.
You can create a table with the **CREATE** query. It's useful to combine this with the **IF NOT EXISTS** statement, which prevents SQLite from clobbering an existing table.
You can't create an empty table in SQLite, so before trying a **CREATE** statement, you must think about what kind of data you anticipate the table will store. In this example, I'll create a table called *member* with these columns:
- A unique identifier
- A person's name
- The date and time of data entry
### Unique ID
It's always good to refer to a record by a unique number, and luckily SQLite recognizes this and does it automatically for you in a column called **rowid**.
No SQL statement is required to create this field.
### Data types
For my example table, I'm creating a *name* column to hold **TEXT** data. To prevent a record from being created without data in a specified field, you can add the **NOT NULL** directive.
The SQL to create this field is: **name TEXT NOT NULL**
There are five data types (actually *storage classes*) in SQLite:
- TEXT: a text string
- INTEGER: a whole number
- REAL: a floating point (unlimited decimal places) number
- BLOB: binary data (for instance, a .jpeg or .webp image)
- NULL: a null value
### Date and time stamp
SQLite includes a convenient date and timestamp function. It is not a data type itself but a function in SQLite that generates either a string or integer, depending on your desired format. In this example, I left it as the default.
The SQL to create this field is: **datestamp DATETIME DEFAULT CURRENT_TIMESTAMP**
## Table creation SQL
The full SQL for creating this example table in SQLite:
```
sqlite> CREATE TABLE
...> IF NOT EXISTS
...> member (name TEXT NOT NULL,
...> datestamp DATETIME DEFAULT CURRENT_TIMESTAMP
```
In this code sample, I pressed **Return** after the logical clauses of the statement to make it easier to read. SQLite won't run your command unless it terminates with a semi-colon (**;**).
You can verify that the table has been created with the SQLite command **.tables**:
```
sqlite> .tables
member
```
## View all columns in a table
You can verify what columns and rows a table contains with the **PRAGMA** statement:
```
sqlite> PRAGMA table_info(member);
0|name|TEXT|1||0
1|datestamp|CURRENT_TIMESTAMP|0||0
```
## Data entry
You can populate your new table with some sample data by using the **INSERT** SQL keyword:
```
> INSERT INTO member (name) VALUES ('Alice');
> INSERT INTO member (name) VALUES ('Bob');
> INSERT INTO member (name) VALUES ('Carol');
> INSERT INTO member (name) VALUES ('David');
```
Verify the data in the table:
```
> SELECT * FROM member;
Alice|2020-12-15 22:39:00
Bob|2020-12-15 22:39:02
Carol|2020-12-15 22:39:05
David|2020-12-15 22:39:07
```
### Adding multiple rows at once
Now create a second table:
```
> CREATE table IF NOT EXISTS linux (
...> distro TEXT NOT NULL)
```
Populate it with some sample data, this time using a little **VALUES** shortcut so you can add multiple rows in just one command. The **VALUES** keyword expects a list in parentheses but can take multiple lists separated by commas:
```
> INSERT INTO linux (distro)
...> VALUES ('Slackware'), ('RHEL'),
...> ('Fedora'),('Debian');
```
## Altering a table
You now have two tables, but as yet, there's no relationship between the two. They each contain independent data, but possibly you might need to associate a member of the first table to a specific item listed in the second.
To do that, you can create a new column for the first table that corresponds to something in the second. Because both tables were designed with unique identifiers (automatically, thanks to SQLite), the easiest way to connect them is to use the **rowid** field of one as a selector for the other.
Create a new column in the first table to represent a value in the second table:
`> ALTER TABLE member ADD os INT;`
Using the unique IDs of the **linux** table, assign a distribution to each member. Because the records already exist, you use the **UPDATE** SQL keyword rather than **INSERT**. Specifically, you want to select one row and then update the value of one column. Syntactically, this is expressed a little in reverse, with the update happening first and the selection matching last:
`> UPDATE member SET os=1 WHERE name='Alice';`
Repeat this process for the other names in the **member** table, just to populate it with data. For variety, assign three different distributions across the four rows (doubling up on one).
## Joining tables
Now that these two tables relate to one another, you can use SQL to display the associated data. There are many kinds of *joins* in databases, but you can try them all once you know the basics. Here's a basic join to correlate the values found in the **os** field of the **member** table to the **id** field of the **linux** table:
```
> SELECT * FROM member INNER JOIN linux ON member.os=linux.rowid;
Alice|2020-12-15 22:39:00|1|Slackware
Bob|2020-12-15 22:39:02|3|Fedora
Carol|2020-12-15 22:39:05|3|Fedora
David|2020-12-15 22:39:07|4|Debian
```
The **os** and **id** fields form the join.
In a graphical application, you can imagine that the **os** field might be set by a drop-down menu, the values for which are drawn from the contents of the **distro** field of the **linux** table. By using separate tables for unique but related sets of data, you ensure the consistency and validity of data, and thanks to SQL, you can associate them dynamically later.
## Learning more
SQLite is an infinitely useful self-contained, portable, open source database. Learning to use it interactively is a great first step toward managing it for web applications or using it through programming language libraries.
If you enjoy SQLite, you might also try [Fossil](https://opensource.com/article/20/11/fossil) by the same author, Dr. Richard Hipp.
As you learn and use SQLite, it may help to have a list of common commands nearby, so download our ** SQLite3 cheat sheet** today!
## 2 Comments |
13,119 | Filmulator:一个简单的、开源的 Raw 图像编辑器 | https://itsfoss.com/filmulator/ | 2021-02-15T10:06:34 | [
"raw"
] | https://linux.cn/article-13119-1.html | 
>
> Filmulator 是一个开源的具有库管理功能的 raw 照片编辑应用,侧重于简单、易用和简化的工作流程。
>
>
>
### Filmulator:适用于 Linux(和 Windows)的 raw 图像编辑器
[Linux 中有一堆 raw 照片编辑器](https://itsfoss.com/raw-image-tools-linux/),[Filmulator](https://filmulator.org/) 就是其中之一。Filmulator 的目标是仅提供基本要素,从而使 raw 图像编辑变得简单。它还增加了库处理的功能,如果你正在为你的相机图像寻找一个不错的应用,这是一个加分项。
对于那些不知道 raw 的人来说,[raw 图像文件](https://www.findingtheuniverse.com/what-is-raw-in-photography/)是一个最低限度处理、未压缩的文件。换句话说,它是未经压缩的数字文件,并且只经过了最低限度的处理。专业摄影师更喜欢用 raw 文件拍摄照片,并自行处理。普通人从智能手机拍摄照片,它通常被压缩为 JPEG 格式或被过滤。
让我们来看看在 Filmulator 编辑器中会有什么功能。
### Filmulator 的功能

Filmulator 宣称,它不是典型的“胶片效果滤镜” —— 这只是复制了胶片的外在特征。相反,Filmulator 从根本上解决了胶片的魅力所在:显影过程。
它模拟了胶片的显影过程:从胶片的“曝光”,到每个像素内“银晶”的生长,再到“显影剂”在相邻像素之间与储槽中大量显影剂的扩散。
Fimulator 开发者表示,这种模拟带来了以下好处:
* 大的明亮区域变得更暗,压缩了输出动态范围。
* 小的明亮区域使周围环境变暗,增强局部对比度。
* 在明亮区域,饱和度得到增强,有助于保留蓝天、明亮肤色和日落的色彩。
* 在极度饱和的区域,亮度会被减弱,有助于保留细节,例如花朵。
以下是经 Filmulator 处理后的 raw 图像的对比,以自然的方式增强色彩,而不会引起色彩剪切。


### 在 Ubuntu/Linux 上安装 Filmulator
Filmulator 有一个 AppImage 可用,这样你就可以在 Linux 上轻松使用它。使用 [AppImage 文件](https://itsfoss.com/use-appimage-linux/)真的很简单。下载后,使它可执行,然后双击运行。
* [下载 Filmulator for Linux](https://filmulator.org/download/)
对 Windows 用户也有一个 Windows 版本。除此之外,你还可以随时前往[它的 GitHub 仓库](https://github.com/CarVac/filmulator-gui)查看它的源代码。
有一份[小文档](https://github.com/CarVac/filmulator-gui/wiki)来帮助你开始使用 Fimulator。
### 总结
Fimulator 的设计理念是为任何工作提供最好的工具,而且只有这一个工具。这意味着牺牲了灵活性,但获得了一个大大简化和精简的用户界面。
我连业余摄影师都不是,更别说是专业摄影师了。我没有单反或其他高端摄影设备。因此,我无法测试和分享我对 Filmulator 的实用性的经验。
如果你有更多处理 raw 图像的经验,请尝试下 Filmulator,并分享你的意见。有一个 AppImage 可以让你快速测试它,看看它是否适合你的需求。
---
via: <https://itsfoss.com/filmulator/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Filmulator is an open source raw photo editing application with library management focusing on simplicity, ease of use and streamlined workflow.*
## Filmulator: Raw Image Editor for Linux (and Windows)
There are a [bunch of raw photo editors for Linux](https://itsfoss.com/raw-image-tools-linux/). [Filmulator](https://filmulator.org/) is one of them. Filmulator aims to make raw image editing simple by giving only the essential elements. It also adds the feature of library handling which is a plus if you are looking for a decent application for your camera images.
For those unaware, [raw image file](https://www.findingtheuniverse.com/what-is-raw-in-photography/) is a minimally processed, uncompressed file. In other words, it is untouched digital file with no compression and minimal processing applied to it. Professional photographers prefer to capture photos in raw file and process it themselves. Normal people take photos from their smartphones and it is usually compressed in JPEG format or filtered.
Let’s see what features you get in the Filmulator editor.
## Features of Filmulator
Filmulator claims that it is not the typical “film effect filter” that merely copies the outward characteristics of film. Instead, Filmulator gets to the root of what makes film so appealing: the development process.
It simulates film development process: from “exposure” of film, to the growth of “silver crystals” within each pixel, to the diffusion of “developer” both between neighboring pixels and with the bulk developer in the tank.
Fimulator developer says that the simulation brings about the following benefits:
- Large bright regions become darker, compressing the output dynamic range.
- Small bright regions make their surroundings darker, enhancing local contrast.
- In bright regions, saturation is enhanced, helping retain color in blue skies, brighter skin tones, and sunsets.
- In extremely saturated regions, the brightness is attenuated, helping retain detail e.g. in flowers.
Here’s a comparison of a raw image processed by Filmulator to enhance colors in a natural manner without inducing color clipping.


## Installing Filmulator on Ubuntu/Linux
There is an AppImage available for Filmulator so that you can use it easily on Linux. [Using AppImage files](https://itsfoss.com/use-appimage-linux/) is really simple. You download it, make it executable and make it run by double-clicking on it.
There is also a Windows version available for Windows users. Apart from that, you can always head over to [its GitHub repository](https://github.com/CarVac/filmulator-gui) and peek into its source code.
There is a [little documentation](https://github.com/CarVac/filmulator-gui/wiki) to help you get started with Fimulator.
## Conclusion
Fimulator’s design ideology is to have the best tool for any job, and only that one tool. This means compromising flexibility, but gaining a greatly simplified and streamlined user interface.
I am not even an amateur photographer, let alone be a professional one. I do not own a DSLR or other high-end photography equipments. For this reason, I cannot test and share my experience on the usefulness of Filmulator.
If you have more experience dealing with raw images, I let you try Filmulator and share your opinion on it. There is an AppImage available so you can quickly test it and see if it fits your needs or not. |
13,120 | 为何开源的成功取决于同理心? | https://opensource.com/article/21/2/open-source-empathy | 2021-02-15T11:06:00 | [
"同理心"
] | https://linux.cn/article-13120-1.html |
>
> 随着对同理心认识的提高和传播同理心的激励,开源生产力将得到提升,协作者将会聚拢,可以充分激发开源软件开发的活力。
>
>
>

开源开发的协调创新精神和社区精神改变了世界。Jim Whitehurst 在[《开放式组织》](https://www.redhat.com/en/explore/the-open-organization-book)中解释说,开源的成功源于“将人们视为社区的一份子,从交易思维转变为基于承诺基础的思维方式”。 但是,开源开发模型的核心仍然存在障碍:它经常性地缺乏人类的<ruby> 同理心 <rt> empathy </rt></ruby>。
同理心是理解或感受他人感受的能力。在开源社区中,面对面的人际互动和协作是很少的。任何经历过 GitHub <ruby> 拉取请求 <rt> Pull request </rt></ruby>或<ruby> 议题 <rt> Issue </rt></ruby>的开发者都曾收到过来自他们可能从未见过的人的评论,这些人往往身处地球的另一端,而他们的交流也可能同样遥远。现代开源开发就是建立在这种异步、事务性的沟通基础之上。因此,人们在社交媒体平台上所经历的同类型的网络欺凌和其他虐待行为,在开源社区中也不足为奇。
当然,并非所有开源交流都会事与愿违。许多人在工作中发展出了尊重并秉持着良好的行为标准。但是很多时候,人们的沟通也常常缺乏常识性的礼仪,他们将人们像机器而非人类一般对待。这种行为是激发开源创新模型全部潜力的障碍,因为它让许多潜在的贡献者望而却步,并扼杀了灵感。
### 恶意交流的历史
代码审查中存在的敌意言论对开源社区来说并不新鲜,它多年来一直被社区所容忍。开源教父<ruby> 莱纳斯·托瓦尔兹 <rt> Linus Torvalds </rt></ruby>经常在代码不符合他的标准时[抨击](https://arstechnica.com/information-technology/2013/07/linus-torvalds-defends-his-right-to-shame-linux-kernel-developers/) Linux 社区,并将贡献者赶走。埃隆大学计算机科学教授 Megan Squire 借助[机器学习](http://flossdata.syr.edu/data/insults/hicssInsultsv2.pdf)分析了托瓦尔兹的侮辱行为,发现它们在四年内的数量高达数千次。2018 年,莱纳斯因自己的不良行为而自我放逐,责成自己学习同理心,道歉并为 Linux 社区制定了行为准则。
2015 年,[Sage Sharp](https://en.wikipedia.org/wiki/Sage_Sharp) 虽然在技术上受人尊重,但因其缺乏对个人的尊重,被辞去了 FOSS 女性外展计划中的 Linux 内核协调员一职。
PR 审核中存在的贬低性评论对开发者会造成深远的影响。它导致开发者在提交 PR 时产生畏惧感,让他们对预期中的反馈感到恐惧。这吞噬了开发者对自己能力的信心。它逼迫工程师每次都只能追求完美,从而减缓了开发速度,这与许多社区采用的敏捷方法论背道而驰。
### 如何缩小开源中的同理心差距?
通常情况下,冒犯的评论常是无意间的,而通过一些指导,作者则可以学会如何在不带负面情绪的情况下表达意见。GitHub 不会监控议题和 PR 的评论是否有滥用内容,相反,它提供了一些工具,使得社区能够对其内容进行审查。仓库的所有者可以删除评论和锁定对话,所有贡献者可以报告滥用和阻止用户。
制定社区行为准则可为所有级别的贡献者提供一个安全且包容的环境,并且能让所有级别的贡献者参与并定义降低协作者之间冲突的过程。
我们能够克服开源中存在的同理心问题。面对面的辩论比文字更有利于产生共鸣,所以尽可能选择视频通话。以同理心的方式分享反馈,树立榜样。如果你目睹了一个尖锐的评论,请做一个指导者而非旁观者。如果你是受害者,请大声说出来。在面试候选人时,评估同理心能力,并将同理心能力与绩效评估和奖励挂钩。界定并执行社区行为准则,并管理好你的社区。
随着对同理心认识的提高和传播同理心的激励,开源生产力将得到提升,协作者将会聚拢,可以充分激发开源软件开发的活力。
---
via: <https://opensource.com/article/21/2/open-source-empathy>
作者:[Bronagh Sorota](https://opensource.com/users/bsorota) 选题:[lujun9972](https://github.com/lujun9972) 译者:[scvoet](https://github.com/scvoet) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Open source development's collaborative innovation and community ethos have changed the world. In [ The Open Organization](https://www.redhat.com/en/explore/the-open-organization-book), Jim Whitehurst explains that success in open source is found by "thinking of people as members of a community, moving from a transactional mindset to one built on commitment." However, there is still a barrier at the core of the open source development model: Frequently, it lacks human empathy.
Empathy is the ability to understand and share another person's feelings. In open source communities, face-to-face human interaction and collaboration are rare. Any developer experienced with a GitHub pull request (PR) or issue has received comments from people they may never meet, often halfway across the globe—and the communication can be just as distant. Modern open source development is built upon this type of asynchronous, transactional communication. So, it is no surprise that the same types of cyberbullying and other abuses people experience on social media platforms are also seen in open source communities.
Of course, not all open source communication is counterproductive. Many people develop respect and commit to good behavioral standards in their craft. But all too often, people lack common-sense etiquette in communications and treat people like machines rather than human beings. This behavior is a barrier to realizing the open source innovation model's full potential because it turns off many would-be contributors and kills inspiration.
## A history of hostile communications
Hostile rhetoric in code reviews is not new to open source communities; it has been tolerated for years. The godfather of open source, Linus Torvalds, routinely [barraged](https://arstechnica.com/information-technology/2013/07/linus-torvalds-defends-his-right-to-shame-linux-kernel-developers/) the Linux community when code did not meet his standards, driving contributors away. Elon University computer science professor Megan Squire used [machine learning](http://flossdata.syr.edu/data/insults/hicssInsultsv2.pdf) to analyze Torvalds' insults and found they numbered in the thousands during a four-year period. In 2018, Linus put himself on a timeout for bad behavior, tasked himself with learning empathy, apologized, and established a code of conduct for the Linux community.
In 2015, [Sage Sharp](https://en.wikipedia.org/wiki/Sage_Sharp) stepped down as the Linux kernel coordinator for the FOSS Outreach Program for Women due to a lack of personal respect, despite being technically respected.
The impact of disparaging comments in PR reviews has a profound effect on developers. It creates trepidation in making PRs and dread at anticipated feedback, and it eats at developers' confidence in their abilities. It slows velocity by forcing engineers to strive for perfection every time, which runs counter to the agile methodology many communities have adopted.
## How to close the empathy gap in open source
Often, offensive comments are unintentional, and with some coaching, the author can learn how to express opinions without negative emotion. GitHub does not monitor comments on issues and PRs for abusive content; instead, it provides tools to enable communities to moderate their content. Repo owners can delete comments and lock conversations, and all contributors can report abuse and block users.
Defining a community code of conduct establishes a safe and inclusive environment for contributors at all levels to participate and defines the process to de-escalate conflict between collaborators.
We can overcome the empathy challenge in open source. Face-to-face debate is much more conducive to empathy than text, so opt for a video call when possible. Set an example by sharing feedback in an empathetic way. Be a coach instead of a bystander if you witness a scathing review. Speak up if you are the victim. Assess empathy skills when interviewing a candidate. Tie empathy skills to performance reviews and rewards. Define and enforce a community code of conduct, and moderate your community.
With heightened awareness about empathy and the inspiration to spread it, open source productivity will grow, collaborators will lean in, and the power of open source software development can be fully harnessed.
## Comments are closed. |
13,123 | 命名空间是 Python 之禅的精髓 | https://opensource.com/article/19/12/zen-python-namespaces | 2021-02-16T10:59:33 | [
"Python",
"命名空间"
] | https://linux.cn/article-13123-1.html |
>
> 这是 Python 之禅特别系列的一部分,重点是一个额外的原则:命名空间。
>
>
>

著名的<ruby> 光明节 <rt> Hanukkah </rt></ruby>有八个晚上的庆祝活动。然而,光明节的灯台有九根蜡烛:八根普通的蜡烛和总是偏移的第九根蜡烛。它被称为 “shamash” 或 “shamos”,大致可以翻译为“仆人”或“看门人”的意思。
shamos 是点燃所有其它蜡烛的蜡烛:它是唯一一支可以用火的蜡烛,而不仅仅是观看。当我们结束 Python 之禅系列时,我看到命名空间提供了类似的作用。
### Python 中的命名空间
Python 使用命名空间来处理一切。虽然简单,但它们是稀疏的数据结构 —— 这通常是实现目标的最佳方式。
>
> *命名空间* 是一个从名字到对象的映射。
>
>
> —— [Python.org](https://docs.python.org/3/tutorial/classes.html)
>
>
>
模块是命名空间。这意味着正确地预测模块语义通常只需要熟悉 Python 命名空间的工作方式。类是命名空间,对象是命名空间。函数可以访问它们的本地命名空间、父命名空间和全局命名空间。
这个简单的模型,即用 `.` 操作符访问一个对象,而这个对象又通常(但并不总是)会进行某种字典查找,这使得 Python 很难优化,但很容易解释。
事实上,一些第三方模块也采取了这个准则,并以此来运行。例如,[variants](https://pypi.org/project/variants/) 包把函数变成了“相关功能”的命名空间。这是一个很好的例子,说明 [Python 之禅](https://www.python.org/dev/peps/pep-0020/) 是如何激发新的抽象的。
### 结语
感谢你和我一起参加这次以光明节为灵感的 [我最喜欢的语言](https://opensource.com/article/19/10/why-love-python) 的探索。
静心参禅,直至悟道。
---
via: <https://opensource.com/article/19/12/zen-python-namespaces>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hanukkah famously has eight nights of celebration. The Hanukkah menorah, however, has nine candles: eight regular candles and a ninth that is always offset. It is called the **shamash** or **shamos**, which loosely translates to meaning "servant" or "janitor."
The shamos is the candle that lights all the others: it is the only candle whose fire can be used, not just watched. As we wrap up our series on the Zen of Python, I see how namespaces provide a similar service.
## Namespaces in Python
Python uses namespaces for everything. Though simple, they are sparse data structures—which is often the best way to achieve a goal.
A
namespaceis a mapping from names to objects.
Modules are namespaces. This means that correctly predicting module semantics often just requires familiarity with how Python namespaces work. Classes are namespaces. Objects are namespaces. Functions have access to their local namespace, their parent namespace, and the global namespace.
The simple model, where the **.** operator accesses an object, which in turn will usually, but not always, do some sort of dictionary lookup, makes Python hard to optimize, but easy to explain.
Indeed, some third-party modules take this guideline and run with it. For example, the** variants** package turns functions into namespaces of "related functionality." It is a good example of how the
[Zen of Python](https://www.python.org/dev/peps/pep-0020/)can inspire new abstractions.
## In conclusion
Thank you for joining me on this Hanukkah-inspired exploration of [my favorite language](https://opensource.com/article/19/10/why-love-python). Go forth and meditate on the Zen until you reach enlightenment.
## Comments are closed. |
13,125 | 用 Podman Compose 管理容器 | https://fedoramagazine.org/manage-containers-with-podman-compose/ | 2021-02-16T22:21:41 | [
"Podman",
"容器"
] | https://linux.cn/article-13125-1.html | 
容器很棒,让你可以将你的应用连同其依赖项一起打包,并在任何地方运行。从 2013 年的 Docker 开始,容器已经让软件开发者的生活变得更加轻松。
Docker 的一个缺点是它有一个中央守护进程,它以 root 用户的身份运行,这对安全有影响。但这正是 Podman 的用武之地。Podman 是一个 [无守护进程容器引擎](https://podman.io),用于开发、管理和在你的 Linux 系统上以 root 或无 root 模式运行 OCI 容器。
下面这些文章可以用来了解更多关于 Podman 的信息:
* [使用 Podman 以非 root 用户身份运行 Linux 容器](/article-10156-1.html)
* [在 Fedora 上使用 Podman 的 Pod](https://fedoramagazine.org/podman-pods-fedora-containers/)
* [在 Fedora 中结合权能使用 Podman](/article-12859-1.html)
如果你使用过 Docker,你很可能也知道 Docker Compose,它是一个用于编排多个可能相互依赖的容器的工具。要了解更多关于 Docker Compose 的信息,请看它的[文档](https://docs.docker.com/compose/)。
### 什么是 Podman Compose?
[Podman Compose](https://github.com/containers/podman-compose) 项目的目标是作为 Docker Compose 的替代品,而不需要对 docker-compose.yaml 文件进行任何修改。由于 Podman Compose 使用<ruby> 吊舱 <rt> pod </rt></ruby> 工作,所以最好看下“吊舱”的最新定义。
>
> 一个“<ruby> 吊舱 <rt> pod </rt></ruby> ”(如一群鲸鱼或豌豆荚)是由一个或多个[容器](https://kubernetes.io/docs/concepts/containers/)组成的组,具有共享的存储/网络资源,以及如何运行容器的规范。
>
>
> [Pods - Kubernetes 文档](https://kubernetes.io/docs/concepts/workloads/pods/)
>
>
>
(LCTT 译注:容器技术领域大量使用了航海比喻,pod 一词,意为“豆荚”,在航海领域指“吊舱” —— 均指盛装多个物品的容器。常不翻译,考虑前后文,可译做“吊舱”。)
Podman Compose 的基本思想是,它选中 `docker-compose.yaml` 文件里面定义的服务,为每个服务创建一个容器。Docker Compose 和 Podman Compose 的一个主要区别是,Podman Compose 将整个项目的容器添加到一个单一的吊舱中,而且所有的容器共享同一个网络。如你在例子中看到的,在创建容器时使用 `--add-host` 标志,它甚至用和 Docker Compose 一样的方式命名容器。
### 安装
Podman Compose 的完整安装说明可以在[项目页面](https://github.com/containers/podman-compose)上找到,它有几种方法。要安装最新的开发版本,使用以下命令:
```
pip3 install https://github.com/containers/podman-compose/archive/devel.tar.gz
```
确保你也安装了 [Podman](https://podman.io/getting-started/installation),因为你也需要它。在 Fedora 上,使用下面的命令来安装Podman:
```
sudo dnf install podman
```
### 例子:用 Podman Compose 启动一个 WordPress 网站
想象一下,你的 `docker-compose.yaml` 文件在一个叫 `wpsite` 的文件夹里。一个典型的 WordPress 网站的 `docker-compose.yaml` (或 `docker-compose.yml`) 文件是这样的:
```
version: "3.8"
services:
web:
image: wordpress
restart: always
volumes:
- wordpress:/var/www/html
ports:
- 8080:80
environment:
WORDPRESS_DB_HOST: db
WORDPRESS_DB_USER: magazine
WORDPRESS_DB_NAME: magazine
WORDPRESS_DB_PASSWORD: 1maGazine!
WORDPRESS_TABLE_PREFIX: cz
WORDPRESS_DEBUG: 0
depends_on:
- db
networks:
- wpnet
db:
image: mariadb:10.5
restart: always
ports:
- 6603:3306
volumes:
- wpdbvol:/var/lib/mysql
environment:
MYSQL_DATABASE: magazine
MYSQL_USER: magazine
MYSQL_PASSWORD: 1maGazine!
MYSQL_ROOT_PASSWORD: 1maGazine!
networks:
- wpnet
volumes:
wordpress: {}
wpdbvol: {}
networks:
wpnet: {}
```
如果你用过 Docker,你就会知道你可运行 `docker-compose up` 来启动这些服务。Docker Compose 会创建两个名为 `wpsite_web_1` 和 `wpsite_db_1` 的容器,并将它们连接到一个名为 `wpsite_wpnet` 的网络。
现在,看看当你在项目目录下运行 `podman-compose up` 时会发生什么。首先,一个以执行命令的目录命名的吊舱被创建。接下来,它寻找 YAML 文件中定义的任何名称的卷,如果它们不存在,就创建卷。然后,在 YAML 文件的 `services` 部分列出的每个服务都会创建一个容器,并添加到吊舱中。
容器的命名与 Docker Compose 类似。例如,为你的 web 服务创建一个名为 `wpsite_web_1` 的容器。Podman Compose 还为每个命名的容器添加了 `localhost` 别名。之后,容器仍然可以通过名字互相解析,尽管它们并不像 Docker 那样在一个桥接网络上。要做到这一点,使用选项 `-add-host`。例如,`-add-host web:localhost`。
请注意,`docker-compose.yaml` 包含了一个从主机 8080 端口到容器 80 端口的 Web 服务的端口转发。现在你应该可以通过浏览器访问新 WordPress 实例,地址为 `http://localhost:8080`。

### 控制 pod 和容器
要查看正在运行的容器,使用 `podman ps`,它可以显示 web 和数据库容器以及吊舱中的基础设施容器。
```
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a364a8d7cec7 docker.io/library/wordpress:latest apache2-foregroun... 2 hours ago Up 2 hours ago 0.0.0.0:8080-&gt;80/tcp, 0.0.0.0:6603-&gt;3306/tcp wpsite_web_1
c447024aa104 docker.io/library/mariadb:10.5 mysqld 2 hours ago Up 2 hours ago 0.0.0.0:8080-&gt;80/tcp, 0.0.0.0:6603-&gt;3306/tcp wpsite_db_1
12b1e3418e3e k8s.gcr.io/pause:3.2
```
你也可以验证 Podman 已经为这个项目创建了一个吊舱,以你执行命令的文件夹命名。
```
POD ID NAME STATUS CREATED INFRA ID # OF CONTAINERS
8a08a3a7773e wpsite Degraded 2 hours ago 12b1e3418e3e 3
```
要停止容器,在另一个命令窗口中输入以下命令:
```
podman-compose down
```
你也可以通过停止和删除吊舱来实现。这实质上是停止并移除所有的容器,然后再删除包含的吊舱。所以,同样的事情也可以通过这些命令来实现:
```
podman pod stop podname
podman pod rm podname
```
请注意,这不会删除你在 `docker-compose.yaml` 中定义的卷。所以,你的 WordPress 网站的状态被保存下来了,你可以通过运行这个命令来恢复它。
```
podman-compose up
```
总之,如果你是一个 Podman 粉丝,并且用 Podman 做容器工作,你可以使用 Podman Compose 来管理你的开发和生产中的容器。
---
via: <https://fedoramagazine.org/manage-containers-with-podman-compose/>
作者:[Mehdi Haghgoo](https://fedoramagazine.org/author/powergame/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Containers are awesome, allowing you to package your application along with its dependencies and run it anywhere. Starting with Docker in 2013, containers have been making the lives of software developers much easier.
One of the downsides of Docker is it has a central daemon that runs as the root user, and this has security implications. But this is where Podman comes in handy. Podman is a [daemonless container engine](https://podman.io) for developing, managing, and running OCI Containers on your Linux system in root or rootless mode.
There are other articles on Fedora Magazine you can use to learn more about Podman. Two examples follow:
If you have worked with Docker, chances are you also know about Docker Compose, which is a tool for orchestrating several containers that might be interdependent. To learn more about Docker Compose see its [documentation](https://docs.docker.com/compose/).
## What is Podman Compose?
[Podman Compose](https://github.com/containers/podman-compose) is a project whose goal is to be used as an alternative to Docker Compose without needing any changes to be made in the docker-compose.yaml file. Since Podman Compose works using pods, it’s good to check a refresher definition of a pod.
A
Pod(as in a pod of whales or pea pod) is a group of one or more[containers], with shared storage/network resources, and a specification for how to run the containers.[Pods – Kubernetes Documentation]
The basic idea behind Podman Compose is that it picks the services defined inside the *docker-compose.yaml* file and creates a container for each service. A major difference between Docker Compose and Podman Compose is that Podman Compose adds the containers to a single pod for the whole project, and all the containers share the same network. It even names the containers the same way Docker Compose does, using the *‐‐add-host* flag when creating the containers, as you will see in the example.
## Installation
Complete install instructions for Podman Compose are found on its [project page](https://github.com/containers/podman-compose), and there are several ways to do it. To install the latest development version, use the following command:
pip3 install https://github.com/containers/podman-compose/archive/devel.tar.gz
Make sure you also have [Podman installed](https://podman.io/getting-started/installation) since you’ll need it as well. On Fedora, to install Podman use the following command:
sudo dnf install podman
## Example: launching a WordPress site with Podman Compose
Imagine your *docker-compose.yaml* file is in a folder called *wpsite*. A typical *docker-compose.yaml* (or *docker-compose.yml*) for a WordPress site looks like this:
version: "3.8" services: web: image: wordpress restart: always volumes: - wordpress:/var/www/html ports: - 8080:80 environment: WORDPRESS_DB_HOST: db WORDPRESS_DB_USER: magazine WORDPRESS_DB_NAME: magazine WORDPRESS_DB_PASSWORD: 1maGazine! WORDPRESS_TABLE_PREFIX: cz WORDPRESS_DEBUG: 0 depends_on: - db networks: - wpnet db: image: mariadb:10.5 restart: always ports: - 6603:3306 volumes: - wpdbvol:/var/lib/mysql environment: MYSQL_DATABASE: magazine MYSQL_USER: magazine MYSQL_PASSWORD: 1maGazine! MYSQL_ROOT_PASSWORD: 1maGazine! networks: - wpnet volumes: wordpress: {} wpdbvol: {} networks: wpnet: {}
If you come from a Docker background, you know you can launch these services by running *docker-compose up*. Docker Compose will create two containers named *wpsite_web_1* and *wpsite_db_1*, and attaches them to a network called *wpsite_wpnet*.
Now, see what happens when you run *podman-compose up* in the project directory. First, a pod is created named after the directory in which the command was issued. Next, it looks for any named volumes defined in the YAML file and creates the volumes if they do not exist. Then, one container is created per every service listed in the *services* section of the YAML file and added to the pod.
Naming of the containers is done similar to Docker Compose. For example, for your web service, a container named *wpsite_web_1* is created. Podman Compose also adds localhost aliases to each named container. Then, containers can still resolve each other by name, although they are not on a bridge network as in Docker. To do this, use the option *–add-host*. For example, *–add-host web:localhost*.
Note that *docker-compose.yaml* includes a port forwarding from host port 8080 to container port 80 for the web service. You should now be able to access your fresh WordPress instance from the browser using the address *http://localhost:8080*.
## Controlling the pod and containers
To see your running containers, use *podman ps*, which shows the web and database containers along with the infra container in your pod.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a364a8d7cec7 docker.io/library/wordpress:latest apache2-foregroun... 2 hours ago Up 2 hours ago 0.0.0.0:8080->80/tcp, 0.0.0.0:6603->3306/tcp wpsite_web_1
c447024aa104 docker.io/library/mariadb:10.5 mysqld 2 hours ago Up 2 hours ago 0.0.0.0:8080->80/tcp, 0.0.0.0:6603->3306/tcp wpsite_db_1
12b1e3418e3e k8s.gcr.io/pause:3.2
You can also verify that a pod has been created by Podman for this project, named after the folder in which you issued the command.
POD ID NAME STATUS CREATED INFRA ID # OF CONTAINERS
8a08a3a7773e wpsite Degraded 2 hours ago 12b1e3418e3e 3
To stop the containers, enter the following command in another command window:
podman-compose down
You can also do that by stopping and removing the pod. This essentially stops and removes all the containers and then the containing pod. So, the same thing can be achieved with these commands:
podman pod stop podname podman pod rm podname
Note that this does not remove the volumes you defined in *docker-compose.yaml*. So, the state of your WordPress site is saved, and you can get it back by running this command:
podman-compose up
In conclusion, if you’re a Podman fan and do your container jobs with Podman, you can use Podman Compose to manage your containers in development and production.
## Oscar
Thanks. Another way to do the more or less the same is https://www.redhat.com/sysadmin/compose-podman-pods
## Mehdi Haghgoo
Yes Oscar, that’s also another useful feature of Podman. However, in order for “podman kube generate” to work, a pod needs to be running with the containers added to it manually. It’s very interesting though, and I might write a future article about it on Fedora Magazine.
## James
Thanks, that’s really useful to me as I am working with podman to create a django site, using a pod. I have used podman build to build the container images, and have added their containers to a pod using the podman run command with the –pod switch.
I recently switch to using Silverblue, but on both Silverblue and Workstation 33 if I forgot to stop the pod when closing down, it would take an absolute age, something like 2 minutes, before the laptop finally shut down.
So, I made a simple systemd service file to shutdown podman on power off of the laptop…
[Unit]
Description=Podman shutdown service
DefaultDependencies=no
Before=poweroff.target halt.target shutdown.target
[Service]
Type=oneshot
User=dev
ExecStart=/usr/bin/podman pod stop --all
RemainAfterExit=yes
TimeoutStartSec=0
TimeoutSec=3600
[Install]
WantedBy=shutdown.target halt.target
I enabled the service using ‘sytemctl enable podman-shutdown.service’ and now my laptop shuts down cleanly and immediately.
I just have one question left. Is there a way to open ports individually to running containers inside a pod?
With the publish option when creating a pod, a port mapping is created, but that port is then open for all the containers, not just one, and without peeking, I seem to recall that only one port can be published.
## Mehdi Haghgoo
James, for your use case, if you don’t want to use podman-compose, you can use “podman generate kube” feature to generate a kubernetes YAML that you will be able to run using “podman play kube” later on to quickly restore your pod and its containers.
Regarding your question to individually map ports of a container within a pod to a specific host port, it is not possible as far as I know. Instead, you configure port mapping in the form of HOST_PX:CON_PX on the pod when creating it. Later, when you run a container inside the pod that exposes port CON_PX, that port from the container will automatically be published to HOST_PX on the host.
## Gwyn Ciesla
podman-compose is also installable in Fedora via dnf.
## Mehdi Haghgoo
Yes Gwyn, but the latest developer version has to be installed from GitHub, as we did.
## Gwyn Ciesla
It’s actually in rawhide and updates-testing for f33.
## Laszlo Jagusztin
Unfortunately podman compose unable to handle anything that newer than Docker compose 1.0
Most of the projects use newer syntax
## Mehdi Haghgoo
Laszlo I have not had problem with it so far working with my podman-compose.yml files. Do you have specific commands that are not supported by Podman Compose?
## Stefano Stagnaro
I often appreciate Fedora Magazine blog posts but this time I must respectfully disagree. Podman Compose is nothing more than an (awesome) experimental project. There are dozen of forgotten issues and unmerged pull requests and moreover, it’s hard to deal with most of the docker-compose.yml found on the net. Since Podman 3.0 is now GA with the new RESTful API, there aren’t any strong reasons for not using the original Docker Compose directly with Podman… except for this three:
1) Compose is bad, DON’T COMPOSE! Docker Compose works well with Docker ecosystem only, therefore it lacks support for modern container features like Pods and other Kubernetes resources. Unlike Docker, Podman can definitely deal with them but unfortunately not through Compose.
2) Compose is a Docker-only provisioning system, while IT guys usually prefers all-around automation technologies like Ansible. Just write an Ansible playbook with Podman modules instead of the docker-compose.yml. Same effort, only benefits.
3) Compose and Docker may works for developers, certainly not when it comes to enterprise application deployment. Even if Kubernetes is the preferred way for container deployments, in specific contexts a stand-alone Podman managed by systemd units and monitored by journald will do the trick.
In conclusion, since I’m a big Fedora fan, I can’t help but suggesting an awesome new article for Fedora Magazine called… DON’T COMPOSE 😀
## Erik Sjölund
The upcoming Podman 3.0 supports the Docker REST API well enough to be used as back-end for docker-compose. It is planned to be released in a few weeks.
Caveats:
Running Podman as root is supported, but not yet running as a normal user, i.e. running “rootless”. (See feature request https://github.com/containers/podman/issues/9169)
Functionality relating to Swarm is not supported
To enable Podman as the back-end for docker-compose, run
sudo systemctl enable –now start podman.socket
Podman will then listen on the UNIX domain socket /var/run/docker.sock
See also: https://www.redhat.com/sysadmin/podman-docker-compose
## Mehdi Haghgoo
Stefano I appreciate your arguments regarding Podman and against Podman-Compose. As far as I know the new Podman 3.0 feature allowing running docker-compose.yaml files only works in root mode. I don’t think many people prefer rootless containers.
Personally, I have found docker-compose super useful for development environments. Then, thanks to Podman Compose, I was able to switch back and forth from macOS to Fedora for development very easily. It is amazing!
## Viktor Ransmayr
@Mehdi : I assume you wanted to say “I
dothink many people prefer rootless containers”. – Correct?## Mehdi Haghgoo
That is right. Unfortunately, I didn’t have the option to revise the comment. Thank you Viktor for correcting.
## Werner
I had some issues running a simple nginx pod using podman-compose on Fedora 33: it was impossible to access the volume mounts for http document root. Adding a
privileged: true
solved the security issues. Probably there is a better solution, though I was not able to find one. Tried even to make it world readable did not help. Just in case somebody has the same problem.
## Mehdi Haghgoo
Yes Werner, it happens with volumes and it is caused by SELinux. I used to solve it using setenforce 0, but “privileged: true” seems a better option.
Thanks for sharing.
## Blake
Hi, @Werner @Mehdi Another way which I believe is more suitable for the volume issue mentioned here is mapping the volume with :z at the end.
E.g: podman -v /my/host/path:/etc/containerpath:z
https://www.redhat.com/sysadmin/user-namespaces-selinux-rootless-containers |
13,126 | 如何在 Linux 中创建和管理归档文件 | https://training.linuxfoundation.org/announcements/how-to-create-and-manage-archive-files-in-linux/ | 2021-02-17T12:10:16 | [
"tar"
] | https://linux.cn/article-13126-1.html | 
简而言之,归档是一个包含一系列文件和(或)目录的单一文件。归档文件通常用于在本地或互联网上传输,或作为一个一系列文件和目录的备份副本,从而允许你使用一个文件来工作(如果压缩,则其大小会小于所有文件的总和)。同样的,归档也用于软件应用程序打包。为了方便传输,可以很容易地压缩这个单一文件,而存档中的文件会保留原始结构和权限。
我们可以使用 `tar` 工具来创建、列出和提取归档中的文件。用 `tar` 生成的归档通常称为“tar 文件”、“tar 归档”或者“压缩包”(因为所有已归档的文件被合成了一个文件)。
本教程会展示如何使用 `tar` 创建、列出和提取归档中的内容。这三个操作都会使用两个公共选项 `-f` 和 `-v`:使用 `-f` 指定归档文件的名称,使用 `-v`(“冗余”)选项使 `tar` 在处理文件时输出文件名。虽然 `-v` 选项不是必需的,但是它可以让你观察 `tar` 操作的过程。
在本教程的下面部分中,会涵盖 3 个主题:1、创建一个归档文件;2、列出归档文件内容;3、提取归档文件内容。另外我们会回答归档文件管理的 6 个实际问题来结束本教程。你从本教程学到的内容对于执行与[网络安全](https://learn.coding-bootcamps.com/p/essential-practical-guide-to-cybersecurity-for-system-admin-and-developers)和[云技术](https://learn.coding-bootcamps.com/p/introduction-to-cloud-technology)相关的任务至关重要。
### 1、创建一个归档文件
要使用 `tar` 创建一个归档文件,使用 `-c`(“创建”)选项,然后用 `-f` 选项指定要创建的归档文件名。通常的做法是使用带有 `.tar` 扩展名的名称,例如 `my-backup.tar`。注意,除非另有特别说明,否则本文其余部分中使用的所有命令和参数都以小写形式使用。记住,在你的终端上输入本文的命令时,无需输入每个命令行开头的 `$` 提示符。
输入要归档的文件名作为参数;如果要创建一个包含所有文件及其子目录的归档文件,提供目录名称作为参数。
要归档 `project` 目录内容,输入:
```
$ tar -cvf project.tar project
```
这个命令将创建一个名为 `project.tar` 的归档文件,包含 `project` 目录的所有内容,而原目录 `project` 将保持不变。
使用 `-z` 选项可以对归档文件进行压缩,这样产生的输出与创建未压缩的存档然后用 `gzip` 压缩是一样的,但它省去了额外的步骤。
要从 `project` 目录创建一个 `project.tar.gz` 的压缩包,输入:
```
$ tar -zcvf project.tar.gz project
```
这个命令将创建一个 `project.tar.gz` 的压缩包,包含 `project` 目录的所有内容,而原目录 `project` 将保持不变。
**注意:** 在使用 `-z` 选项时,你应该使用 `.tar.gz` 扩展名而不是 `.tar` 扩展名,这样表示已压缩。虽然不是必须的,但这是一个很好的实践。
gzip 不是唯一的压缩形式,还有 bzip2 和 xz。当我们看到扩展名为 `.xz` 的文件时,我们知道该文件是使用 `xz` 压缩的,扩展名为 `.bz2` 的文件是用 `bzip2` 压缩的。随着 bzip2 不再维护,我们将远离它而关注 xz。使用 `xz` 压缩时,需要花费更长的时间。然而,等待通常是值得的,因为压缩效果要好的多,这意味着压缩包通常比使用其它压缩形式要小。更好的是,不同压缩形式之间的解压缩或提取文件并没有太大区别。下面我们将看到一个使用 `tar` 压缩文件时如何使用 xz 的示例:
```
$ tar -Jcvf project.tar.xz project
```
我们只需将 `gzip` 的 `-z` 选项转换为 `xz` 的大写 `-J` 即可。以下是一些输出,显示压缩形式之间的差异:


如你所见,`xz` 的压缩时间最长。但是,它在减小文件大小方面做的最好,所以值得等待。文件越大,压缩效果也越好。
### 2、列出归档文件的内容
要列出 tar 归档文件的内容但不提取,使用 `-t` 选项。
要列出 `project.tar` 的内容,输入:
```
$ tar -tvf project.tar
```
这个命令列出了 `project.tar` 归档的内容。`-v` 和 `-t` 选项一起使用会输出每个文件的权限和修改时间,以及文件名。这与 `ls` 命令使用 `-l` 选项时使用的格式相同。
要列出 `project.tar.gz` 压缩包的内容,输入:
```
$ tar -tzvf project.tar.gz
```
### 3、从归档中提取内容
要提取(解压)tar 归档文件中的内容,使用 `-x`(“提取”)选项。
要提取 `project.tar` 归档的内容,输入:
```
$ tar -xvf project.tar
```
这个命令会将 `project.tar` 归档的内容提取到当前目录。
如果一个归档文件被压缩,通常来说它的扩展名为 `.tar.gz` 或 `.tgz`,请包括 "-z" 选项。
要提取 `project.tar.gz` 压缩包的内容,输入:
```
$ tar -zxvf project.tar.gz
```
**注意**: 如果当前目录中有文件或子目录与归档文件中的内容同名,那么在提取归档文件时,这些文件或子目录将被覆盖。如果你不知道归档中包含哪些文件,请考虑先查看归档文件的内容。
在提取归档内容之前列出其内容的另一个原因是,确定归档中的内容是否包含在目录中。如果没有,而当前目录中包含许多不相关的文件,那么你可能将它们与归档中提取的文件混淆。
要将文件提取到它们自己的目录中,新建一个目录,将归档文件移到该目录,然后你就可以在新目录中提取文件。
### FAQ
现在我们已经学习了如何创建归档文件并列出和提取其内容,接下来我们可以继续讨论 Linux 专业人员经常被问到的 9 个实用问题。
#### 可以在不解压缩的情况下添加内容到压缩包中吗?
很不幸,一旦文件将被压缩,就无法向其添加内容。你需要解压缩或提取其内容,然后编辑或添加内容,最后再次压缩文件。如果文件很小,这个过程不会花费很长时间,否则请等待一会。
#### 可以在不解压缩的情况下删除归档文件中的内容吗?
这取决压缩时使用的 tar 版本。较新版本的 `tar` 支持 `-delete` 选项。
例如,假设归档文件中有 `file1` 和 `file2`,可以使用以下命令将它们从 `file.tar` 中删除:
```
$ tar -vf file.tar –delete file1 file2
```
删除目录 `dir1`:
```
$ tar -f file.tar –delete dir1/*
```
#### 压缩和归档之间有什么区别?
查看归档和压缩之间差异最简单的方法是查看其解压大小。归档文件时,会将多个文件合并为一个。所以,如果我们归档 10 个 100kb 文件,则最终会得到一个 100kb 大小的文件。而如果压缩这些文件,则最终可能得到一个只有几 kb 或接近 100kb 的文件。
#### 如何压缩归档文件?
如上所说,你可以使用带有 `cvf` 选项的 `tar` 命令来创建和归档文件。要压缩归档文件,有两个选择:通过压缩程序(例如 `gzip`)运行归档文件,或在使用 `tar` 命令时使用压缩选项。最常见的压缩标志 `-z` 表示 `gzip`,`-j` 表示 `bzip`,`-J` 表示 `xz`。例如:
```
$ gzip file.tar
```
或者,我们可以在使用 `tar` 命令时使用压缩标志,以下命令使用 `gzip` 标志 `z`:
```
$ tar -cvzf file.tar /some/directory
```
#### 如何一次创建多个目录和/或文件的归档?
一次要归档多个文件,这种情况并不少见。一次归档多个文件和目录并不像你想的那么难,你只需要提供多个文件或目录作为 tar 的参数即可:
```
$ tar -cvzf file.tar file1 file2 file3
```
或者
```
$ tar -cvzf file.tar /some/directory1 /some/directory2
```
#### 创建归档时如何跳过目录和/或文件?
你可能会遇到这样的情况:要归档一个目录或文件,但不是所有文件,这种情况下可以使用 `--exclude` 选项:
```
$ tar –exclude ‘/some/directory’ -cvf file.tar /home/user
```
在示例中,`/home/user` 目录中除了 `/some/directory` 之外都将被归档。将 `--exclude` 选项放在源和目标之前,并用单引号将要排除的文件或目录引起来,这一点很重要。
### 总结
`tar` 命令对展示不需要的文件创建备份或压缩文件很有用。在更改文件之前备份它们是一个很好的做法。如果某些东西在更改后没有按预期正常工作,你始终可以还原到旧文件。压缩不再使用的文件有助于保持系统干净,并降低磁盘空间使用率。还有其它实用程序可以归档或压缩,但是 `tar` 因其多功能、易用性和受欢迎程度而独占鳌头。
### 资源
如果你想了解有关 Linux 的更多信息,强烈建议阅读以下文章和教程:
* [Linux 文件系统架构和管理综述](https://blockchain.dcwebmakers.com/blog/linux-os-file-system-architecture-and-management.html)
* [Linux 文件和目录系统工作原理的全面回顾](https://coding-bootcamps.com/linux/filesystem/index.html)
* [所有 Linux 系统发行版的综合列表](https://myhsts.org/tutorial-list-of-all-linux-operating-system-distributions.php)
* [特殊用途 Linux 发行版的综合列表](https://coding-bootcamps.com/list-of-all-special-purpose-linux-distributions.html)
* [Linux 系统管理指南 - 制作和管理备份操作的最佳实践](https://myhsts.org/tutorial-system-admin-best-practices-for-managing-backup-operations.php)
* [Linux 系统管理指南 - Linux 虚拟内存和磁盘缓冲区缓存概述](https://myhsts.org/tutorial-how-linux-virtual-memory-and-disk-buffer-cache-work.php)
* [Linux 系统管理指南 - 监控 Linux 的最佳实践](https://myhsts.org/tutorial-system-admin-best-practices-for-monitoring-linux-systems.php)
* [Linux 系统管理指南 - Linux 启动和关闭的最佳实践](https://myhsts.org/tutorial-best-practices-for-performing-linux-boots-and-shutdowns.php)
### 关于作者
**Matt Zand** 是一位创业者,也是 3 家科技创业公司的创始人: [DC Web Makers](https://blockchain.dcwebmakers.com/)、[Coding Bootcamps](http://coding-bootcamps.com/) 和 [High School Technology Services](https://myhsts.org/)。他也是 [使用 Hyperledger Fabric 进行智能合约开发](https://www.oreilly.com/library/view/hands-on-smart-contract/9781492086116/) 一书的主要作者。他为 Hyperledger、以太坊和 Corda R3 平台编写了 100 多篇关于区块链开发的技术文章和教程。在 DC Web Makers,他领导了一个区块链专家团队,负责咨询和部署企业去中心化应用程序。作为首席架构师,他为编码训练营设计和开发了区块链课程和培训项目。他拥有马里兰大学工商管理硕士学位。在区块链开发和咨询之前,他曾担任一些初创公司的高级网页和移动应用程序开发和顾问、天使投资人和业务顾问。你可以通过以下这个网址和他取得联系: <https://www.linkedin.com/in/matt-zand-64047871>。
**Kevin Downs** 是 Red Hat 认证的系统管理员和 RHCSA。他目前在 IBM 担任系统管理员,负责管理数百台运行在不同 Linux 发行版上的服务器。他是[编码训练营](https://coding-bootcamps.com/)的首席 Linux 讲师,并且他会讲授 [5 个自己的课程](https://learn.coding-bootcamps.com/courses/author/758905)。
---
via: <https://www.linux.com/news/how-to-create-and-manage-archive-files-in-linux-2/>
作者:[LF Training](https://training.linuxfoundation.org/announcements/how-to-create-and-manage-archive-files-in-linux/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *By Matt Zand and Kevin Downs*
How can you create and manage Linux archive files? In a nutshell, an archive is a single file that contains a collection of other files and/or directories. Archive files are typically used for a transfer (locally or over the internet) or make a backup copy of a collection of files and directories which allow you to work with only one file (if compressed, it has a lower size than the sum of all files within it) instead of many. Likewise, archives are used for software application packaging. This single file can be easily compressed for ease of transfer while the files in the archive retain the structure and permissions of the original files.
We can use the tar tool to create, list, and extract files from archives. Archives made with tar are normally called “tar files,” “tar archives,” or—since all the archived files are rolled into one—“tarballs.”
This tutorial shows how to use tar to create an archive, list the contents of an archive, and extract the files from an archive. Two common options used with all three of these operations are ‘-f’ and ‘-v’: to specify the name of the archive file, use ‘-f’ followed by the file name; use the ‘-v’ (“verbose”) option to have tar output the names of files as they are processed. While the ‘-v’ option is not necessary, it lets you observe the progress of your tar operation.
For the remainder of this tutorial, we cover 3 topics: 1- Create an archive file, 2- List contents of an archive file, and 3- Extract contents from an archive file. We conclude this tutorial by surveying 6 practical questions related to archive file management. What you take away from this tutorial is essential for performing tasks related to [cybersecurity](https://learn.coding-bootcamps.com/p/essential-practical-guide-to-cybersecurity-for-system-admin-and-developers) and [cloud technology](https://learn.coding-bootcamps.com/p/introduction-to-cloud-technology).
### 1- Creating a Linux Archive File
To create an archive with tar, use the ‘-c’ (“create”) option, and specify the name of the archive file to create with the ‘-f’ option. It’s common practice to use a name with a ‘.tar’ extension, such as ‘my-backup.tar’. Note that unless specifically mentioned otherwise, all commands and command parameters used in the remainder of this article are used in lowercase. Keep in mind that while typing commands in this article on your terminal, you need not type the $ prompt sign that comes at the beginning of each command line.
Give as arguments the names of the files to be archived; to create an archive of a directory and all of the files and subdirectories it contains, give the directory’s name as an argument.
* *To create an archive called ‘project.tar’ from the contents of the ‘project’ directory, type:
$ *tar -cvf project.tar project*
This command creates an archive file called ‘project.tar’ containing the ‘project’ directory and all of its contents. The original ‘project’ directory remains unchanged.
Use the ‘-z’ option to compress the archive as it is being written. This yields the same output as creating an uncompressed archive and then using gzip to compress it, but it eliminates the extra step.
* *To create a compressed archive called ‘project.tar.gz’ from the contents of the ‘project’ directory, type:
$ *tar -zcvf project.tar.gz project*
This command creates a compressed archive file, ‘project.tar.gz’, containing the ‘project’ directory and all of its contents. The original ‘project’ directory remains unchanged.
**NOTE: **While using the ‘-z’ option, you should specify the archive name with a ‘.tar.gz’ extension and not a ‘.tar’ extension, so the file name shows that the archive is compressed. Although not required, it is a good practice to follow.
Gzip is not the only form of compression. There is also bzip2 and and xz. When we see a file with an extension of xz we know it has been compressed using xz. When we see a file with the extension of .bz2 we can infer it was compressed using bzip2. We are going to steer away from bzip2 as it is becoming unmaintained and focus on xz. When compressing using xz it is going to take longer for the files to compressed. However, it is typically worth the wait as the compression is much more effective, meaning the resulting file will usually be smaller than other compression methods used. Even better is the fact that decompression, or expanding the file, is not much different between the different methods of compression. Below we see an example of how to utilize xz when compressing a file using tar
$ *tar -Jcvf project.tar.xz project*
We simply switch -z for gzip to uppercase -J for xz. Here are some outputs to display the differences between the forms of compression:
As you can see xz does take the longest to compress. However it does the best job of reducing files size, so it’s worth the wait. The larger the file is the better the compression becomes too!
### 2- Listing Contents of a Linux Archive File
To list the contents of a tar archive without extracting them, use tar with the ‘-t’ option.
* *To list the contents of an archive called ‘project.tar’, type:
$ *tar -tvf project.tar ** *
This command lists the contents of the ‘project.tar’ archive. Using the ‘-v’ option along with the ‘-t’ option causes tar to output the permissions and modification time of each file, along with its file name—the same format used by the ls command with the ‘-l’ option.
* *To list the contents of a compressed archive called ‘project.tar.gz’, type:
$ *tar -tvf project.tar*
* *3- Extracting contents from an Archive File
To extract (or *unpack*) the contents of a tar archive, use tar with the ‘-x’ (“extract”) option.
* *To extract the contents of an archive called ‘project.tar’, type:
$ *tar -xvf project.tar*
This command extracts the contents of the ‘project.tar’ archive into the current directory.
If an archive is compressed, which usually means it will have a ‘.tar.gz’ or ‘.tgz’ extension, include the ‘-z’ option.
* *To extract the contents of a compressed archive called ‘project.tar.gz’, type:
$ *tar -zxvf project.tar.gz*
**NOTE: **If there are files or subdirectories in the current directory with the same name as any of those in the archive, those files will be overwritten when the archive is extracted. If you don’t know what files are included in an archive, consider listing the contents of the archive first.
Another reason to list the contents of an archive before extracting them is to determine whether the files in the archive are contained in a directory. If not, and the current directory contains many unrelated files, you might confuse them with the files extracted from the archive.
To extract the files into a directory of their own, make a new directory, move the archive to that directory, and change to that directory, where you can then extract the files from the archive.
Now that we have learned how to create an Archive file and list/extract its contents, we can move on to discuss the following 9 practical questions that are frequently asked by Linux professionals.
- Can we add content to an archive file without unpacking it?
Unfortunately, once a file has been compressed there is no way to add content to it. You would have to “unpack” it or extract the contents, edit or add content, and then compress the file again. If it’s a small file this process will not take long. If it’s a larger file then be prepared for it to take a while.
- Can we delete content from an archive file without unpacking it?
This depends on the version of tar being used. Newer versions of tar will support a –delete.
For example, let’s say we have files file1 and file2 . They can be removed from file.tar with the following:
*$ tar -vf file.tar –delete file1 file2*
To remove a directory dir1:
*$ tar -f file.tar –delete dir1/**
- What are the differences between compressing a folder and archiving it?
The simplest way to look at the difference between archiving and compressing is to look at the end result. When you archive files you are combining multiple files into one. So if we archive 10 100kb files you will end up with one 1000kb file. On the other hand if we compress those files we could end up with a file that is only a few kb or close to 100kb.
- How to compress archive files?
As we saw above you can create and archive files using the tar command with the cvf options. To compress the archive file we made there are two options; run the archive file through compression such as gzip. Or use a compression flag when using the tar command. The most common compression flags are- z for gzip, -j for bzip and -J for xz. We can see the first method below:
*$ gzip file.tar*
Or we can just use a compression flag when using the tar command, here we’ll see the gzip flag “z”:
*$ tar -cvzf file.tar /some/directory*
- How to create archives of multiple directories and/or files at one time?
It is not uncommon to be in situations where we want to archive multiple files or directories at once. And it’s not as difficult as you think to tar multiple files and directories at one time. You simply supply which files or directories you want to tar as arguments to the tar command:
*$ tar -cvzf file.tar file1 file2 file3*
or
*$ tar -cvzf file.tar /some/directory1 /some/directory2*
- How to skip directories and/or files when creating an archive?
You may run into a situation where you want to archive a directory or file but you don’t need certain files to be archived. To avoid archiving those files or “exclude” them you would use the –exclude option with tar:
*$ tar –exclude ‘/some/directory’ -cvf file.tar /home/user*
So in this example /home/user would be archived but it would exclude the /some/directory if it was under /home/user. It’s important that you put the –exclude option before the source and destination as well as to encapsulate the file or directory being excluded with single quotation marks.
### Summary
The tar command is useful for creating backups or compressing files you no longer need. It’s good practice to back up files before changing them. If something doesn’t work how it’s intended to after the change you will always be able to revert back to the old file. Compressing files no longer in use helps keep systems clean and lowers the disk space usage. There are other utilities available but tar has reigned supreme for its versatility, ease of use and popularity.
### Resources
If you like to learn more about Linux, reading the following articles and tutorials are highly recommended:
[Comprehensive Review of Linux File System Architecture and Management](https://blockchain.dcwebmakers.com/blog/linux-os-file-system-architecture-and-management.html)[Comprehensive Review of How Linux File and Directory System Works](https://coding-bootcamps.com/linux/filesystem/index.html)[Comprehensive list of all Linux OS distributions](https://myhsts.org/tutorial-list-of-all-linux-operating-system-distributions.php)[Comprehensive list of all special purpose Linux distributions](https://coding-bootcamps.com/list-of-all-special-purpose-linux-distributions.html)[Linux System Admin Guide- Best Practices for Making and Managing Backup Operations](https://myhsts.org/tutorial-system-admin-best-practices-for-managing-backup-operations.php)[Linux System Admin Guide- Overview of Linux Virtual Memory and Disk Buffer Cache](https://myhsts.org/tutorial-how-linux-virtual-memory-and-disk-buffer-cache-work.php)[Linux System Admin Guide- Best Practices for Monitoring Linux Systems](https://myhsts.org/tutorial-system-admin-best-practices-for-monitoring-linux-systems.php)[Linux System Admin Guide- Best Practices for Performing Linux Boots and Shutdowns](https://myhsts.org/tutorial-best-practices-for-performing-linux-boots-and-shutdowns.php)
### About the Authors
**Matt Zand** is a serial entrepreneur and the founder of 3 tech startups:[ DC Web Makers](https://blockchain.dcwebmakers.com/),[ Coding Bootcamps](http://coding-bootcamps.com/) and[ High School Technology Services](https://myhsts.org/). He is a leading author of [Hands-on Smart Contract Development with Hyperledger Fabric](https://www.oreilly.com/library/view/hands-on-smart-contract/9781492086116/) book by O’Reilly Media. He has written more than 100 technical articles and tutorials on blockchain development for Hyperledger, Ethereum and Corda R3 platforms. At DC Web Makers, he leads a team of blockchain experts for consulting and deploying enterprise decentralized applications. As chief architect, he has designed and developed blockchain courses and training programs for Coding Bootcamps. He has a master’s degree in business management from the University of Maryland. Prior to blockchain development and consulting, he worked as senior web and mobile App developer and consultant, angel investor, business advisor for a few startup companies. You can connect with him on LI: [https://www.linkedin.com/in/matt-zand-64047871](https://www.linkedin.com/in/matt-zand-64047871)
**Kevin Downs** is Red Hat Certified System Administrator or RHCSA. At his current job at IBM as Sys Admin, he is in charge of administering hundreds of servers running on different Linux distributions. He is a Lead Linux Instructor at [Coding Bootcamps](https://coding-bootcamps.com/) where he has authored [5 self-paced Courses](https://learn.coding-bootcamps.com/courses/author/758905). |
13,129 | 一种为 Linux ARM 设备构建跨平台 UI 的新方法 | https://opensource.com/article/20/5/linux-arm-ui | 2021-02-18T12:37:52 | [
"UI"
] | https://linux.cn/article-13129-1.html |
>
> AndroidXML 和 TotalCross 的运用为树莓派和其他设备创建 UI 提供了更简单的方法。
>
>
>

为应用程序创建良好的用户体验(UX)是一项艰巨的任务,尤其是在开发嵌入式应用程序时。今天,有两种图形用户界面(GUI)工具通常用于开发嵌入式软件:它们要么涉及复杂的技术,要么非常昂贵。
然而,我们已经创建了一个概念验证(PoC),它提供了一种新的方法来使用现有的、成熟的工具为运行在桌面、移动、嵌入式设备和低功耗 ARM 设备上的应用程序构建用户界面(UI)。我们的方法是使用 Android Studio 绘制 UI;使用 [TotalCross](https://totalcross.com/) 在设备上呈现 Android XML;采用被称为 [KnowCode](https://github.com/TotalCross/KnowCodeXML) 的新 [TotalCross API](https://yourapp.totalcross.com/knowcode-app);以及使用 [树莓派 4](https://www.raspberrypi.org/) 来执行应用程序。
### 选择 Android Studio
可以使用 TotalCross API 为应用程序构建一个美观的响应式用户体验,但是在 Android Studio 中创建 UI 缩短了制作原型和实际应用程序之间的时间。
有很多工具可以用来为应用程序构建 UI,但是 [Android Studio](https://developer.android.com/studio) 是全世界开发者最常使用的工具。除了它被大量采用以外,这个工具的使用也非常直观,而且它对于创建简单和复杂的应用程序都非常强大。在我看来,唯一的缺点是使用该工具所需的计算机性能,它比其他集成开发环境 (IDE) 如 VSCode 或其开源替代方案 [VSCodium](https://vscodium.com/) 要庞大得多。
通过思考这些问题,我们创建了一个概念验证,使用 Android Studio 绘制 UI,并使用 TotalCross 直接在设备上运行 AndroidXML。
### 构建 UI
对于我们的 PoC,我们想创建一个家用电器应用程序来控制温度和其他东西,并在 Linux ARM 设备上运行。

我们想为树莓派开发我们的应用程序,所以我们使用 Android 的 [ConstraintLayout](https://codelabs.developers.google.com/codelabs/constraint-layout/index.html#0) 来构建 848x480(树莓派的分辨率)的固定屏幕大小的 UI,不过你可以用其他布局构建响应性 UI。
Android XML 为 UI 创建增加了很多灵活性,使得为应用程序构建丰富的用户体验变得容易。在下面的 XML 中,我们使用了两个主要组件:[ImageView](https://developer.android.com/reference/android/widget/ImageView) 和 [TextView](https://developer.android.com/reference/android/widget/TextView)。
```
<ImageView
android:id="@+id/imageView6"
android:layout_width="273dp"
android:layout_height="291dp"
android:background="@drawable/Casa"
tools:layout_editor_absoluteX="109dp"
tools:layout_editor_absoluteY="95dp" />
<TextView
android:id="@+id/insideTempEdit"
android:layout_width="94dp"
android:layout_height="92dp"
android:background="#F5F5F5"
android:text="20"
android:textAlignment="center"
android:gravity="center"
android:textColor="#000000"
android:textSize="67dp"
android:textStyle="bold"
tools:layout_editor_absoluteX="196dp"
tools:layout_editor_absoluteY="246dp" />
```
TextView 元素用于向用户显示一些数据,比如建筑物内的温度。大多数 ImageView 都用作用户与 UI 交互的按钮,但它们也需要实现屏幕上组件提供的事件。
### 用 TotalCross 整合
这个 PoC 中的第二项技术是 TotalCross。我们不想在设备上使用 Android 的任何东西,因为:
1。我们的目标是为 Linux ARM 提供一个出色的 UI。 2。我们希望在设备上实现低占用。 3。我们希望应用程序在低计算能力的低端硬件设备上运行(例如,没有 GPU、 低 RAM 等)。
首先,我们使用 [VSCode 插件](https://medium.com/totalcross-community/totalcross-plugin-for-vscode-4f45da146a0a) 创建了一个空的 TotalCross 项目。接下来,我们保存了 `drawable` 文件夹中的图像副本和 `xml` 文件夹中的 Android XML 文件副本,这两个文件夹都位于 `resources` 文件夹中:

为了使用 TotalCross 模拟器运行 XML 文件,我们添加了一个名为 KnowCode 的新 TotalCross API 和一个主窗口来加载 XML。下面的代码使用 API 加载和呈现 XML:
```
public void initUI() {
XmlScreenAbstractLayout xmlCont = XmlScreenFactory.create("xml / homeApplianceXML.xml");
swap(xmlCont);
}
```
就这样!只需两个命令,我们就可以使用 TotalCross 运行 Android XML 文件。以下是 XML 如何在 TotalCross 的模拟器上执行:

完成这个 PoC 还有两件事要做:添加一些事件来提供用户交互,并在树莓派上运行它。
### 添加事件
KnowCode API 提供了一种通过 ID(`getControlByID`) 获取 XML 元素并更改其行为的方法,如添加事件、更改可见性等。
例如,为了使用户能够改变家中或其他建筑物的温度,我们在 UI 底部放置了加号和减号按钮,并在每次单击按钮时都会出现“单击”事件,使温度升高或降低一度:
```
Button plus = (Button) xmlCont.getControlByID("@+id/plus");
Label insideTempLabel = (Label) xmlCont.getControlByID("@+id/insideTempLabel");
plus.addPressListener(new PressListener() {
@Override
public void controlPressed(ControlEvent e) {
try {
String tempString = insideTempLabel.getText();
int temp;
temp = Convert.toInt(tempString);
insideTempLabel.setText(Convert.toString(++temp));
} catch (InvalidNumberException e1) {
e1.printStackTrace();
}
}
});
```
### 在树莓派 4 上测试
最后一步!我们在一台设备上运行了应用程序并检查了结果。我们只需要打包应用程序并在目标设备上部署和运行它。[VNC](https://tigervnc.org/) 也可用于检查设备上的应用程序。
整个应用程序,包括资源(图像等)、Android XML、TotalCross 和 Knowcode API,在 Linux ARM 上大约是 8MB。
下面是应用程序的演示:

在本例中,该应用程序仅为 Linux ARM 打包,但同一应用程序可以作为 Linux 桌面应用程序运行,在Android 设备 、Windows、windows CE 甚至 iOS 上运行。
所有示例源代码和项目都可以在 [HomeApplianceXML GitHub](https://github.com/TotalCross/HomeApplianceXML) 存储库中找到。
### 现有工具的新玩法
为嵌入式应用程序创建 GUI 并不需要像现在这样困难。这种概念证明为如何轻松地完成这项任务提供了新的视角,不仅适用于嵌入式系统,而且适用于所有主要的操作系统,所有这些系统都使用相同的代码库。
我们的目标不是为设计人员或开发人员创建一个新的工具来构建 UI 应用程序;我们的目标是为使用现有的最佳工具提供新的玩法。
你对这种新的应用程序开发方式有何看法?在下面的评论中分享你的想法。
---
via: <https://opensource.com/article/20/5/linux-arm-ui>
作者:[Bruno Muniz](https://opensource.com/users/brunoamuniz) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Creating a great user experience (UX) for your applications is a tough job, especially if you are developing embedded applications. Today, there are two types of graphical user interface (GUI) tools generally available for developing embedded software: either they involve complex technologies, or they are extremely expensive.
However, we have created a proof of concept (PoC) for a new way to use existing, well-established tools to build user interfaces (UIs) for applications that run on desktop, mobile, embedded devices, and low-power Linux ARM devices. Our method uses Android Studio to draw the UI; [TotalCross](https://totalcross.com/) to render the Android XML on the device; a new [TotalCross API](https://yourapp.totalcross.com/knowcode-app) called [KnowCode](https://github.com/TotalCross/KnowCodeXML); and a [Raspberry Pi 4](https://www.raspberrypi.org/) to execute the application.
## Choosing Android Studio
It's possible to build a responsive and beautiful UX for an application using the TotalCross API, but creating the UI in Android Studio shortens the time between prototyping and the real application.
There are a lot of tools available to build UIs for applications, but [Android Studio](https://developer.android.com/studio) is the one developers worldwide use most often. In addition to its massive adoption, this tool is also super-intuitive to use, and it's really powerful for creating both simple and complex applications. The only drawback, in my opinion, is the computing power required to use the tool, which is way heavier than other integrated development environments (IDEs) like VSCode or its open source alternative, [VSCodium](https://vscodium.com/).
By thinking through these issues, we created a proof of concept using Android Studio to draw the UI and TotalCross to run the Android XML directly on the device.
## Building the UI
For our PoC, we wanted to create a home-appliance application to control temperature and other things and that would run on a Linux ARM device.
(Bruno Muniz, CC BY-SA 4.0)
We wanted to develop our application for a Raspberry Pi, so we used Android's [ConstraintLayout](https://codelabs.developers.google.com/codelabs/constraint-layout/index.html#0) to build a fixed-screen-size UI of 848x480 (the Raspberry Pi's resolution), but you can build responsive UIs with other layouts.
Android XML adds a lot of flexibility for UI creation, making it easy to build rich user experiences for applications. In the XML below, we used two main components: [ImageView](https://developer.android.com/reference/android/widget/ImageView) and [TextView](https://developer.android.com/reference/android/widget/TextView).
```
<ImageView
android:id="@+id/imageView6"
android:layout_width="273dp"
android:layout_height="291dp"
android:background="@drawable/Casa"
tools:layout_editor_absoluteX="109dp"
tools:layout_editor_absoluteY="95dp" />
<TextView
android:id="@+id/insideTempEdit"
android:layout_width="94dp"
android:layout_height="92dp"
android:background="#F5F5F5"
android:text="20"
android:textAlignment="center"
android:gravity="center"
android:textColor="#000000"
android:textSize="67dp"
android:textStyle="bold"
tools:layout_editor_absoluteX="196dp"
tools:layout_editor_absoluteY="246dp" />
```
The TextView elements are used to show some data to the user, like the temperature inside a building. Most ImageViews are used as buttons for user interaction with the UI, but they're also needed to implement the Events provided by the components on the screen.
## Integrating with TotalCross
The second technology in this PoC is TotalCross. We don't want to use anything from Android on the device because:
- Our goal is to provide a great UI for Linux ARM.
- We want to achieve a low footprint on the device.
- We want the application to run on low-end hardware devices with low computing power (e.g., no GPU, low RAM, etc.).
To begin, we created an empty TotalCross project using our [VSCode plugin](https://medium.com/totalcross-community/totalcross-plugin-for-vscode-4f45da146a0a). Next, we saved a copy of the images inside the **drawable** folder and a copy of the Android XML file inside the **XML** folder—both are located inside the **Resources** folder:
(Bruno Muniz, CC BY-SA 4.0)
To run the XML file using the TotalCross Simulator, we added a new TotalCross API called KnowCode and a MainWindow to load the XML. The code below uses the API to load and render the XML:
```
public void initUI() {
XmlScreenAbstractLayout xmlCont = XmlScreenFactory.create(“xml / homeApplianceXML.xml”);
swap(xmlCont);
}
```
That's it! With only two commands, we can run an Android XML file using TotalCross. Here is how the XML performs on TotalCross' simulator:
(Bruno Muniz, CC BY-SA 4.0)
There are two things remaining to finish this PoC: adding some events to provide user interaction and running it on a Raspberry Pi.
## Adding events
The KnowCode API provides a way to get an XML element by its ID (getControlByID) and change its behavior to do things like adding events, changing visibility, and more.
For example, to enable users to change the temperature in their home or other building, we put plus and minus buttons on the bottom of the UI and a "click" event that increases or decreases the temperature one degree every time the buttons are clicked:
```
Button plus = (Button) xmlCont.getControlByID("@+id/plus");
Label insideTempLabel = (Label) xmlCont.getControlByID("@+id/insideTempLabel");
plus.addPressListener(new PressListener() {
@Override
public void controlPressed(ControlEvent e) {
try {
String tempString = insideTempLabel.getText();
int temp;
temp = Convert.toInt(tempString);
insideTempLabel.setText(Convert.toString(++temp));
} catch (InvalidNumberException e1) {
e1.printStackTrace();
}
}
});
```
## Testing on a Raspberry Pi 4
Finally, the last step! We ran the application on a device and checked the results. We just needed to package the application and deploy and run it on the target device. A [VNC](https://tigervnc.org/) can also be used to check the application on the device.
The entire application, including assets (images, etc.), Android XML, TotalCross, and the KnowCode API, is about 8MB on Linux ARM.
Here's a demo of the application:
(Bruno Muniz, CC BY-SA 4.0)
In this example, the application was packaged only for Linux ARM, but the same app will run as a Linux desktop app, Android devices, Windows, Windows CE, and even iOS.
All of the sample source code and the project are available in the [HomeApplianceXML GitHub](https://github.com/TotalCross/HomeApplianceXML) repository.
## New possibilities with existing tools
Creating GUIs for embedded applications doesn't need to be as hard as it is today. This proof of concept brings a new perspective on how to do this task easily—not only for embedded systems but for all major operating systems, all using the same code base.
We are not aiming to create a new tool for designers or developers to build UI applications; our goal is to provide new possibilities for using the best tools that are already available.
What's your opinion of this new way to build apps? Share your thoughts in the comments below.
## 2 Comments |
13,130 | Web 的成长,就是一篇浏览器的故事 | https://opensource.com/article/19/3/when-web-grew | 2021-02-18T16:18:08 | [
"Web",
"浏览器"
] | https://linux.cn/article-13130-1.html |
>
> 互联网诞生之时我的个人故事。
>
>
>

最近,我和大家 [分享了](https://opensource.com/article/18/11/how-web-was-won) 我在 1994 年获得英国文学和神学学位离开大学后,如何在一个人们还不知道 Web 服务器是什么的世界里成功找到一份运维 Web 服务器的工作。我说的“世界”,并不仅仅指的是我工作的机构,而是泛指所有地方。Web 那时当真是全新的 —— 人们还正尝试理出头绪。
那并不是说我工作的地方(一家学术出版社)特别“懂” Web。这是个大部分人还在用 28.8K 猫(调制解调器,俗称“猫”)访问网页的世界。我还记得我拿到 33.6K 猫时有多激动。至少上下行速率不对称的日子已经过去了,<sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup> 以前 1200/300 的带宽描述特别常见。这意味着(在同一家机构的)印刷人员制作的设计复杂、色彩缤纷、纤毫毕现的文档是完全不可能放在 Web 上的。我不能允许在网站的首页出现大于 40k 的 GIF 图片,这对我们的许多访问者来说是很难接受的。大于大约 60k 图片的会作为独立的图片,以缩略图链接过去。
如果说市场部只有这一点不喜欢,那是绝对是轻描淡写了。更糟的是布局问题。“浏览器决定如何布局文档,”我一遍又一遍地解释,“你可以使用标题或者段落,但是文档在页面上如何呈现并不取决于文档,而是取决于渲染器!”他们想控制这些,想要不同颜色的背景。后来明白了那些不能实现。我觉得我就像是参加了第一次讨论层叠样式表(CSS)的 W3C 会议,并进行了激烈地争论。关于文档编写者应控制布局的建议真令人厌恶。<sup class="footnote-ref"> <a href="#fn2" id="fnref2"> [2] </a></sup> CSS 花了一些时间才被人们采用,与此同时,关心这些问题的人搭上了 PDF 这种到处都是安全问题的列车。
如何呈现文档不是唯一的问题。作为一个实体书出版社,对于市场部来说,拥有一个网站的全部意义在于,让客户(或者说潜在的客户)不仅知道一本书的内容,而且知道买这本书需要花多少钱。但这有一个问题,你看,互联网,包括快速发展的万维网,是开放的,是所有都免费的自由之地,没有人会在意钱;事实上,在那里谈钱是要回避和避免的。
我和主流“网民”的看法一致,认为没必要把价格信息放在线上。我老板,以及机构里相当多的人都持相反的意见。他们觉得消费者应该能够看到书要花多少钱。他们也觉得我的银行经理也会想看到我的账户里每个月进了多少钱,如果我不认同他们的观点的话,那我的收入就可能堪忧。
幸运的是,在我被炒鱿鱼之前,我已经自己认清了一些 —— 可能是在我开始迈入 Web 的几星期之后,Web 已经发生变化,有其他人公布他们的产品价格信息。这些新来者通常被那些从早期就开始运行 Web 服务器的老派人士所看不起,<sup class="footnote-ref"> <a href="#fn3" id="fnref3"> [3] </a></sup> 但很明显,风向是往那边吹的。然而,这并不意味着我们的网站就赢得了战争。作为一个学术出版社,我们和大学共享一个域名(在 “[ac.uk](http://ac.uk)” 下)。大学不太相信发布价格信息是合适的,直到出版社的一些资深人士指出,普林斯顿大学出版社正在这样做,如果我们不做……看起来是不是有点傻?
有趣的事情还没完。在我担任站点管理员(“webmaster@…”)的短短几个月后,我们和其他很多网站一样开始看到了一种令人担忧的趋势。某些访问者可以轻而易举地让我们的 Web 服务器跪了。这些访问者使用了新的网页浏览器:网景浏览器(Netscape)。网景浏览器实在太恶劣了,它居然是多线程的。
这为什么是个问题呢?在网景浏览器之前,所有的浏览器都是单线程。它们一次只进行一个连接,所以即使一个页面有五张 GIF 图,<sup class="footnote-ref"> <a href="#fn4" id="fnref4"> [4] </a></sup> 也会先请求 HTML 基本文件进行解析,然后下载第一张 GIF,完成,接着第二张,完成,如此类推。事实上,GIF 的顺序经常出错,使得页面加载得非常奇怪,但这也是常规思路。而粗暴的网景公司的人决定,它们可以同时打开多个连接到 Web 服务器,比如说,可以同时请求所有的 GIF!为什么这是个问题呢?好吧,问题就在于大多数 Web 服务器都是单线程的。它们不是设计来一次进行多个连接的。确实,我们运行的 HTTP 服务的软件(MacHTTP)是单线程的。尽管我们花钱购买了它(最初是共享软件),但我们用的这版无法同时处理多个请求。
互联网上爆发了大量讨论。这些网景公司的人以为他们是谁,能改变世界的运作方式?它应该如何工作?大家分成了不同阵营,就像所有的技术争论一样,双方都用各种技术热词互丢。问题是,网景浏览器不仅是多线程的,它也比其他的浏览器更好。非常多 Web 服务器代码维护者,包括 MacHTTP 作者 Chuck Shotton 在内,开始坐下来认真地在原有代码基础上更新了多线程测试版。几乎所有人立马转向测试版,它们变得稳定了,最终,浏览器要么采用了这种技术,变成多线程,要么就像所有过时产品一样销声匿迹了。<sup class="footnote-ref"> <a href="#fn5" id="fnref5"> [5] </a></sup>
对我来说,这才是 Web 真正成长起来的时候。既不是网页展示的价格,也不是设计者能定义你能在网页上看到什么,<sup class="footnote-ref"> <a href="#fn6" id="fnref6"> [6] </a></sup> 而是浏览器变得更易用,以及成千上万的浏览者向数百万浏览者转变的网络效应,使天平向消费者而不是生产者倾斜。在我的旅程中,还有更多故事,我将留待下次再谈。但从这时起,我的雇主开始看我们的月报,然后是周报、日报,并意识到这将是一件大事,真的需要关注。
---
1. 它们又是怎么回来的? [↩︎](#fnref1)
2. 你可能不会惊讶,我还是在命令行里最开心。 [↩︎](#fnref2)
3. 大约六个月前。 [↩︎](#fnref3)
4. 莽撞,没错,但它确实发生了 <sup class="footnote-ref"> <a href="#fn7" id="fnref7"> [7] </a></sup> [↩︎](#fnref4)
5. 没有真正的沉寂:总有一些坚持他们的首选解决方案具有技术上的优势,并哀叹互联网的其他人都是邪恶的死硬爱好者。 <sup class="footnote-ref"> <a href="#fn8" id="fnref8"> [8] </a></sup> [↩︎](#fnref5)
6. 我会指出,为那些有各种无障碍需求的人制造严重而持续的问题。 [↩︎](#fnref6)
7. 噢,不,是 GIF 或 BMP,JPEG 还是个好主意,但还没有用上。 [↩︎](#fnref7)
8. 我不是唯一一个说“我还在用 Lynx”的人。 [↩︎](#fnref8)
---
via: <https://opensource.com/article/19/3/when-web-grew>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XYenChi](https://github.com/XYenChi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, I [shared how](https://opensource.com/article/18/11/how-web-was-won) upon leaving university in 1994 with a degree in English literature and theology, I somehow managed to land a job running a web server in a world where people didn't really know what a web server was yet. And by "in a world," I don't just mean within the organisation in which I worked, but the world in general. The web was new—really new—and people were still trying to get their heads around it.
That's not to suggest that the place where I was working—an academic publisher—particularly "got it" either. This was a world in which a large percentage of the people visiting their website were still running 28k8 modems. I remember my excitement in getting a 33k6 modem. At least we were past the days of asymmetric upload/download speeds,[ 1](#1) where 1200/300 seemed like an eminently sensible bandwidth description. This meant that the high-design, high-colour, high-resolution documents created by the print people (with whom I shared a floor) were completely impossible on the web. I wouldn't allow anything bigger than a 40k GIF on the front page of the website, and that was pushing it for many of our visitors. Anything larger than 60k or so would be explicitly linked as a standalone image from a thumbnail on the referring page.
To say that the marketing department didn't like this was an understatement. Even worse was the question of layout. "Browsers decide how to lay out documents," I explained, time after time, "you can use headers or paragraphs, but how documents appear on the page isn't defined by the document, but by the renderer!" They wanted control. They wanted different coloured backgrounds. After a while, they got that. I went to what I believe was the first W3C meeting at which the idea of Cascading Style Sheets (CSS) was discussed. And argued vehemently against them. The suggestion that document writers should control layout was anathema.[ 2](#2) It took some while for CSS to be adopted, and in the meantime, those who cared about such issues adopted the security trainwreck that was Portable Document Format (PDF).
How documents were rendered wasn't the only issue. Being a publisher of actual physical books, the whole point of having a web presence, as far as the marketing department was concerned, was to allow customers—or potential customers—to know not only what a book was about, but also how much it was going to cost them to buy. This, however, presented a problem. You see, the internet—in which I include the rapidly growing World Wide Web—was an open, free-for-all libertarian sort of place where nobody was interested in money; in fact, where talk of money was to be shunned and avoided.
I took the mainstream "Netizen" view that there was no place for pricing information online. My boss—and, indeed, pretty much everybody else in the organisation—took a contrary view. They felt that customers should be able to see how much books would cost them. They also felt that my bank manager would like to see how much money was coming into my bank account on a monthly basis, which might be significantly reduced if I didn't come round to their view.
Luckily, by the time I'd climbed down from my high horse and got over myself a bit—probably only a few weeks after I'd started digging my heels in—the web had changed, and there were other people putting pricing information up about their products. These newcomers were generally looked down upon by the old schoolers who'd been running web servers since the early days,[ 3](#3) but it was clear which way the wind was blowing. This didn't mean that the battle was won for our website, however. As an academic publisher, we shared an academic IP name ("ac.uk") with the University. The University was
*less*than convinced that publishing pricing information was appropriate until some senior folks at the publisher pointed out that Princeton University Press was doing it, and wouldn't we look a bit silly if…?
The fun didn't stop there, either. A few months into my tenure as webmaster ("webmaster@…"), we started to see a worrying trend, as did lots of other websites. Certain visitors were single-handedly bringing our webserver to its knees. These visitors were running a new web browser: Netscape. Netscape was badly behaved. Netscape was *multi-threaded*.
Why was this an issue? Well, before Netscape, all web browsers had been single-threaded. They would open one connection at a time, so even if you had, say five GIFs on a page,[ 4](#4) they would request the HTML base file, parse that, then download the first GIF, complete that, then the second, complete that, and so on. In fact, they often did the GIFs in the wrong order, which made for very odd page loading, but still, that was the general idea. The rude people at Netscape decided that they could open multiple connections to the webserver at a time to request all the GIFs at the same time, for example! And why was this a problem? Well, the problem was that most webservers were single-threaded. They weren't designed to have multiple connections open at any one time. Certainly, the HTTP server that we ran (MacHTTP) was single-threaded. Even though we had paid for it (it was originally shareware), the version we had couldn't cope with multiple requests at a time.
The debate raged across the internet. Who did these Netscape people think they were, changing how the world worked? How it was supposed to work? The world settled into different camps, and as with all technical arguments, heated words were exchanged on both sides. The problem was that not only was Netscape multi-threaded, it was also just better than the alternatives. Lots of web server code maintainers, MacHTTP author Chuck Shotton among them, sat down and did some serious coding to produce multi-threaded beta versions of their existing code. Everyone moved almost immediately to the beta versions, they got stable, and in the end, single-threaded browsers either adapted and became multi-threaded themselves, or just went the way of all outmoded products and died a quiet death.6
This, for me, is when the web really grew up. It wasn't prices on webpages nor designers being able to define what you'd see on a page,[ 8](#8) but rather when browsers became easier to use and when the network effect of thousands of viewers moving to many millions tipped the balance in favour of the consumer, not the producer. There were more steps in my journey—which I'll save for another time—but from around this point, my employers started looking at our monthly, then weekly, then daily logs, and realising that this was actually going to be something big and that they'd better start paying some real attention.
[1. How did they come back, again?]
[2. It may not surprise you to discover that I'm still happiest at the command line.]
[4. Reckless, true, but it was beginning to happen.]5
[5. Oh, and no—it was GIFs or BMP. JPEG was still a bright idea that hadn't yet taken off.]
[6. It's never actually quiet: there are always a few diehard enthusiasts who insist that their preferred solution is technically superior and bemoan the fact that the rest of the internet has gone to the devil.]7
[7. I'm not one to talk: I still use Lynx from time to time.]
[8. Creating major and ongoing problems for those with different accessibility needs, I would point out.]
## Comments are closed. |
13,132 | 2021 年开始使用开源的 10 种方式 | https://opensource.com/article/21/1/getting-started-open-source | 2021-02-19T11:10:24 | [
"开源"
] | https://linux.cn/article-13132-1.html |
>
> 如果你刚开始接触开源,那么下面的 2020 年十篇好文章有助于指导你的发展之路。
>
>
>

我们存在的意义是为了向世界宣传开源的一切,从新工具到框架拓展到社区。我们的目标是让想要使用开源或为开源做贡献的人更容易参与其中。
入门开源可能很难,所以我们定期分享如何参与其中的提示和建议。如果你想要学习 Python,帮助抗击 COVID-19,或者加入 K8s 设置,我们将为你服务。
为了帮助你开始,我们总结了 2020 年发布的 10 篇最流行的开源入门文章。希望它们能激发你在 2021 年学习一些新知识。
### 《利用 Python 爬取网站的新手指南》
你是否想通过实践而不是阅读来学习 Python?在本教程中,Julia Piaskowski 将会指导你完成她的第一个[Python 网页爬取项目](/article-13047-1.html)。她具体展示了如何使用 Python 的 `requests` 库访问网页内容。
Julia 详细介绍了每一步,从安装 Python3 到使用 Pandas 来清理 Web 抓取结果。她利用了大量截图解释了如何以最终目标为目的进行爬取。
有关爬取相关内容的部分特别有用;当遇到困难处时,她会详细解释。但是,与本文的其余部分一样,她会指导你完成每个步骤。
### 《在 Linux 上使用 SSH 进行远程连接的初学者指南》
如果你之前从未使用过安全 shell(SSH),那么你在第一次使用时可能会感到困惑。在本教程中,Seth Kenlon 展示了[如何为两台计算机之间配置 SSH 连接](https://opensource.com/article/20/9/ssh),以及如何不使用密码而安全地进行连接。
Seth 解释了建立 SSH 连接的每个步骤,从你应该了解的四个关键术语到在每个主机上激活 SSH 的步骤。他还提供了有关查找计算机 IP 地址、创建 SSH 密钥以及对远程计算机的远程访问权限的建议。
### 《五步学会任何编程语言》
如果你已经掌握了一种编程语言,你就能[学习所有的语言](/article-12842-1.html)。这是 Seth Kenlon 编写本文的前提,他认为了解一些基本编程逻辑便可以跨语言拓展。
Seth 分享了程序员在学习一种新的编程语言或编码方式时所需要的五种东西。语法、内置函数和解析器是这五种之一,他对每一种都附上了行动步骤。
那么将它们统一起来的关键方式是?一旦了解了代码工作原理,你就可以跨语言拓展。对你来说,没有什么是太难学的。
### 《为 COVID-19 贡献开源医疗项目》
你是否知道一家意大利医院通过 3D 打印机设备挽救了 COVID-19 患者的生命?这是开源贡献者为 2020 年 COVID-19 大流行[建立的众多解决方案之一](https://opensource.com/article/20/3/volunteer-covid19)。
在本文中,Joshua Pearce 分享了针对 COVID-19 的开源志愿服务项目。虽然 Open Air 是最大的项目,但 Joshua 解释了如何为开源呼吸机的维基工作,编写开源 COVID-19 医疗供应要求,测试开源氧气浓缩机原型等。
### 《GNOME 入门建议》
GNOME 是最受欢迎的 Linux 桌面之一,但是它适合你吗?本文分享了[来自 GNOME 用户的建议](https://opensource.com/article/20/6/gnome-users),以及有关此主题的文章。
想要在配置桌面上寻找一些灵感吗?本文包含了有关 GNOME 扩展入门,将 Dash 安装到 Dock,使用 GNOME Tweak 工具等的链接。
不过,你仍然可能会认为 GNOME 不适合你——不用担心,最后你将找到指向其他 Linux 桌面和窗口管理器的链接。
### 《现在开始为开源做贡献的 3 个理由》
截至到 2020 年 6 月,Github 托管了超过 180,000 个公共仓库。现如今加入开源社区比过去更容易,但这是否意味着你应该加入开源?在本文中,Jason Blais [分享了三个投身开源的原因](https://opensource.com/article/20/6/why-contribute-open-source)。
为开源做贡献可以增强你的信心、简历和专业网络。Jason 还解释了如何利用有用的信息,从如何在领英个人资料中添加开源信息,到如何将这些贡献转变为付费角色。最后还列出了供初学者参与的出色项目。
### 《作为 Linux 系统管理员为开源做贡献的 4 种方法》
系统管理员是开源的无名英雄。他们在代码背后做了大量工作,这些代码非常有价值,但通常是看不见的。
在本文中,Elizabeth K. Joseph 介绍了她如何以 Linux 系统管理员的身份[来改善开源项目](https://opensource.com/article/20/7/open-source-sysadmin)。用户支持、托管项目资源、寻找新的网站环境是让社区比她发现时变得更好的几种方式。
也许最重要的贡献是什么?文档!Elizabeth 在开源领域的起步是她为使用的项目重写了快速入门指南。向你经常使用的项目提交错误和补丁报告是参与其中的理想方法。
### 《为 Slack 的开源替代品做出贡献的 6 种方法》
Mattermost 是一个很受欢迎的平台,适合那些想要一个开源消息传递系统的团队的平台。其活跃、充满活力的社区是让用户保持忠诚度的关键因素,尤其是对那些具有 Go、React 和 DevOps 经验的用户。
如果你想[为 Mattermost 做出贡献](https://opensource.com/article/20/7/mattermost),Jason Blais 具体介绍了如何参与其中。将本文视为你的入门文档:Blais 分享了你要采取的步骤,并介绍了你可以做出的六种贡献。
无论你是要构建一个集成还是本地化你的语言,本文都将介绍如何进行。
### 《如何为 Kubernetes 做贡献》
当我走进 2018 年温哥华青年开源峰会时,还很年轻,对 Kubernetes 一无所知。主题演讲结束后,我离开会场后依然是一个有所改变而依然困惑的女人。毫不夸张地说,Kubernetes 已经彻底改变了开源,这并不夸张:很难找到一个更受欢迎、更有影响力的项目。
如果你想做出贡献,那么 IBM 工程师 Tara Gu 介绍了[她是如何开始的](https://opensource.com/article/20/1/contributing-kubernetes-all-things-open-2019)。本文介绍了她在 All Things Open 2019 会议上的闪电演讲的回顾以及包括她亲自演讲的视频。还记得吗?
### 《任何人如何在工作中为开源软件做出贡献》
需求是发明之母,尤其是在开源领域。许多人针对自己遇到的问题构建开源解决方案。但是如果开发人员在没有收集目标用户反馈的情况下通过构建产品而错过了目标,会发生什么呢?
在企业中,产品和设计团队通常会填补这一空白。如果开源团队中不存在这样的角色,开发人员应该怎么做?
在本文中,Catherine Robson 介绍了开源团队如何从目标用户那里[收集反馈](https://opensource.com/article/20/10/open-your-job)。它为希望与开发人员分享他们的工作经验,从而将他们的反馈贡献到开源项目的人们而编写。
Catherine 概述的步骤将帮助你与开源团队分享你的见解,并在帮助团队开发更好的产品方面发挥关键作用。
### 你想要学习什么?
你想了解开源入门哪些方面的知识?请在评论中分享你对文章主题的建议。同时如果你有故事可以分享,以帮助他人开始使用开源软件,请考虑[撰写文章](https://opensource.com/how-submit-article)。
---
via: <https://opensource.com/article/21/1/getting-started-open-source>
作者:[Lauren Maffeo](https://opensource.com/users/lmaffeo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Opensource.com exists to educate the world about everything open source, from new tools and frameworks to scaling communities. We aim to make open source more accessible to anyone who wants to use or contribute to it.
Getting started in open source can be hard, so we regularly share tips and advice on how you can get involved. If you want to learn Python, help fight COVID-19, or join the Kubernetes community, we've got you covered.
To help you begin, we curated the 10 most popular articles on getting started in open source we published in 2020. We hope they'll inspire you to learn something new in 2021.
## A beginner's guide to web scraping with Python
Want to learn Python through doing, not reading? In this tutorial, Julia Piaskowski guides you through her first [web scraping project in Python](https://opensource.com/article/20/5/web-scraping-python). She shows how to access webpage content with Python library requests.
Julia walks through each step, from installing Python 3 to cleaning web scraping results with pandas. Aided by screenshots galore, she explains how to scrape with an end goal in mind.
The section on extracting relevant content is especially helpful; she doesn't mince words when saying this can be tough. But, like the rest of the article, she guides you through each step.
## A beginner's guide to SSH for remote connections on Linux
If you've never opened a secure shell (SSH) before, the first time can be confusing. In this tutorial, Seth Kenlon shows how to [configure two computers for SSH connections](https://opensource.com/article/20/9/ssh) and securely connect them without a password.
From four key phrases you should know to steps for activating SSH on each host, Seth explains every step of making SSH connections. He includes advice on finding your computer's IP address, creating an SSH key, and verifying your access to a remote machine.
## 5 steps to learn any programming language
If you know one programming language, you can [learn them all](https://opensource.com/article/20/10/learn-any-programming-language). That's the premise of this article by Seth Kenlon, which argues that knowing some basic programming logic can scale across languages.
Seth shares five things programmers look for when considering a new language to learn to code in. Syntax, built-ins, and parsers are among the five, and he accompanies each with steps to take action.
The key argument uniting them all? Once you know the theory of how code works, it scales across languages. Nothing is too hard for you to learn.
## Contribute to open source healthcare projects for COVID-19
Did you know that an Italian hospital saved COVID-19 patients' lives by 3D printing valves for reanimation devices? It's one of many ways open source contributors [built solutions for the pandemic](https://opensource.com/article/20/3/volunteer-covid19) in 2020.
In this article, Joshua Pearce shares several ways to volunteer with open source projects addressing COVID-19. While Project Open Air is the largest, Joshua explains how you can also work on a wiki for an open source ventilator, write open source COVID-19 medical supply requirements, test an open source oxygen concentrator prototype, and more.
## Advice for getting started with GNOME
GNOME is one of the most popular Linux desktops, but is it right for you? This article shares [advice from GNOME](https://opensource.com/article/20/6/gnome-users) users interspersed with Opensource.com's take on this topic.
Want some inspiration for configuring your desktop? This article includes links to get started with GNOME extensions, installing Dash to Dock, using the GNOME Tweak tool, and more.
After all that, you might decide that GNOME still isn't for you—and that's cool. You'll find links to other Linux desktops and window managers at the end.
## 3 reasons to contribute to open source now
As of June 2020, GitHub hosted more than 180,000 public repositories. It's never been easier to join the open source community, but does that mean you should? In this article, Opensource.com Correspondent Jason Blais [shares three reasons](https://opensource.com/article/20/6/why-contribute-open-source) to take the plunge.
Contributing to open source can boost your confidence, resume, and professional network. Jason explains how to leverage your contributions in helpful detail, from sharing how to add open source contributions on your LinkedIn profile to turning these contributions into paid roles. There's even a list of great projects for first-time contributors at the end.
## 4 ways I contribute to open source as a Linux systems administrator
Sysadmins are the unsung heroes of open source. They do lots of work behind the code that's deeply valuable but often unseen.
In this article, Elizabeth K. Joseph explains how she [improves open source projects](https://opensource.com/article/20/7/open-source-sysadmin) as a Linux sysadmin. User support, hosting project resources, and finding new website environments are just a few ways she leaves communities better than she found them.
Perhaps the most crucial contribution of all? Documentation! Elizabeth got her start in open source rewriting a quickstart guide for a project she used. Submitting bugs and patch reports to projects you use often is an ideal way to get involved.
## 6 ways to contribute to an open source alternative to Slack
Mattermost is a popular platform for teams that want an open source messaging system. Its active, vibrant community is a key plus that keeps users loyal to the product, especially those with experience in Go, React, and DevOps.
If you'd like to [contribute to Mattermost](https://opensource.com/article/20/7/mattermost), Jason Blais explains how. Consider this article your Getting Started documentation: Blais shares steps to take, organized by six types of contributions you can make.
Whether you'd like to build an integration or localize your language, this article shares how to get going.
## How to contribute to Kubernetes
I walked into Open Source Summit 2018 in Vancouver young and unaware of Kubernetes. After the keynotes, I walked out of the ballroom a changed-yet-confused woman. It's not hyperbole to say that Kubernetes has changed open source for good: It's tough to find a more popular, impactful project.
If you'd like to contribute, IBM Engineer Tara Gu explains [how she got started.](https://opensource.com/article/20/1/contributing-kubernetes-all-things-open-2019) This recap of her lightning talk at All Things Open 2019 includes a video of the talk she gave in person. At a conference. Remember those…?
## How anyone can contribute to open source software in their job
Necessity is the mother of invention, especially in open source. Many folks build open source solutions to their own problems. But what happens when developers miss the mark by building products without gathering feedback from their target users?
Product and design teams often fill this gap in enterprises. What should developers do if such roles don't exist on their open source teams?
In this article, Catherine Robson explains how open source teams [can collect feedback](https://opensource.com/article/20/10/open-your-job) from their target users. It's written for folks who want to share their work experiences with developers, thus contributing their feedback to open source projects.
The steps Catherine outlines will help you share your insights with open source teams and play a key role helping teams build better products.
## What do you want to learn?
What would you like to know about getting started in open source? Please share your suggestions for article topics in the comments. And if you have a story to share to help others get started in open source, please consider [writing an article](https://opensource.com/how-submit-article) for Opensource.com.
## Comments are closed. |
13,133 | 让 Linux 成为理想的工作站的 3 个开源工具 | https://opensource.com/article/21/2/linux-workday | 2021-02-19T13:49:42 | [
"开源",
"Linux"
] | https://linux.cn/article-13133-1.html |
>
> Linux 不但拥有你认为所需的一切,还有更多可以让你高效工作的工具。
>
>
>

在 2021 年,有更多让人们喜欢 Linux 的理由。在这个系列中,我将分享 21 种使用 Linux 的不同理由。今天,我将与你分享为什么 Linux 是你工作的最佳选择。
每个人都希望在工作期间提高工作效率。如果你的工作通常涉及到文档、演示文稿和电子表格的工作,那么你可能已经习惯了特定的例行工作。问题在于,这个*惯常的例行工作*通常是由一两个特定的应用程序决定的,无论是某个办公套件还是桌面操作系统。当然,习惯并不意味着它是理想的,但是它往往会毫无疑义地持续存在,甚至影响到企业的运作架构。
### 更聪明地工作
如今,许多办公应用程序都在云端运行,因此如果你愿意的话,你可以在 Linux 上使用相同的方式。然而,由于许多典型的知名办公应用程序并不符合 Linux 上的文化预期,因此你可能会发现自己受到启发,想去探索其他的选择。正如任何渴望走出“舒适区”的人所知道的那样,这种微妙的打破可能会出奇的有用。很多时候,你不知道自己效率低下,因为你实际上并没有尝试过以不同的方式做事。强迫自己去探索其他方式,你永远不知道会发现什么。你甚至不必完全知道要寻找的内容。
### LibreOffice
Linux(或任何其他平台)上显而易见的开源办公主力之一是 [LibreOffice](http://libreoffice.org)。它具有多个组件,包括文字处理器、演示软件、电子表格、关系型数据库界面、矢量绘图等。它可以从其他流行的办公应用程序中导入许多文档格式,因此从其他工具过渡到 LibreOffice 通常很容易。
然而,LibreOffice 不仅仅是一个出色的办公套件。LibreOffice 支持宏,所以机智的用户可以自动完成重复性任务。它还具有终端命令的功能,因此你可以在不启动 LibreOffice 界面的情况下执行许多任务。
想象一下,比如要打开 21 个文档,导航到**文件**菜单,到**导出**或**打印**菜单项,并将文件导出为 PDF 或 EPUB。这至少需要 84 次以上的点击,可能要花费一个小时的时间。相比之下,打开一个文档文件夹,并转换所有文件为 PDF 或 EPUB,只需要执行一个迅速的命令或菜单操作。转换将在后台运行,而你可以处理其他事情。只需要四分之一的时间,可能更少。
```
$ libreoffice --headless --convert-to epub *.docx
```
这是一个小改进,是由 Linux 工具集和你可以自定义环境和工作流程的便利性所潜在带来的鼓励。
### Abiword 和 Gnumeric
有时,你并不需要一个大而全的办公套件。如果你喜欢简化你的办公室工作,那么使用一个轻量级和针对特定任务的应用程序可能更好。例如,我大部分时间都是用文本编辑器写文章,因为我知道在转换为 HTML 的过程中,所有的样式都会被丢弃。但有些时候,文字处理器是很有用的,无论是打开别人发给我的文档,还是因为我想用一种快速简单的方法来生成一些样式漂亮的文本。
[Abiword](https://www.abisource.com) 是一款简单的文字处理器,它基本支持流行的文档格式,并具备你所期望的文字处理器的所有基本功能。它并不意味着是一个完整的办公套件,这是它最大的特点。虽然没有太多的选择,但我们仍然处于信息过载的时代,这正是一个完整的办公套件或文字处理器有时会犯的错误。如果你想避免这种情况,那就用一些简单的东西来代替。
同样,[Gnumeric](http://www.gnumeric.org) 项目提供了一个简单的电子表格应用程序。Gnumeric 避免了任何严格意义上的电子表格所不需要的功能,所以你仍然可以获得强大的公式语法、大量的函数,以及样式和操作单元格的所有选项。我不怎么使用电子表格,所以我发现自己在极少数需要查看或处理分类账中的数据时,对 Gnumeric 相当满意。
### Pandoc
通过专门的命令和文件处理程序,可以最小化。`pandoc` 命令专门用于文件转换。它就像 `libreoffice --headless` 命令一样,只是要处理的文档格式数量是它的十倍。你甚至可以用它来生成演示文稿! 如果你的工作之一是从一个文档中提取源文本,并以多种格式交付它,那么 Pandoc 是必要的,所以你应该[下载我们的攻略](https://opensource.com/article/20/5/pandoc-cheat-sheet)看看。
广义上讲,Pandoc 代表的是一种完全不同的工作方式。它让你脱离了办公应用的束缚。它将你从试图将你的想法写成文字,并同时决定这些文字应该使用什么字体的工作中分离出来。在纯文本中工作,然后转换为各种交付格式,让你可以使用任何你想要的应用程序,无论是移动设备上的记事本,还是你碰巧坐在电脑前的简单文本编辑器,或者是云端的文本编辑器。
### 寻找替代品
Linux 有很多意想不到的替代品。你可以从你正在做的事情中退后一步,分析你的工作流程,评估你所需的结果,并调查那些声称可以完全你的需求的新应用程序来找到它们。
改变你所使用的工具、工作流程和日常工作可能会让你迷失方向,特别是当你不知道你要找的到底是什么的时候。但 Linux 的优势在于,你有机会重新评估你在多年的计算机使用过程中潜意识里形成的假设。如果你足够努力地寻找答案,你最终会意识到问题所在。通常,你最终会欣赏你学到的东西。
---
via: <https://opensource.com/article/21/2/linux-workday>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. Today, I'll share with you why Linux is a great choice for your workday.
Everyone wants to be productive during the workday. If your workday generally involves working on documents, presentations, and spreadsheets, then you might be accustomed to a specific routine. The problem is that *usual routine* is usually dictated by one or two specific applications, whether it's a certain office suite or a desktop OS. Of course, just because something's a habit doesn't mean it's ideal, and yet it tends to persist unquestioned, even to the point of influencing the very structure of how a business is run.
## Working smarter
Many office applications these days run in the cloud, so you can work with the same constraints on Linux if you really want to. However, because many of the typical big-name office applications aren't cultural expectations on Linux, you might find yourself inspired to explore other options. As anyone eager to get out of their "comfort zone" knows, this kind of subtle disruption can be surprisingly useful. All too often, you don't know what you're doing inefficiently because you haven't actually tried doing things differently. Force yourself to explore other options, and you never know what you'll find. You don't even have to know exactly what you're looking for.
## LibreOffice
One of the most obvious open source office stalwarts on Linux (or any other platform) is [LibreOffice](http://libreoffice.org). It features several components, including a word processor, presentation software, a spreadsheet, relational database interface, vector drawing, and more. It can import many document formats from other popular office applications, so transitioning to LibreOffice from another tool is usually easy.
There's more to LibreOffice than just being a great office suite, however. LibreOffice has macro support, so resourceful users can automate repetitive tasks. It also features terminal commands so you can perform many tasks without ever launching the LibreOffice interface.
Imagine, for instance, opening 21 documents, navigating to the **File** menu, to the **Export** or **Print** menu item, and exporting the file to PDF or EPUB. That's over 84 clicks, at the very least, and probably an hour of work. Compare that to opening a folder of documents and converting all of them to PDF or EPUB with just one swift command or menu action. The conversion would run in the background while you work on other things. You'd be finished in a quarter of the time, possibly less.
`$ libreoffice --headless --convert-to epub *.docx`
It's the little improvements that Linux encourages, not explicitly but implicitly, through its toolset and the ease with which you can customize your environment and workflow.
## Abiword and Gnumeric
Sometimes, a big office suite is exactly what you *don't* need. If you prefer to keep your office work simple, you might do better with a lightweight and task-specific application. For instance, I mostly write articles in a text editor because I know all styles are discarded during conversion to HTML. But there are times when a word processor is useful, either to open a document someone has sent to me or because I want a quick and easy way to generate some nicely styled text.
[Abiword](https://www.abisource.com) is a simple word processor with basic support for popular document formats and all the essential features you'd expect from a word processor. It isn't meant as a full office suite, and that's its best feature. While there's no such a thing as too many options, there definitely is such a thing as information overload, and that's exactly what a full office suite or word processor is sometimes guilty of. If you're looking to avoid that, then use something simple instead.
Similarly, the [Gnumeric](http://www.gnumeric.org) project provides a simple spreadsheet application. Gnumeric avoids any features that aren't strictly necessary for a spreadsheet, so you still get a robust formula syntax, plenty of functions, and all the options you need for styling and manipulating cells. I don't do much with spreadsheets, so I find myself quite happy with Gnumeric on the rare occasions I need to review or process data in a ledger.
## Pandoc
It's possible to get even more minimal with specialized commands and document processors. The `pandoc`
command specializes in document conversion. It's like the `libreoffice --headless`
command, except with ten times the number of document formats to work with. You can even generate presentations with it! If part of your work is taking source text from one document and formatting it for several modes of delivery, then Pandoc is a necessity, and so you should [download our cheat sheet](https://opensource.com/article/20/5/pandoc-cheat-sheet).
Broadly, Pandoc is representative of a completely different way of working. It gets you away from the confines of office applications. It separates you from trying to get your thoughts down into typed words and deciding what font those words ought to use, all at the same time. Working in plain text and then converting to all of your delivery targets afterward lets you work with any application you want, whether it's a notepad on your mobile device, a simple text editor on whatever computer you happen to be sitting in front of, or a text editor in the cloud.
## Look for the alternatives
There are lots of unexpected alternatives available for Linux. You can find them by taking a step back from what you're doing, analyzing your work process, assessing your required results, and investigating new applications that claim to do just the things you rely upon.
Changing the tools you use, your workflow, and your daily routine can be disorienting, especially when you don't know exactly where it is you're looking to go. But the advantage to Linux is that you're afforded the opportunity to re-evaluate the assumptions you've subconsciously developed over years of computer usage. If you look hard enough for an answer, you'll eventually realize what the question was in the first place. And oftentimes, you'll end up appreciating what you learn.
## 7 Comments |
13,135 | 为什么选择 Plausible 作为 Google Analytics 的开源替代品? | https://opensource.com/article/21/2/plausible | 2021-02-19T23:36:35 | [
"分析软件"
] | https://linux.cn/article-13135-1.html |
>
> Plausible 作为 Google Analytics 的可行、有效的替代方案正在引起用户的关注。
>
>
>

替代 Google Analytics 似乎是一个巨大的挑战。实际上,你可以说这听起来似乎不合理(LCTT 译注:Plausible 意即“貌似合理”)。但这正是 [Plausible.io](https://plausible.io/) 取得巨大成功的原因,自 2018 年以来已注册了数千名新用户。
Plausible 的联合创始人 Uku Taht 和 Marko Saric 最近出现在 [The Craft of Open Source](https://www.flagsmith.com/podcast/02-plausible) 播客上,谈论了这个项目以及他们是如何:
* 创建了一个可行的替代 Google Analytics 的方案
* 在不到两年的时间里获得了如此大的发展势头
* 通过开源他们的项目实现其目标
请继续阅读他们与播客主持人和 Flagsmith 创始人 Ben Rometsch 的对话摘要。
### Plausible 是如何开始的
2018 年冬天,Uku 开始编写一个他认为急需的项目:一个可行的、有效的 Google Analytics 替代方案。因为他对 Google 产品的发展方向感到失望,而且所有其他数据解决方案似乎都把 Google 当作“数据处理中间人”。
Uku 的第一直觉是利用现有的数据库解决方案专注于分析方面的工作。马上,他就遇到了一些挑战。开始尝试使用了 PostgreSQL,这在技术上很幼稚,因为它很快就变得不堪重负,效率低下。因此,他的目标蜕变成了做一个分析产品,可以处理大量的数据点,而且性能不会有明显的下降。简而言之,Uku 成功了,Plausible 现在每月可以收取超过 8000 万条记录。
Plausible 的第一个版本于 2019 年夏天发布。2020 年 3 月,Marko 加入,负责项目的传播和营销方面的工作。从那时起,它它的受欢迎程度有了很大的增长。
### 为什么要开源?
Uku 热衷于遵循“独立黑客”的软件开发路线:创建一个产品,把它投放出去,然后看看它如何成长。开源在这方面是有意义的,因为你可以迅速发展一个社区并获得人气。
但 Plausible 一开始并不是开源的。Uku 最初担心软件的敏感代码,比如计费代码,但他很快就发布了,因为这对没有 API 令牌的人来说是没有用的。
现在,Plausible 是在 [AGPL](https://www.gnu.org/licenses/agpl-3.0.en.html) 下完全开源的,他们选择了 AGPL 而不是 MIT 许可。Uku 解释说,在 MIT 许可下,任何人都可以不受限制地对代码做任何事情。在 AGPL 下,如果有人修改代码,他们必须将他们的修改开源,并将代码回馈给社区。这意味着,大公司不能拿着原始代码在此基础上进行构建,然后获得所有的回报。他们必须共享,使得竞争环境更加公平。例如,如果一家公司想插入他们的计费或登录系统,他们有法律义务发布代码。
在播客中,Uku 向我询问了关于 Flagsmith 的授权,目前 Flagsmith 的授权采用 BSD 三句版许可,该许可证是高度开放的,但我即将把一些功能移到更严格的许可后面。到目前为止,Flagsmith 社区已经理解了这一变化,因为他们意识到这将带来更多更好的功能。
### Plausible vs. Google Analytics
Uku 说,在他看来,开源的精神是,代码应该是开放的,任何人都可以进行商业使用,并与社区共享,但你可以把一个闭源的 API 模块作为专有附加组件保留下来。这样一来,Plausible 和其他公司就可以通过创建和销售定制的 API 附加许可来满足不同的使用场景。
Marko 职位上是一名开发者,但从营销方面来说,他努力让这个项目在 Hacker News 和 Lobster 等网站上得到报道,并建立了 Twitter 帐户以帮助产生动力。这种宣传带来的热潮也意味着该项目在 GitHub 上起飞,从 500 颗星到 4300 颗星。随着流量的增长,Plausible 出现在 GitHub 的趋势列表中,这让其受欢迎程度像滚雪球一样。
Marko 还非常注重发布和推广博客文章。这一策略得到了回报,在最初的 6 个月里,有四五篇文章进入了病毒式传播,他利用这些峰值来放大营销信息,加速了增长。
Plausible 成长过程中最大的挑战是让人们从 Google Analytics 上转换过来。这个项目的主要目标是创建一个有用、高效、准确的网络分析产品。它还需要符合法规,并为企业和网站访问者提供高度的隐私。
Plausible 现在已经在 8000 多个网站上运行。通过与客户的交谈,Uku 估计其中约 90% 的客户运行过 Google Analytics。
Plausible 以标准的软件即服务 (SaaS) 订阅模式运行。为了让事情更公平,它按月页面浏览量收费,而不是按网站收费。对于季节性网站来说,这可能会有麻烦,比如说电子商务网站在节假日会激增,或者美国大选网站每四年激增一次。这些可能会导致月度订阅模式下的定价问题,但它通常对大多数网站很好。
### 查看播客
想要了解更多关于 Uku 和 Marko 如何以惊人的速度发展开源 Plausible 项目,并使其获得商业上的成功,请[收听播客](https://www.flagsmith.com/podcast/02-plausible),并查看[其他剧集](https://www.flagsmith.com/podcast),了解更多关于“开源软件社区的来龙去脉”。
---
via: <https://opensource.com/article/21/2/plausible>
作者:[Ben Rometsch](https://opensource.com/users/flagsmith) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Taking on the might of Google Analytics may seem like a big challenge. In fact, you could say it doesn't sound plausible… But that's exactly what [Plausible.io](https://plausible.io/) has done with great success, signing up thousands of new users since 2018.
Plausible's co-founders Uku Taht and Marko Saric recently appeared on [The Craft of Open Source](https://www.flagsmith.com/podcast/02-plausible) podcast to talk about the project and how they:
- Created a viable alternative to Google Analytics
- Gained so much momentum in less than two years
- Achieved their goals by open sourcing the project
Read on for a summary of their conversation with podcast host and Flagsmith founder Ben Rometsch.
## How Plausible got started
In winter 2018, Uku started coding a project that he thought was desperately needed—a viable, effective alternative to Google Analytics—after becoming disillusioned with the direction Google products were heading and the fact that all other data solutions seemed to use Google as a "data-handling middleman."
Uku's first instinct was to focus on the analytics side of things using existing database solutions. Right away, he faced some challenges. The first attempt, using PostgreSQL, was technically naïve, as it became overwhelmed and inefficient pretty quickly. Therefore, his goal morphed into making an analytics product that can handle large quantities of data points with no discernable decline in performance. To cut a long story short, Uku succeeded, and Plausible can now ingest more than 80 million records per month.
The first version of Plausible was released in summer 2019. In March 2020, Marko came on board to head up the project's communications and marketing side. Since then, its popularity has grown with considerable momentum.
## Why open source?
Uku was keen to follow the "indie hacker" route of software development: create a product, put it out there, and see how it grows. Open source makes sense in this respect because you can quickly grow a community and gain popularity.
But Plausible didn't start out as open source. Uku was initially concerned about the software's sensitive code, such as billing codes, but he soon released that this was of no use to people without the API token.
Now, Plausible is fully open source under [AGPL](https://www.gnu.org/licenses/agpl-3.0.en.html), which they chose instead of the MIT License. Uku explains that under an MIT License, anyone can do anything to the code without restriction. Under AGPL, if someone changes the code, they must open source their changes and contribute the code back to the community. This means that large corporations cannot take the original code, build from it, then reap all the rewards. They must share it, making for a more level playing field. For instance, if a company wanted to plug in their billing or login system, they would be legally obliged to publish the code.
During the podcast, Uku asked me about Flagsmith's license which is currently under a BSD 3-Clause license, which is highly permissive, but I am about to move some features behind a more restrictive license. So far, the Flagsmith community has been understanding of the change as they realize this will lead to more and better features.
## Plausible vs. Google Analytics
Uku says, in his opinion, the spirit of open source is that the code should be open for commercial use by anyone and shared with the community, but you can keep back a closed-source API module as a proprietary add-on. In this way, Plausible and other companies can cater to different use-cases by creating and selling bespoke API add-on licenses.
Marko is a developer by trade, but from the marketing side of things, he worked to get the project covered on sites such as Hacker News and Lobster and build a Twitter presence to help generate momentum. The buzz created by this publicity also meant that the project took off on GitHub, going from 500 to 4,300 stars. As traffic grew, Plausible appeared on GitHub's trending list, which helped its popularity snowball.
Marko also focused heavily on publishing and promoting blog posts. This strategy paid off, as four or five posts went viral within the first six months, and he used those spikes to amplify the marketing message and accelerate growth.
The biggest challenge in Plausible's growth was getting people to switch from Google Analytics. The project's main goal was to create a web analytics product that is useful, efficient, and accurate. It also needed to be compliant with regulations and offer a high degree of privacy for both the business and website visitors.
Plausible is now running on more than 8,000 websites. From talking to customers, Uku estimates that around 90% of them would have run Google Analytics.
Plausible runs on a standard software-as-a-service (SaaS) subscription model. To make things fairer, it charges per page view on a monthly basis, rather than charging per website. This can prove tricky with seasonal websites, say e-commerce sites that spike at the holidays or US election sites that spike once every four years. These can cause pricing problems under the monthly subscription model, but it generally works well for most sites.
## Check out the podcast
To discover more about how Uku and Marko grew the open source Plausible project at a phenomenal rate and made it into a commercial success, [listen to the podcast](https://www.flagsmith.com/podcast/02-plausible) and check out [other episodes](https://www.flagsmith.com/podcast) to learn more about "the ins-and-outs of the open source software community."
## 1 Comment |
13,136 | 使用 LaTeX 和 TeXstudio 排版文档 | https://fedoramagazine.org/typeset-latex-texstudio-fedora/ | 2021-02-20T09:45:28 | [
"LaTeX"
] | https://linux.cn/article-13136-1.html | 
LaTeX 是一个服务于高质量排版的[文档准备系统](http://www.latex-project.org/about/)。通常用于大量的技术和科学文档的排版。不过,你也可以使用 LaTex 排版各种形式的文档。教师可以编辑他们的考试和教学大纲,学生可以展示他们的论文和报告。这篇文章让你尝试使用 TeXstudio。TeXstudio 是一个便于编辑 LaTeX 文档的软件。
### 启动 TeXstudio
如果你使用的是 Fedora Workstation,请启动软件管理,然后输入 TeXstudio 以搜索该应用程序。然后选择安装并添加 TeXstudio 到你的系统。你可以从软件管理中启动这个程序,或者像以往一样在概览中启动这个软件。
或者,如果你使用终端,请输入 `texstudio`。如果未安装该软件包,系统将提示你安装它。键入 `y` 开始安装。
```
$ texstudio
bash: texstudio: command not found...
Install package 'texstudio' to provide command 'texstudio'? [N/y] y
```
### 你的第一份文档
LaTeX 命令通常以反斜杠 `\` 开头,命令参数用大括号 `{}` 括起来。首先声明 `documentclass` 的类型。这个例子向你展示了该文档的类是一篇文章。
然后,在声明 `documentclass` 之后,用 `begin` 和 `end` 标记文档的开始和结束。在这些命令之间,写一段类似以下的内容:
```
\documentclass{article}
\begin{document}
The Fedora Project is a project sponsored by Red Hat primarily to co-ordinate the development of the Linux-based Fedora operating system, operating with the vision that the project "creates a world where free culture is welcoming and widespread, collaboration is commonplace, and people control their content and devices". The Fedora Project was founded on 22 September 2003 when Red Hat decided to split Red Hat Linux into Red Hat Enterprise Linux (RHEL) and a community-based operating system, Fedora.
\end{document}
```

### 使用间距
要创建段落分隔符,请在文本之间保留一个或多个换行符。下面是一个包含四个段落的示例:

从该示例中可以看出,多个换行符不会在段落之间创建额外的空格。但是,如果你确实需要留出额外的空间,请使用 `hspace` 和 `vspace` 命令。这两个命令分别添加水平和垂直空间。下面是一些示例代码,显示了段落周围的附加间距:
```
\documentclass{article}
\begin{document}
\hspace{2.5cm} The four essential freedoms
\vspace{0.6cm}
A program is free software if the program's users have the 4 essential freedoms:
The freedom to run the program as you wish, for any purpose (freedom 0).\vspace{0.2cm}
The freedom to study how the program works, and change it so it does your computing as you wish (freedom 1). Access to the source code is a precondition for this.\vspace{0.2cm}
The freedom to redistribute copies so you can help your neighbour (freedom 2).\vspace{0.2cm}
The freedom to distribute copies of your modified versions to others (freedom 3). By doing this you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this.
\end{document}
```
如果需要,你也可以使用 `noindent` 命令来避免缩进。这里是上面 LaTeX 源码的结果:

### 使用列表和格式
如果把自由软件的四大基本自由列为一个清单,这个例子看起来会更好。通过在列表的开头使用`\begin{itemize}`,在末尾使用 `\end{itemize}` 来设置列表结构。在每个项目前面加上 `\item` 命令。
额外的格式也有助于使文本更具可读性。用于格式化的有用命令包括粗体、斜体、下划线、超大、大、小和 textsc 以帮助强调文本:
```
\documentclass{article}
\begin{document}
\hspace{2cm} {\huge The four essential freedoms}
\vspace{0.6cm}
\noindent {\large A program is free software if the program's users have the 4 essential freedoms}:
\begin{itemize}
\item \vspace{0.2cm}
\noindent \textbf{The freedom to run} the program as you wish, for any purpose \textit{(freedom 0)}. \vspace{0.2cm}
\item \noindent \textbf{The freedom to study} how the program works, and change it so it does your computing as you wish \textit{(freedom 1)}. Access to the source code is a precondition for this.\vspace{0.2cm}
\item \noindent \textbf{The freedom to redistribute} copies so you can help your neighbour \textit{(freedom 2)}.\vspace{0.2cm}
\item \noindent \textbf{The freedom to distribute copies of your modified versions} to others \textit{(freedom 3)}. \tiny{By doing this you can give the whole community a chance to benefit from your changes.\underline{\textsc{ Access to the source code is a precondition for this.}}}
\end{itemize}
\end{document}
```

### 添加列、图像和链接
列、图像和链接有助于为文本添加更多信息。LaTeX 包含一些高级功能的函数作为宏包。`\usepackage` 命令加载宏包以便你可以使用这些功能。
例如,要使用图像,可以使用命令 `\usepackage{graphicx}`。或者,要设置列和链接,请分别使用 `\usepackage{multicol}` 和 `\usepackage{hyperref}`。
`\includegraphics` 命令将图像内联放置在文档中。(为简单起见,请将图形文件包含在与 LaTeX 源文件相同的目录中。)
下面是一个使用所有这些概念的示例。它还使用下载的两个 PNG 图片。试试你自己的图片,看看它们是如何工作的。
```
\documentclass{article}
\usepackage{graphicx}
\usepackage{multicol}
\usepackage{hyperref}
\begin{document}
\textbf{GNU}
\vspace{1cm}
GNU is a recursive acronym for "GNU's Not Unix!", chosen because GNU's design is Unix-like, but differs from Unix by being free software and containing no Unix code.
Richard Stallman, the founder of the project, views GNU as a "technical means to a social end". Stallman has written about "the social aspects of software and how Free Software can create community and social justice." in his "Free Society" book.
\vspace{1cm}
\textbf{Some Projects}
\begin{multicols}{2}
Fedora
\url{https://getfedora.org}
\includegraphics[width=1cm]{fedora.png}
GNOME
\url{https://getfedora.org}
\includegraphics[width=1cm]{gnome.png}
\end{multicols}
\end{document}
```

这里的功能只触及 LaTeX 功能的表面。你可以在该项目的[帮助和文档站点](https://www.latex-project.org/help/)了解更多关于它们的信息。
---
via: <https://fedoramagazine.org/typeset-latex-texstudio-fedora/>
作者:[Julita Inca Chiroque](https://fedoramagazine.org/author/yulytas/) 选题:[Chao-zhi](https://github.com/Chao-zhi) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | LaTeX is [a document preparation system](http://www.latex-project.org/about/) for high-quality typesetting. It’s often used for larger technical or scientific documents. However, you can use LaTeX for almost any form of publishing. Teachers can edit their exams and syllabi, and students can present their thesis and reports for classes. This article gets you started with the TeXstudio app. TeXstudio makes it easy to edit LaTeX documents.
**Launching TeXstudio**
If you’re using Fedora Workstation, launch *Software**, *and type **TeXstudio** to search for the app. Then select *Install* to add TeXstudio to your system. You can also launch the app from *Software*, or go to the shell overview as usual.
Alternately, if you use a terminal, type **texstudio**. If the package isn’t installed, the system prompts you to install it. Type *y* to start the installation.
$texstudiobash: texstudio: command not found... Install package 'texstudio' to provide command 'texstudio'? [N/y] y
**Your first document**
LaTeX commands typically start with a backslash (), and command parameters are enclosed in curly braces { }. Start by declaring the type of the *documentclass*. This example shows you the document class is an *article*.
Then, once you declare the *documentclass*, mark the beginning and the end of the document with *begin* and *end*. In between these commands, write a paragraph similar to the following:
\documentclass{article} \begin{document} The Fedora Project is a project sponsored by Red Hat primarily to co-ordinate the development of the Linux-based Fedora operating system, operating with the vision that the project "creates a world where free culture is welcoming and widespread, collaboration is commonplace, and people control their content and devices". The Fedora Project was founded on 22 September 2003 when Red Hat decided to split Red Hat Linux into Red Hat Enterprise Linux (RHEL) and a community-based operating system, Fedora. \end{document}
LaTeX is like source code compiled into an app you can run. The LaTeX source is processed so you can view the output document. To run (or process) the project, click on the green play icon. To display a preview, click on the magnifying-glass icon.
### Working with spacing
To create a paragraph break, leave one or more blank spaces between text. Here’s an example with four paragraphs:
You can see from the example that more than one line break doesn’t create additional blank space between paragraphs. However, if you do need to leave additional space, use the commands* hspace* and
*vspace.*These add horizontal and vertical space, respectively. Here is some example code that shows additional spacing around paragraphs:
\documentclass{article} \begin{document} \hspace{2.5cm} The four essential freedoms \vspace{0.6cm} A program is free software if the program's users have the 4 essential freedoms: The freedom to run the program as you wish, for any purpose (freedom 0).\vspace{0.2cm} The freedom to study how the program works, and change it so it does your computing as you wish (freedom 1). Access to the source code is a precondition for this.\vspace{0.2cm} The freedom to redistribute copies so you can help your neighbour (freedom 2).\vspace{0.2cm} The freedom to distribute copies of your modified versions to others (freedom 3). By doing this you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this. \end{document}
If needed, you can also use the *noindent* command to avoid indentation. Here is the result of the LaTeX source above:
### Using Lists and Formats
This example would look better if it presented the four essential freedoms of free software as a list. Set the list structure by using *\begin{itemize}* at the beginning of the list, and *\end{itemize} *at the end. Precede each item with the command *\item.*
Additional format also helps make the text more readable. Useful commands for formatting include *bold, italic, underline, huge, large, tiny *and *textsc *to help emphasize text:
\documentclass{article} \begin{document} \hspace{2cm} {\huge The four essential freedoms} \vspace{0.6cm} \noindent {\large A program is free software if the program's users have the 4 essential freedoms}: \begin{itemize} \item \vspace{0.2cm} \noindent \textbf{The freedom to run} the program as you wish, for any purpose \textit{(freedom 0)}. \vspace{0.2cm} \item \noindent \textbf{The freedom to study} how the program works, and change it so it does your computing as you wish \textit{(freedom 1)}. Access to the source code is a precondition for this.\vspace{0.2cm} \item \noindent \textbf{The freedom to redistribute} copies so you can help your neighbour \textit{(freedom 2)}.\vspace{0.2cm} \item \noindent \textbf{The freedom to distribute copies of your modified versions} to others \textit{(freedom 3)}. \tiny{By doing this you can give the whole community a chance to benefit from your changes.\underline{\textsc{ Access to the source code is a precondition for this.}}} \end{itemize} \end{document}
### Adding columns, images and links
Columns, images and links help add further information to your text. LaTeX includes functions for some advanced features as packages. The *\usepackage* command loads the package so you can make use of these features.
For example, to make an image visible, you might use the command *\usepackage{graphicx}*. Or, to set up columns and links, use *\usepackage{multicol}* and *\usepackage{hyperref}*, respectively.
The *\includegraphics* command places an image inline in your document. (For simplicity, include the graphics file in the same directory as your LaTeX source file.)
Here’s an example that uses all these concepts. It also uses two PNG graphics files that were downloaded. Try your own graphics to see how they work.
\documentclass{article} \usepackage{graphicx} \usepackage{multicol} \usepackage{hyperref} \begin{document} \textbf{GNU} \vspace{1cm} GNU is a recursive acronym for "GNU's Not Unix!", chosen because GNU's design is Unix-like, but differs from Unix by being free software and containing no Unix code. Richard Stallman, the founder of the project, views GNU as a "technical means to a social end". Stallman has written about "the social aspects of software and how Free Software can create community and social justice." in his "Free Society" book. \vspace{1cm} \textbf{Some Projects} \begin{multicols}{2} Fedora \url{https://getfedora.org} \includegraphics[width=1cm]{fedora.png} GNOME \url{https://getfedora.org} \includegraphics[width=1cm]{gnome.png} \end{multicols} \end{document}
The features here only scratch the surface of LaTeX capabilities. You can learn more about them at the project [help and documentation site](https://www.latex-project.org/help/).
## Chris
Nice article!
Anyway: The example in “Using Lists and Formats” has an error:
The third last line ends with two curly braces but needs three ones:
## Paul W. Frields
@Chris: Thanks, fixed!
## Mark
Does latex now automatically download required packages?
I used to download ALL of latex. This would be OK except when updating from say F25->F26 where it would have to install 4000+ latex related packages all over again.
## David Potter
As far as I know, the only version of Latex that does “on-the-fly installation” of any packages you need for a particular document is MikTex. MikTex is only available for Windows.
## Horst H. von Brand
Most packages are small (a few KiB), to update hundreds of them is no big deal.
## Son Nguyen
This article is just a beginning, a brief tutorial, but it’s still very helpful for the beginner like me. Hope you continue to write some more article about Latex tutorial.
Thank you.
## Steve
I am a Solution Provider and integrator of industrial automation products. I create all of my customers manuals using TeXstudio. I was familiar with latex, but had never really used it until I began using TeXstudio about 6 years ago. Even after 6 years of use, I have barely scratched the surface of the potential of TeXstudio, or latex for that matter. Good article Paul. These types of Open Source projects, such a TeXstudio, latex, etc… are able to compete against the proprietary over priced offerings being shilled by the giant corporations. Now if only I could program every PLC I come across with Open Source solutions I would feel … free.
## Jim
Another minor error: In the “includegraphics” example, in the text pane above the TeXstudio image the url for gnome is a duplicate of the fedora url. The Testudio image has a the correct url. At one time I used LaTeX extensively for technical documents with many mathematical formulae. Nothing does a better job of printing complex formulae correctly.
## eee
why not commandline and viewer? for example gs
## Horst H. von Brand
xemacs with AUC-TeX… 😉
## Renato
Dont worry anymore with anoinyg package installation. Use sharelatex or openleaf. Both are online editor like Google doc. Allways with the last latex and package vertion
## ken
Have been using Texmaker for creating latex documents. Would be interesting to hear
any comments on advantages and disadvantages of one over the other or whether
they complement one another.
Nice article, Will spend more time going through it
## Momme
Hi,
I want to ask how to install new packages for tex. With texlive it works with tlmgr, but I do not know how to handle it in the automtic installed tex package.
Thanks
## Horst H. von Brand
The tutorials that come with TeX are useful starting points (lshort is the “not so short” introduction to LaTeX). To dig deeper, the wikibook at https://en.wikibooks.org/wiki/LaTeX is useful, if somewhat incomplete and with errors and uses obsolete packages or some that (to my taste!) aren’t the best options. For the full details, most everything is extensely documented, and if that doesn’t help or you are completely lost, looking around in http://tex.stackexhange.com usually saves the day.
## Frank
I do like ConTeXt MUCH more:
• Way smaller headers,
• unicode,
• almost all useful packages are already included,
• so no package conflicts,
• Lua scripting, and
• the syntax is more generalized – so the handling of several commands feels the same and is very intuitive and guessable – in contrast to LaTeX, where you have all these drawbacks.
## Mehdi
Thanks
This is a great article. TeX is really hard though and boring job! LibreOffice works much easier I think, though it might not be that under your control.
## Hiisi
Any benefit of using this redactor compare to vim or any other text editor?
## Mark
I think texstudio vs VIM is a little bit like the difference between “Text editors vs IDEs”. I wrote my thesis in TexStudio and before that, was a avid VIM user.
Here are some of the features that would have been difficult (maybe just taken alot more time to setup than I had) in VIM
Nicer formatting on error messages and warning message. Latex by no means gives you “useful” messages, but at least in TexStudio the mssages are organized and I can double click on the first one. Sometimes that was useful. Other times, it was no slower than trying to piece together an error message that was spread over multiple lines on the command line.
Cross platform. You can use it on Windows which might make collaborative projects easier since not everybody uses Linux.
You can click on the PDF preview and say “Go to source”. This was very useful during the review process.
Honestly though, for certain problems like: having greek letters in my bibtex files, TexStudio didn’t help anymore than VIM. But I think that is a latex problem, and not a TexStudio problem. |
13,137 | 用 ranger 在 Linux 文件的海洋中导航 | https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html | 2021-02-20T12:19:38 | [
"ranger",
"导航"
] | https://linux.cn/article-13137-1.html |
>
> ranger 是一个很好的工具,它为你的 Linux 文件提供了一个多级视图,并允许你使用方向键和一些方便的命令进行浏览和更改。
>
>
>

`ranger` 是一款独特且非常方便的文件系统导航器,它允许你在 Linux 文件系统中移动,进出子目录,查看文本文件内容,甚至可以在不离开该工具的情况下对文件进行修改。
它运行在终端窗口中,并允许你按下方向键进行导航。它提供了一个多级的文件显示,让你很容易看到你在哪里、在文件系统中移动、并选择特定的文件。
要安装 `ranger`,请使用标准的安装命令(例如,`sudo apt install ranger`)。要启动它,只需键入 `ranger`。它有一个很长的、非常详细的手册页面,但开始使用 `ranger` 非常简单。
### ranger 的显示方式
你需要马上习惯的最重要的一件事就是 `ranger` 的文件显示方式。一旦你启动了 `ranger`,你会看到四列数据。第一列是你启动 `ranger` 的位置的上一级。例如,如果你从主目录开始,`ranger` 将在第一列中列出所有的主目录。第二列将显示你的主目录(或者你开始的目录)中的目录和文件的第一屏内容。
这里的关键是超越你可能有的任何习惯,将每一行显示的细节看作是相关的。第二列中的所有条目与第一列中的单个条目相关,第四列中的内容与第二列中选定的文件或目录相关。
与一般的命令行视图不同的是,目录将被列在第一位(按字母数字顺序),文件将被列在第二位(也是按字母数字顺序)。从你的主目录开始,显示的内容可能是这样的:
```
shs@dragonfly /home/shs/backups <== current selection
bugfarm backups 0 empty
dory bin 59
eel Buttons 15
nemo Desktop 0
shark Documents 0
shs Downloads 1
^ ^ ^ ^
| | | |
homes directories # files listing
in selected in each of files in
home directory selected directory
```
`ranger` 显示的最上面一行告诉你在哪里。在这个例子中,当前目录是 `/home/shs/backups`。我们看到高亮显示的是 `empty`,因为这个目录中没有文件。如果我们按下方向键选择 `bin`,我们会看到一个文件列表:
```
shs@dragonfly /home/shs/bin <== current selection
bugfarm backups 0 append
dory bin 59 calcPower
eel Buttons 15 cap
nemo Desktop 0 extract
shark Documents 0 finddups
shs Downloads 1 fix
^ ^ ^ ^
| | | |
homes directories # files listing
in selected in each of files in
home directory selected directory
```
每一列中高亮显示的条目显示了当前的选择。使用右方向键可移动到更深的目录或查看文件内容。
如果你继续按下方向键移动到列表的文件部分,你会注意到第三列将显示文件大小(而不是文件的数量)。“当前选择”行也会显示当前选择的文件名,而最右边的一列则会尽可能地显示文件内容。
```
shs@dragonfly /home/shs/busy_wait.c <== current selection
bugfarm BushyRidge.zip 170 K /*
dory busy_wait.c 338 B * program that does a busy wait
eel camper.jpg 5.55 M * it's used to show ASLR, and that's it
nemo check_lockscreen 80 B */
shark chkrootkit-output 438 B #include <stdio.h>
^ ^ ^ ^
| | | |
homes files sizes file content
```
在该显示的底行会显示一些文件和目录的详细信息:
```
-rw-rw-r—- shs shs 338B 2019-01-05 14:44 1.52G, 365G free 67/488 11%
```
如果你选择了一个目录并按下回车键,你将进入该目录。然后,在你的显示屏中最左边的一列将是你的主目录的内容列表,第二列将是该目录内容的文件列表。然后你可以检查子目录的内容和文件的内容。
按左方向键可以向上移动一级。
按 `q` 键退出 `ranger`。
### 做出改变
你可以按 `?` 键,在屏幕底部弹出一条帮助行。它看起来应该是这样的:
```
View [m]an page, [k]ey bindings, [c]commands or [s]ettings? (press q to abort)
```
按 `c` 键,`ranger` 将提供你可以在该工具内使用的命令信息。例如,你可以通过输入 `:chmod` 来改变当前文件的权限,后面跟着预期的权限。例如,一旦选择了一个文件,你可以输入 `:chmod 700` 将权限设置为 `rwx------`。
输入 `:edit` 可以在 `nano` 中打开该文件,允许你进行修改,然后使用 `nano` 的命令保存文件。
### 总结
使用 `ranger` 的方法比本篇文章所描述的更多。该工具提供了一种非常不同的方式来列出 Linux 系统上的文件并与之交互,一旦你习惯了它的多级的目录和文件列表方式,并使用方向键代替 `cd` 命令来移动,就可以很轻松地在 Linux 的文件中导航。
---
via: <https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
13,139 | Viper 浏览器:一款注重隐私和简约的轻量级 Qt5 浏览器 | https://itsfoss.com/viper-browser/ | 2021-02-21T11:02:00 | [
"Viper",
"浏览器"
] | https://linux.cn/article-13139-1.html |
>
> Viper 浏览器是一个基于 Qt 的浏览器,它提供了简单易用的用户体验,同时考虑到隐私问题。
>
>
>

虽然大多数流行的浏览器都运行在 Chromium 之上,但像 [Firefox](https://www.mozilla.org/en-US/firefox/new/)、[Beaker 浏览器](https://itsfoss.com/beaker-browser-1-release/)以及其他一些 [chrome 替代品](https://itsfoss.com/open-source-browsers-linux/)这样独特的替代品不应该停止存在。
尤其是考虑到谷歌最近可能想到从 Chromium 中剥离[谷歌浏览器特有的功能](https://www.bleepingcomputer.com/news/google/google-to-kill-chrome-sync-feature-in-third-party-browsers/),并给出了滥用的借口。
在寻找更多的 Chrome 替代品时,我在 [Mastodon](https://mastodon.social/web/accounts/199851) 上看到了一个有趣的项目 “[Viper 浏览器](https://github.com/LeFroid/Viper-Browser)”。
### Viper 浏览器:一个基于 Qt5 的开源浏览器
**注意**:Viper 浏览器是一个只有几个贡献者的相当新的项目。它缺乏某些功能,我将在下文提及。
Viper 是一款有趣的 Web 浏览器,在利用 [QtWebEngine](https://wiki.qt.io/QtWebEngine) 的同时,它专注于成为一个强大而又轻巧的选择。
QtWebEngine 借用了 Chromium 的代码,但它不包括连接到 Google 平台的二进制文件和服务。
我花了一些时间使用它并进行一些日常浏览活动,我必须说,我对它相当感兴趣。不仅仅是因为它是一个简单易用的东西(浏览器可以那么复杂),而且它还专注于增强你的隐私,为你提供添加不同的广告阻止选项以及一些有用的选项。

虽然我认为它并不是为所有人准备的,但还是值得一看的。在你继续尝试之前,让我简单介绍一下它的功能。
### Viper 浏览器的功能

我将列出一些你会发现有用的关键功能:
* 管理 cookies 的能力
* 多个预设选项以选择不同的广告屏蔽器网络。
* 简单且易于使用
* 隐私友好的默认搜索引擎 - [Startpage](https://www.startpage.com) (你可以更改)
* 能够添加用户脚本
* 能够添加新的 user-agent
* 禁用 JavaScript 的选项
* 能够阻止图像加载
除了这些亮点之外,你还可以轻松地调整隐私设置,以删除你的历史记录、清理已有 cookies,以及一些更多的选项。

### 在 Linux 上安装 Viper 浏览器
它只是在[发布页](https://github.com/LeFroid/Viper-Browser/releases)提供了一个 AppImage 文件,你可以利用它在任何 Linux 发行版上进行测试。
如果你需要帮助,你也可以参考我们的[在 Linux 上使用 AppImage 文件](https://itsfoss.com/use-appimage-linux/)指南。如果你好奇,你可以在 [GitHub](https://github.com/LeFroid/Viper-Browser) 上探索更多关于它的内容。
* [Viper 浏览器](https://github.com/LeFroid/Viper-Browser)
### 我对使用 Viper 浏览器的看法
我不认为这是一个可以立即取代你当前浏览器的东西,但如果你有兴趣测试尝试提供 Chrome 替代品的新项目,这肯定是其中之一。
当我试图登录我的谷歌账户时,它阻止了我,说它可能是一个不安全的浏览器或不支持的浏览器。因此,如果你依赖你的谷歌帐户,这是一个令人失望的消息。
但是,其他社交媒体平台也可以与 YouTube 一起正常运行(无需登录)。不支持 Netflix,但总体上浏览体验是相当快速和可用的。
你可以安装用户脚本,但 Chrome 扩展还不支持。当然,这要么是有意为之,要么是在开发过程中特别考虑到它是一款隐私友好型的网络浏览器。
### 总结
考虑到这是一个鲜为人知但对某些人来说很有趣的东西,你对我们有什么建议吗? 是一个值得关注的开源项目么?
请在下面的评论中告诉我。
---
via: <https://itsfoss.com/viper-browser/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Viper Browser is a Qt-based browser that offers a simple user experience keeping privacy in mind.*
While the majority of the popular browsers run on top of Chromium, unique alternatives like [Firefox](https://www.mozilla.org/en-US/firefox/new/), [Beaker Browser](https://itsfoss.com/beaker-browser-1-release/), and some other [chrome alternatives](https://itsfoss.com/open-source-browsers-linux/) should not cease to exist.
Especially, considering Google’s recent potential thought of stripping [Google Chrome-specific features from Chromium](https://www.bleepingcomputer.com/news/google/google-to-kill-chrome-sync-feature-in-third-party-browsers/) giving an excuse of abuse.
In the look-out for more Chrome alternatives, I came across an interesting project “[Viper Browser](https://github.com/LeFroid/Viper-Browser)” as per our reader’s suggestion on [Mastodon](https://mastodon.social/web/accounts/199851).
## Viper Browser: An Open-Source Qt5-based Browser
**Note**: Viper Browser is fairly a new project with a couple of contributors. It lacks certain features which I’ll be mentioning as you read on.
Viper is an interesting web browser that focuses on being a powerful yet lightweight option while utilizing [QtWebEngine](https://wiki.qt.io/QtWebEngine).
QtWebEngine borrows the code from Chromium but it does not include the binaries and services that connect to the Google platform.
I spent some time using it and performing some daily browsing activities and I must say that I’m quite interested. Not just because it is something simple to use (how complicated a browser can be), but it also focuses on enhancing your privacy by giving you the option to add different Ad blocking options along with some useful options.
Even though I think it is not meant for everyone, it is still worth taking a look. Let me highlight the features briefly before you can proceed trying it out.
## Features of Viper Browser
I’ll list some of the key features that you can find useful:
- Ability to manage cookies
- Multiple preset options to choose different Adblocker networks
- Simple and easy to use
- Privacy-friendly default search engine –
[Startpage](https://www.startpage.com)(you can change this) - Ability to add user scripts
- Ability to add new user agents
- Option to disable JavaScript
- Ability to prevent images from loading up
In addition to all these highlights, you can easily tweak the privacy settings to remove your history, clean cookies when existing, and some more options.
## Installing Viper Browser on Linux
It just offers an AppImage file on its [releases section](https://github.com/LeFroid/Viper-Browser/releases) that you can utilize to test on any Linux distribution.
In case you need help, you may refer to our guide on [using AppImage file on Linux](https://itsfoss.com/use-appimage-linux/) as well. If you’re curious, you can explore more about it on [GitHub](https://github.com/LeFroid/Viper-Browser).
## My Thoughts on Using Viper Browser
I don’t think it is something that could replace your current browser immediately but if you are interested to test out new projects that are trying to offer Chrome alternatives, this is surely one of them.
When I tried logging in my Google account, it prevented me by mentioning that it is potentially an insecure browser or unsupported browser. So, if you rely on your Google account, it is a disappointing news.
However, other social media platforms work just fine along with YouTube (without signing in). Netflix is not something supported but overall the browsing experience is quite fast and usable.
You can install user scripts, but Chrome extensions aren’t supported yet. Of course, it is either intentional or something to be looked after as the development progresses considering it as a privacy-friendly web browser.
## Wrapping Up
Considering that this is a less-known yet something interesting for some, do you have any suggestions for us to take a look at? An open-source project that deserves coverage?
Let me know in the comments down below. |
13,140 | JavaScript 闭包实践 | https://opensource.com/article/21/2/javascript-closures | 2021-02-21T16:31:50 | [
"JavaScript",
"闭包"
] | https://linux.cn/article-13140-1.html |
>
> 通过深入了解 JavaScript 的高级概念之一:闭包,更好地理解 JavaScript 代码的工作和执行方式。
>
>
>

在《[JavaScript 如此受欢迎的 4 个原因](/article-12830-1.html)》中,我提到了一些高级 JavaScript 概念。在本文中,我将深入探讨其中的一个概念:<ruby> 闭包 <rt> closure </rt></ruby>。
根据 [Mozilla 开发者网络](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures)(MDN),“闭包是将一个函数和对其周围的状态(词法环境)的引用捆绑在一起(封闭)的组合。”简而言之,这意味着在一个函数内部的函数可以访问其外部(父)函数的变量。
为了更好地理解闭包,可以看看作用域及其执行上下文。
下面是一个简单的代码片段:
```
var hello = "Hello";
function sayHelloWorld() {
var world = "World";
function wish() {
var year = "2021";
console.log(hello + " " + world + " "+ year);
}
wish();
}
sayHelloWorld();
```
下面是这段代码的执行上下文:

每次创建函数时(在函数创建阶段)都会创建闭包。每个闭包有三个作用域。
* 本地作用域(自己的作用域)
* 外部函数范围
* 全局范围
我稍微修改一下上面的代码来演示一下闭包:
```
var hello = "Hello";
var sayHelloWorld = function() {
var world = "World";
function wish() {
var year = "2021";
console.log(hello + " " + world + " "+ year);
}
return wish;
}
var callFunc = sayHelloWorld();
callFunc();
```
内部函数 `wish()` 在执行之前就从外部函数返回。这是因为 JavaScript 中的函数形成了**闭包**。
* 当 `sayHelloWorld` 运行时,`callFunc` 持有对函数 `wish` 的引用。
* `wish` 保持对其周围(词法)环境的引用,其中存在变量 `world`。
### 私有变量和方法
本身,JavaScript 不支持创建私有变量和方法。闭包的一个常见和实用的用途是模拟私有变量和方法,并允许数据隐私。在闭包范围内定义的方法是有特权的。
这个代码片段捕捉了 JavaScript 中闭包的常用编写和使用方式:
```
var resourceRecord = function(myName, myAddress) {
var resourceName = myName;
var resourceAddress = myAddress;
var accessRight = "HR";
return {
changeName: function(updateName, privilege) {
// only HR can change the name
if (privilege === accessRight ) {
resourceName = updateName;
return true;
} else {
return false;
}
},
changeAddress: function(newAddress) {
// any associate can change the address
resourceAddress = newAddress;
},
showResourceDetail: function() {
console.log ("Name:" + resourceName + " ; Address:" + resourceAddress);
}
}
}
// Create first record
var resourceRecord1 = resourceRecord("Perry","Office");
// Create second record
var resourceRecord2 = resourceRecord("Emma","Office");
// Change the address on the first record
resourceRecord1.changeAddress("Home");
resourceRecord1.changeName("Perry Berry", "Associate"); // Output is false as only an HR can change the name
resourceRecord2.changeName("Emma Freeman", "HR"); // Output is true as HR changes the name
resourceRecord1.showResourceDetail(); // Output - Name:Perry ; Address:Home
resourceRecord2.showResourceDetail(); // Output - Name:Emma Freeman ; Address:Office
```
资源记录(`resourceRecord1` 和 `resourceRecord2`)相互独立。每个闭包通过自己的闭包引用不同版本的 `resourceName` 和 `resourceAddress` 变量。你也可以应用特定的规则来处理私有变量,我添加了一个谁可以修改 `resourceName` 的检查。
### 使用闭包
理解闭包是很重要的,因为它可以更深入地了解变量和函数之间的关系,以及 JavaScript 代码如何工作和执行。
---
via: <https://opensource.com/article/21/2/javascript-closures>
作者:[Nimisha Mukherjee](https://opensource.com/users/nimisha) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In [ 4 reasons why JavaScript is so popular](https://opensource.com/article/20/11/javascript-popular), I touched on a few advanced JavaScript concepts. In this article, I will dive into one of them: closures.
According to [Mozilla Developer Network](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures) (MDN), "A closure is the combination of a function bundled together (enclosed) with references to its surrounding state (the lexical environment)." Simplified, this means that a function inside another function can access the variables from the outer (parent) function.
To better understand closures, take a look at scopes and their execution context.
Here is a simple code snippet:
```
var hello = "Hello";
function sayHelloWorld() {
var world = "World";
function wish() {
var year = "2021";
console.log(hello + " " + world + " "+ year);
}
wish();
}
sayHelloWorld();
```
Here's the execution context for this code:
(Nimisha Mukherjee, CC BY-SA 4.0)
Closures are created every time a function is created (at function-creation time). Every closure has three scopes:
- Local scope (own scope)
- Outer functions scope
- Global scope
I'll modify the above code slightly to demonstrate closure:
```
var hello = "Hello";
var sayHelloWorld = function() {
var world = "World";
function wish() {
var year = "2021";
console.log(hello + " " + world + " "+ year);
}
return wish;
}
var callFunc = sayHelloWorld();
callFunc();
```
The inner function `wish()`
is returned from the outer function before it's executed. This happens because functions in JavaScript form **closures**.
`callFunc`
holds a reference to the function`wish`
when`sayHelloWorld`
runs`wish`
maintains a reference to its surrounding (lexical) environment where the variable`world`
exists.
## Private variables and methods
Natively, JavaScript does not support the creation of private variables and methods. A common and practical use of closure is to emulate private variables and methods and allow data privacy. Methods defined within the closure scope are privileged.
This code snippet captures how closures are commonly written and used in JavaScript:
```
var resourceRecord = function(myName, myAddress) {
var resourceName = myName;
var resourceAddress = myAddress;
var accessRight = "HR";
return {
changeName: function(updateName, privilege) {
//only HR can change the name
if(privilege === accessRight ) {
resourceName = updateName;
return true;
} else {
return false;
}
},
changeAddress: function(newAddress) {
//any associate can change the address
resourceAddress = newAddress;
},
showResourceDetail: function() {
console.log ("Name:" + resourceName + " ; Address:" + resourceAddress);
}
}
}
//Create first record
var resourceRecord1 = resourceRecord("Perry","Office");
//Create second record
var resourceRecord2 = resourceRecord("Emma","Office");
//Change the address on the first record
resourceRecord1.changeAddress("Home");
resourceRecord1.changeName("Perry Berry", "Associate"); //Output is false as only an HR can change the name
resourceRecord2.changeName("Emma Freeman", "HR"); //Output is true as HR changes the name
resourceRecord1.showResourceDetail(); //Output - Name:Perry ; Address:Home
resourceRecord2.showResourceDetail(); //Output - Name:Emma Freeman ; Address:Office
```
The resource records (`resourceRecord1`
and `resourceRecord2`
) are independent of one another. Each closure references a different version of the `resourceName`
and `resourceAddress`
variable through its own closure. You can also apply specific rules to how private variables need to be handled—I added a check on who can modify `resourceName`
.
## Use closures
Understanding closure is important, as it enables deeper knowledge of how variables and functions relate to one another and how JavaScript code works and executes.
## Comments are closed. |
13,142 | Ansible 自动化工具安装、配置和快速入门指南 | https://www.2daygeek.com/install-configure-ansible-automation-tool-linux-quick-start-guide/ | 2021-02-22T12:48:20 | [
"Ansible"
] | https://linux.cn/article-13142-1.html | 
市面上有很多自动化工具。我可以举几个例子,例如 Puppet、Chef、CFEngine、Foreman、Katello、Saltstock、Space Walk,它们被许多组织广泛使用。
### 自动化工具可以做什么?
自动化工具可以自动执行例行任务,无需人工干预,从而使 Linux 管理员的工作变得更加轻松。这些工具允许用户执行配置管理,应用程序部署和资源调配。
### 为什么喜欢 Ansible?
Ansible 是一种无代理的自动化工具,使用 SSH 执行所有任务,但其它工具需要在客户端节点上安装代理。
### 什么是 Ansible?
Ansible 是一个开源、易于使用的功能强大的 IT 自动化工具,通过 SSH 在客户端节点上执行任务。
它是用 Python 构建的,这是当今世界上最流行、最强大的编程语言之一。两端都需要使用 Python 才能执行所有模块。
它可以配置系统、部署软件和安排高级 IT 任务,例如连续部署或零停机滚动更新。你可以通过 Ansible 轻松执行任何类型的自动化任务,包括简单和复杂的任务。
在开始之前,你需要了解一些 Ansible 术语,这些术语可以帮助你更好的创建任务。
### Ansible 如何工作?
Ansible 通过在客户端节点上推送称为 ansible 模块的小程序来工作,这些模块临时存储在客户端节点中,通过 JSON 协议与 Ansible 服务器进行通信。
Ansible 通过 SSH 运行这些模块,并在完成后将其删除。
模块是用 Python 或 Perl 等编写的一些脚本。

*控制节点,用于控制剧本的全部功能,包括客户端节点(主机)。*
* <ruby> 控制节点 <rt> Control node </rt></ruby>:使用 Ansible 在受控节点上执行任务的主机。你可以有多个控制节点,但不能使用 Windows 系统主机当作控制节点。
* <ruby> 受控节点 <rt> Managed node </rt></ruby>:控制节点配置的主机列表。
* <ruby> 清单 <rt> Inventory </rt></ruby>:控制节点管理的一个主机列表,这些节点在 `/etc/ansible/hosts` 文件中配置。它包含每个节点的信息,比如 IP 地址或其主机名,还可以根据需要对这些节点进行分组。
* <ruby> 模块 <rt> Module </rt></ruby>:每个模块用于执行特定任务,目前有 3387 个模块。
* <ruby> 点对点 <rt> ad-hoc </rt></ruby>:它允许你一次性运行一个任务,它使用 `/usr/bin/ansible` 二进制文件。
* <ruby> 任务 <rt> Task </rt></ruby>:每个<ruby> 动作 <rt> Play </rt></ruby>都有一个任务列表。任务按顺序执行,在受控节点中一次执行一个任务。
* <ruby> 剧本 <rt> Playbook </rt></ruby>:你可以使用剧本同时执行多个任务,而使用点对点只能执行一个任务。剧本使用 YAML 编写,易于阅读。将来,我们将会写一篇有关剧本的文章,你可以用它来执行复杂的任务。
### 测试环境
此环境包含一个控制节点(`server.2g.lab`)和三个受控节点(`node1.2g.lab`、`node2.2g.lab`、`node3.2g.lab`),它们均在虚拟环境中运行,操作系统分别为:
| System Purpose | Hostname | IP Address | OS |
| --- | --- | --- | --- |
| Ansible Control Node | server.2g.lab | 192.168.1.7 | Manjaro 18 |
| Managed Node1 | node1.2g.lab | 192.168.1.6 | CentOS7 |
| Managed Node2 | node2.2g.lab | 192.168.1.5 | CentOS8 |
| Managed Node3 | node3.2g.lab | 192.168.1.9 | Ubuntu 18.04 |
| User: daygeek | | | |
### 前置条件
* 在 Ansible 控制节点和受控节点之间启用无密码身份验证。
* 控制节点必须是 Python 2(2.7 版本) 或 Python 3(3.5 或更高版本)。
* 受控节点必须是 Python 2(2.6 或更高版本) 或 Python 3(3.5 或更高版本)。
* 如果在远程节点上启用了 SELinux,则在 Ansible 中使用任何与复制、文件、模板相关的功能之前,还需要在它们上安装 `libselinux-python`。
### 如何在控制节点上安装 Ansible
对于 Fedora/RHEL 8/CentOS 8 系统,使用 [DNF 命令](https://www.2daygeek.com/linux-dnf-command-examples-manage-packages-fedora-centos-rhel-systems/) 来安装 Ansible。
注意:你需要在 RHEL/CentOS 系统上启用 [EPEL 仓库](https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-oracle-linux/),因为 Ansible 软件包在发行版官方仓库中不可用。
```
$ sudo dnf install ansible
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 Ansible。
配置下面的 PPA 以便在 Ubuntu 上安装最新稳定版本的 Ansible。
```
$ sudo apt update
$ sudo apt install software-properties-common
$ sudo apt-add-repository --yes --update ppa:ansible/ansible
$ sudo apt install ansible
```
对于 Debian 系统,配置以下源列表:
```
$ echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu trusty main" | sudo tee -a /etc/apt/sources.list.d/ansible.list
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
$ sudo apt update
$ sudo apt install ansible
```
对于 Arch Linux 系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 Ansible:
```
$ sudo pacman -S ansible
```
对于 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 Ansible:
```
$ sudo yum install ansible
```
对于 openSUSE 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 Ansible:
```
$ sudo zypper install ansible
```
或者,你可以使用 [Python PIP 包管理工具](https://www.2daygeek.com/install-pip-manage-python-packages-linux/) 来安装:
```
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
$ sudo python get-pip.py
$ sudo pip install ansible
```
在控制节点上检查安装的 Ansible 版本:
```
$ ansible --version
ansible 2.9.2
config file = /etc/ansible/ansible.cfg
configured module search path = ['/home/daygeek/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.8/site-packages/ansible
executable location = /usr/bin/ansible
python version = 3.8.1 (default, Jan 8 2020, 23:09:20) [GCC 9.2.0]
```
### 如何在受控节点上安装 Python?
使用以下命令在受控节点上安装 python:
```
$ sudo yum install -y python
$ sudo dnf install -y python
$ sudo zypper install -y python
$ sudo pacman -S python
$ sudo apt install -y python
```
### 如何在 Linux 设置 SSH 密钥身份验证(无密码身份验证)
使用以下命令创建 ssh 密钥,然后将其复制到远程计算机。
```
$ ssh-keygen
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
```
具体参考这篇文章《[在 Linux 上设置 SSH 密钥身份验证(无密码身份验证)](https://www.2daygeek.com/configure-setup-passwordless-ssh-key-based-authentication-linux/)》。
### 如何创建 Ansible 主机清单
在 `/etc/ansible/hosts` 文件中添加要管理的节点列表。如果没有该文件,则可以创建一个新文件。以下是我的测试环境的主机清单文件:
```
$ sudo vi /etc/ansible/hosts
[web]
node1.2g.lab
node2.2g.lab
[app]
node3.2g.lab
```
让我们看看是否可以使用以下命令查找所有主机。
```
$ ansible all --list-hosts
hosts (3):
node1.2g.lab
node2.2g.lab
node3.2g.lab
```
对单个组运行以下命令:
```
$ ansible web --list-hosts
hosts (2):
node1.2g.lab
node2.2g.lab
```
### 如何使用点对点命令执行任务
一旦完成主机清单验证检查后,你就可以上路了。干的漂亮!
**语法:**
```
ansible [pattern] -m [module] -a "[module options]"
Details:
========
ansible: A command
pattern: Enter the entire inventory or a specific group
-m [module]: Run the given module name
-a [module options]: Specify the module arguments
```
使用 Ping 模块对主机清单中的所有节点执行 ping 操作:
```
$ ansible all -m ping
node3.2g.lab | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
node1.2g.lab | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
node2.2g.lab | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/libexec/platform-python"
},
"changed": false,
"ping": "pong"
}
```
所有系统都返回了成功,但什么都没有改变,只返回了 `pong` 代表成功。
你可以使用以下命令获取可用模块的列表。
```
$ ansible-doc -l
```
当前有 3387 个内置模块,它们会随着 Ansible 版本的递增而增加:
```
$ ansible-doc -l | wc -l
3387
```
使用 command 模块对主机清单中的所有节点执行命令:
```
$ ansible all -m command -a "uptime"
node3.2g.lab | CHANGED | rc=0 >>
18:05:07 up 1:21, 3 users, load average: 0.12, 0.06, 0.01
node1.2g.lab | CHANGED | rc=0 >>
06:35:06 up 1:21, 4 users, load average: 0.01, 0.03, 0.05
node2.2g.lab | CHANGED | rc=0 >>
18:05:07 up 1:25, 3 users, load average: 0.01, 0.01, 0.00
```
对指定组执行 command 模块。
检查 app 组主机的内存使用情况:
```
$ ansible app -m command -a "free -m"
node3.2g.lab | CHANGED | rc=0 >>
total used free shared buff/cache available
Mem: 1993 1065 91 6 836 748
Swap: 1425 0 1424
```
要对 web 组运行 `hostnamectl` 命令,使用以下格式:
```
$ ansible web -m command -a "hostnamectl"
node1.2g.lab | CHANGED | rc=0 >>
Static hostname: CentOS7.2daygeek.com
Icon name: computer-vm
Chassis: vm
Machine ID: 002f47b82af248f5be1d67b67e03514c
Boot ID: dc38f9b8089d4b2d9304e526e00c6a8f
Virtualization: kvm
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-957.el7.x86_64
Architecture: x86-64
node2.2g.lab | CHANGED | rc=0 >>
Static hostname: node2.2g.lab
Icon name: computer-vm
Chassis: vm
Machine ID: e39e3a27005d44d8bcbfcab201480b45
Boot ID: 27b46a09dde546da95ace03420fe12cb
Virtualization: oracle
Operating System: CentOS Linux 8 (Core)
CPE OS Name: cpe:/o:centos:centos:8
Kernel: Linux 4.18.0-80.el8.x86_64
Architecture: x86-64
```
参考:[Ansible 文档](https://docs.ansible.com/ansible/latest/user_guide/index.html)。
---
via: <https://www.2daygeek.com/install-configure-ansible-automation-tool-linux-quick-start-guide/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
13,143 | 如何在 Linux 中创建 USB 启动盘来拯救 Windows 用户 | https://opensource.com/article/21/2/linux-woeusb | 2021-02-22T14:38:39 | [
"USB",
"启动盘"
] | https://linux.cn/article-13143-1.html |
>
> WoeUSB 可以在 Linux 中制作 Windows 启动盘,并帮助你的朋友解锁他们罢工的机器。
>
>
>

人们经常要求我帮助他们恢复被锁死或损坏的 Windows 电脑。有时,我可以使用 Linux USB 启动盘来挂载 Windows 分区,然后从损坏的系统中传输和备份文件。
有的时候,客户丢失了他们的密码或以其他方式锁死了他们的登录账户凭证。解锁账户的一种方法是创建一个 Windows 启动盘来修复计算机。微软允许你从网站下载 Windows 的副本,并提供创建 USB 启动盘的工具。但要使用它们,你需要一台 Windows 电脑,这意味着,作为一个 Linux 用户,我需要其他方法来创建一个 DVD 或 USB 启动盘。我发现在 Linux 上创建 Windows USB 很困难。我的可靠工具,如 [Etcher.io](https://etcher.io/)、[Popsicle](https://github.com/pop-os/popsicle)(适用于 Pop!\_OS)和 [UNetbootin](https://github.com/unetbootin/unetbootin),或者从命令行使用 `dd` 来创建可启动媒体,都不是很成功。
直到我发现了 [WoeUSB-ng](https://github.com/WoeUSB/WoeUSB-ng),一个 [GPL 3.0](https://github.com/WoeUSB/WoeUSB-ng/blob/master/COPYING) 许可的 Linux 工具,它可以为 Windows Vista、7、8 和 10 创建一个 USB 启动盘。这个开源软件有两个程序:一个命令行工具和一个图形用户界面 (GUI) 版本。
### 安装 WoeUSB-ng
GitHub 仓库包含了在 Arch、Ubuntu、Fedora 或使用 pip3 [安装](https://github.com/WoeUSB/WoeUSB-ng#installation) WoeUSB-ng 的说明。
如果你是受支持的 Linux 发行版,你可以使用你的包管理器安装 WoeUSB-ng。或者,你可以使用 Python 的包管理器 [pip](https://opensource.com/downloads/pip-cheat-sheet) 来安装应用程序。这在任何 Linux 发行版中都是通用的。这些方法在功能上没有区别,所以使用你熟悉的任何一种。
我运行的是 Pop!\_OS,它是 Ubuntu 的衍生版本,但由于对 Python 很熟悉,我选择了 pip3 安装:
```
$ sudo pip3 install WoeUSB-ng
```
### 创建一个启动盘
你可以从命令行或 GUI 版本使用 WoeUSB-ng。
要从命令行创建一个启动盘,语法要求命令包含 Windows ISO 文件的路径和一个设备。(本例中是 `/dev/sdX`。使用 `lsblk` 命令来确定你的驱动器)
```
$ sudo woeusb --device Windows.iso /dev/sdX
```
你也可以启动该程序,以获得简单易用的界面。在 WoeUSB-ng 应用程序窗口中,找到 `Windows.iso` 文件并选择它。选择你的 USB 目标设备(你想变成 Windows 启动盘的驱动器)。这将会删除这个驱动器上的所有信息,所以要谨慎选择,然后仔细检查(再三检查)你的选择!
当你确认正确选择目标驱动器后,点击 **Install** 按钮。

创建该介质需要 5 到 10 分钟,这取决于你的 Linux 电脑的处理器、内存、USB 端口速度等。请耐心等待。
当这个过程完成并验证后,你将有可用的 Windows USB 启动盘,以帮助其他人修复 Windows 计算机。
### 帮助他人
开源就是为了帮助他人。很多时候,你可以通过使用基于 Linux 的[系统救援 CD](https://www.system-rescue.org/) 来帮助 Windows 用户。但有时,唯一的帮助方式是直接从 Windows 中获取,而 WoeUSB-ng 是一个很好的开源工具,它可以让这成为可能。
---
via: <https://opensource.com/article/21/2/linux-woeusb>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | People regularly ask me to help them rescue Windows computers that have become locked or damaged. Sometimes, I can use a Linux USB boot drive to mount Windows partitions and then transfer and back up files from the damaged systems.
Other times, clients lose their passwords or otherwise lock their login account credentials. One way to unlock an account is to create a Windows boot disk to repair the computer. Microsoft allows you to download copies of Windows from its website and offers tools to create a USB boot device. But to use them, you need a Windows computer, which means, as a Linux user, I need another way to create a boot DVD or USB drive. I have found it difficult to create Windows USBs on Linux. My reliable tools, like [Etcher.io](https://etcher.io/), [Popsicle](https://github.com/pop-os/popsicle) (for Pop!_OS), and [UNetbootin](https://github.com/unetbootin/unetbootin), or using `dd`
from the command line to create bootable media, have not been very successful.
That is until I discovered [WoeUSB-ng](https://github.com/WoeUSB/WoeUSB-ng), a [GPL 3.0](https://github.com/WoeUSB/WoeUSB-ng/blob/master/COPYING) Linux tool that creates a bootable USB drive for Windows Vista, 7, 8, and 10. The open source software has two programs: a command-line utility and a graphical user interface (GUI) version.
## Install WoeUSB-ng
The GitHub repository contains instructions for [installing](https://github.com/WoeUSB/WoeUSB-ng#installation) WoeUSB-ng on Arch, Ubuntu, Fedora, or with pip3.
If you're on a supported Linux operating system, you can install WoeUSB-ng using your package manager. Alternatively, you can use Python's package manager, [pip](https://opensource.com/downloads/pip-cheat-sheet), to install the application. This is universal across any Linux distribution. There's no functional difference between these methods, so use whichever's familiar to you.
I'm running Pop!_OS, which is an Ubuntu derivative, but being comfortable with Python, I chose the pip3 install:
`$ sudo pip3 install WoeUSB-ng`
## Create a boot disk
You can use WoeUSB-ng from the command line or the GUI version.
To create a boot disk from the command line, the syntax requires the command, a path to your Windows ISO file (`/dev/sdX`
in this example; use the `lsblk`
command to determine your drive), and a device:
`$ sudo woeusb --device Windows.iso /dev/sdX`
You can also launch the program for an easy-to-use interface. In the WoeUSB-ng application window, find the Windows.iso file and select it. Choose your USB target device—the drive you want to make into a Windows boot drive. This will ERASE all information on this drive, so choose carefully—and then double-check (and triple-check) your choice!
Once you're sure you have the right destination drive selected, click the **Install** button.
(Don Watkins, CC BY-SA 4.0)
Creating media takes five to 10 minutes, depending on your Linux computer's processor, memory, USB port speed, etc. Be patient.
Once the process is finished and verified, you have a functional Windows USB boot device to help someone repair their Windows computer.
## Help others
Open source is all about helping other people. Very often, you can help Windows users by using the Linux-based [System Rescue CD](https://www.system-rescue.org/). But sometimes, the only way to help is directly from Windows, and WoeUSB-ng is a great open source tool to make that possible.
## Comments are closed. |
13,145 | 初级:在 Linux 中自定义 Cinnamon 桌面的 7 种方法 | https://itsfoss.com/customize-cinnamon-desktop/ | 2021-02-23T09:57:09 | [
"Cinnamon"
] | https://linux.cn/article-13145-1.html | 
Linux Mint 是最好的 [适合初学者的 Linux 发行版](https://itsfoss.com/best-linux-beginners/) 之一。尤其是想 [转战 Linux](https://itsfoss.com/reasons-switch-linux-windows-xp/) 的 Windows 用户,会发现它的 Cinnamon 桌面环境非常熟悉。
Cinnamon 给人一种传统的桌面体验,很多用户喜欢它的样子。这并不意味着你必须满足于它提供的东西。Cinnamon 提供了几种自定义桌面的方式。
在阅读了 [MATE](https://itsfoss.com/ubuntu-mate-customization/) 和 [KDE 自定义](https://itsfoss.com/kde-customization/) 指南后,很多读者要求为 Linux Mint Cinnamon 也提供类似的教程。因此,我创建了这个关于调整 Cinnamon 桌面的外观和感觉的基本指南。
### 7 种自定义 Cinnamon 桌面的不同方法
在本教程中,我使用的是 [Linux Mint Debian Edition](https://itsfoss.com/lmde-4-release/)(LMDE 4)。你可以在任何运行 Cinnamon 的 Linux 发行版上使用这篇文章的方法。如果你不确定,这里有 [如何检查你使用的桌面环境](https://itsfoss.com/find-desktop-environment/)。
当需要改变 Cinnamon 桌面外观时,我发现非常简单,因为只需点击两下即可。如下图所示,点击菜单图标,然后点击“设置”。

所有的外观设置都放在该窗口的顶部。在“系统设置”窗口上的一切都显得整齐划一。

#### 1、效果
效果选项简单,不言自明,一目了然。你可以开启或关闭桌面不同元素的特效,或者通过改变特效风格来改变窗口过渡。如果你想改变效果的速度,可以通过自定义标签来实现。

#### 2、字体选择
在这个部分,你可以区分整个系统中使用的字体大小和类型,通过字体设置,你可以对外观进行微调。

#### 3、主题和图标
我曾经做了几年的 Linux Mint 用户,一个原因是你不需要到处去改变你想要的东西。窗口管理器、图标和面板定制都在一个地方!
你可以将面板改成深色或浅色,窗口边框也可以根据你要的而改变。默认的 Cinnamon 外观设置在我眼里是最好的,我甚至在测试 [Ubuntu Cinnamon Remix](https://itsfoss.com/ubuntu-cinnamon-remix-review/) 时也应用了一模一样的设置,不过是橙色的。

#### 4、Cinnamon 小程序
Cinnamon 小程序是所有包含在底部面板的元素,如日历或键盘布局切换器。在管理选项卡中,你可以添加/删除已经安装的小程序。
你一定要探索一下可以下载的小程序,如天气和 [CPU 温度](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/)指示小程序是我额外选择的。

#### 5、Cinnamon Desklets
Cinnamon Desklets 是可以直接放置在桌面上的应用。和其他所有的自定义选项一样,Desklets 可以从设置菜单中访问,各种各样的选择可以吸引任何人的兴趣。谷歌日历是一个方便的应用,可以直接在桌面上跟踪你的日程安排。

#### 6、桌面壁纸
要改变 Cinnamon 桌面的背景,只需在桌面上点击右键,选择“改变桌面背景”。它将打开一个简单易用的窗口,在左侧列出了可用的背景系统文件夹,右侧有每个文件夹内的图片预览。

你可以通过点击加号(`+`)并选择路径来添加自己的文件夹。在“设置”选项卡中,你可以选择你的背景是静态还是幻灯片,以及背景在屏幕上的位置。

#### 7、自定义桌面屏幕上的内容
背景并不是你唯一可以改变的桌面元素。如果你在桌面上点击右键,然后点击“自定义”,你可以找到更多的选项。

你可以改变图标的大小,将摆放方式从垂直改为水平,并改变它们在两个轴上的间距。如果你不喜欢你所做的,点击重置网格间距回到默认值。

此外,如果你点击“桌面设置”,将显示更多的选项。你可以禁用桌面上的图标,将它们放在主显示器或副显示器上,甚至两个都可以。如你所见,你可以选择一些图标出现在桌面上。

### 总结
Cinnamon 桌面是最好的选择之一,尤其是当你正在 [从 windows 切换到 Linux](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/) 的时候,同时对一个简单而优雅的桌面追求者也是如此。
Cinnamon 桌面非常稳定,在我手上从来没有崩溃过,这也是在各种 Linux 发行版之间,我使用它这么久的主要原因之一。
我没有讲得太详细,但给了你足够的指导,让你自己去探索设置。欢迎反馈你对 Cinnamon 的定制。
---
via: <https://itsfoss.com/customize-cinnamon-desktop/>
作者:[Dimitrios](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Mint is one the best [Linux distributions for beginners](https://itsfoss.com/best-linux-beginners/). Especially Windows users that want to [switch to Linux](https://itsfoss.com/reasons-switch-linux-windows-xp/), will find its flagship Cinnamon desktop environment very familiar.
Cinnamon gives a traditional desktop experience and many users like it as it is. It doesn’t mean you have to be content with what it provides. Cinnamon provides several ways to customize the desktop.
Reading about [MATE](https://itsfoss.com/ubuntu-mate-customization/) and [KDE customization](https://itsfoss.com/kde-customization/) guides, many readers requested similar tutorials for Linux Mint Cinnamon as well. Hence, I created this basic guide on tweaking the looks and feel of Cinnamon desktop.
## 7 Different Ways for Customizing Cinnamon Desktop
For this tutorial, I’m using [Linux Mint Debian Edition](https://itsfoss.com/lmde-4-release/) (LMDE 4). You can use this on any Linux distribution that is running Cinnamon. If you are unsure, here’s [how to check which desktop environment](https://itsfoss.com/find-desktop-environment/) you are using.
When it comes to changing the cinnamon desktop appearance, I find it very easy to do so as it is just 2 clicks away. Click on the menu icon and then on settings as shown below.
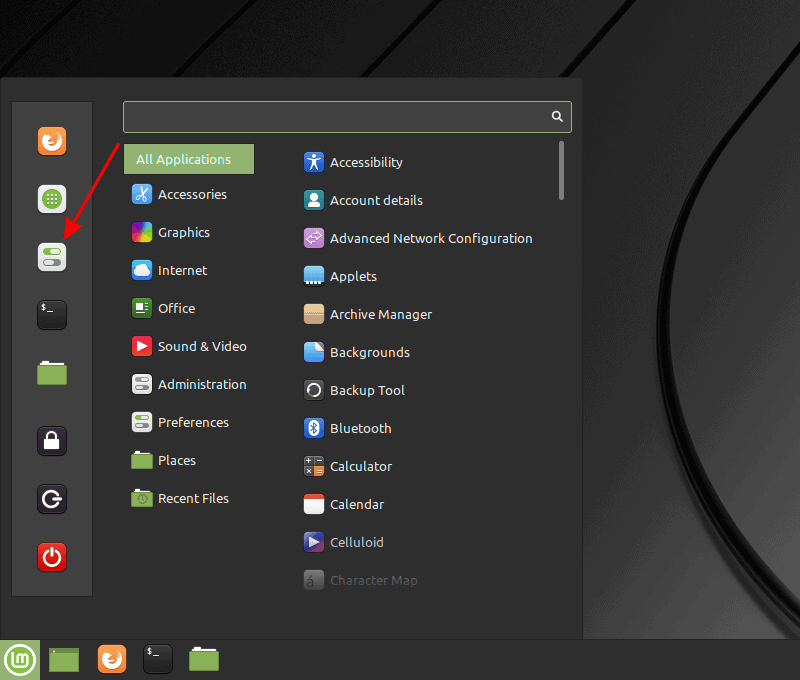
All the appearance settings are placed on the top of the window. Everything on “System Settings” window looks neat and tidy.
### 1. Effects
The effects options are simple, self-explanatory and straightforward. You can turn on and off the effects for different elements of the desktop or change the window transitioning by changing the effects style. If you want to change the speed of the effects, you can do it through the customise tab.
### 2. Font Selection
In this section, you can differentiate the fonts you use throughout the system in size and type, and through the font settings you can fine-tune the appearance.
### 3. Themes and icons
A reason that I used to be a Linux Mint user for a few years is that you don’t need to go all over the place to change what you want. Window manager, icon and panel customization all in one place!
You can change your panel to a dark or light colour and the window borders to suit your changes. The default Cinnamon appearance settings look the best in my eyes, and I even applied the exact same when I was testing the [Ubuntu Cinnamon Remix](https://itsfoss.com/ubuntu-cinnamon-remix-review/) but in orange colour.
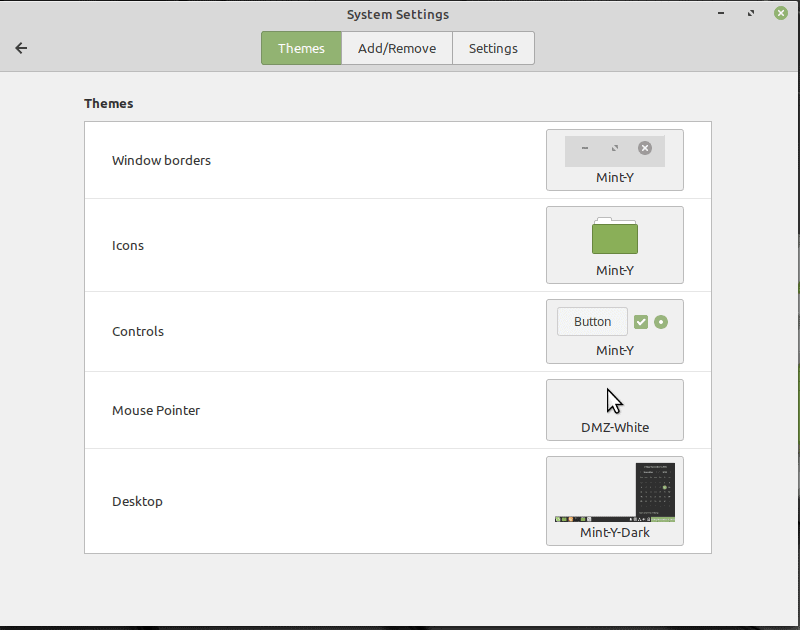
### 4. Cinnamon Applets
Cinnamon applets are all the elements included at your bottom panel like the calendar or the keyboard layout switcher. In the manage tab, you can add/remove the already installed applets.
You should definitely explore the applets you can download; the weather and [CPU temperature](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/) Indicator applets were my choices from the extras.

### 5. Cinnamon Desklets
Cinnamon Desklets are applications that can be placed directly on your desktop. Like all the other customization options, Desklets can be accessed from the settings menu and the wide variety of choices can attract anyone’s interest. Google Calendar is a handy app to keep track of your schedule directly on your desktop.
### 6. Desktop wallpaper
To change the desktop background on Cinnamon desktop, simply right click on the desktop and choose “Change Desktop Background. It will open an easy to use window, where on the left side the available background system folders are listed and on the ride pane there is a preview of the images within each folder.
You can add your own folders by clicking the plus (+) symbol by navigating to its path. At the Settings tab you can choose if you background will be static or slideshow and how the background is being positioned on the screen.
### 7. Customize what’s on your desktop screen
The background is not the only desktop element that you can change. You can find more options if you right click on the desktop and click on “Customise”.
You can change the icon size, change the placement from vertical to horizontal and the spacing among them on both axis. If you don’t like what you did, click in reset grid spacing to go back to the default.
Additionally, if you click on “Desktop Settings”, more options will be revealed. You can disable the icons on the desktop, place them on the primary or secondary monitor, or even both. As you can see, you can select some of the icons to appear on your desktop.
## Conclusion
Cinnamon desktop is one of the best to choose from, especially if you are [switching from windows to Linux](https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/), but also for someone who is looking to a simple yet elegant desktop.
Cinnamon desktop is very stable and never crashes on my hands, and it is one of the main reasons why it served me for so long on a variety of Linux distributions.
I didn’t go into much detail but gave you enough pointers to explore the settings on your own. Your feed to improve Cinnamon customization is welcome.
We have a similar customization guide for other desktop environments too.
[How to Customize Ubuntu MATE Desktop [Complete Guide]Brief: This beginners guide shows you various ways to customize your MATE desktop environment to change its look and feel. MATE is one of the best desktop environments for Linux distributions. It was developed as a continuation of GNOME 2’s traditional look as GNOME 3 took a different route.](https://itsfoss.com/ubuntu-mate-customization/)

The [KDE customization](https://itsfoss.com/kde-customization/) guide is here.
[KDE Customization Guide: Here are 11 Ways You Can Change the Look and Feel of Your KDE-Powered Linux DesktopKDE Plasma desktop is unarguably the pinnacle of customization, as you can change almost anything you want. You can go to the extent of making it act as a tiling window manager. KDE Plasma can confuse a beginner by the degree of customization it offers. As options tend to pile](https://itsfoss.com/kde-customization/)

Enjoy Linux on your desktop :) |
13,146 | LaTex 排版 (2):表格 | https://fedoramagazine.org/latex-typesetting-part-2-tables/ | 2021-02-23T11:36:54 | [
"LaTeX"
] | https://linux.cn/article-13146-1.html | 
LaTeX 提供了许多工具来创建和定制表格,在本系列中,我们将使用 `tabular` 和 `tabularx` 环境来创建和定制表。
### 基础表格
要创建表,只需指定环境 `\begin{tabular}{列选项}`:
```
\begin{tabular}{c|c}
Release &Codename \\ \hline
Fedora Core 1 &Yarrow \\
Fedora Core 2 &Tettnang \\
Fedora Core 3 &Heidelberg \\
Fedora Core 4 &Stentz \\
\end{tabular}
```

在上面的示例中,花括号中的 ”{c|c}” 表示文本在列中的位置。下表总结了位置参数及其说明。
| 参数 | 位置 |
| --- | --- |
| `c` | 将文本置于中间 |
| `l` | 将文本左对齐 |
| `r` | 将文本右对齐 |
| `p{宽度}` | 文本对齐单元格顶部 |
| `m{宽度}` | 文本对齐单元格中间 |
| `b{宽度}` | 文本对齐单元格底部 |
>
> `m{宽度}` 和 `b{宽度}` 都要求在最前面指定数组包。
>
>
>
使用上面的例子,让我们来详细讲解使用的要点,并描述你将在本系列中看到的更多选项:
| 选项 | 意义 |
| --- | --- |
| `&` | 定义每个单元格,这个符号仅用于第二列 |
| `\\` | 这将终止该行并开始一个新行 |
| `|` | 指定表格中的垂直线(可选) |
| `\hline` | 指定表格中的水平线(可选) |
| `*{数量}{格式}` | 当你有许多列时,可以使用这个,并且是限制重复的有效方法 |
| `||` | 指定表格中垂直双线 |
### 定制表格
学会了这些选项,让我们使用这些选项创建一个表。
```
\begin{tabular}{*{3}{|l|}}
\hline
\textbf{Version} &\textbf{Code name} &\textbf{Year released} \\
\hline
Fedora 6 &Zod &2006 \\ \hline
Fedora 7 &Moonshine &2007 \\ \hline
Fedora 8 &Werewolf &2007 \\
\hline
\end{tabular}
```

### 管理长文本
如果列中有很多文本,那么它的格式就不好处理,看起来也不好看。
下面的示例显示了文本的格式长度,我们将在导言区中使用 `blindtext`,以便生成示例文本。
```
\begin{tabular}{|l|l|}\hline
Summary &Description \\ \hline
Test &\blindtext \\
\end{tabular}
```

正如你所看到的,文本超出了页面宽度;但是,有几个选项可以克服这个问题。
* 指定列宽,例如 `m{5cm}`
* 利用 `tablarx` 环境,这需要在导言区中引用 `tablarx` 宏包。
#### 使用列宽管理长文本
通过指定列宽,文本将被折行为如下示例所示的宽度。
```
\begin{tabular}{|l|m{14cm}|} \hline
Summary &Description \\ \hline
Test &\blindtext \\ \hline
\end{tabular}\vspace{3mm}
```

#### 使用 tabularx 管理长文本
在我们利用表格之前,我们需要在导言区中加上它。`tabularx` 方法见以下示例:`\begin{tabularx}{宽度}{列选项}`。
```
\begin{tabularx}{\textwidth}{|l|X|} \hline
Summary & Tabularx Description\\ \hline
Text &\blindtext \\ \hline
\end{tabularx}
```

请注意,我们需要处理长文本的列在花括号中指定了大写 `X`。
### 合并行合并列
有时需要合并行或列。本节描述了如何完成。要使用 `multirow` 和 `multicolumn`,请将 `multirow` 添加到导言区。
#### 合并行
`multirow` 采用以下参数 `\multirow{行的数量}{宽度}{文本}`,让我们看看下面的示例。
```
\begin{tabular}{|l|l|}\hline
Release &Codename \\ \hline
Fedora Core 4 &Stentz \\ \hline
\multirow{2}{*}{MultiRow} &Fedora 8 \\
&Werewolf \\ \hline
\end{tabular}
```

在上面的示例中,指定了两行,`*` 告诉 LaTeX 自动管理单元格的大小。
#### 合并列
`multicolumn` 参数是 `{multicolumn{列的数量}{单元格选项}{位置}{文本}`,下面的示例演示合并列。
```
\begin{tabular}{|l|l|l|}\hline
Release &Codename &Date \\ \hline
Fedora Core 4 &Stentz &2005 \\ \hline
\multicolumn{3}{|c|}{Mulit-Column} \\ \hline
\end{tabular}
```

### 使用颜色
可以为文本、单个单元格或整行指定颜色。此外,我们可以为每一行配置交替的颜色。
在给表添加颜色之前,我们需要在导言区引用 `\usepackage[table]{xcolor}`。我们还可以使用以下颜色参考 [LaTeX Color](https://latexcolor.com) 或在颜色前缀后面添加感叹号(从 0 到 100 的阴影)来定义颜色。例如,`gray!30`。
```
\definecolor{darkblue}{rgb}{0.0, 0.0, 0.55}
\definecolor{darkgray}{rgb}{0.66, 0.66, 0.66}
```
下面的示例演示了一个具有各种颜色的表,`\rowcolors` 采用以下选项 `\rowcolors{起始行颜色}{偶数行颜色}{奇数行颜色}`。
```
\rowcolors{2}{darkgray}{gray!20}
\begin{tabular}{c|c}
Release &Codename \\ \hline
Fedora Core 1 &Yarrow \\
Fedora Core 2 &Tettnang \\
Fedora Core 3 &Heidelberg \\
Fedora Core 4 &Stentz \\
\end{tabular}
```

除了上面的例子,`\rowcolor` 可以用来指定每一行的颜色,这个方法在有合并行时效果最好。以下示例显示将 `\rowColors` 与合并行一起使用的影响以及如何解决此问题。

你可以看到,在合并行中,只有第一行能显示颜色。想要解决这个问题,需要这样做:
```
\begin{tabular}{|l|l|}\hline
\rowcolor{darkblue}\textsc{\color{white}Release} &\textsc{\color{white}Codename} \\ \hline
\rowcolor{gray!10}Fedora Core 4 &Stentz \\ \hline
\rowcolor{gray!40}&Fedora 8 \\
\rowcolor{gray!40}\multirow{-2}{*}{Multi-Row} &Werewolf \\ \hline
\end{tabular}
```

让我们讲解一下为解决合并行替换颜色问题而实施的更改。
* 第一行从合并行上方开始
* 行数从 `2` 更改为 `-2`,这意味着从上面的行开始读取
* `\rowcolor` 是为每一行指定的,更重要的是,多行必须具有相同的颜色,这样才能获得所需的结果。
关于颜色的最后一个注意事项是,要更改列的颜色,需要创建新的列类型并定义颜色。下面的示例说明了如何定义新的列颜色。
```
\newcolumntype{g}{>{\columncolor{darkblue}}l}
```
我们把它分解一下:
* `\newcolumntype{g}`:将字母 `g` 定义为新列
* `{>{\columncolor{darkblue}}l}`:在这里我们选择我们想要的颜色,并且 `l` 告诉列左对齐,这可以用 `c` 或 `r` 代替。
```
\begin{tabular}{g|l}
\textsc{Release} &\textsc{Codename} \\ \hline
Fedora Core 4 &Stentz \\
&Fedora 8 \\
\multirow{-2}{*}{Multi-Row} &Werewolf \\
\end{tabular}\
```

### 横向表
有时,你的表可能有许多列,纵向排列会很不好看。在导言区加入 `rotating` 包,你将能够创建一个横向表。下面的例子说明了这一点。
对于横向表,我们将使用 `sidewaystable` 环境并在其中添加表格环境,我们还指定了其他选项。
* `\centering` 可以将表格放置在页面中心
* `\caption{}` 为表命名
* `\label{}` 这使我们能够引用文档中的表
```
\begin{sidewaystable}
\centering
\caption{Sideways Table}
\label{sidetable}
\begin{tabular}{ll}
\rowcolor{darkblue}\textsc{\color{white}Release} &\textsc{\color{white}Codename} \\
\rowcolor{gray!10}Fedora Core 4 &Stentz \\
\rowcolor{gray!40} &Fedora 8 \\
\rowcolor{gray!40}\multirow{-2}{*}{Multi-Row} &Werewolf \\
\end{tabular}\vspace{3mm}
\end{sidewaystable}
```

### 列表和表格
要将列表包含到表中,可以使用 `tabularx`,并将列表包含在指定的列中。另一个办法是使用表格格式,但必须指定列宽。
#### 用 tabularx 处理列表
```
\begin{tabularx}{\textwidth}{|l|X|} \hline
Fedora Version &Editions \\ \hline
Fedora 32 &\begin{itemize}[noitemsep]
\item CoreOS
\item Silverblue
\item IoT
\end{itemize} \\ \hline
\end{tabularx}\vspace{3mm}
```

#### 用 tabular 处理列表
```
\begin{tabular}{|l|m{6cm}|}\hline
Fedora Version &amp;amp;Editions \\\ \hline
Fedora 32 &amp;amp;\begin{itemize}[noitemsep]
\item CoreOS
\item Silverblue
\item IoT
\end{itemize} \\\ \hline
\end{tabular}
```

### 总结
LaTeX 提供了许多使用 `tablar` 和 `tablarx` 自定义表的方法,你还可以在表环境 (`\begin\table`) 中添加 `tablar` 和 `tablarx` 来添加表的名称和定位表。
### LaTeX 宏包
所需的宏包有如下这些:
```
\usepackage{fullpage}
\usepackage{blindtext} % add demo text
\usepackage{array} % used for column positions
\usepackage{tabularx} % adds tabularx which is used for text wrapping
\usepackage{multirow} % multi-row and multi-colour support
\usepackage[table]{xcolor} % add colour to the columns
\usepackage{rotating} % for landscape/sideways tables
```
### 额外的知识
这是一堂关于表的小课,有关表和 LaTex 的更多高级信息,请访问 [LaTex Wiki](https://en.wikibooks.org/wiki/LaTeX/Tables)

---
via: <https://fedoramagazine.org/latex-typesetting-part-2-tables/>
作者:[Earl Ramirez](https://fedoramagazine.org/author/earlramirez/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | LaTeX offers a number of tools to create and customise tables, in this series we will be using the tabular and tabularx environment to create and customise tables.
## Basic table
To create a table you simply specify the environment \begin{tabular}{columns}
\begin{tabular}{c|c} Release &Codename \\ \hline Fedora Core 1 &Yarrow \\ Fedora Core 2 &Tettnang \\ Fedora Core 3 &Heidelberg \\ Fedora Core 4 &Stentz \\ \end{tabular}

In the above example “{c|c}” in the curly bracket refers to the position of the text in the column. The below table summarises the positional argument together with the description.
Position | Argument |
---|---|
c | Position text in the centre |
l | Position text left-justified |
r | Position text right-justified |
p{width} | Align the text at the top of the cell |
m{width} | Align the text in the middle of the cell |
b{width} | Align the text at the bottom of the cell |
Both m{width} and b{width} requires the array package to be specified in the preamble.
Using the example above, let us breakdown the important points used and describe a few more options that you will see in this series
Option | Description |
---|---|
& | Defines each cell, the ampersand is only used from the second column |
\\ | This terminates the row and start a new row |
| | Specifies the vertical line in the table (optional) |
\hline | Specifies the horizontal line (optional) |
*{num}{form} | This is handy when you have many columns and is an efficient way of limiting the repetition |
|| | Specifies the double vertical line |
## Customizing a table
Now that some of the options available are known, let us create a table using the options described in the previous section.
\begin{tabular}{*{3}{|l|}} \hline \textbf{Version} &\textbf{Code name} &\textbf{Year released} \\ \hline Fedora 6 &Zod &2006 \\ \hline Fedora 7 &Moonshine &2007 \\ \hline Fedora 8 &Werewolf &2007 \\ \hline \end{tabular}
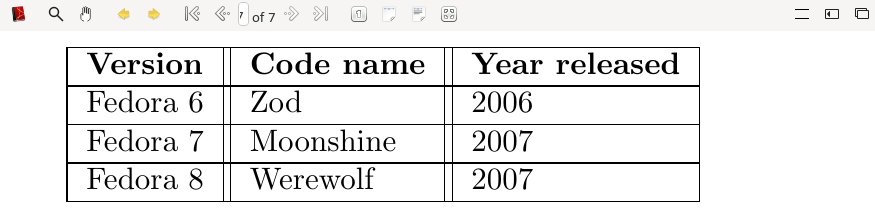
## Managing long text
With LaTeX, if there are many texts in a column it will not be formatted well and does not look presentable.
The below example shows how long text is formatted, we will use “blindtext” in the preamble so that we can produce sample text.
\begin{tabular}{|l|l|}\hline Summary &Description \\ \hline Test &\blindtext \\ \end{tabular}

As you can see the text exceeds the page width; however, there are a couple of options to overcome this challenge.
- Specify the column width, for example, m{5cm}
- Utilise the tabularx environment, this requires tabularx package in the preamble.
### Managing long text with column width
By specifying the column width the text will be wrapped into the width as shown in the example below.
\begin{tabular}{|l|m{14cm}|} \hline Summary &Description \\ \hline Test &\blindtext \\ \hline \end{tabular}\vspace{3mm}

### Managing long text with tabularx
Before we can leverage tabularx we need to add it in the preamble. Tabularx takes the following example
**\begin{tabularx}{width}{columns}** \begin{tabularx}{\textwidth}{|l|X|} \hline Summary & Tabularx Description\\ \hline Text &\blindtext \\ \hline \end{tabularx}

Notice that the column that we want the long text to be wrapped has a capital “X” specified.
## Multi-row and multi-column
There are times when you will need to merge rows and/or column. This section describes how it is accomplished. To use multi-row and multi-column add multi-row to the preamble.
### Multirow
Multirow takes the following argument *\multirow{number_of_rows}{width}{text}*, let us look at the below example.
\begin{tabular}{|l|l|}\hline Release &Codename \\ \hline Fedora Core 4 &Stentz \\ \hline \multirow{2}{*}{MultiRow} &Fedora 8 \\ &Werewolf \\ \hline \end{tabular}

In the above example, two rows were specified, the ‘*’ tells LaTeX to automatically manage the size of the cell.
### Multicolumn
Multicolumn argument is *\multicolumn{number_of_columns}{cell_position}{text}*, below example demonstrates multicolumn.
\begin{tabular}{|l|l|l|}\hline Release &Codename &Date \\ \hline Fedora Core 4 &Stentz &2005 \\ \hline \multicolumn{3}{|c|}{Mulit-Column} \\ \hline \end{tabular}

## Working with colours
Colours can be assigned to the text, an individual cell or the entire row. Additionally, we can configure alternating colours for each row.
Before we can add colour to our tables we need to include *\usepackage[table]{xcolor}* into the preamble. We can also define colours using the following colour reference [LaTeX Colour](https://latexcolor.com) or by adding an exclamation after the colour prefixed by the shade from 0 to 100. For example, *gray!30*
\definecolor{darkblue}{rgb}{0.0, 0.0, 0.55} \definecolor{darkgray}{rgb}{0.66, 0.66, 0.66}
Below example demonstrate this a table with alternate colours, \rowcolors take the following options *\rowcolors{row_start_colour}{even_row_colour}{odd_row_colour}*.
\rowcolors{2}{darkgray}{gray!20} \begin{tabular}{c|c} Release &Codename \\ \hline Fedora Core 1 &Yarrow \\ Fedora Core 2 &Tettnang \\ Fedora Core 3 &Heidelberg \\ Fedora Core 4 &Stentz \\ \end{tabular}

In addition to the above example, \rowcolor can be used to specify the colour of each row, this method works best when there are multi-rows. The following examples show the impact of using the \rowcolours with multi-row and how to work around it.

As you can see the *multi-row* is visible in the first row, to fix this we have to do the following.
\begin{tabular}{|l|l|}\hline \rowcolor{darkblue}\textsc{\color{white}Release} &\textsc{\color{white}Codename} \\ \hline \rowcolor{gray!10}Fedora Core 4 &Stentz \\ \hline \rowcolor{gray!40}&Fedora 8 \\ \rowcolor{gray!40}\multirow{-2}{*}{Multi-Row} &Werewolf \\ \hline \end{tabular}

Let us discuss the changes that were implemented to resolve the multi-row with the alternate colour issue.
- The first row started above the multi-row
- The number of rows was changed from 2 to -2, which means to read from the line above
- \rowcolor was specified for each row, more importantly, the multi-rows must have the same colour so that you can have the desired results.
One last note on colour, to change the colour of a column you need to create a new column type and define the colour. The example below illustrates how to define the new column colour.
\newcolumntype{g}{>{\columncolor{darkblue}}l}
Let’s break it down:
- \newcolumntype{g}: defines the letter
*g*as the new column - {>{\columncolor{darkblue}}l}: here we select our desired colour, and
*l*tells the column to be left-justified, this can be subsitued with*c*or*r*
\begin{tabular}{g|l} \textsc{Release} &\textsc{Codename} \\ \hline Fedora Core 4 &Stentz \\ &Fedora 8 \\ \multirow{-2}{*}{Multi-Row} &Werewolf \\ \end{tabular}\

## Landscape table
There may be times when your table has many columns and will not fit elegantly in portrait. With the *rotating* package in preamble you will be able to create a sideways table. The below example demonstrates this.
For the landscape table, we will use the *sidewaystable* environment and add the tabular environment within it, we also specified additional options.
- \centering to position the table in the centre of the page
- \caption{} to give our table a name
- \label{} this enables us to reference the table in our document
\begin{sidewaystable} \centering \caption{Sideways Table} \label{sidetable} \begin{tabular}{ll} \rowcolor{darkblue}\textsc{\color{white}Release} &\textsc{\color{white}Codename} \\ \rowcolor{gray!10}Fedora Core 4 &Stentz \\ \rowcolor{gray!40} &Fedora 8 \\ \rowcolor{gray!40}\multirow{-2}{*}{Multi-Row} &Werewolf \\ \end{tabular}\vspace{3mm} \end{sidewaystable}
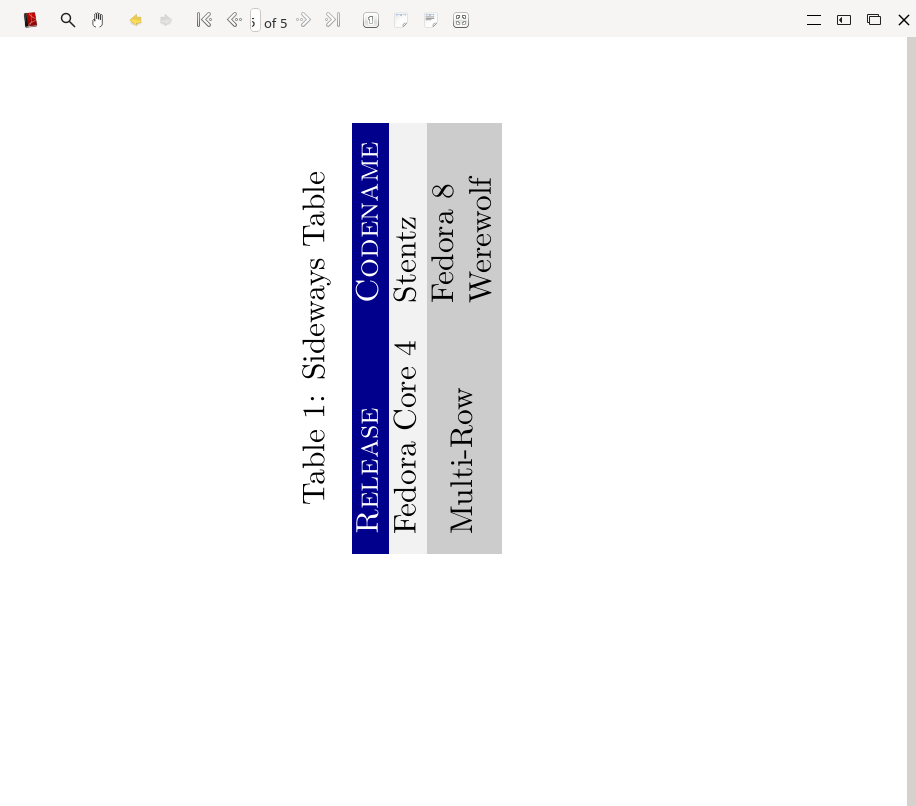
## Lists in tables
To include a list into a table you can use tabularx and include the list in the column where the *X* is specified. Another option will be to use tabular but you must specify the column width.
### List in tabularx
\begin{tabularx}{\textwidth}{|l|X|} \hline Fedora Version &Editions \\ \hline Fedora 32 &\begin{itemize}[noitemsep] \item CoreOS \item Silverblue \item IoT \end{itemize} \\ \hline \end{tabularx}\vspace{3mm}

### List in tabular
\begin{tabular}{|l|m{6cm}|}\hline Fedora Version &Editions \\ \hline Fedora 32 &\begin{itemize}[noitemsep] \item CoreOS \item Silverblue \item IoT \end{itemize} \\ \hline \end{tabular}

## Conclusion
LaTeX offers many ways to customise your table with tabular and tabularx, you can also add both tabular and tabularx within the table environment (\begin\table) to add the table name and to position the table.
The packages used in this series are:
\usepackage{fullpage} \usepackage{blindtext} % add demo text \usepackage{array} % used for column positions \usepackage{tabularx} % adds tabularx which is used for text wrapping \usepackage{multirow} % multi-row and multi-colour support \usepackage[table]{xcolor} % add colour to the columns \usepackage{rotating} % for landscape/sideways tables
## Additional Reading
This was an intermediate lesson on tables. For more advanced information about tables and LaTex in general, you can go to the [LaTeX Wiki](https://en.wikibooks.org/wiki/LaTeX/Tables).
## bgd
In addition to the rotating package, the package pdflscape will allow one to create a table (or other text) that is rotated, which in addition will be oriented correctly when viewed online by using \begin{landscape} and \end{landscape}.
## Earl Ramirez
Thanks, bgd
## nated
The part about resizing tables was really helpful. I’ve struggled with that in the past.
## rthrt
nice
please write some about lilipond
## Earl Ramirez
Are you referring to the LiliPond for music?
## Göran Uddeborg
Thanks! I’ve used LaTeX for many years (if somewhat sporadically) but there is always something more to learn. You taught me some new nice things.
A little mistake to correct: in the list of “options”, to be used in tables in the beginning you say that a single backslash starts a new line. That should be a double backslash, I believe.
## Earl Ramirez
Glad that it was helpful for you, good catch, yes, it’s a double backslash that starts a new row. Must have missed the escape character.
Thanks.
## Kenedy
You’re right, is a double backslash.
## ydor9e
Talking about tables, an interesting subject is how to brake a table when it does not fit in a single page. I always struggle to do that.
## Earl Ramirez
The longtable package (https://www.ctan.org/pkg/longtable) will resolve this for you, here is an example that you can use.
\documentclass[a4paper,11pt]{article}
\usepackage{blindtext}
\usepackage{longtable}
\usepackage{array}
\usepackage{multirow}
\usepackage{fullpage}
%opening
\title{}
\author{}
\begin{document}
\maketitle
\section{Long Table}
\begin{longtable}{|l|p{14cm}|}
\caption{Multi-page Table} \
\hline
\multicolumn{2}{|c|}{Begin Table} \
\hline
Name &Description \
\endfirsthead % Specify the header, this will be shown on each page
\multicolumn{2}{|c|}{Table Continues} \\ \hline
{\bfseries Name} &{\bfseries Description} \\
\endhead % Tells ``Table Continues'' to show above the header
\hline
\endfoot
\hline
\multicolumn{2}{|c|}{End of Table} \\
\hline
\endlastfoot %
Text1 &\blindtext \\
Text2 &\blindtext \\
Text3 &\blindtext\\
Text4 &\blindtext \\
Text5 &\blindtext \\
Text6 &\blindtext \\
Text7 &\blindtext \\
Text8 &\blindtext \\
Text9 &\blindtext \\
Text10 &\blindtext \\
\end{longtable}
\end{document}
## galeon
Please consider writting part 3 about for loop’s (ex forloop package) which can be used to automatic genereation of tables. I use them once to insert many (more than 20) similar figures.
## Earl Ramirez
I will try and squeeze it in to one of the future articles, thanks. |
13,148 | 5 款值得拥有的 Linux 媒体播放器 | https://opensource.com/article/21/2/linux-media-players | 2021-02-24T10:18:32 | [
"媒体播放器"
] | https://linux.cn/article-13148-1.html |
>
> 无论是电影还是音乐,Linux 都能为你提供一些优秀的媒体播放器。
>
>
>

在 2021 年,人们有更多的理由喜欢 Linux。在这个系列中,我将分享 21 个使用 Linux 的不同理由。媒体播放是我最喜欢使用 Linux 的理由之一。
你可能更喜欢黑胶唱片和卡带,或者录像带和激光影碟,但你很有可能还是在数字设备上播放你喜欢的大部分媒体。电脑上的媒体有一种无法比拟的便利性,这主要是因为我们大多数人一天中的大部分时间都在电脑附近。许多现代电脑用户并没有过多考虑有哪些应用可以用来听音乐和看电影,因为大多数操作系统都默认提供了媒体播放器,或者因为他们订阅了流媒体服务,因此并没有把媒体文件放在自己身边。但如果你的口味超出了通常的热门音乐和节目列表,或者你以媒体工作为乐趣或利润,那么你就会有你想要播放的本地文件。你可能还对现有用户界面有意见。在 Linux 上,*选择*是一种权利,因此你可以选择无数种播放媒体的方式。
以下是我在 Linux 上必备的五个媒体播放器。
### 1、mpv

一个现代、干净、简约的媒体播放器。得益于它的 Mplayer、[ffmpeg](https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats) 和 `libmpv` 后端,它可以播放你可能会扔给它的任何类型媒体。我说“扔给它”,是因为播放一个文件的最快捷、最简单的方法就是把文件拖到 mpv 窗口中。如果你拖动多个文件,mpv 会为你创建一个播放列表。
当你把鼠标放在上面时,它提供了直观的覆盖控件,但最好还是通过键盘操作界面。例如,`Alt+1` 会使 mpv 窗口变成全尺寸,而 `Alt+0` 会使其缩小到一半大小。你可以使用 `,` 和 `.` 键逐帧浏览视频,`[` 和 `]` 键调整播放速度,`/` 和 `*` 调整音量,`m` 静音等等。这些主控功能可以让你快速调整,一旦你学会了这些功能,你几乎可以在想到要调整播放的时候快速调整。无论是工作还是娱乐,mpv 都是我播放媒体的首选。
### 2、Kaffeine 和 Rhythmbox

KDE Plasma 和 GNOME 桌面都提供了音乐应用([Kaffeine](https://apps.kde.org/en/kaffeine) 和 [Rhythmbox][]),可以作为你个人音乐库的前端。它们会让你为你的音乐文件提供一个标准的位置,然后扫描你的音乐收藏,这样你就可以根据专辑、艺术家等来浏览。这两款软件都很适合那些你无法完全决定你想听什么,而又想用一种简单的方式来浏览现有音乐的时候。
[Kaffeine](https://apps.kde.org/en/kaffeine) 其实不仅仅是一个音乐播放器。它可以播放视频文件、DVD、CD,甚至数字电视(假设你有输入信号)。我已经整整几天没有关闭 Kaffeine 了,因为不管我是想听音乐还是看电影,Kaffeine 都能让我轻松地开始播放。
### 3、Audacious

[Audacious](https://audacious-media-player.org/) 媒体播放器是一个轻量级的应用,它可以播放你的音乐文件(甚至是 MIDI 文件)或来自互联网的流媒体音乐。对我来说,它的主要吸引力在于它的模块化架构,它鼓励开发插件。这些插件可以播放几乎所有你能想到的音频媒体格式,用图形均衡器调整声音,应用效果,甚至可以重塑整个应用,改变其界面。
很难把 Audacious 仅仅看作是一个应用,因为它很容易让它变成你想要的应用。无论你是 Linux 上的 XMMS、Windows 上的 WinAmp,还是任何其他替代品,你大概都可以用 Audacious 来近似它们。Audacious 还提供了一个终端命令,`audtool`,所以你可以从命令行控制一个正在运行的 Audacious 实例,所以它甚至可以近似于一个终端媒体播放器!
### 4、VLC

[VLC](http://videolan.org) 播放器可能是向用户介绍开源的应用之首。作为一款久经考验的多媒体播放器,VLC 可以播放音乐、视频、光盘。它还可以通过网络摄像头或麦克风进行流式传输和录制,从而使其成为捕获快速视频或语音消息的简便方法。像 mpv 一样,大多数情况下都可以通过按单个字母的键盘操作来控制它,但它也有一个有用的右键菜单。它可以将媒体从一种格式转换为另一种格式、创建播放列表、跟踪你的媒体库等。VLC 是最好的,大多数播放器甚至无法在功能上与之匹敌。无论你在什么平台上,它都是一款必备的应用。
### 5、Music player daemon

[music player daemon(mpd)](https://www.musicpd.org/) 是一个特别有用的播放器,因为它在服务器上运行。这意味着你可以在 [树莓派](https://opensource.com/article/21/1/raspberry-pi-hifi) 上启动它,然后让它处于空闲状态,这样你就可以在任何时候播放一首曲子。mpd 的客户端有很多,但我用的是 [ncmpc](https://www.musicpd.org/clients/ncmpc/)。有了 ncmpc 或像 [netjukebox](http://www.netjukebox.nl/) 这样的 Web 客户端,我可以从本地主机或远程机器上连接 mpd,选择一张专辑,然后从任何地方播放它。
### Linux 上的媒体播放
在 Linux 上播放媒体是很容易的,这要归功于它出色的编解码器支持和惊人的播放器选择。我只提到了我最喜欢的五个播放器,但还有更多的播放器供你探索。试试它们,找到最好的,然后坐下来放松一下。
---
via: <https://opensource.com/article/21/2/linux-media-players>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. Playing media is one of my favorite reasons to use Linux.
You may prefer vinyl and cassette tapes or VHS and Laserdisc, but it's still most likely that you consume the majority of the media you enjoy on a digital device. There's a convenience to media on a computer that can't be matched, largely because most of us are near a computer for most of the day. Many modern computer users don't give much thought to what applications are available for listening to music and watching movies because most operating systems provide a media player by default or because they subscribe to a streaming service and don't keep media files around themselves. But if your tastes go beyond the usual hit list of popular music and shows, or if you work with media for fun or profit, then you have local files you want to play. You probably also have opinions about the available user interfaces. On Linux, *choice* is a mandate, and so your options for media playback are endless.
Here are five of my must-have media players on Linux.
## 1. mpv

mvp License: Creative Commons Attribution-ShareAlike
A modern, clean, and minimal media player. Thanks to its Mplayer, [ffmpeg](https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats), and `libmpv`
backends, it can play any kind of media you're likely to throw at it. And I do mean "throw at it" because the quickest and easiest way to start a file playing is just to drag the file onto the mpv window. Should you drag more than one file, mpv creates a playlist for you.
While it provides intuitive overlay controls when you mouse over it, the interface is best when operated through the keyboard. For instance, **Alt+1** causes your mpv window to become full-size, and **Alt+0** reduces it to half-size. You can use the **,** and **.** keys to step through the video frame by frame, the **[** and **]** keys to adjust playback speed, **/** and ***** to adjust volume, **m** to mute, and so on. These master controls make for quick adjustments, and once you learn them, you can adjust playback almost as quickly as the thought occurs to you to do so. For both work and entertainment, mpv is my top choice for media playback.
## 2. Kaffeine and Rhythmbox
The Kaffeine interface License: Creative Commons Attribution-ShareAlike
Both the KDE Plasma and GNOME desktops provide music applications that can act as frontends to your personal music library. They invite you to establish a standard location for your music files and then scan through your music collection so you can browse according to album, artist, and so on. Both are great for those times when you just can't quite decide what you want to listen to and want an easy way to rummage through what's available.
[Kaffeine](https://apps.kde.org/en/kaffeine) is actually much more than just a music player. It can play video files, DVDs, CDs, and even digital TV (assuming you have an incoming signal). I've gone whole days without closing Kaffeine, because no matter whether I'm in the mood for music or movies, Kaffeine makes it easy to start something playing.
## 3. Audacious
The Audacious interface License: Creative Commons Attribution-ShareAlike
The [Audacious](https://audacious-media-player.org/) media player is a lightweight application that can play your music files (even MIDI files) or stream music from the Internet. Its main appeal, for me, is its modular architecture, which encourages the development of plugins. These plugins enable playback of nearly every audio media format you can think of, adjust the sound with a graphic equalizer, apply effects, and even reskin the entire application to change its interface.
It's hard to think of Audacious as just one application because it's so easy to make it into the application you want it to be. Whether you're a fan of XMMS on Linux, WinAmp on Windows, or any number of alternatives, you can probably approximate them with Audacious. Audacious also provides a terminal command, `audtool`
, so you can control a running instance of Audacious from the command line, so it even approximates a terminal media player!
## 4. VLC
The VLC interface License: Creative Commons Attribution-ShareAlike
The [VLC](http://videolan.org) player is probably at the top of the list of applications responsible for introducing users to open source. A tried and true player of all things multimedia, VLC can play music, video, optical discs. It can also stream and record from a webcam or microphone, making it an easy way to capture a quick video or voice message. Like mpv, it can be controlled mostly through single-letter keyboard presses, but it also has a helpful right-click menu. It can convert media from one format to another, create playlists, track your media library, and much more. VLC is the best of the best, and most players don't even attempt to match its capabilities. It's a must-have application no matter what platform you're on.
## 5. Music player daemon
mpd and ncmpc License: Creative Commons Attribution-ShareAlike
The [music player daemon (mpd)](https://www.musicpd.org/) is an especially useful player, because it runs on a server. That means you can fire it up on a [Raspberry Pi](https://opensource.com/article/21/1/raspberry-pi-hifi) and leave it idling so you can tap into it whenever you want to play a tune. There are many clients for mpd, but I use [ncmpc](https://www.musicpd.org/clients/ncmpc/). With ncmpc or a web client like [netjukebox](http://www.netjukebox.nl/), I can contact mpd from the local host or a remote machine, select an album, and play it from anywhere.
## Media on Linux
Playing media on Linux is easy, thanks to its excellent codec support and an amazing selection of players. I've only mentioned five of my favorites, but there are many, many more for you to explore. Try them all, find the best, and then sit back and relax.
## 8 Comments |
13,149 | 用 Linux 释放你 Chromebook 的隐藏潜能 | https://opensource.com/article/21/2/chromebook-linux | 2021-02-24T11:43:18 | [
"Chromebook"
] | /article-13149-1.html |
>
> Chromebook 是令人惊叹的工具,但通过解锁它内部的 Linux 系统,你可以让它变得更加不同凡响。
>
>
>

Google Chromebook 运行在 Linux 系统之上,但通常它运行的 Linux 系统对普通用户而言,并不是十分容易就能访问得到。Linux 被用作基于开源的 [Chromium OS](https://www.chromium.org/chromium-os) 运行时环境的后端技术,然后 Google 将其转换为 Chrome OS。大多数用户体验到的界面是一个电脑桌面,可以用来运行 Chrome 浏览器及其应用程序。然而,在这一切的背后,有一个 Linux 系统等待被你发现。如果你知道怎么做,你可以在 Chromebook 上启用 Linux,把一台可能价格相对便宜、功能相对基础的电脑变成一个严谨的笔记本,获取数百个应用和你需要的所有能力,使它成为一个通用计算机。
### 什么是 Chromebook?
Chromebook 是专为 Chrome OS 创造的笔记本电脑,它本身专为特定的笔记本电脑型号而设计。Chrome OS 不是像 Linux 或 Windows 这样的通用操作系统,而是与 Android 或 iOS 有更多的共同点。如果你决定购买 Chromebook,你会发现有许多不同制造商的型号,包括惠普、华硕和联想等等。有些是为学生而设计,而另一些是为家庭或商业用户而设计的。主要的区别通常分别集中在电池功率或处理能力上。
无论你决定买哪一款,Chromebook 都会运行 Chrome OS,并为你提供现代计算机所期望的基本功能。有连接到互联网的网络管理器、蓝牙、音量控制、文件管理器、桌面等等。

*Chrome OS 桌面截图*
不过,想从这个简单易用的操作系统中获得更多,你只需要激活 Linux。
### 启用 Chromebook 的开发者模式
如果我让你觉得启用 Linux 看似简单,那是因为它确实简单但又有欺骗性。之所以说有欺骗性,是因为在启用 Linux 之前,你*必须*备份数据。
这个过程虽然简单,但它确实会将你的计算机重置回出厂默认状态。你必须重新登录到你的笔记本电脑中,如果你有数据存储在 Google 云盘帐户上,你必须得把它重新同步回计算机中。启用 Linux 还需要为 Linux 预留硬盘空间,因此无论你的 Chromebook 硬盘容量是多少,都将减少一半或四分之一(自主选择)。
在 Chromebook 上接入 Linux 仍被 Google 视为测试版功能,因此你必须选择使用开发者模式。开发者模式的目的是允许软件开发者测试新功能,安装新版本的操作系统等等,但它可以为你解锁仍在开发中的特殊功能。
要启用开发者模式,请首先关闭你的 Chromebook。假定你已经备份了设备上的所有重要信息。
接下来,按下键盘上的 `ESC` 和 `⟳`,再按 **电源键** 启动 Chromebook。

*ESC 键和 ⟳ 键*
当提示开始恢复时,按键盘上的 `Ctrl+D`。
恢复结束后,你的 Chromebook 已重置为出厂设置,且没有默认的使用限制。
### 开机启动进入开发者模式
在开发者模式下运行意味着每次启动 Chromebook 时,都会提醒你处于开发者模式。你可以按 `Ctrl+D` 跳过启动延迟。有些 Chromebook 会在几秒钟后发出蜂鸣声来提醒你处于开发者模式,使得 `Ctrl+D` 操作几乎是强制的。从理论上讲,这个操作很烦人,但在实践中,我不经常启动我的 Chromebook,因为我只是唤醒它,所以当我需要这样做的时候,`Ctrl+D` 只不过是整个启动过程中小小的一步。
启用开发者模式后的第一次启动时,你必须重新设置你的设备,就好像它是全新的一样。你只需要这样做一次(除非你在未来某个时刻停用开发者模式)。
### 启用 Chromebook 上的 Linux
现在,你已经运行在开发者模式下,你可以激活 Chrome OS 中的 **Linux Beta** 功能。要做到这一点,请打开 **设置**,然后单击左侧列表中的 **Linux Beta**。
激活 **Linux Beta**,并为你的 Linux 系统和应用程序分配一些硬盘空间。在最糟糕的时候,Linux 是相当轻量级的,所以你真的不需要分配太多硬盘空间,但它显然取决于你打算用 Linux 来做多少事。4 GB 的空间对于 Linux 以及几百个终端命令还有二十多个图形应用程序是足够的。我的 Chromebook 有一个 64 GB 的存储卡,我给了 Linux 系统 30 GB,那是因为我在 Chromebook 上所做的大部分事情都是在 Linux 内完成的。
一旦你的 **Linux Beta** 环境准备就绪,你可以通过按键盘上的**搜索**按钮和输入 `terminal` 来启动终端。如果你还是 Linux 新手,你可能不知道当前进入的终端能用来安装什么。当然,这取决于你想用 Linux 来做什么。如果你对 Linux 编程感兴趣,那么你可能会从 Bash(它已经在终端中安装和运行了)和 Python 开始。如果你对 Linux 中的那些迷人的开源应用程序感兴趣,你可以试试 GIMP、MyPaint、LibreOffice 或 Inkscape 等等应用程序。
Chrome OS 的 **Linux Beta** 模式不包含图形化的软件安装程序,但 [应用程序可以从终端安装](https://opensource.com/article/18/1/how-install-apps-linux)。可以使用 `sudo apt install` 命令安装应用程序。
* `sudo` 命令可以允许你使用超级管理员权限来执行某些命令(即 Linux 中的 `root`)。
* `apt` 命令是一个应用程序的安装工具。
* `install` 是命令选项,即告诉 `apt` 命令要做什么。
你还必须把想要安装的软件包的名字和 `apt` 命令写在一起。以安装 LibreOffice 举例:
```
sudo apt install libreoffice
```
当有提示是否继续时,输入 `y`(代表“确认”),然后按 **回车键**。
一旦应用程序安装完毕,你可以像在 Chrome OS 上启动任何应用程序一样启动它:只需要在应用程序启动器输入它的名字。
了解 Linux 应用程序的名字和它的包名需要花一些时间,但你也可以用 `apt search` 命令来搜索。例如,可以用以下的方法是找到关于照片的应用程序:
```
apt search photo
```
因为 Linux 中有很多的应用程序,所以你可以找一些感兴趣的东西,然后尝试一下!
### 与 Linux 共享文件和设备
**Linux Beta** 环境运行在 [容器](https://opensource.com/resources/what-are-linux-containers) 中,因此 Chrome OS 需要获得访问 Linux 文件的权限。要授予 Chrome OS 与你在 Linux 上创建的文件的交互权限,请右击要共享的文件夹并选择 **管理 Linux 共享**。

*Chrome OS 的 Linux 管理共享界面*
你可以通过 Chrome OS 的 **设置** 程序来管理共享设置以及其他设置。

*Chrome OS 设置菜单*
### 学习 Linux
如果你肯花时间学习 Linux,你不仅能够解锁你 Chromebook 中隐藏的潜力,还能最终学到很多关于计算机的知识。Linux 是一个有价值的工具,一个非常有趣的玩具,一个通往比常规计算更令人兴奋的事物的大门。去了解它吧,你可能会惊讶于你自己和你 Chromebook 的无限潜能。
---
源自: <https://opensource.com/article/21/2/chromebook-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[max27149](https://github.com/max27149) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,151 | 认识 Plots:一款适用于 Linux 桌面的数学图形绘图应用 | https://itsfoss.com/plots-graph-app/ | 2021-02-25T14:03:47 | [
"绘图",
"数学"
] | https://linux.cn/article-13151-1.html | 
Plots 是一款图形绘图应用,它可以轻松实现数学公式的可视化。你可以用它来绘制任意三角函数、双曲函数、指数函数和对数函数的和与积。
### 在 Linux 上使用 Plots 绘制数学图形
[Plots](https://github.com/alexhuntley/Plots/) 是一款简单的应用,它的灵感来自于像 [Desmos](https://www.desmos.com/) 这样的 Web 图形绘图应用。它能让你绘制不同数学函数的图形,你可以交互式地输入这些函数,还可以自定义绘图的颜色。
Plots 是用 Python 编写的,它使用 [OpenGL](https://www.opengl.org/) 来利用现代硬件。它使用 GTK 3,因此可以很好地与 GNOME 桌面集成。

使用 Plots 非常直白。要添加一个新的方程,点击加号。点击垃圾箱图标可以删除方程。还可以选择撤销和重做。你也可以放大和缩小。

你输入方程的文本框是友好的。菜单中有一个“帮助”选项可以访问文档。你可以在这里找到关于如何编写各种数学符号的有用提示。你也可以复制粘贴方程。

在深色模式下,侧栏公式区域变成了深色,但主绘图区域仍然是白色。我相信这也许是这样设计的。
你可以使用多个函数,并将它们全部绘制在一张图中:

我发现它在尝试粘贴一些它无法理解的方程时崩溃了。如果你写了一些它不能理解的东西,或者与现有的方程冲突,所有图形都会消失,去掉不正确的方程就会恢复图形。
不幸的是,没有导出绘图或复制到剪贴板的选项。你可以随时 [在 Linux 中截图](https://itsfoss.com/take-screenshot-linux/),并在你要添加图像的文档中使用它。
### 在 Linux 上安装 Plots
Plots 为各种发行版提供了不同的安装方式。
Ubuntu 20.04 和 20.10 用户可以[使用 PPA](https://itsfoss.com/ppa-guide/):
```
sudo add-apt-repository ppa:apandada1/plots
sudo apt update
sudo apt install plots
```
对于其他基于 Debian 的发行版,你可以使用 [这里](https://launchpad.net/~apandada1/+archive/ubuntu/plots/+packages) 的 [deb 文件安装](https://itsfoss.com/install-deb-files-ubuntu/)。
我没有在 AUR 软件包列表中找到它,但是作为 Arch Linux 用户,你可以使用 Flatpak 软件包或者使用 Python 安装它。
* [Plots Flatpak 软件包](https://flathub.org/apps/details/com.github.alexhuntley.Plots)
如果你感兴趣,可以在它的 GitHub 仓库中查看源代码。如果你喜欢这款应用,请考虑在 GitHub 上给它 star。
* [GitHub 上的 Plots 源码](https://github.com/alexhuntley/Plots/)
### 结论
Plots 主要用于帮助学生学习数学或相关科目,但它在很多其他场景下也能发挥作用。我知道不是每个人都需要,但肯定会对学术界和学校的人有帮助。
不过我倒是希望能有导出图片的功能。也许开发者可以在未来的版本中加入这个功能。
你知道有什么类似的绘图应用吗?Plots 与它们相比如何?
---
via: <https://itsfoss.com/plots-graph-app/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Plots is an [open source graph plotting application](https://itsfoss.com/open-source-plotting-apps/) that makes it easy to visualize mathematical formulae. You can use it for trigonometric, hyperbolic, exponential and logarithmic functions along with arbitrary sums and products.
## Plot mathematical graphs with Plots on Linux
[Plots](https://github.com/alexhuntley/Plots/) is a simple application inspired by graph plotting web apps like [Desmos](https://www.desmos.com/). It allows you to plot graphs of different math functions, which you can enter interactively, as well as customizing the color of your plots.
Written in Python, Plots takes advantage of modern hardware using [OpenGL](https://www.opengl.org/). It uses GTK 3 and thus integrates well with the GNOME desktop.
Using plots is straightforward. To add a new equation, click the plus sign. Clicking the trash icon deletes the equation. There is also the option to undo and redo. You can also zoom in and zoom out.
The text box where you type is equation friendly. The hamburger menu has a ‘help’ option to access the documentation. You’ll find useful tips on how to write various mathematical notations here. You can also copy-paste the equations.
In dark mode, the sidebar equation area turns dark but the main plotting area remains white. I believe that’s by design perhaps.
You can use multiple functions and plot them all in one graph:
I found it crashing while trying to paste some equations it could not understand. If you write something that it cannot understand or conflicts with existing equations, all plots disappear, Removing the incorrect equation brings back the plot.
No option to export the plots or copy them to clipboard unfortunately. You can always [take screenshots in Linux](https://itsfoss.com/take-screenshot-linux/) and use the image in your document where you have to add the graphs.
**Recommended Read:**
## Installing Plots on Linux
Plots has different installation options available for various kinds of distributions.
Ubuntu 20.04 and 20.10 users can [take advantage of the PPA](https://itsfoss.com/ppa-guide/):
```
sudo add-apt-repository ppa:apandada1/plots
sudo apt update
sudo apt install plots
```
For other Debian based distributions, you can [install it from the deb file](https://itsfoss.com/install-deb-files-ubuntu/) available [here](https://launchpad.net/~apandada1/+archive/ubuntu/plots/+packages).
For Arch users, [Plots has been added to AUR](https://aur.archlinux.org/packages/plots/) after this article was published.
Apart from that, you can also use the Flatpak package or install it using Python.
If interested, you may check out the source code on its GitHub repository. If you like the application, please consider giving it a star on GitHub.
**Conclusion**
The primary use case for Plots is for students learning math or related subjects, but it can be useful in many other scenarios. I know not everyone would need that but surely helpful for the people in the academics and schools.
I would have liked the option to export the images though. Perhaps the developers can add this feature in the future releases.
Do you know any similar applications for plotting graphs? How does Plots stack up against them? |
13,152 | Starship:跨 shell 的可定制的提示符 | https://itsfoss.com/starship/ | 2021-02-25T14:24:00 | [
"提示符"
] | https://linux.cn/article-13152-1.html | 
>
> 如果你很在意你的终端的外观的话,一个跨 shell 的提示符可以让你轻松地定制和配置 Linux 终端提示符。
>
>
>
虽然我已经介绍了一些帮助你 [自定义终端外观](https://itsfoss.com/customize-linux-terminal/) 的技巧,但我也发现了一些有趣的跨 shell 提示符的建议。
### Starship:轻松地调整你的 Linux Shell 提示符

[Starship](https://starship.rs/) 是一个用 [Rust](https://www.rust-lang.org/) 编写的开源项目,它可以帮助你建立一个精简、快速、可定制的 shell 提示符。
无论你是使用 bash、fish、还是 Windows 上的 PowerShell,抑或其他 shell,你都可以利用Starship 来定制外观。
请注意,你必须了解它的 [官方文档](https://starship.rs/config/) 才能对所有你喜欢的东西进行高级配置,但在这里,我将包括一个简单的示例配置,以有一个良好的开端,以及一些关于 Startship 的关键信息。
Startship 专注于为你提供一个精简的、快速的、有用的默认 shell 提示符。它甚至会记录并显示执行一个命令所需的时间。例如,这里有一张截图:

不仅如此,根据自己的喜好定制提示符也相当简单。下面是一张官方 GIF,展示了它的操作:

让我帮你设置一下。我是在 Ubuntu 上使用 bash shell 来测试的。你可以参考我提到的步骤,或者你可以看看 [官方安装说明](https://starship.rs/guide/#%F0%9F%9A%80-installation),以获得在你的系统上安装它的更多选择。
### Starship 的亮点
* 跨平台
* 跨 shell 支持
* 能够添加自定义命令
* 定制 git 体验
* 定制使用特定编程语言时的体验
* 轻松定制提示符的每一个方面,而不会对性能造成实质影响
### 在 Linux 上安装 Starship
>
> 安装 Starship 需要下载一个 bash 脚本,然后用 root 权限运行该脚本。
>
>
> 如果你不习惯这样做,你可以使用 snap。
>
>
>
> ```
> sudo snap install starship
>
> ```
>
>
**注意**:你需要安装 [Nerd 字体](https://www.nerdfonts.com) 才能获得完整的体验。
要开始使用,请确保你安装了 [curl](https://curl.se/)。你可以通过键入如下命令来轻松安装它:
```
sudo apt install curl
```
完成后,输入以下内容安装 Starship:
```
curl -fsSL https://starship.rs/install.sh | bash
```
这应该会以 root 身份将 Starship 安装到 `usr/local/bin`。你可能会被提示输入密码。看起来如下:

### 在 bash 中添加 Starship
如截图所示,你会在终端本身得到设置的指令。在这里,我们需要在 `.bashrc` 用户文件的末尾添加以下一行:
```
eval "$(starship init bash)"
```
要想轻松添加,只需键入:
```
nano .bashrc
```
然后,通过向下滚动导航到文件的末尾,并在文件末尾添加如下图所示的行:

完成后,只需重启终端或重启会话即可看到一个精简的提示符。对于你的 shell 来说,它可能看起来有点不同,但默认情况下应该是一样的。

设置好后,你就可以继续自定义和配置提示符了。让我给你看一个我做的配置示例:
### 配置 Starship 提示符:基础
开始你只需要在 `.config` 目录下制作一个配置文件([TOML文件](https://en.wikipedia.org/wiki/TOML))。如果你已经有了这个目录,直接导航到该目录并创建配置文件。
下面是创建目录和配置文件时需要输入的内容:
```
mkdir -p ~/.config && touch ~/.config/starship.toml
```
请注意,这是一个隐藏目录。所以,当你试图使用文件管理器从主目录访问它时,请确保在继续之前 [启用查看隐藏文件](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/)。
接下来如果你想探索一些你喜欢的东西,你应该参考配置文档。
举个例子,我配置了一个简单的自定义提示,看起来像这样:

为了实现这个目标,我的配置文件是这样的:

根据他们的官方文档,这是一个基本的自定义格式。但是,如果你不想要自定义格式,只是想用一种颜色或不同的符号来自定义默认的提示,那就会像这样:

上述定制的配置文件是这样的:

当然,这不是我能做出的最好看的提示符,但我希望你能理解其配置方式。
你可以通过包括图标或表情符来定制目录的外观,你可以调整变量、格式化字符串、显示 git 提交,或者根据使用特定编程语言而调整。
不仅如此,你还可以创建在你的 shell 中使用的自定义命令,让事情变得更简单或舒适。
你可以在他们的 [官方网站](https://starship.rs/) 和它的 [GitHub 页面](https://github.com/starship/starship) 中探索更多的信息。
* [Starship.rs](https://starship.rs/)
### 结论
如果你只是想做一些小的调整,这文档可能会太复杂了。但是,即使如此,它也可以让你用很少的努力实现一个自定义的提示符或精简的提示符,你可以应用于任何普通的 shell 和你正在使用的系统。
总的来说,我不认为它非常有用,但有几个读者建议使用它,看来人们确实喜欢它。我很想看看你是如何 [自定义 Linux 终端](https://itsfoss.com/customize-linux-terminal/) 以适应不同的使用方式。
欢迎在下面的评论中分享你的看法,如果你喜欢的话。
---
via: <https://itsfoss.com/starship/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

While I’ve already covered a few tips to help you [customize the looks of your terminal](https://itsfoss.com/customize-linux-terminal/), I also came across suggestions for an interesting cross-shell prompt.
## Starship: Tweak your Linux Shell Prompt Easily
[Starship](https://starship.rs/) is an open-source project that’s written in [Rust](https://www.rust-lang.org/) to help you set up a minimal, fast, and customizable shell prompt.
No matter whether you’re using bash, fish, PowerShell on Windows or any other shell, you can utilize Starship to customize the appearance.
Do note that you do have to go through its [official documentation](https://starship.rs/config/) to be able to perform advanced configuration for everything you like but here I will include a simple sample configuration to get a head start along with some key information about Startship.
Starship focuses on giving you a minimal, fast, and useful shell prompt by default. It even records and shows the time taken to perform a command as well. For instance, here’s a screenshot:
Not just limited to that, it is also fairly easy to customize the prompt to your liking. Here’s an official GIF that shows it in action:

Let me help you set it up. I am using bash shell on Ubuntu to test this out. You can refer to the steps I mention, or you can take a look at the [official installation instructions](https://starship.rs/guide/#%F0%9F%9A%80-installation) for more options to install it on your system.
## Key Highlights of Starship
- Cross-platform
- Cross-shell support
- Ability to add custom commands
- Customize git experience
- Customize the experience while using specific programming languages
- Easily customize every aspect of the prompt without taking a hit on performance in a meaningful way
## Installing Starship on Linux
`sudo snap install starship`
To get started, ensure that you have [curl](https://curl.se/) installed. You can install it easily by typing in:
`sudo apt install curl`
Once you do that, type in the following to install Starship:
`curl -fsSL https://starship.rs/install.sh | bash`
This should install Starship to **usr/local/bin** as root. You might be prompted for the password. Here’s how it would look:
*You need to have*[Nerd Font](https://www.nerdfonts.com/)installed to get the complete experience.## Add startship to bash
As the screenshot suggests, you will get the instruction to set it up in the terminal itself. But, in this case, we need to add the following line at the end of our **bashrc **user file:
`eval "$(starship init bash)"`
To add it easily, simply type in:
`nano .bashrc`
Now, navigate to the end of the file by scrolling down and add the line at the end of the file as shown in the image below:
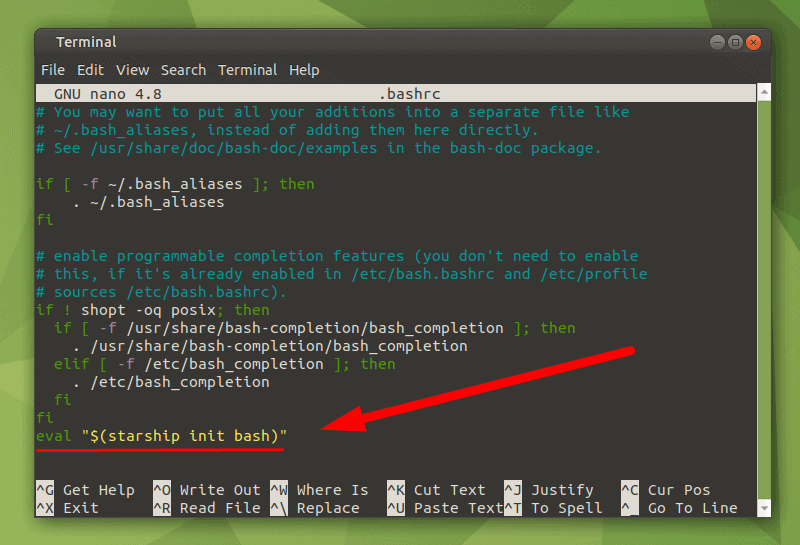
Once done, simply restart the terminal or restart your session to see the minimal prompt. It might look a bit different for your shell, but more or less it should be the same by default.
Once you set it up, you can proceed customizing and configuring the prompt. Let me show you an example configuration that I did.
## Configure Starship Shell Prompt: The Basics
To get started, you just need to make a configuration file ([TOML file](https://en.wikipedia.org/wiki/TOML)) inside a .config directory. If you already have one, you should simply navigate to the directory and just create the configuration file.
Here’s what you have to type to create the directory and the config file:
`mkdir -p ~/.config && touch ~/.config/starship.toml`
Do note that this is a hidden directory. So, when you try to access it from your home directory using the file manager, make sure to [enable viewing hidden files](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/) before proceeding.
From this point onwards, you should refer to the configuration documentation if you want to explore something you like.
For example, I configured a simple custom prompt that looks like:
To achieve this, my configuration file looks like this:
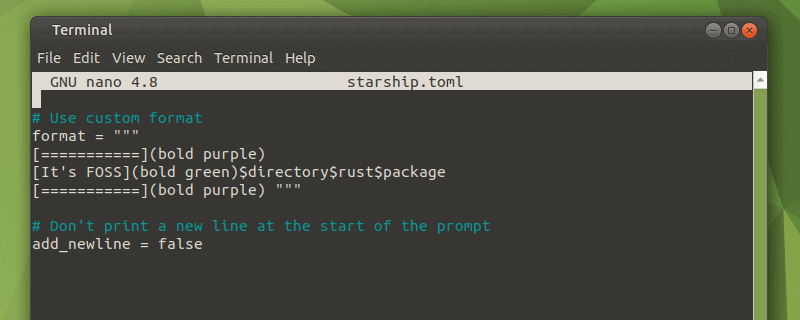
It is a basic custom format as per their official documentation. But, if you do not want a custom format and simply want to customize the default prompt with a color or a different symbol, that would look like:
And, the configuration file for the above customization looks like:
Of course, that’s not the best-looking prompt one can make but I hope you get the idea.
You can customize how the directory looks by including icons/emojis, you can tweak the variables, format strings git commits, or while using specific programming languages.
Not just limited to that, you can also create custom commands to use in your shell to make things easier or more comfortable for yourself.
You should explore more about on their [official website](https://starship.rs/) and its [GitHub page](https://github.com/starship/starship).
## Concluding Thoughts
If you just want minor tweaks, the documentation might be too overwhelming. But, even then, it lets you achieve a custom or minimal prompt with little effort that you can apply on any common shell and any system you’re working on.
Perosnally, I don’t think it’s very useful but several readers suggested it and it seems people do love it. I am eager to see how you [customize the Linux terminal](https://itsfoss.com/customize-linux-terminal/) for different kinds of usage.
Feel free to share what you think about it and if you like it, in the comments down below. |
13,154 | LaTeX 排版(3):排版 | https://fedoramagazine.org/latex-typesetting-part-3-formatting/ | 2021-02-26T11:31:33 | [
"LaTeX"
] | https://linux.cn/article-13154-1.html | 
本 [系列](https://fedoramagazine.org/tag/latex/) 介绍了 LaTeX 中的基本格式。[第 1 部分](/article-13112-1.html) 介绍了列表。[第 2 部分](/article-13146-1.html) 阐述了表格。在第 3 部分中,你将了解 LaTeX 的另一个重要特性:细腻灵活的文档排版。本文介绍如何自定义页面布局、目录、标题部分和页面样式。
### 页面维度
当你第一次编写 LaTeX 文档时,你可能已经注意到默认边距比你想象的要大一些。页边距与指定的纸张类型有关,例如 A4、letter 和 documentclass(article、book、report) 等等。要修改页边距,有几个选项,最简单的选项之一是使用 [fullpage](https://www.ctan.org/pkg/fullpage) 包。
>
> 该软件包设置页面的主体,可以使主体几乎占满整个页面。
>
>
> —— FULLPAGE PACKAGE DOCUMENTATION
>
>
>
另一个选择是使用 [geometry](https://www.ctan.org/geometry) 包。在探索 `geometry` 包如何操纵页边距之前,请首先查看如下所示的页面尺寸。

1. 1 英寸 + `\hoffset`
2. 1 英寸 + `\voffset`
3. `\oddsidemargin` = 31pt
4. `\topmargin` = 20pt
5. `\headheight` = 12pt
6. `\headsep` = 25pt
7. `\textheight` = 592pt
8. `\textwidth` = 390pt
9. `\marginparsep` = 35pt
10. `\marginparwidth` = 35pt
11. `\footskip` = 30pt
要使用 `geometry` 包将边距设置为 1 英寸,请使用以下示例
```
\usepackage{geometry}
\geometry{a4paper, margin=1in}
```
除上述示例外,`geometry` 命令还可以修改纸张尺寸和方向。要更改纸张尺寸,请使用以下示例:
```
\usepackage[a4paper, total={7in, 8in}]{geometry}
```

要更改页面方向,需要将横向(`landscape`)添加到 `geometery` 选项中,如下所示:
```
\usepackage{geometery}
\geometry{a4paper, landscape, margin=1.5in
```

### 目录
默认情况下,目录的标题为 “contents”。有时,你想将标题更改为 “Table of Content”,更改目录和章节第一节之间的垂直间距,或者只更改文本的颜色。
若要更改文本,请在导言区中添加以下行,用所需语言替换英语(`english`):
```
\usepackage[english]{babel}
\addto\captionsenglish{
\renewcommand{\contentsname}
{\bfseries{Table of Contents}}}
```
要操纵目录与图、小节和章节列表之间的虚拟间距,请使用 `tocloft` 软件包。本文中使用的两个选项是 `cftbeforesecskip` 和 `cftaftertoctitleskip`。
>
> tocloft 包提供了控制目录、图表列表和表格列表的排版方法。
>
>
> —— TOCLOFT PACKAGE DOUCMENTATION
>
>
>
```
\usepackage{tocloft}
\setlength\ctfbeforesecskip{2pt}
\setlength\cftaftertoctitleskip{30pt}
```

*默认目录*

*定制目录*
### 边框
在文档中使用包 [hyperref](https://www.ctan.org/pkg/hyperref) 时,目录中的 LaTeX 章节列表和包含 `\url` 的引用都有边框,如下图所示。

要删除这些边框,请在导言区中包括以下内容,你将看到目录中没有任何边框。
```
\usepackage{hyperref}
\hypersetup{ pdfborder = {0 0 0}}
```
要修改标题部分的字体、样式或颜色,请使用程序包 [titlesec](https://www.ctan.org/pkg/titlesec)。在本例中,你将更改节、子节和三级子节的字体大小、字体样式和字体颜色。首先,在导言区中增加以下内容。
```
\usepackage{titlesec}
\titleformat*{\section}{\Huge\bfseries\color{darkblue}}
\titleformat*{\subsection}{\huge\bfseries\color{darkblue}}
\titleformat*{\subsubsection}{\Large\bfseries\color{darkblue}}
```
仔细看看代码,`\titleformat*{\section}` 指定要使用的节的深度。上面的示例最多使用第三个深度。`{\Huge\bfseries\color{darkblue}}` 部分指定字体大小、字体样式和字体颜色。
### 页面样式
要自定义的页眉和页脚,请使用 [fancyhdr](https://www.ctan.org/pkg/fancyhdr)。此示例使用此包修改页面样式、页眉和页脚。下面的代码简要描述了每个选项的作用。
```
\pagestyle{fancy} %for header to be on each page
\fancyhead[L]{} %keep left header blank
\fancyhead[C]{} %keep centre header blank
\fancyhead[R]{\leftmark} %add the section/chapter to the header right
\fancyfoot[L]{Static Content} %add static test to the left footer
\fancyfoot[C]{} %keep centre footer blank
\fancyfoot[R]{\thepage} %add the page number to the right footer
\setlength\voffset{-0.25in} %space between page border and header (1in + space)
\setlength\headheight{12pt} %height of the actual header.
\setlength\headsep{25pt} %separation between header and text.
\renewcommand{\headrulewidth}{2pt} % add header horizontal line
\renewcommand{\footrulewidth}{1pt} % add footer horizontal line
```
结果如下所示:

*页眉*

*页脚*
### 小贴士
#### 集中导言区
如果要编写许多 TeX 文档,可以根据文档类别创建一个包含所有导言区的 `.tex` 文件并引用此文件。例如,我使用结构 `.tex` 如下所示。
```
$ cat article_structure.tex
\usepackage[english]{babel}
\addto\captionsenglish{
\renewcommand{\contentsname}
{\bfseries{\color{darkblue}Table of Contents}}
} % Relable the contents
%\usepackage[margin=0.5in]{geometry} % specifies the margin of the document
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{graphicx} % allows you to add graphics to the document
\usepackage{hyperref} % permits redirection of URL from a PDF document
\usepackage{fullpage} % formate the content to utilise the full page
%\usepackage{a4wide}
\usepackage[export]{adjustbox} % to force image position
%\usepackage[section]{placeins} % to have multiple images in a figure
\usepackage{tabularx} % for wrapping text in a table
%\usepackage{rotating}
\usepackage{multirow}
\usepackage{subcaption} % to have multiple images in a figure
%\usepackage{smartdiagram} % initialise smart diagrams
\usepackage{enumitem} % to manage the spacing between lists and enumeration
\usepackage{fancyhdr} %, graphicx} %for header to be on each page
\pagestyle{fancy} %for header to be on each page
%\fancyhf{}
\fancyhead[L]{}
\fancyhead[C]{}
\fancyhead[R]{\leftmark}
\fancyfoot[L]{Static Content} %\includegraphics[width=0.02\textwidth]{virgin_voyages.png}}
\fancyfoot[C]{} % clear center
\fancyfoot[R]{\thepage}
\setlength\voffset{-0.25in} %Space between page border and header (1in + space)
\setlength\headheight{12pt} %Height of the actual header.
\setlength\headsep{25pt} %Separation between header and text.
\renewcommand{\headrulewidth}{2pt} % adds horizontal line
\renewcommand{\footrulewidth}{1pt} % add horizontal line (footer)
%\renewcommand{\oddsidemargin}{2pt} % adjuct the margin spacing
%\renewcommand{\pagenumbering}{roman} % change the numbering style
%\renewcommand{\hoffset}{20pt}
%\usepackage{color}
\usepackage[table]{xcolor}
\hypersetup{ pdfborder = {0 0 0}} % removes the red boarder from the table of content
%\usepackage{wasysym} %add checkbox
%\newcommand\insq[1]{%
% \Square\ #1\quad%
%} % specify the command to add checkbox
%\usepackage{xcolor}
%\usepackage{colortbl}
%\definecolor{Gray}{gray}{0.9} % create new colour
%\definecolor{LightCyan}{rgb}{0.88,1,1} % create new colour
%\usepackage[first=0,last=9]{lcg}
%\newcommand{\ra}{\rand0.\arabic{rand}}
%\newcolumntype{g}{>{\columncolor{LightCyan}}c} % create new column type g
%\usesmartdiagramlibrary{additions}
%\setcounter{figure}{0}
\setcounter{secnumdepth}{0} % sections are level 1
\usepackage{csquotes} % the proper was of using double quotes
%\usepackage{draftwatermark} % Enable watermark
%\SetWatermarkText{DRAFT} % Specify watermark text
%\SetWatermarkScale{5} % Toggle watermark size
\usepackage{listings} % add code blocks
\usepackage{titlesec} % Manipulate section/subsection
\titleformat{\section}{\Huge\bfseries\color{darkblue}} % update sections to bold with the colour blue \titleformat{\subsection}{\huge\bfseries\color{darkblue}} % update subsections to bold with the colour blue
\titleformat*{\subsubsection}{\Large\bfseries\color{darkblue}} % update subsubsections to bold with the colour blue
\usepackage[toc]{appendix} % Include appendix in TOC
\usepackage{xcolor}
\usepackage{tocloft} % For manipulating Table of Content virtical spacing
%\setlength\cftparskip{-2pt}
\setlength\cftbeforesecskip{2pt} %spacing between the sections
\setlength\cftaftertoctitleskip{30pt} % space between the first section and the text ``Table of Contents''
\definecolor{navyblue}{rgb}{0.0,0.0,0.5}
\definecolor{zaffre}{rgb}{0.0, 0.08, 0.66}
\definecolor{white}{rgb}{1.0, 1.0, 1.0}
\definecolor{darkblue}{rgb}{0.0, 0.2, 0.6}
\definecolor{darkgray}{rgb}{0.66, 0.66, 0.66}
\definecolor{lightgray}{rgb}{0.83, 0.83, 0.83}
%\pagenumbering{roman}
```
在你的文章中,请参考以下示例中所示的方法引用 `structure.tex` 文件:
```
\documentclass[a4paper,11pt]{article}
\input{/path_to_structure.tex}}
\begin{document}
......
\end{document}
```
#### 添加水印
要在 LaTeX 文档中启用水印,请使用 [draftwatermark](https://www.ctan.org/pkg/draftwatermark) 软件包。下面的代码段和图像演示了如何在文档中添加水印。默认情况下,水印颜色为灰色,可以将其修改为所需的颜色。
```
\usepackage{draftwatermark}
\SetWatermarkText{\color{red}Classified} %add watermark text
\SetWatermarkScale{4} %specify the size of the text
```

### 结论
在本系列中,你了解了 LaTeX 提供的一些基本但丰富的功能,这些功能可用于自定义文档以满足你的需要或将文档呈现给的受众。LaTeX 海洋中,还有许多软件包需要大家自行去探索。
---
via: <https://fedoramagazine.org/latex-typesetting-part-3-formatting/>
作者:[Earl Ramirez](https://fedoramagazine.org/author/earlramirez/) 选题:[Chao-zhi](https://github.com/Chao-zhi) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This [series](https://fedoramagazine.org/tag/latex/) covers basic formatting in LaTeX. [Part 1](https://fedoramagazine.org/latex-typesetting-part-1/) introduced lists. [Part 2](https://fedoramagazine.org/latex-typesetting-part-2-tables/) covered tables. In part 3, you will learn about another great feature of LaTeX: the flexibility of granular document formatting. This article covers customizing the page layout, table of contents, title sections, and page style.
## Page dimension
When you first wrote your LaTeX document you may have noticed that the default margin is slightly bigger than you may imagine. The margins have to do with the type of paper you specified, for example, a4, letter, and the document class: article, book, report, and so on. To modify the page margins there are a few options, one of the simplest options is using the * fullpage* package.
This package sets the body of the page such that the page is almost full.
Fullpage package documentation
The illustration below demonstrates the LaTeX default body compared to using the fullpage package.
Another option is to use the [geometry](https://www.ctan.org/geometry) package. Before you explore how the geometry package can manipulate margins, first look at the page dimensions as depicted below.
- one inch + \hoffset
- one inch + \voffset
- \oddsidemargin = 31pt
- \topmargin = 20pt
- \headheight = 12pt
- \headsep = 25pt
- \textheight = 592pt
- \textwidth = 390pt
- \marginparsep = 35pt
- \marginparwidth = 35pt
- \footskip = 30pt
To set the margin to 1 (one) inch using the geometry package use the following example
\usepackage{geometry} \geometry{a4paper, margin=1in}
In addition to the above example, the geometry command can modify the paper size, and orientation. To change the size of the paper, use the example below:
\usepackage[a4paper, total={7in, 8in}]{geometry}


To change the page orientation, you need to add *landscape* to the geometry options as shown below:
\usepackage{geometery} \geometry{a4paper, landscape, margin=1.5in

## Table of contents
By default, a LaTeX table of contents is titled “Contents”. There are times when you prefer to relabel the text to be “Table of Content”, change the vertical spacing between the ToC and your first section of chapter, or simply change the color of the text.
To change the text you add the following lines to your preamble, substitute *english* with your desired language :
\usepackage[english]{babel} \addto\captionsenglish{ \renewcommand{\contentsname} {\bfseries{Table of Contents}}}
To manipulate the virtual spacing between ToC and the list of figures, sections, and chapters, use the [tocloft](https://www.ctan.org/pkg/tocloft) package. The two options used in this article are *cftbeforesecskip* and *cftaftertoctitleskip*.
The tocloft package provides means of controlling the typographic design of the ToC, List of Figures and List of Tables.
Tocloft package doucmentation
\usepackage{tocloft} \setlength\ctfbeforesecskip{2pt} \setlength\cftaftertoctitleskip{30pt}
*cftbeforesecskip* is the spacing between the sections in the ToC, while*cftaftertoctitleskip* is the space between text “Table of Contents” and the first section in the ToC. The below image shows the differences between the default and the modified ToC.


## Borders
When using the package * hyperref* in your document, LaTeX section lists in the ToC and references including
*\url*have a border, as shown in the images below.

To remove these borders, include the following in the preamble, In the previous section, “Table of Contents,” you will see that there are not any borders in the ToC.
\usepackage{hyperref} \hypersetup{ pdfborder = {0 0 0}}
## Title section
To modify the title section font, style, and/or color, use the package * titlesec*. In this example, you will change the font size, font style, and font color of the section, subsection, and subsubsection. First, add the following to the preamble.
\usepackage{titlesec} \titleformat*{\section}{\Huge\bfseries\color{darkblue}} \titleformat*{\subsection}{\huge\bfseries\color{darkblue}} \titleformat*{\subsubsection}{\Large\bfseries\color{darkblue}}

Taking a closer look at the code, *\titleformat*{\section}* specifies the depth of section to use. The above example, uses up to the third depth. The* {\Huge\bfseries\color{darkblue}}* portion specifies the size of the font, font style and, font color
## Page style
To customize the page headers and footers one of the packages, use * fancyhdr*. This example uses this package to modify the page style, header, and footer. The code below provides a brief description of what each option does.
\pagestyle{fancy} %for header to be on each page \fancyhead[L]{} %keep left header blank \fancyhead[C]{} %keep centre header blank \fancyhead[R]{\leftmark} %add the section/chapter to the header right \fancyfoot[L]{Static Content} %add static test to the left footer \fancyfoot[C]{} %keep centre footer blank \fancyfoot[R]{\thepage} %add the page number to the right footer \setlength\voffset{-0.25in} %space between page border and header (1in + space) \setlength\headheight{12pt} %height of the actual header. \setlength\headsep{25pt} %separation between header and text. \renewcommand{\headrulewidth}{2pt} % add header horizontal line \renewcommand{\footrulewidth}{1pt} % add footer horizontal line
The results of this change are shown below:


## Tips
### Centralize the preamble
If write many TeX documents, you can create a .tex file with all your preamble based on your document categories and reference this file. For example, I use a *structure.tex* as shown below.
$ cat article_structure.tex \usepackage[english]{babel} \addto\captionsenglish{ \renewcommand{\contentsname} {\bfseries{\color{darkblue}Table of Contents}} } % Relable the contents %\usepackage[margin=0.5in]{geometry} % specifies the margin of the document \usepackage[utf8]{inputenc} \usepackage[T1]{fontenc} \usepackage{graphicx} % allows you to add graphics to the document \usepackage{hyperref} % permits redirection of URL from a PDF document \usepackage{fullpage} % formate the content to utilise the full page %\usepackage{a4wide} \usepackage[export]{adjustbox} % to force image position %\usepackage[section]{placeins} % to have multiple images in a figure \usepackage{tabularx} % for wrapping text in a table %\usepackage{rotating} \usepackage{multirow} \usepackage{subcaption} % to have multiple images in a figure %\usepackage{smartdiagram} % initialise smart diagrams \usepackage{enumitem} % to manage the spacing between lists and enumeration \usepackage{fancyhdr} %, graphicx} %for header to be on each page \pagestyle{fancy} %for header to be on each page %\fancyhf{} \fancyhead[L]{} \fancyhead[C]{} \fancyhead[R]{\leftmark} \fancyfoot[L]{Static Content} %\includegraphics[width=0.02\textwidth]{virgin_voyages.png}} \fancyfoot[C]{} % clear center \fancyfoot[R]{\thepage} \setlength\voffset{-0.25in} %Space between page border and header (1in + space) \setlength\headheight{12pt} %Height of the actual header. \setlength\headsep{25pt} %Separation between header and text. \renewcommand{\headrulewidth}{2pt} % adds horizontal line \renewcommand{\footrulewidth}{1pt} % add horizontal line (footer) %\renewcommand{\oddsidemargin}{2pt} % adjuct the margin spacing %\renewcommand{\pagenumbering}{roman} % change the numbering style %\renewcommand{\hoffset}{20pt} %\usepackage{color} \usepackage[table]{xcolor} \hypersetup{ pdfborder = {0 0 0}} % removes the red boarder from the table of content %\usepackage{wasysym} %add checkbox %\newcommand\insq[1]{% % \Square\ #1\quad% %} % specify the command to add checkbox %\usepackage{xcolor} %\usepackage{colortbl} %\definecolor{Gray}{gray}{0.9} % create new colour %\definecolor{LightCyan}{rgb}{0.88,1,1} % create new colour %\usepackage[first=0,last=9]{lcg} %\newcommand{\ra}{\rand0.\arabic{rand}} %\newcolumntype{g}{>{\columncolor{LightCyan}}c} % create new column type g %\usesmartdiagramlibrary{additions} %\setcounter{figure}{0} \setcounter{secnumdepth}{0} % sections are level 1 \usepackage{csquotes} % the proper was of using double quotes %\usepackage{draftwatermark} % Enable watermark %\SetWatermarkText{DRAFT} % Specify watermark text %\SetWatermarkScale{5} % Toggle watermark size \usepackage{listings} % add code blocks \usepackage{titlesec} % Manipulate section/subsection \titleformat{\section}{\Huge\bfseries\color{darkblue}} % update sections to bold with the colour blue \titleformat{\subsection}{\huge\bfseries\color{darkblue}} % update subsections to bold with the colour blue \titleformat*{\subsubsection}{\Large\bfseries\color{darkblue}} % update subsubsections to bold with the colour blue \usepackage[toc]{appendix} % Include appendix in TOC \usepackage{xcolor} \usepackage{tocloft} % For manipulating Table of Content virtical spacing %\setlength\cftparskip{-2pt} \setlength\cftbeforesecskip{2pt} %spacing between the sections \setlength\cftaftertoctitleskip{30pt} % space between the first section and the text ``Table of Contents'' \definecolor{navyblue}{rgb}{0.0,0.0,0.5} \definecolor{zaffre}{rgb}{0.0, 0.08, 0.66} \definecolor{white}{rgb}{1.0, 1.0, 1.0} \definecolor{darkblue}{rgb}{0.0, 0.2, 0.6} \definecolor{darkgray}{rgb}{0.66, 0.66, 0.66} \definecolor{lightgray}{rgb}{0.83, 0.83, 0.83} %\pagenumbering{roman}
In your articles, refer to the *structure.tex* file as shown in the example below:
\documentclass[a4paper,11pt]{article} \input{/path_to_structure.tex}} \begin{document} …... \end{document}
### Add watermarks
To enable watermarks in your LaTeX document, use the * draftwatermark* package. The below code snippet and image demonstrates the how to add a watermark to your document. By default the watermark color is grey which can be modified to your desired color.
\usepackage{draftwatermark} \SetWatermarkText{\color{red}Classified} %add watermark text \SetWatermarkScale{4} %specify the size of the text

## Conclusion
In this series you saw some of the basic, but rich features that LaTeX provides for customizing your document to cater to your needs or the audience the document will be presented to. With LaTeX, there are many packages available to customize the page layout, style, and more.
## ¿Hablas español?
Nice article. Any suggestions for documents in other languages, and multi-language documents, eg. Spanish, Arabic, Mandarin, Russian
## Earl Ramirez
Thanks, for other languages and multi-language documents you want to use the babel package (https://www.ctan.org/pkg/babel), you can specify the language/s as follows
\begin{otherlanguage}{french}
.....
\end{otherlanguage}
\begin{otherlanguage}{german}
.....
\end{otherlanguage}
<\code>
Additionally, you can use \setlanguage
## Pablo Girollet
Where it says:
\titleformat{\section}{\Huge\bfseries\color{darkblue}}
\titleformat*{\subsubsection}{\Large\bfseries\color{darkblue}}
should say:
\titleformat{\thesection}{\Huge\bfseries\color{darkblue}}
\titleformat*{\thesubsubsection}{\Large\bfseries\color{darkblue}}
## Earl Ramirez
\section and \subsection worked, if \thesection and \thesubsection is used LaTeX throws an error.
## Pablo Girollet
Sorry Earl, but:
In structure.tex: \definecolor{darkblue}{rgb}{0.0, 0.2, 0.6} must be defined before using \titleformat, because since it uses darkblue color.
In main article: \input{/path_to_structure.tex}}, –> here’s a bracket left over (to the right).
And I insist:
If you use \section instead of \thesection in \titleformat definition, it does not compile when you define a section in the main article (try to compile, defining \section{Hola mundo} in the main article).
I’m using Fedora 32.
Greetings. Pablo.
## Earl Ramirez
Pablo,
Good catch with the extra curly bracket for the input command will have it sorted.
Regarding title format, don’t take my work for it, you can look at the titlesec package documentation for details https://mirror.pregi.net/tex-archive/macros/latex/contrib/titlesec/titlesec.pdf.
Rember the \titlelable takes \thesection as a command and \titleformat* takes the command \section, \subsection, and so on. This code was tested to provide the image in this article.
Regarding the defined colour, there are a few packages where order does matter in the preamble; however, I did not ran into any issues with the order in the format_structure. I am using TeXstudio version 2.12.22.
## Andrey
It is trivial formatting. How about formatting a newspaper with many columns, floats?
## Earl Ramirez
This series is geared to help newcomers; therefore, it aims to help with basic formatting; however, in the future, there will be more advance touchpoint in these subjects that will cater to an intermediate and advance audience
## K. de Jong
Excellent documentation! It will surely help people to get going with LaTeX faster.
## Rama Chandra Padhy
Very nice! This is very helpful for new and middle level learners. Hope some new topics will include for next level.
Thank you
## Dr. Udaysinh sutar
Very informative article. Essentials are given in very detail and and inshort. Useful.
## Gilles Séguin
search for doucmentation
typo error
## GaleonAD
can’t wait for part with adding mathematical expressions 🙂 |
13,155 | Kubernetes 调度器是如何工作的 | https://opensource.com/article/20/11/kubernetes-scheduler | 2021-02-26T12:35:01 | [
"Kubernetes"
] | https://linux.cn/article-13155-1.html |
>
> 了解 Kubernetes 调度器是如何发现新的吊舱并将其分配到节点。
>
>
>

[Kubernetes](https://kubernetes.io/) 已经成为容器和容器化工作负载的标准编排引擎。它提供一个跨公有云和私有云环境的通用和开源的抽象层。
对于那些已经熟悉 Kuberbetes 及其组件的人,他们的讨论通常围绕着如何尽量发挥 Kuberbetes 的功能。但当你刚刚开始学习 Kubernetes 时,尝试在生产环境中使用前,明智的做法是从一些关于 Kubernetes 相关组件(包括 [Kubernetes 调度器](https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/)) 开始学习,如下抽象视图中所示:

Kubernetes 也分为控制平面和工作节点:
1. **控制平面:** 也称为主控,负责对集群做出全局决策,以及检测和响应集群事件。控制平面组件包括:
* etcd
* kube-apiserver
* kube-controller-manager
* 调度器
2. **工作节点:** 也称节点,这些节点是工作负载所在的位置。它始终和主控联系,以获取工作负载运行所需的信息,并与集群外部进行通讯和连接。工作节点组件包括:
* kubelet
* kube-proxy
* CRI
我希望这个背景信息可以帮助你理解 Kubernetes 组件是如何关联在一起的。
### Kubernetes 调度器是如何工作的
Kubernetes <ruby> <a href="https://kubernetes.io/docs/concepts/workloads/pods/"> 吊舱 </a> <rt> pod </rt></ruby> 由一个或多个容器组成组成,共享存储和网络资源。Kubernetes 调度器的任务是确保每个吊舱分配到一个节点上运行。
(LCTT 译注:容器技术领域大量使用了航海比喻,pod 一词,意为“豆荚”,在航海领域指“吊舱” —— 均指盛装多个物品的容器。常不翻译,考虑前后文,可译做“吊舱”。)
在更高层面下,Kubernetes 调度器的工作方式是这样的:
1. 每个需要被调度的吊舱都需要加入到队列
2. 新的吊舱被创建后,它们也会加入到队列
3. 调度器持续地从队列中取出吊舱并对其进行调度
[调度器源码](https://github.com/kubernetes/kubernetes/blob/e4551d50e57c089aab6f67333412d3ca64bc09ae/plugin/pkg/scheduler/scheduler.go)(`scheduler.go`)很大,约 9000 行,且相当复杂,但解决了重要问题:
#### 等待/监视吊舱创建的代码
监视吊舱创建的代码始于 `scheduler.go` 的 8970 行,它持续等待新的吊舱:
```
// Run begins watching and scheduling. It waits for cache to be synced, then starts a goroutine and returns immediately.
func (sched *Scheduler) Run() {
if !sched.config.WaitForCacheSync() {
return
}
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
```
#### 负责对吊舱进行排队的代码
负责对吊舱进行排队的功能是:
```
// queue for pods that need scheduling
podQueue *cache.FIFO
```
负责对吊舱进行排队的代码始于 `scheduler.go` 的 7360 行。当事件处理程序触发,表明新的吊舱显示可用时,这段代码将新的吊舱加入队列中:
```
func (f *ConfigFactory) getNextPod() *v1.Pod {
for {
pod := cache.Pop(f.podQueue).(*v1.Pod)
if f.ResponsibleForPod(pod) {
glog.V(4).Infof("About to try and schedule pod %v", pod.Name)
return pod
}
}
}
```
#### 处理错误代码
在吊舱调度中不可避免会遇到调度错误。以下代码是处理调度程序错误的方法。它监听 `podInformer` 然后抛出一个错误,提示此吊舱尚未调度并被终止:
```
// scheduled pod cache
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return assignedNonTerminatedPod(t)
default:
runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))
return false
}
},
```
换句话说,Kubernetes 调度器负责如下:
* 将新创建的吊舱调度至具有足够空间的节点上,以满足吊舱的资源需求。
* 监听 kube-apiserver 和控制器是否创建新的吊舱,然后调度它至集群内一个可用的节点。
* 监听未调度的吊舱,并使用 `/binding` 子资源 API 将吊舱绑定至节点。
例如,假设正在部署一个需要 1 GB 内存和双核 CPU 的应用。因此创建应用吊舱的节点上需有足够资源可用,然后调度器会持续运行监听是否有吊舱需要调度。
### 了解更多
要使 Kubernetes 集群工作,你需要使以上所有组件一起同步运行。调度器有一段复杂的的代码,但 Kubernetes 是一个很棒的软件,目前它仍是我们在讨论或采用云原生应用程序时的首选。
学习 Kubernetes 需要精力和时间,但是将其作为你的专业技能之一能为你的职业生涯带来优势和回报。有很多很好的学习资源可供使用,而且 [官方文档](https://kubernetes.io/docs/home/) 也很棒。如果你有兴趣了解更多,建议从以下内容开始:
* [Kubernetes the hard way](https://github.com/kelseyhightower/kubernetes-the-hard-way)
* [Kubernetes the hard way on bare metal](https://github.com/Praqma/LearnKubernetes/blob/master/kamran/Kubernetes-The-Hard-Way-on-BareMetal.md)
* [Kubernetes the hard way on AWS](https://github.com/Praqma/LearnKubernetes/blob/master/kamran/Kubernetes-The-Hard-Way-on-AWS.md)
你喜欢的 Kubernetes 学习方法是什么?请在评论中分享吧。
---
via: <https://opensource.com/article/20/11/kubernetes-scheduler>
作者:[Mike Calizo](https://opensource.com/users/mcalizo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MZqk](https://github.com/MZqk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Kubernetes](https://kubernetes.io/) has emerged as the standard orchestration engine for containers and containerized workloads. It provides a common, open source abstraction layer that spans public and private cloud environments.
For those already familiar with Kubernetes and its components, the conversation is usually around maximizing Kubernetes' power. But when you're just learning Kubernetes, it's wise to begin with some general knowledge about Kubernetes and its components (including the [Kubernetes scheduler](https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/)), as shown in this high-level view, before trying to use it in production.
Kubernetes also uses control planes and nodes.
**Control plane:**Also known as master, these nodes are responsible for making global decisions about the clusters and detecting or responding to cluster events. The control plane components are:- etcd
- kube-apiserver
- kube-controller-manager
- scheduler
**Nodes:**Also called worker nodes, these sets of nodes are where a workload resides. They should always talk to the control plane to get the information necessary for the workload to run and to communicate and connect outside the cluster. Worker nodes' components are:- kubelet
- kube-proxy
- container runtime Interface.
I hope this background helps you understand how the Kubernetes components are stacked together.
## How Kubernetes scheduler works
A Kubernetes [pod](https://kubernetes.io/docs/concepts/workloads/pods/) is comprised of one or more containers with shared storage and network resources. The Kubernetes scheduler's task is to ensure that each pod is assigned to a node to run on.
At a high level, here is how the Kubernetes scheduler works:
- Every pod that needs to be scheduled is added to a queue
- When new pods are created, they are also added to the queue
- The scheduler continuously takes pods off that queue and schedules them
The [scheduler's code](https://github.com/kubernetes/kubernetes/blob/e4551d50e57c089aab6f67333412d3ca64bc09ae/plugin/pkg/scheduler/scheduler.go) (`scheduler.go`
) is large, around 9,000 lines, and fairly complex, but the important bits to tackle are:
-
**Code that waits/watches for pod creation**
The code that watches for pod creation begins on line 8970 of`scheduler.go`
; it waits indefinitely for new pods:`// Run begins watching and scheduling. It waits for cache to be synced, then starts a goroutine and returns immediately. func (sched *Scheduler) Run() { if !sched.config.WaitForCacheSync() { return } go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)`
-
**Code that is responsible for queuing the pod**
The function responsible for pod queuing is:`// queue for pods that need scheduling podQueue *cache.FIFO`
The code responsible for queuing the pod begins on line 7360 of
`scheduler.go`
. When the event handler is triggered to indicate that a new pod is available, this piece of code automatically puts the new pod in the queue:`func (f *ConfigFactory) getNextPod() *v1.Pod { for { pod := cache.Pop(f.podQueue).(*v1.Pod) if f.ResponsibleForPod(pod) { glog.V(4).Infof("About to try and schedule pod %v", pod.Name) return pod } } }`
-
**Code that handles errors**
You will inevitably encounter scheduling errors in pod scheduling. The following code is how the scheduler handles the errors. It listens to`podInformer`
and then spits out an error that the pod was not scheduled and terminates:`// scheduled pod cache podInformer.Informer().AddEventHandler( cache.FilteringResourceEventHandler{ FilterFunc: func(obj interface{}) bool { switch t := obj.(type) { case *v1.Pod: return assignedNonTerminatedPod(t) default: runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj)) return false } },`
In other words, the Kubernetes scheduler is responsible for:
- Scheduling the newly created pods on nodes with enough space to satisfy the pod's resource needs
- Listening to the kube-apiserver and the controller for the presence of newly created pods and then scheduling them to an available node on the cluster
- Watching for unscheduled pods and binding them to nodes by using the
`/binding`
pod sub-resource API.
For example, imagine an application is being deployed that requires 1GB of memory and two CPU cores. Therefore, the pods for the application are created on a node that has enough resources available. Then, the scheduler continues to run forever, watching to see if there are pods that need to be scheduled.
## Learn more
To have a working Kubernetes cluster, you need to get all the components above working together in sync. The scheduler is a complex piece of code, but Kubernetes is awesome software, and currently, it's the default choice when talking about adopting cloud-native applications.
Learning Kubernetes requires time and effort, but having it as one of your skills will give you an edge that should bring rewards in your career. There are a lot of good learning resources available, and the [documentation](https://kubernetes.io/docs/home/) is good. If you are interested in learning more, I recommend starting with:
What are your favorite ways to learn about Kubernetes? Please share in the comments.
## Comments are closed. |
13,157 | 选择 Linux 来做艺术设计的 4 个理由 | https://opensource.com/article/21/2/linux-art-design | 2021-02-27T13:57:28 | [
"设计"
] | https://linux.cn/article-13157-1.html |
>
> 开源会强化你的创造力。因为它把你带出专有的思维定势,开阔你的视野,从而带来更多的可能性。让我们探索一些开源的创意项目。
>
>
>

2021 年,人们比以前的任何时候都更有理由来爱上 Linux。在这个系列,我会分享 21 个选择 Linux 的原因。今天,让我来解释一下,为什么 Linux 是艺术设计的绝佳选择。
Linux 在服务器和云计算方面获得很多的赞誉。让不少人感到惊讶的是,Linux 刚好也有一系列的很棒的创意设计工具,并且这些工具在用户体验和质量方面可以媲美那些流行的创意设计工具。我第一次使用开源的设计工具时,并不是因为我没有其他工具可以选择。相反的,我是在接触了大量的这些领先的公司提供的专有设计工具后,才开始使用开源设计工具。我之所以最后选择开源设计工具是因为开源更有意义,而且我能获得更好的产出。这些都是一些笼统的说法,所以请允许我解释一下。
### 高可用性意味着高生产力
“生产力”这一次对于不同的人来说含义不一样。当我想到生产力,就是当你坐下来做事情,并能够完成你给自己设定的所有任务的时候,这时就很有成就感。但是当你总是被一些你无法掌控的事情打断,那你的生产力就下降了。
计算机看起来是不可预测的,诚然有很多事情会出错。电脑是由很多的硬件组成的,它们任何一个都有可能在任何时间出问题。软件会有 bug,也有修复这些 bug 的更新,而更新后又会带来新的 bug。如果你对电脑不了解,它可能就像一个定时炸弹,等着爆发。带着数字世界里的这么多的潜在问题,去接受一个当某些条件不满足(比如许可证,或者订阅费)就会不工作的软件,对我来说就显得很不理智。

开源的创意设计应用不需要订阅费,也不需要许可证。在你需要的时候,它们都能获取得到,并且通常都是跨平台的。这就意味着,当你坐在工作的电脑面前,你就能确定你能用到那些必需的软件。而如果某天你很忙碌,却发现你面前的电脑不工作了,解决办法就是找到一个能工作的,安装你的创意设计软件,然后开始工作。
例如,要找到一台无法运行 Inkscape 的电脑,比找到一台可以运行那些专有软件的电脑要难得多。这就叫做高可用。这是游戏规则的改变者。我从来不曾遇到因为软件用不了而不得不干等,浪费我数小时时间的事情。
### 开放访问更有利于多样性
我在设计行业工作的时候,我的很多同事都是通过自学的方式来学习艺术和技术方面的知识,这让我感到惊讶。有的通过使用那些最新的昂贵的“专业”软件来自学,但总有一大群人是通过使用自由和开源的软件来完善他们的数字化的职业技能。因为,对于孩子,或者没钱的大学生来说,这才是他们能负担的起,而且很容易就能获得的。
这是一种不同的高可用性,但这对我和许多其他用户来说很重要,如果不是因为开源,他们就不会从事创意行业。即使那些有提供付费订阅的开源项目,比如 Ardour,都能确保他的用户在不需要支付任何费用的时候也能使用软件。

当你不限制别人用你的软件的时候,你其实拥有了更多的潜在用户。如果你这样做了,那么你就开放了一个接收多样的创意声音的窗口。艺术钟爱影响力,你可以借鉴的经验和想法越多就越好。这就是开源设计软件所带来的可能性。
### 文件格式支持更具包容性
我们都知道在几乎所有行业里面包容性的价值。在各种意义上,邀请更多的人到派对可以造就更壮观的场面。知道这一点,当看到有的项目或者创新公司只邀请某些人去合作,只接受某些文件格式,就让我感到很痛苦。这看起来很陈旧,就像某个远古时代的精英主义的遗迹,而这是即使在今天都在发生的真实问题。
令人惊讶和不幸的是,这不是因为技术上的限制。专有软件可以访问开源的文件格式,因为这些格式是开源的,而且可以自由地集成到各种应用里面。集成这些格式不需要任何回报。而相比之下,专有的文件格式被笼罩在秘密之中,只被限制于提供给几个愿意付钱的人使用。这很糟糕,而且常常,你无法在没有这些专有软件的情况下打开一些文件来获取你的数据。令人惊喜的是,开源的设计软件却是尽力的支持更多的专有文件格式。以下是一些 Inkscape 所支持的令人难以置信的列表样本:

而这大部分都是在没有这些专有格式厂商的支持下开发出来的。
支持开放的文件格式可以更包容,对所有人都更好。
### 对新的创意没有限制
我之所以爱上开源的其中一个原因是,解决一个指定任务时,有彻底的多样性。当你在专有软件周围时,你所看到的世界是基于你所能够获取得到的东西。比如说,你过你打算处理一些照片,你通常会把你的意图局限在你所知道的可能性上面。你从你的架子上的 4 款或 10 款应用中,挑选出 3 款,因为它们是目前你唯一能够获取得到的选项。
在开源领域,你通常会有好几个“显而易见的”必备解决方案,但同时你还有一打的角逐者在边缘转悠,供你选择。这些选项有时只是半成品,或者它们超级专注于某项任务,又或者它们学起来有点挑战性,但最主要的是,它们是独特的,而且充满创新的。有时候,它们是被某些不按“套路”出牌的人所开发的,因此处理的方法和市场上现有的产品截然不同。其他时候,它们是被那些熟悉做事情的“正确”方式,但还是在尝试不同策略的人所开发的。这就像是一个充满可能性的巨大的动态的头脑风暴。
这种类型的日常创新能够引领出闪现的灵感、光辉时刻,或者影响广泛的通用性改进。比如说,著名的 GIMP 滤镜,(用于从图像中移除项目并自动替换背景)是如此的受欢迎以至于后来被专有图片编辑软件商拿去“借鉴”。这是成功的一步,但是对于一个艺术家而言,个人的影响才是最关键的。我常感叹于新的 Linux 用户的创意,而我只是在技术展会上展示给他们一个简单的音频,或者视频滤镜,或者绘图应用。没有任何的指导,或者应用场景,从简单的交互中喷发出来的关于新的工具的主意,是令人兴奋和充满启发的,通过实验中一些简单的工具,一个全新的艺术系列可以轻而易举的浮现出来。
只要在适当的工具集都有的情况下,有很多方式来更有效的工作。虽然私有软件通常也不会反对更聪明的工作习惯的点子,专注于实现自动化任务让用户可以更轻松的工作,对他们也没有直接的收益。Linux 和开源软件就是很大程度专为 [自动化和编排](https://opensource.com/article/20/11/orchestration-vs-automation) 而建的,而不只是服务器。像 [ImageMagick](https://opensource.com/life/16/6/fun-and-semi-useless-toys-linux#imagemagick) 和 [GIMP 脚本](https://opensource.com/article/21/1/gimp-scripting) 这样的工具改变了我的处理图片的方式,包括批量处理方面和纯粹实验方面。
你永远不知道你可以创造什么,如果你有一个你从来想象不到会存在的工具的话。
### Linux 艺术家
这里有 [使用开源的艺术家社区](https://librearts.org),从 [photography](https://pixls.us) 到 [makers](https://www.redhat.com/en/blog/channel/red-hat-open-studio) 到 [musicians](https://linuxmusicians.com),还有更多更多。如果你想要创新,试试 Linux 吧。
---
via: <https://opensource.com/article/21/2/linux-art-design>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amorsu](https://github.com/amorsu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. Today I'll explain why Linux is an excellent choice for creative work.
Linux gets a lot of press for its amazing server and cloud computing software. It comes as a surprise to some that Linux happens to have a great set of creative tools, too, and that they easily rival popular creative apps in user experience and quality. When I first started using open source creative software, it wasn't because I didn't have access to the other software. Quite the contrary, I started using open source tools when I had the greatest access to the proprietary tools offered by several leading companies. I chose to switch to open source because open source made more sense and produced better results. Those are some big claims, so allow me to explain.
## High availability means high productivity
The term *productivity* means different things to different people. When I think of productivity, it's that when you sit down to do something, it's rewarding when you're able to meet whatever goal you've set for yourself. If you get interrupted or stopped by something outside your control, then your productivity goes down.
Computers can seem unpredictable, and there are admittedly a lot of things that can go wrong. There are lots of hardware parts to a computer, and any one of them can break at any time. Software has bugs and updates to fix bugs, and then new bugs introduced by those updates. If you're not comfortable with computers, it can feel a little like a timebomb just waiting to ensnare you. With so much potentially working *against* you in the digital world, it doesn't make sense to me to embrace software that guarantees not to work when certain requirements (like a valid license, or more often, an up-to-date subscription) aren't met.
Inkscape
Open source creative apps have no required subscription fee and no licensing requirements. They're available when you need them and usually on any platform. That means when you sit down at a working computer, you know you have access to your must-have software. And if you're having a rough day and you find yourself sitting in front of a computer that isn't working, the fix is to find one that does work, install your creative suite, and get to work.
It's far harder to find a computer that *can't* run Inkscape, for instance, than it is to find a computer that *is* running a similar proprietary application. That's called high availability, and it's a game-changer. I've never found myself wasting hours of my day for lack of the software I want to run to get things done.
## Open access is better for diversity
When I was working in the creative industry, it sometimes surprised me how many of my colleagues were self-taught both in their artistic and technical disciplines. Some taught themselves on expensive rigs with all the latest "professional" applications, but there was always a large group of people who perfected their digital trade on free and open source software because, as kids or as poor college students, that was what they could afford and obtain easily.
That's a different kind of high availability, but it's one that's important to me and many other users who wouldn't be in the creative industry but for open source. Even open source projects that do offer a paid subscription, like [Ardour](https://community.ardour.org/subscribe), ensure that users have access to the software regardless of an ability to pay.
Ardour
When you don't restrict who gets to use your software, you're implicitly inviting more users. And when you do that, you enable a greater diversity of creative voices. Art loves influence, and the greater the variety of experiences and ideas you have to draw from, the better. That's what's possible with open source creative software.
## Resolute format support is more inclusive
We all acknowledge the value of inclusivity in basically every industry. Inviting *more people* to the party results in a greater spectacle, in nearly every sense. Knowing this, it's painful when I see a project or initiative that invites people to collaborate, only to limit what kind of file formats are acceptable. It feels archaic, like a vestige of elitism out of the far past, and yet it's a real problem even today.
In a surprise and unfortunate twist, it's not because of technical limitations. Proprietary software has access to open file formats because they're open source and free to integrate into any application. Integrating these formats requires no reciprocation. By stark contrast, proprietary file formats are often shrouded in secrecy, locked away for use by the select few who pay to play. It's so bad, in fact, that quite often, you can't open some files to get to your data without the proprietary software available. Amazingly, open source creative applications nevertheless include support for as many proprietary formats as they possibly can. Here's just a sample of Inkscape's staggering support list:
opensource.com
And that's largely without contribution from the companies owning the file formats.
Supporting open file formats is more inclusive, and it's better for everyone.
## No restrictions for fresh ideas
One of the things I've come to love about open source is the sheer diversity of how any given task is interpreted. When you're around proprietary software, you tend to start to see the world based on what's available to you. For instance, if you're thinking of manipulating some photos, then you generally frame your intent based on what you know to be possible. You choose from the three of four or ten applications on the shelf because they're the only options presented.
You generally have several obligatory "obvious" solutions in open source, but you also get an additional *dozen* contenders hanging out on the fringe. These options are sometimes only half-complete, or they're hyper-focused on a specific task, or they're challenging to learn, but most importantly, they're unique and innovative. Sometimes they've been developed by someone who's never seen the way a task is "supposed to be done," and so the approach is wildly different than anything else on the market. Other times, they're developed by someone familiar with the "right way" of doing something but is trying a different tactic anyway. It's a big, dynamic brainstorm of possibility.
These kinds of everyday innovations can lead to flashes of inspiration, moments of brilliance, or widespread common improvements. For instance, the famous GIMP filter that removes items from photographs and automatically replaces the background was so popular that it later got "borrowed" by proprietary photo editing software. That's one metric of success, but it's the personal impact that matters most for an artist. I marvel at the creativity of new Linux users when I've shown them just one simple audio or video filter or paint application at a tech demo. Without any instruction or context, the ideas that spring out of a simple interaction with a new tool can be exciting and inspiring, and a whole new series of artwork can easily emerge from experimentation with just a few simple tools.
There are also ways of working more efficiently, provided the right set of tools are available. While proprietary software usually isn't opposed to the idea of smarter work habits, there's rarely a direct benefit from concentrating on making it easy for users to automate tasks. Linux and open source are largely built exactly for [automation and orchestration](https://opensource.com/article/20/11/orchestration-vs-automation), and not just for servers. Tools like [ImageMagick](https://opensource.com/life/16/6/fun-and-semi-useless-toys-linux#imagemagick) and [GIMP scripts](https://opensource.com/article/21/1/gimp-scripting) have changed the way I work with images, both for bulk processing and idle experimentation.
You never know what you might create, given tools that you've never imagined existed.
## Linux artists
There's a whole [community of artists using open source](https://librearts.org), from [photography](https://pixls.us) to [makers](https://www.redhat.com/en/blog/channel/red-hat-open-studio) to [musicians](https://linuxmusicians.com), and much much more. If you want to get creative, give Linux a go.
## 2 Comments |
13,158 | 不习惯在终端使用 youtube-dl?可以使用这些 GUI 应用 | https://itsfoss.com/youtube-dl-gui-apps/ | 2021-02-27T14:40:18 | [
"youtube-dl"
] | https://linux.cn/article-13158-1.html | 
如果你一直在关注我们,可能已经知道 [youtube-dl 项目曾被 GitHub 暂时下架](https://itsfoss.com/youtube-dl-github-takedown/) 以合规。但它现在已经恢复并完全可以访问,可以说它并不是一个非法的工具。
它是一个非常有用的命令行工具,可以让你 [从 YouTube](https://itsfoss.com/download-youtube-videos-ubuntu/) 和其他一些网站下载视频。使用 [youtube-dl](https://itsfoss.com/download-youtube-linux/) 并不复杂,但我明白使用命令来完成这种任务并不是每个人都喜欢的方式。
好在有一些应用为 `youtube-dl` 工具提供了 GUI 前端。
### 使用 youtube-dl GUI 应用的先决条件
在你尝试下面提到的一些选择之前,你可能需要在你的系统上安装 `youtube-dl` 和 [FFmpeg](https://ffmpeg.org/),才能够下载/选择不同的格式进行下载。
你可以按照我们的 [ffmpeg 使用完整指南](https://itsfoss.com/ffmpeg/#install) 进行设置,并探索更多关于它的内容。
要安装 [youtube-dl](https://youtube-dl.org/),你可以在 Linux 终端输入以下命令:
```
sudo curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dl
```
下载最新版本后,你只需要输入以下内容使其可执行就可使用:
```
sudo chmod a+rx /usr/local/bin/youtube-dl
```
如果你需要其他方法安装它,也可以按照[官方安装说明](https://ytdl-org.github.io/youtube-dl/download.html)进行安装。
### Youtube-dl GUI 应用
大多数 Linux 上的下载管理器也允许你从 YouTube 和其他网站下载视频。然而,youtube-dl GUI 应用可能有额外的选项,如只提取音频或下载特定分辨率和视频格式。
请注意,下面的列表没有特别的排名顺序。你可以根据你的要求选择。
#### 1、AllTube Download

**主要特点:**
* Web GUI
* 开源
* 可以自托管
AllTube 是一个开源的 web GUI,你可以通过 <https://alltubedownload.net/> 来访问。
如果你选择使用这款软件,你不需要在系统上安装 youtube-dl 或 ffmpeg。它提供了一个简单的用户界面,你只需要粘贴视频的 URL,然后继续选择你喜欢的文件格式下载。你也可以选择将其部署在你的服务器上。
请注意,你不能使用这个工具提取视频的 MP3 文件,它只适用于视频。你可以通过他们的 [GitHub 页面](https://github.com/Rudloff/alltube)探索更多关于它的信息。
* [AllTube Download Web GUI](https://alltubedownload.net/)
#### 2、youtube-dl GUI

**主要特点:**
* 跨平台
* 显示预计下载大小
* 有音频和视频下载选择
一个使用 electron 和 node.js 制作的有用的跨平台 GUI 应用。你可以很容易地下载音频和视频,以及选择各种可用的文件格式的选项。
如果你愿意的话,你还可以下载一个频道或播放列表的部分内容。特别是当你下载高质量的视频文件时,预计的下载大小绝对是非常方便的。
如上所述,它也适用于 Windows 和 MacOS。而且,你会在它的 [GitHub 发布](https://github.com/jely2002/youtube-dl-gui/releases/tag/v1.8.7)中得到一个适用于 Linux 的 AppImage 文件。
* [Youtube-dl GUI](https://github.com/jely2002/youtube-dl-gui)
#### 3、Videomass

**主要特点:**
* 跨平台
* 转换音频/视频格式
* 支持多个 URL
* 适用于也想使用 FFmpeg 的用户
如果你想从 YouTube 下载视频或音频,并将它们转换为你喜欢的格式,Videomass 可以是一个不错的选择。
要做到这点,你需要在你的系统上同时安装 youtube-dl 和 ffmpeg。你可以轻松的添加多个 URL 来下载,还可以根据自己的喜好设置输出目录。

你还可以获得一些高级设置来禁用 youtube-dl,改变文件首选项,以及随着你的探索,还有一些更方便的选项。
它为 Ubuntu 用户提供了一个 PPA,为任何其他 Linux 发行版提供了一个 AppImage 文件。在它的 [Github 页面](https://github.com/jeanslack/Videomass)探索更多信息。
* [Videomass](https://jeanslack.github.io/Videomass/)
#### 附送:Haruna Video Player

**主要特点:**
* 播放/流式传输 YouTube 视频
Haruna Video Player 原本是 [MPV](https://mpv.io/) 的前端。虽然使用它不能下载 YouTube 视频,但可以通过 youtube-dl 观看/流式传输 YouTube 视频。
你可以在我们的[文章](https://itsfoss.com/haruna-video-player/)中探索更多关于视频播放器的内容。
### 总结
尽管你可能会在 GitHub 和其他平台上找到更多的 youtube-dl GUI,但它们中的大多数都不能很好地运行,最终会显示出多个错误,或者不再积极开发。
[Tartube](https://github.com/axcore/tartube) 就是这样的一个选择,你可以尝试一下,但可能无法达到预期的效果。我用 Pop!\_OS 和 Ubuntu MATE 20.04(全新安装)进行了测试。每次我尝试下载一些东西时,无论我怎么做都会失败(即使系统中安装了 youtube-dl 和 ffmpeg)。
所以,我个人最喜欢的似乎是 Web GUI([AllTube Download](https://github.com/Rudloff/alltube)),它不依赖于安装在你系统上的任何东西,也可以自托管。
如果我错过了你最喜欢的选择,请在评论中告诉我什么是最适合你的。
---
via: <https://itsfoss.com/youtube-dl-gui-apps/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you’ve been following us, you probably already know that [youtube-dl project was taken down temporarily by GitHub](https://itsfoss.com/youtube-dl-github-takedown/) to comply with a request.
Considering that it’s now restored and completely accessible, it is safe to say that it not an illegal tool out there.
It is a very useful command-line tool that lets you [download videos from YouTube](https://itsfoss.com/download-youtube-videos-ubuntu/) and some other websites. [Using youtube-dl](https://itsfoss.com/download-youtube-linux/) is not that complicated but I understand that using commands for such tasks is not everyone’s favorite way.
The good thing is that there are a few applications that provide GUI frontend for youtube-dl tool.
## Prerequisites for Using youtube-dl GUI Apps
Before you try some of the options mentioned below, you may need to have youtube-dl and [FFmpeg](http://ffmpeg.org/) installed on your system to be able to download / choose different format to download.
You can follow our [complete guide on using ffmpeg](https://itsfoss.com/ffmpeg/#install) to set it up and explore more about it.
To install [youtube-dl](https://youtube-dl.org/), you can type in the following commands in your Linux terminal:
`sudo curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dl`
Once you download the latest version, you just need to make it executable and ready for use by typing in:
`sudo chmod a+rx /usr/local/bin/youtube-dl`
You can also follow the [official setup instructions](http://ytdl-org.github.io/youtube-dl/download.html) if you need other methods to install it.
## Youtube-dl GUI Apps
Most download managers on Linux also allow you to download videos from YouTube and other websites. However, the youtube-dl GUI apps might have additional options like extracting only audio or downloading the videos in a particular resolution and video format.
Do note that the list below is in no particular order of ranking. You may choose what suits your requirements.
### 1. AllTube Download

**Key Features:**
- Web GUI
- Open-Source
- Self-host option
AllTube is an open-source web GUI that you can access by visiting [https://alltubedownload.net/](https://alltubedownload.net/)
If you choose to utilize this, you do not need to install youtube-dl or ffmpeg on your system. It offers a simple user interface where you just have to paste the URL of the video and then proceed to choose your preferred file format to download. You can also choose to deploy it on your server.
Do note that you cannot extract the MP3 file of a video using this tool, it is only applicable for videos. You can explore more about it through their [GitHub page](https://github.com/Rudloff/alltube).
### 2. youtube-dl GUI
**Key Features:**
- Cross-platform
- Displays estimated download size
- Audio and video download option available
A useful cross-platform GUI app made using electron and node.js. You can easily download both audio and video along with the option to choose various file formats available.
You also get the ability to download parts of a channel or playlist, if you want. The estimated download size definitely comes in handy especially if you are downloading high quality video files.
As mentioned, it is also available for Windows and macOS. And, you will get an AppImage file available for Linux in its [GitHub releases](https://github.com/jely2002/youtube-dl-gui/releases/tag/v1.8.7).
### 3. Videomass
**Key Features:**
- Cross-platform
- Convert audio/video format
- Multiple URLs supported
- Suitable for users who also want to utilize FFmpeg
If you want to download video or audio from YouTube and also convert them to your preferred format, Videomass can be a nice option.
To make this work, you need both youtube-dl and ffmpeg installed on your system. You can easily add multiple URLs to download and also set the output directory as you like.
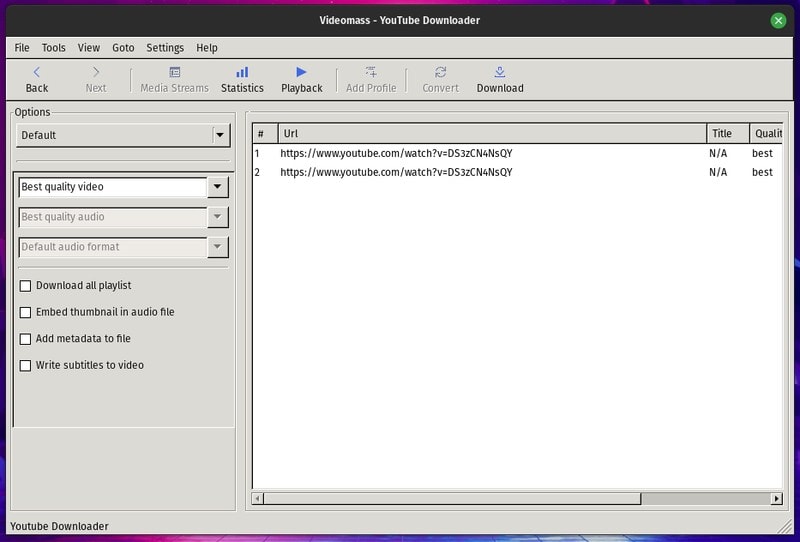
You also get some advanced settings to disable youtube-dl, change file preferences, and a few more handy options as you explore.
It offers a PPA for Ubuntu users and an AppImage file for any other Linux distribution. Explore more about it in its [GitHu](https://github.com/jeanslack/Videomass)[b](https://github.com/jeanslack/Videomass)[ page](https://github.com/jeanslack/Videomass).
### Additional Mention: Haruna Video Player
**Key Features:**
- Play/Stream YouTube videos
Haruna video player is originally a front-end for [MPV](https://mpv.io/). Even though you cannot download YouTube videos using it, you can watch/stream YouTube videos through youtube-dl.
You can explore more about the video player in our [original article](https://itsfoss.com/haruna-video-player/) about it.
## Wrapping Up
Even though you may find more youtube-dl GUIs on GitHub and other platforms, most of them do not function well and end up showing multiple errors or aren’t actively developed anymore.
[Tartube](https://github.com/axcore/tartube) is one such option that you can try, but it may not work as expected. I tested it with Pop!_OS and on Ubuntu MATE 20.04 (fresh install). Every time I try to download something, it fails, no matter what I do (even with youtube-dl and ffmpeg installed in the system).
So, my personal favorite seems to be the web GUI ([AllTube Download](https://github.com/Rudloff/alltube)) that does not depend on anything installed on your system and can be self-hosted as well.
Let me know in the comments what works for you best and if I’ve missed any of your favorite options. |
13,160 | 使用 Linux 软件包管理器的 5 个理由 | https://opensource.com/article/21/2/linux-package-management | 2021-02-28T12:30:21 | [
"包管理器"
] | https://linux.cn/article-13160-1.html |
>
> 包管理器可以跟踪你安装的软件的所有组件,使得更新、重装和故障排除更加容易。
>
>
>

在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。今天,我将谈谈软件仓库。
在我使用 Linux 之前,我认为在计算机上安装的应用是理所当然的。我会根据需要安装应用,如果我最后没有使用它们,我就会把它们忘掉,让它们占用我的硬盘空间。终于有一天,我的硬盘空间会变得稀缺,我就会疯狂地删除应用,为更重要的数据腾出空间。但不可避免的是,应用只能释放出有限的空间,所以我将注意力转移到与这些应用一起安装的所有其他零碎内容上,无论是媒体内容还是配置文件和文档。这不是一个管理电脑的好方法。我知道这一点,但我并没有想过要有其他的选择,因为正如人们所说,你不知道自己不知道什么。
当我改用 Linux 时,我发现安装应用的方式有些不同。在 Linux 上,会建议你不要去网站上找应用的安装程序。取而代之的是,运行一个命令,应用就会被安装到系统上,并记录每个单独的文件、库、配置文件、文档和媒体资产。
### 什么是软件仓库?
在 Linux 上安装应用的默认方法是从发行版软件仓库中安装。这可能听起来像应用商店,那是因为现代应用商店借鉴了很多软件仓库的概念。[Linux 也有应用商店](http://flathub.org),但软件仓库是独一无二的。你通过一个*包管理器*从软件仓库中获得一个应用,它使你的 Linux 系统能够记录和跟踪你所安装的每一个组件。
这里有五个原因可以让你确切地知道你的系统上有什么东西,可以说是非常有用。
#### 1、移除旧应用
当你的计算机知道应用安装的每一个文件时,卸载你不再需要的文件真的很容易。在 Linux 上,安装 [31 个不同的文本编辑器](https://opensource.com/article/21/1/text-editor-roundup),然后卸载 30 个你不喜欢的文本编辑器是没有问题的。当你在 Linux 上卸载的时候,你就真的卸载了。
#### 2、按你的意思重新安装
不仅卸载要彻底,*重装*也很有意义。在许多平台上,如果一个应用出了问题,有时会建议你重新安装它。通常情况下,谁也说不清为什么要重装一个应用。不过,人们还是经常会隐隐约约地怀疑某个地方的文件已经损坏了(换句话说,数据写入错误),所以希望重装可以覆盖坏的文件以让软件重新工作。这是个不错的建议,但对于任何技术人员来说,不知道是什么地方出了问题都是令人沮丧的。更糟糕的是,如果不仔细跟踪,就不能保证所有的文件都会在重装过程中被刷新,因为通常没有办法知道与应用程序一起安装的所有文件在第一时间就删除了。有了软件包管理器,你可以强制彻底删除旧文件,以确保新文件的全新安装。同样重要的是,你可以研究每个文件并可能找出导致问题的文件,但这是开源和 Linux 的一个特点,而不是包管理。
#### 3、保持你应用的更新
不要听别人告诉你的 Linux 比其他操作系统“更安全”。计算机是由代码组成的,而我们人类每天都会以新的、有趣的方式找到利用这些代码的方法。因为 Linux 上的绝大多数应用都是开源的,所以许多漏洞都会以“<ruby> 常见漏洞和暴露 <rt> Common Vulnerability and Exposures </rt></ruby>”(CVE)的形式公开。大量涌入的安全漏洞报告似乎是一件坏事,但这绝对是一个*知道*远比*不知道*好的案例。毕竟,没有人告诉你有问题,并不意味着没有问题。漏洞报告是好的。它们对每个人都有好处。而且,当开发人员修复安全漏洞时,对你而言,及时获得这些修复程序很重要,最好不用自己记着动手修复。
包管理器正是为了实现这一点而设计的。当应用收到更新时,无论是修补潜在的安全问题还是引入令人兴奋的新功能,你的包管理器应用都会提醒你可用的更新。
#### 4、保持轻便
假设你有应用 A 和应用 B,这两个应用都需要库 C。在某些操作系统上,通过得到 A 和 B,就会得到了两个 C 的副本。这显然是多余的,所以想象一下,每个应用都会发生几次。冗余的库很快就会增加,而且由于对一个给定的库没有单一的“正确”来源,所以几乎不可能确保你使用的是最新的甚至是一致的版本。
我承认我不会整天坐在这里琢磨软件库,但我确实记得我琢磨的日子,尽管我不知道这就是困扰我的原因。在我还没有改用 Linux 之前,我在处理工作用的媒体文件时遇到错误,或者在玩不同的游戏时出现故障,或者在阅读 PDF 时出现怪异的现象,等等,这些都不是什么稀奇的事情。当时我花了很多时间去调查这些错误。我仍然记得,我的系统上有两个主要的应用分别捆绑了相同(但有区别)的图形后端技术。当一个程序的输出导入到另一个程序时,这种不匹配会导致错误。它本来是可以工作的,但是由于同一个库文件集合的旧版本中的一个错误,一个应用的热修复程序并没有给另一个应用带来好处。
包管理器知道每个应用需要哪些后端(被称为*依赖关系*),并且避免重新安装已经在你系统上的软件。
#### 5、保持简单
作为一个 Linux 用户,我要感谢包管理器,因为它帮助我的生活变得简单。我不必考虑我安装的软件,我需要更新的东西,也不必考虑完成后是否真的将其卸载了。我毫不犹豫地试用软件。而当我在安装一台新电脑时,我运行 [一个简单的 Ansible 脚本](https://opensource.com/article/20/9/install-packages-ansible) 来自动安装我所依赖的所有软件的最新版本。这很简单,很智能,也是一种独特的解放。
### 更好的包管理
Linux 从整体看待应用和操作系统。毕竟,开源是建立在其他开源工作基础上的,所以发行版维护者理解依赖*栈*的概念。Linux 上的包管理了解你的整个系统、系统上的库和支持文件以及你安装的应用。这些不同的部分协调工作,为你提供了一套高效、优化和强大的应用。
---
via: <https://opensource.com/article/21/2/linux-package-management>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. Today, I'll talk about software repositories
Before I used Linux, I took the applications I had installed on my computer for granted. I would install applications as needed, and if I didn't end up using them, I'd forget about them, letting them languish as they took up space on my hard drive. Eventually, space on my drive would become scarce, and I'd end up frantically removing applications to make room for more important data. Inevitably, though, the applications would only free up so much space, and so I'd turn my attention to all of the other bits and pieces that got installed along with those apps, whether it was media assets or configuration files and documentation. It wasn't a great way to manage my computer. I knew that, but it didn't occur to me to imagine an alternative, because as they say, you don't know what you don't know.
When I switched to Linux, I found that installing applications worked a little differently. On Linux, you were encouraged not to go out to websites for an application installer. Instead, you ran a command, and the application was installed on the system, with every individual file, library, configuration file, documentation, and asset recorded.
## What is a software repository?
The default method of installing applications on Linux is from a distribution software repository. That might sound like an app store, and that's because modern app stores have borrowed much from the concept of software repositories. [Linux has app stores, too](http://flathub.org), but software repositories are unique. You get an application from a software repository through a *package manager*, which enables your Linux system to record and track every component of what you've installed.
Here are five reasons that knowing exactly what's on your system can be surprisingly useful.
### 1. Removing old applications
When your computer knows every file that was installed with any given application, it's really easy to uninstall files you no longer need. On Linux, there's no problem with installing [31 different text editors](https://opensource.com/article/21/1/text-editor-roundup) only to later uninstall the 30 you don't love. When you uninstall on Linux, you really uninstall.
### 2. Reinstall like you mean it
Not only is an uninstall thorough, a *reinstall* is meaningful. On many platforms, should something go wrong with an application, you're sometimes advised to reinstall it. Usually, nobody can say why you should reinstall an application. Still, there's often the vague suspicion that some file somewhere has become corrupt (in other words, data got written incorrectly), and so the hope is that a reinstall might overwrite the bad files and make things work again. It's not bad advice, but it's frustrating for any technician not to know what's gone wrong. Worse still, there's no guarantee, without careful tracking, that all files will be refreshed during a reinstall because there's often no way of knowing that all the files installed with an application were removed in the first place. With a package manager, you can force a complete removal of old files to ensure a fresh installation of new files. Just as significantly, you can account for every file and probably find out which one is causing problems, but that's a feature of open source and Linux rather than package management.
### 3. Keep your applications updated
Don't let anybody tell you that Linux is "more secure" than other operating systems. Computers are made of code, and we humans find ways to exploit that code in new and interesting ways every day. Because the vast majority of applications on Linux are open source, many exploits are filed publically as Common Vulnerability and Exposures (CVE). A flood of incoming security bug reports may seem like a bad thing, but this is definitely a case when *knowing* is far better than *not knowing*. After all, just because nobody's told you that there's a problem doesn't mean that there's not a problem. Bug reports are good. They benefit everyone. And when developers fix security bugs, it's important for you to be able to get those fixes promptly, and preferably without having to remember to do it yourself.
A package manager is designed to do exactly that. When applications receive updates, whether it's to patch a potential security problem or introduce an exciting new feature, your package manager application alerts you of the available update.
### 4. Keep it light
Say you have application A and application B, both of which require library C. On some operating systems, by getting A and B, you get two copies of C. That's obviously redundant, so imagine it happening several times per application. Redundant libraries add up quickly, and by having no single source of "truth" for a given library, it's nearly impossible to ensure you're using the most up-to-date or even just a consistent version of it.
I admit I don't tend to sit around pondering software libraries all day, but I do remember the days when I did, even though I didn't know that's what was troubling me. Before I had switched to Linux, it wasn't uncommon for me to encounter errors when dealing with media files for work, or glitches when playing different video games, or quirks when reading a PDF, and so on. I spent a lot of time investigating these errors back then. I still remember learning that two major applications on my system each had bundled the same (but different) graphic backend technologies. The mismatch was causing errors when the output of one was imported into the other. It was meant to work, but because of a bug in an older version of the same collection of library files, a hotfix for one application didn't benefit the other.
A package manager knows what backends (referred to as a *dependency*) are needed for each application and refrains from reinstalling software that's already on your system.
### 5. Keep it simple
As a Linux user, I appreciate a good package manager because it helps make my life simple. I don't have to think about the software I install, what I need to update, or whether something's really been uninstalled when I'm finished with it. I audition software without hesitation. And when I'm setting up a new computer, I run [a simple Ansible script](https://opensource.com/article/20/9/install-packages-ansible) to automate the installation of the latest versions of all the software I rely upon. It's simple, smart, and uniquely liberating.
## Better package management
Linux takes a holistic view of applications and the operating system. After all, open source is built upon the work of other open source, so distribution maintainers understand the concept of a dependency *stack*. Package management on Linux has an awareness of your whole system, the libraries and support files on it, and the applications you install. These disparate parts work together to provide you with an efficient, optimized, and robust set of applications.
## 1 Comment |
13,161 | 在裸机上建立 Linux 云实例 | https://opensource.com/article/21/1/cloud-image-virt-install | 2021-02-28T13:01:00 | [
"云镜像"
] | https://linux.cn/article-13161-1.html |
>
> 在 Fedora 上用 virt-install 创建云镜像。
>
>
>

虚拟化是使用最多的技术之一。Fedora Linux 使用 [Cloud Base 镜像](https://alt.fedoraproject.org/cloud/) 来创建通用虚拟机(VM),但设置 Cloud Base 镜像的方法有很多。最近,用于调配虚拟机的 `virt-install` 命令行工具增加了对 `cloud-init` 的支持,因此现在可以使用它在本地配置和运行云镜像。
本文介绍了如何在裸机上设置一个基本的 Fedora 云实例。同样的步骤可以用于任何 raw 或Qcow2 Cloud Base 镜像。
### 什么是 --cloud-init?
`virt-install` 命令使用 `libvirt` 创建一个 KVM、Xen 或 [LXC](https://www.redhat.com/sysadmin/exploring-containers-lxc) 客户机。`--cloud-init` 选项使用一个本地文件(称为 “nocloud 数据源”),所以你不需要网络连接来创建镜像。在第一次启动时,`nocloud` 方法会从 iso9660 文件系统(`.iso` 文件)中获取访客机的用户数据和元数据。当你使用这个选项时,`virt-install` 会为 root 用户账户生成一个随机的(临时)密码,提供一个串行控制台,以便你可以登录并更改密码,然后在随后的启动中禁用 `--cloud-init` 选项。
### 设置 Fedora Cloud Base 镜像
首先,[下载一个 Fedora Cloud Base(for OpenStack)镜像](https://alt.fedoraproject.org/cloud/)。

然后安装 `virt-install` 命令:
```
$ sudo dnf install virt-install
```
一旦 `virt-install` 安装完毕并下载了 Fedora Cloud Base 镜像,请创建一个名为`cloudinit-user-data.yaml` 的小型 YAML 文件,其中包含 `virt-install` 将使用的一些配置行:
```
#cloud-config
password: 'r00t'
chpasswd: { expire: false }
```
这个简单的云配置可以设置默认的 `fedora` 用户的密码。如果你想使用会过期的密码,可以将其设置为登录后过期。
创建并启动虚拟机:
```
$ virt-install --name local-cloud18012709 \
--memory 2000 --noreboot \
--os-variant detect=on,name=fedora-unknown \
--cloud-init user-data="/home/r3zr/cloudinit-user-data.yaml" \
--disk=size=10,backing_store="/home/r3zr/Downloads/Fedora-Cloud-Base-33-1.2.x86_64.qcow2"
```
在这个例子中,`local-cloud18012709` 是虚拟机的名称,内存设置为 2000MiB,磁盘大小(虚拟硬盘)设置为 10GB,`--cloud-init` 和 `backing_store` 分别带有你创建的 YAML 配置文件和你下载的 Qcow2 镜像的绝对路径。
### 登录
在创建镜像后,你可以用用户名 `fedora` 和 YAML 文件中设置的密码登录(在我的例子中,密码是 `r00t`,但你可能用了别的密码)。一旦你第一次登录,请更改你的密码。
要关闭虚拟机的电源,执行 `sudo poweroff` 命令,或者按键盘上的 `Ctrl+]`。
### 启动、停止和销毁虚拟机
`virsh` 命令用于启动、停止和销毁虚拟机。
要启动任何停止的虚拟机:
```
$ virsh start <vm-name>
```
要停止任何运行的虚拟机:
```
$ virsh shutdown <vm-name>
```
要列出所有处于运行状态的虚拟机:
```
$ virsh list
```
要销毁虚拟机:
```
$ virsh destroy <vm-name>
```

### 快速而简单
`virt-install` 命令与 `--cloud-init` 选项相结合,可以快速轻松地创建云就绪镜像,而无需担心是否有云来运行它们。无论你是在为重大部署做准备,还是在学习容器,都可以试试`virt-install --cloud-init`。
在云计算工作中,你有喜欢的工具吗?请在评论中告诉我们。
---
via: <https://opensource.com/article/21/1/cloud-image-virt-install>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Virtualization is one of the most used technologies. Fedora Linux uses [Cloud Base images](https://alt.fedoraproject.org/cloud/) to create general-purpose virtual machines (VM), but there are many ways to set up Cloud Base images. Recently, the virt-install command-line tool for provisioning VMs added support for **cloud-init**, so it can now be used to configure and run a cloud image locally.
This article walks through how to set up a base Fedora cloud instance on bare metal. The same steps can be used with any raw or Qcow2 Cloud Base image.
## What is --cloud-init?
The **virt-install** command creates a KVM, Xen, or [LXC](https://www.redhat.com/sysadmin/exploring-containers-lxc) guest using **libvirt**. The `--cloud-init`
option uses a local file (called a **nocloud datasource**) so you don't need a network connection to create an image. The **nocloud** method derives user data and metadata for the guest from an iso9660 filesystem (an `.iso`
file) during the first boot. When you use this option, **virt-install** generates a random (and temporary) password for the root user account, provides a serial console so you can log in and change your password, and then disables the `--cloud-init`
option for subsequent boots.
## Set up a Fedora Cloud Base image
First, [download a Fedora Cloud Base (for OpenStack) image](https://alt.fedoraproject.org/cloud/).
(Sumantro Mukherjee, CC BY-SA 4.0)
Then install the **virt-install** command:
`$ sudo dnf install virt-install`
Once **virt-install **is installed and the Fedora Cloud Base image is downloaded, create a small YAML file named `cloudinit-user-data.yaml`
to contain a few configuration lines that virt-install will use.
```
#cloud-config
password: 'r00t'
chpasswd: { expire: false }
```
This simple cloud-config sets the password for the default **fedora** user. If you want to use a password that expires, you can set it to expire after logging in.
Create and boot the VM:
```
$ virt-install --name local-cloud18012709 \
--memory 2000 --noreboot \
--os-variant detect=on,name=fedora-unknown \
--cloud-init user-data="/home/r3zr/cloudinit-user-data.yaml" \
--disk=size=10,backing_store="/home/r3zr/Downloads/Fedora-Cloud-Base-33-1.2.x86_64.qcow2"
```
In this example, `local-cloud18012709`
is the name of the virtual machine, RAM is set to 2000MiB, disk size (the virtual hard drive) is set to 10GB, and `--cloud-init`
and `backing_store`
contain the absolute path to the YAML config file you created and the Qcow2 image you downloaded.
## Log in
After the image is created, you can log in with the username **fedora** and the password set in the YAML file (in my example, this is **r00t**, but you may have used something different). Change your password once you've logged in for the first time.
To power off your virtual machine, execute the `sudo poweroff`
command, or press **Ctrl**+**]** on your keyboard.
## Start, stop, and kill VMs
The `virsh`
command is used to start, stop, and kill VMs.
To start any VM that is running:
`$ virsh start <vm-name>`
To stop any running VM:
`$ virsh shutdown <vm-name>`
To list all VMs that are in a running state:
`$ virsh list`
To destroy the VMs:
`$ virsh destroy <vm-name>`

(Sumantro Mukherjee, CC BY-SA 4.0)
## Fast and easy
The **virt-install** command combined with the `--cloud-init`
option makes it fast and easy to create cloud-ready images without worrying about whether you have a cloud to run them on yet. Whether you're preparing for a a major deployment or just learning about containers, give `virt-install --cloud-init`
a try.
Do you have a favourite tool for your work in the cloud? Tell us about them in the comments.
## Comments are closed. |
13,163 | Ansible 点对点命令快速入门指南示例 | https://www.2daygeek.com/ansible-ad-hoc-command-quick-start-guide-with-examples/ | 2021-02-28T22:16:00 | [
"Ansible"
] | https://linux.cn/article-13163-1.html | 
之前,我们写了一篇有关 [Ansible 安装和配置](/article-13142-1.html) 的文章。在那个教程中只包含了一些使用方法的示例。如果你是 Ansible 新手,建议你阅读上篇文章。一旦你熟悉了,就可以继续阅读本文了。
默认情况下,Ansible 仅使用 5 个并行进程。如果要在多个主机上执行任务,需要通过添加 `-f [进程数]` 选项来手动设置进程数。
### 什么是<ruby> 点对点 <rt> ad-hoc </rt></ruby>命令?
点对点命令用于在一个或多个受控节点上自动执行任务。它非常简单,但是不可重用。它使用 `/usr/bin/ansible` 二进制文件执行所有操作。
点对点命令最适合运行一次的任务。例如,如果要检查指定用户是否可用,你可以使用一行命令而无需编写剧本。
#### 为什么你要了解点对点命令?
点对点命令证明了 Ansible 的简单性和强大功能。从 2.9 版本开始,它支持 3389 个模块,因此你需要了解和学习要定期使用的 Ansible 模块列表。
如果你是一个 Ansible 新手,可以借助点对点命令轻松地练习这些模块及参数。
你在这里学习到的概念将直接移植到剧本中。
**点对点命令的一般语法:**
```
ansible [模式] -m [模块] -a "[模块选项]"
```
点对点命令包含四个部分,详细信息如下:
| 部分 | 描述 |
| --- | --- |
| `ansible` | 命令 |
| 模式 | 输入清单或指定组 |
| 模块 | 运行指定的模块名称 |
| 模块选项 | 指定模块参数 |
#### 如何使用 Ansible 清单文件
如果使用 Ansible 的默认清单文件 `/etc/ansible/hosts`,你可以直接调用它。否则你可以使用 `-i` 选项指定 Ansible 清单文件的路径。
#### 什么是模式以及如何使用它?
Ansible 模式可以代指某个主机、IP 地址、清单组、一组主机或者清单中的所有主机。它允许你对它们运行命令和剧本。模式非常灵活,你可以根据需要使用它们。
例如,你可以排除主机、使用通配符或正则表达式等等。
下表描述了常见的模式以及用法。但是,如果它不能满足你的需求,你可以在 `ansible-playbook` 中使用带有 `-e` 参数的模式中的变量。
| 描述 | 模式 | 目标 |
| --- | --- | --- |
| 所有主机 | `all`(或 `*`) | 对清单中的所有服务器运行 Ansible |
| 一台主机 | `host1` | 只针对给定主机运行 Ansible |
| 多台主机 | `host1:host2`(或 `host1,host2`) | 对上述多台主机运行 Ansible |
| 一组 | `webservers` | 在 `webservers` 群组中运行 Ansible |
| 多组 | `webservers:dbservers` | `webservers` 中的所有主机加上 `dbservers` 中的所有主机 |
| 排除组 | `webservers:!atlanta` | `webservers` 中除 `atlanta` 以外的所有主机 |
| 组之间的交集 | `webservers:&staging` | `webservers` 中也在 `staging` 的任何主机 |
#### 什么是 Ansible 模块,它干了什么?
模块,也称为“任务插件”或“库插件”,它是一组代码单元,可以直接或通过剧本在远程主机上执行指定任务。
Ansible 在远程目标节点上执行指定模块并收集其返回值。
每个模块都支持多个参数,可以满足用户的需求。除少数模块外,几乎所有模块都采用 `key=value` 参数。你可以一次添加带有空格的多个参数,而 `command` 或 `shell` 模块会直接运行你输入的字符串。
我们将添加一个包含最常用的“模块选项”参数的表。
列出所有可用的模块,运行以下命令:
```
$ ansible-doc -l
```
运行以下命令来阅读指定模块的文档:
```
$ ansible-doc [模块]
```
### 1)如何在 Linux 上使用 Ansible 列出目录的内容
可以使用 Ansible `command` 模块来完成这项操作,如下所示。我们列出了 `node1.2g.lab` 和 `nod2.2g.lab`\* 远程服务器上 `daygeek` 用户主目录的内容。
```
$ ansible web -m command -a "ls -lh /home/daygeek"
node1.2g.lab | CHANGED | rc=0 >>
total 12K
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Desktop
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Documents
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Downloads
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Music
-rwxr-xr-x. 1 daygeek daygeek 159 Mar 4 2019 passwd-up.sh
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Pictures
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Public
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Templates
-rwxrwxr-x. 1 daygeek daygeek 138 Mar 10 2019 user-add.sh
-rw-rw-r--. 1 daygeek daygeek 18 Mar 10 2019 user-list1.txt
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Videos
node2.2g.lab | CHANGED | rc=0 >>
total 0
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Desktop
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Documents
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Downloads
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Music
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Pictures
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Public
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Templates
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Videos
```
### 2)如何在 Linux 使用 Ansible 管理文件
Ansible 的 `copy` 模块将文件从本地系统复制到远程系统。使用 Ansible `command` 模块将文件移动或复制到远程计算机。
```
$ ansible web -m copy -a "src=/home/daygeek/backup/CentOS7.2daygeek.com-20191025.tar dest=/home/u1" --become
node1.2g.lab | CHANGED => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": true,
"checksum": "ad8aadc0542028676b5fe34c94347829f0485a8c",
"dest": "/home/u1/CentOS7.2daygeek.com-20191025.tar",
"gid": 0,
"group": "root",
"md5sum": "ee8e778646e00456a4cedd5fd6458cf5",
"mode": "0644",
"owner": "root",
"secontext": "unconfined_u:object_r:user_home_t:s0",
"size": 30720,
"src": "/home/daygeek/.ansible/tmp/ansible-tmp-1579726582.474042-118186643704900/source",
"state": "file",
"uid": 0
}
node2.2g.lab | CHANGED => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/libexec/platform-python"
},
"changed": true,
"checksum": "ad8aadc0542028676b5fe34c94347829f0485a8c",
"dest": "/home/u1/CentOS7.2daygeek.com-20191025.tar",
"gid": 0,
"group": "root",
"md5sum": "ee8e778646e00456a4cedd5fd6458cf5",
"mode": "0644",
"owner": "root",
"secontext": "unconfined_u:object_r:user_home_t:s0",
"size": 30720,
"src": "/home/daygeek/.ansible/tmp/ansible-tmp-1579726582.4793239-237229399335623/source",
"state": "file",
"uid": 0
}
```
我们可以运行以下命令进行验证:
```
$ ansible web -m command -a "ls -lh /home/u1" --become
node1.2g.lab | CHANGED | rc=0 >>
total 36K
-rw-r--r--. 1 root root 30K Jan 22 14:56 CentOS7.2daygeek.com-20191025.tar
-rw-r--r--. 1 root root 25 Dec 9 03:31 user-add.sh
node2.2g.lab | CHANGED | rc=0 >>
total 36K
-rw-r--r--. 1 root root 30K Jan 23 02:26 CentOS7.2daygeek.com-20191025.tar
-rw-rw-r--. 1 u1 u1 18 Jan 23 02:21 magi.txt
```
要将文件从一个位置复制到远程计算机上的另一个位置,使用以下命令:
```
$ ansible web -m command -a "cp /home/u2/magi/ansible-1.txt /home/u2/magi/2g" --become
```
移动文件,使用以下命令:
```
$ ansible web -m command -a "mv /home/u2/magi/ansible.txt /home/u2/magi/2g" --become
```
在 `u1` 用户目录下创建一个名为 `ansible.txt` 的新文件,运行以下命令:
```
$ ansible web -m file -a "dest=/home/u1/ansible.txt owner=u1 group=u1 state=touch" --become
```
在 `u1` 用户目录下创建一个名为 `magi` 的新目录,运行以下命令:
```
$ ansible web -m file -a "dest=/home/u1/magi mode=755 owner=u2 group=u2 state=directory" --become
```
将 `u1` 用户目录下的 `ansible.txt`\* 文件权限更改为 `777`,运行以下命令:
```
$ ansible web -m file -a "dest=/home/u1/ansible.txt mode=777" --become
```
删除 `u1` 用户目录下的 `ansible.txt` 文件,运行以下命令:
```
$ ansible web -m file -a "dest=/home/u2/magi/ansible-1.txt state=absent" --become
```
使用以下命令删除目录,它将递归删除指定目录:
```
$ ansible web -m file -a "dest=/home/u2/magi/2g state=absent" --become
```
### 3)用户管理
你可以使用 Ansible 轻松执行用户管理活动。例如创建、删除用户以及向一个组添加用户。
```
$ ansible all -m user -a "name=foo password=[crypted password here]"
```
运行以下命令删除用户:
```
$ ansible all -m user -a "name=foo state=absent"
```
### 4)管理包
使用合适的 Ansible 包管理器模块可以轻松地管理安装包。例如,我们将使用 `yum` 模块来管理 CentOS 系统上的软件包。
安装最新的 Apache(httpd):
```
$ ansible web -m yum -a "name=httpd state=latest"
```
卸载 Apache(httpd) 包:
```
$ ansible web -m yum -a "name=httpd state=absent"
```
### 5)管理服务
使用以下 Ansible 模块命令可以在 Linux 上管理任何服务。
停止 httpd 服务:
```
$ ansible web -m service -a "name=httpd state=stopped"
```
启动 httpd 服务:
```
$ ansible web -m service -a "name=httpd state=started"
```
重启 httpd 服务:
```
$ ansible web -m service -a "name=httpd state=restarted"
```
---
via: <https://www.2daygeek.com/ansible-ad-hoc-command-quick-start-guide-with-examples/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
13,164 | 安装 Linux,只需三步 | https://opensource.com/article/21/2/linux-installation | 2021-03-01T20:43:00 | [
"Linux"
] | https://linux.cn/article-13164-1.html |
>
> 操作系统的安装看似神秘,但其实很简单。以下是成功安装 Linux 的步骤。
>
>
>

在 2021 年,有更多让人们喜欢 Linux 的理由。在这个系列中,我将分享 21 种使用 Linux 的不同理由。下面是如何安装 Linux。
安装一个操作系统(OS)总是令人生畏。对大多数人来说,这是一个难题。安装操作系统不能从操作系统内部进行,因为它要么没有被安装,要么即将被另一个操作系统取代,那么它是如何发生的呢?更糟糕的是,它通常会涉及到硬盘格式、安装位置、时区、用户名、密码等一系列你通常不会想到的混乱问题。Linux 发行版知道这一点,所以它们多年来一直在努力将你在操作系统安装程序中花费的时间减少到最低限度。
### 安装时发生了什么
无论你安装的是一个应用程序还是整个操作系统,*安装*的过程只是将文件从一种媒介复制到另一种媒介的一种花哨方式。不管是什么用户界面,还是用动画将安装过程伪装成多么高度专业化的东西,最终都是一回事:曾经存储在光盘或驱动器上的文件被复制到硬盘上的特定位置。
当安装的是一个应用程序时,放置这些文件的有效位置被高度限制在你的*文件系统*或你的操作系统知道它可以使用的硬盘驱动器的部分。这一点很重要,因为它可以将硬盘分割成不同的空间(苹果公司在本世纪初的 Bootcamp 中使用了这一技巧,允许用户将 macOS 和 Windows 安装到一个硬盘上,但作为单独的实体)。当你安装一个操作系统时,一些特殊的文件会被安装到硬盘上通常是禁区的地方。更重要的是,至少在默认情况下,你的硬盘上的所有现有数据都会被擦除,以便为新系统腾出空间,所以创建一个备份是*必要的*。
### 安装程序
从技术上讲,你实际上不需要用安装程序来安装应用程序甚至操作系统。不管你信不信,有些人通过挂载一块空白硬盘、编译代码并复制文件来手动安装 Linux。这是在一个名为 [Linux From Scratch(LFS)](http://www.linuxfromscratch.org) 的项目的帮助下完成的。这个项目旨在帮助爱好者、学生和未来的操作系统设计者更多地了解计算机的工作原理以及每个组件执行的功能。这并不是安装 Linux 的推荐方法,但你会发现,在开源中,通常是这样的:*如果*有些事情可以做,那么就有人在做。而这也是一件好事,因为这些小众的兴趣往往会带来令人惊讶的有用的创新。
假设你不是想对 Linux 进行逆向工程,那么正常的安装方式是使用安装光盘或镜像。
### 3 个简单的步骤来安装 Linux
当你从一个 Linux 安装 DVD 或 U 盘启动时,你会置身于一个最小化的操作环境中,这个环境是为了运行一个或多个有用的应用程序。安装程序是最主要的应用程序,但由于 Linux 是一个如此灵活的系统,你通常也可以运行标准的桌面应用程序,以在你决定安装它之前感受一下这个操作系统是什么样子的。
不同的 Linux 发行版有不同的安装程序界面。下面是两个例子。
Fedora Linux 有一个灵活的安装程序(称为 Anaconda),能够进行复杂的系统配置:

*Fedora 上的 Anaconda 安装程序*
Elementary OS 有一个简单的安装程序,主要是为了在个人电脑上安装而设计的:

*Elementary OS 安装程序*
#### 1、获取安装程序
安装 Linux 的第一步是下载一个安装程序。你可以从你选择尝试的发行版中获得一个 Linux 安装镜像。
* [Fedora](http://getfedora.org) 以率先更新软件而闻名。
* [Linux Mint](http://linuxmint.com) 提供了安装缺失驱动程序的简易选项。
* [Elementary](http://elementary.io) 提供了一个美丽的桌面体验和几个特殊的、定制的应用程序。
Linux 安装程序是 `.iso` 文件,是 DVD 介质的“蓝图”。如果你还在使用光学介质,你可以把 `.iso` 文件刻录到 DVD-R 上,或者你可以把它烧录到 U 盘上(确保它是一个空的 U 盘,因为当镜像被烧录到它上时,它的所有内容都会被删除)。要将镜像烧录到 U 盘上,你可以 [使用开源的 Etcher 应用程序](https://opensource.com/article/18/7/getting-started-etcherio)。

*Etcher 应用程序可以烧录 U 盘。*
现在你可以安装 Linux 了。
#### 2、引导顺序
要在电脑上安装操作系统,你必须引导到操作系统安装程序。这对于一台电脑来说并不是常见的行为,因为很少有人这样做。理论上,你只需要安装一次操作系统,然后你就会不断更新它。当你选择在电脑上安装不同的操作系统时,你就中断了这个正常的生命周期。这不是一件坏事。这是你的电脑,所以你有权力对它进行重新规划。然而,这与电脑的默认行为不同,它的默认行为是开机后立即启动到硬盘上找到的任何操作系统。
在安装 Linux 之前,你必须备份你在目标计算机上的任何数据,因为这些数据在安装时都会被清除。
假设你已经将数据保存到了一个外部硬盘上,然后你将它秘密地存放在安全的地方(而不是连接到你的电脑上),那么你就可以继续了。
首先,将装有 Linux 安装程序的 U 盘连接到电脑上。打开电脑电源,观察屏幕上是否有一些如何中断其默认启动序列的指示。这通常是像 `F2`、`F8`、`Esc` 甚至 `Del` 这样的键,但根据你的主板制造商不同而不同。如果你错过了这个时间窗口,只需等待默认操作系统加载,然后重新启动并再次尝试。
当你中断启动序列时,电脑会提示你引导指令。具体来说,嵌入主板的固件需要知道该到哪个驱动器寻找可以加载的操作系统。在这种情况下,你希望计算机从包含 Linux 镜像的 U 盘启动。如何提示你这些信息取决于主板制造商。有时,它会直接问你,并配有一个菜单:

*启动设备选择菜单*
其他时候,你会被带入一个简陋的界面,你可以用来设置启动顺序。计算机通常默认设置为先查看内部硬盘。如果引导失败,它就会移动到 U 盘、网络驱动器或光驱。你需要告诉你的计算机先寻找一个 U 盘,这样它就会绕过自己的内部硬盘驱动器,而引导 U 盘上的 Linux 镜像。

*BIOS 选择屏幕*
起初,这可能会让人望而生畏,但一旦你熟悉了界面,这就是一个快速而简单的任务。一旦安装了Linux,你就不必这样做了,因为,在这之后,你会希望你的电脑再次从内部硬盘启动。这是一个很好的技巧,因为在 U 盘上使用 Linux 的关键原因,是在安装前测试计算机的 Linux 兼容性,以及无论涉及什么操作系统的一般性故障排除。
一旦你选择了你的 U 盘作为引导设备,保存你的设置,让电脑复位,然后启动到 Linux 镜像。
#### 3、安装 Linux
一旦你启动进入 Linux 安装程序,就只需通过提示进行操作。
Fedora 安装程序 Anaconda 为你提供了一个“菜单”,上面有你在安装前可以自定义的所有事项。大多数设置为合理的默认值,可能不需要你的互动,但有些则用警示符号标记,表示不能安全地猜测出你的配置,因此需要设置。这些配置包括你想安装操作系统的硬盘位置,以及你想为账户使用的用户名。在你解决这些问题之前,你不能继续进行安装。
对于硬盘的位置,你必须知道你要擦除哪个硬盘,然后用你选择的 Linux 发行版重新写入。对于只有一个硬盘的笔记本来说,这可能是一个显而易见的选择。

*选择要安装操作系统的硬盘(本例中只有一个硬盘)。*
如果你的电脑里有不止一个硬盘,而你只想在其中一个硬盘上安装 Linux,或者你想把两个硬盘当作一个硬盘,那么你必须帮助安装程序了解你的目标。最简单的方法是只给 Linux 分配一个硬盘,让安装程序执行自动分区和格式化,但对于高级用户来说,还有很多其他的选择。
你的电脑必须至少有一个用户,所以要为自己创建一个用户账户。完成后,你可以最后点击 **Done** 按钮,安装 Linux。

*Anaconda 选项已经完成,可以安装了*
其他的安装程序可能会更简单,所以你看到的可能与本文中的图片不同。无论怎样,除了预装的操作系统之外,这个安装过程都是最简单的操作系统安装过程之一,所以不要让安装操作系统的想法吓到你。这是你的电脑。你可以、也应该安装一个你拥有所有权的操作系统。
### 拥有你的电脑
最终,Linux 成为了你的操作系统。它是一个由来自世界各地的人们开发的操作系统,其核心是一个:创造一种参与、共同拥有、合作管理的计算文化。如果你有兴趣更好地了解开源,那么就请你迈出一步,了解它的一个光辉典范 Linux,并安装它。
---
via: <https://opensource.com/article/21/2/linux-installation>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. Here's how to install Linux.
Installing an operating system (OS) is always daunting. It's something of a puzzle to most people: Installing an OS can't happen from inside the OS because it either hasn't been installed, or it's about to be replaced by a different one, so how does it happen? And worse yet, it usually involves confusing questions about hard drive formats, install destinations, time zones, user names, passwords, and a bunch of other stuff that you just don't normally think about. Linux distributions know this, and so they've worked diligently over the years to reduce the time you spend in the OS installer down to the absolute minimum.
## What happens when you install
Whether you're installing just an application or a whole operating system, the process of *installation* is just a fancy way to copy files from one medium to another. Regardless of any user interface or animations used to disguise the procedure as something highly specialized, it all amounts to the same thing in the end: Files that were once stored on a disc or drive are copied to specific locations on your hard drive.
When it's an application being installed, the valid locations for those files are highly restricted to your *file system* or the part of your hard drive that your operating system knows it can use. This is significant because it's possible to partition a hard drive into separate spaces (Apple used this trick back in the early '00s for what they called "Bootcamp", allowing users to install both macOS and Windows onto a drive, but as separate entities). When you install an operating system, some special files are installed into places on your drive that are normally off-limits. More importantly, all existing data on your drive is, at least by default, erased to make room for the new system, so creating a backup is *essential*.
## Installers
Technically speaking, you don't actually *need* an installer to install applications or even operating systems. Believe it or not, some people install Linux manually, by mounting a blank hard drive, compiling code, and copying files. This is accomplished with the help of a project called [Linux From Scratch (LFS)](http://www.linuxfromscratch.org). This project aims to help enthusiasts, students, and future OS designers to learn more about how computers work and what function each component performs. This isn't the recommended method of installing Linux, but you'll find that in open source, it's usually true that *if* something can be done, then somebody's doing it. And it's a good thing, too, because these niche interests very often lead to surprisingly useful innovations.
Assuming you're not trying to reverse engineer Linux, though, the normal way to install it is with an install disc or install image.
## 3 easy steps to install Linux
When you boot from a Linux install DVD or thumb drive, you're placed into a minimal operating environment designed to run one or more useful applications. The installer is the primary application, but because Linux is such a flexible system, you can usually also run standard desktop applications to get a feel for what the OS is like before you commit to installing it.
Different Linux distributions have different installer interfaces. Here are two examples:
Fedora Linux has a flexible installer (called **Anaconda**) capable of complex system configuration.
The Anaconda installer on Fedora
Elementary OS has a simple installer designed primarily for an install on a personal computer:
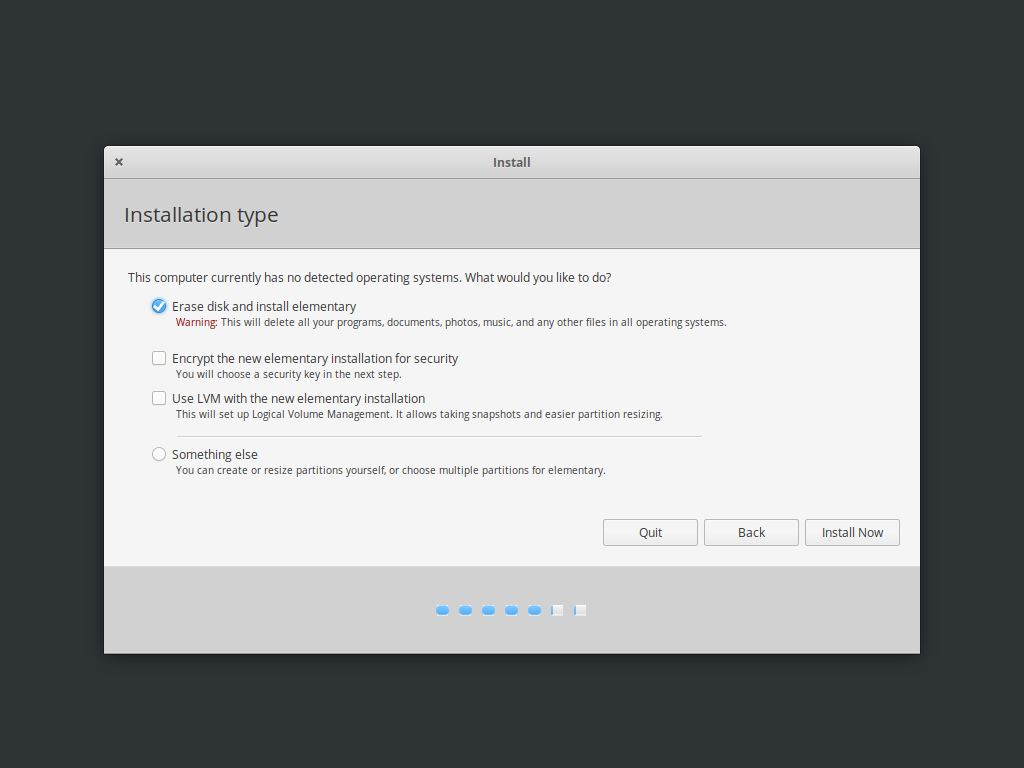
Elementary OS installer
### 1. Get an installer
The first step toward installing Linux is to download an installer. You obtain a Linux install image from the distribution you've chosen to try.
[Fedora](http://getfedora.org)is famous for being the first to update its software[Linux Mint](http://linuxmint.com)provides easy options to install missing drivers[Elementary](http://elementary.io)provides a beautiful desktop experience and several special, custom-built applications
Linux installers are `.iso`
files, which are "blueprints" for DVD media. You can burn the `.iso`
file to a DVD-R if you still use optical media, or you can *flash* it to a USB drive (make sure it's an empty USB drive, as all of its contents are erased when the image is flashed onto it). To flash an image to a USB drive, you can [use the open source Etcher application](https://opensource.com/article/18/7/getting-started-etcherio).
Etcher application can flash a USB thumb drive
You're now ready to install Linux.
### 2. Boot order
To install an OS onto a computer, you must boot to the OS installer. This is not common behavior for a computer because it's so rarely done. In theory, you install an OS once, and then you update it. When you opt to install a different operating system onto a computer, you're interrupting that normal lifecycle. That's not a bad thing. It's your computer, so you have the authority to do re-image it. However, it's different from the default behavior of a computer, which is to boot to whatever operating system it finds on the hard drive immediately after being powered on.
Before installing Linux, you must back up any data you have on your target computer because it will all be erased upon installation.
Assuming you've saved your data to an external hard drive, which you've then secreted away to somewhere safe (and not attached to your computer), then you're ready to proceed.
First, attach the USB drive containing your Linux installer to your computer. Power on the computer and watch the screen for some indication of how to interrupt its default boot sequence. This is usually a key like **F2**, **F8**, **Esc**, or even **Del**, but it varies depending on your motherboard manufacturer. If you miss your window of opportunity, just wait for the default OS to load, and then reboot and try again.
When you interrupt the boot sequence, your computer prompts you for boot instructions. Specifically, the firmware embedded into the motherboard needs to know what drive to look to for an operating system it can load. In this case, you want the computer to boot from the USB drive containing the Linux image. How you're prompted for this information varies, depending on the motherboard manufacturer. Sometimes, it's a very direct question complete with a menu:
The boot device selection menu
Other times, you're taken into a rudimentary interface you can use to set the boot order. Computers are usually set by default to look to the internal hard drive first. Failing that, it moves on to a USB drive, a network drive, or an optical drive. You need to tell your computer to look for a USB drive *first* so that it bypasses its own internal hard drive and instead boots the Linux image on your USB drive.
BIOS selection screen
This may seem daunting at first, but once you get familiar with the interface, it's a quick and easy task. You won't have to do this once Linux is installed because, after that, you'll want your computer to boot off the internal hard drive again. This is a great trick to get comfortable with, though, because it's the key to using Linux off of a thumb drive, testing a computer for Linux compatibility before installing, and general troubleshooting regardless of what OS is involved.
Once you've selected your USB drive as the boot device, save your settings, let the computer reset, and boot to the Linux image.
### 3. Install Linux
Once you've booted into the Linux installer, it's just a matter of stepping through prompts.
The Fedora installer, Anaconda, presents you a "menu" of all the things you can customize prior to installation. Most are set to sensible defaults and probably require no interaction from you, but others are marked with alert symbols to indicate that your configurations can't safely be guessed and so need to be set. These include the location of the hard drive you want the OS installed onto and the user name you want to use for your account. Until you resolve these issues, you can't proceed with the installation.
For the hard drive location, you must know which drive you want to erase and re-image with your Linux distribution of choice. This might be an obvious choice on a laptop that has only one drive, to begin with:
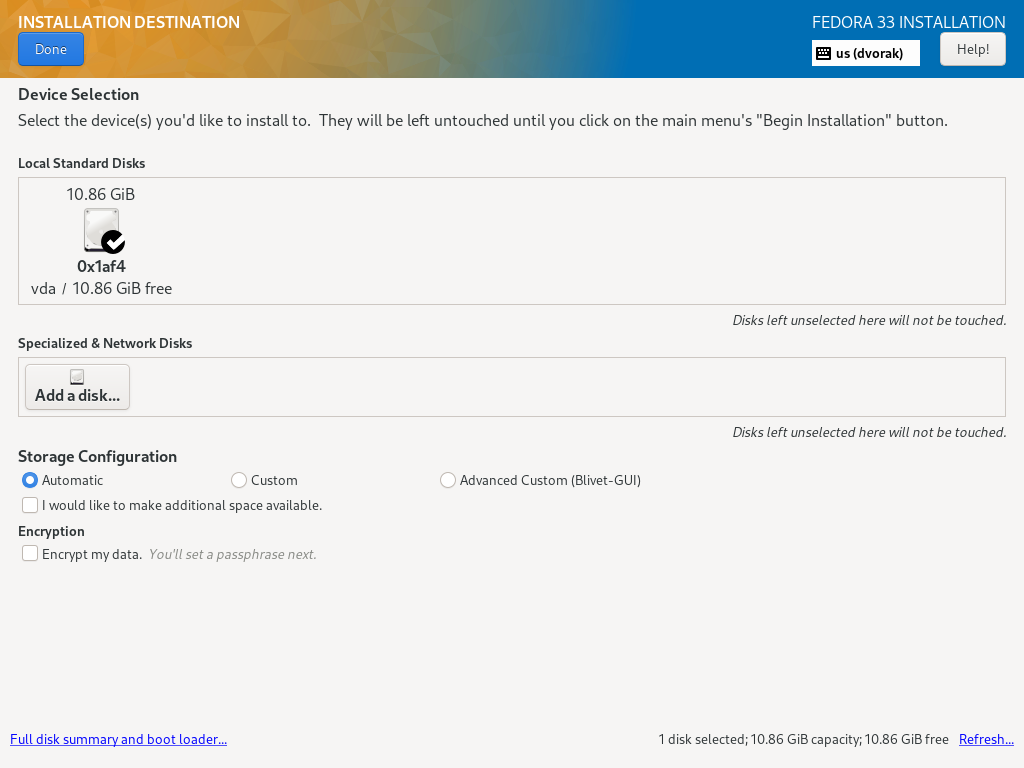
Select the drive to install the OS to (there's only one drive in this example)
If you've got more than one drive in your computer, and you only want Linux on one of them, or else you want to treat both drives as one, then you must help the installer understand your goal. It's easiest to assign just one drive to Linux, letting the installer perform automatic partitioning and formatting, but there are plenty of other options for advanced users.
Your computer must have at least one user, so create a user account for yourself. Once that's done, you can click the **Done** button at last and install Linux.
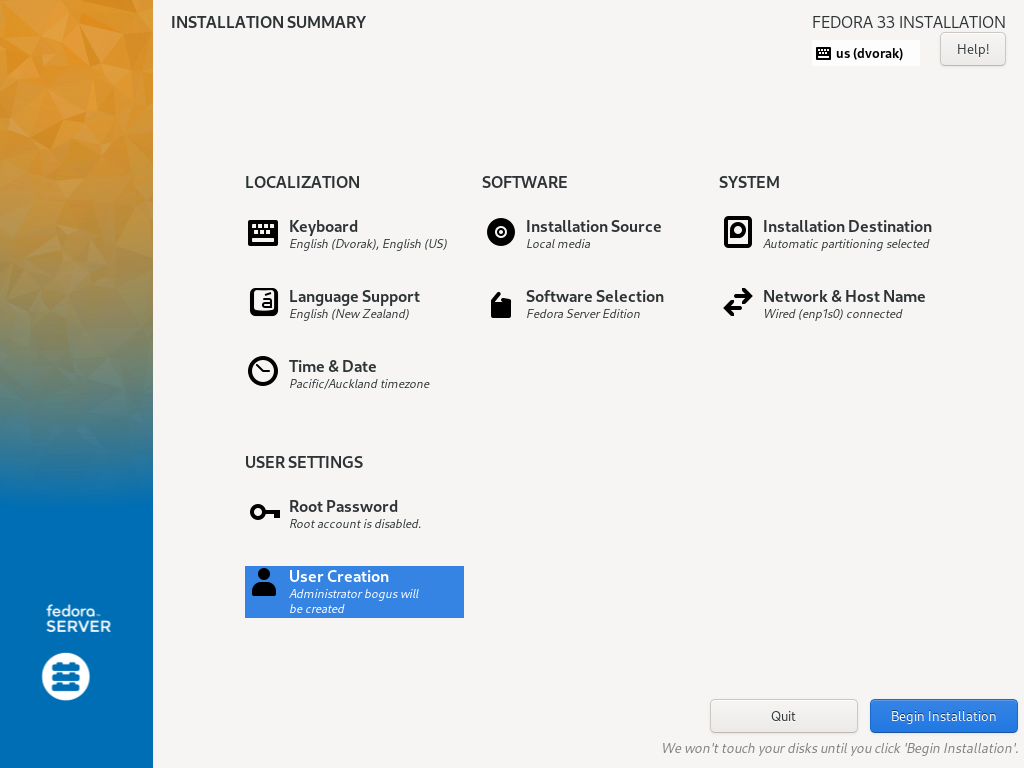
Anaconda options are complete and you're ready to install
Other installers can be even simpler, believe it or not, so your experience may differ from the images in this article. No matter what, the install process is one of the easiest operating system installations available outside of getting something pre-installed for you, so don't let the idea of installing an OS intimidate you. This is your computer. You can and should install an OS in which you have ownership.
## Own your computer
Ultimately, Linux is your OS. It's an operating system developed by people from all over the world, with one interest at heart: Create a computing culture of participation, mutual ownership, and co-operative stewardship. If you're interested in getting to know open source better, then take the step to know one of its shining examples and install Linux.
## 4 Comments |
13,165 | 使用 duf 终端工具检查你的磁盘使用情况 | https://itsfoss.com/duf-disk-usage/ | 2021-03-01T09:15:42 | [
"duf",
"du",
"df"
] | https://linux.cn/article-13165-1.html | 
>
> `duf` 是一个终端工具,旨在增强传统的 Linux 命令 `df` 和 `du`。它可以让你轻松地检查可用磁盘空间,对输出进行分类,并以用户友好的方式呈现。
>
>
>
### duf:一个用 Golang 编写的跨平台磁盘使用情况工具

在我知道这个工具之前,我更喜欢使用像 [Stacer](https://itsfoss.com/optimize-ubuntu-stacer/) 这样的 GUI 程序或者预装的 GNOME 磁盘使用情况程序来 [检查可用的磁盘空间](https://itsfoss.com/check-free-disk-space-linux/) 和系统的磁盘使用量。
不过,[duf](https://github.com/muesli/duf) 似乎是一个有用的终端工具,可以检查磁盘使用情况和可用空间,它是用 [Golang](https://golang.org/) 编写的。Abhishek 建议我试一试它,但我对它很感兴趣,尤其是考虑到我目前正在学习 Golang,真是太巧了!
无论你是终端大师还是只是一个对终端不适应的初学者,它都相当容易使用。当然,它比 [检查磁盘空间利用率命令 df](https://linuxhandbook.com/df-command/) 更容易理解。
在你把它安装到你的系统上之前,让我重点介绍一下它的一些主要功能和用法。
### duf 的特点

* 提供所有挂载设备的概览且易于理解。
* 能够指定目录/文件名并检查该挂载点的可用空间。
* 更改/删除输出中的列。
* 列出 [inode](https://linuxhandbook.com/inode-linux/) 信息。
* 输出排序。
* 支持 JSON 输出。
* 如果不能自动检测终端的主题,可以指定主题。
### 在 Linux 上安装和使用 duf
你可以在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到一个 Arch Linux 的软件包。如果你使用的是 [Nix 包管理器](https://github.com/NixOS/nixpkgs),也可以找到一个包。
对于基于 Debian 的发行版和 RPM 包,你可以去它的 [GitHub 发布区](https://github.com/muesli/duf/releases) 中获取适合你系统的包。
它也适用于 Windows、Android、macOS 和 FreeBSD。
在我这里,我需要 [安装 DEB 包](https://itsfoss.com/install-deb-files-ubuntu/),然后就可以使用了。安装好后,使用起来很简单,你只要输入:
```
duf
```
这应该会给你提供所有本地设备、已挂载的任何云存储设备以及任何其他特殊设备(包括临时存储位置等)的详细信息。
如果你想一目了然地查看所有 `duf` 的可用命令,你可以输入:
```
duf --help
```

例如,如果你只想查看本地连接设备的详细信息,而不是其他的,你只需要输入:
```
duf --only local
```
另一个例子是根据大小按特定顺序对输出进行排序,下面是你需要输入的内容:
```
duf --sort size
```
输出应该是像这样的:

你可以探索它的 [GitHub 页面](https://github.com/muesli/duf),以获得更多关于额外命令和安装说明的信息。
* [下载 duf](https://github.com/muesli/duf)
### 结束语
我发现终端工具 `duf` 相当方便,可以在不需要使用 GUI 程序的情况下,随时查看可用磁盘空间或使用情况。
你知道有什么类似的工具吗?欢迎在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/duf-disk-usage/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: duf is a terminal tool meant as an enhancement to the traditional “df” and “du” Linux commands. It lets you easily check for free disk space, sort the output, and present it in a user-friendly manner.*
## duf: A Cross-Platform disk usage utility written in Golang
Before I knew about this utility, I preferred using a GUI program like [Stacer](https://itsfoss.com/optimize-ubuntu-stacer/) or the pre-installed GNOME Disk usage app to [check free disk space](https://itsfoss.com/check-free-disk-space-linux/) and the disk usage numbers for my system.
However, [duf](https://github.com/muesli/duf) seems to be a useful terminal tool to check disk usage and free space that is written in [Golang](https://golang.org/). Even though Abhishek suggested me to give this a try, I found it more interesting, especially considering that I’m currently learning Golang, what a coincidence!
It is fairly easy to use no matter whether you are a terminal guru or just a beginner not comfortable with the terminal. It is certainly easier to understand than the [df command for checking disk space utilization](https://linuxhandbook.com/df-command/).
Let me highlight some of the key features and its usage before you get it installed on your system.
## Features of duf
- Gives you an overview of all the devices mounted which is easy to understand
- Ability to specify a directory/file name and check free space for that mount point
- Change/Remove columns from the output
- List
[inode](https://linuxhandbook.com/inode-linux/)information - Sort the output
- JSON output supported
- Ability to specify the theme if it does not detect your terminal’s theme automatically
## Installing & Using duf on Linux
You can find a package for Arch Linux in [AUR](https://itsfoss.com/aur-arch-linux/). There’s also a package available if you’re using the [Nix package manager](https://github.com/NixOS/nixpkgs).
For Debian-based distros and RPM packages, you can go to its [GitHub releases section](https://github.com/muesli/duf/releases) and grab the package suitable for your system.
It’s also available for Windows, Android, macOS, and FreeBSD as well.
In my case, I had to [install the DEB package](https://itsfoss.com/install-deb-files-ubuntu/), and it was good to go. Once you set it up, using it is quite simple, all you have to do is type in:
`duf`
This should give you the details for all the local devices, any cloud storage devices mounted, and any other special devices (that includes temporary storage locations and more).
If you want to take a look at all the available commands using **duf** at a glance, you can type in:
`duf --help`
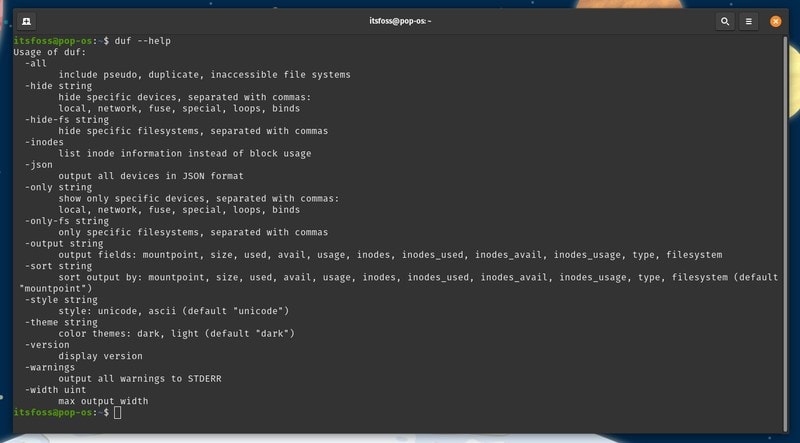
For instance, if you just want to see the details of the local devices connected and nothing else, all you have to type is:
`duf --only local`
Another example would be sorting the output based on the size in a particular order, here’s what you need to type:
`duf --sort size`
And, the output should look like:
You can explore its [GitHub page](https://github.com/muesli/duf) for more information on additional commands and installation instructions.
## Closing Thoughts
I find the terminal tool ‘duf’ quite handy to keep an eye on the free disk space or the usage stats without needing to use a GUI program.
Is there anything similar to this tool that you know of? Feel free to let me know your thoughts in the comments down below. |
13,167 | Ansible 剧本快速入门指南 | https://www.2daygeek.com/ansible-playbooks-quick-start-guide-with-examples/ | 2021-03-01T22:57:33 | [
"Ansible"
] | https://linux.cn/article-13167-1.html | 
我们已经写了两篇关于 Ansible 的文章,这是第三篇。
如果你是 Ansible 新手,我建议你阅读下面这两篇文章,它会教你一些 Ansible 的基础以及它是什么。
* 第一篇: [Ansible 自动化工具安装、配置和快速入门指南](/article-13142-1.html)
* 第二篇: [Ansible 点对点命令快速入门指南示例](/article-13163-1.html)
如果你已经阅读过了,那么在阅读本文时你才不会感到突兀。
### 什么是 Ansible 剧本?
<ruby> 剧本 <rt> playbook </rt></ruby>比点对点命令模式更强大,而且完全不同。
它使用了 `/usr/bin/ansible-playbook` 二进制文件,并且提供丰富的特性使得复杂的任务变得更容易。
如果你想经常运行一个任务,剧本是非常有用的。此外,如果你想在服务器组上执行多个任务,它也是非常有用的。
剧本是由 YAML 语言编写。YAML 代表一种标记语言,它比其它常见的数据格式(如 XML 或 JSON)更容易读写。
下面这张 Ansible 剧本流程图将告诉你它的详细结构。

### 理解 Ansible 剧本的术语
* <ruby> 控制节点 <rt> Control node </rt></ruby>:Ansible 安装的机器,它负责管理客户端节点。
* <ruby> 受控节点 <rt> Managed node </rt></ruby>:控制节点管理的主机列表。
* <ruby> 剧本 <rt> playbook </rt></ruby>:一个剧本文件包含一组自动化任务。
* <ruby> 主机清单 <rt> Inventory </rt></ruby>:这个文件包含有关管理的服务器的信息。
* <ruby> 任务 <rt> Task </rt></ruby>:每个剧本都有大量的任务。任务在指定机器上依次执行(一个主机或多个主机)。
* <ruby> 模块 <rt> Module </rt></ruby>: 模块是一个代码单元,用于从客户端节点收集信息。
* <ruby> 角色 <rt> Role </rt></ruby>:角色是根据已知文件结构自动加载一些变量文件、任务和处理程序的方法。
* <ruby> 动作 <rt> Play </rt></ruby>:每个剧本含有大量的动作,一个动作从头到尾执行一个特定的自动化。
* <ruby> 处理程序 <rt> Handler </rt></ruby>: 它可以帮助你减少在剧本中的重启任务。处理程序任务列表实际上与常规任务没有什么不同,更改由通知程序通知。如果处理程序没有收到任何通知,它将不起作用。
### 基本的剧本是怎样的?
下面是一个剧本的模板:
```
--- [YAML 文件应该以三个破折号开头]
- name: [脚本描述]
hosts: group [添加主机或主机组]
become: true [如果你想以 root 身份运行任务,则标记它]
tasks: [你想在任务下执行什么动作]
- name: [输入模块选项]
module: [输入要执行的模块]
module_options-1: value [输入模块选项]
module_options-2: value
.
module_options-N: value
```
### 如何理解 Ansible 的输出
Ansible 剧本的输出有四种颜色,下面是具体含义:
* **绿色**:`ok` 代表成功,关联的任务数据已经存在,并且已经根据需要进行了配置。
* **黄色**:`changed` 指定的数据已经根据任务的需要更新或修改。
* **红色**:`FAILED` 如果在执行任务时出现任何问题,它将返回一个失败消息,它可能是任何东西,你需要相应地修复它。
* **白色**:表示有多个参数。
为此,创建一个剧本目录,将它们都放在同一个地方。
```
$ sudo mkdir /etc/ansible/playbooks
```
### 剧本-1:在 RHEL 系统上安装 Apache Web 服务器
这个示例剧本允许你在指定的目标机器上安装 Apache Web 服务器:
```
$ sudo nano /etc/ansible/playbooks/apache.yml
---
- hosts: web
become: yes
name: "Install and Configure Apache Web server"
tasks:
- name: "Install Apache Web Server"
yum:
name: httpd
state: latest
- name: "Ensure Apache Web Server is Running"
service:
name: httpd
state: started
```
```
$ ansible-playbook apache1.yml
```

### 如何理解 Ansible 中剧本的执行
使用以下命令来查看语法错误。如果没有发现错误,它只显示剧本文件名。如果它检测到任何错误,你将得到一个如下所示的错误,但内容可能根据你的输入文件而有所不同。
```
$ ansible-playbook apache1.yml --syntax-check
ERROR! Syntax Error while loading YAML.
found a tab character that violate indentation
The error appears to be in '/etc/ansible/playbooks/apache1.yml': line 10, column 1, but may
be elsewhere in the file depending on the exact syntax problem.
The offending line appears to be:
state: latest
^ here
There appears to be a tab character at the start of the line.
YAML does not use tabs for formatting. Tabs should be replaced with spaces.
For example:
- name: update tooling
vars:
version: 1.2.3
# ^--- there is a tab there.
Should be written as:
- name: update tooling
vars:
version: 1.2.3
# ^--- all spaces here.
```
或者,你可以使用这个 URL [YAML Lint](http://www.yamllint.com/) 在线检查 Ansible 剧本内容。
执行以下命令进行“演练”。当你运行带有 `--check` 选项的剧本时,它不会对远程机器进行任何修改。相反,它会告诉你它将要做什么改变但不是真的执行。
```
$ ansible-playbook apache.yml --check
PLAY [Install and Configure Apache Webserver] ********************************************************************
TASK [Gathering Facts] *******************************************************************************************
ok: [node2.2g.lab]
ok: [node1.2g.lab]
TASK [Install Apache Web Server] *********************************************************************************
changed: [node2.2g.lab]
changed: [node1.2g.lab]
TASK [Ensure Apache Web Server is Running] ***********************************************************************
changed: [node1.2g.lab]
changed: [node2.2g.lab]
PLAY RECAP *******************************************************************************************************
node1.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
node2.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
如果你想要知道 ansible 剧本实现的详细信息,使用 `-vv` 选项,它会展示如何收集这些信息。
```
$ ansible-playbook apache.yml --check -vv
ansible-playbook 2.9.2
config file = /etc/ansible/ansible.cfg
configured module search path = ['/home/daygeek/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.8/site-packages/ansible
executable location = /usr/bin/ansible-playbook
python version = 3.8.1 (default, Jan 8 2020, 23:09:20) [GCC 9.2.0]
Using /etc/ansible/ansible.cfg as config file
PLAYBOOK: apache.yml *****************************************************************************************************
1 plays in apache.yml
PLAY [Install and Configure Apache Webserver] ****************************************************************************
TASK [Gathering Facts] ***************************************************************************************************
task path: /etc/ansible/playbooks/apache.yml:2
ok: [node2.2g.lab]
ok: [node1.2g.lab]
META: ran handlers
TASK [Install Apache Web Server] *****************************************************************************************
task path: /etc/ansible/playbooks/apache.yml:6
changed: [node2.2g.lab] => {"changed": true, "msg": "Check mode: No changes made, but would have if not in check mod
e", "rc": 0, "results": ["Installed: httpd"]}
changed: [node1.2g.lab] => {"changed": true, "changes": {"installed": ["httpd"], "updated": []}, "msg": "", "obsolet
es": {"urw-fonts": {"dist": "noarch", "repo": "@anaconda", "version": "2.4-16.el7"}}, "rc": 0, "results": []}
TASK [Ensure Apache Web Server is Running] *******************************************************************************
task path: /etc/ansible/playbooks/apache.yml:10
changed: [node1.2g.lab] => {"changed": true, "msg": "Service httpd not found on host, assuming it will exist on full run"}
changed: [node2.2g.lab] => {"changed": true, "msg": "Service httpd not found on host, assuming it will exist on full run"}
META: ran handlers
META: ran handlers
PLAY RECAP ***************************************************************************************************************
node1.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
node2.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
### 剧本-2:在 Ubuntu 系统上安装 Apache Web 服务器
这个示例剧本允许你在指定的目标节点上安装 Apache Web 服务器。
```
$ sudo nano /etc/ansible/playbooks/apache-ubuntu.yml
---
- hosts: web
become: yes
name: "Install and Configure Apache Web Server"
tasks:
- name: "Install Apache Web Server"
yum:
name: apache2
state: latest
- name: "Start the Apache Web Server"
service:
name: apaceh2
state: started
- name: "Enable mod_rewrite module"
apache2_module:
name: rewrite
state: present
notify:
- start apache
handlers:
- name: "Ensure Apache Web Server is Running"
service:
name: apache2
state: restarted
enabled: yes
```
### 剧本-3:在 Red Hat 系统上安装软件包列表
这个示例剧本允许你在指定的目标节点上安装软件包。
**方法-1:**
```
$ sudo nano /etc/ansible/playbooks/packages-redhat.yml
---
- hosts: web
become: yes
name: "Install a List of Packages on Red Hat Based System"
tasks:
- name: "Installing a list of packages"
yum:
name:
- curl
- httpd
- nano
- htop
```
**方法-2:**
```
$ sudo nano /etc/ansible/playbooks/packages-redhat-1.yml
---
- hosts: web
become: yes
name: "Install a List of Packages on Red Hat Based System"
tasks:
- name: "Installing a list of packages"
yum: name={{ item }} state=latest
with_items:
- curl
- httpd
- nano
- htop
```
**方法-3:使用数组变量**
```
$ sudo nano /etc/ansible/playbooks/packages-redhat-2.yml
---
- hosts: web
become: yes
name: "Install a List of Packages on Red Hat Based System"
vars:
packages: [ 'curl', 'git', 'htop' ]
tasks:
- name: Install a list of packages
yum: name={{ item }} state=latest
with_items: "{{ packages }}"
```
### 剧本-4:在 Linux 系统上安装更新
这个示例剧本允许你在基于 Red Hat 或 Debian 的 Linux 系统上安装更新。
```
$ sudo nano /etc/ansible/playbooks/security-update.yml
---
- hosts: web
become: yes
name: "Install Security Update"
tasks:
- name: "Installing Security Update on Red Hat Based System"
yum: name=* update_cache=yes security=yes state=latest
when: ansible_facts['distribution'] == "CentOS"
- name: "Installing Security Update on Ubuntu Based System"
apt: upgrade=dist update_cache=yes
when: ansible_facts['distribution'] == "Ubuntu"
```
---
via: <https://www.2daygeek.com/ansible-playbooks-quick-start-guide-with-examples/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
13,168 | “技术”是什么意思? | https://opensource.com/article/21/2/what-technical | 2021-03-02T20:30:00 | [
"技术"
] | https://linux.cn/article-13168-1.html |
>
> 用“技术”和“非技术”的标签对人们进行分类,会伤害个人和组织。本文作为本系列的第 1 篇,将阐述这个问题。
>
>
>

“<ruby> 技术 <rt> technical </rt></ruby>”一词描述了许多项目和学科:**技术**淘汰赛、**技术性**犯规、攀岩比赛的**技术**课程和花样滑冰运动的**技术**得分。广受欢迎的烹饪节目 “*The Great British Bake-Off*” 包括一个“烘焙**技术**挑战”。任何参加过剧院演出的人都可能熟悉**技术**周,即戏剧或音乐剧首演前的一周。
如你所见,**技术**一词并不严格适用于软件工程和软件操作,所以当我们称一个人或一个角色为“技术”时,我们的意思是什么,为什么使用这个术语?
在我 20 年的技术生涯中,这些问题引起了我的兴趣,所以我决定通过一系列的采访来探讨这个问题。我不是工程师,也不写代码,但这并不意味着我是**非技术型**的。但我经常被贴上这样的标签。我认为自己是**技术型**的,通过这个系列,我希望你会明白为什么。
我知道我不是孤独一个人。群众讨论是很重要的,因为如何定义和看待一个人或一个角色会影响他们做好工作的信心和能力。如果他们感到被压垮或不受尊重,就会降低他们的工作质量,挤压创新和新思想。你看,这一切都是循序渐进的,那么我们怎样才能改善这种状况呢?
我首先采访了 7 个不同角色的人。
在本系列中,我将探讨“技术”一词背后的含义、技术的连续性、将人分类为技术型或非技术型的意外副作用,以及通常被认为是非技术性的技术角色。
### 定义技术和非技术
首先,我们需要做个名词解释。根据字典网,“技术/技术性的”是一个具有多重含义的形容词,包括:
* 属于或与艺术、科学等学科有关的
* 精通或熟悉某一特定的艺术或行业的实际操作
* 技术要求高或困难(通常用于体育或艺术)
而“非技术性”一词在科技公司中经常被用来描述非工程人员。但是“非技术性”的定义是“不涉及、不具有某个特定活动领域及其术语的特点,或不熟练”。
作为一个写作和谈论技术的人,我认为自己是技术型的。如果你不熟悉这个领域和术语,就不可能书写或谈论一个技术主题。有了这种理解,每个从事技术工作的人都是技术人员。
### 为什么要分配标签?
那么,为什么划分技术与非技术?这在技术领域有什么意义呢?我们试图通过分配这些标签来实现什么?有没有一个好的理由?而我们有没有重新评估这些理由?让我们讨论一下。
当我听到人们谈论技术人员和非技术人员时,我不禁想起 Seuss 教授写的童话故事 《[The Sneetches](https://en.wikipedia.org/wiki/The_Sneetches_and_Other_Stories)》。Sneetches 有没有星星被演化为一种渴望。Sneetches 们进入了一个无限循环,试图达到正确的状态。
标签可以起到一定的作用,但当它们迫使一个群体的等级被视为比另一个更好时,它们就会变得危险。想想你的组织或部门:销售、资源、营销、质控、工程等,哪一组的在重要性上高于或低于另一组?
即使它不是直接说的或写在什么地方,也可能是被人们默认的。这些等级划分通常也存在于规章制度中。技术内容经理 Liz Harris 表示,“在技术写作界存在着一个技术含量的评级,你越是偏技术的文章,你得到的报酬就越高,而且往往在技术写作社区里你得到的关注就越多。”
术语“技术”通常用于指一个人在某一主题上的深度或专业知识水平。销售人员也有可能会要求需要懂技术以更好的帮助客户。从事技术工作的人,他们是技术型的,但是也许更专业的技术人员才能胜任这个项目。因此,请求技术支援可能是含糊不清的表述。你需要一个对产品有深入了解的人吗?你需要一位了解基础设施堆栈的人员吗?还是需要一个能写下如何配置 API 的步骤的人?
我们应该要把技术能力看作是一个连续体,而不是把人简单的看作技术型的或非技术型的。这是什么意思?开发人员关系主管 Mary thengwall 描述了她如何对特定角色所需的不同深度的技术知识进行分类。例如,项目可能需要一个开发人员、一个具有开发人员背景的人员,或一个精通技术的人员。就是那些被归类为精通技术的人也经常被贴上非技术的标签。
根据 Mary 的说法,如果“你能解释(一个技术性的)话题,你知道你的产品工作方式,你知道该说什么和不该说什么的基本知识,那么你就是技术高手。你不必有技术背景,但你需要知道高层次的技术信息,然后还要知道向谁提供更多信息。”
### 标签带来的问题
当我们使用标签来具体说明我们需要完成一项工作时,它们可能会很有帮助,比如“开发人员”、“有开发人员背景”和“技术达人”。但是当我们使用标签的范围太广时,将人们分为两组中的一组可能会产生“弱于”和“优于”的感觉
当一个标签成为现实时,无论是有意还是无意,我们都必须审视自己,重新评估自己的措辞、标签和意图。
高级产品经理 Leon Stigter 提出了他的观点:“作为一个集体行业,我们正在构建更多的技术,让每个人都更容易参与。如果我们对每个人说:‘你不是技术型的’,或者说:‘你是技术型的’,然后把他们分成几个小组,那些被贴上非技术型标签的人可能永远不会去想:‘其实我自己就能完成这个项目’,实际上,我们需要所有这些人真正思考我们行业和社区的发展方向,我认为每一个人都应该有这个主观能动性。”
#### 身份
如果我们把我们的身份贴在一个标签上,当我们认为这个标签不再适用时会发生什么?当 Adam Gordon Bell 从一个开发人员转变为一个管理人员时,他很纠结,因为他总是认为自己是技术人员,而作为一个管理人员,这些技术技能没有被使用。他觉得自己不再有价值了。编写代码并不能提供比帮助团队成员发展事业或确保项目按时交付更大的价值。所有角色都有价值,因为它们都是确保商品和服务的创建、执行和交付所必需的。
“我想我成为一名经理的原因是,我们有一支非常聪明的团队和很多非常有技能的人,但是我们并不总是能完成最出色的工作。所以技术不是限制因素,对吧?”Adam 说:“我想通常不是技术限制了团队的发挥”。
Leon Stigter 说,让人们一起合作并完成令人惊叹的工作的能力是一项很有价值的技能,不应低于技术角色的价值。
#### 自信
<ruby> <a href="https://opensource.com/business/15/9/tips-avoiding-impostor-syndrome"> 冒充者综合症 </a> <rt> Impostor syndrome </rt></ruby> 是指无法认识到自己的能力和知识,从而导致信心下降,以及完成工作和做好工作的能力下降。当你申请在会议上发言,向科技刊物提交文章,或申请工作时,冒充者综合症就会发作。冒充者综合症是一种微小的声音,它说:
* “我技术不够胜任这个角色。”
* “我认识更多的技术人员,他们在演讲中会做得更好。”
* “我在市场部工作,所以我无法为这样的技术网站写文章。”
当你把某人或你自己贴上非技术型标签的时候,这些声音就会变得更响亮。这很容易导致在会议上听不到新的声音或失去团队中的人才。
#### 刻板印象
当你认为某人是技术人员时,你会看到什么样的印象?他们穿什么?他们还有什么特点?他们是外向健谈,还是害羞安静?
Shailvi Wakhlu 是一位高级数据总监,她的职业生涯始于软件工程师,并过渡到数据和分析领域。“当我是一名软件工程师的时候,很多人都认为我不太懂技术,因为我很健谈,很明显这就意味着你不懂技术。他们认为你不孤独的待在角落就是不懂技术。”她说。
我们对谁是技术型与非技术型的刻板印象会影响招聘决策或我们的社区是否具有包容性。你也可能冒犯别人,甚至是能够帮助你的人。几年前,我在某个展台工作,问别人我能不能帮他们。“我要找最专业的人帮忙”他回答说。然后他就出发去寻找他的问题的答案。几分钟后,摊位上的销售代表和那位先生走到我跟前说:“Dawn,你是回答这个人问题的最佳人选。”
#### 污名化
随着时间的推移,我们夸大了“技术”技能的重要性,这导致了“非技术”的标签被贬义地使用。随着技术的蓬勃发展,编程人员的价值也随之增加,因为这种技能为市场带来了新产品和新的商业方式,并直接帮助了盈利。然而,现在我们看到人们故意将技术角色凌驾于非技术角色之上,阻碍了公司的发展和成功。
人际交往技能通常被称为非技术技能。然而,它们有着高度的技术性,比如提供如何完成一项任务的分步指导,或者确定最合适的词语来传达信息或观点。这些技能往往也是决定你能否在工作中取得成功的更重要因素。
通读“<ruby> 城市词典 <rt> Urban Dictionary </rt></ruby>”上的文章和定义,难怪人们会觉得自己的标签有道理,而其他人会患上冒充者综合症,或者觉得自己失去了身份。在线搜索时,“城市词典”定义通常出现在搜索结果的顶部。这个网站大约 20 年前开始是一个定义俚语、文化表达和其他术语的众包词典,现在变成了一个充满敌意和负面定义的网站。
这里有几个例子:“城市词典”将非技术经理定义为“不知道他们管理的人应该做什么的人”
提供如何与“非技术”人员交谈技巧的文章包括以下短语:
* “如果我抗争,非技术人员究竟是如何应对的?”
* “在当今的职业专业人士中,开发人员和工程师拥有一些最令人印象深刻的技能,这些技能是由多年的技术培训和实际经验磨练而成的。”
这些句子意味着非工程师是低人一等的,他们多年的训练和现实世界的经验在某种程度上没有那么令人印象深刻。对于这样的说辞,我可以举一个反例:Therese Eberhard,她的工作被许多人认为是非技术性的。她是个风景画家。她为电影和戏剧画道具和风景。她的工作是确保像甘道夫的手杖这样的道具看起来栩栩如生,而不是像塑料玩具。要想在这个角色上取得成功,需要有很多解决问题和实验化学反应的方法。Therese 在多年的实战经验中磨练了这些技能,对我来说,这相当令人印象深刻。
#### 守门人行为
使用标签会设置障碍,并导致守门人行为,这决定谁可以进入我们的组织,我们的团队,我们的社区。
据一位开源开发者 Eddie Jaoude 所说,“‘技术’、‘开发人员’或‘测试人员’的头衔在不应该出现的地方制造了障碍或权威。我们应该将重点放在谁能为团队或项目增加价值,而头衔是无关紧要的。”
如果我们把每个人看作一个团队成员,他们应该以这样或那样的方式贡献价值,而不是看他们是否编写文档、测试用例或代码,那么我们将根据真正重要的东西来重视他们,并创建一个能完成惊人工作的团队。如果测试工程师想学习编写代码,或者程序员想学习如何在活动中与人交谈,为什么要设置障碍来阻止这种成长呢?拥抱团队成员学习、改变和向任何方向发展的渴望,为团队和公司的使命服务。
如果有人在某个角色上失败了,与其把他们说成“技术不够”,不如去看看问题到底是什么。你是否需要一个精通 JavaScript 的人,而这个人又是另一种编程语言的专家?并不是说他们不专业,是技能和知识不匹配。你需要合适的人来扮演合适的角色。如果你强迫一个精通业务分析和编写验收标准的人去编写自动化测试用例,他们就会失败。
### 如何取消标签
如果你已经准备好改变你对技术性和非技术性标签的看法,这里有帮助你改变的提示。
#### 寻找替代词
我问我采访过的每个人,我们可以用什么词来代替技术和非技术。没有人能回答!我认为这里的挑战是我们不能把它归结为一个词。要替换术语,你需要使用更多的词。正如我之前写的,我们需要做的是变得更加具体。
你说过或听到过多少次这样的话:
* “我正在为这个项目寻找技术资源。”
* “那个候选人技术不够。”
* “我们的软件是为非技术用户设计的。”
技术和非技术词语的这些用法是模糊的,不能表达它们的全部含义。更真实、更详细地了解你的需求那么你应该说:
* “我想找一个对如何配置 Kubernetes 有深入了解的人。”
* “那个候选人对 Go 的了解不够深入。”
* “我们的软件是为销售和营销团队设计的。”
#### 拥抱成长心态
知识和技能不是天生的。它们是经过数小时或数年的实践和经验形成的。认为“我只是技术不够”或“我不能学习如何做营销”反映了一种固定的心态。你可以向任何你想发展的方向学习技能。列一张清单,列出你认为哪些是技术技能,或非技术技能,但要具体(如上面的清单)。
#### 认可每个人的贡献
如果你在科技行业工作,你就是技术人员。在一个项目或公司的成功中,每个人都有自己的作用。与所有做出贡献的人分享荣誉,而不仅仅是少数人。认可提出新功能的产品经理,而不仅仅是开发新功能的工程师。认可一个作家,他的文章在你的公司迅速传播并产生了新的线索。认可在数据中发现新模式的数据分析师。
### 下一步
在本系列的下一篇文章中,我将探讨技术中经常被标记为“非技术”的非工程角色。
---
via: <https://opensource.com/article/21/2/what-technical>
作者:[Dawn Parzych](https://opensource.com/users/dawnparzych) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The word "technical" describes many subjects and disciplines: *technical* knock-out, *technical* foul, *technical* courses for rock-climbing competitions, and *technical* scores for figure skating in sports. The popular cooking show *The Great British Bake-Off* includes a *technical* baking challenge. Anybody who has participated in the theatre may be familiar with *technical* week, the week before the opening night of play or musical.
As you can see, the word *technical* does not apply strictly to software engineering and operations, so when we call a person or a role "technical," what do we mean, and why do we use the term?
Over my 20-year career in tech, these questions have intrigued me, so I decided to explore this through a series of interviews. I am not an engineer, and I don't write code, yet this does not make me non-technical. But I'm regularly labeled such. I consider myself technical, and through this series, I hope you will come to understand why.
I know I'm not alone in this. It is important to discuss because how a person or role is defined and viewed affects their confidence and ability to do their job well. If they feel crushed or disrespected, it will bring down their work quality and squash innovation and new ideas. It all trickles down, you see, so how can we improve this situation?
I started by interviewing seven people across a variety of roles.
In this series, I'll explore the meaning behind the word "technical," the technical continuum, the unintended side effects of categorizing people as technical or non-technical, and technical roles that are often considered non-technical.
## Defining technical and non-technical
To start, we need definitions. According to Dictionary.com, "technical" is an adjective with multiple meanings, including:
- Belonging or pertaining to an art, science, or the like
- Skilled in or familiar in a practical way with a particular art or trade
- Technically demanding or difficult (typically used in sports or arts)
The term "non-technical" is often used in tech companies to describe people in non-engineering roles. The definition of "non-technical" is "not relating to, characteristic of, or skilled in a particular field of activity and its terminology."
As somebody who writes and speaks about technology, I consider myself technical. It is impossible to write or speak about a technical subject if you aren't familiar with the field and the terminology. With this understanding, everyone who works in tech is technical.
## Why we assign labels
So why does technical vs. non-technical matter in the technology field? What are we trying to achieve by assigning these labels? Is there a good reason, was there a good reason, and have we gotten away from those reasons and need to re-evaluate? Let's discuss.
When I hear people talk about technical vs. non-technical people, I can't help but think of the Dr. Seuss story [ The Sneetches](https://en.wikipedia.org/wiki/The_Sneetches_and_Other_Stories). Having a star (or not) was seen as something to aspire to. The Sneetches got into an infinite loop trying to achieve the right status.
Labels can serve a purpose, but when they force a hierarchy of one group being viewed as better than another, they can become dangerous. Think about your organization or your department: Which group—sales, support, marketing, QA, engineering, etc.—is above or below another in importance?
Even if it's not spoken directly or written somewhere, there is likely an understood hierarchy. These hierarchies often exist within disciplines, as well. Liz Harris, a technical content manager, says there are degrees of "technicalness" within the technical writing community. "Within technical writers, there's a hierarchy where the more technical you are, the more you get paid, and often the more you get listened to in the technical writing community."
The term "technical" is often used to refer to the level of depth or expertise a person has on a subject. A salesperson may ask for a technical resource to help a customer. By working in tech, they are technical, but they need somebody with deeper expertise and knowledge about a subject than they have. So requesting a technical resource may be vague. Do you need a person with in-depth knowledge of the product? Do you need a person with knowledge of the infrastructure stack? Or somebody to write down steps on how to configure the API?
Instead of viewing people as either technical or not, we need to start viewing technical ability as a continuum. What does this mean? Mary Thengvall, a director of developer relations, describes how she categorizes the varying depths of technical knowledge needed for a particular role. For instance, projects can require a developer, someone with a developer background, or someone tech-savvy. It's the people who fall into the tech-savvy category who often get labeled as non-technical.
According to Mary, you're tech-savvy if "you can explain [a technical] topic, you know your way around the product, you know the basics of what to say and what not to say. You don't have to have a technical background, but you need to know the high-level technical information and then also who to point people to for more information."
## The problem with labels
When we're using labels to get specific about what we need to get a job done, they can be helpful, like "developer," "developer background," and "tech-savvy." But when we use labels too broadly, putting people into one of two groups can lead to a sense of "less than" and "better than."
When a label becomes a reality, whether intended or not, we must look at ourselves and reassess our words, labels, and intentions.
Senior product manager Leon Stigter offers his perspective: "As a collective industry, we are building more technology to make it easier for everyone to participate. If we say to everyone, 'you're not technical, or 'you are technical' and divide them into groups, people that are labeled as non-technical may never think, 'I can do this myself.' We actually need all those people to really think about where we are going as an industry, as a community, and I would almost say as human beings."
### Identity
If we attach our identities to a label, what happens when we think that label no longer applies? When Adam Gordon Bell moved from being a developer to a manager, he struggled because he always identified as technical, and as a manager, those technical skills weren't being used. He felt he was no longer contributing value. Writing code does not provide more value than helping team members grow their careers or making sure a project is delivered on time. There is value in all roles because they are all needed to ensure the creation, execution, and delivery of goods and services.
"I think that the reason I became a manager was that we had a very smart team and a lot of really skilled people on it, and we weren't always getting the most amazing work done. So the technical skills were not the limiting factor, right? And I think that often they're not," says Adam.
Leon Stigter says that the ability to get people to work together and get amazing work done is a highly valued skill and should not be less valued than a technical role.
### Confidence
[Impostor syndrome](https://opensource.com/business/15/9/tips-avoiding-impostor-syndrome) is the inability to recognize your competence and knowledge, leading to reduced confidence and the ability to get your work done and done well. Impostor syndrome can kick in when you apply to speak at a conference, submit an article to a tech publication, or apply for a job. Impostor syndrome is the tiny voice that says:
- "I'm not technical enough for this role."
- "I know more technical people that would do a better job delivering this talk."
- "I can't write for a technical publication like Opensource.com. I work in marketing."
These voices can get louder the more often you label somebody or yourself as non-technical. This can easily result in not hearing new voices at conferences or losing talented people on your team.
### Stereotypes
What image do you see when you think of somebody as technical? What are they wearing? What other characteristics do they have? Are they outgoing and talkative, or are they shy and quiet?
Shailvi Wakhlu, a senior director of data, started her career as a software engineer and transitioned to data and analytics. "When I was working as a software engineer, a lot of people made assumptions about me not being very technical because I was very talkative, and apparently that automatically means you're not technical. They're like, 'Wait. You're not isolating in a corner. That means you're not technical,'" she reports.
Our stereotypes of who is technical vs. non-technical can influence hiring decisions or whether our community is inclusive. You may also offend somebody—even a person you need help from. Years ago, I was working at the booth at a conference and asked somebody if I could help them. "I'm looking for the most technical person here," he responded. He then went off in search of an answer to his question. A few minutes later, the sales rep in the booth walked over to me with the gentleman and said, "Dawn, you're the best person to answer this man's question."
### Stigma
Over time, we've inflated the importance of "technical" skills, which has led to the label "non-technical" being used in a derogatory way. As technology boomed, the value placed on people who code increased because that skill brought new products and ways of doing business to market and directly helped the bottom line. However, now we see people intentionally place technical roles above non-technical roles in ways that hinder their companies' growth and success.
Interpersonal skills are often referred to as non-technical skills. Yet, there are highly technical aspects to them, like providing step-by-step instructions on how to complete a task or determining the most appropriate words to convey a message or a point. These skills also are often more important in determining your ability to be successful at work.
**[Read next: Goodbye soft skills, hello core skills: Why IT must rebrand this critical competency]**
Reading through articles and definitions on Urban Dictionary, it's no wonder people feel justified in their labeling and others develop impostor syndrome or feel like they've lost their identity. When performing a search online, Urban Dictionary definitions often appear in the top search results. The website started about 20 years ago as a crowdsourced dictionary defining slang, cultural expressions, and other terms, and it has turned into a site filled with hostile and negative definitions.
Here are a few examples: Urban Dictionary defines a non-technical manager as "a person that does not know what the people they manage are meant to do."
Articles that provide tips for how to talk to "non-technical" people include phrases like:
- "If I struggled, how on earth did the non-technical people cope?"
- "Among today's career professionals, developers and engineers have some of the most impressive skill sets around, honed by years of tech training and real-world experience."
These sentences imply that non-engineers are inferior, that their years of training and real-world experiences are somehow not as impressive. One person I spoke to for this project was Therese Eberhard. Her job is what many consider non-technical. She's a scenic painter. She paints props and scenery for film and theatre. Her job is to make sure props like Gandalf's cane appear lifelike rather than like a plastic toy. There's a lot of problem-solving and experimenting with chemical reactions required to be successful in this role. Therese honed these skills over years of real-world experience, and, to me, that's quite impressive.
### Gatekeeping
Using labels erects barriers and can lead to gatekeeping to decide who can be let into our organization, our teams, our communities.
According to Eddie Jaoude, an open source developer, "The titles 'technical,' 'developer,' or 'tester' create barriers or authority where it shouldn't be. And I've really come to the point of view where it's about adding value to the team or for the project—the title is irrelevant."
If we view each person as a team member who should contribute value in one way or another, not on whether they write documentation or test cases or code, we will be placing importance based on what really matters and creating a team that gets amazing work done. If a test engineer wants to learn to write code or a coder wants to learn how to talk to people at events, why put up barriers to prevent that growth? Embrace team members' eagerness to learn and change and evolve in any direction that serves the team and the company's mission.
If somebody is failing in a role, instead of writing them off as "not technical enough," examine what the problem really is. Did you need somebody skilled at JavaScript, and the person is an expert in a different programming language? It's not that they're not technical. There is a mismatch in skills and knowledge. You need the right people doing the right role. If you force somebody skilled at business analysis and writing acceptance criteria into a position where they have to write automated test cases, they'll fail.
## How to retire the labels
If you're ready to shift the way you think about the labels technical and non-technical, here are a few tips to get started.
### Find alternative words
I asked everyone I interviewed what words we could use instead of technical and non-technical. No one had an answer! I think the challenge here is that we can't boil it down to a single word. To replace the terms, you need to use more words. As I wrote earlier, what we need to do is get more specific.
How many times have you said or heard a phrase like:
- "I'm looking for a technical resource for this project."
- "That candidate isn't technical enough."
- "Our software is designed for non-technical users."
These uses of the words technical and non-technical are vague and don't convey their full meaning. A truer and more detailed look at what you need may result in:
- "I'm looking for a person with in-depth knowledge of how to configure Kubernetes."
- "That candidate didn't have deep enough knowledge of Go."
- "Our software is designed for sales and marketing teams."
### Embrace a growth mindset
Knowledge and skills are not innate. They are developed over hours or years of practice and experience. Thinking, "I'm just not technical enough" or "I can't learn how to do marketing" reflects a fixed mindset. You can learn technical abilities in any direction you want to grow. Make a list of your skills—ones you think of as technical and some as non-technical—but make them specific (like in the list above).
### Recognize everyone's contributions
If you work in the tech industry, you're technical. Everyone has a part to play in a project's or company's success. Share the accolades with everyone who contributes, not only a select few. Recognize the product manager who suggested a new feature, not only the engineers who built it. Recognize the writer whose article went viral and generated new leads for your company. Recognize the data analyst who found new patterns in the data.
## Next steps
In the next article in this series, I'll explore non-engineering roles in tech that are often labeled "non-technical."
## 1 Comment |
13,170 | 6 个必知必会的关于容器的概念 | https://opensource.com/article/20/12/containers-101 | 2021-03-02T20:47:59 | [
"容器"
] | https://linux.cn/article-13170-1.html |
>
> 容器现在是无所不在,它们已经快速的改变了 IT 格局。关于容器你需要知道一些什么呢?
>
>
>

因为容器给企业所带来的巨大的价值和大量的好处,它快速的改变了 IT 格局。几乎所有最新的业务创新,都有容器化贡献的一部分因素,甚至是主要因素。
在现代化应用架构中,能够快速的把变更交付到生产环境的能力,让你比你的竞争对手更胜一筹。容器通过使用微服务架构,帮助开发团队开发功能、更小的失败、更快的恢复,从而加快交付速度。容器化还让应用软件能够快速启动、按需自动扩展云资源。还有,[DevOps](https://opensource.com/resources/devops) 通过灵活性、移动性、和有效性让产品可以尽快进入市场,从而将容器化的所能带来的好处最大化。
在 DevOps 中,虽然速度、敏捷、灵活是容器化的主要保障,但安全则是一个重要的因素。这就导致了 DevSecOps 的出现。它从一开始,到贯穿容器化应用的整个生命周期,都始终将安全融合到应用的开发中。默认情况下,容器化大大地增强了安全性,因为它将应用和宿主机以及其他的容器化应用相互隔离开来。
### 什么是容器?
容器是单体式应用程序所遗留的问题的解决方案。虽然单体式有它的优点,但是它阻碍了组织以敏捷的方式快速前进。而容器则让你能够将单体式分解成 [微服务](https://opensource.com/resources/what-are-microservices)。
本质上来说,容器只是一些轻量化组件的应用集,比如软件依赖、库、配置文件等等,然后运行在一个隔离的环境之中,这个隔离的环境又是运行在传统操作系统之上的,或者为了可移植性和灵活性而运行在虚拟化环境之上。

总而言之,容器通过利用像 cgroup、 [内核命名空间](https://opensource.com/article/19/10/namespaces-and-containers-linux) 和 [SELinux](https://opensource.com/article/20/11/selinux-containers) 这样的内核技术来实现隔离。容器跟宿主机共用一个内核,因此比虚拟机占用更少的资源。
### 容器的优势
这种架构所带来的敏捷性是虚拟机所不可能做到的。此外,在计算和内存资源方面,容器支持一种更灵活的模型,而且它支持突发资源模式,因此应用程序可以在需要的时候,在限定的范围内,使用更多的资源。用另一句话来说,容器提供的扩展性和灵活性,是你在虚拟机上运行的应用程序中所无法实现的。
容器让在公有云或者私有云上部署和分享应用变得非常容易。更重要的是,它所提供的连贯性,帮助运维和开发团队降低了在跨平台部署的过程中的复杂度。
容器还可以实现一套通用的构建组件,可以在开发的任何阶段拿来复用,从而可以重建出一样的环境供开发、测试、预备、生产使用,将“一次编写、到处执行”的概念加以扩展。
和虚拟化相比,容器使实现灵活性、连贯性和快速部署应用的能力变得更加简单 —— 这是 DevOps 的主要原则。
### Docker 因素
[Docker](https://opensource.com/resources/what-docker) 已经变成了容器的代名词。Docker 让容器技术发生彻底变革并得以推广普及,虽然早在 Docker 之前容器技术就已经存在。这些容器技术包括 AIX 工作负载分区、 Solaris 容器、以及 Linux 容器([LXC](https://linuxcontainers.org/)),后者被用来 [在一台 Linux 宿主机上运行多个 Linux 环境](https://opensource.com/article/18/11/behind-scenes-linux-containers)。
### Kubernetes 效应
Kubernetes 如今已被广泛认为是 [编排引擎](https://opensource.com/article/20/11/orchestration-vs-automation) 中的领导者。在过去的几年里,[Kubernetes 的普及](https://enterprisersproject.com/article/2020/6/kubernetes-statistics-2020) 加上容器技术的应用日趋成熟,为运维、开发、以及安全团队可以拥抱日益变革的行业,创造了一个理想的环境。
Kubernetes 为容器的管理提供了完整全面的解决方案。它可以在一个集群中运行容器,从而实现类似自动扩展云资源这样的功能,这些云资源包括:自动的、分布式的事件驱动的应用需求。这就保证了“免费的”高可用性。(比如,开发和运维都不需要花太大的劲就可以实现)
此外,在 OpenShift 和 类似 Kubernetes 这样的企业的帮助下,容器的应用变得更加的容易。

### 容器会替代虚拟机吗?
[KubeVirt](https://kubevirt.io/) 和类似的 [开源](https://opensource.com/resources/what-open-source) 项目很大程度上表明,容器将会取代虚拟机。KubeVirt 通过将虚拟机转化成容器,把虚拟机带入到容器化的工作流中,因此它们就可以利用容器化应用的优势。
现在,容器和虚拟机更多的是互补的关系,而不是相互竞争的。容器在虚拟机上面运行,因此增加可用性,特别是对于那些要求有持久性的应用。同时容器可以利用虚拟化技术的优势,让硬件的基础设施(如:内存和网络)的管理更加便捷。
### 那么 Windows 容器呢?
微软和开源社区方面都对 Windows 容器的成功实现做了大量的推动。Kubernetes <ruby> 操作器 <rt> Operator </rt></ruby> 加速了 Windows 容器的应用进程。还有像 OpenShift 这样的产品现在可以启用 [Windows 工作节点](https://www.openshift.com/blog/announcing-the-community-windows-machine-config-operator-on-openshift-4.6) 来运行 Windows 容器。
Windows 的容器化创造出巨大的诱人的可能性。特别是对于使用混合环境的企业。在 Kubernetes 集群上运行你最关键的应用程序,是你成功实现混合云/多种云环境的目标迈出的一大步。
### 容器的未来
容器在 IT 行业日新月异的变革中扮演着重要的角色,因为企业在向着快速、敏捷的交付软件及解决方案的方向前进,以此来 [超越竞争对手](https://www.imd.org/research-knowledge/articles/the-battle-for-digital-disruption-startups-vs-incumbents/)。
容器会继续存在下去。在不久的将来,其他的使用场景,比如边缘计算中的无服务器,将会浮现出来,并且更深地影响我们对从数字设备来回传输数据的速度的认知。唯一在这种变化中存活下来的方式,就是去应用它们。
---
via: <https://opensource.com/article/20/12/containers-101>
作者:[Mike Calizo](https://opensource.com/users/mcalizo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[AmorSu](https://github.com/amorsu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Containerization has radically changed the IT landscape because of the significant value and wide array of benefits it brings to business. Nearly any recent business innovation has containerization as a contributing factor, if not the central element.
In modern application architectures, the ability to deliver changes quickly to the production environment gives you an edge over your competitors. Containers deliver speed by using a microservices architecture that helps development teams create functionality, fail small, and recover faster. Containerization also enables applications to start faster and automatically scale cloud resources on demand. Furthermore, [DevOps](https://opensource.com/resources/devops) maximizes containerization's benefits by enabling the flexibility, portability, and efficiency required to go to market early.
While speed, agility, and flexibility are the main promises of containerization using DevOps, security is a critical factor. This led to the rise of DevSecOps, which incorporates security into application development from the start and throughout the lifecycle of a containerized application. By default, containerization massively improves security because it isolates the application from the host and other containerized applications.
## What are containers?
Containers are the solution to problems inherited from monolithic architectures. Although monoliths have strengths, they prevent organizations from moving fast the agile way. Containers allow you to break monoliths into [microservices](https://opensource.com/resources/what-are-microservices).
Essentially, a container is an application bundle of lightweight components, such as application dependencies, libraries, and configuration files, that run in an isolated environment on top of traditional operating systems or in virtualized environments for easy portability and flexibility.
(Michael Calizo, CC BY-SA 4.0)
To summarize, containers provide isolation by taking advantage of kernel technologies like cgroups, [kernel namespaces](https://opensource.com/article/19/10/namespaces-and-containers-linux), and [SELinux](https://opensource.com/article/20/11/selinux-containers). Containers share a kernel with the host, which allows them to use fewer resources than a virtual machine (VM) would require.
## Container advantages
This architecture provides agility that is not feasible with VMs. Furthermore, containers support a more flexible model when it comes to compute and memory resources, and they allow resource-burst modes so that applications can consume more resources, when required, within the defined boundaries. In other words, containers provide scalability and flexibility that you cannot get from running an application on top of a VM.
Containers make it easy to share and deploy applications on public or private clouds. More importantly, they provide consistency that helps operations and development teams reduce the complexity that comes with multi-platform deployment.
Containers also enable a common set of building blocks that can be reused in any stage of development to recreate identical environments for development, testing, staging, and production, extending the concept of "write-once, deploy anywhere."
Compared to virtualization, containers make it simpler to achieve flexibility, consistency, and the ability to deploy applications faster—the main principles of DevOps.
## The Docker factor
[Docker](https://opensource.com/resources/what-docker) has become synonymous with containers. Docker revolutionized and popularized containers, even though the technology existed before Docker. Examples include AIX Workload partitions, Solaris Containers, and Linux containers ([LXC](https://linuxcontainers.org/)), which was created to [run multiple Linux environments in a single Linux host](https://opensource.com/article/18/11/behind-scenes-linux-containers).
## The Kubernetes effect
Kubernetes is widely recognized as the leading [orchestration engine](https://opensource.com/article/20/11/orchestration-vs-automation). In the last few years, [Kubernetes' popularity](https://enterprisersproject.com/article/2020/6/kubernetes-statistics-2020) coupled with maturing container adoption created the ideal scenario for ops, devs, and security teams to embrace the changing landscape.
Kubernetes provides a holistic approach to managing containers. It can run containers across a cluster to enable features like autoscaling cloud resources, including event-driven application requirements, in an automated and distributed way. This ensures high availability "for free" (i.e., neither developers nor admins expend extra effort to make it happen).
In addition, OpenShift and similar Kubernetes enterprise offerings make container adoption much easier.
## Will containers replace VMs?
[KubeVirt](https://kubevirt.io/) and similar [open source](https://opensource.com/resources/what-open-source) projects show a lot of promise that containers will replace VMs. KubeVirt brings VMs into containerized workflows by converting the VMs into containers, where they run with the benefits of containerized applications.
Right now, containers and VMs work as complementary solutions rather than competing technologies. Containers run atop VMs to increase availability, especially for applications that require persistency, and take advantage of virtualization technology that makes it easier to manage the hardware infrastructure (like storage and networking) required to support containers.
## What about Windows containers?
There is a big push from Microsoft and the open source community to make Windows containers successful. Kubernetes Operators have fast-tracked Windows container adoption, and products like OpenShift now enable [Windows worker nodes](https://www.openshift.com/blog/announcing-the-community-windows-machine-config-operator-on-openshift-4.6) to run Windows containers.
Windows containerization creates a lot of enticing possibilities, especially for enterprises with mixed environments. Being able to run your most critical applications on top of a Kubernetes cluster is a big advantage towards achieving a hybrid- or multi-cloud environment.
## The future of containers
Containers play a big role in the shifting IT landscape because enterprises are moving towards fast, agile delivery of software and solutions to [get ahead of competitors](https://www.imd.org/research-knowledge/articles/the-battle-for-digital-disruption-startups-vs-incumbents/).
Containers are here to stay. In the very near future, other use cases, like serverless on the edge, will emerge and further change how we think about the speed of getting information to and from digital devices. The only way to survive these changes is to adapt to them.
## Comments are closed. |
13,172 | KDE 桌面环境定制指南 | https://itsfoss.com/kde-customization/ | 2021-03-03T23:48:12 | [
"KDE"
] | https://linux.cn/article-13172-1.html | 
[KDE Plasma 桌面](https://kde.org/plasma-desktop/) 无疑是定制化的巅峰,因为你几乎可以改变任何你想要的东西。你甚至可以让它充当 [平铺窗口管理器](https://github.com/kwin-scripts/kwin-tiling)。
KDE Plasma 提供的定制化程度会让初学者感到困惑。用户会迷失在层层深入的选项之中。
为了解决这个问题,我将向你展示你应该注意的 KDE Plasma 定制的关键点。这里有 11 种方法可以改变你的 KDE 桌面的外观和感觉。

### 定制 KDE Plasma
我在本教程中使用了 [KDE Neon](https://itsfoss.com/kde-neon-review/),但你可以在任何使用 KDE Plasma 桌面的发行版中遵循这些方法。
#### 1、Plasma 桌面小工具
桌面小工具可以增加用户体验的便利性,因为你可以立即访问桌面上的重要项目。
现在学生和专业人士使用电脑的时候越来越多,其中一个有用的小部件是便签。
右键点击桌面,选择“<ruby> 添加小工具 <rt> Add Widgets </rt></ruby>”。

选择你喜欢的小部件,然后简单地将其拖放到桌面上。

#### 2、桌面壁纸
不用说,更换壁纸可以改变桌面的外观。

在“<ruby> 壁纸 <rt> Wallpaper </rt></ruby>”选项卡中,你可以改变的不仅仅是壁纸。从“<ruby> 布局 <rt> Layout </rt></ruby>”下拉菜单中,你还可以选择桌面是否放置图标。
“<ruby> 文件夹视图 <rt> Folder View </rt></ruby>”布局的命名来自于主目录中的传统桌面文件夹,你可以在那里访问你的桌面文件。因此,“<ruby> 文件夹视图 <rt> Folder View </rt></ruby>”选项将保留桌面上的图标。
如果你选择“<ruby> 桌面 <rt> Desktop </rt></ruby>”布局,它会使你的桌面图标保持自由而普通。当然,你仍然可以访问主目录下的桌面文件夹。

在“<ruby> 壁纸类型 <rt> Wallpaper Type </rt></ruby>”中,你可以选择是否要壁纸,是静止的还是变化的,最后在“<ruby> 位置 <rt> Positioning </rt></ruby>”中,选择它在屏幕上的样子。
#### 3、鼠标动作
每一个鼠标按键都可以配置为以下动作之一:
* <ruby> 切换窗口 <rt> Switch Window </rt></ruby>
* <ruby> 切换桌面 <rt> Switch Desktop </rt></ruby>
* <ruby> 粘贴 <rt> Paste </rt></ruby>
* <ruby> 标准菜单 <rt> Standard Menu </rt></ruby>
* <ruby> 应用程序启动器 <rt> Application Launcher </rt></ruby>
* <ruby> 切换活动区 <rt> Switch Activity </rt></ruby>
右键默认设置为<ruby> 标准菜单 <rt> Standard Menu </rt></ruby>,也就是在桌面上点击右键时的菜单。点击旁边的设置图标可以更改动作。

#### 4、桌面内容的位置
只有在壁纸选项卡中选择“文件夹视图”时,该选项才可用。默认情况下,桌面上显示的内容是你在主目录下的“<ruby> 桌面 <rt> Desktop </rt></ruby>”文件夹中的内容。这个位置选项卡让你可以选择不同的文件夹来改变桌面上的内容。

#### 5、桌面图标
在这里,你可以选择图标的排列方式(水平或垂直)、左右对齐、排序标准及其大小。如果这些还不够,你还可以探索其他的美学功能。

#### 6、桌面过滤器
让我们坦然面对自己吧! 相信每个用户最后都会在某些时候出现桌面凌乱的情况。如果你的桌面变得乱七八糟,找不到文件,你可以按名称或类型应用过滤器,找到你需要的文件。虽然,最好是养成一个良好的文件管理习惯!

#### 7、应用仪表盘
如果你喜欢 GNOME 3 的应用程序启动器,那么你可以试试 KDE 应用程序仪表板。你所要做的就是右击菜单图标 > “<ruby> 显示替代品 <rt> Show Alternatives </rt></ruby>”。

点击“<ruby> 应用仪表盘 <rt> Application Dashboard </rt></ruby>”。

#### 8、窗口管理器主题
就像你在 [Xfce 自定义教程](https://itsfoss.com/customize-xfce/) 中看到的那样,你也可以在 KDE 中独立改变窗口管理器的主题。这样你就可以为面板选择一种主题,为窗口管理器选择另外一种主题。如果预装的主题不够用,你可以下载更多的主题。
不过受 [MX Linux](https://itsfoss.com/mx-linux-kde-edition/) Xfce 版的启发,我还是忍不住选择了我最喜欢的 “Arc Dark”。
导航到“<ruby> 设置 <rt> Settings </rt></ruby>” > “<ruby> 应用风格 <rt> Application Style </rt></ruby>” > “<ruby> 窗口装饰 <rt> Window decorations </rt></ruby>” > “<ruby> 主题 <rt> Theme </rt></ruby>”。

#### 9、全局主题
如上所述,KDE Plasma 面板的外观和感觉可以从“<ruby> 设置 <rt> Settings </rt></ruby>” > “<ruby> 全局主题 <rt> Global theme </rt></ruby>”选项卡中进行配置。预装的主题数量并不多,但你可以下载一个适合自己口味的主题。不过默认的 “Breeze Dark” 是一款养眼的主题。

#### 10、系统图标
系统图标样式对桌面的外观有很大的影响。无论你选择哪一种,如果你的全局主题是深色的,你应该选择深色图标版本。唯一的区别在于图标文字对比度上,图标文字对比度应该与面板颜色反色,使其具有可读性。你可以在系统设置中轻松访问“<ruby> 图标 <rt> Icons </rt></ruby>”标签。

#### 11、系统字体
系统字体并不是定制的重点,但如果你每天有一半的时间都在屏幕前,它可能是眼睛疲劳的因素之一。有阅读障碍的用户会喜欢 [OpenDyslexic](https://www.opendyslexic.org/about) 字体。我个人选择的是 Ubuntu 字体,不仅我觉得美观,而且是在屏幕前度过一天的好字体。
当然,你也可以通过下载外部资源来 [在 Linux 系统上安装更多的字体](https://itsfoss.com/install-fonts-ubuntu/)。

### 总结
KDE Plasma 是 Linux 社区最灵活和可定制的桌面之一。无论你是否是一个修理工,KDE Plasma 都是一个不断发展的桌面环境,具有惊人的现代功能。更好的是,它也可以在性能中等的系统配置上进行管理。
现在,我试图让本指南对初学者友好。当然,可以有更多的高级定制,比如那个 [窗口切换动画](https://itsfoss.com/customize-task-switcher-kde/)。如果你知道一些别的技巧,为什么不在评论区与我们分享呢?
---
via: <https://itsfoss.com/kde-customization/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[KDE Plasma desktop](https://kde.org/plasma-desktop/?ref=itsfoss.com) is unarguably the pinnacle of customization, as you can change almost anything you want. You can go to the extent of making it act as a [tiling window manager](https://github.com/kwin-scripts/kwin-tiling?ref=itsfoss.com).
KDE Plasma can confuse a beginner by the degree of customization it offers. As options tend to pile on top of options, the user starts getting lost.
To address that issue, I’ll show you the key points of KDE Plasma customization that you should be aware of. This is some
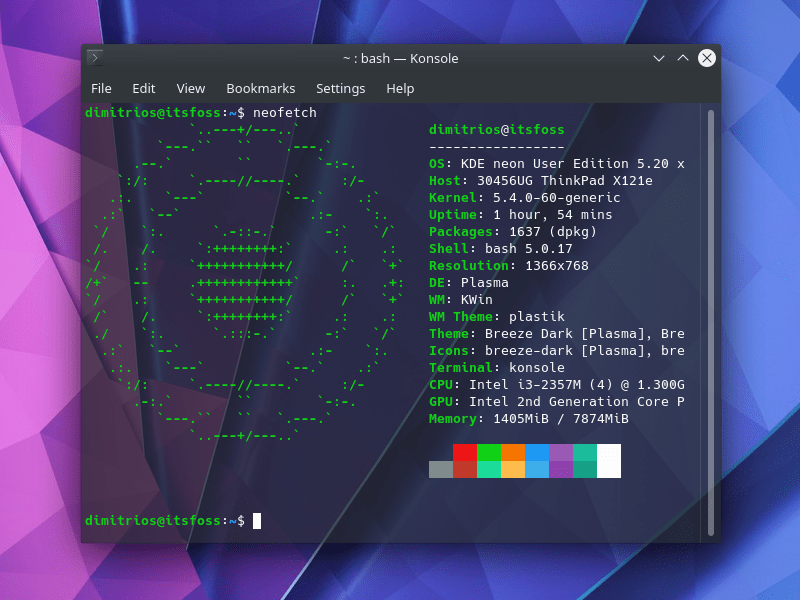
I have used [KDE Neon](https://itsfoss.com/kde-neon-review/) in this tutorial, but you may follow it with any distribution that uses KDE Plasma desktop.
## 1. Plasma Widgets
Desktop widgets can add convenience to the user experience, as you can immediately access important items on the desktop.
Students and professionals nowadays are working with computers more than ever before, a useful widget can be sticky notes.
Right-click on the desktop and select “Add Widgets”.
Choose the widget you like, and simply drag and drop it to the desktop.
## 2. Desktop wallpaper
This one is too obvious. Changing the wallpaper to change the looks of your desktop.
At the wallpaper tab you can change more than just the wallpaper. From the **“Layout”** pulldown menu, you can select if your desktop will have icons or not.
The **“Folder View”** layout is named from the traditional desktop folder in your home directory, where you can access your desktop files. Thus, the **“Folder View”** option will retain the icons on the desktop.
If you select the **“Desktop”** layout, it will leave your desktop icon free and plain. However, you will still be able to access the desktop folder at the home directory.
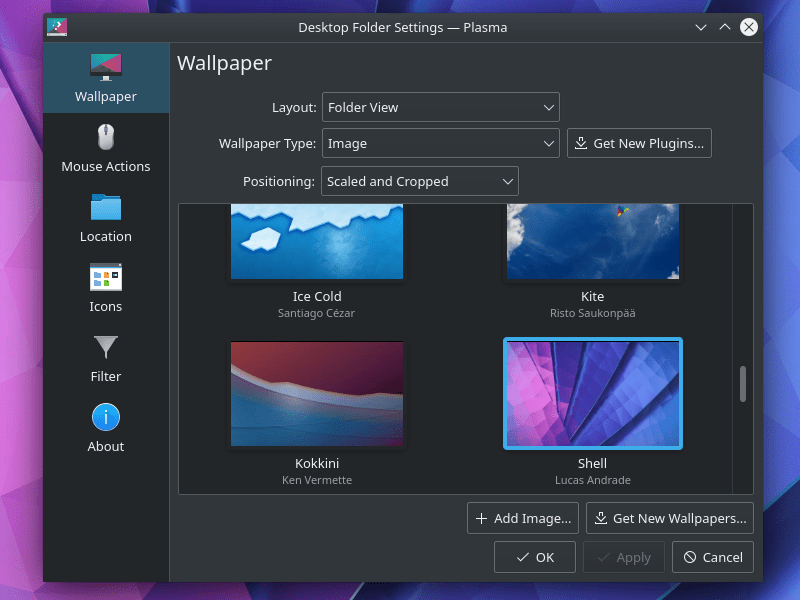
In **Wallpaper Type**, you can select if you want a wallpaper or not, to be still or to change and finally in **Positioning**, how it looks on your screen.
## 3. Mouse Actions
Each mouse button can be configured to one of the following actions:
- Switch Desktop
- Paste
- Switch Window
- Standard Menu
- Application Launcher
- Switch Activity
The right-click is set to **Standard Menu**, which is the menu when you right-click on the desktop. The contents of the menu can be changed by clicking on the settings icon next to it.
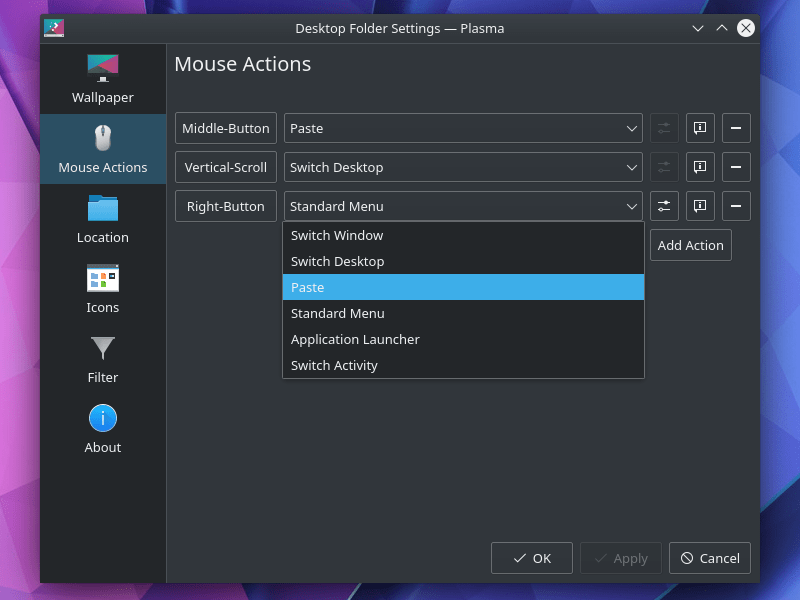
## 4. Location of your desktop content
This option is only available if you select the “Folder View” in the wallpaper tab. By default, the content shown on your desktop is what you have at the desktop folder at the home directory. The location tab gives you the option to change the content on your desktop, by selecting a different folder.
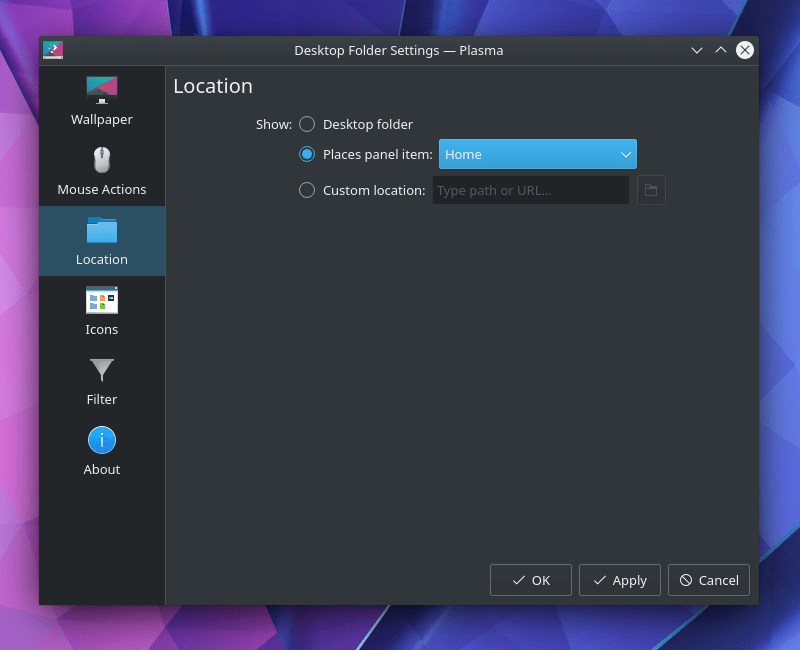
## 5. Desktop Icons
Here you can select how the icons will be arranged (horizontally or vertically), right or left, the sorting criteria and their size. If this is not enough, you have additional aesthetic features to explore.
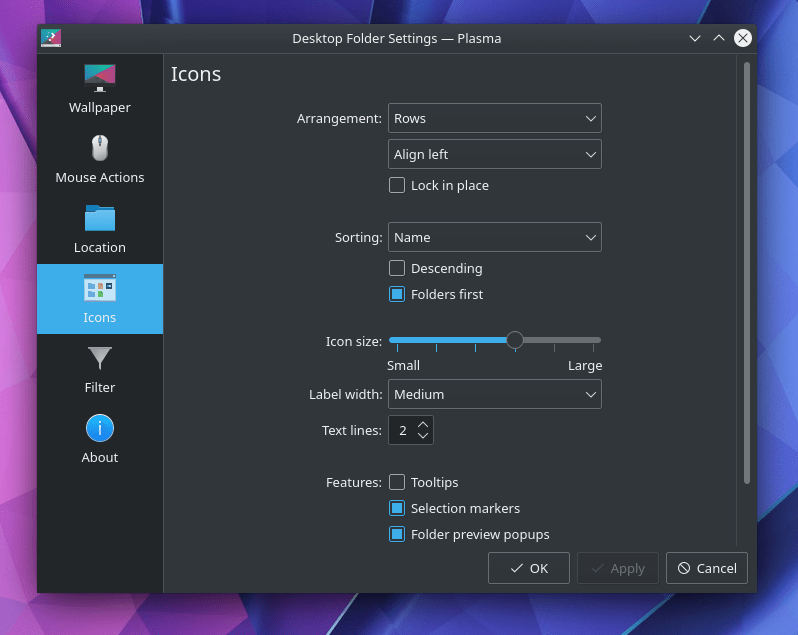
## 6. Desktop Filters
Let’s be honest with ourselves! I believe every user ends up with a cluttered desktop at some point. If your desktop becomes messy and can’t find a file, you can apply a filter either by name or type and find what you need. Although, it’s better to make a good file housekeeping a habit!
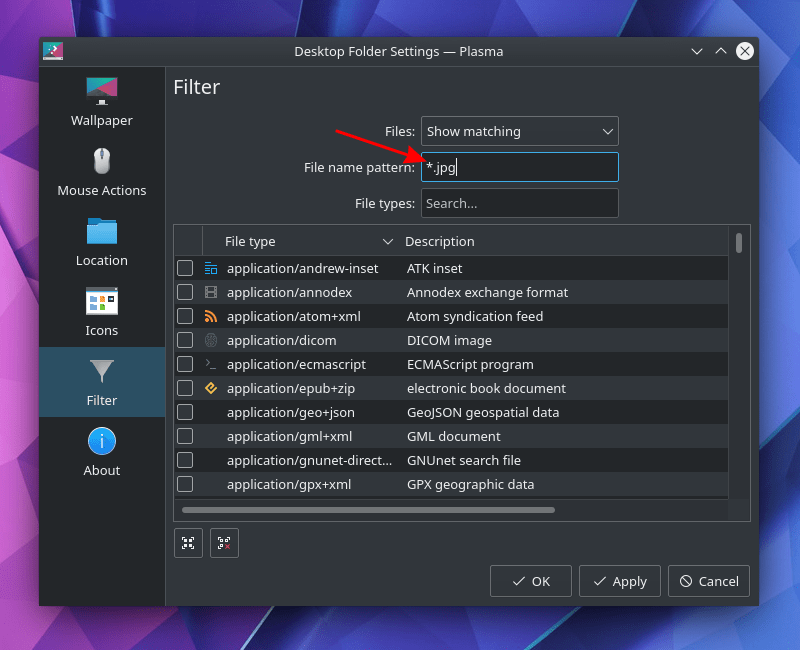
## 7. Application Dashboard
If you like the GNOME 3 application launcher, you may try the KDE application dashboard. All you have to do is to right click on the menu icon > Show Alternatives.
Click on “Application Dashboard”.
## 8. Window Manager Theme
Like you saw in [Xfce customization tutorial](https://itsfoss.com/customize-xfce/), you can change the window manager theme independently in KDE as well. This way you can choose a different theme for the panel and a different theme for the window manager. If the preinstalled themes are not enough, you can download more.
Inspired from [MX Linux](https://itsfoss.com/mx-linux-kde-edition/) Xfce edition though, I couldn’t resist to my favourite “Arc Dark”.
Navigate to Settings > Application Style > Window decorations > Theme
## 9. Global theme
As mentioned above, the look and feel of the KDE plasma panel can be configured from the Settings > Global theme tab. There isn’t a good number of themes preinstalled, but you can download a theme to suit your taste. The default Breeze Dark is an eye candy, though.
## 10. System Icons
The system icon style can have significant impact on how the desktop looks. Whichever is your choice, you should choose the dark icon version if your global theme is dark. The only difference lies on the icon text contrast, which is inverted to the panel colour to make it readable. You can easy access the icon tab at the system settings.
## 11. System fonts
System fonts are not at the spotlight of customization, but if you spend half of your day in front of a screen can be one factor of the eye strain. Users with dyslexia will appreciate the [OpenDyslexic ](https://www.opendyslexic.org/about?ref=itsfoss.com)font. My personal choice is the Ubuntu font, which not only I find aesthetically pleasing but also a good font to spend my day in front of a screen.
You can, of course, [install more fonts on your Linux system](https://itsfoss.com/install-fonts-ubuntu/) by downloading them for external sources.
## Conclusion
KDE Plasma is one of the most flexible and customizable desktops available to the Linux community. Whether you are a tinkerer or not, KDE Plasma is a constantly evolving desktop environment with amazing modern features. The best part is that it can also manage moderate system configurations.
Use some other DE? No worries. We have guides for them too.
[4 Ways You Can Make Xfce Look Modern and BeautifulXfce is a great lightweight desktop environment but it looks old. Let’s see how you can customize Xfce to give it a modern and beautiful look.](https://itsfoss.com/customize-xfce/)

[7 Ways to Customize Cinnamon Desktop in Linux MintThe traditional Cinnamon desktop can be tweaked to look different and customized for your needs. Here’s how to do that.](https://itsfoss.com/customize-cinnamon-desktop/)

[15 Simple Tips to Customize Ubuntu GNOMESome basic and interesting GNOME customization tips for enriching your experience and getting more out of your Ubuntu desktop.](https://itsfoss.com/gnome-tricks-ubuntu/)

Now I tried to make this guide beginner-friendly. Of course, there can be more advanced customization like that [window switching ani](https://itsfoss.com/customize-task-switcher-kde/)[mation](https://itsfoss.com/customize-task-switcher-kde/). If you are aware of some, why not share it with us in the comment section? |
13,174 | 使用 virtualenvwrapper 构建 Python 虚拟环境 | https://opensource.com/article/21/2/python-virtualenvwrapper | 2021-03-04T20:22:00 | [
"Python",
"虚拟环境"
] | https://linux.cn/article-13174-1.html |
>
> 虚拟环境是安全地使用不同版本的 Python 和软件包组合的关键。
>
>
>

Python 对管理虚拟环境的支持,已经提供了一段时间了。Python 3.3 甚至增加了内置的 `venv` 模块,用于创建没有第三方库的环境。Python 程序员可以使用几种不同的工具来管理他们的环境,我使用的工具叫做 [virtualenvwrapper](https://virtualenvwrapper.readthedocs.io/en/latest/index.html)。
虚拟环境是将你的 Python 项目及其依赖关系与你的系统安装的 Python 分离的一种方式。如果你使用的是基于 macOS 或 Linux 的操作系统,它很可能在安装中附带了一个 Python 版本,事实上,它很可能依赖于那个特定版本的 Python 才能正常运行。但这是你的计算机,你可能想用它来达到自己的目的。你可能需要安装另一个版本的 Python,而不是操作系统提供的版本。你可能还需要安装一些额外的库。尽管你可以升级你的系统 Python,但不推荐这样做。你也可以安装其他库,但你必须注意不要干扰系统所依赖的任何东西。
虚拟环境是创建隔离的关键,你需要安全地修改不同版本的 Python 和不同组合的包。它们还允许你为不同的项目安装同一库的不同版本,这解决了在相同环境满足所有项目需求这个不可能的问题。
为什么选择 `virtualenvwrapper` 而不是其他工具?简而言之:
* 与 `venv` 需要在项目目录内或旁边有一个 `venv` 目录不同,`virtualenvwrapper` 将所有环境保存在一个地方:默认在 `~/.virtualenvs` 中。
* 它提供了用于创建和激活环境的命令,而且激活环境不依赖于找到正确的 `activate` 脚本。它只需要(从任何地方)`workon projectname`而不需要 `source ~/Projects/flashylights-env/bin/activate`。
### 开始使用
首先,花点时间了解一下你的系统 Python 是如何配置的,以及 `pip` 工具是如何工作的。
以树莓派系统为例,该系统同时安装了 Python 2.7 和 3.7。它还提供了单独的 `pip` 实例,每个版本一个:
* 命令 `python` 运行 Python 2.7,位于 `/usr/bin/python`。
* 命令 `python3` 运行 Python 3.7,位于 `/usr/bin/python3`。
* 命令 `pip` 安装 Python 2.7 的软件包,位于 `/usr/bin/pip`。
* 命令 `pip3` 安装 Python 3.7 的包,位于 `/usr/bin/pip3`。

在开始使用虚拟环境之前,验证一下使用 `python` 和 `pip` 命令的状态是很有用的。关于你的 `pip` 实例的更多信息可以通过运行 `pip debug` 或 `pip3 debug` 命令找到。
在我运行 Ubuntu Linux 的电脑上几乎是相同的信息(除了它是 Python 3.8)。在我的 Macbook 上也很相似,除了唯一的系统 Python 是 2.6,而我用 `brew` 安装 Python 3.8,所以它位于 `/usr/local/bin/python3`(和 `pip3` 一起)。
### 安装 virtualenvwrapper
你需要使用系统 Python 3 的 `pip` 安装 `virtualenvwrapper`:
```
sudo pip3 install virtualenvwrapper
```
下一步是配置你的 shell 来加载 `virtualenvwrapper` 命令。你可以通过编辑 shell 的 RC 文件(例如 `.bashrc`、`.bash_profile` 或 `.zshrc`)并添加以下几行:
```
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/bin/virtualenv
source /usr/local/bin/virtualenvwrapper.sh
```

如果你的 Python 3 位于其他地方,请根据你的设置修改第一行。
关闭你的终端,然后重新打开它,这样才能生效。第一次打开终端时,你应该看到 `virtualenvwrapper` 的一些输出。这只会发生一次,因为一些目录是作为设置的一部分被创建的。
现在你应该可以输入 `mkvirtualenv --version` 命令来验证 `virtualenvwrapper` 是否已经安装。
### 创建一个新的虚拟环境
假设你正在进行一个名为 `flashylights` 的项目。要用这个名字创建一个虚拟环境,请运行该命令:
```
mkvirtualenv flashylights
```
环境已经创建并激活,所以你会看到 `(flashlylights)` 出现在你的提示前:

现在环境被激活了,事情发生了变化。`python` 现在指向一个与你之前在系统中识别的 Python 实例完全不同的 Python 实例。它为你的环境创建了一个目录,并在其中放置了 Python 3 二进制文件、pip 命令等的副本。输入 `which python` 和 `which pip` 来查看它们的位置。

如果你现在运行一个 Python 程序,你可以用 `python` 代替 `python3` 来运行,你可以用 `pip` 代替 `pip3`。你使用 `pip`安装的任何包都将只安装在这个环境中,它们不会干扰你的其他项目、其他环境或系统安装。
要停用这个环境,运行 `deactivate` 命令。要重新启用它,运行 `workon flashylights`。
你可以用 `workon` 或使用 `lsvirtualenv` 列出所有可用的环境。你可以用 `rmvirtualenv flashylights` 删除一个环境。
在你的开发流程中添加虚拟环境是一件明智的事情。根据我的经验,它可以防止我在系统范围内安装我正在试验的库,这可能会导致问题。我发现 `virtualenvwrapper` 是最简单的可以让我进入流程的方法,并无忧无虑地管理我的项目环境,而不需要考虑太多,也不需要记住太多命令。
### 高级特性
* 你可以在你的系统上安装多个 Python 版本(例如,在 Ubuntu 上使用 [deadsnakes PPA](https://tooling.bennuttall.com/deadsnakes/)),并使用该版本创建一个虚拟环境,例如,`mkvirtualenv -p /usr/bin/python3.9 myproject`。
* 可以在进入和离开目录时自动激活、停用。
* 你可以使用 `postmkvirtualenv` 钩子在每次创建新环境时安装常用工具。
更多提示请参见[文档](https://virtualenvwrapper.readthedocs.io/en/latest/tips.html)。
*本文基于 Ben Nuttall 在 [Tooling Tuesday 上关于 virtualenvwrapper 的帖子](https://tooling.bennuttall.com/virtualenvwrapper/),经许可后重用。*
---
via: <https://opensource.com/article/21/2/python-virtualenvwrapper>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For some time, Python has included support for managing virtual environments. Python 3.3 even added the built-in **venv** module for creating environments without third-party libraries. Python programmers use several different tools to manage their environments, and the one I use is called [ virtualenvwrapper](https://virtualenvwrapper.readthedocs.io/en/latest/index.html).
Virtual environments are a way of separating your Python project and its dependencies from your system-installed Python. If you use a macOS or Linux-based operating system, it very likely comes with a version of Python as part of the installation, and in fact, it will probably be dependent on that particular version of Python to function properly. But it's your computer, and you may want to use it for your own purposes. You may need to install another version of Python than the operating system provides. You may need to install some additional libraries, too. Although it's possible to upgrade your system Python, it's not recommended. It's also possible to install other libraries, but you must take care not to interfere with anything the system relies on.
Virtual environments are key to creating the isolation you need to safely tinker with different versions of Python and different combinations of packages. They also allow you to install different versions of the same library for different projects, which resolves what would be impossible if all of your projects' requirements were installed in the same environment.
Why virtualenvwrapper over other tools? In short:
- Rather than having a
`venv`
directory inside or alongside your project directory, virtualenvwrapper keeps all your environments in one place:`~/.virtualenvs`
by default. - It provides commands for creating and activating environments easily, and the activation doesn't rely on locating the right
`activate`
script. It's just`workon projectname`
(from anywhere) rather than`source ~/Projects/flashylights-env/bin/activate`
.
## Getting started
First of all, it's important to take the time to understand how your system Python is configured and a bit about how the **pip** tool works.
To use the Raspberry Pi OS as an example, the operating system comes with both Python 2.7 and 3.7 installed. It also provides separate instances of **pip**, one for each version:
- The command
`python`
runs Python 2.7 and is located at`/usr/bin/python`
. - The command
`python3`
runs Python 3.7 and is located at`/usr/bin/python3`
. - The command
`pip`
installs packages for Python 2.7 and is located at`/usr/bin/pip`
. - The command
`pip3`
installs packages for Python 3.7 and is located at`/usr/bin/pip3`
.
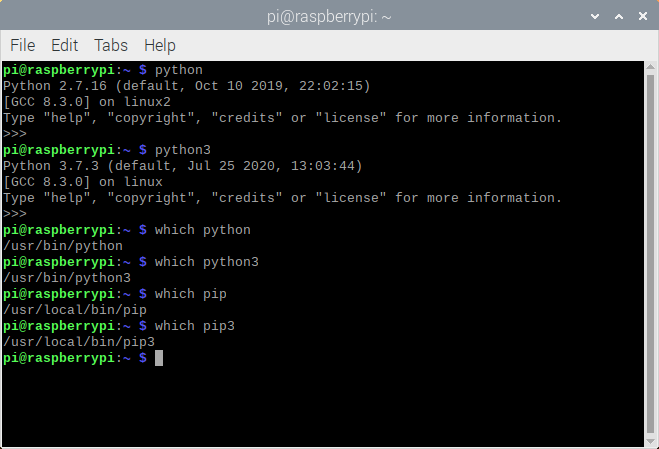
(Ben Nuttall, CC BY-SA 4.0)
It's useful to verify your own state of affairs when it comes to the `python`
and `pip`
commands before starting to use virtual environments. More information about your `pip`
instances can be found by running the command `pip debug`
or `pip3 debug`
.
The equivalent information on my Linux computer, which runs Ubuntu, is almost identical (except that it's Python 3.8); and it's very similar on my Macbook, except that the only system Python is 2.6, and I used `brew`
to install Python 3.8, so it's located at `/usr/local/bin/python3`
instead (along with `pip3`
).
## Installing virtualenvwrapper
You'll need to install virtualenvwrapper using your system `pip`
for Python 3:
`sudo pip3 install virtualenvwrapper`
The next step is to configure your shell to load the virtualenvwrapper commands. You do this by editing your shell's RC file (e.g. `.bashrc`
, `.bash_profile`
, or `.zshrc`
) and adding the following lines:
```
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/bin/virtualenv
source /usr/local/bin/virtualenvwrapper.sh
```
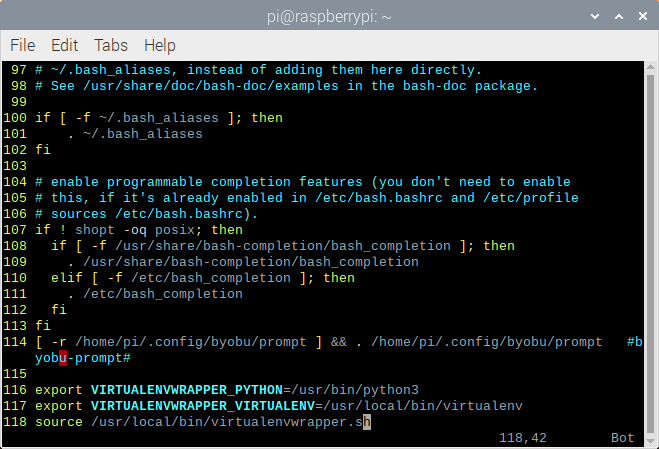
(Ben Nuttall, CC BY-SA 4.0)
If your Python 3 is located elsewhere, change the first line according to your setup.
Close your terminal and reopen it for this to take effect. The first time you open the terminal, you should see some output from virtualenvwrapper. This will only happen once, as some directories are created as part of the setup.
Now you should be able to type the command `mkvirtualenv --version`
to verify that virtualenvwrapper is installed.
## Creating a new virtual environment
Say you're working on a project called **flashylights**. To create a virtual environment with this name, run the command:
`mkvirtualenv flashylights`
The environment has been created and activated, so you'll see that `(flashlylights)`
appears before your prompt:
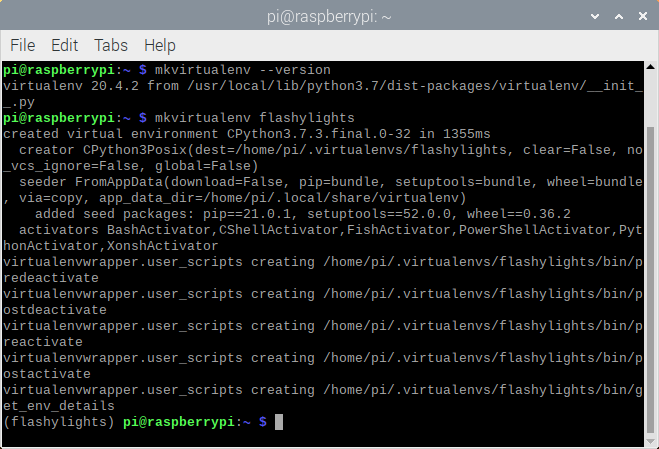
(Ben Nuttall, CC BY-SA 4.0)
Now that the environment is activated, things have changed. The `python`
now points at a completely different Python instance than the one(s) you identified on your system earlier. It's created a directory for your environment and placed a copy of the Python 3 binary, the pip command, and more inside it. Type `which python`
and `which pip`
to see where they're located:
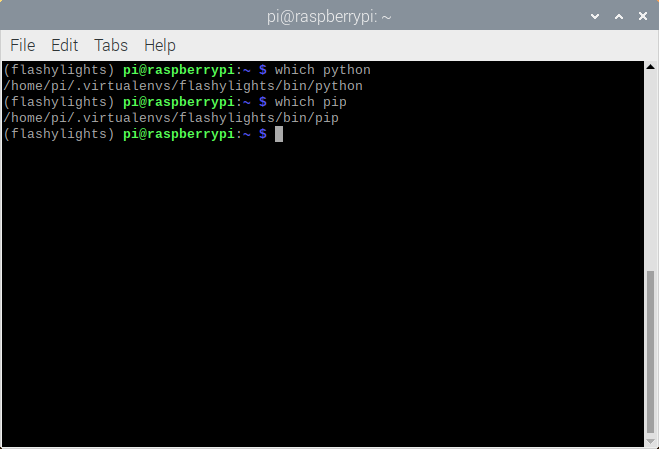
(Ben Nuttall, CC BY-SA 4.0)
If you run a Python program now, you can run it with `python`
instead of `python3`
, and you can use `pip`
instead of `pip3`
. Any packages you install using `pip`
will be installed within this environment alone, and they will not interfere with your other projects, other environments, or your system installation.
To deactivate the environment, run the command `deactivate`
. To re-enable it, run `workon flashylights`
.
You can list all available environments with `workon`
or use `lsvirtualenv`
. You can delete an environment with `rmvirtualenv flashylights`
.
Adding virtual environments to your development routine is a sensible thing to do. In my experience, it keeps me from installing libraries I'm experimenting with system-wide, which can lead to problems. I find virtualenvwrapper the easiest way for me to get into that routine and manage my project environments hassle-free without thinking too much or remembering too many commands.
## Advanced features
- You can install multiple Python versions on your system (e.g., using the
[deadsnakes PPA](https://tooling.bennuttall.com/deadsnakes/)on Ubuntu) and create a virtual environment with that particular version using, for example,`mkvirtualenv -p /usr/bin/python3.9 myproject`
. - You can automate activation/deactivation upon entering/leaving a directory.
- You can use the
`postmkvirtualenv`
hook to install common tools every time a new environment is created.
See more tips in [the docs](https://virtualenvwrapper.readthedocs.io/en/latest/tips.html).
*This article is based on Ben Nuttall's Tooling Tuesday post on virtualenvwrapper and is reused with permission.*
## Comments are closed. |
13,178 | 不懂代码的人也可以干的 4 种技术工作 | https://opensource.com/article/21/2/non-engineering-jobs-tech | 2021-03-06T09:40:52 | [
"非技术"
] | /article-13178-1.html |
>
> 对于不是工程师的人来说也有很多技术工作可以做。本文作为本系列的第二篇,就具体阐述这些工作。
>
>
>

在 [本系列的第一篇文章](/article-13168-1.html) 中,我解释了技术行业如何将人员和角色划分为“技术”或“非技术”类别,以及与此相关的问题。科技行业使得那些对科技感兴趣但不懂编程的人很难找到适合自己的角色。
如果你对技术或开源感兴趣,但对编程不感兴趣,这也有一些工作适合你。科技公司的任何一个职位都可能需要一个精通科技但不一定会写代码的人。但是,你确实需要了解术语并理解产品。
我最近注意到,在诸如技术客户经理、技术产品经理、技术社区经理等职位头衔上增加了“技术”一词。这反映了几年前的趋势,即在头衔上加上“工程师”一词,以表示该职位的技术需要。过了一段时间,每个人的头衔中都有“工程师”这个词,这样的分类就失去了一些吸引力。
当我坐下来写这些文章时,Tim Banks 的这条推特出现在我的通知栏上:
>
> 已经将职业生涯规划为技术行业的非开发人员(除了信息安全、数据科学/分析师、基础设施工程师等以外的人员)的女性,你希望知道的事情有哪些,有价值的资源有哪些,或者对希望做出类似改变的人有哪些建议?
>
>
> —— Tim Banks is a buttery biscuit (@elchefe) [December 15,2020](https://twitter.com/elchefe/status/1338933320147750915?ref_src=twsrc%5Etfw)
>
>
>
这遵循了我第一篇文章中的建议:Tim 并不是简单地询问“非技术角色”;他提供了更重要的详细描述。在 Twitter 这样的媒体上,每一个字符都很重要,这些额外的字符会产生不同的效果。这些是技术角色。如果为了节约笔墨,而简单的称呼他们为“非技术人员”,会改变你的原意,产生不好的影响。
以下是需要技术知识的非工程类角色的示例。
### 技术作者
[技术作者的工作](https://opensource.com/article/17/5/technical-writing-job-interview-tips) 是在两方或多方之间传递事实信息。传统上,技术作者提供有关如何使用技术产品的说明或文档。最近,我看到术语“技术作者”指的是写其他形式内容的人。科技公司希望一个人为他们的开发者读者写博客文章,而这种技巧不同于文案或内容营销。
**需要的技术技能:**
* 写作
* 特定技术或产品的用户知识或经验
* 快速跟上新产品或新特性的速度的能力
* 在各种环境中创作的技能
**适合人群:**
* 可以清楚地提供分步说明
* 享受合作
* 对活跃的声音和音乐有热情
* 喜欢描述事物和解释原理
### 产品经理
[产品经理](https://opensource.com/article/20/2/product-management-open-source-company) 负责领导产品战略。职责可能包括收集客户需求并确定其优先级,撰写业务案例,以及培训销售人员。产品经理跨职能工作,利用创造性和技术技能的结合,成功地推出产品。产品经理需要深厚的产品专业知识。
**所需技术技能:**
* 掌握产品知识,并且会配置或运行演示模型
* 与产品相关的技术生态系统知识
* 分析和研究技能
**适合以下人群:**
* 享受制定战略和规划下一步的工作
* 在不同的人的需求中可以看到一条共同的线索
* 能够清楚地表达业务需求和要求
* 喜欢描述原因
### 数据分析师
数据分析师负责收集和解释数据,以帮助推动业务决策,如是否进入新市场、瞄准哪些客户或在何处投资。这个角色需要知道如何使用所有可用的潜在数据来做出决策。我们常常希望把事情简单化,而数据分析往往过于简单化。获取正确的信息并不像编写查询 `select all limit 10` 来获取前 10 行那么简单。你需要知道要加入哪些表。你需要知道如何分类。你需要知道是否需要在运行查询之前或之后以某种方式清理数据。
**所需技术技能:**
* 了解 SQL、Python 和 R
* 能够看到和提取数据中的样本
* 了解事物如何端到端运行
* 批判性思维
* 机器学习
**适合以下人群:**
* 享受解决问题的乐趣
* 渴望学习和提出问题
### 开发者关系
[开发者关系](https://www.marythengvall.com/blog/2019/5/22/what-is-developer-relations-and-why-should-you-care) 是一门相对较新的技术学科。它包括 <ruby> <a href="https://opensource.com/article/20/10/open-source-developer-advocates"> 开发者代言人 </a> <rt> developer advocate </rt></ruby>、<ruby> 开发者传道者 <rt> developer evangelist </rt></ruby>和<ruby> 开发者营销 <rt> developer marketing </rt></ruby>等角色。这些角色要求你与开发人员沟通,与他们建立关系,并帮助他们提高工作效率。你向公司倡导开发者的需求,并向开发者代表公司。开发者关系可以包括撰写文章、创建教程、录制播客、在会议上发言以及创建集成和演示。有人说你需要做过开发才能进入开发者关系。我没有走那条路,我知道很多人没有。
**所需技术技能:**
这些将高度依赖于公司和具体角色。你需要部分技能(不是全部)取决于你自己。
* 了解与产品相关的技术概念
* 写作
* 教程和播客的视频和音频编辑
* 说话
**适合以下人群:**
* 有同情心,想要教导和授权他人
* 可以为他人辩护
* 你很有创意
### 无限的可能性
这并不是一个完整的清单,并没有列出技术领域中所有的非工程类角色,而是一些不喜欢每天编写代码的人可以尝试的工作。如果你对科技职业感兴趣,看看你的技能和什么角色最适合。可能性是无穷的。为了帮助你完成旅程,在本系列的最后一篇文章中,我将与这些角色的人分享一些建议。
---
via: <https://opensource.com/article/21/2/non-engineering-jobs-tech>
作者:[Dawn Parzych](https://opensource.com/users/dawnparzych) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,180 | 逐行解读 MIT 许可证 | https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html | 2021-03-07T22:38:00 | [
"MIT",
"许可证"
] | https://linux.cn/article-13180-1.html | 
>
> 每个程序员都应该明白的 171 个字。
>
>
>
[MIT 许可证](http://spdx.org/licenses/MIT) 是世界上最流行的开源软件许可证。以下是它的逐行解读。
### 阅读许可证
如果你参与了开源软件,但还没有花时间从头到尾的阅读过这个许可证(它只有 171 个单词),你需要现在就去读一下。尤其是如果许可证不是你日常每天都会接触的,把任何看起来不对劲或不清楚的地方记下来,然后继续阅读。我会分段、按顺序、加入上下文和注释,把每一个词再重复一遍。但最重要的还是要有个整体概念。
>
> The MIT License (MIT)
>
>
> Copyright (c) <year> <copyright holders>
>
>
> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
>
>
> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
>
>
> *The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the Software.*
>
>
>
(LCTT 译注:MIT 许可证并无官方的中文文本,我们也没找到任何可靠的、精确的非官方中文文本。在本文中,我们仅作为参考目的提供一份逐字逐行而没有经过润色的中文翻译文本,但该文本及对其的理解**不能**作为 MIT 许可证使用,我们也不为此中文翻译文本的使用承担任何责任,这份中文文本,我们贡献给公共领域。)
>
> MIT 许可证(MIT)
>
>
> 版权 (c) <年份> <版权人>
>
>
> 特此免费授予任何获得本软件副本和相关文档文件(下称“软件”)的人不受限制地处置该软件的权利,包括不受限制地使用、复制、修改、合并、发布、分发、转授许可和/或出售该软件副本,以及再授权被配发了本软件的人如上的权利,须在下列条件下:
>
>
> 上述版权声明和本许可声明应包含在该软件的所有副本或实质成分中。
>
>
> 本软件是“如此”提供的,没有任何形式的明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和不侵权的保证。在任何情况下,作者或版权持有人都不对任何索赔、损害或其他责任负责,无论这些追责来自合同、侵权或其它行为中,还是产生于、源于或有关于本软件以及本软件的使用或其它处置。
>
>
>
该许可证分为五段,按照逻辑划分如下:
* **头部**
+ **许可证名称**:“MIT 许可证”
+ **版权说明**:“版权 (c) …”
* **许可证授予**:“特此授予 …”
+ **授予范围**:“… 处置软件 …”
+ **条件**:“… 须在 …”
- **归因和声明**:“上述 … 应包含在 …”
- **免责声明**:“本软件是‘如此’提供的 …”
- **责任限制**:“在任何情况下 …”
接下来详细看看。
### 头部
#### 许可证名称
>
> The MIT License (MIT)
>
>
>
>
> MIT 许可证(MIT)
>
>
>
“MIT 许可证”不是一个单一的许可证,而是根据<ruby> 麻省理工学院 <rt> Massachusetts Institute of Technology </rt></ruby>(MIT)为发行版本准备的语言衍生出来一系列许可证形式。多年来,无论是对于使用它的原始项目,还是作为其他项目的范本,它经历了许多变化。Fedora 项目一直保持着 [收藏 MIT 许可证的好奇心](https://fedoraproject.org/wiki/Licensing:MIT?rd=Licensing/MIT),以纯文本的方式记录了那些平淡的变化,如同泡在甲醛中的解剖标本一般,追溯了它的各种演变。
幸运的是,<ruby> <a href="https://opensource.org"> 开放源码倡议组织 </a> <rt> Open Source Initiative </rt></ruby>(OSI) 和 <ruby> <a href="https://spdx.org"> 软件数据包交换 </a> <rt> Software Package Data eXchange </rt></ruby>组织(SPDX)已经将一种通用的 MIT 式的许可证形式标准化为“<ruby> MIT 许可证 <rt> The MIT License </rt></ruby>”。OSI 反过来又采用了 SPDX 通用开源许可证的标准化 [字符串标志符](http://spdx.org/licenses/),并将其中的 “MIT” 明确指向了标准化形式的“MIT 许可证”。如果你想为一个新项目使用 MIT 式的条款,请使用其 [标准化的形式](http://spdx.org/licenses/MIT)。
即使你在 `LICENSE` 文件中包含 “The MIT License” 或 “SPDX:MIT”,任何负责的审查者仍会将文本与标准格式进行比较,以确保安全。尽管自称为“MIT 许可证”的各种许可证形式只在细微的细节上有所不同,但所谓的“MIT 许可证”的松散性已经诱使了一些作者加入麻烦的“自定义”。典型的糟糕、不好的、非常坏的例子是 [JSON 许可证](https://spdx.org/licenses/JSON),一个 MIT 家族的许可证被加上了“本软件应用于善,而非恶”。这件事情可能是“非常克罗克福特”的(LCTT 译者注,Crockford 是 JSON 格式和 [JSON.org](http://JSON.org) 的作者)。这绝对是一件麻烦事,也许这个玩笑本来是开在律师身上的,但他们却笑得前仰后合。
这个故事的寓意是:“MIT 许可证”本身就是模棱两可的。大家可能很清楚你的意思,但你只需要把标准的 MIT 许可证文本复制到你的项目中,就可以节省每个人的时间。如果使用元数据(如包管理器中的元数据文件)来指定 “MIT 许可证”,请确保 `LICENSE` 文件和任何头部的注释都使用标准的许可证文本。所有的这些都可以 [自动化完成](https://www.npmjs.com/package/licensor)。
#### 版权声明
>
> Copyright (c)
>
>
>
>
> 版权 (c) <年份> <版权持有人>
>
>
>
在 1976 年(美国)《版权法》颁布之前,美国的版权法规要求采取具体的行动,即所谓的“手续”来确保创意作品的版权。如果你不遵守这些手续,你起诉他人未经授权使用你的作品的权力就会受到限制,往往会完全丧失权力,其中一项手续就是“<ruby> 声明 <rt> notice </rt></ruby>”。在你的作品上打上记号,以其他方式让市场知道你拥有版权。“©” 是一个标准符号,用于标记受版权保护的作品,以发出版权声明。ASCII 字符集没有 © 符号,但 `Copyright (c)` 可以表达同样的意思。
1976 年的《版权法》“落实”了国际《<ruby> 伯尔尼公约 <rt> Berne Convention </rt></ruby>》的许多要求,取消了确保版权的手续。至少在美国,著作权人在起诉侵权之前,仍然需要对自己的版权作品进行登记,如果在侵权行为开始之前进行登记,可能会获得更高的赔偿。但在实践中,很多人在对某个人提起诉讼之前,都会先注册版权。你并不会因为没有在上面贴上声明、注册它、向国会图书馆寄送副本等而失去版权。
即使版权声明不像过去那样绝对必要,但它们仍然有很多用处。说明作品的创作年份和版权属于谁,可以让人知道作品的版权何时到期,从而使作品纳入公共领域。作者或作者们的身份也很有用。美国法律对个人作者和“公司”作者的版权条款的计算方式不同。特别是在商业用途中,公司在使用已知竞争对手的软件时,可能也要三思而行,即使许可条款给予了非常慷慨的许可。如果你希望别人看到你的作品并想从你这里获得许可,版权声明可以很好地起到归属作用。
至于“<ruby> 版权持有人 <rt> copyright holder </rt></ruby>”。并非所有标准形式的许可证都有写明这一点的空间。最新的许可证形式,如 [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) 和 [GPL 3.0](https://www.gnu.org/licenses/gpl-3.0.en.html),发布的许可证文本是要逐字复制的,并在其他地方加上标题注释和单独文件,以表明谁拥有版权并提供许可证。这些办法巧妙地阻止了对“标准”文本的意外或故意的修改。这还使自动许可证识别更加可靠。
MIT 许可证是从为机构发布的代码而写的语言演变而来。对于机构发布的代码,只有一个明确的“版权持有人”,即发布代码的机构。其他机构抄袭了这些许可证,用他们自己的名字代替了 “MIT”,最终形成了我们现在拥有的通用形式。这一过程同样适用于该时代的其他简短的机构许可证,特别是加州大学伯克利分校的最初的 <ruby> <a href="http://spdx.org/licenses/BSD-4-Clause"> 四条款 BSD 许可证 </a> <rt> four-clause BSD License </rt></ruby> 成为了现在使用的 [三条款](https://spdx.org/licenses/BSD-3-Clause) 和 [两条款](https://spdx.org/licenses/BSD-2-Clause) 变体,以及 MIT 许可证的变体<ruby> 互联网系统联盟 <rt> Internet Systems Consortium </rt></ruby>的 [ISC 许可证](http://www.isc.org/downloads/software-support-policy/isc-license/)。
在每一种情况下,该机构都根据版权所有权规则将自己列为版权持有人,这些规则称为“[雇佣作品](http://worksmadeforhire.com/)”规则,这些规则赋予雇主和客户在其雇员和承包商代表其从事的某些工作中的版权所有权。这些规则通常不适用于自愿提交代码的分布式协作者。这给项目监管型基金会(如 Apache 基金会和 Eclipse 基金会)带来了一个问题,因为它们接受来自更多不同的贡献者的贡献。到目前为止,通常的基础方法是使用一个单一的许可证,它规定了一个版权持有者,如 [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) 和 [EPL 1.0](https://www.eclipse.org/legal/epl-v10.html),并由<ruby> 贡献者许可协议 <rt> contributor license agreements </rt></ruby> [Apache CLA](https://www.apache.org/licenses/#clas) 以及 [Eclipse CLA](https://wiki.eclipse.org/ECA) 为后盾,以从贡献者中收集权利。在像 GPL 这样的<ruby> 左版 <rt> copyleft </rt></ruby>许可证下,将版权所有权收集在一个地方就更加重要了,因为 GPL 依靠版权所有者来执行许可证条件,以促进软件自由的价值。
如今,大量没有机构或商业管理人的项目都在使用 MIT 风格的许可条款。SPDX 和 OSI 通过标准化不涉及特定实体或机构版权持有人的 MIT 和 ISC 之类的许可证形式,为这些用例提供了帮助。有了这些许可证形式,项目作者的普遍做法是在许可证的版权声明中尽早填上自己的名字...也许还会在这里或那里填上年份。至少根据美国的版权法,由此产生的版权声明并不能说明全部情况。
软件的原始所有者保留其工作的所有权。但是,尽管 MIT 风格的许可条款赋予了他人开发和更改软件的权利,创造了法律上所谓的“衍生作品”,但它们并没有赋予原始作者对他人的贡献的所有权。相反,每个贡献者在以现有代码为起点所做的任何作品都拥有版权,[即使是稍做了一点创意](https://en.wikipedia.org/wiki/Feist_Publications,_Inc.,_v._Rural_Telephone_Service_Co.)。
这些项目大多数也对接受<ruby> 贡献者许可协议 <rt> contributor license agreements </rt></ruby>(CLA)的想法嗤之以鼻,更不用说签署版权转让协议了。这既幼稚又可以理解。尽管一些较新的开源开发人员认为,在 GitHub 上发送<ruby> 拉取请求 <rt> Pull Request </rt></ruby>,就会“自动”根据项目现有的许可证条款授权分发贡献,但美国法律不承认任何此类规则。强有力的版权保护是默认的,而不是宽松许可。
>
> 更新:GitHub 后来修改了全站的服务条款,包括试图至少在 [GitHub.com](http://GitHub.com) 上改变这一默认值。我在 [另一篇文章](https://writing.kemitchell.com/2017/02/16/Against-Legislating-the-Nonobvious.html) 中写了一些对这一发展的想法,并非所有想法都是积极的。
>
>
>
为了填补法律上有效的、有据可查的贡献权利授予与完全没有纸质痕迹之间的差距,一些项目采用了 <ruby> <a href="http://developercertificate.org/"> 开发者原创证书 </a> <rt> Developer Certificate of Origin </rt></ruby>,这是贡献者在 Git 提交中使用 `Signed-Off-By` 元数据标签暗示的标准声明。开发者原创证书是在臭名昭著的 SCO 诉讼之后为 Linux 内核开发而开发的,该诉讼称 Linux 的大部分代码源自 SCO 拥有的 Unix 源代码。作为创建显示 Linux 的每一行都来自贡献者的书面记录的一种方法,开发者原创证书的功能良好。尽管开发者原创证书不是许可证,但它确实提供了大量证据,证明提交代码的人希望项目分发其代码,并让其他人根据内核现有的许可证条款使用该代码。内核还维护着一个机器可读的 `CREDITS` 文件,其中列出了贡献者的名字、所属机构、贡献领域和其他元数据。我做了 [一些](https://github.com/berneout/berneout-pledge) [实验](https://github.com/berneout/authors-certificate),把这种方法改编成适用于不使用内核开发流程的项目。
### 许可证授权
>
> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”),
>
>
>
>
> 特此免费授予任何获得本软件副本和相关文档文件(下称“软件”)的人
>
>
>
MIT 许可证的实质是许可证(你猜对了)。一般来说,许可证是一个人或法律实体(“<ruby> 许可人 <rt> licensor </rt></ruby>”)给予另一个人(“<ruby> 被许可人 <rt> licensee </rt></ruby>”)做一些法律允许他们起诉的事情的许可。MIT 许可证是一种不起诉的承诺。
法律有时将许可证与给予许可证的承诺区分开来。如果有人违背了提供许可证的承诺,你可以起诉他们违背了承诺,但你最终可能得不到许可证。“<ruby> 特此 <rt> Hereby </rt></ruby>”是律师们永远摆脱不了的一个矫揉造作、老生常谈的词。这里使用它来表明,许可证文本本身提供了许可证,而不仅仅是许可证的承诺。这是一个合法的 [即调函数表达式(IIFE)](https://en.wikipedia.org/wiki/Immediately-invoked_function_expression)。
尽管许多许可证都是授予特定的、指定的被许可人的,但 MIT 许可证是一个“<ruby> 公共许可证 <rt> public license </rt></ruby>”。公共许可证授予所有人(整个公众)许可。这是开源许可中的三大理念之一。MIT 许可证通过“向任何获得……软件副本的人”授予许可证来体现这一思想。稍后我们将看到,获得此许可证还有一个条件,以确保其他人也可以了解他们的许可。
在美国式法律文件中,括号中带引号的首字母大写词汇是赋予术语特定含义的标准方式(“定义”)。当法庭看到文件中其他地方使用了一个已定义的大写术语时,法庭会可靠地回顾定义中的术语。
#### 授权范围
>
> to deal in the Software without restriction,
>
>
>
>
> 不受限制地处置该软件的权利,
>
>
>
从被许可人的角度来看,这是 MIT 许可证中最重要的七个字。主要的法律问题就是因侵犯版权而被起诉,和因侵犯专利而被起诉。无论是版权法还是专利法都没有将 “<ruby> 处置 <rt> to deal in </rt></ruby>” 作为一个术语,它在法庭上没有特定的含义。因此,任何法庭在裁决许可人和被许可人之间的纠纷时,都会询问当事人对这一措辞的含义和理解。法庭将看到的是,该措辞有意宽泛和开放。它为被许可人提供了一个强有力的论据,反对许可人提出的任何主张 —— 即他们不允许被许可人使用该软件做那件特定的事情,即使在授予许可证时双方都没有明显想到。
>
> including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
>
>
>
>
> 包括不受限制地使用、复制、修改、合并、发布、分发、转授许可和/或出售该软件副本,以及再授权被配发了本软件的人如上的权利,
>
>
>
没有一篇法律是完美的、“意义上完全确定”、或明确无误的。小心那些假装不然的人。这是 MIT 许可证中最不完美的部分。主要有三个问题:
首先,“<ruby> 包括不受限制地 <rt> including without limitation </rt></ruby>”是一种法律反模式。它有多种衍生:
* <ruby> 包括,但不受限制 <rt> including, without limitation </rt></ruby>
* <ruby> 包括,但不限于前述的一般性 <rt> including, without limiting the generality of the foregoing </rt></ruby>
* <ruby> 包括,但不限于 <rt> including, but not limited to </rt></ruby>
* 很多、很多毫无意义的变化
所有这些都有一个共同的目标,但都未能可靠地实现。从根本上说,使用它们的起草者也会尽量试探着去做。在 MIT 许可证中,这意味着引入“<ruby> 处置软件 <rt> dealing in the Software </rt></ruby>”的具体例子 — “使用、复制、修改”等等,但不意味着被许可方的行为必须与给出的例子类似,才能算作“处置”。问题是,如果你最终需要法庭来审查和解释许可证的条款,法庭将把它的工作看作是找出这些语言的含义。如果法庭需要决定“<ruby> 处置 <rt> deal in </rt></ruby>”的含义,它不能“无视”这些例子,即使你告诉它。我认为,“不受限制地处置本软件”本身对被许可人更好,也更短。
其次,作为“<ruby> 处置 <rt> deal in </rt></ruby>”的例子的那些动词是一个大杂烩。有些在版权法或专利法下有特定的含义,有些稍微有或根本没有含义:
* “<ruby> 使用 <rt> use </rt></ruby>”出现在 [《美国法典》第 35 篇,第 271(a)节](https://www.govinfo.gov/app/details/USCODE-2017-title35/USCODE-2017-title35-partIII-chap28-sec271),这是专利法中专利权人可以起诉他人未经许可的行为的清单。
* “<ruby> 复制 <rt> copy </rt></ruby>”出现在 [《美国法典》第 17 篇,第 106 节](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106),即版权法列出的版权所有人可以起诉他人未经许可的行为。
* “<ruby> 修改 <rt> modify </rt></ruby>”既不出现在版权法中,也不出现在专利法中。它可能最接近版权法下的“<ruby> 准备衍生作品 <rt> prepare derivative works </rt></ruby>”,但也可能涉及改进或其他衍生发明。
* 无论是在版权法还是专利法中,“<ruby> 合并 <rt> merge </rt></ruby>”都没有出现。“<ruby> 合并 <rt> merger </rt></ruby>”在版权方面有特定的含义,但这显然不是这里的意图。相反,法庭可能会根据其在行业中的含义来解读“合并”,如“合并代码”。
* 无论是在版权法还是专利法中,都没有“<ruby> 发布 <rt> publish </rt></ruby>”。由于“软件”是被发布的内容,根据《[版权法](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106)》,它可能最接近于“<ruby> 分发 <rt> distribute </rt></ruby>”。该法令还包括“公开”表演和展示作品的权利,但这些权利只适用于特定类型的受版权保护的作品,如戏剧、录音和电影。
* “<ruby> 分发 <rt> distribute </rt></ruby>”出现在《[版权法](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106)》中。
* “<ruby> 转授许可 <rt> sublicense </rt></ruby>”是知识产权法中的一个总称。转授许可的权利是指把自己的许可证授予他人,有权进行你所许可的部分或全部活动。实际上,MIT 许可证的转授许可的权利在开源代码许可证中并不常见。通常的做法是 Heather Meeker 所说的“<ruby> 直接许可 <rt> direct licensing </rt></ruby>”方式,在这种方法中,每个获得该软件及其许可证条款副本的人都直接从所有者那里获得授权。任何可能根据 MIT 许可证获得转授许可的人都可能会得到一份许可证副本,告诉他们其也有直接许可证。
* “<ruby> 出售副本 <rt> sell copies </rt></ruby>”是个混杂品。它接近于《[专利法](https://www.govinfo.gov/app/details/USCODE-2017-title35/USCODE-2017-title35-partIII-chap28-sec271)》中的“<ruby> 要约出售 <rt> offer to sell </rt></ruby>”和“<ruby> 出售 <rt> sell </rt></ruby>”,但指的是“<ruby> 副本 <rt> coyies </rt></ruby>”,这是一种版权概念。在版权方面,它似乎接近于“<ruby> 分发 <rt> distribute </rt></ruby>”,但《[版权法](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106)》没有提到销售。
* “<ruby> 允许被配发了本软件的人这样做 <rt> permit persons to whom the Software is furnished to do so </rt></ruby>”似乎是多余的“转授许可”。这也是不必要的,因为获得副本的人也可以直接获得许可证。
最后,由于这种法律、行业、一般知识产权和一般使用条款的混杂,并不清楚 MIT 许可证是否包括专利许可。一般性语言“<ruby> 处置 <rt> deal in </rt></ruby>”和一些例子动词,尤其是“使用”,指向了一个专利许可,尽管是一个非常不明确的许可。许可证来自于版权持有人,而版权持有人可能对软件中的发明拥有或不拥有专利权,以及大多数的例子动词和“<ruby> 软件 <rt> the Software </rt></ruby>”本身的定义,都强烈地指向版权许可证。诸如 [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) 之类的较新的宽容开源许可分别具体地处理了版权、专利甚至商标问题。
#### 三个许可条件
>
> subject to the following conditions:
>
>
>
>
> 须在下列条件下:
>
>
>
总有一个陷阱!MIT 许可证有三个!
如果你不遵守 MIT 许可证的条件,你就得不到许可证提供的许可。因此,如果不能履行条件,至少从理论上说,会让你面临一场诉讼,很可能是一场版权诉讼。
开源软件的第二个伟大思想是,利用软件对被许可人的价值来激励被许可人遵守条件,即使被许可人没有支付任何许可费用。最后一个伟大思想,在 MIT 许可证中没有,它构建了许可证条件:像 [GNU 通用公共许可证](https://www.gnu.org/licenses/gpl-3.0.en.html)(GPL)这样的左版许可证,使用许可证条件来控制如何对修改后的版本进行许可和发布。
#### 声明条件
>
> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
>
>
>
>
> 上述版权声明和本许可声明应包含在该软件的所有副本或实质成分中。
>
>
>
如果你给别人一份软件的副本,你需要包括许可证文本和任何版权声明。这有几个关键目的:
1. 给别人一个声明,说明他们有权使用该公共许可证下的软件。这是直接授权模式的一个关键部分,在这种模式下,每个用户直接从版权持有人那里获得许可证。
2. 让人们知道谁是软件的幕后人物,这样他们就可以得到赞美、荣耀和冷冰冰的现金捐赠。
3. 确保保修免责声明和责任限制(在后面)伴随该软件。每个得到该副本的人也应该得到一份这些许可人保护的副本。
没有什么可以阻止你对提供一个副本、甚至是一个没有源代码的编译形式的副本而收费。但是当你这么做的时候,你不能假装 MIT 代码是你自己的专有代码,也不能在其他许可证下提供。接受的人要知道自己在“公共许可证”下的权利。
坦率地说,遵守这个条件正在崩溃。几乎所有的开源许可证都有这样的“<ruby> 归因 <rt> attribution </rt></ruby>”条件。系统和装机软件的制作者往往明白,他们需要为自己的每一个发行版本编制一个声明文件或“许可证信息”屏,并附上库和组件的许可证文本副本。项目监管型基金会在教授这些做法方面起到了重要作用。但是整个 Web 开发者群体还没有取得这种经验。这不能用缺乏工具来解释,工具有很多,也不能用 npm 和其他资源库中的包的高度模块化来解释,它们统一了许可证信息的元数据格式。所有好的 JavaScript 压缩器都有保存许可证标题注释的命令行标志。其他工具可以从包树中串联 `LICENSE` 文件。这实在是没有借口。
#### 免责声明
>
> The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement.
>
>
>
>
> 本软件是“如此”提供的,没有任何形式的明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和不侵权的保证。
>
>
>
美国几乎每个州都颁布了一个版本的《<ruby> 统一商业法典 <rt> Uniform Commercial Code </rt></ruby>》(UCC),这是一部规范商业交易的示范性法律。UCC 的第 2 条(加利福尼亚州的“第 2 部分”)规定了商品销售合同,包括了从二手汽车的购买到向制造厂运送大量工业化学品。
UCC 关于销售合同的某些规则是强制性的。这些规则始终适用,无论买卖双方是否喜欢。其他只是“默认”。除非买卖双方以书面形式选择不适用这些默认,否则 UCC 潜在视作他们希望在 UCC 文本中找到交易的基准规则。默认规则中包括隐含的“<ruby> 免责 <rt> warranties </rt></ruby>”,或卖方对买方关于所售商品的质量和可用性的承诺。
关于诸如 MIT 许可证之类的公共许可证是合同(许可方和被许可方之间的可执行协议)还是仅仅是许可证(单向的,但可能有附加条件),这在理论上存在很大争议。关于软件是否被视为“商品”,从而触发 UCC 规则的争论较少。许可人之间没有就赔偿责任进行辩论:如果他们免费提供的软件出现故障、导致问题、无法正常工作或以其他方式引起麻烦,他们不想被起诉和被要求巨额赔偿。这与“<ruby> 默示保证 <rt> implied warranty </rt></ruby>”的三个默认规则完全相反:
1. 据 [UCC 第 2-314 节](https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2314.&lawCode=COM),“<ruby> 适销性 <rt> merchantability </rt></ruby>”的默示保证是一种承诺:“商品”(即软件)的质量至少为平均水平,并经过适当包装和标记,并适用于其常规用途。仅当提供该软件的人是该软件的“商人”时,此保证才适用,这意味着他们从事软件交易,并表现出对软件的熟练程度。
2. 据 [UCC 第 2-315 节](https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2315.&lawCode=COM),当卖方知道买方依靠他们提供用于特定目的的货物时,“<ruby> 适用于某一特定目的 <rt> fitness for a particular purpose </rt></ruby>”的默示保证就会生效。商品实际上需要“适用”这一目的。
3. “<ruby> 非侵权 <rt> noninfringement </rt></ruby>”的默示保证不是 UCC 的一部分,而是一般合同法的共同特征。如果事实证明买方收到的商品侵犯了他人的知识产权,则这种默示的承诺将保护买方。如果根据 MIT 许可证获得的软件实际上并不属于尝试许可该软件的许可人,或者属于他人拥有的专利,那就属于这种情况。
UCC 的 [第2-316(3)节](https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2316.&lawCode=COM) 要求,选择不适用或“排除”适销性和适用于某一特定目的的默示保证措辞必须醒目。“醒目”意味着书面化或格式化,以引起人们的注意,这与旨在从不小心的消费者身边溜走的细小字体相反。各州法律可以对不侵权的免责声明提出类似的引人注目的要求。
长期以来,律师们都有一种错觉,认为用“全大写”写任何东西都符合明显的要求。这是不正确的。法庭曾批评律师协会自以为是,而且大多数人都认为,全大写更多的是阻止阅读,而不是强制阅读。同样的,大多数开源许可证的形式都将其免责声明设置为全大写,部分原因是这是在纯文本的 `LICENSE` 文件中唯一明显的方式。我更喜欢使用星号或其他 ASCII 艺术,但那是很久很久以前的事了。
#### 责任限制
>
> In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the Software or the use or other dealings in the Software.
>
>
>
>
> 在任何情况下,作者或版权持有人都不对任何索赔、损害或其他责任负责,无论这些追责来自合同、侵权或其它行为中,还是产生于、源于或有关于本软件以及本软件的使用或其它处置。
>
>
>
MIT 许可证授予软件“免费”许可,但法律并不认为接受免费许可证的人在出错时放弃了起诉的权利,而许可人应该受到责备。“责任限制”,通常与“损害赔偿排除”条款搭配使用,其作用与许可证很像,是不起诉的承诺。但这些都是保护许可人免受被许可人起诉的保护措施。
一般来说,法庭对责任限制和损害赔偿排除条款的解读非常谨慎,因为这些条款可以将大量的风险从一方转移到另一方。为了保护社会的切身利益,让民众有办法纠正在法庭上所犯的错误,他们“严格地”用措辞限制责任,尽可能地对受其保护的一方进行解读。责任限制必须具体才能成立。特别是在“消费者”合同和其他放弃起诉权的人缺乏成熟度或讨价还价能力的情况下,法庭有时会拒绝尊重那些似乎被埋没在视线之外的措辞。部分是出于这个原因,部分是出于习惯,律师们往往也会给责任限制以全大写处理。
再往下看,“责任限制”部分是对被许可人可以起诉的金额上限。在开源许可证中,这个上限总是没有钱,0 元,“不承担责任”。相比之下,在商业许可证中,它通常是过去 12 个月内支付的许可证费用的倍数,尽管它通常是经过谈判的。
“排除”部分具体列出了各种法律主张,即请求赔偿的理由,许可人不能使用。像许多其他法律形式一样,MIT 许可证 提到了“<ruby> 违约 <rt> of contract </rt></ruby>”行为(即违反合同)和“<ruby> 侵权 <rt> of tort </rt></ruby>”行为。侵权规则是防止粗心或恶意伤害他人的一般规则。如果你在发短信时在路上撞倒了人,你就犯了侵权行为。如果你的公司销售的有问题的耳机会烧伤人们的耳朵,则说明贵公司已经侵权。如果合同没有明确排除侵权索赔,那么法庭有时会在合同中使用排除措辞以防止合同索赔。出于很好的考虑,MIT 许可证抛出“或其它”字样,只是为了截住奇怪的海事法或其它异国情调的法律主张。
“<ruby> 产生于、源于或有关于 <rt> arising from, out of or in connection with </rt></ruby>”这句话是法律起草人固有的、焦虑的不安全感反复出现的症状。关键是,任何与软件有关的诉讼都被这些限制和排除范围所覆盖。万一某些事情可以“<ruby> 产生于 <rt> arising from </rt></ruby>”,但不能“<ruby> 源于 <rt> out of </rt></ruby>”或“<ruby> 有关于 <rt> in connection with </rt></ruby>”,那就最好把这三者都写在里面,所以要把它们打包在一起。更不用说,任何被迫在这部分内容中斤斤计较的法庭将不得不为每个词提出不同的含义,前提是专业的起草者不会在一行中使用不同的词来表示同一件事。更不用说,在实践中,如果法庭对一开始就不利的限制感觉不好,那么他们会更愿意狭隘地解读范围触发器。但我离题了,同样的语言出现在数以百万计的合同中。
### 总结
所有这些诡辩都有点像在进教堂的路上吐口香糖。MIT 许可证是一个法律经典,且有效。它绝不是解决所有软件知识产权弊病的灵丹妙药,尤其是它比已经出现的软件专利灾难还要早几十年。但 MIT 风格的许可证发挥了令人钦佩的作用,实现了一个狭隘的目的,用最少的、谨慎的法律工具组合扭转了版权、销售和合同法等棘手的默认规则。在计算机技术的大背景下,它的寿命是惊人的。MIT 许可证已经超过、并将要超过绝大多数软件许可证。我们只能猜测,当它最终失去青睐时,它能提供多少年的忠实法律服务。对于那些无法提供自己的律师的人来说,这尤其慷慨。
我们已经看到,我们今天所知道的 MIT 许可证是如何成为一套具体的、标准化的条款,使机构特有的、杂乱无章的变化终于有了秩序。
我们已经看到了它对归因和版权声明的处理方法如何为学术、标准、商业和基金会机构的知识产权管理实践提供信息。
我们已经看到了 MIT 许可证是如何运行所有人免费试用软件的,但前提是要保护许可人不受担保和责任的影响。
我们已经看到,尽管有一些生硬的措辞和律师的矫揉造作,但一百七十一个小词可以完成大量的法律工作,为开源软件在知识产权和合同的密集丛林中开辟一条道路。
我非常感谢所有花时间阅读这篇相当长的文章的人,让我知道他们发现它很有用,并帮助改进它。一如既往,我欢迎你通过 [e-mail](mailto:[email protected])、[Twitter](https://twitter.com/kemitchell) 和 [GitHub](https://github.com/kemitchell/writing/tree/master/_posts/2016-09-21-MIT-License-Line-by-Line.md) 发表评论。
---
有很多人问,他们在哪里可以读到更多的东西,或者找到其他许可证,比如 GNU 通用公共许可证或 Apache 2.0 许可证。无论你的兴趣是什么,我都会向你推荐以下书籍:
* Andrew M. St. Laurent 的 [Understanding Open Source & Free Software Licensing](https://lccn.loc.gov/2006281092),来自 O’Reilly。
>
> 我先说这本,因为虽然它有些过时,但它的方法也最接近上面使用的逐行方法。O'Reilly 已经把它[放在网上](http://www.oreilly.com/openbook/osfreesoft/book/)。
>
>
>
* Heather Meeker 的 [Open (Source) for Business](https://www.amazon.com/dp/1511617772)
>
> 在我看来,这是迄今为止关于 GNU 通用公共许可证和更广泛的左版的最佳著作。这本书涵盖了历史、许可证、它们的发展,以及兼容性和合规性。这本书是我给那些考虑或处理 GPL 的客户的书。
>
>
>
* Larry Rosen 的 [Open Source Licensing](https://lccn.loc.gov/2004050558),来自 Prentice Hall。
>
> 一本很棒的入门书,也可以免费 [在线阅读](http://www.rosenlaw.com/oslbook.htm)。对于从零开始的程序员来说,这是开源许可和相关法律的最好介绍。这本在一些具体细节上也有点过时了,但 Larry 的许可证分类法和对开源商业模式的简洁总结经得起时间的考验。
>
>
>
所有这些都对我作为一个开源许可律师的教育至关重要。它们的作者都是我的职业英雄。请读一读吧 — K.E.M
我将此文章基于 [Creative Commons Attribution-ShareAlike 4.0 license](https://creativecommons.org/licenses/by-sa/4.0/legalcode) 授权
---
via: <https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html>
作者:[Kyle E. Mitchell](https://kemitchell.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # The MIT License, Line by Line171 words every programmer should understand
This post is part of a series, [Line by Line](/series/line-by-line).
[The MIT License](http://spdx.org/licenses/MIT) is the most popular open-source software
license. Here’s one read of it, line by line.
## Read the License
If you’re involved in open-source software and haven’t taken the time to read the license from top to bottom—it’s only 171 words—you need to do so now. Especially if licenses aren’t your day-to-day. Make a mental note of anything that seems off or unclear, and keep trucking. I’ll repeat every word again, in chunks and in order, with context and commentary. But it’s important to have the whole in mind.
The MIT License (MIT)
Copyright (c) <year> <copyright holders>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the Software.
The license is arranged in five paragraphs, but breaks down logically like this:
**Header****License Title**: “The MIT License”**Copyright Notice**: “Copyright (c) …”
**License Grant**: “Permission is hereby granted …”**Grant Scope**: “… to deal in the Software …”**Conditions**: “… subject to …”**Attribution and Notice**: “The above … shall be included …”**Warranty Disclaimer**: “*The software is provided ‘as is’ …*”**Limitation of Liability**: “*In no event …*”
Here we go:
## Header
### License Title
The MIT License (MIT)
“The MIT License” is a not a single license, but a family of
license forms derived from language prepared for releases from the
Massachusetts Institute of Technology. It has seen a lot of changes
over the years, both for the original projects that used it, and also
as a model for other projects. The Fedora Project maintains a [kind of
cabinet of MIT license curiosities](https://fedoraproject.org/wiki/Licensing:MIT?rd=Licensing/MIT), with insipid variations
preserved in plain text like anatomical specimens in formaldehyde,
tracing a wayward kind of evolution.
Fortunately, the [Open Source Initiative](https://opensource.org) and [Software Package
Data eXchange](https://spdx.org) groups have standardized a generic MIT-style
license form as “The MIT License”. OSI in turn has adopted SPDX’
standardized [string identifiers](http://spdx.org/licenses/) for common open-source
licenses, with `MIT`
pointing unambiguously to the standardized form
“MIT License”. If you want MIT-style terms for a new project, use
[the standardized form](http://spdx.org/licenses/MIT).
Even if you include “The MIT License” or “SPDX:MIT” in a `LICENSE`
file, any responsible reviewer will still run a comparison of the text
against the standard form, just to be sure. While various license
forms calling themselves “MIT License” vary only in minor details, the
looseness of what counts as an “MIT License” has tempted some authors
into adding bothersome “customizations”. The canonical horrible,
no good, very bad example of this is [the JSON license](https://spdx.org/licenses/JSON),
an MIT-family license plus “The Software shall be used for Good,
not Evil.”. This kind of thing might be “very Crockford”. It is
definitely a pain in the ass. Maybe the joke was supposed to be on
the lawyers. But they laughed all the way to the bank.
Moral of the story: “MIT License” alone is ambiguous. Folks probably
have a good idea what you mean by it, but you’re only going to save
everyone—yourself included—time by copying the text of the standard
MIT License form into your project. If you use metadata, like the
`license`
property in package manager metadata files, to designate the
`MIT`
license, make sure your `LICENSE`
file and any header comments
use the standard form text. All of this can be [automated](https://www.npmjs.com/package/licensor).
### Copyright Notice
Copyright (c) <year> <copyright holders>
Until the 1976 Copyright Act, United States copyright law required
specific actions, called “formalities”, to secure copyright in
creative works. If you didn’t follow those formalities, your rights
to sue others for unauthorized use of your work were limited, often
completely lost. One of those formalities was “notice”: Putting
marks on your work and otherwise making it known to the market that
you were claiming copyright. The © is a standard symbol for
marking copyrighted works, to give notice of copyright. The ASCII
character set doesn’t have the © symbol, but `Copyright (c)`
gets the same point across.
The 1976 Copyright Act, which “implemented” many requirements of the international Berne Convention, eliminated formalities for securing copyright. At least in the United States, copyright holders still need to register their copyrighted works before suing for infringement, with potentially higher damages if they register before infringement begins. In practice, however, many register copyright right before bringing suit against someone in particular. You don’t lose your copyright just by failing to put notices on it, registering, sending a copy to the Library of Congress, and so on.
Even if copyright notices aren’t as absolutely necessary as they used to be, they are still plenty useful. Stating the year a work was authored and who the copyright belonged to give some sense of when copyright in the work might expire, bringing the work into the public domain. The identity of the author or authors is also useful: United States law calculates copyright terms differently for individual and “corporate” authors. Especially in business use, it may also behoove a company to think twice about using software from a known competitor, even if the license terms give very generous permission. If you’re hoping others will see your work and want to license it from you, copyright notices serve nicely for attribution.
As for “copyright holder”: Not all standard form licenses have a space
to write this out. More recent license forms, like [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
and [GPL 3.0](https://www.gnu.org/licenses/gpl-3.0.en.html), publish `LICENSE`
texts that are meant to be copied
verbatim, with header comments and separate files elsewhere to indicate
who owns copyright and is giving the license. Those approaches neatly
discourage changes to the “standard” texts, accidental or intentional.
They also make automated license identification more reliable.
The MIT License descends from language written for releases of
code by institutions. For institutional releases, there was
just one clear “copyright holder”, the institution releasing
the code. Other institutions cribbed these licenses, replacing
“MIT” with their own names, leading eventually to the generic
forms we have now. This process repeated for other short-form
institutional licenses of the era, notably the [original four-clause
BSD License](http://spdx.org/licenses/BSD-4-Clause) for the University of California, Berkeley,
now used in [three-clause](https://spdx.org/licenses/BSD-3-Clause) and [two-clause](https://spdx.org/licenses/BSD-2-Clause)
variants, as well as [The ISC License](http://www.isc.org/downloads/software-support-policy/isc-license/) for the Internet Systems
Consortium, an MIT variant.
In each case, the institution listed itself as the copyright holder
in reliance on rules of copyright ownership, called “[works made
for hire](http://worksmadeforhire.com/)” rules, that give employers and clients ownership of
copyright in some work their employees and contractors do on their
behalf. These rules don’t usually apply to distributed collaborators
submitting code voluntarily. This poses a problem for project-steward
foundations, like the Apache Foundation and Eclipse Foundation, that
accept contributions from a more diverse group of contributors.
The usual foundation approach thus far has been to use a house
license that states a single copyright holder—[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) and
[EPL 1.0](https://www.eclipse.org/legal/epl-v10.html)—backed up by contributor license agreements—[Apache
CLAs](https://www.apache.org/licenses/#clas) and [Eclipse CLAs](https://wiki.eclipse.org/ECA)—to collect rights from contributors.
Collecting copyright ownership in one place is even more important
under “copyleft” licenses like the GPL, which rely on copyright owners
to enforce license conditions to promote software-freedom values.
These days, loads of projects without any kind of institutional or business steward use MIT-style license terms. SPDX and OSI have helped these use cases by standardizing forms of licenses like MIT and ISC that don’t refer to a specific entity or institutional copyright holder. Armed with those forms, the prevailing practice of project authors is to fill their own name in the copyright notice of the form very early on … and maybe bump the year here and there. At least under United States copyright law, the resulting copyright notice doesn’t give a full picture.
The original owner of a piece of software retains ownership of their
work. But while MIT-style license terms give others rights to build
on and change the software, creating what the law calls “derivative
works”, they don’t give the original author ownership of copyright in
others’ contributions. Rather, each contributor has copyright in any
[even marginally creative](https://en.wikipedia.org/wiki/Feist_Publications,_Inc.,_v._Rural_Telephone_Service_Co.) work they make using the existing
code as a starting point.
Most of these projects also balk at the idea of taking contributor
license agreements, to say nothing of signed copyright assignments.
That’s both naive and understandable. Despite the assumption of
some newer open-source developers that sending a pull request on
GitHub “automatically” licenses the contribution for distribution
on the terms of the project’s existing license, United States law
doesn’t recognize any such rule. Strong copyright *protection*,
not permissive licensing, is the default.
*Update: GitHub later changed its site-wide terms of service to
include an attempt to flip this default, at least on GitHub.com.
I’ve written up some thoughts on that development, not all of them
positive, in another post.*
To fill the gap between legally effective, well-documented grants
of rights in contributions and no paper trail at all, some projects
have adopted the [Developer Certificate of Origin](http://developercertificate.org/), a standard
statement contributors allude to using `Signed-Off-By`
metadata tags in
their Git commits. The Developer Certificate of Origin was developed
for Linux kernel development in the wake of the infamous SCO lawsuits,
which alleged that chunks of Linux’ code derived from SCO-owned Unix
source. As a means of creating a paper trail showing that each line
of Linux came from a contributor, the Developer Certificate of Origin
functions nicely. While the Developer Certificate of Origin isn’t a
license, it does provide lots of good evidence that those submitting
code expected the project to distribute their code, and for others
to use it under the kernel’s existing license terms. The kernel also
maintains a machine-readable `CREDITS`
file listing contributors with
name, affiliation, contribution area, and other metadata. I’ve done
[some](https://github.com/berneout/berneout-pledge) [experiments](https://github.com/berneout/authors-certificate) adapting that approach for
projects that don’t use the kernel’s development flow.
## License Grant
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”),
The meat of The MIT License is, you guessed it, a license. In general terms, a license is permission that one person or legal entity—the “licensor”—gives another—the “licensee”—to do something the law would otherwise let them sue for. The MIT License is a promise not to sue.
The law sometimes distinguishes licenses from promises to give
licenses. If someone breaks a promise to give a license, you may be
able to sue them for breaking their promise, but you may not end up
with a license. “Hereby” is one of those hokey, archaic-sounding
words lawyers just can’t get rid of. It’s used here to show that
the license text itself gives the license, and not just a promise of
a license. It’s a legal [IIFE](https://en.wikipedia.org/wiki/Immediately-invoked_function_expression).
While many licenses give permission to a specific, named licensee, The MIT License is a “public license”. Public licenses give everybody—the public at large—permission. This is one of the three great ideas in open-source licensing. The MIT License captures this idea by giving a license “to any person obtaining a copy of … the Software”. As we’ll see later, there is also a condition to receiving this license that ensures others will learn about their permission, too.
The parenthetical with a capitalized term in quotation marks (a “Definition”), is the standard way to give terms specific meanings in American-style legal documents. Courts will reliably look back to the terms of the definition when they see a defined, capitalized term used elsewhere in the document.
### Grant Scope
to deal in the Software without restriction,
From the licensee’s point of view, these are the seven most important
words in The MIT License. The key legal concerns are getting sued
for copyright infringement and getting sued for patent infringement.
Neither copyright law nor patent law uses “to deal in” as a term of
art; it has no specific meaning in court. As a result, any court
deciding a dispute between a licensor and a licensee would ask what
the parties meant and understood by this language. What the court
will see is that the language is intentionally broad and open-ended.
It gives licensees a strong argument against any claim by a licensor
that they didn’t give permission for the licensee to do *that* specific
thing with the software, even if the thought clearly didn’t occur to
either side when the license was given.
including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
No piece of legal writing is perfect, “fully settled in meaning”, or unmistakably clear. Beware anyone who pretends otherwise. This is the least perfect part of The MIT License. There are three main issues:
First, “including without limitation” is a legal antipattern. It crops up in any number of flavors:
- “including, without limitation”
- “including, without limiting the generality of the foregoing”
- “including, but not limited to”
- many, many pointless variations
All of these share a common purpose, and they all fail to achieve it reliably. Fundamentally, drafters who use them try to have their cake and eat it, too. In The MIT License, that means introducing specific examples of “dealing in the Software”—“use, copy, modify” and so on—without implying that licensee action has to be something like the examples given to count as “dealing in”. The trouble is that, if you end up needing a court to review and interpret the terms of a license, the court will see its job as finding out what those fighting meant by the language. If the court needs to decide what “deal in” means, it cannot “unsee” the examples, even if you tell it to. I’d argue that “deal in the Software without restriction” alone would be better for licensees. Also shorter.
Second, the verbs given as examples of “deal in” are a hodgepodge. Some have specific meanings under copyright or patent law, others almost do or just plain don’t:
-
“use” appears in
[United States Code title 35, section 271(a)](https://www.govinfo.gov/app/details/USCODE-2017-title35/USCODE-2017-title35-partIII-chap28-sec271), the patent law’s list of what patent owners can sue others for doing without permission. -
“copy” appears in
[United States Code title 17, section 106](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106), the copyright law’s list of what copyright owners can sue others for doing without permission. -
“modify” doesn’t appear in either copyright or patent statute. It is probably closest to “prepare derivative works” under the copyright statute, but may also implicate improving or otherwise derivative inventions.
-
“merge” doesn’t appear in either copyright or patent statute. “Merger” has a specific meaning in copyright, but that’s clearly not what’s intended here. Rather, a court would probably read “merge” according to its meaning in industry, as in “to merge code”.
-
“publish” doesn’t appear in either copyright or patent statute. Since “the Software” is what’s being published, it probably hews closest to “distribute” under the
[copyright statute](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106). That statute also covers rights to perform and display works “publicly”, but those rights apply only to specific kinds of copyrighted work, like plays, sound recordings, and motion pictures. -
“distribute” appears in the
[copyright statute](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106). -
“sublicense” is a general term of intellectual property law. The right to sublicense means the right to give others licenses of their own, to do some or all of what you have permission to do. The MIT License’s right to sublicense is actually somewhat unusual in open-source licenses generally. The norm is what Heather Meeker calls a “direct licensing” approach, where everyone who gets a copy of the software and its license terms gets a license direct from the owner. Anyone who might get a sublicense under the MIT License will probably end up with a copy of the license telling them they have a direct license, too.
-
“sell copies of” is a mongrel. It is close to “offer to sell” and “sell” in the
[patent statute](https://www.govinfo.gov/app/details/USCODE-2017-title35/USCODE-2017-title35-partIII-chap28-sec271), but refers to “copies”, a copyright concept. On the copyright side, it seems close to “distribute”, but the[copyright statute](https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106)makes no mention of sales. -
“permit persons to whom the Software is furnished to do so” seems redundant of “sublicense”. It’s also unnecessary to the extent folks who get copies also get a direct license.
Lastly, as a result of this mishmash of legal, industry,
general-intellectual-property, and general-use terms, it isn’t clear
whether The MIT License includes a patent license. The general
language “deal in” and some of the example verbs, especially “use”,
point toward a patent license, albeit a very unclear one. The fact
that the license comes from the *copyright holder*, who may or may not
have patent rights in inventions in the software, as well as most of
the example verbs and the definition of “the Software” itself, all
point strongly toward a copyright license. More recent permissive
open-source licenses, like [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0), address copyright, patent,
and even trademark separately and specifically.
### Three License Conditions
subject to the following conditions:
There’s always a catch! MIT has three!
If you don’t follow The MIT License’s conditions, you don’t get the permission the license offers. So failing to do what the conditions say at least theoretically leaves you open to a lawsuit, probably a copyright lawsuit.
Using the value of the software to the licensee to motivate
compliance with conditions, even though the licensee paid nothing
for the license, is the second great idea of open-source licensing.
The last, not found in The MIT License, builds off license conditions:
“Copyleft” licenses like the [GNU General Public License](https://www.gnu.org/licenses/gpl-3.0.en.html)
use license conditions to control how those making changes can license
and distribute their changed versions.
### Notice Condition
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
If you give someone a copy of the software, you need to include the license text and any copyright notice. This serves a few critical purposes:
-
Gives others notice that they have permission for the software under the public license. This is a key part of the direct-licensing model, where each user gets a license direct from the copyright holder.
-
Makes known who’s behind the software, so they can be showered in praises, glory, and cold, hard cash donations.
-
Ensures the warranty disclaimer and limitation of liability (coming up next) follow the software around. Everyone who gets a copy should get a copy of those licensor protections, too.
There’s nothing to stop you charging for providing a copy, or even a copy in compiled form, without source code. But when you do, you can’t pretend that the MIT code is your own proprietary code, or provided under some other license. Those receiving get to know their rights under the “public license”.
Frankly, compliance with this condition is breaking down. Nearly every
open-source license has such an “attribution” condition. Makers of
system and installed software often understand they’ll need to compile
a notices file or “license information” screen, with copies of license
texts for libraries and components, for each release of their own.
The project-steward foundations have been instrumental in teaching
those practices. But web developers, as a whole, haven’t got the
memo. It can’t be explained away by a lack of tooling—there is
plenty—or the highly modular nature of packages from npm and other
repositories—which uniformly standardize metadata formats for license
information. All the good JavaScript minifiers have command-line flags
for preserving license header comments. Other tools will concatenate
`LICENSE`
files from package trees. There’s really no excuse.
### Warranty Disclaimer
The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement.
Nearly every state in the United States has enacted a version of the Uniform Commercial Code, a model statute of laws governing commercial transactions. Article 2 of the UCC—“Division 2” in California—governs contracts for sales of goods, from used automobiles bought off the lot to large shipments of industrial chemicals to manufacturing plants.
Some of the UCC’s rules about sales contracts are mandatory. These rules always apply, whether those buying and selling like them or not. Others are just “defaults”. Unless buyers and sellers opt out in writing, the UCC implies that they want the baseline rule found in the UCC’s text for their deal. Among the default rules are implied “warranties”, or promises by sellers to buyers about the quality and usability of the goods being sold.
There is a big theoretical debate about whether public licenses like The MIT License are contracts—enforceable agreements between licensors and licensees—or just licenses, which go one way, but may come with strings attached, their conditions. There is less debate about whether software counts as “goods”, triggering the UCC’s rules. There is no debate among licensors on liability: They don’t want to get sued for lots of money if the software they give away for free breaks, causes problems, doesn’t work, or otherwise causes trouble. That’s exactly the opposite of what three default rules for “implied warranties” do:
-
The implied warranty of “merchantability” under
[UCC section 2-314](https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2314.&lawCode=COM)is a promise that “the goods”—the Software—are of at least average quality, properly packaged and labeled, and fit for the ordinary purposes they are intended to serve. This warranty applies only if the one giving the software is a “merchant” with respect to the software, meaning they deal in software and hold themselves out as skilled in software. -
The implied warranty of “fitness for a particular purpose” under
[UCC section 2-315](https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2315.&lawCode=COM)kicks in when the seller knows the buyer is relying on them to provide goods for a particular purpose. The goods need to actually be “fit” for that purpose. -
The implied warranty of “noninfringement” is not part of the UCC, but is a common feature of general contract law. This implied promise protects the buyer if it turns out the goods they received infringe somebody else’s intellectual property rights. That would be the case if the software under The MIT License didn’t actually belong to the one trying to license it, or if it fell under a patent owned by someone else.
[Section 2-316(3)](https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2316.&lawCode=COM) of the UCC requires language opting
out of, or “excluding”, implied warranties of merchantability and
fitness for a particular purpose to be conspicuous. “Conspicuous”
in turn means written or formatted to call attention to itself, the
opposite of microscopic fine print meant to slip past unwary consumers.
State law may impose a similar attention-grabbing requirement for
disclaimers of noninfringement.
Lawyers have long suffered under the delusion that writing anything
in `ALL-CAPS`
meets the conspicuous requirement. That isn’t true.
Courts have criticized the Bar for pretending as much, and most
everyone agrees all-caps does more to discourage reading than compel
it. All the same, most open-source-license forms set their warranty
disclaimers in all-caps, in part because that’s the only obvious way
to make it stand out in plain-text `LICENSE`
files. I’d prefer to
use asterisks or other ASCII art, but that ship sailed long, long ago.
### Limitation of Liability
In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the Software or the use or other dealings in the Software.
The MIT License gives permission for software “free of charge”, but
the law does not assume that folks receiving licenses free of charge
give up their rights to sue when things go wrong and the licensor is
to blame. “Limitations of liability”, often paired with “damages
exclusions”, work a lot like licenses, as promises not to sue.
But these are protections for the *licensor* against lawsuits
by *licensees*.
In general, courts read limitations of liability and damages exclusions warily, since they can shift an incredible amount of risk from one side to another. To protect the community’s vital interest in giving folks a way to redress wrongs done in court, they “strictly construe” language limiting liability, reading it against the one protected by it where possible. Limitations of liability have to be specific to stand up. Especially in “consumer” contracts and other situations where those giving up the right to sue lack sophistication or bargaining power, courts have sometimes refused to honor language that seemed buried out of sight. Partly for that reason, partly by sheer force of habit, lawyers tend to give limits of liability the all-caps treatment, too.
Drilling down a bit, the “limitation of liability” part is a cap on the amount of money a licensee can sue for. In open-source licenses, that limit is always no money at all, $0, “not liable”. By contrast, in commercial licenses, it’s often a multiple of license fees paid in the last 12-month period, though it’s often negotiated.
The “exclusion” part lists, specifically, kinds of legal claims—reasons to sue for damages—the licensor cannot use. Like many, many legal forms, The MIT License mentions actions “of contract”—for breaching a contract—and “of tort”. Tort rules are general rules against carelessly or maliciously harming others. If you run someone down on the road while texting, you have committed a tort. If your company sells faulty headphones that burn peoples’ ears off, your company has committed a tort. If a contract doesn’t specifically exclude tort claims, courts sometimes read exclusion language in a contract to prevent only contract claims. For good measure, The MIT License throws in “or otherwise”, just to catch the odd admiralty law or other, exotic kind of legal claim.
The phrase “arising from, out of or in connection with” is a recurring tick symptomatic of the legal draftsman’s inherent, anxious insecurity. The point is that any lawsuit having anything to do with the software is covered by the limitation and exclusions. On the off chance something can “arise from”, but not “out of”, or “in connection with”, it feels better to have all three in the form, so pack ‘em in. Never mind that any court forced to split hairs in this part of the form will have to come up with different meanings for each, on the assumption that a professional drafter wouldn’t use different words in a row to mean the same thing. Never mind that in practice, where courts don’t feel good about a limitation that’s disfavored to begin with, they’ll be more than ready to read the scope trigger narrowly. But I digress. The same language appears in literally millions of contracts.
## Overall
All these quibbles are a bit like spitting out gum on the way into church. The MIT License is a legal classic. The MIT License works. It is by no means a panacea for all software IP ills, in particular the software patent scourge, which it predates by decades. But MIT-style licenses have served admirably, fulfilling a narrow purpose—reversing troublesome default rules of copyright, sales, and contract law—with a minimal combination of discreet legal tools. In the greater context of computing, its longevity is astounding. The MIT License has outlasted and will outlast the vast majority of software licensed under it. We can only guess how many decades of faithful legal service it will have given when it finally loses favor. It’s been especially generous to those who couldn’t have afforded their own lawyer.
We’ve seen how the The MIT License we know today is a specific, standardized set of terms, bringing order at long last to a chaos of institution-specific, haphazard variations.
We’ve seen how its approach to attribution and copyright notice informed intellectual property management practices for academic, standards, commercial, and foundation institutions.
We’ve seen how The MIT Licenses grants permission for software to all, for free, subject to conditions that protect licensors from warranties and liability.
We’ve seen that despite some crusty verbiage and lawyerly affectation, one hundred and seventy one little words can get a hell of a lot of legal work done, clearing a path for open-source software through a dense underbrush of intellectual property and contract.
I’m so grateful for all who’ve taken the time to read this rather long
post, to let me know they found it useful, and to help improve it.
As always, I welcome your comments via [e-mail](mailto:[email protected]), [Twitter](https://twitter.com/kemitchell), and
[GitHub](https://github.com/kemitchell/writing.kemitchell.com/tree/main/_posts/2016-09-21-MIT-License-Line-by-Line.md).
[A number of folks have asked where
they can read more, or find run-downs of other licenses, like the
GNU General Public License or the Apache 2.0 license. No matter what
your particular continuing interest may be, I heartily recommend the
following books:]
-
Andrew M. St. Laurent’s
, from O’Reilly.[Understanding Open Source & Free Software Licensing](http://lccn.loc.gov/2006281092)I start with this one because, while it’s somewhat dated, its approach is also closest to the line-by-line approach used above. O’Reilly has made it
[available online](http://www.oreilly.com/openbook/osfreesoft/book/). -
Heather Meeker’s
[Open (Source) for Business](https://www.amazon.com/dp/B086G6XDM1/)In my opinion, by far the best writing on the GNU General Public License and copyleft more generally. This book covers the history, the licenses, their development, as well as compatibility and compliance. It’s the book I lend to clients considering or dealing with the GPL.
-
Larry Rosen’s
, from Prentice Hall.[Open Source Licensing](https://lccn.loc.gov/2004050558)A great first book, also available for free
[online](http://www.rosenlaw.com/oslbook.htm). This is the best introduction to open-source licensing and related law for programmers starting from scratch. This one is also a bit dated in some specific details, but Larry’s taxonomy of licenses and succinct summary of open-source business models stand the test of time.
All of these were crucial to my own education as an open-source licensing lawyer. Their authors are professional heroes of mine. Have a read! — K.E.M
I license this article under a
[Creative Commons Attribution-ShareAlike 4.0 license](https://creativecommons.org/licenses/by-sa/4.0/legalcode).
[Russian](http://www.opensourceinitiative.net/edu/MIT-License/), [Japanese](http://postd.cc/mit-license-line-by-line/), [Ukrainian](https://clipart-library.com/p28.html), and [Chinese](https://linux.cn/article-13180-1.html) translations are available.
Your thoughts and feedback are
[always welcome by e-mail](mailto:[email protected]). |
13,181 | 定制你的 Linux 终端外观的 5 项调整 | https://itsfoss.com/customize-linux-terminal/ | 2021-03-06T23:24:00 | [
"终端"
] | https://linux.cn/article-13181-1.html | 
终端仿真器(或简称终端)是任何 Linux 发行版中不可或缺的一部分。
当你改变发行版的主题时,往往终端也会自动得到改造。但这并不意味着你不能进一步定制终端。
事实上,很多读者都问过我们,为什么我们截图或视频中的终端看起来那么酷,我们用的是什么字体等等。
为了回答这个经常被问到的问题,我将向你展示一些简单或复杂的调整来改变终端的外观。你可以在下图中对比一下视觉上的差异:

### 自定义 Linux 终端
本教程利用 Pop!\_OS 上的 GNOME 终端来定制和调整终端的外观。但是,大多数建议也应该适用于其他终端。
对于大多数元素,如颜色、透明度和字体,你可以利用 GUI 来调整它,而不需要输入任何特殊的命令。
打开你的终端。在右上角寻找汉堡菜单。在这里,点击 “偏好设置”,如下图所示:

在这里你可以找到改变终端外观的所有设置。
#### 技巧 0:使用独立的终端配置文件进行定制
我建议你建立一个新的配置文件用于你的定制。为什么要这样做?因为这样一来,你的改变就不会影响到终端的主配置文件。假设你做了一些奇怪的改变,却想不起默认值?配置文件有助于分离你的定制。
如你所见,我有个单独的配置文件,用于截图和制作视频。

你可以轻松地更改终端配置文件,并使用新的配置文件打开一个新的终端窗口。

这就是我想首先提出的建议。现在,让我们看看这些调整。
#### 技巧 1:使用深色/浅色终端主题
你可以改变系统主题,终端主题也会随之改变。除此之外,如果你不想改变系统主题。你也可以切换终端的深色主题或浅色主题,
一旦你进入“偏好设置”,你会注意到在“常规”选项中可以改变主题和其他设置。

#### 技巧 2:改变字体和大小
选择你要自定义的配置文件。现在你可以选择自定义文本外观、字体大小、字体样式、间距、光标形状,还可以切换终端铃声。
对于字体,你只能改成你系统上可用的字体。如果你想要不同的字体,请先在你的 Linux 系统上下载并安装字体。
还有一点! 要使用等宽字体,否则字体可能会重叠,文字可能无法清晰阅读。如果你想要一些建议,可以选择 [Share Tech Mono](https://fonts.google.com/specimen/Share+Tech+Mono)(开源)或 [Larabiefont](https://www.dafont.com/larabie-font.font)(不开源)。
在“文本”选项卡下,选择“自定义字体”,然后更改字体及其大小(如果需要)。

#### 技巧 3:改变调色板和透明度
除了文字和间距,你还可以进入“颜色”选项,改变终端的文字和背景的颜色。你还可以调整透明度,让它看起来更酷。
正如你所注意到的那样,你可以从一组预先配置的选项中选择调色板,也可以自己调整。

如果你想和我一样启用透明,点击“使用透明背景”选项。
如果你想要和你的系统主题类似的颜色设置,你也可以选择使用系统主题的颜色。

#### 技巧 4:调整 bash 提示符变量
通常当你启动终端时,无需任何修改你就会看到你的用户名和主机名(你的发行版名称)作为 bash 提示符。
例如,在我的例子中,它会是 “ankushdas@pop-os:~$”。然而,我把 [主机名永久地改成了](https://itsfoss.com/change-hostname-ubuntu/) “itsfoss”,所以现在看起来像这样:

要改变主机名,你可以键入:
```
hostname 定制名称
```
然而,这只适用于当前会话。因此,当你重新启动时,它将恢复到默认值。要永久地更改主机名,你需要输入:
```
sudo hostnamectl set-hostname 定制名称
```
同样,你也可以改变你的用户名,但它需要一些额外的配置,包括杀死所有与活动用户名相关联的当前进程,所以我们会跳过用它来改变终端的外观/感觉。
#### 技巧 5:不推荐:改变 bash 提示符的字体和颜色(面向高级用户)
然而,你可以使用命令调整 bash 提示符的字体和颜色。
你需要利用 `PS1` 环境变量来控制提示符的显示内容。你可以在 [手册页](https://linux.die.net/man/1/bash) 中了解更多关于它的信息。
例如,当你键入:
```
echo $PS1
```
在我这里输出:
```
\[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$
```
我们需要关注的是该输出的第一部分:
```
\[\e]0;\u@\h: \w\a\]$
```
在这里,你需要知道以下几点:
* `\e` 是一个特殊的字符,表示一个颜色序列的开始。
* `\u` 表示用户名,后面可以跟着 `@` 符号。
* `\h` 表示系统的主机名。
* `\w` 表示基本目录。
* `\a` 表示活动目录。
* `$` 表示非 root 用户。
在你的情况下输出可能不一样,但变量是一样的,所以你需要根据你的输出来试验下面提到的命令。
在你这样做之前,请记住这些:
* 文本格式代码:`0` 代表正常文本,`1` 代表粗体,`3` 代表斜体,`4` 代表下划线文本。
* 背景色的颜色范围:`40` - `47`。
* 文本颜色的颜色范围:`30` - `37`。
你只需要键入以下内容来改变颜色和字体:
```
PS1="\e[41;3;32m[\u@\h:\w\a\$]"
```
这是输入该命令后 bash 提示符的样子:

如果你注意到这个命令,就像上面提到的,`\e` 可以帮助我们分配一个颜色序列。
在上面的命令中,我先分配了一个**背景色**,然后是**文字样式**,接着是**字体颜色**,然后是 `m`。这里,`m` 表示颜色序列的结束。
所以,你要做的就是,调整这部分:
```
41;3;32
```
命令其余部分应该是不变的,你只需要分配不同的数字来改变背景色、文字样式和文字颜色。
要注意的是,这并没有特定的顺序,你可以先指定文字样式,再指定背景色,最后指定文字颜色,如 `3;41;32`,这里的命令就变成了:
```
PS1="\e[3;41;32m[\u@\h:\w\a\$]"
```

正如你所注意到的,无论顺序如何,颜色的定制都是一样的。所以,只要记住自定义的代码,并在你确定你想把它作为一个永久的变化之前,试试它。
上面我提到的命令会临时定制当前会话的 bash 提示符。如果你关闭了会话,你将失去这个自定义设置。
所以,要想把它变成一个永久的改变,你需要把它添加到 `.bashrc` 文件中(这是一个配置文件,每次加载会话时都会加载)。

简单键入如下命令来访问该文件:
```
nano ~/.bashrc
```
除非你明确知道你在做什么,否则不要改变任何东西。而且,为了可以恢复设置,你应该把 `PS1` 环境变量的备份(默认情况下复制粘贴其中的内容)保存到一个文本文件中。
所以,即使你需要默认的字体和颜色,你也可以再次编辑 `.bashrc` 文件并粘贴 `PS1` 环境变量。
#### 附赠技巧:根据你的墙纸改变终端的调色板
如果你想改变终端的背景和文字颜色,但又不知道该选哪种颜色,你可以使用一个基于 Python 的工具 Pywal,它可以 [根据你的壁纸](https://itsfoss.com/pywal/) 或你提供的图片自动改变终端的颜色。

如果你有兴趣使用这个工具,我之前已经详细[介绍](https://itsfoss.com/pywal/)过了。
### 总结
当然,使用 GUI 定制很容易,同时也可以更好地控制你可以改变的东西。但是,需要知道命令也是必要的,万一你开始 [使用 WSL](https://itsfoss.com/install-bash-on-windows/) 或者使用 SSH 访问远程服务器,无论如何都可以定制你的体验。
你是如何定制 Linux 终端的?在评论中与我们分享你的秘方。
---
via: <https://itsfoss.com/customize-linux-terminal/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The terminal emulator or simply the terminal is an integral part of any Linux distribution.
When you change the theme of your distribution, the terminal often gets a makeover automatically. But that doesn’t mean you cannot customize the terminal further.
Many It’s FOSS readers have asked us how come the terminal in our screenshots or videos look so cool, what fonts do we use, etc.
To answer this frequent question, I’ll show you some simple and some complex tweaks to change the appearance of the terminal. You can compare the visual difference in the image below:
## Customizing Linux Terminal
For most elements like color, transparency, and fonts, you can utilize the GUI to tweak it without requiring you to enter any special commands.
Open your terminal. In the top right corner, look for the hamburger menu. Here, click on “**Preferences**” as shown in the screenshot below:
This is where you’ll find all the settings to change the appearance of the terminal.
### Tip 0: Use separate terminal profiles for your customization
I would advise you to create a new profile for your customization. Why? Because this way, your changes won’t impact the main terminal profile. Suppose you make some weird changes and cannot recall the default value. Profiles help separate the customization.
As you can see, Abhishek has separate profiles for taking screenshots and making videos.
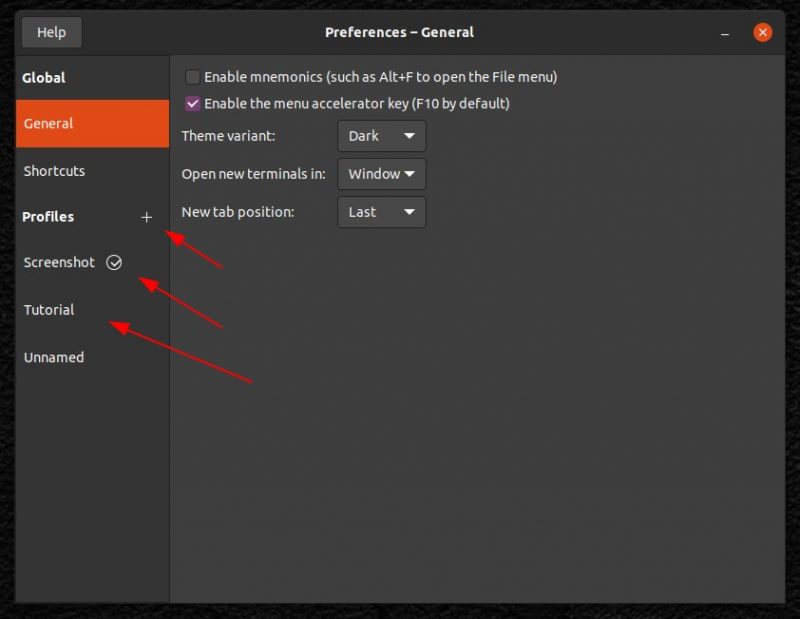
You can easily change the terminal profiles and open a new terminal window with the new profile.
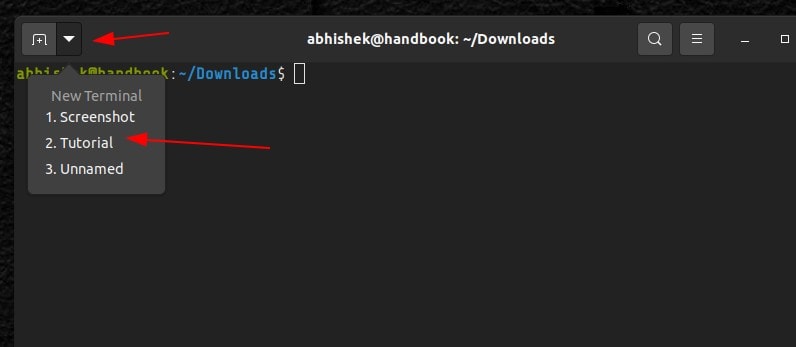
That was the suggestion I wanted to put forward. Now, let’s see those tweaks.
### Tip 1: Use a dark/light terminal theme
You may change the system theme and the terminal theme gets changed. Apart from that, you may switch between the dark or light theme, if you do not want to change the system theme.
Once you head into the preferences, you will notice the General options to change the theme and other settings.
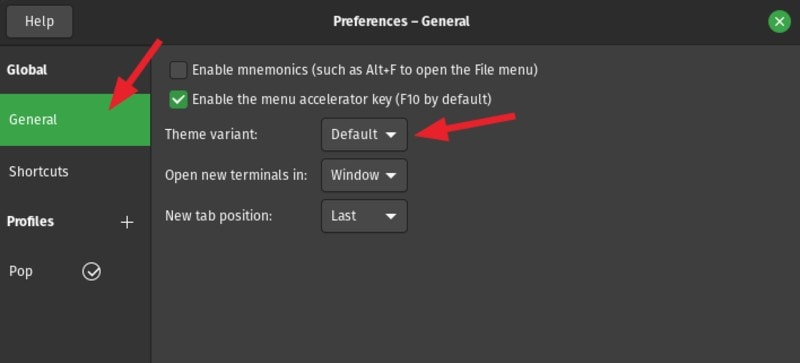
### Tip 2: Change the font and size
Select the profile that you want to customize. Now you’ll get the option to customize the text appearance, font size, font style, spacing, cursor shape, and toggle the terminal bell sound as well.
For [changing the terminal font](https://itsfoss.com/change-terminal-font-ubuntu/), you can only change to what’s available on your system. If you want something different, download and install the font on your Linux system first.
[Share Tech Mono](https://fonts.google.com/specimen/Share+Tech+Mono)(open source) or
[Larabiefont](https://www.dafont.com/larabie-font.font)(not open source).
Under the Text tab, select Custom font and then change the font and size (if required).
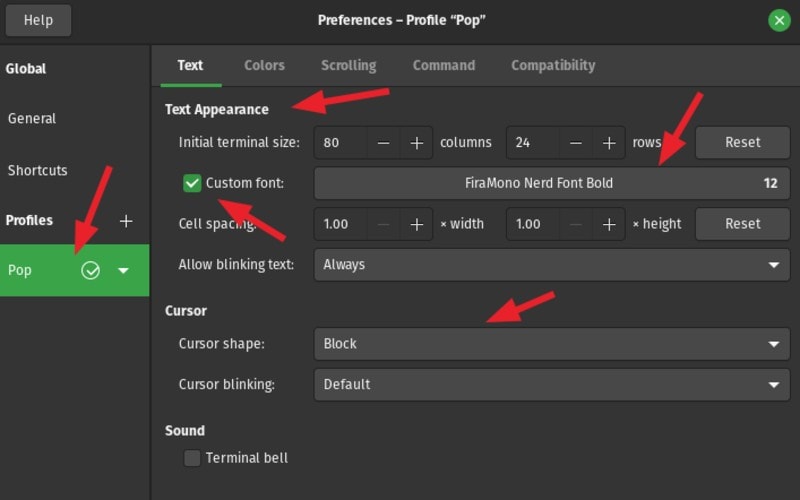
### Tip 3: Change the color pallet and transparency
Apart from the text and spacing, you can access the “Colors” tab and [change the color of the text and background of your terminal](https://itsfoss.com/change-terminal-color-ubuntu/). You can also adjust the transparency to make it look even cooler.
As you can notice, you can change the color palette from a set of pre-configured options or tweak it yourself.
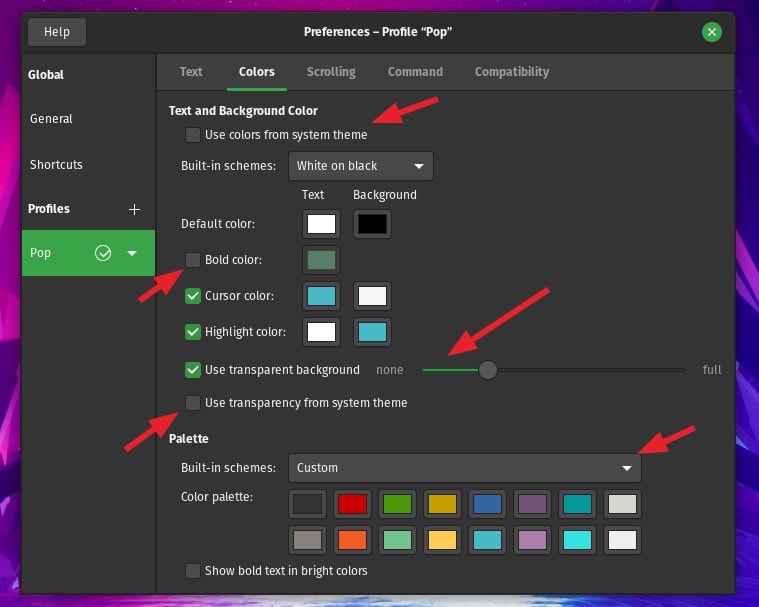
If you want to enable transparency just like I did, you click on “**Use transparent background**” option.
You can also choose to use colors from your system theme if you want a similar color setting to your theme.
### Tip 4: Tweaking the bash prompt variables
Usually, you will see your username and hostname (your distribution) as the bash prompt when launching the terminal without any changes.
For instance, it would be “ankushdas**@**pop-os**:~$**” in my case. However, I [permanently changed the hostname](https://itsfoss.com/change-hostname-ubuntu/) to “**itsfoss**“, so now it looks like this:
To change the hostname, you can type in the following:
`hostname CUSTOM_NAME`
However, this will be applicable only to the current sessions. So, when you restart, it will revert to the default. To permanently change the hostname, you need to type in the following:
`sudo hostnamectl set-hostname CUSTOM_NAME`
Similarly, you can also change your username, but it requires some additional configuration that includes killing all the current processes associated with the active username, so we’ll avoid it to change the look/feel of the terminal.
### Tip 5: Changing the font and color of the bash prompt (for advanced users)
You can tweak the font and color of the bash prompt (**ankushdas@itsfoss:~$**) using commands.
You will need to utilize the **PS1** environment variable which controls what is being displayed as the prompt. You can learn more about it on the [man page](https://linux.die.net/man/1/bash).
For instance, when you type in:
`echo $PS1`
The output in my case is:
`\[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$`
We need to focus on the first part of the output:
`\[\e]0;\u@\h: \w\a\]$`
Here, you need to know the following:
**\e**is a special character that denotes the start of a color sequence**\u**indicates the username followed by the @ symbol**\h**denotes the hostname of the system**\w**denotes the base directory**\a**indicates the active directory**$**indicates non-root user
The output in your case can be different, but the variables will be the same, so you need to play with the commands mentioned below depending on your output.
Before you do that, keep these in mind:
- Codes for text format:
**0**for normal text,**1**for bold,**3**for italic and**4**for underline text - Color range for background colors:
**40-47** - Color range for text color:
**30-37**
You just need to type in the following to change the color and font:
`PS1="\e[41;3;32m[\u@\h:\w\a\$]"`
This is how your bash prompt will look like after typing the command:
If you notice the command properly, as mentioned above, \e helps us assign a color sequence.
In the command above, I’ve assigned a **background color first**, then the **text style**, and then the **font color** followed by “**m**“.
Here, “**m**” indicates the end of the color sequence.
So, all you have to do is, play around with this part:
`41;3;32`
The rest of the command should remain the same, you just need to assign different numbers to change the background color, text style, and text color.
Do note that this is in no particular order; you can assign the text style first, background color next, and the text color at the end as “**3;41;32**“, where the command becomes:
`PS1="\e[3;41;32m[\u@\h:\w\a\$]"`

As you can notice, the color customization is the same no matter the order. So, keep the codes for customization in mind and play around with it until you’re sure you want this as a permanent change.
The above command that I mentioned temporarily customizes the bash prompt for the current session. If you close the session, you will lose the customization.
So, to make this a permanent change, you need to add it to **.bashrc** file (this is a configuration file that loads up every time you load up a session).
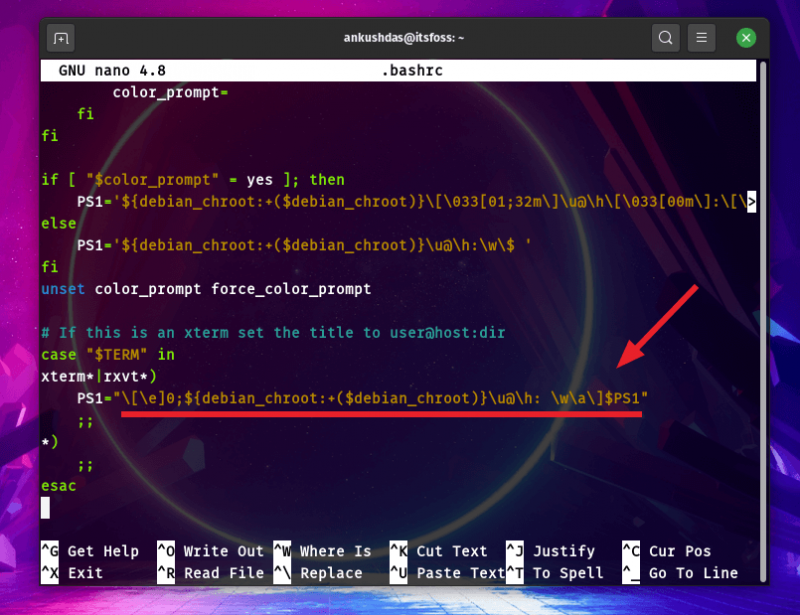
You can access the file by simply typing:
`nano ~/.bashrc`
Unless you’re sure what you’re doing, do not change anything. And, just for the sake of restoring the settings back, you should keep a backup of the PS1 environment variable (copy-paste what’s in it by default) to a text file.
So, even if you need the default font and color, you can again edit the **.bashrc file** and paste the PS1 environment variable.
### Bonus Tip: Change the terminal color pallet based on your wallpaper
If you want to change the terminal's background and text color but are unsure which colors to pick, you can use a Python-based tool, Pywal. It [automatically changes the color of the terminal based on your wallpaper](https://itsfoss.com/pywal/) or the image you provide to it.
If you are interested in using this tool, I have written about it in detail.
## Wrapping Up
Of course, it is easy to customize using the GUI while getting better control of what you can change. But, knowing the commands is also necessary in case you start [using WSL](https://itsfoss.com/install-bash-on-windows/) or access a remote server using SSH; you can customize your experience no matter what.
If you are not much into customizing, you can try [using other Linux terminals](https://itsfoss.com/linux-terminal-emulators/) like Tilix or Terminator.
[Top 14 Terminal Emulators for Linux (With Extra Features or Amazing Looks)Want a terminal that looks cool or has extra features? Here are the best Linux terminal emulators you can get.](https://itsfoss.com/linux-terminal-emulators/)

How do you customize the Linux terminal? Share your secret ricing recipe with us in the comments. |
13,182 | 如何在 Ubuntu Linux 上安装最新的 Erlang | https://itsfoss.com/install-erlang-ubuntu/ | 2021-03-07T00:18:00 | [
"Erlang"
] | https://linux.cn/article-13182-1.html | 
[Erlang](https://www.erlang.org/) 是一种用于构建大规模可扩展实时系统的函数式编程语言。Erlang 最初是由 [爱立信](https://www.ericsson.com/en) 创建的专有软件,后来被开源。
Erlang 在 [Ubuntu 的 Universe 仓库](https://itsfoss.com/ubuntu-repositories/) 中可用。启用该仓库后,你可以使用下面的命令轻松安装它:
```
sudo apt install erlang
```

但是,*Ubuntu 仓库提供的 Erlang 版本可能不是最新的*。
如果你想要 Ubuntu 上最新的 Erlang 版本,你可以添加 [Erlang Solutions 提供的](https://www.erlang-solutions.com/downloads/)仓库。它们为各种 Linux 发行版、Windows 和 macOS 提供了预编译的二进制文件。
如果你之前安装了一个名为 `erlang` 的包,那么它将会被升级到由添加的仓库提供的较新版本。
### 在 Ubuntu 上安装最新版本的 Erlang
你需要[在 Linux 终端下载密钥文件](https://itsfoss.com/download-files-from-linux-terminal/)。你可以使用 `wget` 工具,所以请确保你已经安装了它:
```
sudo apt install wget
```
接下来,使用 `wget` 下载 Erlang Solution 仓库的 GPG 密钥,并将其添加到你的 apt 打包系统中。添加了密钥后,你的系统就会信任来自该仓库的包。
```
wget -O- https://packages.erlang-solutions.com/ubuntu/erlang_solutions.asc | sudo apt-key add -
```
现在,你应该在你的 APT `sources.list.d` 目录下为 Erlang 添加一个文件,这个文件将包含有关仓库的信息,APT 包管理器将使用它来获取包和未来的更新。
对于 Ubuntu 20.04(和 Ubuntu 20.10),使用以下命令:
```
echo "deb https://packages.erlang-solutions.com/ubuntu focal contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list
```
我知道上面的命令提到了 Ubuntu 20.04 focal,但它也适用于 Ubuntu 20.10 groovy。
对于 **Ubuntu 18.04**,使用以下命令:
```
echo "deb https://packages.erlang-solutions.com/ubuntu bionic contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list
```
你必须更新本地的包缓存,以通知它关于新添加的仓库的包。
```
sudo apt update
```
你会注意到,它建议你进行一些升级。如果你列出了可用的升级,你会在那里找到 erlang 包。要更新现有的 erlang 版本或重新安装,使用这个命令:
```
sudo apt install erlang
```
安装好后,你可以测试一下。

要退出 Erlang shell,使用 `Ctrl+g`,然后输入 `q`,由于我从来没有用过 Erlang,所以我只好尝试了一些按键,然后发现了操作方法。
#### 删除 erlang
要删除该程序,请使用以下命令:
```
sudo apt remove erlang
```
还会有一些依赖关系。你可以用下面的命令删除它们:
```
sudo apt autoremove
```
如果你愿意,你也可以删除添加的仓库文件。
```
sudo rm /etc/apt/sources.list.d/erlang-solution.list
```
就是这样。享受在 Ubuntu Linux 上使用 Erlang 学习和编码的乐趣。
---
via: <https://itsfoss.com/install-erlang-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Erlang](https://www.erlang.org/) is a functional programming language for building massive scalable real-time systems. Originally created by [Ericsson](https://www.ericsson.com/en) as a proprietary software, Erlang was later open sourced.
Erlang is available in the [Universe repository of Ubuntu](https://itsfoss.com/ubuntu-repositories/). With that repository enabled, you can easily install it using the following command:
`sudo apt install erlang`
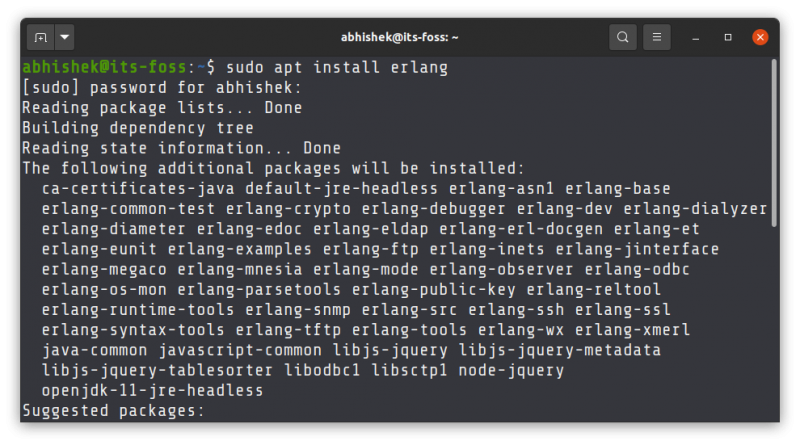
However, the *Erlang version offered by Ubuntu repositories may not be the latest*.
If you want the **latest Erlang version on Ubuntu**, you have two ways:
- Use a PPA maintained by RabbitMQ team
- Add the repository
[offered by Erlang Solutions](https://www.erlang-solutions.com/downloads/)
If you had installed a package named `erlang`
previously, it will be upgraded to the newer version offered by the added repository.
## Method 1: Install the latest Erlang using PPA
The good thing is that the [RabbitMQ team maintains a PPA](https://launchpad.net/~rabbitmq/+archive/ubuntu/rabbitmq-erlang) that lets you easily install the latest version of Erlang on Ubuntu-based distributions.
This is valid for Ubuntu 22.04 and 20.04.
Open a terminal and use the following commands one by one:
```
sudo add-apt-repository ppa:rabbitmq/rabbitmq-erlang
sudo apt update
sudo apt install erlang
```
If you already have Erlang installed from Ubuntu's repositories, it will be upgraded to the version provided by the PPA.
### Remove Erlang and the PPA
To uninstall the Erlang version removed from the PPA and move it back to the version provided by the Ubuntu repositories, use PPA Purge.
```
sudo apt install ppa-purge
sudo ppa-purge ppa:rabbitmq/rabbitmq-erlang
```
You can remove Erlang completely instead of downgrading it with:
`sudo apt remove erlang`
[What is PPA Purge? How to Use it in Ubuntu?PPA Purge not only disables a PPA from the system but also reverts the packages it installed to their official version. Learn more about it.](https://itsfoss.com/ppa-purge/)

## Method 2: Installing the latest version of Erlang on Ubuntu 20.04 and 18.04
Erlang developers provide prebuilt binaries for various Linux distributions, Windows and macOS.
You’ll need to [download the key file in Linux terminal](https://itsfoss.com/download-files-from-linux-terminal/). You can use wget tool for that so make sure that you have it installed:
`sudo apt install wget`
Next, use wget to download the GPG key of the Erlang Solution repository and add it your apt packaging system. With the key added, your system will trust the packages coming from the repository.
`wget -O- https://packages.erlang-solutions.com/ubuntu/erlang_solutions.asc | sudo apt-key add -`
Now, you should add a file for Erlang in your APT sources.list.d directory. This file will contain the information about the repository and the APT package manager will use it for getting the packages and any future updates to it.
**For Ubuntu 20.04 (and Ubuntu 20.10) **use the following:
`echo "deb https://packages.erlang-solutions.com/ubuntu focal contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list`
I know that the above command mentions focal (for Ubuntu 20.04) but it also works for Ubuntu 20.10 groovy.
For **Ubuntu 18.04**, use the following:
`echo "deb https://packages.erlang-solutions.com/ubuntu bionic contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list`
You must update the local package cache to inform it about the packages from the newly added repository:
`sudo apt update`
You’ll notice that it suggests several upgrades. If you list the available upgrades, you’ll find erlang packages there. To update the existing erlang version or install it afresh, use this command:
`sudo apt install erlang`
Once installed, you can test it out.
To quit the Erlang shell, use Ctrl+g and then enter q. I had to do a hit and try to figure that out because I had never used Erlang before.
### Removing Erlang
To remove the program, use the following command:
`sudo apt remove erlang`
There will be a few dependencies left. You can remove them with the following command:
`sudo apt autoremove`
If you want, you may also remove the added repository file:
`sudo rm /etc/apt/sources.list.d/erlang-solution.list`
That’s about it. Enjoy learning and coding with Erlang on Ubuntu Linux. |
13,184 | 在 Linux 上运行你最喜欢的 Windows 应用程序 | https://opensource.com/article/21/2/linux-wine | 2021-03-07T23:12:29 | [
"WINE"
] | https://linux.cn/article-13184-1.html |
>
> WINE 是一个开源项目,它可以协助很多 Windows 应用程序在 Linux 上运行,就好像它们是原生程序一样。
>
>
>

在 2021 年,有很多比以往更喜欢 Linux 的原因。在这系列中,我将分享使用 Linux 的 21 种原因。这里是如何使用 WINE 来实现从 Windows 到 Linux 的无缝切换。
你有只能在 Windows 上运行的应用程序吗?那一个应用程序阻碍你切换到 Linux 的唯一因素吗?如果是这样的话,你将会很高兴知道 WINE,这是一个开源项目,它几乎重新发明了关键的 Windows 库,使为 Windows 编译的应用程序可以在 Linux 上运行。
WINE 代表着“Wine Is Not an Emulator” ,它指的是驱动这项技术的代码。开源开发者从 1993 年就开始致力将应用程序的任何传入 Windows API 调用翻译为 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 调用。
这是一个令人十分惊讶的编程壮举,尤其是考虑到这个项目是独立运行的,没有来自微软的帮助(至少可以这样说),但是也有局限性。一个应用程序偏离 Windows API 的 “内核” 越远,WINE 就越不能预期应用程序的请求。有一些供应商可以弥补这一点,尤其是 [Codeweavers](https://www.codeweavers.com/crossover) 和 [Valve Software](https://github.com/ValveSoftware/Proton)。在需要翻译应用程序的制作者和翻译的人们及公司之间没有协调配合,因此,比如说一个更新的软件作品和从 [WINE 总部](http://winehq.org) 获得完美适配状态之间可能会有一些时间上的滞后。
然而,如果你想在 Linux 上运行一个著名的 Windows 应用程序,WINE 可能已经为它准备好了可能性。
### 安装 WINE
你可以从你的 Linux 发行版的软件包存储库中安装 WINE 。在 Fedora、CentOS Stream 或 RHEL 系统上:
```
$ sudo dnf install wine
```
在 Debian、Linux Mint、Elementary 及相似的系统上:
```
$ sudo apt install wine
```
WINE 不是一个你自己启动的应用程序。当启动一个 Windows 应用程序时,它是一个被调用的后端。你与 WINE 的第一次交互很可能就发生在你启动一个 Windows 应用程序的安装程序时。
### 安装一个应用程序
[TinyCAD](https://sourceforge.net/projects/tinycad/) 是一个极好的用于设计电路的开源应用程序,但是它仅在 Windows 上可用。虽然它是一个小型的应用程序,但是它确实包含一些 .NET 组件,因此应该能对 WINE 进行一些压力测试。
首先,下载 TinyCAD 的安装程序。Windows 安装程序通常都是这样,它是一个 `.exe` 文件。在下载后,双击文件来启动它。

*TinyCAD 的 WINE 安装向导*
像你在 Windows 上一样逐步完成安装程序。通常最好接受默认选项,尤其是与 WINE 有关的地方。WINE 环境基本上是独立的,隐藏在你的硬盘驱动器上的一个 `drive_c` 目录中,作为 Windows 应用程序使用的一个文件系统的仿真根目录。

*WINE TinyCAD 目标驱动器*
安装完成后,应用程序通常会为你提供启动机会。如果你正准备测试一下它的话,启动应用程序。
### 启动 Windows 应用程序
除了在安装后的第一次启动外,在正常情况下,你启动一个 WINE 应用程序的方式与你启动一个本地 Linux 应用程序相同。不管你使用应用程序菜单、活动屏幕或者只是在运行器中输入应用程序的名称,在 WINE 中运行的桌面 Windows 应用程序都会被视为在 Linux 上的本地应用程序。

*通过 WINE 的支持来运行 TinyCAD*
### 当 WINE 失败时
我在 WINE 中的大多数应用程序,包括 TinyCAD ,都能如期运行。不过,也会有例外。在这些情况下,你可以等几个月来查看 WINE 开发者 (或者,如果是一款游戏,就等候 Valve Software)是否进行追加修补,或者你可以联系一个像 Codeweavers 这样的供应商来查看他们是否出售对你所需要的应用程序的服务支持。
### WINE 是种欺骗,但它用于正道
一些 Linux 用户觉得:如果你使用 WINE 的话,你就是在“欺骗” Linux。它可能会让人有这种感觉,但是 WINE 是一个开源项目,它使用户能够切换到 Linux ,并且仍然能够运行工作或爱好所需的应用程序。如果 WINE 解决了你的问题,让你使用 Linux,那就使用它,并拥抱 Linux 的灵活性。
---
via: <https://opensource.com/article/21/2/linux-wine>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. Here's how running Windows apps on Linux can be made seamless with WINE.
Do you have an application that only runs on Windows? Is that one application the one and only thing holding you back from switching to Linux? If so, you'll be happy to know about WINE, an open source project that has all but reinvented key Windows libraries so that applications compiled for Windows can run on Linux.
WINE stands for "Wine Is Not an Emulator," which references the code driving this technology. Open source developers have worked since 1993 to translate any incoming Windows API calls an application makes to [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) calls.
This is an astonishing feat of programming, especially given that the project operated independently, with no help from Microsoft (to say the least), but there are limits. The farther an application strays from the "core" of the Windows API, the less likely it is that WINE could have anticipated its requests. There are vendors that may make up for this, notably [Codeweavers](https://www.codeweavers.com/crossover) and [Valve Software](https://github.com/ValveSoftware/Proton). There's no coordination between the producers of the applications requiring translation and the people and companies doing the translation, so there can be some lag time between, for instance, an updated software title and when it earns a "gold" status from [WINE headquarters](http://winehq.org).
However, if you're looking to run a well-known Windows application on Linux, the chances are good that WINE is ready for it.
## Installing WINE
You can install WINE from your Linux distribution's software repository. On Fedora, CentOS Stream, or RHEL:
`$ sudo dnf install wine`
On Debian, Linux Mint, Elementary, and similar:
`$ sudo apt install wine`
WINE isn't an application that you launch on its own. It's a backend that gets invoked when a Windows application is launched. Your first interaction with WINE will most likely occur when you launch the installer of a Windows application.
## Installing an application
[TinyCAD](https://sourceforge.net/projects/tinycad/) is a nice open source application for designing circuits, but it's only available for Windows. While it is a small application, it does incorporate some .NET components, so that ought to stress test WINE a little.
First, download the installer for TinyCAD. As is often the case for Windows installers, it's a `.exe`
file. Once downloaded, double-click the file to launch it.
WINE installation wizard for TinyCAD
Step through the installer as you would on Windows. It's usually best to accept the defaults, especially where WINE is concerned. The WINE environment is largely self-contained, hidden away on your hard drive in a **drive_c** directory that gets used by a Windows application as the fake root directory of the file system.
WINE TinyCAD destination drive
Once it's installed, the application usually offers to launch for you. If you're ready to test it out, launch the application.
## Launching a Windows application
Aside from the first launch immediately after installation, you normally launch a WINE application the same way as you launch a native Linux application. Whether you use an applications menu or an Activities screen or just type the application's name into a runner, desktop Windows applications running in WINE are treated essentially as native applications on Linux.
TinyCAD running with WINE support
## When WINE fails
Most applications I run in WINE, TinyCAD included, run as expected. There are exceptions, however. In those cases, you can either wait a few months to see whether WINE developers (or, if it's a game, Valve Software) manage to catch up, or you can contact a vendor like Codeweavers to find out whether they sell support for the application you require.
## WINE is cheating, but in a good way
Some Linux users feel that if you use WINE, you're "cheating" on Linux. It might feel that way, but WINE is an open source project that's enabling users to switch to Linux and still run required applications for their work or hobbies. If WINE solves your problem and lets you use Linux, then use it, and embrace the flexibility of Linux.
## Comments are closed. |
13,186 | 值得尝试的 3 个 Linux 终端 | https://opensource.com/article/21/2/linux-terminals | 2021-03-09T05:41:03 | [
"终端"
] | /article-13186-1.html |
>
> Linux 让你能够选择你喜欢的终端界面,而不是它强加的界面。
>
>
>

在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。能够选择自己的终端是使用 Linux 的一个重要原因。
很多人认为一旦你用过一个终端界面,你就已经用过所有的终端了。但喜欢终端的用户都知道,它们之间有一些细微但重要的区别。本文将介绍我最喜欢的三种。
不过在深入研究它们之前,先要了解 shell 和<ruby> 终端 <rt> terminal </rt></ruby>之间的区别。终端(技术上说是<ruby> 终端模拟器 <rt> terminal emulator </rt></ruby>,因为终端曾经是物理硬件设备)是一个在桌面上的窗口中运行的应用。shell 是在终端窗口中对你可见的引擎。流行的 shell 有 [Bash](https://opensource.com/resources/what-bash)、[tcsh](https://opensource.com/article/20/8/tcsh) 和 [zsh](https://opensource.com/article/19/9/getting-started-zsh),它们都在终端中运行。
在现代 Linux 上几乎不用说,至少本文中所有的终端都有标签界面。
### Xfce 终端

[轻量级 Xfce 桌面](https://opensource.com/article/19/12/xfce-linux-desktop) 提供了一个轻量级的终端,很好地平衡了功能和简单性。它提供了对 shell 的访问(如预期的那样),并且它可以轻松访问几个重要的配置选项。你可以设置当你双击文本时哪些字符会断字、选择你的默认字符编码,并禁用终端窗口的 Alt 快捷方式,这样你最喜欢的 Bash 快捷方式就会传递到 shell。你还可以设置字体和新的颜色主题,或者从常用预设列表中加载颜色主题。它甚至在顶部有一个可选的工具栏,方便你访问你最喜欢的功能。
对我来说,Xfce 的亮点功能是可以非常容易地为你打开的每一个标签页改变背景颜色。当在服务器上运行远程 shell 时,这是非常有价值的。它让我知道自己在哪个标签页中,从而避免了我犯愚蠢的错误。
### rxvt-unicode

[rxvt 终端](https://opensource.com/article/19/10/why-use-rxvt-terminal) 是我最喜欢的轻量级控制台。它有许多老式 [xterm](https://opensource.com/article/20/7/xterm) 终端仿真器的功能,但它的扩展性更强。它的配置是在 `~/.Xdefaults` 中定义的,所以没有偏好面板或设置菜单,但这使得它很容易管理和备份你的设置。通过使用一些 Perl 库,rxvt 可以有标签,并且通过 xrdb,它可以访问字体和任何你能想到的颜色主题。你可以设置像 `URxvt.urlLancher: firefox` 这样的属性来设置当你打开 URL 时启动的网页浏览器,改变滚动条的外观,修改键盘快捷键等等。
最初的 rxvt 不支持 Unicode(因为当时 Unicode 还不存在),但 `rxvt-unicode`(有时也叫 `urxvt`)包提供了一个完全支持 Unicode 的补丁版本。
我在每台电脑上都有 rxvt,因为对我来说它是最好的通用终端。它不一定是所有用户的最佳终端(例如,它没有拖放界面)。不过,对于寻找快速和灵活终端的中高级用户来说,rxvt 是一个简单的选择。
### Konsole

Konsole 是 KDE Plasma 桌面的终端,是我转到 Linux 后使用的第一个终端,所以它是我对所有其他终端的标准。它确实设定了一个很高的标准。Konsole 有所有通常的不错的功能(还有些其他的),比如简单的颜色主题加上配置文件支持、字体选择、编码、可分离标签、可重命名标签等等。但这在现代桌面上是可以预期的(至少,如果你的桌面运行的是 Plasma 的话)。
Konsole 比其他终端领先许多年(或者几个月)。它可以垂直或水平地分割窗口。你可以把输入复制到所有的标签页上(就像 [tmux](https://opensource.com/article/20/1/tmux-console) 一样)。你可以将其设置为监视自身是否静音或活动并配置通知。如果你在 Android 手机上使用 KDE Connect,这意味着当一个任务完成时,你可以在手机上收到通知。你可以将 Konsole 的输出保存到文本或 HTML 文件中,为打开的标签页添加书签,克隆标签页,调整搜索设置等等。
Konsole 是一个真正的高级用户终端,但它也非常适合新用户。你可以将文件拖放到 Konsole 中,将目录改为硬盘上的特定位置,也可以将路径粘贴进去,甚至可以将文件复制到 Konsole 的当前工作目录中。这让使用终端变得很简单,这也是所有用户都能理解的。
### 尝试一个终端
你的审美观念是黑暗的办公室和黑色背景下绿色文字的温暖光芒吗?还是喜欢阳光明媚的休息室和屏幕上舒缓的墨黑色字体?无论你对完美电脑设置的愿景是什么,如果你喜欢通过输入命令高效地与操作系统交流,那么 Linux 已经为你提供了一个接口。
---
via: <https://opensource.com/article/21/2/linux-terminals>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,187 | Guake 终端:一个灵感来自于 FPS 游戏的 Linux 终端 | https://itsfoss.com/guake-terminal/ | 2021-03-09T06:17:00 | [
"终端",
"Guake"
] | https://linux.cn/article-13187-1.html |
>
> 使用 Guake 终端这个可自定义且强大的适合各种用户的工具快速访问你的终端。
>
>
>
### Guake 终端:GNOME 桌面中自上而下终端

[Guake](http://guake-project.org/) 是一款为 GNOME 桌面量身定做的终端模拟器,采用下拉式设计。
它最初的灵感来自于一款 FPS 游戏([Quake](https://quake.bethesda.net/en))中的终端。尽管它最初是作为一个快速和易于使用的终端而设计的,但它的功能远不止于此。
Guake 终端提供了大量的功能,以及可定制的选项。在这里,我将重点介绍终端的主要功能,以及如何将它安装到你的任何 Linux 发行版上。
### Guake 终端的特点

* 按下键盘快捷键(`F12`)以覆盖方式在任何地方启动终端
* Guake 终端在后台运行,以便持久访问
* 能够横向和纵向分割标签页
* 从可用的 shell 中(如果有的话)更改默认的 shell
* 重新对齐
* 从多种调色板中选择改变终端的外观
* 能够使用 GUI 方式将终端内容保存到文件中
* 需要时切换全屏
* 你可以轻松地保存标签,或在需要时打开新的标签
* 恢复标签的能力
* 可选择配置和学习新的键盘快捷键,以快速访问终端和执行任务
* 改变特定选项卡的颜色
* 轻松重命名标签,快速访问你需要的内容
* 快速打开功能,只需点击一下,就可直接在终端中用你最喜欢的编辑器打开文件
* 能够在启动或显示 Guake 终端时添加自己的命令或脚本。
* 支持多显示器

只是出于乐趣,你可以做很多事情。但是,我也相信,高级用户可以利用这些功能使他们的终端体验更轻松,更高效。
就我用它来测试一些东西和写这篇文章的时候,说实话,我觉得我是在召唤终端。所以,我绝对觉得它很酷!
### 在 Linux 上安装 Guake

在 Ubuntu、Fedora 和 Arch 的默认仓库中都有 Guake 终端。
你可以按照它的官方说明来了解你可以使用的命令,如果你使用的是基于 Ubuntu 的发行版,只需输入:
```
sudo apt install guake
```
请注意,使用这种方法可能无法获得最新版本。所以,如果你想获得最新的版本,你可以选择使用 [Linux Uprising](https://www.linuxuprising.com/) 的 PPA 来获得最新版本:
```
sudo add-apt-repository ppa:linuxuprising/guake
sudo apt update
sudo apt install guake
```
无论是哪种情况,你也可以使用 [Pypi](https://pypi.org/) 或者参考[官方文档](https://guake.readthedocs.io/en/latest/user/installing.html)或从 [GitHub 页面](https://github.com/Guake/guake)获取源码。
* [Guake Terminal](https://github.com/Guake/guake)
你觉得 Guake 终端怎么样?你认为它是一个有用的终端仿真器吗?你知道有什么类似的软件吗?
欢迎在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/guake-terminal/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Quickly access your terminal that is customizable and powerful for a variety of users with Guake Terminal emulator.*
## Guake Terminal: Top-Down Terminal for GNOME Desktop
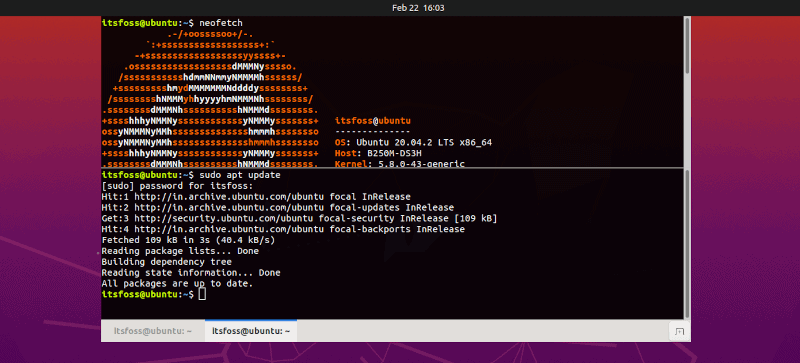
[Guake](http://guake-project.org/) is a terminal emulator that’s tailored for GNOME desktop with a top-down design.
It was originally inspired from the terminal seen in an FPS game ([Quake](https://quake.bethesda.net/en)). Even though it was initially built as a quick and accessible terminal, it is much more than that.
Guake terminal offers a ton of features, and customizable options. Here, I’ll highlight the key features of the terminal along with the process of getting it installed on any of your Linux distribution.
## Features of Guake Terminal
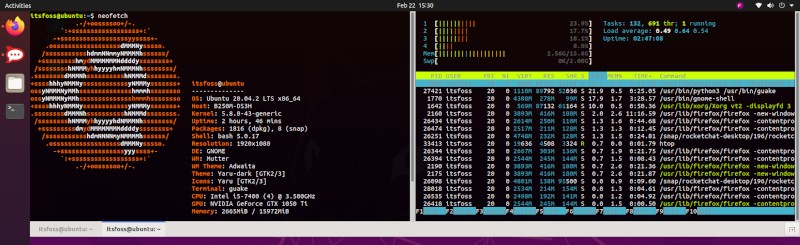
- Keyboard Shortcut (
**F12**) to launch the terminal anywhere as an overlay - Guake terminal runs in the background for persistent access
- Ability to split tabs horizontally and vertically
- Change the default shell from available options (if any)
- Re-alignment option
- Change appearance of the terminal from a wide selection of color palettes
- Ability to save the content of the terminal to a file using GUI option
- Toggle Full screen option when needed
- You can easily save the tabs or open new tabs when needed
- Ability to restore tabs
- Option to configure and learn new keyboard shortcuts to quickly access the terminal and perform tasks
- Change colors of specific tabs
- Easily rename the tabs to quickly access what you already need
- Quick open feature to open text files directly from your terminal on your favorite editor with a click
- Ability to add your own command or scripts when starting up or showing up the Guake terminal
- Multi-monitor support
Just to have fun, you can do a great deal of things. But, I also believe that power users can make use of the features to make their terminal experience easier and more productive.
For the time I used it to test out a few things and write this article, I felt like I was summoning the terminal to be honest. So, I definitely find it cool!
## Installing Guake Terminal on Linux
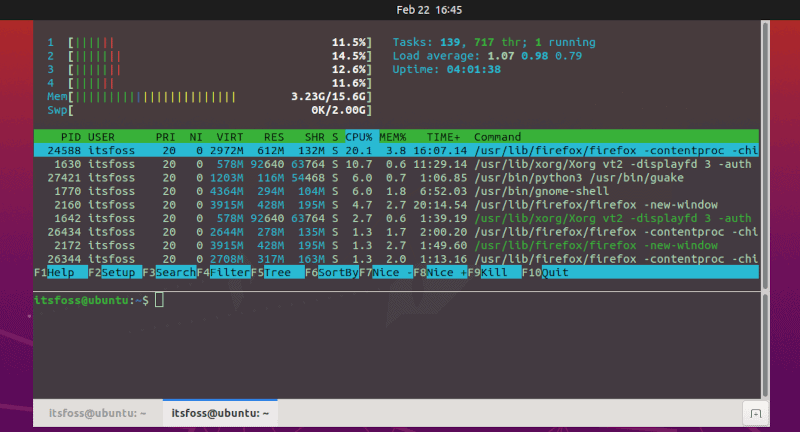
**Guake Terminal is available through the default repositories on Ubuntu, Fedora, and Arch**.
You can follow its official instructions to know the commands you can use or if you’re using an Ubuntu-based distro, simply type in:
`sudo apt install guake`
Do note that you may not get the latest version using this method. So, if you want to have the latest version, you can opt to use the PPA by [Linux Uprising](https://www.linuxuprising.com/) to get the latest version:
```
sudo add-apt-repository ppa:linuxuprising/guake
sudo apt update
sudo apt install guake
```
In either case, you can also get it using [Pypi](https://pypi.org/) or from source by referring to the [official documentation](https://guake.readthedocs.io/en/latest/user/installing.html) or the [GitHub page](https://github.com/Guake/guake).
What do you think about Guake Terminal? Do you think of it as a useful terminal emulator? Anything similar that you know of?
Feel free to let me know what you think in the comments down below. |
13,189 | SysMonTask:一个类似于 Windows 任务管理器的 Linux 系统监控器 | https://itsfoss.com/sysmontask/ | 2021-03-09T23:23:10 | [
"系统监控",
"任务管理器"
] | https://linux.cn/article-13189-1.html | 
得益于桌面环境,几乎所有的 [Linux 发行版都带有任务管理器应用程序](https://itsfoss.com/task-manager-linux/)。除此之外,还有 [一些其他的 Linux 的系统监控应用程序](https://itsfoss.com/linux-system-monitoring-tools/),它们具有更多的功能。
但最近我遇到了一个为 Linux 创建的任务管理器,它看起来像……嗯……Windows 的任务管理器。
你自己看看就知道了。

就我个人而言,我不确定用户界面的相似性是否有意义,但开发者和其他一些 Linux 用户可能不同意我的观点。
### SysMonTask: 一个具有 Windows 任务管理器外观的系统监控器

开源软件 [SysMonTask](https://github.com/KrispyCamel4u/SysMonTask) 将自己描述为“具有 Windows 任务管理器的紧凑性和实用性的 Linux 系统监控器,以实现更高的控制和监控”。
SysMonTask 以 Python 编写,拥有以下功能:
* 系统监控图。
* 显示 CPU、内存、磁盘、网络适配器、单个 Nvidia GPU 的统计数据。
* 在最近的版本中增加了对挂载磁盘列表的支持。
* 用户进程选项卡可以进行进程过滤,显示递归-CPU、递归-内存和列头的汇总值。
* 当然,你可以在进程选项卡中杀死一个进程。
* 还支持系统主题(深色和浅色)。
### 体验 SysMonTask
SysMonTask 需要提升权限。当你启动它时,你会被要求提供你的管理员密码。我不喜欢一个任务管理器一直用 `sudo` 运行,但这只是我的喜好。
我玩了一下,探索它的功能。磁盘的使用量基本稳定不变,所以我把一个 10GB 的文件从外部 SSD 复制到笔记本的磁盘上几次。你可以看到文件传输时对应的峰值。

进程标签也很方便。它在列的顶部显示了累积的资源利用率。
杀死按钮被添加在底部,所以你要做的就是选择一个进程,然后点击“Killer” 按钮。它在 [杀死进程](https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/) 之前会询问你的确认。

### 在 Linux 发行版上安装 SysMonTask
对于一个简单的应用程序,它需要下载 50 MB 的存档文件,并占用了大约 200 MB 的磁盘。我想这是因为 Python 的依赖性。
还有就是它读取的是 env。
在写这篇文章的时候,SysMonTask 可以通过 [PPA](https://itsfoss.com/ppa-guide/) 在基于 Ubuntu 的发行版上使用。
在基于 Ubuntu 的发行版上,打开一个终端,使用以下命令添加 PPA 仓库:
```
sudo add-apt-repository ppa:camel-neeraj/sysmontask
```
当然,你会被要求输入密码。在新版本中,仓库列表会自动更新。所以,你可以直接安装应用程序:
```
sudo apt install sysmontask
```
基于 Debian 的发行版也可以尝试从 deb 文件中安装它。它可以在发布页面找到。
对于其他发行版,没有现成的软件包。令我惊讶的是,它基本上是一个 Python 应用程序,所以可以为其他发行版添加一个 PIP 安装程序。也许开发者会在未来的版本中添加它。
由于它是开源软件,你可以随时得到源代码。
* [SysMonTask Deb 文件和源代码](https://github.com/KrispyCamel4u/SysMonTask/releases)
安装完毕后,在菜单中寻找 SysMonTask,并从那里启动它。
#### 删除 SysMonTask
如果你想删除它,使用以下命令:
```
sudo apt remove sysmontask
```
最好也 [删除 PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/):
```
sudo add-apt-repository -r ppa:camel-neeraj/sysmontask
```
你也可以在这里 [使用 PPA 清除](https://itsfoss.com/ppa-purge/) 工具,这是一个处理 PPA 应用程序删除的方便工具。
### 你会尝试吗?
对我来说,功能比外观更重要。SysMonTask 确实有额外的功能,监测磁盘性能和检查 GPU 统计数据,这是其他系统监视器通常不包括的东西。
如果你尝试并喜欢它,也许你会喜欢添加 `Ctrl+Alt+Del` 快捷键来启动 SysMonTask,以获得完整的感觉 :smiley:
---
via: <https://itsfoss.com/sysmontask/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Thanks to the desktop environments, almost all[ Linux distributions come with a task manager application](https://itsfoss.com/task-manager-linux/). In addition to that, there are [several other system monitoring applications for Linux](https://itsfoss.com/linux-system-monitoring-tools/) that have additional features.
But recently I came across a task manager created for Linux that looks like … wait for it … the task manager of Windows.
You take a look at it and decide for yourself.
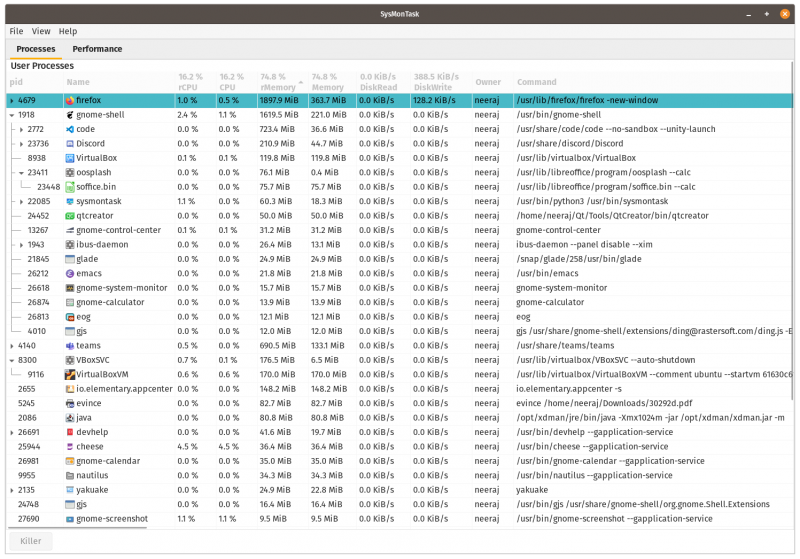
Personally, I am not sure if the likeness in the user interface is such a big deal but the developer and probably some other Linux users might disagree with me.
## SysMonTask: A system monitor with the looks of Windows task manager
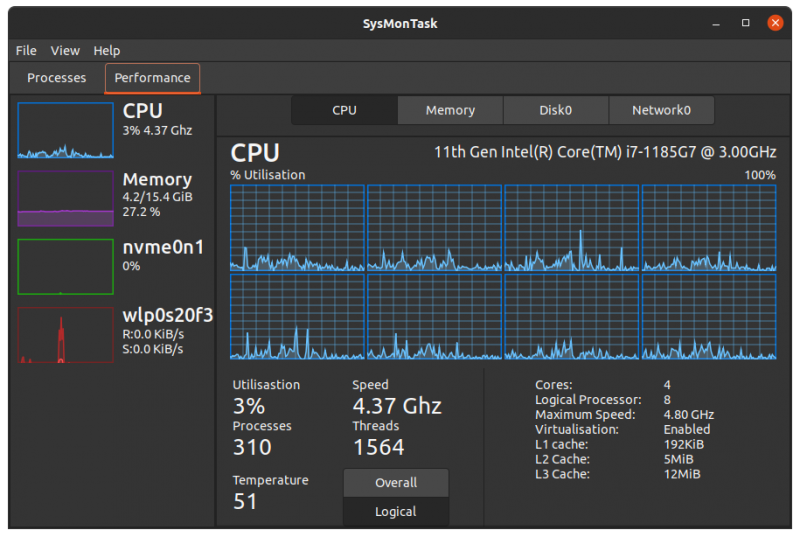
The open source software, [SysMonTask](https://github.com/KrispyCamel4u/SysMonTask), describes itself as a “Linux system monitor with the compactness and usefulness of windows task manager to allow higher control and monitoring”.
Coded in Python, SysMonTask boasts of the following features:
- System monitoring graphs.
- Shows stats for CPU, Memory, Disks, Network adapters, single Nvidia GPU.
- Support for listing mounted disks was added in recent version.
- User Processess tab can do process filtering, show recursive-CPU, recursive-Memery and aggregate values on coloumn headers.
- You can, of course, kill a process from the processes tab.
- Also supports system themes (dark and light).
## Experience with SysMonTask
SysMonTask needs elevated privileges. You’ll be asked for your admin password when you launch it. I don’t like a task manager running with sudo all the time but that’s just my preference.
I played with a little to explore its features. The disk usage was pretty constant so I copied a 10 GB file from external SSD to my laptop’s disk a couple of times. You can see the spikes corresponding to the file transfer.
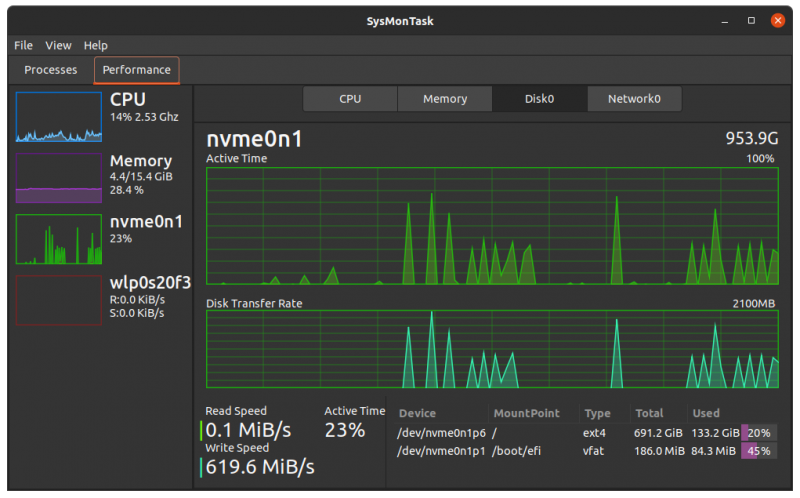
The process tab is also handy. It shows the accumulated resource utilization on the top of the columns.
The kill button is added at the bottom so all you have to do is to select a process and hit the ‘Killer’ button. It asks for your conformation before [killing the process](https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/).
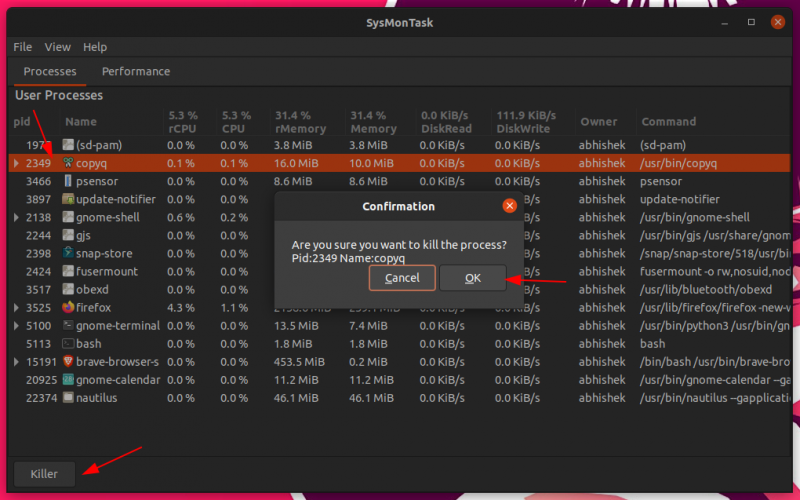
## Installing SysMonTask on Linux distributions
For a simple application, it downloads 50 MB of archive files and takes around 200 MB on the disk. I think it is because of the Python dependencies.
At the moment of writing this article, SysMonTask is available for Ubuntu-based distributions via [PPA](https://itsfoss.com/ppa-guide/).
On an Ubuntu-based distribution, open a terminal and use the following command to add the PPA repository:
`sudo add-apt-repository ppa:camel-neeraj/sysmontask`
You’ll be asked to enter your password, of course. On newer versions, the repository list is automatically updated. So, you can install the application straightaway:
`sudo apt install sysmontask`
Debian-based distributions may also try to install it from the deb file. It can be found at the release page.
There is no ready-to-use package for other distributions. Whayt surprises me is that it is basically a Python application so a PIP installer could have been added for other distributions. Perhaps the developers will add it in the future version.
Since it is open source software, you can always get the source code.
Once installed, look for SysMonTask in the menu and start it from there.
### Remove SysMonTask
If you want to remove it, use the following command:
`sudo apt remove sysmontask`
It will be a good idea to [delete the PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/) as well:
`sudo add-apt-repository -r ppa:camel-neeraj/sysmontask`
You may also [use PPA Purge](https://itsfoss.com/ppa-purge/) tool here which is a handy utility for dealing with PPA application removal.
## Would you try it?
For me, the features are more important than the looks. SysMonTask does have the additional feature of monitoring disk performance and checking GPU stats which is something other system monitors usually do not include.
If you try and like it, perhaps you’ll like to add Ctrl+Alt+Del shortcut to launch SysMonTask to get the complete feel :) |
13,190 | 基于 Linux 的 Moodle 虚拟课堂教学 | https://opensource.com/article/20/10/moodle | 2021-03-10T09:42:13 | [
"Moodle"
] | /article-13190-1.html |
>
> 基于 Linux 的 Moodle 学习管理系统进行远程教学。
>
>
>

这次大流行对远程教育的需求比以往任何时候都更大。使得像 [Moodle](https://moodle.org/) 这样的<ruby> 学习管理系统 <rt> learning management system </rt></ruby>(LMS)比以往任何时候都重要,因为越来越多的学校教育是借助虚拟现实技术的提供。
Moodle 是用 PHP 编写的免费 LMS,并以开源 [GNU 公共许可证](https://docs.moodle.org/19/en/GNU_General_Public_License)(GPL)分发。它是由 [Martin Dougiamas](https://dougiamas.com/about/) 开发的,自 2002 年发布以来一直在不断发展。Moodle 可用于混合学习、远程学习、<ruby> 翻转课堂 <rt> flipped classroom </rt></ruby>和其他形式的在线学习。目前,全球有超过 [1.9 亿用户](https://docs.moodle.org/39/en/History) 和 145,000 个注册的 Moodle 网站。
我曾作为 Moodle 管理员、教师和学生等角色使用过 Moodle,在本文中,我将向你展示如何设置并开始使用它。
### 在 Linux 系统上安装 Moodle
Moodle 对 [系统要求](https://docs.moodle.org/39/en/Installation_quick_guide#Basic_Requirements) 适中,并且有大量文档可为你提供帮助。我最喜欢的安装方法是从 [Turnkey Linux](https://www.turnkeylinux.org/) 下载并制作 ISO,然后在 VirtualBox 中安装 Moodle 网站。
首先,下载 [Moodle ISO](https://www.turnkeylinux.org/download?file=turnkey-moodle-16.0-buster-amd64.iso) 保存到电脑中。
下一步,安装 VirtualBox 的 Linux 命令行如下:
```
$ sudo apt install virtualbox
```
或,
```
$ sudo dnf install virtualbox
```
当下载完成后,启动 VirtualBox 并在控制台中选择“<ruby> 新建 <rt> New </rt></ruby>”按钮。

选择使用的虚拟机的名称、操作系统(Linux)和 Linux 类型(例如 Debian 64 位)。

下一步,配置虚拟机内存大小,使用默认值 1024 MB。接下来选择 “<ruby> 动态分配 <rt> dynamically allocated </rt></ruby>”虚拟磁盘并在虚拟机中添加 `Moodle.iso` 镜像。

将你的网络设置从 NAT 更改为 “<ruby> 桥接模式 <rt> Bridged adapter </rt></ruby>”。然后启动虚拟机并安装 ISO 以创建 Moodle 虚拟机。在安装过程中,系统将提示为 root 帐户、MySQL 和Moodle 创建密码。Moodle 密码必须至少包含八个字符,至少一个大写字母和至少一个特殊字符。
重启虚拟机。安装完成后,请确保将 Moodle 应用配置内容记录在安全的地方。(安装后,可以根据需要删除 ISO 文件。)

重要提示,在互联网上的任何人还看不到你的 Moodle 实例。它仅存在于你的本地网络中:现在只有建筑物中与你连接到相同的路由器或 wifi 接入点的人可以访问你的站点。全世界的互联网无法连接到它,因为你位于防火墙(可能嵌入在路由器中,还可能嵌入在计算机中)的后面。有关网络配置的更多信息,请阅读 Seth Kenlon 关于 [打开端口和通过防火墙进行流量路由](https://opensource.com/article/20/9/firewall) 的文章。
### 开始使用 Moodle
现在你可以登录到 Moodle 机器并熟悉该软件了。使用默认的用户名 `admin` 和创建 Moodle VM 时设置的密码登录 Moodle。

首次登录后,你将看到初始的 Moodle 网站的主仪表盘。

默认的应用名称是 “Turnkey Moodle”,但是可以很容易地对其进行更改以适合你的学校、课堂或其他需要和选择。要使你的 Moodle 网站个性化,请在用户界面左侧的菜单中,选择“站点首页Site home”。然后,点击屏幕右侧的 “<ruby> 设置 <rt> Settings </rt></ruby>” 图标,然后选择 “<ruby> 编辑设置 <rt> Edit settings </rt></ruby>”。

你可以根据需要更改站点名称,并添加简短名称和站点描述。

确保滚动到底部并保存更改。现在,你的网站已定制好。

默认类别为其他,这不会帮助人们识别你网站的目的。要添加类别,请返回主仪表盘,然后从左侧菜单中选择 “<ruby> 站点管理 <rt> Site administration </rt></ruby>”。 在 “<ruby> 课程 <rt> Courses </rt></ruby>”下,选择 “<ruby> 添加类别 <rt> Add a category </rt></ruby>”并输入有关你的网站的详细信息。

要添加课程,请返回 “<ruby> 站点管理 <rt> Site administration </rt></ruby>”,然后单击 “<ruby> 添加新课程 <rt> Add a new course </rt></ruby>”。你将看到一系列选项,例如为课程命名、提供简短名称、设定类别以及设置课程的开始和结束日期。你还可以为课程形式设置选项,例如社交、每周式课程、主题,以及其外观、文件上传大小、完成情况跟踪等等。

### 添加和管理用户
现在,你已经设置了课程,你可以添加用户。有多种方法可以做到这一点。如果你是家庭教师,则手动输入是一个不错的开始。Moodle 支持基于电子邮件的注册、[LDAP](https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol)、[Shibboleth(口令或暗语)](https://www.shibboleth.net/) 和许多其他方式等。校区和其他较大的机构可以用逗号分隔的文件上传用户。也可以批量添加密码,并在首次登录时强制更改密码。有关更多信息,一定要查阅 Moodle [文档](https://docs.moodle.org/39/en/Main_page)。
Moodle 是一个非常细化的、面向许可的环境。使用 Moodle 的菜单将策略和角色分配给用户并执行这些分配很容易。
Moodle 中有许多角色,每个角色都有特定的特权和许可。默认角色有管理员、课程创建者、教师、非编辑教师、学生、来宾和经过身份验证的用户,但你可以添加其他角色。
### 为课程添加内容
一旦搭建了 Moodle 网站并设置了课程,就可以向课程中添加内容。Moodle 拥有创建出色内容所需要的所有工具,并且它建立在强调 [社会建构主义](https://docs.moodle.org/39/en/Pedagogy#How_Moodle_tries_to_support_a_Social_Constructionist_view) 观点的坚实教学法之上。
我创建了一个名为 “Code with [Mu](https://opensource.com/article/20/9/teach-python-mu)” 的示例课程。它在 “<ruby> 编程 <rt> Programming </rt></ruby>” 类别和 “Python” 子类别中。

我为课程选择了每周式课程,默认为四个星期。使用编辑工具,我隐藏了除课程第一周以外的所有内容。这样可以确保我的学生始终专注于材料。
作为教师或 Moodle 管理员,我可以通过单击 “<ruby> 添加活动或资源 <rt> Add an activity or resource </rt></ruby>” 来将活动添加到每周的教学中。

我会看到一个弹出窗口,其中包含可以分配给我的学生的各种活动。

Moodle 的工具和活动使我可以轻松地创建学习材料,并以一个简短的测验来结束一周的学习。

你可以使用 1600 多个插件来扩展 Moodle,包括新的活动、问题类型,与其他系统的集成等等。例如,[BigBlueButton](https://moodle.org/plugins/mod_bigbluebuttonbn) 插件支持幻灯片共享、白板、音频和视频聊天以及分组讨论。其他值得考虑的包括用于视频会议的 [Jitsi](https://moodle.org/plugins/mod_jitsi) 插件、[抄袭检查器](https://moodle.org/plugins/plagiarism_unicheck) 和用于颁发徽章的 [开放徽章工厂](https://moodle.org/plugins/local_obf)。
### 继续探索 Moodle
Moodle 是一个功能强大的 LMS,我希望此介绍能引起你的兴趣,以了解更多信息。有很多出色的 [指南](https://learn.moodle.org/) 可以帮助你提高技能,如果想要查看 Moodle 的内容,可以在其 [演示站点](https://school.moodledemo.net/) 上查看运行中的 Moodle;如果你想了解 Moodle 的底层结构或为开发做出 [贡献](https://git.in.moodle.com/moodle/moodle/-/blob/master/CONTRIBUTING.txt),也可以访问 [Moodle 的源代码](https://git.in.moodle.com/moodle/moodle)。如果你喜欢在旅途中工作,Moodle 也有一款出色的 [移动应用](https://download.moodle.org/mobile/),适用于 iOS 和 Android。在 [Twitter](https://twitter.com/moodle)、[Facebook](https://www.facebook.com/moodle) 和 [LinkedIn](https://www.linkedin.com/company/moodle/) 上关注 Moodle,以了解最新消息。
---
via: <https://opensource.com/article/20/10/moodle>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,192 | 4 个打造多媒体和共享服务器的开源工具 | https://opensource.com/article/21/3/linux-server | 2021-03-10T20:05:59 | [
"媒体",
"共享"
] | /article-13192-1.html |
>
> 通过 Linux,你可以将任何设备变成服务器,以共享数据、媒体文件,以及其他资源。
>
>
>

在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。这里有四个开源工具,可以将任何设备变成 Linux 服务器。
有时,我会发现有关服务器概念的某种神秘色彩。许多人,如果他们在脑海中有一个形象的话,他们认为服务器一定是又大又重的机架式机器,由一个谨慎的系统管理员和一群神奇的修理工精心维护。另一些人则把服务器设想成虚无缥缈的云朵,以某种方式为互联网提供动力。
虽然这种敬畏对 IT 工作的安全性是有好处的,但事实上,在开源计算中,没有人认为服务器是或应该是专家的专属领域。文件和资源共享是开源不可或缺的,而开源让它变得比以往任何时候都更容易,正如这四个开源服务器项目所展示的那样。
### Samba
[Samba 项目](http://samba.org) 是 Linux 和 Unix 的 Windows 互操作程序套件。尽管它是大多数用户从未与之交互的底层代码,但它的重要性却不容小觑。从历史上看,早在微软争相消灭 Linux 和开源的时候,它就是最大最重要的目标。时代变了,微软已经与 Samba 团队会面以提供支持(至少目前是这样),在这一切中,该项目继续确保 Linux 和 Windows 计算机可以轻松地在同一网络上共存。换句话说,无论你使用什么平台,Samba 都可以让你可以轻松地在本地网络上共享文件。
在 [KDE Plasma](https://opensource.com/article/19/12/linux-kde-plasma) 桌面上,你可以右键点击自己的任何目录,选择**属性**。在**属性**对话框中,点击**共享**选项卡,并启用**与 Samba 共享(Microsoft Windows)**。

就这样,你已经为本地网络上的用户打开了一个只读访问的目录。也就是说,当你在家的时候,你家同一个 WiFi 网络上的任何人都可以访问该文件夹,如果你在工作,工作场所网络上的任何人都可以访问该文件夹。当然,要访问它,其他用户需要知道在哪里可以找到它。通往计算机的路径可以用 [IP 地址](https://opensource.com/article/18/5/how-find-ip-address-linux) 表示,也可以根据你的网络配置,用主机名表示。
### Snapdrop
如果通过 IP 地址和主机名来打开网络是令人困惑的,或者如果你不喜欢打开一个文件夹进行共享而忘记它是开放的,那么你可能更喜欢 [Snapdrop](https://github.com/RobinLinus/snapdrop)。这是一个开源项目,你可以自己运行,也可以使用互联网上的演示实例通过 WebRTC 连接计算机。WebRTC 可以通过 Web 浏览器实现点对点的连接,也就是说同一网络上的两个用户可以通过 Snapdrop 找到对方,然后直接进行通信,而不需要通过外部服务器。

一旦两个或更多的客户端连接了同一个 Snapdrop 服务,用户就可以通过本地网络来回交换文件和聊天信息。传输的速度很快,而且你的数据也保持在本地。
### VLC
流媒体服务比以往任何时候都更常见,但我在音乐和电影方面有非常规的口味,所以典型的服务似乎很少有我想要的东西。幸运的是,通过连接到媒体驱动器,我可以很容易地将自己的内容从我的电脑上传送到我的房子各个角落。例如,当我想在电脑显示器以外的屏幕上观看一部电影时,我可以在我的网络上串流电影文件,并通过任何可以接收 HTTP 的应用来播放它,无论该应用是在我的电视、游戏机还是手机上。
[VLC](https://www.videolan.org/index.html) 可以轻松设置流媒体。事实上,它是**媒体**菜单中的一个选项,或者你可以按下键盘 `Ctrl+S`。将一个文件或一组文件添加到你的流媒体队列中,然后点击 **Stream** 按钮。

VLC 通过配置向导来帮助你决定流媒体数据时使用什么协议。我倾向于使用 HTTP,因为它通常在任何设备上可用。当 VLC 开始播放文件时,请进入播放文件计算机的 IP 或主机名以及给它分配的端口 (当使用 HTTP 时,默认是 8080), 然后坐下来享受。
### PulseAudio
我最喜欢的现代 Linux 功能之一是 [PulseAudio](https://www.freedesktop.org/wiki/Software/PulseAudio/)。Pulse 为 Linux 上的音频实现了惊人的灵活性,包括可自动发现的本地网络流媒体。这个功能对我来说的好处是,我可以在办公室的工作站上播放播客和技术会议视频,并通过手机串流音频。无论我走进厨房、休息室还是后院最远的地方,我都能获得完美的音频。此功能在 PulseAudio 之前很久就存在,但是 Pulse 使它像单击按钮一样容易。
需要进行一些设置。首先,你必须确保安装 PulseAudio 设置包(**paprefs**),以便在 PulseAudio 配置中启用网络音频。

在 **paprefs** 中,启用网络访问你的本地声音设备,可能不需要认证(假设你信任本地网络上的其他人),并启用你的计算机作为 **Multicast/RTP 发送者**。我通常只选择串流通过我的扬声器播放的任何音频,但你可以在 Pulse 输出选项卡中创建一个单独的音频设备,这样你就可以准确地选择串流的内容。你在这里有三个选项:
* 串流任何在扬声器上播放的音频
* 串流所有输出的声音
* 只将音频直接串流到多播设备(按需)。
一旦启用,你的声音就会串流到网络中,并可被其他本地 Linux 设备接收。这是简单和动态的音频共享。
### 分享的不仅仅是代码
Linux 是共享的。它在服务器领域很有名,因为它很擅长*服务*。无论是提供音频流、视频流、文件,还是出色的用户体验,每一台 Linux 电脑都是一台出色的 Linux 服务器。
---
via: <https://opensource.com/article/21/3/linux-server>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,194 | 利用 BATS 测试 Bash 脚本和库 | https://opensource.com/article/19/2/testing-bash-bats | 2021-03-11T21:47:14 | [
"Bash",
"测试"
] | https://linux.cn/article-13194-1.html |
>
> Bash 自动测试系统可以使 Bash 代码也通过 Java、Ruby 和 Python 开发人员所使用的同类测试过程。
>
>
>

用 Java、Ruby 和 Python 等语言编写应用程序的软件开发人员拥有复杂的库,可以帮助他们随着时间的推移保持软件的完整性。他们可以创建测试,以在结构化环境中通过执行一系列动作来运行应用程序,以确保其软件所有的方面均按预期工作。
当这些测试在持续集成(CI)系统中自动进行时,它们的功能就更加强大了,每次推送到源代码库都会触发测试,并且在测试失败时会立即通知开发人员。这种快速反馈提高了开发人员对其应用程序功能完整性的信心。
<ruby> Bash 自动测试系统 <rt> Bash Automated Testing System </rt></ruby>([BATS](https://github.com/sstephenson/bats))使编写 Bash 脚本和库的开发人员能够将 Java、Ruby、Python 和其他开发人员所使用的相同惯例应用于其 Bash 代码中。
### 安装 BATS
BATS GitHub 页面包含了安装指令。有两个 BATS 辅助库提供更强大的断言或允许覆写 BATS 使用的 Test Anything Protocol([TAP](http://testanything.org/))输出格式。这些库可以安装在一个标准位置,并被所有的脚本引用。更方便的做法是,将 BATS 及其辅助库的完整版本包含在 Git 仓库中,用于要测试的每组脚本或库。这可以通过 [git 子模块](https://git-scm.com/book/en/v2/Git-Tools-Submodules) 系统来完成。
以下命令会将 BATS 及其辅助库安装到 Git 知识库中的 `test` 目录中。
```
git submodule init
git submodule add https://github.com/sstephenson/bats test/libs/bats
git submodule add https://github.com/ztombol/bats-assert test/libs/bats-assert
git submodule add https://github.com/ztombol/bats-support test/libs/bats-support
git add .
git commit -m 'installed bats'
```
要克隆 Git 仓库并同时安装其子模块,请在 `git clone` 时使用 `--recurse-submodules` 标记。
每个 BATS 测试脚本必须由 `bats` 可执行文件执行。如果你将 BATS 安装到源代码仓库的 `test/libs` 目录中,则可以使用以下命令调用测试:
```
./test/libs/bats/bin/bats <测试脚本的路径>
```
或者,将以下内容添加到每个 BATS 测试脚本的开头:
```
#!/usr/bin/env ./test/libs/bats/bin/bats
load 'libs/bats-support/load'
load 'libs/bats-assert/load'
```
并且执行命令 `chmod +x <测试脚本的路径>`。 这将 a、使它们可与安装在 `./test/libs/bats` 中的 BATS 一同执行,并且 b、包含这些辅助库。BATS 测试脚本通常存储在 `test` 目录中,并以要测试的脚本命名,扩展名为 `.bats`。例如,一个测试 `bin/build` 的 BATS 脚本应称为 `test/build.bats`。
你还可以通过向 BATS 传递正则表达式来运行一整套 BATS 测试文件,例如 `./test/lib/bats/bin/bats test/*.bats`。
### 为 BATS 覆盖率而组织库和脚本
Bash 脚本和库必须以一种有效地方式将其内部工作原理暴露给 BATS 进行组织。通常,在调用或执行时库函数和运行诸多命令的 Shell 脚本不适合进行有效的 BATS 测试。
例如,[build.sh](https://github.com/dmlond/how_to_bats/blob/preBats/build.sh) 是许多人都会编写的典型脚本。本质上是一大堆代码。有些人甚至可能将这堆代码放入库中的函数中。但是,在 BATS 测试中运行一大堆代码,并在单独的测试用例中覆盖它可能遇到的所有故障类型是不可能的。测试这堆代码并有足够的覆盖率的唯一方法就是把它分解成许多小的、可重用的、最重要的是可独立测试的函数。
向库添加更多的函数很简单。额外的好处是其中一些函数本身可以变得出奇的有用。将库函数分解为许多较小的函数后,你可以在 BATS 测试中<ruby> 援引 <rt> source </rt></ruby>这些库,并像测试任何其他命令一样运行这些函数。
Bash 脚本也必须分解为多个函数,执行脚本时,脚本的主要部分应调用这些函数。此外,还有一个非常有用的技巧,可以让你更容易地用 BATS 测试 Bash 脚本:将脚本主要部分中执行的所有代码都移到一个函数中,称为 `run_main`。然后,将以下内容添加到脚本的末尾:
```
if [[ "${BASH_SOURCE[0]}" == "${0}" ]]
then
run_main
fi
```
这段额外的代码做了一些特别的事情。它使脚本在作为脚本执行时与使用<ruby> 援引 <rt> source </rt></ruby>进入环境时的行为有所不同。通过援引并测试单个函数,这个技巧使得脚本的测试方式和库的测试方式变得一样。例如,[这是重构的 build.sh,以获得更好的 BATS 可测试性](https://github.com/dmlond/how_to_bats/blob/master/bin/build.sh)。
### 编写和运行测试
如上所述,BATS 是一个 TAP 兼容的测试框架,其语法和输出对于使用过其他 TAP 兼容测试套件(例如 JUnit、RSpec 或 Jest)的用户来说将是熟悉的。它的测试被组织成单个测试脚本。测试脚本被组织成一个或多个描述性 `@test` 块中,它们描述了被测试应用程序的单元。每个 `@test` 块将运行一系列命令,这些命令准备测试环境、运行要测试的命令,并对被测试命令的退出和输出进行断言。许多断言函数是通过 `bats`、`bats-assert` 和 `bats-support` 库导入的,这些库在 BATS 测试脚本的开头加载到环境中。下面是一个典型的 BATS 测试块:
```
@test "requires CI_COMMIT_REF_SLUG environment variable" {
unset CI_COMMIT_REF_SLUG
assert_empty "${CI_COMMIT_REF_SLUG}"
run some_command
assert_failure
assert_output --partial "CI_COMMIT_REF_SLUG"
}
```
如果 BATS 脚本包含 `setup`(安装)和/或 `teardown`(拆卸) 函数,则 BATS 将在每个测试块运行之前和之后自动执行它们。这样就可以创建环境变量、测试文件以及执行一个或所有测试所需的其他操作,然后在每次测试运行后将其拆卸。[Build.bats](https://github.com/dmlond/how_to_bats/blob/master/test/build.bats) 是对我们新格式化的 `build.sh` 脚本的完整 BATS 测试。(此测试中的 `mock_docker` 命令将在以下关于模拟/打标的部分中进行说明。)
当测试脚本运行时,BATS 使用 `exec`(执行)来将每个 `@test` 块作为单独的子进程运行。这样就可以在一个 `@test` 中导出环境变量甚至函数,而不会影响其他 `@test` 或污染你当前的 Shell 会话。测试运行的输出是一种标准格式,可以被人理解,并且可以由 TAP 使用端以编程方式进行解析或操作。下面是 `CI_COMMIT_REF_SLUG` 测试块失败时的输出示例:
```
✗ requires CI_COMMIT_REF_SLUG environment variable
(from function `assert_output' in file test/libs/bats-assert/src/assert.bash, line 231,
in test file test/ci_deploy.bats, line 26)
`assert_output --partial "CI_COMMIT_REF_SLUG"' failed
-- output does not contain substring --
substring (1 lines):
CI_COMMIT_REF_SLUG
output (3 lines):
./bin/deploy.sh: join_string_by: command not found
oc error
Could not login
--
** Did not delete , as test failed **
1 test, 1 failure
```
下面是成功测试的输出:
```
✓ requires CI_COMMIT_REF_SLUG environment variable
```
### 辅助库
像任何 Shell 脚本或库一样,BATS 测试脚本可以包括辅助库,以在测试之间共享通用代码或增强其性能。这些辅助库,例如 `bats-assert` 和 `bats-support` 甚至可以使用 BATS 进行测试。
库可以和 BATS 脚本放在同一个测试目录下,如果测试目录下的文件数量过多,也可以放在 `test/libs` 目录下。BATS 提供了 `load` 函数,该函数接受一个相对于要测试的脚本的 Bash 文件的路径(例如,在我们的示例中的 `test`),并援引该文件。文件必须以后缀 `.bash` 结尾,但是传递给 `load` 函数的文件路径不能包含后缀。`build.bats` 加载 `bats-assert` 和 `bats-support` 库、一个小型 [helpers.bash](https://github.com/dmlond/how_to_bats/blob/master/test/helpers.bash) 库以及 `docker_mock.bash` 库(如下所述),以下代码位于测试脚本的开头,解释器魔力行下方:
```
load 'libs/bats-support/load'
load 'libs/bats-assert/load'
load 'helpers'
load 'docker_mock'
```
### 打标测试输入和模拟外部调用
大多数 Bash 脚本和库运行时都会执行函数和/或可执行文件。通常,它们被编程为基于这些函数或可执行文件的输出状态或输出(`stdout`、`stderr`)以特定方式运行。为了正确地测试这些脚本,通常需要制作这些命令的伪版本,这些命令被设计成在特定测试过程中以特定方式运行,称为“<ruby> 打标 <rt> stubbing </rt></ruby>”。可能还需要监视正在测试的程序,以确保其调用了特定命令,或者使用特定参数调用了特定命令,此过程称为“<ruby> 模拟 <rt> mocking </rt></ruby>”。有关更多信息,请查看在 Ruby RSpec 中 [有关模拟和打标的讨论](https://www.codewithjason.com/rspec-mocks-stubs-plain-english/),它适用于任何测试系统。
Bash shell 提供了一些技巧,可以在你的 BATS 测试脚本中使用这些技巧进行模拟和打标。所有这些都需要使用带有 `-f` 标志的 Bash `export` 命令来导出一个覆盖了原始函数或可执行文件的函数。必须在测试程序执行之前完成此操作。下面是重写可执行命令 `cat` 的简单示例:
```
function cat() { echo "THIS WOULD CAT ${*}" }
export -f cat
```
此方法以相同的方式覆盖了函数。如果一个测试需要覆盖要测试的脚本或库中的函数,则在对函数进行打标或模拟之前,必须先声明已测试脚本或库,这一点很重要。否则,在声明脚本时,打标/模拟将被原函数替代。另外,在运行即将进行的测试命令之前确认打标/模拟。下面是`build.bats` 的示例,该示例模拟 `build.sh` 中描述的`raise` 函数,以确保登录函数会引发特定的错误消息:
```
@test ".login raises on oc error" {
source ${profile_script}
function raise() { echo "${1} raised"; }
export -f raise
run login
assert_failure
assert_output -p "Could not login raised"
}
```
一般情况下,没有必要在测试后复原打标/模拟的函数,因为 `export`(输出)仅在当前 `@test` 块的 `exec`(执行)期间影响当前子进程。但是,可以模拟/打标 BATS `assert` 函数在内部使用的命令(例如 `cat`、`sed` 等)是可能的。在运行这些断言命令之前,必须对这些模拟/打标函数进行 `unset`(复原),否则它们将无法正常工作。下面是 `build.bats` 中的一个示例,该示例模拟 `sed`,运行 `build_deployable` 函数并在运行任何断言之前复原 `sed`:
```
@test ".build_deployable prints information, runs docker build on a modified Dockerfile.production and publish_image when its not a dry_run" {
local expected_dockerfile='Dockerfile.production'
local application='application'
local environment='environment'
local expected_original_base_image="${application}"
local expected_candidate_image="${application}-candidate:${environment}"
local expected_deployable_image="${application}:${environment}"
source ${profile_script}
mock_docker build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t "${expected_deployable_image}" -
function publish_image() { echo "publish_image ${*}"; }
export -f publish_image
function sed() {
echo "sed ${*}" >&2;
echo "FROM application-candidate:environment";
}
export -f sed
run build_deployable "${application}" "${environment}"
assert_success
unset sed
assert_output --regexp "sed.*${expected_dockerfile}"
assert_output -p "Building ${expected_original_base_image} deployable ${expected_deployable_image} FROM ${expected_candidate_image}"
assert_output -p "FROM ${expected_candidate_image} piped"
assert_output -p "build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t ${expected_deployable_image} -"
assert_output -p "publish_image ${expected_deployable_image}"
}
```
有的时候相同的命令,例如 `foo`,将在被测试的同一函数中使用不同的参数多次调用。这些情况需要创建一组函数:
* `mock_foo`:将期望的参数作为输入,并将其持久化到 TMP 文件中
* `foo`:命令的模拟版本,该命令使用持久化的预期参数列表处理每个调用。必须使用 `export -f` 将其导出。
* `cleanup_foo`:删除 TMP 文件,用于拆卸函数。这可以进行测试以确保在删除之前成功完成 `@test` 块。
由于此功能通常在不同的测试中重复使用,因此创建一个可以像其他库一样加载的辅助库会变得有意义。
[docker\_mock.bash](https://github.com/dmlond/how_to_bats/blob/master/test/docker_mock.bash) 是一个很棒的例子。它被加载到 `build.bats` 中,并在任何测试调用 Docker 可执行文件的函数的测试块中使用。使用 `docker_mock` 典型的测试块如下所示:
```
@test ".publish_image fails if docker push fails" {
setup_publish
local expected_image="image"
local expected_publishable_image="${CI_REGISTRY_IMAGE}/${expected_image}"
source ${profile_script}
mock_docker tag "${expected_image}" "${expected_publishable_image}"
mock_docker push "${expected_publishable_image}" and_fail
run publish_image "${expected_image}"
assert_failure
assert_output -p "tagging ${expected_image} as ${expected_publishable_image}"
assert_output -p "tag ${expected_image} ${expected_publishable_image}"
assert_output -p "pushing image to gitlab registry"
assert_output -p "push ${expected_publishable_image}"
}
```
该测试建立了一个使用不同的参数两次调用 Docker 的预期。在对Docker 的第二次调用失败时,它会运行测试命令,然后测试退出状态和对 Docker 调用的预期。
一方面 BATS 利用 `mock_docker.bash` 引入 `${BATS_TMPDIR}` 环境变量,BATS 在测试开始的位置对其进行了设置,以允许测试和辅助程序在标准位置创建和销毁 TMP 文件。如果测试失败,`mock_docker.bash` 库不会删除其持久化的模拟文件,但会打印出其所在位置,以便可以查看和删除它。你可能需要定期从该目录中清除旧的模拟文件。
关于模拟/打标的一个注意事项:`build.bats` 测试有意识地违反了关于测试声明的规定:[不要模拟没有拥有的!](https://github.com/testdouble/contributing-tests/wiki/Don't-mock-what-you-don't-own) 该规定要求调用开发人员没有编写代码的测试命令,例如 `docker`、`cat`、`sed` 等,应封装在自己的库中,应在使用它们脚本的测试中对其进行模拟。然后应该在不模拟外部命令的情况下测试封装库。
这是一个很好的建议,而忽略它是有代价的。如果 Docker CLI API 发生变化,则测试脚本不会检测到此变化,从而导致错误内容直到经过测试的 `build.sh` 脚本在使用新版本 Docker 的生产环境中运行后才显示出来。测试开发人员必须确定要严格遵守此标准的程度,但是他们应该了解其所涉及的权衡。
### 总结
在任何软件开发项目中引入测试制度,都会在以下两方面产生权衡: a、增加开发和维护代码及测试所需的时间和组织,b、增加开发人员在对应用程序整个生命周期中完整性的信心。测试制度可能不适用于所有脚本和库。
通常,满足以下一个或多个条件的脚本和库才可以使用 BATS 测试:
* 值得存储在源代码管理中
* 用于关键流程中,并依靠它们长期稳定运行
* 需要定期对其进行修改以添加/删除/修改其功能
* 可以被其他人使用
一旦决定将测试规则应用于一个或多个 Bash 脚本或库,BATS 就提供其他软件开发环境中可用的全面测试功能。
致谢:感谢 [Darrin Mann](https://github.com/dmann) 向我引荐了 BATS 测试。
---
via: <https://opensource.com/article/19/2/testing-bash-bats>
作者:[Darin London](https://opensource.com/users/dmlond) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Software developers writing applications in languages such as Java, Ruby, and Python have sophisticated libraries to help them maintain their software's integrity over time. They create tests that run applications through a series of executions in structured environments to ensure all of their software's aspects work as expected.
These tests are even more powerful when they're automated in a continuous integration (CI) system, where every push to the source repository causes the tests to run, and developers are immediately notified when tests fail. This fast feedback increases developers' confidence in the functional integrity of their applications.
The Bash Automated Testing System ([BATS](https://github.com/sstephenson/bats)) enables developers writing Bash scripts and libraries to apply the same practices used by Java, Ruby, Python, and other developers to their Bash code.
## Installing BATS
The BATS GitHub page includes installation instructions. There are two BATS helper libraries that provide more powerful assertions or allow overrides to the Test Anything Protocol ([TAP](http://testanything.org/)) output format used by BATS. These can be installed in a standard location and sourced by all scripts. It may be more convenient to include a complete version of BATS and its helper libraries in the Git repository for each set of scripts or libraries being tested. This can be accomplished using the ** git submodule** system.
The following commands will install BATS and its helper libraries into the **test** directory in a Git repository.
```
git submodule init
git submodule add https://github.com/sstephenson/bats test/libs/bats
git submodule add https://github.com/ztombol/bats-assert test/libs/bats-assert
git submodule add https://github.com/ztombol/bats-support test/libs/bats-support
git add .
git commit -m 'installed bats'
```
To clone a Git repository and install its submodules at the same time, use the
**--recurse-submodules** flag to **git clone**.
Each BATS test script must be executed by the **bats** executable. If you installed BATS into your source code repo's **test/libs** directory, you can invoke the test with:
`./test/libs/bats/bin/bats <path to test script>`
Alternatively, add the following to the beginning of each of your BATS test scripts:
```
#!/usr/bin/env ./test/libs/bats/bin/bats
load 'libs/bats-support/load'
load 'libs/bats-assert/load'
```
and **chmod +x <path to test script>**. This will a) make them executable with the BATS installed in **./test/libs/bats** and b) include these helper libraries. BATS test scripts are typically stored in the **test** directory and named for the script being tested, but with the **.bats** extension. For example, a BATS script that tests **bin/build** should be called **test/build.bats**.
You can also run an entire set of BATS test files by passing a regular expression to BATS, e.g., **./test/lib/bats/bin/bats test/*.bats**.
## Organizing libraries and scripts for BATS coverage
Bash scripts and libraries must be organized in a way that efficiently exposes their inner workings to BATS. In general, library functions and shell scripts that run many commands when they are called or executed are not amenable to efficient BATS testing.
For example, [build.sh](https://github.com/dmlond/how_to_bats/blob/preBats/build.sh) is a typical script that many people write. It is essentially a big pile of code. Some might even put this pile of code in a function in a library. But it's impossible to run a big pile of code in a BATS test and cover all possible types of failures it can encounter in separate test cases. The only way to test this pile of code with sufficient coverage is to break it into many small, reusable, and, most importantly, independently testable functions.
It's straightforward to add more functions to a library. An added benefit is that some of these functions can become surprisingly useful in their own right. Once you have broken your library function into lots of smaller functions, you can **source** the library in your BATS test and run the functions as you would any other command to test them.
Bash scripts must also be broken down into multiple functions, which the main part of the script should call when the script is executed. In addition, there is a very useful trick to make it much easier to test Bash scripts with BATS: Take all the code that is executed in the main part of the script and move it into a function, called something like **run_main**. Then, add the following to the end of the script:
```
if [[ "${BASH_SOURCE[0]}" == "${0}" ]]
then
run_main
fi
```
This bit of extra code does something special. It makes the script behave differently when it is executed as a script than when it is brought into the environment with **source**. This trick enables the script to be tested the same way a library is tested, by sourcing it and testing the individual functions. For example, here is [build.sh refactored for better BATS testability](https://github.com/dmlond/how_to_bats/blob/master/bin/build.sh).
## Writing and running tests
As mentioned above, BATS is a TAP-compliant testing framework with a syntax and output that will be familiar to those who have used other TAP-compliant testing suites, such as JUnit, RSpec, or Jest. Its tests are organized into individual test scripts. Test scripts are organized into one or more descriptive **@test** blocks that describe the unit of the application being tested. Each **@test** block will run a series of commands that prepares the test environment, runs the command to be tested, and makes assertions about the exit and output of the tested command. Many assertion functions are imported with the **bats**, **bats-assert**, and **bats-support** libraries, which are loaded into the environment at the beginning of the BATS test script. Here is a typical BATS test block:
```
@test "requires CI_COMMIT_REF_SLUG environment variable" {
unset CI_COMMIT_REF_SLUG
assert_empty "${CI_COMMIT_REF_SLUG}"
run some_command
assert_failure
assert_output --partial "CI_COMMIT_REF_SLUG"
}
```
If a BATS script includes **setup** and/or **teardown** functions, they are automatically executed by BATS before and after each test block runs. This makes it possible to create environment variables, test files, and do other things needed by one or all tests, then tear them down after each test runs. [ Build.bats](https://github.com/dmlond/how_to_bats/blob/master/test/build.bats) is a full BATS test of our newly formatted
**build.sh**script. (The
**mock_docker**command in this test will be explained below, in the section on mocking/stubbing.)
When the test script runs, BATS uses **exec** to run each **@test** block as a separate subprocess. This makes it possible to export environment variables and even functions in one **@test** without affecting other **@test**s or polluting your current shell session. The output of a test run is a standard format that can be understood by humans and parsed or manipulated programmatically by TAP consumers. Here is an example of the output for the **CI_COMMIT_REF_SLUG** test block when it fails:
```
✗ requires CI_COMMIT_REF_SLUG environment variable
(from function `assert_output' in file test/libs/bats-assert/src/assert.bash, line 231,
in test file test/ci_deploy.bats, line 26)
`assert_output --partial "CI_COMMIT_REF_SLUG"' failed
-- output does not contain substring --
substring (1 lines):
CI_COMMIT_REF_SLUG
output (3 lines):
./bin/deploy.sh: join_string_by: command not found
oc error
Could not login
--
** Did not delete , as test failed **
1 test, 1 failure
```
Here is the output of a successful test:
`✓ requires CI_COMMIT_REF_SLUG environment variable`
## Helpers
Like any shell script or library, BATS test scripts can include helper libraries to share common code across tests or enhance their capabilities. These helper libraries, such as **bats-assert** and **bats-support**, can even be tested with BATS.
Libraries can be placed in the same test directory as the BATS scripts or in the **test/libs** directory if the number of files in the test directory gets unwieldy. BATS provides the **load** function that takes a path to a Bash file relative to the script being tested (e.g., **test**, in our case) and sources that file. Files must end with the prefix **.bash**, but the path to the file passed to the **load** function can't include the prefix. **build.bats** loads the **bats-assert** and **bats-support** libraries, a small ** helpers.bash** library, and a
**docker_mock.bash**library (described below) with the following code placed at the beginning of the test script below the interpreter magic line:
```
load 'libs/bats-support/load'
load 'libs/bats-assert/load'
load 'helpers'
load 'docker_mock'
```
## Stubbing test input and mocking external calls
The majority of Bash scripts and libraries execute functions and/or executables when they run. Often they are programmed to behave in specific ways based on the exit status or output (**stdout**, **stderr**) of these functions or executables. To properly test these scripts, it is often necessary to make fake versions of these commands that are designed to behave in a specific way during a specific test, a process called "stubbing." It may also be necessary to spy on the program being tested to ensure it calls a specific command, or it calls a specific command with specific arguments, a process called "mocking." For more on this, check out this great [discussion of mocking and stubbing](https://www.codewithjason.com/rspec-mocks-stubs-plain-english/) in Ruby RSpec, which applies to any testing system.
The Bash shell provides tricks that can be used in your BATS test scripts to do mocking and stubbing. All require the use of the Bash **export** command with the **-f** flag to export a function that overrides the original function or executable. This must be done before the tested program is executed. Here is a simple example that overrides the **cat** executable:
```
function cat() { echo "THIS WOULD CAT ${*}" }
export -f cat
```
This method overrides a function in the same manner. If a test needs to override a function within the script or library being tested, it is important to source the tested script or library before the function is stubbed or mocked. Otherwise, the stub/mock will be replaced with the actual function when the script is sourced. Also, make sure to stub/mock before you run the command you're testing. Here is an example from **build.bats** that mocks the **raise** function described in **build.sh** to ensure a specific error message is raised by the login fuction:
```
@test ".login raises on oc error" {
source ${profile_script}
function raise() { echo "${1} raised"; }
export -f raise
run login
assert_failure
assert_output -p "Could not login raised"
}
```
Normally, it is not necessary to unset a stub/mock function after the test, since **export** only affects the current subprocess during the **exec** of the current **@test** block. However, it is possible to mock/stub commands (e.g. **cat**, **sed**, etc.) that the BATS **assert*** functions use internally. These mock/stub functions must be **unset** before these assert commands are run, or they will not work properly. Here is an example from **build.bats** that mocks **sed**, runs the **build_deployable** function, and unsets **sed** before running any assertions:
```
@test ".build_deployable prints information, runs docker build on a modified Dockerfile.production and publish_image when its not a dry_run" {
local expected_dockerfile='Dockerfile.production'
local application='application'
local environment='environment'
local expected_original_base_image="${application}"
local expected_candidate_image="${application}-candidate:${environment}"
local expected_deployable_image="${application}:${environment}"
source ${profile_script}
mock_docker build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t "${expected_deployable_image}" -
function publish_image() { echo "publish_image ${*}"; }
export -f publish_image
function sed() {
echo "sed ${*}" >&2;
echo "FROM application-candidate:environment";
}
export -f sed
run build_deployable "${application}" "${environment}"
assert_success
unset sed
assert_output --regexp "sed.*${expected_dockerfile}"
assert_output -p "Building ${expected_original_base_image} deployable ${expected_deployable_image} FROM ${expected_candidate_image}"
assert_output -p "FROM ${expected_candidate_image} piped"
assert_output -p "build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t ${expected_deployable_image} -"
assert_output -p "publish_image ${expected_deployable_image}"
}
```
Sometimes the same command, e.g. foo, will be invoked multiple times, with different arguments, in the same function being tested. These situations require the creation of a set of functions:
- mock_foo: takes expected arguments as input, and persists these to a TMP file
- foo: the mocked version of the command, which processes each call with the persisted list of expected arguments. This must be exported with export -f.
- cleanup_foo: removes the TMP file, for use in teardown functions. This can test to ensure that a @test block was successful before removing.
Since this functionality is often reused in different tests, it makes sense to create a helper library that can be loaded like other libraries.
A good example is ** docker_mock.bash**. It is loaded into
**build.bats**and used in any test block that tests a function that calls the Docker executable. A typical test block using
**docker_mock**looks like:
```
@test ".publish_image fails if docker push fails" {
setup_publish
local expected_image="image"
local expected_publishable_image="${CI_REGISTRY_IMAGE}/${expected_image}"
source ${profile_script}
mock_docker tag "${expected_image}" "${expected_publishable_image}"
mock_docker push "${expected_publishable_image}" and_fail
run publish_image "${expected_image}"
assert_failure
assert_output -p "tagging ${expected_image} as ${expected_publishable_image}"
assert_output -p "tag ${expected_image} ${expected_publishable_image}"
assert_output -p "pushing image to gitlab registry"
assert_output -p "push ${expected_publishable_image}"
}
```
This test sets up an expectation that Docker will be called twice with different arguments. With the second call to Docker failing, it runs the tested command, then tests the exit status and expected calls to Docker.
One aspect of BATS introduced by **mock_docker.bash** is the **${BATS_TMPDIR}** environment variable, which BATS sets at the beginning to allow tests and helpers to create and destroy TMP files in a standard location. The **mock_docker.bash** library will not delete its persisted mocks file if a test fails, but it will print where it is located so it can be viewed and deleted. You may need to periodically clean old mock files out of this directory.
One note of caution regarding mocking/stubbing: The **build.bats** test consciously violates a dictum of testing that states: [Don't mock what you don't own!](https://github.com/testdouble/contributing-tests/wiki/Don't-mock-what-you-don't-own) This dictum demands that calls to commands that the test's developer didn't write, like **docker**, **cat**, **sed**, etc., should be wrapped in their own libraries, which should be mocked in tests of scripts that use them. The wrapper libraries should then be tested without mocking the external commands.
This is good advice and ignoring it comes with a cost. If the Docker CLI API changes, the test scripts will not detect this change, resulting in a false positive that won't manifest until the tested **build.sh** script runs in a production setting with the new version of Docker. Test developers must decide how stringently they want to adhere to this standard, but they should understand the tradeoffs involved with their decision.
## Conclusion
Introducing a testing regime to any software development project creates a tradeoff between a) the increase in time and organization required to develop and maintain code and tests and b) the increased confidence developers have in the integrity of the application over its lifetime. Testing regimes may not be appropriate for all scripts and libraries.
In general, scripts and libraries that meet one or more of the following should be tested with BATS:
- They are worthy of being stored in source control
- They are used in critical processes and relied upon to run consistently for a long period of time
- They need to be modified periodically to add/remove/modify their function
- They are used by others
Once the decision is made to apply a testing discipline to one or more Bash scripts or libraries, BATS provides the comprehensive testing features that are available in other software development environments.
*Acknowledgment: I am indebted to Darrin Mann for introducing me to BATS testing.*
## 3 Comments |
13,195 | 在 Linux 上安装官方 Evernote 客户端 | https://itsfoss.com/install-evernote-ubuntu/ | 2021-03-12T06:45:00 | [
"Evernote"
] | https://linux.cn/article-13195-1.html | 
[Evernote](https://evernote.com/) 是一款流行的笔记应用。它在推出时是一个革命性的产品。从那时起,已经有好几个这样的应用,可以将网络剪报、笔记等保存为笔记本格式。
多年来,Evernote 一直没有在 Linux 上使用的桌面客户端。前段时间 Evernote 承诺推出 Linux 应用,其测试版终于可以在基于 Ubuntu 的发行版上使用了。
>
> 非 FOSS 警报!
>
>
> Evernote Linux 客户端不是开源的。之所以在这里介绍它,是因为该应用是在 Linux 上提供的,我们也会不定期地介绍 Linux 用户常用的非 FOSS 应用。这对普通桌面 Linux 用户有帮助。
>
>
>
### 在 Ubuntu 和基于 Debian 的 Linux 发行版上安装 Evernote
进入这个 Evernote 的[网站页面](https://evernote.com/intl/en/b1433t1422)。
向下滚动一点,接受“早期测试计划”的条款和条件。你会看到一个“立即安装”的按钮出现在屏幕上。点击它来下载 DEB 文件。

要 [从 DEB 文件安装应用](https://itsfoss.com/install-deb-files-ubuntu/),请双击它。它应该会打开软件中心,并给你选择安装它。

安装完成后,在系统菜单中搜索 Evernote 并启动它。

当你第一次启动应用时,你需要登录到你的 Evernote 账户。

第一次运行会带你进入“主页面”,在这里你可以整理你的笔记本,以便更快速地访问。

你现在可以享受在 Linux 上使用 Evernote 了。
### 体验 Evernote 的 Linux 测试版客户端
由于软件处于测试版,因此这里或那里会有些问题。
如上图所示,Evernote Linux 客户端检测到 [Ubuntu 中的深色模式](https://itsfoss.com/dark-mode-ubuntu/) 并自动切换到深色主题。然而,当我把系统主题改为浅色或标准主题时,它并没有立即改变应用主题。这些变化是在我重启 Evernote 应用后才生效的。
另一个问题是关于关闭应用。如果你点击 “X” 按钮关闭 Evernote,程序会进入后台而不是退出。
有一个似乎可以启动最小化的 Evernote 的应用指示器,就像 [Linux 上的 Skype](https://itsfoss.com/install-skype-ubuntu-1404/)。不幸的是,事实并非如此。它打开了便笺,让你快速输入笔记。
这为你提供了另一个 [Linux 上的笔记应用](https://itsfoss.com/note-taking-apps-linux/),但它也带来了一个问题。这里没有退出 Evernote 的选项。它只用于打开快速记事应用。

那么,如何退出 Evernote 应用呢?为此,再次打开 Evernote 应用。如果它在后台运行,在菜单中搜索它,并启动它,就像你重新打开它一样。
当 Evernote 应用在前台运行时,点击 “文件->退出” 来退出 Evernote。

这一点开发者应该在未来的版本中寻求改进。
我也不能说测试版的程序将来会如何更新。它没有添加任何仓库。我只是希望程序本身能够通知用户有新的版本,这样用户就可以下载新的 DEB 文件。
我并没有订阅 Evernote Premium,但我仍然可以在没有网络连接的情况下访问保存的网络文章和笔记。很奇怪,对吧?
总的来说,我很高兴看到 Evernote 终于努力把这个应用带到了 Linux 上。现在,你不必再尝试第三方应用来在 Linux 上使用 Evernote 了,至少在 Ubuntu 和基于 Debian 的发行版上是这样。当然,你可以使用 [Evernote 替代品](https://itsfoss.com/5-evernote-alternatives-linux/),比如 [Joplin](https://itsfoss.com/joplin/),它们都是开源的。
---
via: <https://itsfoss.com/install-evernote-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Evernote](https://evernote.com/?ref=itsfoss.com) is a popular note-taking application. It was a revolutionary product at the time of its launch. Since then, there have been several such application that allow you to save web clippings, notes etc into notebook formats.
For years, the desktop client of Evernote was not available for Linux. Evernote promised a Linux application some time ago and its beta version is finally available for Ubuntu-based distributions.
## Installing Evernote on Ubuntu and Debian-based Linux distributions
Go to the following page on Evernote’s website:
Scroll down a bit to accept the terms and conditions of ‘early testing program’. You’ll see a ‘Install Now’ button appearing on the screen. Click on it to download the DEB file.
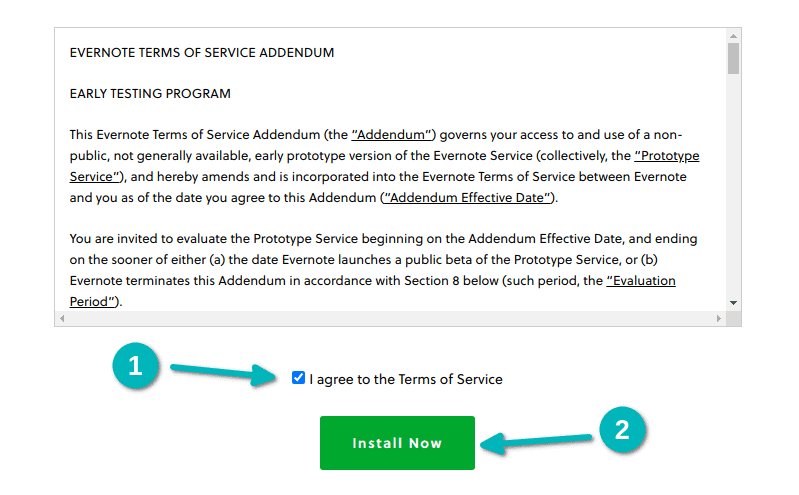
To [install the application from the DEB file](https://itsfoss.com/install-deb-files-ubuntu/), double-click on it. It should open the Software Center app and give you the option to install it.
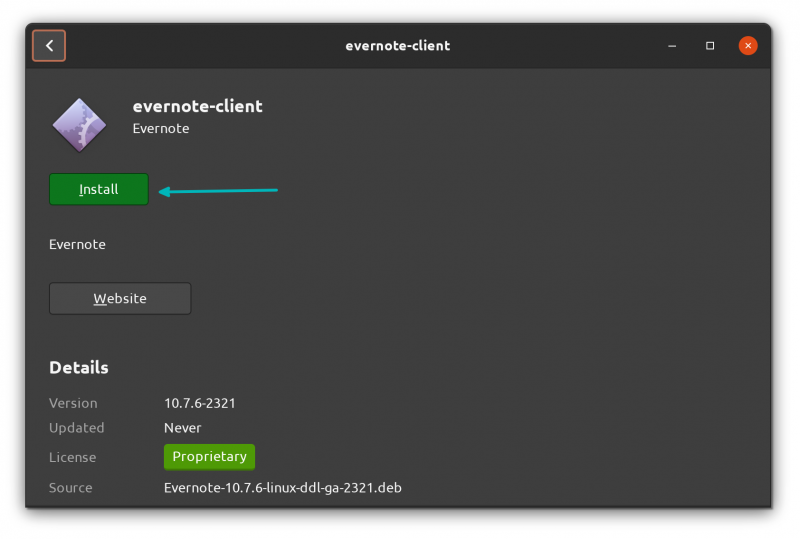
Once the installation completes, search for Evernote in the system menu and launch it.
When you start the application for the first time, you’ll need to log in to your Evernote account.
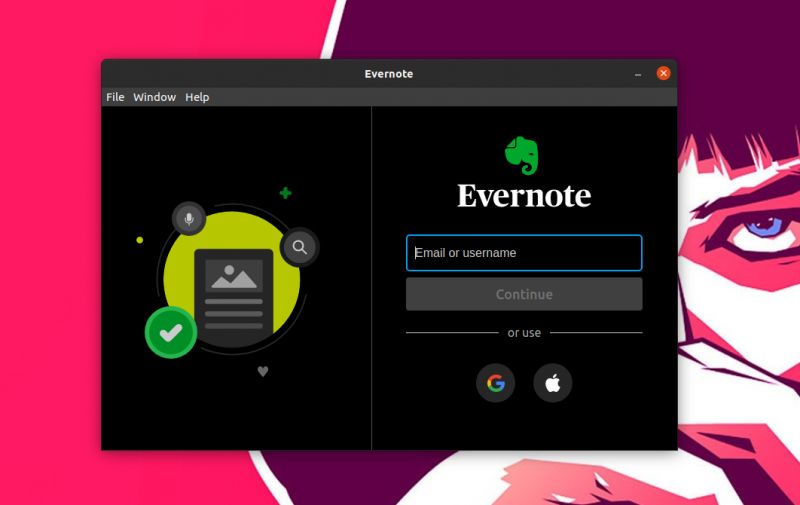
The first run brings you to the ‘Home screen’ where you can organize your notebooks for even quicker access.
You may enjoy using Evernote on Linux now.
## Experiencing the beta version of Evernote Linux client
There are a few annoyances here and there with the software being in beta.
As you can notice in the image above, Evernote Linux client detected the [dark mode in Ubuntu](https://itsfoss.com/dark-mode-ubuntu/) and switched to dark theme automatically. However, when I changed the system theme to light or standard, it didn’t change theme application theme immediately. The changes took into effect only after I restarted Evernote app.
Another issue is about closing the application. If you click on the X button to close the Evernote application, the program goes in background instead of exiting.
There is an app indicator that seems like a way to launch a minimized Evernote application, like [Skype on Linux](https://itsfoss.com/install-skype-ubuntu-1404/). Unfortunately, that’s not the case. It opens the Scratch Pad for you to type a quick note.
This gives you another [note taking application on Linux](https://itsfoss.com/note-taking-apps-linux/) but it also presents a problem. There is no option to quit Evernote here. It is only for opening the quick note taking app.
So, how do you quit the Evernote application? For that, open the Evernote application again. If it is running in the background, search for it in the menu and launch it as if you are opening it afresh.
When Evernote application is running in the foreground, go to File->Quit Evernote.
This is something the developers should look to improve in the future versions.
I also cannot say how will the beta version of the program be updated in the future. It doesn’t add any repository. I just hope that the application itself notifies about the availability of a newer version so that users could download the new DEB file.
I do NOT have a premium Evernote subscription but still, I could access the saved web articles and notes without internet connection. Strange, right?
Overall, I am happy to see that Evernote finally made the effort to bring the application to Linux. Now you don’t have to try third-party applications to use Evernote on Linux, at least on Ubuntu and Debian-based distributions. You may, of course, use an [Evernote alternative](https://itsfoss.com/5-evernote-alternatives-linux/) like [Joplin](https://itsfoss.com/joplin/) that are actually open source. |
13,197 | WebAssembly 介绍 | https://www.linux.com/news/an-introduction-to-webassembly/ | 2021-03-12T22:30:27 | [
"WebAssembly"
] | https://linux.cn/article-13197-1.html | 
### 到底什么是 WebAssembly?
[WebAssembly](https://webassembly.org/),也叫 Wasm,是一种为 Web 优化的代码格式和 API(应用编程接口),它可以大大提高网站的性能和能力。WebAssembly 的 1.0 版本于 2017 年发布,并于 2019 年成为 W3C 官方标准。
该标准得到了所有主流浏览器供应商的积极支持,原因显而易见:官方列出的 [“浏览器内部”用例](https://webassembly.org/docs/use-cases/) 中提到了,其中包括视频编辑、3D 游戏、虚拟和增强现实、p2p 服务和科学模拟。除了让浏览器的功能比JavaScript 强大得多,该标准甚至可以延长网站的寿命:例如,正是 WebAssembly 为 [互联网档案馆的 Flash 动画和游戏](https://blog.archive.org/2020/11/19/flash-animations-live-forever-at-the-internet-archive/) 提供了持续的支持。
不过,WebAssembly 并不只用于浏览器,目前它还被用于移动和基于边缘环境的 Cloudflare Workers 等产品中。
### WebAssembly 如何工作?
.wasm 格式的文件包含低级二进制指令(字节码),可由使用通用栈的虚拟机以“接近 CPU 原生速度”执行。这些代码被打包成模块(可以被浏览器直接执行的对象),每个模块可以被一个网页多次实例化。模块内部定义的函数被列在一个专用数组中,或称为<ruby> 表 <rt> Table </rt></ruby>,相应的数据被包含在另一个结构中,称为 <ruby> 缓存数组 <rt> arraybuffer </rt></ruby>。开发者可以通过 Javascript `WebAssembly.memory()` 的调用,为 .wasm 代码显式分配内存。
.wasm 格式也有纯文本版本,它可以大大简化学习和调试。然而,WebAssembly 并不是真的要供人直接使用。从技术上讲,.wasm 只是一个与浏览器兼容的**编译目标**:一种用高级编程语言编写的软件编译器可以自动翻译的代码格式。
这种选择正是使开发人员能够使用数十亿人熟悉的语言(C/C++、Python、Go、Rust 等)直接为用户界面进行编程的方式,但以前浏览器无法对其进行有效利用。更妙的是,至少在理论上程序员可以利用它们,无需直接查看 WebAssembly 代码,也无需担心物理 CPU 实际运行他们的代码(因为目标是一个**虚拟**机)。
### 但是我们已经有了 JavaScript,我们真的需要 WebAssembly 吗?
是的,有几个原因。首先,作为二进制指令,.wasm 文件比同等功能的 JavaScript 文件小得多,下载速度也快得多。最重要的是,Javascript 文件必须在浏览器将其转换为其内部虚拟机可用的字节码之前进行完全解析和验证。
而 .wasm 文件则可以一次性验证和编译,从而使“流式编译”成为可能:浏览器在开始**下载它们**的那一刻就可以开始编译和执行它们,就像串流电影一样。
这就是说,并不是所有可以想到的 WebAssembly 应用都肯定会比由专业程序员手动优化的等效 JavaScript 应用更快或更小。例如,如果一些 .wasm 需要包含 JavaScript 不需要的库,这种情况可能会发生。
### WebAssembly 是否会让 JavaScript 过时?
一句话:不会。暂时不会,至少在浏览器内不会。WebAssembly 模块仍然需要 JavaScript,因为在设计上它们不能访问文档对象模型 (DOM)—— [主要用于修改网页的 API](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction)。此外,.wasm 代码不能进行系统调用或读取浏览器的内存。WebAssembly 只能在沙箱中运行,一般来说,它能与外界的交互甚至比 JavaScript 更少,而且只能通过 JavaScript 接口进行。
因此,至少在不久的将来 .wasm 模块将只是通过 JavaScript 提供那些如果用 JavaScript 语言编写会消耗更多带宽、内存或 CPU 时间的部分。
### Web 浏览器如何运行 WebAssembly?
一般来说,浏览器至少需要两块来处理动态应用:运行应用代码的虚拟机(VM),以及可以同时修改浏览器行为和网页显示的 API。
现代浏览器内部的虚拟机通过以下方式同时支持 JavaScript 和 WebAssembly:
1. 浏览器下载一个用 HTML 标记语言编写的网页,然后进行渲染
2. 如果该 HTML 调用 JavaScript 代码,浏览器的虚拟机就会执行该代码。但是...
3. 如果 JavaScript 代码中包含了 WebAssembly 模块的实例,那么就按照上面的描述获取该实例,然后根据需要通过 JavaScript 的 WebAssembly API 来使用该实例
4. 当 WebAssembly 代码产生的东西将修改 DOM(即“宿主”网页)的结构,JavaScript 代码就会接收到,并继续进行实际的修改。
### 我如何才能创建可用的 WebAssembly 代码?
越来越多的编程语言社区支持直接编译到 Wasm,我们建议从 [webassembly.org](http://webassembly.org) 的 [入门指南](https://webassembly.org/getting-started/developers-guide/) 开始,这取决于你使用什么语言。请注意,并不是所有的编程语言都有相同水平的 Wasm 支持,因此你的工作量可能会有所不同。
我们计划在未来几个月内发布一系列文章,提供更多关于 WebAssembly 的信息。要自己开始使用它,你可以报名参加 Linux 基金会的免费 [WebAssembly 介绍](https://training.linuxfoundation.org/training/introduction-to-webassembly-lfd133/)在线培训课程。
这篇[WebAssembly 介绍](https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/)首次发布在 [Linux Foundation – Training](https://training.linuxfoundation.org/)。
---
via: <https://www.linux.com/news/an-introduction-to-webassembly/>
作者:[Dan Brown](https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *By Marco Fioretti*
**What on Earth is WebAssembly?**
[WebAssembly, also called Wasm](https://webassembly.org/), is a Web-optimized code format and API (Application Programming Interface) that can greatly improve the performances and capabilities of websites. Version 1.0 of WebAssembly, was released in 2017, and became an official W3C standard in 2019.
The standard is actively supported by all major browser suppliers, for obvious reasons: the official list of [“inside the browser” use cases](https://webassembly.org/docs/use-cases/) mentions, among other things, video editing, 3D games, virtual and augmented reality, p2p services, and scientific simulations. Besides making browsers much more powerful than JavaScript could, this standard may even extend the lifespan of websites: for example, it is WebAssembly that powers the continued support of [Flash animations and games at the Internet Archive](https://blog.archive.org/2020/11/19/flash-animations-live-forever-at-the-internet-archive/).
WebAssembly isn’t just for browsers though; it is currently being used in mobile and edge based environments with such products as Cloudflare Workers.
**How WebAssembly works**
Files in .wasm format contain low level binary instructions (bytecode), executable at “near CPU-native speed” by a virtual machine that uses a common stack. The code is packaged in modules – that is objects that are directly executable by a browser – and each module can be instantiated multiple times by a web page. The functions defined inside modules are listed in one dedicated array, or Table, and the corresponding data are contained in another structure, called arraybuffer. Developers can explicitly allocate memory for .wasm code with the Javascript WebAssembly.memory() call.
A pure text version of the .wasm format – that can greatly simplify learning and debugging – is also available. WebAssembly, however, is not really intended for direct human use. Technically speaking, .wasm is just a browser-compatible **compilation target**: a format in which software compilers can automatically translate code written in high-level programming languages.
This choice is exactly what allows developers to program directly for the preferred user interface of billions of people, in languages they already know (C/C++, Python, Go, Rust and others) but could not be efficiently used by browsers before. Even better, programmers would get this – at least in theory – without ever looking directly at WebAssembly code or worrying (since the target is a **virtual** machine) about which physical CPUs will actually run their code.
**But we already have JavaScript. Do we really need WebAssembly?**
Yes, for several reasons. To begin with, being binary instructions, .wasm files can be much smaller – that is much faster to download – than JavaScript files of equivalent functionality. Above all, Javascript files must be fully parsed and verified before a browser can convert them to bytecode usable by its internal virtual machine.
.wasm files, instead, can be verified and compiled in a single pass, thus making “Streaming Compilation” possible: a browser can start to compile and execute them the moment it starts **downloading them**, just like happens with streaming movies.
This said, not all conceivable WebAssembly applications would surely be faster – or smaller – than equivalent JavaScript ones that are manually optimized by expert programmers. This may happen, for example, if some .wasm needed to include libraries that are not needed with JavaScript.
**Does WebAssembly make JavaScript obsolete?**
In a word: no. Certainly not for a while, at least inside browsers. WebAssembly modules still need JavaScript because by design they cannot access the Document Object Model (DOM), that is the [main API made to modify web pages](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction). Besides, .wasm code cannot make system calls or read the browser’s memory. WebAssembly only runs in a sandbox and, in general, can interact with the outside world even less than JavaScript can, and only through JavaScript interfaces.
Therefore – at least in the near future – .wasm modules will just provide, through JavaScript, the parts that would consume much more bandwidth, memory or CPU time if they were written in that language.
**How web browsers run WebAssembly**
In general, a browser needs at least two pieces to handle dynamic applications: a virtual machine (VM) that runs the app code and standard APIs that that code can use to modify both the behaviour of the browser, and the content of the web page that it displays.
The VMs inside modern browsers support both JavaScript and WebAssembly in the following way:
- The browser downloads a web page written in the HTML markup language, and renders it
- if that HTML calls JavaScript code, the browser’s VM executes it. But…
- if that JavaScript code contains an instance of a WebAssembly module, that one is fetched as explained above, and then used as needed by JavaScript, via the WebAssembly APIs
- and when the WebAssembly code produces something that would alter the DOM – that is the structure of the “host” web page – the JavaScript code receives it and proceeds to the actual alteration.
**How can I create usable WebAssembly code?**
There are more and more programming language communities that are supporting compiling to Wasm directly, we recommend looking at the [introductory guides](https://webassembly.org/getting-started/developers-guide/) from webassembly.org as a starting point depending what language you work with. Note that not all programming languages have the same level of Wasm support, so your mileage may vary.
We plan to release a series of articles in the coming months providing more information about WebAssembly. To get started using it yourself, you can enroll in The Linux Foundation’s free [Introduction to WebAssembly](https://training.linuxfoundation.org/training/introduction-to-webassembly-lfd133/) online training course.
The post [An Introduction to WebAssembly](https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/) appeared first on [Linux Foundation – Training](https://training.linuxfoundation.org/). |
13,199 | 如何更新 openSUSE Linux 系统 | https://itsfoss.com/update-opensuse/ | 2021-03-13T11:09:46 | [
"openSUSE"
] | https://linux.cn/article-13199-1.html | 
就我记忆所及,我一直是 Ubuntu 的用户。我曾经转向过其他发行版,但最终还是一次次回到 Ubuntu。但最近,我开始使用 openSUSE 来尝试一些非 Debian 的东西。
随着我对 [openSUSE](https://www.opensuse.org/) 的不断探索,我不断发现 SUSE 中略有不同的东西,并打算在教程中介绍它们。
第一篇我写的是更新 openSUSE 系统。有两种方法可以做到:
* 使用终端(适用于 openSUSE 桌面和服务器)
* 使用图形工具(适用于 openSUSE 桌面)
### 通过命令行更新 openSUSE
更新 openSUSE 的最简单方法是使用 `zypper` 命令。它提供了补丁和更新管理的全部功能。它可以解决文件冲突和依赖性问题。更新也包括 Linux 内核。
如果你正在使用 openSUSE Leap,请使用这个命令:
```
sudo zypper update
```
你也可以用 `up` 代替 `update`,但我觉得 `update` 更容易记住。
如果你正在使用 openSUSE Tumbleweed,请使用 `dist-upgrade` 或者 `dup`(简称)。Tumbleweed 是[滚动发行版](https://itsfoss.com/rolling-release/),因此建议使用 `dist-upgrade` 选项。
```
sudo zypper dist-upgrade
```
它将显示要升级、删除或安装的软件包列表。

如果你的系统需要重启,你会得到通知。
如果你只是想刷新仓库(像 `sudo apt update` 一样),你可以使用这个命令:
```
sudo zypper refresh
```
如果你想列出可用的更新,也可以这样做:
```
sudo zypper list-updates
```
### 以图形方式更新 openSUSE
如果你使用 openSUSE 作为桌面,你可以选择使用 GUI 工具来安装更新。这个工具可能会根据 [你使用的桌面环境](https://itsfoss.com/find-desktop-environment/) 而改变。
例如,KDE 有自己的软件中心,叫做 “Discover”。你可以用它来搜索和安装新的应用。你也可以用它来安装系统更新。

事实上,KDE 会在通知区通知你可用的系统更新。你必须打开 Discover,因为点击通知不会自动进入 Discover。

如果你觉得这很烦人,你可以使用这些命令禁用它:
```
sudo zypper remove plasma5-pk-updates
sudo zypper addlock plasma5-pk-updates
```
不过我不推荐。最好是获取可用的更新通知。
还有一个 YAST 软件管理 [GUI 工具](https://itsfoss.com/gui-cli-tui/),你可以用它来对软件包管理进行更精细的控制。

就是这些了。这是一篇简短的文章。在下一篇 SUSE 教程中,我将通过实例向大家展示一些常用的 `zypper` 命令。敬请期待。
---
via: <https://itsfoss.com/update-opensuse/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I have been an Ubuntu user for as long as I remember. I distrohopped a little but keep on coming back to Ubuntu. But recently, I have started using openSUSE to try something non-Debian.
As I keep exploring [openSUSE](https://www.opensuse.org/), I keep on stumbling upon things that are slightly different in SUSE-worse and I plan to cover them in tutorials on It’s FOSS.
As a first, I am writing about updating openSUSE system. There are two ways you can do that:
- Using terminal (valid for openSUSE desktops and servers)
- Using a graphical tool (valid for openSUSE desktops)
## Update openSUSE via command line
The simplest way to update openSUSE is by using the zypper command. It provides full functionality of patches and updates management. It takes care of the file conflicts and dependency problems. These system updates also include Linux kernel.
There is a slight [difference between openSUSE Leap and Tumbleweed](https://itsfoss.com/opensuse-leap-vs-tumbleweed/) update command.
If you are using openSUSE Leap, use this command:
`sudo zypper update`
You may also use `up`
instead of `update`
but I find it easier to remember.
If you are using openSUSE Tumbleweed, use the `dist-upgrade`
or `dup`
(in short). Tumbleweed is [rolling release distribution](https://itsfoss.com/rolling-release/) and hence it is advised to use dist-upgrade option.
`sudo zypper dist-upgrade`
It will show you the list of the packages to be upgraded, removed or installed.
You’ll be notified if your system requires reboots.
If you just want to refresh the repositories (like sudo apt update), you may use this command:
`sudo zypper refresh`
If you want to list the available updates, you can also do that:
`sudo zypper list-updates`
## Graphical way to update openSUSE
If you are using openSUSE as a desktop, you’ll have the additional option of using the GUI tools for installing the updates. This tool may change depending on [which desktop environment you are using](https://itsfoss.com/find-desktop-environment/).
For example, KDE has its own Software center called Discover. You can use it to search and install new applications. You can also use it to install system updates.
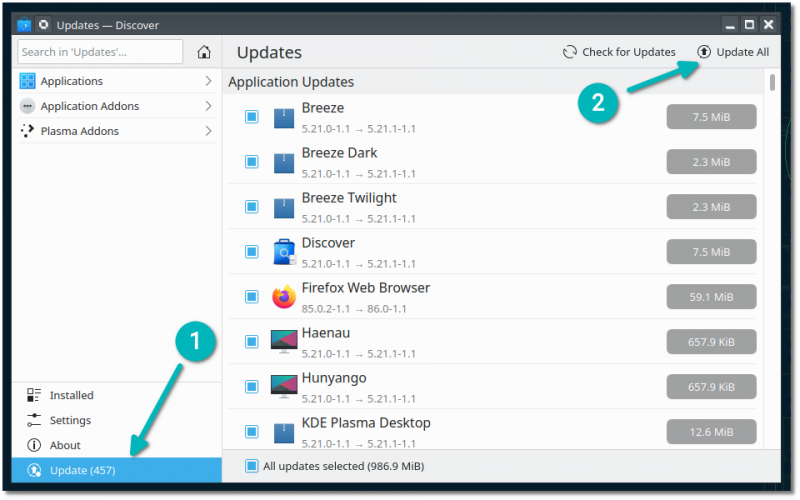
In fact, KDE notifies you of available system updates in the notification area. You’ll have to open Discover explicitly because clicking on the notification doesn’t automatically take you to Discover.
If you find that annoying, you may disable it using these commands:
```
sudo zypper remove plasma5-pk-updates
sudo zypper addlock plasma5-pk-updates
```
I wouldn’t recommend it though. It’s better to get notified of available updates.
There is also the YAST Software Management [GUI tool](https://itsfoss.com/gui-cli-tui/) which you can use for more granular control on package managements.
That’s it. It was a short one. In the next SUSE tutorial, I’ll show you some common zypper commands with examples. Stay tuned. |
13,200 | 6 个最佳的 Git 仓库管理实践 | https://opensource.com/article/20/7/git-repos-best-practices | 2021-03-13T22:59:38 | [
"Git",
"仓库"
] | https://linux.cn/article-13200-1.html |
>
> 抵制在 Git 中添加一些会增加管理难度的东西的冲动;这里有替代方法。
>
>
>

有权访问源代码使对安全性的分析以及应用程序的安全成为可能。但是,如果没有人真正看过代码,问题就不会被发现,即使人们主动地看代码,通常也要看很多东西。幸运的是,GitHub 拥有一个活跃的安全团队,最近,他们 [发现了已提交到多个 Git 仓库中的特洛伊木马病毒](https://securitylab.github.com/research/octopus-scanner-malware-open-source-supply-chain/),甚至仓库的所有者也偷偷溜走了。尽管我们无法控制其他人如何管理自己的仓库,但我们可以从他们的错误中吸取教训。为此,本文回顾了将文件添加到自己的仓库中的一些最佳实践。
### 了解你的仓库

这对于安全的 Git 仓库来可以说是头号规则。作为项目维护者,无论是你自己创建的还是采用别人的,你的工作是了解自己仓库中的内容。你可能无法记住代码库中每一个文件,但是你需要了解你所管理的内容的基本组成部分。如果在几十个合并后出现一个游离的文件,你会很容易地发现它,因为你不知道它的用途,你需要检查它来刷新你的记忆。发生这种情况时,请查看该文件,并确保准确了解为什么它是必要的。
### 禁止二进制大文件

Git 是为文本而生的,无论是用纯文本编写的 C 或 Python 还是 Java 文本,亦或是 JSON、YAML、XML、Markdown、HTML 或类似的文本。Git 对于二进制文件不是很理想。
两者之间的区别是:
```
$ cat hello.txt
This is plain text.
It's readable by humans and machines alike.
Git knows how to version this.
$ git diff hello.txt
diff --git a/hello.txt b/hello.txt
index f227cc3..0d85b44 100644
--- a/hello.txt
+++ b/hello.txt
@@ -1,2 +1,3 @@
This is plain text.
+It's readable by humans and machines alike.
Git knows how to version this.
```
和
```
$ git diff pixel.png
diff --git a/pixel.png b/pixel.png
index 563235a..7aab7bc 100644
Binary files a/pixel.png and b/pixel.png differ
$ cat pixel.png
�PNG
▒
IHDR7n�$gAMA��
�abKGD݊�tIME�
-2R��
IDA�c`�!�3%tEXtdate:create2020-06-11T11:45:04+12:00��r.%tEXtdate:modify2020-06-11T11:45:04+12:00��ʒIEND�B`�
```
二进制文件中的数据不能像纯文本一样被解析,因此,如果二进制文件发生任何更改,则必须重写整个内容。一个版本与另一个版本之间唯一的区别就是全部不同,这会快速增加仓库大小。
更糟糕的是,Git 仓库维护者无法合理地审计二进制数据。这违反了头号规则:应该对仓库的内容了如指掌。
除了常用的 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 工具之外,你还可以使用 `git diff` 检测二进制文件。当你尝试使用 `--numstat` 选项来比较二进制文件时,Git 返回空结果:
```
$ git diff --numstat /dev/null pixel.png | tee
- - /dev/null => pixel.png
$ git diff --numstat /dev/null file.txt | tee
5788 0 /dev/null => list.txt
```
如果你正在考虑将二进制大文件(BLOB)提交到仓库,请停下来先思考一下。如果它是二进制文件,那它是由什么生成的。是否有充分的理由不在构建时生成它们,而是将它们提交到仓库?如果你认为提交二进制数据是有意义的,请确保在 `README` 文件或类似文件中指明二进制文件的位置、为什么是二进制文件的原因以及更新它们的协议是什么。必须谨慎对其更新,因为你每提交一个二进制大文件的变化,它的存储空间实际上都会加倍。
### 让第三方库留在第三方
第三方库也不例外。尽管它是开源的众多优点之一,你可以不受限制地重用和重新分发不是你编写的代码,但是有很多充分的理由不把第三方库存储在你自己的仓库中。首先,除非你自己检查了所有代码(以及将来的合并),否则你不能为第三方完全担保。其次,当你将第三方库复制到你的 Git 仓库中时,会将焦点从真正的上游源代码中分离出来。从技术上讲,对库有信心的人只对该库的主副本有把握,而不是对随机仓库的副本有把握。如果你需要锁定特定版本的库,请给开发者提供一个合理的项目所需的发布 URL,或者使用 [Git 子模块](https://git-scm.com/book/en/v2/Git-Tools-Submodules)。
### 抵制盲目的 git add

如果你的项目已编译,请抵制住使用 `git add .` 的冲动(其中 `.` 是当前目录或特定文件夹的路径),因为这是一种添加任何新东西的简单方法。如果你不是手动编译项目,而是使用 IDE 为你管理项目,这一点尤其重要。用 IDE 管理项目时,跟踪添加到仓库中的内容会非常困难,因此仅添加你实际编写的内容非常重要,而不是添加项目文件夹中出现的任何新对象。
如果你使用了 `git add .`,请在推送之前检查暂存区里的内容。如果在运行 `make clean` 或等效命令后,执行 `git status` 时在项目文件夹中看到一个陌生的对象,请找出它的来源,以及为什么仍然在项目的目录中。这是一种罕见的构建工件,不会在编译期间重新生成,因此在提交前请三思。
### 使用 Git ignore

许多为程序员打造的便利也非常杂乱。任何项目的典型项目目录,无论是编程的,还是艺术的或其他的,到处都是隐藏的文件、元数据和遗留的工件。你可以尝试忽略这些对象,但是 `git status` 中的提示越多,你错过某件事的可能性就越大。
你可以通过维护一个良好的 `gitignore` 文件来为你过滤掉这种噪音。因为这是使用 Git 的用户的共同要求,所以有一些入门级的 `gitignore` 文件。[Github.com/github/gitignore](https://github.com/github/gitignore) 提供了几个专门创建的 `gitignore` 文件,你可以下载这些文件并将其放置到自己的项目中,[Gitlab.com](https://about.gitlab.com/releases/2016/05/22/gitlab-8-8-released) 在几年前就将`gitignore` 模板集成到了仓库创建工作流程中。使用这些模板来帮助你为项目创建适合的 `gitignore` 策略并遵守它。
### 查看合并请求

当你通过电子邮件收到一个合并/拉取请求或补丁文件时,不要只是为了确保它能正常工作而进行测试。你的工作是阅读进入代码库的新代码,并了解其是如何产生结果的。如果你不同意这个实现,或者更糟的是,你不理解这个实现,请向提交该实现的人发送消息,并要求其进行说明。质疑那些希望成为版本库永久成员的代码并不是一种社交失误,但如果你不知道你把什么合并到用户使用的代码中,那就是违反了你和用户之间的社交契约。
### Git 责任
社区致力于开源软件良好的安全性。不要鼓励你的仓库中不良的 Git 实践,也不要忽视你克隆的仓库中的安全威胁。Git 功能强大,但它仍然只是一个计算机程序,因此要以人为本,确保每个人的安全。
---
via: <https://opensource.com/article/20/7/git-repos-best-practices>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Having access to source code makes it possible to analyze the security and safety of applications. But if nobody actually looks at the code, the issues won’t get caught, and even when people are actively looking at code, there’s usually quite a lot to look at. Fortunately, GitHub has an active security team, and recently, they [revealed a Trojan that had been committed into several Git repositories](https://securitylab.github.com/research/octopus-scanner-malware-open-source-supply-chain/), having snuck past even the repo owners. While we can’t control how other people manage their own repositories, we can learn from their mistakes. To that end, this article reviews some of the best practices when it comes to adding files to your own repositories.
## Know your repo
This is arguably Rule Zero for a secure Git repository. As a project maintainer, whether you started it yourself or you’ve adopted it from someone else, it’s your job to know the contents of your own repository. You might not have a memorized list of every file in your codebase, but you need to know the basic components of what you’re managing. Should a stray file appear after a few dozen merges, you’ll be able to spot it easily because you won’t know what it’s for, and you’ll need to inspect it to refresh your memory. When that happens, review the file and make sure you understand exactly why it’s necessary.
## Ban binary blobs
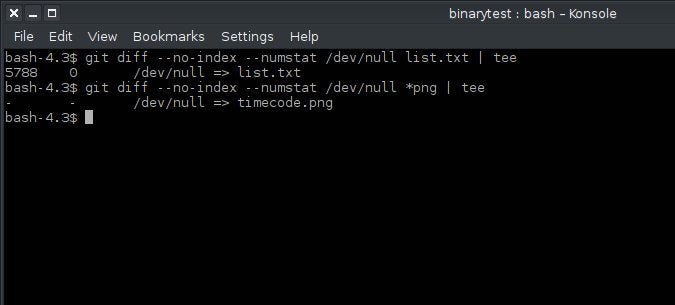
Git is meant for text, whether it’s C or Python or Java written in plain text, or JSON, YAML, XML, Markdown, HTML, or something similar. Git isn’t ideal for binary files.
It’s the difference between this:
```
$ cat hello.txt
This is plain text.
It's readable by humans and machines alike.
Git knows how to version this.
$ git diff hello.txt
diff --git a/hello.txt b/hello.txt
index f227cc3..0d85b44 100644
--- a/hello.txt
+++ b/hello.txt
@@ -1,2 +1,3 @@
This is plain text.
+It's readable by humans and machines alike.
Git knows how to version this.
```
and this:
```
$ git diff pixel.png
diff --git a/pixel.png b/pixel.png
index 563235a..7aab7bc 100644
Binary files a/pixel.png and b/pixel.png differ
$ cat pixel.png
�PNG
▒
IHDR7n�$gAMA��
�abKGD݊�tIME�
-2R��
IDA�c`�!�3%tEXtdate:create2020-06-11T11:45:04+12:00��r.%tEXtdate:modify2020-06-11T11:45:04+12:00��ʒIEND�B`�
```
The data in a binary file can’t be parsed in the same way plain text can be parsed, so if anything is changed in a binary file, the whole thing must be rewritten. The only difference between one version and the other is everything, which adds up quickly.
Worse still, binary data can’t be reasonably audited by you, the Git repository maintainer. That’s a violation of Rule Zero: know what’s in your repository.
In addition to the usual [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) tools, you can detect binaries using `git diff`
. When you try to diff a binary file using the `--numstat`
option, Git returns a null result:
```
$ git diff --numstat /dev/null pixel.png | tee
- - /dev/null => pixel.png
$ git diff --numstat /dev/null file.txt | tee
5788 0 /dev/null => list.txt
```
If you’re considering committing binary blobs to your repository, stop and think about it first. If it’s binary, it was generated by something. Is there a good reason not to generate them at build time instead of committing them to your repo? Should you decide it does make sense to commit binary data, make sure you identify, in a README file or similar, where the binary files are, why they’re binary, and what the protocol is for updating them. Updates must be performed sparingly, because, for every change you commit to a binary blob, the storage space for that blob effectively doubles.
## Keep third-party libraries third-party
Third-party libraries are no exception to this rule. While it’s one of the many benefits of open source that you can freely re-use and re-distribute code you didn’t write, there are many good reasons not to house a third-party library in your own repository. First of all, you can’t exactly vouch for a third party, unless you’ve reviewed all of its code (and future merges) yourself. Secondly, when you copy third party libraries into your Git repo, it splinters focus away from the true upstream source. Someone confident in the library is technically only confident in the master copy of the library, not in a copy lying around in a random repo. If you need to lock into a specific version of a library, either provide developers with a reasonable URL the release your project needs or else use [Git Submodule](https://git-scm.com/book/en/v2/Git-Tools-Submodules).
## Resist a blind git add
If your project is compiled, resist the urge to use `git add .`
(where `.`
is either the current directory or the path to a specific folder) as an easy way to add anything and everything new. This is especially important if you’re not manually compiling your project, but are using an IDE to manage your project for you. It can be extremely difficult to track what’s gotten added to your repository when an IDE manages your project, so it’s important to only add what you’ve actually written and not any new object that pops up in your project folder.
If you do use `git add .`
, review what’s in staging before you push. If you see an unfamiliar object in your project folder when you do a `git status`
, find out where it came from and why it’s still in your project directory after you’ve run a `make clean`
or equivalent command. It’s a rare build artifact that won’t regenerate during compilation, so think twice before committing it.
## Use Git ignore
Many of the conveniences built for programmers are also very noisy. The typical project directory for any project, programming, or artistic or otherwise, is littered with hidden files, metadata, and leftover artifacts. You can try to ignore these objects, but the more noise there is in your `git status`
, the more likely you are to miss something.
You can Git filter out this noise for you by maintaining a good gitignore file. Because that’s a common requirement for anyone using Git, there are a few starter gitignore files available. [Github.com/github/gitignore](https://github.com/github/gitignore) offers several purpose-built gitignore files you can download and place into your own project, and [Gitlab.com](https://about.gitlab.com/releases/2016/05/22/gitlab-8-8-released) integrated gitignore templates into the repo creation workflow several years ago. Use these to help you build a reasonable gitignore policy for your project, and stick to it.
## Review merge requests
When you get a merge or pull request or a patch file through email, don’t just test it to make sure it works. It’s your job to read new code coming into your codebase and to understand how it produces the result it does. If you disagree with the implementation, or worse, you don’t comprehend the implementation, send a message back to the person submitting it and ask for clarification. It’s not a social faux pas to question code looking to become a permanent fixture in your repository, but it’s a breach of your social contract with your users to not know what you merge into the code they’ll be using.
## Git responsible
Good software security in open source is a community effort. Don’t encourage poor Git practices in your repositories, and don’t overlook a security threat in repositories you clone. Git is powerful, but it’s still just a computer program, so be the human in the equation and keep everyone safe.
## 3 Comments |
13,202 | 如何在 Fedora 上使用 Poetry 来管理你的 Python 项目? | https://fedoramagazine.org/how-to-use-poetry-to-manage-your-python-projects-on-fedora/ | 2021-03-14T06:59:15 | [
"Python"
] | https://linux.cn/article-13202-1.html | 
Python 开发人员经常创建一个新的虚拟环境来分离项目依赖,然后用 `pip`、`pipenv` 等工具来管理它们。Poetry 是一个简化 Python 中依赖管理和打包的工具。这篇文章将向你展示如何在 Fedora 上使用 Poetry 来管理你的 Python 项目。
与其他工具不同,Poetry 只使用一个配置文件来进行依赖管理、打包和发布。这消除了对不同文件的需求,如 `Pipfile`、`MANIFEST.in`、`setup.py` 等。这也比使用多个工具更快。
下面详细介绍一下开始使用 Poetry 时使用的命令。
### 在 Fedora 上安装 Poetry
如果你已经使用 Fedora 32 或以上版本,你可以使用这个命令直接从命令行安装 Poetry:
```
$ sudo dnf install poetry
```
编者注:在 Fedora Silverblue 或 CoreOs上,Python 3.9.2 是核心提交的一部分,你可以用下面的命令安装 Poetry:
```
rpm-ostree install poetry
```
### 初始化一个项目
使用 `new` 命令创建一个新项目:
```
$ poetry new poetry-project
```
用 Poetry 创建的项目结构是这样的:
```
├── poetry_project
│ └── init.py
├── pyproject.toml
├── README.rst
└── tests
├── init.py
└── test_poetry_project.py
```
Poetry 使用 `pyproject.toml` 来管理项目的依赖。最初,这个文件看起来类似于这样:
```
[tool.poetry]
name = "poetry-project"
version = "0.1.0"
description = ""
authors = ["Kadermiyanyedi <[email protected]>"]
[tool.poetry.dependencies]
python = "^3.9"
[tool.poetry.dev-dependencies]
pytest = "^5.2"
[build-system]
requires = ["poetry>=0.12"]
build-backend = "poetry.masonry.api"
```
这个文件包含 4 个部分:
* 第一部分包含描述项目的信息,如项目名称、项目版本等。
* 第二部分包含项目的依赖。这些依赖是构建项目所必需的。
* 第三部分包含开发依赖。
* 第四部分描述的是符合 [PEP 517](https://www.python.org/dev/peps/pep-0517/) 的构建系统。
如果你已经有一个项目,或者创建了自己的项目文件夹,并且你想使用 Poetry,请在你的项目中运行 `init` 命令。
```
$ poetry init
```
在这个命令之后,你会看到一个交互式的 shell 来配置你的项目。
### 创建一个虚拟环境
如果你想创建一个虚拟环境或激活一个现有的虚拟环境,请使用以下命令:
```
$ poetry shell
```
Poetry 默认在 `/home/username/.cache/pypoetry` 项目中创建虚拟环境。你可以通过编辑 Poetry 配置来更改默认路径。使用下面的命令查看配置列表:
```
$ poetry config --list
cache-dir = "/home/username/.cache/pypoetry"
virtualenvs.create = true
virtualenvs.in-project = true
virtualenvs.path = "{cache-dir}/virtualenvs"
```
修改 `virtualenvs.in-project` 配置变量,在项目目录下创建一个虚拟环境。Poetry 命令是:
```
$ poetry config virtualenv.in-project true
```
### 添加依赖
使用 `poetry add` 命令为项目安装一个依赖:
```
$ poetry add django
```
你可以使用带有 `--dev` 选项的 `add` 命令来识别任何只用于开发环境的依赖:
```
$ poetry add black --dev
```
`add` 命令会创建一个 `poetry.lock` 文件,用来跟踪软件包的版本。如果 `poetry.lock` 文件不存在,那么会安装 `pyproject.toml` 中所有依赖项的最新版本。如果 `poetry.lock` 存在,Poetry 会使用文件中列出的确切版本,以确保每个使用这个项目的人的软件包版本是一致的。
使用 `poetry install` 命令来安装当前项目中的所有依赖:
```
$ poetry install
```
通过使用 `--no-dev` 选项防止安装开发依赖:
```
$ poetry install --no-dev
```
### 列出软件包
`show` 命令会列出所有可用的软件包。`--tree` 选项将以树状列出软件包:
```
$ poetry show --tree
django 3.1.7 A high-level Python Web framework that encourages rapid development and clean, pragmatic design.
├── asgiref >=3.2.10,<4
├── pytz *
└── sqlparse >=0.2.2
```
包含软件包名称,以列出特定软件包的详细信息:
```
$ poetry show requests
name : requests
version : 2.25.1
description : Python HTTP for Humans.
dependencies
- certifi >=2017.4.17
- chardet >=3.0.2,<5
- idna >=2.5,<3
- urllib3 >=1.21.1,<1.27
```
最后,如果你想知道软件包的最新版本,你可以通过 `--latest` 选项:
```
$ poetry show --latest
idna 2.10 3.1 Internationalized Domain Names in Applications
asgiref 3.3.1 3.3.1 ASGI specs, helper code, and adapters
```
### 更多信息
Poetry 的更多详情可在[文档](https://python-poetry.org/docs/)中获取。
---
via: <https://fedoramagazine.org/how-to-use-poetry-to-manage-your-python-projects-on-fedora/>
作者:[Kader Miyanyedi](https://fedoramagazine.org/author/moonkat/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python developers often create a new virtual environment to separate project dependencies and then manage them with tools such as *pip, pipenv, etc.* Poetry is a tool for simplifying dependency management and packaging in Python. This post will show you how to use Poetry to manage your Python projects on Fedora.
Unlike other tools, Poetry uses only a single configuration file for dependency management, packaging, and publishing. This eliminates the need for different files such as *Pipfile, MANIFEST.in, setup.py*, etc. It is also faster than* *using multiple tools.
Detailed below is a brief overview of commands used when getting started with Poetry.
**Installing Poetry on Fedora**
If you already use Fedora 32 or above, you can install Poetry directly from the command line using this command:
$ sudo dnf install poetry
*Editor note: on Fedora Silverblue or CoreOs Python 3.9.2 is part of the core commit, you would layer Poetry with ‘*rpm-ostree install poetry*‘*
## Initialize a project
Create a new project using the* new *command.
$ poetry new poetry-project
The structure of a project created with Poetry looks like this:
├── poetry_project │ └──init.py ├── pyproject.toml ├── README.rst └── tests ├──init.py └── test_poetry_project.py
Poetry uses *pyproject.toml *to manage the dependencies of your project. Initially, this file will look similar to this:
[tool.poetry] name = "poetry-project" version = "0.1.0" description = "" authors = ["Someone <[email protected]>"] [tool.poetry.dependencies] python = "^3.9" [tool.poetry.dev-dependencies] pytest = "^5.2" [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"
This file contains 4 sections:
- The first section contains information describing the project such as project name, project version, etc.
- The second section contains project dependencies. These dependencies are necessary to build the project.
- The third section contains development dependencies.
- The fourth section describes a building system as in
[PEP 517](https://www.python.org/dev/peps/pep-0517/)
If you already have a project, or create your own project folder, and you want to use poetry, run the *init* command within your project.
$ poetry init
After this command, you will see an interactive shell to configure your project.
## Create a virtual environment
If you want to create a virtual environment or activate an existing virtual environment, use the command below:
$ poetry shell
Poetry creates the virtual environment in the* /home/username/.cache/pypoetry* project by default. You can change the default path by editing the poetry config. Use the command below to see the config list:
$ poetry config --listcache-dir = "/home/username/.cache/pypoetry" virtualenvs.create = true virtualenvs.in-project = true virtualenvs.path = "{cache-dir}/virtualenvs"
Change the *virtualenvs.in-project* configuration variable to create a virtual environment within your project directory. The Poetry command is:
$ poetry config virtualenvs.in-project true
## Add dependencies
Install a dependency for the project with the* poetry add *command.
$ poetry add django
You can identify any dependencies that you use only for the development environment using the *add* command with the *–dev* option.
$ poetry add black --dev
The **add **command creates a *poetry.lock file* that is used to track package versions. If the *poetry.lock* file doesn’t exist, the latest versions of all dependencies in *pyproject.toml* are installed. If *poetry.lock* does exist, Poetry uses the exact versions listed in the file to ensure that the package versions are consistent for everyone working on your project.
Use the poetry *install* command to install all dependencies in your current project.
$ poetry install
Prevent development dependencies from being installed by using the *no-dev *option.
$ poetry install --no-dev
## List packages
The *show* command lists all of the available packages. The *tree* option will list packages as a tree.
$ poetry show --treedjango3.1.7A high-level Python Web framework that encourages rapid development and clean, pragmatic design. ├── asgiref >=3.2.10,<4 ├── pytz * └── sqlparse >=0.2.2
Include the package name to list details of a specific package.
$ poetry show requestsname : requests version :2.25.1description : Python HTTP for Humans. dependencies - certifi>=2017.4.17- chardet>=3.0.2,<5- idna>=2.5,<3- urllib3>=1.21.1,<1.27
Finally, if you want to learn the latest version of the packages, you can pass the *latest* option.
$ poetry show --latestidna2.103.1 Internationalized Domain Names in Applications asgiref3.3.13.3.1 ASGI specs, helper code, and adapters
## Further information
More details on Poetry are available in the [documentation](https://python-poetry.org/docs/).
## Artur
Small tip: you can use dephell (https://dephell.readthedocs.io/) to change from other formats like requirements.txt or Pipfile to poetry.
Install dephell, add below to pyproject.toml and run “dephell deps convert”.
[tool.dephell.main]
from = {format = “pip”, path = “requirements.txt”}
to = {format = “poetry”, path = “pyproject.toml”}
## Ryan
This is nifty!
Poetry does have the ability to export a requirements.txt file natively(poetry export -f requirements.txt), if this is all that is desired.
## Katsuharu Tanaka
Thank you for introducing a useful tool. I will try it in a future project.
## Daniel Eguia
Nice write up… Will try this out soon
## Tim Hughes
Nice and clearly explained. It may also be worth doing a followup on this article to include building as a wheel and publishing to pypi as a project.
I use poetry for all my new projects so I built a cookiecutter template for it which others may find useful (or not).
– https://github.com/timhughes/cookiecutter-poetry
## besiw93427
Nice.
Maybe I’ll give this a try.
## ojnny
Thank you! Found a typo here:
poetry config virtualenv.in-project true
should be:
poetry config virtualenvs.in-project true
## Ryan
A shortcut for adding requirements for an existing project is something like:
poetry add $(cat requirements.txt)
Has definitely come in handy for us.
## thunderbirdtr
Thank you for the nice article, It is a very hand tool as well. |
13,203 | 学习使用 GDB 调试代码 | https://opensource.com/article/21/3/debug-code-gdb | 2021-03-14T21:06:00 | [
"调试",
"GDB"
] | https://linux.cn/article-13203-1.html |
>
> 使用 GNU 调试器来解决你的代码问题。
>
>
>

GNU 调试器常以它的命令 `gdb` 称呼它,它是一个交互式的控制台,可以帮助你浏览源代码、分析执行的内容,其本质上是对错误的应用程序中出现的问题进行逆向工程。
故障排除的麻烦在于它很复杂。[GNU 调试器](https://www.gnu.org/software/gdb/) 并不是一个特别复杂的应用程序,但如果你不知道从哪里开始,甚至不知道何时和为何你可能需要求助于 GDB 来进行故障排除,那么它可能会让人不知所措。如果你一直使用 `print`、`echo` 或 [printf 语句](https://opensource.com/article/20/8/printf)来调试你的代码,当你开始思考是不是还有更强大的东西时,那么本教程就是为你准备的。
### 有错误的代码
要开始使用 GDB,你需要一些代码。这里有一个用 C++ 写的示例应用程序(如果你一般不使用 C++ 编写程序也没关系,在所有语言中原理都是一样的),其来源于 [猜谜游戏系列](/article-12985-1.html) 中的一个例子。
```
#include <iostream>
#include <stdlib.h> //srand
#include <stdio.h> //printf
using namespace std;
int main () {
srand (time(NULL));
int alpha = rand() % 8;
cout << "Hello world." << endl;
int beta = 2;
printf("alpha is set to is %s\n", alpha);
printf("kiwi is set to is %s\n", beta);
return 0;
} // main
```
这个代码示例中有一个 bug,但它确实可以编译(至少在 GCC 5 的时候)。如果你熟悉 C++,你可能已经看到了,但这是一个简单的问题,可以帮助新的 GDB 用户了解调试过程。编译并运行它就可以看到错误:
```
$ g++ -o buggy example.cpp
$ ./buggy
Hello world.
Segmentation fault
```
### 排除段故障
从这个输出中,你可以推测变量 `alpha` 的设置是正确的,因为否则的话,你就不会看到它*后面*的那行代码执行。当然,这并不总是正确的,但这是一个很好的工作理论,如果你使用 `printf` 作为日志和调试器,基本上也会得出同样的结论。从这里,你可以假设 bug 在于成功打印的那一行之后的*某行*。然而,不清楚错误是在下一行还是在几行之后。
GNU 调试器是一个交互式的故障排除工具,所以你可以使用 `gdb` 命令来运行错误的代码。为了得到更好的结果,你应该从包含有*调试符号*的源代码中重新编译你的错误应用程序。首先,看看 GDB 在不重新编译的情况下能提供哪些信息:
```
$ gdb ./buggy
Reading symbols from ./buggy...done.
(gdb) start
Temporary breakpoint 1 at 0x400a44
Starting program: /home/seth/demo/buggy
Temporary breakpoint 1, 0x0000000000400a44 in main ()
(gdb)
```
当你以一个二进制可执行文件作为参数启动 GDB 时,GDB 会加载该应用程序,然后等待你的指令。因为这是你第一次在这个可执行文件上运行 GDB,所以尝试重复这个错误是有意义的,希望 GDB 能够提供进一步的见解。很直观,GDB 用来启动它所加载的应用程序的命令就是 `start`。默认情况下,GDB 内置了一个*断点*,所以当它遇到你的应用程序的 `main` 函数时,它会暂停执行。要让 GDB 继续执行,使用命令 `continue`:
```
(gdb) continue
Continuing.
Hello world.
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
(gdb)
```
毫不意外:应用程序在打印 “Hello world” 后不久就崩溃了,但 GDB 可以提供崩溃发生时正在发生的函数调用。这有可能就足够你找到导致崩溃的 bug,但为了更好地了解 GDB 的功能和一般的调试过程,想象一下,如果问题还没有变得清晰,你想更深入地挖掘这段代码发生了什么。
### 用调试符号编译代码
要充分利用 GDB,你需要将调试符号编译到你的可执行文件中。你可以用 GCC 中的 `-g` 选项来生成这个符号:
```
$ g++ -g -o debuggy example.cpp
$ ./debuggy
Hello world.
Segmentation fault
```
将调试符号编译到可执行文件中的结果是得到一个大得多的文件,所以通常不会分发它们,以增加便利性。然而,如果你正在调试开源代码,那么用调试符号重新编译测试是有意义的:
```
$ ls -l *buggy* *cpp
-rw-r--r-- 310 Feb 19 08:30 debug.cpp
-rwxr-xr-x 11624 Feb 19 10:27 buggy*
-rwxr-xr-x 22952 Feb 19 10:53 debuggy*
```
### 用 GDB 调试
加载新的可执行文件(本例中为 `debuggy`)以启动 GDB:
```
$ gdb ./debuggy
Reading symbols from ./debuggy...done.
(gdb) start
Temporary breakpoint 1 at 0x400a44
Starting program: /home/seth/demo/debuggy
Temporary breakpoint 1, 0x0000000000400a44 in main ()
(gdb)
```
如前所述,使用 `start` 命令进行:
```
(gdb) start
Temporary breakpoint 1 at 0x400a48: file debug.cpp, line 9.
Starting program: /home/sek/demo/debuggy
Temporary breakpoint 1, main () at debug.cpp:9
9 srand (time(NULL));
(gdb)
```
这一次,自动的 `main` 断点可以指明 GDB 暂停的行号和该行包含的代码。你可以用 `continue` 恢复正常操作,但你已经知道应用程序在完成之前就会崩溃,因此,你可以使用 `next` 关键字逐行步进检查你的代码:
```
(gdb) next
10 int alpha = rand() % 8;
(gdb) next
11 cout << "Hello world." << endl;
(gdb) next
Hello world.
12 int beta = 2;
(gdb) next
14 printf("alpha is set to is %s\n", alpha);
(gdb) next
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
(gdb)
```
从这个过程可以确认,崩溃不是发生在设置 `beta` 变量的时候,而是执行 `printf` 行的时候。这个 bug 在本文中已经暴露了好几次(破坏者:向 `printf` 提供了错误的数据类型),但暂时假设解决方案仍然不明确,需要进一步调查。
### 设置断点
一旦你的代码被加载到 GDB 中,你就可以向 GDB 询问到目前为止代码所产生的数据。要尝试数据自省,通过再次发出 `start` 命令来重新启动你的应用程序,然后进行到第 11 行。一个快速到达 11 行的简单方法是设置一个寻找特定行号的断点:
```
(gdb) start
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Temporary breakpoint 2 at 0x400a48: file debug.cpp, line 9.
Starting program: /home/sek/demo/debuggy
Temporary breakpoint 2, main () at debug.cpp:9
9 srand (time(NULL));
(gdb) break 11
Breakpoint 3 at 0x400a74: file debug.cpp, line 11.
```
建立断点后,用 `continue` 继续执行:
```
(gdb) continue
Continuing.
Breakpoint 3, main () at debug.cpp:11
11 cout << "Hello world." << endl;
(gdb)
```
现在暂停在第 11 行,就在 `alpha` 变量被设置之后,以及 `beta` 被设置之前。
### 用 GDB 进行变量自省
要查看一个变量的值,使用 `print` 命令。在这个示例代码中,`alpha` 的值是随机的,所以你的实际结果可能与我的不同:
```
(gdb) print alpha
$1 = 3
(gdb)
```
当然,你无法看到一个尚未建立的变量的值:
```
(gdb) print beta
$2 = 0
```
### 使用流程控制
要继续进行,你可以步进代码行来到达将 `beta` 设置为一个值的位置:
```
(gdb) next
Hello world.
12 int beta = 2;
(gdb) next
14 printf("alpha is set to is %s\n", alpha);
(gdb) print beta
$3 = 2
```
另外,你也可以设置一个观察点,它就像断点一样,是一种控制 GDB 执行代码流程的方法。在这种情况下,你知道 `beta` 变量应该设置为 `2`,所以你可以设置一个观察点,当 `beta` 的值发生变化时提醒你:
```
(gdb) watch beta > 0
Hardware watchpoint 5: beta > 0
(gdb) continue
Continuing.
Breakpoint 3, main () at debug.cpp:11
11 cout << "Hello world." << endl;
(gdb) continue
Continuing.
Hello world.
Hardware watchpoint 5: beta > 0
Old value = false
New value = true
main () at debug.cpp:14
14 printf("alpha is set to is %s\n", alpha);
(gdb)
```
你可以用 `next` 手动步进完成代码的执行,或者你可以用断点、观察点和捕捉点来控制代码的执行。
### 用 GDB 分析数据
你可以以不同格式查看数据。例如,以八进制值查看 `beta` 的值:
```
(gdb) print /o beta
$4 = 02
```
要查看其在内存中的地址:
```
(gdb) print /o &beta
$5 = 0x2
```
你也可以看到一个变量的数据类型:
```
(gdb) whatis beta
type = int
```
### 用 GDB 解决错误
这种自省不仅能让你更好地了解什么代码正在执行,还能让你了解它是如何执行的。在这个例子中,对变量运行的 `whatis` 命令给了你一个线索,即你的 `alpha` 和 `beta` 变量是整数,这可能会唤起你对 `printf` 语法的记忆,使你意识到在你的 `printf` 语句中,你必须使用 `%d` 来代替 `%s`。做了这个改变,就可以让应用程序按预期运行,没有更明显的错误存在。
当代码编译后发现有 bug 存在时,特别令人沮丧,但最棘手的 bug 就是这样,如果它们很容易被发现,那它们就不是 bug 了。使用 GDB 是猎取并消除它们的一种方法。
### 下载我们的速查表
生活的真相就是这样,即使是最基本的编程,代码也会有 bug。并不是所有的错误都会导致应用程序无法运行(甚至无法编译),也不是所有的错误都是由错误的代码引起的。有时,bug 是基于一个特别有创意的用户所做的意外的选择组合而间歇性发生的。有时,程序员从他们自己的代码中使用的库中继承了 bug。无论原因是什么,bug 基本上无处不在,程序员的工作就是发现并消除它们。
GNU 调试器是一个寻找 bug 的有用工具。你可以用它做的事情比我在本文中演示的要多得多。你可以通过 GNU Info 阅读器来了解它的许多功能:
```
$ info gdb
```
无论你是刚开始学习 GDB 还是专业人员的,提醒一下你有哪些命令是可用的,以及这些命令的语法是什么,都是很有帮助的。
* [下载 GDB 速查表](https://opensource.com/downloads/gnu-debugger-cheat-sheet)
---
via: <https://opensource.com/article/21/3/debug-code-gdb>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The GNU Debugger, more commonly known by its command, `gdb`
, is an interactive console to help you step through source code, analyze what gets executed, and essentially reverse-engineer what's going wrong in a buggy application.
The trouble with troubleshooting is that it's complex. [GNU Debugger](https://www.gnu.org/software/gdb/) isn't exactly a complex application, but it can be overwhelming if you don't know where to start or even when and why you might need to turn to GDB to do your troubleshooting. If you've been using print, echo, or [printf statements](https://opensource.com/article/20/8/printf) to debug your code, but you're beginning to suspect there may be something more powerful, then this tutorial is for you.
## Code is buggy
To get started with GDB, you need some code. Here's a sample application written in C++ (it's OK if you don't typically write in C++, the principles are the same across all languages), derived from one of the examples in the [guessing game series](https://opensource.com/article/20/12/learn-c-game) here on Opensource.com:
```
#include <iostream>
#include <stdlib.h> //srand
#include <stdio.h> //printf
using namespace std;
int main () {
srand (time(NULL));
int alpha = rand() % 8;
cout << "Hello world." << endl;
int beta = 2;
printf("alpha is set to is %s\n", alpha);
printf("kiwi is set to is %s\n", beta);
return 0;
} // main
```
There's a bug in this code sample, but it does compile (at least as of GCC 5). If you're familiar with C++, you may already see it, but it's a simple problem that can help new GDB users understand the debugging process. Compile it and run it to see the error:
```
$ g++ -o buggy example.cpp
$ ./buggy
Hello world.
Segmentation fault
```
## Troubleshooting a segmentation fault
From this output, you can surmise that the variable `alpha`
was set correctly because otherwise, you wouldn't expect the line of code that came *after* it. That's not always true, of course, but it's a good working theory, and it's essentially the same conclusion you'd likely come to if you were using `printf`
as a log and debugger. From here, you can assume that the bug lies in *some line* after the one that printed successfully. However, it's not clear whether the bug is in the very next line or several lines later.
GNU Debugger is an interactive troubleshooter, so you can use the `gdb`
command to run buggy code. For best results, you should recompile your buggy application from source code with *debug symbols* included. First, take a look at what information GDB can provide without recompiling:
```
$ gdb ./buggy
Reading symbols from ./buggy...done.
(gdb) start
Temporary breakpoint 1 at 0x400a44
Starting program: /home/seth/demo/buggy
Temporary breakpoint 1, 0x0000000000400a44 in main ()
(gdb)
```
When you start GDB with a binary executable as the argument, GDB loads the application and then waits for your instructions. Because this is the first time you're running GDB on this executable, it makes sense to try to repeat the error in hopes that GDB can provide further insight. GDB's command to launch the application it has loaded is, intuitively enough, `start`
. By default, there's a *breakpoint* built into GDB so that when it encounters the `main`
function of your application, it pauses execution. To allow GDB to proceed, use the command `continue`
:
```
(gdb) continue
Continuing.
Hello world.
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
(gdb)
```
No surprises here: the application crashed shortly after printing "Hello world," but GDB can provide the function call that was happening when the crash occurred. This could potentially be all you need to find the bug that's causing the crash, but to get a better idea of GDB's features and the general debugging process, imagine that the problem hasn't become clear yet, and you want to dig even deeper into what's happening with this code.
## Compiling code with debug symbols
To get the most out of GDB, you need debug symbols compiled into your executable. You can generate this with the `-g`
option in GCC:
```
$ g++ -o debuggy example.cpp
$ ./debuggy
Hello world.
Segmentation fault
```
Compiling debug symbols into an executable results in a much larger file, so they're usually not distributed with the added convenience. However, if you're debugging open source code, it makes sense to recompile with debug symbols for testing:
```
$ ls -l *buggy* *cpp
-rw-r--r-- 310 Feb 19 08:30 debug.cpp
-rwxr-xr-x 11624 Feb 19 10:27 buggy*
-rwxr-xr-x 22952 Feb 19 10:53 debuggy*
```
## Debugging with GDB
Launch GDB with your new executable (`debuggy`
, in this example) loaded:
```
$ gdb ./debuggy
Reading symbols from ./debuggy...done.
(gdb) start
Temporary breakpoint 1 at 0x400a44
Starting program: /home/seth/demo/debuggy
Temporary breakpoint 1, 0x0000000000400a44 in main ()
(gdb)
```
As before, use the `start`
command to proceed:
```
(gdb) start
Temporary breakpoint 1 at 0x400a48: file debug.cpp, line 9.
Starting program: /home/sek/demo/debuggy
Temporary breakpoint 1, main () at debug.cpp:9
9 srand (time(NULL));
(gdb)
```
This time, the automatic `main`
breakpoint can specify what line number GDB paused on and what code the line contains. You could resume normal operation with `continue`
but you already know that the application crashes before completion, so instead, you can step through your code line-by-line using the `next`
keyword:
```
(gdb) next
10 int alpha = rand() % 8;
(gdb) next
11 cout << "Hello world." << endl;
(gdb) next
Hello world.
12 int beta = 2;
(gdb) next
14 printf("alpha is set to is %s\n", alpha);
(gdb) next
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
(gdb)
```
From this process, you can confirm that the crash didn't happen when the `beta`
variable was being set but when the `printf`
line was executed. The bug has been exposed several times in this article (spoiler: the wrong data type is being provided to `printf`
), but assume for a moment that the solution remains unclear and that further investigation is required.
## Setting breakpoints
Once your code is loaded into GDB, you can ask GDB about the data that the code has produced so far. To try some data introspection, restart your application by issuing the `start`
command again and then proceed to line 11. An easy way to get to 11 quickly is to set a breakpoint that looks for a specific line number:
```
(gdb) start
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Temporary breakpoint 2 at 0x400a48: file debug.cpp, line 9.
Starting program: /home/sek/demo/debuggy
Temporary breakpoint 2, main () at debug.cpp:9
9 srand (time(NULL));
(gdb) break 11
Breakpoint 3 at 0x400a74: file debug.cpp, line 11.
```
With the breakpoint established, continue the execution with `continue`
:
```
(gdb) continue
Continuing.
Breakpoint 3, main () at debug.cpp:11
11 cout << "Hello world." << endl;
(gdb)
```
You're now paused at line 11, just after the `alpha`
variable has been set, and just before `beta`
gets set.
## Doing variable introspection with GDB
To see the value of a variable, use the `print`
command. The value of `alpha`
is random in this example code, so your actual results may vary from mine:
```
(gdb) print alpha
$1 = 3
(gdb)
```
Of course, you can't see the value of a variable that has not yet been established:
```
(gdb) print beta
$2 = 0
```
## Using flow control
To proceed, you could step through the lines of code to get to the point where `beta`
is set to a value:
```
(gdb) next
Hello world.
12 int beta = 2;
(gdb) next
14 printf("alpha is set to is %s\n", alpha);
(gdb) print beta
$3 = 2
```
Alternatively, you could set a watchpoint. A watchpoint, like a breakpoint, is a way to control the flow of how GDB executes the code. In this case, you know that the `beta`
variable should be set to `2`
, so you could set a watchpoint to alert you when the value of `beta`
changes:
```
(gdb) watch beta > 0
Hardware watchpoint 5: beta > 0
(gdb) continue
Continuing.
Breakpoint 3, main () at debug.cpp:11
11 cout << "Hello world." << endl;
(gdb) continue
Continuing.
Hello world.
Hardware watchpoint 5: beta > 0
Old value = false
New value = true
main () at debug.cpp:14
14 printf("alpha is set to is %s\n", alpha);
(gdb)
```
You can step through the code execution manually with `next`
, or you can control how the code executes with breakpoints, watchpoints, and catchpoints.
## Analyzing data with GDB
You can see data in different formats. For instance, to see the value of `beta`
as an octal value:
```
(gdb) print /o beta
$4 = 02
```
To see its address in memory:
```
(gdb) print /o beta
$5 = 0x2
```
You can also see the data type of a variable:
```
(gdb) whatis beta
type = int
```
## Solving bugs with GDB
This kind of introspection better informs you about not only what code is getting executed but how it's getting executed. In this example, the `whatis`
command on a variable gives you a clue that your `alpha`
and `beta`
variables are integers, which might jog your memory about `printf`
syntax, making you realize that instead of `%s`
in your `printf`
statements, you must use the `%d`
designator. Making that change causes the application to run as expected, with no more obvious bugs present.
It's especially frustrating when code compiles but then reveals that there are bugs present, but that's how the trickiest of bugs work. If they were easy to catch, they wouldn't be bugs. Using GDB is one way to hunt them down and eliminate them.
## Download our cheatsheet
It's a fact of life, in even the most basic forms of programming, that code has bugs. Not all bugs are so crippling that they stop an application from running (or even from compiling), and not all bugs are caused by incorrect code. Sometimes bugs happen intermittently based on an unexpected combination of choices made by a particularly creative user. Sometimes programmers inherit bugs from the libraries they use in their own code. Whatever the cause, bugs are basically everywhere, and it's part of the programmer's job to find and neutralize them.
GNU Debugger is a useful tool in finding bugs. There's a lot more you can do with it than I demonstrated in this article. You can read about its many functions with the GNU Info reader:
`$ info gdb`
Whether you're just learning GDB or you're a pro at it, it never hurts to have a reminder of what commands are available to you and what the syntax for those commands are.
## Comments are closed. |
13,205 | 在 Linux 上使用 gImageReader 从图像和 PDF 中提取文本 | https://itsfoss.com/gimagereader-ocr/ | 2021-03-15T13:46:00 | [
"OCR"
] | https://linux.cn/article-13205-1.html |
>
> gImageReader 是一个 GUI 工具,用于在 Linux 中利用 Tesseract OCR 引擎从图像和 PDF 文件中提取文本。
>
>
>
[gImageReader](https://github.com/manisandro/gImageReader) 是 [Tesseract 开源 OCR 引擎](https://tesseract-ocr.github.io/)的一个前端。Tesseract 最初是由 HP 公司开发的,然后在 2006 年开源。
基本上,OCR(光学字符识别)引擎可以让你从图片或文件(PDF)中扫描文本。默认情况下,它可以检测几种语言,还支持通过 Unicode 字符扫描。
然而,Tesseract 本身是一个没有任何 GUI 的命令行工具。因此,gImageReader 就来解决这点,它可以让任何用户使用它从图像和文件中提取文本。
让我重点介绍一些有关它的内容,同时说下我在测试期间的使用经验。
### gImageReader:一个跨平台的 Tesseract OCR 前端

为了简化事情,gImageReader 在从 PDF 文件或包含任何类型文本的图像中提取文本时非常方便。
无论你是需要它来进行拼写检查还是翻译,它都应该对特定的用户群体有用。
以列表总结下功能,这里是你可以用它做的事情:
* 从磁盘、扫描设备、剪贴板和截图中添加 PDF 文档和图像
* 能够旋转图像
* 常用的图像控制,用于调整亮度、对比度和分辨率。
* 直接通过应用扫描图像
* 能够一次性处理多个图像或文件
* 手动或自动识别区域定义
* 识别纯文本或 [hOCR](https://en.wikipedia.org/wiki/HOCR) 文档
* 编辑器显示识别的文本
* 可对对提取的文本进行拼写检查
* 从 hOCR 文件转换/导出为 PDF 文件
* 将提取的文本导出为 .txt 文件
* 跨平台(Windows)
### 在 Linux 上安装 gImageReader
**注意**:你需要安装 Tesseract 语言包,才能从软件管理器中的图像/文件中进行检测。

你可以在一些 Linux 发行版如 Fedora 和 Debian 的默认仓库中找到 gImageReader。
对于 Ubuntu,你需要添加一个 PPA,然后安装它。要做到这点,下面是你需要在终端中输入的内容:
```
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt update
sudo apt install gimagereader
```
你也可以从 openSUSE 的构建服务中找到它,Arch Linux 用户可在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到。
所有的仓库和包的链接都可以在他们的 [GitHub 页面](https://github.com/manisandro/gImageReader)中找到。
### gImageReader 使用经验
当你需要从图像中提取文本时,gImageReader 是一个相当有用的工具。当你尝试从 PDF 文件中提取文本时,它的效果非常好。
对于从智能手机拍摄的图片中提取,检测很接近,但有点不准确。也许当你进行扫描时,从文件中识别字符可能会更好。
所以,你需要亲自尝试一下,看看它是否对你而言工作良好。我在 Linux Mint 20.1(基于 Ubuntu 20.04)上试过。
我只遇到了一个从设置中管理语言的问题,我没有得到一个快速的解决方案。如果你遇到此问题,那么可能需要对其进行故障排除,并进一步了解如何解决该问题。

除此之外,它工作良好。
试试吧,让我知道它是如何为你服务的!如果你知道类似的东西(和更好的),请在下面的评论中告诉我。
---
via: <https://itsfoss.com/gimagereader-ocr/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: gImageReader is a GUI tool to utilize tesseract OCR engine for extracting texts from images and PDF files in Linux. *
[gImageReader](https://github.com/manisandro/gImageReader) is a front-end for [Tesseract Open Source OCR Engine](https://tesseract-ocr.github.io/). *Tesseract* was originally developed at HP and then was open-sourced in 2006.
Basically, the OCR (Optical Character Recognition) engine lets you scan texts from a picture or a file (PDF). It can detect several languages by default and also supports scanning through Unicode characters.
However, the Tesseract by itself is a command-line tool without any GUI. So, here, gImageReader comes to the rescue to let any user utilize it to extract text from images and files.
Let me highlight a few things about it while mentioning my experience with it for the time I tested it out.
## gImageReader: A Cross-Platform Front-End to Tesseract OCR
To simplify things, gImageReader comes in handy to extract text from a PDF file or an image that contains any kind of text.
Whether you need it for spellcheck or translation, it should be useful for a specific group of users.
To sum up the features in a list, here’s what you can do with it:
- Add PDF documents and images from disk, scanning devices, clipboard and screenshots
- Ability to rotate images
- Common image controls to adjust brightness, contrast, and resolution
- Scan images directly through the app
- Ability to process multiple images or files in one go
- Manual or automatic recognition area definition
- Recognize to plain text or to
[hOCR](https://en.wikipedia.org/wiki/HOCR)documents - Editor to display the recognized text
- Can spellcheck the text extracted
- Convert/Export to PDF documents from hOCR document
- Export extracted text as a .txt file
- Cross-platform (Windows)
## Installing gImageReader on Linux
**Note**: *You need to explicitly install Tesseract language packs to detect from images/files from your software manager.*
You can find gImageReader in the default repositories for some Linux distributions like Fedora and Debian.
For Ubuntu, you need to add a PPA and then install it. To do that, here’s what you need to type in the terminal:
```
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt update
sudo apt install gimagereader
```
You can also find it for openSUSE from its build service and [AUR](https://itsfoss.com/aur-arch-linux/) will be the place for Arch Linux users.
All the links to the repositories and the packages can be found in their [GitHub page](https://github.com/manisandro/gImageReader).
## Experience with gImageReader
gImageReader is a quite useful tool for extracting texts from images when you need them. It works great when you try from a PDF file.
For extracting images from a picture shot on a smartphone, the detection was close but a bit inaccurate. Maybe when you scan something, recognition of characters from the file could be better.
So, you’ll have to try it for yourself to see how well it works for your use-case. I tried it on Linux Mint 20.1 (based on Ubuntu 20.04).
I just had an issue to manage languages from the settings and I didn’t get a quick solution for that. If you encounter the issue, you might want to troubleshoot it and explore more about it how to fix it.
Other than that, it worked just fine.
Do give it a try and let me know how it worked for you! If you know of something similar (and better), do let me know about it in the comments below. |
13,206 | 9 个 Node.js 开发人员最喜欢的开源工具 | https://opensource.com/article/20/1/open-source-tools-nodejs | 2021-03-15T23:37:00 | [
"Node.js"
] | https://linux.cn/article-13206-1.html |
>
> 在众多可用于简化 Node.js 开发的工具中,以下 9 种是最佳选择。
>
>
>

我最近在 [StackOverflow](https://insights.stackoverflow.com/survey/2019#technology-_-other-frameworks-libraries-and-tools) 上读到了一项调查,该调查称超过 49% 的开发人员在其项目中使用了 Node.js。这结果对我来说并不意外。
作为一个狂热的技术使用者,我可以肯定地说 Node.js 的引入引领了软件开发的新时代。现在,它是软件开发最受欢迎的技术之一,仅次于JavaScript。
### Node.js 是什么,为什么如此受欢迎?
Node.js 是一个跨平台的开源运行环境,用于在浏览器之外执行 JavaScript 代码。它也是建立在 Chrome 的 JavaScript 运行时之上的首选运行时环境,主要用于构建快速、可扩展和高效的网络应用程序。
我记得当时我们要花费几个小时来协调前端和后端开发人员,他们分别编写不同脚本。当 Node.js 出现后,所有这些都改变了。我相信,促使开发人员采用这项技术是因为它的双向效率。
使用 Node.js,你可以让你的代码同时运行在客户端和服务器端,从而加快了整个开发过程。Node.js 弥合了前端和后端开发之间的差距,并使开发过程更加高效。
### Node.js 工具浪潮
对于 49% 的开发人员(包括我)来说,Node.js 处于在前端和后端开发的金字塔顶端。有大量的 [Node.js 用例](https://www.simform.com/nodejs-use-case/) 帮助我和我的团队在截止日期之内交付复杂的项目。幸运的是,Node.js 的日益普及也产生了一系列开源项目和工具,以帮助开发人员使用该环境。
近来,对使用 Node.js 构建的项目的需求突然增加。有时,我发现管理这些项目,并同时保持交付高质量项目的步伐非常具有挑战性。因此,我决定使用为 Node.js 开发人员提供的许多开源工具中一些最高效的,使某些方面的开发自动化。
根据我在 Node.js 方面的丰富经验,我使用了许多的工具,这些工具对整个开发过程都非常有帮助:从简化编码过程,到监测再到内容管理。
为了帮助我的 Node.js 开发同道,我整理了这个列表,其中包括我最喜欢的 9 个简化 Node.js 开发的开源工具。
### Webpack
[Webpack](https://webpack.js.org/) 是一个容易使用的 JavaScript <ruby> 模块捆绑程序 <rt> module bundler </rt></ruby>,用于简化前端开发。它会检测具有依赖的模块,并将其转换为描述模块的静态<ruby> 素材 <rt> asset </rt></ruby>。
可以通过软件包管理器 npm 或 Yarn 安装该工具。
利用 npm 命令安装如下:
```
npm install --save-dev webpack
```
利用 Yarn 命令安装如下:
```
yarn add webpack --dev
```
Webpack 可以创建在运行时异步加载的单个捆绑包或多个素材链。不必单独加载。使用 Webpack 工具可以快速高效地打包这些素材并提供服务,从而改善用户整体体验,并减少开发人员在管理加载时间方面的困难。
### Strapi
[Strapi](https://strapi.io/) 是一个开源的<ruby> 无界面 <rt> headless </rt></ruby>内容管理系统(CMS)。无界面 CMS 是一种基础软件,可以管理内容而无需预先构建好的前端。它是一个使用 RESTful API 函数的只有后端的系统。
可以通过软件包管理器 Yarn 或 npx 安装 Strapi。
利用 Yarn 命令安装如下:
```
yarn create strapi-app my-project --quickstart
```
利用 npx 命令安装如下:
```
npx create-strapi-app my-project --quickstart
```
Strapi 的目标是在任何设备上以结构化的方式获取和交付内容。CMS 可以使你轻松管理应用程序的内容,并确保它们是动态的,可以在任何设备上访问。
它提供了许多功能,包括文件上传、内置的电子邮件系统、JSON Web Token(JWT)验证和自动生成文档。我发现它非常方便,因为它简化了整个 CMS,并为我提供了编辑、创建或删除所有类型内容的完全自主权。
另外,通过 Strapi 构建的内容结构非常灵活,因为你可以创建和重用内容组和可定制的 API。
### Broccoli
[Broccoli](https://broccoli.build/) 是一个功能强大的构建工具,运行在 [ES6](https://en.wikipedia.org/wiki/ECMAScript#6th_Edition_-_ECMAScript_2015) 模块上。构建工具是一种软件,可让你将应用程序或网站中的所有各种素材(例如图像、CSS、JavaScript 等)组合成一种可分发的格式。Broccoli 将自己称为 “雄心勃勃的应用程序的素材管道”。
使用 Broccoli 你需要一个项目目录。有了项目目录后,可以使用以下命令通过 npm 安装 Broccoli:
```
npm install --save-dev broccoli
npm install --global broccoli-cli
```
你也可以使用 Yarn 进行安装。
当前版本的 Node.js 就是使用该工具的最佳版本,因为它提供了长期支持。它可以帮助你避免进行更新和重新安装过程中的麻烦。安装过程完成后,可以在 `Brocfile.js` 文件中包含构建规范。
在 Broccoli 中,抽象单位是“树”,该树将文件和子目录存储在特定子目录中。因此,在构建之前,你必须有一个具体的想法,你希望你的构建是什么样子的。
最好的是,Broccoli 带有用于开发的内置服务器,可让你将素材托管在本地 HTTP 服务器上。Broccoli 非常适合流线型重建,因为其简洁的架构和灵活的生态系统可提高重建和编译速度。Broccoli 可让你井井有条,以节省时间并在开发过程中最大限度地提高生产力。
### Danger
[Danger](https://danger.systems/) 是一个非常方便的开源工具,用于简化你的<ruby> 拉取请求 <rt> pull request </rt></ruby>(PR)检查。正如 Danger 库描述所说,该工具可通过管理 PR 检查来帮助 “正规化” 你的代码审查系统。Danger 可以与你的 CI 集成在一起,帮助你加快审核过程。
将 Danger 与你的项目集成是一个简单的逐步过程:你只需要包括 Danger 模块,并为每个项目创建一个 Danger 文件。然而,创建一个 Danger 帐户(通过 GitHub 或 Bitbucket 很容易做到),并且为开源软件项目设置访问令牌更加方便。
可以通过 NPM 或 Yarn 安装 Danger。要使用 Yarn,请添加 `danger -D` 到 `package.JSON` 中。
将 Danger 添加到 CI 后,你可以:
* 高亮显示重要的创建工件
* 通过强制链接到 Trello 和 Jira 之类的工具来管理 sprint
* 强制生成更新日志
* 使用描述性标签
* 以及更多
例如,你可以设计一个定义团队文化并为代码审查和 PR 检查设定特定规则的系统。根据 Danger 提供的元数据及其广泛的插件生态系统,可以解决常见的<ruby> 议题 <rt> issue </rt></ruby>。
### Snyk
网络安全是开发人员的主要关注点。[Snyk](https://snyk.io/) 是修复开源组件中漏洞的最著名工具之一。它最初是一个用于修复 Node.js 项目漏洞的项目,并且已经演变为可以检测并修复 Ruby、Java、Python 和 Scala 应用程序中的漏洞。Snyk 主要分四个阶段运行:
* 查找漏洞依赖性
* 修复特定漏洞
* 通过 PR 检查预防安全风险
* 持续监控应用程序
Snyk 可以集成在项目的任何阶段,包括编码、CI/CD 和报告。我发现这对于测试 Node.js 项目非常有帮助,可以测试或构建 npm 软件包时检查是否存在安全风险。你还可以在 GitHub 中为你的应用程序运行 PR 检查,以使你的项目更安全。Synx 还提供了一系列集成,可用于监控依赖关系并解决特定问题。
要在本地计算机上运行 Snyk,可以通过 NPM 安装它:
```
npm install -g snyk
```
### Migrat
[Migrat](https://github.com/naturalatlas/migrat) 是一款使用纯文本的数据迁移工具,非常易于使用。 它可在各种软件堆栈和进程中工作,从而使其更加实用。你可以使用简单的代码行安装 Migrat:
```
$ npm install -g migrat
```
Migrat 并不需要特别的数据库引擎。它支持多节点环境,因为迁移可以在一个全局节点上运行,也可以在每个服务器上运行一次。Migrat 之所以方便,是因为它便于向每个迁移传递上下文。
你可以定义每个迁移的用途(例如,数据库集、连接、日志接口等)。此外,为了避免随意迁移,即多个服务器在全局范围内进行迁移,Migrat 可以在进程运行时进行全局锁定,从而使其只能在全局范围内运行一次。它还附带了一系列用于 SQL 数据库、Slack、HipChat 和 Datadog 仪表盘的插件。你可以将实时迁移状况发送到这些平台中的任何一个。
### Clinic.js
[Clinic.js](https://clinicjs.org/) 是一个用于 Node.js 项目的开源监视工具。它结合了三种不同的工具 Doctor、Bubbleprof 和 Flame,帮助你监控、检测和解决 Node.js 的性能问题。
你可以通过运行以下命令从 npm 安装 Clinic.js:
```
$ npm install clinic
```
你可以根据要监视项目的某个方面以及要生成的报告,选择要使用的 Clinic.js 包含的三个工具中的一个:
* Doctor 通过注入探针来提供详细的指标,并就项目的总体运行状况提供建议。
* Bubbleprof 非常适合分析,并使用 `async_hooks` 生成指标。
* Flame 非常适合发现代码中的热路径和瓶颈。
### PM2
监视是后端开发过程中最重要的方面之一。[PM2](https://pm2.keymetrics.io/) 是一款 Node.js 的进程管理工具,可帮助开发人员监视项目的多个方面,例如日志、延迟和速度。该工具与 Linux、MacOS 和 Windows 兼容,并支持从 Node.js 8.X 开始的所有 Node.js 版本。
你可以使用以下命令通过 npm 安装 PM2:
```
$ npm install pm2 --g
```
如果尚未安装 Node.js,则可以使用以下命令安装:
```
wget -qO- https://getpm2.com/install.sh | bash
```
安装完成后,使用以下命令启动应用程序:
```
$ pm2 start app.js
```
关于 PM2 最好的地方是可以在集群模式下运行应用程序。可以同时为多个 CPU 内核生成一个进程。这样可以轻松增强应用程序性能并最大程度地提高可靠性。PM2 也非常适合更新工作,因为你可以使用 “热重载” 选项更新应用程序并以零停机时间重新加载应用程序。总体而言,它是为 Node.js 应用程序简化进程管理的好工具。
### Electrode
[Electrode](https://www.electrode.io/) 是 Walmart Labs 的一个开源应用程序平台。该平台可帮助你以结构化方式构建大规模通用的 React/Node.js 应用程序。
Electrode 应用程序生成器使你可以构建专注于代码的灵活内核,提供一些出色的模块以向应用程序添加复杂功能,并附带了广泛的工具来优化应用程序的 Node.js 包。
可以使用 npm 安装 Electrode。安装完成后,你可以使用 Ignite 启动应用程序,并深入研究 Electrode 应用程序生成器。
你可以使用 NPM 安装 Electrode:
```
npm install -g electrode-ignite xclap-cli
```
### 你最喜欢哪一个?
这些只是不断增长的开源工具列表中的一小部分,在使用 Node.js 时,这些工具可以在不同阶段派上用场。你最喜欢使用哪些开源 Node.js 工具?请在评论中分享你的建议。
---
via: <https://opensource.com/article/20/1/open-source-tools-nodejs>
作者:[Hiren Dhadhuk](https://opensource.com/users/hirendhadhuk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently read a survey on [StackOverflow](https://insights.stackoverflow.com/survey/2019#technology-_-other-frameworks-libraries-and-tools) that said more than 49% of developers use Node.js for their projects. This came as no surprise to me.
As an avid user of technology, I think it's safe to say that the introduction of Node.js led to a new era of software development. It is now one of the most preferred technologies for software development, right next to JavaScript.
## What is Node.js, and why is it so popular?
Node.js is a cross-platform, open source runtime environment for executing JavaScript code outside of the browser. It is also a preferred runtime environment built on Chrome's JavaScript runtime and is mainly used for building fast, scalable, and efficient network applications.
I remember when we used to sit for hours and hours coordinating between front-end and back-end developers who were writing different scripts for each side. All of this changed as soon as Node.js came into the picture. I believe that the one thing that drives developers towards this technology is its two-way efficiency.
With Node.js, you can run your code simultaneously on both the client and the server side, speeding up the whole process of development. Node.js bridges the gap between front-end and back-end development and makes the development process much more efficient.
## A wave of Node.js tools
For 49% of all developers (including me), Node.js is at the top of the pyramid when it comes to front-end and back-end development. There are tons of [Node.js use cases](https://www.simform.com/nodejs-use-case/) that have helped me and my team deliver complex projects within our deadlines. Fortunately, Node.js' rising popularity has also produced a wave of open source projects and tools to help developers working with the environment.
Recently, there has been a sudden increase in demand for projects built with Node.js. Sometimes, I find it quite challenging to manage these projects and keep up the pace while delivering high-quality results. So I decided to automate certain aspects of development using some of the most efficient of the many open source tools available for Node.js developers.
In my extensive experience with Node.js, I've worked with a wide range of tools that have helped me with the overall development process—from streamlining the coding process to monitoring to content management.
To help my fellow Node.js developers, I compiled this list of 9 of my favorite open source tools for simplifying Node.js development.
## Webpack
[Webpack](https://webpack.js.org/) is a handy JavaScript module bundler used to simplify front-end development. It detects modules with dependencies and transforms them into static assets that represent the modules.
You can install the tool through either the npm or Yarn package manager.
With npm:
`npm install --save-dev webpack`
With Yarn:
`yarn add webpack --dev`
Webpack creates single bundles or multiple chains of assets that can be loaded asynchronously at runtime. Each asset does not have to be loaded individually. Bundling and serving assets becomes quick and efficient with the Webpack tool, making the overall user experience better and reducing the developer's hassle in managing load time.
## Strapi
[Strapi](https://strapi.io/) is an open source headless content management system (CMS). A headless CMS is basically software that lets you manage your content devoid of a prebuilt frontend. It is a backend-only system that functions using RESTful APIs.
You can install Strapi through Yarn or npx packages.
With Yarn:
`yarn create strapi-app my-project --quickstart`
With npx:
`npx create-strapi-app my-project --quickstart`
Strapi's goal is to fetch and deliver your content in a structured manner across any device. The CMS makes it easy to manage your applications' content and make sure they are dynamic and accessible across any device.
It provides a lot of features, including file upload, a built-in email system, JSON Web Token (JWT) authentication, and auto-generated documentation. I find it very convenient, as it simplifies the overall CMS and gives me full autonomy in editing, creating, or deleting all types of contents.
In addition, the content structure built through Strapi is extremely flexible because you can create and reuse groups of content and customizable APIs.
## Broccoli
[Broccoli](https://broccoli.build/) is a powerful build tool that runs on an [ES6](https://en.wikipedia.org/wiki/ECMAScript#6th_Edition_-_ECMAScript_2015) module. Build tools are software that let you assemble all the different assets within your application or website, e.g., images, CSS, JavaScript, etc., into one distributable format. Broccoli brands itself as the "asset pipeline for ambitious applications."
You need a project directory to work with Broccoli. Once you have the project directory in place, you can install Broccoli with npm using:
```
npm install --save-dev broccoli
npm install --global broccoli-cli
```
You can also use Yarn for installation.
The current version of Node.js would be the best version for the tool as it provides long-time support. This helps you avoid the hassle of updating and reinstalling as you go. Once the installation process is completed, you can include the build specification in your Brocfile.js.
In Broccoli, the unit of abstraction is a tree, which stores files and subdirectories within specific subdirectories. Therefore, before you build, you must have a specific idea of what you want your build to look like.
The best part about Broccoli is that it comes with a built-in server for development that lets you host your assets on a local HTTP server. Broccoli is great for streamlined rebuilds, as its concise architecture and flexible ecosystem boost rebuild and compilation speeds. Broccoli lets you get organized to save time and maximize productivity during development.
## Danger
[Danger](https://danger.systems/) is a very handy open source tool for streamlining your pull request (PR) checks. As Danger's library description says, the tool helps you "formalize" your code review system by managing PR checks. Danger integrates with your CI and helps you speed up the review process.
Integrating Danger with your project is an easy step-by-step process—you just need to include the Danger module and create a Danger file for each project. However, it's more convenient to create a Danger account (easy to do through GitHub or Bitbucket), then set up access tokens for your open source software projects.
Danger can be installed via NPM or Yarn. To use Yarn, add danger -D to add it to your package.JSON.
After you add Danger to your CI, you can:
- Highlight build artifacts of importance
- Manage sprints by enforcing links to tools like Trello and Jira
- Enforce changelogs
- Utilize descriptive labels
- And much more
For example, you can design a system that defines the team culture and sets out specific rules for code review and PR checks. Common issues can be solved based on the metadata Danger provides along with its extensive plugin ecosystem.
## Snyk
Cybersecurity is a major concern for developers. [Snyk](https://snyk.io/) is one of the most well-known tools to fix vulnerabilities in open source components. It started as a project to fix vulnerabilities in Node.js projects and has evolved to detect and fix vulnerabilities in Ruby, Java, Python, and Scala apps as well. Snyk mainly runs in four stages:
- Finding vulnerability dependencies
- Fixing specific vulnerabilities
- Preventing security risks by PR checks
- Monitoring apps continuously
Snyk can be integrated with your project at any stage, including coding, CI/CD, and reporting. I find it extremely helpful for testing Node.js projects to test out npm packages for security risks or at build-time. You can also run PR checks for your applications in GitHub to make your projects more secure. Synx also provides a range of integrations that you can use to monitor dependencies and fix specific problems.
To run Snyk on your machine locally, you can install it through NPM:
`npm install -g snyk`
## Migrat
[Migrat](https://github.com/naturalatlas/migrat) is an extremely easy to use data-migration tool that uses plain text. It works across a diverse range of stacks and processes that make it even more convenient. You can install Migrat with a simple line of code:
`$ npm install -g migrat`
Migrat is not specific to a particular database engine. It supports multi-node environments, as migrations can run on one node globally or once per server. What makes Migrat convenient is the facilitation of passing context to each migration.
You can define what each migration is for (e.g.,. database sets, connections, logging interfaces, etc.). Moreover, to avoid haphazard migrations, where multiple servers are running migrations globally, Migrat facilitates global lockdown while the process is running so that it can run only once globally. It also comes with a range of plug-ins for SQL databases, Slack, HipChat, and the Datadog dashboard. You can send live migrations to any of these platforms.
## Clinic.js
[Clinic.js](https://clinicjs.org/) is an open source monitoring tool for Node.js projects. It combines three different tools—Doctor, Bubbleprof, and Flame—that help you monitor, detect, and solve performance issues with Node.js.
You can install Clinic.js from npm by running this command:
`$ npm install clinic`
You can choose which of the three tools that comprise Clinic.js you want to use based on which aspect of your project you want to monitor and the report you want to generate:
- Doctor provides detailed metrics by injecting probes and provides recommendations on the overall health of your project.
- Bubbleprof is great for profiling and generates metrics using async_hooks.
- Flame is great for uncovering hot paths and bottlenecks in your code.
## PM2
Monitoring is one of the most important aspects of any backend development process. [PM2](https://pm2.keymetrics.io/) is a process management tool for Node.js that helps developers monitor multiple aspects of their projects such as logs, delays, and speed. The tool is compatible with Linux, MacOS, and Windows and supports all Node.js versions starting from Node.js 8.X.
You can install PM2 with npm using:
`$ npm install pm2 --g`
If you do not already have Node.js installed, you can use:
`wget -qO- https://getpm2.com/install.sh | bash`
Once it's installed, start the application with:
`$ pm2 start app.js`
The best part about PM2 is that it lets you run your apps in cluster mode. You can spawn a process for multiple CPU cores at a time. This makes it easy to enhance application performance and maximize reliability. PM2 is also great for updates, as you can update your apps and reload them with zero downtime using the "hot reload" option. Overall, it's a great tool to simplify process management for Node.js applications.
## Electrode
[Electrode](https://www.electrode.io/) is an open source application platform from Walmart Labs. The platform helps you build large-scale, universal React/Node.js applications in a structured manner.
The Electrode app generator lets you build a flexible core focused on the code, provides some great modules to add complex features to the app, and comes with a wide range of tools to optimize your app's Node.js bundle.
Electrode can be installed using npm. Once the installation is finished, you can start the app using Ignite and dive right in with the Electrode app generator.
You can install Electrode using NPM:
`npm install -g electrode-ignite xclap-cli`
## Which are your favorite?
These are just a few of the always-growing list of open source tools that can come in handy at different stages when working with Node.js. Which are your go-to open source Node.js tools? Please share your recommendations in the comments.
## 3 Comments |
13,208 | 了解 FreeDOS 中的文件名和目录 | https://opensource.com/article/21/3/files-freedos | 2021-03-16T09:45:53 | [
"FreeDOS"
] | https://linux.cn/article-13208-1.html |
>
> 了解如何在 FreeDOS 中创建,编辑和命名文件。
>
>
>

开源操作系统 [FreeDOS](https://www.freedos.org/) 是一个久经考验的项目,可帮助用户玩复古游戏、更新固件、运行过时但受欢迎的应用以及研究操作系统设计。FreeDOS 提供了有关个人计算历史的见解(因为它实现了 80 年代初的事实上的操作系统),但是它是在现代环境中进行的。在本文中,我将使用 FreeDOS 来解释文件名和扩展名是如何发展的。
### 了解文件名和 ASCII 文本
FreeDOS 文件名遵循所谓的 *8.3 惯例*。这意味着所有的 FreeDOS 文件名都有两个部分,分别包含最多八个和三个字符。第一部分通常被称为*文件名*(这可能会让人有点困惑,因为文件名和文件扩展名的组合也被称为文件名)。这一部分可以有一个到八个字符。之后是*扩展名*,可以有零到三个字符。这两部分之间用一个点隔开。
文件名可以使用任何字母或数字。键盘上的许多其他字符也是允许的,但不是所有的字符。这是因为许多其他字符在 FreeDOS 中被指定了特殊用途。一些可以出现在 FreeDOS 文件名中的字符有:
```
~ ! @ # $ % ^ & ( ) _ - { } `
```
扩展 [ASCII](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tmp.2sISc4Tp3G#ASCII) 字符集中也有一些字符可以使用,例如 `�`。
在 FreeDOS 中具有特殊意义的字符,因此不能用于文件名中,包括:
```
* / + | \ = ? [ ] ; : " . < > ,
```
另外,你不能在 FreeDOS 文件名中使用空格。FreeDOS 控制台[使用空格将命令的与选项和参数分隔](https://opensource.com/article/21/2/set-your-path-freedos)。
FreeDOS 是*不区分大小写*的,所以不管你是使用大写字母还是小写字母都无所谓。所有的字母都会被转换为大写字母,所以无论你做什么,你的文件最终都会在名称中使用大写字母。
#### 文件扩展名
FreeDOS 中的文件不需要有扩展名,但文件扩展名确实有一些用途。某些文件扩展名在 FreeDOS 中有内置的含义,例如:
* **EXE**:可执行文件
* **COM**:命令文件
* **SYS**:系统文件
* **BAT**:批处理文件
特定的软件程序使用其他扩展名,或者你可以在创建文件时使用它们。这些扩展名没有绝对的文件关联,因此如果你使用 FreeDOS 的文字处理器,你的文件使用什么扩展名并不重要。如果你愿意,你可以发挥创意,将扩展名作为你的文件系统的一部分。例如,你可以用 `*.JAN`、`*.FEB`、`*.MAR`、`*.APR` 等等来命名你的备忘录。
### 编辑文件
FreeDOS 自带的 Edit 应用可以快速方便地进行文本编辑。它是一个简单的编辑器,沿屏幕顶部有一个菜单栏,可以方便地访问所有常用的功能(如复制、粘贴、保存等)。

正如你所期望的那样,还有很多其他的文本编辑器可以使用,包括小巧但用途广泛的 [e3 编辑器](https://opensource.com/article/20/12/e3-linux)。你可以在 GitLab 上找到各种各样的 [FreeDOS 应用](https://gitlab.com/FDOS/) 。
### 创建文件
你可以在 FreeDOS 中使用 `touch` 命令创建空文件。这个简单的工具可以更新文件的修改时间或创建一个新文件。
```
C:\>touch foo.txt
C:\>dir
FOO TXT 0 01-12-2021 10:00a
```
你也可以直接从 FreeDOS 控制台创建文件,而不需要使用 Edit 文本编辑器。首先,使用 `copy` 命令将控制台中的输入(简称 `con`)复制到一个新的文件对象中。用 `Ctrl+Z` 终止输入,然后按**回车**键:
```
C:\>copy con test.txt
con => test.txt
This is a test file.
^Z
```
`Ctrl+Z` 字符在控制台中显示为 `^Z`。它并没有被复制到文件中,而是作为文件结束(EOF)的分隔符。换句话说,它告诉 FreeDOS 何时停止复制。这是一个很好的技巧,可以用来做快速的笔记或开始一个简单的文档,以便以后工作。
### 文件和 FreeDOS
FreeDOS 是开源的、免费的且 [易于安装](https://opensource.com/article/18/4/gentle-introduction-freedos)。探究 FreeDOS 如何处理文件,可以帮助你了解多年来计算的发展,不管你平时使用的是什么操作系统。启动 FreeDOS,开始探索现代复古计算吧!
*本文中的部分信息曾发表在 [DOS 课程 7:DOS 文件名;ASCII](https://www.ahuka.com/dos-lessons-for-self-study-purposes/dos-lesson-7-dos-filenames-ascii/) 中(CC BY-SA 4.0)。*
---
via: <https://opensource.com/article/21/3/files-freedos>
作者:[Kevin O'Brien](https://opensource.com/users/ahuka) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The open source operating system [FreeDOS](https://www.freedos.org/) is a tried-and-true project that helps users play retro games, update firmware, run outdated but beloved applications, and study operating system design. FreeDOS offers insights into the history of personal computing (because it implements the de facto operating system of the early '80s) but in a modern context. In this article, I'll use FreeDOS to explain how file names and extensions developed.
## Understanding file names and ASCII text
FreeDOS file names follow what is called the *8.3 convention*. This means that all FreeDOS file names have two parts that contain up to eight and three characters, respectively. The first part is often referred to as the *file name* (which can be a little confusing because the combination of the file name and the file extension is also called a file name). This part can have anywhere from one to eight characters in it. This is followed by the *extension*, which can have from zero to three characters. These two parts are separated by a dot.
File names can use any letter of the alphabet or any numeral. Many of the other characters found on a keyboard are also allowed, but not all of them. That's because many of these other characters have been assigned a special use in FreeDOS. Some of the characters that can appear in a FreeDOS file name are:
`~ ! @ # $ % ^ & ( ) _ - { } ``
There are also characters in the extended [ASCII](#ASCII) set that can be used, such as �.
Characters with a special meaning in FreeDOS that, therefore, cannot be used in file names include:
`*/ + | \ = ? [ ] ; : " . < > ,`
Also, you cannot use a space in a FreeDOS file name. The FreeDOS console [uses spaces to separate commands](https://opensource.com/article/21/2/set-your-path-freedos) from options and parameters.
FreeDOS is case *insensitive*, so it doesn't matter whether you use uppercase or lowercase letters. All letters are converted to uppercase, so your files end up with uppercase letters in the name, no matter what you do.
### File extensions
A file in FreeDOS isn't required to have an extension, but file extensions do have some uses. Certain file extensions have built-in meanings in FreeDOS, such as:
**EXE**: executable file**COM**: command file**SYS**: system file**BAT**: batch file
Specific software programs use other extensions, or you can use them when you create a file. These extensions have no absolute file associations, so if you use a FreeDOS word processor, it doesn't matter what extension you use for your files. You could get creative and use extensions as part of your filing system if you want. For instance, you could name your memos using *.JAN, *.FEB, *.MAR, *.APR, and so on.
## Editing files
FreeDOS comes with the Edit application for quick and easy text editing. It's a simple editor with a menu bar along the top of the screen for easy access to all the usual functions (such as copy, paste, save, and so on.)
(Kevin O'Brien, CC BY-SA 4.0)
As you might expect, many other text editors are available, including the tiny but versatile [e3 editor](https://opensource.com/article/20/12/e3-linux). You can find a good variety of [FreeDOS applications](https://gitlab.com/FDOS/) on GitLab.
## Creating files
You can create empty files in FreeDOS using the `touch`
command. This simple utility updates a file's modification time or creates a new file:
```
C:\>touch foo.txt
C:\>dir
FOO TXT 0 01-12-2021 10:00a
```
You can also create a file directly from the FreeDOS console without using the Edit text editor. First, use the `copy`
command to copy input in the console (`con`
for short) into a new file object. Terminate input with **Ctrl**+**Z** followed by the **Return** or **Enter** key:
```
C:\>copy con test.txt
con => test.txt
This is a test file.
^Z
```
The **Ctrl**+**Z** character shows up in the console as `^Z`
. It isn't copied to the file but serves as an End of File (EOF) delimiter. In other words, it tells FreeDOS when to stop copying. This is a neat trick for making quick notes or starting a simple document to work on later.
## Files and FreeDOS
FreeDOS is open source, free, and [easy to install](https://opensource.com/article/18/4/gentle-introduction-freedos). Exploring how FreeDOS treats files can help you understand how computing has developed over the years, regardless of your usual operating system. Boot up FreeDOS and start exploring modern retro computing!
*Some of the information in this article was previously published in DOS lesson 7: DOS filenames; ASCII (CC BY-SA 4.0).*
## Comments are closed. |
13,209 | 把你的树莓派变成一个 HiFi 音乐系统 | https://opensource.com/article/21/1/raspberry-pi-hifi | 2021-03-17T09:48:30 | [
"HiFi",
"音乐",
"树莓派"
] | https://linux.cn/article-13209-1.html |
>
> 为你的朋友、家人、同事或其他任何拥有廉价发烧设备的人播放音乐。
>
>
>

在过去的 10 年里,我大部分时间都是远程工作,但当我走进办公室时,我坐在一个充满内向的同伴的房间里,他们很容易被环境噪音和谈话所干扰。我们发现,听音乐可以抑制办公室的噪音,让声音不那么扰人,用愉快的音乐提供一个愉快的工作环境。
起初,我们的一位同事带来了一些老式的有源电脑音箱,把它们连接到他的桌面电脑上,然后问我们想听什么。它可以工作,但音质不是很好,而且只有当他在办公室的时候才可以使用。接下来,我们又买了一对 Altec Lansing 音箱。音质有所改善,但没有什么灵活性。
不久之后,我们得到了一台通用 ARM 单板计算机(SBC),这意味着任何人都可以通过 Web 界面控制播放列表和音箱。但一块普通的 ARM 开发板意味着我们不能使用流行的音乐设备软件。由于非标准的内核,更新操作系统是一件很痛苦的事情,而且 Web 界面也经常出现故障。
当团队壮大并搬进更大的房间后,我们开始梦想着有更好音箱和更容易处理软件和硬件组合的方法。
为了用一种相对便宜、灵活、音质好的方式解决我们的问题,我们用树莓派、音箱和开源软件开发了一个办公室 HiFi。
### HiFi 硬件
用一个专门的 PC 来播放背景音乐就有点过分了。它昂贵、嘈杂(除非是静音的,但那就更贵了),而且不环保。即使是最便宜的 ARM 板也能胜任这个工作,但从软件的角度来看,它们往往存在问题。树莓派还是比较便宜的,虽然不是标准的计算机,但在硬件和软件方面都有很好的支持。
接下来的问题是:用什么音箱。质量好的、有源的音箱很贵。无源音箱的成本较低,但需要一个功放,这需要为这套设备增加另一个盒子。它们还必须使用树莓派的音频输出;虽然可以工作,但并不是最好的,特别是当你已经在高质量的音箱和功放上投入资金的时候。
幸运的是,在数以千计的树莓派硬件扩展中,有内置数字模拟转换器(DAC)的功放。我们选择了 [HiFiBerry 的 Amp](https://www.hifiberry.com/products/amp/)。它在我们买来后不久就停产了(被采样率更好的 Amp+ 型号取代),但对于我们的目的来说,它已经足够好了。在开着空调的情况下,我想无论如何你也听不出 48kHz 或 192kHz 的 DAC 有什么不同。
音箱方面,我们选择了 [Audioengine P4](https://audioengineusa.com/shop/passivespeakers/p4-passive-speakers/),是在某店家清仓大甩卖的时候买的,价格超低。它很容易让我们的办公室房间充满了声音而不失真(并且还能传到我们的房间之外,有一些失真,隔壁的工程师往往不喜欢)。
### HiFi 软件
在我们旧的通用 ARM SBC 上我们需要维护一个 Ubuntu,使用一个固定的、古老的、在软件包仓库外的系统内核,这是有问题的。树莓派操作系统包括一个维护良好的内核包,使其成为一个稳定且易于更新的基础系统,但它仍然需要我们定期更新 Python 脚本来访问 Spotify 和 YouTube。对于我们的目的来说,这有点过于高维护。
幸运的是,使用树莓派作为基础意味着有许多现成的软件设备可用。
我们选择了 [Volumio](https://volumio.org/),这是一个将树莓派变成音乐播放设备的开源项目。安装是一个简单的*一步步完成*的过程。安装和升级是完全无痛的,而不用辛辛苦苦地安装和维护一个操作系统,并定期调试破损的 Python 代码。配置 HiFiBerry 功放不需要编辑任何配置文件,你只需要从列表中选择即可。当然,习惯新的用户界面需要一定的时间,但稳定性和维护的便捷性让这个改变是值得的。

### 播放音乐并体验
虽然大流行期间我们都在家里办公,不过我把办公室的 HiFi 安装在我的家庭办公室里,这意味着我可以自由支配它的运行。一个不断变化的用户界面对于一个团队来说会很痛苦,但对于一个有研发背景的人来说,自己玩一个设备,变化是很有趣的。
我不是一个程序员,但我有很强的 Linux 和 Unix 系统管理背景。这意味着,虽然我觉得修复坏掉的 Python 代码很烦人,但 Volumio 对我来说却足够完美,足够无聊(这是一个很好的“问题”)。幸运的是,在树莓派上播放音乐还有很多其他的可能性。
作为一个终端狂人(我甚至从终端窗口启动 LibreOffice),我主要使用 Music on Console([MOC](https://en.wikipedia.org/wiki/Music_on_Console))来播放我的网络存储(NAS)中的音乐。我有几百张 CD,都转换成了 [FLAC](https://xiph.org/flac/) 文件。而且我还从 [BandCamp](https://bandcamp.com/) 或 [Society of Sound](https://realworldrecords.com/news/society-of-sound-statement/) 等渠道购买了许多数字专辑。
另一个选择是 [音乐播放器守护进程(MPD)](https://www.musicpd.org/)。把它运行在树莓派上,我可以通过网络使用 Linux 和 Android 的众多客户端之一与我的音乐进行远程交互。
### 音乐不停歇
正如你所看到的,创建一个廉价的 HiFi 系统在软件和硬件方面几乎是无限可能的。我们的解决方案只是众多解决方案中的一个,我希望它能启发你建立适合你环境的东西。
---
via: <https://opensource.com/article/21/1/raspberry-pi-hifi>
作者:[Peter Czanik](https://opensource.com/users/czanik) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For the past 10 years, I've worked remotely most of the time, but when I go into the office, I sit in a room full of fellow introverts who are easily disturbed by ambient noise and talking. We discovered that listening to music can suppress office noise, make voices less distracting, and provide a pleasant working environment with enjoyable music.
Initially, one of our colleagues brought in some old powered computer speakers, connected them to his desktop, and asked us what we wanted to listen to. It did its job, but the sound quality wasn't great, and it only worked when he was in the office. Next, we bought a pair of Altec Lansing speakers. The sound quality improved, but flexibility did not.
Not much later, we got a generic Arm single-board computer (SBC). This meant anyone could control the playlist and the speakers over the network using a web interface. But a random Arm developer board meant we could not use popular music appliance software. Updating the operating system was a pain due to a non-standard kernel, and the web interface broke frequently.
When the team grew and moved into a larger room, we started dreaming about better speakers and an easier way to handle the software and hardware combo.
To solve our issue in a way that is relatively inexpensive, flexible, and has good sound quality, we developed an office HiFi with a Raspberry Pi, speakers, and open source software.
## HiFi hardware
Having a dedicated PC for background music is overkill. It's expensive, noisy (unless it's silent, but then it's even more expensive), and not environmentally friendly. Even the cheapest Arm boards are up to the job, but they're often problematic from the software point of view. The Raspberry Pi is still on the cheap end and, while not standards-compliant, is well-supported on the hardware and the software side.
The next question was: what speakers to use. Good-quality, powered speakers are expensive. Passive speakers cost less but need an amplifier, and that would add another box to the setup. They would also have to use the Pi's audio output; while it works, it's not exactly the best, especially when you're already spending money on quality speakers and an amplifier.
Luckily, among the thousands of Raspberry Pi hardware extensions are amplifiers with built-in digital-analog converters (DAC). We selected [HiFiBerry's Amp](https://www.hifiberry.com/products/amp/). It was discontinued soon after we bought it (replaced by an Amp+ model with a better sample rate), but it's good enough for our purposes. With air conditioning on, I don't think you can hear the difference between a DAC capable of 48kHz or 192kHz anyway.
For speakers, we chose the [Audioengine P4](https://audioengineusa.com/shop/passivespeakers/p4-passive-speakers/), which we bought when a shop had a clearance sale with extra-low prices. It easily fills our office room with sound without distortion (and fills much more than our room with some distortion, but neighboring engineers tend to dislike that).
## HiFi software
Maintaining Ubuntu on our old generic Arm SBC with a fixed, ancient, out-of-packaging system kernel was problematic. The Raspberry Pi OS includes a well-maintained kernel package, making it a stable and easily updated base system, but it still required us to regularly update a Python script to access Spotify and YouTube. That was a little too high-maintenance for our purposes.
Luckily, using the Raspberry Pi as a base means there are many ready-to-use software appliances available.
We settled on [Volumio](https://volumio.org/), an open source project that turns a Pi into a music-playing appliance. Installation is a simple *next-next-finish* process. Instead of painstakingly installing and maintaining an operating system and regularly debugging broken Python code, installation and upgrades are completely pain-free. Configuring the HiFiBerry amplifier doesn't require editing any configuration files; you can just select it from a list. Of course, getting used to a new user interface takes some time, but the stability and ease of maintenance made this change worthwhile.
Screenshot courtesy of Volumeio (© Michelangelo Guarise)
## Playing music and experimenting
While we're all working from home during the pandemic, the office HiFi is installed in my home office, which means I have free reign over what it runs. A constantly changing user interface would be a pain for a team, but for someone with an R&D background, playing with a device on my own, change is fun.
I'm not a programmer, but I have a strong Linux and Unix sysadmin background. That means that while I find fixing broken Python code tiresome, Volumio is just perfect enough to be boring for me (a great "problem" to have). Luckily, there are many other possibilities to play music on a Raspberry Pi.
As a terminal maniac (I even start LibreOffice from a terminal window), I mostly use Music on Console ([MOC](https://en.wikipedia.org/wiki/Music_on_Console)) to play music from my network-attached storage (NAS). I have hundreds of CDs, all turned into [FLAC](https://xiph.org/flac/) files. And I've also bought many digital albums from sources like [BandCamp](https://bandcamp.com/) or [Society of Sound](https://realworldrecords.com/news/society-of-sound-statement/).
Another option is the [Music Player Daemon (MPD)](https://www.musicpd.org/). With it running on the Raspberry Pi, I can interact with my music remotely over the network using any of the many clients available for Linux and Android.
## Can't stop the music
As you can see, the possibilities for creating an inexpensive HiFi system are almost endless on both the software and the hardware side. Our solution is just one of many, and I hope it inspires you to build something that fits your environment.
## Comments are closed. |
13,210 | 如何入门 Bash 编程 | https://opensource.com/article/20/4/bash-programming-guide | 2021-03-17T11:07:52 | [
"Bash",
"脚本",
"编程"
] | https://linux.cn/article-13210-1.html |
>
> 了解如何在 Bash 中编写定制程序以自动执行重复性操作任务。
>
>
>

Unix 最初的希望之一是,让计算机的日常用户能够微调其计算机,以适应其独特的工作风格。几十年来,人们对计算机定制的期望已经降低,许多用户认为他们的应用程序和网站的集合就是他们的 “定制环境”。原因之一是许多操作系统的组件未不开源,普通用户无法使用其源代码。
但是对于 Linux 用户而言,定制程序是可以实现的,因为整个系统都围绕着可通过终端使用的命令啦进行的。终端不仅是用于快速命令或深入排除故障的界面;也是一个脚本环境,可以通过为你处理日常任务来减少你的工作量。
### 如何学习编程
如果你以前从未进行过任何编程,可能面临考虑两个不同的挑战:一个是了解怎样编写代码,另一个是了解要编写什么代码。你可以学习 *语法*,但是如果你不知道 *语言* 中有哪些可用的关键字,你将无法继续。在实践中,要同时开始学习这两个概念,是因为如果没有关键字的堆砌就无法学习语法,因此,最初你要使用基本命令和基本编程结构来编写简单的任务。一旦熟悉了基础知识,就可以探索更多编程语言的内容,从而使你的程序能够做越来越重要的事情。
在 [Bash](https://opensource.com/resources/what-bash) 中,你使用的大多数 *关键字* 是 Linux 命令。 *语法* 就是 Bash。如果你已经频繁地使用过了 Bash,则向 Bash 编程的过渡相对容易。但是,如果你不曾使用过 Bash,你会很高兴地了解到它是一种为清晰和简单而构建的简单语言。
### 交互设计
有时,学习编程时最难搞清楚的事情就是计算机可以为你做些什么。显然,如果一台计算机可以自己完成你要做的所有操作,那么你就不必再碰计算机了。但是现实是,人类很重要。找到你的计算机可以帮助你的事情的关键是注意到你一周内需要重复执行的任务。计算机特别擅长于重复的任务。
但是,为了能告知计算机为你做某事,你必须知道怎么做。这就是 Bash 擅长的领域:交互式编程。在终端中执行一个动作时,你也在学习如何编写脚本。
例如,我曾经负责将大量 PDF 书籍转换为低墨和友好打印的版本。一种方法是在 PDF 编辑器中打开 PDF,从数百张图像(页面背景和纹理都算作图像)中选择每张图像,删除它们,然后将其保存到新的 PDF中。仅仅是一本书,这样就需要半天时间。
我的第一个想法是学习如何编写 PDF 编辑器脚本,但是经过数天的研究,我找不到可以编写编辑 PDF 应用程序的脚本(除了非常丑陋的鼠标自动化技巧)。因此,我将注意力转向了从终端内找出完成任务的方法。这让我有了几个新发现,包括 GhostScript,它是 PostScript 的开源版本(PDF 基于的打印机语言)。通过使用 GhostScript 处理了几天的任务,我确认这是解决我的问题的方法。
编写基本的脚本来运行命令,只不过是复制我用来从 PDF 中删除图像的命令和选项,并将其粘贴到文本文件中而已。将这个文件作为脚本运行,大概也会产生同样的结果。
### 向 Bash 脚本传参数
在终端中运行命令与在 Shell 脚本中运行命令之间的区别在于前者是交互式的。在终端中,你可以随时进行调整。例如,如果我刚刚处理 `example_1.pdf` 并准备处理下一个文档,以适应我的命令,则只需要更改文件名即可。
Shell 脚本不是交互式的。实际上,Shell *脚本* 存在的唯一原因是让你不必亲自参与。这就是为什么命令(以及运行它们的 Shell 脚本)会接受参数的原因。
在 Shell 脚本中,有一些预定义的可以反映脚本启动方式的变量。初始变量是 `$0`,它代表了启动脚本的命令。下一个变量是 `$1` ,它表示传递给 Shell 脚本的第一个 “参数”。例如,在命令 `echo hello` 中,命令 `echo` 为 `$0,`,关键字 `hello` 为 `$1`,而 `world` 是 `$2`。
在 Shell 中交互如下所示:
```
$ echo hello world
hello world
```
在非交互式 Shell 脚本中,你 *可以* 以非常直观的方式执行相同的操作。将此文本输入文本文件并将其另存为 `hello.sh`:
```
echo hello world
```
执行这个脚本:
```
$ bash hello.sh
hello world
```
同样可以,但是并没有利用脚本可以接受输入这一优势。将 `hello.sh` 更改为:
```
echo $1
```
用引号将两个参数组合在一起来运行脚本:
```
$ bash hello.sh "hello bash"
hello bash
```
对于我的 PDF 瘦身项目,我真的需要这种非交互性,因为每个 PDF 都花了几分钟来压缩。但是通过创建一个接受我的输入的脚本,我可以一次将几个 PDF 文件全部提交给脚本。该脚本按顺序处理了每个文件,这可能需要半小时或稍长一点时间,但是我可以用半小时来完成其他任务。
### 流程控制
创建 Bash 脚本是完全可以接受的,从本质上讲,这些脚本是你开始实现需要重复执行任务的准确过程的副本。但是,可以通过控制信息流的方式来使脚本更强大。管理脚本对数据响应的常用方法是:
* `if`/`then` 选择结构语句
* `for` 循环结构语句
* `while` 循环结构语句
* `case` 语句
计算机不是智能的,但是它们擅长比较和分析数据。如果你在脚本中构建一些数据分析,则脚本会变得更加智能。例如,基本的 `hello.sh` 脚本运行后不管有没有内容都会显示:
```
$ bash hello.sh foo
foo
$ bash hello.sh
$
```
如果在没有接收输入的情况下提供帮助消息,将会更加容易使用。如下是一个 `if`/`then` 语句,如果你以一种基本的方式使用 Bash,则你可能不知道 Bash 中存在这样的语句。但是编程的一部分是学习语言,通过一些研究,你将了解 `if/then` 语句:
```
if [ "$1" = "" ]; then
echo "syntax: $0 WORD"
echo "If you provide more than one word, enclose them in quotes."
else
echo "$1"
fi
```
运行新版本的 `hello.sh` 输出如下:
```
$ bash hello.sh
syntax: hello.sh WORD
If you provide more than one word, enclose them in quotes.
$ bash hello.sh "hello world"
hello world
```
### 利用脚本工作
无论你是从 PDF 文件中查找要删除的图像,还是要管理混乱的下载文件夹,抑或要创建和提供 Kubernetes 镜像,学习编写 Bash 脚本都需要先使用 Bash,然后学习如何将这些脚本从仅仅是一个命令列表变成响应输入的东西。通常这是一个发现的过程:你一定会找到新的 Linux 命令来执行你从未想象过可以通过文本命令执行的任务,你会发现 Bash 的新功能,使你的脚本可以适应所有你希望它们运行的不同方式。
学习这些技巧的一种方法是阅读其他人的脚本。了解人们如何在其系统上自动化死板的命令。看看你熟悉的,并寻找那些陌生事物的更多信息。
另一种方法是下载我们的 [Bash 编程入门](https://opensource.com/downloads/bash-programming-guide) 电子书。它向你介绍了特定于 Bash 的编程概念,并且通过学习的构造,你可以开始构建自己的命令。当然,它是免费的,并根据 [创作共用许可证](https://opensource.com/article/20/1/what-creative-commons) 进行下载和分发授权,所以今天就来获取它吧。
* [下载我们介绍用 Bash 编程的电子书!](https://opensource.com/downloads/bash-programming-guide)
---
via: <https://opensource.com/article/20/4/bash-programming-guide>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the original hopes for Unix was that it would empower everyday computer users to fine-tune their computers to match their unique working style. The expectations around computer customization have diminished over the decades, and many users consider their collection of apps and websites to be their "custom environment." One reason for that is that the components of many operating systems are not open, so their source code isn't available to normal users.
But for Linux users, custom programs are within reach because the entire system is based around commands available through the terminal. The terminal isn't just an interface for quick commands or in-depth troubleshooting; it's a scripting environment that can reduce your workload by taking care of mundane tasks for you.
## How to learn programming
If you've never done any programming before, it might help to think of it in terms of two different challenges: one is to understand how code is written, and the other is to understand what code to write. You can learn *syntax*—but you won't get far without knowing what words are available to you in the *language*. In practice, you start learning both concepts all at once because you can't learn syntax without words to arrange, so initially, you write simple tasks using basic commands and basic programming structures. Once you feel comfortable with the basics, you can explore more of the language so you can make your programs do more and more significant things.
In [Bash](https://opensource.com/resources/what-bash), most of the *words* you use are Linux commands. The *syntax* is Bash. If you already use Bash on a frequent basis, then the transition to Bash programming is relatively easy. But if you don't use Bash, you'll be pleased to learn that it's a simple language built for clarity and simplicity.
## Interactive design
Sometimes, the hardest thing to figure out when learning to program is what a computer can do for you. Obviously, if a computer on its own could do everything you do with it, then you wouldn't have to ever touch a computer again. But the reality is that humans are important. The key to finding something your computer can help you with is to take notice of tasks you repeatedly do throughout the week. Computers handle repetition particularly well.
But for you to be able to tell your computer to do something, you must know how to do it. This is an area Bash excels in: interactive programming. As you perform an action in the terminal, you are also learning how to script it.
For instance, I was once tasked with converting a large number of PDF books to versions that would be low-ink and printer-friendly. One way to do this is to open the PDF in a PDF editor, select each one of the hundreds of images—page backgrounds and textures counted as images—delete them, and then save it to a new PDF. Just one book would take half a day this way.
My first thought was to learn how to script a PDF editor, but after days of research, I could not find a PDF editing application that could be scripted (outside of very ugly mouse-automation hacks). So I turned my attention to finding out to accomplish the task from within a terminal. This resulted in several new discoveries, including GhostScript, the open source version of PostScript (the printer language PDF is based on). By using GhostScript for the task for a few days, I confirmed that it was the solution to my problem.
Formulating a basic script to run the command was merely a matter of copying the command and options I used to remove images from a PDF and pasting them into a text file. Running the file as a script would, presumably, produce the same results.
## Passing arguments to a Bash script
The difference between running a command in a terminal and running a command in a shell script is that the former is interactive. In a terminal, you can adjust things as you go. For instance, if I just processed **example_1.pdf** and am ready to process the next document, to adapt my command, I only need to change the filename.
A shell script isn't interactive, though. In fact, the only reason a shell *script* exists is so that you don't have to attend to it. This is why commands (and the shell scripts that run them) accept arguments.
In a shell script, there are a few predefined variables that reflect how a script starts. The initial variable is **$0**, and it represents the command issued to start the script. The next variable is **$1**, which represents the first "argument" passed to the shell script. For example, in the command **echo hello**, the command **echo** is **$0,** and the word **hello** is **$1**. In the command **echo hello world**, the command **echo** is **$0**, **hello** is **$1**, and **world** is **$2**.
In an interactive shell:
```
$ echo hello world
hello world
```
In a non-interactive shell script, you *could* do the same thing in a very literal way. Type this text into a text file and save it as **hello.sh**:
`echo hello world`
Now run the script:
```
$ bash hello.sh
hello world
```
That works, but it doesn't take advantage of the fact that a script can take input. Change **hello.sh** to this:
`echo $1`
Run the script with two arguments grouped together as one with quotation marks:
```
$ bash hello.sh "hello bash"
hello bash
```
For my PDF reduction project, I had a real need for this kind of non-interactivity, because each PDF took several minutes to condense. But by creating a script that accepted input from me, I could feed the script several PDF files all at once. The script processed each one sequentially, which could take half an hour or more, but it was a half-hour I could use for other tasks.
## Flow control
It's perfectly acceptable to create Bash scripts that are, essentially, transcripts of the exact process you took to achieve the task you need to be repeated. However, scripts can be made more powerful by controlling how information flows through them. Common methods of managing a script's response to data are:
- if/then
- for loops
- while loops
- case statements
Computers aren't intelligent, but they are good at comparing and parsing data. Scripts can feel a lot more intelligent if you build some data analysis into them. For example, the basic **hello.sh** script runs whether or not there's anything to echo:
```
$ bash hello.sh foo
foo
$ bash hello.sh
$
```
It would be more user-friendly if it provided a help message when it receives no input. That's an if/then statement, and if you're using Bash in a basic way, you probably wouldn't know that such a statement existed in Bash. But part of programming is learning the language, and with a little research you'd learn about if/then statements:
```
if [ "$1" = "" ]; then
echo "syntax: $0 WORD"
echo "If you provide more than one word, enclose them in quotes."
else
echo "$1"
fi
```
Running this new version of **hello.sh** results in:
```
$ bash hello.sh
syntax: hello.sh WORD
If you provide more than one word, enclose them in quotes.
$ bash hello.sh "hello world"
hello world
```
## Working your way through a script
Whether you're looking for something to remove images from PDF files, or something to manage your cluttered Downloads folder, or something to create and provision Kubernetes images, learning to script Bash is a matter of using Bash and then learning ways to take those scripts from just a list of commands to something that responds to input. It's usually a process of discovery: you're bound to find new Linux commands that perform tasks you never imagined could be performed with text commands, and you'll find new functions of Bash to make your scripts adaptable to all the different ways you want them to run.
One way to learn these tricks is to read other people's scripts. Get a feel for how people are automating rote commands on their systems. See what looks familiar to you, and look for more information about the things that are unfamiliar.
Another way is to download our [introduction to programming with Bash](https://opensource.com/downloads/bash-programming-guide) eBook. It introduces you to programming concepts specific to Bash, and with the constructs you learn, you can start to build your own commands. And of course, it's free to download and licensed under a [Creative Commons](https://opensource.com/article/20/1/what-creative-commons) license, so grab your copy today.
## 1 Comment |
13,212 | 使用 Jupyter 改善你的时间管理 | https://opensource.com/article/20/9/calendar-jupyter | 2021-03-18T09:55:48 | [
"Jupyter",
"日历",
"Python"
] | https://linux.cn/article-13212-1.html |
>
> 在 Jupyter 里使用 Python 来分析日历,以了解你是如何使用时间的。
>
>
>

[Python](https://opensource.com/resources/python) 在探索数据方面具有令人难以置信的可扩展性。利用 [Pandas](https://pandas.pydata.org/) 或 [Dask](https://dask.org/),你可以将 [Jupyter](https://jupyter.org/) 扩展到大数据领域。但是小数据、个人资料、私人数据呢?
JupyterLab 和 Jupyter Notebook 为我提供了一个绝佳的环境,可以让我审视我的笔记本电脑生活。
我的探索是基于以下事实:我使用的几乎每个服务都有一个 Web API。我使用了诸多此类服务:待办事项列表、时间跟踪器、习惯跟踪器等。还有一个几乎每个人都会使用到:*日历*。相同的思路也可以应用于其他服务,但是日历具有一个很酷的功能:几乎所有 Web 日历都支持的开放标准 —— CalDAV。
### 在 Jupyter 中使用 Python 解析日历
大多数日历提供了导出为 CalDAV 格式的方法。你可能需要某种身份验证才能访问这些私有数据。按照你的服务说明进行操作即可。如何获得凭据取决于你的服务,但是最终,你应该能够将这些凭据存储在文件中。我将我的凭据存储在根目录下的一个名为 `.caldav` 的文件中:
```
import os
with open(os.path.expanduser("~/.caldav")) as fpin:
username, password = fpin.read().split()
```
切勿将用户名和密码直接放在 Jupyter Notebook 的笔记本中!它们可能会很容易因 `git push` 的错误而导致泄漏。
下一步是使用方便的 PyPI [caldav](https://pypi.org/project/caldav/) 库。我找到了我的电子邮件服务的 CalDAV 服务器(你可能有所不同):
```
import caldav
client = caldav.DAVClient(url="https://caldav.fastmail.com/dav/", username=username, password=password)
```
CalDAV 有一个称为 `principal`(主键)的概念。它是什么并不重要,只要知道它是你用来访问日历的东西就行了:
```
principal = client.principal()
calendars = principal.calendars()
```
从字面上讲,日历就是关于时间的。访问事件之前,你需要确定一个时间范围。默认一星期就好:
```
from dateutil import tz
import datetime
now = datetime.datetime.now(tz.tzutc())
since = now - datetime.timedelta(days=7)
```
大多数人使用的日历不止一个,并且希望所有事件都在一起出现。`itertools.chain.from_iterable` 方法使这一过程变得简单:
```
import itertools
raw_events = list(
itertools.chain.from_iterable(
calendar.date_search(start=since, end=now, expand=True)
for calendar in calendars
)
)
```
将所有事件读入内存很重要,以 API 原始的本地格式进行操作是重要的实践。这意味着在调整解析、分析和显示代码时,无需返回到 API 服务刷新数据。
但 “原始” 真的是原始,事件是以特定格式的字符串出现的:
```
print(raw_events[12].data)
```
```
BEGIN:VCALENDAR
VERSION:2.0
PRODID:-//CyrusIMAP.org/Cyrus
3.3.0-232-g4bdb081-fm-20200825.002-g4bdb081a//EN
BEGIN:VEVENT
DTEND:20200825T230000Z
DTSTAMP:20200825T181915Z
DTSTART:20200825T220000Z
SUMMARY:Busy
UID:
1302728i-040000008200E00074C5B7101A82E00800000000D939773EA578D601000000000
000000010000000CD71CC3393651B419E9458134FE840F5
END:VEVENT
END:VCALENDAR
```
幸运的是,PyPI 可以再次使用另一个辅助库 [vobject](https://pypi.org/project/vobject/) 解围:
```
import io
import vobject
def parse_event(raw_event):
data = raw_event.data
parsed = vobject.readOne(io.StringIO(data))
contents = parsed.vevent.contents
return contents
```
```
parse_event(raw_events[12])
```
```
{'dtend': [<DTEND{}2020-08-25 23:00:00+00:00>],
'dtstamp': [<DTSTAMP{}2020-08-25 18:19:15+00:00>],
'dtstart': [<DTSTART{}2020-08-25 22:00:00+00:00>],
'summary': [<SUMMARY{}Busy>],
'uid': [<UID{}1302728i-040000008200E00074C5B7101A82E00800000000D939773EA578D601000000000000000010000000CD71CC3393651B419E9458134FE840F5>]}
```
好吧,至少好一点了。
仍有一些工作要做,将其转换为合理的 Python 对象。第一步是 *拥有* 一个合理的 Python 对象。[attrs](https://opensource.com/article/19/5/python-attrs) 库提供了一个不错的开始:
```
import attr
from __future__ import annotations
@attr.s(auto_attribs=True, frozen=True)
class Event:
start: datetime.datetime
end: datetime.datetime
timezone: Any
summary: str
```
是时候编写转换代码了!
第一个抽象从解析后的字典中获取值,不需要所有的装饰:
```
def get_piece(contents, name):
return contents[name][0].value
get_piece(_, "dtstart")
datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc())
```
日历事件总有一个“开始”、有一个“结束”、有一个 “持续时间”。一些谨慎的解析逻辑可以将两者协调为同一个 Python 对象:
```
def from_calendar_event_and_timezone(event, timezone):
contents = parse_event(event)
start = get_piece(contents, "dtstart")
summary = get_piece(contents, "summary")
try:
end = get_piece(contents, "dtend")
except KeyError:
end = start + get_piece(contents, "duration")
return Event(start=start, end=end, summary=summary, timezone=timezone)
```
将事件放在 *本地* 时区而不是 UTC 中很有用,因此使用本地时区:
```
my_timezone = tz.gettz()
from_calendar_event_and_timezone(raw_events[12], my_timezone)
Event(start=datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc()), end=datetime.datetime(2020, 8, 25, 23, 0, tzinfo=tzutc()), timezone=tzfile('/etc/localtime'), summary='Busy')
```
既然事件是真实的 Python 对象,那么它们实际上应该具有附加信息。幸运的是,可以将方法添加到类中。
但是要弄清楚哪个事件发生在哪一天不是很直接。你需要在 *本地* 时区中选择一天:
```
def day(self):
offset = self.timezone.utcoffset(self.start)
fixed = self.start + offset
return fixed.date()
Event.day = property(day)
```
```
print(_.day)
2020-08-25
```
事件在内部始终是以“开始”/“结束”的方式表示的,但是持续时间是有用的属性。持续时间也可以添加到现有类中:
```
def duration(self):
return self.end - self.start
Event.duration = property(duration)
```
```
print(_.duration)
1:00:00
```
现在到了将所有事件转换为有用的 Python 对象了:
```
all_events = [from_calendar_event_and_timezone(raw_event, my_timezone)
for raw_event in raw_events]
```
全天事件是一种特例,可能对分析生活没有多大用处。现在,你可以忽略它们:
```
# ignore all-day events
all_events = [event for event in all_events if not type(event.start) == datetime.date]
```
事件具有自然顺序 —— 知道哪个事件最先发生可能有助于分析:
```
all_events.sort(key=lambda ev: ev.start)
```
现在,事件已排序,可以将它们加载到每天:
```
import collections
events_by_day = collections.defaultdict(list)
for event in all_events:
events_by_day[event.day].append(event)
```
有了这些,你就有了作为 Python 对象的带有日期、持续时间和序列的日历事件。
### 用 Python 报到你的生活
现在是时候编写报告代码了!带有适当的标题、列表、重要内容以粗体显示等等,有醒目的格式是很意义。
这就是一些 HTML 和 HTML 模板。我喜欢使用 [Chameleon](https://chameleon.readthedocs.io/en/latest/):
```
template_content = """
<html><body>
<div tal:repeat="item items">
<h2 tal:content="item[0]">Day</h2>
<ul>
<li tal:repeat="event item[1]"><span tal:replace="event">Thing</span></li>
</ul>
</div>
</body></html>"""
```
Chameleon 的一个很酷的功能是使用它的 `html` 方法渲染对象。我将以两种方式使用它:
* 摘要将以粗体显示
* 对于大多数活动,我都会删除摘要(因为这是我的个人信息)
```
def __html__(self):
offset = my_timezone.utcoffset(self.start)
fixed = self.start + offset
start_str = str(fixed).split("+")[0]
summary = self.summary
if summary != "Busy":
summary = "<REDACTED>"
return f"<b>{summary[:30]}</b> -- {start_str} ({self.duration})"
Event.__html__ = __html__
```
为了简洁起见,将该报告切成每天的:
```
import chameleon
from IPython.display import HTML
template = chameleon.PageTemplate(template_content)
html = template(items=itertools.islice(events_by_day.items(), 3, 4))
HTML(html)
```
渲染后,它将看起来像这样:
**2020-08-25**
* **<REDACTED>** -- 2020-08-25 08:30:00 (0:45:00)
* **<REDACTED>** -- 2020-08-25 10:00:00 (1:00:00)
* **<REDACTED>** -- 2020-08-25 11:30:00 (0:30:00)
* **<REDACTED>** -- 2020-08-25 13:00:00 (0:25:00)
* Busy -- 2020-08-25 15:00:00 (1:00:00)
* **<REDACTED>** -- 2020-08-25 15:00:00 (1:00:00)
* **<REDACTED>** -- 2020-08-25 19:00:00 (1:00:00)
* **<REDACTED>** -- 2020-08-25 19:00:12 (1:00:00)
### Python 和 Jupyter 的无穷选择
通过解析、分析和报告各种 Web 服务所拥有的数据,这只是你可以做的事情的表面。
为什么不对你最喜欢的服务试试呢?
---
via: <https://opensource.com/article/20/9/calendar-jupyter>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Python](https://opensource.com/resources/python) has incredibly scalable options for exploring data. With [Pandas](https://pandas.pydata.org/) or [Dask](https://dask.org/), you can scale [Jupyter](https://jupyter.org/) up to big data. But what about small data? Personal data? Private data?
JupyterLab and Jupyter Notebook provide a great environment to scrutinize my laptop-based life.
My exploration is powered by the fact that almost every service I use has a web application programming interface (API). I use many such services: a to-do list, a time tracker, a habit tracker, and more. But there is one that almost everyone uses: *a calendar*. The same ideas can be applied to other services, but calendars have one cool feature: an open standard that almost all web calendars support: `CalDAV`
.
## Parsing your calendar with Python in Jupyter
Most calendars provide a way to export into the `CalDAV`
format. You may need some authentication for accessing this private data. Following your service's instructions should do the trick. How you get the credentials depends on your service, but eventually, you should be able to store them in a file. I store mine in my root directory in a file called `.caldav`
:
```
import os
with open(os.path.expanduser("~/.caldav")) as fpin:
username, password = fpin.read().split()
```
Never put usernames and passwords directly in notebooks! They could easily leak with a stray `git push`
.
The next step is to use the convenient PyPI [caldav](https://pypi.org/project/caldav/) library. I looked up the CalDAV server for my email service (yours may be different):
```
import caldav
client = caldav.DAVClient(url="https://caldav.fastmail.com/dav/", username=username, password=password)
```
CalDAV has a concept called the `principal`
. It is not important to get into right now, except to know it's the thing you use to access the calendars:
```
principal = client.principal()
calendars = principal.calendars()
```
Calendars are, literally, all about time. Before accessing events, you need to decide on a time range. One week should be a good default:
```
from dateutil import tz
import datetime
now = datetime.datetime.now(tz.tzutc())
since = now - datetime.timedelta(days=7)
```
Most people use more than one calendar, and most people want all their events together. The `itertools.chain.from_iterable`
makes this straightforward:` `
```
import itertools
raw_events = list(
itertools.chain.from_iterable(
calendar.date_search(start=since, end=now, expand=True)
for calendar in calendars
)
)
```
Reading all the events into memory is important, and doing so in the API's raw, native format is an important practice. This means that when fine-tuning the parsing, analyzing, and displaying code, there is no need to go back to the API service to refresh the data.
But "raw" is not an understatement. The events come through as strings in a specific format:
`print(raw_events[12].data)`
```
BEGIN:VCALENDAR
VERSION:2.0
PRODID:-//CyrusIMAP.org/Cyrus
3.3.0-232-g4bdb081-fm-20200825.002-g4bdb081a//EN
BEGIN:VEVENT
DTEND:20200825T230000Z
DTSTAMP:20200825T181915Z
DTSTART:20200825T220000Z
SUMMARY:Busy
UID:
1302728i-040000008200E00074C5B7101A82E00800000000D939773EA578D601000000000
000000010000000CD71CC3393651B419E9458134FE840F5
END:VEVENT
END:VCALENDAR
```
Luckily, PyPI comes to the rescue again with another helper library, [vobject](https://pypi.org/project/vobject/):
```
import io
import vobject
def parse_event(raw_event):
data = raw_event.data
parsed = vobject.readOne(io.StringIO(data))
contents = parsed.vevent.contents
return contents
```
`parse_event(raw_events[12])`
```
{'dtend': [<DTEND{}2020-08-25 23:00:00+00:00>],
'dtstamp': [<DTSTAMP{}2020-08-25 18:19:15+00:00>],
'dtstart': [<DTSTART{}2020-08-25 22:00:00+00:00>],
'summary': [<SUMMARY{}Busy>],
'uid': [<UID{}1302728i-040000008200E00074C5B7101A82E00800000000D939773EA578D601000000000000000010000000CD71CC3393651B419E9458134FE840F5>]}
```
Well, at least it's a little better.
There is still some work to do to convert it to a reasonable Python object. The first step is to *have* a reasonable Python object. The [attrs](https://opensource.com/article/19/5/python-attrs) library provides a nice start:
```
import attr
from __future__ import annotations
@attr.s(auto_attribs=True, frozen=True)
class Event:
start: datetime.datetime
end: datetime.datetime
timezone: Any
summary: str
```
Time to write the conversion code!
The first abstraction gets the value from the parsed dictionary without all the decorations:
```
def get_piece(contents, name):
return contents[name][0].value
```
`get_piece(_, "dtstart")`
` datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc())`
Calendar events always have a start, but they sometimes have an "end" and sometimes a "duration." Some careful parsing logic can harmonize both into the same Python objects:
```
def from_calendar_event_and_timezone(event, timezone):
contents = parse_event(event)
start = get_piece(contents, "dtstart")
summary = get_piece(contents, "summary")
try:
end = get_piece(contents, "dtend")
except KeyError:
end = start + get_piece(contents, "duration")
return Event(start=start, end=end, summary=summary, timezone=timezone)
```
Since it is useful to have the events in your *local* time zone rather than UTC, this uses the local timezone:
`my_timezone = tz.gettz()`
`from_calendar_event_and_timezone(raw_events[12], my_timezone)`
` Event(start=datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc()), end=datetime.datetime(2020, 8, 25, 23, 0, tzinfo=tzutc()), timezone=tzfile('/etc/localtime'), summary='Busy')`
Now that the events are real Python objects, they really should have some additional information. Luckily, it is possible to add methods retroactively to classes.
But figuring which *day* an event happens is not that obvious. You need the day in the *local* timezone:
```
def day(self):
offset = self.timezone.utcoffset(self.start)
fixed = self.start + offset
return fixed.date()
Event.day = property(day)
```
`print(_.day)`
` 2020-08-25`
Events are always represented internally as start/end, but knowing the duration is a useful property. Duration can also be added to the existing class:
```
def duration(self):
return self.end - self.start
Event.duration = property(duration)
```
`print(_.duration)`
` 1:00:00`
Now it is time to convert all events into useful Python objects:
```
all_events = [from_calendar_event_and_timezone(raw_event, my_timezone)
for raw_event in raw_events]
```
All-day events are a special case and probably less useful for analyzing life. For now, you can ignore them:
```
# ignore all-day events
all_events = [event for event in all_events if not type(event.start) == datetime.date]
```
Events have a natural order—knowing which one happened first is probably useful for analysis:
`all_events.sort(key=lambda ev: ev.start)`
Now that the events are sorted, they can be broken into days:
```
import collections
events_by_day = collections.defaultdict(list)
for event in all_events:
events_by_day[event.day].append(event)
```
And with that, you have calendar events with dates, duration, and sequence as Python objects.
## Reporting on your life in Python
Now it is time to write reporting code! It is fun to have eye-popping formatting with proper headers, lists, important things in bold, etc.
This means HTML and some HTML templating. I like to use [Chameleon](https://chameleon.readthedocs.io/en/latest/):
```
template_content = """
<html><body>
<div tal:repeat="item items">
<h2 tal:content="item[0]">Day</h2>
<ul>
<li tal:repeat="event item[1]"><span tal:replace="event">Thing</span></li>
</ul>
</div>
</body></html>"""
```
One cool feature of Chameleon is that it will render objects using its `html`
method. I will use it in two ways:
- The summary will be in
**bold** - For most events, I will remove the summary (since this is my personal information)
```
def __html__(self):
offset = my_timezone.utcoffset(self.start)
fixed = self.start + offset
start_str = str(fixed).split("+")[0]
summary = self.summary
if summary != "Busy":
summary = "<REDACTED>"
return f"<b>{summary[:30]}</b> -- {start_str} ({self.duration})"
Event.__html__ = __html__
```
In the interest of brevity, the report will be sliced into one day's worth.
```
import chameleon
from IPython.display import HTML
template = chameleon.PageTemplate(template_content)
html = template(items=itertools.islice(events_by_day.items(), 3, 4))
HTML(html)
```
### When rendered, it will look something like this:
### 2020-08-25
**<REDACTED>**-- 2020-08-25 08:30:00 (0:45:00)**<REDACTED>**-- 2020-08-25 10:00:00 (1:00:00)**<REDACTED>**-- 2020-08-25 11:30:00 (0:30:00)**<REDACTED>**-- 2020-08-25 13:00:00 (0:25:00)**Busy**-- 2020-08-25 15:00:00 (1:00:00)**<REDACTED>**-- 2020-08-25 15:00:00 (1:00:00)**<REDACTED>**-- 2020-08-25 19:00:00 (1:00:00)**<REDACTED>**-- 2020-08-25 19:00:12 (1:00:00)
## Endless options with Python and Jupyter
This only scratches the surface of what you can do by parsing, analyzing, and reporting on the data that various web services have on you.
Why not try it with your favorite service?
## Comments are closed. |
13,213 | Cinnamon vs MATE vs Xfce:你应该选择那一个 Linux Mint 口味? | https://itsfoss.com/linux-mint-cinnamon-mate-xfce/ | 2021-03-18T11:17:00 | [
"Mint"
] | https://linux.cn/article-13213-1.html | 
Linux Mint 无疑是 [最适合初学者的 Linux 发行版之一](https://itsfoss.com/best-linux-beginners/)。尤其是对于刚刚迈向 Linux 世界的 Windows 用户来说,更是如此。
2006 年以来(也就是 Linux Mint 首次发布的那一年),他们开发了一系列的提高用户的体验的 [工具](https://linuxmint-developer-guide.readthedocs.io/en/latest/mint-tools.html#)。此外,Linux Mint 是基于 Ubuntu 的,所以你有一个可以寻求帮助的庞大的用户社区。
我不打算讨论 Linux Mint 有多好。如果你已经下定决心 [安装Linux Mint](https://itsfoss.com/install-linux-mint/),你可能会对它网站上的 [下载部分](https://linuxmint.com/download.php) 感到有些困惑。
它给了你三个选择:Cinnamon、MATE 和 Xfce。不知道该如何选择吗?我将在本文中帮你解决这个问题。

如果你是个 Linux 的绝对新手,对上面的东西一无所知,我建议你了解一下 [什么是 Linux 桌面环境](https://itsfoss.com/what-is-desktop-environment/)。如果你能再多花点时间,请阅读这篇关于 [什么是 Linux,以及为什么有这么多看起来相似的 Linux 操作系统](https://itsfoss.com/what-is-linux/) 的优秀解释。
有了这些信息,你就可以了解各种 Linux Mint 版本之间的区别了。如果你不知道该选择哪一个,通过这篇文章,我将帮助你做出一个有意识的选择。
### 你应该选择哪个 Linux Mint 版本?

简单来说,可供选择的有以下几种:
* **Cinnamon 桌面**:具有现代感的传统桌面。
* **MATE 桌面**:类似 GNOME 2 时代的传统外观桌面。
* **Xfce 桌面**:一个流行的轻量级桌面环境。
我们来逐一看看 Mint 的各个变种。
#### Linux Mint Cinnamon 版
Cinnamon 桌面是由 Linux Mint 团队开发的,显然它是 Linux Mint 的主力版本。
早在近十年前,当 GNOME 桌面选择了非常规的 GNOME 3 用户界面时,人们就开始了 Cinnamon 的开发,通过复刻 GNOME 2 的一些组件来保持桌面的传统外观。
很多 Linux 用户喜欢 Cinnamon,就是因为它有像 Windows 7 一样的界面。

##### 性能和相应能力
Cinnamon 桌面的性能比过去的版本有所提高,但如果没有固态硬盘,你会觉得有点迟钝。上一次我使用 Cinnamon 桌面是在 4.4.8 版,开机后的内存消耗在 750MB 左右。现在的 4.8.6 版有了很大的改进,开机后减少了 100MB 内存消耗。
为了获得最佳的用户体验,应该考虑双核 CPU,最低 4GB 内存。

##### 优势
* 从 Windows 无缝切换
* 赏心悦目
* 高度 [可定制](https://itsfoss.com/customize-cinnamon-desktop/)
##### 劣势
* 如果你的系统只有 2GB 内存,可能还是不够理想
**附加建议**:如果你喜欢 Debian 而不是 Ubuntu,你可以选择 [Linux Mint Debian 版](https://itsfoss.com/lmde-4-release/)(LMDE)。LMDE 和带有 Cinnamon 桌面的 Debian 主要区别在于 LMDE 向其仓库提供最新的桌面环境。
#### Linux Mint Mate 版
[MATE 桌面环境](https://mate-desktop.org/) 也有类似的故事,它的目的是维护和支持 GNOME 2 的代码库和应用程序。它的外观和感觉与 GNOME 2 非常相似。
在我看来,到目前为止,MATE 桌面的最佳实现是 [Ubuntu MATE](https://itsfoss.com/ubuntu-mate-20-04-review/)。在 Linux Mint 中,你会得到一个定制版的 MATE 桌面,它符合 Cinnamon 美学,而不是传统的 GNOME 2 设定。

##### 性能和响应能力
MATE 桌面以轻薄著称,这一点毋庸置疑。与 Cinnamon 桌面相比,其 CPU 的使用率始终保持在较低的水平,换言之,在笔记本电脑上会有更好的电池续航时间。
虽然感觉没有 Xfce 那么敏捷(在我看来),但不至于影响用户体验。内存消耗在 500MB 以下起步,这对于功能丰富的桌面环境来说是令人印象深刻的。

##### 优势
* 不影响 [功能](https://mate-desktop.org/blog/2020-02-10-mate-1-24-released/) 的轻量级桌面
* 足够的 [定制化](https://itsfoss.com/ubuntu-mate-customization/) 可能性
##### 劣势
* 传统的外观可能会给你一种过时的感觉
#### Linux Mint Xfce 版
Xfce 项目始于 1996 年,受到了 UNIX 的 [通用桌面环境(CDE)](https://en.wikipedia.org/wiki/Common_Desktop_Environment) 的启发。Xfce 是 “[XForms](https://en.wikipedia.org/wiki/XForms_(toolkit)) Common Environment” 的缩写,但由于它不再使用 XForms 工具箱,所以名字拼写为 “Xfce”。
它的目标是快速、轻量级和易于使用。Xfce 是许多流行的 Linux 发行版的主要桌面,如 [Manjaro](https://itsfoss.com/manjaro-linux-review/) 和 [MX Linux](https://itsfoss.com/mx-linux-19/)。
Linux Mint 提供了一个精致的 Xfce 桌面,但即使是黑暗主题也无法与 Cinnamon 桌面的美感相比。

##### 性能和响应能力
Xfce 是 Linux Mint 提供的最精简的桌面环境。通过点击开始菜单、设置控制面板或探索底部面板,你会发现这是一个简单而又灵活的桌面环境。
尽管我觉得极简主义是一个积极的属性,但 Xfce 并不是一个养眼的产品,反而留下的是比较传统的味道。但对于一些用户来说,经典的桌面环境才是他们的首选。
在第一次开机时,内存的使用情况与 MATE 桌面类似,但并不尽如人意。如果你的电脑没有配备 SSD,Xfce 桌面环境可以让你的系统复活。

##### 优势
* 使用简单
* 非常轻巧,适合老式硬件
* 坚如磐石的稳定
##### 劣势
* 过时的外观
* 与 Cinnamon 相比,可能没有那么多的定制化服务
### 总结
由于这三款桌面环境都是基于 GTK 工具包的,所以选择哪个纯属个人喜好。它们都很节约系统资源,对于 4GB 内存的适度系统来说,表现良好。Xfce 和 MATE 可以更低一些,支持低至 2GB 内存的系统。
Linux Mint 并不是唯一提供多种选择的发行版。Manjaro、Fedora和 [Ubuntu 等发行版也有各种口味](https://itsfoss.com/which-ubuntu-install/) 可供选择。
如果你还是无法下定决心,我建议先选择默认的 Cinnamon 版,并尝试 [在虚拟机中使用 Linux Mint](https://itsfoss.com/install-linux-mint-in-virtualbox/)。看看你是否喜欢这个外观和感觉。如果不喜欢,你可以用同样的方式测试其他变体。如果你决定了这个版本,你可以继续 [在你的主系统上安装它](https://itsfoss.com/install-linux-mint/)。
希望我的这篇文章能够帮助到你。如果你对这个话题还有疑问或建议,请在下方留言。
---
via: <https://itsfoss.com/linux-mint-cinnamon-mate-xfce/>
作者:[Dimitrios](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Mint is undoubtedly [one of the best Linux distributions for beginners](https://itsfoss.com/best-linux-beginners/). This is especially true for Windows users that walking their first steps to Linux world.
Since 2006, the year that Linux Mint made its first release, a selection of [tools](https://linuxmint-developer-guide.readthedocs.io/en/latest/mint-tools.html?ref=itsfoss.com#) has been developed to enhance user experience. Furthermore, Linux Mint is based on Ubuntu, so you have a large community of users to seek help.
I am not going to discuss how good Linux Mint is. If you have already made your mind to [install Linux Mint](https://itsfoss.com/install-linux-mint/), you probably get a little confused on the [download section](https://linuxmint.com/download.php?ref=itsfoss.com) on its website.
It gives you three options to choose from: Cinnamon, MATE and Xfce. Confused? I’ll help you with that in this article.

If you are absolutely new to Linux and have no idea about what the above things are, I recommend you to understand a bit on [what is a desktop environment in Linux](https://itsfoss.com/what-is-desktop-environment/). And if you could spare some more minutes, read this excellent explanation on [what is Linux and why there are so many of Linux operating systems that look similar to each other](https://itsfoss.com/what-is-linux/).
With that information, you are ready to understand the difference between the various Linux Mint editions. If you are unsure which to choose, with this article I will help you to make a conscious choice.
## Which Linux Mint version should you choose?

Briefly, the available choices are the following:
**Cinnamon desktop:**A modern touch on traditional desktop**MATE desktop:**A traditional looking desktop resembling the GNOME 2 era.**Xfce desktop:**A popular lightweight desktop environment.
Let’s have a look at the Mint variants one by one.
### Linux Mint Cinnamon edition
Cinnamon desktop is developed by Linux Mint team and clearly it is the flagship edition of Linux Mint.
Almost a decade back when the GNOME desktop opted for the unconventional UI with GNOME 3, Cinnamon development was started to keep the traditional looks of the desktop by forking some components of GNOME 2.
Many Linux users like Cinnamon for its similarity with Windows 7 like interface.

#### Performance and responsiveness
The cinnamon desktop performance has improved from the past releases but without an SSD you can feel a bit sluggish. The last time I used cinnamon desktop was in version 4.4.8, the RAM consumption right after boot was around 750mb. There is a huge improvement in the current version 4.8.6, reduced by 100 MB after boot.
To get the best user experience, a dual-core CPU with 4 GB of RAM as a minimum should be considered.
#### Pros 👍
- Seamless switch from Windows
- Pleasing aesthetics
- Highly
[customizable](https://itsfoss.com/customize-cinnamon-desktop/)
#### Cons 👎
- May still not be ideal if you have a system with 2 GB RAM
**Bonus Tip**: If you prefer Debian instead of Ubuntu you have the option of [Linux Mint Debian Edition](https://itsfoss.com/lmde-4-release/). The main difference between LMDE and Debian with Cinnamon desktop is that LMDE ships the latest desktop environment to its repositories.
### Linux Mint Mate edition
[MATE desktop environment](https://mate-desktop.org/?ref=itsfoss.com) shares a similar story as it aims to maintain and support the GNOME 2 code base and applications. The Look and feel is very similar to GNOME 2.
In my opinion, the best implementation of MATE desktop is by far [Ubuntu MATE](https://itsfoss.com/ubuntu-mate-20-04-review/). In Linux Mint you get a customized version of MATE desktop, which is in line with Cinnamon aesthetics and not to the traditional GNOME 2 set out.

#### Performance and responsiveness
MATE desktop has a reputation of its lightweight nature and there is no doubt about that. Compared to Cinnamon desktop, the CPU usage always remains a bit lower, and this can be translated to a better battery life on a laptop.
Although it doesn’t feel as snappy as Xfce (in my opinion), but not to an extent to compromise user experience. RAM consumption starts under 500 MB which is impressive for a feature rich desktop environment.
#### Pros 👍
- Lightweight desktop without compromising on
[features](https://mate-desktop.org/blog/2020-02-10-mate-1-24-released/?ref=itsfoss.com) - Enough
[customization](https://itsfoss.com/ubuntu-mate-customization/)potential
#### Cons 👎
- Traditional looks may give you a dated feel
### Linux Mint Xfce edition
XFCE project started in 1996 inspired by the [Common Desktop Environment](https://en.wikipedia.org/wiki/Common_Desktop_Environment?ref=itsfoss.com) of UNIX. XFCE” stands for “[XForms](https://en.wikipedia.org/wiki/XForms_(toolkit)?ref=itsfoss.com) Common Environment”, but since it no longer uses the XForms toolkit, the name is spelled as “Xfce”.
It aims to be fast, lightweight and easy to use. Xfce is the flagship desktop of many popular Linux distributions like [Manjaro](https://itsfoss.com/manjaro-linux-review/) and [MX Linux](https://itsfoss.com/mx-linux-19/).
Linux Mint offers a polished Xfce desktop but can’t match the beauty of Cinnamon desktop even in a Dark theme.

#### Performance and responsiveness
Xfce is the leanest desktop environment Linux Mint has to offer. By clicking the start menu, the settings control panel or exploring the bottom panel you will notice that this is a simple yet a flexible desktop environment.
Despite I find minimalism a positive attribute, Xfce is not an eye candy, leaving a more traditional taste. For some users a classic desktop environment is the one to go for.
At the first boot the ram usage is similar to MATE desktop but not quite as good. If your computer isn’t equipped with an SSD, Xfce desktop environment can resurrect your system.
#### Pros 👍
- Simple to use
- Very lightweight – suitable for older hardware
- Rock-solid stable
#### Cons 👎
- Outdated look
- May not have as much customization to offer in comparison to Cinnamon
### Conclusion
Since all these three desktop environments are based on GTK toolkit, the choice is purely a matter of taste. All of them are easy on system resources and perform well for a modest system with 4 GB RAM. Xfce and MATE can go a bit lower by supporting systems with as low as 2 GB RAM.
Linux Mint is not the only distribution that provides multiple choices. Distros like Manjaro, Fedora and [Ubuntu have various flavors](https://itsfoss.com/which-ubuntu-install/) to choose from as well.
If you still cannot make your mind, I’ll say go with the default Cinnamon edition first and try to [use Linux Mint in a virtual box](https://itsfoss.com/install-linux-mint-in-virtualbox/). See if you like the look and feel. If not, you can test other variants in the same fashion. If you decide on the version, you can go on and [install it on your main system](https://itsfoss.com/install-linux-mint/).
I hope I was able to help you with this article. If you still have questions or suggestions on this topic, please leave a comment below. |
13,215 | 在 Linux 上使用 kill 和 killall 命令来管理进程 | https://opensource.com/article/20/1/linux-kill-killall | 2021-03-18T23:06:42 | [
"kill",
"进程"
] | /article-13215-1.html |
>
> 了解如何使用 ps、kill 和 killall 命令来终止进程并回收系统资源。
>
>
>

在 Linux 中,每个程序和<ruby> 守护程序 <rt> daemon </rt></ruby>都是一个“<ruby> 进程 <rt> process </rt></ruby>”。 大多数进程代表一个正在运行的程序。而另外一些程序可以派生出其他进程,比如说它会侦听某些事件的发生,然后对其做出响应。并且每个进程都需要一定的内存和处理能力。你运行的进程越多,所需的内存和 CPU 使用周期就越多。在老式电脑(例如我使用了 7 年的笔记本电脑)或轻量级计算机(例如树莓派)上,如果你关注过后台运行的进程,就能充分利用你的系统。
你可以使用 `ps` 命令来查看正在运行的进程。你通常会使用 `ps` 命令的参数来显示出更多的输出信息。我喜欢使用 `-e` 参数来查看每个正在运行的进程,以及 `-f` 参数来获得每个进程的全部细节。以下是一些例子:
```
$ ps
PID TTY TIME CMD
88000 pts/0 00:00:00 bash
88052 pts/0 00:00:00 ps
88053 pts/0 00:00:00 head
```
```
$ ps -e | head
PID TTY TIME CMD
1 ? 00:00:50 systemd
2 ? 00:00:00 kthreadd
3 ? 00:00:00 rcu_gp
4 ? 00:00:00 rcu_par_gp
6 ? 00:00:02 kworker/0:0H-events_highpri
9 ? 00:00:00 mm_percpu_wq
10 ? 00:00:01 ksoftirqd/0
11 ? 00:00:12 rcu_sched
12 ? 00:00:00 migration/0
```
```
$ ps -ef | head
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 13:51 ? 00:00:50 /usr/lib/systemd/systemd --switched-root --system --deserialize 36
root 2 0 0 13:51 ? 00:00:00 [kthreadd]
root 3 2 0 13:51 ? 00:00:00 [rcu_gp]
root 4 2 0 13:51 ? 00:00:00 [rcu_par_gp]
root 6 2 0 13:51 ? 00:00:02 [kworker/0:0H-kblockd]
root 9 2 0 13:51 ? 00:00:00 [mm_percpu_wq]
root 10 2 0 13:51 ? 00:00:01 [ksoftirqd/0]
root 11 2 0 13:51 ? 00:00:12 [rcu_sched]
root 12 2 0 13:51 ? 00:00:00 [migration/0]
```
最后的例子显示最多的细节。在每一行,`UID`(用户 ID)显示了该进程的所有者。`PID`(进程 ID)代表每个进程的数字 ID,而 `PPID`(父进程 ID)表示其父进程的数字 ID。在任何 Unix 系统中,进程是从 1 开始编号,是内核启动后运行的第一个进程。在这里,`systemd` 是第一个进程,它催生了 `kthreadd`,而 `kthreadd` 还创建了其他进程,包括 `rcu_gp`、`rcu_par_gp` 等一系列进程。
### 使用 kill 命令来管理进程
系统会处理大多数后台进程,所以你不需要操心这些进程。你只需要关注那些你所运行的应用创建的进程。虽然许多应用一次只运行一个进程(如音乐播放器、终端模拟器或游戏等),但其他应用则可能创建后台进程。其中一些应用可能当你退出后还在后台运行,以便下次你使用的时候能快速启动。
当我运行 Chromium(作为谷歌 Chrome 浏览器所基于的开源项目)时,进程管理便成了问题。 Chromium 在我的笔记本电脑上运行非常吃力,并产生了许多额外的进程。现在我仅打开五个选项卡,就能看到这些 Chromium 进程:
```
$ ps -ef | fgrep chromium
jhall 66221 [...] /usr/lib64/chromium-browser/chromium-browser [...]
jhall 66230 [...] /usr/lib64/chromium-browser/chromium-browser [...]
[...]
jhall 66861 [...] /usr/lib64/chromium-browser/chromium-browser [...]
jhall 67329 65132 0 15:45 pts/0 00:00:00 grep -F chromium
```
我已经省略一些行,其中有 20 个 Chromium 进程和一个正在搜索 “chromium" 字符的 `grep` 进程。
```
$ ps -ef | fgrep chromium | wc -l
21
```
但是在我退出 Chromium 之后,这些进程仍旧运行。如何关闭它们并回收这些进程占用的内存和 CPU 呢?
`kill` 命令能让你终止一个进程。在最简单的情况下,你告诉 `kill` 命令终止你想终止的进程的 PID。例如,要终止这些进程,我需要对 20 个 Chromium 进程 ID 都执行 `kill` 命令。一种方法是使用命令行获取 Chromium 的 PID,而另一种方法针对该列表运行 `kill`:
```
$ ps -ef | fgrep /usr/lib64/chromium-browser/chromium-browser | awk '{print $2}'
66221
66230
66239
66257
66262
66283
66284
66285
66324
66337
66360
66370
66386
66402
66503
66539
66595
66734
66848
66861
69702
$ ps -ef | fgrep /usr/lib64/chromium-browser/chromium-browser | awk '{print $2}' > /tmp/pids
$ kill $(cat /tmp/pids)
```
最后两行是关键。第一个命令行为 Chromium 浏览器生成一个进程 ID 列表。第二个命令行针对该进程 ID 列表运行 `kill` 命令。
### 介绍 killall 命令
一次终止多个进程有个更简单方法,使用 `killall` 命令。你或许可以根据名称猜测出,`killall` 会终止所有与该名字匹配的进程。这意味着我们可以使用此命令来停止所有流氓 Chromium 进程。这很简单:
```
$ killall /usr/lib64/chromium-browser/chromium-browser
```
但是要小心使用 `killall`。该命令能够终止与你所给出名称相匹配的所有进程。这就是为什么我喜欢先使用 `ps -ef` 命令来检查我正在运行的进程,然后针对要停止的命令的准确路径运行 `killall`。
你也可以使用 `-i` 或 `--interactive` 参数,来让 `killkill` 在停止每个进程之前提示你。
`killall` 还支持使用 `-o` 或 `--older-than` 参数来查找比特定时间更早的进程。例如,如果你发现了一组已经运行了好几天的恶意进程,这将会很有帮助。又或是,你可以查找比特定时间更晚的进程,例如你最近启动的失控进程。使用 `-y` 或 `--young-than` 参数来查找这些进程。
### 其他管理进程的方式
进程管理是系统维护重要的一部分。在我作为 Unix 和 Linux 系统管理员的早期职业生涯中,杀死非法作业的能力是保持系统正常运行的关键。在如今,你可能不需要亲手在 Linux 上的终止流氓进程,但是知道 `kill` 和 `killall` 能够在最终出现问题时为你提供帮助。
你也能寻找其他方式来管理进程。在我这个案例中,我并不需要在我退出浏览器后,使用 `kill` 或 `killall` 来终止后台 Chromium 进程。在 Chromium 中有个简单设置就可以进行控制:

不过,始终关注系统上正在运行哪些进程,并且在需要的时候进行干预是一个明智之举。
---
via: <https://opensource.com/article/20/1/linux-kill-killall>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,216 | 在树莓派上设置家庭网络的家长控制 | https://opensource.com/article/21/3/raspberry-pi-parental-control | 2021-03-19T09:24:23 | [
"家长控制",
"家庭网络",
"树莓派"
] | https://linux.cn/article-13216-1.html |
>
> 用最少的时间和金钱投入,就能保证孩子上网安全。
>
>
>

家长们一直在寻找保护孩子们上网的方法,从防止恶意软件、横幅广告、弹出窗口、活动跟踪脚本和其他问题,到防止他们在应该做功课的时候玩游戏和看 YouTube。许多企业使用工具来规范员工的网络安全和活动,但问题是如何在家里实现这一点?
简短的答案是一台小巧、廉价的树莓派电脑,它可以让你为孩子和你在家的工作设置<ruby> 家长控制 <rt> parental controls </rt></ruby>。本文将引导你了解使用树莓派构建自己的启用了家长控制功能的家庭网络有多么容易。
### 安装硬件和软件
对于这个项目,你需要一个树莓派和一个家庭网络路由器。如果你在线购物网站花上 5 分钟浏览,就可以发现很多选择。[树莓派 4](https://www.raspberrypi.org/products/) 和 [TP-Link 路由器](https://www.amazon.com/s?k=tp-link+router&crid=3QRLN3XRWHFTC&sprefix=TP-Link%2Caps%2C186&ref=nb_sb_ss_ts-doa-p_3_7) 是初学者的好选择。
有了网络设备和树莓派后,你需要在 Linux 容器或者受支持的操作系统中安装 [Pi-hole](https://pi-hole.net/)。有几种 [安装方法](https://github.com/pi-hole/pi-hole/#one-step-automated-install),但一个简单的方法是在你的树莓派上执行以下命令:
```
curl -sSL https://install.pi-hole.net | bash
```
### 配置 Pi-hole 作为你的 DNS 服务器
接下来,你需要在路由器和 Pi-hole 中配置 DHCP 设置:
1. 禁用路由器中的 DHCP 服务器设置
2. 在 Pi-hole 中启用 DHCP 服务器
每台设备都不一样,所以我没有办法告诉你具体需要点击什么来调整设置。一般来说,你可以通过浏览器访问你家的路由器。你的路由器的地址有时会印在路由器的底部,它以 192.168 或 10 开头。
在浏览器中,打开你的路由器的地址,并用你的凭证登录。它通常是简单的 `admin` 和一个数字密码(有时这个密码也打印在路由器上)。如果你不知道登录名,请打电话给你的供应商并询问详情。
在图形界面中,寻找你的局域网内关于 DHCP 的部分,并停用 DHCP 服务器。 你的路由器界面几乎肯定会与我的不同,但这是一个我设置的例子。取消勾选 **DHCP 服务器**:

接下来,你必须在 Pi-hole 上激活 DHCP 服务器。如果你不这样做,除非你手动分配 IP 地址,否则你的设备将无法上网!
### 让你的网络适合家庭
设置完成了。现在,你的网络设备(如手机、平板电脑、笔记本电脑等)将自动找到树莓派上的 DHCP 服务器。然后,每个设备将被分配一个动态 IP 地址来访问互联网。
注意:如果你的路由器设备支持设置 DNS 服务器,你也可以在路由器中配置 DNS 客户端。客户端将把 Pi-hole 作为你的 DNS 服务器。
要设置你的孩子可以访问哪些网站和活动的规则,打开浏览器进入 Pi-hole 管理页面,`http://pi.hole/admin/`。在仪表板上,点击“Whitelist”来添加你的孩子可以访问的网页。你也可以将不允许孩子访问的网站(如游戏、成人、广告、购物等)添加到“Blocklist”。

### 接下来是什么?
现在,你已经在树莓派上设置了家长控制,你可以让你的孩子更安全地上网,同时让他们访问经批准的娱乐选项。这也可以通过减少你的家庭串流来降低你的家庭网络使用量。更多高级使用方法,请访问 Pi-hole 的[文档](https://docs.pi-hole.net/)和[博客](https://pi-hole.net/blog/#page-content)。
---
via: <https://opensource.com/article/21/3/raspberry-pi-parental-control>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Parents are always looking for ways to protect their kids online—from malware, banner ads, pop-ups, activity-tracking scripts, and other concerns—and to prevent them from playing games and watching YouTube when they should be doing their schoolwork. Many businesses use tools that regulate their employees' online safety and activities, but the question is how to make this happen at home?
The short answer is a tiny, inexpensive Raspberry Pi computer that enables you to set parental controls for your kids and your work at home. This article walks you through how easy it is to build your own parental control-enabled home network with a Raspberry Pi.
## Install the hardware and software
For this project, you'll need a Raspberry Pi and a home network router. If you spend only five minutes exploring online shopping sites, you will find a lot of options. The [Raspberry Pi 4](https://www.raspberrypi.org/products/) and a [TP-Link router](https://www.amazon.com/s?k=tp-link+router&crid=3QRLN3XRWHFTC&sprefix=TP-Link%2Caps%2C186&ref=nb_sb_ss_ts-doa-p_3_7) are good options for beginners.
Once you have your network device and Pi, you need to install [Pi-hole](https://pi-hole.net/) as a Linux container or a supported operating system. There are several [ways to install it](https://github.com/pi-hole/pi-hole/#one-step-automated-install), but an easy way is to issue the following command on your Pi:
`curl -sSL https://install.pi-hole.net | bash`
## Configure Pi-hole as your DNS server
Next, you need to configure the DHCP settings in both your router and Pi-hole:
- Disable the DHCP server setting in your router
- Enable the DHCP server in Pi-hole
Every device is different, so there's no way for me to tell you exactly what you need to click on to adjust your settings. Generally, you access your home router through a web browser. Your router's address is sometimes printed on the bottom of the router, and it begins with either 192.168 or 10.
In your web browser, navigate to your router's address and log in with the credentials you received when you got your internet service. It's often as simple as `admin`
with a numeric password (sometimes this password is also printed on the router). If you don't know the login, call your internet provider and ask for details.
In the graphical interface, look for a section within your LAN about DHCP, and deactivate the DHCP server. Your router's interface will almost certainly look different from mine, but this is an example of what I saw when setting it up. Uncheck **DHCP server**:
(Daniel Oh, CC BY-SA 4.0)
Next, you *must* activate the DHCP server on the Pi-hole. If you don't do that, none of your devices will be able to get online unless you manually assign IP addresses!
## Make your network family-friendly
You're all set. Now, your network devices (i.e., mobile phone, tablet PC, laptop, etc.) will automatically find the DHCP server on the Raspberry Pi. Then, each device will be assigned a dynamic IP address to access the internet.
Note: If your router device supports setting a DNS server, you can also configure the DNS clients in your router. The client will refer to the Pi-hole as your DNS server.
To set up rules for which sites and activities your kids can access, open a web browser to the Pi-hole admin page, `http://pi.hole/admin/`
. On the dashboard, click on **Whitelist **to add web pages your kids are allowed to access. You can also add sites that your kids aren't allowed to access (e.g., gaming, adult, ads, shopping, etc.) to the **Blocklist**.
(Daniel Oh, CC BY-SA 4.0)
## What's next?
Now that you've set up your Raspberry Pi for parental control, you can keep your kids safer online while giving them access to approved entertainment options. This can also decrease your home internet usage by reducing how much your family is streaming. For more advanced usage, access Pi-hole's [documentation](https://docs.pi-hole.net/) and [blogs](https://pi-hole.net/blog/#page-content).
## 3 Comments |
13,218 | 在 FreeDOS 中设置你的路径 | https://opensource.com/article/21/2/path-freedos | 2021-03-20T10:30:11 | [
"FreeDOS",
"路径"
] | https://linux.cn/article-13218-1.html |
>
> 学习 FreeDOS 路径的知识,如何设置它,并且如何使用它。
>
>
>

你在开源 [FreeDOS](https://www.freedos.org/) 操作系统中所做的一切工作都是通过命令行完成的。命令行以一个 *提示符* 开始,这是计算机说法的方式,“我准备好了。请给我一些事情来做。”你可以配置你的提示符的外观,但是默认情况下,它是:
```
C:\>
```
从命令行中,你可以做两件事:运行一个内部命令或运行一个程序。外部命令是在你的 `FDOS` 目录中可找到的以单独文件形式存在的程序,以便运行程序包括运行外部命令。它也意味着你可以使用你的计算机运行应用程序软件来做一些东西。你也可以运行一个批处理文件,但是在这种情况下,你所做的全部工作就变成了运行批处理文件中所列出的一系列命令或程序。
### 可执行应用程序文件
FreeDOS 可以运行三种类型的应用程序文件:
1. **COM** 是一个用机器语言写的,且小于 64 KB 的文件。
2. **EXE** 也是一个用机器语言写的文件,但是它可以大于 64 KB 。此外,在 EXE 文件的开头部分有信息,用于告诉 DOS 系统该文件是什么类型的以及如何加载和运行。
3. **BAT** 是一个使用文本编辑器以 ASCII 文本格式编写的 *批处理文件* ,其中包含以批处理模式执行的 FreeDOS 命令。这意味着每个命令都会按顺序执行到文件的结尾。
如果你所输入的一个文件名称不能被 FreeDOS 识别为一个内部命令或一个程序,你将收到一个错误消息 “Bad command or filename” 。如果你看到这个错误,它意味着会是下面三种情况中的其中一种:
1. 由于某些原因,你所给予的名称是错误的。你可能拼错了文件名称,或者你可能正在使用错误的命令名称。检查名称和拼写,并再次尝试。
2. 可能你正在尝试运行的程序并没有安装在计算机上。请确认它已经安装了。
3. 文件确实存在,但是 FreeDOS 不知道在哪里可以找到它。
在清单上的最后一项就是这篇文章的主题,它被称为路径。如果你已经习惯于使用 Linux 或 Unix ,你可能已经理解 [PATH 变量](https://opensource.com/article/17/6/set-path-linux) 的概念。如果你是命令行的新手,那么路径是一个非常重要的足以让你舒适的东西。
### 路径
当你输入一个可执行应用程序文件的名称时,FreeDOS 必须能找到它。FreeDOS 会在一个具体指定的位置层次结构中查找文件:
1. 首先,它查找当前驱动器的活动目录(称为 *工作目录*)。如果你正在目录 `C:\FDOS` 中,接着,你输入名称 `FOOBAR.EXE`,FreeDOS 将在 `C:\FDOS` 中查找带有这个名称的文件。你甚至不需要输入完整的名称。如果你输入 `FOOBAR` ,FreeDOS 将查找任何带有这个名称的可执行文件,不管它是 `FOOBAR.EXE`,`FOOBAR.COM`,或 `FOOBAR.BAT`。只要 FreeDOS 能找到一个匹配该名称的文件,它就会运行该可执行文件。
2. 如果 FreeDOS 不能找到你所输入名称的文件,它将查询被称为 `PATH` 的一些东西。每当 DOS 不能在当前活动命令中找到文件时,会指示 DOS 检查这个列表中目录。
你可以随时使用 `path` 命令来查看你的计算机的路径。只需要在 FreeDOS 提示符中输入 `path` ,FreeDOS 就会返回你的路径设置:
```
C:\>path
PATH=C:\FDOS\BIN
```
第一行是提示符和命令,第二行是计算机返回的东西。你可以看到 DOS 第一个查看的位置就是位于 `C` 驱动器上的 `FDOS\BIN`。如果你想更改你的路径,你可以输入一个 `path` 命令以及你想使用的新路径:
```
C:\>path=C:\HOME\BIN;C:\FDOS\BIN
```
在这个示例中,我设置我的路径到我个人的 `BIN` 文件夹,我把它放在一个叫 `HOME` 的自定义目录中,然后再设置为 `FDOS/BIN`。现在,当你检查你的路径时:
```
C:\>path
PATH=C:\HOME\BIN;C:\FDOS\BIN
```
路径设置是按所列目录的顺序处理的。
你可能会注意到有一些字符是小写的,有一些字符是大写的。你使用哪一种都真的不重要。FreeDOS 是不区分大小写的,并且把所有的东西都作为大写字母对待。在内部,FreeDOS 使用的全是大写字母,这就是为什么你看到来自你命令的输出都是大写字母的原因。如果你以小写字母的形式输入命令和文件名称,在一个转换器将自动转换它们为大写字母后,它们将被执行。
输入一个新的路径来替换先前设置的路径。
### autoexec.bat 文件
你可能遇到的下一个问题的是 FreeDOS 默认使用的第一个路径来自何处。这与其它一些重要的设置一起定义在你的 `C` 驱动器的根目录下的 `AUTOEXEC.BAT` 文件中。这是一个批处理文件,它在你启动 FreeDOS 时会自动执行(由此得名)。你可以使用 FreeDOS 程序 `EDIT` 来编辑这个文件。为查看或编辑这个文件的内容,输入下面的命令:
```
C:\>edit autoexec.bat
```
这一行出现在顶部附近:
```
SET PATH=%dosdir%\BIN
```
这一行定义默认路径的值。
在你查看 `AUTOEXEC.BAT` 后,你可以通过依次按下面的按键来退出 EDIT 应用程序:
1. `Alt`
2. `f`
3. `x`
你也可以使用键盘快捷键 `Alt+X`。
### 使用完整的路径
如果你在你的路径中忘记包含 `C:\FDOS\BIN` ,那么你将不能快速访问存储在这里的任何应用程序,因为 FreeDOS 不知道从哪里找到它们。例如,假设我设置我的路径到我个人应用程序集合:
```
C:\>path=C:\HOME\BIN
```
内置在命令行中应用程序仍然能正常工作:
```
C:\cd HOME
C:\HOME>dir
ARTICLES
BIN
CHEATSHEETS
GAMES
DND
```
不过,外部的命令将不能运行:
```
C:HOME\ARTICLES>BZIP2 -c example.txt
Bad command or filename - "BZIP2"
```
通过提供命令的一个 *完整路径* ,你可以总是执行一个在你的系统上且不在你的路径中的命令:
```
C:HOME\ARTICLES>C:\FDOS\BIN\BZIP2 -c example.txt
C:HOME\ARTICLES>DIR
example.txb
```
你可以使用同样的方法从外部介质或其它目录执行应用程序。
### FreeDOS 路径
通常情况下,你很可能希望在路径中保留 `C:\PDOS\BIN` ,因为它包含所有使用 FreeDOS 分发的默认应用程序。
除非你更改 `AUTOEXEC.BAT` 中的路径,否则将在重新启动后恢复默认路径。
现在,你知道如何在 FreeDOS 中管理你的路径,你能够以最适合你的方式了执行命令和维护你的工作环境。
*致谢 [DOS 课程 5: 路径](https://www.ahuka.com/dos-lessons-for-self-study-purposes/dos-lesson-5-the-path/) (在 CC BY-SA 4.0 协议下发布) 为本文提供的一些信息。*
---
via: <https://opensource.com/article/21/2/path-freedos>
作者:[Kevin O'Brien](https://opensource.com/users/ahuka) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Everything you do in the open source [FreeDOS](https://www.freedos.org/) operating system is done from the command line. The command line begins with a *prompt*, which is the computer's way of saying, "I'm ready. Give me something to do." You can configure your prompt's appearance, but by default, it's:
`C:\>`
From the command line, you can do two things: Run an internal command or run a program. External commands are programs found in separate files in your `FDOS`
directory, so running programs includes running external commands. It also means running the application software you use to do things with your computer. You can also run a batch file, but in that case, all you're doing is running a series of commands or programs that are listed in the batch file.
## Executable application files
FreeDOS can run three types of application files:
**COM**is a file in machine language less than 64KB in size.**EXE**is a file in machine language that can be larger than 64KB. EXE files also have information at the beginning of the file telling DOS what type of file it is and how to load and run it.**BAT**is a*batch file*written with a text editor in ASCII text format containing FreeDOS commands that are executed in batch mode. This means each command is executed in sequence until the file ends.
If you enter an application name that FreeDOS does not recognize as either an internal command or a program, you get the error message *Bad command or filename*. If you see this error, it means one of three things:
- The name you gave is incorrect for some reason. Possibly you misspelled the file name, or maybe you're using the wrong command name. Check the name and the spelling and try again.
- Maybe the program you are trying to run is not installed on the computer. Verify that it is installed.
- The file does exist, but FreeDOS doesn't know where to find it.
The final item on this list is the subject of this article, and it's referred to as the `PATH`
. If you're used to Linux or Unix already, you may already understand the concept of [the PATH variable](https://opensource.com/article/17/6/set-path-linux). If you're new to the command line, the path is an important thing to get comfortable with.
## The path
When you enter the name of an executable application file, FreeDOS has to find it. FreeDOS looks for the file in a specific hierarchy of locations:
- First, it looks in the active directory of the current drive (called the
*working directory*). If you're in the directory`C:\FDOS`
, and you type in the name`FOOBAR.EXE`
, FreeDOS looks in`C:\FDOS`
for a file with that name. You don't even need to type in the entire name. If you type in`FOOBAR`
, FreeDOS looks for any executable file with that name, whether it's`FOOBAR.EXE`
,`FOOBAR.COM`
, or`FOOBAR.BAT`
. Should FreeDOS find a file matching that name, it runs it. - If FreeDOS does not find a file with the name you've entered, it consults something called the
`PATH`
. This is a list of directories that DOS has been instructed to check whenever it cannot find a file in the current active directory.
You can see your computer's path at any time by using the `PATH`
command. Just type `path`
at the FreeDOS prompt, and FreeDOS returns your path setting:
```
C:\>path
PATH=C:\FDOS\BIN
```
The first line is the prompt and the command, and the second line is what the computer returned. You can see that the first place DOS looks is `FDOS\BIN`
, which is located on the `C`
drive. If you want to change your path, you can enter a path command and the new path you want to use:
`C:\>path=C:\HOME\BIN;C:\FDOS\BIN`
In this example, I set my path to my personal `BIN`
folder, which I keep in a custom directory called `HOME`
, and then to `FDOS\BIN`
. Now when you check your path:
```
C:\>path
PATH=C:\HOME\BIN;C:\FDOS\BIN
```
The path setting is processed in the order that directories are listed.
You may notice that some characters are lower case and some upper case. It really doesn't matter which you use. FreeDOS is not case-sensitive and treats everything as an upper-case letter. Internally, FreeDOS uses all upper-case letters, which is why you see the output from your commands in upper case. If you type commands and file names in lower case, a converter automatically converts them to upper case, and they are executed.
Entering a new path replaces whatever the path was set to previously.
## The autoexec.bat file
The next question you might have is where that first path, the one FreeDOS uses by default, came from. That, along with several other important settings, is defined in the `AUTOEXEC.BAT`
file located at the root of your `C`
drive. This is a batch file that automatically executes (hence the name) when you start FreeDOS. You can edit this file with the FreeDOS program `EDIT`
. To see or edit the contents of this file, enter the following command:
`C:\>edit autoexec.bat`
This line appears near the top:
`SET PATH=%dosdir%\BIN`
This line defines the value of the default path.
After you look at `AUTOEXEC.BAT`
, you can exit the EDIT application by pressing the following keys in order:
- Alt
- f
- x
You can also use the keyboard shortcut **Alt**+**X**.
## Using the full path
If you forget to include `C:\FDOS\BIN`
in your path, you won't have immediate access to any of the applications stored there because FreeDOS won't know where to find them. For instance, imagine I set my path to my personal collection of applications:
`C:\>path=C:\HOME\BIN`
Applications built into the command line still work:
```
C:\cd HOME
C:\HOME>dir
ARTICLES
BIN
CHEATSHEETS
GAMES
DND
```
However, external commands fail:
```
C:HOME\ARTICLES>BZIP2 -c example.txt
Bad command or filename - "BZIP2"
```
You can always execute a command that you know is on your system but not in your path by providing the *full path* to the file:
```
C:HOME\ARTICLES>C:\FDOS\BIN\BZIP2 -c example.txt
C:HOME\ARTICLES>DIR
example.txb
```
You can execute applications from external media or other directories the same way.
## FreeDOS path
Generally, you probably want to keep `C:\PDOS\BIN`
in your path because it contains all the default applications distributed with FreeDOS.
Unless you change the path in `AUTOEXEC.BAT`
, the default path is restored after a reboot.
Now that you know how to manage your path in FreeDOS, you can execute commands and maintain your working environment in whatever way works best for you.
*Thanks to DOS Lesson 5: The Path (published under a CC BY-SA 4.0 license) for some of the information in this article.*
## 2 Comments |
13,219 | 5 个用命令行操作 LibreOffice 的技巧 | https://opensource.com/article/21/3/libreoffice-command-line | 2021-03-20T11:02:11 | [
"LibreOffice",
"命令行"
] | https://linux.cn/article-13219-1.html |
>
> 直接在命令行中对文件进行转换、打印、保护等操作。
>
>
>

LibreOffice 拥有所有你想要的办公软件套件的生产力功能,使其成为微软 Office 或谷歌套件的流行的开源替代品。LibreOffice 的能力之一是可以从命令行操作。例如,Seth Kenlon 最近解释了如何使用 LibreOffice 用全局 [命令行选项将多个文件](https://opensource.com/article/21/2/linux-workday) 从 DOCX 转换为 EPUB。他的文章启发我分享一些其他 LibreOffice 命令行技巧和窍门。
在查看 LibreOffice 命令的一些隐藏功能之前,你需要了解如何使用应用选项。并不是所有的应用都接受选项(除了像 `--help` 选项这样的基本选项,它在大多数 Linux 应用中都可以使用)。
```
$ libreoffice --help
```
这将返回 LibreOffice 接受的其他选项的描述。有些应用没有太多选项,但 LibreOffice 好几页有用的选项,所以有很多东西可以玩。
就是说,你可以在终端上使用 LibreOffice 进行以下五项有用的操作,来让使软件更加有用。
### 1、自定义你的启动选项
你可以修改你启动 LibreOffice 的方式。例如,如果你想只打开 LibreOffice 的文字处理器组件:
```
$ libreoffice --writer # 启动文字处理器
```
你可以类似地打开它的其他组件:
```
$ libreoffice --calc # 启动一个空的电子表格
$ libreoffice --draw # 启动一个空的绘图文档
$ libreoffice --web # 启动一个空的 HTML 文档
```
你也可以从命令行访问特定的帮助文件:
```
$ libreoffice --helpwriter
```

或者如果你需要电子表格应用方面的帮助:
```
$ libreoffice --helpcalc
```
你可以在不显示启动屏幕的情况下启动 LibreOffice:
```
$ libreoffice --writer --nologo
```
你甚至可以在你完成当前窗口的工作时,让它在后台最小化启动:
```
$ libreoffice --writer --minimized
```
### 2、以只读模式打开一个文件
你可以使用 `--view` 以只读模式打开文件,以防止意外地对重要文件进行修改和保存:
```
$ libreoffice --view example.odt
```
### 3、打开一个模板文档
你是否曾经创建过用作信头或发票表格的文档?LibreOffice 具有丰富的内置模板系统,但是你可以使用 `-n` 选项将任何文档作为模板:
```
$ libreoffice --writer -n example.odt
```
你的文档将在 LibreOffice 中打开,你可以对其进行修改,但保存时不会覆盖原始文件。
### 4、转换文档
当你需要做一个小任务,比如将一个文件转换为新的格式时,应用启动的时间可能与完成任务的时间一样长。解决办法是 `--headless` 选项,它可以在不启动图形用户界面的情况下执行 LibreOffice 进程。
例如,在 LibreOffic 中,将一个文档转换为 EPUB 是一个非常简单的任务,但使用 `libreoffice` 命令就更容易:
```
$ libreoffice --headless --convert-to epub example.odt
```
使用通配符意味着你可以一次转换几十个文档:
```
$ libreoffice --headless --convert-to epub *.odt
```
你可以将文件转换为多种格式,包括 PDF、HTML、DOC、DOCX、EPUB、纯文本等。
### 5、从终端打印
你可以从命令行打印 LibreOffice 文档,而无需打开应用:
```
$ libreoffice --headless -p example.odt
```
这个选项不需要打开 LibreOffice 就可以使用默认打印机打印,它只是将文档发送到你的打印机。
要打印一个目录中的所有文件:
```
$ libreoffice -p *.odt
```
(我不止一次执行了这个命令,然后用完了纸,所以在你开始之前,确保你的打印机里有足够的纸张。)
你也可以把文件输出成 PDF。通常这和使用 `--convert-to-pdf` 选项没有什么区别,但是很容易记住:
```
$ libreoffice --print-to-file example.odt --headless
```
### 额外技巧:Flatpak 和命令选项
如果你是使用 [Flatpak](https://www.libreoffice.org/download/flatpak/) 安装的 LibreOffice,所有这些命令选项都可以使用,但你必须通过 Flatpak 传递。下面是一个例子:
```
$ flatpak run org.libreoffice.LibreOffice --writer
```
它比本地安装要麻烦得多,所以你可能会受到启发 [写一个 Bash 别名](https://opensource.com/article/19/7/bash-aliases) 来使它更容易直接与 LibreOffice 交互。
### 令人惊讶的终端选项
通过查阅手册页面,了解如何从命令行扩展 LibreOffice 的功能:
```
$ man libreoffice
```
你是否知道 LibreOffice 具有如此丰富的命令行选项? 你是否发现了其他人似乎都不了解的其他选项? 请在评论中分享它们!
---
via: <https://opensource.com/article/21/3/libreoffice-command-line>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | LibreOffice has all the productivity features you'd want from an office software suite, making it a popular open source alternative to Microsoft Office or Google Suite. One of LibreOffice's powers is the ability to operate from the command line. For example, Seth Kenlon recently explained how he uses a global [command-line option to convert multiple files](https://opensource.com/article/21/2/linux-workday) from DOCX to EPUB with LibreOffice. His article inspired me to share some other LibreOffice command-line tips and tricks.
Before we look at some hidden features of LibreOffice commands, you need to understand how to use options with applications. Not all applications accept options (aside from the basics like the `--help`
option, which works in most Linux applications).
`$ libreoffice --help`
This returns descriptions of other options LibreOffice accepts. Some applications don't have many options, but LibreOffice has a few screens worth, so there's plenty to play with.
That said, here are five useful things you can do with LibreOffice at the terminal to make the software even more useful.
## 1. Customize your launch options
You can modify how you launch LibreOffice. For instance, if you want to open just LibreOffice's word processor component:
`$ libreoffice --writer #starts the word processor`
You can open its other components similarly:
```
$ libreoffice --calc #starts the Calc document
$ libreoffice --draw #starts an empty Draw document
$ libreoffice --web #starts and empty HTML document
```
You also can access specific help files from the command line:
`$ libreoffice --helpwriter`
(Don Watkins, CC BY-SA 4.0)
Or if you need help with the spreadsheet application:
`$ libreoffice --helpcalc`
You can start LibreOffice without the splash screen:
`$ libreoffice --writer --nologo`
You can even have it launch minimized in the background while you finish working in your current window:
`$ libreoffice --writer --minimized`
## 2. Open a file in read-only mode
You can open files in read-only mode using `--view`
to prevent accidentally making and saving changes to an important file:
`$ libreoffice --view example.odt`
## 3. Open a document as a template
Have you ever created a document to use as a letterhead or invoice form? LibreOffice has a rich built-in template system, but you can make any document a template with the `-n`
option:
`$ libreoffice --writer -n example.odt`
Your document will open in LibreOffice and you can make changes to it, but you won't overwrite the original file when you save it.
## 4. Convert documents
When you need to do a small task like converting a file to a new format, it can take as long for the application to launch as it takes to do the task. The solution is the `--headless`
option, which executes LibreOffice processes without launching the graphical user interface.
For example, converting a document to EPUB is a pretty simple task in LibreOffice—but it's even easier with the `libreoffice`
command:
`$ libreoffice --headless --convert-to epub example.odt`
Using wildcards means you can convert dozens of documents at once:
`$ libreoffice --headless --convert-to epub *.odt`
You can convert files to several formats, including PDF, HTML, DOC, DOCX, EPUB, plain text, and many more.
## 5. Print from the terminal
You can print LibreOffice documents from the command line without opening the application:
`$ libreoffice --headless -p example.odt`
This option prints to the default printer without opening LibreOffice; it just sends the document to your printer.
To print all the files in a directory:
`$ libreoffice -p *.odt`
(More than once, I've issued this command and then run out of paper, so make sure you have enough paper loaded in your printer before you start.)
You can also print files to PDF. There's usually no difference between this and using the `--convert-to-pdf`
option but it's easy to remember:
`$ libreoffice --print-to-file example.odt --headless`
## Bonus: Flatpak and command options
If you installed LibreOffice as a [Flatpak](https://www.libreoffice.org/download/flatpak/), all of these command options work, but you have to pass them through Flatpak. Here's an example:
`$ flatpak run org.libreoffice.LibreOffice --writer`
It's a lot more verbose than a local install, so you might be inspired to [write a Bash alias](https://opensource.com/article/19/7/bash-aliases) to make it easier to interact with LibreOffice directly.
## Surprising terminal options
Find out how you can extend the power of LibreOffice from the command line by consulting the man pages:
`$ man libreoffice`
Were you aware that LibreOffice had such a rich set of command-line options? Have you discovered other options that nobody else seems to know about? Share them in the comments!
## 1 Comment |
13,221 | 10 个常见的 Linux 终端仿真器 | https://itsfoss.com/linux-terminal-emulators/ | 2021-03-21T07:31:54 | [
"终端"
] | https://linux.cn/article-13221-1.html | 
默认情况下,所有的 Linux 发行版都已经预装了“<ruby> 终端 <rt> terminal </rt></ruby>”应用程序或“<ruby> 终端仿真器 <rt> terminal emulator </rt></ruby>”(这才是正确的技术术语)。当然,根据桌面环境的不同,它的外观和感觉会有所不同。
Linux 的特点是,你可以不用局限于你的发行版所提供的东西,你可以用你所选择的替代应用程序。终端也不例外。有几个提供了独特功能的终端仿真器令人印象深刻,可以获得更好的用户体验或更好的外观。
在这里,我将整理一个有趣的终端应用程序的列表,你可以在你的 Linux 发行版上尝试它们。
### 值得赞叹的 Linux 终端仿真器
此列表没有特别的排名顺序,我会先列出一些有趣的,然后是一些最流行的终端仿真器。此外,我还强调了每个提到的终端仿真器的主要功能,你可以选择你喜欢的终端仿真器。
#### 1、Terminator

主要亮点:
* 可以在一个窗口中使用多个 GNOME 终端
[Terminator](https://gnome-terminator.org) 是一款非常流行的终端仿真器,目前仍在维护中(从 Launchpad 移到了 GitHub)。
它基本上是在一个窗口中为你提供了多个 GNOME 终端。在它的帮助下,你可以轻松地对终端窗口进行分组和重组。你可能会觉得这像是在使用平铺窗口管理器,不过有一些限制。
##### 如何安装 Terminator?
对于基于 Ubuntu 的发行版,你只需在终端输入以下命令:
```
sudo apt install terminator
```
你应该可以在大多数 Linux 发行版的默认仓库中找到它。但是,如果你需要安装帮助,请访问它的 [GitHub 页面](https://github.com/gnome-terminator/terminator)。
#### 2、Guake 终端

主要亮点:
* 专为在 GNOME 上快速访问终端而设计
* 工作速度快,不需要大量的系统资源
* 访问的快捷键
[Guake](https://github.com/Guake/guake) 终端最初的灵感来自于一款 FPS 游戏 Quake。与其他一些终端仿真器不同的是,它的工作方式是覆盖在其他的活动窗口上。
你所要做的就是使用快捷键(`F12`)召唤该仿真器,它就会从顶部出现。你可以自定义该仿真器的宽度或位置,但大多数用户使用默认设置就可以了。
它不仅仅是一个方便的终端仿真器,还提供了大量的功能,比如能够恢复标签、拥有多个标签、对每个标签进行颜色编码等等。你可以查看我关于 [Guake 的单独文章](https://itsfoss.com/guake-terminal/) 来了解更多。
##### 如何安装 Guake 终端?
Guake 在大多数 Linux 发行版的默认仓库中都可以找到,你可以参考它的 [官方安装说明](https://guake.readthedocs.io/en/latest/user/installing.html#system-wide-installation)。
如果你使用的是基于 Debian 的发行版,只需输入以下命令:
```
sudo apt install guake
```
#### 3、Tilix 终端

主要亮点:
* 平铺功能
* 支持拖放
* 下拉式 Quake 模式
[Tilix](https://gnunn1.github.io/tilix-web/) 终端提供了与 Guake 类似的下拉式体验 —— 但它允许你在平铺模式下拥有多个终端窗口。
如果你的 Linux 发行版中默认没有平铺窗口,而且你有一个大屏幕,那么这个功能就特别有用,你可以在多个终端窗口上工作,而不需要在不同的工作空间之间切换。
如果你想了解更多关于它的信息,我们之前已经 [单独介绍](https://itsfoss.com/tilix-terminal-emulator/) 过了。
##### 如何安装 Tilix?
Tilix 在大多数发行版的默认仓库中都有。如果你使用的是基于 Ubuntu 的发行版,只需输入:
```
sudo apt install tilix
```
#### 4、Hyper

主要亮点:
* 基于 HTML/CSS/JS 的终端
* 基于 Electron
* 跨平台
* 丰富的配置选项
[Hyper](https://hyper.is/) 是另一个有趣的终端仿真器,它建立在 Web 技术之上。它并没有提供独特的用户体验,但看起来很不一样,并提供了大量的自定义选项。
它还支持安装主题和插件来轻松定制终端的外观。你可以在他们的 [GitHub 页面](https://github.com/vercel/hyper) 中探索更多关于它的内容。
##### 如何安装 Hyper?
Hyper 在默认的资源库中是不可用的。然而,你可以通过他们的 [官方网站](https://hyper.is/#installation) 找到 .deb 和 .rpm 包来安装。
如果你是新手,请阅读文章以获得 [使用 deb 文件](https://itsfoss.com/install-deb-files-ubuntu/) 和 [使用 rpm 文件](https://itsfoss.com/install-rpm-files-fedora/) 的帮助。
#### 5、Tilda

主要亮点:
* 下拉式终端
* 搜索栏整合
[Tilda](https://github.com/lanoxx/tilda) 是另一款基于 GTK 的下拉式终端仿真器。与其他一些不同的是,它提供了一个你可以切换的集成搜索栏,还可以让你自定义很多东西。
你还可以设置热键来快速访问或执行某个动作。从功能上来说,它是相当令人印象深刻的。然而,在视觉上,我不喜欢覆盖的行为,而且它也不支持拖放。不过你可以试一试。
##### 如何安装 Tilda?
对于基于 Ubuntu 的发行版,你可以简单地键入:
```
sudo apt install tilda
```
你可以参考它的 [GitHub 页面](https://github.com/lanoxx/tilda),以了解其他发行版的安装说明。
#### 6、eDEX-UI

主要亮点:
* 科幻感的外观
* 跨平台
* 自定义主题选项
* 支持多个终端标签
如果你不是特别想找一款可以帮助你更快的完成工作的终端仿真器,那么 [eDEX-UI](https://github.com/GitSquared/edex-ui) 绝对是你应该尝试的。
对于科幻迷和只想让自己的终端看起来独特的用户来说,这绝对是一款漂亮的终端仿真器。如果你不知道,它的灵感很大程度上来自于电影《创:战纪》。
不仅仅是设计或界面,总的来说,它为你提供了独特的用户体验,你会喜欢的。它还可以让你 [自定义终端](https://itsfoss.com/customize-linux-terminal/)。如果你打算尝试的话,它确实需要大量的系统资源。
你不妨看看我们 [专门介绍 eDEX-UI](https://itsfoss.com/edex-ui-sci-fi-terminal/) 的文章,了解更多关于它的信息和安装步骤。
##### 如何安装 eDEX-UI?
你可以在一些包含 [AUR](https://itsfoss.com/aur-arch-linux/) 的仓库中找到它。无论是哪种情况,你都可以从它的 [GitHub 发布部分](https://github.com/GitSquared/edex-ui/releases) 中抓取一个适用于你的 Linux 发行版的软件包(或 AppImage 文件)。
#### 7、Cool Retro Terminal

主要亮点:
* 复古主题
* 动画/效果调整
[Cool Retro Terminal](https://github.com/Swordfish90/cool-retro-term) 是一款独特的终端仿真器,它为你提供了一个复古的阴极射线管显示器的外观。
如果你正在寻找一些额外功能的终端仿真器,这可能会让你失望。然而,令人印象深刻的是,它在资源上相当轻盈,并允许你自定义颜色、效果和字体。
##### 如何安装 Cool Retro Terminal?
你可以在其 [GitHub 页面](https://github.com/Swordfish90/cool-retro-term) 中找到所有主流 Linux 发行版的安装说明。对于基于 Ubuntu 的发行版,你可以在终端中输入以下内容:
```
sudo apt install cool-retro-term
```
#### 8、Alacritty

主要亮点:
* 跨平台
* 选项丰富,重点是整合。
[Alacritty](https://github.com/alacritty/alacritty) 是一款有趣的开源跨平台终端仿真器。尽管它被认为是处于“测试”阶段的东西,但它仍然可以工作。
它的目标是为你提供广泛的配置选项,同时考虑到性能。例如,使用键盘点击 URL、将文本复制到剪贴板、使用 “Vi” 模式进行搜索等功能可能会吸引你去尝试。
你可以探索它的 [GitHub 页面](https://github.com/alacritty/alacritty) 了解更多信息。
##### 如何安装 Alacritty?
官方 GitHub 页面上说可以使用包管理器安装 Alacritty,但我在 Linux Mint 20.1 的默认仓库或 [synaptic 包管理器](https://itsfoss.com/synaptic-package-manager/) 中找不到它。
如果你想尝试的话,可以按照 [安装说明](https://github.com/alacritty/alacritty/blob/master/INSTALL.md#debianubuntu) 来手动设置。
#### 9、Konsole

主要亮点:
* KDE 的终端
* 轻巧且可定制
如果你不是新手,这个可能不用介绍了。[Konsole](https://konsole.kde.org/) 是 KDE 桌面环境的默认终端仿真器。
不仅如此,它还集成了很多 KDE 应用。即使你使用的是其他的桌面环境,你也可以试试 Konsole。它是一个轻量级的终端仿真器,拥有众多的功能。
你可以拥有多个标签和多个分组窗口。以及改变终端仿真器的外观和感觉的大量的自定义选项。
##### 如何安装 Konsole?
对于基于 Ubuntu 的发行版和大多数其他发行版,你可以使用默认的版本库来安装它。对于基于 Debian 的发行版,你只需要在终端中输入以下内容:
```
sudo apt install konsole
```
#### 10、GNOME 终端

主要亮点:
* GNOME 的终端
* 简单但可定制
如果你使用的是任何基于 Ubuntu 的 GNOME 发行版,它已经是天生的了,它可能不像 Konsole 那样可以自定义,但它可以让你轻松地配置终端的大部分重要方面。它可能不像 Konsole 那样可以自定义(取决于你在做什么),但它可以让你轻松配置终端的大部分重要方面。
总的来说,它提供了良好的用户体验和易于使用的界面,并提供了必要的功能。
如果你好奇的话,我还有一篇 [自定义你的 GNOME 终端](https://itsfoss.com/customize-linux-terminal/) 的教程。
##### 如何安装 GNOME 终端?
如果你没有使用 GNOME 桌面,但又想尝试一下,你可以通过默认的软件仓库轻松安装它。
对于基于 Debian 的发行版,以下是你需要在终端中输入的内容:
```
sudo apt install gnome-terminal
```
### 总结
有好几个终端仿真器。如果你正在寻找不同的用户体验,你可以尝试任何你喜欢的东西。然而,如果你的目标是一个稳定的和富有成效的体验,你需要测试一下,然后才能依靠它们。
对于大多数用户来说,默认的终端仿真器应该足够好用了。但是,如果你正在寻找快速访问(Quake 模式)、平铺功能或在一个终端中的多个窗口,请试试上述选择。
你最喜欢的 Linux 终端仿真器是什么?我有没有错过列出你最喜欢的?欢迎在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/linux-terminal-emulators/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

By default, all Linux distributions already come pre-installed with a terminal application or terminal emulator (correct technical term). Of course, depending on the desktop environment, it will look and feel different.
Here’s the thing about Linux. You are not restricted to what your distribution provides. You can opt for an alternative application of your choice. The terminal is no different. Several impressive terminal emulators offer unique features for a better user experience or better looks.
Here, I will be compiling a list of such interesting terminal applications that you can try on your Linux distribution.
## Awesome Terminal Emulators for Linux
The list is in no particular order of ranking. I’ve tried to list the interesting ones first followed by some of the most popular terminal emulators. Also, I have highlighted the key features for every terminal emulator mentioned; choose what you prefer.
### 1. Terminator
**Key Highlights:**
- Multiple GNOME terminals in one window
[Terminator](https://itsfoss.com/terminator/) is decently popular terminal emulator which is still being maintained (moved from Launchpad to GitHub).
It provides you with multiple GNOME terminals in one window. You can easily group and re-group terminal windows with its help. You may feel like using a tiling window manager but with some restrictions.
**How to install Terminator?**
For Ubuntu-based distros, all you have to do is type in the following command in the terminal:
`sudo apt install terminator`
You should find it in most Linux distributions through the default repositories. But, if you need help installing, go through the [GitHub page](https://github.com/gnome-terminator/terminator).
### 2. Guake Terminal

**Key Highlights:**
- Tailored for quick access to terminal on GNOME
- Works fast and does not need a lot of system resource
- Shortcut key to access
An FPS game, Quake, initially inspired the Guake terminal. Unlike some other terminal emulators, it works as an overlay on every other active window.
All you have to do is summon the emulator using a shortcut key (F12) and it will appear from the top. You get to customize the emulator's width or position, but most users should be fine with the default setting.
Not just as a handy terminal emulator, it offers many features like restoring tabs, having multiple tabs, color-coding each tab, and more. You can check out my separate article on [Guake](https://itsfoss.com/guake-terminal/) to learn more.
**How to install Guake Terminal?**
Guake is available in the default repositories of most Linux distributions. You can refer to its [official installation instructions](https://guake.readthedocs.io/en/latest/user/installing.html#system-wide-installation).
Or if you’re using a Debian-based distro, just type in the following command:
`sudo apt install guake`
### 3. Tilix Terminal
**Key Highlights:**
- Tiling feature
- Drag and drop support
- Drop down Quake mode
Tilix Terminal offers a similar drop-down experience that you find with Guake – but it also lets you have multiple terminal windows in tiling mode.
This is particularly useful if you do not have tiling windows by default in your Linux distribution and have a big screen to work on multiple terminal windows without switching between workspaces.
We’ve already covered it [separately](https://itsfoss.com/tilix-terminal-emulator/) if you’re curious to learn more about it.
**How to install Tilix?**
Tilix is available in the default repositories for most of the distributions. If you’re using an Ubuntu-based distro, simply type in:
`sudo apt install tilix`
[Tilix: Advanced Tiling Terminal Emulator for Power UsersDo you ever get bored of the default terminal emulator that comes with your Linux distro? If your distro uses GNOME shell or something similar, chances are you are using GNOME terminal or one of its variants. Well, that works alright most of the time. But if you spend a](https://itsfoss.com/tilix-terminal-emulator/)

### 4. Hyper
**Key Highlights:**
- Terminal built on HTML/CSS/JS
- Electron-based
- Cross-platform
- Extensive configuration options
Hyper is yet another interesting terminal emulator that is built on web technologies. It doesn’t provide a unique user experience, but it looks quite different and offers many customization options.
It also supports installing themes and plugins to easily customize the appearance of the terminal. You can explore more about it in their [GitHub page](https://github.com/vercel/hyper).
**How to install Hyper?**
Hyper is not available in the default repositories. However, you can find both .deb and .rpm packages available to install through their [official website](https://hyper.is/#installation).
If you’re new, read through the articles to get help [using deb files](https://itsfoss.com/install-deb-files-ubuntu/) and [using RPM files](https://itsfoss.com/install-rpm-files-fedora/).
### 5. Tilda
**Key Highlights:**
- Drop-down terminal
- Search bar integrated
Tilda is another drop-down GTK-based terminal emulator. Unlike some others, it focuses on providing an integrated search bar that you can toggle and also lets you customize many things.
You can also set hotkeys for quick access or a particular action. Functionally, it is pretty impressive. However, visually, I don’t like how the overlay behaves and does not support drag and drop as well. You might give it a try though.
**How to install Tilda?**
For Ubuntu-based distros, you can simply type in:
`sudo apt install tilda`
You can refer to its [GitHub page](https://github.com/lanoxx/tilda) for installation instructions on other distributions.
### 6. Cool Retro Terminal
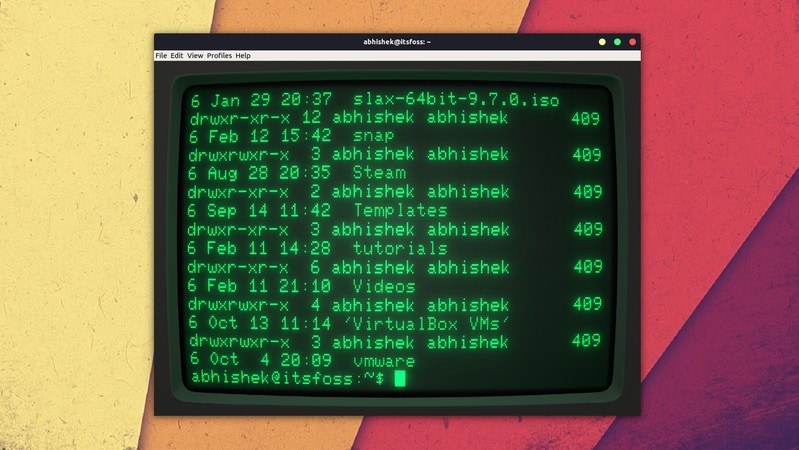
**Key Highlights:**
- Retro Theme
- Animation/Effects to tweak
[Cool Retro Terminal](https://itsfoss.com/cool-retro-term/) is a unique terminal emulator that looks like a vintage cathode ray tube monitor.
This may disappoint you if you’re looking for an extra-functionality terminal emulator. However, it is impressive that it is decently light on resources and allows you to customize the color, effects, and fonts.
**How to install Cool Retro Terminal?**
You can find all the installation instructions for major Linux distributions on its [GitHub page](https://github.com/Swordfish90/cool-retro-term). For Ubuntu-based distros, you can type in the following in the terminal:
`sudo apt install cool-retro-term`
[Get a Vintage Linux Terminal with Cool Retro TerminalNostalgic about the past? Get a slice of the past by installing retro terminal app cool-retro-term which, as the name suggests, is both cool and retro at the same. Do you remember the time when there were CRT monitors everywhere and the terminal screen used to flicker? You don’t](https://itsfoss.com/cool-retro-term/)

### 7. Alacritty
**Key Highlights:**
- Cross-platform
- Extension options and focuses on integration
Alacritty is an interesting open-source cross-platform terminal emulator. Even though it is considered as something in “beta” phase, it still works.
It aims to provide you with extensive configuration options while keeping performance in mind. For instance, the ability to click through a URL using a keyboard, copy text to a clipboard, and perform a search using “Vi” mode may intrigue you to try it.
You can explore its GitHub page for more information.
**How to install Alacritty?**
Alacritty can be installed using package managers says the official GitHub page, but I couldn’t find it in the default repository or [synaptic package manager](https://itsfoss.com/synaptic-package-manager/) on Linux Mint 20.1.
You can follow the [installation instructions](https://github.com/alacritty/alacritty/blob/master/INSTALL.md#debianubuntu) to set it up manually if you want to try it.
### 8. Konsole
**Key Highlights:**
- KDE’s terminal
- Lightweight and customizable
If you’re not a newbie, this probably needs no introduction. Konsole is the default terminal emulator for KDE desktop environments.
Not just limited to that, it also comes integrated with a lot of KDE apps as well. Even if you’re using some other desktop environment, you can still try Konsole. It is a lightweight terminal emulator with a host of features.
You can have multiple tabs and multiple grouped windows as well. Lot of customization options to change the look and feel of the terminal emulator as well.
**How to install Konsole?**
For Ubuntu-based distros and most other distributions, you can install it using the default repository. With Debian-based distros, you just need to type this in the terminal:
`sudo apt install konsole`
### 9. GNOME Terminal
**Key Highlights:**
- GNOME’s terminal
- Simple yet customizable
It already comes in if you’re utilizing any Ubuntu-based GNOME distribution. It may not be as customizable as Konsole (depends on what you’re doing) but it lets you configure most of the important aspects of the terminal easily.
Overall, it offers a good user experience and an easy-to-use interface with essential functions.
I’ve also covered a tutorial to [customize your GNOME terminal](https://itsfoss.com/customize-linux-terminal/) if you’re curious.
**How to install GNOME Terminal?**
If you’re not using GNOME desktop but want to try it out, you can easily install it through the default repositories.
For Debian-based distros, here’s what you need to type in the terminal:
`sudo apt install gnome-terminal`
### 10. Yakuake
**Key Highlights:**
- Drop down terminal
- Based on KDE’s Konsole
Yakuake is yet another impressive terminal emulator that can replace Guake depending on your liking. It is based on KDE’s Konsole technologies, a powerful terminal emulator loaded by default with KDE Desktop.
It supports customizing the width and height and gives you the option of a full-screen mode. You can add multiple shells as well.
You can also create/manage profiles and assign keyboard shortcuts to adapt to your workflow.
**How to install Yakuake?**
You should find it in your default repositories. To install on any Ubuntu-based distro, all you have to type in the terminal is:
`sudo apt install yakuake`
If you do not find it in the repository of your Linux distribution, you can try to build and install it by following the instructions on its [GitHub page](https://github.com/KDE/yakuake).
### 11. Kitty
**Key Highlights:**
- Feature-rich
- GPU-based
- Fast performance
- Cross-platform (macOS)
Kitty is an underrated and popular option among terminal emulator users that I seemed to have missed in the first version of this article.
It offers plenty of useful features while supporting tiling windows as well. Also, it is a GPU-based emulator which depends on the GPU and takes the load off the CPU when you work on it.
Especially, if you are a power keyboard user, this will be an exciting option for you to try!
**How to install Kitty?**
Kitty should be available in all the default repositories of your Linux distributions. For Ubuntu-based systems, you can install it by typing:
`sudo apt install kitty`
To integrate it with your desktop or if you want an alternative installation method for your system, you can refer to the [official installation instructions](https://sw.kovidgoyal.net/kitty/binary.html).
### 12. Simple Terminal (st)
**Key Highlights:**
- Simple terminal with essential features
- Wayland supported
Simple Terminal, popularly known as **st,** is an alternative for users who dislike bloated terminal emulators like [xterm](https://invisible-island.net/xterm/) or [rxvt](https://en.wikipedia.org/wiki/Rxvt).
It offers a couple of valuable features like 256-color support and more.
**How to install st?**
For Ubuntu-based distros, you can install it by typing in the following:
`sudo apt install stterm`
You can try looking for the same package on your distro. It should be available as st in [AUR](https://itsfoss.com/aur-arch-linux/) for Arch-based distros as well. If you don’t find it, you can simply download the [archive file from its official website](https://st.suckless.org/) to build it from the source.
### 13. XTERM
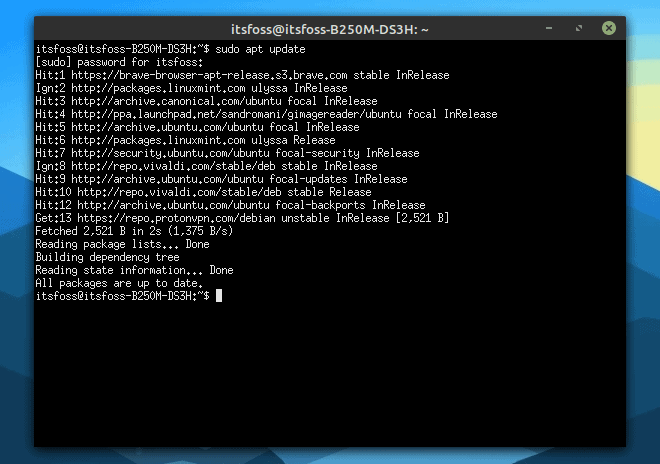
**Key Highlights:**
- Feature-rich
- One of the oldest terminal emulators
XTERM is one of the most popular terminal emulators out there. Even though it might seem to be a bloated option when compared to st, it’s still a decent option that you can try for X Window System.
It’s been actively developed for more than two decades now and seems to be constantly evolving. This is neither visually appealing nor offers drop-down mode, but you can try it out.
**How to install XTERM?**
You can easily find it in your system repositories. For Ubuntu-based distros, you can install it by the following command:
`sudo apt install xterm`
You can find other packages (including NetBSD) on its [official website](https://invisible-island.net/xterm/#download).
### 14. Warp terminal (not open source)
**Key Highlights:**
- IDE like interface
- Built-in AI agent
- Persistent SSH connections
Perhaps the only non-foss entry in the list but Warp has gained quite some following thanks to the feature it offers.
The IDE like interface makes terminal less scary for people who don't like CLI. The built-in AI agent lets you query for command examples, write commands and more.
## Honorable Mention
urxvt is a fork of rxvt terminal emulator with [Unicode support](https://itsfoss.com/unicode-linux/) that you might want to know. It allows you to have multiple windows on different displays and many other features.
Unfortunately, the official website is being flagged by Firefox due to SSL certificates being messed up, and the changelog seems to be last updated in 2016. Hence, I’ve avoided linking it here, you’re free to explore more if you’re curious.
## Wrapping Up
There are several terminal emulators available out there. You can try anything you like if you want a different user experience. However, if you’re aiming for a stable and productive experience, you need to test the terminal emulators before you can rely on them.
For most users, the default terminal emulators should be good enough. You can even customize its looks.
[5 Tweaks to Customize the Look of Your Linux TerminalThe terminal emulator or simply the terminal is an integral part of any Linux distribution. When you change the theme of your distribution, often the terminal also gets a makeover automatically. But that doesn’t mean you cannot customize the terminal further. In fact, many It’s FOSS reader…](https://itsfoss.com/customize-linux-terminal/)

But, if you’re looking for quick access (Quake Mode) or Tiling feature or multiple windows in a terminal, feel free to try out the options mentioned above.
And if you are new to the Terminal, this article will help you a great deal ⬇️
[19 Basic But Essential Linux Terminal Tips You Must KnowLearn some small, basic but often ignored things about the terminal. With the small tips, you should be able to use the terminal with slightly more efficiency.](https://itsfoss.com/basic-terminal-tips-ubuntu/)

What’s your favorite terminal emulator on Linux? Did I miss listing your favorite? Feel free to let me know your thoughts in the comments down below. |
13,222 | 利用树莓派和低功耗显示器来跟踪你的家庭日程表 | https://opensource.com/article/21/3/family-calendar-raspberry-pi | 2021-03-21T09:15:24 | [
"日程",
"日历",
"树莓派"
] | https://linux.cn/article-13222-1.html |
>
> 通过利用开源工具和电子墨水屏,让每个人都清楚家庭的日程安排。
>
>
>

有些家庭的日程安排很复杂:孩子们有上学活动和放学后的活动,你想要记住的重要事情,每个人都有多个约会等等。虽然你可以使用手机和应用程序来关注所有事情,但在家中放置一个大型低功耗显示器以显示家人的日程不是更好吗?电子墨水日程表刚好满足!

### 硬件
这个项目是作为假日项目开始,因此我试着尽可能多的旧物利用。其中包括一台已经闲置了太长时间树莓派 2。由于我没有电子墨水屏,因此我需要购买一个。幸运的是,我找到了一家供应商,该供应商为支持树莓派的屏幕提供了 [开源驱动程序和示例](https://github.com/waveshare/e-Paper),该屏幕使用 [GPIO](https://opensource.com/article/19/3/gpio-pins-raspberry-pi) 端口连接。
我的家人还想在不同的日程表之间切换,因此需要某种形式的输入。我没有添加 USB 键盘,而是选择了一种更简单的解决方案,并购买了一个类似于在 [这篇文章](https://www.instructables.com/1x4-Membrane-Keypad-w-Arduino/) 中所描述 1x4 大小的键盘。这使我可以将键盘连接到树莓派中的某些 GPIO 端口。
最后,我需要一个相框来容纳整个设置。虽然背面看起来有些凌乱,但它能完成工作。

### 软件
我从 [一个类似的项目](https://github.com/zli117/EInk-Calendar) 中获得了灵感,并开始为我的项目编写 Python 代码。我需要从两个地方获取数据:
* 天气信息:从 [OpenWeather API](https://openweathermap.org) 获取
* 时间信息:我打算使用 [CalDav 标准](https://en.wikipedia.org/wiki/CalDAV) 连接到一个在我家服务器上运行的日程表
由于必须等待一些零件的送达,因此我使用了模块化的方法来进行输入和显示,这样我可以在没有硬件的情况下调试大多数代码。日程表应用程序需要驱动程序,于是我编写了一个 [Pygame](https://github.com/pygame/pygame) 驱动程序以便能在台式机上运行它。
编写代码最好的部分是能够重用现有的开源项目,所以访问不同的 API 很容易。我可以专注于设计用户界面,其中包括每个人的周历和每个人的日历,以及允许使用小键盘来选择日程。并且我花时间又添加了一些额外的功能,例如特殊日子的自定义屏幕保护程序。

最后的集成步骤将确保我的日程表应用程序将在启动时运行,并且能够容错。我使用了一个基本的 [树莓派系统](https://www.raspberrypi.org/software/) 镜像,并将该应用程序配置到 systemd 服务,以便它可以在出现故障和系统重新启动依旧运行。
做完所有工作,我把代码上传到了 [GitHub](https://github.com/javierpena/eink-calendar)。因此,如果你要创建类似的日历,可以随时查看并重构它!
### 结论
日程表已成为我们厨房中的日常工具。它可以帮助我们记住我们的日常活动,甚至我们的孩子在上学前,都可以使用它来查看日程的安排。
对我而言,这个项目让我感受到开源的力量。如果没有开源的驱动程序、库以及开放 API,我们依旧还在用纸和笔来安排日程。很疯狂,不是吗?
需要确保你的日程不冲突吗?学习如何使用这些免费的开源项目来做到这点。
---
via: <https://opensource.com/article/21/3/family-calendar-raspberry-pi>
作者:[Javier Pena](https://opensource.com/users/jpena) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some families have a complex schedule: the kids have school and afterschool activities, you have important events you want to remember, everyone has multiple appointments, and so forth. While you can keep track of everything using your cellphone and an app, wouldn't it be better to have a large, low-power display at home to show your family's calendar? Meet the E Ink calendar!

(Javier Pena, CC BY-SA 4.0)
## The hardware
The calendar started as a holiday project, so I tried to reuse as much as I could. This included a Raspberry Pi 2 that had been unused for too long. I did not have an E Ink display, so I had to buy it. Fortunately, I found a vendor that provided [open source drivers and examples](https://github.com/waveshare/e-Paper) for its Raspberry Pi-ready screen, which is connected using some [GPIO](https://opensource.com/article/19/3/gpio-pins-raspberry-pi) ports.
My family also wanted to switch between different calendars, and that required some form of input. Instead of adding a USB keyboard, I opted for a simpler solution and bought a 1x4 matrix keypad, similar to the one described in [this article](https://www.instructables.com/1x4-Membrane-Keypad-w-Arduino/). This allowed me to connect the keypad to some GPIO ports in the Raspberry Pi.
Finally, I needed a photo frame to house the whole setup. It looks a bit messy on the back, but it gets the job done.

(Javier Pena, CC BY-SA 4.0)
## The software
I took inspiration from a [similar project](https://github.com/zli117/EInk-Calendar) and started writing the Python code for my project. I needed to get data from two areas:
- Weather data, which I got from the
[OpenWeather API](https://openweathermap.org) - Calendar data; I decided to use the
[CalDav standard](https://en.wikipedia.org/wiki/CalDAV), which lets me connect to a calendar running on my home server
Since I had to wait for some parts to arrive, I used a modular approach for the input and display so that I could debug most of the code without the hardware. The calendar application supports drivers, and I wrote a [Pygame](https://github.com/pygame/pygame) driver to run it on a desktop PC.
The best part of writing the code was being able to reuse existing open source projects, so accessing the different APIs was easy. I could focus on the user interface—having per-person weekly and everyone daily calendars, allowing calendar selection using the keypad—and I had time to add some extra touches, like custom screen savers for special days.

(Javier Pena, CC BY-SA 4.0)
The final integration step was making sure my calendar application would run on startup and be resilient to errors. I used a base [Raspberry Pi OS](https://www.raspberrypi.org/software/) image and installed the application as a systemd service so that it would survive failures and system restarts.
Once I finished everything, I uploaded the code [to GitHub](https://github.com/javierpena/eink-calendar). So if you want to create a similar calendar, feel free to have a look and reuse it!
## The result
The calendar has become an everyday appliance in our kitchen. It helps us remember our daily activities, and even our kids use it to check their schedule before going to school.
On a personal note, the project helped me appreciate the *power of open*. Without open source drivers and libraries and open APIs, we would still be organizing our schedule with paper and a pen. Crazy, isn't it?
## Comments are closed. |
13,224 | 四个新式开源许可证 | https://opensource.com/article/21/2/osi-licenses-cal-cern-ohl | 2021-03-21T22:10:33 | [
"许可证",
"OSI",
"开源"
] | https://linux.cn/article-13224-1.html |
>
> 让我们来看看 OSI 最新批准的加密自治许可证和 CERN 开源硬件许可协议。
>
>
>

作为 <ruby> <a href="https://opensource.org/osd"> 开源定义 </a> <rt> Open Source Defintion </rt></ruby>(OSD)的管理者,<ruby> <a href="https://opensource.org/"> 开源促进会 </a> <rt> Open Source Initiative </rt></ruby>(OSI)20 年来一直在批准“开源”许可证。这些许可证是开源软件生态系统的基础,可确保每个人都可以使用、改进和共享软件。当一个许可证获批为“开源”时,是因为 OSI 认为该许可证可以促进相互的协作和共享,从而使得每个参与开源生态的人获益。
在过去的 20 年里,世界发生了翻天覆地的变化。现如今,软件以新的甚至是无法想象的方式在被使用。OSI 已经预料到,曾经被人们所熟知的开源许可证现已无法满足如今的要求。因此,许可证管理者已经加强了工作,为更广泛的用途提交了几个新的许可证。OSI 所面临的挑战是在评估这些新的许可证概念是否会继续推动共享和合作,是否被值得称为“开源”许可证,最终 OSI 批准了一些用于特殊领域的新式许可证。
### 四个新式许可证
第一个是 <ruby> <a href="https://opensource.org/licenses/CAL-1.0"> 加密自治许可证 </a> <rt> Cryptographic Autonomy License </rt></ruby>(CAL)。该许可证是为分布式密码应用程序而设计的。此许可证所解决的问题是,现有的开源许可证无法保证开放性,因为如果没有义务也与其他对等体共享数据,那么一个对等体就有可能损害网络的运行。因此,除了是一个强有力的版权保护许可外,CAL 还包括向第三方提供独立使用和修改软件所需的权限和资料的义务,而不会让第三方有数据或功能的损失。
随着越来越多的人使用加密结构进行点对点共享,那么更多的开发人员发现自己需要诸如 CAL 之类的法律工具也就不足为奇了。 OSI 的两个邮件列表 License-Discuss 和 License-Review 上的社区,讨论了拟议的新开源许可证,并询问了有关此许可证的诸多问题。我们希望由此产生的许可证清晰易懂,并希望对其他开源从业者有所裨益。
接下来是,欧洲核研究组织(CERN)提交的 CERN <ruby> 开放硬件许可证 <rt> Open Hardware Licence </rt></ruby>(OHL)系列许可证以供审议。它包括三个许可证,其主要用于开放硬件,这是一个与开源软件相似的开源访问领域,但有其自身的挑战和细微差别。硬件和软件之间的界线现已变得相当模糊,因此应用单独的硬件和软件许可证变得越来越困难。欧洲核子研究组织(CERN)制定了一个可以确保硬件和软件自由的许可证。
OSI 可能在开始时就没考虑将开源硬件许可证添加到其开源许可证列表中,但是世界早已发生变革。因此,尽管 CERN 许可证中的措词涵盖了硬件术语,但它也符合 OSI 认可的所有开源软件许可证的条件。
CERN 开源硬件许可证包括一个 [宽松许可证](https://opensource.org/CERN-OHL-P)、一个 [弱互惠许可证](https://opensource.org/CERN-OHL-W) 和一个 [强互惠许可证](https://opensource.org/CERN-OHL-S)。最近,该许可证已被一个国际研究项目采用,该项目正在制造可用于 COVID-19 患者的简单、易于生产的呼吸机。
### 了解更多
CAL 和 CERN OHL 许可证是针对特殊用途的,并且 OSI 不建议把它们用于其它领域。但是 OSI 想知道这些许可证是否会按预期发展,从而有助于在较新的计算机领域中培育出健壮的开源生态。
可以从 OSI 获得关于 [许可证批准过程](https://opensource.org/approval) 的更多信息。
---
via: <https://opensource.com/article/21/2/osi-licenses-cal-cern-ohl>
作者:[Pam Chestek](https://opensource.com/users/pchestek) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As the steward of the [Open Source Defintion](https://opensource.org/osd), the [Open Source Initiative](https://opensource.org/) has been designating licenses as "open source" for over 20 years. These licenses are the foundation of the open source software ecosystem, ensuring that everyone can use, improve, and share software. When a license is approved, it is because the OSI believes that the license fosters collaboration and sharing for the benefit of everyone who participates in the ecosystem.
The world has changed over the past 20 years, with software now used in new and even unimaginable ways. The OSI has seen that the familiar open source licenses are not always well-suited for these new situations. But license stewards have stepped up, submitting several new licenses for more expansive uses. The OSI was challenged to evaluate whether these new concepts in licensing would continue to advance sharing and collaboration and merit being referred to as "open source" licenses, ultimately approving some new special purpose licenses.
## Four new licenses
First is the [Cryptographic Autonomy License](https://opensource.org/licenses/CAL-1.0). This license is designed for distributed cryptographic applications. The challenge of this use case was that the existing open source licenses wouldn't assure openness because it would be possible for one peer to impair the functioning of the network if there was no obligation to also share data with the other peers. So, in addition to being a strong copyleft license, the CAL also includes an obligation to provide third parties the permissions and materials needed to independently use and modify the software without that third party having a loss of data or capability.
As more and more uses arise for peer-to-peer sharing using a cryptographic structure, it wouldn't be surprising if more developers found themselves in need of a legal tool like the CAL. The community on License-Discuss and License-Review, OSI's two mailing lists where proposed new open source licenses are discussed, asked many questions about this license. We hope that the resulting license is clear and easy to understand and that other open source practitioners will find it useful.
Next, the European Organization for Nuclear Research, CERN, submitted the CERN Open Hardware Licence (OHL) family of licenses for consideration. All three of its licenses are primarily intended for open hardware, a field of open access that is similar to open source software but with its own challenges and nuances. The line between hardware and software has blurred considerably, so applying separate hardware and software licenses has become more and more difficult. CERN undertook crafting a license that would ensure freedom for both hardware and software.
The OSI probably would not have considered adding an open hardware license to its list of open source licenses back when it started, but the world has changed. So while the wording in the CERN licenses encompasses hardware concepts, it also meets all the qualifications to be approved by the OSI as an open source software license.
The suite of CERN Open Hardware licenses includes a [permissive license](https://opensource.org/CERN-OHL-P), a [weak reciprocal license](https://opensource.org/CERN-OHL-W), and a [strong reciprocal license](https://opensource.org/CERN-OHL-S). Most recently, the license has been adopted by an international research project that is building simple, easily replicable ventilators to use with COVID-19 patients.
## Learn more
The CAL and CERN OHL licenses are special-purpose, and the OSI does not recommend their use outside the fields for which they were designed. But the OSI is eager to see whether these licenses will work as intended, fostering robust open ecosystems in these newer computing arenas.
More information on the [license approval process](https://opensource.org/approval) is available from the OSI.
## Comments are closed. |
13,226 | 《代码英雄》第四季(1):小型机 —— 旧机器的灵魂 | https://www.redhat.com/en/command-line-heroes/season-4/minicomputers | 2021-03-22T14:30:00 | [
"大型机",
"小型机",
"代码英雄"
] | https://linux.cn/article-13226-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第四季(1):小型机 —— 旧机器的灵魂](https://www.redhat.com/en/command-line-heroes/season-4/minicomputers)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/2b74a070-f1ae-411f-80e0-7ad69cb04220/clh-s4-ep1-minicomputer-the-soul-of-an-old-machine_tc.mp3)脚本。
>
> 导语:它们不适合放在你的口袋里。但在当时,<ruby> 小型机 <rt> minicomputer </rt></ruby>比之前的房间大小的<ruby> 大型机 <rp> ( </rp> <rt> mainframe </rt> <rp> ) </rp></ruby>的尺寸小了一个数量级。它们为可以装进包里的<ruby> 个人电脑 <rt> Personal Computer </rt></ruby>(PC),以及最终你口袋里的手机铺平了道路。
>
>
> 16 位小型机改变了 20 世纪 70 年代的 IT 世界。他们让公司的每个工程师都有机会拥有自己的计算机。但这还不够,直到 32 位版本的到来。
>
>
> Carl Alsing 和 Jim Guyer 讲述了他们在<ruby> 数据通用 <rt> Data General </rt></ruby>公司创造革命性的新 32 位计算机的工作。但他们如今被视作传奇的工作是在秘密中完成的。他们的机器代号为 “Eagle”,其设计目的是为了与自己公司的另一个团队正在制造的机器竞争。这些工程师们回忆了为使项目继续进行而做的公司政治和阴谋,以及他们如何将限制转化为优势。Neal Firth 则讨论了如何在一个令人兴奋但要求很高的项目中的生活。在这个项目中,代码英雄们一起工作,只是因为他们想这样做,而不是期望获奖或成名。这三个人都讨论了这个故事如何在 Tracy Kidder 的非虚构工程经典《<ruby> 新机器的灵魂 <rt> The Soul of a New Machine </rt></ruby>》中所成就的不朽。
>
>
>
**00:00:03 - Saron Yitbarek**:
那是 1978 年,小型机业界激战正酣。就在一年前,<ruby> 数字设备公司 <rt> Digital Equipment Corporation </rt></ruby>(DEC)发布了其 32 位的 VAX 11 780 计算机。它比市面上的 16 位机器要强大得多。 VAX 的销售迅速地超越了那些步履缓慢的竞争对手。其主要竞争对手<ruby> 数据通用 <rt> Data General </rt></ruby>公司迫切需要一台新机器来和 VAX 竞争。他们需要一台属于自己的 32 位计算机,而且要够快才行,但数据通用公司和 DEC 之间的竞争并不是唯一的战斗。数据通用公司内部还正酝酿一场地盘争夺战,而这两场战斗的战利品都是在令人难以置信的环境下创造令人难以置信的机器。一台 13 英寸的笔记本电脑大概有 3 磅重。如今,我们认为计算机的便携性及方便的尺寸是理所应当的,但是在 20 世纪 70 年代,大多数计算机仍然有着整个机房大小的大型机、重达数吨,而且价值数百万美金。而当硬件成本急剧下降后,开发更小、更快、更便宜的机器的竞争就开始了。小型机为工程师和科学家打开了拥有自己的终端机的大门。正是小型机引领我们到了今天的样子。
**00:01:37**:
在上一季的《代码英雄》中,我们深入探究了对软件开发至关重要的领域 —— 编程语言的世界。诸如 JavaScript、Python 和 C、Perl、COBOL 以及 Go 之类的语言,我们审视了它们的历史、它们所解决的问题,以及它们是怎样随着时间推移而演变的。在这一季中,也就是第四季,我们将再一次深入探索,这一次是我们软件运行于其上的硬件。我们将为大家讲述七个特别的故事,讲述那些敢于改变硬件规则的人和团队。你桌上的笔记本电脑、口袋里的手机,如今你所拥有的每一件硬件设备,以及它们的前代产品,都是代码英雄们全身心投入的结果。他们的激情打造、他们的大胆举动,让我们的硬件成为现实,彻底改变了我们现如今的编程方式。
**00:02:36**:
我是 Saron Yitbarek。这里是代码英雄,一档来自<ruby> 红帽 <rt> Red Hat </rt></ruby>的原创播客节目。
**00:02:45**:
在我们本季的首播中,将讲述一个工程团队竞相设计、调试和交付下一代计算机的故事。他们工作的故事变成了 1981 年 Tracy Kidder 获得了普利策奖的畅销书《<ruby> 新机器的灵魂 <rt> The Soul of a New Machine </rt></ruby>》的主题。在这本书中讲述了这一集中你将听到的众多嘉宾的故事。
**00:03:07**:
让我们说回到数据通用公司。该公司主席 Ed de Castro 制定了与 DEC 竞争的计划。他拆分了工程部门,将一支团队从其位于<ruby> 马萨诸塞州 <rt> Massachusetts </rt></ruby><ruby> 韦斯特伯勒 <rt> Westborough </rt></ruby>的总部迁移到了<ruby> 北卡罗来那州 <rt> North Carolina </rt></ruby>的新办公室。他们的任务是开发一款领先的 32 位的机器设计,以粉碎 VAX。他们将项目命名为 “Fountainhead”。Ed de Castro 为这支团队提供了几乎无限的支持和资源,他将 Fountainhead 视为他公司的救星。而剩下的几名工程师被留在了马萨诸塞州,他们觉得自己被严重轻视了。他们认为自己能够开发一个干掉 VAX 的杀手,可能会比 Fountainhead 项目所能开发的更好,但是 Ed de Castro 不会给他们机会。因此,这个小组的负责人 Tom West 决定自己动手。Tom West 是一名自学成才的计算机工程师,他负责数据通用公司的 Eclipse 部门。 Eclipse 是数据通用公司最成功的 16 位小型机产品线。Tom 能造机器,也能卖货,而且他知道市场需求是什么。Fountainhead 项目成立以后,Ed de Castro 让剩下的工程师们继续致力于优化去年的产品线。 而 Tom 和其他人都对此不以为然。
**00:04:31 - Carl Alsing**:
我们对此一点都不满意。我们中有些人离开去做其他工作,而另一些人则感到十分沮丧,担心自己的事业,而且感觉没意思。而且我们觉得另一组人肯定会失败。
**00:04:46 - Saron Yitbarek**:
Carl Alsing 是数据通用公司微编程小组的经理。他是 Tom 的副手。他们决定提出自己的项目计划。
**00:04:56 - Carl Alsing**:
这将是使用最新技术进行的全新设计,构建一个能够击败 DEC 的 VAX 的 32 位计算机。所以我们为此提出了一项建议,并去找了主席 Ed de Castro,他说:“不,没门儿。北卡罗来那州的小组在负责这项工作。你们不必操心。”因此,我们感到十分灰心,回去提出了另一个名为 Victor 的计划。我们研究了如何使去年的老产品更好的方法。我们在里面设置了一个小开关,即系统里的一个模式位,当你打开它时,它将使得计算机能够像现代 32 位小型机一样运行,尽管比较慢。然后我们向 Ed de Castro 提出了这个功能。最后他说:“你们在这里有个模式位。我不想再看到其他任何带有模式位的设计。北卡罗来那州那边正在负责新设计。”于是乎又一次,我们深感沮丧,我想就是在那会儿 Tom West 决定要做一些秘密的事情。
**00:06:06 - Saron Yitbarek**:
Tom 想出了两个故事。一个是讲给 Ed de Castro 的:他们将会对旧的 Eclipse 产品线进行加强,使它运行得更快一点,增加几个新按钮,并且换个新颜色。Tom 把它说成保险措施,以防万一北卡罗来那州那边出了什么问题。Ed de Castro 同意了。然后 Tom 给他的团队讲了另一个更棒的故事。
**00:06:32 - Carl Alsing**:
Tom West 向我们团队中的一些人提议,我们要开发一款真正优秀的现代机器,它对以前的机器完全兼容,并且采用我们所需的所有最新高科技的东西,有虚拟内存、32 位和纠错代码,以及所有这类东西:多任务、多处理、大量内存。“伙计们,我们将打造出最新的、能在市场上大杀四方的新机器。”
**00:07:04 - Saron Yitbarek**:
这款极具市场杀伤力的新机器的代号是 “Eagle”。现如今,人们觉得我们的电脑中的内存是没有任何限制的,但是在那时候,当从 16 位转换到 32 位时,发生了重大的突破。突然之间,你的地址空间就从能够存储 65000 字节的信息变成了 40 多亿字节。随着这一增长,软件也可以处理更加大量的数据。这给计算机公司带来了两个基本的挑战:从 16 位过渡到 32 位,这是肯定的,但是他们还得让使用旧软件的老客户感到满意。因此,他们必须得开发一款能够让旧软件继续运行的机器,即一款向后兼容的 32 位计算机。VAX 尽其所能也没有找到第二个问题的完美解决方案,但是 Tom 坚信他的 Eagle 可以做到。
**00:08:14**:
Eagle 的总部位于韦斯特伯勒 14 号楼 AB 的地下室。Tom 指派 Carl 负责<ruby> 微码 <rt> micro coding </rt></ruby>。Carl 指派 Chuck Holland 来管理<ruby> 编码员 <rt> coder </rt></ruby>,他们被称为<ruby> 微码小子 <rt> Micro Kids </rt></ruby>。同时,Ed Rasala 将负责硬件。他委派了 Ken Holberger 负责管理团队,这个团队被恰当地称为<ruby> 哈迪男孩 <rt> Hardy Boys </rt></ruby>。(LCTT 译注:《哈迪男孩》是一部 1977 年的美国电视剧。) Tom 有一个盟友,就是工程副总裁 Carl Carman。 Carman 也对 Ed de Castro 有意见,因为 Ed de Castro 拒绝让他来负责北卡罗来那州的小组。
**00:08:51 - Carl Alsing**:
Carl Carman 知道我们在干什么,却什么都没有对他的老板说。所以他给我们提供了资金,但我们需要保持较低的薪水,并且需要一些非常聪明的工程师。因此,我们决定去招收大学毕业生。这样做的好处之一是他们不知道什么是你做不到的。他们以为你无所不能。
**00:09:15 - Saron Yitbarek**:
那时 Jim Guyer 刚从大学毕业两年,在数据通用公司工作时被分派到了哈迪男孩。
**00:09:21 - Jim Guyer**:
北卡罗来那州那边正在开发的机器更多是高端计算,本质上几乎是大型机。而且,嗯,我的意思是,这在当时确实是投入到与 IBM 以及其他大型机公司的竞争中去的相当重要的一步。我们认为我们有优势,因为我们想做的事情并不那么雄心勃勃,而且我们真的、真的专注于一种简洁、干净、简单的实现方案,用最低的成本、最少的组件等等。
**00:09:51 - Saron Yitbarek**:
成本低廉,设计简单。他们意识到他们需要使用<ruby> 固件 <rt> firmware </rt></ruby>来控制一切。与硬件相比,把越多的功能置于固件控制之下,所开发的机器就越便宜、越灵活。
**00:10:03**:
而且它们能够根据需求进行修改。当然,现代计算机都是以这种方式构建而成的,但在 1978 年,这种方法是全新的。
**00:10:15 - Carl Alsing**:
我们所做的设计非常简约。我们正在研究能够使事情简单明了的方法。因为我们知道,它不可能变成一个庞大而又昂贵的机器。它必须只是几块板子、几个电路,这是让使它快速发展的一个优势。设计一款安全的、无风险的产品,和设计一款用于制胜的产品是有区别的。而我们并不担心风险,我们在意的是取胜。我们希望它既快速又便宜,我们希望快速地开发它。因此,我们只用了三、四块板子,这是最低限度的硬件,我们通过固件来弥补这些。
**00:11:06 - Saron Yitbarek**:
Eagle 团队面临着很多严苛的限制。 VAX 是这个星球上(当时)性能最高的 32 位计算机。 Eagle 必须与之匹敌。但最重要的是,它还必须兼容他们的 16 位架构。要用比其他团队更少的金钱和时间来做到所有这一切,这使得 Eagle 感觉像是在赌博。但 Tom West 的团队全力以赴投身于其中。
**00:11:32 - Jim Guyer**:
有两套无时无刻都在运行着的系统,我们有两班工程师为之工作。我们所有人都必须全盘掌握。因此,我们不得不学会其他每一个人的岗位所要做的工作。这对我而言既具有挑战性又极其富有教育意义。但是我们大家都参与其中努力着,“要解决这个问题下一步该做什么?我们需要着眼于何处?”每个人都仔细钻研原理图和其他文档,试图找出办法,“看看这个信号,看看那台计算机的状态,看看微码正在执行的步骤顺序。它在正常运转吗?哦等等,它出错了。呃,为什么它会这样运行呢?”
**00:12:13 - Carl Alsing**:
这是件严肃的事情,这就是工作态度。小组里的工作很紧张。有时候人们会对于采用何种方式去做某件事情而发生争论。可能有一种方法会花费稍微多一点的钱,而另一种方法则更便宜,但是可能速度稍慢或效率稍低。为了达成共识,可能会开展激烈的讨论或会议。但我们还是做出了这些选择,然后我们协作努力。
**00:12:44**:
我们没日没夜地工作,在<ruby> 原型 <rt> prototype </rt></ruby>上付出了很多时间。我们只有两个原型,两个团队都能在这两个原型上工作着实很重要。因此,晚班和白班都有人在工作,人们都很疲惫,但这让人感到非常兴奋 —— 这是值得的。所以没有人过多地抱怨工作条件。
**00:13:11 - Saron Yitbarek**:
工作条件 —— 据传当时 Tom West 为了让团队完成他所期望的东西,实行了一种被称为“<ruby> 蘑菇管理 <rt> mushroom management </rt></ruby>”的方法。喂养它们然后看着它们成长。在狭窄而炎热的工作空间里,时间很漫长,日程安排也不切实际。Tom 本人被形容为神秘、冷酷、无情的人。有位工程师甚至称他为“<ruby> 黑暗王子 <rt> the Prince of Darkness </rt></ruby>”。 Tom West 是否如此渴望取胜以至于剥削了他的团队吗?他是否为了得到完美的机器而牺牲了微码小子们和哈迪男孩们的福祉?
**00:13:56 - Jim Guyer**:
Tom 是个有趣的家伙。他对你期望很高,但不会给你很多指导。他希望你可以自己弄清楚需要做什么,而如果你不能做到的话,你就会被踢出团队。
**00:14:10 - Saron Yitbarek**:
指导来自于 Carl 或是 Ed, 他们是 Jim 和团队其他成员每天都与之工作的部门经理。但这些年轻的工程师也为了取胜而参与其中,他们喜欢自己所获得的机会,愿意自己去搞清楚。
**00:14:26 - Jim Guyer**:
我个人获得了第一届微码小子通宵荣誉奖。我不知道是什么理由,也许我们都是能力超群、豪气冲天、无知无畏的年轻后浪。我们很自信,我们觉得自己相当聪明,可以解决问题,我们相互依靠,也许这就是自负。我乐在其中。我认为我们大部分人都乐在其中。
**00:14:56 - Saron Yitbarek**:
Carl 不同意“蘑菇管理”这一说法。他说情况恰恰相反。他们都确切地知道正在发生什么,以及预期是什么。反而是高层管理人员不知道。同时,Tom West 正在承受着来自多条战线的巨大压力,而这种压力也传递给了他的团队。
**00:15:18 - Carl Alsing**:
Tom 对这个项目的真实性质保持着低调。因此,他并没有对工程师们说很多,他保持着超然的态度,当然他也告诉他们,他们不能在团队之外或是家中讨论该项目。甚至不能使用 “Eagle” 一词。因此,我们还传达了这个项目非常紧急,我们必须在一年之内完成,竞争已在市场中展开,如果我们要通过这个东西来占据市场之巅,我们必须现在就把它完成。因此他们承受着很大的压力,并且团队期望他们在夜晚和周末也参加工作,没有时间留给他们去和家人野餐或是做其他任何与工作不相关的事情。
**00:16:06 - Saron Yitbarek**:
我想知道在 14 号楼 AB 的战壕里奋战是怎样的感受。所以我邀请 Neal Firth 来到身边。他是微码小子中的一员,刚毕业就加入了团队。
**00:16:20**:
和 Tom West 共事的感觉如何?你和他有过很多互动吗?
**00:16:24 - Neal Firth**:
不一定。他是那种幽灵般的人物。我们能看到他在身边。他一般也不会不干预,以便我们能够领导自己、实现目标。我们正在做的事情是全新的,他不想把上一代处理器要做的工作强加给我们。
**00:16:49 - Saron Yitbarek**:
这听起来像是一个工作十分紧张的地方,在这里你真切地想不断前进并完成工作。你是怎样应对没有太多时间这一事实的?
**00:16:57 - Neal Firth**:
老实说,这并不是问题。想要时间充裕实际上并没有什么问题。我们可能会花费一些时间来实现结果。这需要家里人非常支持与理解,因为她们并不一定会立马同意。你可以将其等同于当时的一些硅谷人,或是像<ruby> 乔布斯 <rt> Jobs </rt></ruby>、<ruby> 沃兹尼亚克 <rt> Wozniak </rt></ruby>之类的人,我们投身其中并搞定它。我们确实不全是“<ruby> 住在同一间公寓 <rt> live-in-the-same-apartment </rt></ruby>”或“<ruby> 在地板上写代码 <rt> code-on-the-floor </rt></ruby>”那样的人,但具有其中的一些特征。
**00:17:35 - Saron Yitbarek**:
在那段时间里,是什么让你坚持了下来?为什么你这么有动力?
**00:17:39 - Neal Firth**:
坦率地说,就是在解决问题。我一直是一个喜欢思考并善于解决问题的人。事实上,团队里的大部分人都是这样的。我们所有人都有着类似的背景,并且我们都很享受解决问题这件事。就是,解决那些难题,找到一种前所未有的方式去做事。
**00:18:01 - Saron Yitbarek**:
那么在这个项目中,你最难忘的时刻是什么?
**00:18:05 - Neal Firth**:
当时,项目已经进行了相当长的时间,我们正在运行微码模拟器,它实际上是被提议当作生产模拟器来运行的,已经运行了 10 到 12 个小时了。突然,字母 E 出现在了控制台上,然后我们等了一会儿,又是一个字母,接着又是一个字母,然后我们突然意识到我们运行的是测试代码,是正在设计运行的诊断程序。因此,微码模拟器正在模拟运行这份微码的硬件,并且它开始打印字母,就好像它真的在运行一样。所以当它真正问世并运行时,可能比实际上要慢了十万倍,但这仍是我最难忘的时刻之一。
**00:19:02 - Saron Yitbarek**:
现在回过头想想,你觉得自己当时有被剥削吗?
**00:19:07 - Neal Firth**:
没有。我可以意识到正在发生着什么。我知道正在发生什么。所以,没有,我没觉得被剥削。实际上,这是我大学毕业时候的期望,否则我永远都不可能参与这么重大的项目,或是有机会在这样的一个项目中扮演那么重要的角色。
**00:19:31 - Saron Yitbarek**:
我想知道你如何看待发明的牺牲,因为如果你要考虑所有我们所创造的伟大事物,通常来说我们不得不放弃一些东西,是这样吗?必须舍弃一些东西来做出真正惊人的东西。这样的情况你遇到过吗?如果有的话,你不得不放弃的东西是什么呢?
**00:19:48 - Neal Firth**:
我不会说我放弃某些东西是有一个思想驱动的过程,我认为更重要的是,我更能适应自己正在做的事情以及所做的事对周围人的影响。
**00:20:03**:
但我从来没把它看作是一种牺牲,而与我亲近的人们,他们生活在就是这样的一个世界里。我听说过一些可怕的故事,如果你愿意的话,在今天,在这里都是,你醒来,插上你的咖啡机,拿一些披萨或点心,然后你开始写代码,最后你在你的键盘上睡着。然后你在下一个早晨醒来,重复这个过程。
**00:20:35**:
我们当然远没有达到那种牺牲的程度,我仍然有妻子,我仍然有朋友,我们仍然在一起。这当然不是份<ruby> 朝九晚五 <rt> nine-to-five </rt></ruby>的工作,但是它给我带来了许多个人层面与技术层面的成就,我能把这些和我的妻子、姐妹、父亲、母亲以及岳父分享,这些人可以欣赏这些。
**00:20:59 - Saron Yitbarek**:
是啊。那么,你认为使某件事情变得真正伟大的关键是什么呢?
**00:21:06 - Neal Firth**:
使某件事情变得真正伟大的关键 —— 有趣的问题 —— 我认为这取决于参与其中的人员,因为他们想要这样做,而不是因为他们对成就、财富或是名望的渴望。因为那些东西都转瞬即逝,而且永远无法使人满足。但是如果你要努力地去实现一个目标,而且你和一群人共同努力并去实现它,那么当你最终实现目标的时候,这确确实实是能令人心满意足的。
**00:21:42 - Saron Yitbarek**:
Neal Firth 是 Eagle 项目中微码小子中的一员。他目前是一家名为 VIZIM Worldwide 的软件公司的总裁。
**00:21:57**:
正如 Tracy Kidder 书中所记载的那样, Tom West 的超然和距离感是刻意为之的。这是他试图在日常交谈中保持头脑清醒,从而能使 Eagle 的目标保持原样。不过更重要的是,他想保护团队,将他们与周遭发生的政治与企业边缘化相隔绝。他也保护了微码小子们和哈迪男孩们不受先入为主的观念影响。
**00:22:28**:
1980 年, Eagle 完成了。比 Tom 所承诺的要晚了一年,但至少还是完成了,不像 Fountainhead。就像资深团队所预料的那样, Fountainhead 团队失败了,他们的项目遭到了搁置。这位是 Bill Foster,当时的软件开发总监,他谈到了 Fountainhead 的挣扎。
**00:22:50 - Bill Foster**:
我认为所犯下的最大错误在于没有对其设置任何限制。或多或少地,就是让我们去开发世界上最好的计算机。嗯,它应该在什么时候被完成?哦,我们对此确实没有个明确的期限。它应该花费多少成本?好吧,我们也不确定。我不得不让 Ed 失望了。他没有在程序员和工程师之间设置足够的界限。
**00:23:15**:
而且如果你让一群程序员和工程师放任自流,猜猜怎么着,他们将使事情变得复杂,设计出过分庞大的东西,以至于永远不能完成。
**00:23:26 - Saron Yitbarek**:
让我们回忆一下。从 Tom 和他的团队决定秘密开发 Eagle 开始,这已经进行了两年了。整个过程中,公司总裁并不知道正在发生了什么。当现在已经正式命名为 Eclipse MV/8000 的这款机器准备交付时,市场营销负责人去找了 Ed de Castro,为营销活动放行。 Carl Alsing 将对此作出解释。
**00:23:53 - Carl Alsing**:
市场营销负责人说道:“好吧,我们已经准备好为 Eagle 进行推广了,我们需要数千美元。我们将在全球六个不同的城市举行新闻发布会。我们将进行一个巡演,去到很多城市,我们将拍摄一部影片来展示它,这将轰动一时。”
**00:24:14 - Carl Alsing**:
然后 Ed de Castro 说:“我不明白。你们为什么要那样做?”这只不过是在 Eclipse 那边的另一个包而已,表面工夫的工作而已。市场经理说:“不,这是一款全新的机器。这是一款 32 位的机器,有虚拟内存,具备兼容性。它将击败 VAX。所有你要的东西都在这里了。”
**00:24:37 - Carl Alsing**:
Ed de Castro 着实有点儿困惑。他以为我们在北卡罗来那州遭遇了失败,将成为事情的终结,但我们拯救了他。因此,是的,他邀请了我们所有人,我们举行了一次小型的午餐会。午餐会上有三明治和苏打水,他说:“嗯,你们做得很好,我很吃惊。我此前并没有意识到你们在做这个,但是我们会推广它,我知道将会安排一部影片、一些巡游,而且你们将成为这其中的一部分,所以,感谢你们,请吃你们的三明治吧。”
**00:25:19 - Saron Yitbarek**:
现如今被命名为 MV/8000 的 Eagle 出现在了《<ruby> 计算机世界 <rt> Computer World </rt></ruby>》杂志的封面上。推出期间,媒体的炒作使得这支原本秘密的、深居地下室的团队成员们变成了小名人。毕竟,他们拯救了数据通用公司。
**00:25:38**:
但好景不长。 Tom West 再也无法让团队免受公司内部政治的影响。团队面对敌意毫无准备。公司里的其他人都嫉妒他们的成就,并对他们能在秘密项目中逃离如此之久感到震惊。
**00:25:57**:
不久后,一个新的工程副总裁取代了他们的盟友 Carl Carman。这个新来的人在第一台 MV/8000 被售出之前就拆分了 Eagle 小组,并把 Tom 发配到了数据通用公司的日本办事处。
**00:26:13 - Jim Guyer**:
我认为我们开发出了花钱所能够买到的最好的 32 位超级小型机,我认为这对数据通用公司来说是一件很棒的事情,我认为它将能把 DEC 稍微踢开一点,而不是我们把世界从他们身边夺走。那时候的竞争太艰难了,在高科技领域很难成为赢家,但我认为我们已经做了一些有价值的事情。
**00:26:42 - Saron Yitbarek**:
当 Eagle 发行时,它确实拯救了数据通用公司,但在市场份额被 DEC 夺走三年后,该公司从未真正恢复过来,而行业却发展了。小型机不再是大势所趋。<ruby> 微型计算机 <rt> microcomputer </rt></ruby>的竞争已经开始了,这为<ruby> 个人计算机 <rt> personal computer </rt></ruby>革命铺平了道路。
**00:27:04 - Carl Alsing**:
数据通用公司继续开发了其他的版本,并在其他的型号上进行了改进,这样进行了一段时间,取得了一些成功。但是世事无常。市场发生了变化,他们自己转型成了一家软件公司,然后最终被其他人收购了。如今,我认为他们在马萨诸塞州<ruby> 霍普金顿 <rt> Hopkinton </rt></ruby>某家公司的文件抽屉里。
**00:27:36 - Saron Yitbarek**:
一年后, Eagle 团队中的许多人离开了数据通用公司。有人感到精疲力竭。有些人准备好要去开发一些不一样的东西。一些人前往西部的硅谷,热衷于寻找下一个创意火花。无论如何,在一个不承认他们为拯救公司所做的一切的公司里,继续待下去似乎没有什么意义。1981 那一年 Tracy Kidder 的《<ruby> 新机器的灵魂 <rt> The Soul of a New Machine </rt></ruby>》出版了。现如今,全世界都知道 Eagle 是如何构建起来了。
**00:28:14 - Carl Alsing**:
如果你问我新机器的灵魂是什么,我想我会说是他们所经历的人和事,他们所做出的牺牲,他们所做出的努力,他们对此所感到的兴奋,以及他们所希望得到的满足感。也许得到了,也许没有,但他们为之而努力。
**00:28:35 - Jim Guyer**:
从某种意义上说,这款机器是有点儿个性。但真正有个性的是这些有勇气的人。
**00:28:47 - Saron Yitbarek**:
在我们有关硬件的全新一季的下一集里,我们会将时光倒回大型机世界,讲述另一群叛逆员工的故事。他们制造的计算机催生了一门改变世界的编程语言。
**00:29:04 - Saron Yitbarek**:
《<ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>》是<ruby> 红帽 <rt> Red Hat </rt></ruby>的一档原创播客节目。这一季,我们正在为你整理一些出色的研究,以便你可以更多地了解到我们正在谈论的硬件的历史。请前往 [redhat.com/commandlineheroes](file:///Users/xingyuwang/develop/LCRH-wxy/translated/www.redhat.com/commandlineheroes) 深入了解 Eagle 及其背后的团队。我是 Saron Yitbarek。下集之前,编码不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/minicomputers>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[windgeek](https://github.com/windgeek), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
They don’t fit in your pocket. But in their day, minicomputers were an order of magnitude smaller than the room-sized mainframes that preceded them. And they paved the way for the personal computers that could fit in a bag and, eventually, the phones in your pocket.
16-bit minicomputers changed the world of IT in the 1970s. They gave companies the opportunity for each engineer to have their own machines. But it wasn’t quite enough, not until the arrival of 32-bit versions.
Carl Alsing and Jim Guyer recount their work at Data General to create a revolutionary new 32-bit machine. But their now legendary work was done in secret. Codenamed “Eagle,” their machine was designed to compete with one being built by another team in their own company. These engineers recall the corporate politics and intrigue required to keep the project going—and how they turned restrictions into advantages. Neal Firth discusses life on an exciting-but-demanding project. One where the heroes worked together because they wanted to, without expectations of awards or fame. And all three discuss how this story was immortalized in the non-fiction engineering classic, The Soul of a New Machine by Tracy Kidder.

**00:03** - *Saron Yitbarek*
The year was 1978 and a battle was raging in the mini-computer industry. Just a year earlier, Digital Equipment Corporation released its 32-bit VAX 11 780 computer. It was much more powerful than the 16-bit machines in the market. Sales of the VAX quickly overtook their slower competition. Archrival, Data General, was desperate for a new machine to compete with the VAX. They needed a 32-bit computer of their own and they needed it fast, but that competition between Data General and DEC wasn't the only battle going on. There was also a turf war brewing inside Data General and the spoils of both wars would be the creation of an incredible machine under incredible circumstances. A 13-inch laptop weighs maybe three pounds. We take for granted our computers’ portability and convenient size, but back in the 70s, most computers were still room-sized mainframes, multi-million dollar machines weighing several tons. Then, when hardware costs plummeted, the race to smaller, faster, cheaper machines began. The mini computer opened the door for engineers and scientists to have a terminal of their own. It was the machine that led us to where we are today.
**01:37** - *Saron Yitbarek*
Last season on Command Line Heroes, we took a deep dive into an area that is central to software development, the world of programming languages. We looked at their history, the problems they solved, and how they've evolved over time. Languages like JavaScript, Python, and C, Perl, COBOL, and Go. This season, season four for those of you counting, we are diving deep again, this time into the hardware that our software runs on. We're going to tell you seven special stories about the people and teams who dared to change the rules of hardware. That laptop on your desk, that phone in your pocket, command line heroes put their soul into every piece of hardware you've owned and heroes before them. Their passion for building their bold moves to make our hardware a reality has revolutionized the way we program today.
**02:36** - *Saron Yitbarek*
I'm Saron Yitbarek and this is Command Line Heroes, an original podcast from Red Hat.
**02:45** - *Saron Yitbarek*
In our season premiere, the story of an engineering team racing to design, debug, and deliver a next-generation computer. Their work became the subject of the 1981 bestseller and Pulitzer-winning book, The Soul of a New Machine by Tracy Kidder. The book follows many of the guests you'll hear in this episode.
**03:07** - *Saron Yitbarek*
Back to Data General. Company president, Ed de Castro, hatches a plan to compete with DEC. He splits up the engineering department, moving a team from its Westboro, Massachusetts headquarters to a new office in North Carolina. Their assignment? Develop an advanced 32-bit design that would crush the VAX. They named their project, Fountainhead. De Castro gave the team almost unlimited support and resources. Fountainhead was going to be his company's savior. The few remaining engineers left behind in Massachusetts, they felt seriously slighted. They knew they could build a VAX killer, probably a better one than what Fountainhead could build, but de Castro wouldn't give them a chance. So the leader of that group, Tom West, decided to take matters into his own hands. A self-taught computer engineer, Tom West ran Data General's Eclipse division. Eclipse was data General's most successful line of 16-bit mini computers. Tom could build machines, he could ship them, and he knew what the market wanted. After setting up Fountainhead, de Castro told the remaining engineers to keep working on improving last year's product line. Tom and the others were unimpressed.
**04:31** - *Carl Alsing*
We were not happy with that at all. Some of us left for other jobs and others of us were depressed and worried about our careers and not feeling very excited. And we predicted that the other group was going to fail.
**04:46** - *Saron Yitbarek*
Carl Alsing was the manager of the micro programming group at Data General. He was Tom's second in command. They decided to come up with their own project.
**04:56** - *Carl Alsing*
This'll be a whole new design using the latest techniques, build a 32-bit computer that would beat the DECs’ VAXs. So we put together a proposal for that and went to the president, Ed de Castro, and he says, "Nope, no way. No, the North Carolina groups taking care of that. You don't have to worry about it." So we were discouraged and we went back and came up with another proposal called Victor. We looked at ways of making the old last year's product better. And we had in there a little switch, a mode bit in the system, that when you turned it on, it would enable the computer to act like a modern 32-bit mini computer, although slow. And we took that to Ed de Castro and proposed it. And at the end he said, "You have a mode bit in here. I don't want to see any design with a mode bit. North Carolina's taking care of the new designs." So again, we were discouraged and I think this is when Tom West decided that we were going to do something clandestine.
**06:06** - *Saron Yitbarek*
Tom came up with two stories. One was for de Castro. They would work on an enhancement of the old Eclipse product line, make it a little faster, add a few new buttons, a different color. Tom pitched it as insurance just in case something went wrong in North Carolina. De Castro approved it. And then Tom told another story, a better story to his team.
**06:32** - *Carl Alsing*
So Tom West proposed to a few of us in the team that we build a really good modern machine that's completely compatible with the previous machines and did all the latest high tech stuff that we needed and virtual memory and 32-bits and error correcting codes and all those kinds of things. Multitasking, multiprocessing, lots of memory. "Guys, we're going to build the latest market-killing new machine."
**07:04** - *Saron Yitbarek*
The code name for this market-killing new machine, was the Eagle. Nowadays, it feels like there's no limit to what you can do with the memory built into our computers, but back then, a big breakthrough happened when 16-bits gave way to 32-bits. All of a sudden, your address space went from 65,000 bytes of information to over 4 billion. And with that increase, software could deal with larger amounts of data. That left computer companies with two basic challenges: transitioning from 16-bits to 32-bits, sure, but they also had to keep their old customers, the ones using the old software, happy. So, they had to create a machine that would keep old software running, a 32-bit computer that could be backward compatible. The VAXs, for all its power, didn't have an elegant solution to that second problem, but Tom was determined that his Eagle would.
**08:14** - *Saron Yitbarek*
Eagle HQ was located in the basement of Westborough building, 14 AB. Tom assigned Carl to head up micro coding. Carl assigned Chuck Holland to manage the coders, who became known as the Micro Kids. Meanwhile, Ed Rasala would oversee hardware. He assigned Ken Holberger to manage that team, which was appropriately called the Hardy Boys. Tom had an ally in VP of Engineering, Carl Carman. Carman also had a bone to pick with de Castro because de Castro refused to put him in charge of the North Carolina group.
**08:51** - *Carl Alsing*
Carl Carman knew what we were up to and said nothing to his boss. And so he was funding us, but we needed to keep the salaries down, and we needed some really good smart engineers. So we decided to go after college recruits. One advantage of that is that they don't know what you can't do. They think that you can do anything.
**09:15** - *Saron Yitbarek*
Jim Guyer was two years out of college and working at Data General when he got assigned to the Hardy boys.
**09:21** - *Jim Guyer*
The machine that was being developed down in North Carolina was much more high-end computing, almost mainframe in nature. And well, I mean, that's a pretty big thing to jump into to compete with IBM and the other mainframe companies at the time. We thought we had the edge because we were trying to do something that was not quite as ambitious and we were really, really, really focused on a neat, clean, simple implementation with low cost and fewest components and so forth.
**09:51** - *Saron Yitbarek*
Low cost, simple design. They realized that they needed to use firmware to control everything. The more functionality they could put under firmware as opposed to hardware, the cheaper and more flexible it could be.
**10:03** - *Saron Yitbarek*
And they'd be able to make changes as needed. Of course, modern-day computers are all built this way, but in 1978 the approach was brand new.
**10:15** - *Carl Alsing*
The kind of design we were doing was very minimal. We were looking at ways of making things simple and straightforward, uncomplicated. Because we knew that it couldn't grow to be a big, expensive machine. It had to be just a few boards, a few circuits, and that's actually an advantage in making it fast. There's a difference between designing a product that's safe, risk-free, and a product that's going to win. And we were not worried about risk. We were worried about winning. We wanted it to be fast and cheap and we wanted to design it quickly. So, we only had three or four boards in there, a minimum amount of hardware, and we made up for that with firmware.
**11:06** - *Saron Yitbarek*
The Eagle team faced a lot of tough constraints. The VAX was the highest performance, 32-bit computer on the planet. Eagle had to match it. But on top of that, it had to be compatible with their 16-bit architecture, too. Getting all that done with less money and time than any other team, made Eagle feel like a serious gamble. But Tom West's team was all in.
**11:32** - *Jim Guyer*
There were two systems running 24/7 that we had two shifts of engineers working on them. We all have to be trying to figure out everything. So, we had to learn what everybody else's part did. That was both challenging and extremely educational for me. But we were all engaged with each other to try and go, "What's the next step to figure out this problem? What do we need to look at?" Everybody poring through schematics and other pieces of documentation to figure out, "Look at this signal, look at that computer state, look at the sequence of steps that the microcode is going through. Is it doing the right thing? Oh wait, it's going the wrong direction. Uh oh, why did it do that?"
**12:13** - *Carl Alsing*
This was serious business and that was the work ethic. It was intense in the group. There were sometimes arguments about which way to do something. There might be one way that costs a little bit more money and another way that was cheaper but not as fast or not as effective. And there'd be heated discussions and meetings with some effort to make a consensus. And we made those choices though. And then we worked together.
**12:44** - *Carl Alsing*
We worked day and night, we divided up the hours for the prototype. We only had two prototypes and it was really important that both teams get to work on those prototypes. So, there were people working the night shift and people working the day shift and people getting tired. But there was enough excitement about it that it was rewarding. And so nobody complained too much about the working conditions.
**13:11** - *Saron Yitbarek*
The working conditions. Some accounts from that time say that to get what he wanted from the team, Tom West practiced something called mushroom management. Feed them [beep] and watch them grow. Inside a cramped and hot workspace, the hours were long and the schedules unrealistic. Tom himself has been described as enigmatic, cold, uncaring. One engineer even referred to him as the Prince of Darkness. Was Tom West so intent on winning that he exploited his team? Did he sacrifice the wellbeing of the Micro Kids and the Hardy Boys to get the perfect machine?
**13:56** - *Jim Guyer*
Tom was an interesting guy to work with. He expected a lot of you, and he didn't give you a lot of direction. He expected you to figure out what you needed to do, and pretty much if you weren't able to do that, you weren't on the team.
**14:10** - *Saron Yitbarek*
Direction came from Carl or Ed, the line managers that Jim and the rest of the team worked with on a daily basis. But these young engineers were also in it to win and they liked the opportunity they were given, to figure it out for themselves.
**14:26** - *Jim Guyer*
I personally won the first honorary Micro Kid allnighter award. I don't know, maybe we were over competent, brash, young upstarts who didn't know any better. We were confident. We thought we were pretty smart and could figure things out, and we fed on each other's, maybe those are egos, in that sense. I was having a lot of fun doing it. I think most of us were having a lot of fun doing it.
**14:56** - *Saron Yitbarek*
Carl disagrees with the term mushroom management. He said it was just the opposite. They all knew exactly what was going on and what was expected. It was upper management who didn't. At the same time, Tom West was under a tremendous amount of pressure from multiple fronts, and that pressure got passed along to the group.
**15:18** - *Carl Alsing*
Tom was keeping the true nature of the project quiet. So, he didn't speak much to the engineers, and he remained aloof and he told them, of course, that they weren't to discuss the project outside the group or at home. Not even to use the word Eagle. So we also conveyed that this was very urgent, that we had to do this in a year, that the competition was already in the market, and if we were going to hit the peak of the market with this thing, we had to get it done now. And so they were under a lot of pressure and there was an expectation that they would work nights and weekends and there would be no time for going on picnics with their family or anything that wasn't work-related.
**16:06** - *Saron Yitbarek*
I wanted to find out what it was like working in the trenches of Building 14 AB. So, I sat down with Neal Firth. He was one of the Micro Kids. He joined the team fresh out of school.
**16:20** - *Saron Yitbarek*
What was it like to work for Tom West? Did you get to interact with him a lot?
**16:24** - *Neal Firth*
Not necessarily. He was this ghosty figure. We saw him around. He tried not to interfere so that we could lead ourselves and achieve the goals. This was brand new stuff for what they were doing, and he didn't want to influence us by trying to impose things that had to be done for the previous generation of processors.
**16:49** - *Saron Yitbarek*
It sounds like an intense place where you really want to keep moving and keep getting things done. How did you deal with the fact that there wasn't a ton of time?
**16:57** - *Neal Firth*
It wasn't a factor to be honest. There was really no issue with there being enough time. We would take the time it took to achieve the result. That's where the spouses had to be very supportive and understanding, because they didn't necessarily say yes immediately. You could equate it to some of the Silicon Valley people at the time or the Jobs, Wozniak type, let's just get in and get this done. We are not quite all live-in-the-same-apartment and code-on-the-floor type people, but it had some of those characteristics.
**17:35** - *Saron Yitbarek*
And during that time, what kept you going? Why were you so motivated?
**17:39** - *Neal Firth*
Quite frankly it was solving a problem. I've always been a puzzle and problem-solving guy. In fact, most of the team was that way. All of us had that in our background, and we all enjoyed it. So, solving those puzzles, getting those things solved, discovering a way to do something that had never been done before.
**18:01** - *Saron Yitbarek*
So what was your most memorable moment on the project?
**18:05** - *Neal Firth*
At the time, it was quite a ways into the project, and we were running the microcode simulator, and it was actually running what was proposed to be the production simulator, and it had been running for about 10, 12 hours. And all of a sudden, the letter E shows up on the console and then we waited a little while and another letter, then another letter, and then we suddenly realized what we were running for test code was the diagnostics that were being designed to run. And so the microcode simulator was simulating the hardware running this microcode, and it was starting to print characters as if it was actually operating. So, it was maybe a hundred thousand times slower than real life, when it actually came out and operated, but that was one of my most memorable moments.
**19:02** - *Saron Yitbarek*
Looking back on it now, do you feel like you were exploited?
**19:07** - *Neal Firth*
No. I was aware of what was happening. I knew what was happening. So, no. I do not feel exploited. It was actually my expectations coming out of college, it would have never been that I would be in a project that significant, or have an opportunity to play such a significant role in a project like that.
**19:31** - *Saron Yitbarek*
I'm wondering how you think about the sacrifice of invention, because if you think about all the great things that we make, usually we have to give up something, right? Something's got to give to make something truly amazing. Did that happen for you? And if so, what was that thing that you had to give up?
**19:48** - *Neal Firth*
I wouldn't say that there was a thought-driven process on my part for giving up something. I think it was much more that I became a little more attuned to what I was doing and how I did it impacted those around me.
**20:03** - *Neal Firth*
But I never necessarily saw it as a sacrifice, and the people I was close to, they lived in a world where that's just the way things happen. I hear the horror stories, if you will, about today, where 24/7 you wake up, you plug in your coffee IVs, grab some pizza or dim sum, and you start coding, and eventually you fall asleep in your keyboard. And then you wake up the next morning and repeat the process.
**20:35** - *Neal Firth*
We certainly were nowhere near that level of sacrifice. I still had a wife, I still had friends, we still got together. It certainly wasn't a nine-to-five job, but it provided me with a lot of personal and technical achievement, and I was able to share that with my wife, and my sister, and my mother and my father, and my father-in-law. So, those people could appreciate that.
**20:59** - *Saron Yitbarek*
Yeah. So, what do you think is the key to making something truly great?
**21:06** - *Neal Firth*
Key to making something truly great. Interesting question. I think it depends on the people involved doing it, because they want to, not because they have expectations of achievement, or wealth or fame. Because those things are very fleeting and almost never satisfied. But if you're going in trying to achieve a goal, and you and a bunch of people work together on it and achieve it, that really is satisfaction when you achieve that.
**21:42** - *Saron Yitbarek*
Neal Firth was one of the Micro Kids on the Eagle Project. He's currently the president of VIZIM Worldwide, a software company.
**21:57** - *Saron Yitbarek*
As chronicled in Tracy Kidder's book, Tom West's aloofness and distance was deliberate. It was his attempt to keep a clear head above all the day-to-day chatter so that Eagle's goal could remain intact. Even more than that though, he wanted to protect the team, isolate them from the politics and corporate brinkmanship happening around them. He also protected the Micro Kids and the Hardy Boys from preconceived ideas about what was possible.
**22:28** - *Saron Yitbarek*
In 1980, the Eagle was complete. A year later than Tom had promised, but done nonetheless, unlike Fountainhead. Just as the senior team had predicted, the Fountainhead group had failed and their project was shelved. Here's Bill Foster, director of software development at the time, on Fountainhead's struggle.
**22:50** - *Bill Foster*
I think the biggest mistake that was made was it wasn't given any limitations. More or less, it was let's do the world's best computer. Well, when should it be done? Oh, we don't really have a date for that. How much should it cost? Well, we're not sure about either. And I have to fail Ed with this. He didn't put enough boundaries on the programmers and the engineers.
**23:15** - *Bill Foster*
And if you turn a bunch of programmers and engineers loose, guess what, they're going to make something so complex, design something so big, it will never get done.
**23:26** - *Saron Yitbarek*
Let's remember for a moment. Back when Tom and his team decided they would build the Eagle in secret, for two years this was happening. And the whole time, the president of the company had no idea what was going on. When the machine now officially called the Eclipse MV/8000 was ready to ship, the head of marketing went to Ed de Castro to green light the marketing campaign. Carl Alsing explains.
**23:53** - *Carl Alsing*
The head of marketing, he said, "Well, we're ready to do the rollout for the Eagle and we're going to need several thousand dollars. We're going to have a press conference in six different cities around the world. And we're going to do a tour, and we're going to go to many cities, and we're going to shoot a film and show it, and it's going to be a big splash."
**24:14** - *Carl Alsing*
And Ed de Castro said, "I don't understand. Why are you doing that?" This is just another bag on the side of the Eclipse. A skin job. And the marketing manager said, "Nope, this is a whole new machine. This is a 32-bit machine. It's got virtual memory. It's compatible. It's going to beat the VAX. We've got the whole thing here."
**24:37** - *Carl Alsing*
And Ed de Castro was really confused for a bit. He thought we were failing in North Carolina and that was going to be the end of it, and we had saved his bacon. So, yeah, he invited us all up, and we had a little lunch meeting. There were sandwiches and soda and he said, "Well, you guys did a good job, and I'm surprised. And I didn't realize you were doing this, but we are going to roll this out, and I understand there's going to be a film, and some tours, and you guys are going to be part of that, so thank you and eat your sandwiches."
**25:19** - *Saron Yitbarek*
The Eagle, now christened the MV/8000 appeared on the front cover of Computer World Magazine. All the media hoopla during the rollout turn that team of secretive, basement-dwelling employees into minor celebrities. After all, they had saved Data General.
**25:38** - *Saron Yitbarek*
But the good times were short-lived. Tom West could no longer shield the group from the company's internal politics. The team was unprepared for the animosity. Others within the corporation envied their accomplishments and were appalled that they got away with the secret project for so long.
**25:57** - *Saron Yitbarek*
Soon, a new VP of Engineering replaced their ally, Carl Carman. The new guy broke up the Eagle group and shipped Tom off to Data General's Japan office all before a single MV/8000 was sold.
**26:13** - *Jim Guyer*
I thought we built the best 32-bit super-mini computer that money could buy, and I thought that was a great thing for Data General, and I thought it was going to kick Digital around a little bit, and not that we ever took the world away from them. Competition in that time was just way too tough, and it's hard to be a winner in high tech, but I thought that we had done something worthwhile.
**26:42** - *Saron Yitbarek*
When the Eagle was released, it did save Data General, but after losing market share to DEC for three years, the company never really recovered, and the industry had moved on. Mini computers were no longer the big thing. The microcomputer race had already begun, paving the way to the personal computer revolution.
**27:04** - *Carl Alsing*
Data General went on and did other versions of that, and improvements on it in other models, and it carried them for a while, and so they enjoyed some success. But things change. The market changed and they turned themselves into a software company, and then they ended up being bought out by somebody else. Now, I think they're a file drawer at some company in Hopkinton, Massachusetts.
**27:36** - *Saron Yitbarek*
A year later, many in the Eagle group had left Data General. Some were burned out. Some were ready to build something different. A few headed out west to Silicon Valley, keen to find that next creative spark. Regardless, there didn't seem to be much point in staying on at a company that didn't recognize all they'd done to save it. That same year in 1981, Tracy Kidder's Soul of a New Machine was published. Now, the world would know how the Eagle got built.
**28:14** - *Carl Alsing*
If you're asking me what the soul of a new machine is, I guess I would say it's the people and the things that they go through, the sacrifices they make, and the effort they make, and the excitement they feel about that, and the satisfactions they're hoping to get. Maybe get, maybe don't, but they strive for that.
**28:35** - *Jim Guyer*
The machine, in a way, was kind of a bit character. It was the people who were the real guts of what it was about.
**28:47** - *Saron Yitbarek*
In the next episode of our all new season on hardware, we go back in time to the world of mainframes and tell the story of another group of rebel employees. The computer they built gave birth to a programming language that changed the world.
**29:04** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. This season, we're compiling some great research for you so you can learn more about the history of the hardware we're talking about. Head on over to [redhat.com/commandlineheroes](//www.redhat.com/commandlineheroes) to dive deeper into the Eagle and the team behind it. I'm Saron Yitbarek. Until next time, keep on coding.
### Further reading
[ The Soul of a New Machine](//en.wikipedia.org/wiki/The_Soul_of_a_New_Machine) by Tracy Kidder
[ The New Golden Age of Building with Soul](//blog.jessfraz.com/post/new-golden-age-of-building-with-soul) by Jessie Frazelle
[ The Minicomputers of the 70s](//www.inf.fu-berlin.de/lehre/SS01/hc/minicomp) by Georg Wittenburg
[ Rise and Fall of Minicomputers](//ethw.org/Rise_and_Fall_of_Minicomputers) by Gordon Bell
### Bonus episode
The Soul of a New Machine is a bestselling book that almost wasn’t. Hear about the obstacles author Tracy Kidder had to overcome in order to bring his engineering classic to life. |
13,227 | Kooha:一款支持 Wayland 的新生 GNOME 屏幕录像机 | https://itsfoss.com/kooha-screen-recorder/ | 2021-03-22T21:23:36 | [
"屏幕录制",
"Wayland"
] | https://linux.cn/article-13227-1.html | Linux 中没有一个 [像样的支持 Wayland 显示服务器的屏幕录制软件](https://itsfoss.com/gnome-screen-recorder/)。
如果你使用 Wayland 的话,[GNOME 内置的屏幕录像机](https://itsfoss.com/gnome-screen-recorder/) 可能是少有的(也是唯一的)支持的软件。但是那个屏幕录像机没有可视界面和你所期望的标准屏幕录像软件的功能。
值得庆幸的是,有一个新的应用正在开发中,它提供了比 GNOME 屏幕录像机更多一点的功能,并且在 Wayland 上也能正常工作。
### 遇见 Kooha:一个新的 GNOME 桌面屏幕录像机

[Kooha](https://github.com/SeaDve/Kooha) 是一个处于开发初期阶段的应用,它可以在 GNOME 中使用,是用 GTK 和 PyGObject 构建的。事实上,它利用了与 GNOME 内置屏幕录像机相同的后端。
以下是 Kooha 的功能:
* 录制整个屏幕或选定区域
* 在 Wayland 和 Xorg 显示服务器上均可使用
* 在视频里用麦克风记录音频
* 包含或忽略鼠标指针的选项
* 可以在开始录制前增加 5 秒或 10 秒的延迟
* 支持 WebM 和 MKV 格式的录制
* 允许更改默认保存位置
* 支持一些键盘快捷键
### 我的 Kooha 体验

它的开发者 Dave Patrick 联系了我,由于我急需一款好用的屏幕录像机,所以我马上就去试用了。
目前,[Kooha 只能通过 Flatpak 安装](https://flathub.org/apps/details/io.github.seadve.Kooha)。我安装了 Flatpak,当我试着使用时,它什么都没有记录。我和 Dave 进行了快速的邮件讨论,他告诉我这是由于 [Ubuntu 20.10 中 GNOME 屏幕录像机的 bug](https://bugs.launchpad.net/ubuntu/+source/gnome-shell/+bug/1901391)。
你可以想象我对支持 Wayland 的屏幕录像机的绝望,我 [将我的 Ubuntu 升级到 21.04 测试版](https://itsfoss.com/upgrade-ubuntu-beta/)。
在 21.04 中,可以屏幕录像,但仍然无法录制麦克风的音频。
我注意到了另外几件无法按照我的喜好顺利进行的事情。
例如,在录制时,计时器在屏幕上仍然可见,并且包含在录像中。我不会希望在视频教程中出现这种情况。我想你也不会喜欢看到这些吧。

另外就是关于多显示器的支持。没有专门选择某一个屏幕的选项。我连接了两个外部显示器,默认情况下,它录制所有三个显示器。可以使用设置捕捉区域,但精确拖动屏幕区域是一项耗时的任务。
它也没有 [Kazam](https://itsfoss.com/kazam-screen-recorder/) 或其他传统屏幕录像机中有的设置帧率或者编码的选项。
### 在 Linux 上安装 Kooha(如果你使用 GNOME)
请确保在你的 Linux 发行版上启用 Flatpak 支持。目前它只适用于 GNOME,所以请检查你使用的桌面环境。
使用此命令将 Flathub 添加到你的 Flatpak 仓库列表中:
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
然后用这个命令来安装:
```
flatpak install flathub io.github.seadve.Kooha
```
你可以通过菜单或使用这个命令来运行它:
```
flatpak run io.github.seadve.Kooha
```
### 总结
Kooha 并不完美,但考虑到 Wayland 领域的巨大空白,我希望开发者努力修复这些问题并增加更多的功能。考虑到 [Ubuntu 21.04 将默认切换到 Wayland](https://news.itsfoss.com/ubuntu-21-04-wayland/),以及其他一些流行的发行版如 Fedora 和 openSUSE 已经默认使用 Wayland,这一点很重要。
---
via: <https://itsfoss.com/kooha-screen-recorder/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There is not a single [decent screen recording software for Linux](https://itsfoss.com/gnome-screen-recorder/) that supports Wayland display server.
[GNOME’s built-in screen recorder](https://itsfoss.com/gnome-screen-recorder/) is probably the rare (and lone) one that works if you are using Wayland. But that screen recorder has no visible interface and features you expect in a standard screen recording software.
Thankfully, there is a new application in development that provides a bit more feature than GNOME screen recorder and works okay-ish on Wayland.
## Meet Kooha: a new screen recorder for GNOME desktop
[Kooha](https://github.com/SeaDve/Kooha) is an application in the nascent stage of development. It can be used in GNOME and it is built with GTK and PyGObject. In fact, it utilizes the same backend as the GNOME’s built-in screen recorder.
Here are the features Kooha has:
- Record the entire screen or a selected area
- Works on both Wayland and Xorg display servers
- Records audio from microphone along with the video
- Option to include or omit mouse pointer
- Can add a delay of 5 or 10 seconds before start the recording
- Supports recording in WebM and MKV formats
- Allows to change the default saving location
- Supports a few keyboard shortcuts
## My experience with Kooha
I was contacted by its developer, Dave Patrick and since I desperately want a good screen recorder, I immediately went on to try it.
At present, [Kooha is only available to install via Flatpak](https://flathub.org/apps/details/io.github.seadve.Kooha). I installed Flatpak and when I tried to use it, nothing was recorded. I had a quick email discussion with Dave and he told me that it was due to a [bug with GNOME screen recorder in Ubuntu 20.10](https://bugs.launchpad.net/ubuntu/+source/gnome-shell/+bug/1901391).
You can imagine my desperation for a screen recorder with Wayland support that I [upgraded my Ubuntu to the beta version](https://itsfoss.com/upgrade-ubuntu-beta/) of 21.04.
The screen recording worked in 21.04 but it could still not record the audio from the microphone.
There are a few more things that I noticed and didn’t work smoothly to my liking.
For example, while recording the counter remains visible on the screen and is included in the recording. I wouldn’t want that in a video tutorial. You wouldn’t like to see that either I guess.
Another thing is about multi-monitor support. There is no option to exclusively select a particular screen. I connect with two external monitors and by default it recorded all three of them. Setting a capture region could be used but dragging it to exact pixels of a screen is a time-consuming task.
There is no option to set the frame rate or encoding that comes with [Kazam](https://itsfoss.com/kazam-screen-recorder/) or other legacy screen recorders.
## Installing Kooha on Linux (if you are using GNOME)
Please make sure to enable Flatpak support on your Linux distribution. It only works with GNOME for now so please check which desktop environment you are using.
Use this command to add Flathub to your Flatpak repositories list:
`flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo`
And then use this command to install it:
`flatpak install flathub io.github.seadve.Kooha`
You may run it from the menu or by using this command:
`flatpak run io.github.seadve.Kooha`
## Conclusion
Kooha is not perfect but considering the huge void in the Wayland domain, I hope that the developers work on fixing the issues and adding more features. This is important considering [Ubuntu 21.04 is switching to Wayland by default](https://news.itsfoss.com/ubuntu-21-04-wayland/) and some other popular distros like Fedora and openSUSE already use Wayland by default. |
13,229 | 使用 Grafana Tempo 进行分布式跟踪 | https://opensource.com/article/21/2/tempo-distributed-tracing | 2021-03-23T22:14:03 | [
"跟踪",
"分布式"
] | https://linux.cn/article-13229-1.html |
>
> Grafana Tempo 是一个新的开源、大容量分布式跟踪后端。
>
>
>

Grafana 的 [Tempo](https://grafana.com/oss/tempo/) 是出自 Grafana 实验室的一个简单易用、大规模的、分布式的跟踪后端。Tempo 集成了 [Grafana](http://grafana.com/oss/grafana)、[Prometheus](https://prometheus.io/) 以及 [Loki](https://grafana.com/oss/loki/),并且它只需要对象存储进行操作,因此成本低廉,操作简单。
我从一开始就参与了这个开源项目,所以我将介绍一些关于 Tempo 的基础知识,并说明为什么云原生社区会注意到它。
### 分布式跟踪
想要收集对应用程序请求的遥测数据是很常见的。但是在现在的服务器中,单个应用通常被分割为多个微服务,可能运行在几个不同的节点上。
分布式跟踪是一种获得关于应用的性能细粒度信息的方式,该应用程序可能由离散的服务组成。当请求到达一个应用时,它提供了该请求的生命周期的统一视图。Tempo 的分布式跟踪可以用于单体应用或微服务应用,它提供 [请求范围的信息](https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html),使其成为可观察性的第三个支柱(另外两个是度量和日志)。
接下来是一个分布式跟踪系统生成应用程序甘特图的示例。它使用 Jaeger [HotROD](https://github.com/jaegertracing/jaeger/tree/master/examples/hotrod) 的演示应用生成跟踪,并把它们存到 Grafana 云托管的 Tempo 上。这个图展示了按照服务和功能划分的请求处理时间。

### 减少索引的大小
在丰富且定义良好的数据模型中,跟踪包含大量信息。通常,跟踪后端有两种交互:使用元数据选择器(如服务名或者持续时间)筛选跟踪,以及筛选后的可视化跟踪。
为了加强搜索,大多数的开源分布式跟踪框架会对跟踪中的许多字段进行索引,包括服务名称、操作名称、标记和持续时间。这会导致索引很大,并迫使你使用 Elasticsearch 或者 [Cassandra](https://opensource.com/article/19/8/how-set-apache-cassandra-cluster) 这样的数据库。但是,这些很难管理,而且大规模运营成本很高,所以我在 Grafana 实验室的团队开始提出一个更好的解决方案。
在 Grafana 中,我们的待命调试工作流从使用指标报表开始(我们使用 [Cortex](https://cortexmetrics.io/) 来存储我们应用中的指标,它是一个云原生基金会孵化的项目,用于扩展 Prometheus),深入研究这个问题,筛选有问题服务的日志(我们将日志存储在 Loki 中,它就像 Prometheus 一样,只不过 Loki 是存日志的),然后查看跟踪给定的请求。我们意识到,我们过滤时所需的所有索引信息都可以在 Cortex 和 Loki 中找到。但是,我们需要一个强大的集成,以通过这些工具实现跟踪的可发现性,并需要一个很赞的存储,以根据跟踪 ID 进行键值查找。
这就是 [Grafana Tempo](http://github.com/grafana/tempo) 项目的开始。通过专注于给定检索跟踪 ID 的跟踪,我们将 Tempo 设计为最小依赖性、大容量、低成本的分布式跟踪后端。
### 操作简单,性价比高
Tempo 使用对象存储后端,这是它唯一的依赖。它既可以被用于单一的二进制下,也可以用于微服务模式(请参考仓库中的 [例子](https://grafana.com/docs/tempo/latest/getting-started/example-demo-app/),了解如何轻松上手)。使用对象存储还意味着你可以存储大量的应用程序的痕迹,而无需任何采样。这可以确保你永远不会丢弃那百万分之一的出错或具有较高延迟的请求的跟踪。
### 与开源工具的强大集成
[Grafana 7.3 包括了 Tempo 数据源](https://grafana.com/blog/2020/10/29/grafana-7.3-released-support-for-the-grafana-tempo-tracing-system-new-color-palettes-live-updates-for-dashboard-viewers-and-more/),这意味着你可以在 Grafana UI 中可视化来自Tempo 的跟踪。而且,[Loki 2.0 的新查询特性](https://grafana.com/blog/2020/11/09/trace-discovery-in-grafana-tempo-using-prometheus-exemplars-loki-2.0-queries-and-more/) 使得 Tempo 中的跟踪更简单。为了与 Prometheus 集成,该团队正在添加对<ruby> 范例 <rt> exemplar </rt></ruby>的支持,范例是可以添加到时间序列数据中的高基数元数据信息。度量存储后端不会对它们建立索引,但是你可以在 Grafana UI 中检索和显示度量值。尽管范例可以存储各种元数据,但是在这个用例中,存储跟踪 ID 是为了与 Tempo 紧密集成。
这个例子展示了使用带有请求延迟直方图的范例,其中每个范例数据点都链接到 Tempo 中的一个跟踪。

### 元数据一致性
作为容器化应用程序运行的应用发出的遥测数据通常具有一些相关的元数据。这可以包括集群 ID、命名空间、吊舱 IP 等。这对于提供基于需求的信息是好的,但如果你能将元数据中包含的信息用于生产性的东西,那就更好了。 例如,你可以使用 [Grafana 云代理将跟踪信息导入 Tempo 中](https://grafana.com/blog/2020/11/17/tracing-with-the-grafana-cloud-agent-and-grafana-tempo/),代理利用 Prometheus 服务发现机制轮询 Kubernetes API 以获取元数据信息,并且将这些标记添加到应用程序发出的跨域数据中。由于这些元数据也在 Loki 中也建立了索引,所以通过元数据转换为 Loki 标签选择器,可以很容易地从跟踪跳转到查看给定服务的日志。
下面是一个一致元数据的示例,它可用于Tempo跟踪中查看给定范围的日志。

### 云原生
Grafana Tempo 可以作为容器化应用,你可以在如 Kubernetes、Mesos 等编排引擎上运行它。根据获取/查询路径上的工作负载,各种服务可以水平伸缩。你还可以使用云原生的对象存储,如谷歌云存储、Amazon S3 或者 Tempo Azure 博客存储。更多的信息,请阅读 Tempo 文档中的 [架构部分](https://grafana.com/docs/tempo/latest/architecture/architecture/)。
### 试一试 Tempo
如果这对你和我们一样有用,可以 [克隆 Tempo 仓库](https://github.com/grafana/tempo)试一试。
---
via: <https://opensource.com/article/21/2/tempo-distributed-tracing>
作者:[Annanay Agarwal](https://opensource.com/users/annanayagarwal) 选题:[lujun9972](https://github.com/lujun9972) 译者:[RiaXu](https://github.com/ShuyRoy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Grafana's [Tempo](https://grafana.com/oss/tempo/) is an easy-to-use, high-scale, distributed tracing backend from Grafana Labs. Tempo has integrations with [Grafana](http://grafana.com/oss/grafana), [Prometheus](https://prometheus.io/), and [Loki](https://grafana.com/oss/loki/) and requires only object storage to operate, making it cost-efficient and easy to operate.
I've been involved with this open source project since its inception, so I'll go over some of the basics about Tempo and show why the cloud-native community has taken notice of it.
## Distributed tracing
It's common to want to gather telemetry on requests made to an application. But in the modern server world, a single application is regularly split across many microservices, potentially running on several different nodes.
Distributed tracing is a way to get fine-grained information about the performance of an application that may consist of discreet services. It provides a consolidated view of the request's lifecycle as it passes through an application. Tempo's distributed tracing can be used with monolithic or microservice applications, and it gives you [request-scoped information](https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html), making it the third pillar of observability (alongside metrics and logs).
The following is an example of a Gantt chart that distributed tracing systems can produce about applications. It uses the Jaeger [HotROD](https://github.com/jaegertracing/jaeger/tree/master/examples/hotrod) demo application to generate traces and stores them in Grafana Cloud's hosted Tempo. This chart shows the processing time for the request, broken down by service and function.
(Annanay Agarwal, CC BY-SA 4.0)
## Reducing index size
Traces have a ton of information in a rich and well-defined data model. Usually, there are two interactions with a tracing backend: filtering for traces using metadata selectors like the service name or duration, and visualizing a trace once it's been filtered.
To enhance search, most open source distributed tracing frameworks index a number of fields from the trace, including the service name, operation name, tags, and duration. This results in a large index and pushes you to use a database like Elasticsearch or [Cassandra](https://opensource.com/article/19/8/how-set-apache-cassandra-cluster). However, these can be tough to manage and costly to operate at scale, so my team at Grafana Labs set out to come up with a better solution.
At Grafana, our on-call debugging workflows start with drilling down for the problem using a metrics dashboard (we use [Cortex](https://cortexmetrics.io/), a Cloud Native Computing Foundation incubating project for scaling Prometheus, to store metrics from our application), sifting through the logs for the problematic service (we store our logs in Loki, which is like Prometheus, but for logs), and then viewing traces for a given request. We realized that all the indexing information we need for the filtering step is available in Cortex and Loki. However, we needed a strong integration for trace discoverability through these tools and a complimentary store for key-value lookup by trace ID.
This was the start of the [Grafana Tempo](http://github.com/grafana/tempo) project. By focusing on retrieving traces given a trace ID, we designed Tempo to be a minimal-dependency, high-volume, cost-effective distributed tracing backend.
## Easy to operate and cost-effective
Tempo uses an object storage backend, which is its only dependency. It can be used in either single binary or microservices mode (check out the [examples](https://grafana.com/docs/tempo/latest/getting-started/example-demo-app/) in the repo on how to get started easily). Using object storage also means you can store a high volume of traces from applications without any sampling. This ensures that you never throw away traces for those one-in-a-million requests that errored out or had higher latencies.
## Strong integration with open source tools
[Grafana 7.3 includes a Tempo data source](https://grafana.com/blog/2020/10/29/grafana-7.3-released-support-for-the-grafana-tempo-tracing-system-new-color-palettes-live-updates-for-dashboard-viewers-and-more/), which means you can visualize traces from Tempo in the Grafana UI. Also, [Loki 2.0's new query features](https://grafana.com/blog/2020/11/09/trace-discovery-in-grafana-tempo-using-prometheus-exemplars-loki-2.0-queries-and-more/) make trace discovery in Tempo easy. And to integrate with Prometheus, the team is working on adding support for exemplars, which are high-cardinality metadata information you can add to time-series data. The metric storage backends do not index these, but you can retrieve and display them alongside the metric value in the Grafana UI. While exemplars can store various metadata, trace-IDs are stored to integrate strongly with Tempo in this use case.
This example shows using exemplars with a request latency histogram where each exemplar data point links to a trace in Tempo.
(Annanay Agarwal, CC BY-SA 4.0)
## Consistent metadata
Telemetry data emitted from applications running as containerized applications generally has some metadata associated with it. This can include information like the cluster ID, namespace, pod IP, etc. This is great for providing on-demand information, but it's even better if you can use the information contained in metadata for something productive.
For instance, you can use the [Grafana Cloud Agent to ingest traces into Tempo](https://grafana.com/blog/2020/11/17/tracing-with-the-grafana-cloud-agent-and-grafana-tempo/), and the agent leverages the Prometheus Service Discovery mechanism to poll the Kubernetes API for metadata information and adds these as tags to spans emitted by the application. Since this metadata is also indexed in Loki, it makes it easy for you to jump from traces to view logs for a given service by translating metadata into Loki label selectors.
The following is an example of consistent metadata that can be used to view the logs for a given span in a trace in Tempo.
## Cloud-native
Grafana Tempo is available as a containerized application, and you can run it on any orchestration engine like Kubernetes, Mesos, etc. The various services can be horizontally scaled depending on the workload on the ingest/query path. You can also use cloud-native object storage, such as Google Cloud Storage, Amazon S3, or Azure Blog Storage with Tempo. For further information, read the [architecture section](https://grafana.com/docs/tempo/latest/architecture/architecture/) in Tempo's documentation.
## Try Tempo
If this sounds like it might be as useful for you as it has been for us, [clone the Tempo repo](https://github.com/grafana/tempo) or sign up for [Grafana Cloud](https://grafana.com/products/cloud/) and give it a try.
## Comments are closed. |
13,230 | 在 Firefox 上使用 WebAssembly 要了解的 6 件事 | https://opensource.com/article/21/3/webassembly-firefox | 2021-03-23T22:39:11 | [
"WebAssembly"
] | https://linux.cn/article-13230-1.html |
>
> 了解在 Firefox 上运行 WebAssembly 的机会和局限性。
>
>
>

WebAssembly 是一种可移植的执行格式,由于它能够以近乎原生的速度在浏览器中执行应用而引起了人们的极大兴趣。WebAssembly 本质上有一些特殊的属性和局限性。但是,通过将其与其他技术结合,将出现全新的可能性,尤其是与浏览器中的游戏有关的可能性。
本文介绍了在 Firefox 上运行 WebAssembly 的概念、可能性和局限性。
### 沙盒
WebAssembly 有 [严格的安全策略](https://webassembly.org/docs/security/)。 WebAssembly 中的程序或功能单元称为*模块*。每个模块实例都运行在自己的隔离内存空间中。因此,即使同一个网页加载了多个模块,它们也无法访问另一个模块的虚拟地址空间。设计上,WebAssembly 还考虑了内存安全性和控制流完整性,这使得(几乎)确定性的执行成为可能。
### Web API
通过 JavaScript [Web API](https://developer.mozilla.org/en-US/docs/Web/API) 可以访问多种输入和输出设备。根据这个 [提案](https://github.com/WebAssembly/gc/blob/master/README.md),将来可以不用绕道到 JavaScript 来访问 Web API。C++ 程序员可以在 [Emscripten.org](https://emscripten.org/docs/porting/connecting_cpp_and_javascript/Interacting-with-code.html) 上找到有关访问 Web API 的信息。Rust 程序员可以使用 [rustwasm.github.io](https://rustwasm.github.io/wasm-bindgen/) 中写的 [wasm-bindgen](https://github.com/rustwasm/wasm-bindgen) 库。
### 文件输入/输出
因为 WebAssembly 是在沙盒环境中执行的,所以当它在浏览器中执行时,它无法访问主机的文件系统。但是,Emscripten 提供了虚拟文件系统形式的解决方案。
Emscripten 使在编译时将文件预加载到内存文件系统成为可能。然后可以像在普通文件系统上一样从 WebAssembly 应用中读取这些文件。这个 [教程](https://emscripten.org/docs/api_reference/Filesystem-API.html) 提供了更多信息。
### 持久化数据
如果你需要在客户端存储持久化数据,那么必须通过 JavaScript Web API 来完成。请参考 Mozilla 开发者网络(MDN)关于 [浏览器存储限制和过期标准](https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API/Browser_storage_limits_and_eviction_criteria) 的文档,了解不同方法的详细信息。
### 内存管理
WebAssembly 模块作为 [堆栈机](https://en.wikipedia.org/wiki/Stack_machine) 在线性内存上运行。这意味着堆内存分配等概念是没有的。然而,如果你在 C++ 中使用 `new` 或者在 Rust 中使用 `Box::new`,你会期望它会进行堆内存分配。将堆内存分配请求转换成 WebAssembly 的方式在很大程度上依赖于工具链。你可以在 Frank Rehberger 关于 [WebAssembly 和动态内存](https://frehberg.wordpress.com/webassembly-and-dynamic-memory/) 的文章中找到关于不同工具链如何处理堆内存分配的详细分析。
### 游戏!
与 [WebGL](https://en.wikipedia.org/wiki/WebGL) 结合使用时,WebAssembly 的执行速度很高,因此可以在浏览器中运行原生游戏。大型专有游戏引擎 [Unity](https://beta.unity3d.com/jonas/AngryBots/) 和[虚幻 4](https://www.youtube.com/watch?v=TwuIRcpeUWE) 展示了 WebGL 可以实现的功能。也有使用 WebAssembly 和 WebGL 接口的开源游戏引擎。这里有些例子:
* 自 2011 年 11 月起,[id Tech 4](https://en.wikipedia.org/wiki/Id_Tech_4) 引擎(更常称之为 Doom 3 引擎)可在 [GitHub](https://github.com/id-Software/DOOM-3) 上以 GPL 许可的形式获得。此外,还有一个 [Doom 3 的 WebAssembly 移植版](https://wasm.continuation-labs.com/d3demo/)。
* Urho3D 引擎提供了一些 [令人印象深刻的例子](https://urho3d.github.io/samples/),它们可以在浏览器中运行。
* 如果你喜欢复古游戏,可以试试这个 [Game Boy 模拟器](https://vaporboy.net/)。
* [Godot 引擎也能生成 WebAssembly](https://docs.godotengine.org/en/stable/development/compiling/compiling_for_web.html)。我找不到演示,但 [Godot 编辑器](https://godotengine.org/editor/latest/godot.tools.html) 已经被移植到 WebAssembly 上。
### 有关 WebAssembly 的更多信息
WebAssembly 是一项很有前途的技术,我相信我们将来会越来越多地看到它。除了在浏览器中执行之外,WebAssembly 还可以用作可移植的执行格式。[Wasmer](https://github.com/wasmerio/wasmer) 容器主机使你可以在各种平台上执行 WebAssembly 代码。
如果你需要更多的演示、示例和教程,请看一下这个 [WebAssembly 主题集合](https://github.com/mbasso/awesome-wasm)。Mozilla 的 [游戏和示例合集](https://developer.mozilla.org/en-US/docs/Games/Examples) 并非全是 WebAssembly,但仍然值得一看。
---
via: <https://opensource.com/article/21/3/webassembly-firefox>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | WebAssembly is a portable execution format that has drawn a lot of interest due to its ability to execute applications in the browser at near-native speed. By its nature, WebAssembly has some special properties and limitations. However, by combining it with other technologies, completely new possibilities arise, especially related to gaming in the browser.
This article describes the concepts, possibilities, and limitations of running WebAssembly on Firefox.
## The sandbox
WebAssembly has a [strict security policy](https://webassembly.org/docs/security/). A program or functional unit in WebAssembly is called a *module*. Each module instance runs its own isolated memory space. Therefore, one module cannot access another module's virtual address space, even if they are loaded on the same web page. By design, WebAssembly also considers memory safety and control-flow integrity, which enables an (almost-) deterministic execution.
## Web APIs
Access to many kinds of input and output devices is granted via JavaScript [Web APIs](https://developer.mozilla.org/en-US/docs/Web/API). In the future, access to Web APIs will be available without the detour over to JavaScript, according to this [proposal](https://github.com/WebAssembly/gc/blob/master/README.md). C++ programmers can find information about accessing the Web APIs on [Emscripten.org](https://emscripten.org/docs/porting/connecting_cpp_and_javascript/Interacting-with-code.html). Rust programmers can use the [wasm-bindgen](https://github.com/rustwasm/wasm-bindgen) library that is documented on [rustwasm.github.io](https://rustwasm.github.io/wasm-bindgen/).
## File input/output
Because WebAssembly is executed in a sandboxed environment, it cannot access the host's filesystem when it is executed in a browser. However, Emscripten offers a solution in the form of a virtual filesystem.
Emscripten makes it possible to preload files to the memory filesystem at compile time. Those files can then be read from within the WebAssembly application, just as you would on an ordinary filesystem. This [tutorial](https://emscripten.org/docs/api_reference/Filesystem-API.html) offers more information.
## Persistent data
If you need to store persistent data on the client-side, it must be done over a JavaScript Web API. Refer to Mozilla Developer Network's documentation on [browser storage limits and eviction criteria](https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API/Browser_storage_limits_and_eviction_criteria) for more detailed information about the different approaches.
## Memory management
WebAssembly modules operate on linear memory as a [stack machine](https://en.wikipedia.org/wiki/Stack_machine). This means that concepts like heap memory allocations are not available. However, if you are using `new`
in C++ or `Box::new`
in Rust, you would expect it to result in a heap memory allocation. The way heap memory allocation requests are translated into WebAssembly relies heavily upon the toolchain. You can find a detailed analysis of how different toolchains deal with heap memory allocations in Frank Rehberger's post about [ WebAssembly and dynamic memory](https://frehberg.wordpress.com/webassembly-and-dynamic-memory/).
## Games!
In combination with [WebGL](https://en.wikipedia.org/wiki/WebGL), WebAssembly enables native gaming in the browser due to its high execution speed. The big proprietary game engines [Unity](https://beta.unity3d.com/jonas/AngryBots/) and [Unreal Engine 4](https://www.youtube.com/watch?v=TwuIRcpeUWE) show what is possible with WebGL. There are also open source game engines that use WebAssembly and the WebGL interface. Here are some examples:
- Since November 2011, the
[id Tech 4](https://en.wikipedia.org/wiki/Id_Tech_4)engine (better known as the Doom 3 engine) is available under the GPL license on[GitHub](https://github.com/id-Software/DOOM-3). There is also a[WebAssembly port of Doom 3](https://wasm.continuation-labs.com/d3demo/). - The Urho3D engine provides some
[impressive examples](https://urho3d.github.io/samples/)that can run in the browser. - If you like retro games, try this
[Game Boy emulator](https://vaporboy.net/). - The
[Godot engine is also capable of producing WebAssembly](https://docs.godotengine.org/en/stable/development/compiling/compiling_for_web.html). I couldn't find a demo, but the[Godot editor](https://godotengine.org/editor/latest/godot.tools.html)has been ported to WebAssembly.
## More about WebAssembly
WebAssembly is a promising technology that I believe we will see more frequently in the future. In addition to executing in the browser, WebAssembly can also be used as a portable execution format. The [Wasmer](https://github.com/wasmerio/wasmer) container host enables you to execute WebAssembly code on various platforms.
If you want more demos, examples, and tutorials, take a look at this [extensive collection of WebAssembly topics](https://github.com/mbasso/awesome-wasm). Not exclusive to WebAssembly but still worth a look are Mozilla's [collection of games and demos](https://developer.mozilla.org/en-US/docs/Games/Examples).
## Comments are closed. |
13,233 | 利用 Python 探究 Google 的自然语言 API | https://opensource.com/article/19/7/python-google-natural-language-api | 2021-03-24T23:21:00 | [
"谷歌",
"搜索",
"自然语言"
] | https://linux.cn/article-13233-1.html |
>
> Google API 可以凸显出有关 Google 如何对网站进行分类的线索,以及如何调整内容以改进搜索结果的方法。
>
>
>

作为一名技术性的搜索引擎优化人员,我一直在寻找以新颖的方式使用数据的方法,以更好地了解 Google 如何对网站进行排名。我最近研究了 Google 的 [自然语言 API](https://cloud.google.com/natural-language/#natural-language-api-demo) 能否更好地揭示 Google 是如何分类网站内容的。
尽管有 [开源 NLP 工具](https://opensource.com/article/19/3/natural-language-processing-tools),但我想探索谷歌的工具,前提是它可能在其他产品中使用同样的技术,比如搜索。本文介绍了 Google 的自然语言 API,并探究了常见的自然语言处理(NLP)任务,以及如何使用它们来为网站内容创建提供信息。
### 了解数据类型
首先,了解 Google 自然语言 API 返回的数据类型非常重要。
#### 实体
<ruby> 实体 <rt> Entities </rt></ruby>是可以与物理世界中的某些事物联系在一起的文本短语。<ruby> 命名实体识别 <rt> Named Entity Recognition </rt></ruby>(NER)是 NLP 的难点,因为工具通常需要查看关键字的完整上下文才能理解其用法。例如,<ruby> 同形异义字 <rt> homographs </rt></ruby>拼写相同,但是具有多种含义。句子中的 “lead” 是指一种金属:“铅”(名词),使某人移动:“牵领”(动词),还可能是剧本中的主要角色(也是名词)?Google 有 12 种不同类型的实体,还有第 13 个名为 “UNKNOWN”(未知)的统称类别。一些实体与维基百科的文章相关,这表明 [知识图谱](https://en.wikipedia.org/wiki/Knowledge_Graph) 对数据的影响。每个实体都会返回一个显著性分数,即其与所提供文本的整体相关性。

#### 情感
<ruby> 情感 <rt> Sentiment </rt></ruby>,即对某事的看法或态度,是在文件和句子层面以及文件中发现的单个实体上进行衡量。情感的<ruby> 得分 <rt> score </rt></ruby>范围从 -1.0(消极)到 1.0(积极)。<ruby> 幅度 <rt> magnitude </rt></ruby>代表情感的<ruby> 非归一化 <rt> non-normalized </rt></ruby>强度;它的范围是 0.0 到无穷大。

#### 语法
<ruby> 语法 <rt> Syntax </rt></ruby>解析包含了大多数在较好的库中常见的 NLP 活动,例如 <ruby> <a href="https://en.wikipedia.org/wiki/Lemmatisation"> 词形演变 </a> <rt> lemmatization </rt></ruby>、<ruby> <a href="https://en.wikipedia.org/wiki/Part-of-speech_tagging"> 词性标记 </a> <rt> part-of-speech tagging </rt></ruby> 和 <ruby> <a href="https://en.wikipedia.org/wiki/Parse_tree#Dependency-based_parse_trees"> 依赖树解析 </a> <rt> dependency-tree parsing </rt></ruby>。NLP 主要处理帮助机器理解文本和关键字之间的关系。语法解析是大多数语言处理或理解任务的基础部分。

#### 分类
<ruby> 分类 <rt> Categories </rt></ruby>是将整个给定内容分配给特定行业或主题类别,其<ruby> 置信度 <rt> confidence </rt></ruby>得分从 0.0 到 1.0。这些分类似乎与其他 Google 工具使用的受众群体和网站类别相同,如 AdWords。

### 提取数据
现在,我将提取一些示例数据进行处理。我使用 Google 的 [搜索控制台 API](https://developers.google.com/webmaster-tools/) 收集了一些搜索查询及其相应的网址。Google 搜索控制台是一个报告人们使用 Google Search 查找网站页面的术语的工具。这个 [开源的 Jupyter 笔记本](https://github.com/MLTSEO/MLTS/blob/master/Demos.ipynb) 可以让你提取有关网站的类似数据。在此示例中,我在 2019 年 1 月 1 日至 6 月 1 日期间生成的一个网站(我没有提及名字)上提取了 Google 搜索控制台数据,并将其限制为至少获得一次点击(而不只是<ruby> 曝光 <rt> impressions </rt></ruby>)的查询。
该数据集包含 2969 个页面和在 Google Search 的结果中显示了该网站网页的 7144 条查询的信息。下表显示,绝大多数页面获得的点击很少,因为该网站侧重于所谓的长尾(越特殊通常就更长尾)而不是短尾(非常笼统,搜索量更大)搜索查询。

为了减少数据集的大小并仅获得效果最好的页面,我将数据集限制为在此期间至少获得 20 次曝光的页面。这是精炼数据集的按页点击的柱状图,其中包括 723 个页面:

### 在 Python 中使用 Google 自然语言 API 库
要测试 API,在 Python 中创建一个利用 [google-cloud-language](https://pypi.org/project/google-cloud-language/) 库的小脚本。以下代码基于 Python 3.5+。
首先,激活一个新的虚拟环境并安装库。用环境的唯一名称替换 `<your-env>` 。
```
virtualenv <your-env>
source <your-env>/bin/activate
pip install --upgrade google-cloud-language
pip install --upgrade requests
```
该脚本从 URL 提取 HTML,并将 HTML 提供给自然语言 API。返回一个包含 `sentiment`、 `entities` 和 `categories` 的字典,其中这些键的值都是列表。我使用 Jupyter 笔记本运行此代码,因为使用同一内核注释和重试代码更加容易。
```
# Import needed libraries
import requests
import json
from google.cloud import language
from google.oauth2 import service_account
from google.cloud.language import enums
from google.cloud.language import types
# Build language API client (requires service account key)
client = language.LanguageServiceClient.from_service_account_json('services.json')
# Define functions
def pull_googlenlp(client, url, invalid_types = ['OTHER'], **data):
html = load_text_from_url(url, **data)
if not html:
return None
document = types.Document(
content=html,
type=language.enums.Document.Type.HTML )
features = {'extract_syntax': True,
'extract_entities': True,
'extract_document_sentiment': True,
'extract_entity_sentiment': True,
'classify_text': False
}
response = client.annotate_text(document=document, features=features)
sentiment = response.document_sentiment
entities = response.entities
response = client.classify_text(document)
categories = response.categories
def get_type(type):
return client.enums.Entity.Type(entity.type).name
result = {}
result['sentiment'] = []
result['entities'] = []
result['categories'] = []
if sentiment:
result['sentiment'] = [{ 'magnitude': sentiment.magnitude, 'score':sentiment.score }]
for entity in entities:
if get_type(entity.type) not in invalid_types:
result['entities'].append({'name': entity.name, 'type': get_type(entity.type), 'salience': entity.salience, 'wikipedia_url': entity.metadata.get('wikipedia_url', '-') })
for category in categories:
result['categories'].append({'name':category.name, 'confidence': category.confidence})
return result
def load_text_from_url(url, **data):
timeout = data.get('timeout', 20)
results = []
try:
print("Extracting text from: {}".format(url))
response = requests.get(url, timeout=timeout)
text = response.text
status = response.status_code
if status == 200 and len(text) > 0:
return text
return None
except Exception as e:
print('Problem with url: {0}.'.format(url))
return None
```
要访问该 API,请按照 Google 的 [快速入门说明](https://cloud.google.com/natural-language/docs/quickstart) 在 Google 云主控台中创建一个项目,启用该 API 并下载服务帐户密钥。之后,你应该拥有一个类似于以下内容的 JSON 文件:

命名为 `services.json`,并上传到项目文件夹。
然后,你可以通过运行以下程序来提取任何 URL(例如 [Opensource.com](http://Opensource.com))的 API 数据:
```
url = "https://opensource.com/article/19/6/how-ssh-running-container"
pull_googlenlp(client,url)
```
如果设置正确,你将看到以下输出:

为了使入门更加容易,我创建了一个 [Jupyter 笔记本](https://github.com/MLTSEO/MLTS/blob/master/Tutorials/Google_Language_API_Intro.ipynb),你可以下载并使用它来测试提取网页的实体、类别和情感。我更喜欢使用 [JupyterLab](https://github.com/jupyterlab/jupyterlab),它是 Jupyter 笔记本的扩展,其中包括文件查看器和其他增强的用户体验功能。如果你不熟悉这些工具,我认为利用 [Anaconda](https://www.anaconda.com/distribution/) 是开始使用 Python 和 Jupyter 的最简单途径。它使安装和设置 Python 以及常用库变得非常容易,尤其是在 Windows 上。
### 处理数据
使用这些函数,可抓取给定页面的 HTML 并将其传递给自然语言 API,我可以对 723 个 URL 进行一些分析。首先,我将通过查看所有页面中返回的顶级分类的数量来查看与网站相关的分类。
#### 分类

这似乎是该特定站点的关键主题的相当准确的代表。通过查看一个效果最好的页面进行排名的单个查询,我可以比较同一查询在 Google 搜索结果中的其他排名页面。
* URL 1 |顶级类别:/法律和政府/与法律相关的(0.5099999904632568)共 1 个类别。
* 未返回任何类别。
* URL 3 |顶级类别:/互联网与电信/移动与无线(0.6100000143051147)共 1 个类别。
* URL 4 |顶级类别:/计算机与电子产品/软件(0.5799999833106995)共有 2 个类别。
* URL 5 |顶级类别:/互联网与电信/移动与无线/移动应用程序和附件(0.75)共有 1 个类别。
* 未返回任何类别。
* URL 7 |顶级类别:/计算机与电子/软件/商业与生产力软件(0.7099999785423279)共 2 个类别。
* URL 8 |顶级类别:/法律和政府/与法律相关的(0.8999999761581421)共 3 个类别。
* URL 9 |顶级类别:/参考/一般参考/类型指南和模板(0.6399999856948853)共有 1 个类别。
* 未返回任何类别。
上方括号中的数字表示 Google 对页面内容与该分类相关的置信度。对于相同分类,第八个结果比第一个结果具有更高的置信度,因此,这似乎不是定义排名相关性的灵丹妙药。此外,分类太宽泛导致无法满足特定搜索主题的需要。
通过排名查看平均置信度,这两个指标之间似乎没有相关性,至少对于此数据集而言如此:

这两种方法对网站进行规模审查是有意义的,以确保内容类别易于理解,并且样板或销售内容不会使你的页面与你的主要专业知识领域无关。想一想,如果你出售工业用品,但是你的页面返回 “Marketing(销售)” 作为主要分类。似乎没有一个强烈的迹象表明,分类相关性与你的排名有什么关系,至少在页面级别如此。
#### 情感
我不会在情感上花很多时间。在所有从 API 返回情感的页面中,它们分为两个区间:0.1 和 0.2,这几乎是中立的情感。根据直方图,很容易看出情感没有太大价值。对于新闻或舆论网站而言,测量特定页面的情感到中位数排名之间的相关性将是一个更加有趣的指标。

#### 实体
在我看来,实体是 API 中最有趣的部分。这是在所有页面中按<ruby> 显著性 <rt> salience </rt></ruby>(或与页面的相关性)选择的顶级实体。请注意,对于相同的术语(销售清单),Google 会推断出不同的类型,可能是错误的。这是由于这些术语出现在内容中的不同上下文中引起的。

然后,我分别查看了每个实体类型,并一起查看了该实体的显著性与页面的最佳排名位置之间是否存在任何关联。对于每种类型,我匹配了与该类型匹配的顶级实体的显著性(与页面的整体相关性),按显著性排序(降序)。
有些实体类型在所有示例中返回的显著性为零,因此我从下面的图表中省略了这些结果。

“Consumer Good(消费性商品)” 实体类型具有最高的正相关性,<ruby> 皮尔森相关度 <rt> Pearson correlation </rt></ruby>为 0.15854,尽管由于较低编号的排名更好,所以 “Person” 实体的结果最好,相关度为 -0.15483。这是一个非常小的样本集,尤其是对于单个实体类型,我不能对数据做太多的判断。我没有发现任何具有强相关性的值,但是 “Person” 实体最有意义。网站通常都有关于其首席执行官和其他主要雇员的页面,这些页面很可能在这些查询的搜索结果方面做得好。
继续,当从整体上看站点,根据实体名称和实体类型,出现了以下主题。

我模糊了几个看起来过于具体的结果,以掩盖网站的身份。从主题上讲,名称信息是在你(或竞争对手)的网站上局部查看其核心主题的一种好方法。这样做仅基于示例网站的排名网址,而不是基于所有网站的可能网址(因为 Search Console 数据仅记录 Google 中展示的页面),但是结果会很有趣,尤其是当你使用像 [Ahrefs](https://ahrefs.com/) 之类的工具提取一个网站的主要排名 URL,该工具会跟踪许多查询以及这些查询的 Google 搜索结果。
实体数据中另一个有趣的部分是标记为 “CONSUMER\_GOOD” 的实体倾向于 “看起来” 像我在看到 “<ruby> 知识结果 <rt> Knowledge Results </rt></ruby>”的结果,即页面右侧的 Google 搜索结果。

在我们的数据集中具有三个或三个以上关键字的 “Consumer Good(消费性商品)” 实体名称中,有 5.8% 的知识结果与 Google 对该实体命名的结果相同。这意味着,如果你在 Google 中搜索术语或短语,则右侧的框(例如,上面显示 Linux 的知识结果)将显示在搜索结果页面中。由于 Google 会 “挑选” 代表实体的示例网页,因此这是一个很好的机会,可以在搜索结果中识别出具有唯一特征的机会。同样有趣的是,5.8% 的在 Google 中显示这些知识结果名称中,没有一个实体的维基百科 URL 从自然语言 API 中返回。这很有趣,值得进行额外的分析。这将是非常有用的,特别是对于传统的全球排名跟踪工具(如 Ahrefs)数据库中没有的更深奥的主题。
如前所述,知识结果对于那些希望自己的内容在 Google 中被收录的网站所有者来说是非常重要的,因为它们在桌面搜索中加强高亮显示。假设,它们也很可能与 Google [Discover](https://www.blog.google/products/search/introducing-google-discover/) 的知识库主题保持一致,这是一款适用于 Android 和 iOS 的产品,它试图根据用户感兴趣但没有明确搜索的主题为用户浮现内容。
### 总结
本文介绍了 Google 的自然语言 API,分享了一些代码,并研究了此 API 对网站所有者可能有用的方式。关键要点是:
* 学习使用 Python 和 Jupyter 笔记本可以为你的数据收集任务打开到一个由令人难以置信的聪明和有才华的人建立的不可思议的 API 和开源项目(如 Pandas 和 NumPy)的世界。
* Python 允许我为了一个特定目的快速提取和测试有关 API 值的假设。
* 通过 Google 的分类 API 传递网站页面可能是一项很好的检查,以确保其内容分解成正确的主题分类。对于竞争对手的网站执行此操作还可以提供有关在何处进行调整或创建内容的指导。
* 对于示例网站,Google 的情感评分似乎并不是一个有趣的指标,但是对于新闻或基于意见的网站,它可能是一个有趣的指标。
* Google 发现的实体从整体上提供了更细化的网站的主题级别视图,并且像分类一样,在竞争性内容分析中使用将非常有趣。
* 实体可以帮助定义机会,使你的内容可以与搜索结果或 Google Discover 结果中的 Google 知识块保持一致。我们将 5.8% 的结果设置为更长的(字计数)“Consumer Goods(消费商品)” 实体,显示这些结果,对于某些网站来说,可能有机会更好地优化这些实体的页面显著性分数,从而有更好的机会在 Google 搜索结果或 Google Discovers 建议中抓住这个重要作用的位置。
---
via: <https://opensource.com/article/19/7/python-google-natural-language-api>
作者:[JR Oakes](https://opensource.com/users/jroakes) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As a technical search engine optimizer, I am always looking for ways to use data in novel ways to better understand how Google ranks websites. I recently investigated whether Google's [Natural Language API](https://cloud.google.com/natural-language/#natural-language-api-demo) could better inform how Google may be classifying a site's content.
Although there are [open source NLP tools](https://opensource.com/article/19/3/natural-language-processing-tools), I wanted to explore Google's tools under the assumption it might use the same tech in other products, like Search. This article introduces Google's Natural Language API and explores common natural language processing (NLP) tasks and how they might be used to inform website content creation.
## Understanding the data types
To begin, it is important to understand the types of data that Google's Natural Language API returns.
### Entities
Entities are text phrases that can be tied back to something in the physical world. Named entity recognition (NER) is a difficult part of NLP because tools often need to look at the full context around words to understand their usage. For example, homographs are spelled the same but have multiple meanings. Does "lead" in a sentence refer to a metal (a noun), causing someone to move (a verb), or the main character in a play (also a noun)? Google has 12 distinct types of entities, as well as a 13th catch-all category called "UNKNOWN." Some of the entities tie back to Wikipedia articles, suggesting [Knowledge Graph](https://en.wikipedia.org/wiki/Knowledge_Graph) influence on the data. Each entity returns a salience score, which is its overall relevance to the supplied text.
### Sentiment
Sentiment, a view of or attitude towards something, is measured at the document and sentence level and for individual entities discovered in the document. The score of the sentiment ranges from -1.0 (negative) to 1.0 (positive). The magnitude represents the non-normalized strength of emotion; it ranges between 0.0 and infinity.
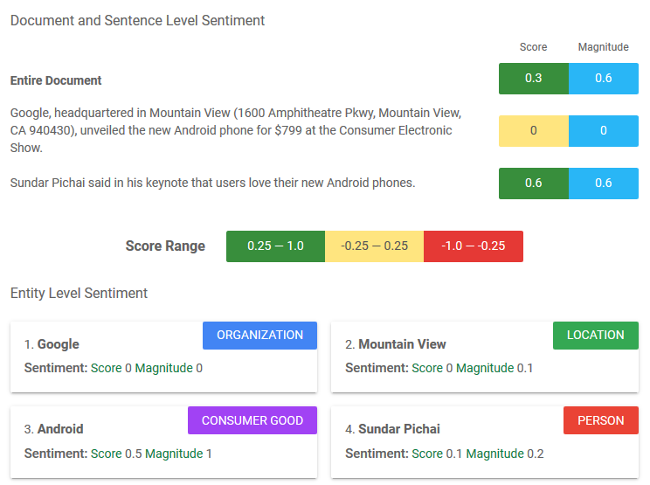
### Syntax
Syntax parsing contains most of the common NLP activities found in better libraries, like [lemmatization](https://en.wikipedia.org/wiki/Lemmatisation), [part-of-speech tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging), and [dependency-tree parsing](https://en.wikipedia.org/wiki/Parse_tree#Dependency-based_parse_trees). NLP mainly deals with helping machines understand text and the relationship between words. Syntax parsing is a foundational part of most language-processing or understanding tasks.
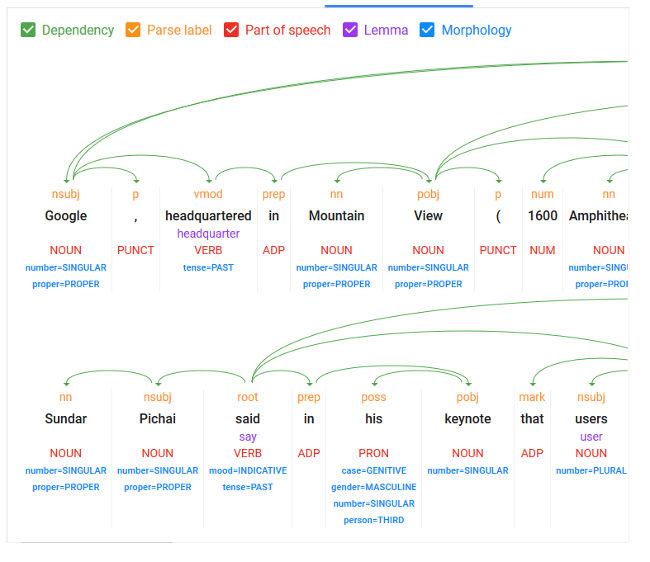
### Categories
Categories assign the entire given content to a specific industry or topical category with a confidence score from 0.0 to 1.0. The categories appear to be the same audience and website categories used by other Google tools, like AdWords.
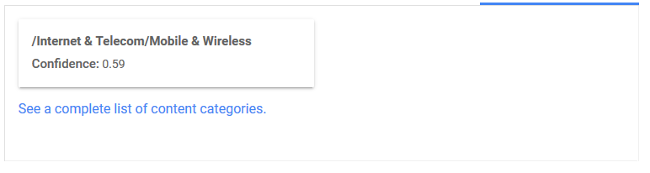
## Pulling some data
Now I'll pull some sample data to play around with. I gathered some search queries and their corresponding URLs using Google's [Search Console API](https://developers.google.com/webmaster-tools/). Google Search Console is a tool that reports the terms people use to find a website's pages with Google Search. This [open source Jupyter notebook](https://github.com/MLTSEO/MLTS/blob/master/Demos.ipynb) allows you to pull similar data about your website. For this example, I pulled Google Search Console data on a website (which I won't name) generated between January 1 and June 1, 2019, and restricted it to queries that received at least one click (as opposed to just impressions).
This dataset contains information on 2,969 pages and 7,144 queries that displayed the website's pages in Google Search results. The table below shows that the vast majority of pages received very few clicks, as this site focuses on what is called long-tail (more specific and usually longer) as opposed to short-tail (very general, higher search volume) search queries.
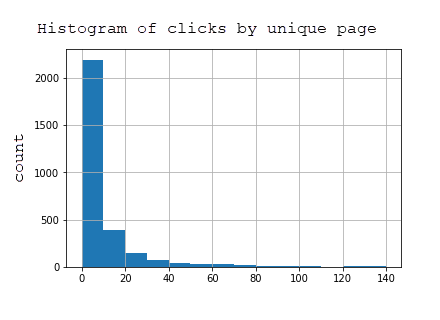
To reduce the dataset size and get only top-performing pages, I limited the dataset to pages that received at least 20 impressions over the period. This is the histogram of clicks by page for this refined dataset, which includes 723 pages:
## Using Google's Natural Language API library in Python
To test out the API, create a small script that leverages the ** google-cloud-language** library in Python. The following code is Python 3.5+.
First, activate a new virtual environment and install the libraries. Replace **<your-env>** with a unique name for the environment.
```
virtualenv <your-env>
source <your-env>/bin/activate
pip install --upgrade google-cloud-language
pip install --upgrade requests
```
This script extracts HTML from a URL and feeds the HTML to the Natural Language API. It returns a dictionary of **sentiment**, **entities**, and **categories**, where the values for these keys are all lists. I used a Jupyter notebook to run this code because it makes it easier to annotate and retry code using the same kernel.
```
# Import needed libraries
import requests
import json
from google.cloud import language
from google.oauth2 import service_account
from google.cloud.language import enums
from google.cloud.language import types
# Build language API client (requires service account key)
client = language.LanguageServiceClient.from_service_account_json('services.json')
# Define functions
def pull_googlenlp(client, url, invalid_types = ['OTHER'], **data):
html = load_text_from_url(url, **data)
if not html:
return None
document = types.Document(
content=html,
type=language.enums.Document.Type.HTML )
features = {'extract_syntax': True,
'extract_entities': True,
'extract_document_sentiment': True,
'extract_entity_sentiment': True,
'classify_text': False
}
response = client.annotate_text(document=document, features=features)
sentiment = response.document_sentiment
entities = response.entities
response = client.classify_text(document)
categories = response.categories
def get_type(type):
return client.enums.Entity.Type(entity.type).name
result = {}
result['sentiment'] = []
result['entities'] = []
result['categories'] = []
if sentiment:
result['sentiment'] = [{ 'magnitude': sentiment.magnitude, 'score':sentiment.score }]
for entity in entities:
if get_type(entity.type) not in invalid_types:
result['entities'].append({'name': entity.name, 'type': get_type(entity.type), 'salience': entity.salience, 'wikipedia_url': entity.metadata.get('wikipedia_url', '-') })
for category in categories:
result['categories'].append({'name':category.name, 'confidence': category.confidence})
return result
def load_text_from_url(url, **data):
timeout = data.get('timeout', 20)
results = []
try:
print("Extracting text from: {}".format(url))
response = requests.get(url, timeout=timeout)
text = response.text
status = response.status_code
if status == 200 and len(text) > 0:
return text
return None
except Exception as e:
print('Problem with url: {0}.'.format(url))
return None
```
To access the API, follow Google's [quickstart instructions](https://cloud.google.com/natural-language/docs/quickstart) to create a project in Google Cloud Console, enable the API, and download a service account key. Afterward, you should have a JSON file that looks similar to this:

Upload it to your project folder with the name **services.json**.
Then you can pull the API data for any URL (such as Opensource.com) by running the following:
```
url = "https://opensource.com/article/19/6/how-ssh-running-container"
pull_googlenlp(client,url)
```
If it's set up correctly, you should see this output:

To make it easier to get started, I created a [Jupyter Notebook](https://github.com/MLTSEO/MLTS/blob/master/Tutorials/Google_Language_API_Intro.ipynb) that you can download and use to test extracting web pages' entities, categories, and sentiment. I prefer using [JupyterLab](https://github.com/jupyterlab/jupyterlab), which is an extension of Jupyter Notebooks that includes a file viewer and other enhanced user experience features. If you're new to these tools, I think [Anaconda](https://www.anaconda.com/distribution/) is the easiest way to get started using Python and Jupyter. It makes installing and setting up Python, as well as common libraries, very easy, especially on Windows.
## Playing with the data
With these functions that scrape the HTML of the given page and pass it to the Natural Language API, I can run some analysis across the 723 URLs. First, I'll look at the categories relevant to the site by looking at the count of returned top categories across all pages.
### Categories
This seems to be a fairly accurate representation of the key themes of this particular site. Looking at a single query that one of the top-performing pages ranks for, I can compare the other ranking pages in Google's results for that same query.
*URL 1 | Top Category: /Law & Government/Legal (0.5099999904632568) of 1 total categories.**No categories returned.**URL 3 | Top Category: /Internet & Telecom/Mobile & Wireless (0.6100000143051147) of 1 total categories.**URL 4 | Top Category: /Computers & Electronics/Software (0.5799999833106995) of 2 total categories.**URL 5 | Top Category: /Internet & Telecom/Mobile & Wireless/Mobile Apps & Add-Ons (0.75) of 1 total categories.**No categories returned.**URL 7 | Top Category: /Computers & Electronics/Software/Business & Productivity Software (0.7099999785423279) of 2 total categories.**URL 8 | Top Category: /Law & Government/Legal (0.8999999761581421) of 3 total categories.**URL 9 | Top Category: /Reference/General Reference/Forms Guides & Templates (0.6399999856948853) of 1 total categories.**No categories returned.*
The numbers in parentheses above represent Google's confidence that the content of the page is relevant for that category. The eighth result has much higher confidence than the first result for the same category, so this doesn't seem to be a magic bullet for defining relevance for ranking. Also, the categories are much too broad to make sense for a specific search topic.
Looking at average confidence by ranking position, there doesn't seem to be a correlation between these two metrics, at least for this dataset:
Both of these approaches make sense to review for a website at scale to ensure the content categories seem appropriate, and boilerplate or sales content isn't moving your pages out of relevance for your main expertise area. Think if you sell industrial supplies, but your pages return *Marketing* as the main category. There doesn't seem to be a strong suggestion that category relevancy has anything to do with how well you rank, at least at a page level.
### Sentiment
I won't spend much time on sentiment. Across all the pages that returned a sentiment from the API, they fell into two bins: 0.1 and 0.2, which is almost neutral sentiment. Based on the histogram, it is easy to tell that sentiment doesn't provide much value. It would be a much more interesting metric to run for a news or opinion site to measure the correlation of sentiment to median rank for particular pages.
### Entities
Entities were the most interesting part of the API, in my opinion. This is a selection of the top entities, across all pages, by salience (or relevancy to the page). Notice that Google is inferring different types for the same terms (Bill of Sale), perhaps incorrectly. This is caused by the terms appearing in different contexts in the content.
Then I looked at each entity type individually and all together to see if there was any correlation between the salience of the entity and the best-ranking position of the page. For each type, I matched the salience (overall relevance to the page) of the top entity matching that type ordered by salience (descending).
Some of the entity types returned zero salience across all examples, so I omitted those results from the charts below.
The **Consumer Good** entity type had the highest positive correlation, with a Pearson correlation of 0.15854, although since lower-numbered rankings are better, the **Person** entity had the best result with a -0.15483 correlation. This is an extremely small sample set, especially for individual entity types, so I can't make too much of the data. I didn't find any value with a strong correlation, but the **Person** entity makes the most sense. Sites usually have pages about their chief executive and other key employees, and these pages are very likely to do well in search results for those queries.
Moving on, while looking at the site holistically, the following themes emerge based on **entity** **name** and **entity type**.
I blurred a few results that seem too specific to mask the site's identity. Thematically, the name information is a good way to look topically at your (or a competitor's) site to see its core themes. This was done based only on the example site's ranking URLs and not all the site's possible URLs (Since Search Console data only reports on pages that received impressions in Google), but the results would be interesting, especially if you were to pull a site's main ranking URLs from a tool like [Ahrefs](https://ahrefs.com/), which tracks many, many queries and the Google results for those queries.
The other interesting piece in the entity data is that entities marked **CONSUMER_GOOD** tended to "look" like results I have seen in Knowledge Results, i.e., the Google Search results on the right-hand side of the page.
Of the **Consumer Good** entity names from our data set that had three or more words, 5.8% had the same Knowledge Results as Google's results for the entity name. This means, if you searched for the term or phrase in Google, the block on the right (eg. the Knowledge Results showing Linux above), would display in the search result page. Since Google "picks" an exemplar webpage to represent the entity, it is a good opportunity to identify opportunities to be singularly featured in search results. Also of interest, of the 5.8% names that displayed these Knowledge Results in Google, none of the entities had Wikipedia URLs returned from the Natural Language API. This is interesting enough to warrant additional analysis. It would be very useful, especially for more esoteric topics that traditional global rank-tracking tools, like Ahrefs, don't have in their databases.
As mentioned, the Knowledge Results can be important to site owners who want to have their content featured in Google, as they are strongly highlighted on desktop search. They are also more than likely, hypothetically, to line up with knowledge-base topics from Google [Discover](https://www.blog.google/products/search/introducing-google-discover/), an offering for Android and iOS that attempts to surface content for users based on topics they are interested in but haven't searched explicitly for.
## Wrapping up
This article went over Google's Natural Language API, shared some code, and investigated ways this API may be useful for site owners. The key takeaways are:
- Learning to use Python and Jupyter Notebooks opens your data-gathering tasks to a world of incredible APIs and open source projects (like Pandas and NumPy) built by incredibly smart and talented people.
- Python allows me to quickly pull and test my hypothesis about the value of an API for a particular purpose.
- Passing a website's pages through Google's categorization API may be a good check to ensure its content falls into the correct thematic categories. Doing this for competitors' sites may also offer guidance on where to tune-up or create content.
- Google's sentiment score didn't seem to be an interesting metric for the example site, but it may be for news or opinion-based sites.
- Google's found entities gave a much more granular topic-level view of the website holistically and, like categorization, would be very interesting to use in competitive content analysis.
- Entities may help define opportunities where your content can line up with Google Knowledge blocks in search results or Google Discover results. With 5.8% of our results set for longer (word count)
**Consumer Goods**entities, displaying these results, there may be opportunities, for some sites, to better optimize their page's salience score for these entities to stand a better chance of capturing this featured placement in Google search results or Google Discovers suggestions.
## Comments are closed. |
13,234 | 使用 gdu 进行更快的磁盘使用情况检查 | https://itsfoss.com/gdu/ | 2021-03-24T23:38:25 | [
"磁盘",
"du",
"df"
] | https://linux.cn/article-13234-1.html | 
在 Linux 终端中有两种常用的 [检查磁盘使用情况的方法](https://linuxhandbook.com/df-command/):`du` 命令和 `df` 命令。[du 命令更多的是用来检查目录的使用空间](https://linuxhandbook.com/find-directory-size-du-command/),`df` 命令则是提供文件系统级别的磁盘使用情况。
还有更友好的 [用 GNOME “磁盘” 等图形工具在 Linux 中查看磁盘使用情况的方法](https://itsfoss.com/check-free-disk-space-linux/)。如果局限于终端,你可以使用像 [ncdu](https://dev.yorhel.nl/ncdu) 这样的 [TUI](https://itsfoss.com/gui-cli-tui/) 工具,以一种图形化的方式获取磁盘使用信息。
### gdu: 在 Linux 终端中检查磁盘使用情况
[gdu](https://github.com/dundee/gdu) 就是这样一个用 Go 编写的工具(因此是 gdu 中的 “g”)。gdu 开发者的 [基准测试](https://github.com/dundee/gdu#benchmarks) 表明,它的磁盘使用情况检查速度相当快,特别是在 SSD 上。事实上,gdu 主要是针对 SSD 的,尽管它也可以在 HDD 上工作。
如果你在使用 `gdu` 命令时没有使用任何选项,它就会显示你当前所在目录的磁盘使用情况。

由于它具有文本用户界面(TUI),你可以使用箭头浏览目录和磁盘。你也可以按文件名或大小对结果进行排序。
你可以用它做到:
* 向上箭头或 `k` 键将光标向上移动
* 向下箭头或 `j` 键将光标向下移动
* 回车选择目录/设备
* 左箭头或 `h` 键转到上级目录
* 使用 `d` 键删除所选文件或目录
* 使用 `n` 键按名称排序
* 使用 `s` 键按大小排序
* 使用 `c` 键按项目排序
你会注意到一些条目前的一些符号。这些符号有特定的意义。

* `!` 表示读取目录时发生错误。
* `.` 表示在读取子目录时发生错误,大小可能不正确。
* `@` 表示文件是一个符号链接或套接字。
* `H` 表示文件已经被计数(硬链接)。
* `e` 表示目录为空。
要查看所有挂载磁盘的磁盘利用率和可用空间,使用选项 `d`:
```
gdu -d
```
它在一屏中显示所有的细节:

看起来是个方便的工具,对吧?让我们看看如何在你的 Linux 系统上安装它。
### 在 Linux 上安装 gdu
gdu 是通过 [AUR](https://itsfoss.com/aur-arch-linux/) 提供给 Arch 和 Manjaro 用户的。我想,作为一个 Arch 用户,你应该知道如何使用 AUR。
它包含在即将到来的 Ubuntu 21.04 的 universe 仓库中,但有可能你现在还没有使用它。这种情况下,你可以使用 Snap 安装它,这可能看起来有很多条 `snap` 命令:
```
snap install gdu-disk-usage-analyzer
snap connect gdu-disk-usage-analyzer:mount-observe :mount-observe
snap connect gdu-disk-usage-analyzer:system-backup :system-backup
snap alias gdu-disk-usage-analyzer.gdu gdu
```
你也可以在其发布页面找到源代码:
* [下载 gdu 的源代码](https://github.com/dundee/gdu/releases)
我更习惯于使用 `du` 和 `df` 命令,但我觉得一些 Linux 用户可能会喜欢 gdu。你是其中之一吗?
---
via: <https://itsfoss.com/gdu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There are two popular [ways to check disk usage in Linux terminal](https://linuxhandbook.com/df-command/?ref=itsfoss.com): du command and df command.
The [du command is more for checking the space used by a directory](https://linuxhandbook.com/find-directory-size-du-command/?ref=itsfoss.com) and the df command gives you the disk utilization on filesystem level.
The gdu tool sorts of combined the functionality of both.
You can use it to check the size of directories as well as disk utilization. The built in sorting feature makes it easier to use as you don't need to combine the sort command here.
## Gdu: Disk usage checking in Linux terminal
[Gdu](https://github.com/dundee/gdu?ref=itsfoss.com) is a tool written in Go (hence the ‘g’ in gdu). Gdu developer has [benchmark tests](https://github.com/dundee/gdu?ref=itsfoss.com#benchmarks) to show that it is quite fast for disk usage checking, specifically on SSDs. In fact, gdu is intended primarily for SSDs though it can work for HDD as well.
If you use the gdu command without any options, it shows the disk usage for the current directory you are in.
Since it has a terminal user interface (TUI), you can navigate through directories and disk using arrows. You can also sort the result by file names or size.
Here’s how to do that:
- Use the Up arrow or
**k**to move the cursor up. Similarly, use the down arrow or**j**to move the cursor down - Enter to select directory / device
- Left arrow or
**h**to go to parent directory
- Use
**d**to delete the selected file or directory
- Use
**n**to sort by name and use**s**to sort by size.
- Use
**c**to sort by items
You’ll notice some symbols before some file entries. Those have specific meaning.
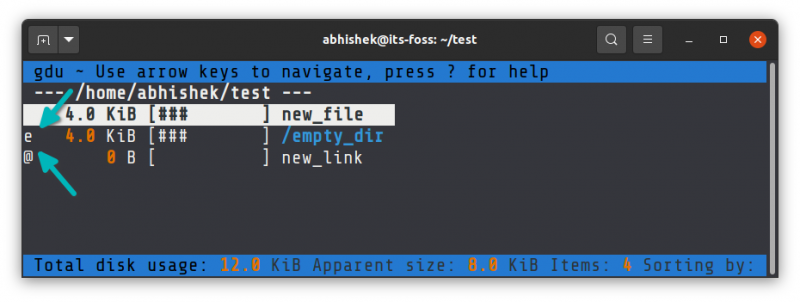
`!`
means an error occurred while reading the directory.`.`
means an error occurred while reading a subdirectory, size may not be correct.`@`
means file is a symlink or socket.`H`
means the file was already counted (hard link).`e`
means directory is empty.
To see the disk utilization and free space for all mounted disks, use the option `d`
:
```
gdu -d
```
It shows all the details in one screen:
Sounds like a handy tool, right?
## More Gdu options for Disk Usage Analysis
Here are some more options, that you can use with Gdu.
Command | Usage |
---|---|
gdu -H | Ignore Hidden Directories |
gdu -i /sys,/proc / | Ignore the specified directories and do gdu on root dorectory |
gdu -d | Show all mounted disks |
gdu -n | Run in a non-interactive mode |
## Installing gdu on Linux
Interested in trying gdu. Here are a few ways of installing it.
### From Official Repositories
Gdu is available in the repositories of Ubuntu, Debian, Arch Linux etc. In Debian/Ubuntu, you can install it [using the apt command](https://itsfoss.com/apt-command-guide/).
So, open a terminal and run:
```
sudo apt update
sudo apt install gdu
```
If you are an Arch Linux user, you can install it [using the pacman command](https://itsfoss.com/pacman-command/).
```
sudo pacman -Syu gdu
```
### Alternatively, install gdu using the official binary
Gdu provides a binary, which you can download and use. First, make sure you have [curl installed](https://itsfoss.com/install-curl-ubuntu/).
`sudo apt install curl`
Then, download the file and extract it using the commands below:
```
curl -L https://github.com/dundee/gdu/releases/latest/download/gdu_linux_amd64.tgz | tar xz
```
Now, give it execution permission and move the binary file [somewhere that is in the path](https://itsfoss.com/add-directory-to-path-linux/). You can do it by:
```
chmod +x gdu_linux_amd64
mv gdu_linux_amd64 /usr/bin/gdu
```
## Wrapping Up
There are more friendly [ways to see the disk usage in Linux with graphical tools like GNOME Disks](https://itsfoss.com/check-free-disk-space-linux/). If you are confined to the terminal, you can use a [TUI](https://itsfoss.com/gui-cli-tui/) tool like [ncdu](https://dev.yorhel.nl/ncdu?ref=itsfoss.com) to get the disk usage information with a sort of graphical touch. Gdu is one such entry to this list.
Gdu is a neat tool, that does not come with overwhelming options. It provides some necessary functions with speed in mind. It's something you can add to your toolbox. |
13,236 | 用 Jupyter 学习 Python 字典 | https://opensource.com/article/21/3/dictionary-values-python | 2021-03-26T09:47:59 | [
"Python",
"Jupyter",
"字典"
] | https://linux.cn/article-13236-1.html |
>
> 字典数据结构可以帮助你快速访问信息。
>
>
>

字典是 Python 编程语言使用的数据结构。一个 Python 字典由多个键值对组成;每个键值对将键映射到其关联的值上。
例如你是一名老师,想把学生姓名与成绩对应起来。你可以使用 Python 字典,将学生姓名映射到他们关联的成绩上。此时,键值对中键是姓名,值是对应的成绩。
如果你想知道某个学生的考试成绩,你可以从字典中访问。这种快捷查询方式可以为你节省解析整个列表找到学生成绩的时间。
本文介绍了如何通过键访问对应的字典值。学习前,请确保你已经安装了 [Anaconda 包管理器](https://docs.anaconda.com/anaconda/)和 [Jupyter 笔记本](https://opensource.com/article/18/3/getting-started-jupyter-notebooks)。
### 1、在 Jupyter 中打开一个新的笔记本
首先在 Web 浏览器中打开并运行 Jupyter。然后,
1. 转到左上角的 “File”。
2. 选择 “New Notebook”,点击 “Python 3”。

开始时,新建的笔记本是无标题的,你可以将其重命名为任何名称。我为我的笔记本取名为 “[OpenSource.com](http://OpenSource.com) Data Dictionary Tutorial”。
笔记本中标有行号的位置就是你写代码的区域,也是你输入的位置。
在 macOS 上,可以同时按 `Shift + Return` 键得到输出。在创建新的代码区域前,请确保完成上述动作;否则,你写的任何附加代码可能无法运行。
### 2、新建一个键值对
在字典中输入你希望访问的键与值。输入前,你需要在字典上下文中定义它们的含义:
```
empty_dictionary = {}
grades = {
"Kelsey": 87,
"Finley": 92
}
one_line = {a: 1, b: 2}
```

这段代码让字典将特定键与其各自的值关联起来。字典按名称存储数据,从而可以更快地查询。
### 3、通过键访问字典值
现在你想查询指定的字典值;在上述例子中,字典值指特定学生的成绩。首先,点击 “Insert” 后选择 “Insert Cell Below”。

在新单元格中,定义字典中的键与值。
然后,告诉字典打印该值的键,找到需要的值。例如,查询名为 Kelsey 的学生的成绩:
```
# 访问字典中的数据
grades = {
"Kelsey": 87,
"Finley": 92
}
print(grades["Kelsey"])
87
```

当你查询 Kelsey 的成绩(也就是你想要查询的值)时,如果你用的是 macOS,只需要同时按 `Shift+Return` 键。
你会在单元格下方看到 Kelsey 的成绩。
### 4、更新已有的键
当把一位学生的错误成绩添加到字典时,你会怎么办?可以通过更新字典、存储新值来修正这类错误。
首先,选择你想更新的那个键。在上述例子中,假设你错误地输入了 Finley 的成绩,那么 Finley 就是你需要更新的键。
为了更新 Finley 的成绩,你需要在下方插入新的单元格,然后创建一个新的键值对。同时按 `Shift+Return` 键打印字典全部信息:
```
grades["Finley"] = 90
print(grades)
{'Kelsey': 87; "Finley": 90}
```

单元格下方输出带有 Finley 更新成绩的字典。
### 5、添加新键
假设你得到一位新学生的考试成绩。你可以用新键值对将那名学生的姓名与成绩补充到字典中。
插入新的单元格,以键值对形式添加新学生的姓名与成绩。当你完成这些后,同时按 `Shift+Return` 键打印字典全部信息:
```
grades["Alex"] = 88
print(grades)
{'Kelsey': 87, 'Finley': 90, 'Alex': 88}
```

所有的键值对输出在单元格下方。
### 使用字典
请记住,键与值可以是任意数据类型,但它们很少是<ruby> <a href="https://www.datacamp.com/community/tutorials/data-structures-python"> 扩展数据类型 </a> <rt> non-primitive types </rt></ruby>。此外,字典不能以指定的顺序存储、组织里面的数据。如果你想要数据有序,最好使用 Python 列表,而非字典。
如果你考虑使用字典,首先要确认你的数据结构是否是合适的,例如像电话簿的结构。如果不是,列表、元组、树或者其他数据结构可能是更好的选择。
---
via: <https://opensource.com/article/21/3/dictionary-values-python>
作者:[Lauren Maffeo](https://opensource.com/users/lmaffeo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Dictionaries are the Python programming language's way of implementing data structures. A Python dictionary consists of several key-value pairs; each pair maps the key to its associated value.
For example, say you're a teacher who wants to match students' names to their grades. You could use a Python dictionary to map the keys (names) to their associated values (grades).
If you need to find a specific student's grade on an exam, you can access it from your dictionary. This lookup shortcut should save you time over parsing an entire list to find the student's grade.
This article shows you how to access dictionary values through each value's key. Before you begin the tutorial, make sure you have the [Anaconda package manager](https://docs.anaconda.com/anaconda/) and [Jupyter Notebook](https://opensource.com/article/18/3/getting-started-jupyter-notebooks) installed on your machine.
## 1. Open a new notebook in Jupyter
Begin by opening Jupyter and running it in a tab in your web browser. Then:
- Go to
**File**in the top-left corner. - Select
**New Notebook**, then**Python 3**.
(Lauren Maffeo, CC BY-SA 4.0)
Your new notebook starts off untitled, but you can rename it anything you'd like. I named mine **OpenSource.com Data Dictionary Tutorial**.
The line number you see in your new Jupyter notebook is where you will write your code. (That is, your input.)
On macOS, you'll hit **Shift** then **Return** to receive your output. Make sure to do this before creating new line numbers; otherwise, any additional code you write might not run.
## 2. Create a key-value pair
Write the keys and values you wish to access in your dictionary. To start, you'll need to define what they are in the context of your dictionary:
```
empty_dictionary = {}
grades = {
"Kelsey": 87,
"Finley": 92
}
one_line = {a: 1, b: 2}
```

(Lauren Maffeo, CC BY-SA 4.0)
This allows the dictionary to associate specific keys with their respective values. Dictionaries store data by name, which allows faster lookup.
## 3. Access a dictionary value by its key
Say you want to find a specific dictionary value; in this case, a specific student's grade. To start, hit **Insert** then **Insert Cell Below**.
(Lauren Maffeo, CC BY-SA 4.0)
In your new cell, define the keys and values in your dictionary.
Then, find the value you need by telling your dictionary to print that value's key. For example, look for a specific student's name—Kelsey:
```
# Access data in a dictionary
grades = {
"Kelsey": 87,
"Finley": 92
}
print(grades["Kelsey"])
87
```

(Lauren Maffeo, CC BY-SA 4.0)
Once you've asked for Kelsey's grade (that is, the value you're trying to find), hit **Shift** (if you're on macOS), then **Return**.
You see your desired value—Kelsey's grade—as an output below your cell.
## 4. Update an existing key
What if you realize you added the wrong grade for a student to your dictionary? You can fix it by updating your dictionary to store an additional value.
To start, choose which key you want to update. In this case, say you entered Finley's grade incorrectly. That is the key you'll update in this example.
To update Finley's grade, insert a new cell below, then create a new key-value pair. Tell your cell to print the dictionary, then hit **Shift** and **Return**:
```
grades["Finley"] = 90
print(grades)
{'Kelsey': 87; "Finley": 90}
```

(Lauren Maffeo, CC BY-SA 4.0)
The updated dictionary, with Finley's new grade, appears as your output.
## 5. Add a new key
Say you get a new student's grade for an exam. You can add that student's name and grade to your dictionary by adding a new key-value pair.
Insert a new cell below, then add the new student's name and grade as a key-value pair. Once you're done, tell your cell to print the dictionary, then hit **Shift** and **Return**:
```
grades["Alex"] = 88
print(grades)
{'Kelsey': 87, 'Finley': 90, 'Alex': 88}
```

(Lauren Maffeo, CC BY-SA 4.0)
All key-value pairs should appear as output.
## Using dictionaries
Remember that keys and values can be any data type, but it's rare for them to be [non-primitive types](https://www.datacamp.com/community/tutorials/data-structures-python). Additionally, dictionaries don't store or structure their content in any specific order. If you need an ordered sequence of items, it's best to create a list in Python, not a dictionary.
If you're thinking of using a dictionary, first confirm if your data is structured the right way, i.e., like a phone book. If not, then using a list, tuple, tree, or other data structure might be the best option.
## 1 Comment |
13,237 | 为什么我在 Linux 上使用 exa 而不是 ls? | https://opensource.com/article/21/3/replace-ls-exa | 2021-03-26T10:17:48 | [
"exa",
"ls",
"目录"
] | https://linux.cn/article-13237-1.html |
>
> exa 是一个 Linux ls 命令的现代替代品。
>
>
>

我们生活在一个繁忙的世界里,当我们需要查找文件和数据时,使用 `ls` 命令可以节省时间和精力。但如果不经过大量调整,默认的 `ls` 输出并不十分舒心。当有一个 exa 替代方案时,为什么要花时间眯着眼睛看黑白文字呢?
[exa](https://the.exa.website/docs) 是一个常规 `ls` 命令的现代替代品,它让生活变得更轻松。这个工具是用 [Rust](https://opensource.com/tags/rust) 编写的,该语言以并行性和安全性而闻名。
### 安装 exa
要安装 `exa`,请运行:
```
$ dnf install exa
```
### 探索 exa 的功能
`exa` 改进了 `ls` 文件列表,它提供了更多的功能和更好的默认值。它使用颜色来区分文件类型和元数据。它能识别符号链接、扩展属性和 Git。而且它体积小、速度快,只有一个二进制文件。
#### 跟踪文件
你可以使用 `exa` 来跟踪某个 Git 仓库中新增的文件。

#### 树形结构
这是 `exa` 的基本树形结构。`--level` 的值决定了列表的深度,这里设置为 2。如果你想列出更多的子目录和文件,请增加 `--level` 的值。

这个树包含了每个文件的很多元数据。

#### 配色方案
默认情况下,`exa` 根据 [内置的配色方案](https://the.exa.website/features/colours) 来标识不同的文件类型。它不仅对文件和目录进行颜色编码,还对 `Cargo.toml`、`CMakeLists.txt`、`Gruntfile.coffee`、`Gruntfile.js`、`Makefile` 等多种文件类型进行颜色编码。
#### 扩展文件属性
当你使用 `exa` 探索 xattrs(扩展的文件属性)时,`--extended` 会显示所有的 xattrs。

#### 符号链接
`exa` 能识别符号链接,也能指出实际的文件。

#### 递归
当你想递归当前目录下所有目录的列表时,`exa` 能进行递归。

### 总结
我相信 `exa 是最简单、最容易适应的工具之一。它帮助我跟踪了很多 Git 和 Maven 文件。它的颜色编码让我更容易在多个子目录中进行搜索,它还能帮助我了解当前的 xattrs。
你是否已经用 `exa` 替换了 `ls`?请在评论中分享你的反馈。
---
via: <https://opensource.com/article/21/3/replace-ls-exa>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We live in a busy world and can save time and effort by using the ls command when we need to look for files and data. But without a lot of tweaking, the default ls output isn't quite soothing to the eyes. Why spend your time squinting at black and white text when you have an alternative in exa?
[Exa](https://the.exa.website/docs) is a modern-day replacement for the regular ls command, and it makes life easier. The tool is written in [Rust](https://opensource.com/tags/rust), which is known for its parallelism and safety.
## Install exa
To install exa, run:
`$ dnf install exa`
## Explore exa's features
Exa improves upon the ls file list with more features and better defaults. It uses colors to distinguish file types and metadata. It knows about symlinks, extended attributes, and Git. And it's small, fast, and has just a single binary.
### Track files
You can use exa to track a new file added in a given Git repo.
(Sudeshna Sur, CC BY-SA 4.0)
### Tree structure
This is exa's basic tree structure. The level determines the depth of the listing; this is set to two. If you want to list more subdirectories and files, increase the level's value.
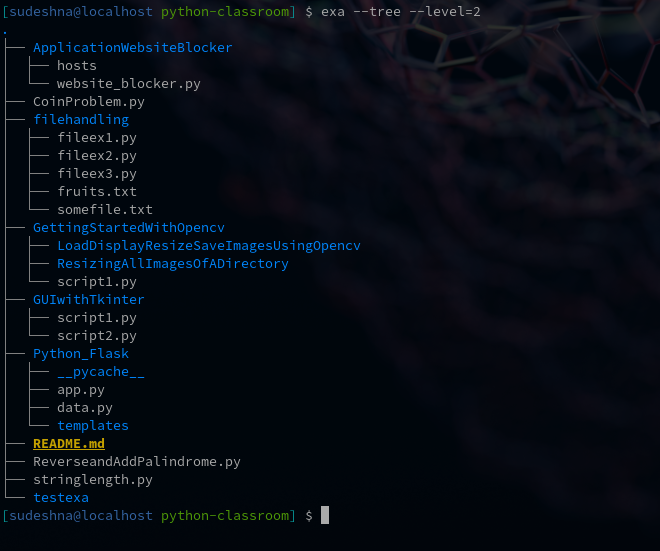
(Sudeshna Sur, CC BY-SA 4.0)
This tree includes a lot of metadata about each file.
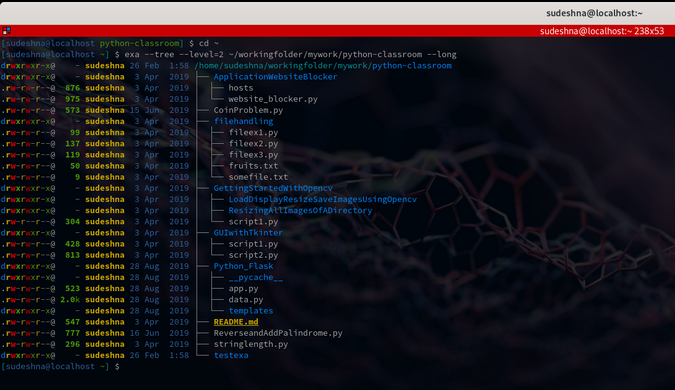
(Sudeshna Sur, CC BY-SA 4.0)
### Color schemes
By default, exa segregates different file types according to [built-in color schemes](https://the.exa.website/features/colours). It not only color-codes files and directories, but also Cargo.toml, CMakeLists.txt, Gruntfile.coffee, Gruntfile.js, Makefile, and many other file types.
### Extended file attributes
When you're exploring xattrs (extended file attributes) in exa, `--extended`
will show up in all the xattrs.

(Sudeshna Sur, CC BY-SA 4.0)
### Symlinks
Exa understands symlinks and also points out the actual file.
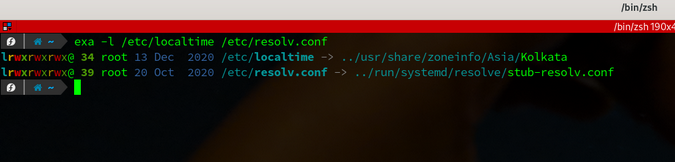
(Sudeshna Sur, CC BY-SA 4.0)
### Recurse
When you want to loop listings for all directories under the current directory, exa brings in recurse.
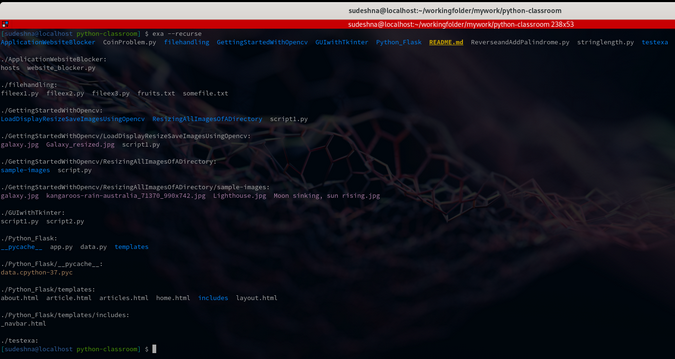
(Sudeshna Sur, CC BY-SA 4.0)
## Conclusion
I believe exa is one of the easiest, most adaptable tools. It helps me track a lot of Git and Maven files. Its color-coding makes it easier for me to search through multiple subdirectories, and it helps me to understand the current xattrs.
Have you replaced ls with exa? Please share your feedback in the comments.
## 16 Comments |
13,239 | 多云融合和安全集成推动 SD-WAN 的大规模应用 | https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html | 2021-03-27T09:52:05 | [
"SD-WAN",
"多云",
"安全"
] | https://linux.cn/article-13239-1.html |
>
> 2022 年 SD-WAN 市场 40% 的同比增长主要来自于包括 Cisco、VMWare、Juniper 和 Arista 在内的网络供应商和包括 AWS、Microsoft Azure,Google Anthos 和 IBM RedHat 在内的服务提供商之间的紧密联系。
>
>
>

越来越多的云应用,以及越来越完善的网络安全性、可视化特性和可管理性,正以惊人的速度推动企业<ruby> 软件定义广域网 <rt> software-defined WAN </rt></ruby>([SD-WAN](https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html))的部署。
IDC(LCTT 译注:International Data Corporation)公司的网络基础架构副总裁 Rohit Mehra 表示,根据 IDC 的研究,过去一年中,特别是软件和基础设施即服务(SaaS 和 IaaS)产品推动了 SD-WAN 的实施。
例如,IDC 表示,根据其最近的客户调查结果,有 95% 的客户将在两年内使用 [SD-WAN](https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html) 技术,而 42% 的客户已经部署了它。IDC 还表示,到 2022 年,SD-WAN 基础设施市场将达到 45 亿美元,此后每年将以每年 40% 的速度增长。
“SD-WAN 的增长是一个广泛的趋势,很大程度上是由企业希望优化远程站点的云连接性的需求推动的。” Mehra 说。
思科最近撰文称,多云网络的发展正在促使许多企业改组其网络,以更好地使用 SD-WAN 技术。SD-WAN 对于采用云服务的企业至关重要,它是园区网、分支机构、[物联网](https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html)、[数据中心](https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html) 和云之间的连接中间件。思科公司表示,根据调查,平均每个思科的企业客户有 30 个付费的 SaaS 应用程序,而他们实际使用的 SaaS 应用会更多——在某些情况下甚至超过 100 种。
这种趋势的部分原因是由网络供应商(例如 Cisco、VMware、Juniper、Arista 等)(LCTT 译注:这里的网络供应商指的是提供硬件或软件并可按需组网的厂商)与服务提供商(例如 Amazon AWS、Microsoft Azure、Google Anthos 和 IBM RedHat 等)建立的关系推动的。
去年 12 月,AWS 为其云产品发布了关键服务,其中包括诸如 [AWS Transit Gateway](https://aws.amazon.com/transit-gateway/) 等新集成技术的关键服务,这标志着 SD-WAN 与多云场景关系的日益重要。使用 AWS Transit Gateway 技术,客户可以将 AWS 中的 VPC(<ruby> 虚拟私有云 <rt> Virtual Private Cloud </rt></ruby>)和其自有网络均连接到相同的网关。Aruba、Aviatrix Cisco、Citrix Systems、Silver Peak 和 Versa 已经宣布支持该技术,这将简化和增强这些公司的 SD-WAN 产品与 AWS 云服务的集成服务的性能和表现。
Mehra 说,展望未来,对云应用的友好兼容和完善的性能监控等增值功能将是 SD-WAN 部署的关键部分。
随着 SD-WAN 与云的关系不断发展,SD-WAN 对集成安全功能的需求也在不断增长。
Mehra 说,SD-WAN 产品集成安全性的方式比以往单独打包的广域网安全软件或服务要好得多。SD-WAN 是一个更加敏捷的安全环境。SD-WAN 公认的主要组成部分包括安全功能,数据分析功能和广域网优化功能等,其中安全功能则是下一代 SD-WAN 解决方案的首要需求。
Mehra 说,企业将越来越少地关注仅解决某个具体问题的 SD-WAN 解决方案,而将青睐于能够解决更广泛的网络管理和安全需求的 SD-WAN 平台。他们将寻找可以与他们的 IT 基础设施(包括企业数据中心网络、企业园区局域网、[公有云](https://www.networkworld.com/article/2159885/cloud-computing-gartner-5-things-a-private-cloud-is-not.html) 资源等)集成更紧密的 SD-WAN 平台。他说,企业将寻求无缝融合的安全服务,并希望有其他各种功能的支持,例如可视化、数据分析和统一通信功能。
“随着客户不断将其基础设施与软件集成在一起,他们可以做更多的事情,例如根据其局域网和广域网上的用户、设备或应用程序的需求,实现一致的管理和安全策略,并最终获得更好的整体使用体验。” Mehra 说。
一个新兴趋势是 SD-WAN 产品包需要支持 [SD-branch](https://www.networkworld.com/article/3250664/sd-branch-what-it-is-and-why-youll-need-it.html) 技术。 Mehra 说,超过 70% 的 IDC 受调查客户希望在明年使用 SD-Branch。在最近几周,[Juniper](https://www.networkworld.com/article/3487801/juniper-broadens-sd-branch-management-switch-options.html) 和 [Aruba](https://www.networkworld.com/article/3513357/aruba-reinforces-sd-branch-with-security-management-upgrades.html) 公司已经优化了 SD-branch 产品,这一趋势预计将在今年持续下去。
SD-Branch 技术建立在 SD-WAN 的概念和支持的基础上,但更专注于满足分支机构中局域网的组网和管理需求。展望未来,SD-Branch 如何与其他技术集成,例如数据分析、音视频、统一通信等,将成为该技术的主要驱动力。
---
via: <https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html>
作者:[Michael Cooney](https://www.networkworld.com/author/Michael-Cooney/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cooljelly](https://github.com/cooljelly) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
13,240 | 在 Linux 上将你的 Windows 系统转换为虚拟机 | https://opensource.com/article/21/1/virtualbox-windows-linux | 2021-03-27T10:51:00 | [
"Linux",
"Windows",
"VirtualBox"
] | https://linux.cn/article-13240-1.html |
>
> 下面是我如何配置 VirtualBox 虚拟机以在我的 Linux 工作站上使用物理的 Windows 操作系统。
>
>
>

我经常使用 VirtualBox 来创建虚拟机来测试新版本的 Fedora、新的应用程序和很多管理工具,比如 Ansible。我甚至使用 VirtualBox 来测试创建一个 Windows 访客主机。
我从来没有在我的任何一台个人电脑上使用 Windows 作为我的主要操作系统,甚至也没在虚拟机中执行过一些用 Linux 无法完成的冷门任务。不过,我确实为一个需要使用 Windows 下的财务程序的组织做志愿者。这个程序运行在办公室经理的电脑上,使用的是预装的 Windows 10 Pro。
这个财务应用程序并不特别,[一个更好的 Linux 程序](https://opensource.com/article/20/7/godbledger) 可以很容易地取代它,但我发现许多会计和财务主管极不愿意做出改变,所以我还没能说服我们组织中的人迁移。
这一系列的情况,加上最近的安全恐慌,使得我非常希望将运行 Windows 的主机转换为 Fedora,并在该主机上的虚拟机中运行 Windows 和会计程序。
重要的是要明白,我出于多种原因极度不喜欢 Windows。主要原因是,我不愿意为了在新的虚拟机上安装它而再花钱购买一个 Windows 许可证(Windows 10 Pro 大约需要 200 美元)。此外,Windows 10 在新系统上设置时或安装后需要足够的信息,如果微软的数据库被攻破,破解者就可以窃取一个人的身份。任何人都不应该为了注册软件而需要提供自己的姓名、电话号码和出生日期。
### 开始
这台实体电脑已经在主板上唯一可用的 m.2 插槽中安装了一个 240GB 的 NVMe m.2 的 SSD 存储设备。我决定在主机上安装一个新的 SATA SSD,并将现有的带有 Windows 的 SSD 作为 Windows 虚拟机的存储设备。金士顿在其网站上对各种 SSD 设备、外形尺寸和接口做了很好的概述。
这种方法意味着我不需要重新安装 Windows 或任何现有的应用软件。这也意味着,在这台电脑上工作的办公室经理将使用 Linux 进行所有正常的活动,如电子邮件、访问 Web、使用 LibreOffice 创建文档和电子表格。这种方法增加了主机的安全性。唯一会使用 Windows 虚拟机的时间是运行会计程序。
### 先备份
在做其他事情之前,我创建了整个 NVMe 存储设备的备份 ISO 镜像。我在 500GB 外置 USB 存储盘上创建了一个分区,在其上创建了一个 ext4 文件系统,然后将该分区挂载到 `/mnt`。我使用 `dd` 命令来创建镜像。
我在主机中安装了新的 500GB SATA SSD,并从<ruby> 临场 <rt> live </rt></ruby> USB 上安装了 Fedora 32 Xfce <ruby> 偏好版 <rt> spin </rt></ruby>。在安装后的初次重启时,在 GRUB2 引导菜单上,Linux 和 Windows 操作系统都是可用的。此时,主机可以在 Linux 和 Windows 之间进行双启动。
### 在网上寻找帮助
现在我需要一些关于创建一个使用物理硬盘或 SSD 作为其存储设备的虚拟机的信息。我很快就在 VirtualBox 文档和互联网上发现了很多关于如何做到这一点的信息。虽然 VirtualBox 文档初步帮助了我,但它并不完整,遗漏了一些关键信息。我在互联网上找到的大多数其他信息也很不完整。
在我们的记者 Joshua Holm 的帮助下,我得以突破这些残缺的信息,并以一个可重复的流程来完成这项工作。
### 让它发挥作用
这个过程其实相当简单,虽然需要一个玄妙的技巧才能实现。当我准备好这一步的时候,Windows 和 Linux 操作系统已经到位了。
首先,我在 Linux 主机上安装了最新版本的 VirtualBox。VirtualBox 可以从许多发行版的软件仓库中安装,也可以直接从 Oracle VirtualBox 仓库中安装,或者从 VirtualBox 网站上下载所需的包文件并在本地安装。我选择下载 AMD64 版本,它实际上是一个安装程序而不是一个软件包。我使用这个版本来规避一个与这个特定项目无关的问题。
安装过程总是在 `/etc/group` 中创建一个 `vboxusers` 组。我把打算运行这个虚拟机的用户添加到 `/etc/group` 中的 `vboxusers` 和 `disk` 组。将相同的用户添加到 `disk` 组是很重要的,因为 VirtualBox 是以启动它的用户身份运行的,而且还需要直接访问 `/dev/sdx` 特殊设备文件才能在这种情况下工作。将用户添加到 `disk` 组可以提供这种级别的访问权限,否则他们就不会有这种权限。
然后,我创建了一个目录来存储虚拟机,并赋予它 `root.vboxusers` 的所有权和 `775` 的权限。我使用 `/vms` 用作该目录,但可以是任何你想要的目录。默认情况下,VirtualBox 会在创建虚拟机的用户的子目录中创建新的虚拟机。这将使多个用户之间无法共享对虚拟机的访问,从而不会产生巨大的安全漏洞。将虚拟机目录放置在一个可访问的位置,可以共享虚拟机。
我以非 root 用户的身份启动 VirtualBox 管理器。然后,我使用 VirtualBox 的“<ruby> 偏好 <rt> Preferences </rt></ruby> => <ruby> 一般 <rt> General </rt></ruby>”菜单将“<ruby> 默认机器文件夹 <rt> Default Machine Folder </rt></ruby>”设置为 `/vms` 目录。
我创建的虚拟机没有虚拟磁盘。“<ruby> 类型 <rt> Type </rt> <rt> </rt></ruby>” 应该是 `Windows`,“<ruby> 版本 <rt> Version </rt></ruby>”应该设置为 `Windows 10 64-bit`。为虚拟机设置一个合理的内存量,但只要虚拟机处于关闭状态,以后可以更改。在安装的“<ruby> 硬盘 <rt> Hard disk </rt></ruby>”页面,我选择了 “<ruby> 不要添加虚拟硬盘 <rt> Do not add a virtual hard disk </rt></ruby>”,点击“<ruby> 创建 <rt> Create </rt></ruby>”。新的虚拟机出现在VirtualBox 管理器窗口中。这个过程也创建了 `/vms/Test1` 目录。
我使用“<ruby> 高级 <rt> Advanced </rt></ruby>”菜单在一个页面上设置了所有的配置,如图 1 所示。“<ruby> 向导模式 <rt> Guided Mode </rt></ruby>”可以获得相同的信息,但需要更多的点击,以通过一个窗口来进行每个配置项目。它确实提供了更多的帮助内容,但我并不需要。

*图 1:创建一个新的虚拟机,但不要添加硬盘。*
然后,我需要知道 Linux 给原始 Windows 硬盘分配了哪个设备。在终端会话中以 root 身份使用 `lshw` 命令来发现 Windows 磁盘的设备分配情况。在本例中,代表整个存储设备的设备是 `/dev/sdb`。
```
# lshw -short -class disk,volume
H/W path Device Class Description
=========================================================
/0/100/17/0 /dev/sda disk 500GB CT500MX500SSD1
/0/100/17/0/1 volume 2047MiB Windows FAT volume
/0/100/17/0/2 /dev/sda2 volume 4GiB EXT4 volume
/0/100/17/0/3 /dev/sda3 volume 459GiB LVM Physical Volume
/0/100/17/1 /dev/cdrom disk DVD+-RW DU-8A5LH
/0/100/17/0.0.0 /dev/sdb disk 256GB TOSHIBA KSG60ZMV
/0/100/17/0.0.0/1 /dev/sdb1 volume 649MiB Windows FAT volume
/0/100/17/0.0.0/2 /dev/sdb2 volume 127MiB reserved partition
/0/100/17/0.0.0/3 /dev/sdb3 volume 236GiB Windows NTFS volume
/0/100/17/0.0.0/4 /dev/sdb4 volume 989MiB Windows NTFS volume
[root@office1 etc]#
```
VirtualBox 不需要把虚拟存储设备放在 `/vms/Test1` 目录中,而是需要有一种方法来识别要从其启动的物理硬盘。这种识别是通过创建一个 `*.vmdk` 文件来实现的,该文件指向将作为虚拟机存储设备的原始物理磁盘。作为非 root 用户,我创建了一个 vmdk 文件,指向整个 Windows 设备 `/dev/sdb`。
```
$ VBoxManage internalcommands createrawvmdk -filename /vms/Test1/Test1.vmdk -rawdisk /dev/sdb
RAW host disk access VMDK file /vms/Test1/Test1.vmdk created successfully.
```
然后,我使用 VirtualBox 管理器 “<ruby> 文件 <rt> File </rt></ruby> => <ruby> 虚拟介质管理器 <rt> Virtual Media Manager </rt></ruby>” 对话框将 vmdk 磁盘添加到可用硬盘中。我点击了“<ruby> 添加 <rt> Add </rt></ruby>”,文件管理对话框中显示了默认的 `/vms` 位置。我选择了 `Test1` 目录,然后选择了 `Test1.vmdk` 文件。然后我点击“<ruby> 打开 <rt> Open </rt></ruby>”,`Test1.vmdk` 文件就显示在可用硬盘列表中。我选择了它,然后点击“<ruby> 关闭 <rt> Close </rt></ruby>”。
下一步就是将这个 vmdk 磁盘添加到我们的虚拟机的存储设备中。在 “Test1 VM” 的设置菜单中,我选择了 “<ruby> 存储 <rt> Storage </rt></ruby>”,并点击了添加硬盘的图标。这时打开了一个对话框,在一个名为“<ruby> 未连接 <rt> Not attached </rt></ruby>”的列表中显示了 `Test1vmdk` 虚拟磁盘文件。我选择了这个文件,并点击了“<ruby> 选择 <rt> Choose </rt></ruby>”按钮。这个设备现在显示在连接到 “Test1 VM” 的存储设备列表中。这个虚拟机上唯一的其他存储设备是一个空的 CD/DVD-ROM 驱动器。
我点击了“<ruby> 确定 <rt> OK </rt></ruby>”,完成了将此设备添加到虚拟机中。
在新的虚拟机工作之前,还有一个项目需要配置。使用 VirtualBox 管理器设置对话框中的 “Test1 VM”,我导航到 “<ruby> 系统 <rt> System </rt></ruby> => <ruby> 主板 <rt> Motherboard </rt></ruby>”页面,并在 “<ruby> 启用 EFI <rt> Enable EFI </rt></ruby>”的方框中打上勾。如果你不这样做,当你试图启动这个虚拟机时,VirtualBox 会产生一个错误,说明它无法找到一个可启动的介质。
现在,虚拟机从原始的 Windows 10 硬盘驱动器启动。然而,我无法登录,因为我在这个系统上没有一个常规账户,而且我也无法获得 Windows 管理员账户的密码。
### 解锁驱动器
不,本节并不是要破解硬盘的加密,而是要绕过众多 Windows 管理员账户之一的密码,而这些账户是不属于组织中某个人的。
尽管我可以启动 Windows 虚拟机,但我无法登录,因为我在该主机上没有账户,而向人们索要密码是一种可怕的安全漏洞。尽管如此,我还是需要登录这个虚拟机来安装 “VirtualBox Guest Additions”,它可以提供鼠标指针的无缝捕捉和释放,允许我将虚拟机调整到大于 1024x768 的大小,并在未来进行正常的维护。
这是一个完美的用例,Linux 的功能就是更改用户密码。尽管我是访问之前的管理员的账户来启动,但在这种情况下,他不再支持这个系统,我也无法辨别他的密码或他用来生成密码的模式。我就直接清除了上一个系统管理员的密码。
有一个非常不错的开源软件工具,专门用于这个任务。在 Linux 主机上,我安装了 `chntpw`,它的意思大概是:“更改 NT 的密码”。
```
# dnf -y install chntpw
```
我关闭了虚拟机的电源,然后将 `/dev/sdb3` 分区挂载到 `/mnt` 上。我确定 `/dev/sdb3` 是正确的分区,因为它是我在之前执行 `lshw` 命令的输出中看到的第一个大的 NTFS 分区。一定不要在虚拟机运行时挂载该分区,那样会导致虚拟机存储设备上的数据严重损坏。请注意,在其他主机上分区可能有所不同。
导航到 `/mnt/Windows/System32/config` 目录。如果当前工作目录(PWD)不在这里,`chntpw` 实用程序就无法工作。请启动该程序。
```
# chntpw -i SAM
chntpw version 1.00 140201, (c) Petter N Hagen
Hive <SAM> name (from header): <\SystemRoot\System32\Config\SAM>
ROOT KEY at offset: 0x001020 * Subkey indexing type is: 686c <lh>
File size 131072 [20000] bytes, containing 11 pages (+ 1 headerpage)
Used for data: 367/44720 blocks/bytes, unused: 14/24560 blocks/bytes.
<>========<> chntpw Main Interactive Menu <>========<>
Loaded hives: <SAM>
1 - Edit user data and passwords
2 - List groups
- - -
9 - Registry editor, now with full write support!
q - Quit (you will be asked if there is something to save)
What to do? [1] ->
```
`chntpw` 命令使用 TUI(文本用户界面),它提供了一套菜单选项。当选择其中一个主要菜单项时,通常会显示一个次要菜单。按照明确的菜单名称,我首先选择了菜单项 `1`。
```
What to do? [1] -> 1
===== chntpw Edit User Info & Passwords ====
| RID -|---------- Username ------------| Admin? |- Lock? --|
| 01f4 | Administrator | ADMIN | dis/lock |
| 03eb | john | ADMIN | dis/lock |
| 01f7 | DefaultAccount | | dis/lock |
| 01f5 | Guest | | dis/lock |
| 01f8 | WDAGUtilityAccount | | dis/lock |
Please enter user number (RID) or 0 to exit: [3e9]
```
接下来,我选择了我们的管理账户 `john`,在提示下输入 RID。这将显示用户的信息,并提供额外的菜单项来管理账户。
```
Please enter user number (RID) or 0 to exit: [3e9] 03eb
================= USER EDIT ====================
RID : 1003 [03eb]
Username: john
fullname:
comment :
homedir :
00000221 = Users (which has 4 members)
00000220 = Administrators (which has 5 members)
Account bits: 0x0214 =
[ ] Disabled | [ ] Homedir req. | [ ] Passwd not req. |
[ ] Temp. duplicate | [X] Normal account | [ ] NMS account |
[ ] Domain trust ac | [ ] Wks trust act. | [ ] Srv trust act |
[X] Pwd don't expir | [ ] Auto lockout | [ ] (unknown 0x08) |
[ ] (unknown 0x10) | [ ] (unknown 0x20) | [ ] (unknown 0x40) |
Failed login count: 0, while max tries is: 0
Total login count: 47
- - - - User Edit Menu:
1 - Clear (blank) user password
2 - Unlock and enable user account [probably locked now]
3 - Promote user (make user an administrator)
4 - Add user to a group
5 - Remove user from a group
q - Quit editing user, back to user select
Select: [q] > 2
```
这时,我选择了菜单项 `2`,“<ruby> 解锁并启用用户账户 <rt> Unlock and enable user account </rt></ruby>”,这样就可以删除密码,使我可以不用密码登录。顺便说一下 —— 这就是自动登录。然后我退出了该程序。在继续之前,一定要先卸载 `/mnt`。
我知道,我知道,但为什么不呢! 我已经绕过了这个硬盘和主机的安全问题,所以一点也不重要。这时,我确实登录了旧的管理账户,并为自己创建了一个新的账户,并设置了安全密码。然后,我以自己的身份登录,并删除了旧的管理账户,这样别人就无法使用了。
网上也有 Windows Administrator 账号的使用说明(上面列表中的 `01f4`)。如果它不是作为组织管理账户,我可以删除或更改该账户的密码。还要注意的是,这个过程也可以从目标主机上运行临场 USB 来执行。
### 重新激活 Windows
因此,我现在让 Windows SSD 作为虚拟机在我的 Fedora 主机上运行了。然而,令人沮丧的是,在运行了几个小时后,Windows 显示了一条警告信息,表明我需要“激活 Windows”。
在看了许许多多的死胡同网页之后,我终于放弃了使用现有激活码重新激活的尝试,因为它似乎已经以某种方式被破坏了。最后,当我试图进入其中一个在线虚拟支持聊天会话时,虚拟的“获取帮助”应用程序显示我的 Windows 10 Pro 实例已经被激活。这怎么可能呢?它一直希望我激活它,然而当我尝试时,它说它已经被激活了。
### 或者不
当我在三天内花了好几个小时做研究和实验时,我决定回到原来的 SSD 启动到 Windows 中,以后再来处理这个问题。但后来 Windows —— 即使从原存储设备启动,也要求重新激活。
在微软支持网站上搜索也无济于事。在不得不与之前一样的自动支持大费周章之后,我拨打了提供的电话号码,却被自动响应系统告知,所有对 Windows 10 Pro 的支持都只能通过互联网提供。到现在,我已经晚了将近一天才让电脑运行起来并安装回办公室。
### 回到未来
我终于吸了一口气,购买了一份 Windows 10 Home,大约 120 美元,并创建了一个带有虚拟存储设备的虚拟机,将其安装在上面。
我将大量的文档和电子表格文件复制到办公室经理的主目录中。我重新安装了一个我们需要的 Windows 程序,并与办公室经理验证了它可以工作,数据都在那里。
### 总结
因此,我的目标达到了,实际上晚了一天,花了 120 美元,但使用了一种更标准的方法。我仍在对权限进行一些调整,并恢复 Thunderbird 通讯录;我有一些 CSV 备份,但 `*.mab` 文件在 Windows 驱动器上包含的信息很少。我甚至用 Linux 的 `find` 命令来定位原始存储设备上的所有。
我走了很多弯路,每次都要自己重新开始。我遇到了一些与这个项目没有直接关系的问题,但却影响了我的工作。这些问题包括一些有趣的事情,比如把 Windows 分区挂载到我的 Linux 机器的 `/mnt` 上,得到的信息是该分区已经被 Windows 不正确地关闭(是的,在我的 Linux 主机上),并且它已经修复了不一致的地方。即使是 Windows 通过其所谓的“恢复”模式多次重启后也做不到这一点。
也许你从 `chntpw` 工具的输出数据中发现了一些线索。出于安全考虑,我删掉了主机上显示的其他一些用户账号,但我从这些信息中看到,所有的用户都是管理员。不用说,我也改了。我仍然对我遇到的糟糕的管理方式感到惊讶,但我想我不应该这样。
最后,我被迫购买了一个许可证,但这个许可证至少比原来的要便宜一些。我知道的一点是,一旦我找到了所有必要的信息,Linux 这一块就能完美地工作。问题是处理 Windows 激活的问题。你们中的一些人可能已经成功地让 Windows 重新激活了。如果是这样,我还是想知道你们是怎么做到的,所以请把你们的经验添加到评论中。
这是我不喜欢 Windows,只在自己的系统上使用 Linux 的又一个原因。这也是我将组织中所有的计算机都转换为 Linux 的原因之一。只是需要时间和说服力。我们只剩下这一个会计程序了,我需要和财务主管一起找到一个适合她的程序。我明白这一点 —— 我喜欢自己的工具,我需要它们以一种最适合我的方式工作。
---
via: <https://opensource.com/article/21/1/virtualbox-windows-linux>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I use VirtualBox frequently to create virtual machines for testing new versions of Fedora, new application programs, and lots of administrative tools like Ansible. I have even used VirtualBox to test the creation of a Windows guest host.
Never have I ever used Windows as my primary operating system on any of my personal computers or even in a VM to perform some obscure task that cannot be done with Linux. I do, however, volunteer for an organization that uses one financial program that requires Windows. This program runs on the office manager's computer on Windows 10 Pro, which came preinstalled.
This financial application is not special, and [a better Linux program](https://opensource.com/article/20/7/godbledger) could easily replace it, but I've found that many accountants and treasurers are extremely reluctant to make changes, so I've not yet been able to convince those in our organization to migrate.
This set of circumstances, along with a recent security scare, made it highly desirable to convert the host running Windows to Fedora and to run Windows and the accounting program in a VM on that host.
It is important to understand that I have an extreme dislike for Windows for multiple reasons. The primary ones that apply to this case are that I would hate to pay for another Windows license – Windows 10 Pro costs about $200 – to install it on a new VM. Also, Windows 10 requires enough information when setting it up on a new system or after an installation to enable crackers to steal one's identity, should the Microsoft database be breached. No one should need to provide their name, phone number, and birth date in order to register software.
## Getting started
The physical computer already had a 240GB NVMe m.2 storage device installed in the only available m.2 slot on the motherboard. I decided to install a new SATA SSD in the host and use the existing SSD with Windows on it as the storage device for the Windows VM. Kingston has an excellent overview of various SSD devices, form factors, and interfaces on its web site.
That approach meant that I wouldn't need to do a completely new installation of Windows or any of the existing application software. It also meant that the office manager who works at this computer would use Linux for all normal activities such as email, web access, document and spreadsheet creation with LibreOffice. This approach increases the host's security profile. The only time that the Windows VM would be used is to run the accounting program.
## Back it up first
Before I did anything else, I created a backup ISO image of the entire NVMe storage device. I made a partition on a 500GB external USB storage drive, created an ext4 filesystem on it, and then mounted that partition on **/mnt**. I used the **dd** command to create the image.
I installed the new 500GB SATA SSD in the host and installed the Fedora 32 Xfce spin on it from a Live USB. At the initial reboot after installation, both the Linux and Windows drives were available on the GRUB2 boot menu. At this point, the host could be dual-booted between Linux and Windows.
## Looking for help in all the internet places
Now I needed some information on creating a VM that uses a physical hard drive or SSD as its storage device. I quickly discovered a lot of information about how to do this in the VirtualBox documentation and the internet in general. Although the VirtualBox documentation helped me to get started, it is not complete, leaving out some critical information. Most of the other information I found on the internet is also quite incomplete.
With some critical help from one of our Opensource.com Correspondents, Joshua Holm, I was able to break through the cruft and make this work in a repeatable procedure.
## Making it work
This procedure is actually fairly simple, although one arcane hack is required to make it work. The Windows and Linux operating systems were already in place by the time I was ready for this step.
First, I installed the most recent version of VirtualBox on the Linux host. VirtualBox can be installed from many distributions' software repositories, directly from the Oracle VirtualBox repository, or by downloading the desired package file from the VirtualBox web site and installing locally. I chose to download the AMD64 version, which is actually an installer and not a package. I use this version to circumvent a problem that is not related to this particular project.
The installation procedure always creates a **vboxusers** group in **/etc/group**. I added the users intended to run this VM to the **vboxusers** and **disk** groups in **/etc/group**. It is important to add the same users to the **disk** group because VirtualBox runs as the user who launched it and also requires direct access to the** /dev/sdx** device special file to work in this scenario. Adding users to the **disk** group provides that level of access, which they would not otherwise have.
I then created a directory to store the VMs and gave it ownership of **root.vboxusers** and **775** permissions. I used **/vms** for the directory, but it could be anything you want. By default, VirtualBox creates new virtual machines in a subdirectory of the user creating the VM. That would make it impossible to share access to the VM among multiple users without creating a massive security vulnerability. Placing the VM directory in an accessible location allows sharing the VMs.
I started the VirtualBox Manager as a non-root user. I then used the VirtualBox **Preferences ==> General** menu to set the Default Machine Folder to the directory **/vms**.
I created the VM without a virtual disk. The **Type** should be **Windows**, and the **Version** should be set to **Windows 10 64-bit**. Set a reasonable amount of RAM for the VM, but this can be changed later so long as the VM is off. On the **Hard disk** page of the installation, I chose the "Do not add a virtual hard disk" and clicked on **Create**. The new VM appeared in the VirtualBox Manager window. This procedure also created the **/vms/Test1** directory.
I did this using the **Advanced** menu and performed all of the configurations on a single page, as seen in Figure 1. The **Guided Mode** obtains the same information but requires more clicks to go through a window for each configuration item. It does provide a little more in the way of help text, but I did not need that.
opensource.com
Figure 1: Create a new virtual machine but do not add a hard disk.
Then I needed to know which device was assigned by Linux to the raw Windows drive. As root in a terminal session, use the **lshw** command to discover the device assignment for the Windows disk. In this case, the device that represents the entire storage device is **/dev/sdb**.
```
# lshw -short -class disk,volume
H/W path Device Class Description
=========================================================
/0/100/17/0 /dev/sda disk 500GB CT500MX500SSD1
/0/100/17/0/1 volume 2047MiB Windows FAT volume
/0/100/17/0/2 /dev/sda2 volume 4GiB EXT4 volume
/0/100/17/0/3 /dev/sda3 volume 459GiB LVM Physical Volume
/0/100/17/1 /dev/cdrom disk DVD+-RW DU-8A5LH
/0/100/17/0.0.0 /dev/sdb disk 256GB TOSHIBA KSG60ZMV
/0/100/17/0.0.0/1 /dev/sdb1 volume 649MiB Windows FAT volume
/0/100/17/0.0.0/2 /dev/sdb2 volume 127MiB reserved partition
/0/100/17/0.0.0/3 /dev/sdb3 volume 236GiB Windows NTFS volume
/0/100/17/0.0.0/4 /dev/sdb4 volume 989MiB Windows NTFS volume
[root@office1 etc]#
```
Instead of a virtual storage device located in the **/vms/Test1** directory, VirtualBox needs to have a way to identify the physical hard drive from which it is to boot. This identification is accomplished by creating a ***.vmdk** file, which points to the raw physical disk that will be used as the storage device for the VM. As a non-root user, I created a **vmdk** file that points to the entire Windows device, **/dev/sdb**.
```
$ VBoxManage internalcommands createrawvmdk -filename /vms/Test1/Test1.vmdk -rawdisk /dev/sdb
RAW host disk access VMDK file /vms/Test1/Test1.vmdk created successfully.
```
I then used the **VirtualBox Manager File ==> Virtual Media Manager** dialog to add the **vmdk** disk to the available hard disks. I clicked on **Add**, and the default **/vms** location was displayed in the file management dialog. I selected the **Test1** directory and then the **Test1.vmdk** file. I then clicked **Open**, and the **Test1.vmdk** file was displayed in the list of available hard drives. I selected it and clicked on **Close**.
The next step was to add this **vmdk** disk to the storage devices for our VM. In the settings menu for the **Test1 VM**, I selected **Storage** and clicked on the icon to add a hard disk. This opened a dialog that showed the **Test1vmdk** virtual disk file in a list entitled **Not attached.** I selected this file and clicked on the **Choose** button. This device is now displayed in the list of storage devices connected to the **Test1 VM**. The only other storage device on this VM is an empty CD/DVD-ROM drive.
I clicked on **OK** to complete the addition of this device to the VM.
There was one more item to configure before the new VM would work. Using the **VirtualBox Manager Settings** dialog for the **Test1 VM**, I navigated to the **System ==> Motherboard** page and placed a check in the box for **Enable EFI**. If you do not do this, VirtualBox will generate an error stating that it cannot find a bootable medium when you attempt to boot this VM.
The virtual machine now boots from the raw Windows 10 hard drive. However, I could not log in because I did not have a regular account on this system, and I also did not have access to the password for the Windows administrator account.
## Unlocking the drive
No, this section is not about breaking the encryption of the hard drive. Rather, it is about bypassing the password for one of the many Windows administrator accounts, which no one at the organization had.
Even though I could boot the Windows VM, I could not log in because I had no account on that host and asking people for their passwords is a horrible security breach. Nevertheless, I needed to log in to the VM to install the **VirtualBox Guest Additions**, which would provide seamless capture and release of the mouse pointer, allow me to resize the VM to be larger than 1024x768, and perform normal maintenance in the future.
This is a perfect use case for the Linux capability to change user passwords. Even though I am accessing the previous administrator's account to start, in this case, he will no longer support this system, and I won't be able to discern his password or the patterns he uses to generate them. I will simply clear the password for the previous sysadmin.
There is a very nice open source software tool specifically for this task. On the Linux host, I installed **chntpw**, which probably stands for something like, "Change NT PassWord."
`# dnf -y install chntpw`
I powered off the VM and then mounted the **/dev/sdb3** partition on** /mnt**. I determined that **/dev/sdb3** is the correct partition because it is the first large NTFS partition I saw in the output from the **lshw** command I performed previously. Be sure not to mount the partition while the VM is running; that could cause significant corruption of the data on the VM storage device. Note that the correct partition might be different on other hosts.
Navigate to the **/mnt/Windows/System32/config** directory. The **chntpw** utility program does not work if that is not the present working directory (PWD). Start the program.
```
# chntpw -i SAM
chntpw version 1.00 140201, (c) Petter N Hagen
Hive <SAM> name (from header): <\SystemRoot\System32\Config\SAM>
ROOT KEY at offset: 0x001020 * Subkey indexing type is: 686c <lh>
File size 131072 [20000] bytes, containing 11 pages (+ 1 headerpage)
Used for data: 367/44720 blocks/bytes, unused: 14/24560 blocks/bytes.
<>========<> chntpw Main Interactive Menu <>========<>
Loaded hives: <SAM>
1 - Edit user data and passwords
2 - List groups
- - -
9 - Registry editor, now with full write support!
q - Quit (you will be asked if there is something to save)
What to do? [1] ->
```
The **chntpw** command uses a TUI (Text User Interface), which provides a set of menu options. When one of the primary menu items is chosen, a secondary menu is usually displayed. Following the clear menu names, I first chose menu item **1**.
```
What to do? [1] -> 1
===== chntpw Edit User Info & Passwords ====
| RID -|---------- Username ------------| Admin? |- Lock? --|
| 01f4 | Administrator | ADMIN | dis/lock |
| 03ec | john | ADMIN | dis/lock |
| 01f7 | DefaultAccount | | dis/lock |
| 01f5 | Guest | | dis/lock |
| 01f8 | WDAGUtilityAccount | | dis/lock |
Please enter user number (RID) or 0 to exit: [3e9]
```
Next, I selected our admin account, **john**, by typing the RID at the prompt. This displays information about the user and offers additional menu items to manage the account.
```
Please enter user number (RID) or 0 to exit: [3e9] 03eb
================= USER EDIT ====================
RID : 1003 [03eb]
Username: john
fullname:
comment :
homedir :
00000221 = Users (which has 4 members)
00000220 = Administrators (which has 5 members)
Account bits: 0x0214 =
[ ] Disabled | [ ] Homedir req. | [ ] Passwd not req. |
[ ] Temp. duplicate | [X] Normal account | [ ] NMS account |
[ ] Domain trust ac | [ ] Wks trust act. | [ ] Srv trust act |
[X] Pwd don't expir | [ ] Auto lockout | [ ] (unknown 0x08) |
[ ] (unknown 0x10) | [ ] (unknown 0x20) | [ ] (unknown 0x40) |
Failed login count: 0, while max tries is: 0
Total login count: 47
- - - - User Edit Menu:
1 - Clear (blank) user password
2 - Unlock and enable user account [probably locked now]
3 - Promote user (make user an administrator)
4 - Add user to a group
5 - Remove user from a group
q - Quit editing user, back to user select
Select: [q] > 2
```
At this point, I chose menu item **2**, "Unlock and enable user account," which deletes the password and enables me to log in without a password. By the way – this is an automatic login. I then exited the program. Be sure to unmount **/mnt** before proceeding.
I know, I know, but why not! I have already bypassed security on this drive and host, so it matters not one iota. At this point, I did log in to the old administrative account and created a new account for myself with a secure password. I then logged in as myself and deleted the old admin account so that no one else could use it.
There are also instructions on the internet for using the Windows Administrator account (01f4 in the list above). I could have deleted or changed the password on that account had there not been an organizational admin account in place. Note also that this procedure can be performed from a live USB running on the target host.
## Reactivating Windows
So I now had the Windows SSD running as a VM on my Fedora host. However, in a frustrating turn of events, after running for a few hours, Windows displayed a warning message indicating that I needed to "Activate Windows."
After following many more dead-end web pages, I finally gave up on trying to reactivate using an existing code because it appeared to have been somehow destroyed. Finally, when attempting to follow one of the on-line virtual support chat sessions, the virtual "Get help" application indicated that my instance of Windows 10 Pro was already activated. How can this be the case? It kept wanting me to activate it, yet when I tried, it said it was already activated.
## Or not
By the time I had spent several hours over three days doing research and experimentation, I decided to go back to booting the original SSD into Windows and come back to this at a later date. But then Windows – even when booted from the original storage device – demanded to be reactivated.
Searching the Microsoft support site was unhelpful. After having to fuss with the same automated support as before, I called the phone number provided only to be told by an automated response system that all support for Windows 10 Pro was only provided by internet. By now, I was nearly a day late in getting the computer running and installed back at the office.
## Back to the future
I finally sucked it up, purchased a copy of Windows 10 Home – for about $120 – and created a VM with a virtual storage device on which to install it.
I copied a large number of document and spreadsheet files to the office manager's home directory. I reinstalled the one Windows program we need and verified with the office manager that it worked and the data was all there.
## Final thoughts
So my objective was met, literally a day late and about $120 short, but using a more standard approach. I am still making a few adjustments to permissions and restoring the Thunderbird address book; I have some CSV backups to work from, but the ***.mab** files contain very little information on the Windows drive. I even used the Linux **find** command to locate all the ones on the original storage device.
I went down a number of rabbit holes and had to extract myself and start over each time. I ran into problems that were not directly related to this project, but that affected my work on it. Those problems included interesting things like mounting the Windows partition on **/mnt** on my Linux box and getting a message that the partition had been improperly closed by Windows (yes – on my Linux host) and that it had fixed the inconsistency. Not even Windows could do that after multiple reboots through its so-called "recovery" mode.
Perhaps you noticed some clues in the output data from the **chntpw** utility. I cut out some of the other user accounts that were displayed on my host for security reasons, but I saw from that information that all of the users were admins. Needless to say, I changed that. I am still surprised by the poor administrative practices I encounter, but I guess I should not be.
In the end, I was forced to purchase a license, but one that was at least a bit less expensive than the original. One thing I know is that the Linux piece of this worked perfectly once I had found all the necessary information. The issue was dealing with Windows activation. Some of you may have been successful at getting Windows reactivated. If so, I would still like to know how you did it, so please add your experience to the comments.
This is yet another reason I dislike Windows and only ever use Linux on my own systems. It is also one of the reasons I am converting all of the organization's computers to Linux. It just takes time and convincing. We only have this one accounting program left, and I need to work with the treasurer to find one that works for her. I understand this – I like my own tools, and I need them to work in a way that is best for me.
## 11 Comments |
13,242 | 如何使用 Python 来自动交易加密货币 | https://opensource.com/article/20/4/python-crypto-trading-bot | 2021-03-28T09:40:48 | [
"加密货币",
"自动交易",
"Python"
] | /article-13242-1.html |
>
> 在本教程中,教你如何设置和使用 Pythonic 来编程。它是一个图形化编程工具,用户可以很容易地使用现成的函数模块创建 Python 程序。
>
>
>

然而,不像纽约证券交易所这样的传统证券交易所一样,有一段固定的交易时间。对于加密货币而言,则是 7×24 小时交易,这使得任何人都无法独自盯着市场。
在以前,我经常思考与加密货币交易相关的问题:
* 一夜之间发生了什么?
* 为什么没有日志记录?
* 为什么下单?
* 为什么不下单?
通常的解决手段是使用加密交易机器人,当在你做其他事情时,例如睡觉、与家人在一起或享受空闲时光,代替你下单。虽然有很多商业解决方案可用,但是我选择开源的解决方案,因此我编写了加密交易机器人 [Pythonic](https://github.com/hANSIc99/Pythonic)。 正如去年 [我写过的文章](https://opensource.com/article/19/5/graphically-programming-pythonic) 一样,“Pythonic 是一种图形化编程工具,它让用户可以轻松使用现成的函数模块来创建 Python 应用程序。” 最初它是作为加密货币机器人使用,并具有可扩展的日志记录引擎以及经过精心测试的可重用部件,例如调度器和计时器。
### 开始
本教程将教你如何开始使用 Pythonic 进行自动交易。我选择 <ruby> <a href="https://www.binance.com/"> 币安 </a> <rt> Binance </rt></ruby> 交易所的 <ruby> <a href="https://tron.network/"> 波场 </a> <rt> Tron </rt></ruby> 与 <ruby> <a href="https://opensource.com/article/19/5/graphically-programming-pythonic"> 比特币 </a> <rt> Bitcoin </rt></ruby> 交易对为例。我之所以选择这个加密货币对,是因为它们彼此之间的波动性大,而不是出于个人喜好。
机器人将根据 <ruby> <a href="https://www.investopedia.com/terms/e/ema.asp"> 指数移动平均 </a> <rt> exponential moving averages </rt></ruby> (EMA)来做出决策。

*TRX/BTC 1 小时 K 线图*
EMA 指标通常是一个加权的移动平均线,可以对近期价格数据赋予更多权重。尽管移动平均线可能只是一个简单的指标,但我对它很有经验。
上图中的紫色线显示了 EMA-25 指标(这表示要考虑最近的 25 个值)。
机器人监视当前的 EMA-25 值(t0)和前一个 EMA-25 值(t-1)之间的差距。如果差值超过某个值,则表示价格上涨,机器人将下达购买订单。如果差值低于某个值,则机器人将下达卖单。
差值将是做出交易决策的主要指标。在本教程中,它称为交易参数。
### 工具链
将在本教程使用如下工具:
* 币安专业交易视图(已经有其他人做了数据可视化,所以不需要重复造轮子)
* Jupyter 笔记本:用于数据科学任务
* Pythonic:作为整体框架
* PythonicDaemon :作为终端运行(仅适用于控制台和 Linux)
### 数据挖掘
为了使加密货币交易机器人尽可能做出正确的决定,以可靠的方式获取资产的<ruby> 美国线 <rt> open-high-low-close chart </rt></ruby>([OHLC](https://en.wikipedia.org/wiki/Open-high-low-close_chart))数据是至关重要。你可以使用 Pythonic 的内置元素,还可以根据自己逻辑来对其进行扩展。
一般的工作流程:
1. 与币安时间同步
2. 下载 OHLC 数据
3. 从文件中把 OHLC 数据加载到内存
4. 比较数据集并扩展更新数据集
这个工作流程可能有点夸张,但是它能使得程序更加健壮,甚至在停机和断开连接时,也能平稳运行。
一开始,你需要 <ruby> <strong> 币安 OHLC 查询 </strong> <rt> Binance OHLC Query </rt></ruby> 元素和一个 <ruby> <strong> 基础操作 </strong> <rt> Basic Operation </rt></ruby> 元素来执行你的代码。

*数据挖掘工作流程*
OHLC 查询设置为每隔一小时查询一次 **TRXBTC** 资产对(波场/比特币)。

*配置 OHLC 查询元素*
其中输出的元素是 [Pandas DataFrame](https://pandas.pydata.org/pandas-docs/stable/getting_started/dsintro.html#dataframe)。你可以在 **基础操作** 元素中使用 <ruby> <strong> 输入 </strong> <rt> input </rt></ruby> 变量来访问 DataFrame。其中,将 Vim 设置为 **基础操作** 元素的默认代码编辑器。

*使用 Vim 编辑基础操作元素*
具体代码如下:
```
import pickle, pathlib, os
import pandas as pd
outout = None
if isinstance(input, pd.DataFrame):
file_name = 'TRXBTC_1h.bin'
home_path = str(pathlib.Path.home())
data_path = os.path.join(home_path, file_name)
try:
df = pickle.load(open(data_path, 'rb'))
n_row_cnt = df.shape[0]
df = pd.concat([df,input], ignore_index=True).drop_duplicates(['close_time'])
df.reset_index(drop=True, inplace=True)
n_new_rows = df.shape[0] - n_row_cnt
log_txt = '{}: {} new rows written'.format(file_name, n_new_rows)
except:
log_txt = 'File error - writing new one: {}'.format(e)
df = input
pickle.dump(df, open(data_path, "wb" ))
output = df
```
首先,检查输入是否为 DataFrame 元素。然后在用户的家目录(`~/`)中查找名为 `TRXBTC_1h.bin` 的文件。如果存在,则将其打开,执行新代码段(`try` 部分中的代码),并删除重复项。如果文件不存在,则触发异常并执行 `except` 部分中的代码,创建一个新文件。
只要启用了复选框 <ruby> <strong> 日志输出 </strong> <rt> log output </rt></ruby>,你就可以使用命令行工具 `tail` 查看日志记录:
```
$ tail -f ~/Pythonic_2020/Feb/log_2020_02_19.txt
```
出于开发目的,现在跳过与币安时间的同步和计划执行,这将在下面实现。
### 准备数据
下一步是在单独的 <ruby> 网格 <rt> Grid </rt></ruby> 中处理评估逻辑。因此,你必须借助<ruby> <strong> 返回元素 </strong> <rt> Return element </rt></ruby> 将 DataFrame 从网格 1 传递到网格 2 的第一个元素。
在网格 2 中,通过使 DataFrame 通过 <ruby> <strong> 基础技术分析 </strong> <rt> Basic Technical Analysis </rt></ruby> 元素,将 DataFrame 扩展包含 EMA 值的一列。

*在网格 2 中技术分析工作流程*
配置技术分析元素以计算 25 个值的 EMA。

*配置技术分析元素*
当你运行整个程序并开启 <ruby> <strong> 技术分析 </strong> <rt> Technical Analysis </rt></ruby> 元素的调试输出时,你将发现 EMA-25 列的值似乎都相同。

*输出中精度不够*
这是因为调试输出中的 EMA-25 值仅包含六位小数,即使输出保留了 8 个字节完整精度的浮点值。
为了能进行进一步处理,请添加 **基础操作** 元素:

*网格 2 中的工作流程*
使用 **基础操作** 元素,将 DataFrame 与添加的 EMA-25 列一起转储,以便可以将其加载到 Jupyter 笔记本中;

*将扩展后的 DataFrame 存储到文件中*
### 评估策略
在 Juypter 笔记本中开发评估策略,让你可以更直接地访问代码。要加载 DataFrame,你需要使用如下代码:

*用全部小数位表示*
你可以使用 [iloc](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html) 和列名来访问最新的 EMA-25 值,并且会保留所有小数位。
你已经知道如何来获得最新的数据。上面示例的最后一行仅显示该值。为了能将该值拷贝到不同的变量中,你必须使用如下图所示的 `.at` 方法方能成功。
你也可以直接计算出你下一步所需的交易参数。

*买卖决策*
### 确定交易参数
如上面代码所示,我选择 0.009 作为交易参数。但是我怎么知道 0.009 是决定交易的一个好参数呢? 实际上,这个参数确实很糟糕,因此,你可以直接计算出表现最佳的交易参数。
假设你将根据收盘价进行买卖。

*回测功能*
在此示例中,`buy_factor` 和 `sell_factor` 是预先定义好的。因此,发散思维用直接计算出表现最佳的参数。

*嵌套的 for 循环,用于确定购买和出售的参数*
这要跑 81 个循环(9x9),在我的机器(Core i7 267QM)上花费了几分钟。

*在暴力运算时系统的利用率*
在每个循环之后,它将 `buy_factor`、`sell_factor` 元组和生成的 `profit` 元组追加到 `trading_factors` 列表中。按利润降序对列表进行排序。

*将利润与相关的交易参数按降序排序*
当你打印出列表时,你会看到 0.002 是最好的参数。

*交易要素和收益的有序列表*
当我在 2020 年 3 月写下这篇文章时,价格的波动还不足以呈现出更理想的结果。我在 2 月份得到了更好的结果,但即使在那个时候,表现最好的交易参数也在 0.002 左右。
### 分割执行路径
现在开始新建一个网格以保持逻辑清晰。使用 **返回** 元素将带有 EMA-25 列的 DataFrame 从网格 2 传递到网格 3 的 0A 元素。
在网格 3 中,添加 **基础操作** 元素以执行评估逻辑。这是该元素中的代码:

*实现评估策略*
如果输出 `1` 表示你应该购买,如果输出 `2` 则表示你应该卖出。 输出 `0` 表示现在无需操作。使用 <ruby> <strong> 分支 </strong> <rt> Branch </rt></ruby> 元素来控制执行路径。

*分支元素:网格 3,2A 位置*
因为 `0` 和 `-1` 的处理流程一样,所以你需要在最右边添加一个分支元素来判断你是否应该卖出。

*分支元素:网格 3,3B 位置*
网格 3 应该现在如下图所示:

*网格 3 的工作流程*
### 下单
由于无需在一个周期中购买两次,因此必须在周期之间保留一个持久变量,以指示你是否已经购买。
你可以利用 <ruby> <strong> 栈 </strong> <rt> Stack </rt></ruby> 元素来实现。顾名思义,栈元素表示可以用任何 Python 数据类型来放入的基于文件的栈。
你需要定义栈仅包含一个布尔类型,该布尔类型决定是否购买了(`True`)或(`False`)。因此,你必须使用 `False` 来初始化栈。例如,你可以在网格 4 中简单地通过将 `False` 传递给栈来进行设置。

*将 False 变量传输到后续的栈元素中*
在分支树后的栈实例可以进行如下配置:

*设置栈元素*
在栈元素设置中,将 <ruby> 对输入的操作 <rt> Do this with input </rt></ruby> 设置成 <ruby> 无 <rt> Nothing </rt></ruby>。否则,布尔值将被 `1` 或 `0` 覆盖。
该设置确保仅将一个值保存于栈中(`True` 或 `False`),并且只能读取一个值(为了清楚起见)。
在栈元素之后,你需要另外一个 **分支** 元素来判断栈的值,然后再放置 <ruby> 币安订单 <rt> Binance Order </rt></ruby> 元素。

*判断栈中的变量*
将币安订单元素添加到分支元素的 `True` 路径。网格 3 上的工作流现在应如下所示:

*网格 3 的工作流程*
币安订单元素应如下配置:

*编辑币安订单元素*
你可以在币安网站上的帐户设置中生成 API 和密钥。

*在币安账户设置中创建一个 API 密钥*
在本文中,每笔交易都是作为市价交易执行的,交易量为 10,000 TRX(2020 年 3 月约为 150 美元)(出于教学的目的,我通过使用市价下单来演示整个过程。因此,我建议至少使用限价下单。)
如果未正确执行下单(例如,网络问题、资金不足或货币对不正确),则不会触发后续元素。因此,你可以假定如果触发了后续元素,则表示该订单已下达。
这是一个成功的 XMRBTC 卖单的输出示例:

*成功卖单的输出*
该行为使后续步骤更加简单:你可以始终假设只要成功输出,就表示订单成功。因此,你可以添加一个 **基础操作** 元素,该元素将简单地输出 **True** 并将此值放入栈中以表示是否下单。
如果出现错误的话,你可以在日志信息中查看具体细节(如果启用日志功能)。

*币安订单元素中的输出日志信息*
### 调度和同步
对于日程调度和同步,请在网格 1 中将整个工作流程置于 <ruby> 币安调度器 <rt> Binance Scheduler </rt></ruby> 元素的前面。

*在网格 1,1A 位置的币安调度器*
由于币安调度器元素只执行一次,因此请在网格 1 的末尾拆分执行路径,并通过将输出传递回币安调度器来强制让其重新同步。

*网格 1:拆分执行路径*
5A 元素指向 网格 2 的 1A 元素,并且 5B 元素指向网格 1 的 1A 元素(币安调度器)。
### 部署
你可以在本地计算机上全天候 7×24 小时运行整个程序,也可以将其完全托管在廉价的云系统上。例如,你可以使用 Linux/FreeBSD 云系统,每月约 5 美元,但通常不提供图形化界面。如果你想利用这些低成本的云,可以使用 PythonicDaemon,它能在终端中完全运行。

*PythonicDaemon 控制台*
PythonicDaemon 是基础程序的一部分。要使用它,请保存完整的工作流程,将其传输到远程运行的系统中(例如,通过<ruby> 安全拷贝协议 <rt> Secure Copy </rt></ruby> SCP),然后把工作流程文件作为参数来启动 PythonicDaemon:
```
$ PythonicDaemon trading_bot_one
```
为了能在系统启动时自启 PythonicDaemon,可以将一个条目添加到 crontab 中:
```
# crontab -e
```

*在 Ubuntu 服务器上的 Crontab*
### 下一步
正如我在一开始时所说的,本教程只是自动交易的入门。对交易机器人进行编程大约需要 10% 的编程和 90% 的测试。当涉及到让你的机器人用金钱交易时,你肯定会对编写的代码再三思考。因此,我建议你编码时要尽可能简单和易于理解。
如果你想自己继续开发交易机器人,接下来所需要做的事:
* 收益自动计算(希望你有正收益!)
* 计算你想买的价格
* 比较你的预订单(例如,订单是否填写完整?)
你可以从 [GitHub](https://github.com/hANSIc99/Pythonic) 上获取完整代码。
---
via: <https://opensource.com/article/20/4/python-crypto-trading-bot>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,243 | COPR 仓库中 4 个很酷的新项目(2021.03) | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-march-2021/ | 2021-03-28T11:13:49 | [
"COPR",
"Fedora",
"软件"
] | https://linux.cn/article-13243-1.html | 
>
> COPR 是个人软件仓库 [集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
>
>
>
本文介绍了 COPR 中一些有趣的新项目。如果你第一次使用 COPR,请参阅 [COPR 用户文档](https://docs.pagure.org/copr.copr/user_documentation.html)。
### Ytfzf
[Ytfzf](https://github.com/pystardust/ytfzf) 是一个简单的命令行工具,用于搜索和观看 YouTube 视频。它提供了围绕模糊查找程序 [fzf](https://github.com/junegunn/fzf) 构建的快速直观的界面。它使用 [youtube-dl](http://ytdl-org.github.io/youtube-dl/) 来下载选定的视频,并打开外部视频播放器来观看。由于这种方式,`ytfzf` 比使用浏览器观看 YouTube 资源占用要少得多。它支持缩略图(通过 [ueberzug](https://github.com/seebye/ueberzug))、历史记录保存、多个视频排队或下载它们以供以后使用、频道订阅以及其他方便的功能。多亏了像 [dmenu](https://tools.suckless.org/dmenu/) 或 [rofi](https://github.com/davatorium/rofi) 这样的工具,它甚至可以在终端之外使用。

#### 安装说明
目前[仓库](https://copr.fedorainfracloud.org/coprs/bhoman/ytfzf/)为 Fedora 33 和 34 提供 Ytfzf。要安装它,请使用以下命令:
```
sudo dnf copr enable bhoman/ytfzf
sudo dnf install ytfzf
```
### Gemini 客户端
你有没有想过,如果万维网走的是一条完全不同的路线,不采用 CSS 和客户端脚本,你的互联网浏览体验会如何?[Gemini](https://gemini.circumlunar.space/) 是 HTTPS 协议的现代替代品,尽管它并不打算取代 HTTPS 协议。[stenstorp/gemini](https://copr.fedorainfracloud.org/coprs/stenstorp/gemini/) COPR 项目提供了各种客户端来浏览 Gemini *网站*,有 [Castor](https://git.sr.ht/~julienxx/castor)、[Dragonstone](https://gitlab.com/baschdel/dragonstone)、[Kristall](https://kristall.random-projects.net/) 和 [Lagrange](https://github.com/skyjake/lagrange)。
[Gemini](https://gemini.circumlunar.space/servers/) 站点提供了一些使用该协议的主机列表。以下显示了使用 Castor 访问这个站点的情况:

#### 安装说明
该 [仓库](https://copr.fedorainfracloud.org/coprs/stenstorp/gemini/) 目前为 Fedora 32、33、34 和 Fedora Rawhide 提供 Gemini 客户端。EPEL 7 和 8,以及 CentOS Stream 也可使用。要安装浏览器,请从这里显示的安装命令中选择:
```
sudo dnf copr enable stenstorp/gemini
sudo dnf install castor
sudo dnf install dragonstone
sudo dnf install kristall
sudo dnf install lagrange
```
### Ly
[Ly](https://github.com/nullgemm/ly) 是一个 Linux 和 BSD 的轻量级登录管理器。它有一个类似于 ncurses 的基于文本的用户界面。理论上,它应该支持所有的 X 桌面环境和窗口管理器(其中很多都 [经过测试](https://github.com/nullgemm/ly#support))。Ly 还提供了基本的 Wayland 支持(Sway 也工作良好)。在配置的某个地方,有一个复活节彩蛋选项,可以在背景中启用著名的 [PSX DOOM fire](https://fabiensanglard.net/doom_fire_psx/index.html) 动画,就其本身而言,值得一试。

#### 安装说明
该 [仓库](https://copr.fedorainfracloud.org/coprs/dhalucario/ly/) 目前为 Fedora 32、33 和 Fedora Rawhide 提供 Ly。要安装它,请使用以下命令:
```
sudo dnf copr enable dhalucario/ly
sudo dnf install ly
```
在将 Ly 设置为系统登录界面之前,请在终端中运行 `ly` 命令以确保其正常工作。然后关闭当前的登录管理器,启用 Ly。
```
sudo systemctl disable gdm
sudo systemctl enable ly
```
最后,重启计算机,使其更改生效。
### AWS CLI v2
[AWS CLI v2](https://aws.amazon.com/blogs/developer/aws-cli-v2-is-now-generally-available/) 带来基于社区反馈进行的稳健而有条理的演变,而不是对原有客户端的大规模重新设计。它引入了配置凭证的新机制,现在允许用户从 AWS 控制台中生成的 `.csv` 文件导入凭证。它还提供了对 AWS SSO 的支持。其他主要改进是服务端自动补全,以及交互式参数生成。一个新功能是交互式向导,它提供了更高层次的抽象,并结合多个 AWS API 调用来创建、更新或删除 AWS 资源。

#### 安装说明
该 [仓库](https://copr.fedorainfracloud.org/coprs/spot/aws-cli-2/) 目前为 Fedora Linux 32、33、34 和 Fedora Rawhide 提供 AWS CLI v2。要安装它,请使用以下命令:
```
sudo dnf copr enable spot/aws-cli-2
sudo dnf install aws-cli-2
```
自然地,访问 AWS 账户凭证是必要的。
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-march-2021/>
作者:[Jakub Kadlčík](https://fedoramagazine.org/author/frostyx/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Copr is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora Linux. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open-source. Copr can offer these projects outside the Fedora set of packages. Software in Copr isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
This article presents a few new and interesting projects in Copr. If you’re new to using Copr, see the [Copr User Documentation](https://docs.pagure.org/copr.copr/user_documentation.html) for how to get started.
## Ytfzf
[Ytfzf](https://github.com/pystardust/ytfzf) is a simple command-line tool for searching and watching YouTube videos. It provides a fast and intuitive interface built around fuzzy find utility [fzf](https://github.com/junegunn/fzf). It uses [youtube-dl](http://ytdl-org.github.io/youtube-dl/) to download selected videos and opens an external video player to watch them. Because of this approach, *ytfzf* is significantly less resource-heavy than a web browser with YouTube. It supports thumbnails (via [ueberzug](https://github.com/seebye/ueberzug)), history saving, queueing multiple videos or downloading them for later, channel subscriptions, and other handy features. Thanks to tools like [dmenu](https://tools.suckless.org/dmenu/) or [rofi](https://github.com/davatorium/rofi), it can even be used outside the terminal.
Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/bhoman/ytfzf/) currently provides Ytfzf for Fedora 33 and 34. To install it, use these commands:
sudo dnf copr enable bhoman/ytfzf sudo dnf install ytfzf
Gemini clients
Have you ever wondered what your internet browsing experience would be if the World Wide Web went an entirely different route and didn’t adopt CSS and client-side scripting? [Gemini](https://gemini.circumlunar.space/) is a modern alternative to the HTTPS protocol, although it doesn’t intend to replace it. The [stenstorp/gemini](https://copr.fedorainfracloud.org/coprs/stenstorp/gemini/) Copr project provides various clients for browsing Gemini *websites*, namely [Castor](https://git.sr.ht/~julienxx/castor), [Dragonstone](https://gitlab.com/baschdel/dragonstone), [Kristall](https://kristall.random-projects.net/), and [Lagrange](https://github.com/skyjake/lagrange).
The [Gemini](//gemini.circumlunar.space/servers/) site provides a list of some hosts that use this protocol. Using Castor to visit this site is shown here:
Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/stenstorp/gemini/) currently provides Gemini clients for Fedora 32, 33, 34, and Fedora Rawhide. Also available for EPEL 7 and 8, and CentOS Stream. To install a browser, choose from the install commands shown here:
sudo dnf copr enable stenstorp/gemini sudo dnf install castor sudo dnf install dragonstone sudo dnf install kristall sudo dnf install lagrange
Ly
[Ly](https://github.com/nullgemm/ly) is a lightweight login manager for Linux and BSD. It features a ncurses-like text-based user interface. Theoretically, it should support all X desktop environments and window managers (many of them [were tested](https://github.com/nullgemm/ly#support)). Ly also provides basic Wayland support (Sway works very well). Somewhere in the configuration, there is an easter egg option to enable the famous [PSX DOOM fire](https://fabiensanglard.net/doom_fire_psx/index.html) animation in the background, which on its own, is worth checking out.
Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/dhalucario/ly/) currently provides Ly for Fedora 32, 33, and Fedora Rawhide. To install it, use these commands:
sudo dnf copr enable dhalucario/ly sudo dnf install ly
Before setting up Ly to be your system login screen, run *ly* command in the terminal to make sure it works properly. Then proceed with disabling your current login manager and enabling Ly instead.
sudo systemctl disable gdm sudo systemctl enable ly
Finally, restart your computer for the changes to take an effect.
AWS CLI v2
[AWS CLI v2](https://aws.amazon.com/blogs/developer/aws-cli-v2-is-now-generally-available/) brings a steady and methodical evolution based on the community feedback, rather than a massive redesign of the original client. It introduces new mechanisms for configuring credentials and now allows the user to import credentials from the *.csv* files generated in the AWS Console. It also provides support for AWS SSO. Other big improvements are server-side auto-completion, and interactive parameters generation. A fresh new feature is interactive wizards, which provide a higher level of abstraction and combines multiple AWS API calls to create, update, or delete AWS resources.

Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/spot/aws-cli-2/) currently provides AWS CLI v2 for Fedora Linux 32, 33, 34, and Fedora Rawhide. To install it, use these commands:
sudo dnf copr enable spot/aws-cli-2 sudo dnf install aws-cli-2
Naturally, access to an AWS account is necessary.
## Vernay Bruno
Gemini is fun, there is also a Flatpack browser https://flathub.org/apps/details/fi.skyjake.Lagrange
## Moritz Barsnick
ytfzf uses ueberzug for thumbnails, as mentioned in the article, but ueberzug doesn’t work on Wayland, which Fedora defaults to. So too bad about that killer feature. (But nice tool anyway!)
smtube (formerly from smplayer) is a graphical YouTube browser, in case anyone is looking for such an alternative.
## Rômulo
Here on my Fedora 33, i just have to click on the gears right bottom of the login screen just before enter my credentials and choose the option GNOME over Xorg. And Voila!
I can use the ytfzf with tumbnails and everything.
## Miki
man i love them copro repos
## Pace
I really like ytfzf, but even on X11 I just couldn’t get ueberzug to install :-S
Would be a really nice project if the installation would be easier, and available on both X11 and Wayland.
## Jakub Kadlčík
Hello Pace,
I recently packaged ueberzug and it is available in this repo
https://copr.fedorainfracloud.org/coprs/frostyx/ueberzug/
You can give it a try.
## Pace
Hey thanks for the response, I can now enjoy the thumbnails via ueberzug, thanks for packaging this.
## Nick
Nothing to do with the repositories above, and maybe it will not help, but in my opinion a noteworthy project is this:
https://copr.fedorainfracloud.org/coprs/matteoguadrini/dinosay/
A simple cowsay alternative … but with dinosaurs!
## Jakub Kadlčík
Thank you for the suggestion. I will check it out and eventually mention it in the next article 🙂
## Anil
Hello,
I am getting the following error when trying to install ytfzf as detailed here;
Error:
Problem: conflicting requests
– nothing provides mpv needed by ytfzf-20210316-1.fc33.x86_64
Any help is appreciated.
thank you,
## Jakub Kadlčík
Hello Anil,
it’s unfortunate that ytfzf depends on mpv. Theoretically, it should work with any video player, it should be a matter of configuration. For example, if I want to force ytfzf to use vlc instead of mpv, I can do
YTFZF_PLAYER=vlc ytfzf
You can try to contact the repo author to drop the dependency or at least change it from Requires to Suggests or Recommends.
Or you can install the mpv package from RPM Fusion free repository. |
13,247 | 练习使用 Linux 的 grep 命令 | https://opensource.com/article/21/3/grep-cheat-sheet | 2021-03-29T09:33:30 | [
"grep",
"搜索",
"正则表达式"
] | https://linux.cn/article-13247-1.html |
>
> 来学习下搜索文件中内容的基本操作,然后下载我们的备忘录作为 grep 和正则表达式的快速参考指南。
>
>
>

`grep`(<ruby> 全局正则表达式打印 <rt> Global Regular Expression Print </rt></ruby>)是由 Ken Thompson 早在 1974 年开发的基本 Unix 命令之一。在计算领域,它无处不在,通常被用作为动词(“搜索一个文件中的内容”)。如果你的谈话对象有极客精神,那么它也能在真实生活场景中使用。(例如,“我会 `grep` 我的内存条来回想起那些信息。”)简而言之,`grep` 是一种用特定的字符模式来搜索文件中内容的方式。如果你感觉这听起来像是文字处理器或文本编辑器的现代 Find 功能,那么你就已经在计算行业感受到了 `grep` 的影响。
`grep` 绝不是被现代技术抛弃的远古命令,它的强大体现在两个方面:
* `grep` 可以在终端操作数据流,因此你可以把它嵌入到复杂的处理中。你不仅可以在一个文本文件中*查找*文字,还可以提取文字后把它发给另一个命令。
* `grep` 使用正则表达式来提供灵活的搜索能力。
虽然需要一些练习,但学习 `grep` 命令还是很容易的。本文会介绍一些我认为 `grep` 最有用的功能。
* 下载我们免费的 [grep 备忘录](https://opensource.com/downloads/grep-cheat-sheet)
### 安装 grep
Linux 默认安装了 `grep`。
MacOS 默认安装了 BSD 版的 `grep`。BSD 版的 `grep` 跟 GNU 版有一点不一样,因此如果你想完全参照本文,那么请使用 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 或 [MacPorts](https://opensource.com/article/20/11/macports) 安装 GNU 版的 `grep`。
### 基础的 grep
所有版本的 `grep` 基础语法都一样。入参是匹配模式和你需要搜索的文件。它会把匹配到的每一行输出到你的终端。
```
$ grep gnu gpl-3.0.txt
along with this program. If not, see <http://www.gnu.org/licenses/>.
<http://www.gnu.org/licenses/>.
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
```
`grep` 命令默认大小写敏感,因此 “gnu”、“GNU”、“Gnu” 是三个不同的值。你可以使用 `--ignore-case` 选项来忽略大小写。
```
$ grep --ignore-case gnu gpl-3.0.txt
GNU GENERAL PUBLIC LICENSE
The GNU General Public License is a free, copyleft license for
the GNU General Public License is intended to guarantee your freedom to
GNU General Public License for most of our software; it applies also to
[...16 more results...]
<http://www.gnu.org/licenses/>.
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
```
你也可以通过 `--invert-match` 选项来输出所有没有匹配到的行:
```
$ grep --invert-match \
--ignore-case gnu gpl-3.0.txt
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/>
[...648 lines...]
Public License instead of this License. But first, please read
```
### 管道
能搜索文件中的文本内容是很有用的,但是 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 的真正强大之处是可以通过“管道”来连接多条命令。我发现我使用 `grep` 最好的方式是把它与其他工具如 `cut`、`tr` 或 [curl](https://opensource.com/downloads/curl-command-cheat-sheet) 联合使用。
假如现在有一个文件,文件中每一行是我想要下载的技术论文。我可以打开文件手动点击每一个链接,然后点击火狐浏览器的选项把每一个文件保存到我的硬盘,但是需要点击多次且耗费很长时间。而我还可以搜索文件中的链接,用 `--only-matching` 选项*只*打印出匹配到的字符串。
```
$ grep --only-matching http\:\/\/.*pdf example.html
http://example.com/linux_whitepaper.pdf
http://example.com/bsd_whitepaper.pdf
http://example.com/important_security_topic.pdf
```
输出是一系列的 URL,每行一个。而这与 Bash 处理数据的方式完美契合,因此我不再把 URL 打印到终端,而是把它们通过管道传给 `curl`:
```
$ grep --only-matching http\:\/\/.*pdf \
example.html | curl --remote-name
```
这条命令可以下载每一个文件,然后以各自的远程文件名命名保存在我的硬盘上。
这个例子中我的搜索模式可能很晦涩。那是因为它用的是正则表达式,一种在大量文本中进行模糊搜索时非常有用的”通配符“语言。
### 正则表达式
没有人会觉得<ruby> 正则表达式 <rt> regular expression </rt></ruby>(简称 “regex”)很简单。然而,我发现它的名声往往比它应得的要差。诚然,很多人在使用正则表达式时“过于炫耀聪明”,直到它变得难以阅读,大而全,以至于复杂得换行才好理解,但是你不必过度使用正则。这里简单介绍一下我使用正则表达式的方式。
首先,创建一个名为 `example.txt` 的文件,输入以下内容:
```
Albania
Algeria
Canada
0
1
3
11
```
最基础的元素是不起眼的 `.` 字符。它表示一个字符。
```
$ grep Can.da example.txt
Canada
```
模式 `Can.da` 能成功匹配到 `Canada` 是因为 `.` 字符表示任意*一个*字符。
可以使用下面这些符号来使 `.` 通配符表示多个字符:
* `?` 匹配前面的模式零次或一次
* `*` 匹配前面的模式零次或多次
* `+` 匹配前面的模式一次或多次
* `{4}` 匹配前面的模式 4 次(或是你在括号中写的其他次数)
了解了这些知识后,你可以用你认为有意思的所有模式来在 `example.txt` 中做练习。可能有些会成功,有些不会成功。重要的是你要去分析结果,这样你才会知道原因。
例如,下面的命令匹配不到任何国家:
```
$ grep A.a example.txt
```
因为 `.` 字符只能匹配一个字符,除非你增加匹配次数。使用 `*` 字符,告诉 `grep` 匹配一个字符零次或者必要的任意多次直到单词末尾。因为你知道你要处理的内容,因此在本例中*零次*是没有必要的。在这个列表中一定没有单个字母的国家。因此,你可以用 `+` 来匹配一个字符至少一次且任意多次直到单词末尾:
```
$ grep A.+a example.txt
Albania
Algeria
```
你可以使用方括号来提供一系列的字母:
```
$ grep [A,C].+a example.txt
Albania
Algeria
Canada
```
也可以用来匹配数字。结果可能会震惊你:
```
$ grep [1-9] example.txt
1
3
11
```
看到 11 出现在搜索数字 1 到 9 的结果中,你惊讶吗?
如果把 13 加到搜索列表中,会出现什么结果呢?
这些数字之所以会被匹配到,是因为它们包含 1,而 1 在要匹配的数字中。
你可以发现,正则表达式有时会令人费解,但是通过体验和练习,你可以熟练掌握它,用它来提高你搜索数据的能力。
### 下载备忘录
`grep` 命令还有很多文章中没有列出的选项。有用来更好地展示匹配结果、列出文件、列出匹配到的行号、通过打印匹配到的行周围的内容来显示上下文的选项,等等。如果你在学习 `grep`,或者你经常使用它并且通过查阅它的`帮助`页面来查看选项,那么你可以下载我们的备忘录。这个备忘录使用短选项(例如,使用 `-v`,而不是 `--invert-matching`)来帮助你更好地熟悉 `grep`。它还有一部分正则表达式可以帮你记住用途最广的正则表达式代码。 [现在就下载 grep 备忘录!](https://opensource.com/downloads/grep-cheat-sheet)
---
via: <https://opensource.com/article/21/3/grep-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the classic Unix commands, developed way back in 1974 by Ken Thompson, is the Global Regular Expression Print (grep) command. It's so ubiquitous in computing that it's frequently used as a verb ("grepping through a file") and, depending on how geeky your audience, it fits nicely into real-world scenarios, too. (For example, "I'll have to grep my memory banks to recall that information.") In short, grep is a way to search through a file for a specific pattern of characters. If that sounds like the modern Find function available in any word processor or text editor, then you've already experienced grep's effects on the computing industry.
Far from just being a quaint old command that's been supplanted by modern technology, grep's true power lies in two aspects:
- Grep works in the terminal and operates on streams of data, so you can incorporate it into complex processes. You can not only
*find*a word in a text file; you can extract the word, send it to another command, and so on. - Grep uses regular expression to provide a flexible search capability.
Learning the `grep`
command is easy, although it does take some practice. This article introduces you to some of its features I find most useful.
**[Download our free grep cheat sheet]**
## Installing grep
If you're using Linux, you already have grep installed.
On macOS, you have the BSD version of grep. This differs slightly from the GNU version, so if you want to follow along exactly with this article, then install GNU grep from a project like [Homebrew](https://opensource.com/article/20/6/homebrew-mac) or [MacPorts](https://opensource.com/article/20/11/macports).
## Basic grep
The basic grep syntax is always the same. You provide the `grep`
command a pattern and a file you want it to search. In return, it prints each line to your terminal with a match.
```
$ grep gnu gpl-3.0.txt
along with this program. If not, see <http://www.gnu.org/licenses/>.
<http://www.gnu.org/licenses/>.
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
```
By default, the `grep`
command is case-sensitive, so "gnu" is different from "GNU" or "Gnu." You can make it ignore capitalization with the `--ignore-case`
option.
```
$ grep --ignore-case gnu gpl-3.0.txt
GNU GENERAL PUBLIC LICENSE
The GNU General Public License is a free, copyleft license for
the GNU General Public License is intended to guarantee your freedom to
GNU General Public License for most of our software; it applies also to
[...16 more results...]
<http://www.gnu.org/licenses/>.
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
```
You can also make the `grep`
command return all lines *without* a match by using the `--invert-match`
option:
```
$ grep --invert-match \
--ignore-case gnu gpl-3.0.txt
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/>
[...648 lines...]
Public License instead of this License. But first, please read
```
## Pipes
It's useful to be able to find text in a file, but the true power of [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) is its ability to chain commands together through "pipes." I find that my best use of grep is when it's combined with other tools, like cut, tr, or [curl](https://opensource.com/downloads/curl-command-cheat-sheet).
For instance, assume I have a file that lists some technical papers I want to download. I could open the file and manually click on each link, and then click through Firefox options to save each file to my hard drive, but that's a lot of time and clicking. Instead, I could grep for the links in the file, printing *only* the matching string by using the `--only-matching`
option:
```
$ grep --only-matching http\:\/\/.*pdf example.html
http://example.com/linux_whitepaper.pdf
http://example.com/bsd_whitepaper.pdf
http://example.com/important_security_topic.pdf
```
The output is a list of URLs, each on one line. This is a natural fit for how Bash processes data, so instead of having the URLs printed to my terminal, I can just pipe them into `curl`
:
```
$ grep --only-matching http\:\/\/.*pdf \
example.html | curl --remote-name
```
This downloads each file, saving it according to its remote filename onto my hard drive.
My search pattern in this example may seem cryptic. That's because it uses regular expression, a kind of "wildcard" language that's particularly useful when searching broadly through lots of text.
## Regular expression
Nobody is under the illusion that regular expression ("regex" for short) is easy. However, I find it often has a worse reputation than it deserves. Admittedly, there's the potential for people to get a little *too clever* with regex until it's so unreadable and so broad that it folds in on itself, but you don't have to overdo your regex. Here's a brief introduction to regex the way I use it.
First, create a file called `example.txt`
and enter this text into it:
```
Albania
Algeria
Canada
0
1
3
11
```
The most basic element of regex is the humble `.`
character. It represents a single character.
```
$ grep Can.da example.txt
Canada
```
The pattern `Can.da`
successfully returned `Canada`
because the `.`
character represented any *one* character.
The `.`
wildcard can be modified to represent more than one character with these notations:
`?`
matches the preceding item zero or one time`*`
matches the preceding item zero or more times`+`
matches the preceding item one or more times`{4}`
matches the preceding item four (or any number you enter in the braces) times
Armed with this knowledge, you can practice regex on `example.txt`
all afternoon, seeing what interesting combinations you come up with. Some won't work; others will. The important thing is to analyze the results, so you understand why.
Advanced regex requires the **--extended-regexp** or** -E** option.
For instance, this fails to return any country:
`$ grep -E A.a example.txt`
It fails because the `.`
character can only ever match a single character unless you level it up. Using the `*`
character, you can tell `grep`
to match a single character zero or as many times as necessary until it reaches the end of the word. Because you know the list you're dealing with, you know that *zero times* is useless in this instance. There are definitely no three-letter country names in this list. So instead, you can use `+`
to match a single character at least once and then again as many times as necessary until the end of the word:
```
$ grep -E A.+a example.txt
Albania
Algeria
```
You can use square brackets to provide a list of letters:
```
$ grep -E [AC].+a example.txt
Albania
Algeria
Canada
```
This works for numbers, too. The results may surprise you:
```
$ grep [1-9] example.txt
1
3
11
```
Are you surprised to see 11 in a search for digits 1 to 9?
What happens if you add 13 to your list?
These numbers are returned because they include 1, which is among the list of digits to match.
As you can see, regex is something of a puzzle, but through experimentation and practice, you can get comfortable with it and use it to improve the way you grep through your data.
## Download the cheatsheet
The `grep`
command has far more options than I demonstrated in this article. There are options to better format results, list files and line numbers containing matches, provide context for results by printing the lines surrounding a match, and much more. If you're learning grep, or you just find yourself using it often and resorting to searching through its `info`
pages, you'll do yourself a favor by downloading our cheat sheet for it. The cheat sheet uses short options (`-v`
instead of `--invert-matching`
, for instance) as a way to get you familiar with common grep shorthand. It also contains a regex section to help you remember the most common regex codes. [Download the grep cheat sheet today!](https://opensource.com/downloads/grep-cheat-sheet)
## 9 Comments |
13,249 | 2021 年要尝试的 3 个新的 Java 工具 | https://opensource.com/article/21/3/enterprise-java-tools | 2021-03-29T21:27:22 | [
"Java",
"容器",
"微服务"
] | https://linux.cn/article-13249-1.html |
>
> 通过这三个工具和框架,为你的企业级 Java 应用和你的职业生涯提供助力。
>
>
>

尽管在 Kubernetes 上广泛使用 [Python](https://opensource.com/resources/python)、[Go](https://opensource.com/article/18/11/learning-golang) 和 [Node.js](https://opensource.com/article/18/7/node-js-interactive-cli) 实现 [人工智能](https://opensource.com/article/18/12/how-get-started-ai) 和机器学习应用以及 [无服务函数](https://opensource.com/article/19/4/enabling-serverless-kubernetes),但 Java 技术仍然在开发企业应用中发挥着关键作用。根据 [开发者经济学](https://developereconomics.com/) 的数据,在 2020 年第三季度,全球有 800 万名企业 Java 开发者。
虽然这门语言已经存在了超过 25 年,但 Java 世界中总是有新的趋势、工具和框架,可以为你的应用和你的职业生涯赋能。
绝大多数 Java 框架都是为具有动态行为的长时间运行的进程而设计的,这些动态行为用于运行可变的应用服务器,例如物理服务器和虚拟机。自从 Kubernetes 容器在 2014 年发布以来,情况已经发生了变化。在 Kubernetes 上使用 Java 应用的最大问题是通过减少内存占用、加快启动和响应时间以及减少文件大小来优化应用性能。
### 3 个值得考虑的新 Java 框架和工具
Java 开发人员也一直在寻找更简便的方法,将闪亮的新开源工具和项目集成到他们的 Java 应用和日常工作中。这极大地提高了开发效率,并激励更多的企业和个人开发者继续使用 Java 栈。
当试图满足上述企业 Java 生态系统的期望时,这三个新的 Java 框架和工具值得你关注。
#### 1、Quarkus
[Quarkus](https://quarkus.io/) 旨在以惊人的快速启动时间、超低的常驻内存集(RSS)和高密度内存利用率,在 Kubernetes 等容器编排平台中开发云原生的微服务和无服务。根据 JRebel 的 [第九届全球 Java 开发者生产力年度报告](https://www.jrebel.com/resources/java-developer-productivity-report-2021),Java 开发者对 Quarkus 的使用率从不到 1% 上升到 6%,[Micronaut](https://micronaut.io/) 和 [Vert.x](https://vertx.io/) 均从去年的 1% 左右分别增长到 4% 和 2%。
#### 2、Eclipse JKube
[Eclipse JKube](https://www.eclipse.org/jkube/) 使 Java 开发者能够使用 [Docker](https://opensource.com/resources/what-docker)、[Jib](https://github.com/GoogleContainerTools/jib) 或 [Source-To-Image](https://www.openshift.com/blog/create-s2i-builder-image) 构建策略,基于云原生 Java 应用构建容器镜像。它还能在编译时生成 Kubernetes 和 OpenShift 清单,并改善开发人员对调试、观察和日志工具的体验。
#### 3、MicroProfile
[MicroProfile](https://opensource.com/article/18/1/eclipse-microprofile) 解决了与优化企业 Java 的微服务架构有关的最大问题,而无需采用新的框架或重构整个应用。此外,MicroProfile [规范](https://microprofile.io/)(即 Health、Open Tracing、Open API、Fault Tolerance、Metrics、Config)继续与 [Jakarta EE](https://opensource.com/article/18/5/jakarta-ee) 的实现保持一致。
### 总结
很难说哪个 Java 框架或工具是企业 Java 开发人员实现的最佳选择。只要 Java 栈还有改进的空间,并能加速企业业务的发展,我们就可以期待新的框架、工具和平台的出现,比如上面的三个。花点时间看看它们是否能在 2021 年改善你的企业 Java 应用。
---
via: <https://opensource.com/article/21/3/enterprise-java-tools>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Despite the popularity of [Python](https://opensource.com/resources/python), [Go](https://opensource.com/article/18/11/learning-golang), and [Node.js](https://opensource.com/article/18/7/node-js-interactive-cli) for implementing [artificial intelligence](https://opensource.com/article/18/12/how-get-started-ai) and machine learning applications and [serverless functions](https://opensource.com/article/19/4/enabling-serverless-kubernetes) on Kubernetes, Java technologies still play a key role in developing enterprise applications. According to [ Developer Economics](https://developereconomics.com/), in Q3 2020, there were 8 million enterprise Java developers worldwide.
Although the programming language has been around for more than 25 years, there are always new trends, tools, and frameworks in the Java world that can empower your applications and your career.
The vast majority of Java frameworks are designed for long-running processes with dynamic behaviors for running mutable application servers such as physical servers and virtual machines. Things have changed since Kubernetes containers were unleashed in 2014. The biggest issue with using Java applications on Kubernetes is with optimizing application performance by decreasing memory footprints, speeding start and response times, and reducing file sizes.
## 3 new Java frameworks and tools to consider
Java developers are also always looking for easier ways to integrate shiny new open source tools and projects into their Java applications and daily work. This significantly increases development productivity and motivates more enterprises and individual developers to keep using the Java stack.
When trying to meet the expectations listed above for the enterprise Java ecosystem, these three new Java frameworks and tools are worth your attention.
### 1. Quarkus
[Quarkus](https://quarkus.io/) is designed to develop cloud-native microservices and serverless with amazingly fast boot time, incredibly low resident set size (RSS) memory, and high-density memory utilization in container orchestration platforms like Kubernetes. According to JRebel's [9th annual global Java developer productivity report](https://www.jrebel.com/resources/java-developer-productivity-report-2021 ), the usage of Quarkus by Java developers rose 6% from less than 1%, and [Micronaut](https://micronaut.io/ ) and [Vert.x](https://vertx.io/) grew to 4% and 2%, respectively, both up from roughly 1% last year.
### 2. Eclipse JKube
[Eclipse JKube](https://www.eclipse.org/jkube/) enables Java developers to build container images based on cloud-native Java applications using [Docker](https://opensource.com/resources/what-docker), [Jib](https://github.com/GoogleContainerTools/jib), or [Source-To-Image](https://www.openshift.com/blog/create-s2i-builder-image) build strategies. It also generates Kubernetes and OpenShift manifests at compile time and improves developers' experience with debug, watch, and logging tools.
### 3. MicroProfile
[MicroProfile](https://opensource.com/article/18/1/eclipse-microprofile) solves the biggest problems related to optimizing enterprise Java for a microservices architecture without adopting new frameworks or refactoring entire applications. Furthermore, MicroProfile [specifications](https://microprofile.io/) (i.e., Health, Open Tracing, Open API, Fault Tolerance, Metrics, Config) continue to develop in alignment with [Jakarta EE](https://opensource.com/article/18/5/jakarta-ee) implementation.
## Conclusion
It's hard to say which Java frameworks or tools are the best choices for enterprise Java developers to implement. As long as there is room for improvement in the Java stack and accelerating enterprise businesses, we can expect new frameworks, tools, and platforms, like the three above, to become available. Spend some time looking at them to see if they can improve your enterprise Java applications in 2021.
## Comments are closed. |
13,250 | 如何在 WebAssembly 中写 “Hello World”? | https://opensource.com/article/21/3/hello-world-webassembly | 2021-03-30T09:59:00 | [
"WebAssembly"
] | https://linux.cn/article-13250-1.html |
>
> 通过这个分步教程,开始用人类可读的文本编写 WebAssembly。
>
>
>

WebAssembly 是一种字节码格式,[几乎所有的浏览器](https://developer.mozilla.org/en-US/docs/WebAssembly#browser_compatibility) 都可以将它编译成其宿主操作系统的机器代码。除了 JavaScript 和 WebGL 之外,WebAssembly 还满足了将应用移植到浏览器中以实现平台独立的需求。作为 C++ 和 Rust 的编译目标,WebAssembly 使 Web 浏览器能够以接近原生的速度执行代码。
当谈论 WebAssembly 应用时,你必须区分三种状态:
1. **源码(如 C++ 或 Rust):** 你有一个用兼容语言编写的应用,你想把它在浏览器中执行。
2. **WebAssembly 字节码:** 你选择 WebAssembly 字节码作为编译目标。最后,你得到一个 `.wasm` 文件。
3. **机器码(opcode):** 浏览器加载 `.wasm` 文件,并将其编译成主机系统的相应机器码。
WebAssembly 还有一种文本格式,用人类可读的文本表示二进制格式。为了简单起见,我将其称为 **WASM-text**。WASM-text 可以比作高级汇编语言。当然,你不会基于 WASM-text 来编写一个完整的应用,但了解它的底层工作原理是很好的(特别是对于调试和性能优化)。
本文将指导你在 WASM-text 中创建经典的 “Hello World” 程序。
### 创建 .wat 文件
WASM-text 文件通常以 `.wat` 结尾。第一步创建一个名为 `helloworld.wat` 的空文本文件,用你最喜欢的文本编辑器打开它,然后粘贴进去:
```
(module
;; 从 JavaScript 命名空间导入
(import "console" "log" (func $log (param i32 i32))) ;; 导入 log 函数
(import "js" "mem" (memory 1)) ;; 导入 1 页 内存(64kb)
;; 我们的模块的数据段
(data (i32.const 0) "Hello World from WebAssembly!")
;; 函数声明:导出 helloWorld(),无参数
(func (export "helloWorld")
i32.const 0 ;; 传递偏移 0 到 log
i32.const 29 ;; 传递长度 29 到 log(示例文本的字符串长度)
call $log
)
)
```
WASM-text 格式是基于 S 表达式的。为了实现交互,JavaScript 函数用 `import` 语句导入,WebAssembly 函数用 `export` 语句导出。在这个例子中,从 `console` 模块中导入 `log` 函数,它需要两个类型为 `i32` 的参数作为输入,以及一页内存(64KB)来存储字符串。
字符串将被写入偏移量 为 `0` 的数据段。数据段是你的内存的<ruby> 叠加投影 <rt> overlay </rt></ruby>,内存是在 JavaScript 部分分配的。
函数用关键字 `func` 标记。当进入函数时,栈是空的。在调用另一个函数之前,函数参数会被压入栈中(这里是偏移量和长度)(见 `call $log`)。当一个函数返回一个 `f32` 类型时(例如),当离开函数时,一个 `f32` 变量必须保留在栈中(但在本例中不是这样)。
### 创建 .wasm 文件
WASM-text 和 WebAssembly 字节码是 1:1 对应的,这意味着你可以将 WASM-text 转换成字节码(反之亦然)。你已经有了 WASM-text,现在将创建字节码。
转换可以通过 [WebAssembly Binary Toolkit](https://github.com/webassembly/wabt)(WABT)来完成。从该链接克隆仓库,并按照安装说明进行安装。
建立工具链后,打开控制台并输入以下内容,将 WASM-text 转换为字节码:
```
wat2wasm helloworld.wat -o helloworld.wasm
```
你也可以用以下方法将字节码转换为 WASM-text:
```
wasm2wat helloworld.wasm -o helloworld_reverse.wat
```
一个从 `.wasm` 文件创建的 `.wat` 文件不包括任何函数或参数名称。默认情况下,WebAssembly 用它们的索引来识别函数和参数。
### 编译 .wasm 文件
目前,WebAssembly 只与 JavaScript 共存,所以你必须编写一个简短的脚本来加载和编译 `.wasm` 文件并进行函数调用。你还需要在 WebAssembly 模块中定义你要导入的函数。
创建一个空的文本文件,并将其命名为 `helloworld.html`,然后打开你喜欢的文本编辑器并粘贴进去:
```
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Simple template</title>
</head>
<body>
<script>
var memory = new WebAssembly.Memory({initial:1});
function consoleLogString(offset, length) {
var bytes = new Uint8Array(memory.buffer, offset, length);
var string = new TextDecoder('utf8').decode(bytes);
console.log(string);
};
var importObject = {
console: {
log: consoleLogString
},
js : {
mem: memory
}
};
WebAssembly.instantiateStreaming(fetch('helloworld.wasm'), importObject)
.then(obj => {
obj.instance.exports.helloWorld();
});
</script>
</body>
</html>
```
`WebAssembly.Memory(...)` 方法返回一个大小为 64KB 的内存页。函数 `consoleLogString` 根据长度和偏移量从该内存页读取一个字符串。这两个对象作为 `importObject` 的一部分传递给你的 WebAssembly 模块。
在你运行这个例子之前,你可能必须允许 Firefox 从这个目录中访问文件,在地址栏输入 `about:config`,并将 `privacy.file_unique_origin` 设置为 `true`:

>
> **注意:** 这样做会使你容易受到 [CVE-2019-11730](https://www.mozilla.org/en-US/security/advisories/mfsa2019-21/#CVE-2019-11730) 安全问题的影响。
>
>
>
现在,在 Firefox 中打开 `helloworld.html`,按下 `Ctrl+K` 打开开发者控制台。

### 了解更多
这个 Hello World 的例子只是 MDN 的 [了解 WebAssembly 文本格式](https://developer.mozilla.org/en-US/docs/WebAssembly/Understanding_the_text_format) 文档中的教程之一。如果你想了解更多关于 WebAssembly 的知识以及它的工作原理,可以看看这些文档。
---
via: <https://opensource.com/article/21/3/hello-world-webassembly>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | WebAssembly is a bytecode format that [virtually every browser](https://developer.mozilla.org/en-US/docs/WebAssembly#browser_compatibility) can compile to its host system's machine code. Alongside JavaScript and WebGL, WebAssembly fulfills the demand for porting applications for platform-independent use in the web browser. As a compilation target for C++ and Rust, WebAssembly enables web browsers to execute code at near-native speed.
When you talk about a WebAssembly, application, you must distinguish between three states:
**Source code (e.g., C++ or Rust):**You have an application written in a compatible language that you want to execute in the browser.**WebAssembly bytecode:**You choose WebAssembly bytecode as your compilation target. As a result, you get a`.wasm`
file.**Machine code (opcode):**The browser loads the`.wasm`
file and compiles it to the corresponding machine code of its host system.
WebAssembly also has a text format that represents the binary format in human-readable text. For the sake of simplicity, I will refer to this as **WASM-text**. WASM-text can be compared to high-level assembly language. Of course, you would not write a complete application based on WASM-text, but it's good to know how it works under the hood (especially for debugging and performance optimization).
This article will guide you through creating the classic *Hello World* program in WASM-text.
## Creating the .wat file
WASM-text files usually end with `.wat`
. Start from scratch by creating an empty text file named `helloworld.wat`
, open it with your favorite text editor, and paste in:
```
(module
;; Imports from JavaScript namespace
(import "console" "log" (func $log (param i32 i32))) ;; Import log function
(import "js" "mem" (memory 1)) ;; Import 1 page of memory (54kb)
;; Data section of our module
(data (i32.const 0) "Hello World from WebAssembly!")
;; Function declaration: Exported as helloWorld(), no arguments
(func (export "helloWorld")
i32.const 0 ;; pass offset 0 to log
i32.const 29 ;; pass length 29 to log (strlen of sample text)
call $log
)
)
```
The WASM-text format is based upon S-expressions. To enable interaction, JavaScript functions are imported with the `import`
statement, and WebAssembly functions are exported with the `export`
statement. For this example, import the `log `
function from the `console`
module, which takes two parameters of type `i32`
as input and one page of memory (64KB) to store the string.
The string will be written into the `data`
section at offset `0`
. The `data`
section is an overlay of your memory, and the memory is allocated in the JavaScript part.
Functions are marked with the keyword `func`
. The stack is empty when entering a function. Function parameters are pushed onto the stack (here offset and length) before another function is called (see `call $log`
). When a function returns an `f32`
type (for example), an `f32`
variable must remain on the stack when leaving the function (but this is not the case in this example).
## Creating the .wasm file
The WASM-text and the WebAssembly bytecode have 1:1 correspondence. This means you can convert WASM-text into bytecode (and vice versa). You already have the WASM-text, and now you want to create the bytecode.
The conversion can be performed with the [WebAssembly Binary Toolkit](https://github.com/webassembly/wabt) (WABT). Make a clone of the repository at that link and follow the installation instructions.
After you build the toolchain, convert WASM-text to bytecode by opening a console and entering:
`wat2wasm helloworld.wat -o helloworld.wasm`
You can also convert bytecode to WASM-text with:
`wasm2wat helloworld.wasm -o helloworld_reverse.wat`
A `.wat`
file created from a `.wasm`
file does not include any function nor parameter names. By default, WebAssembly identifies functions and parameters with their index.
## Compiling the .wasm file
Currently, WebAssembly only coexists with JavaScript, so you have to write a short script to load and compile the `.wasm`
file and do the function calls. You also need to define the functions you will import in your WebAssembly module.
Create an empty text file and name it `helloworld.html`
, then open your favorite text editor and paste in:
```
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Simple template</title>
</head>
<body>
<script>
var memory = new WebAssembly.Memory({initial:1});
function consoleLogString(offset, length) {
var bytes = new Uint8Array(memory.buffer, offset, length);
var string = new TextDecoder('utf8').decode(bytes);
console.log(string);
};
var importObject = {
console: {
log: consoleLogString
},
js : {
mem: memory
}
};
WebAssembly.instantiateStreaming(fetch('helloworld.wasm'), importObject)
.then(obj => {
obj.instance.exports.helloWorld();
});
</script>
</body>
</html>
```
The `WebAssembly.Memory(...)`
method returns one page of memory that is 64KB in size. The function `consoleLogString`
reads a string from that memory page based on the length and offset. Both objects are passed to your WebAssembly module as part of the `importObject`
.
Before you can run this example, you may have to allow Firefox to access files from this directory by typing `about:config`
in the address line and setting `privacy.file_unique_origin`
to `true`
:
(Stephan Avenwedde, CC BY-SA 4.0)
Caution:This will make you vulnerable to the[CVE-2019-11730]security issue.
Now, open `helloworld.html`
in Firefox and enter **Ctrl**+**K** to open the developer console.

(Stephan Avenwedde, CC BY-SA 4.0)
## Learn more
This Hello World example is just one of the detailed tutorials in MDN's [Understanding WebAssembly text format](https://developer.mozilla.org/en-US/docs/WebAssembly/Understanding_the_text_format) documentation. If you want to learn more about WebAssembly and how it works under the hood, take a look at these docs.
## Comments are closed. |
13,252 | 学习如何用 C 语言来进行文件输入输出操作 | https://opensource.com/article/21/3/file-io-c | 2021-03-30T22:28:47 | [
"I/O",
"读写",
"C语言"
] | https://linux.cn/article-13252-1.html |
>
> 理解 I/O 有助于提升你的效率。
>
>
>

如果你打算学习 C 语言的输入、输出,可以从 `stdio.h` 包含文件开始。正如你从其名字中猜到的,该文件定义了所有的标准(“std”)的输入和输出(“io”)函数。
大多数人学习的第一个 `stdio.h` 的函数是打印格式化输出的 `printf` 函数。或者是用来打印一个字符串的 `puts` 函数。这些函数非常有用,可以将信息打印给用户,但是如果你想做更多的事情,则需要了解其他函数。
你可以通过编写一个常见 Linux 命令的副本来了解其中一些功能和方法。`cp` 命令主要用于复制文件。如果你查看 `cp` 的帮助手册,可以看到 `cp` 命令支持非常多的参数和选项。但最简单的功能,就是复制文件:
```
cp infile outfile
```
你只需使用一些读写文件的基本函数,就可以用 C 语言来自己实现 `cp` 命令。
### 一次读写一个字符
你可以使用 `fgetc` 和 `fputc` 函数轻松地进行输入输出。这些函数一次只读写一个字符。该用法被定义在 `stdio.h`,并且这也很浅显易懂:`fgetc` 是从文件中读取一个字符,`fputc` 是将一个字符保存到文件中。
```
int fgetc(FILE *stream);
int fputc(int c, FILE *stream);
```
编写 `cp` 命令需要访问文件。在 C 语言中,你使用 `fopen` 函数打开一个文件,该函数需要两个参数:文件名和打开文件的模式。模式通常是从文件读取(`r`)或向文件写入(`w`)。打开文件的方式也有其他选项,但是对于本教程而言,仅关注于读写操作。
因此,将一个文件复制到另一个文件就变成了打开源文件和目标文件,接着,不断从第一个文件读取字符,然后将该字符写入第二个文件。`fgetc` 函数返回从输入文件中读取的单个字符,或者当文件完成后返回文件结束标记(`EOF`)。一旦读取到 `EOF`,你就完成了复制操作,就可以关闭两个文件。该代码如下所示:
```
do {
ch = fgetc(infile);
if (ch != EOF) {
fputc(ch, outfile);
}
} while (ch != EOF);
```
你可以使用此循环编写自己的 `cp` 程序,以使用 `fgetc` 和 `fputc` 函数一次读写一个字符。`cp.c` 源代码如下所示:
```
#include <stdio.h>
int
main(int argc, char **argv)
{
FILE *infile;
FILE *outfile;
int ch;
/* parse the command line */
/* usage: cp infile outfile */
if (argc != 3) {
fprintf(stderr, "Incorrect usage\n");
fprintf(stderr, "Usage: cp infile outfile\n");
return 1;
}
/* open the input file */
infile = fopen(argv[1], "r");
if (infile == NULL) {
fprintf(stderr, "Cannot open file for reading: %s\n", argv[1]);
return 2;
}
/* open the output file */
outfile = fopen(argv[2], "w");
if (outfile == NULL) {
fprintf(stderr, "Cannot open file for writing: %s\n", argv[2]);
fclose(infile);
return 3;
}
/* copy one file to the other */
/* use fgetc and fputc */
do {
ch = fgetc(infile);
if (ch != EOF) {
fputc(ch, outfile);
}
} while (ch != EOF);
/* done */
fclose(infile);
fclose(outfile);
return 0;
}
```
你可以使用 `gcc` 来将 `cp.c` 文件编译成一个可执行文件:
```
$ gcc -Wall -o cp cp.c
```
`-o cp` 选项告诉编译器将编译后的程序保存到 `cp` 文件中。`-Wall` 选项告诉编译器提示所有可能的警告,如果你没有看到任何警告,则表示一切正常。
### 读写数据块
通过每次读写一个字符来实现自己的 `cp` 命令可以完成这项工作,但这并不是很快。在复制“日常”文件(例如文档和文本文件)时,你可能不会注意到,但是在复制大型文件或通过网络复制文件时,你才会注意到差异。每次处理一个字符需要大量的开销。
实现此 `cp` 命令的一种更好的方法是,读取一块的输入数据到内存中(称为缓存),然后将该数据集合写入到第二个文件。这样做的速度要快得多,因为程序可以一次读取更多的数据,这就就减少了从文件中“读取”的次数。
你可以使用 `fread` 函数将文件读入一个变量中。这个函数有几个参数:将数据读入的数组或内存缓冲区的指针(`ptr`),要读取的最小对象的大小(`size`),要读取对象的个数(`nmemb`),以及要读取的文件(`stream`):
```
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
```
不同的选项为更高级的文件输入和输出(例如,读取和写入具有特定数据结构的文件)提供了很大的灵活性。但是,在从一个文件读取数据并将数据写入另一个文件的简单情况下,可以使用一个由字符数组组成的缓冲区。
你可以使用 `fwrite` 函数将缓冲区中的数据写入到另一个文件。这使用了与 `fread` 函数有相似的一组选项:要从中读取数据的数组或内存缓冲区的指针,要读取的最小对象的大小,要读取对象的个数以及要写入的文件。
```
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
```
如果程序将文件读入缓冲区,然后将该缓冲区写入另一个文件,则数组(`ptr`)可以是固定大小的数组。例如,你可以使用长度为 200 个字符的字符数组作为缓冲区。
在该假设下,你需要更改 `cp` 程序中的循环,以将数据从文件读取到缓冲区中,然后将该缓冲区写入另一个文件中:
```
while (!feof(infile)) {
buffer_length = fread(buffer, sizeof(char), 200, infile);
fwrite(buffer, sizeof(char), buffer_length, outfile);
}
```
这是更新后的 `cp` 程序的完整源代码,该程序现在使用缓冲区读取和写入数据:
```
#include <stdio.h>
int
main(int argc, char **argv)
{
FILE *infile;
FILE *outfile;
char buffer[200];
size_t buffer_length;
/* parse the command line */
/* usage: cp infile outfile */
if (argc != 3) {
fprintf(stderr, "Incorrect usage\n");
fprintf(stderr, "Usage: cp infile outfile\n");
return 1;
}
/* open the input file */
infile = fopen(argv[1], "r");
if (infile == NULL) {
fprintf(stderr, "Cannot open file for reading: %s\n", argv[1]);
return 2;
}
/* open the output file */
outfile = fopen(argv[2], "w");
if (outfile == NULL) {
fprintf(stderr, "Cannot open file for writing: %s\n", argv[2]);
fclose(infile);
return 3;
}
/* copy one file to the other */
/* use fread and fwrite */
while (!feof(infile)) {
buffer_length = fread(buffer, sizeof(char), 200, infile);
fwrite(buffer, sizeof(char), buffer_length, outfile);
}
/* done */
fclose(infile);
fclose(outfile);
return 0;
}
```
由于你想将此程序与其他程序进行比较,因此请将此源代码另存为 `cp2.c`。你可以使用 `gcc` 编译程序:
```
$ gcc -Wall -o cp2 cp2.c
```
和之前一样,`-o cp2` 选项告诉编译器将编译后的程序保存到 `cp2` 程序文件中。`-Wall` 选项告诉编译器打开所有警告。如果你没有看到任何警告,则表示一切正常。
### 是的,这真的更快了
使用缓冲区读取和写入数据是实现此版本 `cp` 程序更好的方法。由于它可以一次将文件的多个数据读取到内存中,因此该程序不需要频繁读取数据。在小文件中,你可能没有注意到使用这两种方案的区别,但是如果你需要复制大文件,或者在较慢的介质(例如通过网络连接)上复制数据时,会发现明显的差距。
我使用 Linux `time` 命令进行了比较。此命令可以运行另一个程序,然后告诉你该程序花费了多长时间。对于我的测试,我希望了解所花费时间的差距,因此我复制了系统上的 628 MB CD-ROM 镜像文件。
我首先使用标准的 Linux 的 `cp` 命令复制了映像文件,以查看所需多长时间。一开始通过运行 Linux 的 `cp` 命令,同时我还避免使用 Linux 内置的文件缓存系统,使其不会给程序带来误导性能提升的可能性。使用 Linux `cp` 进行的测试,总计花费不到一秒钟的时间:
```
$ time cp FD13LIVE.iso tmpfile
real 0m0.040s
user 0m0.001s
sys 0m0.003s
```
运行我自己实现的 `cp` 命令版本,复制同一文件要花费更长的时间。每次读写一个字符则花了将近五秒钟来复制文件:
```
$ time ./cp FD13LIVE.iso tmpfile
real 0m4.823s
user 0m4.100s
sys 0m0.571s
```
从输入读取数据到缓冲区,然后将该缓冲区写入输出文件则要快得多。使用此方法复制文件花不到一秒钟:
```
$ time ./cp2 FD13LIVE.iso tmpfile
real 0m0.944s
user 0m0.224s
sys 0m0.608s
```
我演示的 `cp` 程序使用了 200 个字符大小的缓冲区。我确信如果一次将更多文件数据读入内存,该程序将运行得更快。但是,通过这种比较,即使只有 200 个字符的缓冲区,你也已经看到了性能上的巨大差异。
---
via: <https://opensource.com/article/21/3/file-io-c>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you want to learn input and output in C, start by looking at the `stdio.h`
include file. As you might guess from the name, that file defines all the standard ("std") input and output ("io") functions.
The first `stdio.h`
function that most people learn is the `printf`
function to print formatted output. Or the `puts`
function to print a simple string. Those are great functions to print information to the user, but if you want to do more than that, you'll need to explore other functions.
You can learn about some of these functions and methods by writing a replica of a common Linux command. The `cp`
command will copy one file to another. If you look at the `cp`
man page, you'll see that `cp`
supports a broad set of command-line parameters and options. But in the simplest case, `cp`
supports copying one file to another:
`cp infile outfile`
You can write your own version of this `cp`
command in C by using only a few basic functions to *read* and *write* files.
## Reading and writing one character at a time
You can easily do input and output using the `fgetc`
and `fputc`
functions. These read and write data one character at a time. The usage is defined in `stdio.h`
and is quite straightforward: `fgetc`
reads (gets) a single character from a file, and `fputc`
puts a single character into a file.
```
int fgetc(FILE *stream);
int fputc(int c, FILE *stream);
```
Writing the `cp`
command requires accessing files. In C, you open a file using the `fopen`
function, which takes two arguments: the *name* of the file and the *mode* you want to use. The mode is usually `r`
to read from a file or `w`
to write to a file. The mode supports other options too, but for this tutorial, just focus on reading and writing.
Copying one file to another then becomes a matter of opening the source and destination files, then *reading one character at a time* from the first file, then *writing that character* to the second file. The `fgetc`
function returns either the single character read from the input file or the *end of file* (`EOF`
) marker when the file is done. Once you've read `EOF`
, you've finished copying and you can close both files. That code looks like this:
```
do {
ch = fgetc(infile);
if (ch != EOF) {
fputc(ch, outfile);
}
} while (ch != EOF);
```
You can write your own `cp`
program with this loop to read and write one character at a time by using the `fgetc`
and `fputc`
functions. The `cp.c`
source code looks like this:
```
#include <stdio.h>
int
main(int argc, char **argv)
{
FILE *infile;
FILE *outfile;
int ch;
/* parse the command line */
/* usage: cp infile outfile */
if (argc != 3) {
fprintf(stderr, "Incorrect usage\n");
fprintf(stderr, "Usage: cp infile outfile\n");
return 1;
}
/* open the input file */
infile = fopen(argv[1], "r");
if (infile == NULL) {
fprintf(stderr, "Cannot open file for reading: %s\n", argv[1]);
return 2;
}
/* open the output file */
outfile = fopen(argv[2], "w");
if (outfile == NULL) {
fprintf(stderr, "Cannot open file for writing: %s\n", argv[2]);
fclose(infile);
return 3;
}
/* copy one file to the other */
/* use fgetc and fputc */
do {
ch = fgetc(infile);
if (ch != EOF) {
fputc(ch, outfile);
}
} while (ch != EOF);
/* done */
fclose(infile);
fclose(outfile);
return 0;
}
```
And you can compile that `cp.c`
file into a full executable using the GNU Compiler Collection (GCC):
`$ gcc -Wall -o cp cp.c`
The `-o cp`
option tells the compiler to save the compiled program into the `cp`
program file. The `-Wall`
option tells the compiler to turn on all warnings. If you don't see any warnings, that means everything worked correctly.
## Reading and writing blocks of data
Programming your own `cp`
command by reading and writing data one character at a time does the job, but it's not very fast. You might not notice when copying "everyday" files like documents and text files, but you'll really notice the difference when copying large files or when copying files over a network. Working on one character at a time requires significant overhead.
A better way to write this `cp`
command is by reading a chunk of the input into memory (called a *buffer*), then writing that collection of data to the second file. This is much faster because the program can read more of the data at one time, which requires fewer "reads" from the file.
You can read a file into a variable by using the `fread`
function. This function takes several arguments: the array or memory buffer to read data into (`ptr`
), the size of the smallest thing you want to read (`size`
), how many of those things you want to read (`nmemb`
), and the file to read from (`stream`
):
`size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);`
The different options provide quite a bit of flexibility for more advanced file input and output, such as reading and writing files with a certain data structure. But in the simple case of *reading data from one file* and *writing data to another file*, you can use a buffer that is an array of characters.
And you can write the buffer to another file using the `fwrite`
function. This uses a similar set of options to the `fread`
function: the array or memory buffer to read data from, the size of the smallest thing you need to write, how many of those things you need to write, and the file to write to.
`size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);`
In the case where the program reads a file into a buffer, then writes that buffer to another file, the array (`ptr`
) can be an array of a fixed size. For example, you can use a `char`
array called `buffer`
that is 200 characters long.
With that assumption, you need to change the loop in your `cp`
program to *read data from a file into a buffer* then *write that buffer to another file*:
```
while (!feof(infile)) {
buffer_length = fread(buffer, sizeof(char), 200, infile);
fwrite(buffer, sizeof(char), buffer_length, outfile);
}
```
Here's the full source code to your updated `cp`
program, which now uses a buffer to read and write data:
```
#include <stdio.h>
int
main(int argc, char **argv)
{
FILE *infile;
FILE *outfile;
char buffer[200];
size_t buffer_length;
/* parse the command line */
/* usage: cp infile outfile */
if (argc != 3) {
fprintf(stderr, "Incorrect usage\n");
fprintf(stderr, "Usage: cp infile outfile\n");
return 1;
}
/* open the input file */
infile = fopen(argv[1], "r");
if (infile == NULL) {
fprintf(stderr, "Cannot open file for reading: %s\n", argv[1]);
return 2;
}
/* open the output file */
outfile = fopen(argv[2], "w");
if (outfile == NULL) {
fprintf(stderr, "Cannot open file for writing: %s\n", argv[2]);
fclose(infile);
return 3;
}
/* copy one file to the other */
/* use fread and fwrite */
while (!feof(infile)) {
buffer_length = fread(buffer, sizeof(char), 200, infile);
fwrite(buffer, sizeof(char), buffer_length, outfile);
}
/* done */
fclose(infile);
fclose(outfile);
return 0;
}
```
Since you want to compare this program to the other program, save this source code as `cp2.c`
. You can compile that updated program using GCC:
`$ gcc -Wall -o cp2 cp2.c`
As before, the `-o cp2`
option tells the compiler to save the compiled program into the `cp2`
program file. The `-Wall`
option tells the compiler to turn on all warnings. If you don't see any warnings, that means everything worked correctly.
## Yes, it really is faster
Reading and writing data using buffers is the better way to write this version of the `cp`
program. Because it reads chunks of a file into memory at once, the program doesn't need to read data as often. You might not notice a difference in using either method on smaller files, but you'll really see the difference if you need to copy something that's much larger or when copying data on slower media like over a network connection.
I ran a runtime comparison using the Linux `time`
command. This command runs another program, then tells you how long that program took to complete. For my test, I wanted to see the difference in time, so I copied a 628MB CD-ROM image file I had on my system.
I first copied the image file using the standard Linux `cp`
command to see how long that takes. By running the Linux `cp`
command first, I also eliminated the possibility that Linux's built-in file-cache system wouldn't give my program a false performance boost. The test with Linux `cp`
took much less than one second to run:
```
$ time cp FD13LIVE.iso tmpfile
real 0m0.040s
user 0m0.001s
sys 0m0.003s
```
Copying the same file using my own version of the `cp`
command took significantly longer. Reading and writing one character at a time took almost five seconds to copy the file:
```
$ time ./cp FD13LIVE.iso tmpfile
real 0m4.823s
user 0m4.100s
sys 0m0.571s
```
Reading data from an input into a buffer and then writing that buffer to an output file is much faster. Copying the file using this method took less than a second:
```
$ time ./cp2 FD13LIVE.iso tmpfile
real 0m0.944s
user 0m0.224s
sys 0m0.608s
```
My demonstration `cp`
program used a buffer that was 200 characters. I'm sure the program would run much faster if I read more of the file into memory at once. But for this comparison, you can already see the huge difference in performance, even with a small, 200 character buffer.
## Comments are closed. |
13,253 | 用一个开源工具实现多线程 Python 程序的可视化 | https://opensource.com/article/21/3/python-viztracer | 2021-03-30T23:04:00 | [
"Python",
"可视化"
] | https://linux.cn/article-13253-1.html |
>
> VizTracer 可以跟踪并发的 Python 程序,以帮助记录、调试和剖析。
>
>
>

并发是现代编程中必不可少的一部分,因为我们有多个核心,有许多需要协作的任务。然而,当并发程序不按顺序运行时,就很难理解它们。对于工程师来说,在这些程序中发现 bug 和性能问题不像在单线程、单任务程序中那么容易。
在 Python 中,你有多种并发的选择。最常见的可能是用 `threading` 模块的多线程,用`subprocess` 和 `multiprocessing` 模块的多进程,以及最近用 `asyncio` 模块提供的 `async` 语法。在 [VizTracer](https://readthedocs.org/projects/viztracer/) 之前,缺乏分析使用了这些技术程序的工具。
VizTracer 是一个追踪和可视化 Python 程序的工具,对日志、调试和剖析很有帮助。尽管它对单线程、单任务程序很好用,但它在并发程序中的实用性是它的独特之处。
### 尝试一个简单的任务
从一个简单的练习任务开始:计算出一个数组中的整数是否是质数并返回一个布尔数组。下面是一个简单的解决方案:
```
def is_prime(n):
for i in range(2, n):
if n % i == 0:
return False
return True
def get_prime_arr(arr):
return [is_prime(elem) for elem in arr]
```
试着用 VizTracer 以单线程方式正常运行它:
```
if __name__ == "__main__":
num_arr = [random.randint(100, 10000) for _ in range(6000)]
get_prime_arr(num_arr)
```
```
viztracer my_program.py
```

调用堆栈报告显示,耗时约 140ms,大部分时间花在 `get_prime_arr` 上。

这只是在数组中的元素上一遍又一遍地执行 `is_prime` 函数。
这是你所期望的,而且它并不有趣(如果你了解 VizTracer 的话)。
### 试试多线程程序
试着用多线程程序来做:
```
if __name__ == "__main__":
num_arr = [random.randint(100, 10000) for i in range(2000)]
thread1 = Thread(target=get_prime_arr, args=(num_arr,))
thread2 = Thread(target=get_prime_arr, args=(num_arr,))
thread3 = Thread(target=get_prime_arr, args=(num_arr,))
thread1.start()
thread2.start()
thread3.start()
thread1.join()
thread2.join()
thread3.join()
```
为了配合单线程程序的工作负载,这就为三个线程使用了一个 2000 元素的数组,模拟了三个线程共享任务的情况。

如果你熟悉 Python 的全局解释器锁(GIL),就会想到,它不会再快了。由于开销太大,花了 140ms 多一点的时间。不过,你可以观察到多线程的并发性:

当一个线程在工作(执行多个 `is_prime` 函数)时,另一个线程被冻结了(一个 `is_prime` 函数);后来,它们进行了切换。这是由于 GIL 的原因,这也是 Python 没有真正的多线程的原因。它可以实现并发,但不能实现并行。
### 用多进程试试
要想实现并行,办法就是 `multiprocessing` 库。下面是另一个使用 `multiprocessing` 的版本:
```
if __name__ == "__main__":
num_arr = [random.randint(100, 10000) for _ in range(2000)]
p1 = Process(target=get_prime_arr, args=(num_arr,))
p2 = Process(target=get_prime_arr, args=(num_arr,))
p3 = Process(target=get_prime_arr, args=(num_arr,))
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
```
要使用 VizTracer 运行它,你需要一个额外的参数:
```
viztracer --log_multiprocess my_program.py
```

整个程序在 50ms 多一点的时间内完成,实际任务在 50ms 之前完成。程序的速度大概提高了三倍。
为了和多线程版本进行比较,这里是多进程版本:

在没有 GIL 的情况下,多个进程可以实现并行,也就是多个 `is_prime` 函数可以并行执行。
不过,Python 的多线程也不是一无是处。例如,对于计算密集型和 I/O 密集型程序,你可以用睡眠来伪造一个 I/O 绑定的任务:
```
def io_task():
time.sleep(0.01)
```
在单线程、单任务程序中试试:
```
if __name__ == "__main__":
for _ in range(3):
io_task()
```

整个程序用了 30ms 左右,没什么特别的。
现在使用多线程:
```
if __name__ == "__main__":
thread1 = Thread(target=io_task)
thread2 = Thread(target=io_task)
thread3 = Thread(target=io_task)
thread1.start()
thread2.start()
thread3.start()
thread1.join()
thread2.join()
thread3.join()
```

程序耗时 10ms,很明显三个线程是并发工作的,这提高了整体性能。
### 用 asyncio 试试
Python 正在尝试引入另一个有趣的功能,叫做异步编程。你可以制作一个异步版的任务:
```
import asyncio
async def io_task():
await asyncio.sleep(0.01)
async def main():
t1 = asyncio.create_task(io_task())
t2 = asyncio.create_task(io_task())
t3 = asyncio.create_task(io_task())
await t1
await t2
await t3
if __name__ == "__main__":
asyncio.run(main())
```
由于 `asyncio` 从字面上看是一个带有任务的单线程调度器,你可以直接在它上使用 VizTracer:

依然花了 10ms,但显示的大部分函数都是底层结构,这可能不是用户感兴趣的。为了解决这个问题,可以使用 `--log_async` 来分离真正的任务:
```
viztracer --log_async my_program.py
```

现在,用户任务更加清晰了。在大部分时间里,没有任务在运行(因为它唯一做的事情就是睡觉)。有趣的部分是这里:

这显示了任务的创建和执行时间。Task-1 是 `main()` 协程,创建了其他任务。Task-2、Task-3、Task-4 执行 `io_task` 和 `sleep` 然后等待唤醒。如图所示,因为是单线程程序,所以任务之间没有重叠,VizTracer 这样可视化是为了让它更容易理解。
为了让它更有趣,可以在任务中添加一个 `time.sleep` 的调用来阻止异步循环:
```
async def io_task():
time.sleep(0.01)
await asyncio.sleep(0.01)
```

程序耗时更长(40ms),任务填补了异步调度器中的空白。
这个功能对于诊断异步程序的行为和性能问题非常有帮助。
### 看看 VizTracer 发生了什么?
通过 VizTracer,你可以在时间轴上查看程序的进展情况,而不是从复杂的日志中想象。这有助于你更好地理解你的并发程序。
VizTracer 是开源的,在 Apache 2.0 许可证下发布,支持所有常见的操作系统(Linux、macOS 和 Windows)。你可以在 [VizTracer 的 GitHub 仓库](https://github.com/gaogaotiantian/viztracer)中了解更多关于它的功能和访问它的源代码。
---
via: <https://opensource.com/article/21/3/python-viztracer>
作者:[Tian Gao](https://opensource.com/users/gaogaotiantian) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Concurrency is an essential part of modern programming, as we have multiple cores and many tasks that need to cooperate. However, it's harder to understand concurrent programs when they are not running sequentially. It's not as easy for engineers to identify bugs and performance issues in these programs as it is in a single-thread, single-task program.
With Python, you have multiple options for concurrency. The most common ones are probably multi-threaded with the threading module, multiprocess with the subprocess and multiprocessing modules, and the more recent async syntax with the asyncio module. Before [VizTracer](https://readthedocs.org/projects/viztracer/), there was a lack of tools to analyze programs using these techniques.
VizTracer is a tool for tracing and visualizing Python programs, which is helpful for logging, debugging, and profiling. Even though it works well for single-thread, single-task programs, its utility in concurrent programs is what makes it unique.
## Try a simple task
Start with a simple practice task: Figure out whether the integers in an array are prime numbers and return a Boolean array. Here is a simple solution:
```
def is_prime(n):
for i in range(2, n):
if n % i == 0:
return False
return True
def get_prime_arr(arr):
return [is_prime(elem) for elem in arr]
```
Try to run it normally, in a single thread, with VizTracer:
```
if __name__ == "__main__":
num_arr = [random.randint(100, 10000) for _ in range(6000)]
get_prime_arr(num_arr)
```
`viztracer my_program.py`

(Tian Gao, CC BY-SA 4.0)
The call-stack report indicates it took about 140ms, with most of the time spent in `get_prime_arr`
.
(Tian Gao, CC BY-SA 4.0)
It's just doing the `is_prime`
function over and over again on the elements in the array.
This is what you would expect, and it's not that interesting (if you know VizTracer).
## Try a multi-thread program
Try doing it with a multi-thread program:
```
if __name__ == "__main__":
num_arr = [random.randint(100, 10000) for i in range(2000)]
thread1 = Thread(target=get_prime_arr, args=(num_arr,))
thread2 = Thread(target=get_prime_arr, args=(num_arr,))
thread3 = Thread(target=get_prime_arr, args=(num_arr,))
thread1.start()
thread2.start()
thread3.start()
thread1.join()
thread2.join()
thread3.join()
```
To match the single-thread program's workload, this uses a 2,000-element array for three threads, simulating a situation where three threads are sharing the task.

(Tian Gao, CC BY-SA 4.0)
As you would expect if you are familiar with Python's Global Interpreter Lock (GIL), it won't get any faster. It took a little bit more than 140ms due to the overhead. However, you can observe the concurrency of multiple threads:

(Tian Gao, CC BY-SA 4.0)
When one thread was working (executing multiple `is_prime`
functions), the other one was frozen (one `is_prime`
function); later, they switched. This is due to GIL, and it is the reason Python does not have true multi-threading. It can achieve concurrency but not parallelism.
## Try it with multiprocessing
To achieve parallelism, the way to go is the multiprocessing library. Here is another version with multiprocessing:
```
if __name__ == "__main__":
num_arr = [random.randint(100, 10000) for _ in range(2000)]
p1 = Process(target=get_prime_arr, args=(num_arr,))
p2 = Process(target=get_prime_arr, args=(num_arr,))
p3 = Process(target=get_prime_arr, args=(num_arr,))
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
```
To run it with VizTracer, you need an extra argument:
`viztracer --log_multiprocess my_program.py`

(Tian Gao, CC BY-SA 4.0)
The whole program finished in a little more than 50ms, with the actual task finishing before the 50ms mark. The program's speed roughly tripled.
To compare it with the multi-thread version, here is the multiprocess version:

(Tian Gao, CC BY-SA 4.0)
Without GIL, multiple processes can achieve parallelism, which means multiple `is_prime`
functions can execute in parallel.
However, Python's multi-thread is not useless. For example, for computation-intensive and I/O-intensive programs, you can fake an I/O-bound task with sleep:
```
def io_task():
time.sleep(0.01)
```
Try it in a single-thread, single-task program:
```
if __name__ == "__main__":
for _ in range(3):
io_task()
```

(Tian Gao, CC BY-SA 4.0)
The full program took about 30ms; nothing special.
Now use multi-thread:
```
if __name__ == "__main__":
thread1 = Thread(target=io_task)
thread2 = Thread(target=io_task)
thread3 = Thread(target=io_task)
thread1.start()
thread2.start()
thread3.start()
thread1.join()
thread2.join()
thread3.join()
```

(Tian Gao, CC BY-SA 4.0)
The program took 10ms, and it's clear how the three threads worked concurrently and improved the overall performance.
## Try it with asyncio
Python is trying to introduce another interesting feature called async programming. You can make an async version of this task:
```
import asyncio
async def io_task():
await asyncio.sleep(0.01)
async def main():
t1 = asyncio.create_task(io_task())
t2 = asyncio.create_task(io_task())
t3 = asyncio.create_task(io_task())
await t1
await t2
await t3
if __name__ == "__main__":
asyncio.run(main())
```
As asyncio is literally a single-thread scheduler with tasks, you can use VizTracer directly on it:

<p class="rtecenter"><sup>(Tian Gao, <a href="https://opensource.com/%3Ca%20href%3D"https://creativecommons.org/licenses/by-sa/4.0/" rel="ugc">https://creativecommons.org/licenses/by-sa/4.0/" target="_blank">CC BY-SA 4.0</a>)</sup></p>
It still took 10ms, but most of the functions displayed are the underlying structure, which is probably not what users are interested in. To solve this, you can use `--log_async`
to separate the real task:
`viztracer --log_async my_program.py`
(Tian Gao, CC BY-SA 4.0)
Now the user tasks are much clearer. For most of the time, no tasks are running (because the only thing it does is sleep). Here's the interesting part:
(Tian Gao, CC BY-SA 4.0)
This shows when the tasks were created and executed. Task-1 was the `main()`
co-routine and created other tasks. Tasks 2, 3, and 4 executed `io_task`
and `sleep`
then waited for the wake-up. As the graph shows, there is no overlap between tasks because it's a single-thread program, and VizTracer visualized it this way to make it more understandable.
To make it more interesting, add a `time.sleep`
call in the task to block the async loop:
```
async def io_task():
time.sleep(0.01)
await asyncio.sleep(0.01)
```

(Tian Gao, CC BY-SA 4.0)
The program took much longer (40ms), and the tasks filled the blanks in the async scheduler.
This feature is very helpful for diagnosing behavior and performance issues in async programs.
## See what's happening with VizTracer
With VizTracer, you can see what's going on with your program on a timeline, rather than imaging it from complicated logs. This helps you understand your concurrent programs better.
VizTracer is open source, released under the Apache 2.0 license, and supports all common operating systems (Linux, macOS, and Windows). You can learn more about its features and access its source code in [VizTracer's GitHub repository](https://github.com/gaogaotiantian/viztracer).
## Comments are closed. |
13,255 | 在家就能用得起的高温 3D 打印机 | https://opensource.com/article/21/3/desktop-3d-printer | 2021-03-31T23:05:17 | [
"3D打印机"
] | https://linux.cn/article-13255-1.html |
>
> 有多实惠?低于 1000 美元。
>
>
>

3D 打印机从 20 世纪 80 年代就已经出现了,但是由于 [RepRap](https://reprap.org/wiki/RepRap) 项目的出现,它们直到获得开源才受到人们的关注。RepRap 意即<ruby> 自我复制快速原型机 <rt> self-replicating rapid prototyper </rt></ruby>,它是一种基本上可以自己打印的 3D 打印机。它的开源计划[2004 年](https://reprap.org/wiki/Wealth_Without_Money) 发布之后,导致 3D 打印机的成本从几十万美金降到了几百美金。
这些开源的桌面工具一直局限于 ABS 等低性能、低温热塑性塑料(如乐高积木)。市场上有几款高温打印机,但其高昂的成本(几万到几十万美元)使大多数人无法获得。直到最近,它们才参与了很多竞争,因为它们被一项专利 (US6722872B1) 锁定,该专利于 2021 年 2 月 27 日[到期](https://3dprintingindustry.com/news/stratasys-heated-build-chamber-for-3d-printer-patent-us6722872b1-set-to-expire-this-week-185012/)。
随着这个路障的消除,我们即将看到高温、低成本、熔融纤维 3D 打印机的爆发。
价格低到什么程度?低于 1000 美元如何。
在疫情最严重的时候,我的团队赶紧发布了一个 [开源高温 3D 打印机](https://doi.org/10.1016/j.ohx.2020.e00130) 的设计,用于制造可高温消毒的个人防护装备(PPE)。该项目的想法是让人们能够 [用高温材料打印 PPE](https://www.appropedia.org/Open_Source_High-Temperature_Reprap_for_3-D_Printing_Heat-Sterilizable_PPE_and_Other_Applications)(如口罩),并将它放入家用烤箱进行消毒。我们称我们的设备为 Cerberus,它具有以下特点:
1. 可达到 200℃ 的加热床
2. 可达到 500℃ 的热源
3. 带有 1kW 加热器核心的隔离式加热室。
4. 主电源(交流电源)电压室和床身加热,以便快速启动。
你可以用现成的零件来构建这个项目,其中一些零件你可以打印,价格不到 1000 美元。它可以成功打印聚醚酮酮 (PEKK) 和聚醚酰亚胺(PEI,以商品名 Ultem 出售)。这两种材料都比现在低成本打印机能打印的任何材料强得多。

这款高温 3D 打印机的设计是有三个头,但我们发布的时候只有一个头。Cerberus 是以希腊神话中的三头冥界看门狗命名的。通常情况下,我们不会发布只有一个头的打印机,但疫情改变了我们的优先级。[开源社区团结起来](https://opensource.com/article/20/3/volunteer-covid19),帮助解决早期的供应不足,许多桌面 3D 打印机都在产出有用的产品,以帮助保护人们免受 COVID 的侵害。
那另外两个头呢?
其他两个头是为了高温熔融颗粒制造(例如,这个开源的 [3D打印机](https://www.liebertpub.com/doi/10.1089/3dp.2019.0195) 的高温版本)并铺设金属线(像在 [这个设计](https://www.appropedia.org/Open_Source_Multi-Head_3D_Printer_for_Polymer-Metal_Composite_Component_Manufacturing) 中),以建立一个开源的热交换器。Cerberus 打印机的其他功能可能是一个自动喷嘴清洁器和在高温下打印连续纤维的方法。另外,你还可以在转台上安装任何你喜欢的东西来制造高端产品。
把一个盒子放在 3D 打印机周围,而把电子元件留在外面的 [专利](https://www.academia.edu/17609790/A_Novel_Approach_to_Obviousness_An_Algorithm_for_Identifying_Prior_Art_Concerning_3-D_Printing_Materials) 到期,为高温家用 3D 打印机铺平了道路,这将使这些设备以合理的成本从单纯的玩具变为工业工具。
已经有公司在 RepRap 传统的基础上,将这些低成本系统推向市场(例如,1250 美元的 [Creality3D CR-5 Pro](https://creality3d.shop/collections/cr-series/products/cr-5-pro-h-3d-printer) 3D 打印机可以达到 300℃)。Creality 销售最受欢迎的桌面 3D 打印机,并开源了部分设计。
然而,要打印超高端工程聚合物,这些打印机需要达到 350℃ 以上。开源计划已经可以帮助桌面 3D 打印机制造商开始与垄断公司竞争,这些公司由于躲在专利背后,已经阻碍了 3D 打印 20 年。期待低成本、高温桌面 3D 打印机的竞争将真正升温!
---
via: <https://opensource.com/article/21/3/desktop-3d-printer>
作者:[Joshua Pearce](https://opensource.com/users/jmpearce) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 3D printers have been around since the 1980s, but they didn't gain popular attention until they became open source, thanks to the [RepRap](https://reprap.org/wiki/RepRap) project. RepRap stands for self-replicating rapid prototyper; it's a 3D printer that can largely print itself. The open source plans were released [in 2004](https://reprap.org/wiki/Wealth_Without_Money) and led to 3D printer costs dropping from hundreds of thousands of dollars to a few hundred dollars.
These open source desktop tools have been limited to low-performance, low-temperature thermoplastics like ABS (e.g., Lego blocks). There are several high-temperature printers on the market, but their high costs (tens to hundreds of thousands of dollars) make them inaccessible to most people. They didn't have a lot of competition until recently because they were locked up by a patent (US6722872B1), which [expired](https://3dprintingindustry.com/news/stratasys-heated-build-chamber-for-3d-printer-patent-us6722872b1-set-to-expire-this-week-185012/) on February 27, 2021.
With this roadblock removed, we are about to see an explosion of high-temperature, low-cost, fused-filament 3D printers.
How low? How about under $1,000.
During the height of the pandemic, my team rushed to publish designs for an [open source high-temperature 3D printer](https://doi.org/10.1016/j.ohx.2020.e00130) for manufacturing heat-sterilizable personal protective equipment (PPE). The project's idea is to enable people [to print PPE](https://www.appropedia.org/Open_Source_High-Temperature_Reprap_for_3-D_Printing_Heat-Sterilizable_PPE_and_Other_Applications) (e.g., masks) with high-temperature materials and pop them in their home oven to sterilize them. We call our device the Cerberus, and it has the following features:
- 200°C capable heated bed
- 500°C capable hot end
- Isolated heated chamber with 1kW space heater core
- Mains (AC power) voltage chamber and bed heating for rapid start
You can build this project from readily available parts, some of which you can print, for under $1,000. It successfully prints polyetherketoneketone (PEKK) and polyetherimide (PEI, which sells under the trade name Ultem). Both materials are much stronger than anything that can be printed today on low-cost printers.

(J.M.Pearce, GNU Free Documentation License)
The high-temperature 3D printer was designed to have three heads, but we released it with only one. The Cerberus is named after Greek mythology's three-headed watchdog of the underworld. Normally we would not have released the printer with only one head, but the pandemic shifted our priorities. The [open source community rallied](https://opensource.com/article/20/3/volunteer-covid19) to help solve supply deficits early on, and many desktop 3D printers were spitting out useful products to help protect people from COVID.
What about the other two heads?
The other two heads were intended for high-temperature fused particle fabricators (e.g., the high-temperature version of this open source [3D printer hack](https://www.liebertpub.com/doi/10.1089/3dp.2019.0195)) and laying in metal wire (like in [this design](https://www.appropedia.org/Open_Source_Multi-Head_3D_Printer_for_Polymer-Metal_Composite_Component_Manufacturing)) to build an open source heat exchanger. Other functionalities for the Cerberus printer might be an automatic nozzle cleaner and a method to print continuous fibers at high temperatures. Also, you can mount anything you like on the turret to manufacture high-end products.
The expiration of the [obvious patent](https://www.academia.edu/17609790/A_Novel_Approach_to_Obviousness_An_Algorithm_for_Identifying_Prior_Art_Concerning_3-D_Printing_Materials) for putting a box around a 3D printer while leaving the electronics on the outside paves the way for high-temperature home 3D printers, which will enable these devices to graduate from mere toys to industrial tools at reasonable costs.
Companies are already building on the RepRap tradition and bringing these low-cost systems to the market (e.g., the $1,250 [Creality3D CR-5 Pro](https://creality3d.shop/collections/cr-series/products/cr-5-pro-h-3d-printer) 3D printer that can get to 300°C). Creality sells the most popular desktop 3D printer and has open sourced some of its designs.
To print super-high-end engineering polymers, however, these printers will need to get over 350°C. Open source plans are already available to help desktop 3D printer manufacturers start competing with the lumbering companies that have held back 3D printing for 20 years as they hid behind patents. Expect the competition for low-cost, high-temperature desktop 3D printers to really heat up!
## Comments are closed. |
13,256 | 用 Ansible 自动化系统管理员的 5 个日常任务 | https://opensource.com/article/21/3/ansible-sysadmin | 2021-03-31T23:39:12 | [
"Ansible"
] | https://linux.cn/article-13256-1.html |
>
> 通过使用 Ansible 自动执行可重复的日常任务,提高工作效率并避免错误。
>
>
>

如果你讨厌执行重复性的任务,那么我有一个提议给你,去学习 [Ansible](https://www.ansible.com/)!
Ansible 是一个工具,它可以帮助你更轻松、更快速地完成日常任务,这样你就可以更有效地利用时间,比如学习重要的新技术。对于系统管理员来说,它是一个很好的工具,因为它可以帮助你实现标准化,并在日常活动中进行协作,包括:
1. 安装、配置和调配服务器和应用程序;
2. 定期更新和升级系统;
3. 监测、减轻和排除问题。
通常,许多这些基本的日常任务都需要手动步骤,而根据个人的技能的不同,可能会造成不一致并导致配置发生漂移。这在小规模的实施中可能是可以接受的,因为你管理一台服务器,并且知道自己在做什么。但当你管理数百或数千台服务器时会发生什么?
如果不小心,这些手动的、可重复的任务可能会因为人为的错误而造成延误和问题,而这些错误可能会影响你及你的组织的声誉。
这就是自动化的价值所在。而 [Ansible](https://opensource.com/tags/ansible) 是自动化这些可重复的日常任务的完美工具。
自动化的一些原因是:
1. 你想要一个一致和稳定的环境。
2. 你想要促进标准化。
3. 你希望减少停机时间,减少严重事故案例,以便可以享受生活。
4. 你想喝杯啤酒,而不是排除故障问题!
本文提供了一些系统管理员可以使用 Ansible 自动化的日常任务的例子。我把本文中的剧本和角色放到了 GitHub 上的 [系统管理员任务仓库](https://github.com/mikecali/6_sysadmin_tasks) 中,以方便你使用它们。
这些剧本的结构是这样的(我的注释前面有 `==>`)。
```
[root@homebase 6_sysadmin_tasks]# tree -L 2
.
├── ansible.cfg ==> 负责控制 Ansible 行为的配置文件
├── ansible.log
├── inventory
│ ├── group_vars
│ ├── hosts ==> 包含我的目标服务器列表的清单文件
│ └── host_vars
├── LICENSE
├── playbooks ==> 包含我们将在本文中使用的剧本的目录
│ ├── c_logs.yml
│ ├── c_stats.yml
│ ├── c_uptime.yml
│ ├── inventory
│ ├── r_cron.yml
│ ├── r_install.yml
│ └── r_script.yml
├── README.md
├── roles ==> 包含我们将在本文中使用的角色的目录
│ ├── check_logs
│ ├── check_stats
│ ├── check_uptime
│ ├── install_cron
│ ├── install_tool
│ └── run_scr
└── templates ==> 包含 jinja 模板的目录
├── cron_output.txt.j2
├── sar.txt.j2
└── scr_output.txt.j2
```
清单类似这样的:
```
[root@homebase 6_sysadmin_tasks]# cat inventory/hosts
[rhel8]
master ansible_ssh_host=192.168.1.12
workernode1 ansible_ssh_host=192.168.1.15
[rhel8:vars]
ansible_user=ansible ==> 请用你的 ansible 用户名更新它
```
这里有五个你可以用 Ansible 自动完成的日常系统管理任务。
### 1、检查服务器的正常运行时间
你需要确保你的服务器一直处于正常运行状态。机构会拥有企业监控工具来监控服务器和应用程序的正常运行时间,但自动监控工具时常会出现故障,你需要登录进去验证一台服务器的状态。手动验证每台服务器的正常运行时间需要花费大量的时间。你的服务器越多,你需要花费的时间就越长。但如果有了自动化,这种验证可以在几分钟内完成。
使用 [check\_uptime](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_uptime) 角色和 `c_uptime.yml` 剧本:
```
[root@homebase 6_sysadmin_tasks]# ansible-playbook -i inventory/hosts playbooks/c_uptime.yml -k
SSH password:
PLAY [Check Uptime for Servers] ****************************************************************************************************************************************
TASK [check_uptime : Capture timestamp] *************************************************************************************************
.
截断...
.
PLAY RECAP *************************************************************************************************************************************************************
master : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
[root@homebase 6_sysadmin_tasks]#
```
剧本的输出是这样的:
```
[root@homebase 6_sysadmin_tasks]# cat /var/tmp/uptime-master-20210221004417.txt
-----------------------------------------------------
Uptime for master
-----------------------------------------------------
00:44:17 up 44 min, 2 users, load average: 0.01, 0.09, 0.09
-----------------------------------------------------
[root@homebase 6_sysadmin_tasks]# cat /var/tmp/uptime-workernode1-20210221184525.txt
-----------------------------------------------------
Uptime for workernode1
-----------------------------------------------------
18:45:26 up 44 min, 2 users, load average: 0.01, 0.01, 0.00
-----------------------------------------------------
```
使用 Ansible,你可以用较少的努力以人类可读的格式获得多个服务器的状态,[Jinja 模板](https://docs.ansible.com/ansible/latest/user_guide/playbooks_templating.html) 允许你根据自己的需要调整输出。通过更多的自动化,你可以按计划运行,并通过电子邮件发送输出,以达到报告的目的。
### 2、配置额外的 cron 作业
你需要根据基础设施和应用需求定期更新服务器的计划作业。这似乎是一项微不足道的工作,但必须正确且持续地完成。想象一下,如果你对数百台生产服务器进行手动操作,这需要花费多少时间。如果做错了,就会影响生产应用程序,如果计划的作业重叠,就会导致应用程序停机或影响服务器性能。
使用 [install\_cron](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/install_cron) 角色和 `r_cron.yml` 剧本:
```
[root@homebase 6_sysadmin_tasks]# ansible-playbook -i inventory/hosts playbooks/r_cron.yml -k
SSH password:
PLAY [Install additional cron jobs for root] ***************************************************************************************************************************
.
截断...
.
PLAY RECAP *************************************************************************************************************************************************************
master : ok=10 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=10 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
验证剧本的结果:
```
[root@homebase 6_sysadmin_tasks]# ansible -i inventory/hosts all -m shell -a "crontab -l" -k
SSH password:
master | CHANGED | rc=0 >>
1 2 3 4 5 /usr/bin/ls /tmp
#Ansible: Iotop Monitoring
0 5,2 * * * /usr/sbin/iotop -b -n 1 >> /var/tmp/iotop.log 2>> /var/tmp/iotop.err
workernode1 | CHANGED | rc=0 >>
1 2 3 4 5 /usr/bin/ls /tmp
#Ansible: Iotop Monitoring
0 5,2 * * * /usr/sbin/iotop -b -n 1 >> /var/tmp/iotop.log 2>> /var/tmp/iotop.err
```
使用 Ansible,你可以以快速和一致的方式更新所有服务器上的 crontab 条目。你还可以使用一个简单的点对点 Ansible 命令来报告更新后的 crontab 的状态,以验证最近应用的变化。
### 3、收集服务器统计和 sars
在常规的故障排除过程中,为了诊断服务器性能或应用程序问题,你需要收集<ruby> 系统活动报告 <rt> system activity reports </rt></ruby>(sars)和服务器统计。在大多数情况下,服务器日志包含非常重要的信息,开发人员或运维团队需要这些信息来帮助解决影响整个环境的具体问题。
安全团队在进行调查时非常特别,大多数时候,他们希望查看多个服务器的日志。你需要找到一种简单的方法来收集这些文档。如果你能把收集任务委托给他们就更好了。
通过 [check\_stats](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_stats) 角色和 `c_stats.yml` 剧本来完成这个任务:
```
$ ansible-playbook -i inventory/hosts playbooks/c_stats.yml
PLAY [Check Stats/sar for Servers] ***********************************************************************************************************************************
TASK [check_stats : Get current date time] ***************************************************************************************************************************
changed: [master]
changed: [workernode1]
.
截断...
.
PLAY RECAP ***********************************************************************************************************************************************************
master : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
输出看起来像这样:
```
$ cat /tmp/sar-workernode1-20210221214056.txt
-----------------------------------------------------
sar output for workernode1
-----------------------------------------------------
Linux 4.18.0-193.el8.x86_64 (node1) 21/02/21 _x86_64_ (2 CPU)
21:39:30 LINUX RESTART (2 CPU)
-----------------------------------------------------
```
### 4、收集服务器日志
除了收集服务器统计和 sars 信息,你还需要不时地收集日志,尤其是当你需要帮助调查问题时。
通过 [check\_logs](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_logs) 角色和 `r_cron.yml` 剧本来实现:
```
$ ansible-playbook -i inventory/hosts playbooks/c_logs.yml -k
SSH password:
PLAY [Check Logs for Servers] ****************************************************************************************************************************************
.
截断...
.
TASK [check_logs : Capture Timestamp] ********************************************************************************************************************************
changed: [master]
changed: [workernode1]
PLAY RECAP ***********************************************************************************************************************************************************
master : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
为了确认输出,打开转储位置生成的文件。日志应该是这样的:
```
$ cat /tmp/logs-workernode1-20210221214758.txt | more
-----------------------------------------------------
Logs gathered: /var/log/messages for workernode1
-----------------------------------------------------
Feb 21 18:00:27 node1 kernel: Command line: BOOT_IMAGE=(hd0,gpt2)/vmlinuz-4.18.0-193.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel
-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet
Feb 21 18:00:27 node1 kernel: Disabled fast string operations
Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
Feb 21 18:00:27 node1 kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
Feb 21 18:00:27 node1 kernel: x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'compacted' format.
```
### 5、安装或删除软件包和软件
你需要能够持续快速地在系统上安装和更新软件和软件包。缩短安装或更新软件包和软件所需的时间,可以避免服务器和应用程序不必要的停机时间。
通过 [install\_tool](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/install_tool) 角色和 `r_install.yml` 剧本来实现这一点:
```
$ ansible-playbook -i inventory/hosts playbooks/r_install.yml -k
SSH password:
PLAY [Install additional tools/packages] ***********************************************************************************
TASK [install_tool : Install specified tools in the role vars] *************************************************************
ok: [master] => (item=iotop)
ok: [workernode1] => (item=iotop)
ok: [workernode1] => (item=traceroute)
ok: [master] => (item=traceroute)
PLAY RECAP *****************************************************************************************************************
master : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
这个例子安装了在 vars 文件中定义的两个特定包和版本。使用 Ansible 自动化,你可以比手动安装更快地安装多个软件包或软件。你也可以使用 vars 文件来定义你要安装的软件包的版本。
```
$ cat roles/install_tool/vars/main.yml
---
# vars file for install_tool
ins_action: absent
package_list:
- iotop-0.6-16.el8.noarch
- traceroute
```
### 拥抱自动化
要成为一名有效率的系统管理员,你需要接受自动化来鼓励团队内部的标准化和协作。Ansible 使你能够在更少的时间内做更多的事情,这样你就可以将时间花在更令人兴奋的项目上,而不是做重复的任务,如管理你的事件和问题管理流程。
有了更多的空闲时间,你可以学习更多的知识,让自己可以迎接下一个职业机会的到来。
---
via: <https://opensource.com/article/21/3/ansible-sysadmin>
作者:[Mike Calizo](https://opensource.com/users/mcalizo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you hate performing repetitive tasks, then I have a proposition for you. Learn [Ansible](https://www.ansible.com/)!
Ansible is a tool that will help you do your daily tasks easier and faster, so you can use your time in more effective ways, like learning new technology that matters. It's a great tool for sysadmins because it helps you achieve standardization and collaborate on daily activities, including:
- Installing, configuring, and provisioning servers and applications
- Updating and upgrading systems regularly
- Monitoring, mitigating, and troubleshooting issues
Typically, many of these essential daily tasks require manual steps that depend upon an individual's skills, creating inconsistencies and resulting in configuration drift. This might be OK in a small-scale implementation where you're managing one server and know what you are doing. But what happens when you are managing hundreds or thousands of servers?
**[ Advance your automation expertise. Get the Ansible checklist: 5 reasons to migrate to Red Hat Ansible Automation Platform 2 ]**
If you are not careful, these manual, repeatable tasks can cause delays and issues because of human errors, and those errors might impact you and your organization's reputation.
This is where the value of automation comes into the picture. And [Ansible](https://opensource.com/tags/ansible) is a perfect tool for automating these repeatable daily tasks.
Some of the reasons to automate are:
- You want a consistent and stable environment.
- You want to foster standardization.
- You want less downtime and fewer severe incident cases so you can enjoy your life.
- You want to have a beer instead of troubleshooting issues!
This article offers some examples of the daily tasks a sysadmin can automate using Ansible. I put the playbooks and roles from this article into a [sysadmin tasks repository](https://github.com/mikecali/6_sysadmin_tasks) on GitHub to make it easier for you to use them.
These playbooks are structured like this (my notes are preceded with `==>`
):
```
``````
[root@homebase 6_sysadmin_tasks]# tree -L 2
.
├── ansible.cfg ===> Ansible config file that is responsible for controlling how ansible behave
├── ansible.log
├── inventory
│ ├── group_vars
│ ├── hosts ==> the inventory file that contains the list of my target server
│ └── host_vars
├── LICENSE
├── playbooks ==> the directory that contains playbooks that we will be using for this article
│ ├── c_logs.yml
│ ├── c_stats.yml
│ ├── c_uptime.yml
│ ├── inventory
│ ├── r_cron.yml
│ ├── r_install.yml
│ └── r_script.yml
├── README.md
├── roles ==> the directory that contains the roles that we will be using in this article.
│ ├── check_logs
│ ├── check_stats
│ ├── check_uptime
│ ├── install_cron
│ ├── install_tool
│ └── run_scr
└── templates ==> the directory that contains the jinja template
├── cron_output.txt.j2
├── sar.txt.j2
└── scr_output.txt.j2
```
The inventory looks like this:
```
``````
[root@homebase 6_sysadmin_tasks]# cat inventory/hosts
[rhel8]
master ansible_ssh_host=192.168.1.12
workernode1 ansible_ssh_host=192.168.1.15
[rhel8:vars]
ansible_user=ansible ==> Please update this with your preferred ansible user
```
Here are five daily sysadmin tasks that you can automate with Ansible.
## 1. Check server uptime
You need to make sure your servers are up and running all the time. Organizations have enterprise monitoring tools to monitor server and application uptime, but from time to time, the automated monitoring tools fail, and you need to jump in and verify a server's status. It takes a lot of time to verify each server's uptime manually. The more servers you have, the longer time you have to spend. But with automation, this verification can be done in minutes.
Use the [check_uptime](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_uptime) role and the `c_uptime.yml`
playbook:
```
``````
[root@homebase 6_sysadmin_tasks]# ansible-playbook -i inventory/hosts playbooks/c_uptime.yml -k
SSH password:
PLAY [Check Uptime for Servers] ****************************************************************************************************************************************
TASK [check_uptime : Capture timestamp] *************************************************************************************************
.
snip...
.
PLAY RECAP *************************************************************************************************************************************************************
master : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
[root@homebase 6_sysadmin_tasks]#
```
The playbook's output looks like this:
```
``````
[root@homebase 6_sysadmin_tasks]# cat /var/tmp/uptime-master-20210221004417.txt
-----------------------------------------------------
Uptime for master
-----------------------------------------------------
00:44:17 up 44 min, 2 users, load average: 0.01, 0.09, 0.09
-----------------------------------------------------
[root@homebase 6_sysadmin_tasks]# cat /var/tmp/uptime-workernode1-20210221184525.txt
-----------------------------------------------------
Uptime for workernode1
-----------------------------------------------------
18:45:26 up 44 min, 2 users, load average: 0.01, 0.01, 0.00
-----------------------------------------------------
```
Using Ansible, you can get the status of multiple servers in a human-readable format with less effort, and the [Jinja template](https://docs.ansible.com/ansible/latest/user_guide/playbooks_templating.html) allows you to adjust the output based on your needs. With more automation, you can run this on a schedule and send the output through email for reporting purposes.
## 2. Configure additional cron jobs
You need to update your servers' scheduled jobs regularly based on infrastructure and application requirements. This may seem like a menial job, but it has to be done correctly and consistently. Imagine the time this takes if you are doing this manually with hundreds of production servers. If it is done wrong, it can impact production applications, which can cause application downtime or impact server performance if scheduled jobs overlap.
Use the [install_cron](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/install_cron) role and the `r_cron.yml`
playbook:
```
``````
[root@homebase 6_sysadmin_tasks]# ansible-playbook -i inventory/hosts playbooks/r_cron.yml -k
SSH password:
PLAY [Install additional cron jobs for root] ***************************************************************************************************************************
.
snip
.
PLAY RECAP *************************************************************************************************************************************************************
master : ok=10 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=10 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
Verify the playbook's results:
```
``````
[root@homebase 6_sysadmin_tasks]# ansible -i inventory/hosts all -m shell -a "crontab -l" -k
SSH password:
master | CHANGED | rc=0 >>
1 2 3 4 5 /usr/bin/ls /tmp
#Ansible: Iotop Monitoring
0 5,2 * * * /usr/sbin/iotop -b -n 1 >> /var/tmp/iotop.log 2>> /var/tmp/iotop.err
workernode1 | CHANGED | rc=0 >>
1 2 3 4 5 /usr/bin/ls /tmp
#Ansible: Iotop Monitoring
0 5,2 * * * /usr/sbin/iotop -b -n 1 >> /var/tmp/iotop.log 2>> /var/tmp/iotop.err
```
Using Ansible, you can update the crontab entry on all your servers in a fast and consistent way. You can also report the updated crontab's status using a simple ad-hoc Ansible command to verify the recently applied changes.
## 3. Gather server stats and sars
During routine troubleshooting and to diagnose server performance or application issues, you need to gather system activity reports (sars) and server stats. In most scenarios, server logs contain very important information that developers or ops teams need to help solve specific problems that affect the overall environment.
Security teams are very particular when conducting investigations, and most of the time, they want to look at logs for multiple servers. You need to find an easy way to collect this documentation. It's even better if you can delegate the collection task to them.
Do this with the [check_stats](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_stats) role and the `c_stats.yml`
playbook:
```
``````
$ ansible-playbook -i inventory/hosts playbooks/c_stats.yml
PLAY [Check Stats/sar for Servers] ***********************************************************************************************************************************
TASK [check_stats : Get current date time] ***************************************************************************************************************************
changed: [master]
changed: [workernode1]
.
snip...
.
PLAY RECAP ***********************************************************************************************************************************************************
master : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
The output will look like this:
```
``````
$ cat /tmp/sar-workernode1-20210221214056.txt
-----------------------------------------------------
sar output for workernode1
-----------------------------------------------------
Linux 4.18.0-193.el8.x86_64 (node1) 21/02/21 _x86_64_ (2 CPU)
21:39:30 LINUX RESTART (2 CPU)
-----------------------------------------------------
```
## 4. Collect server logs
In addition to gathering server stats and sars information, you will also need to collect logs from time to time, especially if you need to help investigate issues.
Do this with the [check_logs](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_logs) role and the `r_cron.yml`
playbook:
```
``````
$ ansible-playbook -i inventory/hosts playbooks/c_logs.yml -k
SSH password:
PLAY [Check Logs for Servers] ****************************************************************************************************************************************
.
snip
.
TASK [check_logs : Capture Timestamp] ********************************************************************************************************************************
changed: [master]
changed: [workernode1]
PLAY RECAP ***********************************************************************************************************************************************************
master : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
To confirm the output, open the files generated in the dump location. The logs should look like this:
```
``````
$ cat /tmp/logs-workernode1-20210221214758.txt | more
-----------------------------------------------------
Logs gathered: /var/log/messages for workernode1
-----------------------------------------------------
Feb 21 18:00:27 node1 kernel: Command line: BOOT_IMAGE=(hd0,gpt2)/vmlinuz-4.18.0-193.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel
-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet
Feb 21 18:00:27 node1 kernel: Disabled fast string operations
Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
Feb 21 18:00:27 node1 kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
Feb 21 18:00:27 node1 kernel: x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'compacted' format.
```
## 5. Install or remove packages and software
You need to be able to install and update software and packages on your systems consistently and rapidly. Reducing the time it takes to install or update packages and software avoids unnecessary downtime of servers and applications.
Do this with the [install_tool](https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/install_tool) role and the `r_install.yml`
playbook:
```
``````
$ ansible-playbook -i inventory/hosts playbooks/r_install.yml -k
SSH password:
PLAY [Install additional tools/packages] ***********************************************************************************
TASK [install_tool : Install specified tools in the role vars] *************************************************************
ok: [master] => (item=iotop)
ok: [workernode1] => (item=iotop)
ok: [workernode1] => (item=traceroute)
ok: [master] => (item=traceroute)
PLAY RECAP *****************************************************************************************************************
master : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
workernode1 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
This example installs two specific packages and versions defined in a vars file. Using Ansible automation, you can install multiple packages or software faster than doing it manually. You can also use the vars file to define the version of the packages that you want to install:
```
``````
$ cat roles/install_tool/vars/main.yml
---
# vars file for install_tool
ins_action: absent
package_list:
- iotop-0.6-16.el8.noarch
- traceroute
```
## Embrace automation
To be an effective sysadmin, you need to embrace automation to encourage standardization and collaboration within your team. Ansible enables you to do more in less time so that you can spend your time on more exciting projects instead of doing repeatable tasks like managing your incident and problem management processes.
With more free time on your hands, you can learn more and make yourself available for the next career opportunity that comes your way.
## Comments are closed. |
13,258 | 一次 Docker 镜像的逆向工程 | https://theartofmachinery.com/2021/03/18/reverse_engineering_a_docker_image.html | 2021-04-01T21:55:31 | [
"Docker",
"镜像",
"逆向工程"
] | https://linux.cn/article-13258-1.html | 
这要从一次咨询的失误说起:政府组织 A 让政府组织 B 开发一个 Web 应用程序。政府机构 B 把部分工作外包给某个人。后来,项目的托管和维护被外包给一家私人公司 C。C 公司发现,之前外包的人(已经离开很久了)构建了一个自定义的 Docker 镜像,并将其成为系统构建的依赖项,但这个人没有提交原始的 Dockerfile。C 公司有合同义务管理这个 Docker 镜像,可是他们他们没有源代码。C 公司偶尔叫我进去做各种工作,所以处理一些关于这个神秘 Docker 镜像的事情就成了我的工作。
幸运的是,Docker 镜像的格式比想象的透明多了。虽然还需要做一些侦查工作,但只要解剖一个镜像文件,就能发现很多东西。例如,这里有一个 [Prettier 代码格式化](https://github.com/tmknom/prettier) 的镜像可供快速浏览。
首先,让 Docker <ruby> 守护进程 <rt> daemon </rt></ruby>拉取镜像,然后将镜像提取到文件中:
```
docker pull tmknom/prettier:2.0.5
docker save tmknom/prettier:2.0.5 > prettier.tar
```
是的,该文件只是一个典型 tarball 格式的归档文件:
```
$ tar xvf prettier.tar
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/VERSION
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/json
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar
88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/VERSION
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/json
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/VERSION
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/json
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/layer.tar
manifest.json
repositories
```
如你所见,Docker 在命名时经常使用<ruby> 哈希 <rt> hash </rt></ruby>。我们看看 `manifest.json`。它是以难以阅读的压缩 JSON 写的,不过 [JSON 瑞士军刀 jq](https://stedolan.github.io/jq/) 可以很好地打印 JSON:
```
$ jq . manifest.json
[
{
"Config": "88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json",
"RepoTags": [
"tmknom/prettier:2.0.5"
],
"Layers": [
"a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar",
"d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/layer.tar",
"6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar"
]
}
]
```
请注意,这三个<ruby> 层 <rt> Layer </rt></ruby>对应三个以哈希命名的目录。我们以后再看。现在,让我们看看 `Config` 键指向的 JSON 文件。它有点长,所以我只在这里转储第一部分:
```
$ jq . 88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json | head -n 20
{
"architecture": "amd64",
"config": {
"Hostname": "",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
],
"Cmd": [
"--help"
],
"ArgsEscaped": true,
"Image": "sha256:93e72874b338c1e0734025e1d8ebe259d4f16265dc2840f88c4c754e1c01ba0a",
```
最重要的是 `history` 列表,它列出了镜像中的每一层。Docker 镜像由这些层堆叠而成。Dockerfile 中几乎每条命令都会变成一个层,描述该命令对镜像所做的更改。如果你执行 `RUN script.sh` 命令创建了 `really_big_file`,然后用 `RUN rm really_big_file` 命令删除文件,Docker 镜像实际生成两层:一个包含 `really_big_file`,一个包含 `.wh.really_big_file` 记录来删除它。整个镜像文件大小不变。这就是为什么你会经常看到像 `RUN script.sh && rm really_big_file` 这样的 Dockerfile 命令链接在一起——它保障所有更改都合并到一层中。
以下是该 Docker 镜像中记录的所有层。注意,大多数层不改变文件系统镜像,并且 `empty_layer` 标记为 `true`。以下只有三个层是非空的,与我们之前描述的相符。
```
$ jq .history 88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json
[
{
"created": "2020-04-24T01:05:03.608058404Z",
"created_by": "/bin/sh -c #(nop) ADD file:b91adb67b670d3a6ff9463e48b7def903ed516be66fc4282d22c53e41512be49 in / "
},
{
"created": "2020-04-24T01:05:03.92860976Z",
"created_by": "/bin/sh -c #(nop) CMD [\"/bin/sh\"]",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:06.617130538Z",
"created_by": "/bin/sh -c #(nop) ARG BUILD_DATE",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:07.020521808Z",
"created_by": "/bin/sh -c #(nop) ARG VCS_REF",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:07.36915054Z",
"created_by": "/bin/sh -c #(nop) ARG VERSION",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:07.708820086Z",
"created_by": "/bin/sh -c #(nop) ARG REPO_NAME",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:08.06429638Z",
"created_by": "/bin/sh -c #(nop) LABEL org.label-schema.vendor=tmknom org.label-schema.name=tmknom/prettier org.label-schema.description=Prettier is an opinionated code formatter. org.label-schema.build-date=2020-04-29T06:34:01Z org
.label-schema.version=2.0.5 org.label-schema.vcs-ref=35d2587 org.label-schema.vcs-url=https://github.com/tmknom/prettier org.label-schema.usage=https://github.com/tmknom/prettier/blob/master/README.md#usage org.label-schema.docker.cmd=do
cker run --rm -v $PWD:/work tmknom/prettier --parser=markdown --write '**/*.md' org.label-schema.schema-version=1.0",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:08.511269907Z",
"created_by": "/bin/sh -c #(nop) ARG NODEJS_VERSION=12.15.0-r1",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:08.775876657Z",
"created_by": "/bin/sh -c #(nop) ARG PRETTIER_VERSION",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:26.399622951Z",
"created_by": "|6 BUILD_DATE=2020-04-29T06:34:01Z NODEJS_VERSION=12.15.0-r1 PRETTIER_VERSION=2.0.5 REPO_NAME=tmknom/prettier VCS_REF=35d2587 VERSION=2.0.5 /bin/sh -c set -x && apk add --no-cache nodejs=${NODEJS_VERSION} nodejs-np
m=${NODEJS_VERSION} && npm install -g prettier@${PRETTIER_VERSION} && npm cache clean --force && apk del nodejs-npm"
},
{
"created": "2020-04-29T06:34:26.764034848Z",
"created_by": "/bin/sh -c #(nop) WORKDIR /work"
},
{
"created": "2020-04-29T06:34:27.092671047Z",
"created_by": "/bin/sh -c #(nop) ENTRYPOINT [\"/usr/bin/prettier\"]",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:27.406606712Z",
"created_by": "/bin/sh -c #(nop) CMD [\"--help\"]",
"empty_layer": true
}
]
```
太棒了!所有的命令都在 `created_by` 字段中,我们几乎可以用这些命令重建 Dockerfile。但不是完全可以。最上面的 `ADD` 命令实际上没有给我们需要添加的文件。`COPY` 命令也没有全部信息。我们还失去了 `FROM` 语句,因为它们扩展成了从基础 Docker 镜像继承的所有层。
我们可以通过查看<ruby> 时间戳 <rt> timestamp </rt></ruby>,按 Dockerfile 对层进行分组。大多数层的时间戳相差不到一分钟,代表每一层构建所需的时间。但是前两层是 `2020-04-24`,其余的是 `2020-04-29`。这是因为前两层来自一个基础 Docker 镜像。理想情况下,我们可以找出一个 `FROM` 命令来获得这个镜像,这样我们就有了一个可维护的 Dockerfile。
`manifest.json` 展示第一个非空层是 `a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar`。让我们看看它:
```
$ cd a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/
$ tar tf layer.tf | head
bin/
bin/arch
bin/ash
bin/base64
bin/bbconfig
bin/busybox
bin/cat
bin/chgrp
bin/chmod
bin/chown
```
看起来它可能是一个<ruby> 操作系统 <rt> operating system </rt></ruby>基础镜像,这也是你期望从典型 Dockerfile 中看到的。Tarball 中有 488 个条目,如果你浏览一下,就会发现一些有趣的条目:
```
...
dev/
etc/
etc/alpine-release
etc/apk/
etc/apk/arch
etc/apk/keys/
etc/apk/keys/[email protected]
etc/apk/keys/[email protected]
etc/apk/keys/[email protected]
etc/apk/protected_paths.d/
etc/apk/repositories
etc/apk/world
etc/conf.d/
...
```
果不其然,这是一个 [Alpine](https://www.alpinelinux.org/) 镜像,如果你注意到其他层使用 `apk` 命令安装软件包,你可能已经猜到了。让我们解压 tarball 看看:
```
$ mkdir files
$ cd files
$ tar xf ../layer.tar
$ ls
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
$ cat etc/alpine-release
3.11.6
```
如果你拉取、解压 `alpine:3.11.6`,你会发现里面有一个非空层,`layer.tar` 与 Prettier 镜像基础层中的 `layer.tar` 是一样的。
出于兴趣,另外两个非空层是什么?第二层是包含 Prettier 安装包的主层。它有 528 个条目,包含 Prettier、一堆依赖项和证书更新:
```
...
usr/lib/libuv.so.1
usr/lib/libuv.so.1.0.0
usr/lib/node_modules/
usr/lib/node_modules/prettier/
usr/lib/node_modules/prettier/LICENSE
usr/lib/node_modules/prettier/README.md
usr/lib/node_modules/prettier/bin-prettier.js
usr/lib/node_modules/prettier/doc.js
usr/lib/node_modules/prettier/index.js
usr/lib/node_modules/prettier/package.json
usr/lib/node_modules/prettier/parser-angular.js
usr/lib/node_modules/prettier/parser-babel.js
usr/lib/node_modules/prettier/parser-flow.js
usr/lib/node_modules/prettier/parser-glimmer.js
usr/lib/node_modules/prettier/parser-graphql.js
usr/lib/node_modules/prettier/parser-html.js
usr/lib/node_modules/prettier/parser-markdown.js
usr/lib/node_modules/prettier/parser-postcss.js
usr/lib/node_modules/prettier/parser-typescript.js
usr/lib/node_modules/prettier/parser-yaml.js
usr/lib/node_modules/prettier/standalone.js
usr/lib/node_modules/prettier/third-party.js
usr/local/
usr/local/share/
usr/local/share/ca-certificates/
usr/sbin/
usr/sbin/update-ca-certificates
usr/share/
usr/share/ca-certificates/
usr/share/ca-certificates/mozilla/
usr/share/ca-certificates/mozilla/ACCVRAIZ1.crt
usr/share/ca-certificates/mozilla/AC_RAIZ_FNMT-RCM.crt
usr/share/ca-certificates/mozilla/Actalis_Authentication_Root_CA.crt
...
```
第三层由 `WORKDIR /work` 命令创建,它只包含一个条目:
```
$ tar tf 6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar
work/
```
[原始 Dockerfile 在 Prettier 的 git 仓库中](https://github.com/tmknom/prettier/blob/35d2587ec052e880d73f73547f1ffc2b11e29597/Dockerfile)。
---
via: <https://theartofmachinery.com/2021/03/18/reverse_engineering_a_docker_image.html>
作者:[Simon Arneaud](https://theartofmachinery.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This started with a consulting snafu: Government organisation A got government organisation B to develop a web application. Government organisation B subcontracted part of the work to somebody. Hosting and maintenance of the project was later contracted out to a private-sector company C. Company C discovered that the subcontracted somebody (who was long gone) had built a custom Docker image and made it a dependency of the build system, but without committing the original Dockerfile. That left company C with a contractual obligation to manage a Docker image they had no source code for. Company C calls me in once in a while to do various things, so doing something about this mystery meat Docker image became my job.
Fortunately, the Docker image format is a lot more transparent than it could be. A little detective work is needed,
but a lot can be figured out just by pulling apart an image file. As an example, here’s a quick walkthrough of an image
for [the Prettier code formatter](https://github.com/tmknom/prettier). (In fact, it’s so easy, there’s
[a tool for it](https://github.com/wagoodman/dive). Thanks Ezequiel Gonzalez Rial.)
First let’s get the Docker daemon to pull the image, then extract the image to a file:
```
docker pull tmknom/prettier:2.0.5
docker save tmknom/prettier:2.0.5 > prettier.tar
```
Yes, the file is just an archive in the classic tarball format:
```
$ tar xvf prettier.tar
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/VERSION
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/json
6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar
88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/VERSION
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/json
a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/VERSION
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/json
d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/layer.tar
manifest.json
repositories
```
As you can see, Docker uses hashes a lot for naming things. Let’s have a look at the `manifest.json`
. It’s in hard-to-read compacted JSON, but the [ jq JSON Swiss Army knife](https://stedolan.github.io/jq/)
can pretty print it for us:
```
$ jq . manifest.json
[
{
"Config": "88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json",
"RepoTags": [
"tmknom/prettier:2.0.5"
],
"Layers": [
"a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar",
"d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/layer.tar",
"6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar"
]
}
]
```
Note that the three layers correspond to the three hash-named directories. We’ll look at them later. For now, let’s
look at the JSON file pointed to by the `Config`
key. It’s a
little long, so I’ll just dump the first bit here:
```
$ jq . 88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json | head -n 20
{
"architecture": "amd64",
"config": {
"Hostname": "",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
],
"Cmd": [
"--help"
],
"ArgsEscaped": true,
"Image": "sha256:93e72874b338c1e0734025e1d8ebe259d4f16265dc2840f88c4c754e1c01ba0a",
```
The most interesting part is the `history`
list, which lists
every single layer in the image. A Docker image is a stack of these layers. Almost every statement in a Dockerfile
turns into a layer that describes the changes to the image made by that statement. If you have a `RUN script.sh`
statement that creates `really_big_file`
that you then delete with `RUN rm really_big_file`
, you actually get two layers in the Docker image:
one that contains `really_big_file`
, and one that contains a
`.wh.really_big_file`
tombstone to cancel it out. The overall
image file isn’t any smaller. That’s why you often see Dockerfile statements chained together like `RUN script.sh && rm really_big_file`
— it ensures all changes are
coalesced into one layer.
Here are all the layers recorded in the Docker image. Notice that most layers don’t change the filesystem image and
are marked `"empty_layer": true`
. Only three are non-empty,
which matches up with what we saw before.
```
$ jq .history 88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json
[
{
"created": "2020-04-24T01:05:03.608058404Z",
"created_by": "/bin/sh -c #(nop) ADD file:b91adb67b670d3a6ff9463e48b7def903ed516be66fc4282d22c53e41512be49 in / "
},
{
"created": "2020-04-24T01:05:03.92860976Z",
"created_by": "/bin/sh -c #(nop) CMD [\"/bin/sh\"]",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:06.617130538Z",
"created_by": "/bin/sh -c #(nop) ARG BUILD_DATE",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:07.020521808Z",
"created_by": "/bin/sh -c #(nop) ARG VCS_REF",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:07.36915054Z",
"created_by": "/bin/sh -c #(nop) ARG VERSION",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:07.708820086Z",
"created_by": "/bin/sh -c #(nop) ARG REPO_NAME",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:08.06429638Z",
"created_by": "/bin/sh -c #(nop) LABEL org.label-schema.vendor=tmknom org.label-schema.name=tmknom/prettier org.label-schema.description=Prettier is an opinionated code formatter. org.label-schema.build-date=2020-04-29T06:34:01Z org
.label-schema.version=2.0.5 org.label-schema.vcs-ref=35d2587 org.label-schema.vcs-url=https://github.com/tmknom/prettier org.label-schema.usage=https://github.com/tmknom/prettier/blob/master/README.md#usage org.label-schema.docker.cmd=do
cker run --rm -v $PWD:/work tmknom/prettier --parser=markdown --write '**/*.md' org.label-schema.schema-version=1.0",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:08.511269907Z",
"created_by": "/bin/sh -c #(nop) ARG NODEJS_VERSION=12.15.0-r1",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:08.775876657Z",
"created_by": "/bin/sh -c #(nop) ARG PRETTIER_VERSION",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:26.399622951Z",
"created_by": "|6 BUILD_DATE=2020-04-29T06:34:01Z NODEJS_VERSION=12.15.0-r1 PRETTIER_VERSION=2.0.5 REPO_NAME=tmknom/prettier VCS_REF=35d2587 VERSION=2.0.5 /bin/sh -c set -x && apk add --no-cache nodejs=${NODEJS_VERSION} nodejs-np
m=${NODEJS_VERSION} && npm install -g prettier@${PRETTIER_VERSION} && npm cache clean --force && apk del nodejs-npm"
},
{
"created": "2020-04-29T06:34:26.764034848Z",
"created_by": "/bin/sh -c #(nop) WORKDIR /work"
},
{
"created": "2020-04-29T06:34:27.092671047Z",
"created_by": "/bin/sh -c #(nop) ENTRYPOINT [\"/usr/bin/prettier\"]",
"empty_layer": true
},
{
"created": "2020-04-29T06:34:27.406606712Z",
"created_by": "/bin/sh -c #(nop) CMD [\"--help\"]",
"empty_layer": true
}
]
```
Fantastic! All the statements are right there in the `created_by`
fields, so we can almost reconstruct the Dockerfile just from
this. Almost. The `ADD`
statement at the very top doesn’t
actually give us the file we need to `ADD`
. `COPY`
statements are also going to be opaque. We also lose `FROM`
statements because they expand out to all the layers inherited from
the base Docker image.
We can group the layers by Dockerfile by looking at the timestamps. Most layer timestamps are under a minute apart,
representing how long each layer took to build. However, the first two layers are from `2020-04-24`
, and the rest of the layers are from `2020-04-29`
. This would be because the first two layers are from a base
Docker image. Ideally we’d figure out a `FROM`
statement that
gets us that image, so that we have a maintainable Dockerfile.
The `manifest.json`
says that the first non-empty layer is
`a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar`
.
Let’s take a look:
```
$ cd a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/
$ tar tf layer.tf | head
bin/
bin/arch
bin/ash
bin/base64
bin/bbconfig
bin/busybox
bin/cat
bin/chgrp
bin/chmod
bin/chown
```
Okay, that looks like it might be an operating system base image, which is what you’d expect from a typical Dockerfile. There are 488 entries in the tarball, and if you scroll through them, some interesting ones stand out:
```
...
dev/
etc/
etc/alpine-release
etc/apk/
etc/apk/arch
etc/apk/keys/
etc/apk/keys/[email protected]
etc/apk/keys/[email protected]
etc/apk/keys/[email protected]
etc/apk/protected_paths.d/
etc/apk/repositories
etc/apk/world
etc/conf.d/
...
```
Sure enough, it’s an [Alpine](https://www.alpinelinux.org/) image, which you might have guessed if you
noticed that the other layers used an `apk`
command to install
packages. Let’s extract the tarball and look around:
```
$ mkdir files
$ cd files
$ tar xf ../layer.tar
$ ls
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
$ cat etc/alpine-release
3.11.6
```
If you pull `alpine:3.11.6`
and extract it, you’ll find that
there’s one non-empty layer inside it, and the `layer.tar`
is
identical to the `layer.tar`
in the base layer of the Prettier
image.
Just for the heck of it, what’s in the other two non-empty layers? The second layer is the main layer containing the Prettier installation. It has 528 entries, including Prettier, a bunch of dependencies and certificate updates:
```
...
usr/lib/libuv.so.1
usr/lib/libuv.so.1.0.0
usr/lib/node_modules/
usr/lib/node_modules/prettier/
usr/lib/node_modules/prettier/LICENSE
usr/lib/node_modules/prettier/README.md
usr/lib/node_modules/prettier/bin-prettier.js
usr/lib/node_modules/prettier/doc.js
usr/lib/node_modules/prettier/index.js
usr/lib/node_modules/prettier/package.json
usr/lib/node_modules/prettier/parser-angular.js
usr/lib/node_modules/prettier/parser-babel.js
usr/lib/node_modules/prettier/parser-flow.js
usr/lib/node_modules/prettier/parser-glimmer.js
usr/lib/node_modules/prettier/parser-graphql.js
usr/lib/node_modules/prettier/parser-html.js
usr/lib/node_modules/prettier/parser-markdown.js
usr/lib/node_modules/prettier/parser-postcss.js
usr/lib/node_modules/prettier/parser-typescript.js
usr/lib/node_modules/prettier/parser-yaml.js
usr/lib/node_modules/prettier/standalone.js
usr/lib/node_modules/prettier/third-party.js
usr/local/
usr/local/share/
usr/local/share/ca-certificates/
usr/sbin/
usr/sbin/update-ca-certificates
usr/share/
usr/share/ca-certificates/
usr/share/ca-certificates/mozilla/
usr/share/ca-certificates/mozilla/ACCVRAIZ1.crt
usr/share/ca-certificates/mozilla/AC_RAIZ_FNMT-RCM.crt
usr/share/ca-certificates/mozilla/Actalis_Authentication_Root_CA.crt
...
```
The third layer is created by the `WORKDIR /work`
statement,
and it contains exactly one entry:
```
$ tar tf 6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar
work/
``` |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.