
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
12,764 | Fedora 33 正式发布了 | https://fedoramagazine.org/announcing-fedora-33/ | 2020-10-28T15:50:19 | [
"Fedora"
] | https://linux.cn/article-12764-1.html | 
>
> 本文译自 Fedora 官方发布公告。
>
>
>
今天,我很兴奋地与大家分享数千名 Fedora 项目贡献者辛勤工作的成果:我们的最新版本 Fedora 33 来了! 这是一个有着很多变化的大版本,但我相信所有这些工作也会让您感到舒适,实现我们的目标:即为您带来最新的稳定、强大、健壮的自由和开源软件,并提供许多易于使用的产品。
如果您不想耽误时间,直接体验,现在就去 <https://getfedora.org/> 下载吧,欲了解详情请继续阅读!
### 找到适合您的 Fedora 风味!
Fedora Edition 是针对桌面、服务器和云环境中各种“体现”特定用途的目标产品,现在它也适用于物联网。
Fedora Workstation 专注于桌面,尤其是面向那些想要“只管去用”的 Linux 操作系统体验的软件开发者。这个版本的特点是 [GNOME 3.38](https://www.gnome.org/news/2020/09/gnome-3-38-released/),它一如既往地有很多很棒的改进。新增的 Tour 应用可以帮助新用户学习它们的操作方式。和我们所有其他面向桌面的变体一样,Fedora Workstation 现在使用 [BTRFS 作为默认文件系统](https://fedoramagazine.org/btrfs-coming-to-fedora-33/)。这些发布的版本中带来了很多伟大的增强功能,这个先进的文件系统为之奠定了基础。为了您的视觉享受,Fedora 33 Workstation 现在默认提供了一个动画背景(它会基于一天中的时间变化)。
Fedora CoreOS 是一个新兴的 Fedora 版本。它是一个自动更新的、最小化的操作系统,用于安全地、大规模地运行容器化工作负载。它提供了几个[更新流](https://docs.fedoraproject.org/en-US/fedora-coreos/update-streams/),可以遵循大致每两周一次的自动更新。目前 **next** 流是基于 Fedora 33 的,**testing** 和 **stable** 流后继也会跟进。您可以从[下载页面](https://getfedora.org/en/coreos/download?stream=next)中找到关于跟随 **next** 流发布的工件的信息,并在 [Fedora CoreOS 文档](https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/)中找到关于如何使用这些工件的信息。
新晋升为 Edition 状态的 [Fedora IoT](https://getfedora.org/iot),为物联网生态系统和边缘计算用例提供了坚实的基础。在许多功能之外,Fedora 33 IoT 还引入了<ruby> 平台抽象安全 <rt> Platform AbstRaction for SECurity </rt></ruby>(PARSEC),这是一个开源倡议,以平台无关的方式为硬件安全和加密服务提供了通用 API。
当然,我们制作的不仅仅是“官方版本”,还有 [Fedora Spin](https://spins.fedoraproject.org/)和 [Lab](https://labs.fedoraproject.org/)。[Fedora Spin](https://spins.fedoraproject.org/) 和 [Lab](https://labs.fedoraproject.org/) 针对不同的受众和用例,包括 [Fedora CompNeuro](https://labs.fedoraproject.org/en/comp-neuro/),它为神经科学带来了大量的开源计算建模工具,以及 [KDE Plasma](https://spins.fedoraproject.org/en/kde/) 和 [Xfce](https://spins.fedoraproject.org/en/xfce/)等桌面环境。
此外,别忘了我们还有备用架构:[ARM AArch64、Power 和 S390x](https://alt.fedoraproject.org/alt/)。在 Fedora 33 中提供的新功能,AArch64 用户可以使用 .NET Core 语言进行跨平台开发。我们改进了对 Pine64 设备、NVidia Jetson 64 位平台以及 Rockchip 片上系统(SoC)设备的支持,包括 Rock960、RockPro64 和 Rock64。(不过,有个最新的说明:在其中一些设备上可能会出现启动问题。从现有的 Fedora 32 升级是没问题的。更多信息将在[常见错误](https://fedoraproject.org/wiki/Common_F33_bugs)页面上公布。)
我们也很高兴地宣布,Fedora 云镜像和 Fedora CoreOS 将首次与 Fedora 33 一起在亚马逊的 [AWS 市场](https://aws.amazon.com/marketplace) 中提供。Fedora 云镜像在亚马逊云中已经存在了十多年,您可以通过 AMI ID 或[点击一下](https://getfedora.org/en/coreos/download?tab=cloud_launchable&stream=stable)来启动我们的官方镜像。该市场提供了获得同样东西的另一种方式,显著扩大了 Fedora 的知名度。这也将使我们的云镜像可以更快地在新的 AWS 区域中可用。特别感谢 David Duncan 让这一切成为现实!
### 常规改进
无论您使用的是哪种版本的 Fedora,您都会得到开源世界提供的最新版本。遵循我们的 [First](https://docs.fedoraproject.org/en-US/project/#_first) 原则,我们更新了关键的编程语言和系统库包,包括 Python 3.9、Ruby on Rails 6.0 和 Perl 5.32。在 Fedora KDE 中,我们沿用了 Fedora 32 Workstation 中的工作,默认启用了 EarlyOOM 服务,以改善低内存情况下的用户体验。
为了让 Fedora 的默认体验更好,我们将 nano 设置为默认编辑器。nano 是一个对新用户友好的编辑器。当然,那些想要像 vi 这样强大的编辑器的用户可以自己设置默认编辑器。
我们很高兴您能试用新版本! 前往 <https://getfedora.org/> 并立即下载它。或者如果您已经在运行 Fedora 操作系统,请按照这个简单的[升级说明](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/)进行升级。关于 Fedora 33 新特性的更多信息,请参见[发布说明](https://docs.fedoraproject.org/en-US/fedora/f33/release-notes/)。
### 关于安全启动的说明
<ruby> 安全启动 <rt> Secure Boot </rt></ruby>是一种安全标准,它确保只有官方签署的操作系统软件才能加载到您的计算机上。这对于防止持久恶意软件非常重要,因为这些恶意软件可能会隐藏在您的计算机固件中,甚至在重新安装操作系统时也能存活。然而,在 [Boot Hole](https://access.redhat.com/security/vulnerabilities/grub2bootloader) 漏洞发生后,用于签署 Fedora <ruby> 引导加载器 <rt> Bootloader </rt></ruby>软件的加密证书将被撤销,并被新的证书取代。由于这将产生大范围的影响,撤销应该要到 2021 年第二季度或更晚才会广泛推行。
然而,一些用户可能已经从其他操作系统或固件更新中收到了这种撤销。在这种情况下,Fedora 将不能在启用了安全启动时进行安装。要说明的是,这不会影响大多数用户。如果它确实影响到了您,您可以暂时禁用安全启动。我们会在大范围的证书撤销之前发布一个用新证书签署的更新,在所有支持的版本上都可以使用,到那时,安全启动应该可以重新启用。
### 万一出现问题时……
如果您遇到问题,请查看 [Fedora 33 常见错误](https://fedoraproject.org/wiki/Common_F33_bugs)页面;如果您有疑问,请访问我们的 [Ask Fedora](http://ask.fedoraproject.org) 用户支持平台。
### 谢谢大家
感谢在这个发布周期中为 Fedora 项目做出贡献的成千上万的人,尤其是那些在疫情大流行期间为使这个版本准时发布而付出额外努力的人。Fedora 是一个社区,很高兴看到我们如此互相支持。
---
via: <https://fedoramagazine.org/announcing-fedora-33/>
作者:[Matthew Miller](https://fedoramagazine.org/author/mattdm/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today, I’m excited to share the results of the hard work of thousands of contributors to the Fedora Project: our latest release, Fedora 33, is here! This is a big release with a lot of change, but I believe all that work will also make it a comfortable one, fulfilling our goal of bringing you the latest stable, powerful, and robust free and open source software in many easy to use offerings.
If you just want to get to the bits without delay, head over to[ https://getfedora.org/](https://getfedora.org/) right now. For details, read on!
**Find the Fedora flavor that’s right for you!**
Fedora Editions are targeted outputs geared toward specific “showcase” uses on the desktop, in server and cloud environments—and now for Internet of Things as well.
Fedora Workstation focuses on the desktop, and in particular, it’s geared toward software developers who want a “just works” Linux operating system experience. This release features [GNOME 3.38](https://www.gnome.org/news/2020/09/gnome-3-38-released/), which has plenty of great improvements as usual. The addition of the Tour application helps new users learn their way around. And like all of our other desktop-oriented variants, Fedora Workstation now uses [BTRFS as the default filesystem](https://fedoramagazine.org/btrfs-coming-to-fedora-33/). This advanced filesystem lays the foundation for bringing a lot of great enhancements in upcoming releases. For your visual enjoyment, Fedora 33 Workstation now features an animated background (based on time of day) by default.
Fedora CoreOS is an emerging Fedora Edition. It’s an automatically-updating, minimal operating system for running containerized workloads securely and at scale. It offers several [update streams](https://docs.fedoraproject.org/en-US/fedora-coreos/update-streams/) that can be followed for automatic updates that occur roughly every two weeks. Currently the **next** stream is based on Fedora 33, with the **testing** and **stable** streams to follow. You can find information about released artifacts that follow the **next** stream from [the download page](https://getfedora.org/en/coreos/download?stream=next) and information about how to use those artifacts in the [Fedora CoreOS Documentation](https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/).
[Fedora IoT](https://getfedora.org/iot), newly promoted to Edition status, provides a strong foundation for IoT ecosystems and edge computing use cases. Among many other features, Fedora 33 IoT introduces the Platform AbstRaction for SECurity (PARSEC), an open-source initiative to provide a common API to hardware security and cryptographic services in a platform-agnostic way.
Of course, we produce more than just the Editions.[ Fedora Spins](https://spins.fedoraproject.org/) and[ Labs](https://labs.fedoraproject.org/) target a variety of audiences and use cases, including [Fedora CompNeuro](https://labs.fedoraproject.org/en/comp-neuro/), which brings a plethora of open source computational modelling tools for neuroscience, and desktop environments like[ KDE Plasma](https://spins.fedoraproject.org/en/kde/) and[ Xfce](https://spins.fedoraproject.org/en/xfce/).
And, don’t forget our alternate architectures: [ARM AArch64, Power, and S390x](https://alt.fedoraproject.org/alt/). New in Fedora 33, AArch64 users can use the .NET Core language for cross-platform development. We have improved support for Pine64 devices, NVidia Jetson 64 bit platforms, and the Rockchip system-on-a-chip devices including the Rock960, RockPro64, and Rock64. (However, a late-breaking note: there may be problems booting on some of these devices. Upgrading from existing Fedora 32 will be fine. More info will be on the [Common Bugs](https://fedoraproject.org/wiki/Common_F33_bugs) page as we have it.)
We’re also excited to announce that the Fedora Cloud Base Image and Fedora CoreOS will be available in Amazon’s [AWS Marketplace](https://aws.amazon.com/marketplace) for the first time with Fedora 33. Fedora cloud images have been available in the Amazon cloud for over a decade, and you can launch our official images by AMI ID or [with a click](https://getfedora.org/en/coreos/download?tab=cloud_launchable&stream=stable). The Marketplace provides an alternate way to get the same thing, with significantly wider visibility for Fedora. This will also make our cloud images available in new AWS regions more quickly. Thank you especially to David Duncan for making this happen!
## General improvements
No matter what variant of Fedora you use, you’re getting the latest the open source world has to offer. Following our “[First](https://docs.fedoraproject.org/en-US/project/#_first)” foundation, we’ve updated key programming language and system library packages, including Python 3.9, Ruby on Rails 6.0, and Perl 5.32. In Fedora KDE, we’ve followed the work in Fedora 32 Workstation and enabled the EarlyOOM service by default to improve the user experience in low-memory situations.
To make the default Fedora experience better, we’ve set nano as the default editor. nano is a friendly editor for new users. Those of you who want the power of editors like vi can, of course, set your own default.
We’re excited for you to try out the new release! Go to[ https://getfedora.org/](https://getfedora.org/) and download it now. Or if you’re already running a Fedora operating system, follow the easy[ upgrade instructions](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/). For more information on the new features in Fedora 33, see the[ release notes](https://docs.fedoraproject.org/en-US/fedora/f33/release-notes/).
**A note on Secure Boot**
Secure Boot is a security standard which ensures that only officially-signed operating system software can load on your computer. This is important for preventing persistent malware which could hide itself in your computer’s firmware and survive even an operating system reinstallation. However, in the wake of the [Boot Hole](https://access.redhat.com/security/vulnerabilities/grub2bootloader) vulnerability, the cryptographic certificate used to sign Fedora bootloader software will be revoked and replaced with a new one. Because this will have a broad impact, revocation should not happen widely until the second quarter of 2021 or later.
However, some users may have received this revocation from other operating systems or firmware updates already. In that case, Fedora installations will not boot with Secure Boot enabled. To be clear, this will not affect most users. If it does affect you, you can boot with Secure Boot disabled for the time being. We will release an update signed with the new certificate to be available on all supported releases well before broad-scale certificate revocation takes place, and at that point Secure Boot should be reenabled.
**In the unlikely event of a problem….**
If you run into a problem, check out the[ Fedora 33 Common Bugs](https://fedoraproject.org/wiki/Common_F33_bugs) page, and if you have questions, visit our[ Ask Fedora](http://ask.fedoraproject.org) user-support platform.
**Thank you everyone**
Thanks to the thousands of people who contributed to the Fedora Project in this release cycle, and especially to those of you who worked extra hard to make this another on-time release during a pandemic. Fedora is a community, and it’s great to see how much we’ve supported each other.
## Brad Smith
Outstanding! I applaud all the work accomplished by the Fedora team and open source contributors everywhere.
## Michal Konečný
Is EarlyOOM enabled automatically when doing upgrade or is this only for new installations?
## monotux
My installation is a few years old and earlyoom.service is enabled on my machine. So I think it’s default and has been default since 32?
## Abhi
i am using fedora from about 5 years it was my first linux distro. and i love it sometimes it makes me feel that i am made for it.
## Matthias
Thank you.
## Leslie Satenstein, Montreal,Que,Canada
I have been using the beta version for the past month. Never a burp, never an issue.
What a great relief to have the distribution work, “Right out of the Box”.
Congratulations to all who worked to deliver this version, and the past versions.
## Truls Gulbrandsen
The same goes for me – almost – I have experienced a couple of bugs. They have been reported and were solved promptly.
Thank you and keep up the good work-
## Tobias, Germany
Vielen Dank für das großartige Release.
## Roberto
And Fedora Silverblue?
🙁
## Eduard Lucena
Silverblue got updated too: https://silverblue.fedoraproject.org/download
## Calvin Walton
If you have an existing Silverblue install, you can rebase to 33 using the instructions here: https://docs.fedoraproject.org/en-US/fedora-silverblue/updates-upgrades-rollbacks/ (distribution release upgrades are not yet integrated into the Software gui tool in Silverblue)
## Grey the earthling
Yes they are!
I upgraded from Silverblue 31 to 32 using GNOME Software (I disabled third-party repos using the terminal first) and those instructions now say:
## Calvin Walton
Heh, serves me right, I should have actually read the page I was linking! Very nice 🙂
## Sriniwas
Thank you fedora team, I hope someday I can contribute to this amazing project
## martin
A big thanks to everyone involved in making this great distribution!
## Lyes Saadi
The fedora background in the illustration of the article is outdated 😛 !
## flowers
Thank you
## Robert
Thanks for taking bold steps like BTRFS by default! Together with Wayland, Pipewire, fwupd, Silverblue etc. Fedora pushes for great innovation in the desktop space and I’m happily riding with you 🙂
## Rui Quaresma
Great distribution for those who like packages packaged by the distribution itself, good system for hackers.
## XHess
Ich liebe Fedora 33. btrfs rockt und Wayland made my day. 👍🏻 Alles andere natürlich auch.
Danke!
## Arek P.
The greatest gift on my birthday 🙂 Thank you !!! 🙂
## Dinu Radhakrishnan
Thank you team Fedora.
I have been using the beta version of both the Workstation and the Server editions since release, without any issues.
## 荒野无灯
I do like Fedora.
Thanks to all of you guys made this great Linux dist
## tfks
Brilliant work as always!
## Patrick
Thank you so much for your hard and complicated work Fedora team for this new exciting release!!!
## stephane keglo
Thank You ,Fedora Teams for your amazing work
## Dutchy
This is a huge release for home and office users!
– Btrfs offers lots of flexibility and safety, finally a step into the future fs-wise (option to use snapshots, no more lengthy integrity checks and corrupted files when the laptop runs out of juice)
– EarlyOOM and zram means no more systems getting swapped to death, this is a HUGE usability improvement that end users will notice (or actually, they will no longer notice anything besides their browser tabs oopsing now and then)
While many users will shrug off these features as being unnecessary, to regular users these could mean the difference between having a system that works very reliably vs one that often causes troubles, and losing data and having to watch at a stuck desktop after opening too many browser tabs isn’t part of the former.
Great work from all the devs!
## Anon Ymous
Fedora 33 is awesome! Someone should write an article here on the “Docker support” features of fedora 33 tho. I boot it up, no docker manager or anything installed by default, I take it one has to download something? Anyway, Fedora 33 is really nice, does anyone know if CENTos or RHEL is planning to go to btrfs by default? That would be interesting to know!
## Matthew Miller
## Anon Ymous
to: Matthew Miller Thank you for the reply and answering ppl’s questions, that is how articles are done right!
In the release notes, there are supposed to be new “Docker support” features – im not sure what the writer meant by that. Maybe it was a reference to podman, although that is not “new”, so i wonder why someone wrote it in the release notes. No biggie, time will tell. Again, thanks.
## Jaranguda
I’m glad didn’t upgrade before too late 🙂 I have a lot of docker images for testing purpose. Will try podman before doing the upgrade to make sure everything works perfectly
## Badtux
BTRFS is not production-ready. It has failed at every production load I’ve thrown at it. Red Hat is not going to go to BTRFS until that is consistently not true.
## monotux
I’m not a proponent for BTRFS (I like my ZFS for important stuff), but there’s a lot of FUD regarding BTRFS thrown around in places like this. Had it not been ready for production use, why would major players (hello FB) and at least two major distros (SuSE, Fedora, probably more?) use it by default?
## Dutchy
Btrfs is a poor fit for high performance cattle servers. It is great for end users’ pets systems however. Fedora is only making btrfs the default for the workstation edition so what you say doesn’t apply.
## Anon Ymous
NVIDIA with Fedora 33
I have a dell g5 gaming rig with geforce rtx 2080 installed. after about 10 min of fedora 33 boot up the screen goes blank. Here is a VERY simple way to fix it in less than a minute!
1) sudo dnf update
2) sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
3) sudo dnf install https://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
4) sudo dnf install akmod-nvidia
sudo reboot or reboot the computer.
BAM! Problem fixed!
Notice when you go to settings/about it will show “NVIDIA Corporation TU104 [GeForce RTX 2080]”
for the graphics driver and the system will not blank the screen out. You are welcome 🙂
## Sergey
Thank you for the instruction !
What is you DE ? I read that the drivers NVIDIA you like do not work properly with wayland and therefore you need to use X11, otherwise steam and proton will not work.
Thank you.
## Stan Genchev
I have bad news for you. Fedora devs are testing the 5.9 version of the Linux kernel and it will probably appear as an update next week. The problem is that Nvidia will not support kernel 5.9 for a few more months (1 to 2 probably, but it could be more). They stated it themselves. So you have two options:
1 – Do not update your system for a few months and check every once in a while if the driver has picked up support and is in the rpmfusion repos.
2 – Get an AMD GPU (or and Intel if you don’t play games) and live a happy life 😀
Personally, I would go with the second option.
## Alexander Borro
If that’s true. There is no way kernel 5.9 should be pushed out to Fedora users. Nvidia is far too widespread in use, it would break systems without notice. I feel confident the Fedora Team know this. and wouldn’t do such an (unprofessional) thing.
Congrats Fedora 33 team. Running great here with my current RTX card. 🙂
## Vaclav
This one is related to GAMING workloads only (CUDA).
System update went surprisingly smoothly and guickly. It was super easy – One button click (upgrade) did the trick. (also have a CUDA GPU)
Great work Fedora team!
## Heliosstyx
Thanks to all contributors for their work building this high-quality and innovative Fedora product-line. It’s very impressive to see what people can do with common objectives to give their best creating Fedora. Thank you Mr. Miller for your above easy to understand article.
## polaris
I just switched to Fedora 32 yesterday…
## Filipe Guarino
Awsome to see the great work that fedora team have done. Thanks to community too.
## Francisco Reyes
Gracias a todo el equipo de Fedora. Excelente trabajo. 👍
## garcia88jose
Thank you for all effort. Just amazing.
## Chucho Linux
Fedora 33
gnome-shell[42352]: segfault at 18 ip 00007ffa91fae87f sp 00007fff957cf790 error 4 in libmutter-7.so.0.0.0[7ffa91f29000+10a000]
Any idea?
## William Whinn
I rebased to Silverblue 33 from 32 without an issue but because of the new BTrFS system, I think I’m going to nuke and pave so I can take advantage of that. Think I’ll stick to Silverblue over vanilla Workstation though, it’s a solid workhorse that got me through a data science master’s degree and is currently getting me through another in bioinformatics. Thank you all for your hard work, I celebrate every release.
## I
Just to ask about Raspberry pi 4 support. Will that be also?
## frantisekz
Fedora 33 works on Raspberry Pi 4. However:
It’s not officially supported
There is no 3D acceleration support just yet (that should come with Linux 5.10)
## Mario Soto
Fantastic!!!…Thank you all that made this possible and be safe.
## Dong Nguyen
Thank you Fedora team for your great work.
## Rey
Congratulation Fedora team, you really do an amazing work, thank you!
## max
Amazing, been on beta 33 for a while, and thoroughly impressed. Also, the advanced partioner finally fixed some long standing snags for me, which always made it a pain to do a fresh install they way I wanted it to, so no more workarounds needed, yay!
Now it only needs a kernel-lts package and it will be the perfect distro… pretty please?? 🙂
Congratulations everyone involved!
## Sam
Thank you guys, thank you fedora team, amazing work 👏🏻!
## Wang
Fedora 33 default deny ssh-rsa, through a new /etc/crypto-policies/back-ends/opensshserver.config which did not contain ssh-rsa config.
## Jonathan
Just noting as Wang pointed out that ssh-rsa signatures on public keys are off by default in Fedora 33. If at all possible, I recommend leaving the default policy in place, and upgrading your SSH server and/or client keys, rather than downgrading security as many are doing. I wrote up my experiences at https://dev.to/bowmanjd/upgrade-ssh-client-keys-and-remote-servers-after-fedora-33-s-new-crypto-policy-47ag
## Tim
Hi Jonathan, Thanks for the explaination and suggestions. What I failed to get what why they removed rsa keys from the policy list. Where would that rationale be documented?
## Bad Tux
ssh-rsa was deprecated because it uses the SHA1 hash algorithm for signature digests, and it is trivially easy to create payloads that have an equivalent SHA1 hash. This deprecation came from upstream, not from Fedora. See, e.g.,
https://lwn.net/Articles/821544/
## Ben
nice
## Christopher Augustus
I was able to get an old HP BlueStream upgraded to 33. Fairly difficult due to a 50 GB hard drive that was almost full. Ended up tinkering with the DNF configuration file to tell it to download the upgrade files to an attached flashdrive. When that did not free up enough space, I removed GIMP (sorry little critter) and some shared library files. USB 2.0 is very slow, but it is now upgraded. I have been using the old HP BlueStream running Fedora for Zoom meetings, internet browsing, and playing with Linux features for almost a year and half now. Very happy I can stay on the cutting edge of Open Source software with Fedora 33! (And yes, I reset the DNF configuration back so update will work.)
## Daniel Berto
Fedora 33 is just amazing!!! Thanks guys!!!
## Emerson Lima
Congratulations Fedora team and the whole community too! More productivity, less headache.
Fedora 33 (Thirty Three) 64-bit
Intel® Core™ i7-9750HF CPU @ 2.60GHz × 12
NVIDIA Corporation TU117M [GeForce GTX 1650 Mobile / Max-Q]
## Atul Kumar Pandey
Kudos to the Fedora team, congratulations for your efforts in this critical time.
## Jens
If you click on “learn more” in the Fedora 33 announcement (in F32’s Software), it points to https://fedoramagazine.org/whats-new-fedora-33-workstation, which gives you a 404. Maybe that should be fixed 😉
## Zaro
Thanks!
Installed it on my new Thinkpad T14, and so far it’s awesome! Keep up the greak work.
## Hunter B
Can we set mount point options like ‘compress’ before installation within Anaconda?
## Jorge
Congratulations for the new release!
Matthew, Gnome Software shows a banner announcing the new Fedora 33 release. If you click on “More info” button it goes to https://fedoramagazine.org/whats-new-fedora-33-workstation, which doesn’t have any info (Page not found)
## Hyuho
Congratulations, Thanks to All~!
what is fedora 33’s kernel version?
## Marcel Hergaarden
Fedora 33 is really great. Thanks for all the hard work, much appreciated.
## rolf deenen
I am updating right now after receiving a notification that a Fedora 33 was available. I did notice that the fedora updater has a button reading: “Learn more”. This refers to a page: https://fedoramagazine.org/whats-new-fedora-33-workstation but this page doesn’t exist (Yet?).
## Zhao
Good news, thanks for your work!
## svsv sarma
Thank you Fedora 33, so far so good.
I am using Fedora-cinnamon-33 live. I am unable to install Samsung Printer ML-1670 with:
sudo dnf config-manager –add-repo=https://negativo17.org/repos/fedora-uld.repo
sudo yum -y install uld.
It worked well with F32. Perhaps I have to wait for some time.
## Wolfram Volpi
I had the same issue installing Samsung SL-M2020W printer:
# yum -y install uld
Error: Unable to find a match: uld
## Priyatam
Congratulations !! And a HUUGE thanks to the fedora team !
## Silvia
It doesn’t how to upgrade from a previous version :-/
## Matthew Miller
https://docs.fedoraproject.org/en-US/quick-docs/upgrading/
## PK
F33 the best releae yet!
## Franklin
Muchas Gracias a todo el equipo de Fedora!!
## Llaith
Superb. Sounds like the Fedora Project is going from strength to strength. I’ve been a Fedora user since Fedora 22, and I literally cant praise about the teams and their choices enough!
There is so much to get excited about with the IoT and AWS offerings, not to mention the ARM version, that I think it’s starting to be a open-and-shut case to use Fedora for modern cloud/enterprise development.
## Wyoming USA
The video software added to 33 is much better than 32. Fedora has become my favorite OS. Thanks for all the hard work everyone has contributed!
## e5r5
prosze zróbcie fedorę w moim języku.
pokażcie jak tłumaczyc i jak ustawić tak by moja angielska zaczęła gadać poprawnie
## Juergen
Is it possible to setup F33 and btrfs with luks encrypted disks?
## Chris Murphy
Yes. Simple check “Encrypt my data” when using Automatic partitioning. When using Custom (Manual) partitioning, you’ll find it in a dialog revealed by clicking the Volume:Modify button. (Figure 21 in the install guide.)
## Antonio Retali
Congratulations for your excellent work Fedora Team!
I have a small doubt about the last IoT as an ‘Official Edition’, where is the corresponding IoT subfolder at download.fedora.project.org/pub/fedora/linux/releases/33/?
I knew that this release is available at download.fedoraproject.org/pub/alt/iot/33/IoT/, but many mirrors don’t take the pub/alt branch into account because sometimes it’s considered that all the official editions are only in the releases/ subfolder.
## C Narayanan
Although I continue to update to newer versions, shutdown is usually an issue where it simply hangs many times. It’s an unresolved issue for as long as I remember with Fedora.
## Metcomm
Once again a seamless and trouble-free upgrade. I use 2 encrypted partitions on my ageing laptop, one for “/” and one for “home” and the install was perfect. I have already noticed a significant improvement in overall performance.
Many thank Fedora team!
## Malik
Thank you fedora team
## Ivan
I switched to Debian a few months ago due to performance issues with Fedora, memory running out a lot, but now that zRAM and Btrfs are implemented to improve that performance, I’m wanting to switch back 🙂
## lemc
As I have been doing for two years, I did a fresh install of Fedora Workstation 33 using the netinst server image. When there was the option for the “Base Environment”, I just changed from “Fedora Server Edition” to “Fedora Workstation”. Other than that, I used mostly default settings of the Anaconda installer. However, when checking “File Systems” in the Gnome System Monitor utility, the “Type” of the first two partitions, “/” and “/boot”, is “xfs”. Shouldn’t it be BTRFS, the new default ?
## Dave Hugh
Thanks for all the good work. Another flawless DNF based upgrade of my DIY wireless router and laptop. Very happy with Fedora, a great combination of stability, ease of use, and rapid advance in software technology
## Robert Varga
I’m surprised how much Fedora has progressed since my last adventure with it (very long ago). I’m by no means new to Linux, avid user since 2005, and have had dire bad experiences with much earlier Fedora releases in the past, but this is incredible. The ease of use and amount of polish is astounding.
Thank you for your work!
## Sebastian
Hi guys , im trying to upgrade from fredora 30 to 31 and i have a problem when i using this command at the end :
sudo dnf system-upgrade download –releasever=31
an this is the error:
Error: Transaction test error:
el archivo /usr/include/X11/extensions/XKBgeom.h de la instalación de libX11-devel-1.6.12-1.fc31.x86_64 entra en conflicto con el archivo del paquete xorg-x11-proto-devel-7.7-23.fc27.noarch
Can anyone help me ? becouse i want to update to this version , from 30 > 31 > 32 > 33
## Gregory Bartholomew
Since they are just -devel packages, I’d try adding
.
## Sebastian
Nop, keeps popping up the same message,
i did this command :
sudo dnf system-upgrade download –releasever=31 –allowerasing
and
sudo dnf –refresh –allowerasing upgrade
Maybe is another thing.
## Sebastian
Didnt work
i tried :
sudo dnf –allowerasing upgrade
sudo dnf –refresh –allowerasing upgrade
sudo dnf system-upgrade download –releasever=31 –allowerasing
## Matthew Miller
It’s unclear why a F27 package (xorg-x11-proto-devel-7.7-23.fc27.noarch) is still around — something is not right on your system. I’d suggest running
to see what it reports.
But as noted, since this is a devel package, try just removing it, and any other devel packages that are reported as problems. (sudo dnf remove xorg-x11-proto-devel). You can always add back any you need after the update.
## Sebastian
I been doing systems upgrades since fedora 27 , but recently someone told me that i must to avoid the https://www.if-not-true-then-false.com/ guide for installing the Nvidia drivers, also i have to rebuild manualy grub2 after kernel updates, maybe that guide messed something ( i been doing this since fedora 24 )
I just run dnf check i got nothing.
and i runned the sudo dnf remove …. and nothing happend :
All matches were filtered out by exclude filtering for argument: xorg-x11-proto-devel
No se han seleccionado paquetes para eliminar.
Dependencias resueltas.
Nada por hacer.
¡Listo!
Maybe is better if ill do an clean install.
## Gregory Bartholomew
It is very strange/unusual that the package is “there, but not there”. I’m sure there is a way to fix it. Maybe try
and/or
## Sebastian
Thanks for the quick response , the first command didn’t output anything.
and the second one throwed this :
error: Error de dependencias:
pkgconfig(compositeproto) >= 0.4 es necesario por (instalado) libXcomposite-devel-0.4.4-16.fc30.x86_64
pkgconfig(damageproto) >= 1.1 es necesario por (instalado) libXdamage-devel-1.1.4-16.fc30.x86_64
pkgconfig(fixesproto) >= 5.0 es necesario por (instalado) libXfixes-devel-5.0.3-9.fc30.x86_64
pkgconfig(inputproto) es necesario por (instalado) libXi-devel-1.7.10-1.fc30.x86_64
pkgconfig(kbproto) es necesario por (instalado) libX11-devel-1.6.7-1.fc30.x86_64
pkgconfig(randrproto) >= 1.5 es necesario por (instalado) libXrandr-devel-1.5.1-9.fc30.x86_64
pkgconfig(recordproto) es necesario por (instalado) libXtst-devel-1.2.3-9.fc30.x86_64
pkgconfig(renderproto) >= 0.9 es necesario por (instalado) libXrender-devel-0.9.10-9.fc30.x86_64
pkgconfig(videoproto) es necesario por (instalado) libXv-devel-1.0.11-9.fc30.x86_64
pkgconfig(xextproto) es necesario por (instalado) libXext-devel-1.3.3-11.fc30.x86_64
pkgconfig(xextproto) es necesario por (instalado) libXtst-devel-1.2.3-9.fc30.x86_64
pkgconfig(xf86vidmodeproto) es necesario por (instalado) libXxf86vm-devel-1.1.4-11.fc30.x86_64
pkgconfig(xineramaproto) es necesario por (instalado) libXinerama-devel-1.1.4-3.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXau-devel-1.0.9-1.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXv-devel-1.0.11-9.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXcursor-devel-1.1.15-5.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXdamage-devel-1.1.4-16.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXft-devel-2.3.2-12.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libICE-devel-1.0.9-15.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXfixes-devel-5.0.3-9.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libSM-devel-1.2.3-2.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXrandr-devel-1.5.1-9.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libX11-devel-1.6.7-1.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXcomposite-devel-0.4.4-16.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXt-devel-1.1.5-11.20190424gitba4ec9376.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) libXrender-devel-0.9.10-9.fc30.x86_64
pkgconfig(xproto) es necesario por (instalado) qt-devel-1:4.8.7-49.fc30.x86_64
xorg-x11-proto-devel es necesario por (instalado) libXau-devel-1.0.9-1.fc30.x86_64
xorg-x11-proto-devel es necesario por (instalado) libXi-devel-1.7.10-1.fc30.x86_64
Any thoughts ?
## Gregory Bartholomew
I think the first command may have fixed things even though it didn’t output anything. Try using “dnf remove xorg-x11-proto-devel-7.7-23.fc27.noarch” now and dnf should let you remove all those dependencies at once.
## Sebastian
Sorry , i have to reply over your first comment.
I did that and nothing, this didnt remove anything, this is the output :
All matches were filtered out by exclude filtering for argument: xorg-x11-proto-devel-7.7-23.fc27.noarch
No se han seleccionado paquetes para eliminar.
Dependencias resueltas.
Nada por hacer.
¡Listo!
## Gregory Bartholomew
Do you have any “exclude=” lines in /etc/dnf/dnf.conf? That might be causing this issue.
## Sebastian
Yes …. 🙁
exclude=xorg-x11* kernel*
i do not remember why i have excluded xorg-x11 .. but i remember that i exclude kernel* because i was so sick to every time the kernel was upgraded or updated, i have to reinstall the nvidia drivers , if not , i got no desktop so i have manage to boot in init mode 3 and make the install
this is happening for the guide that everybody told me that i do not need to follow.
I do not remember why is that there.
## Gregory Bartholomew
No problem. Glad you figured it out. It’s not an unreasonable thing to do. I exclude kernel-* from time to time as well when the latest kernels don’t work with zfs. 🙂
## Sebastian
Now works …
Sorry , everything is in spanish maybe this weekend a will try to update this system to 31 and then to 32 one after other.
Ejecutando verificación de operación
Verificación de operación exitosa.
Ejecutando prueba de operaciones
Prueba de operación exitosa.
¡Listo!
¡Descarga completa! Use ‘dnf system-upgrade reboot’ para iniciar la actualización.
Para limpiar la caché de metadatos y transacción, use ‘dnf system-upgrade clean’
Los paquetes descargados se han guardado en caché para la próxima transacción.
Puede borrar los paquetes de la caché ejecutando ‘dnf clean packages’.
Thanks for the help !!!
## nitz
When will anaconda installer will be changed? It’s intuitive.
## Eddy
after pulling off my hair using this uber shit called opensuse Fedora ROCKS!
## irlm
Mais um utilizador a usar Fedora Rawhide 34 no Dell E5570, esta distrobuição está perfeita, mesmo em fase de desenvolvimento.
## ivo magalhaes
Fedora user from Portugal, very good work…
## gombosg
I waited the usual 1 week safety period after release, then updated via GNOME Software.
It was literally 2 clicks. Unbelievable! All external repos updated automatically. Nothing left to do.
Been using Fedora exclusively for >3 years, this was probably one of the easiest updates. Thanks guys! (Or thanks us, because I also maintain a few packages… :))
Next up: converting my main filesystem to BTRFS somehow 😛
## Jatin
Unreal Engine 4.25 (latest stable unreal) .. Projects requires CoreMinimal.h header file which needs sys/sysctl.h as an include which is not there in fedora 33 and was in fedora 32 🙁
## Casque Fou
Upgrade stalles on 83%…
Upgrade from 32 unfinished and no boot possible anymore!
Hopefully a reinstall will do.
## John M
I have used Fedora for a few years now and have updated the previous versions without any issues, but 32 to 33 did not go well. I use the Cinnamon desk, GIGABYTE X470 board, AMD Ryzen 5 3600, Radeon RX 5600.
I upgraded from within Fedora 32.. The upgrade down loaded, installed and appeared to launch without a hitch. When I ran GPARTED I saw that all the partitions were ext4 other than efi, none were btrfs. I do not remember seeing an option to pick my file system. The deal breaking though was that Virtual Box 6.1 was uninstalled which contained a virtual machine that I had spent a bit of time to configure to my liking(poof gone). Fortunately I imaged the disk prior and restored Fedora 32, with no loss other than time.
So my questions are:
Did I miss an option choice to install btrfs, I thought Fedora 33 default was btrfs.
Why is Virtual Box not supported?
## Marius Qayin
As a Linux Noob, trying to rid myself of a system that want to decide how i am using my computer, trying to avoid a culture where a computer is an appliance that you have to throw away if broken or to old. Trying to be more free…. Is Fedora a good choice?
## Rafał
Czy w Fedora 33 można zmienić język na polski? / Is it possible to change the language in Polish in Fedora 33? |
12,766 | 使用 Ansible 的 Kubernetes 模块实现容器编排自动化 | https://opensource.com/article/20/9/ansible-modules-kubernetes | 2020-10-28T21:19:13 | [
"Kubernetes",
"Ansible"
] | https://linux.cn/article-12766-1.html |
>
> 将 Kubernetes 与 Ansible 结合实现云端自动化。此外,还可以参照我们的 Ansible 的 k8s 模块速查表。
>
>
>

[Ansible](https://opensource.com/resources/what-ansible) 是实现自动化工作的优秀工具,而 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 则是容器编排方面的利器,要是把两者结合起来,会有怎样的效果呢?正如你所猜测的,Ansible + Kubernetes 的确可以实现容器编排自动化。
### Ansible 模块
实际上,Ansible 本身只是一个用于解释 YAML 文件的框架。它真正强大之处在于它[丰富的模块](https://docs.ansible.com/ansible/latest/modules/modules_by_category.html),所谓<ruby> 模块 <rt> module </rt></ruby>,就是在 Ansible <ruby> 剧本 <rt> playbook </rt></ruby> 中让你得以通过简单配置就能调用外部应用程序的一些工具。
Ansible 中有模块可以直接操作 Kubernetes,也有对一些相关组件(例如 [Docker](https://opensource.com/resources/what-docker) 和 [Podman](http://podman.io))实现操作的模块。学习使用一个新模块的过程和学习新的终端命令、API 一样,可以先从文档中了解这个模块在调用的时候需要接受哪些参数,以及这些参数在外部应用程序中产生的具体作用。
### 访问 Kubernetes 集群
在使用 Ansible Kubernetes 模块之前,先要有能够访问 Kubernetes 集群的权限。在没有权限的情况下,可以尝试使用一个短期在线试用账号,但我们更推荐的是按照 Kubernetes 官网上的指引,或是参考 Braynt Son 《[入门 Kubernetes](https://opensource.com/article/18/10/getting-started-minikube)》的教程安装 [Minikube](https://kubernetes.io/docs/tasks/tools/install-minikube)。Minikube 提供了一个单节点 Kubernetes 实例的安装过程,你可以像使用一个完整集群一样对其进行配置和交互。
* 下载 [Ansible k8s 速记表](https://opensource.com/downloads/ansible-k8s-cheat-sheet)(需注册)
在安装 Minikube 之前,你需要确保你的环境支持虚拟化并安装 `libvirt`,然后对 `libvirt` 用户组授权:
```
$ sudo dnf install libvirt
$ sudo systemctl start libvirtd
$ sudo usermod --append --groups libvirt `whoami`
$ newgrp libvirt
```
#### 安装 Python 模块
为了能够在 Ansible 中使用 Kubernetes 相关的模块,你需要安装以下这些 Python 模块:
```
$ pip3.6 install kubernetes --user
$ pip3.6 install openshift --user
```
#### 启动 Kubernetes
如果你使用的是 Minikube 而不是完整的 Kubernetes 集群,请使用 `minikube` 命令在本地创建一个最精简化的 Kubernetes 实例:
```
$ minikube start --driver=kvm2 --kvm-network default
```
然后等待 Minikube 完成初始化,这个过程所需的时间会因实际情况而异。
### 获取集群信息
集群启动以后,通过 `cluster-info` 选项就可以获取到集群相关信息了:
```
$ kubectl cluster-info
Kubernetes master is running at https://192.168.39.190:8443
KubeDNS is running at https://192.168.39.190:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
```
### 使用 k8s 模块
Ansible 使用 `k8s` 这个模块来实现对 Kubernetes 的操作,在剧本中使用 `k8s` 模块就可以对 Kuvernetes 对象进行管理。这个模块描述了 `kubectl` 命令的最终状态,例如对于以下这个使用 `kubectl` 创建新的[命名空间](https://opensource.com/article/19/10/namespaces-and-containers-linux)的操作:
```
$ kubectl create namespace my-namespace
```
这是一个很简单的操作,而对这个操作的最终状态用 YAML 文件来描述是这样的:
```
- hosts: localhost
tasks:
- name: create namespace
k8s:
name: my-namespace
api_version: v1
kind: Namespace
state: present
```
如果你使用的是 Minikube,那么主机名(`hosts`)应该定义为 `localhost`。需要注意的是,所使用的模块也定义了可用参数的语法(例如 `api_version` 和 `kind` 参数)。
在运行这个剧本之前,先通过 `yamllint` 命令验证是否有错误:
```
$ yamllint example.yaml
```
确保没有错误之后,运行剧本:
```
$ ansible-playbook ./example.yaml
```
可以验证新的命名空间是否已经被创建出来:
```
$ kubectl get namespaces
NAME STATUS AGE
default Active 37h
kube-node-lease Active 37h
kube-public Active 37h
kube-system Active 37h
demo Active 11h
my-namespace Active 3s
```
### 使用 Podman 拉取容器镜像
容器是个 Linux 系统,几乎是最小化的,可以由 Kubernetes 管理。[LXC 项目](https://www.redhat.com/sysadmin/exploring-containers-lxc)和 Docker 定义了大部分的容器规范。最近加入容器工具集的是 Podman,它不需要守护进程就可以运行,为此受到了很多用户的欢迎。
通过 Podman 可以从 Docker Hub 或者 [Quay.io](http://Quay.io) 等存储库拉取容器镜像。这一操作对应的 Ansible 语法也很简单,只需要将存储库网站提供的镜像路径写在剧本中的相应位置就可以了:
```
- name: pull an image
podman_image:
name: quay.io/jitesoft/nginx
```
使用 `yamllint` 验证:
```
$ yamllint example.yaml
```
运行剧本:
```
$ ansible-playbook ./example.yaml
[WARNING]: provided hosts list is empty, only localhost is available.
Note that the implicit localhost does not match 'all'
PLAY [localhost] ************************
TASK [Gathering Facts] ************************
ok: [localhost]
TASK [create k8s namespace] ************************
ok: [localhost]
TASK [pull an image] ************************
changed: [localhost]
PLAY RECAP ************************
localhost: ok=3 changed=1 unreachable=0 failed=0
skipped=0 rescued=0 ignored=0
```
### 使用 Ansible 实现部署
Ansible 除了可以执行小型维护任务以外,还可以通过剧本实现其它由 `kubectl` 实现的功能,因为两者的 YAML 文件之间只有少量的差异。在 Kubernetes 中使用的 YAML 文件只需要稍加改动,就可以在 Ansible 剧本中使用。例如下面这个用于使用 `kubectl` 命令部署 Web 服务器的 YAML 文件:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-webserver
spec:
selector:
matchLabels:
run: my-webserver
replicas: 1
template:
metadata:
labels:
run: my-webserver
spec:
containers:
- name: my-webserver
image: nginx
ports:
- containerPort: 80
```
如果你对其中的参数比较熟悉,你只要把 YAML 文件中的大部分内容放到剧本中的 `definition` 部分,就可以在 Ansible 中使用了:
```
- name: deploy a web server
k8s:
api_version: v1
namespace: my-namespace
definition:
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deploy
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: my-webserver
image: quay.io/jitesoft/nginx
ports:
- containerPort: 80
protocol: TCP
```
执行完成后,使用 `kubectl` 命令可以看到预期中的的<ruby> 部署 <rt> deployment </rt></ruby>:
```
$ kubectl -n my-namespace get pods
NAME READY STATUS
nginx-deploy-7fdc9-t9wc2 1/1 Running
```
### 在云上使用模块
随着现在越来越多的开发和部署工作往云上转移的趋势,我们必须了解如何在云上实现自动化。其中 `k8s` 和 `podman_image` 这两个模块只是云开发中的其中一小部分。你可以在你的工作流程中寻找一些需要自动化的任务,并学习如何使用 Ansible 让你在这些任务上事半功倍。
---
via: <https://opensource.com/article/20/9/ansible-modules-kubernetes>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Ansible](https://opensource.com/resources/what-ansible) is one of the best tools for automating your work. [Kubernetes](https://opensource.com/resources/what-is-kubernetes) is one of the best tools for orchestrating containers. What happens when you combine the two? As you might expect, Ansible combined with Kubernetes lets you automate your container orchestration.
## Ansible modules
On its own, Ansible is basically just a framework for interpreting YAML files. Its true power comes from its [many modules](https://docs.ansible.com/ansible/latest/modules/modules_by_category.html). Modules are what enable you to invoke external applications with just a few simple configuration settings in a playbook.
There are a few modules that deal directly with Kubernetes, and a few that handle related technology like [Docker](https://opensource.com/resources/what-docker) and [Podman](http://podman.io). Learning a new module is often similar to learning a new terminal command or a new API. You get familiar with a module from its documentation, you learn what arguments it accepts, and you equate its options to how you might use the application it interfaces with.
## Access a Kubernetes cluster
To try out Kubernetes modules in Ansible, you must have access to a Kubernetes cluster. If you don't have that, then you might try to open a trial account online, but most of those are short term. Instead, you can install [Minikube](https://kubernetes.io/docs/tasks/tools/install-minikube), as described on the Kubernetes website or in Bryant Son's excellent article on [getting started with Minikube](https://opensource.com/article/18/10/getting-started-minikube). Minikube provides a local instance of a single-node Kubernetes install, allowing you to configure and interact with it as you would a full cluster.
**[Download the Ansible k8s cheat sheet]**
Before installing Minikube, you must ensure that your environment is ready to serve as a virtualization backend. You may need to install `libvirt`
and grant yourself permission to the `libvirt`
group:
```
$ sudo dnf install libvirt
$ sudo systemctl start libvirtd
$ sudo usermod --append --groups libvirt `whoami`
$ newgrp libvirt
```
### Install Python modules
To prepare for using Kubernetes-related Ansible modules, you should also install a few helper Python modules:
```
$ pip3.6 install kubernetes --user
$ pip3.6 install openshift --user
```
### Start Kubernetes
If you're using Minikube instead of a Kubernetes cluster, use the `minikube`
command to start up a local, miniaturized Kubernetes instance on your computer:
`$ minikube start --driver=kvm2 --kvm-network default`
Wait for Minikube to initialize. Depending on your internet connection, this could take several minutes.
## Get information about your cluster
Once you've started your cluster successfully, you can get information about it with the `cluster-info`
option:
```
$ kubectl cluster-info
Kubernetes master is running at https://192.168.39.190:8443
KubeDNS is running at https://192.168.39.190:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
```
## Use the k8s module
The entry point for using Kubernetes through Ansible is the `k8s`
module, which enables you to manage Kubernetes objects from your playbooks. This module describes states resulting from `kubectl`
instructions. For instance, here's how you would create a new [namespace](https://opensource.com/article/19/10/namespaces-and-containers-linux) with `kubectl`
:
`$ kubectl create namespace my-namespace`
It's a simple action, and the YAML representation of the same result is similarly terse:
```
- hosts: localhost
tasks:
- name: create namespace
k8s:
name: my-namespace
api_version: v1
kind: Namespace
state: present
```
In this case, the host is defined as `localhost`
, under the assumption that you're running this against Minikube. Notice that the module in use defines the syntax of the parameters available (such as `api_version`
and `kind`
).
Before using this playbook, verify it with `yamllint`
:
`$ yamllint example.yaml`
Correct any errors, and then run the playbook:
`$ ansible-playbook ./example.yaml`
Verify that the new namespace has been created:
```
$ kubectl get namespaces
NAME STATUS AGE
default Active 37h
kube-node-lease Active 37h
kube-public Active 37h
kube-system Active 37h
demo Active 11h
my-namespace Active 3s
```
## Pull a container image with Podman
Containers are Linux systems, almost impossibly minimal in scope, that can be managed by Kubernetes. Much of the container specifications have been defined by the [LXC project](https://www.redhat.com/sysadmin/exploring-containers-lxc) and Docker. A recent addition to the container toolset is Podman, which is popular because it runs without requiring a daemon.
With Podman, you can pull a container image from a repository, such as Docker Hub or Quay.io. The Ansible syntax for this is simple, and all you need to know is the location of the container, which is available from the repository's website:
```
- name: pull an image
podman_image:
name: quay.io/jitesoft/nginx
```
Verify it with `yamllint`
:
`$ yamllint example.yaml`
And then run the playbook:
```
$ ansible-playbook ./example.yaml
[WARNING]: provided hosts list is empty, only localhost is available.
Note that the implicit localhost does not match 'all'
PLAY [localhost] ************************
TASK [Gathering Facts] ************************
ok: [localhost]
TASK [create k8s namespace] ************************
ok: [localhost]
TASK [pull an image] ************************
changed: [localhost]
PLAY RECAP ************************
localhost: ok=3 changed=1 unreachable=0 failed=0
skipped=0 rescued=0 ignored=0
```
## Deploy with Ansible
You're not limited to small maintenance tasks with Ansible. Your playbook can interact with Ansible in much the same way a configuration file does with `kubectl`
. In fact, in many ways, the YAML you know by using Kubernetes translates to your Ansible plays. Here's a configuration you might pass directly to `kubectl`
to deploy an image (in this example, a web server):
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-webserver
spec:
selector:
matchLabels:
run: my-webserver
replicas: 1
template:
metadata:
labels:
run: my-webserver
spec:
containers:
- name: my-webserver
image: nginx
ports:
- containerPort: 80
```
If you know these parameters, then you mostly know the parameters required to accomplish the same with Ansible. You can, with very little modification, move that YAML into a `definition`
element in your Ansible playbook:
```
- name: deploy a web server
k8s:
api_version: v1
namespace: my-namespace
definition:
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deploy
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: my-webserver
image: quay.io/jitesoft/nginx
ports:
- containerPort: 80
protocol: TCP
```
After running this, you can see the deployment with `kubectl`
, as usual:
```
$ kubectl -n my-namespace get pods
NAME READY STATUS
nginx-deploy-7fdc9-t9wc2 1/1 Running
```
## Modules for the cloud
As more development and deployments move to the cloud, it's important to understand how to automate the important aspects of your cloud. The `k8s`
and `podman_image`
modules are only two examples of modules related to Kubernetes and a mere fraction of modules developed for the cloud. Take a look at your workflow, find the tasks you want to track and automate, and see how Ansible can help you do more by doing less.
## 1 Comment |
12,768 | 我的第一次开源贡献:做出决定 | https://opensource.com/article/19/11/my-first-open-source-contribution-mistake-decisions | 2020-10-30T11:24:01 | [
"开源",
"贡献"
] | /article-12768-1.html |
>
> 一位新的开源贡献者告诉你如何加入到开源项目中。
>
>
>

先前,我把我的第一次开源贡献的拖延归咎于[冒牌综合症](https://opensource.com/article/19/10/my-first-open-source-contribution-mistakes)。但还有一个我无法忽视的因素:我做出决定太艰难了。在[成千上百万](https://github.blog/2018-02-08-open-source-project-trends-for-2018/)的开源项目中选择时,选择一个要做贡献的项目是难以抉择的。如此重负,以至于我常常不得不关掉我的笔记本去思考:“或许我改天再做吧”。
错误之二是让我对做出决定的恐惧妨碍了我做出第一次贡献。在理想世界里,也许开始我的开源之旅时,心中就已经有了一个真正关心和想去做的具体项目,但我有的只是总得为开源项目做出贡献的模糊目标。对于那些处于同一处境的人来说,这儿有一些帮助我挑选出合适的项目(或者至少是一个好的项目)来做贡献的策略。
### 经常使用的工具
一开始,我不认为有必要将自己局限于已经熟悉的工具或项目。有一些项目我之前从未使用过,但由于它们的社区很活跃,或者它们解决的问题很有趣,因此看起来很有吸引力。
但是,考虑我投入到这个项目中的时间有限,我决定继续投入到我了解的工具上去。要了解工具需求,你需要熟悉它的工作方式。如果你想为自己不熟悉的项目做贡献,则需要完成一个额外的步骤来了解代码的功能和目标。这个额外的工作量可能是有趣且值得的,但也会使你的工作时间加倍。因为我的目标主要是贡献,投入到我了解的工具上是缩小范围的很好方式。回馈一个你认为有用的项目也是有意义的。
### 活跃而友好的社区
在选择项目的时候,我希望在那里有人会审查我写的代码才会觉得有信心。当然,我也希望审核我代码的人是个和善的人。毕竟,把你的作品放在那里接受公众监督是很可怕的。虽然我对建设性的反馈持开放态度,但开发者社区中的一些有毒角落是我希望避免的。
为了评估我将要加入的社区,我查看了我正在考虑加入的仓库的<ruby> 议题 <rt> issue </rt></ruby>部分。我要查看核心团队中是否有人定期回复。更重要的是,我试着确保没有人在评论中互相诋毁(这在议题讨论中是很常见的)。我还留意了那些有行为准则的项目,概述了什么是适当的和不适当的在线互动行为。
### 明确的贡献准则
因为这是我第一次为开源项目做出贡献,在此过程中我有很多问题。一些项目社区在流程的文档记录方面做的很好,可以用来指导挑选其中的议题并发起拉取请求。 [Gatsby](https://www.gatsbyjs.org/contributing/) 是这种做法的典范,尽管那时我没有选择它们,因为在此之前我从未使用过该产品。
这种清晰的文档帮助我们缓解了一些不知如何去做的不安全感。它也给了我希望:项目对新的贡献者是开放的,并且会花时间来查看我的工作。除了贡献准则外,我还查看了议题部分,看看这个项目是否使用了“<ruby> 第一个好议题 <rt> good first issue </rt></ruby>”标志。这是该项目对初学者开放的另一个迹象(并可以帮助你学会要做什么)。
### 总结
如果你还没有计划好选择一个项目,那么选择合适的领域进行你的第一个开源贡献更加可行。列出一系列标准可以帮助自己缩减选择范围,并为自己的第一个拉取请求找到一个好的项目。
---
via: <https://opensource.com/article/19/11/my-first-open-source-contribution-mistake-decisions>
作者:[Galen Corey](https://opensource.com/users/galenemco) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,769 | 用这个创建可引导 USB 的工具在电脑上尝试 Linux | https://opensource.com/article/20/10/fedora-media-writer | 2020-10-30T12:21:59 | [
"USB"
] | /article-12769-1.html |
>
> Fedora Media Writer 是创建临场版 USB 以尝试 Linux 的方便方法。
>
>
>

[Fedora Media Writer](https://github.com/FedoraQt/MediaWriter) 是一个小巧、轻量、全面的工具,它简化了 Linux 的入门体验。它可以下载 Fedora 的 Workstation 或 Server 版本并写入到一个可以在任何系统上引导的 USB 驱动器上,使你无需将其安装到硬盘上就可以试用 Fedora Linux。
Media Writer 工具可以用来创建一个<ruby> 临场体验的 <rt> Live </rt></ruby>、可引导的 USB 驱动器。在你的平台上安装 Fedora Media Writer 应用后,你可以下载并烧录最新的 Fedora Workstation 或 Server 稳定版,也可以选择烧录你下载的任何其他镜像。而且它并不局限于英特尔 64 位设备。它还可以用于 ARM 设备,如[树莓派](https://fedoraproject.org/wiki/Architectures/ARM/Raspberry_Pi),这些设备日益变得更加强大和有用。

### 安装 Fedora Media Writer
[安装 Fedora Media Writer](https://docs.fedoraproject.org/en-US/fedora/f32/install-guide/install/Preparing_for_Installation/#_fedora_media_writer) 有几种方式。你可以通过 GitHub [从源码编译](https://github.com/FedoraQt/MediaWriter#building)、下载 MacOS 或 Windows 版本、使用 `dnf` 或 `yum` 安装 RPM 包,或者以 Flatpak 的形式获得。
在 Fedora 上:
```
$ sudo dnf install mediawriter
```
最新版本请参见 GitHub 仓库的[发布](https://github.com/FedoraQt/MediaWriter/releases)部分。
### 准备好你的媒体介质
首先,你需要一个 USB 驱动器来安装你的 Linux 操作系统。这就是 Fedora Media Writer 要烧录的设备。这个驱动器必须是空白或可擦除的,因为 **该 USB 驱动器上的所有数据都会被删除**。如果有任何数据,哪怕只是一个文件,如果你不想丢失,那么你必须在继续之前备份它!
确认你的 USB 驱动器是可擦除的之后,将它插入你的电脑并启动 Fedora Media Writer。
### 使用 Fedora Media Writer
当你启动 Fedora Media Writer 时,你会看到一个页面,提示你从互联网上获取一个可引导的镜像,或者从你的硬盘上加载一个自定义镜像。第一个选择是 Fedora 的最新版本。Workstation 版本适用于台式机和笔记本电脑,Server 版本适用于虚拟化、机架服务器或任何你想作为服务器运行的情况。
如果你选择了 Fedora 镜像,Media Writer 会下载一个光盘镜像(通常称为 “iso”,文件扩展名为 .iso),并将其保存到你的下载文件夹中,这样你就可以重复使用它来烧录另一个驱动器。

另外还有 Fedora Spins,这是来自 Fedora 社区的镜像,它旨在满足小众的兴趣。例如,如果你是 [MATE 桌面](https://opensource.com/article/19/12/mate-linux-desktop)的粉丝,那么你会很高兴地发现 Media Writer 提供了 MATE spin。它有很多,所以请滚动查看所有的选择。如果你是 Linux 的新手,不要被吓到或感到困惑:这些额外的选项是为老用户准备的,这些用户除了默认的选项外,还发展出了自己的偏好,所以对你来说,只使用 Workstation 或 Server 选项就行,这取决于你是想把 Fedora 作为一个桌面还是作为一个服务器操作系统来运行。
如果你需要一个与你当前使用的 CPU 不同架构的镜像,从窗口右上角的下拉菜单中选择 CPU 架构。
如果你已经将镜像保存在硬盘上,请选择“Custom Image”选项,并选择你要烧录到 USB 的发行版的 .iso 文件。
### 写入 USB 驱动器
当你下载或选择了一个镜像,你必须确认你要将该镜像写入驱动器。
驱动器选择下拉菜单只显示了外部驱动器,所以你不会意外地覆盖自己的硬盘驱动器。这是 Fedora Media Writer 的一个重要功能,它比你在网上看到的许多手动说明要安全得多。然而,如果你的计算机上连接了多个外部驱动器,除了你想覆盖的那个,你应该将它们全部移除,以增加安全性。
选择你要安装镜像的驱动器,然后单击“Write to Disk”按钮。

稍等一会儿,镜像就会被写入到你的驱动器,然后可以看看 Don Watkins 对[如何从 USB 驱动器启动到 Linux](https://opensource.com/article/20/4/first-linux-computer)的出色介绍。
### 开始使用 Linux
Fedora Media Writer 是一种将 Fedora Workstation 或 Server,或任何 Linux 发行版烧录到 USB 驱动器的方法,因此你可以在安装它到设备上之前试用它。试试吧,并在评论中分享你的经验和问题。
---
via: <https://opensource.com/article/20/10/fedora-media-writer>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,770 | 《代码英雄》第二季(9):特别篇 - 开发者推广大使圆桌会议 | https://www.redhat.com/en/command-line-heroes/season-2/developer-advocacy-roundtable | 2020-10-30T14:41:00 | [
"开发者",
"代码英雄"
] | https://linux.cn/article-12770-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(9):特别篇 - 开发人员拥护者圆桌会议](https://www.redhat.com/en/command-line-heroes/season-2/developer-advocacy-roundtable)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/7a9b329b.mp3)脚本。
>
> 导语:<ruby> 开发者推广大使 <rt> developer advocate </rt></ruby>在开源社区中起到的作用是举足轻重的。我们邀请了几位这样的推广大使来到本期节目中,以向我们揭示他们的工作方式,并阐述这份工作背后的意义。
>
>
> 来自 Mozilla 的 Sandra Persing、Twilio 的 Ricky Robinett 与 红帽的 Robyn Bergerron 将在此接受 Saron 的采访,分享他们的工作内容、他们支持社区的方式,以及他们对 2019 年的展望。
>
>
>
**00:00:06 - Saron Yitbarek**:
大家好,我是 Saron Yitbarek,这里是红帽的原创播客节目《<ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>》的特别篇。我们的节目在第 2 季去了很多地方。我们探索了[编程语言](/article-12595-1.html)、[数据大爆炸](/article-12649-1.html)、[安全危机](/article-12641-1.html)以及[无服务器](/article-12717-1.html)时代的到来,我们甚至去了[火星](/article-12744-1.html)。
**00:00:28**:
但是在结束了第 2 季之后,我们还有一个地方要去。我们要走进推广大使和思想领袖们的认识当中,他们帮着塑造了开发人员所做的全部工作。有时,他们被称为<ruby> 开发者推广大使 <rt> developer advocate </rt></ruby>,或者说他们担任开发者关系的职位,或开发者布道师。
**00:00:50**:
从开发人员的角度来看,无论他们的具体头衔是什么,他们似乎都做着许多相同的事情。你在会议上见过他们发表主题演讲。你在播客上听过他们接受采访,就像在本期节目中一样。你可能还阅读过他们的博文。但是他们是谁呢?他们到底在用自己的声音做了些什么?
**00:01:10**:
为了迎接 2019 年的到来,我们为大家召集了一个优秀人物的圆桌会议。尽管他们的头衔各不相同,但他们的目的是一致的。他们来到这里,是为了帮助开发人员,并确保其声音和需求能被大众听到。这些人都是典型的代码英雄。
**00:01:29**:
来自<ruby> 湾区 <rt> Bay Area </rt></ruby>的 Sandra Persing 是 Mozilla 的<ruby> 全球策略师 <rt> Global Strategist </rt></ruby>,也是 DevRel 峰会的创始人。
**00:01:38 - Sandra Persing**:
嗨, Saron。
**00:01:39 - Saron Yitbarek**:
你好。还有同样来自旧金山的 Ricky Robinett。他是 Twilio 的开发人员网络总监。
**00:01:47 - Ricky Robinett**:
你好。
**00:01:49 - Saron Yitbarek**:
从凤凰城外和我一起来的是 Robyn Bergeron,Red Hat 的社区架构师。
**00:01:55 - Robyn Bergeron**:
嗨!你好吗?
**00:01:56 - Saron Yitbarek**:
我很好。
**00:01:57 - Robyn Bergeron**:
看到你真高兴。
**00:01:57 - Saron Yitbarek**:
在不同的地方,这份工作的践行者被冠以不同的头衔。有<ruby> 开发者推广大使 <rt> Developer Advocate </rt></ruby>、<ruby> 开发者布道师 <rt> Developer Evangelist </rt></ruby>、<ruby> 开发者关系 <rt> Developer Relations </rt></ruby>;对于新事物来说,基本定义非常重要。因此,我认为一个好的起点是来定义这些东西是什么,尤其是定义你可以在这个领域做什么。所以,你能告诉我你的头衔以及这个头衔实质上的含义吗? Ricky,让我们从你开始吧。
**00:02:22 - Ricky Robinett**:
好的,听起来很棒。我的头衔是<ruby> 开发者网络总监 <rt> Director of the Developer Network </rt></ruby>。我有幸供职于一个开发者关系专家团队。我们有一个布道师团队、一个教育团队和一个社区团队。因此,这绝对是一个大杂烩,有你听说过的各种不同的头衔,我们将其汇集在这个团队之中。
**00:02:43 - Saron Yitbarek**:
厉害啊。Sandra,你呢?
**00:02:45 - Sandra Persing**:
我在 Mozilla 担任活动和赞助的<ruby> 全球策略师 <rt> Global Strategist </rt></ruby>,并与 Mozilla 新兴技术小组的开发者拓展团队合作。我通常会将我的日常活动解释为大量的研究、交流和探索,而这都将最终影响我们评估与决策应当如何投资我们的资源:我们的时间、金钱、纪念品、演说者等等,以回馈开发者社区,同时也从开发者社区得到反馈。这份工作既有布道的一面,也有倡导的一面。
**00:03:24 - Saron Yitbarek**:
很棒。 Robyn,该你了。
**00:03:26 - Robyn Bergeron**:
你好。好吧,我的正式头衔是<ruby> 社区架构师 <rt> Community Architect </rt></ruby>。人们就我这个头衔有过很多问题。我曾被称为<ruby> 社区经理 <rt> Community Manager </rt></ruby>,也曾被称为<ruby> 开发者推广大使 <rt> Developer Advocate </rt></ruby>,甚至还在过去的一份工作中做过<ruby> 运维推广大使 <rt> Operations Advocate </rt></ruby>。但是我想我所做的是……嗯,你知道,像是“社区经理”之类头衔所暗示的“你在管理着社区中发自内心为项目做出贡献的人”的这种想法,其实相当愚蠢,因此,我喜欢把我所做的事情看作是构建一个框架,人们可以真正顺利地参与其中,确保过程中没有障碍,并确保他们可以完成所有他们想要做的事情。
**00:04:02 - Saron Yitbarek**:
Ricky,由于你基本上是负责整个开发者网络的总监,你不仅仅是置身于推广大使团队、布道团队,也是社区团队之中,这有点儿像是你在运行着整个项目。你是怎样理解的这个的,是向开发者推广还是推广开发者?
**00:04:20 - Ricky Robinett**:
是的,这是个很棒的问题。 Phil Nash 是我们团队中的一名布道师,他对此有一个很好的认识,而我要将它剽窃过来。我们可以从很多不同的角度来解释这份工作,但说到底,我们的工作其实大体上就是帮助他人。
**00:04:33 - Saron Yitbarek**:
我喜欢这一点。是的。
**00:04:35 - Ricky Robinett**:
我们帮助开发人员,有时候这些帮助看起来就像是在 Stack Overflow 上回答问题,有时看起来像是构建一款新工具,有时看起来像组织一个活动,有时看起来又像是发起一次产品的内部改动。因此,我认为这就是我所听说过的最好的认识 —— 我们的责任是帮助。
**00:04:57 - Saron Yitbarek**:
的确。Sandra,你的职位让我感兴趣的一点是,你不光是策略师,还是全球策略师。让世界各地的开发人员组织起来,并且帮助他们,这是你在 Mozilla 的工作的一部分。在全球范围内的推广倡导会是什么样的呢?在不同的国家、不同的大洲之间,这份工作的含义会有所不同吗?
**00:05:20 - Sandra Persing**:
对,确实存在一些不同。我们今年刚刚在新加坡举办了第三届 DevRel 年度峰会。在过去的两年间,我们在西雅图主办了这项活动,而到了新加坡,我们看到了不同的视角。当我们走出湾区时,就连某些最基本的组织方式都需要做出改变。比如,如何确保一切都能在线下运转,因为连接性是一个大问题;再比如,我们该怎样使一名工作于印尼的开发人员能在峰会过程中与社区充分互动,无论他是在线上参加聚会,还是来到现场。
**00:05:59 - Sandra Persing**:
我们总会发现,所谓的“基础”,一些对我们来说如此寻常的事,比如在湾区举办一次简单的聚会——这再常见不过了,对吧?你高呼一声“我要参会”,就会发现到处都有聚会可以参加。然而对于,比如,越南的开发者来说,此事可以是具有特殊意义,且对他们而言相当重要的。这种聚会很宝贵,丰富了他们的开发者生活。
**00:06:27 - Saron Yitbarek**:
我注意到的一件事是,大家都以某种方式提到了社区。而我自己也运营着一个社区,Code Newbie,而且我经常被一些公司聘用为他们的布道师或社区经理。有一件事我一直都有点儿担心,也许有点畏惧;我在想,在过去的三四年里,我一直在尽我所能,尽心尽力地负责着这个社区。
**00:06:55**:
但如果我为一家公司工作,我就必须要牺牲这些吗?我是不是必须要将公司置于社区的需求之上?我该如何平衡这种关系呢?
**00:07:06**:
所以我在想,Robyn,或许我们可以问问你这个<ruby> 社区架构师 <rt> Community Architect </rt></ruby>,你是如何区分这两者的呢?或者说,你是如何平衡这两者的?
**00:07:16 - Robyn Bergeron**:
好吧,这当然是一个有趣的平衡。我的意思是,我以前的一个工作实际上是担任 Fedora 项目负责人。而你知道,Fedora 是 Red Enterprise Linux 的上游,在这里,你角色的一部分确实是某种找寻平衡的行为,对吧?两者之间的平衡是让社区里的人们开心,让公司对社区所做的事情高兴,同时要确保每个人都是快乐大家庭的一员。
**00:07:41**:
而且,你知道,我想当你在这个职位上做得最好的时候,你肯定会时不时地激怒公司决策层的某些人。但是你知道的,最终还是要用结果来证明,对吧?
**00:07:59**:
人们总是问我,你是如何平衡 Ansible 和红帽之间的关系的,你知道,当 Ansible 被红帽收购时,就像是 —— 哦我的天哪,红帽会接管它,然后对它做些糟糕的事情,并摆脱 Ubuntu 的支持吗?
**00:08:12**:
而这就像是,拥有整个项目的全部目的就是为了破坏它,就像是为了不要吸引 4000 名贡献者而故意变得糟糕一样。
**00:08:22**:
确保你的管理层信任你,并始终与人们保持清晰的沟通以了解实际发生的事情,并确保沟通通道的两侧都不会出现意外,这是成功与否的部分原因,也许并不总是会成功,但肯定会让人感到惊讶。
**00:08:41 - Saron Yitbarek**:
嗯嗯。确实。Ricky,你呢?当你在做这么多不同事情的时候,你是如何看待这种关系中的平衡的?
**00:08:49 - Ricky Robinett**:
我认为你必须相信公司和技术。你必须相信,你所带给开发人员的东西将会对他们的生活、职业生涯以及公司产生影响。
**00:09:03**:
另一方面,你必须让高管们相信这种方法。因此,我们非常幸运的一点是我们的 CEO 是一名开发人员,而且在很多方面,他是我们和开发者社区打交道的原动力。我们的布道师们的使命是激励并装备开发人员。因此,有时候我们会说这能激励并装备他们吗?因为如果不能的话,我们就不应该这么做,因为这超出了我们的职权限范围。
**00:09:36 - Saron Yitbarek**:
嗯嗯。Sandra,我觉得你有点儿优势,因为 Mozilla 是一个非营利性组织,对吧?所以我觉得或许 ——
**00:09:44 - Sandra Persing**:
我刚想说。
**00:09:46 - Saron Yitbarek**:
跟我讲讲这个吧。
**00:09:47 - Sandra Persing**:
Mozilla 的历史就是我们是一家叛逆的公司。我们一直在反抗企业家,对吗?出走 Netscape ,并与我们的创始人之一 Mitchell Baker 一起走过的整段历史,确保了 Web ——
**00:10:01**:
—— 乃至互联网是面向所有人的开放而自由的资源。我的意思是,我们仍然,我们每个人,每一个 Mozilla 人,都信奉这一口号,我们对此深信不疑。因此,这绝对是一家令人惊叹的、100% 拥抱了社区的公司。
**00:10:22 - Saron Yitbarek**:
确实。所以,Ricky,我还清楚地记得那件红色的运动夹克,我还记得你亲自出马做的那些很棒的演示,感觉那种联系并帮助开发人员的方式非常新颖。这个想法是怎么在 Twilio 上产生的?
**00:10:41 - Ricky Robinett**:
嗯,你这么说真是太好了。我们确实相信我们是站在巨人的肩膀之上。你会想到 Apple 公司的 Guy Kawasaki,有人在我们之前就采用了这种营销方式。我认为我们很幸运能在正确的时间把它带给开发人员。
**00:11:03**:
而且有这么多的人进来,带着我们如何能够做到这一点以及如何能够不断提高方法水平的想法。但是我实际上不知道是谁发明了红色运动夹克,因此现在我需要去探寻历史 ——
**00:11:19 - Saron Yitbarek**:
你一定得找到答案。
**00:11:19 - Ricky Robinett**:
—— 有关这是何时开始的历史。
**00:11:20 - Saron Yitbarek**:
这是件很棒的夹克。
**00:11:21 - Ricky Robinett**:
知道了,我今天下午就去找。
**00:11:25 - Saron Yitbarek**:
而我想知道的是,布道和推广的想法在 Twilio 是如何随着时间而发生变化的。你知道,曾经你们只是一家小小的初创公司,一家叛逆的初创公司,然后现如今成了一家大公司。随着公司本身的变化,布道的形式又是如何变化的呢?
**00:11:46 - Ricky Robinett**:
是的,开始时,我觉得我本可以一年 365 天都在<ruby> 黑客马拉松 <rt> hackathon </rt></ruby>上渡过,而在纽约,每个周末你都要从五到六个黑客马拉松之中抉择一个。我们在布道方面所做的许多事情都是黑客马拉松场景,而现在,场景不同了。确实,最大的变化在于公司外部而不是内部。
**00:12:11**:
因此,我谈到了布道师的激励和装备。所以令人高兴的是,这些年来这个任务并没有发生任何变化,他们激励和装备的方式一直在变化,但任务本身并没有什么改变。
**00:12:26 - Saron Yitbarek**:
那么 Robyn,随着 DevOps 和 DevSecOps 的兴起,推广大使在你和社区架构师看来如何呢?会有运维推广大使吗?
**00:12:39 - Robyn Bergeron**:
嗯,实际上那是 …… 我的意思是说,孩子们,那是我辍学后的第一份工作。我不建议这样做,不要在家做这个事情。
**00:12:47 - Saron Yitbarek**:
留在学校里继续上学。
**00:12:48 - Robyn Bergeron**:
听着。你看,小姑娘,我的第一份工作实际上是在 Motorola 担任<ruby> 系统管理员 <rt> SysAdmin </rt></ruby>多年,而当我从担任 Fedora 负责人跳槽时,我在 Elastic Search 工作了一段时间,你知道,那个头衔是开发者推广大使,因此我花了几个学期在大学里攻读 C。但是我的心一直都在运维这边。我开始对自己真的是一名开发者推广大使感到疑惑?我觉得我只是在推广运维人员而已。我开始自称是一名运维推广大使,每个人都为之注目。
**00:13:22**:
每个人都说,嗯,这真的是一个很酷的头衔。我的意思是,你知道,我基本上只是在公司内部倡导其他人在做什么。
**00:13:33 - Saron Yitbarek**:
所以,Sandra,我们谈到了推广大使和布道师在世界不同地区看起来如何不同,但是我想知道,随着我们变得越来越全球化,联系越来越紧密,更大范围和形式的布道对你来说是不是也在随着时间流逝而变化?
**00:13:52 - Sandra Persing**:
你知道什么是开发者关系吗?我们是在推销我们的产品吗?你知道,而我注意到的是,即使是大公司也正在远离这种策略。要明白的是,做一个真实的人,真正留心倾听并回应开发人员的需求是最为重要的,而不是去推销产品。
**00:14:17**:
我总是回过头来和我在 Mozilla 的团队分享一个理念,开发者们实际上是我们所合作过的最聪明、最具有创造力的客户群体之一。他们可以大老远就闻到商业销售的气味。因此,我们必须对于如何共享信息保持精明,就像它必须是一群有着才华和智慧的人聚集在一起,成为我们与开发者社区进行沟通的创新方式。
**00:14:48 - Saron Yitbarek**:
嗯,真的,我很喜欢这样的想法,需要将不同的技能,我想,还有不同的背景,集合在一起,才能很好地服务于开发者,也能帮助开发者自助。
**00:15:01**:
当我想到开发者推广大使的兴起时,在我看来,它与开源的兴起息息相关。这感觉几乎就像是开源贡献者越多,开源就变得越重要,重视它的大公司也越多,他们几乎必须与这些开源贡献者、这些开发人员建立起更好的关系,并且我感觉这二者真的是紧密相关的。
**00:15:27**:
因此我很好奇你的想法。那么 Robyn,让我们从你开始吧。是这样的吗?推广大使的这个想法与开源的兴起有所联系吗?
**00:15:37 - Robyn Bergeron**:
如果你是一家销售软件或是销售许可证和长期支持的公司,你知道,无论你的开源公司的业务模型是什么,如果你没有这种反馈回路,或者你没有真正关注人们在说什么,那你最终会犯下一个众所周知的错误。我认为,真正能在全世界范围内每天都做到这一点,就是成功和失败之间的区别,没有人愿意花时间去做错误的事情。那是个坏主意。
**00:16:10 - Saron Yitbarek**:
是的,这通常是个坏主意。很好。因此,我想知道你们每个人各自都在关注什么,都真正在思考什么。因此,Ricky,让我们从你开始吧。在你的 Twilio 角色中,你试图为开发者文化带来什么样的改进呢?
**00:16:27 - Ricky Robinett**:
如果我要说的我与开发者交谈时听到过最多的一个短语,那就是“我不是开发者,但是 …… ”,而这可能是一直萦绕在我脑海中的最大的事情之一 —— 开发者定义的扩大化。
**00:16:45**:
对我们很多人来说,“冒牌综合症”是一个非常真实的现象。令人惊讶的是,即使是你所认识的一些最好的开发者也在为此努力。而对我来说,我们所有人能在我们的文化中做的最重要的事情之一,就是让人们说,“你知道吗?我是一名开发者。我用代码解决问题。”
**00:17:08**:
因此,我最喜欢的故事之一是,我们社区有一个名为 Doug McKenziethat 的成员,他是个魔术师。他自学了 PHP,以便在魔术中使用技术。
**00:17:23 - Saron Yitbarek**:
噢,很棒。
**00:17:23 - Ricky Robinett**:
Doug 之所以如此之酷,是因为他超级谦虚,就像是:“哦,我不是一名开发者。”而突然之间你发现,他正在编写比许多人所见过的更为复杂的代码,可以完成令人震惊的事情。因此,我感觉世界上有许多 Doug McKenzies 这样的人,他们都在用代码做着伟大的事情,我们有机会让他们成为社区的一份子,并且在这项工作中拥有自己的身份。
**00:17:51 - Saron Yitbarek**:
我喜欢这个故事,因为它让我想起了我曾经为 Code Newbie 播客采访过的一个人,她是一名作家而且有很多写作任务,必须学习 Git 才能撰写有关 Git 的文章,她写了很多这方面的文章,又逐渐转向了其他的编程主题,最终,你知道,几年过去之后,她实际上已经成为了一名开发者却不自知。
**00:18:13**:
在我采访她的时候,我说:“嘿,你知道自己是一名开发者吗?”她说:“不,我是个作家。”而我说:“你可以二者兼备。它们并不互相排斥。”但是,是的,这种说法换个角度说,“嘿,我实际上是在编程和创造,因此现在我可以自称为一名码农了”,这种认识对人们来说很难,要做到这样需要一段时间。
**00:18:32 - Ricky Robinett**:
是的,当然是这样。
**00:18:33 - Saron Yitbarek**:
是的。因此,Robyn,对你来说,最近几年来你一直在努力推动的最积极的变化是什么?
**00:18:41 - Robyn Bergeron**:
只是确保在我们的成长过程中,我们不会失去对大局观的把握。我们的主要目标是使人们易于使用、易于贡献、易于实际完成生活中的事情,确保我们不会偏离这个目标,或者在实际项目的某些结构层面获得更多的工程帮助,并确保我们保持所有这些东西都井井有条。我们在这方面做得很好,我不知道是不是,但我认为这很重要。我不知道自己会不会因此而获得诺贝尔和平奖,但我知道这对许多贡献者都非常重要。
**00:19:19 - Saron Yitbarek**:
这对我来说很有用。Sandra,你呢?作为全球策略师,你近些年来所推动的最积极的变化是什么?
**00:19:26 - Sandra Persing**:
在我脑海中真正突出的两件事是扩展开发者角色这个定义,这一点非常重要。我们想要发展我们的社区,对吗?那么为什么要限制开发者的定义和描述呢?
**00:19:43**:
当我们在 Sundance 与 Reggie Watts 和 Chris Milk 等著名人物进行座谈时,我们给电影制作人、制片人、决策者一个机会,让他们说:“哦,我们也能做到。我们不需要受限于作为创意电影制作人能做些什么。”
**00:20:00**:
我们可以采纳技术,也可以成为开发者,而这相当令人耳目一新。我们在 Mozilla 经历的另一个时刻是让一位芝加哥的灯光艺术家 Ian Brill 与我们合作进行一个项目,我们把这个项目标记为 Arch,我们为今年两个重要的 JavaScript 开发者活动带来了这种巨型的塑料灯,LED 灯,带着七个可编程的树莓派结构。这是为了邀请更多的程序员(无论他们是否自称为开发者)来尝试 Mozilla 今年大力倡导的两种语言: WebAssembly 和 Rust。
**00:20:49**:
因此,我们创建了两个简单的模板,说,“尝试一下吧”,但这不是我们所想要推动的编程。这不是编程,而是“是的,有几行代码。它是编程语言,但你要做的是创建几行代码,现在可以将它们转化为艺术”,而这让许许多多的新人进入到了我们的群体之中,也就是把他们带到我们的桌子旁边,然后他们会编写他们的代码行,在 Arch 之下走过,去查看目前正在结构中循环着的灯光表现。这真是太神奇了。
**00:21:22 - Saron Yitbarek**:
哇。这听上去很美,确实美。因此,我想知道的是,当我们谈论到为开发者做推广大使时,我们谈论了很多有关社区的话题,也谈论了那个最终的想法,无论我们的职业头衔是什么,我们真的只是想要帮助人们,开发者需要什么方面的帮助? Ricky,让我们从你开始吧。开发者们说他们需要从你这里得到什么呢?
**00:21:44 - Ricky Robinett**:
哇。是的,这是个好问题。我认为,我们所发现的其中一件事是,科技变化如此之快,我们被问到的很多问题都是,“我从哪里开始?我首先要做什么?我怎么知道我走的路是正确的呢?”对我们来说,这可能是我们投入最多的领域之一,我们称之为帮助人们发现他们用代码改变世界的能力。
**00:22:16 - Saron Yitbarek**:
噢,这很美妙。我赞成。
**00:22:18 - Ricky Robinett**:
嗯,谢谢你。是的,这令人兴奋。因此我们构建了一款名为 TwilioQuest 的工具,以帮助人们发现这种力量,帮助他们知道从何处开始。但我只是感觉,你知道,人们一直在寻找自己的身份或获得允许使用该身份的方式,而对每个人而言这就已经是写代码,是用代码或软件解决问题。有许多人想这么做,然而却不知道从哪里开始。所以这是我们经常思考的一件事。
**00:22:51 - Saron Yitbarek**:
是的。因此,Robyn,对于你们红帽来说,红帽的开发者所寻求的是什么呢?
**00:23:00 - Robyn Bergeron**:
很多时候,是有人来找你,他们遇到了一些障碍,也许是“不知怎么的,我的公关人员被机器人遗漏了”,但是很多时候,也有人会说,“嘿,我有一个很酷的想法。或许它不太适合这里,但是我认为它可能会改善社区的运行方式,或者可能会是其它我们正在研究的东西的不错的辅助工具。我该怎么办呢?”这就像是,“好吧,我该如何帮你入门呢?”你知道吗?“我能怎么做呢?比如说,你只是需要有人同意吗?因为我在这儿整天都基本上是对任何事情点头,让人们知道,这行得通,你当然有权力这样做”,所以这是我所认为最好的事情是,你可以做。至少在我看来,就是确保人们在自己的前进道路上没有阻碍,或者如果阻碍他们前进的一件事是正等着某人说可以,我一直在重申,你不需要别人的许可,但是如果有人需要,那么看在上帝的份上,请给他们许可。
**00:23:58 - Saron Yitbarek**:
所以,最后一个问题,我们需要总结一下,我将向你们逐一询问。你在 2019 年将要倡导的最重要的事情是什么呢?如果你有魔杖,那么你想要改变的下一件大事是什么呢? Sandra,让我们从你开始吧。
**00:24:15 - Sandra Persing**:
嘿,我就知道你会这么做。好吧,我们将在 2019 年进行的最大挑战和最为激动人心的项目是真正兑现我们的承诺,使 Web 成为最棒、最大、最易于访问的平台之一。我们总是告诉开发者这是你应当为之构建并部署的地方,但是我们知道 Web 本身非常复杂,而且有着多个浏览器供应商,有时候这并不是一个正确的说法,这对我们而言是一个长期的挑战,尤其是在 Mozilla,在这里我们想要保持 Web 开放、自由,并且能被所有人访问。我们想要继续确保能够兑现对开发人员的承诺,确保网络确实是开放的、可访问的,对所有人都开放。
**00:25:10 - Saron Yitbarek**:
嗯,爱了。Ricky,你呢?
**00:25:13 - Ricky Robinett**:
只需要确保我们为开发人员提供服务,使得他们能够在全世界范围内进行线上或是线下的聚会。更容易专注于你所看到的内容,并且无需记得开发人员是在何处,即使你没有看到他们。因此,我会挥舞我的魔杖,并在全世界更多的地方,找出我们如何能够帮助那里的开发人员。
**00:25:36 - Sandra Persing**:
我只想说,我喜欢 Jarod 有关<ruby> 暗物质开发者 <rt> dark matter developer </rt></ruby>的演讲。实在是太棒了。
**00:25:42 - Ricky Robinett**:
当你第一次听到它的时候,感觉像是一个了不起的概念,就像是,“哇,真的是一回事儿。”
**00:25:50 - Saron Yitbarek**:
那就给我们讲讲吧,什么是暗物质开发者呢?
**00:25:52 - Sandra Persing**:
本质上,有一些开发者,他们不参与你的聚会,不参与 GitHub 和在线社区,不为 Stack Overflow 做贡献。这些开发者仍在努力工作并作出贡献,但我们不知道。我们知道他们就在那里,但我们看不到他们。我们无法认出他们,而这些人实际上是开发者社区中非常重要的一部分,我们往往会忽略他们,但不能这样。忽略那些不愿发表意见的社区将损害我们与开发者的关系,我们需要更加积极主动地寻找宇宙中那些暗物质开发者。
**00:26:34 - Saron Yitbarek**:
哦,我喜欢。这很酷。是的,Jarod 实际上在 Twilio 工作,对吗?
**00:26:38 - Sandra Persing**:
是的。是的,他负责运营亚太区的 DevRel。
**00:26:42 - Robyn Bergeron**:
我从前在红帽的同事之一 Chris Grams,现在在一家名为 Tidelift 的公司里工作,他曾经有一个名为<ruby> 暗物质很重要 <rt> Dark Matter Matters </rt></ruby>的博客,因为它有点儿像是 ——
**00:26:52 - Saron Yitbarek**:
嗯嗯。
**00:26:54 - Robyn Bergeron**:
你知道,你所看不到的东西实际上仍然很重要,所以 ——
**00:26:58 - Saron Yitbarek**:
确实是这样。 Robyn,你呢?你会用你的魔杖做什么呢?
**00:27:03 - Robyn Bergeron**:
哦,用我的魔杖,有很多事情,但是根据这次谈话,我想我会更好地管理彼此之间的依赖关系,而且也许并不令人惊讶,尤其是当我们之中有许多人在 OpenStack、 OPNFV、 Ansible 以及所有这些建立在彼此之上的东西工作时。只是确保我们项目之间的关系比你筋疲力尽时所能看到的关系更加明显。因此,我非常期待来年的事情,因为我们在事物上越来越受关注。现在这非常令人兴奋。
**00:27:39 - Saron Yitbarek**:
吸引力总是那么好。它是如此令人兴奋。好吧,我想感谢你们所有人,非常感谢你们今天加入我们并分享你们的思维、想法和故事。非常感谢大家。那么现在说再见?
**00:27:51 - Robyn Bergeron**:
再见,各位。
**00:27:54 - Sandra Persing**:
很好。非常感谢你, Saron。能上这期节目很荣幸。
**00:27:58 - Ricky Robinett**:
它已经开始了,游戏工作室对于开源的态度已经开始转变。
**00:27:59 - Saron Yitbarek**:
确实。今天的圆桌会议包括红帽的社区架构师 Robyn Bergeron、 Mozilla 的全球策略师 Sandra Persing 以及 Twilio 的开发者网络总监 Ricky Robinet。我认为自己很幸运,能有这样的平台让我分享对于我们社区将何去何从的愿景,无论是这档播客节目还是在其他地方,但我想要指出的是,你无需拥有自己的播客就能够成为推广大使。成为推广大使只是意味着睁大眼睛并代表他人大声疾呼。这确实可以是每个人的工作。因此,我希望 Robyn、 Sandra 和 Ricky 给了你一点儿有关倡导你觉得重要的事情的启发。
**00:28:50 - Saron Yitbarek**:
同时,《代码英雄》第 3 季已经在制作中了。当新剧集在今年春天推出时,你可以成为最早了解新剧集的人之一。如果你尚未注册,请在 Apple Podcasts、 Google Podcasts 或任何你获得播客节目的地方进行订阅。只需点击一下,100% 免费。我是 Saron Yitbarek。非常感谢你的收听,在第 3 季到来之前,继续编程。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/developer-advocacy-roundtable>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[windgeek](https://github.com/windgeek), [Northurland](https://github.com/Northurland), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Developer advocates play important roles in open source communities. We brought a few of them together to explain how and why they do what they do.
Sandra Persing (Mozilla), Ricky Robinett (Twilio), and Robyn Bergeron (Red Hat) sit down with Saron to share what they're working on, how they support their communities, and what they're looking forward to in 2019.
**00:06** - *Saron Yitbarek*
Hi everybody, I'm Saron Yitbarek and this is a special bonus episode of Command Line Heroes, an original podcast from Red Hat. This podcast went a lot of places in Season 2. We explored programming languages, data overload, security crises, the advent of serverless. I mean, we even went to Mars.
**00:28** - *Saron Yitbarek*
But after closing out Season 2, there was still one more place we wanted to go. We wanted to go inside the minds of the advocates and thought leaders who help shape all the work that developers do. Sometimes they're called developer advocates or they're in developer relations or they're developer evangelists.
**00:50** -*Saron Yitbarek*
Whatever their exact titles, from the developer's perspective, they seem to do a lot of the same things. You've seen them give keynotes at conferences. You've heard them getting interviewed on podcasts, like this one. You've probably read their blog posts. But who are they, and what exactly are they using their voices to get done?
**01:10** - *Saron Yitbarek*
To ring in 2019, we've pulled together a roundtable of amazing people for you. While their titles are all different, their purpose is the same. They're here to help developers and make sure their needs and voices are heard. These folks are classic command line heroes.
**01:29** - *Saron Yitbarek*
From the Bay Area, Sandra Persing is a Mozilla Global Strategist and creator of the DevRel Summit.
**01:38** - *Sandra Persing*
Hi, Saron.
**01:39** - *Saron Yitbarek*
Hello. And also in San Francisco we have Ricky Robinett. He's the Director of the Developer Network over at Twilio.
**01:47** - *Ricky Robinett*
What's up?
**01:49** - *Saron Yitbarek*
Joining me from just outside of Phoenix is Robyn Bergeron, a community architect at Red Hat.
**01:55** - *Robyn Bergeron*
Hi there. How are you?
**01:56** - *Saron Yitbarek*
I'm doing great.
**01:57** - *Robyn Bergeron*
Excellent.
**01:57** - *Saron Yitbarek*
So there are a lot of titles floating around. There's Developer Advocate, Developer Evangelist, Developer Relations, and with all these new things, basic definitions are super important. So, I think a good place to start is just to define what these things are and specifically, what you all do in this space. So, can you tell me your job title and what that title actually means? Ricky, let's start with you.
**02:22** - *Ricky Robinett*
Okay, sounds good. My title is the Director of the Developer Network. What I have the privilege of doing is serving a team of developer relations professionals. We have an evangelism team, we have a education team and we have a community team. So, it's definitely a mishmash of all the different titles of you hear, we kind of collect them on the team.
**02:43** - *Saron Yitbarek*
Awesome. And Sandra, what about you?
**02:45** - *Sandra Persing*
I am at Mozilla as the Global Strategist for events and sponsorship and I work with our developer outreach team in the emerging tech group at Mozilla.I usually explain my day to day activities as a lot of research and communications and explorations that really leads to evaluating and deciding, you know, how we should all invest our resources: our time, money, swag, speakers, et cetera, in order to give back to the developer community, but also to receive feedback from the developer community. So both the evangelism side and the advocate side.
**03:24** - *Saron Yitbarek*
Awesome. And Robyn, you're up next.
**03:26** - *Robyn Bergeron*
Hi. Well so, my official title is Community Architect. I get a lot of questions about this title. I've gone by Community Manager. I've gone by Developer Advocate. I've even gone by Operations Advocate at one job in the past. But I like to think of what I do is, you know, when you're a community manager, like the idea that you're really managing all these people who are contributing out of the goodness of their heart is sort of a silly notion. So, I like to think of what I do as building frameworks in which people can actually successfully participate and make sure that roadblocks aren't in their way and that they can get done all the things they want to get done.
**04:02** - *Saron Yitbarek*
And Ricky, since you are essentially the Director of the entire network, you're not just in advocacy or evangelism or community, it kind of feels like you're running the whole show. How do you understand this idea of being an advocate either for developers or advocating to developers?
**04:20** - *Ricky Robinett*
Yeah, that's a great question. Phil Nash, who's one of the evangelists on our team had a great framing for this that I'm going to steal, which is we have a lot of different ways of describing what we do, but ultimately a lot of them just being help.
**04:33** - *Saron Yitbarek*
I like that. Yeah.
**04:35** - *Ricky Robinett*
We help developers, and so sometimes that help looks like answering a question on Stack Overflow. Sometimes it looks like building a new tool. Sometimes it looks like organizing an event and then sometimes it looks like initiating a product change internally. So, I think that's the best framing I've heard is really our responsibility is to help.
**04:57** - *Saron Yitbarek*
Absolutely. Sandra, what I'm so interested in about your position is that you're not just a Strategist, you're a Global Strategist and you're all over the world trying to bring developers together and help them as part of your job at Mozilla. When we think about advocacy on a global scale, what does that look like? Does it mean something different across different countries, continents?
**05:20** - *Sandra Persing*
Yeah, absolutely. We just wrapped our third annual DevRel Summit this year in Singapore and the past two years, we hosted the event in Seattle and getting out to Singapore, we saw a different perspective. When we get outside of the Bay Area, it can be something as basic as, you know, how do we make sure everything just works offline, because connectivity is such an issue or something like how do we just make sure a developer who's working in Indonesia feels just connected to a developer community, whether that's online or onsite through meetups.
**05:59** - *Sandra Persing*
And always going back to recognizing that some of our quote unquote "basic things," some of our easy things like creating a simple meetup in the Bay Area, which is so a dime a dozen, right? You throw a rock and there's a meetup everywhere is still something really special and something that a developer in let's say Vietnam still sees to be incredibly important and valuable and enriching their developer community life.
**06:27** - *Saron Yitbarek*
And one thing I'm noticing is that everyone has mentioned community in some way. And I run a community myself. I do Code Newbie and I regularly get recruited by companies to be an evangelist or a community manager for their company and one thing that I've always been a little worried about, maybe a little squeamish about is thinking, okay, I've spent the last three, four years taking care of this community with no strings attached, on my terms,I'm doing what I think is best.
**06:55** - *Saron Yitbarek*
But if I work for a company, then will I have to sacrifice that? Am I going to be in a position where I have to put the company before the needs of the community and how do I balance that relationship?
**07:06** - *Saron Yitbarek*
So I'm wondering, Robyn, maybe we could start with you as a Community Architect, how do you separate that? How do you maintain that church and state relationship, so to speak?
**07:16** - *Robyn Bergeron*
Well, it's certainly an interesting balance. I mean, one of my former jobs was actually being the Fedora project leader. And you know, Fedora is the upstream for Red Hat Enterprise Linux, you know, part of your role there is really to be sort of the balancing act, right? The balancebetween are people happy in the community, is the company happy with what the community is doing and making sure that basically everybody's one big happy family.
**07:41** - *Robyn Bergeron*
And you know, I think when you're doing your job best in that position yeah, you're pretty much bound to probably anger someone at the corporate headquarters once in a while. But you know, the proof is in the pudding at the end of the day. Right?
**07:59** - *Robyn Bergeron*
People ask me all the time like, how do you balance, what's going on with Ansible and Red Hat and you know, like when Ansible got bought by Red Hat, like, oh my God, is Red Hat going to take it over and do something terrible to it and get rid of, Ubuntu support?
**08:12** - *Robyn Bergeron*
And it was like, that would be defeating the whole purpose of having this entire project. Like, we haven't gotten to 4,000 contributors by being terrible.
**08:22** - *Robyn Bergeron*
Making sure that your management trusts in you and that you have clear communication with folks all the time about what's actually going on and that there aren't surprises on either side of the aisle is part of what makes the difference between success and maybe not always success, but certainly people being surprised.
**08:41** - *Saron Yitbarek*
Mm-hmm (affirmative). Absolutely. And Ricky, what about you? How do you think about church and state in that relationship when you're doing so many different things?
**08:49** - *Ricky Robinett*
I think you have to believe in the company and the technology. You have to believe that what you are bringing to developers is going to have an impact on their lives and their careers and their companies.
**09:03** - *Ricky Robinett*
And then on the flip side, you have to have executives who believe in this approach to your work. So, we're very lucky that our CEO is a developer and in many ways was the driving force behind the way that we approach our developer community. Our evangelists have a mission to inspire and equip developers. And so, there are times when we say, is this going to inspire and equip them?Because if it's not, we shouldn't really be doing it because it's something that's outside of our purview.
**09:36** - *Saron Yitbarek*
Mm-hmm (affirmative). Sandra, I feel like you're a little bit at an advantage because Mozilla's a nonprofit, right? So I feel like maybe—
**09:44** - *Sandra Persing*
I was going to say.
**09:46** - *Saron Yitbarek*
Tell me about that.
**09:47** - *Sandra Persing*
The history of Mozilla is that we're a rebellious company. We've always rebelled against the corporate man, right? The whole history of coming out of Netscape and with one of our founders, Mitchell Baker, in making sure that the web is
**10:01** - *Sandra Persing*
and the Internet is an open and free resource for all. I mean, we still, every one of us, every Mozillian believes this mantra and we hold it dear to our heart. So it's absolutely an amazing company that has embraced the community side 100%.
**10:22** - *Saron Yitbarek*
Absolutely. So Ricky, I vividly remember the red-like sports jacket and I remember seeing you personally onstage doing these awesome demos and it feels like that whole approach to connecting with developers and helping developers was very new. Where did that idea even come from at Twilio?
**10:41** - *Ricky Robinett*
Well, that's very kind of you to say. We do really believe we stand on the shoulders of giants here. You think of Guy Kawasaki with Apple, of people doing this style of marketing way before us. I think that we got to be fortunate enough to be at the right time to take this to developers.
**11:03** - *Ricky Robinett*
And there's just so many people who came in with the idea of how we can do this and how to keep leveling up how we approached it. I don't actually know who invented the red track jacket though, so now I need to go find the history—
**11:19** - *Saron Yitbarek*
You gotta find that out.
**11:19** - *Ricky Robinett*
—of where that started.
**11:20** - *Saron Yitbarek*
That's a great jacket.
**11:21** - *Ricky Robinett*
I know. That's my mission for this afternoon now.
**11:25** - *Saron Yitbarek*
And I'm wondering how has that idea of evangelism, and advocacy, how has that changed over time at Twilio, given the fact that, you know, at one point you were a small little startup or a little rebellious startup, and then now you're kind of a big company. How is the shape of evangelism changed as the company itself has changed?
**11:46** - *Ricky Robinett*
Yeah, when I started here, I feel like I could have spent 365 days a year at hackathons and in New York every weekend you had to pick from five or six hackathons. So much of what we did with evangelism was the hackathon scene and now, that's not the same scene. Really, the biggest changes have been driven outside the company rather than inside.
**12:11** - *Ricky Robinett*
So I talk about evangelists inspiring and equipping. And so the nice thing is that hasn't changed in all the years, so the ways that they inspire and equip keep going differently, but the mission itself doesn't change.
**12:26** - *Saron Yitbarek*
And Robyn, with the rise of DevOps and DevSecOps, what does advocacy look like for you and for being that community architect? Is there gonna be a Ops advocate?
**12:39** - *Robyn Bergeron*
Well, actually that was ... I mean, my first job after dropping out of school, don't recommend it, kids. Don't do that at home.
**12:47** - *Saron Yitbarek*
Stay in school.
**12:48** - *Robyn Bergeron*
Listening. Look at looking at you, daughter. My first job was actually as a SysAdmin at Motorola for a number of years and when I moved on from being in charge of Fedora, I worked at Elastic Search for a while and you know, had this title of Developer Advocate and was like, yeah, so I hacked my way through several semesters of C in college. But my heart was always in operations. I started feeling like am I really a developer advocate? I feel like I'm just advocating to ops folks mostly. And I just started calling myself an operations advocate which nobody blinked an eye at.
**13:22** - *Robyn Bergeron*
Everyone said, well, that's a really cool title. I'm like, you know, I'm just advocating in general mostly to the inside of my company about what everybody else is doing.
**13:33** - *Saron Yitbarek*
So Sandra, we talked about how advocacy and evangelism looks different in different parts of the world, but I'm wondering over the years as we become increasingly more global and more connected, has the larger picture, the larger shape of evangelism shifted over time for you?
**13:52** - *Sandra Persing*
You know, what is developer relations? Are we pitching our product being more salesy? You know, and I notice that even large corporations are moving away from that tactic. Understanding that being authentic, being truly mindful of listening and responding to the needs of developers is key above all else, not pitching product.
**14:17** - *Sandra Persing*
I always go back and share with my team at Mozilla that developers are actually one of the smartest and creative customer base that we'll ever work with. They can smell that BS from miles away. So, we have to be smart about how we are sharing information, like it has to be a diverse group of talented and intelligent minds all coming together to become creative in our approach of communicating to our developer community.
**14:48** - *Saron Yitbarek*
Oh, I really like that. I like this idea of many different skill sets, I guess, backgrounds need to come together to really serve developers well and to help developers help themselves, too.
**15:01** - *Saron Yitbarek*
When I think about the rise of developer advocates, to me it feels very connected to the rise of open source. It almost feels like the more open source contributors there were and the bigger deal open source became and the more big companies took it seriously, they almost had to establish better relationships with these open source contributors, these developers, and it feels like those two are really connected to me.
**15:27** - *Saron Yitbarek*
So I'm curious about your ideas about that. So Robyn, let's start with you. Is that true at all? Is that idea of advocacy connected at all to the rise of open source?
**15:37** - *Robyn Bergeron*
If you are a company who is selling software that or selling whatever licenses, long termsupport, you know, whatever your open source company's business model actually is, if you don't have that feedback loop or you're not actually paying attention to what people are saying, you're going to wind up delivering the proverbial wrong thing. And really being able to encompass that, you know, around the world and just day to day in what you do is the difference between success and I guess making the wrong thing, which nobody wants to spend time doing. That's a bad idea.
**16:10** - *Saron Yitbarek*
Yeah, that's generally a bad idea. Cool. So, I want to know from each of you what you all have been focusing on, really thinking about. So Ricky, let's start with you. What kind of improvements do you try to bring about in the developer culture in your role at Twilio?
**16:27** - *Ricky Robinett*
If I were to say the phrase I've heard the most when I talk to developers, it's, "I'm not a developer, but," and that's probably one of the biggest things that's always on my mind is broadening the definition of developer.
**16:45** - *Ricky Robinett*
Imposter syndrome for so many of us is a very real thing. It's just amazing how even some of the best developers you know are struggling with it. And for me, that's one of the biggest things we can all do in our culture is give people permission to say, "You know what? I am a developer. I am solving problems with code."
**17:08** - *Ricky Robinett*
And so, one of my favorite stories is we have a member of our community named Doug McKenziethat's a magician. And he taught himself PHP so he could use tech in his magic tricks.
**17:23** - *Saron Yitbarek*
Oh, neat.
**17:23** - *Ricky Robinett*
Doug is so cool because he was super humble about like, "Oh, I'm not a developer." And suddenly you see, like, he's writing more complicated code than many people have ever seen, to do things that blow minds. And so, I just feel like there's so many Doug McKenzies in the world who are doing great things with code and we have the opportunity to give them permission to be part of the community and to have an identity in that work.
**17:51** - *Saron Yitbarek*
I love that story because it reminds me of someone I interviewed for the Code Newbie podcast actually, and she was a writer and she had a bunch of assignments where she had to learn Git in order to write about Git and she'd written so many of these articles and it grew to be on other coding topics and eventually, you know, a couple of years had passed and she'd essentially become a developer and didn't know it.
**18:13** - *Saron Yitbarek*
And by the time I interviewed her and I said, "Hey, do you know that you're a developer?" She's like, "No, I'm a writer." And I said, "You can be both. They're not mutually exclusive." But yeah, that shift in perspective of saying, "Hey, I'm actually coding and creating, therefore I can now call myself a coder," it's tough for people. It takes a while to get there.
**18:32** - *Ricky Robinett*
Yeah, absolutely.
**18:33** - *Saron Yitbarek*
Yeah. So Robyn, for you, what's been the most positive change that you've managed to push forward in recent years?
**18:41** - *Robyn Bergeron*
Just making sure that as we grow, that we're not losing track of the big picture, that our main goals around keeping it simple for people to use, simple for people to contribute to, simple to actually get stuff done with in your life, making sure we're not losing track of that or getting more engineering help to just work on some of the structure of the actual project and make sure that we're doing a good job of keeping all that stuff in order was, I don't know, I thought that was important. I don't know that I'm going to win a Nobel Peace Prize for that, but I know it's something that mattered a lot to lots of the contributors.
**19:19** - *Saron Yitbarek*
That works for me. Sandra, what about you? What's been the most positive change that you've managed to push forward in recent years as a Global Strategist?
**19:26** - *Sandra Persing*
Two things that really stand out from my mind is expanding this definition, the persona of developer, has been something that's been very important. We'd love to grow our community, right? So why restrict the definition and description of a developer?
**19:43** - *Sandra Persing*
When we did a panel at Sundance with some famous names like Reggie Watts and Chris Milk, we gave an opportunity for filmmakers, producers, decision makers to say, "Oh, we can do that, too. We don't have to be bound by restrictions of what can we do as creative filmmakers."
**20:00** - *Sandra Persing*
We can adopt technology, and we too can become developers, and that was very refreshing to see. Another moment that we had at Mozilla was bringing an artist, Ian Brill, a light artist in Chicago, to work with us on a project that we label Arch, and we brought this huge plastic light, LED light, with seven Raspberry Pis being programmed structure, to two significant JavaScript developer events this year. And in order to invite more programmers, whether they call themselves developers or not, to try out two languages that Mozilla was advocating this year pretty strongly, WebAssembly and Rust.
**20:49** - *Sandra Persing*
So we created two simple templates, to say, "Try it out," but it's not programming that we wanted to push towards. It's not coding. It was, "Yes, there's some lines of code. It's language, but what you want to do is create a few lines that now can translate into art," and that brought so many new people into our fold, literally brought them to our table, and then they would write their lines of code, go and walk over under the Arch, to see their light expressions now being looped in the structure. That was amazing.
**21:22** - *Saron Yitbarek*
Wow. That sounds beautiful, absolutely beautiful. So, I'm wondering, when we talk about advocating for developers, and we talked a ton about community, and this idea of at the end of the day, whatever our job titles are, we're really just trying to help people, what do developers need help with? Ricky, let's start with you. What do developers say that they need from you?
**21:44** - *Ricky Robinett*
Wow. Yeah, that is a good question. I think that one of the things that we've found is that, like technology's changing so quickly, and a lot of what we get asked about is just, "Where do I start? What do I do first? How do I know I'm on the right path?" For us, that's probably one of the areas we have been investing the most, is we call it like helping people discover their power to change the world with code.
**22:16** - *Saron Yitbarek*
Oh, that's beautiful. I approve.
**22:18** - *Ricky Robinett*
Well, thank you. Yes. That's exciting. So we built a tool called TwilioQuest, to help people discover that power, to help them know where to get started, but I just sense, you know, there's been this theme of people finding their identity, or getting permission to have that identity, and for every person that's writing code already, or solving problems with code or software, there's so many more who want to, and just don't know where to start yet. So that's a thing that's on our mind a lot.
**22:51** - *Saron Yitbarek*
Yeah. So Robyn, for you at Red Hat, what are Red Hat developers looking for?
**23:00** - *Robyn Bergeron*
A lot of times, it's people who come to you and they've got some roadblock in their way, whether it's, you know, "Somehow my PR fell through the robot cracks," but a lot of times, it's also people who are like, "Hey, I had this cool idea. Maybe it doesn't quite fit in here, but I thought maybe it might improve how the community is running, or might be a good companion tool to other stuff that we're working on. What do I do?" And it's like, "Well, you know, how can I help you get started," you know? " What can I do? Like, do you just need someone to say yes? Because I am here to say yes all day long, to basically anything, and just let people know that yes, of course you have permission to do that," so that's, you know, I think the best thing that you can do, at least in my position, is make sure people don't have things in their way, or if the one thing that's in their way is waiting for someone to just say yes, I keep reiterating all the time that you don't need permission, but if someone needs it, then by god, give it to them.
**23:58** - *Saron Yitbarek*
So, the last question, we need to wrap things up, so I'm going to ask you each something. What is the single-most important thing that you're going to be advocating for in 2019? If you had a magic wand, what's the next big thing you'd want to change? Sandra, let's start with you.
**24:15** - *Sandra Persing*
Oh, I knew you were going to do that. Well, the biggest challenges, and yet the most exciting projects that we're going to be working on for 2019, is to truly deliver on our promise of the web being one of the greatest, biggest, most accessible platform. We always tell developers it's where you should build, and deploy everywhere, but knowing that the web itself is incredibly complex, and that we have multiple browser vendors out there, sometimes that's not a true statement, and it's been a perennial challenge for us, especially at Mozilla, where we want to keep the web open, and free, and accessible for all. We want to continue to make sure that we are fulfilling that promise to our developers, that the web is indeed open, accessible, and available to all.
**25:10** - *Saron Yitbarek*
Oh, love that. Ricky, what about you?
**25:13** - *Ricky Robinett*
Just making sure we're serving developers where they gather, online and offline, throughout the entire world. It canbe super easy to get focused on what you see and forget that there's developers everywhere, even when you don't see them. So, I would wave my magic wand and just be more places all over the world, finding out how we can help developers there.
**25:36** - *Sandra Persing*
I just want to say, I loved Jarod's talk about dark matter developers. It was incredible.
**25:42** - *Ricky Robinett*
It's like such an amazing concept when you hear it for the first time. It's like, "Wow, that really is a thing."
**25:50** - *Saron Yitbarek*
So tell us about that. What's a dark matter developer?
**25:52** - *Sandra Persing*
Essentially, there are developers out there, there are those who do not show up to your meetups, who do not participate in GitHub, online communities, do not contribute to Stack Overflow. Those are the developers who are still actively working and contributing, but we do not know. We know that they're there, but we cannot see them. We cannot identify them, and those are actually a very important segment of the developer community that we tend to ignore, and we cannot. It will be to our detriment working in developer relations, to ignore the community that does not speak up, and we need to be more proactive in searching those dark matter developers out in our universe.
**26:34** - *Saron Yitbarek*
Oh, I love ... Oh, that's very cool. Yeah, and Jarod actually works at Twilio, right?
**26:38** - *Sandra Persing*
Yes. Yes, he runs the APAC DevRel.
**26:42** - *Robyn Bergeron*
One of my former Red Hat colleagues, who's now at a company called Tidelift, Chris Grams, actually used to have a blog that was titled Dark Matter Matters, because it's sort of the—
**26:52** - *Saron Yitbarek*
Mm-hmm (affirmative).
**26:54** - *Robyn Bergeron*
You know, the things you don't see still actually matter, so—
**26:58** - *Saron Yitbarek*
Absolutely. And Robyn, what about you. What would you do with your magic wand?
**27:03** - *Robyn Bergeron*
Oh, with my magic wand, so many things, but I guess pursuant to this conversation, getting better at managing our dependencies upon each other, and maybe not surprising each other, especially when so many of us work in OpenStack, and OPNFV, and Ansible, and all of these things that build on top of each other. Just making sure that the relationships between our projects is more obvious than things can be when you're head-down in stuff. So that's a thing I'm really looking forward to over the coming year, because we're getting traction on stuff. It's very exciting right now.
**27:39** - *Saron Yitbarek*
Traction is always just so good. It's so exciting. Well, I want to thank all of you so, so much for joining us today and sharing your minds, and your thoughts, and your stories. Thank you all so much. You want to say goodbye?
**27:51** - *Robyn Bergeron*
Bye, y'all.
**27:54** - *Sandra Persing*
Nice. Thank you so much, Saron. It's been a pleasure being on this panel.
**27:58** - *Ricky Robinett*
It's already starting to happen, a shift towards open source attitudes in the gaming studios.
**27:59** - *Saron Yitbarek*
Absolutely. Today's roundtable included Robyn Bergeron, Community Architect at Red Hat, Sandra Persing, Global Strategist at Mozilla, and Ricky Robinet, Director of the Developer Network at Twilio. I consider myself hugely lucky to have platforms where I get to share my vision for what our community could become, whether here on this podcast or elsewhere, but I want to point out, you do not have to have your own podcast to be an advocate. Being an advocate simply means you keep your eyes open and you speak up on behalf of others. It really can be everybody's job. So I'm hoping Robyn, Sandra, and Ricky give you a little inspiration to advocate for matters to you.
**28:50** - *Saron Yitbarek*
Meanwhile, Season 3of Command Line Heroes is already in the works. You can be one of the first to learn about new episodes when they drop this spring. If you haven't already, subscribe over at Apple Podcasts, Google Podcasts, or wherever you get your podcasts. It's one click, and it's 100% free. I'm Saron Yitbarek. Thank you so much for listening, and until season 3, keep on coding. |
12,772 | 使用 curl 从命令行访问互联网 | https://opensource.com/article/20/5/curl-cheat-sheet | 2020-10-31T00:06:15 | [
"curl"
] | https://linux.cn/article-12772-1.html |
>
> 下载我们整理的 curl 备忘录。要在不使用图形界面的情况下从互联网上获取所需的信息,curl 是一种快速有效的方法。
>
>
>

`curl` 通常被视作一款非交互式 Web 浏览器,这意味着它能够从互联网上获取信息,并在你的终端中显示,或将其保存到文件中。从表面看,这是 Web 浏览器,类似 Firefox 或 Chromium 所做的工作,只是它们默认情况下会*渲染*信息,而 `curl` 会下载并显示原始信息。实际上,`curl` 命令可以做更多的事情,并且能够使用多种协议与服务器进行双向传输数据,这些协议包括 HTTP、FTP、SFTP、IMAP、POP3、LDAP、SMB、SMTP 等。对于普通终端用户来说,这是一个有用的工具;而对于系统管理员,这非常便捷;对于微服务和云开发人员来说,它是一个质量保证工具。
`curl` 被设计为在没有用户交互的情况下工作,因此与 Firefox 不同,你必须从头到尾考虑与在线数据的交互。例如,如果想要在 Firefox 中查看网页,你需要启动 Firefox 窗口。打开 Firefox 后,在地址栏或搜索引擎中输入要访问的网站。然后,导航到网站,然后单击要查看的页面。
对于 `curl` 来说也是如此,不同之处在于你需要一次执行所有操作:在启动 `curl` 的同时提供需要访问的互联网地址,并告诉它是否要将数据保存在终端或文件中。当你必须与需要身份验证的网站或 API 进行交互时,会变得有点复杂,但是一旦你学习了 `curl` 命令语法,它就会变得自然而然。为了帮助你掌握它,我们在一个方便的[备忘录](https://opensource.com/downloads/curl-command-cheat-sheet)中收集了相关的语法信息。
### 使用 curl 下载文件
你可以通过提供指向特定 URL 的链接来使用 `curl` 命令下载文件。如果你提供的 URL 默认为 `index.html`,那么将下载此页面,并将下载的文件显示在终端屏幕上。你可以将数据通过管道传递到 `less`、`tail` 或任何其它命令:
```
$ curl "http://example.com" | tail -n 4
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div></body></html>
```
由于某些 URL 包含特殊字符,shell 通常会将其解释,因此最安全的做法用引号将 URL 包起来。
某些文件无法很好的在终端中转换显示。你可以使用 `--remote-name` 选项使文件根据服务器上的命名进行保存:
```
$ curl --remote-name "https://example.com/linux-distro.iso"
$ ls
linux-distro.iso
```
或者,你可以使用 `--output` 选项来命名你想要下载的内容:
```
curl "http://example.com/foo.html" --output bar.html
```
### 使用 curl 列出带有远程目录的内容
因为 `curl` 不是交互式的,所以很难浏览页面上的可下载元素。如果你要连接的远程服务器允许,可以使用 `curl` 来列出目录的内容:
```
$ curl --list-only "https://example.com/foo/"
```
### 继续中断下载
如果你正在下载一个非常大的文件,你可能会发现有时候必须中断下载。`curl` 非常智能,可以确定下载从何处中断并继续下载。这意味着,下一次当你下载一个 4GB 的 Linux 发行版的 ISO 出现问题时,就不必重新开始了。`--continue-at` 的语法有点不寻常:如果你知道下载中断时的字节数,你可以提供给 `curl`;否则,你可以使用单独的一个破折号(`-`)指示 curl 自动检测:
```
$ curl --remote-name --continue-at - "https://example.com/linux-distro.iso"
```
### 下载文件序列
如果你需要下载多个文件而不是一个大文件,那么 `curl` 可以帮助你解决这个问题。假设你知道要下载的文件的位置和文件名模式,则可以使用 `curl` 的序列标记:中括号里是整数范围的起点和终点。对于输出文件名,使用 `#1` 表示第一个变量:
```
$ curl "https://example.com/file_[1-4].webp" --output "file_#1.webp"
```
如果你需要使用其它变量来表示另一个序列,按照每个变量在命令中出现的顺序表示它们。例如,在这个命令中,`#1` 指目录 `images_000` 到 `images_009`,而 `#2` 指目录 `file_1.webp` 至 `file_4.webp`:
```
$ curl "https://example.com/images_00[0-9]/file_[1-4].webp" --output "file_#1-#2.webp"
```
### 从站点下载所有 PNG 文件
你也可以仅使用 `curl` 和 `grep` 进行一些基本的 Web 抓取操作,以找到想要下载的内容。例如,假设你需要下载与正在归档网页关联的所有图像,首先,下载引用了图像的页面。将页面内通过管道传输到 `grep`,搜索所需的图片类型(在此示例中为 PNG)。最后,创建一个 `while` 循环来构造下载 URL,并将文件保存到你的计算机:
```
$ curl https://example.com |\
grep --only-matching 'src="[^"]*.[png]"' |\
cut -d\" -f2 |\
while read i; do \
curl https://example.com/"${i}" -o "${i##*/}"; \
done
```
这只是一个示例,但它展示了 `curl` 与 Unix 管道和一些基本而巧妙的解析结合使用时是多么的灵活。
### 获取 HTML 头
用于数据交换的协议在计算机发送通信的数据包中嵌入了大量元数据。HTTP 头是数据初始部分的组件。在连接一个网站出现问题时,查看这些报文头(尤其是响应码)会有所帮助:
```
curl --head "https://example.com"
HTTP/2 200
accept-ranges: bytes
age: 485487
cache-control: max-age=604800
content-type: text/html; charset=UTF-8
date: Sun, 26 Apr 2020 09:02:09 GMT
etag: "3147526947"
expires: Sun, 03 May 2020 09:02:09 GMT
last-modified: Thu, 17 Oct 2019 07:18:26 GMT
server: ECS (sjc/4E76)
x-cache: HIT
content-length: 1256
```
### 快速失败
响应 200 通常是 HTTP 成功指示符,这是你与服务器连接时通常期望的结果。著名的 404 响应表示找不到页面,而 500 则表示服务器在处理请求时出现了错误。
要查看协商过程中发生了什么错误,添加 `--show-error` 选项:
```
$ curl --head --show-error "http://opensource.ga"
```
除非你可以访问要连接的服务器,否则这些问题将很难解决,但是 `curl` 通常会尽力连接你指定的地址。有时在网络上进行测试时,无休止的重试似乎只会浪费时间,因此你可以使用 `--fail-early` 选项来强制 `curl` 在失败时迅速退出:
```
curl --fail-early "http://opensource.ga"
```
### 由 3xx 响应指定的重定向查询
300 这个系列的响应更加灵活。具体来说,301 响应意味着一个 URL 已被永久移动到其它位置。对于网站管理员来说,重新定位内容并留下“痕迹”是一种常见的方式,这样访问旧地址的人们仍然可以找到它。默认情况下,`curl` 不会进行 301 重定向,但你可以使用 `--localtion` 选项使其继续进入 301 响应指向的目标:
```
$ curl "https://iana.org" | grep title
<title>301 Moved Permanently</title>
$ curl --location "https://iana.org"
<title>Internet Assigned Numbers Authority</title>
```
### 展开短网址
如果你想要在访问短网址之前先查看它们,那么 `--location` 选项非常有用。短网址对于有字符限制的社交网络(当然,如果你使用[现代和开源的社交网络](https://opensource.com/article/17/4/guide-to-mastodon)的话,这可能不是问题),或者对于用户不能复制粘贴长地址的印刷媒体来说是有用处的。但是,它们也可能存在风险,因为其目的地址本质上是隐藏的。通过结合使用 `--head` 选项仅查看 HTTP 头,`--location` 选项可以查看一个 URL 的最终地址,你可以查看一个短网址而无需加载其完整的资源:
```
$ curl --head --location "<https://bit.ly/2yDyS4T>"
```
### 下载我们的 curl 备忘录
一旦你开始考虑了将探索 web 由一条命令来完成,那么 `curl` 就成为一种快速有效的方式,可以从互联网上获取所需的信息,而无需麻烦图形界面。为了帮助你适应到工作流中,我们创建了一个 [curl 备忘录](https://opensource.com/downloads/curl-command-cheat-sheet),它包含常见的 `curl` 用法和语法,包括使用它查询 API 的概述。
---
via: <https://opensource.com/article/20/5/curl-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Curl is commonly considered a non-interactive web browser. That means it's able to pull information from the internet and display it in your terminal or save it to a file. This is literally what web browsers, such as Firefox or Chromium, do except they *render* the information by default, while curl downloads and displays raw information. In reality, the curl command does much more and has the ability to transfer data to or from a server using one of many supported protocols, including HTTP, FTP, SFTP, IMAP, POP3, LDAP, SMB, SMTP, and many more. It's a useful tool for the average terminal user, a vital convenience for the sysadmin, and a quality assurance tool for microservices and cloud developers.
Curl is designed to work without user interaction, so unlike Firefox, you must think about your interaction with online data from start to finish. For instance, if you want to view a web page in Firefox, you launch a Firefox window. After Firefox is open, you type the website you want to visit into the URL field or a search engine. Then you navigate to the site and click on the page you want to see.
The same concepts apply to curl, except you do it all at once: you launch curl at the same time you feed it the internet location you want and tell it whether you want to the data to be saved in your terminal or to a file. The complexity increases when you have to interact with a site that requires authentication or with an API, but once you learn the **curl** command syntax, it becomes second nature. To help you get the hang of it, we collected the pertinent syntax information in a handy [cheat sheet](https://opensource.com/downloads/curl-command-cheat-sheet).
## Download a file with curl
You can download a file with the **curl** command by providing a link to a specific URL. If you provide a URL that defaults to **index.html**, then the index page is downloaded, and the file you downloaded is displayed on your terminal screen. You can pipe the output to less or tail or any other command:
```
``````
$ curl "http://example.com" | tail -n 4
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div></body></html>
```
Because some URLs contain special characters that your shell normally interprets, it's safest to surround your URL in quotation marks.
Some files don't translate well to being displayed in a terminal. You can use the **--remote-name** option to cause the file to be saved according to what it's called on the server:
```
``````
$ curl --remote-name "https://example.com/linux-distro.iso"
$ ls
linux-distro.iso
```
Alternatively, you can use the **--output** option to name your download whatever you want:
```
````curl "http://example.com/foo.html" --output bar.html`
## List contents of a remote directory with curl
Because curl is non-interactive, it's difficult to browse a page for downloadable elements. Provided that the remote server you're connecting to allows it, you can use **curl** to list the contents of a directory:
```
````$ curl --list-only "https://example.com/foo/"`
## Continue a partial download
If you're downloading a very large file, you might find that you have to interrupt the download. Curl is intelligent enough to determine where you left off and continue the download. That means the next time you're downloading a 4GB Linux distribution ISO and something goes wrong, you never have to go back to the start. The syntax for **--continue-at** is a little unusual: if you know the byte count where your download was interrupted, you can provide it; otherwise, you can use a lone dash (**-**) to tell curl to detect it automatically:
```
````$ curl --remote-name --continue-at - "https://example.com/linux-distro.iso"`
## Download a sequence of files
If you need to download several files—rather than just one big file—curl can help with that. Assuming you know the location and file-name pattern of the files you want to download, you can use curl's sequencing notation: the start and end point between a range of integers, in brackets. For the output filename, use **#1** to indicate the first variable:
```
````$ curl "https://example.com/file_[1-4].webp" --output "file_#1.webp"`
If you need to use another variable to represent another sequence, denote each variable in the order it appears in the command. For example, in this command, **#1** refers to the directories **images_000** through **images_009**, while **#2** refers to the files **file_1.webp** through **file_4.webp**:
```
``````
$ curl "https://example.com/images_00[0-9]/file_[1-4].webp" \
--output "file_#1-#2.webp"
```
## Download all PNG files from a site
You can do some rudimentary web scraping to find what you want to download, too, using only **curl** and **grep**. For instance, say you need to download all images associated with a web page you're archiving. First, download the page referencing the images. Pipe the page to grep with a search for the image type you're targeting (PNG in this example). Finally, create a **while** loop to construct a download URL and to save the files to your computer:
```
``````
$ curl https://example.com |\
grep --only-matching 'src="[^"]*.[png]"' |\
cut -d\" -f2 |\
while read i; do \
curl https://example.com/"${i}" -o "${i##*/}"; \
done
```
This is just an example, but it demonstrates how flexible curl can be when combined with a Unix pipe and some clever, but basic, parsing.
## Fetch HTML headers
Protocols used for data exchange have a lot of metadata embedded in the packets that computers send to communicate. HTTP headers are components of the initial portion of data. It can be helpful to view these headers (especially the response code) when troubleshooting your connection to a site:
```
``````
curl --head "https://example.com"
HTTP/2 200
accept-ranges: bytes
age: 485487
cache-control: max-age=604800
content-type: text/html; charset=UTF-8
date: Sun, 26 Apr 2020 09:02:09 GMT
etag: "3147526947"
expires: Sun, 03 May 2020 09:02:09 GMT
last-modified: Thu, 17 Oct 2019 07:18:26 GMT
server: ECS (sjc/4E76)
x-cache: HIT
content-length: 1256
```
## Fail quickly
A 200 response is the usual HTTP indicator of success, so it's what you usually expect when you contact a server. The famous 404 response indicates that a page can't be found, and 500 means there was a server error.
To see what errors are happening during negotiation, add the **--show-error** flag:
```
````$ curl --head --show-error "http://opensource.ga"`
These can be difficult for you to fix unless you have access to the server you're contacting, but curl generally tries its best to resolve the location you point it to. Sometimes when testing things over a network, seemingly endless retries just waste time, so you can force curl to exit upon failure quickly with the **--fail-early** option:
```
````curl --fail-early "http://opensource.ga"`
## Redirect query as specified by a 3xx response
The 300 series of responses, however, are more flexible. Specifically, the 301 response means that a URL has been moved permanently to a different location. It's a common way for a website admin to relocate content while leaving a "trail" so people visiting the old location can still find it. Curl doesn't follow a 301 redirect by default, but you can make it continue on to a 301 destination by using the **--location** option:
```
``````
$ curl "https://iana.org" | grep title
<title>301 Moved Permanently</title>
$ curl --location "https://iana.org"
<title>Internet Assigned Numbers Authority</title>
```
## Expand a shortened URL
The **--location** option is useful when you want to look at shortened URLs before visiting them. Shortened URLs can be useful for social networks with character limits (of course, this may not be an issue if you use a [modern and open source social network](https://opensource.com/article/17/4/guide-to-mastodon)) or for print media in which users can't just copy and paste a long URL. However, they can also be a little dangerous because their destination is, by nature, concealed. By combining the **--head** option to view just the HTTP headers and the **--location** option to unravel the final destination of a URL, you can peek into a shortened URL without loading the full resource:
```
``````
$ curl --head --location \
"https://bit.ly/2yDyS4T"
```
[Download our curl cheat sheet](https://opensource.com/downloads/curl-command-cheat-sheet)
Once you practice thinking about the process of exploring the web as a single command, curl becomes a fast and efficient way to pull the information you need from the internet without bothering with a graphical interface. To help you build it into your usual workflow, we've created a [curl cheat sheet](https://opensource.com/downloads/curl-command-cheat-sheet) with common curl uses and syntax, including an overview of using it to query an API.
## 7 Comments |
12,773 | Linux 黑话解释:什么是显示管理器? | https://itsfoss.com/display-manager/ | 2020-10-31T12:51:00 | [
"显示管理器",
"黑话"
] | https://linux.cn/article-12773-1.html |
>
> 在这篇 Linux 黑话解释中,你将了解 Linux 中的显示管理器。它是桌面环境的一部分吗?它的作用是什么?
>
>
>
### 什么是 Linux 中的显示管理器?
简单来说,<ruby> 显示管理器 <rt> display manager </rt></ruby>(DM)是一个为你的 Linux 发行版提供图形登录功能的程序。它控制用户会话并管理用户认证。显示管理器会在你输入用户名和密码后,立即启动[显示服务器](https://itsfoss.com/display-server/)并加载[桌面环境](https://itsfoss.com/what-is-desktop-environment/)。
显示管理器通常是登录界面的代名词。毕竟它是可见的部分。然而,可见的登录屏幕,也叫<ruby> 欢迎页 <rt> greeter </rt></ruby>,只是显示管理器的一部分。

像[各种桌面环境](https://itsfoss.com/best-linux-desktop-environments/)和显示服务器一样,也有各种显示管理器。我们来看看它们。
### 不同的显示管理器
有些人认为显示管理器是桌面环境的一部分,但事实并非如此。它是一个独立的程序。
桌面环境可能会推荐某个显示管理器,但这并不意味着它不能与其它一些显示管理器一起工作。如果你曾经在同一个系统中安装过不止一个桌面环境,你会记得,登录界面(即显示管理器)允许你切换桌面环境。

虽然显示管理器不是桌面环境本身的一部分,但它往往与桌面环境由同一个开发团队开发。它也成为桌面环境的代表。
例如,GNOME 桌面环境开发了 GDM(GNOME Display Manager),光看登录界面就会想到 GNOME 桌面环境。

一些流行的显示管理器有:
* [GDM](https://wiki.gnome.org/Projects/GDM)(<ruby> GNOME 显示管理器 <rt> GNOME Display Manager </rt></ruby>):GNOME 的首选。
* [SDDM](https://github.com/sddm)(<ruby> 简单桌面显示管理器 <rt> Simple Desktop Display Manager </rt></ruby>):KDE 首选。
* LightDM:由 Ubuntu 为 Unity 桌面开发。
### 显示管理器可以定制
有这么多的桌面环境可供选择,它们都有自己的显示管理器吗?不,不是这样的。
正如我之前提到的,可见的登录屏幕被称为欢迎页。这个欢迎页可以进行自定义来改变登录屏幕的外观。
事实上,许多发行版和/或桌面环境都制作了自己的欢迎页,以给用户提供一个类似于他们品牌的登录屏幕。
例如,Mint 的 Cinnamon 桌面使用了 LightDM,但有自己的欢迎页来给它更多的 Mint 式(或者我应该说是 Cinnamon)的外观。

来看看 Kali Linux 的登录界面:

如果你喜欢编码和调整,你可以根据自己的喜好修改或编码自己的欢迎页。
### 改变显示管理器
如果你愿意,可以[更改显示管理器](https://itsfoss.com/switch-gdm-and-lightdm-in-ubuntu-14-04/)。你需要先安装显示管理器。安装时你会看到切换显示管理器的选项。

如果当时没有做切换,那么以后可以通过手动配置来改变显示管理器。不同的发行版重新配置显示管理器的方法略有不同,这不在本文讨论范围内。
### 结语
希望大家对 Linux 中的显示管理器这个术语有一点了解。本黑话解释系列的目的是用非技术性的语言解释常见的 Linux 俗语和技术术语,而不涉及太多的细节。
欢迎大家提出意见和建议。
---
via: <https://itsfoss.com/display-manager/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

GDM, LightDM, SSDM. You'll come across these terms in various Linux forum discussions.
These are display managers usually associated with certain desktop environments. Learn more about them in this article.
## What is display manager in Linux?
In simple terms, a display manager is a program that provides graphical login capabilities for your Linux distribution. It controls the user sessions and manages user authentication. Display manager starts the [display server](https://itsfoss.com/display-server/) and loads the [desktop environment](https://itsfoss.com/what-is-desktop-environment/) right after you enter your username and password.
The display manager is often synonymous with the login screen. It is the visible part of it after all. However, the visible login screen, also called greeter, is only a part of the display manager.
As with [various desktop environments](https://itsfoss.com/best-linux-desktop-environments/) and display servers, there are various display managers available as well. Let’s have a look at them.
## Different display managers
Some people think of the display manager as part of the desktop environment but that’s not the case. It is a separate program.
A desktop environment may recommend a certain display manager but it doesn’t mean that it won’t work with some other display manager. If you ever installed more than one desktop environment in the same system, you might remember that a login screen (i.e., the display manager) allows you to switch the desktop environments.

Though the display manager is not part of the desktop environment, it is often developed by the same team as the desktop environment. It also becomes part of the identity of the desktop environment.
For example, the GNOME desktop environment develops GDM (GNOME Display Manager) and just by looking at the login screen, you would think of GNOME desktop environment.
Some popular display managers are:
- GDM (
[GNOME Display Manager](https://wiki.gnome.org/Projects/GDM?ref=itsfoss.com)): preferred by GNOME [SDDM](https://github.com/sddm?ref=itsfoss.com)(Simple Desktop Display Manager): preferred by KDE- LightDM: developed by Ubuntu for Unity desktop
## Display managers can be customized
There are so many desktop environments available. Do they all have their own display managers? No, that’s not the case.
As I mentioned previously, the visible login screen is called a greeter. This greeter can be customized to change the looks of the login screen.
In fact, many distributions and/or desktop environments have written their own greeters to give users a login screen that resembles their brand.
For example, Mint’s Cinnamon desktop uses LightDM but has its own greeter to give it more Mint-like (or should I say Cinnamon-like) looks.

Take a look at Kali Linux’s login screen:

If you are into coding and tweaking, you can modify or code your own greeter as per your liking.
## Changing display manager
You can [change the display manager](https://itsfoss.com/switch-gdm-and-lightdm-in-ubuntu-14-04/) if you want. You need to install the display manager first. You’ll see the option to switch the display manager while installing.
If you didn’t do it initialy, then you can change the display manager by manually configuring it later. The method to reconfigure the display manager is slightly different for different distributions and not in the scope of this article.
**Conclusion**
I hope you have a slightly better understanding of the term “display manager” in Linux. The aim of this jargon buster series is to explain common Linux colloquial and technical terms in non-technical language without going into too much detail.
I welcome your comments and suggestion. |
12,775 | 文档基金会希望 Apache 放弃陷入困境的 OpenOffice,转而支持 LibreOffice | https://itsfoss.com/libreoffice-letter-openoffice/ | 2020-11-01T10:07:02 | [
"OpenOffice",
"LibreOffice"
] | https://linux.cn/article-12775-1.html | 对于 Linux 用户来说,当我们想到[微软 Office 的开源替代品](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/)时,Apache OpenOffice 仍然是一个相关的推荐,这是不言而喻的。然而,在过去的几年里,OpenOffice 的发展几乎是停滞的。
当然,考虑到 Abhishek 早在 2016 年就写过 [Apache OpenOffice 关闭的可能性](https://itsfoss.com/openoffice-shutdown/),这并不令人震惊。
现在,在一封[文档基金会的公开信](https://blog.documentfoundation.org/blog/2020/10/12/open-letter-to-apache-openoffice/)中,他们呼吁 Apache OpenOffice 推荐用户开始使用更好的替代品,比如 LibreOffice。在本文中,我将提到文档基金会的博文中的一些重点,以及它对 Apache OpenOffice 的意义。

### Apache OpenOffice 是历史,LibreOffice 是未来?
尽管我当年没有使用过 OpenOffice,但可以肯定地说,它绝对不是微软 Office 的现代开源替代品。至少现在不是了。
是的,Apache OpenOffice 对于传统用户来说仍然是很重要的东西,在几年前是一个很好的替代品。
以下是 OpenOffice 和 LibreOffice 的主要发布时间线:

现在 OpenOffice 已经没有重大的开发了,Apache OpenOffice 的未来是什么?一个相当活跃的项目,这个最大的开源基金会会不发布重大版本?
这听起来并不乐观,而这正是文档基金会在他们的公开信中所强调的:
>
> OpenOffice(.org),是 LibreOffice 的”父项目“,它是一个伟大的办公套件,它改变了世界。它有着引人入胜的历史,但**自从 2014 年以来,Apache OpenOffice (它现在的家)还没有一个重大的版本**。没错,六年多来,没有重大的新功能或重大更新到来,也很少发布次要版本,而且在及时的安全更新方面也存在问题。
>
>
>
对于一个普通用户来说,如果他们不知道 [LibreOffice](https://itsfoss.com/libreoffice-tips/),我肯定希望他们知道。但是,Apache 基金会是否应该建议 OpenOffice 用户尝试使用 LibreOffice 来体验更好或更高级的办公套件呢?
我不知道,也许是,或者不是?
>
> ...很多用户不知道 LibreOffice 的存在。OpenOffice 的品牌仍然如此强大,尽管该软件已经有六年多没有重大的版本发布,而且几乎没有人开发或支持它。
>
>
>
正如在公开信中提到的,文档基金会强调了 LibreOffice 相对于 OpenOffice的 优势/改进,并呼吁 Apache OpenOffice 开始推荐他们的用户尝试更好的东西(即 LibreOffice):
>
> 我们呼吁 Apache OpenOffice 做正确的事情。我们的目标应该是**把强大的、最新的、维护良好的生产力工具送到尽可能多的人手中**。让我们一起努力吧!
>
>
>
### Apache OpenOffice 应该做什么?
如果 OpenOffice 能完成工作,用户可能不需要努力寻找替代品。那么,因为他们的缓慢开发而呼唤另一个项目,建议用户采用未来工具并推荐它是一个好主意么?
在争论中,有人可能会说,如果你已经完成了你的目标,并且对改进 OpenOffice 没有兴趣,那么推广你的竞争对手才是公平的。而且,这并没有错,开源社区应该一直合作,以确保新用户得到最好的选择。
从另一个侧面来看,我们可以说,文档基金会对于 OpenOffice 到了 2020 年即使没有任何重大改进却仍然有重要意义感到沮丧。
我不会去评判,但当我看了这封公开信时,这些矛盾的想法就浮现在我的脑海里。
### 你认为是时候把 OpenOffice 搁置起来,依靠 LibreOffice 了吗?
即使 LibreOffice 似乎是一个更优越的选择,并且绝对值得关注,你认为应该怎么做?Apache 是否应该停止 OpenOffice,并将用户重定向到 LibreOffice?
欢迎你的意见。
---
via: <https://itsfoss.com/libreoffice-letter-openoffice/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It is a no-brainer that Apache OpenOffice is still a relevant recommendation when we think about [open source alternatives to Microsoft Office](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/) for Linux users. However, for the past several years, the development of OpenOffice is pretty much stale.
Of course, it is not a shocker, considering Abhishek wrote about the [possibility of Apache OpenOffice shutting down](https://itsfoss.com/openoffice-shutdown/) back in 2016.
Now, in an [open letter from The Document Foundation](https://blog.documentfoundation.org/blog/2020/10/12/open-letter-to-apache-openoffice/), they appeal Apache OpenOffice to recommend users to start using better alternatives like LibreOffice. In this article, I shall mention some highlights from the blog post by The Document Foundation and what it means to Apache OpenOffice.

## Apache OpenOffice is History, LibreOffice is the Future?
Even though I didn’t use OpenOffice back in the day, it is safe to say that it is definitely not a modern open-source alternative to Microsoft Office. Not anymore, at least.
Yes, Apache OpenOffice is still something important for legacy users and was a great alternative a few years back.
Here’s the timeline of major releases for OpenOffice and LibreOffice:
Now that there’s no significant development taking place for OpenOffice, what’s the future of Apache OpenOffice? A fairly active project with no major releases by the largest open source foundation?
It does not sound promising and that is exactly what The Document Foundation highlights in their open letter:
OpenOffice(.org) – the “father project” of LibreOffice – was a great office suite, and changed the world. It has a fascinating history, but
since 2014, Apache OpenOffice (its current home) hasn’t had a single major release. That’s right – no significant new features or major updates have arrived in over six years. Very few minor releases have been made, and there have been issues with timely security updates too.
For an average user, if they don’t know about [LibreOffice](https://itsfoss.com/libreoffice-tips/), I would definitely want them to know. But, should the Apache Foundation suggest OpenOffice users to try LibreOffice to experience a better or advanced office suite?
I don’t know, maybe yes, or no?
…many users don’t know that LibreOffice exists. The OpenOffice brand is still so strong, even though the software hasn’t had a significant release for over six years, and is barely being developed or supported
As mentioned in the open letter, The Document Foundation highlights the advantages/improvements of LibreOffice over OpenOffice and appeals to Apache OpenOffice that they start recommending their users to try something better (i.e. LibreOffice):
We appeal to Apache OpenOffice to do the right thing. Our goal should be to
get powerful, up-to-date and well-maintained productivity tools into the hands of as many people as possible. Let’s work together on that!
## What Should Apache OpenOffice Do?
If OpenOffice does the work, users may not need the effort to look for alternatives. So, is it a good idea to call out another project about their slow development and suggest them to embrace the future tools and recommend them instead?
In an argument, one might say it is only fair to promote your competition if you’re done and have no interest in improving OpenOffice. And, there’s nothing wrong in that, the open-source community should always work together to ensure that new users get the best options available.
On another side, one might say that The Document Foundation is frustrated about OpenOffice still being something relevant in 2020, even without any significant improvements.
I won’t judge, but I think these conflicting thoughts come to my mind when I take a look at the open letter.
## Do you think it is time to put OpenOffice to rest and rely on LibreOffice?
Even though LibreOffice seems to be a superior choice and definitely deserves the limelight, what do you think should be done? Should Apache discontinue OpenOffice and redirect users to LibreOffice?
Your opinion is welcome. |
12,776 | 开源是如何支撑区块链技术发展的 | https://opensource.com/article/20/10/open-source-blockchain | 2020-11-01T15:51:37 | [
"区块链",
"开源"
] | https://linux.cn/article-12776-1.html |
>
> 创造出区块链安全性和可靠性的原因:是开放,而非监管。
>
>
>

当人们发现以安全性而闻名的区块链技术居然是建立在开源软件代码之上时,通常会感到非常惊讶。事实上,正是这种开放性才赋予了区块链技术的安全性和可靠性。
以开源方式构建的任何事物,其核心价值之一就是为了提高效率。建立起一个有着不同观点和技能的开发人员社区,这些开发人员工作在同一个代码库的时候,可以成倍增加构建出来的应用程序数量以及复杂性。
### 开源比人们想象中的要更加普遍
开源的 Linux,就是一种比较流行的操作系统。Linux 为服务器提供了许多服务,这些服务让我们可以轻松地共享个人信息。其中包括 Google、Facebook 和数千个主要网站。当我们使用这些服务时,就是在和这些在网络上运行着 Linux 系统的计算机进行交互。Chromebook 也使用 Linux,Android 手机使用的操作系统也是基于 Linux 的。
Linux 不属于任何一家公司,人们可以免费使用并且可以共同协作来完善创造它。自 2005 年推出以来,已经有来自 1,700 多家公司的 20,000 多名开发人员 [为其中的代码做出了贡献](https://www.linuxfoundation.org/wp-content/uploads/2020/08/2020_kernel_history_report_082720.pdf) 。
这就是开源软件的运作方式。大量的人为此贡献,并不断添加、修改或构建开源代码库来创建新的应用程序和平台。区块链和加密货币的大部分代码都是使用开源软件开发的。开源软件是由充满热情的用户构建的,这些用户对错误、故障或缺陷时刻保持警惕。当发现问题时,开源社区中的开发人员将一起努力来解决问题。
### 区块链和开源
整个开源区块链开发者社区都在不断地添加和完善代码库。
以下是区块链的基本表现方式:
* 区块链平台具有一个交易数据库,该交易数据库允许对等方在任何时候彼此进行交易。
* 附有用户识别标签,以方便交易。
* 平台一定有一种安全的方式来在交易批准前对交易进行验证。
* 无法被验证的交易不会进行。
开源软件允许开发者在 [去中心化应用程序(Dapp)](https://www.freecodecamp.org/news/what-is-a-dapp-a-guide-to-ethereum-dapps/)中创建这些平台,这是区块链中交易的安全、保障和可变性的关键。
这种去中心化的方式意味着没有中央权威机构来调解交易,没有人能控制发生的事情。直接的点对点的交易可以更快速、安全的进行。由于交易被记录在分类账簿中,它们也会分发到整个生态系统中。
区块链使用密码学来保证安全。每一笔交易都携带着与前一笔交易相关联的信息,以验证其真实性。这可以防止威胁者篡改数据,因为一旦数据被添加到公共分类账中,其他用户就不能更改。
### 区块链是开源的吗?
虽然区块链本身在技术上可以是不开源的,但区块链系统通常是使用开源软件实现的,因为没有政府机构对其进行监管,所以这些开源软件使用的概念体现了一种开放文化。私人公司开发的用于处理金融交易的专有软件很可能受到 [政府机构](https://www.investopedia.com/ask/answers/063015/what-are-some-major-regulatory-agencies-responsible-overseeing-financial-institutions-us.asp) 的监管。在美国,这可能包括美国证券交易委员会(SEC)、联邦储备委员会和联邦存款保险公司(FDIC)。区块链技术在开放环境下使用不需要政府监管,实际上,用来验证交易的是用户社区。
你可以称它为一种极端的众包形式,既用于开发构建区块链平台的开源软件,也用于验证交易。这就是区块链得到如此多关注的原因之一:它有可能颠覆整个行业,因为它可以作为处理和验证交易的权威中介。
### 比特币,以太坊和其他加密货币
截至 2020 年 6 月,超过 [5000 万人拥有区块链钱包](https://www.statista.com/statistics/647374/worldwide-blockchain-wallet-users/) 。他们大多数用于金融交易,例如交易比特币、以太坊和其他加密货币。对许多人来说,像交易员观察股票价格一样,[查看加密货币价格](https://www.okex.com/markets) 已成为主流。
加密货币平台也使用开源软件。[以太坊项目](https://ethereum.org/en/) 开发出了任何人都可以免费使用的开源软件,社区中大量的开发者都为此贡献了代码。比特币客户端的参考实现版是由 450 多个开发人员和工程师进行开发的,他们已经贡献了超过 150,000 个贡献。
加密货币区块链是一个持续增长的记录。每个被称作为块的记录按顺序链接在一起,它们互相链接形成一条链。每个块都有其自己的唯一标记,这个标记称为 [哈希](https://opensource.com/article/18/7/bitcoin-blockchain-and-open-source) 。一个块包含自身的哈希值和前一个块的加密计算出的哈希值。从本质上讲,每个块都链接到前一个块,形成了无法中断的长链,每个块都包含其它区块的信息,用于验证交易。
在金融或是加密货币的区块链中没有中央银行。这些分布在整个互联网中的区块,建立了一个性能强大的审计跟踪系统。任何人都能够通过区块链来验证交易,但却不能更改上面的记录。
### 牢不可破的区块链
尽管区块链不受任何政府或机构的监管,但分布式的网络保证了它们的安全。随着链的增长,每一笔交易都会增加伪造的难度。区块分布在世界各地的网络中,它们使用的信任标记不可被改变,这条链条几乎变得牢不可破。
这种去中心化的网络,其背后的代码是开源的,这也是用户在交易中不必使用诸如银行或经纪人之类的中介就可以相互信任的原因之一。支撑加密货币平台的软件是由相互独立的开发者组建的联盟创建的,并且任何人都可以免费使用。这创造了世界上最大的制衡体系之一。
---
via: <https://opensource.com/article/20/10/open-source-blockchain>
作者:[Matt Shealy](https://opensource.com/users/mshealy) 选题:[lujun9972](https://github.com/lujun9972) 译者:[xiao-song-123](https://github.com/xiao-song-123) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | People are often surprised when they find out that blockchain technology, which is known for its security, is built on open source software code. In fact, this openness is what creates its security and reliability.
One of the core values of building anything as open source is gaining efficiency. Creating a community of developers with different perspectives and skillsets, all working on the same code base, can exponentially increase the number and complexity of applications built.
## Open source: more common than people think
One of the more popular operating systems, Linux, is open source. Linux powers the servers for many of the services we feel comfortable sharing personal information on every day. This includes Google, Facebook, and thousands of major websites. When you're interacting with these services, you're doing so on computer networks that are running Linux. Chromebooks are using Linux. Android phones use an operating system based on Linux.
Linux is not owned by a corporation. It's free to use and created by collaborative efforts. More than 20,000 developers from more than 1,700 companies [have contributed to the code](https://www.linuxfoundation.org/wp-content/uploads/2020/08/2020_kernel_history_report_082720.pdf) since its origins in 2005.
That's how open source software works. Tons of people contribute and constantly add, modify, or build off the open source codebase to create new apps and platforms. Much of the software code for blockchain and cryptocurrency has been developed using open source software. Open source software is built by passionate users that are constantly on guard for bugs, glitches, or flaws. When a problem is discovered, a community of developers works separately and together on the fix.
## Blockchain and open source
An entire community of open source blockchain developers is constantly adding to and refining the codebase.
Here are the fundamental ways blockchain performs:
- Blockchain platforms have a transactional database that allows peers to transact with each other at any time.
- User-identification labels are attached that facilitate the transactions.
- The platforms must have a secure way to verify transactions before they become approved.
- Transactions that cannot be verified will not take place.
Open source software allows developers to create these platforms in a [decentralized application (Dapp)](https://www.freecodecamp.org/news/what-is-a-dapp-a-guide-to-ethereum-dapps/), which is key to the safety, security, and variability of transactions in the blockchain.
This decentralized approach means there is no central authority to mediate transactions. That means no one person controls what happens. Direct peer-to-peer interactions can happen quickly and securely. As transactions are recorded in the ledger, they are distributed across the ecosystem.
Blockchain uses cryptography to keep things secure. Each transaction carries information connecting it with previous transactions to verify its authenticity. This prevents threat actors from tampering with the data because once it's added to the public ledger, it can't be changed by other users.
## Is blockchain open source?
Although blockchain itself may not technically be open source, blockchain *systems* are typically implemented with open source software using a concept that embodies an open culture because no government authority regulates it. Proprietary software developed by a private company to handle financial transactions is likely regulated by [government agencies](https://www.investopedia.com/ask/answers/063015/what-are-some-major-regulatory-agencies-responsible-overseeing-financial-institutions-us.asp). In the US, that might include the Securities and Exchange Commission (SEC), the Federal Reserve Board, and the Federal Deposit Insurance Corporation (FDIC). Blockchain technology doesn't require government oversight when it's used in an open environment. In effect, the community of users is what verifies transactions.
You might call it an extreme form of crowdsourcing, both for developing the open source software that's used to build the blockchain platforms and for verifying transactions. That's one of the reasons blockchain has gotten so much attention: It has the potential to disrupt entire industries because it acts as an authoritative intermediary to handle and verify transactions.
## Bitcoin, Ethereum, and other cryptocurrencies
As of June 2020, more than [50 million people have blockchain wallets](https://www.statista.com/statistics/647374/worldwide-blockchain-wallet-users/). Most are used for financial transactions, such as trading Bitcoin, Ethereum, and other cryptocurrencies. It's become mainstream for many to [check cryptocurrency prices](https://www.okex.com/markets) the same way traders watch stock prices.
Cryptocurrency platforms also use open source software. The [Ethereum project](https://ethereum.org/en/) developed free and open source software that anyone can use, and a large community of developers contributes to the code. The Bitcoin reference client was developed by more than 450 developers and engineers that have made more than 150,000 contributions to the code-writing effort.
A cryptocurrency blockchain is a continuously growing record. Each record is linked together in a sequence, and the records are called blocks. When linked together, they form a chain. Each block has its own [unique marker called a hash](https://opensource.com/article/18/7/bitcoin-blockchain-and-open-source). A block contains its hash and a cryptographic hash from a previous block. In essence, each block is linked to the previous block, forming long chains that are impossible to break, with each containing information about other blocks that are used to verify transactions.
There's no central bank in financial or cryptocurrency blockchains. The blocks are distributed throughout the internet, creating a robust audit trail that can be tracked. Anyone with access to the chain can verify a transaction but cannot change the records.
## An unbreakable chain
While blockchains are not regulated by any government or agency, the distributed network keeps them secure. As chains grow, each transaction makes it more difficult to fake. Blocks are distributed all over the world in networks using trust markers that can't be changed. The chain becomes virtually unbreakable.
The code behind this decentralized network is open source and is one of the reasons users trust each other in transactions rather than having to use an intermediary such as a bank or broker. The software underpinning cryptocurrency platforms is open to anyone and free to use, created by consortiums of developers that are independent of each other. This has created one of the world's largest check-and-balance systems.
## Comments are closed. |
12,779 | 如何在 Ubuntu Linux 上释放 /boot 分区的空间? | https://itsfoss.com/free-boot-partition-ubuntu/ | 2020-11-02T09:52:00 | [
"分区",
"boot"
] | https://linux.cn/article-12779-1.html | 前几天,我收到一个警告,`/boot` 分区已经几乎满了,没有剩余空间了。是的,我有一个独立的 `/boot` 分区,我相信现在很少有人这样做了。(LCTT 译注:个人认为保留单独的 /boot 分区是个好的运维经验,除此以外,/tmp、/var 也单独划定分区比较好。)
这是我第一次看到这样一个错误,它让我很迷惑。现在,这里有一些 [方法来释放在 Ubuntu (或基于 Ubuntu 的分区)上的分区](https://itsfoss.com/free-up-space-ubuntu-linux/) ,但是在这种情况下并不是所有的方法都能用。
这就是为什么我决定写这些我释放 `/boot` 分区空间的步骤的原因。
### 如何在 Ubuntu 上释放 /boot 分区的空间

我建议你仔细阅读这些解决方案,并由此得出最适合你情况的解决方案。解决方案的操作很容易,但是你需要在你的生产力系统上小心的执行这些解决方案。
#### 方法 1: 使用 apt autoremove
你不必是一名终端专家来做这件事,它只需要一个命令,你将移除未使用的内核来释放 `/boot` 分区中是空间。
你所有要做的事情是,输入:
```
sudo apt autoremove
```
这个命令不仅仅可以移除未使用的内核,而且也将移除你不需要的或工具安装后所不需要的依赖项。
在你输入命令后,它将列出将被移除的东西,你只需要确认操作即可。如果你很好奇它将移除什么,你可以仔细检查一下看看它实际移除了什么。
这里是它应该看起来的样子:

你必须按 `Y` 按键来继续。
**值得注意的是,这种方法只在你还剩余一点点空间,并且得到警告的情况下才有效。但是,如果你的 `/boot` 分区已经满了,APT 甚至可能不会工作。**
在接下来的方法中,我将重点介绍两种不同的方法,通过这些方法你可以使用 GUI 和终端来移除旧内核来释放空间。
#### 方法 2: 手动移除未使用的内核
在你尝试 [移除一些旧内核](https://itsfoss.com/remove-old-kernels-ubuntu/) 来释放空间前,你需要识别当前活动的内核,并且确保你不会删除它。
为 [检查你的内核的版本](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/) ,在终端中输入下面的命令:
```
uname -r
```
[uname 命令通常用于获取 Linux 系统信息](https://linuxhandbook.com/uname/)。在这里,这个命令显示当前正在被使用的 Linux 内核。它看起来应该是这样:

现在,你已经知道你当前的 Linux 内核是什么,你必须移除一个不同于这个版本的内核。你应该把它记录在某些地方,以便你不会不知不觉地移除它。
接下来,要移除它,你可以使用终端或 GUI。
>
> 警告!
>
>
> 在删除内核时一定要额外的小心。只识别和删除旧内核,而不是当前你正在使用的内核,否则你将会拥有一个残缺的系统。
>
>
>
##### 使用一个 GUI 工具来移除旧的 Linux 内核
你可以使用 [Synaptic 软件包管理器](https://itsfoss.com/synaptic-package-manager/) 或一个类似 [Stacer](https://itsfoss.com/optimize-ubuntu-stacer/) 的工具来开始。就我个人而言,当我遇到一个满满的 `/boot` 分区且 APT 损坏时,我使用 [Stacer](https://linuxhandbook.com/uname/) 来丢弃旧内核。因此,让我向你展示一下它看起的样子。
首先,你需要启动 Stacer ,然后导航到软件包卸载器,如下面屏幕截图所示。

在这里,搜索 “image” ,你将找到你所拥有的 Linux 内核。你只需要删除旧内核版本的镜像,而不是当前内核的镜像。
在上面的屏幕截图中,我已经指出了我系统上的当前内核和旧内核,因此你必须注意你系统上的内核。
你没有必要删除任何其它东西,只需要删除旧的内核版本。
同样的,只需要在软件包列表中搜索 “headers” ,并删除如下显示的旧的 “headers” 版本。

作为提醒,你 **不会希望移除 `linux-headers-generic`** 。只关注一下那些与其相关的有版本号的就行。
然后,就这样,你完成了所有的工作,APT 将会再次工作,并且你将成功地释放来自 `/boot` 分区的一些空间。同样地,你也可以使用任意其它的软件包管理器来完成这些工作。
#### 使用命令行来移除旧内核
使用命令行来移除旧内核与使用 GUI 来移除旧内核是一样的。因此,如果你没有选择使用 GUI 软件(如果它是一台远程机器/一项远程服务)的权利,或者如果你只是对终端情有独钟,你可以仿效下面的步骤。
首先,使用下面的命令列出所有已安装的内核:
```
ls -l /boot
```
它应该看起来像这样:

标记为 “old” 的内核,或者不匹配你当前内核版本,都是未使用的内核,你可以删除它们。
现在,你可以使用 `rm` 命令来移除具体指定来自 `/boot` 分区中的内核,使用下面的命令(一个命令对应一个内核):
```
sudo rm /boot/vmlinuz-5.4.0-7634-generic
```
务必检查系统的版本 — 这里可能与你的系统的版本不同。
如果你有很多未使用的内核,这将需要一些时间。因此,你也可以下面的命令丢弃多个内核:
```
sudo rm /boot/*-5.4.0-{7634}-*
```
为了清晰起见,你需要用逗号分隔内核版本号的最后一部分/编码,以便同时删除它们。
假设,我有两个旧的内核 5.4.0-7634-generic 和 5.4.0-7624 ,那么命令将是:
```
sudo rm /boot/*-5.4.0-{7634,7624}-*
```
如果你不希望在 grub 启动菜单中再看到这些旧的内核版本,你可以使用下面的命令简单地 [更新 grub](https://itsfoss.com/update-grub/):
```
sudo update-grub
```
就这样,你完成了所有的工作。你已经释放了空间,还修复了可能潜在的破损的 APT 问题,如果它是一个在你的 `/boot` 分区填满后出现的重要的问题的话。
在一些情况下,你需要输入这些命令来修复破损的(正如我在论坛中注意到的):
```
sudo dpkg --configure -a
sudo apt install -f
```
注意,除非你发现 APT 已破损,否则你不需要输入上面的命令。就我个人而言,我不需要这些命令,但是我发现这些命令对论坛上的一些人很有用。
---
via: <https://itsfoss.com/free-boot-partition-ubuntu/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The other day, I got a warning that boot partition is almost full or has no space left. Yes, I have a separate boot partition, not many people do that these days, I believe.
This was the first time I saw such an error and it left me confused. Now, there are several [ways to free up space on Ubuntu](https://itsfoss.com/free-up-space-ubuntu-linux/) (or Ubuntu-based distros) but not all of them are useful in this case.
This is why I decided to write about the steps I followed to free some space in the /boot partition.
## Free up space in /boot partition on Ubuntu (if your boot partition is running out of space)

I’d advise you to carefully read through the solutions and follow the one best suited for your situation. It’s easy but you need to be cautious about performing some of these on your production systems.
### Method 1: Using apt autoremove
You don’t have to be a terminal expert to do this, it’s just one command and you will be removing unused kernels to free up space in the /boot partition.
All you have to do is, type in:
`sudo apt autoremove`
This will not just remove unused kernels but also get rid of the dependencies that you don’t need or isn’t needed by any of the tools installed.
Once you enter the command, it will list the things that will be removed and you just have to confirm the action. If you’re curious, you can go through it carefully and see what it actually removes.
Here’s how it will look like:
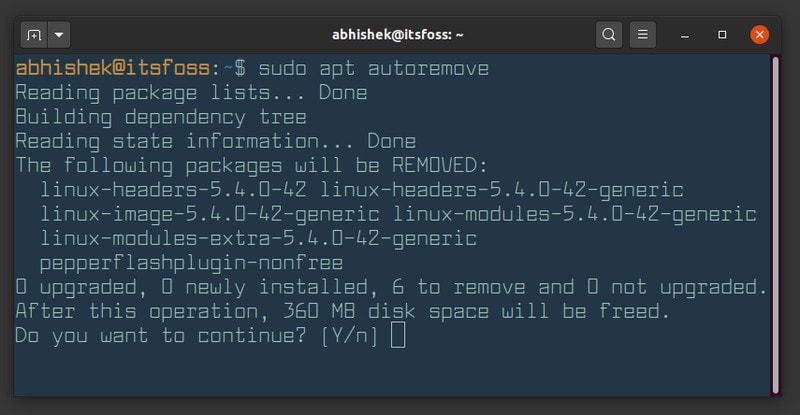
You have to press **Y** to proceed.
*It’s worth noting that this method will only work if you’ve a tiny bit of space left and you get the warning. But, if your /boot partition is full, APT may not even work.*
In the next method, I’ll highlight two different ways by which you can remove old kernels to free up space using a GUI and also the terminal.
### Method 2: Remove Unused Kernel Manually (if apt autoremove didn’t work)
Before you try to [remove any older kernels](https://itsfoss.com/remove-old-kernels-ubuntu/) to free up space, you need to identify the current active kernel and make sure that you don’t delete that.
To [check your kernel version](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/), type in the following command in the terminal:
`uname -r`
The [uname command is generally used to get Linux system information](https://linuxhandbook.com/uname/?ref=itsfoss.com). Here, this command displays the current Linux kernel being used. It should look like this:
Now, that you know what your current Linux Kernel is, you just have to remove the ones that do not match this version. You should note it down somewhere so that you ensure you do not remove it accidentally.
Next, to remove it, you can either utilize the terminal or the GUI.
Warning!
Be extra careful while deleting kernels. Identify and delete old kernels only, not the current one you are using otherwise you’ll have a broken system.
#### Using a GUI tool to remove old Linux kernels
You can use the [Synaptic Package Manager](https://itsfoss.com/synaptic-package-manager/) or a tool like [Stacer](https://itsfoss.com/optimize-ubuntu-stacer/) to get started. Personally, when I encountered a full /boot partition with apt broken, I used [Stacer](https://linuxhandbook.com/uname/?ref=itsfoss.com) to get rid of older kernels. So, let me show you how that looks.
First, you need to launch “**Stacer**” and then navigate your way to the package uninstaller as shown in the screenshot below.
Here, search for “**image**” and you will find the images for the Linux Kernels you have. You just have to delete the old kernel versions and not your current kernel image.
I’ve pointed out my current kernel and old kernels in my case in the screenshot above, so you have to be careful with your kernel version on your system.
You don’t have to delete anything else, just the ones that are the older kernel versions.
Similarly, just search for “**headers**” in the list of packages and delete the old ones as shown below.
Just to warn you, you **don’t want to remove “linux-headers-generic”**. Only focus on the ones that have version numbers with them.
And, that’s it, you’ll be done and apt will be working again and you have successfully freed up some space from your /boot partition. Similarly, you can do this using any other package manager you’re comfortable with.
### Using the command-line to remove old kernels
It’s the same thing but just using the terminal. So, if you don’t have the option to use a GUI (if it’s a remote machine/server) or if you’re just comfortable with the terminal, you can follow the steps below.
First, list all your kernels installed using the command below:
`ls -l /boot`
It should look something like this:
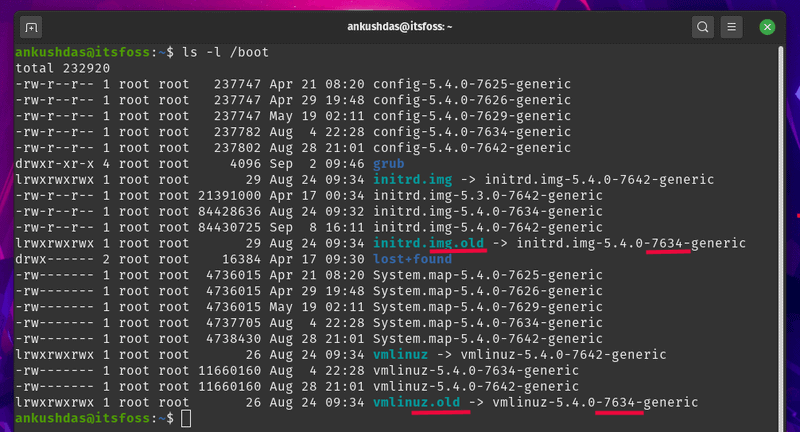
The ones that are mentioned as “**old**” or the ones that do not match your current kernel version are the unused kernels that you can delete.
Now, you can use the **rm** command to remove the specific kernels from the boot partition using the command below (a single command for each):
`sudo rm /boot/vmlinuz-5.4.0-7634-generic`
Make sure to check the version for your system — it may be different for your system.
If you have a lot of unused kernels, this will take time. So, you can also get rid of multiple kernels using the following command:
`sudo rm /boot/*-5.4.0-{7634}-*`
To clarify, you need to write the last part/code of the Kernel versions separated by commas to delete them all at once.
Suppose, I have two old kernels 5.4.0-7634-generic and 5.4.0-7624, the command will be:
`sudo rm /boot/*-5.4.0-{7634,7624}-*`
If you don’t want to see the old kernel version in the grub boot menu, you can simply [update grub](https://itsfoss.com/update-grub/) using the following command:
`sudo update-grub`
That’s it. You’re done. You’ve freed up space and also potentially fixed the broken APT if it was an issue after your /boot partition filled up.
In some cases, you may need to enter these commands to fix the broken apt (as I’ve noticed in the forums):
```
sudo dpkg --configure -a
sudo apt install -f
```
Do note that you don’t need to enter the above commands unless you find APT broken. Personally, I didn’t need these commands but I found them handy for some on the forums. |
12,782 | Go 语言在极小硬件上的运用(三) | https://ziutek.github.io/2018/05/03/go_on_very_small_hardware3.html | 2020-11-03T00:06:00 | [
"Go"
] | https://linux.cn/article-12782-1.html | 
在本系列的 [第一](/article-11383-1.html) 和 [第二](/article-12747-1.html) 部分中讨论的大多数示例都是以某种方式闪烁的 LED。起初它可能很有趣,但是一段时间后变得有些无聊。让我们做些更有趣的事情……
…让我们点亮更多的 LED!

### WS281x LED
[WS281x](http://www.world-semi.com/solution/list-4-1.html) RGB LED(及其克隆品)非常受欢迎。你可以以单个元素购买、链成长条或组装成矩阵、环或其他形状。

它们可以串联连接,基于这个事实,你可以只用 MCU 的单个引脚就可以控制一个很长的 LED 灯条。不幸的是,它们的内部控制器使用的物理协议不能直接适用于你在 MCU 中可以找到的任何外围设备。你必须使用 <ruby> 位脉冲 <rt> bit-banging </rt></ruby>或以特殊方式使用可用的外设。
哪种可用的解决方案最有效取决于同时控制的 LED 灯条数量。如果你必须驱动 4 到 16 个灯条,那么最有效的方法是 [使用定时器和 DMA](http://www.martinhubacek.cz/arm/improved-stm32-ws2812b-library)(请不要忽略这篇文章末尾的链接)。
如果只需要控制一个或两个灯条,请使用可用的 SPI 或 UART 外设。对于 SPI,你只能在发送的一个字节中编码两个 WS281x 位。由于巧妙地使用了起始位和停止位,UART 允许更密集的编码:每发送一个字节 3 位。
我在 [此站点](http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-2.html) 上找到了有关 UART 协议如何适用于 WS281x 协议的最佳解释。如果你不懂波兰语,这里是 [英文翻译](https://translate.google.pl/translate?sl=pl&tl=en&u=http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-2.html)。
基于 WS281x 的 LED 仍然是最受欢迎的,但市场上也有 SPI 控制的 LED:[APA102](http://neon-world.com/en/product.php)、[SK9822](http://www.normandled.com/index.php/Product/view/id/800.html)。关于它们的三篇有趣的文章在这里:[1](https://cpldcpu.wordpress.com/2014/08/27/apa102/)、[2](https://cpldcpu.wordpress.com/2014/11/30/understanding-the-apa102-superled/)、[3](https://cpldcpu.wordpress.com/2016/12/13/sk9822-a-clone-of-the-apa102/)。
### LED 环
市场上有许多基于 WS2812 的环。我有一个这样的:

它具有 24 个可单独寻址的 RGB LED(WS2812B),并暴露出四个端子:GND、5V、DI 和 DO。通过将 DI(数据输入)端子连接到上一个的 DO(数据输出)端子,可以链接更多的环或其他基于 WS2812 的东西。
让我们将这个环连接到我们的 STM32F030 板上。我们将使用基于 UART 的驱动程序,因此 DI 应连接到 UART 接头连接器上的 TXD 引脚。 WS2812B LED 需要至少 3.5V 的电源。 24 个 LED 会消耗大量电流,因此在编程/调试期间,最好将环上的 GND 和 5V 端子直接连接到 ST-LINK 编程器上可用的 GND 和 5V 引脚:

我们的 STM32F030F4P6 MCU 和整个 STM32 F0、F3、F7、L4 系列具有 F1、F4、L1 MCU 不具备的一项重要功能:它可以反转 UART 信号,因此我们可以将环直接连接到 UART TXD 引脚。如果你不知道我们需要这种反转,那么你可能没有读过我上面提到的 [文章](https://translate.google.pl/translate?sl=pl&tl=en&u=http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-2.html)。
因此,你不能以这种方式使用流行的 [Blue Pill](https://jeelabs.org/article/1649a/) 或 [STM32F4-DISCOVERY](http://www.st.com/en/evaluation-tools/stm32f4discovery.html)。使用其 SPI 外设或外部反相器。有关使用 SPI 的 NUCLEO-F411RE,请参见 [圣诞树灯](https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/examples/minidev/treelights) 项目作为 UART + 逆变器的示例或 [WS2812示例](https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/examples/nucleo-f411re/ws2812)。
顺便说一下,大多数 DISCOVERY 板可能还有一个问题:它们在 VDD = 3V 而不是 3.3V 的情况下工作。 对于高 DI,WS281x 至少要求电源电压 \* 0.7。如果是 5V 电源,则为 3.5V;如果是 4.7V 电源,则为 3.3V;可在 DISCOVERY 的 5V 引脚上找到。如你所见,即使在我们的情况下,第一个 LED 的工作电压也低于规格 0.2V。对于 DISCOVERY 板,如果供电 4.7V,它将工作在低于规格的 0.3V 下;如果供电 5V,它将工作在低于规格 0.5V 下。
让我们结束这段冗长的介绍并转到代码:
```
package main
import (
"delay"
"math/rand"
"rtos"
"led"
"led/ws281x/wsuart"
"stm32/hal/dma"
"stm32/hal/gpio"
"stm32/hal/irq"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
"stm32/hal/usart"
)
var tts *usart.Driver
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(true)
tx := gpio.A.Pin(9)
tx.Setup(&gpio.Config{Mode: gpio.Alt})
tx.SetAltFunc(gpio.USART1_AF1)
d := dma.DMA1
d.EnableClock(true)
tts = usart.NewDriver(usart.USART1, d.Channel(2, 0), nil, nil)
tts.Periph().EnableClock(true)
tts.Periph().SetBaudRate(3000000000 / 1390)
tts.Periph().SetConf2(usart.TxInv)
tts.Periph().Enable()
tts.EnableTx()
rtos.IRQ(irq.USART1).Enable()
rtos.IRQ(irq.DMA1_Channel2_3).Enable()
}
func main() {
var rnd rand.XorShift64
rnd.Seed(1)
rgb := wsuart.GRB
strip := wsuart.Make(24)
black := rgb.Pixel(0)
for {
c := led.Color(rnd.Uint32()).Scale(127)
pixel := rgb.Pixel(c)
for i := range strip {
strip[i] = pixel
tts.Write(strip.Bytes())
delay.Millisec(40)
}
for i := range strip {
strip[i] = black
tts.Write(strip.Bytes())
delay.Millisec(20)
}
}
}
func ttsISR() {
tts.ISR()
}
func ttsDMAISR() {
tts.TxDMAISR()
}
//c:__attribute__((section(".ISRs")))
var ISRs = [...]func(){
irq.USART1: ttsISR,
irq.DMA1_Channel2_3: ttsDMAISR,
}
```
#### 导入部分
与前面的示例相比,导入部分中的新内容是 `rand/math` 包和带有 `led/ws281x` 子树的 `led` 包。 `led` 包本身包含 `Color` 类型的定义。 `led/ws281x/wsuart` 定义了 `ColorOrder`、`Pixel` 和 `Strip` 类型。
我想知道如何使用 `image/color` 中的 `Color` 或 `RGBA` 类型,以及如何以它将实现 `image.Image` 接口的方式定义 `Strip`。 但是由于使用了 [gamma 校正](https://en.wikipedia.org/wiki/Gamma_correction) 和 大开销的 `color/draw` 包,我以简单的方式结束:
```
type Color uint32
type Strip []Pixel
```
使用一些有用的方法。然而,这种情况在未来可能会改变。
#### init 函数
`init` 函数没有太多新颖之处。 UART 波特率从 115200 更改为 3000000000/1390 ≈ 2158273,相当于每个 WS2812 位 1390 纳秒。 CR2 寄存器中的 TxInv 位设置为反转 TXD 信号。
#### main 函数
`XorShift64` 伪随机数生成器用于生成随机颜色。 [XORSHIFT](https://en.wikipedia.org/wiki/Xorshift) 是目前由 `math/rand` 包实现的唯一算法。你必须使用带有非零参数的 `Seed` 方法显式初始化它。
`rgb` 变量的类型为 `wsuart.ColorOrder`,并设置为 WS2812 使用的 GRB 颜色顺序(WS2811 使用 RGB 顺序)。然后用于将颜色转换为像素。
`wsuart.Make(24)` 创建 24 像素的初始化条带。它等效于:
```
strip := make(wsuart.Strip, 24)
strip.Clear()
```
其余代码使用随机颜色绘制类似于 “Please Wait…” 微调器的内容。
`strip` 切片充当帧缓冲区。 `tts.Write(strip.Bytes())` 将帧缓冲区的内容发送到环。
#### 中断
该程序由处理中断的代码组成,与先前的 [UART 示例](https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html#uart) 中的代码相同。
让我们编译并运行:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
14088 240 204 14532 38c4 cortexm0.elf
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; reset run; exit'
```
我跳过了 `openocd` 的输出。下面的视频显示了该程序的工作原理:
### 让我们做些有用的事情...
在 [第一部分](/article-11383-1.html) 的开头,我曾问过:“Go 能深入到多低层,而还能做一些有用的事情?”。 我们的 MCU 实际上是一种低端设备(8 比特的人可能会不同意我的看法),但到目前为止,我们还没有做任何有用的事情。
所以... 让我们做些有用的事情... 让我们做个时钟!
在互联网上有许多由 RGB LED 构成的时钟示例。让我们用我们的小板子和 RGB 环制作自己的时钟。我们按照下面的描述更改先前的代码。
#### 导入部分
删除 `math/rand` 包,然后添加 `stm32/hal/exti`。
#### 全局变量
添加两个新的全局变量:`btn` 和 `btnev`:
```
var (
tts *usart.Driver
btn gpio.Pin
btnev rtos.EventFlag
)
```
它们将用来处理那些用于设置时钟的 “按钮”。我们的板子除了重置之外没有其他按钮,但是如果没有它,我们仍然可以通过某种方式进行管理。
#### init 函数
将这段代码添加到 `init` 函数:
```
btn = gpio.A.Pin(4)
btn.Setup(&gpio.Config{Mode: gpio.In, Pull: gpio.PullUp})
ei := exti.Lines(btn.Mask())
ei.Connect(btn.Port())
ei.EnableFallTrig()
ei.EnableRiseTrig()
ei.EnableIRQ()
rtos.IRQ(irq.EXTI4_15).Enable()
```
在内部<ruby> 上拉电阻 <rt> pull-up resistor </rt></ruby>启用的情况下,将 PA4 引脚配置为输入。它已连接至板载 LED,但这不会妨碍任何事情。更重要的是它位于 GND 引脚旁边,所以我们可以使用任何金属物体来模拟按钮并设置时钟。作为奖励,我们还有来自板载 LED 的其他反馈。
我们使用 EXTI 外设来跟踪 PA4 状态。它被配置为在发生任何更改时都会产生中断。
#### btnWait 函数
定义一个新的辅助函数:
```
func btnWait(state int, deadline int64) bool {
for btn.Load() != state {
if !btnev.Wait(1, deadline) {
return false // timeout
}
btnev.Reset(0)
}
delay.Millisec(50) // debouncing
return true
}
```
它等待 “按钮” 引脚上的指定状态,但只等到最后期限出现。这是稍微改进的轮询代码:
```
for btn.Load() != state {
if rtos.Nanosec() >= deadline {
// timeout
}
}
```
我们的 `btnWait` 函数不是忙于等待 `state` 或 `deadline`,而是使用 `rtos.EventFlag` 类型的 `btnev` 变量休眠,直到有事情发生。你当然可以使用通道而不是 `rtos.EventFlag`,但是后者便宜得多。
#### main 函数
我们需要全新的 `main` 函数:
```
func main() {
rgb := wsuart.GRB
strip := wsuart.Make(24)
ds := 4 * 60 / len(strip) // Interval between LEDs (quarter-seconds).
adjust := 0
adjspeed := ds
for {
qs := int(rtos.Nanosec() / 25e7) // Quarter-seconds since reset.
qa := qs + adjust
qa %= 12 * 3600 * 4 // Quarter-seconds since 0:00 or 12:00.
hi := len(strip) * qa / (12 * 3600 * 4)
qa %= 3600 * 4 // Quarter-seconds in the current hour.
mi := len(strip) * qa / (3600 * 4)
qa %= 60 * 4 // Quarter-seconds in the current minute.
si := len(strip) * qa / (60 * 4)
hc := led.Color(0x550000)
mc := led.Color(0x005500)
sc := led.Color(0x000055)
// Blend the colors if the hands of the clock overlap.
if hi == mi {
hc |= mc
mc = hc
}
if mi == si {
mc |= sc
sc = mc
}
if si == hi {
sc |= hc
hc = sc
}
// Draw the clock and write to the ring.
strip.Clear()
strip[hi] = rgb.Pixel(hc)
strip[mi] = rgb.Pixel(mc)
strip[si] = rgb.Pixel(sc)
tts.Write(strip.Bytes())
// Sleep until the button pressed or the second hand should be moved.
if btnWait(0, int64(qs+ds)*25e7) {
adjust += adjspeed
// Sleep until the button is released or timeout.
if !btnWait(1, rtos.Nanosec()+100e6) {
if adjspeed < 5*60*4 {
adjspeed += 2 * ds
}
continue
}
adjspeed = ds
}
}
}
```
我们使用 `rtos.Nanosec` 函数代替 `time.Now` 来获取当前时间。这样可以节省大量的闪存,但也使我们的时钟变成了不知道日、月、年的老式设备,最糟糕的是它无法处理夏令时的变化。
我们的环有 24 个 LED,因此秒针的显示精度可以达到 2.5 秒。为了不牺牲这种精度并获得流畅的运行效果,我们使用 1/4 秒作为基准间隔。半秒就足够了,但四分之一秒更准确,而且与 16 和 48 个 LED 配合使用也很好。
红色、绿色和蓝色分别用于时针、分针和秒针。这允许我们使用简单的“逻辑或操作”进行颜色混合。我们 `Color.Blend` 方法可以混合任意颜色,但是我们闪存不多,所以我们选择最简单的解决方案。
我们只有在秒针移动时才重画时钟。
```
btnWait(0, int64(qs+ds)*25e7)
```
上面的这行代码等待的正是那一刻,或者是按钮的按下。
每按一下按钮就会把时钟向前调一调。按住按钮一段时间会加速调整。
#### 中断
定义新的中断处理程序:
```
func exti4_15ISR() {
pending := exti.Pending() & 0xFFF0
pending.ClearPending()
if pending&exti.Lines(btn.Mask()) != 0 {
btnev.Signal(1)
}
}
```
并将 `irq.EXTI4_15: exti4_15ISR` 条目添加到 ISR 数组。
该处理程序(或中断服务程序)处理 EXTI4\_15 IRQ。 Cortex-M0 CPU 支持的 IRQ 明显少于其较大的同类兄弟处理器,因此你经常可以看到一个 IRQ 被多个中断源共享。在我们的例子中,一个 IRQ 由 12 个 EXTI 线共享。
exti4\_15ISR 读取所有挂起的位,并从中选择 12 个更高的有效位。接下来,它清除 EXTI 中选中的位并开始处理它们。在我们的例子中,仅检查第 4 位。 `btnev.Signal(1)` 引发 `btnev.Wait(1, deadline)` 唤醒并返回 `true`。
你可以在 [Github](https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/examples/f030-demo-board/ws2812-clock) 上找到完整的代码。让我们来编译它:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15960 240 216 16416 4020 cortexm0.elf
```
这里所有的改进只得到 184 个字节。让我们再次重新构建所有内容,但这次在 typeinfo 中不使用任何类型和字段名:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15120 240 216 15576 3cd8 cortexm0.elf
```
现在,有了千字节的空闲空间,你可以改进一些东西。让我们看看它是如何工作的:
我不知道我是怎么精确打到 3:00 的!?
以上就是所有内容!在第 4 部分(本系列的结束)中,我们将尝试在 LCD 上显示一些内容。(LCTT 译注:然而烂尾了,第三篇写于 2018 年,整个博客当年就停更了。)
---
via: <https://ziutek.github.io/2018/05/03/go_on_very_small_hardware3.html>
作者:[Michał Derkacz](https://ziutek.github.io) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Go on very small hardware (Part 3)
Most of the examples discussed in the [first](/2018/03/30/go_on_very_small_hardware.html) and [second](/2018/04/14/go_on_very_small_hardware2.html) part of this series are blinking LEDs in one or another way. It may have been interesting at first, but after a while it has become a bit boring. Let’s do something more entertaining…
…let’s light more LEDs!
## WS281x LEDs
The [WS281x](http://www.world-semi.com/solution/list-4-1.html) RGB LEDs (and their clones) are very popular. You can buy them as single elements, chained into long strips or assembled into matrices, rings or other form-factors.
They can be connected in series and thanks to this fact, you can control a long LED strip with only single pin of your MCU. Unfortunately, the phisical protocol used by their internal controller doesn’t fit straight into any peripheral you can find in a MCU. You have to use bit-banging or use available peripherals in unusual way.
Which of the available solutions is the most efficient depends on the number of LED strips controlled at the same time. If you have to drive 4 to 16 strips the most efficient way is to [use timers and DMA](http://www.martinhubacek.cz/arm/improved-stm32-ws2812b-library) (don’t overlook the links at the end of Martin’s article).
If you have to control only one or two strips, use the available SPI or UART peripherals. In case of SPI you can encode only two WS281x bits in one byte sent. UART allows more dense coding thanks to clever use of the start and stop bits: 3 bits per one byte sent.
The best explanation of how the UART protocol fits into WS281x protocol I found on [this site](http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-2.html). If you don’t know Polish, here is the [English translation](https://translate.google.pl/translate?sl=pl&tl=en&u=http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-2.html).
The WS281x based LEDs are still the most popular but there are also SPI controlled LEDs on the market: [APA102](http://neon-world.com/en/product.php), [SK9822](http://www.normandled.com/index.php/Product/view/id/800.html). Three interesting articles about them: [1](https://cpldcpu.wordpress.com/2014/08/27/apa102/), [2](https://cpldcpu.wordpress.com/2014/11/30/understanding-the-apa102-superled/), [3](https://cpldcpu.wordpress.com/2016/12/13/sk9822-a-clone-of-the-apa102/).
## LED ring
There are many WS2812 based rings on the marker. I have this one:
It has 24 individually addressable RGB LEDs (WS2812B) and exposes four terminals: GND, 5V, DI and DO. You can chain more rings or other WS2812 based things by connecting DI (data in) terminal to the DO (data out) terminal of the previous one.
Let’s connect this ring to our STM32F030 board. We will use the UART based driver so the DI should be connected to the TXD pin on the UART header. The WS2812B LED requires a power supply with at least 3.5V. 24 LEDs can consume quite a lot of current, so during the programming/debuggin it’s best to connect the GND and 5V terminals on the ring directly to the GND and 5V pins available on ST-LINK programmer:
Our STM32F030F4P6 MCU and the whole STM32 F0, F3, F7, L4 families have one important thing that the F1, F4, L1 MCUs don’t have: it allows to invert the UART signals and therefore we can connect the ring directly to the UART TXD pin. If you don’t known that we need such inversion you probably didn’t read the [article](https://translate.google.pl/translate?sl=pl&tl=en&u=http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-2.html) I mentioned above.
So you can’t use the popular [Blue Pill](https://jeelabs.org/article/1649a/) or the [STM32F4-DISCOVERY](http://www.st.com/en/evaluation-tools/stm32f4discovery.html) this way. Use their SPI peripheral or an external inverter. See the [Christmas Tree Lights](https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/examples/minidev/treelights) project as an example of UART+inverter or the [WS2812 example](https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/examples/nucleo-f411re/ws2812) for NUCLEO-F411RE that uses SPI.
By the way, probably the most of DISCOVERY boards have one more problem: they work with VDD = 3V instead of 3.3V. The WS281x requires at least the *supply voltage* * 0.7 for DI high. This is 3.5V in case of 5V supply and 3.3V in case of 4.7V you can find on the 5V pins of the DISCOVERY. As you can see, even in our case the first LED works 0.2V below spec. In case of DISCOVERY it will work 0.3V bellow spec if powered 4.7V and 0.5V bellow spec if powered 5V.
Let’s finish this lengthy introduction and go to the code:
```
package main
import (
"delay"
"math/rand"
"rtos"
"led"
"led/ws281x/wsuart"
"stm32/hal/dma"
"stm32/hal/gpio"
"stm32/hal/irq"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
"stm32/hal/usart"
)
var tts *usart.Driver
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(true)
tx := gpio.A.Pin(9)
tx.Setup(&gpio.Config{Mode: gpio.Alt})
tx.SetAltFunc(gpio.USART1_AF1)
d := dma.DMA1
d.EnableClock(true)
tts = usart.NewDriver(usart.USART1, d.Channel(2, 0), nil, nil)
tts.Periph().EnableClock(true)
tts.Periph().SetBaudRate(3000000000 / 1390)
tts.Periph().SetConf2(usart.TxInv)
tts.Periph().Enable()
tts.EnableTx()
rtos.IRQ(irq.USART1).Enable()
rtos.IRQ(irq.DMA1_Channel2_3).Enable()
}
func main() {
var rnd rand.XorShift64
rnd.Seed(1)
rgb := wsuart.GRB
strip := wsuart.Make(24)
black := rgb.Pixel(0)
for {
c := led.Color(rnd.Uint32()).Scale(127)
pixel := rgb.Pixel(c)
for i := range strip {
strip[i] = pixel
tts.Write(strip.Bytes())
delay.Millisec(40)
}
for i := range strip {
strip[i] = black
tts.Write(strip.Bytes())
delay.Millisec(20)
}
}
}
func ttsISR() {
tts.ISR()
}
func ttsDMAISR() {
tts.TxDMAISR()
}
//c:__attribute__((section(".ISRs")))
var ISRs = [...]func(){
irq.USART1: ttsISR,
irq.DMA1_Channel2_3: ttsDMAISR,
}
```
#### The *import* section
The new things in the *import* section compared to the previous examples are the *rand/math* package and *led* package with its *led/ws281x* subtree. The *led* package itself contains definition of *Color* type. The *led/ws281x/wsuart* defines the *ColorOrder*, *Pixel* and *Strip* types.
I was wondering about using the *Color* or *RGBA* type from *image/color* and about defining the *Strip* in the way that it will implement *image.Image* interface but because of using a [gamma correction](https://en.wikipedia.org/wiki/Gamma_correction) and the big overhead of *image/draw* package I ended with simple:
```
type Color uint32
type Strip []Pixel
```
with a few useful methods. However, this can change in the future.
#### The *init* function
There aren’t so much novelties in the *init* function. The UART baud rate was changed from 115200 to 3000000000/1390 ≈ 2158273 which corresponds to 1390 nanoseconds per WS2812 bit. The *TxInv* bit in CR2 register is set to invert TXD signal.
#### The *main* function
The *XorShift64* pseudorandom number generator is used to generate random colors. [XORSHIFT](https://en.wikipedia.org/wiki/Xorshift) is currently the only algorithm implemented by *math/rand* package. You have to explicitly initialize it using its *Seed* method with nonzero argument.
The *rgb* variable is of type *wsuart.ColorOrder* and is set to the GRB color order used by WS2812 (WS2811 uses RGB order). It’s then used to translate colors to pixels.
The `wsuart.Make(24)`
creates initialized strip of 24 pixels. It is equivalent of:
```
strip := make(wsuart.Strip, 24)
strip.Clear()
```
The rest of the code uses random colors to draw something similar to “Please Wait…” spinner.
The *strip* slice acts as a framebuffer. The `tts.Write(strip.Bytes())`
sends the content of the framebuffer to the ring.
#### Interrupts
The program is ened with the code that handles interrupts, the same as in the
previous [UART example](/2018/04/14/go_on_very_small_hardware2.html#uart).
Let’s compile it and run:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
14088 240 204 14532 38c4 cortexm0.elf
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; reset run; exit'
```
I’ve skipped the openocd output. The video bellow shows how this program works:
## Let’s do something useful…
At the beginning of the [first part](/2018/03/30/go_on_very_small_hardware.html) I’ve asked: “How low we can Go and still do something useful?”. Our MCU is actually a low-end device (8-bitters will probably disagree with me) but we haven’t done anything useful so far.
So… Let’s do something useful… *Let’s make a Clock!*
There are many examples of clocks built of RGB LEDs on the Internet. Let’s make our own using our little board and RGB ring. We change the previous code as described below.
#### The *import* section
Remove the *math/rand* package and add *stm32/hal/exti*.
#### Global variables
Add two new global variables: *btn* and *btnev*:
```
var (
tts *usart.Driver
btn gpio.Pin
btnev rtos.EventFlag
)
```
They will be used to handle the “button” that will be used to set our clock. Our board has no button except reset, but somehow we can manage without it.
#### The *init* function
Add this code to the *init* function:
```
btn = gpio.A.Pin(4)
btn.Setup(&gpio.Config{Mode: gpio.In, Pull: gpio.PullUp})
ei := exti.Lines(btn.Mask())
ei.Connect(btn.Port())
ei.EnableFallTrig()
ei.EnableRiseTrig()
ei.EnableIRQ()
rtos.IRQ(irq.EXTI4_15).Enable()
```
The PA4 pin is configured as input with the internal pull-up resistor enabled. It’s connected to the onboard LED but that doesn’t hinder anything. More important is that it’s located next to the GND pin so we can use any metal object to simulate the button and set the clock. As a bonus we have additional feedback from the onboard LED.
We use the EXTI peripheral to track the PA4 state. It’s configured to generate an interrupt on any change.
#### The *btnWait* function
Define a new auxiliary function:
```
func btnWait(state int, deadline int64) bool {
for btn.Load() != state {
if !btnev.Wait(1, deadline) {
return false // timeout
}
btnev.Reset(0)
}
delay.Millisec(50) // debouncing
return true
}
```
It waits for the specified *state* on the “button” pin, but only until the *deadline* occurs. This is slightly improved polling code:
```
for btn.Load() != state {
if rtos.Nanosec() >= deadline {
// timeout
}
}
```
Our *btnWait* function, instead of busy waiting for *state* or *deadline*, uses the *btnev* variable of type *rtos.EventFlag* to sleep until something will happen. You can of course use a channel instead of *rtos.EventFlag* but the latter one is much cheaper.
#### The *main* function
We need completly new *main* function:
```
func main() {
rgb := wsuart.GRB
strip := wsuart.Make(24)
ds := 4 * 60 / len(strip) // Interval between LEDs (quarter-seconds).
adjust := 0
adjspeed := ds
for {
qs := int(rtos.Nanosec() / 25e7) // Quarter-seconds since reset.
qa := qs + adjust
qa %= 12 * 3600 * 4 // Quarter-seconds since 0:00 or 12:00.
hi := len(strip) * qa / (12 * 3600 * 4)
qa %= 3600 * 4 // Quarter-seconds in the current hour.
mi := len(strip) * qa / (3600 * 4)
qa %= 60 * 4 // Quarter-seconds in the current minute.
si := len(strip) * qa / (60 * 4)
hc := led.Color(0x550000)
mc := led.Color(0x005500)
sc := led.Color(0x000055)
// Blend the colors if the hands of the clock overlap.
if hi == mi {
hc |= mc
mc = hc
}
if mi == si {
mc |= sc
sc = mc
}
if si == hi {
sc |= hc
hc = sc
}
// Draw the clock and write to the ring.
strip.Clear()
strip[hi] = rgb.Pixel(hc)
strip[mi] = rgb.Pixel(mc)
strip[si] = rgb.Pixel(sc)
tts.Write(strip.Bytes())
// Sleep until the button pressed or the second hand should be moved.
if btnWait(0, int64(qs+ds)*25e7) {
adjust += adjspeed
// Sleep until the button is released or timeout.
if !btnWait(1, rtos.Nanosec()+100e6) {
if adjspeed < 5*60*4 {
adjspeed += 2 * ds
}
continue
}
adjspeed = ds
}
}
}
```
We use the *rtos.Nanosec* function instead of *time.Now* to obtain the current time. This saves much of Flash but also reduces our clock to antique device that has no idea about days, months and years and worst of all it doesn’t handle daylight saving changes.
Our ring has 24 LEDs, so the second hand can be presented with the accuracy of 2.5s. To don’t sacrifice this accuracy and get smooth operation we use quarter-second as base interval. Half-second would be enough but quarter-second is more accurate and works also well with 16 and 48 LEDs.
The red, green and blue colors are used respectively for hour, minute and second hands. This allows us to use simple *logical or* operation for color blending. We have the *Color.Blend* method that can blend arbitrary colors but we’re low of Flash so we prefer simplest possible solution.
We redraw the clock only when the second hand moved. The:
```
btnWait(0, int64(qs+ds)*25e7)
```
is waiting for exactly that moment or for the press of the button.
Every press of the button adjust the clock forward. There is an acceleration when the button is held down for some time.
#### Interrupts
Define new interrupt handler:
```
func exti4_15ISR() {
pending := exti.Pending() & 0xFFF0
pending.ClearPending()
if pending&exti.Lines(btn.Mask()) != 0 {
btnev.Signal(1)
}
}
```
and add `irq.EXTI4_15: exti4_15ISR,`
entry to the *ISRs* array.
This handler (or Interrupt Service Routine) handles EXTI4_15 IRQ. The Cortex-M0 CPU supports significantly fewer IRQs than its bigger brothers, so you can often see that one IRQ is shared by multiple interrupt sources. In our case one IRQ is shared by 12 EXTI lines.
The *exti4_15ISR* reads all *pending* bits and selects 12 more significant of them. Next it clears the seleced bits in EXTI and starts to handle them. In our case only bit 4 is checked. The `btnev.Signal(1)`
causes that the `btnev.Wait(1, deadline)`
wakes up and returns *true*.
You can find the complete code on [Github](https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/examples/f030-demo-board/ws2812-clock). Let’s compile it:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15960 240 216 16416 4020 cortexm0.elf
```
There are only 184 bytes for any iprovements. Let’s rebuild everything one more time but this time without any type and field names in typeinfo:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15120 240 216 15576 3cd8 cortexm0.elf
```
Now, with a kilobyte of free space you can improve something. Let’s see how it works:
I don’t know how I managed to hit exactly 3:00 !?
That’s all Folks! In the part 4 (ending this series) we’ll try to display something on a LCD. |
12,783 | 如何在树莓派上安装 Ubuntu 服务器? | https://itsfoss.com/install-ubuntu-server-raspberry-pi/ | 2020-11-03T10:28:00 | [
"树莓派"
] | https://linux.cn/article-12783-1.html | 
[树莓派](https://www.raspberrypi.org/)是最著名的[单板计算机](https://itsfoss.com/raspberry-pi-alternatives/)。最初,树莓派项目的范围旨在促进学校和发展中国家的计算机基础科学的教学。
它的低成本、便携性和极低的功耗,使得它的受欢迎程度远远超过预期。从气象站到家庭自动化,玩家们用树莓派搭建了许多[酷炫的项目](https://itsfoss.com/raspberry-pi-projects/)。
[第四代树莓派](https://itsfoss.com/raspberry-pi-4/)具备了普通台式电脑的功能和处理能力。但本文并不是要介绍如何使用树莓派作为桌面。相反,我会告诉你如何在树莓派上安装 Ubuntu 服务器。
在本教程中,我将使用树莓派 4,以下是我将介绍的内容:
* 在 microSD 卡上安装 Ubuntu 服务器
* 在树莓派上设置无线网络连接
* 通过 SSH 访问你的树莓派

**本教程需要以下设备**:
* 一张 micro SD 卡(建议使用 8GB 或更大的卡)
* 一台带有 micro SD 卡读卡器的计算机(运行 Linux、Windows 或 macOS)
* 树莓派 2、3 或 4
* 良好的互联网连接
* 用于树莓派 2 和 3 的 HDMI 线和用于树莓派 4 的 micro HDMI 线(可选)
* 一套 USB 键盘(可选)
### 在树莓派上安装 Ubuntu 服务器
在本教程中,我使用 Ubuntu 来创建树莓派 SD 卡,但你可以在其他 Linux 发行版、macOS 和 Windows 上创建它。这是因为准备 SD 卡的步骤对 Raspberry Pi Imager 工具而言是一样的。
Raspberry Pi Imager 工具会自动下载你[选择的树莓派系统](https://itsfoss.com/raspberry-pi-os/)镜像。这意味着你需要一个良好的网络连接来下载 1GB 左右的数据。
#### 步骤 1:用 Raspberry Pi Imager 准备 SD 卡
确保你已将 microSD 卡插入电脑,并在电脑上安装 Raspberry Pi Imager。
你可以从这些链接中下载适合你操作系统的 Imager 工具:
* [用于 Ubuntu/Debian 的 Raspberry Pi Imager](https://downloads.raspberrypi.org/imager/imager_amd64.deb)
* [用于 Windows 的 Raspberry Pi Imager](https://downloads.raspberrypi.org/imager/imager.exe)
* [用于 MacOS 的 Raspberry Pi Imager](https://downloads.raspberrypi.org/imager/imager.dmg)
尽管我使用的是 Ubuntu,但我不会使用上面列出的 Debian 软件包,而是使用命令行安装 snap 包。这个方法可以适用于更广泛的 Linux 发行版。
```
sudo snap install rpi-imager
```
安装好 Raspberry Pi Imager 工具后,找到并打开它,点击 “CHOOSE OS” 菜单。

滚动菜单并点击 “Ubuntu” (“核心”和“服务器”镜像)。

从可用的镜像中,我选择了 Ubuntu 20.04 LTS 64 位。如果你有一个树莓派 2,那你只能选择 32 位镜像。
**重要提示:如果你使用的是最新的树莓派 4 - 8 GB 内存型号,你应该选择 64 位操作系统,否则只能使用 4 GB 内存。**

从 “SD Card” 菜单中选择你的 microSD 卡,然后点击 “WRITE”。

如果它显示一些错误,请尝试再次写入它。现在它将下载 Ubuntu 服务器镜像并将其写入 micro SD 卡。
当这个过程完成时,它将通知你。

#### 步骤 2:在 Ubuntu 服务器上添加 WiFi 支持
烧录完 micro SD 卡后,你就差不多可以使用它了。在使用它之前,有一件事情你可能想做,那就是添加 Wi-Fi 支持。
SD 卡仍然插入读卡器中,打开文件管理器,找到卡上的 “system-boot” 分区。
你要找的和需要编辑的文件名为 `network-config`。

这个过程也可以在 Windows 和 MacOS 上完成。如前所述,编辑 `network-config` 文件,添加你的 Wi-Fi 凭证。
首先,取消矩形框内的行的注释(删除开头的标签 `#`)。
之后,将 `myhomewifi` 替换为你的 Wi-Fi 网络名,比如 `"itsfoss"`,将 `"S3kr1t"` 替换为 Wi-Fi 密码,用引号括起来,比如 `"12345679"`。

它可能看上去像这样:
```
wifis:
wlan0:
dhcp4: true
optional: true
access-points:
"your wifi name":
password: "your_wifi_password"
```
保存文件并将 micro SD 卡插入到你的树莓派中。在第一次启动时,如果你的树莓派无法连接到 Wi-Fi 网络,只需重启你的设备。
#### 步骤 3:在树莓派上使用 Ubuntu 服务器(如果你有专门的显示器、键盘和鼠标的话)
如果你有一套额外的鼠标,键盘和显示器,你可以很容易地像其他电脑一样使用树莓派(但没有 GUI)。
只需将 micro SD 卡插入树莓派,连接显示器、键盘和鼠标。现在[打开你的树莓派](https://itsfoss.com/turn-on-raspberry-pi/)。它将出现 TTY 登录屏幕(黑色终端屏幕)并询问用户名和密码。
* 默认用户名:`ubuntu`
* 默认密码:`ubuntu`
看到提示符时,用 `ubuntu` 作为密码。登录成功后,[Ubuntu 会要求你更改默认密码](https://itsfoss.com/change-password-ubuntu/)。
享受你的 Ubuntu 服务器吧!
#### 步骤 3:通过 SSH 远程连接到你的树莓派(如果你没有树莓派的显示器、键盘和鼠标的话)
如果你没有专门与树莓派一起使用的显示器也没关系。当你可以直接通过 SSH 进入它并按照你的方式使用它时,谁还需要一个带有显示器的服务器呢?
**在 Ubuntu 和 Mac OS**上,通常已经安装了一个 SSH 客户端。要远程连接到你的树莓派,你需要找到它的 IP 地址。检查[连接到你的网络的设备](https://itsfoss.com/how-to-find-what-devices-are-connected-to-network-in-ubuntu/),看看哪个是树莓派。
由于我没有 Windows 机器,你可以访问[微软](https://docs.microsoft.com/en-us/windows-server/administration/openssh/openssh_install_firstuse)提供的综合指南。
打开终端,运行以下命令:
```
ssh ubuntu@raspberry_pi_ip_address
```
你可能会看到以下信息确认连接:
```
Are you sure you want to continue connecting (yes/no/[fingerprint])?
```
输入 `yes`,然后点击回车键。

当提示时,用前面提到的 `ubuntu` 作为密码。当然,你会被要求更改密码。
完成后,你将自动注销,你必须使用新密码重新连接。
你的 Ubuntu 服务器就可以在树莓派上运行了!
### 总结
在树莓派上安装 Ubuntu 服务器是一个简单的过程,而且它的预配置程度很高,使用起来很愉快。
我不得不说,在所有[我在树莓派上尝试的操作系统](https://itsfoss.com/raspberry-pi-os/)中,Ubuntu 服务器是最容易安装的。我并没有夸大其词。请查看我的[在树莓派上安装 Arch Linux](https://itsfoss.com/install-arch-raspberry-pi/) 的指南,以供参考。
希望这篇指南也能帮助你在树莓派上安装 Ubuntu 服务器。如果你有问题或建议,请在评论区告诉我。
---
via: <https://itsfoss.com/install-ubuntu-server-raspberry-pi/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The [Raspberry Pi](https://www.raspberrypi.org/) is the best-known [single-board computer](https://itsfoss.com/raspberry-pi-alternatives/). Initially, the scope of the Raspberry Pi project was targeted to the promotion of teaching of basic computer science in schools and in developing countries.
Its low cost, portability and very low power consumption, made the models far more popular than anticipated. From weather station to home automation, tinkerers built so many [cool projects using Raspberry Pi](https://itsfoss.com/raspberry-pi-projects/).
The [4th generation of the Raspberry Pi](https://itsfoss.com/raspberry-pi-4/), is equipped with features and processing power of a regular desktop computer. But this article is not about using RPi as desktop. Instead, I’ll show you how to install Ubuntu server on Raspberry Pi.
In this tutorial I will use a Raspberry Pi 4 and I will cover the following:
- Installing Ubuntu Server on a microSD card
- Setting up a wireless network connection on the Raspberry Pi
- Accessing your Raspberry Pi via SSH
**You’ll need the following things for this tutorial**:
- A micro SD card (8 GB or greater recommended)
- A computer (running Linux, Windows or macOS) with a micro SD card reader
- A Raspberry Pi 2, 3 or 4
- Good internet connection
- An HDMI cable for the Pi 2 & 3 and a micro HDMI cable for the Pi 4 (optional)
- A USB keyboard set (optional)
## Installing Ubuntu Server on a Raspberry Pi
I have used Ubuntu for creating Raspberry Pi SD card in this tutorial but you may follow it on other Linux distributions, macOS and Windows as well. This is because the steps for preparing the SD card is the same with Raspberry Pi Imager tool.
The Raspberry Pi Imager tool downloads the image of your [choice of Raspberry Pi OS](https://itsfoss.com/raspberry-pi-os/) automatically. This means that you need a good internet connection for downloading data around 1 GB.
### Step 1: Prepare the SD Card with Raspberry Pi Imager
Make sure you have inserted the microSD card into your computer, and install the Raspberry Pi Imager at your computer.
You can download the Imager tool for your operating system from these links:
Despite I use Ubuntu, I won’t use the Debian package that is listed above, but I will install the snap package using the command line. This method can be applied to wider range of Linux distributions.
`sudo snap install rpi-imager`
Once you have installed Raspberry Pi Imager tool, find and open it and click on the “CHOOSE OS” menu.
Scroll across the menu and click on “Ubuntu” (Core and Server Images).
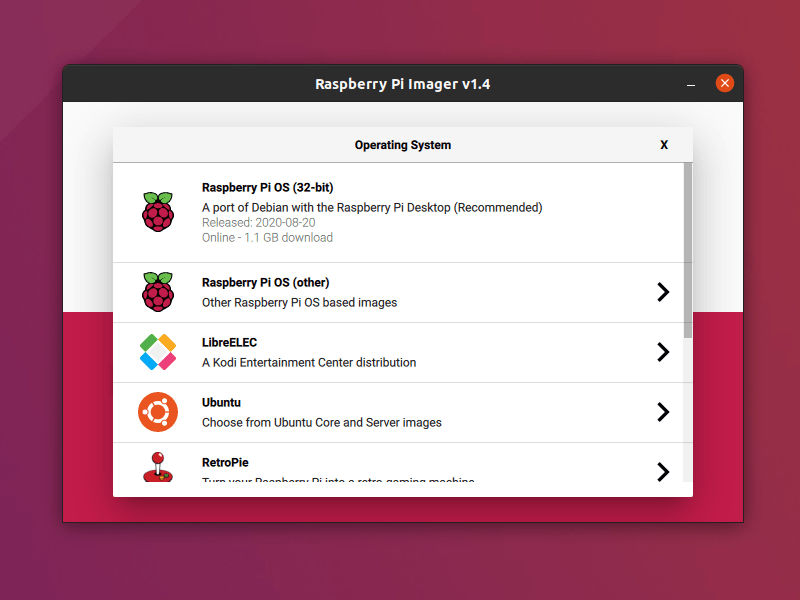
From the available images, I choose the Ubuntu 20.04 LTS 64 bit. If you have a Raspberry Pi 2, you are limited to the 32bit image.
**Important Note: If you use the latest Raspberry Pi 4 – 8 GB RAM model, you should choose the 64bit OS, otherwise you will be able to use 4 GB RAM only.**
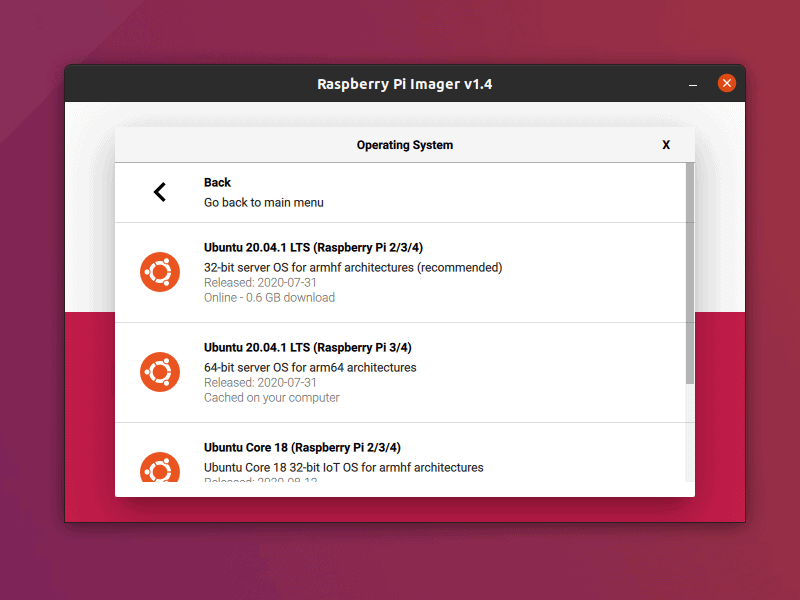
Select your microSD card from the “SD Card” menu, and click on “WRITE”after.
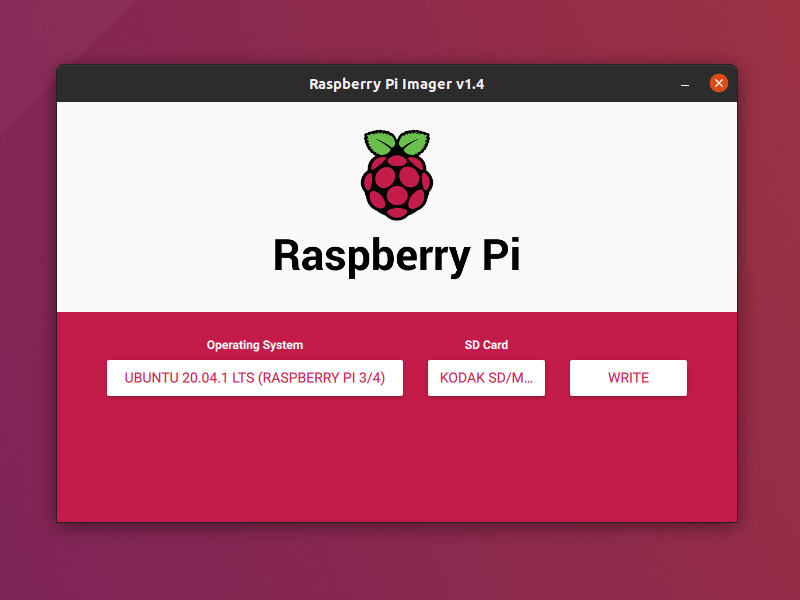
If it shows some error, try writing it again. It will now download the Ubuntu server image and write it to the micro SD card.
It will notify you when the process is completed.
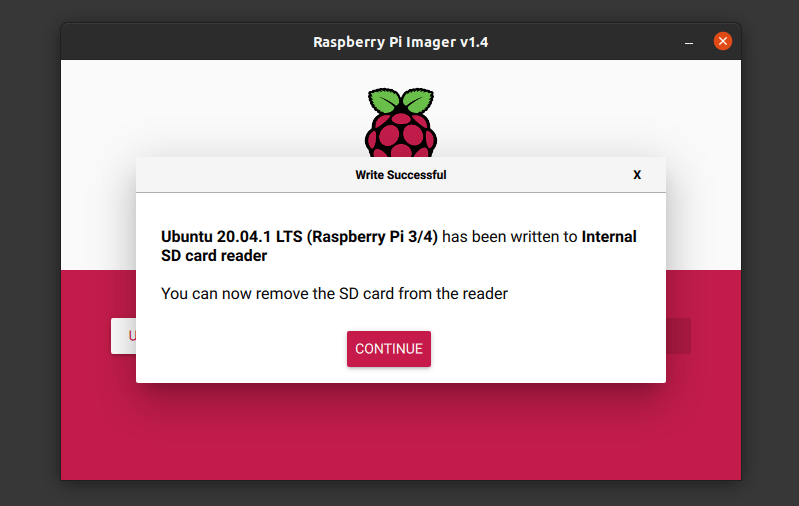
### Step 2: Add WiFi support to Ubuntu server
Once the micro SD card flashing is done, you are almost ready to use it. There is one thng that you may want to do before using it and that is to add Wi-Fi support. If you don’t do it right now, you’ll have to put extra effort later in [connecting to wifi from terminal in Ubuntu server](https://itsfoss.com/connect-wifi-terminal-ubuntu/).
With the SD card still inserted in the card reader, open the file manager and locate the “system-boot” partition on the card.
The file that you are looking for and need to edit is named
.**network-config**
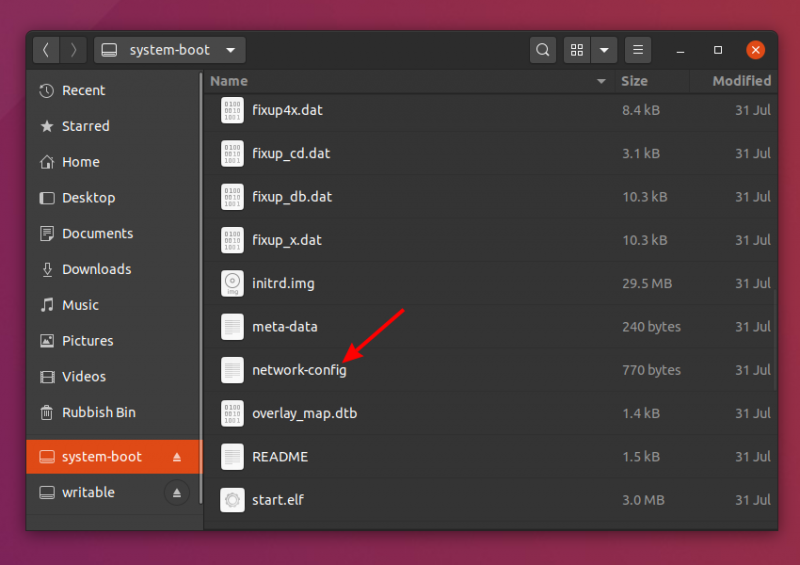
This process can be done on Windows and MacOS too. Edit the** network-config** file as already mentioned to add your Wi-Fi credentials.
Firstly, uncomment (remove the hashtag “#” at the beginning) from lines that are included in the rectangular box.
After that, replace myhomewifi with your Wi-Fi network name enclosed in quotation marks, such as “itsfoss” and the “S3kr1t” with the Wi-Fi password enclosed in quotation marks, such as “12345679”.
It may look like this:
```
wifis:
wlan0:
dhcp4: true
optional: true
access-points:
"your wifi name":
password: "your_wifi_password"
```
Save the file and insert the micro SD card into your Raspberry Pi. During the first boot, if your Raspberry Pi fails connect to the Wi-Fi network, simply reboot your device.
### Step 3: Use Ubuntu server on Raspberry Pi (if you have dedicated monitor, keyboard and mouse for Raspberry Pi)
If you have got an additional set of mouse, keyboard and a monitor for the Raspberry Pi, you can use easily use it like any other computer (but without GUI).
Simply insert the micro SD card to the Raspberry Pi, plug in the monitor, keyboard and mouse. Now [turn on your Raspberry Pi](https://itsfoss.com/turn-on-raspberry-pi/). It will present [TTY login screen](https://itsfoss.com/what-is-tty-in-linux/) (black terminal screen) and aks for username and password.
- Default username: ubuntu
- Default password: ubuntu
When prompted, use “**ubuntu**” for the password. Right after a successful login, [Ubuntu will ask you to change the default password](https://itsfoss.com/change-password-ubuntu/).
Enjoy your Ubuntu Server!
### Step 3: Connect remotely to your Raspberry Pi via SSH (if you don’t have monitor, keyboard and mouse for Raspberry Pi)
It is okay if you don’t have a dedicated monitor to be used with Raspberry Pi. Who needs a monitor with a server when you can just SSH into it and use it the way you want?
**On Ubuntu and Mac OS**, an SSH client is usually already installed. To connect remotely to your Raspberry Pi, you need to discover its IP address. Check the [devices connected to your network](https://itsfoss.com/how-to-find-what-devices-are-connected-to-network-in-ubuntu/) and see which one is the Raspberry Pi.
Since I don’t have access to a Windows machine, you can access a comprehensive guide provided by [Microsoft](https://docs.microsoft.com/en-us/windows-server/administration/openssh/openssh_install_firstuse).
Open a terminal and run the following command:
`ssh ubuntu@raspberry_pi_ip_address`
You will be asked to confirm the connection with the message:
`Are you sure you want to continue connecting (yes/no/[fingerprint])?`
Type “yes” and click the enter key.
When prompted, use “ubuntu” for the password as mentioned earlier. You’ll be asked to change the password of course.
Once done, you will be automatically logged out and you have to reconnect, using your new password.
Your Ubuntu server is up and running on a Raspberry Pi!
**Conclusion**
Installing Ubuntu Server on a Raspberry Pi is an easy process and it comes pre-configured at a great degree which the use a pleasant experience.
I have to say that among all the [operating systems that I tried on my Raspberry Pi](https://itsfoss.com/raspberry-pi-os/), Ubuntu Server was the easiest to install. I am not exaggerating. Check my guide on [installing Arch Linux on Raspberry Pi](https://itsfoss.com/install-arch-raspberry-pi/) for reference.
I hope this guide helped you in installing Ubuntu server on your Raspberry Pi as well. If you have questions or suggestions, please let me know in the comment section. |
12,786 | 如何在 Debian、Ubuntu 中使用 apt-cache 命令 | https://itsfoss.com/apt-cache-command/ | 2020-11-04T10:14:16 | [
"apt"
] | https://linux.cn/article-12786-1.html |
>
> 使用 apt-cache 命令,你可以在本地 APT 缓存中搜索软件包的详细信息。在本教程中学习使用 apt-cache 命令。
>
>
>
### apt-cache 命令是用来干什么的?
[APT](https://wiki.debian.org/Apt) [包管理器](https://itsfoss.com/package-manager/)工作在软件包元数据的本地缓存上。元数据通常由包名、版本、描述、依赖关系、仓库和开发者等信息组成。通过 `apt-cache` 命令,你可以查询这个本地 APT 缓存并获得相关信息。
你可以搜索一个包的可用性、它的版本号、它的依赖关系等等。我将通过实例告诉你如何使用 `apt-cache`命令。
APT 缓存的位置是 `/var/lib/apt/lists/` 目录。缓存哪些仓库元数据取决于你的源列表中 `/etc/apt/sources.list` 文件中添加的仓库,以及位于 `/etc/apt/sources.list.d` 目录下的额外仓库文件。
令人惊讶的是,`apt-cache` 并不能清除 APT 缓存。为此,你必须[使用 apt-get clean 命令](https://itsfoss.com/clear-apt-cache/)。
不用说,APT 打包系统是在 Debian 和基于 Debian 的 Linux 发行版上使用的,比如 Ubuntu、Linux Mint、Elementary OS 等。你不能在 Arch 或 Fedora 上使用它。
### 使用 apt-cache 命令

就像其他 Linux 命令一样,`apt-cache` 也有一些可用的选项,你可以随时参考它的手册页来了解这些选项。
然而,你可能并不需要使用所有的选项。这就是为什么我在本教程中只向你展示 `apt-cache` 命令中最常见和最有用的例子。
#### 始终更新
更新本地 APT 缓存以与远程仓库同步是一个好主意。如何做到这一点呢?你可以使用命令:
```
sudo apt update
```
#### 搜索软件包
`apt-cache` 命令最常见的用途是查找软件包。你可以使用一个正则表达式来搜索本地 APT 缓存中的包。
```
apt-cache search package_name
```
默认情况下,它会在软件包的名称和描述中查找搜索关键词。它按字母顺序显示匹配的软件包及其简短的描述。

你也可以缩小搜索范围,只在软件包名称中查找搜索词。
```
apt-cache search --names-only package_name
```

如果你想知道所有匹配软件包的完整细节,你可以使用 `--full` 标志。

#### 获取详细的包装信息
如果你知道确切的软件包名称(或者你已经成功地通过搜索找到了它),你可以得到软件包的详细元数据信息。
```
apt-cache show package_name
```

你可以看到软件包元数据中的所有细节,比如名称、版本、开发者、维护者、仓库、长短描述、软件包大小甚至是校验和。
还有一个选项 `showpkg` 可以显示软件包的名称、版本、正向和反向依赖关系等信息。
```
apt-cache showpkg package_name
```
#### apt-cache 的策略
这是 `apt-cache` 命令中很少使用的一个选项。`policy` 选项可以帮助你调试与 [preference 文件](https://debian-handbook.info/browse/stable/sect.apt-get.html#sect.apt.priorities)相关的问题。
如果你指定了软件包的名称,它将显示该软件包是否已经安装,在哪个版本的仓库中可用,以及它的优先级。

默认情况下,每个已安装的软件包版本的优先级为 100,未安装的软件包的优先级为 500。同一软件包可能有多个不同优先级的版本。APT 会安装优先级较高的版本,除非安装的版本较新。
如果不理解这个部分,也没关系。对于一个普通的 Linux 用户来说,会极少纠结于这么深的软件包管理知识。
#### 检查软件包的依赖关系和反向依赖关系。
你可以在安装之前(甚至在安装之后)[检查一个包的依赖关系](https://itsfoss.com/check-dependencies-package-ubuntu/)。它还会显示所有可能满足依赖关系的软件包。
```
apt-cache depends package
```

你也可以通过 `apt-cahce` 检查反向依赖关系来检查哪些包是依赖于某个包的。

坦白说,看到 Ansible 这样的 DevOps 工具对 [Cowsay 这样有趣的 Linux 命令](https://itsfoss.com/funny-linux-commands/)有依赖性,我也很惊讶。我想可能是因为在[安装 Ansible](https://linuxhandbook.com/install-ansible-linux/)之后,它会在节点上显示一些信息。
#### 检查未满足的依赖性
你可能会被 [Ubuntu 中未满足的依赖问题](https://itsfoss.com/held-broken-packages-error/)所困扰,其他 Linux 也有类似问题。`apt-cache` 命令提供了一个选项来检查系统中各种可用软件包的所有未满足的依赖关系。
```
apt-cache unmet
```

### 结论
你可以用 `apt-cache` 命令列出所有可用的软件包。输出结果会很庞大,所以我建议将其与 [wc 命令](https://linuxhandbook.com/wc-command/) 结合起来,得到可用软件包的总数,就像这样:
```
apt-cache pkgnames | wc -l
```
你是否注意到你不需要成为 [root 用户](https://itsfoss.com/root-user-ubuntu/)就可以使用 `apt-cache` 命令?
较新的 [apt 命令](https://itsfoss.com/apt-command-guide/)也有一些与 `apt-cache` 命令相对应的功能选项。由于 `apt` 比较新,所以在脚本中还是首选使用 `apt-get` 及其相关的 `apt-cache` 等命令。
希望你觉得本教程对你有帮助。如果你对上面讨论的任何一点有疑问或者有改进的建议,请在评论中告诉我。
---
via: <https://itsfoss.com/apt-cache-command/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

## What is apt-cache command used for?
The [apt](https://wiki.debian.org/Apt) [package manager](https://itsfoss.com/package-manager/) works on a local cache of package metadata. The metadata usually consists of information like the package name, version, description, dependencies, repository and developers. With the apt-cache command, you can query this local APT cache and get relevant information.
You can search for the availability of a package, its version number, its dependencies among other things. I’ll show you how to use the apt-cache command with examples.
The **location of APT cache** is /var/lib/apt/lists/ directory. Which repository metadata to cache depends on the repositories added in your source list in the `/etc/apt/sources.list`
file and additional repository files located in `ls /etc/apt/sources.list.d`
directory.
Surprisingly, apt-cache doesn’t clear the APT cache. For that you’ll have to [use the apt-get clean command](https://itsfoss.com/clear-apt-cache/).
Needless to say, the APT packaging system is used on Debian and Debian-based Linux distributions like Ubuntu, Linux Mint, elementary OS etc. You cannot use it on Arch or Fedora.
## Using apt-cache command

Like any other Linux command, there are several options available with apt-cache and you can always refer to its man page to read about them.
However, you probably won’t need to use all of them. This is why I will show only the most common and useful examples of the apt-cache command in this tutorial.
`sudo apt update`
### Search for packages
The most common use of apt-cache command is for finding packages. You can use a regex pattern to search for a package in the local APT cache.
`apt-cache search package_name`
By default, it looks for the search term in both the name and description of the package. It shows the matching package along with its short description in alphabetical order.
You can narrow down your search to look for the search term in package names only.
`apt-cache search --names-only package_name`
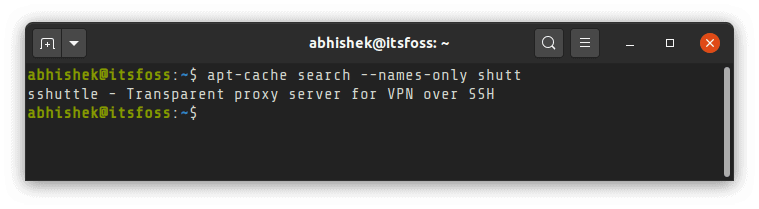
If you want complete details of all the matched packages, you may use the `--full`
flag. It can also be used with `--names-only`
flag.
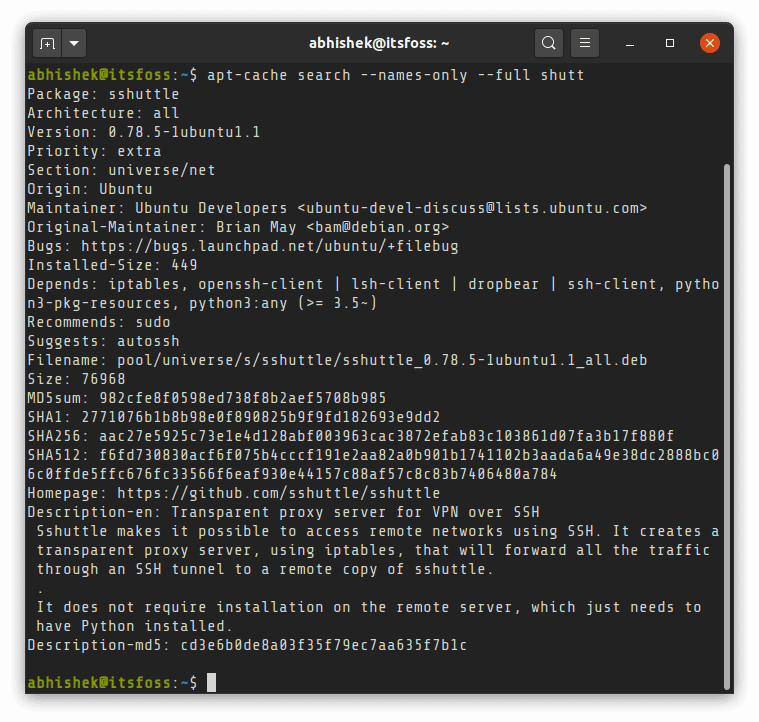
### Get detailed package information
If you know the exact package name (or if you have managed to find it with the search), you can get the detailed metadata information on the package.
`apt-cache show package_name`
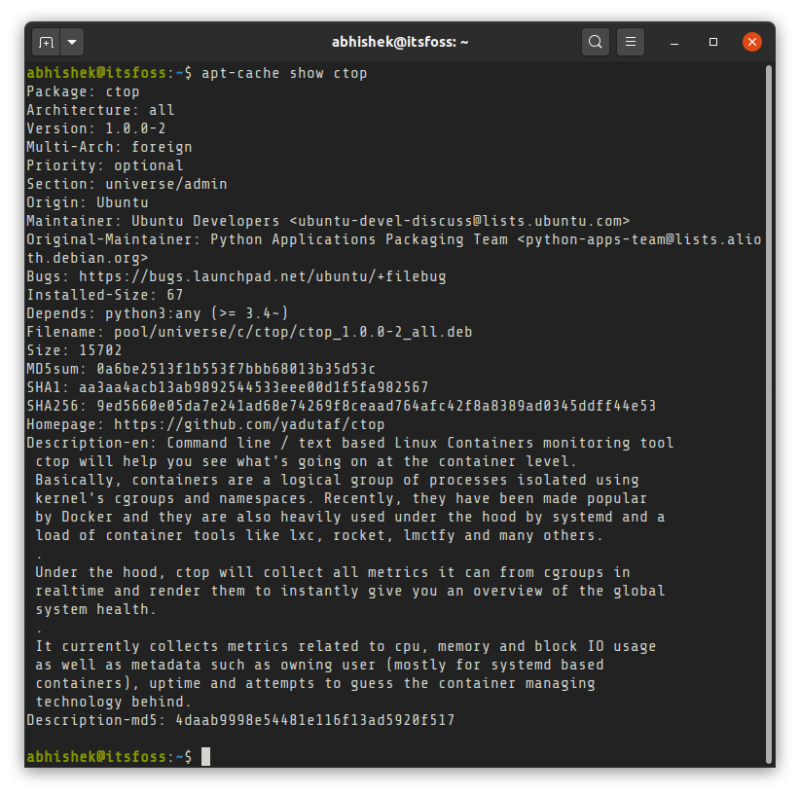
You can see all kinds of details in the package metadata like name, version, developer, maintainer, repository, short and long description, package size, and even checksum.
There is another option `showpkg`
that displays information about the package name, version and its forward and reverse dependencies.
`apt-cache showpkg package_name`
### apt-cache policy
This is one of the rarely used options of apt-cache command. The policy option helps you debug the issue related to the [preference file](https://debian-handbook.info/browse/stable/sect.apt-get.html#sect.apt.priorities).
Specifying the package name will show whether the package is installed, which version is available from which repository and its priority.
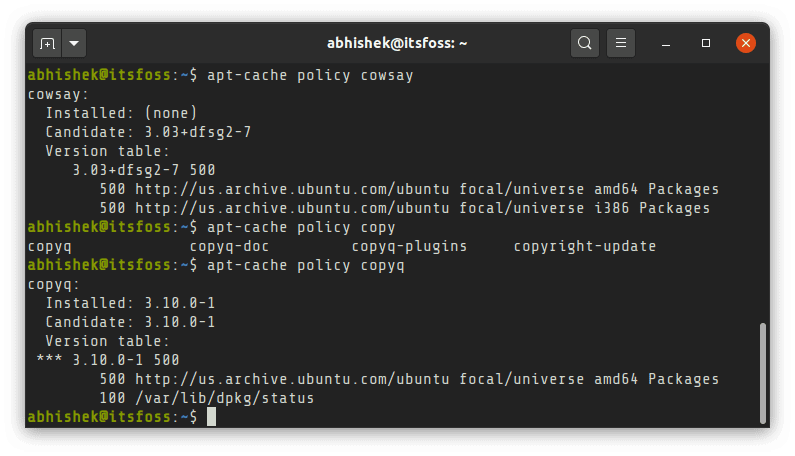
By default, each installed package version has a priority of 100 and a non-installed package has a priority of 500. The same package may have more than one version with a different priority. APT installs the version with higher priority unless the installed version is newer.
If this doesn’t make sense, it’s okay. It will be extremely rare for a regular Linux user to dwell this deep into package management.
### Check dependencies and reverse dependencies of a package
You can [check the dependencies of a package](https://itsfoss.com/check-dependencies-package-ubuntu/) before (or even after) installing it. It also shows all the possible packages that can fulfill the dependency.
`apt-cache depends package`
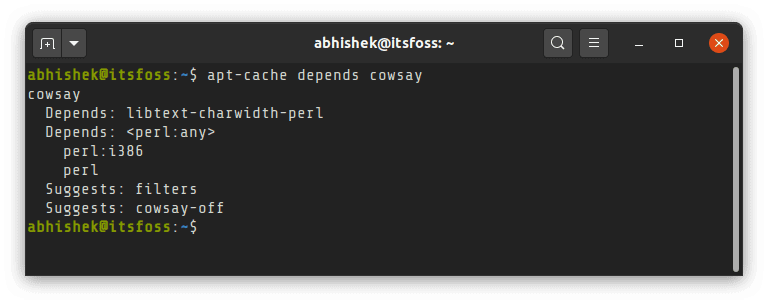
You may also check which packages are dependent on a certain package by checking the reverse dependencies with apt-cache.
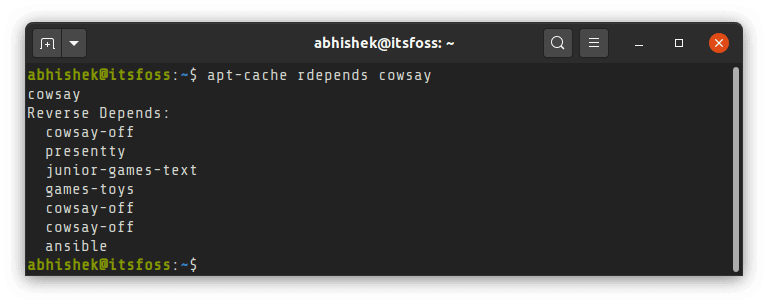
Frankly, I was also surprised to see that a DevOps tool like Ansible has a dependency on a [funny Linux command like Cowsay](https://itsfoss.com/funny-linux-commands/). I think it’s perhaps because after [installing Ansible](https://linuxhandbook.com/install-ansible-linux/), it displays some message on the nodes.
### Check unmet dependencies
You may get troubled with [unmet dependencies issue in Ubuntu](https://itsfoss.com/held-broken-packages-error/) or other Linux. The apt-cache command provides the option to check all the unmet dependencies of various available packages on your system.
`apt-cache unmet`
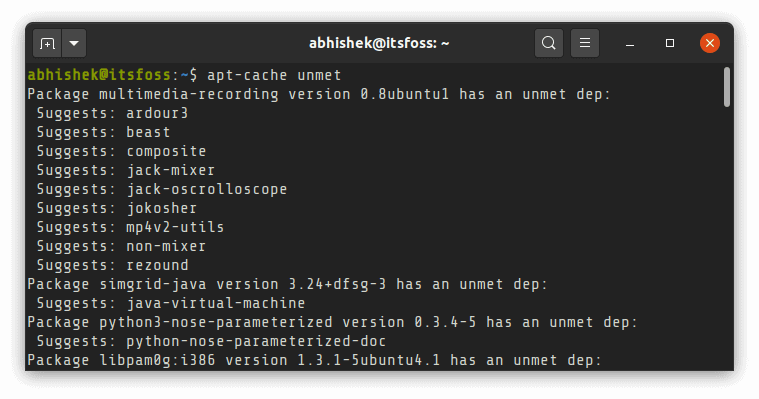
# Conclusion
You can list all available packages with the apt-cache command. The output would be huge, so I suggest combining it with [wc command](https://linuxhandbook.com/wc-command/) to get a total number of available packages like this:
`apt-cache pkgnames | wc -l`
Did you notice that you don’t need to be [root user](https://itsfoss.com/root-user-ubuntu/) for using apt-cache command?
The newer [apt command](https://itsfoss.com/apt-command-guide/) has a few options available to match the features of apt-cache command. Since apt is new, apt-get and its associated commands like apt-cache are still preferred to be used in scripts. That’s one of the [major differences between apt and apt-get commands](https://itsfoss.com/apt-vs-apt-get-difference/).
[Difference Between apt and apt-get ExplainedBrief: This article explains the difference between apt and apt-get commands of Linux. It also lists some of the most commonly used apt commands that replace the older apt-get commands. One of the noticeable new features of Ubuntu 16.04 was the ‘introduction’ of apt command. The reality is that](https://itsfoss.com/apt-vs-apt-get-difference/)

I hope you find this tutorial helpful. If you have questions about any point discussed above or suggestions to improve it, please let me know in the comments. |
12,787 | 如何清除 APT 缓存来回收宝贵的磁盘空间 | https://itsfoss.com/clear-apt-cache/ | 2020-11-04T10:29:00 | [
"apt"
] | https://linux.cn/article-12787-1.html | 
如何清除 APT 缓存?你只需使用这个 [apt-get 命令](https://itsfoss.com/apt-get-linux-guide/)选项:
```
sudo apt-get clean
```
但是,清理 APT 缓存不仅仅是运行上面的命令。
在本教程中,我将解释什么是 APT 缓存、为什么会使用它、为什么你要清理它,以及关于清理 APT 缓存你应该知道的其他事情。
我将在这里使用 Ubuntu 作为参考,但由于这是关于 APT 的,因此它也适用于 [Debian](https://www.debian.org/) 和其他基于 Debian 和 Ubuntu 的发行版,比如 Linux Mint、Deepin 等等。
### 什么是 APT 缓存?为什么要使用它?
当你使用 `apt-get` 或 [apt 命令](https://itsfoss.com/apt-command-guide/)安装一个软件包时(或在软件中心安装 DEB 包),APT [包管理器](https://itsfoss.com/package-manager/)会以 .deb 格式下载软件包及其依赖关系,并将其保存在 `/var/cache/apt/archives` 文件夹中。

下载时,`apt` 将 deb 包保存在 `/var/cache/apt/archives/partial` 目录下。当 deb 包完全下载完毕后,它会被移到 `/var/cache/apt/archives` 目录下。
下载完包的 deb 文件及其依赖关系后,你的系统就会[从这些 deb 文件中安装包](https://itsfoss.com/install-deb-files-ubuntu/)。
现在你明白缓存的用途了吧?系统在安装软件包之前,需要一个地方把软件包文件存放在某个地方。如果你了解 [Linux 目录结构](https://linuxhandbook.com/linux-directory-structure/),你就会明白,`/var/cache` 是合适的地方。
#### 为什么安装包后要保留缓存?
下载的 deb 文件在安装完成后并不会立即从目录中删除。如果你删除了一个软件包,然后重新安装,你的系统会在缓存中查找这个软件包,并从这里获取它,而不是重新下载(只要缓存中的软件包版本与远程仓库中的版本相同)。
这样就快多了。你可以自己尝试一下,看看一个程序第一次安装,删除后再安装需要多长时间。你可以[使用 time 命令来了解完成一个命令需要多长时间](https://linuxhandbook.com/time-command/):`time sudo apt install package_name`。
我找不到任何关于缓存保留策略的内容,所以我无法说明 Ubuntu 会在缓存中保留下载的包多长时间。
#### 你应该清理 APT 缓存吗?
这取决于你。如果你的根目录下的磁盘空间用完了,你可以清理 APT 缓存来回收磁盘空间。这是 [Ubuntu 上释放磁盘空间的几种方法](https://itsfoss.com/free-up-space-ubuntu-linux/)之一。
使用 [du 命令](https://linuxhandbook.com/find-directory-size-du-command/)检查缓存占用了多少空间:

有的时候,这可能会占用几百兆,如果你正在运行一个服务器,这些空间可能是至关重要的。
#### 如何清理 APT 缓存?
如果你想清除 APT 缓存,有一个专门的命令来做。所以不要去手动删除缓存目录。只要使用这个命令就可以了:
```
sudo apt-get clean
```
这将删除 `/var/cache/apt/archives` 目录的内容(除了锁文件)。以下是 `apt-get clean` 命令模拟删除内容:

还有一个命令是关于清理 APT 缓存的:
```
sudo apt-get autoclean
```
与 `clean` 不同的是,`autoclean` 只删除那些无法从仓库中下载的包。
假设你安装了包 xyz。它的 deb 文件仍然保留在缓存中。如果现在仓库中有新的 xyz 包,那么缓存中现有的这个 xyz 包就已经过时了,没有用了。`autoclean` 选项会删除这种不能再下载的无用包。
#### 删除 apt 缓存安全吗?
是的,清除 APT 创建的缓存是完全安全的。它不会对系统的性能产生负面影响。也许如果你重新安装软件包,下载时间会更长一些,但也仅此而已。
再说一次,使用 `apt-get clean` 命令。它比手动删除缓存目录更快、更简单。
你也可以使用像 [Stacer](https://itsfoss.com/optimize-ubuntu-stacer/) 或 [Bleachbit](https://itsfoss.com/use-bleachbit-ubuntu/) 这样的图形工具来实现这个目的。
#### 总结
在写这篇文章的时候,新的 `apt` 命令没有这样的内置选项。不过,为了保持向后的兼容性,仍然可以运行 `apt clean` (内部应该是运行了 `apt-get clean`)。请参考这篇文章来[了解 apt 和 apt-get 的区别](https://itsfoss.com/apt-vs-apt-get-difference/)。
我希望你觉得这个关于 APT 缓存的解释很有趣。虽然这不是什么必要的东西,但了解这些小东西会让你对你的 Linux 系统更加了解。
欢迎你在评论区提出反馈和建议。
---
via: <https://itsfoss.com/clear-apt-cache/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

How do you clear the apt cache? You simply use this [apt-get command](https://itsfoss.com/apt-get-linux-guide/) option:
`sudo apt-get clean`
But there is more to cleaning apt cache than just running the above command.
In this tutorial, I’ll explain what is apt cache, why is it used, why you would want to clean it and what other things you should know about purging apt cache.
I am going to use Ubuntu here for reference but since this is about apt, it is applicable to [Debian](https://www.debian.org/?ref=itsfoss.com) and other Debian and Ubuntu-based distributions like Linux Mint, Deepin and more.
## What is apt cache? Why is it used?
When you install a package using apt-get or [apt command](https://itsfoss.com/apt-command-guide/) (or DEB packages in the software center), the apt [package manager](https://itsfoss.com/package-manager/) downloads the package and its dependencies in .deb format and keeps it in /var/cache/apt/archives folder.
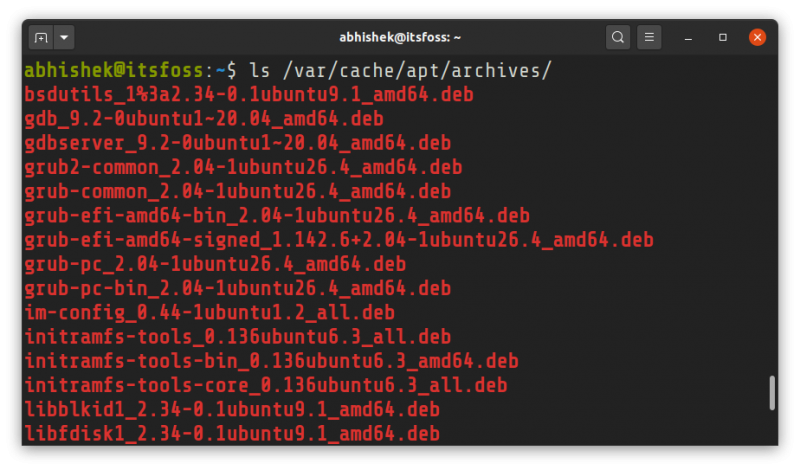
While downloading, apt keeps the deb package in /var/cache/apt/archives/partial directory. When the deb package is downloaded completely, it is moved out to /var/cache/apt/archives directory.
Once the deb files for the package and its dependencies are downloaded, your system [installs the package from these deb files](https://itsfoss.com/install-deb-files-ubuntu/).
Now you see the use of cache? The system needs a place to keep the package files somewhere before installing them. If you are aware of the [Linux directory structure](https://linuxhandbook.com/linux-directory-structure/?ref=itsfoss.com), you would understand that /var/cache is the appropriate here.
### Why keep the cache after installing the package?
The downloaded deb files are not removed from the directory immediately after the installation is completed. If you remove a package and reinstall it, your system will look for the package in the cache and get it from here instead of downloading it again (as long as the package version in the cache is the same as the version in remote repository).
This is much quicker. You can try this on your own and see how long a program takes to install the first time, remove it and install it again. You can [use the time command to find out how long does it take to complete a command](https://linuxhandbook.com/time-command/?ref=itsfoss.com): **time sudo apt install package_name**.
I couldn’t find anything concrete on the cache retention policy so I cannot say how long does Ubuntu keep the downloaded packages in the cache.
### Should you clean apt cache?
It depends on you. If you are running out of disk space on root, you could clean apt cache and reclaim the disk space. It is one of the [several ways to free up disk space on Ubuntu](https://itsfoss.com/free-up-space-ubuntu-linux/).
Check how much space the cache takes with the [du command](https://linuxhandbook.com/find-directory-size-du-command/?ref=itsfoss.com):
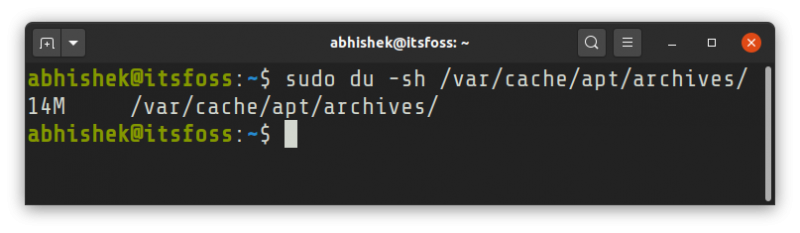
Sometime this could go in 100s of MB and this space could be crucial if you are running a server.
### How to clean apt cache?
If you want to clear the apt cache, there is a dedicated command to do that. So don’t go about manually deleting the cache directory.
You may think it is [apt-cache command](https://itsfoss.com/apt-cache-command/) but that’s deceiving. Simply use the apt-get command with clean as argument:
`sudo apt-get clean`
This will remove the content of the /var/cache/apt/archives directory (except the lock file). Here’s a dry run (simulation) of what the apt-get clean command deletes:
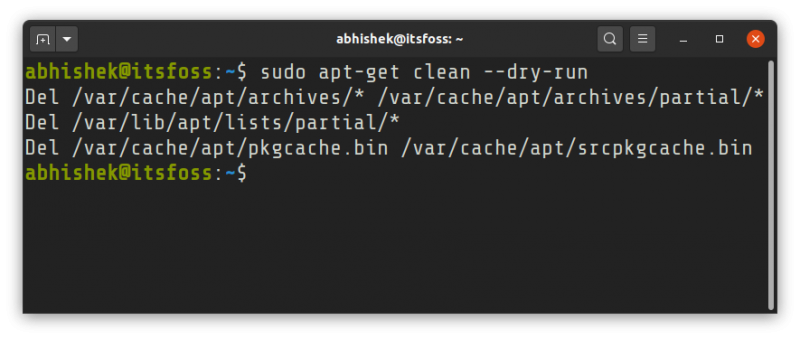
There is another command that deals with cleaning the apt cache:
`sudo apt-get autoclean`
Unlike clean, autoclean only removes the packages that are not possible to download from the repositories.
Suppose you installed package xyz. Its deb files remain in the cache. If there is now a new version of xyz package available in the repository, this existing xyz package in the cache is now outdated and useless. The autoclean option will delete such useless packages that cannot be downloaded anymore.
### Is it safe to delete apt cache?
Yes. It is completely safe to clear the cache created by apt. It won’t negatively impact the performance of the system. Maybe if you reinstall the package it will take a bit longer to download but that’s about it.
Again, use the apt-get clean command. It is quicker and easier than manually deleting cache directory.
You may also use graphical tools like [Stacer](https://itsfoss.com/optimize-ubuntu-stacer/) or [Bleachbit](https://itsfoss.com/use-bleachbit-ubuntu/) for this purpose.
### Conclusion
At the time of writing this article, there is no built-in option with the newer apt command. However, keeping backward compatibility, **apt clean** can still be run (which should be running apt-get clean underneath it). Please refer to this article to
[know the difference between apt and apt-get](https://itsfoss.com/apt-vs-apt-get-difference/).
I hope you find this explanation about apt cache interesting. It is not something essential but knowing this little things make you more knowledgeable about your Linux system.
I welcome your feedback and suggestions in the comment section. |
12,791 | 如何在 Apache Cassandra 4.0 中使用虚拟表 | https://opensource.com/article/20/10/virtual-tables-apache-cassandra | 2020-11-04T23:45:33 | [
"Cassandra"
] | https://linux.cn/article-12791-1.html |
>
> 虚拟表是什么以及如何使用。
>
>
>

在最近的发布的 [Apache Cassandra 4.0 测试版](https://cassandra.apache.org/download/)中的[众多新增功能](https://www.instaclustr.com/apache-cassandra-4-0-beta-released/)中,<ruby> 虚拟表 <rt> virtual table </rt></ruby>是一个值得关注的功能。
在以前的 Cassandra 版本中,用户需要访问 <ruby> Java 管理扩展 <rt> Java Management Extensions </rt></ruby>([JMX](https://en.wikipedia.org/wiki/Java_Management_Extensions)) 来查看 Cassandra 的细节,如运行中的<ruby> 压实 <rt> compaction </rt></ruby>、客户端、度量和各种配置设置。虚拟表消除了这些挑战。Cassandra 4.0 测试版让用户能够从一个只读的系统表中以 <ruby> Cassandra 查询语言 <rt> Cassandra Query Language </rt></ruby>(CQL)行的形式查询这些细节和数据。
以下是之前 Cassandra 版本中基于 JMX 的机制是如何工作的。想象一下,一个用户想要检查集群中某个节点的压实状态。用户首先要建立一个 JMX 连接,在节点上运行 `nodetool compactionstats`。这个要求马上就给用户带来了一些复杂的问题。用户的客户端是否配置了 JMX 访问?Cassandra 节点和防火墙是否配置为允许 JMX 访问?是否准备好了适当的安全和审计措施,并落实到位?这些只是用户在处理 Cassandra 以前版本时必须面对的其中一些问题。
在 Cassandra 4.0 中,虚拟表使得用户可以利用之前配置的驱动来查询所需信息。这一变化消除了与实现和维护 JMX 访问相关的所有开销。
Cassandra 4.0 创建了两个新的<ruby> 键空间 <rt> keyspace </rt></ruby>来帮助用户利用虚拟表:`system_views` 和 `system_virtual_schema`。`system_views` 键空间包含了用户查询的所有有价值的信息,有用地存储在一些表中。`system_virtual_schema` 键空间,顾名思义,存储了这些虚拟表的所有必要的模式信息。

重要的是要明白,每个虚拟表的范围仅限于其节点。任何虚拟表查询都将返回的数据,只对其协调器的节点有效,而不管一致性如何。为了简化这一要求,已经在几个驱动中添加了支持,以便在这些查询中指定协调器节点 (Python、DataStax Java 和其他驱动现在提供了这种支持)。
为了说明这一点,请查看这个 `sstable_tasks` 虚拟表。这个虚拟表显示了对 [SSTables](https://cassandra.apache.org/doc/latest/architecture/storage_engine.html#sstables) 的所有操作,包括压实、清理、升级等。

如果用户在以前的 Cassandra 版本中运行 `nodetool compactionstats`,则会显示相同类型的信息。 在这里,这个查询发现该节点当前有一个活动的压缩。它还显示了它的进度以及它的键空间和表。得益于虚拟表,用户可以快速收集这些信息,并同样有效地获得正确诊断集群健康状况所需的能力。
需要说明的是,Cassandra 4.0 并没有去除对 JMX 访问的需求。JMX 仍然是查询某些指标的唯一选择。尽管如此,用户会欢迎简单地使用 CQL 来获取关键集群指标的能力。由于虚拟表提供的便利,用户可能会将之前投入到 JMX 工具的时间和资源重新投入到 Cassandra 本身。客户端工具也应该开始利用虚拟表提供的优势。
如果你对 Cassandra 4.0 测试版及其虚拟表功能感兴趣,请[试试试它](https://cassandra.apache.org/download/)。
---
via: <https://opensource.com/article/20/10/virtual-tables-apache-cassandra>
作者:[Ben Bromhead](https://opensource.com/users/ben-bromhead) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Among the [many additions](https://www.instaclustr.com/apache-cassandra-4-0-beta-released/) in the recent [Apache Cassandra 4.0 beta release](https://cassandra.apache.org/download/), virtual tables is one that deserves some attention.
In previous versions of Cassandra, users needed access to Java Management Extensions ([JMX](https://en.wikipedia.org/wiki/Java_Management_Extensions)) to examine Cassandra details such as running compactions, clients, metrics, and a variety of configuration settings. Virtual tables removes these challenges. Cassandra 4.0 beta enables users to query those details and data as Cassandra Query Language (CQL) rows from a read-only system table.
Here is how the JMX-based mechanism in previous Cassandra versions worked. Imagine a user wants to check on the compaction status of a particular node in a cluster. The user first has to establish a JMX connection to run `nodetool compactionstats`
on the node. This requirement immediately presents the user with a few complications. Is the user's client configured for JMX access? Are the Cassandra nodes and firewall configured to allow JMX access? Are the proper measures for security and auditing prepared and in place? These are only some of the concerns users had to contend with when dealing with in previous versions of Cassandra.
With Cassandra 4.0, virtual tables make it possible for users to query the information they need by utilizing their previously configured driver. This change removes all overhead associated with implementing and maintaining JMX access.
Cassandra 4.0 creates two new keyspaces to help users leverage virtual tables: `system_views`
and `system_virtual_schema`
. The `system_views`
keyspace contains all the valuable information that users seek, usefully stored in a number of tables. The `system_virtual_schema`
keyspace, as the name implies, stores all necessary schema information for those virtual tables.

(Ben Bromhead, CC BY-SA 4.0)
It's important to understand that the scope of each virtual table is restricted to its node. Any query of virtual tables will return data that is valid only for the node that acts as its coordinator, regardless of consistency. To simplify for this requirement, support has been added to several drivers to specify the coordinator node in these queries (the Python, DataStax Java, and other drivers now offer this support).
To illustrate, examine this `sstable_tasks`
virtual table. This virtual table displays all operations on [SSTables](https://cassandra.apache.org/doc/latest/architecture/storage_engine.html#sstables), including compactions, cleanups, upgrades, and more.
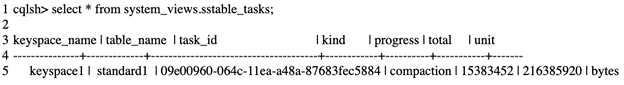
(Ben Bromhead, CC BY-SA 4.0)
If a user were to run `nodetool compactionstats`
in a previous Cassandra version, this is the same type of information that would be displayed. Here, the query finds that the node currently has one active compaction. It also displays its progress and its keyspace and table. Thanks to the virtual table, a user can gather this information quickly, and just as efficiently gain the insight needed to correctly diagnose the cluster's health.
To be clear, Cassandra 4.0 doesn't eliminate the need for JMX access: JMX is still the only option for querying some metrics. That said, users will welcome the ability to pull key cluster metrics simply by using CQL. Thanks to the convenience afforded by virtual tables, users may be able to reinvest time and resources previously devoted to JMX tools into Cassandra itself. Client-side tooling should also begin to leverage the advantages offered by virtual tables.
If you are interested in the Cassandra 4.0 beta release and its virtual tables feature, [try it out](https://cassandra.apache.org/download/).
## Comments are closed. |
12,793 | 新的树莓派 400:一台藏身于键盘内微型计算机 | https://itsfoss.com/raspberry-pi-400/ | 2020-11-05T19:17:51 | [
"树莓派"
] | https://linux.cn/article-12793-1.html | 树莓派是什么已经无需介绍。这台起初是为 DIY 爱好者打造的低规格电脑,现在可以作为全功能桌面使用了。
随着树莓派 400 的发布,使得它更加适合作为家庭电脑使用。树莓派 400 基本上是一台藏身于键盘内微型计算机。
如果你还记得,[Commodore 64](https://en.wikipedia.org/wiki/Commodore_64) 在 1982 年时也是一台键盘形式的电脑。尽管树莓派 400 并不是独一无二的,但对于树莓派这样的成功产品来说,这是一个令人心仪的产品。
### 树莓派 400 概观

它是基于树莓派 4 的(带有 4GB 内存),并已调整附加了冷却器。它采用四核处理器,速度比以往更快。
除了易用性和便携性,它还可以为你节省很多桌面空间。而且,就像我一样,如果你打算买一台备用电脑来测试东西,我想我可能会选择树莓派 400,而不是组装另一台 PC 或[基于 Linux 的迷你 PC](https://itsfoss.com/linux-based-mini-pc/)。
尽管我在下面提到了它的技术规格,但你可以观看官方视频来了解它的外观,以及它所承诺的是否可以满足作为你的家用电脑的需求。
### 树莓派 400 技术规格
* 博通 BCM2711 四核 Cortex-A72(ARM v8)64 位 SoC @ 1.8GHz
* 4GB LPDDR4-3200
* 双频(2.4GHz 和 5.0GHz)IEEE 802.11b/g/n/ac 无线局域网
* 蓝牙 5.0,BLE
* 千兆以太网
* 2 个 USB 3.0 和 1 个 USB 2.0 端口
* 水平 40 针 GPIO 头
* 2 个 micro HDMI 端口(支持最高 4Kp60)
* H.265(4Kp60 解码);H.264(1080p60 解码,1080p30 编码);OpenGL ES 3.0 图形
* micro SD 卡插槽,用于操作系统和数据存储
* 78 或 79 键的小型键盘(取决于地区差异)
* 5V DC,通过 USB 连接器
* 工作温度:环境温度 0℃ 至 +50℃。
* 最大尺寸 286 毫米 × 122 毫米 × 23 毫米

### 定价与供应
这是你付出 **70** 美元,所能得到的最好的现代家用电脑,只需一个键盘就可以简单的携带到任何地方(你只需要一个屏幕连接)。
你可以花 70 美元只买树莓派 400,也可以花 100 美元买完整的套装,它还包括一个 USB 鼠标、micro HDMI 转 HDMI 线、USB-C 电源、一本初学者指南和一张预装了树莓派操作系统的 SD 卡。
如果你想知道,对于键盘布局的支持,新闻稿中是这样提到的:
>
> 在发布时,我们支持英语(英国和美国)、法语、意大利语、德语和西班牙语的键盘布局,并(首次)提供翻译版的新手指南。在不久的将来,我们计划支持与我们的[官方键盘](https://www.raspberrypi.org/products/raspberry-pi-keyboard-and-hub/)相同的语言集。
>
>
>
换句话说,一开始他们就支持所有主要的键盘布局。所以,对于大多数人来说,这应该不是问题。
除了键盘布局的细节外,下面是你如何获得树莓派 400 的方法:
>
> 英国、美国和法国的树莓派 400 [套件](https://www.raspberrypi.org/products/raspberry-pi-400/)和[电脑](https://www.raspberrypi.org/products/raspberry-pi-400-unit/)现在就可以购买。意大利、德国和西班牙的产品正在送往树莓派授权经销商的路上,他们应该在下周就会有货。
>
>
> 我们预计,印度、澳大利亚和新西兰的授权经销商将在今年年底前拿到套件和电脑。我们也在迅速推出其他地区的合规认证,因此树莓派 400 将在 2021 年的前几个月在全球范围内上市。
>
>
> 当然,如果你在剑桥附近的任何地方,你可以前往[树莓派商店](https://www.raspberrypi.org/raspberry-pi-store/),今天就可以领取你的树莓派 400。
>
>
>
* [树莓派 400](https://www.raspberrypi.org/products/raspberry-pi-400)
### 总结
在远程办公成为新常态的当下,树莓派 400 绝对是令人印象深刻的好东西,也是非常有用的。
你对新的树莓派 400 有什么看法?打算买一台吗?在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/raspberry-pi-400/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi needs no introduction. What started as a low-spec computer for DIY enthusiasts, it can now be used as full-featured desktop.
With the Raspberry Pi 400 release, they are making it more friendly for home computer usage. The Raspberry Pi 400 is basically a computer in the form of a keyboard.
If you remember, [Commodore 64](https://en.wikipedia.org/wiki/Commodore_64) was also a computer in the form of a keyboard back in 1982. Even though it isn’t unique, for a successful product like Raspberry Pi, it is a sweet deal.
## Raspberry Pi 400: Overview

It is based on the Raspberry Pi 4 (with 4 GB RAM) and has been tweaked to run cooler as well. With a Quad-core processor, it is faster than ever.
Not just limited to the ease of use and portability, but it should save you a lot of desk space. And, just like me, if you were planning to get a spare computer to test stuff, I think I may want to go with the Raspberry Pi 400 instead of building another PC or [Linux-based mini PC](https://itsfoss.com/linux-based-mini-pc/).
Even though I’ve mentioned the tech specs below, you can watch the official video to get an idea on how it looks and if it’s promising enough as your home computer:
## Raspberry Pi 400 specification
Here’s the tech specs for the Pi 400:
- Broadcom BCM2711 quad-core Cortex-A72 (ARM v8) 64-bit SoC @ 1.8GHz
- 4GB LPDDR4-3200
- Dual-band (2.4GHz and 5.0GHz) IEEE 802.11b/g/n/ac wireless LAN
- Bluetooth 5.0, BLE
- Gigabit Ethernet
- 2 × USB 3.0 and 1 × USB 2.0 ports
- Horizontal 40-pin GPIO header
- 2 × micro HDMI ports (supports up to 4Kp60)
- H.265 (4Kp60 decode); H.264 (1080p60 decode, 1080p30 encode); OpenGL ES 3.0 graphics
- MicroSD card slot for operating system and data storage
- 78- or 79-key compact keyboard (depending on regional variant)
- 5V DC via USB connector
- Operating temperature: 0°C to +50°C ambient
- Maximum dimensions 286 mm × 122 mm × 23 mm

## Pricing & Availability
For **$70**, this is the best modern home computer that you can get with the simplicity of just having a keyboard and being able to carry it anywhere (you just need a screen to connect to).
You can either get just the Raspberry Pi 400 for **$70** or get the complete kit for **$100** with a USB mouse, micro HDMI to HDMI cable, USB-C power supply, a beginners guide, and an SD card with Raspberry Pi OS pre-installed.
If you’re wondering, for the keyboard layout support, here’s what the press release mentioned:
At launch, we are supporting English (UK and US), French, Italian, German, and Spanish keyboard layouts, with (for the first time) translated versions of the Beginner’s Guide. In the near future, we plan to support the same set of languages as our
[official keyboard].
In other words, they support every major keyboard layout to start with. So, it shouldn’t be an issue for the majority.
In addition to the details for keyboard layout, here’s how you can get your hands on a Raspberry Pi 400:
UK, US, and French Raspberry Pi 400
[kits]and[computers]are available to buy right now. Italian, German, and Spanish units are on their way to Raspberry Pi Approved Resellers, who should have them in stock in the next week.We expect that Approved Resellers in India, Australia, and New Zealand will have kits and computers in stock by the end of the year. We’re rapidly rolling out compliance certification for other territories too, so that Raspberry Pi 400 will be available around the world in the first few months of 2021.
Of course, if you’re anywhere near Cambridge, you can head over to the
[Raspberry Pi Store]to pick up your Raspberry Pi 400 today.
## Wrapping Up
Raspberry Pi 400 is definitely something impressive and useful in the current time when remote work is becoming the new norm.
What do you think about the new Raspberry Pi 400? Planning to get one? Let me know your thoughts in the comments below. |
12,794 | 编程语言排行榜:Python 排名第二,首次领先于 Java | https://www.zdnet.com/article/programming-language-pythons-popularity-ahead-of-java-for-first-time-but-still-trailing-c/ | 2020-11-05T22:11:51 | [
"Python"
] | https://linux.cn/article-12794-1.html |
>
> 在 Tiobe 指数近 20 年的历史中,Python 第一次成为第二大流行语言。
>
>
>

Tiobe 这么多年以来发布的指数中,29 岁的 Python 首次超过了 25 岁 Java,成为第二受欢迎的编程语言。
**在[最新的 Tiobe 指数](https://www.tiobe.com/tiobe-index/)中,数据科学和机器学习项目的首选语言 Python,现在排名仅次于 C 语言,排在第二位,将 Java 打落到第三位。**

*2020 年 10 月编程排行榜前 3 名*
这是 Tiobe 指数近 20 年的历史上,第一次出现 Java 和 C 语言不是两大顶级语言的情况。第三也是 Java 在 Tiobe 指数中的最低位置。Tiobe 指数使用多个搜索引擎上的查询来得出其[评级](https://www.tiobe.com/tiobe-index/programming-languages-definition/)。
Python 显示比一年前的位置上升了 2.27%,这与同期 Java 下降了 -4.47% 形成鲜明对比。

*历年前 10 名编程语言的年度平均排名*
在 [7 月份开发者分析机构 RedMonk 的编程语言受欢迎程度排名](https://www.zdnet.com/article/programming-language-popularity-python-overtakes-java-as-rust-reaches-top-20/)中,Python 也从 Java 手中抢走了第二名。不过,RedMonk 将 JavaScript 列为顶级语言。这是 RedMonk 的前两名首次不由 Java 或 JavaScript 组成。
根据电气工程出版物《IEEE Spectrum》的最新流行度排名,[Python 已经是最受欢迎的语言](https://www.zdnet.com/article/top-programming-languages-python-rules-still-but-old-cobol-gets-a-pandemic-bump/)。
虽然 Python 在机器学习和数值计算等不断增长的科技领域获得了广泛的应用,但 Tiobe 首席执行官 Paul Jansen 认为,Python 最近的流行度激增是因为它足够简单,非程序员也能使用,而不是一种只适合高级程序员的语言。
“我相信 Python 的流行与普遍需求有关”,Jansen 写道,“过去,大多数编程活动都是由软件工程师完成的,但现在到处都需要编程技能,而且缺乏优秀的软件开发人员。”
“因此,我们需要一些简单的、可以由非软件工程师处理的东西,需要一些容易学习、编写周期快、部署流畅的东西。Python 满足了所有这些需求。”
RedMonk 的 Stephen O'Grady 对 Python 近年来的崛起有一个稍微不同的解释。
O'Grady [将 Python 与全盛时期的 Perl 相提并论](https://www.zdnet.com/article/programming-language-popularity-python-overtakes-java-as-rust-reaches-top-20/),因为 Python 已经成为成千上万个小型项目的“首选语言”和“粘合剂”,同时在数据科学等不断增长的类别中享有很高的采用率。
但正如 Perl 今天所显示的那样(它在 Tiobe 指数中排名第 12 位),即使是曾经在某些开发者社区中大受欢迎的语言,也会相对迅速地衰落。
同样,Python 的未来也无法保证,它在构建移动和浏览器应用或任何有用户界面的东西方面也有明显的局限性。

*C、Python、Java 编程语言的评分变化*
流行的 Python 数据科学发行版的开发商 Anaconda 的 CEO Peter Wang 最近[告诉 ZDNet](https://www.zdnet.com/article/programming-language-python-is-a-big-hit-for-machine-learning-but-now-it-needs-to-change/),Python 作为后端系统自动化和脚本的语言的价值使它很难被取代。
虽然他是 Python 的主要支持者,但他也认为 Python 需要制定一个清晰的愿景,以保持与数据科学以外的其他应用开发语言的竞争力。
---
via: <https://www.zdnet.com/article/programming-language-pythons-popularity-ahead-of-java-for-first-time-but-still-trailing-c/>
作者:[Liam Tung](https://www.zdnet.com/meet-the-team/eu/liam-tung/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12791-1.html) 荣誉推出
| 200 | OK | # Programming language Python's popularity: Ahead of Java for first time but still trailing C

For the first time in Tiobe's long-running index, 35-year-old Python has overtaken Java to become the second-most popular programming language.
Python, a top choice for data-science and machine-learning projects, is now in second spot behind C in [Tiobe's latest index](https://www.tiobe.com/tiobe-index/), knocking Java down into third place.
### Developer
It's the first time in the Tiobe index's nearly 20-year history that Java and C aren't the two top languages. Third is also the lowest position Java has ever held in the Tiobe index, which uses queries on several search engines to come up with its ratings.
**SEE: ****Hiring Kit: Python developer**** (TechRepublic Premium)**
Python shows a 2.27% rise over its position a year ago, which contrasts with a decline of -4.47% for Java over the same period.
Python also snatched second place from Java in developer analyst [RedMonk's programming-language popularity rankings in July](https://www.zdnet.com/article/programming-language-popularity-python-overtakes-java-as-rust-reaches-top-20/). However, RedMonk ranks JavaScript as the top language. It was the first time RedMonk's top two did not consist of Java or JavaScript.
Python is already the top language, according to electrical engineering publication IEEE Spectrum's [latest popularity rankings](https://www.zdnet.com/article/top-programming-languages-python-rules-still-but-old-cobol-gets-a-pandemic-bump/).
While Python has gained wide adoption in growing areas of tech like machine learning and numerical computing, Tiobe CEO Paul Jansen argues that Python's recent surge in popularity is because it's simple enough to use by non-programmers, rather than being a language only for advanced programmers.
"I believe that Python's popularity has to do with general demand," writes Jansen. "In the past, most programming activities were performed by software engineers. But programming skills are needed everywhere nowadays and there is a lack of good software developers.
"As a consequence, we need something simple that can be handled by non-software engineers, something easy to learn with fast edit cycles and smooth deployment. Python meets all these needs."
RedMonk's Stephen O'Grady had a slightly different explanation for Python's ascent in recent years.
O'Grady [compared Python to Perl in its heyday](https://www.zdnet.com/article/programming-language-popularity-python-overtakes-java-as-rust-reaches-top-20/) because Python has become a "language of first resort" and the "glue" for thousands of small projects, while enjoying high adoption in growing categories such as data science.
But as Perl today shows – it's ranked 12th in Tiobe's index – even languages that were once hugely popular with certain communities of developers can fade relatively quickly.
**SEE: ****Linux and open-source jobs are hotter than ever**
Likewise Python's future isn't guaranteed and it has notable limitations in building mobile and browser apps or anything with a user interface.
Peter Wang, CEO of Anaconda, the maker of a popular Python distribution for data science, [recently told ZDNet](https://www.zdnet.com/article/programming-language-python-is-a-big-hit-for-machine-learning-but-now-it-needs-to-change/) that Python's value as a lingua franca for backend system automation and scripting made it a tough thing to displace.
While he is a major supporter of Python, he also argued Python needs to lay out a clear vision to stay competitive with other application development languages outside data science.
Python has recorded the largest percentage increase in popularity of any language in Tiobe's top 20 listing.
### More on Python and programming languages
**These 11 programming languages now work with Kite's AI code-completion tool**
[2020's fastest-rising tech jobs? Programming language PHP leads the way](https://www.zdnet.com/article/2020s-fastest-rising-tech-jobs-programming-language-php-leads-the-way/)
**Programming language popularity: JavaScript leads – 5 million new developers since 2017**
[Python set to overtake Java in latest programming language rankings](https://www.zdnet.com/article/python-set-to-overtake-java-in-latest-programming-language-rankings/)
[Microsoft: Playwright for Python language lets you test web apps in all major browsers](https://www.zdnet.com/article/microsoft-playwright-for-python-language-lets-you-test-web-apps-in-all-major-browsers/)
[Python programming language: Here's what's new in version 3.9 RC2](https://www.zdnet.com/article/python-programming-language-heres-whats-new-in-version-3-9-rc2/)
**Python programming: Microsoft's latest beginners' course looks at developing for NASA projects**
**Programming language popularity: Python overtakes Java – as Rust reaches top 20**
[Top programming languages: Python still rules but old Cobol gets a pandemic bump](https://www.zdnet.com/article/top-programming-languages-python-rules-still-but-old-cobol-gets-a-pandemic-bump/)
[Kotlin programming language: How Google is using it to squash the code bugs that cause most crashes](https://www.zdnet.com/article/google-were-using-kotlin-programming-language-to-squash-the-bugs-that-cause-most-crashes/)
**Microsoft: We're pulling the plug on Windows builds of programming language PHP**
**Kotlin programming language: Google offers free course for Android development**
**Programming languages: Now Rust project looks for a way into the Linux kernel**
[Programming language rankings: R makes a comeback but there's debate about its rise](https://www.zdnet.com/article/programming-language-rankings-r-makes-a-comeback-but-theres-debate-about-its-rise/)
[Programming languages: Julia touts its speed edge over Python and R](https://www.zdnet.com/article/programming-languages-julia-touts-its-speed-edge-over-python-and-r/)
[Microsoft lead engineer: Programming language TypeScript took off thanks to Google's Angular](https://www.zdnet.com/article/microsoft-lead-engineer-programming-language-typescript-took-off-thanks-to-googles-angular/)
[JavaScript creator Eich: My take on 20 years of the world's top programming language](https://www.zdnet.com/article/javascript-creator-eich-my-take-on-20-years-of-the-worlds-top-programming-language/)
[Programming languages: Java still rules over Python and JavaScript as primary language](https://www.zdnet.com/article/programming-languages-java-still-rules-over-python-and-javascript-as-primary-language/)
**Julia programming language: Users reveal what they love and hate the most about it**
[Mozilla is funding a way to support Julia in Firefox](https://www.zdnet.com/article/mozilla-is-funding-a-way-to-support-julia-in-firefox/)
[MIT: We're building on Julia programming language to open up AI coding to novices](https://www.zdnet.com/article/mit-were-building-on-julia-programming-language-to-open-up-ai-coding-to-novices/)
**Programming languages: Developers reveal what they love and loathe, and what pays best**
**Programming languages: Rust enters top 20 popularity rankings for the first time**
[Microsoft: Here's why we love programming language Rust and kicked off Project Verona](https://www.zdnet.com/article/microsoft-heres-why-we-love-programming-language-rust-and-kicked-off-project-verona/)
**Microsoft: Bosque is a new programming language built for AI in the cloud**
**Programming languages: Python apps might soon be running on Android**
[Is Julia the next big programming language? MIT thinks so, as version 1.0 lands](https://www.techrepublic.com/article/is-julia-the-next-big-programming-language-mit-thinks-so-as-version-1-0-lands/?ftag=CMG-01-10aaa1b)TechRepublic
[Mozilla's radical open-source move helped rewrite rules of tech](https://www.cnet.com/news/mozilla-open-source-firefox-move-helped-rewrite-tech-rules-anniversary/?ftag=CMG-01-10aaa1b)CNET[Editorial standards](/editorial-guidelines/) |
12,795 | 《代码英雄》第三季(1):Python 的故事 | https://www.redhat.com/en/command-line-heroes/season-3/pythons-tale | 2020-11-06T01:21:00 | [
"Python"
] | https://linux.cn/article-12795-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第三季(1):Python 的故事](https://www.redhat.com/en/command-line-heroes/season-3/pythons-tale)的[音频](https://dts.podtrac.com/redirect.mp3/cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/b16fc81d-60c7-4991-9773-e9fce88ca3ba/CLH_S3E1_Pythons_Tale_vFINAL_tc.mp3)脚本。
>
> 导语:一位“<ruby> 仁慈的终身独裁者 <rt> benevolent dictator for life </rt></ruby>(BDFL)”的辞职,永久改变了 Python 语言的命运,Guido van Rossum 那个名为《移交权利》的备忘录,让大家的注意力集中到了语言发展这件事情上。
>
>
> 在这一期里,Emily Morehouse 将 Python 技术层面的拓展性和它的包容性社区联系在了一起。Michael Kennedy 解释了 Python 是如何做到在简单易学的同时,又强大到足以担当的起像 Youtube 和 Instagram 这样的大项目。而 Diane Mueller 则强调了 Python 社区是如何率先在科技领域传播了许多包容性的实践 —— 包括社区主导的决策的兴起。
>
>
> 有时候,一位仁慈的终身独裁者可以让一个语言开始发展,但 Python 证明了,是社区让语言兴旺起来的。
>
>
>
**00:00:06 - Saron Yitbarek**:
在 2018 年 7 月 12 日的早晨,世界各地的 Python 社区成员起床之后,他们拿起一杯咖啡,打开了自己的电脑。随后一个接着一个地,看见了一条来自他们仁慈的独裁者的消息。
**00:00:24**:
Guido van Rossum,世界上最伟大的编程语言之一 Python 的创造者,也许没有之一。他面向 Python 社区的全体成员写下这条消息,我们不难想象出 Python 的粉丝们阅读这条消息时的画面。
**00:00:38 - 多个配音演员**:
我没想到在我已经如此努力的情况下,仍有这么多人对我的决策不满。我想把自己从决策过程中完全抽离出来,给自己一个永久的假期,让自己一辈子都不做仁慈的独裁者。你们都要靠自己了,我不会指定继任者。那么你们接下来要如何做呢,创立民主制度吗?或者保持无政府状态?
**00:01:00 - Saron Yitbarek**:
在这条简短却惊人的消息发布之后,Guido van Rossum,这个被 Python 社区追随了几十年的人……好吧,他基本上就这样退出了。这条消息被命名为《<ruby> 移交权利 <rt> Transfer of Power </rt></ruby>》,它将永久的改变 Python 的格局。
**00:01:19**:
不过除此之外,它又引出一个问题,那就是不光是 Python,所有的这些编程语言在未来要怎样衍变与壮大呢?是否应该由一个仁慈的独裁者把控,赋予它们形状和一致性?又或者,在开源世界里,编程语言的发展与变化是否应该更像口语,取决于所有语言使用者的行为?Python 社区,这个成长速度远超其他语言的社区,需要找到这个问题的答案。
**00:01:56**:
我是 Saron Yitbarek ,这里是《代码英雄》第三季,一个来自红帽的原创播客。在上一季的《代码英雄》里,我们探索了广袤天地,从[游戏主题](/article-12578-1.html)出发,到[失败的艺术](/article-12625-1.html),再到[无服务器开发](/article-12717-1.html),最后我们甚至追踪了一台在火星表面,来自 NASA 的[火星车](/article-12744-1.html)。但是真正抓住每个人想象力的一集,似乎是 [Grace Hopper 的故事](/article-12595-1.html)。她参与开发的编译器创造出了世上第一个高级编程语言,COBOL。我们随后意识到,Grace Hopper 的故事不过是万千个塑造了软件开发与运维的世界的故事之一。新的编程语言使得我们可以连通人类与机器,它们为我们打开了一扇通往无限可能的大门。
**00:02:51**:
因此,第三季将全部围绕这些语言展开。我们会谈论 JavaScript、BASIC、Go 以及 Perl,当然,还有 Python。我们的旅程将从 Python 开始,顺着 Python 的故事,我们会学到一个与所有编程语言未来相关的至关重要的事实。
**00:03:16**:
在 Python 的仁慈的独裁者放弃王座之后,整个 Python 社区……呃,有些迷茫。你要如何在独裁者退位之后组织工作呢?有人提议采用<ruby> 长老会 <rt> Presbyterian church </rt></ruby>结构,不过没能奏效。要弄清楚 Python 是如何重新找到领导方式的,并了解这对其它语言的未来有什么意义,我们必须要回到 Python 故事的源头。
**00:03:46 - Guido van Rossum**:
好吧,让我用 C 来完成全部代码,这事情变得有些枯燥。
**00:03:51 - Saron Yitbarek**:
本尊驾到,Guido van Rossum,Python 的仁慈的独裁者。Van Rossum 曾在为阿姆斯特丹著名的 Centrum Wiskunde & Informatica 工作数年,在那里他协助开发了 ABC 编程语言。现在,他将描述他使用 C 工作时,发现对一个全新编程语言产生需求的时刻。
**00:04:13 - Guido van Rossum**:
仍然感觉还是有着很多 bug,并且开发速度缓慢。我在想,呃,如果这里支持 ABC 语言,我可以在十五分钟内写出整个登录程序,然后我可以接着开发账户管理之类的功能,但是用 C 进行开发,却要花掉我一整个星期。我开始设想,要提出一种可以在 Amoeba 环境中使用 ABC 语言特性的方法。
**00:04:47 - Saron Yitbarek**:
在研究编程语言的历史时我们发现,没有什么东西是全新的。它们全都是为了拼凑出解决方案而从旧语言借鉴来的。语言会不断的变化、发展、开枝散叶。当 van Rossum 被种种可能性弄得迷茫时,他设想出一个可以弥合 C 与 Shell 编程两者间隙的编程语言。一些场景下使用 C 语言往往是牛刀杀鸡,与此同时,用 Shell 脚本又常常让人感到繁琐,二者之间的最佳结合点,正是 Python 的栖身之处。当 van Rossum 在 1991 年首次发布 Python 时,它给大家都带来了启发,尤其是对系统管理员而言。这是一种前无来者,功能全面的脚本语言。
**00:05:35 - Emily Morehouse**:
第一次使用 Python 时,我立即就爱上了它。
**00:05:39 - Saron Yitbarek**:
这是 Emily Morehouse,目前 Python 担任核心开发者的五位女性之一。
**00:05:44 - Emily Morehouse**:
我认为当你从接触到的像 C++ 这样的第一门语言跨越到 Python 时,发现二者之间如此显著的差异,会真的会意识到语言与其设计的优美之处。你不必去应付内存管理的毛糙的底层实现细节,它可以既快又好的构建一些项目,更不必说它还有着如此广泛的应用领域。
**00:06:18 - Saron Yitbarek**:
Python 吸引力的关键之处,就在于它的可扩展性。举个例子,像 ABC 这样的语言,在设计上是固化单一的,无法形成一个能够真正帮助改善它的社区。反观 Python,van Rossum 在设计之初就希望 Python 是开放的、易于扩展的。
**00:06:37 - Emily Morehouse**:
进行软件设计时,你往往需要用到一些现有的软件或系统,并且要让它们能够协同工作,其实软件设计的核心价值之一就在于确保它的可扩展性。
**00:06:58 - Saron Yitbarek**:
听起来不怎么费脑子,但并非每一个语言都像 Python 这样,有着与生俱来的强可扩展性。事实上,一门不具备可扩展性的语言,大概率会随着自身的发展而崩溃。
**00:07:16 - Emily Morehouse**:
Python 有一个非常有趣的设计,它允许在其内核上进行扩展。实际上,你可以在运行时环境上对系统的不同片段打补丁,假如你想要改变模块导入的方式,或者你想改变你的字符串类型或整数类型,Python 允许你用相当容易的方式去实现这些事。
**00:07:44**:
Python 可扩展性的核心是所谓的 C 扩展,或者说是 C 模块。因此,Python 实际上被设计出来的意图,是为你提供对其它语言的切入点。本质上来讲,如果你可以写出 C 扩展或 C 模块,可以用它去桥接其它数百种语言,那么你在某种角度上算是破解了 Python 的设计,再造了一个它。
**00:08:16 - Saron Yitbarek**:
这完全取决于用户根据自身需求调整语言的能力。所以说 Python,按照 Guido van Rossum 的设想,绝不会局限于独裁者的个人视野。他的《移交权利》备忘录由来已久。Van Rossum 明白社区影响力所能产生的力量,这是一种能够使所有人都聚集于同一顶“大帐篷”之下的力量。没错,他最终被冠以独裁者称号,但却是一名仁慈的独裁者。
**00:08:44 - Emily Morehouse**:
我认为 Python 社区变得如此多元化,原因之一就是 Guido。Python 现在能够拥有女性核心开发者,正是因为 Guido 希望有这样的改变,并一手推动其实现。
**00:09:01 - Saron Yitbarek**:
Python 软件基金会的主席 Naomi Ceder 曾在一次演讲中说:“Python,因语言而来,为社区而留。”这可能正是 Guido van Rossum 留下的最棒的礼物。不仅仅是 Python 语言,他更是为整个 Python 社区都创造了空间。他不仅在语法意义上为 Python 提供了可扩展性,某种角度来讲,他也在社会意义上提供了扩展性。永远都为新来者留有位置。
**00:09:29 - Emily Morehouse**:
Python 有着大量不同的应用领域,而社区又如此多元化。。所以它真的、真的扩展了社区的边界。
**00:09:51**:
Emily Morehouse 是 Python 核心开发者与 Cuttlesoft 的工程总监。
**00:09:59**:
Python 降世之后,它就开始了前所未有的增长。我看到一个 Stack Overflow 上的图表,统计了每门语言被提及的次数,对应着 Python 的那条线仿佛坐上了火箭。2018 年,在 Google 搜索 Python 的人数比搜索金-卡戴珊的还多。另一个令人振奋的消息是,Python 开始和 Java、C 以及 C++ 之类的语言争夺最常用语言的头衔。
**00:10:26**:
那么,这些人们对 Python 的偏爱究竟来源何处呢?为了找到答案,我找到 Michael Kennedy,他活跃在 Python 时代的中心。他主持着两个专注于 Python 的播客:Talk Python to Me 和 Python Bytes。我们会在展示内容里放上对应的链接以便大家查看。Michael 将要和我一起讨论 Python 是如何真正迈出大步的。
**00:10:52 - Michael Kennedy**:
如果你看过分析报告或总结报告一类的东西,会发现 2012 年是一个重要拐点,而发生在 2012 年左右最具意义的事情莫过于,数据科学社区换掉了 R 之类的东西,开始真正专注于 Python。这件事发生以后,Pyton 社区就有了更充足的劲头,也有了更多的机器学习库。像许多流行的机器学习库,都会首先考虑使用 Python 来实现,此后才会考虑其他语言。
**00:11:22 - Saron Yitbarek**:
嗯,我也这么认为。当我想到 Python 时,我知道它可以被用作 Web 开发,我也认识许多仍然在使用 Python 来写 Web 应用的人。但我感到 Python 如今真正的核心更多是在数据科学领域。你认为是什么导致了这件事情发生?为什么数据科学社区抛弃了那些,或者我不应该叫抛弃,而是远离了 R 之类的工具。
**00:11:44 - Michael Kennedy**:
对,正是如此。
**00:11:45 - Saron Yitbarek**:
从何而来呢?
**00:11:46 - Michael Kennedy**:
我认为这种转变中是有两件事在起作用。其中之一就是 Python 作为一种“真正的” —— 引号引起来的 —— 编程语言,它既可以写一些简单的东西,例如构建图形或数据分析工具等等,但是,它也可以用来构建 Instagram 和 YouTube 以及其他类似的复杂应用……
**00:12:08 - Saron Yitbarek**:
是的,显而易见。
**00:12:09 - Michael Kennedy**:
相对于 R …… 之类的东西而言。对,这很显而易见。很多应用都是由 Python 来编写的。所以他们之前在使用一些其它的编程语言时,例如 R,这门专精数据科学工作的,科学统计类的编程语言,如果他们想要写一个 Web 应用来展示他们的结果,那么,他们要用什么来实现呢?Node 或者 Python 还是……这导致他们没办法一直使用那些语言。
**00:12:31 - Saron Yitbarek**:
对,说的很好。
**00:12:31 - Michael Kennedy**:
所以说 Python 拥有相当棒的能力 …… 基本上,它是一种真正的编程语言,这是其一。第二点是,Python 十分独特,被我称为……全频谱语言。我所谓的全频谱的意思是指,假如我是一名生物学家、天文学家或别的什么,当我想要处理一些数据,想要加载一个 CSV 文件并运行一些指令得到图像时,我无需理解什么是类、静态方法、主函数、编译或者链接。你不需要像一些编程语言那样,为了入门而去学会这些。我只用写几行代码,键入指令,程序就可以运行。
**00:13:14**:
但是,你也可以用它去搭建像 Instagram 之类的软件。它可以成长为绝对专业的系统,你能使用,但是你不会在一开始就被逼迫着,去理解大型应用的一切深层抽象,你可以根据自身需要来使用它。这有意义吗?
**00:13:30 - Saron Yitbarek**:
对,对。说的非常贴切。刚才我们谈论到 2012 年的拐点时,我搜索了一些关于 Python 的资料,Python 的确是世界上被 Google 次数最多的编程语言。
**00:13:42 - Michael Kennedy**:
哇。
**00:13:43 - Saron Yitbarek**:
你感觉它现在确实被大家青睐,并且仍在成长之中吗?
**00:13:47 - Michael Kennedy**:
我认为它真的被青睐并处于成长之中。在我们谈论到的过去几年里,有相当多的企业集团都选择使用 Python。而他们曾经的选择是 .NET、Java,甚至是 C 。这就是回答,并且现在 Python 开始走出属于自己的路,我认为它在某些场景下被格外倚重,关于这个,我指的是那些数据科学家们。就像,显然我们用到的 Jupyter Lab 那类炫酷笔记本应用,这些的东西,全都是 Python 造就的。
**00:14:17**:
数据科学没有祖传代码的负担。如果我想开发一个新的项目,用来探索广告活动或科学结果,就不会对一堆陈旧的东西,保持着庞大的依赖关系。模型和数据都会过时,因此对于数据科学世界而言,切换技术栈或保持最新状态要容易得多。
**00:14:37 - Saron Yitbarek**:
说的不错。
**00:14:39 - Michael Kennedy**:
嗯,谢谢。
**00:14:42 - Saron Yitbarek**:
嗯,听上去 Python 不会很快停止成长,而是保持增长的趋势,甚至这种增长的势头仍在向前发展。你认为对这种增长与前进的势头影响最大的事情是什么呢?
**00:14:52 - Michael Kennedy**:
我感觉这就像滚雪球。Python 有如此多我们可以使用的库和软件包。现在更是多到难以置信。一两年前,这个数字大概只有 10 万。而现在我们已经有了 17 万个包或项目。
**00:15:10 - Saron Yitbarek**:
哇。
**00:15:10 - Michael Kennedy**:
你可以仅仅写几行代码,然后说,噢,我要做机器学习。有人在会议上向我们展示了一个例子,她们训练一个机器学习系统,给它提供大量人脸的图像,并告诉系统他们拥有什么类型的眼睛。是圆眼睛?或者椭圆形眼睛之类的东西。似乎这会帮助你决定妆容之类的。
**00:15:30 - Saron Yitbarek**:
噢,哇。
**00:15:31 - Michael Kennedy**:
这位女士的演讲十分精彩,然后她说,这是训练模型的代码,让大家提问。而代码从头到尾只有十五行。
**00:15:40 - Saron Yitbarek**:
哇。
**00:15:40 - Michael Kennedy**:
接着你看,就像她说的那样,你提供一张照片,模型就会知道你的眼睛像什么。
**00:15:44 - Saron Yitbarek**:
噢,天哪。
**00:15:45 - Michael Kennedy**:
这种类型的项目势头十足。这些简洁,却又极具能量的东西,你可以直接通过一些包来导入,这真是厉害极了。
**00:15:53 - Saron Yitbarek**:
哇,这好酷。
**00:15:54 - Michael Kennedy**:
是不是很疯狂。
**00:15:56 - Saron Yitbarek**:
好吧。让我们暂停一下对话。我们会在稍后听到更多 Michael 的观点,但我现在想要回头来强调一些事情。使 Python 这些令人惊叹的特质成为可能的源头,Python 社区。Python 成功的一个决定性因素就是这个庞大的、反应迅速的社区。
**00:16:21**:
此时此刻,正如我们在 van Rossum 离开时看到的那样,社区的规模已经庞大到让人难以接受。想象一下你不得不背着整个语言包袱的样子。某种角度来说,吸引了如此庞大的社区,让保有一个终生独裁者的主意变得站不住脚。Van Rossum 未曾设想他的语言会收到如此巨大的反响,但是,几乎完全自发的,社区成员将 Python 的邮箱列表、新闻组、网站,以及最终通过 PEP 讨论语言变化的流程汇集在一起。PEP 是 <ruby> Python 增强建议 <rt> Python Enhancement Proposals </rt></ruby> 的缩写。
**00:17:05**:
所以,尽管有着独裁者的名号,van Rossum 仍致力于搭建一个用户可以真正传达意见,参与构建的语言。我敢打赌,尽管他在离开的那一刻感到沮丧,但 van Rossum 明白,一个活跃的社区给他的语言带去的好处,要远胜他离去而折损的。
**00:17:25 - Diane Mueller**:
我叫 Diane Mueller。
**00:17:27 - Saron Yitbarek**:
Diane 是红帽云平台的社区开发总监。在过去的 30 年里,她目睹了开源社区的强劲发展,尤其是 Python 社区,给她留下了极为深刻的印象。
**00:17:42 - Diane Mueller**:
Python 社区做的太棒了……他们带来了大量行为准则的概念,关于会议、多样性奖金,所有这类东西。通过引入不同的声音以及不同的观点,我们得到了一个更好、更具创新性的项目,它必定能够留存得更久,并有望为更多的人带去更好的体验。
**00:18:03**:
即便他们犯错了,也会开诚布公的进行处理。在看到这种精神弥漫进硅谷和初创公司的兄弟文化中之后,通过与社区的合作,Python 就像带我回到了我创业的地方,围绕着它的社区也像是回到了往日。它真的相当鼓舞人心,非常惊艳。
**00:18:33 - Saron Yitbarek**:
能够鼓舞如此多的人,缘由是 Python 在最初就重新定义了成为社区一员的含义。我讲过 Guido van Rossum 即使是在引退之际,仍倡导了在社区里对女性的拥护。此外他也在更宽泛的意义上帮助了社区的拓展。
**00:18:50 - Diane Mueller**:
个人为集体带来的远远不止是代码贡献。绝大多数社区管理者或是项目主管,都把精力集中在如何促进大家为他们的项目做出贡献。而在 Python 社区里,大家会鼓励你参与文档工作,或是帮助会议的举办,以及对多样性的促进。这里有许多不同类型的事让你参与,都可以使你成为 Python 社区的一份子。
**00:19:19**:
所以这个想法,即社区贡献不仅仅局限于代码,像参与活动、相互学习和教育,以及大量的文档工作,这些对大多数人而言都是融入 Python 社区的方法。
**00:19:35 - Saron Yitbarek**:
当然,我们还有许多路要走。
**00:19:37 - Diane Mueller**:
精英阶层仍然注重于技术。没人会怀疑这个。但我想你也看见社区管理和社区管理者的理念了……我们都是社区重要的一份子,而不是被雇佣来干事的。
**00:19:55**:
对 Diane 而言,van Rossum 正式放弃他独裁者角色的决定,是全局变化的一部分。这代表着编程语言的建设开始摆脱陈旧与单一。
**00:20:07**:
我想我们可能已经摆脱了这种模式,尽管在一段时间里,我经常听见人说:“是的,我终生都是这个项目的仁慈独裁者。”但我并不认同。
**00:20:21**:
Diane Mueller 是红帽社区发展总监。
**00:20:28**:
在 Guido van Rossum 发出那份令人瞠目结舌的《移交权利》之后,Python 社区自身便成为了权力中心。随着项目的成熟发展,出现新的治理模式是正常的,并且正如我们所见,这些人已经做好准备,要来管理自己的语言了。但我仍然好奇,整件事最终是如何收场的?van Rossum 退场之后究竟发生了什么。让我们回到与 Michael Kennedy 的对话中来寻找一些答案吧。
**00:20:59**:
……他离开了 Python,社区在没有他的情况下过得怎么样呢?
**00:21:05 - Michael Kennedy**:
嗯,社区的状态其实还不错,但我们陷在一个……制高点,有点像是卡住了。运行时和语言基本上陷停滞不前。有一些有趣的提案,有些比较麻烦,有些又挺简单。比如,嘿,要不然我们每一年发布一次 Python,而不是每 18 个月,这样跟年度会议绑在一起,语言变化会变得更有可预测性。诸如此类的事情。
**00:21:33 - Saron Yitbarek**:
噢,嗯。
**00:21:33 - Michael Kennedy**:
这些都是无法做出定夺的。因为在他引退之后,还没有方法去做决策。他基本上只留下一句,我去度假了,全靠你们了,你们必须得弄清楚怎么才能继续运行下去。我不会告诉你们怎样去做决策或怎么去运营。麻烦现在是你们的了。
**00:21:48 - Saron Yitbarek**:
哇。这听起来非常有戏剧性,但仔细一想。还记得那些<ruby> Python 增强建议 <rt> Python Enhancement Proposals </rt></ruby>(PEP)吗,那些用于接受社区反馈的 PEP?它们可以拯救大伙。
**00:22:02 - Michael Kennedy**:
有一系列他们试图为 Python 社区确立的新治理模型。好吧,最大的新闻是他们最终决定选择其中之一,叫做<ruby> 指导委员会 <rt> Steering Council </rt></ruby>,委员会由五人组成 —— 我相信他们都有着平等的投票权 —— 他们最近选举出了五个人。。所以,这不是一个人的责任,而是所有的人的责任。
**00:22:23**:
我感到十分高兴的一件事是, Guido van Rossum 也是他们的一员。他引退后说,我不能作为……所有这些人们想要改变和反馈的压力的唯一的发泄口。但是他还在,他没有完全抛弃这门语言。他仍然是一个核心开发者,并且加入了指导委员会。因此他仍然保留了发言权,但无需再独自承受一切,这真是非常棒。
**00:22:47 - Saron Yitbarek**:
我很好奇,这一切在现实世界里是怎么奏效的?我感觉如果我是指导委员会的一员,和语言的创造者坐在一起,我可能会倾向于赞同他所说的任何意见。
**00:22:58 - Michael Kennedy**:
对,确实如此。在平局的情况下,最终取决于 Guido。
**00:23:03 - Saron Yitbarek**:
嗯,的确。
**00:23:03 - Michael Kennedy**:
我不确定。但我认识指导委员会的一些人,他们一直以来都是社区的贡献者和开发者,可能超过了……在代码水平上,比 Guido 还多十五年。他们也都是非常深入的参与者,并且相当有主见,所以……
**00:23:23 - Saron Yitbarek**:
……而且相当投入。
**00:23:25 - Michael Kennedy**:
对,投入巨大。所以我认为这是行之有效的。另外,我觉得 Guido 的态度是,我仍然想参与其中,但不愿把自己的意志强加于人,否则一切都和原先没什么两样……我认为他可能倾向于选择一个更轻松的立场。
**00:23:43 - Saron Yitbarek**:
好的。我想知道,你是否认为在语言的初创阶段,为了项目能够启动运行,以便语言可以变得激进,从而得到那些突破性的好处,拥有一个<ruby> 终生仁慈独裁者 <rt> benevolent dictator for life </rt></ruby>(BDFL)的管理模型是必要的?
**00:24:00 - Michael Kennedy**:
我认同。我有考虑过,大多数由委员会进行的设计,并不惊艳。在早期,有太多决策需要进行,语言如何工作?要不要用分号?怎么做这,怎么做那?所有这些内容都很难由委员会来决定,但是 Python 至今已经有 25 年的历史了。它有这么多人参与其中。我认为现在,它执行的是一个非常好的模型。
**00:24:29 - Michael Kennedy**:
他们还有过辩论,是否应该换上一个替补的 BDFL ,这次我们又要选出谁来做我们的领袖呢?好在他们最后决定反对这个提议。
**00:24:37 - Saron Yitbarek**:
好。如果 BDFL 的位置是极其重要的,我想知道,社区需要依赖他多久呢?听上去 Guido 是自行做出决定:嘿,太过分了,这不是一个可以延续的状态,我不干了。但是,假如他没有做出这样的决策,我想知道,是否有一个最佳的时机让这个人退出,让大家走向一个更民主的状态呢?
**00:25:01 - Michael Kennedy**:
嗯,一定会有的,对吧?我认为这个时机应该存在。一个人难以与社区、技术的脉搏以及新的趋势一直保持紧密联系,说个数,大概 40 年。这是件极其困难的事,因此一定要有这个转换。我不能确切的说究竟在什么时候,但我认为必须得等到其他人相比 BDFL 做出了更多的贡献。随着核心贡献者和开发者越来越多,然后你就,嗯,我在度假,看看这些新的事情发生了,它还能活下来。类似这样的事情。
**00:25:39 - Saron Yitbarek**:
嗯。就好像是社区在准备好后会自己告诉你。
**00:25:42 - Michael Kennedy**:
对,正是如此。
**00:25:48 - Saron Yitbarek**:
由于 Python 社区仍在自己的生命历程中,因此这里就是我们暂时告一段落的地方。Michael Kennedy 的两个播客会持续追踪 Python 之后的历程。欢迎订阅 Talk Python to Me 和 Python Bytes。
**00:26:07 - Saron Yitbarek**:
你听说过被称为古代雅典立法者的<ruby> 梭伦 <rt> Solon </rt></ruby>的故事吗? 他是个很酷的家伙。 在梭伦为<ruby> 民主雅典 <rt> Athenian democracy </rt></ruby>建立宪法之后,他选择了自行流放。因为他清楚,继续执政只会增加他成为暴君的风险。我觉得 Guido van Rossum 就像是当代梭伦,为我们提供了数十年的标准实践,有点像是一部宪法。他建立起一个出色的编程语言,一个真正由开源社区自己创作的语言。然后他给予他们一个权力转移的时刻,他在那时告诉他们,你们由自己掌控,我不再是你们的独裁者了。
**00:26:54 - Saron Yitbarek**:
他确保了一定是由社区,而非他本人,来推动 Python 前行。某种意义上,Guido van Rossum 的“移交权利”是开源世界中所有编程语言的共同宣言,因为任何语言随着其社区的发展,终将面临唯有社区才可以解决的挑战。
**00:27:19 - Saron Yitbarek**:
在《代码英雄》的第三季中,我们会对编程语言的世界进行深入的挖掘。语言影响力的来源,正是它们如何通过强力的新方法去解决新的问题。在本季的剩余时间里,我们会探索 JavaScript、Perl、COBOL、Go,以及更多语言所具备的超能力。在下一集,我们会学习 BASIC 的故事,此外还会谈论到母语究竟教会了我们什么。
**00:27:47 - Saron Yitbarek**:
如果你想更深入地研究 Python 或你在本集里听到的任何内容,请转至 [redhat.com/commandlineheroes。最后,我是](http://redhat.com/commandlineheroes%E3%80%82%E6%9C%80%E5%90%8E%EF%BC%8C%E6%88%91%E6%98%AF) Saron Yitbarek。直到下期,请坚持编程。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-3/pythons-tale>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[caiichenr](https://github.com/caiichenr) 校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
A benevolent dictator for life steps down and changes the course of the Python language forever. Guido van Rossum's "Transfer of Power" memo brings attention to the way programming languages evolve.
In this episode, Emily Morehouse makes the connection between Python's technical extensibility and its inclusive community. Michael Kennedy explains how Python is both easy to learn and powerful enough to build YouTube and Instagram. And Diane Mueller highlights how the Python community took the lead on so many inclusive practices that are spreading in tech—including the rise of community-led decision-making.
Sometimes, a benevolent dictator can get a language started. But Python shows it's communities that make languages thrive.
**00:06** - *Saron Yitbarek*
On the morning of July 12, 2018, members of the Python community all around the globe woke up, grabbed a cup of coffee and popped open their laptops. Then one by one, they discovered a message from their benevolent dictator.
**00:24** - *Saron Yitbarek*
Guido van Rossum, the man who invented Python, one of the world's greatest programming languages, maybe the greatest programming language, had written to them all. So imagine all those Python fans reading these words.
**00:38** - *Multiple voice actors*
I don't ever want to have to fight so hard and find that so many people despise my decisions. I would like to remove myself entirely from the decision process by giving myself a permanent vacation from being benevolent dictator for life. You will all be on your own. I am not going to appoint a successor. What are you going to do. Create a democracy? Anarchy?
**01:00** - *Saron Yitbarek*
With that simple but earth-shattering note, Guido van Rossum, the man that the Python community had been following for decades ... Well, he basically just bowed out. His message was titled "Transfer of Power," and it would change the landscape of the Python language forever.
**01:19** - *Saron Yitbarek*
But more than that, it called into question how all our programing languages were going to evolve and thrive in the future. Were languages supposed to be run by one Benevolent Dictator, giving them shape and coherence? Or, in our open source world, were languages more like spoken languages, things that grow and react according to the behavior of a whole bunch of different speakers? The Python community, the fastest growing community of any language out there, was about to find out.
**01:56** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is season 3 of Command Line Heroes, an original podcast from Red Hat. Last season on Command Line Heroes, we explored a huge stretch of territory, from gaming, to the art of the fail, to serverless development. We even ended up tracking one of NASA's rovers across the surface of Mars. But there is one episode that seemed to really capture everyone's imagination, the story of Grace Hopper. Her work on compilers led to the first high-level programming language, COBOL. We realized afterward that Grace Hopper's story was just one of so many stories of languages shaping the world of development and ops. New programming languages allow us to bridge humans and machines. They open gateways toward amazing new possibilities.
**02:51** - *Saron Yitbarek*
So, season 3 is all about those languages. We're talking JavaScript, we're talking BASIC, Go, Perl. And yes, we're talking Python. Python is where our journey begins because by following the tale of Python, we learn a crucial truth about the future of all our programming languages.
**03:16** - *Saron Yitbarek*
After Python's benevolent dictator abandoned his throne, the Python community was ... yeah, a bit lost. How do you organize things after a dictator steps down? Somebody suggested they can model their structure after the Presbyterian church. That idea didn't stick. To understand how Python did reorganize and what it means for the future of languages in general, we have to go back to the origin of the Python tale.
**03:46** - *Guido van Rossum*
Well, I'm writing all this code in C and it's getting kind of tedious.
**03:51** - *Saron Yitbarek*
That's the man himself, Guido van Rossum, Python's Benevolent Dictator. Van Rossum had worked for years at Amsterdam's famous Centrum Wiskunde & Informatica, where he helped develop the ABC programming language. Here, he's describing the moment he was working in C and saw a need for a brand new language.
**04:13** - *Guido van Rossum*
It still felt like there were lots of bugs and it was just slow going. I was thinking, hmm, if we had an ABC implementation here, I would just write a whole login program in 15 minutes, and then I would move onto the account management program or something, and in C, it takes me a week each. I somehow started thinking about coming up with a way to use some of ABC's features in the Amoeba environment.
**04:47** - *Saron Yitbarek*
Here's something we discovered in studying the history of programming languages. There's no such thing as brand new. They all borrow from old languages in order to cobble together solutions. Languages morph, they evolve, they branch. When van Rossum was getting frustrated with the possibilities out there, he imagined a language that could bridge the gap between C and shell programming. C was often overkill, but at the same time, shell scripts felt too cumbersome. There was a sweet spot between the two, and that was a spot that Python filled. When van Rossum first released Python in 1991, it was a revelation, for sysadmins especially. Here was a full-featured scripting language unlike anything that had come before.
**05:35** - *Emily Morehouse*
The first time that I used Python, I absolutely fell in love with it.
**05:39** - *Saron Yitbarek*
That's Emily Morehouse, one of five women currently working as a core developer on Python.
**05:44** - *Emily Morehouse*
I think seeing such a stark difference between a first language like C++ and then moving into something like Python, you are really able to see the elegance of the language and the language design itself. You're not necessarily having to deal with any of the hairy implementation details of memory management, and it was such a great way to build things so much faster, and build things for a much wider variety of applications.
**06:18** - *Saron Yitbarek*
Key to Python's attractiveness was its extensibility. A language like ABC, for example, is monolithic in design. There's no way for a real community to help define how the language will work. By contrast, van Rossum wanted Python to be open and extensible from the beginning.
**06:37** - *Emily Morehouse*
When approaching software design, you often will have to take either existing software or other software systems, and get them all to work together, and one of the very true values of how you can design software is making sure that it's extensible.
**06:58** - *Saron Yitbarek*
It sounds like a no-brainer, but not every language has achieved the level of extensibility that Python had right from the start. The truth is, if a language doesn't have extensibility baked into it, there's a good chance it will end up collapsing under its own weight as it grows.
**07:16** - *Emily Morehouse*
Python has been designed in a very interesting way that allows it to be extensible at its core. You can actually patch different pieces of the system at runtime, so if you want to switch out how modules are imported, or you want to switch out your string types or your integer types, Python allows you to do all these things fairly easily.
**07:44** - *Emily Morehouse*
At the heart of Python's extensibility is something called C extensions, or C modules. So Python has actually been designed to give you an entry point to other languages, and essentially, if you can write a C extension or a C module that can then bridge to hundreds of other languages, you can kind of hack Python.
**08:16** - *Saron Yitbarek*
It's all about the user's ability to adapt the language to their own needs. So Python, as Guido van Rossum envisioned it, was never going to be limited to one dictator's vision. His “Transfer of Power” memo was a long-time coming. Van Rossum understood the power of community influence, the power of bringing everyone under a big tent. Yes, he ended up getting called a dictator, but it was benevolent dictator.
**08:44** - *Emily Morehouse*
I think one of the reasons why Python has become such a diverse community is because of Guido. Python has female core developers now because Guido wanted that change to be made, and made it happen himself.
**09:01** - *Saron Yitbarek*
Naomi Ceder, the chair of the Python Software Foundation, once gave a keynote where she said, "Python. Come for the language, and stay for the community." And that may be Guido van Rossum's greatest legacy. Not just Python, but the Python community he made room for. He made Python seriously extensible, but it was, in a way, socially extensible, too. It always had room for human additions.
**09:29** - *Emily Morehouse*
You have so many different applications of Python that your community is then, by definition, and by construct, very diverse. So it's really, really broadened the community reach.
**09:51** - *Saron Yitbarek*
Emily Morehouse is a core Python developer and Director of Engineering at Cuttlesoft.
**09:59** - *Saron Yitbarek*
Once Python hatched, it started to grow like nothing before. I'm looking at a Stack Overflow chart that shows the amount of chatter they get on each language, and Python's line is rocketing. In 2018, more people did Google searches for Python than for Kim Kardashian. All that excitement has it jostling for the title of most-used language against options like Java, C, and C++.
**10:26** - *Saron Yitbarek*
So, what's with all that love, anyway? To find out, I caught up with developer Michael Kennedy, who lives at the center of the Python zeitgeist. Michael hosts not one, but two podcasts devoted to Python. Talk Python to Me, and Python Bytes. We'll throw some links in the show notes so you can check them out. Michael and I got chatting about how Python really hit its stride.
**10:52** - *Michael Kennedy*
If you look at the analytics and the surveys and stuff like that, it really seems to be that 2012 is a strong inflection point, and the most significant thing that happened around 2012 is the data science community switched away from things like R, some other stuff, to really focus on Python. Ever since that's happened, there's been even more momentum there, more machine learning libraries. A lot of the popular machine learning libraries, for example, are Python first, and then they'll consider other languages.
**11:22** - *Saron Yitbarek*
Yeah, that's been my understanding, too. When I think about Python, I know it can be used for web development; I know a lot of people who still use it to build web apps. But I feel like the heart of it nowadays is more in the data science part of things. What do you think led to that happening? Why did the data science community leave things, or I can't say leave, but move away from things like R?
**11:44** - *Michael Kennedy*
Right, exactly.
**11:45** - *Saron Yitbarek*
Where'd that come from?
**11:46** - *Michael Kennedy*
I think there's two things at play in that transition. One of those things certainly has to do with Python being a real, in quotes, "real" programming language, in the sense that you can build simple things. You can build graphs and data analysis tools and whatnot. But you can also build Instagram and YouTube and all these other ...
**12:08** - *Saron Yitbarek*
Yeah, literally.
**12:09** - *Michael Kennedy*
Whereas things like R ... Yeah, literally, quite literally. Those are written in Python. So there are other languages they were using, like R at the time, was sort of scientific, statistics type programming language that did data sciencey stuff. But if you wanted to go build a web app to show off your results, well, what are you going to use? Node or Python or ... You couldn't stick with it.
**12:31** - *Saron Yitbarek*
Yeah, that's a good point.
**12:31** - *Michael Kennedy*
So Python has this really nice ability that it ... Basically, it's a real programming language. So that's number one. Number two is, Python is pretty unique in this, what I call ... It's a full-spectrum language. What I mean by full spectrum is, I can be a biologist or astrophysicist or something, and I want to explore a little bit of data, I want to load up a CSV file and run some commands and get a picture. I don't need to understand classes, static methods, static main void, compilation, linking. You don't have to go through all the stuff that some programming languages do just to get started. You can do just a couple lines of code, type a command, and it runs.
**13:14** - *Michael Kennedy*
Yet, you can build things like Instagram and so on. It can grow into this absolutely professional system that you can use, but you're not forced to understand all these deep abstractions that are meant for large applications right away. You can adopt them as you need it. Does that make sense?
**13:30** - *Saron Yitbarek*
Yeah, yeah. That makes a lot of sense. So we talked about that inflection point around 2012, and when I was looking and doing some research about Python, Python is actually one of the world's most Googled, Google searched, coding languages.
**13:42** - *Michael Kennedy*
Wow.
**13:43** - *Saron Yitbarek*
Do you feel like it's really picking up and growing at this point?
**13:47** - *Michael Kennedy*
I do think it's picking up and that it's growing. In those last number of years we talked about, there's certainly more enterprise groups that are using Python. It used to be .NET, Java, maybe some C. That was the answer, and now Python is starting to make its way in, and I think it's getting sideloaded into those environments somewhat, and by that, I mean the data science folks. It's like, well, obviously we're going to use Jupyter Lab and all the cool notebook stuff. That's Python.
**14:17** - *Michael Kennedy*
Data science doesn't have such a legacy code base story. If I'm going to start a new project where we're exploring some ad campaign or some science results, that doesn't have a huge dependency on old stuff. Models and data expire, so it's more easy for the data science world to switch technologies or stay more current.
**14:37** - *Saron Yitbarek*
That's a good point.
**14:39** - *Michael Kennedy*
Yeah, thanks.
**14:42** - *Saron Yitbarek*
Yeah. And it sounds like it's not going to stop growing anytime soon. It sounds like it's going to keep growing, and the momentum is still going to carry it forward. What do you think is going to influence that growth the most, moving forward?
**14:52** - *Michael Kennedy*
I feel like it's this ball rolling downhill. We have all the libraries and packages you can use with Python. It's a ridiculous number that we have now. A year or two ago, it was 100,000. Now it's 170,000 packages or projects.
**15:10** - *Saron Yitbarek*
Wow.
**15:10** - *Michael Kennedy*
You can just, in a couple lines of code, oh, I'd like to do machine learning. Someone at the conference showed us an example of, here's how we're going to train a machine learning system to be given a bunch of faces of people, choose what type of eyes they have. Do they have round eyes, do they have oval eyes, things like that. Apparently this drives the kind of makeup you have or something.
**15:30** - *Saron Yitbarek*
Oh, wow.
**15:31** - *Michael Kennedy*
This woman did a great presentation, and she said, here's the code to train this model, and then to ask it questions. And it was 15 lines of code from beginning to end.
**15:40** - *Saron Yitbarek*
Wow.
**15:40** - *Michael Kennedy*
And then you have, here's your thing that tells you, given a picture, what your eyes are like.
**15:44** - *Saron Yitbarek*
Oh my goodness.
**15:45** - *Michael Kennedy*
The momentum of those types of things, these little, super powerful things, you can just bring in through these packages is ridiculous.
**15:53** - *Saron Yitbarek*
Wow, that's so cool.
**15:54** - *Michael Kennedy*
Isn't that crazy?
**15:56** - *Saron Yitbarek*
Okay. Let's pause that conversation for a sec. We're going to hear more from Michael later on, but I want to go back and underline something. It's what makes all those amazing Python qualities possible in the first place. The Python community. A defining part of Python's success is that huge, responsive community.
**16:21** - *Saron Yitbarek*
At the same time, as we saw with van Rossum's departure, the size of that community can be overwhelming. Imagine having to carry the hangups of an entire language around with you. In a way, attracting such a massive community made the idea of a single dictator for life just untenable. Van Rossum wasn't necessarily prepared for how huge a response his language was going to receive, but, almost organically, community members pulled together Python's mailing list, its newsgroup, its website, and eventually, the process for discussing language changes via PEPs. That stands for Python Enhancement Proposals.
**17:05** - *Saron Yitbarek*
So, despite the dictator title, van Rossum was building a language that you could really talk back to, a language that users could help build. I'm betting that despite his frustration at that moment of departure, van Rossum knew that a dynamic community would give more to his language than it could ever take away.
**17:25** - *Diane Mueller*
My name is Diane Mueller.
**17:27** - *Saron Yitbarek*
Diane's the Director of Community Development at Red Hat for the cloud platform. Over the past 30 years, she's witnessed a powerful evolution in the strength of open source communities, and she's been impressed by Python's community in particular.
**17:42** - *Diane Mueller*
The Python community has done amazing ... They brought in the concept of codes of conduct for conferences, diversity scholarships, all of that sort of stuff. By bringing in the different voices and the different perspectives, we get a better and more innovative project that will live on longer, and hopefully work better for more people.
**18:03** - *Diane Mueller*
Even the mistakes they made, they handled openly and transparently and through collaboration with the community after seeing that sort of spirit wither away into a bro culture from Silicon Valley and startups, Python felt like coming back home to the roots of where I got started, and the community that had been around back in the day. So it was pretty inspiring and pretty awesome.
**18:33** - *Saron Yitbarek*
Inspiring largely because Python redefined what it means to be part of the community in the first place. I mentioned that Guido van Rossum started championing women in the community, even as he stepped down. But he also helped widen the tent in a more general way.
**18:50** - *Diane Mueller*
Individuals bring a lot more to the table than just code contributions. Mostly community managers and project leads focus on trying to get people to contribute to their project, and in the Python community, people were really highly encouraging you to work on documentation, to help run the conferences, to help promote diversity. There were all sorts of other things you could do to be part of the Python community.
**19:19** - *Diane Mueller*
So that idea, that contribution isn't just about code, it's about participation, it's about learning and education, and it's a lot about documentation, was the way into community for a lot of people.
**19:35** - *Saron Yitbarek*
Of course, we've still got a ways to go.
**19:37** - *Diane Mueller*
Meritocracy is still very technically focused. No one's going to doubt that. But I think you also see the belief that community management and community managers ... We're skilled parts of a community, as opposed to just the person we hired to create our events for us.
**19:55** - *Saron Yitbarek*
For Diane, van Rossum's decision to officially abdicate his dictator role is part of a global shift. It's moving away from older, monolithic kinds of language-building.
**20:07** - *Saron Yitbarek*
I think we might have moved on from that model, though every once in a while, I hear someone say, yeah, I'm the benevolent dictator for life of this project, and I'm like, yeah, I don't think so.
**20:21** - *Saron Yitbarek*
Diane Mueller is a Director of Community Development at Red Hat.
**20:28** - *Saron Yitbarek*
By the time Guido van Rossum sent that jaw-dropping “Transfer of Power” memo, the Python community was a powerhouse unto itself. It's common for projects to adopt new governance models as they grow, and in many ways, as we've seen, these folks were ready to take charge of their own language. But I still want to know, how exactly did that pan out? What happened after van Rossum stepped away. Let's go back to our conversation with Michael Kennedy to get some answers.
**20:59** - *Saron Yitbarek*
... back and away from Python, how has the community been doing without him?
**21:05** - *Michael Kennedy*
Well, the community has been okay, but we've been in ... at the highest level, kind of a stasis. The runtime and the language just basically had to go into a coma. There were proposals for interesting things, and they were sometimes complicated, but sometimes really simple. Like, hey, wouldn't it be great if we could ship Python yearly instead of every 18 months, so it's a little more predictable, tied around the yearly conference, things like that.
**21:33** - *Saron Yitbarek*
Sure, yeah.
**21:33** - *Michael Kennedy*
That couldn't be decided, because there was no way to make decisions after he stepped down. He basically said, I'm going to go on vacation. This is up to you guys, you have to figure out how to keep running this. I'm not even going to tell you how to decide how to keep running it. This is your problem now.
**21:48** - *Saron Yitbarek*
Wow. That sounds dramatic, but check this out. Remember those Python Enhancement Proposals, the PEPs that allowed the community to give feedback? Well, PEPs to the rescue.
**22:02** - *Michael Kennedy*
There was a series of them trying to determine new governance models for the Python community. Well, the big news is they've decided on one of those, called the Steering Council, which is five people—I believe they all have equal votes—and they've recently elected those five. So instead of it being on one person's shoulders, it's on all of them.
**22:23** - *Michael Kennedy*
One thing that I think is really nice is that we have Guido van Rossum as one of those members. He stepped away and said, I cannot be the single source of ... all the pressure of people wanting changes and feedback. But he still, he didn't completely run away from the language. He's still a core developer, and he's on the Steering Council. So he still has some say, but he doesn't have to take it on entirely, which is pretty cool.
**22:47** - *Saron Yitbarek*
I'm wondering how that works out in reality, because I feel like if I'm on the Steering Council and I'm sitting next to the creator of the language, I'd probably tend to agree with whatever he says.
**22:58** - *Michael Kennedy*
Right, exactly. All things being equal, ties go to Guido.
**23:03** - *Saron Yitbarek*
Yeah, exactly.
**23:03** - *Michael Kennedy*
I don't know. I do know some of the people on the Steering Council, and they've been constant contributors and developers, maybe even to ... at a code level, more so than Guido for 15 years. So they're also pretty deeply involved and pretty opinionated, so-
**23:23** - *Saron Yitbarek*
And invested.
**23:25** - *Michael Kennedy*
Yeah, certainly invested. So I feel like it's going to be okay. Also, I feel like Guido's probably like, I still want to be involved, but he's probably done trying to impose his will on people, because that will just put him right back into the same ... I think he's probably going to take a more relaxed position.
**23:43** - *Saron Yitbarek*
Okay. I'm wondering, do you feel like this model of having a benevolent dictator for life (BDFL), is that model almost required at the beginning of a language, in order to get it up and running, in order for it to be radical and have these breakthrough advances?
**24:00** - *Michael Kennedy*
I do. I think stuff, mostly design by committee, is not super. So in the early days, so many decisions about, how does the language work? Does it use semicolons? How does it do this, does it do that? All that stuff is really hard to committee decide, but Python is over 25 years old now. It's got so many people involved in it. I think now, that this is a pretty good model.
**24:29** - *Michael Kennedy*
They also debated whether or not there should just be a replacement BDFL, who do we elect now to be our king? They decided against that, though.
**24:37** - *Saron Yitbarek*
Okay. If that BDFL position is so important, I'm wondering, how long does a community need one? It sounds like Guido decided on his own, hey, this is too much. This is not sustainable anymore, I'm not doing this anymore. But if it wasn't his decision, I'm wondering, is there an optimal time where that person should step down and we should move to something a little bit more democratic?
**25:01** - *Michael Kennedy*
Yeah, there has to be, right? I think that there probably is. It's hard for one person to still be completely connected with the pulse of the community and technology and the new trends, let's say, 40 years out. That would be super difficult, so there's got to be this switchover. I don't really know where it is, but I feel like it's got to be after you have other people doing more work than the BDFL is doing. More core contributors and developers, and you're just like, well, I was on vacation, and look at all these new things that happened, and it survived. Something to that effect.
**25:39** - *Saron Yitbarek*
Yeah. It's almost like the community will tell you when it's ready.
**25:42** - *Michael Kennedy*
Right, exactly.
**25:48** - *Saron Yitbarek*
The Python community is still taking on a life of its own, so that's where we'll leave them for now. Michael Kennedy is the host of two podcasts that'll keep on tracking their progression in the meantime. You can check out Talk Python to Me and Python Bytes.
**26:07** - *Saron Yitbarek*
Have you ever heard the story of Solon, the guy known as the lawgiver of ancient Athens? Pretty cool guy. After Solon established a constitution for Athenian democracy, he went off into a state of voluntary exile. That's because he knew there was a danger he'd become a tyrant if he stayed in power. I guess Guido van Rossum is a latter day Solon, giving us decades of standard practice, which is a bit like a constitution. Here's a guy who set up a brilliant programming language, a language where an open source community could really make it their own. Then, he also gave them that transfer of power moment, where he told them, you're on your own. I'm no longer your dictator.
**26:54** - *Saron Yitbarek*
He made sure that it had to be the community, not himself, that carried the Python mantle forward. In a way, Guido van Rossum's “Transfer of Power” memo is a manifesto for all programming languages in an open source world, because as any language grows its community, it ends up taking on challenges that only the community can solve.
**27:19** - *Saron Yitbarek*
In season 3 of Command Line Heroes, we're doing a deep dive into the world of programming languages. Languages gain influence because they solve a new problem in some powerful new way, and for the rest of the season, we're uncovering the superpowers baked into JavaScript, Perl, COBOL, Go, and so much more. Next episode, we'll learn the story of BASIC, and what it teaches us about everybody's first language.
**27:47** - *Saron Yitbarek*
If you want to dive deeper into Python or anything else you've heard on this episode, head over to redhat.com/commandlineheroes. Until then, I'm Saron Yitbarek. Keep on coding.
### Keep going
### Python's Past, Present, and Future
On opensource.com, Matthew Broberg takes a closer look at Python's potential and how its community has been pushing for change long before van Rossum stepped down.
### Red Hat Software Collections: Python
Check out this step by step guide to get Python running on Red Hat Enterprise Linux.
### Enjoy this episode's artwork on your device
Download the Command Line Heroes artwork and set it as your background. |
12,798 | ninja:一个简单的构建方式 | https://jvns.ca/blog/2020/10/26/ninja--a-simple-way-to-do-builds/ | 2020-11-07T10:54:41 | [
"构建"
] | https://linux.cn/article-12798-1.html | 
大家好!每隔一段时间,我就会发现一款我非常喜欢的新软件,今天我想说说我最近喜欢的一款软件:[ninja](https://ninja-build.org/)!
### 增量构建很有用
我做了很多小项目,在这些项目中,我想设置增量构建。例如,现在我正在写一本关于 bash 的杂志,杂志的每一页都有一个 `.svg`文件。我需要将 SVG 转换为 PDF,我的做法是这样的:
```
for i in *.svg
do
svg2pdf $i $i.pdf # or ${i/.svg/.pdf} if you want to get really fancy
done
```
这很好用,但是我的 `svg2pdf` 脚本有点慢(它使用 Inkscape),而且当我刚刚只更新了一页的时候,必须等待 90 秒或者其他什么时间来重建所有的 PDF 文件,这很烦人。
### 构建系统是让人困惑的
在过去,我对使用 `make` 或 `bazel` 这样的构建系统来做我的小项目一直很反感,因为 `bazel` 是个大而复杂的东西,而 `make` 对我来说感觉有点神秘。我真的不想使用它们中的任何一个。
所以很长时间以来,我只是写了一个 bash 脚本或者其他的东西来进行构建,然后就认命了,有时候只能等一分钟。
### ninja 是一个极其简单的构建系统
但 `ninja` 并不复杂!以下是我所知道的关于 ninja 构建文件的语法:创建一个 `rule` 和一个 `build`:
`rule` 有一个命令(`command`)和描述(`description`)参数(描述只是给人看的,所以你可以知道它在构建你的代码时在做什么)。
```
rule svg2pdf
command = inkscape $in --export-text-to-path --export-pdf=$out
description = svg2pdf $in $out
```
`build` 的语法是 `build output_file: rule_name input_files`。下面是一个使用 `svg2pdf` 规则的例子。输出在规则中的 `$out` 里,输入在 `$in` 里。
```
build pdfs/variables.pdf: svg2pdf variables.svg
```
这就完成了!如果你把这两个东西放在一个叫 `build.ninja` 的文件里,然后运行 `ninja`,ninja 会运行 `inkscape variables.svg --export-text-to-path --export-pdf=pdfs/variables.pdf`。然后如果你再次运行它,它不会运行任何东西(因为它可以告诉你已经构建了 `pdfs/variables.pdf`,而且是最新的)。
Ninja 还有一些更多的功能(见[手册](https://ninja-build.org/manual.html)),但我还没有用过。它最初是[为 Chromium](http://neugierig.org/software/chromium/notes/2011/02/ninja.html) 构建的,所以即使只有一个小的功能集,它也能支持大型构建。
### ninja 文件通常是自动生成的
ninja 的神奇之处在于,你不必使用一些混乱的构建语言,它们很难记住,因为你不经常使用它(比如 `make`),相反,ninja 语言超级简单,如果你想做一些复杂的事情,那么你只需使用任意编程语言生成你想要的构建文件。
我喜欢写一个 `build.py` 文件,或者像这样的文件,创建 ninja 的构建文件,然后运行 `ninja`:
```
with open('build.ninja', 'w') as ninja_file:
# write some rules
ninja_file.write("""
rule svg2pdf
command = inkscape $in --export-text-to-path --export-pdf=$out
description = svg2pdf $in $out
""")
# some for loop with every file I need to build
for filename in things_to_convert:
ninja_file.write(f"""
build {filename.replace('svg', 'pdf')}: svg2pdf {filename}
""")
# run ninja
import subprocess
subprocess.check_call(['ninja'])
```
我相信有一堆 `ninja` 的最佳实践,但我不知道。对于我的小项目而言,我发现它很好用。
### meson 是一个生成 ninja 文件的构建系统
我对 [Meson](https://mesonbuild.com/Tutorial.html) 还不太了解,但最近我在构建一个 C 程序 ([plocate](https://blog.sesse.net/blog/tech/2020-09-28-00-37_introducing_plocate),一个比 `locate` 更快的替代方案)时,我注意到它有不同的构建说明,而不是通常的 `./configure; make; make install`:
```
meson builddir
cd builddir
ninja
```
看起来 Meson 是一个可以用 ninja 作为后端的 C/C++/Java/Rust/Fortran 构建系统。
### 就是这些!
我使用 ninja 已经有几个月了。我真的很喜欢它,而且它几乎没有给我带来让人头疼的构建问题,这让我感觉非常神奇。
---
via: <https://jvns.ca/blog/2020/10/26/ninja--a-simple-way-to-do-builds/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! Every so often I find a new piece of software I really like, and today
I want to talk about one of my recent favourites: [ninja](https://ninja-build.org/)!
### incremental builds are useful
I do a lot of small projects where I want to set up incremental builds – for
example, right now I’m writing a zine about bash, and I have one `.svg`
file
for each page of the zine. I need to convert the SVGs to PDFs, and I’d been
doing it something like this:
```
for i in *.svg
do
svg2pdf $i $i.pdf # or ${i/.svg/.pdf} if you want to get really fancy
done
```
This works fine, but my `svg2pdf`
script is a little slow (it uses Inkscape), and it’s annoying
to have to wait 90 seconds or whatever to rebuild all the PDFs when I’ve just updated 1 page.
### build systems are confusing
In the past I’ve been pretty put off by using a Build System like make or bazel
for my small projects because bazel is this Big Complicated Thing and `make`
feels a little arcane to me. I don’t really know how to use either of them.
So for a long time I’ve just written a bash script or something for my builds and resigned myself to just waiting for a minute sometimes.
### ninja is an EXTREMELY SIMPLE build system
But ninja is not complicated! Here is literally everything I know about ninja
build file syntax: how to create a `rule`
and a `build`
:
a `rule`
has a command and description (the description is just for humans to read so you can tell what it’s doing when it’s building your code)
```
rule svg2pdf
command = inkscape $in --export-text-to-path --export-pdf=$out
description = svg2pdf $in $out
```
the syntax for `build`
is `build output_file: rule_name input_files`
. Here’s
one using the `svg2pdf`
rule. The output goes in `$out`
in the rule and the
input goes in `$in`
.
```
build pdfs/variables.pdf: svg2pdf variables.svg
```
That’s it! If you put those two things in a file called `build.ninja`
and then run `ninja`
,
ninja will run `inkscape variables.svg --export-text-to-path --export-pdf=pdfs/variables.pdf`
. And then if you run it again, it won’t run
anything (because it can tell that you’ve already built `pdfs/variables.pdf`
and you’re up to date)
Ninja has a few more features than this (see [the manual](https://ninja-build.org/manual.html)), but I haven’t used them yet. It was
originally built [for Chromium](http://neugierig.org/software/chromium/notes/2011/02/ninja.html), so even with a small feature set it can support large builds.
### ninja files are usually automatically generated
The magic of ninja is that instead of having to use some confusing Build
Language that’s hard to remember because you use it so infrequently (like
make), instead the ninja language is SUPER simple, and if you want to do
something complicated then you can generate the build file you want using any
programming language you want. I find this this a lot easier because I know
Python, but I can never remember anything about how the `make`
language works.
I like to make a `build.py`
file or that looks something like this, that
creates the ninja build file and then runs `ninja`
:
```
with open('build.ninja', 'w') as ninja_file:
# write some rules
ninja_file.write("""
rule svg2pdf
command = inkscape $in --export-text-to-path --export-pdf=$out
description = svg2pdf $in $out
""")
# some for loop with every file I need to build
for filename in things_to_convert:
ninja_file.write(f"""
build {filename.replace('svg', 'pdf')}: svg2pdf {filename}
""")
# run ninja
import subprocess
subprocess.check_call(['ninja'])
```
I’m sure there are a bunch of ninja best practices, but I don’t know them and for my small projects I find this works well.
### meson is a build system that generates ninja files
I don’t know too much about [Meson](https://mesonbuild.com/Tutorial.html) yet,
but recently I was building a C program ([plocate](https://blog.sesse.net/blog/tech/2020-09-28-00-37_introducing_plocate), a faster alternative to `locate`
)
and I noticed that instead of the usual `./configure; make; make install`
,
there were different build instructions:
```
meson builddir
cd builddir
ninja
```
It seems like Meson is a build system for C/C++/Java/Rust/Fortran that can use ninja as a backend.
### that’s all!
I’ve been using ninja for a few months now. I really like it and it’s caused me approximately 0 build-related headaches which feels pretty magical to me. |
12,801 | Fedora 33 Workstation 的新功能 | https://fedoramagazine.org/whats-new-fedora-33-workstation/ | 2020-11-08T08:07:17 | [
"Fedora"
] | https://linux.cn/article-12801-1.html | 
Fedora 33 Workstation 是我们这个免费的、领先的操作系统的[最新版本](https://fedoramagazine.org/announcing-fedora-33/)。你现在就可以从[官方网站](https://getfedora.org/workstation)下载它。Fedora 33 Workstation 中有一些新的和值得注意的变化。请阅读如下更多细节。
### GNOME 3.38
Fedora 33 Workstation 为各类用户提供了最新版本的 GNOME 桌面环境。在 Fedora 33 Workstation 中的 GNOME 3.38 包含了许多更新和改进,包括:
#### 一个新的 GNOME Tour 应用
现在,新用户会看到一个“新的 Tour 应用,重点展示了桌面的主要功能,并为第一次使用 GNOME 的用户提供一个很好的欢迎页”。

#### 拖动重排序应用
GNOME 3.38 用一个单一的可定制的、一致的视图取代了之前分开的“常用”和“所有”应用视图,这允许你重新排列应用并将它们组织到自定义文件夹中。只需点击并拖动即可移动应用。

#### 改进屏幕录制
GNOME Shell 中的屏幕录制基础架构已被改进,以利用 PipeWire 和内核 API。这将有助于减少资源消耗并提高响应速度。
GNOME 3.38 还提供了许多额外的功能和改进。查看 [GNOME 3.38 发行说明](https://help.gnome.org/misc/release-notes/3.38/)以获得更多信息。
#### B-tree 文件系统
正如[之前宣布的](https://fedoramagazine.org/btrfs-coming-to-fedora-33/),新安装的 Fedora 33 将默认使用 [Btrfs](https://en.wikipedia.org/wiki/Btrfs)。每一个新的内核版本都会为 Btrfs 增加一些特性和增强功能。[变更日志](https://btrfs.wiki.kernel.org/index.php/Changelog#By_feature)有一个完整的总结,它介绍了每个新内核版本给 Btrfs 带来的功能。
#### Swap on ZRAM
Anaconda 和 Fedora IoT 多年来一直默认使用 swap-on-zram。在 Fedora 33 中,将默认启用 swap-on-zram,而不是交换分区。查看 [Fedora wiki 页面](https://fedoraproject.org/wiki/Changes/SwapOnZRAM)了解更多关于 swap-on-zram 的细节。
#### 默认使用 Nano
新的 Fedora 33 将把 `EDITOR` 环境变量默认设置为 [nano](https://fedoraproject.org/wiki/Changes/UseNanoByDefault)。这个变化影响了一些命令行工具,当它们需要用户输入时,会打开一个文本编辑器。在早期的版本中,这个环境变量的默认值并没有被指定,而是由各个应用程序来选择一个默认的编辑器。通常情况下,应用程序会使用 [vi](https://en.wikipedia.org/wiki/Vi) 作为它们的默认编辑器,因为它是一个小应用,通常在大多数 Unix/Linux 操作系统的基础安装中都可以使用。由于 Fedora 33 的基本安装中包含了 nano,而且 nano 对于初学者来说更加直观,所以 Fedora 33 将默认使用 nano。当然,想要使用 vi 的用户可以在自己的环境中覆盖 `EDITOR` 变量的值。详见[Fedora 修改请求](https://fedoraproject.org/wiki/Changes/UseNanoByDefault)获取更多信息。
---
via: <https://fedoramagazine.org/whats-new-fedora-33-workstation/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora 33 Workstation is the [latest release](https://fedoramagazine.org/announcing-fedora-33/) of our free, leading-edge operating system. You can download it from [the official website here](https://getfedora.org/workstation) right now. There are several new and noteworthy changes in Fedora 33 Workstation. Read more details below.
## GNOME 3.38
Fedora 33 Workstation includes the latest release of GNOME Desktop Environment for users of all types. GNOME 3.38 in Fedora 33 Workstation includes many updates and improvements, including:
### A new GNOME Tour app
New users are now greeted by “a new *Tour* application, highlighting the main functionality of the desktop and providing first time users a nice welcome to GNOME.”
### Drag to reorder apps
GNOME 3.38 replaces the previously split Frequent and All apps views with a single customizable and consistent view that allows you to reorder apps and organize them into custom folders. Simply click and drag to move apps around.
### Improved screen recording
The screen recording infrastructure in GNOME Shell has been improved to take advantage of PipeWire and kernel APIs. This will help reduce resource consumption and improve responsiveness.
GNOME 3.38 also provides many additional features and enhancements. Check out the [GNOME 3.38 Release Notes](https://help.gnome.org/misc/release-notes/3.38/) for further information.
## B-tree file system
As [announced previously](https://fedoramagazine.org/btrfs-coming-to-fedora-33/), new installations of Fedora 33 will default to using [Btrfs](https://en.wikipedia.org/wiki/Btrfs). Features and enhancements are added to Btrfs with each new kernel release. The [change log](https://btrfs.wiki.kernel.org/index.php/Changelog#By_feature) has a complete summary of the features that each new kernel version brings to Btrfs.
## Swap on ZRAM
Anaconda and Fedora IoT have been using swap-on-zram by default for years. With Fedora 33, swap-on-zram will be enabled by default instead of a swap partition. Check out [the Fedora wiki page](https://fedoraproject.org/wiki/Changes/SwapOnZRAM) for more details about swap-on-zram.
## Nano by default
Fresh Fedora 33 installations will set the EDITOR environment variable to [ nano by default](https://fedoraproject.org/wiki/Changes/UseNanoByDefault). This change affects several command line tools that spawn a text editor when they require user input. With earlier releases, this environment variable default was unspecified, leaving it up to the individual application to pick a default editor. Typically, applications would use
*as their default editor due to it being a small application that is traditionally available on the base installation of most Unix/Linux operating systems. Since Fedora 33 includes nano in its base installation, and since nano is more intuitive for a beginning user to use, Fedora 33 will use nano by default. Users who want vi can, of course, override the value of the EDITOR variable in their own environment. See*
[vi](https://en.wikipedia.org/wiki/Vi)[the Fedora change request](https://fedoraproject.org/wiki/Changes/UseNanoByDefault)for more details.
## Mike
Might try Fedora 33 out I’ve always used deb based distros looking for a stable OS hate W10
## Octi
I hate it too. I only use it because I’m a gamer and it’s the best OS for video games…
I have a buch of computers and my gaming laptop is the only one not running Linux.
## Patrick O'Callaghan
There are ways round that: https://www.quora.com/Is-it-possible-to-run-all-Windows-games-on-Fedora-Linux/answer/Patrick-OCallaghan-4
## Sergey
As far as I know, wayland is not properly supported by nvidia drivers (EGLStreams) and that’s why it’s bad as opposed to AMD video cards.
https://www.phoronix.com/scan.php?page=article&item=ubuntu-2004-waylandgame&num=2
## Roland Hughes
Well, that may or may not be true. It really doesn’t explain whole seconds between mouse wheel scroll and a document actually moving. That’s not a video driver problem. We are talking a machine with 16 Gig of RAM having 8 Gig free every time I check. BOINC automatically hibernates once I touch the keyboard to enter my password so that isn’t grabbing the resources either. Not a mouse problem either as I have it on KVM and works just fine with other even lesser machines. Yes, I’ve tried moving the machine to different KVM port with different KVM cable set.
More to the point, the kludge of an install that must be done means you basically have to turn security off just to get the native NVidia driver so BOINC can access CUDA and I can have the machine help fight COVID-19, HIV, and other killer medical conditions. If Fedora wants to be that finicky it needs to have pre-builts for Nvidia in the repos. Not installed by default, you have to do like Ubuntu does, they are just in the repos and you use a “drivers” utility to identify the one(s) you need.
## Frederik
Nvidia is the bad apple when it comes to hardware support; if nvidia wants to sell its products to linux users, they should start playing nice with the kernel — currently, it seems they are doing everything in their power to play dirty.
If you want to fight various medical problems and use a linux based operating system, consider spending your money on products that are not actively fighting you.
Having prebuilt nvidia drivers in the Fedora repos would make Fedora a solid non-free operating system. Not having them installed by default make little difference. Fedora has plenty of problems on that front already.
## Roland Hughes
Ya know, I’m sure you really believe that, but there isn’t much truth in it.
I have been in IT over 30+ years. I have worked on great big computers all the way down to tiny medical devices. The first versions of Linux I ran I downloaded via 1200baud modem from a BBS and they fit on a single floppy.
Nvida works just fine. The only distros having any issue with it in the past decade (that I have personally tried) are all RPM based. It has been well over a decade since any of the Debian based distros I use have had a problem with it. They all have prebuilt drivers in their non-free repos. Whether the “prebuilt” is actually a full-on pre-built or just a really well tested build from source script with all the black magic hidden from the user I neither know nor care. What I do know is it “just works.” You install Nvidia driver, Boinc, and you can help save lives around the world by crunching numbers for medical research projects, clean water, climate change, and a host of other projects to better the human species.
The last Debian based distro I have personally experienced problems with was Linux Mint in the very last release they did of KDE desktop soooo many years ago. It was something
theydid too. The Ubuntu version they were based on had no issues and neither did the other distros based on the same Ubuntu version.Ubuntu
Puppy
Bhodi
Elementary
It all just works. Nvidia and Boinc happily pair up and run without issue.
Even Arch Linux worked for me in this respect.
Fedora and OpenSuSE are the only two RPM based distros I try and they are also the only two to have continual issues with Nvidia. Everybody else just seems to work.
Please don’t take my word for it. I believe these are the cards I have.
https://www.newegg.com/asus-geforce-gt-630-gt630-sl-2gd3-l/p/N82E16814121778?Item=9SIAGSC8CE2530&Description=nvida%20gt%20630&cm_re=nvida_gt%20630-
-14-121-778--Product&quicklink=trueLooks like they’ve really went up in price too. I paid about $50 for the three I have. Might be one of these
https://www.gpuzoo.com/GPU-ZOTAC/GeForce_GT_630_ZONE_Edition_-_ZT-60415-20L.html
GT 630 based. 2GB RAM. 384 CUDA core.
Find some old machine on the cheap (or a spare you already have) that one will work in.
Visit http://distrowatch.org/ every week and pull down whatever new desktop ISO comes out and install it on that test machine. Install the Nvidia driver, reboot, install Boinc; add a project.
Change to the “Advanced” view of Boinc manager. Under tools you will find an entry that says “Event Log.” When all is right with the world, at the top you will normally see something like this:
Mon 02 Nov 2020 03:58:51 PM CST | | Starting BOINC client version 7.16.6 for x86_64-pc-linux-gnu
Mon 02 Nov 2020 03:58:51 PM CST | | log flags: file_xfer, sched_ops, task, cpu_sched_debug, rr_simulation, work_fetch_debug
Mon 02 Nov 2020 03:58:51 PM CST | | Libraries: libcurl/7.68.0 OpenSSL/1.1.1f zlib/1.2.11 brotli/1.0.7 libidn2/2.2.0 libpsl/0.21.0 (+libidn2/2.2.0) libssh/0.9.3/openssl/zlib nghttp2/1.40.0 librtmp/2.3
Mon 02 Nov 2020 03:58:51 PM CST | | Data directory: /var/lib/boinc-client
Mon 02 Nov 2020 03:58:59 PM CST | | CUDA: NVIDIA GPU 0: GeForce GT 630 (driver version 450.80, CUDA version 11.0, compute capability 3.5, 1999MB, 1958MB available, 692 GFLOPS peak)
Mon 02 Nov 2020 03:58:59 PM CST | | OpenCL: NVIDIA GPU 0: GeForce GT 630 (driver version 450.80.02, device version OpenCL 1.2 CUDA, 1999MB, 1958MB available, 692 GFLOPS peak)
Mon 02 Nov 2020 03:59:03 PM CST | | libc: Ubuntu GLIBC 2.31-0ubuntu9.1 version 2.31
Mon 02 Nov 2020 03:59:03 PM CST | | Host name: roland-amd-desktop
Mon 02 Nov 2020 03:59:03 PM CST | | Processor: 6 AuthenticAMD AMD FX(tm)-6100 Six-Core Processor [Family 21 Model 1 Stepping 2]
Mon 02 Nov 2020 03:59:03 PM CST | | Processor features: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 cx16 sse4_1 sse4_2 popcnt aes xsave avx lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs xop skinit wdt fma4 nodeid_msr topoext perfctr_core perfctr_nb cpb hw_pstate ssbd ibpb vmmcall arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold
Mon 02 Nov 2020 03:59:03 PM CST | | OS: Linux Ubuntu: Ubuntu 20.04.1 LTS [5.4.0-52-generic|libc 2.31 (Ubuntu GLIBC 2.31-0ubuntu9.1)]
Mon 02 Nov 2020 03:59:03 PM CST | | Memory: 23.45 GB physical, 2.00 GB virtual
Mon 02 Nov 2020 03:59:03 PM CST | | Disk: 227.74 GB total, 179.73 GB free
Mon 02 Nov 2020 03:59:03 PM CST | | Local time is UTC -6 hours
Mon 02 Nov 2020 03:59:03 PM CST | | VirtualBox version: 6.1.10_Ubuntur138449
I have a number of machines in my office. Actually, I finally tossed out about half of them last year. For the first time in years I’m down to six. When I don’t need them all for my current project(s) I set them up to run boinc to keep them busy because there was an unfortunate period of time during hardware evolution if you had a system that ran non-stop for over a year then was shut off for months it simply wouldn’t work again no matter what you replaced. File servers back in the Netware days were notorious for this. You never wanted to get the used file server as your desktop computer at work.
I know there is a tiny number of distros that complain profusely about Nvida, but everywhere else it just seems to work.
## Gregory Bartholomew
As I understand it, the problems with nvidia drivers on linux pertain to certain kernels (e.g. https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1860306). I don’t think it really has anything to do with the distro’s packaging system being “rpm based”. Fedora probably sees more of the errors simply because it runs a newer kernel than the other distros.
## Enric
Hmmm, I work at a supercompunting facility (Cartesius and the Lisa clsuter here in the Netherlands). Guess what? We do use NVIDIA hardware, even experimental and betas that NVIDIA themselves provide for us to test.
I assume that you can guess that neither the supercomputer nor the cluster runs on (say) iOS.
Ever heard of CUDA ? Good look with that on Windows.
## Barry Schofield
Here is how to install Nvidia on Fedora 33.
https://www.youtube.com/watch?v=G4MeG_oI6Pc
## Tomas
Have you looked at your NVidia card memory usage? If you are running BOINC on your graphics card and also using it to run your displays your problem may be that your video card is running out of graphics memory. Even if you have plenty of system memory. You might check with nvidia-smi
## Roland Hughes
Well, Fedora 32 is no longer on the machine. It is incredibly doubtful that was the problem. How can I say that?
That machine, equipped as it is, ran
Ubuntu 16 & 18
Puppy from that era
Elementary from that era
and a couple of others I don’t remember
It always ran BOINC. It always had the NVidia driver installed and it never had any “stutter” issues.
I cannot tell you about Fedora 33 because, while I can get the NVidia driver to install, there is a bug in the BOINC package that doesn’t find the CUDA.
What you are talking about is something that would happen once or twice. It wouldn’t consistently be a problem over months. Sometimes there is no work for my BOINC projects.
## George Kowalski
Used to be , nice installation of NVidia specific drives has been dropped.
## Mark Kolesar
I have used both and found Fedora and CentOS to be far more reliable and secure.
Security wise you get the powerful security provided by the SELinux kernel module.
And the packaging system on Fedora is far more sophisticated and reliable than that provided on Debian.
## Lerans
I’m used Fedora for designing and retouch image with gimp. I’m very happy with this Os
## Roland Hughes
It’s too bad SELinux doesn’t play nice with Nvidia (or really any) third party drivers. Makes SELinux just too big of a pain.
## Mark Kolesar
Running AMD, so not had any issues of that sort. But SELinux has earned my respect when I’ve tangled with it a few times in doing doing scripting work on various subsystems. In that case it can be frustrating to work with if you don’t have a solid understanding of it.
## Ars
I have an nvidia card 750TI and had no any problem with it on Fedora 33. The Fedora supports russian file names out from the box. In Ubuntu it was a real problem to make right file names, I have not solved it yet. The only problem I had with Fedora 33 that I had to add win7 to grub for dual booting manually. To me, the Fedora was appeared to be the best distribution for home use.
## Roland Hughes
“No problem with it” != “No problem with NVidia drivers”
There are default generic drivers that will allow it to display something on the monitor. The only way you get access to the CUDA cores for Boinc or anything else is with the actual NVidia driver.
## Roland Hughes
Weeellll, I’ve been to RPM Hell more times than I care to admit over my career. An RPM partially installs and dies at some truly unfortunate step leaving things in such a state you can neither remove it nor install anything else.
Tomato, tomato. Your mileage may very. With .deb files basically being zip files, one can usually fix things. Unpack the .deb and you know exactly what to delete (worst case).
These definitions, while detailed, are too kind.
http://wiki.c2.com/?RpmHell
http://www.softpanorama.org/Commercial_linuxes/Troubleshooting/rpm_hell.shtml
Every time I land in RPM Hell it has little to do with dependency Hell. It’s because an RPM install just died. Many times without any helpful error message. Leaving the system in a state where I can neither remove nor install anything. I had that happen with my very first install attempt with Fedora 32 not all that long ago and that was after my attempt to use OpenSuSE met with failure.
The real problem with security is that when things go sideways you can rarely fix anything.
## Gregory Bartholomew
The pages you linked are very old. The higher-level wrappers — yum and dnf — should solve most of those sort of low-level dependency resolution problems that users may have experience in years past. These days there is even the much higher level “Software” GUI in GNOME. That said, there are way to fix those sort of things if you know how.
For example, to list all the files packaged with an rpm:
To rebuild the rpm database based on what is actually installed:
Usually the simplest solution is to just reinstall the package:
## Roland Hughes
As I stated. Every time I get sent to RPM Hell (and it happened again on my first attempt at installing Fedora 32 not to mention during the OpenSuSE attempt immediately in front of it) it has nothing to do with dependencies. The installation of an RPM dies in such a way that one cannot remove, re-install, or fix it. One cannot remove or install anything else.
This has been a time honored tradition in the world of RPM since SuSE used to sell me a box of disks and two printed manuals. RPM is just a really horrible packaging methodology and that is why there are so many others out there.
As far as package manager being able to “fix” dependency issues, that hasn’t worked for Virtualbox. Right now, today, even if you install python38 Oracle Virtualbox will not install.
[roland@localhost ~]$ sudo dnf install python38
Last metadata expiration check: 0:16:51 ago on Fri 30 Oct 2020 12:45:45 PM CDT.
Package python3.8-3.8.6-1.fc33.x86_64 is already installed.
Dependencies resolved.
Nothing to do.
Complete!
[roland@localhost ~]$ python –version
Python 3.9.0
[roland@localhost ~]$ python3.8
Python 3.8.6 (default, Sep 25 2020, 00:00:00)
[GCC 10.2.1 20200826 (Red Hat 10.2.1-3)] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
[roland@localhost ~]$ sudo dnf install VirtualBox-6.1
Last metadata expiration check: 0:55:29 ago on Fri 30 Oct 2020 01:35:48 PM CDT.
Error:
Problem: conflicting requests
– nothing provides python(abi) = 3.8 needed by VirtualBox-6.1-6.1.16_140961_fedora32-1.x86_64
(try to add ‘–skip-broken’ to skip uninstallable packages)
That exists right now, today, in Fedora 33.
## Gregory Bartholomew
It is odd that your VirtualBox version reports “fedora32” on a Fedora 33 system. Did you perhaps add something like “exclude=VirtualBox” to /etc/dnf/dnf.conf? Anyway, it’s been rare that I’ve really had much trouble with RPM. I think your experience is more of an exception than the rule.
## Roland Hughes
Well, it has been every RPM distro I’ve ever tried for more than a decade so for myself and most of the customers I’ve spoken with, it is the norm. I’ve even had a huge multi-national advertising client tell me that it usually takes them 4-5 times to get CentOS to install.
From my side of the fence, having an RPM distro, any RPM distro, install clean on the first try is a once-in-a-decade kind of thing.
## Mark Kolesar
Very odd, opposite of my experience, never have problems with RPM and find it a pleasure to work with. By far the best experience I’ve had with a package manager.
## Matheus Barreto Marques de Carvalho
O Fedora é muito mais estável que qualquer Distro Debian-like, eu comecei através do Ubuntu e hoje alterno entre o Fedora e o openSUSE. A causa são os pacotes RPM que tem uma estabilidade corporativa, fazendo com que o Fedora se mantenha estável mesmo no Wayland.
## Bart
My route was debian – mint – ubuntu – manjaroo – fedora. I know I’ll stay longer now.
## Schykle
This release is a fantastic one! I’ve been following along closely for months now, especially excited by the move to BTRFS as a default. After using it during the Beta, and now the final release, I am convinced that this is the best Fedora release to date. Amazing work, folks! Thanks!
## Shreepad S
I understand that Fedora is a bleeding edge distro where RedHat/ IBM gets to try out new things before bringing them to RHEL but they really shouldn’t do that with features that may affect user data.
I’m opposed to using BTRFS as the default, just as I didn’t like that the default LVM2 partitioning scheme and the resulting boot slowdown from the udev configuration to wait for all devices to settle (which causes problems in devices e.g. Thinkpad T470 where a lot of time is spent waiting for a wireless modem to settle see http://0pointer.de/blog/projects/blame-game.html)
## Schykle
BTRFS isn’t bleeding edge. It’s actually rather reliable, and the defaults are pretty basic, not really touching much in the way of advanced features.
## Steve
Fedora is Leading Edge. If you want to go bleeding, I would suggest Fedora Rawhide… tried installing it a few years ago on the latest spin and it immediately failed even though the checksum matched. I hear it is much better these days.
If you are looking for more stability, you may want to move to CentOS (the rolling distro one), as that one should be more stable than Fedora and still have great features. Since it is downsteam of Fedora, eventually features will be incorporated into CentOS, prior to going into RHEL.
## Vernon Van Steenkist
Enabling swap to RAM, even on upgrades, is the final straw for me. After all, the reason programs get swapped to disk in the first place is because you don’t have enough RAM. With swap on zram, you just create additional CPU load, use even more RAM and exacerbate the situation.
The nice thing is that Fedora keeps its repositories around forever so there is no need to rush to change to another faster, less bloated Linux distribution.
## Matthew Miller
Have you tried swap on zram? The thing is, it actually works. Contents of memory tend to compress very well, and modern compression algorithms on modern hardware — even lower-powered ARM hardware — aren’t onerous. So this is a clear benefit for most low-RAM situations, low overhead in almost every other one, and easy to disable if you have a special case.
## Alexander Borro
It’s fair to say that RAM use is getting uncomfortably high in Fedora, compared to latest POP_OS GNOME with tiling on which stays around 1.2 GB under the same circumstances . 1 FireFox tab, vscode session and a terminal. I get this right now, it’s fairly typical of day to day use.
[afb@localhost ~/chemistrydev/hfscf/cm_build]$ free -h
total used free shared buff/cache available
Mem: 31Gi 4.0Gi 19Gi 964Mi 7.6Gi 26Gi
Swap: 4.0Gi 0B 4.0Gi
It says something how Fedora is configured. It has always been high compared to other distros seems to me and seems to keep growing with releases where others are bringing it down. Take note perhaps ?
Cheers.
## Gregory Bartholomew
FWIW, I’ve heard mention that a concept/practice called “memory overcommit” is largely responsible for the exorbitant memory usage seen in many modern programs. See the below links for some discussion of the topic. I’m not sure that “Fedora” per se is to blame.
stackoverflow.com: why-so-many-applications-allocate
serverfault.com: how-does-vm-overcommit-memory-work
Bear in mind also that sometimes new programs are just plain buggy (e.g. the infamous gnome memory leak) and sometimes Fedora is just the first (or only) platform to see the issue simply because Fedora boldly goes where others dare not tread.
## Roland Hughes
Ubuntu 20.04 LTS, Boinc running with multiple projects. FireFox open with multiple tabs including the one I’m typing in here. Thunderbird open. Submline Text 3 open and whatever the file manager is open.
roland@roland-HP-EliteDesk-800-G2-SFF:~$ free -h
total used free shared buff/cache available
Mem: 23Gi 3.8Gi 15Gi 364Mi 3.5Gi 18Gi
Swap: 2.0Gi 0B 2.0Gi
roland@roland-HP-EliteDesk-800-G2-SFF:~$
I honestly expected Boinc to consume all available RAM with as many projects as it has running.
Keep in mind that most Linux distros use a big chunk of RAM for disk caching. An extra couple of Gig for Read/Write cache can make a world of difference when it comes to I/O throughput, at least as it appears to the end user.
## jgetsoian
The memory hog is primarily Gnome. More like 500-600mB RAM consumed in a fully dressed out KDE desktop install.
## Vernon Van Steenkist
“Have you tried swap on zram? The thing is, it actually works. ”
What does this mean works? Works at what? Nobody doubts that you can create a ramdisk and use it as a swap partition. The point is if the kernel is sending programs to swap, you already have a low RAM situation. Why would you want to make the low RAM situation worse by allocating some of it for a RAM disk? zram is especially onerous for servers where you want the kernel to be able to allocate as much memory as possible for disk caching.
Rather than working to make Fedora more memory efficient reducing the need for swap, Fedora has decided to implement gimmicks like memory compression and add even more bloat becoming more and more like Windows after every new release.
## Gregory Bartholomew
Hi Vernon.
There are three resources at interplay — I/O, RAM, and CPU. With traditional swap, insufficient RAM is compensated for by using disk storage which creates additional I/O. Unfortunately, on modern systems, using traditional swap tends to cause the computer to become severely I/O bound (this makes the system seem extremely slow or unresponsive and might also be indicated by a hard drive activity LED flashing very intensely).
The real problem is, of course, that the system has insufficient RAM and the real solution is to buy more RAM (or to fix whatever program is hogging too much RAM). Because offloading to disk storage was not working in many situations on modern systems, some systems have switched to using a combination of ZRAM and process throttling. ZRAM is effectively offloading some of the extra “load” on RAM to the CPU (compression requires extra CPU cycles) and selective process throttling is used to ensure that only the few programs that are using too much RAM suffer reduced performance rather than the whole system.
Again, all of this only kicks in when/if the system starts to run low on RAM. On systems that have sufficient RAM for the tasks they are trying to perform, no significant performance penalty should be noticeable.
## Alexander Borro
@ Gegroy Note that I specified “same programs, same scenario”.POP_OS doesn’t get close to that use of memory, … just to clear. I have monitored it a bit more since, it seems to VARY a lot. I have seen it down to 1.6 Gb no apps- running at all. where only 865 MB is used in POP_OS i.e well below 1G mark on POP, considering it’s GNOME that’s very good indeed, so .. it has something to do with Fedora configuration.
Anyway, It’s no big deal to me;. I have plenty RAM but I use plenty of it for my calculations that is capable of eating most of that … if I want, I just would have liked to seen lower RAM use for what is essentially vanilla GNOME. I used GNOME Manjaro for a wile last year too, that had a similar footprint to POP_OS. Fedora is the hungry one (ubuntu is pretty much up there also with Fedora too).
## David Stockwell
“The real problem is, of course, that the system has insufficient RAM”
Actually, the real problem is that current browsers (Chrome, Edge, etc.) assume that every system has 32GB+ of RAM and thus spawns as many sub-processes as possible.
My aging everyday desktop has 16GB (and due to motherboard limitation, will not take any more), and I can look at W10 task manager and see 20 Chrome background processes just hanging around…three largest take up 479MB, 295MB, and 113MB. And then 21 foreground processes. About a couple of Gig right there, sitting idle.
## Roland Hughes
“Modern hardware” being code for “bleeding edge.” Massive number of corporate computers out there running i7-gen4 and i5-gen5. Even larger number of users who bought off-lease versions of those because they were well under $300 and more than a regular user needed.
Well, until a bloated OS wanting “modern hardware” plopped its thousand pound behind on the machine and made it run like an NCR PC4 from the 1980s.
I’ve got the previous release of Fedora running on an i7-gen4 HP Elite something or other. Man is it bursty-sluggish-stuttery. Previously had NEON on same machine and it didn’t perform like this. Needed to do some RPM building/testing so had to pick one and OpenSuSE failed spectacularly on the machine.
Fedora really really really really really needs to improve its support for BOINC and NVidia drivers, especially during COVID-19 when many of us are running projects crunching numbers for a cure. That’s what all my “spare” desktop machines do. When I don’t need them for a current consulting project they get a Linux distro, NVidia drivers, and run BOINC.
For those who have never heard of BOINC.
https://boinc.berkeley.edu/
Your spare computer time can help make the world a better place . . . just less and less with Fedora.
## Stephen Snow
I have Fedora 33 WS running on a Dell Inspirion 1500e, this is a Turion CPU and 4G ram, 160GB HDD. It isn’t sluggish.
## Roland Hughes
Well, there are entire seconds that pass between mouse wheel scroll and a document in a text editor actually moving and that’s on an i7-gen4 having 16Gig of RAM.
I can move the same document via thumb drive to the lesser i5-gen4 hooked to the same KVM using same mouse and have snappy response to scroll in editor. That lesser machine currently has Ubuntu 20.04 LTS.
Given your comments about Vim, I would hazard a guess you are mostly in a terminal, not using graphical editors or word processors, correct? Probably not even using a mouse in the terminal, correct?
## Stephen Snow
I use both actually, as the needs determine. I didn’t say my Dell was “snappy”, just that it isn’t sluggish. What exactly is your problem with vi or vim? If you don’t like it, don’t use it, nano is available in the terminal too.
## Roland Hughes
Certain system utilities that “popped up an editor” used to remove the option of “don’t use it” by throwing vi at us. A token few were polite enough to look around for Jed.
https://www.jedsoft.org/jed/
In a terminal for a quick edit Nano is fine. I usually keep a copy of Jed installed on all Linux distros just so fewer things would force vi upon me.
As has been said many times in many places:
vi is from a time when programmers lived in caves and ate their young.
vim is from a time when programmers left the caves but still ate their young.
Emacs is from a time when programmers moved back into the caves and really seriously tried to stop eating their young.
And that is coming from a guy that has a GUI Emacs book ready for first round editing.
Current “idle time” project is adding Themes and EDT keypad navigation to Diamond.
https://github.com/RolandHughes/diamond
You want the diamond-themes branch
It’s still got a ways to go but is quite usable now. Working on dev_doc so that others might participate. Fedora is on a machine because I’ve already added a Debian creation script and now need to add an RPM. After that an MSYS package. Then I ask Barb (Diamond creator) if she wants to pull to make this official. If not, a shiny new OpenSource project named RedDiamond will suddenly appear.
As they say in the land of Emacs:
If Emacs had an editor it would be one heck of an operating system!
## Gregory Bartholomew
Hi Vernon:
You (and others) may find the October 13th Fedora Council Update (beginning at time index 34:35) interesting: https://youtu.be/BywEXtMf4Oc?t=2075 If nothing else, it shows that the folks working on the Fedora Project are trying to improve Fedora’s performance and resource management. It is a complex topic that requires many parts to work together.
## jrau9115
macOS has done something similar for years and it works quite well. Give it a shot before deciding not to upgrade. VirtualBox with a test VM is easy enough to setup 🙂
## aji sudarmawan
SALAM AJI SUDARMAWAN .. SAYA SUDAH KEMBALI LAGI KE RED HAT 7.1 , 7.2 ..MAHASISWA MENYEBALKAN DIBAYAR UNTUK PAKAI UBUNTU 5.0 MALAH KETERUSAN DISTRO memakai YAnG LAIN selama 20 tahun .. GEBUKIN pukuL SAJA..MAUNYA GRATIS MULU GAK BAYAR BAYAR..MURAH ANN SEMUA..semuaya terLibat meyingkirkan saya
## EL CHURROS
concuerdo
## ok
good for you, i guess?
## ichimokucode
Congrats Fedora team for new released. Gonna try it.
## Doug
About zram + full disk encryption.
Are there any disadvantages from a security standpoint? I was thinking about a cold boot attack extracting swapped data from RAM. Is that possible?
## Patrick O'Callaghan
I don’t see how that would be less secure than swapping to disk.
## Eivind
I think Doug is right about that. The swapped out data on the disk would be encrypted, whereas the data “swapped out to ZRAM” would be compressed, but not encrypted. So it would be marginally(*) less secure than swapping out to the encrypted disk.
(*) Keep in mind that the regular data in RAM also is unencrypted (assuming that no “encrypted RAM” scheme is in use to counter for cold boot attacks).
## Onyeibo
Users who want vi can, of course, override the value of the EDITOR variable in their own environment.
Which is exactly the first thing I did when I was greeted by this surprise. Any way, its good that people can exercise their right to choose.
## Daniel Martin
Doesn’t the ‘SWAP on ZRam’ make hibernation impossible? – I wonder if it’s such a good idea to apply that change to upgrades (as another commenter has stated is the case).
Personally I would like swap on disk for hibernation and ONLY for hibernation.
## Shreepad S
I had exactly this question, hope its clarified…
## Alan
I’m excited about Fedora 33!
## FolkyouAll
Mimimi Windows, mimimi….
## svsv sarma
Some how I am averse to The Gnome Work Station. I am after the GUI and user friendliness. I like and use Cinnamon, as the DE suited me fine, a normal user. Being the official version the WS may have many advantages, but the Cinnamon DE is comfortable enough with features I want. I earnestly hope that all Fedora flavors are carved out of the original Fedora and in no way different from the WS basically.
## Shrihari Alawani
Having issues; 3 errors below – Can someone help?
root@localhost Shri]# sudo dnf system-upgrade download –refresh –releasever=33 –skip-broken
< … CONTENT CLIPPED BY MODERATOR … >
– problem with installed package eclipse-mylyn-tasks-bugzilla-3.25.0-3.fc32.noarch
[root@localhost Shri]#
## Gregory Bartholomew
Hi Shrihari. This isn’t the best place for support. Can you re-post your request to https://ask.fedoraproject.org/ ?
## DeathStalkr
Is there any exciting features in Fedora 33 KDE Plasma Desktop?
## w56
please dont delete vi. if people need nano no problem but sometimes i install fedora without internet. and vi is usefull.
## Stephen Snow
vi isn’t going anywhere. For those of us who use Vim, and have it set as default already, the upgrade won’t cause a change, the nano as default only applies to fresh installs I thought.
## Roland Hughes
vim /action shudder
vi /action double shudder and point out man has finally invented fire
## Vinícius
I use Fedora 32 with ext4, when update for 33, the file system goes change automatically?
## Stephen Snow
No, with an upgrade you will keep whatever filesystem you had. Only fresh installs get btrfs as default.
## Cuesta
Some peoples know if this update crash Play on Linux and Wine
## Markus
Congratulations to the Fedora Team!
I was about to return my new Lenovo X13 amd since I was unable to adjust the screen brightness on three other linux distributions. How my eyes hurt, this laptop does have a bright screen! I read about the new Fedora, installed it and so far, everything works just fine. Great job!
## Benson
Do you have the 500 nits Privacy Guard display or just the standard FHD 300 nits display?
## Asiri Iroshan
Upgraded from Fedora 32(Workstation) to 33. It went smooth. It was an overnight upgrade and I slept through it. Woke up to Fedora 33 login screen. Fedora upgrade process has been improved significantly. Great work by Fedora contributors as always.
## Marko
Good to be aware as tripped me trying to connect to older Windows RDP: https://fedoraproject.org/wiki/Changes/StrongCryptoSettings2
## Taras Shevchenko
Nano by default? This decision makes me sad.
## Baback Ashtari
After many years of using macOS, I decided to check out Linux distros. I do dislike Windows, and do “LOVE” macOS. But well, I can’t afford it anymore. So… I tested 10 distros based on YouTube intros, but suddenly I watched a Linux professional explained the differences fairly and logically. He Introduced Mint, Manjaro and on top of them, Fedora. I disapproved Mint in the first hour of working with it. Manjaro was really good, but it had some bugs in home networking especially that it did not support afp protocol. So I tried fedora. I fell in love with it in live testing! Seriously this is amazing! Pretty fast, solid, stable, supports afp and many other lovely things. I am currently waiting for Virtualbox update so I can install and use pro apps that I used in mac. I am little by little switching!
## Roland Hughes
Nano by default.
This decision is phenomenal!!!!!
Vi is from a time when programmers lived in caves and ate their young.
Vim is from a time when programmers left the caves but still ate their young.
Emacs is from a time when programmers returned to living in caves and
reallyreally really tried to stop eating their young.And I say this as someone who wrote a book on Emacs that is headed off for editing followed by print.
I too am waiting for a Virtualbox release. There seems to be no way of getting around Virtualbox wanting Python 3.8 when Python 3.9 is installed. Even installing 3.8 won’t make things work.
There is a rather substantial Boinc bug as well.
Nvidia driver 450.80.02 worked with Boinc under Fedora 32 but Boinc can’t find any available GPU under Fedora 33.
## jesse
Why don’t we ever hear about Plasma workstation?
It is a great Desktop Environment and deserves a lot of focus too. It is much improved from several years ago.
Is there going to be any focus on it in the future?
## Roland Hughes
Agreed. If you have a Buffalo NAS you probably have to fix it no matter what distro you are running. I had to fix it no Ubuntu as well.
https://www.logikalsolutions.com/wordpress/information-technology/make-ubuntu-work-with-your-network-drives/
## lemc
As I have been doing for two years, I did a fresh install of Fedora Workstation 33 using the Fedora-Server-netinst-x86_64 image. When there was the option for the “Base Environment”, I just changed from “Fedora Server Edition” to “Fedora Workstation”. Other than that, I used mostly default settings of the Anaconda installer. However, when checking “File Systems” in the Gnome System Monitor utility, the “Type” of the first two partitions, “/” and “/boot”, is “xfs”. Shouldn’t it be BTRFS, the new default for the Workstation edition ?
## Tamim
Awesome guys.Am just loving it. I was breaking my head on Windows 10 to connect HDMI video and audio. HDMI Audio never worked on Windows 10 at all. Tried just live version of Fedora and it is working out of the box.
Great software.
## Brian Chadwick
I find the comments by Mr. Hughes to be somewhat odd. I have Fedora 33 running on an i7-4790, and an i7-2600, and a Core 2 Quad Q9500 (8GB RAM) … and an old old laptop, running an i5 M430 (4GB RAM). On the old old laptop, yes, loading applications is slow. BUT, once in memory, I don’t find this sluggishness that is referred to. And in the case of the i7’s I have NEVER experienced a situation where one moves the mouse, and one second later the display moves. And as for the Core 2 Quad, it’s working quite fine here and is perfectly acceptable in responsiveness.
And further, who suffers RPM dependency hell in the last 5 years or probably more? … I am damned sure I haven’t. If one uses RPM directly, then sure, you will probably have dependency hell. But DNF/YUM long ago sorted that out.
And, I have installed countless Fedora and CentOS installations, and NEVER had an installation fail on the first install. Just what sort of hardware is it that requires 4 or 5 attempts at installation? … BUGGY/broken hardware I think.
One does wonder why it is that “some” people seem to have all these problems, when most others, like me, rarely have any issue with Fedora. In fact, I am still with Fedora after 15 years, because I have tried all of the other distributions and find them quite a lot more buggy, than leading edge Fedora.
As for vi vs nano etc etc … give me vi anyday. If one can’t remember a few basic keystrokes, then frankly, I just have to wonder.
## Barry Schofield
Unable to upgrade I go to software and click on fedora 33. I get the same problem
Cannot upgrade to fedora 33. Cannot download rpms/MaraiDB-client-10-4.14.1fc30x68664rpms. ..cannot find in Mirrors.
I have removed MariaDB still will not upgrade. I have put in the latest MariaDB but still always the same message.
## Gregory Bartholomew
Hi Barry. This isn’t the best place for support. Can you repost your question on https://ask.fedoraproject.org/ ?
## joha
do you know how long will F32 be maintained?
## Patrick O'Callaghan
Version N is EOL’ed about a month after version N+2 is released, so F32 should have roughly 6 months to go as of now.
## Aji sudarmawan
Call Fedora and buy hardisk to take all repository of F32… And say dirumah ranjang 10 meter x 20 meter ada pegas memantul using theory of fisika |
12,803 | 大多数企业网络无法处理大数据负载 | https://www.networkworld.com/article/3440519/most-enterprise-networks-cant-handle-big-data-loads.html | 2020-11-08T18:34:40 | [
"企业",
"大数据"
] | https://linux.cn/article-12803-1.html |
>
> 随着网络中流动着越来越多的数据,由于领导力和技术问题,网络正在滞后于数据的发展速度。
>
>
>

又过了一周,另一项调查发现,IT 已经无法跟上不断膨胀的数据过载。这次的问题将主要是网络带宽和整体性能。
管理咨询公司埃森哲对 [300 名 IT 专业人士进行的一项调查](https://www.accenture.com/_acnmedia/pdf-107/accenture-network-readiness-survey.pdf#zoom=50) 发现,大多数人认为他们企业网络无法胜任处理大数据的任务和物联网部署的任务。只有 43% 的受访公司表示他们的网络已经准备好支持云服务、物联网和其他数字技术。
一个关键原因(58%)是“IT 与商业需求之间的错位”,这延缓了这些项目的进展。这是一个不同寻常的发现,因为 85% 的受访者还表示他们的网络已经完全或者大体上已经准备好支持企业的数字化计划。那么,究竟是哪一种情况呢?
第二和第三大时常提及的障碍是“业务需求和运营需求间固有的复杂性”以及“对带宽、性能等方面的需求超过交付能力”,各占 45%。
由于分析技术和其他大数据技术的推动,大量传输的数据持续涌入网络线路,网络瓶颈持续增长。调查发现,带宽需求并未得到满足,目前的网络性能依旧达不到要求。
其他原因还包括缺乏网络技术、设备扩展和设备老化。
### 网络性能问题的一个解决方案:SDN
埃森哲发现,大多数公司表示 [软件定义网络(SDN)](https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html) 是应对带宽和性能挑战的解决方案,77% 的受访企业在调查中表示正在部署 SDN 或者已完成部署。它指出,虽然 SDN 可能在组织的某部分中存在,它并不总是在整个企业范围内统一地推出。
如今看来,似乎从未有人有足够的预算来满足他们所有的 IT 雄心,但 31% 受访者认为为网络改善提供资金是“简单的”,而且是在网络基础设施团队的控制范围内,相较于直接下属(13%)或基础设施/网络主管和副总裁(19%),首席信息官/首席技术官更可能将融资过程报告为“轻松”(40%)。
报告指出,“仅靠传统网络无法支持数字时代所需的创新和性能。”报告呼吁拥抱新技术,但没有提到 SDN 的名字。同时它还呼吁首席执行官和他们直接下属间加强合作,因为很明显,双方在看待问题的方式上存在分歧。
报告总结说,“我们认为需要一种新的网络范式来确保网络满足当前和未来的业务需求。然而,尽管有进步的迹象,但变革的步伐缓慢。公司必须承担起重担,才能实现统一和标准化企业能力,提供必要的带宽、性能和安全,以支持当前和未来的业务需求”。
---
via: <https://www.networkworld.com/article/3440519/most-enterprise-networks-cant-handle-big-data-loads.html>
作者:[Andy Patrizio](https://www.networkworld.com/author/Andy-Patrizio/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,804 | 5 个我不可或缺的开源工具 | https://opensource.com/article/20/10/open-source-tools | 2020-11-08T18:58:25 | [
"效率"
] | https://linux.cn/article-12804-1.html |
>
> 通过将这些工具放在自己的技能包中,提高你在终端内、外的工作效率。
>
>
>

前段时间,我参与了一个在科技人士中广为流传的 Twitter 话题。“挑战?只挑选五个你不能没有的工具。”我开始结合我的日常生活来思考这个问题,只挑出五个工具并不容易。我使用了许多我认为必不可少的工具,比如用来与同事和朋友联系的 [IRC](https://en.wikipedia.org/wiki/Internet_Relay_Chat) 客户端(是的,我仍然使用 IRC),一个用来做各种事情的出色的文本编辑器,一个用来保持有条不紊的日历应用,以及当需要更直接的互动时的一个视频会议平台。
所以,让我给这个挑战来个变化:选出五个能提高你工作效率的开源工具。这是我的清单。请在评论中分享你的清单。
### tmate

哦,我喜欢这个工具。`tmate` 是著名的 [tmux](https://opensource.com/article/20/7/tmux-cheat-sheet) 终端多路复用器的一个复刻,它允许你启动一个 `tmux` 会话并通过 SSH 共享。你可以用它来进行[结对编程](https://en.wikipedia.org/wiki/Pair_programming)(这是我的主要使用场景),也可以用来进行远程控制。
如果你经常与你的团队成员合作,并且你想要一个简单的、与发行版无关的、开源的方式与他们一起编程(而且共享终端访问对你来说已经足够了),这绝对是你必须加到列表中的东西。
在 [tmate 的网站](https://tmate.io/)上获取更多信息,或者在 [GitHub](https://github.com/tmate-io/tmate) 上查看代码。
### ix
`ix` 是一个命令行粘贴板。你不需要安装任何东西。你可以通过 `curl` 到 [ix.io](http://ix.io/) 站点来创建新的粘贴。例如,`echo Hello world. | curl -F 'f:1=<-' ix.io` 会给你一个到 [ix.io](http://ix.io) 的链接,那里粘贴了消息 “Hello world” 的信息。当你想分享日志用于调试或在没有桌面环境的服务器上保存配置文件时,这非常方便。
有一个缺点是源码还没有公布,尽管它的目的是自由开源。如果你是作者,并且正在阅读这篇文章,请发布代码,这样我们就可以为打磨它的过程做出贡献。
### asciinema
是的,这是另一个终端工具,`asciinema` 可以让你记录你的终端。使用它的方法有很多,但我一般用它来制作演示。它非常容易使用,而且有很多 Linux 发行版和其他平台的软件包。
要想知道它是如何工作的,可以看看这个[酷炫的演示](https://asciinema.org/a/239367)。是不是很棒?
在 [asciinema 的网站](https://asciinema.org/)上获取更多信息,在 [GitHub](https://github.com/asciinema/asciinema) 上访问其源代码。
### GNOME Pomodoro

好了,关于终端工具的介绍就到此为止。现在我想和大家分享一下这个简单的宝物,它让你的工作变得有条不紊。你听说过 [番茄工作法](https://en.wikipedia.org/wiki/Pomodoro_Technique) 吗?Pomodoro 基本上是一个时间管理工具。它使用一个番茄形状的计时器,帮助你将时间分成工作时间和休息时间(默认情况下,25 分钟的工作后有 5 分钟的休息时间)。而且,每隔 4 个“番茄”之后,你就会有更长的休息时间(默认为 15 分钟)。这样做的目的是让你在工作时间内保持专注,而在休息时间内进行伸展和放松。
这听起来非常非常简单,你可能会对让一个番茄形状的时钟来控制你的生活感到犹豫,但它确实帮助我变得跟有条理,并且在试图同时专注于许多事情时避免感到疲惫。
无论你是什么角色,我都强烈推荐这种做法。而在众多实现它的不同工具中,我推荐 GNOME Pomodoro 应用。它适用于主要的 GNU/Linux 发行版,所以它需要你使用 GNOME 桌面环境(这可能是它的缺点)。
在 [GNOME Pomodoro 的网站](https://gnomepomodoro.org/)上查看更多信息,并访问其 [GitHub](https://github.com/codito/gnome-pomodoro) 仓库来获取源码并了解如何做出贡献。
### Jitsi
最后但同样重要的是 Jitsi。当你在一个远程、遍布全球的团队中工作时,你需要一种与人们联系的方式。即时通讯是好的,但有时最好还是开个快速会议,面对面地讨论事情(嗯,看到对方的脸)。有很多[视频会议工具](https://opensource.com/article/20/5/open-source-video-conferencing)可用,但我很喜欢 Jitsi。不仅因为它是免费和开源的,还因为它提供了一个简洁、实用的界面。你可以设置自己的 Jitsi 服务器(用于商业目的),但你也可以通过访问 [Jitsi Meet](https://meet.jit.si/) 网站来试用一个公共的 Jitsi 实例。
设置这种会议的一个好做法是:只有在你心中有明确的议程时才使用它。而且要时刻问自己,这个会议能不能用电子邮件代替?遵循这些准则,谨慎使用 Jitsi,你的工作日将会非常高效!
在 [Jitsi 网站](https://jitsi.org/)上了解更多信息,并通过访问其 [GitHub](https://github.com/jitsi) 仓库开始贡献。
---
我希望我的清单能帮助你在生产力上达到一个新的水平。你的 5 个不能离开的开源生产力工具是什么?在评论中告诉我。
---
via: <https://opensource.com/article/20/10/open-source-tools>
作者:[Victoria Martinez de la Cruz](https://opensource.com/users/vkmc) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some time ago, I engaged with a Twitter thread that went viral among techies. The challenge? Pick only five tools that you cannot live without. I started to think about this in relation to my everyday life, and picking just five tools was not easy. I use many tools that I consider essential, such as my [IRC](https://en.wikipedia.org/wiki/Internet_Relay_Chat) client to connect with my colleagues and friends (yes, I still use IRC), a good text editor to hack on things, a calendar app to keep organized, and a videoconferencing platform when more direct interaction is needed.
So let me put a twist on this challenge: Pick just five open source tools that boost your productivity. Here's my list; please share yours in the comments.
## tmate
Victoria Marinez de la Cruz, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)
Oh, I love this tool. tmate is a fork of the well-known [tmux](https://opensource.com/article/20/7/tmux-cheat-sheet) terminal multiplexer that allows you to start a tmux session and share it over SSH. You can use it for [pair programming](https://en.wikipedia.org/wiki/Pair_programming) (which is my primary use case) or for remote control.
If you collaborate often with your team members, and you want an easy, distro-agnostic, open source way to program with them (and sharing terminal access is enough for you), this is definitely a must-add to your list.
Get more info on [tmate's website](https://tmate.io/), or check out the code on [GitHub](https://github.com/tmate-io/tmate).
## ix
ix is a command-line pastebin. You don't need to install anything; you can create new pastes just by `curl`
ing to the [ix.io](http://ix.io/) site. For example, `echo Hello world. | curl -F 'f:1=<-' ix.io`
will give you a link to ix.io where the message "Hello world" is pasted. This is very convenient when you want to share logs for debugging purposes or to save config files in servers where you don't have a desktop environment.
One downside is that the source code is not yet published, even though it is intended to be free and open source. If you are the author and are reading this post, please post the code so that we can contribute to the polishing process.
## asciinema
Yes, this is another terminal tool. asciinema allows you to record your terminal. There are many ways to use it, but I generally use it to make demos for presentations. It's very easy to use, and there are packages available for many Linux distributions and other platforms.
To see how it works, check out this [cool demo](https://asciinema.org/a/239367). Isn't it great?
Get more information on [asciinema's website](https://asciinema.org/) and access its source code on [GitHub](https://github.com/asciinema/asciinema).
## GNOME Pomodoro

Victoria Martinez de la Cruz, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)
OK, that's enough with the terminal tools. Now I want to share this simple gem for getting and staying organized. Have you heard about the [Pomodoro Technique](https://en.wikipedia.org/wiki/Pomodoro_Technique)? Pomodoro is basically a time-management tool. It uses a tomato-shaped timer that helps you split your time into work chunks and breaks (by default, 25 minutes of work followed by five-minute breaks). And, after every four pomodoros, you take a longer break (15 minutes by default). The idea is that you stay focused during the work time, and you stretch and relax on the breaks.
This sounds very, very simple, and you might be hesitant to allow a tomato-shaped clock to control your life, but it definitely helped me get better organized and avoid exhaustion when trying to focus on many things at the same time.
Whatever your role, I highly recommend this practice. And among the many different tools that implement it, I recommend the GNOME Pomodoro app. It's available for major GNU/Linux distros, so it requires that you use the GNOME desktop environment (this might be its downside).
Check out more information on [GNOME Pomodoro's website](https://gnomepomodoro.org/), and access its [GitHub](https://github.com/codito/gnome-pomodoro) repo to get the source code and learn how you can contribute.
## Jitsi
Last but not least is Jitsi. When you're working on a remote, globally distributed team, you need a way to connect with people. Instant messaging is good, but sometimes it's better to have a quick meeting to discuss things face to face (well, seeing each other faces). There are a lot of [videoconferencing tools](https://opensource.com/article/20/5/open-source-video-conferencing) available, but I like Jitsi a lot. Not only because it's free and open source, but also because it provides a clean, functional interface. You can set up your own Jitsi server (for business purposes), but you can also try out a public Jitsi instance by going to the [Jitsi Meet](https://meet.jit.si/) website.
A good practice for setting up this kind of meeting: use it only when you have a clear agenda in mind. And always ask yourself, can this meeting be an email instead? Follow these guidelines and use Jitsi with caution, and your workday will be extremely productive!
Learn more on [Jitsi's website](https://jitsi.org/) and start contributing by accessing its [GitHub](https://github.com/jitsi) repository.
I hope my list helps you reach the next level in productivity. What are your five, can't-do-without-them, open source productivity tools? Let me know in the comments!
## 10 Comments |
12,806 | 如何清除 Ubuntu 和其他 Linux 发行版的终端屏幕 | https://itsfoss.com/clear-terminal-ubuntu/ | 2020-11-09T10:38:44 | [
"屏幕"
] | https://linux.cn/article-12806-1.html | 
在终端上工作时,通常会发现终端屏幕上显示了太多的命令及其输出。
你可能需要清除终端屏幕并专注于要执行的下一个任务。相信我,清除 Linux 终端屏幕会很有帮助。
### 使用 clear 命令清除 Linux 终端
那么,如何清除 Linux 中的终端?最简单,最常见的方法是使用 `clear` 命令:
```
clear
```
`clear` 命令无需选项。就是这么简单,但是你还需要了解其他一些内容。

`clear` 命令和其他清除屏幕的方法可能取决于你使用的终端模拟器。终端模拟器是用于访问 Linux Shell(命令行)的终端应用。
如果你在带有 GNOME 终端的 Ubuntu 上使用 `clear` 命令,它将清除屏幕,并且你将无法看到之前屏幕上的内容。
在许多其他终端模拟器或 Putty 中,它可能只清除一页屏幕。如果使用鼠标或 `PageUp` 和 `PageDown` 键滚动,那么仍然可以看到以前的屏幕输出。
坦白说,这取决于你的需要。如果你突然意识到需要引用以前运行的命令的输出,那么也许可以使用该方式。
### 在 Linux 中清除终端屏幕的其他方法
`clear` 命令不是清除终端屏幕的唯一方法。
你可以在 Linux 中使用 `Ctrl+L` [键盘快捷键](https://linuxhandbook.com/linux-shortcuts/)来清除屏幕。它适用于大多数终端模拟器。
```
Ctrl+L
```
如果你在 GNOME 终端(Ubuntu 中默认)中使用 `Ctrl+L` 和 `clear` 命令,那么你会注意到它们的影响有所不同。`Ctrl+L` 将屏幕向下移动一页,给人一种干净的错觉,但是你仍然可以通过向上滚动来访问命令输出历史。
**某些其他终端模拟器将此键盘快捷键设置为 `Ctrl+Shift+K`**。
你也可以使用 `reset` 命令清除终端屏幕。实际上,此命令执行完整的终端重新初始化。但是,它可能比 `clear` 命令要花费更长的时间。
```
reset
```
当你想完全清除屏幕时,还有几种其他复杂的方法可以清除屏幕。但是由于命令有点复杂,所以最好将它作为 [Linux 中的别名](https://linuxhandbook.com/linux-alias-command/):
```
alias cls='printf "\033c"'
```
你可以将此别名添加到你的 bash 配置文件中,以便作为命令使用。
我知道这是一个非常基本的主题,大多数 Linux 用户可能已经知道了,但这对于为新 Linux 用户介绍基本主题并没有什么坏处。是不是?
在清除终端屏幕上有些秘密提示吗?为什么不与我们分享呢?
---
via: <https://itsfoss.com/clear-terminal-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you are working in the terminal, often you’ll find that your terminal screen is filled up with too many commands and their outputs.
You may want to clear the terminal to declutter the screen and focus on the next task you are going to perform. Clearing the Linux terminal screen helps a lot, trust me.
## Clear Linux terminal with clear command
So, how do you clear terminal in Linux? The simplest and the most common way is to use the clear command:
`clear`
You need no option with the clear command. It’s that simple but there are some additional things you need to know about it.
*The clear command and other methods of clearing the screen may depend on the terminal emulator you are using. *Terminal emulator is the terminal application that you use for accessing the Linux shell (command line).
If you use clear command on Ubuntu with GNOME Terminal, it will clear the screen and you won’t be able to see what else you had on the screen previously.
In many other [terminal emulators](https://itsfoss.com/linux-terminal-emulators/) or [Putty](https://itsfoss.com/putty-linux/), it may just clear the screen for one page. If you scroll with mouse or PageUp and PageDown keys, you can still access the old screen outputs.
Frankly, it depends on your need. If you suddenly realize that you need to refer to the output of a previously run command, perhaps having that option available will be helpful.
## Other ways to clear terminal screen in Linux

Clear command is not the only way to clear the terminal screen.
You can use Ctrl+L [keyboard shortcut in Linux](https://linuxhandbook.com/linux-shortcuts/?ref=itsfoss.com) to clear the screen. It works in most terminal emulators.
`Ctrl+L`
If you use Ctrl+L and clear command in GNOME terminal (default in Ubuntu), you’ll notice the difference between their impact. Ctrl+L moves the screen one page down giving the illusion of a clean screen but you can still access the command output history by scrolling up.
**Some other terminal emulators have this keyboard shortcut set at Ctrl+Shift+K.**
You can also use reset command for clearing the terminal screen. Actually, this command performs a complete terminal re-initialization. It could take a bit longer than clear command, though.
`reset`
There are a couple of other complicated ways to clear the screen when you want to clear the screen completely. But since the command is a bit complicated, it’s better to use it as [alias in Linux](https://linuxhandbook.com/linux-alias-command/?ref=itsfoss.com):
`alias cls='printf "\033c"'`
You can add this alias to your bash profile so that it is available as a command.
I know this was a pretty basic topic and most Linux users probably already knew it but it doesn’t harm in covering the elementary topics for the new Linux users. Isn’t it?
[13 Linux Terminal Shortcuts Every Power Linux User Must Know [Free Cheatsheet]Use Linux command line like a pro by mastering these Linux terminal shortcuts and increase your productivity. It’s a must for any power Linux user.](https://linuxhandbook.com/linux-shortcuts/)

Got some secretive tip on clearing terminal screen? Why not share it with us? |
12,807 | Linux 内核 5.10 LTS 的一些令人兴奋的改进 | https://itsfoss.com/kernel-5-10/ | 2020-11-09T10:59:52 | [
"内核"
] | https://linux.cn/article-12807-1.html |
>
> Linux 内核 5.10 的开发正在进行中。已确认这是一个长期支持的版本,将带来更新的硬件支持和其他承诺的功能。
>
>
>
### Linux Kernel 5.10 将是长期支持版本
主要稳定内核维护者 **Greg Kroah-Hartman** 在 Linux 基金会欧洲开源峰会的 “Ask the Expert” 环节上发言,确认 Linux 5.10 将是下一个 LTS 版本。
尽管早期有一些关于 5.9 是 LTS 版本的猜测,但 Greg 澄清说,**一年的最后一个内核版本永远是 LTS 版本**。
目前来看,[Linux 内核 5.4](https://itsfoss.com/linux-kernel-5-4/) 系列恰好是最新的 LTS 版本,它增加了很多改进和硬件支持。另外,考虑到开发进度,Linux [内核 5.8](https://itsfoss.com/kernel-5-8-release/) 是目前最大的版本,而 Linux 5.10 的第一个候选版本也很接近,所以下面有很多事情要做。
让我们来看看 Linux 内核 5.10 的一些功能和改进。
### Linux 内核 5.10 特性

**注意:** Linux 内核 5.10 仍处于早期开发阶段。因此,我们将定期更新文章,以更新最新的补充/功能。
#### AMD Zen 3 处理器支持
新的 [Ryzen 5000](https://www.tomsguide.com/news/amd-ryzen-5000-revealed-what-it-means-for-pc-gaming) 产品线是 2020 年最大的看点之一。所以,随着 Linux 内核 5.10 发布候选版本的推出,针对 Zen 3 处理器的各种新增功能也在陆续推出。
#### Intel Rocket Lake 支持
我并不对 Intel 的 Rocket Lake 芯片组在明年(2021 年) Q1 出货报太大希望。但是,考虑到英特尔在不断地压榨 14 纳米制程,看到 Intel Rocket Lake 在 Linux 内核 5.10 上所做的工作,绝对是一件好事。
#### Radeon RX 6000 系列开源驱动
尽管我们是在 Big Navi 揭晓前一天才报道的,但 Radeon RX 6000 系列绝对会是一个令人印象深刻的东西,可以和 NVIDIA RTX 3000 系列竞争。
当然,除非它和 Vega 系列或 5000 系列遇到的同样问题。
很高兴在 Linux 内核 5.10 上看到下一代 Radeon GPU 的开源驱动已经完成。
#### 文件系统优化和存储改进
[Phoronix](https://www.phoronix.com/scan.php?page=article&item=linux-510-features&num=1) 报道了 5.10 也对文件系统进行了优化和存储改进。所以,从这一点来看,我们应该会看到一些性能上的改进。
#### 其他改进
毫无疑问,你应该期待新内核带来大量的驱动更新和硬件支持。
目前,对 SoundBlaster AE-7 的支持、对 NVIDIA Orin(AI 处理器)的早期支持以及 Tiger Lake GPU 的改进似乎是主要亮点。
Linux 内核 5.10 的稳定版本应该会在 12 月中旬左右发布。它将被支持至少 2 年,但可能一直会有安全和 bug 修复更新,直到 2026 年。因此,我们将继续关注下一个 Linux 内核 5.10 LTS 版本的发展,以获得任何令人兴奋的东西。
你对即将发布的 Linux 内核 5.10 有什么看法?请在评论中告诉我们你的想法。
---
via: <https://itsfoss.com/kernel-5-10/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,809 | Linux 黑话解释:什么是 Linux 中的 GUI、CLI 和 TUI? | https://itsfoss.com/gui-cli-tui/ | 2020-11-10T09:21:00 | [
"GUI",
"CLI",
"黑话解释",
"TUI"
] | https://linux.cn/article-12809-1.html | 
当你开始使用 Linux 并关注关于 Linux 的网站和论坛时,你会经常遇到诸如 GUI、CLI 等术语,有时还会遇到 TUI。
这一章的 Linux 黑话解释简要解释了这些术语,以便你作为一个(新的)Linux 用户在使用这些缩写词时能够更好地理解上下文。
说实话,像 GUI、CLI 或 TUI 这样的术语并不是 Linux 的专属术语。这些都是通用的计算术语,你会发现在非 Linux 的讨论中也会用到它们。
### GUI - <ruby> 图形用户界面 <rt> Graphical User Interface </rt></ruby>
这可能是你在这里最常遇到的词汇。这是因为我们专注于桌面 Linux 用户,并试图涵盖易于使用的图形化方法和应用程序。
GUI 应用程序(或图形应用程序)基本上是指任何可以与你的鼠标、触摸板或触摸屏交互的东西。有了图标和其他视觉概念,你可以使用鼠标指针来访问功能。

在 Linux 上,[桌面环境](https://itsfoss.com/what-is-desktop-environment/)为你提供了与系统交互的图形界面,然后,你可以使用 GUI 应用程序,如 GIMP,VLC、Firefox、LibreOffice、文件管理器等来完成各种任务。
GUI 使普通用户的计算机使用变得更加容易,否则它将仍然是一个极客专用区。
### CLI - <ruby> 命令行界面 <rt> Command Line Interface </rt></ruby>
CLI 基本上是一个接受输入来执行某种功能的命令行程序。基本上,任何可以在终端中通过命令使用的应用程序都属于这一类。

早期的电脑与操作系统交互没有鼠标,你必须使用命令与机器互动。
如果你认为这都算困难,那你应该知道,早期的计算机甚至没有一个屏幕可以看到正在输入的东西,他们用实体的纸质打印机看到他们的输入命令。我从来没有用过这样的电脑,也没有在现实生活中看到过。我用过的最接近的东西是学习期间的单片机套件。

现在的 CLI 还有用吗?当然有。命令总是有它的好处,特别是当你处理操作系统的核心功能和配置时,比如设置防火墙、管理网络甚至[包管理](https://itsfoss.com/package-manager/)。
你可能会有一个基于 GUI 的应用程序来完成同样的任务,但命令可以让你更精细地访问这些功能。在一些情况下,你会发现 GUI 应用程序也会用命令(在它们的代码中使用)与操作系统交互。

许多流行的 GUI 应用程序往往是基于 CLI 工具的。以[Handbrake](https://itsfoss.com/handbrake/) 为例。这是一个流行的开源媒体转换器,它底层使用的是 [FFMPEG 命令行](https://itsfoss.com/ffmpeg/)工具。
很明显,使用命令行工具没有图形工具那么简单。不要担心。除非你有特殊需要,否则你应该可以用图形化的方式使用 Linux 系统。然而,了解基本的 Linux 命令会有很大的帮助。
### TUI - <ruby> 终端用户界面 <rt> Terminal User Interface </rt></ruby>(也称为<ruby> 基于文本的用户界面 <rt> Text-based User Interface </rt></ruby>)
这是三者中最不常见的名词。TUI 基本上部分是 GUI,部分是 CLI。糊涂了吗?让我为你解释一下。
你已经知道,早期的计算机使用 CLI。在实际的 GUI 出现之前,基于文本的用户界面在终端中提供了一种非常基本的图形交互。你会有更多的视觉效果,也可以使用鼠标和键盘与应用程序进行交互。

TUI 是基于文本的用户界面或终端用户界面的缩写。“基于文本”这个说法主要是因为你在屏幕上有一堆文本,而“终端用户界面”的说法是因为它们只在终端中使用。
TUI 的应用虽然不是那么常见,但你还是有一些的。[基于终端的 Web 浏览器](https://itsfoss.com/terminal-web-browsers/)是 TUI 程序的好例子。[基于终端的游戏](https://itsfoss.com/best-command-line-games-linux/)也属于这一类。

当你在 [Ubuntu 中安装多媒体编解码器](https://itsfoss.com/install-media-codecs-ubuntu/)时,你可能会遇到 TUI,你必须接受 EULA 或做出选择。
TUI 应用程序不像 GUI 应用程序那样用户友好,它们经常会有学习曲线,但它们比命令行工具更容易使用一些。
### 最后……
TUI 应用程序通常也被认为是 CLI 应用程序,因为它们被限制在终端上。在我看来,你是否认为它们与 CLI 不同,这取决于你。
我希望你喜欢这篇 Linux 黑话解释。如果你对这个系列的主题有什么建议,请在评论中告诉我,我将在以后尽量涵盖它们。
---
via: <https://itsfoss.com/gui-cli-tui/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you start using Linux and following Linux-based websites and forums, you’ll often come across terms like GUI, CLI and sometimes TUI.
This chapter of Linux Jargon Buster briefly explains these terms so that you, as a (new) Linux user, can understand the context better when these acronyms are used.
To be honest, the terms GUI, CLI, and TUI are not exclusive to Linux. These are generic computing terms that you’ll find used in non-Linux discussions as well.
## GUI – Graphical User Interface
“GUI” is probably the most common term you’ll come across on It’s FOSS because we focus on desktop Linux users and try to cover the [easy-to-use graphical methods and applications](https://itsfoss.com/essential-linux-applications/).
A GUI application or graphical application is basically anything that you can interact with using your mouse, touchpad, or touch screen. You have icons and other visual prompts that you can activate with your mouse pointer to access the functionalities.
In a Linux distribution, a [desktop environment](https://itsfoss.com/what-is-desktop-environment/) provides the graphical interface for you to interact with your system. Then you can use GUI applications such as GIMP, VLC, Firefox, LibreOffice, and file manager for various tasks.
The GUI has made computing easier for the average user.
## CLI – Command Line Interface
CLI is basically a command line program that accepts inputs to perform a certain function. Any application that you can use via commands in the terminal falls into this category.
*command executed*
*apt-cache*Early computers didn’t have a mouse to interact with the operating system, only keyboards.
If you think that’s difficult, you should know that the earlier computers didn’t even have a screen to see what was being typed; they had actual paper printers to display the typed commands. I have never used such a computer, or even seen one. The closest thing I used were the microcontroller kits during my studies.

*Ken Thompson And Dennis Ritchie Working on developing UNIX operating system on PDP 11 computer. |*[Image Credit](https://liucs.net/cs101f16/n8-os.html?ref=itsfoss.com)
Is CLI relevant these days? Absolutely. Commands always have benefits, especially when you are dealing with the core functioning and configuration of the operating system, such as [setting up a firewall](https://itsfoss.com/ufw-ubuntu/), managing a network or [package management](https://itsfoss.com/package-manager/).
You may have a GUI-based application to do the same task, but commands give you more granular access to those features. In any case, you’ll find that GUI applications also interact with the operating system with commands (used in their code).
Many popular GUI applications are often based on CLI tools. Consider [Handbrake](https://itsfoss.com/handbrake/) for example. It’s a popular open source media converter that uses the [FFMPEG command](https://itsfoss.com/ffmpeg/) line tool underneath.
Quite evidently, using command line tools is not as easy as the graphical ones. Don’t worry. Unless you have specific needs, you should be able to use your Linux system graphically. However, [knowing the basic Linux commands](https://itsfoss.com/essential-ubuntu-commands/) helps a great deal.
**Suggested Read 📖**
[Getting Started With Linux TerminalWant to know the basics of the Linux command line? Here’s a tutorial series with a hands-on approach.](https://itsfoss.com/linux-terminal-basics/)

## TUI – Terminal User Interface
TUI is also known as Text-based User Interface. This is the most uncommon term of the three. TUI is basically part GUI and part CLI. Confused? Let me explain it for you.
You already know that early computers used CLI. Before the advent of the GUI, the text-based user interface provided a very basic kind of graphical interaction in the terminal. You have more visuals and could use a mouse and keyboard to interact with the application.
*nnn File Browser in terminal*TUI stands for text-based user interface or terminal user interface. Text-based because primarily, you have a bunch of text on the screen and terminal user interface because they are used only in the terminal.
TUI applications are not well-known to many users, but there are a bunch of them. [Terminal-based web browsers](https://itsfoss.com/terminal-web-browsers/) are a good example of TUI programs. [Terminal-based games](https://itsfoss.com/best-command-line-games-linux/) also fall into this category.
*CMUS is a terminal-based music player*You may come across TUI when you are [installing multimedia codecs in Ubuntu](https://itsfoss.com/install-media-codecs-ubuntu/) where you have to accept EULA or make a choice.
TUI apps are not as user-friendly as GUI applications, and they often have a learning curve involved, but they are a bit easier to use than the command line tools.
## In the end …
TUI apps are often also considered as CLI applications because they are restricted to the terminal. In my opinion, it’s up to you if you consider them different from CLI.
I hope you liked this part of Linux Jargon Buster. If you have any suggestions for topics in this series, please let me know in the comments, and I’ll try to cover them in the future. |
12,810 | COPR 仓库中 4 个很酷的新项目(2020.10) | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-from-october-2020/ | 2020-11-10T09:57:13 | [
"COPR"
] | https://linux.cn/article-12810-1.html | 
COPR 是个人软件仓库[集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
本文介绍了 COPR 中一些有趣的新项目。如果你第一次使用 COPR,请参阅 [COPR 用户文档](https://docs.pagure.org/copr.copr/user_documentation.html)。
### Dialect
[Dialect](https://github.com/gi-lom/dialect) 使用谷歌翻译将文本翻译成外语。它可以记住你的翻译历史,并支持自动语言检测和文本到语音等功能。用户界面简约,模仿谷歌翻译工具本身,所以它真的很容易使用。

#### 安装说明
目前[仓库](https://copr.fedorainfracloud.org/coprs/lyessaadi/dialect/)在 Fedora 33 和 Fedora Rawhide 中提供了 Dialect。要安装它,请使用下面的命令:
```
sudo dnf copr enable lyessaadi/dialect
sudo dnf install dialect
```
### GitHub CLI
[gh](https://github.com/cli/cli) 是一个官方的 GitHub 命令行客户端。它在终端提供了快速的访问,并完全控制你的项目问题、拉取请求和发布。议题(和其他东西)也可以在浏览器中轻松查看,以获得更标准的用户界面,或与他人分享。

#### 安装说明
目前[仓库](https://copr.fedorainfracloud.org/coprs/jdoss/github-cli/)在 Fedora 33 和 Fedora Rawhide 中提供了 `gh` 。要安装它,请使用下面的命令:
```
sudo dnf copr enable jdoss/github-cli
sudo dnf install github-cli
```
### Glide
[Glide](https://github.com/philn/glide) 是一个基于 GStreamer 的极简主义媒体播放器。它可以播放任何 GStreamer 支持的多媒体格式的本地和远程文件。如果你需要一个多平台的具有简单用户界面的媒体播放器,你可能会想试试 Glide。

#### 安装说明
目前[仓库](https://copr.fedorainfracloud.org/coprs/atim/glide-rs/)在 Fedora 32、33 和 Rawhide 中提供了 Glide。要安装它,请使用下面的命令:
```
sudo dnf copr enable atim/glide-rs
sudo dnf install glide-rs
```
### Vim ALE
[ALE](https://github.com/dense-analysis/ale) 是 Vim 文本编辑器的一个插件,它提供了语法和语义错误检查。它还带来了诸如代码修复和许多其他类似于 IDE 的功能,如 TAB 补全、跳转到定义、查找引用、查看文档等。

#### 安装说明
目前[仓库](https://copr.fedorainfracloud.org/coprs/praiskup/vim-ale/)在 Fedora 31、32、33 和 Rawhide 还有 EPEL8 中提供了 `vim-ale` 。要安装它,请使用下面的命令:
```
sudo dnf copr enable praiskup/vim-ale
sudo dnf install vim-ale
```
编者注:可在[此处](https://fedoramagazine.org/?s=COPR)查阅以前的 COPR 文章。
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-from-october-2020/>
作者:[frostyx](https://fedoramagazine.org/author/frostyx/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software
that isn’t carried in Fedora. Some software doesn’t conform to
standards that allow easy packaging. Or it may not meet other Fedora
standards, despite being free and open-source. COPR can offer these
projects outside the Fedora set of packages. Software in COPR isn’t
supported by Fedora infrastructure or signed by the project. However,
it can be a neat way to try new or experimental software.
This article presents a few new and interesting projects in COPR. If
you’re new to using COPR, see the [COPR User Documentation](https://docs.pagure.org/copr.copr/user_documentation.html)
for how to get started.
## Dialect
[Dialect](https://github.com/gi-lom/dialect) translates text to foreign languages using Google Translate. It remembers your translation history and supports features such as automatic language detection and text to speech. The user interface is minimalistic and mimics the Google Translate tool itself, so it is really easy to use.
### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/lyessaadi/dialect/) currently provides Dialect for Fedora 33 and Fedora
Rawhide. To install it, use these commands:
sudo dnf copr enable lyessaadi/dialect sudo dnf install dialect
## GitHub CLI
[gh](https://github.com/cli/cli) is an official GitHub command-line client. It provides fast
access and full control over your project issues, pull requests, and
releases, right in the terminal. Issues (and everything else) can also
be easily viewed in the web browser for a more standard user interface
or sharing with others.
### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/jdoss/github-cli/) currently provides *gh* for Fedora 33 and Fedora
Rawhide. To install it, use these commands:
sudo dnf copr enable jdoss/github-cli sudo dnf install github-cli
## Glide
[Glide](https://github.com/philn/glide) is a minimalistic media player based on GStreamer. It
can play both local and remote files in any multimedia format
supported by GStreamer itself. If you are in need of a multi-platform
media player with a simple user interface, you might want to give Glide a try.
### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/atim/glide-rs/) currently provides Glide for Fedora 32, 33, and
Rawhide. To install it, use these commands:
sudo dnf copr enable atim/glide-rs sudo dnf install glide-rs
## Vim ALE
[ALE](https://github.com/dense-analysis/ale) is a plugin for Vim text editor, providing syntax and
semantic error checking. It also brings support for fixing code and
many other IDE-like features such as TAB-completion, jumping to
definitions, finding references, viewing documentation, etc.
### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/praiskup/vim-ale/) currently provides *vim-ale* for Fedora 31,
32, 33, and Rawhide, as well as for EPEL8. To install it, use these
commands:
sudo dnf copr enable praiskup/vim-ale sudo dnf install vim-ale
Editors note: Previous COPR articles can be found [here](https://fedoramagazine.org/?s=COPR).
## Lyes Saadi
Ummm… Dialect is now in Fedora 33… Like from today XD… Sorry, for the bad timing 😛 ! I was keeping the COPR until Dialect was in the official repos…
## frostyx
A bit of bad timing indeed, but on a positive note, I am really happy that you managed to get the package to the official Fedora repositories.
This is a nice example of how simple it is to build packages in Copr and using it as a test environment and a stepping stone towards moving the package to Fedora itself.
## Lyes Saadi
Yeah, sorry again for that bad timing :P.
But yes! COPR is really useful for packagers willing to package something in the official repos. Not all my COPR packages are submitted for Fedora (none of my current repos are for instance… except Dialect), but all my packages which are destined to Fedora go through COPR first to check for eventual problems and to make it available to everyone while waiting for the review process to finish :D.
## hammerhead corvette
Is there a flatpak ???
## Lyes Saadi
On Flathub, yes !
Would you want me to create a Flatpak for Fedora? I’ve never done it, but I’m not against trying 🙂 !
Anyway, you should still be pretty safe with the RPM since it is official.
## Esteban
Why use the gh copr repo instead of the one provided by github? Especially since it seems like the copr repo isn’t staying up-to-date with the official releases?
## frostyx
Thank you Esteban,
the last time I checked there still wasn’t any official repo, so personally, I was very happy that this project appeared.
I cannot tell you whether the project is obsolete now or the author improves those RPM packages somehow, we will need to ask the author.
## Esteban
Yes, when you install the rpm provided by GitHub it sets up a repo for updates.
## Lyes Saadi
Hi! The reason why Joe Doss have a Github Cli COPR repo is because he is trying to get it packaged into the official Fedora repositories ;)! There are several e-mail about that in the devel mailing list.
I guess he is using that repo in order to facilitate the package reviews, and to test those RPM packages and provide them for those who want to test it before it getting approved.
Here is the review request ticket: https://bugzilla.redhat.com/show_bug.cgi?id=1803302 !
## Anon Ymous
COPR or any non supported distro is a threat to the integrity and security of your system. Going back a couple articles to the “web of trust” two part series, one can see that there are problems as is- no need to further complicate security with new packaging systems. Moreover, COPR is not future proof. Looking to something like Flatpak that is containerized and more modern is much better for the future. Many things in Linux are outdated because they are based on Unix theory of 1964- literally. COPR is not really a way forward, it seems a huge threat to security and something to avoid. Thank you for the article, you taught me about something I did not know about. Honestly tho, you also provided a warning for people of an outdated security threat.
## frostyx
Thank you for sharing your perspective on this. I partially agree with some of your points but IMHO the negatives you described needs to be balanced with the added-value that Copr brings to the table. Then it is up to everyone to decide whether to use Copr in their situation or not.
I am not trying to convince anybody that every package in every Copr repo is perfectly safe, well written, and up-to-date. In fact, you get a warning message every time you want to enable a Copr repository in your system and you need to consciously confirm that.
of the main distribution, and quality may vary.
[...]
and packages are not held to any quality or security level.
You will most likely not install a low-level system package from an unknown Copr project on your server. However, in many cases, you want to install some client tool that you trust (it is a popular project on GitHub or something) and Copr is the only place where it is available as an RPM package. You can ditch the tool altogether but then you might be missing out on something, you can clone it and use it from git repo but I would argue that it brings even more issues, you can package it yourself, but then you are wasting a lot of time for packaging it in the first place but also for maintaining the package for new upstream versions. IMHO the least time-consuming and most comfortable option is to use a package from Copr – and optionally reviewing its spec file if you are really concerned about what it does.
Copr is not a new packaging system for Fedora. It is merely a (third-party) build system. Internally it uses Mock to build the packages – which can be also used locally and which is also internally used by Koji (the official Fedora build system). The configuration might differ in few minor details, but in all of those cases, the output is always the same – an RPM package, which can be installed via standard Fedora package managers (Dnf, rpm). Copr provides those packages within a Dnf/Yum repository, which is also a native thing, so you don’t need anything non-standard to work with them.
Only the future will tell, I don’t want to make any predictions. I would say though, that the growing popularity of Copr shows that it is useful for many use-cases, and for me and many people it makes some everyday tasks easier.
## BBBBbbBB
It doesnt matter if you install an rpm for system stuff or some single use thing for cli, like cat with a toaster background.
Any package can compromise the system via postinstall scripts.
## frostyx
True, that’s why I deliberately wrote “want to install some client
tool that you trust” and “optionally reviewing its spec file
if you are really concerned about what it does”.
There is no dark magic regarding Copr, you can always see the spec file and
everything it does. In case you are concerned about your security,
you can always do your own review – nobody is trying to force a
black box upon you.
I agree that security shouldn’t be taken lightly but …
… taking it to the opposite extreme, what would you recommend? Not
installing any software ever because it can potentially have bugs?
## leslie Satenstein
Hi Matt and authors.
It would be fantastic if the fedoramagazine.org was on youtube. I do know that Fedora has a presence there, but that presence is more about administration than it is about the wonderful packages and how-to’s that will attract and keep Fedora fans.
## Anon Ymous
To : frostyx
Thanks for the reply. By “new” i meant in the literal sense, introduction of non officially fedora supported code is “new’, and it was not vetted by Fedora. I really like Fedora, they have an outstanding security record any anything not vetted by the fedora team is both “new” and a security risk. An unnecessary security risk.
Unix practices that can be traced to 1964 are holding Linux (and humanity) back. I believe that things like COPR should be discontinued entirely and replaced with modern approaches such as Flatpak. There is nothing that COPR can do that Flatpak can not do. Have a problem with an app? With COPR it is likely to mess up your file structure, with sandboxed Flatpak you simply remove the container and there is no harm or changes done to your file system.
COPR is the equivalent of batch files in windows. Yes it can be fun to work with and yes it is a tool that can do many things. It is old technology tho, outdated and long ago replaced by far superior, more efficient and safer methods.
Why isn’t COPR supported by Fedora? Fedora is modern, efficient, and has outstanding security practices. COPR is outdated and waste of efficiency and time to tinker with. COPR is not a good fit to the Fedora value system. And sandboxed systems like Flatpak make COPR laughable by comparison. Flatpak is great to use, COPR is a rabbit hole and a time warp that distorts security and growth.
## Artem
COPR is a repository of RPM packages. Technically i suppose COPR could be used for distributing Flatpak packages bases on fedora runtimes 1 as well.
## tsccof
As frostyx rightly pointed out, COPR isn’t a package management system, it’s a package build system.
COPR isn’t outdated, it stems from this idea: that builds should be reproducible from a fresh and minimal Fedora base system, ensuring packages correctly declare all their build-time dependencies. This provides Fedora users with a way to both improve on Fedora itself (by using these packages as references to get merged into Fedora itself), and also enhances the distribution’s usability, since users create an ecosystem of packages around the distro that aren’t part of the main repositories.
Meanwhile, take a look at this link: http://flatkill.org/
Flatpak isn’t inherently more secure because dependencies are distributed as part of the Flatpaks themselves(this is what makes them portable across distros), and security fixes aren’t being provided as quickly. Also, the sandbox is easily broken since most Flatpak applications aren’t really sandboxed.
## BillT
Would be great if the Koha library software was available for fedora. It looks like it is only packaged for Debian and Ubuntu.
## Shlomi Fish
dialect tip: you can use ctrl+tab to switch to different GUI widgets in its window. Took me a while to find out.
## Julius
“you might want to give Glide a try.”
Well, I did it but on my fresh installed f33 it crashes when loading a mp4 file …
## frostyx
Hello Julius,
thank you for the feedback.
It is hard to debug without seeing the traceback. I managed to get
it crashing by
accidentallyuninstalling. Maybe you can check if you have all
gstreamer plugins correctly installed. Please see e.g.
https://docs.fedoraproject.org/en-US/quick-docs/assembly_installing-plugins-for-playing-movies-and-music/
It might be worth creating an upstream issue, so this problem gets
either fixed or documented. Please see
https://github.com/philn/glide/issues
## Artem
You need to enable 3rd-party repositories to play patented or non-free codecs unfortunately. COPR Glide build already have weak deps for them but this only works if you already enabled such repos. Nothing much more maintainer can’t do there, sorry. Only tip in .spec file.
Also thanks @frostyx a lot for help with debugging this issue.
should been added as hard dep. This already fixed.
Please keep in mind that often COPR packages lack of testing and QA. And in general COPR packages it is somewhat something is better then nothing. In same time don’t take my remarks too literally. IMO it still nice to have opportunity to play with package and easy way to install it.
## Al
Do you really want to enable copr.fedorainfracloud.org/lyessaadi/dialect? [y/N]: y
Error: This repository does not have any builds yet so you cannot enable it now.
## Artem
Package available in official repos now.
## sandip rajbhar
Would be great if the Koha library software was available for fedora. thanks for sharing informative articals. |
12,812 | NetMarketShare 报告停止发布:不再跟踪浏览器和操作系统份额 | https://venturebeat.com/2020/11/06/probeat-net-applications-will-no-longer-track-the-browser-wars/ | 2020-11-12T00:50:00 | [
"浏览器",
"NetMarketShare"
] | https://linux.cn/article-12812-1.html | 
十多年来,我一直使用 Net Applications 的 [NetMarketShare](https://www.netmarketshare.com/) 工具来跟踪桌面计算机的浏览器和操作系统市场。这些月度报告对于衡量[哪些浏览器](https://venturebeat.com/2015/05/01/chrome-passes-25-market-share-ie-and-firefox-slip/)和[新版本的操作系统](https://venturebeat.com/2019/09/01/net-applications-windows-10-windows-7-market-share/)正在获得或失去市场份额至关重要。最近,Net Applications 发布了[最后一份 NetMarketShare 报告](https://www.netmarketshare.com/?options=%7B%22filter%22%3A%7B%22%24and%22%3A%5B%7B%22deviceType%22%3A%7B%22%24in%22%3A%5B%22Desktop%2Flaptop%22%5D%7D%7D%5D%7D%2C%22dateLabel%22%3A%22Custom%22%2C%22attributes%22%3A%22share%22%2C%22group%22%3A%22browser%22%2C%22sort%22%3A%7B%22share%22%3A-1%7D%2C%22id%22%3A%22browsersDesktop%22%2C%22dateInterval%22%3A%22Monthly%22%2C%22dateStart%22%3A%222020-10%22%2C%22dateEnd%22%3A%222020-10%22%2C%22segments%22%3A%22-1000%22%7D)。简直不能再糟糕了。
在 Chrome 浏览器巩固了它作为世界上事实上的浏览器的地位之后,一直没有太多的动作。但这种情况可能要改变了。Chrome 浏览器的创造者谷歌,正面临着[一代人以来最大的美国反垄断案件](https://venturebeat.com/2020/10/20/u-s-department-of-justice-files-antitrust-lawsuit-against-google/)。几乎所有收入都依赖谷歌的 Mozilla,[理所当然地会担心“殃及池鱼”](https://venturebeat.com/2020/10/21/mozilla-rightly-fears-collateral-damage-in-google-antitrust-case/)。而与此同时,火狐似乎也无法阻止[市场份额的流失](https://venturebeat.com/2014/11/04/firefox-cant-seem-to-stop-bleeding-market-share/)。相反,凭借其新的 [Chromium Edge 浏览器](https://venturebeat.com/2020/01/15/microsoft-launches-chromium-edge-for-windows-7-windows-8-windows-10-and-macos/),微软正在稳步获得市场份额,而这还是在没有将其[纳入 Windows 10](https://venturebeat.com/2020/10/20/microsoft-windows-10-october-2020-update-chromium-edge/) 的情况下。像 [Brave](https://venturebeat.com/2019/11/13/ad-blocking-browser-brave-launches-out-of-beta/) 这样的新浏览器比以往任何时候都更受欢迎。哦,对[苹果搜索引擎的猜测](https://venturebeat.com/2008/11/13/apples-search-engine-its-probably-not-what-youre-thinking/)[再次](https://www.ft.com/content/fd311801-e863-41fe-82cf-3d98c4c47e26)浮出水面,引发了人们对[谷歌向苹果支付数十亿美元](https://venturebeat.com/2018/11/19/apple-ceo-tim-cook-defends-google-search-deal-but-expects-new-privacy-law/)以使其成为 Safari 中的默认搜索选项的疑问。
默认设置很重要。无论是你的祖母,还是在家工作的同事,这样的普通用户几乎从不改变他们的默认浏览器或搜索引擎。这反过来又影响了谷歌、微软和苹果等科技巨头的底线,更不用说威胁到 Mozilla 等小公司的生存。此外,浏览器的改变经常会导致依靠网站提供服务和销售产品的数百万企业争夺市场。
### 永久损失
浏览器市场份额数据在商业决策中起着至关重要的作用。如果没有确保 Web 服务能够在 Chrome 浏览器中完美运行,那么没人能成功发布 Web 服务。直到在大量浏览器中都能正常工作之前,企业也不会推出新功能。
那么,为什么 Net Applications 要干掉 NetMarketShare 呢?当我告诉你这与这个无可争议的市场领导者有关时,不要表现得很惊讶。
1 月份,谷歌[提议](https://github.com/WICG/ua-client-hints)废除用于识别正在使用的浏览器和操作系统的 User-Agent 字符串,以应对[访客指纹战争](https://venturebeat.com/2019/05/07/google-promises-to-block-cross-site-cookies-and-fingerprinting-in-chrome-announces-ads-transparency-extension/)。Net Applications 表示,这一变化将破坏 NetMarketShare 的设备检测技术,并会“造成长期不准确”。再加上一直以来需要过滤掉爬虫机器人以防止结果歪曲,Net Applications 决定在 14 年后放弃了。
Net Applications 提供的报告是基于每个月从数千个网站的 1 亿次会话中获取的数据。因为它的数据是全球性的,而且该公司不依赖调查或跟踪组件,所以它被普遍认为是一个准确的来源。Net Applications 报告了我所说的<ruby> 用户市场份额 <rp> ( </rp> <rt> user market share </rt> <rp> ) </rp></ruby>:它追踪了每个用户的浏览器和操作系统。还有另外一个<ruby> 使用市场份额 <rp> ( </rp> <rt> usage market share </rt> <rp> ) </rp></ruby>的报告 StatCounter,它每个月都会查看 200 亿次页面浏览量,以确定什么浏览器和操作系统被使用得最多。访问了多个页面的用户被 Net Applications 算作单个用户,而 StatCounter 则在其总数中给予该用户更多的权重。
比起使用市场份额数据,我更喜欢追踪用户市场份额的数据,但从两种资源变成一种资源,无论如何都是一个很大的打击。
### 最终数字
以下是 Net Applications 的最终数据(10 月 1 日报道,覆盖 2020 年 9 月)。
排名前五的桌面浏览器:
* Chrome 浏览器:69.25%
* Edge:10.22%
* 火狐浏览器:7.22%
* IE:5.57%
* Safari - 3.40%
五大桌面操作系统:
* Windows:87.67%
* Mac OS:9.42%
* Linux:2.34%
* Chrome OS:0.42%
* 未知:0.14%
为方便,以下是 Net Applications 公司的公告全文:
>
> **重要通知**
>
>
> 经过 14 年的服务,并被数以万计的文章和出版物作为主要来源,我们将以当前形式淘汰 NetMarketShare。2020 年 10 月是最后一个月的数据。现有账户的所有计费都已停止。所有未付余额将被退还。
>
>
> 为什么要这样做?浏览器(<https://github.com/WICG/ua-client-hints>)即将发生的变化将破坏我们的设备检测技术,并将在很长一段时间内导致不准确。
>
>
> 此外,我们将检测和删除爬虫机器人作为质量控制流程的关键部分。这是我们代码库中最复杂的部分。随着时间的推移,管理这个过程变得越来越困难。因此,与其接受越来越多的不准确程度,我们认为这是一个很好的时间来结束它。
>
>
> **未来**
>
>
> NetMarketShare 将在某个时间点重新出现,专注于电子商务趋势和可验证的用户数据。
>
>
> 我们要感谢多年来使用 NetMarketShare 的所有人。这段旅程始于报道浏览器大战,是每个人都希望从事开发的最迷人和最有趣的产品之一。
>
>
> 祝大家一切顺利。
>
>
> NetMarketshare 团队
>
>
>
我很高兴地看到,NetMarketshare 有一天会回归。但如果没有浏览器和操作系统的数据,就不一样了。
---
via: <https://venturebeat.com/2020/11/06/probeat-net-applications-will-no-longer-track-the-browser-wars/>
作者:[Emil Protalinski](https://venturebeat.com/author/emil-protalinski/ "Posts by Emil Protalinski") 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12810-1.html) 荣誉推出
| 301 | Moved Permanently | null |
12,813 | JavaScript 是如何成为一门严肃的编程语言的 | https://opensource.com/article/20/10/history-javascript | 2020-11-12T01:10:40 | [
"JavaScript"
] | https://linux.cn/article-12813-1.html |
>
> 从最开始作为一种使网站变得漂亮的方式,JavaScript 已转变为一种严肃的编程语言。
>
>
>

JavaScript 的卑微起步始于 1995 年,是由当时在 Netscape 通信公司工作的 Brendan Eich [在短短 10 天内创建的](https://en.wikipedia.org/wiki/JavaScript)。从那时起,JavaScript 已经走过了漫长的道路,从一个让网站变得漂亮的工具变成了一种严肃的编程语言。
在其早期,JavaScript 被认为是一种视觉工具,它使网站变得更有趣和更有吸引力。像 [Jakarta Server Pages](https://en.wikipedia.org/wiki/Jakarta_Server_Pages)(即 JSP,以前称作 JavaServer Pages)这样的语言曾经用来完成渲染网页的繁重工作,而 JavaScript 则被用来创建基本的交互、视觉增强和动画。
长期以来,HTML、CSS 和 JavaScript 之间的分界并不明确。前端开发主要由 HTML、CSS 和 JavaScript 组成,形成了标准 Web 技术的“[多层蛋糕](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/First_steps/What_is_JavaScript)”。

*标准网络技术的“[多层蛋糕](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/First_steps/What_is_JavaScript)”(Mozilla 开发者网络,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
HTML 和 CSS 为内容提供结构、格式和样式。一旦网页要做一些超越了显示静态内容的事情,就是 JavaScript 的用武之地。Ecma 国际部开发了 JavaScript 规范,<ruby> 万维网联盟 <rt> World Wide Web Consortium </rt></ruby>(W3C)开发了 HTML 和 CSS 规范。
### JavaScript 是如何获得突出地位的
JavaScript 是如何成为[最受欢迎的](https://octoverse.github.com/)编程语言的,背后有一段漫长的[历史](https://blog.logrocket.com/history-of-frontend-frameworks/)。早在 20 世纪 90 年代,Java 是王者,不可避免的人们会与它进行比较。许多工程师认为 JavaScript 不是一门好的编程语言,因为它缺乏对面向对象编程的支持。尽管当时并不明显,但其实 JavaScript 的对象模型和功能特性在其第一个版本中就已经出现了。
1995 年 JavaScript 匆匆发布后,网景公司将其提交给了<ruby> 欧洲计算机制造商协会 <rt> European Computer Manufacturers Association </rt></ruby>(ECMA)国际部进行标准化。由此产生了 [ECMAScript](https://en.wikipedia.org/wiki/ECMAScript),这是一个 JavaScript 标准,旨在确保不同 Web 浏览器之间网页的互操作性。ECMAScript 1 于 1997 年 6 月问世,帮助推进了 JavaScript 的标准化。
在此期间,PHP 和 JSP 成为了服务器端编程语言的流行选择。JSP 作为<ruby> 通用网关接口 <rt> Common Gateway Interface </rt></ruby>([CGI](https://en.wikipedia.org/wiki/Common_Gateway_Interface))的首选替代方案获得了突出的地位,因为它可以在 HTML 中嵌入 Java 代码。虽然它很受欢迎,但开发人员发现将 Java 嵌入 HTML 中是不自然的。此外,即使是 HTML 上最简单的文本变化,JSP 也必须经历一个耗时的生命周期。在今天的微服务世界里,面向 JSP 的页面被认为是技术债务。
[PHP](https://en.wikipedia.org/wiki/PHP#:~:text=PHP%20development%20began%20in%201994,Interpreter%22%20or%20PHP%2FFI.) 的工作原理与 JSP 类似,但 PHP 代码以一个通用网关接口([CGI](https://en.wikipedia.org/wiki/Common_Gateway_Interface))的可执行文件来处理。基于 PHP 的 Web 应用比基于 JSP 的应用更容易部署。总的来说,使用 PHP 更容易上手和运行。今天,PHP 和 JavaScript 是创建动态网站最流行的组合之一:PHP 作为服务器端脚本,JavaScript 作为客户端脚本。
伴随着 2006 年 [jQuery](https://en.wikipedia.org/wiki/JQuery) 的发布,JavaScript 的应用越来越多。jQuery 是一个多用途的 JavaScript 库,简化了繁琐的<ruby> 文档对象模型 <rt> Document Object Model </rt></ruby>(DOM)管理、事件处理和 [Ajax](https://en.wikipedia.org/wiki/Ajax_(programming))。
2009 年 [Node.js](https://en.wikipedia.org/wiki/Node.js) 的发布是 JavaScript 发展的转折点。开发者现在可以用 JavaScript 编写服务器端脚本了。紧随其后的是 2010 年发布的 [Backbone.js](https://en.wikipedia.org/wiki/Backbone.js) 和 [AngularJS](https://en.wikipedia.org/wiki/AngularJS) 等框架。这导致了出现了使用单一语言进行全栈开发的概念。
2015 年,Ecma 国际部发布了 ECMAScript 6(ES6),它为编写复杂的应用程序增加了包括类声明在内的重要新语法。其他新特性还包括迭代器、箭头函数表达式、`let` 和 `const` 关键字、类型化数组、新的集合(映射、集合和 WeakMap)、Promise、字符串的模板字元以及许多其它很酷的特性。后来的版本又继续增加了更多的功能,使 JavaScript 更加强大、精简和可靠。
### 总结
在过去的 20 年里,JavaScript 有了长足的进步。现在大多数浏览器都在争相满足合规性,因此最新的规范推出得更快。
根据你的项目需求,有大量稳定的 JavaScript 框架可供选择,包括最流行的 [React](https://reactjs.org/)、[Angular](https://angular.io/) 和 [Vue.js](https://vuejs.org/) 等等。在本系列的下一篇文章中,我将深入探讨为什么 JavaScript 如此受欢迎。
---
via: <https://opensource.com/article/20/10/history-javascript>
作者:[Nimisha Mukherjee](https://opensource.com/users/nimisha) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | JavaScript's humble start began in 1995, when it was [created in just 10 days](https://en.wikipedia.org/wiki/JavaScript) by Brendan Eich, then an employee with Netscape Communications Corporation. JavaScript has come a long way since then, from a tool to make websites pretty to a serious programming language.
In its early days, JavaScript was considered a visual tool that made websites a little more fun and attractive. Languages like [Jakarta Server Pages](https://en.wikipedia.org/wiki/Jakarta_Server_Pages) (JSP; formerly JavaServer Pages) used to do all the heavy lifting on rendered web pages, and JavaScript was used to create basic interactions, visual enhancements, and animations.
For a long time, the demarcations between HTML, CSS, and JavaScript were not clear. Frontend development primarily consists of HTML, CSS, and JavaScript, forming a "[layer cake](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/First_steps/What_is_JavaScript)" of standard web technologies.
opensource.com
HTML and CSS provide structure, format, and style to content. JavaScript comes into play once a web page does something beyond displaying static content. Ecma International develops JavaScript specifications, and the World Wide Web Consortium (W3C) develops HTML and CSS specifications.
## How JavaScript gained prominence
There is a long [history](https://blog.logrocket.com/history-of-frontend-frameworks/) behind how JavaScript came to be the [most popular](https://octoverse.github.com/) programming language. Back in the 1990s, Java was king, and comparisons to it were inevitable. Many engineers thought JavaScript was not a good programming language due to lack of support for object-oriented programming. Even though it was not evident, JavaScript's object-model and functional features were already present in its first version.
After JavaScript's rushed release in 1995, Netscape submitted it to the European Computer Manufacturers Association (ECMA) International for standardization. This led to [ECMAScript](https://en.wikipedia.org/wiki/ECMAScript), a JavaScript standard meant to ensure interoperability of web pages across different web browsers. ECMAScript 1 came out in June 1997 and helped to advance the standardization of JavaScript.
During this time, PHP and JSP became popular server-side language choices. JSP had gained prominence as the preferred alternative to Common Gateway Interface ([CGI](https://en.wikipedia.org/wiki/Common_Gateway_Interface)) because it enabled embedding Java code in HTML. While it was popular, developers found it unnatural to have Java inside HTML. In addition, even for the simplest text change on HTML, JSP had to undergo a time-consuming lifecycle. In today's microservice world, JSP-oriented pages are considered technical debt.
[PHP](https://en.wikipedia.org/wiki/PHP#:~:text=PHP%20development%20began%20in%201994,Interpreter%22%20or%20PHP%2FFI.) works similarly to JSP but the PHP code is processed as a Common Gateway Interface ([CGI](https://en.wikipedia.org/wiki/Common_Gateway_Interface)) executable. PHP-based web applications are easier to deploy than those based on JSP. Overall, it is easier to get up and running with PHP. Today, PHP and JavaScript are one of the most popular combinations for creating dynamic websites. PHP serves as the server-side scripting and JavaScript as the client-side scripting.
JavaScript's adoption grew with the release of [jQuery](https://en.wikipedia.org/wiki/JQuery), a multi-purpose JavaScript library that simplifies tedious Document Object Model (DOM) management, event handling, and [Ajax](https://en.wikipedia.org/wiki/Ajax_(programming)), in 2006.
The turning point for JavaScript came in 2009 when [Node.js](https://en.wikipedia.org/wiki/Node.js) was released. Developers could now write server-side scripting with JavaScript. Closely following were frameworks like [Backbone.js](https://en.wikipedia.org/wiki/Backbone.js) and [AngularJS](https://en.wikipedia.org/wiki/AngularJS), both released in 2010. This led to the concept of full-stack development using a single language.
In 2015, Ecma International released ECMAScript 6 (ES6), which added significant new syntax for writing complex applications, including class declarations. Other new features included iterators, arrow function expressions, let and const keywords, typed arrays, new collections (maps, sets, and WeakMap), promises, template literals for strings, and many other cool features. Later editions have gone on to add more features that have made JavaScript more robust, streamlined, and reliable.
## Conclusion
JavaScript has advanced significantly over the past two decades. Most browsers now compete to meet compliance, so the latest specifications are rolled out faster.
There are a host of stable JavaScript frameworks to choose from, depending on your project requirements, including the most popular ones: [React](https://reactjs.org/), [Angular](https://angular.io/), and [Vue.js](https://vuejs.org/). In the next article in this series, I'll dive into why JavaScript is so popular.
## 2 Comments |
12,814 | 调整你的 Git 配置以适应多个用户 ID 的需要 | https://opensource.com/article/20/10/git-config | 2020-11-12T01:38:16 | [
"Git"
] | https://linux.cn/article-12814-1.html |
>
> 可以使用相同的机器用于工作和个人的 Git 提交,而无需手动重置你的配置。
>
>
>

Git 的 [git config](https://git-scm.com/docs/git-config) 命令可以让你为 Git 设置仓库或全局选项。它有很多选项,其中的一个选项 `includeIf` 在你使用在 Git 时有双重角色时非常方便,比如说,你既是全职的开发者,又在业余时间为开源项目做贡献。在这种情况下,大多数人都不想为两个角色使用一个共同的配置,或者,至少,他们肯定希望保持配置的某些部分是不同的,尤其是当他们在两个角色中使用同一台计算机时。
我的情况就是这样,所以我在 Git 配置中保留了两组不同的邮件 ID。这样一来,在我工作场所的项目仓库中提交的内容就会使用我办公室的邮件 ID,而在我个人 GitHub 帐户中提交的内容则使用我个人的邮件 ID。
以下是我的全局配置(维护在 `$HOME/.gitconfig`)中的一个片段,我将在下文中介绍。
```
[includeIf "gitdir:~/priv_scm/"]
path = ~/priv_scm/.gitconfig
[includeIf "gitdir:~/work_scm/"]
path = ~/work_scm/.gitconfig
```
### 什么是 includeIf?
`includeIf.condition.path` 变量,是 `include` 配置指令的一部分,允许你有条件地设置自定义配置。同时,自定义配置的路径也可以作为指令的一部分来设置。
这个指令支持三个关键字:`gitdir`、`gitdir/I` 和 `onbranch`。我将简单解释一下 `gitdir`,我在上面的代码片段中使用了它。你可以在[文档](https://git-scm.com/docs/git-config#_conditional_includes)中了解其他两个关键词。
在 `includeIf` 指令中使用 `gitdir` 关键字会对模式进行条件检查。根据规则,如果当前工作目录与 `gitdir` 中指定的目录模式相匹配,那么它就会从给定的路径中选取配置。我将在配置片段上应用这个规则来展示它是如何被应用的。
在配置片段中,你可以看到一个简单的模式,`~/`,它与 `gitdir` 关键字一起使用。这个模式会被存储在 `$HOME` 环境变量中的值所替代。
### 如何使用它
如果你使用同一个系统在 GitHub 或 GitLab 上的开源项目上工作,并在工作中提交到 Git 仓库,你可以有两个顶级目录,比如 `$HOME/priv_scm` 和 `$HOME/work_scm`。在这两个目录中,你可以有两个单独的 `.gitconfig` 文件,其中包含与你的 `user.name` 和 `user.email` 相关的设置。然而,它们也可以包含存储在 `$HOME` 的全局 `.gitconfig` 中,它可以保存两个环境通用的所有自定义项。
这里是一个例子 `$HOME/priv_scm/.gitconfig` 的片段:
```
$ cat $HOME/priv_scm/.gitconfig
[user]
name = Ramanathan Muthiah
email = <personal-mailid-goes-here>
```
有了这个配置,你就可以切换目录,并开始在开源项目上工作,而无需手动重置一些与 Git 相关的配置。这些更改会在主 `.gitconfig` 中借助 `includeIf` 条件指令自动处理。
### Git 小贴士
希望这个小贴士能帮助你组织 Git 项目。你最喜欢的 Git 小贴士是什么?请在评论中分享吧!
---
via: <https://opensource.com/article/20/10/git-config>
作者:[Ramanathan M](https://opensource.com/users/muthiahramanathan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Git's [git config](https://git-scm.com/docs/git-config) command (hereafter referred to as "config") enables you to set repository or global options for Git. It has many options, and one of them, `includeIf`
, is handy when you have dual roles using Git, for example, working full time as a developer and contributing to open source projects in your spare time. Most people in this situation don't want to use a common config for both roles or, at the very least, would rather keep certain portions of their config distinct, especially if they use the same computer in both roles.
This is my situation, so I keep two separate sets of mail IDs as part of my Git config. This way, commits in repositories related to projects at my workplace carry my office mail ID, whereas the commits made to repositories hosted in my personal GitHub account use my personal mail ID.
To illustrate, here is a sample snippet from my global config (maintained at `$HOME/.gitconfig`
), which I will describe below.
```
[includeIf "gitdir:~/priv_scm/"]
path = ~/priv_scm/.gitconfig
[includeIf "gitdir:~/work_scm/"]
path = ~/work_scm/.gitconfig
```
## What's includeIf?
The `includeIf.condition.path`
variable, part of the `include`
config directives, allows you to set a custom config conditionally. Also, the path to the custom config can be set as part of the directive.
This directive supports three keywords: `gitdir`
, `gitdir/I`
, and `onbranch`
. I will briefly explain `gitdir`
, which I use in the code snippet above; you can learn about the other two in the [docs](https://git-scm.com/docs/git-config#_conditional_includes).
Using the `gitdir`
keyword in the `includeIf`
directive causes a conditional check to be performed on the pattern. Per the rule, if the current working directory matches the specified directory pattern in `gitdir`
, then it picks the config from the given path. I'll apply this rule on the config snippet to show how it's evaluated.
In the config snippet, you can see a simple pattern, `~/`
, used along with the `gitdir`
keyword. This pattern is substituted with the value stored in the `$HOME`
environment variable.
## How to use it
If you're using the same system to work on open source projects hosted on GitHub or GitLab and committing to Git repositories at work, you can have two top-level directories, like `$HOME/priv_scm`
and `$HOME/work_scm`
. Within these two directories, you can have two separate `.gitconfig`
files with settings related to your `user.name`
and `user.email`
. However, they can also be included in a global `.gitconfig`
stored at `$HOME`
that can hold all the customizations common to both environments.
Here is a snippet of an example `$HOME/priv_scm/.gitconfig`
:
```
$ cat $HOME/priv_scm/.gitconfig
[user]
name = Ramanathan Muthiah
email = <personal-mailid-goes-here>
```
With this config in place, you can switch directories and start working on open source projects without resetting some of the config related to Git manually. These changes are handled automatically in the main `.gitconfig`
with the aid of the `includeIf`
conditional directive.
## Git tips
I hope this tip helps you organize your Git projects. What are your favorite Git tips? Share them in the comments!
## Comments are closed. |
12,816 | 5 种令人惊讶的使用 Jupyter 的方式 | https://opensource.com/article/20/11/surprising-jupyter | 2020-11-12T22:42:16 | [
"Jupyter"
] | https://linux.cn/article-12816-1.html |
>
> Jupyter 不仅仅是一个数据分析工具,让我们看看如何以最有创意的方式使用这个基于 Python 的软件。
>
>
>

[Jupyter](https://jupyter.org/) 项目提供了用 JupyterLab 和 Jupyter Notebook 等交互式编写软件的技术方式。这个软件通常用于数据分析,但你可能不知道(Jupyter 社区也没有想到),你可以用它做多少事情。
以下是我使用 Jupyter 的五大意想不到的创造性方法。
### 1、处理图像
在[图像编辑和处理](https://opensource.com/life/12/6/design-without-debt-five-tools-for-designers)方面,有很多很好的开源工具 —— 从那些可以与 Photoshop 媲美的工具到实验性的 [Glimpse](https://glimpse-editor.github.io/)。但即使有这么多选择,有时我还是不想离开 [Python](https://opensource.com/resources/python) 的世界。
幸运的是,Jupyter 是一个做轻量级图像处理的好选择。利用 Jupyter 直接将 [Pillow](https://pillow.readthedocs.io/en/stable/index.html) 对象显示为图像的优势,让你可以尽情地对图片进行实验。我甚至还用它给孩子[做了一个涂色画](https://opensource.com/article/20/8/edit-images-python)。
### 2、做一个 SSH 跳板遥控器
由于 JupyterLab 可以让你[上传和下载](https://jupyterlab.readthedocs.io/en/stable/user/files.html#uploading-and-downloading)文件、[编辑](https://jupyterlab.readthedocs.io/en/stable/user/files.html#opening-files)文件,甚至[运行终端](https://jupyterlab.readthedocs.io/en/stable/user/terminal.html),所以它拥有制作 SSH 跳板环境所需的所有部件。
通过一些 SSH 转发魔法,你可以让 Jupyter 成为防火墙另一边的[远程控制台](https://opensource.com/article/20/8/remote-management-jupyter)。
### 3、开发 Web 应用程序
我最喜欢的使用 Jupyter 的方式之一是用于一种意想不到的软件开发。我[做了一次演讲](https://opensource.com/article/20/8/write-talk-using-jupyter-notebooks),在演讲中,我使用 Jupyter Notebook 实时开发了一个 [Web 应用](https://github.com/moshez/interactive-web-development/blob/e31ae72d8cab7637d18bc734c4e8afc10c60251f/interactive-web-development.ipynb)。讲演的最后是一个简单的表单,它是 XSS 和 CSS 安全的,并包括一些轻量级的服务器端计算。
一个日常的 Jupyter 用户可能不会期望它是一个最棒的 Web 开发环境,但它是一个非常强大的环境。
### 4、从你喜欢的服务中提取报告
JupyterLab 中的数据分析是一种常见的用法,但<ruby> 自我提升分析 <rt> self-improvement analysis </rt></ruby>呢?
你可以使用 Jupyter 来[分析你的日历](https://opensource.com/article/20/9/analyze-your-life-jupyter)。如果你最喜欢的服务允许 API 导出,甚至可以让你导出一个 CSV,你可以将这些与你的日历进行关联。如果你发现你在社交媒体上发帖的时候,你的日历上写着你应该和你的经理开会,那 Jupyter 也救不了你!
### 5、开发游戏
对于扩大对 Jupyter Notebook 的期望值,我最喜欢的方式是和孩子一起建立一个游戏。我之前写过这方面的文章,有一个使用 [PursuedPyBear](https://ppb.dev/) 和 Jupyter [编写游戏](https://opensource.com/article/20/5/python-games)的分步教程。
在试图弄清游戏机制时,这种迭代式的游戏开发方法特别有用。能够在游戏中途改变规则(对不起,我必须得这样做)是一个改变游戏规则的方法。
你甚至可以使用 IPywidgets 来修改数字参数,就像[这个视频](https://www.youtube.com/watch?v=JaTf_ZT7tE8)所示。
### 下载电子书
JupyterLab 和 Jupyter Notebooks 提供了一个不可思议的实验环境。[下载这本指南](https://opensource.com/downloads/jupyter-guide),其中包含了以令人吃惊的方式使用 Jupyter 的教程。
你是如何以创造性的方式使用它的?在下面的评论中分享你的最爱。
---
via: <https://opensource.com/article/20/11/surprising-jupyter>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Jupyter](https://jupyter.org/) project offers interactive ways to write software with technology like JupyterLab and Jupyter Notebook. This software is commonly used for data analysis, but what you might not know (and the Jupyter community didn't expect) is how many things you can do with it.
Here are my top five unexpected and creative ways to use Jupyter.
## 1. Manipulate images
There are great open source tools out there for [image editing and manipulation](https://opensource.com/life/12/6/design-without-debt-five-tools-for-designers)—from those that rival Photoshop to the experimental work of [Glimpse](https://glimpse-editor.github.io/). Even with all those options, sometimes I just don't want to leave the world of [Python](https://opensource.com/resources/python).
Luckily, Jupyter is a great option for doing light image manipulation. Taking advantage of the fact that Jupyter directly shows [Pillow](https://pillow.readthedocs.io/en/stable/index.html) objects as images lets you experiment with pictures as much as you want. I even used it to [make a coloring book page](https://opensource.com/article/20/8/edit-images-python) for my child.
## 2. Make an SSH jumpbox remote control
Since JupyterLab lets you [upload and download](https://jupyterlab.readthedocs.io/en/stable/user/files.html#uploading-and-downloading) files, [edit](https://jupyterlab.readthedocs.io/en/stable/user/files.html#opening-files) files, and even [run terminals](https://jupyterlab.readthedocs.io/en/stable/user/terminal.html), it has all the pieces necessary to make an SSH jumpbox environment.
With some SSH-forwarding magic, you can make Jupyter your [remote console](https://opensource.com/article/20/8/remote-management-jupyter) on the other side of a firewall.
## 3. Develop web applications
One of my favorite ways to use Jupyter is for an unexpected kind of software development. I [gave a talk](https://opensource.com/article/20/8/write-talk-using-jupyter-notebooks) where I developed a [web application in real time](https://github.com/moshez/interactive-web-development/blob/e31ae72d8cab7637d18bc734c4e8afc10c60251f/interactive-web-development.ipynb) using a Jupyter notebook. The talk concluded with a simple form that is XSS- and CSS-safe and included some light server-side computation.
A day-to-day Jupyter user may not expect it to be a great web development environment, but it's a remarkably powerful one.
## 4. Pull reports from your favorite services
Data analysis in JupyterLab is a common use, but what about self-improvement analysis?
You can use Jupyter to [analyze your calendar](https://opensource.com/article/20/9/analyze-your-life-jupyter). If your favorite services allow API export, or even let you export a CSV, you can correlate those against your calendar. If you find out that you were posting on social media when your calendar said you were supposed to be in a meeting with your manager, however, Jupyter can't do much to help you!
## 5. Develop games
My favorite way to expand the expectations of what I can accomplish in a Jupyter Notebook is by building a game with my child. I wrote about this previously, with a step-by-step tutorial on [writing a game](https://opensource.com/article/20/5/python-games) using [PursuedPyBear](https://ppb.dev/) and Jupyter.
This iterative approach to game development is especially helpful when trying to figure out game mechanics. It's a game-changer (sorry, I had to) to be able to change the rules mid-game.
You can even use IPywidgets to modify the numeric parameters, as [this video](https://www.youtube.com/watch?v=JaTf_ZT7tE8) shows.
[Download the eBook](https://opensource.com/downloads/jupyter-guide)
JupyterLab and Jupyter Notebooks offer an incredible environment for experimenting. [Download this guide](https://opensource.com/downloads/jupyter-guide) that contains tutorials on the surprising ways to use Jupyter.
How are you using it in creative ways? Share your favorites in the comments below.
## 1 Comment |
12,817 | 当 Wi-Fi 成为关键业务时,混合信道架构是最好的多信道选择 | https://www.networkworld.com/article/3386376/when-wi-fi-is-mission-critical-a-mixed-channel-architecture-is-the-best-option.html | 2020-11-12T23:13:15 | [
"Wi-Fi"
] | https://linux.cn/article-12817-1.html |
>
> 混合信道架构是最好的多信道选择,但它并不总是最佳的选择。当需要可靠的 Wi-Fi 时,单信道和混合 AP 提供了令人信服的替代方案。
>
>
>

我曾与许多实施数字项目的公司合作过,结果却发现它们失败了。正确的想法,健全地施行,现存的市场机遇。哪里是薄弱的环节?是 Wi-Fi 网络。
例如,一家大型医院希望通过将遥测信息发送到移动设备,来提高临床医生对患者警报的响应时间。如果没有这个系统,护士了解病人警报的唯一途径就是通过声音警报。在所有嘈杂的背景音中,通常很难分辨噪音来自哪里。问题是这家医院中的 Wi-Fi 网络已经很多年未升级了,这导致信息传递严重延迟(通常需要 4~5 分钟)。过长的信息传递导致人们对该系统失去信心,因此许多临床医生停止使用该系统,转而使用手动警报。最终,人们认为这个项目是失败的。
我曾在制造业、K-12 教育、娱乐和其他行业中见过类似的案例。企业竞争的基础是客户体验,而竞争的动力来自不断扩展又无处不在的无线优势。好的 Wi-Fi 并不意味着市场领导地位,但是劣质的 Wi-Fi 将会对客户和员工产生负面影响。而在当今竞争激烈的环境下,这是灾难的根源。
### Wi-Fi 性能历来不一致
Wi-Fi 的问题在于它本身就很脆弱。我相信每个阅读这篇文章的人都经历过下载失败、连接中断、性能不一致以及连接公用热点的漫长等待时间等缺陷。
想象一下,你在一个会议上,在一个主题演讲之前,你可以随意地发推特、发电子邮件、浏览网页以及做其他事情。然后主讲人上台,所有观众开始拍照,上传并流传信息——然后网络崩溃了。我发现这不仅仅是一个例外,更是一种常态,强调了对[无损 Wi-Fi](https://www.alliedtelesis.com/blog/no-compromise-wi-fi)的需求。
对于网络技术人员的问题是如何让一个地方的 Wi-Fi 达到全部时间都保持不间断。有人说只要加强现存的网络可以做到,这也许可以,但在某些情况下,Wi-Fi 的类型可能并不合适。
最常见的 Wi-Fi 部署类型是多信道,也称为微蜂窝,每个客户端通过无线信道连接到接入点(AP)。高质量的通话体验基于两点:良好的信号强度和最小的干扰。有几个因素会导致干扰,例如接入点距离太近、布局问题或者来自其他设备的干扰。为了最大程度地减少干扰,企业需要投入大量的时间和资金在[现场调查中规划最佳的信道地图](https://www.networkworld.com/article/3315269/wi-fi-site-survey-tips-how-to-avoid-interference-dead-spots.html),但即使这些做得很好,Wi-Fi 故障仍然可能发生。
多通道 Wi-Fi 并非总是最佳选择
------------------
对于许多铺着地毯的办公室来说,多通道 Wi-Fi 可能是可靠的,但在某些环境中,外部环境会影响性能。一个很好的例子是多租户建筑,其中有多个 Wi-Fi 网络在同一信道上传输并相互干扰。另一个例子是医院,这里有许多工作人员在多个接入点间流动。客户端将试图连接到最佳接入点,导致客户端不断断开连接并重新连接,从而导致会话中断。还有一些环境,例如学校、机场和会议设施,那里存在大量的瞬态设备,而多通道则难以跟上。
单通道 Wi-Fi 提供更好的可靠性但与此同时性能会受到影响
------------------------------
网络管理器要做什么?不一致的 Wi-Fi 只是一个既成事实吗?多信道是一种标准,但它并非是为动态物理环境或那些需要可靠的连接环境而设计的。
几年前提出了一项解决这些问题的替代架构。顾名思义,“单信道”Wi-Fi 在网络中为所有接入点使用单一的无线频道。可以把它想象成在一个信道上运行的单个 Wi-Fi 结构。这种架构中,接入点的位置无关紧要,因为它们都利用相同的通道,因此不会互相干扰。这有一个显而易见的简化优势,比如,如果覆盖率很低,那就没有理由再做一次昂贵的现场调查。相反,只需在需要的地方布置接入点就可以了。
单通道的缺点之一是总网络吞吐量低于多通道,因为只能使用一个通道。在可靠性高于性能的环境中,这可能会很好,但许多组织希望二者兼而有之。
混合接入点提供了两全其美的优势
---------------
单信道系统制造商最近进行了创新,将信道架构混合在一起,创造了一种“两全其美”的部署,可提供多信道的吞吐量和单信道的可靠性。举个例子,Allied Telesis 提供了混合接入点,可以同时在多信道和单信道模式下运行。这意味着可以分配一些 Web 客户端到多信道以获得最大的吞吐量,而其他的 Web 客户端则可使用单信道来获得无缝漫游体验。
这种混合的实际用例可能是物流设施,办公室工作人员使用多通道,但叉车操作员在整个仓库移动时使用单一通道持续连接。
Wi-Fi 曾是一个便利的网络,但如今它或许是所有网络中最关键的任务。传统的多信道体系也许可以工作,但应该做一些尽职调查来看看它在重负下如何运转。IT 领导者需要了解 Wi-Fi 对数字转型计划的重要性,并进行适当的测试,以确保它不是基础设施链中的薄弱环节,并为当今环境选择最佳技术。
---
via: <https://www.networkworld.com/article/3386376/when-wi-fi-is-mission-critical-a-mixed-channel-architecture-is-the-best-option.html#tk.rss_all>
作者:[Zeus Kerravala](https://www.networkworld.com/author/Zeus-Kerravala/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,819 | 使用开源可视化工具来理解你的 Python 代码 | https://opensource.com/article/20/11/python-code-viztracer | 2020-11-13T22:56:48 | [
"Python",
"可视化"
] | https://linux.cn/article-12819-1.html |
>
> VizTracer 工具可以可视化并跟踪 Python 代码,让你可以更深入地了解其工作原理。
>
>
>

随着 Python 项目变得越来越大、越复杂,理解起它来就变得充满挑战性。即使是你自己独自编写了整个项目,也不可能完全知道项目是如何工作的。为了能更好的理解你的代码,调试和分析代码变得至关重要。
[VizTracer](https://github.com/gaogaotiantian/viztracer) 是一个这样的工具,它通过跟踪和可视化 Python 代码的执行过程,来帮助你对代码的理解。无需对源代码进行任何更改,VizTracer 即可记录函数的入口 / 出口,函数参数 / 返回值以及任意变量,然后通过 [Trace-Viewer](http://google.github.io/trace-viewer/) 使用直观的谷歌前端界面来显示数据。
下面是一个运行[蒙特卡洛树搜索](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search)的例子:

每个函数都在时间线上以堆栈的形式记录和可视化,这样你就可以看到在运行程序时发生了什么。你可以放大查看任意特定点的详细信息:

VizTracer 还可以自动记录函数参数和返回值。你可以单击函数条目并查看详细信息:

或者你可以创建一个全新的信号,并用它来记录变量。例如,这显示了执行梯度下降时的成本值:

与其他设置复杂的工具相比,VizTracer 使用起来非常简单,并且没有任何依赖关系。你可以从 pip 安装它:
```
pip install viztracer
```
你也可以通过输入来跟踪你的程序(`<your_script.py>` 是你脚本的名称):
```
viztracer <your_script.py>
```
VizTracer 将在你的工作目录中生成一个 HTML 报告,你可以在 Chrome 浏览器中打开它。
VizTracer 还提供了其他高级功能,比如过滤器功能,你可以使用它过滤掉不想跟踪的函数,获得更清晰的报告。例如,要仅包含文件中的函数,你需要:
```
viztracer include_files ./ --run <your_script.py>
```
记录函数参数和返回值:
```
viztracer --log_function_args --log_return_value <your_script.py>
```
记录与某个正则表达式匹配的任意变量:
```
# log variables starts with a
viztracer --log_var a.* --run <your_script.py>
```
你可以通过对源代码进行较小的修改来获得其他功能,例如自定义事件来记录数值和对象。
VizTracer 还包括一个虚拟调试器(vdb),它可以调试 VizTracer 的日志文件。可以用 vdb 调试你运行中的代码(与 [pdb](https://docs.python.org/3/library/pdb.html) 非常相似)以便你了解代码流。有用的是,它还支持时间回溯,因为它知道发生的一切。
与一些原型不同,VizTracer 使用纯 C 语言实现其核心,这将极大地减少开销,使其达到类似于 [cProfile](https://docs.python.org/2/library/profile.html#module-cProfile) 的水平。
VizTracer 是开源的,在 Apache 2.0 许可下发布,支持所有常见的操作系统平台(Linux、macOS 和 Windows)。你可以在 [GitHub](https://github.com/gaogaotiantian/viztracer) 上了解关于它的更多特性并访问源代码。
---
via: <https://opensource.com/article/20/11/python-code-viztracer>
作者:[Tian Gao](https://opensource.com/users/gaogaotiantian) 选题:[lujun9972](https://github.com/lujun9972) 译者:[xiao-song-123](https://github.com/xiao-song-123) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's challenging to understand your Python project as it gets larger and more complex. Even when you write the entire project, it's impossible to know how it works fully. Debugging and profiling your code is essential to better understanding it.
[VizTracer](https://github.com/gaogaotiantian/viztracer) is a tool to help you understand Python code by tracing and visualizing its execution. Without making any changes to your source code, VizTracer can log function entries/exits, function arguments/returns, and any arbitrary variables, then display the data using an intuitive front-end Google [Trace-Viewer](http://google.github.io/trace-viewer/).
Here is an example of running a [Monte Carlo tree search](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search):
(Tian Gao, CC BY-SA 4.0)
Every function is logged and visualized in stack style on a timeline so that you can see what is happening when you run a program. You can zoom in to see the details at any specific point:

(Tian Gao, CC BY-SA 4.0)
VizTracer can also automatically log function arguments and return value; you can click on the function entry and see the detail info:

(Tian Gao, CC BY-SA 4.0)
Or you can create a whole new signal and use it to log variables. For example, this shows the cost value when you do a gradient descent:

(Tian Gao, CC BY-SA 4.0)
In contrast to other tools with complicated setups, VizTracer is super-easy to use and does not have any dependencies. You can install it from pip with:
`pip install viztracer`
And trace your program by entering (where `<your_script.py>`
is the name of your script):
`viztracer <your_script.py>`
VizTracer will generate an HTML report in your working directory that you can open in Chrome.
VizTracer offers other advanced features, such as filters, which you can use to filter out the functions that you do not want to trace so that you'll have a cleaner report. For example, to include only the functions in files, you are interested in:
`viztracer include_files ./ --run <your_script.py>`
To record the function arguments and return value:
`viztracer --log_function_args --log_return_value <your_script.py>`
To log any arbitrary variables matching a certain regex:
```
# log variables starts with a
viztracer --log_var a.* --run <your_script.py>
```
You can get other features, like custom events to log numeric values and objects, by making minor modifications to your source code.
VizTracer also includes a virtual debugger (vdb) that can debug VizTracer's log file. vdb debugs your executed code (much like [pdb](https://docs.python.org/3/library/pdb.html)) so that you can understand the code flow. Helpfully, it supports running back in time because it knows everything that happened.
Unlike some prototypes, VizTracer implements its core in pure C, which significantly reduces the overhead to a level similar to [cProfile](https://docs.python.org/2/library/profile.html#module-cProfile).
VizTracer is open source, released under the Apache 2.0 License, and supports all common operating systems platforms (Linux, macOS, and Windows). You can learn more about its features and access its source code on [GitHub](https://github.com/gaogaotiantian/viztracer).
## 1 Comment |
12,820 | 如何在 Linux 上扫描/检测新的 LUN 和 SCSI 磁盘 | https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/ | 2020-11-14T00:16:21 | [
"iSCSI"
] | https://linux.cn/article-12820-1.html | 
当 Linux 系统连接到 SAN(存储区域网络)后,你需要重新扫描 iSCSI 服务以发现新的 LUN。
要做到这一点,你必须向存储团队提供 Linux 主机的 WWN 号和所需的 LUN 大小。
这篇文章将帮助你[查找 Linux 主机的 WWN 号](https://www.2daygeek.com/how-to-find-wwn-wwnn-wwpn-number-of-hba-card-in-linux/)。
当存储团队将 LUN 与给定的 Linux 主机进行了映射,他们将为你提供新的 LUN 详细信息。
LUN 在存储术语中被称为 LUN 的串行十六进制。
你需要扫描 SCSI 主机来寻找存储团队分配的新 LUN。
这可以通过两种方式进行,扫描每个 scsi 主机设备或运行 `rescan-scsi-bus.sh` 脚本来检测新磁盘。
扫描后可以在 `/dev/disk/by-id` 目录下找到它们。
```
# ll /dev/disk/by-id
total 0
lrwxrwxrwx 1 root root 10 Jul 9 17:52 scsi-60a98000486e542d4f5a2f47694d684b -> ../../sdah
lrwxrwxrwx 1 root root 9 Jul 9 17:52 scsi-60a98000486e542d4f5a2f47694d684c -> ../../sdw
.
.
lrwxrwxrwx 1 root root 10 Jul 9 17:52 scsi-60a98000486e542d4f5a2f47694d684d -> ../../sdjk
lrwxrwxrwx 1 root root 10 Jul 9 17:52 scsi-60a98000486e542d4f5a2f47694d684e -> ../../sdaa
lrwxrwxrwx 1 root root 9 Jul 9 17:52 scsi-60a98000486e542d4f5a2f47694d684f -> ../../sdh
```
另外,如果你已经用 `multipath` 配置了它们,那么可以用 `multipath` 命令找到。
`multipath 主要是配置到 Oracle 数据库服务器中,以提高性能。
```
# multipath -ll
60a98000486e542d4f5a2f47694d684b dm-37 NETAPP,LUN C-Mode
size=512G features='3 queue_if_no_path pg_init_retries 50' hwhandler='1 alua' wp=rw
|-+- policy='round-robin 0' prio=50 status=active
| |- 1:0:4:18 sdoe 128:416 active ready running
| |- 0:0:4:18 sdpq 131:256 active ready running
| |- 0:0:5:18 sdsr 135:496 active ready running
| `- 1:0:5:18 sdsq 135:480 active ready running
`-+- policy='round-robin 0' prio=10 status=enabled
|- 1:0:1:18 sdfw 131:32 active ready running
|- 1:0:0:18 sdci 69:96 active ready running
|- 0:0:1:18 sdbz 68:208 active ready running
|- 0:0:0:18 sds 65:32 active ready running
|- 1:0:3:18 sdmd 69:336 active ready running
|- 1:0:2:18 sdjj 8:464 active ready running
|- 0:0:3:34 sdjt 65:368 active ready running
`- 0:0:2:34 sdgi 131:224 active ready running
```
这个过程适用于基于 Red Hat 6.x、7.x 和 8.x(RHEL - Red Hat Enterprise Linux)的系统,如 CentOS 和 Oracle Linux。
### 方法 1:如何使用 /sys 类文件在 Linux 上扫描新的 LUN 和 SCSI 磁盘
sysfs 文件系统是一个伪文件系统,它为内核数据结构提供了一个接口。
sysfs 下的文件提供了关于设备、内核模块、文件系统和其他内核组件的信息。
sysfs 文件系统通常被挂载在 `/sys`。通常,它是由系统自动挂载的。
你可以使用 `echo` 命令来扫描每个 SCSI 主机设备,如下所示:
```
# echo "- - -" > /sys/class/scsi_host/host[n]/scan
```
当你运行上面的重新扫描所有的命令时,三个破折号(`- – -`)指的是通配符选项。这些值如下:
```
# echo "c t l" > /sys/class/scsi_host/host[n]/scan
```
这里:
* `c`:HBA 上的通道
* `t`:SCSI 目标 ID
* `l`:LUN ID
* `n`:HBA 编号
运行下面的命令来查找系统中所有的主机总线编号:
```
# ls /sys/class/scsi_host
host0 host1 host2
```
得到主机总线编号后,运行以下命令来发现新的磁盘:
```
# echo "- - -" > /sys/class/scsi_host/host0/scan
# echo "- - -" > /sys/class/scsi_host/host1/scan
# echo "- - -" > /sys/class/scsi_host/host2/scan
```
另外,还可以用 `for` 循环用一条命令进行扫描。
```
# for host in ls /sys/class/scsi_host/;do echo "- - -" >/sys/class/scsi_host/${host}/scan; done
```
你可以使用文章开头提到的 [ls 命令](https://www.2daygeek.com/linux-unix-ls-command-display-directory-contents/)来检查它们。
```
# ls /dev/disk/by-id | grep -i "serial-hex of LUN"
```
### 方法 2:如何使用 [rescan-scsi-bus.sh](http://rescan-scsi-bus.sh) 脚本在 Linux 上扫描新的 LUN 和 SCSI 磁盘
确保你已经安装了 `sg3_utils` 包来使用这个脚本。否则,运行以下命令来安装它。
对于 RHEL/CentOS 6/7 系统,使用 [yum 命令](https://www.2daygeek.com/linux-yum-command-examples-manage-packages-rhel-centos-systems/)安装 `sg3_utils`。
```
# yum install -y sg3_utils
```
对于 RHEL/CentOS 8 和 Fedora 系统,使用 [dnf 命令](https://www.2daygeek.com/linux-dnf-command-examples-manage-packages-fedora-centos-rhel-systems/)安装 sg3\_utils。
```
# dnf install -y sg3_utils
```
现在你可以使用 `rescan-scsi-bus.sh` 脚本重新扫描 LUN。
```
# ./rescan-scsi-bus.sh
```
---
via: <https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,822 | 备忘单:提升你的 MariaDB 和 MySQL 数据库技能 | https://opensource.com/article/20/10/mariadb-mysql-cheat-sheet | 2020-11-14T10:48:00 | [
"MariaDB",
"MySQL"
] | https://linux.cn/article-12822-1.html |
>
> 阅读本文并下载我们的免费备忘单,去使用开源的数据库吧。
>
>
>

当你写一个程序或配置一个服务时,你最终都要持久化存储信息。有时候,你只需要一个 INI 或者 [YAML](https://www.redhat.com/sysadmin/yaml-tips) 配置文件就够了。而有时候,一个自定义格式的 XML 或者 JSON 或其他类似的文件会更好。
但也有时候你需要校验输入、快速查询信息、关联数据、通常还要熟练地处理你的用户的请求。这就是设计数据库的目的,而 [MariaDB](https://mariadb.org/)(由 [MySQL](https://www.mysql.com/) 的原始开发人员开发的一个分支) 是一个极佳的选项。在本文中我使用的是 MariaDB,但这些信息同样适用于 MySQL。
通过编程语言与数据库进行交互是很普遍的。正因如此,出现了大量 Java、Python、Lua、PHP、Ruby、C++ 和其他语言的 [SQL](https://en.wikipedia.org/wiki/SQL) 库。然而,在使用这些库之前,理解数据库引擎做了什么以及为什么选择数据库是重要的对我们会很有帮助。本文介绍 MariaDB 和 `mysql` 命令来帮助你熟悉数据库处理数据的基本原理。
如果你还没有安装 MariaDB,请查阅我的文章 [在 Linux 上安装 MariaDB](https://opensource.com/article/20/10/install-mariadb-and-mysql-linux)。如果你没有使用 Linux,请参照 MariaDB [下载页面](https://mariadb.org/download)提供的指导方法。
### 与 MariaDB 交互
你可以使用 `mysql` 命令与 MariaDB 进行交互。首先使用子命令 `ping` 确认你的服务是运行着的,在提示后输入密码:
```
$ mysqladmin -u root -p ping
Enter password:
mysqld is alive
```
为了易于读者理解,打开一个交互式的 MariaDB 会话:
```
$ mysql -u root -p
Enter password:
Welcome to the MariaDB monitor.
Commands end with ; or \g.
[...]
Type 'help;' or '\h' for help.
Type '\c' to clear the current input statement.
MariaDB [(none)]>
```
你现在是在一个 MariaDB 子 shell 中,提示符是 MariaDB 提示符。普通的 Bash 命令在这里不能使用,只能用 MariaDB 命令。输入 `help` (或 `?`)查看命令列表。这些是你的 MariaDB shell 的管理命令,使用它们可以定制你的 shell,但它们不属于 SQL 语言。
### 学习 SQL 基本知识
[结构化查询语言](https://publications.opengroup.org/c449)是基于它们的能力定义的:一种通过有规则且一致的语法来查询数据库中的内容以得到有用的结果的方法。SQL 看起来像是普通的英文语句,有一点点生硬。例如,如果你登入数据库服务器,想查看有哪些库,输入 `SHOW DATABASES;` 并回车就能看到结果。
SQL 命令以分号作为结尾。如果你忘记输入分号,MariaDB 会认为你是想在下一行继续输入你的查询命令,在下一行你可以继续输入命令也可以输入分号结束命令。
```
MariaDB [(NONE)]> SHOW DATABASES;
+--------------------+
| DATABASE |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 ROWS IN SET (0.000 sec)
```
上面的例子显示当前有四个数据库:`information_schema`、`mysql`、`performance_schema` 和 `test`。你必须指定 MariaDB 使用哪个库,才能对该库使用查询语句。指定数据库的命令是 `use`。当你选择了一个库后,MariaDB 提示框会切换为选择的库。
```
MariaDB [(NONE)]> USE test;
MariaDB [(test)]>
```
#### 显示数据库的表
数据库里有*表*,与电子表格类似:有一系列的行(在数据库中称为*记录*)和列。一个行和一个列唯一确定一个*字段*。
查看一个数据库中可用的表(可以理解为多表单电子表格中的一页),使用 SQL 关键字 `SHOW`:
```
MariaDB [(test)]> SHOW TABLES;
empty SET
```
`test` 数据库是空的,所以使用 `use` 命令切换到 `mysql` 数据库:
```
MariaDB [(test)]> USE mysql;
MariaDB [(mysql)]> SHOW TABLES;
+---------------------------+
| Tables_in_mysql |
+---------------------------+
| column_stats |
| columns_priv |
| db |
[...]
| time_zone_transition_type |
| transaction_registry |
| USER |
+---------------------------+
31 ROWS IN SET (0.000 sec)
```
这个数据库中有很多表!`mysql` 数据库是这个 MariaDB 实例的系统管理数据库。它里面包含重要数据,比如用来管理数据库权限的用户结构。这个数据库很重要,你不需要经常直接与它交互,但是使用 SQL 脚本来操作它却很常见。当你学习 MariaDB 时理解 `mysql` 数据库很有用,因为它有助于说明一些基本的 SQL 命令。
#### 检查一个表
这个实例的 `mysql` 数据库的最后一个表名为 `USER`。这个表包含了可以访问这个数据库的用户。当前里面只有一个 root 用户,但是你可以添加不同权限的用户,赋予它们查看、更新或创建数据的权限。你可以查看一个表的列首来了解一个 MariaDB 用户的所有属性:
```
> SHOW COLUMNS IN USER;
MariaDB [mysql]> SHOW COLUMNS IN USER;
+-------------+---------------+------+-----+----------+
| FIELD | TYPE | NULL | KEY | DEFAULT |
+-------------+---------------+------+-----+----------+
| Host | CHAR(60) | NO | PRI | |
| USER | CHAR(80) | NO | PRI | |
| Password | CHAR(41) | NO | | |
| Select_priv | enum('N','Y') | NO | | N |
| Insert_priv | enum('N','Y') | NO | | N |
| Update_priv | enum('N','Y') | NO | | N |
| Delete_priv | enum('N','Y') | NO | | N |
| Create_priv | enum('N','Y') | NO | | N |
| Drop_priv | enum('N','Y') | NO | | N |
[...]
47 ROWS IN SET (0.001 sec)
```
#### 创建一个新的用户
不论你是否需要一个普通的账号来管理数据库或者为计算机配置数据库(例如安装 WordPress、Drupal 或 Joomla时),在 MariaDB 中多建一个用户账号是很普遍的。你可以通过向 `mysql` 数据库的 `USER` 表中添加一个用户或使用 SQL 关键字 `CREATE` 来提示 MariaDB 创建一个 MariaDB 用户。使用 `CREATE` 来创建新用户会默认执行一些有用的方法,因此你不需要手动生成所有的信息:
```
> CREATE USER 'tux'@'localhost' IDENTIFIED BY 'really_secure_password';
```
#### 查看表的字段
你可以使用 `SELECT` 关键字来查看数据库表的字段和值。这本例中,你创建了一个名为 `tux` 的用户,因此查询 `USER` 表中的列:
```
> SELECT USER,host FROM USER;
+------+------------+
| USER | host |
+------+------------+
| root | localhost |
[...]
| tux | localhost |
+------+------------+
7 ROWS IN SET (0.000 sec)
```
#### 为一个用户赋予权限
通过查看 `USER` 表列出的信息,你可以看到用户的状态。例如,新用户 `tux` 对这个数据库没有任何权限。使用 `WHERE` 语句你可以只查 `tux` 那一条记录。
```
> SELECT USER,select_priv,insert_priv,update_priv FROM USER WHERE USER='tux';
+------+-------------+-------------+-------------+
| USER | select_priv | insert_priv | update_priv |
+------+-------------+-------------+-------------+
| tux | N | N | N |
+------+-------------+-------------+-------------+
```
使用 `GRANT` 命令修改用户的权限:
```
> GRANT SELECT ON *.* TO 'tux'@'localhost';
> FLUSH PRIVILEGES;
```
验证你的修改:
```
> SELECT USER,select_priv,insert_priv,update_priv FROM USER WHERE USER='tux';
+------+-------------+-------------+-------------+
| USER | select_priv | insert_priv | update_priv |
+------+-------------+-------------+-------------+
| tux | Y | N | N |
+------+-------------+-------------+-------------+
```
`tux` 用户现在有了从所有表中查询记录的权限。
### 创建自定义的数据库
到目前为止,你一直在与默认的数据库进行交互。除了用户管理,大部分人很少会与默认的数据库进行交互。通常,你会用自定义的数据来填充创建的数据库。
#### 创建一个 MariaDB 数据库
你可能已经可以自己在 MariaDB 中创建新数据库了。创建数据库跟新建用户差不多。
```
> CREATE DATABASE example;
Query OK, 1 ROW affected (0.000 sec)
> SHOW DATABASES;
+--------------------+
| DATABASE |
+--------------------+
| example |
[...]
```
使用 `use` 命令来把这个新建的数据库作为当前使用的库:
```
> USE example;
```
#### 创建一个表
创建表比创建数据库要复杂,因为你必须定义列首。MariaDB 提供了很多方便的函数,可以用于创建列,引入数据类型定义,自增选项,对空值的约束,自动时间戳等等。
下面是用来描述一系列用户的一个简单的表:
```
> CREATE TABLE IF NOT EXISTS member (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> name VARCHAR(128) NOT NULL,
-> startdate TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
Query OK, 0 ROWS affected (0.030 sec)
```
这个表通过使用一个自动递增的方法来唯一标识每一行。表示用户名字的字段不能为空(或 `null`),每一行被创建时会自动生成时间戳。
使用 SQL 关键字 `INSERT` 向这个表填充一些示例数据:
```
> INSERT INTO member (name) VALUES ('Alice');
Query OK, 1 ROW affected (0.011 sec)
> INSERT INTO member (name) VALUES ('Bob');
Query OK, 1 ROW affected (0.011 sec)
> INSERT INTO member (name) VALUES ('Carol');
Query OK, 1 ROW affected (0.011 sec)
> INSERT INTO member (name) VALUES ('David');
Query OK, 1 ROW affected (0.011 sec)
```
验证一下表里的数据:
```
> SELECT * FROM member;
+----+-------+---------------------+
| id | name | startdate |
+----+-------+---------------------+
| 1 | Alice | 2020-10-03 15:25:06 |
| 2 | Bob | 2020-10-03 15:26:43 |
| 3 | Carol | 2020-10-03 15:26:46 |
| 4 | David | 2020-10-03 15:26:51 |
+----+-------+---------------------+
4 ROWS IN SET (0.000 sec)
```
#### 同时增加多行数据
再创建一个表:
```
> CREATE TABLE IF NOT EXISTS linux (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> distro VARCHAR(128) NOT NULL);
Query OK, 0 ROWS affected (0.030 sec)
```
填充一些示例数据,这次使用 `VALUES` 快捷方式,这样你可以一次添加多行数据。`VALUES` 关键字需要一个用括号包围的列表作为参数,也可以用逗号分隔的多个列表作为参数。
```
> INSERT INTO linux (distro)
-> VALUES ('Slackware'), ('RHEL'),('Fedora'),('Debian');
Query OK, 4 ROWS affected (0.011 sec)
Records: 4 Duplicates: 0 Warnings: 0
> SELECT * FROM linux;
+----+-----------+
| id | distro |
+----+-----------+
| 1 | Slackware |
| 2 | RHEL |
| 3 | Fedora |
| 4 | Debian |
+----+-----------+
```
### 关联多个表
现在你有两个表,之间没有关联。两个表的数据是独立的,但是你可能需要表一中的一个值来识别表二的记录。
你可以在表一中新增一列对应表二中的值。因为两个表都有唯一的标识符(自动递增的 `id` 字段),关联的它们的最简单的方式是,使用表一中的 `id` 字段作为表二的查询条件。
在表一中创建一列用来表示表二中的一个值:
```
> ALTER TABLE member ADD COLUMN (os INT);
Query OK, 0 ROWS affected (0.012 sec)
Records: 0 Duplicates: 0 Warnings: 0
> DESCRIBE member;
DESCRIBE member;
+-----------+--------------+------+-----+---------+------+
| FIELD | TYPE | NULL | KEY | DEFAULT | Extra|
+-----------+--------------+------+-----+---------+------+
| id | INT(11) | NO | PRI | NULL | auto_|
| name | VARCHAR(128) | NO | | NULL | |
| startdate | TIMESTAMP | NO | | cur[...]| |
| os | INT(11) | YES | | NULL | |
+-----------+--------------+------+-----+---------+------+
```
把 `linux` 表中的唯一 ID 分配给每个成员。因为记录已经存在,使用 `UPDATE` 关键字而不是 `INSERT`。尤其是当你想查询某行然后再更新某列值时。语法上,表达方式有点倒装,先更新后查询:
```
> UPDATE member SET os=1 WHERE name='Alice';
Query OK, 1 ROW affected (0.007 sec)
ROWS matched: 1 Changed: 1 Warnings: 0
```
要填充数据,请对其他名字重复执行这个过程。为了数据的多样性,在四行记录中分配三个不同的值。
#### 连接表
现在这两个表彼此有了关联,你可以使用 SQL 来展示关联的数据。数据库中有很多种连接方式,你可以尽请尝试。下面的例子是关联 `member` 表中 `os` 字段和 `linux` 表中 `id` 字段:
```
SELECT * FROM member JOIN linux ON member.os=linux.id;
+----+-------+---------------------+------+----+-----------+
| id | name | startdate | os | id | distro |
+----+-------+---------------------+------+----+-----------+
| 1 | Alice | 2020-10-03 15:25:06 | 1 | 1 | Slackware |
| 2 | Bob | 2020-10-03 15:26:43 | 3 | 3 | Fedora |
| 4 | David | 2020-10-03 15:26:51 | 3 | 3 | Fedora |
| 3 | Carol | 2020-10-03 15:26:46 | 4 | 4 | Debian |
+----+-------+---------------------+------+----+-----------+
4 ROWS IN SET (0.000 sec)
```
连接 `os` 和 `id` 字段。
在图形化的应用中,你可以想象 `os` 字段可以在下拉菜单中设置,值的来源是 `linux` 表中的 `distro` 字段。通过使用多个表中独立却有关联的数据,你可以保证数据的一致性和有效性,使用 SQL 你可以动态地关联它们。
### 下载 MariaDB 和 MySQL 备忘单
MariaDB 是企业级的数据库。它是健壮、强大、高效的数据库引擎。学习它是你向管理 web 应用和编写语言库迈出的伟大的一步。你可以[下载 MariaDB 和 MySQL 备忘单](https://opensource.com/downloads/mariadb-mysql-cheat-sheet),在你使用 MariaDB 时可以快速参考。
---
via: <https://opensource.com/article/20/10/mariadb-mysql-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you're writing an application or configuring one for a server, eventually, you will need to store persistent information. Sometimes, a configuration file, such as an INI or [YAML](https://www.redhat.com/sysadmin/yaml-tips) file will do. Other times, a custom file format designed in XML or JSON or similar is better.
But sometimes you need something that can validate input, search through information quickly, make connections between related data, and generally handle your users' work adeptly. That's what a database is designed to do, and [MariaDB](https://mariadb.org/) (a fork of [MySQL](https://www.mysql.com/) by some of its original developers) is a great option. I use MariaDB in this article, but the information applies equally to MySQL.
It's common to interact with a database through programming languages. For this reason, there are [SQL](https://en.wikipedia.org/wiki/SQL) libraries for Java, Python, Lua, PHP, Ruby, C++, and many others. However, before using these libraries, it helps to have an understanding of what's happening with the database engine and why your choice of database is significant. This article introduces MariaDB and the `mysql`
command to familiarize you with the basics of how a database handles data.
If you don't have MariaDB yet, follow the instructions in my article about [installing MariaDB on Linux](https://opensource.com/article/20/10/install-mariadb-and-mysql-linux). If you're not on Linux, use the instructions provided on the MariaDB [download page](https://mariadb.org/download).
## Interact with MariaDB
You can interact with MariaDB using the `mysql`
command. First, verify that your server is up and running using the `ping`
subcommand, entering your MariaDB password when prompted:
```
$ mysqladmin -u root -p ping
Enter password:
mysqld is alive
```
To make exploring SQL easy, open an interactive MariaDB session:
```
$ mysql -u root -p
Enter password:
Welcome to the MariaDB monitor.
Commands end with ; or \g.
[...]
Type 'help;' or '\h' for help.
Type '\c' to clear the current input statement.
MariaDB [(none)]>
```
This places you in a MariaDB subshell, and your prompt is now a MariaDB prompt. Your usual Bash commands don't work here. You must use MariaDB commands. To see a list of MariaDB commands, type `help`
(or just `?`
). These are administrative commands for your MariaDB shell, so they're useful for customizing your shell, but they aren't part of the SQL language.
## Learn SQL basics
The [Structured Query Language (SQL)](https://publications.opengroup.org/c449) is named after what it provides: a method to inquire about the contents of a database in a predictable and consistent syntax in order to receive useful results. SQL reads a lot like an ordinary English sentence, if a little robotic. For instance, if you've signed into a database server and you need to understand what you have to work with, type `SHOW DATABASES;`
and press Enter for the results.
SQL commands are terminated with a semicolon. If you forget the semicolon, MariaDB assumes you want to continue your query on the next line, where you can either do so or terminate the query with a semicolon.
```
MariaDB [(none)]> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.000 sec)
```
This shows there are four databases present: information_schema, mysql, performance_schema, and test. To issue queries to a database, you must select which database you want MariaDB to use. This is done with the MariaDB command `use`
. Once you choose a database, your MariaDB prompt changes to reflect the active database.
```
MariaDB [(none)]> use test;
MariaDB [(test)]>
```
### Show database tables
Databases contain *tables*, which can be visualized in the same way a spreadsheet is: as a series of rows (called *records* in a database) and columns. The intersection of a row and a column is called a *field*.
To see the tables available in a database (you can think of them as tabs in a multi-sheet spreadsheet), use the SQL keyword `SHOW`
again:
```
MariaDB [(test)]> SHOW TABLES;
empty set
```
The `test`
database doesn't have much to look at, so use the `use`
command to switch to the `mysql`
database.
```
MariaDB [(test)]> use mysql;
MariaDB [(mysql)]> SHOW TABLES;
+---------------------------+
| Tables_in_mysql |
+---------------------------+
| column_stats |
| columns_priv |
| db |
[...]
| time_zone_transition_type |
| transaction_registry |
| user |
+---------------------------+
31 rows in set (0.000 sec)
```
There are a lot more tables in this database! The `mysql`
database is the system management database for this MariaDB instance. It contains important data, including an entire user structure to manage database privileges. It's an important database, and you don't always have to interact with it directly, but it's not uncommon to manipulate it in SQL scripts. It's also useful to understand the `mysql`
database when you're learning MariaDB because it can help demonstrate some basic SQL commands.
### Examine a table
The last table listed in this instance's `mysql`
database is titled `user`
. This table contains data about users permitted to access the database. Right now, there's only a root user, but you can add other users with varying privileges to control whether each user can view, update, or create data. To get an idea of all the attributes a MariaDB user can have, you can view column headers in a table:
```
> SHOW COLUMNS IN user;
MariaDB [mysql]> SHOW columns IN user;
+-------------+---------------+------+-----+----------+
| Field | Type | Null | Key | Default |
+-------------+---------------+------+-----+----------+
| Host | char(60) | NO | PRI | |
| User | char(80) | NO | PRI | |
| Password | char(41) | NO | | |
| Select_priv | enum('N','Y') | NO | | N |
| Insert_priv | enum('N','Y') | NO | | N |
| Update_priv | enum('N','Y') | NO | | N |
| Delete_priv | enum('N','Y') | NO | | N |
| Create_priv | enum('N','Y') | NO | | N |
| Drop_priv | enum('N','Y') | NO | | N |
[...]
47 rows in set (0.001 sec)
```
### Create a new user
Whether you need help from a fellow human to administer a database or you're setting up a database for a computer to use (for example, in a WordPress, Drupal, or Joomla installation), it's common to need an extra user account within MariaDB. You can create a MariaDB user either by adding it to the `user`
table in the `mysql`
database, or you can use the SQL keyword `CREATE`
to prompt MariaDB to do it for you. The latter features some helper functions so that you don't have to generate all the information manually:
`> CREATE USER 'tux'@'localhost' IDENTIFIED BY 'really_secure_password';`
### View table fields
You can view fields and values in a database table with the `SELECT`
keyword. In this example, you created a user called `tux`
, so select the columns in the `user`
table:
```
> SELECT user,host FROM user;
+------+------------+
| user | host |
+------+------------+
| root | localhost |
[...]
| tux | localhost |
+------+------------+
7 rows in set (0.000 sec)
```
### Grant privileges to a user
By looking at the column listing on the `user`
table, you can explore a user's status. For instance, the new user `tux`
doesn't have permission to do anything with the database. Using the `WHERE`
statement, you can view only the record for `tux`
:
```
> SELECT user,select_priv,insert_priv,update_priv FROM user WHERE user='tux';
+------+-------------+-------------+-------------+
| user | select_priv | insert_priv | update_priv |
+------+-------------+-------------+-------------+
| tux | N | N | N |
+------+-------------+-------------+-------------+
```
Use the `GRANT`
command to modify user permissions:
```
> GRANT SELECT on *.* TO 'tux'@'localhost';
> FLUSH PRIVILEGES;
```
Verify your change:
```
> SELECT user,select_priv,insert_priv,update_priv FROM user WHERE user='tux';
+------+-------------+-------------+-------------+
| user | select_priv | insert_priv | update_priv |
+------+-------------+-------------+-------------+
| tux | Y | N | N |
+------+-------------+-------------+-------------+
```
User `tux`
now has privileges to select records from all tables.
## Create a custom database
So far, you've interacted just with the default databases. Most people rarely interact much with the default databases outside of user management. Usually, you create a database and populate it with tables full of custom data.
### Create a MariaDB database
You may already be able to guess how to create a new database in MariaDB. It's a lot like creating a new user:
```
> CREATE DATABASE example;
Query OK, 1 row affected (0.000 sec)
> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| example |
[...]
```
Make this new database your active one with the `use`
command:
`> use example;`
### Create a table
Creating a table is more complex than creating a database because you must define column headings. MariaDB provides many convenience functions for you to use when creating columns, including data type definitions, automatic incrementing options, constraints to avoid empty values, automated timestamps, and more.
Here's a simple table to describe a set of users:
```
> CREATE table IF NOT EXISTS member (
-> id INT auto_increment PRIMARY KEY,
-> name varchar(128) NOT NULL,
-> startdate TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
Query OK, 0 rows affected (0.030 sec)
```
This table provides a unique identifier to each row by using an auto-increment function. It contains a field for a user's name, which cannot be empty (or `null`
), and generates a timestamp when the record is created.
Populate this table with some sample data using the `INSERT`
SQL keyword:
```
> INSERT INTO member (name) VALUES ('Alice');
Query OK, 1 row affected (0.011 sec)
> INSERT INTO member (name) VALUES ('Bob');
Query OK, 1 row affected (0.011 sec)
> INSERT INTO member (name) VALUES ('Carol');
Query OK, 1 row affected (0.011 sec)
> INSERT INTO member (name) VALUES ('David');
Query OK, 1 row affected (0.011 sec)
```
Verify the data in the table:
```
> SELECT * FROM member;
+----+-------+---------------------+
| id | name | startdate |
+----+-------+---------------------+
| 1 | Alice | 2020-10-03 15:25:06 |
| 2 | Bob | 2020-10-03 15:26:43 |
| 3 | Carol | 2020-10-03 15:26:46 |
| 4 | David | 2020-10-03 15:26:51 |
+----+-------+---------------------+
4 rows in set (0.000 sec)
```
### Add multiple rows at once
Now create a second table:
```
> CREATE table IF NOT EXISTS linux (
-> id INT auto_increment PRIMARY KEY,
-> distro varchar(128) NOT NULL,
Query OK, 0 rows affected (0.030 sec)
```
Populate it with some sample data, this time using a little `VALUES`
shortcut so you can add multiple rows in one command. The `VALUES`
keyword expects a list in parentheses, but it can take multiple lists separated by commas:
```
> INSERT INTO linux (distro)
-> VALUES ('Slackware'), ('RHEL'),('Fedora'),('Debian');
Query OK, 4 rows affected (0.011 sec)
Records: 4 Duplicates: 0 Warnings: 0
> SELECT * FROM linux;
+----+-----------+
| id | distro |
+----+-----------+
| 1 | Slackware |
| 2 | RHEL |
| 3 | Fedora |
| 4 | Debian |
+----+-----------+
```
## Create relationships between tables
You now have two tables, but there's no relationship between them. They each contain independent data, but you might need to associate a member of the first table to a specific item listed in the second.
To do that, you can create a new column for the first table that corresponds to something in the second. Because both tables were designed with unique identifiers (the auto-incrementing `id`
field), the easiest way to connect them is to use the `id`
field of one as a selector for the other.
Create a new column in the first table to represent a value in the second table:
```
> ALTER TABLE member ADD COLUMN (os INT);
Query OK, 0 rows affected (0.012 sec)
Records: 0 Duplicates: 0 Warnings: 0
> DESCRIBE member;
DESCRIBE member;
+-----------+--------------+------+-----+---------+------+
| Field | Type | Null | Key | Default | Extra|
+-----------+--------------+------+-----+---------+------+
| id | int(11) | NO | PRI | NULL | auto_|
| name | varchar(128) | NO | | NULL | |
| startdate | timestamp | NO | | cur[...]| |
| os | int(11) | YES | | NULL | |
+-----------+--------------+------+-----+---------+------+
```
Using the unique IDs of the `linux`
table, assign a distribution to each member. Because the records already exist, use the `UPDATE`
SQL keyword rather than `INSERT`
. Specifically, you want to select one row and then update the value of one column. Syntactically, this is expressed a little in reverse, with the update happening first and the selection matching last:
```
> UPDATE member SET os=1 WHERE name='Alice';
Query OK, 1 row affected (0.007 sec)
Rows matched: 1 Changed: 1 Warnings: 0
```
Repeat this process for the other names in the `member`
table to populate it with data. For variety, assign three different distributions across the four rows (doubling up on one).
### Join tables
Now that these two tables relate to one another, you can use SQL to display the associated data. There are many kinds of joins in databases, and you can try them all once you know the basics. Here's a basic join to correlate the values found in the `os`
field of the `member`
table to the `id`
field of the `linux`
table:
```
SELECT * FROM member JOIN linux ON member.os=linux.id;
+----+-------+---------------------+------+----+-----------+
| id | name | startdate | os | id | distro |
+----+-------+---------------------+------+----+-----------+
| 1 | Alice | 2020-10-03 15:25:06 | 1 | 1 | Slackware |
| 2 | Bob | 2020-10-03 15:26:43 | 3 | 3 | Fedora |
| 4 | David | 2020-10-03 15:26:51 | 3 | 3 | Fedora |
| 3 | Carol | 2020-10-03 15:26:46 | 4 | 4 | Debian |
+----+-------+---------------------+------+----+-----------+
4 rows in set (0.000 sec)
```
The `os`
and `id`
fields form the join.
In a graphical application, you can imagine that the `os`
field might be set by a drop-down menu, the values for which are drawn from the contents of the `distro`
field of the `linux`
table. By using separate tables for unique but related sets of data, you ensure the consistency and validity of data, and thanks to SQL, you can associate them dynamically later.
[Download the MariaDB and MySQL cheat sheet](https://opensource.com/downloads/mariadb-mysql-cheat-sheet)
MariaDB is an enterprise-grade database. It's designed and proven to be a robust, powerful, and fast database engine. Learning it is a great step toward using it to do things like managing web applications or programming language libraries. As a quick reference when you're using MariaDB, [download our MariaDB and MySQL cheat sheet](https://opensource.com/downloads/mariadb-mysql-cheat-sheet).
## Comments are closed. |
12,823 | GnuCash:一个强大的开源会计软件 | https://itsfoss.com/gnucash/ | 2020-11-14T12:02:00 | [
"GnuCash"
] | https://linux.cn/article-12823-1.html |
>
> GnuCash 是一款流行的自由开源的会计软件,可用于管理个人财务和商业交易。
>
>
>

考虑到管理个人财务和商业交易的复杂性,你会发现有很多旨在简化这些的在线服务或软件工具。有些工具只是让你添加支出和收入来跟踪你的储蓄,而其他一些工具则提供不同的功能。
我在过去已经介绍过几个[开源会计软件](https://itsfoss.com/open-source-accounting-software/)。在这里,我将重点介绍其中一个 — **GnuCash**,它是一款很流行的免费会计软件,为所有用户提供了很多功能。
### GnuCash: 自由开源的会计软件

GnuCash 是一款为专业需求量身定做的免费会计软件,可以追踪交易、股票等。它适用于 Linux、BSD、macOS 和 Windows。
虽然刚开始使用可能会让人不知所措,但对于管理个人交易而言很容易使用。在你开始管理一个账户,并添加交易后,你可以得到一个详细的报告。
### GnuCash 的功能

正如我前面提到的,GnuCash 带来了一大堆功能,这对于一个刚接触会计的人来说可能会让人不知所措,但我认为它应该是值得的:
* 复式记账
* 股票/债券/共同基金账户
* 有税务支持的小企业会计(如印度的商品和服务税)
* 详细的分类报告
* 便于分析的图表
* 支持财务计算
* 自动保存功能
* 彩色编码
* 网上银行向导
* 日志
* 贷款还款计算器
* 用于快速计算的价格数据库
* 每个类别的预算平衡表、流程、图表
* 能够以 CSV 格式导出
* 分别添加客户、供应商和雇员记录。
* 计划交易记录
* 制定预算的能力
* 配置账单生成器,以简化会计程序。
我不是专家,但这只是冰山一角。你会发现有很多选项可以根据你的会计需求进行定制和设置。

### 在 Linux 上安装 GnuCash
你可以在你的 Linux 发行版的软件中心找到 GnuCash。从那里安装或使用[发行版的软件包管理器](https://itsfoss.com/package-manager/)。
对于那些想要最新版本的人来说,还可以使用 [Flatpak 包](https://flathub.org/apps/details/org.gnucash.GnuCash)。如果你不知道它,我建议你去看看我们的 [Flatpak 指南](https://itsfoss.com/flatpak-guide/)。
另外,你也可以从源码构建,或者你可以前往他们的[官方下载页面](https://www.gnucash.org/download.phtml#distribution)来探索适合你的 Linux 发行版选项。
* [GnuCash](https://www.gnucash.org)
### 总结
对于基本的个人理财来说,这对我来说有点复杂,因为我更喜欢安卓应用的简单。不过,如果你试上几分钟,就会发现它很容易理解,GnuCash 似乎可以灵活地满足大多数要求。
如果你想管理自己或企业的财务,你可以尝试一下。它绝对比在电子表格中保存数据要好。 :smiley:
---
via: <https://itsfoss.com/gnucash/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: GnuCash is a popular free and open-source accounting software that can be used to manage personal finance as well as business transactions.*
Considering the complexities of managing personal finances and business transactions, you will find a lot of online services or software tools that aim to simplify things. Some tools simply let you add expenses and income to keep track of your savings while others offer different features.
I have already covered several [open source account software](https://itsfoss.com/open-source-accounting-software/) in the past. Here, I will be focusing on one of the options — **GnuCash**, which is a popular free accounting software with plenty of features for every user.
## GnuCash: Free & Open Source Accounting Software
GnuCash is a free accounting software tailored for professional requirements to track transactions, stocks, etc. It is available for Linux, BSD, macOS, and Windows as well.
Even though it can be overwhelming to start with, it is easy to use for managing personal transactions as well. You can get a detailed report to analyze after you’ve started managing an account and added transactions to it.
## Features of GnuCash
As I mentioned earlier, GnuCash comes loaded with a bunch of features which could be overwhelming for someone new to accounting, but I think it should be worth it:
- Double-entry Accounting
- Stock/Bond/Mutual Fund accounts
- Small-business accounting with tax support (like GST in India)
- Detailed report for breakdown
- Graph for easy analysis
- Financial calculations support
- Auto-saving feature
- Color coding
- Online Banking Wizard
- Journal
- Loan repayment calculator
- Price database for quick calculation
- Budget balance sheet, flow, graph for each category
- Ability to export as CSV
- Add Customer, Vendor, and Employee records separately
- Scheduled transactions
- Ability to set a Budget
- Configuring bill generator to ease up the accounting process
I’m no expert but this is just the tip of the iceberg. You will find a host of options to customize and set for your accounting needs.
## Installing GnuCash on Linux
You can find GnuCash in the software center of your Linux distribution. Install it from there or use the [package manager of your distribution](https://itsfoss.com/package-manager/).
A [Flatpak package](https://flathub.org/apps/details/org.gnucash.GnuCash) is also available for those who want the latest version. In case you didn’t know, I’d suggest you to go through our [Flatpak guide](https://itsfoss.com/flatpak-guide/).
Alternatively, you can build it from source or you can head to their [official download page](https://www.gnucash.org/download.phtml#distribution) to explore options for your Linux distribution.
## Wrapping Up
For basic personal finance management, it was a little overwhelming for me because I prefer to use an Android app for simplicity. However, if you take a look around for a few minutes, it is easy to understand and GnuCash seems flexible for most requirements.
If you like to manage your or your business’s finances, you may give it a try. It is definitely better than keeping data in spreadsheet :) |
12,825 | 本地运行 Kubernetes 的 4 种方法 | https://opensource.com/article/20/11/run-kubernetes-locally | 2020-11-16T13:23:30 | [
"Kubernetes"
] | https://linux.cn/article-12825-1.html |
>
> 设置一个本地开发环境,或者直接用这些工具尝试容器编排平台。
>
>
>

[Kubernetes](https://kubernetes.io/) 是一个开源的容器编排平台。它由 Google 开发,为自动化部署、扩展和管理容器化应用提供了一个开源系统。虽然大多数人在云环境中运行 Kubernetes,但在本地运行 Kubernetes 集群不仅是可能的,它还至少有两个好处:
* 在决定使用 Kubernetes 作为主要平台部署应用之前,你可以快速试用它。
* 在将任何东西推送到公共云之前,你可以将其设置为本地开发环境,从而实现开发环境和生产环境之间的分离。
无论你的情况如何,将本地 Kubernetes 环境设置为你的开发环境都是推荐的选择,因为这种设置可以创建一个安全而敏捷的应用部署流程。
幸运的是,有多个平台可以让你尝试在本地运行 Kubernetes,它们都是开源的,并且都是 [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) 许可。
* [Minikube](https://github.com/kubernetes/minikube) 的主要目标是成为本地 Kubernetes 应用开发的最佳工具,并支持所有适合的 Kubernetes 特性。
* [kind](https://github.com/kubernetes-sigs/kind) 使用 Docker 容器“节点”运行本地 Kubernetes 集群。
* [CodeReady Containers](https://github.com/code-ready/crc)(CRC)用来管理为测试和开发目的优化的本地 OpenShift 4.x 集群。
* [Minishift](https://github.com/minishift/minishift) 通过在虚拟机 (VM) 内运行单节点的 OpenShift 集群,帮助你在本地运行 OpenShift 3.x 集群。
### Minikube

[Minikube](https://minikube.sigs.k8s.io/docs/) 是在本地计算机上运行 Kubernetes 环境的最知名、最流行的选择。无论你使用什么操作系统,[Minikube 的文档](https://minikube.sigs.k8s.io/docs)都会为你提供一个简单的[安装](https://minikube.sigs.k8s.io/docs/start/)指南。一般来说,安装 Minikube 只需运行两条命令:
```
$ curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-PLATFORM-amd64
$ sudo install minikube-PLATFORM-amd64 /usr/local/bin/minikube
```
Minikube 可在 Linux、macOS 或 Windows 上快速设置本地 Kubernetes 集群,其功能如下:
* 支持最新的 Kubernetes 版本(包括 6 个以前的小版本)
* 跨平台(Linux、macOS、Windows)
* 以虚拟机、容器或裸机的形式部署
* 支持多个容器运行时(CRI-O、containerd、Docker)
* 用于快速推送镜像的 Docker API 端点
* 负载均衡器、文件系统挂载、FeatureGates 和其他高级功能
* 用于轻松安装 Kubernetes 应用的附加组件
因为 Minikube 是一个开源项目,你可以对它的[源代码](https://github.com/kubernetes/minikube)做贡献。
### kind

[kind](https://kind.sigs.k8s.io) 的开发者将其描述为“一个使用 Docker 容器‘节点’运行本地 Kubernetes 集群的工具”。它是为测试 Kubernetes 而设计的,但也可能用于本地开发或持续集成。
kind 支持:
* 多节点(包括高可用性)集群
* 从源码构建 Kubernetes 版本
* Make/Bash/Docker 或 Bazel,以及预发布构建
* Linux、MacOS 和 Windows
此外,kind 是一个经过云原生计算基金会(CNCF)认证的 Kubernetes 合规安装程序。因为它是开源的,你可以在它的 GitHub 仓库中找到 kind 的[源码](https://github.com/kubernetes-sigs/kind)。
### CodeReady Container (CRC)

如果你想在本地尝试最新版本的 OpenShift,可以尝试红帽的 [CodeReady Containers](https://code-ready.github.io/crc) (CRC)。CRC 将一个最小的 OpenShift 4.x 集群带到你的本地计算机上,为开发和测试目的提供一个最小的环境。CRC 主要针对开发者的桌面使用。
你可以在 GitHub 上找到 CodeReady Container 的[源码](https://github.com/code-ready/crc),也是在 Apache 2.0 许可下提供的。
### Minishift

[Minishift](https://github.com/minishift/minishift) 项目帮助你在本地用 [OKD](https://www.okd.io/) 在虚拟机内的单节点 OpenShift 集群[运行一个版本的 OpenShift](https://www.redhat.com/sysadmin/kubernetes-cluster-laptop)。你可以用它来[尝试 OpenShift](https://www.redhat.com/sysadmin/learn-openshift-minishift),或者在你的本地主机上为云开发。
和这个列表中的其他工具一样,Minishift 也是开源的,你可以在 GitHub 上访问它的[源码](https://github.com/minishift/minishift)。
### 为人服务的 Kubernetes
正如你所看到的,有几种方法可以在本地环境中试用 Kubernetes。我有遗漏么?欢迎留言提问或提出建议。
---
via: <https://opensource.com/article/20/11/run-kubernetes-locally>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Kubernetes](https://kubernetes.io/) is an open source orchestration platform for containers. Developed by Google, it offers an open source system for [automating deployment](https://www.kubernetesbyexample.com/en/concept/deployments), scaling, and managing containerized applications. Although most people run Kubernetes in a cloud environment, running a Kubernetes cluster locally is not only possible, it has at least two benefits:
- You can quickly try out Kubernetes before deciding to use it as your primary platform to deploy your application.
- You can set it up as a local development environment before pushing anything to a public cloud, thus allowing separation between the development environment and the production environment.
Setting up a local Kubernetes environment as your development environment is the recommended option, no matter your situation, because this setup can create a safe and agile application-deployment process.
Fortunately, there are multiple platforms that you can try out to run Kubernetes locally, and they are all open source and available under the [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) license.
[Minikube](https://github.com/kubernetes/minikube)has the primary goals of being the best tool for local Kubernetes application development, and to support all Kubernetes features that fit.[kind](https://github.com/kubernetes-sigs/kind)runs local Kubernetes clusters using Docker container "nodes."[CodeReady Containers](https://github.com/code-ready/crc)(CRC) manages a local OpenShift 4.x cluster optimized for testing and development purposes.[Minishift](https://github.com/minishift/minishift)helps you run OpenShift 3.x clusters locally by running a single-node OpenShift cluster inside a virtual machine (VM).
## Minikube
(Bryant Son, CC BY-SA 4.0)
[Minikube](https://minikube.sigs.k8s.io/docs/) is the most well-known and popular choice to run a Kubernetes environment on a local computer. No matter what operating system you use, [Minikube's documentation](https://minikube.sigs.k8s.io/docs) offers an easy [installation](https://minikube.sigs.k8s.io/docs/start/) guide for you. Generally, installing Minikube is as simple as running two commands:
```
$ curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-PLATFORM-amd64
$ sudo install minikube-PLATFORM-amd64 /usr/local/bin/minikube
```
Minikube quickly sets up a local Kubernetes cluster on Linux, macOS, or Windows with the following features:
- Supports the latest Kubernetes release (+6 previous minor versions)
- Cross-platform (Linux, macOS, Windows)
- Deploys as a VM, a container, or on bare-metal
- Multiple container runtimes (CRI-O, containerd, Docker)
- Docker API endpoint for blazing-fast image pushes
- LoadBalancer, filesystem mounts, FeatureGates, and other advanced features
- Add-ons for easily installing Kubernetes applications
Because Minikube is an open source project, you can contribute to its [source code](https://github.com/kubernetes/minikube).
## kind
(Bryant Son, CC BY-SA 4.0)
[kind](https://kind.sigs.k8s.io)'s developers describe it as "a tool for running local Kubernetes clusters using Docker container 'nodes.'" It was designed for testing Kubernetes but may also be used for local development or continuous integration.
kind supports:
- Multi-node (including high-availability) clusters
- Building Kubernetes release builds from source
- Make/Bash/Docker or Bazel, in addition to pre-published builds
- Linux, macOS, and Windows
In addition, kind is a Cloud Native Computing Foundation (CNCF)-certified conformant Kubernetes installer. Because it's open source, you can find kind's [source code](https://github.com/kubernetes-sigs/kind) in its GitHub repository.
## CodeReady Container (CRC)

(Bryant Son, CC BY-SA 4.0)
If you want to try the latest version of OpenShift locally, try Red Hat [CodeReady Containers](https://code-ready.github.io/crc) (CRC). CRC brings a minimal OpenShift 4.x cluster to your local computer that provides a minimal environment for development and testing purposes. CRC is mainly targeted for use on developers' desktops.
You can find CodeReady Container's [source code](https://github.com/code-ready/crc) on GitHub, also available under the Apache 2.0 license.
## Minishift
(Bryant Son, CC BY-SA 4.0)
The [Minishift](https://github.com/minishift/minishift) project [helps you run a version of OpenShift](https://www.redhat.com/sysadmin/kubernetes-cluster-laptop) with [OKD](https://www.okd.io/) locally with a single-node OpenShift cluster inside a virtual machine. You can use it to [try OpenShift](https://www.redhat.com/sysadmin/learn-openshift-minishift) or to develop for the cloud, on your local host.
Like the other tools on this list, Minishift is open source, and you can access its [source code](https://github.com/minishift/minishift) on GitHub.
## Kubernetes for the people
As you can see, there are several ways to try out Kubernetes in your local environment. Did I miss anything? Feel free to leave a comment to ask a question or make a suggestion.
## Comments are closed. |
12,826 | 四款安卓开源电子书阅读器 | https://opensource.com/article/19/10/open-source-ereaders-android | 2020-11-16T13:57:45 | [
"电子书"
] | https://linux.cn/article-12826-1.html |
>
> 你在寻找新的电子书阅读软件吗?来看看这四款适用于安卓的可靠的开源电子书阅读器吧。
>
>
>

谁不想有一个好的阅读体验?与其将时间浪费在社交媒体或[即时消息软件](https://opensource.com/article/19/3/open-messenger-client)上,不如在自己的安卓手机或平板上阅读一本书、杂志或其他文档。
要做到这一点,你需要的是一个适合的电子书阅读软件。接下来让我们来看一看四款可靠的、开源安卓电子书阅读器。
### Book Reader
那我们先从我最喜欢的一款开源安卓电子书阅读器开始:[Book Reader](https://f-droid.org/en/packages/com.github.axet.bookreader/)。它基于现在专有的 FBReader 应用的开源老版本。像 FBReader 的早期版本一样,Book Reader 小而简单,但是好用。
**优点:**
* 易于操作。
* 该应用界面遵循安卓的 [Material Design 指南](https://material.io/design/),因此非常干净。
* 你可以为电子书添加书签,并将文本分享至你设备上的其他应用。
* 不断提供除英语外的其他语言的支持。
**缺点**
* Book Reader 的自定义选项较少。
* 没有内置词典或支持外部词典的功能。
**支持的电子书格式:**
Book Reader 支持 EPUB、.mobi、PDF、[DjVu](https://opensource.com/article/19/3/comic-book-archive-djvu)、HTML、纯文本、 Word 文档、RTF 和 [FictionBook](https://en.wikipedia.org/wiki/FictionBook)。

Book Reader 的源码在 GNU GPL 3.0 下授权,你可以在[GitLab](https://gitlab.com/axet/android-book-reader/tree/HEAD)中找到它。
### Cool Reader
[Cool Reader](https://f-droid.org/en/packages/org.coolreader/) 是一个灵活易用的电子书软件。虽然我觉得该软件的图标会让想起 Windows vista 中的图标,但它确实有一些好用的功能。
**优点**
* 高度自定义,你可以更改字体、行宽、段间距、连字符、字体大小、页边距以及背景色。
* 你可以覆盖书中的样式表。我发现这对于两三本将所有文本设置为小写字母的书很有用。
* 它会在设备启动时自动搜寻设备中的新书资源。你也可以查阅[古腾堡计划](https://www.gutenberg.org/)和[互联网档案馆](https://archive.org)中的书籍。
**缺点**
* Cool Reader 的界面并不是极简或者说最现代化的。
* 虽然它开箱即用,但实际上你需要调整一些配置来更舒适地使用 Cool Reader。
* 应用的默认词典是专有的,尽管你可以用[开源的词典](http://aarddict.org/)来替换掉它。
**支持的电子书格式:**
你可以使用 Cool Reader 来浏览 EPUB、小说、纯文本、RTF、HTML、[CHM](https://fileinfo.com/extension/chm) 和 TCR(Psion 系列掌上电脑的电子书格式)文件。

Cool Reader 的源码在 GNU GPL 2 下授权,你可以在 [Sourceforge](https://sourceforge.net/projects/crengine/) 中找到它。
### KOReader
[KOReader](https://f-droid.org/en/packages/org.koreader.launcher/) 最初是为了 [E Ink](https://en.wikipedia.org/wiki/E_Ink) 电子书阅读器创建的,但后来发现它可用于安卓。在测试它时,我发现 KOReader 在同等程度下既有用又令人沮丧。很明显它绝不是一款不好的应用,但不会是我的首选。
**优点**
* 高度自定义。
* 支持多种语言。
* 它允许你使用[词典](https://github.com/koreader/koreader/wiki/Dictionary-support)(若你已安装)或者 Wikipedia(若你已连接至网络)来查单词。
**缺点**
* 每一本书你都需要改变设置。在你打开一本新书时,KOReader 不会记住相关设置
* 它的界面会让人觉得是一款专门的电子书阅读器。该应用没有安卓的外形和感受。
**支持的电子书格式:**
你可以查阅 PDF、DjVu、CBT、以及 [CBZ](https://opensource.com/article/19/3/comic-book-archive-djvu) 电子书。它也支持 EPUB、小说、.mobi、Word 文档、文本文件和 [CHM](https://fileinfo.com/extension/chm) 文件。

Cool Reader 的源码在 GNU Affero GPL 3.0 下授权,你可以在 [GitHub](https://github.com/koreader/koreader) 上找到它。
### Booky McBookface
是的,这确实是[这款电子书阅读器](https://f-droid.org/en/packages/com.quaap.bookymcbookface/)的名字。它是这篇文章中最基础的电子书阅读器,但不要因此(或者这个傻乎乎的名字)使你失望。Booky McBookface 易于使用,并且有一件事它做的很好。
**优点**
* 没有多余的装饰。只有你和你的电子书。
* 界面简洁。
* 在安卓启动栏中的长按软件图标会弹出一个菜单,你可以从中打开正在阅读的最后一本书、获得未读书籍的列表、或者查找并打开设备上的一本书。
**缺点**
* 软件中几乎没有配置选项——你可以更改字体大小和亮度,仅此而已。
* 你需要使用屏幕底部的按钮浏览电子书。点击屏幕边缘无法操作。
* 无法为电子书添加书签。
**支持的电子书格式**
你可以使用该软件阅读 EPUB 格式、HTML 文档,或纯文本格式的电子书。

Booky McBookface 的源码在 GNU GPL 3.0 下授权,你可以在 [GitHub](https://github.com/quaap/BookyMcBookface) 中找到它。
你有最喜欢的安卓开源电子书阅读器吗?在社区中留言分享一下吧。
---
via: <https://opensource.com/article/19/10/open-source-ereaders-android>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Who doesn't like a good read? Instead of frittering away your time on social media or a [messaging app](https://opensource.com/article/19/3/open-messenger-client), you can enjoy a book, magazine, or another document on your Android-powered phone or tablet.
To do that, all you need is the right eBook reader app. So let's take a look at four solid, open source eBook readers for Android.
## Book Reader
Let's start off with my favorite open source Android eBook reader: [Book Reader](https://f-droid.org/en/packages/com.github.axet.bookreader/). It's based on the older, open source version of the now-proprietary FBReader app. Like earlier versions of its progenitor, Book Reader is simple and minimal, but it does a great job.
**Pros of Book Reader:**
- It's easy to use.
- The app's interface follows Android's
[Material Design guidelines](https://material.io/design/), so it's very clean. - You can add bookmarks to an eBook and share text with other apps on your device.
- There's growing support for languages other than English.
**Cons of Book Reader:**
- Book Reader has a limited number of configuration options.
- There's no built-in dictionary or support for an external dictionary.
**Supported eBook formats:**
Book Reader supports EPUB, .mobi, PDF, [DjVu](https://opensource.com/article/19/3/comic-book-archive-djvu), HTML, plain text, Word documents, RTF, and [FictionBook](https://en.wikipedia.org/wiki/FictionBook).
Book Reader's source code is licensed under the GNU General Public License version 3.0, and you can find it on [GitLab](https://gitlab.com/axet/android-book-reader/tree/HEAD).
## Cool Reader
[Cool Reader](https://f-droid.org/en/packages/org.coolreader/) is a zippy and easy-to-use eBook app. While I think the app's icons are reminiscent of those found in Windows Vista, Cool Reader does have several useful features.
**Pros of Cool Reader:**
- It's highly configurable. You can change fonts, line and paragraph spacing, hyphenation, font sizes, margins, and background colors.
- You can override the stylesheet in a book. I found this useful with two or three books that set all text in small capital letters.
- It automatically scans your device for new books when you start it up. You can also access books on
[Project Gutenberg](https://www.gutenberg.org/)and the[Internet Archive](https://archive.org).
**Cons of Cool Reader:**
- Cool Reader doesn't have the cleanest or most modern interface.
- While it's usable out of the box, you really need to do a bit of configuration to make Cool Reader comfortable to use.
- The app's default dictionary is proprietary, although you can swap it out for
[an open one](http://aarddict.org/).
**Supported eBook formats:**
You can use Cool Reader to browse EPUB, FictionBook, plain text, RTF, HTML, [Compiled HTML Help](https://fileinfo.com/extension/chm) (.chm), and TCR (the eBook format for the Psion series of handheld computers) files.

Cool Reader's source code is licensed under the GNU General Public License version 2, and you can find it on [Sourceforge](https://sourceforge.net/projects/crengine/).
## KOReader
[KOReader](https://f-droid.org/en/packages/org.koreader.launcher/) was originally created for [E Ink](https://en.wikipedia.org/wiki/E_Ink) eBook readers but found its way to Android. While testing it, I found KOReader to be both useful and frustrating in equal measures. It's definitely not a bad app, but it's not my first choice.
**Pros of KOReader:**
- It's highly configurable.
- It supports multiple languages.
- It allows you to look up words using a
[dictionary](https://github.com/koreader/koreader/wiki/Dictionary-support)(if you have one installed) or Wikipedia (if you're connected to the internet).
**Cons of KOReader:**
- You need to change the settings for each book you read. KOReader doesn't remember settings when you open a new book.
- The interface is reminiscent of a dedicated eBook reader. The app doesn't have that Android look and feel.
**Supported eBook formats:**
You can view PDF, DjVu, CBT, and [CBZ](https://opensource.com/article/19/3/comic-book-archive-djvu) eBooks. It also supports EPUB, FictionBook, .mobi, Word documents, text files, and [Compiled HTML Help](https://fileinfo.com/extension/chm) (.chm) files.

KOReader's source code is licensed under the GNU Affero General Public License version 3.0, and you can find it on [GitHub](https://github.com/koreader/koreader).
## Booky McBookface
Yes, that really is the name of [this eBook reader](https://f-droid.org/en/packages/com.quaap.bookymcbookface/). It's the most basic of the eBook readers in this article but don't let that (or the goofy name) put you off. Booky McBookface is easy to use and does the one thing it does quite well.
**Pros of Booky McBookface:**
- There are no frills. It's just you and your eBook.
- The interface is simple and clean.
- Long-tapping the app's icon in the Android Launcher pops up a menu from which you can open the last book you were reading, get a list of unread books, or find and open a book on your device.
**Cons of Booky McBookface:**
- The app has few configuration options—you can change the size of the font and the brightness, and that's about it.
- You need to use the buttons at the bottom of the screen to navigate through an eBook. Tapping the edges of the screen doesn't work.
- You can't add bookmarks to an eBook.
**Supported eBook formats:**
You can read eBooks in EPUB, HTML, or plain text formats with Booky McBookface.

Booky McBookface's source code is available under the GNU General Public License version 3.0, and you can find it [on GitHub](https://github.com/quaap/BookyMcBookface).
Do you have a favorite open source eBook reader for Android? Share it with the community by leaving a comment.
## 7 Comments |
12,828 | 《代码英雄》第三季(2):学习 BASIC | https://www.redhat.com/en/command-line-heroes/season-3/learning-the-basics | 2020-11-16T16:14:06 | [
"代码英雄",
"BASIC"
] | https://linux.cn/article-12828-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第三季(2):学习 BASIC](https://www.redhat.com/en/command-line-heroes/season-3/learning-the-basics)的[音频](http://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/7ca8389a-086b-490a-b3c6-62e765ea901c/CLH_S3E2_Learning_the_BASICs_vFINAL_tc.mp3)脚本。
>
> 导语:以前,成为程序员需要博士学位,还要能够接触到像服务器之类有着举足轻重地位的硬件。直到 1965 年,一群工程师有了个激进的想法:让编程变得更易学、亲民。
>
>
> 像 BASIC 这样专为初学者设计的语言为许多人打开了编程世界的大门。Tom Cormen 和 Denise Dumas 回忆了 BASIC 是如何改变一切的。Avi Flombaum 和 Saron 则会向这个软件开发新时代的编程新手们提供关于挑选第一门语言的建议。最后,Femi Owolade-Coombes 和 Robyn Bergeron 会向我们讲述,新一代的程序员们,是如何通过游戏来接触编程的。
>
>
> 这些初学者语言的诞生,让每个人都有机会踏入编程的大门。同时,这也让整个产业欣欣向荣。
>
>
>
**00:00:02 - Saron Yitbarek**:
1965 年是美国历史上发生重大变化的一年。《民权法案》就是在那年签署的。
**00:00:09 - 新闻档案**:
国会通过了史上影响最为广泛的《民权法案》,并将它写进了法律里。
**00:00:12 - Saron Yitbarek**:
作战部队被第一次被派往越南,男人们烧掉了他们的征兵证。
**00:00:19 - 新闻档案**:
征兵名单被放在波士顿法院的台阶上,一群高中男生挥拳抗议。
**00:00:25 - Saron Yitbarek**:
在纽约,披头士乐队举行了世界上第一场体育馆内的音乐会。但在距离这些大新闻很远的地方,一场与众不同的革命正在酝酿。
**00:00:39**:
5 月 1 号,凌晨 4 点。<ruby> 约翰·凯梅尼 <rt> John Kemeny </rt></ruby> 教授和一名本科生正在<ruby> 达特茅斯 <rt> Dartmouth </rt></ruby>的 GE 225 型电脑上忙碌着。他们运行了一个方才写好的程序。电传打字机的三行输出,永远地改变了计算机编程领域。
**00:01:04**:
欢迎来到红帽原创播客《代码英雄》的第三季第 2 集。我是主持人,Saron Yitbarek。在这一集,我们将继续“编程语言的过去与未来”的旅程。在第 1 集中,我们深入研究了 Python,并了解了开源社区如何在其领导阶层的大动荡中生存下来。比起上一期节目,本次节目则会更注重于个人。我会先聊聊我邂逅入门语言时的体验,这种体验我们应该都有。我将带领你们领略我学习的第一门语言 Ruby,以及某些新手语言是如何用游戏的形式,来到我们身边的。
**00:01:50**:
不过,我得先举个例子,好让大家都能明白“新手语言”到底是什么意思。这个例子就是 BASIC,它诞生于之前提到的<ruby> 达特茅斯 <rt> Dartmouth </rt></ruby>实验室的三行输出。在 1965 年的那个黎明,<ruby> 约翰·凯梅尼 <rt> John Kemeny </rt></ruby>作为创造者之一,见证了 BASIC 的诞生。
**00:02:14**:
BASIC 的意思是“<ruby> 初学者的泛用符号指令代码 <rt> Beginner's All Purpose Symbolic Instruction Code </rt></ruby>”。这里面的第一个词 “初学者” 正是其不凡之处所在。在那时候,即使是少量的编程工作,也需要一名博士来完成。这是一种极高的要求,需要有人接受专业教育,更不用说那些高级的硬件了。但是<ruby> 凯梅尼 <rt> Kemeny </rt></ruby>教授和他的团队希望改变现状。他们想知道:如果要编写一种所有人都可以使用的编程语言,那会是什么样的?当美国各地的青年们剧烈地抗议,要求变革时,<ruby> 达特茅斯 <rt> Dartmouth </rt></ruby>团队提出了一种另类的革命。
**00:02:57**:
他们的秘密武器是一个房间那么大的大型电脑 —— GE 225。它重达 2000 磅,和这份不得了的重量相匹配的是,它具备某些全新的功能。那就是分时功能(LCTT 译注:也就是时间片,实现了多用户多进程快速切换的技术)。突然间,编程不再需要复杂的打孔卡系统或庞大的开关墙了。分时意味着程序们都可以同时执行,因为系统会根据不同用户的需要来回切换其处理内容。
**00:03:31**:
分时意味着使用者可以用惊人的新方式来访问计算机。这是来自<ruby> 达特茅斯 <rt> Dartmouth </rt></ruby>的些许录音,记录了 BASIC 刚诞生的时候,65 班的一位本科生 John McGeachie 学习的实况。
**00:03:47 - John McGeachie**:
我们把这台相当贵的、原本只能一次让一个人用的计算机变成了可以……让超过 30 人使用的东西。30 名本科生可以同时在这上面编程,还能快速得到输出。它是史无前例的简洁直接。
**00:04:15 - Saron Yitbarek**:
<ruby> 约翰·凯梅尼 <rt> John Kemeny </rt></ruby>联合另一位计算机文化的布道师<ruby> 托马斯·卡茨 <rt> Thomas Kurtz </rt></ruby>共同开发了 BASIC 语言。他们发现,分时让计算机使用变得更亲民,因此准入门槛降低了许多。而剩下的工作则是编写一门简单直白的编程语言。 一门像 BASIC 那样的语言。
**00:04:39**:
他们开发了像 `HELLO` 和 `GOODBYE` 这样的指令,来代替 `LOG ON` 和 `LOG OFF` 命令。事实上,初版 BASIC 只有 14 个简单的指令,比如条件判断 `IF`,和 `GOTO` 之类的简单选项。
**00:04:54 - Tom Cormen**:
我是 Tom Cormen。我是<ruby> 达特茅斯 <rt> Dartmouth </rt> <ruby> 大学的一名计算机科学教授。 </ruby></ruby>
**00:04:59 - Saron Yitbarek**:
Cormen 教授将与我们谈论所谓“初学者的革命”,以及 BASIC 的出现如何成为时代精神的一部分。它带来了一个新世界,在其中,计算机技术对更多人来说不仅不再遥不可及,甚至还是激动人心的——编程甚至变得有点时髦了。
**00:05:14 - Tom Cormen**:
据说在 1960 年时,男学生会在这里(计算机中心)约会,我真是不能想象如果发生在现在会是什么样子。但在那个时候,计算机中心一度是约会的最佳场所。
**00:05:24 - Saron Yitbarek**:
这种在校园兴起的编程热潮,是“初学者语言”诞生所带来的直接结果。
**00:05:31 - Tom Cormen**:
就如同我们过去说的那样,BASIC 为那些计算机爱好者降低了准入门槛。不想学习 FORTRAN 这类编程语言的社会科学家可以使用 BASIC。从事人文艺术的人们可以用它做文本处理,甚至用来创作艺术作品,这些完全可以用 BASIC 来完成。
**00:05:55**:
没过几年,人们就开始写电脑游戏,也时常在编程中实现 GUI。
**00:06:03 - Saron Yitbarek**:
对于所有那些认为自己不太可能成为程序员的孩子们,编程领域的大门,突然间以一种近乎直观的方式打开了。它使得我想起来<ruby> 葛丽丝·哈伯 <rt> Grace Hopper </rt></ruby> (LCTT 译注:参见上一季。元祖级程序员,美国海军准将,COBOL 的重要编写者。她也是世界上第一个在计算机领域使用 “bug” 这个词的人。)所追求的那种世界。当我们上一季谈到<ruby> 哈伯 <rt> Hopper </rt></ruby>时,我们谈到了她的语言创新如何将编程带到更多人眼前。BASIC 的此时此刻就像是<ruby> 哈伯 <rt> Hopper </rt></ruby>梦想的延续。
**00:06:29 - Tom Cormen**:
我非常确信,如果<ruby> 葛丽丝·哈伯 <rt> Grace Hopper </rt></ruby>能看到更多人开始写代码,她会非常高兴。她可能会喜欢 BASIC 和 COBOL 的不同之处,因为这种不同为人们提供了更多的选择。他们可以写 COBOL,可以写 FORTRAN,可以写 BASIC,可以写 ALGOL,可以选择当时任何流行的语言。
**00:06:54 - Saron Yitbarek**:
Tom Cormen 是<ruby> 达特茅斯 <rt> Dartmouth </rt></ruby>计算机科学系的一名教授。当初,计算机技术中的几大变化催生了新一代的程序员。分时功能使并发工作成为可能,而 BASIC 使入门编程变得简单了。这两个因素结合在一起,创造出了改变游戏规则的星星之火。很快,编程就不仅是大型机构的专利。这一代程序员中有像<ruby> 比尔·盖茨 <rt> Bill Gates </rt></ruby>和<ruby> 史蒂夫·沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>这样的特立独行者,也有在个人电脑上每天默默耕耘的开发者。
**00:07:32 - Denise Dumas**:
BASIC 能够在程序出错时立即给使用者以反馈。这让它的使用体验变得不同,它将你吸在一起,使你继续前进;这种交互是有意义的,就因为它是一种交互。
**00:07:50 - Saron Yitbarek**:
这位是 Denise Dumas,她带领“<ruby> 红帽企业版操作系统 <rt> Red Hat® Enterprise Linux® </rt></ruby>”工程师团队。
**00:07:55 - Denise Dumas**:
我认为 BASIC 使编程变得民主了许多,因为 BASIC 把它自身交予学生、大众,当时的其他语言——像是 COBOL、FORTRAN 之类——根本做不到这一点。当 CRT(阴极射线管)流行的时候,BASIC 更为火爆,因为在你输入了信息之后,输出不再是被打印在一张纸上,而是显示在你面前的屏幕上。
**00:08:26 - Denise Dumas**:
我们现在有时候会嘲笑命令行,对吧?一切都图形化了,命令行还是一如往常,但它比命令行之前的时代有了很大的改进。这一重大改进就是,你输入指令能够立即得到回应了。我认为 BASIC 降低了准入门槛,虽然我是那种控制狂,我喜欢汇编,但我还是会这么说的。BASIC 使编程变得更加平易近人。
**00:08:59 - Saron Yitbarek**:
BASIC 在 1980 年代带来的这份激情一直延续到了今日。现在,有许多语言能被初学者用作进入编程世界的光明大道。但如今发生了另一些重要的改变:编程入门不再只有进入大学学习一途。如果将入门的方式比作道路,那么,今日,条条大路通罗马。
**00:09:29**:
尽管 BASIC 很神奇,但<ruby> 葛丽丝·哈伯 <rt> Grace Hopper </rt></ruby>的梦想不会止步于此。如今,初学者有上百种方法可以开始编程。就我而言,我是在纽约市一家名为 Flatiron 的编程学校学习的第一门语言。我为那个项目准备了几个月,我阅读了所有可能的编程资源和教程,以确保它们也许能让我在训练营中获得最大收益。我想了解当今人们是如何接触自己的入门语言的。所以,今天我采访了自己当初的那位老师。
**00:10:03 - Avi Flombaum**:
我是 Avi Flombaum。
**00:10:04 - Saron Yitbarek**:
Avi 是 Flatiron 学校的创始人之一。对我来说,探究所有有关入门语言的思想,以及我们对入门语言的方法与 BASIC 的旧时代相比有什么变化,是一种享受。
**00:10:26**:
当你教别人该如何编程时,先从哪里下手呢?我记得当我学习第一门编程语言时,我觉得这一切可真是太奇怪了。我在大学读的是英语专业,在学校里我很喜欢数学,也喜欢有机化学。我喜欢很多不同类型的科目,各种各样的东西,但是没有什么是和编程有关的。因此,我也没办法将编程比作什么。它自成一套,就像一个自己的小世界。所以,作为老师,你会从哪里开始呢?
**00:10:49 - Avi Flombaum**:
我认为生活中你所熟悉的任何事物,曾经都是陌生的。只有经历过,真正花时间去做,才会让你对它感到习惯。这是不断重复练习的问题,只关乎你投入的时间的多少。我认为编程之所以困难,之所以让人感觉如此陌生,是因为它用极其特殊的语法来表达一些东西。没有任何歧义,没有错误的余地。要么成功,要么失败。当我们互相交流的时候,我们一般没有那种要求。一切都必须完全正确。一个逗号丢了,一个括号缺了,就全坏了。
**00:11:32**:
我总是说,计算机是愚蠢的,为了使计算机理解我们的意思,我们必须做到完美。
**00:11:37 - Saron Yitbarek**:
你说的这一点我喜欢。我同意,这很棒。
**00:11:43 - Avi Flombaum**:
是啊。
**00:11:44 - Saron Yitbarek**:
对我来说,我喜欢的入门语言是 Ruby。根据经验,我可以告诉你,这是一种非常可爱的入门语言。当你阅读代码时,感觉就像你在阅读英语。它有很多不错的库;这里插播一则知识补充。Ruby 的创造者 <ruby> 松本行弘 <rt> Yukihiro Matsumoto </rt></ruby> 是通过学习 BASIC 进入编程领域的。
**00:12:06**:
如今,许多新手可能会改用 Python 或 JavaScript,而我想知道,Avi 你是否认为有最理想的入门语言。
**00:12:18**:
我想知道,是否有首选的入门语言?如果某人没有技术背景,没有编程经验,也没有计算机科学学历而进入这个领域,那么他们就是从一开始,甚至说从零开始……随着时间的推移,有没有更好的初始语言冒出来呢?
**00:12:39 - Avi Flombaum**:
好吧,首先,我要说的是每个人都没有背景。没有谁是天生的程序员,因此,无论你是有计算机科学学历,还是在社区中心里学习,抑或读书自学,每个人都是从初学者开始的。然后,就初学者的首选语言而言,我认为你最先看到的语言就是最好的。我对初学者的建议始终是,选择一种语言并学习它,不要改变。我认为,初学者最容易犯错的是,我先学习 Python,然后对它感到沮丧,说 Python 很烂,现在我要去用 JavaScript 了。他们学习 JavaScript,然后对 JavaScript 感到沮丧,然后又换了起来。
**00:13:22**:
如你所知,我个人认为 Ruby 是一种很棒的初学者语言。我认为它的语法真的很漂亮。它的价值,明确地就是要使你(程序员)感到高兴。我不知道是否有其他任何使程序员开心的语言。我知道人们发明了许多语言来使机器开心,但我认为 Ruby 确实很自然。
**00:13:44 - Saron Yitbarek**:
这一点我们可以达成共识。但是同样,这里没有错误的答案。毕竟,入门语言就是这样。它只是开始。我们所有人都有一生的时间用来学习,而且,选择一种语言而不是另一种语言,并不会阻止你成为出色的程序员。
**00:14:05**:
我喜欢画画,但我不会为了一支笔而死去活来。我不会因为我使用的笔而大动干戈,我为我所创造的东西而激动。那么从你的经验来看,为什么会这样呢?在大家面前辩护,让大家相信你对一种编程语言的看法是正确的,这样的一种思潮是从何而来的呢?
**00:14:23 - Avi Flombaum**:
我也不知道。因为我很喜欢你关于笔与作品的比喻,我首先想到的是……在我的设想中,人们死死地抓住工具,恐怕是因为作品并不吸引人。
**00:14:41 - Saron Yitbarek**:
哈哈,那真好笑。
**00:14:42 - Avi Flombaum**:
如果你做的东西就是不厉害,不伟大,对这个世界也没有太大的价值,你还想捍卫你的手艺,你唯一能指出的就是,是啊,看我把那把锤子挥得多好。当然,房子虽然倒了,但那把锤子,那把锤子真的很棒,我知道怎么用。作为一个人……我也觉得建造出的东西比你建造它的方式更重要。
**00:15:09 - Saron Yitbarek**:
说得好。现在,初学者不止可以选择 BASIC 或者 FORTRAN,我们已经拥有一整套的入门语言清单,但总有一种危险,那就是你忘记了这些语言仍然是达到目的的一种手段。语言是工具,不是你要制作的东西。
**00:15:27 - Avi Flombaum**:
我认为技术的价值在于,为人们创造有意义的事物。说到底,如果你确实是一名非常非常好的程序员,但是你做的东西没有人需要,没有人喜欢……它没有为世界增加价值,但是你真的真的非常擅长这门手艺,只是找不到能产生影响的方法,我想你可能会深入研究并讨论所使用的工具。
**00:15:56 - Saron Yitbarek**:
好吧,非常感谢 Avi,感谢你分享你的所有经验以及对编程语言的想法。那我们就谈到这里?
**00:16:01 - Avi Flombaum**:
是的,这非常好玩,很高兴再次跟你交流,我希望大家都找到自己喜欢的语言,每天都能用它来工作。
**00:16:10 - Saron Yitbarek**:
听起来不错。
**00:16:13**:
Avi Flombaum 是 Flatiron 学校的联合创始人之一。
**00:16:20 - Saron Yitbarek**:
编程学校可以将教育和知识获取的精神提升到一个全新的高度。这是我们在<ruby> 达特茅斯 <rt> Dartmouth </rt></ruby>看到的一切的延续;但如今,在一个多样化的开发生态系统中,新的、更加自然的入门方式将会不断涌现,初学者们已经有了更理想的手段来开始他们的编程“游戏”;有时,他们甚至会以玩游戏的方式入门。
**00:16:45 - CO.LAB 参与者**:
你试过其他键吗?试试 G 键。
**00:16:52 - Saron Yitbarek**:
现在,在这暂停。这不是一群年轻的程序员在默默地背诵 O'Reilly 的课本,也不是在 Flatiron 学校的讲座。这其实是红帽在伦敦<ruby> 泰特现代美术馆 <rt> Tate Modern </rt></ruby>里运行的一个小实验室。那些孩子呢?他们在学习写代码。对于新一代来说,编程的乐趣就是他们首先体会到的。
**00:17:13 - Femi Owolade-Coombes**:
好的。嗨,我叫 Femi,也叫 Hackerfemo。
**00:17:17 - Saron Yitbarek**:
Femi Owolade-Coombes 只有 13 岁,但他已经是新一代程序员中的一名领袖。
**00:17:26 - Femi Owolade-Coombes**:
我八岁的时候第一次接触到编程,那时我去<ruby> 约克 <rt> York </rt></ruby>参加一项活动。活动本身其实是数学主题的,不过我在那里看到了个很酷的东西——合法地黑入 Minecraft。作为八岁的孩子,那时候的我认为那真的很酷。所以我就这样喜欢上了编程。
**00:17:47 - Saron Yitbarek**:
他并不孤单。Minecraft 已经将一代人引入了编程领域,而且它做到了没有过去几代人所经历的痛苦和枯燥的学习。游戏的魔力正在消除障碍。 Minecraft 是基于 Java™ 的,它也为该语言注入了新的活力,催生了一大群新的 Java 粉丝。
**00:18:11**:
但不一定是 Java。对于 Femi来 说,Python 是他在 Minecraft 中发现的语言。
**00:18:16 - Femi Owolade-Coombes**:
当你使用<ruby> 树莓派 <rt> Raspberry Pi </rt></ruby>版的 Minecraft 时,你可以用 Python,因为树莓派上的 Minecraft 是特殊编写的版本。它很酷,只要导入这个库,你就可以黑进去,到处放置爆炸性的 TNT;你可以在自己身后创建方块,也可以创造建筑物。你可以拿它做各种各样的事。
**00:18:42**:
当我第一次玩它时,我发现可以添加很多类似 mod 的东西(LCTT 译注:一类加载于电子游戏上的插件,玩家可以通过 mod 改变游戏的行为方式),这很酷。mod 这东西本身就有点像黑进游戏一样,但 mod 的存在让我意识到,我们也可以用正规的方法改变游戏,让它以你希望的方式行事。我认为这真的很酷。
**00:18:57 - Saron Yitbarek**:
Femi 打开了一个编程世界,而通往世界的大门是他最喜欢的游戏。然后,他做了一件了不起的事情。他开始向其他孩子分享那扇门。
**00:19:10 - Femi Owolade-Coombes**:
嗯,我想与同伴分享我的知识。因为我觉得,你知道吗?他们会非常喜欢的,我也会因此度过愉快的时光。我想与其他所有人共享这些,这样他们就能了解它,甚至可以参与编程。
**00:19:30 - Saron Yitbarek**:
Femi 将此事贯彻到底,创办了<ruby> 南伦敦树莓酱 <rt> South London Raspberry Jam </rt></ruby>(LCTT 译注:这个名称典出“树莓派”;jam 也有即兴演奏的意思,常用于一些赛事。),在那里,他已经看到了全新一代的编程者,他们正挑战人们以往对编程初体验的预判。除了那些 Minecraft 黑客,像 Scratch 或 Fruit 这样的可视化语言也让越来越年轻的用户拥有基础知识可以实现编程。
**00:19:54 - Femi Owolade-Coombes**:
我确实喜欢玩游戏这个点子,比起在课堂上学习代码,我最喜欢的是能够控制游戏中发生的事情,而代码是背后的魔法,代码给了你那种非常酷的能力,让游戏做你想要的事情。
**00:20:15 - Saron Yitbarek**:
Femi 的妈妈告诉我们,当她发现玩游戏并非一种弊大于利的追求时,她有多么高兴。我喜欢他的故事,因为这故事是从游戏开始的,却没有结束于游戏。他建立了一个属于年轻程序员的、了不起的社区;Femi 自己的代码生涯也在起飞,不再是围绕着 Minecraft 了。他在 HTML、JavaScript 和 CSS 领域工作,建立网站,做网页设计。他甚至在用 Unity 打造自己的游戏。
**00:20:44 - Femi Owolade-Coombes**:
每个人都应该有权利学习编程,因为这是未来。
**00:20:53 - Saron Yitbarek**:
Minecraft 真的是一所巨型编程大学吗?明日的程序员,是否会通过游戏和玩耍来吸收新的语言呢?只通过环境渗透能否真正地学习语言?
**00:21:06 - Robyn Bergeron**:
嗨,我叫 Robyn Bergeron。
**00:21:08 - Saron Yitbarek**:
Robyn 是 Red Hat 的 Ansible® <ruby> 社区架构师 <rt> community architect </rt></ruby>,她有几个孩子,这些孩子们偶然间接触到了编程。
**00:21:18 - Robyn Bergeron**:
那是晚饭时刻。我在做饭,每个人对这件事情都印象深刻。我的女儿来到厨房,她说:“妈妈,我在 Minecraft 中提交了一个错误!”我从事软件工作,我看到过很多很多错误报告,而且我真的很好奇,在那个宇宙中,这意味着什么。是说我在 Twitter 上和别人聊了聊,说它坏了,还是什么?我让她给我看看,于是她打开了电脑,她已经在 Mojang 的系统中创建了一个 JIRA 帐户。
**00:21:53 - Saron Yitbarek**:
我们应该注意到,罗宾的女儿在当时只有 11 岁。
**00:21:57 - Robyn Bergeron**:
她把表格填得像模像样。我见过很多内容不完整的错误报告,也见过很多口吻过于尖锐的错误报告。但这是一个完美的报告……这份报告里有说“发生了什么事”,“我预期会发生什么事”,以及“如何重现错误”。对于很多人来说,这是他们与项目的第一次互动,无论是商业的、专有的软件项目,比如一个电子游戏,还是一个开源软件项目。我很自豪,我告诉她,之后我们完全可以去参加 Minecraft 大会,因为他们一直很想去。
**00:22:33 - Saron Yitbarek**:
Robyn 意识到,当我们其他人从事日常工作时,孩子们却开始了一场革命。以下是在那场 Minecraft 大会上发生的事情。
**00:22:43 - Robyn Bergeron**:
我们去参加主题演讲,我说,就算我们在最后一刻去也会没事的,会在第二排找到位置。但我的设想完全错了,我们坐得就跟房间后面那 10 个大屏幕一样靠后。不过这并没有减少孩子们的热情。大会的其中一天,全体开发人员也在会议上出场了。当工程师们出来的时候,所有在场的孩子都站起来尖叫。如果你看过披头士乐队表演的视频,那这时候就像披头士乐队来美国时一样。我不能相信他们就在我们眼前,这是难以置信的一幕!在会议期间,人们都在试图得到他们的签名,这是……我和我的孩子坐在那里,我在想,我开发操作系统,连接互联网,这样你们才能在一起玩游戏吧?我们做错了什么,才会如此默默无闻呢?
**00:23:36 - Robyn Bergeron**:
但是孩子们就像,我长大后要成为使用 JavaScript 的人!是的,那个活动带来的热烈氛围令人着迷,但……这是一个电子游戏。
**00:23:51 - Saron Yitbarek**:
在 70 年代的某一段时间,每个人的入门语言都是 BASIC;然后可能是 C。近来,人们开始使用 Java 或 Python,但是可视化语言编程和游戏正在催生我们鲜有设想的编程未来。
**00:24:10 - Robyn Bergeron**:
尽管对于已经从事多年编程工作的人来说,这似乎微不足道,但我开始游玩的那一刻,我甚至没有意识到,我其实是在学习一种可以让我受益终生的东西。
**00:24:23 - Saron Yitbarek**:
Robyn Bergeron 是红帽的 Ansible <ruby> 社区架构师 <rt> community architect </rt></ruby>。
**00:24:32**:
BASIC 邀请大学生进入编程世界,而 Minecraft 等游戏则邀请小学生进入当今编程世界。但是从某种意义上说,创造的动力并没有改变。那些大学生在学习 BASIC?是的,他们经常用它来编写游戏。最常见的似乎是足球题材。
**00:24:54**:
创新精神是驱使我们学习编程语言的第一推动力。这种驱动力让我们使世界变得更好,或变得更加有趣。
**00:25:08**:
下次,在第 3 集中,我们会讲述,全新的编程语言究竟从何而来?我们会了解到,巨大挑战是如何推动着开发人员从过去的语言中走出来,并在今天创造出新事物的。
**00:25:26**:
《代码英雄》是 Red Hat 的原创播客。如果你想更深入地了解 BASIC 的起源或在本集中听到的其他内容,请转至 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 。
**00:25:37**:
我是 Saron Yitbarek。在下期节目到来之前,也请继续编程。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-3/learning-the-basics>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[erlinux](https://github.com/erlinux) 校对:[acyanbird](https://github.com/acyanbird), [Northurland](https://github.com/Northurland), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Becoming a programmer used to require a PhD and having access to some serious hardware. Then, in 1965, a couple of engineers had a radical idea: make it easier for people to get started.
Beginner languages, like BASIC, burst the doors to coding wide open. Tom Cormen and Denise Dumas recall how BASIC changed everything. Avi Flombaum and Saron share tips on picking a first language in this new era of software development. And we hear from Femi Owolade-Coombes and Robyn Bergeron about how the next generation of coders are getting their start with video games.
Beginner languages give everyone an opportunity to get their foot in the door. And that helps the industry as a whole.
**00:02** - *Saron Yitbarek*
1965 was a year of massive change in America. The Civil Rights Act was signed.
**00:09** - *Archival news*
Congress passes the most sweeping Civil Rights bill ever to be written into the law.
**00:12** - *Saron Yitbarek*
Combat troops were sent to Vietnam for the first time. Men burned their draft cards.
**00:19** - *Archival news*
Draft cards on the steps of a Boston courthouse. A group of high school boys set upon them with fists.
**00:25** - *Saron Yitbarek*
The Beatles delivered the world's first stadium concert in New York. But, far from all those headlines, a revolution of a different kind was underway.
**00:39** - *Saron Yitbarek*
4:00 AM, May 1. Professor John Kemeny and an undergrad student were working at a GE 225 computer at Dartmouth. They ran a program they'd been working on, and then the teletypewriter produced three short lines of output. Those three lines changed computer programming forever.
**01:04** - *Saron Yitbarek*
Welcome to episode 2 of Command Line Heroes, an original podcast from Red Hat. I'm your host, Saron Yitbarek. In this episode, we continue our season-long journey into the history and future of programming languages. In episode 1, we dove into Python, and learned how open source language communities survive major upheavals in their leadership. But this time, we're getting more personal. We're looking at an experience we've all had, the experience of encountering our very first language. We'll take a look at my first language, Ruby, and we'll learn how some first languages come to us in the form of a game.
**01:50** - *Saron Yitbarek*
But we're beginning with an example that can help us understand what "first languages" really means. It's the language that was born in that Dartmouth laboratory with those three short lines of output. At that pre-dawn meeting in 1965, John Kemeny witnessed the birth of his co-creation, BASIC.
**02:14** - *Saron Yitbarek*
BASIC. It stands for Beginner's All Purpose Symbolic Instruction Code. That first word, “beginner's,” is where the magic lies. In the early days of programming, you pretty much needed a PhD in order to do a little coding. It was an elite pursuit that required major education, not to mention major hardware. But Professor Kemeny and his team wanted to change all that. What would it look like, they wondered, to produce a programming language that anybody could use? While teenage baby boomers were demanding change all across America, the team at Dartmouth proposed a shakeup of another kind.
**02:57** - *Saron Yitbarek*
Their secret weapon was a room-sized mainframe computer, that GE 225. Weighing in at a healthy 2,000 pounds, it was capable of something brand new. The GE 225 was capable of time-sharing. Suddenly, the complicated system of punch cards, or enormous walls of switches, wasn't necessary anymore. Time-sharing meant that a whole bunch of programs could be executed almost simultaneously, with the machine's attention bouncing between users.
**03:31** - *Saron Yitbarek*
Time-sharing meant that access to computing could expand in amazing new ways. Here's some audio from Dartmouth, featuring one of the undergrad’s studying there when BASIC first appeared. He's John McGeachie, class of '65.
**03:47** - *John McGeachie*
We had taken a fairly expensive computer that could only be used by one person at a time, and converted it into something where it wasn't just 30 users who could use it. It was 30 undergraduate students using this computer simultaneously, writing programs, getting answers quickly. It was a combination of immediacy and simplicity that had not previously existed.
**04:15** - *Saron Yitbarek*
John Kemeny had teamed up with Thomas Kurtz, another evangelist for computer literacy, to develop the BASIC language. They saw how time-sharing democratized things, and knew that the barrier for entry was suddenly so much lower. All that was needed was a language that prioritized simplicity and immediacy. A language like BASIC.
**04:39** - *Saron Yitbarek*
They developed commands like "hello" and "goodbye" instead of "log on" and "log off." In fact, the first version of BASIC only had 14 simple commands, just easy options like if, then, and go to.
**04:54** - *Tom Cormen*
I am Tom Cormen. I'm a professor of computer science at Dartmouth College.
**04:59** - *Saron Yitbarek*
Professor Cormen spoke with us about that beginner's revolution, and how the creation of BASIC really did feel like part of a new zeitgeist, a world where computing was exciting to more people. Even a little bit hip.
**05:14** - *Tom Cormen*
At the time in the 1960s, it's said that the male students would bring their dates there, and I can't really imagine that happening now. But at the time, the computer center was the cool place to be.
**05:24** - *Saron Yitbarek*
This new interest in computing on campus was the immediate result of that first beginner's language.
**05:31** - *Tom Cormen*
BASIC opened up computing to people who weren't just computer jocks, as we used to say back then. Social scientists who really didn't want to get into the weeds of a language like FORTRAN could use BASIC, and people doing work in the arts and humanities, if they were doing text analysis, or even trying to create art, they could use BASIC for that.
**05:55** - *Tom Cormen*
After a few years, people were doing things like writing computer games, and also incorporating computer graphics routinely into their work.
**06:03** - *Saron Yitbarek*
All those kids who didn't necessarily see themselves as programmers suddenly got into programming on an almost intuitive level. It reminds me of the kind of world Grace Hopper pushed for. When we talked about Hopper last season, we saw how her language innovations brought programming to a wider circle. This BASIC moment, it was like a continuation of Hopper's dream.
**06:29** - *Tom Cormen*
I'm sure Grace Hopper would've liked seeing more people coding. She probably would've liked that BASIC had a different slant from COBOL, and that it just opened things up to people even more and gave them a choice. They could write in COBOL, they could write in FORTRAN, they could write in BASIC, they could write in ALGOL. Any of the popular languages of the time.
**06:54** - *Saron Yitbarek*
Tom Cormen is a professor in Dartmouth's computer science department. A new generation of computer programmers was ushered in thanks to a couple of major changes. Simultaneous work made possible by time-sharing, and a new simple language, BASIC. Those two factors combined to create a game-changing spark. Soon, it wasn't just massive institutions that could get into programming. It was mavericks like Bill Gates and Steve Wozniak. It was also everyday programmers just exploring on their personal computers.
**07:32** - *Denise Dumas*
To be able to interact with a language to get immediate feedback when something was wrong, that made all the difference in the world, because it sucked you in, it kept you going, and the interaction was meaningful, because it was an interaction.
**07:50** - *Saron Yitbarek*
This is Denise Dumas. She runs the Red Hat® Enterprise Linux® engineering team.
**07:55** - *Denise Dumas*
I mean BASIC democratized programming in a big way, because it put it in the hands of students, in the hands of people, in a way that COBOL, FORTRAN, the other languages of the day ... it just wasn't possible. It became really popular at a time when CRTs (cathode ray tubes) became popular, so instead of typing something in and getting it printed on a piece of paper, it displayed on a screen in front of you.
**08:26** - *Denise Dumas*
We laugh at command line sometimes now, right? Everything is graphics, but the command line is what there was, and it was such an improvement over what had been. That was huge, just to type something in and get a response. I think that BASIC lowered the bar, and I say this as someone who actually loves assembler, because that's the kind of control freak I am. But I think BASIC made it much more approachable.
**08:59** - *Saron Yitbarek*
The excitement BASIC created in the 1980s lives on today, with a whole fleet of languages that beginners use as shiny red doors into the world of programming. Yet something important has changed, because those entrances don't just show up on university campuses anymore. The way into programming is becoming even more open.
**09:29** - *Saron Yitbarek*
As amazing as BASIC was, Grace Hopper's dream wasn't going to stop there. Today, beginners have a hundred ways to find their start, and for me, learning a first language meant attending an institution called the Flatiron School in New York City. I prepared for months for that program. I read every single programming resource and tutorial that I possibly could to make sure I got the most out of my bootcamp. I wanted to learn about how people today discover that first language. So, I headed back to interview my old teacher.
**10:03** - *Avi Flombaum*
I'm Avi Flombaum.
**10:04** - *Saron Yitbarek*
Avi's one of the founders of the Flatiron School, so it was a treat for me to dig into all these thoughts about first languages, and how our approaches to first languages have changed since the old days of BASIC.
**10:26** - *Saron Yitbarek*
So when you are teaching someone how to code, where do you begin? I remember when I first learned my first programming language, thinking, this is so weird. I was an English major, I really liked math when I was in school. I liked organic chemistry. There were a lot of things that I was really into, a lot of different subjects, but there was nothing I could connect coding to. There was nothing that was a good analogy. It just felt like its own little world, so as a teacher, where do you start?
**10:49** - *Avi Flombaum*
I think that anything that is familiar to you in life was once foreign, and experiencing it and wading in its waters and actually spending time with it is what makes you comfortable with it, and it's just a question of reps, and really just time that you put into it. I think what makes programming difficult, and what makes it feel so foreign, is that it is a tremendously particular syntax for expressing something. There's zero ambiguity. There's no margin of error. It either works or it doesn't. When we communicate to each other, we generally don't have that kind of requirement, where everything has to be exactly correct. One comma is off, one parenthesis is missing, and it's all broken.
**11:32** - *Avi Flombaum*
I always say that computers are stupid, and we have to just be perfect in order to get them to understand what we mean.
**11:37** - *Saron Yitbarek*
I like that. I like this idea of the machine being the stupid one and me being the smart one. I approve of this. This is great.
**11:43** - *Avi Flombaum*
Yeah.
**11:44** - *Saron Yitbarek*
For me, that first language, the one I cut my teeth on, was Ruby. From experience, I can tell you, it's a pretty sweet first language. When you read the code, it feels like you're reading English. It's got tons of great libraries, and here's a bit of trivia. The creator of Ruby, Yukihiro Matsumoto, he got into programming by learning BASIC.
**12:06** - *Saron Yitbarek*
These days, a lot of newbies might be tackling Python or JavaScript instead, and I wanted to know whether Avi thought any one language was a better front door than all the others.
**12:18** - *Saron Yitbarek*
I'm wondering, are there preferred starter languages? If someone's coming into this with no tech background, no coding experience, no CS degree, they're kind of starting from absolutely nothing, from square one, square zero even ... Are there preferred languages that are good starting points that have changed over time?
**12:39** - *Avi Flombaum*
Well, first, I'll say that everyone comes into it with no background. No one is born a programmer, so whether you formally learned it in a CS program or in your community center or read books and taught yourself, everyone started as a beginner. Then in terms of the preferred beginner language, I think it's really whatever speaks to you first. My advice to beginners is always just pick a language and learn it. Don't change. I think the biggest thing that beginners do is start learning Python, and then get frustrated with it and say, Python sucks, now I'm going to go do JavaScript. Then they learn JavaScript and then they get frustrated with JavaScript and they jump again.
**13:22** - *Avi Flombaum*
I personally, as you know, think that Ruby's a great beginner language. I think that its syntax is just really beautiful. Its value explicitly is to make you, the programmer, happy. I don't know any other language that was invented to make a programmer happy. I know a lot of languages are invented to make machines happy, but I think Ruby's really natural.
**13:44** - *Saron Yitbarek*
We can agree on that one. But again, there's no wrong answer here. A first language, after all, is just that. A first. We've all got a whole lifetime of language learning ahead of us, and besides, choosing one language over another isn't going to stop you from becoming the awesome programmer you were destined to be.
**14:05** - *Saron Yitbarek*
I like to draw, but I will not live and die by a particular pen. I don't get all worked up over the pen that I use. I get worked up over the things I create, so from your experience, where does that come from? Where does that need to defend and convince everyone that you are right about a programming language, where does that come from?
**14:23** - *Avi Flombaum*
I guess I don't know. The first thing that came into my head, because I loved your metaphor of the pen versus the output ... I just imagine that some of the output is not that great, so the only thing that people can hold onto is the tool.
**14:41** - *Saron Yitbarek*
That's hilarious.
**14:42** - *Avi Flombaum*
If the things you make just aren't awesome and aren't great and don't have a lot of value for the world, and you want to still defend your craft, the only thing you can point to is, yeah, look how well I swung that hammer. Sure. The house fell apart, but that hammer, that hammer's really great and I know how to use it. As someone ... I was also more interested in the things I built than the manner in which I built them.
**15:09** - *Saron Yitbarek*
That's a good point. Now that beginners have more to choose from than just BASIC, or, I don't know, FORTRAN, now that we have a whole menu of first languages, there's always the danger that you forget these languages are still a means to an end. The language is the tool, it's not the thing you're making.
**15:27** - *Avi Flombaum*
I think that the value of technology is to create meaningful things for people. Ultimately, if you're a programmer and you're really, really good, but you're building things that no one needs and no one likes and don't ... aren't adding value to the world, but you're really, really good at the craft and just can't find a way to actually make the impact you want, I imagine that you'd probably dig in and talk about the tool you used.
**15:56** - *Saron Yitbarek*
Well, thank you so much, Avi, for sharing all your experiences and your thoughts about programming languages. You want to say goodbye?
**16:01** - *Avi Flombaum*
Yeah, this was super fun, it was nice connecting again, and I hope you all find a language that you love, and get to work in it every day.
**16:10** - *Saron Yitbarek*
Sounds good.
**16:13** - *Saron Yitbarek*
Avi Flombaum is one of the co-founders of Flatiron School.
**16:20** - *Saron Yitbarek*
Coding schools can bring that spirit of access and education to a whole new level. It's a continuation of what we saw at Dartmouth, but in a rich development ecosystem, we'll keep getting more and more natural points of entry, and first time coders are already discovering next-level ways to get into the game, sometimes literally.
**16:45** - *CO.LAB participants*
Have you tried a different key? Try the G key.
**16:52** - *Saron Yitbarek*
Now, hold on. That is not a bunch of young coders silently memorizing an O'Reilly textbook, and it's not a lecture at the Flatiron School either. It's actually a little lab that Red Hat ran at the Tate Modern in London. And those kids? They're learning to code. For a new generation, the joy of coding is what they first encounter.
**17:13** - *Femi Owolade-Coombes*
Okay. Hi, my name is Femi, AKA Hackerfemo.
**17:17** - *Saron Yitbarek*
Femi Owolade-Coombes is only 13 years old, but he's already a leader in a new wave of young coders.
**17:26** - *Femi Owolade-Coombes*
I first encountered coding when I was eight, and I went to an event in York, actually, about maths, and there I saw this cool thing, hacking Minecraft ethically. As an eight-year old, I thought that was really cool. So that's how I got into coding.
**17:47** - *Saron Yitbarek*
He's not alone. Minecraft has introduced a whole generation to coding, and it's done that without any of the pain or dry studying that past generations suffered through. The magic of gaming is dropping barriers. Minecraft is Java™-based, and it's been accredited with breathing new life into that language, spawning a whole crowd of fresh-faced Java fans.
**18:11** - *Saron Yitbarek*
But it doesn't have to be Java. For Femi, Python was the language he discovered in Minecraft.
**18:16** - *Femi Owolade-Coombes*
You can use Python when you're using the Raspberry Pi in Minecraft, because Minecraft have created this special edition for the Raspberry Pi, which is so cool, 'cause you can hack it by just importing this library, and you can put exploding TNT everywhere, and you can create blocks behind you, you can create whole buildings. All sorts of things.
**18:42** - *Femi Owolade-Coombes*
When I first played it, I knew there were quite a few things like mods you could add on, which were pretty cool. Those were like little hacks in themselves, but this was the first time I realized you could properly hack it and really make it do what you want. I thought it was really cool.
**18:57** - *Saron Yitbarek*
A world of coding opened up for Femi, and the door to that world was his favorite game. Then, Femi did something kind of amazing. He started showing other kids that door.
**19:10** - *Femi Owolade-Coombes*
Well, I wanted to share my knowledge with my peers, because I thought, you know what? They will really enjoy this, and I had a great time. I want to share this with everyone else so that they can learn about it, and so that they can even get into coding.
**19:30** - *Saron Yitbarek*
Femi went ahead and founded the South London Raspberry Jam, and there, he's been able to watch a whole new generation of coders defy expectations about what a first language experience should look like. Besides those Minecraft hacks, visual languages like Scratch or Fruit are making the basics of coding achievable to younger and younger users.
**19:54** - *Femi Owolade-Coombes*
I do like the idea of playing a game, and I most certainly do it over learning to code in a classroom, but it's the idea of being able to control what happens in that game, and code is behind that, and code gives you that really cool ability to make the game do what you want.
**20:15** - *Saron Yitbarek*
Femi's mom told us how happy she was to discover that gaming didn't have to be a passive pursuit. What I love about his story is that it starts with gaming, sure. But it doesn't end there. He built an amazing community of young coders, and Femi's own coding life is taking off. It's not just Minecraft anymore. He works in HTML, JavaScript, and CSS, building websites and doing web design. He's even building his own games using Unity.
**20:44** - *Femi Owolade-Coombes*
Everyone really should have a right to learn how to code, because it is the future.
**20:53** - *Saron Yitbarek*
Is Minecraft really a giant programming university? Are the coders of tomorrow going to absorb new languages through games and simply messing around? Will languages be learned just through osmosis?
**21:06** - *Robyn Bergeron*
Hi, my name's Robyn Bergeron.
**21:08** - *Saron Yitbarek*
Robyn's the community architect for Ansible® over at Red Hat, and she also happens to have a couple kids who stumbled into programming themselves.
**21:18** - *Robyn Bergeron*
There was a moment at dinner one night. I was actually cooking, everyone was impressed. My daughter came into the kitchen area, and she said, "Mommy, I filed a bug in Minecraft!" I work in software, I see lots and lots and lots of bug reports, and I was just really curious about what that meant in that universe. Is that like, I talked to someone on Twitter and said it's broken, or what? I asked her to show me, so she opened up her computer, and she had created a JIRA account in Mojang's system.
**21:53** - *Saron Yitbarek*
We should note, Robyn's daughter was 11 when she did this.
**21:57** - *Robyn Bergeron*
She had filled out their form exactly, and I see lots of bug reports that are not well-formed, or they're very mean. I see a lot of that, too. But it was a perfectly ... Here's what happened, here's what I expected to happen, and here's all of the steps to reproduce, which is, for a lot of people, that's their first interaction with any project, whether it's commercial, proprietary software project, like a video game, or an open source software project. I was so proud, and I told her we can totally go to the Minecraft conference after that, because they had been dying to go.
**22:33** - *Saron Yitbarek*
Robyn was about to realize that while the rest of us were going about our day jobs, the kids were starting a revolution. Here's what happened at that conference.
**22:43** - *Robyn Bergeron*
We went to the keynotes, and I said, oh, we'll go at the last second, we'll be fine, we'll totally be in the second row. Oh, no. No, no, no. We were like 10 of those gigantic, big screens back in the room. But it was nonstop cool stuff for kids, and they had a moment on one of the days where they brought out all of the developers, and when the engineers came out, literally every kid in this audience was standing on their chairs screaming. If you've ever seen here's the Beatles, like the Beatles come to America video, it was like that. It was like, I can't believe we're near them and they're amazing! During the sessions, people were trying to get their autographs, and it was ... I'm sitting there with my kids being like, I work on operating systems that connect the internet so that you guys can actually game together? What are we doing wrong?
**23:36** - *Robyn Bergeron*
But kids are just being like, I'm going to be a JavaScript person when I grow up, yes! And just watching the level of enthusiasm at that event was fascinating, but ... it's a video game.
**23:51** - *Saron Yitbarek*
There was a time back in the '70s when everyone's first language was BASIC, and then maybe it was C. More recently, people have been starting with Java or Python, but visual languages and games are ushering in a coding future that we're only beginning to imagine.
**24:10** - *Robyn Bergeron*
Even though it may seem trivial to someone who's been programming for years, it's that first moment of, I'm playing, and I don't even realize that I'm actually learning something that could turn into a lifelong skill.
**24:23** - *Saron Yitbarek*
Robyn Bergeron is the community architect of Ansible at Red Hat.
**24:32** - *Saron Yitbarek*
BASIC invited college students into the world of programming, and games like Minecraft invite elementary school students into that world today. But in a way, the creative impulse behind all this hasn't changed. Those college kids exploring BASIC? Yeah, they were often using it to build their own games. Lots of fantasy football, apparently.
**24:54** - *Saron Yitbarek*
Our creative spirit is what drives us toward programming languages in the first place. That drive to tweak the world, make it better, or just more fun.
**25:08** - *Saron Yitbarek*
Next time, in episode 3, where do brand new programming languages come from, anyway? We're learning how incredible challenges pushed developers to walk away from the languages of yesterday and build something totally new today.
**25:26** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. If you want to dive deeper into the origins of BASIC or anything else you heard on this episode, head on over to redhat.com/commandlineheroes.
**25:37** - *Saron Yitbarek*
I'm Saron Yitbarek. Until next time, keep on coding.
### Keep going
### BASIC: A nostalgic look back
Find out more about why BASIC is a beloved first language and how the next generation will learn to code on Opensource.com.
### Red Hat Software Collections: Ruby
Run Ruby on Red Hat Enterprise Linux with this walkthrough.
### Enjoy this episode's artwork on your device
Download the Command Line Heroes artwork and set it as your background. |
12,830 | JavaScript 如此受欢迎的 4 个原因 | https://opensource.com/article/20/11/javascript-popular | 2020-11-17T10:30:14 | [
"JavaScript"
] | https://linux.cn/article-12830-1.html |
>
> JavaScript 之所以能在编程语言中名列前茅,是有充分的理由的。
>
>
>

如 GitHub 的 [The State of the Octoverse](https://octoverse.github.com/) 报告的这张图所示,如果按 GitHub 上项目的贡献者数量统计,[JavaScript](https://en.wikipedia.org/wiki/JavaScript) 一直是最受欢迎的编程语言。

*热门语言,根据《The State of the Octoverse》(©2019,[GitHub Corp](https://octoverse.github.com/))*
在本系列的 [上一篇](/article-12813-1.html) 中,我们深入了解了 JavaScript 的历史。在这篇文章中,我将分享它如此受欢迎的四个[原因](https://medium.com/paul-heintzelman/so-why-is-javascript-so-popular-f35bd6cfeb39)。
### 1、JavaScript 适合初级、中级和高级开发人员
JavaScript 不需要任何环境设置,只要打开浏览器,比如 Chrome 浏览器,导航到[开发者工具](https://developers.google.com/web/tools/chrome-devtools),就可以开始编码。编写一个 “Hello World” 的程序,就这么简单:
```
console.log("Hello World");
```
JavaScript 的灵活性最适合中级开发人员。该语言通过让开发人员专注于解决问题来帮助你完成任务。开发者可以混合使用插件和自己的代码片段来让一个应用程序工作。
虽然 JavaScript 比较容易上手,但它也并不是一下子就能掌握的。如果你想达到高级水平,这里有一些你需要了解的概念:
* **JavaScript 的[多范式](https://medium.com/javascript-in-plain-english/what-are-javascript-programming-paradigms-3ef0f576dfdb)特性:** JavaScript 同时支持函数式编程和面向对象编程(OOP)。
* **在 JavaScript 中应用[设计模式](https://addyosmani.com/resources/essentialjsdesignpatterns/book/):** 模型-视图-\*([MV\*](https://developpaper.com/javascript-mv-pattern/))设计模式一直是最流行的模式之一,并促成了[多个现代框架](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel#JavaScript_frameworks)的发展。
* **[带原型链的继承](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Inheritance_and_the_prototype_chain):** JavaScript 由于其动态的特性,无法实现传统的 Java 基于类的模式下的 OOP。JavaScript 中的 OOP 是通过原型继承模型实现的。
* **[闭包](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures):** 闭包可以从内部函数中访问外部函数的作用域。
* **<ruby> <a href="https://javascript.info/currying-partials"> 柯里化 </a> <rt> Currying </rt></ruby>:** 柯里化是函数的一种转换,它将函数从 `f(a, b, c)` 的调用形式转换为 `f(a)(b)(c)` 调用形式。
* **[Promises](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) 和 [Observables](https://rxjs-dev.firebaseapp.com/guide/observable):** 这些可以帮助你处理异步函数。
* **[TypeScript](https://en.wikipedia.org/wiki/TypeScript):** 在 JavaScript 中添加了静态类型。
### 2、全平台
JavaScript 可以在任何地方运行,包括:
* 手机、平板电脑和笔记本电脑等设备。
* 在客户端和服务器端。
这种在任何地方都能运行的能力使 JavaScript 成为一种通用语言。
### 3、开放标准和社区
[ECMAScript](https://en.wikipedia.org/wiki/ECMAScript) 是 JavaScript 的标准化版本,也是一种开放的标准语言。公司可以使用 ECMAScript 来创建 JavaScript 的实现。根据[维基百科](https://en.wikipedia.org/wiki/List_of_ECMAScript_engines),“ECMAScript 引擎是执行以 ECMAScript 语言标准编写的源代码(例如,JavaScript)的程序”。最流行的引擎 [V8](https://en.wikipedia.org/wiki/V8_%28JavaScript_engine%29) 和 [SpiderMonkey](https://en.wikipedia.org/wiki/SpiderMonkey) 是开源项目。
JavaScript 已经存在了 25 年,背后有一个庞大的社区。开发者们简直目不暇接,社区已经构建了如此多的插件和框架,以至于创造了“[框架疲劳](https://teropa.info/blog/2015/07/15/overcoming-javascript-framework-fatigue.html)”这个词。
### 4、现代框架
现代框架如 [React](https://en.wikipedia.org/wiki/React_%28web_framework%29)、[Angular](https://en.wikipedia.org/wiki/Angular_%28web_framework%29) 和 [Vue.js](https://en.wikipedia.org/wiki/Vue.js) 已经稳定下来,并且正在进行优化以获得更好的性能。大多数框架对开发者非常友好,有良好的社区支持。
### 未来
JavaScript 将长期存在。全栈开发和现代前端框架继续帮助 JavaScript 巩固其作为最受欢迎的编程语言之一的地位。
JavaScript 的[下一波](https://medium.com/@rangleio/the-future-of-javascript-in-the-front-end-world-2544c1814e2)可能会将焦点放在。
* **[Deno](https://en.wikipedia.org/wiki/Deno_%28software%29):** JavaScript 的现代安全运行时。
* **网络组件:** 可重复使用的自定义元素。
* **与 AI 和 ML 的整合:** 像 [Supernova](https://techcrunch.com/2018/03/13/supernova-studio/) 和 [BAYOU](https://futurism.com/military-created-ai-learned-to-program) 这样的项目在将 JavaScript 与人工智能和机器学习整合方面取得了实质性的突破。
---
via: <https://opensource.com/article/20/11/javascript-popular>
作者:[Nimisha Mukherjee](https://opensource.com/users/nimisha) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As this chart from GitHub's * State of the Octoverse* report shows,
[JavaScript](https://en.wikipedia.org/wiki/JavaScript)has consistently been most popular programming language based on the number of contributors to projects on GitHub.
opensource.com
In the [previous article](https://opensource.com/article/20/10/javascript-part-1) in this series, I dove into the history of JavaScript. In this article, I'll share four of [the reasons](https://medium.com/paul-heintzelman/so-why-is-javascript-so-popular-f35bd6cfeb39) it is so popular.
## 1. JavaScript caters to beginner, intermediate, and advanced developers
JavaScript does not need any environment setup; just open a browser, like Chrome, navigate to [Developer Tools](https://developers.google.com/web/tools/chrome-devtools), and start coding. Writing a "Hello World" program is as simple as:
`console.log("Hello World");`
JavaScript's flexibility is best suited for intermediate developers. The language just helps get things done by letting the developer focus on solving the problem. Developers can use a mix of plugins and their own code snippets to get an application working.
While JavaScript is relatively easy to get started with, it is not straightforward to master. If you want to get to an advanced level, here are some of the concepts you need to know:
**JavaScript's**JavaScript supports both functional programming and object-oriented programming (OOP).[multi-paradigm](https://medium.com/javascript-in-plain-english/what-are-javascript-programming-paradigms-3ef0f576dfdb)nature:**Applying**The model-view-* ([design patterns](https://addyosmani.com/resources/essentialjsdesignpatterns/book/)in JavaScript:[MV*](https://developpaper.com/javascript-mv-pattern/)) design patterns have been among the most popular and have led to the development of[several modern frameworks](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel#JavaScript_frameworks).JavaScript cannot implement OOP in the traditional Java class-based model due to its dynamic nature. OOP in JavaScript is achieved through the prototypal inheritance model.[Inheritance with prototype chain](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Inheritance_and_the_prototype_chain):A closure gives access to an outer function's scope from an inner function.[Closures](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures):Currying is a transformation of functions that translates a function from callable as f(a, b, c) into callable as f(a)(b)(c).[Currying](https://javascript.info/currying-partials):These help you work with asynchronous functions.[Promises](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise)and[Observables](https://rxjs-dev.firebaseapp.com/guide/observable):This adds static typing to JavaScript.[TypeScript](https://en.wikipedia.org/wiki/TypeScript):
## 2. Omni-platform
JavaScript can run everywhere, including:
- Devices like mobiles, tablets, and laptops
- On the client-side as well as the server-side
This ability to run everywhere makes JavaScript a universal language.
## 3. Open standards and community
[ECMAScript](https://en.wikipedia.org/wiki/ECMAScript) is the standardized version of JavaScript as well as an open standard language. Companies can use ECMAScript to create a JavaScript implementation. According to [Wikipedia](https://en.wikipedia.org/wiki/List_of_ECMAScript_engines), "an ECMAScript engine is a program that executes source code written in a version of the ECMAScript language standard, for example, JavaScript." The most popular engines, [V8](https://en.wikipedia.org/wiki/V8_%28JavaScript_engine%29) and [SpiderMonkey](https://en.wikipedia.org/wiki/SpiderMonkey), are open source projects.
JavaScript has been around for 25 years and has a vast community behind it. A developer is spoiled for choice. The community has built so many plugins and frameworks that the phrase "[framework fatigue](https://teropa.info/blog/2015/07/15/overcoming-javascript-framework-fatigue.html)" was coined.
## 4. Modern frameworks
Modern frameworks like [React](https://en.wikipedia.org/wiki/React_%28web_framework%29), [Angular](https://en.wikipedia.org/wiki/Angular_%28web_framework%29), and [Vue.js](https://en.wikipedia.org/wiki/Vue.js) have stabilized and are being optimized for better performance. Most frameworks are very developer-friendly with good community support.
## The future
JavaScript is here to stay. Full-stack development and the modern frontend framework continue to help JavaScript cement its position as one of the most popular programming languages.
The [next wave of JavaScript](https://medium.com/@rangleio/the-future-of-javascript-in-the-front-end-world-2544c1814e2) might put the spotlight on:
## 1 Comment |
12,831 | 如何在 Linux 上检查可用的磁盘空间 | https://itsfoss.com/check-free-disk-space-linux/ | 2020-11-17T11:14:00 | [
"磁盘"
] | https://linux.cn/article-12831-1.html |
>
> 我已经使用了多少磁盘空间?
>
>
>

在 Linux 上查找可用磁盘空间的最简单的方法是[使用 df 命令](https://linuxhandbook.com/df-command/) 。`df` 命令从字面意思上代表着<ruby> 磁盘可用空间 <rt> disk free </rt></ruby>,很明显,它将向你显示在 Linux 系统上的可用磁盘空间。
```
df -h
```
使用 `-h` 选项,它将以人类可读的格式(MB 和 GB)来显示磁盘空间。
这里是针对我 Dell XPS 系统的 `df` 命令的输出,它使用了加密磁盘并且只安装了 Linux:

如果上面的输出使你感到困惑,不用担心。我将介绍一些关于在 Linux 中检查可用磁盘空间的东西。我也将为桌面 Linux 用户展示 GUI 方法。
### 方法 1: 使用 df 命令来检查在 Linux 中的可用磁盘空间(并理解它的输出)
当你使用 `df` 命令来检查磁盘空间时,它将显示一组“文件系统”,包括它们的大小、使用的空间和可用的空间。你实际的磁盘通常应该下面列表中的一个:
* `/dev/sda`
* `/dev/sdb`
* `/dev/nvme0n1p`
这不是硬性的标准,但是它可以给予你一个指示,它可以让你能够很容易地从一堆文字中辨别出真正的磁盘。
你的 Linux 系统在你的磁盘上可能有一些用于引导 分区、EFI 分区、根分区、交换分区、家目录等的分区。在这种情况下,这些分区在“磁盘名称”的结尾处使用一个数字来标示,像 `/dev/sda1`、`/dev/nvme0n1p2` 等等。
你可以从它们的挂载点来辨认出哪个分区是用于做什么的。根分区挂载在 `/`、EFI 分区在 `/boot/EFI` 等等。
就我的情况来说,我已经使用了根分区下磁盘空间(232 GB)的 41% 。如果你有 2 到 3 个大分区(像根分区、家目录分区等等),你将不得不在这里计算一下已使用的磁盘空间。

* `tmpfs`:[tmpfs](https://www.kernel.org/doc/html/latest/filesystems/tmpfs.html)(临时文件系统)用于在虚拟存储器中保持文件。你可以随意地忽略这个虚拟文件系统。
* `udev`:[udev 文件系统](https://wiki.debian.org/udev) 用于存储插入到你系统的设备(像 USB、网卡、CD ROM 等等)的相关信息。你也可以忽略它。
* `/dev/loop`: 它们是环回设备。由于 snap 应用程序,在 Ubuntu 中查看磁盘时,你将看到很多的这样的设备。环回设备是虚拟设备,它们允许普通文件作为块设备文件来访问。使用环回设备,snap 应用程序在它们自己的虚拟磁盘中进行沙盒处理。尽管它们是在根分区下,但是你不需要单独计算它们使用的磁盘空间。
#### 丢失了磁盘空间?检查你是否挂载了所有是磁盘和分区
记住,`df` 命令仅显示已挂载文件系统的磁盘空间。如果你在同一块磁盘上使用多个 Linux 发行版(或者多个操作系统),或者在你的系统上有多个磁盘,你需要先挂载它们,以便查看在这些分区和磁盘上的可用磁盘空间。
例如,我的 [Intel NUC](https://itsfoss.com/install-linux-on-intel-nuc/) 有两个 SSD 磁盘,并且在其上有 4 个或 5 个 Linux 分区。仅当我明确地挂载它们时,`df` 命令才会显示更多磁盘。

你可以使用 `lsblk` 命令来查看在你系统上的所有磁盘和分区。

在你有了磁盘分区名称后,你可以用这种方式来挂载它:
```
sudo mount /dev/sdb2 /mnt
```
我希望这种方法能够给你提供一个在 Linux 上检查硬盘驱动器空间的好主意。让我们看看如何在 GUI 下来完成。
### 方法 2: 在 GUI 下检查可用磁盘使用情况
在 Ubuntu 中使用 “Disk Usage Analyzer” 工具来在 GUI 的方式下检查可用磁盘空间是很容易的。

在这里,你将看到所有实际的磁盘和分区。你可能需要单击一些分区来挂载它们。它显示所有已挂载分区的磁盘使用情况。

#### 使用 GNOME 的 Disks 实用程序来检查可用磁盘空间
除此之外,GNOME 的 Disks 实用程序也是非常容易使用的工具。

启动工具和选择磁盘。选择一个分区来查看可用磁盘空间。如果没有挂载分区,那么先通过单击 “▶” 图标来挂载它。

我认为在 Linux 上的所有主要桌面环境都有某种图形工具来检查磁盘使用情况。你可以在你是桌面 Linux 系统的菜单中搜索它。
### 结束语
当然,有很多方法和工具来检查磁盘空间。为此,我向你显示了最常用的命令行方法和 GUI 方法。
我也解释一些可能会让你很难理解磁盘使用情况的东西。希望你喜欢它。
如果你有问题或建议,请在评论区告诉我。
---
via: <https://itsfoss.com/check-free-disk-space-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

**How much disk space have I utilized?**
The simplest way to find the free disk space on Linux is to [use df command](https://linuxhandbook.com/df-command/). The df command stands for disk-free and quite obviously, it shows you the free and available disk space on Linux systems.
`df -h`
With `-h`
option, it shows the disk space in human-readable format (MB and GB).
Here’s the output of the df command for my Dell XPS system that has only Linux installed with encrypted disk:
If the above output is confusing for you, don’t worry. I’ll explain a few things about checking available disk space on Linux. *I’ll also show the GUI method for desktop Linux users.*
Overall, I’ll mention three methods:
With the information you gather, you can go about [making some free space on Ubuntu](https://itsfoss.com/free-up-space-ubuntu-linux/).
## Method 1: Checking free disk space in Linux with df command (and understanding its output)
When you use the df command to check disk space, it will show a bunch of ‘file systems’ with their size, used space and free space. Your actual disks should normally be listed as one of the following:
- /dev/sda
- /dev/sdb
- /dev/nvme0n1p
This is not a hard and fast rule but it gives you an indication to easily recognize the actual disk from the crowd.
Your Linux system might have several partitions on your disk for boot, EFI, root, swap, home etc. In such cases, these partitions are reflected with a number at the end of the ‘disk name’, like /dev/sda1, /dev/nvme0n1p2 etc.
You could identify which partition is used for what purpose from its mount point. Root is mounted on /, EFI in /boot/EFI etc.
In my case, I have used 41% of the 232 GB of disk space under root. If you have 2-3 big partitions (like root, home etc), you’ll have to make a calculation here.
**tmpfs**: The[tmpfs](https://www.kernel.org/doc/html/latest/filesystems/tmpfs.html)(temporary filesystem) used for keeping files in virtual memory. You can ignore this virtual filesystem comfortably.**udev**: The[udev filesystem](https://wiki.debian.org/udev)is used for storing information related to devices (like USB, network card, CD ROM etc) plugged to your system. You may ignore it as well.**/dev/loop**: These are loop devices. You’ll see plenty of them while checking disk space in Ubuntu because of snap applications. Loops are virtual devices that allow normal files to be accessed as block devices. With the loop devices, snap applications are sandboxed in their own virtual disk. Since they are under root, you don’t need to count their used disk space separately.
And, if you want to view the disk usage with more details like filesystem type and blocks, you can use the command:
`df -T`
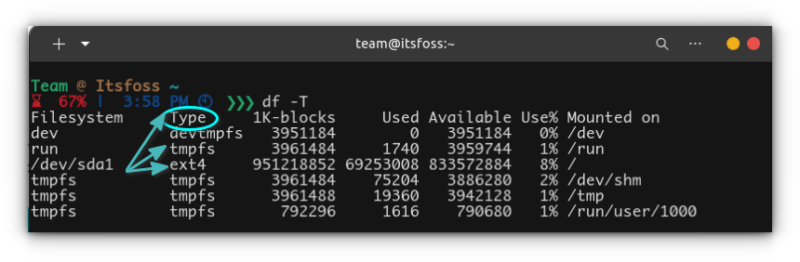
### Missing disk space? Check if you have mounted all disks and partitions
Keep in mind that the df command only shows disk space for mounted filesystems. If you are using more than one Linux distribution (or operating systems) on the same disk or you have multiple disks on your system, you need to mount them first in order to see the free space available on those partitions and disks.
For example, my [Intel NUC](https://itsfoss.com/install-linux-on-intel-nuc/) has two SSDs and 4 or 5 Linux distributions installed on them. It shows additional disks only when I mount them explicitly.
You can use the lsblk command to see all the disks and partitions on your system.
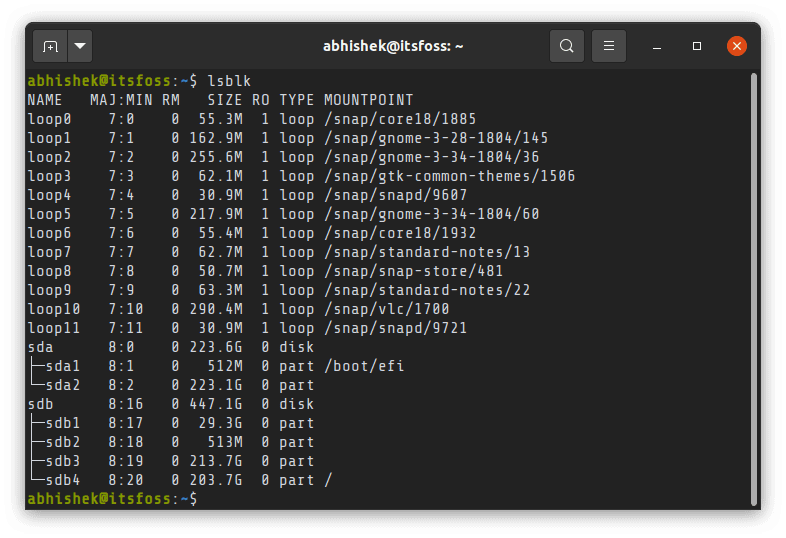
Once you have the disk partition name, you can mount it in this fashion:
`sudo mount /dev/sdb2 /mnt`
I hope this gives you a pretty good idea about checking hard drive space on Linux. Let’s see how to do it graphically.
## Method 2: Using du, ls, and Other Commands
While df command is quite popular and should be enough for the use case, there are other alternatives that you can try including:
**du -h**→ Shows disk usage in human-readable format for all directories and subdirectories.**du -a**→Shows disk usage for all files.**du -s**Provides the total disk space used by a particular file or directory.**ls -al**→Lists the entire contents, along with their size, of a particular directory.**stat <file/directory>**→Displays the size and other stats of a file/directory or a file system.**fdisk -l**→Shows disk size along with disk partitioning information (may require sudo privileges).**dust**→ An interesting alternative to the**du**command written in Rust, available for Arch Linux in the repositories. For other Linux distros, you can refer to its[GitHub releases section](https://github.com/bootandy/dust).
## Method 3: Check free disk usage graphically
Checking free disk space graphically is much easier in Ubuntu with the Disk Usage Analyzer tool.
You’ll see all the actual disks and partitions here. You may have to mount some partitions by clicking on them. It displays the disk usage for all the mounted partitions.
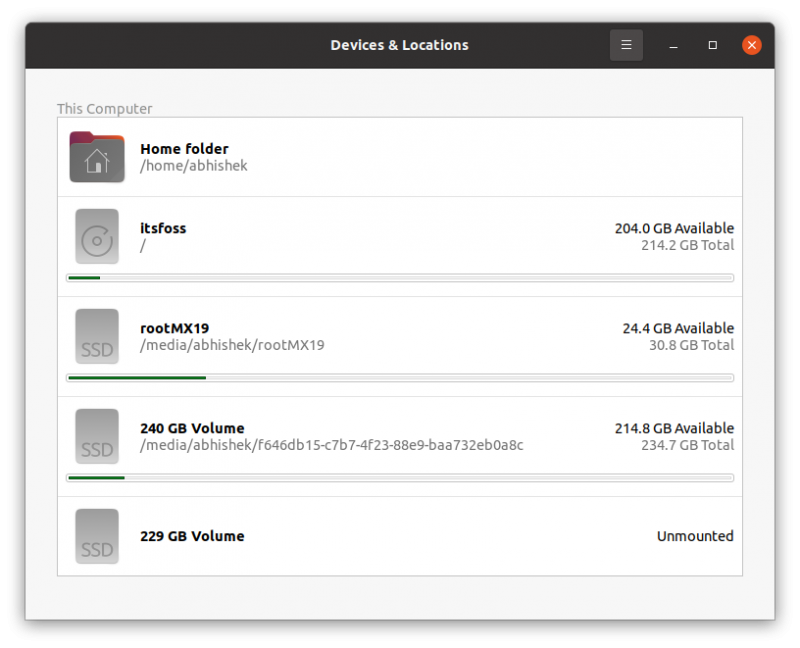
### Checking free disk space with GNOME Disks utility
Otherwise, the GNOME Disks utility is also a pretty handy tool.
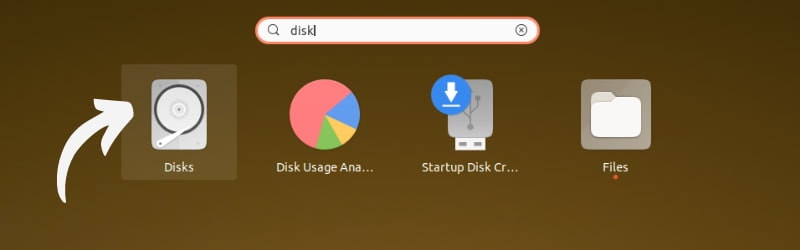
Start the tool and select the disk. Select a partition to see the free disk space. If a partition is not mounted, mount it first by clicking the ‘play’ icon.
I think all major desktop environments have some sort of graphical tool to check the disk usage on Linux. You can search for it in the menu of your desktop Linux system.
## Conclusion
Of course, there can be more ways and tools to check disk space. I showed you the most common command line and GUI methods for this purpose.
I also explained a few things that might trouble you in understanding disk usage. I hope you like it.
Running out of disk space? How about cleaning it up and get it back?
[7 Simple Ways to Free Up Space on Ubuntu and Linux MintBrief: Running out of space on your Linux system? Here are several ways you can clean up your system to free up space on Ubuntu and other Ubuntu based Linux distributions. Over time, any operating system can become cluttered as programs are added and removed. If you have like a](https://itsfoss.com/free-up-space-ubuntu-linux/)

Please let me know in the comment section if you have questions or suggestions. |
12,834 | KDE Neon vs Kubuntu:这两款 KDE 发行版有什么区别? | https://itsfoss.com/kde-neon-vs-kubuntu/ | 2020-11-17T23:59:00 | [
"KDE"
] | https://linux.cn/article-12834-1.html | 当你发现两款基于 [Ubuntu](https://ubuntu.com/) 并由 [KDE](https://kde.org/) 驱动的 Linux 发行版,你会选择哪一个?
* [Kubuntu](https://kubuntu.org) 是 Ubuntu 的官方 KDE 版本。
* [KDE Neon](https://neon.kde.org) 是 KDE 自己发布的基于 Ubuntu 的发行版。
我知道这常常会让人感到困惑,尤其是当你从来没有使用过这两个版本,但有人推荐你使用它们。因此,为了帮助你做出决定,我想整理一份 KDE Neon 和 Kubuntu 的区别(和相似之处)。
让我们先开始了解相似之处,然后再继续了解不同之处。
注:根据你的系统,你对这两个发行版的体验可能有所不同。所以,请把这篇文章作为一个参考,而不是一个”哪个更好“的比较。
### KDE Neon vs Kubuntu:功能上的比较

基于相似性比较发行版是一个不错的做法。所以,从理论上,我试图把最重要的区别写下来。
然而,值得注意的是,发行版的兼容性、性能和稳定性会根据你的硬件而有所不同,而这里没有考虑到这一点。
#### Ubuntu 作为基础

是的,这两个 Linux 发行版都是基于 Ubuntu 的,但 KDE Neon 只基于最新的 Ubuntu LTS 版本,而 Kubuntu 则提供了基于 Ubuntu LTS 的版本和非 LTS 版本。
所以,如果使用 KDE Neon,你可以期望在下一个 Ubuntu LTS 版本(每 2 年)的几个月后就能用上最新的 Ubuntu 功能。但是,对于 Kubuntu 来说,你可以选择一个非 LTS 版本,并尝试使用带有 6 个月的软件更新的最新 Ubuntu 版本。
KDE Neon 确实提供了测试版和开发者版,但这些都是为了测试预发布的 KDE 软件而提供的。
#### KDE Plasma 桌面

尽管这两个发行版都采用了 KDE plasma 桌面,而且你可以获得相同程度的定制,但 KDE Neon 会首先获得最新的 KDE Plasma 桌面。
如果你还不知道,KDE Neon 是由 KDE 官方团队开发的,由 Jonathan Riddell(Kubuntu 创始人)在[被 Canonical 强制赶出 Kubuntu](https://lwn.net/Articles/645973/) 后宣布的。
所以,不仅限于最新的 Plasma 桌面,如果你想尽快获得最新最好的 KDE,KDE Neon 是最佳选择。
Kubuntu 最终会得到更新的 KDE 软件的更新,但这需要时间。如果你不太确定需要最新的 KDE 软件/桌面,而只是需要一个稳定的 KDE 系统,你应该选择 Kubuntu LTS 版本。
#### 预装软件
开箱即用,你会发现 Kubuntu 已经预装了一些必要的工具和应用程序,但是,对于 KDE Neon,你需要找到并安装一些应用和工具。
从某些方面看,与 Kubuntu 相比,KDE Neon 可能是一个轻量级的发行版。然而,对于新的 Linux 用户来说,他们可能会发现 Kubuntu 是一个易于使用的体验,并预装了更多必要的软件和工具。
#### 软件更新
如果你没有使用按流量计费的连接,这可能根本不重要。但是,我应该提一下,考虑到常规的 Ubuntu LTS 修复/更新以及 KDE 软件更新,KDE Neon 会有更多的软件更新。
对于 Kubuntu,你只会得到 Ubuntu LTS 的更新(除非你使用的是非 LTS 版本)。所以,从技术上讲,你会有更少的更新数量。
#### Ubuntu KDE 版与 Plasma 的体验差异

我知道如果你没有尝试过这两个版本,你可能会认为它们很相似。但是,Kubuntu 是 Ubuntu 的官方版本,它更注重 Ubuntu 在 KDE 桌面环境上的使用体验。
而 KDE Neon 在技术上是一样的,但它的目的是为了获得一流的 Plasma 桌面体验,并搭载最新的东西。
尽管这两个发行版开箱即可完美工作,但它们有不同的愿景和相应的开发工作。你只需要决定你自己想要什么,然后选择其中之一。
#### 硬件兼容性

正如我前面提到的,这不是一个基于事实的观点。但是,根据我在网上快速了解用户分享的反馈或经验,似乎 Kubuntu 可以与各种旧硬件以及新硬件(可能追溯到 2012 年)一起工作,而 KDE Neon 可能不能。
只需要记住,如果你尝试 KDE Neon,但由于某些原因不能工作。你知道该怎么做。
### 总结
那么,你会选择哪个呢?KDE Neon 还是 Kubuntu?这完全是你的选择。
两者都是[初学者友好的 Linux 发行版](https://itsfoss.com/best-linux-beginners/)的不错选择,但如果你想要最新的 KDE Plasma 桌面,KDE Neon 会更有优势。你可以在我们的 [KDE Neon 评测](https://itsfoss.com/kde-neon-review/)中阅读更多关于它的内容。
欢迎在下面的评论中告诉我你的想法,你觉得它们中的任何一个有什么好的/坏的地方。
---
via: <https://itsfoss.com/kde-neon-vs-kubuntu/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you find two Linux distributions based on [Ubuntu](https://ubuntu.com/?ref=itsfoss.com) and powered up by [KDE](https://kde.org/?ref=itsfoss.com), which one do you choose?
[Kubuntu](https://kubuntu.org/?ref=itsfoss.com)is the official KDE flavor of Ubuntu.[KDE Neon](https://neon.kde.org/?ref=itsfoss.com)is the Ubuntu-based distribution by KDE itself.
I know it is often confusing especially if you have never used either of them but got them as recommendations for usage. Hence, to help you make a decision, I thought of compiling a list of differences (and similarities) between KDE Neon and Kubuntu, the two of the [best KDE-based distros](https://itsfoss.com/best-kde-distributions/).
Let’s start with getting to know the similarities and then proceed with the differences.
## KDE Neon vs Kubuntu: Feature wise comparison

It’s always good to compare distributions based on their similarities. So, theoretically, I’ve tried to put down the most important differences.
However, it is worth noting that the compatibility, performance, and stability of the distros will vary depending on your hardware and hence, that has not been accounted here.
### Ubuntu as the Base
Yes, both the Linux distributions are based on Ubuntu. However, KDE Neon is based only on the latest Ubuntu LTS release while Kubuntu offers an Ubuntu LTS based edition and a non-LTS edition as well.
So, with KDE Neon, you would expect to get your hands on the latest Ubuntu features right after a few months of the next Ubuntu LTS release (2 years). But, with Kubuntu, you have got the option to opt for a non-LTS release and try on the latest Ubuntu releases with 6 months of software updates.
KDE Neon does offer testing editions and developer editions but those are meant to test pre-release KDE software.
### KDE Plasma Desktop
Even though both of the distros feature KDE plasma desktop and you can get the same level of customization, KDE Neon gets the latest KDE Plasma desktop release first.
If you did not know already, KDE Neon is developed by the official KDE team and was announced by Jonathan Riddell (Founder of Kubuntu) after he was [forced out of Kubuntu by Canonical](https://lwn.net/Articles/645973/?ref=itsfoss.com).
So, not just limited to the latest Plasma desktop, but if you want the latest and greatest of KDE as soon as possible, KDE Neon is the perfect choice for that.
Kubuntu will eventually get the update for newer KDE software — but it will take time. If you’re not too sure about the latest KDE software/desktop and all you need is a stable KDE-powered system, you should go with Kubuntu LTS releases.
### Pre-installed Software
Out of the box, you will find Kubuntu to have several essential tools and applications pre-installed. But, with KDE Neon, you would need to find and install several applications and tools.
To give you some perspective, KDE Neon might turn out to be a lightweight distro when compared to Kubuntu. However, for new Linux users, they might find Kubuntu as an easy-to-use experience with more essential software and tools pre-installed.
### Software Updates
If you are not using a metered connection, this may not matter at all. But, just for the sake of it, I should mention that KDE Neon gets more software updates considering the regular Ubuntu LTS fixes/updates along with KDE software updates.
With Kubuntu, you just get the Ubuntu LTS updates (unless you’re using the non-LTS edition). So, technically, you can expect less number of updates.
### Ubuntu with KDE vs Plasma Experience
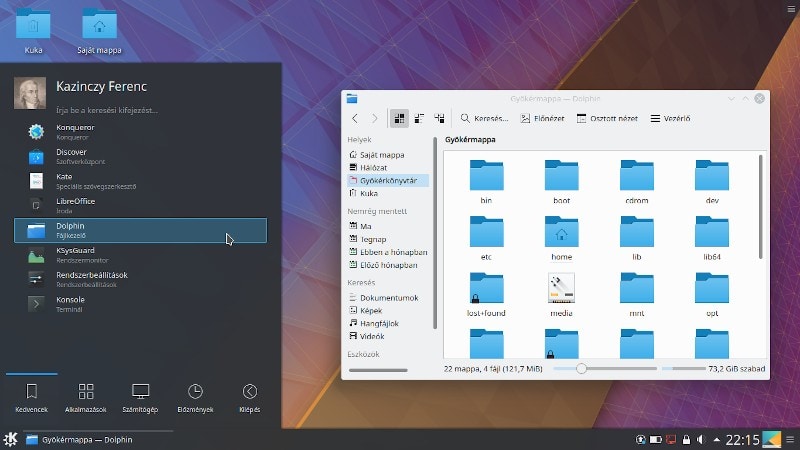
I know if you haven’t tried both of them, you might think of them as pretty similar. But, Kubuntu is an official flavour of Ubuntu that focused more on the experience with Ubuntu on a KDE desktop environment.
While KDE Neon is technically the same thing, but it is all about getting the best-in-class Plasma desktop experience with the latest stuff on board.
Even though both the distributions work amazing out of the box, they have a different vision and the development proceeds on both them accordingly. You just have to decide what you want for yourself and choose one of them.
### Hardware Compatibility

As I mentioned earlier, this is not a fact-based point here. But, as per my quick look on the feedback or experiences shared by the users online, it seems that Kubuntu works with a wide range of old hardware along with new hardware (potentially dating back to 2012) while KDE Neon may not.
It’s just a thing to keep in mind if you try KDE Neon and it doesn’t work for some reason. You know what to do.
## Wrapping Up
So, what would it be? KDE Neon or Kubuntu? That’s really is your choice.
Both are good choices for a [beginner-friendly Linux distribution](https://itsfoss.com/best-linux-beginners/) but if you want the latest KDE Plasma desktop, KDE Neon gets the edge here. You can read more about it in our [review of KDE Neon](https://itsfoss.com/kde-neon-review/).
Feel free to let me know your thoughts in the comments down below and what do you find good/bad on either of them. |
12,835 | 有孩子吗?使用 Timekpr-nExt 限制 Linux 中每个账户的电脑使用 | https://itsfoss.com/timekpr-next/ | 2020-11-18T00:41:13 | [
"限制",
"孩子"
] | https://linux.cn/article-12835-1.html | 
>
> 本周的开源软件亮点是 Timekpr-nExt。它是一个 GUI 应用,用于限制 Linux 系统中某些账户的电脑使用。对于不想让孩子花太多时间在电脑上的父母来说,这是一个方便的工具。
>
>
>
### 使用 Timekpr-nExt 在 Linux 上限制电脑使用
如果你家里有小孩,他们花太多时间在电脑上,你可能想对他们的使用进行一些限制。
可以让你根据一天的时间、一天、一周或者一月的小时数来限制某些账户的电脑使用。你也可以设置时间间隔来强制账户用户休息。

给定的时间超过后,用户会自动登出,直到满足限制条件才可以重新登录。

当然,这意味着你需要为孩子们单独设置非管理员(无 `sudo` 权限)账户。如果孩子们的账户也有管理员权限,他们可以很容易地改变设置。孩子们很聪明,你知道的。
### Timekpr-nExt 的功能
除了一个令人讨厌的风格化的名字,Timekpr-nExt 有以下功能:
* 将系统使用限制设置为按日智能限制、每日、每周或每月限制
* 你还可以根据时间和小时设置访问限制
* 用户可以看到关于他们还剩多少时间的通知
* 设置锁定动作(终止会话、关闭、暂停或锁定屏幕)
* 追踪账户的时间使用情况
请注意以下事项:
* 仔细检查你正在配置的账户。**不要把自己锁定**
* 每次更改配置时,请点击应用或设置按钮,否则更改将不会被设置
* 儿童帐户不应该有管理员操作,否则他们会覆盖设置
这里阅读[关于使用 Timekpr-nExt 的更多信息的文档](https://mjasnik.gitlab.io/timekpr-next/)。
### 在 Linux 中安装 Timekpr-nExt
对于基于 Ubuntu 的 Linux 发行版(如 Mint、Linux Lite 等),有一个[官方 PPA 可用](https://launchpad.net/~mjasnik/+archive/ubuntu/ppa)。你可以通过以下命令逐步安装它:
```
sudo add-apt-repository ppa:mjasnik/ppa
sudo apt update
sudo apt install timekpr-next
```
Arch Linux 用户可以[在 AUR 中找到它](https://aur.archlinux.org/packages/timekpr-next/)。对于其他用户,请检查你的发行版仓库。如果没有这样的包,你可以尝试使用源码。
* [Timekpr-nExt 源码](https://launchpad.net/timekpr-next)
**再说一次,不要在主账户中使用 Timekpr-nExt。你可能会把自己锁在外面。**
你会看到两个应用的实例。使用开头有 (SU) 的那个。

#### 删除 Timekpr-nExt
我不能确定删除 Timekpr-nExt 是否也会删除你为用户设置的限制。手动恢复他们(间隔一天 24 小时)会是一个好主意。这里没有重置按钮。
要删除这个应用(如果你使用 PPA 安装它),使用以下命令:
```
sudo apt-get remove --purge timekpr-next
```
同时删除 PPA 仓库:
```
sudo add-apt-repository -r ppa:mjasnik/ppa
```
和[在 Linux 上屏蔽成人内容](https://itsfoss.com/how-to-block-porn-by-content-filtering-on-ubuntu/)一样,这个应用也是专门针对儿童的。并不是每个人都会觉得它有用,但家里有小孩的人如果觉得有必要的话,可以使用它。
你是否使用其他应用来监控/限制儿童访问计算机?
---
via: <https://itsfoss.com/timekpr-next/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Open source software highlight of this week is Timekpr-nExt. It is a GUI application to limit the computer usage for certain accounts on a Linux system. This is a handy utility for parents who do not want children to spend excessive time on the computer.*
## Use Timekpr-nExt to limit computer usage on Linux
If you have young children at home who spend too much time on computer, you may want to put some sort of restriction on the usage.
Timekpr-nExt enables you to limit computer usage for certain accounts based on the time of day, number of hours a day, week or month. You may also set time interval to force the account user to take break.
After the given time expires, the user is automatically logged out and cannot log back in until the restriction conditions are satisfied.

Of course, this means that you need to have separate non-admin (no sudo access) accounts for the children. If the kids accounts also have admin access, they can change the settings easily. Kids are smart, you know.
## Features of Timekpr-nExt
Apart from an annoyingly stylized name, Timekpr-nExt has the following features:
- Limit system usage as day wise limit, daily limit, weekly or monthly limit
- You can also set access restrictions based on time and hour
- Users can be shown notification about how much time they have left
- Set the lockout action (terminate session, shutdown, suspend or lock screen)
- Track the time usage of the accounts
Keep the following things in mind:
- Check carefully which account you are configuring.
.*Do not lock yourself out* - Hit the apply or set button for each configuration changes otherwise the changes won’t be set.
- Children accounts should not have admin action otherwise they can overwrite the settings.
Read the [documents about more information on using Timekpr-nExt](https://mjasnik.gitlab.io/timekpr-next/).
## Installing Timekpr-nExt on Linux
For Ubuntu-based Linux distributions (like Mint, Linux Lite etc), there is an [official PPA available](https://launchpad.net/~mjasnik/+archive/ubuntu/ppa). You can install it by using the following commands one by one:
```
sudo add-apt-repository ppa:mjasnik/ppa
sudo apt update
sudo apt install timekpr-next
```
Arch Linux users can [find it in AUR](https://aur.archlinux.org/packages/timekpr-next/). For others, please check your distribution’s repository. If there is no such package, you may try using the source code.
*Again, do not use Timekpr-nExt for your own main account. You may lock yourself out.*
You’ll see two instances of the application. Use the one with (SU) at the beginning.
### Removing Timekpr-nExt
I cannot say for certain if removing Timekpr-nExt will also remove the restrictions you put in place for the users. It will be a good idea to manually restore them (putting 24 hr interval a day). There is no reset button here.
To remove this application (if you used PPA to install it), use the following command:
`sudo apt-get remove --purge timekpr-next`
Delete the PPA repository as well:
`sudo add-apt-repository -r ppa:mjasnik/ppa`
Like [blocking adult content on Linux](https://itsfoss.com/how-to-block-porn-by-content-filtering-on-ubuntu/), this application is also children specific. Not everyone would find it useful but people with young children at home may use it if they feel the need.
Do you use some other application to monitor/restrict children from accessing computer? |
12,839 | 我喜欢最新的 GNOME 桌面 | https://opensource.com/article/20/11/new-gnome | 2020-11-18T22:52:00 | [
"GNOME"
] | /article-12839-1.html |
>
> 看看 GNOME 3.38 桌面最重要的新功能。
>
>
>

Fedora 33 [刚出来](https://fedoramagazine.org/announcing-fedora-33/),我就马上安装了它。在这个新版 Linux 发行版的众多功能中,其中之一是最新的 GNOME 桌面。GNOME 3.38 于 2020 年 9 月发布,我很喜欢它。
### 我为什么喜欢 GNOME 3.38?
GNOME 3.38 [发布说明](https://help.gnome.org/misc/release-notes/3.38/)中列出了这次更新中的一些重大的新功能。其中,新用户的欢迎页面有了重大改版,现在更加容易使用,如果你是新用户的话,它提供了更多有用的信息。

我还喜欢在 GNOME 应用概览中拖动来重新排列应用图标的功能。这让我在 GNOME 下组织我一直使用的应用变得轻而易举。你甚至可以将图标拖放到一起,并自动将它们放入一个文件夹。

我的家人在不同的时区,更新后的 GNOME 时钟使得添加新的世界时钟变得更加容易,所以当我给家人打电话时,我不必弄清楚现在是什么时间,他们是早一个小时还是晚一个小时?我只需查看 GNOME 时钟,就能一目了然地看到每个人的当地时间。另外,虽然我并不经常使用闹钟功能,但我喜欢我可以自己设置铃声持续时间和每个闹钟的默认“打盹”时间。

除了所有这些功能更新之外,GNOME 3.38 中最大的改进是性能。正如 GNOME 开发者 Emmanuele Bassi [今年早些时候的解释](https://opensource.com/article/20/7/new-gnome-features):“GNOME 中的每个人都为使速度更快而做了很多工作,即使是在树莓派等这样受限的系统上运行的人也是如此。为了让 GNOME 表现得更好,大家做了很多工作。因为人们真的很关心它”。而这一点在新版本中体现得淋漓尽致!GNOME 桌面感觉反应更灵敏。

作为我的咨询和培训业务的一部分,我经常在几个打开的应用之间切换,包括 LibreOffice、GIMP、Inkscape、Web 浏览器等。在 GNOME 3.38 中,启动一个新的应用或在打开的应用之间切换感觉更快。
### 除了一件事
如果说新版 GNOME 中有什么我不喜欢的地方,那就是重新设计的屏幕截图工具。我一直使用这个工具来抓取屏幕上的一部分内容,并将其插入到我的演示文稿和培训文档中。

当我浏览用户界面或电脑屏幕时,我自然会像阅读书籍或杂志那样浏览:从左到右,从上到下。当我使用新的屏幕截图工具进行屏幕截图时,我从左上角开始,然后进行选择。大多数时候,我只需要改变选区的捕捉区域,所以我点击那个按钮,然后寻找截图的按钮。但我总是要花点时间才能找到左上角的**截图**按钮。它并不在窗口的底部,也不是我希望找到它的地方。

到目前为止,这似乎是我在 GNOME 3.38 中唯一的烦恼。总的来说,我对新的 GNOME 感到非常兴奋。我希望你也是!
要了解更多关于 GNOME 3.38 的信息,请访问 [GNOME 网站](https://www.gnome.org/)或阅读 [GNOME 3.38 公告](https://www.gnome.org/news/2020/09/gnome-3-38-released/)。
---
via: <https://opensource.com/article/20/11/new-gnome>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,840 | 日本超算领跑 TOP500,各国展开百万兆级计算竞赛 | https://searchdatacenter.techtarget.com/news/252492169/Japan-named-HPC-leader-as-world-races-to-exascale | 2020-11-19T00:13:00 | [
"超算"
] | https://linux.cn/article-12840-1.html |
>
> 百万兆级计算机将于 2021 年在美国和中国问世。
>
>
>

在[最新的 Top500 榜单](https://top500.org/lists/top500/2020/11/highs/)中,基于 ARM 的日本 [Fugaku 超级计算机](https://top500.org/preview/system/179807)是世界上最强大的超级计算机,它创造了 442 PetaFLOPS 的世界纪录。但真正的竞争 —— 第一批百万兆级系统 —— 将在 2021 年到来。

Top500 榜单是对世界上最快的 HPC 系统的排名。据<ruby> 田纳西大学 <rp> ( </rp> <rt> University of Tennessee </rt> <rp> ) </rp></ruby><ruby> 创新计算实验室 <rp> ( </rp> <rt> Innovative Computing Laboratory </rt> <rp> ) </rp></ruby>主任、这个每年两次的排行榜背后的学者之一 Jack Dongarra 说,该榜单也出现了“性能曲线趋于平坦”的情况。他说,这是[摩尔定律](https://whatis.techtarget.com/definition/Moores-Law)放缓的结果,同时也是旧系统更新换代速度放缓的结果。根据摩尔定律,处理器上的晶体管数量每两年左右就会增加一倍,但这种进步现在遇到了技术障碍。
“处理器技术是有限制的,但还有很大的发展空间。”Dongarra 说。“因为这不仅仅是处理器的问题,我们正在适应开发更好的算法和软件系统来处理这种情况。”
美国有望在 2021 年在<ruby> 橡树岭国家实验室 <rp> ( </rp> <rt> Oak Ridge National Laboratory </rt> <rp> ) </rp></ruby>交付一台使用 AMD 芯片的<ruby> 百万兆级 <rp> ( </rp> <rt> exascale </rt> <rp> ) </rp></ruby>的计算机,这是 [Cray 公司一台名为 Frontier 的系统](https://searchdatacenter.techtarget.com/news/252468294/Cray-exascale-computer-to-modernize-aging-nuclear-weapon-stockpile)。百万兆级系统可以达到每秒一万亿次计算,也就是一个 1 后面跟着 18 个 0。百万兆级即 1000 PetaFLOPS。
德国汉堡的<ruby> 马克斯•普朗克气象研究所 <rp> ( </rp> <rt> Max Planck Institute for Meteorology </rt> <rp> ) </rp></ruby>教授 Bjorn Stevens 说,现在确实需要百万兆级的计算能力,特别是在处理气候科学所产生的大量数据集时。
### 百万兆级计算机的全球竞赛
中国有 3 个百万兆级项目正在进行,并将在明年至少交付其中一个项目。欧洲也在迅速发展“准百万兆级”系统,或可以扩展到百万兆级的系统的设计。
“这是真正的全球竞争,”Hyperion Research 的 HPC 市场动态高级顾问 Steve Conway 说。例如,到 2021 年底,[欧洲将拥有 8 个这样的大型系统](https://searchdatacenter.techtarget.com/news/252456813/France-HPE-are-building-Europes-most-powerful-AI-supercomputer)。
在芬兰的一个这样的系统是一台 550 PetaFLOPS 的 HPE 的系统,这是一个由欧盟资助的欧洲高性能计算联合企业项目。这个耗资 1.6 亿美元的系统将于明年建成。
Conway 说,x86 芯片仍然是超级计算的主导,并且在未来五年内可能会继续保持。
### 基于 ARM 的方式
但基于 ARM 的方法,正如日本使用的方法,正在引起大家的兴趣。Conway 说,ARM 芯片是可定制的,对那些有专用用例的系统开发者很有吸引力,比如 AI 开发。
日本的系统是<ruby> 日本理研计算科学中心 <rp> ( </rp> <rt> Riken Center for Computational Science in Japan </rt> <rp> ) </rp></ruby>与<ruby> 富士通有限公司 <rp> ( </rp> <rt> Fujitsu Limited </rt> <rp> ) </rp></ruby>共同开发的。
在 Top500 榜单上,排名第二的系统是 [IBM Power Systems](https://top500.org/preview/system/179397),其性能接近 149 PetaFLOPS,使用了 IBM 的 Power9 CPU 和 Nvidia 的 Tesla GPU。它位于<ruby> 田纳西州 <rp> ( </rp> <rt> Tennessee </rt> <rp> ) </rp></ruby>的<ruby> 橡树岭国家实验室 <rp> ( </rp> <rt> Oak Ridge National Lab </rt> <rp> ) </rp></ruby>。
第三名是 [Sierra 超级计算机](https://top500.org/preview/system/179398),它也使用 Power 9 CPU 和 Nvidia GPU,约 95 PetaFLOPS。它位于<ruby> 加州利弗莫尔 <rp> ( </rp> <rt> Livermore, Calif. </rt> <rp> ) </rp></ruby>的<ruby> 劳伦斯•利弗莫尔国家实验室 <rp> ( </rp> <rt> Lawrence Livermore National Laboratory </rt> <rp> ) </rp></ruby>。
第四位是中国的[神威·太湖之光](https://top500.org/preview/system/178764),由中国国家并行计算机工程与技术研究中心研制,安装在无锡的国家超级计算中心。它采用了中国自主研发的神威 SW26010 处理器,它是一个 93 PetaFLOPS 的系统。
---
via: <https://searchdatacenter.techtarget.com/news/252492169/Japan-named-HPC-leader-as-world-races-to-exascale>
作者:[Patrick Thibodeau](https://www.techtarget.com/contributor/Patrick-Thibodeau) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12835-1.html) 荣誉推出
| 301 | Moved Permanently | null |
12,842 | 五步学会任何编程语言 | https://opensource.com/article/20/10/learn-any-programming-language | 2020-11-19T22:59:35 | [
"编程语言"
] | https://linux.cn/article-12842-1.html |
>
> 只需一点编程经验,你就可以在短短几天内(有时更少)学会一种新编程语言。
>
>
>

有些人喜欢学习新的编程语言,也有一些人觉得学习一种都是可望不可及的事情。在本文中,我将向你展示如何像程序员一样思考,这样你就可以自信地学习任何一门你想要学习的编程语言。
事实上,一旦你学会了如何编程,你使用的编程语言就不再是一个障碍,而更像是一种形式。实际上,这就是教育家们倡导 [让孩子尽早学习编程](https://opensource.com/article/20/9/scratch) 的众多原因之一。不管他们的入门语言有多简单,这种编程的逻辑和儿童们(或成人学习者)以后可能遇到的其他语言的逻辑有着想通之处。
只需有一点编程经验(你可以从我们这里的几篇介绍性文章中获得),你就可以在短短几天内(有时更短)学习任何编程语言。这并不是魔法,你也确实要为此付出一些努力。诚然,学习一种编程语言每个的可用库,或者学习打包代码以及进行交付的细微差别,需要的时间远远不止几天。但是,就入门来说,比你想像中的要容易许多,剩下的则要通过不断练习来完成。
当有经验的程序员静下心来学习一门新的编程语言时,他们会寻找五样东西。只要你知道了这五件事,你就可以开始编码了。
### 1、语法

语言的语法描述了代码的结构。这包括如何逐行编写代码,以及用于构造代码语句的实际单词。
例如,[Python](https://opensource.com/downloads/cheat-sheet-python-37-beginners) 以使用缩进来指示一个代码块在哪里结束以及另一代码块在哪里开始而闻名:
```
while j < rows:
while k < columns:
tile = Tile(k * w)
board.add(tile)
k += 1
j += 1
k = 0
```
[Lua](https://opensource.com/article/20/2/lua-cheat-sheet) 只是使用关键字 `end`:
```
for i,obj in ipairs(hit) do
if obj.moving == 1 then
obj.x,obj.y = v.mouse.getPosition()
end
end
```
[Java](https://opensource.com/downloads/java-cheat-sheet)、[C](https://opensource.com/downloads/c-programming-cheat-sheet)、C++ 之类的编程语言使用花括号:
```
while (std::getline(e,r)) {
wc++;
}
```
编程语言的语法还包括包括库、设置变量和终止行等内容。通过练习,你将学会在阅读示例代码时下意识地识别语法需求(和惯例)。
#### 实践
当学习一门新的编程语言时,要努力理解它的语法。你不需要去记住它,只需要知道如果忘记了以后去哪里查找。使用好的 [IDE](https://opensource.com/resources/what-ide) 也很有帮助,因为很多 IDE 在出现语法错误时会提醒你。
### 2、内置函数和条件

就像自然语言一样,编程语言可以识别的合法单词是有限的。这个词汇表可以使用其他库进行扩展,但是核心语言知道一组特定的关键字。大多数语言并没有你想的那么多关键字。即使在像 C 语言这样非常低级的语言中,也只有 32 个关键字,比如 `for`、`do`、`while`、`int`、`float`、`char`、`break` 等等。
了解了这些关键字,你就可以编写基本的表达式,也就是构建程序的代码块。许多内置的关键字能帮助你构建条件语句,这些条件语句影响整个程序的流程。例如,如果你想编写一个允许单击和拖动图标的程序,那么你的代码就必须检测用户的鼠标指针何时位于图标上。只有当鼠标光标位于图标外部边缘相同的坐标时,才执行导致使鼠标抓取图标的代码。这是一个经典的 `if` / `then` 语句,但不同的语言可以用不同的方式表达。
Python 使用 `if`、`elif`和 `else` 的组合来实现条件语句,但是并不显式的关闭语句:
```
if var == 1:
# action
elif var == 2:
# some action
else:
# some other action
```
[Bash](https://opensource.com/downloads/bash-cheat-sheet) 使用 `if`、`elif`、`else`,并且使用 `fi` 来结束语句:
```
if [ "$var" = "foo" ]; then
# action
elif [ "$var" = "bar" ]; then
# some action
else
# some other action
fi
```
然而 C 和 Java, 使用 `if`、`else` 和 `else if`,用花括号把它们括起来:
```
if (boolean) {
// action
} else if (boolean) {
// some action
} else {
// some other action
}
```
各种编程语言虽然在关键字的选择和语法上有细微的变化,但基本是相同的。学习如何在编程语言中定义条件语句,包括 `if` / `then`、`do...while` 和 `case` 语句。
#### 实践
要熟悉编程语言能够理解的关键字集。在实践中,你的代码将不仅仅包含编程语言的关键字,可以肯定的是,有包含很多简单函数的库来帮助你做一些事情,诸如将输出打印到屏幕或显示窗口之类。然而,驱动这些库的逻辑始于编程语言的内置关键字。
### 3、数据类型

代码是用来处理数据的,因此你必须学习编程语言如何识别不同类型的数据。所有编程语言都能理解整数,大多数的语言能理解小数和单个字符(`a`、`b`、`c` 等等)。它们通常被表示为 `int`、 `float`、`double` 和 `char`,当然,语言的内置词汇表会告诉你如何引用这些实体。
有时候,在编程语言中内置了一些额外的数据类型,也有时是通过引用库来启用复杂的数据类型。例如,Python 可以识别关键字为 `str` 的字符串,但是 C 语言的代码中必须包含 `string.h` 头文件才能实现字符串特性。
#### 实践
库可以为你的代码解锁各种类型的数据,但是学习编程语言中包含的基本数据类型是一个明智的起点。
### 4、运算符和解析器

一旦你理解了编程语言可处理的数据类型,就可以学习如何分析这些数据了。幸运的是,数学这门学科是相当稳定的,所以算数运算符在许多语言中通常是相同的(或至少非常相似)。例如,两个整数相加通常用 `+` 符号完成,而测试一个整数是否大于另一个整数通常用 `>` 符号完成。测试是否相等通常使用 `==` 来完成(是的,是两个等号,因为通常一个等号用来赋值)。
当然也有一些例外,比如像 Lisp 和 Bash 语言算数运算符就不是如此,但与其他语言一样,这只是一个心理翻译的问题。一旦你了解了表达方式有何不同,很快就可以适应它。快速浏览一下一门编程语言的算数运算符通常足以让你了解算数操作是如何完成的。
你还需要知道如何比较和操作非数值数据,比如字符和字符串。这些通常是通过编程语言的核心库来进行的的。例如,Python 提供了 `split()` 方法,而 C 语言需要引入头文件 `string.h` 来提供 `strtok()` 函数。
#### 实践
了解用于处理基本数据类型的基本函数和关键字,并寻找可帮助你完成复杂操作的核心库。
### 5、函数

代码不只是计算机的待办清单。通常情况下,在编写代码时你往往希望向计算机提供一组理论条件和一组操作指令,当满足每个条件时计算机就会采取这些操作。尽管使用条件语句以及数学和逻辑运算符进行流控制可以做很多事情,但是引入了函数和类之后,代码会变得更加高效,因为它们使你可以定义子程序。例如,如果应用程序非常频繁地需要一个确认对话框,那么将其作为类的实例编写一次要比每次需要它时重新编写实现起来要容易得多。
你需要学习如何在编程语言中定义类和函数。更准确地说,你首先需要了解编程语言中是否支持类和函数。大多数现代语言都支持函数,但是类是面向对象的编程语言中所特有的。
#### 实践
学习语言中可用的结构,这些结构可以帮助你高效地编写和使用代码。
### 你可以学到任何东西
学习编程语言,就其本身而言,是一种编码过程中的子程序。一旦理解了代码如何工作,你所使用的语言就只是一种传递逻辑的媒介。学习一门新编程语言的过程几乎都是一样的:通过简单的练习来学习语法,通过学习词汇来积累进行复杂动作的能力,然后练习、练习、再练习。
---
via: <https://opensource.com/article/20/10/learn-any-programming-language>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[xiao-song-123](https://github.com/xiao-song-123) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some people love learning new programming languages. Other people can't imagine having to learn even one. In this article, I'm going to show you how to think like a coder so that you can confidently learn any programming language you want.
The truth is, once you've learned how to program, the language you use becomes less of a hurdle and more of a formality. In fact, that's just one of the many reasons educators say to [teach kids to code early](https://opensource.com/article/20/9/scratch). Regardless of how simple their introductory language may be, the logic remains the same across everything else children (or adult learners) are likely to encounter later.
With just a little programming experience, which you can gain from any one of several introductory articles here on Opensource.com, you can go on to learn *any* programming language in just a few days (sometimes less). Now, this isn't magic, and you do have to put some effort into it. And admittedly, it takes a lot longer than just a few days to learn every library available to a language or to learn the nuances of packaging your code for delivery. But getting started is easier than you might think, and the rest comes naturally with practice.
When experienced programmers sit down to learn a new language, they're looking for five things. Once you know those five things, you're ready to start coding.
## 1. Syntax

(Seth Kenlon, CC BY-SA 4.0)
The syntax of a language describes the structure of code. This encompasses both how the code is written on a line-by-line basis as well as the actual words used to construct code statements.
[Python](https://opensource.com/downloads/cheat-sheet-python-37-beginners), for instance, is known for using indentation to indicate where one block ends and another one starts:
```
while j < rows:
while k < columns:
tile = Tile(k * w)
board.add(tile)
k += 1
j += 1
k = 0
```
[Lua](https://opensource.com/article/20/2/lua-cheat-sheet) just uses the keyword `end`
:
```
for i,obj in ipairs(hit) do
if obj.moving == 1 then
obj.x,obj.y = v.mouse.getPosition()
end
end
```
[Java](https://opensource.com/downloads/java-cheat-sheet), [C](https://opensource.com/downloads/c-programming-cheat-sheet), C++, and similar languages use braces:
```
while (std::getline(e,r)) {
wc++;
}
```
A language's syntax also involves things like including libraries, setting variables, and terminating lines. With practice, you'll learn to recognize syntactical requirements (and conventions) almost subliminally as you read sample code.
### Take action
When learning a new programming language, strive to understand its syntax. You don't have to memorize it, just know where to look, should you forget. It also helps to use a good [IDE](https://opensource.com/resources/what-ide), because many of them alert you of syntax errors as they occur.
## 2. Built-ins and conditionals

(Seth Kenlon, CC BY-SA 4.0)
A programming language, just like a natural language, has a finite number of words it recognizes as valid. This vocabulary can be expanded with additional libraries, but the core language knows a specific set of keywords. Most languages don't have as many keywords as you probably think. Even in a very low-level language like C, there are only 32 words, such as `for`
, `do`
, `while`
, `int`
, `float`
, `char`
, `break`
, and so on.
Knowing these keywords gives you the ability to write basic expressions, the building blocks of a program. Many of the built-in words help you construct conditional statements, which influence the flow of your program. For instance, if you want to write a program that lets you click and drag an icon, then your code must detect when the user's mouse cursor is positioned over an icon. The code that causes the mouse to grab the icon must execute only *if* the mouse cursor is within the same coordinates as the icon's outer edges. That's a classic if/then statement, but different languages can express that differently.
Python uses a combination of `if`
, `elif`
, and `else`
but doesn't explicitly close the statement:
```
if var == 1:
# action
elif var == 2:
# some action
else:
# some other action
```
[Bash](https://opensource.com/downloads/bash-cheat-sheet) uses `if`
, `elif`
, `else`
, and uses `fi`
to end the statement:
```
if [ "$var" = "foo" ]; then
# action
elif [ "$var" = "bar" ]; then
# some action
else
# some other action
fi
```
C and Java, however, use `if`
, `else`
, and `else if`
, enclosed by braces:
```
if (boolean) {
// action
} else if (boolean) {
// some action
} else {
// some other action
}
```
While there are small variations in word choice and syntax, the basics are always the same. Learn the ways to define conditions in the programming language you're learning, including `if/then`
, `do...while`
, and `case`
statements.
### Take action
Get familiar with the core set of keywords a programming language understands. In practice, your code will contain more than just a language's core words, because there are almost certainly libraries containing lots of simple functions to help you do things like print output to the screen or display a window. The logic that drives those libraries, however, starts with a language's built-in keywords.
## 3. Data types
(Seth Kenlon, CC BY-SA 4.0)
Code deals with data, so you must learn how a programming language recognizes different kinds of data. All languages understand integers and most understand decimals and individual characters (a, b, c, and so on). These are often denoted as `int`
, `float`
and `double`
, and `char`
, but of course, the language's built-in vocabulary informs you of how to refer to these entities.
Sometimes a language has extra data types built into it, and other times complex data types are enabled with libraries. For instance, Python recognizes a string of characters with the keyword `str`
, but C code must include the `string.h`
header file for string features.
### Take action
Libraries can unlock all manner of data types for your code, but learning the basic ones included with a language is a sensible starting point.
## 4. Operators and parsers
(Seth Kenlon, CC BY-SA 4.0)
Once you understand the types of data a programming language deals in, you can learn how to analyze that data. Luckily, the discipline of mathematics is pretty stable, so math operators are often the same (or at least very similar) across many languages. For instance, adding two integers is usually done with a `+`
symbol, and testing whether one integer is greater than another is usually done with the `>`
symbol. Testing for equality is usually done with `==`
(yes, that's two equal symbols, because a single equal symbol is usually reserved to *set* a value).
There are notable exceptions to the obvious in languages like Lisp and Bash, but as with everything else, it's just a matter of mental transliteration. Once you know *how* the expression is different, it's trivial for you to adapt. A quick review of a language's math operators is usually enough to get a feel for how math is done.
You also need to know how to compare and operate on non-numerical data, such as characters and strings. These are often done with a language's core libraries. For instance, Python features the `split()`
method, while C requires `string.h`
to provide the `strtok()`
function.
### Take action
Learn the basic functions and keywords for manipulating basic data types, and look for core libraries that help you accomplish complex actions.
## 5. Functions
(Seth Kenlon, CC BY-SA 4.0)
Code usually isn't just a to-do list for a computer. Typically when you write code, you're looking to present a computer with a set of theoretical conditions and a set of instructions for actions that must be taken when each condition is met. While flow control with conditional statements and math and logic operators can do a lot, code is a lot more efficient once functions and classes are introduced because they let you define subroutines. For instance, should an application require a confirmation dialogue box very frequently, it's a lot easier to write that box *once* as an instance of a class rather than re-writing it each time you need it to appear throughout your code.
You need to learn how classes and functions are defined in the programming language you're learning. More precisely, first, you need to learn whether classes and functions are available in the programming language. Most modern languages do support functions, but classes are specialized constructs common to object-oriented languages.
### Take action
Learn the constructs available in a language that help you write and use code efficiently.
## You can learn anything
Learning a programming language is, in itself, a sort of subroutine of the coding process. Once you understand the theory behind how code works, the language you use is just a medium for delivering logic. The process of learning a new language is almost always the same: learn syntax through simple exercises, learn vocabulary so you can build up to performing complex actions, and then practice, practice, practice.
## 5 Comments |
12,844 | 微软为 Linux 服务器添加了保护 | https://www.zdnet.com/article/microsoft-defender-for-linux-adds-new-security-feature/ | 2020-11-20T11:54:00 | [
"微软",
"安全"
] | https://linux.cn/article-12844-1.html |
>
> 微软基于服务器的 Linux 保护计划的公开预览现在提供了改进的端点检测和响应功能。
>
>
>

我知道你们中的一些人还很难接受,但微软最近确实在支持 Linux。一个案例是:早在 6 月份,微软就发布了面向 Linux 的 [Microsoft Defender Advanced Threat Protection(ATP)](https://www.zdnet.com/article/microsoft-releases-defender-atp-for-linux/),供普通用户使用。现在,微软改进了 Linux 版本的 Microsoft Defender,[公开预览版增加了端点检测和响应(EDR)功能](https://techcommunity.microsoft.com/t5/microsoft-defender-for-endpoint/edr-for-linux-is-now-available-in-public-preview/ba-p/1890536)。
这并不是一个你可以在独立的 Linux 桌面上运行的 Microsoft Defender 版本。它的主要工作仍然是保护 Linux 服务器免受服务器和网络威胁。如果你想为你的独立桌面提供保护,可以使用 [ClamAV](https://www.clamav.net/) 或 [Sophos Antivirus for Linux](https://www.sophos.com/en-us/products/free-tools/sophos-antivirus-for-linux.aspx) 等程序。
但对于企业来说,由于现在在家上班的人在各种地方使用他们的 Mac 和 Windows PC,这就是另外一个需求了。虽然基于 Linux 服务器,但你能够使用它来[保护运行 macOS、Windows 8.1 和 Windows 10 的 PC](https://techcommunity.microsoft.com/t5/microsoft-defender-for-endpoint/secure-your-remote-workforce-with-microsoft-defender-atp/ba-p/1271806)。
通过这些新的 EDR 功能,Linux Defender 用户可以检测到涉及 Linux 服务器的高级攻击,利用丰富的经验,并快速补救威胁。这是在现有的[预防性防病毒功能](https://techcommunity.microsoft.com/t5/microsoft-defender-for-endpoint/microsoft-defender-atp-for-linux-is-now-generally-available/ba-p/1482344)和通过 Microsoft Defender 安全中心提供的集中报告基础上发展起来的。
具体来说,它包括:
* 丰富的调查体验,包括机器时间线、进程创建、文件创建、网络连接、登录事件和高级狩猎。
* 在编译过程和大型软件部署中优化了性能增强的 CPU 利用率。
* 上下文反病毒检测。就像 Windows 版一样,你可以深入了解威胁的来源以及恶意进程或活动是如何创建的。
要运行更新后的程序,你需要以下 Linux 服务器之一:RHEL 7.2+、CentOS Linux 7.2+、Ubuntu 16.04 或更高的 LTS 版本、SLES 12+、Debian 或更高版本、或 Oracle Linux 7.2。
接下来,要尝试这些公共预览功能,你需要在 Microsoft Defender 安全中心里打开预览功能。在这样做之前,请确保你运行的是 101.12.99 或更高版本。你可以通过命令找出你正在运行的版本:
```
mdatp health
```
在任何情况下,你都不应该将在 Linux 上运行 Microsoft Defender for Endpoint 的所有服务器都切换到预览模式。相反,微软建议你仅将部分 Linux 服务器配置为预览模式,使用以下命令切换:
```
$ sudo mdatp edr early-preview enable
```
这样做了之后,如果你觉得自己很勇敢,想亲自看看它是否有效,微软提供了一种运行模拟攻击的方法。要做到这一点,请按照下面的步骤在你的 Linux 服务器上模拟检测,并调查情况:
* 验证在场的 Linux 服务器是否出现在 Microsoft Defender 安全中心中。如果这是该机器的第一次上线,可能需要长达 20 分钟才能出现。
* 从 [aka.ms/LinuxDIY](https://aka.ms/LinuxDIY) 这里下载并解压脚本文件到已在场的 Linux 服务器上,并运行以下命令:`./mde_linux_edr_diy.sh`。
* 几分钟后,应该会在 Microsoft Defender 安全中心发出警报。
* 查看警报详情、机器时间线,并执行典型的调查步骤。
祝你好运!
---
via: <https://www.zdnet.com/article/microsoft-defender-for-linux-adds-new-security-feature/>
作者:[Steven J. Vaughan-Nichols](https://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12842-1.html) 荣誉推出
| 200 | OK | # Microsoft Defender for Linux adds new security feature

I know it's still hard for some of you to wrap your minds around it, but Microsoft really does support Linux these days. A case in point: Back in June, Microsoft released [Microsoft Defender Advanced Threat Protection (ATP) for Linux for general use](https://www.zdnet.com/article/microsoft-releases-defender-atp-for-linux/). Now, Microsoft has improved the Linux version of Defender, by adding a [public preview of endpoint detection and response (EDR) capabilities](https://techcommunity.microsoft.com/t5/microsoft-defender-for-endpoint/edr-for-linux-is-now-available-in-public-preview/ba-p/1890536).
This is still not a version of Microsoft Defender you can run on a standalone Linux desktop. Its primary job remains to protect Linux servers from server and network threats. If you want protection for your standalone desktop, use such programs as [ClamAV](https://www.clamav.net/) or [Sophos Antivirus for Linux](https://www.sophos.com/en-us/products/free-tools/sophos-antivirus-for-linux.aspx).
For businesses, though, with workers from home now using their Macs and Windows PCs here, there, and everywhere, it's a different story. While based on Linux servers, you'll be able to use it to [protect PCs running macOS, Windows 8.1, and Windows 10](https://techcommunity.microsoft.com/t5/microsoft-defender-for-endpoint/secure-your-remote-workforce-with-microsoft-defender-atp/ba-p/1271806).
With these new EDR capabilities, Linux Defender users can detect advanced attacks that involve Linux servers, utilize rich experiences, and quickly remediate threats. This builds on the existing [preventative antivirus capabilities](https://techcommunity.microsoft.com/t5/microsoft-defender-for-endpoint/microsoft-defender-atp-for-linux-is-now-generally-available/ba-p/1482344) and centralized reporting available via the Microsoft Defender Security Center.
Specifically, it includes:
- Rich investigation experience, which includes machine timeline, process creation, file creation, network connections, login events, and advanced hunting.
- Optimized performance-enhanced CPU utilization in compilation procedures and large software deployments.
- In-context AV detection. Just like with the Windows edition, you'll get insight into where a threat came from and how the malicious process or activity was created.
To run the updated program, you'll need one of the following Linux servers: RHEL 7.2+; CentOS Linux 7.2+; Ubuntu 16.04 or higher LTS; SLES 12+; Debian or higher; or Oracle Linux 7.2.
Next, to try these public preview capabilities, you'll need to turn on the[ preview features in Microsoft Defender Security Center.](https://docs.microsoft.com/en-us/windows/security/threat-protection/microsoft-defender-atp/preview) Before you do this, make sure you're running version 101.12.99 or higher. You can find out which version you're running with the command:
mdatp health
You shouldn't switch all your servers running Microsoft Defender for Endpoint on Linux to the preview in any case. Instead, Microsoft recommends you configure only some of your Linux servers to Preview mode, with the following command:
$ sudo mdatp edr early-preview enable
Once that's done, if you're feeling brave and want to see for yourself if it works, Microsoft is offering a way to run a simulated attack. To do this, follow the steps below to simulate a detection on your Linux server and investigate the case.
Verify that the onboarded Linux server appears in Microsoft Defender Security Center. If this is the first onboarding of the machine, it can take up to 20 minutes until it appears.
Download and extract the script file from here aka.ms/LinuxDIY to an onboarded Linux server and run the following command:
./mde_linux_edr_diy.shAfter a few minutes, it should be raised in Microsoft Defender Security Center.
Look at the alert details, machine timeline, and perform your typical investigation steps.
Good luck!
**Related Stories:**
[Editorial standards](/editorial-guidelines/) |
12,845 | 通过微软的 WSL2 使用 Fedora 33 | https://fedoramagazine.org/wsl-fedora-33/ | 2020-11-20T20:03:36 | [
"WSL"
] | https://linux.cn/article-12845-1.html | 
如果你像我一样,你可能会发现自己因为各种原因而运行 Windows,无论是因为工作还是游戏。当然,你可以在虚拟机或容器中运行 Fedora,但这些并不像 Windows 的 Linux 子系统(WSL)那样容易融合到普通的 Windows 体验中。通过 WSL 使用 Fedora 可以让你将这两种环境融合在一起,创造一个奇妙的开发环境。
### 先决条件
为了达成这一目标,你需要一些基本条件。你应该运行 Windows 10,并且已经安装了 WSL2。如果没有,请查看[微软文档说明](https://docs.microsoft.com/en-us/windows/wsl/install-win10),完成后再回来这里。微软建议为了简单起见,将 WSL2 设置为发行版的默认设置。本指南假设你已经这样做了。
接下来,你将需要一些解压 xz 压缩文件的方法。你可以用另一个基于 WSL 的发行版来解压,或者使用 [7zip](https://www.7-zip.org/download.html)。
### 下载 Fedora 33 rootfs
由于 Fedora 并没有提供实际的 rootfs 存档,所以我们将借用一个用于生成 Dockerhub 容器镜像的存档。你需要从 fedora-cloud 的 GitHub 仓库下载该 [tar.xz 文件](https://github.com/fedora-cloud/docker-brew-fedora/tree/33/x86_64) 。一旦你有了这个 tar.xz 文件,解压它,但不要展开 tar 包。你会得到一个类似 `fedora-33-时间标签.tar` 的文件。有了这个文件,你就可以构建镜像了。
### 组合 WSL Fedora 的构建版本
我喜欢使用 `c:\distros` 目录,但你可以选择几乎任何你想要的位置。无论你选择什么目录,在你导入该构建版本之前,确保其顶层路径存在。现在打开一个 CMD 或 Powershell 提示符,因为是时候导入了:
```
wsl.exe --import Fedora-33 c:\distros\Fedora-33 $HOME\Downloads\fedora-33.tar
```
你会看到 Fedora-33 显示在 WSL 的列表当中:
```
PS C:\Users\jperrin> wsl.exe -l -v
NAME STATE VERSION
Fedora-33 Stopped 2
```
下面,你就可以开始在 WSL 中摆弄 Fedora 了,但我们还需要做一些事情来使它真正成为一个有用的 WSL 发行版。
```
wsl -d Fedora-33
```
这将以 root 用户的身份启动 Fedora 的 WSL 实例。下面,你将安装一些核心包并设置一个新的默认用户。你还需要配置 `sudo`,否则你将无法在以后需要安装其他东西时轻松提升权限。
```
dnf update
dnf install wget curl sudo ncurses dnf-plugins-core dnf-utils passwd findutils
```
`wslutilites` 使用 `curl` 和 `wget` 来实现与 VS Code 的集成,所以它们很有用。由于你需要使用 COPR 仓库,你需要增加 `dnf` 功能。
### 添加你的用户
现在是时候添加你的用户,并将其设置为默认用户。
```
useradd -G wheel 用户名
passwd 用户名
```
现在,你已经创建了你的用户名,并添加了密码,确保它们可以工作。退出 WSL 实例,并再次启动它,这次指定用户名。你还要测试 `sudo`,并检查你的 uid。
```
wsl -d Fedora-33 -u 用户名
$id -u
1000
$ sudo cat /etc/shadow
```
假设一切正常,你现在已经准备好在 Windows 中为你的 Fedora 环境设置默认用户。要做到这一点,请退出 WSL 实例并回到 Powershell 中。这个 Powershell 单行代码可以正确配置你的用户:
```
Get-ItemProperty Registry::HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Lxss\\*\ DistributionName | Where-Object -Property DistributionName -eq Fedora-33 | Set-ItemProperty -Name DefaultUid -Value 1000
```
现在你应该可以再次启动 WSL,而不需要指定就可以成为自己的用户而不是 root。
### 自定义!
至此,你已经有了可以在 WSL 中运行的基本 Fedora 33 环境,但它还没有 Windows 集成的部分。如果你想要这个,有一个 COPR 仓库可以启用。如果你选择添加这部分,你就可以直接在 shell 里面运行 Windows 应用,也可以轻松地将你的 Linux 环境与 VS Code 集成。需要注意的是,COPR 并没有得到 Fedora 基础架构的官方支持。使用该软件包,风险自担。
```
dnf copr enable trustywolf/wslu
```
现在你可以去配置终端、设置一个 Python 开发环境,或者其它你想使用 Fedora 33 的方式。享受吧!
---
via: <https://fedoramagazine.org/wsl-fedora-33/>
作者:[Jim Perrin](https://fedoramagazine.org/author/jperrin/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you’re like me, you may find yourself running Windows for a variety of reasons from work to gaming. Sure you could run Fedora in a virtual machine or as a container, but those don’t blend into a common windows experience as easily as the Windows Subsystem for Linux (WSL). Using Fedora via WSL will let you blend the two environments together for a fantastic development environment.
### Prerequisites
There are a few basics you’ll need in order to make this all work. You should be running Windows 10, and have WSL2 installed already. If not, check out the [Microsoft documentation for instructions](https://docs.microsoft.com/en-us/windows/wsl/install-win10), and come back here when you’re finished. Microsoft recommends setting wsl2 as the distro default for simplicity. This guide assumes you’ve done that.
Next, you’re going to need some means of unpacking xz compressed files. You can do this with another WSL-based distribution, or use [7zip](https://www.7-zip.org/download.html).
### Download a Fedora 33 rootfs
Since Fedora doesn’t ship an actual rootfs archive, we’re going to abuse the one used to generate the container image for dockerhub. You will want to download the [tar.xz file](https://github.com/fedora-cloud/docker-brew-fedora/tree/33/x86_64) from the fedora-cloud GitHub repository. Once you have the tar.xz, uncompress it, but don’t unpack it. You want to end up with something like fedora-33-*datestamp*.tar. Once you have that, you’re ready to build the image.
### Composing the WSL Fedora build
I prefer to use *c:\distros*, but you can choose nearly whatever location you want. Whatever you choose, make sure the top level path exists before you import the build. Now open a cmd or powershell prompt, because it’s time to import:
wsl.exe --import Fedora-33 c:\distros\Fedora-33 $HOME\Downloads\fedora-33.tar
You will see Fedora-33 show up in wsl’s list
PS C:\Users\jperrin> wsl.exe -l -v
NAME STATE VERSION
Fedora-33 Stopped 2
From here, you can start to play around with Fedora in wsl, but we have a few things we need to do to make it actually *useful* as a wsl distro.
wsl -d Fedora-33
This will launch Fedora’s wsl instance as the root user. From here, you’re going to install a few core packages and set a new default user. You’re also going to need to configure sudo, otherwise you won’t be able to easily elevate privileges if you need to install something else later.
dnf update
dnf install wget curl sudo ncurses dnf-plugins-core dnf-utils passwd findutils
*wslutilites* uses *curl* and *wget* for things like VS Code integration, so they’re useful to have around. Since you need to use a Copr repo for this, you want the added dnf functionality.
### Add your user
Now it’s time to add your user, and set it as the default.
useradd -G wheel yourusername
passwd yourusername
Now that you’ve created your username and added a password, make sure they work. Exit the wsl instance, and launch it again, this time specifying the username. You’re also going to test sudo, and check your uid.
wsl -d Fedora-33 -u yourusername
$id -u
1000
$ sudo cat /etc/shadow
Assuming everything worked fine, you’re now ready to set the default user for your Fedora setup in Windows. To do this, exit the wsl instance and get back into Powershell. This Powershell one-liner configures your user properly:
Get-ItemProperty Registry::HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Lxss\*\ DistributionName | Where-Object -Property DistributionName -eq Fedora-33 | Set-ItemProperty -Name DefaultUid -Value 1000
Now you should be able to launch WSL again without specifying a user, and be yourself instead of root.
### Customize!
From here, you’re done getting the basic Fedora 33 setup running in wsl, but it doesn’t have the Windows integration piece yet. If this is something you want, there’s a Copr repo to enable. If you choose to add this piece, you’ll be able to run Windows apps directly from inside your shell, as well as integrate your Linux environment easily with VS Code. Note that Copr is not officially supported by Fedora infrastructure. Use packages at your own risk
dnf copr enable trustywolf/wslu
Now you can go configure your terminal, setup a Python development environment, or however else you want to use Fedora 33. Enjoy!
## Max Borowsky
Unfortunately, no one has yet created the official Fedora’s app for Microsoft Store.
## Matthew Miller
Actually, someone did create it; it’s just that actually getting something into the app store requires acceptance of legal terms Fedora can’t agree to. We’re still working on finding alternate solutions.
## Daniel
Now the details on those issues and what work-arounds are considered would be an interesting article for the Magazine!
## Yannick
And if you create an Appx file that users can install by double clicking on it, is there still the isse of legal Terms ?
## Enric
I just activated WSL, went to the Microsoft Store and downloaded the app. It’s working. I was actually surprised while reading the article that there was so much work involved.
(I’m writing from a proper 100% Fedora 33 Dell laptop, BTW)
## Sheogorath
Mhm, while the article is hopefully helpful for people out there, I’m disappointed to see content marketing for Microsoft Windows on Fedora Magazine. But hey, we live in strange times.
## Jeffersonian
I go along this.
MS and Apple alike have made it difficult to dual boot, and it is no accident.
It did not take long for github after being acquired by MS to exhibit Linux issues…
Consequently Fedora Magazine, should restrain to advertise MS products, Apple too.
But documenting new attempts to preempt hardware platforms so Linux cannot be run there, should be documented, ideally with workarounds.
## Joe Pesco
I agree fully.
## Dave Cross
“It did not take long for github after being acquired by MS to exhibit Linux issues…”
Can you please explain what you mean by this?
## Dave Cross
Would it not be a bit easier to install the “Fedora Remix for WSL” product from the Windows store?
## Klein Kravis
Yeah, it costs $20 USD
## silhano
I was still hoping Fedora one day appears in official Microsoft store (same as Ubuntu, SUSE, Debian, …) special when RedHat(IBM) is partner with Microsoft in Azure. This is kind of sad, but thanks for the guide.
## Heliosstyx
Thank you for your easy to understand article. So everybody has the choice when and where he/she wants to use the different OS’s. This links different “fascinating worlds” seamlessly.
## ja.
It is not going to appear anytime soon – the reason why it is not there is legal. Microsoft wants indemnification agreement and the Fedora legal obviously declined.
For more info, see here: https://lists.fedoraproject.org/archives/list/[email protected]/thread/JA4FEGORE53RXKOPRADODTBUCQN3XVJE/
## Rex Fury
Isn’t WSL essentially a Microsoft distro of Linux?
Isn’t this an appeal to the hoi polli of users?
## Matthew Miller
No, WSL is a system whereby packages from a Linux distribution are run in a container-like environment on Windows. It uses a Microsoft-provided version of the standard Linux kernel.
## billings
These instructions are for WSL2, which means Fedora is running in a Hyper-V VM, so not the container-like OS in WSL1.
## Will Kaiser
Excellent guide, thanks! Got this up and running in minutes and learned a bit more about how WSL works in the process (compared to just pulling in an app).
## Leon Gladston
Tensorflow and pytorch GPU setup for Machine learning is difficult in Fedora,so we are forced to take up debian packages like ubuntu.
## David Yaffe
When changing the password, I received the following error:
/usr/share/cracklib/pw_dict.pwd.gz: No such file or directory
BAD PASSWORD: The password fails the dictionary check – error loading dictionary
Retype new password:
passwd: all authentication tokens updated successfully.
running
solved the problem
## MartinP
There is a slightly easier way to set the default user, create a file called /etc/wsl.conf and set the user there:
[user]
default=username
WSL reads that file on start, there are other options that can be set such as mounts, check the official Microsoft doco for options.
## minkiu
If only this guide had been written earlier, this is so much better and easier than if you where to try to do it following Microsoft’s instructions, I was attempting it with CentOS, and like Fedora, the LiveISO has no rootfs, so my distro failed, didn’t even think of looking at the Docker image.
Thanks for this, this makes it so much saner and easy.
## Bayu Sanjaya
Ok, can we do vice versa?
I think we can copy windows core, or at least remove Windows bloatware(cortana, edge, etc). Then use KVM to run and expose the necessary apps only. For example steam.
We can do hardware (VGA or LAN) passthrough using kvm.
## docmoriarty
People use different operating systems the way they need it, this is called freedom of choice. The Edge is not bloatware, but essentially just another Chromium based browser, by the way, available not only for Windows, but also for Linux – please don’t use hate speech.
## Adam Chance
I’ve created a PowerShell script to create the WSL distribution automatically, it only requires that xz be available on the system path.
https://github.com/SocMinarch/fedora-wsl
Still need to write actual documentation but I’m getting there.
## Juergen
Will wait until there is a LSW Linux Subsystem for Windows
## Donald Sebastian Leung
That’s just Wine, no?
## Alan
WINE or the Codeweaver’s version called Crossover
## Barry
Did you miss out what to install from the copr?
dnf install wslu
## Jim Perrin
yeah. I thought I had that in there, but you’re right. I missed it. Thanks for adding the comment here for folks to find.
## Patrick
You know that for the customize part there is an official one by
## Jim Perrin
That one (at the time of writing this anyway) doesn’t support f33 yet.
## Silesh K Nair
https://github.com/yosukes-dev/FedoraWSL
## Jonathan D Bowman
Nice write-up. Very thoughtful to include wslu. Thanks!
## jenrry
hola y para cuando tendremos un sistema windows en fedora ,así como si fuera una aplicación como cualquier otra, hasta cuando gnu/linux sera usado como aplicación de una tienda, a caso no se quieren ustedes mismos? que pretende microsoft con estas jugadas? traer mas gente a su sistema las personas pueden decir, “bueno aqui lo tengo todo para voy a instalar linux”, si esto sigue así cada vez habrá menos personas que puedan usarlo, y los fabricantes de hardware podrán decir “para que hago driver de hardware que nadie usa” por eso es importante tomar buenas deciciones para que no afecten el futuro de Fedora y de todo gnu/linux en general.
## Don Pool
Hi,
Is there a way to create a shortcut, somo sort of launcher to avoid Opening Powershell and launching wsl?
## Jonathan D Bowman
Have you tried Windows Terminal? https://github.com/microsoft/terminal
## Carvel Baus
Does this work for Windows Arm laptops as well?
## Ranvir
Is there a way to find the image by navigating the Fedora GitHub account? Just to make this article more future proof.
For example when Fedora 34 comes out we need a sane way of finding its rootfs image.
## Joe Pesco
I’ll remain out of the legal debate and only frown at MS content on Fedora Magazine!!! My instinct is that the WSL is important to MS customers.
One note: To get preview 20262 I needed to change my insider ring to
dev from beta. Everything was smooth sailing after that!
Thanks for a good article! |
12,847 | 如何在 Linux 上安装和使用 Etcher 来制作 Linux 临场 USB | https://itsfoss.com/install-etcher-linux/ | 2020-11-21T21:43:00 | [] | https://linux.cn/article-12847-1.html | 
>
> Etcher 是一款流行的 USB 烧录应用,可用于创建可启动的 Linux USB。让我来告诉你如何安装它,以及如何使用它来制作一个 Linux 临场盘。
>
>
>
### Etcher:一个用于在 SD 卡和 USB 驱动器中烧录 Linux ISO 的开源工具
Etcher 是一个由 [Balena](https://www.balena.io/) 开发的开源项目,来用于为树莓派烧录 SD 卡。事实上,我们在[如何在 SD 卡上安装 Raspbian OS](https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/) 的教程中就使用了它。
它不仅仅局限于 SD 卡,你还可以使用 Etcher 来[制作一个可启动的 USB 驱动器](https://itsfoss.com/create-bootable-ubuntu-usb-drive-mac-os/),我们就通过它的帮助在 Linux 中制作了一个 [Manjaro 的临场 USB](https://itsfoss.com/create-live-usb-manjaro-linux/)。
自首次发布以来,Etcher 就以其整洁的界面和简单的使用方式引起了人们的注意。

在本文中,我将重点介绍帮助你在 Linux 上安装 Etcher 的步骤。然后,我还将展示如何使用它。在这之前,让我先给大家介绍一下它的功能。
### Etcher 的功能
* 在烧录前验证驱动器
* 漂亮的用户界面
* 自动检测 USB 驱动器/SD 卡,防止电脑上的硬盘被擦除。
* 跨平台支持(Windows、macOS 和 Linux)。
* 快速烧录
* 简单的三步过程
理论上,你已经有了在 SD 卡和 USB 驱动器上烧录操作系统镜像所需的一切。同样令人激动的是,根据他们的[路线图](https://github.com/balena-io/etcher/milestones),他们计划增加对多个设备的同步写入支持。
### 在 Linux 上安装 Etcher
要开始使用,你需要从它的官方网站上下载它提供的 AppImage 文件(适用于任何 Linux 发行版)。
你只需要前往它的[主页](https://www.balena.io/etcher),并根据你的系统(32 位/64 位)下载一个程序:

在我的例子中,我下载了 Ubuntu 的 64 位 AppImage 文件。你可以通过我们的指南来了解[在 Linux 上使用 AppImage文件](https://itsfoss.com/use-appimage-linux/),但我会让你先知道下一步需要做什么。
你需要给文件执行权限,你可以右击**AppImage 文件 -> 属性**来实现。

接下来,点击权限选项卡下的“**允许作为程序执行**”,如下图所示。

现在,只需双击 AppImage 文件即可启动 Etcher!
这应该可以在任何 Linux 发行版上运行。在任何情况下,如果你想从源码构建或者直接使用 .rpm 或 .deb 文件安装,你也可以前往它的 [Github 发布页](https://github.com/balena-io/etcher/releases/tag/v1.5.109)找到 RPM、DEB 和源码。
你也可以参考我们的[在 Ubuntu 中使用 deb 文件](https://itsfoss.com/install-deb-files-ubuntu/)来安装应用。
>
> 注意!
>
>
> 我们注意到,当你使用 Etcher 创建 Linux 发行版的临场 USB 时,它会使 USB 处于明显的不可使用状态,即它只有几 MB 的空闲空间,并且不能直接格式化。在 Linux 上,你可以[使用磁盘工具手动删除分区,然后格式化它](https://itsfoss.com/cant-format-usb-disk/)。
>
>
>
### 在 Linux 上使用 Etcher
只需三步就可以开始使用 Etcher。在你启动它之后,根据屏幕上的提示应该是清晰的,但为了给你一个好的开始,以下是你要做的事情:
**步骤 1:** 选择合适的 ISO 镜像文件或你需要烧录的文件的 URL(如下图所示)。

**步骤 2:** 接下来,你需要选择目标设备。它会自动检测并高亮显示可移动设备,以防止你选择任何内部存储位置。

在这里,我连接了一个 USB 驱动器,我也选择了它(如下图所示)。

**步骤 3:** 现在,你所有需要做的就是烧录镜像并等待它成功完成。

这是进度的样子:

完成了!

* [下载 balenaEtcher](https://www.balena.io/etcher)
### 总结
Etcher 是一个有用的工具,可以为 SD 卡和 USB 驱动器烧录操作系统镜像。我倾向于主要使用它来创建临场 USB 驱动器来测试 Linux 发行版,我对它很满意。
你更喜欢用什么来创建可启动驱动器?你是否已经尝试过 Etcher?请在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/install-etcher-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

## Etcher: An open source tool to flash Linux ISO on SD Cards & USB drives
Etcher is an open-source project by [Balena](https://www.balena.io/?ref=itsfoss.com) to help flash SD cards for Raspberry Pi. In fact, we used it in our tutorial on [how to install Raspbian OS on a SD Card](https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/).
Not just limited to SD Cards, you can also use Etcher to [make a bootable USB drive](https://itsfoss.com/create-bootable-ubuntu-usb-drive-mac-os/) just like we created a [live USB of Manjaro in Linux](https://itsfoss.com/create-live-usb-manjaro-linux/) with the help of it.
Ever since its first release, Etcher caught the attention for its neat interface and simplicity of use.
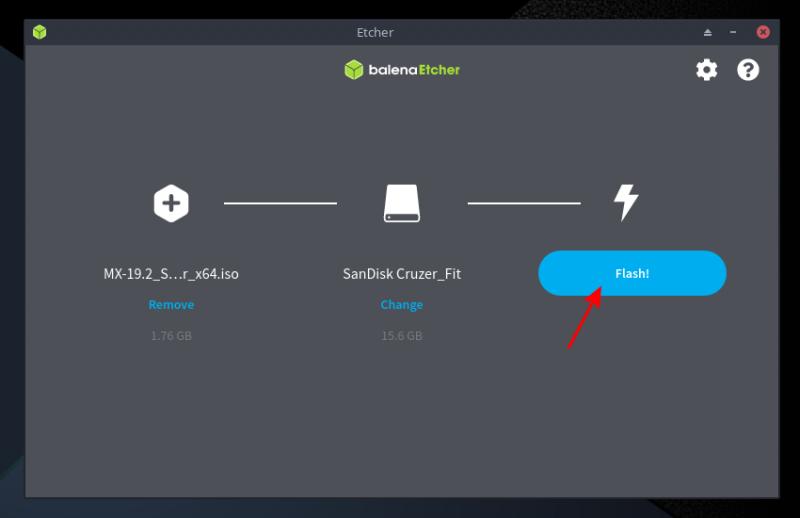
In this article, I will be focusing on the steps to help you install Etcher on Linux. And then, I’ll also show how to use it. Before I do that, let me give you an overview of the features it offers:
## Features of Etcher
- Validate drive before flashing
- Beautiful user interface
- Auto-detects USB drive/SD card to prevent wiping the HDD on your computer
- Cross-platform support (Windows, macOS, and Linux)
- Fast flashing
- Simple three-step process
On paper, you get everything one would need to flash OS images on an SD card and a USB drive. It is also exciting to know that they plan to add the support simultaneous writing to multiple devices as per their [roadmap](https://github.com/balena-io/etcher/milestones?ref=itsfoss.com).
## Installing Etcher on Linux
To get started, you have to grab the AppImage file that it offers (suitable for any Linux distribution) from its official website.
You just need to head on to its [homepage](https://www.balena.io/etcher?ref=itsfoss.com) and download the one for your system (32-bit/64-bit):
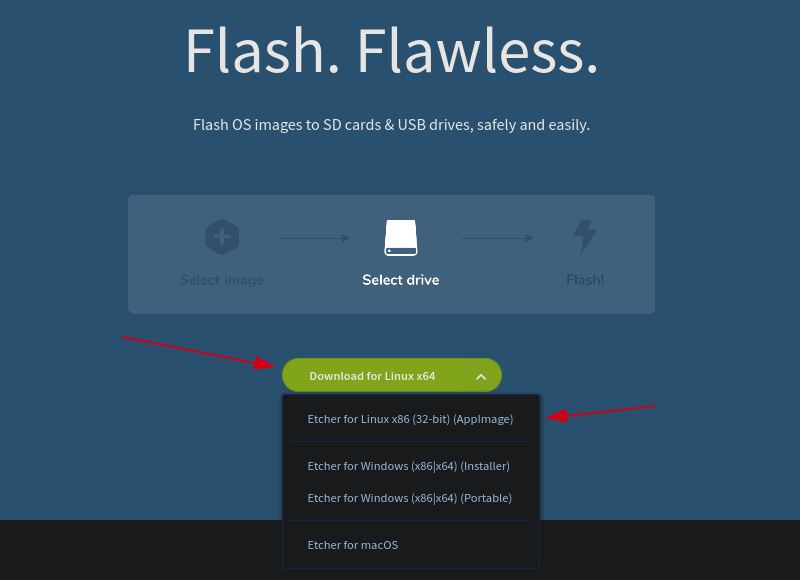
In my case, I got the 64-bit AppImage file for Ubuntu. You can go through our guide on [using AppImage files on Linux](https://itsfoss.com/use-appimage-linux/), but I’ll give you a head start on what you need to do next.
You need to give the file permissions to execute and you can do that by right-clicking on the **AppImage file -> Properties**.
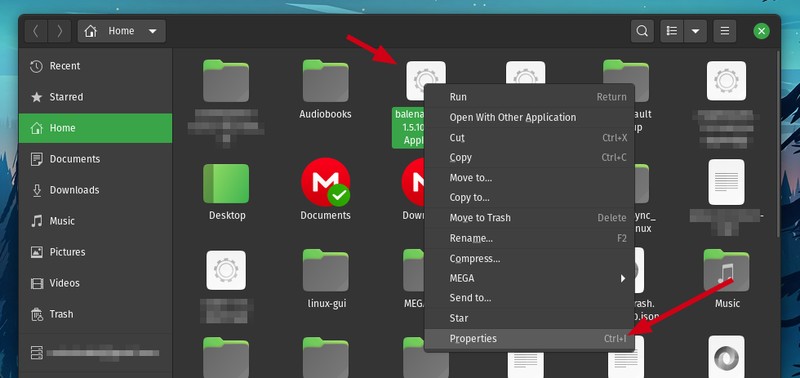
Next, click on “**Allow executing as a program**” under the Permissions tab as shown in the image below.
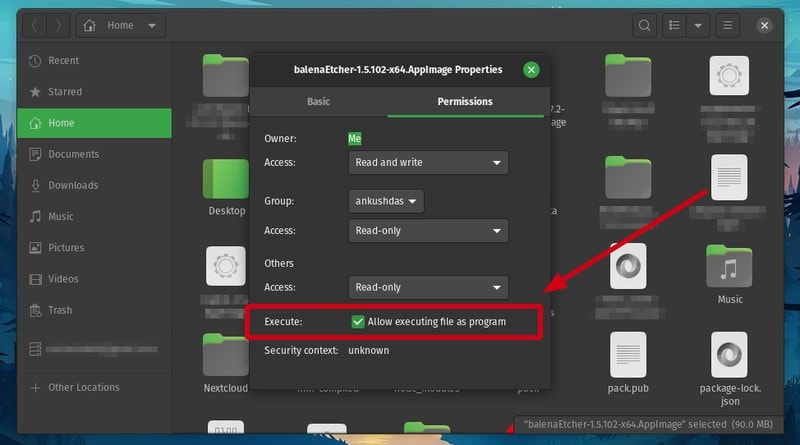
Now, just double-click on the AppImage file to launch balenaEtcher!
This should work on any Linux distribution. In either case, you can also head over to its [GitHub releases se](https://github.com/balena-io/etcher/releases/tag/v1.5.109?ref=itsfoss.com)[c](https://github.com/balena-io/etcher/releases/tag/v1.5.109?ref=itsfoss.com)[tion](https://github.com/balena-io/etcher/releases/tag/v1.5.109?ref=itsfoss.com) to find RPM, DEB, and the source file if you want to build it from source or just install it using the .rpm or .deb files.
You can also refer to our guide on [using deb file in Ubuntu](https://itsfoss.com/install-deb-files-ubuntu/) to install applications.
[use the Disks tool to manually delete the partitions and then format it](https://itsfoss.com/cant-format-usb-disk/).
## Using Etcher on Linux
It is just a three-step process to get started using Etcher. It should be self-explanatory as per the on-screen instructions after you launch it, but just to give you a head start, here’s what you have to do:
**Step 1:** Select the appropriate ISO image file or the URL of the file that you need to flash (as shown in the image below).
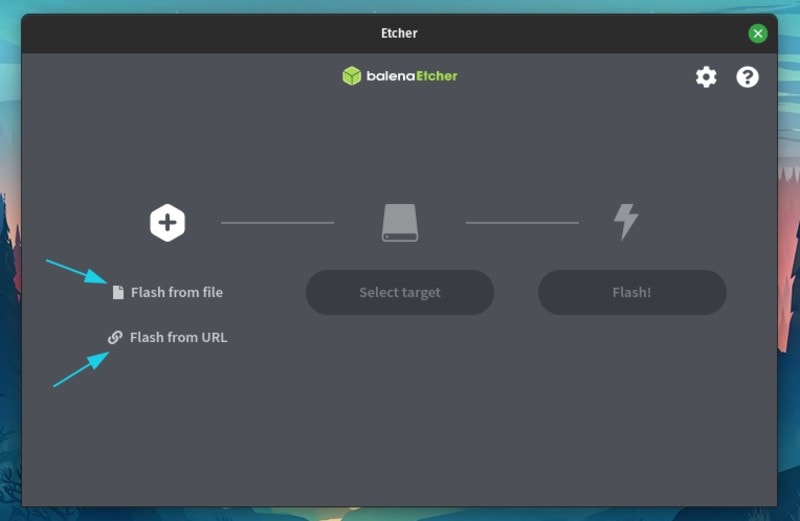
**Step 2**: Next, you will have to select the target device. It automatically detects and highlights removable devices to help you prevent selecting any internal storage locations.
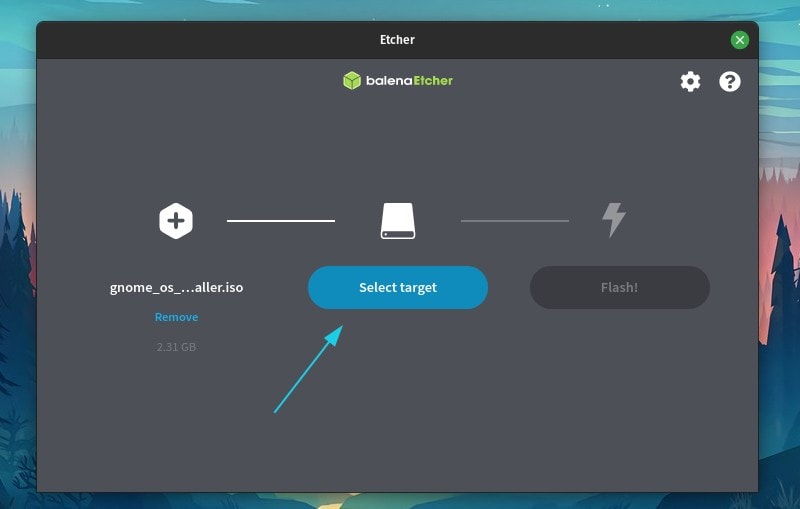
In this case, I have a USB drive connected, and I have it selected as well (as shown in the screenshot below).
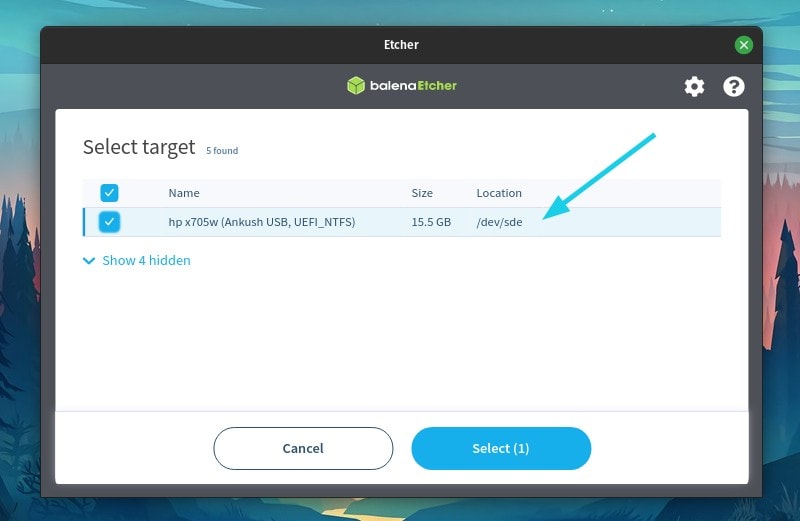
**Step 3:** Now, all you have to do is — flash the image and wait for it to complete successfully.
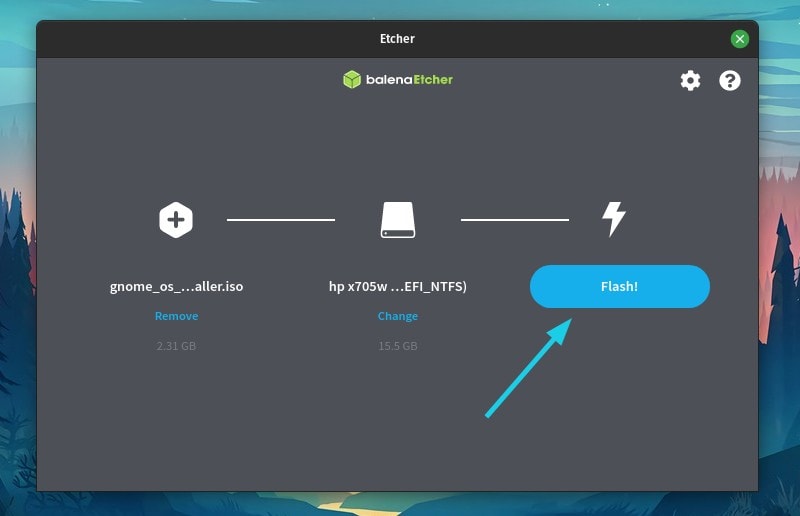
Here’s how the progress looks:
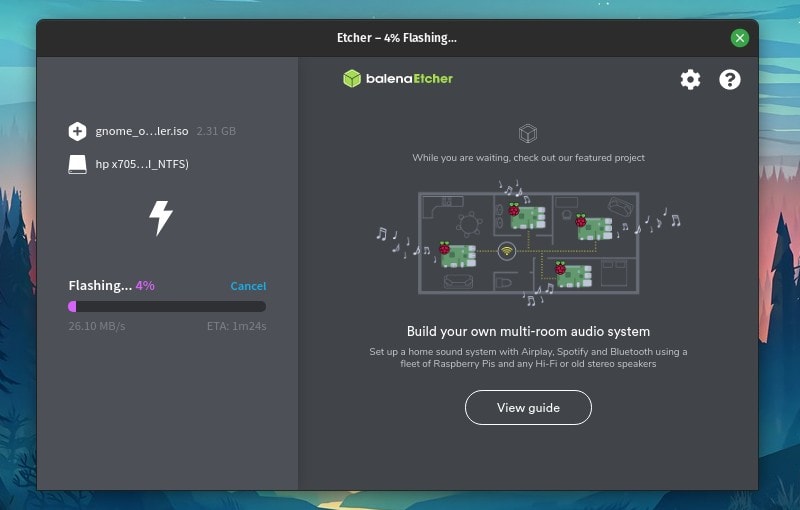
And, it is done!
## Wrapping Up
Etcher is a useful tool to flash OS images for both SD cards and USB drives. I tend to use it primarily to create live USB drives to test Linux distros and I’m happy with it.
What do you prefer to use to create bootable drives? Have you tried Etcher already? Let me know your thoughts in the comments down below. |
12,850 | 使用命令行浏览器在 Linux 终端上网浏览 | https://itsfoss.com/terminal-web-browsers/ | 2020-11-22T21:27:41 | [
"终端",
"浏览器"
] | https://linux.cn/article-12850-1.html | 
我猜你阅读这篇文章可能是用 Firefox 或基于 Chrome 的浏览器(如 [Brave](https://itsfoss.com/brave-web-browser/)),或者,也可能是 Chrome 浏览器或 [Chromium](https://itsfoss.com/install-chromium-ubuntu/)。
换句话说,你正在利用基于 GUI 的方式浏览网页。然而,在以前,人们使用终端来获取资源和浏览网页,因为所有的东西大多是基于文本的。
虽然现在不能从终端上获取每个信息,但对于一些文本信息,还是可以尝试使用命令行浏览器,从 Linux 终端上打开网页。
不仅如此,如果你访问的是远程服务器,或者只有一个没有 GUI 的终端,终端网页浏览器就可以发挥用处了。
因此,在本文中,我将介绍一些基于终端的 Web 浏览器,你可以在 Linux 上尝试它们。
### Linux 用户的最佳终端 Web 浏览器
注:此榜单排名不分先后。
#### 1、W3M

`w3m` 是一个流行的基于文本的开源终端 Web 浏览器。尽管其初始项目已经不再活跃,但另一个开发者 Tatsuya Kinoshita 正在维护着它的一个活跃分支。
`w3m` 相当简单,支持 SSL 连接、色彩,也支持内嵌图片。当然,根据你试图访问的资源,你那边的情况可能会有所不同。根据我的简单测试,它似乎无法加载 [DuckDuckGo](https://duckduckgo.com/),但我可以[在终端中使用 Google](https://itsfoss.com/review-googler-linux/)就够了。
安装后,你可以简单的在终端中输入 `w3m` 以得到帮助。如果你感兴趣的话,也可以到 [GitHub](https://github.com/tats/w3m) 上去查看它的仓库。
**如何安装和使用 w3m?**
`w3m` 在任何基于 Debian 的 Linux 发行版的默认仓库中都是可用的。如果你有一个基于 Arch 的发行版,但没有直接可用的软件包,你可能需要查看一下 [AUR](https://itsfoss.com/aur-arch-linux/)。
对于 Ubuntu,你可以通过键入以下内容来安装它:
```
sudo apt install w3m w3m-img
```
在这里,我们将 w3m 包和图片扩展一起安装,以支持内嵌图片。接下来,要开始安装,你只需要按照下面的命令进行操作即可:
```
w3m xyz.com
```
当然,你需要将 `xyz.com` 替换成任何你想浏览或测试的网站。最后,你应该知道,你可以使用键盘上的方向键来导航,当你想采取一个动作时,按回车键。
要退出,你可以按 `SHIFT+Q`,返回上一页是 `SHIFT+B`。其他快捷键包括用 `SHIFT+T` 打开新标签页和用 `SHIFT+U` 打开新的 URL。
你可以通过访问它的手册页来了解更多信息。
#### 2、Lynx

Lynx 是另一个开源的命令行浏览器,你可以试试。幸运的是,很多的网站在使用 Lynx 时往往能正常工作,所以我说它在这方面肯定更好。我能够加载 DuckDuckGo,并使其工作。
除此之外,我还注意到它可以让你在访问各种 Web 资源时接受或拒绝 cookie。你也可以将它设置为总是接受或拒绝。所以,这是件好事。
另一方面,在终端上使用时,窗口不能很好地调整大小。我还没有寻找到任何解决方法,所以如果你正在尝试这个,你可能会想要这样做。不论如何,它都很好用,当你在终端启动它时,你会得到所有键盘快捷键的说明。
请注意,它与系统终端主题不匹配,所以无论你的终端看起来如何,它都会看起来不同。
**如何安装 Lynx?**
与 w3m 不同的是,如果你有兴趣尝试的话,确实可以找到一些 Win32 上的安装程序。不过,在 Linux 上,它在大多数的默认仓库中都是可用的。
对于 Ubuntu 来说,你只需要输入:
```
sudo apt install lynx
```
要想使用,你只需要按照下面的命令进行操作:
```
lynx examplewebsite.com
```
在这里,你只需要将示例网站替换成你想要访问的资源即可。
如果你想找其他 Linux 发行版的软件包,可以查看他们的[官网资源](https://lynx.invisible-island.net/lynx-resources.html)。
#### 3、Links2

Links2 是一款有趣的基于文本的浏览器,你可以在你的终端上轻松使用,用户体验良好。它提供了一个很好的界面,你启动它后,只要输入网址就可以了。

值得注意的是,主题将取决于你的终端设置,我设置为“黑绿色”主题,因此你看到的就是这个。当你以命令行浏览器的方式启动它后,你只需要按任意键就会出现 URL 提示,或者按 `Q` 键退出。它相当好用,可以渲染大多数网站的文字。
与 Lynx 不同的是,你没有接受或拒绝 cookie 的功能。除此之外,它似乎工作的还不错。
**如何安装 Links2?**
正如你所期望的,你会发现它在大多数默认的仓库中都有。对于 Ubuntu,你可以在终端输入以下命令来安装它:
```
sudo apt install links2
```
如果你想在其他 Linux 发行版上安装它,你可以参考它的[官方网站](http://links.twibright.com/download.php)获取软件包或文档。
#### 4、eLinks

eLinks 类似于 Links2,但它已经不再维护了。你仍然可以在各种发行版的默认仓库中找到它,因此,我把它保留在这个列表中。
它不会与你的系统终端主题相融合。所以,如果你需要的话,作为一个没有“黑暗”模式的文本型浏览器,这可能不是一个漂亮的体验。
**如何安装 eLinks?**
在 Ubuntu 上,安装它很容易。你只需要在终端中输入以下内容:
```
sudo apt install elinks
```
对于其他 Linux 发行版,你应该可以在标准软件仓库中找到它。但是,如果你在软件仓库中找不到它,你可以参考[官方安装说明](http://elinks.or.cz/documentation/installation.html)。
### 总结
在终端上运行的基于文本的 Web 浏览器并不多,这并不奇怪。一些项目,如 [Browsh](https://www.brow.sh/),试图呈现一个现代的 Linux 命令行浏览器,但在我这里它不能工作。
虽然像 `curl` 和 `wget` 这样的工具允许你[从 Linux 命令行下载文件](https://itsfoss.com/download-files-from-linux-terminal/),但这些基于终端的 Web 浏览器提供了额外的功能。
除了命令行浏览器之外,如果你想在终端上玩玩,也可以尝试一些[Linux 命令行游戏](https://itsfoss.com/best-command-line-games-linux/)。
对于 Linux 终端上的文本型 Web 浏览器,你有什么看法?欢迎在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/terminal-web-browsers/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I’m guessing that you are probably using Firefox or a Chrome-based browser like [Brave](https://itsfoss.com/brave-web-browser/) to read this article. Or, maybe, Google Chrome or [Chromium](https://itsfoss.com/install-chromium-ubuntu/) or other [web browsers available for Linux](https://itsfoss.com/best-browsers-ubuntu-linux/).
In other words, you are utilizing a GUI-based approach to browse the web. However, back in the days, people used the terminal to fetch resources and browse the web because everything was mostly text-based information.
Even though you cannot get every information from a terminal now, you can still try the command line browsers for some text-based information and open a web page from the Linux terminal.
Not just limited to that, but if you are accessing a remote server or stuck in a terminal without a GUI, a terminal web browser can prove to be useful as well.
So, in this article, I will be mentioning some terminal based web browsers that you can try on Linux.
**Note:** The list is in no particular order of ranking.
## 1. W3M
w3m is a popular open-source text-based web browser for the terminal. Even though the original project is no longer active, an active version of it is being maintained by a different developer Tatsuya Kinoshita.
w3m is quite simple, supports SSL connections, colors, and in-line images as well. Of course, depending on what resource you are trying to access, things might look different on your end. As per my quick test, it didn’t seem to load up [DuckDuckGo](https://duckduckgo.com/?ref=itsfoss.com) but I could [use Google in terminal](https://itsfoss.com/review-googler-linux/) just fine.
You can simply type **w3m** in the terminal to get help after installation. If you’re curious, you can also check out the repository at [GitHub](https://github.com/tats/w3m?ref=itsfoss.com).
### How to install and use w3m?
W3M is available on most of the default repositories for any Debian-based Linux distribution. If you have an Arch-based distro, you might want to check [AUR](https://itsfoss.com/aur-arch-linux/) if it’s not available directly.
For Ubuntu, you can install it by typing in:
`sudo apt install w3m w3m-img`
Here, we are installing the w3m package along with image extension for in-line image support. Next, to get started, you have to simply follow the command below:
`w3m xyz.com`
Of course, you need to replace xyz.com to any website that you want to browse/test. Finally, you should know that you can use the keyboard arrow keys to navigate and press enter when you want to take an action.
To quit, you can press **SHIFT+Q**, and to go back to the previous page — **SHIFT+B**. Additional shortcuts include **SHIFT + T** to open a new tab and **SHIFT + U** to open a new URL.
You can explore more about it by heading to its man page as well.
## 2. Lynx
Lynx is yet another open source command line browser which you can try. Fortunately, more websites tend to work when using Lynx, so I’d say it is definitely better in that aspect. I was able to load up DuckDuckGo and make it work.
In addition to that, I also noticed that it lets you accept/deny cookies when visiting various web resources. You can set it to always accept or deny as well. So, that’s a good thing.
On the other hand, the window does not re-size well while using it from the terminal. I haven’t looked for any solutions to that, so if you’re trying this out, you might want to do that. In either case, it works great and you get all the instructions for the keyboard shortcuts right when you launch it in the terminal.
Note that it does not match the system terminal theme, so it will look different no matter how your terminal looks like.
### How to install Lynx?
Unlike w3m, you do get some Win32 installers if you’re interested to try. But, on Linux, it is available on the most of the default repositories.
For Ubuntu, you just need to type in:
`sudo apt install lynx`
To get started, you just have to follow the command below:
`lynx examplewebsite.com`
Here, you just need to replace the example website with the resource you want to visit.
If you want to explore the packages for other Linux distros, you can check out their [official website resources](https://lynx.invisible-island.net/lynx-resources.html?ref=itsfoss.com).
## 3. Links2
Links2 is an interesting text-based browser that you can easily utilize on your terminal with a good user experience. It gives you a nice interface to type in the URL and then proceed as soon as you launch it.
It is worth noting that the theme will depend on your terminal settings, I have it set as “black-green”, hence this is what you see. Once you launch it as a command line browser, you just need to press any key to bring the URL prompt or Q to quit it. It works good enough and renders text from most of the sites.
Unlike Lynx, you do not get the ability to accept/reject cookies. Other than that, it seems to work just fine.
### How to install Links2?
As you’d expect, you will find it available in the most of the default repositories. For Ubuntu, you can install it by typing the following command in the terminal:
`sudo apt install links2`
You can refer to its [official](http://links.twibright.com/download.php?ref=itsfoss.com)[ ](http://links.twibright.com/download.php?ref=itsfoss.com)[website](http://links.twibright.com/download.php?ref=itsfoss.com) for packages or documentations if you want to install it on any other Linux distribution.
## 4. eLinks
eLinks is similar to Links2 — but it is no longer maintained. You will still find it in the default repositories of various distributions, hence, I kept it in this list.
It does not blend in with your system terminal theme. So, this may not be a pretty experience as a text-based browser without a “dark” mode if you needed that.
### How to install eLinks?
On Ubuntu, it is easy to install it. You just have to type in the following in the terminal:
`sudo apt install elinks`
For other Linux distributions, you should find it available on the standard repositories. But, you can refer to the [official installation instructions](http://elinks.or.cz/documentation/installation.html?ref=itsfoss.com) if you do not find it in the repository.
## More such terminal stuff
It’s no surprise that there aren’t a lot of text-based web browsers to run on the terminal. Some projects like [Browsh](https://www.brow.sh/?ref=itsfoss.com) have tried to present a modern Linux command-line browser but it did not work in my case.
While tools like curl and wget allow you to [download files from the Linux command line](https://itsfoss.com/download-files-from-linux-terminal/), these terminal-based web browsers provide additional features.
[How to Download Files From Terminal in Ubuntu & Other LinuxIf you are stuck to the Linux terminal, say on a server, how do you download a file from the terminal? Here are some commands to download files and webpages.](https://itsfoss.com/download-files-from-linux-terminal/)

In addition to command-line browsers, you may also like to try some [command line games for Linux](https://itsfoss.com/best-command-line-games-linux/), if you want to play around in the terminal.
[Top 10 Command Line Games For LinuxYou can play games on the Linux terminal. Here are the best command line games for you.](https://itsfoss.com/best-command-line-games-linux/)

Browsing web in the Linux terminal or [using the Linux terminal in a web browser](https://itsfoss.com/online-linux-terminals/), you can do it all.
What do you think about the text-based web browsers for Linux terminal? Feel free to let me know your thoughts in the comments below. |
12,851 | 自动解锁 Linux 上的加密磁盘 | https://opensource.com/article/20/11/nbde-linux | 2020-11-23T10:47:54 | [
"加密",
"磁盘"
] | https://linux.cn/article-12851-1.html |
>
> 通过使用网络绑定磁盘加密(NBDE),无需手动输入密码即可打开加密磁盘。
>
>
>

从安全的角度来看,对敏感数据进行加密以保护其免受窥探和黑客的攻击是很重要的。<ruby> Linux 统一密钥设置 <rt> Linux Unified Key Setup </rt></ruby>([LUKS](https://en.wikipedia.org/wiki/Linux_Unified_Key_Setup))是一个很好的工具,也是 Linux 磁盘加密的通用标准。因为它将所有相关的设置信息存储在分区头部中,所以它使数据迁移变得简单。
要使用 LUKS 配置加密磁盘或分区,你需要使用 [cryptsetup](https://gitlab.com/cryptsetup/cryptsetup) 工具。不幸的是,加密磁盘的一个缺点是,每次系统重启或磁盘重新挂载时,你都必须手动提供密码。
然而,<ruby> 网络绑定磁盘加密 <rt> Network-Bound Disk Encryption </rt></ruby>(NBDE) 可以在没有任何用户干预的情况下自动安全地解锁加密磁盘。它可以在一些 Linux 发行版中使用,包括从 Red Hat Enterprise Linux 7.4、CentOS 7.4 和 Fedora 24 开始,以及之后的后续版本。
NBDE 采用以下技术实现:
* [Clevis 框架](https://github.com/latchset/clevis):一个可插拔的框架工具,可自动解密和解锁 LUKS 卷
* [Tang 服务器](https://github.com/latchset/tang):用于将加密密钥绑定到网络状态的服务
Tang 向 Clevis 客户端提供加密密钥。据 Tang 的开发人员介绍,这为密钥托管服务提供了一个安全、无状态、匿名的替代方案。
由于 NBDE 使用客户端-服务器架构,你必须同时配置客户端和服务器。你可以在你的本地网络上使用一个虚拟机作为 Tang 服务器。
### 服务器安装
用 sudo 安装 Tang:
```
sudo yum install tang -y
```
启用 Tang 服务器:
```
sudo systemctl enable tangd.socket --now
```
Tang 服务器工作在 80 端口,需加入到 firewalld 防火墙。添加相应的 firewalld 规则:
```
sudo firewall-cmd --add-port=tcp/80 --perm
sudo firewall-cmd --reload
```
现在安装好了服务器。
### 客户端安装
在本例中,假设你已经添加了一个名为 `/dev/vdc` 的新的 1GB 磁盘到你的系统中。
使用 `fdisk` 或 `parted` 创建主分区:
```
sudo fdisk /dev/vdc
```
完成以下步骤来安装客户端:
```
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x4a6812d4.
Command (m for help):
```
输入 `n` 来创建新的分区:
```
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p):
```
按下**回车**键选择主分区:
```
Using default response p
Partition number (1-4, default 1):
```
按下回车键选择默认分区号:
```
First sector (2048-2097151, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151):
```
按回车键选择最后一个扇区:
```
Using default value 2097151
Partition 1 of type Linux and of size 1023 MiB is set
Command (m for help): wq
```
输入 `wq` 保存更改并退出 `fdisk`:
```
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
```
运行 `partprobe` 通知系统分区表的变化:
```
sudo partprobe
```
使用 `sudo` 安装 cryptsetup 软件包:
```
sudo yum install cryptsetup -y
```
使用 `cryptsetup luksFormat` 命令对磁盘进行加密。当提示时,你需要输入大写的 `YES`,并输入密码来加密磁盘:
```
sudo cryptsetup luksFormat /dev/vdc1
WARNING!
========
This will overwrite data on /dev/vdc1 irrevocably.
Are you sure? (Type uppercase yes):
Enter passphrase for /dev/vdc1:
Verify passphrase:
```
使用 `cryptsetup luksOpen` 命令将加密的分区映射到一个逻辑设备上。例如,使用 `encryptedvdc1` 作为名称。你还需要再次输入密码:
```
sudo cryptsetup luksOpen /dev/vdc1 encryptedvdc1
Enter passphrase for /dev/vdc1:
```
加密分区现在在 `/dev/mapper/encryptedvdc1` 中可用。
在加密的分区上创建一个 XFS 文件系统:
```
sudo mkfs.xfs /dev/mapper/encryptedvdc1
```
创建一个挂载加密分区的目录:
```
sudo mkdir /encrypted
```
使用 `cryptsetup luksClose` 命令锁定分区:
```
cryptsetup luksClose encryptedvdc1
```
使用 `sudo` 安装 Clevis 软件包:
```
sudo yum install clevis clevis-luks clevis-dracut -y
```
修改 `/etc/crypttab`,在启动时打开加密卷:
```
sudo vim /etc/crypttab
```
增加以下一行:
```
encryptedvdc1 /dev/vdc1 none _netdev
```
修改 `/etc/fstab`,在重启时或启动时自动挂载加密卷:
```
sudo vim /etc/fstab
```
增加以下一行:
```
/dev/mapper/encryptedvdc1 /encrypted xfs _netdev 1 2
```
在这个例子中,假设 Tang 服务器的 IP 地址是 `192.168.1.20`。如果你喜欢,也可以使用主机名或域名。
运行以下 `clevis` 命令:
```
sudo clevis bind luks -d /dev/vdc1 tang '{"url":"http://192.168.1.20"}'
The advertisement contains the following signing keys:
rwA2BAITfYLuyNiIeYUMBzkhk7M
Do you wish to trust these keys? [ynYN] Y
Enter existing LUKS password:
```
输入 `Y` 接受 Tang 服务器的密钥,并提供现有的 LUKS 密码进行初始设置。
通过 `systemctl` 启用 `clevis-luks-askpass.path`,以防止非根分区被提示输入密码。
```
sudo systemctl enable clevis-luks-askpass.path
```
客户端已经安装完毕。现在,每当你重启服务器时,加密后的磁盘应该会自动解密,并通过 Tang 服务器取回密钥进行挂载。
如果 Tang 服务器因为任何原因不可用,你需要手动提供密码,才能解密和挂载分区。
---
via: <https://opensource.com/article/20/11/nbde-linux>
作者:[Curt Warfield](https://opensource.com/users/rcurtiswarfield) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | From a security viewpoint, it's important to encrypt your sensitive data to protect it from prying eyes and hackers. Linux Unified Key Setup ([LUKS](https://en.wikipedia.org/wiki/Linux_Unified_Key_Setup)) is a great tool and a common standard for Linux disk encryption. Because it stores all pertinent setup information in the partition header, it makes migrating data easy.
To configure encrypted disks or partitions with LUKS, you will need to use the [cryptsetup](https://gitlab.com/cryptsetup/cryptsetup) utility. Unfortunately, one of the downsides of encrypting your disks is that you have to manually provide the password every time the system is rebooted or the disk is remounted.
However, Network-Bound Disk Encryption (NBDE) can automatically and securely unlock encrypted disks without any user intervention. It is available in several Linux distributions, beginning with Red Hat Enterprise Linux 7.4, CentOS 7.4, and Fedora 24, and in later versions of each.
NBDE is implemented with the following technologies:
A pluggable framework tool that automatically decrypts and unlocks LUKS volumes[Clevis framework](https://github.com/latchset/clevis):A service for binding cryptographic keys to network presence[Tang server](https://github.com/latchset/tang):
Tang provides the encryption keys to the Clevis client. According to Tang's developers, this provides a secure, stateless, anonymous alternative to key escrow services.
Because NBDE uses the client-server architecture, you must configure both the client and the server. You can use a virtual machine on your local network for your Tang server.
## Server installation
Install Tang using sudo:
`sudo yum install tang -y`
Enable the Tang server:
`sudo systemctl enable tangd.socket --now`
The Tang server works on port 80 and must be added to firewalld. Add the appropriate firewalld rule:
```
sudo firewall-cmd --add-port=tcp/80 --perm
sudo firewall-cmd --reload
```
The server should now be installed.
## Client installation
For this example, assume you have added a new 1GB disk named `/dev/vdc`
to your system.
Create the primary partition using fdisk or parted:
```
sudo fdisk /dev/vdc
```
Complete the following steps to install the client.
```
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x4a6812d4.
Command (m for help):
```
Enter **n** to create the new partition:
```
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p):
```
Hit the **Enter** key to select the primary partition:
```
Using default response p
Partition number (1-4, default 1):
```
Hit the **Enter** key to select the default partition number:
```
First sector (2048-2097151, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151):
```
Hit the **Enter** key to select the last sector:
```
Using default value 2097151
Partition 1 of type Linux and of size 1023 MiB is set
Command (m for help): wq
```
Type **wq** to save the changes and exit fdisk:
```
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
```
Run `partprobe`
to inform the system of the partition table changes:
`sudo partprobe`
Install the cryptsetup package using sudo:
`sudo yum install cryptsetup -y`
Use the `cryptsetup luksFormat`
command to encrypt the disk. You will need to type **YES** when prompted and also choose and enter a passphrase to encrypt the disk:
```
sudo cryptsetup luksFormat /dev/vdc1
WARNING!
========
This will overwrite data on /dev/vdc1 irrevocably.
Are you sure? (Type uppercase yes):
Enter passphrase for /dev/vdc1:
Verify passphrase:
```
Use the `cryptsetup luksOpen`
command to map the encrypted partition to a logical device. For example, use `encryptedvdc1`
as the name. You will also need to enter the passphrase again:
```
sudo cryptsetup luksOpen /dev/vdc1 encryptedvdc1
Enter passphrase for /dev/vdc1:
```
The encrypted partition is now available at `/dev/mapper/encryptedvdc1`
.
Create an XFS filesystem on the encrypted partition:
`sudo mkfs.xfs /dev/mapper/encryptedvdc1`
Create a directory for mounting the encrypted partition:
`sudo mkdir /encrypted`
Use the `cryptsetup luksClose`
command to lock the partition:
`cryptsetup luksClose encryptedvdc1`
Install the Clevis packages using sudo:
`sudo yum install clevis clevis-luks clevis-dracut -y`
Modify /etc/crypttab to open the encrypted volume at boot time:
`sudo vim /etc/crypttab`
Add the following line:
`encryptedvdc1 /dev/vdc1 none _netdev`
Modify /etc/fstab to automatically mount the encrypted volume during a reboot or at boot time:
`sudo vim /etc/fstab`
Add the following line:
`/dev/mapper/encryptedvdc1 /encrypted xfs _netdev 1 2`
For this example, assume the Tang server's IP address is `192.168.1.20`
. You can also use the hostname or domain if you prefer.
Run the following `clevis`
command:
```
sudo clevis bind luks -d /dev/vdc1 tang '{"url":"http://192.168.1.20"}'
The advertisement contains the following signing keys:
rwA2BAITfYLuyNiIeYUMBzkhk7M
Do you wish to trust these keys? [ynYN] Y
Enter existing LUKS password:
```
Type **Y** to accept the keys for the Tang server and provide the existing LUKS password for the initial setup.
Enable clevis-luks-askpass.path via systemctl in order to prevent being prompted for the passphrase for non-root partitions.
`sudo systemctl enable clevis-luks-askpass.path`
The client is installed. Now, whenever you reboot the server, the encrypted disk should automatically be decrypted and mounted by retrieving the keys from the Tang server.
If the Tang server is unavailable for any reason, you'll need to provide the passphrase manually in order to decrypt and mount the partition.
## 1 Comment |
12,853 | 《代码英雄》第三季(3):创造 JavaScript | https://www.redhat.com/en/command-line-heroes/season-3/creating-javascript | 2020-11-24T10:10:56 | [
"代码英雄",
"JavaScript"
] | https://linux.cn/article-12853-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第三季(2):创造 JavaScript](https://www.redhat.com/en/command-line-heroes/season-3/creating-javascript)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/5f79465e-c5fc-4f18-a2cc-c053fe4947d1/CLH_S3E3_Creating_JavaScript_vFINAL_tc.mp3)脚本。
>
> 导语:一个在 WWW 初期就确立了它的发展方向的任务,在 10 天内完成,结果呢?它成了一种改变了一切的、不可或缺的语言。
>
>
> JavaScript 是战胜了一切困难的弱者。Clive Thompson 回顾了浏览器大战,以及这场战争对互联网未来的影响。Charles Severance 解释了 JavaScript 是如何从一个几近不太可能实现的任务变成默认的 Web 开发语言的。Michael Clayton 坦言,他和其他许多人一样,低估了 JavaScript。而 Klint Finley 则描述了一个没有它的阴暗的互联网。
>
>
>
**00:00:00 - Saron Yitbarek**:
嗨,大家好。我们回来了。我们很高兴能推出《代码英雄》第三季。我们要感谢你们中很多人在这个节目中讲述的故事,因为每一季都源于我们与开发人员、SIS 管理员、IT 架构师、工程师以及开源社区的人们讨论你最感兴趣的的主题和技术。现在,我们正在进一步开放这种方式。我们希望大家都能参与进来,帮助塑造《代码英雄》的未来。你可以通过我们的简短调查来做到这一点。你喜欢这个节目的什么地方?你还希望我们多谈论哪些内容?亲爱的听众,我们想进一步了解你。你是开发人员吗?你是在运维部门工作,还是在做一些与技术完全无关的工作?请访问 [commandlineheroes.com/survey](http://commandlineheroes.com/survey) ,以帮助我们提升第四季及以后的播客内容。现在,让我们进入第三季。
**00:01:00**:
Brendan Eich 34 岁时,在<ruby> 网景 <rt> Netscape </rt></ruby>公司总部任职。他正致力于一场为期 10 天的大规模编码冲刺。一种新的语言,一种全新的编程语言,将在在短短 10 天内诞生。那是在 1995 年,编程语言的世界即将永远改变。
**00:01:26**:
我是 Saron Yitbarek,这里是《代码英雄》,一个来自红帽的原创播客。整季节目中,我们都在探索编程语言的威力和前景,探索我们的语言是如何塑造开发世界的,以及它们是如何推动我们的工作的。 这一次,我们将追踪 JavaScript 的创建历程。也许你以前听过 Brendan Eich 的故事,但是像 JavaScript 这种计算机语言是如何真正创造出来的呢?其中肯定是来自 Brendan 的努力,但是这个故事还有更多的内容。
**00:02:02**:
我们的 JavaScript 故事始于一场战争,一场浏览器之战。20 世纪 90 年代的浏览器大战似乎已经成为历史,但它的影响无疑是巨大的。战场的一方,是与<ruby> 升阳微系统 <rt> Sun Microsystems </rt></ruby>结成了联盟的网景公司;另一方,你看到的是软件巨头,微软。他们争夺的战利品是什么?赌注已经大得不能再大了,因为这是一场决定谁将成为互联网看门人的对决。
**00:02:40**:
为了真正了解浏览器之战是如何进行的,我找来了我最喜欢的科技史学家之一,作家 Clive Thompson。他的最新著作是 ——
**00:02:50 - Clive Thompson**:
《<ruby> 编码者:新部落的形成和世界的重塑 <rt> Coders: The Making of a New Tribe and The Remaking of The World </rt></ruby>》。
**00:02:54 - Saron Yitbarek**:
Clive 和我谈论的是浏览器之战,让我来为你做个背景铺垫吧。你会看到网景公司意识到浏览器将会是人们用来上网的关键软件。还有微软,他们的整个商业模式就是将东西打包到 Windows 中。直到 20 世纪 90 年代,他们才真正对浏览器感兴趣,微软意识到也许他们一直在打瞌睡。世界正在向网上转移,而微软的 Windows 内没有任何东西可以帮助他们实现这一目标。但是有些人已经在这么做了,一家名为网景的公司,他们正在提供一个通往互联网的入口。突然之间,微软在整个行业的主导地位看起来并不是那么绝对了。浏览器之战始于那一刻,微软意识到了互联网的力量,并开始打量他们新竞争对手。好了,这就是我的铺垫。这里我和 Clive 讨论接下来发生的事情。
**00:04:03 - Clive Thompson**:
这场战争是抢夺谁将成为上网的主要入口。你需要意识到,在 20 世纪 90 年代初期,没有人真正的在线。当 Mosaic 浏览器出现并最终变成网景浏览器时,它们是第一款任何人都可以下载的并让人能够浏览 Web 的浏览器。它们于 1994 年 12 月上线。所以突然之间,成千上万的人能够以这种图形方式使用互联网。他们获得了巨量的下载和大量的新闻报道。基本上每个人都在说:“是的,网景是这种被称之为互联网的事物的未来。”
**00:04:40**:
所以在西雅图,你可以看到微软非常警惕地关注着这件事,因为他们几乎忽略了互联网。他们只专注于销售 Windows,而实际上并没有对这种被称为互联网的疯狂新事物给予任何关注。因此,他们不得不加入到一场急速追赶游戏当中。近一年后,他们才推出自己的浏览器。在 1995 年秋天,他们的浏览器问世了,这实质上是浏览器大战的开始,微软也正在努力成为人们上网的门户。
**00:05:13 - Saron Yitbarek**:
好吧,花费一年的时间才让浏览器面世听起来不算太糟,对吧?时间不算太长,对吧?这似乎是一个合理的时间。
**00:05:21 - Clive Thompson**:
是的,没错。这听起来好像不是很长时间,但那时是发展的是如此之快。而且人们有一种强烈的先发优势意识,那就是第一家能够以自己的品牌形象作为你上网的方式的公司将是多年甚至是永远的赢家。我还记得当时的开发速度有多快。我的意思是,网景公司每两三个月就会推出一款新的浏览器版本。他们会说,“哇。现在,我们已经将电子邮件集成到浏览器中了。现在,我们在顶部有了一个小小的搜索栏。” 它一直在变得越来越好。你可以在某种程度上看到,可以在网上做的所有事情都进入了视线,因为他们可以快速迭代并快速将其推出。
**00:06:01**:
微软习惯于非常缓慢的开发模式。可以是长达四年的开发过程,它是我们能买到的没有 bug 的版本,把它封盒,投放到商店去,然后四年都不发布新版本。现在网景出现了,它是第一家说,“不,我们将推出一款不怎么合格的产品,但它运行得足够好,我们将在三个月、三个月又三个月内推出一个新的版本供你下载。” 这完全破坏了微软的稳定的步骤。
**00:06:30 - Saron Yitbarek**:
好吧。如果我是微软,我可以看着它说,“哦,天哪。这就是未来。我需要迎头赶上。我需要与之竞争。” 或者我可以说,“啊,这只是一时流行而已。” 那么浏览器到底是什么呢?它让微软选择了第一个选项。它让微软说,“哦,天哪。这是个值得的东西。我要与之竞争。”
**00:06:51 - Clive Thompson**:
浏览器本身具有大量的文化传播和积淀作用。你在互联网上可以做的第一件事,一般是获得像文化之类的乐趣。你可以突然进入某个乐队的网页,查看他们的帖子和他们的照片。你可以培养你的爱好,找到佛罗里达州所有的人偶模型。在此之前,关于互联网的一切都看起来很呆板。电子邮件、文件传输、诸如此类。我的意思是,突然之间,浏览器使互联网看起来像一本杂志,像一个有趣的互动对象。报纸、CNN 和杂志前所未有的以这种非常激动人心的方式对此进行了报道。就在这一刻,科技相关的新闻被从《纽约时报》上排在后面的商业版块移动到了报纸的头版。
**00:07:41 - Saron Yitbarek**:
那么,对于开发人员而言,网景浏览器甚至说一般的浏览器能有什么吸引力呢?他们为什么如此着迷呢?
**00:07:48 - Clive Thompson**:
为此我拜访过很多开发人员。突然间,随着浏览器的出现,互联网出现了,有一个 Web 页面,上面写着:“下载我那酷酷的软件吧。” 因此,它开启了我们今天看到的软件打造的整个世界。
**00:08:04 - Saron Yitbarek**:
我在这里应该提一下,起初微软实际上提出要收购网景公司。他们出价很低,网景公司拒绝了他们。因此,微软不得不打造自己的浏览器,他们称自己的浏览器为<ruby> 探索者 <rt> Explorer </rt></ruby>(IE)。
**00:08:21 - Clive Thompson**:
微软花了一年的时间疯狂地开发浏览器,并于 1995 年秋天将其推出。他们做的事情与网景差不多。他们快速推出了一些东西,并不担心它是否完美,因为它会越来越好。但是,在 20 世纪 90 年代后半叶真正出现的一场战争是谁的浏览器最有趣、最具交互性、最功能复杂。
**00:08:53 - Saron Yitbarek**:
请记住,网景在这方面绝不是占了上风。
**00:08:57 - Clive Thompson**:
微软拥有非常强大的地位。当全球的 80% ~ 90% 的计算机都安装了 Windows 时,很容易就可以把软件设置为默认软件。而这正是他们所做的。所以你可以看到 Internet Explorer (IE)的不断崛起。
**00:09:16 - Saron Yitbarek**:
在某种程度上,可怜的老网景在这场战斗中一直处于劣势。但问题是,在战斗结束之前,他们做了一个<ruby> 孤注一掷 <rt> Hail Mary </rt></ruby>的选择,事实证明,这将成为整个编程世界的一个令人难以置信的成绩。
**00:09:35 - Clive Thompson**:
这就是 JavaScript 创建过程中迷人而怪异的故事。
**00:09:43 - Saron Yitbarek**:
所有围绕 Web 的热议,围绕浏览器生活的热议,都非常清楚地表明了一件事。我们需要一种新的编程语言,一种远远超出 HTML 的语言。我们需要一种为所有新的基于 Web 的开发量身定做的语言。我们想要一种不仅能在网上生存,而且在那里蓬勃发展的语言。
**00:10:10 - Clive Thompson**:
如何为浏览器创建编程语言呢?
**00:10:15 - Saron Yitbarek**:
我的朋友,这是一个价值数十亿美元的问题。在网景看到微软与他们竞争的时候,他们开始关注 Java™。Java 会成为 Web 开发的语言吗?Java 是一种丰富的编译语言。它表现得和 C++ 一样好。但它仍然需要编译。开发人员确实想要一些更轻量级的东西,一些可以解释执行而不是编译的东西,一些可以吸引所有涌入 Web 的非专业程序员的东西。毕竟,那些新的程序员想要直接在网页上工作。那是我们的梦想。
**00:11:05 - Saron Yitbarek**:
网景公司需要一种可以在浏览器内部运行的编程语言,让开发人员能够让这些静态网页动起来。他们想,如果他们能在发布 Netscape 2.0 测试版的同时,发布一种新的轻量级语言,为 Web 编程创造奇迹,那不是很棒吗?只是有一个问题,他们只有 10 天的时间来创造一门新的语言。实际上,只给了一个叫 Brendan Eich 的人 10 天的时间。他就是那个负责完成这件事的人。毫无疑问,如果有人能做到这一点,那就是他。在 Brendan 还是伊利诺伊大学的学生时,他常常为了好玩而创造新的语言,只是为了摆弄一下语法。
**00:11:57 - Charles Severance**:
Brendan Eich 的关键在于,在构建 JavaScript 时,Brendan Eich 已经是编程语言狂热分子了。
**00:12:05 - Saron Yitbarek**:
为了了解 Eich 到底取得了什么成果,我们联系了<ruby> 密歇根大学信息学院 <rt> University of Michigan School of Information </rt></ruby>的教授 Charles Severance。
**00:12:14 - Charles Severance**:
JavaScript 在某种程度上是在 Java 被视为未来的环境中创建的,在 1994 年,我们认为它(Java)将解决一切问题。一年后,那个真正能解决一切的东西即将出现,但它不能说,“嘿,我已经解决了一切”,因为每个人,包括我自己,就像都相信 1994、1995 年的我们已经看到了未来一样,这个未来就是 Java 编程语言。他们必须建立一种看似无关紧要、看似愚蠢、看似毫无意义,但却是正确的解决方案的语言。
**00:12:56 - Saron Yitbarek**:
但是 Eich 提供的可不仅仅是一种玩具语言。它以隐藏的方式进行了复杂处理,并从以前的语言中汲取了主要灵感。
**00:13:07 - Charles Severance**:
如果你看一下基本语法,很明显它的灵感来自于带有花括号和分号的 C 语言。一些字符串模式取自 Java 编程语言。但面向对象的底层模式取自名为 Modula-2 的编程语言,它有<ruby> 头等函数 <rt> first class functions </rt></ruby>的概念,对我来说,这确实是使 JavaScript 成为如此强大以及可扩展语言的最令人惊叹的选择之一,即函数、函数的主体、构成函数本身的代码也是数据。
**00:13:41**:
另一个真正的灵感来源于 HyperCard。JavaScript 总是在浏览器中运行,这意味着它有<ruby> 文档对象模型 <rt> Document Object Model </rt></ruby>(DOM)的基本数据上下文,文档对象模型是网页的面向对象表示。它不像传统的编程语言。JavaScript 代码不是从一开始就有的,最初它是一个网页,最终演变成了这种面向事件的编程。
**00:14:12 - Saron Yitbarek**:
1995 年 11 月 30 日,当 JavaScript 与网景的 Navigator 2.0 一起发布时,所有的魔力都被植入到一粒强大的语言小种子中。包括<ruby> 美国在线 <rt> America Online </rt></ruby>(AOL)和 AT&T(美国电话电报公司)在内的 28 家公司同意将其作为一种开放标准的语言使用。当它发布时,有一些老派的专业人士对 JavaScript 嗤之以鼻。他们认为这只是一种新手的语言。他们忽略了它革命性的潜力。
**00:14:46 - Charles Severance**:
这些超级先进的概念来自不太知名但又非常像高级面向对象的语言当中,Brendan 决定将所有这想概念融入其中。所以 JavaScript 就像一只特洛伊木马。它在某种程度上潜入了我们的集体意识,认为它很傻、像个玩笑、简单、轻巧。但是几乎从一开始它就建立了一个功能强大的、深思熟虑的编程语言,它几乎能做计算机科学中的任何事情。
**00:15:17 - Saron Yitbarek**:
其结果是成为了一种浏览器原生语言,可以随着我们在线生活的发展而不断进化。没过多久,JavaScript 就成为了事实上的 Web 开发选择。
**00:15:29 - Charles Severance**:
JavaScript 是一种不二之选的编程语言,我只能学习它,事实上学习 JavaScript 的人通常别无选择,因为他们会说,“我想构建一个浏览器应用程序,我想让它有交互元素。” 答案是你必须学习 JavaScript。如果你想象一下,比如说,你最喜欢的编程语言是什么,那么这个问题的答案几乎就是某某加上 JavaScript,对吧?有人可能会说,“我喜欢 Python 和 JavaScript ”,或者 “我喜欢 Scala 和 JavaScript”,因为它就像是每个人都需要学习的语言。
**00:16:05 - Saron Yitbarek**:
Charles Severance 是<ruby> 密歇根大学信息学院 <rt> University of Michigan School of Information </rt></ruby>的教授。他说,网景公司一开始非常强大,他们在浏览器之战中奋力拼搏,但最终……
**00:16:22 - Clive Thompson**:
网景浏览器作为一款严肃的产品就这样消失了。
**00:16:27 - Saron Yitbarek**:
微软在整个行业的主导地位是一股压倒性的力量。尽管在浏览器竞争上晚了一年,但他们还是能够力挽狂澜,赢得了今天的胜利。但你知道,网景公司最后一击,它创造的 JavaScript,是成功的,在战斗结束很久之后,这种从浏览器战争中诞生的语言瑰宝,将有一个改变一切的后世。
**00:17:01**:
如果你是最近才开始编程的,很可能会理所当然地认为,你可以开发可更改和更新的交互式 Web 页面,而无需从服务器拉取页面的全新副本。但是,想像一下,当这样做成为一种全新的选择时会是什么样子的。我们有请红帽公司的软件工程师 Michael Clayton 帮助我们了解那是一个多么巨大的转变。
**00:17:28 - Michael Clayton**:
我想说,在 2004 年 Google Mail 发布了。Gmail,据我所知,它是第一个真正将 JavaScript 带到更高水平的 Web 应用程序,它使用 JavaScript 来动态地切换你正在查看的内容。
**00:17:49 - Saron Yitbarek**:
假设你正在查看收件箱,然后单击了一封电子邮件。在过去,你的电子邮件查看器会在你的浏览器中加载一个全新的页面,仅仅是为了向你显示那封电子邮件。当你关闭该电子邮件时,它会重新加载整个收件箱。
**00:18:05 - Michael Clayton**:
这造成了很多延迟。当你在视图之间来回切换时要等待很多时间,Gmail 改变了这一切。他们使用 JavaScript 在后台获取你想要查看的内容,然后将其展现在你面前,而无需等待全新的页面视图。
**00:18:23 - Saron Yitbarek**:
这节省了大量的时间和精力。但是仔细想想,它改变的不仅仅是速度。它改变了我们工作的本质。
**00:18:35 - Michael Clayton**:
所以,Web 开发者作为一种职业,已经从类似幕后角色的服务端走到了离用户仅薄薄一层之隔的位置,因为他们直接在浏览器中编写代码,而用户也正是通过浏览器查看 Web 页面。
**00:18:52 - Saron Yitbarek**:
它改变了一切。事实上,你完全可以把引领 Web 2.0 革命的功劳都归功于 JavaScript。任何有 Web 浏览器的人都突然之间拥有了一个摆在他们面前的开发环境。但是,正如我之前提到的,老保守派对民主性并不一定感到舒服。
**00:19:16 - Michael Clayton**:
早期反对 JavaScript 的人当中,我也是其中的一员。我有个阻止 JavaScript 运行的浏览器扩展。我认为它是一种无用的玩具语言,每当我访问一个网页,该网页的某些关键功能需要 JavaScript 时,我都会感到愤怒。我想,“你应该在没有 JavaScript 的情况下以正确的方式构建你的网站。”
**00:19:43 - Saron Yitbarek**:
然而,很快,Brendan Eich 仅仅用 10 天创建的语言,它所蕴含的美和潜力对每个人来说都变得显而易见了。现在,它不仅征服了浏览器,也征服了服务器。有了 Node.js,这种小众语言的全新领域已经打开。
**00:20:03 - Michael Clayton**:
当我听说 JavaScript 打算在服务器上运行时,我想,“为什么会有人想这么做?”那时,我已经是一名专业的 JavaScript 开发人员了。我每天都写很多 JS,但我还是不太明白为什么它可以归属到服务器端,事实证明,像很多听众都知道的那样,Node.js 现在是这个行业的一支巨大的力量。我认为这是有充分理由的。
**00:20:32**:
Node.js 如此成功的原因之一,就是它拥有庞大的前端 JavaScript 开发人员和客户端开发人员社区。他们写代码,他们在用 JavaScript 为浏览器编写代码。这么多的开发者,现在又可以用同样的语言来为服务器端编程,这让他们立刻就拥有了大量的可以立即开始为服务器端做贡献的人员。这个工具已经在你的工具包中,你只需将其拿出来,安装上 Node.js,然后就可以加入到编码竞赛中去了。
**00:21:11 - Saron Yitbarek**:
先是在浏览器中,然后又在服务器上。JavaScript 是这种朴实无华、暗自芬芳,有时候也会有点古怪的编程语言。这个浏览器战争中的幸存者,被大家低估了。
**00:21:25 - Michael Clayton**:
JavaScript 算是编程语言中的灰姑娘故事,它始于基本上是在 10 天内拼凑起来的初态。中间经历了来自其他编程社区的许多嘲笑,然而仍以某种方式继续取得成功和增长。最后到现在稳居世界上最流行的编程语言中排名第一、第二的位置。JavaScript 基本上无处不在。在网页内部运行的能力意味着 JavaScript 和 Web 一样普及、非常普遍。
**00:22:08 - Saron Yitbarek**:
Michael Clayton 是红帽公司的工程师。JavaScript 吞噬了世界吗?它是否搭上了 Web 的顺风车,才成了一种主流语言?我想找出 JavaScript 的实际边界在哪里。
**00:22:25 - Klint Finley**:
嗨,我叫 Klint Finley。我是 Wired.com 网站的撰稿人。
**00:22:28 - Saron Yitbarek**:
Klint 对同样的事情也很好奇。他越是关注今天 JavaScript 的运行方式,就越发意识到它已经渗透到他的在线生活的每一个环节。
**00:22:40 - Klint Finley**:
在你还没来得及决定是否要让所有这些不同的应用程序在你的电脑上运行之前,JavaScript 已经成为一种可以增强整个应用程序能力的工具。它们就那么运行了,它们参与了广告或促进广告商使用的跟踪。所以,在你的浏览器中,有很多事情在无形中发生,你甚至可能根本不知道,也不希望发生。
**00:23:07 - Saron Yitbarek**:
因此,Klint 决定做一个小实验。
**00:23:10 - Klint Finley**:
我决定试着在没有 JavaScript 的情况下使用 Web 一段时间。我决定试一试,花一周时间禁用浏览器中的 JavaScript。
**00:23:21 - Saron Yitbarek**:
听起来很简单,但是放弃所有 JavaScript 产生了一些令人惊讶的效果。因为 JavaScript 已经变得如此之大,如此之全,这种以轻量级著称的语言现在实际上占用了大量的空间和能源。当 Klint 屏蔽了那种语言时才发现……
**00:23:39 - Klint Finley**:
总体而言,这在很多方面都是一种更好的 Web 体验,比如页面加载更快,页面更干净,我电脑的电池续航时间更长,并且我对电脑上发生的事情有了更多的控制感,因为没有这些奇怪的、看不见的随机程序在后台运行。
**00:24:02 - Saron Yitbarek**:
想象一下第一次过上没有弹出式广告的生活是多么幸福。
**00:24:07 - Klint Finley**:
很多东西很大程度上依赖于 JavaScript 来加载。所以网页变得简单多了,广告少了,干扰也少了。
**00:24:17 - Saron Yitbarek**:
不过,这种整洁的 Web 体验并不是全部。如果你拔掉 JavaScript 的插头,Web 的某些部分就完全不能工作了。
**00:24:26 - Klint Finley**:
很多内容都不能正常运行了。Gmail 把我重定向到了一个为旧手机设计的不同版本。Facebook 也一样,很多流畅的互动没有了,它变得更像是一系列的网页。因此,Netflix 无法正常工作。YouTube 无法正常运行。是的,任何非常依赖互动的东西都不能运行了。拿掉了 JavaScript,有好处也有坏处,最终我不得不做出抉择,有 JavaScript 总比什么都没有要好。
**00:25:05 - Saron Yitbarek**:
Klint Finley 是 Wired.com 的撰稿人。大多数人预测 JavaScript 只会继续主导移动和桌面应用程序开发。像基于浏览器的游戏、基于浏览器的艺术项目等等,它们的复杂程度正在飞涨。不断增长的 JavaScript 社区正在最大限度地利用这一潜力。
**00:25:34**:
值得回想一下,就在 1995 年,就在几十年前,Brendan Eich 坐在一个房间里,设计出一门新的语言。今天,这种语言渗透到我们所做的每一件事中。也许说一串新的代码会改变世界听起来有点陈词滥调,但它确实发生了。一位代码英雄将他对语言的所有热爱汇聚到 10 天的冲刺中,世界的 DNA 也将永远改变。
**00:26:10**:
我们可以为 Google Docs、YouTube 和 Netflix 而感谢 JavaScript。但是你知道,“能力越大,责任越大”,随着 JavaScript 的影响力在大量开源库的推动下不断增长,责任不再仅仅落在一个人身上了。一个更广泛的社区已经接过了责任。SlashData 最近估计 JavaScript 开发人员的数量为 970 万,在 GitHub 上,JavaScript 有比任何其他语言都多的 PR(<ruby> 拉取请求 <rt> Pull Requests </rt></ruby>)。 JavaScript 在全世界代码英雄们的力量加持下,正在走向美好未来。
**00:26:59**:
下一期的《代码英雄》,我们将遇到另外一种 Web 语言,我们将探索 Perl 是如何在一个广阔的新领域蓬勃发展的。
**00:28:04**:
最后,有听众在网上分享了我们上一季的 Hello World 那一期,在该期中我们也谈到了 Brendan Eich 和 JavaScript。在那一期,有嘉宾说,在那 10 天里,Brendan 可能没有睡过多少觉,如果有的话,也是很少。好吧,Brendan 在推特上回应说,他确实在那次冲刺过程中睡过觉。想要更多地了解这 10 天发生了什么,请查看 Devchat 对 Brendan 的采访播客。我们会在我们的节目记录里加个链接。我是 Saron Yitbarek。下期之前,编码不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-3/creating-javascript>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[gxlct008](https://github.com/gxlct008) 校对:[windgeek](https://github.com/windgeek), [FineFan](https://github.com/FineFan), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
A mission to set the course of the world wide web in its early days. 10 days to get it done. The result? An indispensable language that changed everything.
JavaScript was the underdog that won against all odds. Clive Thompson recounts the browser wars and how much the fallout influenced the future of the internet. Charles Severance explains how JavaScript went from a last-minute moonshot to the default web development language. Michael Clayton confesses he, like many others, underestimated JavaScript. And Klint Finley describes a gloomy internet without it.
**00:00** - *Saron Yitbarek*
Hi, everyone. We're back. We're excited to launch season three of Command Line Heroes. We have so many of you to thank for the stories featured on this show because each and every season begins with us talking to developers, SIS admins, IT architects, engineers, and folks in the open source community about the topics and technologies you're most interested in. Now, we're opening up this approach even more. We want all of you to weigh in and help shape the future of Command Line Heroes. You could do this by taking our short survey. What do you like about the show? What would you like us to talk about more? Dear listener, we want to know more about you. Are you a developer? Do you work in operations, or do you do something completely separate from the world of tech? Go to commandlineheroes.com/survey to help us level up the podcast for season four and beyond. Now, onto season three.
**01:00** - *Saron Yitbarek*
Brendan Eich was 34 years old when he sat down at his desk in the Netscape headquarters. He was committing himself to a massive 10-day sprint of coding. A new language, a whole new programming language in just 10 days. It was 1995 and the world of programming languages was about to change forever.
**01:26** - *Saron Yitbarek*
I am Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat. All season long, we're exploring the power and promise of programming languages, discovering how our language has shaped the world of development and how they supercharge our work. This time, we're tracking the creation of JavaScript. Maybe you've heard the story of Brendan Eich before, but how does something like JavaScript really get created? There was Brendan's sprint, sure. But there's so much more to the story.
**02:02** - *Saron Yitbarek*
Our JavaScript tale begins in the midst of a war, a browser war. The browser wars of the 1990s may seem like history, but they were hugely consequential. On one side of the battlefield, Netscape, which had formed an alliance with Sun Microsystems. On the other, you've got Microsoft, software behemoth. And what were the spoils they were fighting over? It was a battle to decide who would be the gatekeeper of the internet. The stakes could not be larger.
**02:40** - *Saron Yitbarek*
To really understand how the browser wars went down, I called up one of my favorite tech historians, author Clive Thompson. His most recent book-
**02:50** - *Clive Thompson*
Coders: The Making of a New Tribe and The Remaking of The World.
**02:54** - *Saron Yitbarek*
Clive and I got talking about the browser wars, but let me really set the scene for you. You've got Netscape realizing that the browser was this key piece of software that people were going to use to get online. And then you've got Microsoft, their whole business model was packaging stuff inside Windows. They hadn't really been interested in browsers until in the 1990s, Microsoft realized that maybe they'd been sleeping at the wheel. The world was moving online, and there was nothing inside of Microsoft Windows that would help them get there. But these guys over here, some company called Netscape, they're offering an on-ramp to the internet. All of a sudden, Microsoft's industry wide dominance doesn't look so absolute. The browser wars begin in that moment, the moment when Microsoft wakes up to the power of the internet and squints its eye at their new competition. So, that's my setup. Here's me and Clive hashing out what happened next.
**04:03** - *Clive Thompson*
The fight was over who was going to be the main portal to going online. You have to realize that in the early '90s, no one was really online very much. And when Mosaic came along and eventually turned into Netscape, they were the first browser that anyone could download that will let you look at the web. They went online in December of 1994. So, suddenly, you know thousands and millions of people are able to use the internet in this kind of graphical way. They're just getting massive, massive downloads and huge amounts of press. Everyone's basically saying, "Yeah, Netscape is kind of the future of this thing called the internet."
**04:40** - *Clive Thompson*
So over in Seattle, you've got Microsoft watching this with enormous alarm because they had pretty much ignored the internet. They were focused on selling Windows, and they had really not paid any attention to this crazy newfangled thing called the internet. So they had to play a very rapid game of catch up. They did not get their own browser out for almost a year later. In the fall of 1995, their browser came out, and that was essentially the beginning of the browser wars, the moment when Microsoft was trying to fight to be the portal by which people went online.
**05:13** - *Saron Yitbarek*
Okay. So a year to meet doesn't sound like too bad, right? That’s not too long. Right? That seems like a reasonable amount of time.
**05:21** - *Clive Thompson*
No, it's true. It doesn't sound like a long time, but things were moving so rapidly back then. And there was a strong sense of first mover advantage, that the first company that could sort of brand themselves as the way you get online would be the winner for years and years and maybe forever. I remember how rapid the pace of development was. I mean, Netscape was putting out a new browser every couple of months, right? They would be, "Wow. Now, we've got email integrated into the browser. Now, we've got a sort of a little search bar up top." It just kept on becoming better and better. You could sort of see you know all the things you could do online swimming into view as they've rapidly iterated and rapidly pushed things out.
**06:01** - *Clive Thompson*
Microsoft was accustomed to developing very slowly. Here's your four-year-long development process at the end. It's as bug-free as we can get it. Put it in a box, goes out to the stores, and we don't release a new version for four years. Netscape comes along, and it's the first company to say, "No, we're going to put out kind of a substandard product, but it works well enough, and we're going to have a new one for you to download in three months and three months and three months." This completely destabilized Microsoft.
**06:30** - *Saron Yitbarek*
Okay. So if I'm Microsoft, I can look at it and go, "Oh my goodness. This is the future. I need to catch up. I need to compete," or I can say, "Ah, it's a fad." So what is it about the browser that made Microsoft pick the first option? That made Microsoft go, "Oh my goodness. This is a real thing. I need to compete."
**06:51** - *Clive Thompson*
The thing with the browser was that it had a huge amount of cultural cache. It was the first thing you could do on the internet that was like culturally fun. You could go to suddenly a band's webpage and see posts by them and photos by them. You could go and research your hobby by finding all the model train people in Florida, right? So, everything about the internet before that had seemed nerdy. Email, file transfers, whatnot. I mean, suddenly the browser made the internet look like a magazine, like a fun thing to interact with. Newspapers and CNN and magazines were sort of writing about it in this very excited way for the first time. This was the moment that technology moved from being very deep inside the business section to being on page A1 of the New York Times.
**07:41** - *Saron Yitbarek*
So what was appealing about Netscape or even just the browser in general when it comes to developers? Why were they so into it?
**07:48** - *Clive Thompson*
I've met a lot of developers. Suddenly, the internet comes along with the browser, and you can just have a web page that says, "Just download my cool piece of software." So, it unlocked the entire world of the way that we see software being made today.
**08:04** - *Saron Yitbarek*
I should mention here that at first Microsoft actually offered to buy Netscape. Though they were offering a pretty tiny amount, but Netscape turned them down. So Microsoft had to build a browser of their own. They called theirs Explorer.
**08:21** - *Clive Thompson*
Microsoft spent a year frantically working on a browser, and they got it out in the fall of 1995. They did sort of the same thing that Netscape did. They produced something quickly without worrying if it was perfect and it got better and better. But what really emerged over the latter half of the '90s was a war over whose browser would be the most interesting, the most sort of interactive and sophisticated.
**08:53** - *Saron Yitbarek*
Keep in mind that Netscape by no means had the upper hand here.
**08:57** - *Clive Thompson*
Microsoft had a very powerful position. When you ship Windows on the order of 80 to 90% of all computers on the planet, it's pretty easy to make your software the default. And that's exactly what they did. So you see Explorer sort of rise and rise and rise.
**09:16** - *Saron Yitbarek*
In a way, poor old Netscape was always the underdog in that battle, but here's the thing. Before the battle was over, they threw a beautiful Hail Mary, and it turns out that would become an incredible score for the whole world of programming.
**09:35** - *Clive Thompson*
That is the fascinating and weird story of the creation of JavaScript.
**09:43** - *Saron Yitbarek*
All that heat around the web, around the potential of life in a browser had made one thing very clear. We needed a new programming language, something that went far beyond HTML. We needed a language tailor made for all that new web-based development. We wanted a language that didn't just survive online but thrived there.
**10:10** - *Clive Thompson*
How do you create a programming language for the browser?
**10:15** - *Saron Yitbarek*
That, my friend, was the billion dollar question. So around the time Netscape saw that Microsoft was competing with them, they took a look at Java™. Was Java going to be the language for web development? Java was this rich compiled language. It performed just as well as C++. But it did still need to be compiled. Developers really wanted something more lightweight, something that could be interpreted instead of compiled, something that would appeal to all those non-professional programmers that were swarming to the web. Those new programmers wanted to work directly on the webpage after all. That was the dream.
**11:05** - *Saron Yitbarek*
Netscape needed a programming language that would run inside their browser, something that would allow developers to bring those static webpages to life. Wouldn't it be great, they thought, if they could release a new lightweight language that worked wonders for web programming, at the same time that they released Netscape 2.0 in beta. There was only one hitch. That gave them exactly 10 days to create a new language. Actually, it gave one guy, Brendan Eich, 10 days. He was the one tasked with pulling this off. There was no doubt that if anybody could do it, this guy could. When Brendan was a student at the University of Illinois, he used to create new languages for fun, just to play around with syntax.
**11:57** - *Charles Severance*
The key to Brendan Eich is that Brendan Eich, when he built JavaScript, had become sort of a language junkie.
**12:05** - *Saron Yitbarek*
To understand what Eich actually pulled off, we reached out to Charles Severance, a professor at the University of Michigan’s School of Information.
**12:14** - *Charles Severance*
JavaScript was sort of created in an environment where Java was seen as the future, and so in 1994, we thought that it was the thing that was going to solve everything. One year later, the thing that would actually solve everything was about to appear, but it couldn't say, "Hey, I've solved everything," because everybody, myself included, believed in '94, '95 that we had seen the future of rock and roll, and it was the Java programming language. They had to build a language that seemed irrelevant, seemed silly, seemed meaningless, and yet was the right solution.
**12:56** - *Saron Yitbarek*
What Eich delivered was not just a toy language though. It was sophisticated in hidden ways, drawing on major inspirations from languages that had come before.
**13:07** - *Charles Severance*
If you look at the basic syntax, it's very clear that it’s inspired by the C language with its curly braces and semicolons. Some of the string patterns were taken from the Java programming language, but the object oriented underlying patterns taken from a programming language called Modula-2, which had this notion of first class functions, which, to me, is really one of the most amazing choices that made JavaScript such a powerful and extensible language, and that is the function, the body of the function, the code that makes up a function itself is also data.
**13:41** - *Charles Severance*
The other thing that really was a part of the inspiration was HyperCard. JavaScript was always running in a browser, which meant it had a basic data context of the document object model, which is an object-oriented representation of a webpage. It is not like a traditional programming language. The JavaScript code didn't start at the beginning. The first thing that it was was a webpage, and so it ended up with this event-oriented programming.
**14:12** - *Saron Yitbarek*
When JavaScript was released along with Netscape Navigator 2.0 on November 30th, 1995, all that magic was housed into a powerful little seed of a language. 28 companies, including America Online and AT&T, agreed to use it as an open standard language. When it was released, there were some old pros looking down their noses at JavaScript. They thought it was just a language for newbies. They missed its revolutionary potential.
**14:46** - *Charles Severance*
Brendan decided he would sneak in all these super advanced concepts from languages that are not well known that were very like advanced object-oriented languages. So JavaScript is almost like a Trojan horse. It sort of sneaked into our collective consciousness with the idea that it was silly, and fun, and easy and lightweight. But then built in from almost the very beginning was a powerful, deeply thought, well thought-out programming language that's capable of doing literally almost anything in computer science.
**15:17** - *Saron Yitbarek*
The result was a language native to the browser that could evolve as our online lives evolved. It didn't take long before JavaScript became the de facto web development option.
**15:29** - *Charles Severance*
JavaScript was a language that I had no choice but to learn, and literally people that learn JavaScript usually have no choice because they're like, "I want to build a browser application, and I want it to have interactive elements." The answer is therefore you must learn JavaScript. If you imagine, like, what is your favorite language, the answer to that question is almost got to be x plus JavaScript, right? Someone might say, "I like Python and JavaScript," or, "I like Scala and JavaScript," because it's like the one language everyone is required to learn.
**16:05** - *Saron Yitbarek*
Charles Severance is a professor at the University of Michigan School of Information. Netscape had been incredibly strong coming out of the gate, and they fought hard during the browser war, but in the end ...
**16:22** - *Clive Thompson*
Netscape just disappears as a serious product.
**16:27** - *Saron Yitbarek*
Microsoft's industry-wide domination was an overwhelming force. Despite being a year late to the browser game, they were able to pull themselves back on top and win the day. But you know, Netscape's Hail Mary, its creation of JavaScript, was a success because long after the fight was over, this gem of a language that came out of their browser war, it would have an afterlife that changed everything.
**17:01** - *Saron Yitbarek*
If you started coding more recently, you might take for granted that you can develop interactive web pages that change and update without pulling a whole new copy of the page from the server. But imagine for a sec what it was like when doing that became a brand new option. We asked Michael Clayton, a Software Engineer at Red Hat, to help us understand what a huge shift that was.
**17:28** - *Michael Clayton*
In, I want to say 2004, Google Mail was released, Gmail, and it was, to my knowledge, the first web application that really took JavaScript to the next level, that used it to dynamically switch content out that you were looking at.
**17:49** - *Saron Yitbarek*
Say you're looking at your inbox, and you click on an email. In the old days, your email viewer would load a whole new page in your browser just to show you that email. Then you close that email and it would reload the whole inbox.
**18:05** - *Michael Clayton*
It created a lot of latency. There was a lot of waiting when you would switch back and forth between views, Gmail changed all that. They used JavaScript to in the background fetch the content that you wanted to view, and just put it in front of you without you having to wait for a brand new page view.
**18:23** - *Saron Yitbarek*
That saved a ton of time and energy. But really think about it, it changed more than just the speed. It changed the very nature of our work.
**18:35** - *Michael Clayton*
So web developer as a job title has gone from being a server-side, kind of behind the scenes role, to being just a very thin layer away from the user since they're writing code directly in the browser that the user is viewing the webpage through.
**18:52** - *Saron Yitbarek*
It changed everything. In fact, you can pretty much credit JavaScript with ushering in the web 2.0 revolution. Anybody with a web browser suddenly had a development environment right in front of them. But, as I mentioned before, the old guard didn't necessarily feel comfortable with how democratic things were getting.
**19:16** - *Michael Clayton*
That early antagonism of JavaScript, I was part of that myself. I had the browser extensions that would prevent JavaScript from running. I thought it was a useless toy language, and I kind of had this feeling of anger whenever I went to a webpage that had JavaScript required for some critical feature of the site. I was like, "You should build your website the right way without JavaScript."
**19:43** - *Saron Yitbarek*
Soon enough, though, the beauty and the potential inherent in Brendan Eich's 10-day language became obvious to everyone. And now, it's conquering not just the browser but the server, too. With Node.js, a whole new territory for that little-language-that-could has opened up.
**20:03** - *Michael Clayton*
When I heard that JavaScript was going to be run on servers, I thought, “Why would anyone want to do that?” At that point, I was already a JavaScript developer professionally. I wrote a lot of JS every day, and I still didn't quite see why it belonged on servers, and it's turned out, as many listeners will know, Node.js is a huge force in the industry now. I think there's good reason for that.
**20:32** - *Michael Clayton*
One of the things that Node.js taps into that's made it so successful is the huge community of front-end JavaScript developers, client-side developers. They write code. They write JavaScript for the browser. There are a lot of those developers out there, and by making the same programming language available for writing servers, they just immediately have a huge population of people who can start contributing to servers. The tool is already in your toolkit, and you can simply pull it out, install Node.js, and you're off to the races.
**21:11** - *Saron Yitbarek*
So first in the browser and then on servers. JavaScript was this unpretentious, secretly elegant, sometimes buggy, language. A survivor from the browser war that everybody underestimated.
**21:25** - *Michael Clayton*
JavaScript has been kind of a Cinderella story of programming languages, starting in that early state of being essentially whipped together in 10 days, going through a lot of derision from the rest of the programming community, and still somehow continuing to find success and growth and then coming to the point we're at now where JavaScript is either first or second place in the most popular programming languages in the world. JavaScript is essentially everywhere. The ability to run inside of a webpage meant that JavaScript was as pervasive as the web is, which is quite pervasive.
**22:08** - *Saron Yitbarek*
Michael Clayton is an Engineer at Red Hat. Did JavaScript eat the world? Did it ride on the coattails of the web to a kind of language domination? I wanted to find out where the edges of JavaScript actually are.
**22:25** - *Klint Finley*
Hi, my name is Klint Finley. I'm a writer for Wired.com.
**22:28** - *Saron Yitbarek*
Klint was curious about the same thing. And the more he looked at the way JavaScript runs today, the more he realized it's got its fingers in every part of his online life.
**22:40** - *Klint Finley*
JavaScript has become something that can empower entire applications before you even have a chance to decide whether you want all of these different applications to run on your computer. They just start running, and some of them are, they're involved with advertising or facilitating the tracking that advertisers use. So, there's a lot of things happening invisibly in your browser that you might not really even know about or want to have happened.
**23:07** - *Saron Yitbarek*
So Klint decided to run a little experiment.
**23:10** - *Klint Finley*
I decided to try just using the web without JavaScript for a while. I decided to give it a shot and spent a week with JavaScript disabled in my browser.
**23:21** - *Saron Yitbarek*
Sounds simple enough, but forgoing all JavaScript had some surprising effects. Because JavaScript has become so big, so all-consuming, the language famous for being lightweight actually takes up a lot of space and energy now. When Klint blocked that one language ...
**23:39** - *Klint Finley*
In general, it was just a much better web experience in a lot of ways in terms of pages loading quicker, pages being cleaner, the battery life on my computer lasting longer, and just having a more of a sense of control over what was happening on my computer because there's not all of these just weird invisible random programs running in the background.
**24:02** - *Saron Yitbarek*
And just imagine the bliss of living without pop-up ads for the first time.
**24:07** - *Klint Finley*
So much of it depends on JavaScript to even load. So webpages came out a lot simpler, fewer ads, fewer distractions.
**24:17** - *Saron Yitbarek*
That clutter-free web experience isn't the whole picture though. Parts of the web can't function at all if you unplug JavaScript.
**24:26** - *Klint Finley*
A lot of things just didn't work. Gmail redirected me I think to a different version that's designed for old mobile phones. Facebook did sort of the same thing where a lot of the smooth interactions weren't there. It became more like a series of webpages. So Netflix didn't work. YouTube didn't work. Yeah, anything that's really heavily based on interactivity just didn't work. Ultimately taking JavaScript away, there was good and bad, and I had to decide that it's better to have JavaScript than to not have it at all.
**25:05** - *Saron Yitbarek*
Klint Finley is a staff writer for Wired.com. Most predict that JavaScript will only continue to dominate mobile and desktop app development. The level of complexity possible for things like browser-based games, browser-based art projects, etc., is shooting through the roof. And the ever-growing JavaScript community is making the most of that potential.
**25:34** - *Saron Yitbarek*
It's worth taking a step back and remembering here, in 1995, just a couple of decades ago, Brendan Eich was sitting in a room, hammering out a new language. And today, that language permeates everything we do. It might sound a bit cliché to say that some new string of code is going to change the world, but it does happen. A command line hero marshalls all their love for languages into a 10-day sprint, and the world's DNA is changed forever.
**26:10** - *Saron Yitbarek*
We can thank JavaScript for Google Docs, for YouTube, for Netflix. But you know, “with great power, comes great responsibility,” and as JavaScript's influence continues to grow, pushed along by a huge number of open source libraries, that responsibility doesn't just lie with one person anymore. A broader community has taken the reins. SlashData recently estimated the number of JavaScript developers at 9.7 million, and over at GitHub, JavaScript has more pull requests than any other language. Power lies with the whole world of Command Line Heroes helping JavaScript grow as we develop our tomorrow.
**26:59** - *Saron Yitbarek*
Next time, Command Line Heroes gets caught in a web of languages, and we'll explore how Perl came to thrive in a wild new frontier.
**28:04** - *Saron Yitbarek*
Finally, a listener shared our Hello World episode from last season where we also spoke about Brendan Eich and JavaScript. In that one, a guest said that during those 10 days, Brendan probably didn't get much, if any, sleep. Well, Brendan responded on Twitter to say he did indeed get sleep during that sprint. To learn even more about what happened during those 10 days, check out the Devchat podcast interview with Brendan. We'll throw a link in our show notes. I'm Saron Yitbarek. Until next time, keep on coding.
### Keep going
### JavaScript's surprising rise from the ashes of the browser wars
A single Netscape employee wrote JavaScript in 10 days. It's now one of the most pervasive programming languages in the world.
### The browser wars and the birth of JavaScript
Born of the browser wars of the 1990s, JavaScript has gone from a simple scripting language to be the most important ecosystem of the development world. Learn how and why JavaScript came to power.
### Enjoy this episode's artwork on your device
Download the Command Line Heroes artwork and set it as your background. |
12,854 | 如何在 VirtualBox 中安装 Fedora | https://itsfoss.com/install-fedora-in-virtualbox/ | 2020-11-24T11:35:00 | [
"VirtualBox"
] | https://linux.cn/article-12854-1.html | 如果你对 Fedora Linux 感兴趣,这有几种方式可以尝试它。
最简单还不影响你操作系统的方式是 [制作 Fedora 的 USB 临场启动盘](https://itsfoss.com/create-fedora-live-usb-ubuntu/)。
>
> **LCTT 译注**:
>
>
> 在 Linux 发行版的使用方式上,有一种可以无需安装而通过光盘或 USB 存储棒直接在计算机上启动完整的 Linux 操作系统的方式,这种方式称之为 “Live” 方式,如 Live CD、Live USB。
>
>
> 通常,Live 一词并不翻译,不过,我认为,除了英文缩写和部分历史原因造成直接使用的英文单词,大部分场景都应该使用本地化的语言来描述,否则,中英文混杂的港台式中文,实在有些不伦不类;抑或,外文翻译本身就不存在意义了。
>
>
> 因此,对于 “Live” 一词如何翻译,我们也颇费心思。这个词,在维基百科中文中,被翻译为“[自生系统](https://zh.wikipedia.org/wiki/Live_CD)”,在某些场景下偶见 “现场”、“临场” 等翻译。考虑到 Live CD/USB 的特性,我认为翻译为 “临场” 比较好。
>
>
> 于此抛出愚见,希望得到大家的积极反馈。wxy@LCTT
>
>
>
另一种方式是安装 VirtualBox 利用虚拟化技术来尝试 Fedora。这样,你可以在你的操作系统上像使用应用程序一样使用 Fedora。
通过这种方式,你可以执行更彻底的测试,而不会搞乱当前的操作系统。
你甚至可以复制你的虚拟环境,并在其他系统上重新安装它。听起来方便吗?让我来教你怎么做。
### 在 VirtualBox 上安装 Fedora

让我们分步在 Oracle VirtualBox 上安装 Fedora。
#### 步骤一:安装 VirtualBox
如果你的系统还没有安装 VirtualBox,你可以从官方网站下载。你可以找到 Windows、MacOs 和 Linux 的说明。 [Ubuntu 用户可以参考这个关于安装 VirtualBox 的详细教程。](https://itsfoss.com/install-virtualbox-ubuntu/)

* [下载 VirtualBox](https://www.virtualbox.org/)
#### 步骤二: 下载 Fedora ISO
如果你不熟悉 Fedora,那么这些镜像你需要知道。
[Fedora IoT](https://getfedora.org/en/iot/) 是用于可扩展基础设施的,[Fedora workstation](https://getfedora.org/en/workstation/) 是一个带有一组面向普通 GNOME 桌面环境中的桌面工具的镜像。[Fedora server](https://getfedora.org/en/server/) 顾名思义,是为服务器或数据中心定制的。
如果 GNOME 不是你的首选,你可以下载一个带有替代桌面环境的[定制版](https://spins.fedoraproject.org/) Fedora 桌面。对于本教程,我选择了带有 GNOME 桌面环境的[Fedora 33](https://itsfoss.com/fedora-33/)。
* [下载 Fedora](https://getfedora.org/)
#### 步骤三: 创建一个空虚拟机并对其进行配置
要成功安装和运行 Fedora,至少需要 20GB 磁盘空间和 2GB RAM。不过,为了获得更流畅的用户体验,建议增加一倍。在此基础上,我将创建并配置虚拟机。
开启 Virtual Box 点击 “New”。

需要注意,最重要的选项是 **将类型设置为 Linux ,版本设置为 Fedora (64-bit)**。如果你在名称提示符处开始输入 “Fedora”,VirtualBox 将自动为你选择正确的设置。虽然名字不一定非得是 Fedora,它可以是任何你喜欢的。
\*如果你只能访问 32 位版本,那么你需要在 BIOS 上启用虚拟化技术,如果你有一个 AMD CPU,它被称为 SVM。最坏的情况是你的 CPU 不支持虚拟化技术。如果你不确定,先检查这个。
如果你的设置和我类似,点击 “create” 按钮。

如前所述,至少需要 20GB 的磁盘空间才能安装 Fedora。我的系统上有 32GB 的内存,所以我分配了 8GB 内存。3 GB 的内存应该也没问题。
顺便说下内存的使用,只有在运行虚拟机时,虚拟机才会使用内存。否则,它将可用于常规使用。
确保其余设置与示例匹配,并点击 “Create” 按钮。

在你点击虚拟机的 Start 按钮之前,你需要加载如下所示的 ISO [光驱]。

因为你的虚拟硬盘是空的,虚拟机将从这个 ISO 启动。可以把它看作是使用临场 USB 或磁盘安装 Linux。

然后,如果你有一个多核 CPU,建议为虚拟机分配 2 个或更多的核。你可以在 “System” 选项卡下找到 CPU 核心。配置系统时,单击 “OK” 并启动虚拟机。

配置好所有内容后,单击 “Start” 按钮开始安装。
#### 步骤四:在 VirtualBox 中安装 Fedora。
如果你正确地遵循了这个过程,那么当你启动虚拟机时,你将直接从 ISO 文件启动。当你看到类似下面的屏幕时,选择 “Start Fedora”,并按回车键。

要启动安装对话框,单击 “Install To Hard Drive”。

在你继续安装之前,有必要定义你的键盘布局、你的时区以及最终安装操作系统的位置。

分区过程很简单。你像前面的 VDI 那样划分一些空闲空间。它应该被自动识别。
选择你的磁盘并将存储配置设置为 “Automatic”。单击 “Done” 进入上一个对话框。

一旦你配置完了上面的,点击 “Begin Installation”。

现在只需等待 5 - 6 分钟即可完成安装。安装完成后,点击 “Finish installation” 按钮。
最后一步,需要关闭系统的电源。如果你不熟悉 GNOME 桌面环境,你可以如下这样做。

你必须手动卸载在初始步骤中加载的 ISO 文件。

下一次使用 Fedora 启动虚拟机时,系统将提示你为 Fedora Linux 创建用户帐户并设置密码。
### 使用 VirtualBox Guest Additions 的附加功能,如剪贴板共享,文件夹共享等
[Guest Additions](https://www.virtualbox.org/manual/ch04.html) 设计为在<ruby> 访客 <rt> guest </rt></ruby>操作系统安装后安装在虚拟机中。它们包含对客户操作系统进行优化的设备驱动程序和系统应用程序,以获得更好的性能和可用性。
Guest Additions ISO 文件被安装为虚拟 CD-ROM 以便安装。
这是一个简单的过程。只需单击设备选项卡,然后单击 “Insert Guest Additions CD image”。

当提示单击 “Download” 时,系统将弹出下载 Guest Additions 镜像界面。

#### 共享剪贴板
有时候,你需要在虚拟机和<ruby> 宿主机 <rt> host </rt></ruby>操作系统之间移动一些内容。共享剪贴板/拖放支持将允许你在一个平台上复制项目,并将它们粘贴到另一个平台上。
要启用此功能,请在 VirtualBox 主页上选择 “Settings”,并按照下面的说明操作。“Bidirectional” 的选项是最方便的。

#### 共享文件夹
有两种类型的分享:
* 永久共享,与虚拟机设置一起保存。
* 暂时共享,当虚拟机关闭时就会消失。可以使用 VirtualBox 管理器中的复选框创建暂时共享。
在本教程中,我将创建一个永久共享文件夹。在 VM 设置中添加你想要共享的宿主机系统文件夹,并选择你想要在 VM 中出现的名称。

下次启动虚拟机时,该文件夹应该显示为网络驱动器。

#### 更好的视频支持
虽然 Oracle VirtualBox 提供了具有基本功能的虚拟显卡,但访客系统添加的自定义视频驱动程序为你提供了超高和非标准的视频模式,以及视频加速。
使用 Guest Additions,操作系统的分辨率将随着你调整计算机上的 VirtualBox 窗口而动态调整大小。
最后,Guest Additions 可以利用你的计算机的显卡。如果你是一名游戏玩家或在 WM 中使用高效软件,这就会产生巨大的改变。
#### USB 和网络设备共享
有了 VirtualBox,用户就可以使用一个功能齐全的操作系统,而不必在不同的硬件上进行设置。然而,在宿主机和访客机器之间共享 USB 和网络设备并不像想的那样简单。
要访问 USB 设备,你将需要安装 [VirtualBox 扩展包](https://download.virtualbox.org/virtualbox/6.1.16/Oracle_VM_VirtualBox_Extension_Pack-6.1.16.vbox-extpack)。

**下面这些仅对 Linux**,因为我使用的是 Linux。
为了使 VirtualBox 能够访问 USB 子系统,运行 VirtualBox 的用户(在宿主机系统上)必须属于 `vboxuser` 组。为此,打开一个终端并发出以下命令:
```
sudo usermod -aG vboxusers 'your username'
```
运行该命令后,你应该注销并重新登录,或者重新启动主机。
在这一步,插入你的 U 盘,通过你的 VM 设置,你应该能够找到并添加介质,如例子中所示。

当你下次启动虚拟机,你的 USB 将是可访问的。

### 额外提示:保存并导出虚拟机,以便以后可以在任何系统上使用它
你可能想在另一台计算机上使用虚拟机,或者是时候构建一台新机器了,并且你需要保持虚拟机的原样。只需几个简单的步骤,就可以轻松地导出当前设置并将其导入到另一台机器。
在 VirtualBox 主面板上,单击 “file”、“Export Appliance”。如果你喜欢键盘快捷键,你可以简单地点击 `Ctrl+E`。

选择要导出的虚拟机,然后单击 “Next”。

“Format” 选项需要注意一下。有三种不同的选项:<ruby> 开放虚拟化格式 <rt> Open Virtualization Format </rt></ruby> 0.9、1.0 和 2.0 ,可以是 ovf 或 ova 扩展名。
使用 ovf 扩展名,会分别写入几个文件,而 ova 扩展名则将所有文件合并到一个开放虚拟化格式归档文件中。
默认格式 OVF 1.0 应该没问题。

要完成该过程,单击 “Next”,然后在下一个对话框中单击 “Export”。
### 总结
通过使用虚拟机,你不仅可以测试操作系统,还可以部署与物理机器同等重要的功能完整的系统。如今,硬件已经变得如此强大和廉价,它的大部分功能都没有被利用。
通过虚拟化技术,你可以使用这些浪费的资源。对物理机器的需求减少了,因此能源消耗也减少了。你可以从硬件和降低运行成本两方面省钱。
在大规模服务环境中,服务器虚拟化更多的是一种基本需求,而不是一种高级概念。
我希望本教程对你在 VirtualBox 中安装 Fedora Linux 有帮助。如果你遇到任何问题,请在评论中告诉我。
---
via: <https://itsfoss.com/install-fedora-in-virtualbox/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[frogOAO](https://github.com/frogOAO) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you are curious about Fedora Linux, there are several ways to try it. You could [install Fedora Linux alongside Windows](https://itsfoss.com/dual-boot-fedora-windows/) but that’s a bit of an effort. An easier way that won’t affect your current operating system is to [create a live USB of Fedora.](https://itsfoss.com/create-fedora-live-usb-ubuntu/)
An alternative way to try Fedora, is to get advantage of virtualization technology through an installation in VirtualBox. This way, you use Fedora like an application on your current operating system.
This way, you can perform more thorough testing without messing up your current operating system.
You can even copy your virtual setup and re-install it on some other system. Sounds handy? Let me show you how to do it.
## Installing Fedora in VirtualBox

Let’s see the steps for installing Fedora Linux in Oracle VirtualBox.
### Step 1: Install VirtualBox
If you haven’t already installed VirtualBox on your system, you can download it from the official website. You can find instructions for Windows, Mac OS and Linux. [Ubuntu users can refer to this detailed tutorial on installing VirtualBox](https://itsfoss.com/install-virtualbox-ubuntu/).


**Step 2: Download the Fedora ISO**
If you are not familiar with fedora, there are a few images to be aware of.
[Fedora IoT](https://getfedora.org/en/iot/?ref=itsfoss.com) is to be used for scalable infrastructure, [Fedora workstation](https://getfedora.org/en/workstation/?ref=itsfoss.com) is an image with a set of tools oriented for a desktop in a vanilla GNOME desktop environment and [Fedora server](https://getfedora.org/en/server/?ref=itsfoss.com) as its name reveals, is tailored for a server or data center.
If GNOME isn’t your first choice, you can download a [spin](https://spins.fedoraproject.org/?ref=itsfoss.com) of Fedora desktop with an alternative desktop environment. For this tutorial, I chose [Fedora 33](https://itsfoss.com/fedora-33/) with the GNOME desktop environment.
### Step 3: Create an empty virtual machine and configure it
Fedora requires a minimum of 20GB disk space & 2GB RAM, to install and run successfully. Although double those amounts is recommended for a smoother user experience. Based on that I will create and configure the virtual machine.
Start Virtual Box and click on New.
The most important option to pay attention, is the **type to be set to Linux and the version to Fedora (64-bit)**. If you start typing Fedora at the name prompt, VirtualBox will automatically pick the correct settings for you. Although the name doesn’t have to be Fedora, it can be anything you like.
*If you have access to 32-bit version only, you need to enable virtualization technology on BIOS, if you have an AMD CPU it is called SVM. Worst-case scenario is that your CPU doesn’t support virtualization technology. If you are not sure, check this first.*
Once you have similar settings with me, click on the create button.
As mentioned before, you need at least 20 GB of disk space to be able to install Fedora. I have 32 GB of RAM on my system so I assigned 8 GB here. You should be fine with 3 GB of RAM.
A word about RAM consumption, the RAM will only be consumed by the virtual machine when you are running it. Otherwise, it will be available for regular usage.
Make sure that the rest of the settings match the example and click Create.
Before you click the start button of your virtual machine, you need to load the ISO as shown below [Optical Drive].
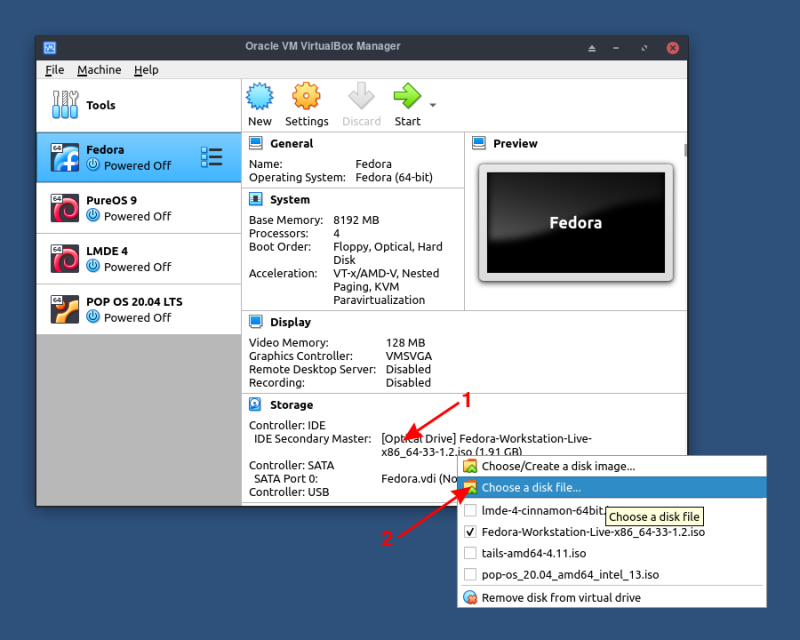
As your virtual hard drive is empty, the virtual machine will boot from this ISO. Think of it as using a live USB or disk for installing Linux.
Then, if you have a multi-core CPU it is recommended to assign 2 or more cores for your virtual machine. You may find the CPU cores under the system tab. When you configure your system click ok and start the virtual machine.
Once you have configured everything, click on the start button to begin the installation.
### Step 4: Install Fedora in VirtualBox
If you have followed the process correctly, when you start the virtual machine you will boot directly from the ISO file. When you see a similar to below screen select Start Fedora, and press the enter key.
To start the installation dialog box, click on Install to Hard Drive.
Before you proceed to the installation, it is essential to define your keyboard layout, your timezone and finally where the operating system will be installed.
The partitioning process is straight forward. You made some free space as VDI earlier. It should be automatically recognized.
Select your disk and set the storage configuration to automatic. Click on Done to go to the previous dialog box.
Once you have configured the above, click on “Begin Installation”.
Now you just need to wait for five-six minutes for installation completion. Click on the “Finish installation” button when installation is finished.
As a last step, you need to power off your system. If you are unfamiliar with the GNOME desktop environment you can do it like so.
You have to manually unload the ISO file that you loaded at the initial steps.
The next time you start the virtual machine with Fedora, you will be prompted to create a user account and set your password for Fedora Linux.
## Use VirtualBox guest additions for additional features like clipboard sharing, folder sharing and more
[Guest Additions](https://www.virtualbox.org/manual/ch04.html?ref=itsfoss.com) are designed to be installed inside a virtual machine post installation of the guest operating system. They contain device drivers and system applications that optimize the guest operating system for better performance and usability.
The Guest Additions ISO file is mounted as a virtual CD-ROM in order to be installed.
This is a straightforward process. Simply click on the devices tab and then click on “Insert Guest Additions CD image”
You will be prompted to download the guest additions image, when prompt click on Download.
**Shared clipboard**
At some point you’ll need to move some content between your virtual machine and the host operating system. The shared clipboard/drag and drop support will allow you to copy items on one platform and paste them on the other.
To enable this feature, choose **Settings** on the VirtualBox home page and follow the instructions as below. I find the **Bidirectional** option the most convenient.
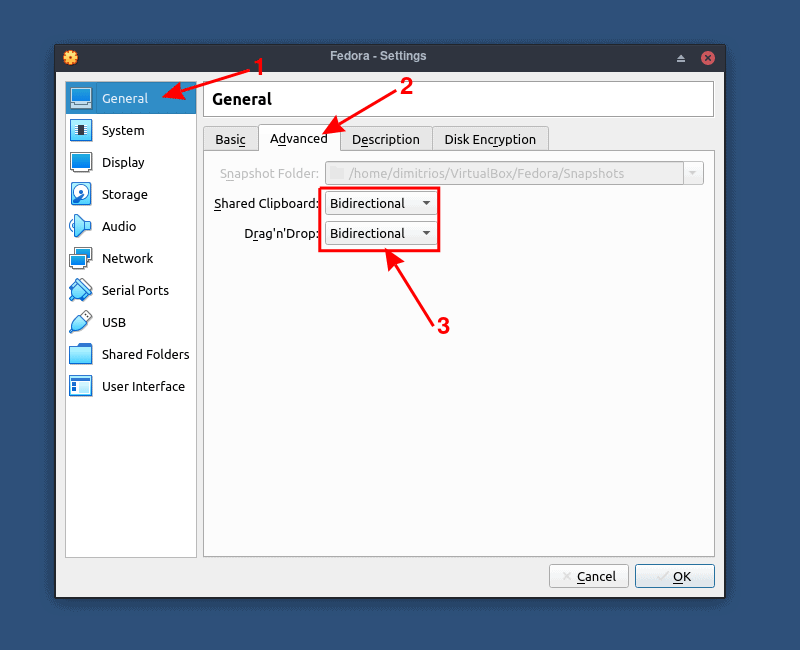
**Shared folders**
There are two types of shares:
- Permanent shares, that are saved with the Virtual Machine settings.
- Transient shares, that are disappear when the Virtual Machine is powered off. These can be created using a checkbox in the VirtualBox Manager.
In this tutorial, I will make a permanent shared folder. In the VM settings add the host system folder you want to share and choose the name that you want to appear at your VM.
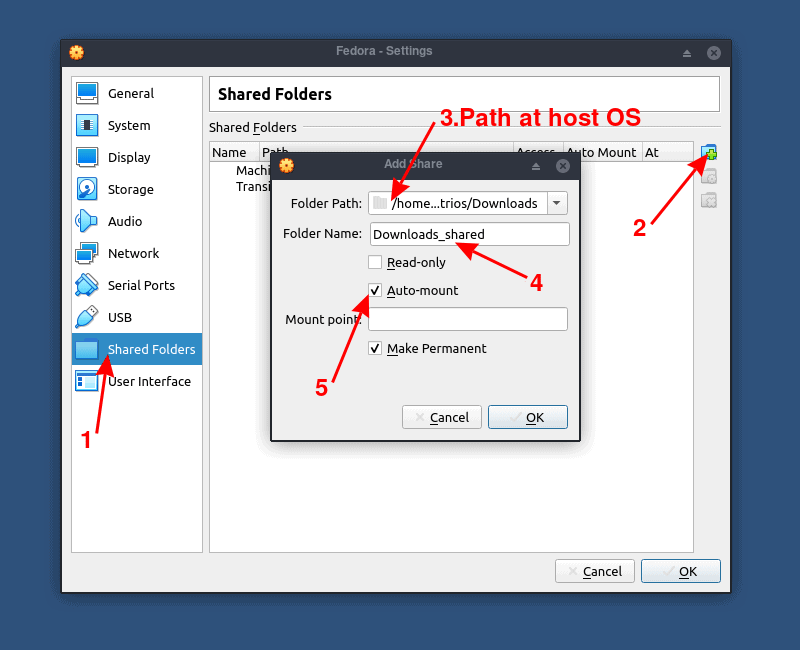
The next time you start the virtual machine, the folder should appear as a network drive.
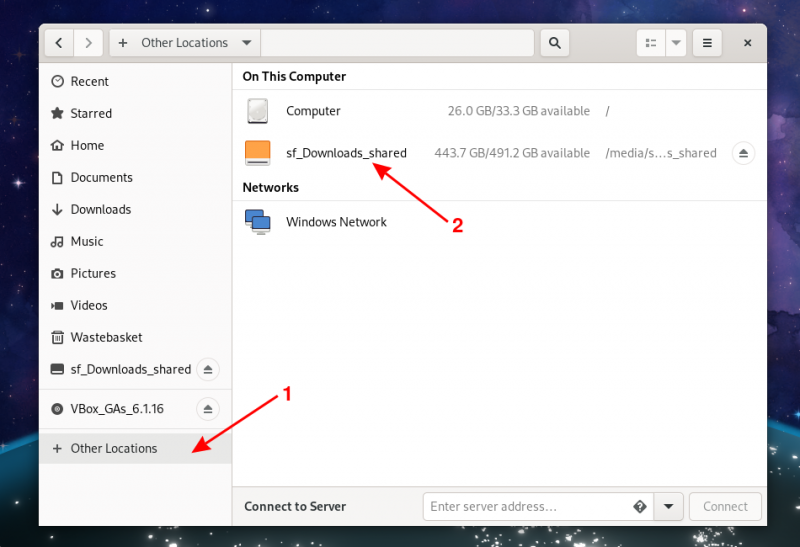
**Better video support**
While the virtual graphics card which Oracle VirtualBox provides all the basic features, the custom video drivers that are installed with the Guest Additions provide you with extra high and non-standard video modes, as well as accelerated video performance.
Using Guest Additions, the guest OS’s resolution will dynamically resize as you adjust the VirtualBox window on your computer.
Finally, Guest Additions can take advantage of your computer’s graphics card. If you’re a gamer or using productivity software in a WM, this makes a huge difference.
### USB and Network Devices sharing
With VirtualBox, users have the ability to use a fully-functional operating system, without having to do the setup on different hardware. However, sharing USB and network devices between the host and guest machine is not as straightforward as it should be.
To access USB devices, you will need to install [the VirtualBox extension pack](https://download.virtualbox.org/virtualbox/6.1.16/Oracle_VM_VirtualBox_Extension_Pack-6.1.16.vbox-extpack?ref=itsfoss.com).
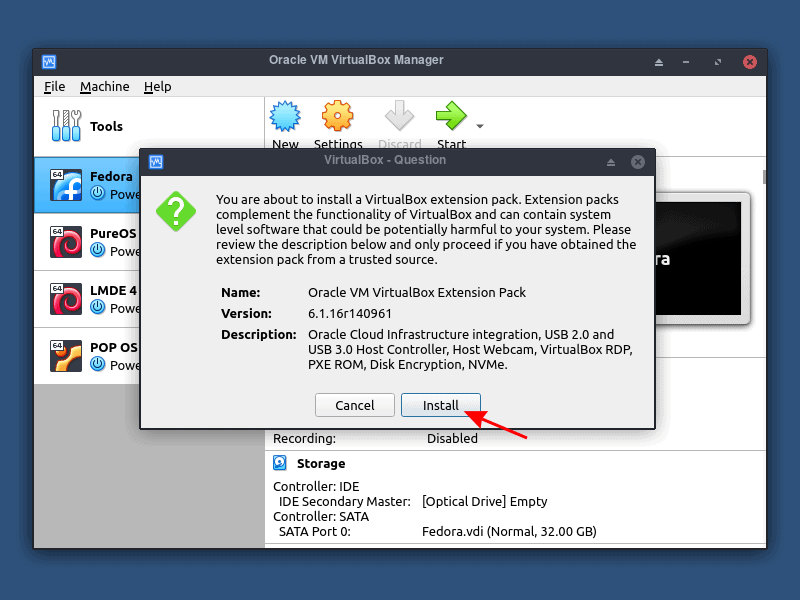
** This is for Linux only** because I am using all this in Linux.
In order for VirtualBox to have access to the USB subsystem, the user (on host system) running VirtualBox must belong to the vboxuser group. To do this, open up a terminal and issue the following command:
`sudo usermod -aG vboxusers 'your username'`
Once you run the command, you should either log out and log back in, or restart your host machine.
At this step, plug in your USB stick and through your VM settings you should be able to find and add the medium as shown at the example.
Your USB will be accessible the next time you start your virtual machine.
## Bonus Tip: Save and export the Virtual Machine so that you can use it later on any system
You may want to use your virtual machine to another computer or it is time to build a new machine and you need to keep your virtual machine as it is. You can easily export your current setup and import it to another machine at a few easy steps.
At the VirtualBox home panel, click on file and the export appliance. If you prefer keyboard shortcuts, you can simply click **Ctrl+E**.
Choose the virtual machine you want to export and click on next.
The Format option needs some attention. There are three different options of Open Virtualization Format 0.9, 1.0 and 2.0, which can be either ovf or ova extensions.
With ovf extension, several files will be written separately, compared to ova extension, which combines all the files into one Open Virtualization Format archive.
The default format, Open Virtualization Format 1.0, should be fine.
To finish the process, click next and at the next dialog box click export.
### Conclusion
By using a virtual machine you can’t just test an operating system but deploy a fully functioning system, equally comparable to a physical machine. Nowadays, hardware has become so powerful and affordable that most of its power is not being utilized.
Through virtualization technology, you can use those wasted resources. The need for physical machines is reduced, and consequently the energy consumption is less. You can save money both from hardware and reduced running costs.
On a larger scale, server virtualization is more of a basic requirement than an advanced concept.
I hope you found this tutorial helpful in installing Fedora Linux in VirtualBox. If you face any issues, please let me know in the comments. |
12,856 | 如何在 Fedora 上安装 Google Chrome 浏览器 | https://itsfoss.com/install-google-chrome-fedora/ | 2020-11-25T09:44:00 | [
"Chrome"
] | https://linux.cn/article-12856-1.html | 
Fedora 的默认网页浏览器是 Firefox。尽管它是一个优秀的网络浏览器,你可能更喜欢流行的 Google Chrome 浏览器。
如果你想知道如何在 Fedora 上安装 Google Chrome 浏览器,让我告诉你两种安装 Google Chrome 浏览器的方式:图形化方式和命令行方式。
* [图形化方式 1:通过启用 Fedora 第三方仓库从软件中心安装 Chrome 浏览器](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tmp.VFVwBw56ac#gui-method-1)
* [图形化方式 2:从谷歌浏览器网站下载 RPM 文件](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tmp.VFVwBw56ac#gui-method-2)
* [命令行方式:从 Fedora 第三方仓库安装 Chrome,一切使用命令(与 GUI 方式 1 相同)](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tmp.VFVwBw56ac#cli-method)
这全取决于你喜欢哪种方式。你在 [Fedora](https://getfedora.org/) 上的 Google Chrome 浏览器都将通过这三种方式的系统更新获取定期更新。
### 方式 1:在 Fedora 中从软件中心安装 Google Chrome
Fedora 提供了一个第三方仓库,其中包含了一些流行的专有软件、图形驱动程序。Google Chrome 就是其中之一。
第一步,确保在 Fedora 中启用第三方仓库。你应该在软件中心中看到这个选项。

启用后,只需在软件中心搜索 Chrome:

并从那里安装它:

还有比这更简单的吗?我觉得没有。
### 方式 2:在 Fedora 上从 Chrome 网站安装 Google Chrome
如果你不想启用第三方仓库,也没关系。你不必这样做。你可以从 Chrome 的网站上下载 RPM 文件,双击并安装它。
访问 Google Chrome 的网站,点击下载按钮。
* [获取 Google Chrome](https://www.google.com/chrome/)

然后选择 .rpm 包,点击“接受并安装”。

下载结束后,双击文件,在包管理器提示时点击安装。输入密码,等待安装完成。

这是超级简单的,对吧?让我们来看看有点复杂的方式(如果你不是一个终端爱好者)。
### 方式 3:使用命令行在 Fedora 上安装 Chrome
首先,你需要添加额外的 Fedora 仓库(你在方式 1 中看到的):
```
sudo dnf install fedora-workstation-repositories
```
然后启用 Google Chrome 仓库。
```
sudo dnf config-manager --set-enabled google-chrome
```

要安装 Google Chrome 稳定版,请在终端运行以下命令。
```
sudo dnf install google-chrome-stable
```
你会看到一个导入 GPG 密钥的警告,输入 `y` 继续。

你正在添加 Google Chrome 仓库。这个软件包来自这个仓库,它直接来自 Google。
### 总结
即使你使用命令行,在 Fedora 上安装 Google chrome 也相当简单。除了第三方仓库的部分,这和[在 Ubuntu 上安装 Chrome](https://itsfoss.com/install-chrome-ubuntu/) 差不多。
现在你已经安装好了,你可能会想[查看我们的 Google Chrome 键盘快捷键列表](https://itsfoss.com/google-chrome-shortcuts/)来更快地使用浏览器。
---
via: <https://itsfoss.com/install-google-chrome-fedora/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Fedora comes with Firefox as the default web browser. Despite it being an excellent web browser, you may prefer the popular Google Chrome browser.
If you are wondering how to install Google Chrome on Fedora, let me show you two ways of installing Google Chrome, graphical method and command line method.
- GUI method 1: Install Chrome from the software center by enabling Fedora third-party repository
- GUI method 2: Download RPM file from Google Chrome’s website
- CLI method: Install Chrome from the Fedora third-party repository, everything using commands (same as GUI method 1)
It is up to you which method you prefer. Your Google Chrome on [Fedora](https://getfedora.org/?ref=itsfoss.com) will be getting regular updates via the system updates in all three methods.
## Method 1: Install Google Chrome on Fedora from the Software Center
Fedora provides a third-party repository that contains some popular proprietary software, and graphics driver. Google Chrome is one of them.
First step: [make sure to enable third-party repositories in Fedora](https://itsfoss.com/fedora-third-party-repos/). You should see this option in the software center itself.
Once you have it enabled, simply search for Chrome in the software center:
And install it from there:
Can it be any easier than this? I don’t think either :)
## Method 2: Installing Google Chrome on Fedora from Chrome website
If you do not want to enable the third-party repository, that’s okay. You don’t have to. You can download the RPM file from Chrome’s website, double-click on it and install it. Yes, [installing RPM file on Fedora](https://itsfoss.com/install-rpm-files-fedora/) is that simple.
Visit Google Chrome’s website and click on the download button.

Then select the .rpm package and click on “Accept and Install”.
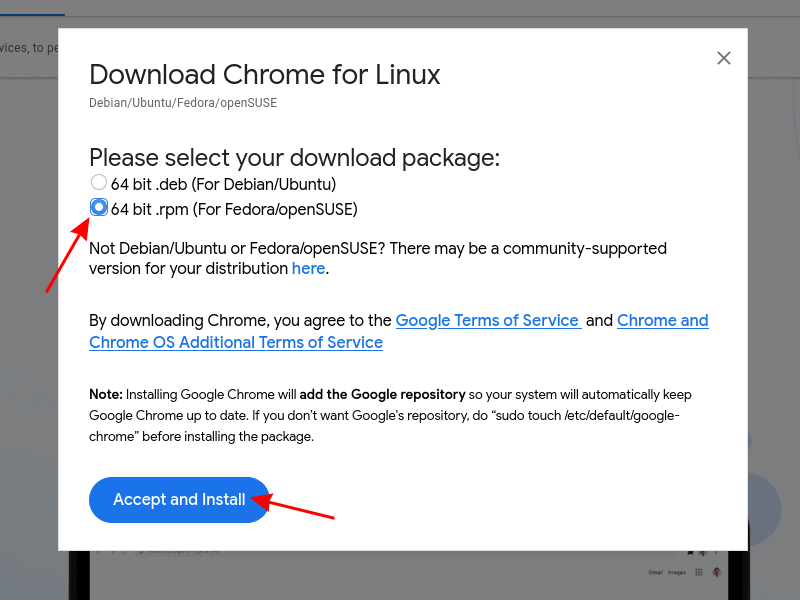
Once the download is over, double click on the file and click install when prompted at the package manager. Type your password and wait until the process is done.
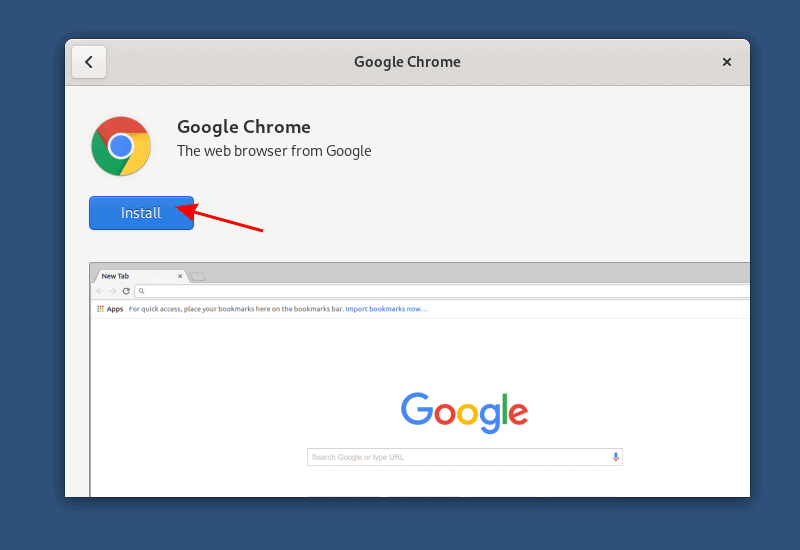
That’s super easy, right? Let’s see somewhat complicated method (if you are not a terminal fan).
## Method 3: Install Chrome on Fedora using command line
Firstly, you need to add extra Fedora repositories (that you saw in method 1):
`sudo dnf install fedora-workstation-repositories`
And then enable Google Chrome repository.
`sudo dnf config-manager --set-enabled google-chrome`
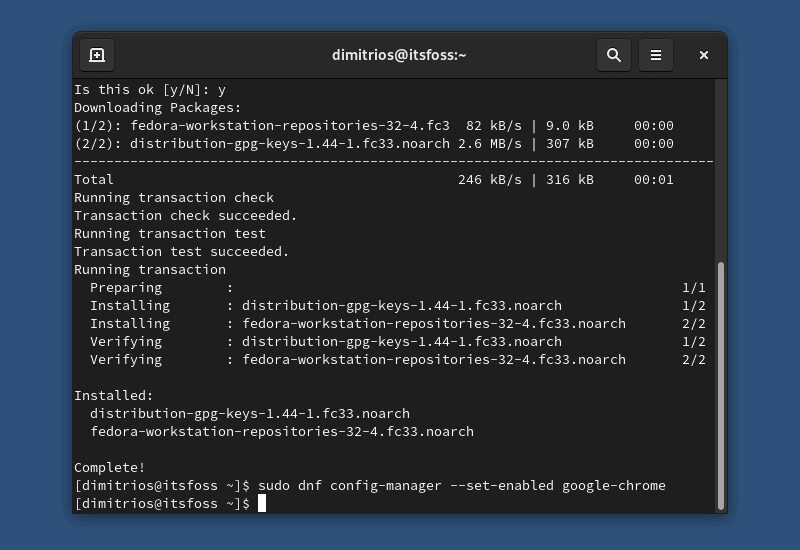
To install the Google Chrome stable release, run the following command at your terminal.
`sudo dnf install google-chrome-stable`
You should get a warning for importing the GPG key, enter y to continue.
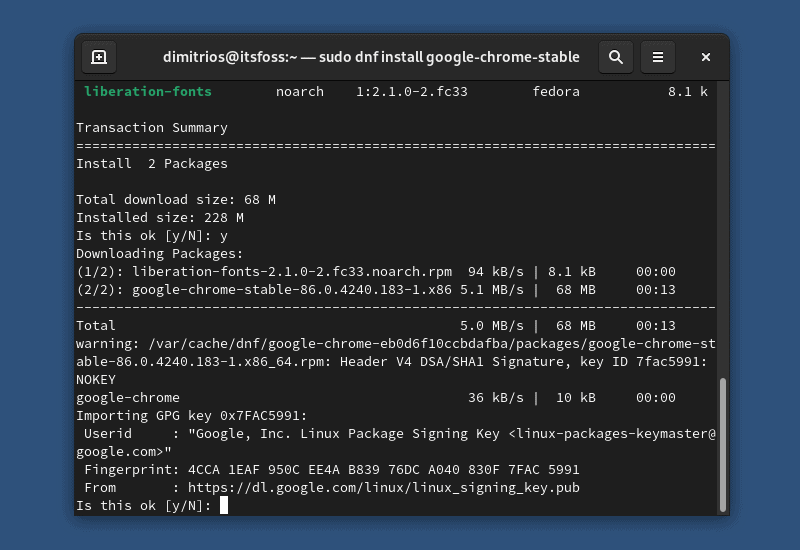
You are adding the Google Chrome repository. The package comes from this repository, directly from Google.
## Conclusion
Installing Google chrome on Fedora is fairly easy, even if you use the command line. It’s pretty much the [same as installing Chrome on Ubuntu](https://itsfoss.com/install-chrome-ubuntu/) except the third-party repository part.
Now that you have installed it, you may want to [check our list of Google Chrome keyboard shortcuts](https://itsfoss.com/google-chrome-shortcuts/) to use the browser faster.
Don’t forget to subscribe to get the latest news and tutorials about Fedora, and if you have any questions, please leave a comment below. |
12,858 | LazPaint:一个自由开源的 Paint.NET 替代品 | https://itsfoss.com/lazpaint/ | 2020-11-25T12:09:19 | [
"LazPaint"
] | https://linux.cn/article-12858-1.html | 
>
> LazPaint 是一款开源 Paint.NET 替代品,支持跨平台。它是一个轻量级的程序,拥有一堆快速编辑图像的基本选项。下面是 LazPaint 的概述。
>
>
>
### LazPaint:Linux 下的开源 Paint.NET 替代品

如果你喜欢使用工具来快速编辑和处理图像和截图,你可能听说过 Paint.NET,但它只适用于 Windows 系统。
它是一个流行的小工具,可以完成很多基本的编辑任务,同时还有一堆可用的选项。你可能知道一些[图像编辑工具](https://itsfoss.com/image-applications-ubuntu-linux/),但 Paint.NET 是一个相当受欢迎的选择,因为对于一个普通用户来说,它易于使用,且没有任何臃肿的功能。
[LazPaint](https://lazpaint.github.io/) 作为 Linux、Windows 和 macOS 上 Paint.NET 的令人印象深刻的开源替代品而出现。它提供了操作图像所需的大部分基本功能,同时又易于使用。

由于它是跨平台的应用,即使你不使用 Linux 系统,你仍然可以以自由开源工具使用它,这并非没有意义。现在,让我们看一下它提供的一些功能。
### LazPaint 的功能

正如我前面提到的,LazPaint 提供了一堆必要的功能。在这里,我将列出关键的部分,这可以帮助你决定是否需要它。然而,我建议你去探索它,以了解更多关于它的信息。
* 支持所有主要的文件格式(包括分层位图和 3D 文件)
* 选区工具、裁剪选区、选区笔、反转选区
* 支持导出到 [Krita](https://krita.org/en)
* 以各种质量设置对图像进行重新采样
* 运动模糊、自定义模糊、径向模糊和像素化工具
* 可以移除透明度和扁平化图像
* 旋转和翻转图像
* 将图像转换为负片
* 能够调整画布的大小
* 变形工具(透视)
* 高级绘图工具
* 设置工作区颜色
* 黑暗主题
* 支持脚本功能
* 具有基本管理选项的层支持
* 层效果
* 过滤器
* 灰度效果
* 能够启用/禁用工具栏或将其添加到 Dock 上
### 在 Linux 上安装 LazPaint
你应该可以在你的官方软件仓库中找到它,通过你的默认软件包管理器来安装它,但要获得最新版本,你需要下载 .deb 文件,或者在非 Debian 的发行版上从源码编译它。
我希望有一个可以在每个 Linux 发行版上获得最新的版本的 Flatpak 软件包,但目前还没有。
它也适用于 Windows 和 macOS。你会发现 Windows 还有一个便携版,可以派上用场。
* [LazPaint](https://lazpaint.github.io/)
### 关于 LazPaint 的总结
我发现它真的很容易使用,以各种质量设置来重新采样(或调整大小)图像绝对是一个加分项。如果你已经安装了它,你一定注意到,它不需要大量的存储空间,总体上是一个轻量级的程序。
它的速度很快,我在快速测试中的大部分功能都相当好用,没有任何问题。
你觉得 LazPaint 作为 Paint.NET 的替代品怎么样?请在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/lazpaint/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: LazPaint is an open-source Paint.NET alternative with cross-platform support. It is a lightweight program with a bunch of essential options to edit images quickly. Here’s an overview of LazPaint. *
## LazPaint: Open Source Paint.NET Alternative for Linux
If you are fond of using tools to quickly edit and manipulate images and screenshots, you may have heard about [Paint.NET](https://www.getpaint.net), which is available only for Windows systems.
It is a popular nifty tool to get a lot of basic editing tasks done along with a bunch of options available. You might be aware of several [ima](https://itsfoss.com/image-applications-ubuntu-linux/)[ge editing tools](https://itsfoss.com/image-applications-ubuntu-linux/) but Paint.NET is a pretty popular option just because it is easy to use without any bloated feature for an average user.
[LazPaint](https://lazpaint.github.io/) comes to the rescue as an impressive open source replacement to Paint.NET for Linux, Windows, and macOS. It offers most of the essential features one would need to manipulate images while being easy to use.
Since it is cross-platform application, even if you’re not using a Linux system, you could still start using it as a no-nonsense free and open-source tool, if that’s your priority. Now, let us take a look at some features it offers.
## Features of LazPaint
As I mentioned earlier, LazPaint offers a bunch of essential features. Here, I’ll list the key highlights that can help you decide if you need it. However, I’d recommend you to explore it to know more about it.
- All major file formats supported (including layered Bitmaps and 3D files)
- Selection Tools, Crop to Selection, Selection Pen, Invert Selection
- Export to
[Krita](https://krita.org/en)supported - Image resampling with various quality settings
- Motion Blur, Custom Blur, Radial Blur, and Pixelate tool
- Ability to remove transparency and flatten the image
- Rotate and Flip images
- Convert images to Negatives
- Ability to re-size Canvas
- Deforming tool (perspective)
- Advanced Drawing tools
- Set workspace color
- Dark theme
- Supports script functionality
- Layer support with essential management options
- Layer effects
- Filters
- Grayscale effect
- Ability to enable/disable the toolbar in or attach them to the Dock
**Recommended Read:**
## Installing LazPaint on Linux
You should find it available in your official repositories to install it via your default package manager but to get the latest version, you will have to download the .**deb** file or compile it from source on non-Debian based Distributions.
I wish there was a Flatpak available to get the latest version on every Linux distribution — but nothing as of now.
It is available for Windows and macOS as well. You will also find a portable version available for Windows, that could come in handy.
## Closing Thoughts on LazPaint
I found it really easy to use and the variety of quality settings to re-sample (or resize) an image is definitely a good addition. If you’ve already installed it, you must have noticed that it does not take a significant amount of storage to get installed and is a lightweight program overall.
It’s snappy, and most of the functions that I tested in my quick usage worked quite well without any issues.
What do you think about LazPaint as a Paint.NET alternative? Let me know your thoughts in the comments below. |
12,859 | 在 Fedora 中结合权能使用 Podman | https://fedoramagazine.org/podman-with-capabilities-on-fedora/ | 2020-11-25T22:06:57 | [
"Podman",
"权能"
] | https://linux.cn/article-12859-1.html | 
容器化是一项蓬勃发展的技术。在不久的将来,多达百分之七十五的全球组织可能会运行某种类型的容器化技术。由于广泛使用的技术更容易成为黑客攻击的目标,因此保护容器的安全就显得尤为重要。本文将演示如何使用 POSIX <ruby> <a href="https://www.linuxjournal.com/magazine/making-root-unprivileged"> 权能 </a> <rt> Capability </rt></ruby> 来保护 Podman 容器的安全。Podman 是 RHEL8 中默认的容器管理工具。
### 确定 Podman 容器的权限模式
容器以特权模式或无特权模式运行。在特权模式下,[容器的 uid 0 被映射到宿主机的 uid 0](https://linuxcontainers.org/lxc/security/#privileged-containers)。对于某些情况,无特权的容器[缺乏对宿主机资源的充分访问能力](https://github.com/containers/podman/blob/master/rootless.md)。但不管其操作模式如何,包括<ruby> 强制访问控制 <rt> Mandatory Access Control </rt></ruby>(MAC:如 apparmor、SELinux 等)、seccomp 过滤器、删除<ruby> 权能 <rt> Capability </rt></ruby>、命名空间等在内的技术有助于确保容器的安全。
要从容器外部确定特权模式:
```
$ podman inspect --format="{{.HostConfig.Privileged}}" <container id>
```
如果上面的命令返回 `true`,那么容器在特权模式下运行。如果返回 `false`,那么容器在非特权模式下运行。
要从容器内部确定特权模式:
```
$ ip link add dummy0 type dummy
```
如果该命令允许你创建一个接口,那么你运行的是一个特权容器,否则你运行的是一个非特权容器。
### 权能
命名空间隔离了容器的进程,使其无法任意访问宿主机的资源,也无法访问在同一宿主机上运行的其他容器的资源。然而,在**特权**容器内的进程仍然可以做一些事情,如改变 IP 路由表、跟踪任意进程和加载内核模块。<ruby> 权能 <rt> Capability </rt></ruby>允许人们对容器内的进程可以访问或更改的资源施加更细微的限制,即使容器在特权模式下运行也一样。权能还允许人们为无特权的容器分配它本来不会拥有的特权。
例如,如果要将 `NET_ADMIN` 功能添加到一个无特权的容器中,以便在容器内部创建一个网络接口,你可以用下面的参数运行 `podman`:
```
[root@vm1 ~]# podman run -it --cap-add=NET_ADMIN centos
[root@b27fea33ccf1 /]# ip link add dummy0 type dummy
[root@b27fea33ccf1 /]# ip link
```
上面的命令演示了在一个无特权的容器中创建一个 `dummy0` 接口。如果没有 `NET_ADMIN` 权能,非特权容器将无法创建接口。上面的命令演示了如何将一个权能授予一个无特权的容器。
目前,大约有 [39 种权能](https://man7.org/linux/man-pages/man7/capabilities.7.html)可以被授予或拒绝。特权容器默认会被授予许多权能。建议从特权容器中删除不需要的权能,以使其更加安全。
要从容器中删除所有权能:
```
$ podman run -it -d --name mycontainer --cap-drop=all centos
```
列出一个容器的权能:
```
$ podman exec -it 48f11d9fa512 capsh --print
```
上述命令显示没有向容器授予任何权能。
请参考 `capabilities` 手册页以获取完整的权能列表:
```
$ man capabilities
```
可以使用 `capsh` 命令来列出目前拥有的权能:
```
$ capsh --print
```
作为另一个例子,下面的命令演示了如何从容器中删除 `NET_RAW` 权能。如果没有 `NET_RAW` 权能,就不能从容器中 `ping` 互联网上的服务器。
```
$ podman run -it --name mycontainer1 --cap-drop=net_raw centos
>>> ping google.com (will output error, operation not permitted)
```
最后一个例子,如果你的容器只需要 `SETUID` 和 `SETGID` 权能,你可以删除所有权能,然后只重新添加这两个权能来实现这样的权限设置。
```
$ podman run -d --cap-drop=all --cap-add=setuid --cap-add=setgid fedora sleep 5 > /dev/null; pscap | grep sleep
```
上面的 `pscap` 命令会显示容器被授予的权能。
我希望你喜欢这个关于如何使用权能来保护 Podman 容器的简短探索。
谢谢!
---
via: <https://fedoramagazine.org/podman-with-capabilities-on-fedora/>
作者:[shiwanibiradar](https://fedoramagazine.org/author/shiwanibiradar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Containerization is a booming technology. As many as seventy-five percent of global organizations could be running some type of containerization technology in the near future. Since widely used technologies are more likely to be targeted by hackers, securing containers is especially important. This article will demonstrate how [POSIX capabilities](https://www.linuxjournal.com/magazine/making-root-unprivileged) are used to secure Podman containers. Podman is the default container management tool in RHEL8.
## Determine the Podman container’s privilege mode
Containers run in either privileged or unprivileged mode. In privileged mode, [the container uid 0 is mapped to the host’s uid 0](https://linuxcontainers.org/lxc/security/#privileged-containers). For some use cases, unprivileged containers [lack sufficient access](https://github.com/containers/podman/blob/master/rootless.md) to the resources of the host machine. Technologies and techniques including Mandatory Access Control (apparmor, SELinux), seccomp filters, dropping of capabilities, and namespaces help to secure containers regardless of their mode of operation.
**To determine the privilege mode from outside the container:**
$ podman inspect --format="{{.HostConfig.Privileged}}" <container id>
If the above command returns *true* then the container is running in privileged mode. If it returns *false* then the container is running in unprivileged mode.
**To determine the privilege mode from inside the container:**
$ ip link add dummy0 type dummy
If this command allows you to create an interface then you are running a privileged container. Otherwise you are running an unprivileged container.
## Capabilities
Namespaces isolate a container’s processes from arbitrary access to the resources of its host and from access to the resources of other containers running on the same host. Processes within *privileged* containers, however, might still be able to do things like alter the IP routing table, trace arbitrary processes, and load kernel modules. Capabilities allow one to apply finer-grained restrictions on what resources the processes within a container can access or alter; even when the container is running in privileged mode. Capabilities also allow one to assign privileges to an unprivileged container that it would not otherwise have.
For example, to add the *NET_ADMIN* capability to an unprivileged container so that a network interface can be created inside of the container, you would run *podman* with parameters similar to the following:
[root@vm1 ~]# podman run -it --cap-add=NET_ADMIN centos [root@b27fea33ccf1 /]# ip link add dummy0 type dummy [root@b27fea33ccf1 /]# ip link
The above commands demonstrate a *dummy0* interface being created in an unprivileged container. Without the *NET_ADMIN* capability, an unprivileged container would not be able to create an interface. The above commands demonstrate how to grant a capability to an unprivileged container.
Currently, there are about [39 capabilities](https://man7.org/linux/man-pages/man7/capabilities.7.html) that can be granted or denied. Privileged containers are granted many capabilities by default. It is advisable to drop unneeded capabilities from privileged containers to make them more secure.
**To drop all capabilities from a container:**
$ podman run -it -d --name mycontainer --cap-drop=all centos
**To list a container’s capabilities:**
$ podman exec -it 48f11d9fa512 capsh --print
The above command should show that no capabilities are granted to the container.
**Refer to the capabilities man page for a complete list of capabilities:**
$ man capabilities
**Use the capsh command to list the capabilities you currently possess:**
$ capsh --print
As another example, the below command demonstrates dropping the *NET_RAW* capability from a container. Without the *NET_RAW* capability, servers on the internet cannot be pinged from within the container.
$ podman run -it --name mycontainer1 --cap-drop=net_raw centos >>> ping google.com (will output error, operation not permitted)
As a final example, if your container were to only need the *SETUID* and *SETGID* capabilities, you could achieve such a permission set by dropping all capabilities and then re-adding only those two.
$ podman run -d --cap-drop=all --cap-add=setuid --cap-add=setgid fedora sleep 5 > /dev/null; pscap | grep sleep
The *pscap* command shown above should show the capabilities that have been granted to the container.
I hope you enjoyed this brief exploration of how capabilities are used to secure Podman containers.
Thank You!
## Jeffrey Goh
Thanks, finally switching from docker to podman everywhere on Fedora to reduce privilege whenever possible, so this handy guide is extremely timely.
## Pavan Wankhade
Nice, Helpful tricks are included.
## Joe
Thanks for that! A lot of good commands.
I also spent some time playing with getting a LAMP stack running in across 3 Podman containers. The SELinux and network setup threw me a bit, but got it working. Details below in case it’s helpful for anyone else.
https://opensourcetechtrn.blogspot.com/2020/08/yet-another-lamp-stack-build-podman.html
## Lakshya Tyagi
This article is very helpful
## heiko
Podman is really a great approch. Unfortunately I still don’t find a working CUDA intergration for GPU and have still to use Docker
## Anchit
Nvidia container toolkit supports Podman.
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/overview.html
## laolux
Great article. Setting capabilities in podman seems to be straight forward. However, I have trouble finding out which capabilities are actually needed. For example, when I want to run a postgres container which is only available in the same pod, then what capabilities are required to run and which are safe to drop?
## Stephen Snow
I believe that capabilities are more for the level of isolation between the host and the container. The infra container of the pod you want to run a postgres container in should be where the capabilities are set I would think. The containers in the pod would then only have the capabilities of the infra container. If you go to Opensource.com and search there is some article on this topic.
## laolux
Thanks for pointing me to opensource.com, where I have found some info related to SELinux, but capabilities with podman are quite scarce.
About trying to set the capabilities of an entire pod: podman pod create does not allow for capabilities to be set. And it works perfectly fine to set the capabilities of the containers added to a pod. They can even have different capabilities.
However, all of this does not solve my underlying problem of finding out which capabilities are required by a container during normal operation.
## Stephen Snow
Hello laolux,
sorry you were unable to find what you wanted there. I may have read it on the RedHat Developer site. In any case this post seems relevant to your question https://www.redhat.com/sysadmin/container-networking-podman. Or at least in the proximity of it. Or maybe this one that does talk directly about capabilities and containers https://www.redhat.com/sysadmin/privileged-flag-container-engines.
## laolux
Hello Stephen Snow,
thank you very much for the links! They are very informative. They also pointed me to another site where it is explained how to trace syscalls of a container in order to restrict those later: https://podman.io/blogs/2019/10/15/generate-seccomp-profiles.html
Not quite about capabilites, but similar direction. I guess a somewhat similar approach should work for finding out which capabilities are needed.
## Ondrej
Podman is so nice. I really love it. The way it integrates with systemd + auto-updates, it makes it very simple to create an deployment well integrated in one infra container.
I just really love it!
## William Whinn
Great stuff, thank you! I use toolbox more for bootstrapping an R/RStudio and C/C++ development environment but it has made me interested in containers as a technology. This’ll make a great first step in digging a bit deeper into the technology I take for granted everyday. |
12,860 | 用 NTS 保证 NTP 的安全 | https://fedoramagazine.org/secure-ntp-with-nts/ | 2020-11-26T11:17:00 | [
"NTP",
"NTS"
] | https://linux.cn/article-12860-1.html | 
许多计算机使用<ruby> 网络时间协议 <rt> Network Time Protocol </rt></ruby>(NTP)通过互联网来同步系统时钟。NTP 是少数几个仍在普遍使用的不安全的互联网协议之一。攻击者如果能够观察到客户端和服务器之间的网络流量,就可以向客户端提供虚假的数据,并根据客户端的实现和配置,强迫其将系统时钟设置为任何时间和日期。如果客户端的系统时钟不准确,一些程序和服务就可能无法工作。例如,如果根据客户端的系统时钟,Web 服务器的证书似乎已经过期,Web 浏览器将无法正常工作。可以使用<ruby> 网络时间安全 <rt> Network Time Security </rt></ruby>(NTS)来保证 NTP 的安全。
Fedora 33 <sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup> 是第一个支持 NTS 的 Fedora 版本。NTS 是一种新的 NTP 验证机制。它使客户端能够验证它们从服务器接收的数据包在传输过程中有没有被修改。当 NTS 启用时,攻击者唯一能做的就是丢弃或延迟数据包。关于 NTS 的更多细节,请参见 [RFC8915](https://tools.ietf.org/html/rfc8915)。
使用对称密钥可以很好地保证 NTP 的安全。遗憾的是,服务器必须为每个客户端配备不同的密钥,而且密钥必须安全地分发才行。这对于本地网络上的私有服务器来说可能是实用的,但它不能扩展到有着数百万客户端的公共服务器上。
NTS 包括一个<ruby> 密钥建立 <rt> Key Establishment </rt></ruby>(NTS-KE)协议,它可以自动创建服务器与其客户端之间使用的加密密钥。它在 TCP 端口 4460 上使用<ruby> 传输层安全 <rt> Transport Layer Security </rt></ruby>(TLS)。它被设计成可以扩展到非常多的客户端,而对准确性的影响最小。服务器不需要保存任何客户端特定的状态。它为客户提供 cookie,cookie 是加密的,包含验证 NTP 数据包所需的密钥。隐私是 NTS 的目标之一。客户端在每次服务器响应时都会得到一个新的 cookie,所以它不必重复使用 cookie。这可以防止被动观察者跟踪在网络之间迁移的客户端。
Fedora 中默认的 NTP 客户端是 Chrony。Chrony 在 4.0 版本中增加了 NTS 支持,但并没有改变默认配置。Chrony 仍然使用 [pool.ntp.org](https://www.pool.ntp.org) 项目中的公共服务器,而且默认情况下 NTS 没有启用。
目前,支持 NTS 的公共 NTP 服务器非常少。两个主要的提供商是 Cloudflare 和 Netnod。[Cloudflare 服务器](https://developers.cloudflare.com/time-services/nts/usage)分布在世界各地的不同地方。他们使用的是<ruby> 任播 <rt> anycast </rt></ruby>地址,应该可以让大多数客户到达一个接近的服务器。[Netnod 服务器](https://www.netnod.se/time-and-frequency/how-to-use-nts)位于瑞典。在未来,我们可能会看到更多支持 NTS 的公共 NTP 服务器。
为了获得最佳的可靠性,配置 NTP 客户端的一般建议是至少有三个工作的服务器。为了达到最好的精度,建议选择距离较近的服务器,以减少网络延迟和非对称网络路由造成的不对称性。如果你不关心细粒度的精度,你可以忽略这个建议,使用任何你信任的 NTS 服务器,无论它们位于哪里。
如果你确实想要高准确度,但又没有近距离的 NTS 服务器,你可以将远处的 NTS 服务器和近处的非 NTS 服务器混合使用。但是,这样的配置不如只使用 NTS 服务器的配置安全。攻击者仍然不能强迫客户机接受任意时间,但他们确实对客户机的时钟及其估计精度有更大的控制权,这在某些环境下可能是不可接受的。
### 在安装程序中启用客户端 NTS
安装 Fedora 33 时,你可以在“Time & Date”对话框的“Network Time”配置中启用 NTS。在点击“+”(添加)按钮之前,请输入服务器的名称并检查 NTS 支持情况。你可以添加一个或多个具有 NTS 的服务器或池。要删除默认的服务器池(`2.fedora.pool.ntp.org`),请取消选中“Use”列中的相应标记。

### 在配置文件中启用客户端 NTS
如果你从之前的 Fedora 版本升级,或者你没有在安装程序中启用 NTS,你可以直接在 `/etc/chrony.conf` 中启用 NTS。除了推荐的 `iburst` 选项外,还可以对指定服务器使用 `nts` 选项。例如:
```
server time.cloudflare.com iburst nts
server nts.sth1.ntp.se iburst nts
server nts.sth2.ntp.se iburst nts
```
你还应该允许客户端将 NTS 密钥和 cookie 保存到磁盘上,这样它就不必在每次启动时重复 NTS-KE 会话。在 `chrony.conf` 中添加以下一行,如果还没有的话:
```
ntsdumpdir /var/lib/chrony
```
如果不想让 DHCP 提供的 NTP 服务器与你指定的服务器混在一起,请在 `chrony.conf` 中删除或注释以下一行:
```
sourcedir /run/chrony-dhcp
```
当你完成编辑 `chrony.conf` 后,保存你的更改并重新启动 `chronyd` 服务:
```
systemctl restart chronyd
```
### 检查客户端状态
在 root 用户下运行以下命令,检查 NTS 密钥建立是否成功:
```
# chronyc -N authdata
Name/IP address Mode KeyID Type KLen Last Atmp NAK Cook CLen
=========================================================================
time.cloudflare.com NTS 1 15 256 33m 0 0 8 100
nts.sth1.ntp.se NTS 1 15 256 33m 0 0 8 100
nts.sth2.ntp.se NTS 1 15 256 33m 0 0 8 100
```
`KeyID`、`Type` 和 `KLen` 列应该有非零值。如果它们为零,请检查系统日志中是否有来自 `chronyd` 的错误信息。一个可能的故障原因是防火墙阻止了客户端与服务器的 TCP 端口(端口 4460)的连接。
另一个可能的故障原因是由于客户机的时钟错误而导致证书无法验证。这是 NTS 的先有鸡还是先有蛋的问题。你可能需要手动修正日期或暂时禁用 NTS,以使 NTS 正常工作。如果你的电脑有实时时钟,几乎所有的电脑都有,而且有好的电池做备份,这种操作应该只需要一次。
如果计算机没有实时时钟或电池,就像一些常见的小型 ARM 计算机(如树莓派)那样,你可以在 `/etc/sysconfig/chronyd` 中添加 `-s` 选项来恢复上次关机或重启时保存的时间。时钟会落后于真实时间,但如果电脑没有关机太久,服务器的证书也没有在离到期时间太近的时候更新,应该足以让时间检查成功。作为最后的手段,你可以用 `nocerttimecheck` 指令禁用时间检查。详情请参见`chrony.conf(5)` 手册页。
运行下面的命令来确认客户端是否在进行 NTP 测量:
```
# chronyc -N sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* time.cloudflare.com 3 6 377 45 +355us[ +375us] +/- 11ms
^+ nts.sth1.ntp.se 1 6 377 44 +237us[ +237us] +/- 23ms
^+ nts.sth2.ntp.se 1 6 377 44 -170us[ -170us] +/- 22ms
```
`Reach` 列应该有一个非零值,最好是 377。上图所示的值 377 是一个八进制数,它表示最后八个请求都有有效的响应。如果启用了 NTS 的话,验证检查将包括 NTS 认证。如果该值一直很少或从未达到 377,则表明 NTP 请求或响应在网络中丢失了。众所周知,一些主要的网络运营商有中间设备,它可以阻止或限制大的 NTP 数据包的速率,以缓解利用 `ntpd` 的监控协议进行的放大攻击。不幸的是,这影响了受 NTS 保护的 NTP 数据包,尽管它们不会引起任何放大。NTP 工作组正在考虑为 NTP 提供一个替代端口,作为解决这个问题的办法。
### 在服务器上启用 NTS
如果你有自己的 NTP 服务器,运行着 `chronyd`,你可以启用服务器的 NTS 支持,让它的客户端安全同步。如果该服务器是其他服务器的客户端,它应该使用 NTS 或对称密钥与之同步。客户端假设同步链在所有服务器到主时间服务器之间是安全的。
启用服务器 NTS 类似于在 Web 服务器上启用 HTTPS。你只需要一个私钥和证书。例如,证书可以由 Let's Encrypt 权威机构使用 `certbot` 工具签署。当你有了密钥和证书文件(包括中间证书),在 `chrony.conf` 中用以下指令指定它们:
```
ntsserverkey /etc/pki/tls/private/foo.example.net.key
ntsservercert /etc/pki/tls/certs/foo.example.net.crt
```
确保之前在客户端配置中提到的 `ntsdumpdir` 指令存在于 `chrony.conf` 中。它允许服务器将其密钥保存到磁盘上,这样服务器的客户端在重启服务器时就不必获取新的密钥和 cookie 了。
重新启动 `chronyd` 服务:
```
systemctl restart chronyd
```
如果系统日志中没有来自 `chronyd` 的错误信息,那么它应该是可以接受客户端连接的,如果服务器有防火墙,则需要同时允许 UDP 123 和 TCP 4460 端口的 NTP 和 NTS-KE 服务。
你可以用下面的命令在客户端机器上进行快速测试:
```
$ chronyd -Q -t 3 'server foo.example.net iburst nts maxsamples 1'
2020-10-13T12:00:52Z chronyd version 4.0 starting (+CMDMON +NTP +REFCLOCK +RTC +PRIVDROP +SCFILTER +SIGND +ASYNCDNS +NTS +SECHASH +IPV6 +DEBUG)
2020-10-13T12:00:52Z Disabled control of system clock
2020-10-13T12:00:55Z System clock wrong by -0.001032 seconds (ignored)
2020-10-13T12:00:55Z chronyd exiting
```
如果你看到一个“System clock wrong”消息,说明它是正确工作的。
在服务器上,你可以使用下面的命令来检查它已经处理了多少个 NTS-KE 连接和认证的 NTP 数据包:
```
# chronyc serverstats
NTP packets received : 2143106240
NTP packets dropped : 117180834
Command packets received : 16819527
Command packets dropped : 0
Client log records dropped : 574257223
NTS-KE connections accepted: 104
NTS-KE connections dropped : 0
Authenticated NTP packets : 52139
```
如果你看到非零的 “NTS-KE connections accepted” 和 “Authenticated NTP packets”,这意味着至少有一些客户端能够连接到 NTS-KE 端口,并发送一个认证的 NTP 请求。
1. Fedora 33 Beta 安装程序包含一个较旧的 Chrony 预发布版本,它不能与当前的 NTS 服务器一起工作,因为 NTS-KE 端口已经改变。因此,在安装程序中的网络时间配置中,服务器总是显示为不工作。安装后,需要更新 chrony 包,才能与当前的服务器配合使用。 [↩︎](#fnref1)
---
via: <https://fedoramagazine.org/secure-ntp-with-nts/>
作者:[Miroslav Lichvar](https://fedoramagazine.org/author/mlichvar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many computers use the Network Time Protocol (NTP) to synchronize their system clocks over the internet. NTP is one of the few unsecured internet protocols still in common use. An attacker that can observe network traffic between a client and server can feed the client with bogus data and, depending on the client’s implementation and configuration, force it to set its system clock to any time and date. Some programs and services might not work if the client’s system clock is not accurate. For example, a web browser will not work correctly if the web servers’ certificates appear to be expired according to the client’s system clock. Use Network Time Security (NTS) to secure NTP.
Fedora 33 1 is the first Fedora release to support NTS. NTS is a new authentication mechanism for NTP. It enables clients to verify that the packets they receive from the server have not been modified while in transit. The only thing an attacker can do when NTS is enabled is drop or delay packets. See
[RFC8915](https://tools.ietf.org/html/rfc8915)for further details about NTS.
NTP can be secured well with symmetric keys. Unfortunately, the server has to have a different key for each client and the keys have to be securely distributed. That might be practical with a private server on a local network, but it does not scale to a public server with millions of clients.
NTS includes a Key Establishment (NTS-KE) protocol that automatically creates the encryption keys used between the server and its clients. It uses Transport Layer Security (TLS) on TCP port 4460. It is designed to scale to very large numbers of clients with a minimal impact on accuracy. The server does not need to keep any client-specific state. It provides clients with cookies, which are encrypted and contain the keys needed to authenticate the NTP packets. Privacy is one of the goals of NTS. The client gets a new cookie with each server response, so it doesn’t have to reuse cookies. This prevents passive observers from tracking clients migrating between networks.
The default NTP client in Fedora is *chrony*. Chrony added NTS support in version 4.0. The default configuration hasn’t changed. Chrony still uses public servers from the [pool.ntp.org](https://www.pool.ntp.org) project and NTS is not enabled by default.
Currently, there are very few public NTP servers that support NTS. The two major providers are Cloudflare and Netnod. The [Cloudflare servers](https://developers.cloudflare.com/time-services/nts/usage) are in various places around the world. They use anycast addresses that should allow most clients to reach a close server. The [Netnod servers](https://www.netnod.se/time-and-frequency/how-to-use-nts) are located in Sweden. In the future we will probably see more public NTP servers with NTS support.
A general recommendation for configuring NTP clients for best reliability is to have at least three working servers. For best accuracy, it is recommended to select close servers to minimize network latency and asymmetry caused by asymmetric network routing. If you are not concerned about fine-grained accuracy, you can ignore this recommendation and use any NTS servers you trust, no matter where they are located.
If you do want high accuracy, but you don’t have a close NTS server, you can mix distant NTS servers with closer non-NTS servers. However, such a configuration is less secure than a configuration using NTS servers only. The attackers still cannot force the client to accept arbitrary time, but they do have a greater control over the client’s clock and its estimate of accuracy, which may be unacceptable in some environments.
## Enable client NTS in the installer
When installing Fedora 33, you can enable NTS in the *Time & Date* dialog in the *Network Time* configuration. Enter the name of the server and check the NTS support before clicking the **+** (Add) button. You can add one or more servers or pools with NTS. To remove the default pool of servers (*2.fedora.pool.ntp.org*), uncheck the corresponding mark in the *Use* column.
## Enable client NTS in the configuration file
If you upgraded from a previous Fedora release, or you didn’t enable NTS in the installer, you can enable NTS directly in */etc/chrony.conf*. Specify the server with the *nts* option in addition to the recommended *iburst* option. For example:
server time.cloudflare.com iburst nts server nts.sth1.ntp.se iburst nts server nts.sth2.ntp.se iburst nts
You should also allow the client to save the NTS keys and cookies to disk,
so it doesn’t have to repeat the NTS-KE session on each start. Add the
following line to *chrony.conf*, if it is not already present:
ntsdumpdir /var/lib/chrony
If you don’t want NTP servers provided by DHCP to be mixed with the servers you
have specified, remove or comment out the following line in
*chrony.conf*:
sourcedir /run/chrony-dhcp
After you have finished editing *chrony.conf*, save your changes and restart the *chronyd* service:
systemctl restart chronyd
## Check client status
Run the following command under the root user to check whether the NTS key establishment was successful:
#chronyc -N authdataName/IP address Mode KeyID Type KLen Last Atmp NAK Cook CLen ========================================================================= time.cloudflare.com NTS 1 15 256 33m 0 0 8 100 nts.sth1.ntp.se NTS 1 15 256 33m 0 0 8 100 nts.sth2.ntp.se NTS 1 15 256 33m 0 0 8 100
The *KeyID*, *Type*, and *KLen* columns should have non-zero values. If they are zero, check the system log for error messages from *chronyd*. One possible cause of failure is a firewall is blocking the client’s connection to the server’s TCP port ( port 4460).
Another possible cause of failure is a certificate that is failing to verify because the client’s clock is wrong. This is a chicken-or-the-egg type problem with NTS. You may need to manually correct the date or temporarily disable NTS in order to get NTS working. If your computer has a real-time clock, as almost all computers do, and it’s backed up by a good battery, this operation should be needed only once.
If the computer doesn’t have a real-time clock or battery, as is common with
some small ARM computers like the Raspberry Pi, you can add the *-s*
option to */etc/sysconfig/chronyd* to restore time saved on the last
shutdown or reboot. The clock will be behind the true time, but if the
computer wasn’t shut down for too long and the server’s certificates were not
renewed too close to their expiration, it should be sufficient for the time
checks to succeed. As a last resort, you can disable the time checks with the
*nocerttimecheck* directive. See the *chrony.conf(5)* man page
for details.
Run the following command to confirm that the client is making NTP measurements:
#chronyc -N sourcesMS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* time.cloudflare.com 3 6 377 45 +355us[ +375us] +/- 11ms ^+ nts.sth1.ntp.se 1 6 377 44 +237us[ +237us] +/- 23ms ^+ nts.sth2.ntp.se 1 6 377 44 -170us[ -170us] +/- 22ms
The *Reach* column should have a non-zero value; ideally 377. The value 377 shown above is an octal number. It indicates that the last eight requests all had a valid response. The validation check will include NTS authentication if enabled. If the value only rarely or never gets to 377, it indicates that NTP requests or responses are getting lost in the network. Some major network operators are known to have middleboxes that block or limit rate of large NTP packets as a mitigation for amplification attacks that exploit the monitoring protocol of *ntpd*. Unfortunately, this impacts NTS-protected NTP packets, even though they don’t cause any amplification. The NTP working group is considering an alternative port for NTP as a workaround for this issue.
## Enable NTS on the server
If you have your own NTP server running *chronyd*, you can enable server NTS support to allow its clients to be synchronized securely. If the server is a client of other servers, it should use NTS or a symmetric key for its own synchronization. The clients assume the synchronization chain is secured between all servers up to the primary time servers.
Enabling server NTS is similar to enabling HTTPS on a web server. You just need a private key and certificate. The certificate could be signed by the Let’s Encrypt authority using the *certbot* tool, for example. When you have the key and certificate file (including intermediate certificates), specify them in *chrony.conf* with the following directives:
ntsserverkey /etc/pki/tls/private/foo.example.net.key ntsservercert /etc/pki/tls/certs/foo.example.net.crt
Make sure the *ntsdumpdir* directive mentioned previously in the
client configuration is present in *chrony.conf*. It allows the server
to save its keys to disk, so the clients of the server don’t have to get new
keys and cookies when the server is restarted.
Restart the *chronyd* service:
systemctl restart chronyd
If there are no error messages in the system log from *chronyd*, it should be
accepting client connections. If the server has a firewall, it needs to allow
both the UDP 123 and TCP 4460 ports for NTP and NTS-KE respectively.
You can perform a quick test from a client machine with the following command:
$chronyd -Q -t 3 'server foo.example.net iburst nts maxsamples 1'2020-10-13T12:00:52Z chronyd version 4.0 starting (+CMDMON +NTP +REFCLOCK +RTC +PRIVDROP +SCFILTER +SIGND +ASYNCDNS +NTS +SECHASH +IPV6 +DEBUG) 2020-10-13T12:00:52Z Disabled control of system clock 2020-10-13T12:00:55Z System clock wrong by -0.001032 seconds (ignored) 2020-10-13T12:00:55Z chronyd exiting
If you see a *System clock wrong* message, it’s working
correctly.
On the server, you can use the following command to check how many NTS-KE connections and authenticated NTP packets it has handled:
#chronyc serverstatsNTP packets received : 2143106240 NTP packets dropped : 117180834 Command packets received : 16819527 Command packets dropped : 0 Client log records dropped : 574257223 NTS-KE connections accepted: 104 NTS-KE connections dropped : 0 Authenticated NTP packets : 52139
If you see non-zero *NTS-KE connections accepted* and *Authenticated
NTP packets*, it means at least some clients were able to connect to the
NTS-KE port and send an authenticated NTP request.
*— Cover photo by Louis. K on Unsplash —*
[1]. The Fedora 33 *Beta* installer contains an older chrony prerelease which doesn’t work with current NTS servers because the NTS-KE port has changed. Consequently, in the Network Time configuration in the installer, the servers will always appear as not working. After installation, the chrony package needs to be updated before it will work with current servers.
## Osqui
What about systemd-timesyncd? Is it compatible with NTS? Thanks!
## Miroslav Lichvar
systemd-timesyncd doesn’t support NTS yet.
## Jaranguda
what’s the best practice to choose NTP server or the recommended one?
any tips to check if NTP server already supports NTS ?
## Miroslav Lichvar
Some recommended NTS servers are mentioned in the article. NTS is still very new, so the selection is limited. To check if a server supports NTS, try the nts option and see if it works. Note that the server needs to be specified with a name and not just an IP address, so the certificate of the server can be verified.
## Anon Ymous
Does NTS account for daylight savings time?
## Alex Vanderveen
It would be nice to see this expanded into CentOS 8 as well. I just tried implementing it on my laptop with Fedora and confirm it is working as expected.
## Alex Vanderveen
I am pretty sure it works the same with DST… I have it enabled and it shows regions normally in PST mode, are now in PDT mode to reflect the DST change. My own personal area, ofc, has no DST at all 🙂 We are magic.
## Anon Ymous
to : Alex Vanderveen
Yeah i was just seeing if i could sneak the DST one through lol 🙂
## Miroslav Lichvar
Daylight savings time is handled locally by applications using system tzdata. NTP (with or without NTS) doesn’t care about timezones. It works in UTC.
## Anon Ymous
to : Miroslav Lichvar
Okay, thanks that clears up my DST concerns 🙂
## Christer Weinigel
“Does NTS account for daylight savings time?”
Yes and no. 🙂 NTP, and thus NTS, uses the UTC timescale. UTC does not change for DST. The timezone settings of the local computer specifies how it should translate UTC into local time and also how it should handle DST.
For example: European countries will stop using DST from 2021. This means that all computers using an European timezone will have to update
their timezone databases to account for this. The NTP/NTS protocols, servers or clients will not need any changes.
## efee
fedora powinna postawić własny serwer z własnym zegarem a nie promować jakieś niepotrzebne programiki
## Sergey
Will it also work with a self-signed certificate ?
## Miroslav Lichvar
Yes, you can use a self-signed certificate if the clients have the certificate specified in chrony.conf with the
directive.
## Tomasz
Thanks for implementing NTS!
But wouldn’t it be better to have opportunistic NTS? I.e. try NTS with each specified
and fallback to classic NTP on failure. Then the keyword could be turned around to
to disable this for specific servers, but we would get NTS by default without special configuration.
## Miroslav Lichvar
Opportunistic NTS might be an interesting feature, but if there was no option to force NTS, or it wasn’t forced by default, it would enable a downgrade attack. A man-in-the-middle attacker could just block the NTS-KE connection.
In any case, it would generate extra traffic and load for the servers. As an operator of several servers included in the pool.ntp.org pool, I probably wouldn’t be very happy with a large number of clients trying TLS with a wrong server name, which would fail in the certificate validation. If pool.ntp.org supports NTS at some point, it will probably have an NTS-specific zone. We cannot expect that all NTP servers will support NTS.
## Andrew
couldnt get it working. I followed the instructions above but chronyc sources is empty with any individual server active or even all three of them. I comment them all out and use the standard fedora pool again and chronyc sources shows correct info again. what am i missing?
## Andrew
I got help with this from Miroslav (credit where credit’s due). I was doing it wrong, because i’d seen an article/howto on NetNods website explaining how to configure (primarily) ntpd for NTS and in their config example they’d listed the server with the port number at the end:
https://www.netnod.se/time-and-frequency/how-to-use-nts
server nts.ntp.se:3443 nts iburst
server nts.sth1.ntp.se:3443 nts iburst
server nts.sth2.ntp.se:3443 nts iburst
with a update note below that informing of the port change to 4460. I hadnt engaged my brain when I just pasted that into chrony.conf. When I removed the “:4460” bit then everything worked perfectly.
The article above is correct; I didn’t want to use Cloudfares server, but it didn’t click that the server entries below that were the Swedish servers, which were appropriate for me, so i’d been searching other sites for other NTS enabled servers and came across NetNod.
## Florencia Fotorello
Great article! |
12,862 | 使用你喜欢的编程语言,将基础设施作为代码进行配置 | https://opensource.com/article/20/8/infrastructure-as-code-pulumi | 2020-11-27T15:11:43 | [
"IaC",
"基础架构即代码"
] | https://linux.cn/article-12862-1.html |
>
> 用 Node.js 或其他编程语言为你提供启动基础设施所需的一切服务。
>
>
>

当你在 IT 和技术的世界里遨游时,你会反复遇到一些术语。其中有些术语很难量化,随着时间的推移,可能会有不同的含义。[“DevOps”](https://opensource.com/resources/devops) 就是一个例子,这个词似乎(在我看来)会根据使用它的人而改变;最初的 DevOps 先驱者可能甚至不认识我们今天所说的 DevOps。
如果你是一个软件开发者,“<ruby> 基础架构即代码 <rt> Infrastructure as Code </rt></ruby>”(IaC)可能是其中一个术语。IaC 是使用与你编写面向用户的功能相同的软件开发实践来声明应用程序运行的基础设施。这通常意味着使用 [Git](https://git-scm.com/) 或 [Mercurial](https://www.mercurial-scm.org/) 等工具进行版本控制,使用 Puppet、Chef 或 Ansible 进行[配置管理](https://opensource.com/article/18/12/configuration-management-tools)。在基础设施供应层,最常见的技术是 CloudFormation(专用于 AWS),或开源替代品 [Terraform](https://opensource.com/article/20/7/terraform-kubernetes),用来创建供你的应用程序运行的混合云资源。
在配置管理领域有很好产品可供选择,可以将 IaC 写成配置文件或首选的编程语言,但这种选择在基础设施供应领域并不常见。
[Pulumi](https://www.pulumi.com/) 提供了一个使用标准编程语言来定义基础设施的方式。它支持一系列语言,包括 [JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript)、[TypeScript](https://www.typescriptlang.org/)、[Go](https://golang.org/)、[Python](https://www.python.org/) 和 [C#](https://en.wikipedia.org/wiki/C_Sharp_(programming_language))。就像 Terraform 一样,Pulumi 对许多熟悉的云提供商有一流的支持,比如 [AWS](https://www.pulumi.com/docs/intro/cloud-providers/aws/)、[Azure](https://www.pulumi.com/docs/intro/cloud-providers/azure/)、[Google Cloud](https://www.pulumi.com/docs/intro/cloud-providers/gcp/) 和[其他提供商](https://www.pulumi.com/docs/reference/pkg/)。
在本文中,我将向你展示如何使用 Pulumi 以 Node.js 编写基础设施。
### 先决条件
首先,确保你已经做好了使用 Pulumi 的准备。Pulumi 支持所有主流的操作系统,所以你安装其先决条件的方法取决于你使用的操作系统。
首先,安装你喜欢的编程语言的解释器。我将使用 TypeScript,所以我需要安装 `node` 二进制。请查阅 Node 的[安装说明](https://nodejs.org/en/download/),了解你的操作系统的信息。你可以在 [Mac](https://opensource.com/article/20/6/homebrew-mac) 或 [Linux](https://opensource.com/article/20/6/homebrew-linux) 上使用 [Homebrew](https://brew.sh/) 来安装:
```
brew install node
```
在 Linux 上,你可以使用你常用的软件包管理器,如 `apt` 或 `dnf`。
```
$ sudo dnf install nodejs
```
无论哪种情况,结果都应该是 `node` 二进制文件在你的 `$PATH` 中可用。要确认它是可访问的,运行:
```
node --version
```
接下来,安装 Pulumi 命令行界面(CLI)。你可以在 Pulumi 的文档中找到针对不同操作系统的[安装说明](https://www.pulumi.com/docs/get-started/install/)。在 Mac 或 Linux 上使用 `brew`:
```
brew install pulumi
```
另外,你也可以使用安装脚本。首先下载并审查它,然后执行它:
```
$ curl -fsSL --output pulumi_installer.sh https://get.pulumi.com/
$ more pulumi_installer.sh
$ sh ./pulumi_installer.sh
```
同样,我们所希望的结果是在你的路径上有 `pulumi` 二进制。检查版本以确保你已经准备好了:
```
pulumi version
v2.5.0
```
### 配置 Pulumi
在你开始配置任何基础设施之前,给 Pulumi 一个存储其[状态](https://www.pulumi.com/docs/intro/concepts/state/)的地方。
Pulumi 将其状态存储在后端。默认的后端是 Pulumi 的软件即服务(它有一个针对个人用户的免费计划),但在这个例子中,我使用替代的文件后端。文件后端将在你的本地文件系统上创建一个文件来存储状态:
```
pulumi login --local
```
如果你打算和别人分享这个项目,文件后台可能不是一个好的起点。Pulumi 还可以将其状态存储在 AWS S3 等云对象存储中。要使用它,请创建一个 S3 bucket 并登录:
```
pulumi login --cloud-url s3://my-pulumi-state-bucket
```
现在你已经登录到了状态后端,你可以创建一个项目和一个堆栈了!
在你开始创建 Pulumi 项目之前,请先了解以下 Pulumi 术语,你将在本教程中看到这些术语。
#### 项目
<ruby> <a href="https://www.pulumi.com/docs/intro/concepts/project/"> 项目 </a> <rt> project </rt></ruby>是一个包含 `Pulumi.yaml` 文件的目录。这个文件包含了 Pulumi 需要知道的元数据,以便进行它的工作。在 `Pulumi.yaml` 文件中可以找到的示例字段有:
* 运行时(例如,Python、Node、Go、.Net)
* 项目说明(如“我的第一个 Pulumi 项目”)
* 项目名称
项目是一个松散的概念,可以满足你的需求。一般来说,一个项目包含了一系列的*资源*,这些资源是你想要提供和控制的东西。你可以选择拥有资源很少的小型 Pulumi 项目,也可以选择包含所有你需要的资源的大型项目。随着你对 Pulumi 越来越熟悉,你想如何布局你的项目会变得更加清晰。
#### 堆栈
Pulumi <ruby> <a href="https://www.pulumi.com/docs/intro/concepts/stack/"> 堆栈 </a> <rt> stack </rt></ruby>允许你根据可配置的值来区分你的 Pulumi 项目。一个常见的用途是将一个项目部署到不同的环境,如开发或生产环境,或不同的地区,如欧洲、中东和非洲以及美国。
在入门时,你不大需要一个复杂的堆栈设置,所以本演练使用默认的堆栈名称 `dev`。
### 在 IaC 中使用 TypeScript
你可以使用方便的 `pulumi new` 命令来<ruby> 初建 <rt> bootstrap </rt></ruby>一个 Pulumi 项目。`new` 命令有一大堆标志和选项,可以帮助你入门 Pulumi,所以请继续创建你的第一个项目:
```
$ pulumi new typescript
This command will walk you through creating a new Pulumi project.
Enter a value or leave blank to accept the (default), and press <ENTER>.
Press ^C at any time to quit.
project name: (pulumi) my-first-project
project description: (A minimal TypeScript Pulumi program) My very first Pulumi program
Created project 'my-first-project'
Please enter your desired stack name.
To create a stack in an organization, use the format <org-name>/<stack-name> (e.g. `acmecorp/dev`).
stack name: (dev) dev
Created stack 'dev'
Installing dependencies...
> node scripts/postinstall
added 82 packages from 126 contributors and audited 82 packages in 2.84s
13 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Finished installing dependencies
Your new project is ready to go! ✨
To perform an initial deployment, run 'pulumi up'
```
这里发生了很多事情,我将其展开来说:
第一部分是为你的 Pulumi 项目确定一个模板。我选择了通用的 `typescript` 选项,但是有[很多选项可供选择](https://github.com/pulumi/templates)。
这个 `new` 命令从你的模板库中抓取模板,并将这个文件复制到本地,包括运行时的依赖关系(在本例中是 `package.json`)。
`new` 命令通过在这个目录下运行 `npm install` 来安装这些依赖关系。然后 `npm install` 下载并安装运行 Pulumi 程序所需的一切,在这种情况下就是:`@pulumi/pulumi` NPM 包。
你已经准备好创建你的第一个资源了!
### 创建你的第一个云资源
资源是一个由你的基础设施供应软件生命周期进行管理的东西。资源一般是一个<ruby> 云提供商对象 <rt> cloud provider object </rt></ruby>,比如 S3 桶。Pulumi 的提供商处理 Pulumi 资源,提供商是具体的云提供商。Pulumi 有大约 [40 个提供商](https://www.pulumi.com/docs/intro/cloud-providers/)可供你使用,但对于你的第一个资源,使用一个最简单的:<ruby> <a href="https://www.pulumi.com/docs/intro/cloud-providers/random/"> 随机提供商 </a> <rt> random provider </rt></ruby>。
随机提供者顾名思义:它幂等地创建一个随机资源(例如,可以是一个字符串),并将其存储在 Pulumi 状态中。
使用 `npm` 将其添加到你的 Pulumi 项目中作为依赖关系:
```
npm install @pulumi/random
```
npm 包管理器下载并安装随机提供者包,并为你安装。现在你已经准备好编写你的 Pulumi 程序了。
当你之前生成你的项目时,Pulumi 的初建过程创建了一个 `index.ts` TypeScript 文件。在你喜欢的集成开发环境(IDE)中打开它,并添加你的第一个资源:
```
import * as pulumi from "@pulumi/pulumi";
import * as random from "@pulumi/random";
const password = new random.RandomString(`password`, {
length: 10
})
```
如果你对 TypeScript 或 JavaScript 非常熟悉,这看起来会非常熟悉,因为它是用你熟悉的编程语言编写的。如果你使用的是 Pulumi 支持的其他语言之一,也是一样的。这里是之前的那个随机资源,但这次是用 Python 写的:
```
import pulumi_random as random
password = random.RandomString("password", length=10)
```
一个 Pulumi 项目目前只支持单一一种语言,但每个项目都可以引用其他语言编写的项目,这对于多语言团队的成员来说是一个很有用的技巧。
你已经编写了第一个 Pulumi 资源。现在你需要部署它。
离开编辑器,回到命令行。在你的项目目录下,运行 `pulumi up`,然后看着神奇的事情发生:
```
pulumi up
Previewing update (dev):
Type Name Plan
+ pulumi:pulumi:Stack my-first-project-dev create
+ └─ random:index:RandomString password create
Resources:
+ 2 to create
Do you want to perform this update? yes
Updating (dev):
Type Name Status
+ pulumi:pulumi:Stack my-first-project-dev created
+ └─ random:index:RandomString password created
Resources:
+ 2 created
Duration: 2s
Permalink: file:///Users/lbriggs/.pulumi/stacks/dev.json
```
太好了,你有了第一个 Pulumi 资源! 虽然你可能很享受这种成就感,但不幸的是,这个随机资源并没有那么有用:它只是一个随机的字符串,你甚至看不到它是什么。先解决这部分问题。修改你之前的程序,在你创建的常量中加入 `export`:
```
import * as pulumi from "@pulumi/pulumi";
import * as random from "@pulumi/random";
export const password = new random.RandomString(`password`, {
length: 10
})
```
重新运行 `pulumi up`,看看输出:
```
pulumi up
Previewing update (dev):
Type Name Plan
pulumi:pulumi:Stack my-first-project-dev
Outputs:
+ password: {
+ id : "&+r?{}J$J7"
+ keepers : output<string>
+ length : 10
+ lower : true
+ minLower : 0
+ minNumeric : 0
+ minSpecial : 0
+ minUpper : 0
+ number : true
+ overrideSpecial: output<string>
+ result : "&+r?{}J$J7"
+ special : true
+ upper : true
+ urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
2 unchanged
Do you want to perform this update? yes
Updating (dev):
Type Name Status
pulumi:pulumi:Stack my-first-project-dev
Outputs:
+ password: {
+ id : "&+r?{}J$J7"
+ length : 10
+ lower : true
+ minLower : 0
+ minNumeric: 0
+ minSpecial: 0
+ minUpper : 0
+ number : true
+ result : "&+r?{}J$J7"
+ special : true
+ upper : true
+ urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
2 unchanged
Duration: 1s
Permalink: file:///Users/lbriggs/.pulumi/stacks/dev.json
```
现在你可以在 `Outputs` 的 `result` 部分下看到一个随机生成的字符串。你现在可以看到你创建的资源有很多属性。
这一切都很好,但如果你想享受 IaC,你得提供一些随机字符串以外的东西。试试吧。
### 部署一个容器
到目前为止,你已经通过安装依赖关系和注册一个简单的随机资源来 体验了初建你的 Pulumi。现在部署一些实际的基础设施,尽管是在你的本地机器上。
首先,将 `@pulumi/docker` 提供者添加到你的堆栈中。使用你选择的包管理器将其添加到项目中:
```
npm install @pulumi/docker
```
你已经从 `npm` 下拉了 Pulumi Docker 提供商包,这意味着你现在可以在你的项目中创建 Docker 镜像。
如果你的机器上还没有安装 Docker,现在是一个极好的时机去安装它。说明将取决于你的操作系统,所以看看 [Docker 的安装页面](https://docs.docker.com/get-docker/)了解信息。
再次打开你喜欢的 IDE,运行一个 Docker 容器。修改你之前的 `index.ts` 文件,让它看起来像这样:
```
import * as pulumi from "@pulumi/pulumi";
import * as random from "@pulumi/random";
import * as docker from "@pulumi/docker";
const password = new random.RandomString(`password`, {
length: 10
})
const container = new docker.Container(`my-password`, {
image: 'hashicorp/http-echo',
command: [ pulumi.interpolate`-text=Your super secret password is: ${password.result}` ],
ports: [{
internal: 5678,
external: 5678,
}]
})
export const id = container.id
```
这将创建一个容器,创建一个 Web 服务器。Web 服务器的输出是你随机生成的字符串,在本例中是一个密码。运行这个,看看会发生什么:
```
pulumi up
Previewing update (dev):
Type Name Plan
pulumi:pulumi:Stack my-first-project-dev
+ └─ docker:index:Container my-password create
Outputs:
+ id : output<string>
~ password: {
id : "&+r?{}J$J7"
length : 10
lower : true
minLower : 0
minNumeric: 0
minSpecial: 0
minUpper : 0
number : true
result : "&+r?{}J$J7"
special : true
upper : true
urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
+ 1 to create
2 unchanged
Do you want to perform this update? yes
Updating (dev):
Type Name Status
pulumi:pulumi:Stack my-first-project-dev
+ └─ docker:index:Container my-password created
Outputs:
+ id : "e73b34aeca34a64b72b61b0b9b8438637ce28853937bc359a1528ca99f49ddda"
password: {
id : "&+r?{}J$J7"
length : 10
lower : true
minLower : 0
minNumeric: 0
minSpecial: 0
minUpper : 0
number : true
result : "&+r?{}J$J7"
special : true
upper : true
urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
+ 1 created
2 unchanged
Duration: 2s
Permalink: file:///Users/lbriggs/.pulumi/stacks/dev.json
```
你会注意到在 `Outputs` 部分,你输出的值已经改变了,它只是一个 Docker 容器 ID。检查你的非常简单的密码生成器是否工作:
```
curl http://localhost:5678
Your super secret password is: &+r?{}J$J7
```
就是这样! 你刚刚用 TypeScript 配置了你的第一个基础架构。
#### 关于 Pulumi 输出的快速说明
你会注意到在创建 Docker 容器的代码中,它使用了一个特殊的 `pulumi.interpolate` 调用。如果你熟悉 TypeScript,你可能会好奇为什么需要这样做(因为它是 Pulumi 特有的)。这有一个有趣的原因。
当 Pulumi 创建一个资源时,直到程序执行时有一些值是 Pulumi 不知道的。在 Pulumi 中,这些值被称为 `Outputs`。这些 `Outputs` 可以在上面的代码中看到,例如,在你的第一个随机资源中,你使用 `export` 关键字来输出随机资源的属性,你还输出了你创建的容器的容器 ID。
因为 Pulumi 直到执行时才知道这些 `Outputs` 的值,所以在操作字符串时,它需要特殊的助手来使用它们。如果你想了解更多关于这个特殊的编程模型,请观看[这个短视频](https://www.youtube.com/watch?v=lybOxul2otM)。
### 总结
随着混合云基础架构中出现的复杂性,IaC 在很多方面都有了发展。在基础设施供应领域,Pulumi 是一个很好的选择,它可以使用你最喜欢的编程语言来供应你所需要的一切基础设施,然后你可以在你最喜欢的配置管理工具中进行标记,以采取下一步措施。
---
via: <https://opensource.com/article/20/8/infrastructure-as-code-pulumi>
作者:[Lee Briggs](https://opensource.com/users/lbriggs) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As you navigate the world of IT and technology, there are some terms you come across repeatedly. Some of them are hard to quantify and may take on different meanings as time goes on. ["DevOps"](https://opensource.com/resources/devops) is an example of a word that seems (to me) to change depending on the person using it; the original DevOps pioneers might not even recognize what we call DevOps today.
If you're a software developer, "Infrastructure as Code" (IaC) may be one of those terms. IaC is using the same software-development practices you'd use to write user-facing features to declare the infrastructure that applications run on. This often means using tools like [Git](https://git-scm.com/) or [Mercurial](https://www.mercurial-scm.org/) for version control and Puppet, Chef, or Ansible for [configuration management](https://opensource.com/article/18/12/configuration-management-tools). At the infrastructure-provisioning layer, the most common technology is CloudFormation (for AWS specifically) or [Terraform](https://opensource.com/article/20/7/terraform-kubernetes) as an open source alternative for creating hybrid-cloud resources for your applications to run on.
There are great options in the configuration-management space to write IaC as either configuration files or preferred programming languages, but this choice is not well-known in the infrastructure-provisioning space.
[Pulumi](https://www.pulumi.com/) offers an option to use standard programming languages to define infrastructure. It supports an array of languages, including [JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript), [TypeScript](https://www.typescriptlang.org/), [Go](https://golang.org/), [Python](https://www.python.org/) and [C#](https://en.wikipedia.org/wiki/C_Sharp_(programming_language)). Much like Terraform, Pulumi has first-class support for many familiar cloud providers, like [AWS](https://www.pulumi.com/docs/intro/cloud-providers/aws/), [Azure](https://www.pulumi.com/docs/intro/cloud-providers/azure/), [Google Cloud](https://www.pulumi.com/docs/intro/cloud-providers/gcp/), and [other providers](https://www.pulumi.com/docs/reference/pkg/).
In this article, I'll show you how to use Pulumi to write infrastructure in Node.js.
## Prerequisites
First, make sure you're ready to use Pulumi. Pulumi supports all major operating systems, so the methods you use to install its prerequisites depend on the operating system you're using.
First, install the interpreter for your preferred programming language. I'll be using TypeScript, so I need to install the `node`
binary. Consult Node's [installation instructions](https://nodejs.org/en/download/) for information about your operating system. You can use [Homebrew](https://brew.sh/) on [Mac](https://opensource.com/article/20/6/homebrew-mac) or [Linux](https://opensource.com/article/20/6/homebrew-linux) to install:
`brew install node`
On Linux, you can alternately use your usual package manager, such as **apt** or **dnf**:
`$ sudo dnf install nodejs`
In either case, the result should be that the `node`
binary is available in your `$PATH`
. To confirm it's accessible, run:
`node --version`
Next, install the Pulumi command-line interface (CLI). You can find operating system-specific [installation instructions](https://www.pulumi.com/docs/get-started/install/) in Pulumi's docs. With `brew`
on a Mac or Linux:
`brew install pulumi`
Alternately, you can use the install script. First download it and review it, and then execute it:
```
$ curl -fsSL --output pulumi_installer.sh \
https://get.pulumi.com/
$ more pulumi_installer.sh
$ sh ./pulumi_installer.sh
```
Again, the desired result is to have the `pulumi`
binary available in your path. Check the version to make sure you're ready to proceed:
```
pulumi version
v2.5.0
```
## Configure Pulumi
Before you start provisioning any infrastructure, give Pulumi somewhere to store its [state](https://www.pulumi.com/docs/intro/concepts/state/).
Pulumi stores its state in a backend. The default backend is Pulumi's software-as-a-service (which has a free plan for individual users), but for this example, use the alternative file backend. The file backend will create a file on your local filesystem to store the state with:
`pulumi login --local`
If you're planning on sharing this project with someone else, the file backend might not be a good starting point. Pulumi can also store its state in a cloud object store like AWS S3. To use it, create an S3 bucket and log in:
`pulumi login --cloud-url s3://my-pulumi-state-bucket`
Now that you've logged into a state backend, you can create a project and a stack!
Before you start creating a Pulumi project, get to know the following Pulumi terminology, which you'll see in this tutorial.
### Project
A [project](https://www.pulumi.com/docs/intro/concepts/project/) is a directory that contains a Pulumi.yaml file. This file contains metadata Pulumi needs to know to do its thing. Example fields you'll find in a Pulumi.yaml file are:
- The runtime (e.g., Python, Node, Go, .Net)
- A description of the project (e.g., "my first Pulumi project")
- A name for the project
A project is a loosely defined concept that can fit your needs. Generally, a project contains a bunch of *resources*, which are things you want to provision and control. You might choose to have small Pulumi projects with very few resources or large projects that contain all the resources you need. As you become more familiar with Pulumi, it'll become more apparent how you want to lay out your projects.
### Stack
A Pulumi [stack](https://www.pulumi.com/docs/intro/concepts/stack/) allows you to differentiate your Pulumi projects depending on configurable values. A common use is to deploy a project to different environments like development or production or different regions like Europe, the Middle East and Africa, and the US.
When getting started, you're not likely to need a complex stack setup, so this walkthrough uses the default stack name, `dev`
.
## Use TypeScript for IaC
You can bootstrap a Pulumi project using the handy `pulumi new`
command. The `new`
command has a whole host of flags and options that should help you get started with Pulumi, so go ahead and create your first project:
```
$ pulumi new typescript
This command will walk you through creating a new Pulumi project.
Enter a value or leave blank to accept the (default), and press <ENTER>.
Press ^C at any time to quit.
project name: (pulumi) my-first-project
project description: (A minimal TypeScript Pulumi program) My very first Pulumi program
Created project 'my-first-project'
Please enter your desired stack name.
To create a stack in an organization, use the format <org-name>/<stack-name> (e.g. `acmecorp/dev`).
stack name: (dev) dev
Created stack 'dev'
Installing dependencies...
> node scripts/postinstall
added 82 packages from 126 contributors and audited 82 packages in 2.84s
13 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Finished installing dependencies
Your new project is ready to go! ✨
To perform an initial deployment, run 'pulumi up'
```
A lot happened here, so I'll break it down:
The first part identifies a template for your Pulumi project. I chose the generic `typescript`
option, but there are [many options available](https://github.com/pulumi/templates).
This `new`
command grabbed the template from your templates repository and copied this file locally, including the runtime dependencies (in this case, `package.json`
).
The `new`
command took care of installing those dependencies by running `npm install`
inside this directory. Then `npm install`
downloaded and installed everything needed to run your Pulumi program, which, in this case, is very straightforward: the `@pulumi/pulumi`
NPM package.
You're ready to create your very first resource!
## Create your first cloud resource
A resource is a thing that is managed by your infrastructure-provisioning software lifecycle. Resources are generally a cloud provider object, like an S3 bucket. Pulumi providers handle Pulumi resources, and providers are specific to the cloud provider they manage. Pulumi has around [40 providers](https://www.pulumi.com/docs/intro/cloud-providers/) you can use, but for your first resource, use one of the simplest—the [random provider](https://www.pulumi.com/docs/intro/cloud-providers/random/).
The random provider does what the name suggests: it idempotently creates a random resource (which could be a string, for example) and stores it in the Pulumi state.
Add this as a dependency to your Pulumi project using npm:
`npm install @pulumi/random`
The npm package manager downloads and installs the random provider package and installs it for you. Now you're ready to write your Pulumi program.
When you generated your project earlier, Pulumi's bootstrap process created an `index.ts`
TypeScript file. Open it in your favorite integrated development environment (IDE) and add your first resource:
```
import * as pulumi from "@pulumi/pulumi";
import * as random from "@pulumi/random";
const password = new random.RandomString(`password`, {
length: 10
})
```
If you're at all familiar with TypeScript or JavaScript, this will look very familiar because it's written in a programming language you know. This also applies if you're using one of Pulumi's other supported languages. Here's that same random resource from before, but this time in Python:
```
import pulumi_random as random
password = random.RandomString("password", length=10)
```
Pulumi projects currently support only a single language, but each project can reference other projects written in other languages—a useful trick for members of the polyglot team.
You've written your first Pulumi resource. Now you need to deploy it.
Leave your editor and head back to the command line. From your project directory, run `pulumi up`
and watch the magic happen:
```
pulumi up
Previewing update (dev):
Type Name Plan
+ pulumi:pulumi:Stack my-first-project-dev create
+ └─ random:index:RandomString password create
Resources:
+ 2 to create
Do you want to perform this update? yes
Updating (dev):
Type Name Status
+ pulumi:pulumi:Stack my-first-project-dev created
+ └─ random:index:RandomString password created
Resources:
+ 2 created
Duration: 2s
Permalink: file:///Users/lbriggs/.pulumi/stacks/dev.json
```
Excellent, you have your first Pulumi resource! While you might be enjoying this sense of achievement, unfortunately, this random resource isn't that useful—it's just a random string, and you can't even see what it is. Address that part first: Modify your earlier program and add `export`
to the constant you created:
```
import * as pulumi from "@pulumi/pulumi";
import * as random from "@pulumi/random";
export const password = new random.RandomString(`password`, {
length: 10
})
```
Rerun `pulumi up`
and look at the output:
```
pulumi up
Previewing update (dev):
Type Name Plan
pulumi:pulumi:Stack my-first-project-dev
Outputs:
+ password: {
+ id : "&+r?{}J$J7"
+ keepers : output<string>
+ length : 10
+ lower : true
+ minLower : 0
+ minNumeric : 0
+ minSpecial : 0
+ minUpper : 0
+ number : true
+ overrideSpecial: output<string>
+ result : "&+r?{}J$J7"
+ special : true
+ upper : true
+ urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
2 unchanged
Do you want to perform this update? yes
Updating (dev):
Type Name Status
pulumi:pulumi:Stack my-first-project-dev
Outputs:
+ password: {
+ id : "&+r?{}J$J7"
+ length : 10
+ lower : true
+ minLower : 0
+ minNumeric: 0
+ minSpecial: 0
+ minUpper : 0
+ number : true
+ result : "&+r?{}J$J7"
+ special : true
+ upper : true
+ urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
2 unchanged
Duration: 1s
Permalink: file:///Users/lbriggs/.pulumi/stacks/dev.json
```
Now you can see a randomly generated string under the `result`
section of the `Outputs`
. The resource you created has a number of properties that you can see now.
This is all well and good, but if you want to enjoy IaC, you're going to have to provision something other than a random string. Give it a try!
## Deploy a container
So far, you've bootstrapped your Pulumi experience by installing dependencies and registered a simple random resource. Now deploy some actual infrastructure, albeit to your local machine.
First, add the `@pulumi/docker`
provider to your stack. Use your chosen package manager to add it to the project:
`npm install @pulumi/docker`
You've pulled down the Pulumi Docker provider package from npm, which means you can now create Docker images in your project.
If you don't have Docker installed on your machine, now is an excellent time to get it. Instructions will depend on your operating system, so take a look at [Docker's installation page](https://docs.docker.com/get-docker/) for information.
Open up your favorite IDE again and run a Docker container. Modify your `index.ts`
file from earlier to make it look like this:
```
import * as pulumi from "@pulumi/pulumi";
import * as random from "@pulumi/random";
import * as docker from "@pulumi/docker";
const password = new random.RandomString(`password`, {
length: 10
})
const container = new docker.Container(`my-password`, {
image: 'hashicorp/http-echo',
command: [ pulumi.interpolate`-text=Your super secret password is: ${password.result}` ],
ports: [{
internal: 5678,
external: 5678,
}]
})
export const id = container.id
```
This creates a container that creates a web server. The output of the web server is your randomly generated string, in this case, a password. Run this and see what happens:
```
pulumi up
Previewing update (dev):
Type Name Plan
pulumi:pulumi:Stack my-first-project-dev
+ └─ docker:index:Container my-password create
Outputs:
+ id : output<string>
~ password: {
id : "&+r?{}J$J7"
length : 10
lower : true
minLower : 0
minNumeric: 0
minSpecial: 0
minUpper : 0
number : true
result : "&+r?{}J$J7"
special : true
upper : true
urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
+ 1 to create
2 unchanged
Do you want to perform this update? yes
Updating (dev):
Type Name Status
pulumi:pulumi:Stack my-first-project-dev
+ └─ docker:index:Container my-password created
Outputs:
+ id : "e73b34aeca34a64b72b61b0b9b8438637ce28853937bc359a1528ca99f49ddda"
password: {
id : "&+r?{}J$J7"
length : 10
lower : true
minLower : 0
minNumeric: 0
minSpecial: 0
minUpper : 0
number : true
result : "&+r?{}J$J7"
special : true
upper : true
urn : "urn:pulumi:dev::my-first-project::random:index/randomString:RandomString::password"
}
Resources:
+ 1 created
2 unchanged
Duration: 2s
Permalink: file:///Users/lbriggs/.pulumi/stacks/dev.json
```
You'll notice in the `Outputs`
section that the values you're outputting have changed; it's just a Docker container ID. Check whether your very simple password generator works:
```
curl http://localhost:5678
Your super secret password is: &+r?{}J$J7
```
It does! You just provisioned your first piece of infrastructure with TypeScript!
### A quick note on Pulumi outputs
You'll notice in the code that creates the Docker container that it uses a special `pulumi.interpolate`
call. If you're familiar with TypeScript, you might be curious why that's needed (as it's Pulumi-specific). There's an interesting reason.
When Pulumi creates a resource, there are values that Pulumi doesn't know until the program executes. In Pulumi, these are called `Outputs`
. These `Outputs`
can be seen in the code above; for example, in your first random resource, you used the `export`
keyword to output the random resource's properties, and you also exported the container ID of the container you created.
Because Pulumi doesn't know the value of these `Outputs`
until execution time, it needs special helpers to use them when manipulating strings. If you want to know more about this special programming model, watch [this short video](https://www.youtube.com/watch?v=lybOxul2otM).
## Wrapping up
IaC has evolved in many ways as complexity has arisen in hybrid-cloud infrastructures. In the infrastructure-provisioning space, Pulumi is a great choice for using your favorite programming language to provision everything you need to get your infrastructure off the ground, then you can tag in your favorite configuration management tooling to take the next steps.
## Comments are closed. |
12,864 | 使用 LVM 扩展卷空间 | https://fedoramagazine.org/reclaim-hard-drive-space-with-lvm/ | 2020-11-27T19:38:52 | [
"LVM"
] | https://linux.cn/article-12864-1.html | 
LVM 是一个逻辑卷管理工具,包括分配磁盘、条带化、镜像和调整逻辑卷的大小。它在 Fedora 安装中被普遍使用(在 BTRFS 作为默认文件系统之前是 LVM + Ext4)。但是你是否曾经遇到过启动系统时,GNOME 提示 home 卷几乎没有空间了!幸运的是,很有可能有一些空间在另一个卷中,而未被使用,可以用于重新分配。下面就来看看如何用 LVM 回收硬盘空间。
在卷之间轻松重新分配空间的关键是[逻辑卷管理器(LVM)](http://sourceware.org/lvm2/)。Fedora 32 及以前的系统默认使用 LVM 来划分磁盘空间。这种技术类似于标准的硬盘分区,但 LVM 更加灵活。LVM 不仅可以实现灵活的卷大小管理,还可以实现一些高级功能,比如读写快照、在多个硬盘上进行数据条带化或镜像、将高速硬盘作为慢速硬盘的缓存等等。所有这些高级选项可能会让人有点不知所措,但调整卷的大小很简单的。
### LVM 基础
**卷组**(VG)作为 LVM 系统中的主要容器。默认情况下,Fedora 只定义了一个卷组,但你可以根据需要定义多个卷组。实际的硬盘和硬盘分区被添加到卷组中作为**物理卷**(PV)。物理卷会将可用的空间添加到卷组中。一个典型的 Fedora 安装有一个格式化的启动分区,其余的硬盘是一个配置为 LVM 物理卷的分区。
从这个可用空间池中,卷组分配了一个或多个**逻辑卷**(LV)。这些卷类似于硬盘分区,但没有磁盘上连续空间的限制。LVM 的逻辑卷甚至可以跨越多个设备!就像硬盘分区一样,逻辑卷有一个定义的大小,可以包含任何文件系统,然后可以挂载到特定的目录。
### 需要什么
在 gnome-disks 应用中确认系统使用 LVM ,并确保其他卷中有可用的空间。如果没有可以从另一个卷中回收的空间,这个指南就没有用。还需要一个 [Fedora 临场 CD/USB](https://getfedora.org/en/workstation/download/)。任何需要收缩的文件系统都必须卸载。从<ruby> 临场 <rt> Live </rt></ruby>镜像运行,可以让硬盘上的所有卷保持未挂载状态,甚至包括像 `/` 和 `/home` 这样的重要目录。

### 一句话警告
按照这个指南,应该不会丢失任何数据,但它确实会使用一些非常底层和强大的命令。一个错误可能会破坏硬盘上的所有数据。所以要先备份磁盘上的所有数据!
### 调整 LVM 卷的大小
开始时,启动 Fedora 临场镜像并在对话框中选择 “Try Fedora”。接下来,使用 “Run Command” 启动 “blivet-gui” 应用(按 `Alt-F2`,输入 `blivet-gui`,然后按回车)。选择左侧 “LVM” 下的卷组。逻辑卷在右边。

逻辑卷标签由卷组名称和逻辑卷名称组成。在本例中,卷组是 `fedora_localhost-live`,分配了 `home`、`root` 和 `swap` 逻辑卷。要找到完整的卷,选择每一个卷,点击“齿轮”图标,然后选择 “resize”。调整大小对话框中的滑块表示卷的允许大小。左边的最小值是文件系统中已经使用的空间,所以这是最小可能的尺寸大小(不删除数据)。右边的最大值是基于卷组中的最大可用空间。

灰色的 “resize” 选项意味着该卷已经满了,而且卷组中没有可用空间。
现在可以更改大小了!查看所有的卷,就像上面的截图那样,找到一个有足够空间的卷。并像上面的截图那样,在所有的卷中找到一个有大量额外空间的卷。向左移动滑块来设置新的大小。腾出足够的空间对整个卷有用,但仍然要为未来的数据增长留出足够的空间。否则,这个卷将是下一个被填满的卷。
点击 “resize”,注意卷列表中出现了一个新项目:“free space”。现在选择这次要调整的卷,并将滑块一直向右移动。按 “resize” 键,并查看新改进的卷的布局。然而,硬盘驱动器上的任何东西现在都还没有改变。点击“勾选”选项将更改提交到磁盘。

查看更改的摘要,如果一切看起来都是正确的,点击 “Ok” 继续。等待 “blivet-gui” 完成。现在重新启动回到 Fedora,可以使用之前被充满的卷上的新空间了。
### 为未来计划
要知道任何特定卷在未来需要多少空间是很困难的。与其立即分配所有可用的空闲空间,不如考虑在卷组中留出空闲空间。事实上,Fedora Server 默认在卷组中保留空间。当一个卷处于在线和使用中时,扩展卷是可能的。不需要临场镜像或重启。当一个卷几乎满的时候,可以使用部分可用空间轻松扩展卷并继续工作。遗憾的是,默认的磁盘管理器 gnome-disks 不支持 LVM 卷的大小调整,所以安装 [blivet-gui](https://fedoraproject.org/wiki/Blivet-gui) 作为图形化管理工具。另外,还有一个简单的终端命令来扩展卷:
```
lvresize -r -L +1G /dev/fedora_localhost-live/root
```
### 总结
用 LVM 回收硬盘空间只是 LVM 功能的表面。大多数人,特别是在桌面中,可能不需要更高级的功能。然而,当需要的时候,LVM 就在那里,尽管它的实现可能会变得有点复杂。从 [Fedora 33](https://fedoramagazine.org/whats-new-fedora-33-workstation/) 开始,[BTRFS](https://fedoramagazine.org/btrfs-coming-to-fedora-33/) 是默认的文件系统,没有 LVM。BTRFS 可以更容易管理,同时对于大多数常见的使用来说也足够灵活。查看最近 [Fedora Magazine 关于 BTRFS 的文章](https://fedoramagazine.org/btrfs-snapshots-backup-incremental/)了解更多。
---
via: <https://fedoramagazine.org/reclaim-hard-drive-space-with-lvm/>
作者:[Troy Curtis Jr](https://fedoramagazine.org/author/troycurtisjr/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | LVM is a tool for logical volume management which includes allocating disks, striping, mirroring and resizing logical volumes. It is commonly used on Fedora installations (prior to BTRFS as default it was LVM+Ext4). But have you ever started up your system to find out that Gnome just said the home volume is almost out of space! Luckily, there is likely some space sitting around in another volume, unused and ready to re-alocate. Here’s how to reclaim hard-drive space with LVM.
The key to easily re-alocate space between volumes is the [Logical Volume Manager (LVM)](http://sourceware.org/lvm2/). Fedora 32 and before use LVM to divide disk space by default. This technology is similar to standard hard-drive partitions, but LVM is a lot more flexible. LVM enables not only flexible volume size management, but also advanced capabilities such as read-write snapshots, striping or mirroring data across multiple drives, using a high-speed drive as a cache for a slower drive, and much more. All of these advanced options can get a bit overwhelming, but resizing a volume is straight-forward.
## LVM basics
The *volume group* serves as the main container in the LVM system. By default Fedora only defines a single volume group, but there can be as many as needed. Actual hard-drive and hard-drive partitions are added to the *volume group* as *physical volumes*. *Physical volumes* add available free space to the *volume group*. A typical Fedora install has one formatted boot partition, and the rest of the drive is a partition configured as an LVM *physical volume*.
Out of this pool of available space, the *volume group* allocates one or more *logical volumes*. These volumes are similar to hard-drive partitions, but without the limitation of contiguous space on the disk. LVM *logical volumes* can even span multiple devices! Just like hard-drive partitions, *logical volumes *have a defined size and can contain any filesystem which can then be mounted to specific directories.
## What’s needed
Confirm the system uses LVM with the *gnome-disks* application, and make sure there is free space available in some other volume. Without space to reclaim from another volume, this guide isn’t useful. A [Fedora live CD/USB](https://getfedora.org/en/workstation/download/) is also needed. Any file system that needs to shrink must be unmounted. Running from a live image allows all the volumes on the hard-disk to remain unmounted, even important directories like */* and */home*.
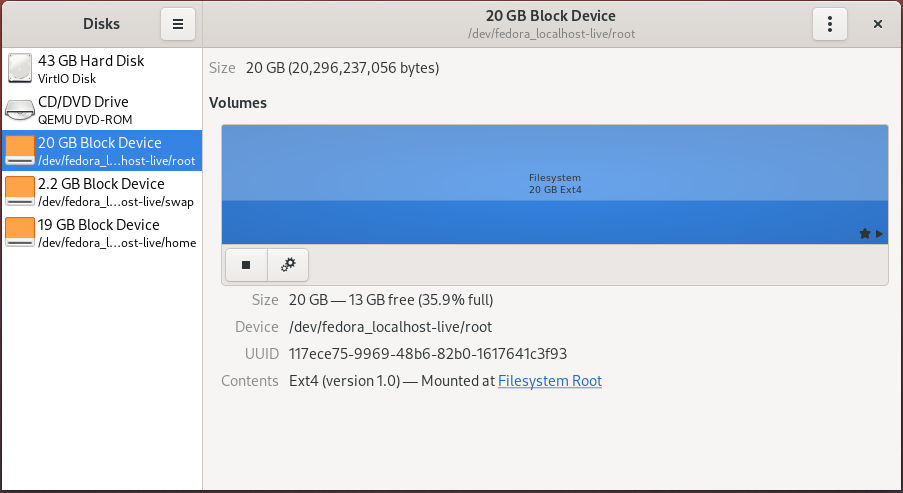
## A word of warning
No data should be lost by following this guide, but it does muck around with some very low-level and powerful commands. One mistake could destroy all data on the hard-drive. So backup all the data on the disk first!
## Resizing LVM volumes
To begin, boot the Fedora live image and select *Try Fedora* at the dialog. Next, use the *Run Command* to launch the *blivet-gui* application (accessible by pressing *Alt-F2*, typing *blivet-gui*, then pressing *enter*). Select the volume group on the left under *LVM*. The logical volumes are on the right.
The logical volume labels consist of both the volume group name and the logical volume name. In the example, the volume group is “fedora_localhost-live” and there are “home”, “root”, and “swap” logical volumes allocated. To find the full volume, select each one, click on the *gear* icon, and choose *resize*. The slider in the resize dialog indicates the allowable sizes for the volume. The minimum value on the left is the space already in use within the file system, so this is the minimum possible volume size (without deleting data). The maximum value on the right is the greatest size the volume can have based on available free space in the *volume group*.
A grayed out *resize* option means the volume is full and there is no free space in the volume group. It’s time to change that! Look through all of the volumes to find one with plenty of extra space, like in the screenshot above. Move the slider to the left to set the new size. Free up enough space to be useful for the full volume, but still leave plenty of space for future data growth. Otherwise, this volume will be the next to fill up.
Click *resize* and note that a new item appears in the volume listing: *free space*. Now select the full volume that started this whole endeavor, and move the slider all the way to the right. Press *resize* and marvel at the new improved volume layout. However, nothing has changed on the hard drive yet. Click on the *check-mark* to commit the changes to disk.
Review the summary of the changes, and if everything looks right, click *Ok* to proceed. Wait for *blivet-gui* to finish. Now reboot back into the main Fedora install and enjoy all the new space in the previously full volume.
## Planning for the future
It is challenging to know how much space any particular volume will need in the future. Instead of immediately allocating all available free space, consider leaving it free in the volume group. In fact, Fedora Server reserves space in the volume group by default. Extending a volume is possible while it is online and in use. No live image or reboot needed. When a volume is almost full, easily extend the volume using part of the available free space and keep working. Unfortunately the default disk manager, *gnome-disks*, does not support LVM volume resizing, so install * blivet-gui* for a graphical management tool. Alternately, there is a simple terminal command to extend a volume:
lvresize -r -L +1G /dev/fedora_localhost-live/root
## Wrap-up
Reclaiming hard-drive space with LVM just scratches the surface of LVM capabilities. Most people, especially on the desktop, probably don’t need the more advanced features. However, LVM is there when the need arises, though it can get a bit complex to implement. [BTRFS](https://fedoramagazine.org/btrfs-coming-to-fedora-33/) is the default filesystem, without LVM, starting with [Fedora 33](https://fedoramagazine.org/whats-new-fedora-33-workstation/). BTRFS can be easier to manage while still flexible enough for most common usages. Check out the recent [Fedora Magazine articles on BTRFS](https://fedoramagazine.org/btrfs-snapshots-backup-incremental/) to learn more.
## Esc
Thank You
## Sergey
Thanks.
## Simon
XFS cannot be shrunk
## Jeffrey Goh
ooh – such perfect timing – I’m just now trying to figure out if it’s safe to downsize my root partition so my home partition can grow.
## Troy Curtis Jr
I’ll be very interested to hear how it goes Jeffrey!
## Doug
Thanks for listening to my article suggestion. Having a ~120 GB SSD means that, using the automatic setup, you end up with a very small /home partition. This is useful to tweak it after the installation is completed, although you can also use Anaconda’s custom partitioning functionality to customize the default setup yourself (it’s not so difficult).
## Troy Curtis Jr
It was perfect for me to pick up! I am a big LVM fan and I was happy to have a way to contribute to Fedora. Definitely a great idea (even if BTRFS is the new default 😁).
## Cornel Panceac
How can i shrink the volume group so that i can allocate more storage space to the other, more storage-hungry OS?
## Troy Curtis Jr
It is definitely possible to shrink the volume group, but it is a bit more complex and a lot more manual. My
untestedandunverifiedapproach would go something like:Reduce logical volumes (similar to the article) to add free space to the volume group
Use pvresize to shrink the physical volume slightly less the intended size (and hope that extents aren’t already allocated past the new size, pvresize
shouldfail to change the size in this case).Resize the underlying partition
Use pvresize again, but do not specify a size so that it fills up to exactly the new size of the partition
Add a new partition to the now free space on the hard disk.
There is definitely a decent chance to get various steps wrong here, so definitely make sure there are backups before attempting.
Doing 2 calls to pvresize isn’t strictly necessary, but with only 1 call the size calculation must be exactly right. This is challenging because the units are not always obvious (bytes, blocks, etc). That is why it is best to shrink a little more than necessary with the first pvresize to provide a bit of buffer, and then allow the second pvresize (after shrinking the partition) to calculate the precise values.
Also if extents have been allocated past the end of where the desired pv size would be, then some clever shuffling of extent ranges with a combination of “lvdisplay -m” and “pvmove ..” will be necessary to relocate the extents into an earlier part of the physical volume.
## Guus
I currently have LVM + ext4 and am still running F32, but I want to get to F33 and if possible convert to btrfs. So I wonder, does LVM play any roll at all with btrfs? Or is the roll that LVM plays now, being taken over by btrfs?
## Troy Curtis Jr
It’s definitely possible to have BTRFS on a LVM logical volume, and there are some reasons you may want to go with that approach. However, there are definitely some trade offs. For the most common use cases, especially for desktop, using BTRFS directly on the harddrive probably gives most of features you might want. In particular, subvolumes allow for easy and fast snapshot creation for backups. However, with BTRFS you don’t have some of the features that LVM provides, such as a thinly provisioned volumes for use by different filesystems or direct block device volumes (which are nice for virtual machines). Note that with BTRFS copy on write built in capabilities, and read-write subvolume snapshots, the thinly provisioned use case is completely covered as long as you want the volumes (really subvolumes in BTRFS case) to be BTRFS and not some other filesystem.
So really you have to decide what your needs are. Most likely reformatting the disk and using BTRFS directly makes sense if you want easy subvolume snapshot functionality and to play around with a new modern filesystem.
## Guus
Thank you for your reply. I get that it is my choice, but I don’t have a particular good feeling about the difference yet. My suspicion is that more people would like to know about the differences. Do you think a comparion between the two variants of using btrfs is possible?
Another point is, up to now, I had never heard of thin provisioning. I don’t think that is an issue for me. I do however, sometimes use other filesystems. If I do, does btrfs constrain me to use physical partitions?
I apologize. I have been using Linux for a long time (94 – 98 + 2002 – now) but I am not an advanced user when it comes to storage space. The most advanced I got was repairing a partition I had accidentally removed and that made me pretty anxious, working with fdisk on byte level.
So, if you ever feel the need to use your knowledge to compare btrfs with or without LVM, with different use cases (workstation, server), I would really like that.
## Stephen Brown
There was a recent article titled “Friends Don’t let Friends Use BTRS”, which has somehow, mysteriously disappeared. from this address https://blog.pgaddict.com/posts/friends-dont-let-friends-use-btrfs
While there are some great wins wrt using BTRS, there were two takeaways from this article, that I noted.
Lousy database performance. Which the article attributes to its ‘copy on write’ features. The author did extensive testing across a number of applications and it most definitely is that. I use ‘cow’ a lot. All of my kvm machines are ‘cow2’ disks and it does slow things down. But I want that sparse disk space capability that ‘cow2’ provides so I live with it.
Data recovery and or data corruption is more likely to occur with btrs than ext4, lets say. File systems like XFS are light years ahead of BTRS wrt this.
I use LVM a lot. My biggest complaint with LVM is that it’s not so forgiving wrt shrinking volumes. And I really hate the fact that you can’t change volume names and get away with it, if its a volume that your root file system resides on. So unless you know how to rebuild all of that device ID stuff within grub2 and initramfs, don’t even think about it.
I’m certain that I’m going to waste more disk space with LVM than with BTRS and each year about this time, I’m going to burn incense and wail about it. But in the end, I’ll take all of those file recovery and data recovery capabilities inherent in EXT4 and LVM systems than chance some data corruption with BTRS.
## Patrice
Nice, but funnily anachronistic on Fedora Magazine since BTRFS is the new filesystem on Fedora 33.
I’d like to see some how-to for BTRFS: what’s the benefit, how to manage it and how to make backups.
I’m on Fedora 33 but still using the same LVM+Ext4 filesystem until I get more information on BTRFS, specifically how to manage it for simple day-to-day use and how to perform backups.
## Troy Curtis Jr
It did seem a bit late to the party to write the LVM article right after Fedora 33 came out with a default filesystem of BTRFS. However, I realized that is only for the desktop variants, LVM+ext4 is still the default on the server. Also, many are probably in the same boat as you (and me) if you just upgrade from previous releases. I spent some time considering switching on my desktop install to BTRFS since I was doing a clean install anyway. Ultimately I decided to stick with LVM+ext4 because I had already setup caching volumes, thin pools, and I didn’t necessarily want to wipe and restore my home volume. I am considering BTRFS on my laptop though, if nothing else than for the learning experience.
## Riley
Thanks so much for this guide. It was super helpful!
Years ago I made my laptop’s root partition smaller, so I’d have more space in my home partition. But when Flatpak became a thing, it started eating up space in my root folder. So much so, that I didn’t have enough room to download and install new versions of Fedora.
I was able to follow this simple guide and fix the issue. Now my laptop is running the latest and greatest Fedora. |
12,865 | 2020 年 5 个新 sudo 功能 | https://opensource.com/article/20/10/sudo-19 | 2020-11-28T14:36:00 | [
"sudo"
] | https://linux.cn/article-12865-1.html |
>
> 从集中会话记录、chroot 支持到 Python API,sudo 1.9 提供了许多新功能。
>
>
>

当你想在 [POSIX 系统](https://opensource.com/article/19/7/what-posix-richard-stallman-explains)上执行一个操作时,最安全的方法之一就是使用 `sudo` 命令。与以 root 用户身份登录并执行命令可能是个危险的操作不同,`sudo` 授予任何被系统管理员[指定为 “sudoer”](https://opensource.com/article/17/12/using-sudo-delegate)的用户临时权限,来执行通常受限制的活动。
几十年来,这个系统帮助 Linux、Unix 和 macOS 系统免受愚蠢的错误和恶意攻击,它是当今所有主要 Linux 发行版的默认管理机制。
当在 2020 年 5 月发布 sudo 1.9 时,它带来了许多新功能,包括集中收集会话记录,支持 `sudo` 内的 chroot,以及 Python API。如果你对其中的任何一项感到惊讶,请阅读我的文章,了解一些 [sudo 鲜为人知的功能](https://opensource.com/article/19/10/know-about-sudo)。
`sudo` 不仅仅是一个管理命令的前缀。你可以微调权限,记录终端上发生的事情,使用插件扩展`sudo`,在 LDAP 中存储配置,进行广泛的日志记录,以及更多。
1.9.0 版本和后续的小版本增加了各种新功能(我将在下面介绍),包括:
* 一个集中收集 `sudo` 会话记录的记录服务
* 审计插件 API
* 审批插件 API
* Python 对插件的支持
* `sudo` 内置 chroot 和 CWD 支持(从 1.9.3 开始)
### 哪里可以得到 sudo 1.9?
大多数的 Linux 发行版仍然封装了上一代的 `sudo`(1.8 版本),并且在长期支持(LTS)的发行版中会保持这个版本数年。据我所知,提供了最完整的 sudo 1.9 包的 Linux 发行版是 openSUSE[Tumbleweed](https://software.opensuse.org/distributions/tumbleweed),它是一个滚动发行版,而且该 `sudo` 包的子包中有 Python 支持。最近的 [Fedora](https://getfedora.org/) 版本包含了 sudo 1.9,但没有 Python 支持。[FreeBSD Ports](https://www.freebsd.org/ports/) 有最新的 `sudo` 版本,如果你自己编译 `sudo` 而不是使用软件包,你可以启用 Python 支持。
如果你喜欢的 Linux 发行版还没有包含 sudo 1.9,请查看 [sudo 二进制页面](https://www.sudo.ws/download.html#binary)来查看是否有现成的包可以用于你的系统。这个页面还提供了一些商用 Unix 变种的软件包。
像往常一样,在你开始试验 `sudo` 设置之前,*确保你知道 root 密码*。是的,即使在 Ubuntu 上也是如此。有一个临时的“后门”是很重要的;如果没有这个后门,如果出了问题,你就必须得黑掉自己的系统。记住:语法正确的配置并不意味着每个人都可以在该系统上通过 `sudo` 做任何事情!
### 记录服务
记录服务可以集中收集会话记录。与本地会话记录存储相比,这有很多优势:
* 更方便地在一个地方进行搜索,而不是访问各个机器来寻找记录
* 即使在发送机器停机的情况下也可以进行记录
* 本地用户若想掩盖其轨迹,不能删除记录
为了快速测试,你可以通过非加密连接向记录服务发送会话。我的博客中包含了[说明](https://blog.sudo.ws/posts/2020/03/whats-new-in-sudo-1.9-recording-service/),可以在几分钟内完成设置。对于生产环境,我建议使用加密连接。有很多可能性,所以请阅读最适合你的环境的[文档](https://www.sudo.ws/man/sudo_logsrvd.man.html#EXAMPLES)。
### 审计插件 API
新的审计插件 API 不是一个用户可见的功能。换句话说,你不能从 `sudoers` 文件中配置它。它是一个 API,意味着你可以从插件中访问审计信息,包括用 Python 编写的插件。你可以用很多不同的方式来使用它,比如当一些有趣的事情发生时,从 `sudo` 直接发送事件到 Elasticsearch 或日志即服务(LaaS)上。你也可以用它来进行调试,并以任何你喜欢的格式将其他难以访问的信息打印到屏幕上。
根据你使用它的方式,你可以在 `sudo` 插件手册页(针对 C 语言)和 `sudo` Python 插件手册中找到它的文档。在 `sudo` 源代码中可以找到 [Python 代码示例](https://github.com/sudo-project/sudo/blob/master/plugins/python/example_audit_plugin.py),在我的博客上也有一个[简化的例子](https://blog.sudo.ws/posts/2020/06/sudo-1.9-using-the-new-audit-api-from-python/)。
### 审批插件 API
审批插件 API 可以在命令执行之前加入额外的限制。这些限制只有在策略插件成功后才会运行,因此你可以有效地添加额外的策略层,而无需更换策略插件,进而无需更换 `sudoers`。可以定义多个审批插件,而且所有插件都必须成功,命令才能执行。
与审计插件 API 一样,你可以从 C 和 Python 中使用它。我博客上记录的[示例 Python 代码](https://blog.sudo.ws/posts/2020/08/sudo-1.9-using-the-new-approval-api-from-python/)是对该 API 的一个很好的介绍。一旦你理解了它是如何工作的,你就可以扩展它来将 `sudo` 连接到工单系统,并且只批准有相关开放工单的会话。你也可以连接到人力资源数据库,这样只有当班的工程师才能获得管理权限。
### Python 对插件的支持
尽管我不是程序员,但我最喜欢的 sudo 1.9 新特性是 Python 对插件的支持。你可以用 Python 也能使用 C 语言调用大部分 API。幸运的是,`sudo` 对性能不敏感,所以运行速度相对较慢的 Python 代码对 `sudo` 来说不是问题。使用 Python 来扩展 `sudo` 有很多优势:
* 更简单、更快速的开发
* 不需要编译;甚至可以通过配置管理分发代码
* 许多 API 没有现成的 C 客户端,但有 Python 代码
除了审计和审批插件 API 之外,还有一些其他的 API,你可以用它们做一些非常有趣的事情。
通过使用策略插件 API,你可以取代 `sudo` 策略引擎。请注意,你将失去大部分的 `sudo` 功能,而且没有基于 `sudoers` 的配置。这在小众情况下还是很有用的,但大多数时候,最好还是继续使用 `sudoers`,并使用审批插件 API 创建额外的策略。如果你想尝试一下,我的 [Python 插件介绍](https://blog.sudo.ws/posts/2020/01/whats-new-in-sudo-1.9-python/)提供了一个非常简单的策略:只允许使用 `id` 命令。再次确认你知道 root 密码,因为一旦启用这个策略,它就会阻止任何实际使用 `sudo` 的行为。
使用 I/O 日志 API,你可以访问用户会话的输入和输出。这意味着你可以分析会话中发生了什么,甚至在发现可疑情况时终止会话。这个 API 有很多可能的用途,比如防止数据泄露。你可以监控屏幕上的关键字,如果数据流中出现任何关键字,你可以在关键字出现在用户的屏幕上之前中断连接。另一种可能是检查用户正在输入的内容,并使用这些数据来重建用户正在输入的命令行。例如,如果用户输入 `rm -fr /`,你可以在按下回车键之前就断开用户的连接。
组插件 API 允许非 Unix 组的查找。在某种程度上,这与审批插件 API 类似,因为它也扩展了策略插件。你可以检查一个用户是否属于一个给定的组,并在后面的配置部分基于此采取行动。
### chroot 和 CWD 支持
`sudo` 的最新功能是支持 chroot 和改变工作目录(CWD),这两个选项都不是默认启用的,你需要在 `sudoers` 文件中明确启用它们。当它们被启用时,你可以调整目标目录或允许用户指定使用哪个目录。日志反映了这些设置何时被使用。
在大多数系统中,chroot 只对 root 用户开放。如果你的某个用户需要 chroot,你需要给他们 root 权限,这比仅仅给他们 chroot 权限要大得多。另外,你可以通过 `sudo` 允许访问 chroot 命令,但它仍然允许漏洞,他们可以获得完全的权限。当你使用 `sudo` 内置的 chroot 支持时,你可以轻松地限制对单个目录的访问。你也可以让用户灵活地指定根目录。当然,这可能会导致灾难(例如,`sudo --chroot / -s`),但至少事件会被记录下来。
当你通过 `sudo` 运行一个命令时,它会将工作目录设置为当前目录。这是预期的行为,但可能有一些情况下,命令需要在不同的目录下运行。例如,我记得使用过一个应用程序,它通过检查我的工作目录是否是 `/root` 来检查我的权限。
### 尝试新功能
希望这篇文章能启发你仔细研究一下 sudo 1.9。集中会话记录比在本地存储会话日志更加方便和安全。chroot 和 CWD 支持为你提供了额外的安全性和灵活性。而使用 Python 来扩展 `sudo`,可以很容易地根据你的环境来定制 `sudo`。你可以通过使用最新的 Linux 发行版或 `sudo` 网站上的即用型软件包来尝试这些新功能。
如果你想了解更多关于 sudo 的信息,这里有一些资源:
* [Sudo 官网](https://www.sudo.ws/)
* [Sudo 博客](https://blog.sudo.ws/)
* [Sudo on Twitter](https://twitter.com/sudoproject)
---
via: <https://opensource.com/article/20/10/sudo-19>
作者:[Peter Czanik](https://opensource.com/users/czanik) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you want to perform an action on a [POSIX system](https://opensource.com/article/19/7/what-posix-richard-stallman-explains), one of the safest ways to do so is to use the sudo command. Unlike logging in as the root user and performing what could be a dangerous action, sudo grants any user [designated as a "sudoer"](https://opensource.com/article/17/12/using-sudo-delegate) by the sysadmin temporary permission to perform a normally restricted activity.
This system has helped keep Linux, Unix, and macOS systems safe from silly mistakes and malicious attacks for decades, and it is the default administrative mechanism on all major Linux distributions today.
When it was released in May 2020, sudo 1.9 brought many new features, including central collection of session recordings, support for chroot within sudo, and a Python API. If you are surprised by any of these, read my article about some [lesser-known features of sudo](https://opensource.com/article/19/10/know-about-sudo).
Sudo is a lot more than just a prefix for administrative commands. You can fine-tune permissions, record what is happening on the terminal, extend sudo using plugins, store configurations in LDAP, do extensive logging, and much more.
Version 1.9.0 and subsequent minor releases added a variety of new features (which I'll describe below), including:
- A recording service to collect sudo session recordings centrally
- Audit plugin API
- Approval plugin API
- Python support for plugins
- Chroot and CWD support built into sudo (starting with 1.9.3)
## Where to get sudo 1.9
Most Linux distributions still package the previous generation of sudo (version 1.8), and it will stay that way in long-term support (LTS) releases for several years. The most complete sudo 1.9 package I am aware of in a Linux distribution is openSUSE [Tumbleweed](https://software.opensuse.org/distributions/tumbleweed), which is a rolling distro, and the sudo package has Python support available in a subpackage. Recent [Fedora](https://getfedora.org/) releases include sudo 1.9 but without Python. [FreeBSD Ports](https://www.freebsd.org/ports/) has the latest sudo version available, and you can enable Python support if you build sudo yourself instead of using the package.
If your favorite Linux distribution does not yet include sudo 1.9, check the [sudo binaries page](https://www.sudo.ws/download.html#binary) to see if a ready-to-use package is available for your system. This page also has packages for several commercial Unix variants.
As usual, before you start experimenting with sudo settings, *make sure you know the root password*. Yes, even on Ubuntu. Having a temporary "backdoor" is important; without it, you would have to hack your own system if something goes wrong. And remember: a syntactically correct configuration does not mean that anybody can do anything through sudo on that system!
## Recording service
The recording service collects session recordings centrally. This offers many advantages compared to local session log storage:
- It is more convenient to search in one place instead of visiting individual machines for recordings
- Recordings are available even if the sending machine is down
- Recordings cannot be deleted by local users who want to cover their tracks
For a quick test, you can send sessions through non-encrypted connections to the recording service. My blog contains [instructions](https://blog.sudo.ws/posts/2020/03/whats-new-in-sudo-1.9-recording-service/) for setting it up in just a few minutes. For a production setup, I recommend using encryption. There are many possibilities, so read the [documentation](https://www.sudo.ws/man/sudo_logsrvd.man.html#EXAMPLES) that best suits your environment.
## Audit plugin API
The new audit plugin API is not a user-visible feature. In other words, you cannot configure it from the sudoers file. It is an API, meaning that you can access audit information from plugins, including ones written in Python. You can use it in many different ways, like sending events from sudo directly to Elasticsearch or Logging-as-a-Service (LaaS) when something interesting happens. You can also use it for debugging and print otherwise difficult-to-access information to the screen in whatever format you like.
Depending on how you want to use it, you can find its documentation in the sudo plugin manual page (for C) and the sudo Python plugin manual. [Sample Python code](https://github.com/sudo-project/sudo/blob/master/plugins/python/example_audit_plugin.py) is available in the sudo source code, and there is also a [simplified example](https://blog.sudo.ws/posts/2020/06/sudo-1.9-using-the-new-audit-api-from-python/) on my blog.
## Approval plugin API
The approval plugin API makes it possible to include extra restrictions before a command will execute. These will run only after the policy plugin succeeds, so you can effectively add additional policy layers without replacing the policy plugin and thus sudoers. Multiple approval plugins may be defined, and all must succeed for the command to execute.
As with the audit plugin API, you can use it both from C and Python. The [sample Python code](https://blog.sudo.ws/posts/2020/08/sudo-1.9-using-the-new-approval-api-from-python/) documented on my blog is a good introduction to the API. Once you understand how it works, you can extend it to connect sudo to ticketing systems and approve sessions only with a related open ticket. You can also connect to an HR database so that only the engineer on duty can gain administrative privileges.
## Python support for plugins
Even though I am not a programmer, my favorite new sudo 1.9 feature is Python support for plugins. You can use most of the APIs available from C with Python as well. Luckily, sudo is not performance-sensitive, so the relatively slow speed of running Python code is not a problem for sudo. Using Python for extending sudo has many advantages:
- Easier, faster development
- No need to compile; code might even be distributed by configuration management
- Many APIs do not have ready-to-use C clients, but Python code is available
In addition to the audit and approval plugin APIs, there are a few others available, and you can do very interesting things with them.
By using the policy plugin API, you can replace the sudo policy engine. Note you will lose most sudo features, and there is no more sudoers-based configuration. This can still be useful in niche cases, but most of the time, it is better to keep using sudoers and create additional policies using the approval plugin API. If you want to give it a try, my [introduction to the Python plugin](https://blog.sudo.ws/posts/2020/01/whats-new-in-sudo-1.9-python/) provides a very simple policy: allowing only the `id`
command. Once again, make sure you know the root password, as once this policy is enabled, it prevents any practical use of sudo.
Using the I/O logs API, you can access input and output from user sessions. This means you can analyze what is happening in a session and even terminate it if you find something suspicious. This API has many possible uses, such as data-leak prevention. You can monitor the screen for keywords and, if any of them appear in the data stream, you can break the connection before the keyword can appear on the user's screen. Another possibility is checking what the user is typing and using that data to reconstruct the command line the user is entering. For example, if a user enters `rm -fr /`
, you can disconnect the user even before Enter is hit.
The group plugin API allows non-Unix group lookups. In a way, this is similar to the approval plugin API as it also extends the policy plugin. You can check if a user is part of a given group and act based on this in later parts of the configuration.
## Chroot and CWD support
The latest additions to sudo are chroot and change working directory (CWD) support. Neither option is enabled by default—you need to explicitly enable them in the sudoers file. When they're enabled, you can fine-tune target directories or allow users to specify which directory to use. The logs reflect when these settings were used.
On most systems, chroot is available only to root. If one of your users needs chroot, you need to give them root access, which gives them a lot more power than just chroot. Alternately, you can allow access to the chroot command through sudo, but it still allows loopholes where they can gain full access. When you use sudo's built-in chroot support, you can easily restrict access to a single directory. You can also give users the flexibility to specify the root directory. Of course, this might lead to disasters (e.g., `sudo --chroot / -s`
), but at least the event is logged.
When you run a command through sudo, it sets the working directory to the current directory. This is the expected behavior, but there may be cases when the command needs to be run in a different directory. For example, I recall using an application that checked my privileges by checking whether my working directory was `/root`
.
## Try the new features
I hope that this article inspires you to take a closer look at sudo 1.9. Central session recording is both more convenient and secure than storing session logs locally. Chroot and CWD support give you additional security and flexibility. And using Python to extend sudo makes it easy to custom-tailor sudo to your environment. You can try the new features by using one of the latest Linux distributions or the ready-to-use packages from the sudo website.
If you want to learn more about sudo, here are a few resources:
## 1 Comment |
12,866 | 使用 Meld 在 Linux 中以图形方式比较文件和文件夹 | https://itsfoss.com/meld-gui-diff/ | 2020-11-28T14:59:00 | [
"diff",
"比较"
] | https://linux.cn/article-12866-1.html | 
如何比较两个相似的文件来检查差异?答案显而易见,就是[使用 Linux 中的 diff 命令](https://linuxhandbook.com/diff-command/)。
问题是,并不是每个人都能自如地在 Linux 终端中比较文件,而且 `diff` 命令的输出可能会让一些人感到困惑。
以这个 `diff` 命令的输出为例:

这里肯定涉及到一个学习曲线。然而,如果你使用的是桌面 Linux,你可以使用 [GUI](https://itsfoss.com/gui-cli-tui/) 应用来轻松比较两个文件是否有任何差异。
有几个 Linux 中的 GUI 差异比较工具。我将在本周的 Linux 应用亮点中重点介绍我最喜欢的工具 Meld。
### Meld:Linux(及 Windows)下的可视化比较和合并工具
通过 [Meld](https://meldmerge.org),你可以将两个文件并排比较。不仅如此,你还可以对文件进行相应的修改。这是你在大多数情况下想做的事情,对吗?

Meld 还能够比较目录,并显示哪些文件是不同的。它还会显示而文件是新的或是缺失的。

你也可以使用 Meld 进行三向比较。

图形化的并排比较在很多情况下都有帮助。如果你是开发人员,你可以用它来了解代码补丁。Meld 还支持版本控制系统,如 Git、[Mercurial](https://www.mercurial-scm.org/)、[Subversion](https://subversion.apache.org/) 等。
### Meld 的功能

开源的 Meld 工具具有以下主要功能:
* 进行双向和三向差异比较
* 就地编辑文件,差异比较立即更新
* 在差异和冲突之间进行导航
* 通过插入、更改和冲突相应地标示出全局和局部差异,使其可视化
* 使用正则文本过滤来忽略某些差异
* 语法高亮显示
* 比较两个或三个目录,看是否有新增加、缺失和更改的文件
* 将一些文件排除在比较之外
* 支持流行的版本控制系统,如 Git、Mercurial、Bazaar 和 SVN
* 支持多种国际语言
* 开源 GPL v2 许可证
* 既可用于 Linux,也可用于 Windows
### 在 Linux 上安装 Meld
Meld 是一个流行的应用程序,它在大多数 Linux 发行版的官方仓库中都有。
检查你的发行版的软件中心,看看 Meld 是否可用。

另外,你也可以使用你的发行版的命令行包管理器来安装 Meld。在 [Ubuntu 上,它可以在 Universe 仓库中找到](https://itsfoss.com/ubuntu-repositories/),并且可以[使用 apt 命令安装](https://itsfoss.com/apt-command-guide/):
```
sudo apt install meld
```
你可以在 GNOME 的 GitLab 仓库中找到 Meld 的源码:
[Meld Source Code](https://gitlab.gnome.org/GNOME/meld)
### 它值得使用吗?
我知道[大多数现代开源编辑器](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)都有这个功能,但有时你只是想要一个简单的界面,而不需要安装额外的附加软件来比较文件。Meld 就为你提供了这样的功能。
你是否使用一些其他工具来检查文件之间的差异?是哪种工具呢?如果你用过 Meld,你有什么经验?请在评论区分享你的意见。
---
via: <https://itsfoss.com/meld-gui-diff/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | How do you compare two similar files to check for differences? The obvious answer is [to use the diff command in Linux](https://linuxhandbook.com/diff-command/).
The problem is that not everyone would be comfortable comparing files in Linux terminal. And the diff command output could be confusing for some.
Take this diff command output for example:
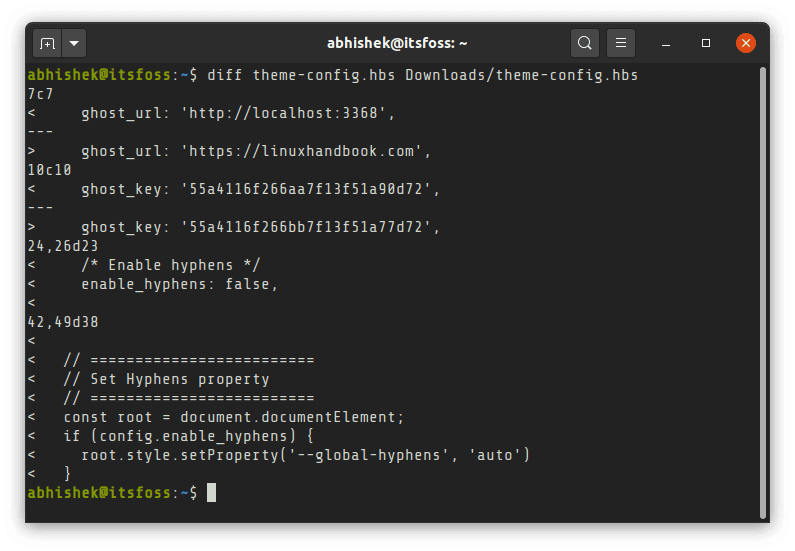
There is definitely a learning curve involved here. However, if you are using desktop Linux, you can use [GUI](https://itsfoss.com/gui-cli-tui/) applications to easily compare two files for any differences.
There are several GUI diff [tools available for Linux to compare files](https://itsfoss.com/compare-files-linux-tools/). I am going to highlight my favorite tool Meld in this week’s Linux application highlight.
## Meld: Visual Diff and Merge tool for Linux (and Windows)
With [Meld](https://meldmerge.org), you can compare two files in side by side view. Not only that, you may also modify the files to make changes accordingly. That’s what you would want to do in most situations, right?
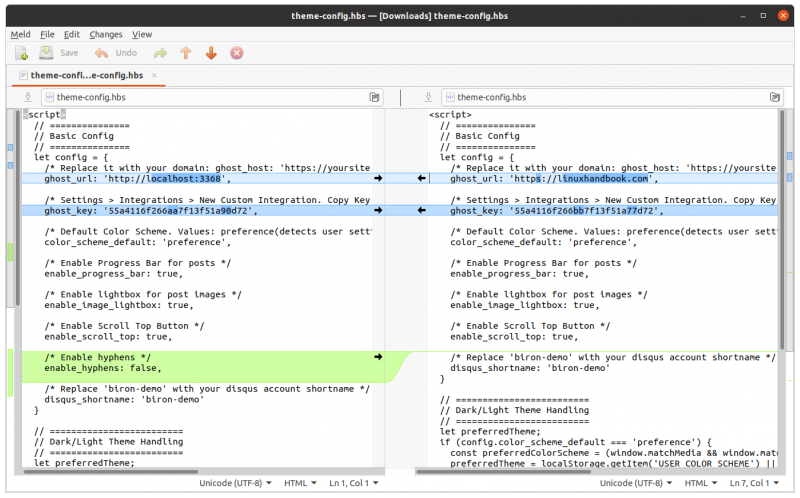
Meld is also capable of comparing directories and show which files are different. It will also show while files are new or missing.
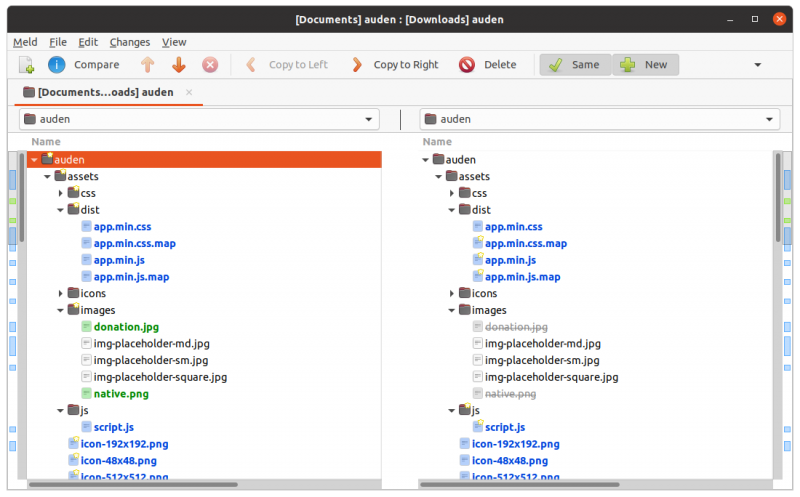
You may also use Meld for a three-way comparison.
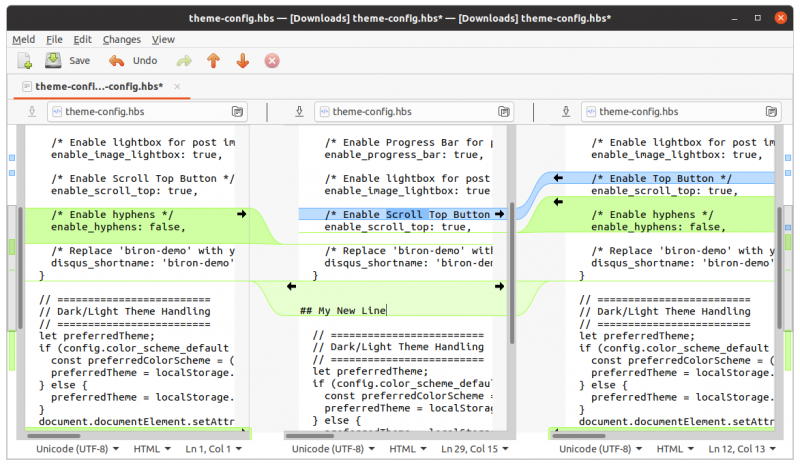
The graphical side-by-side comparison helps in a number of situations. If you are a developer, you can use it to understand code patches. Meld also supports version control systems like Git, [Mercurial](https://www.mercurial-scm.org/), [Subversion](https://subversion.apache.org/) etc.
## Features of Meld
The open source Meld tools has the following main features:
- Perform two and three-way difference comparison
- Edit files in-place and the difference comparison updates immediately
- Navigate between differences and conflicts
- Visualize global and local differences with insertions, changes and conflicts marked accordingly
- Use regex text filtering to ignore certain differences
- Syntax highlighting
- Compare two or three directories for newly added, missing and altered files
- Exclude some files from comparison
- Support for popular version control systems like Git, Mercurial, Bazaar and SVN
- Support for many international languages
- Open source GPL v2 license
- Available for Linux as well as Windows
## Installing Meld on Linux
Meld is a popular application and it is available in the official repositories of most Linux distributions.
Check your distribution’s software center and see if Meld is available.
Alternatively, you can also use command line package manager of your distribution to install Meld. On [Ubuntu, it is available in the Universe repository](https://itsfoss.com/ubuntu-repositories/) and can be [installed using the apt command](https://itsfoss.com/apt-command-guide/):
`sudo apt install meld`
You may find the source code of Meld on GNOME’s GitLab repository:
## Worth it?
I know that [most modern open source code editors](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) come with this feature but sometimes you just want a simple interface without the trouble of installing additional add-ons for comparing files. Meld provides you just that.
Do you use some other tools for checking differences between files? Which tool would that be? What’s your experience with Meld, if you ever used it? The comment sections is all yours for sharing your opinion. |
12,868 | 10 个让你进入 Emacs 世界的技巧 | https://opensource.com/article/20/3/getting-started-emacs | 2020-11-29T10:38:00 | [
"Emacs"
] | /article-12868-1.html |
>
> 10 个技巧,让你深入这个有用的开源文本编辑器的世界。
>
>
>

很多人都说想学 [Emacs](https://opensource.com/downloads/emacs-cheat-sheet),但很多人在短暂的接触后就退缩了。这并不是因为 Emacs 不好,也不是 Emacs 复杂。我相信,问题在于人们其实并不想“学习” Emacs,而是他们想习惯 Emacs 的传统。他们想了解那些神秘的键盘快捷键和不熟悉的术语。他们想按照他们认为的“使用目的”来使用 Emacs。
我很同情这一点,因为我对 Emacs 的感觉就是这样。我以为真正的 Emacs 用户都只会在终端里面运行,从来不用方向键和菜单,更不会用鼠标。这是个阻止自己开始使用 Emacs 的好办法。有足够多的独特的 `.emacs` 配置文件证明,如果说 Emacs 用户有一个共同的变化,那就是每个人使用 Emacs 的方式不同。
学习 Emacs 很容易。爱上 Emacs 才是最难的。要爱上 Emacs,你必须发现它所拥有的功能,而这些功能是你一直在寻找的,有时你并不知道你已经错过了它们。这需要经验。
获得这种经验的唯一方法就是从一开始就积极使用 Emacs。这里有十个小提示,可以帮助你找出最适合你的方法。
### 从 GUI 开始
Emacs(以及它的友好竞争者 [Vim](https://opensource.com/downloads/cheat-sheet-vim))最伟大的事情之一是它可以在终端中运行,这在你 SSH 进入服务器时很有用,但在过去 15 年来制造的计算机上意义不大。Emacs 的 GUI 版本可以在极度[低功耗的设备](https://opensource.com/article/17/2/pocketchip-or-pi)上运行,它有很多实用的功能,无论是新手还是有经验的用户都可以使用它。
例如,如果你不知道如何在 Emacs 中只用键盘快捷键复制一个单词,编辑菜单的复制、剪切和粘贴选择提供了最轻松的路径。没有理由因为选择了 Emacs 而惩罚自己。使用它的菜单,用鼠标选择区域,点击缓冲区内的按钮,不要让陌生感阻碍你的工作效率。

这些功能被内置到 Emacs 中,是因为用户在使用它们。你应该在你需要的时候使用它们,而当你最终在 VT100 终端上通过 SSH 使用 Emacs,没有 `Alt` 或方向键的时候,你才应该使用这些晦涩的命令。
### 习惯术语
Emacs 的 UI 元素有着特殊的术语。个人计算的发展并不是建立在相同的术语上,所以很多术语对现代计算机用户来说比较陌生,还有一些术语虽然相同,但含义不同。下面是一些最常见的术语。
* <ruby> 框架 <rt> Frame </rt></ruby>。在 Emacs 中,“框架”就是现代计算机所说的“窗口”。
* <ruby> 缓冲区 <rt> Buffer </rt></ruby>:“缓冲区”是 Emacs 的一个通信通道。它可以作为 Emacs 进程的命令行,也可以作为 shell,或者只是一个文件的内容。
* <ruby> 窗口 <rt> Window </rt></ruby>:“窗口”是你进入一个缓冲区的视角。
* <ruby> 迷你缓冲区 <rt> Mini-buffer </rt></ruby>。它是主要的命令行,位于 Emacs 窗口的底部。

### 让 Emacs 的修饰键变得更有意义
在 PC 键盘上,`Ctrl` 键被称为 `C`,`Alt` 键被称为 `M`,这些键并不是 `C` 和 `M` 键,由于它们总是与相应的字母或符号键配对,所以在文档中很容易识别。
例如,`C-x` 在现代键盘符号中的意思是 `Ctrl+X`,`M-x` 是 `Alt+X`。就像你从任何应用程序中剪切文本时一样,同时按下这两个键。
不过,还有另一个层次的键盘快捷键,与现代电脑上的任何东西都完全不同。有时,键盘快捷键并不只是一个键组合,而是由一系列的按键组成。
例如,`C-x C-f` 的意思是像往常一样按 `Ctrl+X`,然后再按 `Ctrl+C`。
有时,一个键盘快捷键有混合的键型。组合键 `C-x 3` 意味着像往常一样按 `Ctrl+X`,然后按数字 `3` 键。
Emacs 之所以能做到这些花哨的强力组合,是因为某些键会让 Emacs 进入一种特殊的命令模式。如果你按 `C-X`(也就是 `Ctrl+X`),就是告诉 `Emacs` 进入空闲状态,等待第二个键或键盘快捷键。
Emacs 的文档,无论是官方的还是非官方的,都有很多键盘快捷键。在心里练习把 `C` 键翻译成 `Ctrl` 键,`M` 键翻译成 `Alt` 键,那么这些文档对你来说都会变得更有意义。
### 剪切、复制和粘贴的备用快捷方式
从规范上,复制文本是通过一系列的键盘快捷键进行的,这些快捷键取决于你想要复制或剪切的方式。
例如,你可以用 `M-d`(`Alt+d` 的 Emacs 行话)剪切一整个单词,或者用`C-k`(`Ctrl+K`)剪切一整行,或者用 `M-m`(`Alt+M`)剪切一个高亮区域。如果你想的话,你可以习惯这样,但如果你喜欢 `Ctrl+C` 和 `Ctrl+X` 和 `Ctrl-V`,那么你可以用这些来代替。
启用现代的“剪切-复制-粘贴”需要激活一个名为 CUA(<ruby> 通用用户访问 <rt> Common User Access </rt></ruby>)的功能。要激活 CUA,请单击“选项”菜单并选择“使用 CUA 键”。启用后,`C-c` 复制高亮显示的文本,`C-x` 剪切高亮显示的文本,`C-v` 粘贴文本。这个模式只有在你选择了文本之后才会实际激活,所以你仍然可以学习 Emacs 通常使用的 `C-x` 和 `C-c` 绑定。
### 用哪个都好
Emacs 是一个应用程序,它不会意识到你对它的感情或忠诚度。如果你想只用 Emacs 来完成那些“感觉”适合 Emacs 的任务,而用不同的编辑器(比如 Vim)来完成其他任务,你可以这样做。
你与一个应用程序的交互会影响你的工作方式,所以如果 Emacs 中所需要的按键模式与特定任务不一致,那么就不要强迫自己使用 Emacs 来完成该任务。Emacs 只是众多可供你使用的开源工具之一,没有理由让自己只限于一种工具。
### 探索新功能
Emacs 所做的大部分工作都是一个 elisp 函数,它可以从菜单选择和键盘快捷键调用,或者在某些情况下从特定事件中调用。所有的函数都可以从迷你缓冲区(Emacs 框架底部的命令行)执行。理论上,你甚至可以通过键入 `forward-word` 和 `backward-word` 以及 `next-line` 和 `previous-line` 等函数来导航光标。这肯定是无比低效的,但这就是一种直接访问你运行的代码的方式。在某种程度上,Emacs 就是自己的 API。
你可以通过在社区博客上阅读有关 Emacs 的资料来了解新函数,或者你可以采取更直接的方法,使用描述函数(`describe-function`)。要获得任何函数的帮助,按 `M-x`(也就是 `Alt+X`),然后输入 `describe-function`,然后按回车键。系统会提示你输入一个函数名称,然后显示该函数的描述。
你可以通过键入`M-x(`Alt+X`),然后键入`?` 来获得所有可用函数的列表。
你也可以在输入函数时,通过按 `M-x` 键,然后输入 `auto-complete-mode`,再按回车键,获得弹出的函数描述。激活该模式后,当你在文档中键入任何 Emacs 函数时,都会向你提供自动补完选项,以及函数的描述。

当你找到一个有用的函数并使用它时,Emacs 会告诉你它的键盘绑定,如果有的话。如果没有的话,你可以通过打开你的 `$HOME/.emacs` 配置文件并输入键盘快捷键来自己分配一个。语法是 `global-set-key`,后面是你要使用的键盘快捷键,然后是你要调用的函数。
例如,要将 `screenwriter-slugline` 函数分配一个键盘绑定:
```
(global-set-key (kbd “C-c s”) 'screenwriter-slugline)
```
重新加载配置文件,键盘快捷键就可以使用了:
```
M-x load-file ~/.emacs
```
### 紧急按钮
当你使用 Emacs 并尝试新的函数时,你一定会开始调用一些你并不想调用的东西。Emacs 中通用的紧急按钮是 `C-g`(就是 `Ctrl+G`)。
我通过将 G 与 GNU 联系起来来记住这一点,我想我是在呼吁 GNU 将我从一个错误的决定中拯救出来,但请随意编造你自己的记忆符号。
如果你按几下 `C-g`,Emacs 的迷你缓冲区就会回到潜伏状态,弹出窗口被隐藏,你又回到了一个普通的、无聊的文本编辑器的安全状态。
### 忽略键盘快捷键
潜在的键盘快捷键太多,在这里无法一一总结,更不希望你能记住。这是设计好的。Emacs 的目的是为了定制,当人们为 Emacs 编写插件时,他们可以定义自己的特殊键盘快捷键。
我们的想法不是要马上记住所有的快捷键。相反,你的目标是让你在使用 Emacs 时感到舒适。你在 Emacs 中变得越舒适,你就越会厌倦总是求助于菜单栏,你就会开始记住对你重要的组合键。
根据自己在 Emacs 中通常做的事情,每个人都有自己喜欢的快捷方式。一个整天用 Emacs 写代码的人可能知道运行调试器或启动特定语言模式的所有键盘快捷键,但对 Org 模式或 Artist 模式一无所知。这很自然,也很好。
### 使用 Bash 时练习 Emacs
了解 Emacs 键盘快捷键的一个好处是,其中许多快捷键也适用于 Bash。
* `C-a`:到行首
* `C-e`:到行尾
* `C-k`:剪切整行
* `M-f`:向前一个字
* `M-b`:向后一个字
* `M-d`:剪切一个字
* `C-y`:贴回(粘贴)最近剪切的内容
* `M-Shift-U`:大写一个词
* `C-t`:交换两个字符(例如,`sl` 变成 `ls`)
还有更多的例子,它能让你与 Bash 终端的交互速度超乎你的想象。
### 包
Emacs 有一个内置的包管理器来帮助你发现新的插件。它的包管理器包含了帮助你编辑特定类型文本的模式(例如,如果你经常编辑 JSON 文件,你可以尝试使用 ejson 模式)、嵌入的应用程序、主题、拼写检查选项、linter 等。这就是 Emacs 有可能成为你日常计算的关键所在;一旦你找到一个优秀的 Emacs 包,你可能离不开它了。

你可以按 `M-x`(就是 `Alt+X`)键,然后输入 `package-list-packages` 命令,再按回车键来浏览包。软件包管理器在每次启动时都会更新缓存,所以第一次使用时要耐心等待它下载可用软件包的列表。一旦加载完毕,你可以用键盘或鼠标进行导航(记住,Emacs 是一个 GUI 应用程序)。每一个软件包的名称都是一个按钮,所以你可以将光标移到它上面,然后按回车键,或者直接用鼠标点击它。你可以在 Emacs 框架中出现的新窗口中阅读有关软件包的信息,然后用安装按钮来安装它。
有些软件包需要特殊的配置,有时会在它的描述中列出,但有时需要你访问软件包的主页来阅读更多的信息。例如,自动完成包 `ac-emoji` 很容易安装,但需要你定义一个符号字体。无论哪种方式都可以使用,但你只有在安装了字体的情况下才能看到相应的表情符号,除非你访问它的主页,否则你可能不会知道。
### 俄罗斯方块
Emacs 有游戏,信不信由你。有数独、拼图、扫雷、一个好玩的心理治疗师,甚至还有俄罗斯方块。这些并不是特别有用,但在任何层面上与 Emacs 进行交互都是很好的练习,游戏是让你在 Emacs 中花费时间的好方法。

俄罗斯方块也是我最初接触 Emacs 的方式,所以在该游戏的所有版本中,Emacs 版本才是我真正的最爱。
### 使用 Emacs
GNU Emacs 之所以受欢迎,是因为它的灵活性和高度可扩展性。人们习惯了 Emacs 的键盘快捷键,以至于他们习惯性地尝试在其他所有的应用程序中使用这些快捷键,他们将应用程序构建到 Emacs 中,所以他们永远不需要离开。如果你想让 Emacs 在你的计算生活中扮演重要角色,最终的关键是拥抱未知,开始使用 Emacs。磕磕绊绊地,直到你发现如何让它为你工作,然后安下心来,享受 40 年的舒适生活。
---
via: <https://opensource.com/article/20/3/getting-started-emacs>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,869 | 如何在 VirtualBox 中增加现有虚拟机的磁盘大小 | https://itsfoss.com/increase-disk-size-virtualbox/ | 2020-11-29T11:16:50 | [
"虚拟机"
] | https://linux.cn/article-12869-1.html | 下面是你迟早会遇到的情况。
你在 [VirtualBox](https://www.virtualbox.org/) 中安装了一个或多个操作系统。在创建这些虚拟操作系统的同时,你还在 VirtualBox 中为它们创建了虚拟硬盘。
你指定了虚拟磁盘的最大大小,比如说 15 或 20GB,但现在使用了一段时间后,你发现你的虚拟机已经没有空间了。
虽然[在 Ubuntu 和其他操作系统上有释放磁盘空间的方法](https://itsfoss.com/free-up-space-ubuntu-linux/),但更稳健的处理方式是增加 VirtualBox 中创建的虚拟机的磁盘大小。
是的,你可以在 VirtualBox 中扩大虚拟硬盘,即使在创建之后也可以。虽然这是一个安全且经过测试的过程,但我们强烈建议你在执行这样的操作之前,先创建一个虚拟机的备份。
### 如何扩大 VirtualBox 磁盘大小

我将向你展示如何在 VirtualBox 中以图形和命令行(对于 Linux 极客)方式调整磁盘大小。这两种方法都很简单直接。
#### 方法 1:在 VirtualBox 中使用虚拟媒体管理器
VirtualBox 6 增加了一个调整虚拟磁盘大小的图形化选项。你可以在 VirtualBox 主页的文件选项卡中找到它。
进入 “File -> Virtual Media Manager”:

在列表中选择一个虚拟机,然后使用 “Size” 滑块或输入你需要的大小值。完成后点击 “Apply”。

请记住,虽然你增加了虚拟磁盘的大小,但**如果你的空间是动态分配的,那么实际的分区大小仍然不变**。
#### 方法 2:使用 Linux 命令行增加 VirtualBox 磁盘空间
如果你使用 Linux 操作系统作为宿主机,在宿主机中打开终端并输入以下命令来调整 VDI 的大小:
```
VBoxManage modifymedium "/path_to_vdi_file" --resize <megabytes>
```
在你按下回车执行命令后,调整大小的过程应该马上结束。
>
> 注意事项
>
>
> VirtualBox 早期版本命令中的 `*modifyvdi` 和 `modifyhd` 命令也支持,并在内部映射到 `modifymedium` 命令。
>
>
>

如果你不确定虚拟机的保存位置,可以在 VirtualBox 主页面点击 “Files -> Preferences” 或使用键盘快捷键 `Ctrl+G` 找到默认位置。

### 总结
就我个人而言,我更喜欢在每个 Linux 发行版上使用终端来扩展磁盘,图形化选项是最新的 VirtualBox 版本的一个非常方便的补充。
这是一个简单快捷的小技巧,但对 VirtualBox 基础知识是一个很好的补充。如果你觉得这个小技巧很有用,可以看看 [VirtualBox 客户端增强包](https://itsfoss.com/install-fedora-in-virtualbox/)的几个功能。
---
via: <https://itsfoss.com/increase-disk-size-virtualbox/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Here’s the scenario you may come across sooner or later.
You installed one or more operating systems in [VirtualBox](https://www.virtualbox.org/?ref=itsfoss.com). While creating those virtual operating systems, you also created virtual hard disks for them in VirtualBox.
You specified the maximum size of the virtual disk to say 15 or 20 GB, but now after using it for some time, you realize that your virtual machine is running out of space.
While [there are ways to free up disk space on Ubuntu](https://itsfoss.com/free-up-space-ubuntu-linux/) and other operating systems, a more robust way of handling the situation is to increase the disk size of your virtual machines created in VirtualBox.
Yes, you can enlarge the virtual hard disk in VirtualBox even after creation.
## How to enlarge VirtualBox disk size
I will show you how to resize disk in VirtualBox graphically and via command line (for Linux geeks or experienced users).
Both methods are easy and straightforward. The steps are the same for **Linux and Windows.**
### Method 1: Using the Virtual Media Manager in VirtualBox
VirtualBox 6 added a graphical option for resizing virtual disks. You can find it on the file menu of VirtualBox window.
Go to **File→ Tools → Virtual Media Manager**:
Select one of the hard disks from the list that you want to modify, click on **Properties** from the top, or double-click on the virtual disk name.
Here, you can drag the slider for "**Size**" or type the disk size name in the field where you see 25 GB.
Once done, you just have to hit “**Apply**” as shown below.
If you are not sure of the name, you can go to the list of virtual machines, and check the information under the "**Storage**" tab to check.
Keep in mind that though you increased the size of your virtual disk, the **actual partition size remains the same if your space is dynamically allocated**.
For that, you can download [GParted ISO](https://sourceforge.net/projects/gparted/), mount it as an optical drive from the virtual manager settings to find the extra space as “unallocated” space.
By default, when you add the ISO as an optical drive, and re-launch the VM, it will boot into the GParted partition editor.
**System**" settings of the virtual machine, and adjust the boot order to have Optical Disk boot first.
You can expand the current partition using the unallocated space or choose to make a new one if you like.
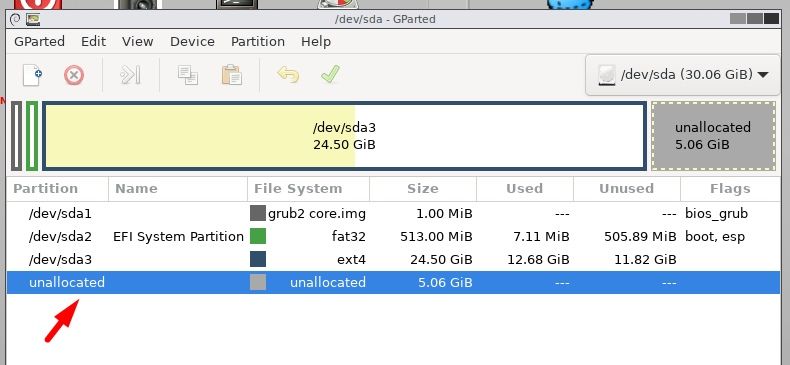
Here's how it looks like when you use the **slider** on top of the window (as shown in the screenshot below) to allocate all the free space and expand the current partition. Just hit "**Resize**" and it will be done.
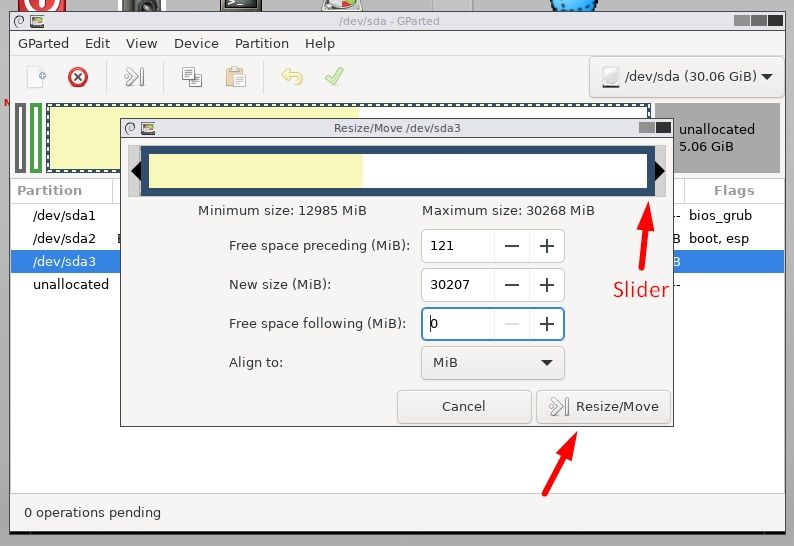
### Method 2: Increase VirtualBox disk space using Linux command line
If you are using a Linux operating system as a host, open the terminal and type the following command to resize VDI:
`VBoxManage modifymedium "/path_to_vdi_file" --resize <megabytes>`
You can convert Gigabytes to Megabytes by simply multiplying 1000 (for deci.
The resize process should finish right after you click the enter button to execute the command.
**modifyvdi**and
**modifyhd**of earlier versions of VirtualBox commands are also supported and mapped internally to the
**modifymedium**command.
If you are not sure where your virtual machines are saved, you can find the default location from the VirtualBox home page by clicking on **Files → Preferences** or by using the keyboard shortcut **Ctrl+G**.
**Suggested Read 📖**
[How to Install & Use VirtualBox Guest Additions on UbuntuInstall VirtualBox Guest Additions in Ubuntu and with this, you’ll be able to copy-paste, drag and drop between the host and guest system. It makes using Ubuntu on virtual machines a lot easier.](https://itsfoss.com/virtualbox-guest-additions-ubuntu/)

## Conclusion
Personally, I prefer to use the terminal on every Linux distribution that I use for expanding disk, the graphical option is a very handy addition to the latest VirtualBox release.
This is an easy and quick tip but a great addition to VirtualBox fundamentals. |
12,871 | Python 突变测试介绍 | https://opensource.com/article/20/7/mutmut-python | 2020-11-29T23:01:53 | [
"测试"
] | https://linux.cn/article-12871-1.html |
>
> 通过突变测试来修复未知的 bug。
>
>
>

你一定对所有内容都进行了测试,也许你甚至在项目仓库中有一个徽章,标明有 100% 的测试覆盖率,但是这些测试真的帮到你了吗?你怎么知道的?
开发人员很清楚单元测试的*成本*。测试必须要编写。有时它们无法按照预期工作:存在假告警或者抖动测试。在不更改任何代码的情况下有时成功,有时失败。通过单元测试发现的小问题很有价值,但是通常它们悄无声息的出现在开发人员的机器上,并且在提交到版本控制之前就已得到修复。但真正令人担忧的问题大多是看不见的。最糟糕的是,*丢失的告警*是完全不可见的:你看不到没能捕获的错误,直到出现在用户手上 —— 有时甚至连用户都看不到。
有一种测试可以使不可见的错误变为可见:<ruby> <a href="https://opensource.com/article/19/8/mutation-testing-evolution-tdd"> 突变测试 </a> <rt> mutation testing </rt></ruby>。
变异测试通过算法修改源代码,并检查每次测试是否都有“变异体”存活。任何在单元测试中幸存下来的变异体都是问题:这意味着对代码的修改(可能会引入错误)没有被标准测试套件捕获。
[Python](https://opensource.com/resources/python) 中用于突变测试的一个框架是 `mutmut`。
假设你需要编写代码来计算钟表中时针和分针之间的角度,直到最接近的度数,代码可能会这样写:
```
def hours_hand(hour, minutes):
base = (hour % 12 ) * (360 // 12)
correction = int((minutes / 60) * (360 // 12))
return base + correction
def minutes_hand(hour, minutes):
return minutes * (360 // 60)
def between(hour, minutes):
return abs(hours_hand(hour, minutes) - minutes_hand(hour, minutes))
```
首先,写一个简单的单元测试:
```
import angle
def test_twelve():
assert angle.between(12, 00) == 0
```
足够了吗?代码没有 `if` 语句,所以如果你查看覆盖率:
```
$ coverage run `which pytest`
============================= test session starts ==============================
platform linux -- Python 3.8.3, pytest-5.4.3, py-1.8.2, pluggy-0.13.1
rootdir: /home/moshez/src/mut-mut-test
collected 1 item
tests/test_angle.py . [100%]
============================== 1 passed in 0.01s ===============================
```
完美!测试通过,覆盖率为 100%,你真的是一个测试专家。但是,当你使用突变测试时,覆盖率会变成多少?
```
$ mutmut run --paths-to-mutate angle.py
<snip>
Legend for output:
? Killed mutants. The goal is for everything to end up in this bucket.
⏰ Timeout. Test suite took 10 times as long as the baseline so were killed.
? Suspicious. Tests took a long time, but not long enough to be fatal.
? Survived. This means your tests needs to be expanded.
? Skipped. Skipped.
<snip>
⠋ 21/21 ? 5 ⏰ 0 ? 0 ? 16 ? 0
```
天啊,在 21 个突变体中,有 16 个存活。只有 5 个通过了突变测试,但是,这意味着什么呢?
对于每个突变测试,`mutmut` 会修改部分源代码,以模拟潜在的错误,修改的一个例子是将 `>` 比较更改为 `>=`,查看会发生什么。如果没有针对这个边界条件的单元测试,那么这个突变将会“存活”:这是一个没有任何测试用例能够检测到的潜在错误。
是时候编写更好的单元测试了。很容易检查使用 `results` 所做的更改:
```
$ mutmut results
<snip>
Survived ? (16)
---- angle.py (16) ----
4-7, 9-14, 16-21
$ mutmut apply 4
$ git diff
diff --git a/angle.py b/angle.py
index b5dca41..3939353 100644
--- a/angle.py
+++ b/angle.py
@@ -1,6 +1,6 @@
def hours_hand(hour, minutes):
hour = hour % 12
- base = hour * (360 // 12)
+ base = hour / (360 // 12)
correction = int((minutes / 60) * (360 // 12))
return base + correction
```
这是 `mutmut` 执行突变的一个典型例子,它会分析源代码并将运算符更改为不同的运算符:减法变加法。在本例中由乘法变为除法。一般来说,单元测试应该在操作符更换时捕获错误。否则,它们将无法有效地测试行为。按照这种逻辑,`mutmut` 会遍历源代码仔细检查你的测试。
你可以使用 `mutmut apply` 来应用失败的突变体。事实证明你几乎没有检查过 `hour` 参数是否被正确使用。修复它:
```
$ git diff
diff --git a/tests/test_angle.py b/tests/test_angle.py
index f51d43a..1a2e4df 100644
--- a/tests/test_angle.py
+++ b/tests/test_angle.py
@@ -2,3 +2,6 @@ import angle
def test_twelve():
assert angle.between(12, 00) == 0
+
+def test_three():
+ assert angle.between(3, 00) == 90
```
以前,你只测试了 12 点钟,现在增加一个 3 点钟的测试就足够了吗?
```
$ mutmut run --paths-to-mutate angle.py
<snip>
⠋ 21/21 ? 7 ⏰ 0 ? 0 ? 14 ? 0
```
这项新测试成功杀死了两个突变体,比以前更好,当然还有很长的路要走。我不会一一解决剩下的 14 个测试用例,因为我认为模式已经很明确了。(你能将它们降低到零吗?)
变异测试和覆盖率一样,是一种工具,它允许你查看测试套件的全面程度。使用它使得测试用例需要改进:那些幸存的突变体中的任何一个都是人类在篡改代码时可能犯的错误,以及潜伏在程序中的隐藏错误。继续测试,愉快地搜寻 bug 吧。
---
via: <https://opensource.com/article/20/7/mutmut-python>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You have tests for everything; maybe you even have a badge in your project repository stating 100% test coverage. But what are these tests helping you do? How do you know?
The *costs* of unit tests are clear to developers. Tests have to be written. Occasionally they don't work as intended: there are false alarms or flapping tests that alternate success and failure without any code changes. The small bugs you can find through unit tests are valuable, but often they happen quietly on a developer machine and are fixed before a commit ever goes into version control. But the truly alarming bugs are mostly invisible. And the worst of all, the *missing alarms* are completely invisible: you don't see the bugs you failed to catch until the code gets into a user's hands—and sometimes not even then.
There is one type of test that makes it possible to make the invisible visible: [mutation testing](https://opensource.com/article/19/8/mutation-testing-evolution-tdd).
Mutation testing algorithmically modifies source code and checks if any "mutants" survived each test. Any mutant that survives the unit test is a problem: it means that a modification to the code, likely introducing a bug, was not caught by the standard test suite.
One framework for mutation testing in [Python](https://opensource.com/resources/python) is `mutmut`
.
Imagine you need to write code that calculates the angle between the hour hand and the minute hand in an analog clock to the nearest degree. The code might look something like:
```
def hours_hand(hour, minutes):
base = (hour % 12 ) * (360 // 12)
correction = int((minutes / 60) * (360 // 12))
return base + correction
def minutes_hand(hour, minutes):
return minutes * (360 // 60)
def between(hour, minutes):
return abs(hours_hand(hour, minutes) - minutes_hand(hour, minutes))
```
To begin, write a simple unit test:
```
import angle
def test_twelve():
assert angle.between(12, 00) == 0
```
Is this enough? The code has no `if`
statement, so if you check coverage:
```
$ coverage run `which pytest`
============================= test session starts ==============================
platform linux -- Python 3.8.3, pytest-5.4.3, py-1.8.2, pluggy-0.13.1
rootdir: /home/moshez/src/mut-mut-test
collected 1 item
tests/test_angle.py . [100%]
============================== 1 passed in 0.01s ===============================
```
Perfect! The tests pass, and coverage is at 100%. Testing expert, you are. But what does that coverage look like when you use mutation testing?
```
$ mutmut run --paths-to-mutate angle.py
<snip>
Legend for output:
? Killed mutants. The goal is for everything to end up in this bucket.
⏰ Timeout. Test suite took 10 times as long as the baseline so were killed.
? Suspicious. Tests took a long time, but not long enough to be fatal.
? Survived. This means your tests needs to be expanded.
? Skipped. Skipped.
<snip>
⠋ 21/21 ? 5 ⏰ 0 ? 0 ? 16 ? 0
```
Oh no. Out of 21 mutants, 16 survived. Only five cases passed the mutation testing. But what does that mean?
For each mutation test, `mutmut`
modified portions of your source code that simulates potential bugs. An example of a modification is changing a `>`
comparison to `>=`
to see what happens. If there is no unit test for this boundary condition, this mutation will "survive": this is a potential bug that none of the tests will detect.
It's time to write better unit tests. It is easy to check which changes were made with `results`
:
```
$ mutmut results
<snip>
Survived ? (16)
---- angle.py (16) ----
4-7, 9-14, 16-21
$ mutmut apply 4
$ git diff
diff --git a/angle.py b/angle.py
index b5dca41..3939353 100644
--- a/angle.py
+++ b/angle.py
@@ -1,6 +1,6 @@
def hours_hand(hour, minutes):
hour = hour % 12
- base = hour * (360 // 12)
+ base = hour / (360 // 12)
correction = int((minutes / 60) * (360 // 12))
return base + correction
```
This is a typical example of a mutation `mutmut`
performs; it analyzes the source code and changes operators to different operators: addition to subtraction or, in this case, multiplication to division. Unit tests, generally speaking, should catch bugs when an operator changes; otherwise, they are not testing the behavior effectively. Following this logic, `mutmut`
twiddles through source code to double-check your tests.
You can use `mutmut apply`
to apply a failed mutant. Wow, it turns out you barely checked whether the `hour`
parameter was used correctly. Fix that:
```
$ git diff
diff --git a/tests/test_angle.py b/tests/test_angle.py
index f51d43a..1a2e4df 100644
--- a/tests/test_angle.py
+++ b/tests/test_angle.py
@@ -2,3 +2,6 @@ import angle
def test_twelve():
assert angle.between(12, 00) == 0
+
+def test_three():
+ assert angle.between(3, 00) == 90
```
Previously, you tested only for 12. Will adding a test for three be enough to improve?
```
$ mutmut run --paths-to-mutate angle.py
<snip>
⠋ 21/21 ? 7 ⏰ 0 ? 0 ? 14 ? 0
```
This new test managed to kill two of the mutants—better than before, but still a long way to go. I won't work through each of the 14 cases left to fix, because I think the pattern is clear. (Can you get them down to zero?)
Mutation testing is another tool, along with coverage measurement, that allows you to see how comprehensive your test suite is. Using it makes the case that tests need to be improved: any one of those surviving mutants is a mistake a human being can make while fat-fingering code, as well as a potential bug creeping into your program. Keep testing and happy hunting.
## 5 Comments |
12,872 | 在你的 Python 游戏中添加投掷机制 | https://opensource.com/article/20/9/add-throwing-python-game | 2020-11-30T12:46:00 | [
"Pygame"
] | https://linux.cn/article-12872-1.html |
>
> 四处奔跑躲避敌人是一回事,反击敌人是另一回事。学习如何在这系列的第十二篇文章中在 Pygame 中创建平台游戏。
>
>
>

这是仍在进行中的关于使用 [Pygame](https://www.pygame.org/news) 模块在 [Python 3](https://www.python.org/) 中创建电脑游戏的第十二部分。先前的文章是:
1. [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
2. [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
3. [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
4. [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
5. [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
6. [在 Pygame 游戏中放置平台](/article-10902-1.html)
7. [在你的 Python 游戏中模拟引力](/article-11780-1.html)
8. [为你的 Python 平台类游戏添加跳跃功能](/article-11790-1.html)
9. [使你的 Python 游戏玩家能够向前和向后跑](/article-11819-1.html)
10. [在你的 Python 平台类游戏中放一些奖励](/article-11828-1.html)
11. [添加计分到你的 Python 游戏](/article-11839-1.html)
我的上一篇文章本来是这一系列文章的最后一篇,它鼓励你为这个游戏编写自己的附加程序。你们很多人都这么做了!我收到了一些电子邮件,要求帮助我还没有涵盖的常用机制:战斗。毕竟,跳起来躲避坏人是一回事,但是有时候让他们走开是一件非常令人满意的事。在电脑游戏中向你的敌人投掷一些物品是很常见的,不管是一个火球、一支箭、一道闪电,还是其它适合游戏的东西。
与迄今为止你在这个系列中为你的平台游戏编程的任何东西不同,可投掷物品有一个*生存时间*。在你投掷一个物品后,它会如期在移动一段距离后消失。如果它是一支箭或其它类似的东西,它可能会在通过屏幕的边缘时而消失。如果它是一个火球或一道闪电,它可能会在一段时间后熄灭。
这意味着每次生成一个可投掷的物品时,也必须生成一个独特的衡量其生存时间的标准。为了介绍这个概念,这篇文章演示如何一次只投掷一个物品。(换句话说,每次仅存在一个投掷物品)。 一方面,这是一个游戏的限制条件,但另一方面,它却是游戏本身的运行机制。你的玩家不能每次同时投掷 50 个火球,因为每次仅允许一个投掷物品,所以当你的玩家释放一个火球来尝试击中一名敌人就成为了一项挑战。而在幕后,这也使你的代码保持简单。
如果你想启用每次投掷多个项目,在完成这篇教程后,通过学习这篇教程所获取的知识来挑战你自己。
### 创建 Throwable 类
如果你跟随学习这系列的其它文章,那么你应该熟悉在屏幕上生成一个新的对象基础的 `__init__` 函数。这和你用来生成你的 [玩家](/article-10858-1.html) 和 [敌人](/article-10883-1.html) 的函数是一样的。这里是生成一个 `throwable` 对象的 `__init__` 函数来:
```
class Throwable(pygame.sprite.Sprite):
"""
生成一个 throwable 对象
"""
def __init__(self, x, y, img, throw):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.firing = throw
```
同你的 `Player` 类或 `Enemy` 类的 `__init__` 函数相比,这个函数的主要区别是,它有一个 `self.firing` 变量。这个变量保持跟踪一个投掷的物品是否在当前屏幕上活动,因此当一个 `throwable` 对象创建时,将变量设置为 `1` 的合乎情理的。
### 判断存活时间
接下来,就像使用 `Player` 和 `Enemy` 一样,你需要一个 `update` 函数,以便投掷的物品在瞄准敌人抛向空中时,它会自己移动。
测定一个投掷的物品存活时间的最简单方法是侦测它何时离开屏幕。你需要监视的屏幕边缘取决于你投掷的物品的物理特性。
* 如果你的玩家正在投掷的物品是沿着水平轴快速移动的,像一只弩箭或箭或一股非常快的魔法力量,而你想监视你游戏屏幕的水平轴极限。这可以通过 `worldx` 定义。
* 如果你的玩家正在投掷的物品是沿着垂直方向或同时沿着水平方向和垂直方向移动的,那么你必须监视你游戏屏幕的垂直轴极限。这可以通过 `worldy` 定义。
这个示例假设你投掷的物品向前移动一点并最终落到地面上。不过,投掷的物品不会从地面上反弹起来,而是继续掉落出屏幕。你可以尝试不同的设置来看看什么最适合你的游戏:
```
def update(self,worldy):
'''
投掷物理学
'''
if self.rect.y < worldy: #垂直轴
self.rect.x += 15 #它向前移动的速度有多快
self.rect.y += 5 #它掉落的速度有多快
else:
self.kill() #移除投掷对象
self.firing = 0 #解除火力发射
```
为使你的投掷物品移动地更快,增加 `self.rect` 的动量值。
如果投掷物品不在屏幕上,那么该物品将被销毁,以及释放其所占用的寄存器。另外,`self.firing` 将被设置回 `0` 以允许你的玩家来进行另一次射击。
### 设置你的投掷对象
就像使用你的玩家和敌人一样,你必须在你的设置部分中创建一个精灵组来保持投掷对象。
此外,你必须创建一个非活动的投掷对象来供开始的游戏使用。如果在游戏开始时却没有一个投掷对象,那么玩家在第一次尝试投掷一柄武器时,投掷将失败。
这个示例假设你的玩家使用一个火球作为开始的武器,因此,每一个投掷实例都是由 `fire` 变量指派的。在后面的关卡中,当玩家获取新的技能时,你可以使用相同的 `Throwable` 类来引入一个新的变量以使用一张不同的图像。
在这代码块中,前两行已经在你的代码中,因此不要重新键入它们:
```
player_list = pygame.sprite.Group() #上下文
player_list.add(player) #上下文
fire = Throwable(player.rect.x,player.rect.y,'fire.png',0)
firepower = pygame.sprite.Group()
```
注意,每一个投掷对象的起始位置都是和玩家所在的位置相同。这使得它看起来像是投掷对象来自玩家。在第一个火球生成时,使用 `0` 来显示 `self.firing` 是可用的。
### 在主循环中获取投掷行为
没有在主循环中出现的代码不会在游戏中使用,因此你需要在你的主循环中添加一些东西,以便能在你的游戏世界中获取投掷对象。
首先,添加玩家控制。当前,你没有火力触发器。在键盘上的按键是有两种状态的:释放的按键,按下的按键。为了移动,你要使用这两种状态:按下按键来启动玩家移动,释放按键来停止玩家移动。开火仅需要一个信号。你使用哪个按键事件(按键按下或按键释放)来触发你的投掷对象取决于你的品味。
在这个代码语句块中,前两行是用于上下文的:
```
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump(platform_list)
if event.key == pygame.K_SPACE:
if not fire.firing:
fire = Throwable(player.rect.x,player.rect.y,'fire.png',1)
firepower.add(fire)
```
与你在设置部分创建的火球不同,你使用一个 `1` 来设置 `self.firing` 为不可用。
最后,你必须更新和绘制你的投掷物品。这个顺序很重要,因此把这段代码放置到你现有的 `enemy.move` 和 `player_list.draw` 的代码行之间:
```
enemy.move() # 上下文
if fire.firing:
fire.update(worldy)
firepower.draw(world)
player_list.draw(screen) # 上下文
enemy_list.draw(screen) # 上下文
```
注意,这些更新仅在 `self.firing` 变量被设置为 1 时执行。如果它被设置为 0 ,那么 `fire.firing` 就不为 `true`,接下来就跳过更新。如果你尝试做上述这些更新,不管怎样,你的游戏都会崩溃,因为在游戏中将不会更新或绘制一个 `fire` 对象。
启动你的游戏,尝试挑战你的武器。
### 检测碰撞
如果你玩使用了新投掷技巧的游戏,你可能会注意到,你可以投掷对象,但是它却不会对你的敌人有任何影响。
原因是你的敌人没有被查到碰撞事故。一名敌人可能会被你的投掷物品所击中,但是敌人却从来不知道被击中了。
你已经在你的 `Player` 类中完成了碰撞检测,这非常类似。在你的 `Enemy` 类中,添加一个新的 `update` 函数:
```
def update(self,firepower, enemy_list):
"""
检测火力碰撞
"""
fire_hit_list = pygame.sprite.spritecollide(self,firepower,False)
for fire in fire_hit_list:
enemy_list.remove(self)
```
代码很简单。每个敌人对象都检查并看看它自己是否被 `firepower` 精灵组的成员所击中。如果它被击中,那么敌人就会从敌人组中移除和消失。
为集成这些功能到你的游戏之中,在主循环中调用位于新触发语句块中的函数:
```
if fire.firing: # 上下文
fire.update(worldy) # 上下文
firepower.draw(screen) # 上下文
enemy_list.update(firepower,enemy_list) # 更新敌人
```
你现在可以尝试一下你的游戏了,大多数的事情都如预期般的那样工作。不过,这里仍然有一个问题,那就是投掷的方向。
### 更改投掷机制的方向
当前,你英雄的火球只会向右移动。这是因为 `Throwable` 类的 `update` 函数将像素添加到火球的位置,在 Pygame 中,在 X 轴上一个较大的数字意味着向屏幕的右侧移动。当你的英雄转向另一个方向时,你可能希望它投掷的火球也抛向左侧。
到目前为止,你已经知道如何实现这一点,至少在技术上是这样的。然而,最简单的解决方案却是使用一个变量,在一定程度上对你来说可能是一种新的方法。一般来说,你可以“设置一个标记”(有时也被称为“翻转一个位”)来标明你的英雄所面向的方向。在你做完后,你就可以检查这个变量来得知火球是向左移动还是向右移动。
首先,在你的 `Player` 类中创建一个新的变量来代表你的游戏所面向的方向。因为我的游戏天然地面向右侧,由此我把面向右侧作为默认值:
```
self.score = 0
self.facing_right = True # 添加这行
self.is_jumping = True
```
当这个变量是 `True` 时,你的英雄精灵是面向右侧的。当玩家每次更改英雄的方向时,变量也必须重新设置,因此,在你的主循环中相关的 `keyup` 事件中这样做:
```
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
player.facing_right = False # 添加这行
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
player.facing_right = True # 添加这行
```
最后,更改你的 `Throwable` 类的 `update` 函数,以检测英雄是否面向右侧,并恰当地添加或减去来自火球位置的像素:
```
if self.rect.y < worldy:
if player.facing_right:
self.rect.x += 15
else:
self.rect.x -= 15
self.rect.y += 5
```
再次尝试你的游戏,清除掉你游戏世界中的一些坏人。

作为一项额外的挑战,当彻底打败敌人时,尝试增加你玩家的得分。
### 完整的代码
```
#!/usr/bin/env python3
# 作者: Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <[http://www.gnu.org/licenses/>][17].
import pygame
import pygame.freetype
import sys
import os
'''
变量
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
forwardx = 600
backwardx = 120
BLUE = (80, 80, 155)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
tx = 64
ty = 64
font_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), "fonts", "amazdoom.ttf")
font_size = tx
pygame.freetype.init()
myfont = pygame.freetype.Font(font_path, font_size)
'''
对象
'''
def stats(score, health):
myfont.render_to(world, (4, 4), "Score:"+str(score), BLUE, None, size=64)
myfont.render_to(world, (4, 72), "Health:"+str(health), BLUE, None, size=64)
class Throwable(pygame.sprite.Sprite):
"""
生成一个投掷的对象
"""
def __init__(self, x, y, img, throw):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.firing = throw
def update(self, worldy):
'''
投掷物理学
'''
if self.rect.y < worldy:
if player.facing_right:
self.rect.x += 15
else:
self.rect.x -= 15
self.rect.y += 5
else:
self.kill()
self.firing = 0
# x 位置, y 位置, img 宽度, img 高度, img 文件
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
"""
生成一名玩家
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.damage = 0
self.score = 0
self.facing_right = True
self.is_jumping = True
self.is_falling = True
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'walk' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def gravity(self):
if self.is_jumping:
self.movey += 3.2
def control(self, x, y):
"""
控制玩家移动
"""
self.movex += x
def jump(self):
if self.is_jumping is False:
self.is_falling = False
self.is_jumping = True
def update(self):
"""
更新精灵位置
"""
# 向左移动
if self.movex < 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# 向右移动
if self.movex > 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = self.images[self.frame // ani]
# 碰撞
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
if self.damage == 0:
for enemy in enemy_hit_list:
if not self.rect.contains(enemy):
self.damage = self.rect.colliderect(enemy)
if self.damage == 1:
idx = self.rect.collidelist(enemy_hit_list)
if idx == -1:
self.damage = 0 # 设置伤害回 0
self.health -= 1 # 减去 1 单位健康度
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.bottom = g.rect.top
self.is_jumping = False # 停止跳跃
# 掉落世界
if self.rect.y > worldy:
self.health -=1
print(self.health)
self.rect.x = tx
self.rect.y = ty
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.is_jumping = False # 停止跳跃
self.movey = 0
if self.rect.bottom <= p.rect.bottom:
self.rect.bottom = p.rect.top
else:
self.movey += 3.2
if self.is_jumping and self.is_falling is False:
self.is_falling = True
self.movey -= 33 # 跳跃多高
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
self.rect.x += self.movex
self.rect.y += self.movey
class Enemy(pygame.sprite.Sprite):
"""
生成一名敌人
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
敌人移动
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance * 2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
def update(self, firepower, enemy_list):
"""
检测火力碰撞
"""
fire_hit_list = pygame.sprite.spritecollide(self, firepower, False)
for fire in fire_hit_list:
enemy_list.remove(self)
class Level:
def ground(lvl, gloc, tx, ty):
ground_list = pygame.sprite.Group()
i = 0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i], worldy - ty, tx, ty, 'tile-ground.png')
ground_list.add(ground)
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return ground_list
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl))
return enemy_list
# x 位置, y 位置, img 宽度, img 高度, img 文件
def platform(lvl, tx, ty):
plat_list = pygame.sprite.Group()
ploc = []
i = 0
if lvl == 1:
ploc.append((200, worldy - ty - 128, 3))
ploc.append((300, worldy - ty - 256, 3))
ploc.append((550, worldy - ty - 128, 4))
while i < len(ploc):
j = 0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0] + (j * tx)), ploc[i][1], tx, ty, 'tile.png')
plat_list.add(plat)
j = j + 1
print('run' + str(i) + str(ploc[i]))
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return plat_list
def loot(lvl):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(tx*5, ty*5, tx, ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
'''
Setup 部分
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # 生成玩家
player.rect.x = 0 # 转到 x
player.rect.y = 30 # 转到 y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
fire = Throwable(player.rect.x, player.rect.y, 'fire.png', 0)
firepower = pygame.sprite.Group()
eloc = []
eloc = [300, worldy-ty-80]
enemy_list = Level.bad(1, eloc)
gloc = []
i = 0
while i <= (worldx / tx) + tx:
gloc.append(i * tx)
i = i + 1
ground_list = Level.ground(1, gloc, tx, ty)
plat_list = Level.platform(1, tx, ty)
enemy_list = Level.bad( 1, eloc )
loot_list = Level.loot(1)
'''
主循环
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump()
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
player.facing_right = False
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
player.facing_right = True
if event.key == pygame.K_SPACE:
if not fire.firing:
fire = Throwable(player.rect.x, player.rect.y, 'fire.png', 1)
firepower.add(fire)
# 向向滚动世界
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list:
l.rect.x -= scroll
# 向后滚动世界
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
for l in loot_list:
l.rect.x += scroll
world.blit(backdrop, backdropbox)
player.update()
player.gravity()
player_list.draw(world)
if fire.firing:
fire.update(worldy)
firepower.draw(world)
enemy_list.draw(world)
enemy_list.update(firepower, enemy_list)
loot_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
stats(player.score, player.health)
pygame.display.flip()
clock.tick(fps)
```
---
via: <https://opensource.com/article/20/9/add-throwing-python-game>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part 12 in an ongoing series about creating video games in [Python 3](https://www.python.org/) using the [Pygame](https://www.pygame.org/news) module. Previous articles are:
[Learn how to program in Python by building a simple dice game](https://opensource.com/article/17/10/python-101)[Build a game framework with Python using the Pygame module](https://opensource.com/article/17/12/game-framework-python)[How to add a player to your Python game](https://opensource.com/article/17/12/game-python-add-a-player)[Using Pygame to move your game character around](https://opensource.com/article/17/12/game-python-moving-player)[What's a hero without a villain? How to add one to your Python game](https://opensource.com/article/18/5/pygame-enemy)[Put platforms in a Python game with Pygame](https://opensource.com/article/18/7/put-platforms-python-game)[Simulate gravity in your Python game](https://opensource.com/article/19/11/simulate-gravity-python)[Add jumping to your Python platformer game](https://opensource.com/article/19/12/jumping-python-platformer-game)[Enable your Python game player to run forward and backward](https://opensource.com/article/19/12/python-platformer-game-run)[Put some loot in your Python platformer game](https://opensource.com/article/19/12/loot-python-platformer-game)[Add scorekeeping to your Python game](https://opensource.com/article/20/1/add-scorekeeping-your-python-game)
My previous article was meant to be the final article in this series, and it encouraged you to go program your own additions to this game. Many of you did! I got emails asking for help with a common mechanic that I hadn't yet covered: combat. After all, jumping to avoid baddies is one thing, but sometimes it's awfully satisfying to just make them go away. It's common in video games to throw something at your enemies, whether it's a ball of fire, an arrow, a bolt of lightning, or whatever else fits the game.
Unlike anything you have programmed for your platformer game in this series so far, throwable items have a *time to live*. Once you throw an object, it's expected to travel some distance and then disappear. If it's an arrow or something like that, it may disappear when it passes the edge of the screen. If it's a fireball or a bolt of lightning, it might fizzle out after some amount of time.
That means each time a throwable item is spawned, a unique measure of its lifespan must also be spawned. To introduce this concept, this article demonstrates how to throw only one item at a time. (In other words, only one throwable item may exist at a time.) On the one hand, this is a game limitation, but on the other hand, it is a game mechanic in itself. Your player won't be able to throw 50 fireballs at once, since you only allow one at a time, so it becomes a challenge for your player to time when they release a fireball to try to hit an enemy. And behind the scenes, this also keeps your code simple.
If you want to enable more throwable items at once, challenge yourself after you finish this tutorial by building on the knowledge you gain.
## Create the throwable class
If you followed along with the other articles in this series, you should be familiar with the basic `__init__`
function when spawning a new object on the screen. It's the same function you used for spawning your [player](https://opensource.com/article/17/12/game-python-add-a-player) and your [enemies](https://opensource.com/article/18/5/pygame-enemy). Here's an `__init__`
function to spawn a throwable object:
```
class Throwable(pygame.sprite.Sprite):
"""
Spawn a throwable object
"""
def __init__(self, x, y, img, throw):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.firing = throw
```
The primary difference in this function compared to your `Player`
class or `Enemy`
class `__init__`
function is that it has a `self.firing`
variable. This variable keeps track of whether or not a throwable object is currently alive on screen, so it stands to reason that when a throwable object is created, the variable is set to `1`
.
## Measure time to live
Next, just as with `Player`
and `Enemy`
, you need an `update`
function so that the throwable object moves on its own once it's thrown into the air toward an enemy.
The easiest way to determine the lifespan of a throwable object is to detect when it goes off-screen. Which screen edge you need to monitor depends on the physics of your throwable object.
- If your player is throwing something that travels quickly along the horizontal axis, like a crossbow bolt or arrow or a very fast magical force, then you want to monitor the horizontal limit of your game screen. This is defined by
`worldx`
. - If your player is throwing something that travels vertically or both horizontally and vertically, then you must monitor the vertical limit of your game screen. This is defined by
`worldy`
.
This example assumes your throwable object goes a little forward and eventually falls to the ground. The object does not bounce off the ground, though, and continues to fall off the screen. You can try different settings to see what fits your game best:
```
def update(self,worldy):
'''
throw physics
'''
if self.rect.y < worldy: #vertical axis
self.rect.x += 15 #how fast it moves forward
self.rect.y += 5 #how fast it falls
else:
self.kill() #remove throwable object
self.firing = 0 #free up firing slot
```
To make your throwable object move faster, increase the momentum of the `self.rect`
values.
If the throwable object is off-screen, then the object is destroyed, freeing up the RAM that it had occupied. In addition, `self.firing`
is set back to `0`
to allow your player to take another shot.
## Set up your throwable object
Just like with your player and enemies, you must create a sprite group in your setup section to hold the throwable object.
Additionally, you must create an inactive throwable object to start the game with. If there isn't a throwable object when the game starts, the first time a player attempts to throw a weapon, it will fail.
This example assumes your player starts with a fireball as a weapon, so each instance of a throwable object is designated by the `fire`
variable. In later levels, as the player acquires new skills, you could introduce a new variable using a different image but leveraging the same `Throwable`
class.
In this block of code, the first two lines are already in your code, so don't retype them:
```
player_list = pygame.sprite.Group() #context
player_list.add(player) #context
fire = Throwable(player.rect.x,player.rect.y,'fire.png',0)
firepower = pygame.sprite.Group()
```
Notice that a throwable item starts at the same location as the player. That makes it look like the throwable item is coming from the player. The first time the fireball is generated, a `0`
is used so that `self.firing`
shows as available.
## Get throwing in the main loop
Code that doesn't appear in the main loop will not be used in the game, so you need to add a few things in your main loop to get your throwable object into your game world.
First, add player controls. Currently, you have no firepower trigger. There are two states for a key on a keyboard: the key can be down, or the key can be up. For movement, you use both: pressing down starts the player moving, and releasing the key (the key is up) stops the player. Firing needs only one signal. It's a matter of taste as to which key event (a key press or a key release) you use to trigger your throwable object.
In this code block, the first two lines are for context:
```
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump(platform_list)
if event.key == pygame.K_SPACE:
if not fire.firing:
fire = Throwable(player.rect.x,player.rect.y,'fire.png',1)
firepower.add(fire)
```
Unlike the fireball you created in your setup section, you use a `1`
to set `self.firing`
as unavailable.
Finally, you must update and draw your throwable object. The order of this matters, so put this code between your existing `enemy.move`
and `player_list.draw`
lines:
```
enemy.move() # context
if fire.firing:
fire.update(worldy)
firepower.draw(world)
player_list.draw(screen) # context
enemy_list.draw(screen) # context
```
Notice that these updates are performed only if the `self.firing`
variable is set to 1. If it is set to 0, then `fire.firing`
is not true, and the updates are skipped. If you tried to do these updates, no matter what, your game would crash because there wouldn't be a `fire`
object to update or draw.
Launch your game and try to throw your weapon.
## Detect collisions
If you played your game with the new throwing mechanic, you probably noticed that you can throw objects, but it doesn't have any effect on your foes.
The reason is that your enemies do not check for a collision. An enemy can be hit by your throwable object and never know about it.
You've already done collision detection in your `Player`
class, and this is very similar. In your `Enemy`
class, add a new `update`
function:
```
def update(self,firepower, enemy_list):
"""
detect firepower collision
"""
fire_hit_list = pygame.sprite.spritecollide(self,firepower,False)
for fire in fire_hit_list:
enemy_list.remove(self)
```
The code is simple. Each enemy object checks to see if it has been hit by the `firepower`
sprite group. If it has, then the enemy is removed from the enemy group and disappears.
To integrate that function into your game, call the function in your new firing block in the main loop:
```
if fire.firing: # context
fire.update(worldy) # context
firepower.draw(screen) # context
enemy_list.update(firepower,enemy_list) # update enemy
```
You can try your game now, and most everything works as expected. There's still one problem, though, and that's the direction of the throw.
## Change the throw mechanic direction
Currently, your hero's fireball moves only to the right. This is because the `update`
function of the `Throwable`
class adds pixels to the position of the fireball, and in Pygame, a larger number on the X-axis means movement toward the right of the screen. When your hero turns the other way, you probably want it to throw its fireball to the left.
By this point, you know how to implement this, at least technically. However, the easiest solution uses a variable in what may be a new way for you. Generically, you can "set a flag" (sometimes also termed "flip a bit") to indicate the direction your hero is facing. Once you do that, you can check that variable to learn whether the fireball needs to move left or right.
First, create a new variable in your `Player`
class to represent which direction your hero is facing. Because my hero faces right naturally, I treat that as the default:
```
self.score = 0
self.facing_right = True # add this
self.is_jumping = True
```
When this variable is `True`
, your hero sprite is facing right. It must be set anew every time the player changes the hero's direction, so do that in your main loop on the relevant `keyup`
events:
```
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
player.facing_right = False # add this line
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
player.facing_right = True # add this line
```
Finally, change the `update`
function of your `Throwable`
class to check whether the hero is facing right or not and to add or subtract pixels from the fireball's position as appropriate:
```
if self.rect.y < worldy:
if player.facing_right:
self.rect.x += 15
else:
self.rect.x -= 15
self.rect.y += 5
```
Try your game again and clear your world of some baddies.

(Seth Kenlon, CC BY-SA 4.0)
As a bonus challenge, try incrementing your player's score whenever an enemy is vanquished.
## The complete code
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import pygame.freetype
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
forwardx = 600
backwardx = 120
BLUE = (80, 80, 155)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
tx = 64
ty = 64
font_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), "fonts", "amazdoom.ttf")
font_size = tx
pygame.freetype.init()
myfont = pygame.freetype.Font(font_path, font_size)
'''
Objects
'''
def stats(score, health):
myfont.render_to(world, (4, 4), "Score:"+str(score), BLUE, None, size=64)
myfont.render_to(world, (4, 72), "Health:"+str(health), BLUE, None, size=64)
class Throwable(pygame.sprite.Sprite):
"""
Spawn a throwable object
"""
def __init__(self, x, y, img, throw):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.firing = throw
def update(self, worldy):
'''
throw physics
'''
if self.rect.y < worldy:
if player.facing_right:
self.rect.x += 15
else:
self.rect.x -= 15
self.rect.y += 5
else:
self.kill()
self.firing = 0
# x location, y location, img width, img height, img file
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.damage = 0
self.score = 0
self.facing_right = True
self.is_jumping = True
self.is_falling = True
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'walk' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def gravity(self):
if self.is_jumping:
self.movey += 3.2
def control(self, x, y):
"""
control player movement
"""
self.movex += x
def jump(self):
if self.is_jumping is False:
self.is_falling = False
self.is_jumping = True
def update(self):
"""
Update sprite position
"""
# moving left
if self.movex < 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = self.images[self.frame // ani]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
if self.damage == 0:
for enemy in enemy_hit_list:
if not self.rect.contains(enemy):
self.damage = self.rect.colliderect(enemy)
if self.damage == 1:
idx = self.rect.collidelist(enemy_hit_list)
if idx == -1:
self.damage = 0 # set damage back to 0
self.health -= 1 # subtract 1 hp
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.bottom = g.rect.top
self.is_jumping = False # stop jumping
# fall off the world
if self.rect.y > worldy:
self.health -=1
print(self.health)
self.rect.x = tx
self.rect.y = ty
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.is_jumping = False # stop jumping
self.movey = 0
if self.rect.bottom <= p.rect.bottom:
self.rect.bottom = p.rect.top
else:
self.movey += 3.2
if self.is_jumping and self.is_falling is False:
self.is_falling = True
self.movey -= 33 # how high to jump
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
self.rect.x += self.movex
self.rect.y += self.movey
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
enemy movement
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance * 2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
def update(self, firepower, enemy_list):
"""
detect firepower collision
"""
fire_hit_list = pygame.sprite.spritecollide(self, firepower, False)
for fire in fire_hit_list:
enemy_list.remove(self)
class Level:
def ground(lvl, gloc, tx, ty):
ground_list = pygame.sprite.Group()
i = 0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i], worldy - ty, tx, ty, 'tile-ground.png')
ground_list.add(ground)
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return ground_list
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl))
return enemy_list
# x location, y location, img width, img height, img file
def platform(lvl, tx, ty):
plat_list = pygame.sprite.Group()
ploc = []
i = 0
if lvl == 1:
ploc.append((200, worldy - ty - 128, 3))
ploc.append((300, worldy - ty - 256, 3))
ploc.append((550, worldy - ty - 128, 4))
while i < len(ploc):
j = 0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0] + (j * tx)), ploc[i][1], tx, ty, 'tile.png')
plat_list.add(plat)
j = j + 1
print('run' + str(i) + str(ploc[i]))
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return plat_list
def loot(lvl):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(tx*5, ty*5, tx, ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 30 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
fire = Throwable(player.rect.x, player.rect.y, 'fire.png', 0)
firepower = pygame.sprite.Group()
eloc = []
eloc = [300, worldy-ty-80]
enemy_list = Level.bad(1, eloc)
gloc = []
i = 0
while i <= (worldx / tx) + tx:
gloc.append(i * tx)
i = i + 1
ground_list = Level.ground(1, gloc, tx, ty)
plat_list = Level.platform(1, tx, ty)
enemy_list = Level.bad( 1, eloc )
loot_list = Level.loot(1)
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump()
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
player.facing_right = False
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
player.facing_right = True
if event.key == pygame.K_SPACE:
if not fire.firing:
fire = Throwable(player.rect.x, player.rect.y, 'fire.png', 1)
firepower.add(fire)
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list:
l.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
for l in loot_list:
l.rect.x += scroll
world.blit(backdrop, backdropbox)
player.update()
player.gravity()
player_list.draw(world)
if fire.firing:
fire.update(worldy)
firepower.draw(world)
enemy_list.draw(world)
enemy_list.update(firepower, enemy_list)
loot_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
stats(player.score, player.health)
pygame.display.flip()
clock.tick(fps)
```
## 3 Comments |
12,874 | 使用 GIMP 轻松地设置图片透明度 | https://opensource.com/article/20/9/chroma-key-gimp | 2020-11-30T22:38:00 | [
"GIMP",
"透明"
] | https://linux.cn/article-12874-1.html |
>
> 使用色键(或绿屏)技巧来设置你电脑游戏中图片的透明度。
>
>
>

不管你是否正在使用 [Python](https://opensource.com/article/17/10/python-101) 或 [Lua](https://opensource.com/article/17/4/how-program-games-raspberry-pi) 编程一个游戏或一个 APP,你都有可能在你的游戏资源中使用 PNG 图像。PNG 格式图像的一个优点是能够存储一个 **alpha 通道**,这在一个 JPEG 格式的图像中是不可能获得的。alpha 在本质上是不可见的或透明的“颜色”。alpha 是你图像 *不可见* 的一部分。例如,你要绘制一个甜甜圈,甜甜圈的空洞将使用 alpha 填充,你就可以看到它后面的任何东西。
一个常见的问题是如何找到一幅图像的 alpha 部分。有时你的编程框架,不管它是 [Python Arcade](https://opensource.com/article/18/4/easy-2d-game-creation-python-and-arcade)、[Pygame](https://opensource.com/article/17/12/game-framework-python)、LÖVE,或者其它的任何东西都会检测出 alpha 通道,(在适当地调用函数后)将其作为透明处理。这意味着它将不会在 alpha 部分来渲染新的像素,而留下甜甜圈的空洞。100% 是透明的,0% 是不透明的,在功能上起到“不可见”的作用。
有些时候,你的框架与你的图像资源在 alpha 通道的位置上是不一致的(或者,alpha 通道根本就不存在),你在你想要透明度的地方却得到像素。
这篇文章描述了我所知道的最可靠的方法来解决透明度的问题。
### 色键
在计算机图形学中,有一些有助于确定每一个像素是如何渲染的值。<ruby> 色度 <rt> Chrominance </rt></ruby>(或者 chroma),描述一个像素的饱和度或强度。<ruby> 色键 <rt> chroma key </rt></ruby>技术(也称为<ruby> 绿屏 <rt> green screening </rt></ruby>)最初是作为一种化学工艺而发展起来的,在复印一张底片时,使用一种特定的 **无光泽** 的颜色(最初是蓝色,后来是绿色)来故意遮掩,以允许使用另一幅图像来取代曾经有蓝色或绿色屏幕的地方。这是一种简化的解释,但是它说明了计算机图形学中被称为 alpha 通道的起源。
alpha 通道是保存在图像中的信息,用以标识要透明的像素。例如,RGB 图像有红、绿、蓝通道。RGBA 图像包含红、绿、蓝通道,以及 alpha 通道。alpha 值的范围可以从 0 到 1 ,使用小数是也有效的。
因为一个 alpha 通道可以用几种不同的方法表达,因此依赖于嵌入的 alpha 通道可能是有问题的。作为替代方案,你可以在你的游戏框架中选择一种颜色并将其转化为一个 0 的 alpha 值。要做到这一点,你必须知道在你图像中的颜色值。
### 准备你的图片
要准备一个专门为色度键保留明确颜色的图形,在你最喜欢的图片编辑器中打开图片。我建议使用 [GIMP](http://gimp.org) 或 [Glimpse](https://glimpse-editor.github.io),但是 [mtPaint](https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs) 或 [Pinta](https://www.pinta-project.com/),甚至 [Inkscape](http://inkscape.org) 也能很好地工作,这取决于你的图像的性质,以及你将这些操作指南转换到一种不同图片编辑器工具的能力。
首先打开这幅 Tux 企鹅的图像:

### 选择图片
在图片打开后,转到 **窗口** 菜单,选择 **可停靠对话框** ,接下来选择 **图层**。在 **图层** 面板中 Tux 图层上右击。从弹出菜单中,选择 **Alpha 到选区** 。如果你的图像没有内置的 alpha 通道,那么你必须手动创建你自己的选区。

为手动创建一个选区,单击来自工具箱的 **路径** 工具。

使用 **路径** 工具,在图像周围移动鼠标,在其轮廓的每个主要交叉点处都单击和释放(不要拖动)。 不要担心沿着曲线走;只需要找到主要的交叉点和拐角。这将在每个点处创建一个节点,并在节点中间绘制一条条线段。你不需要闭合你的路径,因此当你最后到达你开始时的交叉点时,你就完成了。

在你创建你的轮廓路径后,转到 **窗口** 菜单,选择 **可停靠对话框** ,接下来选择 **工具选项** 。在 **工具选项** 面板中,选择 **编辑 (Ctrl)** 。随着这项操作的激活,你可以编辑你刚刚通过单击线或单击节点绘制的路径,并通过调整它们来更好地适应你的图像。你甚至能够将直线弯曲。

现在从 **窗口 > 可停靠对话框** 菜单中选择 **路径** 面板。在 **路径** 面板中,单击 **路径到选区** 按钮。你的绘图现在已经被选中了。
### 扩大选区
如果你觉得你的选区太紧贴了,你可以通过扩大来给予你自己的选区一些富余。当我想在一张图像周围采用或加厚一个边框时,我有时会这么扩大选区。
为扩大一个选区,单击 **选择** 菜单,选择 **扩大** 。输入一个像素值并单击 **确定** 。
### 反转选区
你已经选择了你的图形,但是你真正想选择的东西却 *不包括* 你所选择的图像。这是因为你要创建一个 alpha 蒙版来定义图像中的一些内容的来被其它一些内容所替换。换句话说,你需要标记那些将被转变为不可见的像素。
为了反转选择区,单击 **选择** 菜单,选择 **反转** 。现在除你的图像以外的一切东西都是被选择的。
### 使用 alpha 填充
随着选择了除了你的图像以外的一切东西,再选择你想使用的颜色来指定你的 alpha 蒙版。最常用的颜色是绿色(正如你可能从术语“绿屏”中所猜到的一样)。绿色不是什么神奇的颜色,甚至也不是特定的绿色色调。之所以使用它是因为人们经常处理不包含绿色色素的图像,这样人们能够很容易分离出绿色,而不会意外地分离出图像中重要的部分。当然,如果你的图像是一位绿色的外星人或一枚绿宝石或一些 *确实* 包含绿色的东西,那么你应该使用一种不同的颜色。只要你所选择的颜色是单一的单色,那么你就可以使用你所希望的任意颜色。如果你正在处理很多图像,你的选择应该在所有图像中保持一致。

使用你选择的颜色值来设置你的前景色。为确保你的选择是精确的,使用 [HTML](https://www.w3schools.com/colors/colors_picker.asp) 或 [HSV](https://en.wikipedia.org/wiki/HSL_and_HSV) 表示的颜色。例如,如果你正在使用纯绿色,它可以在 GIMP(以及大多数的开放源码图像应用程序)中表示为 `00ff00`(`00` 是红色,`FF` 是绿色,`00` 是蓝色,`F` 是最大值)。

不管你选择什么颜色,务必记录下 HTML 或 HSV 的值,以便你可以为每一张图像使用完全相同的颜色。
为填充你的 alpha 蒙版,单击 **编辑** 菜单,选择 **使用前景色填充** 。
### 平整和导出
如果你在你的图像周围留下边框,设置背景颜色来着色你想使用的边界笔刷。这通常是黑色或白色,但是它也可以是任何适宜你游戏审美观的颜色。
在你设置背景颜色后,单击 **图像** 菜单,选择 **平整图像**。不管你是否添加了边框,这样做都是安全的。这个过程将从图像中移除 alpha 通道,并使用背景色填充任何“透明的”像素。

你现在已经为你的游戏引擎准备好了一张图像。导出图像为你的游戏引擎喜欢的任何格式,接下来使用游戏引擎所需要的每一个函数来将图像导入的你的游戏中。在的代码中,设置 alpha 值为 `00ff00`(或你使用的任何颜色),接下来使用游戏引擎的图像转换器来将该颜色作为 alpha 通道处理。
### 其它的方法
这不是唯一能在你游戏图像中获取透明度的方法。查看你游戏引擎的文档来找出它是如何默认尝试处理 alpha 通道的,在你不确定的时候,尝试让你的游戏引擎来自动侦测图像中透明度,然后再去编辑它。有时,你游戏引擎的预期值和你图像的预设值恰巧匹配,那么你就可以直接获取透明度,而不需要做任何额外的工作。
不过,当这些尝试都失败时,尝试一下色键。它为电影业工作了将近 100 年,它也可以为你工作。
---
via: <https://opensource.com/article/20/9/chroma-key-gimp>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Whether you're programming a game or an app with [Python](https://opensource.com/article/17/10/python-101) or [Lua](https://opensource.com/article/17/4/how-program-games-raspberry-pi), you're probably using PNG graphics for your game assets. An advantage of the PNG format, which is not available in a JPEG, is the ability to store an **alpha channel**. Alpha is, essentially, the "color" of invisibility or transparency. Alpha is the part of an image you *don't* see. For example, if you were to draw a doughnut, the doughnut hole would be filled with alpha, and you could see whatever was behind it.
A common problem is how to find the alpha part of an image. Sometimes, your programming framework, whether it's [Python Arcade](https://opensource.com/article/18/4/easy-2d-game-creation-python-and-arcade), [Pygame](https://opensource.com/article/17/12/game-framework-python), LÖVE, or anything else, detects the alpha channel and treats it (after the appropriate function calls) as transparency. That means it renders no new pixels where there's alpha, leaving that doughnut hole empty. It's 100% transparent or 0% opaque and functionally "invisible."
Other times, your framework and your graphic asset don't agree on where the alpha channel is located (or that an alpha channel exists at all), and you get pixels where you wanted transparency.
This article describes the most sure-fire way I know to work around that.
## Chroma key
In computer graphics, there are a few values that contribute to how a pixel is rendered. **Chrominance**, or **chroma**, describes the saturation or intensity of a pixel. The **chroma key** technique (also known as **green screening**) was originally developed as a chemical process, in which a specific color (blue at first and later green) was deliberately obscured by a **matte** during the copying of a film negative, allowing another image to be substituted where there once was a blue or green screen. That's a simplified explanation, but it demonstrates the origins of what is known as the alpha channel in computer graphics.
An alpha channel is information saved in a graphic to identify pixels that are meant to be transparent. RGB graphics, for example, have red, green, and blue channels. RGBA graphics contain red, green, blue, and alpha. The value of alpha can range from 0 to 1, with decimal points being valid entries.
Because an alpha channel can be expressed in several different ways, relying on an embedded alpha channel can be problematic. Instead, you can pick a color and turn it into an alpha value of 0 in your game framework. For that to work, you must know the colors in your graphic.
## Prepare your graphic
To prepare a graphic with an explicit color reserved exclusively for a chroma key, open the graphic in your favorite graphic editor. I recommend [GIMP](http://gimp.org) or [Glimpse](https://glimpse-editor.github.io), but [mtPaint](https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs) or [Pinta](https://www.pinta-project.com/) or even [Inkscape](http://inkscape.org) can work just as well, depending on the nature of your graphics and your ability to translate these instructions to a different tool.
Start by opening this graphic of Tux the penguin:

(Seth Kenlon, CC BY-SA 4.0)
## Select the graphic
Once the graphic is open, go to the **Windows** menu and select **Dockable Dialogs** and then **Layers**. Right-click on Tux's layer in the **Layer** palette. From the pop-up menu, select **Alpha to Selection**. If your image does not have a built-in alpha channel, then you must create your own selection manually.
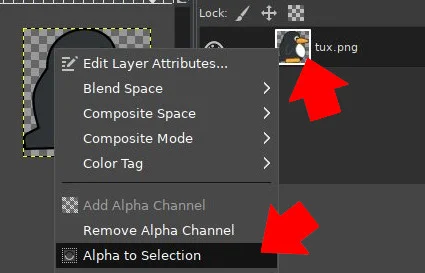
(Seth Kenlon, CC BY-SA 4.0)
To create a selection manually, click the **Paths** tool from the toolbox.
opensource.com
(Seth Kenlon, CC BY-SA 4.0)
Using the **Paths** tool, move your mouse around the graphic, clicking and releasing (do not drag) at each major intersection of its outline. Don't worry about following curves; just find the major intersections and corners. This creates a node at each point, with a straight line drawn between them. You don't need to close your path, so when you reach the final intersection before the one where you started, you're done.

(Seth Kenlon, CC BY-SA 4.0)
Once you've created your outline path, go to the **Windows** menu and select **Dockable Dialogs** and then **Tool Options**. In the **Tool Options** panel, select **Edit (Ctrl)**. With this activated, you can edit the paths you've just drawn by clicking the lines or nodes and adjusting them to fit your graphic better. You can even give the lines curves.

(Seth Kenlon, CC BY-SA 4.0)
Now select the **Paths** panel from the **Windows > Dockable Dialogs** menu. In the **Paths** panel, click the **Path to Selection** button. Your graphic is now selected.
## Grow the selection
If you feel your selection is too tight, you can give yourself a little slack by growing the selection. I sometimes do this when I want to impose or thicken a border around a graphic.
To grow a selection, click the **Select** menu and choose **Grow**. Enter a pixel value and click **OK**.
## Invert the selection
You have your graphic selected, but what you actually want to select is everything *except* your graphic. That's because you're creating an alpha matte to define what in your graphic will be replaced by something else. In other words, you need to mark the pixels that will be turned invisible.
To invert the selection, click on the **Select** menu and choose **Invert**. Now everything except your graphic is selected.
## Fill with alpha
With everything except your graphic selected, choose the color you want to use to designate your alpha matte. The most common color is green (as you might guess from the term "green screen"). There's nothing magical about the color green or even a particular shade of green. It's used because humans, frequent subjects of graphic manipulation, contain no green pigment, so it's easy to key out green without accidentally keying out part of the central subject. Of course, if your graphic is a green alien or an emerald or something that *does* contain green, you should use a different color. You can use any color you want, as long as it's solid and consistent. If you're doing this to many graphics, your choice should be consistent across all graphics.
(Seth Kenlon, CC BY-SA 4.0)
Set your foreground color with the color value you've chosen. To ensure that your choice is exact, use the [HTML](https://www.w3schools.com/colors/colors_picker.asp) or [HSV](https://en.wikipedia.org/wiki/HSL_and_HSV) representation of the color. For example, if you're using pure green, it can be expressed in GIMP (and most open source graphic applications) as `00ff00`
(that's 00 red, FF green, and 00 blue, with F being the maximum amount).
(Seth Kenlon, CC BY-SA 4.0)
Whatever color you choose, make sure you take note of the HTML or HSV values so you use the exact same color for every graphic.
To fill in your alpha matte, click the **Edit** menu and choose **Fill with FG Color**.
## Flatten and export
If you've left a border around your graphic, set your background color to the color you want to use as the border stroke. This is usually either black or white, but it can be anything that suits your game's aesthetic.
Once you have set the background color, click on the **Image** menu and select **Flatten Image**. It's safe to do this whether or not you added a border. This process removes the alpha channel from your image, filling in any "transparent" pixels with the background color.
(Seth Kenlon, CC BY-SA 4.0)
You now have an image ready for your game engine. Export the image to whatever format your game engine prefers, and then import it into your game using whatever function calls it requires. In your code, set the alpha value to `00ff00`
(or whatever color you used), and then use the game engine's graphic transforms to treat that color as an alpha channel.
## Other methods
This isn't the only way to get transparency in your game graphics. Check your game engine's documentation to find out how it tries to process alpha channels by default, and when you're not certain, try letting your game engine auto-detect transparency in your graphic before you go about editing it. Sometimes, your game engine's expectations and your graphic's preset values happen to match, and you get transparency without having to do any extra work.
When that fails, though, try a little chroma key. It's worked for the film industry for nearly 100 years, and it can work for you too.
## 1 Comment |
12,875 | 了解一下 Fossil,一个 Git 的替代品 | https://opensource.com/article/20/11/fossil | 2020-12-01T17:31:09 | [
"Fossil",
"版本控制"
] | https://linux.cn/article-12875-1.html |
>
> Fossil 是一个集版本控制系统、bug 追踪、维基、论坛以及文档解决方案于一体的系统。
>
>
>

每个开发者都知道,追踪代码的修改是至关重要的。有时候你会处于好奇或者教育的目的需要展示你的项目开始和进化的历史。有时候你想让其他的开发者参与到你的项目中,因此你需要一种值得信赖的能合并不同代码分支的方法。更极端一点,有时候你为了解决一个问题而修改的代码导致已有的功能不能正常使用。
[Fossil](https://fossil-scm.org/home/doc/trunk/www/index.wiki) 源码管理系统是由著名的 [SQLite](https://www.sqlite.org/index.html) 数据库的作者开发的一个集版本控制系统、bug 追踪、维基、论坛以及文档解决方案于一体的系统。
### 安装 Fossil
Fossil 是一个独立的 C 程序,因此你可以从它的网站上[下载](https://fossil-scm.org/home/uv/download.html)后放在环境变量 [PATH](https://opensource.com/article/17/6/set-path-linux) 中的任意位置。例如,假定 `/usr/local/bin` 已经在你的环境变量中(默认情况下是在的):
```
$ wget https://fossil-scm.org/home/uv/fossil-linux-x64-X.Y.tar.gz
$ sudo tar xvf fossil-linux-x64-X.Y.tar.gz --directory /usr/local/bin
```
你也可以通过包管理器从软件仓库中找到 Fossil,或者直接从源码编译。
### 创建一个 Fossil 仓库
如果你已经有一个代码项目,想用 Fossil 来追踪,那么第一步就是创建一个 Fossil 仓库:
```
$ fossil init myproject.fossil
project-id: 010836ac6112fefb0b015702152d447c8c1d8604
server-id: 54d837e9dc938ba1caa56d31b99c35a4c9627f44
admin-user: klaatu (initial password is "14b605")
```
创建 Fossil 仓库的过程中会返回三行信息:一个唯一的项目 ID、一个唯一的服务器 ID 以及管理员 ID 和密码。项目 ID 和服务器 ID 是版本数字。管理员凭证表明你对这个仓库的所有权,当你把 Fossil 作为服务器让其他用户来访问时可以使用管理员权限。
### Fossil 仓库工作流
在你使用 Fossil 仓库之前,你需要先为它的数据创建一个工作路径。你可以把这个过程类比为使用 Python 时创建一个虚拟环境或者解压一个只用来备份的 ZIP 文件。
创建一个工作目录并进入:
```
$ mkdir myprojectdir
$ cd myprojectdir
```
把你的 Fossil 打开到刚刚创建的目录:
```
$ fossil open ../myproject
project-name: <unnamed>
repository: /home/klaatu/myprojectdir/../myproject
local-root: /home/klaatu/myprojectdir/
config-db: /home/klaatu/.fossil
project-code: 010836ac6112fefb0b015702152d447c8c1d8604
checkout: 9e6cd96dd675544c58a246520ad58cdd460d1559 2020-11-09 04:09:35 UTC
tags: trunk
comment: initial empty check-in (user: klaatu)
check-ins: 1
```
你可能注意到了,Fossil 在你的家目录下创建了一个名为 `.fossil` 的隐藏文件,用来追踪你的全局 Fossil 配置。这个配置不是只适用于你的一个项目的;这个文件只会在你第一次使用 Fossil 时生成。
#### 添加文件
使用 `add` 和 `commit` 子命令来向你的仓库添加文件。例如,创建一个简单的 `README` 文件,把它添加到仓库:
```
$ echo "My first Fossil project" > README
$ fossil add README
ADDED README
$ fossil commit -m 'My first commit'
New_Version: 2472a43acd11c93d08314e852dedfc6a476403695e44f47061607e4e90ad01aa
```
#### 使用分支
Fossil 仓库开始时默认使用的主分支名为 `trunk`。当你想修改代码而又不影响主干代码时,你可以从 trunk 分支切走。创建新分支需要使用 `branch` 子命令,这个命令需要两个参数:一个新分支的名字,一个新分支的基分支名字。在本例中,只有一个分支 `trunk`,因此尝试创建一个名为 `dev` 的新分支:
```
$ fossil branch --help
Usage: fossil branch new BRANCH-NAME BASIS ?OPTIONS?
$ fossil branch new dev trunk
New branch: cb90e9c6f23a9c98e0c3656d7e18d320fa52e666700b12b5ebbc4674a0703695
```
你已经创建了一个新分支,但是你当前所在的分支仍然是 `trunk`:
```
$ fossil branch current
trunk
```
使用 `checkout` 命令切换到你的新分支 `dev`:
```
$ fossil checkout dev
dev
```
#### 合并修改
假设你在 `dev` 分支中添加了一个新文件,完成了测试,现在想把它合并到 `trunk`。这个过程叫做*合并*。
首先,切回目标分支(本例中目标分支为 `trunk`):
```
$ fossil checkout trunk
trunk
$ ls
README
```
这个分支中没有你的新文件(或者你对其他文件的修改),而那些内容是合并的过程需要的信息:
```
$ fossil merge dev
"fossil undo" is available to undo changes to the working checkout.
$ ls
myfile.lua README
```
### 查看 Fossil 时间线
使用 `timeline` 选项来查看仓库的历史。这个命令列出了你的仓库的所有活动的详细信息,包括用来表示每次修改的哈希值、每次提交时填写的信息以及提交者:
```
$ fossil timeline
=== 2020-11-09 ===
06:24:16 [5ef06e668b] added exciting new file (user: klaatu tags: dev)
06:11:19 [cb90e9c6f2] Create new branch named "dev" (user: klaatu tags: dev)
06:08:09 [a2bb73e4a3] *CURRENT* some additions were made (user: klaatu tags: trunk)
06:00:47 [2472a43acd] This is my first commit. (user: klaatu tags: trunk)
04:09:35 [9e6cd96dd6] initial empty check-in (user: klaatu tags: trunk)
+++ no more data (5) +++
```

### 公开你的 Fossil 仓库
因为 Fossil 有个内置的 web 界面,所以 Fossil 不像 GitLab 和 Gitea 那样需要主机服务。Fossil 就是它自己的主机服务,只要你把它放在一台机器上就行了。在你公开你的 Fossil 仓库之前,你还需要通过 web 用户界面(UI)来配置一些信息:
使用 `ui` 子命令启动一个本地的实例:
```
$ pwd
/home/klaatu/myprojectdir/
$ fossil ui
```
“Users” 和 “Settings” 是安全相关的,“Configuration” 是项目属性相关的(包括一个合适的标题)。web 界面不仅仅是一个方便的功能。 它是能在生产环境中使用并作为 Fossil 项目的宿主机来使用的。它还有一些其他的高级选项,比如用户管理(或者叫自我管理)、在同一个服务器上与其他的 Fossil 仓库进行单点登录(SSO)。
当配置完成后,关掉 web 界面并按下 `Ctrl+C` 来停止 UI 引擎。像提交代码一样提交你的 web 修改。
```
$ fossil commit -m 'web ui updates'
New_Version: 11fe7f2855a3246c303df00ec725d0fca526fa0b83fa67c95db92283e8273c60
```
现在你可以配置你的 Fossil 服务器了。
1. 把你的 Fossil 仓库(本例中是 `myproject.fossil`)复制到服务器,你只需要这一个文件。
2. 如果你的服务器没有安装 Fossil,就在你的服务器上安装 Fossil。在服务器上安装的过程跟在本地一样。
3. 在你的 `cgi-bin` 目录下(或它对应的目录,这取决于你的 HTTP 守护进程)创建一个名为 `repo_myproject.cgi` 的文件:
```
#!/usr/local/bin/fossil
repository: /home/klaatu/public_html/myproject.fossil
```
添加可执行权限:
```
$ chmod +x repo_myproject.cgi
```
你需要做的都已经做完了。现在可以通过互联网访问你的项目了。
你可以通过 CGI 脚本来访问 web UI,例如 `https://example.com/cgi-bin/repo_myproject.cgi`。
你也可以通过命令行来进行交互:
```
$ fossil clone https://[email protected]/cgi-bin/repo_myproject.cgi
```
在本地的克隆仓库中工作时,你需要使用 `push` 子命令把本地的修改推送到远程的仓库,使用 `pull` 子命令把远程的修改拉取到本地仓库:
```
$ fossil push https://[email protected]/cgi-bin/repo_myproject.cgi
```
### 使用 Fossil 作为独立的托管
Fossil 将大量的权力交到了你的手中(以及你的合作者的手中),让你不再依赖托管服务。本文只是简单的介绍了基本概念。你的代码项目还会用到很多有用的 Fossil 功能。尝试一下 Fossil。它不仅会改变你对版本控制的理解;它会让你不再考虑其他的版本控制系统。
---
via: <https://opensource.com/article/20/11/fossil>
作者:[Klaatu](https://opensource.com/users/klaatu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As any programmer knows, there are many reasons it's vital to keep track of code changes. Sometimes you just want a history of how your project started and evolved, as a matter of curiosity or education. Other times, you want to enable other coders to contribute to your project, and you need a reliable way to merge disparate parts. And more critically, sometimes an adjustment you make to fix one problem breaks something else that was working.
The [Fossil](https://fossil-scm.org/home/doc/trunk/www/index.wiki) source code management system is an all-in-one version control system, bug tracker, wiki, forum, and documentation solution from the creator of the famous [SQLite](https://www.sqlite.org/index.html) database.
## Install Fossil
Fossil is a single, self-contained C program, so you can probably just [download Fossil](https://fossil-scm.org/home/uv/download.html) from its website and place it anywhere in your system [PATH](https://opensource.com/article/17/6/set-path-linux). For example, assuming `/usr/local/bin`
is in your path, as it usually is by default:
```
$ wget https://fossil-scm.org/home/uv/fossil-linux-x64-X.Y.tar.gz
$ sudo tar xvf fossil-linux-x64-X.Y.tar.gz \
--directory /usr/local/bin
```
You might also find Fossil in your software repository through your package manager, or you can compile it from source code.
## Create a Fossil repository
If you have a coding project you want to track with Fossil, the first step is to create a Fossil repository:
```
$ fossil init myproject.fossil
project-id: 010836ac6112fefb0b015702152d447c8c1d8604
server-id: 54d837e9dc938ba1caa56d31b99c35a4c9627f44
admin-user: klaatu (initial password is "14b605")
```
Creating a Fossil repo returns three items: a unique project ID, a unique server ID, and an admin ID and password. The project and server IDs are version numbers. The admin credentials establish your ownership of this repository and can be used if you decide to run Fossil as a server for other users to access.
## Work in a Fossil repository
To start working in a Fossil repo, you must create a working location for its data. You might think of this process as creating a virtual environment in Python or unzipping a ZIP file that you intend to zip back up again later.
Create a working directory and change into it:
```
$ mkdir myprojectdir
$ cd myprojectdir
```
Open your Fossil repository into the directory you created:
```
$ fossil open ../myproject
project-name: <unnamed>
repository: /home/klaatu/myprojectdir/../myproject
local-root: /home/klaatu/myprojectdir/
config-db: /home/klaatu/.fossil
project-code: 010836ac6112fefb0b015702152d447c8c1d8604
checkout: 9e6cd96dd675544c58a246520ad58cdd460d1559 2020-11-09 04:09:35 UTC
tags: trunk
comment: initial empty check-in (user: klaatu)
check-ins: 1
```
You might notice that Fossil created a hidden file called `.fossil`
in your home directory to track your global Fossil preferences. This is not specific to your project; it's just an artifact of the first time you use Fossil.
### Add files
To add files to your repository, use the `add`
and `commit`
subcommands. For example, create a simple README file and add it to the repository:
```
$ echo "My first Fossil project" > README
$ fossil add README
ADDED README
$ fossil commit -m 'My first commit'
New_Version: 2472a43acd11c93d08314e852dedfc6a476403695e44f47061607e4e90ad01aa
```
### Use branches
By default, a Fossile repository starts with a main branch called `trunk`
. You can branch off the trunk when you want to work on code without affecting your primary codebase. Creating a new branch requires the `branch`
subcommand, along with a new branch name and the branch you want to use as the basis for your new one. In this example, the only branch is `trunk`
, so try creating a new branch called `dev`
:
```
$ fossil branch --help
Usage: fossil branch new BRANCH-NAME BASIS ?OPTIONS?
$ fossil branch new dev trunk
New branch: cb90e9c6f23a9c98e0c3656d7e18d320fa52e666700b12b5ebbc4674a0703695
```
You've created a new branch, but your current branch is still `trunk`
:
```
$ fossil branch current
trunk
```
To make your new `dev`
branch active, use the `checkout`
command:
```
$ fossil checkout dev
dev
```
### Merge changes
Suppose you add an exciting new file to your `dev`
branch, and having tested it, you're satisfied that it's ready to take its place in `trunk`
. This is called a *merge*.
First, change your branch back to your target branch (in this example, that's `trunk`
):
```
$ fossil checkout trunk
trunk
$ ls
README
```
Your new file (or any changes you made to an existing file) doesn't exist there yet, but that's what performing the merge will take care of:
```
$ fossil merge dev
"fossil undo" is available to undo changes to the working checkout.
$ ls
myfile.lua README
```
## View the Fossil timeline
To see the history of your repository, use the `timeline`
option. This shows a detailed list of all activity in your repository, including a hash representing the change, the commit message you provided when committing code, and who made the change:
```
$ fossil timeline
=== 2020-11-09 ===
06:24:16 [5ef06e668b] added exciting new file (user: klaatu tags: dev)
06:11:19 [cb90e9c6f2] Create new branch named "dev" (user: klaatu tags: dev)
06:08:09 [a2bb73e4a3] *CURRENT* some additions were made (user: klaatu tags: trunk)
06:00:47 [2472a43acd] This is my first commit. (user: klaatu tags: trunk)
04:09:35 [9e6cd96dd6] initial empty check-in (user: klaatu tags: trunk)
+++ no more data (5) +++
```
(Klaatu, CC BY-SA 4.0)
## Make your Fossil repository public
Because Fossil features a built-in web interface, Fossil doesn't need a hosting service like GitLab or Gitea do. Fossil is its own hosting service, as long as you have a server to put it on. Before making your Fossil project public, though, you must configure some attributes through the web user interface (UI).
Launch a local instance with the `ui`
subcommand:
```
$ pwd
/home/klaatu/myprojectdir/
$ fossil ui
```
Specifically, look at **Users** and **Settings** for security, and **Configuration** for project properties (including a proper title). The web interface isn't just a convenience function. It's intended for actual use and is indeed used as the host for the Fossil project. There are several surprisingly advanced options, from user management (or self-management, if you please) to single-sign-on (SSO) with other Fossil repositories on the same server.
Once you're satisfied with your changes, close the web interface and press **Ctrl+C** to stop the UI engine from running. Commit your web changes just as you would any other update:
```
$ fossil commit -m 'web ui updates'
New_Version: 11fe7f2855a3246c303df00ec725d0fca526fa0b83fa67c95db92283e8273c60
```
Now you're ready to set up your Fossil server.
- Copy your Fossil repository (in this example,
`myproject.fossil`
) to your server. You only need the single file. - Install Fossil on your server, if it's not already installed. The process for installing Fossil to your server is the same as it was for your local computer.
- In your
`cgi-bin`
directory (or the equivalent of that directory, depending upon which HTTP daemon you're running), create a file called`repo_myproject.cgi`
:
```
#!/usr/local/bin/fossil
repository: /home/klaatu/public_html/myproject.fossil
```
Make the script executable:
`$ chmod +x repo_myproject.cgi`
That's all there is to it. Your project is now live on the internet.
You can visit the web UI by navigating to your CGI script, such as `https://example.com/cgi-bin/repo_myproject.cgi`
.
Or you can interact with your repository from a terminal through the same URL:
`$ fossil clone https://[email protected]/cgi-bin/repo_myproject.cgi`
Working with a local clone requires you to use the `push`
subcommand to send local changes back to your remote repository and the `pull`
subcommand to get remotely made changes into your local copy:
`$ fossil push https://[email protected]/cgi-bin/repo_myproject.cgi`
## Use Fossil for independent hosting
Fossil places a lot of power into your hands (and the hands of your collaborators) and makes you independent of hosting services. This article only hints at the basics. There's so much more to Fossil that can help you and your teams in your code projects. Give Fossil a try. It won't just change the way you think about version control; it'll help you stop thinking about version control altogether.
## Comments are closed. |
12,877 | 添加声音到你的 Python 游戏 | https://opensource.com/article/20/9/add-sound-python-game | 2020-12-02T09:23:15 | [
"Pygame"
] | https://linux.cn/article-12877-1.html |
>
> 通过添加声音到你的游戏中,听听当你的英雄战斗、跳跃、收集战利品时会发生什么。学习如何在这个 Pygame 系列的第十三篇文章中,创建一个声音平台类精灵。
>
>
>

在 [Python 3](https://www.python.org/) 中使用 [Pygame](https://www.pygame.org/news) 模块来创建电脑游戏的系列文章仍在进行中,这是第十三部分。先前的文章是:
1. [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
2. [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
3. [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
4. [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
5. [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
6. [在 Pygame 游戏中放置平台](/article-10902-1.html)
7. [在你的 Python 游戏中模拟引力](/article-11780-1.html)
8. [为你的 Python 平台类游戏添加跳跃功能](/article-11790-1.html)
9. [使你的 Python 游戏玩家能够向前和向后跑](/article-11819-1.html)
10. [在你的 Python 平台类游戏中放一些奖励](/article-11828-1.html)
11. [添加计分到你的 Python 游戏](/article-11839-1.html)
12. [在你的 Python 游戏中加入投掷机制](/article-12872-1.html)
Pygame 提供了一种简单的方法来集成声音到你的 Python 电脑游戏中。Pygame 的 [mixer 模块](https://www.pygame.org/docs/ref/mixer.html) 可以依据命令播放一个或多个声音,并且你也可以将这些声音混合在一起,例如,你能够在听到你的英雄收集奖励或跳过敌人声音的同时播放背景音乐。
集成 `mixer` 模块到一个已存在的游戏中是很容易的,因此,与其给你代码示例来向你展示放置它们的位置,不如在这篇文章解释在你的应用程序中获得声音所需的四个步骤。
### 启动 mixer
首先,在你代码的设置部分,启动 `mixer` 进程。你的代码已经启动 Pygame 和 Pygame 字体,因此将它们归类到一起是一个很好的主意:
```
pygame.init()
pygame.font.init()
pygame.mixer.init() # add this line
```
### 定义声音
接下来,你必需定义你想要使用的声音。这样就要求你的计算机上有声音文件,就像使用字体就要求你有字体文件,使用图像就要求你有图像文件一样。
你还必需把这些声音与你的游戏捆绑在一起,以便任何玩你游戏的人都有这些声音文件。
为将一个声音与你的游戏捆绑在一起,首先在你的游戏目录中创建一个新的目录,就像你为你图像和字体创建的目录一样。称它为 `sound`:
```
s = 'sound'
```
尽管在互联网上有很多声音文件,下载这些声音文件并将其与你的游戏一起分发并不一定是合法的。这看起来是很奇怪的,因为这么多来自著名电脑游戏的声音是流行文化的一部分,但法律就是这样运作的。如果你想与你的游戏一起分发一个声音文件,你必需找到一个开源或[共创许可](https://opensource.com/article/20/1/what-creative-commons)的声音文件,它们准许与游戏一起提供声音。
这里有一些专门提供自由和合法的声音文件的网站,包括:
* [Freesound](https://freesound.org) 托管存储所有种类的音效。
* [Incompetech](https://incompetech.filmmusic.io) 托管存储背景音乐。
* [Open Game Art](https://opengameart.org) 托管存储一些音效和音乐。
一些声音文件只要你给予作曲家或声音设计师一个致谢就可以自由使用。在与你的游戏捆绑前,仔细阅读使用条件!音乐家和声音设计师在声音上的工作就像你在代码上的工作一样努力,因此即使他们不要求,给予他们致谢也是极好的。
给予你的声音源文件一些致谢,在一个名为 `CREDIT` 的文本文件中列出你使用的声音,并在你的游戏文件夹中放置该文本文件。
你也可以尝试制作你自己的音乐。优秀的 [LMMS](https://opensource.com/life/16/2/linux-multimedia-studio) 音频工作站易于使用,并带有很多有趣的声音。它在所有主要的平台上都可以使用,也可以导出为 [Ogg Vorbis](https://en.wikipedia.org/wiki/Vorbis)(OGG)音频格式。
### 添加声音到 Pygame
当你找到你喜欢的一个声音文件时,下载它。如果它是一个 ZIP 或 TAR 文件,提取它并将其移动到你游戏目录中的 `sound` 文件夹中。
如果声音文件的名字带有空格或特殊字符,重新命名它。文件名称是完全随意的,它的名称越简单,你就越容易输入到你的代码中。
大多数的电脑游戏使用 OGG 格式声音文件,因为这种格式可以占有较小空间而提供高质量的声音。当你下载一个声音文件时,它可能是一个 MP3、WAVE、FLAC 或者其它的音频格式。为保持你的文件的较高兼容性和降低下载文件大小,使用一个像 [fre:ac](https://www.freac.org/index.php/en/downloads-mainmenu-330) 或 [Miro](http://getmiro.com) 这样的工具来转换这些的文件格式为 Ogg 格式。
例如,假设你已经下载一个称为 `ouch.ogg` 的声音文件。
在你代码的设置部分中,创建一个变量,代表你想使用的声音文件:
```
ouch = pygame.mixer.Sound(os.path.join(s, 'ouch.ogg'))
```
### 触发一个声音
为使用一个声音,你所要做的就是在你想触发它的时候调用这个变量。例如,当你的玩家击中一名敌人时,触发 `OUCH` 声音效果:
```
for enemy in enemy_hit_list:
pygame.mixer.Sound.play(ouch)
score -= 1
```
你可以为各种动作创建声音,例如,跳跃、收集奖励、投掷、碰撞,以及其他任何你能想象到的动作。
### 添加背景音乐
如果你有想在你的游戏的背景中播放的音乐或令人激动的音效,你可以使用 Pygame 中的 `mixer` 模块中的 `music` 函数。在你的设置部分中,加载音乐文件:
```
music = pygame.mixer.music.load(os.path.join(s, 'music.ogg'))
```
然后,开始音乐:
```
pygame.mixer.music.play(-1)
```
`-1` 值告诉 Pygame 无限循环音乐文件。你可以将其设置为从 0 到更高的值之间的任意数值,以定义音乐在停止前循环多少次。
### 享受音效
音乐和声音可以为你的游戏添加很多韵味。尝试添加一些声音到你的 Pygame 工程!
---
via: <https://opensource.com/article/20/9/add-sound-python-game>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part 13 in an ongoing series about creating video games in [Python 3](https://www.python.org/) using the [Pygame](https://www.pygame.org/news) module. Previous articles are:
[Learn how to program in Python by building a simple dice game](https://opensource.com/article/17/10/python-101)[Build a game framework with Python using the Pygame module](https://opensource.com/article/17/12/game-framework-python)[How to add a player to your Python game](https://opensource.com/article/17/12/game-python-add-a-player)[Using Pygame to move your game character around](https://opensource.com/article/17/12/game-python-moving-player)[What's a hero without a villain? How to add one to your Python game](https://opensource.com/article/18/5/pygame-enemy)[Add platforms to your game](https://opensource.com/article/18/7/put-platforms-python-game)[Simulate gravity in your Python game](https://opensource.com/article/19/11/simulate-gravity-python)[Add jumping to your Python platformer game](https://opensource.com/article/19/12/jumping-python-platformer-game)[Enable your Python game player to run forward and backward](https://opensource.com/article/19/12/python-platformer-game-run)[Using Python to set up loot in Pygame](https://opensource.com/article/19/12/loot-python-platformer-game)[Add scorekeeping to your Python game](https://opensource.com/article/20/1/add-scorekeeping-your-python-game)[Add throwing mechanics to your Python game](https://opensource.com/article/20/9/add-throwing-python-game)
Pygame provides an easy way to integrate sounds into your Python video game. Pygame's [mixer module](https://www.pygame.org/docs/ref/mixer.html) can play one or more sounds on command, and by mixing those sounds together, you can have, for instance, background music playing at the same time you hear the sounds of your hero collecting loot or jumping over enemies.
It is easy to integrate the mixer module into an existing game, so—rather than giving you code samples showing you exactly where to put them—this article explains the four steps required to get sound in your application.
## Start the mixer
First, in your code's setup section, start the mixer process. Your code already starts Pygame and Pygame fonts, so grouping it together with these is a good idea:
```
pygame.init()
pygame.font.init()
pygame.mixer.init() # add this line
```
## Define the sounds
Next, you must define the sounds you want to use. This requires that you have the sounds on your computer, just as using fonts requires you to have fonts, and using graphics requires you to have graphics.
You also must bundle those sounds with your game so that anyone playing your game has the sound files.
To bundle a sound with your game, first create a new directory in your game folder, right along with the directory you created for your images and fonts. Call it `sound`
:
`s = 'sound'`
Even though there are plenty of sounds on the internet, it's not necessarily *legal* to download them and give them away with your game. It seems strange because so many sounds from famous video games are such a part of popular culture, but that's how the law works. If you want to ship a sound with your game, you must find an open source or [Creative Commons](https://opensource.com/article/20/1/what-creative-commons) sound that gives you permission to give the sound away with your game.
There are several sites that specialize in free and legal sounds, including:
[Freesound](https://freesound.org)hosts sound effects of all sorts.[Incompetech](https://incompetech.filmmusic.io)hosts background music.[Open Game Art](https://opengameart.org)hosts some sound effects and music.
Some sound files are free to use only if you give the composer or sound designer credit. Read the conditions of use carefully before bundling any with your game! Musicians and sound designers work just as hard on their sounds as you work on your code, so it's nice to give them credit even when they don't require it.
To give your sound sources credit, list the sounds that you use in a text file called `CREDIT`
, and place the text file in your game folder.
You might also try making your own music. The excellent [LMMS](https://opensource.com/life/16/2/linux-multimedia-studio) audio workstation is easy to use and ships with lots of interesting sounds. It's available on all major platforms and exports to [Ogg Vorbis](https://en.wikipedia.org/wiki/Vorbis) (OGG) audio format.
## Add sound to Pygame
When you find a sound that you like, download it. If it comes in a ZIP or TAR file, extract it and move the sounds into the `sound`
folder in your game directory.
If the sound file has a complicated name with spaces or special characters, rename it. The filename is completely arbitrary, and the simpler it is, the easier it is for you to type into your code.
Most video games use OGG sound files because the format provides high quality in small file sizes. When you download a sound file, it might be an MP3, WAVE, FLAC, or another audio format. To keep your compatibility high and your download size low, convert these to Ogg Vorbis with a tool like [fre:ac](https://www.freac.org/index.php/en/downloads-mainmenu-330) or [Miro](http://getmiro.com).
For example, assume you have downloaded a sound file called `ouch.ogg`
.
In your code's setup section, create a variable representing the sound file you want to use:
`ouch = pygame.mixer.Sound(os.path.join(s, 'ouch.ogg'))`
## Trigger a sound
To use a sound, all you have to do is call the variable when you want to trigger it. For instance, to trigger the `OUCH`
sound effect when your player hits an enemy:
```
for enemy in enemy_hit_list:
pygame.mixer.Sound.play(ouch)
score -= 1
```
You can create sounds for all kinds of actions, such as jumping, collecting loot, throwing, colliding, and whatever else you can imagine.
## Add background music
If you have music or atmospheric sound effects you want to play in your game's background, you can use the `music`
function of Pygame's mixer module. In your setup section, load the music file:
`music = pygame.mixer.music.load(os.path.join(s, 'music.ogg'))`
And start the music:
`pygame.mixer.music.play(-1)`
The `-1`
value tells Pygame to loop the music file infinitely. You can set it to anything from `0`
and beyond to define how many times the music should loop before stopping.
## Enjoy the soundscapes
Music and sound can add a lot of flavor to your game. Try adding some to your Pygame project!
## Comments are closed. |
12,878 | 用 Recast.AI 创建一个聊天机器人 | https://opensourceforu.com/2019/11/creating-a-chat-bot-with-recast-ai/ | 2020-12-02T10:21:00 | [
"聊天机器人"
] | https://linux.cn/article-12878-1.html | 
>
> 据 Gartner 2018 年 2 月的报告,“到 2020 年,25% 的客户服务和支持业务将在参与渠道中整合虚拟客户助理(VCA)或聊天机器人技术,而 2017 年只有不到 2%。”鉴于此,读者会发现本教程对理解开源的 Recast.AI 机器人创建平台的工作原理很有帮助。
>
>
>
聊天机器人,包括基于语音的以及其他技术的,已经实际使用了有一阵子了。从让用户参与谋杀解密游戏,到帮助完成房地产交易和医疗诊断,聊天机器人已经跨越了多个领域。
有许多平台可以让用户创建和部署机器人。Recast.AI(在被 SAP 收购之后现在是 SAP Conversational AI)是其中的先行者。
酷炫的界面、协作性以及它所提供的分析工具,让它成为流行的选择。
正如 Recast 官方网站说的,“它是一个创建、训练、部署和监控智能机器人的终极协作平台。”
### 创建一个基础的机器人
让我们来看看如何在 Recast 创建一个基础的机器人。
1. 在 <https://cai.tools.sap> 创建一个账户。注册可以使用电子邮箱或者 Github 账户。
2. 在你登录之后,你会进入仪表板。点击右上角 “+” 新建机器人图标新建一个机器人。
3. 在下一个界面,你会看到一系列可选的预定义技能。暂时选择<ruby> 问候 <rt> Greetings </rt></ruby>”(图 1)。这个机器人已经经过训练,能够理解基本的问候。 
4. 给机器人提供一个名字。目前来说,你可以让机器人讲一些笑话,所以我们将它命名为 Joke Bot,选择英语作为默认语言。
5. 因为你不会处理任何敏感信息,所以在数据策略下选择非个人数据。然后选择公共机器人选项并点击创建一个机器人。
所以这就是你在 Recast 平台创建的机器人。
### 开发一个机器人的五个阶段
用 Recast 官方博客的话说,在机器人的生命中有五个阶段。
* 训练——教授机器人需要理解的内容
* 构建——使用机器人构建工具创建你的对话流
* 编写代码——将机器人连接到外部 API 或数据库
* 连接——将机器人发布到一个或多个消息平台
* 监控——训练机器人让它更敏锐,并且了解其使用情况
### 通过意图训练机器人
你可以在仪表板上看到搜索、分叉或创建一个<ruby> 意图 <rt> intent </rt></ruby>的选项。“‘意图’是一系列含义相同但构造不同的表达。‘意图’是你的机器人理解能力的核心。每个‘意图’代表了机器人可以理解的一种想法。”(摘自 Recast.AI 网站)

就像先前定的,你需要一个讲笑话的机器人。所以底线是这个机器人可以理解用户在要求它讲笑话,它不应该在用户仅仅说了“Hi”的情况下回复一个笑话——这可不妙。把用户可能说的话进行分组,比如:
```
Tell me a joke.(给我讲个笑话。)
Tell me a funny fact.(告诉我一个有趣的事实。)
Can you crack a joke?(你可以讲个笑话吗?)
What’s funny today?(今天有什么有趣的?)
```
……
在继续从头开始创建意图之前,让我们来看看搜索/分叉选项。在搜索框输入 “Joke”(图 3)。系统给出了全球的 Recast 用户创建的公开的意图清单,这就是为什么说 Recast 天然就是协作性质的。所以其实没有必要从头开始创建所有的意图,可以在已经创建的基础上进行构建。这就降低了训练具有常见意图的机器人所需的投入。

* 选择列表中的第一个意图并将其分叉到机器人上。
* 点击<ruby> 分叉 <rt> Fork </rt></ruby>按钮。这个意图就添加到了机器人中(图 4)。 
* 点击意图 @joke,会显示出这个意图中已经存在的<ruby> 表达 <rt> expression </rt></ruby>列表(图 5)。 
* 向其添加更多的表达(图 6)。 
添加了一些表达之后,机器人会给出一些建议,像图 7 展示的那样。选择几个将它们添加到意图中。你还可以根据机器人的上下文,标记你自己的自定义实体来检测关键词。

### 技能
<ruby> 技能 <rt> skill </rt></ruby>是一块有明确目的的对话,机器人可以据此运行并达到目标。它可以像打招呼那么简单,也可以更复杂,比如基于用户提供的信息提供电影建议。
技能需要的不能只是一对问答,它需要多次交互。比如考虑一个帮你学习汇率的机器人。它一开始会问原货币,然后是目标货币,最后给出准确回应。结合技能可以创建复杂的对话流。
下面是如何给笑话机器人创建技能:
* 去到 构建(Build) 页。点击 “+” 图标创建技能。
* 给技能命名 “Joke”(图 8) 
* 创建之后,点击这个技能。你会看到四个标签。<ruby> 读我 <rt> Read me </rt></ruby>、<ruby> 触发器 <rt> Triggers </rt></ruby>、<ruby> 需求 <rt> Requirements </rt></ruby>和 <ruby> 动作 <rt> Actions </rt></ruby>。
* 切换到需求页面。只有在笑话意图存在的时候,你才应该存储信息。所以,像图 9 那样添加一个需求。 
由于这个简单的使用范例,你不需要在需求选项卡中考虑任何特定的需求,但可以考虑只有当某些关键字或实体出现时才需要触发响应的情况——在这种情况下你需要需求。
需求是某个技能执行动作之前需要检索的意图或实体。需求是对话中机器人可以使用的重要信息。例如用户的姓名或位置。一旦一个需求完成,相关的值就会存储在机器人的内存中,供整个对话使用。
现在让我们转到动作页面设置<ruby> 回应 <rt> response </rt></ruby>(参见图 10)。

点击添加<ruby> 新消息组 <rt> new message group </rt></ruby>。然后选择<ruby> 发送消息 <rt> Send message </rt></ruby>并添加一条文本消息,在这个例子中可以是任何笑话。当然,你肯定不想让你的机器人每次都说一样的笑话,你可以添加多条消息,每次从中随机选择一条。

### 频道集成
一个成功的机器人还依赖于它的易得性。Recast 有不少的内置消息频道集成,如 Skype for Business、Kik Messenger、Telegram、Line、Facebook Messenger、Slack、Alexa 等等。除此之外,Recast 还提供了 SDK 用于开发自定义的频道。
此外,Recast 还提供一个可立即使用的网页聊天(在连接页面中)。你可以自定义颜色主题、标题、机器人头像等。它给你提供了一个可以添加到页面的脚本标签。你的界面现在就可以使用了(图 12)。

网页聊天的代码是开源的,开发者可以更方便地定制外观、标准回应类型等等。面板提供了如何将机器人部署到各种频道的逐步过程说明。这个笑话机器人部署在 Telegram 和网页聊天上,就像图 13 展示的那样。


### 还有更多
Recast 支持多语言,创建机器人的时候选择一个语言作为基础,但之后你有选项可以添加更多你想要的语言。

这里的例子是一个简单的静态笑话机器人,实际使用中可能需要更多的和不同系统的交互。Recast 有 Web 钩子功能,用户可以连接到不同的系统来获取回应。同时它还有详细的 API 文档来帮助使用平台的每个独立功能。
至于分析,Recast 有一个监控面板,帮助你了解机器人的准确度以及更加深入地训练机器人。
---
via: <https://opensourceforu.com/2019/11/creating-a-chat-bot-with-recast-ai/>
作者:[Athira Lekshmi C.V](https://opensourceforu.com/author/athira-lekshmi/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,880 | 如何在 Silverblue 上变基到 Fedora 33? | https://fedoramagazine.org/how-to-rebase-to-fedora-33-on-silverblue/ | 2020-12-02T23:25:39 | [
"Silverblue"
] | https://linux.cn/article-12880-1.html | 
Silverblue 是[一个建立在 Fedora 之上的桌面操作系统](https://docs.fedoraproject.org/en-US/fedora-silverblue/)。它非常适合日常使用、开发和基于容器的工作流程。它提供了[众多的优势](https://fedoramagazine.org/give-fedora-silverblue-a-test-drive/),例如在出现任何问题时能够回滚。如果你想在你的 Silverblue 系统上更新到 Fedora 33,这篇文章会告诉你如何做。它不仅告诉你该怎么做,还告诉你如果发生了不可预见的事情时该如何回退。
在实际做变基到 Fedora 33 之前,你应该应用任何挂起的更新。在终端中输入以下内容:
```
$ rpm-ostree update
```
或通过 GNOME 软件中心安装更新并重启。
### 使用 GNOME 软件中心变基
GNOME 软件中心会在更新界面显示有新版本的 Fedora 可用。

首先你需要做的是下载新镜像,点击 “Download” 按钮。这将需要一些时间,完成后你会看到更新已经准备好安装了。

点击 “Install” 按钮。这一步只需要几分钟,然后会提示你重启电脑。

点击 “Restart” 按钮就可以了。重启后,你将进入新的 Fedora 33 版本。很简单,不是吗?
### 使用终端变基
如果你喜欢在终端上做所有的事情,那么接下来的指南就适合你。
使用终端变基到 Fedora 33 很简单。首先,检查 33 版本分支是否可用:
```
$ ostree remote refs fedora
```
你应该在输出中看到以下内容:
```
fedora:fedora/33/x86_64/silverblue
```
接下来,将你的系统变基到 Fedora 33 分支。
```
$ rpm-ostree rebase fedora:fedora/33/x86_64/silverblue
```
最后要做的是重启你的电脑并启动到 Fedora 33。
### 如何回滚
如果有什么不好的事情发生。例如,如果你无法启动到 Fedora 33,那很容易回滚回去。在启动时选择 GRUB 菜单中的前一个条目,你的系统就会以切换到 Fedora 33 之前的状态启动。要使这一改变永久化,请使用以下命令:
```
$ rpm-ostree rollback
```
就是这样了。现在你知道如何将 Silverblue 变基为 Fedora 33 并回滚了。那为什么不在今天就做呢?
---
via: <https://fedoramagazine.org/how-to-rebase-to-fedora-33-on-silverblue/>
作者:[Michal Konečný](https://fedoramagazine.org/author/zlopez/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Silverblue is [an operating system for your desktop built on Fedora](https://docs.fedoraproject.org/en-US/fedora-silverblue/). It’s excellent for daily use, development, and container-based workflows. It offers [numerous advantages](https://fedoramagazine.org/give-fedora-silverblue-a-test-drive/) such as being able to roll back in case of any problems. If you want to update to Fedora 33 on your Silverblue system, this article tells you how. It not only shows you what to do, but also how to revert things if something unforeseen happens.
Prior to actually doing the rebase to Fedora 33, you should apply any pending updates. Enter the following in the terminal:
$ rpm-ostree update
or install updates through GNOME Software and reboot.
## Rebasing using GNOME Software
The GNOME Software shows you that there is new version of Fedora available on the Updates screen.
First thing you need to do is to download the new image, so click on the *Download* button. This will take some time and after it’s done you will see that the update is ready to install.
Click on the *Install* button. This step will take only a few moments and then you will be prompted to restart your computer.
Click on *Restart* button and you are done. After restart you will end up in new and shiny release of Fedora 33. Easy, isn’t it?
## Rebasing using terminal
If you prefer to do everything in a terminal, than this next guide is for you.
Rebasing to Fedora 33 using terminal is easy. First, check if the 33 branch is available:
$ ostree remote refs fedora
You should see the following in the output:
fedora:fedora/33/x86_64/silverblue
Next, rebase your system to the Fedora 33 branch.
$ rpm-ostree rebase fedora:fedora/33/x86_64/silverblue
Finally, the last thing to do is restart your computer and boot to Fedora 33.
## How to roll back
If anything bad happens—for instance, if you can’t boot to Fedora 33 at all—it’s easy to go back. Pick the previous entry in the GRUB menu at boot, and your system will start in its previous state before switching to Fedora 33. To make this change permanent, use the following command:
$ rpm-ostree rollback
That’s it. Now you know how to rebase Silverblue to Fedora 33 and roll back. So why not do it today?
## Juanje Ojeda
Thanks for the article. I upgraded yesterday and it was very smooth, but I had to remove the rpmfusion to be able to do the rebase:
rpm-ostree rebase fedora:fedora/33/x86_64/silverblue –uninstall=rpmfusion-nonfree-release-32-1.noarch –uninstall=rpmfusion-free-release-32-1.noarch
Using those parameters, everything was fine.
## Juanje Ojeda
Sorry, the parameters ‘uninstall’ have two dashes (‘–uninstall’) but, for some reason, they don’t show at comment.
## Si Dao
You save my ass, thanks
## Kyra
And then you can also install the next rpmfusion version at the same time!
https://twitter.com/unlambda/status/1328135774093647873
## Dmitriy
$ ostree remote refs fedora
do not work for me:
ostree remote refs fedora
Usage:
ostree remote refs [OPTION…] NAME
List remote refs
Help Options:
-h, –help Show help options
Application Options:
–repo=PATH Path to OSTree repository (defaults to current directory or /sysroot/ostree/repo)
–cache-dir Use custom cache dir
-v, –verbose Print debug information during command processing
–version Print version information and exit
error: Command requires a –repo argument
Any help?
## Michal Konečný
It looks like your fedora remote is named differently.
Could you try
?
## Dmitriy
Thanks but no:
ostree remote list
Usage:
ostree remote list [OPTION…]
List remote repository names
Help Options:
-h, –help Show help options
Application Options:
–repo=PATH Path to OSTree repository (defaults to current directory or /sysroot/ostree/repo)
-u, –show-urls Show remote URLs in list
-v, –verbose Print debug information during command processing
–version Print version information and exit
error: Command requires a –repo argument
## Michal Konečný
Look in the
You should find the remotes available there.
Could you also try running
to check what version of Fedora you are exactly running.
## leslie Satenstein
Nice explanation about work done. Thank you
## Ian
Apologies for the stupid question, I’m not a techhead. I’m assuming this process does not convert any ext4 partitions to btrfs? Is there a way to do that, other than a clean install?
Thanks,
## Stephen Snow
When I converted my Silverblue system to BTRFS, I chose rsync to backup my home to an external storage device. I then did a fresh install and used rsync to restore my home. There is an ext4 to btrfs conversion tool included with the btrfs utilities, but it is currently considered experimental and the general consensus I found was it would be a bad idea. |
12,881 | 《代码英雄》第三季(4):深入 Perl 语言的世界 | https://www.redhat.com/en/command-line-heroes/season-3/diving-for-perl | 2020-12-03T12:37:00 | [
"Perl",
"代码英雄"
] | https://linux.cn/article-12881-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第三季(4):深入 Perl 语言的世界](https://www.redhat.com/en/command-line-heroes/season-3/diving-for-perl)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/be4cc2b9-8548-476d-98d5-874a93439675/CLH_S3E4_The_Perl_Dive_vFINAL_tc.mp3)脚本。
>
> 导语:语言来了又走。只有少数几种语言具备了登峰造极的能力,而能留在那里的则更少。Perl 有过一次惊人的崛起,也有过一次平静的低迷,现在已经在编程世界中找到了自己的位置。
>
>
> Perl似乎注定要统治网络。Michael Stevenson 和 Mike Bursell 描述了 Perl 的设计如何使它成为早期 web 的理想选择。我们从 Conor Myhrvold 那里听到了它的座右铭:“<ruby> 实现它的方法不止一种 <rt> There is more than one way to do it. </rt></ruby>”。Elizabeth Mattijsen 分享了,尽管 Perl 有优势,但漫长的开发周期如何减缓了 Perl 的发展。虽然它不再是最顶级的网络语言,但 John Siracusa 指出,Perl 作为一种小众工具仍然存在。
>
>
>
**00:00:02 - Saron Yitbarek**:
想象一下 Perl 语言的创建者 Larry Wall 在 1999 年的一次会议上站在麦克风前,留着他标志性的浓密胡子和梳理过的刘海,感觉相当好,因为他所发明的语言正在越来越受欢迎。
**00:00:19 - 配音演员**:
声音测试。
**00:00:19 - Saron Yitbarek**:
Perl 语言轻而易举地超越了 COBOL、Visual Basic,而 Python 呢? Python 仍然是一个不入流的竞争者,是Larry Wall 的几个玩笑素材。Wall 展示了 [dice.com](http://dice.com) 报告中的人群数据,在那时来看,Perl 语言的未来是非常、非常光明的。然而之后 Perl 的未来就不再如此了。20 年之后,[dice.com](http://dice.com) 在 2018 年夏天将 Perl 列为最可能灭绝的语言之一。短短 20 年之间发生了什么?
\*\*00:00:59 \*\*:
我是 Saron Yitbarek,这里是《代码英雄》,一档红帽公司的原创播客。这一季是关于我们编程语言的力量和前景的。在上一集我们追踪了搭上了互联网顺风车的 JavaScript 的疯狂崛起。
**00:01:19**:
并不是每一种语言都有一个不停地成长和成功的故事。大多数语言的出现,在当时非常特殊的生态系统中发挥了它们的作用,然后当我们的编程生活里需要其他类型的工具时它们就开始消退。
**00:01:37**:
本集我们将深入了解 Perl 世界。是什么造就了它早期的成功,为什么它的成功突然就被颠覆了?我们所处的环境,我们的基础设施,我们的硬件,各种因素都会决定哪些语言会繁荣,哪些会开始萎缩。这就是 Perl 语言的故事的魅力所在。
**00:02:08**:
我们知道 Perl 并没有统治世界,但是退回到上世纪 90 年代的时候,却看不到这一点。Tim Berners-Lee 在 1991 年发明了<ruby> 万维网 <rt> World Wide Web </rt></ruby>(WWW),它迅速创造了一个全新的基于 Web 的开发领域。谁也说不准会是哪种编程语言在这个新领域取得成功。
**00:02:31 - Michael Stevenson**:
在 Web 出现的时候,所有人都等待着会有什么事情发生。那个时候整个世界都是令人兴奋的。
**00:02:39 - Saron Yitbarek**:
Michael Stevenson 是<ruby> 阿姆斯特丹大学 <rt> University of Amsterdam </rt></ruby>媒体研究的副教授。他为我们描述了早期的 Web。人们见过 Usenet,也见过 ARPANET。他们看到了<ruby> 美国在线 <rt> America Online </rt></ruby>,还有一些其它的东西。但是直到 Web 出现,互联网的全部发展潜力才真正得到体现。突然之间,你就可以通过鼠标和点击进入了这个巨大的互联世界。这是一个出乎意料的事情。
**00:03:09 - Michael Stevenson**:
你要是记得 1993 年,也就是 Web 开始崭露头角的那一年,也是《<ruby> 连线杂志 <rt> Wired Magazine </rt></ruby>》开始出版的那年。在那之前类似《Mondo 2000》这类的杂志真的让电脑看起来像神秘知识的来源,让电脑看起来很酷。
**00:03:32**:
因此从这个意义上说,Web 也到达了一个相当特定的时期,人们已经准备好以这样的方式迎接技术的兴起。
**00:03:43 - Saron Yitbarek**:
故事在这个时候开始了:Larry Wall 在 1987 年创建了 Perl,4 年后万维网才开始兴起。Larry Wall 给世界带来的 Perl 最初只是一种通用的 Unix 脚本语言。当然,它确实很有用,但同时 Perl 还有一些秘密元素,这些元素使它成为即将到来的 Web 开发世界的理想语言。
**00:04:14 - Michael Stevenson**:
比较有名的是 Perl 是 Larry Wall 在参与的一个美国国家安全局(NSA)的秘密项目中发明的,基本上他所做的就是创建一个类似黑客版的新闻栏目,运行在 Usenet 上,因此 Perl 语言从一开始就是操作文本和将数据从一个地方移动到另一个地方,这完全符合 Web 的需求。而 Perl 作为一种易于使用的脚本语言,更加接近于自然语言。它可以用来快速开发东西,所有这些都让 Perl 成为了一个完美的契机,不仅适合专业用户,也适合新加入的业余爱好者。
**00:05:09 - Saron Yitbarek**:
很偶然的是,当 Web 出现时,Perl 已经为 Web 做好了准备。Larry Wall 不可能知道 Web 即将出现。但当它出现时正好相互吻合。但我认为还有一点很关键:Perl 是一种自由语言。Larry Wall 在<ruby> 自由软件基金会 <rt> Free Software Foundation </rt></ruby>开发的 GPL(<ruby> 通用公共许可证 <rt> General Public License </rt></ruby>)下发布了它。
**00:05:37**:
Larry Wall 让他的语言自由开源的决定,这完全符合刚刚开始出现的基于 Web 的新思维方式,同时 Perl 在其他方面也很有前瞻性。
**00:05:50 - Michael Stevenson**:
Perl 的开放性令人难以置信,在某种意义上,它总是愿意整合一些其他的东西,新的东西。这和 Larry Wall 的身份很相配。他是个很开放谦虚的人,总是仔细考虑别人的想法,并试着设身处地为别人着想。对我来说 Perl 作为一种语言,以及作为一个社区的性格,在很长一段时间里,真的很符合这一点。
**00:06:27 - Saron Yitbarek**:
同样 Perl 非常适合 Web 早期的、狂野的西部阶段,也就是黑客时代。实际上 Perl 的座右铭之一就是“<ruby> 实现它的方法不止一种 <rt> There is more than one way to do it. </rt></ruby>”。
**00:06:39 - Michael Stevenson**:
在 Perl 的鼎盛时期和这个试验性的开放 Web 的鼎盛时期之间,存在着一种近乎浪漫的联系,在它变得如此被几个平台所控制之前。
**00:06:56 - Saron Yitbarek**:
记得上世纪 90 年代是互联网历史上的一段启蒙时期,那时人们还在争先恐后地想知道还有哪些是可能的。那时对编程的需求是巨大的,每个人都需要有一个网页,这意味着一群全新的开发人员,他们都对新的做事方法持开放态度。问题变成了“好吧,我们有了一个全新的领域,但用什么语言来完成这项工作呢?”
**00:07:26**:
Perl 虽然并不是这个问题的最终答案,但对于很多人来说 Perl 是他们首选的答案。
**00:07:34 - Michael Stevenson**:
我并不是说我更愿意看到加载速度超慢的网页、也没有谷歌搜索引擎的时代,但我确实认为那个时代有一些特别的东西,当时有一些人,在他们的宿舍里,创建了一个类似 slashdot 的东西。而现在随着 Web 已经变得如此主流、专业化和被集中在几个大公司中,我们确实怀念那个时代。对我来说,Perl 比其他任何早期的故事都更能象征这一点。
**00:08:15 - Saron Yitbarek**:
Michael Stevenson 是阿姆斯特丹大学媒体研究的副教授。
**00:08:24 - Saron Yitbarek**:
之后,随着 90 年代的到来,Perl 作为一种能适应早期互联网发展潜力的语言出现了,它是一个时代的语言。Larry Wall 和他所创造的 Perl 正好明白了 Web 的本质。
**00:08:40 - Mike Bursell**:
在网上你可以随意搜索,也可以随时创建网页,这是互联网的美丽新世界,你可以随时做这些事情。
**00:08:52 - Saron Yitbarek**:
这位是 Mike Bursell,红帽公司的首席安全架构师。Mike 是 90 年代中期发现和使用 Perl 的黑客之一。
**00:09:00 - Mike Bursell**:
对于 Web 来说,Perl 是许多人的起点。Java™ 语言还处于早期阶段,它在文本输入输出方面并不是很出色。如果你想进行查询和生成页面,Perl 是人们都在使用的工具。
**00:09:22**:
Perl 非常适合,因为它擅长获取文本,并使用文本做其他事情,而这正是 Web 所需要的。
**00:09:31 - Saron Yitbarek**:
顺便需要说一下的是,Larry Wall 有语言学背景,这就解释了为什么 Perl 有强大的文本解析能力。正如 Mike Bursell 提到的,这是一笔巨大的好处,因为在早期,Web 主要是一种基于文本的媒介,因为那时候人们没有足够的带宽来处理图像。
**00:09:51 - Mike Bursell**:
它很容易使用,也很容易复制。人们在分享方面非常开放,而且它的输出速度很快,这些都是好东西。
**00:10:02**:
哦,当然还有一点,就是你可以用管道使用它。所以,这是非常多的人所习惯的,而且非常容易测试,甚至离线测试,这都是非常有用的。
**00:10:13 - Saron Yitbarek**:
尤其对那些在 Web 的世界中重新规划自己生活的系统管理员来说非常有用。
**00:10:21 - Mike Bursell**:
Perl 是给系统管理员们的真正礼物。即使在那个年代,如果你做一些事情,你会得到很多日志。管理这些日志,分解它们,搜索它们,并能够以不同的方式显示它们,或获取任何其他大型文本语料库(主要就是日志),甚至可以对它们进行调试。除非你要在命令行里用管道方式传输 `orc`、`sed` 之类的东西,以及 `ed` 命令,那样的话你很快就会变得非常痛苦,而 Perl 正好适合让你去处理这些事情。
**00:10:55 - Saron Yitbarek**:
到上世纪 90 年代后期,Perl 5 已经聚集了一个强大的用户群体。像 Fortran 和 C 这样的旧语言依赖于庞大而昂贵的硬件,而 Perl 更有生命力,也更容易移植。在那样一个硬件成本急剧下降的世界里,Perl 的设计使得它得到了蓬勃发展,Perl 让所有的新程序员快速、轻松地工作。这是因为 Larry Wall 以牺牲 CPU 和内存的需求为代价,使 Perl 语法更人性化。所有这些元素组合在一起,使 Perl 成为一种很受新开发社区欢迎的语言。
**00:11:36 - Mike Bursell**:
在一个正在壮大的社区里,你可以去和他们聊聊社区里的事情,然后 PerlMonks 论坛出现了,那里是一个讨论的好地方,能在论坛里知道正在发生的事情。
**00:11:50 - Saron Yitbarek**:
这个社区确实拥有 Web 所能提供的最好的东西。他们发现了一个巨大的软件模块库,一个叫做 CPAN 的存储库,这些系统管理员都很喜欢它。它给 Perl 提供了更多的灵活性,许多人都可以部署由少数几个编程大师编写的代码。
**00:12:15 - Mike Bursell**:
它有很多库可以做你想做的任何事情,如果你找不到你想要的库,你可以去问一下,然后就会有好心人写出你想要的库。
**00:12:21 - Saron Yitbarek**:
Mike Bursell 是红帽公司的首席安全架构师。
**00:12:28 - Saron Yitbarek**:
正是由于 Perl 是免费的,它受到不断增长的模块库的支持,它是可移植的,而且它有一个蓬勃发展的社区。一切看起来都很好。Perl 可以在上世纪 90 年代 Web 开发新天地中发挥所有优势,但就在 90 年代即将结束的时候,互联网的发展前景又一次发生了变化,时代来了一个大的转变。
**00:12:57 - Alan Greenspan**:
但我们又能如何知道非理性繁荣何时已过度推高了资产价值,进而导致了意料之外的长期经济收缩?
**00:13:12 - Saron Yitbarek**:
“非理性繁荣”是时任美联储主席 Alan Greenspan 在 1996 年对<ruby> 美国企业协会 <rt> American Enterprise Institute </rt></ruby>所说的话。他那句“非理性繁荣”是对 90 年代人人都经历过的网络泡沫的警告。所有早期使用 Perl 的 Web 开发人员都在那个泡沫中乘风破浪,但正如 Greenspan 预测的那样,泡沫在 2000 年破裂了。
**00:14:11 - Conor Myhrvold**:
大家好,我是 Conor Myhrvold 。在过去的五六年里我一直从事编程,现在在技术领域为 Uber 工作。
**00:14:20 - Saron Yitbarek**:
2000 年代初,当 Conor 还在高中的时候,Perl 仍然是一个非常重要的东西。但他越来越意识到一种与之竞争的语言,叫做 Python。
**00:14:31 - Conor Myhrvold**:
Python 所追求的是一种更结构化的语言,做很多不同的事情都有一种更显然的方式,它就是那样设计的。而 Perl 则喜欢做某件事有不止一种方法,但这让很多初学者感到困惑。
**00:14:49 - Saron Yitbarek**:
Perl 有这样一句座右铭“<ruby> 实现它的方法不止一种 <rt> There is more than one way to do it. </rt></ruby>”。而 Python 的理念实际上是相反的,Python 为每个问题都提供了一个明显的解决方案,这意味着查看别人的 Python 代码很容易;而另一方面查看其他人的 Perl 代码可能会令人困惑。Perl 作为一个程序员的第三或第四种语言是有意义的,而正是因为它是一种脚本语言,而脚本是互联网连结的基础。
**00:15:23**:
但是 Python 是一种你可以真正深入研究的语言,即使你是一个新手。Perl 有一套特定的优势,比如在搜索文本和生物信息学上。但是 Python 就是这样一种简单通用的语言。Python 获得了越来越多的信任,成为人们首先想学的语言,这是一件大事。
**00:15:47 - Conor Myhrvold**:
越来越多的人开始上网,越来越多的人开始学习如何编程。尤其是相对于 Perl 而言,Python 受益于它本身相对容易学习,因为它更结构化。而这样结果是,在一个快速增长的世界里,如果你能得到更多增长的份额,那将最终意味着有更多的教程和更多的东西可供你使用。
**00:16:10 - Saron Yitbarek**:
在之前提到过的 CPAN,它是 Perl 用户可以使用的强大的中央存储库。这在 90 年代是一大亮点,但 CPAN 的价值也在变化。
**00:16:24 - Conor Myhrvold**:
这也不能真正帮助你学习一门语言,因为你是在“复制粘贴”,只是用最少的方式替换你需要的东西。从长远来看这是一个劣势,因为如果你让人们通过自己进行原始开发来学习如何使用一种编程语言,即使这需要花费更长的时间,他们也会觉得自己对它投入了更多,而且他们也了解在这中间发生了什么。
**00:16:48 - Saron Yitbarek**:
Python 没有像 CPAN 那样的集中式存储库,但是对于那些在新千年时代来到这里的开发人员来说,在一个互联网搜索功能如此强大的世界里,存储库并没有那么大的价值。
**00:17:05 - Saron Yitbarek**:
最终 Python 有了大量的教程,当然现在也有了像 GitHub 这样的平台。
**00:17:13 - Conor Myhrvold**:
最终发生的事情是 Perl 拥有的许多优势,是来自一个已经过时的时代的网络效应。
**00:17:24 - Saron Yitbarek**:
Conor Myhrvold 是 Uber 的一名工程师。
**00:17:30 - Saron Yitbarek**:
然而语言的兴衰很少是由外部力量单独决定的,而 Perl 的内部问题是,在它的发展过程中它似乎遇到了障碍。Python 正在以一种相当有序的方式发布新的迭代,而正如我们在本季度第一集中所了解到的,Perl 在 2000 年互联网泡沫破裂之时,Python 开始获得更多新开发人员的青睐。
**00:17:59 - Saron Yitbarek**:
每个人都期待着 Perl 6 的发布,人们都很兴奋。他们等啊,等啊,等啊……他们等了 14 年。
**00:18:15 - Elizabeth Mattijsen**:
人们提出了大约 300 多件 Perl 6 应该能够完成的事情,当然其中很多事情基本上都是相互排斥的。
**00:18:26 - Saron Yitbarek**:
这是 Elizabeth Mattijsen,她是 Perl 6 的核心开发人员。2000 年,Elizabeth 参加了在<ruby> 蒙特雷 <rt> Monterey </rt></ruby>举办的 Perl 会议。那时开发者认为他们已经停滞不前了,所以 Perl 6 是必要的。Larry Wall 同意了,但是如果说 Perl 5 是他对 Perl 的重写,那么他希望 Perl 6 是由社区来对 Perl 进行重写。由于团队合作可能需要更长时间,甚至用了 14 年,对于那些开发者来说,这是一条漫长而艰难的道路。
**00:19:01 - Elizabeth Mattijsen**:
我们可以说当前实施的 Perl 6 项目实际上是实现它的第三次尝试。
**00:19:07 - Saron Yitbarek**:
按照 Elizabeth 的说法,在这 14 年里有过多次尝试。中间经历了漫长而痛苦的深度的尝试。开发者们心力交瘁;人们陷入了死胡同。到 2015 年圣诞节那天 Perl 6 终于问世时,世界上的许多地方已经开始了新的发展。而需要注意的是 Perl 6 并没有给予成为某种革命性的新事物,从而实现对 Python 的反击。Perl 6 是对原版进行了深思熟虑的重新设计。
**00:19:43 - Elizabeth Mattijsen**:
我认为 Larry Wall 在他的“<ruby> 洋葱状态 <rt> State of the Onion </rt></ruby>”演讲中使用了一个很好的比喻。对他来说,Perl 5 就像《<ruby> 霍比特人 <rt> The Hobbit </rt></ruby>》,而 Perl 6 就像《<ruby> 指环王 <rt> Lord of the Rings </rt></ruby>》。如果你仔细看过《霍比特人》和《指环王》的故事,你会发现它们基本上是同一个故事。只是《霍比特人》比《指环王》小得多,情节漏洞也更多,没有《指环王》那么宏大的背景。我认为这很好地描述了 Perl 5 和 Perl 6 之间的区别。它基本上是同样的想法,同样的思路,同样的环境,只是对它的重新构想。
**00:20:26 - Saron Yitbarek**:
Elizabeth Mattijsen 是 Perl 6 的核心贡献者。
**00:20:32**:
如今,Perl 甚至可能不在前 20 种语言之列。在外部竞争和内部拖延之间,它还没有向大多数新开发人员证明自己。但这提出了一个大问题,我们真的应该根据一种语言的流行度来判断我们的编程语言吗?或者说我们应该根据其他方面来判断一种编程语言的价值?当昔日的超级巨星成为陪衬时,这到底意味着什么呢?
**00:21:06**:
在世纪之交时互联网泡沫破裂时,Perl 的统治地位开始衰退时,Larry Wall 发表了一个有趣的声明。他认为尽管 Perl 永远不会再成为世界上最流行的编程语言,但它可以成为较小类别中的领先者。Larry Wall 说那才是真正的目标。成为同类中最好的,而不是世界上最好的。正如他所说的,SUV 永远不会和赛车竞争。
**00:21:38 - Saron Yitbarek**:
我想深入研究这个想法,我想了解在细分类别中做到最好对编程语言的真正含义。
**00:21:48 - John Siracusa**:
我是 John Siracusa,我是一个程序员,也是一个播客主。
**00:21:53 - Saron Yitbarek**:
John 实际上共同主持了三个播客:《Accidental Tech Podcast》、《Reconcilable Differences》和《Robot or Not?》。我们刚刚聊到了 Perl 在当今世界的地位。
**00:22:06**:
Perl 在当今世界排名如何?它仍然是最好的计算机语言吗?
**00:22:10 - John Siracusa**:
Perl 6 具有其他语言没有的、其他语言应该具有的东西,我一直在等待其他语言偷学它。例如语法是将常见任务概念化的一种好方法,而在我看来,使用语法来解决解析问题比使用现有的工具更令人愉快、更干净、更好。
**00:22:31**:
在 Perl 中,对象系统的许多部分看起来很琐碎而无关紧要,但我完全期待其他语言最终会采用它,就像许多语言最终采纳了 Perl 5 中的许多思想一样。因此我认为 Perl 6 在许多方面都是最好的。遗憾的是,很少有人有机会使用它。
**00:22:52 - Saron Yitbarek**:
你认为 Perl 6 社区的发展需要做些什么?想让人们更多地参与到 Perl 6 中,需要做些什么?
**00:23:00 - John Siracusa**:
这有点像 Perl 6 的故事,就像它一直在寻找一个真正奇妙的实现一样。这是第二系统问题的一部分……<ruby> 第二系统综合症 <rt> second-system syndrome </rt></ruby>,我想他们是这样称呼……
**00:23:11 - Saron Yitbarek**:
哦。
**00:23:12 - John Siracusa**:
Perl 6 的,人们希望修复世界上的所有问题。他们想要解决的问题之一是运行时环境。是什么在运行我们的代码?运行 Perl 5 和之前的 Perl 4 的东西是一个巨大的 C 程序,这是由具有独特编码风格的开发者编写的。还有大量的宏,它是一种相当难以理解的东西。
**00:23:33**:
Perl 6 的想法是让我们不要再那样做了,让我们不要制造大量的 C 代码。相反,让我们使用一个虚拟机,这在当时是一种时尚,有很多关于如何实现它的伟大想法。最终我们得到了几个中规中矩的虚拟机实现版本,有时这些还会相互竞争,但没有一个达到真正交付语言使用时需要的性能、稳定性和特性。
**00:24:01 - Saron Yitbarek**:
现如今 Perl 到底发生了什么?你对此有什么看法?
**00:24:06 - John Siracusa**:
Perl 5 绝对像是在走下坡路,因为与 Perl 5 同时代的所有其他语言都采纳了它的大部分最佳思想,并获得了更多的支持。也就是说,因为它在很长一段时间内都是王者,所以有很多 Perl 5 代码在运行一些大型的、重要的站点,人们需要维护和扩展这些代码。
**00:24:29**:
这需要很长时间才能消失。只要看看现今仍然存在的 COBOL,人们怎么还在雇佣人在 COBOL 上做维护吧?
**00:24:35 - Saron Yitbarek**:
嗯。是这样。
**00:24:36 - John Siracusa**:
你刚才问 Perl 是不是一门垂死的语言,我提到了 COBOL,这听起来并不乐观。Perl 6 本身会成为主流语言吗?看起来可能性不大。现在对其他语言有非常多的关注,如果 Perl 6 现在还没有得到开发者的关注,我不知道将会需要发生什么变化来让它流行起来。
**00:24:54 - Saron Yitbarek**:
如果你是这样想的,你对 Perl 有什么期望?你希望在 Perl 5 或 Perl 6 中看到什么,以及希望看到将来发生什么?
**00:25:04 - John Siracusa**:
我对 Perl 5 的希望是人们不要忽视它,因为尽管有其它更流行的语言,但今天许多公司仍然采用 Perl 5 做为解决问题的最佳方案。通常这些都是胶水类型语言的问题。如果你发现自己曾经编写过 shell 脚本,并且可能会说:“好吧,我不会用我的‘真正的编程语言’来做这件事。”不管是 Python,还是 Ruby,还是别的什么。但是 shell 脚本可以让我把一堆东西连接起来(胶水类型语言)。Perl 是完成这项工作的更好工具。编写正确的 Perl 脚本要比编写正确的 shell 脚本更容易。
**00:25:40 - Saron Yitbarek**:
我认为归根结底 Perl 可能不再是一个适合入门的语言,但对于经验更丰富的多语言开发人员来说,它是那个你永远不希望扔掉的工具箱中的小工具,而且特定的工具有时让你提升水平的工具。
**00:25:58 - John Siracusa**:
有时我为 Perl 6 感到难过和沮丧,认为它不会有任何进展,有时我想“好吧,这是个不错的小社区”。每个社区都不需要称霸世界,也不需要成为整个行业的主导语言。也许可以就这样一直走下去,就是,无限期地走下去。这就是开源,和编程语言的伟大之处。没人可以阻止你,你可以像以前一样继续开发 Perl 6。
**00:26:27 - Saron Yitbarek**:
John Siracusa 是一名程序员,也是三个科技播客的联合主持人。
**00:26:34**:
语言都是有生命周期的。当新的语言出现时它们能够精确地适应新的现实,像 Perl 这样的选择可能会占据更小的、更小众的领域,但这并不是一件坏事。我们的语言应该随着我们需求的变化而扩大或缩小它们的群体。在互联网开发的早期历史中,Perl 是一个至关重要的角色,它以各种方式与我们联系在一起,只要看一看它的历史就会发现它的存在。
**00:27:11**:
下次在《代码英雄》中,我们将讨论:是什么将一种语言变成了标准?以及在基于云的开发世界中,新的标准将如何出现?
**00:27:26**:
《代码英雄》是红帽的原创播客。如果你想深入了解 Perl 的故事,或者任何我们在第三季中探索的编程语言,请访问 [redhat.com/commandlineheroes](file:///Users/xingyuwang/develop/LCRH-wxy/translated/redhat.com/commandlineheroes) 。我们的网站里有许多精彩内容等你去探索。
**00:27:49**:
我是 Saron Yitbarek。下期之前,编码不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-3/diving-for-perl>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[Mikedkmilk](https://github.com/Mikedkmilk) 校对:[Northurland](https://github.com/Northurland), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Languages come and go. A few have the right stuff to rise to the top—and fewer stay there. Perl had a spectacular rise, a quiet slump, and has now found its place in the world of programming.
Perl seemed destined to rule the web. Michael Stevenson and Mike Bursell describe how Perl’s design made it ideal for the early web. We hear from Conor Myhrvold about its motto: “There is more than one way to do it.” Elizabeth Mattijsen shares how—despite Perl’s strengths—a long development cycle slowed Perl’s growth. And although it’s not the top web language anymore, John Siracusa points out that Perl lives on as a niche tool.
**00:02** - *Saron Yitbarek*
Picture Larry Wall, the creator of the Perl language, stepping up to the mic at a conference in 1999. He's got his signature bushy mustache and swept-over bangs, and he's feeling good. His language has been gathering steam.
**00:19** - *Voice actor*
Testing.
**00:19** - *Saron Yitbarek*
It's easily surpassed COBOL, surpassed Visual Basic, and Python? Python's still a distant contender, fodder for a couple of Wall's jokes. Wall shows the crowd numbers from a dice.com report. Perl's future is very, very bright. And then, it wasn't. Fast forward two decades to the summer of 2018, and dice.com names Perl one of the languages most likely to go extinct. What just happened?
**00:59** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat. This season is all about the power and promise of our programming languages. Last episode, we tracked JavaScript on its crazy rise to success as it hitched its fortunes to the web.
**01:19** - *Saron Yitbarek*
But not every language has a story of non-stop growth and success. Most languages emerge, play their part in a very particular ecosystem of the moment, and then start to recede when our programming lives call for other kinds of tools.
**01:37** - *Saron Yitbarek*
This episode we're taking a deep dive into the world of Perl. What caused its early success, and why did that success suddenly get turned upside down? The environment we live in, our infrastructure, our hardware, all kinds of factors will dictate which languages thrive, and which begin to shrink. And that's what's so fascinating about the story of Perl.
**02:08** - *Saron Yitbarek*
We know that Perl didn't take over the world, but back in the 90s nothing was that clear. Tim Berners-Lee released the World Wide Web in 1991, and it quickly created a whole new frontier of web-based development. It was anybody's guess which programming language was going to succeed in that new terrain.
**02:31** - *Michael Stevenson*
The web emerged at a time that there's a lot of waiting for something to happen. There was excitement.
**02:39** - *Saron Yitbarek*
Michael Stevenson is an Associate Professor in Media Studies at the University of Amsterdam. He described that earlier web for us. People had seen Usenet, and they'd seen the ARPANET. They'd seen America Online, and a few others. But the internet's full development potential really hadn't been expressed until the web came along. Suddenly, you're pointing and clicking your way into this vast, connected world. It was a revelation.
**03:09** - *Michael Stevenson*
You have to remember that 1993, kind of when the web peeked its head up, that was the same year that Wired Magazine started publishing. Before that you had things like Mondo 2000, these magazines that really made computers look like a source of mystical knowledge that made computers seem cool.
**03:32** - *Michael Stevenson*
And so, the web, in that sense, also arrived at a pretty specific time where people were ready to be excited about technology in that way.
**03:43** - *Saron Yitbarek*
Now, here's the thing. Larry Wall created Perl in 1987. That's four years before all this excitement about the World Wide Web. The Perl that Larry Wall first gave the world was just this general-purpose Unix scripting language. Totally helpful for sure, but Perl also had these secret elements that were going to make it an ideal language for a world of web development that was just around the corner.
**04:14** - *Michael Stevenson*
... quite famously was invented in a kind of secret NSA project that Larry Wall was working on. Essentially what he was doing was creating a hacked version of news that Usenet ... the software that Usenet ran on. And so, the language from the beginning was about text manipulation, and moving data from one spot to another. This just completely fit in with what was going to be needed for the web, and Perl, as a scripting language that was easy to use, that more closely resembled natural language. It could be used to develop things quite quickly. All these things made it a perfect fit, not just for the professional users, but also this new group of amateurs that came in.
**05:09** - *Saron Yitbarek*
Almost by accident Perl was ready to capitalize on the web when it came along. Larry Wall couldn't have known that the web was about to show up. But when it did, things dovetailed. But here's something else that I think is key. Perl was a free language. Larry Wall released it under the GPL, the General Public License, that had been developed by the Free Software Foundation.
**05:37** - *Saron Yitbarek*
Wall's decision to make his language free was totally in line with a new web-based way of thinking that was just starting to emerge, and Perl was forward-thinking in other ways, too.
**05:50** - *Michael Stevenson*
Perl was incredibly open in a sense that it was always willing to integrate something else, something new. This really goes with who Larry Wall is. He's a very open person who will ... he was very humble, and will always carefully consider what others think, and try to put himself in their shoes. It's interesting how, for me, Perl's character as a language, and as a community, really fit that for a long time.
**06:27** - *Saron Yitbarek*
Again, Perl was ideally suited to that early, wild west phase of the web, that hacker moment. In fact, one of Perl's mottos is, "There's more than one way to do it."
**06:39** - *Michael Stevenson*
There's a kind of almost romantic connection between the heyday of Perl and the heyday of this experimental open web, before it became so dominated by just a couple of platforms.
**06:56** - *Saron Yitbarek*
Remember that the 90s was a moment in the web's history when people were still rushing to figure out what was possible. There was this huge new need for programming. Everybody had to have a web page, and that meant a whole new army of developers, all of them open to new ways of doing things. The question became, "Okay, we've got a brand-new territory to play in, but what language is going to get the job done?"
**07:26** - *Saron Yitbarek*
Perl didn't turn out to be the final answer to that question. But, for lots of people, Perl was the first answer.
**07:34** - *Michael Stevenson*
I'm not saying that I would rather have super slowly loading web pages, and no Google search engine, but there is something of course really nice about that time when a couple of guys would, from their dorm room, create something like slashdot. There's something special about that time that I do think that as the web has become so mainstream and professionalized, and so concentrated around a few big companies, that we do miss. And for me, Perl symbolizes that more than any other story from that early period.
**08:15** - *Saron Yitbarek*
Michael Stevenson is an Associate Professor in Media Studies at the University of Amsterdam.
**08:24** - *Saron Yitbarek*
So, as the 90s rolled around, Perl emerged as the language that fit in with the early web's possibilities. It was a language of its time. Larry Wall, and Perl by extension, got what the web was all about.
**08:40** - *Mike Bursell*
You could do searches. You could create pages on the fly, and this is the brave new world of the internet, of the web, that you could do this stuff in real time.
**08:52** - *Saron Yitbarek*
That's Mike Bursell, Chief Security Architect over at Red Hat. Mike was one of those hackers who discovered Perl in the mid-90s.
**09:00** - *Mike Bursell*
For the web, Perl was the starting point for many people. Java™> was early days, it wasn't really fantastic at text input/output, and if you wanted to be taking queries and generating pages, well Perl was what people were using anyway.
**09:22** - *Mike Bursell*
Perl was just a good fit, because it's good at taking text, and doing other things with text. And that's what the web was.
**09:31** - *Saron Yitbarek*
Larry Wall has a background in linguistics, by the way, which explains Perl's strong text parsing. And that was a huge bonus, as Mike Bursell mentioned, because the web was largely a text-based medium in those early days.
**09:47** - *Saron Yitbarek*
People didn't really have the bandwidth for graphics.
**09:51** - *Mike Bursell*
It was easy to use. It was easy to copy. People were very open with sharing, and it produced output quickly, and that was all good stuff.
**10:02** - *Mike Bursell*
Oh, and the other thing, of course, is you could pipe things from it. So, it was very much what people are used to, and very easy to test even offline, and that was all very useful.
**10:13** - *Saron Yitbarek*
Useful especially for all those sysadmins, who were reimagining their lives in a web-based world.
**10:21** - *Mike Bursell*
Perl was a real gift for sysadmins. Even in those days, you're getting lots of logs if you are doing anything interesting. Managing those logs, breaking them down, searching them, and being able to present them in different ways, or taking any other large corpus of text, which basically is what logs are, or even debug. Unless you were going to pipe orc, and sed and stuff, and ed on the command line, which gets very painful very quickly, Perl was your go-to for that.
**10:55** - *Saron Yitbarek*
By the late 90s, Perl 5 had pulled together a powerful community of users. Older languages, like Fortran and C, had relied on big, expensive hardware. But Perl was scrappier and more portable. It was designed to thrive in a world where hardware costs were dropping dramatically, letting all those new programmers work fast and easy. That's because Larry Wall made his language more human-like at the expense of CPU and memory requirements. All those elements combined to make Perl a language that welcomed the new development community.
**11:36** - *Mike Bursell*
There was very much a growing community of people out there who you could go and talk to about what there was. PerlMonks started to arrive, it was a great place to discuss things, find out what was going on.
**11:50** - *Saron Yitbarek*
That community really did have the best the web could offer. They discovered a huge repository of software modules, a bank called CPAN, which those sysadmins loved. It gave Perl even more flexibility, lots of people could deploy code written by a few superstars.
**12:15** - *Mike Bursell*
It had libraries to do pretty much anything you wanted, and if you couldn't find it, you asked, and someone wrote it.
**12:21** - *Saron Yitbarek*
Mike Bursell is the Chief Security Architect at Red Hat.
**12:28** - *Saron Yitbarek*
So, Perl was free, it was supported by a growing library of modules, it was portable, and it had a booming community. Things were looking good. Perl could exploit all the best in that new 1990s world of web development. But, just as the 90s came to a close, as if on queue, the development landscape changed again. Changed big time.
**12:57** - *Alan Greenspan*
But how do we know when irrational exuberance has unduly escalated asset values, which then become subject to unexpected and prolonged contractions?
**13:12** - *Saron Yitbarek*
Irrational exuberance. That's Alan Greenspan, then Chair of the Federal Reserve, talking to the American Enterprise Institute in 1996. And that phrase of his, irrational exuberance, was a warning about the dot-com bubble everybody rode through the 90s. All those early web developers using Perl were riding high on that bubble, but it all burst in 2000, just like Greenspan predicted.
**14:11** - *Conor Myhrvold*
Hi, I'm Conor Myhrvold. I've been programming for the last five or six years, and I'm currently in the technology space working for Uber.
**14:20** - *Saron Yitbarek*
When Conor was in high school in the early 2000s, Perl was still a pretty big deal. But he was increasingly aware of a competing language, called Python.
**14:31** - *Conor Myhrvold*
One thing that Python had going for it, is it's a much more structured language in that there's one obvious way to do a lot of different things, and it's set up that way. Whereas Perl kind of relished in being the fact that there's more than one way to do something. But that was confusing to a lot of beginners.
**14:49** - *Saron Yitbarek*
Perl had that motto, "There is more than one way to do it." Python was actually invested in the opposite. Python gave you one obvious solution for each problem, and that meant looking at somebody else's Python code was easy to do. Looking at somebody else's Perl code, on the other hand, could be confusing. Perl made sense as a person's third, or fourth, language. Precisely because it was a scripting language. It was the duct tape of the internet.
**15:23** - *Saron Yitbarek*
But Python was a language you could really dig into, even as a newcomer. Perl had a specific set of strengths; searching for text, bioinformatics. But Python was this easy, general-purpose language. Python gained more and more cred as the language people wanted to learn first. That was a huge deal.
**15:47** - *Conor Myhrvold*
A lot more people were going online, and a lot more people are learning how to program. One thing that Python benefited from, especially relative to Perl during this time period, is that it was relatively easy to learn because it was more structured. And as a consequence of that, in a world where the pie is increasing quickly, if you can get more of that increase in pie, that will eventually mean that there are tutorials and more stuff available to you.
**16:10** - *Saron Yitbarek*
I mentioned CPAN before, that awesome central repository that Perl users could pull from. It was a major draw in the 90s. But the value of CPAN was also changing.
**16:24** - *Conor Myhrvold*
That also doesn't really help you learn a language, because you're “copypastaing” and just replacing what you need to in the minimum amount of fashion. That became a disadvantage over the long run, because if you have people that learn how to use a programming language by doing original development of everything themselves, even if it takes a lot longer, they feel like they're more invested in it, and they understand what's going on.
**16:48** - *Saron Yitbarek*
Python didn't have a centralized repository, like CPAN, but the kind of developers coming to the table in the new millennium, in a world where search on the web was so much more powerful, that repository didn't have as much value anyway.
**17:05** - *Saron Yitbarek*
Python eventually had loads of tutorials, and of course, today you also have platforms, like GitHub.
**17:13** - *Conor Myhrvold*
What ended up happening is a lot of advantages that Perl had were these network effects from an era that was outgrown.
**17:24** - *Saron Yitbarek*
Conor Myhrvold is an engineer at Uber.
**17:30** - *Saron Yitbarek*
Languages rarely rise and fall by external forces alone though, and the internal issue over at Perl was that as it was evolving, it seemed to hit a roadblock. Python was releasing new iterations in a pretty orderly fashion, but over at Perl, well as we learned in episode 1 of this season, in 2000 that dot-com bubble was bursting, and Python started gobbling up new developers.
**17:59** - *Saron Yitbarek*
Everyone was expecting the release of Perl 6, and people were excited. They waited, and waited, and waited. They waited for 14 years.
**18:15** - *Elizabeth Mattijsen*
People came up with about 300 plus things that Perl 6 should be able to do, and of course a lot of these things were basically, mutually exclusive.
**18:26** - *Saron Yitbarek*
That's Elizabeth Mattijsen, who works as a core developer on Perl 6. Elizabeth was at the Perl conference in Monterey in 2000. That's when developers decided they were stagnating, and Perl 6 was necessary. Larry Wall agreed, but if Perl 5 was his rewrite of Perl, he wanted Perl 6 to be the community's rewrite of Perl. And group work can take longer, even 14 years. It was a long and difficult road for those developers.
**19:01** - *Elizabeth Mattijsen*
We could argue that the current implementation of Perl 6 is actually the third attempt of implementing it.
**19:07** - *Saron Yitbarek*
The way Elizabeth tells it, there were attempts throughout those 14 years. Attempts that had long, agonizing depths. People burnt out; people ran into dead ends. By the time Perl 6 finally arrived on Christmas Day, 2015, much of the world had already moved on. And it's important to note that Perl 6 wasn't ramping up into some revolutionary new thing that would strike back at Python. Perl 6 was more a thoughtful reworking of the original.
**19:43** - *Elizabeth Mattijsen*
I think Larry Wall actually used a very nice metaphor in one of his State of the Onion speeches. Perl 5 to him is like The Hobbit, and Perl 6 is like Lord of the Rings. If you really look at the stories of The Hobbit and Lord of the Rings, they basically are more or less the same story. It's just that The Hobbit is much smaller and has more plot holes than Lord of the Rings and isn't as extensive. I think that describes very well what the difference is between Perl 5 and Perl 6. It is basically ... it's the same idea, it's the same mindset, it's the same environment, but a re-imagination of it.
**20:26** - *Saron Yitbarek*
Elizabeth Mattijsen is a core contributor to Perl 6.
**20:32** - *Saron Yitbarek*
Today, Perl might not even place on a list of the top 20 languages. Between external competition, and internal delays, it just hasn't proven itself for most new developers. But that raises a big question, is popularity really how we should judge our programming languages? Or, should we be looking at other values? What does it really mean when the megastar becomes a sidekick?
**21:06** - *Saron Yitbarek*
Around the turn of the century, as the dot-com bubble was bursting, and Perl's dominance began to wane, Larry Wall made an interesting statement. He argued that, while Perl would never again be among the world's most popular programming languages, it could be a leader within a smaller category. And that, said Larry Wall, was the real goal. To be best in category, not best in the world. An SUV, he said, would never compete with a race car.
**21:38** - *Saron Yitbarek*
I wanted to dig into that idea. I wanted to understand what best in category really means for a programming language.
**21:48** - *John Siracusa*
I am John Siracusa I am a programmer, and I'm a podcaster.
**21:53** - *Saron Yitbarek*
John actually co-hosts three podcasts, Accidental Tech Podcast, Reconcilable Differences, and Robot or Not? We got chatting about Perl's position in the world today.
**22:06** - *Saron Yitbarek*
What about today? Does it still hold up as being best in class?
**22:10** - *John Siracusa*
Perl 6 has things that no other language has, that other languages should have, and I keep waiting for other languages to steal from it. Grammars, for example, is a great way to conceptualize a common task, and using grammars to solve parsing problems is, in my opinion, more pleasant, cleaner, and nicer than using the existing tools that we have.
**22:31** - *John Siracusa*
There's lots of parts of the object system in Perl that might seem frivolous, but that I fully expect other languages to eventually adopt just as many of those languages eventually adopted a lot of the ideas that were in Perl 5. So, I think Perl 6 is best in class in many categories. It's just such a shame that so few people will find themselves with an opportunity to use it.
**22:52** - *Saron Yitbarek*
What do you think needs to happen for the Perl 6 community to grow? What needs to happen for people to be more involved in Perl 6?
**23:00** - *John Siracusa*
It's kind of been the story of Perl 6, like it's always been looking for a really fantastic implementation. That was part of the second-system problem ... second-system syndrome, I think they call it-
**23:11** - *Saron Yitbarek*
Mm-hmm.
**23:12** - *John Siracusa*
... of Perl 6, where you want to fix all the problems of the world. One of the problems they wanted to fix was the runtime. What is it that runs our code? The stuff that runs Perl 5, and Perl 4 before it, is a gigantic C program, written by people with very idiosyncratic coding styles and a ton of macros. It's kind of inscrutable.
**23:33** - *John Siracusa*
The idea with Perl 6 is let's not do that again, let's not make a giant wad of C code. Instead, let's come up with a virtual machine, which was the fad at the time, and there were so many grand ideas about how it was going to work. In the end, we got several medium-to-okay implemented versions of virtual machines, sometimes competing with each other, none of them really delivering on the performance, and stability, and features that the language needed to support it.
**24:01** - *Saron Yitbarek*
What is actually going on with Perl today? What's your take on it?
**24:06** - *John Siracusa*
Perl 5 definitely seems like it's on the downward slope, because all the other languages that are contemporaries with Perl 5 took most of its best ideas and have gotten more support. That said, because it was the king for a long time, there's a lot of Perl 5 code out there running some big, important sites, and people need to maintain and expand that code.
**24:29** - *John Siracusa*
It's going to take a long time for that to fade away. Just look at COBOL that's still out there, and how people are still hiring people to work on COBOL, right?
**24:35** - *Saron Yitbarek*
Mm-hmm. That's true.
**24:36** - *John Siracusa*
You're asking about if it's a dying language, and I mention COBOL, that doesn't sound good. Because will Perl 6 itself ever become a dominant language? It's not looking good. There's so much investment surrounding the other languages, and if Perl 6 hasn't gotten that investment now, I'm not sure what's going to change to make it catch on.
**24:54** - *Saron Yitbarek*
If you had it your way, what are your hopes for Perl? What would you like to see in Perl 5, or Perl 6, and what would you like to see happen in the future?
**25:04** - *John Siracusa*
My hope for Perl 5 is that people don't dismiss it, because despite all the other more popular languages, there are still problems today to which Perl 5 is the best solution. Very often those are sort of glue type problems. If you find yourself ever writing a shell script, and you're like, "Well, I'm not going to use my 'real programming language' for this." Whether it's Python, or Ruby, or whatever. But a shell script can let me connect together a bunch of stuff. Perl is a better tool for that job. It is easier to write a correct Perl script than it is to write a correct shell script.
**25:40** - *Saron Yitbarek*
I think what it all comes down to is that Perl might not be the entry point anymore, but for a more seasoned, polyglot developer, you never want to throw out that niche tool in your toolbox. The specified tools are sometimes what allow you to level up.
**25:58** - *John Siracusa*
Sometimes I'm sad, and depressed about Perl 6 and think it's going nowhere, and sometimes I'm like, "You know what? This is a nice little community." And every community doesn't need to take over the world and be the language that dominates the entire industry. And maybe you can just go along like this, essentially, indefinitely. That's the great thing about open source, and programming languages. No one's going to make you stop. You can just keep working on Perl 6 the same way you have been.
**26:27** - *Saron Yitbarek*
John Siracusa is a programmer, and the co-host of three tech podcasts.
**26:34** - *Saron Yitbarek*
Languages have life cycles. When new languages emerge exquisitely adapted to new realities, an option like Perl might occupy a smaller, more niche area. But that's not a bad thing. Our languages should expand and shrink their communities as our needs change. Perl was a crucial player in the early history of web development, and it stays with us in all kinds of ways that become obvious with a little history and a look at the big picture.
**27:11** - *Saron Yitbarek*
Next time on Command Line Heroes, what turns a language into a standard, and how might a new standard emerge in a world of cloud-based development?
**27:26** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. If you want to dive deeper into the story of Perl, or any of the programming languages we're exploring in season 3, head on over to [redhat.com/commandlineheroes](//redhat.com/commandlineheroes). Our web page is packed with bonus material for you to explore.
**27:49** - *Saron Yitbarek*
I'm Saron Yitbarek. Until next time, keep on coding.
### Keep going
### Is Perl going extinct?
Opensource.com explores the meteoric rise of Perl, its fall out of the spotlight, and what's next in a programming language's lifecycle.
### Modular Perl in Red Hat Enterprise Linux 8
Run your Perl applications in Red Hat Enterprise Linux 8.
### Enjoy this episode's artwork on your device
Download the Command Line Heroes artwork and set it as your background. |
12,883 | 十年 Linux 桌面生存指南 | https://hookrace.net/blog/linux-desktop-setup/ | 2020-12-03T22:39:00 | [
"Linux"
] | https://linux.cn/article-12883-1.html | 
从 2006 年开始转战 Linux 系统后,经过几年的实践,我的软件设置在过去十年内出人意料的固定。再过十年回顾一下,看看发生了什么,也许会非常有趣。在写这篇推文时,我迅速回顾了正在运行的内容:

### 动机
我的软件介绍排序不分先后:
* 程序应该运行在本地系统中以便我可以控制它,这其中并不包括云解决方案。
* 程序应在终端中运行,以便于在任何地方连贯地使用它们,包括性能稍差的电脑或手机。
* 通过使用终端软件,可以实现自动聚焦键盘。只有在一些有意义的地方,我会更喜欢使用鼠标,因为在打字期间一直伸手去拿鼠标感觉像在浪费时间。有时候过了一个小时我才注意到甚至还没有插鼠标。
* 最好使用快速高效的软件,我不喜欢听到风扇的声音和感到房间在变热。我还可以继续长久地运行旧硬件,已经使用了 10 年的 Thinkpad x200s 还能很好地支持我所使用的软件。
* 组合。我不想手动执行每个步骤,而是在需要时自动执行更多操作,这时自然是支持 shell。
### 操作系统
十二年前移除 Windows 系统后,我在 Linux 系统上经历了一个艰难的开始,当时我手上只有 [Gentoo Linux](https://gentoo.org/) 系统的安装光盘和一本打印的说明书,要用它们来实现一个可运行的 Linux 系统。虽然花费了几天的时间去编译和修整,但最终还是觉得自己受益颇多。
自此我再也没有转回 Windows 系统,但在持续的编译压力导致风扇失灵后,我将我的电脑系统切换到 [Arch Linux](https://www.archlinux.org/)。之后我将其他的电脑和私人服务器也切换到了 Arch Linux。作为一个滚动发布发行版,你可以随时升级软件包,但 [Arch Linux News](https://www.archlinux.org/news/) 已经详细报道了其中最主要的漏洞。
不过,令人烦恼的是一旦你更新了旧的内核模组,Arch Linux 就会移除旧版的相关信息。我经常注意到一旦我试着插入一个 USB 闪存盘,内核就无法加载相关组件。相反,每次内核升级后都应该进行重启。有一些 [方法](https://www.reddit.com/r/archlinux/comments/4zrsc3/keep_your_system_fully_functional_after_a_kernel/) 可以解决这个问题,但我还没有实际地使用它们。
其他程序也会出现类似的情况,通常 Firefox 、 cron 或者 Samba 在升级后都需要重启,但恼人的是,它们没有警告你存在这种情况。我在工作中使用的 [SUSE](https://www.suse.com/) 很好地提醒了这种情况。
对于 [DDNet](https://ddnet.tw/) 产品服务器,相较于 Arch Linux ,我更倾向于 [Debian](https://www.debian.org/) 系统,这样在每次升级时出现故障的几率更低。我的防火墙和路由器使用了 [OpenBSD](https://www.openbsd.org/) ,它拥有干净系统、文档和强大的 [pf 防火墙](https://www.openbsd.org/faq/pf/),而我现在不需要一个单独的路由器。
### 窗口管理器
从我开始使用 Gentoo 后,我很快注意到 KDE 的编译时间非常长,这让我没办法继续使用它。我四处寻找更简单的解决方案,最初使用了 [Openbox](http://openbox.org/wiki/Main_Page) 和 [Fluxbox](http://fluxbox.org/)。某次,为了能更多进行纯键盘操作,我开始尝试转入平铺窗口管理器,并在研究其初始版本的时候学习了 [dwm](https://dwm.suckless.org/) 和 [awesome](https://awesomewm.org/)。
最终,由于 [xmonad](https://xmonad.org/)的灵活性、可扩展性以及使用纯 [Haskell](https://www.haskell.org/)(一种出色的函数编程语言)编写和配置,最终选择了它。一个例子是,我在家中运行一个 40" 4K 的屏幕,但经常会将它分为四个虚拟屏幕,每个虚拟屏幕显示一个工作区,每个工作区自动排列在我的窗口上。当然, xmonad 有一个对应的 [模块](http://hackage.haskell.org/package/xmonad-contrib-0.15/docs/XMonad-Layout-LayoutScreens.html)。
[dzen](http://robm.github.io/dzen/) 和 [conky](https://github.com/brndnmtthws/conky) 对我来说是一个非常简单的状态栏。我的整体 conky 配置看起来是这样的:
```
out_to_console yes
update_interval 1
total_run_times 0
TEXT
${downspeed eth0} ${upspeed eth0} | $cpu% ${loadavg 1} ${loadavg 2} ${loadavg 3} $mem/$memmax | ${time %F %T}
```
输入命令直接通过管道输入 dzen2:
```
conky | dzen2 -fn '-xos4-terminus-medium-r-normal-*-12-*-*-*-*-*-*-*' -bg '#000000' -fg '#ffffff' -p -e '' -x 1000 -w 920 -xs 1 -ta r
```
对我而言,一项重要功能是在完成工作后使终端发出蜂鸣声。只需要简单地在 zsh 中的 `PR_TITLEBAR` 变量中添加一个 `\a` 字符就可以做到,只要工作完成就可以发出蜂鸣声。当然,我使用了命令:
```
echo "blacklist pcspkr" > /etc/modprobe.d/nobeep.conf
```
将 `pcspkr` 内核模块列入黑名单来禁用实际的蜂鸣声。相反 urxvt 的 `URxvt.urgentOnBell: true` 设置会将声音变为尖锐。之后 xmonad 有一个 urgency 钩子来捕捉这类信号,并且我可以使用组合键自动聚焦到当前的发出紧急信号的窗口。在 dzen 中我可以看到一个漂亮且明亮的 `#ff0000` 紧急窗口。
在我笔记本上所得到的最终成品是:

我听说前几年 [i3](https://i3wm.org/) 变得非常流行,但它要求更多的手动窗口对齐而不是自动对齐。
我意识到也有像 [tmux](https://github.com/tmux/tmux/wiki) 那样的终端多路复用器,但我仍想要一些图形化应用程序,因此最终我没有有效地使用它们。
### 终端连续性
为了使终端保持活跃状态,我使用了 [dtach](http://dtach.sourceforge.net/) ,它只是模拟屏幕分离功能。为了使计算机上的每个终端都可连接和断开,我编写了一个小的封装脚本。 这意味着,即使必须重新启动 X 服务器,我也可以使所有终端都运行良好,包括本地和远程终端。
### Shell & 编程
对于 shell,我使用 [zsh](http://www.zsh.org/) 而不是 [bash](https://www.gnu.org/software/bash/),因为它有众多的功能。
作为终端模拟,我发现 [urxvt](http://software.schmorp.de/pkg/rxvt-unicode.html) 足够轻巧,支持 Unicode 编码和 256 色,具有出色的性能。另一个重要的功能是可以分别运行 urxvt 客户端和守护进程。因此,即使大量终端也几乎不占用任何内存(回滚缓冲区除外)。
对我而言,只有一种字体看起来绝对干净和完美: [Terminus](http://terminus-font.sourceforge.net/)。 由于它是位图字体,因此所有内容都是完美像素,渲染速度极快且 CPU 使用率低。为了能使用 `CTRL-WIN-[1-7]` 在每个终端按需切换字体,我的 `~/.Xdefaults` 包含:
```
URxvt.font: -xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*
dzen2.font: -xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*
URxvt.keysym.C-M-1: command:\033]50;-xos4-terminus-medium-r-normal-*-12-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-2: command:\033]50;-xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-3: command:\033]50;-xos4-terminus-medium-r-normal-*-18-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-4: command:\033]50;-xos4-terminus-medium-r-normal-*-22-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-5: command:\033]50;-xos4-terminus-medium-r-normal-*-24-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-6: command:\033]50;-xos4-terminus-medium-r-normal-*-28-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-7: command:\033]50;-xos4-terminus-medium-r-normal-*-32-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-n: command:\033]10;#ffffff\007\033]11;#000000\007\033]12;#ffffff\007\033]706;#00ffff\007\033]707;#ffff00\007
URxvt.keysym.C-M-b: command:\033]10;#000000\007\033]11;#ffffff\007\033]12;#000000\007\033]706;#0000ff\007\033]707;#ff0000\007
```
对于编程和书写,我使用 [Vim](https://www.vim.org/) 语法高亮显示和 [ctags](http://ctags.sourceforge.net/) 进行索引,以及一些带有 `grep` 、`sed` 和其他用于搜索和操作的常用终端窗口。这可能不像 IDE 那样舒适,但可以实现更多的自动化。
Vim 的一个问题是你已经习惯了它的键映射,因此希望在任何地方都使用它们。
在 shell 功能不够强大时,[Python](https://www.python.org/) 和 [Nim](https://nim-lang.org/) 作为脚本语言也不错。
### 系统监控
[htop](https://hisham.hm/htop/) (查看当前站点的后台运行,是托管服务器的实时视图)非常适合快速了解软件的当前运行状态。 [lm\_sensors](http://lm-sensors.org/) 可以监控硬件温度、风扇和电压。 [powertop](https://01.org/powertop/) 是一款由 Intel 发布的优秀省电小工具。 [ncdu](https://dev.yorhel.nl/ncdu) 可以交互式分析磁盘使用情况。
[nmap](https://nmap.org/)、 iptraf-ng、 [tcpdump](https://www.tcpdump.org/) 和 [Wireshark](https://www.wireshark.org/) 都是分析网络问题的基本工具。
当然还有很多更优秀的工具。
### 邮件 & 同步
在我的家庭服务器上,我为自己所有的邮箱账号运行了 [fetchmail](http://www.fetchmail.info/) 守护进程。fetchmail 只是检索收到的邮件并调用 [procmail](http://www.procmail.org/):
```
#!/bin/sh
for i in /home/deen/.fetchmail/*; do
FETCHMAILHOME=$i /usr/bin/fetchmail -m 'procmail -d %T' -d 60
done
```
配置非常简单,然后等待服务器通知我们有新的邮件:
```
poll imap.1und1.de protocol imap timeout 120 user "[email protected]" password "XXX" folders INBOX keep ssl idle
```
我的 `.procmailrc` 配置包含一些备份全部邮件的规则,并将邮件整理在对应的目录下面。例如,基于邮件列表名或者邮件标题:
```
MAILDIR=/home/deen/shared/Maildir
LOGFILE=$HOME/.procmaillog
LOGABSTRACT=no
VERBOSE=off
FORMAIL=/usr/bin/formail
NL="
"
:0wc
* ! ? test -d /media/mailarchive/`date +%Y`
| mkdir -p /media/mailarchive/`date +%Y`
# Make backups of all mail received in format YYYY/YYYY-MM
:0c
/media/mailarchive/`date +%Y`/`date +%Y-%m`
:0
* ^From: .*(.*@.*.kit.edu|.*@.*.uka.de|.*@.*.uni-karlsruhe.de)
$MAILDIR/.uni/
:0
* ^list-Id:.*lists.kit.edu
$MAILDIR/.uni-ml/
[...]
```
我使用 [msmtp](https://marlam.de/msmtp/) 来发送邮件,它也很好配置:
```
account default
host smtp.1und1.de
tls on
tls_trust_file /etc/ssl/certs/ca-certificates.crt
auth on
from [email protected]
user [email protected]
password XXX
[...]
```
但是到目前为止,邮件还在服务器上。 我的文档全部存储在一个目录中,我使用 [Unison](https://www.cis.upenn.edu/~bcpierce/unison/) 在所有计算机之间进行同步。Unison 可以视为双向交互式 [rsync](https://rsync.samba.org/),我的邮件是这个文件目录下的一部分,因此它们最终存储在我的电脑上。
这也意味着,尽管邮件会立即到达我的邮箱,但我只是按需拿取,而不是邮件一到达时就立即收到通知。
从此我使用 [mutt](http://www.mutt.org/) 阅读邮件,使用侧边栏显示我的邮件目录。 `/etc/mailcap` 文件对于显示非纯文本邮件( HTML, Word 或者 PDF)不可或缺:
```
text/html;w3m -I %{charset} -T text/html; copiousoutput
application/msword; antiword %s; copiousoutput
application/pdf; pdftotext -layout /dev/stdin -; copiousoutput
```
### 新闻 & 通讯
[Newsboat](https://newsboat.org/) 是一个非常棒的终端 RSS/Atom 阅读器。我在一个有约 150 个提要的 `tach` 会话服务器上运行它。也可以在本地选择提要,例如:
```
ignore-article "https://forum.ddnet.tw/feed.php" "title =~ \"Map Testing •\" or title =~ \"Old maps •\" or title =~ \"Map Bugs •\" or title =~ \"Archive •\" or title =~ \"Waiting for mapper •\" or title =~ \"Other mods •\" or title =~ \"Fixes •\""
```
我以同样的方式使用 [Irssi](https://irssi.org/) 进行 IRC 通讯。
### 日历
[remind](https://www.roaringpenguin.com/products/remind) 是一个可以从命令行获取的日历。通过编辑 `rem` 文件可以设置新的提醒:
```
# One time events
REM 2019-01-20 +90 Flight to China %b
# Recurring Holidays
REM 1 May +90 Holiday "Tag der Arbeit" %b
REM [trigger(easterdate(year(today()))-2)] +90 Holiday "Karfreitag" %b
# Time Change
REM Nov Sunday 1 --7 +90 Time Change (03:00 -> 02:00) %b
REM Apr Sunday 1 --7 +90 Time Change (02:00 -> 03:00) %b
# Birthdays
FSET birthday(x) "'s " + ord(year(trigdate())-x) + " birthday is %b"
REM 16 Apr +90 MSG Andreas[birthday(1994)]
# Sun
SET $LatDeg 49
SET $LatMin 19
SET $LatSec 49
SET $LongDeg -8
SET $LongMin -40
SET $LongSec -24
MSG Sun from [sunrise(trigdate())] to [sunset(trigdate())]
[...]
```
遗憾的是,目前 remind 中还没有中国农历的提醒功能,因此中国的节日不易计算。
我给提醒设置了两个名字:
```
rem -m -b1 -q -g
```
按时间顺序查看待办事项清单
```
rem -m -b1 -q -cuc12 -w$(($(tput cols)+1)) | sed -e "s/\f//g" | less
```
显示适应终端宽度的日历:

### 字典
[rdictcc](https://github.com/tsdh/rdictcc) 是鲜为人知的字典工具,它可以使用 [dict.cc](https://www.dict.cc/) 很棒的词典并将他们转存在本地数据库中:
```
$ rdictcc rasch
====================[ A => B ]====================
rasch:
- apace
- brisk [speedy]
- cursory
- in a timely manner
- quick
- quickly
- rapid
- rapidly
- sharpish [Br.] [coll.]
- speedily
- speedy
- swift
- swiftly
rasch [gehen]:
- smartly [quickly]
Rasch {n} [Zittergras-Segge]:
- Alpine grass [Carex brizoides]
- quaking grass sedge [Carex brizoides]
Rasch {m} [regional] [Putzrasch]:
- scouring pad
====================[ B => A ]====================
Rasch model:
- Rasch-Modell {n}
```
### 记录和阅读
我有一个简单记录任务的备忘录,在 Vim 会话中基本上一直处于打开状态。我也使用备忘录作为工作中“已完成”工作的记录,这样就可以检查自己每天完成了哪些任务。
对于写文件、信件和演示文稿,我会使用 [LaTeX](https://www.latex-project.org/) 进行高级排版。德式的简单信件可以这样设置,例如:
```
\documentclass[paper = a4, fromalign = right]{scrlttr2}
\usepackage{german}
\usepackage{eurosym}
\usepackage[utf8]{inputenc}
\setlength{\parskip}{6pt}
\setlength{\parindent}{0pt}
\setkomavar{fromname}{Dennis Felsing}
\setkomavar{fromaddress}{Meine Str. 1\\69181 Leimen}
\setkomavar{subject}{Titel}
\setkomavar*{enclseparator}{Anlagen}
\makeatletter
\@setplength{refvpos}{89mm}
\makeatother
\begin{document}
\begin{letter} {Herr Soundso\\Deine Str. 2\\69121 Heidelberg}
\opening{Sehr geehrter Herr Soundso,}
Sie haben bei mir seit dem Bla Bla Bla.
Ich fordere Sie hiermit zu Bla Bla Bla auf.
\closing{Mit freundlichen Grüßen}
\end{letter}
\end{document}
```
在 [我的私人网站](http://felsin9.de/nnis/research/) 上可以找到更多的示例文档和演示文稿。
[Zathura](https://pwmt.org/projects/zathura/) 读取 PDF 文件速度很快,支持 Vim 类控件,还支持两种不同的 PDF 后端: Poppler 和 MuPDF。另一方面,在偶尔遇到 Zathura 无法打开的文件时,[Evince](https://wiki.gnome.org/Apps/Evince) 则显得更全能一些。
### 图片编辑
简便的选择是,[GIMP](https://www.gimp.org/) 和 [Inkscape](https://inkscape.org/) 分别用于照片编辑和交互式向量图形。
有时 [Imagemagick](https://imagemagick.org/Usage/) 已经足够好了,它可以从命令行直接使用,从而自动编辑图片。同样 [Graphviz](https://www.graphviz.org/) 和 [TikZ](https://sourceforge.net/projects/pgf/) 可以用来绘制曲线图和其他图表。
### Web 浏览器
对于 Web 浏览器,我一直在使用 [Firefox](https://www.mozilla.org/en-US/firefox/new/)。相较于 Chrome,它的可扩展性更好,资源使用率更低。
不幸的是,在 Firefox 完全改用 Chrome 风格的扩展之后, [Pentadactyl](https://github.com/5digits/dactyl) 扩展的开发就停止了,所以我的浏览器中再也没有令人满意的 Vim 类控件了。
### 媒体播放器
通过设置 `vo=gpu` 以及 `hwdec=vaapi`,具有硬件解码功能的 [mpv](https://mpv.io/) 在播放期间 CPU 的占用率保持在 5%。相较于默认的 PulseAudio,mpv 中的 `audio-channels=2` 似乎可以使我的立体扬声器/耳机获得更清晰的降级混频。一个很棒的小功能是用 `Shift-Q` 退出,而不是只用 `Q` 来保存回放位置。当你与母语是其他语言的人一起看视频时,你可以使用 `--secondary-sid=` 同时显示两种字幕,主字幕位于底部,次字幕位于屏幕顶部。
我的无线鼠标可以简单地通过一个小的配置文件( `~/.config/mpv/input.conf` )实现远程控制 mpv :
```
MOUSE_BTN5 run "mixer" "pcm" "-2"
MOUSE_BTN6 run "mixer" "pcm" "+2"
MOUSE_BTN1 cycle sub-visibility
MOUSE_BTN7 add chapter -1
MOUSE_BTN8 add chapter 1
```
[youtube-dl](https://rg3.github.io/youtube-dl/) 非常适合观看在线托管的视频,使用 `-f bestvideo+bestaudio/best --all-subs --embed-subs` 命令可获得最高质量的视频。
作为音乐播放器, [MOC](http://moc.daper.net/) 不再活跃开发,但它仍是一个简易的播放器,可以播放各种可能的格式,包括最不常用的 Chiptune 格式。在 AUR 中有一个 [补丁](https://aur.archlinux.org/packages/moc-pulse/) 增加了 PulseAudio 支持。即使在 CPU 时钟频率降到 800 MHz, MOC 也只使用了单核 CPU 的 1-2% 。

我的音乐收藏夹保存在我的家庭服务器上,因此我可以从任何地方访问它。它使用 [SSHFS](https://github.com/libfuse/sshfs) 挂载并自动安装在 `/etc/fstab/` 目录下:
```
root@server:/media/media /mnt/media fuse.sshfs noauto,x-systemd.automount,idmap=user,IdentityFile=/root/.ssh/id_rsa,allow_other,reconnect 0 0
```
### 跨平台构建
除了 Linux 本身,它对于构建任何主流操作系统的软件包都很优秀! 一开始,我使用 [QEMU](https://www.qemu.org/) 与旧版 Debian、 Windows 以及 Mac OS X VM 一起构建这些平台。
现在我在旧版 Debian 发行版上转而使用 chroot (以获得最大的 Linux 兼容性),在 Windows 上使用 [MinGW](http://www.mingw.org/) 进行交叉编译,在 Mac OS X 上则使用 [OSXCross](https://github.com/tpoechtrager/osxcross)。
用于 [构建 DDNet](https://github.com/ddnet/ddnet-scripts/blob/master/ddnet-release.sh) 的脚本以及 [更新库构建的说明](https://github.com/ddnet/ddnet-scripts/blob/master/ddnet-lib-update.sh) 的脚本都基于这个。
### 备份
通常,我们都会忘记备份。即使这是最后一节,它也不应该成为事后诸葛。
十年前我写了 [rrb](https://github.com/def-/rrb/blob/master/rrb) (反向 rsync 备份)重新封装了 `rsync` ,因此我只需要将备份服务器的 root SSH 权限授予正在备份的计算机。令人惊讶地是,尽管我一直在使用 rrb ,但它在过去十年里没有任何改变。
备份文件直接存储在文件系统中。使用硬链接实现增量备份(`--link-dest`)。一个简单的 [配置](https://github.com/def-/rrb/blob/master/config.example) 定义了备份保存时间,默认为:
```
KEEP_RULES=( \
7 7 \ # One backup a day for the last 7 days
31 8 \ # 8 more backups for the last month
365 11 \ # 11 more backups for the last year
1825 4 \ # 4 more backups for the last 5 years
)
```
因为我的一些计算机没有静态 IP / DNS 但仍想使用 rrb 备份,那我会使用反向安全隧道(作为 systemd 服务):
```
[Unit]
Description=Reverse SSH Tunnel
After=network.target
[Service]
ExecStart=/usr/bin/ssh -N -R 27276:localhost:22 -o "ExitOnForwardFailure yes" server
KillMode=process
Restart=always
[Install]
WantedBy=multi-user.target
```
现在,隧道运行备份时,服务器可以通过 `ssh -p 27276 localhost` 命令或者使用 `.ssh/config` 到达服务器端。
```
Host cr-remote
HostName localhost
Port 27276
```
在谈及 SSH 技巧时,有时由于某些中断的路由会很难访问到服务器。在那种情况下你可以借道其他服务器的 SSH 连接,以获得更好的路由。在这种情况下,你可能通过美国连接访问到我的中国服务器,而来自德国的不可靠连接可能需要几个周:
```
Host chn.ddnet.tw
ProxyCommand ssh -q usa.ddnet.tw nc -q0 chn.ddnet.tw 22
Port 22
```
### 结语
感谢阅读我工具的收藏。这其中我也许遗漏了许多日常中自然成习惯的步骤。让我们来看看我的软件设置在下一年里能多稳定吧。如果你有任何问题,随时联系我 [[email protected]](mailto:[email protected]) 。
在 [Hacker News](https://news.ycombinator.com/item?id=18979731) 下评论吧。
---
via: <https://hookrace.net/blog/linux-desktop-setup/>
作者:[Dennis Felsing](http://felsin9.de/nnis/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux Desktop Setup
2019-01-15 ·[Programming](/blog/programming/)·
[Frugality](/blog/frugality/)
[Russian Translation by Akhmad Karimov](https://vectorified.com/ru-linux-desktop-setup)
My software setup has been surprisingly constant over the last decade, after a few years of experimentation since I initially switched to Linux in 2006. It might be interesting to look back in another 10 years and see what changed. A quick overview of what’s running as I’m writing this post:
## Motivation
My software priorities are, in no specific order:
- Programs should run on my local system so that I’m in control of them, this excludes cloud solutions.
- Programs should run in the terminal, so that they can be used consistently from anywhere, including weak computers or a phone.
- Keyboard focused is nearly automatic by using terminal software. I prefer to use the mouse where it makes sense only, reaching for the mouse all the time during typing feels like a waste of time. Occasionally it took me an hour to notice that the mouse wasn’t even plugged in.
- Ideally use fast and efficient software, I don’t like hearing the fan and feeling the room heat up. I can also keep running older hardware for much longer, my 10 year old Thinkpad x200s is still fine for all the software I use.
- Be composable. I don’t want to do every step manually, instead automate more when it makes sense. This naturally favors the shell.
## Operating Systems
I had a hard start with Linux 12 years ago by removing Windows, armed with just the [Gentoo Linux](https://gentoo.org/) installation CD and a printed manual to get a functioning Linux system. It took me a few days of compiling and tinkering, but in the end I felt like I had learnt a lot.
I haven’t looked back to Windows since then, but I switched to [Arch Linux](https://www.archlinux.org/) on my laptop after having the fan fail from the constant compilation stress. Later I also switched all my other computers and private servers to Arch Linux. As a rolling release distribution you get package upgrades all the time, but the most important breakages are nicely reported in the [Arch Linux News](https://www.archlinux.org/news/).
One annoyance though is that Arch Linux removes the old kernel modules once you upgrade it. I usually notice that once I try plugging in a USB flash drive and the kernel fails to load the relevant module. Instead you’re supposed to reboot after each kernel upgrade. There are a few [hacks](https://www.reddit.com/r/archlinux/comments/4zrsc3/keep_your_system_fully_functional_after_a_kernel/) around to get around the problem, but I haven’t been bothered enough to actually use them.
Similar problems happen with other programs, commonly Firefox, cron or Samba requiring a restart after an upgrade, but annoyingly not warning you that that’s the case. [SUSE](https://www.suse.com/), which I use at work, nicely warns about such cases.
For the [DDNet](https://ddnet.org/) production servers I prefer [Debian](https://www.debian.org/) over Arch Linux, so that I have a lower chance of breakage on each upgrade. For my firewall and router I used [OpenBSD](https://www.openbsd.org/) for its clean system, documentation and great [pf firewall](https://www.openbsd.org/faq/pf/), but right now I don’t have a need for a separate router anymore.
## Window Manager
Since I started out with Gentoo I quickly noticed the huge compile time of KDE, which made it a no-go for me. I looked around for more minimal solutions, and used [Openbox](http://openbox.org/wiki/Main_Page) and [Fluxbox](http://fluxbox.org/) initially. At some point I jumped on the tiling window manager train in order to be more keyboard-focused and picked up [dwm](https://dwm.suckless.org/) and [awesome](https://awesomewm.org/) close to their initial releases.
In the end I settled on [xmonad](https://xmonad.org/) thanks to its flexibility, extendability and being written and configured in pure [Haskell](https://www.haskell.org/), a great functional programming language. One example of this is that at home I run a single 40” 4K screen, but often split it up into four virtual screens, each displaying a workspace on which my windows are automatically arranged. Of course xmonad has a [module](http://hackage.haskell.org/package/xmonad-contrib-0.15/docs/XMonad-Layout-LayoutScreens.html) for that.
[dzen](http://robm.github.io/dzen/) and [conky](https://github.com/brndnmtthws/conky) function as a simple enough status bar for me. My entire conky config looks like this:
```
out_to_console yes
update_interval 1
total_run_times 0
TEXT
${downspeed eth0} ${upspeed eth0} | $cpu% ${loadavg 1} ${loadavg 2} ${loadavg 3} $mem/$memmax | ${time %F %T}
```
And gets piped straight into dzen2 with `conky | dzen2 -fn '-xos4-terminus-medium-r-normal-*-12-*-*-*-*-*-*-*' -bg '#000000' -fg '#ffffff' -p -e '' -x 1000 -w 920 -xs 1 -ta r`
.
One important feature for me is to make the terminal emit a beep sound once a job is done. This is done simply by adding a `\a`
character to the `PR_TITLEBAR`
variable in zsh, which is shown whenever a job is done. Of course I disable the actual beep sound by blacklisting the `pcspkr`
kernel module with `echo "blacklist pcspkr" > /etc/modprobe.d/nobeep.conf`
. Instead the sound gets turned into an urgency by urxvt’s `URxvt.urgentOnBell: true`
setting. Then xmonad has an urgency hook to capture this and I can automatically focus the currently urgent window with a key combination. In dzen I get the urgent windowspaces displayed with a nice and bright `#ff0000`
.
The final result in all its glory on my Laptop:
I hear that [i3](https://i3wm.org/) has become quite popular in the last years, but it requires more manual window alignment instead of specifying automated methods to do it.
I realize that there are also terminal multiplexers like [tmux](https://github.com/tmux/tmux/wiki), but I still require a few graphical applications, so in the end I never used them productively.
## Terminal Persistency
In order to keep terminals alive I use [dtach](http://dtach.sourceforge.net/), which is just the detach feature of screen. In order to make every terminal on my computer detachable I wrote a [small wrapper script](https://github.com/def-/tach/blob/master/tach). This means that even if I had to restart my X server I could keep all my terminals running just fine, both local and remote.
## Shell & Programming
Instead of [bash](https://www.gnu.org/software/bash/) I use [zsh](http://www.zsh.org/) as my shell for its huge number of features.
As a terminal emulator I found [urxvt](http://software.schmorp.de/pkg/rxvt-unicode.html) to be simple enough, support Unicode and 256 colors and has great performance. Another great feature is being able to run the urxvt client and daemon separately, so that even a large number of terminals barely takes up any memory (except for the scrollback buffer).
There is only one font that looks absolutely clean and perfect to me: [Terminus](http://terminus-font.sourceforge.net/). Since it’s a bitmap font everything is pixel perfect and renders extremely fast and at low CPU usage. In order to switch fonts on-demand in each terminal with `CTRL-WIN-[1-7]`
my ~/.Xdefaults contains:
```
URxvt.font: -xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*
dzen2.font: -xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*
URxvt.keysym.C-M-1: command:\033]50;-xos4-terminus-medium-r-normal-*-12-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-2: command:\033]50;-xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-3: command:\033]50;-xos4-terminus-medium-r-normal-*-18-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-4: command:\033]50;-xos4-terminus-medium-r-normal-*-22-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-5: command:\033]50;-xos4-terminus-medium-r-normal-*-24-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-6: command:\033]50;-xos4-terminus-medium-r-normal-*-28-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-7: command:\033]50;-xos4-terminus-medium-r-normal-*-32-*-*-*-*-*-*-*\007
URxvt.keysym.C-M-n: command:\033]10;#ffffff\007\033]11;#000000\007\033]12;#ffffff\007\033]706;#00ffff\007\033]707;#ffff00\007
URxvt.keysym.C-M-b: command:\033]10;#000000\007\033]11;#ffffff\007\033]12;#000000\007\033]706;#0000ff\007\033]707;#ff0000\007
```
For programming and writing I use [Vim](https://www.vim.org/) with syntax highlighting and [ctags](http://ctags.sourceforge.net/) for indexing, as well as a few terminal windows with grep, sed and the other usual suspects for search and manipulation. This is probably not at the same level of comfort as an IDE, but allows me more automation.
One problem with Vim is that you get so used to its key mappings that you’ll want to use them everywhere.
[Python](https://www.python.org/) and [Nim](https://nim-lang.org/) do well as scripting languages where the shell is not powerful enough.
## System Monitoring
[htop](https://hisham.hm/htop/) works great for getting a quick overview of what the software is currently doing. [lm_sensors](http://lm-sensors.org/) allows monitoring the hardware temperatures, fans and voltages. [powertop](https://01.org/powertop/) is a great little tool by Intel to find power savings. [ncdu](https://dev.yorhel.nl/ncdu) lets you analyze disk usage interactively.
[nmap](https://nmap.org/), iptraf-ng, [tcpdump](https://www.tcpdump.org/) and [Wireshark](https://www.wireshark.org/) are essential tools for analyzing network problems.
There are of course many more great tools.
## Mails & Synchronization
On my home server I have a [fetchmail](http://www.fetchmail.info/) daemon running for each email acccount that I have. Fetchmail just retrieves the incoming emails and invokes [procmail](http://www.procmail.org/):
```
#!/bin/sh
for i in /home/deen/.fetchmail/*; do
FETCHMAILHOME=$i /usr/bin/fetchmail -m 'procmail -d %T' -d 60
done
```
The configuration is as simple as it could be and waits for the server to inform us of fresh emails:
`poll imap.1und1.de protocol imap timeout 120 user "`[[email protected]](/cdn-cgi/l/email-protection)" password "XXX" folders INBOX keep ssl idle
My `.procmailrc`
config contains a few rules to backup all mails and sort them into the correct directories, for example based on the mailing list id or from field in the mail header:
```
MAILDIR=/home/deen/shared/Maildir
LOGFILE=$HOME/.procmaillog
LOGABSTRACT=no
VERBOSE=off
FORMAIL=/usr/bin/formail
NL="
"
:0wc
* ! ? test -d /media/mailarchive/`date +%Y`
| mkdir -p /media/mailarchive/`date +%Y`
# Make backups of all mail received in format YYYY/YYYY-MM
:0c
/media/mailarchive/`date +%Y`/`date +%Y-%m`
:0
* ^From: .*(.*@.*.kit.edu|.*@.*.uka.de|.*@.*.uni-karlsruhe.de)
$MAILDIR/.uni/
:0
* ^list-Id:.*lists.kit.edu
$MAILDIR/.uni-ml/
[...]
```
To send emails I use [msmtp](https://marlam.de/msmtp/), which is also great to configure:
```
account default
host smtp.1und1.de
tls on
tls_trust_file /etc/ssl/certs/ca-certificates.crt
auth on
from
```[[email protected]](/cdn-cgi/l/email-protection)
user [[email protected]](/cdn-cgi/l/email-protection)
password XXX
[...]
But so far the emails are still on the server. My documents are all stored in a directory that I synchronize between all computers using [Unison](https://www.cis.upenn.edu/~bcpierce/unison/). Think of Unison as a bidirectional interactive [rsync](https://rsync.samba.org/). My emails are part of this documents directory and thus they end up on my desktop computers.
This also means that while the emails reach my server immediately, I only fetch them on deman instead of getting instant notifications when an email comes in.
From there I read the mails with [mutt](http://www.mutt.org/), using the sidebar plugin to display my mail directories. The `/etc/mailcap`
file is essential to display non-plaintext mails containing HTML, Word or PDF:
```
text/html;w3m -I %{charset} -T text/html; copiousoutput
application/msword; antiword %s; copiousoutput
application/pdf; pdftotext -layout /dev/stdin -; copiousoutput
```
## News & Communication
[Newsboat](https://newsboat.org/) is a nice little RSS/Atom feed reader in the terminal. I have it running on the server in a `tach`
session with about 150 feeds. Filtering feeds locally is also possible, for example:
```
ignore-article "https://forum.ddnet.org/feed.php" "title =~ \"Map Testing •\" or title =~ \"Old maps •\" or title =~ \"Map Bugs •\" or title =~ \"Archive •\" or title =~ \"Waiting for mapper •\" or title =~ \"Other mods •\" or title =~ \"Fixes •\""
```
I use [Irssi](https://irssi.org/) the same way for communication via IRC.
## Calendar
[remind](https://www.roaringpenguin.com/products/remind) is a calendar that can be used from the command line. Setting new reminders is done by editing the `rem`
files:
```
# One time events
REM 2019-01-20 +90 Flight to China %b
# Recurring Holidays
REM 1 May +90 Holiday "Tag der Arbeit" %b
REM [trigger(easterdate(year(today()))-2)] +90 Holiday "Karfreitag" %b
# Time Change
REM Nov Sunday 1 --7 +90 Time Change (03:00 -> 02:00) %b
REM Apr Sunday 1 --7 +90 Time Change (02:00 -> 03:00) %b
# Birthdays
FSET birthday(x) "'s " + ord(year(trigdate())-x) + " birthday is %b"
REM 16 Apr +90 MSG Andreas[birthday(1994)]
# Sun
SET $LatDeg 49
SET $LatMin 19
SET $LatSec 49
SET $LongDeg -8
SET $LongMin -40
SET $LongSec -24
MSG Sun from [sunrise(trigdate())] to [sunset(trigdate())]
[...]
```
Unfortunately there is no Chinese Lunar calendar function in remind yet, so Chinese holidays can’t be calculated easily.
I use two aliases for remind:
```
rem -m -b1 -q -g
```
to see a list of the next events in chronological order and
```
rem -m -b1 -q -cuc12 -w$(($(tput cols)+1)) | sed -e "s/\f//g" | less
```
to show a calendar fitting just the width of my terminal:
## Dictionary
[rdictcc](https://github.com/tsdh/rdictcc) is a little known dictionary tool that uses the excellent dictionary files from [dict.cc](https://www.dict.cc/) and turns them into a local database:
```
$ rdictcc rasch
====================[ A => B ]====================
rasch:
- apace
- brisk [speedy]
- cursory
- in a timely manner
- quick
- quickly
- rapid
- rapidly
- sharpish [Br.] [coll.]
- speedily
- speedy
- swift
- swiftly
rasch [gehen]:
- smartly [quickly]
Rasch {n} [Zittergras-Segge]:
- Alpine grass [Carex brizoides]
- quaking grass sedge [Carex brizoides]
Rasch {m} [regional] [Putzrasch]:
- scouring pad
====================[ B => A ]====================
Rasch model:
- Rasch-Modell {n}
```
## Writing and Reading
I have a simple todo file containing my tasks, that is basically always sitting open in a Vim session. For work I also use the todo file as a “done” file so that I can later check what tasks I finished on each day.
For writing documents, letters and presentations I use [LaTeX](https://www.latex-project.org/) for its superior typesetting. A simple letter in German format can be set like this for example:
```
\documentclass[paper = a4, fromalign = right]{scrlttr2}
\usepackage{german}
\usepackage{eurosym}
\usepackage[utf8]{inputenc}
\setlength{\parskip}{6pt}
\setlength{\parindent}{0pt}
\setkomavar{fromname}{Dennis Felsing}
\setkomavar{fromaddress}{Meine Str. 1\\69181 Leimen}
\setkomavar{subject}{Titel}
\setkomavar*{enclseparator}{Anlagen}
\makeatletter
\@setplength{refvpos}{89mm}
\makeatother
\begin{document}
\begin{letter} {Herr Soundso\\Deine Str. 2\\69121 Heidelberg}
\opening{Sehr geehrter Herr Soundso,}
Sie haben bei mir seit dem Bla Bla Bla.
Ich fordere Sie hiermit zu Bla Bla Bla auf.
\closing{Mit freundlichen Grüßen}
\end{letter}
\end{document}
```
Further example documents and presentations can be found over at [my private site](https://dennis.felsing.org/research/).
To read PDFs [Zathura](https://pwmt.org/projects/zathura/) is fast, has Vim-like controls and even supports two different PDF backends: Poppler and MuPDF. [Evince](https://wiki.gnome.org/Apps/Evince) on the other hand is more full-featured for the cases where I encounter documents that Zathura doesn’t like.
## Graphical Editing
[GIMP](https://www.gimp.org/) and [Inkscape](https://inkscape.org/) are easy choices for photo editing and interactive vector graphics respectively.
In some cases [Imagemagick](https://imagemagick.org/Usage/) is good enough though and can be used straight from the command line and thus automated to edit images. Similarly [Graphviz](https://www.graphviz.org/) and [TikZ](https://sourceforge.net/projects/pgf/) can be used to draw graphs and other diagrams.
## Web Browsing
As a web browser I’ve always used [Firefox](https://www.mozilla.org/en-US/firefox/new/) for its extensibility and low resource usage compared to Chrome.
Unfortunately the [Pentadactyl](https://github.com/5digits/dactyl) extension development stopped after Firefox switched to Chrome-style extensions entirely, so I don’t have satisfying Vim-like controls in my browser anymore.
## Media Players
[mpv](https://mpv.io/) with hardware decoding allows watching videos at 5% CPU load using the `vo=gpu`
and `hwdec=vaapi`
config settings. `audio-channels=2`
in mpv seems to give me clearer downmixing to my stereo speakers / headphones than what PulseAudio does by default. A great little feature is exiting with `Shift-Q`
instead of just `Q`
to save the playback location. When watching with someone with another native tongue you can use `--secondary-sid=`
to show two subtitles at once, the primary at the bottom, the secondary at the top of the screen
My wirelss mouse can easily be made into a remote control with mpv with a small `~/.config/mpv/input.conf`
:
```
MOUSE_BTN5 run "mixer" "pcm" "-2"
MOUSE_BTN6 run "mixer" "pcm" "+2"
MOUSE_BTN1 cycle sub-visibility
MOUSE_BTN7 add chapter -1
MOUSE_BTN8 add chapter 1
```
[youtube-dl](https://rg3.github.io/youtube-dl/) works great for watching videos hosted online, best quality can be achieved with `-f bestvideo+bestaudio/best --all-subs --embed-subs`
.
As a music player [MOC](http://moc.daper.net/) hasn’t been actively developed for a while, but it’s still a simple player that plays every format conceivable, including the strangest Chiptune formats. In the AUR there is a [patch](https://aur.archlinux.org/packages/moc-pulse/) adding PulseAudio support as well. Even with the CPU clocked down to 800 MHz MOC barely uses 1-2% of a single CPU core.
My music collection sits on my home server so that I can access it from anywhere. It is mounted using [SSHFS](https://github.com/libfuse/sshfs) and automount in the `/etc/fstab/`
:
```
root@server:/media/media /mnt/media fuse.sshfs noauto,x-systemd.automount,idmap=user,IdentityFile=/root/.ssh/id_rsa,allow_other,reconnect 0 0
```
## Cross-Platform Building
Linux is great to build packages for any major operating system except Linux itself! In the beginning I used [QEMU](https://www.qemu.org/) to with an old Debian, Windows and Mac OS X VM to build for these platforms.
Nowadays I switched to using chroot for the old Debian distribution (for maximum Linux compatibility), [MinGW](http://www.mingw.org/) to cross-compile for Windows and [OSXCross](https://github.com/tpoechtrager/osxcross) to cross-compile for Mac OS X.
The script used to [build DDNet](https://github.com/ddnet/ddnet-scripts/blob/master/ddnet-release.sh) as well as the [instructions for updating library builds](https://github.com/ddnet/ddnet-scripts/blob/master/ddnet-lib-update.sh) are based on this.
## Backups
As usual, we nearly forgot about backups. Even if this is the last chapter, it should not be an afterthought.
I wrote [rrb](https://github.com/def-/rrb/blob/master/rrb) (reverse rsync backup) 10 years ago to wrap rsync so that I only need to give the backup server root SSH rights to the computers that it is backing up. Surprisingly rrb needed 0 changes in the last 10 years, even though I kept using it the entire time.
The backups are stored straight on the filesystem. Incremental backups are implemented using hard links (`--link-dest`
). A simple [config](https://github.com/def-/rrb/blob/master/config.example) defines how long backups are kept, which defaults to:
```
KEEP_RULES=( \
7 7 \ # One backup a day for the last 7 days
31 8 \ # 8 more backups for the last month
365 11 \ # 11 more backups for the last year
1825 4 \ # 4 more backups for the last 5 years
)
```
Since some of my computers don’t have a static IP / DNS entry and I still want to back them up using rrb I use a reverse SSH tunnel (as a systemd service) for them:
```
[Unit]
Description=Reverse SSH Tunnel
After=network.target
[Service]
ExecStart=/usr/bin/ssh -N -R 27276:localhost:22 -o "ExitOnForwardFailure yes" server
KillMode=process
Restart=always
[Install]
WantedBy=multi-user.target
```
Now the server can reach the client through `ssh -p 27276 localhost`
while the tunnel is running to perform the backup, or in `.ssh/config`
format:
```
Host cr-remote
HostName localhost
Port 27276
```
While talking about SSH hacks, sometimes a server is not easily reachable thanks to some bad routing. In that case you can route the SSH connection through another server to get better routing, in this case going through the USA to reach my Chinese server which had not been reliably reachable from Germany for a few weeks:
```
Host chn.ddnet.org
ProxyCommand ssh -q usa.ddnet.org nc -q0 chn.ddnet.org 22
Port 22
```
## Final Remarks
Thanks for reading my random collection of tools. I probably forgot many programs that I use so naturally every day that I don’t even think about them anymore. Let’s see how stable my software setup stays in the next years. If you have any questions, feel free to get in touch with me at [[email protected]](/cdn-cgi/l/email-protection#c7a3a2a9a9aeb487a1a2abb4aea9a0e9a8b5a0).
Comments on [Hacker News](https://news.ycombinator.com/item?id=19253072). |
12,884 | Rails 之旅第 1 天:一个令人困惑的 Rails 错误信息 | https://jvns.ca/blog/2020/11/09/day-1--a-little-rails-/ | 2020-12-04T08:10:51 | [
"Rails",
"Ruby"
] | https://linux.cn/article-12884-1.html | 
今天,我开始了一个 Recurse Center 的班次学习!我认识了一些人,并开始了一个小小的有趣的 Rails 项目。我想我今天不会谈太多关于这个项目的实际内容,但这里有一些关于 Rails 一天的快速笔记。
### 一些关于开始的笔记
在建立 Rails 项目的过程中,我学到的主要是:
1. 它默认使用 sqlite,你必须告诉它使用 Postgres。
2. Rails 默认包含了大量的东西,你可以禁用。
我安装并 `rm -rf` Rails 大概 7 次后才满意,最后用了这个咒语:
```
rails new . -d postgresql --skip-sprockets --skip-javascript
```
主要是因为我想用 Postgres 而不是 sqlite,而且跳过 sprockets 和 javascript 似乎能让安装 Rails 的速度更快,而且我想如果我决定要它们的话,我可以在以后再安装。
### 官方的 Rails 指南真的很不错
我在创建我的 Rails 入门应用时主要参考了 2 个资源:
* DHH 在 2005 年的 Rails 原版演讲 <https://www.youtube.com/watch?v=Gzj723LkRJY>(这次我没有看,但上次我花了一天时间学习 Rails 时看了,我发现它很有启发和帮助)。
* 官方的 Rails 入门指南,似乎非常简短明了 <https://guides.rubyonrails.org/v5.0/getting_started.html>。
### 一个神秘的错误信息:`undefined method 'user'`
我喜欢 bug,所以今天我遇到了一个奇怪的 Rails 错误! 我有一些看起来像这样的代码:
```
@user = User.new(user_params)
@user.save
```
很简单吧?但当这段代码运行时,我得到了这个令人费解的错误信息:
```
undefined method `user' for #<User:0x00007fb6f4012ab8> Did you mean? super
```
我对这里发生的事情感到**超级**困惑,因为我没有调用一个叫做 `user` 的方法。我调用的是 `.save`。什么嘛?!我对此感到困惑和沮丧,大概呆了 20 分钟,最后我看了看我的 `User` 模型,发现了这段代码:
```
class User < ApplicationRecord
has_secure_password
validates :user, presence: true, uniqueness: true
end
```
`validates :user...` *应该*是一些 Rails 魔法,验证每个 `User` 都有一个 `username`,而且用户名必须是唯一的。但我犯了一个错,我写的是 `user` 而不是 `username`。我把这个问题解决了,然后一切都正常了!万岁。
我仍然不明白我应该如何调试这个问题:堆栈跟踪告诉我问题出在 `@user.save` 行,根本没有提到 `validates :user` 的事情。我觉得一定有办法调试这个问题,但我不知道是什么办法。
我学 Rails 的目的就是想看看 Rails 的魔力在实践中是如何发挥的,所以这是个很有意思的 bug,早早的就掉坑里了。
### 一个简单的用户管理系统
我决定在我的玩具应用中加入用户。我在网上搜索了一下,发现有一个非常流行的叫做 [devise](https://github.com/heartcombo/devise) 的工具可以处理用户。我发现它的 `README` 有点让人不知所措,而且我知道想要在我的玩具应用中建立一个非常简陋的用户管理系统,所以我遵循了这个名为《[Rails 5.2 中从零开始进行用户验证](https://medium.com/@wintermeyer/authentication-from-scratch-with-rails-5-2-92d8676f6836)》的指南,到目前为止,这个指南似乎还不错。Rails 似乎已经有了一大堆管理用户的内置东西,我真的很惊讶于这本指南的短小和我需要写的代码之少。
我在实现用户功能的时候了解到,Rails 有一个内置的神奇的会话管理系统(参见 [Rails 会话如何工作](https://www.justinweiss.com/articles/how-rails-sessions-work/)。默认情况下,所有的会话数据似乎都存储在用户电脑上的 cookie 中,不过我想如果 cookie 太大了,你也可以把会话数据存储在数据库中。
已经有了会话管理系统,有了 cookie 和用户,却不太清楚到底发生了什么,这肯定是有点奇怪的,但也是挺好玩的!我们会看看情况如何。我们将拭目以待。
### 明天:更多的 Rails!
也许明天我可以在实现我的有趣的 rails 应用的想法上取得一些进展!
---
via: <https://jvns.ca/blog/2020/11/09/day-1--a-little-rails-/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today I started an Recurse Center batch! I got to meet a few people, and started on a tiny fun Rails project. I think I won’t talk too much about what the project actually is today, but here are some quick notes on a day with Rails:
### some notes on getting started
The main thing I learned about setting up a Rails project is that
- it uses sqlite by default, you have to tell it to use Postgres
- there are a ton of things that Rails includes by default that you can disable.
I installed and `rm -rf`
’d Rails maybe 7 times before I was satisfied with it and ended up with this incantation:
```
rails new . -d postgresql --skip-sprockets --skip-javascript`
```
Basically because I definitely wanted to use Postgres and not sqlite, and skipping sprockets and javascript seemed to make installing Rails faster, and I figured I could install them later if I decided I wanted them.
### the official Rails guide is really good
I used 2 main resources for creating my starter Rails app:
- DHH’s original Rails talk from 2005
[https://www.youtube.com/watch?v=Gzj723LkRJY](https://www.youtube.com/watch?v=Gzj723LkRJY)(which I didn’t watch this time, but I watched the last time I spent a day with Rails, and I found it pretty inspiring and helpful) - The official Rails “getting started” guide, which seems pretty short and clear
[https://guides.rubyonrails.org/v5.0/getting_started.html](https://guides.rubyonrails.org/v5.0/getting_started.html)
### a mysterious error message: `undefined method 'user'`
I love bugs, so here’s a weird Rails error I ran into today! I had some code that looked like this:
```
@user = User.new(user_params)
@user.save
```
Pretty simple, right? But when that code ran, I got this baffling error message:
```
undefined method `user' for #<User:0x00007fb6f4012ab8> Did you mean? super
```
I was EXTREMELY confused about what was going on here because I hadn’t *called*
a method called `user`
. I’d called `.save`
. What???? I stayed confused and
frustrated about this for maybe 20 minutes, and then finally I looked at my
`User`
model and found this code:
```
class User < ApplicationRecord
has_secure_password
validates :user, presence: true, uniqueness: true
end
```
`validates :user...`
was *supposed* to be some Rails magic validating that every `User`
had a
`username`
, and that usernames had to be unique. But I’d made a typo, and I’d written
`user`
and not `username`
. I fixed this and then everything worked! hooray!
I still don’t understand how I was supposed to debug this though: the stack
trace told me the problem was with the `@user.save`
line, and never mentioned
that `validates :user`
thing at all. I feel like there must be a way to debug
this but I don’t know what it is.
The whole point of me playing with Rails is to see how the Rails magic plays out in practice so this was a fun bug to hit early on.
### a simple user management system
I decided I wanted users in my toy app. Some Googling showed me that
there’s an extremely popular gem called
[devise](https://github.com/heartcombo/devise) that handles users. I found the
README a little overwhelming and I knew that I wanted a very minimal user
management system in my toy app, so instead I followed this guide called
[Authentication from Scratch with Rails
5.2](https://medium.com/@wintermeyer/authentication-from-scratch-with-rails-5-2-92d8676f6836)
which seems to be working out so far. Rails seems to already have a bunch of
built in stuff for managing users – I was really surprised by how short that guide was and how little code I needed to write.
I learned while implementing users that Rails has a built in magical session
management system (see [How Rails Sessions
Work](https://www.justinweiss.com/articles/how-rails-sessions-work/). By
default all the session data seems to be stored in a cookie on the user’s
computer, though I guess you can also store the session data in a database if
it gets too big for a cookie.
It’s definitely kind of strange to already have a session management system and cookies and users without quite knowing what’s going on exactly, but it’s also kind of fun! We’ll see how it goes.
### tomorrow: more rails!
Maybe tomorrow I can actually make some progress on implementing my fun rails app idea! |
12,886 | scanimage:从命令行扫描! | https://jvns.ca/blog/2020/07/11/scanimage--scan-from-the-command-line/ | 2020-12-05T10:58:42 | [
"扫描"
] | https://linux.cn/article-12886-1.html | 
这又是一篇关于我很喜欢的一个命令行工具的文章。
昨晚,出于官僚原因,我需要扫描一些文档。我以前从来没有在 Linux 上使用过扫描仪,我担心会花上好几个小时才弄明白。我从使用 `gscan2pdf` 开始,但在用户界面上遇到了麻烦。我想同时扫描两面(我知道我们的扫描仪支持),但无法使它工作。
### 遇到 scanimage!
`scanimage` 是一个命令行工具,在 `sane-utils` Debian 软件包中。我想所有的 Linux 扫描工具都使用 `sane` (“scanner access now easy”) 库,所以我猜测它和其他扫描软件有类似的能力。在这里,我不需要 OCR,所以我不打算谈论 OCR。
### 用 scanimage -L 得到你的扫描仪的名字
`scanimage -L` 列出了你所有的扫描设备。
一开始我不能让它工作,我有点沮丧,但事实证明,我把扫描仪连接到了我的电脑上,但没有插上电源。
插上后,它马上就能工作了。显然我们的扫描仪叫 `fujitsu:ScanSnap S1500:2314`。万岁!
### 用 --help 列出你的扫描仪选项
显然每个扫描仪有不同的选项(有道理!),所以我运行这个命令来获取我的扫描仪的选项:
```
scanimage --help -d 'fujitsu:ScanSnap S1500:2314'
```
我发现我的扫描仪支持 `--source` 选项(我可以用它来启用双面扫描)和 `--resolution` 选项(我把它改为 150,以减少文件大小,使扫描更快)。
### scanimage 不支持输出 PDF 文件(但你可以写一个小脚本)
唯一的缺点是:我想要一个 PDF 格式的扫描文件,而 scanimage 似乎不支持 PDF 输出。
所以我写了这个 5 行的 shell 脚本在一个临时文件夹中扫描一堆 PNG 文件,并将结果保存到 PDF 中。
```
#!/bin/bash
set -e
DIR=`mktemp -d`
CUR=$PWD
cd $DIR
scanimage -b --format png -d 'fujitsu:ScanSnap S1500:2314' --source 'ADF Front' --resolution 150
convert *.png $CUR/$1
```
我像这样运行脚本:`scan-single-sided output-file-to-save.pdf`
你可能需要为你的扫描仪设置不同的 `-d` 和 `-source`。
### 这真是太简单了!
我一直以为在 Linux 上使用打印机/扫描仪是一个噩梦,我真的很惊讶 `scanimage` 可以工作。我可以直接运行我的脚本 `scan-single-sided receipts.pdf`,它将扫描文档并将其保存到 `receipts.pdf`!
---
via: <https://jvns.ca/blog/2020/07/11/scanimage--scan-from-the-command-line/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Here’s another quick post about a command line tool I was delighted by.
Last night, I needed to scan some documents for some bureaucratic reasons. I’d never used a scanner on Linux before and I was worried it would take hours to figure out. I started by using `gscan2pdf`
and had trouble figuring out the user interface – I wanted to scan both sides of the page at the same time (which I knew our scanner supported) but couldn’t get it to work.
### enter scanimage!
`scanimage`
is a command line tool, in the `sane-utils`
Debian package. I think all Linux scanning tools use the `sane`
libraries (“scanner access now easy”) so my guess is that it has similar abilities to any other scanning software. I didn’t need OCR in this case so we’re not going to talk about OCR.
### get your scanner’s name with `scanimage -L`
`scanimage -L`
lists all scanning devices you have.
At first I couldn’t get this to work and I was a bit frustrated but it turned out that I’d connected the scanner to my computer, but not plugged it into the wall. Oops.
Once everything was plugged in it worked right away. Apparently our scanner is called `fujitsu:ScanSnap S1500:2314`
. Hooray!
### list options for your scanner with `--help`
Apparently each scanner has different options (makes sense!) so I ran this command to get the options for my scanner:
```
scanimage --help -d 'fujitsu:ScanSnap S1500:2314'
```
I found out that my scanner supported a `--source`
option (which I could use to enable duplex scanning) and a `--resolution`
option (which I changed to 150 to decrease the file sizes and make scanning faster).
### scanimage doesn’t output PDFs (but you can write a tiny script)
The only downside was – I wanted a PDF of my scanned document, and scanimage doesn’t seem to support PDF output.
So I wrote this 5-line shell script to scan a bunch of PNGs into a temp directory and convert the resulting PNGs to a PDF.
```
#!/bin/bash
set -e
DIR=`mktemp -d`
CUR=$PWD
cd $DIR
scanimage -b --format png -d 'fujitsu:ScanSnap S1500:2314' --source 'ADF Front' --resolution 150
convert *.png $CUR/$1
```
I ran the script like this. `scan-single-sided output-file-to-save.pdf`
You’ll probably need a different `-d`
and `--source`
for your scanner.
### it was so easy!
I always expect using printers/scanners on Linux to be a nightmare and I was really surprised how `scanimage`
Just Worked – I could just run my script with `scan-single-sided receipts.pdf`
and it would scan a document and save it to `receipts.pdf`
!. |
12,887 | 每天用 Jupyter 写 5 分钟的日记 | https://opensource.com/article/20/11/daily-journal-jupyter | 2020-12-05T13:14:24 | [
"Jupyter",
"日记"
] | https://linux.cn/article-12887-1.html |
>
> 用 Jupyter 和 Python 在你的日常写作背后实现一些自动化。
>
>
>

有些人会遵循传统,制定一年的计划。不过,一年的时间很长,所以我以季节性的主题或轨迹来规划。每个季度,我都会坐下来,看看即将到来的三个月的季节,并决定在这段时间里我将努力做什么。
对于我最新的主题,我决定要每天写一篇日记。我喜欢有明确的承诺,所以我承诺每天写 5 分钟。我也喜欢有可观察的承诺,哪怕只是对我而言,所以我把我的记录放在 Git 里。
我决定在写日记的过程中实现一些自动化,于是我使用了我最喜欢的自动化工具:[Jupyter](https://jupyter.org/)。Jupyter 有一个有趣的功能 [ipywidgets](https://ipywidgets.readthedocs.io/en/latest/),这是一套用于 Jupyter Notebooks、JupyterLab 和 IPython 内核的交互式 HTML 组件。
如果你想跟着本文的代码走,请注意,让你的 JupyterLab 实例支持组件可能有点复杂,请按照[这些说明](https://ipywidgets.readthedocs.io/en/latest/user_install.html)来进行设置。
### 导入 ipywidgets 模块
首先,你需要导入一堆东西,比如 ipywidgets 和 [Twisted](https://twistedmatrix.com/trac/)。Twisted 模块可以用来创建一个异步时间计数器:
```
import twisted.internet.asyncioreactor
twisted.internet.asyncioreactor.install()
from twisted.internet import reactor, task
import ipywidgets, datetime, subprocess, functools, os
```
### 设置定时条目
用 Twisted 实现时间计数器是利用了 `task.LoopingCall`。然而,结束循环调用的唯一方法是用一个异常。倒计时时钟总会停止,所以你需要一个自定义的异常来指示“一切正常;计数器结束”:
```
class DoneError(Exception):
pass
```
现在你已经写好了异常,你可以写定时器了。第一步是创建一个 `ipywidgets.Label` 的文本标签组件。循环使用 `divmod` 计算出分和秒,然后设置标签的文本值:
```
def time_out_counter(reactor):
label = ipywidgets.Label("Time left: 5:00")
current_seconds = datetime.timedelta(minutes=5).total_seconds()
def decrement(count):
nonlocal current_seconds
current_seconds -= count
time_left = datetime.timedelta(seconds=max(current_seconds, 0))
minutes, left = divmod(time_left, minute)
seconds = int(left.total_seconds())
label.value = f"Time left: {minutes}:{seconds:02}"
if current_seconds < 0:
raise DoneError("finished")
minute = datetime.timedelta(minutes=1)
call = task.LoopingCall.withCount(decrement)
call.reactor = reactor
d = call.start(1)
d.addErrback(lambda f: f.trap(DoneError))
return d, label
```
### 从 Jupyter 组件中保存文本
下一步是写一些东西,将你输入的文字保存到一个文件中,并提交到 Git。另外,由于你要写 5 分钟的日记,你需要一个能给你提供写字区域的组件(滚动肯定是可以的,但一次能看到更多的文字就更好了)。
这就用到了组件 `Textarea`,这是一个你可以书写的文本字段,而 `Output` 则是用来给出反馈的。这一点很重要,因为 `git push` 可能会花点时间或失败,这取决于网络。如果备份失败,用反馈提醒用户很重要:
```
def editor(fname):
textarea = ipywidgets.Textarea(continuous_update=False)
textarea.rows = 20
output = ipywidgets.Output()
runner = functools.partial(subprocess.run, capture_output=True, text=True, check=True)
def save(_ignored):
with output:
with open(fname, "w") as fpout:
fpout.write(textarea.value)
print("Sending...", end='')
try:
runner(["git", "add", fname])
runner(["git", "commit", "-m", f"updated {fname}"])
runner(["git", "push"])
except subprocess.CalledProcessError as exc:
print("Could not send")
print(exc.stdout)
print(exc.stderr)
else:
print("Done")
textarea.observe(save, names="value")
return textarea, output, save
```
`continuous_update=False` 是为了避免每个字符都保存一遍并发送至 Git。相反,只要脱离输入焦点,它就会保存。这个函数也返回 `save` 函数,所以可以明确地调用它。
### 创建一个布局
最后,你可以使用 `ipywidgets.VBox` 把这些东西放在一起。这是一个包含一些组件并垂直显示的东西。还有一些其他的方法来排列组件,但这足够简单:
```
def journal():
date = str(datetime.date.today())
title = f"Log: Startdate {date}"
filename = os.path.join(f"{date}.txt")
d, clock = time_out_counter(reactor)
textarea, output, save = editor(filename)
box = ipywidgets.VBox([
ipywidgets.Label(title),
textarea,
clock,
output
])
d.addCallback(save)
return box
```
biu!你已经定义了一个写日记的函数了,所以是时候试试了。
```
journal()
```

你现在可以写 5 分钟了!
---
via: <https://opensource.com/article/20/11/daily-journal-jupyter>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some people follow the tradition of creating New Year's resolutions. A year is a long time, though, so I plan with a seasonal theme or trajectory. Each quarter, I sit down and look at the upcoming three-month season and decide what I'll work on during that time.
For my latest theme, I decided I wanted to write a daily journal. I like having clear commitments, so I committed to writing for five minutes each day. I also like having observable commitments, even if it is just for me, so I put my entries in Git.
I decided I wanted some automation around my journaling and turned to my favorite automation tool: [Jupyter](https://jupyter.org/). One of Jupyter's interesting features is [ipywidgets](https://ipywidgets.readthedocs.io/en/latest/), a set of interactive HTML widgets for Jupyter Notebooks, JupyterLab, and the IPython kernel.
If you want to follow along with the code in this article, note that making your Jupyter lab instance support widgets can be a bit frustrating. Follow [these instructions](https://ipywidgets.readthedocs.io/en/latest/user_install.html) to set things up.
## Import ipywidgets modules
First, you need to import a bunch of things, such as ipywidgets and [Twisted](https://twistedmatrix.com/trac/). The Twisted module helps create an asynchronous time counter:
```
import twisted.internet.asyncioreactor
twisted.internet.asyncioreactor.install()
from twisted.internet import reactor, task
import ipywidgets, datetime, subprocess, functools, os
```
## Set up timed entries
Implementing a time counter with Twisted takes advantage of `task.LoopingCall`
. However, the only way to end a looping call is with an exception. A countdown clock will always stop, so you need a custom exception that indicates "all is well; the counter is done":
```
class DoneError(Exception):
pass
```
Now that you've written the exception, you can write the timer. The first step is to create an `ipywidgets.Label`
with a text label widget. The loop uses `divmod`
to figure out minutes and seconds and then sets the label's text value:
```
def time_out_counter(reactor):
label = ipywidgets.Label("Time left: 5:00")
current_seconds = datetime.timedelta(minutes=5).total_seconds()
def decrement(count):
nonlocal current_seconds
current_seconds -= count
time_left = datetime.timedelta(seconds=max(current_seconds, 0))
minutes, left = divmod(time_left, minute)
seconds = int(left.total_seconds())
label.value = f"Time left: {minutes}:{seconds:02}"
if current_seconds < 0:
raise DoneError("finished")
minute = datetime.timedelta(minutes=1)
call = task.LoopingCall.withCount(decrement)
call.reactor = reactor
d = call.start(1)
d.addErrback(lambda f: f.trap(DoneError))
return d, label
```
## Save text from a Jupyter widget
The next step is to write something that saves the text you type into your journal to a file and commits it to Git. Also, since you will be journaling for five minutes, you want a widget that gives you room to write (scrolling is always possible, but it's nice to see a bit more text at a time).
This uses the widgets `Textarea`
, which is a text field where you can write, and `Output`
to give feedback. This is important since `git push`
can take time or fail, depending on the network. If a backup fails, it's important to alert the user with feedback:
```
def editor(fname):
textarea = ipywidgets.Textarea(continuous_update=False)
textarea.rows = 20
output = ipywidgets.Output()
runner = functools.partial(subprocess.run, capture_output=True, text=True, check=True)
def save(_ignored):
with output:
with open(fname, "w") as fpout:
fpout.write(textarea.value)
print("Sending...", end='')
try:
runner(["git", "add", fname])
runner(["git", "commit", "-m", f"updated {fname}"])
runner(["git", "push"])
except subprocess.CalledProcessError as exc:
print("Could not send")
print(exc.stdout)
print(exc.stderr)
else:
print("Done")
textarea.observe(save, names="value")
return textarea, output, save
```
The `continuous_update=False`
is so that not every character is saved and sent to Git. Instead, it saves whenever you lose focus. The function also returns the `save`
function, so it can be called explicitly.
## Create a layout
Finally, you can put all of these together using `ipywidgets.VBox`
. This is something that contains a few widgets and displays them vertically. There are a few more ways to arrange widgets, but this is simple and good enough:
```
def journal():
date = str(datetime.date.today())
title = f"Log: Startdate {date}"
filename = os.path.join(f"{date}.txt")
d, clock = time_out_counter(reactor)
textarea, output, save = editor(filename)
box = ipywidgets.VBox([
ipywidgets.Label(title),
textarea,
clock,
output
])
d.addCallback(save)
return box
```
Phew! You've defined a function for journaling, so it's time to try it out.
`journal()`
(Moshe Zadka, CC BY-SA 4.0)
You have five minutes—start writing!
## Comments are closed. |
12,889 | 下载 2020 年度 Linux 基金会年度报告 | https://www.linux.com/news/download-the-2020-linux-foundation-annual-report/ | 2020-12-05T20:53:00 | [
"Linux基金会"
] | https://linux.cn/article-12889-1.html | 
2020 年对于 <ruby> Linux 基金会 <rt> Linux Foundation </rt></ruby>(LF)和我们托管的社区来说,是充满挑战的一年。在这次大流行期间,我们都看到我们和世界各地许多同事、朋友和家人的日常生活完全改变了。在我们的社区中,有太多的人也为失去家人和朋友而悲痛。
看到 LF 的成员加入到对抗 COVID-19 的斗争中,令人振奋。我们在世界各地的成员为科研人员贡献了技术资源,为挣扎中的家庭和个人提供了援助,为国家和国际努力做出了贡献,有些人甚至一起在 [LF 公共卫生](https://www.lfph.io/) 下创建了开源项目,以帮助各国应对这场大流行病。
今年,我们的项目社区在继续发展,在许多开放技术领域、开放标准、开放数据和开放硬件方面都有新的举措。今年,我们迎接了 150 多个新社区加入 LF,包括 [FINOS 基金会](https://www.finos.org/),它是开源金融服务项目的保护项目。
我们的 [活动团队](https://events.linuxfoundation.org/) 不得不进行了重大转型,在几周内,从面对面的活动转变为虚拟活动,参与者从不足 100 人到数万人不等。这些虚拟聚会帮助我们社区中的许多人在这个困难时期建立了联系。我们也学到了很多关于未来可能通过提供虚拟体验的<ruby> 混合亲身活动 <rt> hybrid in-person events </rt></ruby>来提供更具包容性的体验。今年,我们很想念在我们的社区中见到的许多朋友,并期待着在安全的情况下再次见到你们。
我们的 [培训和认证](https://training.linuxfoundation.org/) 团队能够帮助 170 多万名报名参加我们免费培训课程的人。我要祝贺今年获得 LF 认证的 4 万多人。
《[LF 的 2020 年度工作报告](https://training.linuxfoundation.org/resources/2020-open-source-jobs-report/)》显示,尽管商业环境充满挑战,但经过培训和认证的开源专业人员仍有大有需求,并能轻松地展示其价值。
作为我们正在进行的多元化努力的一部分,在加入反对不平等的斗争中,我们的社区专注于该如何在项目中使用语言,并寻找导师来指导下一代的贡献者。我们的社区,如 Linux 内核团队和在北美 KubeCon 上发起的 <ruby> <a href="https://inclusivenaming.org/"> 包容性命名倡议 </a> <rt> Inclusive Naming Initiative </rt></ruby>,在加强我们的互动方式上取得了进展。
今年是我们<ruby> 联合发展基金会 <rt> Joint Development Foundation </rt></ruby>(JDF)和<ruby> 开放标准社区 <rt> open standards communities </rt></ruby>的突破性一年。我们迎来了六个建立开放标准的新项目。[JDF 还被批准为 ISO/IEC JTC 1 公开发布规范(PAS)提交者](https://www.linuxfoundation.org/blog/2020/05/joint-development-foundation-recognized-as-an-iso-iec-jtc-1-pas-submitter-and-submits-openchain-for-international-review/)。今年还标志着我们的第一个开放标准社区 OpenChain 通过 PAS 程序,被正式认可为国际标准。今天,Linux 基金会可以把我们的社区,从开源仓库带到一个公认的全球标准。
今年,我们生态系统中的许多人已经站出来帮助安全工作。一个新的社区 <ruby> <a href="https://openssf.org/"> 开源安全基金会 </a> <rt> Open Source Security Foundation </rt></ruby>(OpenSSF)启动了,以协调专注于提高开源软件安全性的努力。
当我们继续在美国与挑战作斗争时,[我们也重申 LF 是全球社区的一部分](https://www.linuxfoundation.org/blog/2020/08/open-source-collaboration-is-a-global-endeavor/)。
我们的成员必须得应对国际贸易政策变化的一年,并了解到开放源码在政治上的蓬勃发展。来自世界各地的我们的成员社区参与了<ruby> 开放合作 <rt> open collaboration </rt></ruby>,因为它是开放、中立和透明的。这些参与者显然希望继续与全球同行合作,以应对大大小小的挑战。
在这困难的一年结束时,所有这些都让我们确信,开放合作是解决世界上最复杂挑战的模式。没有任何一个人、组织或政府能够单独创造出我们解决最紧迫问题所需的技术。我们代表整个 Linux 基金会团队,期待着帮助您和我们的社区应对接下来的任何挑战。

Jim Zemlin,Linux 基金会执行总监
* [下载 Linux 基金会 2020 年度报告](http://linuxfoundation.org/2020-annual-report)
这篇文章首先发布于 [Linux 基金会](https://www.linuxfoundation.org/)。
---
via: <https://www.linux.com/news/download-the-2020-linux-foundation-annual-report/>
作者:[The Linux Foundation](https://www.linuxfoundation.org/blog/2020/12/download-the-2020-linux-foundation-annual-report/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 2020 has been a year of challenges for the Linux Foundation (“LF”) and our hosted communities. During this pandemic, we’ve all seen our daily lives and those of many of our colleagues, friends, and family around the world completely changed. Too many in our community also grieved over the loss of family and friends.
It was uplifting to see LF members join the fight against COVID-19. Our members worldwide contributed technical resources for scientific researchers, offered assistance to struggling families and individuals, contributed to national and international efforts, and some even came together to create open source projects under [LF Public Health](https://www.lfph.io/) to help countries deal with the pandemic.
Our project communities continued to grow this year, with new initiatives across many open technology segments, open standards, open data, and open hardware. We welcomed over 150 new communities to the LF this year, including the [FINOS Foundation](https://www.finos.org/), which serves as an umbrella home for open source financial services projects.
Our [events team](https://events.linuxfoundation.org/) had to undergo a significant transformation, pivoting over a few weeks from in-person to virtual events ranging from under 100 to tens of thousands of participants. These virtual gatherings helped many in our communities connect during this difficult time. We also learned much about potentially offering a more inclusive experience by providing hybrid in-person events with virtual experiences in the future. We’ve missed seeing many in our communities in person this year and look forward to seeing you all again when it is safe to do so.
Our [training and certification](https://training.linuxfoundation.org/) team was able to help over 1.7 million individuals who enrolled in our free training courses. I want to congratulate the more than 40,000 persons who received LF certifications this year.
The [LF’s 2020 Jobs Report](https://training.linuxfoundation.org/resources/2020-open-source-jobs-report/) shows trained and certified open source professionals are in demand and can easily demonstrate their value despite the challenging business environment.
As part of our ongoing diversity efforts and in joining the fight against inequality, our communities are focused on how they use language in their projects and finding mentors to guide the next generation of contributors. Our communities, such as the Linux kernel team and the [Inclusive Naming Initiative](https://inclusivenaming.org/) launched at KubeCon North America, stepped up to enable progress in how we interact.
This year was a breakout year for our Joint Development Foundation and open standards communities. We welcomed six new projects building open standards. [JDF has also been approved as an ISO/IEC JTC 1 Publicly Available Specification (PAS) Submitter](https://www.linuxfoundation.org/blog/2020/05/joint-development-foundation-recognized-as-an-iso-iec-jtc-1-pas-submitter-and-submits-openchain-for-international-review/). This year also marked that our first open standard community, OpenChain, was formally recognized as an international standard through the PAS process. Today the Linux Foundation can take our communities from open source repository to a recognized global standard.
Many in our ecosystem have stepped up to help with security efforts this year. A new community, [Open Source Security Foundation (OpenSSF)](https://openssf.org/), launched to coordinate efforts focused on improving the security of open-source software.
While we continue to battle challenges in the US, [we also reaffirm that the LF is part of a global community](https://www.linuxfoundation.org/blog/2020/08/open-source-collaboration-is-a-global-endeavor/).
Our members had to navigate a year of changes in international trade policies and learned open source thrives despite politics. From around the world, our member communities engage in open collaboration because it is open, neutral, and transparent. Those participants clearly desire to continue collaborating with their global peers on challenges large and small.
At the end of a difficult year, all this taken together leaves us assured that open collaboration is the model for solving the world’s most complex challenges. No single person, organization, or government alone can create the technology we need to solve our most pressing problems. On behalf of the entire Linux Foundation team, we look forward to helping you and our communities take on whatever challenges come next.
Jim Zemlin, Executive Director, *The Linux Foundation*
The post [Download the 2020 Linux Foundation Annual Report](https://www.linuxfoundation.org/blog/2020/12/download-the-2020-linux-foundation-annual-report/) appeared first on [The Linux Foundation](https://www.linuxfoundation.org/). |
12,890 | Rails 之旅第 2 天:Rails 关联和拖动 div | https://jvns.ca/blog/2020/11/10/day-2--rails-associations---dragging-divs-around/ | 2020-12-05T21:24:53 | [
"Rails"
] | https://linux.cn/article-12890-1.html | 
大家好!今天是我搭建这个玩具项目的第 2 天。下面再来记录一下关于 Rails 的一些有趣的事情吧!
### 目标:做一个冰箱诗歌论坛
我想做一种无聊的标准网站来学习 Rails,并且其他人可以与之互动,就像一个论坛一样! 但如果人们真的可以在网站上打字,那就会产生各种各样的问题(如果他们是垃圾邮件发送者怎么办?又或者只是言语刻薄?)。
我想到的第一个想法是,可以让人们与网站互动,但实际上却不能在网站上打字,那就是一个“冰箱诗歌论坛”,只给你一组固定的字,你就可以随意组合。
所以,这就是我们的计划!
我这个项目的目标是想知道我是否能用 Rails 来做其他的小型网络项目(而不是像我通常做的那样,使用一些更基本的东西,比如 Flask,或者放弃后端,用 Javascript 来写所有东西)。
### 怎么把字拖来拖去呢?jQuery 的可拖放 UI!
我想让大家能够把文字拖动起来,但我又不想写很多 Javascript。结果发现这超级简单 —— 有一个 jQuery 库可以做到,它叫做 `draggable`!一开始,拖动并不成功。
一开始拖动在手机上是不行的,但是有一个技巧可以让 jQuery UI 在手机上工作,叫做 [jQuery UI touch punch](https://github.com/furf/jquery-ui-touch-punch)。下面是它的样子(有兴趣看工作原理的可以查看源码,代码很少)。
>
> `banana` `forest` `cake` `is`
>
>
>
### 一个有趣的 Rails 功能:关联
我以前从来没有使用过关系型 ORM,对于 Rails,我很兴奋的一件事就是想看看使用 Active Record 是什么样子的!今天我了解了 Rails 的 ORM 功能之一:[关联](https://guides.rubyonrails.org/association_basics.html)。如果你像我一样对 ORM 完全不了解的话,那就来看看是怎么回事吧。
在我的论坛中,我有:
* 用户
* 话题(我本来想把它叫做“线索”,但显然这在 Rails 中是一个保留词,所以现在叫做“话题”)。
* 帖子
当显示一个帖子时,我需要显示创建该帖子的用户的用户名。所以我想我可能需要写一些代码来加载帖子,并为每个帖子加载用户,就像这样(在 Rails 中,`Post.where` 和 `User.find` 将会运行 SQL 语句,并将结果转化为 Ruby 对象):
```
@posts = Post.where(topic_id: id)
@posts.each do |post|
user = User.find(post.user_id)
post.user = user
end
```
这还不够好,它要为每个帖子做一次单独的 SQL 查询!我知道有一个更好的方法,我发现它叫做[关联](https://guides.rubyonrails.org/association_basics.html)。这个链接是来自 <https://guides.rubyonrails.org> 的指南,到目前为止,它对我很有帮助。
基本上我需要做的就是:
1. 在 `User` 模型中添加一行 `has_many :post`。
2. 在 `Post` 模型中添加一行 `belongs_to :user`。
3. Rails 现在知道如何将这两个表连接起来,尽管我没有告诉它要连接到什么列上!我认为这是因为我按照它所期望的惯例命名了 `posts` 表中的 `user_id` 列。
4. 对 `User` 和 `Topic` 做完全相同的事情(一个主题也有很多帖子:`has_many :posts`)。
然后我加载每一个帖子和它的关联用户的代码就变成了只有一行! 就是这一行:
```
@posts = @topic.posts.order(created_at: :asc).preload(:user)
```
比起只有一行更重要的是,它不是单独做一个查询来获取每个帖子的用户,而是在 1 个查询中获取所有用户。显然,在 Rails 中,有一堆[不同的方法](https://blog.bigbinary.com/2013/07/01/preload-vs-eager-load-vs-joins-vs-includes.html)来做类似的事情(预加载、急切加载、联接和包含?),我还不知道这些都是什么,但也许我以后会知道的。
### 一个有趣的 Rails 功能:脚手架!
Rails 有一个叫 `rails` 的命令行工具,它可以生成很多代码。例如,我想添加一个 `Topic` 模型/控制器。我不用去想在哪里添加所有的代码,可以直接运行
```
rails generate scaffold Topic title:text
```
并生成了一堆代码,这样我已经有了基本的端点来创建/编辑/删除主题(`Topic`)。例如,这是我的[现在的主题控制器](https://github.com/jvns/refrigerator-forum/blob/776b3227cfd7004cb1efb00ec7e3f82a511cbdc4/app/controllers/topics_controller.rb#L13-L15),其中大部分我没有写(我只写了高亮的 3 行)。我可能会删除很多内容,但是有一个起点,让我可以扩展我想要的部分,删除我不想要的部分,感觉还不错。
### 数据库迁移!
`rails` 工具还可以生成数据库迁移! 例如,我决定要删除帖子中的 `title` 字段。
下面是我要做的:
```
rails generate migration RemoveTitleFromPosts title:string
rails db:migrate
```
就是这样 —— 只要运行几个命令行咒语就可以了! 我运行了几个这样的迁移,因为我改变了对我的数据库模式的设想。它是相当直接的,到目前为止 —— 感觉很神奇。
当我试图在一列中的某些字段为空的地方添加一个“不为空”(`not null`)约束时,情况就变得有点有趣了 —— 迁移失败。但我可以修复违例的记录,并轻松地重新运行迁移。
### 今天就到这里吧!
明天,如果我有更多的进展,也许我会把它放在互联网上。
---
via: <https://jvns.ca/blog/2020/11/10/day-2--rails-associations---dragging-divs-around/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! Today was day 2 of building my toy project. Here are a few more notes on things that have been fun about Rails!
### the goal: make a refrigerator poetry forum
I wanted to make kind of a boring standard website to learn Rails, and that other people could interact with. Like a forum! But of course if people can actually type on a website that creates all kinds of problems (what if they’re spammers? or just mean?).
The first idea I came up with that would let people interact with the website but not actually be able to type things into it was a refrigerator poetry forum where you can write poems given only a fixed set of words.
So, that’s the plan!
My goal with this project is to find out if I want to use Rails for other small web projects (instead of what I usually do, which is use something more basic like Flask, or give up on having a backend at all and write everything in Javascript).
### how do you drag the words around? jQuery UI draggable!
I wanted people to be able to drag the words around, but I didn’t feel like writing a lot of Javascript. It turns out that this is SUPER easy – there’s a jQuery library to do it called “draggable”!
At first the dragging didn’t work on mobile,
but there’s a hack to make jQuery UI work on mobile called [jQuery UI touch
punch](https://github.com/furf/jquery-ui-touch-punch). Here’s what it looks
like (you can view source if you’re interested in seeing how it works, there’s
very little code).
### a fun Rails feature: “associations”
I’ve never used a relational ORM before, and one thing I was excited about with
Rails was to see what using Active Record is like! Today I learned about one of Rails’ ORM features: [associations](https://guides.rubyonrails.org/association_basics.html). Here’s what that’s about if you know absolutely nothing about ORMs like me.
In my forum, I have:
- users
- topics (I was going to call this “threads” but apparently that’s a reserved word in Rails so they’re called “topics” for now)
- posts
When displaying a post, I need to show the username of the user who created the
post. So I thought I might need to write some code to load the posts and load
the user for each post like this: (in Rails, `Post.where`
and `User.find`
will
run SQL statements and turn the results into Ruby objects)
```
@posts = Post.where(topic_id: id)
@posts.each do |post|
user = User.find(post.user_id)
post.user = user
end
```
This is no good though – it’s doing a separate SQL
query for every post! I knew there was a better way, and I
found out that it’s called
[Associations](https://guides.rubyonrails.org/association_basics.html). That
link is to the guide from [https://guides.rubyonrails.org](https://guides.rubyonrails.org), which has treated me
well so far.
Basically all I needed to do was:
- Add a
`has_many :posts`
line to the User model - Add a
`belongs_to :user`
line to the Post model - Rails now knows how to join these two tables even though I didn’t tell it
what columns to join on! I think this is because I named the
`user_id`
column in the`posts`
table according to the convention it expects. - Do the exact same thing for
`User`
and`Topic`
(a topic also`has_many :posts`
)
And then my code to load every post along with its associated user becomes just one line! Here’s the line:
```
@posts = @topic.posts.order(created_at: :asc).preload(:user)
```
More importantly than it being just one line, instead of doing a separate query
to get the user for each post, it gets all the users in 1 query. Apparently
there are a bunch of [different ways](https://blog.bigbinary.com/2013/07/01/preload-vs-eager-load-vs-joins-vs-includes.html)
to do similar things in Rails (preload, eager load, joins, and includes?). I
don’t know what all those are yet but maybe I’ll learn that later.
### a fun Rails feature: scaffolding!
Rails has this command line tool called `rails`
and it does a lot of code
generation. For example, I wanted to add a Topic model / controller. Instead of having to go figure
out where to add all the code, I could just run:
```
rails generate scaffold Topic title:text
```
and it generated a bunch of code, so that I already had basic endpoints to
create / edit / delete Topics. For example, here’s my [topic controller right
now](https://github.com/jvns/refrigerator-forum/blob/776b3227cfd7004cb1efb00ec7e3f82a511cbdc4/app/controllers/topics_controller.rb#L13-L15), most of which I did not write (I only wrote the highlighted 3 lines).
I’ll probably delete a lot of it, but it feels kinda nice to have a starting point where I can expand on the
parts I want and delete the parts I don’t want.
### database migrations!
The `rails`
tool can also generate database migrations! For example, I decided
I wanted to remove the `title`
field from posts.
Here’s what I had to do:
```
rails generate migration RemoveTitleFromPosts title:string
rails db:migrate
```
That’s it – just run a couple of command line incantations! I ran a few of these migrations as I changed my mind about what I wanted my database schema to be and it’s been pretty straightforward so far – it feels pretty magical.
It got a tiny bit more interesting when I tried to add a `not null`
constraint
to a column where some of the fields in that column were null – the migration
failed. But I could just fix the offending records and easily rerun the migration.
### that’s all for today!
tomorrow maybe I’ll put it on the internet if I make more progress. |
12,891 | 使用 UEFI 双启动 Windows 和 Linux | https://opensource.com/article/19/5/dual-booting-windows-linux-uefi | 2020-12-06T10:14:00 | [
"双启动",
"UEFI"
] | https://linux.cn/article-12891-1.html |
>
> 这是一份在同一台机器上设置 Linux 和 Windows 双重启动的速成解释,使用统一可扩展固件接口(UEFI)。
>
>
>

我将强调一些重要点,而不是一步一步地指导你来如何配置你的系统以实现双重启动。作为一个示例,我将提到我在几个月之前新买的笔记本计算机。我先是安装 [Ubuntu Linux](https://www.ubuntu.com) 到整个硬盘中,这就摧毁了预装的 [Windows 10](https://www.microsoft.com/en-us/windows) 环境。几个月后,我决定安装一个不同的 Linux 发行版 [Fedora Linux](https://getfedora.org),也决定在双重启动配置中与它一起再次安装 Windows 10 。我将强调一些极其重要的实际情况。让我们开始吧!
### 固件
双重启动不仅仅是软件问题。或者说它算是软件的问题,因为它需要更改你的固件,以告诉你的机器如何开始启动程序。这里有一些和固件相关的重要事项要铭记于心。
#### UEFI vs BIOS
在尝试安装前,确保你的固件配置是最佳的。现在出售的大多数计算机有一个名为 <ruby> <a href="https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface"> 统一可扩展固件接口 </a> <rt> Unified Extensible Firmware Interface </rt></ruby> (UEFI)的新类型固件,UEFI 差不多取代了另一个名为 <ruby> <a href="https://en.wikipedia.org/wiki/BIOS"> 基本输入输出系统 </a> <rt> Basic Input Output System </rt></ruby>(BIOS)的固件类型,(包括很多固件供应商在内的很多人)通常称 BIOS 为<ruby> 传统启动模式 <rt> Legacy Boot </rt></ruby>。
我不需要 BIOS,所以我选择了 UEFI 模式。
#### 安全启动
另一个重要的设置是<ruby> 安全启动 <rt> Secure Boot </rt></ruby>。这个功能将检测启动路径是否被篡改,并阻止未经批准的操作系统的启动。现在,我禁用这个选项来确保我能够安装 Fedora Linux 。依据 Fedora 项目维基“[功能/安全启动](https://fedoraproject.org/wiki/Features/SecureBoot)”部分的介绍可知:Fedora Linux 在安全启动选项启用的时候也可以工作。这对其它的 Linux 发行版来说可能有所不同 — 我打算今后重新研究这项设置。
简而言之,如果你发现在这项设置启用时你不能安装你的 Linux 操作系统,那么禁用安全启动并再次重新尝试安装。
### 对启动驱动器进行分区
如果你选择双重启动并且两个操作系统都在同一个驱动器上,那么你必须将它分成多个分区。即使你使用两个不同的驱动器进行双重启动,出于各种各样的原因,大多数 Linux 环境也最好分成几个基本的分区。这里有一些选项值得考虑。
#### GPT vs MBR
如果你决定手动分区你的启动驱动器,在动手前,我建议使用<ruby> <a href="https://en.wikipedia.org/wiki/GUID_Partition_Table"> GUID 分区表 </a> <rt> GUID Partition Table </rt></ruby>(GPT),而不是使用旧的<ruby> <a href="https://en.wikipedia.org/wiki/Master_boot_record"> 主启动记录 </a> <rt> Master Boot Record </rt></ruby>(MBR) 。这种更改的原因之一是:MBR 有两个特定的限制,而 GPT 却没有:
* MBR 可以最多拥有 15 个分区,而 GPT 可以最多拥有 128 个分区。
* MBR 最多仅支持 2 TB 磁盘,而 GPT 使用 64 位地址,这使得它最多支持 800 万 TB 的磁盘。
如果你最近购买过硬盘,那么你可能会知道现代的很多硬盘都超过了 2 TB 的限制。
#### EFI 系统分区
如果你正在进行一次全新的安装或使用一块新的驱动器,那么这里可能没有可以开始的分区。在这种情况下,操作系统安装程序将先创建一个分区,即<ruby> <a href="https://en.wikipedia.org/wiki/EFI_system_partition"> EFI 系统分区 </a> <rt> EFI System Partition </rt></ruby>(ESP)。如果你选择使用一个诸如 [gdisk](https://sourceforge.net/projects/gptfdisk/) 之类的工具来手动分区你的驱动器,你将需要使用一些参数来创建这个分区。基于现有的 ESP ,我设置它为约 500 MB 的大小,并分配它为 `ef00`( EFI 系统 )分区类型。UEFI 规范要求格式化为 FAT32/msdos ,很可能是因为这种格式被大量的操作系统所支持。

### 操作系统安装
在你完成先前的两个任务后,你就可以安装你的操作系统了。虽然我在这里关注的是 Windows 10 和 Fedora Linux ,当安装其它组合时的过程也是非常相似。
#### Windows 10
我开始 Windows 10 的安装,并创建了一个 20 GB 的 Windows 分区。因为我先前在我的笔记本计算机上安装了 Linux ,所以驱动器已经有了一个 ESP ,我选择保留它。我删除所有的现有 Linux 和交换分区来开始一次全新安装,然后开始我的 Windows 安装。Windows 安装程序自动创建另一个 16 MB 的小分区,称为 <ruby> <a href="https://en.wikipedia.org/wiki/Microsoft_Reserved_Partition"> 微软保留分区 </a> <rt> Microsoft Reserved Partition </rt></ruby>(MSR)。在这完成后,在 512 GB 启动驱动器上仍然有大约 400 GB 的未分配空间。
接下来,我继续完成了 Windows 10 安装过程。随后我重新启动到 Windows 来确保它是工作的,在操作系统第一次启动时,创建我的用户账号,设置 Wi-Fi ,并完成其它必须的任务。
#### Fedora Linux
接下来,我将心思转移到安装 Linux 。我开始了安装过程,当安装进行到磁盘配置的步骤时,我确保不会更改 Windows NTFS 和 MSR 分区。我也不会更改 ESP ,但是我设置它的挂载点为 `/boot/efi`。然后我创建常用的 ext4 格式分区, `/`(根分区)、`/boot` 和 `/home`。我创建的最后一个分区是 Linux 的交换分区(swap)。
像安装 Windows 一样,我继续完成了 Linux 安装,随后重新启动。令我高兴的是,在启动时<ruby> <a href="https://en.wikipedia.org/wiki/GNU_GRUB"> 大一统启动加载程序 </a> <rt> GRand Unified Boot Loader </rt></ruby>(GRUB)菜单提供选择 Windows 或 Linux 的选项,这意味着我不需要再做任何额外的配置。我选择 Linux 并完成了诸如创建我的用户账号等常规步骤。
### 总结
总体而言,这个过程是不难的,在过去的几年里,从 BIOS 过渡到 UEFI 有一些困难需要解决,加上诸如安全启动等功能的引入。我相信我们现在已经克服了这些障碍,可以可靠地设置多重启动系统。
我不再怀念 [Linux LOader](https://en.wikipedia.org/wiki/LILO_(boot_loader))(LILO)!
---
via: <https://opensource.com/article/19/5/dual-booting-windows-linux-uefi>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss/users/ckrzen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Rather than doing a step-by-step how-to guide to configuring your system to dual boot, I’ll highlight the important points. As an example, I will refer to my new laptop that I purchased a few months ago. I first installed [Ubuntu Linux](https://www.ubuntu.com) onto the entire hard drive, which destroyed the pre-installed [Windows 10](https://www.microsoft.com/en-us/windows) installation. After a few months, I decided to install a different Linux distribution, and so also decided to re-install Windows 10 alongside [Fedora Linux](https://getfedora.org) in a dual boot configuration. I’ll highlight some essential facts to get started.
## Firmware
Dual booting is not just a matter of software. Or, it is, but it involves changing your firmware, which among other things tells your machine how to begin the boot process. Here are some firmware-related issues to keep in mind.
### UEFI vs. BIOS
Before attempting to install, make sure your firmware configuration is optimal. Most computers sold today have a new type of firmware known as [Unified Extensible Firmware Interface (UEFI)](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface), which has pretty much replaced the other firmware known as [Basic Input Output System (BIOS)](https://en.wikipedia.org/wiki/BIOS), which is often included through the mode many providers call Legacy Boot.
I had no need for BIOS, so I chose UEFI mode.
### Secure Boot
One other important setting is Secure Boot. This feature detects whether the boot path has been tampered with, and stops unapproved operating systems from booting. For now, I disabled this option to ensure that I could install Fedora Linux. According to the Fedora Project Wiki [Features/Secure Boot ](https://fedoraproject.org/wiki/Features/SecureBoot) Fedora Linux will work with it enabled. This may be different for other Linux distributions —I plan to revisit this setting in the future.
In short, if you find that you cannot install your Linux OS with this setting active, disable Secure Boot and try again.
## Partitioning the boot drive
If you choose to dual boot and have both operating systems on the same drive, you have to break it into partitions. Even if you dual boot using two different drives, most Linux installations are best broken into a few basic partitions for a variety of reasons. Here are some options to consider.
### GPT vs MBR
If you decide to manually partition your boot drive in advance, I recommend using the [GUID Partition Table (GPT)](https://en.wikipedia.org/wiki/GUID_Partition_Table) rather than the older [Master Boot Record (MBR)](https://en.wikipedia.org/wiki/Master_boot_record). Among the reasons for this change, there are two specific limitations of MBR that GPT doesn’t have:
- MBR can hold up to 15 partitions, while GPT can hold up to 128.
- MBR only supports up to 2 terabytes, while GPT uses 64-bit addresses which allows it to support disks up to 8 million terabytes.
If you have shopped for hard drives recently, then you know that many of today’s drives exceed the 2 terabyte limit.
### The EFI system partition
If you are doing a fresh installation or using a new drive, there are probably no partitions to begin with. In this case, the OS installer will create the first one, which is the [EFI System Partition (ESP)](https://en.wikipedia.org/wiki/EFI_system_partition). If you choose to manually partition your drive using a tool such as [gdisk](https://sourceforge.net/projects/gptfdisk/), you will need to create this partition with several parameters. Based on the existing ESP, I set the size to around 500MB and assigned it the ef00 (EFI System) partition type. The UEFI specification requires the format to be FAT32/msdos, most likely because it is supportable by a wide range of operating systems.
## Operating System Installation
Once you accomplish the first two tasks, you can install your operating systems. While I focus on Windows 10 and Fedora Linux here, the process is fairly similar when installing other combinations as well.
### Windows 10
I started the Windows 10 installation and created a 20 Gigabyte Windows partition. Since I had previously installed Linux on my laptop, the drive had an ESP, which I chose to keep. I deleted all existing Linux and swap partitions to start fresh, and then started my Windows installation. The Windows installer automatically created another small partition—16 Megabytes—called the [Microsoft Reserved Partition (MSR)](https://en.wikipedia.org/wiki/Microsoft_Reserved_Partition). Roughly 400 Gigabytes of unallocated space remained on the 512GB boot drive once this was finished.
I then proceeded with and completed the Windows 10 installation process. I then rebooted into Windows to make sure it was working, created my user account, set up wi-fi, and completed other tasks that need to be done on a first-time OS installation.
### Fedora Linux
I next moved to install Linux. I started the process, and when it reached the disk configuration steps, I made sure not to change the Windows NTFS and MSR partitions. I also did not change the EPS, but I did set its mount point to **/boot/efi**. I then created the usual ext4 formatted partitions, **/** (root), **/boot**, and **/home**. The last partition I created was Linux **swap**.
As with Windows, I continued and completed the Linux installation, and then rebooted. To my delight, at boot time the [GRand](https://en.wikipedia.org/wiki/GNU_GRUB)[ Unified Boot Loader (GRUB)](https://en.wikipedia.org/wiki/GNU_GRUB) menu provided the choice to select either Windows or Linux, which meant I did not have to do any additional configuration. I selected Linux and completed the usual steps such as creating my user account.
## Conclusion
Overall, the process was painless. In past years, there has been some difficulty navigating the changes from UEFI to BIOS, plus the introduction of features such as Secure Boot. I believe that we have now made it past these hurdles and can reliably set up multi-boot systems.
I don’t miss the [Linux LOader (LILO)](https://en.wikipedia.org/wiki/LILO_(boot_loader)) anymore!
## 2 Comments |
12,893 | 如何在 LibreOffice 中完全启用深色模式 | https://itsfoss.com/libreoffice-dark-mode/ | 2020-12-07T08:39:00 | [
"LibreOffice",
"深色模式"
] | https://linux.cn/article-12893-1.html | 
[LibreOffice](https://www.libreoffice.org) 是一款自由开源的跨平台办公生产力软件。如果你没有充分利用它,那么必须看下 [LibreOffice 小技巧](https://itsfoss.com/libreoffice-tips/)。
甚至在非编程人员中,深色主题也越来越受欢迎。它减轻了眼睛的压力,特别适合长时间使用屏幕。有人认为,这使文本看起来清晰明了,有助于提高生产率。
如今,某些 Linux 发行版例如 [Ubuntu 带有深色模式](https://itsfoss.com/dark-mode-ubuntu/),使你的系统具有更暗的色彩。当你打开<ruby> 深色模式 <rt> dark mode </rt></ruby>时,某些应用将自动切换到深色模式。
LibreOffice 也会这样,但你编辑的主区域除外:

你可以更改它。如果要让 LibreOffice 进入完全深色模式,只需更改一些设置。让我告诉你如何做。
### 如何在 LibreOffice 中完全启用深色模式
如前所述,你需要先启用系统范围的深色模式。这样可以确保窗口颜色(或标题栏)与应用内深色完全融合。
接下来,打开套件中的**任意** LibreOffice 应用,例如 **Writer**。然后从菜单中,依次点击 **Tools -> Options -> Application Colors**,然后选择 **Document background 和 Application background** 为 **Black** 或 **Automatic**(任意适合你的方式)。

如果图标不是深色,那么可以从菜单(如下图所示)中更改它们,**Tools -> Options -> View** ,我在 MX Linux 上的个人选择是 Ubuntu 的 [Yaru](https://extensions.libreoffice.org/en/extensions/show/yaru-icon-theme) 图标样式(如果你使用的图标包为深色版本,请选择它) 。

当然,你也可以尝试其他 Linux 发行版的 [icon 主题](https://itsfoss.com/best-icon-themes-ubuntu-16-04/)。
最终结果应如下所示:

#### LibreOffice flatpak 软件包的其他技巧
如果你使用的是 LibreOffice 套件的 [Flatpak 软件包](https://itsfoss.com/what-is-flatpak/),那么 LibreOffice 的标题区域(或菜单区域)可能看起来是白色的。在这种情况下,你可以尝试进入 **Tools -> Options -> Personalization**,然后选择 “**灰色主题**”,如下截图所示。

它并不完全是黑色的,但应该可以使外观看起来更好。希望可以帮助你切换到深色主题的 LibreOffice 体验!
#### 总结
深色主题逐渐开始在我们的台式机中占主导地位,它具有现代品味并减少了眼睛疲劳,尤其是在弱光条件下。
LibreOffice 使你可以自由地将工作环境切换为深色主题或保留浅色主题元素。实际上,你将有大量的自定义选项来调整你喜欢的内容。你是否已在 LibreOffice 上切换为深色主题?你首选哪种颜色组合?在下面的评论中让我们知道!
---
via: <https://itsfoss.com/libreoffice-dark-mode/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Want to use LibreOffice in complete dark mode? Here's what you need to do for that in Linux.
[LibreOffice](http://www.libreoffice.org/?ref=itsfoss.com) is a free and open-source cross-platform office productivity software. If you’re not making the most of it, the [LibreOffice Tips](https://itsfoss.com/libreoffice-tips/) article is a must-read.
The dark theme is getting popular even among non-programmers. It is less stressing on the eyes, specially for extended use of the screen. Some people believe that it makes the texts look crisp and clear and that helps improve their productivity.
Some Linux distributions like [Ubuntu come with dark mode](https://itsfoss.com/dark-mode-ubuntu/) these days, giving your systems a darker tint. When you turn on the dark mode, some applications will automatically switch to dark mode.
LibreOffice also does that, except the main area where you write:
You can change that. If you want to go complete dark mode with LibreOffice, you just have to change a few settings. Let me show you how to do that.
## Method 1: Enable complete dark mode in LibreOffice Automatically
As I mentioned earlier, you need to enable a system-wide dark mode first. This will ensure that the window color (or the title bar) blends well with the in-app dark color. On Ubuntu, you can do this by going to **Settings → Appearance → Toggle Dark Mode**.
Next, open ** any** LibreOffice tool from the suite, such as
**Writer**. Then from the menu, click
**Tools → Options**.
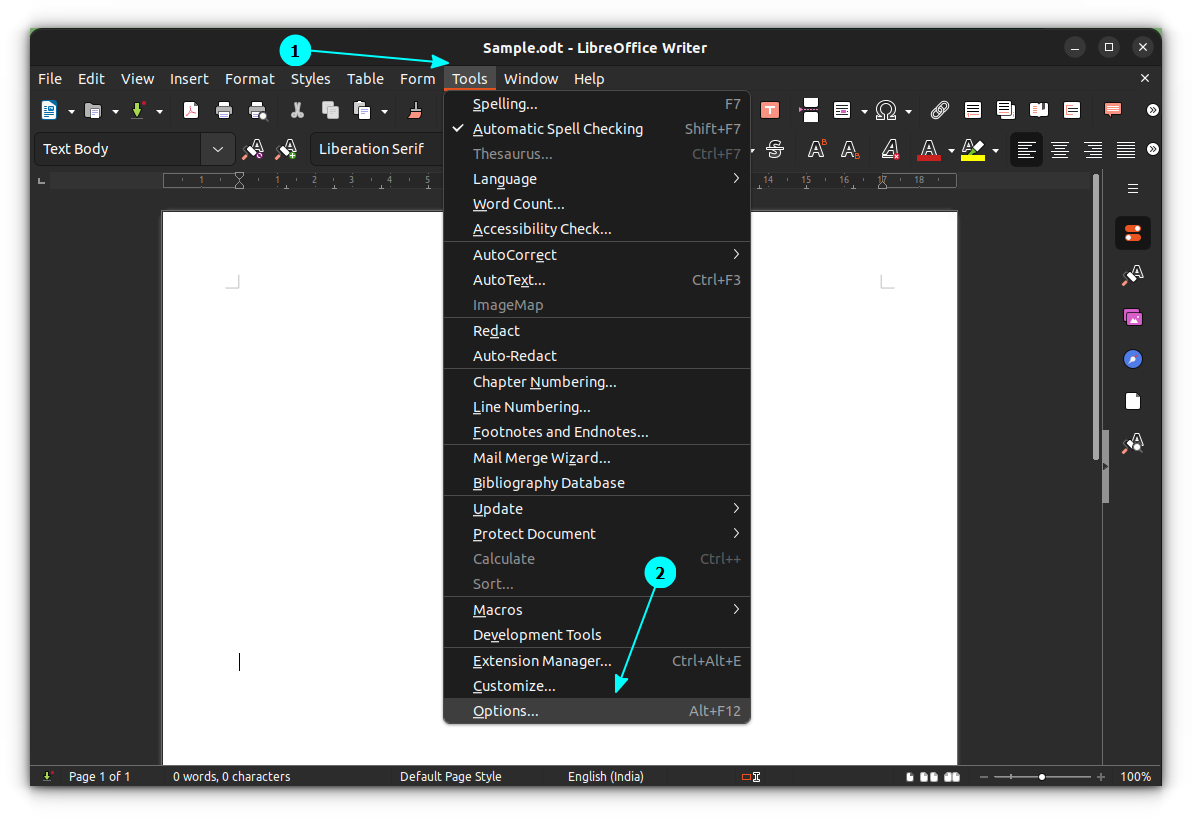
*Tools → Options*In the **Options** window, go to the **Application Colors** tab and change the color scheme to **LibreOffice Dark**.
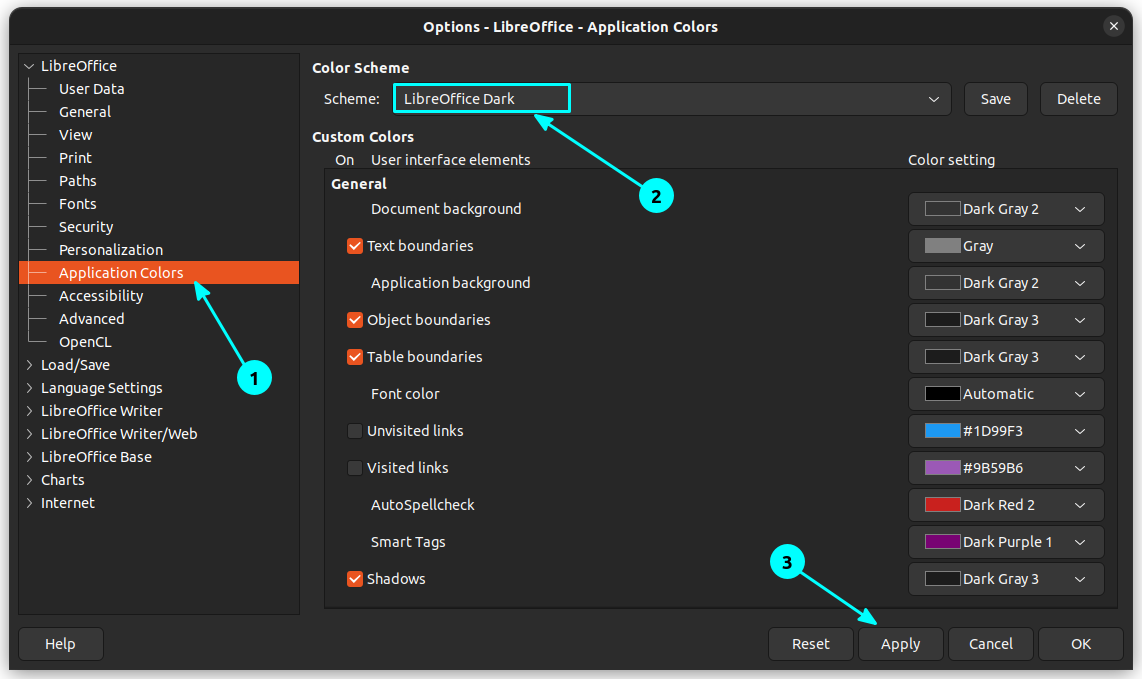
Now, click on **Apply** to apply the changes.
### Dark Mode on Latest LibreOffice Releases
There is a slight change for the process on the latest releases of LibreOffice, like version 7.6. First, go to **Tools → Options → Application Colors**. Here, set the scheme to **Automatic**.
Now, on the adjacent **Automatic** field, set the theme as **System Theme**. Click on Apply.
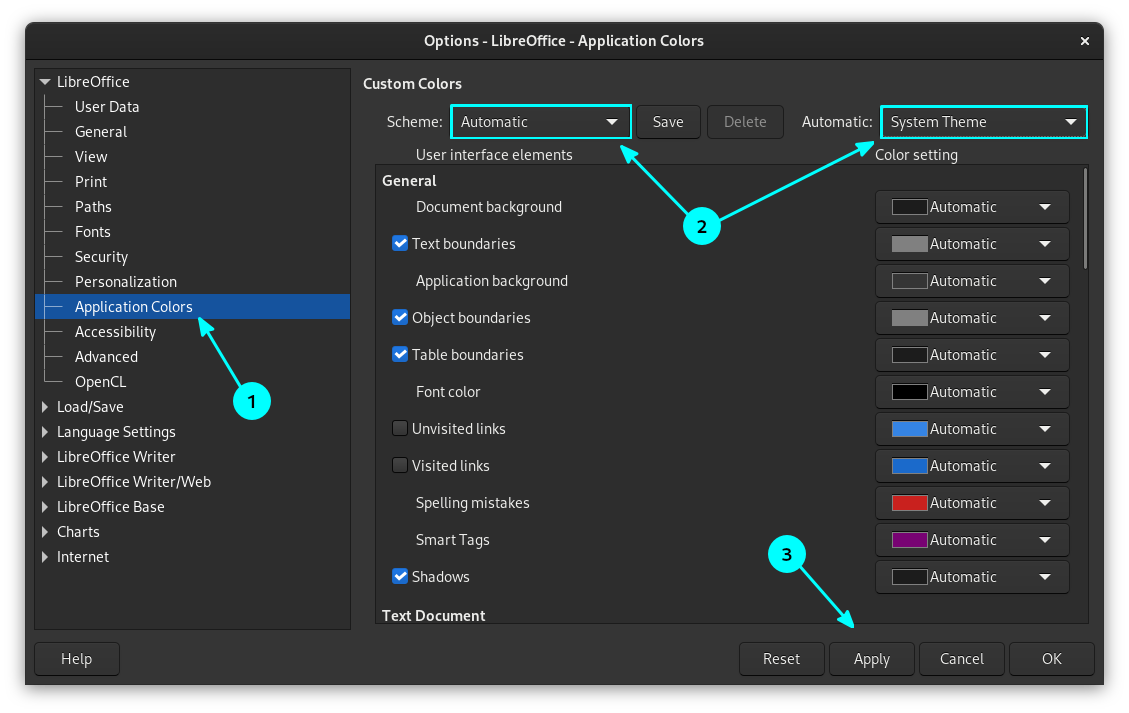
This will make LibreOffice automatically change according to the system theme. That is, when it is dark mode, LibreOffice will be dark and vice versa.
You can also set LibreOffice to permanent dark mode, by changing the **Automatic** value from **System Themes** to **Dark**.
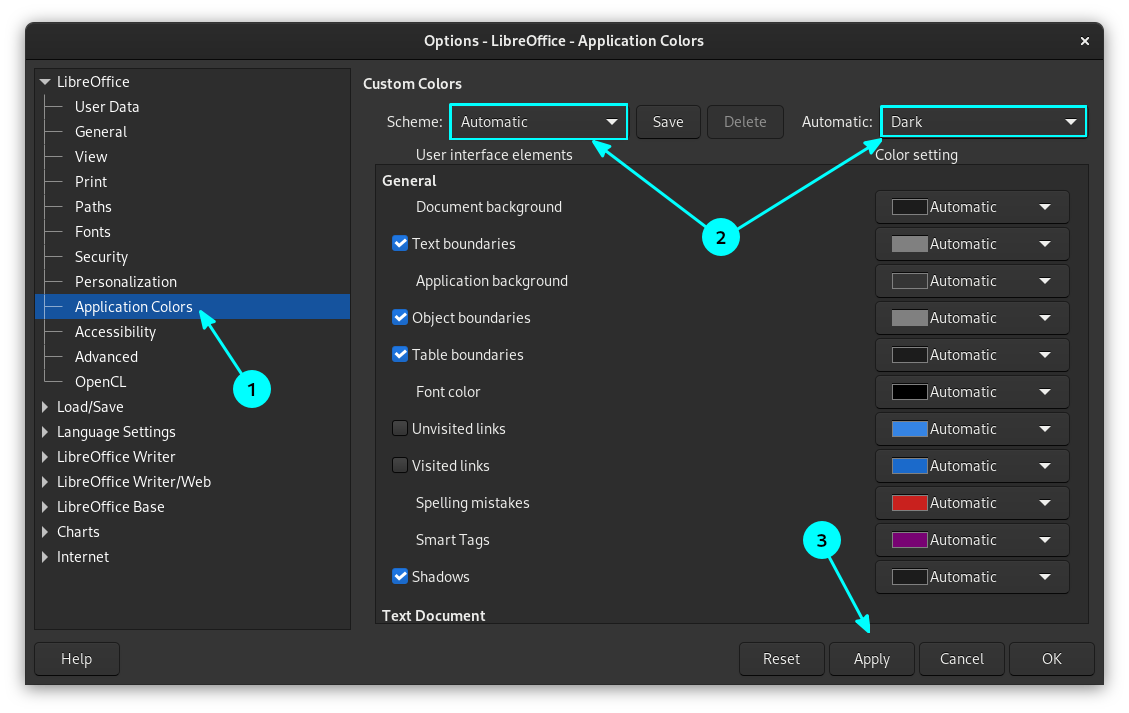
## Method 2: Manually Change Colors
Not fond of the default dark theme in LibreOffice? Don't worry! You can always change the themes manually to your liking.
Open a LibreOffice tool from the suite, such as **Writer**. From the menu, click **Tools→ Options**.
*Tools → Options*From **Application Colors**, select **Document background & Application** background as **Black** or **Automatic** (whichever works for you).
Also, change the colors for other areas too, like font color, table boundaries, etc.
Sometimes, the icons may not be visible when you change the color scheme.
You can change them from as shown in the image below. Go to **Tools → Options**. From the options window, go to the **View** tab. My personal choice, on MX Linux, is the [Yaru](https://extensions.libreoffice.org/en/extensions/show/yaru-icon-theme?ref=itsfoss.com) icon style from Ubuntu (if you have a dark version of the icon pack, select that).
Of course, you can also try some other [icon themes](https://itsfoss.com/best-icon-themes-ubuntu-16-04/) available for Linux distros. Alternatively, you can just click on the “Install icons button” to install some icon theme extensions on LibreOffice.
Here, a pitch-black background is chosen for the document background. The result should look like this:
## Additional tip for LibreOffice Flatpak/Snap package
If you’re using the [Flatpak package](https://itsfoss.com/what-is-flatpak/) or [Snap package](https://itsfoss.com/install-snap-linux/) of LibreOffice suite, the header area (or the menu area) of LibreOffice may look different. In that case, you can try navigating to **Tools→ Options→ Personalization** and then select the “**Grey theme**” as shown in the screenshot below.Additional tip for LibreOffice Flatpak/Snap package.
If you are using Flatpak package of LibreOffice, you can easily manage the dark theme of the main window. Just follow our dedicated guide on [theming Flatpak applications](https://itsfoss.com/flatpak-app-apply-theme/) with GTK themes.
At the same time, if you are using the [Snap package](https://itsfoss.com/install-snap-linux/) of LibreOffice suite, you may not be able to change the look of the main window, apart from what the default is.
So, sometimes, the header area (or the menu area) of LibreOffice may look different. In that case, you can try navigating to **Tools→ Options→ Personalization** and then select the “**Grey theme**” as shown in the screenshot below.
It isn’t completely black, but it should make things look better. Hope that helps you switch to a dark theme LibreOffice experience!
## Conclusion
Dark themes have slowly started to dominate our desktops, giving a modern taste and reducing the eye strain, especially in low light conditions.
LibreOffice gives you the freedom to switch your working environment to a fully dark theme or to keep light themed elements. In fact, you get a decent amount of customization options to tweak what you prefer. Have you switched to a dark theme on LibreOffice? Which color combination is your preferred? Let us know in the comments below! |
12,894 | 改变我使用 Git 工作方式的七个技巧 | https://opensource.com/article/20/10/advanced-git-tips | 2020-12-07T09:29:06 | [
"Git"
] | https://linux.cn/article-12894-1.html |
>
> 这些有用的技巧将改变你使用这个流行的版本控制系统的工作方式。
>
>
>

Git 是目前最常见的版本控制系统之一,无论是私有系统还是公开托管的网站,都在使用它进行各种开发工作。但无论我对 Git 的使用有多熟练,似乎总有一些功能还没有被发现,下面是改变我使用 Git 工作方式的七个技巧。
### 1、Git 中的自动更正
我们有时都会打错字,但如果启用了 Git 的自动更正功能,就可以让 Git 自动修正打错的子命令。
假设你想用 `git status` 检查状态,却不小心输入了 `git stats`。正常情况下,Git 会告诉你 `stats` 不是一条有效的命令:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
The most similar command is
status
```
为了避免类似的情况发生,请在 Git 配置中启用 Git 自动更正功能:
```
$ git config --global help.autocorrect 1
```
如果你希望这个命令只适用于你当前的版本库,请省略 `--global` 选项。
这条命令启用了自动更正功能。更深入的教程可以在 [Git Docs](https://git-scm.com/book/en/v2/Customizing-Git-Git-Configuration#_code_help_autocorrect_code) 中找到,但尝试一下和上面一样的错误命令,就能很好地了解这个配置的作用:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
On branch master
Your branch is up to date with ‘origin/master’.
nothing to commit, working tree clean
```
Git 现在不会建议使用其他子命令,而是直接运行最上面的建议,在本例中是 `git status`。
### 2、计算你的提交量
你需要计算提交数量可能有很多原因。例如,许多开发者通过计算提交数量来判断何时该增加构建版本号,或者只是想了解项目的进展情况。
要计算提交数量其实很简单直接,下面是 Git 的命令:
```
$ git rev-list --count branch-name
```
在上面的命令中,`branch-name` 应该是当前版本库中有效的分支名称:
```
$ git rev-list –count master
32
$ git rev-list –count dev
34
```
### 3、优化你的仓库
你的代码仓库不仅对你有价值,对你的组织也有价值。你可以通过一些简单的做法来保持你的版本库的清洁和更新。其中一个最好的做法是 [使用 .gitignore 文件](/article-12524-1.html)。使用这个文件,就是告诉 Git 不要存储许多不需要的文件,比如二进制文件、临时文件等等。
为了进一步优化你的版本库,你可以使用 Git 的垃圾收集功能:
```
$ git gc --prune=now --aggressive
```
当你或你的团队大量使用 `pull` 或 `push` 命令时,这条命令就会起到帮助作用。
这个命令是一个内部工具,可以清理仓库中无法访问或 “孤儿” Git 对象。
### 4、备份未被跟踪的文件
大多数时候,删除所有未被跟踪的文件是安全的。不过很多时候,你不仅要删除,还要为你的未跟踪文件创建一个备份,以备以后需要。
通过 Git 和一些 Bash 命令管道,可以很容易地为你的未被跟踪的文件创建一个压缩包:
```
$ git ls-files --others --exclude-standard -z |\
xargs -0 tar rvf ~/backup-untracked.zip
```
上面的命令制作了一个名为 `backup-untracked.zip` 的存档(并排除了 `.gitignore` 中列出的文件)。
### 5、了解你的 .git 文件夹
每个版本库都有一个 `.git` 文件夹。它是一个特殊的隐藏文件夹。
```
$ ls -a
. … .git
```
Git 的工作主要依赖于两个部分:
1. 工作树(你当前签出的文件状态)。
2. 你的 Git 仓库的路径(即你的 `.git` 文件夹的位置,其中包含版本信息)。
这个文件夹存储了所有的引用和其他重要的细节,比如配置、仓库数据、HEAD 状态、日志等等。
如果你删除这个文件夹,你的源代码的当前状态不会被删除,但你的远程信息,如你的项目历史记录,会被删除。删除这个文件夹意味着你的项目(至少是本地副本)不再处于版本控制之下。这意味着你不能跟踪你的变化;你不能从远程拉取或推送。
一般来说,不需要在 `.git` 文件夹里做什么,也没有什么应该做的。它是由 Git 管理的,基本上被认为是个禁区。然而,这个目录里有一些有趣的工件,包括 HEAD 的当前状态。
```
$ cat .git/HEAD
ref: refs/heads/master
```
它还可能包含对你的存储库的描述:
```
$ cat .git/description
```
这是一个未命名的仓库,编辑这个 `description` 文件可以命名这个仓库。
Git 钩子文件夹(`hooks`)也在这里,里面有一些钩子示例文件。你可以阅读这些示例来了解通过 Git 钩子可以实现什么,你也可以 [阅读 Seth Kenlon 的 Git 钩子介绍](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6)。
### 6、查看另一个分支的文件
有时你想查看另一个分支的文件的内容。用一个简单的 Git 命令就可以实现,而且不需要切换分支。
假设你有一个名为 [README.md](http://README.md) 的文件,它在 `main` 分支中,而你正在 `dev` 分支上工作。
使用下面的 Git 命令,你可以在终端上完成:
```
$ git show main:README.md
```
一旦你执行了这个命令,你就可以在你的终端上查看文件的内容。
### 7、在 Git 中搜索
只需一个简单的命令,你就可以像专业人士一样在 Git 中搜索。更棒的是,即使你不确定是在哪个提交或分支上做的修改,也可以在 Git 中搜索。
```
$ git rev-list --all | xargs git grep -F 'string'
```
例如,假设你想在你的版本库中搜索 `font-size: 52 px;` 这个字符串:
```
$ git rev-list –all | xargs git grep -F 'font-size: 52 px;'
F3022…9e12:HtmlTemplate/style.css: font-size: 52 px;
E9211…8244:RR.Web/Content/style/style.css: font-size: 52 px;
```
### 试试这些技巧
希望这些高级技巧对你有用,提高你的工作效率,为你节省很多时间。
你有喜欢的 [Git 小技巧](https://acompiler.com/git-tips/) 吗?在评论中分享吧。
---
via: <https://opensource.com/article/20/10/advanced-git-tips>
作者:[Rajeev Bera](https://opensource.com/users/acompiler) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Git is one of the most common version control systems available, and it's used on private systems and publicly hosted websites for all kinds of development work. Regardless of how proficient with Git I become, it seems there are always features left to discover. Here are seven tricks that have changed the way I work with Git.
## 1. Autocorrection in Git
We all make typos sometimes, but if you have Git's auto-correct feature enabled, you can let Git automatically fix a mistyped subcommand.
Suppose you want to check the status with `git status`
but you type `git stats`
by accident. Under normal circumstances, Git tells you that 'stats' is not a valid command:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
The most similar command is
status
```
To avoid similar scenarios, enable Git autocorrection in your Git configuration:
`$ git config --global help.autocorrect 1`
If you want this to apply only to your current repository, omit the `--global`
option.
This command enables the autocorrection feature. An in-depth tutorial is available at [Git Docs](https://git-scm.com/book/en/v2/Customizing-Git-Git-Configuration#_code_help_autocorrect_code), but trying the same errant command as above gives you a good idea of what this configuration does:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
On branch master
Your branch is up to date with ‘origin/master’.
nothing to commit, working tree clean
```
Instead of suggesting an alternative subcommand, Git now just runs the top suggestion, which in this case was **git status**.
## 2. Count your commits
There are many reasons you might need to count your commits. Many developers count the number of commits to judge when to increment the build number, for instance, or just to get a feel for how the project is progressing.
To count your commits is really easy and straightforward; here is the Git command:
`$ git rev-list --count`
In the above command, the **branch-name** should be a valid branch name in your current repository.
```
$ git rev-list –count master
32
$ git rev-list –count dev
34
```
## 3. Optimize your repo
Your code repository is valuable not only for you but also for your organization. You can keep your repository clean and up to date with a few simple practices. One of the best practices is to [use the .gitignore file](https://opensource.com/article/20/8/dont-ignore-gitignore). By using this file, you are telling Git not to store many unwanted files like binaries, temporary files, and so on.
To optimize your repository further, you can use Git garbage collection.
`$ git gc --prune=now --aggressive`
This command helps when you or your team heavily uses **pull** or **push** commands.
This command is an internal utility that cleans up unreachable or "orphaned" Git objects in your repository.
## 4. Take a backup of untracked files
Most of the time, it's safe to delete all the untracked files. But many times, there is a situation wherein you want to delete, but also to create a backup of your untracked files just in case you need them later.
Git, along with some Bash command piping, makes it easy to create a zip archive for your untracked files.
```
$ git ls-files --others --exclude-standard -z |\
xargs -0 tar rvf ~/backup-untracked.zip
```
The above command makes an archive (and excludes files listed in .gitignore) with the name backup-untracked.zip
## 5. Know your .git folder
Every repository has a .git folder. It is a special hidden folder.
```
$ ls -a
. … .git
```
Git mainly works with two things:
- The working tree (the state of files in your current checkout)
- The path of your Git repository (specifically, the location of the .git folder, which contains the versioning information)
This folder stores all references and other important details like configurations, repository data, the state of HEAD, logs, and much more.
If you delete this folder, the current state of your source code is not deleted, but your remote information, such as your project history, is. Deleting this folder means your project (at least, the local copy) isn't under version control anymore. It means you cannot track your changes; you cannot pull or push from a remote.
Generally, there's not much you need to do, or should do, in your .git folder. It's managed by Git and is considered mostly off-limits. However, there are some interesting artifacts in this directory, including the current state of HEAD:
```
$ cat .git/HEAD
ref: refs/heads/master
```
It also contains, potentially, a description of your repository:
`$ cat .git/description`
This is an unnamed repository; edit this file 'description' to name the repository.
The Git hooks folder is also here, complete with example hook files. You can read these samples to get an idea of what's possible through Git hooks, and you can also [read this Git hook introduction by Seth Kenlon](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6).
## 6. View a file of another branch
Sometimes you want to view the content of the file from another branch. It's possible with a simple Git command, and without actually switching your branch.
Suppose you have a file called [README.md](http://README.md), and it's in the **main** branch. You're working on a branch called **dev**.
With the following Git command, you can do it from the terminal.
`$ git show main:README.md`
Once you execute this command, you can view the content of the file in your terminal.
## 7. Search in Git
You can search in Git like a pro with one simple command. Better still, you can search in Git even if you aren't sure which commit—or even branch—you made your changes.
`$ git rev-list --all | xargs git grep -F ‘’`
For example, suppose you want to search for the string "font-size: 52 px;" in your repository:
```
$ git rev-list –all | xargs git grep -F ‘font-size: 52 px;’
F3022…9e12:HtmlTemplate/style.css: font-size: 52 px;
E9211…8244:RR.Web/Content/style/style.css: font-size: 52 px;
```
## Try these tips
I hope these advanced tips are useful and boost your productivity, saving you lots of time.
Do you have [Git tips](https://acompiler.com/git-tips/) you love? Share them in the comments.
## Comments are closed. |
12,897 | 如何在 1 分钟内阻止 7000 台机器的僵尸网络 | https://opensource.com/article/20/12/open-source-vs-ddos-attacks | 2020-12-07T22:05:42 | [
"DDoS"
] | https://linux.cn/article-12897-1.html |
>
> 对 CrowdSec 的配置更改,在不到一分钟的时间内阻止了一个 7000 台机器的僵尸网络的攻击。
>
>
>

2020 年,我们的生活和工作方式在短短几天内被彻底颠覆。随着 COVID-19 开始在全球范围内蔓延,我们将工作带回家,与同事、朋友和家人保持在线联系成为关键的必需品。这为黑客造成破坏打开了大门。例如,根据 Neustar 的数据,今年上半年全球的分布式拒绝服务(DDOS) 攻击[增长了 151%](https://www.businesswire.com/news/home/20200916005046/en/DDoS-Attacks-Increase-by-151-in-First-Half-Of-2020)。
[CrowdSec](https://crowdsec.net/) 是一个开源的安全引擎,它可以分析访问者的行为,并提供适应各种攻击的响应。它能解析来自各种来源的日志,并应用启发式方案来识别攻击性行为,并防范大多数攻击类别。并且,它与其它安装的 CrowdSec 系统共享该情报。每次 IP 地址被阻止时,它都会通知整个用户社区。这就创建了一个[实时、协作的 IP 信誉数据库](https://opensource.com/article/20/10/crowdsec),利用人群的力量使互联网更加安全。
### CrowdSec 如何工作:案例研究
Sorf Networks 是一家总部位于土耳其的技术公司,为客户提供高配置的托管服务器和 DDoS 防护解决方案,它提供了一个 CrowdSec 工作的例子。Sorf 的一个客户每天都会遇到来自 1 万多台机器僵尸网络的 DDoS 攻击,并努力寻找一种能够满足技术要求的解决方案来及时处理这些攻击。
虽然客户采取了一般的预防措施来缓解这些攻击,比如引入 JavaScript(JS)<ruby> 挑战 <rt> challenges </rt></ruby>、限速等,但这些措施在整个攻击面并不可行。一些 URL 需要被非常基本的软件使用,而这些软件不支持 JS 挑战。黑客就是黑客,这正是他们每天的目标:链条上最薄弱的环节。
Sorf Networks 首先使用 [Fail2ban](https://www.fail2ban.org)(这启发了 CrowdSec)为其客户建立了一个 DDoS 缓解策略。它在一定程度上帮助了客户,但它太慢了。它需要 50 分钟来处理日志和处理 7000 到 10000 台机器的 DDoS 攻击。这使得它在这种情况下没有效果。另外,因为它没有禁止 IP,日志会持续堆积,它需要每秒处理几千条日志,这是不可能的。
在使用租用的僵尸网络进行的 DDoS 测试中,一次攻击可以高达每秒 6700 个左右的请求,这些请求来自 8600 个独立 IP。这是对一台服务器流量的捕捉:

虽然 CrowdSec 技术可以应对巨大的攻击,但其默认设置每秒只能处理约 1000 个端点。Sorf 需要一个量身定做的配置来处理单台机器上这么多的流量。
Sorf 的团队对 CrowdSec 的配置进行了修改,以显著提高其吞吐量来处理日志。首先,它去掉了高消耗且非关键的<ruby> 富集 <rt> enrichment </rt></ruby>解析器,例如 [GeoIP 富集](https://hub.crowdsec.net/author/crowdsecurity/configurations/geoip-enrich)。它还将允许的 goroutine 的默认数量从一个增加到五个。之后,团队又用 8000 到 9000 台主机做了一次实测,平均每秒 6000 到 7000 个请求。这个方案是有代价的,因为 CrowdSec 在运行过程中吃掉了 600% 的 CPU,但其内存消耗却保持在 270MB 左右。
然而,结果却显示出明显的成功:
* 在一分钟内,CrowdSec 能够处理所有的日志
* 95% 的僵尸网络被禁止,攻击得到有效缓解
* 15 个域现在受到保护,不受 DDoS 攻击
根据 Sorf Networks 的总监 Cagdas Aydogdu 的说法,CrowdSec 的平台使团队“能够在令人难以置信的短时间内提供一个世界级的高效防御系统”。
---
本文改编自[如何用 CrowdSec 在 1 分钟内阻止 7000 台机器的僵尸网络](https://crowdsec.net/2020/10/21/how-to-stop-a-botnet-with-crowdsec/),原载于 CrowdSec 网站。
---
via: <https://opensource.com/article/20/12/open-source-vs-ddos-attacks>
作者:[Philippe Humeau](https://opensource.com/users/philippe-humeau) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2020, our ways of living and working were turned completely upside down in a matter of days. As COVID-19 began to spread across the globe, we brought our companies home, and staying connected to our colleagues, friends, and family online became a critical necessity. This opened the door for hackers to cause disruption; for example, distributed denial of service (DDoS) attacks around the world were [up 151%](https://www.businesswire.com/news/home/20200916005046/en/DDoS-Attacks-Increase-by-151-in-First-Half-Of-2020) in the first half of the year, according to Neustar.
[CrowdSec](https://crowdsec.net/) is an open source security engine that analyzes visitor behavior and provides an adapted response to all kinds of attacks. It parses logs from any source and applies heuristic scenarios to identify aggressive behavior and protect against most attack classes. It then shares that intelligence with other CrowdSec installations; every time an internet protocol (IP) address is blocked, it informs the entire user community. This creates a [real-time, collaborative IP reputation database](https://opensource.com/article/20/10/crowdsec) that leverages the crowd's power to make the internet safer.
## How CrowdSec works: a case study
Sorf Networks, a Turkey-based technology company that provides high-configuration managed servers and DDoS protection solutions for its clients, offers an example of how CrowdSec works. One of Sorf's customers was experiencing daily DDoS attacks from 10,000+ machine botnets and struggled to find a solution that would meet technical requirements to deal with them in a timely manner.
While the customer took general precautions to mitigate those attacks, such as introducing JavaScript (JS) challenges, rate-limiting, and so on, they weren't viable on the entire attack surface. Some URLs needed to be consumed by very basic software that didn't support JS challenges. Hackers being hackers, this was exactly what they targeted every single day: the weakest link in the chain.
Sorf Networks first set up a DDoS mitigation strategy for its customer using [Fail2ban](https://www.fail2ban.org) (which inspired CrowdSec); it helped to some degree, but it was too slow. It required 50 minutes to process logs and deal with 7,000- to 10,000-machine DDoS attacks—which rendered it ineffective in this situation. Also, logs continued to stack because it did not ban IPs, and it needed to process several thousand logs per second, which was not possible.
In DDoS testing using a rented botnet, an attack reached around 6,700 requests per second from 8,600 unique IPs. This is a capture of one server's traffic.
©2020, CrowdSec
Although CrowdSec technology can cope with huge attacks, its default setup can process only around 1,000 endpoints per second. Sorf needed a tailor-made configuration to deal with this much traffic on a single machine.
Sorf's team made changes in CrowdSec's configuration to significantly improve its throughput to absorb the log volume. First, it removed expensive and non-crucial enrichment parsers, such as [GeoIP enrichment](https://hub.crowdsec.net/author/crowdsecurity/configurations/geoip-enrich). It also increased the default number of allowed go-routines from one to five. Afterward, the team did another live test with 8,000 to 9,000 hosts, averaging between 6,000 and 7,000 requests per second. This solution came at a cost, as CrowdSec was eating 600% CPU during the operation, but its memory consumption stayed around 270MB.
The results, however, showed remarkable success:
- In one minute, CrowdSec was able to ingest all the logs
- 95% of the botnet was banned and the attack efficiently mitigated
- 15 domains are now protected from DDoS attacks
According to Sorf Networks' director Cagdas Aydogdu, CrowdSec's platform enabled the team "to deliver a world-class and efficient defense system … in an incredibly short timeframe."
*This article has been adapted from How to stop a 7k machine botnet in 1 minute with CrowdSec, originally published on CrowdSec's website.*
## Comments are closed. |
12,898 | 如何在 Fedora 中添加第三方存储库以访问大量附加软件 | https://itsfoss.com/fedora-third-party-repos/ | 2020-12-08T07:44:00 | [
"存储库",
"Fedora"
] | https://linux.cn/article-12898-1.html | 
在你安装 Fedora 后。你可能会发现你想要安装和使用的一些软件在软件商店中找不到。出于一些原因,这些软件包不能出现在 Fedora 存储库中。
不用担心,我将告诉你如何为 Fedora 添加第三方存储库来使这些软件包可使用。
### 在 Fedora 中的第三方存储库是什么?
操作系统开发人员通常会决定哪些软件包可以在其存储库中使用,哪些软件包不可以在其存储库中使用。Fedora 也是如此。依据 [Fedora 文档](https://docs.fedoraproject.org/en-US/quick-docs/setup_rpmfusion/#third-party-repositories) ,第三方存储库包含有 “拥有更为宽松的许可政策,并提供 Fedora 因各种原因所排除软件包” 的软件包。
Fedora 强制执行下面的 [准则](https://fedoraproject.org/wiki/Forbidden_items) ,当它打包软件包时:
* 如果它是专有的,它就不能包含在 Fedora 中
* 如果它在法律上被限制,它就不能包含在 Fedora 中
* 如果它违反美国法律(特别是联邦政府或适用于州政府的法律),它就不能包含在 Fedora 中
因此,有一些可以由用户自行添加的存储库。这使得用户能够访问附加的软件包。
### 在 Fedora 中启用 RPM Fusion 存储库
[RPM Fusion](https://rpmfusion.org/RPM%20Fusion) 是 Fedora 的第三方应用程序的主要来源。RPM Fusion 是由三个项目(Dribble、Freshrpms 和 Livna)合并而成的。RPM Fusion 提供两种不同的软件存储库。
* free 存储库:包含开源软件。
* nonfree 存储库:包含没有开源协议的软件,但是它们的源文件代码却是可以自由使用的。
这里有两种方法来启动 RPM Fusion:从终端启用,或通过点击几个按钮来启用。我们将逐一查看。
#### 方法 1:命令行方法
这是启用 RPM Fusion 存储库的最简单的方法。只需要输入下面的命令即可启用两个存储库:
```
sudo dnf install https://mirrors.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm https://mirrors.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
```
会要求你输入密码、确认是否你想要安装这些存储库。在你确认后,安装过程将在几秒钟或几分钟内完成。

#### 方法 2:图形用户界面方法
使用这个方法来启用 RPM Fusion 存储库,你需要访问 [RPM Fusion 网站](https://rpmfusion.org/Configuration) 。你将看到针对不同 Fedora 版本的两个存储库的链接。
RPM Fusion 建议先安装 free 存储库。因此,单击针对你 Fedora 版本的 free 存储库的链接。然后会打开一个窗口来询问你是否想安装该存储库。单击安装。

在安装过程完成后,返回并使用相同的步骤安装 nonfree 存储库。
### 启用 Fedora 的第三方存储库
Fedora 最近开始提供它自己的 [第三方应用程序存储库](https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories) 。在这个存储库中 [可使用的应用程序的数量](https://fedoraproject.org/wiki/Workstation/Third_party_software_list) 是非常少的。你可以 [使用它来在 Fedora 上安装 Chrome 浏览器](https://itsfoss.com/install-google-chrome-fedora/) 。除 Chrome 外,它也包含 Adobe Brackets、Atom、Steam、Vivaldi、Opera 等应用程序。
就像 RPM Fusion 一样,你可以通过终端或图形用户界面的方法来启用这个存储库。
#### 方法 1:命令行方法
为启用 Fedora 的第三方存储库,输入下面的命令到你的终端中:
```
sudo dnf install fedora-workstation-repositories
```
当被提示时,确保输入你的密码并输入 `Y` 来确认安装。
#### 方法 2:图形用户界面方法
如果你不习惯使用终端,你可以使用图形用户界面方法。
首先,你需要打开 Gnome “软件”。接下来,你需要单击右上角的汉堡菜单,并从菜单中选择“软件存储库”。

在软件存储库窗口中,你将在其顶部看到写着 “第三方存储库” 字样的部分。单击“安装”按钮。当你被提示时,输入你的密码。

随着这些附加存储库的启用,你可以安装软件到你的系统当中。你可以从软件中心管理器或使用 DNF 软件包管理器来轻松地安装它们。
如果你发现这篇文章很有趣,请花费一些时间来在社交媒体上分享它。
---
via: <https://itsfoss.com/fedora-third-party-repos/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

After you install Fedora, you may discover that some of the [popular Linux softwar](https://itsfoss.com/essential-linux-applications/)e that you want to install are not available in the software store.
This is because Fedora enforces the following [guidelines](https://fedoraproject.org/wiki/Forbidden_items?ref=itsfoss.com) when it comes to packages:
- If it is proprietary, it cannot be included in Fedora
- If it is legally encumbered, it cannot be included in Fedora
- If it violates United States laws (specifically, Federal or applicable state laws), it cannot be included in Fedora
Don’t lose hope. You can make the additional applications available by adding third party repos for Fedora.
## Third party repositories in Fedora
There are two main third-party repositories in Fedora:
- Fedora’s own third party repositories: Fedora provides an easy way of enabling a third-party repository and accessing a few popular software like Chrome, Steam, Nvidia drivers.
- RPM Fusion repositories: This third-party repository gives you access to a huge number of Linux applications that are not provided from Fedora’s own repositories.
Let’s see how to enable these third party repositories in Fedora.
## Part 1: Enabling RPM Fusion Repositories in Fedora
[RPM Fusion](https://rpmfusion.org/RPM%20Fusion?ref=itsfoss.com) is the main source for third party applications for Fedora. RPM Fusion is the result of three projects (Dribble, Freshrpms, and Livna) merging. RPM Fusion offers two different software repos.
- The free repo contains open-source software.
- The nonfree repo contains software that does not have an open-source license, but the source code is freely available.
There are two ways to enable RPM Fusion: from the terminal or by clicking a couple of buttons. We’ll take a look at each.
### Method 1: Command line method
This is the easiest method to enable the RPM Fusion repos.
Just enter the following command to enable the RPM Fusion repository for open source software:
`sudo dnf install https://mirrors.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm `
For non-free (i.e. not open source) software, add this repository.
`sudo dnf install https://mirrors.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm`
You will be asked to enter your password. You will then be asked to verify that you want to install these repos. Once you approve it, the installation will be completed in a few seconds or minutes.
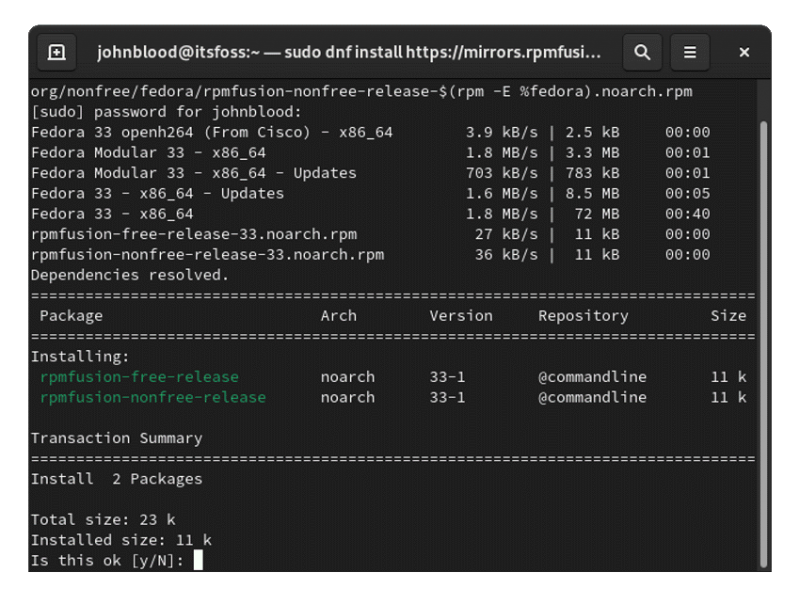
Optionally, you may also use the command below to show the packages from RPM Fusion repository in the GNOME Software Center.
`sudo dnf groupupdate core`
### Method 2: Graphical method
To enable the RPM Fusion repos using this method, you need to visit the [RPM Fusion Website](https://rpmfusion.org/Configuration?ref=itsfoss.com). You will see links for both repos for different Fedora versions.
RPM Fusion recommends installing the free repo first. So, click the link for the free repo for your version of Fedora.
This will download the RPM file for the repo. [Installing RPM file](https://itsfoss.com/install-rpm-files-fedora/) is really easy. Just double-click on it and it will be opened in the Software Center application. Now, just hit the Install button.
Once the installation is completed, go back and install the nonfree repo using the same steps.
**To get the RPM Fusion packages in the software center**, you’ll have to add the appstream metadata using the terminal:
`sudo dnf groupupdate core`
## Part 2: Enable Fedora’s Third Party repositories
Fedora recently started offering its own [repo of third party apps](https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories?ref=itsfoss.com). The [number of applications available](https://fedoraproject.org/wiki/Workstation/Third_party_software_list?ref=itsfoss.com) in this repo is very small. You can [install Chrome browser on Fedora with it](https://itsfoss.com/install-google-chrome-fedora/). Apart from Chrome, it also includes tools like Adobe Brackets, Atom, Steam, Vivaldi, Opera, and more.
Just like RPM Fusion, you can enable this repo via the terminal or graphically.
### Method 1: Command line method
To enable Fedora’s third-party repo, enter the following command into your terminal:
`sudo dnf install fedora-workstation-repositories`
Be sure to ensure your password when prompted and type Y to approve the installation.
### Method 2: Graphical method
If you are not comfortable using the terminal, you can use the graphical method.
First, you need to open Gnome Software. Next, you need to click on the hamburger menu in the top right corner and select “Software Repositories” from the menu.
In the Software Repositories window, you will see a section at the top that says “Third Party Repositories”. Click the Install button. Enter your password when you are prompted and you are done.
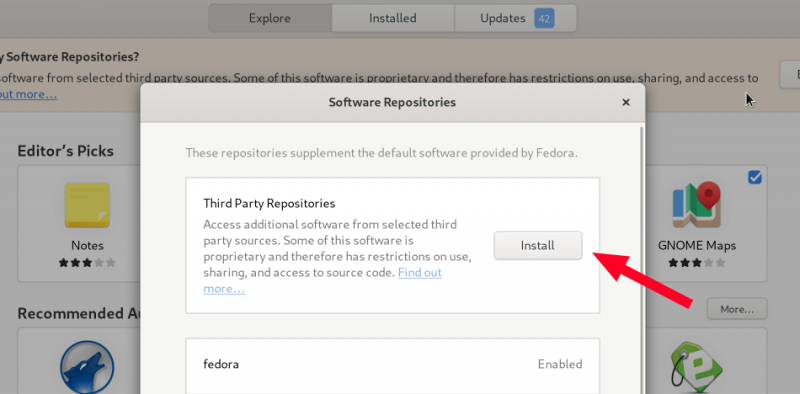
You can see some additional software sources now like Google Chrome, Nvidia etc. To install those applications, you have to enable these ‘sub repositories’.
With these additional repositories enabled, you can install software to your heart’s content. You can easily install them from the software center or use the DNF package manager.
If you found this article interesting, please take a minute to share it on social media, Hacker News, or [Re](https://%0Areddit.com/r/linuxusersgroup)[d](https://%0Areddit.com/r/linuxusersgroup)[dit](https://%0Areddit.com/r/linuxusersgroup). |
12,900 | 如何在 Python Web 框架 Django 中使用序列化器 | https://opensource.com/article/20/11/django-rest-framework-serializers | 2020-12-08T22:09:09 | [
"序列化"
] | https://linux.cn/article-12900-1.html |
>
> 序列化用于将数据转换为方便存储或传输的格式,然后将其重新构建以供使用。DRF 是最具有知名的序列化器。
>
>
>

序列化是将数据转换为可以存储或传输的格式,然后对其进行重新构建的过程。在开发应用程序或将数据存储在数据库、内存或将其转换为文件时,一直会用到它。
我最近帮助 [Labcodes](http://www.labcodes.com.br) 的两名初级开发人员理解序列化器,我想也可以与诸位读者分享一下我的方法。
假设你正在编写一个电子商务网站,你有一个订单,该订单记录了某人在某个日期以某种价格购买了一个产品:
```
class Order:
def __init__(self, product, customer, price, date):
self.product = product
self.customer = customer
self.price = price
self.date = date
```
现在,假设你想从一个键值数据库中存储和检索订单数据。幸运的是,它的接口可以接受和返回字典,因此你需要将对象转换成字典:
```
def serialize_order(order):
return {
'product': order.product,
'customer': order.customer,
'price': order.price,
'date': order.date
}
```
如果你想从数据库中获取一些数据,你可以获取字典数据并将其转换为订单对象(`Order`):
```
def deserialize_order(order_data):
return Order(
product=order_data['product'],
customer=order_data['customer'],
price=order_data['price'],
date=order_data['date'],
)
```
这对于简单的数据非常直接了当,但是当你需要处理一些由复杂属性构成的复杂对象时,这种方法就无法很好地扩展。你还需要处理不同类型字段的验证,这需要手工完成大量工作。
此时框架的序列化可以很方便的派上用场。它们使你可以创建带有少量模板的序列化器,这将适用于复杂的情况。
[Django](https://www.djangoproject.com/) 提供了一个序列化模块,允许你将模型“转换”为其它格式:
```
from django.core import serializers
serializers.serialize('json', Order.objects.all())
```
它涵盖了 Web 应用程序最常用的种类,例如 JSON、YAML 和 XML。但是你也可以使用第三方序列化器或创建自己的序列化器。你只需要在 `settings.py` 文件中注册它:
```
# settings.py
SERIALIZATION_MODULES = {
'my_format': appname.serializers.MyFormatSerializer,
}
```
要创建自己的 `MyFormatSerializer`,你需要实现 `.serialize()` 方法并接受一个查询集和其它选项作为参数:
```
class MyFormatSerializer:
def serialize(self, queryset, **options):
# serious serialization happening
```
现在,你可以将查询集序列化为新格式:
```
from django.core import serializers
serializers.serialize('my_format', Order.objects.all())
```
你可以使用选项参数来定义序列化程序的行为。例如,如果要定义在处理 `ForeignKeys` 时要使用嵌套序列化,或者只希望数据返回其主键,你可以传递一个 `flat=True` 参数作为选项,并在方法中处理:
```
class MyFormatSerializer:
def serializer(self, queryset, **options):
if options.get('flat', False):
# don't recursively serialize relationships
# recursively serialize relationships
```
使用 Django 序列化的一种方法是使用 `loaddata` 和 `dumpdata` 管理命令。
### DRF 序列化器
在 Django 社区中,[Django REST 框架](https://www.django-rest-framework.org/)(DRF)提供了最著名的序列化器。尽管你可以使用 Django 的序列化器来构建将在 API 中响应的 JSON,但 REST 框架中的序列化器提供了更出色的功能,可以帮助你处理并轻松验证复杂的数据。
在订单的例子中,你可以像这样创建一个序列化器:
```
from restframework import serializers
class OrderSerializer(serializers.Serializer):
product = serializers.CharField(max_length=255)
customer = serializers.CharField(max_lenght=255)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
date = serializers.DateField()
```
轻松序列化其数据:
```
order = Order('pen', 'renato', 10.50, date.today())
serializer = OrderSerializer(order)
serializer.data
# {'product': 'pen', 'customer': 'renato', 'price': '10.50', 'date': '2020-08-16'}
```
为了能够从数据返回实例,你需要实现两个方法:`create` 和 `update`:
```
from rest_framework import serializers
class OrderSerializer(serializers.Serializer):
product = serializers.CharField(max_length=255)
customer = serializers.CharField(max_length=255)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
date = serializers.DateField()
def create(self, validated_data):
# 执行订单创建
return order
def update(self, instance, validated_data):
# 执行实例更新
return instance
```
之后,你可以通过调用 `is_valid()` 来验证数据,并通过调用 `save()` 来创建或更新实例:
```
serializer = OrderSerializer(**data)
## 若要验证数据,在调用 save 之前必须执行
serializer.is_valid()
serializer.save()
```
### 模型序列化器
序列化数据时,通常需要从数据库(即你创建的模型)进行数据处理。`ModelSerializer` 与 `ModelForm` 一样,提供了一个 API,用于从模型创建序列化器。假设你有一个订单模型:
```
from django.db import models
class Order(models.Model):
product = models.CharField(max_length=255)
customer = models.CharField(max_length=255)
price = models.DecimalField(max_digits=5, decimal_places=2)
date = models.DateField()
```
你可以像这样为它创建一个序列化器:
```
from rest_framework import serializers
class OrderSerializer(serializers.ModelSerializer):
class Meta:
model = Order
fields = '__all__'
```
Django 会自动在序列化器中包含所有模型字段,并创建 `create` 和 `udpate` 方法。
### 在基于类的视图(CBV)中使用序列化器
像 Django CBV 中的 `Forms` 一样,序列化器可以很好地与 DRF 集成。你可以设置 `serializer_class` 属性,方便序列化器用于视图:
```
from rest_framework import generics
class OrderListCreateAPIView(generics.ListCreateAPIView):
queryset = Order.objects.all()
serializer_class = OrderSerializer
```
你也可以定义 `get_serializer_class()` 方法:
```
from rest_framework import generics
class OrderListCreateAPIView(generics.ListCreateAPIView):
queryset = Order.objects.all()
def get_serializer_class(self):
if is_free_order():
return FreeOrderSerializer
return OrderSerializer
```
在 CBV 中还有其它与序列化器交互的方法。例如,[get\_serializer()](http://www.cdrf.co/3.9/rest_framework.generics/CreateAPIView.html#get_serializer) 返回一个已经实例化的序列化器,[get\_serializer\_context()](http://www.cdrf.co/3.9/rest_framework.generics/CreateAPIView.html#get_serializer_context) 返回创建实例时传递给序列化器的参数。对于创建或更新数据的视图,有 `create` 和 `update`,它们使用 `is_valid` 方法验证数据,还有 [perform\_create](http://www.cdrf.co/3.9/rest_framework.generics/CreateAPIView.html#perform_create) 和 [perform\_update](http://www.cdrf.co/3.9/rest_framework.generics/RetrieveUpdateAPIView.html#perform_update) 调用序列化器的 `save` 方法。
### 了解更多
要了解更多资源,参考我朋友 André Ericson 的[经典 Django REST 框架](http://www.cdrf.co/)网站。它是一个[基于类的经典视图](https://ccbv.co.uk/)的 REST 框架版本,可让你深入查看组成 DRF 的类。当然,官方[文档](https://www.django-rest-framework.org/api-guide/serializers/#serializers)也是一个很棒的资源。
---
via: <https://opensource.com/article/20/11/django-rest-framework-serializers>
作者:[Renato Oliveira](https://opensource.com/users/renato-oliveira) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Serialization is the process of transforming data into a format that can be stored or transmitted and then reconstructing it. It's used all the time when developing applications or storing data in databases, in memory, or converting it into files.
I recently helped two junior developers at [Labcodes](http://www.labcodes.com.br) understand serializers, and I thought it would be good to share my approach with Opensource.com readers.
Suppose you're creating software for an e-commerce site and you have an Order that registers the purchase of a single product, by someone, at a price, on a date:
```
class Order:
def __init__(self, product, customer, price, date):
self.product = product
self.customer = customer
self.price = price
self.date = date
```
Now, imagine you want to store and retrieve order data from a key-value database. Luckily, its interface accepts and return dictionaries, so you need to convert your object into a dictionary:
```
def serialize_order(order):
return {
'product': order.product,
'customer': order.customer,
'price': order.price,
'date': order.date
}
```
And if you want to get some data from that database, you can get the dict data and turn that into your Order object:
```
def deserialize_order(order_data):
return Order(
product=order_data['product'],
customer=order_data['customer'],
price=order_data['price'],
date=order_data['date'],
)
```
This is pretty straightforward to do with simple data, but when you need to deal with complex objects made of complex attributes, this approach doesn't scale well. You also need to handle the validation of different types of fields, and that's a lot of work to do manually.
That's where frameworks' serializers are handy. They allow you to create serializers with little boilerplates that will work for your complex cases.
[Django](https://www.djangoproject.com/) comes with a serialization module that allows you to "translate" Models into other formats:
```
from django.core import serializers
serializers.serialize('json', Order.objects.all())
```
It covers the most-used cases for web applications, such as JSON, YAML, and XML. But you can also use third-party serializers or create your own. You just need to register it in your settings.py file:
```
# settings.py
SERIALIZATION_MODULES = {
'my_format': appname.serializers.MyFormatSerializer,
}
```
To create your own `MyFormatSerializer`
, you need to implement the `.serialize()`
method and accept a queryset and extra options as params:
```
class MyFormatSerializer:
def serialize(self, queryset, **options):
# serious serialization happening
```
Now you can serialize your queryset to your new format:
```
from django.core import serializers
serializers.serialize('my_format', Order.objects.all())
```
You can use the options parameters to define the behavior of your serializer. For example, if you want to define that you're going to work with nested serialization when dealing with `ForeignKeys`
or you just want that data to return its primary keys, you can pass a `flat=True`
param as an option and deal with that within your method:
```
class MyFormatSerializer:
def serializer(self, queryset, **options):
if options.get('flat', False):
# don't recursively serialize relationships
# recursively serialize relationships
```
One way to use Django serialization is with the `loaddata`
and `dumpdata`
management commands.
## DRF serializers
In the Django community, the [Django REST framework](https://www.django-rest-framework.org/) (DRF) offers the best-known serializers. Although you can use Django's serializers to build the JSON you'll respond to in your API, the one from the REST framework comes with nice features that help you deal with and easily validate complex data.
In the Order example, you could create a serializer like this:
```
from restframework import serializers
class OrderSerializer(serializers.Serializer):
product = serializers.CharField(max_length=255)
customer = serializers.CharField(max_lenght=255)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
date = serializers.DateField()
```
And easily serialize its data:
```
order = Order('pen', 'renato', 10.50, date.today())
serializer = OrderSerializer(order)
serializer.data
# {'product': 'pen', 'customer': 'renato', 'price': '10.50', 'date': '2020-08-16'}
```
To be able to return an instance from data, you need to implement two methods—create and update:
```
from rest_framework import serializers
class OrderSerializer(serializers.Serializer):
product = serializers.CharField(max_length=255)
customer = serializers.CharField(max_length=255)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
date = serializers.DateField()
def create(self, validated_data):
# perform order creation
return order
def update(self, instance, validated_data):
# perform instance update
return instance
```
After that, you can create or update instances by calling `is_valid()`
to validate the data and `save()`
to create or update an instance:
```
serializer = OrderSerializer(**data)
## to validate data, mandatory before calling save
serializer.is_valid()
serializer.save()
```
## Model serializers
When serializing data, you often need to do it from a database, therefore, from your models. A ModelSerializer, like a ModelForm, provides an API to create serializers from your models. Suppose you have an Order model:
```
from django.db import models
class Order(models.Model):
product = models.CharField(max_length=255)
customer = models.CharField(max_length=255)
price = models.DecimalField(max_digits=5, decimal_places=2)
date = models.DateField()
```
You can create a serializer for it like this:
```
from rest_framework import serializers
class OrderSerializer(serializers.ModelSerializer):
class Meta:
model = Order
fields = '__all__'
```
Django automatically includes all model fields in the serializer and creates the `create`
and `update`
methods.
## Using serializers in class-based views (CBVs)
Like Forms with Django's CBVs, serializers integrate well with DRFs. You can set the `serializer_class`
attribute so that the serializer will be available to the view:
```
from rest_framework import generics
class OrderListCreateAPIView(generics.ListCreateAPIView):
queryset = Order.objects.all()
serializer_class = OrderSerializer
```
You can also define the `get_serializer_class()`
method:
```
from rest_framework import generics
class OrderListCreateAPIView(generics.ListCreateAPIView):
queryset = Order.objects.all()
def get_serializer_class(self):
if is_free_order():
return FreeOrderSerializer
return OrderSerializer
```
There are other methods in CBVs that interact with serializers. For example, [get_serializer()](http://www.cdrf.co/3.9/rest_framework.generics/CreateAPIView.html#get_serializer) returns an already-instantiated serializer, while [get_serializer_context()](http://www.cdrf.co/3.9/rest_framework.generics/CreateAPIView.html#get_serializer_context) returns the arguments you'll pass to the serializer when creating its instance. For views that create or update data, there are `create`
and `update`
that validate the data with the `is_valid`
method to be saved, and [perform_create](http://www.cdrf.co/3.9/rest_framework.generics/CreateAPIView.html#perform_create) and [perform_update](http://www.cdrf.co/3.9/rest_framework.generics/RetrieveUpdateAPIView.html#perform_update) that call the serializer's save method.
## Learn more
For other resources, see my friend André Ericson's [Classy Django REST Framework](http://www.cdrf.co/) website. It is a [Classy Class-Based Views](https://ccbv.co.uk/) REST Framework version that gives you an in-depth inspection of the classes that compose DRF. Of course, the official [documentation](https://www.django-rest-framework.org/api-guide/serializers/#serializers) is an awesome resource.
## Comments are closed. |
12,901 | 尝试将 Jed 作为你的 Linux 终端文本编辑器 | https://opensource.com/article/20/12/jed | 2020-12-09T08:55:49 | [
"编辑器",
"Jed"
] | https://linux.cn/article-12901-1.html |
>
> Jed 方便的下拉菜单,让新用户可以轻松地使用终端文本编辑器。
>
>
>

你可能听说过 Emacs、Vim 和 Nano 这些典型的 Linux 文本编辑器,但 Linux 有大量的开源文本编辑器,我的目标是在 12 月份对其中的 31 个文本编辑器进行一次公平的测试。
在这篇文章中,我将介绍 [Jed](https://www.jedsoft.org/jed),它是一个基于终端的编辑器,它的特点是有一个方便的下拉菜单,这让那些刚刚接触终端编辑器的用户,以及那些不喜欢记住每个功能的组合键的用户而言变得特别容易。
### 安装 Jed
在 Linux 上,你的发行版软件仓库可能会让 Jed 通过你的软件包管理器安装:
```
$ sudo dnf install jed
```
并不是所有发行版都是如此,但它是一个很容易从源码编译的应用。首先,下载 [S 语言](https://www.jedsoft.org/releases/slang/)(Jed 的编写语言)并安装(其中 `x.y.z` 请替换为对应的版本号):
```
$ wget https://www.jedsoft.org/releases/slang/slang-x.y.z.tar.bz2
$ tar xvf slang*bz2
$ cd slang-x.y.z
$ ./configure ; make
$ sudo make install
```
安装好后,对 [Jed 源码](https://www.jedsoft.org/releases/jed)也同样操作(其中 `x.y.z` 请替换为对应的版本号):
```
$ wget https://www.jedsoft.org/releases/jed/jed-x.y.z.tar.bz2
$ tar xvf jed*bz2
$ cd jed-x.y.z
$ ./configure ; make
$ sudo make install
```
### 启动 Jed
Jed 在终端中运行,所以要启动它,只需打开终端,输入 `jed`:
```
F10 key ==> File Edit Search Buffers Windows System Help
This is a scratch buffer. It is NOT saved when you exit.
To access the menus, press F10 or ESC-m and the use the arrow
keys to navigate.
Latest version information is available on the web from
<http://www.jedsoft.org/jed/>. Other sources of JED
information include the usenet newsgroups comp.editors and
alt.lang.s-lang. To subscribe to the jed-users mailing list, see
<http://www.jedsoft.org/jed/mailinglists.html>.
Copyright (C) 1994, 2000-2009 John E. Davis
Email comments or suggestions to <[email protected]>.
[ (Jed 0.99.19U) Emacs: *scratch* () 1/16 8:49am ]
```
### 如何使用 Jed
Jed 自动加载的说明很清晰且很有帮助。你可以按 `F10` 键或 `Esc` 键,然后按字母 `M` 进入顶部菜单。这将使你的光标进入 Jed 顶部的菜单栏,但它不会打开菜单。要打开菜单,请按键盘上的回车键。使用方向键来浏览每个菜单。
屏幕上的菜单不仅对初次使用的用户很有帮助,对有经验的用户来说,它还提供了很好的键盘快捷键提醒。例如,你大概能猜到如何保存正在处理的文件。进入 **File** 菜单,选择 **Save**。如果你想加快这个过程,你可以记住 `Ctrl+X`,然后 `Ctrl+S` 的组合键(是的,这是连续的两个组合键)。
### 探索 Jed 的功能
对于一个简单的编辑器来说,Jed 拥有一系列令人惊讶的实用功能。它有一个内置的多路复用器,允许你同时打开多个文件,但它会“叠”在另一个文件之上,所以你可以在它们之间切换。你可以分割你的 Jed 窗口,让多个文件同时出现在屏幕上,改变你的颜色主题,或者打开一个 shell。
对于任何有 Emacs 使用经验的人来说,Jed 的许多“没有宣传”的功能,例如用于导航和控制的组合键,都是一目了然的。然而,当一个组合键与你所期望的大相径庭时,就会有一个轻微的学习(或者说没有学习)曲线。例如,GNU Emacs 中的 `Alt+B` 可以将光标向后移动一个字,但在 Jed 中,默认情况下,它是 **Buffers** 菜单的快捷键。这让我措手不及,大约本文每句话都遇到一次。

Jed 也有**模式**,允许你加载模块或插件来帮助你编写特定种类的文本。例如,我使用默认的 text 模式写了这篇文章,但当我在编写 [Lua](https://opensource.com/article/20/2/lua-cheat-sheet) 时,我能够切换到 lua 模式。这些模式提供语法高亮,并帮助匹配括号和其他分隔符。你可以在 `/usr/share/jed/lib` 中查看 Jed 捆绑了哪些模式,而且因为它们是用 S 语言编写的,你可以浏览代码,并可能学习一种新的语言。
### 尝试 Jed
Jed 是一个令人愉快且清新的 Linux 终端文本编辑器。它轻量级,易于使用,设计相对简单。作为 Vi 的替代方案,你可以在你的 `~/.bashrc` 文件中(如果你是 root 用户,在 root 用户的 `~/.bashrc` 文件中)将 Jed 设置为 `EDITOR` 和 `VISUAL` 变量。今天就试试 Jed 吧。
---
via: <https://opensource.com/article/20/12/jed>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You may have heard about Emacs and Vim and Nano, the quintessential Linux text editors, but Linux has an abundance of open source text editors, and it's my goal to spend December giving 31 of them a fair go.
In this article, I look at [Jed](https://www.jedsoft.org/jed), a terminal-based editor featuring a handy drop-down menu, which makes it especially easy for users who are new to terminal editors, as well as those who just don't like remembering keyboard combinations for every function.
## Install Jed
On Linux, your distribution's software repository may make Jed available to install through your package manager:
`$ sudo dnf install jed`
Not all do, but it's an easy application to compile from source code. First, download [S-Lang](https://www.jedsoft.org/releases/slang/) (the language Jed is written in) and install it:
```
$ wget https://www.jedsoft.org/releases/slang/slang-x.y.z.tar.bz2
$ tar xvf slang*bz2
$ cd slang-x.y.z
$ ./configure ; make
$ sudo make install
```
Once that's installed, do the same with the [Jed source code](https://www.jedsoft.org/releases/jed):
```
$ wget https://www.jedsoft.org/releases/jed/jed-x.y.z.tar.bz2
$ tar xvf jed*bz2
$ cd jed-x.y.z
$ ./configure ; make
$ sudo make install
```
## Launch Jed
Jed runs in a terminal, so to start it, just open a terminal and type `jed`
:
```
F10 key ==> File Edit Search Buffers Windows System Help
This is a scratch buffer. It is NOT saved when you exit.
To access the menus, press F10 or ESC-m and the use the arrow
keys to navigate.
Latest version information is available on the web from
<http://www.jedsoft.org/jed/>. Other sources of JED
information include the usenet newsgroups comp.editors and
alt.lang.s-lang. To subscribe to the jed-users mailing list, see
<http://www.jedsoft.org/jed/mailinglists.html>.
Copyright (C) 1994, 2000-2009 John E. Davis
Email comments or suggestions to <[email protected]>.
[ (Jed 0.99.19U) Emacs: *scratch* () 1/16 8:49am ]
```
## How to use Jed
The instructions that Jed auto-loads are clear and helpful. You can press either the **F10** key or the **Esc** key followed by the letter **M** to enter the top menu. This places your cursor into the menu bar at the top of the Jed screen, but it doesn't open a menu. To open a menu, press **Enter** or **Return** on your keyboard. Use the arrow keys to navigate through each menu.
The onscreen menu is not only helpful for first-time users, it also provides great reminders of keyboard shortcuts for experienced users. For instance, you can probably guess how to save a file you've been working on: Go to the **File** menu and select **Save**. If you want to speed that process up, you can learn the keyboard combination of **Ctrl**+**X** and then **Ctrl**+**S** (yes, that's two keyboard shortcuts in succession).
## Explore Jed's features
For a simple editor, Jed has a surprising list of useful features. It's got a built-in multiplexer, allowing you to have multiple files open at once but "stacked" on top of one another, so you can shuffle through them. You can split your Jed window to have multiple files onscreen at once, change your color theme, or open a shell.
For anyone experienced with Emacs, many of Jed's "unadvertised" features, such as keyboard combinations for navigation and control, are instantly familiar. Then again, there's a slight learning (or maybe unlearning) curve when a keyboard combination is drastically different from what you expect. For example, **Alt**+**B** in GNU Emacs moves the cursor back a word, but in Jed, by default, it's a shortcut for the **Buffers** menu. This caught me off-guard about once each sentence of this article.
Jed also has **modes** that allow you to load modules or plugins to help you write specific kinds of text. For instance, I wrote this article using the default `text_mode`
, but I was able to switch over to `lua`
mode when hacking on a [Lua](https://opensource.com/article/20/2/lua-cheat-sheet) script. These modes offer syntax highlighting and help with matching parentheses and other delimiting characters. You can see which modes are bundled with Jed by looking in `/usr/share/jed/lib`
and because they're written in S-Lang, you can review the code and possibly learn a new language.
## Try Jed
Jed is a pleasant and refreshingly clear text editor for your Linux terminal. It's lightweight, easy to use, and relatively uncomplicated in design. As an alternative to Vi for quick edits, you can set Jed as `EDITOR`
and `VISUAL`
in your `~/.bashrc`
file (and in your root user's `~/.bashrc`
file if you're root). Try Jed today.
## 4 Comments |
12,904 | 8 个让我更有效率的 Git 别名 | https://opensource.com/article/20/11/git-aliases | 2020-12-09T20:23:10 | [
"Git"
] | https://linux.cn/article-12904-1.html |
>
> 使用别名为你最常用或复杂的 Git 命令创建快捷方式。
>
>
>

这篇出色的文章《[改变我使用 Git 工作方式的七个技巧](/article-12894-1.html)》启发了我写下另一个对我在命令行上使用 Git 的经验有重大影响的 Git 特性:别名。
定义 Git 的别名来替代命令有两大好处。
* 它简化了有许多选项的长命令,使它们更短,更容易记住。
* 缩短了经常使用的命令,使你的工作更有效率。
### 如何定义和使用别名
要定义 Git 的别名,请使用 `git config` 命令,加上别名和要替换的命令。例如,要为 `git push` 创建别名 `p`:
```
$ git config --global alias.p 'push'
```
你可以通过将别名作为 `git` 的参数来使用别名,就像其他命令一样:
```
$ git p
```
要查看所有的别名,用 `git config` 列出你的配置:
```
$ git config --global -l
user.name=ricardo
[email protected]
alias.p=push
```
你也可以用你喜欢的 shell 来定义别名,比如 Bash 或 Zsh。不过,用 Git 定义别名有几个功能是用 shell 无法实现的。首先,它允许你在不同的 shell 中使用别名,而无需额外配置。此外,它还集成了 Git 的自动更正功能,所以当你输入错误的命令时,Git 可以建议你正确的别名。最后,Git 还会将别名保存在用户配置文件中,你可以通过复制一个文件将别名转移到其他机器上。
无论使用哪种方法,定义别名都能改善你使用 Git 的整体体验。更多关于定义 Git 别名的信息,请看《[Git Book](https://git-scm.com/book/en/v2/Git-Basics-Git-Aliases)》。
### 8 个有用的 Git 别名
现在你知道如何创建和使用别名了,来看看一些有用的别名。
#### 1、Git 状态
Git 命令行用户经常使用 `status` 命令来查看已更改或未跟踪的文件。默认情况下,这个命令提供了很多行的冗长输出,你可能不想要或不需要。你可以使用一个别名来处理这两个组件。定义别名 `st` 来缩短命令,并使用选项 `-sb` 来输出一个不那么啰嗦的状态和分支信息。
```
$ git config --global alias.st 'status -sb'
```
如果你在一个干净的分支上使用这个别名,你的输出就像这样:
```
$ git st
## master
```
在一个带有已更改和未跟踪文件的分支上使用它,会产生这样的输出:
```
$ git st
## master
M test2
?? test3
```
#### 2、Git 单行日志
创建一个别名,以单行方式显示你的提交,使输出更紧凑:
```
$ git config --global alias.ll 'log --oneline'
```
使用这个别名可以提供所有提交的简短列表:
```
$ git ll
33559c5 (HEAD -> master) Another commit
17646c1 test1
```
#### 3、Git 的最近一次提交
这将显示你最近一次提交的详细信息。这是扩展了《Git Book》中 [别名](https://git-scm.com/book/en/v2/Git-Basics-Git-Aliases) 一章的例子:
```
$ git config --global alias.last 'log -1 HEAD --stat'
```
用它来查看最后的提交:
```
$ git last
commit f3dddcbaabb928f84f45131ea5be88dcf0692783 (HEAD -> branch1)
Author: ricardo <[email protected]>
Date: Tue Nov 3 00:19:52 2020 +0000
Commit to branch1
test2 | 1 +
test3 | 0
2 files changed, 1 insertion(+)
```
#### 4、Git 提交
当你对 Git 仓库进行修改时,你会经常使用 `git commit`。使用 `cm` 别名使 `git commit -m` 命令更有效率:
```
$ git config --global alias.cm 'commit -m'
```
因为 Git 别名扩展了命令,所以你可以在执行过程中提供额外的参数:
```
$ git cm "A nice commit message"
[branch1 0baa729] A nice commit message
1 file changed, 2 insertions(+)
```
#### 5、Git 远程仓库
`git remote -v` 命令列出了所有配置的远程仓库。用别名 `rv` 将其缩短:
```
$ git config --global alias.rv 'remote -v'
```
#### 6、Git 差异
`git diff` 命令可以显示不同提交的文件之间的差异,或者提交和工作树之间的差异。用 `d` 别名来简化它:
```
$ git config --global alias.d 'diff'
```
标准的 `git diff` 命令对小的改动很好用,但对于比较复杂的改动,外部工具如 `vimdiff` 就更有用。创建别名 `dv` 来使用 `vimdiff` 显示差异,并使用 `y` 参数跳过确认提示:
```
$ git config --global alias.dv 'difftool -t vimdiff -y'
```
使用这个别名来显示两个提交之间的 `file1` 差异:
```
$ git dv 33559c5 ca1494d file1
```

#### 7、Git 配置列表
`gl` 别名可以更方便地列出所有用户配置:
```
$ git config --global alias.gl 'config --global -l'
```
现在你可以看到所有定义的别名(和其他配置选项):
```
$ git gl
user.name=ricardo
[email protected]
alias.p=push
alias.st=status -sb
alias.ll=log --oneline
alias.last=log -1 HEAD --stat
alias.cm=commit -m
alias.rv=remote -v
alias.d=diff
alias.dv=difftool -t vimdiff -y
alias.gl=config --global -l
alias.se=!git rev-list --all | xargs git grep -F
```
#### 8、搜索提交
Git 别名允许你定义更复杂的别名,比如执行外部 shell 命令,可以在别名前加上 `!` 字符。你可以用它来执行自定义脚本或更复杂的命令,包括 shell 管道。
例如,定义 `se` 别名来搜索你的提交:
```
$ git config --global alias.se '!git rev-list --all | xargs git grep -F'
```
使用这个别名来搜索提交中的特定字符串:
```
$ git se test2
0baa729c1d683201d0500b0e2f9c408df8f9a366:file1:test2
ca1494dd06633f08519ec43b57e25c30b1c78b32:file1:test2
```
### 自动更正你的别名
使用 Git 别名的一个很酷的好处是它与自动更正功能的原生集成。如果你犯了错误,默认情况下,Git 会建议使用与你输入的命令相似的命令,包括别名。例如,如果你把 `status` 打成了 `ts`,而不是 `st`,Git 会推荐正确的别名:
```
$ git ts
git: 'ts' is not a git command. See 'git --help'.
The most similar command is
st
```
如果你启用了自动更正功能,Git 会自动执行正确的命令:
```
$ git config --global help.autocorrect 20
$ git ts
WARNING: You called a Git command named 'ts', which does not exist.
Continuing in 2.0 seconds, assuming that you meant 'st'.
## branch1
?? test4
```
### 优化 Git 命令
Git 别名是一个很有用的功能,它可以优化常见的重复性命令的执行,从而提高你的效率。Git 允许你定义任意数量的别名,有些用户会定义很多别名。我更喜欢只为最常用的命令定义别名 —— 定义太多别名会让人难以记忆,而且可能需要查找才能使用。
更多关于别名的内容,包括其他有用的内容,请参见 [Git 维基的别名页面](https://git.wiki.kernel.org/index.php/Aliases)。
---
via: <https://opensource.com/article/20/11/git-aliases>
作者:[Ricardo Gerardi](https://opensource.com/users/rgerardi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The excellent article * 7 Git tricks that changed my life* inspired me to write about another Git feature that's had a major impact on my experience using Git on the command line: aliases.
Defining Git aliases to serve as substitutes for commands provides two major benefits:
- It simplifies long commands that have many options, making them shorter and easier to remember.
- It shortens frequently used commands so that you can work more efficiently.
## How to define and use aliases
To define a Git alias, use the `git config`
command with the alias and the command you want to substitute. For example, to create the alias `p`
for `git push`
:
```
$ git config --global alias.p 'push'
```
You can use an alias by providing it as an argument to `git`
, just like any other command:
```
$ git p
```
To see all your aliases, list your configuration with `git config`
:
```
$ git config --global -l
user.name=ricardo
[email protected]
alias.p=push
```
You can also define aliases with your favorite shell, such as Bash or Zsh. However, defining aliases using Git offers several features that you don't get using the shell. First, it allows you to use aliases across different shells with no additional configuration. It also integrates with Git's autocorrect feature, so Git can suggest aliases as alternatives when you mistype a command. Finally, Git saves your aliases in the user configuration file, allowing you to transfer them to other machines by copying a single file.
Regardless of the method you use, defining aliases improves your overall experience with Git. For more information about defining Git aliases, take a look at the [Git Book](https://git-scm.com/book/en/v2/Git-Basics-Git-Aliases).
## 8 useful Git aliases
Now that you know how to create and use an alias, take a look at some useful ones.
### 1. Git status
Git command line users often use the `status`
command to see changed or untracked files. By default, this command provides verbose output with many lines, which you may not want or need. You can use a single alias to address both of these components: Define the alias `st`
to shorten the command with the option `-sb`
to output a less verbose status with branch information:
```
$ git config --global alias.st 'status -sb'
```
If you use this alias on a clean branch, your output looks like this:
```
$ git st
## master
```
Using it on a branch with changed and untracked files produces this output:
```
$ git st
## master
M test2
?? test3
```
### 2. Git log --oneline
Create an alias to display your commits as single lines for more compact output:
```
$ git config --global alias.ll 'log --oneline'
```
Using this alias provides a short list of all commits:
```
$ git ll
33559c5 (HEAD -> master) Another commit
17646c1 test1
```
### 3. Git last commit
This shows details about the most recent commit you made. This extends an example in the Git Book's chapter on [Aliases](https://git-scm.com/book/en/v2/Git-Basics-Git-Aliases):
```
$ git config --global alias.last 'log -1 HEAD --stat'
```
Use it to see the last commit:
```
$ git last
commit f3dddcbaabb928f84f45131ea5be88dcf0692783 (HEAD -> branch1)
Author: ricardo <[email protected]>
Date: Tue Nov 3 00:19:52 2020 +0000
Commit to branch1
test2 | 1 +
test3 | 0
2 files changed, 1 insertion(+)
```
### 4. Git commit
You use `git commit`
a lot when you're making changes to a Git repository. Make the `git commit -m`
command more efficient with the `cm`
alias:
```
$ git config --global alias.cm 'commit -m'
```
Because Git aliases expand commands, you can provide additional parameters during their execution:
```
$ git cm "A nice commit message"
[branch1 0baa729] A nice commit message
1 file changed, 2 insertions(+)
```
### 5. Git remote
The `git remote -v`
command lists all configured remote repositories. Shorten it with the alias `rv`
:
```
$ git config --global alias.rv 'remote -v'
```
### 6. Git diff
The `git diff`
command displays differences between files in different commits or between a commit and the working tree. Simplify it with the `d`
alias:
```
$ git config --global alias.d 'diff'
```
The standard `git diff`
command works fine for small changes. But for more complex ones, an external tool such as `vimdiff`
makes it more useful. Create the alias `dv`
to display diffs using `vimdiff`
and use the `-y`
parameter to skip the confirmation prompt:
```
$ git config --global alias.dv 'difftool -t vimdiff -y'
```
Use this alias to display `file1`
differences between two commits:
```
$ git dv 33559c5 ca1494d file1
```
(Ricardo Gerardi, CC BY-SA 4.0)
### 7. Git config list
The `gl`
alias makes it easier to list all user configurations:
```
$ git config --global alias.gl 'config --global -l'
```
Now you can see all defined aliases (and other configuration options):
```
$ git gl
user.name=ricardo
[email protected]
alias.p=push
alias.st=status -sb
alias.ll=log --oneline
alias.last=log -1 HEAD --stat
alias.cm=commit -m
alias.rv=remote -v
alias.d=diff
alias.dv=difftool -t vimdiff -y
alias.gl=config --global -l
alias.se=!git rev-list --all | xargs git grep -F
```
### 8. Git search commit
Git alias allows you to define more complex aliases, such as executing external shell commands, by prefixing them with the `!`
character. You can use this to execute custom scripts or more complex commands, including shell pipes.
For example, define the `se`
alias to search within your commits:
```
$ git config --global alias.se '!git rev-list --all | xargs git grep -F'
```
Use this alias to search for specific strings in your commits:
```
$ git se test2
0baa729c1d683201d0500b0e2f9c408df8f9a366:file1:test2
ca1494dd06633f08519ec43b57e25c30b1c78b32:file1:test2
```
## Autocorrect your aliases
A cool benefit of using Git aliases is its native integration with the autocorrect feature. If you make a mistake, by default Git suggests commands that are similar to what you typed, including aliases. For example, if you type `ts`
instead of `st`
for `status`
, Git will suggest the correct alias:
```
$ git ts
git: 'ts' is not a git command. See 'git --help'.
The most similar command is
st
```
If you have autocorrect enabled, Git will automatically execute the correct command:
```
$ git config --global help.autocorrect 20
$ git ts
WARNING: You called a Git command named 'ts', which does not exist.
Continuing in 2.0 seconds, assuming that you meant 'st'.
## branch1
?? test4
```
## Optimize Git commands
Git alias is a useful feature that improves your efficiency by optimizing the execution of common and repetitive commands. Git allows you to define as many aliases as you want, and some users define many. I prefer to define aliases for just my most used commands—defining too many makes it harder to memorize them and may require me to look them up to use them.
For more about aliases, including other useful ones, see the [Git Wiki's Aliases page](https://git.wiki.kernel.org/index.php/Aliases).
## Comments are closed. |
12,905 | Zotero:一款帮助你收集和分享研究成果的开源应用 | https://itsfoss.com/zotero/ | 2020-12-09T21:32:00 | [
"Zotero"
] | https://linux.cn/article-12905-1.html |
>
> Zotero 是一款令人印象深刻的自由开源的应用,它让你可以收集、组织、引用和共享研究成果。你还可以使用 Zotero 为你的文档即时创建参考文献和书目。
>
>
>

通常,你可以[使用 Linux 上任何一款笔记应用](https://itsfoss.com/note-taking-apps-linux/)来收集和分享你的想法。但是,在这里,我想分享一些专门为你量身定做的东西,来帮助你收集、整理和分享你的研究成果,即 [Zotero](https://www.zotero.org/)。
### Zotero:收集、整理和分享研究成果

Zotero 是一个完全开源的项目,你可以在 [GitHub](https://github.com/zotero/zotero) 上找到它。它的目的是帮助你轻松地收集、整理、添加笔记和分享你的研究成果。
而且,这一切都不需要基于云端的服务,它是完全离线的。所以,你的研究成果是属于你的。当然,除非你出于协作目的想将其同步,为此你可能需要参考[该文档](https://www.zotero.org/support/)。
作为一个好的起点,你可以选择 [WebDAV 存储](https://en.wikipedia.org/wiki/WebDAV),或者直接创建一个 Zotero 帐户来轻松同步和分享你的研究成果。
例如,我创建了一个名为 `ankush9` 的 Zotero 账户,你可以在 <https://www.zotero.org/ankush9> 找到我的研究合集(我添加到我的出版物中)。

这使得它很容易分享你组织的研究成果,你可以选择将哪些部分共享到出版物中。
让我着重介绍一下 Zotero 的主要功能,来帮助你决定是否需要尝试一下。
### Zotero 的功能

* 能够使用浏览器插件从网页直接添加信息
* 为每份资料添加说明
* 支持添加标签
* 支持添加语音记录
* 添加视频作为附件
* 添加软件作为附件
* 将电子邮件作为附件
* 将播客作为附件
* 添加博客文章
* 添加一个文件链接
* 根据项目建立书目
* 离线快照存储(无需连接互联网即可访问保存的网页)
* 可以复制项目
* 整理库中的项目
* 提供了一个垃圾箱,可以删除你的项目,并在需要时轻松恢复。
* 支持同步
* 支持数据导出
* 可整合 LibreOffice 插件
* 使用你的 Zotero 个人资料链接轻松分享你的研究笔记。
* 跨平台支持
如果你只是想快速创建书目,你可以尝试他们的另一个工具,[ZoteroBib](https://zbib.org/)。
### 在 Linux 上安装 Zotero

它适用于 Windows、macOS 和 Linux。对于 Linux,如果你使用的是基于 Ubuntu 的发行版(或 Ubuntu 本身),你可以下载一个 deb 文件(由第三方维护)并安装它。
安装 [deb 文件](https://itsfoss.com/install-deb-files-ubuntu/)很简单,它在 Pop OS 20.04 上工作得很好。如果你使用的是其他 Linux 发行版,你可以[解压 tar 包](https://en.wikipedia.org/wiki/Tarball)并进行安装。
你可以按照[官方安装说明](https://www.zotero.org/support/installation)来找到合适的方法。
* [下载 Zotero](https://www.zotero.org/)
### 总结
它有大量的功能,你可以组织、分享、引用和收集资源,以供你进行搜索。由于支持音频、视频、文本和链接,它应该适合几乎所有的东西。
当然,我会将它推荐给有经验的用户,让它发挥最大的作用。而且,如果你之前使用过树状图(思维导图)笔记工具的人,你就知道要做什么了。
你觉得 Zotero 怎么样?如果它不适合你,你有更好的替代品建议么?请在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/zotero/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Zotero is an impressive free and open-source app that lets you collect, organize, cite, and share research. You can also instantly create references and bibliographies for your documents with Zotero.*
Usually, you can [use any note taking app on Linux](https://itsfoss.com/note-taking-apps-linux/) to collect and share your ideas. But, here, I want to share something tailored specifically to help you collect, organize, and share your research, i.e. [Zotero](https://www.zotero.org/).
## Zotero: Collect, Organize, & Share Research
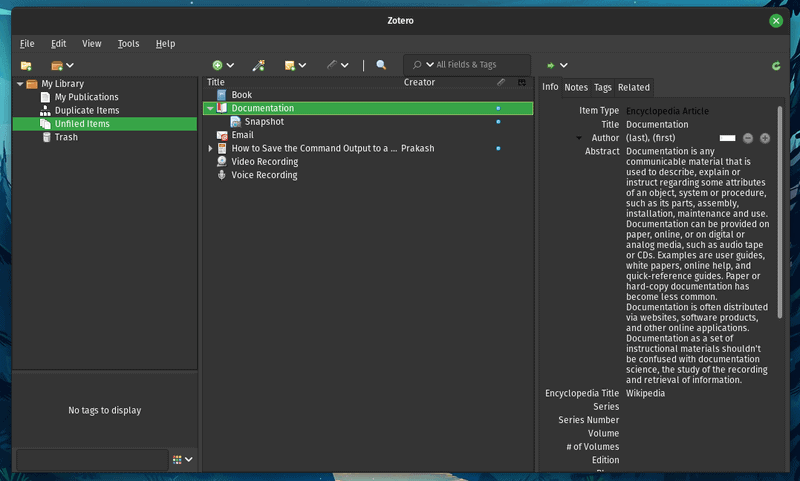
Zotero is a completely open-source project that you can find on [GitHub](https://github.com/zotero/zotero). It aims to help you easily collect, organize, add notes, and share your research.
And, all of that without being a cloud-based service, it is completely offline. So, your research notes belong to you. Of course, unless you want to sync it for collaboration purpose, for which you may have to refer the [documentation](https://www.zotero.org/support/).
To give you a head start, you can either opt for a [WebDAV storage](https:////en.wikipedia.org/wiki/WebDAV) or just create a Zotero account to sync and share your research easily.
For instance, I created a Zotero account with the username **ankush9**, you can find my research collections (that I added to my publication) at [https://www.zotero.org/ankush9](https://www.zotero.org/ankush9)
This makes it easy to share your organized research and you can choose what to share to your publication.
Let me highlight the key features that you get with Zotero to help you decide if you need to try it out.
## Features of Zotero

- Ability to add information right from the web in a click using a browser extension
- Add notes for each information
- Supports adding tags
- Supports adding voice recording
- Add video recording as attachment
- Add software as attachment
- Store an email as attachment
- Store podcast as an attachment
- Add Blog Posts
- Add a link to file
- Create bibliography from item
- Offline snapshot storage (you can access the web pages you saved without needing an Internet connection)
- Ability to duplicate items
- Organize items in a library
- Offers a trash bin to delete your items and easily restore them if needed
- Synchronization support
- Ability to export data
- LibreOffice add-on available for integration
- Easily share your research using your Zotero profile link
- Cross-platform support
If you just want to create quick bibliography, you can try their other tool, [ZoteroBib](https://zbib.org/).
**Recommended Read:**
## Installing Zotero on Linux
It is available for Windows, macOS, and Linux. For Linux, if you are using an Ubuntu-based distribution (or Ubuntu itself), you will get a deb file (maintained by a third-party) to download and install it.
[Installing a deb file](https://itsfoss.com/install-deb-files-ubuntu/) is easy and it worked just fine on Pop OS 20.04. If you are using any other Linux distribution, you can [extract the tarball](https:////en.wikipedia.org/wiki/Tarball) and get it installed.
You can follow the [official installation instructions](https://www.zotero.org/support/installation) to proceed with the suitable method.
## Concluding Thoughts
You get plenty of features to organize, share, cite, and collect resources for your search. With the support for audio, video, text, and link, it should be fit for almost everything.
Of course, I would recommend this to a power user to make the most out of it. And, if you are someone who has previously use tree-view (mind map view) note taking tools, you know what to look for.
What do you think about Zotero? If it’s not for you, what would you suggest as a better alternative to this? Let me know your thoughts in the comments below. |
12,909 | 《代码英雄》第三季(5): 基础设施的影响 | https://www.redhat.com/en/command-line-heroes/season-3/the-infrastructure-effect | 2020-12-11T09:41:00 | [
"代码英雄",
"COBOL"
] | https://linux.cn/article-12909-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第三季(5):基础设施的影响](https://www.redhat.com/en/command-line-heroes/season-3/the-infrastructure-effect)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/0ea5a208-a01f-46f8-902c-27cf4ffd0e6a/CLH_S3_EP5_The_Infrastructure_Effect_vFINAL_tc.mp3)脚本。
>
> 导语:用在 IT 基础设施中的语言是没有有效期的。COBOL 已经存在了 60 年 —— 而且不会很快消失。我们为大型机维护了数十亿行经典代码。但我们也在用 Go 等语言为云构建新的基础设施。
>
>
> COBOL 是计算机的一次巨大飞跃,让各行各业变得更加高效。Chris Short 介绍了学习 COBOL 是如何被视为安全的长期投注的。60 年后的今天,还有数十亿行并不容易被替换掉的 COBOL 代码 —— 懂这门语言的专家也很少。Ritika Trikha 解释说,有些事情必须改变。要么更多的人必须学习 COBOL,要么依赖 COBOL 的行业必须更新他们的代码库。这两个选择都很困难。但未来并不是用 COBOL 编写的。今天的 IT 基础架构是在云端构建的,其中很多是用 Go 编写的。Carmen Hernández Andoh 分享了 Go 的设计者是如何想要设计一种更适合云计算的语言。Kelsey Hightower 指出,语言通常都是超专注于一种任务。但它们正变得越来越开放和灵活。
>
>
>
**00:00:00 - Saron Yitbarek**:
1904 年,纽约市地铁首次开始运营时,它被惊叹为现代的一个奇迹。但是……当今天的通勤者仍依赖一个多世纪前设计的基础设施时,会发生什么?列车挤满了人,而且常常晚点。纽约每年有 20 亿人次地铁出行,再也没有人为此感到惊叹了。我们还在依赖昨日的过时基础设施,我们必须找到新的好办法,让它发挥作用。
**00:00:44**:
过去,基础设施项目通常是些可见的大而具体的事物,例如地铁。而且由于这种物理可见性,它们损坏时也显而易见。高速公路开裂、电线杆倒下,我们很清楚这些东西何时需要维修。为了使我们的生活与老化的基础设施保持协调,大量的工作是必不可少的。
**00:01:12**:
但是事物并不总是那么一是一、二是二。如今,我们还拥有 IT 基础设施,在偏僻地区嗡嗡作响的服务器农场,跨越海洋的光纤电缆,还有软件基础设施。而像遗留的操作系统或没人敢替换的 shell 脚本,这些 IT 基础设施变得陈旧和破旧时,我们是无法看出的。但是,造就了今日发展的基础设施却正在老化,就像旧的地铁轨道一样。这可能会扰乱我们的现代生活。如今命令行英雄们正努力确保我们不会被过去束缚,因此出现了大量新的挑战。
**00:02:02**:
这是我们第三季进入编程语言世界探索的第 5 期。我们将研究两种编程语言,它们与最初设计的目标基础设施密切相关。COBOL 是一种大型机的原生语言,而 Go 是云计算的原生语言。它们都深受其起源的影响。理解这一点可能会让明天的开发者不至于像纽约人一样被塞进宾夕法尼亚州的车站。
**00:02:33**:
我是 Saron Yitbarek,这里是红帽的原创播客,《命令行英雄》的第三季。
>
> **00:02:43 - <ruby> 格蕾丝·赫柏 <rt> Grace Hopper </rt></ruby>**:
>
>
> 我们面前有很多事情需要去做,但是我们首先需要大量相关的且易于访问的信息。我们才刚刚开始。
>
>
>
**00:02:53 - Saron Yitbarek**:
海军上将<ruby> 格蕾丝·赫柏 <rt> Grace Hopper </rt> 在 20 世纪 40、50 年代率先开发了高级编程语言。而她之所以能够实现这种巨大的飞跃,是因为当时的基础设施,大型计算机。</ruby>
**00:03:08 - Chris Short**:
嗨,我叫 Chris Short。
**00:03:10 - Saron Yitbarek**:
Chris 是红帽的首席产品营销经理,而且他也是一位历史爱好者。
**00:03:17 - Chris Short**:
上世纪 40 年代的赫柏上将创造了 FLOW-MATIC,这在当时是革命性的,她被广泛认为是 COBOL 的祖母。因此,她能够坐在那里说:“嘿,只需将其放在大型机上”,或“嘿,只需将其存储在大型机上”即可。
**00:03:31 - Saron Yitbarek**:
这是一个重大的游戏规则改变。突然,你有了这种机器无关的语言,即 COBOL,它是大型机环境特有的。可能性开始逐步打开。
**00:03:42 - Chris Short**:
大型机和 COBOL 真正使得每个组织能够说,它们不再需要充满了带着铅笔、纸、计算器和滑尺的人的办公室,他们可能只需要半个办公室来安装大型机。然后,他们可以雇人用 COBOL 来编写一些应用程序来完成整个财务团队做的所有的数学、逻辑运算以及账目。因此,你需要的财务团队人数少了,仅仅是因为更多的输入可以被数字化,而不是全手动操作。
**00:04:17 - Saron Yitbarek**:
如果你是那些新来的 COBOL 程序员之一,你会觉得你有了一份终身的工作。因为你的工作所基于的基础设施 —— 所有那些大型机 —— 始终会在那里。
**00:04:30 - Chris Short**:
那时侯摩尔定律还未出现,所以你可以整整十年都在同一个大型机上工作,对吧?就像你不用去考虑下一个操作系统,或者下一个类型的容器编排器,又或者下一个出现 AI 之类的东西一样。你可能会整个职业生涯都在从事 COBOL。而且你知道自己的生活将会非常稳定。
**00:04:55 - Saron Yitbarek**:
但是,摩尔定律最终还是来了。新的基础设施也出现了。现如今,程序员不太可能去学习一种半个世纪前的旧语言。但实际上,那些老旧的大型机其实并没有消失。这意味着我们对 COBOL 开发人员的需求也没有消失。
**00:05:17 - Chris Short**:
寻找 COBOL 开发者变得越来越困难。最终会发生的事情是这些大型机可能已经存在了 50 年。这些仍然可以编写出色 COBOL 程序的开发人员将获得巨额收入,以帮助项目运行并完成大型机中的数据重组。而且,该技能肯定会绝迹,并且正在成为一个利润丰厚的职业领域,如果你……现在写 COBOL 绝对可以赚很多钱。
**00:05:49 - Saron Yitbarek**:
尤其是在制造业和金融业。你无法超越几十年前建立的所有基础设施。遗留代码遍及全球。忽略这些老旧的基础设施及其相关的语言,将是一个巨大的错误。
**00:06:08 - Chris Short**:
有两千亿行代码摆在那里,要重构这些代码真的很难。不,我不认为在有生之年我们会看到它消失,真的。
**00:06:21 - Saron Yitbarek**:
Chris Short 是红帽的首席产品营销经理。
**00:06:28**:
我想花一秒钟解释一下 Chris 的观点。你想想看,95% 的 ATM 交易中都有 COBOL 代码,那就是我们与这种语言的联系。但是,COBOL 程序员的平均年龄并不比该语言年轻多少。他们 45 岁,或许 55岁。新人们并不感兴趣这门语言。这就是为什么我想向你介绍一个人。
**00:06:56 - Ritika Trikha**:
嘿,我是 Ritika Trikha。
**00:06:59 - Saron Yitbarek**:
Ritika 是一名技术编辑,曾在 HackerRank 工作。她对 COBOL 的这个问题着迷:人们认为 COBOL 是后大型机时代无意义的残留品。
**00:07:12 - Ritika Trikha**:
如今的开发人员根本不会考虑 COBOL 了,见也没见过,想也没想过。
**00:07:17 - Saron Yitbarek**:
但这可能是灾难的根源。
**00:07:21 - Ritika Trikha**:
如今,仍然有大量的 COBOL 代码在驱动企业的业务。每年至少新增 15 亿行 COBOL 新代码。我认为当你看特定行业时,真的很有意思。就像美国国税局有 5000 万行代码。社会保障局有 6000 万行代码。 因此,这些单位和实体正在处理一些如今最敏感、重要的信息,如果我们不继续为这些大型机提供支持和维护,就会造成很大的破坏。
**00:08:04 - Saron Yitbarek**:
因此,如果我们无法摆脱旧的基础设施,又无法挥舞魔杖来重建整个大型机业务,我们该怎么办?编码人员有时候仅考虑未来,该如何接受过去?我们首先需要直面该问题。
**00:08:25 - Ritika Trikha**:
你知道,年轻一代将不得不重拾这些技能。或者,必须对这些大型机进行某种现代化改造。无论是哪种方式,这个问题都不会消失。这就是为什么 COBOL 还活着的原因。
**00:08:35 - Saron Yitbarek**:
这并不容易。 Ritika 认为我们已经忽略这个问题太长时间了。
**00:08:42 - Ritika Trikha**:
这非常昂贵、艰巨,并且替换数十亿行 COBOL 代码的风险也非常高。它是用于关键任务的代码,比如社会保障和金融信息。COBOL 是专门为此类大量交易而设计的。因此,它由格蕾丝·赫柏在 60 年代为商业交易而设计。自上世纪 60 年代以来,一直存在“如果没坏,为什么要修复它”的说法,现在我们处于这样一个关头,即延续了数十年的大量的高价值数据运行在 COBOL 上。
**00:09:22 - Saron Yitbarek**:
从某种意义上说, Ritika 在呼吁一种文化的转变。改变对 "进 "与 "退 "的态度。由于发展的世界慢慢有了越来越久的历史,我们会更加地接触到自己的历史。你无法摆脱老化的基础设施。这意味着你也不能忽略编程语言的历史。
**00:09:47 - Ritika Trikha**:
有些事情必须得做。当我在 HackerRank 时,我亲眼看到了多少银行和金融机构对 COBOL 开发人员的伤害,几乎是绝望的。这不是一个会被解决的问题,我认为要么必须有某种现代化的系统,要么我们继续培训人员并激励他们。我个人认为将会有 COBOL 再次出现的一天。真的,当所有拥有 COBOL 知识的开发人员退休,并且没有新一代的开发人员学 COBOL 时,将会发生什么?总得做点什么,对吧?所以,当从 COBOL 转向新的基于云的基础设施时,需要有更多的系统化和制度化的改变。
**00:10:37 - Saron Yitbarek**:
Ritika Trikha 是一名旧金山的技术作家。
**00:10:49 - Saron Yitbarek**:
那么 Ritika 提到的那些基于云的基础设施呢?我们今天建立的基础设施是否会将后代绑定到特定的语言,像我们仍绑定找 COBOL 上一样?<ruby> 亚马逊 Web 服务 <rt> Amazon Web Services </rt></ruby>(AWS)可能是最大的单一云基础设施,于 2006 年推出。<ruby> Google 云平台 <rt> Google Cloud Platform </rt></ruby>(GCP)于 2008 年问世,微软 Azure 于 2010 年问世。 Go 语言以并发为重点,定位于在新的云基础设施上蓬勃发展。这是这个时代的语言。
**00:11:26 - Carmen Andoh**:
嗨,我叫 Carmen Andoh, 我是谷歌 Go 团队的项目经理。
**00:11:34 - Saron Yitbarek**:
Carmen 对 Go 语言与今天的基础设施有怎样的联系有深入的理解。这要从 Go 的创作者和编程语言历史的紧密联系说起。
**00:11:47 - Carmen Andoh**:
Robert Pike、Robert Griesemer 和 Ken Thompson。这些名字算是从上世纪 60 年代就开始出现了。Ken Thompson 发明了 B 语言,然后他在夏天的假期继续发明 UNIX 操作系统。Rob Pike 发明了字符串编码 UTF-8,他还发明了 ASCII。他帮助 Ken Thompson 共同编写了 UNIX 编程环境。所以,这两个人是很多、很多年前的同事,他们一直在研究和发明用以前的编程语言编写的操作系统,这些语言包括 Ken Thompson 最终帮助 Dennis Ritchie 一起编写的 C 语言。
**00:12:28 - Saron Yitbarek**:
Pike、Griesemer 和 Thompson 在 Google 工作之后,他们发现了一个严重的问题。并没有出现大规模的并发。人们等待了几个小时编译出来。他们使用的是 C++,并且必须得编写所有这些回调和事件调度器。那是在 2009 年,我们的基础设施再次发生了变化。诸如 C++ 之类的语言越来越不适应这种新的现实。
**00:12:59 - Carmen Andoh**:
多核处理器、网络系统、大规模计算集群和 Web 编程模型等正在引入这些问题。而且,还有这个行业的增长,程序员数量在 2010 年就会达到成千上万。因此,直到那时,所有的编程语言都是在规避问题而不是在正面解决问题。
**00:13:24 - Saron Yitbarek**:
最终,将达到一个临界点,必须开始改变。
**00:13:30 - Carmen Andoh**:
嘿,我们讨厌 C++ ,我说:“好吧,让我们看看我们是否能发明些新的东西。”
**00:13:37 - Saron Yitbarek**:
这种新语言需要完美地适应我们最新的基础设施。
**00:13:43 - Carmen Andoh**:
2005 年云技术到来以后,你不再需要自己的计算机,在某种程度上在其他地方租用它,你就可以得到一个分布式系统。但是在分布式系统中,以及在云计算中,存在并发消息传递问题。你需要确保采用异步对你来说没有问题。Go 缺省就是异步的编程语言。基本上,这意味着你执行的每个操作(例如将所有这些不同的消息发送给系统中的另一个计算机)都无需等待另一个机器对你的响应即可完成。因此,它可以在任何给定时间处理多个消息。
**00:14:28 - Carmen Andoh**:
就是说,云计算是分布式的。因此 Go 的开发就是来满足这一确切需求。Go 早就成为进行这种分布式计算的标准方法之一。这就是为什么我认为它立即引起了开发人员的广泛关注。Go 绝对是云基础设施的语言,无论是其设计,还是所有云基础设施工具,以及在过去十年中如雨后春笋般出现的模块的生态。
**00:15:06 - Saron Yitbarek**:
很快,诸如 Kubernetes 之类的关键应用都用 Go 编写了。谷歌还创建了 Go Cloud,这是一个开源库和一系列工具,使得 Go 更具吸引力。很显然,它是新生态系统的语言。它是云的语言。而且,它的创造者们因开发生命力持久的语言而享有声誉,这绝对没有坏处。
**00:15:33 - Carmen Andoh**:
我认为业界的其他人会说:“嘿,我认为这不会很快消失。”这种语言的发明者恰巧也发明了语言有 50 、60 年了。
**00:15:47 - Saron Yitbarek**:
Carmen Andoh 是谷歌 Go 团队的项目经理。
**00:15:54**:
因此,我们有了一种新的语言 Go ,旨在提供云基础设施必需的并发性。听起来不错。Go 的设计师倾向于创造可以持续半个世纪的语言。这也很棒。但是我的问题是,从现在起,50 年后,当 Go 更像是 COBOL 时,这到底意味着什么?当世界上充满了只有老开发人员才能理解的旧版 Go 代码时,这又意味着什么?在当今的云基础设施老化的时候,我们是否会做好准备?我们是否从 COBOL 和大型机领域吸取了教训,可以帮助我们为 Go 和云设计更美好的未来?
**00:16:40**:
幸运的是,我找到了问所有这些问题的合适人选。这就是下面这位。
**00:16:51**:
我们如何使我们的语言能面向未来?我们知道他们与当今的基础设施息息相关。我们也知道,随着数十年的发展,新的基础设施必将取代旧的基础设施。那么,我们今天做些什么以确保将来能平滑演进?
**00:17:10 - Kelsey Hightower**:
我是 Kelsey Hightower ,我在谷歌,是一名开发人员推广大使,我致力于引入开放性技术并将它们应用于谷歌云上的产品。
**00:17:19 - Saron Yitbarek**:
Kelsey 花了大量时间思考编程的未来。我很好奇,是否有一天我们将陷于握有 Go 语言技能的是另一批老龄化的程序员的问题,就像我们现在缺少 COBOL 的引导一样。我们是否在为这个长远的未来做计划?因此,我和 Kelsey 坐下来进行讨论。
**00:17:42 - Kelsey Hightower**:
...等等。但是,如果你考虑到今天面临的一些新的挑战,如应对互联网,这种网络,你将面临许多用户,成千上万的并发用户,以及不同的机器和架构类型的组合。考虑到这些新的场景,因此你通常希望有一种新的语言来解决。例如, JavaScript 是用于 Web 的,你不会想改造 COBOL 以便可以用它来进行 Web 编程。最终,我们今天已经有了数百种相当完善的语言,而且它们都非常专注于他们的优势。
**00:18:15 - Saron Yitbarek**:
那么,在那种情况下,我们是否需要积极推动人们走向 COBOL ?如果我们正在为这些新问题开发新语言,并且它们是高度定制化的,而 COBOL 仍在坚持不谢幕,我们是否需要鼓励人们选择它,以便我们可以维护我们的旧代码?
**00:18:32 - Kelsey Hightower**:
好吧,我认为这将对企业是个挑战吧?所以,你已经在 COBOL 上投入了 10 到 20 年,没有人会主动想学习一些新的 COBOL。或者你不会像刚从大学毕业那么“我要加倍努力……”。
**00:18:45 - Saron Yitbarek**:
没错。
**00:18:46 - Kelsey Hightower**:
“...这种语言比我父母的年龄都大。” 因此,在那个领域,你必须问自己,继续使用 COBOL 的风险是什么?未来是否仍然有意义?我认为它仍然有益于某些类型的工作任务,但是我们必须问自己一个问题,是时候推进了吗?是时候进化一点了吗?因此,如果你仍然有数十亿行的 COBOL 代码,那么你将必须寻找所有剩余的 COBOL 人才,并将其招进来,但也许我们该开始考虑其他语言能从 COBOL 学习些什么,并将某些功能和库加入到其他语言中。
**00:19:26 - Saron Yitbarek**:
COBOL 终止以后的日子,将会是一个巨大的基础设施项目。用我对纽约地铁的比喻,就像是要替换每条地下隧道。因此,展望未来,我想知道我们是否可以预见到这些问题,甚至将来对自己也能有所帮助。
**00:19:48**:
如果我们将今天的云计算与大型机进行比较,我们是否会在最终到达同一条船上,有着这些旧代码库,使用着旧的但非常稳定的语言,而且我们也到了必须做出选择的时候,我们应该继续前进还是保持不变?
**00:20:05 - Kelsey Hightower**:
云有点不同的是它不是来自一个制造商,对吗?许多云提供商通常提供了一系列技术集合,你就可以选择编程语言、编程范式,无论你是要事件驱动还是基于 HTTP 的全 Web 服务。这意味着你可以选择编程的方式,然后只需专注于要解决的问题。因此,数据进进出出,但是你来选择处理数据的方式。
**00:20:36**:
大型机通常只有一个主界面,对吗?就像你编写一份任务一样,这就是你提交任务的方式,这就是你监控任务的方式,这就是结果。这本身就是一个限制。如果你考虑一些较新的大型机,它们也会支持些较新的技术,因此即使在大型机领域,你也会开始看到可用于运行任务的编程语言扩展。
**00:20:58**:
那么我们开始问自己,好吧,既然我有了新的选项,该什么时候离开这种特定的编程范式继续前进呢?我认为我们不会陷入困境。
**00:21:08 - Saron Yitbarek**:
正确。
**00:21:08 - Kelsey Hightower**:
我认为新的分布式机器很不错,可能起步成本更低,你不必购买整个大型机即可开工。但是我们仍然希望易用性和之前一样:给你我的工作,你为我运行它,完成后告诉我。
**00:21:24 - Saron Yitbarek**:
绝对是这样,你觉得发生的事情,或者说 COBOL 所发生的事情,会发生在今天的任何一种语言上吗? 以 Go 语言做例子,你看到我们在努力地改进 Go 从而吸引人们在 30 年后还想用 Go ?
**00:21:38 - Kelsey Hightower**:
我认为所有语言都会遭受这种命运吧?如果你仔细想一下,其实 Python 已经存在很长时间了。我想差不多 20 年了,甚至更久。因此,我认为会 …… Python 重新流行起来了,它现在是机器学习的基础语言。
**00:21:53 - Saron Yitbarek**:
是的。
**00:21:54 - Kelsey Hightower**:
对于 Tensorflow 之类的库,如果我们仅用时间来衡量,我认为这可能不是看待它的正确方式。还应该有社区是否活跃?语言的适配意愿是否活跃?我认为 Python 做得确实非常出色……社区看到了使其他语言更易于使用的能力。例如,Tensorflow 底层有很多 C++ ,使用这种语言编程可能没有 Python 这样的用户友好性。你可以用 Python,并用它来生成人们正在使用的一些东西,例如 Tensorflow 。现在机器学习非常热门,人们将 Python 引入了这个新领域,那么你猜怎么着? Python 仍然是活跃的,并且在未来的一段时间内都是活跃的。对于 Go 来说,这同样适用。如果 Go 能够继续保持活跃度,那么,它就像许多基础设施工具和许多云库的基层一样,它也将保持活跃。因此,我认为都是这些社区确保了它们将来占有一席之地,并且当未来出现时,确保那里仍有它们的位置。
**00:22:58 - Saron Yitbarek**:
是的。那么,我们如何让我们的语言面向未来呢?就是说,我们如何有意地设计一种语言,使其能持续存在,并在 20、30 年内都保持活跃呢?
**00:23:10 - Kelsey Hightower**:
使用语言的人,我认为这在开源世界中确实是独一无二的。现在,我们已经不再使用商业语言了,对吧,过去曾经来自微软的语言或太阳微系统的如 Java™ ,那时侯,每个人都依赖于供应商来尽心尽力来对语言能干什么以及对运行时环境进行新的改进。现在,我们看到的诸如 Go、Node.js、Ruby 之类的东西,所有这些都是社区支持的,并且社区专注于运行时环境和语言。这样任何人都可以添加新库,对吧?有一个新的 HTTP 规范,对,HTTP/2 几年前问世了,每个社区都有贡献者添加了那些特定的库,猜猜现在怎么样?所有现在这些语言,都兼容于大部分的未来网站。
**00:24:01**:
我认为现在是个人真正地拥有了更多的控制权,如果他们想让语言适用于新的用例,只需要自己贡献即可。因此,我们不再受限于一两家公司。如果公司倒闭,那么运行时环境可能会因此而消亡。我们不再有这个问题了。
**00:24:23 - Saron Yitbarek**:
我们之前在这个播客上已经说过了。未来是开放的。但是,令人着迷的是考虑怎样能做到再过几十年,过去也将是开放的。它们将继承能够变形和演进的基础设施和语言。
**00:24:39 - Kelsey Hightower**:
太棒了,感谢你的加入,我期待人们的工作,而且大型机仍然有意义。它们是经典技术,因此我们不称其为遗产。
**00:24:47 - Saron Yitbarek**:
哦,我喜欢,经典,非常好。
**00:24:51**:
Kelsey Hightower 是 Google 的开发者推广大使。
**00:24:57**:
我正在想象一个充满经典编程语言以及尚未诞生的新语言的未来。那是我为之兴奋的未来。
**00:25:07 - 演讲者**:
请离关着的门远一点。
**00:25:12 - Saron Yitbarek**:
要知道,2017 年 Andrew Cuomo 州长宣布纽约市地铁进入紧急状态。他的政府拨出 90 亿美元投资于老化的基础设施。这应该提醒我们,迟早我们得注意遗留的系统。你不仅需要继续前进,面向未来。你还背着历史包袱。
**00:25:37**:
在开发的世界中,我们倾向于偏向未来。我们认为我们的语言仅在它们流行时才有用。但是,随着信息基础架构的不断老化,开发的历史变得越来越真实。事实证明,过去根本没有过去。记住这一点是我们的工作。
**00:26:05**:
你可以前往 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) ,以了解有关 COBOL 或 Go 或本季我们要介绍的其他语言的更多信息。那里有很多很棒的材料在等你。
**00:26:19 - Saron Yitbarek**:
下一集是关于 Bash 的。我们将探索 shell 脚本的起源以及自动化的关键。
**00:26:30 - Saron Yitbarek**:
《命令行英雄》是红帽的原创播客。我是 Saron Yitbarek 。下期之前,编码不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-3/the-infrastructure-effect>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[messon007](https://github.com/messon007) 校对:[wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Languages used for IT infrastructure don’t have expiration dates. COBOL’s been around for 60 years—and isn’t going anywhere anytime soon. We maintain billions of lines of classic code for mainframes. But we’re also building new infrastructures for the cloud in languages like Go.
COBOL was a giant leap for computers to make industries more efficient. Chris Short describes how learning COBOL was seen as a safe long-term bet. Sixty years later, there are billions of lines of COBOL code that can’t easily be replaced—and few specialists who know the language. Ritika Trikha explains that something must change: Either more people must learn COBOL, or the industries that rely on it have to update their codebase. Both choices are difficult. But the future isn’t being written in COBOL. Today’s IT infrastructure is built in the cloud—and a lot of it is written in Go. Carmen Hernández Andoh shares how Go’s designers wanted a language more suited for the cloud. And Kelsey Hightower points out that languages are typically hyper-focused for one task. But they’re increasingly open and flexible.
**00:00** - *Saron Yitbarek*
When the New York City subway first started running in 1904, it was a marvel of the modern age. But ... what happens when today's commuter depends on infrastructure that was designed more than a century ago? Trains are packed and often late. Two billion subway rides take place each year in New York, and nobody's marveling anymore. We are tied to yesterday's crumbling infrastructure, and we have to find smart, new ways to make it work.
**00:44** - *Saron Yitbarek*
It used to be that infrastructure projects were these big, concrete things we could see—that subway, for example. And because of that physical presence, it was also pretty obvious when they broke down. Highways crack, telephone poles fall over. We know when those things need fixing. Big efforts are necessary to get our lives in sync with aging infrastructure.
**01:12** - *Saron Yitbarek*
But things aren't always so obvious. Today we also have IT infrastructure, server farms humming in isolated fields, fiber optic cables spanning oceans, and software infrastructure, too. Like legacy operation system, or shell scripts that nobody dares to replace. When all that IT infrastructure gets old and creaky, we can't see it for ourselves. And yet, the infrastructure that makes today's development work possible is aging, just like an old subway track. And that can mess with our modern lives. Massive new challenges emerge as today's command line heroes work to make sure we're not being boxed in by the past.
**02:02** - *Saron Yitbarek*
This is episode 5 of our season-long journey into the world of programming languages. We're looking at 2 languages that have intimate ties to the infrastructure they were first designed for. COBOL is a language native to mainframe computing, and Go is native to the cloud. They're both deeply influenced by their origins. Understanding that might save tomorrow's developers from ending up like a New Yorker crammed into Penn Station.
**02:33** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is season 3 of Command Line Heroes, an original podcast from Red Hat.
**02:43** - *Grace Hopper*
So many things ahead that we have to do, but we need tremendous amounts of information, correlated, easy to access. We're only at the beginning.
**02:53** - *Saron Yitbarek*
Admiral Grace Hopper pioneered high-level programming languages in the 1940s and 50s. And she was able to make that great leap forward because of the infrastructure of her time, mainframe computers.
**03:08** - *Chris Short*
Hi, my name's Chris Short.
**03:10** - *Saron Yitbarek*
Chris is a principal product marketing manager at Red Hat, and he's a bit of a history buff, too.
**03:17** - *Chris Short*
Admiral Hopper in the 40s made FLOW-MATIC, and she's widely considered the grandmother of COBOL, which was revolutionary at the time. So being able to sit there and say, "Hey, just put it on the mainframe," or, "Hey, just store it on the mainframe."
**03:31** - *Saron Yitbarek*
It was a major game changer. Suddenly, you've got this machine-independent language, COBOL, that's native to the mainframe environment. Possibilities started opening up.
**03:42** - *Chris Short*
COBOL with mainframes really gave every organization the capability to say instead of having a room full of people with pencils, and paper, and calculators, and slide rules, they could just have half a room with a mainframe in it. And then they could have a few people write some applications in COBOL to do all of the math, and logic, and ledgering that their entire finance team could do. So the team of people that you needed to do your finances became a lot less, just because a lot more of the input could be digital as opposed to all hand jam in manually.
**04:17** - *Saron Yitbarek*
If you were one of those new COBOL programmers, it would've felt like you have a job for life. Because the infrastructure that your work was based on, all those mainframes, they weren't going anywhere.
**04:30** - *Chris Short*
Moore's Law wasn't around back then, so you could go an entire decade working on the same mainframe, potentially, right? Like you didn't have to worry about the next operating system, or the next type of container orchestrator, or the next thing that comes along and AI, or whatever. You could probably spend your whole career working on COBOL. And you knew you were going to be pretty safe.
**04:55** - *Saron Yitbarek*
But, Moore's Law did arrive eventually. New infrastructures showed up, too. And these days, programmers are less likely to learn a half-century old language. But here's the thing, those old mainframes aren't actually gone. And that means our need for COBOL developers hasn't vanished either.
**05:17** - *Chris Short*
It's getting a lot harder to find COBOL developers. What ends up happening is these mainframes have been here for 50 years, potentially. And these COBOL developers that still can write good COBOL will get paid exorbitant amount of monies to help with projects, and reorganization of data within mainframes. And that skillset is definitely dying off and becoming a highly lucrative career field if you ... you can definitely make a lot of money writing COBOL nowadays.
**05:49** - *Saron Yitbarek*
Especially in the manufacturing and finance industries. You can't outrun all that infrastructure that was laid down decades ago. Legacy code permeates work all around the world. It'd be a huge mistake to ignore that old infrastructure and the languages tied to it.
**06:08** - *Chris Short*
With 200 billion lines of code laying around, it's going to be really hard to refactor all that. No, I don't think we'll ever see it disappear in our lifetimes, for sure.
**06:21** - *Saron Yitbarek*
Chris Short is a principal product marketing manager at Red Hat.
**06:28** - *Saron Yitbarek*
I want to drive Chris's point home for a sec. Consider this. COBOL is baked into 95% of all ATM transactions. That's how tied we are to this language. And yet, the average COBOL programmer isn't much younger than the language itself. They are 45, maybe 55 years old. The newbies aren't interested. Which is why I want to introduce you to someone.
**06:56** - *Ritika Trikha*
Hi, my name is Ritika Trikha.
**06:59** - *Saron Yitbarek*
Ritika's a technology writer, formerly with HackerRank. And she's fascinated by this question of COBOL, and the assumption people make that it's a kind of pointless leftover from the mainframe days.
**07:12** - *Ritika Trikha*
Developers today are really not thinking about COBOL, it's out of sight, out of mind.
**07:17** - *Saron Yitbarek*
But that could be a recipe for disaster.
**07:21** - *Ritika Trikha*
There's a huge volume of COBOL lines of code that are still powering businesses today. At least 1.5 billion new lines of code in COBOL every single year. And I think when you look at the specific industries, it's really interesting. Like there's 50 million lines of code at the IRS. There's 60 million lines of code at the Social Security Administration. And so these businesses and entities are handling some of the most sensitive, important information today, and if we don't continue to power and maintain these mainframes, it could be really destructive.
**08:04** - *Saron Yitbarek*
So if we can't escape our old infrastructure, and we can't wave a magic wand to rebuild the whole mainframe universe, what do we do? How do coders, who sometimes only think about the future, start coming to terms with the past? We need to start by facing the problem head on.
**08:25** - *Ritika Trikha*
You know, younger generations are going to have to pick up these skills. Or, there has to be some sort of modernization of these mainframes. Either way, this problem isn't going to go away. That's why COBOL is relevant.
**08:35** - *Saron Yitbarek*
It's not going to be easy. Ritika figures we've ignored the problem for too long already.
**08:42** - *Ritika Trikha*
It's incredibly expensive, hard, and the risk is incredibly high to replace billions of lines of COBOL. It's mission-critical code like Social Security and financial information. And COBOL was specifically designed for these types of large volumes of transactions. So it was designed for business transactions by Grace Hopper in the 60s. And “if it's not broken, why try to fix it” has been the mentality since the 60s, and now we're at a point where we just have decades of very valuable, high volumes of data running on COBOL.
**09:22** - *Saron Yitbarek*
In a way, Ritika's calling for a cultural shift. A change in attitude about what's in and what's out. As the world of development starts to actually gain a deeper and deeper past, we have to become more in touch with our own history. You can't escape the aging infrastructure. And that means you can't ignore the history of languages either.
**09:47** - *Ritika Trikha*
Something has to be done. When I was at HackerRank, I saw firsthand how many banks and financial institutions are hurting, and desperate almost, for COBOL developers. It's not a problem that's going to go away, and I think either there has to be some sort of modernization of the systems, or we need to keep training folks and incentivizing it. I personally think there's going to be a day where COBOL is actually in again. Really, what's going to happen when all of the developers with COBOL knowledge retire, and no new younger generations of developers are learning COBOL? Something has to give, right? So there needs to be more of a systematic and institutionalized change when it comes to shifting away from COBOL and into the new cloud-based infrastructures.
**10:37** - *Saron Yitbarek*
Ritika Trikha is a technology writer based in San Francisco.
**10:49** - *Saron Yitbarek*
So what about those cloud-based infrastructures Ritika mentioned? Are the infrastructures we're building today going to chain future generations to particular languages, the way we're still tied to COBOL? Amazon Web Services (AWS) may be the biggest single piece of cloud infrastructure, launched in 2006. Google Cloud Platform arrived in 2008, and Microsoft Azure started in 2010. The Go language, with its focus on concurrency, was made to thrive inside all that new cloud infrastructure. It's a language of its time.
**11:26** - *Carmen Andoh*
Hi, my name is Carmen Andoh, and I am a program manager for the Go team at Google.
**11:34** - *Saron Yitbarek*
Carmen has an insider's understanding of how Go is tied to today's infrastructure. It starts with the creators of Go having some strong ties to the history of languages.
**11:47** - *Carmen Andoh*
Robert Pike, Robert Griesemer, and Ken Thompson. Those names have kind of come through ever since the 1960s. So Ken Thompson invented the programming language B, and then he would go on to invent the UNIX operating system on a summer off. And Rob Pike invented UTF-8, which is a string in coding. He also invented ASCII. He helped co-author the UNIX programming environment. So these two had been coworkers for a very, very long time, and they had been looking at and inventing operating systems in previous programming languages, including C, which Ken Thompson would eventually help write with Dennis Ritchie.
**12:28** - *Saron Yitbarek*
Once Pike, Griesemer, and Thompson were all working at Google, they discovered a serious problem. Getting concurrency at scale just wasn't happening. People were waiting hours for a bill to compile. They were working in C++, and had to write all these callbacks and event dispatchers. It was 2009, and our infrastructure was changing again. Languages like C++ were becoming less and less in tune with that new reality.
**12:59** - *Carmen Andoh*
The problems were being introduced by things like multicore processors, and network systems, and massive computation clusters, and the web programming model. And then, also, just the growth of the industry and the number of programmers which were going into the thousands and the tens-of-thousands by 2010. And so all of the programming languages up until that point were being worked around, rather than addressing things head on.
**13:24** - *Saron Yitbarek*
Eventually, you reach a breaking point and something's got to give.
**13:30** - *Carmen Andoh*
Hey, we hated C++ and I said, "Well, let's see if we could invent something new."
**13:37** - *Saron Yitbarek*
That new language would need to be exquisitely adapted to our latest infrastructure.
**13:43** - *Carmen Andoh*
What happened with the cloud, which was starting to come of age in 2005, was that you now no longer had to handle your own computes, you sort of were renting it elsewhere, and you get a distributed system. But what happens in a distributed system, and in a cloud, is that you have problems of concurrent messaging between distributed systems. You need to make sure that you have no problems with asynchronicity. Go is a programming language that is asynchronous by default. Basically this means that every operation you perform, like sending all these different messages to another in the system, it's done without waiting for the other system to respond back to you. So it can handle multiple messages at any given time.
**14:28** - *Carmen Andoh*
And that said, cloud computing is distributed. And so Go was developed to address this exact need. Go became, early on, one of the standard ways of doing this kind of distributed computing. And that's why I think that it picked up a lot of the developer mindshare immediately. Go absolutely is the language of cloud infrastructure, both in its design, but also in the ecosystem of all the cloud infrastructure tooling, and building blocks that have sprung up in the last decade.
**15:06** - *Saron Yitbarek*
Soon, major applications like Kubernetes were being written in Go. Google also created Go Cloud, an open source library and set of tools that made Go even more attractive. It became clear, this was the language of a brand new ecosystem. It was the language of the cloud. And it definitely didn't hurt that the creators had reputations for developing languages that lasted.
**15:33** - *Carmen Andoh*
I think that the rest of the industry said, "Hey, I don't think that this is going to be going away anytime soon," and the inventors of the language also happen to invent languages that are now in their 50th year, or 60th year.
**15:47** - *Saron Yitbarek*
Carmen Andoh is a program manager for the Go team at Google.
**15:54** - *Saron Yitbarek*
So we have a new language, Go, designed to deliver the concurrency that cloud infrastructure makes necessary. Sounds great. And Go’s designers tend to create languages that last for a good half century. Also great. But my question is, what will that really mean 50 years from now when Go is more like COBOL? What will it mean when the world is teeming with legacy Go code that only older developers understand? Are we going to be prepared for a time when today's cloud infrastructure is aging? Are we learning lessons from COBOL and the world of mainframe that could help us design a better future for Go and the cloud?
**16:40** - *Saron Yitbarek*
Luckily, I found exactly the right person to ask all these questions. And that's next.
**16:51** - *Saron Yitbarek*
How do we future-proof our languages? We know they're tied to the infrastructure of their day. And we know that new infrastructures are bound to replace the old ones as decades roll by. So what are we doing today to keep things running smoothly tomorrow?
**17:10** - *Kelsey Hightower*
I'm Kelsey Hightower, I'm at Google, I'm a developer advocate and I work bringing open technologies and turning them to products on Google Cloud.
**17:19** - *Saron Yitbarek*
Kelsey spends a lot of time thinking about the future of programming. I was curious whether one day we're going to end up with another aging group of programmers with these wizard-like skills around Go, the same way we have a shortage of COBOL wizards today. Are we even planning for that long range future? So Kelsey and I sat down to hash it out.
**17:42** - *Kelsey Hightower*
... and so forth. But if you think about some of the new challenges today, things like dealing with the internet, the network, you've got multiple users, hundreds of thousands of concurrent users, different collections of machines and architecture types. So given those new use cases, typically you want to have a new language. For example, JavaScript is for the web, you don't want to retrofit COBOL so that we can start doing web programming with it. So we have hundreds of languages that are out and pretty well established today, and they're all kind of hyper-focused on their sweet spots.
**18:15** - *Saron Yitbarek*
So in that case then, do we need to actively push people towards COBOL? If we're developing these new languages for these new problems and they're highly specialized, and COBOL's still sticking around, do we need to encourage folks to pick it up so we can maintain our legacy code?
**18:32** - *Kelsey Hightower*
Well, I think that's going to be a challenge for the enterprise, right? So you've invested 10, 20 years in COBOL, and there is no one actively thinking about learning some new COBOL. Or you don't come out of college just like, "I'm going to double-down..."
**18:45** - *Saron Yitbarek*
Right.
**18:46** - *Kelsey Hightower*
"...on this language that's older than my parents." So in that world, you have to ask yourself, what is the risk of continuing on with COBOL? Is it still relevant going forward? I think it is still relevant for certain types of workloads, but we have to ask ourselves a question, is it time to progress? Is it time to evolve a little bit? So if you still have billions of lines of COBOL, you're in the situation where you're going to have to try to find all the COBOL talent that's remaining and bring them in house, but maybe we start to think about what can other languages learn from COBOL, and incorporate some of that functionality and libraries into other languages.
**19:26** - *Saron Yitbarek*
Life after COBOL, that would be an enormous infrastructure project all on its own. To use my New York subway analogy, it'd be like replacing every underground tunnel. So, going forward, I wanted to know whether we could anticipate those issues, and even do our future selves some favors.
**19:48** - *Saron Yitbarek*
If we compare the cloud today to mainframes, are we going to end up in the same boat where we have these legacy code bases that are using kind of old but very stable languages, and we have to kind of reach this new point of figuring out if we should move on or stay the same?
**20:05** - *Kelsey Hightower*
So the thing that makes the cloud a bit different, it's not from one manufacturer, right? A lot of cloud providers typically bundle up collections of technology so you have your choice of programming language, you have your choice of programming paradigm, whether you want to event-driven, or it's all web services based on [HTTP]. So what that means is you get to choose what you want to program in, and just kind of focus on what gets solved. So data will come in, data will come out, but you choose how you want to process that data.
**20:36** - *Kelsey Hightower*
The mainframe typically just kind of had one main interface, right? Like you write this job, and this is how you submit the job, here's how you monitor the job, and here's where it comes out. So that's very limiting of itself. So if you think about some of the newer mainframes, they also support some of the newer technology, so even in the world of mainframe, you start to see the expansion of programming languages you can use to run your jobs.
**20:58** - *Kelsey Hightower*
So then we start to ask ourselves, okay, given that I have my new choice, when is it time to move on from this particular programming paradigm? So I think we don't get stuck.
**21:08** - *Saron Yitbarek*
Right.
**21:08** - *Kelsey Hightower*
But I think it is going to be nice that there's going to be a new machine that's going to be distributed, maybe there's a lower cost of entry, you don't have to buy the whole mainframe to get started. But we still want that ease of use of here's my job, you run it for me, tell me when it's done.
**21:24** - *Saron Yitbarek*
Absolutely. Do you see what's happening, or what's happened to COBOL, happening to any of today's languages? Like for example, Go, do you see us struggling to maintain Go and getting folks who want to write Go in 30 years?
**21:38** - *Kelsey Hightower*
I think all languages can suffer that fate, right? So if you think about it, Python's been around for a very long time. I think it's, what, close to 20 years if not more. So I think what happens ... and Python's had a resurgence in its usage, right, it's kind of the foundation of language for machine learning.
**21:53** - *Saron Yitbarek*
Yep.
**21:54** - *Kelsey Hightower*
For libraries like Tensorflow. So if we use just time alone, I think that's probably not the right way to look at it. It's like how relevant is that community? How relevant is that language willing to adapt? And I think what Python did really, really well, it ... that community saw the ability to make other languages easier to use. For example, Tensorflow's a lot of C++ underneath it, so programming in such a language is probably not as user friendly as something like Python. And you could take Python and use it to generate some of the stuff that people are using for, example, Tensorflow. So now that machine learning is hot, people have brung Python into that new space, so guess what? Python continues to be relevant, and will be relevant for some time to come. And the same thing's going to be true for Go. If Go can continue to be relevant, right, it's like at the foundation of many of our infrastructure tools, many of the cloud libraries, it too will remain relevant. So I think it's all about those communities ensuring that they have a place in the future, and when the future shows up, making sure that they have a story there.
**22:58** - *Saron Yitbarek*
Yeah. So how do we future-proof our languages? Meaning, how do we intentionally design a language to make it last, and make it relevant 20, 30 years from now?
**23:10** - *Kelsey Hightower*
The people that use the language, so this is something that's really unique I think, in the open source space. Now that we've moved away from commercial languages, right, languages used to come from Microsoft, or Sun Microsystems in the case of Java™, and at that point everyone relied on the vendor to do all the heavy lifting about what the language would be able to do, any new improvements in the run time. Now what we see with things like Go, Node.js, Ruby, all of these are community backed and focused runtimes and languages. So anyone can add new libraries, right? There was a new [HTTP] spec, right, [HTTP/2] came out a few years ago and each of the respective communities just had contributors add those particular libraries, and now guess what? All of those languages are now compatible with the future of the ... kind of the web for the most part.
**24:01** - *Kelsey Hightower*
So I think it's really now that individuals have more control if they want their language to be relevant for new use cases by just contributing that functionality themselves. So we're not restricted to one or two companies. If the company goes out of business, then maybe the runtime dies with it. We don't have that problem as much anymore.
**24:23** - *Saron Yitbarek*
We've said it on this podcast before. The future is open. But it's fascinating to consider how in another couple decades, the past will be open too. They'll be inheriting infrastructure and languages that are able to morph and evolve.
**24:39** - *Kelsey Hightower*
Awesome, thanks for having me, and I look forward to what people do and mainframe is still relevant. So we don't call it legacy, these are classic technologies.
**24:47** - *Saron Yitbarek*
Ooh, I like that, classic, very nice.
**24:51** - *Saron Yitbarek*
Kelsey Hightower is developer advocate at Google.
**24:57** - *Saron Yitbarek*
I'm imagining a future that's rich with classic programming languages, along with new languages that haven't even been born yet. That's a future I'm excited for.
**25:07** - *Speaker*
Stand clear of the closing doors, please.
**25:12** - *Saron Yitbarek*
You know, in 2017 Governor Andrew Cuomo declared a state of emergency about the New York City subway. His government set aside 9 billion dollars to invest in the aging infrastructure. And that should remind us, sooner or later, we have to take care of the systems we inherit. You don't just race onward to whatever comes next. You bring the past with you.
**25:37** - *Saron Yitbarek*
n the world of development, we tend to have a bias towards the future. We think our languages are only useful in the moment, when they're the hot new thing. But, as informational infrastructure continues to age, the history of development becomes more and more real. The past, it turns out, isn't past at all. And it's our job to remember that.
**26:05** - *Saron Yitbarek*
You can learn more about COBOL, or Go, or any of the languages we're covering this season, by heading over to [redhat.com/commandlineheroes](//www.redhat.com/en/command-line-heroes). There's a bunch of great bonus material waiting for you.
**26:19** - *Saron Yitbarek*
Next episode is all about Bash. We're exploring the origins of shell scripts, and the key to automation.
**26:30** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. I'm Saron Yitbarek. Until next time, keep on coding.
### Keep going
### The Infrastructure is Code: A story of COBOL and Go
COBOL was, and still is, the dominant language of mainframes. What can Go learn from its history in order to dominate the cloud?
### Go on Red Hat Enterprise Linux
Get started with Golang on Red Hat Enterprise Linux. Check out this article for instructions and links to more resources to learn more about Go.
### Enjoy this episode's artwork on your device
Download the Command Line Heroes artwork and set it as your background. |
12,911 | 跟踪多个 Git 远程仓库 | https://opensource.com/article/20/11/multiple-git-repositories | 2020-12-11T22:08:54 | [
"Git"
] | /article-12911-1.html |
>
> 拥有一致的命名标准是保持本地和上游 Git 仓库保持一致的关键。
>
>
>

当本地 Git 仓库的命名与远程仓库不一致时,与远程仓库协作就会变得很混乱。
解决此问题的一个方法是标准化两个词的使用和含义:`origin` 指的是你个人的 `example.com/<USER>/*` 仓库,而 `upstream` 指的是你从 `origin` 仓库<ruby> 复刻 <rt> fork </rt></ruby>出来的 `example.com` 仓库。换句话说,`upstream` 指的是公开提交工作的上游仓库,而 `origin` 指的是你对上游仓库的本地复刻,例如,你从这里生成<ruby> 拉取请求 <rt> pull request </rt></ruby>(PR)。
以 [pbench](https://github.com/distributed-system-analysis/pbench) 仓库为例,下面是一个逐步建立新的本地克隆的方法,其中 `origin` 和 `upstream` 的定义是一致的。
1、在大多数 Git 托管服务上,当你想在上面工作时,必须对它进行复刻。当你运行自己的 Git 服务器时,这并不是必要的,但对于一个公开的代码库来说,这是一个在贡献者之间传输差异的简单方法。
创建一个 Git 仓库的复刻。在这个例子中,假设你的复刻位于 `example.com/<USER>/pbench`。
2、接下来,你必须获得一个统一资源标识符 ([URI](https://en.wikipedia.org/wiki/Uniform_Resource_Identifier)),以便通过 SSH 进行<ruby> 克隆 <rt> cloning </rt></ruby>。在大多数 Git 托管服务上,比如 GitLab 或 GitHub,它在一个标有 “Clone” 或 “Clone over SSH” 的按钮或面板上,可以将克隆 URI 复制到剪贴板中。
3、在你的开发系统中,使用你复制的 URI 克隆仓库:
```
$ git clone [email protected]:<USER>/pbench.git
```
这将以默认名称 `origin` 来克隆 Git 仓库,作为你的 `pbench` 仓库复刻副本。
4、切换到刚才克隆的目录:
```
$ cd ~/pbench
```
5、下一步,获取源仓库的 SSH URI(你最初复刻的那个)。这可能和上面的方法一样。找到 “Clone” 按钮或面板,复制克隆地址。在软件开发中,这通常被称为“上游”,因为(理论上)这是大多数提交发生的地方,而你打算让这些提交流向下游的仓库。
6、将 URI 添加到你的本地仓库中。是的,将有*两个不同*的远程仓库分配给你的本地仓库副本:
```
$ git remote add upstream [email protected]:bigproject/pbench.git
```
7、现在你有两个命名远程仓库:`origin` 和 `upstream`。 你可以用 `remote` 子命令查看你的远程仓库:
```
$ git remote -v
```
现在,你的本地 `master` 分支正在跟踪 `origin` 的 `master`,这不一定是你想要的。你可能想跟踪这个分支的 `upstream` 版本,因为大多数开发都在上游进行。这个想法是,你要在从上游获得的内容的基础上添加更改。
8、将你的本地的 `master` 分支改成跟踪 `upstream/master`:
```
$ git fetch upstream
$ git branch --set-upstream-to=upstream/master master
```
你可以对任何你想要的分支这样做,而不仅仅是 `master`。例如,有些项目使用 `dev` 分支来处理所有不稳定的变化,而将 `master` 保留给已批准发布的代码。
9、一旦你设置了你的跟踪分支,一定要变基(`rebase`)你的 `master` 分支,使它与上游仓库的任何新变化保持一致:
```
$ git remote update
$ git checkout master
$ git rebase
```
这是一个保持 Git 仓库在不同复刻之间同步的好方法。如果你想自动完成这项工作,请阅读 Seth Kenlon 关于[使用 Ansible 托管 Git 仓库](https://opensource.com/article/19/11/how-host-github-gitlab-ansible)的文章。
---
via: <https://opensource.com/article/20/11/multiple-git-repositories>
作者:[Peter Portante](https://opensource.com/users/portante) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,912 | Fedora CoreOS 入门 | https://fedoramagazine.org/getting-started-with-fedora-coreos/ | 2020-12-11T23:18:40 | [
"CoreOS"
] | https://linux.cn/article-12912-1.html | 
现在被称为 DevOps 时代,操作系统的关注度似乎比工具要低一些。然而,这并不意味着操作系统没有创新。(编辑注:基于 Linux 内核的众多发行版所提供的多样化产品就是一个很好的例子)。[Fedora CoreOS](https://getfedora.org/coreos/) 就对这个 DevOps 时代的操作系统应该是什么样有着独特的理念。
### Fedora CoreOS 的理念
Fedora CoreOS(FCOS)是由 CoreOS Container Linux 和 Fedora Atomic Host 合并而来。它是一个专注于运行容器化应用程序的精简的独体操作系统。安全性是首要重点,FCOS 提供了自动更新,并带有 SELinux 强化。
为了使自动更新能够很好地工作,它们需要非常健壮,目标是运行 FCOS 的服务器在更新后不会崩溃。这是通过使用不同的发布流(stable、testing 和 next)来实现的。每个流每 2 周发布一次,更新内容会从一个流推广到另一个流(next -> testing -> stable)。这样落地在 stable 流中的更新就有机会经过长时间的测试。
### 入门
对于这个例子,让我们使用 stable 流和一个 QEMU 基础镜像,我们可以作为一个虚拟机运行。你可以使用 [coreos-installer](https://github.com/coreos/coreos-installer/releases) 来下载该镜像。
在你的(Workstation)终端上,更新镜像的链接后,运行以下命令(编辑注:在 Silverblue 上,基于容器的 coreos 工具是最简单的方法,可以尝试一下。说明可以在 <https://docs.fedoraproject.org/en-US/fedora-coreos/tutorial-setup/> 中找到,特别是 “Setup with Podman or Docker” 一节。):
```
$ sudo dnf install coreos-installer
$ coreos-installer download --image-url https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/32.20200907.3.0/x86_64/fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2.xz
$ xz -d fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2.xz
$ ls
fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2
```
#### 创建一个配置
要定制一个 FCOS 系统,你需要提供一个配置文件,[Ignition](https://github.com/coreos/ignition) 将使用这个文件来配置系统。你可以用这个文件来配置诸如创建用户、添加受信任的 SSH 密钥、启用 systemd 服务等等。
以下配置创建了一个 `core` 用户,并在 `authorized_keys` 文件中添加了一个 SSH 密钥。它还创建了一个 systemd 服务,使用 [podman](https://podman.io/) 来运行一个简单的 “hello world” 容器:
```
version: "1.0.0"
variant: fcos
passwd:
users:
- name: core
ssh_authorized_keys:
- ssh-ed25519 my_public_ssh_key_hash fcos_key
systemd:
units:
-
contents: |
[Unit]
Description=Run a hello world web service
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/bin/podman run --pull=always --name=hello --net=host -p 8080:8080 quay.io/cverna/hello
ExecStop=/bin/podman rm -f hello
[Install]
WantedBy=multi-user.target
enabled: true
name: hello.service
```
在配置中加入你的 SSH 密钥后,将其保存为 `config.yaml`。接下来使用 Fedora CoreOS Config Transpiler(`fcct`)工具将这个 YAML 配置转换成有效的 Ignition 配置(JSON 格式)。
直接从 Fedora 的资源库中安装 `fcct`,或者从 [GitHub](https://github.com/coreos/fcct/releases) 中获取二进制文件:
```
$ sudo dnf install fcct
$ fcct -output config.ign config.yaml
```
#### 安装并运行 Fedora CoreOS
要运行镜像,你可以使用 libvirt 堆栈。要在 Fedora 系统上使用 `dnf` 软件包管理器安装它:
```
$ sudo dnf install @virtualization
```
现在让我们创建并运行一个 Fedora CoreOS 虚拟机:
```
$ chcon --verbose unconfined_u:object_r:svirt_home_t:s0 config.ign
$ virt-install --name=fcos \
--vcpus=2 \
--ram=2048 \
--import \
--network=bridge=virbr0 \
--graphics=none \
--qemu-commandline="-fw_cfg name=opt/com.coreos/config,file=${PWD}/config.ign" \
--disk=size=20,backing_store=${PWD}/fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2
```
安装成功后,会显示一些信息并提供登录提示符:
```
Fedora CoreOS 32.20200907.3.0
Kernel 5.8.10-200.fc32.x86_64 on an x86_64 (ttyS0)
SSH host key: SHA256:BJYN7AQZrwKZ7ZF8fWSI9YRhI++KMyeJeDVOE6rQ27U (ED25519)
SSH host key: SHA256:W3wfZp7EGkLuM3z4cy1ZJSMFLntYyW1kqAqKkxyuZrE (ECDSA)
SSH host key: SHA256:gb7/4Qo5aYhEjgoDZbrm8t1D0msgGYsQ0xhW5BAuZz0 (RSA)
ens2: 192.168.122.237 fe80::5054:ff:fef7:1a73
Ignition: user provided config was applied
Ignition: wrote ssh authorized keys file for user: core
```
Ignition 配置文件没有为 `core` 用户提供任何密码,因此无法通过控制台直接登录。(不过,也可以通过 Ignition 配置为用户配置密码。)
使用 `Ctrl + ]` 组合键退出虚拟机的控制台。然后检查 `hello.service` 是否在运行:
```
$ curl http://192.168.122.237:8080
Hello from Fedora CoreOS!
```
使用预先配置的 SSH 密钥,你还可以访问虚拟机并检查其上运行的服务:
```
$ ssh [email protected]
$ systemctl status hello
● hello.service - Run a hello world web service
Loaded: loaded (/etc/systemd/system/hello.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2020-10-28 10:10:26 UTC; 42s ago
```
#### zincati、rpm-ostree 和自动更新
zincati 服务使用自动更新驱动 rpm-ostreed。
检查虚拟机上当前运行的 Fedora CoreOS 版本,并检查 zincati 是否找到了更新:
```
$ ssh [email protected]
$ rpm-ostree status
State: idle
Deployments:
● ostree://fedora:fedora/x86_64/coreos/stable
Version: 32.20200907.3.0 (2020-09-23T08:16:31Z)
Commit: b53de8b03134c5e6b683b5ea471888e9e1b193781794f01b9ed5865b57f35d57
GPGSignature: Valid signature by 97A1AE57C3A2372CCA3A4ABA6C13026D12C944D0
$ systemctl status zincati
● zincati.service - Zincati Update Agent
Loaded: loaded (/usr/lib/systemd/system/zincati.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2020-10-28 13:36:23 UTC; 7s ago
…
Oct 28 13:36:24 cosa-devsh zincati[1013]: [INFO ] initialization complete, auto-updates logic enabled
Oct 28 13:36:25 cosa-devsh zincati[1013]: [INFO ] target release '32.20201004.3.0' selected, proceeding to stage it
... zincati reboot ...
```
重启后,我们再远程登录一次,检查新版的 Fedora CoreOS:
```
$ ssh [email protected]
$ rpm-ostree status
State: idle
Deployments:
● ostree://fedora:fedora/x86_64/coreos/stable
Version: 32.20201004.3.0 (2020-10-19T17:12:33Z)
Commit: 64bb377ae7e6949c26cfe819f3f0bd517596d461e437f2f6e9f1f3c24376fd30
GPGSignature: Valid signature by 97A1AE57C3A2372CCA3A4ABA6C13026D12C944D0
ostree://fedora:fedora/x86_64/coreos/stable
Version: 32.20200907.3.0 (2020-09-23T08:16:31Z)
Commit: b53de8b03134c5e6b683b5ea471888e9e1b193781794f01b9ed5865b57f35d57
GPGSignature: Valid signature by 97A1AE57C3A2372CCA3A4ABA6C13026D12C944D0
```
`rpm-ostree status` 现在显示了两个版本的 Fedora CoreOS,一个是 QEMU 镜像中的版本,一个是更新后的最新版本。有了这两个版本,就可以使用 `rpm-ostree rollback` 命令回滚到之前的版本。
最后,你可以确保 hello 服务仍在运行并提供内容:
```
$ curl http://192.168.122.237:8080
Hello from Fedora CoreOS!
```
更多信息参见:[Fedora CoreOS 更新](https://docs.fedoraproject.org/en-US/fedora-coreos/auto-updates/)。
#### 删除虚拟机
要进行事后清理,使用以下命令删除虚拟机和相关存储:
```
$ virsh destroy fcos
$ virsh undefine --remove-all-storage fcos
```
### 结论
Fedora CoreOS 为在容器中运行应用程序提供了一个坚实而安全的操作系统。它在推荐主机使用声明式配置文件进行配置的 DevOps 环境中表现出色。自动更新和回滚到以前版本的操作系统的能力,可以在服务的运行过程中带来安心的感觉。
通过关注项目[文档](https://docs.fedoraproject.org/en-US/fedora-coreos/tutorials/)中的教程,了解更多关于 Fedora CoreOS 的信息。
---
via: <https://fedoramagazine.org/getting-started-with-fedora-coreos/>
作者:[Clément Verna](https://fedoramagazine.org/author/cverna/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This has been called the age of DevOps, and operating systems seem to be getting a little bit less attention than tools are. However, this doesn’t mean that there has been no innovation in operating systems. [Edit: The diversity of offerings from the plethora of distributions based on the Linux kernel is a fine example of this.] [Fedora CoreOS](https://getfedora.org/coreos/) has a specific philosophy of what an operating system should be in this age of DevOps.
### Fedora CoreOS’ philosophy
Fedora CoreOS (FCOS) came from the merging of CoreOS Container Linux and Fedora Atomic Host. It is a minimal and monolithic OS focused on running containerized applications. Security being a first class citizen, FCOS provides automatic updates and comes with SELinux hardening.
For automatic updates to work well they need to be very robust. The goal being that servers running FCOS won’t break after an update. This is achieved by using different release streams (stable, testing and next). Each stream is released every 2 weeks and content is promoted from one stream to the other (next -> testing -> stable). That way updates landing in the stable stream have had the opportunity to be tested over a long period of time.
### Getting Started
For this example let’s use the stable stream and a QEMU base image that we can run as a virtual machine. You can use [coreos-installer](https://github.com/coreos/coreos-installer/releases) to download that image.
From your (Workstation) terminal, run the following commands after updating the link to the image. [Edit: On Silverblue the container based coreos tools are the simplest method to try. Instructions can be found at [https://docs.fedoraproject.org/en-US/fedora-coreos/tutorial-setup/](https://docs.fedoraproject.org/en-US/fedora-coreos/tutorial-setup/) , in particular “Setup with Podman or Docker”.]
$ sudo dnf install coreos-installer $ coreos-installer download --image-url https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/32.20200907.3.0/x86_64/fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2.xz $ xz -d fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2.xz $ ls fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2
#### Create a configuration
To customize a FCOS system, you need to provide a configuration file that will be used by [Ignition](https://github.com/coreos/ignition) to provision the system. You may use this file to configure things like creating a user, adding a trusted SSH key, enabling systemd services, and more.
The following configuration creates a *‘core’* user and adds an SSH key to the authorized_keys file. It is also creating a systemd service that uses [podman](https://podman.io/) to run a simple hello world container.
version: "1.0.0" variant: fcos passwd: users: - name: core ssh_authorized_keys: - ssh-ed25519 my_public_ssh_key_hash fcos_key systemd: units: - contents: | [Unit] Description=Run a hello world web service After=network-online.target Wants=network-online.target [Service] ExecStart=/bin/podman run --pull=always --name=hello --net=host -p 8080:8080 quay.io/cverna/hello ExecStop=/bin/podman rm -f hello [Install] WantedBy=multi-user.target enabled: true name: hello.service
After adding your SSH key in the configuration save it as *config.yaml*. Next use the Fedora CoreOS Config Transpiler (fcct) tool to convert this YAML configuration into a valid Ignition configuration (JSON format).
Install *fcct* directly from Fedora’s repositories or get the binary from [GitHub](https://github.com/coreos/fcct/releases).
$ sudo dnf install fcct $ fcct -output config.ign config.yaml
#### Install and run Fedora CoreOS
To run the image, you can use the libvirt stack. To install it on a Fedora system using the dnf package manager
$ sudo dnf install @virtualization
Now let’s create and run a Fedora CoreOS virtual machine
$ chcon --verbose unconfined_u:object_r:svirt_home_t:s0 config.ign $ virt-install --name=fcos \ --vcpus=2 \ --ram=2048 \ --import \ --network=bridge=virbr0 \ --graphics=none \ --qemu-commandline="-fw_cfg name=opt/com.coreos/config,file=${PWD}/config.ign" \ --disk=size=20,backing_store=${PWD}/fedora-coreos-32.20200907.3.0-qemu.x86_64.qcow2
Once the installation is successful, some information is displayed and a login prompt is provided.
Fedora CoreOS 32.20200907.3.0 Kernel 5.8.10-200.fc32.x86_64 on an x86_64 (ttyS0) SSH host key: SHA256:BJYN7AQZrwKZ7ZF8fWSI9YRhI++KMyeJeDVOE6rQ27U (ED25519) SSH host key: SHA256:W3wfZp7EGkLuM3z4cy1ZJSMFLntYyW1kqAqKkxyuZrE (ECDSA) SSH host key: SHA256:gb7/4Qo5aYhEjgoDZbrm8t1D0msgGYsQ0xhW5BAuZz0 (RSA) ens2: 192.168.122.237 fe80::5054:ff:fef7:1a73 Ignition: user provided config was applied Ignition: wrote ssh authorized keys file for user: core
The Ignition configuration file did not provide any password for the *core* user, therefore it is not possible to login directly via the console. (Though, it is possible to configure a password for users via Ignition configuration.)
Use Ctrl + ] key combination to exit the virtual machine’s console. Then check if the hello.service is running.
$ curl http://192.168.122.237:8080 Hello from Fedora CoreOS!
Using the preconfigured SSH key, you can also access the VM and inspect the services running on it.
$ ssh [email protected] $ systemctl status hello ● hello.service - Run a hello world web service Loaded: loaded (/etc/systemd/system/hello.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2020-10-28 10:10:26 UTC; 42s ago
#### zincati, rpm-ostree and automatic updates
The zincati service drives rpm-ostreed with automatic updates.
Check which version of Fedora CoreOS is currently running on the VM, and check if Zincati has found an update.
$ ssh [email protected] $ rpm-ostree status State: idle Deployments: ● ostree://fedora:fedora/x86_64/coreos/stable Version: 32.20200907.3.0 (2020-09-23T08:16:31Z) Commit: b53de8b03134c5e6b683b5ea471888e9e1b193781794f01b9ed5865b57f35d57 GPGSignature: Valid signature by 97A1AE57C3A2372CCA3A4ABA6C13026D12C944D0 $ systemctl status zincati ● zincati.service - Zincati Update Agent Loaded: loaded (/usr/lib/systemd/system/zincati.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2020-10-28 13:36:23 UTC; 7s ago … Oct 28 13:36:24 cosa-devsh zincati[1013]: [INFO ] initialization complete, auto-updates logic enabled Oct 28 13:36:25 cosa-devsh zincati[1013]: [INFO ] target release '32.20201004.3.0' selected, proceeding to stage it ... zincati reboot ...
After the restart, let’s remote login once more to check the new version of Fedora CoreOS.
$ ssh [email protected] $ rpm-ostree status State: idle Deployments: ● ostree://fedora:fedora/x86_64/coreos/stable Version: 32.20201004.3.0 (2020-10-19T17:12:33Z) Commit: 64bb377ae7e6949c26cfe819f3f0bd517596d461e437f2f6e9f1f3c24376fd30 GPGSignature: Valid signature by 97A1AE57C3A2372CCA3A4ABA6C13026D12C944D0 ostree://fedora:fedora/x86_64/coreos/stable Version: 32.20200907.3.0 (2020-09-23T08:16:31Z) Commit: b53de8b03134c5e6b683b5ea471888e9e1b193781794f01b9ed5865b57f35d57 GPGSignature: Valid signature by 97A1AE57C3A2372CCA3A4ABA6C13026D12C944D0
*rpm-ostree status* now shows 2 versions of Fedora CoreOS, the one that came in the QEMU image, and the latest one received from the update. By having these 2 versions available, it is possible to rollback to the previous version using the *rpm-ostree rollback* command.
Finally, you can make sure that the hello service is still running and serving content.
$ curl http://192.168.122.237:8080 Hello from Fedora CoreOS!
More information: [Fedora CoreOS updates](https://docs.fedoraproject.org/en-US/fedora-coreos/auto-updates/)
#### Deleting the Virtual Machine
To clean up afterwards, the following commands will delete the VM and associated storage.
$ virsh destroy fcos $ virsh undefine --remove-all-storage fcos
### Conclusion
Fedora CoreOS provides a solid and secure operating system tailored to run applications in containers. It excels in a DevOps environment which encourages the hosts to be provisioned using declarative configuration files. Automatic updates and the ability to rollback to a previous version of the OS, bring a peace of mind during the operation of a service.
Learn more about Fedora CoreOS by following the tutorials available in the project’s [documentation](https://docs.fedoraproject.org/en-US/fedora-coreos/tutorials/).
## Sergey
Thank you for the article.
And where can I read about CoreOS + Kubernetes ?
Or maybe I don’t fully understand the purpose of CoreOS ?
## Clément Verna
OKD (https://www.okd.io/) is using Fedora CoreOS so that might be a good place to look for more info
## Sergey
Excuse me one more question.
Is the information in this article relevant ? Why can’t you use ordinary images from the site ?
https://getfedora.org/en/coreos?stream=stable.
Thank.
## Clément Verna
You can and should use images from getfedora.org, this article is using an old image so that you can experience the auto-update feature.
Does that makes sense ?
## husimo
Hello, using Fedora 33 when I try
i have
. Seems the proper command is
.
Then I have an error using the yaml provided :
## Clément Verna
Thanks for pointing it out. It should be fixed now (fcct got a new release that changes the flags and the yaml formating was lost when adding the file in wordpress 🙂 )
## Anders Jackson
I guessing now, but usually there are Short and Long switches. Long are usually marked with two “-” characters and Short with one “-” characters prefix.
Short switches can be combined, so Short switch -i and -n could be combined into -in. Which isn’t a Long switch,.
So, long argument –input have two – prefix. characters and Short prefix version is just -i.
Markup languages usually change two – to a dash character, which isn’t a minus character… So that is why it can be wrong of you just cutand paste Commands into articles like this.
I would guess that -input is interpreted as the five Short switches -i -n -p -u -t and not the Long switch –input (with two -).
## Ignorante
What are the differences with Fedora Silverblue and Fedora IoT?
## Sergey
As I understand it :
Silverblue – desktop
IOT – rasperberry, router
CoreOS – container launching.
Maybe I am wrong.
## Dennis
Thanks! It’s very useful info for me!
## Sergey
Maybe not quite in the subject, but what are the mechanisms of local update ?
For example, we rock a new image, place it somewhere locally in the network and it is already being updated from …
Recently, using flatpak, SilverBlue and now CoreOS I have difficulties with the organization of a local mirror …
## Dennis K
Many users rely on Pulp (https://pulpproject.org) to create local mirrors of repositories. While Pulp does not support creating mirrors for Flatpak, SilverBlue or CoreOS, we would like to add support for all three.
Would you be interested in helping us understand what kind of workflows you are looking for?
Please file an issue at https://pulp.plan.io/issues/new/.
Thank you!
## Artur
You don’t need to know download address for coreos-installer, you can use in example:
it will download the newest testing image to current directory and decompress it for you.
## Dragnucs
I really like Fedora CoreOS. However, to be able to manage it using Ansible, one needs to install some python stuff in it.
So how can we install software using fcct and rpm-ostree, or precisly, how to manage it via Ansible?
## Dragnucs
To answer my self, one can add a one-shot systemd unit that hooks after system install and run an rpm-ostree install command. |
12,914 | 何时使用 5G,何时使用 Wi-Fi 6 | https://www.networkworld.com/article/3402316/when-to-use-5g-when-to-use-wi-fi-6.html | 2020-12-13T11:50:42 | [
"5G",
"Wi-Fi"
] | https://linux.cn/article-12914-1.html |
>
> 5G 是一种蜂窝服务, Wi-Fi 6 则是短程无线接入技术,这两种技术都有使其在特定企业角色中发挥作用的特性。
>
>
>

我们已经看到了关于 [5G](https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html) 蜂窝还是 [Wi-Fi 6](https://www.networkworld.com/article/3215907/why-80211ax-is-the-next-big-thing-in-wi-fi.html) 将在企业使用中胜出的大肆宣传,但事实却是这两者在很大程度上互补,这将在 21 世纪 20 年代初形成一个有趣的竞争环境。
### 5G 在企业中的潜力
5G 对企业用户的承诺是在更低的延迟下提供更高的连接速度。蜂窝技术使用许可频段,可在很大程度上消除未经许可的 WiFi 频段可能会发生的潜在干涉。像当前的 4G LTE 技术一样,5G 可以由蜂窝无线运营商提供,也可以作为专用网络构建。
5G 的架构需要更多的无线接入点,并且在室内可能会出现连接质量较差或没有连接。因此,典型的组织需要为连接它的 PC、路由器和其他设备评估其 [当前 4G 和潜在 5G 服务配置](https://www.networkworld.com/article/3330603/5g-versus-4g-how-speed-latency-and-application-support-differ.html)。部署室内微蜂窝、中继器以及分布式天线可以帮助解决室内 5G 服务问题。与 4G 一样,5G 最佳的企业应用案例应该是用于真正的移动连接,例如,公共安全车和非地毯式覆盖区域(如采矿,石油与天然气开采、运输、农业和一些制造业)。
除了广泛的移动性,5G 在漫游时的身份验证和部署速度方面也具有优势,这正好满足临时办公室或零售点的广域网连接需求。5G 将会拥有在视频直播这样的数据拥塞的情况下分流的能力。随着 5G 标准的成熟,该技术将提高其低功耗 IoT 连接的选择。
未来四到五年内,5G 将从大城市和特定地区开始逐步推出;4G 技术将在未来数年内继续流行。企业用户将需要新的设备、加密狗和路由器来连接 5G 服务。例如,苹果的 iPhone 预计要到 2020 年才能支持 5G,而物联网设备需要特定的蜂窝网络兼容性才能连接到 5G。(LCTT 译注:原文发表于 2019 年中)
Doyle Research 预计,5G 承诺的 1Gbps 和更高的带宽将对 SD-WAN 市场产生重大影响。4G LTE 已经使蜂窝服务成为主要的 WAN 连接。5G 可能比许多有线 WAN 选项(例如 MPLS 或互联网)更具成本竞争力或更便宜。5G 为企业 WAN 管理员提供了更多选择,为他们的分支站点和远程用户提供更多的带宽 —— 随着时间的推移,或将取代 MPLS。
### Wi-Fi 6 在企业中的潜力
Wi-Fi 几乎无处不在,它可以将便携式笔记本电脑、平板电脑和其他设备连接到企业网络中。Wi-Fi 6(802.11ax)是 Wi-Fi 的最新版本,并有望提高速度、降低延迟、改善聚合带宽并提供高级流量管理。虽然 Wi-Fi 6 与 5G 有一些相似之处(两者均基于正交频分多址),但 Wi-Fi 6 不太容易受到干扰,能耗更低(延长设备电池的寿命),并提高了频谱效率。
与典型的 Wi-Fi 相同,目前许多厂商都有 [Wi-Fi 6 早期厂商专用版本](https://www.networkworld.com/article/3309439/80211ax-preview-access-points-and-routers-that-support-the-wi-fi-6-protocol-on-tap.html)。Wi-Fi 联盟计划在 2020 年获得 Wi-Fi 6 标准设备的认证。大多数企业将按照标准<ruby> 接入点 <rt> access-point </rt></ruby>(AP)的生命周期(三年左右)升级到 Wi-Fi 6,除非他们有特定的性能/延迟要求,这将促使它们更快地升级。
Wi-Fi 接入点仍然会受到干涉的影响。设计和配置接入点以提供适当的覆盖范围将会是一项挑战。企业 LAN 管理者将继续需要供应商提供的工具和合作伙伴来为组织配置最理想的 Wi-Fi 覆盖。Wi-Fi 6 解决方案必须与有线区域基础建设集成。Wi-Fi 供应商需要更好地为企业提供无线和有线解决方案的统一网络管理。
### 有线回程的需求
对于这两种技术,通过无线与有线网络基础设施相结合,可以提供端到端的高速通信。在企业中,Wi-Fi 通常与区域和一些较大分支机构的有线以太网交换机搭配使用。一些设备通过电缆连接到交换机,其他设备则通过 Wi-Fi 连接,而笔记本电脑可能会同时采用这两种方法。Wi-Fi 接入点通过企业内部的以太网连接,并通过光纤连接连接到 WAN 或 Internet。
5G 的架构广泛使用光纤,将分布式无线接入网络连接回 5G 网络的核心。光纤通常需要提供将 5G 端点连接到基于 SaaS 的应用程序所需的高带宽,并提供实时视频和高速互联网访问。专用 5G 网络也必须满足高速有线连接要求。
### 切换问题
随着手机在 5G 和 Wi-Fi 6 之间切换,企业 IT 管理者要注意到切换挑战。这些问题会影响到性能和用户满意度。一些组织正在努力制定标准,以促进 Wi-Fi 6 和 5G 间更好的互操作性。 由于 Wi-Fi 6 的架构与 5G 接轨,在蜂窝网络与 Wi-Fi 网络间移动的体验应该更加顺滑。
### 5G 和 Wi-Fi 6 的对比取决于位置、应用和设备
Wi-Fi 6 和 5G 在企业环境中的特定情况下相互竞争,这取决于位置、应用程序和设备类型。IT 管理者应该仔细评估他们当前和正在出现的连接性需求。Wi-Fi 将继续占领室内环境优势,而移动蜂窝网络将赢得更为广泛的室外覆盖。
一些重叠的情况发生在体育场馆、酒店和其他大型活动场所,许多用户将争夺带宽。政府应用(包括智能城市方面)可适用于 Wi-Fi 和蜂窝。医疗保健设施中有许多分布式医疗设备和需要连接的用户。大型分布式制造环境具有相似的特点。新兴的物联网应用环境可能是最有趣的“重叠使用案例”。
### 对于 IT 领导者的建议
虽然支持它们的无线技术正在融合,但 Wi-Fi 6 和 5G 从根本上来说是不同的网络,在企业连接中都有各自的作用。企业 IT 领导者应关注 Wi-Fi 和蜂窝网络如何相互补足,Wi-Fi 将继续作为内置技术,连接 PC 和笔记本电脑,处理手机和平板电脑数据,并实现一些物联网连接。
4G LTE 升级到 5G 后,仍将是手机和平板电脑连接的真正移动技术,也是 PC 连接的一种选择(通过加密狗),并在连接一些物联网设备方面越来越受欢迎。5G WAN 链路将日益成为标准,作为提高 SD-WAN 可靠性的备份和远程办公室的主要链路。
---
via: <https://www.networkworld.com/article/3402316/when-to-use-5g-when-to-use-wi-fi-6.html>
作者:[Lee Doyle](https://www.networkworld.com/author/Lee-Doyle/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,915 | 如何在 Linux 终端上漂亮地打印 JSON 文件 | https://itsfoss.com/pretty-print-json-linux/ | 2020-12-13T12:24:30 | [
"JSON"
] | https://linux.cn/article-12915-1.html | 
[JSON](https://www.json.org) 文件非常棒,因为它们以人类可读的格式存储数据集合。然而,如果 JSON 文件被最小化过,那么阅读 JSON 文件可能会很痛苦。
以这个为例:

计算机可以很容易地读取它。即使是人也能读,但如果 JSON 文件以合适的格式显示,那么阅读就会简单很多。我的意思是 JSON 文件应该是这样读的:

你可以使用大多数的文本编辑器和一些插件以合适的格式显示它。然而,如果你在终端中,或者你想在你的 shell 脚本中这么做,事情会有所不同。
如果你有一个已最小化过的 JSON 文件,让我来告诉你如何在 Linux 终端中漂亮地输出它。
### 在 Linux 中用 jq 命令漂亮地打印 JSON 文件
[jq](https://stedolan.github.io/jq/) 是一个命令行 JSON 处理器。你可以用它来切分、过滤、映射和转换结构化数据。我在这里不打算详细介绍 `jq` 命令行工具的使用。
要使用 `jq`,你需要先安装它。你可以使用你的[发行版的包管理器](https://itsfoss.com/package-manager/)来安装它。如果启用了 [universe 仓库](https://itsfoss.com/ubuntu-repositories/),你可以使用 `apt` 命令在 Ubuntu 上安装它:
```
sudo apt install jq
```
安装好后,用下面的方法在显示屏上漂亮地打印 JSON 文件:
```
jq . sample.json
```

你可能也想用 `cat`,但我认为 `cat` 在这里没用。
```
cat sample.json | jq
```
请记住,上述命令不会影响原始 JSON 文件。不会向它写入任何更改。
你可能已经知道[如何在 Linux 中把命令输出重定向到一个文件](https://itsfoss.com/save-command-output-to-file-linux/)。你可能也知道不能重定向到同一个文件,而且 `tee` 命令也不能保证一直有效。
如果你想用漂亮的格式修改原来的 JSON 文件,可以把解析后的输出结果用管道传送到一个新的文件中,然后覆盖原来的 JSON 文件。
```
jq . sample.json > pretty.json
```

#### 额外技巧:用 jq 命令对 JSON 文件最小化。
让我们反过来,对一个格式良好的 JSON 文件进行最小化。要最小化 JSON 文件,你可以使用选项 `-c`。
```
jq -c < pretty.json
```

如果你愿意,你也可以使用 `cat` 和重定向:
```
cat pretty.json | jq -c
```
### 在 Linux 中使用 Python 来漂亮地打印 JSON 文件
你更有可能是在系统中安装了 Python。如果是这样的话,你可以用它在终端漂亮地打印 JSON 文件:
```
python3 -m json.tool sample.json
```

我知道还有其他方法可以解析 JSON 文件并以适当的格式打印出来。你可以自己去探索,但这两种方法足以完成漂亮地打印 JSON 文件的工作。
---
via: <https://itsfoss.com/pretty-print-json-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[JSON](https://www.json.org/?ref=its-foss) files are awesome because they store collection of data in a human-readable format. However, reading the JSON file can be a pain if the JSON file is minified.
Take this for an example:
A computer can easily read it. Even a human can still read it but if JSON file is properly formatted to display the content, it will be much easier. I mean JSON files are supposed to read like this after all:
You can use most text editors with some plugins to display it with proper formatting. However, things will be different if you are stuck to a terminal or want to do it in your shell script.
If you got a minified file, let me show you how to pretty print the JSON file in Linux terminal.
## Pretty print JSON with jq command in Linux
[jq](https://stedolan.github.io/jq/?ref=its-foss) is a command line JSON processor. You can use it to slice, filter, map and transform structured data. I am not going into details about using jq command line tool here.
To use jq, you need to install it first. You can use your [distribution’s package manager](https://itsfoss.com/package-manager/) to install it. With [universe repository enabled](https://itsfoss.com/ubuntu-repositories/), you can install it on Ubuntu using the apt command:
`sudo apt install jq`
Once you have it installed, use it in the following manner to pretty print JSON file on the display:
`jq . sample.json`
You may also tempt to use the cat command but I believe it is useless use of cat command.
`cat sample.json | jq`
Keep in mind that the above command will not impact the original JSON file. No changes will be written to it.
You probably already know [how to redirect the command output to a file in Linux](https://itsfoss.com/save-command-output-to-file-linux/). You probably also know that you cannot redirect to the same file and the tee command is not guaranteed to work all the time.
If you want to modify the original JSON file with pretty print format, you can pipe the parsed output to a new file and then copy it to the original JSON file.
`jq . sample.json > pretty.json`
### Bonus: Minify a JSON file with jq command
Let’s take a reverse stance and minify a well-formatted JSON file. To minify a JSON file, you can use the compact option -c.
`jq -c < pretty.json`
You can also use cat and redirection if you want:
`cat pretty.json | jq -c`
## Using Python to pretty print JSON file in Linux
It’s more likely that you have Python installed on your system. If that’s the case, you can use it pretty print the JSON file in the terminal:
`python3 -m json.tool sample.json`
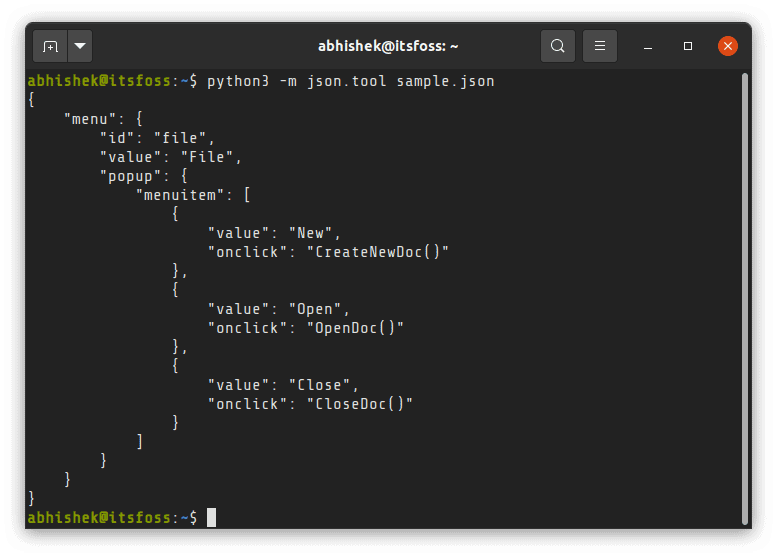
I know there are other ways to parse JSON file and print it in a proper format. You may explore them on your own but these two are sufficient to do the job, which is to pretty print JSON files. |
12,917 | 开源开发者说保护自己的代码是令人心力交瘁的浪费时间 | https://www.techrepublic.com/article/open-source-developers-say-securing-their-code-is-a-soul-withering-waste-of-time/ | 2020-12-13T23:07:23 | [
"安全"
] | https://linux.cn/article-12917-1.html | 
Linux 基金会对<ruby> 自由和开源软件 <rp> ( </rp> <rt> free and open-source software </rt> <rp> ) </rp></ruby>(FOSS)社区进行的一项新调查表明,贡献者花在安全问题上的时间不到 3%,而且几乎没有增加这一比例的意愿。
Linux 基金会和<ruby> 哈佛大学创新科学实验室 <rp> ( </rp> <rt> Laboratory for Innovation Science at Harvard </rt> <rp> ) </rp></ruby>(LISH)根据近 1200 名 FOSS 贡献者的回答所做的一份[报告](https://www.linuxfoundation.org/wp-content/uploads/2020/12/2020FOSSContributorSurveyReport_V7.pdf)显示,随着企业和经济越来越依赖开源软件,开发人员“明显需要”将更多的时间用于 FOSS 项目的安全。
该调查包括了旨在帮助研究人员了解贡献者如何分配他们在 FOSS 上的时间的问题,该调查显示,受访者平均只花了其总贡献时间的 2.27% 来应对安全问题。
此外,这些问题的回答还表明,许多受访者对增加安全方面的时间和精力兴趣不大。一位受访者评论说,他们“觉得安全是一件令人心力交瘁的苦差事,是一个最好留给律师和流程狂人的课题”,而另一位受访者则说:“我发现安全是一个令人难以忍受的、无聊的流程障碍。”
研究人员得出结论,需要对 FOSS 的安全和审计采取一种新的方法,以改善安全实践,同时控制对贡献者的负担。
贡献者需求最多的一些工具是错误和安全修复、免费的安全审计,以及将安全相关工具添加到其持续集成(CI)管道的简化方法。
“显然需要为 FOSS 的安全投入更多的精力,但这个负担不应该只落在贡献者身上。”报告中写道。“开发人员一般不想成为安全审计人员,他们希望得到审计结果。”
研究人员提出的其他解决方案包括:鼓励组织将精力重新投入到识别和解决项目本身的安全问题上。另外,开发人员“可以重写 FOSS 项目中容易出现漏洞的部分或整个组件”,而不是试图修补现有代码。
研究人员继续说道,“提高重写安全性的一种方法是将内存不安全的语言(如 C 或 C++)转换为内存安全的语言(几乎所有的其它语言)。……这将消除一整类漏洞,如缓冲区溢出和双重释放。”
性别多样性 —— 或者说,缺乏多样性 —— 是该报告的另一个关键发现。
在 1196 名调查对象中,91% 的人报告说是男性,年龄在 25 至 44 岁之间。研究人员指出,这一发现“强调了人们对 FOSS 社区缺乏女性代表的持续关注。”并指出,报告中缺乏女性代表表明,结果“偏向于男性贡献者的 FOSS 活动,并不能完全代表女性对 FOSS 的贡献。”
调查的大多数受访者来自北美或欧洲,大多数人从事全职工作。将近一半(48.7%)的人说,他们在开放源码贡献上花费的时间得到了雇主的报酬,而 44.02% 的人说,这是他们唯一得到报酬的途径。
有趣的是,结果表明,COVID-19 大流行病对贡献者的工作状态影响不大,只有极少数受访者报告说已脱离工作。研究人员再次指出,由于调查中缺乏女性代表,“这些调查结果可能并不能反映为 FOSS 做出贡献的女性的经历,特别是那些在大流行期间受到家庭责任增加影响的女性。”
虽然绝大多数受访者(74.8%)都是全职雇员,超过一半(51.6%)的受访者是专门为开发 FOSS 而接受报酬的,但在开发者为开源项目做出贡献的动机中,金钱的得分很低,“渴望得到同行的认可”也是如此。
相反,开发者说他们纯粹是对为他们正在开发的开源项目寻找功能、修复和解决方案感兴趣。其他最主要的动机包括享受和希望回馈他们所使用的 FOSS 项目。
“现代经济 —— 无论是数字经济还是实体经济 —— 越来越依赖于自由和开源软件,”<ruby> 哈佛商学院 <rp> ( </rp> <rt> Harvard Business School </rt> <rp> ) </rp></ruby>助理教授 Frank Nagle 说。
“了解 FOSS 贡献者的动机和行为是确保这一关键基础设施未来安全和可持续性的关键一环。”
---
via: <https://www.techrepublic.com/article/open-source-developers-say-securing-their-code-is-a-soul-withering-waste-of-time/>
作者:[Owen Hughes](https://www.techrepublic.com/meet-the-team/uk/owen-hughes/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12915-1.html) 荣誉推出
| 301 | Moved Permanently | null |
12,920 | 如何将 Linux 终端中命令的输出保存到文件中 | https://itsfoss.com/save-command-output-to-file-linux/ | 2020-12-14T22:40:32 | [
"重定向"
] | https://linux.cn/article-12920-1.html | 
当你在 Linux 终端中运行命令或脚本时,它会在终端中打印输出方便你立即查看。
有时你需要将输出保存到文件中以备将来参考。[当然你可以在 Linux 终端中复制和粘贴](https://itsfoss.com/copy-paste-linux-terminal/),但是有更好的方法可以在 Linux 命令行中保存 shell 脚本或命令的输出,让我演示给你看。
### 方法 1:使用重定向将命令输出保存到文件中
你可以[在 Linux 中使用重定向来达成目的](https://linuxhandbook.com/redirection-linux/)。使用重定向操作符,它会将输出保存到文件中而不是在屏幕上显示。
* `>` 会将命令输出重定向到文件,它会替换文件中的所有内容。
* `>>` 会将命令输出添加到文件现有内容的末尾。
使用标准输出重定向运算符 `>` 将输出重定向到文件:
```
command > file.txt
```
如果 `file.txt` 不存在,它会自动创建。如果你使用 `>` 再次重定向到相同的文件,文件内容将被替换为新的输出。
下面的示例将更好地演示它。它首先会保存 `ls -l` 命令的输出,然后,它将用 `ls *.c` 命令的输出替换文件的内容。

如果你不想在保存脚本或命令的输出时丢失现有文件的内容,可以使用 `>>` :
```
command >> file.txt
```
下面这个例子更好地展示了它:

即使文件不存在,它也会自动创建。
温馨提示:将 Linux 命令输出和错误保存到一个文件中。
如果 Linux 命令返回错误,那么错误不会保存在文件中。你可以使用 `2>&1` 将命令的输出和错误保存到同一个文件中,如下所示:
```
command > file.txt 2>&1
```
通常,`0` 代表标准输入,`1` 代表标准输出,`2` 代表标准错误。在这里,你要将标准错误(`2`) 重定向(`&`)到与标准输出(`1`)相同的地址。
### 方法 2:使用 tee 命令显示输出并将其保存到文件中
顺便说一句,你是否注意到,当你将命令输出发送到一个文件时,你再也无法在终端上看到它了?[Linux 的 tee 命令](https://linuxhandbook.com/tee-command/)解决了这个问题。
类似于将水流发送到两个方向的三通管,`tee` 命令将输出发送到终端以及文件(或作为另一个命令的输入)。你可以像这样使用它:
```
command | tee file.txt
```
同样,如果该文件不存在,它将自动创建。
你还可以使用 `tee` 命令 `-a` 选项进入附加模式:
```
command | tee -a file.txt
```
让我用一些简单的例子来演示:

我在例子中使用了简单的 Linux 命令。但是请放心,你也可以使用这些方法来保存 bash 脚本的输出。
### 注意:将命令输出保存到文件时,避免管道陷阱
你可能对管道重定向很熟悉,可以使用它来组合 Linux 命令,但不能将输出通过管道传输到文件,它显示找不到 `output.txt` 命令:

这是因为管道将一个命令的输出重定向到另一个命令的输入。在本例中,你向它传递一个了一个文件名而它期望一个命令。
如果你是一个 Linux 命令行新手,我希望这个快速教程对你的 Linux 知识有所帮助。[I/O 重定向](https://tldp.org/LDP/abs/html/io-redirection.html#FTN.AEN17894)是一个需要注意的基本概念。
一如既往,欢迎提出问题和建议。
---
via: <https://itsfoss.com/save-command-output-to-file-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you run a command or script in the Linux terminal, it prints the output on the screen for your immediate viewing.
There will be times when you need to save the output to a file for future references. Now, [you can surely copy and paste in Linux terminal](https://itsfoss.com/copy-paste-linux-terminal/) but there are better ways to save the output of a shell script or command in Linux command line. Let me show them to you.
## Method 1: Use redirection to save command output to file in Linux
You can [use redirection in Linux for this purpose](https://linuxhandbook.com/redirection-linux/?ref=itsfoss.com). With redirection operator, instead of showing the output on the screen, it goes to the provided file.
- The
`>`
redirects the command output to a file replacing any existing content on the file. - The
`>>`
redirect adds the command output at the end of the file's existing content (if any).
Use the STDOUT redirection operator > for redirecting the output to a file like this:
`command > file.txt`
If the file.txt doesn’t exist, it will be created automatically. If you use the > redirect again with the same file, the file content is replaced by the new output.
The example below demonstrates it better. It first saves the output of * ls -l* command. And then later, it replaces the content of the file with the output of
*command.*
*ls *.c*
If you don’t want to lose the content of the existing file while saving the output of a script or command, use the redirection operation in append mode with >>.
`command >> file.txt`
This example demonstrates it better:
Even here, if the file doesn’t exist, it is created automatically.
### Bonus Tip: Save Linux command output as well as error to a file
If your Linux command returns an error, it doesn’t get saved in the file. You can save both the command output and command error in the same file using `2>&1`
like this:
`command > file.txt 2>&1`
Basically, 0 stands for standard input, 1 for standard output and 2 for standard error.
Here, you are redirecting (>) standard error (2) to the same address (&) as standard output (1).
## Method 2: Use tee command to display the output and save it to a file as well
By the way, did you notice that when you send the command output to a file, you cannot see it anymore on the display? The [tee command in Linux](https://linuxhandbook.com/tee-command/?ref=itsfoss.com) solves this problem for you.
Like a tee pipe that sends a water stream in two directions, the tee command sends the output to the display as well as to a file (or as input to another command). You can use it like this:
`command | tee file.txt`
Again, the file will be created automatically if it doesn’t exist already.
You may also use the tee command in append mode with option -a in this manner:
`command | tee -a file.txt`
Let me demonstrate it with some easy-to-follow examples:
I have used simple Linux commands in my examples. But rest assured; you can use these methods to save the output of bash scripts as well.
## Note: Avoid pipe pitfall while saving command output to a file
You probably are familiar with pipe redirection. You may use it to combine Linux commands but you cannot pipe the output to a file. It will result in an error that filename command not found:
This is because the pipe redirects one command's output to another command's input. And in this case, you give it a file name while it is expecting a command.
If you are new to the Linux command line, I hope this quick tutorial added to your Linux knowledge a bit. [I/O redirection](https://tldp.org/LDP/abs/html/io-redirection.html?ref=itsfoss.com#FTN.AEN17894) is an essential concept that one should be aware of.
[Linux Command Tutorials for Absolute BeginnersNever used Linux commands before? No worries. This tutorial series is for absolute beginners to the Linux terminal.](https://itsfoss.com/tag/terminal-basics/)

As always, questions and suggestions are always welcome. |
12,921 | 什么 Linux 系统可以替换生产环境的 Linux 服务器上的 CentOS 8 | https://itsfoss.com/rhel-based-server-distributions/ | 2020-12-15T11:49:10 | [
"CentOS"
] | https://linux.cn/article-12921-1.html | CentOS 是世界上最流行的服务器发行版之一。它是<ruby> 红帽企业 Linux <rt> Red Hat Enterprise Linux </rt></ruby>(RHEL)的一个开源分支,提供了 RHEL 的优点,却没有 RHEL 的相关成本。
然而,最近情况发生了变化,[红帽正在将稳定的 CentOS 转换为滚动发布模式,即 CentOS Stream的形式](/article-12902-1.html)。CentOS 8 本来应该支持到 2029 年,但现在到 2021 年底就被迫停止了。
如果你的服务器使用的是 CentOS,这可能会让你不知道该何去何从。
你看,取代 CentOS 8 的首要选择就是 CentOS Stream。将 CentOS 8 升级到 CentOS Stream 的[过程很简单](https://linuxhandbook.com/update-to-centos-stream/),你不用担心需要重新安装任何东西。
不过,由于 CentOS Stream 是滚动发布性质的,你可能要考虑一些对生产服务器来说更稳定的东西。我将在本文中会推荐一些 Linux 系统来帮助你做出这个决定。
### 基于 RHEL 的服务器 Linux 发行版,你可以考虑用来取代 CentOS

我将从一些正在开发的 RHEL 分支版本开始列举,其唯一目的是取代 CentOS 8。之后,我会列出你可以马上使用的服务器发行版。
#### Rocky Linux(正在开发中)

就在红帽宣布计划用滚动发布的 CentOS Stream 取代稳定的 CentOS 8 的同一天,CentOS 的原开发者宣布了一个新项目,为 CentOS 用户提供 RHEL 分支。
这个新项目名为 [Rocky Linux](https://rockylinux.org)。它的名字是为了纪念原 CentOS 项目的共同创始人之一。它是从 RHEL 8 分支出来的,目标是“100% 与 RHEL 兼容”。
该项目正在快速开发中,目前可能无法使用。但这是在 2021 年底 CentOS 8 支持结束时取代它的首选之一。
#### Lenix 项目(开发中)

这是在宣布 CentOS Stream 成为默认版本一天后创建的又一个 RHEL 分支。
[Lenix 项目](https://www.reddit.com/r/ProjectLenix/)是由 CloudLinux 创建的,CloudLinux 是一家面向企业的服务机构,多年来一直在提供定制化的 CentOS 服务器,鉴于他们在 CentOS 和企业服务器方面的多年经验,Lenix 项目应该是一个很有前途的 RHEL 分支,可以取代 CentOS Stream。
#### Oracle Linux

这可能是该列表中唯一能以最佳方式使用的 RHEL 分支。不仅可以随时使用,你甚至可以[从现有的 CentOS 安装迁移到 Oracle Linux](https://github.com/oracle/centos2ol),而无需重新安装。
Oracle Linux 自 2006 年起推出。它的应用二进制 100% 兼容 RHEL,并且它提供了与每个 RHEL 版本相对应的版本。而且,你不需要与 Oracle 签署任何协议来使用 Oracle Linux。
Oracle Linux 有两种 Linux 内核可供选择:Oracle Linux 的<ruby> <a href="https://docs.oracle.com/en/operating-systems/uek/"> 坚不可摧企业级内核 </a> <rt> Unbreakable Enterprise Kernel </rt></ruby>(UEK)或<ruby> 红帽兼容内核 <rt> Red Hat Compatible Kernel </rt></ruby>(RHCK)。
只是,甲骨文在开源项目上有些黑历史,可能这也是为什么选择 CentOS 这种真正的社区分支形式而不是甲骨文 Linux 的原因。随着 CentOS 被 CentOS Stream 所取代,也许现在正是给 Oracle 一个机会的时候?
#### ClearOS(来自惠普)

[ClearOS](https://www.clearos.com) 是惠普在其 HPE ProLiant 服务器上提供的。虽然他们的网站上没有明确提到,但 ClearOS 是基于 RHEL 和 CentOS 的。
[Clear Center](https://www.clearcenter.com) 和 HPE 在这个项目上进行了合作。开源的 ClearOS 免费提供给社区。他们有自己的应用市场,混杂了免费和付费应用。你不需要为操作系统付费,但如果你选择了付费应用,你可能需要为该应用付费。
它可能没有那么流行,但随着 CentOS Stream 成为默认,如果惠普能抓住这个时机,ClearOS 应该能获得一些用户。他们会这么做吗?我不太确定。甲骨文正在努力吸引 CentOS 用户,但我没有看到惠普的这种努力。
#### Springdale Linux(普林斯顿大学的学术项目)

一个由院士维护的红帽分支?这就是 Scientific Linux 吧?但 Scientific Linux 已经死了一年多了。
[Springdale Linux](https://puias.math.ias.edu)(SDL)是普林斯顿大学的另一个这样的项目。它之前被称为 PUIAS Linux(<ruby> 普林斯顿大学高级研究所 <rt> Princeton University Institute for Advanced Study </rt></ruby>)。
目前还没有 RHEL 8 对应的 Springdale Linux,我觉得他们的开发速度可以加快一些。
### 不基于红帽的服务器发行版
好吧,到目前为止,列表中已经提到了基于红帽的发行版。现在是时候看看一些与 RHEL 无关,但仍然是生产服务器的上好选择的服务器发行版了。
#### YunoHost(专门为 Web 服务器定制的)

[YunoHost](https://yunohost.org#/) 是基于 Debian 定制的,目的是为你提供一个托管 Web 服务器的系统。
你可以在[树莓派等 ARM 板](https://itsfoss.com/raspberry-pi-alternatives/)、旧台式机和计算机上使用它,当然也可以在虚拟专用服务器(VPS)上使用。
YunoHost 还提供了一个基于 Web 的管理界面(灵感来自于 [Webmin](https://linuxhandbook.com/use-webmin/)?),这样你就可以用图形化的方式来管理系统。这对于一个想托管 Web 服务器但又不太会命令行的人来说,是一个很大的安慰。
#### Debian Linux

这个通用操作系统提供了一个坚如磐石的服务器发行版。对于那些想要一个稳定系统的人来说,是一个理想的选择。
如果你在 CentOS 上投入了太多的时间和技术,你可能会发现 [Debian](https://www.debian.org) 略有不同,尤其是软件包管理系统。不过,我相信,对于一个经验丰富的 Linux 系统管理员来说,这应该不是什么大问题。
#### openSUSE

SUSE 是红帽的直接竞争对手之一。他们以 [SUSE Linux Enterprise](https://www.suse.com/download/sles/) 的形式提供企业级产品。他们的开源产品 openSUSE 也相当受欢迎,无论是在桌面还是服务器领域。
[openSUSE](https://www.opensuse.org) 是一个服务器 Linux 发行版的好选择。现在的人不会明白 [SUSE 的 YAST 工具](https://yast.opensuse.org)在上世纪 90 年代和 2000 年初给用户带来了怎样的解脱。它仍然是管理 SUSE 系统的一个方便的工具。
openSUSE 有两种形式:滚动发布的 Tumbleweed 和稳定的点发布版的 Leap。我猜测你追求的是稳定性,所以 Leap 是你应该追求的目标。
#### Ubuntu

[Ubuntu](https://ubuntu.com/download/server) 是世界上最流行的发行版,[在服务器上](https://www.datanyze.com/market-share/operating-systems--443/ubuntu-market-share)和台式机上都是如此。这就是为什么没有 Ubuntu 这份清单就不完整的原因。
因为我已经使用 Ubuntu 很长时间了,所以我觉得在 Ubuntu 上托管我的 Web 服务器很舒服。但这只是我个人的想法。如果你是从 RHEL 领域过来的,这里的包管理系统和一些网络和管理组件是不同的。
[Ubuntu LTS 版](https://itsfoss.com/long-term-support-lts/)带有五年的支持,这是 CentOS 版本提供的一半长短。如果你不想升级版本,你可以选择为过时的 LTS 版本购买付费的扩展支持。
#### 你的选择是什么?
我已经列出了一些基于 RHEL 的发行版以及通用服务器发行版的顶级推荐。
现在轮到你了,在上面列出的发行版中,你最喜欢哪个?你有什么其他的建议可以添加到这个列表中吗?请在评论区留言。
---
via: <https://itsfoss.com/rhel-based-server-distributions/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | CentOS is one of the most popular server distributions in the world. It is an open source fork of Red Hat Enterprise Linux (RHEL) and provides the goodness of RHEL without the cost associated with RHEL.
However, things have changed recently. [Red Hat is converting the stable CentOS to a rolling release model in the form of CentOS Stream](https://itsfoss.com/centos-stream-fiasco/). CentOS 8 was supposed to be supported until 2029, but it is now forced discontinued by the end of 2021.
If you are using CentOS for your servers, it may make you wonder where to go from here.
See, the first choice for replacing CentOS 8 is CentOS Stream. The [process to upgrade CentOS 8 to CentOS Stream is simple](https://linuxhandbook.com/update-to-centos-stream/), and you don’t have to worry about reinstalling anything here.
However, since CentOS Stream is of rolling release nature, you may want to consider something more stable for a production server. I’ll help you with that decision by suggesting some recommendations in this article.
## RHEL-based server Linux distributions you may want to consider for replacing CentOS

I’ll start the list with some of the RHEL forks to replace CentOS 8. I’ll also list some server distributions that aren’t precisely RHEL forks but should come in handy.
### Rocky Linux

The same day Red Hat announced its plans to replace stable CentOS 8 with rolling release CentOS Stream, the original developer of CentOS announced a new project to provide RHEL fork to CentOS users.
This new project is called [Rocky Linux](https://rockylinux.org). It is named in the memory of one of the co-creators of the original CentOS project. It’s been forked from RHEL 8 and aims to be “100% bug-for-bug compatible with Red Hat Enterprise Linux”.
It offers easy migration, is supported by the community, and acts as a downstream to RHEL. So, this is one of the obvious choices to replace CentOS.
### AlmaLinux OS
[AlmaLinux](https://almalinux.org) (initially known as Project Lenix) is a CentOS alternative backed by the team behind CloudLinux OS.
While it is an initiative by a well-known organization, it also adopts the same principle of building for the community with their help.
The team behind AlmaLinux is an enterprise-oriented service that has been providing customized CentOS servers for several years now. So, their experience should reflect with AlmaLinux OS and should give you confidence in choosing AlmaLinux for your servers.
### Oracle Linux

Probably the only RHEL fork in this list that is ready to use in the best possible manner. Not only ready to use, but you can also even [migrate from an existing CentOS installation to Oracle Linux](https://github.com/oracle/centos2ol) without reinstalling it.
Oracle Linux has been available since 2006. It is 100% application binary compatible with Red Hat Enterprise Linux (RHEL) and it provides an equivalent to each RHEL release. And no, you don’t need to sign an agreement with Oracle for using Oracle Linux.
Oracle Linux comes with two choices of Linux kernels: the [Unbreakable Enterprise Kernel](https://docs.oracle.com/en/operating-systems/uek/) (UEK) for Oracle Linux or the Red Hat Compatible Kernel (RHCK).
It’s just that the track record of Oracle is not very good with open-source projects, and probably this is the reason a true community fork in the form of CentOS was preferred over Oracle Linux. With CentOS being replaced with CentOS Stream, perhaps it is the right time to give Oracle a chance?
### ClearOS (by HP)

[ClearOS](https://www.clearos.com) is offered by HP on its HPE ProLiant servers. Though it is not clearly mentioned on their website, ClearOS is based on RHEL and CentOS.
[Clear Center](https://www.clearcenter.com) and HPE have partnered on this project. The open source ClearOS available for free to the community. They have their app marketplace with a mix of free and paid applications. You don’t pay for the OS, but you may have to pay for the apps if you opt for a paid one.
It might not be that popular but with CentOS Stream becoming the default, ClearOS stands to gain some user base, if HP plays its cards right. Will they do it? I am not so sure. Oracle is trying to lure CentOS users, but I have seen no such efforts from HP.
### Springdale Linux (academic project from Princeton University)

A Red Hat fork maintained by academicians? That’s Scientific Linux, right? But Scientific Linux has been dead for over a year.
[Springdale Linux ](https://puias.math.ias.edu)(SDL) is another such project by Princeton University. It was previously known as PUIAS (Princeton University Institute for Advanced Study).
There is no RHEL 8 equivalent of Springdale Linux yet, which gives some hint about the speed of development here.
## Server distributions that are not based on Red Hat
Alright! So far, the list mentions the distributions based on Red Hat. It’s time to look at some of the server distributions that have nothing to do with RHEL, but they are still a good choice for your production server.
### YunoHost (Specially customized for web servers)
[YunoHost](https://yunohost.org/) is based on Debian and customized for the purpose of providing you with a system for hosting your web servers.
You can use it on [ARM boards like Raspberry Pi](https://itsfoss.com/raspberry-pi-alternatives/), old desktops, and computers on virtual private servers.
YunoHost also provides a web-based admin interface (inspired by [Webmin](https://linuxhandbook.com/use-webmin/)?) so that you can manage the system graphically. This is a great relief for someone who wants to host a web server without getting too much into the command line stuff.
### Debian Linux

The universal operating system provides a rock-solid server distribution—an ideal choice for those who want a stable system.
If you had invested too much time and skill in CentOS, you might find Debian slightly different, especially the package management system. Though, I believe it should not be much of a trouble for a seasoned Linux sysadmin.
### openSUSE

SUSE is one of the direct competitors of Red Hat. They have the enterprise offering in the form of [SUSE Linux Enterprise](https://www.suse.com/download/sles/). Their open-source offering openSUSE is also quite popular, both as desktop and server.
[openSUSE](https://www.opensuse.org) makes up a good choice for a server Linux distribution. People these days won’t understand what a relief [YAST tool of SUSE](https://yast.opensuse.org) brought for users in the last 90s and early 2000s. It is still a handy utility for managing the SUSE system.
openSUSE comes in two formats: the rolling release Tumbleweed and the stable point release Leap. I am guessing you are looking for stability, so Leap is what you should be aiming for.
### Ubuntu

[Ubuntu](https://ubuntu.com/download/server) is the most popular distribution in the world, [both on servers](https://www.datanyze.com/market-share/operating-systems--443/ubuntu-market-share) and desktops. This is why this list could not have been completed without Ubuntu.
Since I have been using Ubuntu for a long time, I feel comfortable hosting my web servers on Ubuntu. But that’s just me. If you are coming from the RHEL domain, package management is different here, along with a few networking and management components.
[Ubuntu LTS version](https://itsfoss.com/long-term-support-lts/) comes with five years of support, which is half of what a CentOS release provided. You may opt for paid extended support for an outdated LTS version if you want to avoid upgrading versions.
### What’s your choice?
I have listed some top recommendations for RHEL based distributions as well as for generic server distributions.
Now it’s your turn. Which of the above-listed distributions do you like the most? Do you have any other suggestions to add to this list? The comment section is all yours. |
12,923 | 为什么我喜欢 Emacs | https://opensource.com/article/20/12/emacs | 2020-12-15T23:42:33 | [
"Emacs"
] | https://linux.cn/article-12923-1.html |
>
> Emacs 并不是一个单纯的文本编辑器,它将掌控置于你手中,让你几乎可以解决你遇到的任何问题。
>
>
>

我是一个典型的 [Emacs](https://en.wikipedia.org/wiki/Emacs) 用户。不是我选择的 Emacs,而是它选择了我。早在我刚开始学习 Unix 的时候,我偶然发现了一个奇怪的名为 Emacs 的应用程序,它隐藏在我的电脑上,其中有一个鲜为人知的功能。传说中(而且被证明是真的),如果你在终端上输入 `emacs`,按 `Alt+X`,然后输入 `tetris`,你就可以玩一个掉方块的游戏。

那就是我对 GNU Emacs 的印象。虽然这很肤浅,但它也准确地表明了 Emacs 的意义:用户可以重新编程他们的(虚拟)世界,并且可以用一个应用程序做*任何*他们想做的事情。在你的文本编辑器中玩俄罗斯方块可能不是你日常的主要目标,但这说明 Emacs 是一个值得骄傲的编程平台。事实上,你可以把它看作是 [Jupyter](https://opensource.com/article/20/11/surprising-jupyter) 的一种先驱,它把一种强大的编程语言(准确的说叫 elisp)和自己的实时环境结合起来。因此,Emacs 作为一个文本编辑器是灵活的、可定制的、强大的。
如果你习惯于 Bash、Python 或类似的语言,elisp(以及扩展的 Common Lisp)不一定是最容易入门的语言。但是这种 LISP 方言是很强大的,而且因为 Emacs 是一个 LISP 解释器,所以你可以用它构建应用程序,不管它们是 Emacs 插件还是你想开发成一个独立项目的原型。极其流行的 [org 模式项目](https://opensource.com/article/19/1/productivity-tool-org-mode)就是一个例子:它是一个 Emacs 插件,同时也是一个标记语法,有移动应用可以解释和扩展其功能。类似的有用的 Emacs 内应用的例子还有很多,包括电子邮件客户端、PDF 浏览器、Web 浏览器、shell 和文件管理器。
### 两个界面
GNU Emacs 至少有两个用户界面:图形用户界面(GUI)和终端用户界面(TUI)。这有时会让人感到惊讶,因为 Emacs 经常与运行在终端中的 Vi 相提并论(尽管 gVim 为现代 Vi 的实现提供了一个 GUI)。如果你想把 GNU Emacs 以终端程序来运行,你可以用 `-nw` 选项来启动它。
```
$ emacs -nw
```
有了 GUI 程序,你可以直接从应用程序菜单或终端启动 Emacs。
你可能会认为 GUI 会降低 Emacs 的效率,好像“真正的文本编辑器是在终端中运行的”,但 GUI 可以使 Emacs 更容易学习,因为它的 GUI 遵循了一些典型的惯例(菜单栏、可调节的组件、鼠标交互等)。
事实上,如果你把 Emacs 作为一个 GUI 应用程序来运行,你可能在一天的时间里会完全没有意识到你在 Emacs 中。只要你使用过 GUI,大多数常用的惯例都适用。例如,你可以用鼠标选择文本,导航到**编辑**菜单,选择**复制**,然后将光标放在其他地方,选择**粘贴**。要保存文档,你可以进入**文件**,然后选择**保存**或**另存为**。你可以按 `Ctrl` 键并向上滚动,使屏幕字体变大,你可以使用滚动条来浏览你的文档,等等。
了解 Emacs 的 GUI 形式是拉平学习曲线的好方法。
### Emacs 键盘快捷键
GNU Emacs 以复杂的键盘组合而恶名远扬。它们不仅陌生(`Alt+W` 来复制?`Ctrl+Y` 来粘贴?),而且还用晦涩难懂的术语来标注(`Alt` 被称为 `Meta`),有时它们成双成对(`Ctrl+X` 后是 `Ctrl+S` 来保存),有时则单独出现(`Ctrl+S` 来搜索)。为什么有人会故意选择使用这些呢?
嗯,有些人不会。但那些喜欢这些的人是因为这些组合很容易融入到日常打字的节奏中(而且经常让 `Caps Lock` 键充当 `Ctrl` 键)。然而,那些喜欢不同的东西的人有几个选择:
* “邪恶”模式让你在 Emacs 中使用 Vim 键绑定。就是这么简单。你可以保留你的肌肉记忆中的按键组合,并继承最强大的文本编辑器。
* 通用用户访问(CUA)键保留了所有 Emacs 常用的组合键,但最令人头疼的键(复制、剪切、粘贴和撤消)都被映射到现代的键盘绑定中(分别为 `Ctrl+C`、`Ctrl+X`、`Ctrl+V` 和 `Ctrl+Z`)。
* `global-set-key` 函数,是 Emacs 编程的一部分,允许你定义自己的键盘快捷键。传统上,用户定义的快捷键以 `Ctrl+C` 开头,但没有什么能阻止你发明自己的方案。Emacs 并不敝帚自珍,欢迎你按照自己的意愿来扭转它。
### 学习 Emacs
要想很好地使用 Emacs 是需要时间的。对我来说,这意味着打印出一张[速记表](https://opensource.com/downloads/emacs-cheat-sheet),每天都把它放在键盘旁边。当我忘了一个键组合时,我就在我的速记表上查找它。如果它不在我的速记表上,我就学习这个键盘组合,要么通过执行该函数,并注意 Emacs 告诉我如何更快地访问它,要么通过使用 `describe-function`:
```
M-x describe-function: save-buffer
save-buffer is an interactive compiled Lisp function in ‘files.el’.
It is bound to C-x C-s, <menu-bar> <file> <save-buffer>.
[...]
```
当你使用它的时候,你就会学习它。你对它了解得越多,你就越有能力去改进它,使它变成你自己的。
### 尝试 Emacs
人们常开玩笑说 Emacs 是一个包含文本编辑器的操作系统。也许这是在暗示 Emacs 臃肿和过于复杂,当然也有一种说法是文本编辑器根据其默认配置不应该需要 `libpoppler`(你可以不需要它来编译 Emacs)。
但这个笑话背后潜藏着一个更大的真相,它揭示了 Emacs 如此有趣的原因。将 Emacs 与其他文本编辑器,如 Vim、Nano,甚至 [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code) 进行比较是没有意义的,因为 Emacs 真正重要的部分并不是你可以在窗口中输入东西并保存的这种思路。那是连 Bash 都能提供的基本功能。Emacs 的真正意义在于它如何将控制置身于你的手中,以及如何通过 Emacs Lisp([Elisp](https://www.gnu.org/software/emacs/manual/html_node/elisp/))解决几乎任何问题。
---
via: <https://opensource.com/article/20/12/emacs>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I'm a habitual [Emacs](https://en.wikipedia.org/wiki/Emacs) user. I didn't choose Emacs as much as it chose me. Back when I was first learning about Unix, I stumbled upon a little-known feature in a strange application called Emacs, which was apparently hidden away on my computer. Legend had it (and was proven true) that if you typed `emacs`
into a terminal, pressed **Alt**+**X**, and typed `tetris`
, you could play a falling-blocks game.
That was my introduction to GNU Emacs. While it was frivolous, it was also an accurate indication of what Emacs is all about—the idea that users can reprogram their (virtual) worlds and do *whatever* they want with an application. Playing Tetris in your text editor is probably not your primary goal on an everyday basis, but it goes to show that Emacs is, proudly, a programming platform. In fact, you might think of it as a kind of precursor to [Jupyter](https://opensource.com/article/20/11/surprising-jupyter), combining a powerful programming language (called `elisp`
, to be exact) with its own live environment. As a consequence, Emacs is flexible as a text editor, customizable, and powerful.
Elisp (and Common Lisp, by extension) aren't necessarily the easiest languages to start out on, if you're used to Bash or Python or similar languages. But LISP dialects are powerful, and because Emacs is a LISP interpreter, you can build applications, whether they're Emacs plugins or prototypes of something you want to develop into a stand-alone project. The wildly popular [org-mode project](https://opensource.com/article/19/1/productivity-tool-org-mode) is just one example: it's an Emacs plugin as well as a markdown syntax with mobile apps to interpret and extend its capabilities. There are many examples of similarly useful applications-within-Emacs, including an email client, a PDF viewer, web browser, a shell, and a file manager.
## Two interfaces
GNU Emacs has at least two user interfaces: a graphical user interface (GUI) and a terminal user interface (TUI). This sometimes surprises people because Emacs is often pitted against Vi, which runs in a terminal (although gVim provides a GUI for a modern Vi implementation). If you want to run GNU Emacs as a terminal application, you can launch it with the `-nw`
option:
`$ emacs -nw`
With a GUI, you can just launch Emacs from your application menu or a terminal.
You might think that a GUI renders Emacs less effective, as if "real text editors run in a terminal," but a GUI can make Emacs easier to learn because its GUI follows some typical conventions (a menu bar, adjustable widgets, mouse interaction, and so on).
In fact, if you run Emacs as a GUI application, you can probably get through the day without noticing you're in Emacs at all. Most of the usual conventions apply, as long as you use the GUI. For instance, you can select text with your mouse, navigate to the **Edit** menu, select **Copy**, and then place your cursor elsewhere and select **Paste**. To save a document, you can go to **File** and **Save** or **Save As**. You can press **Ctrl** and scroll up to make your screen font larger, you can use the scroll bar to navigate through your document, and so on.
Getting to know Emacs in its GUI form is a great way to flatten the learning curve.
## Emacs keyboard shortcuts
GNU Emacs is infamous for complex keyboard combinations. They're not only unfamiliar (**Alt**+**W** to copy? **Ctrl**+**Y** to paste?), they're also notated with arcane terminology ("Alt" is called "Meta"), and sometimes they come in pairs (**Ctrl**+**X** followed by **Ctrl**+**S** to save) and other times alone (**Ctrl**+**S** to search). Why would anyone willfully choose to use this?
Well, some don't. But those who do are fans of how these combinations easily flow into the rhythm of everyday typing (and often have the **Caps Lock** key serve as a **Ctrl** key). Those who prefer something different, however, have several options.
- The
`evil`
mode lets you use Vim keybindings in Emacs. It's that simple: You get to keep the key combinations you've committed to muscle memory, and you inherit the most powerful text editor available. - Common User Access (CUA) keys keep all of the usual Emacs key combinations but the most jarring ones—copy, cut, paste, and undo—are all mapped to their modern bindings (
**Ctrl**+**C**,**Ctrl**+**X**,**Ctrl**+**V**, and**Ctrl**+**Z**, respectively). - The
`global-set-key`
function, part of the programming side of Emacs, allows you to define your own keyboard shortcuts. Traditionally, user-defined shortcuts start with**Ctrl**+**C**, but nothing is stopping you from inventing your own scheme. Emacs isn't precious of its own identity. You're welcome to bend it to your will.
## Learn Emacs
It takes time to get very good with Emacs. For me, that meant printing out a [cheat sheet](https://opensource.com/downloads/emacs-cheat-sheet) and keeping it next to my keyboard all day, every day. When I forgot a key combo, I looked it up on my cheat sheet. If it wasn't on my cheat sheet, I learned the keyboard combo, either by executing the function and noting how Emacs told me I could access it quicker or by using `describe-function`
:
```
M-x describe-function: save-buffer
save-buffer is an interactive compiled Lisp function in ‘files.el’.
It is bound to C-x C-s, <menu-bar> <file> <save-buffer>.
[...]
```
As you use it, you learn it. And the more you learn about it, the more empowered you become to improve it and make it your own.
## Try Emacs
It's a common joke to say that Emacs is an operating system with a text editor included. Maybe that's meant to insinuate Emacs is bloated and overly complex, and there's certainly an argument that a text editor shouldn't require `libpoppler`
according to its default configuration (you can compile Emacs without it).
But there's a greater truth lurking behind this joke, and it reveals a lot about what makes Emacs so fun. It doesn't make sense to compare Emacs to other text editors, like Vim, Nano, or even [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code), because the really important part of Emacs isn't the idea that you can type stuff into a window and save it. That's basic functionality that even Bash provides. The true significance of Emacs is how it places you in control and how, through Emacs Lisp ([Elisp](https://www.gnu.org/software/emacs/manual/html_node/elisp/)), nearly any problem can be solved.
## 13 Comments |
12,926 | 如何感召人们让其参与到开源活动中 | https://opensource.com/article/20/10/influence-open-source | 2020-12-17T10:30:00 | [
"开源"
] | https://linux.cn/article-12926-1.html |
>
> 向他人介绍开源最有效的办法是,告诉他们开源可以提供给他们想要的。
>
>
>

如果你在浏览这里,可能你会编程,而且或许你正使用某些难以捉摸的 [Linux 发行版](https://distrowatch.com/)的开源浏览器上阅读这些内容。你也许很多年没有看到过浏览器广告了,因为你正运行着一个[开源的广告拦截器](https://opensource.com/article/20/4/ad-blockers)。当你想到企鹅时,你感到温暖而又陌生。
简单地说,你知道开源的力量,并且它已经成了你生活的一部分。不幸的是,并不是每个人都发现了如何利用开源的方式。他们的电脑慢得令人痛苦,当他们上网浏览时他们看到的广告比内容都多,他们把钱花在专利和版权的垃圾上。这些人中可能有些是与你有关系的,例如你的侄女和侄子。
### 知识就是财富
那么你如何向你的侄女和侄子(以及任意一个人)介绍开源?
我尝试着回答这个问题,作为一个教授,一个以长篇大论著称的职业,我最终还是出了一本书:[《使用开源项目创造、分享和省钱》](https://www.appropedia.org/Create,_Share,_and_Save_Money_Using_Open-Source_Projects),由 McGraw-Hill 出版。
我认为诀窍在于先发现你的侄女或侄子想要获取但没有钱去购买的东西,然后向他们展示如何通过开源知识来得到他们想要的东西。

*[可升降的桌子](https://www.appropedia.org/File:Opendesk_furniture_lift-standing-desk.jpg) (Joni Steiner and Nick Ierodiaconou, [CC-BY-SA-NC](https://creativecommons.org/licenses/by-nc-sa/2.0/))*
知识是所有商品里独特的财富。不像黄金或小麦,它不仅在分享时会保留价值,而且可以迅速增值。因为互联网信息分享成本趋近于零,因此无限地扩展了此过程。每个可以访问互联网的人都史无前例地拥有这一财富。例如,我提供[免费的仓库链接](https://www.appropedia.org/Create,_Share,_and_Save_Money_Using_Open-Source_Projects)到关于书籍、教育、电影、攻略、地图、音乐、照片、艺术品、软件和烹饪等内容。
### 不要买,而是去制作它
免费和开源逐渐扩展到现实世界,我们现在有机会从根本上降低通过沃尔玛或亚马逊购买的东西的成本,包括[玩具](http://www.mdpi.com/2227-7080/5/3/45)、[电器](https://doi.org/10.3390/inventions3030064)、[家居用品](https://www.mdpi.com/2227-7080/5/1/7)和衣服。使用 3D 打印或类似的工具,结合开源分享和数字制造,使得每个人可以制造属于他们自己的复杂的、有用的工具。

*[3D 打印的家居用品](https://www.appropedia.org/File:3dprinted_household.JPG) (Joshua M. Pearce, [CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/))*
前些年,科学家已经[在他们的实验室](https://opensource.com/article/20/10/open-source-hardware-savings)中做这些工作了。但是现在,任何人都可以轻松地定制满足他们具体需求的产品。已经有数百万个免费的设计可供使用。

*[Recyclebot](https://www.appropedia.org/File:Recyclebotrep.png) (Joshua M. Pearce, [GPLv3](https://www.gnu.org/licenses/gpl-3.0.html))*
真正降低一个产品的价格,就要[通过垃圾来获取其原材料](https://www.academia.edu/34738483/Tightening_the_Loop_on_the_Circular_Economy_Coupled_Distributed_Recycling_and_Manufacturing_with_Recyclebot_and_RepRap_3-D_Printing)。伴随着小规模的回收利用过程(例如我实验室正在使用的 [Recyclebots](https://www.appropedia.org/Recyclebot))最近得到了改进,这使得人们可以从废物中制造有用的产品,因此产生了一系列让人眼花缭乱的产品。最重要的是,任何人都可以利用专有系统的一小部分成本来获取到这些定制的绿色产品。我们生产出相比常规商品销售税更低的[定制产品](https://opensource.com/article/17/3/how-to-create-consumer-goods-open-hardware)——它们具有相同的功能,更好的定制形式,而且几乎没有成本。
### 了解更多
在[《使用开源项目创建、分享和省钱的项目》](https://www.appropedia.org/Create,_Share,_and_Save_Money_Using_Open-Source_Projects)一书中,我分享了在家庭制造和回收利用的潜力,以及如何利用开源来为大宗商品评分,如房屋、电力。你可以在我和 Megan Krieger 以及 Janet Callahan 三人为密歇根理工学院的 [Husky Bites](https://www.facebook.com/Michigan-Tech-College-of-Engineering-109353424030003/videos/husky-bites-presents-special-guest-joshua-m-pearce/2669023713361207/) 录制的网络研讨会了解更多。
希望这些知识能足够激励你把一到两个侄女或侄子带到开源的路上来!
---
via: <https://opensource.com/article/20/10/influence-open-source>
作者:[Joshua Pearce](https://opensource.com/users/jmpearce) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you are reading Opensource.com, you might be able to code, and you are probably reading this on an open source browser on some elusive [Linux distro](https://distrowatch.com/). You probably have not seen a browser ad in years because you are running an [open source ad blocker](https://opensource.com/article/20/4/ad-blockers). You feel warm and fuzzy when you think about penguins.
Simply, you know the power of the force of open source and have made it part of your life. Sadly, not everyone has found the open source way yet. Their computers are painfully slow; they see more ads than content when they surf the web; they spend their money on patented and copyrighted junk. Some of these people may even be related to you—take your nieces and nephews, for example.
## Knowledge is wealth
So, how do you introduce your nieces and nephews (and everyone else) to open source?
I tried to answer this question and being a professor, a profession well known for being long-winded, I ended up with a book: [ Create, Share, and Save Money Using Open Source Projects](https://www.appropedia.org/Create,_Share,_and_Save_Money_Using_Open-Source_Projects), published by McGraw-Hill
The trick, I think, is finding something that your niece or nephew wants but doesn't have the money to buy, then showing them how open source knowledge can get them what they want.

Lift Standing Desk (Joni Steiner and Nick Ierodiaconou, CC-BY-SA-NC)
Knowledge has a unique property among commodities. Unlike gold or wheat, it not only retains value when it is shared, but it can rapidly increase in value. The internet enables unlimited scaling of this process, as the price of information-sharing approaches zero. Everyone with internet access has historically unprecedented access to this wealth. For example, I provide [free links to repositories](https://www.appropedia.org/Create,_Share,_and_Save_Money_Using_Open-Source_Projects) with books, education, movies, how-tos, maps, music, photographs, art, software, and recipes.
## Don't buy it, make it
Free and open source is expanding further into the physical world, and we all have the opportunity to radically reduce the cost of just about everything you can buy at Walmart or Amazon, including [toys](http://www.mdpi.com/2227-7080/5/3/45), [electronics](https://doi.org/10.3390/inventions3030064), [household goods](https://www.mdpi.com/2227-7080/5/1/7), and clothing. The combination of open source sharing and digital manufacturing—using 3D printers and similar tools—enables individuals to make their own complex, valuable products.

3D-printed household items (Joshua M. Pearce, CC BY-SA 3.0)
For years, scientists have been doing this [in their labs](https://opensource.com/article/20/10/open-source-hardware-savings). But now, anyone can easily customize products to fit their exact needs. There are already millions of free designs available.

Recyclebot (Joshua M. Pearce, CPLv3)
The way to really knock the bottom out of a product's price is to [source the raw materials from trash](https://www.academia.edu/34738483/Tightening_the_Loop_on_the_Circular_Economy_Coupled_Distributed_Recycling_and_Manufacturing_with_Recyclebot_and_RepRap_3-D_Printing). This is possible for a dizzying array of products because of recent improvements in small-scale recycling processes (like [Recyclebots](https://www.appropedia.org/Recyclebot), which I use in my lab) that enable people to make valuable products from waste. Best of all, anyone can get these green, custom creations for a small fraction of the cost of a proprietary system. We can normally produce a custom product for [less than the sales tax](https://opensource.com/article/17/3/how-to-create-consumer-goods-open-hardware) on a conventional product—with the same functionality, a better, customized form, and almost no cost.
## Learn more
In * Create, Share, and Save Money Using Open Source Projects,* I share the potential in at-home manufacturing and recycling and even how to score free big-ticket items, including housing and electricity, with open source. You can also learn more about this on a webinar I recorded with Megan Krieger and Janet Callahan for Michigan Tech's
[Husky Bites](https://www.facebook.com/Michigan-Tech-College-of-Engineering-109353424030003/videos/husky-bites-presents-special-guest-joshua-m-pearce/2669023713361207/).
Hopefully, this knowledge is motivating enough to pull in a niece or nephew or two over to the open source way!
## Comments are closed. |
12,927 | 如何在 CentOS/RHEL 系统中使用带 VLAN 标记的以太网卡 | https://www.linuxtechi.com/vlan-tagged-nic-ethernet-card-centos-rhel-servers/ | 2020-12-17T12:39:00 | [
"VLAN"
] | https://linux.cn/article-12927-1.html | 在某些场景中,我们希望在 Linux 服务器(CentOS/RHEL)的同一块以太网卡(NIC)上分配来自不同 VLAN 的多个 IP。这个可以通过使用 VLAN 标记接口来实现。但是要做到这一点,我们必须确保交换机的端口上连接了多个 VLAN,也就是说我们可以在交换机上添加多个 VLAN 来配置<ruby> 聚合端口 <rt> Trunk port </rt></ruby>(LCTT 译注:一般有<ruby> 聚合端口 <rt> Trunk port </rt></ruby>、<ruby> 接入端口 <rt> Access port </rt></ruby>、<ruby> 混合端口 <rt> Hybird port </rt></ruby>三种)。

假设我们有一个 Linux 服务器,我们在这里有两张以太网卡(`enp0s3` 和 `enp0s8`),第一张网卡(`enp0s3`)会用于数据传输,而第二张网卡(`enp0s8`) 会用于控制/流量管理。我会使用多个 VLAN 用于数据传输(或在数据流量网卡上从不同的 VLAN 中分配多个 IP)。
我假设连接到我服务器的数据网卡的端口,是通过映射多个 VLAN 来配置为聚合端口。
下面是映射到数据传输网卡(NIC)的 VLAN:
* VLAN ID (200), VLAN N/W = 172.168.10.0/24
* VLAN ID (300), VLAN N/W = 172.168.20.0/24
要在 CentOS 7 / RHEL 7 / CentOS 8 / RHEL 8 系统中使用 VLAN 标记接口,必须加载[内核模块](https://www.linuxtechi.com/how-to-manage-kernel-modules-in-linux/) `8021q` 。
加载内核模块 `8021q` 可以使用下面的命令:
```
[root@linuxtechi ~]# lsmod | grep -i 8021q
[root@linuxtechi ~]# modprobe --first-time 8021q
[root@linuxtechi ~]# lsmod | grep -i 8021q
8021q 29022 0
garp 14384 1 8021q
mrp 18542 1 8021q
[root@linuxtechi ~]#
```
可以使用 `modinfo` 命令显示内核模块 `8021q` 的详细信息:
```
[root@linuxtechi ~]# modinfo 8021q
filename: /lib/modules/3.10.0-327.el7.x86_64/kernel/net/8021q/8021q.ko
version: 1.8
license: GPL
alias: rtnl-link-vlan
rhelversion: 7.2
srcversion: 2E63BD725D9DC11C7DA6190
depends: mrp,garp
intree: Y
vermagic: 3.10.0-327.el7.x86_64 SMP mod_unload modversions
signer: CentOS Linux kernel signing key
sig_key: 79:AD:88:6A:11:3C:A0:22:35:26:33:6C:0F:82:5B:8A:94:29:6A:B3
sig_hashalgo: sha256
[root@linuxtechi ~]#
```
现在使用 [ip 命令](https://www.linuxtechi.com/ip-command-examples-for-linux-users/)给 `enp0s3` 网卡标记(或映射)上 `200` 和 `300` 的 VLAN 。
(LCTT 译注:这是先给 `enp0s3` 网卡映射上 `200` 的 VLAN 标签。)
```
[root@linuxtechi ~]# ip link add link enp0s3 name enp0s3.200 type vlan id 200
```
使用下面的 `ip` 命令打开接口:
```
[root@linuxtechi ~]# ip link set dev enp0s3.200 up
```
同理给 `enp0s3` 网卡映射上 `300` 的 VLAN 标签:
```
[root@linuxtechi ~]# ip link add link enp0s3 name enp0s3.300 type vlan id 300
[root@linuxtechi ~]# ip link set dev enp0s3.300 up
```
现在使用 `ip` 命令查看标记后的接口状态:

现在我们可以使用下面的 `ip` 命令从它们各自的 VLAN 为已经标记的接口分配 IP 地址:
```
[root@linuxtechi ~]# ip addr add 172.168.10.51/24 dev enp0s3.200
[root@linuxtechi ~]# ip addr add 172.168.20.51/24 dev enp0s3.300
```
使用下面的 `ip` 命令查看是否为已标记的接口分配到 IP:

重启之后,上面所有通过 `ip` 命令的更改都不会保持(LCTT 译注:修改后可保存至配置文件或数据库中,如果未进行保存处理,则只有当前环境生效,重启后配置失效)。系统重启和网络服务重启(LCTT 译注:`service network restart`,或 `down` 和 `up` 命令)之后这些标记接口将不可用。
因此,要使标记的接口在重启后保持不变,需要使用接口的 `ifcfg` 文件。
编辑接口(`enp0s3`)文件 `/etc/sysconfig/network-scripts/ifcfg-enp0s3`,并且增加下面的内容:
**作者提醒**:替换为你环境中的接口名称。
```
[root@linuxtechi ~]# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
TYPE=Ethernet
DEVICE=enp0s3
BOOTPROTO=none
ONBOOT=yes
```
保存和退出文件。
为 id 是 `200` 的 VLAN 创建接口文件 `/etc/sysconfig/network-scripts/ifcfg-enp0s3.200`,且增加下面的内容:
```
[root@linuxtechi ~]# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3.200
DEVICE=enp0s3.200
BOOTPROTO=none
ONBOOT=yes
IPADDR=172.168.10.51
PREFIX=24
NETWORK=172.168.10.0
VLAN=yes
```
保存并退出此文件。
同理为 id 是 `300` 的 VLAN 创建接口文件 `/etc/sysconfig/network-scripts/ifcfg-enp0s3.300`,且增加下面的内容:
```
[root@linuxtechi ~]# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3.300
DEVICE=enp0s3.300
BOOTPROTO=none
ONBOOT=yes
IPADDR=172.168.20.51
PREFIX=24
NETWORK=172.168.20.0
VLAN=yes
```
保存并退出文件,这时候使用下面的命令重启网络服务,
```
[root@linuxtechi ~]# systemctl restart network
```
现在使用下面的 `ip` 命令检验标记的接口是否已配置和启动,并且正在运行中:

以上就是本文的全部内容,我希望你已经学会了在 CentOS 7 / 8 和 RHEL 7 / 8 服务器上如何去配置和启用 VLAN 标签接口的方法。请分享你的反馈和意见。
---
via: <https://www.linuxtechi.com/vlan-tagged-nic-ethernet-card-centos-rhel-servers/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[quinbyjoe](https://github.com/quinbyjoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are some scenarios where we want to assign multiple IPs from different **VLAN** on the same Ethernet card (nic) on Linux servers (**CentOS** / **RHEL**). This can be done by enabling VLAN tagged interface. But for this to happen first we must make sure multiple VLANs are attached to port on switch or in other words we can say we should configure trunk port by adding multiple VLANs on switch.
Let’s assume we have a Linux Server, there we have two Ethernet cards (enp0s3 & enp0s8), first NIC ( **enp0s3** ) will be used for data traffic and second NIC (**enp0s8**) will be used for control / management traffic. For Data traffic I will using multiple VLANs (or will assign multiple IPs from different VLANs on data traffic ethernet card).
I am assuming the port from switch which is connected to my server data NIC is configured as trunk port by mapping the multiple VLANs to it.
Following are the VLANs which is mapped to data traffic Ethernet Card (NIC):
- VLAN ID (200), VLAN N/W = 172.168.10.0/24
- VLAN ID (300), VLAN N/W = 172.168.20.0/24
To use VLAN tagged interface on CentOS 7 / RHEL 7 / CentOS 8 /RHEL 8 systems, [kernel module](https://www.linuxtechi.com/how-to-manage-kernel-modules-in-linux/) **8021q** must be loaded.
Use the following command to load the kernel module “8021q”
[root@linuxtechi ~]# lsmod | grep -i 8021q [root@linuxtechi ~]# modprobe --first-time 8021q [root@linuxtechi ~]# lsmod | grep -i 8021q 8021q 29022 0 garp 14384 1 8021q mrp 18542 1 8021q [root@linuxtechi ~]#
Use below modinfo command to display information about kernel module “8021q”
[root@linuxtechi ~]# modinfo 8021q filename: /lib/modules/3.10.0-327.el7.x86_64/kernel/net/8021q/8021q.ko version: 1.8 license: GPL alias: rtnl-link-vlan rhelversion: 7.2 srcversion: 2E63BD725D9DC11C7DA6190 depends: mrp,garp intree: Y vermagic: 3.10.0-327.el7.x86_64 SMP mod_unload modversions signer: CentOS Linux kernel signing key sig_key: 79:AD:88:6A:11:3C:A0:22:35:26:33:6C:0F:82:5B:8A:94:29:6A:B3 sig_hashalgo: sha256 [root@linuxtechi ~]#
Now tagged (or mapped) the VLANs 200 and 300 to NIC enp0s3 using the [ip command](https://www.linuxtechi.com/ip-command-examples-for-linux-users/)
[root@linuxtechi ~]# ip link add link enp0s3 name enp0s3.200 type vlan id 200
Bring up the interface using below ip command:
[root@linuxtechi ~]# ip link set dev enp0s3.200 up
Similarly mapped the VLAN 300 to NIC enp0s3
[root@linuxtechi ~]# ip link add link enp0s3 name enp0s3.300 type vlan id 300 [root@linuxtechi ~]# ip link set dev enp0s3.300 up [root@linuxtechi ~]#
Now view the tagged interface status using ip command:
Now we can assign the IP address to tagged interface from their respective VLANs using beneath ip command,
[root@linuxtechi ~]# ip addr add 172.168.10.51/24 dev enp0s3.200 [root@linuxtechi ~]# ip addr add 172.168.20.51/24 dev enp0s3.300
Use below ip command to see whether IP is assigned to tagged interface or not.
All the above changes via ip commands will not be persistent across the reboot. These tagged interfaces will not be available after reboot and after network service restart
So, to make tagged interfaces persistent across the reboot then use interface** ifcfg files**
Edit interface (enp0s3) file “**/etc/sysconfig/network-scripts/ifcfg-enp0s3**” and add the following content,
Note: Replace the interface name that suits to your env,
[root@linuxtechi ~]# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3 TYPE=Ethernet DEVICE=enp0s3 BOOTPROTO=none ONBOOT=yes
Save & exit the file
Create tagged interface file for VLAN id 200 as “**/etc/sysconfig/network-scripts/ifcfg-enp0s3.200**” and add the following contents to it.
[root@linuxtechi ~]# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3.200 DEVICE=enp0s3.200 BOOTPROTO=none ONBOOT=yes IPADDR=172.168.10.51 PREFIX=24 NETWORK=172.168.10.0 VLAN=yes
Save & exit the file
Similarly create interface file for VLAN id 300 as “/etc/sysconfig/network-scripts/ifcfg-enp0s3.300” and add the following contents to it
[root@linuxtechi ~]# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3.300 DEVICE=enp0s3.300 BOOTPROTO=none ONBOOT=yes IPADDR=172.168.20.51 PREFIX=24 NETWORK=172.168.20.0 VLAN=yes
Save and exit file and then restart network services using the beneath command,
[root@linuxtechi ~]# systemctl restart network [root@linuxtechi ~]#
Now verify whether tagged interface are configured and up & running using the ip command,
That’s all from this article, I hope you got an idea how to configure and enable VLAN tagged interface on CentOS 7 / 8 and RHEL 7 /8 Severs. Please do share your feedback and comments. |
12,928 | 为什么 2020 年是使用 Kate 文本编辑器的最佳时机? | https://opensource.com/article/20/12/kate-text-editor | 2020-12-17T13:40:51 | [
"Kate",
"KDE"
] | https://linux.cn/article-12928-1.html |
>
> 了解更多关于长期受喜爱的文本编辑器的信息,它为每个用户提供了一些东西。
>
>
>

KDE Plasma 桌面提供了很多东西:一个很棒的桌面、一个灵活的文件管理器,以及紧密集成的应用。然而,人们很容易忽视它的默认文本编辑器,其中之一就是 [Kate](http://kate-editor.org)。2020 年 12 月 14 日,[Kate 将迎来 20 岁生日](https://kate-editor.org/post/2020/2020-11-08-kate-is-soon-20-years-old/),在其 20 年的发展历程中,它在一个简单明了的编辑器和一个适度的集成开发环境 (IDE) 之间取得了完美的平衡。
### 安装 Kate
如果你正在运行 KDE Plasma 桌面,你可能已经安装了 Kate。如果还没有安装,不管你运行的是哪个桌面,你都可以在你的软件仓库中找到它。
另外,[你可以在 Linux 或 Chromebook 上从](https://flathub.org/apps/details/org.kde.kate) [Flathub.org](http://Flathub.org) 使用 Flatpak 安装 Kate。
在 Windows 上,[你可以从 Windows 商店获得 Kate](https://www.microsoft.com/en-nz/p/kate/9nwmw7bb59hw?rtc=1&activetab=pivot:overviewtab)。
要在 macOS 上安装它,[从 KDE build 网站下载 macOS 版本](https://binary-factory.kde.org/view/MacOS/job/Kate_Release_macos/)。
### 所有的功能
第一眼,Kate 似乎并不显眼。它看起来就像其他的文本编辑器一样:一个巨大的空白窗口,可以接受大量的输入,顶部有一个菜单栏,边缘有一些元数据来指示字符编码和行数。但当你开始使用它的那一刻,你会发现它拥有你所需要的所有功能,就在你想要的地方。
例如,沿着 Kate 窗口的左侧是行数,默认情况下是启用的。更好的是,当你输入常用的编码语言或标记语法时,代码折叠就会被激活。窗口右侧的文件导航面板可以快速、直观地访问文件的不同部分。而窗口底部则包含了常用模式设置,包括插入或覆盖、字符编码(如 UTF-8)和语法高亮。

不过,这还不是全部。听起来可能有很多,但布局很方便,很直观。在菜单和设置中还有更多的功能。
Kate 的功能有集成 Git、文件浏览器、shell、打开文档或项目的面板、单词补全、XML 补全、标签式界面、分屏和插件结构,因此你可以进一步扩展其功能。
### 给所有用户使用的编辑器
Kate 的极强灵活性使它既是一个简单的文本编辑器,又是一个强大的 IDE。通过默认使用的熟悉的界面,它吸引了广大的用户;而通过提供与调试器、编译器和代码检查器集成的能力,它吸引了开发人员。
因为它允许用户控制它的 UI 布局,Kate 确保每个用户都能优化使用它的体验。传统上,这一直是一个难以平衡的问题:一个拥有太多功能的编辑器给人的感觉太像一个臃肿的 IDE,而一个界面简单、功能模糊的编辑器给人的感觉是基础的或不方便的。Kate 将真正有用的功能放在了 UI 的最前面,从而让每个人都能享受到,同时又让高级功能可以被发现,但又不碍事。
坦率地说,Kate 让人难以割舍。它使用起来很愉快,配置起来很简单,探索起来也很有趣。今天就安装 Kate 吧,试一试它。它在所有主要的平台上都可以使用,你没有什么理由不选择 Kate 作为你的新宠编辑器。
---
via: <https://opensource.com/article/20/12/kate-text-editor>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The KDE Plasma Desktop has a lot to offer—a great desktop, a flexible file manager, and tightly integrated applications. However, it can be easy to overlook its default text editors, one of which is [Kate](http://kate-editor.org). On December 14, 2020, [Kate turns 20 years old](https://kate-editor.org/post/2020/2020-11-08-kate-is-soon-20-years-old/), and in its two decades of development, it has achieved a perfect balance between a straightforward editor and a modest Integrated Development Environment (IDE).
## Installing Kate
If you’re running the KDE Plasma Desktop, you probably already have Kate installed. In the event that it’s not installed yet, you can find it in your software repository, regardless of which desktop you’re running.
Alternatively, [you can install Kate from ](https://flathub.org/apps/details/org.kde.kate)[Flathub.org](http://Flathub.org) using Flatpak on Linux or Chromebook.
On Windows, [you can obtain Kate](https://www.microsoft.com/en-nz/p/kate/9nwmw7bb59hw?rtc=1&activetab=pivot:overviewtab) from the Windows store.
To install it on macOS, [download the macOS build from the KDE build site](https://binary-factory.kde.org/view/MacOS/job/Kate_Release_macos/).
## All the right features
Kate seems, at first, unassuming. It looks like every other text editor—a big blank window ready to accept lots of typed input, a menu bar along the top, some metadata around the edges to indicate character encoding and line count. The moment you start using it, though, you realize that it has all the features you need, right where you want them.
For instance, along the left side of the Kate window are line numbers, which are enabled by default. Better still, code collapsing is activated when you type in a common coding language or markdown syntax. A document navigation panel on the right side of the window provides quick and visual access to different parts of your file. And the bottom of the window contains common mode settings, including insert or overwrite, character encoding (such as UTF-8), and syntax highlighting.
That’s not all, though. It might sound like a lot, but the layout is convenient and intuitive. There are even more features available in the menu and settings.
Kate features Git integration, a file browser, shell, open document or project panel, word completion, XML completion, a tabbed interface, split screens, and a plugin structure so you can extend its features even further.
## An editor for every user
Kate’s extreme flexibility allows it to be both a simple text editor and a robust IDE. By defaulting to a familiar interface, it appeals to a wide audience, but by offering the ability to integrate with debuggers, compilers, and code linters, it appeals to developers.
Because it allows the user to control its UI layout, Kate ensures every user can optimize their experience with it. This has been, traditionally, a difficult balance—an editor with too many features feels too much like a bloated IDE, while an editor with a simplistic interface and obfuscated features feels basic or inconvenient. Kate gets it right by placing the really useful features at the forefront of the UI for everyone to enjoy while keeping advanced features discoverable but out of the way.
Kate is, frankly, difficult to walk away from. It’s a pleasure to use, easy to configure, and fun to explore. Install Kate today, and give it a try. Being available on all major platforms, there’s little reason you shouldn’t choose Kate as your new favorite editor.
## 2 Comments |
12,930 | 体验 Xedit 文本编辑器的实用功能 | https://opensource.com/article/20/12/xedit | 2020-12-18T07:59:52 | [
"Xedit"
] | https://linux.cn/article-12930-1.html |
>
> Xedit 是 X11 图形服务器的一部分,它不算好看,但却有足够的隐藏功能,使它成为一个严肃的文本编辑器。
>
>
>

X11 图形服务器由 [X.org](https://www.x.org/wiki/) 发布,它有一些象征性的应用来展示如何使用它提供的工具进行编程。这些应用包括从 [TWM](https://opensource.com/article/19/12/twm-linux-desktop) 桌面到愚蠢但催眠的 Xeyes。它还包括一个名为 Xedit 的文本编辑器,它是一个看似简单的应用,却有足够的隐藏功能,使其成为一个严肃的编辑器。
### 安装 Xedit
如果你使用的是 Linux 或 BSD,你可以从你的发行版软件仓库或 ports 树中安装 Xedit。它有时会出现在一个名为 X11-apps 的软件包中,与其他 X11 应用捆绑在一起。
在 macOS 上,你可以安装 [XQuartz](http://xquartz.org),它提供了 Xedit、Xeyes 和其他一些小程序(以及一个 X11 图形服务器)。
### 启动 Xedit
如果它被列在你的应用菜单的话,你可以从中启动 Xedit。尽管它绝对是一个 GUI 应用,但有些发行版将它视为命令而不是 GUI 应用,所以它可能不会被列在应用菜单中。这时,你可以从终端启动 Xedit。如果你输入 `xedit &` 来启动应用,它就会启动一个空的 Xedit 编辑器,可以随时输入。如果你在输入启动命令的同时输入一个现有的文件名,Xedit 启动时会将文件加载到缓冲区。
```
$ xedit example.txt &
```

### 加载文件
在打开的 Xedit 实例中,你可以在顶部文本输入框中输入文件的路径来加载文件。点击 **Load** 按钮(在文本输入框的左边),将文件读入 Xedit 窗口。

你可以同时打开多个文件。当一个文件被加载时,它将获取焦点并出现在你的主 Xedit 缓冲区(主窗口中的大文本输入框),并将任何现有的文件切换到一个隐藏的缓冲区。
你可以使用组合键在缓冲区之间切换,这对 Emacs 用户而言很熟悉,但对其他用户会感到困惑。首先,按下 `Ctrl+X`。放开然后按 `Ctrl+B`。
### 组合键
一开始执行需要连续*两*个键盘快捷键的操作感觉很奇怪,但过了一段时间,你就会习惯。事实上,作为一个经常使用 Emacs 的用户,我发现复合键组合很有节奏感。我很惊讶也很高兴地发现,我最喜欢的一些快捷键在 Xedit 中也有效。
原来,Xedit 从几个灵感来源借用了键盘快捷键。如果你是 Emacs 用户,你会发现最常见的组合在 Xedit 中有效。例如,`C-x C-f` (即 `Ctrl+X` 后是 `Ctrl+F`)可以回到顶部的文本输入框来加载文件,而 `C-x C-s`(`Ctrl+X` 后是 `Ctrl+S`)可以保存文件。令人惊讶的是,`C-x 3` 甚至可以垂直分割窗口,而 `C-x 2` 则可以水平分割,`C-x 0` 或 `C-x 1` 则可以移除分割。
Emacs 或 Bash 用户熟悉的编辑命令也适用:
* `Ctrl+A` 移动到行首。
* `Ctrl+E` 移至行尾。
* `Alt+B` 向后移动一个单词。
* `Ctrl+B` 向后移动一个字符。
* `Ctrl+F` 向前移动一个字符。
* `Alt+F` 向前移动一个单词。
* `Ctrl+D 删除下一个字符。
还有更多,它们都在 Xedit 手册页面上列出。
### 使用行编辑模式
Xedit 还含有一个类似 `ex` 的行编辑器,这对 [Vi](https://opensource.com/article/20/12/vi-text-editor) 和 `ed` 甚至 `sed` 用户应该很熟悉。要进入行编辑模式,按下 `Esc` 键。这将使你处于顶部的文本输入框,但处于命令模式。编辑命令使用的语法是:*行号*后面跟着一个*命令*和*参数*。
比如说你有这个文本文件:
```
ed is the standard Unix text editor.
This is line number two.
```
你决定将第 1 行的 `ed` 改为 `Xedit`。在 Xedit 中,移动到第 1 行,按下 `Esc`,然后输入 `.,s/ed/Xedit/`。
```
Xedit is the standard Unix text editor.
This is line number two.
```
不用将光标移到下一行,你可以将 `two` 改为 `the second`。按下 `Esc`,然后输入 `2,s/two/the second/`。
各种命令和有效的参数在 Xedit 的手册页中列出。
### 简单但稳定
Xedit 并不算好看,它很简单,没有菜单可言,但它借鉴了一些最好的 Unix 编辑器的流行的便利性。下次你在寻找新的编辑器时,不妨试试 Xedit。
---
via: <https://opensource.com/article/20/12/xedit>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The X11 graphic server, distributed by [X.org](https://www.x.org/wiki/), has a few token applications that show how to program with its provided tools. These range from the [TWM](https://opensource.com/article/19/12/twm-linux-desktop) desktop to the silly but hypnotic Xeyes. It also includes a text editor called Xedit, a seemingly simple application with enough hidden features to make it a serious editor.
## Install Xedit
If you're on Linux or BSD, you can install Xedit from your distribution's software repository or ports tree. It sometimes appears in a package called X11-apps bundled with other X11 apps.
On macOS, you can install [XQuartz](http://xquartz.org), which provides Xedit, Xeyes, and a few other small applications (along with an X11 graphics server).
## Launch Xedit
You can launch Xedit from your application menu, if it's listed. Some distributions treat it more as a command than a GUI app, even though it is definitely a GUI app, so it may not be listed in your application menu. In that case, you can launch Xedit from the terminal. If you type `xedit &`
to launch the application, it launches an empty Xedit editor ready for text. If you enter the launch command along with an existing file's name, Xedit starts with the file loaded into its buffer:
`$ xedit example.txt &`
(Seth Kenlon, CC BY-SA 4.0)
## Load a file
From an open Xedit instance, you can load a file by typing the file's path in the top text field. Click the **Load** button (to the left of the text field) to read the file into the Xedit window.
(Seth Kenlon, CC BY-SA 4.0)
You can have several files open at once. When one file is loaded, it takes focus and appears in your main Xedit buffer (the big text field in the main window) and shuffles any existing file into a hidden buffer.
You can navigate between buffers using a key combo familiar to Emacs users but sometimes confusing to others: First, press **Ctrl+X**. Release those keys, and then press **Ctrl+B**.
## Key combos
It feels strange at first to perform actions that require *two* keyboard shortcuts in a row, but after a while, you get used to it. In fact, as a frequent Emacs user, I find the compound key combinations comfortingly rhythmic. I was surprised and pleased to find that some of my favorite shortcuts were valid in Xedit.
It turns out that Xedit borrows keyboard shortcuts from several sources of inspiration. If you're an Emacs user, you'll find that the most common combinations are valid in Xedit. For instance, **C-x** **C-f** (that's **Ctrl+X** followed **Ctrl+F**) takes you to the top text field to load a file, and **C-x** **C-s** (**Ctrl+X** followed by **Ctrl+S**) saves a file. Surprisingly, **C-x** **3** even splits the window vertically, while **C-x** **2** splits it horizontally, and **C-x** **0** or **1** removes the split.
Edit commands familiar to Emacs or Bash users also apply:
**Ctrl+A**moves to the beginning of a line.**Ctrl+E**moves to the end of a line.**Alt+B**moves back a word.**Ctrl+B**moves back a character.**Ctrl+F**moves forward a character.**Alt+F**moves forward a word.**Ctrl+D**deletes the next character.
There are many more, and they're listed on the Xedit man page.
## Use line-editing mode
Xedit also includes a line editor, similar to **ex**, which ought to be familiar to [Vi](https://opensource.com/article/20/12/vi-text-editor) and `ed`
or even `sed`
users. To enter line-editing mode, press the **Esc** key. This places you in the top text field but in a command mode. Edit commands use the syntax: *line number* followed by a *command* and *parameters*.
Say you have this text file:
```
ed is the standard Unix text editor.
This is line number two.
```
You decide you want to change `ed`
to `Xedit`
in line 1. In Xedit, move to line 1, press **Esc**, and then type `.,s/ed/Xedit/`
.
```
Xedit is the standard Unix text editor.
This is line number two.
```
Without moving your cursor to the next line, you could change `two`
to `the second`
: Press **Esc** and then type `2,s/two/the second/`
.
Possible commands and valid parameters are listed in Xedit's man page.
## Simple but robust
Xedit isn't much to look at. It's simple, it has no menus to speak of, but it borrows some popular conveniences from some of the best Unix editors. The next time you're looking for a new editor, try Xedit.
## Comments are closed. |
12,932 | 用 PyTorch 实现基于字符的循环神经网络 | https://jvns.ca/blog/2020/11/30/implement-char-rnn-in-pytorch/ | 2020-12-19T10:24:00 | [
"神经网络",
"RNN"
] | https://linux.cn/article-12932-1.html | 
在过去的几周里,我花了很多时间用 PyTorch 实现了一个 [char-rnn](https://karpathy.github.io/2015/05/21/rnn-effectiveness/) 的版本。我以前从未训练过神经网络,所以这可能是一个有趣的开始。
这个想法(来自 [循环神经网络的不合理效应](https://karpathy.github.io/2015/05/21/rnn-effectiveness/))可以让你在文本上训练一个基于字符的<ruby> 循环神经网络 <rt> recurrent neural network </rt></ruby>(RNN),并得到一些出乎意料好的结果。
不过,虽然没有得到我想要的结果,但是我还是想分享一些示例代码和结果,希望对其他开始尝试使用 PyTorch 和 RNN 的人有帮助。
这是 Jupyter 笔记本格式的代码:[char-rnn in PyTorch.ipynb](https://gist.github.com/jvns/b6dda36b2fdcc02b833ed5b0c7a09112)。你可以点击这个网页最上面那个按钮 “Open in Colab”,就可以在 Google 的 Colab 服务中打开,并使用免费的 GPU 进行训练。所有的东西加起来大概有 75 行代码,我将在这篇博文中尽可能地详细解释。
### 第一步:准备数据
首先,我们要下载数据。我使用的是<ruby> 古登堡项目 <rt> Project Gutenberg </rt></ruby>中的这个数据:[Hans Christian Anderson’s fairy tales](https://www.gutenberg.org/cache/epub/27200/pg27200.txt)。
```
!wget -O fairy-tales.txt
```
这个是准备数据的代码。我使用 `fastai` 库中的 `Vocab` 类进行数据处理,它能将一堆字母转换成“词表”,然后用这个“词表”把字母变成数字。
之后我们就得到了一个大的数字数组(`training_set`),我们可以用于训练我们的模型。
```
from fastai.text import *
text = unidecode.unidecode(open('fairy-tales.txt').read())
v = Vocab.create((x for x in text), max_vocab=400, min_freq=1)
training_set = torch.Tensor(v.numericalize([x for x in text])).type(torch.LongTensor).cuda()
num_letters = len(v.itos)
```
### 第二步:定义模型
这个是 PyTorch 中 `LSTM` 类的封装。除了封装 `LSTM` 类以外,它还做了三件事:
1. 对输入向量进行 one-hot 编码,使得它们具有正确的维度。
2. 在 `LSTM` 层后一层添加一个线性变换,因为 `LSTM` 输出的是一个长度为 `hidden_size` 的向量,我们需要的是一个长度为 `input_size` 的向量这样才能把它变成一个字符。
3. 把 `LSTM` 隐藏层的输出向量(实际上有 2 个向量)保存成实例变量,然后在每轮运行结束后执行 `.detach()` 函数。(我很难解释清 `.detach()` 的作用,但我的理解是,它在某种程度上“结束”了模型的求导计算)(LCTT 译注:`detach()` 函数是将该张量的 `requires_grad` 参数设置为 `False`,即反向传播到该张量就结束。)
```
class MyLSTM(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.h2o = nn.Linear(hidden_size, input_size)
self.input_size=input_size
self.hidden = None
def forward(self, input):
input = torch.nn.functional.one_hot(input, num_classes=self.input_size).type(torch.FloatTensor).cuda().unsqueeze(0)
if self.hidden is None:
l_output, self.hidden = self.lstm(input)
else:
l_output, self.hidden = self.lstm(input, self.hidden)
self.hidden = (self.hidden[0].detach(), self.hidden[1].detach())
return self.h2o(l_output)
```
这个代码还做了一些比较神奇但是不太明显的功能。如果你的输入是一个向量(比如 `[1,2,3,4,5,6]`),对应六个字母,那么我的理解是 `nn.LSTM` 会在内部使用[沿时间反向传播](https://en.wikipedia.org/wiki/Backpropagation_through_time)更新隐藏向量 6 次。
### 第三步:编写训练代码
模型不会自己训练的!
我最开始的时候尝试用 `fastai` 库中的一个辅助类(也是 PyTorch 中的封装)。我有点疑惑因为我不知道它在做什么,所以最后我自己编写了模型训练代码。
下面这些代码(`epoch()` 方法)就是有关于一轮训练过程的基本信息。基本上就是重复做下面这几件事情:
1. 往 RNN 模型中传入一个字符串,比如 `and they ought not to teas`。(要以数字向量的形式传入)
2. 得到下一个字母的预测结果
3. 计算 RNN 模型预测结果和真实的下一个字母之间的损失函数(`e`,因为 `tease` 这个单词是以 `e` 结尾的)
4. 计算梯度(用 `loss.backward()` 函数)
5. 沿着梯度下降的方向修改模型中参数的权重(用 `self.optimizer.step()` 函数)
```
class Trainer():
def __init__(self):
self.rnn = MyLSTM(input_size, hidden_size).cuda()
self.optimizer = torch.optim.Adam(self.rnn.parameters(), amsgrad=True, lr=lr)
def epoch(self):
i = 0
while i < len(training_set) - 40:
seq_len = random.randint(10, 40)
input, target = training_set[i:i+seq_len],training_set[i+1:i+1+seq_len]
i += seq_len
# forward pass
output = self.rnn(input)
loss = F.cross_entropy(output.squeeze()[-1:], target[-1:])
# compute gradients and take optimizer step
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
```
### 使用 nn.LSTM 沿着时间反向传播,不要自己写代码
开始的时候我自己写代码每次传一个字母到 LSTM 层中,之后定期计算导数,就像下面这样:
```
for i in range(20):
input, target = next(iter)
output, hidden = self.lstm(input, hidden)
loss = F.cross_entropy(output, target)
hidden = hidden.detach()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
```
这段代码每次传入 20 个字母,每次一个,并且在最后训练了一次。这个步骤就被称为[沿时间反向传播](https://en.wikipedia.org/wiki/Backpropagation_through_time),Karpathy 在他的博客中就是用这种方法。
这个方法有些用处,我编写的损失函数开始能够下降一段时间,但之后就会出现峰值。我不知道为什么会出现这种现象,但之后我改为一次传入 20 个字符到 LSTM 之后(按 `seq_len` 维度),再进行反向传播,情况就变好了。
### 第四步:训练模型!
我在同样的数据上重复执行了这个训练代码大概 300 次,直到模型开始输出一些看起来像英文的文本。差不多花了一个多小时吧。
这种情况下我也不关注模型是不是过拟合了,但是如果你在真实场景中训练模型,应该要在验证集上验证你的模型。
### 第五步:生成输出!
最后一件要做的事就是用这个模型生成一些输出。我写了一个辅助方法从这个训练好的模型中生成文本(`make_preds` 和 `next_pred`)。这里主要是把向量的维度对齐,重要的一点是:
```
output = rnn(input)
prediction_vector = F.softmax(output/temperature)
letter = v.textify(torch.multinomial(prediction_vector, 1).flatten(), sep='').replace('_', ' ')
```
基本上做的事情就是这些:
1. RNN 层为字母表中的每一个字母或者符号输出一个数值向量(`output`)。
2. 这个 `output` 向量**并不是**一个概率向量,所以需要 `F.softmax(output/temperature)` 操作,将其转换为概率值(也就是所有数值加起来和为 1)。`temperature` 某种程度上控制了对更高概率的权重,在限制范围内,如果设置 `temperature=0.0000001`,它将始终选择概率最高的字母。
3. `torch.multinomial(prediction_vector)` 用于获取概率向量,并使用这些概率在向量中选择一个索引(如 `12`)。
4. `v.textify` 把 `12` 转换为字母。
如果我们想要处理的文本长度为 300,那么只需要重复这个过程 300 次就可以了。
### 结果!
我把预测函数中的参数设置为 `temperature = 1` 得到了下面的这些由模型生成的结果。看起来有点像英语,这个结果已经很不错了,因为这个模型要从头开始“学习”英语,并且是在字符序列的级别上进行学习的。
虽然这些话没有什么*含义*,但我们也不知道到底想要得到什么输出。
>
> “An who was you colotal said that have to have been a little crimantable and beamed home the beetle. “I shall be in the head of the green for the sound of the wood. The pastor. “I child hand through the emperor’s sorthes, where the mother was a great deal down the conscious, which are all the gleam of the wood they saw the last great of the emperor’s forments, the house of a large gone there was nothing of the wonded the sound of which she saw in the converse of the beetle. “I shall know happy to him. This stories herself and the sound of the young mons feathery in the green safe.”
>
>
> “That was the pastor. The some and hand on the water sound of the beauty be and home to have been consider and tree and the face. The some to the froghesses and stringing to the sea, and the yellow was too intention, he was not a warm to the pastor. The pastor which are the faten to go and the world from the bell, why really the laborer’s back of most handsome that she was a caperven and the confectioned and thoughts were seated to have great made
>
>
>
下面这些结果是当 `temperature=0.1` 时生成的,它选择字符的方式更接近于“每次都选择出现概率最高的字符”。这就使得输出结果有很多是重复的。
>
> ole the sound of the beauty of the beetle. “She was a great emperor of the sea, and the sun was so warm to the confectioned the beetle. “I shall be so many for the beetle. “I shall be so many for the beetle. “I shall be so standen for the world, and the sun was so warm to the sea, and the sun was so warm to the sea, and the sound of the world from the bell, where the beetle was the sea, and the sound of the world from the bell, where the beetle was the sea, and the sound of the wood flowers and the sound of the wood, and the sound of the world from the bell, where the world from the wood, and the sound of the
>
>
>
这段输出对这几个单词 `beetles`、`confectioners`、`sun` 和 `sea` 有着奇怪的执念。
### 总结!
至此,我的结果远不及 Karpathy 的好,可能有一下几个原因:
1. 没有足够多的训练数据。
2. 训练了一个小时之后我就没有耐心去查看 Colab 笔记本上的信息。
3. Karpathy 使用了两层LSTM,包含了更多的参数,而我只使用了一层。
4. 完全是另一回事。
但我得到了一些大致说得过去的结果!还不错!
---
via: <https://jvns.ca/blog/2020/11/30/implement-char-rnn-in-pytorch/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhangxiangping](https://github.com/zxp93) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! I spent a bunch of time in the last couple of weeks implementing a
version of [char-rnn](https://karpathy.github.io/2015/05/21/rnn-effectiveness/)
with PyTorch. I’d never trained a neural network before so this seemed like a
fun way to start.
The idea here (from [The Unreasonable Effectiveness of Recurrent Neural
Networks](https://karpathy.github.io/2015/05/21/rnn-effectiveness/)) is that
you can train a character-based recurrent neural network on some text and get
surprisingly good results.
I didn’t quite get the results I was hoping for, but I wanted to share some example code & results in case it’s useful to anyone else getting started with PyTorch and RNNs.
Here’s the Jupyter notebook with the code: [char-rnn in
PyTorch.ipynb](https://gist.github.com/jvns/b6dda36b2fdcc02b833ed5b0c7a09112).
If you click “Open in Colab” at the top, you can open it in Google’s Colab
service where at least right now you can get a free GPU to do training on. The
whole thing is maybe 75 lines of code, which I’ll attempt to somewhat explain
in this blog post.
### step 1: prepare the data
First up: we download the data! I used [Hans Christian Anderson’s fairy
tales](https://www.gutenberg.org/cache/epub/27200/pg27200.txt) from Project
Gutenberg.
```
!wget -O fairy-tales.txt
```
Here’s the code to prepare the data. I’m using the `Vocab`
class from fastai,
which can turn a bunch of letters into a “vocabulary” and then use that
vocabulary to turn letters into numbers.
Then we’re left with a big array of numbers (`training_set`
) that we can use to
train a model.
```
from fastai.text import *
text = unidecode.unidecode(open('fairy-tales.txt').read())
v = Vocab.create((x for x in text), max_vocab=400, min_freq=1)
training_set = torch.Tensor(v.numericalize([x for x in text])).type(torch.LongTensor).cuda()
num_letters = len(v.itos)
```
### step 2: define a model
This is a wrapper around PyTorch’s LSTM class. It does 3 main things in addition to just wrapping the LSTM class:
- one hot encode the input vectors, so that they’re the right dimension
- add another linear transformation after the LSTM, because the LSTM outputs a
vector with size
`hidden_size`
, and we need a vector that has size`input_size`
so that we can turn it into a character - Save the LSTM hidden vector (which is actually 2 vectors) as an instance
variable and run
`.detach()`
on it after every round. (I struggle to articulate what`.detach()`
does, but my understanding is that it kind of “ends” the calculation of the derivative of the model)
```
class MyLSTM(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.h2o = nn.Linear(hidden_size, input_size)
self.input_size=input_size
self.hidden = None
def forward(self, input):
input = torch.nn.functional.one_hot(input, num_classes=self.input_size).type(torch.FloatTensor).cuda().unsqueeze(0)
if self.hidden is None:
l_output, self.hidden = self.lstm(input)
else:
l_output, self.hidden = self.lstm(input, self.hidden)
self.hidden = (self.hidden[0].detach(), self.hidden[1].detach())
return self.h2o(l_output)
```
This code also does something kind of magical that isn’t obvious at all – if you pass it
in a vector of inputs (like [1,2,3,4,5,6]), corresponding to 6 letters, my
understanding is that `nn.LSTM`
will internally update the hidden vector 6
times using [backpropagation through time](https://en.wikipedia.org/wiki/Backpropagation_through_time).
### step 3: write some training code
This model won’t just train itself!
I started out trying to use a training helper class from the `fastai`
library (which
is a wrapper around PyTorch). I found that kind of confusing because I didn’t
understand what it was doing, so I ended up writing my own training code.
Here’s some code to show basically what 1 round of training looks like (the
`epoch()`
method). Basically what this is doing is repeatedly:
- Give the RNN a string like
`and they ought not to teas`
(as a vector of numbers, of course) - Get the prediction for the next letter
- Compute the loss between what the RNN predicted, and the real next letter
(
`e`
, because tease ends in`e`
) - Calculate the gradient (
`loss.backward()`
) - Change the weights in the model in the direction of the gradient (
`self.optimizer.step()`
)
```
class Trainer():
def __init__(self):
self.rnn = MyLSTM(input_size, hidden_size).cuda()
self.optimizer = torch.optim.Adam(self.rnn.parameters(), amsgrad=True, lr=lr)
def epoch(self):
i = 0
while i < len(training_set) - 40:
seq_len = random.randint(10, 40)
input, target = training_set[i:i+seq_len],training_set[i+1:i+1+seq_len]
i += seq_len
# forward pass
output = self.rnn(input)
loss = F.cross_entropy(output.squeeze()[-1:], target[-1:])
# compute gradients and take optimizer step
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
```
### let `nn.LSTM`
do backpropagation through time, don’t do it myself
Originally I wrote my own code to pass in 1 letter at a time to the LSTM and then periodically compute the derivative, kind of like this:
```
for i in range(20):
input, target = next(iter)
output, hidden = self.lstm(input, hidden)
loss = F.cross_entropy(output, target)
hidden = hidden.detach()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
```
This passes in 20 letters (one at a time), and then takes a training step at
the end. This is called [backpropagation through time](https://en.wikipedia.org/wiki/Backpropagation_through_time) and Karpathy
mentions using this method in his blog post.
This kind of worked, but my loss would go down for a while and then kind of
spike later in training. I still don’t understand why this happened, but when I
switched to instead just passing in 20 characters at a time to the LSTM (as the
`seq_len`
dimension) and letting it do the backpropagation itself, things got a
lot better.
### step 4: train the model!
I reran this training code over the same data maybe 300 times, until I got bored and it started outputting text that looked vaguely like English. This took about an hour or so.
In this case I didn’t really care too much about overfitting, but if you were doing this for a Real Reason it would be good to run it on a validation set.
### step 5: generate some output!
The last thing we need to do is to generate some output from the model! I wrote
some helper methods to generate text from the model (`make_preds`
and
`next_pred`
). It’s mostly just trying to get the dimensions of things right,
but here’s the main important bit:
```
output = rnn(input)
prediction_vector = F.softmax(output/temperature)
letter = v.textify(torch.multinomial(prediction_vector, 1).flatten(), sep='').replace('_', ' ')
```
Basically what’s going on here is that
- the RNN outputs a vector of numbers (
`output`
), one for each letter/punctuation in our alphabet. - The
`output`
vector isn’t**yet**a vector of probabilities, so`F.softmax(output/temperature)`
turns it into a bunch of probabilities (aka “numbers that add up to 1”).`temperature`
kind of controls how much to weight higher probabilities – in the limit if you set temperature=0.0000001, it’ll always pick the letter with the highest probability. `torch.multinomial(prediction_vector)`
takes the vector of probabilities and uses those probabilites to pick an index in the vector (like 12)`v.textify`
turns “12” into a letter
If we want 300 characters worth of text, we just repeat this process 300 times.
### the results!
Here’s some generated output from the model where I set `temperature = 1`
in
the prediction function. It’s kind of like English, which is pretty impressive
given that this model needed to “learn” English from scratch and is totally
based on character sequences.
It doesn’t make any *sense*, but what did we expect really.
“An who was you colotal said that have to have been a little crimantable and beamed home the beetle. “I shall be in the head of the green for the sound of the wood. The pastor. “I child hand through the emperor’s sorthes, where the mother was a great deal down the conscious, which are all the gleam of the wood they saw the last great of the emperor’s forments, the house of a large gone there was nothing of the wonded the sound of which she saw in the converse of the beetle. “I shall know happy to him. This stories herself and the sound of the young mons feathery in the green safe.”
“That was the pastor. The some and hand on the water sound of the beauty be and home to have been consider and tree and the face. The some to the froghesses and stringing to the sea, and the yellow was too intention, he was not a warm to the pastor. The pastor which are the faten to go and the world from the bell, why really the laborer’s back of most handsome that she was a caperven and the confectioned and thoughts were seated to have great made
Here’s some more generated output at `temperature=0.1`
, which weights its
character choices closer to “just pick the highest probability character every
time”. This makes the output a lot more repetitive:
ole the sound of the beauty of the beetle. “She was a great emperor of the sea, and the sun was so warm to the confectioned the beetle. “I shall be so many for the beetle. “I shall be so many for the beetle. “I shall be so standen for the world, and the sun was so warm to the sea, and the sun was so warm to the sea, and the sound of the world from the bell, where the beetle was the sea, and the sound of the world from the bell, where the beetle was the sea, and the sound of the wood flowers and the sound of the wood, and the sound of the world from the bell, where the world from the wood, and the sound of the
It’s weirdly obsessed with beetles and confectioners, and the sun, and the sea. Seems fine!
### that’s all!
my results are nowhere near as good as Karpathy’s so far, maybe due to one of the following:
- not enough training data
- I got bored with training after an hour and didn’t have the patience to babysit the Colab notebook for longer
- he used a 2-layer LSTM with more hidden parameters than me, I have 1 layer
- something else entirely
But I got some vaguely coherent results! Hooray! |
12,933 | 使用 gedit 文本编辑器优化你的 GNOME 体验 | https://opensource.com/article/20/12/gedit | 2020-12-19T11:05:06 | [
"gedit"
] | /article-12933-1.html |
>
> 它是一个可以完成工作的简约编辑器,并以隐藏的增强功能使得事情更简单。
>
>
>

作为默认的文本编辑器是一项吃力不讨好的工作。人们通常把默认文本编辑器几乎看作是一个演示应用、一个稍微好一点的 “hello World” 示例,说明应用在该平台上的是如何运行的。在极少数情况下,当用户需要将一些文本保存到一个可能永远不会再看的文件中时,用户会找到默认文本编辑器。对于“严肃”的工作,他们会转向文字处理器或 IDE,或终端中的编辑器,或者至少是一个不同的文本编辑器,必须像“真正的”应用一样下载和安装。
很奇怪,默认的文本编辑器很难被人重视,然而 GNOME 桌面的编辑器 gedit 却被广泛认为是一个真正有价值的文本编辑器,超越了它所在的桌面。它被用作网页设计课程的必备文本编辑器,是新手开发者和系统管理员的推荐工具,也是许多桌面 Linux 用户最喜欢的可靠伙伴。
### 安装 gedit
如果你运行的是 GNOME 桌面,你可能已经安装了 gedit,尽管它可能只作为“文本编辑器”出现在你的应用菜单中。如果你不确定,只需在你的活动界面中输入 `gedit`,然后在打开的文本编辑器中进入 “About” 菜单项。

在 Windows 上,你可以[从微软商店下载并安装 gedit](https://www.microsoft.com/en-nz/p/gedit)。
在 Mac 上,你可以[使用 Homebrew](https://opensource.com/article/20/6/homebrew-mac)或 [MacPorts](https://opensource.com/article/20/11/macports) 安装 gedit。
### 使用 gedit
当你第一次启动 gedit 时,你会看到一个简约的界面,包括一个文本输入面板、一个标题栏和一个位于窗口底部的状态面板。底部的状态面板提供了一些常用的设置:你想使用哪种语法高亮模式、你喜欢的制表符宽度、以及一些流行的偏好,如行号、文本换行等等。这些选项中的大部分也可以在 “Preferences” 菜单中进行全局设置,它可在应用程序右上角的 “汉堡” 样式的菜单中找到。
### gedit 的隐藏功能
从表面上看,gedit 正是它所标榜的那样:一个不起眼的文本编辑器,它不会妨碍你的工作,因此你可以在屏幕上的框中输入字母。但是,这个简单的文本编辑器却隐藏着一些你可能不知道的令人兴奋的功能,即使你已经使用它多年。
这些键盘功能在 gedit 中并没有被记录下来:
* `Ctrl+D` 删除当前行。这对于编码者或以标记格式(如 Asciidoc、reST 或 CommonMark)写作的人特别有用。
* `Ctrl+I` 会弹出 “Go to Line” 下拉框。输入一个数字,你就会立即跳到该行。
* `Alt+向上箭头` 或 `Alt+向下箭头` 会抓取当前行,并将它在文档中向上或向下移动。
* `Alt+向左箭头` 或 `Alt+向右箭头` 抓取最近的单词(在光标左侧)并将其向左或向右移动。
* 要输入特殊的 Unicode 字符,请按下 `Shift+Ctrl+U` 并松开,然后输入 Unicode 字符代码。你通常必须查找字符代码(除非你已经记住了一些,但谁有记性来记住这些字符代码?)例如,要打出一只企鹅,按下 `Shift+Ctrl+U` 然后松开。当你松开按键后,你会看到一个带下划线的 U,然后输入 `1F427`,后面跟一个空格,你的 Unicode 字符就会变成一个友好的 `?`。诚然,这并不完全是 gedit 所独有的,但这是个很有用的技巧,而且它在 gedit 中也确实有效。
### 稳定简单
Gedit 很像 GNOME 本身。它客观上比许多同类软件(比如 KDE 的 Kate)更简单,但它仍然能够满足你日常 80% 或 90% 的期望。
当然,可能会有一些任务 gedit 不是最佳工具。你可能会发现自己要深入研究一些独特的日志文件,或者需要一个精确的解析器或代码检查器,你会转向专门的应用。这没关系。gedit 并不意味着对所有用户都适用。但对于那些需要文本编辑器的人来说,它是一个很好的文本编辑器,有时这就是所需要的。在 Linux 或者在任何你正在使用的平台上,试一下 gedit,因为它很有可能是一个比默认应用的更好的选择。
---
via: <https://opensource.com/article/20/12/gedit>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.