
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
12,588 | 使用 GraphQL 作为 API 网关来监控微服务 | https://opensource.com/article/20/8/microservices-graphql | 2020-09-06T20:51:36 | [
"GraphQL",
"微服务"
] | https://linux.cn/article-12588-1.html |
>
> 在问题导致关键的微服务瘫痪之前,使用 GraphQL 的监控功能帮助你及早发现问题。
>
>
>

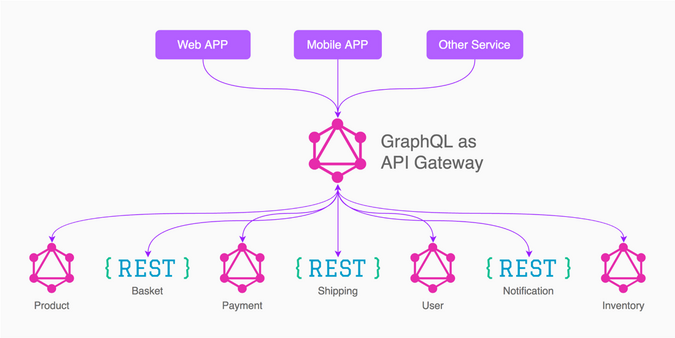
[微服务](https://opensource.com/resources/what-are-microservices)和 [GraphQL](https://opensource.com/article/19/6/what-is-graphql) 就像面包和黄油一样,是一个很好的组合。它们本身都很棒,结合起来就更棒了。了解你的微服务的健康状况是很重要的,因为它们运行着重要的服务。如果等到某个关键的服务崩溃了才诊断问题,那是很愚蠢的。让 GraphQL 帮助你及早发现问题并不需要花费太多精力。

常规的健康检查可以让你观察和测试你的服务,在问题影响到你的业务、客户或项目之前,尽早得到通知。说起来很简单,但健康检查到底要做什么呢?
以下是我在设计服务检查时考虑的因素:
服务器健康检查的要求:
1. 我需要了解我的微服务的可用性状态。
2. 我希望能够管理服务器的负载。
3. 我希望对我的微服务进行端到端(e2e)测试。
4. 我应该能够预测中断。

### 做服务器健康检查的方法
进行健康检查可能比较棘手,因为理论上,你可以检查的东西几乎是无穷无尽的。我喜欢从小处着手,运行最基本的测试:ping 测试。这只是测试运行应用的服务器是否可用。然后,我加强测试以评估特定问题,思考服务器中最重要的元素。我想到那些如果突然消失的话将是灾难性的事情。
1. \*\*Ping 检查:\*\*Ping 是最简单的监控类型。它只是检查你的应用是否在线。
2. \*\*脚本化浏览器:\*\*脚本化浏览器比较高级。像 [Selenium](https://www.selenium.dev/) 这样的浏览器自动化工具可以让你实现自定义的监控规则集。
3. \*\*API 测试:\*\*API 测试用于监控 API 端点。这是 ping 检查模型的高级版本,你可以根据 API 响应来定义监控计划。
### 使用 GraphQL 进行健康检查
在一个典型的基于 REST 的微服务中,你需要从头开始构建健康检查功能。这是一个时间密集型的过程,但使用 GraphQL 就不用担心了。
根据它的[网站](https://graphql.org/)称:
>
> “GraphQL 是一种用于 API 的查询语言,也是一种用现有数据完成这些查询的运行时环境。GraphQL 为你的 API 中的数据提供了一个完整的、可理解的描述,让客户有能力精确地仅查询他们所需要的东西,让 API 更容易随着时间的推移而进化,并实现强大的开发者工具。”
>
>
>
当你启动一个 GraphQL 微服务时,你还可以获得监控微服务的运行状况的供给。这是一个隐藏的宝贝。
正如我上面提到的,你可以用 GraphQL 端点执行 API 测试以及 ping 检查。
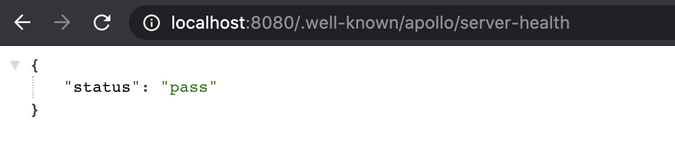
Apollo GraphQL 服务器提供了一个默认的端点,它可以返回有关你的微服务和服务器健康的信息。它不是很复杂:如果服务器正在运行,它就会返回状态码 200。
默认端点是 `<server-host>/.well-known/apollo/server-health`。

### 高级健康检查
在某些情况下,基本的健康检查可能不足以确保系统的完整性。例如,紧密耦合的系统需要更多的业务逻辑来确保系统的健康。
Apollo GraphQL 在定义服务器的同时,通过声明一个 `onHealthCheck` 函数来有效地管理这种情况。
```
* Defining the Apollo Server */
const apollo = new ApolloServer({
playground: process.env.NODE_ENV !== 'production',
typeDefs: gqlSchema,
resolvers: resolver,
onHealthCheck: () => {
return new Promise((resolve, reject) => {
// Replace the `true` in this conditional with more specific checks!
if (true) {
resolve();
} else {
reject();
}
});
}
});
```
当你定义一个 `onHealthCheck` 方法时,它返回一个 promise,如果服务器准备好了,它就会返回 `resolve`,如果有错误,它就会返回 `reject`。
GraphQL 让监控 API 变得更容易。此外,在你的服务器基础架构中使用它可以使代码变得可扩展。如果你想尝试采用 GraphQL 作为你的新基础设施定义,请参见我的 GitHub 仓库中的[示例代码和配置](https://github.com/riginoommen/example-graphql)。
---
via: <https://opensource.com/article/20/8/microservices-graphql>
作者:[Rigin Oommen](https://opensource.com/users/riginoommen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Microservices](https://opensource.com/resources/what-are-microservices) and [GraphQL](https://opensource.com/article/19/6/what-is-graphql) are a great combination, like bread and butter. They're both great on their own and even better together. Knowing the health of your microservices is important because they run important services—it would be foolish to wait until something critical breaks before diagnosing a problem. It doesn't take much effort to let GraphQL help you detect issues early.
Routine health checks allow you to watch and test your services to get early notifications about problems before they affect your business, clients, or project. That's easy enough to say, but what does it really mean to do a health check?
Here are the factors I think about when designing a service checkup:
**Requirements for a server health check:**
- I need to understand the availability status of my microservice.
- I want to be able to manage the server load.
- I want end-to-end (e2e) testing of my microservices.
- I should be able to predict outages.
## Ways to do server health checks
Coming up with health checks can be tricky because, in theory, there's nearly an infinite number of things you could check for. I like to start small and run the most basic test: a ping test. This simply tests whether the server running the application is available. Then I ramp up my tests to evaluate specific concerns, thinking about the elements of my server that are most important. I think about the things that would be disastrous should they disappear suddenly.
**Ping check:**Ping is the simplest monitor type. It just checks that your application is online.**Scripted browser:**Scripted browsers are more advanced; browser automation tools like[Selenium](https://www.selenium.dev/)enable you to implement custom monitoring rule sets.**API tests:**API tests are used to monitor API endpoints. This is an advanced version of the ping check model, where you can define the monitoring plan based on the API responses.
## Health check with GraphQL
In a typical REST-based microservice, you need to build health check features from scratch. It's a time-intensive process, but it's not something you have to worry about with GraphQL.
According to its [website](https://graphql.org/):
"GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools."
When you bootstrap a GraphQL microservice, you also get a provision to monitor the health of the microservice. This is something of a hidden gem.
As I mentioned above, you can perform API tests as well as ping checks with the GraphQL endpoint.
Apollo GraphQL Server provides a default endpoint that returns information about your microservices and server health. It's not very complex: it returns status code 200 if the server is running.
The default endpoint is `<server-host>/.well-known/apollo/server-health`
.
## Advanced health checks
In some cases, basic health checks may not be enough to ensure the integrity of a system. For example, tightly coupled systems require more business logic to ensure the health of the system.
Apollo GraphQL is efficient enough to manage this use case by declaring an `onHealthCheck`
function while defining the server:
```
* Defining the Apollo Server */
const apollo = new ApolloServer({
playground: process.env.NODE_ENV !== 'production',
typeDefs: gqlSchema,
resolvers: resolver,
onHealthCheck: () => {
return new Promise((resolve, reject) => {
// Replace the `true` in this conditional with more specific checks!
if (true) {
resolve();
} else {
reject();
}
});
}
});
```
When you define an `onHealthCheck`
method, it returns a promise that *resolves* if the server is ready and *rejects* if there is an error.
GraphQL makes monitoring APIs easier. In addition, using it for your server infrastructure makes things scalable. If you want to try adopting GraphQL as your new infrastructure definition, see my GitHub repo for [example code and configuration](https://github.com/riginoommen/example-graphql).
## Comments are closed. |
12,589 | Linux 黑话解释:什么是显示服务器,用来做什么? | https://itsfoss.com/display-server/ | 2020-09-06T21:29:00 | [
"显示服务器"
] | https://linux.cn/article-12589-1.html | 
在 Linux 相关的文章、新闻和讨论中,你会经常遇到<ruby> 显示服务器 <rt> display server </rt></ruby>、Xorg、Wayland 等名词。
在这篇解释文章中,我将讨论 Linux 中的显示服务器。
### 什么是显示服务器?
显示服务器是一个程序,它负责协调其客户端与操作系统的其他部分之间,以及硬件和操作系统之间的输入和输出。基本上,多亏了显示服务器,你才能以图形化的方式使用你的计算机(GUI)。如果没有显示服务器,你只能局限于命令行界面(TTY)。
显示服务器提供了一个图形环境的框架,使你可以使用鼠标和键盘与应用程序进行交互。
显示服务器通过[显示服务器协议](https://en.wikipedia.org/wiki/X_Window_System_core_protocol)(如 X11)与客户端进行通信。显示服务器是图形用户界面 —— 特别是窗口系统 —— 中的一个关键组件。
不要把显示服务器和[桌面环境](/article-12579-1.html)混淆。桌面环境的下层使用的是显示服务器。
听起来很熟悉,但又不完全清楚?让我来解释一下。
### Linux 上的显示服务器协议
Linux 中有三种显示服务器协议,分别是 X11、Wayland 和 Mir。下面我就给大家简单介绍一下这些显示服务器。
#### X11
X11(也称 X)是已经存在多年的传统显示服务器。它是 Linux 发行版中最常用的显示服务器。

X11 通信协议,使用显示服务器 [X.org 服务器](https://en.wikipedia.org/wiki/X.Org_Server)。它接收来自[设备驱动程序](https://en.wikipedia.org/wiki/Device_driver)的输入事件,并将它们提供给它的一个客户端。
显示服务器也从客户端接收数据,它处理数据并进行合成,在 Linux 上,它将数据传递给三个内核组件之一:[DRM](https://en.wikipedia.org/wiki/Direct_Rendering_Manager)、[gem](https://en.wikipedia.org/wiki/Graphics_Execution_Manager) 或 [KMS 驱动](https://en.wikipedia.org/wiki/KMS_driver)。
[X.Org](http://X.Org) 服务器是一个显示服务器,它依靠第二个程序:[合成窗口管理器](https://en.wikipedia.org/wiki/Compositing_window_manager),来进行合成。例如 [Mutter](https://en.wikipedia.org/wiki/Mutter_(window_manager)) 或 [KWin](https://en.wikipedia.org/wiki/KWin)。GNOME 使用的是 Mutter。
#### Wayland
按照其网站的说法,Wayland “旨在作为 X 的更简单的替代品,更容易开发和维护”。
而事实上 [Wayland](https://wayland.freedesktop.org/) 就是现代的显示服务器,它应该取代传统的 X 显示服务器。
对它的采用还在普及中。Ubuntu 曾试图在 17.10 版本中改用 Wayland 作为默认的显示服务器,但这个尝试遭到了负面反馈。
很多 GUI 应用程序及其框架都依赖于 X 服务器。这些应用程序在 Wayland 上无法正常工作。
这迫使 Ubuntu 继续使用 X 作为默认显示服务器。它仍然提供了使用 Wayland 的选项,但不再是默认的了。
即使在今天,绝大多数的发行版都默认使用 X 显示服务器。

实施 Wayland 显示服务器协议的显示服务器,被称为 [Wayland 合成器](https://en.wikipedia.org/wiki/Wayland_compositor)。和 X11 上的一样,Wayland 合成器负责处理其客户端的输入和输出,但同时也进行[合成](https://en.wikipedia.org/wiki/Compositing),这与 X11 相反。
几个 Wayland 合成器是 [Weston](https://en.wikipedia.org/wiki/Weston_(software))、[Mutter](https://en.wikipedia.org/wiki/Mutter_(software))、[KWin](https://en.wikipedia.org/wiki/KWin) 或 [Enlightenment](https://en.wikipedia.org/wiki/Enlightenment_(software))。
#### Mir
[Mir 显示服务器](https://mir-server.io/)自带的 Mir 显示服务器协议,与 X11 和 Wayland 使用的协议不同。它是由 [Canonical](https://canonical.com/) 开发的,作为 Unity 开发的一部分,打算成为 [Ubuntu](https://itsfoss.com/install-ubuntu/) 的首选显示服务器。
但在 2017 年,它已经被 [Ubuntu] 桌面版的 Wayland 显示服务器所取代,不过 Mir 的开发还在继续,用于物联网(IoT)应用。
#### 为什么我们还在使用 Xorg?
Wayland 作为比较新的产品,相比 Xorg 来说,还不是很稳定。作为客户端的程序,必须知道如何与显示服务器进行通信。
因此,很多程序在使用 Wayland 时可能无法运行。Ubuntu 默认切换到 Wayland 的实验证实了这一点。
### 结束语
我希望你对 Linux 中的显示服务器概念有了更好的理解。我已经尽量不谈太多的技术细节,但我无法完全避免。
欢迎你的反馈和建议。
---
via: <https://itsfoss.com/display-server/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In Linux related articles, news and discussions, you’ll often come across the term display server, Xorg, Wayland etc.
In this explainer article, I’ll discuss display servers in Linux.
## What is display server in Linux?
A display server is a program which is responsible for the input and output coordination of its clients, to and from the rest of the operating system, and among the hardware and the operating system. Basically, thanks to a display server, you can use your computer graphically (GUI). Without the display server, you would only be restricted to a command line interface ([TTY](https://itsfoss.com/what-is-tty-in-linux/)).
The display server provides the framework for a graphical environment so that you can use mouse and keyboard to interact with applications.
The display server communicates with its clients over the [display server protocol](https://en.wikipedia.org/wiki/X_Window_System_core_protocol), like X11. The display server is a key component in any graphical user interface, specifically the windowing system.
Don’t confuse display server with [desktop environment](https://itsfoss.com/what-is-desktop-environment/). The desktop environment uses display server underneath it.
Sounds familiar but it is not fully clear? Let me explain.
## Display server communications protocols in Linux

There are three display protocols available in Linux, the X11, Wayland and Mir. I’ll give you a brief introduction for these display servers.
### X11
The X11 (also refer as X) is the legacy display server that has been existed for years. It is the most common display server used in Linux distributions.
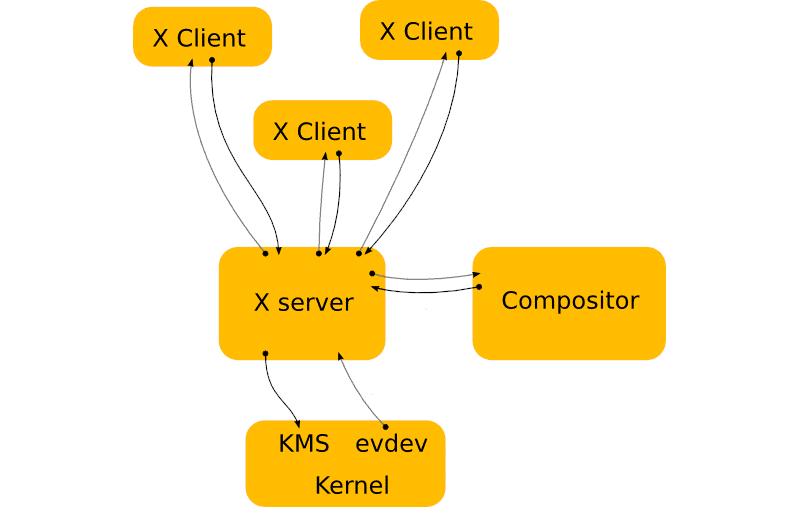
The X11 communication protocol, uses the [X.org Server](https://en.wikipedia.org/wiki/X.Org_Server) display server. It receives input events from [device drivers](https://en.wikipedia.org/wiki/Device_driver) and makes them available to one of its clients.
The display server also receives data from its clients, it processes the data and does the compositing and on Linux it passes the data to one of three kernel components – the [DRM](https://en.wikipedia.org/wiki/Direct_Rendering_Manager), [gem](https://en.wikipedia.org/wiki/Graphics_Execution_Manager) or [KMS driver](https://en.wikipedia.org/wiki/KMS_driver).
The X.Org Server is a display server that relies on a second program, the [compositing window manager](https://en.wikipedia.org/wiki/Compositing_window_manager), to do the compositing. Examples are [Mutter](https://en.wikipedia.org/wiki/Mutter_(window_manager)) or [KWin](https://en.wikipedia.org/wiki/KWin). GNOME uses Mutter.
### Wayland
As per its website, Wayland is “intended as a simpler replacement for X, easier to develop and maintain”.
And indeed [Wayland](https://wayland.freedesktop.org/) is the modern display server that is supposed to replace the legacy X display server.
Its adoption is still a work in progress. Ubuntu tried to switch to Wayland as the default display server with version 17.10 but the experiment met with negative feedback.
A lot of GUI applications and their frameworks depend on the X server. These applications didn’t work as intended on Wayland.
This forced Ubuntu to stay on X as default display server. It still provides the option to use Wayland but it is not default anymore.
An overwhelming majority of distributions use X display server by default even today.
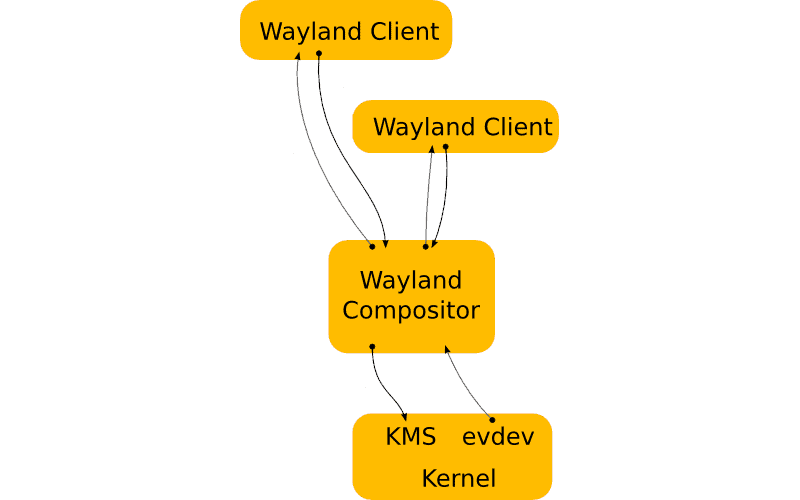
Display servers that put into effect the Wayland display server protocol, are called [Wayland compositors](https://en.wikipedia.org/wiki/Wayland_compositor). Like any X11, a Wayland compositor is responsible for handling input and output for its clients but also does the [compositing](https://en.wikipedia.org/wiki/Compositing) – in contrast to X11.
A few Wayland compositors are [Weston](https://en.wikipedia.org/wiki/Weston_(software)), [Mutter](https://en.wikipedia.org/wiki/Mutter_(software)), [KWin](https://en.wikipedia.org/wiki/KWin) or [Enlightenment](https://en.wikipedia.org/wiki/Enlightenment_(software)).
### Mir
The [Mir display server](https://mir-server.io/) comes with its own Mir display server protocol which differs to those used by X11 and Wayland. It was developed by [Canonical](https://canonical.com/), as part of the development of Unity, and was intended to be the display server of choice for [Ubuntu](https://itsfoss.com/install-ubuntu/).
As of 2017, it has been replaced with the Wayland display server for desktop editions of Ubuntu, although Mir’s development continued for Internet of Things (IoT) applications.
### Why are we still using Xorg?
Wayland as it is relatively new, is not very stable yet, compared to Xorg. The programs, which act as clients, in order to communicate with a display server, must know how to do it.
For this reason, many programs might not run when using Wayland. Ubuntu’s experiment to switch to Wayland by default confirmed this.
### Conclusion
I hope you have a bit better understanding of display server concept in Linux. I have tried to not go into too much technical details but I could not avoid them altogether.
Your feedback and suggestion is welcome. |
12,591 | 通过集中日志记录来减少安全风险 | https://opensource.com/article/19/2/reducing-security-risks-centralized-logging | 2020-09-07T23:10:42 | [
"日志",
"安全"
] | https://linux.cn/article-12591-1.html |
>
> 集中日志并结构化待处理的日志数据可缓解与缺少日志相关的风险
>
>
>

日志记录和日志分析对于保护基础设施安全来说至关重要,尤其是当我们考虑到通用漏洞的时候。这篇文章基于我在 FOSDEM'19 上的闪电秀《[Let's use centralized log collection to make incident response teams happy](https://fosdem.org/2019/schedule/event/lets_use_centralized_log_collection_to_make_incident_response_teams_happy/)》,目的是提高大家对日志匮乏这种安全问题的重视,提供一种避免风险的方法,并且倡议更多的安全实践(利益声明: 我为 NXLog 工作)。
### 为什么要收集日志?为什么要集中日志记录?
确切的说,日志是写入磁盘的仅追加的记录序列。在实际生活中,日志可以在你尝试寻找异常的根源时帮助你调查基础设施的问题。当你有多个使用自己的标准与格式的日志的异构系统,并且想用一种可靠的方法来接收和处理它们的时候,挑战就来临了。这通常以元数据为代价的。集中日志记录解决方案需要共性,这种共性常常会去除许多开源日志记录工具所提供的丰富的元数据。
### 日志记录与监控匮乏的安全风险
<ruby> 开源 Web 应用程序安全项目 <rt> Open Web Application Security Project </rt></ruby>([OWASP](https://www.owasp.org/index.php/Main_Page))是一个为业界贡献了许多杰出项目(包括许多专注于软件安全的[工具](https://github.com/OWASP))的非营利组织。OWASP 定期为应用开发人员和维护者报告最危险的安全挑战。在最新一版《[10 项最严重的 Web 应用程序安全风险](https://www.owasp.org/index.php/Top_10-2017_Top_10)》中,OWASP 将日志记录和监控匮乏加入了列表中。OWASP 警告下列情况会导致日志记录、检测、监控和主动响应的匮乏:
* 未记录重要的可审计性事件,如:登录、登录失败和高额交易。
* 告警和错误事件未能产生、产生不足或不清晰的日志信息。
* 日志信息仅在本地存储。
* 对于实时或准实时的主动攻击,应用程序无法检测、处理和告警。
可以通过集中日志记录(例如,不仅将日志本地存储)和结构化日志数据以进一步分析来缓解上述情形(例如,在告警仪表盘和安全套件中)。
举例来说, 假设一个 DNS 查询会导向名为 [hacked.badsite.net](http://hacked.badsite.net) 的恶意网站。通过 DNS 监控,管理员监控并且主动的分析 DNS 请求与响应。DNS 监控的效果依赖于充足的日志记录与收集来发现潜在问题,同样也依赖于结构化 DNS 日志的结果来进一步分析。
```
2019-01-29
Time (GMT) Source Destination Protocol-Info
12:42:42.112898 SOURCE_IP xxx.xx.xx.x DNS Standard query 0x1de7 A hacked.badsite.net
```
你可以在 [NXLog 社区版](https://nxlog.co/products/nxlog-community-edition/download) 中自己尝试一下这个例子,也可以尝试其他例子和代码片段。 (再次声明:我为 NXLog 工作)
### 重要的一点:非结构化数据与结构化数据
花费一点时间来考虑下日志数据格式是很重要的。例如,让我们来考虑以下日志消息:
```
debug1: Failed password for invalid user amy from SOURCE_IP port SOURCE_PORT ssh2
```
这段日志包含了一个预定义的结构,例如冒号前面的元数据关键词(`debug1`)然而,余下的日志字段是一个未结构化的字符串(`Failed password for invalid user amy from SOURCE_IP port SOURCE_PORT ssh2`)。因此,即便这个消息是人类可轻松阅读的格式,但它不是一个计算机容易解析的格式。
非结构化的事件数据存在局限性,包括难以解析、搜索和分析日志。重要的元数据通常以一种自由字符串的形式作为非结构化数据字段,就像上面的例子一样。日志管理员会在他们尝试标准化/归一化日志数据与集中日志源的过程中遇到这个问题。
### 接下来怎么做
除了集中和结构化日志之外,确保你收集了正确的日志数据——Sysmon、PowerShell、Windows 事件日志、DNS 调试日志、ETW、内核监控、文件完整性监控、数据库日志、外部云日志等等。同样也要选用适当的工具和流程来来收集、汇总和帮助理解数据。
希望这对你从不同日志源中集中日志收集提供了一个起点:将日志发送到仪表盘、监控软件、分析软件以及像安全性资讯与事件管理(SIEM)套件等外部源。
你的集中日志策略会是怎么样?请在评论中分享你的想法。
---
via: <https://opensource.com/article/19/2/reducing-security-risks-centralized-logging>
作者:[Hannah Suarez](https://opensource.com/users/hcs) 选题:[lujun9972](https://github.com/lujun9972) 译者:[leommxj](https://github.com/leommxj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Logging and log analysis are essential to securing infrastructure, particularly when we consider common vulnerabilities. This article, based on my lightning talk * Let's use centralized log collection to make incident response teams happy* at FOSDEM'19, aims to raise awareness about the security concerns around insufficient logging, offer a way to avoid the risk, and advocate for more secure practices
*(disclaimer: I work for NXLog).*
## Why log collection and why centralized logging?
Logging is, to be specific, an append-only sequence of records written to disk. In practice, logs help you investigate an infrastructure issue as you try to find a cause for misbehavior. A challenge comes up when you have heterogeneous systems with their own standards and formats, and you want to be able to handle and process these in a dependable way. This often comes at the cost of metadata. Centralized logging solutions require commonality, and that commonality often removes the rich metadata many open source logging tools provide.
## The security risk of insufficient logging and monitoring
The Open Web Application Security Project ([OWASP](https://www.owasp.org/index.php/Main_Page)) is a nonprofit organization that contributes to the industry with incredible projects (including many [tools](https://github.com/OWASP) focusing on software security). The organization regularly reports on the riskiest security challenges for application developers and maintainers. In its most recent report on the [top 10 most critical web application security risks](https://www.owasp.org/index.php/Top_10-2017_Top_10), OWASP added Insufficient Logging and Monitoring to its list. OWASP warns of risks due to insufficient logging, detection, monitoring, and active response in the following types of scenarios.
- Important auditable events, such as logins, failed logins, and high-value transactions are not logged.
- Warnings and errors generate none, inadequate, or unclear log messages.
- Logs are only being stored locally.
- The application is unable to detect, escalate, or alert for active attacks in real time or near real time.
These instances can be mitigated by centralizing logs (i.e., not storing logs locally) and structuring log data for processing (i.e., in alerting dashboards and security suites).
For example, imagine a DNS query leads to a malicious site named **hacked.badsite.net**. With DNS monitoring, administrators monitor and proactively analyze DNS queries and responses. The efficiency of DNS monitoring relies on both sufficient logging and log collection in order to catch potential issues as well as structuring the resulting DNS log for further processing:
```
2019-01-29
Time (GMT) Source Destination Protocol-Info
12:42:42.112898 SOURCE_IP xxx.xx.xx.x DNS Standard query 0x1de7 A hacked.badsite.net
```
You can try this yourself and run through other examples and snippets with the [NXLog Community Edition](https://nxlog.co/products/nxlog-community-edition/download) *(disclaimer again: I work for NXLog).*
## Important aside: unstructured vs. structured data
It's important to take a moment and consider the log data format. For example, let's consider this log message:
`debug1: Failed password for invalid user amy from SOURCE_IP port SOURCE_PORT ssh2`
This log contains a predefined structure, such as a metadata keyword before the colon (**debug1**). However, the rest of the log field is an unstructured string (**Failed password for invalid user amy from SOURCE_IP port SOURCE_PORT ssh2**). So, while the message is easily available in a human-readable format, it is not a format a computer can easily parse.
Unstructured event data poses limitations including difficulty of parsing, searching, and analyzing the logs. The important metadata is too often set in an unstructured data field in the form of a freeform string like the example above. Logging administrators will come across this problem at some point as they attempt to standardize/normalize log data and centralize their log sources.
## Where to go next
Alongside centralizing and structuring your logs, make sure you're collecting the right log data—Sysmon, PowerShell, Windows EventLog, DNS debug, NetFlow, ETW, kernel monitoring, file integrity monitoring, database logs, external cloud logs, and so on. Also have the right tools and processes in place to collect, aggregate, and help make sense of the data.
Hopefully, this gives you a starting point to centralize log collection across diverse sources; send them to outside sources like dashboards, monitoring software, analytics software, specialized software like security information and event management (SEIM) suites; and more.
What does your centralized logging strategy look like? Share your thoughts in the comments.
## Comments are closed. |
12,592 | 研究人员表示,到 2245 年信息量可能占世界质量的一半 | https://www.networkworld.com/article/3570438/information-could-be-half-the-worlds-mass-by-2245-says-researcher.html | 2020-09-07T23:31:01 | [
"信息",
"质量"
] | https://linux.cn/article-12592-1.html |
>
> 根据一位理论物理学家的说法,由于创建和存储数字信息所使用的能源和资源数量,数据应该被视为物理的,而不仅仅是看不见的一和零。
>
>
>

一位大学学者建议,数字内容应该与气体、液体、等离子体和固体一样,被视为第五种物质状态。
英国朴茨茅斯大学高级讲师、发表在《AIP Advances》杂志上的《[信息灾难](https://aip.scitation.org/doi/10.1063/5.0019941)》一文的作者 Melvin Vopson 称,由于以物理和数字方式创建、存储和分发数据所使用的能量和资源,数据已经发生了演变,现在应该被视为质量。
Vopson 还声称,数字比特正在走向压倒地球的道路,最终将超过原子的数量。
给数字信息分配质量的想法建立在一些现有数据点的基础之上。Vopson 引用了 IBM 的一项估计,发现数据每天以 2.5 万亿字节的速度产生。他还将每英寸超过 1 <ruby> 太比特 <rt> terabit </rt></ruby>的数据存储密度考虑在内,将比特的大小与原子的大小进行比较。
假设数据生成量每年增长 50%,根据宣布 Vopson 研究的[媒体发布](https://publishing.aip.org/publications/latest-content/digital-content-on-track-to-equal-half-earths-mass-by-2245/),“比特的数量将在大约 150 年内等于地球上的原子数量。”
新闻稿中写道:“大约 130 年后,维持数字信息创造所需的动力将等于地球上目前产生的所有动力,到 2245 年,地球上一半的质量将转化为数字信息质量。”
Vopson 补充说,COVID-19 大流行正在提高数字数据创造的速度,并加速这一进程。
他警告说,一个饱和点即将到来:“即使假设未来的技术进步将比特大小降低到接近原子本身的大小,这个数字信息量所占的比重将超过地球的大小,从而导致我们所定义的‘信息灾难’。”Vopson 在[论文](https://aip.scitation.org/doi/full/10.1063/5.0019941)中写道。
“我们正在一点一点地改变这个星球,这是一场看不见的危机,”Vopson 说,他是希捷科技公司的前研发科学家。
Vopson 并不是一个人在探索,信息并不是简单的不可察觉的 1 和 0。根据发布的消息,Vopson 借鉴了爱因斯坦广义相对论中的质能对比;将热力学定律应用于信息的 Rolf Landauer 的工作;以及数字比特的发明者 Claude Shannon 的工作。
“当一个人将信息内容带入现有的物理理论中时,这几乎就像物理学中的一切都多了一个维度,”Vopson 说。
他的论文总结道,随着增长速度似乎不可阻挡,数字信息生产“将消耗地球上大部分的电力能源,从而导致道德和环境问题。”他的论文总结道。
有趣的是,除此以外,Vopson 还提出,如果像他所预测的那样,未来地球的质量主要由信息位组成,并且有足够的动力创造出来(不确定),那么“可以设想未来的世界主要由计算机模拟,并由数字比特和计算机代码主导,”他写道。
---
via: <https://www.networkworld.com/article/3570438/information-could-be-half-the-worlds-mass-by-2245-says-researcher.html>
作者:[Patrick Nelson](https://www.networkworld.com/author/Patrick-Nelson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,594 | 为什么排序的复杂度为 O(N log N) | https://theartofmachinery.com/2019/01/05/sorting_is_nlogn.html | 2020-09-08T14:49:21 | [
"排序"
] | https://linux.cn/article-12594-1.html | 
基本上所有正而八经的算法教材都会解释像<ruby> 快速排序 <rt> quicksort </rt></ruby>和<ruby> 堆排序 <rt> heapsort </rt></ruby>这样的排序算法有多快,但并不需要复杂的数学就能证明你可以逐渐趋近的速度有多快。
>
> 关于标记的一个严肃说明:
>
>
> 大多数计算机专业的科学家使用大写字母 O 标记来指代“趋近,直到到达一个常数比例因子”,这与数学专业所指代的意义是有所区别的。这里我使用的大 O 标记的含义与计算机教材所指相同,但至少不会和其他数学符号混用。
>
>
>
### 基于比较的排序
先来看个特例,即每次比较两个值大小的算法(快速排序、堆排序,及其它通用排序算法)。这种思想后续可以扩展至所有排序算法。
#### 一个简单的最差情况下的计数角度
假设有 4 个互不相等的数,且顺序随机,那么,可以通过只比较一对数字完成排序吗?显然不能,证明如下:根据定义,要对该数组排序,需要按照某种顺序重新排列数字。换句话说,你需要知道用哪种排列方式?有多少种可能的排列?第一个数字可以放在四个位置中的任意一个,第二个数字可以放在剩下三个位置中的任意一个,第三个数字可以放在剩下两个位置中的任意一个,最后一个数字只有剩下的一个位置可选。这样,共有 4×3×2×1=4!=24 种排列可供选择。通过一次比较大小,只能产生两种可能的结果。如果列出所有的排列,那么“从小到大”排序对应的可能是第 8 种排列,按“从大到小”排序对应的可能是第 24 种排列,但无法知道什么时候需要的是其它 22 种排列。
通过 2 次比较,可以得到 2×2=4 种可能的结果,这仍然不够。只要比较的次数少于 5(对应 2<sup> 5</sup> = 32 种输出),就无法完成 4 个随机次序的数字的排序。如果 `W(N)` 是最差情况下对 `N` 个不同元素进行排序所需要的比较次数,那么,

两边取以 2 为底的对数,得:

`N!` 的增长近似于 `N<sup> N</sup>` (参阅 [Stirling 公式](http://hyperphysics.phy-astr.gsu.edu/hbase/Math/stirling.html)),那么,

这就是最差情况下从输出计数的角度得出的 `O(N log N)` 上限。
#### 从信息论角度的平均状态的例子
使用一些信息论知识,就可以从上面的讨论中得到一个更有力的结论。下面,使用排序算法作为信息传输的编码器:
1. 任取一个数,比如 15
2. 从 4 个数字的排列列表中查找第 15 种排列
3. 对这种排列运行排序算法,记录所有的“大”、“小”比较结果
4. 用二进制编码发送比较结果
5. 接收端重新逐步执行发送端的排序算法,需要的话可以引用发送端的比较结果
6. 现在接收端就可以知道发送端如何重新排列数字以按照需要排序,接收端可以对排列进行逆算,得到 4 个数字的初始顺序
7. 接收端在排列表中检索发送端的原始排列,指出发送端发送的是 15
确实,这有点奇怪,但确实可以。这意味着排序算法遵循着与编码方案相同的定律,包括理论所证明的不存在通用的数据压缩算法。算法中每次比较发送 1 比特的比较结果编码数据,根据信息论,比较的次数至少是能表示所有数据的二进制位数。更技术语言点,[平均所需的最小比较次数是输入数据的香农熵,以比特为单位](https://en.wikipedia.org/wiki/Shannon%27s_source_coding_theorem)。熵是衡量信息等不可预测量的数学度量。
包含 `N` 个元素的数组,元素次序随机且无偏时的熵最大,其值为 `log<sub> 2</sub> N!` 个比特。这证明 `O(N log N)` 是一个基于比较的对任意输入排序的最优平均值。
以上都是理论说法,那么实际的排序算法如何做比较的呢?下面是一个数组排序所需比较次数均值的图。我比较的是理论值与快速排序及 [Ford-Johnson 合并插入排序](https://en.wikipedia.org/wiki/Merge-insertion_sort) 的表现。后者设计目的就是最小化比较次数(整体上没比快速排序快多少,因为生活中相对于最大限度减少比较次数,还有更重要的事情)。又因为<ruby> 合并插入排序 <rt> merge-insertion sort </rt></ruby>是在 1959 年提出的,它一直在调整,以减少了一些比较次数,但图示说明,它基本上达到了最优状态。

一点点理论导出这么实用的结论,这感觉真棒!
#### 小结
证明了:
1. 如果数组可以是任意顺序,在最坏情况下至少需要 `O(N log N)` 次比较。
2. 数组的平均比较次数最少是数组的熵,对随机输入而言,其值是 `O(N log N)` 。
注意,第 2 个结论允许基于比较的算法优于 `O(N log N)`,前提是输入是低熵的(换言之,是部分可预测的)。如果输入包含很多有序的子序列,那么合并排序的性能接近 `O(N)`。如果在确定一个位之前,其输入是有序的,插入排序性能接近 `O(N)`。在最差情况下,以上算法的性能表现都不超出 `O(N log N)`。
### 一般排序算法
基于比较的排序在实践中是个有趣的特例,但从理论上讲,计算机的 [CMP](https://c9x.me/x86/html/file_module_x86_id_35.html) 指令与其它指令相比,并没有什么特别之处。在下面两条的基础上,前面两种情形都可以扩展至任意排序算法:
1. 大多数计算机指令有多于两个的输出,但输出的数量仍然是有限的。
2. 一条指令有限的输出意味着一条指令只能处理有限的熵。
这给出了 `O(N log N)` 对应的指令下限。任何物理上可实现的计算机都只能在给定时间内执行有限数量的指令,所以算法的执行时间也有对应 `O(N log N)` 的下限。
#### 什么是更快的算法?
一般意义上的 `O(N log N)` 下限,放在实践中来看,如果听人说到任何更快的算法,你要知道,它肯定以某种方式“作弊”了,其中肯定有圈套,即它不是一个可以处理任意大数组的通用排序算法。可能它是一个有用的算法,但最好看明白它字里行间隐含的东西。
一个广为人知的例子是<ruby> 基数排序 <rt> radix sort </rt></ruby>算法,它经常被称为 `O(N)` 排序算法,但它只能处理所有数字都能放入 `k` 比特的情况,所以实际上它的性能是 `O(kN)`。
什么意思呢?假如你用的 8 位计算机,那么 8 个二进制位可以表示 2<sup> 8</sup>=256 个不同的数字,如果数组有上千个数字,那么其中必有重复。对有些应用而言这是可以的,但对有些应用就必须用 16 个二进制位来表示,16 个二进制位可以表示 2<sup> 16</sup>=65,536 个不同的数字。32 个二进制位可以表示 2<sup> 32</sup>=4,294,967,296 不同的数字。随着数组长度的增长,所需要的二进制位数也在增长。要表示 N 个不同的数字,需要 `k ≥ log<sub> 2</sub> N` 个二进制位。所以,只有允许数组中存在重复的数字时, `O(kN)` 才优于 `O(N log N)`。
一般意义上输入数据的 `O(N log N)` 的性能已经说明了全部问题。这个讨论不那么有趣因为很少需要在 32 位计算机上对几十亿整数进行排序,[如果有谁的需求超出了 64 位计算机的极限,他一定没有告诉别人](https://sortbenchmark.org/)。
---
via: <https://theartofmachinery.com/2019/01/05/sorting_is_nlogn.html>
作者:[Simon Arneaud](https://theartofmachinery.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Any decent algorithms textbook will explain how fast sorting algorithms like quicksort and heapsort are, but it doesn’t take crazy maths to prove that they’re as asymptotically fast as you can possibly get.
### A pedantic note about notation
Most computer scientists use big-O notation to mean “asymptotically equal, up to a constant scaling factor”, which isn’t quite what it means to other mathematicians. Sorry, I’ll use big-O like in CS textbooks, but at least I won’t mix it with other mathematical notation.
## Comparison-based sorting
Let’s look at the special case of algorithms that compare values two at a time (like quicksort and heapsort, and most other popular algorithms). The ideas can be extended to all sorting algorithms later.
### A simple counting argument for the worst case
Suppose you have an array of four elements, all different, in random order. Can you sort it by comparing just one pair of elements? Obviously not, but here’s one good reason that proves you can’t: By definition, to sort the array, you need to how to rearrange the elements to put them in order. In other words, you need to know which permutation is needed. How many possible permutations are there? The first element could be moved to one of four places, the second one could go to one of the remaining three, the third element has two options, and the last element has to take the one remaining place. So there are possible permutations to choose from, but there are only two possible results from comparing two different things: “BIGGER” and “SMALLER”. If you made a list of all the possible permutations, you might decide that “BIGGER” means you need permutation #8 and “SMALLER” means you need permutation #24, but there’s no way you could know when you need the other 22 permutations.
With two comparisons, you have possible outputs, which still isn’t enough. You can’t sort every possible shuffled array unless you do at least five comparisons (). If is the worst-case number of comparisons needed to sort different elements using some algorithm, we can say
Taking a logarithm base 2,
Asymptotically, grows like (see also [Stirling’s
formula](http://hyperphysics.phy-astr.gsu.edu/hbase/Math/stirling.html)), so
And that’s an limit on the worst case just from counting outputs.
### Average case from information theory
We can get a stronger result if we extend that counting argument with a little information theory. Here’s how we could use a sorting algorithm as a code for transmitting information:
- I think of a number — say, 15
- I look up permutation #15 from the list of permutations of four elements
- I run the sorting algorithm on this permutation and record all the “BIGGER” and “SMALLER” comparison results
- I transmit the comparison results to you in binary code
- You re-enact my sorting algorithm run, step by step, referring to my list of comparison results as needed
- Now that you know how I rearranged my array to make it sorted, you can reverse the permutation to figure out my original array
- You look up my original array in the permutation list to figure out I transmitted the number 15
Okay, it’s a bit strange, but it could be done. That means that sorting algorithms are bound by the same laws as
normal encoding schemes, including the theorem proving there’s no universal data compressor. I transmitted one bit per
comparison the algorithm does, so, on average, the number of comparisons must be at least the number of bits needed to
represent my data, according to information theory. More technically, [the average number of comparisons must be at least
the Shannon entropy of my input data, measured in bits](https://en.wikipedia.org/wiki/Shannon%27s_source_coding_theorem). Entropy is a mathematical measure of the information
content, or unpredictability, of something.
If I have an array of elements that could be in any possible order without bias, then entropy is maximised and is bits. That proves that is an optimal average for a comparison-based sort with arbitrary input.
That’s the theory, but how do real sorting algorithms compare? Below is a plot of the average number of comparisons
needed to sort an array. I’ve compared the theoretical optimum against naïve quicksort and the [Ford-Johnson merge-insertion sort](https://en.wikipedia.org/wiki/Merge-insertion_sort), which was designed to
minimise comparisons (though it’s rarely faster than quicksort overall because there’s more to life than minimising
comparisons). Since it was developed in 1959, merge-insertion sort has been tweaked to squeeze a few more comparisons
out, but the plot shows it’s already almost optimal.

It’s nice when a little theory gives such a tight practical result.
### Summary so far
Here’s what’s been proven so far:
- If the array could start in any order, at least comparisons are needed in the worst case
- The average number of comparisons must be at least the entropy of the array, which is for random input
Note that #2 allows comparison-based sorting algorithms to be faster than if the input is low entropy (in other words, more predictable). Merge sort is close to if the input contains many sorted subarrays. Insertion sort is close to if the input is an array that was sorted before being perturbed a bit. None of them beat in the worst case unless some array orderings are impossible as inputs.
## General sorting algorithms
Comparison-based sorts are an interesting special case in practice, but there’s nothing theoretically special about
[ CMP](https://c9x.me/x86/html/file_module_x86_id_35.html) as opposed to any other instruction on a computer. Both arguments
above can be generalised to any sorting algorithm if you note a couple of things:
- Most computer instructions have more than two possible outputs, but still have a limited number
- The limited number of outputs means that one instruction can only process a limited amount of entropy
That gives us the same lower bound on the number of instructions. Any physically realisable computer can only process a limited number of instructions at a time, so that’s an lower bound on the time required, as well.
### But what about “faster” algorithms?
The most useful practical implication of the general bound is that if you hear about any asymptotically faster algorithm, you know it must be “cheating” somehow. There must be some catch that means it isn’t a general purpose sorting algorithm that scales to arbitrarily large arrays. It might still be a useful algorithm, but it’s a good idea to read the fine print closely.
A well-known example is radix sort. It’s often called an sorting algorithm, but the catch is that it only works if all the numbers fit into bits, and it’s really .
What does that mean in practice? Suppose you have an 8-bit machine. You can represent different numbers in 8 bits, so if you have an array of thousands of numbers, you’re going to have duplicates. That might be okay for some applications, but for others you need to upgrade to at least 16 bits, which can represent numbers distinctly. 32 bits will support different numbers. As the size of the array goes up, the number of bits needed will tend to go up, too. To represent different numbers distinctly, you’ll need . So, unless you’re okay with lots of duplicates in your array, is effectively .
The need for of input data in the general case actually proves the overall result by itself. That argument isn’t
so interesting in practice because we rarely need to sort billions of integers on a 32-bit machine, and [if anyone’s hit the limits of a 64-bit machine, they haven’t told the rest of us](https://sortbenchmark.org/). |
12,595 | 《代码英雄》第二季(2):Hello, World | https://www.redhat.com/en/command-line-heroes/season-2/hello-world | 2020-09-08T22:45:36 | [
"代码英雄",
"编程语言"
] | https://linux.cn/article-12595-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(2):Hello, World](https://www.redhat.com/en/command-line-heroes/season-2/hello-world)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/e6ef40b1.mp3)脚本。
>
> 导语:每一种新的编程语言的诞生,都是为了做一些以前无法完成的事情。如今,有非常多编程语言可以选择,但哪些才是你真正需要了解的?
>
>
> 本集将深入探讨编程语言的历史。我们将会了解到被称为 “神奇葛丽丝” 的天才 —— 海军少将葛丽丝·哈伯。多亏了她,开发者不再需要数学博士的学历就能使用机器代码编写程序。参与录制的还有 Jupyter 项目的 Carol Willing,她是 Python 基金会的前理事;以及《<ruby> 纽约时报杂志 <rt> New York Times Magazine </rt></ruby>》和《<ruby> 连线 <rt> Wired </rt></ruby>》的撰稿人 Clive Thompson,他最近正在撰写一本关于程序员如何思考的书。
>
>
>
**00:00:07 - 各种语言**:
“你好,世界。”
**00:00:12** - Saron Yitbarek\*\*:
你好,世界。现在我们发出的是信号还是噪音?我们日日夜夜无休止地写代码,做测试工作,我们追求的事情只有一个:我们是否传递了我们的信号?
**00:00:29 - 各种语言**:
你好。
**00:00:29 - Saron Yitbarek**:
或者我们的信号是不是丢失了?难道我们一直在制造无意义的杂音吗?
**00:00:40**:
我是 Saron Yitbarek,这是代码英雄第二季,来自红帽原创播客。今天的话题将在“翻译”中挖掘。这关于编程语言的故事:它们是怎么来的,如何选择其中一个语言来学习。我们将深入研究如何与机器对话。探究这些语言是如何演化的,以及我们如何用它们来让我们的工作变得更好。
**00:01:08 - Sari**:
Daisy,daisy,来告诉我你的正确回答。
**00:01:11 - Saron Yitbarek**:
如果你像我一样是一个开发者,你可能也经受着去精通多种语言的压力。最起码你得会 Java,更好一些得懂 Python、Go、JavaScript、Node,甚至能够用 C++ 思考。也许为了增加可信度,可能你还要熟悉古典的 COBOL。甚至你还得学点新东西,比如 Dart。实在太累了。
**00:01:36**:
奇怪的是,我们正在讨论的计算机只讲一种语言:机器语言,以二进制形式飘过的 1 和 0。说到底,我们学习的每个语言都是殊途同归。不管有多抽象,它都是用来简化我们工作的道具。
**00:02:03**:
这就是我希望你们记住的,故事开始了,从那一刻,那一个经典辉煌的时刻,一个女人说:“你知道么?我是人类,我不想用二进制来讨论思考,我就想用英语去编程。”
**00:02:22**:
在今天可能看来是一个简单的概念。但曾几何时,使用人类的方式与计算机对话这个主意 —— 说轻点是一个笑话,严重点就是亵渎。
**00:02:37**:
代码英雄第二季,将讲述成就我们基础的螺丝钉展开。这一讲的英雄是一个女主人公,如果你想要进一步了解故事,你必须知道她的经历。在此给你们隆重介绍:软件界的第一夫人。
>
> **00:02:58 - 发言人**:
>
>
> 尊敬的先生们和女士们,我非常荣幸的给你们介绍<ruby> 葛丽丝·玛丽·哈伯 <rt> Grace Mary Hopper </rt></ruby>准将,谢谢。
>
>
> **00:03:02 - 葛丽丝·哈伯**:
>
>
> 我曾到加拿大的圭尔夫大学演讲,那时候我必须在多伦多的机场办理入境手续。我把护照递给移民官,他打量了护照和我说:“你是在哪里工作的?”
>
>
> **00:03:17**:
>
>
> 然后我说,“美国海军。”
>
>
> **00:03:20**:
>
>
> 她再次深深的打量我一下。然后他说:“你一定是海军里最老的。”
>
>
>
**00:03:28 - Saron Yitbarek**:
她就是 1985 年担任海军少将的葛丽丝·哈伯。在麻省理工学院发表了著名的演讲时,她 79 岁。即使在那时,她也是一个传奇人物。她是独立编程语言之母,实现通过编译器,用人类语言替代数学符号编程这一伟大成就的女性。
**00:03:51**:
她获得了国家技术奖章,她去世后(1992 年),被追授国家自由勋章。以上记录纯属真实,他们称她w为“神奇葛丽丝”。
**00:04:03 - Claire Evans**:
如果有人能够被称为天生的程序员,那么这个人一定是葛丽丝。
**00:04:06 - Saron Yitbarek**:
这是 Claire Evans,一个科技记者和《<ruby> 宽带 <rt> Broad Band </rt></ruby>》一书的作者,而这本书讲述了科技领域的女性先锋。Evans 描绘了早期的计算机世界,在 1940 年,当葛丽丝·哈伯还是一个年轻的女孩时,她加入了美军的海军预备役部队。当时的电脑有一个小房子那么大。
**00:04:25 - Claire Evans**:
早期的那些程序员,他们就像一个圣职者。他们是一群擅长做枯燥乏味事情的人,因为那会儿没有编译器,没有编程语言,人们是确实是一个比特一个比特地对机器编程。
**00:04:42**:
想要改变这种现实,你真的必须是一个特别的人,而葛丽丝真的就是那种人。
**00:04:49 - Saron Yitbarek**:
现在,她意识到让人类使用机器语言的是一种多么疯狂的限制。就像走路的时候,去告诉你身体的每个原子该怎么做。这是可能的吗?是,效率呢?不高。
**00:05:06**:
在程序员的意图和计算机的行为之间一定有一条捷径。自从有了算盘,人类一直在将数学思维机械化。一定有一种方法可以在计算机上再次实现这一点。
**00:05:19 - Claire Evans**:
在过去,数学家必须做出所有的步骤。所有这些枯燥的,一步一步的工作都是为了得到一个真实而有趣的答案。然后有了计算机后,它尽可能地承担了这些机械的运算。所以解放了数学家去进行高层面的、更智慧的、面向系统的思考。
**00:05:39**:
只不过,事实并没有如此发展。有了计算机,数学家就变成了程序员。他们又一次被这些枯燥无味的编程所束缚,做着这些一点一滴的繁琐的规则导向的小计算。
**00:05:53**:
因此,我认为,葛丽丝的期望是,她希望计算机能够辅助数学家,然后数学家就可以去更进行宏大的思考,做更伟大的事情,而不至于让他们陷入细节之中。
**00:06:12 - Saron Yitbarek**:
葛丽丝也加入了思想家的行列。我们都知道,<ruby> 帕斯卡 <rt> Pascal </rt></ruby>在 17 世纪发明了第一台计算器。<ruby> 巴比奇 <rt> Babbage </rt></ruby>在 19 世纪发明了分析机。这些伟大的杰作是发明家们解放人类的大脑的创作。这些发明让我们处理数据的能力空前绝后。这就是葛丽丝踏入的领域,发明了所有人都认为不可能的东西。
**00:06:42 - Claire Evans**:
我觉得,葛丽丝的想法是,人们应该用人类语言与计算机沟通。这个语言必须独立于机器的,因此不同计算机可以交互操作,这在当时是革命性的。
**00:06:59**:
早期她称这个为 “自动化编程”,在程序员和计算机人的群体中,被认为是像太空学员一样。
**00:07:12**:
而那些迟迟不上岸的人们被看成了尼安德特人,这在当时是计算机界的一个巨大的分歧。
**00:07:21 - Saron Yitbarek**:
葛丽丝要说服她的上级跨越这个分歧并不容易。但她认为这是她的责任,她必须尝试。
>
> **00:07:30 - 葛丽丝·哈伯**:
>
>
> 这里总是有一条线,那条线代表了你的老板在那个时候会相信什么。当然,如果你过线了是得不到预算的。所以你对那条线有双重责任:不要踩过它,但也要不断教育你的老板,让你把这条线移得更远,这样下次你就能走得更远。
>
>
>
**00:07:52 - Saron Yitbarek**:
她推动的那个未来,就是我们的现在。几乎你我依赖的每一种语言都归功于她和她的第一个编译器。因此太空学员们活了下来,尼安德特人灭亡了。
**00:08:07**:
写代码不用数字,而是用人类风格的语言是她的观点。你敲下“执行操作 8”,或“关闭 文件 C”的精简操作,才是符合人类习惯的编程。
**00:08:21 - Claire Evans**:
葛丽丝独特地意识到,计算将成为改变世界的事情。但是如果没有人知道如何接触并使用计算机,那么它就不会成为改变世界的事情。因此她想确保它对尽可能多的人开放,尽可能多的人可以使用。
**00:08:37 - Claire Evans**:
这就需要编程在可理解性和可读性上做一些妥协。因此最终创造一个编程语言的目标就是给机器提供更多切入点,让它脱离这个神职,让它的开发面向大众和未来新一代。
**00:08:59 - Saron Yitbarek**:
我想在这里打断并强调下 Claire 的说法:现在我们所已知的编程语言,都来源于科技开放的愿望。这让计算机不再是数学博士们的专属玩具,让编程开发变得更容易。
**00:09:14**:
编译器所有工作的本质,是让程序变得更好理解,更有人性。
**00:09:21**:
Claire 有一个猜测,为什么葛丽丝是做出改变的那个人,这与她在二战期间的工作有关。
**00:09:29 - Claire Evans**:
她的工作是解决扫雷问题、弹道问题和海洋学问题。她用很多不同的、交叉的学科来模拟战争里的所有的暴力、混乱和现实的灾难,并将他们转化成在 Mark I 计算机上运行的程序。
**00:09:45**:
她知道如何在语言之间去做翻译转换。我的意思不是说计算机语言,是人类语言。她知道如何倾听一个提出复杂问题的人的意见,并尝试理解问题的背景,其信息和所涉及的专业规律,然后将这些转为计算机可以理解的程序。
**00:10:06**:
从这个角度看她如同早期的编译器。就像一个人类版本的编译器,因为她知道你必须理解他们才能满足他们的需求。
**00:10:17 - Saron Yitbarek**:
编译器干的事情就是一个解释和理解。我觉得我们应该在学习新语言,或想知道为什么有一些东西根本不能编译的时候牢记这个理念。编译器的工作就是满足你使用生活中说的语言来编程。
**00:10:32**:
葛丽丝知道人类一旦可以学会讲编程语言,而编译器可以将我们的意图转换为机器语言,就像为洪水打开了大门一样。
**00:10:43 - Claire Evans**:
她知道如果计算机太孤立和太具体,就不会发展为一个产业,从而成为改变世界的力量。也就是说计算机的从业者,可以让提出问题的人跟机器直接沟通。
**00:11:00**:
因此她真的是一个善于人类语言翻译的专家,至少我是这么想的。这使她有独一无二的机会,去思考和创建编程语言。
**00:11:15 - Saron Yitbarek**:
葛丽丝对英文式数据处理语言的研究最终演变成了 COBOL,它在某种意味上很不错。因为它不浮华,很适合商务用途,葛丽丝·哈伯也是这样的人。
**00:11:28**:
从某种角度看,她给了我们一个很像她的语言。像葛丽丝一样,COBOL 语言也很长寿,它现在已经 60 多了。
**00:11:50**:
葛丽丝的编译器就像一个<ruby> 巴别鱼 <rt> babelfish </rt></ruby>,在程序员和机器之间充当翻译,不过它们翻译的都是高度概括性的语言。
**00:12:03**:
然后,几十年之后,另一个重要的思潮在语言界兴起。想象下画面:自由软件社区在 1980 年出现,但是 Unix 的替代品 GNU 被开发出来后,却没有任何自由开放的编译器随之出现。
**00:12:22**:
为了让 GNU 给我们提供一个真正的开源 UNIX 替代品,为了让编程语言在开源世界蓬勃发展,社区需要找来一个格蕾丝·哈伯 —— 我们需要一个开源编译器。
**00:12:38**:
这是 Langdon White,红帽的平台架构师,来讲讲他对这个事情的理解。
**00:12:45 - Langdon White**:
在 80 年代,你要买一个编译器很轻松就要花上上万块钱。费用是最大的问题,我没有多余的钱去给自己买编译器。再一个事实是,我必须为所有我想要的目标平台买一个对应的编译器。那个时代大部分是 Unix 平台,但是细节和风格各不相同。
**00:13:06**:
因此你就不能买一个,你需要为不同的架构,不同的供应商购买多个编译器。
**00:13:14 - Saron Yitbarek**:
Langdon 指出这不仅仅是成本问题,在一些情况下,对编码工作也带来了问题。
**00:13:21 - Langdon White**:
大家都没有意识到,你如何用很特殊的方式来组织你的代码是很重要的。做嵌套 for 循环或者做嵌套 while 循环之类的事情可能是可以的,这取决于编译器。
**00:13:38**:
因此,大家都应该明白,如果你不知道编译是如何优化你的代码的,就很难知道如何写出最优的代码。
**00:13:49 - Saron Yitbarek**:
必须要提的是,我们需要一个免费的、可获得的、可值得信赖的编译器。这就是 GNU C 语言编译器:GCC。它横空出世在 1987 年,它是格蕾丝·哈伯的编译器革命和自由软件运动的结合。
**00:14:12**:
它是使编译更标准化,从而让所有人可以编译别人写的代码。我们编程语言的丰富性要归功于它。
**00:14:22 - Carol Willing**:
GCC 是开放的,可以说将编程语言推向一个更高的层次。
**00:14:29 - Saron Yitbarek**:
这是 Jupiter 项目成员 Carol Willing,她是 Python 软件基金会的前理事。
**00:14:35 - Carol Willing**:
人们开始意识到,专有的语言会在特定时间内被服务于一个目的,但并不能得到开发者社区的认可和热爱。因为如果你是一个开发者,你希望学习最常用的,以及未来最流行的东西。
**00:14:59**:
我没必要去发展一种将我锁定在一种技术上的技能。我想 Python 成功的一个原因是因为它是开源的,它有非常简洁的语法。
**00:15:11**:
它的特点就是允许人们用常见的方法,快速高效地解决问题,也允许大家合作解决问题。我想这就是好的程序和代码库的标志:如果你可以用最小的工作量完成你的工作,并且与他人分享,这是确实很棒的事情。
**00:15:35 - Saron Yitbarek**:
这么多年过去了,GCC 逐渐的支持了 Java、C++、Ada 和 Fortran 语言,我还可以继续说说它的进步。
**00:15:43 - Carol Willing**:
通过像 GCC 这样的通用底层接口,人们可以根据自己的特殊需求来定制语言。例如,在 Python 的世界里,有大量的库,甚至具体到科学 Python 世界里,我们有 numpy,还有 scikit-image、scikit-learn 这样的东西。
**00:16:08**:
每个库都是为一个特定目的而工作。因此,我们也看到了生物信息学和自然语言处理之类的东西。而人们可以在一个共同的基础上,做出很多不同的事情。而且可以把它们放到编程语言或库里,使他们能够在他们特定的行业或领域中优化问题的解决。
**00:16:42 - Saron Yitbarek**:
因此,这就是编译器技术一头撞进开源运动的结果吧?随着时间的推移,这种不同技术的碰撞,爆炸般地创造了一个新的、被社区支持的语言,大家都可以学习和完善它。
**00:16:58**:
现在有成百上千的编程语言存活着。
**00:17:03 - Carol Willing**:
随着开源软件越来越流行和被广泛接受,我们看到了编程语言的大量激增。现在有大量围绕着手机技术的编程语言,不同的编程语言也让游戏开发更加简单快速便捷。各种用途的语言,如 Python 和 Ruby,它们算是现代网页开发和交付网页应用和网站的基础。
**00:17:34 - Saron Yitbarek**:
这个队伍还会继续壮大。是的,我们建造的这个巴别塔在未来会更加拥挤。但是你可以把它当作一个聚宝盆,一个语言的盛宴。下面我们将会帮你们梳理这个盛宴。
**00:17:55**:
现在我们已经知道编程语言泛滥的原因了。但是这些对我们有什么具体的意义?我们如何选择对我们重要的语言呢?这是个大问题,因此我们找了一些人帮忙:Clive Thompson,是最好的作家之一,他能让科技世界变得更有意义。他是《连线》的专栏记者,《纽约时报》杂志的特约撰稿人,他现在正在写一本关于计算机程序员心理学的书。
**00:18:24**:
当我们挑选我们想要学习的编程语言时,我们需要知道我们到底想要什么。
**00:18:31**:
这是我和 Clive 反复讨论得出的结论。
**00:18:35**:
当我作为一个开发新人第一次入手的时候,我就说:“让我选一个最好的编程语言,然后掌握并熟练运用它,不就完事了么。”
**00:18:44**:
不过事情不会这样简单,否则为什么有那么多的编程语言呢?
**00:18:49 - Clive Thompson**:
每个语言都有那么点它的特长。因此通常来说,有人创造一个新语言是因为现有的语言满足不了他们的需求。JavaScript 就是一个典型的例子。
**00:19:03**:
<ruby> 网景公司 <rt> Netscape </rt></ruby>曾经在 90 年代中开发了一款浏览器,所有的网站管理员想做一些更具交互性的事情。他们希望有一种方法,使其可以在网站上运行一些脚本。
**00:19:16**:
当然这些需求都提给了网景。然后他们说:“好吧,现在我们没有可以做到这一点的办法,我们需要一个可以集成到我们浏览器的脚本语言。”
**00:19:25**:
于是他们雇佣了 Brendan Eich,一个被认为很资深的家伙。他当时 32 岁,其他人 21 岁的样子。
**00:19:32 - Saron Yitbarek**:
这在开发者圈里就很资深了
**00:19:35 - Clive Thompson**:
他们给他 10 天时间开发 JavaScript。因此他真的就 10 天没有睡觉,然后疯狂地捣鼓出一个脚本语言。它看起来有点挫,有点糟,但是可以运行。它允许人们做一些简单的事情,它还有按钮,对话框,弹框和其他东西。
**00:19:54**:
这就是造一个编程语言的例子,用来做在当时没有办法完成的事情。
**00:20:01 - Saron Yitbarek**:
是不是很有意思。
**00:20:03 - Clive Thompson**:
这就是为什么存在这么多编程语言,人们不断进取,去做别人做不到的事。
**00:20:11 - Saron Yitbarek**:
这也是为什么我对开发者和编程语言之间的关系很感兴趣,我们对这些工具有很强的依赖性。为什么呢?
**00:20:22 - Clive Thompson**:
有几个原因。一个是有时你学习你的第一个编程语言完全是一场意外,有点像你的初恋。
**00:20:30**:
我觉得不同性格的人,也会匹配不同类型的编程语言。例如 Facebook 是用 PHP 设计的。PHP 是有点像毛球,它很不规则,它的成长断断续续,Facebook 也有点这种感觉。
**00:20:49**:
与此相反,来自谷歌的伙计决定:“我们想要一个超高性能的语言,因为在谷歌我们的东西都高速运行着,维护着万亿级的用户吞吐。”
**00:21:02**:
因此他们决定开发一个 Go 语言,Go 非常适合高性能计算。
**00:21:08 - Saron Yitbarek**:
让我们深入一点。作为一个开发者,我有自己的个性,我是不是对一部分编程语言有天然的喜欢呢?或者我工作用的编程语言可能会影响我的个性?
**00:21:25 - Clive Thompson**:
两者肯定都存在。但我确实认为当你遇到你喜欢的编程语言的时候,有一种强烈的共鸣感。你上计算机课程时学习了必修语言:他们都教 Java,有时会多教一门 JavaScript 或 Python。
**00:21:46**:
问题是,你被强制要求,所以你学了它。但当你有选择余地时会怎么样呢?这就是你真正看到一个人的那种情感或心理风格是如何倾向于一门语言的地方,因为我和一个人谈过,他试着学了一堆 JavaScript。
**00:22:03**:
这是个看起来有点丑的语言,它简直是花括号的噩梦。所以他试了又试,试了又试,失败了又失败。直到有一天他看到朋友在用 Python。在他看起来,这是多么的纯净和美妙的语言。因为他是个作家,而 Python 被认为是一个书写型的编程语言,缩进使一切都易于阅读。
**00:22:28 - Clive Thompson**:
它和他一拍即合,主要在于 Python 的工作方式和外观,漂亮的排版打动了他。
**00:22:39 - Saron Yitbarek**:
和 Clive 的交流让我意识到,有一些编程语言是硬塞给我们的。我说的是那些古老的编程语言,已经类似于拉丁语了。
**00:22:53**:
其实我们也有很多选择,去选择适合我们个性的编程语言。如果你想知道最新的东西有哪些,你去问问开发者们周末在用什么就知道了。
**00:23:05**:
下面是我们对话的更多内容:
**00:23:08 - Clive Thompson**:
当我问人们:“你闲暇的时候做什么?”回答肯定是些稀奇古怪的东西。我想实际上其中一个好的,最值得称颂的开发者的特点,就是他们是富有好奇心。
**00:23:22**:
我知道有人会说,“我要学习 Erlang了,就是为了好玩。”
**00:23:26 - Saron Yitbarek**:
我尝试想象人们在周末开发这些项目,项目不是最重要的,他们在学习工具,编程语言才是重要的事情。这才是他们真的想要的状态。
**00:23:41 - Clive Thompson**:
确切的说,你将看到为什么大家不停的重复迭代开发这些日历和待办事项,因为这是一个快速的学习方法。但需要指出的是,编程语言做了什么以及如何工作都与我们没关系,我只需要尽可能的构建我的东西。
**00:23:56**:
他们想知道用那样的编程语言思考是什么感觉。是不是会感觉很轻松、刺激、游刃有余?我目前的使用的语言没这个感觉,是不是入门之后一切事情都变得简单了?
**00:24:13 - Clive Thompson**:
很有可能你遇到一个新语言后会非常兴奋,想起来都很兴奋。
**00:24:20 - Saron Yitbarek**:
我是一个 Ruby 从业者,作为 Ruby on Rails 开发者我非常自豪,我想大概是两年前,另一个非常著名的 Ruby 开发者,Justin Serrals 做了一个非常好的演讲,倡导编程语言从实用角度出发,没有必要那么性感。
**00:24:41**:
他的观点是,Ruby 之所以是一个令人兴奋的编程语言的原因在于它很新,而且差不多几年前都已经得到印证了,它已经不需要更新什么了。它已经是一个稳定、成熟的编程语言了。不过因为它的成熟,开发者对它也就不那么兴奋,我们逐步把目光转移到新的花样来了。
**00:25:05**:
从某个意义上说,很有可能我们的好奇心会扼杀了一个编程语言,或者让它变得庸俗,而这与编程语言本身的好坏没有关系。
**00:25:18 - Clive Thompson**:
我认为这是完全正确的。事实上,你看到的开发者这个极度好奇心和自学欲望的特点,会让他们不断地寻找新鲜事物。并用这种语言去复制其他语言已经基本做得很好的东西。
**00:25:37 - Saron Yitbarek**:
是的。
**00:25:37 - Clive Thompson**:
就是这样,好奇心有好处,同时也是一个陷阱。
**00:25:43 - Saron Yitbarek**:
是的,说的很好。
**00:25:49**:
有时我们的好奇心可能是一个陷阱,但是它也是编程语言革命的动力。开发每个新编程语言的时候他们会说,“有没有别的可能?”它们出现的原因在于,开发人员想要做不一样的事情。
**00:26:06**:
我们想要全新的表达方式。
>
> **00:26:08 - 葛丽丝·哈伯**:
>
>
> 我向你们承诺一些事情。
>
>
>
**00:26:11 - Saron Yitbarek**:
我想葛丽丝·哈伯想在这儿最后讲两句。
>
> **00:26:15 - 葛丽丝·哈伯**:
>
>
> 在未来 12 个月里,你们谁要是说我们一直都是这么做的,我将会瞬间实质化在你的旁边,然后我 24 小时围绕着你。我倒是要看看我能不能引起你的注意。我们不能再相信那句话,这是很危险的。
>
>
>
**00:26:34 - Saron Yitbarek**:
葛丽丝的故事和第一款编译器提醒我们,只要能可以找到表达方法,我们总有更好的办法做事情。
**00:26:43**:
不管编程语言有多抽象,不管我们在机器的 1 和 0 高位还是低位浮动,我们都需要确保它是一个明智选择。我们选择一个语言,是让它帮助我们的想法更容易表达出来。
**00:27:03**:
如果你想更深一步学习编程语言和和编译器,你不会很孤独,我们收集了一些很有用的文档帮你深入学习。敬请在我们节目下面留言。请查看 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes)
**00:27:20**:
下一期节目,我们将关注开源贡献者的艰辛之路。那些维护者的真实奋斗生活是什么样的?我们如何提出第一个拉取请求?
**00:27:32**:
我们将带你们简单认识开源贡献。
**00:27:39**:
代码英雄是红帽的原创播客。你可以在苹果播客、谷歌播客以及其他可能的地方免费收听这个节目。
**00:27:48**:
我是 Saron Yitbarek,坚持编程,下期再见。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/hello-world>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[guevaraya](https://github.com/guevaraya) 校对:[acyanbird](https://github.com/acyanbird),[wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Every new programming language is created to do something previously impossible. Today, there are quite a few to choose from. But which ones do you really need to know?
This episode dives into the history of programming languages. We recognize the genius of “Amazing Grace,” also known as Rear Admiral Grace Hopper. It’s thanks to her that developers don’t need a PhD in mathematics to write their programs in machine code. We’re joined by Carol Willing of Project Jupyter, former Director of the Python Software Foundation, and Clive Thompson, a contributor to The New York Times Magazine and Wired who’s writing a book about how programmers think.
**00:07** - *Multiple voices*
Hello world.
**00:12** -*Saron Yitbarek*
Hello world. Is it signal, or is it noise? All the work we do as developers, all the countless hours of coding and stressing and testing, it all comes down to that one question: are we getting our signal across?
**00:29** - *Multiple voices*
Hello.
**00:29** - *Saron Yitbarek*
Or is our signal lost? Are we just making noise.
**00:40** - *Saron Yitbarek*
I'm Saron Yitbarek and this is season two of Command Line Heroes, an original podcast from Red Hat. In today's episode we're found in translation. It's all about programming languages: where they came from, and how we choose which ones to learn. We're doing a deep dive into the ways we talk to our machines. How those languages are evolving. And how we can use them to make our work sing.
**01:08** - *Siri*
Daisy, daisy, give me your answer true.
**01:11** - *Saron Yitbarek*
If you're a developer like me, you probably feel pressure to be a polyglot, to be fluent in a whole bunch of languages. You better know Java. Better know Python. Go JavaScript, Node. Gotta be able to dream in C++. Maybe know a classic like COBOL, just for cred. And you might even be worrying about a newcomer, like Dart... It's exhausting.
**01:36** - *Saron Yitbarek*
The weird thing is, the computers that we're talking to really only speak one language: machine language. All those ones and zeroes flying by, all those bits. Every single language we learn is, at the end of the day, just another pathway to the same place. It all gets boiled down, no matter how abstracted we are when we're doing the work.
**02:03** - *Saron Yitbarek*
And that's what I want you to keep in mind as our story begins, because we're starting with the moment, the completely brilliant moment, when one woman said: "You know what? I'm a human. I don't talk in bits, I don't think in bits. I want to program using English words."
**02:22** - *Saron Yitbarek*
Might seem like a simple concept today, but once upon a time, that idea, the idea you should be able to talk to a computer in your own way was a joke at best, sacrilege at worst.
**02:37** - *Saron Yitbarek*
Season Two of Command Line Heroes is all about the nuts and bolts that underpin everything we do. And this episode's hero is a woman whose journey you need to know if you want to fully understand our reality. So, I give you: the first lady of software.
**02:58** - *Speaker 5*
Ladies and gentlemen, it's with great pleasure that I present Commodore Grace Mary Hopper. Thank you.
**03:02** - *Grace Hopper*
So I went to Canada to speak at the University of Guelph, and I had to go through immigration at Toronto Airport. And I handed my passport to the immigration officer and he looked at it and looked at me and said, "What are you?"
**03:17** - *Grace Hopper*
And I said, "United States Navy."
**03:20** - *Grace Hopper*
He took a second real hard look at me. And then he said, "You must be the oldest one they've got."
**03:28** - *Saron Yitbarek*
That was Rear Admiral Grace Hopper in 1985. She was 79-years old at the time and delivering her famous lecture at M.I.T.. Even then, Grace Hopper was a legend. She was the god mother of independent programming languages. The woman who used compilers so we could use human language instead of mathematical symbols.
**03:51** - *Saron Yitbarek*
She received the National Medal of Technology, and after she died, the National Medal of Freedom. So: not a slouch. They called her " Amazing Grace."
**04:03** - *Claire Evans*
If anybody was born to be a computer programmer, it was Grace.
**04:06** - *Saron Yitbarek*
That's Claire Evans, a tech journalist and the author of a book called Broad Band, about pioneering women in tech. Evans describes that early word of computers, the one Grace Hopper stepped into in the 1940s when she was a young woman in the Navy Reserves and computers were the size of a small room.
**04:25** - *Claire Evans*
All those early programmers, they were like a priesthood. They were people that were specifically good at something that was incredibly tedious, because this is before compilers, before programming languages, when people were really programming at the machine level, bit by bit.
**04:42** - *Claire Evans*
In order to have the constitution to do that kind of thing, you really have to be a specific kind of person, and Grace really was that kind of person.
**04:49** - *Saron Yitbarek*
Right away, she saw how crazy limiting it was for humans to be using a language meant for machines. It was like trying to walk down the street by telling every atom in your body what to do. Possible? Sure. Efficient? No.
**05:06** - *Saron Yitbarek*
There had to be a shortcut between a programmer's intentions and a computer's actions. Humans had been mechanizing mathematical thinking ever since the abacus. There had to be a way to do that again with computers.
**05:19** - *Claire Evans*
In the past, mathematicians used to have to do all this arithmetic. All this tedious step-by-step work in order to get to the really interesting solutions. And then computers came along and offered the possibility of doing that arithmetic by machine, therefore freeing the mathematician to think lofty, intellectual, systems-oriented thoughts.
**05:39** - *Claire Evans*
Except for, that's not really what happened. Ultimately, the computer came along and then the mathematician had to become a programmer. And then they were stuck once again doing all these bit-by-bit tedious rule-oriented, little calculations in order to write the programs.
**05:53** - *Claire Evans*
So, I think, Grace's perspective on it was she wanted to make sure that computers could assist mathematicians to think great thoughts and do great things without bogging them down in the details.
**06:12** - *Saron Yitbarek*
Hopper was joining a long line of thinkers. You've got Pascal in the 17th century with the first calculator. You've got Babbage in the 19th century with the analytical engine. There's this big, beautiful line of inventors who want to build things to supercharge the human brain. Things that let us process more data than we could ever manage on our own. That's the lineage Grace Hopper was stepping into when she invented something that everybody thought was impossible.
**06:42** - *Claire Evans*
I mean, Grace's idea that people should be able to communicate with their computers using natural language, and that language should be machine independent, therefore interoperable between different computing machines was revolutionary in its time.
**06:59** - *Claire Evans*
People that got behind her, this notion that she called, in the early days, "automatic programming," were considered to be like space cadets in the community of programmers and computer people.
**07:12** - *Claire Evans*
And the people who weren't onboard eventually became known as the Neanderthals, it was this huge rift in the computing community.
**07:21** - *Saron Yitbarek*
Hopper did not have an easy time convincing her superiors to cross that rift. But she saw it as her duty to try.
**07:30** - *Grace Hopper*
There's always a line out here. That line represents what your boss will believe at that moment in time. Now, of course, if you step over it, you don't get the budget. So you have a double responsibility to that line: don't step over it, but also keep on educating your boss so you move the line further out, so next time you can go further into the future.
**07:52** - *Saron Yitbarek*
That future she pushed toward is our present. Pretty much every language that you and I rely on owes a debt to Hopper and her first compiler. So that's space cadets “one”, Neanderthals “zero”.
**08:07** - *Saron Yitbarek*
The idea that we could code not with numbers, but with human-style language. All of a sudden you're typing "Go to Operation 8," or, "Close file C." It was programming made human.
**08:21** - *Claire Evans*
Grace was uniquely aware of the fact that computing was going to be a world changing thing, but it wasn't going to be a world changing thing if nobody understood how to access it or use it. And she wanted to make sure that it was as open to as many people as possible and as accessible to as many people as possible.
**08:37** - *Claire Evans*
And that required a certain level of concession to comprehensibility and readability. So ultimately the desire to create programming languages came from wanting to give more points of entry to the machine and taking it away from this priesthood and opening it up to a greater public and a new generation.
**08:59** - *Saron Yitbarek*
I wanna pause here and just underline something Claire said: programming languages as we know them today come from a desire to open the tech up. To take it away from a priesthood of math PhDs and make development accessible.
**09:14** - *Saron Yitbarek*
The spirit of the compiler that does all that work, it's motivated by a sense of empathy and understanding.
**09:21** - *Saron Yitbarek*
Claire's got a theory about why Hopper was the woman to deliver that change. It has to do with Hopper's work during World War II.
**09:29** - *Claire Evans*
She was doing mine sweeping problems, ballistics problems, oceanography problems. She was applying all of these different, diverse disciplines representing all the violent, chaotic, messy realities of the war and translating them into programs to run on the Mark I computer.
**09:45** - *Claire Evans*
She knew how to do that translation between languages. And I don't mean computer languages, I mean like human languages. She understood how to listen to somebody who was presenting a complex problem, try to understand where they were coming from, what the constraints and affordances of their discipline was and then translate that into something that the computer could understand.
**10:06** - *Claire Evans*
In a way she was like the earliest compiler. Like, the embodied human compiler because she understood that you had to meet people on their level.
**10:17** - *Saron Yitbarek*
Compiling as an act of empathy and understanding. I think we can all keep that in mind when we learn new languages, or wonder why something isn't compiling at all. The compiler's job should be to meet your language where it lives.
**10:32** - *Saron Yitbarek*
Grace Hopper knew that once humans could learn to speak programming languages, and once compilers began translating our intentions into machine language, well, it was like opening the floodgates.
**10:43** - *Claire Evans*
She knew that computing could never develop as an industry, as a world changing force if it was too siloed and too specific. And people who were its practitioners couldn't communicate with the people whose problems needed to be put on the machine, so to speak.
**11:00** - *Claire Evans*
So she was really quite expert at that kind of human translation, which I think, yeah, made her uniquely qualified to be thinking about and creating programming languages.
**11:15** - *Saron Yitbarek*
Hopper's work on English-style data processing language eventually evolved into COBOL, which is sort of perfect, because COBOL is not flashy, it's very down to business, and so was Grace Hopper.
**11:28** - *Saron Yitbarek*
In a way, she gave us a language that sounded a lot like her. Also like Hopper, COBOL's got longevity. It's still around 60 years later.
**11:50** - *Saron Yitbarek*
Okay, so Grace Hopper's compilers were like babelfish, parlaying meaning between programmers and their machines. And they were translating things from higher and higher levels of abstraction.
**12:03** - *Saron Yitbarek*
Then, a few decades later, we get another crucial ingredient added to the language mix. So picture this: the free software community took off in the 1980s, but when the Unix alternative, GNU, was created, there weren't any free and open compilers to go with it.
**12:22** - *Saron Yitbarek*
In order for GNU to give us a real open-source alternative to Unix, in order for programming languages to thrive in the open-source world, the community would need to pull a Grace Hopper — we needed an open-source compiler.
**12:38** - *Saron Yitbarek*
Here's Langdon White, a platform architect at Red Hat talking about where things stood.
**12:45** - *Langdon White*
In the 80s, you can still go spend ten grand pretty easily on a compiler. The free part was a big deal. I don't have an extra ten grand lying around to go buy myself a compiler. Plus the fact that I'd have to buy myself a compiler for every platform I want to target. So, in those days it was mostly Unix, but all the different flavors.
**13:06** - *Langdon White*
So you wouldn't be able to just buy one, you would also have to buy multiple for different architectures or different vendors.
**13:14** - *Saron Yitbarek*
Langdon notes that it was more than just costs at stake. In some cases, it was the coding work itself.
**13:21** - *Langdon White*
People don't realize that it matters how you structure your code in very specific ways. So doing nested for loops or doing nested while loops or that kind of thing may be okay, depending on the compiler.
**13:38** - *Langdon White*
So, you know, if you don't know how it's optimizing your code it's very, very difficult to know how to write your code to get the most optimization.
**13:49** - *Saron Yitbarek*
Suffice to say, we needed a free option, an accessible option, a trustworthy option. What we needed was the GNU C compiler, the GCC. That was the beast, first released in 1987, that merged Grace Hopper's compiler revolution with the free software movement.
**14:12** - *Saron Yitbarek*
It standardized things and let everybody compile what anybody else had written. The richness of our languages is thanks to that moment.
**14:22** - *Carol Willing*
The fact that the GCC was open sort of moved languages to a different level.
**14:29** - *Saron Yitbarek*
Carol Willing works at Project Jupiter, and she's the former director of the Python Software Foundation.
**14:35** - *Carol Willing*
People started realizing that proprietary languages, while they served a purpose at the time, they weren't going to gain the acceptance and adoration of the developer community. Because if I'm a developer, I'm going to want to learn what is most commonly used and as well as what is new and on the forefront.
**14:59** - *Carol Willing*
I don't necessarily want to develop a skill that will lock me into one technology. I think one of the reasons that Python was so successful is it was open source, it had a very clean syntax.
**15:11** - *Carol Willing*
What it was doing is it was allowing people in a common way to solve problems quickly, efficiently. And to also allow people to collaborate. And I think those are the signs of good programs and good libraries is: if you can get your work done with a minimum amount of headache and you can share it with others. I think that's golden.
**15:35** - *Saron Yitbarek*
Over the years, the GCC evolved to support Java, C++, Ada, Fortran, I could go on.
**15:43** - *Carol Willing*
By having a common underlying interface like the GCC, it lets people take languages and then customize them to their particular needs. For example, in the Python world, there's many different libraries and even specifically in the scientific Python world, we've got things like numpy, and scikit-image, scikit-learn.
**16:08** - *Carol Willing*
And each of those had sort of a more specific task that they are known for. So, we've also seen things like bioinformatics and natural language processing. And so people are able to do many different things working off a common base. But then putting elements into their languages or libraries that allow them to optimize problem solving in their particular industry or area.
**16:42** - *Saron Yitbarek*
So, this is what happens when compiler technology runs headfirst into the open source movement, right? Over time, the collision creates a big bang of new community-supported languages that anybody can learn and build with.
**16:58** - *Saron Yitbarek*
There are hundreds and hundreds of those languages being used today.
**17:03** - *Carol Willing*
As open source became more popular and more accepted, what we've seen is a proliferation of languages. There are a number of languages around cell phone technology and mobile. Different languages that help make game development more straightforward. All purpose languages, like Python and Ruby that were sort of foundational for the web development and delivery of web applications and websites.
**17:34** - *Saron Yitbarek*
The list goes on. And, yeah, that Tower of Babel we're building is just going to get more packed in the future. But look, you can also see it as a cornucopia, a language feast. And we're going to help you sort through that feast — next.
**17:55** - *Saron Yitbarek*
Okay, so I know where the language flood came from. But how do we make sense of it all? How do we pick out languages that matter to us? It's a big question, so I brought in some help: Clive Thompson's one of the best writers out there for making sense of the tech world. He's a columnist at Wired, a contributing writer at the New York Times Magazine, and he's working on a book now about the psychology of computer programmers.
**18:24** - *Saron Yitbarek*
Which is perfect, because we need to know what's going on in our brains when we choose which ones to learn.
**18:31** - *Saron Yitbarek*
Here's me and Clive hashing it all out.
**18:35** - *Saron Yitbarek*
When I was first starting out as a new developer, I just said, "Lemme find the best one, I'm going to get really good at it. And then I'll be done."
**18:44** - *Saron Yitbarek*
But it's not quite that simple. Why are there so many programming languages?
**18:49** - *Clive Thompson*
Each language has sort of a bias of things that it's good at. So, typically, the reason that someone creates a new language is there's something they want to do that existing languages aren't good for. JavaScript is a good example of that.
**19:03** - *Clive Thompson*
Netscape had created a browser back in the mid '90s and all these web masters wanted to do something a little more interactive. They wanted there to be a way to have a bit of scripting inside their website.
**19:16** - *Clive Thompson*
And so these demands were coming to Netscape. And they were like, "Alright, we need, there's nothing out there that can do this, we need a scripting language that we build inside our browser."
**19:25** - *Clive Thompson*
And so they hired Brendan Eich, who was considered a senior guy. He was like 32, and everyone else was like 21.
**19:32** - *Saron Yitbarek*
That's senior in developer world.
**19:35** - *Clive Thompson*
And they gave him ten days to make JavaScript. So he literally just didn't sleep for ten days and he frantically cranked out a scripting language. And it was kind of ungainly and kind of a mess. But it worked. And it allowed people to do very simple things, it had buttons and dialogs and popups and whatnots.
**19:54** - *Clive Thompson*
And so that's an example of a language that came, was created to do something that wasn't really possible at that point in time.
**20:01** - *Saron Yitbarek*
That's fascinating.
**20:03** - *Clive Thompson*
So that's why so many languages exist, is that people keep on finding a reason to do something that no one else can do.
**20:11** - *Saron Yitbarek*
So what is so interesting to me about the relationship between developers and our programming languages is we have such a strong attachment to these tools, why is that?
**20:22** - *Clive Thompson*
There's a couple reasons why. One is that sometimes it's literally just an accident of what was the first language that you learned. And it's kind of like your first love.
**20:30** - *Clive Thompson*
And I think it's also like different personalities work with different types of languages. Like, you look at Facebook, and it was designed using PHP. And PHP is kind of a hairball of a language. It's very irregular. And it sort of grew in these fits and starts. And that's sort of the way Facebook feels, too.
**20:49** - *Clive Thompson*
In comparison, the guys at Google decided, "We want a super high performance language, because Google, at Google we're all about things running really fast, and things, sustaining trillions of users at once."
**21:02** - *Clive Thompson*
And so they decide to make Go, and Go is a really terrific language for that sort of high-performance computing.
**21:08** - *Saron Yitbarek*
Let's go a little bit deeper. Is it that I, as a developer, with my specific personality, am going to be naturally attracted to certain languages? Or that the language I work in might influence my personality?
**21:25** - *Clive Thompson*
Well, definitely both. But I do think that there is a really strong resonance that people find when they hit a language that they like. You go to a computer science curriculum and you sort of learn what you have to learn: they're all teaching Java. Sometimes more JavaScript or Python.
**21:46** - *Clive Thompson*
But the point is, you're forced to learn it, so you learn it. But what do people do when they have the choice? And this is where you really see how the sort of emotional or psychological style of someone gravitates towards a language, because I talked to one guy who tried learning JavaScript a bunch.
**22:03** - *Clive Thompson*
And it was just sort of, it's kind of an ugly language to look at. It's got the curly bracket nightmare going on. And so he tried and failed and tried and failed and tried and failed. And then one day he saw a friend working in Python. And it just looked so clean and beautiful to him. He was kind of a writer, and it's often regarded as a writerly type of a language, because the indentation makes everything easy to read.
**22:28** - *Clive Thompson*
And it just clicked with him, because there was just something about the way that Python worked and looked, it's beautiful sparseness, that hit him.
**22:39** - *Saron Yitbarek*
So, talking with Clive I realized there are languages that are thrust upon us. I'm talking about those ancient languages that are just baked into everything we work with — the code Latin.
**22:53** - *Saron Yitbarek*
But there're also languages we choose, the languages that fit our personalities. And if you want to know what's new and shaking things up, you want to ask a developer what they use on the weekend.
**23:05** - *Saron Yitbarek*
Here's more of our conversation:
**23:08** - *Clive Thompson*
So when I ask people: "What are you doing in your spare time?" It'll be all this weird stuff. I think it's actually one of the things that sort of, you know, nice and laudatory about developer behavior is that they tend to be very curious people.
**23:22** - *Clive Thompson*
I know people that decided, "I'm going to learn Erlang, just for the hell of it."
**23:26** - *Saron Yitbarek*
I'm trying to imagine these projects that people are working on on the weekends. And it's almost like the project is secondary. It's like the learning of the tool, the language, is more important. That's really what they're there for.
**23:41** - *Clive Thompson*
Exactly. This, is sort of why you'll see people just constantly re-iterating over and over again these calendaring and to-do list things because it's a very quick way, just to figure out, yeah, what does this language do and how does it work and it almost doesn't matter what I'm building, so long as I'm building something.
**23:56** - *Clive Thompson*
They want to know what it feels like to think in that language. Is it going to be, is it going to feel easy, and thrilling and fluent in a way that I'm not experiencing with the current languages? Is it going to open up doors to make things easier to do?
**24:13** - *Clive Thompson*
So there's a possibility space that occurs when you encounter a new language that can be really exciting. Imaginatively exciting.
**24:20** - *Saron Yitbarek*
So I'm a Ruby, a very proud Ruby on Rails developer, I think it was about two years ago that another pretty well known Ruby developer, Justin Serrals, did this really great talk advocating for this idea that a language doesn't need to be sexy to be used.
**24:41** - *Saron Yitbarek*
And his thesis, his whole point was that Ruby was really exciting because it was new. And it kind of got to a point about a couple years ago where it just didn't need any more things. It was done. It was a stable language, it was a mature language, and, as a result of it being mature, it's not as exciting for developers. It's not this new toy to play, and so we kind of slowly moved away from it on to the next shiny thing.
**25:05** - *Saron Yitbarek*
So, in a sense, it's almost our own curiosity that might kill a language, or make it a little more stale, independent of whether the language is actually good or bad.
**25:18** - *Clive Thompson*
I think that's absolutely true. In fact, the downside of this deep curiosity and desire to self-educate that you see amongst developers is that they're constantly trying to find the new shiny thing. And use that language to replicate things that are already basically done pretty well by other languages.
**25:37** - *Saron Yitbarek*
Right.
**25:37** - *Clive Thompson*
So that's that. Curiosity is a benefit and a trap.
**25:43** - *Saron Yitbarek*
Yeah, beautifully put.
**25:49** - *Saron Yitbarek*
Sometimes our curiosity may be a trap. But it's also the thing that fuels the evolution of languages. Every new language is created because someone said, "What if?" They come about because that developer wanted to do something different.
**26:06** - *Saron Yitbarek*
They wanted a whole new way of saying it.
**26:08** - *Grace Hopper*
And I'll promise you something.
**26:11** - *Saron Yitbarek*
I think Grace Hopper deserves a last word here.
**26:15** - *Grace Hopper*
Just during the next 12 months, any one of you says that we've always done it that way, I will instantly materialize beside you and I will haunt for 24-hours. And see if I can get you to take another look. We can no longer afford that phrase, it's a dangerous one.
**26:34** - *Saron Yitbarek*
The story of Grace Hopper and the first compiler reminds us that there's always a better way to do something if we can just find the words.
**26:43** - *Saron Yitbarek*
And, no matter how abstract those languages become, whether we're floating high or low over the ones and zeroes of machine language, we need to make sure it's a smart choice. We choose the language, or maybe even build the language that helps our intentions come closer to reality.
**27:03** - *Saron Yitbarek*
If you want to learn more about languages and compilers, you are not alone. We pulled together some super useful material to help you dive deeper. And it's all waiting for you in our show notes. Check it out at redhat.com/commandlineheroes.
**27:20** - *Saron Yitbarek*
Next episode, we're tracking the complicated path toward making open-source contributions. What are the real life struggles of maintainers? How do we make that very first pull request?
**27:32** - *Saron Yitbarek*
We're taking you through Contributing 101.
**27:39** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Listen for free on Apple Podcasts, Google Podcasts, or wherever you do your thing.
**27:48** - *Saron Yitbarek*
I'm Saron Yitbarek, until next time keep on coding.
### Keep going
### The Importance of a Nanosecond: Remembering Grace Hopper
Grace Hopper inspired many engineers. Here’s one story of a young developer lucky enough to see her in person.
### How many programming languages have you used?
Machines speak one language—but we humans speak to machines in so many ways.
### Command Line Heroes: The Game
This week’s post: How open source game development hones valuable skills. Gaming languages, gaming in open source, and [Open Jam](https://itch.io/jam/open-jam-2018). |
12,596 | 在 Linux 上调整命令历史 | https://www.networkworld.com/article/3537214/tweaking-history-on-linux.html | 2020-09-08T23:25:09 | [
"历史",
"history"
] | https://linux.cn/article-12596-1.html |
>
> 在 Linux 系统上,bash shell 的 history 命令可以方便地回顾和重用命令,但是你要控制它记住多少,忘记多少,有很多事情要做。
>
>
>

Linux 系统中的 bash `history` 命令有助于记住你以前运行过的命令,并重复这些命令,而不必重新输入。
如果可以的话,你肯定会很高兴不用翻阅十几页的手册,每过一会再次列出你的文件,而是通过输入 `history` 查看以前运行的命令。在这篇文章中,我们将探讨如何让 `history` 命令记住你希望它记住的内容,并忘记那些可能没有什么“历史价值”的命令。
### 查看你的命令历史
要查看以前运行过的命令,你只需输入 `history`。你可能会看到一长串命令。记忆的命令数量取决于在 `~/.bashrc` 文件中设置的名为 `$HISTSIZE` 的环境变量,但是如果你想保存更多或更少的命令,你可以根据你的需要改变这个设置。
要查看历史记录,请使用 `history` 命令:
```
$ history
209 uname -v
210 date
211 man chage
...
```
要查看将显示的最大命令数量:
```
$ echo $HISTSIZE
500
```
你可以通过运行这样的命令来改变 `$HISTSIZE` 并使之永久化:
```
$ export HISTSIZE=1000
$ echo "HISTSIZE=1000" >> ~/.bashrc
```
在为你保留多少历史记录和当你输入 `history` 时显示多少历史记录之间也有区别。`$HISTSIZE` 变量控制显示多少历史记录,而 `$HISTFILESIZE` 变量控制在你的 `.bash_history` 文件中保留多少命令。
```
$ echo $HISTSIZE
1000
$ echo $HISTFILESIZE
2000
```
你可以通过计算历史文件中的行数来验证第二个变量:
```
$ wc -l .bash_history
2000 .bash_history
```
需要注意的是,在登录会话中输入的命令在注销前不会被添加到你的 `.bash_history` 文件中,尽管它们会立即显示在 `history` 命令输出中。
### 使用历史
有三种方法可以重发你在 `history` 中发现的命令。最简单的方法,特别是当你想重用的命令是最近运行的时候,通常是输入一个 `!` 后面跟上命令中足够多的首字母来唯一地识别它。
```
$ !u
uname -v
#37-Ubuntu SMP Thu Mar 26 20:41:27 UTC 2020
```
另一种简单的重复命令的方法是,只需按上箭头键,直到显示了该命令,然后按回车键。
另外,如果你运行 `history` 命令,并看到你想重新运行的命令被列出,你可以输入一个 `!` 后面跟着命令左边显示的序号。
```
$ !209
uname -v
#37-Ubuntu SMP Thu Mar 26 20:41:27 UTC 2020
```
### 隐藏历史
如果你想在一段时间内停止记录命令,你可以使用这个命令:
```
$ set +o history
```
当你输入 `history` 时,你输入的命令不会显示出来,当你退出会话或退出终端时,它们也不会被添加到你的 `.bash_history` 文件中。
要取消这个设置,使用 `set -o history`。
要使它永久化,你可以把它添加到你的 `.bashrc` 文件中,尽管不使用命令历史记录通常不是一个好主意。
```
$ echo 'set +o history' >> ~/.bashrc
```
要暂时清除历史记录,这样在输入 `history` 时只显示之后输入的命令,可以使用 `history -c`(清除)命令:
```
$ history | tail -3
209 uname -v
210 date
211 man chage
$ history -c
$ history
1 history
```
注意:在输入 `history -c` 后输入的命令不会被添加到 `.bash_history` 文件中。
### 控制历史
许多系统上的 `history` 命令的设置会默认包括一个名为 `$HISTCONTROL` 的变量,以确保即使你连续运行同一命令七次,也只会被记住一次。它还可以确保你在首先输入一个或多个空格后跟着的命令将从你的命令历史记录中忽略。
```
$ grep HISTCONTROL .bashrc
HISTCONTROL=ignoreboth
```
`ignoreboth` 的意思是“忽略重复的命令和以空格开头的命令”。例如,如果你输入这些命令:
```
$ echo try this
$ date
$ date
$ date
$ pwd
$ history
```
你的 `history` 命令应该像这样报告:
```
$ history
$ echo try this
$ date
$ history
```
请注意,连续的 `date` 命令被缩减为一条,以空格缩进的命令被省略。
### 忽略历史
要忽略某些命令,使它们在你输入 `history` 时不会出现,也不会被添加到你的 `.bash_history` 文件中,可以使用 `$HISTIGNORE` 设置。例如:
```
$ export HISTIGNORE=”history:cd:exit:ls:pwd:man”
```
这个设置将导致所有的 `history`、`cd`、`exit`、`ls`、`pwd` 和 `man` 命令从你的 `history` 命令的输出和 `.bash_history` 文件中被忽略。
如果你想把这个设置变成永久性的,你必须把它添加到你的 `.bashrc` 文件中。
```
$ echo 'HISTIGNORE="history:cd:exit:ls:pwd:man"' >> .bashrc
```
这个设置只是意味着当你回看以前运行的命令时,列表不会被你在查看命令历史记录时不想看到的命令所干扰。
### 记住、忽略和忘记过去的命令
命令历史记录很有用,因为它可以帮助你记住最近使用过的命令,并提醒你最近所做的更改。它还可以让你更容易地重新运行命令,特别是那些有一串参数但你不一定想重新创建的命令。定制你的历史设置可以让你对命令历史的使用变得更容易,更有效率。
---
via: <https://www.networkworld.com/article/3537214/tweaking-history-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,599 | 在命令行中使用 nmcli 来管理网络连接 | https://opensource.com/article/20/7/nmcli | 2020-09-10T10:03:19 | [
"nmcli",
"网络"
] | https://linux.cn/article-12599-1.html |
>
> nmcli 命令赋予你直接在 Linux 命令行操作 NetworkManager 工具的能力。
>
>
>

[nmcli](https://developer.gnome.org/NetworkManager/stable/nmcli.html) 命令赋予你直接在 Linux 命令行操作 NetworkManager 工具的能力。它是 NetworkManager 软件包集成的一部分,通过使用一些 [应用程序接口](https://en.wikipedia.org/wiki/Application_programming_interface)(API)来获取 NetworkManager 的功能。
`nmcli` 发布于 2010 年,用以替代其他配置网络接口和连接的方法,例如 [ifconfig](https://man7.org/linux/man-pages/man8/ifconfig.8.html)。因为它是一个 [命令行界面](https://en.wikipedia.org/wiki/Command-line_interface)(CLI)工具,被设计用在终端窗口和脚本中,所以对于那些工作在没有 [图形用户界面](https://en.wikipedia.org/wiki/Graphical_user_interface)(GUI)的系统的管理员来说,它是一个非常理想的工具。
### ncmli 的语法
`nmcli` 命令可以使用*选项*来更改它的行为,使用*子命令*来告诉 `nmcli` 想使用它的那部分功能,使用*操作*来告诉 `nmcli` 你想执行什么操作。
```
$ nmcli <选项> <子命令> <操作>
```
`nmcli` 一共有 8 个子命令,每个子命令有一些相关的网络操作:
* `help` 提供有关 `nmcli` 命令和使用方法的帮助信息
* `general` 返回 NetworkManager 的状态和总体配置信息
* `networking` 提供命令来查询某个网络连接的状态和启动、禁用连接的功能
* `radio` 提供命令来查询某个 WiFi 网络连接的状态和启动、禁用连接的功能
* `monitor` 提供命令来监控 NetworkManager 的活动并观察网络连接的状态改变
* `connection` 提供命令来启用或禁用网络接口、添加新的连接、删除已有连接等功能
* `device` 主要被用于更改与某个设备(例如接口名称)相关联的连接参数或者使用一个已有的连接来连接设备
* `secret` 注册 `nmcli` 来作为一个 NetworkManager 的秘密代理,用以监听秘密信息。这个子命令很少会被用到,因为当连接到网络时,`nmcli` 会自动做这些事
### 简单的示例
首先,我们验证一下 NetworkManager 正在运行并且 `nmcli` 可以与之通信:
```
$ nmcli general
STATE CONNECTIVITY WIFI-HW WIFI WWAN-HW WWAN
connected full enabled enabled enabled enabled
```
探测总是管理一个系统的首要部分。为了列出内存或磁盘上的网络连接配置,可以使用下面的命令:
```
$ nmcli connection show
NAME UUID TYPE DEVICE
Wired connection 1 ac3241e4-b424-35d6-aaa7-07498561688d ethernet enp0s3
Wired connection 2 2279d917-fa02-390c-8603-3083ec5a1d3e ethernet enp0s8
Wired connection 3 52d89737-de92-35ec-b082-8cf2e5ac36e6 ethernet enp0s9
```
上面的命令使用了 `connection` 子命令中的 `show` 操作。
用来运行上面这个例子的测试机器上运行着 Ubuntu 20.04,它安装了 3 个网络适配器:`enp0s3`、`enp0s8`和 `enp0s9`。
### 连接管理
理解 `nmcli` 的术语是非常重要的。一个网络<ruby> 连接 <rt> connection </rt></ruby>包含了一个连接的所有信息。你可以将它看作一个网络<ruby> 配置 <rt> configuration </rt></ruby>。“连接”包含了与其相关的所有信息,包括 [数据链路层](https://en.wikipedia.org/wiki/Data_link_layer) 和 [IP 地址信息](https://en.wikipedia.org/wiki/IP_address) 。它们是 [OSI 网络模型](https://en.wikipedia.org/wiki/OSI_model) 中的第 2 和第 3 层。
当你在 Linux 上配置网络时,通常来说你是在为某个网络设备(它们是安装在一个电脑中的网络接口)配置连接。当一个连接被某个设备所使用,那么就可以说这个连接被<ruby> 激活 <rt> active </rt></ruby>或者<ruby> 上线 <rt> up </rt></ruby>了,反之是<ruby> 停用 <rt> inactive </rt></ruby>或<ruby> 下线 <rt> down </rt></ruby>。
#### 添加网络连接
`nmcli` 允许你快速地创建网络连接并同时为该连接指定参数。为了通过使用“有线连接 2” `enp0s8` 来创建一个新的连接,你可以利用 `sudo` 来运行下面的命令:
```
$ sudo nmcli connection add type ethernet ifname enp0s8
Connection 'ethernet-enp0s8' (09d26960-25a0-440f-8b20-c684d7adc2f5) successfully added.
```
其中 `type` 选项指定需要一个 [Ethernet](https://en.wikipedia.org/wiki/Ethernet) 类型的连接,而 `ifname`(接口名)选项指定你想要为这个连接使用的网络接口设备。
让我们看看发生了什么变化:
```
$ nmcli connection show
NAME UUID TYPE DEVICE
Wired connection 1 ac3241e4-b424-35d6-aaa7-07498561688d ethernet enp0s3
Wired connection 2 2279d917-fa02-390c-8603-3083ec5a1d3e ethernet enp0s8
Wired connection 3 52d89737-de92-35ec-b082-8cf2e5ac36e6 ethernet enp0s9
ethernet-enp0s8 09d26960-25a0-440f-8b20-c684d7adc2f5 ethernet --
```
通过上图可以看到新的连接 `ethernet-enp0s8` 已经创建好了。它的 <ruby> <a href="https://en.wikipedia.org/wiki/Universally_unique_identifier"> 通用唯一标识符 </a> <rt> Universally Unique IDentifier </rt></ruby>(UUID)也一同被赋予,并且其连接类型为 “Ethernet”。我们可以使用 `up` 子命令再加上连接名称(或 UUID)来使得这个连接被激活:
```
$ nmcli connection up ethernet-enp0s8
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
```
再次查看激活的连接:
```
$ nmcli connection show --active
NAME UUID TYPE DEVICE
Wired connection 1 ac3241e4-b424-35d6-aaa7-07498561688d ethernet enp0s3
ethernet-enp0s8 09d26960-25a0-440f-8b20-c684d7adc2f5 ethernet enp0s8
Wired connection 3 52d89737-de92-35ec-b082-8cf2e5ac36e6 ethernet enp0s9
```
可以看到新的连接 `ethernet-enp0s8` 现在已经被激活了,并且与 `enp0s8` 网络接口设备绑定。
#### 调整连接
`nmcli` 命令使得调整现有连接的参数变得更加容易。也许你想将某个网络接口从 <ruby> <a href="https://en.wikipedia.org/wiki/Dynamic_Host_Configuration_Protocol"> 动态主机配置协议 </a> <rt> Dynamic Host Configuration Protocol </rt></ruby>(DHCP)改为静态 IP 地址。
假设你需要为你的新连接分配一个固定的 IP 地址 `192.168.4.26`,那么你需要使用两个命令,一个用于设定 IP 地址,另一个用来将获取 IP 地址的方法改为 `manual`(手动):
```
$ nmcli connection modify ethernet-enp0s8 ipv4.address 192.168.4.26/24
$ nmcli connection modify ethernet-enp0s8 ipv4.method manual
```
记得指定 [子网掩码](https://en.wikipedia.org/wiki/Subnetwork),在我们这个测试的连接中,它是 <ruby> <a href="https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing"> 无类域间路由 </a> <rt> Classless Inter-Domain Routing </rt></ruby>(CIDR)中的 `255.255.255.0` 或 `/24`
为了使得你的更改生效,你需要通过停止再重新启用该连接。下面的第一个命令是停用该连接,第二个命令则是启用它:
```
$ nmcli connection down ethernet-enp0s8
Connection 'ethernet-enp0s8' successfully deactivated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
$ nmcli connection up ethernet-enp0s8
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/6)
```
假如你想将连接设置为使用 DHCP,则需要将上面的 `manual` 改为 `auto`(自动):
```
$ nmcli connection modify ethernet-enp0s8 ipv4.method auto
```
### 设备管理
`nmcli` 命令中的 `device` 子命令允许你管理安装在你电脑中的网络接口。
#### 检查设备状态
可以使用下面的命令来快速检查所有网络接口的状态:
```
$ nmcli device status
DEVICE TYPE STATE CONNECTION
enp0s3 ethernet connected Wired connection 1
enp0s8 ethernet connected ethernet-enp0s8
enp0s9 ethernet connected Wired connection 3
lo loopback unmanaged --
```
#### 显示设备详情
为了检查某个网络接口的详情,可以使用 `device` 子命令中的 `show` 操作。假如你不提供某个设备的名称,那么会获取并展示所有设备的详情。你可以上下翻动来查看这些信息。
要查看你最近添加的连接所对应的设备 `enp0s8`,你可以使用下面的命令,请注意验证它使用的 IP 地址是否为先前你要求设置的那个:
```
$ nmcli device show enp0s8
GENERAL.DEVICE: enp0s8
GENERAL.TYPE: ethernet
GENERAL.HWADDR: 08:00:27:81:16:20
GENERAL.MTU: 1500
GENERAL.STATE: 100 (connected)
GENERAL.CONNECTION: ethernet-enp0s8
GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveConnection/6
WIRED-PROPERTIES.CARRIER: on
IP4.ADDRESS[1]: 192.168.4.26/24
IP4.GATEWAY: --
IP4.ROUTE[1]: dst = 192.168.4.0/24, nh = 0.0.0.0, mt = 103
IP6.ADDRESS[1]: fe80::6d70:90de:cb83:4491/64
IP6.GATEWAY: --
IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 103
IP6.ROUTE[2]: dst = ff00::/8, nh = ::, mt = 256, table=255
```
上面的输出非常细致,它主要显示了下面这些内容:
* **网络接口名称**,在这个示例中是 `enp0s8`,它是 [udev](https://en.wikipedia.org/wiki/Udev) 分配的
* **网络连接类型**,在这个示例中是物理的 Ethernet 连接
* 设备的<ruby> 媒介访问控制 <rt> media access control </rt></ruby>(MAC)地址,它被用来在网络中识别该设备
* [最大传输单元](https://en.wikipedia.org/wiki/Maximum_transmission_unit),在单个传输中最大协议数据单位的大小,任何大于这个大小的数据将被分为多个包来进行传输
* 该设备**当前已经处于连接状态**
* 这个设备使用的连接名称是 `ethernet-enp0s8`
* 这个设备使用的 IP 地址如上面所要求的那样,被设置为 `192.168.4.26/24`
其他的信息则是与这个设备连接的网络相关的默认路由和网关设置信息。
#### nmcli 的交互式编辑器
尽管 `nmcli` 是一个命令行工具,但它还包含一个基本的交互式编辑器,`edit` 子命令将为你指定的连接打开一个交互式编辑器,例如:
```
$ nmcli connection edit ethernet-enp0s8
```
它将显示少量的帮助文字,接着是 `nmcli` 的命令提示符:
```
===| nmcli interactive connection editor |===
Editing existing '802-3-ethernet' connection: 'ethernet-enp0s8'
Type 'help' or '?' for available commands.
Type 'print' to show all the connection properties.
Type 'describe [<setting>.<prop>]' for detailed property description.
You may edit the following settings: connection, 802-3-ethernet (ethernet), 802-1x, dcb, sriov, ethtool, match, ipv4, ipv6, tc, proxy
nmcli>
```
假如你输入 `print` 然后敲击 `Enter` 键, `nmcli` 将列举出与这个接口相关的所有属性。这些属性有很多,你可以上下翻动来查看这个列表:
```
===============================================================================
Connection profile details (ethernet-enp0s8)
===============================================================================
connection.id: ethernet-enp0s8
connection.uuid: 09d26960-25a0-440f-8b20-c684d7adc2f5
connection.stable-id: --
connection.type: 802-3-ethernet
connection.interface-name: enp0s8
connection.autoconnect: yes
connection.autoconnect-priority: 0
connection.autoconnect-retries: -1 (default)
connection.multi-connect: 0 (default)
connection.auth-retries: -1
connection.timestamp: 1593967212
connection.read-only: no
connection.permissions: --
connection.zone: --
connection.master: --
connection.slave-type: --
connection.autoconnect-slaves: -1 (default)
connection.secondaries: --
```
如果你想将你的连接改为 DHCP,则请输入 `goto ipv4` 然后敲 `Enter` 键:
```
nmcli> goto ipv4
You may edit the following properties: method, dns, dns-search, dns-options, dns-priority, addresses, gateway, routes, route-metric, route-table, routing-rules, ignore-auto-routes, ignore-auto-dns, dhcp-client-id, dhcp-iaid, dhcp-timeout, dhcp-send-hostname, dhcp-hostname, dhcp-fqdn, dhcp-hostname-flags, never-default, may-fail, dad-timeout
nmcli ipv4>
```
你想改变的属性是 `method`,再继续敲 `set method auto` 然后敲 `Enter` 键:
```
nmcli ipv4> set method auto
Do you also want to clear 'ipv4.addresses'? [yes]:
```
假如你想让这个连接清除掉这个静态 IP 地址,则请敲 `Enter` 键,如果要保留,则输入 `no` 然后敲 `Enter` 键。假如你想在将来再次使用它,你可以保留这个 IP 地址。即便存储了一个静态的 IP 地址,如果 `method` 被设置为 `auto` ,它仍然会使用 DHCP。
最后输入 `save` 来保存你的更改:
```
nmcli ipv4> save
Connection 'ethernet-enp0s8' (09d26960-25a0-440f-8b20-c684d7adc2f5) successfully updated.
nmcli ipv4>
```
输入 `quit` 来离开 `nmcli` 的交互式编辑器窗口。假如你不想离开,可以输入 `back` 来回到最开始的命令行提示符界面,然后继续使用这个编辑器。
### nmcli 的更多内容
浏览交互式编辑器,你就可以看到 `nmcli` 有多少设定和每个设定有多少属性。交互式编辑器是一个简洁的工具,但如果需要在命令行或者在脚本中使用 `nmcli`,你还是需要使用常规的命令行版本。
现在你有了这些基础知识,你还可以查看 `nmcli` 的 [man 页面](https://developer.gnome.org/NetworkManager/stable/nmcli.html) 来查看它还可以提供什么更多功能。
---
via: <https://opensource.com/article/20/7/nmcli>
作者:[Dave McKay](https://opensource.com/users/davemckay) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSLC](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [nmcli](https://developer.gnome.org/NetworkManager/stable/nmcli.html) command lets you tap into the power of the NetworkManager tool directly from the Linux command line. It's an integral part of the NetworkManager package that makes use of an [application programmer's interface](https://en.wikipedia.org/wiki/Application_programming_interface) (API) to access NetworkManager's functionality.
nmcli was released in 2010 and replaces other modes of configuring network interfaces and connections, such as [ifconfig](https://man7.org/linux/man-pages/man8/ifconfig.8.html). Because it is a [command-line interface](https://en.wikipedia.org/wiki/Command-line_interface) (CLI) tool designed to be used in terminal windows and scripts, it is ideal for system administrators working on systems without a [graphical user interface](https://en.wikipedia.org/wiki/Graphical_user_interface) (GUI).
## ncmli syntax
The nmcli command accepts *options* that modify nmcli's behavior, *sections* that tell nmcli which of its capabilities you want to use, and *actions* that tell it what you want it to do:
`$ nmcli <options> <section> <action>`
There are eight sections, each related to a specific set of network actions:
**Help**provides help about ncmcli's commands and usage.**General**retrieves NetworkManager's status and global configuration.**Networking**provides commands to query a network connection's status and enable or disable connections.**Radio**provides commands to query a WiFi network connection's status and enable or disable connections.**Monitor**provides commands to monitor NetworkManager activity and observe network connections' status changes.**Connection**provides commands to bring network interfaces up and down, to add new connections, and to delete existing connections.**Device**is mainly used to modify parameters associated with a device (e.g., the interface name) or to connect a device using an existing connection.**Secret**registers nmcli as a NetworkManager secret agent listening for secret messages. This is very rarely required because nmcli does this automatically when connecting to networks.
## Simple examples
As a first check, verify NetworkManager is running and nmcli can communicate with it:
```
$ nmcli general
STATE CONNECTIVITY WIFI-HW WIFI WWAN-HW WWAN
connected full enabled enabled enabled enabled
```
Reconnaissance is often the first part of administering a system. To list all in-memory and on-disk network connection profiles:
```
$ nmcli connection show
NAME UUID TYPE DEVICE
Wired connection 1 ac3241e4-b424-35d6-aaa7-07498561688d ethernet enp0s3
Wired connection 2 2279d917-fa02-390c-8603-3083ec5a1d3e ethernet enp0s8
Wired connection 3 52d89737-de92-35ec-b082-8cf2e5ac36e6 ethernet enp0s9
```
This command uses the `show`
action from the `connection`
section.
The test machine used for this example is running Ubuntu 20.04. It has three network adaptors installed: `enp0s3`
, `enp0s8`
, and `enp0s9`
.
## Connection management
It's important to understand nmcli's nomenclature. A network **connection** is something that holds all the information about a connection. You can think of it as a network **configuration**. A connection encapsulates all the information related to a connection, including the [data-link layer](https://en.wikipedia.org/wiki/Data_link_layer) and the [IP-addressing information](https://en.wikipedia.org/wiki/IP_address). That's layer 2 and layer 3 in the [OSI networking model](https://en.wikipedia.org/wiki/OSI_model).
When you are configuring networking on Linux, you're usually configuring connections that will eventually bind to networking devices, which are the network interfaces installed in a computer. When a connection is used by a device, the connection is said to be **active** or **up**. The opposite of active is **inactive** or **down**.
### Adding network connections
The ncmli command allows you to quickly create network connections and specify elements of their configuration at the same time. To add a new connection using wired connection 2, `enp0s8`
, you need to use `sudo`
:
```
$ sudo nmcli connection add type ethernet ifname enp0s8
Connection 'ethernet-enp0s8' (09d26960-25a0-440f-8b20-c684d7adc2f5) successfully added.
```
The `type`
option requests an [Ethernet](https://en.wikipedia.org/wiki/Ethernet) connection, and the `ifname`
(interface name) option specifies the network interface device you want the connection to use.
Check what happened:
```
$ nmcli connection show
NAME UUID TYPE DEVICE
Wired connection 1 ac3241e4-b424-35d6-aaa7-07498561688d ethernet enp0s3
Wired connection 2 2279d917-fa02-390c-8603-3083ec5a1d3e ethernet enp0s8
Wired connection 3 52d89737-de92-35ec-b082-8cf2e5ac36e6 ethernet enp0s9
ethernet-enp0s8 09d26960-25a0-440f-8b20-c684d7adc2f5 ethernet --
```
Your new connection, `ethernet-enp0s8`
, was created. Its [universally unique identifier](https://en.wikipedia.org/wiki/Universally_unique_identifier) (UUID) was assigned, and the connection type is Ethernet. Make it active with the `up`
command followed by the connection name (or the UUID):
```
$ nmcli connection up ethernet-enp0s8
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
```
Check your active connections once more:
```
$ nmcli connection show --active
NAME UUID TYPE DEVICE
Wired connection 1 ac3241e4-b424-35d6-aaa7-07498561688d ethernet enp0s3
ethernet-enp0s8 09d26960-25a0-440f-8b20-c684d7adc2f5 ethernet enp0s8
Wired connection 3 52d89737-de92-35ec-b082-8cf2e5ac36e6 ethernet enp0s9
```
Your new connection, `ethernet-enp0s8`
, is now active and bound to the `enp0s8`
network interface device.
### Adjusting connections
The ncmli command makes it easy to adjust existing connections' parameters. Perhaps you want to switch one network interface from [Dynamic Host Configuration Protocol](https://en.wikipedia.org/wiki/Dynamic_Host_Configuration_Protocol) (DHCP) to a static IP address.
Suppose you need a fixed IP address of `192.168.4.26`
for your new connection. To achieve that, you need to issue two commands. One to set the IP address, and one to set the connection's method of obtaining an IP address to `manual`
:
```
$ nmcli connection modify ethernet-enp0s8 ipv4.address 192.168.4.26/24
$ nmcli connection modify ethernet-enp0s8 ipv4.method manual
```
Remember to specify the [subnet mask](https://en.wikipedia.org/wiki/Subnetwork). On this test network, it is `255.255.255.0`
, or `/24`
in [Classless Inter-Domain Routing](https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing) (CIDR).
For your changes to take effect, you need to *bounce* the connection by stopping it and bringing it back up again. The first command takes the connection down and the second brings it back up:
```
$ nmcli connection down ethernet-enp0s8
Connection 'ethernet-enp0s8' successfully deactivated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
$ nmcli connection up ethernet-enp0s8
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/6)
```
If you want to set the connection to use DHCP, use `auto`
instead of `manual`
:
`$ nmcli connection modify ethernet-enp0s8 ipv4.method auto`
## Device management
The commands in the `device`
section of the nmcli command allow you to manage the network interfaces installed on your computer.
### Checking device status
To quickly check the status of all the network interfaces:
```
$ nmcli device status
DEVICE TYPE STATE CONNECTION
enp0s3 ethernet connected Wired connection 1
enp0s8 ethernet connected ethernet-enp0s8
enp0s9 ethernet connected Wired connection 3
lo loopback unmanaged --
```
### Showing device details
To examine the details of a network interface, use the `show`
action from the `device`
section. If you do not provide a device name, the details of all devices are retrieved and displayed. You can scroll and page up and down to review them.
Take a look at `enp0s8`
, the device your new connection is using. Verify that the IP address in use is the address that you previously requested:
```
$ nmcli device show enp0s8
GENERAL.DEVICE: enp0s8
GENERAL.TYPE: ethernet
GENERAL.HWADDR: 08:00:27:81:16:20
GENERAL.MTU: 1500
GENERAL.STATE: 100 (connected)
GENERAL.CONNECTION: ethernet-enp0s8
GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveConnection/6
WIRED-PROPERTIES.CARRIER: on
IP4.ADDRESS[1]: 192.168.4.26/24
IP4.GATEWAY: --
IP4.ROUTE[1]: dst = 192.168.4.0/24, nh = 0.0.0.0, mt = 103
IP6.ADDRESS[1]: fe80::6d70:90de:cb83:4491/64
IP6.GATEWAY: --
IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 103
IP6.ROUTE[2]: dst = ff00::/8, nh = ::, mt = 256, table=255
```
The response is quite detailed. Among other things, it shows:
- The
**network interface name**, which in this case is`enp0s8`
, which is assigned to it by[udev](https://en.wikipedia.org/wiki/Udev). - The
**network connection type**, which in this case is a physical Ethernet connection. - The device's
, which identifies the device on the network.[media access control](https://en.wikipedia.org/wiki/MAC_address)(MAC) address - The
[maximum transmission unit](https://en.wikipedia.org/wiki/Maximum_transmission_unit), which is the size of the largest protocol data unit that can be transmitted in a single transaction. Anything larger than this is split into several packets. - This device is
**currently connected**. - The
**name of the connection**using this device is`ethernet-enp0s8`
. - The
**IP address of the connection**using this device. As requested, it is set to`192.168.4.26/24`
.
The other information relates to the default routing and gateway settings that were applied to this connection, according to the network it is connected to.
### nmcli's interactive editor
Although it is a command-line tool, nmcli includes an elementary interactive editor. The `edit`
action will open the interactive editor on the connection you specify:
`$ nmcli connection edit ethernet-enp0s8`
It displays a small amount of help text, then the nmcli command prompt:
```
===| nmcli interactive connection editor |===
Editing existing '802-3-ethernet' connection: 'ethernet-enp0s8'
Type 'help' or '?' for available commands.
Type 'print' to show all the connection properties.
Type 'describe [<setting>.<prop>]' for detailed property description.
You may edit the following settings: connection, 802-3-ethernet (ethernet), 802-1x, dcb, sriov, ethtool, match, ipv4, ipv6, tc, proxy
nmcli>
```
If you type `print`
and hit **Enter**, nmcli will list all the properties associated with the connection. There are many properties. You can scroll up and down through the list:
```
===============================================================================
Connection profile details (ethernet-enp0s8)
===============================================================================
connection.id: ethernet-enp0s8
connection.uuid: 09d26960-25a0-440f-8b20-c684d7adc2f5
connection.stable-id: --
connection.type: 802-3-ethernet
connection.interface-name: enp0s8
connection.autoconnect: yes
connection.autoconnect-priority: 0
connection.autoconnect-retries: -1 (default)
connection.multi-connect: 0 (default)
connection.auth-retries: -1
connection.timestamp: 1593967212
connection.read-only: no
connection.permissions: --
connection.zone: --
connection.master: --
connection.slave-type: --
connection.autoconnect-slaves: -1 (default)
connection.secondaries: --
```
Change your connection back to use DHCP. Type `goto ipv4`
and hit **Enter**:
```
nmcli> goto ipv4
You may edit the following properties: method, dns, dns-search, dns-options, dns-priority, addresses, gateway, routes, route-metric, route-table, routing-rules, ignore-auto-routes, ignore-auto-dns, dhcp-client-id, dhcp-iaid, dhcp-timeout, dhcp-send-hostname, dhcp-hostname, dhcp-fqdn, dhcp-hostname-flags, never-default, may-fail, dad-timeout
nmcli ipv4>
```
The property you want to change is `method`
. Type `set method auto`
and hit **Enter**:
```
nmcli ipv4> set method auto
Do you also want to clear 'ipv4.addresses'? [yes]:
```
If you want the connection to purge the static IP address, press **Enter**. To keep it, type `no`
and hit **Enter**. You can keep it if you think you might use it again in the future. Even with a stored static IP address, if `method`
is set to `auto`
, it will use DHCP.
Type `save`
to save your changes:
```
nmcli ipv4> save
Connection 'ethernet-enp0s8' (09d26960-25a0-440f-8b20-c684d7adc2f5) successfully updated.
nmcli ipv4>
```
Type `quit`
to exit the nmcli interactive editor. If you don't want to quit, type `back`
to go back to the main level, and carry on using the editor.
## There's much more to nmcli
Browse around the interactive editor and see just how many settings there are and how many properties each setting has. The interactive editor is a neat tool, but for nifty one-liners or to use nmcli in scripts, you'll need the regular command-line version.
Now that you have the basics in hand, check out the nmcli [man page](https://developer.gnome.org/NetworkManager/stable/nmcli.html) to see what else it can offer.
## 1 Comment |
12,602 | 什么是 DNS,它是如何工作的? | https://www.networkworld.com/article/3268449/what-is-dns-and-how-does-it-work.html | 2020-09-10T20:43:52 | [
"DNS"
] | https://linux.cn/article-12602-1.html |
>
> 域名系统解析互联网网站的名称及其底层 IP 地址,并在此过程中增加了效率和安全性。
>
>
>

<ruby> 域名系统 <rt> Domain Name System </rt></ruby>(DNS)是互联网的基础之一,然而大多数不懂网络的人可能并不知道他们每天都在使用它来工作、查看电子邮件或在智能手机上浪费时间。
就其本质而言,DNS 是一个与数字匹配的名称目录。这些数字,在这里指的是 IP 地址,计算机用 IP 地址来相互通信。大多数对 DNS 的描述都是用电话簿来比喻,这对于 30 岁以上的人来说是没有问题的,因为他们知道电话簿是什么。
如果你还不到 30 岁,可以把 DNS 想象成你的智能手机的联系人名单,它将人们的名字与他们的电话号码及电子邮件地址进行匹配,然后这个联系人名单的就像地球上的人一样多。
### DNS 简史
当互联网还非常、非常小的时候,人们很容易将特定的 IP 地址与特定的计算机对应起来,但随着越来越多的设备和人加入到不断发展的网络中,这种简单的情况就没法持续多久了。现在仍然可以在浏览器中输入一个特定的 IP 地址来到达一个网站,但当时和现在一样,人们希望得到一个由容易记忆的单词组成的地址,也就是我们今天所认识的那种域名(比如 [linux.cn](http://linux.cn))。在 20 世纪 70 年代和 80 年代早期,这些名称和地址是由一个人指定的,她是[斯坦福大学的 Elizabeth Feinler](https://www.internethalloffame.org/blog/2012/07/23/why-does-net-still-work-christmas-paul-mockapetris),她在一个名为 [HOSTS.TXT](https://tools.ietf.org/html/rfc608) 的文本文件中维护着一个主列表,记录了每一台连接互联网的计算机。
随着互联网的发展,这种局面显然无法维持下去,尤其是因为 Feinler 只处理加州时间下午 6 点之前的请求,而且圣诞节也要请假。1983 年,南加州大学的研究人员 Paul Mockapetris 受命在处理这个问题的多种建议中提出一个折中方案。但他基本上无视了所有提出的建议,而是开发了自己的系统,他将其称为 DNS。虽然从那时起,现今的它显然发生了很大的变化,但在基本层面上,它的工作方式仍然与将近 40 年前相同。
### DNS 服务器是如何工作的
将名字与数字相匹配的 DNS 目录并不是整个藏在互联网的某个黑暗角落。截至 2017 年底,[它记录了超过 3.32 亿个域名](http://www.verisign.com/en_US/domain-names/dnib/index.xhtml?section=cc-tlds),如果作为一个目录确实会非常庞大。就像互联网本身一样,该目录分布在世界各地,存储在域名服务器(一般简称为 DNS 服务器)上,这些服务器都会非常有规律地相互沟通,以提供更新和冗余。
### 权威 DNS 服务器与递归 DNS 服务器的比较
当你的计算机想要找到与域名相关联的 IP 地址时,它首先会向<ruby> 递归 <rt> recursive </rt></ruby> DNS 服务器(也称为递归解析器)提出请求。递归解析器是一个通常由 ISP 或其他第三方提供商运营的服务器,它知道需要向其他哪些 DNS 服务器请求解析一个网站的名称与其 IP 地址。实际拥有所需信息的服务器称为<ruby> 权威 <rt> authoritative </rt></ruby> DNS 服务器。
### DNS 服务器和 IP 地址
每个域名可以对应一个以上的 IP 地址。事实上,有些网站有数百个甚至更多的 IP 地址与一个域名相对应。例如,你的计算机访问 [www.google.com](http://www.google.com) 所到达的服务器,很可能与其他国家的人在浏览器中输入相同的网站名称所到达的服务器完全不同。
该目录的分布式性质的另一个原因是,如果这个目录只在一个位置,在数百万,可能是数十亿在同一时间寻找信息的人中共享,那么当你在寻找一个网站时,你需要花费多少时间才能得到响应 —— 这就像是排着长队使用电话簿一样。
### 什么是 DNS 缓存?
为了解决这个问题,DNS 信息在许多服务器之间共享。但最近访问过的网站的信息也会在客户端计算机本地缓存。你有可能每天使用 [google.com](http://google.com) 好几次。你的计算机不是每次都向 DNS 名称服务器查询 [google.com](http://google.com) 的 IP 地址,而是将这些信息保存在你的计算机上,这样它就不必访问 DNS 服务器来解析这个名称的 IP 地址。额外的缓存也可能出现在用于将客户端连接到互联网的路由器上,以及用户的互联网服务提供商(ISP)的服务器上。有了这么多的缓存,实际上对 DNS 名称服务器的查询数量比看起来要少很多。
### 如何找到我的 DNS 服务器?
一般来说,当你连接到互联网时,你使用的 DNS 服务器将由你的网络提供商自动建立。如果你想看看哪些服务器是你的主要名称服务器(一般是递归解析器,如上所述),有一些网络实用程序可以提供关于你当前网络连接的信息。[Browserleaks.com](https://browserleaks.com/ip) 是一个很好的工具,它提供了很多信息,包括你当前的 DNS 服务器。
### 我可以使用 8.8.8.8 的 DNS 吗?
但要记住,虽然你的 ISP 会设置一个默认的 DNS 服务器,但你没有义务使用它。有些用户可能有理由避开他们 ISP 的 DNS —— 例如,有些 ISP 使用他们的 DNS 服务器将不存在的地址的请求重定向到[带有广告的网页](https://www.networkworld.com/article/2246426/comcast-redirects-bad-urls-to-pages-with-advertising.html)。
如果你想要一个替代方案,你可以将你的计算机指向一个公共 DNS 服务器,以它作为一个递归解析器。最著名的公共 DNS 服务器之一是谷歌的,它的 IP 地址是 8.8.8.8 和 8.8.4.4。Google 的 DNS 服务往往是[快速的](https://www.networkworld.com/article/3194890/comparing-the-performance-of-popular-public-dns-providers.html),虽然对 [Google 提供免费服务的别有用心的动机](https://blog.dnsimple.com/2015/03/why-and-how-to-use-googles-public-dns/)有一定的质疑,但他们无法真正从你那里获得比他们从 Chrome 浏览器中获得的更多信息。Google 有一个页面,详细说明了如何[配置你的电脑或路由器](https://developers.google.com/speed/public-dns/docs/using)连接到 Google 的 DNS。
### DNS 如何提高效率
DNS 的组织结构有助于保持事情的快速和顺利运行。为了说明这一点,让我们假设你想访问 [linux.cn](http://linux.cn)。
如上所述,对 IP 地址的初始请求是向递归解析器提出的。递归解析器知道它需要请求哪些其他 DNS 服务器来解析一个网站([linux.cn](http://linux.cn))的名称与其 IP 地址。这种搜索会传递至根服务器,它知道所有顶级域名的信息,如 .com、.net、.org 以及所有国家域名,如 .cn(中国)和 .uk(英国)。根服务器位于世界各地,所以系统通常会将你引导到地理上最近的一个服务器。
一旦请求到达正确的根服务器,它就会进入一个顶级域名(TLD)名称服务器,该服务器存储二级域名的信息,即在你写在 .com、.org、.net 之前的单词(例如,[linux.cn](http://linux.cn) 的信息是 “linux”)。然后,请求进入域名服务器,域名服务器掌握着网站的信息和 IP 地址。一旦 IP 地址被找到,它就会被发回给客户端,客户端现在可以用它来访问网站。所有这一切都只需要几毫秒的时间。
因为 DNS 在过去的 30 多年里一直在工作,所以大多数人都认为它是理所当然的。在构建系统的时候也没有考虑到安全问题,所以[黑客们充分利用了这一点](https://www.networkworld.com/article/2838356/network-security/dns-is-ubiquitous-and-its-easily-abused-to-halt-service-or-steal-data.html),制造了各种各样的攻击。
### DNS 反射攻击
DNS 反射攻击可以用 DNS 解析器服务器的大量信息淹没受害者。攻击者使用伪装成受害者的 IP 地址来向他们能找到的所有开放的 DNS 解析器请求大量的 DNS 数据。当解析器响应时,受害者会收到大量未请求的 DNS 数据,使其不堪重负。
### DNS 缓存投毒
[DNS 缓存投毒](https://www.networkworld.com/article/2277316/tech-primers/tech-primers-how-dns-cache-poisoning-works.html)可将用户转移到恶意网站。攻击者设法在 DNS 中插入虚假的地址记录,这样,当潜在的受害者请求解析其中一个中毒网站的地址时,DNS 就会以另一个由攻击者控制的网站的 IP 地址作出回应。一旦访问了这些假网站,受害者可能会被欺骗,泄露密码或下载了恶意软件。
### DNS 资源耗尽
[DNS 资源耗尽](https://www.cloudmark.com/releases/docs/whitepapers/dns-resource-exhaustion-v01.pdf)攻击可以堵塞 ISP 的 DNS 基础设施,阻止 ISP 的客户访问互联网上的网站。攻击者注册一个域名,并通过将受害者的名称服务器作为域名的权威服务器来实现这种攻击。因此,如果递归解析器不能提供与网站名称相关的 IP 地址,就会询问受害者的名称服务器。攻击者会对自己注册的域名产生大量的请求,并查询不存在的子域名,这就会导致大量的解析请求发送到受害者的名称服务器,使其不堪重负。
### 什么是 DNSSec?
DNS 安全扩展是为了使参与 DNS 查询的各级服务器之间的通信更加安全。它是由负责 DNS 系统的<ruby> 互联网名称与数字地址分配机构 <rt> Internet Corporation for Assigned Names and Numbers </rt></ruby>(ICANN)设计的。
ICANN 意识到 DNS 顶级、二级和三级目录服务器之间的通信存在弱点,可能会让攻击者劫持查询。这将允许攻击者用恶意网站的 IP 地址来响应合法网站的查询请求。这些网站可能会向用户上传恶意软件,或者进行网络钓鱼和网络欺骗攻击。
DNSSec 将通过让每一级 DNS 服务器对其请求进行数字签名来解决这个问题,这就保证了终端用户发送进来的请求不会被攻击者利用。这就建立了一个信任链,这样在查询的每一步,请求的完整性都会得到验证。
此外,DNSSec 可以确定域名是否存在,如果不存在,它就不会让该欺诈性域名交付给寻求域名解析的无辜请求者。
随着越来越多的域名被创建,越来越多的设备继续通过物联网设备和其他“智能”系统加入网络,随着[更多的网站迁移到 IPv6](https://www.networkworld.com/article/3254575/lan-wan/what-is-ipv6-and-why-aren-t-we-there-yet.html),将需要维持一个健康的 DNS 生态系统。大数据和分析的增长也[带来了对 DNS 管理的更大需求](http://social.dnsmadeeasy.com/blog/opinion/future-big-data-dns-analytics/)。
### SIGRed: 蠕虫病毒 DNS 漏洞再次出现
最近,随着 Windows DNS 服务器缺陷的发现,全世界都看到了 DNS 中的弱点可能造成的混乱。这个潜在的安全漏洞被称为 SIGRed,[它需要一个复杂的攻击链](https://www.csoonline.com/article/3567188/wormable-dns-flaw-endangers-all-windows-servers.html),但利用未打补丁的 Windows DNS 服务器,有可能在客户端安装和执行任意恶意代码。而且该漏洞是“可蠕虫传播”的,这意味着它可以在没有人为干预的情况下从计算机传播到计算机。该漏洞被认为足够令人震惊,以至于美国联邦机构[被要求他们在几天时间内安装补丁](https://federalnewsnetwork.com/cybersecurity/2020/07/cisa-gives-agencies-a-day-to-remedy-windows-dns-server-vulnerability/)。
### DNS over HTTPS:新的隐私格局
截至本报告撰写之时,DNS 正处于其历史上最大的一次转变的边缘。谷歌和 Mozilla 共同控制着浏览器市场的大部分份额,他们正在鼓励向 [DNS over HTTPS](https://www.networkworld.com/article/3322023/dns-over-https-seeks-to-make-internet-use-more-private.html)(DoH)的方向发展,在这种情况下,DNS 请求将被已经保护了大多数 Web 流量的 HTTPS 协议加密。在 Chrome 的实现中,浏览器会检查 DNS 服务器是否支持 DoH,如果不支持,则会将 DNS 请求重新路由到谷歌的 8.8.8.8。
这是一个并非没有争议的举动。早在上世纪 80 年代就在 DNS 协议上做了大量早期工作的 Paul Vixie 称此举对安全来说是“[灾难](https://www.theregister.com/2018/10/23/paul_vixie_slaps_doh_as_dns_privacy_feature_becomes_a_standard/)”:例如,企业 IT 部门将更难监控或引导穿越其网络的 DoH 流量。不过,Chrome 浏览器是无所不在的,DoH 不久就会被默认打开,所以让我们拭目以待。
---
via: <https://www.networkworld.com/article/3268449/what-is-dns-and-how-does-it-work.html>
作者:[Keith Shaw](https://www.networkworld.com/author/Keith-Shaw/), [Josh Fruhlinger](https://www.networkworld.com/author/Josh-Fruhlinger/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,603 | 《代码英雄》第二季(3):准备提交 | https://www.redhat.com/en/command-line-heroes/season-2/ready-to-commit | 2020-09-10T23:22:32 | [
"代码英雄",
"开源",
"贡献"
] | https://linux.cn/article-12603-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(3):准备提交](https://www.redhat.com/en/command-line-heroes/season-2/ready-to-commit)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/ae4cf641.mp3)脚本。
>
> 导语:想进入开源领域但不知道从哪里开始?你是一个贡献者,想知道为什么只有一些<ruby> 拉取请求 <rt> Pull Request </rt></ruby>被接受?或者,你是一个感觉有点不知所措的维护者?
>
>
>
>
> 这一集将探讨投身于一个开源项目的意义。我们将跟随我们的英雄们,跟着他们在开源贡献者的角色中不断进步:从寻找项目并为其做出贡献,到建立和维护繁荣的社区。Shannon Crabill 在 2017 年的 Hacktoberfest 上分享了她是如何开始从事开源工作的,而 Corinne Warnshuis 则介绍了将来自各种背景的人纳入到创造优秀软件的过程中是多么重要。
>
>
>
>
> 为开源做出贡献的方式有很多。让我们一起来了解一下。
>
>
>
**00:00:03 - Nolan Lawson**:
在我刚开始做软件开发的时候,我基本上只做些让自己开心的小项目,像小应用程序、命令行小工具之类的。
**00:00:12 - Lindsey Tulloch**:
我只是真的不知道作出贡献那么容易。而且你不需要解决 P = MP 那样的难题,你的投入依然可以是很有价值的。
**00:00:21 - Kanika Muraka**:
本地社区使我有了足够的信心去做出贡献。
**00:00:28 - Saron Yitbarek**:
当我还完全是个编程新手的时候,我和我的朋友 Dan 一起发起了我的第一个开源<ruby> 拉取请求 <rt> Pull Request </rt></ruby>(PR),这也是我的第一次开源贡献。
**00:00:42**:
我听过很多为开源做贡献的故事,说它有多么神奇,有多么可怕。我很清楚,并非所有社区都和善,也不是所有维护者都很友好。
**00:00:57**:
那个项目本身对新手来说相当不错。我们只是添加了一个 JavaScript 库,让人们可以在线预览网站。这是一个很好的适用范围很广、自成体系的项目。而且如果这玩意儿不起作用,我基本上确信它不会毁掉整个网站。
**00:01:18**:
然而,我对这个 PR 非常紧张。我和 Dan 阅读了这个库的文档,埋头于写我们的代码。我仍记得当我们最终完成的时候,只是互相看着彼此,好像在说:“就这样吗?”我们发起了 PR。它被审查,然后合并,我想我至今还是对这一切感到惊讶,我还是不知道这些机制是怎么运行的。
**00:01:43**:
这并不是什么只有他们才能做到的,也不是什么神秘或神奇的事情。我意识到我确实也可以对开源作出贡献。这是我们在这一集中想要传递的一点知识 —— 为开源做出贡献并不神奇,它也不一定可怕。我们将带你一起走过这个过程。
**00:02:05 - Lindsey Tulloch**:
这是一个突破性的认识,这些项目实际上是完全开放的,我也可以做出贡献。
**00:02:15 - Saron Yitbarek**:
在这一场的开场白中,你会听到像你一样的代码英雄在加入开源行列时,经历着同样的恐惧。他们分别是 Nolan Lawson、 Lindsey Tulloch、 Kanika Muraka,这些是今天来做客的代码英雄。
**00:02:34**:
你正在收听的是红帽公司的原创播客节目《代码英雄》。我是主持人 Saron Yitbarek。
**00:02:47**:
这是一个关于两个代码英雄的故事,他们只是想在广阔的开源世界中,做出更好的东西。他们其中一个人是贡献者,另一个人是维护者。他们都不是真实存在的人物,而是两个虚构人物,用来代表所有的贡献者和维护者,他们和我们分享了他们的故事。希望你也可以在他们的历程中看到一些你自己的影子。
**00:03:16**:
首先来见一见我们的朋友 —— 贡献者。她是个新手,就像曾经的我们那样。她不确定基本的工作流是什么,但是她看到了一个需求,并且认为她可以添加一个功能来提供帮助。我们这个虚构的贡献者很想提交代码,但是该怎么做呢?
**00:03:44 - Corinne Warnshuis**:
你一直在成长,学习新技能。而且你不一定必须在孩提时代拆过电脑,才有资格在成年后学写代码。
**00:03:52 - Saron Yitbarek**:
这位是 Corinne Warnshuis,一个名叫“Girl Develop It” 的很棒的组织的执行董事。该组织的目的是帮助那些可能不太敢提问的,或在聚会中觉得自己不太受欢迎的女性。
**00:04:07**:
Girl Develop It 意识到做出贡献的难度并不是对所有人而言都是一样的 —— 这是社会造成的问题。作为社区,我们的一部分职责,就是要让世界多一点同情心,以及包容健康多元文化。
**00:04:22 - Corinne Warnshuis**:
在我们看来,加入开源的壁垒有很多,但我们喜欢称它们为“没有充分的理由”,有三个这样的壁垒将女性专门排斥在技术之外,它们是:刻板印象、可及性和环境。
**00:04:40 - Saron Yitbarek**:
值得记住的是,促进多元化不仅具有良好的道德意义,同时也有商业意义。
**00:04:48 - Corinne Warnshuis**:
作为一个行业,技术可能拥有着最大潜力,能给当今世界带来最大的变化。你确确实实希望,来自各行各业的人们都为塑造世界的工具、服务和其他事物做出贡献。我认为来自各种背景的人们一起开发软件,并为开源项目做出贡献真的非常重要。
**00:05:13 - Saron Yitbarek**:
事实是,我们并非一开始就拥有同样的优势和经验。下一代的伟大开发者可能看上去并不像硅谷的程序员。
**00:05:23 - Corinne Warnshuis**:
面对面指导对人们而言,历来是非常昂贵而又难以获取到的。再者,我认为从 2014 年至今,情况有所改善。我认为除了 Girl Develop It 之外的组织(比如 Outreachy 和 CodeNewbie ),正通过提供安全的网络或空间,来提出问题并获得更多的舒适感来做到这一点。
**00:05:49**:
为这些想法和问题提供一个安全而友好的测试平台,是一个不错的起点。
**00:06:02 - Saron Yitbarek**:
说到新手,回到我们正在追踪的那个贡献者。倘若你不是来自主流背景时,那么第一次提交可能会压力非常大。感觉就好像你必须得证明你自己。不过一旦我们将加入的壁垒降得足够低,我们在准备做出贡献时,实际需要考虑的是什么呢?
**00:06:23 - Vincent Batts**:
对某些项目感到兴奋这事很酷,但你想要解决的用例是什么呢?
**00:06:31 - Saron Yitbarek**:
Vincent Batts 在红帽主要从事容器架构方面的工作。他鼓励新的贡献者尝试并有针对性地开展工作。找到你和项目一起有意义的那个利基。
**00:06:45 - Vincent Batts**:
我认为一个可让人持续贡献的项目通常来自于互惠关系。它满足了你的一个需求,而且在这个过程中你又发现了满足它的需求的方式。即使它是一个由人构成的社区,它也已经成为了一种共生体系。
**00:07:01 - Saron Yitbarek**:
比方说:
**00:07:02 - Vincent Batts**:
因为朋友的推荐,我最终弄了一台 Slackware Linux 机器。它非常适合我想做的事情,我帮着将其打包到了主流 Slackware Linux 社区,并最终成为了这个项目的贡献者和维护者。这并不是因为我想成为 Slackware Linux 社区的贡献者,而是因为这是最适合我的一个项目,它的用例正好是我一直致力于解决的事情。
**00:07:33**:
我想很多人都会遇到这种情况,他们因自己量身定制的用例而编写一个数据库软件。他们发现用 Golang 编写很合适,因此他们写了这样一个高性能的数据库,所以他们能够对 Golang 做出修复或优化方面的贡献,以帮助他们的数据库运行得更快。
**00:07:54 - Saron Yitbarek**:
你可以找到你自己的小众领域,并开始自然发展。关键在于,从某处开始去做。你不必等待有了学位或绝对的自信才开始。
**00:08:08 - Vincent Batts**:
如果你需要直接编写代码或文档的经历,或是成为一个后端数据库、Web 服务器的系统管理员,那么好消息是,大部分社区都是基于志愿者构成的。你可以参与诸如 Debian、Fedora 或其他一些类似的项目,这些社区都建立起了文档页面。那些项目必须在某处的 Web 服务器上运行,一些人,甚至是一个没有薪酬的、正在积累经验的社区成员,负责去检查 Web 服务器是否停机或出了什么问题。
**00:08:43 - Saron Yitbarek**:
Vincent 强调了开源的平等主义本质。无论你来自哪里,只要你愿意,都可以真正开始做出贡献。如果你想的话,你可以为自己扬名立万。
**00:08:57 - Vincent Batts**:
一旦它被合并,你的名字就会附在某个项目上。你可以公开表示你在某个地方做出了改进,这是相当有意义的事情。
**00:09:11**:
我曾与那些不是从事日常技术工作的电视修理工和教师共事过,他们很有代表性。他们也在社区上做出了很多贡献。另一方面,我也曾和一些开发者合作过,他们有的能有 30 年开发经验,但他们从来没有像那样公开贡献过代码。
**00:09:40 - Saron Yitbarek**:
对了,我们的贡献者怎么样了?嗯,她找到了她的定位。她克服了她的恐惧,并最终发起了她的第一个 PR。现在她可以休息一下,并战战兢兢地等待维护者作出回复。
**00:09:56 - Vincent Batts**:
向上游做贡献有点像第一次上台做才艺表演。你会感到紧张,走上舞台后手心冒汗。你做了一件事,然后它好像就变成了你的成就。你将被彻底改变,跟过去不再一样。
**00:10:17 - Saron Yitbarek**:
彻底改变?或许吧。事实上,维护者有四种可能的回应:沉默 —— 这很有趣,也可能是完全拒绝,或是直接接受,或是柔和的中间立场 —— 要求修改。
**00:10:37**:
提交 PR 的几天后,我们虚构的贡献者终于收到了来自维护者的回复。跪迎结果吧,是要求修改。作为一个新手,她将这视为一场小型灾难。她还不知道要求修改是个实际上是成功的一步。她甚至还对维护者的简略语气感到一点气愤,听上去就像维护者没空搭理她一样。
**00:11:03**:
这里存在着一堵墙,新的贡献者不知道墙的另一边正在发生什么。
**00:11:12**:
我们来认识一位维护者。他正在维护的项目并不是他的全职工作。这是一个周末项目,他时常熬到深夜,给工单排优先级,并且提醒人们发起 PR 时更新文档,然后你就明白了。他相当忙碌,有时甚至出现了一些维护倦怠。
**00:11:38**:
一位现实生活中的维护者,Nolan Lawson 写了一篇很棒的有关倦怠的文章,最近引起了很多关注。
**00:11:51 - Nolan Lawson**:
老实说,我认为那篇博文有一部分实在寻求帮助。这是我表达我自己偶然发现了这个开源的项目,起初我觉得它确实很有趣,但现在却感觉没那么有趣了。我不确定该如何恢复兴致。
**00:12:05 - Saron Yitbarek**:
Nolan 有一份日常工作,但和大多数维护者一样,他在开源项目中投入了大量的休息时间,因为这家伙真的很在意这个项目。讽刺的是,他的部分痛苦来自于,他清楚贡献者也同样很在意这个项目。
**00:12:23 - Nolan Lawson**:
真正使我精疲力竭的实际上只是如潮水般涌来的好心人。你真的想帮他们,真的真的很想。他们所做的只是问一个问题,他们所做的就是 —— 他们在你项目中发现了阻碍他们的 bug,或者他们所做的只是 —— 他们真的费心去下载代码并弄清楚它是如何构建的,并提供 bug 修复。他们只是希望你审查他们贡献的代码。
**00:12:43 - Saron Yitbarek**:
像 Nolan 这样的维护者正不断地审查 PR 库,弄清每个提交将如何发挥作用。他们促使贡献者尽可能做到最好,遵守内部限制,为了能让项目达到更高的水准,用最有意义的方式做出贡献。
**00:13:06**:
我的观点是,那些维护者有可能不是一个新贡献者所担心的混蛋。他们正努力地想去做到一切。他们甚至会花时间标注一些东西保留给新手(很多维护者都这样),以便新手有机会施展自己。
**00:13:27**:
但到最后,PR 和提交总是非常的多。我们要如何确保这种情况不会发生呢?我们该如何为维护者创造合理的环境呢?
**00:13:41**:
一种解决方案是 —— 像 Fedora 这样拥有强大社区的开源项目。Fedora 项目负责人 Mattew Miller 解释了项目吸引维护者和贡献者的地方。
**00:13:55 - Matthew Miller**:
Fedora 项目中许多不光是开发,还有开发过程中所相关的一切。总体来说,IT、 CS(计算机科学)事实上都是如此。开源可能并没有足够的这类围绕开源的支持性的角色。
**00:14:11 - Saron Yitbarek**:
那种支持实际上看起来是怎样的呢?
**00:14:14 - Matthew Miller**:
我们拿来举例的带薪角色之一是 Fedora 项目经理,他帮着让计划按部就班进行,并且监管着人们来保证文书工作完成。让人有酬劳地来做这份工作事实上可以帮着减少官僚主义,因为他们可以把时间花在使项目成为人看懂的事情,而不只是一堆杂乱的文件。
**00:14:34 - Matthew Miller**:
我认为,像这样的企业参与某些角色,可以赋予你无法用志愿者保证的稳定性。
**00:14:43 - Saron Yitbarek**:
这有点让我想起了自由职业者使用的共享工作空间。那里有一个共享的接待区、共享的 WiFi 和共享的咖啡。有一个人在管理它,然后你就可以自由地做你自己的事情。
**00:14:55**:
Matthew 告诉了我们另一个 Fedora 采取的策略。他们让你想在项目中途停下来休息一下时,可以很自然,而不是感觉一切都崩溃了。
**00:15:04 - Matthew Miller**:
我们研究的一个问题是确保领袖角色的漂亮退场,所谓的职位并不一定是终身的委任。你可以重新申请担任角色,并且不会在一年任期后结束后,看起来像被踢出去似的。如果六个月后你想离开,你可以优雅地这样做,而不必觉得这会让人失望。我们已在努力确保人们可以没有障碍地退出。
**00:15:27 - Saron Yitbarek**:
Matthew 认为,找到支持该开源社区的方法,而又不至于重蹈覆辙才是关键。
**00:15:35 - Matthew Miller**:
社区几乎就像一个家庭,而不是工作场所之类的东西。在这里做出贡献很有意义,因为你不仅只在为自己或是某些薪酬或终端产品工作。而且由于共事的是你的朋友,你们一起工作能做出比单人作品更伟大的东西。
**00:15:56 - Saron Yitbarek**:
无论是 Fedora 还是其他社区,它们都造就了一个开源贡献得以持续的世界,这个世界还值得努力让它继续变好。
**00:16:10**:
同时,让我们回到办公桌旁,我们关注的那个贡献者刚完成了维护者要求的修改。她还没意识到,但她即将拥有第一个被接受的 PR。
**00:16:24**:
当我们谈论诸如倦怠之类的长期工作的问题时,很容易忽视那些早期问题。每天都有很多新的贡献者加入进来。这实际上就是为什么我们需要构建可持续的社区,为所有这些开源魔术提供场地。
**00:16:49**:
最终,我们的贡献者和维护者共同努力,推动事情向前发展。故事的最后一句话 —— 记住所有的交流都依赖于 GitHub 和 GitLab 之类的开发平台,这些平台使得我们可以聚集到一起。
**00:17:09**:
我想深入探讨一下这些社区是如何使我们的工作成为可能的。我和 Shannon Crabill 谈过这个问题。Shannon 白天是个电子邮件开发者,但到了晚上,她正在学习前端开发。她也是一个对社区价值有第一手了解的人。
**00:17:28**:
去年她参加了一个长达一个月的名为 Hacktoberfest 的开源活动,该活动旨在让更多的人为开源做出贡献。当时, Shannon 完全是一个开源新手。
**00:17:44 - Shannon Crabill**:
回想起十月那时候,我感觉我没有太多工作要做,而且可能还有更多的新手,没找到需要做的东西。如果我提出一些相对容易的待办事项,他们就可以找到用于尝试和学习的突破口,并且开始习惯使用 Git 和 GitHub。
**00:18:04**:
我认为最困难的部分,在于习惯工作流程并付诸实践。如何推送存储库?如何分享项目?如何处理 PR 和相关的东西?我帮助人们对开源做出了贡献,这事令人惊讶,感觉也确实很棒。
**00:18:21 - Saron Yitbarek**:
真的很恐怖吗?我觉得如果你是个新手 —— 尽管你拥有存储库,也要走出自己的小世界,把自己放在社区里。现在,维护者所在的社区里出现了正在作出贡献的人,你必须和他们交谈,审查他们的代码并发表意见。这听上去是有点吓人。
**00:18:42 - Shannon Crabill**:
我认为最初的反应是,“哦,我的天哪,这太酷了”,还有,“天哪,我让自己陷入了什么境地?”我意识到我只合并过自己的代码,合并过自己的 PR 并将其推送到自己的站点上,以及其他所有只关于自己的事情,我从没处理过别人的东西。我认为我之前尚未完成过真正意味上的合并 PR,所以我不得不把这弄清楚。总的来说,将复杂的东西简单地合并起来,仍然是我要努力熟练解决的问题。
**00:19:09**:
这是旋风一样的感觉,“这很酷,但我不知道该怎么做。”每个人都很友好,并且我也努力保持非常友好和真诚,即使只是,“嘿,我有点不知所措。我看到了每个人提交的 PR。虽然今晚我不会找他们,但我明天会的。”人们对这种情况似乎反应良好。
**00:19:26 - Saron Yitbarek**:
是的。当你维护一个项目时(尤其是作为一个新的开发者时),我一直想知道的是,是不是这意味着你必须是整个存储库贡献者中最聪明的人?你实际上在评估、评判并审查其他人的代码。你是否遇到过,自己懂的东西不如提交 PR 的人那么多的情况?你是如何处理的?
**00:19:55 - Shannon Crabill**:
好问题。我认为,“噢,我需要成为有史以来最聪明最好的开发者”,这样的想法会成为障碍。我觉得自己很幸运,当我进入这个领域的时候,我没有这样想,所以我能像这样说,“让我们先开始,并且期待未来会发生什么吧。”
**00:20:12**:
你无需成为一个有 20 年经验的高级开发人员。你只需要有一个好点子,知道如何使用相应软件,然后愿意去学习自己不知道的东西。
**00:20:22**:
肯定有一两个 PR 为我的项目添加了一些很酷的功能,说实话,如果它们崩溃了,我真不知道该如何修复。我可能会看着代码然后想道,“是的,它崩溃了。”我不知道该怎么做才能从头构建它们。
**00:20:34**:
我认为这就是它酷的地方。如果只有我一个人在做贡献,我可能就做了一些基本的工作,但没法像其他拥有丰富经验的人所作出的贡献一样,将项目变得那么酷。
**00:20:45 - Saron Yitbarek**:
作为一个维护者,在使项目更易于访问,更加友好,更加易于贡献的过程中,你学到了些什么呢?
**00:20:55 - Shannon Crabill**:
哦,确实有件我认为很有帮助,并且我希望我一开始就做的事,那就是尽可能的建立模板,以及文档、文档、文档。
**00:21:07**:
我的确在我的 README 文件里加了很多东西,并且我认为在项目开始时有一个 README 文件确实是很重要的一步。这件事情意味着你对其他人大声说,“嘿,请查看我们的贡献指南。”我认为我制作了一个 PR 模板、一个议题模板,“单击这里查看当前议题”,这样人们才不会多次提交同样的内容。
**00:21:31**:
我认为让项目尽可能简单,或尽可能对用户友好,这是你作为维护者需要迈出的一大步。
**00:21:38 - Saron Yitbarek**:
绝对是这样,我经常看到 README 文件,经常听说他们有多么多么重要。我觉得在 README 文件里还可以做很多事情。归根结底,它就像是一个空白文档,告诉别人去阅读它。你应该在文档里写什么呢?你该如何构建它,来使得它真正与希望做出贡献的人产生关联呢?
**00:22:00 - Shannon Crabill**:
我在我的 README 文件里放了很多 gif。
**00:22:03 - Saron Yitbarek**:
很好。
**00:22:05 - Shannon Crabill**:
我有 gif,也有链接。
**00:22:07 - Saron Yitbarek**:
我一开始就知道 Shannon 已经认识到了合作关系的重要性。她早就知道,如果有人被邀请来协作,这项目就会变得耀眼,大家也会因此度过美好的时光。
**00:22:20 - Shannon Crabill**:
有人用开源项目作出很棒的事情,我也认为这很有趣,而且有个有意思的项目,“嘿,我制作了这些很酷的蝙蝠,每次你单击页面的时候,它们都会随机生成。”
**00:22:33 - Saron Yitbarek**:
我也喜欢人们做不同的事情。如果你真的很喜欢艺术性的东西,你可以做蝙蝠生成功能。如果你想让项目变得整洁,你也可以做。如果你想说,“我会坚持贡献文档,我将花时间为其他的贡献者们打造更干净,更舒适的环境”,那你也可以选择做这个。
**00:22:56 - Shannon Crabill**:
是的。我已经说得很清楚了,无论你想贡献的是什么,都没有问题。如果你发现了一个拼写错误并且想要纠正它,很好。如果你发现某个链接损坏并且想要修复它,也很好。如果你只是想帮着注释这份代码,使得它更易于阅读和理解,那也将很有帮助。
**00:23:12 - Saron Yitbarek**:
我认为,你在社区中获得了积极的反馈真的很棒,因为我听说过很多并不是这样美好的故事。人们在网络上并不十分友好,也不太热情善良,尤其是对我们这一些,可能会问出比他们想象中更简单问题的新手。
**00:23:33**:
你认为,是什么使得你的社区,比起其他社区更加友好呢?
**00:23:41 - Shannon Crabill**:
只是因为在我们社区,贡献是一件很随意的事。如果你想做出贡献,你可以,这很酷。如果你不想,那也很酷。我理解有人认为开源是一件令人恐惧的大事,你需要具备所有这些经验,并且了解所有这些复杂的语言,或是前后端以及其他的一切,才能够做出贡献。
**00:24:03 - Saron Yitbarek**:
绝对是这样。做 Hacktoberfest,它是怎样改变了你现在对开源的想法?
**00:24:11 - Shannon Crabill**:
它肯定对我造成了积极的影响。就像我说的,我有过很棒的经历,而且我希望每一个以某种方式参与我项目的人也能有很好的经历。这毫无疑问促使我想去尝试更多类似的事情,即使它们没有进一步的发展。现在这看起来这些项目更加平易近人了。
**00:24:32 - Saron Yitbarek**:
真是个好消息。
**00:24:34**:
这儿有个信息,来自数百家公司的数千人,以及一些根本没在公司工作的人,为 Linux 内核做出过贡献。这意味着基本上运行着互联网的 Linux 是由一群日常英雄在维护的。如果你渴望为开源作出第一次贡献,或许你会想了解有关 Fedora 社区的更多信息,我们有大量的资料正等着来帮助你。请查阅 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 以获得更多信息。
**00:25:20 - Saron Yitbarek**:
快速提醒一下,这一季我们将构建我们自己的开源《代码英雄》游戏。欢迎你以对你来说合适的方式来做出贡献。快来了解如何成为其中一员吧。我们希望你可以通过 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 和我们一起开发这款游戏。
**00:25:42 - Saron Yitbarek**:
下一集,我们将讨论残酷的达尔文式错误以及开源开发中失败的美丽之处 —— 它如何困扰我们,指导我们,并使我们变得更好。
**00:25:57 - Saron Yitbarek**:
《代码英雄》是红帽的原创播客。你可以在 Apple Podcast、 Google Podcast 或是其他你喜欢的途径免费收听。我是 Saron Yitbarek,坚持编程,下期再见。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/ready-to-commit>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Looking to get into open source but not sure where to start? Are you a contributor trying to understand why only some pull requests get accepted? Or are you a maintainer who's feeling overwhelmed?
This episode looks at what it means to commit to an open source project. We follow our heroes as they progress through the roles of open source contributors: from finding projects and contributing to them, to building and maintaining thriving communities. Shannon Crabill shares how she got her start in open source at Hacktoberfest 2017, and Corinne Warnshuis describes how important it is to include people from all backgrounds to create good software.
There are many ways to contribute to open source. Let's walk through this together.
**00:03** - *Nolan Lawson*
When I started out doing software development, I was mostly just making little projects that amused me, little apps, little command-line tools, and stuff like that.
**00:12** - *Lindsey Tulloch*
I just really didn't know that it was so easy to contribute and that you don't need to have solved P=MP, your input can still be valuable.
**00:21** -*Lindsey Tulloch*
I just really didn't know that it was so easy to contribute and that you don't need to have solved P=MP, your input can still be valuable.
**00:21** - *Kanika Muraka*
Local communities made me confident enough to contribute.
**00:28** - *Saron Yitbarek*
When I was a total newbie to programming, I teamed up with my friend Dan to make my very first open source pull request (PR), which would also make it my very first open source contribution.
**00:42** - *Saron Yitbarek*
I'd heard so much about contributing to open source, about how amazing it was, but also how completely terrifying. I was very aware, not all communities are kind and not all maintainers are nice.
**00:57** - *Saron Yitbarek*
The project itself was a pretty good one for a first timer. We were just adding a JavaScript library, something to let people get a digital walkthrough of the website. Just a nice well–scoped project. Self–contained. Bonus, if the thing didn't work, I was almost positive it wouldn't burn down the whole site.
**01:18** - *Saron Yitbarek*
Yet, I was crazy nervous about this pull request. Dan and I read the docs for the library, plugged away at our code. I still remember when we were finally done, we just looked at each other like, "That's it?" We made our PR, it was reviewed, got merged, and I guess I was surprised by how, I don't know, how mechanical it all was.
**01:43** - *Saron Yitbarek*
It wasn't some big mystery or magical thing that only they could do. I realized, I really could contribute, too. That's a bit of knowledge we're passing on in this episode; making a contribution to open source isn't magic. It doesn't have to be terrifying. We're going to walk through this together.
**02:05** - *Lindsey Tulloch*
It was just such a groundbreaking realization that this is actually totally open, I can just do this.
**02:15** - *Saron Yitbarek*
In that opener, you heard from command line heroes, just like you, who push through that same terror to join the ranks of open source. They were Nolan Lawson, Lindsey Tulloch, and Kanika Muraka, all heroes.
**02:34** - *Saron Yitbarek*
You're listening to Command Line Heroes, an original podcast from Red Hat. I'm your host, Saron Yitbarek.
**02:47** - *Saron Yitbarek*
This is a story about two command line heroes just trying to make something better in the big open source world. One of them is a contributor, the other's a maintainer. Neither of them are real people, instead these two fictional characters represent all the contributors and all the maintainers that shared their stories with us. Hopefully, you'll see some of yourself in their journey, too.
**03:16** - *Saron Yitbarek*
First meet our friend, the contributor. She's a bit of a newbie, just like we all were once upon a time. She's not sure about what the basic workflow is, but she sees a need and she thinks she can add a feature that would help. Our imaginary contributor is keen to make that fix, but how?
**03:44** - *Corinne Warnshuis*
You're always growing new skills and you don't have to have taken apart a computer as a child to know how to code as an adult.
**03:52** - *Saron Yitbarek*
That's Corinne Warnshuis, the executive director of an awesome organization called Girl Develop It. It's designed to help women who maybe don't feel super comfortable asking questions or may not feel entirely welcome at meetups.
**04:07** - *Saron Yitbarek*
Girl Develop It realized that making contributions isn't the same for everybody; culture matters. Part of our job as a community is to build a little empathy and healthy diversity into the process.
**04:22** - *Corinne Warnshuis*
There are many barriers to entry as we see them, but we like to call them "no good reasons." There are three no good reasons that keep women specifically out of technology. They are: stereotypes, they're the accessibility, and the environment.
**04:40** - *Saron Yitbarek*
It's worth remembering here promoting diversity doesn't just make good ethical sense, it makes good business sense, too.
**04:48** - *Corinne Warnshuis*
Technology as an industry has probably the greatest potential to make the most change in the world today. You really want to have people from all backgrounds, from all perspectives contributing to the tools and services and things that are going to shape the world. I think it's really important that people from all backgrounds are creating software and contributing to open source projects.
**05:13** - *Saron Yitbarek*
The fact is, we didn't all start with the same advantages or experiences. The next great coder might not look like a Silicon Valley cliché.
**05:23** - *Corinne Warnshuis*
In–person instruction has been historically incredibly expensive and inaccessible for people. Again, I think from 2014 to today, that has improved. I think groups other than Girl Develop It like Outreachy, like CodeNewbie, are doing that by providing a safety net or a space to ask questions and get more comfortable.
**05:49** - *Corinne Warnshuis*
Having a safe, welcoming testing ground for some of those ideas and some of those questions is a good place to start.
**06:02** - *Saron Yitbarek*
Speaking of newbies, back to that contributor we were tracking. When you're not from a mainstream background, that first commit can carry a lot of weight. It can feel like you have to prove yourself. Once we get those barriers to entry low enough, what do we actually need to think about as we prepare to contribute?
**06:23** - *Vincent Batts*
It's cool to get excited about certain projects, but what is the use case that you're trying to solve?
**06:31** - *Saron Yitbarek*
Vincent Batts works at Red Hat, mostly on container architecture. He encourages new contributors to try and be intentional about the work. Find that niche where you and the project make sense together.
**06:45** - *Vincent Batts*
I think a project to contribute to usually comes out of a reciprocal relationship. It satisfied a need for you, and along the way you found a way to satisfy a need for it, and it becomes a relationship, even if it is a community of people.
**07:01** - *Saron Yitbarek*
For example:
**07:02** - *Vincent Batts*
I ended up standing up a Slackware Linux box out of a recommendation by a friend. It was suitable enough for me to do what I was trying to do that I ended up helping them get it packaged for the mainstream Slackware Linux community. And ended up becoming a maintainer and contributor on that project, not because I sought out to be a contributor to that Slackware Linux community, but it most well suited the other project, the use case that I was actually trying to solve.
**07:33** - *Vincent Batts*
I think that happens a lot for a lot of folks. They seek to write a database because of their tailored use case, and they find that it works well in Golang, and they wrote such a high–performance database that they were able to contribute back fixes or improvements to Golang to help their database run faster.
**07:54** - *Saron Yitbarek*
You can find your little niche and let a certain amount of organic growth take place. The key point is, start somewhere. You don't have to wait for a degree or for absolute confidence.
**08:08** - *Vincent Batts*
If you need direct experience writing code or writing docs, or even being a system administrator for a back-end database web server, most of these communities are volunteer based. You go out to some project like Debian, Fedora, or whatever, and those communities have docs pages that are set up. Those have to run on a web server somewhere and somebody, even a community member that's not being paid to check if the web server's down or something went wrong, is gaining experience.
**08:43** - *Saron Yitbarek*
Vincent stresses that point about the egalitarian nature of open source. Wherever you're coming from, you really can start contributing, if you want to. You can make a name for yourself, if that's what you want to do.
**08:57** - *Vincent Batts*
Once it's merged, then your name is attached to something. You're publicly representable that you have made an improvement somewhere, which is incredibly meaningful.
**09:11** - *Vincent Batts*
I've worked with folks that were television repairmen and teachers, not in a technical day–to–day job, that were very well represented. They contributed a lot in the community. On the flip side of that, I've worked with developers that sometimes have had 30 years of development experience, but they had never publicly contributed code like that.
**09:40** - *Saron Yitbarek*
How's our contributor doing by the way? Well, she found her niche. She conquered her fears and she's finally made her first pull request. Now she can sit back and be terrified while she waits for the maintainer to respond.
**09:56** - *Vincent Batts*
Contributing upstream is kind of like going on stage for the talent show for the first time; you get nervous, and you go out there and your palms get sweaty. You do a thing and then it's like an achievement. You are profoundly changed, you never will be the same.
**10:17** - *Saron Yitbarek*
Profoundly changed? Maybe. There are in fact four possible responses from a maintainer; silence, that's a fun one, or possibly outright rejection, or outright acceptance. Or the squishy middle ground, a request for change.
**10:37** - *Saron Yitbarek*
A couple days after her PR, our imaginary contributor finally gets a ping back from the maintainer. Lo and behold, it's a request for change. Being new, she takes that as a miniature disaster. She doesn't know yet how request for change is really an accomplishment. She even gets a flash of anger at the clipped tone the maintainer is using. It sort of sounds like he doesn't have time for her.
**11:03** - *Saron Yitbarek*
There's a wall up, and that new contributor has got no idea what's happening on the other side.
**11:12** - *Saron Yitbarek*
Meet a maintainer. The project he's maintaining isn't his full time job; it's a weekend project and he stays up till the wee hours lots of nights prioritizing issues, and reminding folks to update docs when they make pull requests, and you get the idea. He's got a full plate. Sometimes he even experiences a little maintenance burnout.
**11:38** - *Saron Yitbarek*
A real life maintainer, Nolan Lawson, wrote a pretty amazing post that got a lot of traction recently about burnout.
**11:51** - *Nolan Lawson*
I think part of that blog post was kind of a cry for help, honestly. It was me expressing that I had stumbled into this open source thing. It was really fun at first, and now it wasn't so fun. I wasn't sure what I should do to recover.
**12:05** - *Saron Yitbarek*
Nolan's got a day job, but like most maintainers he was putting in tons of after hours work on his open source project because the guy honestly cares. Ironically, part of his pain was coming from the fact that he knows the contributors honestly care, too.
**12:23** - *Nolan Lawson*
What really burned me out more than anything was actually just the flood of well–meaning folks. You want to help them; you really, really do. All they're doing is asking a question, all they're doing is—they found a legitimate bug in your project that's blocking them, or all they're doing is—they actually bothered to download the code and figure out how it builds and to contribute a bug fix. They just want you to review their code that they've contributed.
**12:43** - *Saron Yitbarek*
Maintainers like Nolan are constantly reviewing a library of PRs, figuring out how commits will play into things. They're pushing contributors to do the best work possible, to conform to the house constraints, to contribute in ways that are most meaningful to the larger goals of the project.
**13:06** - *Saron Yitbarek*
Here is my point, chances are those maintainers are not the jerks a new contributor might worry about. They're working their butts off trying to get to everything. They even take the time, lots of maintainers do, to label some things as reserved for first–timers only so newbies have a chance to take a swing.
**13:27** - *Saron Yitbarek*
At the end of the day though, the scope of all the PRs and commits gets overwhelming. How do we make sure that doesn't happen? How do we create environments for maintainers that make sense?
**13:41** - *Saron Yitbarek*
One solution is an open source project with a strong community like Fedora. The Fedora project leader Matthew Miller explains what attracts maintainers and contributors to the project.
**13:55** - *Matthew Miller*
A lot of Fedora is not development, it's all the things that go around development. That's actually true with IT in general, CS (computer science) in general. Open source maybe doesn't have enough of it, the sort of support roles around open source.
**14:11** - *Saron Yitbarek*
What does that support actually look like?
**14:14** - *Matthew Miller*
One of the paid roles we have for example is the Fedora program manager who helps keep the schedule on track, and bugs people about making sure the paperwork is done. Having somebody paid to do it actually helps keep the bureaucracy down because they can put the time in to make it a human thing rather than something that is just a bunch of paper shuffling.
**14:34** - *Matthew Miller*
I think having corporate involvement like that gives stability to some of the roles that you can't guarantee with volunteers.
**14:43** - *Saron Yitbarek*
It sort of reminds me of those work spaces freelancers use. There's a shared reception area, shared wifi, and shared coffee. The manager's handling it, and you're free to do your own thing.
**14:55** - *Saron Yitbarek*
Matthew told us about another Fedora fix. They save you from feeling like everything will collapse if you take a break from your project.
**15:04** - *Matthew Miller*
One of the things we've looked at is making natural endings to leadership roles, where you say you sign up for something, it's not necessarily a lifetime commitment. You can re–sign up, you're not kicked out after a year. If after six months you want to move on, you can gracefully go on without feeling like you're letting people down. We've tried to work on making sure people have a clear exit.
**15:27** - *Saron Yitbarek*
Matthew figures that finding ways to support that open source community without being heavy–handed is the key.
**15:35** - *Matthew Miller*
It's almost like a family rather than something like a workplace or something like that. It's meaningful to contribute to because you're working on this not just for yourself, or not just for some paycheck or an end product, but because the people you're working on it with are your friends and it's something that you're working on together to make something that's bigger than this individual effort.
**15:56** - *Saron Yitbarek*
Whether it's thanks to Fedora or something else, a world where open source contributions are sustainable, now that's a world worth fighting for.
**16:10** - *Saron Yitbarek*
Meanwhile, back at her desk, that new contributor we were following just finished the changes the maintainer asked for. She doesn't realize it yet, but she's about to have her first pull request accepted.
**16:24** - *Saron Yitbarek*
It's easy to lose sight of those early steps when we talk about long–term issues like burnout. Every day, there are new contributors all over the world joining the party. That's really why we need to build a sustainable humane place where all this open source magic can happen.
**16:49** - *Saron Yitbarek*
In the end, our contributor and our maintainer work together to nudge things forward. There's one last piece of the story—remember that all that back and forthing depends on development platforms like GitHub and GitLab, places where we can all come together.
**17:09** - *Saron Yitbarek*
I wanted to dive deep into how those communities make our work possible. I got chatting with Shannon Crabill about it. Shannon's an email developer by day, but by night she's learning front–end development. She's also someone who knows first–hand about the value of community.
**17:28** - *Saron Yitbarek*
Last year she participated in a month–long celebration of open source called Hacktoberfest, an initiative to get more people to contribute to open source. At the time, Shannon was very much an open source newbie.
**17:44** - *Shannon Crabill*
Thinking back to that point in October, I felt like I wasn't finding much to work on and there's probably other beginners or maybe even more beginners who were also not finding things to work on. Maybe if I put something out there that's relatively easy, they'll have some place to try and learn, and get used to Git and GitHub.
**18:04** - *Shannon Crabill*
I think the hardest part is getting used to the motions of just how it works and practicing. How do I push repo? How do I share a project? How do I do pull requests and that sort of thing. I got people to contribute, which was surprising, but also really awesome.
**18:21** - *Saron Yitbarek*
Was that scary at all? I feel like if you're new, you're putting yourself out there despite even having the repo, period. Now you have people actually contributing and you have to talk to them, and review their code, and have opinions. That sounds like that can be a little intimidating.
**18:42** - *Shannon Crabill*
I think the initial reactions were like, "Oh my God, this is so cool", and also, "Holy crap, what have I gotten myself into?" I realized I had merged my own code into my own code, I merged my own pull requests and pushed to the site and everything like that. I had not done anyone else's. I think I hadn't done a pull request, merging it before then, so I had to figure that out. Merge complex in general is something that I still struggle with a little bit.
**19:09** - *Shannon Crabill*
It was this whirlwind of feelings, "This is cool. I don't know how to go about this." Everyone was really friendly, and I just tried to stay very friendly and honest, even if it was just, "Hey, I'm overwhelmed. I see everyone's pull request. I won't get to them tonight, but I'll get to them tomorrow." People seemed to respond well to that.
**19:26** - *Saron Yitbarek*
Yes. One thing that I've always wondered when you are maintaining a project—especially as a newer developer—is does it mean that you have to be the smartest person on the repo? You're essentially grading, you're judging and reviewing other people's code. Have you had a situation where you didn't know as much as the person making a pull request? How did you deal with that?
**19:55** - *Shannon Crabill*
That's a really good one. I could see thinking that, "Oh, I need to be the smartest, best developer ever," would maybe be a hindrance. I think I was lucky that I didn't think that when I went into this, so I was able to go into it like, "Let's just go for it, see what happens."
**20:12** - *Shannon Crabill*
You don't need to be senior developer, 20 years experience. You just need to have an idea and just know how to use the software, and just be willing to learn if you don't know.
**20:22** - *Shannon Crabill*
There were definitely one or two pull requests that added some really cool features to my project that to be honest, if it broke, I don't really know how to fix it. I can look at the code and be like, "Yeah, it's broken." To be able to build that from scratch, I wouldn't know how.
**20:34** - *Shannon Crabill*
I think that's the cool thing about it. If it was just me contributing, I might have done some neat stuff but not as cool as what other people are bringing their experiences to the table with to do.
**20:45** - *Saron Yitbarek*
As a maintainer, what are some lessons that you've learned along the way to make the project more accessible, more friendly, easier to contribute to?
**20:55** - *Shannon Crabill*
Sure. The one thing that I think was really helpful, and I wish I had done this initially, is to set up templates wherever possible and documentation, documentation, documentation.
**21:07** - *Shannon Crabill*
I definitely added a lot to my README file as I went, and I think just having a README file to start is a really big step. Just even links to, "Hey, check out our guidelines for contributing." I think I made a pull request template, I made issue templates, "Click here to see current issues," so people aren't submitting the same things multiple times.
**21:31** - *Shannon Crabill*
Making it as easy as possible, or as user friendly as possible, I think is a big step you can do as a maintainer.
**21:38** - *Saron Yitbarek*
Absolutely. READMEs, I see them all the time, I hear about how important they are; I feel like it's also there's so much you can do in a README. At the end of the day, it's kind of a blank document that tells people to read it. What do you do in that document? How do you structure it to make it really connect with people who are looking to contribute?
**22:00** - *Shannon Crabill*
I think in my README I had a lot gifs in there.
**22:03** - *Saron Yitbarek*
Nice.
**22:05** - *Shannon Crabill*
I had gifs, I think I had links to–
**22:07** - *Saron Yitbarek*
What I was starting to hear was that Shannon had quickly learned how important the relationships are. She knew straight away that the work was going to shine if people were invested, and even having a good time.
**22:20** - *Shannon Crabill*
There's people doing great things with open source projects, I also think it can be fun and a fun project to say, "Hey, I made these cool bats that randomly generate on this page every time you click."
**22:33** - *Saron Yitbarek*
I also love that there's so many different types of things that people can do. If you're really into the artistic cool stuff, you can do the bat generation feature. If you want to clean up, you can do that, too. If you're like, "I'm going to stick to the documentation, I'm going to spend my time to make this room, this place, a little bit cleaner for all my other contributors," then there's the option to do that, too.
**22:56** - *Shannon Crabill*
Yeah. I tried to make it clear that whatever you want to contribute is fine with me. If you catch a spelling error and you want to fix that, great. If you notice a link is broken and you want to fix that, great. If you just want to help comment this code so it's easier to read and understand, that would be really helpful.
**23:12** - *Saron Yitbarek*
I think it's really awesome that you had such a positive experience with the community, because I've heard lots of stories where that really wasn't the case. People weren't very nice online, and weren't very welcoming and kind, especially to newbies who we tend to ask some more simpler questions than are expected.
**23:33** - *Saron Yitbarek*
What do you think helped make your community a nicer place compared to what some other communities are like?
**23:41** - *Shannon Crabill*
Just the fact that it was a very casual thing. If you want to contribute, you can, cool. If you don't, that's also cool. I definitely had the thought that open source was this big scary thing, you need to have all this experience and know all these complicated languages, or back–end and front–end and everything in between to be able to contribute to.
**24:03** - *Saron Yitbarek*
Absolutely. How has doing Hacktoberfest, how's that changed your idea of open source now?
**24:11** - *Shannon Crabill*
It's definitely changed it for the better. Like I said, I had a great experience and I hope everyone that was involved with my project in some way or another had a good experience, too. It's definitely given me the push to want to try things like that more often, even if they don't go anywhere. It seems more obtainable now.
**24:32** - *Saron Yitbarek*
Music to my ears.
**24:34** - *Saron Yitbarek*
Here's something; thousands of people from hundreds of companies, and some from no company at all, contribute to the Linux kernel. That means Linux, which basically runs the internet, is maintained by a whole army of everyday heroes. If you're feeling eager to make your first contribution to open source, maybe you want to learn more about the Fedora community, we've got a ton of materials waiting to help you out. Check out redhat.com/commandlineheroes for more.
**25:20** - *Saron Yitbarek*
Quick reminder, this season we're building our very own open source Command Line Heroes game. You are invited to contribute in whatever makes sense for you. Get the deets on how to be a part of it; we would love for you to build this game with us over at redhat.com/commandlineheroes.
**25:42** - *Saron Yitbarek*
Next episode, we're all about the ruthless Darwinian process of errors and the beauty of failure in open source development—how it haunts us, guides us, and makes us better.
**25:57** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Listen for free on Apple Podcast, Google Podcast, or wherever you do your thing. I'm Saron Yitbarek, until next time, keep on coding.
### Keep going
### The evolution of open source contributors: from hobbyists to professionals
Open source contributors aren't easy to recognize—and that's a good thing.
### How to create a pull request: contributing to open source
Working directly on the command line isn't for everyone. But you can still code and contribute.
### What was your first open source pull request or contribution?
People's first contributions aren't always glamorous. Don't let overblown expectations stop you.
### Command Line Heroes: The Game
This week: Committed to open source game development. Get the nitty gritty scoop on how to develop open source games.
### Featured in this episode
### Also in this episode
### Red Hat legal and privacy links
[About Red Hat](/en/about/company)[Jobs](/en/jobs)[Events](/en/events)[Locations](/en/about/office-locations)[Contact Red Hat](/en/contact)[Red Hat Blog](/en/blog)[Diversity, equity, and inclusion](/en/about/our-culture/diversity-equity-inclusion)[Cool Stuff Store](https://coolstuff.redhat.com/)[Red Hat Summit](https://www.redhat.com/en/summit) |
12,605 | Rclone Browser 让你在 Linux 中以图形化的方式与云服务同步数据 | https://itsfoss.com/rclone-browser/ | 2020-09-11T22:22:00 | [
"同步"
] | https://linux.cn/article-12605-1.html |
>
> Rclone Browser 是一款高效的 GUI 程序,它可以让你轻松地使用 Rclone 管理和同步云存储上的数据。在这里,我们来看看它提供的功能和工作方式。
>
>
>
如果你想原生地在 Linux 上毫不费力地使用 One Drive 或 [Google Drive](https://itsfoss.com/use-google-drive-linux/),你可以选择像 [Insync](https://itsfoss.com/recommends/insync/) 这样的高级 GUI 工具。
如果你能在终端上下功夫,你可以使用 [rclone](https://rclone.org/) 与许多 [Linux 上的云存储服务](https://itsfoss.com/cloud-services-linux/)进行同步。我们有一份详细的[在 Linux 中使用 Rclone 与 OneDrive 同步的指南](https://itsfoss.com/use-onedrive-linux-rclone/)。
[rclone](https://rclone.org/) 是一个相当流行且有用的命令行工具。rclone 提供的功能是很多有经验的用户需要的。
然而,即使它足够有用,也不是每个人都能从终端使用它。
因此,在本文中,我将介绍一个令人印象深刻的 GUI “Rclone Browser”,它可以让你轻松地使用 Rclone 管理和同步云存储上的数据。
值得注意的是,rclone 确实提供了一个实验性的基于 Web 的 GUI。但我们将在这里专注于 [Rclone Browser](https://github.com/kapitainsky/RcloneBrowser)。

### Rclone Browser:Rclone 的开源 GUI
Rclone Browser 是一款可以让你浏览、修改、上传/下载、列出文件,并在想充分利用远程存储位置的情况下,做更多你想做的事情的 GUI。
它提供了一个简单的用户界面,并且工作良好(根据我的快速测试)。让我们详细看看它提供的功能以及如何开始使用它。
### Rclone Browser 的功能

它提供了很多选项和控制来管理远程存储位置。根据你的使用情况,你可能会发现它的功能丰富或不知所措。以下是它的功能:
* 浏览和修改 rclone 远程存储位置
* 支持加密云存储
* 支持自定义位置和配置加密
* 不需要额外的配置。它将使用相同的 rclone 配置文件(如果你有的话)
* 在不同的标签页中同时导航多个位置
* 按层次列出文件(按文件名、大小和修改日期)
* rclone 命令的执行是异步的,不会使 GUI 冻结
* 你可以上传、下载、创建新文件夹、重命名、删除文件和文件夹
* 上传文件时支持拖放
* 在 VLC 等播放器中播放流媒体文件
* 挂载和卸载文件夹/云端驱动器
* 能够计算文件夹的大小、导出文件列表,并将 rclone 命令复制到剪贴板
* 支持便携模式
* 支持共享驱动器(如果你使用 Google Drive)。
* 针对支持共享链接的远程存储服务,支持获取共享链接
* 能够创建任务,你可以很容易地保存,以便以后再次运行或编辑。
* 黑暗模式
* 跨平台支持(Windows、macOS 和 Linux)。
### 在 Linux 上安装 Rclone Browser
在使用 Rclone Browser 之前,你需要在你的 Linux 发行版上安装 rclone。请按照[官方安装说明](https://rclone.org/install/)来安装。
你可以在 [GitHub 页面](https://github.com/kapitainsky/RcloneBrowser)的[发布页](https://github.com/kapitainsky/RcloneBrowser/releases/tag/1.8.0)找到 Rclone Browser 的 AppImage 文件。所以,你在任何 Linux 发行版上运行它都不会有问题。
如果你不知道 AppImage,我会推荐你阅读我们的[在 Linux 上使用 AppImage](https://itsfoss.com/use-appimage-linux/) 指南。
你也可以选择构建它。操作说明在 GitHub 页面上。
* [下载 Rclone Browser](https://github.com/kapitainsky/RcloneBrowser)
### 开始使用 Rclone Browser
在这里,我只分享一下使用 Rclone Browser 应该知道的几件事。

如果你在终端中使用 rclone 时有任何现有的远程位置,它将自动显示在 GUI 中。你也可以点击 “Refresh” 按钮来获取最新的新增内容。
如上图所示,当你点击 “Config” 按钮时,它会启动终端,让你轻松地添加一个新的远程或按你的要求配置它。当终端弹出的时候不用担心,Rclone browser 会执行命令来完成所有必要的任务,你只需要在需要的时候设置或编辑一些东西。你不需要执行任何 rclone 命令。
如果你有一些现有的远程位置,你可以使用 “Open” 按钮打开它们,并在不同的标签页中访问云存储,如下所示。

你可以轻松地挂载云驱动器,上传/下载文件,获取详细信息,共享文件夹的公共链接(如果支持),以及直接播放流媒体文件。
如果你想复制、移动或与远程存储位置同步数据,你可以简单地创建一个任务来完成。只需确保设置正确,你可以模拟执行或者直接运行任务。
你可以在 “Jobs” 页面找到所有正在运行的任务,如果需要,你可以取消/停止它们。

除了上面提到的所有基本功能外,你可以前往 “File->Preferences” 更改 rclone 位置、挂载选项、下载文件夹、带宽设置以及代理。

要了解更多关于它的用法和功能,你可能需要前往 [GitHub 页面](https://github.com/kapitainsky/RcloneBrowser)了解所有的技术信息。
### 总结
Rclone Browser 对于每一位想要使用 rclone 强大功能的 Linux 用户来说,绝对是得心应手。
你是否已经尝试过了呢?你更喜欢通过 GUI 还是终端来使用 rclone?请在下面的评论中告诉我你的想法!
---
via: <https://itsfoss.com/rclone-browser/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you want to use One Drive or [Google Drive on Linux](https://itsfoss.com/use-google-drive-linux/) natively and effortlessly, you can opt for a popular and useful command-line tool. Many power users will need it.
If you can put some effort into the terminal, you can use [Rclone](https://rclone.org/?ref=itsfoss.com) to sync with many [cloud storage services on Linux](https://itsfoss.com/cloud-services-linux/). We have a detailed [guide on using Rclone for syncing with OneDrive in Linux](https://itsfoss.com/use-onedrive-linux-rclone/).
[Rclone](https://rclone.org/?ref=itsfoss.com) is a popular and useful command-line tool. Many power users will need it for its features.
However, not everyone is comfortable using it from the terminal, even if it’s useful enough.
So, in this article, I’ll talk about an impressive GUI, “Rclone Browser” that makes it easy to manage and sync your data on cloud storage using Rclone.
It is also worth noting that Rclone does offer an experimental web-based GUI — but we are going to focus on [Rclone Browser](https://github.com/kapitainsky/RcloneBrowser?ref=itsfoss.com) here.
## Rclone Browser: An open-source GUI for Rclone
Rclone Browser is a GUI that lets you browse, modify, upload/download, list files, and do a lot more when you want to make the most of managing a remote storage location.
It offers a simple user interface and works just fine (as per my quick test). Let’s take a detailed look at its features and how to get started using it.
## Features of Rclone Browser
It offers a lot of options and controls to manage remote storage locations. You may find it feature-rich or overwhelming, depending on your use-case. Here they are:
- Browse and modify rclone remote storage locations
- Encrypted cloud storage supported
- Custom location and encryption for configuration supported
- No extra configuration required. It will use the same rclone configuration files (if you have any).
- Simultaneous navigation of multiple locations in separate tabs
- List files hierarchically (by file name, size, and modified date)
- Rclone commands are executed asynchronously without the GUI freezing
- You get the ability to upload, download, create new folders, rename, delete files and folders
- Drag and drop support for dragging files while uploading
- Streaming media files in player like VLC
- Mount and unmount folders/cloud drives
- Ability to calculate size of folder, export list of files, and copy rclone commands to clipboard
- Supports portable mode
- Supports shared drivers (if you’re using Google Drive)
- Gives you the ability to have public link sharing option for remote storage services that offers it
- Ability to create tasks that you can easily save to run it again or edit it later
- Dark mode
- Cross-platform support (Windows, macOS, and Linux)
## Installing Rclone Browser on Linux
*Y*ou need to have rclone installed on your Linux distribution before you use Rclone Browser.
Rclone Browser is available in the default repositories of many Linux distributions. You can install it in Ubuntu using the command:
`sudo apt install rclone-browser`
This installs may install an older version of Rclone Browser. Similarly, Debian, Fedora, etc. also ship this tool in their repositories. Arch Linux users can install it from AUR.
Follow the [official installation instructions](https://rclone.org/install/?ref=itsfoss.com) to do that.
In addition to these, you will find an AppImage file available for Rclone Browser from the [releases section](https://github.com/kapitainsky/RcloneBrowser/releases/tag/1.8.0?ref=itsfoss.com) of its [GitHub page](https://github.com/kapitainsky/RcloneBrowser?ref=itsfoss.com). So, you shouldn’t have an issue running it on any Linux distribution.
If you didn’t know about AppImage, I recommend reading our guide to using [AppImage on Linux](https://itsfoss.com/use-appimage-linux/).
[How to Use AppImage in Linux [Complete Guide]What is AppImage? How to run it? How does it work? Here’s the complete guide about using AppImage in Linux.](https://itsfoss.com/use-appimage-linux/)

You can also choose to build it as well. The instructions to do that is in the GitHub page.
## Getting started with Rclone Browser
Here, I’ll just share a few things that you should know to get started using Rclone Browser.
If you have any existing remote locations using rclone in the terminal, it will automatically show up in the GUI. You can also hit the “**Refresh**” button to get the latest additions.
Now, let’s see how you can add a new drive. Here, we will show an example using a pCloud drive. First, click on the “**Config**” button on the bottom-left. This will launch a terminal, that lets you easily add a new remote or configure it as you want.
Don’t worry, when the terminal pops up, Rclone browser executes the commands to do all the necessary tasks. You just have to set up or edit only a few things when needed. You don’t need to execute any Rclone commands.
**” button and have the cloud storage accessible in a different tab.**
**Open**The text-based commands are straightforward to follow. First, click on **n** to create a new remote. Next, it will ask to name the Drive. Name it *pCloud Drive.*
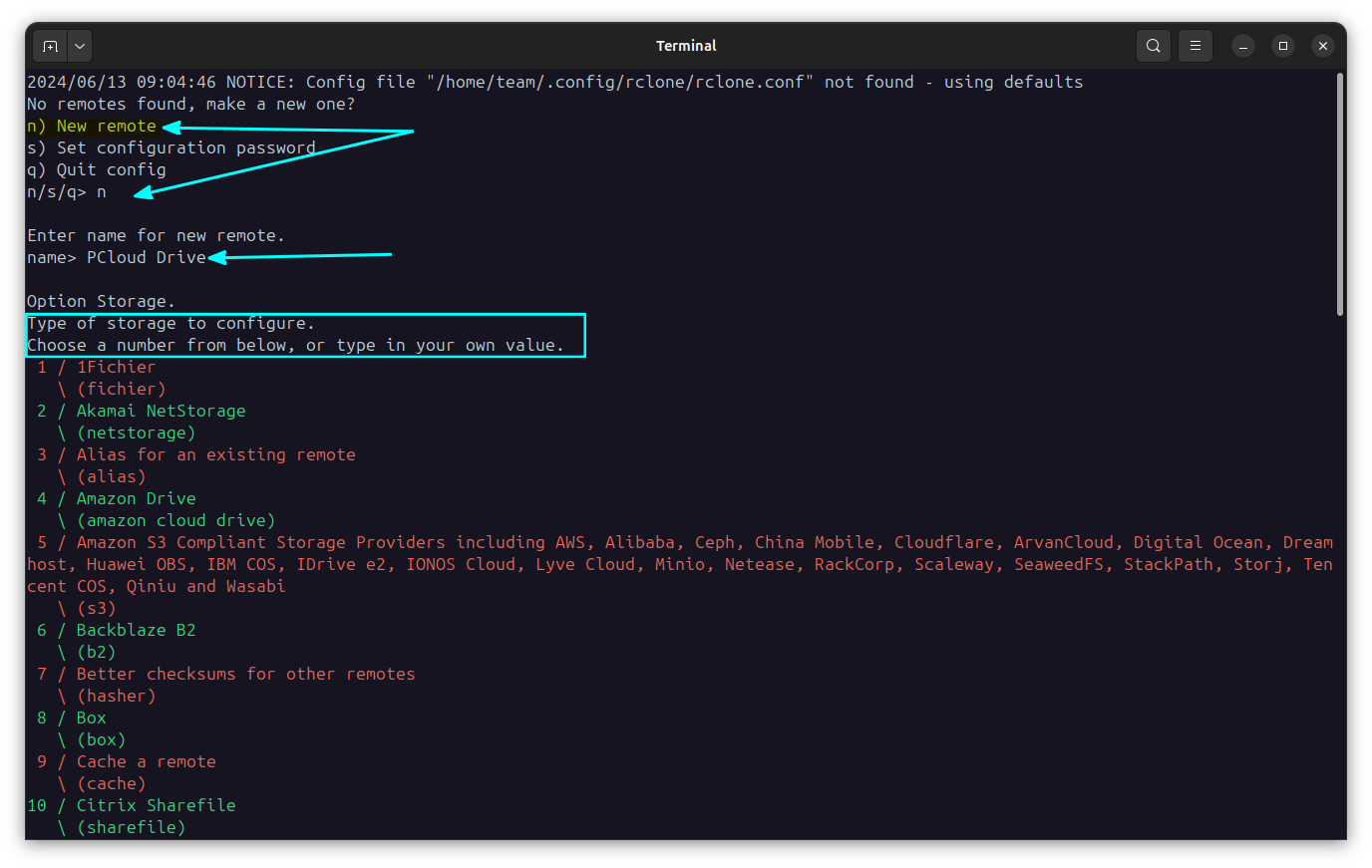
This will take you to the storage selection prompt. You will be given a long list of storage platforms that are supported along with a number. Scroll and find your required service and type the number corresponding to it.
For pCloud, it is 33. The next step varies according to the remote you want to create. In this case, we accepted the default values for the entries.
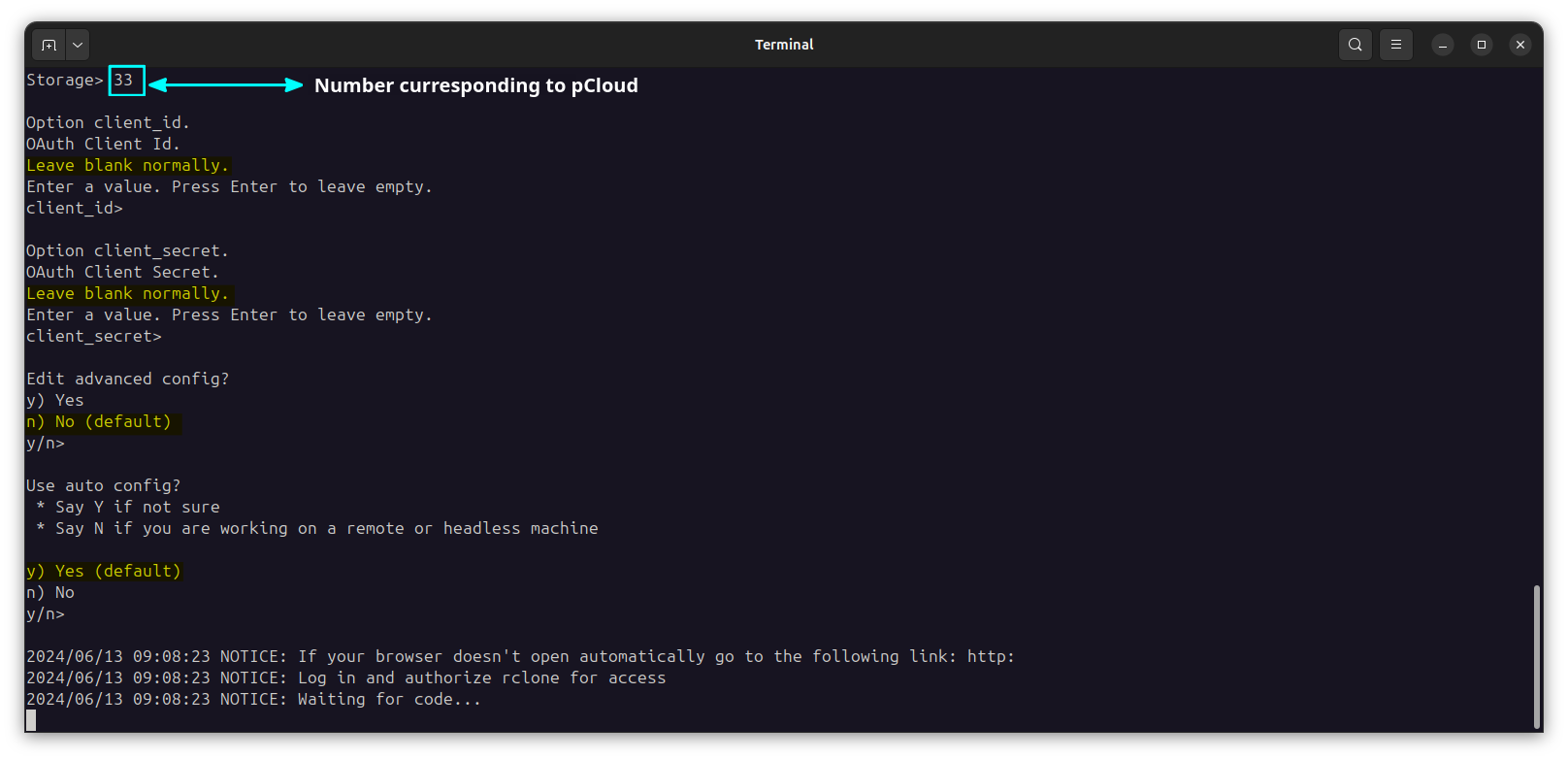
At some point, it will ask you to authenticate through the web browser. Most of the time, a browser tab will be opened on your default browser. Just click **Allow** to approve Rclone access pCloud drive.
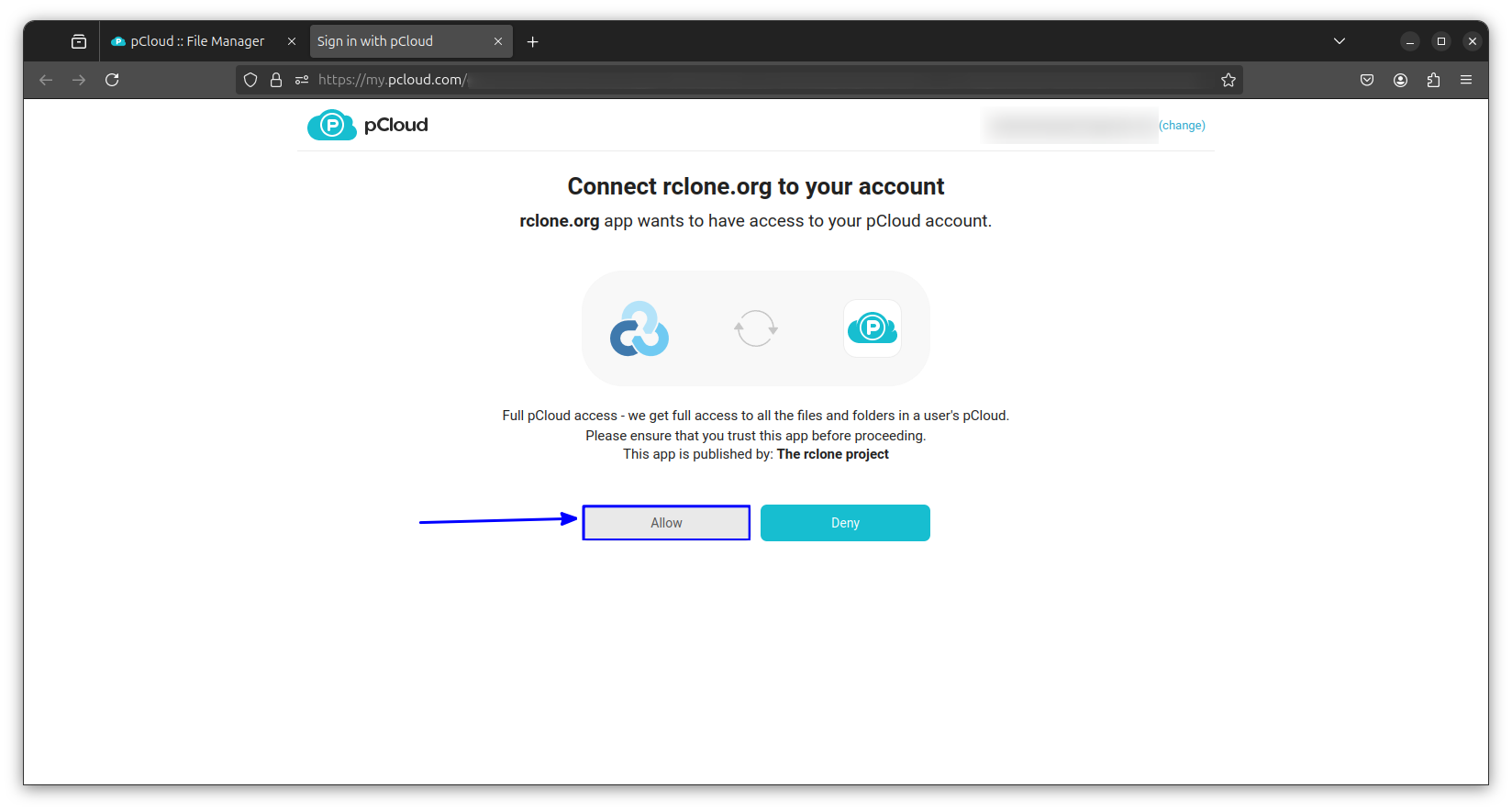
This will give you a success message. You can close the browser and return to Rclone browser.
Most probably, you can quit the configuration by pressing the **q** key.
To open pCloud in Rclone browser, select pCloud and click on the **open** button in the bottom-right corner.
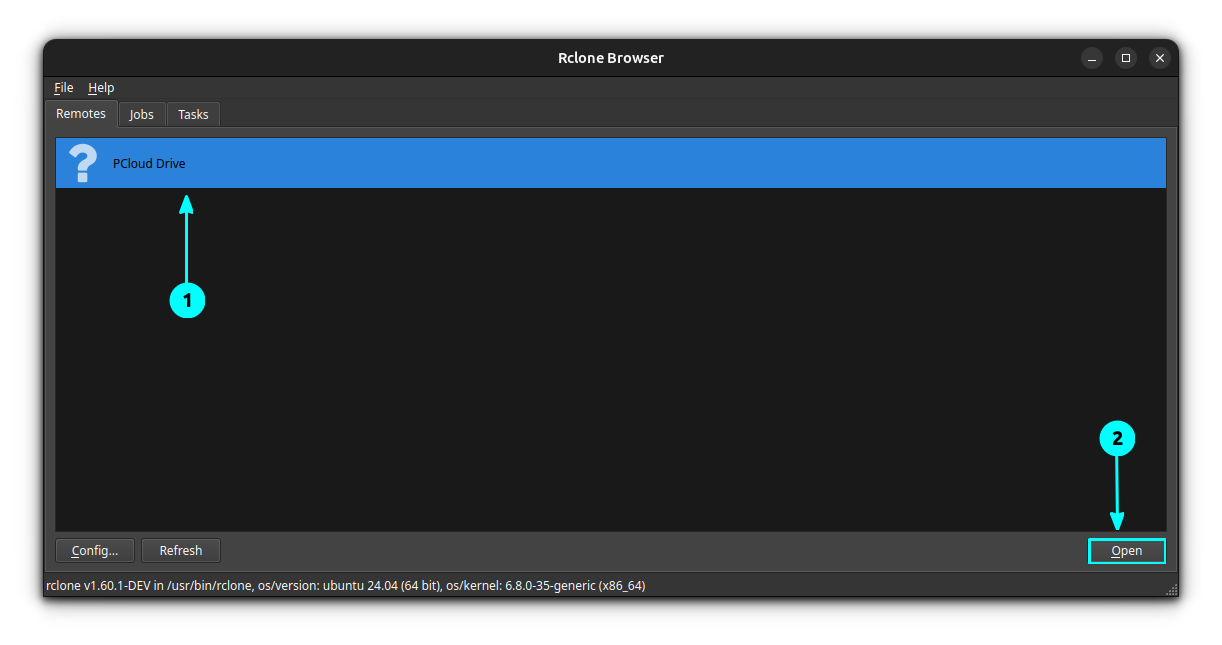
This will open the drive, and you can perform a variety of actions here.
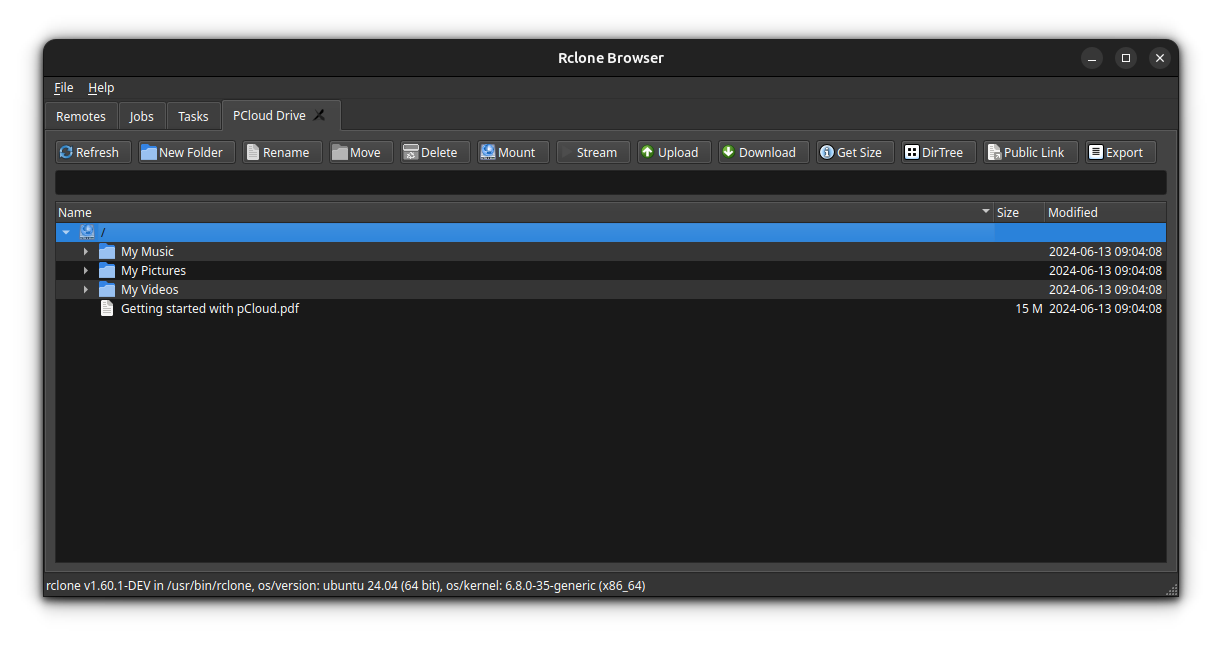
You can easily mount the cloud drive, upload/download files, get the details, share a public link for a folder (if supported), and directly stream media files as well.
If you want to copy, move, or sync data with a remote storage location, you can simply create a task to do it. Buttons like *Upload, Download, etc.,* provide an option to add as a task.
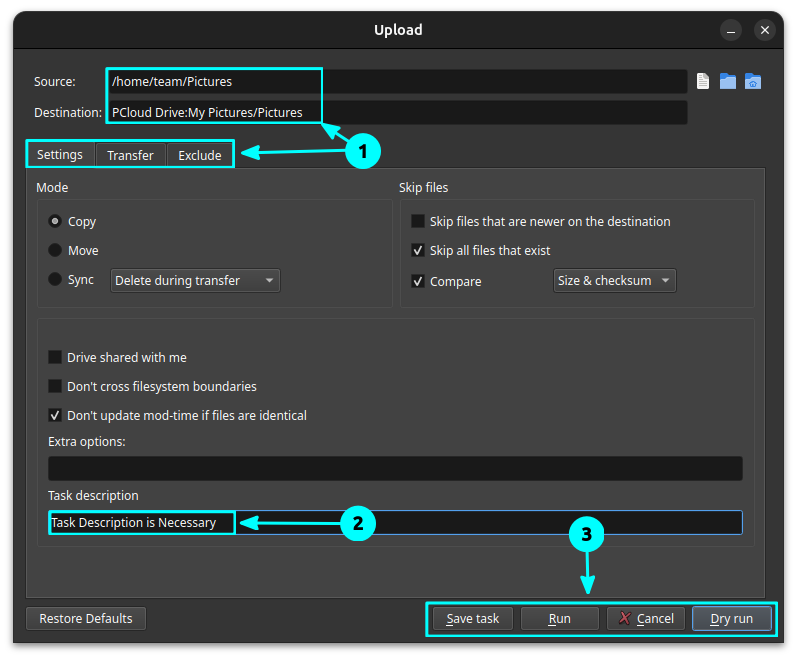
Just to make sure that you have the right settings, you can perform a dry run or go ahead with running the task. Or save the task to run frequently in the future.
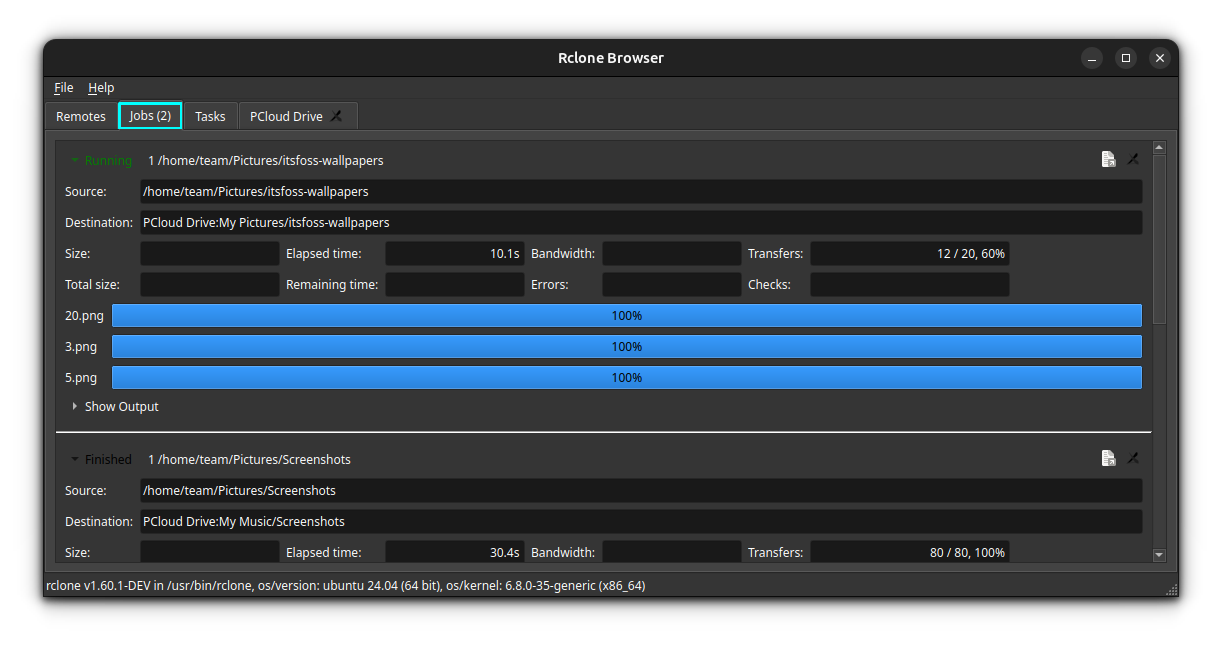
As you can see in the above screenshot, all the running tasks can be found under the “**Jobs**” section, and you can cancel/stop them if needed.
Similarly, all the tasks that you have created are visible in the **Tasks** section.
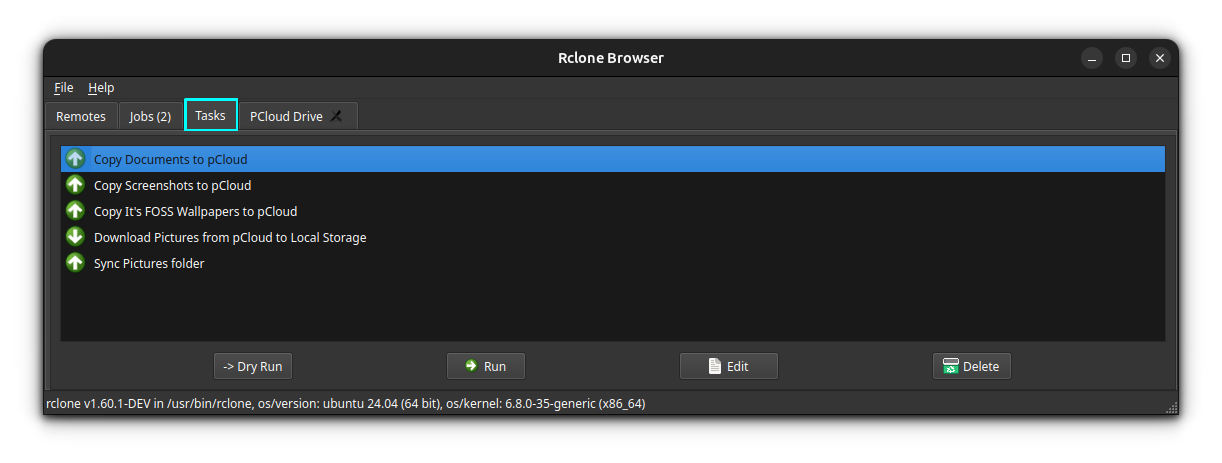
In addition to all the basic functionalities mentioned above, you can just head to File → Preferences to change the rclone location, mount option, download folder, bandwidth settings, and proxy as well.
To learn more about its usage and features, you might want to check out the [GitHub page](https://github.com/kapitainsky/RcloneBrowser?ref=itsfoss.com) for all the technical information.
## Wrapping Up
If you are searching for a [cloud service that provides free storage](https://itsfoss.com/cloud-services-linux/), check these out.
[Top 10 Best Free Cloud Storage Services for LinuxWhich cloud service is the best for Linux? Check out this list of free cloud storage services that you can use in Linux.](https://itsfoss.com/cloud-services-linux/)

Rclone Browser should definitely come in handy for every Linux user looking to use Rclone for its powerful features.
Have you tried it yet? Do you prefer using the GUI or the terminal for using rclone? Let me know your thoughts in the comments below! |
12,606 | 使用 Jupyter Notebooks 构建一个远程管理控制台 | https://opensource.com/article/20/9/remote-management-jupyter | 2020-09-12T11:52:18 | [
"Jupyter"
] | https://linux.cn/article-12606-1.html |
>
> 把 Jupyter 变成一个远程管理控制台。
>
>
>

SSH 是一个强大的远程管理工具,但有些细节还不够好。编写一个成熟的远程管理控制台听起来好像是一件很费劲的事情。当然,开源社区中肯定有人已经写了一些东西吧?
是的,他们已经写出来了,它的名字是 [Jupyter](https://jupyter.org/)。你可能会认为 Jupyter 是那些数据科学家用来分析一周内的广告点击趋势之类的工具。这并没有错,它确实是的,而且它是一个很好的工具。但这仅仅刻画是它的表面。
### 关于 SSH 端口转发
有时,你可以通过 22 端口进入一台服务器。一般你也连接不到其他端口。也许你是通过另一个有更多访问权限的“堡垒机”,或者限制主机或端口的网络防火墙访问 SSH。当然,限制访问的 IP 范围是有充分理由的。SSH 是远程管理的安全协议,但允许任何人连接到任何端口是相当不必要的。
这里有一个替代方案:运行一个简单的 SSH 端口转发命令,将本地端口转发到一个“远程”本地连接上。当你运行像 `-L 8111:127.0.0.1:8888` 这样的 SSH 端口转发命令时,你是在告诉 SSH 将你的*本地*端口 `8111` 转发到它认为的“远程”主机 `127.0.0.1:8888`。远程主机认为 `127.0.0.1` 就是它本身。
就像在《芝麻街》节目一样,“这里”是一个微妙的词。
地址 `127.0.0.1` 就是你告诉网络的“这里”。
### 实际动手学习
这可能听起来很混乱,但运行比解释它更简单。
```
$ ssh -L 8111:127.0.0.1:8888 [email protected]
Linux 6ad096502e48 5.4.0-40-generic #44-Ubuntu SMP Tue Jun 23 00:01:04 UTC 2020 x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Wed Aug 5 22:03:25 2020 from 172.17.0.1
$ jupyter/bin/jupyter lab --ip=127.0.0.1
[I 22:04:29.771 LabApp] JupyterLab application directory is /home/moshez/jupyter/share/jupyter/lab
[I 22:04:29.773 LabApp] Serving notebooks from local directory: /home/moshez
[I 22:04:29.773 LabApp] Jupyter Notebook 6.1.1 is running at:
[I 22:04:29.773 LabApp] http://127.0.0.1:8888/?token=df91012a36dd26a10b4724d618b2e78cb99013b36bb6a0d1
<删节>
```
端口转发 `8111` 到 `127.0.0.1`,并在远程主机上启动 Jupyter,它在 `127.0.0.1:8888` 上监听。
现在你要明白,Jupyter 在撒谎。它认为你需要连接到 `8888` 端口,但你把它转发到 `8111` 端口。所以,当你把 URL 复制到浏览器后,但在点击回车之前,把端口从 `8888` 修改为 `8111`。

这就是你的远程管理控制台。如你所见,底部有一个“终端”图标。点击它可以启动一个终端。

你可以运行一条命令。创建一个文件会在旁边的文件浏览器中显示出来。你可以点击该文件,在本地的编辑器中打开它。

你还可以下载、重命名或删除文件:

点击**上箭头**就可以上传文件了。那就上传上面的截图吧。

最后说个小功能,Jupyter 可以让你直接通过双击远程图像查看。
哦,对了,如果你想用 Python 做系统自动化,还可以用 Jupyter 打开笔记本。
所以,下次你需要远程管理防火墙环境的时候,为什么不使用 Jupyter 呢?
---
via: <https://opensource.com/article/20/9/remote-management-jupyter>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Secure shell (SSH) is a powerful tool for remote administration, but it lacks some niceties. Writing a full-fledged remote administration console sounds like it would be a lot of work. Surely, someone in the open source community has already written something?
They have, and its name is [Jupyter](https://jupyter.org/). You might think Jupyter is one of those tools data scientists use to analyze trends in ad clicks over a week or something. This is not wrong—they do, and it is a great tool for that. But that is just scratching its surface.
## About SSH port forwarding
Sometimes, there is a server that you can SSH into over port 22. There is no reason to assume you can connect to any other port. Maybe you are SSHing through another "jumpbox" server that has more access or there are host or network firewalls that restrict ports. There are good reasons to restrict IP ranges for access, of course. SSH is a secure protocol for remote management, but allowing anyone to connect to any port is quite unnecessary.
Here is an alternative: Run a simple SSH command with port forwarding to forward a local port to a *remote* *local* connection. When you run an SSH port-forwarding command like `-L 8111:127.0.0.1:8888`
, you are telling SSH to forward your *local* port `8111`
to what the *remote* host thinks `127.0.0.1:8888`
is. The remote host thinks `127.0.0.1`
is itself.
Just like on *Sesame Street*, "here" is a subtle word.
The address `127.0.0.1`
is how you spell "here" to the network.
## Learn by doing
This might sound confusing, but running this is less complicated than explaining it:
```
$ ssh -L 8111:127.0.0.1:8888 [email protected]
Linux 6ad096502e48 5.4.0-40-generic #44-Ubuntu SMP Tue Jun 23 00:01:04 UTC 2020 x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Wed Aug 5 22:03:25 2020 from 172.17.0.1
$ jupyter/bin/jupyter lab --ip=127.0.0.1
[I 22:04:29.771 LabApp] JupyterLab application directory is /home/moshez/jupyter/share/jupyter/lab
[I 22:04:29.773 LabApp] Serving notebooks from local directory: /home/moshez
[I 22:04:29.773 LabApp] Jupyter Notebook 6.1.1 is running at:
[I 22:04:29.773 LabApp] http://127.0.0.1:8888/?token=df91012a36dd26a10b4724d618b2e78cb99013b36bb6a0d1
<MORE STUFF SNIPPED>
```
Port-forward `8111`
to `127.0.0.1`
and start Jupyter on the remote host that's listening on `127.0.0.1:8888`
.
Now you need to understand that Jupyter is lying. It thinks you need to connect to port `8888`
, but you forwarded that to port `8111`
. So, after you copy the URL to your browser, but before clicking Enter, modify the port from `8888`
to `8111`
:
(Moshe Zadka, CC BY-SA 4.0)
There it is: your remote management console. As you can see, there is a "Terminal" icon at the bottom. Click it to get a terminal:
(Moshe Zadka, CC BY-SA 4.0)
You can run a command. Creating a file will show it in the file browser on the side. You can click on that file to open it in an editor that is running locally:
(Moshe Zadka, CC BY-SA 4.0)
You can also download, rename, or delete files:
(Moshe Zadka, CC BY-SA 4.0)
Clicking on the little **Up arrow** will let you upload files. Why not upload the screenshot above?
(Moshe Zadka, CC BY-SA 4.0)
As a nice final tidbit, Jupyter lets you view the remote images directly by double-clicking on them.
Oh, right, and if you want to do systems automation using Python, you can also use Jupyter to open a notebook.
So the next time you need to remotely manage a firewalled environment, why not use Jupyter?
## 4 Comments |
12,608 | 在 Windows 和 WSL 2 中访问 Linux 文件系统 | https://devblogs.microsoft.com/commandline/access-linux-filesystems-in-windows-and-wsl-2/ | 2020-09-12T19:44:00 | [
"WSL"
] | https://linux.cn/article-12608-1.html | 
从 [Windows Insiders 预览版 20211](https://blogs.windows.com/windows-insider/2020/09/10/announcing-windows-10-insider-preview-build-20211/) 开始,WSL 2 将提供一个新功能:`wsl --mount`。这个新的参数允许在 WSL 2 中连接和挂载一个物理磁盘,这样你就可以访问 Windows 不支持的文件系统(比如 ext4)。
因此,如果你使用不同的磁盘对 Windows 和 Linux 进行双启动,你现在可以从 Windows 访问你的 Linux 文件了。
### 开始使用
要挂载磁盘,请打开具有管理员权限的 PowerShell 窗口并运行。
```
wsl --mount <DiskPath>
```
要在 Windows 中列出可用的磁盘,请运行。
```
wmic diskdrive list brief
```
要从 WSL 2 上卸载和分离磁盘,请运行以下命令
```
wsl --unmount <Diskpath>
```
磁盘路径可在 `DeviceID` 栏中找到。通常是以 `\\.\\.\PHYSICALDRIVE*` 的格式。下面是一个将指定硬盘的特定分区挂载到 WSL 中并浏览其文件的例子:

### 使用文件资源管理器访问这些文件
一旦挂载,也可以通过 Windows 资源管理器访问这些磁盘,通过导航到 `\wsl$`,然后到挂载文件夹。

### 局限性
默认情况下,`wsl --mount` 会尝试将磁盘挂载为 ext4。要指定一个文件系统,或者更高级的方案,请查看[在 WSL 2 中挂载磁盘](https://docs.microsoft.com/windows/wsl/wsl2-mount-disk)。
另外请注意,这个功能有一个限制,那就是只有物理磁盘可以连接到 WSL 2。目前,还不能附加单个分区。更多关于限制的细节请看[这里](https://docs.microsoft.com/windows/wsl/wsl2-mount-disk#limitations)。
### 反馈
如果你遇到任何问题或反馈,请在 [GitHub](https://github.com/microsoft/wsl/issues) 上提交议题。
| 200 | OK | Starting with [Windows Insiders preview build 20211](https://blogs.windows.com/windows-insider/2020/09/10/announcing-windows-10-insider-preview-build-20211/), WSL 2 will be offering a new feature: `wsl --mount`
. This new parameter allows a physical disk to be attached and mounted inside WSL 2, which enables you to access filesystems that aren’t natively supported by Windows (such as ext4).
So, if you’re dual booting with Windows & Linux using different disks, you can now access your Linux files from Windows!
## Getting started
To mount a disk, open a PowerShell window with administrator privileges and run:
```
wsl --mount <DiskPath>
```
To list the available disks in Windows, run:
```
wmic diskdrive list brief
```
To unmount and detach the disk from WSL 2, run
```
wsl --unmount <Diskpath>
```
The disks paths are available under the ‘DeviceID’ columns. Usually under the `\\.\\\.\PHYSICALDRIVE*`
format. Below is an example of mounting a specific partition of a given hard disk into WSL and browsing its files.
## Accessing these files with File Explorer
Once mounted, it’s also possible to access these disks through the Windows explorer by navigating to \wsl$ and then to the mount folder.
## Limitations
By default, `wsl --mount`
attempts to mount the disk as ext4. To specify a filesystem, or for more advanced scenarios, check out [Mount a disk in WSL 2](https://docs.microsoft.com/windows/wsl/wsl2-mount-disk).
Also please note that this feature comes with the limitation that only physical disks can be attached to WSL 2. At this time, it’s not possible to attach a single partition. More details on the limitations [here](https://docs.microsoft.com/windows/wsl/wsl2-mount-disk#limitations).
## Give us your feedback!
If you run into any issues, or have feedback for our team please file an issue on our [Github](https://github.com/microsoft/wsl/issues) , and if you have general questions about WSL you can find all of our team members that are on Twitter on [this twitter list](https://twitter.com/i/lists/1131397802204864512/members).
“At this time, it’s not possible to attach a single partition.” is confusing me.
But the sample you demonstrates does mount a single partition to wsl.
So may I know what’s real limitation of that?
What is meant by that statement is that it’s not possible to have one partition attached to WSL 2 while the disk is in use in Windows.
Concretely, this means that the entire disk must be attached to WSL 2, regardless of which partitions are mounted in there.
When is this coming to stable release of Windows 10? I need this, but don’t want to go to Dev Preview on my main dev machine.
How disappointing, this Insider build was pulled from service, as they found a bug (see note in the announcement.) Any other way to get this feature without having access to the build, by chance? I was really looking forward to accessing my Linux drives.
The latest insider build has the
`wsl --mount`
feature so you should be able to access it.Thanks for that.
Okay, I've switched to the dev branch and am downloading 20231 as I write this.
This is the only features I need and although I chose not to wait, as I have many ext4 drives, I'd really like to be back on stable again. That said, can I leave Insiders at some point and be back to stable, say, if stable catches up and reaches 20231 will I be moved back again? ...
Jumping in to help with this question:
Yes you can leave Insiders at any point and be back to stable! The only stipulation here is that you can't go backwards to an older Windows release. So for your use case it'd probably make sense to start in the Dev Channel (which gives new builds each week) to get access to wsl --mount, and then in the future you can change your settings to the beta channel...
That's great, thanks Craig!
I'm testing the feature out as we speak...
Okay, I ran into an issues and will detail why and how I fixed it:
The code above is missing any reference to the --partition flag, although I now see it's in the image. I'm leaving this here for others, should they run into the same issue and or until the code above has been clarified.
I get an error and am told:
<code>Which I narrow down...
When will this be available for windows 10 stable? Thanks.
Is it supported WSL1 ?
No. wsl –mount is only supported by WSL 2.
Hello Pierre
Is this functionality only limited to storage devices, or would it enable me to make use of peripheral devices which connect through the same USB receptacles?
An example would be if I could use a wired joystick-controller that makes use of the USB type-A interface, the same way I use USB type-A for my flash drive.
This feature is only limited to storage devices. Unfortunately it can’t be used to pass-through a USB device to WSL 2.
Can WSL2 mount other filesystem like JFS with this function?
The kernel that we officially ship doesn’t support JFS at this time, but if you build your own, you should be able to mount a JFS volume.
Does this make it possible to use a physical disk for a WSL root filesystem? It would be truly amazing if one could have a full-fledged dual-boot setup that could
alsodouble as WSL.That’s an interesting idea.
It’s not possible to boot directly on a mounted disk, but you can chroot into it after mounting it.
Would be cool to have a way to chroot to a specific device quickly, like wsl –chroot \.\PHYSICALDRIVE… without need to mount a drive -> mount all the /dev/… /proc/… etc. -> chroot…
That’s an interesting idea.
I’d recommend creating a feature request
Does the limitation of only working with disks mean it’s not possible to mount Linux partitions if they are on the same physical disk (boot disk) as Windows, e.g. on a laptop?
Yes, this scenario isn’t supported at this time.
Exactly what linux file systems will be accessed?
I use xfs and I would like it to be able to access that file system from windows.
All filesystems supported by the kernel you’re running can be mounted from WSL (in your case, xfs is supported by the kernel we ship).
For more complex use cases, you can run
`wsl --mount <Device> --bare`
, and then manually mount the device from inside WSL.In PowerShell “Invalid command line option: –mount”
There are two dashes (-) on this argument.
If that doesn’t help, please create an issue |
12,609 | Linux 黑话解释:什么是 Linux 发行版?为什么它被称为“发行版”? | https://itsfoss.com/what-is-linux-distribution/ | 2020-09-12T22:06:00 | [
"Linux",
"发行版"
] | https://linux.cn/article-12609-1.html |
>
> 在这一章的 Linux 黑话解释中,我们来讨论一些基本的东西。
>
>
>

让我们来讨论一下什么是 Linux 发行版,为什么它被称为<ruby> 发行版 <rt> distribution </rt></ruby>(或简称 distro),以及,它与 Linux 内核有什么不同。你还会了解到为什么有些人坚称 Linux 为 GNU/Linux。
### 什么是 Linux 发行版?
Linux 发行版是一个由 Linux 内核、[GNU 工具](https://www.gnu.org/manual/blurbs.html)、附加软件和软件包管理器组成的操作系统,它也可能包括[显示服务器](/article-12589-1.html)和[桌面环境](https://itsfoss.com/what-is-desktop-environment/),以用作常规的桌面操作系统。
这个术语之所以是 “Linux 发行版”,是因为像 Debian、Ubuntu 这样的机构“发行”了 Linux 内核以及所有必要的软件及实用程序(如网络管理器、软件包管理器、桌面环境等),使其可以作为一个操作系统使用。
你的发行版还负责提供更新来维护其内核和其他实用程序。
所以,“Linux” 是内核,而 “Linux 发行版”是操作系统。这就是为什么它们有时也被称为基于 Linux 的操作系统的原因。
如果不是很理解以上所有的内容,不要担心。下面我将详细解释一下。
### “Linux 只是一个内核,不是一个操作系统。”这是什么意思?
你可能看到到过这句话,这说的没错。内核是一个操作系统的核心,它接近于具体硬件。你使用应用程序和 shell 与它交互。

为了理解这一点,我就用我在《[什么是 Linux 的详细指南](https://itsfoss.com/what-is-linux/)》中曾用过的那个比喻。把操作系统看成车辆,把内核看成引擎。你不能直接驱动引擎。同样,你也不能直接使用内核。

一个 Linux 发行版可以看作是一个汽车制造商(比如丰田或福特)为你提供的现成的汽车,就像 Ubuntu 或 Fedora 发行版的发行商为你提供的一个基于 Linux 的现成操作系统一样。
### 什么是 GNU/Linux?
让我们再来看看这张图片。1991 年的时候,[Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/) 创造的只是其中的最内圈,即 Linux 内核。

要使用 Linux,即使是以最原始的形式,甚至没有 GUI,你也需要一个 shell。最常见的是 Bash shell。
然后,你需要在 shell 中运行一些命令来完成一些工作。你能记起一些基本的 Linux 命令吗?比如 `cat`、`cp`、`mv`、`grep`、`find`、`diff`、`gzip` 等等。
严格来说,这些所谓的“Linux 命令”并不是只属于 Linux。它们中的很多都来源于 UNIX 操作系统。
在 Linux 诞生之前,Richard Stallman 就已经在 1983 年创建了<ruby> 自由软件项目 <rt> free software project </rt></ruby>中的第一个项目:GNU(GNU 是“GNU is Not Unix” 的递归缩写)。[GNU 项目](https://www.gnu.org/gnu/thegnuproject.en.html)实现了许多流行的 Unix 实用程序,如 `cat`、`grep`、`awk`、shell(`bash`),同时还开发了自己的编译器(GCC)和编辑器(Emacs)。
在 80 年代,UNIX 是专有软件,而且超级昂贵。这就是为什么 Linus Torvalds 开发了一个类似 UNIX 的新内核的原因。为了与 Linux 内核进行交互,Linus Torvalds 使用了 GNU 工具,这些工具在其 GPL 开源许可证下是免费的。
有了这些 GNU 工具,它的行为也像 UNIX 一样。这就是为什么 Linux 也被称为类 UNIX 操作系统的原因。
你无法想象没有 shell 和所有这些命令的 Linux。由于 Linux 与 GNU 工具集成得很深,几乎是完全依赖于 GNU 工具,所以纯粹主义者要求 GNU 应该得到应有的认可,这就是为什么他们坚称它为 GNU Linux(写成 GNU/Linux)。
### 总结
那么,该用哪个术语?Linux、GNU/Linux、Linux 发行版,基于 Linux 的操作系统还是类 UNIX 操作系统?这取决于你的上下文。我已经为你提供了足够的细节,让你对这些相关的术语有更好的理解。
我希望你喜欢这个 Linux 黑话解释系列,并能学习到新的东西。欢迎你的反馈和建议。
---
via: <https://itsfoss.com/what-is-linux-distribution/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this chapter of the Linux Jargon Buster, let’s discuss something elementary.
Let’s discuss what is a Linux distribution, why it is called a distribution (or distro) and how is it different from the Linux kernel. You’ll also learn a thing or two about why some people insist of calling Linux as GNU/Linux.
## What is a Linux distribution?
A Linux distribution is an operating system composed of the Linux kernel, [GNU tools](https://www.gnu.org/manual/blurbs.html), additional software and a package manager. It may also include display server and [desktop environment](https://itsfoss.com/what-is-desktop-environment/) to be used as regular desktop operating system.
The term is Linux distribution (or distro in short form) because an entity like [Debian or Ubuntu](https://itsfoss.com/what-is-linux-distribution/) ‘distributes’ the Linux kernel along with all the necessary software and utilities (like network manager, package manager, desktop environments etc) so that it can be used as an operating system.
Your distributions also takes the responsibility of providing updates to maintain the kernel and other utilities.
So, Linux is the kernel whereas the Linux distribution is the operating system. This is the reason why they are also sometime referred as Linux-based operating systems.
Don’t worry if not all the above makes sense right away. I’ll explain it in a bit more detail.
## Linux is just a kernel, not an operating system: What does it mean?
You might have come across that phrase and that’s entirely correct. The kernel is at the core of an operating system and it is close to the actual hardware. You interact with it using the applications and shell.

To understand that, I’ll use the same analogy that I had used in my [detailed guide on what is Linux](https://itsfoss.com/what-is-linux/). Think of operating systems as vehicles and kernel as engine. You cannot drive an engine directly. Similarly, you cannot use kernel directly.
A Linux distribution can be seen as a vehicle manufacturer like Toyota or Ford that provides you ready to use cars just like Ubuntu or Fedora distributions provide you a ready to use operating systems based on Linux.
## What is GNU/Linux?
Take a look at this picture once again. What [Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/) created in 1991 is just the innermost circle, i.e. the Linux kernel.

To use Linux even in the most primitive form (without even a GUI), you need a shell. Most commonly, it is Bash shell.
And then, you need to run some commands in the shell to do some work. Can you recall some basic Linux commands? There is cat, cp, mv, grep find, diff, gzip and more.
Technically, not all of these so called ‘Linux commands’ belong to Linux exclusively. A lot of them originate mainly from the UNIX operating system.
Even before Linux came into existence, Richard Stallman had created the GNU (recursive acronym for GNU is not Unix) project, the first of the free software project, in 1983. The [GNU project](https://www.gnu.org/gnu/thegnuproject.en.html) implemented many of the popular Unix utilities like cat, grep, awk, shell (bash) along with developing their own compilers (GCC) and editors (Emacs).
Back in the 80s UNIX was proprietary and super expensive. This is why Linus Torvalds developed a new kernel that was like UNIX. To interact with the Linux kernel, Torvalds used GNU tools which were available for free under their open source GPL license.
With the GNU tools, it also behaved like UNIX. This is the reason why Linux is also termed as UNIX-like operating system.
You cannot imagine Linux without the shell and all those commands. Since Linux integrates deeply with the GNU tools, almost dependent on it, the purists demand that GNU should get its fair share of recognition and this is why they insist on calling it GNU Linux (written as GNU/Linux).
## Conclusion

So, what is the correct term? Linux, GNU/Linux, Linux distribution, Linux distro, Linux based operating system or UNIX-like operating system? I say it depends on you and the context. I have provided you enough detail so that you have a better understanding of these related terms.
I hope you are liking this **Linux Jargon Buster** series and learning new things. Your feedback and suggestions are welcome. |
12,611 | 美国军方正探索战场保密通信用紫外网络 | https://www.networkworld.com/article/3572372/military-looks-to-ultraviolet-networks-for-secure-battlefield-communication.html | 2020-09-13T22:00:54 | [
"紫外线"
] | https://linux.cn/article-12611-1.html |
>
> 美国军方想以开放空间传输的紫外线为载体,为士兵开发新的更安全的通讯网络。
>
>
>

美国军方研究者之所以探索战场环境下的紫外光通信的应用,是因为这种技术可能实现敌对方无法侦测的通信。
研究者关注的一个方面是衰减效应,即信号强度随传播距离的增加而减弱的自然现象。他们想知道是否存在一个合适的距离范围,在该范围内,信号强度足够弱,以至于敌对方几乎无法侦测,但又足够强,使得友方可以侦测并建立通信。他们说他们观察到了这种情况,但关于他们相关工作的 [研究论文](https://www.osapublishing.org/DirectPDFAccess/4516B0FD-2152-4663-9A9899BF00560B7C_433781/oe-28-16-23640.pdf?da=1&id=433781&seq=0&mobile=no) 并没有讲这个距离范围究竟是多少。
一份军方出版物提到,“紫外通信具有独特的传输特性,不但可以实现非视距连接,而且让敌对方难以侦测。”
这个研究由美军作战能力发展司令部 [军队研究实验室](https://www.arl.army.mil) 主导,其重点是开发一个基础架构,为未来研究提供可量化环境,在该环境下,己方既可以使用紫外通信,也能够避免敌对方的侦测。研究过程中他们还有另外两个发现:
* 最差情况,即敌对方探测器与己方发射器在视线范围内,但友方接收器不在视线范围内,问题不像想象中严重。
* 转换紫外线发射器的发射方向不是降低敌对方探测到通信信号可能性的有效方式。
研究者计划分析下面四种场景,场景中涵盖了己方紫外发射器、友方接收器、敌对方探测器相对位置关系:
* 友方接收器、敌对方探测器都在发射器的视线范围内。
* 友方接收器在发射器视线范围内,但敌对方探测器不在视线范围内(最佳条件)。
* 敌对方探测器在发射器的视线范围内,但友方接收器不在视线范围内(最差条件)。
* 友方接收器、敌对方探测器均不在视线范围内。
假定敌对方试图通过时域上的光子计数来发现相干通信信号,进而判定正在进行通信。
科学家们承认这么一个事实,即越靠近发射器,信号越容易被侦测。所以紫外通信中发射器的有效使用依赖于对敌对方探测器位置的准确感知。
“我们提供了一个基础框架,使得对紫外通信系统实际可探测性与期望性能间差距的根本限制因素的研究得以进行。” 研究者之一,Robert Drost 博士如是说。
“我们的研究确保了团队对紫外波段用于通信的潜力及有限性有了根本上的理解。我坚信这种理解将影响到未来军队网络通信能力的发展。”
---
via: <https://www.networkworld.com/article/3572372/military-looks-to-ultraviolet-networks-for-secure-battlefield-communication.html>
作者:[Patrick Nelson](https://www.networkworld.com/author/Patrick-Nelson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,612 | 利用这个 USB ID 仓库识别更多 Linux 上的设备 | https://opensource.com/article/20/8/usb-id-repository | 2020-09-13T22:55:42 | [
"USB"
] | /article-12612-1.html |
>
> 这是一个包含了所有已知 USB 设备 ID 的开源项目。
>
>
>

市场上有成千上万的 USB 设备:键盘、扫描仪、打印机、鼠标和其他无数的设备,都能在 Linux 上工作。它们的供应商详情都存储在 USB ID 仓库中。
### lsusb
Linux `lsusb` 命令列出了连接到系统的 USB 设备的信息,但有时信息不完整。例如,我最近注意到我的一个 USB 设备的品牌没有被识别。设备是可以使用的,但是在列出我所连接的 USB 设备的详情中没有提供任何识别信息。以下是我的 `lsusb` 命令的输出:
```
$ lsusb
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 004: ID 046d:082c Logitech, Inc.
Bus 001 Device 003: ID 0951:16d2 Kingston Technology
Bus 001 Device 002: ID 18f8:1486
Bus 001 Device 005: ID 051d:0002 American Power Conversion Uninterruptible Power Supply
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
```
正如你在最后一栏中看到的,有一个设备没有制造商描述。要确定这个设备是什么,我必须对我的 USB 设备树进行更深入的检查。幸运的是,`lsusb` 命令有更多的选项。其中一个选项是 `-D device`,来获取每个设备的详细信息,正如手册页面所解释的那样:
>
> “不会扫描 `/dev/bus/usb` 目录,而只显示给定设备文件所属设备的信息。设备文件应该是类似 `/dev/bus/usb/001/001` 这样的文件。这个选项会像 `v` 选项一样显示详细信息,但你必须是 root 用户才行。"
>
>
>
我认为如何将设备路径传递给 `lsusb` 命令并不容易,但在仔细阅读手册页和初始输出后,我能够确定如何构造它。USB 设备驻留在 UDEV 文件系统中。它们的设备路径始于 USB 设备目录 `/dev/bus/usb/`。路径的其余部分由设备的总线 ID 和设备 ID 组成。我的无描述设备是 `Bus 001 Device 002`,被翻译成了 `001/002`,完成的路径为 `/dev/bus/usb/001/002`。现在我可以把这个路径传给 `lsusb`。我还会用管道传给 `more`,因为这里往往有很多信息:
```
$ lsusb -D /dev/bus/usb/001/002 |more
Device: ID 18f8:1486
Device Descriptor:
bLength 18
bDescriptorType 1
bcdUSB 1.10
bDeviceClass 0 (Defined at Interface level)
bDeviceSubClass 0
bDeviceProtocol 0
bMaxPacketSize0 8
idVendor 0x18f8
idProduct 0x1486
bcdDevice 1.00
iManufacturer 0
iProduct 1
iSerial 0
bNumConfigurations 1
Configuration Descriptor:
bLength 9
bDescriptorType 2
wTotalLength 59
bNumInterfaces 2
bConfigurationValue 1
iConfiguration 0
bmAttributes 0xa0
(Bus Powered)
Remote Wakeup
MaxPower 100mA
Interface Descriptor:
bLength 9
bDescriptorType 4
bInterfaceNumber 0
bAlternateSetting 0
bNumEndpoints 1
bInterfaceClass 3 Human Interface Device
bInterfaceSubClass 1 Boot Interface Subclass
bInterfaceProtocol 2 Mouse
iInterface 0
HID Device Descriptor:
```
不幸的是,这里并没有提供我希望找到的细节。初始输出中出现的两个字段 `idVendor` 和 `idProduct` 都是空的。这有些帮助,因为往下看一下,就会发现 `Mouse` 这个词。所以,这个设备就是我的鼠标。
### USB ID 仓库
这让我不禁想知道如何才能填充这些字段,不仅是为了自己,也是为了其他 Linux 用户。原来已经有了一个开源项目:[USB ID 仓库](http://www.linux-usb.org/usb-ids.html)。它是一个公共仓库,它包含了 USB 设备中使用的所有已知 ID。它也被用于各种程序中,包括 [USB Utilities](https://sourceforge.net/projects/linux-usb/files/),用于显示人类可读的设备名称。

你可以从网站上或通过下载数据库来浏览特定设备的仓库。也欢迎用户提交新的数据。我要为我的鼠标提交数据,因为它没有在里面。
### 更新你的 USB ID
USB ID 数据库存储在一个名为 `usb.ids` 的文件中。这个文件的位置可能会因 Linux 发行版的不同而不同。
在 Ubuntu 18.04 中,这个文件位于 `/var/lib/usbutils`。要更新数据库,使用命令 `update-usbids`,你需要用 root 权限或 `sudo` 来运行。
```
$ sudo update-usbids
```
如果有新文件,它就会被下载。当前的文件将被备份,并被替换为新文件:
```
$ ls -la
total 1148
drwxr-xr-x 2 root root 4096 Jan 15 00:34 .
drwxr-xr-x 85 root root 4096 Nov 7 08:05 ..
-rw-r--r-- 1 root root 614379 Jan 9 15:34 usb.ids
-rw-r--r-- 1 root root 551472 Jan 15 00:34 usb.ids.old
```
最新版本的 Fedora Linux 将数据库文件保存在 `/usr/share/hwdata` 中。而且,没有更新脚本。而是,数据库由一个名为 `hwdata` 的软件包维护。
```
# dnf info hwdata
Installed Packages
Name : hwdata
Version : 0.332
Release : 1.fc31
Architecture : noarch
Size : 7.5 M
Source : hwdata-0.332-1.fc31.src.rpm
Repository : @System
From repo : updates
Summary : Hardware identification and configuration data
URL : https://github.com/vcrhonek/hwdata
License : GPLv2+
Description : hwdata contains various hardware identification and configuration data,
: such as the pci.ids and usb.ids databases.
```
现在我的 USB 设备列表在这个之前未命名的设备旁边显示了一个名字。比较一下上面的输出:
```
$ lsusb
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 004: ID 046d:082c Logitech, Inc. HD Webcam C615
Bus 001 Device 003: ID 0951:16d2 Kingston Technology
Bus 001 Device 014: ID 18f8:1486 [Maxxter]
Bus 001 Device 005: ID 051d:0002 American Power Conversion Uninterruptible Power Supply
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
```
你可能会注意到,随着仓库定期更新新设备和现有设备的详细信息,其他设备的描述也会发生变化。
### 提交新数据
提交新数据有两种方式:使用网站或通过电子邮件发送特殊格式的补丁文件。在开始之前,我阅读了提交指南。首先,我必须注册一个账户,然后我需要使用项目的提交系统提供我鼠标的 ID 和名称。添加任何 USB 设备的过程都是一样的。
你使用过 USB ID 仓库么?如果有,请在评论中分享你的反馈。
---
via: <https://opensource.com/article/20/8/usb-id-repository>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,614 | 离开 Google:五年以来 | https://theartofmachinery.com/2020/08/04/leaving_google.html | 2020-09-14T23:11:32 | [
"Google",
"自由职业"
] | https://linux.cn/article-12614-1.html | 
大约五年前的今天,我上交了 Google 员工证,然后走出了悉尼 Google 办公室,开启了一段自谋职业的崭新生活。我认为我应该详述一下这个故事,因为我通过阅读 [Michael Lynch](https://mtlynch.io/why-i-quit-google/) 的作品而收获颇丰。正如你所看到的,我仍然花费了几年时间才开始考虑写这篇文章,但是最终我告诉自己,倘若我不在五周年纪念日写它,我就永远也不会写了。
这篇文章有点儿长,但是我希望它对那些对于在大型技术公司工作感兴趣的新开发人员或是想要离职的大型企业雇员能够有所帮助。我将谈谈我进入 Google,在 Google 工作和辞职的故事,以及之后我做了什么。如果你想了解更多的细节,可以随时询问,不过我已经有很多博文要写,所以不能保证有什么深入的内容。
同样地,冒着显而易见的劳工风险:我已经有 5 年不在 Google 工作了,所以请不要以这个故事来作为当今 Google 或是 Google 雇员经历全貌的字面描述。但是,我认为其中的许多内容仍然与一般性的技术职业有关。
### 通往 Google 的艰辛道路
2005 年,我获得了第一份带薪的编程工作,是在当地的电力公司工作,把一些旧的 Pascal 代码用不同的编译器在不同的操作系统上运行。这基本上只是我为了挣外快而做的暑期工,同年我还刚刚开始攻读我数学和物理的学位。他们很高兴有一个本科生能够胜任这份工作。我被这些大人吓了一跳,因为他们不仅只是对我的编程爱好感兴趣,而且真的还会为此给我钱。
直到 2007 年毕业以前,我一直在做类似的工作。我喜欢编程工作,而 Google 是一家从事着很酷的编程工作的很酷的公司,因此我申请了实习。 Google 的面试过程以困难而著称,所以我花了好几个星期时间练习了所有我在网上能够找到的 Google 面试题。我认为 13 年里面试流程并没有发生太大的变化 —— 我提交了简历,受邀参加了几轮电话面试,这些面试问的几乎都是算法问题(我记得有一个动态规划问题和一个分治几何问题)。我通过了最初的几轮面试,然后受邀前往悉尼接受了由 Google 的工程师们进行的为期一天的现场面试。我回到家里,等待 Google HR 的电话,这个过程漫长得像是有一辈子。我被拒绝了。
对于我们收到的拒绝和失败感到难过很自然,因此我们并不会经常谈及它们。但是出于同样的原因,其他人也不会去谈论他们自己的失败,这只会使得情况变得更加糟糕。当我后来真的进入 Google 时,我觉得作为一个此前被拒绝过的人,我一定有哪里做得不对,但是有一天我和一群同事坐在一张桌子旁,开始交谈。那时候我才发现,实际上我身边的很多人都至少被拒绝过一次。我甚至都不是“最差的”。有个家伙开玩笑说,他肯定是因为 Google HR 厌倦了拒绝他才得以进来的。我说的也是一些相当厉害的工程师 —— 有些人负责着我一直在用的代码,而我打赌你也在用。
进行面试的公司通常会为每个名额面试两名或更多的候选人。这意味着比起录用,会有更多的拒绝,所以一般面试参与者被拒绝的可能性要大于被录用。然而我们一直忘记了这一点。四个开发人员参加面试,一个被录用了,其他三个在社交媒体上抱怨这场面试是如何的漏洞百出,因为他们个人被拒绝了。当然,面试远非完美,但是我们需要停止如此个人化地谈论它。
只要你能够找到问题所在并知道如何去改进自己,拒绝和失败就没有那么糟糕。Google 的面试主要针对算法,我在其中磕磕拌拌地摸索,但绝对没有能够脱颖而出。
在被 Google 拒绝以后,我得到了两样东西,并进行了为期一年的休假。第一件东西是澳大利亚商务编号(ABN),我用它来提供数学与科学补习课程,以及技术工作合同。我获得的另一样东西是一张大学科技图书馆的借书证。我当时并不打算再次去参加 Google 的面试,但是那次的面试经历告诉我还有很多东西是我所不知道的。我就在图书馆开设课程给大家做辅导,并在期间阅读书籍。顺便说一句,有些人认为我为我的补习业务所做的所有这些财务工作和其他东西很奇怪,而大多数补习老师都只收现金。但是我学到了许多对我日后生活很有帮助的东西,所以我一点儿都不后悔。
2009 年,我根据一个叫 Persi Diaconis 的魔术师转行为数学家的作品,进行了一个数学荣誉课程(也就是学士学位四年级)。计算机科学系让我选修他们的一个算法单元作为其中的一部分。
就像我所说的那样,我本来并没有打算再去 Google 面试,但是让我快速地讲讲这是怎么发生的。我从高中就开始学习日语,因此在 2012 年,我决定尝试在东京生活。这基本上行得通,除了我犯了一个相当大的错误 —— 我没有任何日语方面的纸质资质证明,因此很难获得工作面试。最终,我的一个已经被 Google 录用的朋友建议我再试一次。与 Google 所有的办事处一样, Google 东京的官方商务语言是英语,因此他们不要求我具有日语资质证明。
### Google 面试,再一次
我的朋友向 Google HR 推荐了我。这绝对有帮助,但是如果你自己得到了被推荐的机会,也不要太过于兴奋。它所能够确保的是你的简历会被注意到(不是小事)并且免去一次电话面试,但你仍然得通过剩下的电话面试和现场面试。
这一次我用来自 [Project Euler](https://projecteuler.net) 和 [Google CodeJam](https://codingcompetitions.withgoogle.com/codejam) 的题进行练习。电话面试过程中,我不得不在 Google Doc 上进行一些在线编程,这有点儿尴尬,但是除此以外电话面试一切顺利。然后我受邀前往六本木的 Mori Tower 办公室进行了为期一天的现场面试。

我的首个面试非常糟糕。我的脑子僵住了。我知道我能够解出那些题目,但是直到面试官走出房间我才想出答案。我立刻就感到很放松,并且意识到这是一个三元搜索问题。这是在是很令人沮丧,但是我觉得继续前进,看看剩下的面试进展如何。
其中的两道面试题很糟糕。其中之一直至今日仍然是我遇到过的最糟糕的面试问题。面试官说:“你用同一输入运行一个程序两次,得到了两个不同的结果。告诉我这是为什么。”我回答道:“当这种情况在现代计算机上发生而且并不在我的预期之中时,通常是竞态条件。”他只说:“不,这不是竞态条件。”然后看着我等着我的下一个回答。如果他有兴趣讨论一下的话,这个问题本该是一个很棒的问题,但是很显然他实际上只想玩“猜猜神秘数”。对于我所说的几乎全部内容,他只是回答:“不。”显然,该程序完全是确定性的,不存储任何状态,并且不依赖于环境(例如磁盘或是实时时钟),但却在每次执行时都给出不同的结果。我怀疑我们对于“被存储的状态”或是“环境”的含义还是某些东西有着不同的理解,但是我无法区分。有一次(变得绝望了)我试着问电子元件的温度变化是否会有影响,而他说:“不,那会是一个竞态条件,我已经告诉过你这不是竞态条件了。”最终,面试结束了,而我仍然不知道那个秘密数字是什么。
我讲这个故事的原因是,我听说过许多更为平淡的恐怖故事,用以证明面试官是憎恶面试者的坏人。然而,与流行的刻板印象所相反的是,当天的大多数面试基本上都还可以,面试官也很友好并且很尊重人。面试也着实很困难,因此最好减少面试官的工作量。希望那个“猜数字”面试官从 Google HR 那里得到的反馈是,他的问题对于作出聘用决定没什么帮助。
这次,面试带来了一份要约,但是有一个小问题:这份工作在悉尼,担任站点可靠性工程师(SRE)。我以前从未听说过 SRE,但是我和一位悉尼的资深 SRE 通了电话,他解释说他注意到了我在天然气行业从事嵌入式工程的经历,并且认为 SRE 会和适合我,因为同样强调可靠性与拟合紧密约束。
在东京花了大约一年时间来建立起自己的生活,我不想抛弃一切然后搬到悉尼,但是我绝不可能会拒绝一份来自 Google 的要约。与招聘人员交谈时,我确实犯了一个非常愚蠢的错误:我被问到当时能赚多少钱,然后我就脱口而出。[别这么做](https://www.kalzumeus.com/2012/01/23/salary-negotiation/)。这意味着不管在面试中发生了什么事情,或是你上一份工作中被底薪了多少,或者其它什么。你可能会被拒绝,或者会在原来的薪水基础上得到一些象征性的提升,并且如果你试图进一步协商,会被认为疯狂而又不合理。就我而言,我的收入甚至远远低于 Google 的入门级职位。我无法肯定地说全是这样,但是在 2013 年我搬到了悉尼,在 Google Maps 成为了一名新毕业生级别的 SRE。
### 悉尼的 Google Maps SRE
像 Maps 这样的产品实际上是若干个软件项目,每个都有自己的开发人员团队。甚至诸如路线查找之类的功能实际上也是多个软件项目 —— 从交通时刻表数据收集,到线路计算,再到结果渲染,等等等等。 SRE 的工作包含两个方面:一方面是为各个项目提供待命,实时响应任何生产事故;另一方面(在无需救火时)则是将生产事故中所积攒的经验应用到其他项目中去,并且发现其中可能出错的方式,或是发现使其性能更好的机会。Google 的 SRE 还需要像开发人员的内部咨询小组一样,对部署实践、自动化、监控或是类似的问题提供咨询。
这项工作相当紧张。作为一个团队,我们每周至少需要处理一次生产事故,否则就要为更多的服务提供支持。每个礼拜,悉尼的所有 SRE 都会聚在一起,交流发生过的故障事件或是有关如何使事情更好地运转的新技巧。学习曲线的感觉就像是再次成为了一名本科生。
我有时会感到震惊,听说我选择离开 Google 的人会问:“但是你不会想念那些福利吗?!”物质上的福利(例如伙食等等)绝对很棒,但是它们是你可以买到的东西,因此,不,它们不是我所想念的东西。如果你问我所想念的是什么,我会说是在那里工作的人们。与你可能听说过的不同,傲慢的人不喜欢在 Google 之类的地方工作。有一个臭名昭著的故事,一个自恋的人在 Google 找了份工作,并假装自己是各方面的顶级专家,让自己尴尬不已。他待了不到半年就离开了。总的来说,与我工作过的其他地方相比,这里的文化在傲慢、指责以及政治方面很少。另一方面,Google 并没有垄断好同事。
不过,有一种公司政治是个大问题。晋升需要“展示影响”,而众所周知的是,要做到这一点最简单的方法是发布一些新事物(不是惟一的方法,但是最简单)。结果是 Googler 们比起改进现有的解决方案,对于推广他们自己内测品质的原型方案更感兴趣。在 SRE 之间,我们经常开玩笑说, Google 内部有两种软件:一种是老的东西,工作得很好,但已经废弃了,甚至连考虑使用都是不够谷歌化的;另一种是热门的新东西,尽管它们还不能用,但却是今天 100% 可以使用的官方工具。作为 SRE,我们经常亲眼看到新的热点事物出了什么问题(有时甚至在没出 alpha 之前它就已经成了过时的旧东西)。([我此前已经对这类事物进行了更为深入的讨论。](https://theartofmachinery.com/2019/03/19/hello_world_marketing.html))
这不是我们这些愤世疾俗的 SRE 所想象的东西;这在公司中被公认为是一个问题,而我记得有人向我保证,晋升委员会已经开始通过维护工作等方式寻找关于其影响的证据。
### 晋升申请
2015 年,在 Google 工作了两年之后,我的经理告诉我,现在是时候申请一个高于我新毕业生水准的晋升了。晋升过程是每年两次由晋升委员会进行集中管理的。你可以先提出申请,然后加上一份对你所从事过的项目的简短描述,再加上同事的推荐信。委员会将会进行审查,然后给你赞成或反对的意见。仅仅有你经理的推荐是不够的,因为你的经理有想让你获得晋升的动机。手下有高级别的员工有助于你自己的职业发展。
长话短说,我提交了我的申请,而委员会说不。事实上,这是个相当糟糕的拒绝。我不记得详细的答复了,但感觉就像是委员会在我的申请中寻找可以不屑一顾的东西。例如,我从事过的一个项目是一个内部工具,它出现了功能需求的积压。我查看了这个项目,发现根本问题在于它已经超出了构建它的键值存储,需要一个合适的数据库。我主张切换到关系数据库,并实现了它:模式、数据迁移、查询、实时站点迁移等等。新查询的速度要快得多,而且(更重要的是)可以有效地支持新功能。在进行迁移之前,我必须要解决的一个问题是大部分代码没有被测试所覆盖,而这是由于大部分的代码都不可测试。我使用依赖注入以及[我此前讨论过的其他技巧](https://theartofmachinery.com/2016/03/28/dirtying_pure_functions_can_be_useful.html)重构了代码,而这使我能够构建一组回归测试套件。我记得这个项目被驳回主要是被评价为测试单元的编写是“新毕业生水平的工作”。
我的经理真的很支持我,并且写了上诉。他没有给我看,但是我认为这是可以被缩减成 “WTF” 的若干页(更雄辩而详尽地论述)。以下是一些我也认为这一回复有点 “WTF” 的原因:
Google SRE 有一种“关键人物”的概念。一个项目的关键人物有两个角色:一个是比起其他 SRE 对于软件项目有着更为深入的了解,以便你能够回答他们可能会提出的问题;另一个角色是作为项目本身的开发人员的第一联络人,以便他们的所有 SRE 问题都能得到回答。 Google 的职业阶梯指南说,关键人物不应该处于“新毕业生水准”,而应该晋升。正如我在申请中所写的,我是三个项目的关键人物。
我的关键人物经历使得想要找到同意支持我的晋升申请的资深开发人员很容易。当他们发现我是新毕业生级别时都十分震惊。他们都同意支持我的申请,认可我已经处在了一个更高的级别。
在我的申请之中,我提到曾担任过一组新毕业实习生的导师。当我提出申请时,他们之中的许多人都已经被聘用为了正式雇员。我足够资深,可以去担任他们的导师,但是还绝不足以晋升到比他们更高的级别。
给我经理上诉的回复与最初的审查截然不同。这次,我“大大超出了对于我‘新毕业生’级别工作的期望”,但是问题在于他们需要稍多一些时间来确保我能够晋升到新毕业生加一的级别。我被告知在接下来的 6 个月时间里,倘若我能够继续超出预期,直到下一个晋升周期,也许那时我就会得到晋升。上诉结束了;这就是最终结果。
我写了一封电子邮件,表示我要采取另一种选择。就像许多科技公司一样, Google 也有员工持股计划。在开始工作时,你会得到一笔象征性的补助金,而在各个“投资”里程碑时刻,你会收到真正的股份。我的下一次股票授予是在几个月之后。从那以后,我将不再为 Google 工作。
### 我离开的原因
任何辞职的决定并不容易,而某天你或许会面临同样的抉择。以下是一些有助于我作出决定的因素。([我在以前的一篇贴子里对一些这类想法进行了更深入的解释。](https://theartofmachinery.com/2018/10/07/payrise_by_switching_jobs.html))
如果你思考一下,考虑到我并不是字面意义上真正的应届毕业生, Google 的评价应该是这样的:“你正在做一些非常错误的事情。在 X、 Y 还有 Z 方面有所改进之前,你根本不会得到晋升。”被告知“你远远超出了预期,但是我们还需要 6 个月左右的时间”,这是毫无道理的。没有人关注我是否有能力做好我的工作。我得到了许多借口,但是没有能够帮助我提高的任何有用反馈。(注意:有时候你必须要明确地要求反馈。经理们可能会陷入捍卫自己所给出的绩效评级的陷阱,而不会去考虑报告是否需要反馈。)
我也不确定晋升委员会会在 6 个月里看到什么他们在已经过去的 2 年时间里都没有看到的问题。他们难保不会再要求 6 个月时间?如果我需要花上多年时间来证明自己以获得新毕业生加一的级别晋升,那么我升到新毕业生加二的时候得有多老呢?
刚加入 Google 时,我的工作级别无关紧要,因为我当时学到了那么多东西,并且能在我的简历里写入一家著名的公司。两年过后,等式变得不同了。 Google 所提供给我的未来所具有的价值正在下降,而 Google 之外机会的价值却正在上升。 Google 的职位实际上在 Google 之外几乎毫无意义。在过去的 5 年间,许多人都问过我在 Google 做过什么,但是没有一个人问我在 Google 是什么职位,也没人称我为“新毕业生”。尽管我在短期内受到了财务方面的打击,但实际上在我上交员工证的那天我就已经得到了晋升。
值得称赞的是,Google 没有做过任何类似于以下的事情,但是在其他公司中却很常见:试图让员工对于要求加薪感到内疚。在几年前我工作过的地方,一些工程师在一次成功发布会后,在许多紧要关头要求加薪。管理层扮演起了受害者的角色,并且指责工程师们是在“强迫他们”。(大约 6 个月时间后,他们失去了自己大部分的工程团队。)如果你真的愿意就辞职时间进行配合(例如,在发布日期之后,而不是前一周),并且愿意记录下你的知识并做了整理等等,那么你仅仅是由于雇主支付给你的工资不足而“强迫他们”。
名义上,我在 Google 留下了大量未授予的股票。但是知道你拥有股票时,股票才属于你。我只是得到了未来会有分红的承诺,而我可以将其除以所需的时间来将其转换为同等的工资率。为这项投资工作 2 个月是值得的,为了剩余的投资工作数年是不值得的。不要被授予股票的偏见所迷惑。
什么时候不应该辞职呢?嗯,与在其他地方相比,你能得到的很多吗?公司的职业发展道路不是天上掉下来的,他们是一系列的业务报价,代表着你将为什么样的公司评估而工作。如果你认为自己能得到很多(考虑到所有的薪酬和像是工作环境之类的无形资产),很好!否则,是时候认真考虑一下下一步该做什么了。
### 离开 Google 之后
我应当警告你的是,我采取了高增长的战略,但是牺牲了短期稳定性。如果对你而言稳定性更为重要,你应该做出不一样的选择。我的 A 计划、 B 计划、 C 计划都失败了,我最终花费了几个月时间苦苦找寻出路。最后,我在一家小型网店得到了一份合同,为 [Safety Town](https://www.safetytown.com.au/) 工作,一家政府建立的面向孩子们的道路安全网站。那里的薪水较之于 Google 是一个巨大的缩减,尤其是考虑到这是我几个月以来的第一份工作。但是,你知道,我真的很享受这个项目。当然了,它不像 Google 那么“酷”,而且可能一些学校里的孩子也不觉得它酷。另一方面,在 Google,我只是机器中的一个螺丝钉。 Safety Town 有一个小团队,每个人都扮演着至关重要的角色。在 Safety Town 项目中,我是后端工程师, Safety Town 当时是我唯一需要费心的事情。而且可能一些孩子已经在这个网站上学到了一两件有关道路安全的事情。从那以后,我做了很多项目,大多数都更大,但是我仍然会向人们展示 Safety Town。

我记得 Google 悉尼办事处的一张海报,上面写着:“飞向月球吧!即使你错过了,你也会降落在群星之中!”人们很容易忘记,即使你不是在为知名公司或初创公司做“登月计划”,你也可以拥有高质量的生活。
这儿有一个帮助我获得合同的窍门。我会去参加悉尼的科技活动,站在能看到求职公告板的范围之中,等着看见有人在上面写东西。假设他们正在为一个保险公司项目写 CSS 开发方面的信息。即使我对 CSS 或保险不是特别感兴趣,我也会晃悠过去说:“嗨,这是个什么类型的保险项目?”这是最容易的开启谈话的方式,因为在他们努力往求职公告板上的狭小缝隙中写字的时候,满脑子都是这个项目。通常情况下,这样的谈话仍然不会为我带来一份工作,但是偶尔也会发现一些我能够帮上忙的东西。有些活动没有求职公告板,但是组织者们往往很乐意把麦克风递给别人几分钟。这为他们的活动增添了社区参与度。
我在做了一个政府采购的网站后,我取得了重大的突破,因为我学会了不至于对政府采购一窍不通。很难确切说出这些知识的价值,但是不到一年过后,我就签署了一份政府合同,比我此前所期望的要多了 40%。(不过,我如今没有做那么多的政府和大型企业的工作了。)
大约一年半过后,我有了自己的一人公司。随着我声誉的建立,我逐渐获得了更多类似于 SRE 的工作。基本上,从事开发工作是我的“工作”,然后几个月后就有一个需要 SRE/DevOps 帮助的人联系了我。我事实上既喜欢 SRE,也喜欢纯开发工作,但是供求关系意味着 SRE 工作是个好工作。我仍然可以在空余时间编程。
说起这个,工作与生活的平衡是我在新生活中最喜欢的事情。没有人在两份合同之间给我酬劳,但是我可以通过在业余项目中学习新东西来充分利用这一间隙。在一个漫长而又紧张的合同之后,我休息了一下,[进行了为期一个月的背包徒步旅行,探索了日本乡村][11]。这是我期待了很长时间的一次旅行,但是在入职 Google 之前我需要更多的钱,而在 Google 供职期间我又需要更多的时间。自营职业远非没有压力,也不是适合每一个人的,但是有的压力会让你感到死气沉沉,有的压力则会让你越发充满活力。于我而言,自主营生是第二种,我想说,和在 Google 时相比,过去的 5 年间我的压力总体上有所减轻。对于我来说,至少我能够诚实地说我不后悔当初加入 Google,也不后悔当初离开 Google。
---
via: <https://theartofmachinery.com/2020/08/04/leaving_google.html>
作者:[Simon Arneaud](https://theartofmachinery.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | About five years ago now, I handed in my Google employee badge and walked out of the Sydney Google office to start a
new life of self-employment. I figured I should write up this story because I got a lot out of reading [Michael Lynch’s](https://mtlynch.io/why-i-quit-google/). As you can see, it’s still taken me a couple of years to
get around to writing this post, but I finally told myself that if I don’t write it for the fifth anniversary, I never
will.
This post is kind of long, but I hope it has something useful for new developers who are interested in working at a big tech company, or for big company employees who are wondering what it’s like to quit. I’ll talk about my story of getting into, working at and quitting Google, and what I’ve done since. Feel free to ask if you want more detail about something, though I already have a lot of blog posts to write, so I can’t promise anything in-depth straight away.
Also, at the risk of labouring the obvious: I haven’t worked at Google for five years, so don’t take this story as a literal description of Google today or what all Google employees experience. However, I think a lot of it’s still relevant to tech careers in general.
## The windy road to Google
I got my first paid programming job in 2005. It was working at the local power company, taking some old Pascal code and making it work on a different OS with a different compiler. It was basically just a summer job for extra money while doing the maths and physics degree I’d started that same year. They were happy to have an undergraduate who could do the job; I was just blown away that these grown ups were not only interested in my programming hobby, but actually going to give me real money for it.
I kept doing stuff like that until I graduated in 2007. I liked programming work, and Google was a cool company doing cool programming stuff, so I applied for an internship. The Google interview process was famous for being tough, so I spent several weeks practising on all the Google interview problems I could find online. I don’t think the process has changed much in 13 years: I submitted a résumé, and I got invited to a few rounds of phone interviews that were mostly algorithmic problems (I remember a dynamic programming one and a divide-and-conquer geometric one). I passed the initial interviews, and got invited to come to Sydney for a day of on-site interviews with Google engineers. I went home and waited for what felt like an eternity for the phone call from Google HR. I got rejected.
It’s natural to feel bad about our rejections and failures, so we don’t talk about them much. But for the same
reason, other people don’t talk about theirs, which only makes things worse. When I *did* get into Google later,
I felt like there must be something a bit wrong with me as a “ex-reject”, but one day I was at a table with a bunch of
colleagues and the conversation came up. That’s when I discovered that actually a lot of people around me had been
rejected at least once. I wasn’t even the “worst”. One guy joked that he must have only got in because Google HR got
tired of rejecting him. I’m talking about some pretty impressive engineers, as well — some were responsible for code I
use all the time, and I bet you use, too.
Companies that do interviews usually interview two or more candidates for each hire. That means there are more rejections around than acceptances, so the average interviewee gets rejected more often than not. Yet it’s so easy to forget that. Four developers go into an interview; one gets hired, the other three rant on social media about how the interview was totally flawed because they personally got rejected. Sure, interviews are far from perfect, but we need to stop taking them so personally.
Rejection and failure aren’t so bad as long as you can figure out what went wrong and how you could improve yourself. The Google interviews were heavily algorithm-oriented, and I fumbled through a lot of them but definitely didn’t come out shining.
After the Google rejection, I got two things and took a kind of sabbatical year. The first thing was an Australian Business Number (ABN) that I used to do maths and science tuition, as well as tech job contracts. The other thing I got was a library card at the university science and tech library in my state. I wasn’t planning to interview at Google again, but the interview experience told me there was a lot I didn’t know. I’d give tutorials in the library and read books in between. By the way, a few people thought I was weird for doing all that accounting and stuff for my tuition business, when most tutors just did it cash-in-hand. But I learned a lot that’s helped me later in life, so I don’t regret a thing.
In 2009, I did a maths honours year (a.k.a, bachelors fourth year) based on the work of a magician-turned-mathematician called Persi Diaconis. The computer science department let me take one of their algorithms units as part of it.
As I said, I hadn’t planned to interview for Google again, but let me fast forward to how it happened. I’d been studying Japanese since high school, so in 2012 I decided to try living in Tokyo. That mostly worked out, except I made one pretty big mistake: I didn’t have any paper qualifications in Japanese, so it was really hard to get job interviews. Eventually, a friend of mine who had been accepted at Google suggested I give it another try. Like all Google offices, the official business language at Google Tokyo is English, so they didn’t require me to have Japanese qualifications.
## Google interviews, again
My friend gave me a recommendation to Google HR. That definitely helps, but don’t get too excited if you get a recommendation, yourself. It ensures your résumé gets noticed (not trivial) and cuts one of the phone interviews, but you still have to pass the remaining phone and on-site interviews.
This time I practised using problems from [Project Euler](https://projecteuler.net) and [Google CodeJam](https://codingcompetitions.withgoogle.com/codejam). I had to do some live programming in a Google
Doc during the phone interview, which was a bit awkward, but otherwise the phone interviews went okay. Then I got
invited to the Mori Tower office in Roppongi for a day of onsite interviews.

[Photo from here.](https://commons.wikimedia.org/wiki/File:Roppongi-Mori-Tower-01.jpg))
My first interview went terribly. I got brain freeze. I knew I could solve the problem, but I couldn’t think straight until the interviewer walked out of the room. Instantly I relaxed and recognised it as a ternary search problem. That was pretty frustrating, but I decided to just keep going and see how the rest of the interviews went.
Two of the interviews were bad. One is still today the worst interview question I’ve ever had. The interviewer said, “You run a program twice with the same input and get different results. Tell me why.” I replied, “When that’s happened on modern computers and I didn’t expect it, it’s usually been a race condition.” He just said, “No, it’s not a race condition,” and looked at me waiting for my next answer. The question could have been a great question if he’d been interested in a discussion, but apparently he really did just want to play “guess the secret number”. For almost everything I said, he simply replied, “No.” Apparently the program was fully deterministic, stored no state, and had no dependence on the environment (such as disk or the real time clock), but gave different results each time it was executed. I suspect we had a different understanding of what “stored state” or “environment” meant or something, but I had no way to tell. At one point (getting desperate) I tried asking if temperature changes in the electronic components were having an effect, and he said, “No, that would be a race condition, and I’ve already told you it’s not a race condition.” Eventually the interview ended, and I still don’t know what that secret number was.
I’m telling that story because I’ve heard much tamer horror stories being told as proof that interviewers are terrible people who hate interviewees. But, contrary to popular stereotype, most of the interviews that day were basically okay, and the interviewers were friendly and respectful. Interviewing is genuinely really hard, too, so it’s good to cut interviewers some slack. Hopefully, the “guess the number” interviewer got feedback from Google HR that his question just wasn’t helpful for making hiring decisions.
This time, the interviews resulted in an offer, but with a little catch: the job was in Sydney, working as a site reliability engineer. I’d never heard of SRE before, but I had a phone call with a senior Sydney SRE who explained that he’d noticed my experience doing embedded engineering in the natural gas industry, and thought SRE would be a good fit because of a similar emphasis on reliability and fitting tight constraints.
Having spent about a year building up a life in Tokyo, I didn’t want to drop everything and move to Sydney, but no
way in hell was I in a position to turn down an offer from Google. I did make one very stupid mistake when talking with
the recruiter: I got asked how much money I was making, and I blurted it right out. [Don’t do that.](https://www.kalzumeus.com/2012/01/23/salary-negotiation/) It means it doesn’t matter what happens
in the interview, or how much you were being underpaid at your previous job, or whatever; you’ll probably either be
rejected or get offered some token amount on top of your old pay and be treated as crazy and unreasonable if you try to
negotiate more. In my case, I was making much less than even an entry-level position at Google. I can’t say for sure
that’s the whole story, but in 2013 I moved to Sydney to be a new-grad level SRE on Google Maps.
## Google Maps SRE at Sydney
A product like Maps is really several software projects, each with its own team of developers. Even a feature like route-finding is really multiple software projects — from gathering transport timetable data, to calculating routes, to rendering results, etc. There are two sides to the SRE job: One is being oncall for the various projects, responding in real time to any production incidents. The other side of the job (when there aren’t any fires to fight) is applying experience from production incidents to other projects and pre-emptively finding ways they could go wrong, or opportunities to make them perform better. Google’s SREs also act like an internal consulting group for developers with questions about deployment practices, or automation, or monitoring, or things like that.
The work was pretty intense. As a team, we were expected to deal with at least one production incident a week, or else take on responsibility for more services. Every week, all the SREs in Sydney would get together to swap stories of failures that had happened, or new tips for how to make things work better. The learning curve felt like being an undergraduate again.
I sometimes get a shocked, “But don’t you miss the benefits?!” from people who hear I chose to quit Google. The material benefits (like meals, etc.) are definitely nice, but they’re things that you can buy, so, no, they’re not things I miss. If you ask me what I miss, I’d say it’s the people who worked there. Contrary to what you might have heard, arrogant people don’t enjoy working at places like Google. There’s an infamous story of a narcissist who got a job at Google and kept embarrassing himself by pretending to be a top expert in all kinds of things. He lasted less than half a year before leaving. Overall, the culture was very low on arrogance and blame slinging and politics compared to other places I’ve worked at. On the other hand, Google doesn’t have a monopoly on nice colleagues, and I’ve worked at good places since then.
## The promotion application
In 2015, after working at Google for a couple of years, my manager told me it really was about time to apply for a promotion above my new-grad level. The promotion process was centrally managed through promotion committees twice a year. You’d make your application and back it up with a short description of projects you’d worked on, supported by references from your colleagues. The committee would do a review and give you the thumbs up or down. Your manager’s recommendation alone wasn’t enough because your manager had an incentive to get you promoted. Having high-ranked staff under you helps your own career advancement.
To cut a long story short, I made my application and the committee said no. Actually, it was a pretty damning no. I
don’t remember the response in detail, but it felt like the committee had just gone hunting through my application
looking for things to be dismissive about. For example, one project I’d worked on was an internal tool that was
building up a backlog of feature requests. I’d looked at the project and figured out that the root problem was that it
had outgrown the key-value store it had been built on, and needed a proper database. I argued for switching to a
relational DB, and I went ahead and implemented it: schema, data migration, queries, the live site migration, etc. The
new queries were much faster, and (more importantly) the new features could be supported efficiently. One problem I had
to solve before migrating was that most of the code wasn’t covered by tests, and that was because most of the code
wasn’t testable. I refactored the code using dependency injection and [other tricks I’ve talked about before](/2016/03/28/dirtying_pure_functions_can_be_useful.html), and that let me
build a regression test suite. I remember that project was mostly dismissed with the comment that writing unit tests is
“new-grad-level work”.
My manager was really supportive and wrote an appeal. He didn’t show it to me, but I think it was several pages that could be reduced down to “WTF” (argued more eloquently and with more detail). Here are some of the reasons I also thought this response was a bit WTF:
Google SRE has a concept of “point-personship”. The point person for a project has two roles: One is to know the software project to a greater depth than other SREs, so that you can answer questions they might have. The other role is to be the first point of contact for the devs on the project itself, so that they can get answers to all their SRE questions. The Google job ladder guide said that point-personship wasn’t required at the new-grad level, but looked good for promotion. As my application had said, I was point person for three projects.
My point-personships made it easy to find senior developers who agreed to help support my promotion application. They were all shocked when they found out I was new-grad level. They’d all agreed to support my application assuming I was already at a higher level.
On my application, I mentioned being a mentor for a group of new-grad interns we had. When I made my application, many of them were being hired as permanent employees. I was senior enough to be their mentor, but firmly not enough to be promoted above their level.
The response to my manager’s appeal took a completely different tack from the original review. This time I was “strongly exceeding expections for my [new-grad] job level”, but the problem was that they just needed a little bit more time to be sure I could be promoted to new-grad-plus-one. I was told I could keep strongly exceeding expectations for another six months until the next promotion cycle, and maybe I’d get a promotion then. The appeal was over; that was the deal.
I wrote an email that I was taking another option. Like many tech companies, Google has an employee stock program. You’re given a nominal grant when you start work, and you actually receive real shares at various “vestment” milestones. My next stock vestment was a couple of months away. The day after that, I wouldn’t be working for Google any more.
## My reasons for quitting
The decision to quit any job isn’t easy, and one day you might face the same decision. Here are some of the factors
that helped me make my choice. ([Some of this thinking I explained
in more depth in an older post.](/2018/10/07/payrise_by_switching_jobs.html))
If you think about it, given that I wasn’t literally a new grad, Google’s review should have been something like, “You’re doing some things very wrong. You simply won’t get a promotion until you improve at X and Y and Z.” Being told, “You’re strongly exceeding expectations, but we need another six months or so,” didn’t make any sense. No one raised concerns about whether I was capable of doing my job. I was getting a lot of excuses, but not any useful feedback to help me do better. (NB: sometimes you have to explicitly ask for feedback. Managers can fall into the trap of defending the performance ratings they give, instead of thinking about the report’s need for feedback.)
I also wasn’t sure what the promotion committee might see in six months that they hadn’t already seen in two years. Why wouldn’t they ask for another six months again? If I needed to prove myself for years to get new-grad-plus-one, how old would I be before I got new-grad-plus-two?
When I first started at Google, my job level was irrelevant because I was learning so much and getting a famous company on my résumé. Two years in, the equation was different. The value of the future that Google was offering me was waning, while the value of opportunities outside Google had gone up. Google job levels mean practically nothing outside Google. In the past five years, plenty of people have asked about what I did at Google, but not a single person has asked me what my Google job level was, or called me a new grad. Although I took a financial hit short term, I effectively got a promotion that day I handed in my badge.
Credit where it’s due, Google didn’t do anything like this, but it’s common in other companies: trying to make employees feel guilty about asking for pay rises. At a place I worked a few years ago, some engineers asked for a payrise after a highly successful launch following a lot of crunch time. Management played the victim and accused the engineers of “twisting their arms”. (About six months later they lost most of their engineering team.) If you’re genuinely co-operative about the timing of when you might quit (e.g., after a launch date, not the week before) and willing to document your knowledge and clean up after yourself, etc., you’re only twisting your employers’ arms by as much as they’re underpaying you.
Nominally, I left a large amount of unvested stock behind at Google. But stock isn’t yours until it’s yours. I just had a promise of being paid shares in future, and I could convert it to an equivalent pay rate by dividing it by time required. Working two months for that vestment was worth it. Working years for the remaining vestments wasn’t. Don’t fall for endowment bias.
When shouldn’t you quit? Well, are you’re getting a good deal compared to what you could get elsewhere? Corporate career paths aren’t mandated by heaven; they’re a series of business offers representing what the company estimates you’ll work for. If you think you’re getting a good deal (considering all compensation and intangibles like the work environment), great! Otherwise, it’s time to think hard about what to do next.
## After Google
I should warn you that I took a strategy that was high growth, at the expense of short-term stability. If stability
is more important to you, you’ll do things differently. My plan A, plan B and plan C all fell apart, and I ended up
spending a few months struggling to find a way. Eventually I got a contract at a small web shop, working on [Safety Town](https://www.safetytown.com.au/), a government road safety website for kids. The pay was a big cut from
Google, especially considering it was my first work in months. But, you know, I really enjoyed that project. Sure, it
wasn’t “cool” like Google, and maybe some kids at school didn’t think it was cool. On the other hand, at Google I was a
tiny part of a huge thing. Safety Town had a small team, with everyone playing a crucial role. For part of the Safety
Town project, I was *the* backend engineer, and Safety Town was the only thing I had to worry about at that
time. And, heck, maybe some kids have learned a thing or two about road safety from that website. I’ve done plenty of
projects since then, most of them bigger, but I still show people Safety Town.

I remember a poster in the Sydney Google office that said, “Shoot for the moon! Even if you miss, you’ll land among the stars!” It’s easy to forget that you can have a quality life even if you’re not doing moonshots for famous companies, or doing moonshots for startups.
Here’s one trick that helped me get contracts. I’d go to Sydney tech events, stand within view of the job board, and wait until I saw someone writing on it. Suppose they were writing about CSS development for an insurance company project. Even if I weren’t especially interested in CSS or insurance, I’d wander over and say, “Hi, what kind of insurance project is that?” It’s the easiest conversation starter because their head’s full of the project while they’re trying to fit it into a tiny space on the job board. Usually the conversation still wouldn’t lead to a job for me, but occasionally I’d discover something I could help with. Some events don’t have a job board, but the organisers are often glad to offer the microphone to someone for a few minutes. It adds community engagement to their events.
I got a major break after working on a website for government procurement, just because I learned to not be so clueless about government procurement. It’s hard to say exactly how much that knowledge was worth, but less than a year afterwards I signed a government contract for about 40% more than I would have hoped was possible before. (I don’t do so much government and big enterprise work nowadays, though.)
After about a year and a half, I had my own one-person company. As I built up a reputation, I gradually got more SRE-like work. Basically, doing dev work was my “in”, then several months later I’d get contacted by someone who needed SRE/DevOps help and remembered me. I actually like both SRE and pure dev work, but supply and demand means SRE work is good business. I can still do programming in my spare time.
Speaking of which, work/life balance is my favourite thing about my new lifestyle. No one pays me between contracts,
but I can make the most of it by learning new things doing side projects. After one long, intense contract, I took a
break and did [a month-long backpacking trip exploring rural Japan](/2018/03/23/seto_trip_1.html). It was a
trip I’d wanted to do for a long time, but before Google I needed more money, and during Google I needed more time.
Being self-employed is far from stress free and isn’t for everyone, but there’s stress that makes you feel dead, and
there’s stress that makes you feel more alive. For me, self-employment is the second kind, and I’d say I’ve been less
stressed overall in the past five years than I was while at Google. In my case, at least, I can honestly say I don’t
regret joining Google when I did, and I don’t regret leaving when I did, either. |
12,615 | 在 CentOS/RHEL 7/6 上安装最新 PHP 7 软件包的 3 种方法 | https://www.2daygeek.com/install-php-7-on-centos-6-centos-7-rhel-7-redhat-7/ | 2020-09-14T23:54:47 | [
"PHP"
] | https://linux.cn/article-12615-1.html | 
PHP 是最流行的开源通用脚本语言,被广泛用于 Web 开发。它是 LAMP 栈应用程序套件的一部分,用于创建动态网站。流行的 CMS 应用程序 WordPress,Joomla 和 Drupal 都是用 PHP 语言开发的。这些应用程序的安装和配置都需要 PHP 7。PHP 7 可以更快地加载你的 Web 应用程序,并消耗更少的服务器资源。
在默认情况下,CentOS/RHEL 6 操作系统在其官方存储库中提供 PHP 5.3,而 CentOS/RHEL 7 则提供 PHP 5.4。
在本文中,我们将向你展示如何在 CentOS/RHEL 7 和 CentOS/RHEL 6 系统上安装最新版本的 PHP。
这可以通过在系统中添加必要的 [附加第三方 RPM 存储库](https://www.2daygeek.com/8-additional-thirdparty-yum-repositories-centos-rhel-fedora-linux/) 来完成。
### 方法-1:如何使用软件集合存储库(SCL)在 CentOS 6/7 上安装 PHP 7
现在,SCL 存储库由 CentOS SIG 维护,该组织不仅重新构建了 Red Hat Software Collections,还提供了自己的一些其他软件包。
它包含各种程序的较新版本,这些程序可以与现有的旧软件包一起安装,并可以使用 `scl` 命令调用。
要想在 CentOS 上安装软件集合存储库(SCL),请运行以下 [yum 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/):
```
# yum install centos-release-scl
```
运行以下命令可以验证 SCL 存储库中可用的 PHP 7 版本:
```
# yum --disablerepo="*" --enablerepo="centos-sclo-rh" list *php
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
centos-sclo-rh: centos.mirrors.estointernet.in
Available Packages
php54-php.x86_64 5.4.40-4.el7 centos-sclo-rh
php55-php.x86_64 5.5.21-5.el7 centos-sclo-rh
rh-php70-php.x86_64 7.0.27-2.el7 centos-sclo-rh
rh-php71-php.x86_64 7.1.30-2.el7 centos-sclo-rh
rh-php72-php.x86_64 7.2.24-1.el7 centos-sclo-rh
```
运行以下命令可以从 SCL 中安装 PHP 7.2 到你的系统中:
```
# yum --disablerepo="*" --enablerepo="centos-sclo-rh" install rh-php72-php
```
如果需要为 PHP 7.2 安装其他模块,则可以通过运行以下命令格式来安装它们。 例如,你可以通过执行以下命令来安装 `gd` 和 `pdo` 软件包:
```
# yum --disablerepo="*" --enablerepo="centos-sclo-rh" install rh-php72-php-gd rh-php72-php-pdo
```
### 方法-1a:如何使用软件集合存储库(SCL)在 RHEL 7 上安装 PHP 7
对于 Red Hat 7,启用以下存储库以安装最新的 PHP 7 软件包:
```
# sudo subscription-manager repos --enable rhel-7-server-extras-rpms
# sudo subscription-manager repos --enable rhel-7-server-optional-rpms
# sudo subscription-manager repos --enable rhel-server-rhscl-7-rpms
```
运行以下命令从 RHSCL 库中搜索可用的 PHP 7 版本:
```
# yum search rh-php*
```
运行以下命令,你可以轻松地从 RHSCL 存储库中把 PHP7.3 安装到你的 RHEL 7 计算机上:
```
# yum install rh-php73
```
### 方法-2:如何使用 Remi 存储库在 CentOS 6/7 上安装 PHP 7
[Remi 存储库](https://www.2daygeek.com/install-enable-remi-repository-on-centos-rhel-fedora-linux/) 存储和维护着最新版本的 PHP 软件包,其中包含大量的库,扩展和工具。 有一些是从 Fedora 和 EPEL 反向移植的。
这是 CentOS 社区认可的存储库,它不会修改或影响任何基础软件包。
作为前提条件,如果你的系统上尚未安装 [EPEL 存储库](https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-oracle-linux/),该操作会首先安装它。
你可以轻松地从 Remi 存储库中找到可用的 PHP 7 软件包版本,因为它会为每个版本添加一个单独的存储库。 你可以使用 [ls 命令](https://www.2daygeek.com/linux-unix-ls-command-display-directory-contents/) 查看它们:
```
# ls -lh /etc/yum.repos.d/remi-php*
-rw-r--r--. 1 root root 456 Sep 6 01:31 /etc/yum.repos.d/remi-php54.repo
-rw-r--r--. 1 root root 1.3K Sep 6 01:31 /etc/yum.repos.d/remi-php70.repo
-rw-r--r--. 1 root root 1.3K Sep 6 01:31 /etc/yum.repos.d/remi-php71.repo
-rw-r--r--. 1 root root 1.3K Sep 6 01:31 /etc/yum.repos.d/remi-php72.repo
-rw-r--r--. 1 root root 1.3K Sep 6 01:31 /etc/yum.repos.d/remi-php73.repo
-rw-r--r--. 1 root root 1.3K Sep 6 01:31 /etc/yum.repos.d/remi-php74.repo
```
运行以下命令,你可以轻松地从 Remi 存储库中把 PHP7.4 安装到你的 CentOS 6/7 计算机上:
```
# yum --disablerepo="*" --enablerepo="remi-php74" install php php-mcrypt php-cli php-gd php-curl php-mysql php-ldap php-zip php-fileinfo
```
### 方法-2a:如何使用 Remi 存储库在 RHEL 7 上安装 PHP 7
对于 Red Hat 7,请安装以下存储库以安装最新的 PHP 7 软件包。
在 RHEL 7 上安装 EPEL 存储库:
```
# yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
```
在 RHEL 7 上安装 Remi 存储库:
```
# yum install http://rpms.remirepo.net/enterprise/remi-release-7.rpm
```
启用可选的 RPMS 存储库:
```
# subscription-manager repos --enable=rhel-7-server-optional-rpms
```
运行以下命令,可以轻松地从 remi 存储库中,把 PHP 7.4 安装在 RHEL 7 系统上:
```
# yum --disablerepo="*" --enablerepo="remi-php74" install php php-mcrypt php-cli php-gd php-curl php-mysql php-ldap php-zip php-fileinfo
```
要验证 PHP 7 的安装版本,请运行以下命令:
```
# php -v
PHP 7.4.1 (cli) (built: Dec 17 2019 16:35:58) ( NTS )
Copyright (c) The PHP Group
Zend Engine v3.4.0, Copyright (c) Zend Technologies
```
### 方法-3:如何使用 IUS 社区存储库在 CentOS 6/7 上安装 PHP 7
IUS 社区存储库是 CentOS 社区批准的第三方 RPM 存储库,其中包含 PHP、Python、MySQL 等软件的最新上游版本,以及用于 Enterprise Linux(RHEL 和 CentOS)5、6 和 7 的软件包。
[IUS 社区存储库](https://www.2daygeek.com/install-enable-ius-community-repository-on-rhel-centos/) 与 EPEL 存储库具有依赖性,因此我们必须在安装 IUS 存储库之前先安装 EPEL 存储库。 请按照以下步骤将 EPEL 和 IUS 社区存储库安装并启用到 RPM 系统,然后再安装软件包。
EPEL软件包包含在 CentOS Extras 存储库中,并默认启用,因此,我们可以通过运行以下命令来安装它:
```
# yum install epel-release
```
下载 IUS 社区存储库的 Shell 脚本如下:
```
# curl 'https://setup.ius.io/' -o setup-ius.sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1914 100 1914 0 0 6563 0 --:--:-- --:--:-- --:--:-- 133k
```
安装/启用 IUS 社区存储库:
```
# sh setup-ius.sh
```
运行如下命来检查 IUS 存储库中可用的 PHP 7 版本:
```
# yum --disablerepo="*" --enablerepo="ius" list *php7*
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
Available Packages
mod_php71u.x86_64 7.1.33-1.el7.ius ius
mod_php72u.x86_64 7.2.26-1.el7.ius ius
mod_php73.x86_64 7.3.13-1.el7.ius ius
php71u-bcmath.x86_64 7.1.33-1.el7.ius ius
php71u-cli.x86_64 7.1.33-1.el7.ius ius
php71u-common.x86_64 7.1.33-1.el7.ius ius
php71u-dba.x86_64 7.1.33-1.el7.ius ius
php71u-dbg.x86_64 7.1.33-1.el7.ius ius
php71u-devel.x86_64 7.1.33-1.el7.ius ius
php71u-embedded.x86_64 7.1.33-1.el7.ius ius
```
运行以下命令你可以轻松地从 IUS 存储库中安装 PHP 7.3 到你 CentOS 6/7 系统上:
```
# yum --disablerepo="*" --enablerepo="ius" install php73-common php73-cli php73-gd php73-gd php73-mysqlnd php73-ldap php73-soap php73-mbstring
```
---
via: <https://www.2daygeek.com/install-php-7-on-centos-6-centos-7-rhel-7-redhat-7/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,617 | 用开源工具 Pulp 管理你的软件仓库 | https://opensource.com/article/20/8/manage-repositories-pulp | 2020-09-15T20:54:00 | [
"仓库",
"Pulp"
] | https://linux.cn/article-12617-1.html |
>
> 这篇文章介绍 Pulp,一个开源仓库管理解决方案,它的使用范围和功能在不断增长。
>
>
>

[Foreman](https://opensource.com/article/17/8/system-management-foreman) 是一个强大的管理和自动化产品,它为 Linux 环境的管理员提供了企业级的解决方案,它适用于四个关键场景:供应管理、配置管理、补丁管理和内容管理。Foreman 中内容管理功能的一个主要组成部分是由 Pulp 项目提供的。虽然 Pulp 是这个产品的一个组成部分,但它也是一个独立的、自由开源的项目,自身也在取得巨大的进步。
让我们来看看 Pulp 项目,特别是最新版本 Pulp 3 的功能。
### 什么是 Pulp?
Pulp 是一个管理软件包仓库,并将其提供给大量的消费者的平台。你可以使用 Pulp 在不同环境中镜像、同步、上传和推广各种内容,如 RPM、Python 包、Ansible 集合、容器镜像等。如果你有几十个、几百个甚至上千个软件包,并需要更好的方式来管理它们,Pulp 可以帮助你。
最新的主要版本是 [Pulp 3](https://pulpproject.org/about-pulp-3/),它于 2019 年 12 月发布。Pulp 3 是多年来收集用户需求的结晶,并对现有的 Pulp 架构进行了全面的技术改造,以提高可靠性和灵活性。另外,它还包含了大量的新功能。
### 谁在使用 Pulp?
大多数情况下,在 Pulp 用户管理的企业软件环境中,内容的稳定性和可靠性是最重要的。Pulp 用户希望有一个平台来开发内容,而不用担心仓库可能会消失。他们希望以安全的方式在其生命周期环境的不同阶段推广内容,优化磁盘空间并扩展环境以满足新的需求。他们还需要灵活处理各种内容类型。Pulp 3 提供了这些以及更多功能。
### 在一处管理各类内容
安装 Pulp 后,你可以为你计划管理的内容类型添加[内容插件](https://pulpproject.org/content-plugins/),将内容镜像到本地,添加私人托管的内容,并根据你的需求混合内容。例如,如果你是 Ansible 用户,而你又不想在 Ansible Galaxy 上托管你的私有内容,你可以添加 Pulp Ansible 插件,镜像你所需要的公共 Ansible 内容,并将 Pulp 作为一个内部平台,在你的组织中管理和分发可扩展的公共和私有 Ansible 角色和集合的混合。你可以用任何内容类型执行此操作。有各种各样的内容插件可供选择,包括 RPM、Debian、Python、容器和 Ansible 等等。还有一个文件插件,你可以用它来管理 ISO 镜像等文件。
如果你没有找到你所需的内容类型插件,Pulp 3 引入了新的插件 API 和插件模板,你可以轻松创建一个属于自己的 Pulp 插件。你可以根据[插件编写指南](https://docs.pulpproject.org/plugins/plugin-writer/index.html)自动生成一个最小可用的插件,然后从那里开始构建。
### 高可用性
在 Pulp 3 中,从 MongoDB 到 PostgreSQL 的转变促进了性能和数据完整性的重大改进。Pulp 用户现在有了一个完全开源的技术栈,它可以提供高可用性(HA)和更好的扩展性。
### 仓库版本管理
使用 Pulp 3,你可以毫无风险地进行试验。每次你添加或删除内容时,Pulp 都会创建一个不可变的仓库版本,这样你就可以回滚到早期的版本,从而保证操作的安全性和稳定性。通过使用发布和分发,你可以公开一个仓库的多个版本,你可以将其作为回滚到早期版本的另一种方法。如要回滚,你可以简单地将你的分发指向一个旧的发布。
### 磁盘优化
任何软件开发环境的主要挑战之一是磁盘优化。如果你不断地下载包,例如,你今天需要但明天不再需要的仓库每日构建,那么磁盘空间将很快成为一个问题。Pulp 3 的设计已经考虑到了磁盘优化。当默认下载并保存所有的软件包,你也可以启用“按需”或“流式”选项。“按需”选项只下载和保存客户要求的内容,从而节省了磁盘空间。使用“流式”选项,它也会根据客户的要求进行下载,但它不会将内容保存在 Pulp 中。这对于同步内容是非常理想的,例如,从一个每日仓库同步,并让你在后期免于执行磁盘清理。
### 多种存储选项
即使进行了最好的磁盘优化,随着项目的发展,你可能需要一种方法来扩展你的部署以满足需求。除了本地文件存储,Pulp 还支持一系列的云存储选项,如 Amazon S3 和 Azure,以确保你可以扩展满足你的部署需求。
### 保护你的内容
Pulp 3 可以选择添加 [Certguard](https://pulp-certguard.readthedocs.io/en/latest/) 插件,该插件提供了一个支持 X.509 的 ContentGuard,它要求客户在收到 Pulp 的内容之前提交证明其对内容的权利的证书。
只要客户端的证书没有过期,且由证书颁发机构签署,并在创建时存储在 Certguard 上,任何客户端在请求时提供基于 X.509 或基于 Red Hat 订阅管理证书都将获得授权。客户端使用安全传输层(TLS)提供证书,这证明客户端不仅有证书,还有它的密钥。你可以放心地开发,知道你的内容正在受到保护。
Pulp 团队也在积极为整个 Pulp 部署一个基于角色的访问控制系统,这样管理员就可以确保正确的用户可以访问正确的环境。
### 在容器中试用 Pulp
如果你有兴趣亲自评估 Pulp 3,你可以使用 Docker 或 Podman 轻松[在容器中安装 Pulp 3](https://pulpproject.org/pulp-in-one-container/)。Pulp 团队一直在努力简化安装过程。你也可以使用 [Ansible 剧本](https://pulp-installer.readthedocs.io/en/latest/) 来自动完成 Pulp 3 的全部安装和配置。
---
via: <https://opensource.com/article/20/8/manage-repositories-pulp>
作者:[Melanie Corr](https://opensource.com/users/melanie-corr) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Foreman](https://opensource.com/article/17/8/system-management-foreman) is a robust management and automation product that provides administrators of Linux environments with enterprise-level solutions for four key scenarios: provisioning management, configuration management, patch management, and content management. A major component of the content management functionality in Foreman is provided by the Pulp project. While Pulp is an integral part of this product, it is also a standalone, free, and open source project that is making huge progress on its own.
Let's take a look at the Pulp project, especially the features of the latest release, Pulp 3.
## What is Pulp?
Pulp is a platform for managing repositories of software packages and making them available to a large number of consumers. You can use Pulp to mirror, synchronize, upload, and promote content like RPMs, Python packages, Ansible collections, container images, and more across different environments. If you have dozens, hundreds, or even thousands of software packages and need a better way to manage them, Pulp can help.
The latest major version is [Pulp 3](https://pulpproject.org/about-pulp-3/), which was released in December 2019. Pulp 3 is the culmination of years of gathering user requirements and a complete technical overhaul of the existing Pulp architecture to increase reliability and flexibility. Plus, it includes a vast range of new features.
## Who uses Pulp?
For the most part, Pulp users administer enterprise software environments where the stability and reliability of content are paramount. Pulp users want a platform to develop content without worrying that repositories might disappear. They want to promote content across the different stages of their lifecycle environment in a secure manner that optimizes disk space and scales their environment to meet new demands. They also need the flexibility to work with a wide variety of content types. Pulp 3 provides that and more.
## Manage a wide variety of content in one place
After you install Pulp, you can add [content plugins](https://pulpproject.org/content-plugins/) for the content types that you plan to manage, mirror the content locally, add privately hosted content, and blend content to suit your requirements. If you’re an Ansible user, for example, and you don't want to host your private content on Ansible Galaxy, you can add the Pulp Ansible plugin, mirror the public Ansible content that you require, and use Pulp as an on-premise platform to manage and distribute a scalable blend of public and private Ansible roles and collections across your organization. You can do this with any content type. There is a wide variety of content plugins available, including RPM, Debian, Python, Container, and Ansible, to name but a few. There is also a File plugin, which you can use to manage files like ISO images.
If you don't find a plugin for the content type that you require, Pulp 3 has introduced a new plugin API and plugin template to make it easy to create a Pulp plugin of your own. You can use the [plugin writing guide](https://docs.pulpproject.org/plugins/plugin-writer/index.html) to autogenerate a minimal viable plugin, and then start building from there.
## High availability
With Pulp 3, the change from MongoDB to PostgreSQL facilitated major improvements around performance and data integrity. Pulp users now have a fully open source tech stack that provides high availability (HA) and better scalability.
## Repository versioning
Using Pulp 3, you can experiment without risk. Every time you add or remove content, Pulp creates an immutable repository version so that you can roll back to earlier versions and thereby guarantee the safety and stability of your operation. Using publications and distributions, you can expose multiple versions of a repository, which you can use as another method of rolling back to an earlier version. To roll back, you can simply point your distribution to an older publication.
## Disk optimization
One of the major challenges for any software development environment is disk optimization. If you're downloading a constant stream of packages—for example, nightly builds of repositories that you require today but will no longer require tomorrow—disk space will quickly become an issue. Pulp 3 has been designed with disk optimization in mind. While the default option downloads and saves all software packages, you can also enable either the "on demand" or "streamed" option. The "on demand" option saves disk space by downloading and saving only the content that clients request. With the "streamed" option, you also download upon client request, but you don't save the content in Pulp. This is ideal for synchronizing content, for example, from a nightly repository, and saves you from having to perform a disk cleanup at a later stage.
## Multiple storage options
Even with the best disk optimization, as your project grows, you might need a way to scale your deployment to match your requirements. As well as local file storage, Pulp supports a range of cloud storage options, such as Amazon S3 and Azure, to ensure that you can scale to meet the demands of your deployment.
## Protect your content
Pulp 3 has the option of adding the [Certguard](https://pulp-certguard.readthedocs.io/en/latest/) plugin, which provides an X.509 capable ContentGuard that requires clients to submit a certificate proving their entitlement to content before receiving content from Pulp.
Any client presenting an X.509 or Red Hat Subscription Management-based certificate at request time will be authorized, as long as the client certification is not expired, is signed by the Certificate Authority, and was stored on the Certguard when it was created. The client presents the certificate using transport layer security (TLS), which proves that the client has not only the certificate but also its key. You can develop, confident in the knowledge that your content is being protected.
The Pulp team is also actively working on a role-based access control system for the entire Pulp deployment so that administrators can ensure that the right users have access to the right environments.
## Try Pulp in a container
If you're interested in evaluating Pulp 3 for yourself, you can easily install [Pulp 3 in a Container](https://pulpproject.org/pulp-in-one-container/) using Docker or Podman. The Pulp team is constantly working on simplifying the installation process. You can also use an [Ansible playbook](https://pulp-installer.readthedocs.io/en/latest/) to automate the full installation and configuration of Pulp 3.
## Comments are closed. |
12,618 | Linux 黑话解释:什么是长期支持(LTS)版本?什么是 Ubuntu LTS? | https://itsfoss.com/long-term-support-lts/ | 2020-09-15T21:20:00 | [
"LTS"
] | https://linux.cn/article-12618-1.html | 在 Linux 的世界里,特别是谈到 [Ubuntu](https://ubuntu.com/) 的时候,你会遇到 LTS(<ruby> 长期支持 <rt> Long Term Support </rt></ruby>)这个词。
如果你是一个经验丰富的 Linux 用户,你可能知道 Linux 发行版的各个方面,比如 LTS 版本。但是,新用户或不太懂技术的用户可能不知道。
在这一章 Linux 黑话解释中,你将了解什么是 Linux 发行版的 LTS 版本。
### 什么是长期支持(LTS)版本?
长期支持(LTS)版本通常与应用程序或操作系统有关,你会在较长的时间内获得安全、维护和(有时有)功能的更新。
LTS 版本被认为是最稳定的版本,它经历了广泛的测试,并且大多包含了多年积累的改进。
需要注意的是,LTS 版本的软件不一定涉及功能更新,除非有一个更新的 LTS 版本。但是,你会在 LTS 版本的更新中得到必要的错误修复和安全修复。
LTS 版本被推荐给生产级的消费者、企业和商家,因为你可以获得多年的软件支持,而且软件更新不会破坏系统。
如果你注意到任何软件的非 LTS 版本,它通常是具有新功能和较短支持时间跨度(例如 6-9 个月)的前沿版本,而 LTS 版本的支持时间为 3-5 年。

为了让大家更清楚的了解 LTS 和非 LTS 版本的区别,我们来看看选择 LTS 版本的一些优缺点。
#### LTS 版本的优点
* 软件更新与安全和维护修复的时间很长(Ubuntu 有 5 年支持)
* 广泛的测试
* 软件更新不会带来破坏系统的变化
* 你有足够的时间为下一个 LTS 版本准备系统
#### LTS 版本的缺点
* 不提供最新和最强的功能
* 你可能会错过最新的硬件支持
* 你也可能会错过最新的应用程序升级
现在,你知道了什么是 LTS 版本及其优缺点,是时候了解一下 Ubuntu 的 LTS 版本了。Ubuntu 是最流行的 Linux 发行版之一,也是少数同时拥有 LTS 和非 LTS 版本的发行版之一。
这就是为什么我决定用一整个章节来介绍它。
### 什么是 Ubuntu LTS?
自 2006 年以来,Ubuntu 每六个月发布一个非 LTS 版本,每两年发布一个 LTS 版本,这一点一直如此。
最新的 LTS 版本是 [Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/),它将被支持到 2025 年 4 月。换句话说,Ubuntu 20.04 在那之前都会收到软件更新。非 LTS 版本只支持九个月。
你会发现 Ubuntu LTS 版本总是被标为 “LTS”。至少,在 [Ubuntu 官方网站](https://ubuntu.com)上浏览最新的 Ubuntu 版本时是这样的。
为了让你更清楚,如果你见过 Ubuntu 16.04 LTS,那就意味着:**它早在 2016 年 4 月就已经发布,并且支持到 2021 年**(想想**5 年的软件更新**)。
同样,你也可以通过计算每个 Ubuntu LTS 版本发布日期接下来的**5 年**软件支持期来估计其更新支持情况。
### Ubuntu LTS 软件更新包括什么?

Ubuntu LTS 版本在其发布的生命周期内都会收到安全和维护更新。除非该版本达到[生命末期(EOL)](https://itsfoss.com/end-of-life-ubuntu/),否则你将获得所有必要的安全和错误修复。
在 LTS 版本中你不会注意到任何功能升级。所以,如果你想尝试最新的实验性技术,你可能需要将你的 Ubuntu 版本升级到一个非 LTS 版本。
我建议你参考我们最新的 [Ubuntu 升级指南](https://itsfoss.com/upgrade-ubuntu-version/)来了解更多关于升级 Ubuntu 的信息。
我也建议你阅读我们的文章[安装哪个 Ubuntu 版本](https://itsfoss.com/which-ubuntu-install/),以消除你对不同 Ubuntu 版本的困惑,比如 [Xubuntu](https://xubuntu.org/) 或 [Kubuntu](https://kubuntu.org/),它们有什么不同。
我希望你现在对 LTS 这个术语有了更好的理解,尤其是在 Ubuntu LTS 方面。敬请关注未来更多的 Linux 黑话解释。
---
via: <https://itsfoss.com/long-term-support-lts/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In Linux world, specially when it comes to [Ubuntu](https://ubuntu.com/?ref=itsfoss.com), you’ll come across the term LTS (long term support).
If you’re an experienced Linux user, you probably know the various aspects of a Linux distribution like an LTS release. But, new users or less tech-savvy users may not know about it.
In this chapter of Linux Jargon Buster, you’ll learn about what is an LTS release for Linux distributions.
## What is a Long Term Support (LTS) Release?
Long-Term Support (LTS) release is normally associated with an application or an operating system for which you will get security, maintenance and (sometimes) feature updates for a longer duration of time.
The LTS versions are considered to be the most stable releases which undergoes extensive testing and mostly includes years of improvements along the way.
It is important to note that an LTS version of software does not necessarily involve feature updates unless there’s a newer LTS release. But, you will get the necessary bug fixes and security fixes in the updates of a Long Term Support version.
An LTS release is recommended for production-ready consumers, businesses, and enterprises because you get years of software support and no system-breaking changes with software updates.
If you notice a non-LTS release for any software, it is usually the bleeding-edge version of it with new features and a short span of support (say 6-9 months) when compared to 3-5 years of support on an LTS release.

To give you more clarity on LTS and non-LTS releases, let’s take a look at some pros and cons of choosing an LTS release.
### Pros of LTS releases
- Software updates with security and maintenance fixes for a long time (5 year support for Ubuntu).
- Extensive testing
- No system-breaking changes with software updates
- You get plenty of time to prep your system for the next LTS release
### Cons of LTS releases
- Does not offer the latest and greatest features
- You may miss out on the latest hardware support
- You may also miss out on the latest application upgrades
Now, that you know what is an LTS release and its pros and cons it’s time to know about Ubuntu’s LTS release. Ubuntu is one of the most popular Linux distribution and one of the few distributions that has both LTS and non-LTS releases.
This is why I decided to dedicate an entire section to it.
## What is Ubuntu LTS?
Ubuntu has a non-LTS release every six months and a LTS release every 2 years since 2006 and that’s not going to change.
The latest LTS release is — [Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/) and it will be supported until **April 2025**. In other words, Ubuntu 20.04 will receive software updates till then. The non-LTS releases are supported for nine months only.
You will always find an Ubuntu LTS release to be labelled as “**LTS**“. At least, when it comes to the [official Ubuntu website](https://ubuntu.com/?ref=itsfoss.com) to explore the latest Ubuntu releases.
To give you some clarity, if you notice Ubuntu 22.04 LTS, that means — it was **released back in April 2022 and is supported until 2027** (considering **5 years of software updates**).
Similarly, you can guess the update support for each Ubuntu LTS release by considering the next **5 years** of its release date for software support.
## Ubuntu LTS software updates: What does it include?
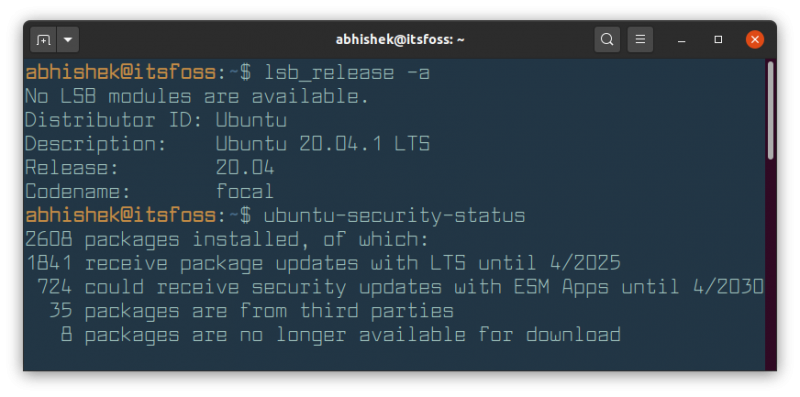
Ubuntu LTS versions receive security and maintenance updates for the lifecycle of their release. Unless the release reaches the [End of Life](https://itsfoss.com/end-of-life-ubuntu/), you will get all the necessary security and bug fixes.
You will not notice any functional upgrades in an LTS release. So, if you want to try the latest experimental technologies, you may want to upgrade your Ubuntu release to a non-LTS release.
I’d suggest you to refer our latest [Ubuntu upgrade guide](https://itsfoss.com/upgrade-ubuntu-version/) to know more about upgrading Ubuntu.
## Further readings…
I would also recommend you to read our article on [which Ubuntu version to install](https://itsfoss.com/which-ubuntu-install/) to clear your confusion on different Ubuntu flavours available like [Xubuntu](https://xubuntu.org/?ref=itsfoss.com) or [Kubuntu](https://kubuntu.org/?ref=itsfoss.com) and how are they different.
[Explained: Which Ubuntu Version Should I Use?Confused about Ubuntu vs Xubuntu vs Lubuntu vs Kubuntu?? Want to know which Ubuntu flavor you should use? This beginner’s guide helps you decide which Ubuntu should you choose.](https://itsfoss.com/which-ubuntu-install/)

Another common term you'll come across is the [rolling release](https://itsfoss.com/rolling-release/). You should learn more on that as well.
[What is a Rolling Release Distribution?What is rolling release? What is a rolling release distribution? How is it different from the point release distributions? All your questions answered.](https://itsfoss.com/rolling-release/)

I hope you have a better understanding of the term LTS now specially when it comes to Ubuntu LTS. Stay tuned for more Linux jargon explainers in the future. |
12,620 | 用 InDesign 的开源替代方案 Scribus 设计书籍封面 | https://opensource.com/article/20/9/open-source-publishing-scribus | 2020-09-16T21:38:54 | [
"书籍",
"InDesign"
] | https://linux.cn/article-12620-1.html |
>
> 使用开源的出版软件 Scribus 来制作你的下一本自出版书籍的封面。
>
>
>

我最近写完了一本关于 [C 语言编程](https://opensource.com/article/20/8/c-programming-cheat-sheet)的书,我通过 [Lulu.com](https://www.lulu.com/) 自行出版。我已经用 Lulu 做了好几个图书项目,它是一个很棒的平台。今年早些时候,Lulu 做了一些改变,让作者在创作图书封面时有了更大的控制权。以前,你只需上传一对大尺寸图片作为书的封面和封底。现在,Lulu 允许作者上传完全按照你的书的尺寸定制的 PDF。
你可以使用 [Scribus](https://www.scribus.net/) 这个开源页面布局程序来创建封面。下面是我的做法。
### 下载一个模板
当你在 Lulu 上输入图书的信息时,最终会进入<ruby> 设计 <rt> Design </rt></ruby>栏。在该页面的<ruby> 设计封面 <rt> Design Your Cover </rt></ruby>部分,你会发现一个方便的<ruby> 下载模板 <rt> Download Template </rt></ruby>按钮,它为你的图书封面提供了一个 PDF 模板。

下载此模板,它为你提供了在 Scribus 中创建自己的书籍封面所需的信息。

最重要的细节是:
* <ruby> 文件总尺寸(含出血) <rt> Total Document Size (with bleed) </rt></ruby>
* <ruby> 出血区(从裁切边缘) <rt> Bleed area (from trim edge) </rt></ruby>
* <ruby> 书脊区 <rt> Spine area </rt></ruby>
<ruby> 出血 <rt> Bleed </rt></ruby>是一个印刷术语,在准备“印刷就绪”文件时,这个术语很重要。它与普通文件中的页边距不同。打印文件时,你会为顶部、底部和侧面设置一个页边距。在大多数文档中,页边距通常为一英寸左右。
但在印刷就绪的文件中,文档的尺寸需要比成品书大一些,因为书籍的封面通常包括颜色或图片,一直到封面的边缘。为了创建这种设计,你要使颜色或图片超出你的边距,印刷厂就会把多余的部分裁切掉,使封面缩小到准确的尺寸。因此,“裁切”就是印刷厂将封面精确地裁剪成相应尺寸。而“出血区”就是印刷厂裁掉的多余部分。
如果你没有出血区,印刷厂就很难完全按照尺寸印刷封面。如果打印机只偏离了一点点,你的封面最终会在边缘留下一个微小的、白色的、没有印刷的边缘。使用出血和修剪意味着你的封面每次都能看起来正确。
### 在 Scribus 中设置书籍的封面文档
要在 Scribus 中创建新文档,请从定义文档尺寸的<ruby> 新文档 <rt> New Document </rt></ruby>对话框开始。单击<ruby> 出血 <rt> Bleeds </rt></ruby>选项卡,并输入 PDF 模板所说的出血尺寸。Lulu 图书通常在所有边缘使用 0.125 英寸的出血量。
对于 Scribus 中的文档总尺寸,你不能只使用 PDF 模板上的文档总尺寸。如果这样做,你的 Scribus 文档的尺寸会出现错误。相反,你需要做一些数学计算来获取正确的尺寸。
看下 PDF 模板中的<ruby> 文件总尺寸(含出血) <rt> Total Document Size (with bleed) </rt></ruby>。这是将要发送给打印机的 PDF 的总尺寸,它包括封底、书脊和封面(包含出血)。要在 Scribus 中输入正确的尺寸,你必须从所有边缘中减去出血。例如,我最新的书的尺寸是<ruby> 四开本 <rt> Crown Quarto </rt></ruby>,装订后尺寸为 7.44" x 9.68",书脊宽度为 0.411"。加上 0.125" 的出血量,文件总尺寸(含出血)是 15.541" × 9.93"。因此,我在 Scribus 中的文档尺寸是:
* 宽:15.541-(2 x 0.125)=15.291"
* 高:9.93-(2 x 0.125)=9.68"

这将设置一个新的适合我的书的封面尺寸的 Scribus 文档。新的 Scribus 文档尺寸应与 PDF 模板上列出的“文件总尺寸(含出血)”完全匹配。
### 从书脊开始
在 Scribus 中创建新的书籍封面时,我喜欢从书脊区域开始。这可以帮助我验证我是否在 Scribus 中正确定义了文档。
使用<ruby> 矩形 <rt> Rectangle </rt></ruby>工具在文档上绘制一个彩色方框,书脊需要出现在那里。你不必完全按照正确的尺寸和位置来绘制,只要大小差不多并使用<ruby> 属性 <rt> Properties </rt></ruby>来设置正确的值即可。在形状的属性中,选择左上角基点,然后输入书脊需要放在的 x、y 位置和尺寸。同样,你需要做一些数学计算,并使用 PDF 模板上的尺寸作为参考。

例如,我的书的修边尺寸是 7.44"×9.68",这是印刷厂修边后的封面和封底的尺寸。我的书的书脊大小是 0.411",出血量是 0.125"。也就是说,书脊的左上角 X、Y 的正确位置是:
* X 位置(出血量+裁剪宽度):0.411+7.44=7.8510"
* Y 位置(减去出血量):-0.125"
矩形的尺寸是我的书封面的全高(包括出血)和 PDF 模板中标明的书脊宽度。
* 宽度:0.411"
* 高度:9.93"
将矩形的<ruby> 填充 <rt> Fill </rt></ruby>设置为你喜欢的颜色,将<ruby> 笔触 <rt> Stroke </rt></ruby>设置为<ruby> 无 <rt> None </rt></ruby>以隐藏边界。如果你正确地定义了 Scribus 文档,你应该最终得到一个矩形,它可以延伸到位于文档中心的图书封面的顶部和底部边缘。

如果矩形与文档不完全匹配,可能是你在创建 Scribus 文档时设置了错误的尺寸。由于你还没有在书的封面上花太多精力,所以可能最容易的做法是重新开始,而不是尝试修复你的错误。
### 剩下的就看你自己了
接下来,你可以创建你的书的封面的其余部分。始终使用 PDF 模板作为指导。封底在左边,封面在右边
我可以做一个简单的书籍封面,但我缺乏艺术能力,无法创造出真正醒目的设计。在自己设计了几个书的封面后,我对那些能设计出好封面的人产生了敬意。但如果你只是需要制作一个简单的封面,你可以通过开源软件自己动手。
---
via: <https://opensource.com/article/20/9/open-source-publishing-scribus>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently finished writing a book about [C programming](https://opensource.com/article/20/8/c-programming-cheat-sheet), which I self-published through [Lulu.com](https://www.lulu.com/). I've used Lulu for several book projects, and it's a great platform. Earlier this year, Lulu made changes that give authors greater control over creating their book covers. Previously, you just uploaded a pair of large-format images for the front and back book covers. Now, Lulu allows authors to upload a custom PDF exactly sized to your book's dimensions.
You can create the cover using [Scribus](https://www.scribus.net/), the open source page layout program. Here's how I do it.
## Download a template
When you're entering your book project information on Lulu's website, eventually, you'll navigate to the **Design** tab. Under the **Design Your Cover** section on this page, you will find a handy **Download Template** button that provides a PDF template for your book cover.
(Jim Hall, CC BY-SA 4.0)
Download this template, which gives you the information you need to create your own book cover in Scribus.

(Jim Hall, CC BY-SA 4.0)
The most important details are:
- Total document size (with bleed)
- Bleed area (from trim edge)
- Spine area
**Bleed** is a printing term that is important when preparing a **print-ready** file for a printer. It is different from a margin in a regular document. When you print a document, you set a page margin for the top, bottom, and sides. In most documents, the margin is usually around an inch.
But in print-ready files, the document size needs to be a little bigger than the finished book because book covers usually include colors or pictures that go all the way to the cover's edge. To create this design, you make the colors or images go beyond your margin, and the print shop trims off the excess to get the cover down to the exact size. Therefore, the **trim** is where the print shop cuts the cover exactly to size. The **bleed area** is the extra part the printer cuts off.
If you didn't have a bleed, the print shop would have a hard time printing the cover exactly to size. If the printer was off by only a little bit, your cover would end up with a tiny, white, unprinted border on one edge. Using a bleed and trim means your cover looks right every time.
## Set up your book cover document in Scribus
To create a new document in Scribus, start with the **New Document** dialog box where you define the document's dimensions. Click on the **Bleeds** tab and enter the bleed size the PDF template says to use. Lulu books usually use 0.125" bleeds on all edges.
For the total document dimension in Scribus, you can't just use the total document size on the PDF template. If you do, your Scribus document will have the wrong dimensions. Instead, you need to do a little math to get the right size.
Look at **Total Document Size (with bleed)** on the PDF template. This is the total size of the PDF that will be sent to the printer, and it includes the back cover, the book spine, and the front cover—including the bleeds. To enter the right dimensions in Scribus, you have to subtract the bleeds from all edges. For example, my latest book is Crown quarto size, which is 7.44" x 9.68" with a spine width of 0.411" after it's bound. With 0.125" bleeds, the **Total Document Size (with bleed)** is 15.541" x 9.93". So, my document size in Scribus is:
- Width: 15.541-(2 x 0.125)=15.291"
- Height: 9.93-(2 x 0.125)=9.68"
(Jim Hall, CC BY-SA 4.0)
This sets up a new Scribus document that's the right size for my book cover. The new Scribus document dimensions should match exactly what is listed as the **Total Document Size (with bleed)** on the PDF template.
## Start with the spine
When I create a new book cover in Scribus, I like to start with the spine area. This helps me verify that I defined the document correctly in Scribus.
Use the **Rectangle** tool to draw a colored box on the document where the book's spine needs to go. You don't have to draw it exactly the right size and location; just get close and use the **Properties** to set the correct values. In the shape's **Properties**, select the upper-left base point, and enter the x,y position and dimensions where the spine needs to go. Again, you'll need to do a little math and use the dimensions on the PDF template as a reference.
(Jim Hall, CC BY-SA 4.0)
For example, my book's trim size is 7.44" x 9.68"; that's the size of the front and back covers after the printer trims it. My book's spine area is 0.411", and its bleed is 0.125". That means the correct upper-left x,y position for the book's spine is:
- X-Pos (bleed + trim width): 0.411+7.44=7.8510"
- Y-Pos (minus bleed): -0.125"
The rectangle's dimensions are the full height (including bleed) of my book cover and the spine width indicated in the PDF template:
- Width: 0.411"
- Height: 9.93"
Set the rectangle's **Fill** to your favorite color and the **Stroke** to **None** to hide the border. If you defined your Scribus document correctly, you should end up with a rectangle that stretches to the top and bottom edges of your book cover positioned in the center of the document.
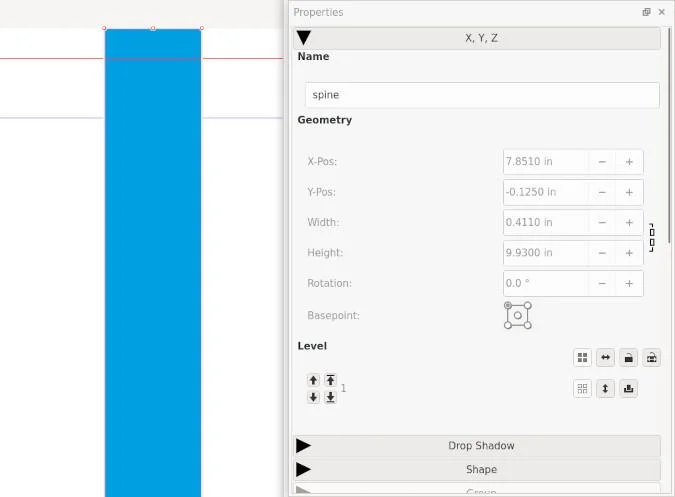
(Jim Hall, CC BY-SA 4.0)
If the rectangle doesn't fit the document exactly, you probably set the wrong dimensions when you created the Scribus document. Since you haven't put a lot of effort into the book cover yet, it's probably easiest to start over rather than trying to fix your mistakes.
## The rest is up to you
From there, you can create the rest of your book's cover. Always use the PDF template as a guide. The back cover is on the left, and the front cover is on the right.
I can manage a simple book cover, but I lack the artistic abilities to create a truly eye-catching design. After designing several of my own book covers, I've gained respect for those who can design a good cover. But if you just need to create a simple book cover, you can do it yourself with open source software.
## 1 Comment |
12,621 | 6 个在团队中使用 Git 的最佳实践 | https://opensource.com/article/20/7/git-best-practices | 2020-09-16T23:50:02 | [
"Git"
] | /article-12621-1.html |
>
> 采用这些 Git 协作策略,让团队工作更高效。
>
>
>

Git 非常有助于小团队管理他们的软件开发进度,但有些方法能让你变得更高效。我发现了许多有助于我的团队的最佳实践,尤其是当不同 Git 水平的新人加入时。
### 在你的团队中正式确立 Git 约定
每个人都应当遵循对于分支命名、标记和编码的规范。每个组织都有自己的规范或者最佳实践,并且很多建议都可以从网上免费获取,而重要的是尽早选择合适的规范并在团队中遵循。
同时,不同的团队成员的 Git 水平参差不齐。你需要创建并维护一组符合团队规范的基础指令,用于执行通用的 Git 操作。
### 正确地合并变更
每个团队成员都需要在一个单独的功能分支上开发。但即使是使用了单独的分支,每个人也会修改一些共同的文件。当把更改合并回 `master` 分支时,合并通常无法自动进行。可能需要手动解决不同的人对同一文件不同变更的冲突。这就是你必须学会如何处理 Git 合并的原因。
现代编辑器具有协助解决 [Git 合并冲突](https://opensource.com/article/20/4/git-merge-conflict)的功能。它们对同一文件的每个部分提供了合并的各种选择,例如,是否保留你的更改,或者是保留另一分支的更改,亦或者是全部保留。如果你的编辑器不支持这些功能,那么可能是时候换一个代码编辑器了。
### 经常变基你的功能分支
当你持续地开发你的功能分支时,请经常对它做<ruby> 变基 <rt> rebase </rt></ruby>:`rebase master`。这意味着要经常执行以下步骤:
```
git checkout master
git pull
git checkout feature-xyz # 假设的功能分支名称
git rebase master # 可能需要解决 feature-xyz 上的合并冲突
```
这些步骤会在你的功能分支上[重写历史](https://opensource.com/article/20/4/git-rebase-i)(这并不是件坏事)。首先,它会使你的功能分支获得 `master` 分支上当前的所有更新。其次,你在功能分支上的所有提交都会在该分支历史的顶部重写,因此它们会顺序地出现在日志中。你可能需要一路解决遇到的合并冲突,这也许是个挑战。但是,这是解决冲突最好的时机,因为它只影响你的功能分支。
在解决完所有冲突并进行回归测试后,如果你准备好将功能分支合并回 `master`,那么就可以在再次执行上述的变基步骤几次后进行合并:
```
git checkout master
git pull
git merge feature-xyz
```
在此期间,如果其他人也将和你有冲突的更改推送到 `master`,那么 Git 合并将再次发生冲突。你需要解决它们并重新进行回归测试。
还有一些其他的合并哲学(例如,只使用合并而不使用变基以防止重写历史),其中一些甚至可能更简单易用。但是,我发现上述方法是一个干净可靠的策略。提交历史日志将以有意义的功能序列进行排列。
如果使用“纯合并”策略(上面所说的,不进行定期的变基),那么 `master` 分支的历史将穿插着所有同时开发的功能的提交。这样混乱的历史很难回顾。确切的提交时间通常并不是那么重要。最好是有一个易于查看的历史日志。
### 在合并前压扁提交
当你在功能分支上开发时,即使再小的修改也可以作为一个提交。但是,如果每个功能分支都要产生五十个提交,那么随着不断地增添新功能,`master` 分支的提交数终将无谓地膨胀。通常来说,每个功能分支只应该往 `master` 中增加一个或几个提交。为此,你需要将多个提交<ruby> 压扁 <rt> Squash </rt></ruby>成一个或者几个带有更详细信息的提交中。通常使用以下命令来完成:
```
git rebase -i HEAD~20 # 查看可进行压扁的二十个提交
```
当这条命令执行后,将弹出一个提交列表的编辑器,你可以通过包括<ruby> 遴选 <rt> pick </rt></ruby>或<ruby> 压扁 <rt> squash </rt></ruby>在内的数种方式编辑它。“遴选”一个提交即保留这个提交。“压扁”一个提交则是将这个提交合并到前一个之中。使用这些方法,你就可以将多个提交合并到一个提交之中,对其进行编辑和清理。这也是一个清理不重要的提交信息的机会(例如,带错字的提交)。
总之,保留所有与提交相关的操作,但在合并到 `master` 分支前,合并并编辑相关信息以明确意图。注意,不要在变基的过程中不小心删掉提交。
在执行完诸如变基之类的操作后,我会再次看看 `git log` 并做最终的修改:
```
git commit --amend
```
最后,由于重写了分支的 Git 提交历史,必须强制更新远程分支:
```
git push -f
```
### 使用标签
当你完成测试并准备从 `master` 分支部署软件到线上时,又或者当你出于某种原因想要保留当前状态作为一个里程碑时,那么可以创建一个 Git 标签。对于一个积累了一些变更和相应提交的分支而言,标签就是该分支在那一时刻的快照。一个标签可以看作是没有历史记录的分支,也可以看作是直接指向标签创建前那个提交的命名指针。
所谓的“配置控制”就是在不同的里程碑上保存代码的状态。大多数项目都有一个需求,能够重现任一里程碑上的软件源码,以便在需要时重新构建。Git 标签为每个代码的里程碑提供了一个唯一标识。打标签非常简单:
```
git tag milestone-id -m "short message saying what this milestone is about"
git push --tags # 不要忘记将标签显式推送到远程
```
考虑这样一种情况:Git 标签对应的软件版本已经分发给客户,而客户报告了一个问题。尽管代码库中的代码可能已经在继续开发,但通常情况下为了准确地重现客户问题以便做出修复,必须回退到 Git 标签对应的代码状态。有时候新代码可能已经修复了那个问题,但并非一直如此。通常你需要切换到特定的标签并从那个标签创建一个分支:
```
git checkout milestone-id # 切换到分发给客户的标签
git checkout -b new-branch-name # 创建新的分支用于重现 bug
```
此外,如果带附注的标记和带签名的标记有助于你的项目,可以考虑使用它们。
### 让软件运行时打印标签
在大多数嵌入式项目中,从代码版本构建出的二进制文件有固定的名称,这样无法从它的名称推断出对应的 Git 标签。在构建时“嵌入标签”有助于将未来发现的问题精准地关联到特定的构建版本。在构建过程中可以自动地嵌入标签。通常,`git describe` 生成的标签字符串会在代码编译前插入到代码中,以便生成的可执行文件能够在启时时输出标签字符串。当客户报告问题时,可以指导他们给你发送启动时输出的内容。
### 总结
Git 是一个需要花时间去掌握的复杂工具。使用这些实践可以帮助团队成功地使用 Git 协作,无论他们的知识水平。
---
via: <https://opensource.com/article/20/7/git-best-practices>
作者:[Ravi Chandran](https://opensource.com/users/ravichandran) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LazyWolfLin](https://github.com/LazyWolfLin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,624 | 免费开源的在线 Markdown 编辑器 | https://itsfoss.com/online-markdown-editors/ | 2020-09-18T00:37:59 | [
"Markdown"
] | https://linux.cn/article-12624-1.html | 
[Markdown](https://en.wikipedia.org/wiki/Markdown) 是一种有用的轻量级[标记语言](https://en.wikipedia.org/wiki/Markup_language),很多人喜欢用它来编写文档或做网页发布。很多人都使用 Markdown 来写文章。
有[几个适用于 Linux 的 Markdown 编辑器](https://itsfoss.com/best-markdown-editors-linux/),你可以安装并使用。
但是,如果你不想在你的系统上安装另一个程序怎么办?也许你暂时使用的系统无法安装一个应用程序?也许你只是想要一个能让你实时协作的 Markdown 编辑器?
无论你的需求是什么,在线 Markdown 编辑器通过提供协作功能、发布集成、笔记同步和一些在线功能,让很多事情变得简单。
因此,我整理了一份在线 Markdown 编辑器列表。
### 免费的在线 Markdown 编辑器
我尽量把重点放在代码开源的在线 Markdown 编辑器上。你可以使用它们的官方网站或将其部署到你的服务器上。
注:本列表没有特定排名顺序。
#### 1、StackEdit

[StackEdit](https://itsfoss.com/stackedit-markdown-editor/) 是目前最流行的开源在线 Markdown 编辑器之一。
它提供了一个很好的用户界面,并有一堆有用的功能。协作能力、同步能力,以及能够将你的文件发布/保存到 Blogger、WordPress、GitHub 和其他一些服务是 StackEdit 的一些关键功能。
不要忘了,你还可以使用一些 Markdown 扩展来支持 LaTeX 数学表达式、UML 图等。它的界面是一个所见即所得的编辑器,可以让你轻松使用 Markdown。它还可以离线工作,如果你需要的话,它还提供了一个 chrome 应用程序和扩展。
在 StackEdit 上导入/导出文件也很容易。如果你需要在你的服务器上托管它,你可以看看它在 [GitHub](https://github.com/benweet/stackedit) 上的源代码,了解更多细节。
* [StackEdit](https://stackedit.io/)
#### 2、Dillinger

Dillinger 也是一个有趣的开源在线 Markdown 编辑器。与 StackEdit 类似,你也可以与 Dropbox、GitHub、Medium、Google Drive、Bitbucket 和 OneDrive 链接并保存文件。
你也可以选择在需要时简单地导入/导出文件。Dillinger 的用户界面比你在 StackEdit 上看到的更简单,但它也可以工作。与 StackEdit 不同的是,你没有 LaTeX 表达式或图表的 Markdown 扩展支持,如果你只是需要一个简单的在线 Markdown 编辑器,这是一个不错的选择。
如果你需要,你可以选择将它部署在服务器上的 Docker 容器中。关于它的更多技术细节,你不妨看看它的 [GitHub 页面](https://github.com/joemccann/dillinger)。
* [Dillinger](https://dillinger.io/)
#### 3、[Write.as](http://Write.as)

[Write.as](http://Write.as) 基于该团队开发的自由开源软件 [WriteFreely](https://writefreely.org/),所以如果你愿意的话,你可以简单地把它托管在自己的服务器上免费使用它。
你也可以使用 [Write.as](http://Write.as) 服务作为一个具有基本功能的免费在线 Markdown 编辑器。为了使它发挥最大的作用,你可能想选购一份付费订阅。付费的功能包括自定义主题、新闻通讯、照片托管和多个博客等等。
它支持 Markdown,可以让 [Mastodon](https://itsfoss.com/mastodon-open-source-alternative-twitter/)、[ActivityPub](https://en.wikipedia.org/wiki/ActivityPub) 和 [Pleroma](https://pleroma.social/) 上的任何人轻松关注和分享你的博客文章。
你可以在它的 [GitHub 页面](https://github.com/writeas/writefreely)上探索更多关于 WriteFreely 的信息,或者使用 [Write.as](http://Write.as) 开始。
* [Write.as](https://write.as/)
#### 4、[Editor.md](http://Editor.md)

这是一个有趣的开源 Markdown 编辑器,还可以嵌入到自己的网页上。
它支持实时预览、GitHub 风格的 Markdown,它有一个所见即所得的编辑器以及一堆有用的功能。除了基本的 Markdown 支持外,它还支持表情符、LaTeX 表达式、流程图等。
你也可以选择自己托管,更多信息请看它的 [GitHub 页面](https://github.com/pandao/editor.md)。
* [Editor.md](http://editor.md.ipandao.com/en.html)
#### 5、CodiMD

CodiMD 从一开始就不是一个成熟的在线服务。但是,它是一个开源项目,通过托管在服务器上,你可以实时协作文档或笔记。
它基于 [HackMD](https://hackmd.io/) 的源代码,并提供了一个[演示实例](https://demo.codimd.org/)来提供测试。我个人很喜欢它还提供了一个黑暗模式,而且很容易使用。
对于它未来的发布版本(在写这篇文章的时候),它将改名为 “HedgeDoc”。
你可以在它的 [GitHub 页面](https://github.com/codimd/server)上找到所有关于通过 Docker/Kubernetes 在服务器上部署它的相关信息以及其他手动配置选项。
* [CodiMD](https://demo.codimd.org)
#### 6、[Wri.pe](http://Wri.pe)

[Wri.pe](http://Wri.pe) 是一款简单的开源在线 Markdown 编辑器,虽然已经不再维护,但它仍然活着而且可用。
它的特点是实时预览和可以导出或保存你的笔记到 Dropbox/Evernote。考虑到它没有积极维护,你可能不会依赖它,但当我测试它时,它和预期一样可以工作。
你可以看看它的 [GitHub 页面](https://github.com/masuidrive/open-wripe)或官方网站来了解更多关于它的信息。
* [Wri.pe](https://wri.pe/)
### 附带提名
下面是一些提供 Markdown 访问的工具。
#### Markdown Web Dingus

这是由 Markdown 语言的创造者提供的一个简单而免费的在线 Markdown 编辑器。它并不是一个成熟的在线编辑器,也不支持导入/导出,
但是,如果你只是想要一个在线编辑器来预览你的 Markdown 代码,这可能是一个不错的选择。不仅仅局限于编辑器,你还可以在网站的侧边栏得到一个语法速查表。所以,你也可以在这里尝试和学习。
* [Markdown Web Dingus](https://daringfireball.net/projects/markdown/dingus)
#### Markdown Journal

[Markdown Journal](https://markdownjournal.com/) 是 [GitHub](https://github.com/maciakl/MarkdownJournal) 上的一个有趣的开源项目,但已经停止开发了。你可以通过它的在线编辑器使用 Markdown 语言创建日记,并直接保存在你的 Dropbox 账户上。当我试图创建日志时,我注意到发生了内部服务器错误,但你可以了解一下它。
#### Etherpad

[Etherpad](https://etherpad.org/) 是另一个令人印象深刻的开源在线编辑器,但它并没有开箱即用的 Markdown 支持。你可能会注意到通过一些插件可以在你的服务器上启用 Markdown 编辑,但还不够完美。所以,你可能要注意一点。它有一个[公共实例](https://github.com/ether/etherpad-lite/wiki/Sites-that-run-Etherpad-Lite)的列表,也可以尝试一下。
### 总结
考虑到很多在线编辑器、CMS 和记事本服务都支持 Markdown,如果你想把它发布到网站上,像 [WordPress](https://wordpress.com/) 这样的服务/应用也是一个不错的选择。
你更喜欢用哪个 Markdown 编辑器?我是否错过了你最喜欢的东西?请在下面的评论中告诉我。
---
via: <https://itsfoss.com/online-markdown-editors/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Markdown](https://en.wikipedia.org/wiki/Markdown) is a useful lightweight [markup language](https://en.wikipedia.org/wiki/Markup_language) and a lot of people prefer for writing documentation or web publishing. Many of us at It’s FOSS use markdown for writing our articles.
There are [several Markdown editors available for Linux](https://itsfoss.com/best-markdown-editors-linux/) that you can install and use.
But, what if you don’t want to install another program on your system? Perhaps you are using a system temporarily and cannot install an application. Maybe you just want a markdown editor that lets you collaborate in real time?
No matter what you require, online markdown editors make a lot of things easy by providing collaboration features, publishing integration, note synchronization, and some online-only features.
Hence, I’ve compiled a list of the best online markdown editors.
## Free Online Markdown Editors
I have tried to keep the focus on online markdown editor with open source code. You may use the official website or deploy them on your server.
**Note: ***The list is in no particular order of ranking.*
### 1. StackEdit
[StackEdit](https://itsfoss.com/stackedit-markdown-editor/) is one of the most popular open-source online Markdown editors available.
It provides a great user interface and offers a bunch of useful features. The ability to collaborate, synchronizing capability, and being able to publish/save your files to Blogger, WordPress, GitHub, and a couple of other services are some key features that you get with StackEdit.
Not to forget, you also get extended markdown support with some extensions available to support LaTeX mathematical expressions, UML diagrams, and more. It presents a [WYSIWYG editor](https://itsfoss.com/open-source-wysiwyg-editors/) that makes it easy for you to work with Markdown. It also works offline and offers a chrome app and extension — if that’s your requirement.
It’s easy to import/export files on StackEdit as well. You can take a look at its source code on [GitHub](https://github.com/benweet/stackedit) for more details if you need to host it on your server.
### 2. Dillinger
Dillinger is yet another interesting open-source online Markdown editor. Similar to StackEdit, you also get the ability to link and save the documents with Dropbox, GitHub, Medium, Google Drive, Bitbucket, and OneDrive.
You can also choose to simply import/export files when needed. The user interface for Dillinger is simpler than what you get on StackEdit — but it gets the job intended. Unlike StackEdit, you may not get extended Markdown support with LaTeX expressions or diagrams but if you just need simple online Markdown editor, this is a good pick.
If you need, you can choose to deploy it in a Docker container on your server. For more technical details on it, you might want to check out its [GitHub page](https://github.com/joemccann/dillinger).
### 3. Write.as
Write.as is based on the free and open source software [WriteFreely](https://writefreely.org/), developed by the same team. So you can simply host it on your own server and start using it for free if you want.
You can also use Write.as service as a free online Markdown editor with basic features. To make the most out of it, you may want to choose a subscription. Some paid features include custom themes, newsletters, photo hosting, and multiple blogs.
It supports Markdown and also lets anyone on [Mastodon](https://itsfoss.com/mastodon-open-source-alternative-twitter/), [ActivityPub](https://en.wikipedia.org/wiki/ActivityPub), and [Pleroma](https://pleroma.social/) to follow and share your blog posts easily.
You can explore more about WriteFreely on its [GitHub page](https://github.com/writeas/writefreely) or get started using Write.as.
### 4. Editor.md

An interesting open-source Markdown editor that you can also embed on your own web pages if you require.
It supports real-time preview, GitHub flavored markdown, and also presents a WYSIWYG editor along with a bunch of useful features. In addition to the basic Markdown support, it also supports emojis, LaTeX expressions, Flowchart, and more.
You can choose to configure your own by hosting it yourself as well. Take a look at its [GitHub page](https://github.com/pandao/editor.md) for more information.
### 5. CodiMD
CodiMD isn’t available as a full-fledged online service from the get-go. But, it is an open-source project that lets you collaborate on documentations or notes in real-time by giving you the ability to host it on your server.
It’s based on [HackMD](https://hackmd.io/)‘s source code and offers a [demo instance](https://demo.codimd.org/) to test it out. Personally, I like the fact that it also offers a dark mode and it’s easy to use.
For its future release (at the time of writing this), it will be renamed as “**HedgeDoc**“.
You can find all the relevant information on deploying it on your server through Docker/Kubernetes and other manual configuration options on its [GitHub page](https://github.com/codimd/server).
### 6. Wri.pe
Wri.pe is a simple open-source online Markdown editor that’s no longer maintained but it is still active and usable.
It features real-time preview and the options to export or save your notes to Dropbox/Evernote. Considering that it’s not actively maintained — you may not rely on it but it works as expected when I tested it.
You can take a look at its [GitHub page](https://github.com/masuidrive/open-wripe) or the official site to learn more about it.
## Honorable Mentions
Here are a few tools that provide markdown access.
### Markdown Web Dingus
A simple and free online Markdown editor by the creator of Markdown language. It’s not a full-fledged online editor with integrations or that supports import/export.
But, if you just want an online editor to get a preview for your Markdown source, this could be a great option to use. Not just limited to the editor, but you also get a syntax cheatsheet in the sidebar of the website. So, you can try and learn here as well.
### Markdown Journal
[Markdown Journal](https://markdownjournal.com/) was an interesting open-source project on [GitHub](https://github.com/maciakl/MarkdownJournal) which has been discontinued. It gave you the ability to use its online editor to create journals using Markdown language and save them directly on your Dropbox account. I noticed Internal Server error when I tried to create a journal — but you can take a look at it.
### Etherpad
[Etherpad](https://etherpad.org/) is yet another impressive open-source online editor but it doesn’t come with Markdown support out of the box. You might notice some plugins available to enable Markdown editing on your server — but that’s not something that works flawlessly yet. So, you might want to keep an eye out for it. There’s a list of [public instances](https://github.com/ether/etherpad-lite/wiki/Sites-that-run-Etherpad-Lite) to try it out as well.
## Wrapping Up
Considering that a lot of online editors, CMSs, and note-taking services support Markdown, services/applications like [WordPress](https://wordpress.com/) can also be a good option if you want to publish it to the web.
Which one do you prefer to use as a Markdown editor? Did I miss any of your favorites? Let me know in the comments below! |
12,625 | 《代码英雄》第二季(4):更好的失败 | https://www.redhat.com/en/command-line-heroes/season-2/fail-better | 2020-09-18T10:29:25 | [
"失败"
] | https://linux.cn/article-12625-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(4):更好的失败](https://www.redhat.com/en/command-line-heroes/season-2/fail-better)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/fce7f007.mp3)脚本。
>
> 导语:失败是探索时的心跳。我们会在尝试新事物时会多次跌倒。其中秘诀是放弃快速失败,取而代之的是,更好地失败。
>
>
> 本期节目关注在科技领域如何拥抱失败。(对于科技领域来说)以好奇和开放的态度来对待失败是过程中的一部分。Jennifer Petoff 分享了 Google 是如何建立起一种从失败中学习和改进的文化;Jessica Rudder 通过视角的转变,展示了拥抱错误如何能带来意想不到的成功。而 Jen Krieger 则介绍了敏捷框架如何帮助我们为失败做计划。
>
>
> 失败未必是终点。它可以是迈向更伟大事物中的一步。
>
>
>
**00:00:00 - Saron Yitbarek**:
如果你没有听过这个笑话 —— 两个工程师在编译他们的代码。新手举手喊道:“哇,我的代码编译好了!”;老手则会眯着眼睛喃喃道:“唔,我的代码居然编译好了”。
**00:00:18**:
如果你已经做过一段时间编程,当你开始思考失败这件事,对有些事情的看法可能就会有所不同。那些过去无法解决的问题,如今开始看起来像一个更大的解决方案中的一个正常组成部分。那些你曾经称之为“失败”的东西,现在看起来像是变相的成功。
你开始希望你的代码无法通过编译。你希望可以一路摆弄和实验它们,调试和修订和重构这些代码。
**00:00:37**:
你正在收听的是红帽公司的原创播客节目《代码英雄》。我是主持人 Saron Yitbarek。
老实说,那句“<ruby> 快速失败 <rt> fail fast </rt></ruby>”的口号经常被用来作为通往成功的捷径。但是,如果我们不是告诉彼此加快速度并快速失败,而是鼓励彼此更好地失败呢?
**00:01:20**:
《代码英雄》的第二季将介绍的是开发工作中真实的体验:“当我们生活在代码中,到底感觉如何?又是如何变化的?这也是为什么我们要用一整集的时间来讨论失败,因为正是这些失败时刻促使我们适应它。我们称之为“失败”的东西,是进化的心跳,而开源开发者正在拥抱这种进化。当然,这说起来容易做起来难。
**00:01:59**:
想象一下,如果一首全新的莎士比亚的十四行诗被发现了。网络上会兴起一阵热潮,每个人都想去搜索它。但这时,有个小小的设计缺陷导致了所谓的“文件描述符耗尽”。这会造成一连串的失败。突然之间,这所有的流量都在越来越少的服务器之间流动。很快,在 Google 上的“莎士比亚”搜索崩溃了,并崩溃了一个多小时。
**00:02:33**:
现在,你丢掉了 12 亿次搜索查询。这是一场莎士比亚式的悲剧,所有的一切,在网站可靠性工程师(SRE)四处补救的同时上演。
>
> **00:02:45 - 配音**:
>
>
> 还有你吗,布鲁特?那就倒下吧,凯撒!
>
>
>
**00:02:54 - Saron Yitbarek**:
不好意思,我打断一下。但上面说的这个莎士比亚事件其实并不存在。事实上,这是一本书《SRE:Google 运维解密》中一系列灾难性场景的一部分。从这本书中学到的重要的一课就是你必须超越灾难本身。这就是我的意思。
**00:03:13**:
在这个莎士比亚的例子中,当流量被集火到一个被牺牲的单独集群时,这个死亡查询问题就解决了。这为团队赢得了扩充容量的足够时间。但你不能就此止步。尽管这个问题很糟糕,但解决它并不是真正的重点所在。因为失败不一定以痛苦告终,失败也可以引导你的学习。
**00:03:38 - Jennifer Petoff**:
嗨,我是 Jennifer Petoff。
**00:03:41 - Saron Yitbarek**:
Jennifer 在谷歌工作。她是 SRE(<ruby> 站点可靠性工程 <rt> site reliability engineering </rt></ruby>)团队的高级项目经理,领导谷歌的全球 SRE 教育计划,她也是这本描述了莎士比亚场景的书的作者之一。对于 Jennifer 来说,钻研这样的灾难才能使事情变得更好,但前提是你需要有一个拥抱错误和意外的文化。
**00:04:08**:
所以,让我们再拿莎士比亚举例子。有一个直接的办法,减少负载可以让你免于这种连锁故障。但,真正的工作将在一切恢复正常之后开始,重点在于事后分析报告。
**00:04:25 - Jennifer Petoff**:
事件解决后,我们会创建一个事后分析报告。谷歌的每一个事件都需要有一个事后分析和相应的行动项目,以防止将来再次出现问题,以及更有效地检测和缓解未来出现类似事件或整类问题的可能。
**00:04:42 - Saron Yitbarek**:
这是一个关键的区别。不仅仅是解决这个特定事件,而是看到这个事件告诉你的一系列问题。真正有效的事后分析,不只是告诉你昨天哪里出现了问题。而是让你对今天所做的工作以及对未来的计划有深刻的见解。这种更广泛的思想,灌输了对所有这些事故和失败的尊重,使它们成为日常工作生活中至关重要的一部分。
**00:05:12 - Jennifer Petoff**:
所以,一个真正好的事后分析不仅仅要解决手头的单个问题,它还解决了整个问题。事后分析的重点是什么地方作对了,什么地方做错了,在何处幸运的解决了问题,以及可以采取哪些优先行动来确保这种情况不会再次发生。如果你不采取行动,历史必将重演。
**00:05:32 - Saron Yitbarek**:
在谷歌,人们关注的是<ruby> 无责任的事后分析 <rt> blameless post-mortems </rt></ruby>,这就造成了根本的不同。如果出了问题而没有人要责怪,那么每个人都可以诚实地挖掘错误,真正地从错误中吸取教训,而不必掩盖任何线索,也不必争吵。这些无责任的事后分析已经成为谷歌文化的一个重要组成部分,其结果是一个不必害怕失败的工作场所。这是一种正常情况。
**00:06:01 - Jennifer Petoff**:
谷歌如何看待失败?100% 的在线时间是一个不可能的目标。如果你认为这是可以实现的,那就是在自欺欺人。所以,失败会发生只是时间和方式的问题。在谷歌,失败是值得庆祝的,因为我们可以从中吸取教训,而事后分析也会在团队中广泛分享,以确保学到的东西可以广泛使用。
**00:06:23 - Jennifer Petoff**:
错误是不可避免的,但你永远不想以同样的方式失败两次。犯错是人之常情,但反复犯错是可以避免的。
**00:06:34 - Saron Yitbarek**:
听到 Jennifer 讨论失败的方式,这真是太有趣了,因为就像她在犯那些错误一样。比如,当事情出错的时候,这意味着你已经走到了一个可以挖掘价值的地方。
**00:06:50 - Jennifer Petoff**:
你会现场处理这种情况,但事后花时间把发生的事情写出来,让别人可以从中学习。发生任何事件时,你都需要付出代价。如果你不写出事后分析,并真正从这个经验中吸取教训,你就不会重新收回解决问题所花费的成本。在我看来,这是至关重要的一课。在谷歌,我们坚信无责任文化。你不会因为指责别人而获得任何好处,那只会让人们去掩盖失败,而失败,总是会发生。
**00:07:27 - Saron Yitbarek**:
这里非常重要的一点是,要记住 Jennifer 之前说过的一些话,没有错误的工作是一种幻想,总会有出错的地方。归根结底这是思想的转变。我们可以抛弃那种认为只有一个单一的、可确定的最终目标,即一切最终都会按照我们想象的方式发展的想法。我们没有人试图达到这一目标,事实证明,这是非常强大和积极的东西。
谷歌拥抱失败的做法很有意义。超级实用。但我想知道,这只是口头上的么?我们是否有一些具体的让事情变得更好的失败例子,或者这只是一种当我们进行第 200 次编译时,让我们感觉更好的一种方法。
**00:08:26**:
事实证明,有人可以回答这个问题。
**00:08:29 - Jessica Rudder**:
我的名字叫 Jessica Rudder。我是 Github 的软件工程师。
**00:08:33 - Saron Yitbarek**:
Jessica 在 Github 经历过失败。从某种意义上说,这是一个失败的舞台,在这一过程中,她收集了一些关于失败是通往巨大成功的故事。比如这个:
**00:08:50 - Jessica Rudder**:
90 年代有个游戏开发公司正在开发一款全新的游戏。从本质上说,这是一款赛车游戏,但他们的转折之处在于将其改为街头赛车。所以当赛车手在街道上飙车时,他们不仅是在互相飙车,而且他们也是与在追赶他们的警车(非玩家角色)赛车。如果一辆警车抓住了你,它会让你靠边停车,然后你就输掉了比赛。然后他们把这些代码衔接起来,然后开始运行,他们发现他们完全调校错了算法:警车只是尖叫着从侧街冲出来,直接撞向玩家的车,而不是追赶玩家的车。
**00:09:37**:
所以这里简直是一团糟。他们想,不要惊慌,让我们继续前进,看看人们如何看待它的,这样我们就知道该怎么调整算法了。所以他们把它交给了游戏测试人员,他们发现游戏测试人员在逃离警察并试图躲避被这些流氓暴力警车抓捕的过程中获得了更多乐趣。而事实上,它是如此的有趣,以至于开发团队改变了他们为游戏打造的整个理念。
**00:10:17 - Saron Yitbarek**:
你能猜出这是怎么回事吗?
**00:10:21 - Jessica Rudder**:
所以我们才有了《<ruby> 侠盗猎车手 <rt> Grand Theft Auto </rt></ruby>》。我的意思是,它确实是有史以来最畅销的电子游戏,它能存在的全部原因都是因为当时他们没有使用正确的算法时所导致的失误,他们想,好吧,让我们来试试;看看我们得到了什么,看看我们能从中学到什么。
**00:10:41 - Saron Yitbarek**:
很神奇吧?但这里有个技巧,《侠盗猎车手》团队在遭遇失败时必须保持宽容;他们必须保持好奇心。
**00:10:52 - Jessica Rudder**:
所以,如果这些开发者没有开放的思想,并决定从这个错误中去学到什么,我们将永远不会有《侠盗猎车手》,我们只能玩一些无聊的、普通的街头赛车游戏了。
**00:11:07 - Saron Yitbarek**:
让我们再就游戏主题讨论一分钟,类似的事情也发生在《<ruby> 寂静岭 <rt> Silent Hill </rt></ruby>》的制作过程中。这是一个大型的、3A 级的大制作游戏。但他们遇到了严重的弹出问题。局部景观的处理速度不够快,因此突然之间,你会突然发现一堵墙或一条小路突然冒出来。这是一个破坏性的问题,而且他们的开发已经到非常后期。他们是怎么做的?完全放弃游戏,举手投降?还是将错就错。
**00:11:42 - Jessica Rudder**:
他们所做的就是让这个世界充满了非常浓郁、诡异的雾气。因为事实证明,雾对处理器来说非常容易渲染,而且不会有任何延迟。而且另外,雾使你看不到远处的东西,所以在现实中,那些建筑物仍然会突然出现,但由于雾遮挡了你的视线,你看不到它们。所以当它们进入视野时,它们已经被渲染了,看起来它们是从雾中出来的。
**00:12:15 - Saron Yitbarek**:
雾是变得如此受欢迎,它基本上被认为是《寂静岭》系列中的一个特点。它限制了玩家的视野,使游戏变得更加恐怖。甚至当处理器的速度快到不需要再掩盖那些弹出的时候,他们也保留了雾气。
**00:12:33 - Jessica Rudder**:
你无法在没有雾的情况下玩《寂静岭》。而这些雾最初所做的一切都是在掩盖一个错误。
**00:12:40 - Saron Yitbarek**:
我喜欢这个故事!他们拥抱失败而不是逃避失败,从而挽救了一个重大的发展。这条关于不怕失败的原则也适用于个人的小事,而不仅仅是全公司的决策。从容面对失败是我们一点一点地变得更好的方法。
**00:13:01 - Jessica Rudder**:
很多时候人们脑子里想的太多了,他们认为失败意味着我不擅长某样东西。并不是代码坏了我还不知道如何修复它,而是“我不知道如何编写 JavaScript”。而且,你永远不会通过说“我不知道如何编写 JavaScript”来学习所需的知识。但是如果你能确定,“哦,我不知道如何在 JavaScript 中实现这个循环”,那么你可以通过 Google 找到答案,而且效果很好。我是说,你仍然需要努力,但你遇到的麻烦会少的多。
**00:13:36 - Saron Yitbarek**:
因此,无论你是新开发人员还是大型工作室的负责人,我们的错误将我们推向更大的领域,那些实验,那些失败,那些英勇的尝试,它们占据了旅程的大部分。在我所熟悉和喜爱的开源社区里,这是最真实的情况了。失败在开源中可能是一件美好的事情,这就是我们接下来的故事。
**00:14:14**:
我们在前面看到了失败是如何带来惊喜 —— 那些我们甚至不知道自己想尝试的事情。在最好的情况下,开源开发文化正好符合这一点。它让失败变得正常。为了理解这种愿意失败的想法是如何被引入开源开发的,我和 Jen Krieger 聊了聊。她是 Red Hat 的首席敏捷架构师。我们讨论了对开源失败的态度,以及这些态度是如何塑造无限可能的。请听:
**00:14:47**:
我想谈谈这个口号,我觉得这也许是一个很好的表达方式。“<ruby> 快速失败,打破现状 <rt> fail fast and break things </rt></ruby>”,这几乎是为我们社区所设计的一个巨大的召集口号。你怎么看?
**00:15:04 - Jen Krieger**:
我对此有很多想法。
**00:15:06 - Saron Yitbarek**:
我也觉得你会有。
**00:15:06 - Jen Krieger**:
快速失败,在失败中前进,所有这些都是一个意思。所以,在我刚刚参加工作的时候,我在一家没有失败空间的公司工作。如果你做错了什么事情,你就可以准备辞职了。任何人都不能做错事,没有任何空间、途径允许你犯错。这令人们困扰。你绝对没有失败的余地,导致我们几乎陷入一场文化运动。愿意的话,这会催生出一个很棒词 —— 敏捷,以及催生出另一个很棒的词 —— DevOps。当我看到这些词的时候,我看到的是我们只是要求团队做一系列非常小的实验,帮助他们修正方向。
**00:16:02**:
这是个,哦,你已经做出了选择,而这实际上是一件积极的事情。你可能会做一个冒险的决定,然后你赢了,因为你做出了正确的决定。或者反之,就是你做了错误的决定,然后你明白了,那不是正确的方向。
**00:16:18 - Saron Yitbarek**:
是的,这是有道理的。所以,当你把“快速失败,打破现状”当成这个运动的时候,感觉在如何失败,如何以正确的方式失败上还是有一些方式,有一些最佳的实践的。那么,如何以一种正确的方式失败,有哪些最佳实践和原则呢?
**00:16:44 - Jen Krieger**:
我总是喜欢告诉工程师,他们需要尽早和尽可能多地破坏构建。如果他们正在破坏他们的构建,并且他们意识到他们已经破坏了构建,他们在当下还有机会真正修复它。而这一切都围绕着“<ruby> 反馈循环 <rt> feedback loops </rt></ruby>”这个概念,并确保你在工作中得到的反馈循环尽可能小。
**00:17:08**:
所以在开源开发中,我提交了一个补丁,然后有人说,“出于这九个原因,我不会接受你的补丁”,或者“我认为你的补丁很棒,继续吧”。或者,你提交了一个补丁,但是机器人告诉你它失败了,因为它没有正确构建。有各种不同类型的反馈。
**00:17:25**:
然后在开源开发中,你可能会遇到更长的反馈循环,你可能会说,“我想设计这个新功能,但我不确定所有的规则应该是什么。有人能帮我设计吗?”因此,你进入了一个漫长的过程,在这个过程中,你要进行长时间和详细的对话,而人们参与进来,提出最好的想法。
**00:17:45**:
所以有各种各样的反馈循环可以帮助你完成这个。
**00:17:50 - Saron Yitbarek**:
Jennifer 认为,每个公司的反馈循环看起来都不一样。它们是可定制的,人们可以使它们以 100 种不同的方式工作。但重点是,她甚至没有把它们称为失败或错误。她只是称它们为“反馈循环”。这是一个有机系统,这是一种思考整个过程的健康方式。
**00:18:11**:
与此同时,对这些小毛病的另外一种态度却产生了完全相反的效果。
**00:18:18 - Jen Krieger**:
有些组织所做的事情是完全错误的。
**00:18:23 - Saron Yitbarek**:
嗯是啊。
**00:18:24 - Jen Krieger**:
让你的领导团队(或者,在一个很高的层面上,比如组织)认为,羞辱做错事情的人,或者在绩效结果方面灌输恐惧;就像是,“如果你工作做得不好,就拿不到奖金”或者“如果你工作做得不好,我会把你列入绩效计划。”这些都是会产生敌意的事情。
**00:18:50 - Saron Yitbarek**:
她描述的是一个不正确的失败。不能接受失败就是失败。她也在呼应 Jennifer Petoff 的态度,对吧?就是我们在这集开头提到的那个无责任的事后分析?
**00:19:07**:
是的,这很有趣。就好像如果我们在如何一起工作上要求更严格一点,或者只是更用心,更有目的性的在一起工作,我们几乎就会被迫在失败中表现得更好。
**00:19:23 - Jen Krieger**:
是的。有一些公司已经学会了这一点,而且他们很久以前就学会了,丰田就是一个很好的例子,它接受了这种不断学习和改进的理念,这是我在其他公司很少看到的。就是这样一种想法,任何人在任何时候都可以指出某些东西不能正常工作。不管他们是谁,在公司的哪个级别。在他们的文化中,认为这是对的。这种持续学习和改进的环境,我想说,是一种领先的实践,这是我希望公司能够做到的事情,能够适应失败并允许它发生。
**00:20:06 - Saron Yitbarek**:
嗯,没错。
**00:20:07 - Jen Krieger**:
如果你问的是为什么事情进展不顺利,而不是指责或试图隐藏事情,或责怪别人,这就会造成完全不同的情况。那就是改变对话方式。
**00:20:23 - Saron Yitbarek**:
这很有趣,因为你之前提到过“快速失败,打破现状”这句话是这种文化,这种对过去做事方式的反击。 但这听起来似乎是一种口头禅,也许也创造了一种在公司内部、技术团队内部的不同的团队工作方式。再给我讲讲这个问题,它是如何改变了开发人员看待自己角色的方式,以及他们与公司其他人互动的方式?
**00:20:55 - Jen Krieger**:
我早期和工程师一起工作的时候差不多是这样的,工程师们都坐在一个小区域,他们互相交谈。他们从未真正与任何商业人士进行过交流。他们从来没有真正理解他们的任何需求,我们花了很多时间真正专注于成功所需的东西,而不一定是企业实际完成工作所需的东西。所以,它更像是,“我是一个工程师,我需要什么才能编写这个功能片段?”我观察到,今天在几乎每一个和我一起工作的团队中,对话方式已经发生了巨大的变化,“作为工程师我需要什么才能完成工作”变成了“客户是谁,或者用户需要什么才能真正感觉到这我做的这块功能对他们来说是成功的?他们如何使用产品?我该怎样做才能让他们更轻松?”
**00:21:56**:
很多这样的对话已经改变了,我认为这就是为什么如今公司在提供有意义的技术方面做得更好的原因。我还想说的是,我们发布的速度越快,我们就越容易知道我们的假设和决定是否真正实现了。所以,如果我们对用户可能想要什么做了假设,在此之前,我们需要等待,比如,一年到两年才能确定这是不是真的。
**00:22:25**:
而现在,如果你看看亚马逊或奈飞的模式,你会发现,他们每天会发布数百次假设的客户需求。他们从使用他们的应用程序的人们那里得到的反馈,会告诉他们他们是否在做用户需要他们做的事情。
**00:22:46 - Saron Yitbarek**:
是的,这听起来需要更多的合作,因为即使是你之前提出的关于构建、破坏构建、经常破坏它的建议,这就需要工程团队或开发人员与 DevOps 保持步调一致,以便他们能够破坏它,并了解尽早发布并经常发布是什么样子的。听起来这需要双方更多的合作。
**00:23:15 - Jen Krieger**:
是的,对于拥有敏捷教练这个头衔的人来说,或者以我作为首席敏捷架构师看来,总是很有趣,因为《敏捷宣言》的初衷是让人们从不同的角度来考虑这些事情。我们通过开发和帮助别人开发来发现更好的开发软件的方法。它确实是敏捷所要做的的核心、根本和基础。因此,如果你将 10 年,15 年以上的时间快速推进到 DevOps 的到来,并坚持我们需要持续进行集成和部署。我们有监控,我们开始以不同的方式思考如何将代码扔出墙外。
**00:23:56**:
所有这些东西都是我们最初开始讨论敏捷时应该想到的。
**00:24:03 - Saron Yitbarek**:
嗯。绝对是的。所以,不管人们如何实践这种失败的理念,我认为我们都可以接受失败,将失败规范化只是过程的一部分,是我们需要做的事情,是我们可以管理的事情,是我们可以用“正确的方式”做的事情,这是一件好事。它对开源有好处。跟我说说这个新运动的好处,这种接受失败是过程的一部分的新文化的一些好处。
**00:24:36 - Jen Krieger**:
看着这个过程发生是一件美妙的事情。对一个人来说,从一个他们害怕可能发生事情的环境,到一个他们可以尝试实验、尝试成长、尝试找出正确答案的环境。真的很高兴,就像它们已经盛开花朵。他们的士气提高了,他们真正意识到他们可以拥有的是什么,他们可以自己做决定,而不必等待别人为他们做决定。
**00:25:05 - Saron Yitbarek**:
失败即自由。啊,我喜欢! Jen Krieger 是红帽公司的首席敏捷架构师。
**00:25:19**:
并不是所有的开源项目都像 Rails、Django 或 Kubernetes 那样声名鹊起。事实上,大多数都没有。大多数都是只有一个贡献者的小项目,解决一小群开发人员面临的小问题的小众项目,或者它们已经被抛弃,很久没有人碰了。但它们仍然有价值。事实上,很多这样的项目仍然非常有用,可以被回收、升级,被其他项目蚕食。
**00:25:54**:
而另一些人通过他们的错误启发我们,教导我们。因为在一个健康的、开放的舞台上,失败会带给你比胜利更好的东西。它给了你洞察力。还有一点。尽管有那些死胡同,尽管有各种冒险的尝试和惊呼,但开源项目的数量每年都在翻倍;我们的社区正在繁荣,事实证明,尽管因失败我们没有繁荣,但因失败我们正在繁荣。
下一集预告,DevOps 世界中的安全性如何变化。持续部署意味着安全正在渗透到开发的每个阶段,这正在改变我们的工作方式。同时,如果你想了解更多关于开源文化的知识,以及我们如何改变围绕失败的文化,请访问 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) ,免费资源等着你。
**00:26:54 - Saron Yitbarek**:
《代码英雄》是红帽的原创播客。你可以在 Apple Podcast、Google Podcast 或是其他你喜欢的途径免费收听。我是 Saron Yitbarek,坚持编程,下期再见。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/fail-better>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Failure is the heartbeat of discovery. We stumble a lot trying new things. The trick is to give up on failing fast. Instead, fail better.
This episode looks at how tech embraces failure. Approaching failure with curiosity and openness is part of our process. Jennifer Petoff shares how Google has built a culture of learning and improvement from failure. With a shift in perspective, Jessica Rudder shows how embracing mistakes can lead to unexpected successes. And Jen Krieger explains how agile frameworks help us plan for failure.
Failure doesn't have to be the end. It can be a step to something greater.
**00:00** - *Saron Yitbarek*
Stop me if you've heard this one. Two engineers are compiling their code. The newcomer raises his hands and shouts, "Woo, my code compiled!" The veteran narrows her eyes and mutters, "Hm. My code compiled."
**00:18** - *Saron Yitbarek*
If you've been in the coding game a little while, something changes when you think about failure. Things that used to look like impossible problems begin to look like healthy parts of a larger solution. The stuff you used to call “failure,” begins to look like success in disguise.
You expect your code to not compile. You expect to play and experiment all along the way, fiddling, revising, refactoring.
**00:37** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat.
That whole "fail fast" mantra, let's be honest, it often gets used as a way to try and shortcut things towards success. But what if, instead of telling each other to hurry up and fail fast, we encourage each other to actually fail better.
**01:20** - *Saron Yitbarek*
Season Two of Command Line Heroes is all about the lived experience of working in development, what it really feels like and how it really pans out when we're living on the command line. And that's why we're devoting a whole episode to dealing with failure, because it's those moments that push us to adapt. The stuff we call failure, it's the heartbeat of evolution, and open source developers are embracing that evolution. Of course, that's a lot easier said than done.
**01:59** - *Saron Yitbarek*
Imagine this: a brand-new sonnet from the man himself, Shakespeare, gets discovered. There's a huge rush of interest online. Everybody's googling. But then! This one little design flaw leads to something called, "file descriptor exhaustion." That creates a cascading failure. Suddenly, you've got all that traffic moving across fewer and fewer servers. Pretty soon, Google's Shakespeare search has crashed, and it stays crashed for over an hour.
**02:33** - *Saron Yitbarek*
Now you've lost 1.2 billion search queries. It's a tragedy of Shakespearean proportions, all playing out while site reliability engineers are scrambling to catch up.
**02:45** - *Actor*
Et tu, Brute? Then fall, Caesar.
**02:54** - *Saron Yitbarek*
Okay, hate to break it to you. The Shakespearean incident isn't real. In fact, it's part of a series of disastrous scenarios in a book called, Site Reliability Engineering. And one of the big lessons from that book is that you've got to look beyond the disaster itself. Here's what I mean.
**03:13** - *Saron Yitbarek*
In the Shakespeare case, the query of death gets resolved when that laser beam of traffic gets pushed onto a single, sacrificial cluster. That buys the team enough time to add more capacity. But you can't stop there. As bad as that issue was, resolving it isn't where the real focus should be. Because failure doesn't have to end in suffering, failure can lead to learning.
**03:38** - *Jennifer Petoff*
Hi. I'm Jennifer Petoff.
**03:41** - *Saron Yitbarek*
Jennifer works over at Google. She's a senior program manager for their SRE (site reliability engineering) team and leads Google's global SRE education program, and she's also one of the authors of that book, the one that describes the Shakespeare scenario. For Jennifer, digging into disasters like that is how things get better. But only if you have a culture where mistakes and surprises are embraced.
**04:08** - *Saron Yitbarek*
So take the Shakespeare snafu again. There is a straightforward solution. Load shedding can save you from that cascading failure. But the real work starts after things are back to normal. The real work is in the post-mortem.
**04:25** - *Jennifer Petoff*
After the incident is resolved, a post-mortem would be created. Every incident at Google is required to have a post-mortem and corresponding action items to prevent, but also to more effectively detect and mitigate similar incidents or whole classes of issues in the future.
**04:42** - *Saron Yitbarek*
That's a key distinction right there. Not just solving for this particular incident, but seeing what the incident tells you about a class of issues. Post-mortems, really effective ones, don't just tell you what went wrong yesterday. They give you insights about the work you're doing today, and about what you're planning for the future. That broader kind of thinking instills a respect for all those accidents and failures, makes them a vital part of everyday work life.
**05:12** - *Jennifer Petoff*
So, a really good post–mortem addresses more than just the single issue at hand, it addresses the whole class of issues. And the post-mortems focus on what went well, what went wrong, where we got lucky, and what prioritized action we can take to make sure this doesn't happen again. If you don't take action, history is destined to repeat itself.
**05:32** - *Saron Yitbarek*
At Google, there's a focus on blameless post-mortems, and that makes all the difference. If nobody's to blame when something goes wrong, then everybody can dig into errors in an honest way and really learn from them without covering tracks, or arguing. Those blameless post-mortems have become a key part of the culture at Google, and the result is a workplace where failure isn't something to be afraid of. It's normalized.
**06:01** - *Jennifer Petoff*
How does Google look at failure? 100% of time is an impossible goal, like, you're kidding yourself if you think that's achievable. So failure's going to happen, it's just a matter of when and how. Failure is celebrated at Google, so it's something we can learn from, and post-mortems are shared widely among teams to make sure that the things that are learned are widely available.
**06:23** - *Jennifer Petoff*
Failure is inevitable, but you never want to fail the same way twice. To err is human, but to err repeatedly is something that would be better avoided.
**06:34** - *Saron Yitbarek*
It's so interesting hearing the way Jennifer talks about failures, because it's like she's leaning into those mistakes. Like, when things go wrong, it means you've arrived at a place you can actually mine for value.
**06:50** - *Jennifer Petoff*
You deal with the situation in real time, but then afterwards taking time to write up what happened so that others can learn from that. With any incidents, you pay the price when it happens, and you're not re–collecting some of that cost if you don't write up a post–mortem and actually learn from that experience, and I think that's a critical lesson. We believe very strongly here at Google in a blameless culture. You don't gain anything by pointing fingers at people, and that just then sends people to cover up failure, which is going to happen, regardless.
**07:27** - *Saron Yitbarek*
It's so important here to remember something Jennifer said earlier, that error-free work is a fantasy. There will always be things that go wrong. What it comes down to is a shift in thinking. We can put away that idea that there's a single, definable end goal, where everything will finally go the way we imagined. There is no single there that we're trying to get to, and it turns out, that's a hugely powerful and positive thing.
Google's push for embracing failure makes a lot of sense. Super practical. But I wanted to know, is this just lip-service? Do we have some concrete examples of failure actually making things better, or is it all just a way to make ourselves feel better when we're hitting compile for the 200th time?
**08:26** - *Saron Yitbarek*
Turns out, there's someone who can answer that.
**08:29** - *Jessica Rudder*
My name is Jessica Rudder. I'm a software engineer at GitHub.
**08:33** - *Saron Yitbarek*
Jessica has seen her share of failure over at GitHub. It's a failure arena, in one sense, and along the way, she's collected some stories about times when failure was the doorway to massive success. Like this one:
**08:50** - *Jessica Rudder*
So there was a game development company that was working on a brand-new game in the '90s. Essentially, it was a racing game, but their twist on it was that it was going to be street racing. So as the racers are racing through the streets, they're not only racing each other, but they're also NPCs (non-player characters) that are cop cars that are chasing them down. And if a cop car catches you, it's supposed to pull you over and then you lose the race. So they get this code all wired up, and they start running it, and what they discovered is that they completely calibrated the algorithm wrong, and instead of the cop cars chasing the players' vehicles, they would just come screaming out of side streets and slam right into them.
**09:37** - *Jessica Rudder*
So it was just a total mess. And instead of freaking out, they thought, let's go ahead and see how people like it, and that way we know what to tweak about the algorithm. So they sent it over to the play testers, and what they found was that the play testers had way more fun running away from the cops and trying to dodge being captured by these rogue, violent cop cars than they ever had with just the racing game itself. And it was so much fun, in fact, that the development team shifted the entire concept that they were building the game around.
**10:17** - *Saron Yitbarek*
Can you guess where this is going?
**10:21** - *Jessica Rudder*
And that's how we ended up with Grand Theft Auto. I mean, it's literally the best-selling video game franchise of all time, and the whole reason it exists is because when they failed to get the algorithm right, they thought, well, let's try it out. Let's see what we've got, and let's see what we can learn from it.
**10:41** - *Saron Yitbarek*
Sort of amazing, right? But here's the trick. The Grand Theft Auto team had to stay receptive when they were hit with a failure. They had to stay curious.
**10:52** - *Jessica Rudder*
So if those developers hadn't been open–minded about it, and decided to see what they could learn from this mistake, we would never have had Grand Theft Auto. We would have had some boring, run–of–the–mill street race game.
**11:07** - *Saron Yitbarek*
Sticking with the game theme for a minute, something similar happened when Silent Hill was being produced. This was a huge, triple-A game—big-time production. But they had serious problems with pop-up. Parts of the landscape weren't being processed fast enough, so all of a sudden you get a wall or a bit of road popping up out of nowhere. This was a deal-breaker problem, and they were late in their development cycle. So what do they do? Scrap the game entirely? Throw their hands up? Or embrace the problem itself?
**11:42** - *Jessica Rudder*
What they did was fill the world with a very dense, eerie fog. Because fog, as it turns out, is really easy for the processors to render and not get any kind of delays. But additionally, fog prevents you from seeing things at a distance, so in reality, those buildings are still popping in, but you can't see it anymore because the fog is blocking your view. So when they do come into view, they're already rendered, and it looks like they're coming out of the fog, instead.
**12:15** - *Saron Yitbarek*
The fog became so well-loved that it's basically considered another character in the Silent Hill franchise. It makes the game play way scarier by limiting the player's vision. And even when the processors got so fast that they didn't need to cover up those pop-ups anymore, they kept the fog.
**12:33** - *Jessica Rudder*
You cannot have a Silent Hill game without fog. And all that fog was doing initially was covering up a mistake.
**12:40** - *Saron Yitbarek*
I love it! They saved a major development by embracing their failure instead of running from it. And that rule about not fearing failure applies to little, individual things, too, not just company-wide decisions. Looking failure calmly in the face is how we get better, bit by bit.
**13:01** - *Jessica Rudder*
A lot of times people get too much into their own head and they think a failure means I'm bad at x. It's not, oh, this code is broken and I don't know how to fix it, yet. It's, “I don't know how to write JavaScript.” And you are never going to learn what you need to learn by saying, “I don't know how to write JavaScript.” But if you can identify, oh, I don't know how to make this loop work in JavaScript, then you have something that you can Google, and you can find that answer, and it just works perfect. I mean, you're still going to struggle, but you're going to struggle a whole lot less.
**13:36** - *Saron Yitbarek*
So our mistakes nudge us toward bigger things, those experiments, those fails, those heroic attempts, they make up most of the journey, whether you're a new developer or the head of a major studio. And nowhere is that more true than in the open source communities I've come to know and love. Failure can be a beautiful thing in open source, and that's where our story goes next.
**14:14** - *Saron Yitbarek*
We saw earlier how failing well can lead to happy surprises, things we didn't even know we wanted to try. And at its best, open source development culture hits that mark. It makes failure okay. To understand how that willingness to fail gets baked into open source development, I got chatting with Jen Krieger. She's Red Hat's chief agile architect. We talked about attitudes toward failure in open source, and how those attitudes shape what's possible. Take a listen:
**14:47** - *Saron Yitbarek*
I want to touch on this mantra, I feel is probably a good way to put it. The "fail fast and break things," which is a big rally cry, almost, I feel like, for our community. What are your thoughts on that?
**15:04** - *Jen Krieger*
I have a lot of thoughts on that.
**15:06** - *Saron Yitbarek*
I thought you might.
**15:06** - *Jen Krieger*
Fail fast, fail forward, fail quickly—all those things. So to put that into context, in the early days of my career, I worked in a company where there was no room for failure. If you did something wrong, you brought down the one application. There was really no way, no room, really, for anybody to do anything wrong. And that just really wraps people around the axle, that idea that you have absolutely no room for failure, led us into almost like a cultural movement, if you would, that then spawned into that wonderful word, agile, into the wonderful word, DevOps. When I look at those words, all I'm seeing is that we're simply asking teams to do a series of very small experiments that help them course-correct.
**16:02** - *Jen Krieger*
It's about, oh, you've made a choice, and that's actually a positive thing. You might take a risky decision, and then you win, because you've made the right decision. Or the other side, which is, you've made the wrong decision and you understand now that that wasn't the right direction to go in.
**16:18** - *Saron Yitbarek*
Yeah, that makes sense. So when you think about "fail fast and break things" as being this movement, it feels like there's still some structure, some best practices in how to fail, how to do that the right way. What are some of the best practices and the principles around failing in a way that is good in the end?
**16:44** - *Jen Krieger*
I always like to tell engineers that they need to break the build as early and as often as possible. If they're breaking their build and they're aware that they've broken the build, they have the opportunity in the moment to actually fix it. And it's all wrapped around that concept of feedback loops, and ensuring that the feedback loops that you're getting on the work that you're doing are as small as possible.
**17:08** - *Jen Krieger*
And so in open source development, I submit a patch, and somebody says, “I'm not going to accept your patch for these nine reasons,” or “I think your patch is great, move forward.” Or, you might be submitting a patch and having a bot tell you that it's failed because it hasn't built properly. There's all sorts of different types of feedback.
**17:25** - *Jen Krieger*
And then in open source development, you might also have longer feedback loops where you say, “I want to design this new functionality, but I'm not entirely sure what all the rules should be. Can somebody help me design that?” And so you go into this long process where you're having long and detailed conversations where folks are participating and coming up with the best idea.
**17:45** - *Jen Krieger*
And so there's all sorts of different feedback loops that can help you accomplish that.
**17:50** - *Saron Yitbarek*
Jen figures those feedback loops can look different for every company. They're customizable, and people can make them work in 100 different ways. But the point is, she's not even calling them failures or mistakes. She's just calling them, "feedback loops." It's an organic system. Such a healthy way of thinking about the whole process.
**18:11** - *Saron Yitbarek*
Meanwhile, there's one attitude toward those little glitches that has the exact opposite effect.
**18:18** - *Jen Krieger*
There are things that organizations do that are just flat-out the wrong thing to do.
**18:23** - *Saron Yitbarek*
Mm-hmm (affirmative).
**18:24** - *Jen Krieger*
Having your leadership team, or, at a very high level, the organization thinking that shaming people for doing something wrong or instilling fear in relation to performance results; and that looks like, “If you don't do a good job, you won't get a bonus,” or “If you don't do a good job, I'm going to put you on a performance plan.” Those are the types of things that create hostility.
**18:50** - *Saron Yitbarek*
What she's describing there is a failure fail. A failure to embrace what failure can be. And she's echoing Jennifer Petoff's attitude too, right? That idea about blame-free post-mortems we heard about at the top of the episode?
**19:07** - *Saron Yitbarek*
Yeah, that's interesting. It's like if we are a little bit more strict around how we work together, or maybe just more mindful, more purposeful in how we work together, we will be almost forced to be better at our own failure.
**19:23** - *Jen Krieger*
Yes. And there's companies out there that have learned this already, and they've learned it a long time ago, and Toyota is a perfect example of a company that embraces this concept of continuous learning and improvement in a way that I rarely see at companies. There is just this idea that anyone at any point can point out something that isn't working properly. It doesn't matter who they are, what level of the company they're in. It's just understood in their culture that that's okay. And that environment of continuous learning and improvement, I would say, would be one of those leading practices, the things that I would expect a company to do to be able to accommodate failure and to allow it to occur.
**20:06** - *Saron Yitbarek*
Mm-hmm (affirmative). Yeah.
**20:07** - *Jen Krieger*
If you're asking questions about why things aren't going well, instead of pointing fingers or trying to hide things, or blaming others for things not going well, it creates an entirely different situation. Changes the conversation.
**20:23** - *Saron Yitbarek*
And it's interesting because you mentioned earlier how the break things "fail fast and break things" mantra was this culture, this kind of push-back against the way things used to be done. But it sounds like that mantra has also created maybe a different way that teams work within a company, within a tech team. Tell me a little bit more about that. How has it changed the way developers see their roles and how they interact with other people in the company.
**20:55** - *Jen Krieger*
My early days of working with engineers pretty much looked like, the engineers all sat in a small area. They all talked to one another. They never really interacted with any of the business people. They never really understood any of their incoming requirements, and we spent an awful lot of time really focused on what they needed to be successful, and not necessarily what the business needed to actually get their work done. So it was much more of a, “I'm an engineer, what do I need in order to code this piece of functionality?” What I observe today in pretty much every team that I work with, the conversation has shifted significantly to not, “What do I need as an engineer to get my job done,” but “What does the customer, or what does the user need to actually feel like this piece of functionality that I'm making is going to be successful for them? How are they using the product? What can I do to make it easier for them?”
**21:56** - *Jen Krieger*
A lot of those conversations have changed, and I think that's why companies are doing better today on delivering technology that makes sense. I will also say that the faster we get at releasing, the easier it is for us to know whether or not our assumptions and our decisions are actually coming true. So, if we make an assumption about what a user might want, before, we were having to wait, like, a year to two years to really find out whether or not that was actually true.
**22:25** - *Jen Krieger*
Now, if you look at the model of an Amazon or Netflix, they're releasing their assumptions about what their customers want, like, hundreds of times a day. And the response they get from folks using their applications will tell them whether or not they're doing what it is the users need them to be doing.
**22:46** - *Saron Yitbarek*
Yeah, and it sounds like it requires more cooperation, because even the piece of advice you gave earlier about build, break the build, break it often. That kind of requires the engineering team or the developers to be more in step with DevOps, right, in order for them to break it, and to see what that looks like to do those releases early and to do them often. It sounds like it requires more cooperation between the two.
**23:15** - *Jen Krieger*
Yeah, and it's always amusing to somebody who has that title, agile coach, or in my case, chief agile architect, because the original intent of the Agile Manifesto is to get folks to think about those things differently. We are uncovering better ways of developing software by doing it and helping others do it. It is really the core, heart, and foundation of what agile is supposed to do. And so, if you fast forward the 10, 15+ years to the arrival of DevOps and the insistence that we have continuous integration and deployment. We have monitoring, we start thinking differently about throwing code over the wall.
**23:56** - *Jen Krieger*
All that stuff is really what we were supposed to be thinking back when we originally started talking about agile.
**24:03** - *Saron Yitbarek*
Mm-hmm (affirmative). Absolutely. So regardless of how people implement this idea of failure, I think that we can both agree that the acceptance of failure, the normalizing of failure is just a part of the process, something that we need to do, something that happens that we can manage, that we can maybe do the "right way," is a good thing. It has done some good for open source. Tell me about some of the benefits of having this new movement, this new culture of accepting failure as part of the process.
**24:36** - *Jen Krieger*
It's a beautiful thing to watch that process happen. For somebody to go from being really in a situation where they're fearful of what might happen, to a place in which they can try to experiment and try to grow, and try to figure out what might be the right answer. It's really great to see. It's like they blossom. Their morale improves, they actually realize that they can own what it is that they are. They can make decisions for themselves, they don't have to wait for somebody to make the decision for them.
**25:05** - *Saron Yitbarek*
Failure as freedom. Ah, I love it! Jen Krieger is Red Hat's chief agile architect.
**25:19** - *Saron Yitbarek*
Not all open source projects reach the fame and success of big ones, like Rails or Django, or Kubernetes. In fact, most don't. Most are smaller projects with just a single contributor. Niche projects that solve little problems that a small group of developers face, or they've been abandoned and haven't been touched in ages. But they still have value. In fact, a lot of those projects are still hugely useful, getting recycled, upcycled, cannibalized by other projects.
**25:54** - *Saron Yitbarek*
And others simply inspire us, teach us by their very instructive wrongness. Because failure, in a healthy, open source arena, gives you something better than a win. It gives you insight. And here's something else. Despite all those dead ends, the number of open source projects is doubling about every year, despite all the risky attempts and Hail Marys; our community is thriving, and it turns out, we're not thriving despite our failures, we're thriving because of them. Next episode, how security changes in a DevOps world. Constant deployment means security's working its way into every stage of development, and that is changing the way we work. Meantime, if you want to learn more about open source culture and how we can all change the culture around failing, check out the free resources waiting for you at redhat.com/commandlineheroes.
**26:54** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Listen for free on Apple Podcast, Google Podcast, or wherever you do your thing. I'm Saron Yitbarek. Until next time, keep on coding.
### Keep going
### Failure as a catalyst: Designing a feedback loop for success
Don't give up after a rejection. Using feedback loops can straighten a winding career path.
### Living on the command line: Why mistakes are a good thing
Does failure grant freedom? See how healthy teams treat failure.
### Command Line Heroes: Failure != Game Over
When "Game Over" really means "Give it another go." |
12,628 | 如何在 Linux 终端中连接 WiFi? | https://itsfoss.com/connect-wifi-terminal-ubuntu/ | 2020-09-18T17:13:47 | [
"WiFi"
] | https://linux.cn/article-12628-1.html |
>
> 在本教程中,你将学习如何在 Ubuntu 中从终端连接到无线网络。如果你在使用 Ubuntu 服务器时,无法访问常规的[桌面环境](https://itsfoss.com/what-is-desktop-environment/),这将对你非常有帮助。
>
>
>
我的家用电脑主要使用桌面 Linux。我也有多台 Linux 服务器用于托管网站以及开源软件,如 [Nextcloud](https://itsfoss.com/nextcloud/)、[Discourse](https://www.discourse.org/)、Ghost、Rocket Chat 等。
我可以使用 [Linode](https://itsfoss.com/recommends/linode/) 在云端几分钟内快速部署 Linux 服务器。但最近,我在我的树莓派上安装了 [Ubuntu 服务器](https://itsfoss.com/install-ubuntu-server-raspberry-pi/)。这是我第一次在物理设备上安装服务器,我不得不做一些额外的事情来通过命令行将 Ubuntu 服务器连接到 WiFi。
在本教程中,我将展示在 Ubuntu Linux 中使用终端连接到 WiFi 的步骤。你应该:
* 不要害怕使用终端编辑文件。
* 知道 wifi 接入点名称 (SSID) 和密码。
### 在 Ubuntu 中从终端连接到 WiFi

当你使用 Ubuntu 桌面时,连接到 WiFi 是很容易的,因为你有图形用户界面,可以很容易地做到这一点。但当你使用 Ubuntu 服务器时就不一样了,因为你只能使用命令行。
Ubuntu 使用 [Netplan](https://netplan.io/) 工具来轻松配置网络。在 Netplan 中,你可以创建一个包含网络接口描述的 YAML 文件,然后在 `netplan` 命令行工具的帮助下,生成所有需要的配置。
让我们看看如何使用 Netplan 从终端连接到无线网络。
#### 步骤 1:确定你的无线网络接口名称
有几种方法可以识别你的网络接口名称。你可以使用 `ip` 命令、过时的 `ipconfig` 命令或查看这个文件:
```
ls /sys/class/net
```
这应该会展示所有可用的网络接口(以太网、WiFi 和环回)。无线网络接口名称以 `w` 开头,通常命名类似 `wlanX`、`wlpxyz`。
```
[email protected]:~$ ls /sys/class/net
eth0 lo wlan0
```
记下这个接口名。你将在下一步使用它。
#### 步骤 2:编辑 Netplan 配置文件中的 wifi 接口详细信息
Netplan 配置文件在 `/etc/netplan` 目录下。如果你查看这个目录的内容,你应该看到类似 `01-network-manager-all.yml` 或 `50-cloud-init.yaml` 等文件。
如果是 Ubuntu 服务器,你应该有 `50-cloud-init.yaml` 文件。如果是桌面计算机,应该是 `01-network-manager-all.yml` 文件。
Linux 桌面计算机的 Network Manager 允许你选择一个无线网络。你可以在它的配置中硬编码写入 WiFi 接入点。这可以在自动掉线的情况下(比如挂起)时帮助到你。
不管是哪个文件,都可以打开编辑。我希望你对 Nano 编辑器有一点[熟悉](https://itsfoss.com/nano-editor-guide/),因为 Ubuntu 预装了它。
```
sudo nano /etc/netplan/50-cloud-init.yaml
```
YAML 文件对空格、缩进和对齐方式非常敏感。不要使用制表符,在看到缩进的地方使用 4 个空格(或 2 个,以 YAML 文件中已经使用的为准)代替。
基本上,你需要添加以下几行,引号中是接入点名称(SSID) 和密码(通常):
```
wifis:
wlan0:
dhcp4: true
optional: true
access-points:
"SSID_name":
password: "WiFi_password"
```
再说一次,保持我所展示的对齐方式,否则 YAML 文件不能被解析,它会抛出一个错误。
你的完整配置文件可能是这样的:
```
# This file is generated from information provided by the datasource. Changes
# to it will not persist across an instance reboot. To disable cloud-init's
# network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:
ethernets:
eth0:
dhcp4: true
optional: true
version: 2
wifis:
wlan0:
dhcp4: true
optional: true
access-points:
"SSID_name":
password: "WiFi_password"
```
我觉得很奇怪,尽管有消息说更改不会在实例重启后保留,但它仍然可以工作。
不管怎样,用这个命令生成配置:
```
sudo netplan generate
```
现在应用它:
```
sudo netplan apply
```
如果你幸运的话,你应该连上网络。尝试 `ping` 一个网站或运行 `apt` 更新命令。
然而,事情可能不会那么顺利,你可能会看到一些错误。如果是这种情况,请尝试一些额外的步骤。
#### 可能的故障排除
当你使用 `netplan apply` 命令时,你有可能在输出中看到类似这样的错误。
```
Failed to start netplan-wpa-wlan0.service: Unit netplan-wpa-wlan0.service not found.
Traceback (most recent call last):
File "/usr/sbin/netplan", line 23, in <module>
netplan.main()
File "/usr/share/netplan/netplan/cli/core.py", line 50, in main
self.run_command()
File "/usr/share/netplan/netplan/cli/utils.py", line 179, in run_command
self.func()
File "/usr/share/netplan/netplan/cli/commands/apply.py", line 46, in run
self.run_command()
File "/usr/share/netplan/netplan/cli/utils.py", line 179, in run_command
self.func()
File "/usr/share/netplan/netplan/cli/commands/apply.py", line 173, in command_apply
utils.systemctl_networkd('start', sync=sync, extra_services=netplan_wpa)
File "/usr/share/netplan/netplan/cli/utils.py", line 86, in systemctl_networkd
subprocess.check_call(command)
File "/usr/lib/python3.8/subprocess.py", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['systemctl', 'start', '--no-block', 'systemd-networkd.service', 'netplan-wpa-wlan0.service']' returned non-zero exit status 5.
```
可能是 `wpa_supplicant` 服务没有运行。运行这个命令:
```
sudo systemctl start wpa_supplicant
```
再次运行 `netplan apply`。如果它能解决这个问题,那就太好了。否则,使用下面的命令[关闭 Ubuntu 系统](https://itsfoss.com/schedule-shutdown-ubuntu/):
```
shutdown now
```
重新启动 Ubuntu 系统,登录并再次生成和运行 `netplan apply`:
```
sudo netplan generate
sudo netplan apply
```
现在可能会显示警告(而不是错误)。这是警告而不是错误。我检查了[正在运行的 systemd 服务](https://linuxhandbook.com/systemd-list-services/),发现 `netplan-wpa-wlan0.service` 已经在运行了。可能是因为它已经在运行了,而且 `netplan apply` 更新了配置文件(即使没有任何改变),所以显示了警告。
```
Warning: The unit file, source configuration file or drop-ins of netplan-wpa-wlan0.service changed on disk. Run 'systemctl daemon-reload' to reload units.
```
这并不重要,你可以通过运行 `apt update` 来检查网络是否已经正常工作。
我希望你能够在本教程的帮助下,在 Ubuntu 中使用命令行连接到 WiFi。如果你仍然遇到困难,请在评论区告诉我。
---
via: <https://itsfoss.com/connect-wifi-terminal-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I primarily use desktop Linux on my home computers. I also have multiple Linux servers for hosting It’s FOSS and related websites and open source software like [Nextcloud](https://itsfoss.com/nextcloud/), [Discourse](https://www.discourse.org/?ref=itsfoss.com), Ghost, Rocket Chat etc.
I use for quickly deploying Linux servers in cloud in minutes. But recently, I installed [Ubuntu server on my Raspberry Pi](https://itsfoss.com/install-ubuntu-server-raspberry-pi/). This is the first time I installed a server on a physical device and I had to do extra stuff to connect Ubuntu server to WiFi via command line.
In this tutorial, I’ll show the steps to connect to WiFi using terminal in Ubuntu Linux. You should
- not be afraid of using terminal to edit files
- know the wifi access point name (SSID) and the password
## Connect to WiFi from terminal in Ubuntu

It is easy when you are using Ubuntu desktop because you have the GUI to easily do that. It’s not the same when you are using Ubuntu server and restricted to the command line.
Ubuntu uses [Netplan](https://netplan.io/?ref=itsfoss.com) utility for easily configuring networking. In Netplan, you create YAML file with the description of network interface and with the help of the netplan command line tool, you generate all the required configuration.
Let’s see how to connect to wireless networking from the terminal using Netplan.
### Step 1: Identify your wireless network interface name
There are several ways to identify your network interface name. You can use the ip command, the deprecated ipconfig command or check this file:
`ls /sys/class/net`
This should give you all the available networking interface (Ethernet, wifi and loopback). The wireless network interface name starts with ‘w’ and it is usually named similar to wlanX, wlpxyz.
```
abhishek@itsfoss:~$ ls /sys/class/net
eth0 lo wlan0
```
Take a note of this interface name. You’ll use it in the next step.
### Step 2: Edit the Netplan configuration file with the wifi interface details
The Netplan configuration file resides in /etc/netplan directory. If you check the contents of this directory, you should see files like 01-network-manager-all.yml or 50-cloud-init.yaml.
If it is Ubuntu server, you should have cloud-init file. For desktops, it should be network-manager file. This is one of the [several ways Ubuntu desktop differs from Ubuntu server](https://itsfoss.com/ubuntu-server-vs-desktop/).
The Network Manager on the Linux desktop allows you to choose a wireless network. You may hard code the wifi access point in its configuration. This could help you in some cases (like suspend) where connection drops automatically.
Whichever file it is, open it for editing. I hope you are a tad bit [familiar with Nano editor](https://itsfoss.com/nano-editor-guide/) because Ubuntu comes pre-installed with it.
`sudo nano /etc/netplan/50-cloud-init.yaml`
YAML files are very sensitive about spaces, indention and alignment. Don’t use tabs, use 4 (or 2, whichever is already used in the YAML file) spaces instead where you see an indention.
Basically, you’ll have to add the following lines with the access point name (SSID) and its password (usually) in quotes:
```
wifis:
wlan0:
dhcp4: true
optional: true
access-points:
"SSID_name":
password: "WiFi_password"
```
Again, keep the alignment as I have shown or else YAML file won’t be parsed and it will throw an error.
Your complete configuration file may look like this:
```
# This file is generated from information provided by the datasource. Changes
# to it will not persist across an instance reboot. To disable cloud-init's
# network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:
ethernets:
eth0:
dhcp4: true
optional: true
version: 2
wifis:
wlan0:
dhcp4: true
optional: true
access-points:
"SSID_name":
password: "WiFi_password"
```
I find it strange that despite the message that changes will not persist across an instance reboot, it still works.
Anyway, generate the configuration using this command:
`sudo netplan generate`
And now apply this:
`sudo netplan apply`
If you are lucky, you should have network connected. Try to ping a website or run apt update command.
However, things may not go as smooth and you may see some errors. Try some extra steps if that’s the case.
### Possible troubleshooting
It is possible that when you use the netplan apply command, you see an error in the output that reads something like this:
```
Failed to start netplan-wpa-wlan0.service: Unit netplan-wpa-wlan0.service not found.
Traceback (most recent call last):
File "/usr/sbin/netplan", line 23, in <module>
netplan.main()
File "/usr/share/netplan/netplan/cli/core.py", line 50, in main
self.run_command()
File "/usr/share/netplan/netplan/cli/utils.py", line 179, in run_command
self.func()
File "/usr/share/netplan/netplan/cli/commands/apply.py", line 46, in run
self.run_command()
File "/usr/share/netplan/netplan/cli/utils.py", line 179, in run_command
self.func()
File "/usr/share/netplan/netplan/cli/commands/apply.py", line 173, in command_apply
utils.systemctl_networkd('start', sync=sync, extra_services=netplan_wpa)
File "/usr/share/netplan/netplan/cli/utils.py", line 86, in systemctl_networkd
subprocess.check_call(command)
File "/usr/lib/python3.8/subprocess.py", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['systemctl', 'start', '--no-block', 'systemd-networkd.service', 'netplan-wpa-wlan0.service']' returned non-zero exit status 5.
```
It is possible that wpa_supplicant service is not running. Run this command:
`sudo systemctl start wpa_supplicant`
Run netplan apply once again. If it fixes the issue well and good. Otherwise, [shutdown your Ubuntu system](https://itsfoss.com/schedule-shutdown-ubuntu/) using:
`shutdown now`
Start your Ubuntu system again, log in and generate and apply netplan once again:
```
sudo netplan generate
sudo netplan apply
```
It may show warning (instead of error) now. It is warning and not an error. I checked the [running systemd services](https://linuxhandbook.com/systemd-list-services/?ref=itsfoss.com) and found that netplan-wpa-wlan0.service was already running. Probably it showed the warning because it was already running and ‘netplan apply’ updated the config file (even without any changes).
`Warning: The unit file, source configuration file or drop-ins of netplan-wpa-wlan0.service changed on disk. Run 'systemctl daemon-reload' to reload units.`
It is not crtical and you may check that the internet is probably working already by running apt update.
I hope you were able to connect to wifi using the command line in Ubuntu with the help of this tutorial. If you are still facing trouble with it, do let me know in the comment section. |
12,630 | 全新的 YubiKey 5C NFC 安全密钥让你可以使用 NFC 轻松认证你的安全设备 | https://itsfoss.com/yubikey-5c-nfc/ | 2020-09-18T17:43:34 | [
"YubiKey"
] | https://linux.cn/article-12630-1.html | 如果你格外谨慎,会使用最好的认证方法来保护你的在线帐户的安全,你可能知道 [Yubico](https://itsfoss.com/recommends/yubikey/)。他们制作的硬件认证安全密钥可以取代[双因素认证](https://ssd.eff.org/en/glossary/two-factor-authentication),并摆脱在线账户的密码认证系统。
基本上,你只需将安全密钥插在电脑上,或者使用智能手机上的 NFC 来解锁访问账户。这样一来,你的认证方式就会完全保持离线状态。

当然,你可以随时使用 [Linux 中好用的密码管理器](https://itsfoss.com/password-managers-linux/)。但如果你拥有一家公司,或为公司工作,或者只是对自己的隐私和安全格外谨慎,想增加一层额外的安全保护,这些硬件安全密钥可能值得一试。这些设备最近得到的进一步普及。
Yubico 的最新产品 [YubiKey 5C NFC](https://itsfoss.com/recommends/yubico-5c-nfc/) 可能令人印象深刻,因为它既可以作为 Type-C 的 USB 密钥使用,也可以作为 NFC 使用(只要用密钥碰触你的设备)。
下面,让我们来看看这款安全密钥的概况。
(LCTT 译注:请注意本文中的购买连接是原文作者的受益链接,如果你对此担心,请阅读其[受益政策](https://itsfoss.com/affiliate-policy/)。)
### Yubico 5C NFC:概述

YubiKey 5C NFC 是最新的产品,它同时使用 USB-C 和 NFC。因此,你可以轻松地将它插入 Windows、macOS 和 Linux 电脑。除了电脑,你还可以将其与 Android 或 iOS 智能手机或平板电脑配合使用。
不仅仅局限于 USB-C 和 NFC 的支持(这是件好事),它也恰好是世界上第一个支持智能卡的多协议安全密钥。
对于普通消费者来说,硬件安全密钥并不那么常见,因为它的成本很高。但在疫情流行的过程中,随着远程办公的兴起,一个更安全的认证系统肯定会派上用场。
以下是 Yubico 在其新闻稿中提到的内容:
>
> Yubico 首席产品官 Guido Appenzeller 表示:“如今人们工作和上网的方式与几年前大不相同,尤其是在过去几个月内。用户不再仅仅被一种设备或服务所束缚,也不再希望受限于此。这就是为什么 YubiKey 5C NFC 是我们最受欢迎的安全密钥之一。它与大多数现代电脑和手机兼容,并可以在一系列传统和现代应用中良好运行。归根结底,我们的客户渴望的是无论如何都能“正常工作”的安全性。”
>
>
>
YubiKey 5C NFC 支持的协议有 FIDO2、WebAuthn、FIDO U2F、PIV(智能卡)、OATH-HOTP 和 OATH-TOTP (基于哈希和时间的一次性密码)、[OpenPGP](https://www.openpgp.org/)、YubiOTP 和挑战应答认证。
考虑到所有这些协议,你可以轻松地保护任何支持硬件认证的在线帐户,同时还可以访问身份访问管理 (IAM) 解决方案。因此,这对个人用户和企业来说都是一个很好的选择。
### 定价和渠道
YubiKey 5C NFC 的价格为 55 美元。你可以直接从他们的[在线商店](https://itsfoss.com/recommends/yubico-5c-nfc/)订购,或者从你所在国家的任何授权经销商处购买。花费可能也会根据运输费用的不同而有所不同,但对于那些想要为他们的在线账户提供最佳安全级别的用户而言,55 美元似乎是个不错的价格。
值得注意的是,如果你订购两个以上的 YubiKeys,你可以获得批量折扣。
* [订购 YubiKey 5C NFC](https://itsfoss.com/recommends/yubico-5c-nfc/)
### 总结
无论你是想保护你的云存储帐户还是其他在线帐户的安全,如果你不介意花点钱来保护你的数据安全,Yubico 的最新产品是值得一试的。
你是否使用过 YubiKey 或其他安全密钥,如 LibremKey 等?你对它的体验如何?你认为这些设备值得花钱吗?
---
via: <https://itsfoss.com/yubikey-5c-nfc/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you are extra cautious about securing your online accounts with the best possible authentication method, you probably know about . They make hardware authentication security keys to replace [two-factor authentication](https://ssd.eff.org/en/glossary/two-factor-authentication) and get rid of the password authentication system for your online accounts.
Basically, you just plug the security key on your computer or use the NFC on your smartphone to unlock access to accounts. In this way, your authentication method stays completely offline.

Of course, you can always use a [good password manager for Linux](https://itsfoss.com/password-managers-linux/) available out there. But if you own or work for a business or just extra cautious about your privacy and security and want to add an extra layer of security, these hardware security keys could be worth a try. These devices have gained some popularity lately.
Yubico’s latest product – ‘‘ is probably something impressive because it can be used both as USB type C key and NFC (just touch your device with the key).
Here, let’s take a look at an overview of this security key.
*Please note that It’s FOSS is an affiliate partner of Yubico. Please read our affiliate policy.*
## Yubico 5C NFC: Overview

YubiKey 5C NFC is the latest offering that uses both USB-C and NFC. So, you can easily plug it in on Windows, macOS, and Linux computers. In addition to the computers, you can also use it with your Android or iOS smartphones or tablets.
Not just limited to USB-C and NFC support (which is a great thing), it also happens to be the world’s first multi-protocol security key with smart card support as well.
Hardware security keys aren’t that common because of their cost for an average consumer. But, amidst the pandemic, with the rise of remote work, a safer authentication system will definitely come in handy.
Here’s what Yubico mentioned in their press release:
“The way that people work and go online is vastly different today than it was a few years ago, and especially within the last several months. Users are no longer tied to just one device or service, nor do they want to be. That’s why the YubiKey 5C NFC is one of our most sought-after security keys — it’s compatible with a majority of modern-day computers and mobile phones and works well across a range of legacy and modern applications. At the end of the day, our customers crave security that ‘just works’ no matter what.” said Guido Appenzeller, Chief Product Officer, Yubico.
The protocols that YubiKey 5C NFC supports are FIDO2, WebAuthn, FIDO U2F, PIV (smart card), OATH-HOTP and OATH-TOTP (hash-based and time-based one-time passwords), [OpenPGP](https://www.openpgp.org/), YubiOTP, and challenge-response.
Considering all those protocols, you can easily secure any online account that supports hardware authentication while also having the ability to access identity access management (IAM) solutions. So, it’s a great option for both individual users and enterprises.
## Pricing & Availability
The YubiKey 5C NFC costs $55. You can order it directly from their or get it from any authorized resellers in your country. The cost might also vary depending on the shipping charges but $55 seems to be a sweet spot for serious users who want the best-level of security for their online accounts.
It’s also worth noting that you get volume discounts if you order more than two YubiKeys.
## Wrapping Up
No matter whether you want to secure your cloud storage account or any other online account, Yubico’s latest offering is something that’s worth taking a look at if you don’t mind spending some money to secure your data.
Have you ever used YubiKey or some other secure key like LibremKey etc? How is your experience with it? Do you think these devices are worth spending the extra money? |
12,632 | 使用开源工具 nccm 管理 SSH 连接 | https://opensource.com/article/20/9/ssh-connection-manager | 2020-09-19T23:40:33 | [
"SSH"
] | /article-12632-1.html |
>
> 使用 nccm 让你的终端连接 SSH 会话更快、更稳、更轻松。
>
>
>

OpenSSH 很常用,但没有一个知名的连接管理器,因此我开发了 ncurses SSH 连接管理器(`nccm`)来填补这个重要的空白。 `nccm` 是一个简单的 SSH 连接管理器,具有非常便于移植的终端界面(就如项目名称所示,使用 ncurses 编写)。最重要的是,它使用起来非常简单。有了 `nccm`,你可以花费最少的精力和最少的按键连接到你选择的 SSH 会话。
### 安装 nccm
最快的方式是从它的 [Git 仓库](https://github.com/flyingrhinonz/nccm)克隆该项目:
```
$ git clone https://github.com/flyingrhinonz/nccm nccm.git
```
在 `nccm.git/nccm` 的文件夹中有两个文件:`nccm` 自身和 `nccm.yml` 配置文件。
首先将 `nccm` 脚本复制到系统目录 `/usr/local/bin/` 中并添加执行权限,也可以通过使用`install` 命令来完成操作:
```
$ sudo install -m755 nccm –target-directory /usr/local/bin
```
文件 `nccm.yml` 可以拷贝到以下任意一个位置,默认从找到的第一个位置获取配置:
* `~/.config/nccm/nccm.yml`
* `~/.nccm.yml`
* `~/nccm.yml`
* `/etc/nccm.yml`
`nccm` 需要在 Python 3 的环境中运行,这在大部分的 Linux 环境是没问题的。大多数 Python 库的依赖包已经作为 Python 3 的一部分存在,但是,有一些 YAML 的依赖包和实用程序是你必须安装的。
如果你没有安装 `pip`,你可以使用包管理器来安装它。在安装的同时,也请安装 `yamllint` 应用程序来帮助你验证 `nccm.yml` 文件。
在 Debian 或类似系统使用 `apt` 命令:
```
$ sudo apt install python3-pip yamllint
```
在 Fedora 或者类似系统使用 `dnf` 命令:
```
$ sudo dnf install python3-pip yamllint
```
`PyYAML` 也是必须安装的,可以通过使用 `pip` 来安装:
```
$ pip3 install --user PyYAML
```
### 使用 nccm
开始之前,需要修改 `nccm.yml` 文件来添加 SSH 连接配置,可以参照示例文件格式化 YAML 文件。仿照示例文件在开头添加连接名称,配置项使用两个空格缩进。不要忘了冒号(`:`),这是 YAML 的语言的格式。
不要担心你的 SSH 会话信息以何顺序排列,因为 `nccm` 在程序内提供了排序的方式。
如果修改完成,可以使用 `yamllint` 来校验配置:
```
$ yamllint ~/.config/nccm/nccm.yml
```
如果没有错误信息返回,说明文件的内容格式是正确的,可以进行下面的步骤。
如果 `nccm` 可以[从你的路径](https://opensource.com/article/17/6/set-path-linux)中找到并且可以执行,那么输入 `nccm` 就可以启动 TUI(文本用户界面)了。如果你看到 Python 3 抛出的异常,请检查依赖包是否正确安装,任何异常都应该提到缺少的依赖包。
只要你没有在 YAML 配置文件中更改 `ncm_config_control` 模式,那么你可以使用以下的键盘按键来控制:
* `Up`/`Down` 方向键 - 移动光标
* `Home`/`End` - 跳转到文件开始和结尾
* `PgUp`/`PgDn` - 以页为单位查看
* `Left`/`Right` 方向键 - 水平滚动
* `TAB` - 在文本框之间移动
* 回车 - 连接选中的 SSH 会话
* `Ctrl-h` - 显示帮助菜单
* `Ctrl-q`/`Ctrl-c` - 退出
* `F1`-`F5` 或 `!` `@` `#` `$` `%` - 按 1-5 列排序
使用 `F1` 到 `F5` 来按 1-5 列排序,如果你的设备占用了这些 `F1` - `F5` 键,你可以使用`!` `@` `#` `$` `%` 来替代。默认界面显示 4 列内容,但我们将用户名和服务器地址作为单独的列来排序,这样我们就有了 5 个排序方式。你也可以通过再次按下排序的按键来逆转排序。在选中的行上按回车可以建立会话。

在 `Filter` 文本框中输入过滤内容,会用输入的内容以“与”的关系来过滤输出内容。这是不区分大小写的,而条目间用空白分隔。在 `Conn` 部分也是如此,但在这里按回车键可以连接到那个特定的条目编号。
这个工具还有许多功能需要你去发掘,比如专注模式,这些部分留下等待你去探索,也可以查看项目主页或者内置的帮助文档查看更多细节内容。
项目的 YAML 配置文件的文档是完善的,所以你可以查阅修改使 `nccm` 使用起来更加顺手。`nccm` 项目是非常希望得到你的反馈的,所以你可以复刻该项目然后添加更多新功能,欢迎大家提出拉取请求。
### 使用 nccm 来放松连接 SSH 的压力
像我一样,我希望这个工具可以对你有用,感谢能够为开源工作增加自己的贡献,请接受 `nccm` 作为我对开源项目自由、高效工作所做的贡献。
---
via: <https://opensource.com/article/20/9/ssh-connection-manager>
作者:[Kenneth Aaron](https://opensource.com/users/flyingrhino) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hom](https://github.com/hom) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,634 | 用 Portainer.io 来监控和管理 Docker 容器(1) | https://www.linuxtechi.com/monitor-manage-docker-containers-portainer-part1/ | 2020-09-20T22:55:00 | [
"容器",
"Docker"
] | https://linux.cn/article-12634-1.html | 
随着 Docker 的使用量越来越大,监控 Docker 容器正在变得更有挑战性。每天都有大量的 Docker 容器被创建,因此如何监控它们就变得非常重要。目前已经有一些内置的工具和技术,不过对它们进行配置有一些复杂。随着基于微服务的架构正在变成接下来事实上的标准,学会这种技术将为你的知识库再添一项新技能。
基于上述场景,对一种轻量、健壮的镜像管理工具的需求日益增加。Portainer.io 解决了这个问题。 Portainer.io(最新版本是 1.20.2)非常轻量,只需 2-3 个命令就可以配置好,已经在 Docker 用户中流行起来。
比起其他工具,这个工具有很多优势,其中一些如下所示:
* 轻量(安装此工具仅需 2 到 3 个命令,与此同时安装镜像的大小在 26 M 到 30 M 之间)
* 健壮且易用
* 可用于 Docker 监控和构建
* 提供对 Docker 环境的详细概况
* 可以管理容器、镜像、网络和卷
* Portainer 部署方便,仅需一个 Docker 命令(可以在任意地方运行)
* 可以对完整的 Docker 容器环境进行监控
Portainer 同时具有以下服务:
* 社区支持
* 企业支持
* 与合作伙伴 OEM 服务一起的专业服务
Portainer 的功能和特性如下:
```
1. 配备了漂亮的仪表盘,易于使用和监控
2. 自带大量内置模板,便于操作和创建
3. 服务支持(仅 OEM 和企业用户)
4. 对容器、镜像、网络、卷以及配置进行几乎实时的监控
5. 包含 Docker 集群监控功能
6. 功能多样的用户管理
```
另请阅读:[如何在 Ubuntu 16.04 / 18.04 LTS 版本中安装 Docker CE](https://www.linuxtechi.com/how-to-setup-docker-on-ubuntu-server-16-04/)
### 如何在 Ubuntu Linux / RHEL / CentOS 系统上安装和配置 Portainer.io
注意:下面的安装过程是在 Ubuntu 18.04 上完成的,但是对 RHEL 和 CentOS 同样适用,同时假设你已经在系统上安装了 Docker CE。
```
root@linuxtechi:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04 LTS
Release: 18.04
Codename: bionic
root@linuxtechi:~$
```
为 Portainer 创建卷:
```
root@linuxtechi:~$ sudo docker volume create portainer_data
portainer_data
root@linuxtechi:~$
```
使用下面的 Docker 命令来运行 Portainer 容器:
```
root@linuxtechi:~$ sudo docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer
Unable to find image 'portainer/portainer:latest' locally
latest: Pulling from portainer/portainer
d1e017099d17: Pull complete
0b1e707a06d2: Pull complete
Digest: sha256:d6cc2c20c0af38d8d557ab994c419c799a10fe825e4aa57fea2e2e507a13747d
Status: Downloaded newer image for portainer/portainer:latest
35286de9f2e21d197309575bb52b5599fec24d4f373cc27210d98abc60244107
root@linuxtechi:~$
```
安装完成之后,通过主机或 Docker 的 IP 加上 Docker 引擎使用的 9000 端口在浏览器中打开 Portainer。
注意:如果 Docker 所在主机的系统防火墙开启,需要确保 9000 端口被放行,否则浏览器页面将无法打开。
在我这边,我的 Docker 主机/引擎的 IP 是 `192.168.1.16`,所以 URL 就是 `http://192.168.1.16:9000`

在创建管理员用户时,请确保密码是 8 个字符,同时用户名为 `admin`,然后点击 “Create User”。
接下来进入如下所示的页面,选中 “Local” 矩形框。

点击 “Connect”,
可以看到 admin 用户的漂亮首页如下所示,

现在 Portainer 已经准备好运行和管理你的 Docker 容器了,同时也可用于容器监控。
### 在 Portainer 中管理容器镜像

检查当前的状态,可以看到有两个容器已经在运行了,如果你创建另一个也会立即显示出来。
像下面这样,在命令行中启动一个或两个容器,
```
root@linuxtechi:~$ sudo docker run --name test -it debian
Unable to find image 'debian:latest' locally
latest: Pulling from library/debian
e79bb959ec00: Pull complete
Digest: sha256:724b0fbbda7fda6372ffed586670573c59e07a48c86d606bab05db118abe0ef5
Status: Downloaded newer image for debian:latest
root@linuxtechi:/#
```
然后在 Portainer 页面中点击刷新按钮(会出现一条让你确认的消息,点击上面的 “Continue”),就可以像下面高亮显示的一样看到 3 个容器了。

点击上图中红圈圈出来的 “containers”,下一个页面会显示 “Dashboard Endpoint summary”。

在这个页面中,点击上图高亮和红圈圈出来的 “Containers”,就可以对容器进行监控了。
### 以简单的方式对容器进行监控
继续上面的步骤,就会出现一个如下所示精致、漂亮的 “Container list” 页面。

所有的容器都可以在这里进行控制(停止、启动等等)。
1、在这个页面上,停止我们之前启动的 “test” 容器(这是一个我们早先启动的 debian 容器)。
选中此容器前面的复选框,然后点击上面的“Stop”按钮来停止。

在命令行中,你也会看到这个容器现在已经停止或退出了:
```
root@linuxtechi:~$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d45902e717c0 debian "bash" 21 minutes ago Exited (0) 49 seconds ago test
08b96eddbae9 centos:7 "/bin/bash" About an hour ago Exited (137) 9 minutes ago mycontainer2
35286de9f2e2 portainer/portainer "/portainer" 2 hours ago Up About an hour 0.0.0.0:9000->9000/tcp compassionate_benz
root@linuxtechi:~$
```
2、现在,在 Portainer 页面中启动已经停止的两个容器(test 和 mycontainer2)
选中已停止的这两个容器前面的复选框,然后点击 “Start”。

你会立即看到两条窗口提醒,内容是“容器成功启动”,并且两个容器的状态变为正在运行。

### 一步步探索其他多种选项和特性
1、点击高亮的“Images”,你会看到如下页面:

这是可用的容器列表,其中一些可能没在运行。这些容器可以被导入、导出或者上传到不同的位置,截图如下所示。

2、点击高亮的“Volumes”,显示如下页面:

3、通过下面的操作,可以很容易的添加卷。点击添加卷按钮,出现如下页面,在名称输入框中输入卷名称,例如 “myvol”,然后点击 “Create the volume” 按钮:

新创建的卷如下所示(状态为未使用):

### 结论
通过上面的安装步骤,你可以到配置和使用 Portainer.io 的多种选项是多么简单和精美,它提供了用于构建和监控 Docker 容器的多种功能和选项。如前所述,这个一个非常轻量的工具,因此不会给主机系统增加任何负担。下一组选项将在本系列的第 2 部分中进行探讨。
另请阅读: [用 Portainer.io 来监控和管理 Docker 容器(2)](https://www.linuxtechi.com/monitor-manage-docker-containers-portainer-io-part-2/)
---
via: https://www.linuxtechi.com/monitor-manage-docker-containers-portainer-part1/
作者:[Shashidhar Soppin](https://www.linuxtechi.com/author/shashidhar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jlztan](https://github.com/jlztan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As **Docker** usage and adoption is growing faster and faster, monitoring **Docker container** images is becoming more challenging. As multiple Docker container images are getting created day-by-day, monitoring them is very important. There are already some in built tools and technologies, but configuring them is little complex. As micro-services based architecture is becoming the de-facto standard in coming days, learning such tool adds one more arsenal to your tool-set.
Based on the above scenarios, there was in need of one light weight and robust tool requirement was growing. So Portainer.io addressed this. “**Portainer.io**“,(Latest version is 1.20.2) the tool is very light weight(with 2-3 commands only one can configure it) and has become popular among Docker users.
**This tool has advantages over other tools; some of these are as below**,
- Light weight (requires only 2-3 commands to be required to run to install this tool) {Also installation image is only around 26-30MB of size)
- Robust and easy to use
- Can be used for Docker monitor and Build
- This tool provides us a detailed overview of your Docker environments
- This tool allows us to manage your containers, images, networks and volumes.
- Portainer is simple to deploy – this requires just one Docker command (can be run from anywhere.)
- Complete Docker-container environment can be monitored easily
**Portainer is also equipped with**,
- Community support
- Enterprise support
- Has professional services available(along with partner OEM services)
**Functionality and features of Portainer tool are,**
- It comes-up with nice Dashboard, easy to use and monitor.
- Many in-built templates for ease of operation and creation
- Support of services (OEM, Enterprise level)
- Monitoring of Containers, Images, Networks, Volume and configuration at almost real-time.
- Also includes Docker-Swarm monitoring
- User management with many fancy capabilities
**Read Also : How to Install Docker CE on Ubuntu 16.04 / 18.04 LTS System**
#### How to install and configure Portainer.io on Ubuntu Linux / RHEL / CentOS
**Note: **This installation is done on Ubuntu 18.04 but the installation on RHEL & CentOS would be same. We are assuming Docker CE is already installed on your system.
```
shashi@linuxtechi:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04 LTS
Release: 18.04
Codename: bionic
shashi@linuxtechi:~$
```
Create the Volume for portainer
```
shashi@linuxtechi:~$ sudo docker volume create portainer_data
portainer_data
shashi@linuxtechi:~$
```
Launch and start Portainer Container using the beneath docker command,
```
shashi@linuxtechi:~$ sudo docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer
Unable to find image 'portainer/portainer:latest' locally
latest: Pulling from portainer/portainer
d1e017099d17: Pull complete
0b1e707a06d2: Pull complete
Digest: sha256:d6cc2c20c0af38d8d557ab994c419c799a10fe825e4aa57fea2e2e507a13747d
Status: Downloaded newer image for portainer/portainer:latest
35286de9f2e21d197309575bb52b5599fec24d4f373cc27210d98abc60244107
shashi@linuxtechi:~$
```
Once the complete installation is done, use the ip of host or Docker using port 9000 of the Docker engine where portainer is running using your browser.
**Note:** If OS firewall is enabled on your Docker host then make sure 9000 port is allowed else its GUI will not come up.
In my case, IP address of my Docker Host / Engine is “192.168.1.16” so URL will be,
http://192.168.1.16:9000
Please make sure that you enter 8-character passwords. Let the admin be the user as it is and then click “Create user”.
Now the following screen appears, in this select “Local” rectangle box.
Click on “Connect”
Nice GUI with admin as user home screen appears as below,
Now Portainer is ready to launch and manage your Docker containers and it can also be used for containers monitoring.
#### Bring-up container image on Portainer tool
Now check the present status, there are two container images are already running, if you create one more that appears instantly.
From your command line kick-start one or two containers as below,
```
shashi@linuxtechi:~$ sudo docker run --name test -it debian
Unable to find image 'debian:latest' locally
latest: Pulling from library/debian
e79bb959ec00: Pull complete
Digest: sha256:724b0fbbda7fda6372ffed586670573c59e07a48c86d606bab05db118abe0ef5
Status: Downloaded newer image for debian:latest
root@d45902e717c0:/#
```
Now click Refresh button (Are you sure message appears, click “continue” on this) in Portainer GUI, you will now see 3 container images as highlighted below,
Click on the “**containers**” (in which it is red circled above), next window appears with “**Dashboard Endpoint summary**”
In this page, click on “**Containers**” as highlighted in red color. Now you are ready to monitor your container image.
#### Simple Docker container image monitoring
From the above step, it appears that a fancy and nice looking “Container List” page appears as below,
All the container images can be controlled from here (stop, start, etc)
**1)** Now from this page, stop the earlier started {“test” container (this was the debian image that we started earlier)}
To do this select the check box in front of this image and click stop button from above,
From the command line option, you will see that this image has been stopped or exited now,
```
shashi@linuxtechi:~$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d45902e717c0 debian "bash" 21 minutes ago Exited (0) 49 seconds ago test
08b96eddbae9 centos:7 "/bin/bash" About an hour ago Exited (137) 9 minutes ago mycontainer2
35286de9f2e2 portainer/portainer "/portainer" 2 hours ago Up About an hour 0.0.0.0:9000->9000/tcp compassionate_benz
shashi@linuxtechi:~$
```
**2)** Now start the stopped containers (test & mycontainer2) from Portainer GUI,
Select the check box in front of stopped containers, and the click on Start
You will get a quick window saying, “**Container successfully started**” and with running state
#### Various other options and features are explored as below step-by-step
**1)** Click on “**Images**” which is highlighted, you will get the below window,
This is the list of container images that are available but some may not running. These images can be imported, exported or uploaded to various locations, below screen shot shows the same,
**2)** Click on “**volumes”** which is highlighted, you will get the below window,
**3)** Volumes can be added easily with following option, click on add volume button, below window appears,
Provide the name as “**myvol**” in the name box and click on “**create the volume**” button.
The newly created volume appears as below, (with unused state)
##### Conclusion:
As from the above installation steps, configuration and playing around with various options you can see how easy and fancy looking is Portainer.io tool is. This provides multiple features and options to explore on building, monitoring docker container. As explained this is very light weight tool, so doesn’t add any overload to host system. Next set-of options will be explored in part-2 of this series.
Read Also: [Monitor and Manage Docker Containers with Portainer.io (GUI tool) – Part-2](https://www.linuxtechi.com/monitor-manage-docker-containers-portainer-io-part-2/) |
12,635 | 关机时间太长的调查和解决的方法 | https://itsfoss.com/long-shutdown-linux/ | 2020-09-20T23:39:00 | [
"关机"
] | https://linux.cn/article-12635-1.html | 
>
> 你的 Linux 系统关机时间太长么?以下是你可以采取的步骤,来找出导致延迟关机的原因并解决这个问题。
>
>
>
我希望你对 [sigterm 和 sigkill](https://linuxhandbook.com/sigterm-vs-sigkill/) 的概念有一点熟悉。
当你[关闭 Linux 系统](https://itsfoss.com/schedule-shutdown-ubuntu/)时,它会发送终止信号(sigterm),并礼貌地要求正在运行的进程停止。有些进程不符合该行为,它们会忽略终止信号并继续运行。
这可能会导致关机过程的延迟,因为你的系统会在一个预定义的时间段内等待运行的进程停止。在这个时间段之后,它会发送 `kill` 信号来强制停止所有剩余的运行进程并关闭系统。
事实上,在某些情况下,你会在黑屏上看到一个类似 “a stop job is running” 的信息。
如果你的系统关闭时间太长,你可以做以下工作:
* 检查哪个进程/服务耗时过长,以及你是否能删除或重新配置它,使其正常运行。
* 更改系统强制停止运行进程前的默认等待时间。(快速而不优雅的方式)
我的操作系统是使用 systemd 的 Ubuntu。这里的命令和步骤适用于任何使用 systemd 的 Linux 发行版(大多数发行版都是这样)。
### 检查哪些进程会导致 Linux 的长时间关机
如果你想找出问题所在,你应该检查上次关机时发生了什么。使用这个命令来获得“我知道你上个会话做了什么”(I Know What You Did Last Summer 的双关语)的力量。
```
journalctl -rb -1
```
[journalctl 命令](https://linuxhandbook.com/journalctl-command/)能让你读取系统日志。使用选项 `-b -1` 可以过滤最后一次启动会话的日志。使用选项 `-r` 时,日志将按时间倒序显示。
换句话说,`journalctl -rb -1` 命令将显示最后一次关闭 Linux 系统之前的系统日志。这里就是你需要分析 Linux 系统长时间关机问题的地方。
#### 没有 journal 日志?下面是你应该做的。
如果没有 journal 日志,请确认你的发行版是否使用 systemd。
即使在一些使用 systemd 的 Linux 发行版上,journal 日志也没有被默认激活。
请确认 `/var/log/journal` 是否存在。如果不存在,请创建它:
```
sudo mkdir /var/log/journal
```
你还应该检查 `/etc/systemd/journald.conf` 文件的内容,并确保 `Storage` 的值被设置为自动(`auto`)或持久(`persistent`)。
你是否在日志中发现可疑的东西?是否有一个进程/服务拒绝停止?如果是,调查一下是否可以在没有副作用的情况下删除它,或者是否可以重新配置它。请不要在这里盲目地去删除东西。你应该对这个进程有所了解。
### 通过减少默认停止超时来加快 Linux 中的关机速度(快速修复)
关机的默认等待时间通常设置为 90 秒。在这个时间之后,你的系统会尝试强制停止服务。
如果你想让你的 Linux 系统快速关闭,你可以改变这个等待时间。
你可以在位于 `/etc/systemd/system.conf` 的配置文件中找到所有的 systemd 设置。这个文件中应该有很多以 `#` 开头的行。它们代表了文件中各条目的默认值。
在开始之前,最好先复制一份原始文件。
```
sudo cp /etc/systemd/system.conf /etc/systemd/system.conf.orig
```
在这里寻找 `DefaultTimeoutStopSec`。它可能被设置为 90 秒。
```
#DefaultTimeoutStopSec=90s
```
你得把这个值改成更方便的,比如 5 秒或 10 秒。
```
DefaultTimeoutStopSec=5s
```
如果你不知道如何在终端中编辑配置文件,可以使用这个命令在系统默认的文本编辑器(如 Gedit)中打开文件进行编辑:
```
sudo xdg-open /etc/systemd/system.conf
```

不要忘记**删除 DefaultTimeoutStopSec 前的 `#` 号**。保存文件并重启系统。
这将帮助你减少 Linux 系统的关机延迟。
#### 看门狗问题!
Linux 有一个名为看门狗的模块,用于监控某些服务是否在运行。它可以被配置为在系统因软件错误而挂起时自动重启系统。
在桌面系统上使用看门狗是不常见的,因为你可以手动关闭或重启系统。它经常被用于远程服务器上。
首先检查看门狗是否在运行:
```
ps -af | grep watch*
```
如果你的系统正在运行看门狗,你可以在 systemd 配置文件 `/etc/systemd/system.conf` 中将 `ShutdownWatchdogSec` 的值从 10 分钟改为更低的值。
### 你能解决关机时间过长的问题吗?
希望本教程能帮助你解决系统长时间关机的问题。如果你成功解决了这个问题,请在评论中告诉我。
---
via: https://itsfoss.com/long-shutdown-linux/
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I hope you are a tad bit familiar with the [sigterm and sigkill](https://linuxhandbook.com/sigterm-vs-sigkill/?ref=itsfoss.com) concept.
When you [shut down your Linux system](https://itsfoss.com/schedule-shutdown-ubuntu/), it sends the sigterm and politely asks the running processes to stop. Some processes misbehave and they ignore the sigterm and keep on running.
This could cause a delay to the shutdown process as your system will wait for the running processes to stop for a predefined time period. After this time period, it sends the kill signal to force stop all the remaining running processes and shuts down the system. I recommend [reading about sigterm vs sigkill to understand the difference](https://linuxhandbook.com/sigterm-vs-sigkill/?ref=itsfoss.com).
In fact, in some cases, you would see a message like ‘a stop job is running’ on the black screen.
If your system is taking too long in shutting down, you can do the following:
- Check which process/service is taking too long and if you can remove or reconfigure it to behave properly.
- Change the default waiting period before your system force stops the running processes. [Quick and dirty fix]
I am using Ubuntu here which uses [systemd](https://wiki.debian.org/systemd?ref=itsfoss.com). The commands and steps here are valid for any Linux distribution that uses systemd (most of them do).

## Check which processes are causing long shutdown in Linux
If you want to figure out what’s wrong, you should check what happened at the last shutdown. Use this command to get the power of ‘I know what you did last session’ (pun intended):
`journalctl -rb -1`
The [journalctl command](https://linuxhandbook.com/journalctl-command/?ref=itsfoss.com) allows you to read system logs. With options ‘-b -1’ you filter the logs for the last boot session. With option ‘-r’, the logs are shown in reverse chronological order.
In other words, the ‘journalctl -rb -1’ command will show the system logs just before your Linux system was shutdown the last time. This is what you need to analyze the long shutdown problem in Linux.
### No journal logs? Here’s what you should do
If there are no journal logs, please make sure that your distribution uses systemd.
Even on some Linux distributions with systemd, the journal logs are not activated by default.
Make sure that /var/log/journal exists. If it doesn’t, create it:
`sudo mkdir /var/log/journal`
You should also check the content of /etc/systemd/journald.conf file and make sure that the value of Storage is set to either auto or persistent.
Do you find something suspicious in the logs? Is there a process/service refusing to stop? If yes, investigate if you could remove it without side effects or if you could reconfigure it. Don’t go blindly removing stuff here, please. You should have knowledge of the process.
## Speed up shutdown in Linux by reducing default stop timeout [Quick fix]
The default wait period for the shut down is usually set at 90 seconds. Your system tries to force stop the services after this time period.
If you want your Linux system to shut down quickly, you can change this waiting period.
You’ll find all the systemd settings in the config file located at /etc/systemd/system.conf. This file should be filled with lots of line starting with #. They represent the default values of the entries in the file.
Before you do anything, it will be a good idea to make a copy of the original file.
`sudo cp /etc/systemd/system.conf /etc/systemd/system.conf.orig`
Look for DefaultTimeoutStopSec here. It should probably be set to 90 sec.
`#DefaultTimeoutStopSec=90s`
You have to change this value to something more convenient like 5 or 10 seconds.
`DefaultTimeoutStopSec=5s`
If you don’t know how to edit the config file in terminal, use this command to open the file for editing in your system’s default text editor (like Gedit):
`sudo xdg-open /etc/systemd/system.conf`
Don’t forget to **remove the # before DefaultTimeoutStopSec**. Save the file and reboot your system.
This should help you reduce the shutdown delay for your Linux system.
### Watchdog issue!
Linux has a module named watchdog that is used for monitoring whether certain services are running or not. It could be configured to automatically reboot systems if they are hanged due to software error.
It is unusual to use Watchdog on desktop systems because you can manually shutdown or reboot the system. It is often used on remote servers.
First check watchdog is running:
`ps -af | grep watch*`
If watchdog is running on your system, you can change the ShutdownWatchdogSec value from 10 minutes to something lower in the systemd config file /etc/systemd/system.conf.
**Were you able to fix the lengthy shutdown?**
I hope this tutorial helped you in investigating and fixing the long shutdown issue on your system. Do let me know in the comments if you managed to fix it. |
12,637 | 使用 Linux stat 命令创建灵活的文件列表 | https://www.networkworld.com/article/3573802/using-the-linux-stat-command-to-create-flexible-file-listings.html | 2020-09-21T22:32:11 | [
"stat"
] | https://linux.cn/article-12637-1.html | 
`stat` 命令提供了很多关于文件的详细信息。
它不仅提供了文件最近变化的日期/时间,还显示了最近访问文件的时间和权限变化。它可以同时告诉你文件的字节大小和块的数量。它可以显示文件使用的 inode 以及文件类型。它包括了文件所有者和相关用户组的名称和 UID/GID。它以 “rwx”(被称为 “人类可读” 格式)和数字方式显示文件权限。在某些系统中,它甚至可能包括文件创建的日期和时间(称为“出生”)。
除了提供所有这些信息外,`stat` 命令还可以用来创建文件列表。这些列表非常灵活,你可以选择包含上述任何或全部信息。
要生成一个自定义列表,你只需要使用 `stat` 命令的 `-c`(或 `--format`)选项,并指定你想要包含的字段。例如,要创建一个以两种格式显示文件权限的列表,使用这个命令:
```
$ stat -c '%n %a %A' my*
my.banner 664 -rw-rw-r--
mydir 775 drwxrwxr-x
myfile 664 -rw-rw-r--
myjunk 777 lrwxrwxrwx
mykey 664 -rw-rw-r--
mylog 664 -rw-rw-r--
myscript 755 -rwxr-xr-x
mytext 664 -rw-rw-r--
mytext.bak 664 -rw-rw-r--
mytwin 50 -rw-r-----
mywords 664 -rw-rw-r--
```
如上例所示,`%n` 代表文件名,`%a` 代表八进制的权限,`%A` 代表 `rwx` 形式的权限。完整的列表如后面所示。
要为这个命令创建一个别名,输入这个命令,或在 `.bashrc` 文件中添加这个定义。
```
$ alias ls_perms="stat -c '%n %a %A'"
```
要创建一个非常接近 `ls -l` 提供的长列表,可以这样做:
```
$ stat -c '%A %h %U %G %s %y %n' my*
-rw-rw-r-- 1 shs shs 255 2020-04-01 16:20:00.899374215 -0400 my.banner
drwxrwxr-x 2 shs shs 4096 2020-09-07 12:50:20.224470760 -0400 mydir
-rw-rw-r-- 1 shs shs 6 2020-05-16 11:12:00.460355387 -0400 myfile
lrwxrwxrwx 1 shs shs 11 2020-05-28 18:49:21.666792608 -0400 myjunk
-rw-rw-r-- 1 shs shs 655 2020-01-14 15:56:08.540540488 -0500 mykey
-rw-rw-r-- 1 shs shs 8 2020-03-04 17:13:21.406874246 -0500 mylog
-rwxr-xr-x 1 shs shs 201 2020-09-07 12:50:41.316745867 -0400 myscript
-rw-rw-r-- 1 shs shs 40 2019-06-06 08:54:09.538663323 -0400 mytext
-rw-rw-r-- 1 shs shs 24 2019-06-06 08:48:59.652712578 -0400 mytext.bak
-rw-r----- 2 shs shs 228 2019-04-12 19:37:12.790284604 -0400 mytwin
-rw-rw-r-- 1 shs shs 1983 2020-08-10 14:39:57.164842370 -0400 mywords
```
不同之处包括: 1、不试图将字段排成可辨认的一列,2、日期是 `yy-mm-dd` 格式,3、时间字段更精确,4、增加了时区(-0400 是 EDT)。
如果你想根据最后一次访问的日期来列出文件(例如,用 `cat` 命令来显示),使用这样的命令:
```
$ stat -c '%n %x' my* | sort -k2
mytwin 2019-04-22 11:25:20.656828964 -0400
mykey 2020-08-20 16:10:34.479324431 -0400
mylog 2020-08-20 16:10:34.527325066 -0400
myfile 2020-08-20 16:10:57.815632794 -0400
mytext.bak 2020-08-20 16:10:57.935634379 -0400
mytext 2020-08-20 16:15:42.323391985 -0400
mywords 2020-08-20 16:15:43.479407259 -0400
myjunk 2020-09-07 10:04:26.543980300 -0400
myscript 2020-09-07 12:50:41.312745815 -0400
my.banner 2020-09-07 13:22:38.105826116 -0400
mydir 2020-09-07 14:53:10.171867194 -0400
```
用 `stat` 列出文件细节时,可用的选项包括:
* `%a` - 八进制的访问权限(注意 `#` 和 `0` 的 printf 标志)
* `%A` – 人类可读的访问权限
* `%b` – 分配的块数(见 `%B`)
* `%B` – `%b` 报告的每个块的字节数
* `%C` – SELinux 安全上下文字符串
* `%d` – 十进制的设备编号
* `%D` – 十六进制的设备编号
* `%f` – 十六进制的原始模式
* `%F` – 文件类型
* `%g` – 所有者的组 ID
* `%G` – 所有者的组名
* `%h` – 硬链接的数量
* `%i` – inode 编号
* `%m` – 挂载点
* `%n` – 文件名
* `%N` – 如果是符号链接,会解引用为指向的文件名
* `%o` – 最佳 I/O 传输大小提示
* `%s` – 以字节为单位的总大小
* `%t` – 十六进制的主要设备类型,用于字符/块设备特殊文件
* `%T` – 十六进制的次要设备类型,用于字符/块设备特殊文件
* `%u` – 所有者的用户 ID
* `%U` – 所有者的用户名
* `%w` – 文件创建时间,以人类可读形式; 如果未知,则为 `-`。
* `%W` – 文件创建时间,以 UNIX 纪元以来的秒数形式;如果未知,则为 `0`。
* `%x` – 上次访问时间,以人类可读形式
* `%X` – 上次访问时间,以 UNIX 纪元以来的秒数形式
* `%y` – 上次数据修改时间,以人类可读形式
* `%Y` – 上次数据修改时间,以 UNIX 纪元以来的秒数形式
* `%z` – 上次状态改变的时间,以人类可读形式
* `%Z` – 上次状态改变的时间,以 UNIX 纪元以来的秒数形式
这些字段的选择都列在手册页中,你可以选择任何一个,不过用你喜欢的选项创建一些别名应该可以省去很多麻烦。有些选项,如 SELinux 安全上下文字符串,除非在系统中有使用,它将不可用。文件创建时间只有在你的系统保留该信息的情况下才可用。
---
via: <https://www.networkworld.com/article/3573802/using-the-linux-stat-command-to-create-flexible-file-listings.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,639 | Linux 黑话解释:什么是滚动发行版? | https://itsfoss.com/rolling-release/ | 2020-09-21T22:58:00 | [
"滚动发行版"
] | https://linux.cn/article-12639-1.html | 在了解了[什么是 Linux](https://itsfoss.com/what-is-linux/)、[什么是 Linux 发行版](/article-12609-1.html)之后,当你开始使用 Linux 时,你可能会在 Linux 论坛的讨论中遇到“<ruby> 滚动发布 <rt> rolling release </rt></ruby>”这个名词。
在这篇 Linux 黑话解释文章中,你将了解到 Linux 发行版的滚动发布模式。
### 什么是滚动发布?
在软件开发中,滚动发布是一种模式,在这种模式下,软件的更新是连续推出的,而不是分批的版本。这样软件就能始终保持更新。<ruby> 滚动发行版 <rt> rolling release distribution </rt></ruby>遵循同样的模式,它提供最新的 Linux 内核和软件版本,在它们一发布就提供。
[Arch Linux](https://www.archlinux.org/) 是滚动发行版中最流行的例子,然而 [Gentoo](https://www.gentoo.org/) 是最古老的滚动发行版,目前仍在开发中。
当你使用一个滚动发行版时,你会得到小而频繁的更新。这里没有像 Ubuntu 那样的重大 XYZ 版本发布。你会定期[更新 Arch](https://itsfoss.com/update-arch-linux/)或其他滚动发行版,你将永远拥有最新版本的发行版。
滚动发布也是以测试为代价的。当最新的更新开始给你的系统带来问题时,你也许会受到“惊吓”。
### 对比滚动式发布与点版本式发布的发行版

许多 Linux 发行版,如 Debian、Ubuntu、Linux Mint、Fedora 等都遵循<ruby> 点版本 <rt> point release </rt></ruby>模式。他们每隔几个月/年就会发布一个主要的 XYZ 版本。
点版本由 Linux 内核、桌面环境和其他软件的新版本组成。
当一个新的点版本发行版的主要版本发布时,你必须[专门来升级你的系统](https://itsfoss.com/upgrade-ubuntu-version/)。
相反,在滚动发行版中,当它从开发者那里发布时,你会不断地获得新的功能更新。这样,你不需要在几个月或几年后进行版本升级。你总是拥有最新的东西。
**哦,但我的 Ubuntu 也会定期更新,几乎每周一次。这是否意味着 Ubuntu 也在滚动发布?**

不,Ubuntu 不是滚动发布。你看,你通常从 Ubuntu 得到的更新是安全和维护更新(除了一些软件,比如 Mozilla Firefox),而不是新功能的发布。
例如,GNOME 3.38 已经发布了,但 Ubuntu LTS 20.04 版不会给你 GNOME 3.38。它将坚持使用 3.36 版本。如果 GNOME 3.36 有安全或维护更新,你会在 Ubuntu 的更新中得到它。
LibreOffice 版本也是如此。Ubuntu 20.04 LTS 坚持使用 LibreOffice 6.x 系列,而 LibreOffice 7 已经发布了。请记住,我说的是官方软件库中的软件版本。你可以自由地从他们的官方网站上下载一个更新版本的 LibreOffice,或者使用 PPA。但你不会从 Ubuntu 的软件库中得到它。
当 Ubuntu 发布下一个版本 Ubuntu 20.10 时,你会得到 LibreOffice 7 和 GNOME 3.38。
**为什么一些滚动发行版有“版本号”和发行版名称?**

这是一个合理的问题。Arch Linux 是滚动发布的,它总是让你的系统保持更新,然而你会看到像 Arch Linux 2020.9.01 这样的版本号。
现在想象一下,你在 2018 年安装了 Arch Linux。你定期更新你的 Arch Linux 系统,所以你在 2020 年 9 月拥有所有最新的内核和软件。
但是,如果你决定在 2020 年 9 月在一个新系统上安装 Arch Linux 会发生什么?如果你使用 2018 年使用的相同的安装介质,你将不得不安装过去两年或更长时间内发布的所有系统更新。这很不方便,不是吗?
这就是为什么 Arch Linux(和其他滚动发行版)每个月或每隔几个月都会提供一个新的 ISO(操作系统安装程序镜像文件),其中包含所有最新的软件。**这就是所谓的 ISO 刷新**。这样一来,新用户就会得到一个更新的 Linux 发行版。
如果你已经在使用滚动发行版,你就不用担心新的 ISO 刷新了。你的系统已经和它对等了。ISO 刷新对那些要在新系统上安装它的人是有帮助的。
### 滚动式发布的利与弊
滚动发布模式的好处是,你可以得到小而频繁的更新。你总是可以从你的发行版的仓库中获得最新的内核和最新的软件版本。
然而,这也可能带来新软件不可预见的问题。点版本发行版通常会对系统中集成的基本组件进行测试,以避免带来令人不便的错误。而在滚动发行版中,情况就不一样了,在滚动发行版中,软件一经开发者发布就会被推出。
### 你应该使用滚动发行版还是点版本发行版?

这取决于你。如果你是一个新的 Linux 用户,或者如果你不习惯于排除你的 Linux 系统的故障,请坚持使用你选择的点版本发行版。这也建议用于你的生产和关键任务的机器,在这里你会想要一个稳定的系统。
如果你想要最新的和最棒的 Linux 内核和软件,并且你不害怕花费一些时间在故障排除上(时常发生),你可以选择滚动发行版。
在这一点上,我还想提到 Manjaro Linux 的混合滚动发布模式。Manjaro 确实遵循滚动发布模式,你不必将系统升级到较新的版本。不过,Manjaro 也会对基本的软件组件进行测试,而不是盲目的向用户推出。这也是[为什么这么多人使用 Manjrao Linux](https://itsfoss.com/why-use-manjaro-linux/) 的原因之一。
### 我讲清楚了吗?
希望你现在对“滚动发行版”这个词有了稍微的了解。如果你对它仍有一些疑问,请留言,我会尽力回答。我可能会更新文章以涵盖你的问题。祝你愉快 :smiley:
---
via: <https://itsfoss.com/rolling-release/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

After understanding [what Linux is](https://itsfoss.com/what-is-linux/), [what a Linux distribution is](https://itsfoss.com/what-is-linux-distribution/), when you start using Linux, you might come across the term “rolling release” in Linux forum discussions.
In this Linux jargon buster, you’ll learn about the rolling release model of Linux distributions.
## What is a rolling release distribution?
In software development, rolling release is a model in which updates to a software are continuously rolled out, rather than in batches of versions. This way the software always remains up to date. A rolling release distribution follows the same model and it provides the latest Linux kernel and the software version as they are released.
[Arch Linux](https://www.archlinux.org/) is the most popular example of a rolling release distribution however [Gentoo](https://www.gentoo.org/) is the oldest rolling release distribution still in development.
When you use a rolling release distribution, you get small but frequent updates. There are no major XYZ version releases, as with Ubuntu. If you regularly [update Arch](https://itsfoss.com/update-arch-linux/) or the other rolling release distributions, you’ll always have the latest version of your distribution.
The rolling release also comes at the cost of testing. You may have surprises when the latest update starts creating problem for your system.
## Rolling release vs point release distributions

Many Linux distributions such as Debian, Ubuntu, Linux Mint, and Fedora, follow the point release model. They will release a major XYZ version after every few months/years.
The point release consists of new versions of the Linux kernel, desktop environments and other software.
When a new major version of a point release distribution is released, you’ll have to make [special effort to upgrade your system](https://itsfoss.com/upgrade-ubuntu-version/). You need to make backup, the third-party repositories are disabled and it takes around an hour to complete the upgrade.
On the other hand, you keep getting new features updates in a rolling release distribution as it gets released from the developers. This way, you don’t need to do a version upgrade after some months or years. You always have the latest stuff.
### Oh, but my Ubuntu also gets regular updates, almost on a weekly basis. Does it mean Ubuntu is also rolling release?
No. Ubuntu is not a rolling release. You see, the updates you usually get from Ubuntu are security and maintenance updates, except for some software such as Mozilla Firefox, not new feature release.
For example, GNOME 3.38 has been released but Ubuntu LTS release 20.04 won’t give you GNOME 3.38. It will stick to the 3.36 version. If there are security or maintenance updates to GNOME 3.36, you’ll get them with your Ubuntu updates.
The same goes for the LibreOffice release. Ubuntu 20.04 LTS sticks with LibreOffice 6.x series whereas LibreOffice 7 is already out. Keep in mind that I am talking about software versions available in the official repositories. You are free to download a newer version of LibreOffice from their official website or use a PPA. But you won’t get it from Ubuntu’s repositories.
When Ubuntu releases the next version Ubuntu 20.10, you’ll get LibreOffice 7 and GNOME 3.38.
### Why do some rolling release distributions have ‘version number’ and release names?
That’s a fair question. Arch Linux is a rolling release, which always keeps your system updated and yet you’ll see something like Arch Linux 2020.9.01 version number.
Now imagine you installed Arch Linux in 2018. You regularly update your Arch Linux system, so you have the latest kernel and all the latest software in September 2020.
But what happens if you decide to install Arch Linux in September 2020 on a new system? If you use the same installation medium you used in 2018, you’ll have to install all the system updates released in the last two years or more. That’s inconvenient, isn’t it?
This is why Arch Linux and other rolling release distributions provide a new ISO (OS installer image file) with all the latest software every month or every few months. **This is called ISO refresh**. Thus, new users get a more recent copy of the Linux distribution.
If you are already using a rolling release distribution, you don’t to worry about the new refreshed ISO. Your system is already at par with it. The ISO refresh is helpful to people who are going to install it on a new system.
## Pros and cons of rolling release distributions
The benefit of the rolling release model is that you get small but more frequent updates. You always have the latest kernel and the latest software releases available from your distribution’s repositories.
However, this could also bring unforeseen problems with the new software. Point release usually test essential components for system integration to avoid inconvenient bugs. This is not the case in rolling release distribution, as the software is rolled out as soon it is released by their developers.
## Should you use rolling release or point release distribution?

That’s up to you. If you are a new Linux user or if you are not comfortable troubleshooting your Linux system, stick with a point release distribution of your choice. This is also recommended for your production and mission-critical machines. For them, you are better off with a stable system.
If you want the latest and greatest Linux kernel and software and you are not afraid of spending some time in troubleshooting (it happens from time to time) then you may choose a rolling release distribution.
At this point, I would also like to mention the hybrid rolling releasing model of Manjaro Linux. Manjaro does follow a rolling release model, in which you don’t have to upgrade your system to a newer version. However, Manjaro also performs testing of the essential software components instead of just blindly rolling it out to the users. This is one of the[ reasons why so many people use Manjrao Linux](https://itsfoss.com/why-use-manjaro-linux/).
**Was it clear enough?**
I hope you have a slightly better understanding of the term “rolling release distribution” now. If you still have some doubts around it, please leave a comment and I’ll try to answer. I might update the article to cover your questions. Enjoy :) |
12,641 | 《代码英雄》第二季(5):关于 DevSecOps 的故事 | https://www.redhat.com/en/command-line-heroes/season-2/the-one-about-devsecops | 2020-09-23T05:09:00 | [
"DevSecOps",
"代码英雄"
] | https://linux.cn/article-12641-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(5):关于 DevSecOps 的故事](https://www.redhat.com/en/command-line-heroes/season-2/the-one-about-devsecops)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/5cfd48a4.mp3)脚本。
>
> 导语:不良的安全和可靠性实践会导致影响数百万人的中断。现在是时候让安全加入 DevOps 运动了。并且,在 DevSecOps 的世界中,我们可以创造性的提升安全性。
>
>
> 每月发现一个漏洞曾经是常态。而现在,由于敏捷流程和 DevOps 团队,软件开发的进展迅速。Vincent Danen 告诉我们,这如何导致被认为是漏洞的东西急剧增加。前亚马逊灾难主管 Jesse Robbins 介绍了公司如何为灾难性故障和漏洞做好准备。而 Elastic 的产品安全主管 Josh Bressers 则展望了科技领域安全的未来。
>
>
> 我们不应该把安全团队当成脾气暴躁的妖怪。听听 DevSecOps 团队如何将英雄们聚集在一起,以实现更好的安全。
>
>
>
**00:00:01 - 众议院小组委员会代表**:
1991 年 6 月 26 日,在华盛顿特区,马里兰州和西弗吉尼亚州的大部分地区,以及我的家乡的大部分地区都因公共电话网络的大规模故障而瘫痪了。然而,随着技术变得越来越复杂,网络系统越来越相互依存,反复发生故障的可能性也会增加。似乎并没有警告说会发生这种情况。
**00:00:23 - Saron Yitbarek**:
在 20 世纪 90 年代初,有 1200 万美国人遭受了大规模的电话网络故障。人们不能给医院打电话,企业不能给客户打电话,父母不能打电话给托儿所。对于一个基础设施严重依赖于万物互联的计算机系统的国家来说,这是一场混乱也是一记警钟。这些计算机网络变得越来越大,然后当它们出现故障时,故障时间就会很长。
**00:01:01**:
电脑故障会导致电话系统崩溃。在今天代码中的一行小错误的后果比以往时候都要严重。
**00:01:15**:
我是 Saron Yitbarek,这里是是红帽公司的原创播客节目《代码英雄》。
**00:01:24**:
因此,软件安全性和可靠性比以往任何时候都重要。传统的瀑布式开发方法,安全性只是一个附加流程而已,已经不再适用。我们生活在一个 DevOps 的世界里,一切都变得更快、更敏捷、扩展性更强,这在电话网络崩溃时是他们无法想象的。这意味着我们的安全和可靠性标准必须不断改进,以应对这些挑战。
**00:01:55**:
在本集中,我们将研究如何将安全性集成到 DevOps 中,我们还将探索在运营中构建可靠性和弹性的新方法。即使在介绍了所有这些之后,我们知道还有很多东西可以讨论,因为在 DevSecOps 的世界里,对于开发人员和运营人员来说,事情都在快速变化。这些变化意味着不同的事情,这取决于你的立场,但这是我们的看法。我们也很想听到你们的消息——所以如果你认为我们错过了什么,不要害羞——在网上联系我们。
**00:02:34**:
好了,让我们开始探索这个全新的领域吧。
**00:02:43**:
事情就是这样,让安全性和可靠性跟上时代的步伐,并为 DevOps 世界做好准备,这意味着我们必须对工作方式进行一些关键的调整。第一,我们必须拥抱自动化。我的意思是,想想双因子认证的逻辑。想想那些难以想象的艰巨任务吧。很显然,你不能仅仅通过增加员工来解决问题,所以第一点就是拥抱自动化。
**00:03:15**:
然后,第二点,这个可能不是那么明显,那就是它真的改变了文化,使安全不再是一个祸害。稍后我将解释我所说的改变文化的含义。但是让我们一个一个的解释这两点。首先,拥抱自动化。
**00:03:42**:
以前,应用程序的部署在每个单独的发布之前都涉及到一个人为的安全审查,我不知道你是否注意到了,但是人为的审查可能会有点慢。这就是为什么自动化是在 DevOps 构建安全性的关键部分。以 Verizon 最近的数据泄露报告为例。他们发现,81% 的与黑客相关入侵涉及密码被盗或者弱密码。从表面上看,这是一个非常简单的问题,但是规模却很大。就像我之前所提及到的,你不能用工作人员去解决 3000 万个密码问题,对吧?问题在于解决大规模问题,而每次的答案都是一样的。那就是自动化,自动化。
**00:04:36 - Vincent Danen**:
如果你等待人参与进来,那么规模就不会扩大。
**00:04:41 - Saron Yitbarek**:
Vincent Danen 是红帽公司产品安全部门的主管,在过去的 20 年里,他见证了 DevOps 的快速发展。安全团队不得不竞相追赶。
**00:04:56 - Vincent Danen**:
刚开始的时候,每个月都有漏洞,后来变成了每隔一周,然后是每周都有。现在,每天都能找到几百个漏洞。
**00:05:08 - Saron Yitbarek**:
有趣的是,Vincent 说,随着安全团队的发展,实际上会出现更多的漏洞,而不是更少。
**00:05:17 - Vincent Danen**:
我们永远不会说,哦,我们现在安全了,我们做完了,我们的工作结束了。安全审计会一直存在,就像呼吸一样,这是必须要有的。
**00:05:27 - Saron Yitbarek**:
事实证明,对于安全性和可靠性团队来说,细节的问题变得越来越重要。
**00:05:35 - Vincent Danen**:
当我们在寻找这些漏洞时,我们会发现更多的东西,而且这个趋势还将继续。因为你会发现新的漏洞类型和一些我们可能认为不太重要的东西,或者以前甚至不知道它们存在的东西。我们会发现这些东西发展的速度很快,而且数量更多,因此规模爆炸性增长。知识、软件的数量、消费者的数量都促进了该领域安全性以及漏洞的增加。
**00:06:06 - Saron Yitbarek**:
一旦你将安全视为一个不断发展的问题,而不是随着时间的推移而 “得到解决” 的问题,那么自动化的理由就会变得更加充分。
**00:06:18 - Vincent Danen**:
嗯,我认为有了自动化,你可以以一种非常快的方式将这些东西集成到你的开发流水线中,这是其一。其二,你不需要人类来做这些工作,对吧?计算机不需要睡觉,所以你可以在处理器允许的情况下以最快速度浏览代码,而不是等待人类通过一些可能相当乏味的命令行来查找漏洞。
**00:06:44**:
然后通过模式匹配和启发式方法,甚至在开始编写代码的时候,你就可以知道代码中那些地方是易受攻击的。如果在你编写代码的时候,在你的 IDE 或者工具中有一个插件,它能告诉你。嘿,这看起来有点可疑,或者你刚刚引入了一个漏洞。在你提交代码之前你都可以纠正这些可疑点或者漏洞。
**00:07:08 - Saron Yitbarek**:
安全在进步。这真是一笔巨大的奖励。
**00:07:12 - Vincent Danen**:
每一天,甚至每一小时,都会有很多东西涌现出来。通过持续集成和持续部署,你写了代码,10 分钟后它就被部署了。因此,在代码被推送之前自动进行验证是非常关键的。
**00:07:32 - Saron Yitbarek**:
我们可以使用各种各样的工具来完成这个任务,不管是静态代码分析,还是 IDE 的插件,或者是一大堆其他选项。我们将在 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 上分享一些我们最喜欢的片段。
**00:07:53**:
一旦我们有了这些工具,它们将帮助我们把安全放在首位。结果就是,DevOps 被重新定义为 DevSecOps。安全被纳入到流程中。
**00:08:08 - Vincent Danen**:
就像开发人员和运维人员结合的方式一样,你将这两个规则合成到了一个规则。现在,你有了 DevOps,并将安全这第三个组件与开发和运维集成到一起,我认为这非常重要。因为事后才考虑安全性,这会使安全性变得非常被动、昂贵以及可能会损害消费者。当你一开始就把安全代入其中,你就可以完成开发工作,从头到尾进行安全检查并开始运作。
**00:08:44 - Saron Yitbarek**:
当然,就像我们在这一集的开头提到的,自动化只是一个大蛋糕的一半,而 Vincent 也明白这一点。
**00:08:53 - Vincent Danen**:
并不仅仅是一部分。不能仅仅在你的 CI/CD 流水线中随便引入一个工具就期望一切都变好。为了达到我们希望看到的最终有益结果,需要使用各种技术和行为。
**00:09:15 - Saron Yitbarek**:
自动化确实让我们做到了一半,但我们必须记住另一部分 —— 稍微模糊一点的那一部分。让我们一起来说,那就是文化部分,让开发者和运维人员都一起参与进来,这样这些问题就不再是可怕的问题。
**00:09:33**:
我们必须改变一种文化,而有些人正在学习以一种最不痛苦的方式,通过游戏的方式来做到这一点。
**00:09:44**:
现在让我们来看看事情的另一面。如今建立庞大的基础设施很容易,但这并不意味着我们应该做粗制滥造的工作。我们仍然应该努力改进我们的系统,确保可靠性,未雨绸缪。这就是 Jesse Robbins 正在努力实现的。
**00:10:08**:
如今,Jesse 是 Orion Labs 的 CTO,但在此之前,他因在亚马逊被称为灾难大师而名声大噪。在那里,Jesse 特别是在让大家至少意识到这些问题这件事上几乎是个奇才。他通过一个叫做 “游戏日” 的活动来做到这一点。让其中可能涉及成千上万的员工进行故障演练,通过灾难演练来习惯系统被破坏并了解发生的原因和方式。
**00:10:39**:
下面是 Jesse 和我在讨论,尤其是在运营方面如何建立可靠性和弹性。
**00:10:47**:
大家都知道你做了很多非常酷的事情,其中之一就是你在亚马逊做的活动 —— “游戏日”。那是什么? 是什么游戏?
**00:10:58 - Jesse Robbins**:
“游戏日” 是我创建的一个项目,通过大规模破坏来测试最脆弱系统的运行情况。如果你是 Netflix 的 “混乱猴子” 的粉丝,“游戏日” 则是我的一个可以实现类似的所有事情的东西。实际上,它非常专注于建立一种卓越的运营文化,建立大规模测试系统的能力,当系统崩溃时能了解它们是如何崩溃的以改进它们。然后还要建立一种文化,能够对事件做出反应并能恢复。它是按照事故指挥系统建模的,这是世界各地的消防部门用来处理任何规模事故的系统。
**00:11:56**:
它的诞生源于...
**00:11:58 - Saron Yitbarek**:
旁白,Jesse 早在 2005 年就经过训练成为一名消防员。在那儿,他了解了这个事故指挥系统,最终激发了 “游戏日” 的灵感。因此,所有做这些故障演练的开发人员,都要感谢 Jesse 对消防和应急管理的激情。好了,回到我们的谈话。
**00:12:22 - Jesse Robbins**:
弹性是一个系统的能力,这包括人和这些人建立的适应变化、应对失败和干扰的能力。而建立这种文化最好的方法之一 —— 建立一种文化,能够对这种类型的环境做出反应,并真正理解这些环境是如何工作的 —— 就是提供人员培训演习。这些演习可以很简单,比如重启服务器,也可以很复杂,比如关闭整个数据中心造成大规模故障等等。所以,“游戏日” 首先是一个过程。在这个过程中,你通过让整个组织聚集在一起,讨论系统如何发生故障,并思考人类对故障发生的预期。而这个演习本身就是 “游戏日” 开始时最有价值的部分之一。
**00:13:24**:
但是,当你实际对系统做了一个或大或小的破坏后。当你这样做的时候,你就可以看到每个人是如何反应的。你看到系统崩溃了,可能是之前安全的东西崩溃了,一个很容易理解的组件或者是某个东西暴露了一个潜在的缺陷。这些问题隐藏在软件、技术或者大规模的系统中,只有当你遇到极端或者意外事件时,我们才能发现。“游戏日” 的目的是为了训练员工并且建立系统让你了解他们如何在压力下工作。
**00:14:12 - Saron Yitbarek**:
所以当我听到 “游戏日” 的时候,我就会想,“这是对某个特定事件的回应吗? 它是从哪儿来的?”
**00:14:20 - Jesse Robbins**:
因此,“游戏日” 刚开始的一段时间内,因为我知道自己的角色以及作为消防员和应急管理人员的背景,因此将文化方法从注重预防失败的观念转变为拥抱失败非常重要,接受失败发生。激发我这样做的部分原因是我自己的经历,你知道,了解系统,比如建筑是如何倒塌的,市政基础设施是如何倒塌的,以及灾难是如何发生的,以及灾难给人们的压力。所以说,如果环顾我所在工作场所所具有的复杂性和运营规模就会知道,想要真的构建成一个高可靠性、持续在线环境的唯一办法就是拥抱消防服务的方法。我们知道失败会发生,这不是如果的问题,而是什么时候的问题。就像我之前的消防队长说的,不是你选择时机,而是时机选择你。你只需要在它发生的时候准备好即可。
**00:15:28 - Saron Yitbarek**:
哦,这个不错。所以当你第一次开始做 “游戏日” 并思考如何为灾难场景做准备时,每个人都同意了吗?你得到任何反对意见了吗?
**00:15:40 - Jesse Robbins**:
每个人都认为我疯了。因此,肯定有人反对。有趣的是,有一种非常简单的方法可以克服这种抵制,那就是首先创造出我称之为 “冠军” 的东西。你要教一小群人,如何以非常安全的方式工作,然后你能够使用一些信服的指标。你能够说,看,让我们只需衡量发生了多少分钟的中断,我的团队经过了这种培训并以这种方式进行操作的停机时间有多少分钟。相反,你的团队没有这个,并且似乎认为进行这种类型的培训和练习没有价值或者不重要。
**00:16:25 - Jesse Robbins**:
你一旦完成了这种事情,基本上就会有我所说的引人注目的事件。因此,经常会有断电或其他事情让组织突然意识到:哦,我的天哪,我们不能再像以前那样继续做事了。这就是你用来说服怀疑论者的方法。你一方面使用数据和性能数据,再结合指标,然后讲故事,然后等待一个大的故障或者可怕的事情发生。然后,你就可以说,如果我们要在 web 规模或者互联网规模上运维,整个组织都需要这种应变能力。
**00:17:06 - Saron Yitbarek**:
嗯嗯。所以我喜欢它的原因是它不只是停留在亚马逊内部。相反,它在传播。很多其他公司也在这么做。很多人最终接受了要为故障做好准备这个知识和过程。那下一步是要做什么?我们如何将从 “游戏日” 中学到的知识继续运用到未来的项目和公司中?
**00:17:31 - Jesse Robbins**:
我喜欢把它称为趋同进化。每个在 web 上运行的大型组织现在都采用了我提倡的事件管理基础的一个版本,并创建了他们自己的 “游戏日” 测试。比如,Netflix 将其称为 “混乱猴子”。谷歌有他们的 Dirt 计划。
**00:17:57 - Saron Yitbarek**:
那么你对未来的 “游戏日” 有什么寄望呢?
**00:18:00 - Jesse Robbins**:
首先让我感到兴奋的是,我们可以看到人们从闭门造车思维的转变。系统从根本上是相互联系,相互依赖的,而且由世界各地试图有所成就的聪明人构建和运行的。
**00:18:22**:
几年前,当我刚参加工作时,对运维工作毫不关心,我觉得那非常无趣。然后突然的,我们发现自己能够传播这样一种理念:开发人员和运营人员一起工作是在互联世界中构建和运行有意义的技术的唯一途径。
**00:18:44**:
所以我对未来的希望是,第一,我们看到越来越多的人接受这些想法并学习它。明白了当你建造了人们依赖的东西时,你有义务确保它是可信赖的、可用的、可靠的,它是人们可以作为日常生活的一部分来使用的东西。
**00:19:05**:
而且我们也看到了一种新的学科的诞生。“游戏日” 的这种思维模式正在被研究,也有博士正基于这个撰写博士学位论文。它正在不断建立中。
**00:19:16 - Saron Yitbarek**:
这真的是太棒了。
**00:19:16 - Jesse Robbins**:
也有写这方面的书,但是包含这些新资源的没有。只有少数人在会议上谈论他们认为世界应该怎么运转。所以我的那种鼓舞人心的希望是,你要明白如果你正在构建软件和技术,那么你真的成为了社会基础设施的一部分。所以作为一名消防员,我所努力贡献的一系列技能和正在出现的技术,这些技术将使它走得更远,它们是建造人们日常生活所依赖的东西的基础的一部分。
**00:19:53 - Saron Yitbarek**:
很好。这是一个很好的结束方式。Jesse,谢谢你抽出时间来。
**00:19:56 - Jesse Robbins**:
是的,谢谢。
**00:11:59 - Saku Panditharatne**:
我认为所有这些因素都不利于采用最佳软件。
**00:20:02 - Saron Yitbarek**:
在 Jesse 看来,像 “游戏日” 或者 “混乱猴子” 这样的演习是我们不断发展的科技文化的重要组成部分,但它们对于整个社会也至关重要。我很喜欢他很重视这个,因为他是对的。我们的世界取决于我们所做的工作。早在 90 年代,当电话网络开始崩溃时,这一点就很明显了。
**00:20:26 - 众议院小组委员会代表**:
我们所知道的现代生活几乎陷于停顿。
**00:20:31 - Saron Yitbarek**:
这是一种伴随的责任。我们有责任关心安全和可靠性,关心我们所建造东西的弹性。当然,当谈到在 DevOps 中的构建安全性时,我们才刚刚开始。
**00:20:53 - Saron Yitbarek**:
这是 Josh Bressers。他是数据搜索软件公司 Elastic 的产品安全主管。对 Josh 来说,尽管计算机行业已经成熟了半个世纪左右,但我们在这里讨论的安全问题却让人觉得它是刚刚才出现的。
**00:21:11 - Josh Bressers**:
实际上,就像我想说也行作为一个专业,安全仍然是非常新的东西,有很多事情我们还不是很了解。
**00:21:19 - Saron Yitbarek**:
但我们确实明白,在 DevSecOps 的世界中,有一些非常好的机会可以创造性的思考安全能达到什么成就。
**00:21:29 - Josh Bressers**:
我最近和一些人讨论了一个概念,他们利用用户行为来决定用户是否应该能够访问系统。每个人都有特定的行为,比如他们来自哪里,他们访问系统的时间,他们打字的方式,他们移动鼠标的方式。所以我认为,如果我们做得好,他们的这些行为,可以产生一些非常强大结果,如果我们能做到这一点,我们可以注意到有人在做什么。然后假设我表现的很奇怪,因为我刚刚扭伤了手臂。但你知道,另一端并不知道。
**00:22:05 - Josh Bressers**:
因此,它可能会说,这种行为就有些奇怪,我们就会希望你使用双因子认证登录,并且还会向您发送条短信或其他内容,对吧?这就从用户名和密码变成了更有趣的东西。所以我认为用新的和独特的方式来看待这些问题将是关键。在很多情况下,我们只是还没到那一步。
**00:22:27 - Saron Yitbarek**:
实现这一目标需要我们所描述的两大步骤。第一步,就是自动化,这很重要,因为……
**00:22:35 - Josh Bressers**:
人类很不擅长重复地做同一件事。
**00:22:38 - Saron Yitbarek**:
很公平。然后,我们有了第二步,就是文化,无论我们的职称是什么,我们所有人都有不安全感和责任感。
**00:22:49 - Josh Bressers**:
当大多数人想到安全团队时,他们不会认为那是一群快乐的好好先生,对吧? 一般来说,这些人都很可怕,脾气暴躁,令人讨厌,如果他们出现了,就会毁了你的一天。没有人想要这样,对吧?
**00:23:10 - Saron Yitbarek**:
但我认为我们可以克服这种偏见,因为我们必须这样想——每天都有更多的安全威胁发生,而且 IT 基础设施每天都在变得更大、更强。把这两个事实放在一起,你最好可以生活在一个被安全环绕的世界里。一个非常 DevSecOps 的世界,在这个世界里,开发人员和运营人员都在提升他们的安全,提高他们的可靠性。我所谈论的是一个自动化被整合到每个阶段的未来,每个人对这些问题的态度变得更加全面。这就是我们保护未来系统安全的方法。这是我们保持电话响,灯开,所有现代生活健康强壮的方法。如果你查一下《福布斯》全球 2000 家公司的名单,也就是前 2000 家上市公司,你会发现其中整整四分之一的公司都采用了 DevOps。集成的敏捷工作场所正在成为规则。并且在几年之内,关于 DevSecOps 的思考可能会成为第二天性。我们希望尽可能快,但是当团队中的每个成员都齐心协力时,长距离比赛实际上会更快。
**00:24:40 - Saron Yitbarek**:
下一集,我们将面临数据的大爆炸。人类已经进入了<ruby> 泽字节 <rt> Zettabyte </rt></ruby>时代。到 2020 年,我们将在服务器上存储大约 40 泽字节的数据,而这些信息大部分甚至现在还不存在。但是我们该如何让这些数据有用呢?我们如何使用高性能计算和开源项目让我们的数据为我们所用呢?我们会在 Command Line Heroes 第 6 集中找到答案。
**00:25:13 - Saron Yitbarek**:
提醒一下,我们整季都在致力于《代码英雄游戏》的开发。这是我们自己的开源项目,我们很喜欢看着它的诞生,但是我们需要你来帮助我们完成。如果你点击 [redhat.com/commandlineheroes,你可以发现如何贡献。你也可以深入了解我们在这节课中讨论过的任何内容。](http://redhat.com/commandlineheroes%EF%BC%8C%E4%BD%A0%E5%8F%AF%E4%BB%A5%E5%8F%91%E7%8E%B0%E5%A6%82%E4%BD%95%E8%B4%A1%E7%8C%AE%E3%80%82%E4%BD%A0%E4%B9%9F%E5%8F%AF%E4%BB%A5%E6%B7%B1%E5%85%A5%E4%BA%86%E8%A7%A3%E6%88%91%E4%BB%AC%E5%9C%A8%E8%BF%99%E8%8A%82%E8%AF%BE%E4%B8%AD%E8%AE%A8%E8%AE%BA%E8%BF%87%E7%9A%84%E4%BB%BB%E4%BD%95%E5%86%85%E5%AE%B9%E3%80%82)
**00:25:39 - Saron Yitbarek**:
《代码英雄》是红帽原创播客。你可以在 Apple Podcast、Google Podcast 或任何你想做的事情上免费收听。我是 Saron Yitbarek。坚持编程,下期再见。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/the-one-about-devsecops>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[mrpingan](https://github.com/mrpingan) 校对:[bestony](https://github.com/bestony), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 200 | OK | Bad security and reliability practices can lead to outages that affect millions. It's time for security to join the DevOps movement. And in a DevSecOps world, we can get creative about improving security.
Discovering one vulnerability per month used to be the norm. Now, software development moves quickly thanks to agile processes and DevOps teams. Vincent Danen tells us how that's led to a drastic increase in what's considered a vulnerability. Jesse Robbins, the former master of disaster at Amazon, explains how companies prepare for catastrophic breakdowns and breaches. And Josh Bressers, head of product security at Elastic, looks to the future of security in tech.
We can't treat security teams like grumpy boogeymen. Hear how DevSecOps teams bring heroes together for better security.
**00:01** - *House subcommittee representative*
On June the 26th, 1991, Washington DC, much of Maryland and West Virginia, major portions of my home state were paralyzed by massive failure in the public telephone network. And yet, as technology becomes more sophisticated and network systems more interdependent, the likelihood of recurrent failures increases. It's not as though there wasn't warning that this would happen.
**00:23** - *Saron Yitbarek*
In the early 1990s, 12 million Americans were hit with massive phone network failures. People couldn't call the hospital. Businesses couldn't call customers. Parents couldn't call their daycares. It was chaos and it was also a serious wake-up call, a wake-up call for a country whose infrastructure relied heavily on the computer systems that networked everything. Those computer networks were growing larger and larger, and then when they failed, yeah, they failed big time.
**01:01** - *Saron Yitbarek*
A computer failure caused that phone system crash. This tiny one line bug in the code, and today the consequences of little bugs like that are higher than ever.
**01:15** - *Saron Yitbarek*
I'm Saron Yitbarek and this is Command Line Heroes, an original podcast from Red Hat.
**01:24** - *Saron Yitbarek*
So software security and reliability matter more than ever. The old waterfall approach to development, where security was just tacked onto the end of things, that doesn't cut it anymore. We're living in a DevOps world where everything is faster, more agile, and scalable in ways they couldn't even imagine back when that phone network crashed. That means our security and reliability standards have to evolve to meet those challenges.
**01:55** - *Saron Yitbarek*
In this episode, we're going to figure out how to integrate security into DevOps, and we're also exploring new approaches to building reliability and resilience into operations. Even after covering all that, we know there's so much more we could talk about because in a DevSecOps world, things are changing fast for both the developers and operations. These changes mean different things depending on where you're standing, but this is our take. We'd love to hear yours too—so don't be shy if you think we've missed something—hit us up online.
**02:34** - *Saron Yitbarek*
All right, let's dig in and start exploring this brand new territory.
**02:43** - *Saron Yitbarek*
Here's the thing, getting security and reliability up to speed, getting it ready for a DevOps world, means we have to make a couple of key adjustments to the way we work. Number one, we have to embrace automation. I mean, think about the logistics of say two-factor authentication. Think of the impossibly huge task that poses. It's pretty obvious you're not going to solve things by just adding more staff, so that's number one, embracing automation.
**03:15** - *Saron Yitbarek*
And then, number two, and this one's maybe less obvious, it's really changing the culture so security isn't a boogeyman anymore. I'm going to explain what I mean by changing the culture later on, but let's tackle these two steps one at a time. First up, embracing automation.
**03:42** - *Saron Yitbarek*
Once upon a time app deployment involved a human-driven security review before every single release, and I don't know if you've noticed, but humans, they can be a little slow. That's why automation is such a key part of building security into DevOps. Take, for example, this recent data breach report from Verizon. They found that 81% of all hacking–related breaches involve stolen or weak passwords, and that's on the face of it such a simple problem. But it's a simple problem at a huge scale. Like I mentioned before, you're not going to staff your way out of 30 million password issues, right? The hurdle is addressing that problem of scale, the huge size of it, and the answer is the same every time. It's automation, automation.
**04:36** - *Vincent Danen*
If you wait for a human being to get involved, it's not going to scale.
**04:41** - *D20 Babes player 2*
Vincent Danen is the director of product security at Red Hat and over the 20 years he's been at this, he's watched as DevOps created a faster and faster environment. Security teams have had to race to keep up.
**04:56** - *Vincent Danen*
When I started, it was a vulnerability per month and then it started becoming every other week and then every week, and now we're into the, you know, literally finding hundreds of these things every day.
**05:08** - *Saron Yitbarek*
What's interesting here is that Vincent says there are actually more vulnerabilities showing up as security teams evolve, not less.
**05:17** - *Vincent Danen*
We'll never get to the point where we say, oh, we're secure now, we're done. Our job is over. It'll always be there. It's just something that has to be as normal as breathing now.
**05:27** - *Saron Yitbarek*
It turns out what counts as an issue for security and reliability teams is becoming more and more nuanced.
**05:35** - *Vincent Danen*
As we're looking for these things, we're finding more and this trend is going to continue as you find new classes of vulnerabilities and things we maybe didn't think were important or didn't even know they existed before. We're finding out about these things much faster and there's more of them. And so the scale kind of explodes. It's knowledge. It's volume of software. It's number of consumers. All of these things contribute to the growth of security in this area and the vulnerabilities that we're finding.
**06:06** - *Saron Yitbarek*
Once you see security as an evolving issue rather than one that gets "solved" over time, the case for automation, well, it gets even stronger.
**06:18** - *Vincent Danen*
Well, I think with automation you can integrate this stuff into your development pipelines in a way that is very fast, for one. For two, you don't require human beings to do this effort, right? Computers don't need to sleep, so you can churn through code as fast as your processors will allow rather than waiting for a human to pour through some maybe rather tedious lines of code to go looking for vulnerabilities.
**06:44** - *Vincent Danen*
And then with pattern-matching and heuristics, you can actually determine what's vulnerable even at the time of writing the code to begin with. So if you have, like, a plug-in, you know, for your IDE or your tool that you're using to write your code, it can tell you as you're writing it, like, hey, maybe this looks a little fishy, or you've just introduced a vulnerability and you can correct these things before you even commit the code.
**07:08** - *Saron Yitbarek*
Security on the move. That's a huge bonus.
**07:12** - *Vincent Danen*
There's just so much that's coming out every, every day, every hour even. With continuous integration and continuous delivery, you write code and it's deployed 10 minutes later. All right, so it's really critical to get that validation of that code automatically prior to it being pushed out.
**07:32** - *Saron Yitbarek*
A whole breadth of tools are available so we can actually get this done, whether it's static code analysis or plug-ins for your IDE or a whole bunch of other options. We'll share some of our favorites in the show notes for this episode over at redhat.com/commandlineheroes.
**07:53** - *Saron Yitbarek*
Once we've got those tools in place, they help keep security top of mind. The result, DevOps gets re-imagined as DevSecOps. Security gets baked into the process.
**08:08** - *Vincent Danen*
In the same way that developers and operations kind of combined, you took those two disciplines to generate one. Now you have DevOps, and taking that third component of security and integrating that in with development and operations, I think is really important because having security as the afterthought is what makes security so reactive, so expensive, so damaging or potentially damaging to consumers. And when you plug that in right at the beginning, you have development being done, securities in there from start to finish and the operations work.
**08:44** - *Saron Yitbarek*
Of course, like we mentioned at the top of the episode, automation is really just one half of a bigger pie and Vincent gets that.
**08:53** - *Vincent Danen*
It's not just one piece. You can't just, you know, throw a tool in your CI/CD pipeline and expect everything to be okay. There's a whole gamut of different techniques and technologies and behaviors that are required to produce those ultimate beneficial results that we want to see.
**09:15** - *Saron Yitbarek*
Automation does get us partway there, but we've got to remember the other piece—that slightly fuzzier piece. Say it with me, the culture piece, getting developers and ops both on board so that these issues aren't boogeyman anymore.
**09:33** - *Saron Yitbarek*
We have to change a culture and some folks are learning to do that in the least painful way possible, with games.
**09:44** - *Saron Yitbarek*
Let's take a swing over to the op side of things now. It's so easy to stand up huge infrastructure these days, but that doesn't mean we should be doing shoddy work. We should still be hammering on our systems, ensuring reliability, figuring out how to prepare for the unexpected. That's the mindset Jesse Robbins is working to bring about.
**10:08** - *Saron Yitbarek*
Today Jesse is the CEO of Orion Labs, but before that he was known as the master of disaster over at Amazon. During his time there, Jesse was pretty much a wizard at getting everybody at least aware of these issues. And he did it with something called Game Day. These can involve thousands of employees running through disaster scenario drills, getting used to the idea of things breaking and getting intimate with the why and the how.
**10:39** - *Saron Yitbarek*
Here's Jesse and me talking it over, looking especially at how reliability and resilience get built into the operation side.
**10:47** - *Saron Yitbarek*
Very cool. So you are known for many things, but one of those things is the exercise Game Day, what you did at Amazon. What is that? What's Game Day?
**10:58** - *Jesse Robbins*
So Game Day was a program that I created to test the operational readiness of the most vulnerable systems by breaking things at massive scale. So if you're a fan of what's called Chaos Monkey Now by the Netflix people and others, Game Day was the name for my program that definitely proceeded all of that. It was really heavily focused on building a culture of operational excellence, building the capability to test systems at massive scale when they're breaking, learn how they break to improve them. And then also to build a culture that is capable of responding to and recovering from incidents in situations. And it was all modeled and is all modeled after the incident command system, which is what the fire departments use around the world for dealing with incidents of any size.
**11:56** - *Jesse Robbins*
It was sort of born from ...
**11:58** - *Saron Yitbarek*
Crazy side note, Jesse trained to be a firefighter back in 2005. And that's where he learned this incident command system that ended up inspiring Game Day. So all the developers doing these disaster scenarios out there, you've got Jesse's passion for firefighting and emergency management to thank for that. Okay, back to our chat.
**12:22** - *Jesse Robbins*
Resilience is the ability of a system, and that includes people and the things that those people build to adapt to change, to respond to failures and disturbances. And one of the best ways to build that—to build a culture that can respond to those types of environments and really understands how those work—is to provide people training exercises. And those exercises can be as simple as something like, you know, rebooting a server or as complicated as a injecting massive scale faults by turning off entire datacenters and kind of everything in between. And so what a Game Day is is first of all a process where you prepare for something by getting an entire organization together and kind of talking about how systems fail and thinking about what human beings know about how they expect failure to happen. And that exercise by itself is often one of the most valuable parts of kind of the beginning of a Game Day.
**13:24** - *Jesse Robbins*
But then you actually run an exercise where you break something. It could be something big, it could be something small. It could be something that breaks all the time. And when you do that, you're able to study how everyone responds where things can move to. You can see the system breaking and that might be something that is safe to break, a well-understood component or it might be something that exposes what we call a latent defect. Those are those problems hiding in software or in technology or in a system at scale that we only can find out about when you have an extreme or an unexpected event. It's really designed to train people and to build systems that you understand how they're going to work under stress and under strain.
**14:12** - *Saron Yitbarek*
And so when I hear Game Day, it makes me think, “Was this a response to something very specific that happened, that inspired it? Where'd it come from?”
**14:20** - *Jesse Robbins*
So Game Day started during a period of time where I knew because of my role and because of my unique background as a firefighter and emergency manager, that it was important to change the cultural approach from focusing on the idea of preventing failure to instead embracing failure, accepting that failure happens. And part of what inspired that was both my own experience, you know, understanding systems, how like buildings fail and how civic infrastructure fails, and how disasters happened, and the strain that that puts on people. And saying, well, if we look at the complexity and operational scale that we have at the place of employment that I was at, the only way that we're really going to build and change and become a high-reliability, always-on environment, is truly to embrace the fire service approach. Where we know that failures will happen. It's not a question of if, it's a question of when. And then as my old fire chief would say, you don't choose the moment, the moment chooses you. You only choose how prepared you are when it does.
**15:28** - *Saron Yitbarek*
Oh, that's a good one. So when you first started doing the Game Days and thinking about how to be prepared for disaster scenarios, was everyone on board with this or did you get any pushback?
**15:40** - *Jesse Robbins*
Everyone thought I was crazy. So definitely there were people that resisted it. And it's interesting because there was a really simple way of overcoming that resistance, which is first creating what I call champions. You want to teach people, a small group, how to work in a way that is very safe and then you want to give them some exposure and then you want to use a set of metrics where you're able to say, look, let's just measure how many minutes of outage there is, how many minutes of downtime my team has that has this training and operates this way. Versus, I don't know, your team, who does not have that and who seems to think that doing this type of training and exercises isn't valuable or isn't important.
**16:25** - *Jesse Robbins*
And once you do that kind of thing, you basically end up with what I call a compelling event. So, often there'll be an outage or some other thing where the organization suddenly and starkly realizes, oh my goodness, we can't keep doing things the way that we've been doing them before. And that becomes the method you use to overcome the skeptics. You use a combination of data and performance information on the one hand, coupled with metrics, and then great storytelling, and then you wait for the big one or the scary incident that happens and you say, you know, the whole organization needs this ability if we're going to operate at web scale or internet scale.
**17:06** - *Saron Yitbarek*
Mm-hmm (affirmative). So what I love about this is that it didn't just stay within Amazon. It spread. A lot of other companies are doing it. A lot of people have ended up embracing this knowledge and this process to, you know, to be prepared. What is next? How do we continue carrying on the knowledge from Game Day into future projects and future companies?
**17:31** - *Jesse Robbins*
I like to talk about it as convergent evolution. So every large organization that operates on the web has now adopted a version of both the incident management foundation that I certainly advocated for and has created their own Game Day testing. You know, Netflix calls it the Chaos Monkey. And Google has their Dirt program.
**17:57** - *Saron Yitbarek*
So what are your hopes and dreams for Game Day in the future?
**18:00** - *Jesse Robbins*
What I am excited about first of all is that we are seeing this evolution now from a thinking of silos and thinking of systems as being disconnected. Systems being fundamentally interconnected, interdependent and built and run by smart people around the world that are trying to do great and big things.
**18:22** - *Jesse Robbins*
Years ago when I got my start, caring about operations was a backwater. It was not an interesting place. And suddenly we found ourselves being able to propagate the idea that developers and operations people working together are the only way that meaningful technology gets built and run in a connected world.
**18:44** - *Jesse Robbins*
And so my hope for the future is number one, we're seeing more and more people embracing these ideas and learning about them. Understanding that when you build something that people depend on, you have an obligation to make sure that it's reliable, it's usable, it's dependable, it's something that people can use as part of their daily lives.
**19:05** - *Jesse Robbins*
But also we're seeing a new discipline emerge. It's being studied, you know, there's PhD theses being written on it. It's being built out constantly.
**19:16** - *Saron Yitbarek*
That's awesome.
**19:16** - *Jesse Robbins*
There's books being written, there's all these new resources that aren't, you know, just a couple of people talking at a conference about how they think the world should work. And so my sort of inspirational hope is one, understand that if you're building software and technology that people use, you're really becoming part of the civic infrastructure. And so the set of skills that I've tried to contribute as a firefighter to technology and the skills that are now emerging that are taking that so much farther are part of the foundation for building things that people depend on everyday.
**19:53** - *Saron Yitbarek*
Very nice. Oh, that's a great way to end. Thank you so much Jesse for your time.
**19:56** - *Jesse Robbins*
Yeah, thank you.
**11:59** - *Saku Panditharatne*
And I think all these factors work against adopting the best possible software.
**20:02** - *Saron Yitbarek*
In Jesse's vision, exercises like Game Day or Chaos Monkey are a crucial part of our tech culture growing up, but they are also crucial for society at large. And I love that he's putting the stakes that high because he's right. Our world depends on the work we do. That much was obvious back in the 90s when telephone networks started crashing.
**20:26** - *House subcommittee representative*
Modern life as we know it almost ground to a halt.
**20:31** - *Saron Yitbarek*
And there's a duty that goes along with that. A duty to care about security and reliability, about the resilience of the things we build. Of course, when it comes to building security into DevOps, we're just getting started.
**20:53** - *Saron Yitbarek*
That's Josh Bressers. He's the head of product security at a data search software startup called Elastic. For Josh, even though the computer industry's been maturing for a half-century or so, the kind of security we've been talking about here feels like it just came into its own.
**21:11** - *Josh Bressers*
Practically speaking, as what I would say maybe a profession, security is still very new and there's a lot of things we don't understand.
**21:19** - *Saron Yitbarek*
Here's what we do understand though, in a DevSecOps world, there are some pretty sweet opportunities to get creative about what security can achieve.
**21:29** - *Josh Bressers*
I was recently talking to somebody about a concept where they're using user behavior to decide if a user should be able to access the system. Everybody has certain behaviors, be it where they're coming from, time of day they're accessing a system, the way they type, the way they move their mouse. And so they're actually one of those places that I think could have some very powerful results if we can do it right, where we can pay attention to what someone's doing. And then let's say I'm acting weird and you know, I'm weird because I just sprained my wrist. But you know, the other end doesn't know that.
**22:05** - *Josh Bressers*
And so it might say, all right, something's weird, we want you to log in with your two-factor auth and we're going to also send you a text message or something. Right? And so we've just gone from essentially username and password to something more interesting. And so I think looking at a lot of these problems in new and unique ways is really going to be key. And in many instances, we're just not there yet.
**22:27** - *Saron Yitbarek*
Getting there requires those two big steps we've been describing. Step one, it's that automation, so crucial because ...
**22:35** - *Josh Bressers*
Humans are terrible at doing the same thing over and over again.
**22:38** - *Saron Yitbarek*
Fair. And then we've got step two, the culture, all of us having a stake in security and the liability, no matter what our job title might say.
**22:49** - *Josh Bressers*
When most people think of the security team, they don't think of happy nice people, right? It's generally speaking terrible, grumpy, annoying people, who if they show up, they're going to ruin your day. And nobody wants that, right?
**23:10** - *Saron Yitbarek*
But I think we can get over that bias because we have to, think of it this way—more security threats happen every day and every day IT infrastructure is growing larger and more powerful. Put those two truths together and you better live in a world where security gets embraced. A very DevSecOps world where developers and operations are upping their security games, upping their reliability games. What I'm talking about is a future where automation is integrated into every stage and everybody's attitudes toward these issues become more holistic. That's how we're going to keep tomorrow's systems safe. That's how we're going to keep the phones ringing, the lights on, all of modern life healthy and strong. If you pull up Forbes’ list of the global 2000 organizations, that's the top 2000 public companies, it turns out a full quarter of them have embraced DevOps. Integrated agile workplaces are becoming the rule of the land. And in a few years thinking in terms of DevSecOps might become second nature. We want to go as fast as possible, but the long game is actually faster when every part of the team is in the race together.
**24:40** - *Saron Yitbarek*
Next episode, we're getting hit by the data explosion. Humans have entered the Zettabyte era. By 2020, we'll be storing about 40 zettabytes of information on servers that mostly don't even exist yet. But how are we supposed to make all that data useful? How do we use high-performance computing and open source projects to get our data working for us? We find out in episode 6 of Command Line Heroes.
**25:13** - *Saron Yitbarek*
And a reminder, all season long we're working on Command Line Heroes: The Game. It's our very own open source project and we've loved watching it all come together, but we need you to help us finish. If you hit up redhat.com/commandlineheroes, you can discover how to contribute. And you can also dive deeper into anything we've talked about in this episode.
**25:39** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Listen for free on Apple Podcasts, Google Podcasts, or wherever you do your thing. I'm Saron Yitbarek. Until next time, keep on coding. |
12,642 | KeePassXC:社区驱动的开源密码管理器(不基于云服务) | https://itsfoss.com/keepassxc/ | 2020-09-23T05:43:00 | [
"密码",
"KeePassXC"
] | https://linux.cn/article-12642-1.html | 
>
> KeePassXC 是一款有用的开源跨平台密码管理器,即使它不是云端工具,在功能上也毫不逊色。下面,我们就来快速了解一下它。
>
>
>
### KeePassXC:一个跨平台的开源密码管理器

KeePassXC 是 [KeePassX](https://www.keepassx.org/) 的社区复刻版本,旨在成为 [KeePass Password Safe](https://keepass.info)(适用于 Windows)的跨平台移植。它是完全免费使用和跨平台的(Windows、Linux 和 macOS)。
事实上,它是目前 [Linux 最佳密码管理器](https://itsfoss.com/password-managers-linux/)之一。它的功能选项既适合新手,也适合那些想要进一步控制以保护系统上的密码数据库的高级用户。
是的,与我[最喜欢的 Bitwarden 密码管理器](https://itsfoss.com/bitwarden/)不同,KeePassXC 不是基于云端的,密码永远不会离开系统。有些用户确实喜欢不把密码和秘密保存在云服务器中。
当你开始使用密码管理器时,你应该能在它上找到你所需要的所有基本功能。但是,在这里,为了让你初步了解,我会强调提到一些它提供的功能。
### KeePassXC 的功能

值得注意的是,对于一个新手来说,这些功能可能会让人有点不知所措。但是,考虑到你想充分使用它,我想你应该真正了解它所提供的功能:
* 密码生成器
* 能够从 1Password、KeePass 1 和任何 CSV 文件导入密码。
* 通过导出和同步 SSL 证书支持,轻松共享数据库。
* 支持数据库加密 (256 位 AES)
* 浏览器集成(可选)
* 能够搜索你的凭证
* 在应用中自动输入密码
* 数据库报告,以检查密码的健康状况和其他统计数字
* 支持导出为 CSV 和 HTML
* 支持双因素认证令牌
* 支持将文件附加到密码中
* 支持 YubiKey
* 支持命令行
* 支持集成 SSH 代理
* 必要时改变加密算法
* 能够使用 DuckDuckGO 下载网站图标
* 数据库超时自动锁定
* 清除剪贴板和搜索查询的能力
* 自动保存文件
* 支持文件夹/嵌套文件夹
* 设置密码的有效期
* 提供黑暗主题
* 跨平台支持
正如你所看到的,它的确是一款功能丰富的密码管理器。所以,我建议你如果想使用提供的每一个功能,就好好探索它。

### 在 Linux 上安装 KeePassXC
你应该能在你安装的发行版的软件中心找到它。
你也可以从官方网站上获得 AppImage 文件。如果你还不知道的话,我建议你去看看我们的[在 Linux 中使用 AppImage 文件](https://itsfoss.com/use-appimage-linux/)的指南。
另外,你还会发现有一个 snap 包可以用。除此之外,你还可以得到 Ubuntu PPA、Debian 包、Fedora 包和 Arch 包。
如果你好奇,你可以直接探索[官方下载页面](https://keepassxc.org/download/)的可用包,并查看他们的 [GitHub 页面](https://github.com/keepassxreboot/keepassxc)的源代码。
* [下载 KeePassXC](https://keepassxc.org)
### 总结
如果你不是 [Bitwarden](https://itsfoss.com/bitwarden/) 等云端开源密码管理器的粉丝,KeePassXC 应该是你的绝佳选择。
在这里你得到的功能数量可以让你可以在多个平台上保证密码的安全和易于维护。即使没有开发团队的“官方”移动应用,你也可以尝试他们的一些[推荐应用](https://keepassxc.org/docs/#faq-platform-mobile),它们与其数据库兼容,并提供相同的功能。
你尝试过 KeePassXC 吗?你更喜欢使用什么作为你的密码管理器?请在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/keepassxc/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

KeePassXC is a community fork of [KeePassX](https://www.keepassx.org/?ref=itsfoss.com) which aims to be a cross-platform port for [KeePass Password Safe](https://keepass.info/?ref=itsfoss.com) (available for Windows). It is completely free to use and cross-platform as well (Windows, Linux, and macOS)
In fact, it is one of the [best password managers for Linux](https://itsfoss.com/password-managers-linux/) out there. It features options for both newbies and power users who want advanced controls to secure their password database on their system.
Yes, unlike my [favorite Bitwarden password manager](https://itsfoss.com/bitwarden/), KeePassXC is not cloud-based and the passwords never leave the system. Some users do prefer to not save their passwords and secrets in cloud servers.
You should find all the essential features you will ever need on a password manager when you start using it. But, here, to give you a head start, I’ll highlight some features offered.
## Features of KeePassXC
It is worth noting that the features might prove to be a little overwhelming for a newbie. But, considering that you want to make the most out of it, I think you should actually know what it offers:
- Password Generator
- Ability to import passwords from 1Password, KeePass 1, and any CSV files
- Easily share databases by exporting and synchronizing with SSL certificate support
- Database Encryption supported (256 bit AES)
- Browser Integration Available (optional)
- Ability to search for your credentials
- Auto-type passwords into applications
- Database reports to check password health and other stats
- Supports exporting to CSV and HTML
- 2-factor authentication token support
- Attach files to passwords
- YubiKey support
- Command line option available
- SSH Agent integration available
- Change encryption algorithms if required
- Ability to use DuckDuckGO to download the website icons
- Database auto-lock timeout
- Ability to clear the clipboard and the search query
- Auto-file save
- Folder/Nested Folder support
- Set expiration of a credential
- Dark theme available
- Cross-platform support
As you can observe, it is a feature-rich password manager indeed. So, I’d advise you to properly explore it if you want to utilize every option present.
## Installing KeePassXC on Linux
You should find it listed in your software center of the distribution you’ve installed.
You can also get the AppImage file from the official website. I’d suggest you to check out our guide on [using AppImage files in Linux](https://itsfoss.com/use-appimage-linux/) if you didn’t know already.
In either case, you will also find a snap available for it. In addition to that, you also get an Ubuntu PPA, Debian package, Fedora package, and Arch package.
If you’re curious, you can just explore the [official download page](https://keepassxc.org/download/?ref=itsfoss.com) for the available packages and check out their [GitHub page](https://github.com/keepassxreboot/keepassxc?ref=itsfoss.com) for the source code as well.
## Wrapping Up
If you’re not a fan of cloud-based open-source password managers like [Bitwarden](https://itsfoss.com/bitwarden/), KeePassXC should be an excellent choice for you.
The number of options that you get here lets you keep your password secure and easy to maintain across multiple platforms. Even though you don’t have an “official” mobile app from the developer team, you may try some of their [recommended apps](https://keepassxc.org/docs/?ref=itsfoss.com#faq-platform-mobile) which are compatible with the database and offer the same functionalities.
Have you tried KeePassXC yet? What do you prefer using as your password manager? Let me know your thoughts in the comments below. |
12,646 | 用 Jupyter Notebook 教 Python | https://opensource.com/article/20/9/teach-python-jupyter | 2020-09-24T04:57:41 | [
"Jupyter"
] | /article-12646-1.html |
>
> 有了 Jupyter、PyHamcrest,用一点测试的代码把它们连在一起,你就可以教任何适用于单元测试的 Python 内容。
>
>
>

关于 Ruby 社区的一些事情一直让我印象深刻,其中两个例子是对测试的承诺和对易于上手的强调。这两方面最好的例子是 [Ruby Koans](https://github.com/edgecase/ruby_koans),在这里你可以通过修复测试来学习 Ruby。
要是我们能把这些神奇的工具也用于 Python,我们应该可以做得更好。是的,使用 [Jupyter Notebook](https://jupyter.org/)、[PyHamcrest](https://github.com/hamcrest/PyHamcrest),再加上一点类似于胶带的粘合代码,我们可以做出一个包括教学、可工作的代码和需要修复的代码的教程。
首先,需要一些“胶布”。通常,你会使用一些漂亮的命令行测试器来做测试,比如 [pytest](https://docs.pytest.org/en/stable/) 或 [virtue](https://github.com/Julian/Virtue)。通常,你甚至不会直接运行它。你使用像 [tox](https://tox.readthedocs.io/en/latest/) 或 [nox](https://nox.thea.codes/en/stable/) 这样的工具来运行它。然而,对于 Jupyter 来说,你需要写一小段粘合代码,可以直接在其中运行测试。
幸运的是,这个代码又短又简单:
```
import unittest
def run_test(klass):
suite = unittest.TestLoader().loadTestsFromTestCase(klass)
unittest.TextTestRunner(verbosity=2).run(suite)
return klass
```
现在,装备已经就绪,可以进行第一次练习了。
在教学中,从一个简单的练习开始,建立信心总是一个好主意。
那么,让我们来修复一个非常简单的测试:
```
@run_test
class TestNumbers(unittest.TestCase):
def test_equality(self):
expected_value = 3 # 只改这一行
self.assertEqual(1+1, expected_value)
```
```
test_equality (__main__.TestNumbers) ... FAIL
======================================================================
FAIL: test_equality (__main__.TestNumbers)
----------------------------------------------------------------------
Traceback (most recent call last):
File "<ipython-input-7-5ebe25bc00f3>", line 6, in test_equality
self.assertEqual(1+1, expected_value)
AssertionError: 2 != 3
----------------------------------------------------------------------
Ran 1 test in 0.002s
FAILED (failures=1)
```
“只改这一行” 对学生来说是一个有用的标记。它准确地表明了需要修改的内容。否则,学生可以通过将第一行改为 `return` 来修复测试。
在这种情况下,修复很容易:
```
@run_test
class TestNumbers(unittest.TestCase):
def test_equality(self):
expected_value = 2 # 修复后的代码行
self.assertEqual(1+1, expected_value)
```
```
test_equality (__main__.TestNumbers) ... ok
----------------------------------------------------------------------
Ran 1 test in 0.002s
OK
```
然而,很快,`unittest` 库的原生断言将被证明是不够的。在 `pytest` 中,通过重写 `assert` 中的字节码来解决这个问题,使其具有神奇的属性和各种启发式方法。但这在 Jupyter notebook 中就不容易实现了。是时候挖出一个好的断言库了:PyHamcrest。
```
from hamcrest import *
@run_test
class TestList(unittest.TestCase):
def test_equality(self):
things = [1,
5, # 只改这一行
3]
assert_that(things, has_items(1, 2, 3))
```
```
test_equality (__main__.TestList) ... FAIL
======================================================================
FAIL: test_equality (__main__.TestList)
----------------------------------------------------------------------
Traceback (most recent call last):
File "<ipython-input-11-96c91225ee7d>", line 8, in test_equality
assert_that(things, has_items(1, 2, 3))
AssertionError:
Expected: (a sequence containing <1> and a sequence containing <2> and a sequence containing <3>)
but: a sequence containing <2> was <[1, 5, 3]>
----------------------------------------------------------------------
Ran 1 test in 0.004s
FAILED (failures=1)
```
PyHamcrest 不仅擅长灵活的断言,它还擅长清晰的错误信息。正因为如此,问题就显而易见了。`[1, 5, 3]` 不包含 `2`,而且看起来很丑:
```
@run_test
class TestList(unittest.TestCase):
def test_equality(self):
things = [1,
2, # 改完的行
3]
assert_that(things, has_items(1, 2, 3))
```
```
test_equality (__main__.TestList) ... ok
----------------------------------------------------------------------
Ran 1 test in 0.001s
OK
```
使用 Jupyter、PyHamcrest 和一点测试的粘合代码,你可以教授任何适用于单元测试的 Python 主题。
例如,下面可以帮助展示 Python 从字符串中去掉空白的不同方法之间的差异。
```
source_string = " hello world "
@run_test
class TestList(unittest.TestCase):
# 这是个赠品:它可以工作!
def test_complete_strip(self):
result = source_string.strip()
assert_that(result,
all_of(starts_with("hello"), ends_with("world")))
def test_start_strip(self):
result = source_string # 只改这一行
assert_that(result,
all_of(starts_with("hello"), ends_with("world ")))
def test_end_strip(self):
result = source_string # 只改这一行
assert_that(result,
all_of(starts_with(" hello"), ends_with("world")))
```
```
test_complete_strip (__main__.TestList) ... ok
test_end_strip (__main__.TestList) ... FAIL
test_start_strip (__main__.TestList) ... FAIL
======================================================================
FAIL: test_end_strip (__main__.TestList)
----------------------------------------------------------------------
Traceback (most recent call last):
File "<ipython-input-16-3db7465bd5bf>", line 19, in test_end_strip
assert_that(result,
AssertionError:
Expected: (a string starting with ' hello' and a string ending with 'world')
but: a string ending with 'world' was ' hello world '
======================================================================
FAIL: test_start_strip (__main__.TestList)
----------------------------------------------------------------------
Traceback (most recent call last):
File "<ipython-input-16-3db7465bd5bf>", line 14, in test_start_strip
assert_that(result,
AssertionError:
Expected: (a string starting with 'hello' and a string ending with 'world ')
but: a string starting with 'hello' was ' hello world '
----------------------------------------------------------------------
Ran 3 tests in 0.006s
FAILED (failures=2)
```
理想情况下,学生们会意识到 `.lstrip()` 和 `.rstrip()` 这两个方法可以满足他们的需要。但如果他们不这样做,而是试图到处使用 `.strip()` 的话:
```
source_string = " hello world "
@run_test
class TestList(unittest.TestCase):
# 这是个赠品:它可以工作!
def test_complete_strip(self):
result = source_string.strip()
assert_that(result,
all_of(starts_with("hello"), ends_with("world")))
def test_start_strip(self):
result = source_string.strip() # 改完的行
assert_that(result,
all_of(starts_with("hello"), ends_with("world ")))
def test_end_strip(self):
result = source_string.strip() # 改完的行
assert_that(result,
all_of(starts_with(" hello"), ends_with("world")))
```
```
test_complete_strip (__main__.TestList) ... ok
test_end_strip (__main__.TestList) ... FAIL
test_start_strip (__main__.TestList) ... FAIL
======================================================================
FAIL: test_end_strip (__main__.TestList)
----------------------------------------------------------------------
Traceback (most recent call last):
File "<ipython-input-17-6f9cfa1a997f>", line 19, in test_end_strip
assert_that(result,
AssertionError:
Expected: (a string starting with ' hello' and a string ending with 'world')
but: a string starting with ' hello' was 'hello world'
======================================================================
FAIL: test_start_strip (__main__.TestList)
----------------------------------------------------------------------
Traceback (most recent call last):
File "<ipython-input-17-6f9cfa1a997f>", line 14, in test_start_strip
assert_that(result,
AssertionError:
Expected: (a string starting with 'hello' and a string ending with 'world ')
but: a string ending with 'world ' was 'hello world'
----------------------------------------------------------------------
Ran 3 tests in 0.007s
FAILED (failures=2)
```
他们会得到一个不同的错误信息,显示去除了过多的空白:
```
source_string = " hello world "
@run_test
class TestList(unittest.TestCase):
# 这是个赠品:它可以工作!
def test_complete_strip(self):
result = source_string.strip()
assert_that(result,
all_of(starts_with("hello"), ends_with("world")))
def test_start_strip(self):
result = source_string.lstrip() # Fixed this line
assert_that(result,
all_of(starts_with("hello"), ends_with("world ")))
def test_end_strip(self):
result = source_string.rstrip() # Fixed this line
assert_that(result,
all_of(starts_with(" hello"), ends_with("world")))
```
```
test_complete_strip (__main__.TestList) ... ok
test_end_strip (__main__.TestList) ... ok
test_start_strip (__main__.TestList) ... ok
----------------------------------------------------------------------
Ran 3 tests in 0.005s
OK
```
在一个比较真实的教程中,会有更多的例子和更多的解释。这种使用 Jupyter Notebook 的技巧,有的例子可以用,有的例子需要修正,可以用于实时教学,可以用于视频课,甚至,可以用更多的其它零散用途,让学生自己完成一个教程。
现在就去分享你的知识吧!
---
via: <https://opensource.com/article/20/9/teach-python-jupyter>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,649 | 《代码英雄》第二季(6):数据大爆炸 | https://www.redhat.com/en/command-line-heroes/season-2/the-data-explosion | 2020-09-25T06:18:42 | [
"大数据",
"代码英雄"
] | https://linux.cn/article-12649-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(6):数据大爆炸](https://www.redhat.com/en/command-line-heroes/season-2/the-data-explosion)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/4c5f676c.mp3)脚本。
>
> 导语:大数据将有助于解决大问题:我们如何种植粮食、如何向需要的人运送物资、如何治疗疾病。但首先,我们需要弄清楚如何处理它。
>
>
> 现代生活充满了相互联系的组件。我们现在一天产生的数据比几千年来的数据还要多。 Kenneth Cukier 解释了数据是如何发生变化的,以及它是如何开始改变我们的。Ellen Grant 博士告诉我们波士顿儿童医院是如何使用开源软件将堆积如山的数据转化为个性化治疗方法。Sage Weil 则分享了 Ceph 的可扩展和弹性云存储如何帮助我们管理数据洪流。
>
>
> 收集信息是了解我们周围世界的关键。大数据正在帮助我们拓展永不停歇的探索使命。
>
>
>
**00:00:03 - Saron Yitbarek**:
如果你把从人类历史早期到 2003 年创建的所有数据计算在内,你将得到大约 500 万 GB 的数据。我们昨天创建了多少 GB 数据?
**00:00:15 - 问卷调查答案 1**:
哦,天哪,10 万。
**00:00:21 - 问卷调查答案 2**:
可能是 500 万 GB 数据。
**00:00:23 - 问卷调查答案 3**:
我们在昨天一天之内创建了多少 GB 的数据?1000 万 GB 数据?
**00:00:31 - 问卷调查答案 4**:
我不太知道,可能是 200 万 GB 数据?
**00:00:36 - 问卷调查答案 5**:
也许一天就有 100 万 GB 数据?
**00:00:40 - Saron Yitbarek**:
答案是?超过 25 亿 GB 数据!
**00:00:44 - 问卷调查答案 1**:
哇哦。
**00:00:44 - 问卷调查答案 2**:
25 亿?
**00:00:45 - 问卷调查答案 3**:
所以,我们已经打破了世界纪录。
**00:00:45 - 问卷调查答案 4**:
那可真是很多个 G 啊。
**00:00:45 - 问卷调查答案 5**:
我都不敢相信那有这么多的数据。
**00:00:52 - Saron Yitbarek**:
在 2016 年,我们的年度在线数据流量首次超过了 1ZB。一个 ZB 是 1000^7 字节。好,记住这个数字了吗?现在把它乘以 3,因为那是我们将在 2021 年拥有的数据量大小。
**00:01:10**:
我知道,大脑不是以 ZB 为单位进行思考的,但请你至少暂时记住这个数。 我们的 IP 流量将在五年内翻三番。 这是数据的洪流,而我们正处于其中。
**00:01:24**:
在刚过去的一分钟里,人们发出了 1600 万条短信;与此同时,在我说出这句话的时间里,谷歌处理了 20 万条搜索。
**00:01:37**:
如果我们能在数据洪流来临时做好准备、站稳脚跟,那么隐藏在其中的模式、答案和秘密可以极大地改善我们的生活。
**00:01:50**:
我是 Saron Yitbarek,这里是《代码英雄》,一款红帽公司原创的播客节目。浪潮近在眼前。这里是第二季第六集,数据大爆炸。
**00:02:17**:
我们如何处理如此大量的数据? 采集到这些数据后,我们如何利用它们? 大数据将为我们解决一些最复杂的问题:
**00:02:29**:
如何管理交通、如何种植粮食、如何向需要的人提供物资,但这一切的前提是,我们必须弄清楚该怎么使用这些数据、以及该怎么在短得不能再短的时间内完成对它们的处理。
**00:02:43 - Kenneth Cukier**:
通过获取更多的数据,我们可以深入到这些子群体、这些细节,而这是我们以前从来没有过的方式。
**00:02:53 - Saron Yitbarek**:
Kenneth Cukier 是《<ruby> 经济学人 <rt> The Economist </rt></ruby>》的高级编辑,他也和我都在科技播客《Babbage》里。
**00:03:01 - Kenneth Cukier**:
这并不是说我们以前无法收集数据。我们可以,但这真的、真的很昂贵。真正的革命性突破是,我们使数据搜集变得十分容易。
**00:03:10**:
现在收集数据的成本极低,而且处理起来也超级简单,因为都是由电脑完成的。这已经成为我们这个时代的巨大革命,它可能是现代生活最显著的特征,在未来几十年甚至下个世纪都会如此。这也是大数据如此重要的原因。
**00:03:33 - Saron Yitbarek**:
历史可以提醒我们这种变化是翻天覆地的。想想看,4000 年前,我们把所有的数据都刻在了干泥板上。
**00:03:46 - Kenneth Cukier**:
这些黏土盘很重。黏土盘被烤干后,刻在其中的数据就无法更改。从古至今,信息处理、存储、传输、创建的方式都发生了变化,对吗?
**00:04:04 - Saron Yitbarek**:
时代巨变。大约在 1450 年,印刷机的发明带来了第一次信息革命。今天,我们也迎来了一场革命。
**00:04:16 - Kenneth Cukier**:
现在的存储介质很轻巧。信息的修改变得极度简单,借助现有的处理器,我们只需要使用删除键就能修改我们所拥有的信息实例,无论那是储存在磁带上还是晶体管里。我们可以以光速传输数据,不用携带什么黏土盘。
**00:04:37 - Saron Yitbarek**:
在 15 世纪,借助印刷机,大量的数据得以传播。这些知识提升了人们对事物的认识,并促成了启蒙运动。
**00:04:45**:
今天,大数据可以再次提升我们的知识水平,但我们必须要想办法充分利用这些数据。唯有修好大坝、备好轮机,才能让浪潮为人所用。
**00:05:00 - Kenneth Cukier**:
当下,人们远没有做到对数据的充分利用。这一点非常重要,因为我们已经看到,数据中存在这种潜在的价值,而收集、存储和处理数据的成本在近百年来,乃至于近十年来,已经显著地降低了。
**00:05:22 - Kenneth Cukier**:
这很振奋人心。但问题是,我们在文化上、在我们的组织流程上,甚至我们的 CFO 和 CIO 们拨给相关方面的预算中,并不重视这种价值,
**00:05:35 - Saron Yitbarek**:
想着这种事肯定让人极度沮丧。启蒙运动在敲门,却无人应答。然而,我们不回答的部分原因是:门后到底是谁?这些数据能带来什么?
**00:05:51**:
Kenneth 认为,某些公司不采用大数据,乃是因为它太过于新奇。
**00:05:56 - Kenneth Cukier**:
一旦你收集了大量数据后,你能拿它干什么?我就直说吧,只有傻子才会以为自己知道。你绝对无法设想你今天收集到的数据明天能拿来做什么用。
**00:06:12**:
最重要的是要有数据,并以开放的思想对待所有可以使用的方式。
**00:06:18 - Saron Yitbarek**:
如果我们按照 Kenneth 说的那样以正确的方式对待大数据,我们将会发现一切的全新可能性。这将是一个人人 —— 而不只是数据科学家 —— 都能洞察趋势、分析细节的世界。
**00:06:33 - Kenneth Cukier**:
如果我们能意识到,这个世界是可以通过收集经验证据来理解、改变和改善的,并且可以用一种自动化的方式进行改善,我们将会得到看待它的全新角度。我个人认为,现如今,在世界各地,上至政策制定者、下至星巴克咖啡师,都在经历这种引人深思的文化上或心理上的变化。
**00:07:00**:
各行各业的人都有点数据基因,就像是被感染了似的。现在,无论他们专注于什么方面,他们都以大数据的方式思考。
**00:07:15 - Saron Yitbarek**:
Kenneth Cukier 给我们讲了一个简短的故事来展现这种新数据思维方式的力量。微软的一些研究人员开始着手研究胰腺癌问题。
**00:07:27**:
人们发现胰腺癌往往为时已晚,早期发现可以挽救生命。因此,研究人员开始询问这些患者,在开始搜索有关胰腺癌的信息之前几个月,他们搜索了什么? 而早在发现前数年,他们又搜索了什么?
**00:07:46**:
研究人员开始寻找埋藏在所有搜索数据中的线索和模式。
**00:07:54 - Kenneth Cukier**:
他们有了重大发现。通过分析患者在最终开始搜索“胰腺癌”之前的这段时间中所搜索的关键词,他们识别出了一套规律,可以非常准确地预测搜索者是否患有胰腺癌。
**00:08:09**:
在这里,我们能学到一点:想象力与数据中潜在规律的结合,是可以挽救生命的。他们现在所要做的就是找到一种方法,通过方法来解释这一发现,这样当人们在搜索这些术语时,他们可以以一种微妙的方式干预,说,“你可能要去诊所检查一下。”
**00:08:29**:
像这样使用数据,就能救人于水火之中。
**00:08:37 - Saron Yitbarek**:
研究人员偶然发现的是一种新的癌症筛查方式,通过这种方法,患者可以提前一个月得知自己可能患癌。利用数据不仅仅是一个利润或效率最大化的问题。
**00:08:52**:
它的意义远不止于此。对于人类而言,这些数据中确确实实存在着大量的潜在利好。抗拒使用大数据可能只是自欺欺人。接下来,我们要关注的是,这场将数据投入工作的持久战。
**00:09:18**:
哈佛医学院的波士顿儿童医院去年完成了 26000 多台手术,进行约 25 万人次的儿童放射检查。
**00:09:31**:
医护人员的表现令人称道,但有一个巨大的障碍挡在他们面前。
**00:09:37 - Ellen Grant**:
在医院的环境中,尤其是作为医生,我们经常会遇到难以获取数据的问题。
**00:09:45 - Saron Yitbarek**:
这位是 Ellen Grant 医生,她是波士顿儿童医院的儿科神经放射科医生,她在诊疗时依靠访问数据和分析医学图像。
**00:09:56 - Ellen Grant**:
如果没有专门设置的环境,想要从 packs 里存储的图像进行额外的数据分析绝非易事。当你在一个只提供了普通的医院电脑的读片室里时,要做到这一点并不容易。
**00:10:14**:
获取数据实际上是有障碍的。
**00:10:17 - Saron Yitbarek**:
其实许多医院都会大量抛弃数据,因为存储它们的成本实在过于高昂。这部分数据就像这样丢失了。像 Grant 这样的放射科医生可能是第一批因为数据实在太多而感到沮丧的医务人员。
**00:10:33**:
当医院走向数字化后,他们开始创造大量的数据,很快,这个量就大到无法处理了。
**00:10:41 - Ellen Grant**:
我,作为一名临床医生,在读片室里的时候希望能将所有复杂的分析工作在研究环境中做完。但我无法随便就从 packs 中拿出来图像,拿到一些可以进行分析的地方,再拿回到我手里。
**00:10:59 - Saron Yitbarek**:
顺便说一句,packs 就是医院存储其图像的数据仓库。Grant 医生知道有一些工具可以让这些图像 packs 发挥更大的功能,但成本太高。
**00:11:12 - Ellen Grant**:
随着机器学习和 AI 时代的到来,数据的生产量将会日渐加大,我们会需要更多计算资源来进行这类大规模的数据库分析。
**00:11:27 - Saron Yitbarek**:
数据已经堆积如山了,但处理能力却没有相称的增长。在这一前提下,对数据的彻底处理将变得遥不可及。而复杂、昂贵的超级计算机并不是医院的选择。
**00:11:41**:
Grant 医生深感沮丧。
**00:11:44 - Ellen Grant**:
我们能不能想出一个更好的办法,让我把数据拿到这里来,分析一下,然后放回去,这样我就可以在会诊的时候,一边解释临床图像,一边把分析做完,因为我希望可以在会诊上展示数据,在此同时进行快速分析。
**00:11:56**:
我可不想在不同的电脑和存储器之间把这些数据挪来挪去,这不是我的工作。我的工作是理解非常复杂的医学疾病,并把相关的事实真相记在脑子里。
**00:12:10**:
我想专注于我的技术领域,在此同时利用计算机领域的新兴技术;而不必这方面过于深入钻研。
**00:12:21 - Saron Yitbarek**:
Grant 和世界各地的放射科医生们需要的是一种方法,只要点击图像就能运行详细分析,并让这一切都发生在云端,这样医院就不必建立自己的服务器场地,也不必把医务人员变成程序员。
**00:12:40**:
他们需要一种方法来使他们的数据尽可能地拯救生命。这正是 Grant 医生和几位代码英雄决定去做的事。
**00:12:55**:
Grant 在波士顿儿童医院的团队正在与红帽和马萨诸塞州开放云(MOC)合作。关于 MOC 的更多内容稍后再说。首先,我们需要请出 Rudolph Pienaar,他是医院的一名生物化学工程师,来描述一下他们的解决方案。它是一个开源的、基于容器的成像平台。
**00:13:15 - Saron Yitbarek**:
它完全是在云端运行的,所以你不受医院本身计算能力的限制。他们称这一作品为 ChRIS。
**00:13:24 - Rudolph Pienaar**:
ChRIS 有一个后台数据库,其实就是一个 Django Python 机器。它可以跟踪用户,并跟踪这些用户使用过的数据以及分析结果。
**00:13:35**:
围绕这个数据库,有大量的服务群,这些服务都是作为自己的实例存在于容器中。它们处理与医院资源的通信,比如与医院数据库的通信。这些服务从资源中提取复杂的数据,将其推送给云端的、或者另一个实验室的、或者别的什么地方的其他服务处理。在计算数据的地方,有 Kubernetes 之类的编排服务,以及你需要使用的分析程序。数据处理结束之后,结果就会被发送回来。
**00:14:11 - Saron Yitbarek**:
对于 Grant 医生来说,ChRIS 成像平台是一种让数据活起来的方法。更重要的是,这种数据处理方式能让她成为更好的医生。
**00:14:21 - Ellen Grant**:
优秀的医生之所以优秀,是因为他们在一生中积累了丰富的从业经验。如果我们能把这一点融入到数据分析中,以此来获得更多的信息,我们就能知道得更多,并更有效地整合这些经验。
**00:14:39**:
例如,我对特定病患的特定受伤方式的认识,取决于我的从医经验和对这些经验的整体理解。
**00:14:52**:
现在,我可以根据真实数据创建受伤症状分布的概率图,并将其公之于众;我也可以寻找有相似模式的患者,并告诉他们在接受治疗时,什么对他们最有效,以便更接近精准医疗。
**00:15:10**:
整合大量的数据,尝试探索我们过去的知识,并尽你所能,点明治疗病人的最佳方式。
**00:15:21 - Saron Yitbarek**:
这对被送到医院的孩子意味着什么?Grant 医生说,ChRIS 平台能提供更有针对性的诊断和更个性化的护理。
**00:15:31 - Ellen Grant**:
如果我们拥有更复杂的数据库,我们就能更好地理解信息之间繁杂的相互作用,因此就能更好地指导每个患者。我认为 ChRIS 就像是我进入超级大脑的接口,它能让我比平时更聪明,因为我不能一次把所有数据保存在我的大脑中。
**00:15:53 - Saron Yitbarek**:
当赌注如此沉重时,我们要突破人类大脑的极限。这位是 Máirín Duffy。她是红帽团队中的设计师,她让 ChRIS 成为现实,而根据个人经验,她知道这件事其中的风险。
**00:16:15 - Máirín Duffy**:
我父亲中风了,所以我一直作为病人家属等待医疗技术诊断,因为当一个人中风并被送到医院之后,医务人员必须弄清楚是哪种类型的中风。根据中风类型,有不同的治疗方法。
**00:16:31**:
如果使用了错误的治疗方案,就可能发生极其糟糕的事。所以,在这种情况下,你能越快地把病人送来做核磁共振,就能越快地得到治疗方案。速度越快就有可能挽救他们的生命。
**00:16:43**:
想想看,仅仅是把图像处理从云端推送出来,并行化处理,就能让它快很多。这样就能将这个过程从几小时、几天,缩短到几分钟。
**00:16:55 - Saron Yitbarek**:
医学可能正迎来一个新的拐点。一个不是由药理学驱动,而是由计算机科学驱动的拐点。另外,想想像 ChRIS 这种东西的拓展性。
**00:17:08**:
发展中国家的医生也可以受益于波士顿儿童医院的专业知识和数据集。任何有手机服务的人都可以通过网络访问能够拯救生命的数据和计算结果。
**00:17:24**:
除了医学,很多其他领域也可能出现类似的拐点。但前提是,人们得知道如何从自己的数据中找到隐藏信息。为了做到这一点,他们需要探索一个全新的计算领域。
**00:17:46**:
世界各地的人们都在学习如何利用数据。就像在波士顿儿童医院一样,将数据洪流导向目标。
**00:17:56**:
换句话说,我们在处理这些数据。但我们之所以能做到这一点,是因为新一代的云计算使之成为可能。
**00:18:11**:
对于像 ChRIS 这样的平台来说,一个关键因素是基于云计算的新型存储方式。请记住,很多医院都会把收集到的数据扔掉,因为他们根本无法容纳所有数据。
**00:18:25**:
这就是我想重点讨论的数据泛滥的最后一块拼图:存储解决方案。对于 ChRIS 来说,存储解决方案是一个叫 Ceph 的开源项目。它使用的马萨诸塞州开放云,就基于 Ceph。
**00:18:45**:
我和 Ceph 的创建者 Sage Weil 聊了聊,想了解更多关于像波士顿儿童医院这样的地方是如何在闪电般的时间内处理海量数据的。以下是我与 Sage 的对话。我认为,第一个重要问题是,什么是 Ceph,它能做什么?
**00:19:05 - Sage Weil**:
当然,Ceph 是一个由软件定义的存储系统,它允许你提供可靠的存储服务,并在不可靠的硬件上提供各种协议。
**00:19:14**:
它的设计从开始就是满足可扩展性,所以你可以拥有非常非常大的存储系统、非常大的数据集。于此同时,系统对硬件故障和网络故障有优秀的容忍性,所以即使出现了一些这类问题,存储中的数据仍然不会变得难于访问。
**00:19:29 - Saron Yitbarek**:
现在,数据太多了。
**00:19:31 - Sage Weil**:
是的。
**00:19:33 - Saron Yitbarek**:
如此大的工作量。要处理的东西实在是太多了。你认为这个解决方案出现得是时候吗?
**00:19:39 - Sage Weil**:
是的,肯定是这样。在当时,行业中这方面的严重不足是显而易见的。没有开源的解决方案可以解决可扩展的存储问题。所以,我们显然得造个轮子。
**00:19:53 - Saron Yitbarek**:
考虑到我们每天要处理的数据量,以及它将来只会越来越多、越来越难管理的事实,你认为当今该怎么做才能解决这种日益增长的需求?
**00:20:09 - Sage Weil**:
我认为有几方面。一方面,有令人难以置信的数据量正在产生,所以你需要可扩展的系统。它不仅可以在硬件和数据规模上进行扩展,而且,它的管理成本应该是一定的,至少应该基本固定。
**00:20:25 - Saron Yitbarek**:
嗯。
**00:20:26 - Sage Weil**:
你不会想就为每多 10PB 存储空间或类似的东西就多雇一个员工吧?我认为这套系统在运维上也必须可扩展。
**00:20:33 - Saron Yitbarek**:
是的。
**00:20:35 - Sage Weil**:
这是其中的一部分。我认为,人们利用存储空间的方式也在改变。一开始,都是文件存储,然后我们有了虚拟机的块存储,我觉得对象存储在某种程度上是行业的重要趋势。
**00:20:51**:
我认为,下一个阶段的目标并不局限于提供一个对象存储端点,并将数据存储在集群中;我们需要将解决方案进一步升级,好让它能管理集群的集群,抑或是对分布于不同地理位置的云空间及私有数据中心储存空间中的数据进行管理。
**00:21:13**:
例如说,你现在将数据写入一个位置,随着时间的推移,你可能会想将数据分层到到其他位置,因为它更便宜、或者服务器离你更近;或者,一旦数据太老、不会频繁使用了,你就需要将其移动到性能更低、容量更大的层次上,以保证存储的成本较低。
**00:21:27**:
你可能也会为了遵循地方法规而移动数据。在欧洲的一些地区接收数据时,数据来源必须保持在特定的政治边界内。
**00:21:39**:
在某些行业,像 HIPAA 这样的东西限制了数据的移动方式。我认为,随着现代 IT 组织越来越多地分布在不同的数据中心、公有和私有云中,统一地、自动化地管理它们的能力正变得越加重要。
**00:21:58 - Saron Yitbarek**:
当你想到未来我们要如何管理和存储数据,以及如何处理数据的时候,开源在其中扮演了怎样的角色?你曾提到,你之所以要创建一个开源的解决方案,是因为你个人的理念和你对自由和开源软件的强烈感情。
**00:22:16**:
你如何看待开源对未来其他解决方案的影响?
**00:22:21 - Sage Weil**:
我认为,特别是在基础设施领域,解决方案正在向开源靠拢。我认为原因是基础设施领域的成本压力很大,特别是对于构建软件即服务(SaaS)或云服务的人来说,低成本的基础设施很重要,从他们的角度来看,开源显然是一个非常好的方法。
**00:22:48**:
第二个原因更多地是社会因素,在这个快速发展的领域里有如此多新的工具、新的框架、新的协议、新的数据思维方式,这个领域中有这么多创新和变化,有这么多不同的产品和项目在相互作用,所以很难以传统方式做到这一点,比如说,让不同的公司互相签订合作协议,共同开发。
**00:23:20**:
开源可以消除此事上的所有阻力。
**00:23:28 - Saron Yitbarek**:
Sage Weil 是红帽公司的高级咨询工程师,也是 Ceph 项目的负责人。我要绕回到《经济学人》的 Kenneth Cukier,以从一个更整体的视角上进行讨论,因为我希望,我们能够记住他关于人与数据之间关系的看法,以及我们从泥板,到印刷机,再到像 Sage 打造的云端奇迹的进步历程。
**00:23:55 - Kenneth Cukier**:
这关乎人类的进步,关乎我们如何更好地理解世界,如何从现实中总结经验,以及如何改善世界。这进步也是人类一直以来的使命。
**00:24:08 - Saron Yitbarek**:
使命永无止境。但是,与此同时,学会处理我们收集到的数据并将其投入使用,是整整一代人的开源任务。我们将在田纳西州的<ruby> 橡树岭国家实验室 <rt> Oak Ridge National Laboratory </rt></ruby>短暂停留,结束我们的数据之旅。它是世界上最快的超级计算机 Summit 的所在地,至少在 2018 年是最快的超级计算机。
**00:24:43**:
这台机器每秒能处理 20 万亿次计算。换个计量单位,就是 200 petaflops。这样的处理速度,对于医院、银行或者今天所有受益于高性能计算的成千上万的组织来说并不现实。
**00:25:04**:
像 Summit 这样的超级计算机更多的是留给强子对撞机的领域。不过话说回来,我们曾经在泥板上记录的只是 100 字节的信息。
**00:25:16**:
在数据存储和数据处理的领域中,非凡的壮举不断成为新的常态。有一天,我们或许能将 Summit 级别的超级计算机装进口袋。想一想,到时候我们能够搜索到的答案。
**00:25:42**:
下一集,我们聊聊无服务器。第 7 集将会讲述我们与基于云的开发之间不断发展的关系。我们将会探究,在我们的工作中有多少可以抽象化的部分,以及在这个过程可能会失去的东西。
**00:25:58 - Saron Yitbarek**:
同时,如果你想深入了 ChRIS 的故事,请访问 [redhat.com/chris](https://www.redhat.com/chris) ,了解它是如何构建的,以及如何为项目本身做出贡献。
**00:26:12 - Saron Yitbarek**:
《代码英雄》是一款红帽公司原创的播客。你可以在 Apple Podcast、Google Podcast 或任何你想做的事情上免费收听。
**00:26:24 - Saron Yitbarek**:
我是 Saron Yitbarek。坚持编程,下期再见。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/the-data-explosion>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[TimeBear](https://github.com/TimeBear) 校对:[Northurland](https://github.com/Northurland), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Big data is going to help solve big problems: how we grow food; how we deliver supplies to those in need; how we cure disease. But first, we need to figure out how to handle it.
Modern life is filled with connected gadgets. We now produce more data in a day than we did over thousands of years. Kenneth Cukier explains how data has changed, and how it's beginning to change us. Dr. Ellen Grant tells us how Boston Children's Hospital is using open source software to transform mountains of data into individualized treatments. And Sage Weil shares how Ceph's scalable and resilient cloud storage helps us manage the data flood.
Gathering information is key to understanding the world around us. Big data is helping us expand our never ending mission of discovery.
**00:03** - *Saron Yitbarek*
If you take all human data created from the dawn of time to 2003, you'd get about five million gigabytes of data. How many gigabytes of data did we create yesterday?
**00:15** - *Poll response 1*
Oh gosh, 100,000.
**00:21** -*Poll response 2*
Like five million gigabytes.
**00:23** - *Poll response 3*
How many gigabytes of data did we create yesterday in one day? 10 million gigabytes?
**00:31** - *Poll response 4*
I would say, I don't know, like two million maybe?
**00:36** - *Poll response 5*
Maybe a million gigabytes in a day?
**00:40** - *Saron Yitbarek*
Answer? More than 2.5 billion.
**00:44** - *Poll response 1*
Oh wow.
**00:44** - *Poll response 2*
2.5 billion?
**00:45** - *Poll response 3*
So, we already beat the world record.
**00:45** - *Poll response 4*
That's a lot of gigabytes.
**00:45** - *Poll response 5*
That's a lot of data right there. I don't believe it.
**00:52** - *Saron Yitbarek*
In 2016, our annual data traffic online passed one zetabyte for the first time. That's one sextillion bites, if it helps. Okay, got that number in your head? Now triple it, because that's how much data we'll have by 2021.
**01:10** - *Saron Yitbarek*
I know, the brain wasn't made to think in zetabytes, but just hold onto this one little fact for a second. Our IP traffic will triple in five years. It's a data flood and we're in the middle of it.
**01:24** - *Saron Yitbarek*
That last minute that went by, people sent 16 million text messages and in the time it took me to say that sentence, Google processed 200,000 searches.
**01:37** - *Saron Yitbarek*
Hidden inside that data flood are patterns, answers, and secrets that can massively improve our lives if we can just keep ourselves standing upright when the flood comes in.
**01:50** - *Saron Yitbarek*
I'm Saron Yitbarek and this is Command Line Heroes, an original podcast from Red Hat. The tidal waves are on the horizon. This is episode 6 of season 2, the data flood.
**02:17** - *Saron Yitbarek*
How do we handle such enormous amounts of data? How will we make use of that data once it's captured? Big data is going to solve some of our most complicated problems:
**02:29** - *Saron Yitbarek*
How we manage traffic. How we grow food. How we deliver supplies to those in need. But only once we figure out how to work with all that data, how to process it, and at breakneck speed.
**02:43** - *Kenneth Cukier*
By having more data, we can drill down into these sub-groups, these particulars, and these details in ways that we never could before.
**02:53** - *Saron Yitbarek*
Kenneth Cukier is a senior editor at The Economist and he's also the Saron Yitbarek of their tech podcast called Babbage.
**03:01** - *Kenneth Cukier*
It's not to say that we couldn't collect the data before. We could, it just was really, really expensive. The real revolution is that we can collect this data very easily.
**03:10** - *Kenneth Cukier*
It's very inexpensive and the processing is super simple because it's all done by a computer. This has become the huge revolution of our era and it is probably the most defining aspect of modern life and will be for the next several decades, if not the next century. That's why big data's such a big deal.
**03:33** - *Saron Yitbarek*
A little history can remind us how radical that change has been. Think about it, 4,000 years ago, we were scratching all our data into dried slabs of mud.
**03:46** - *Kenneth Cukier*
These clay disks were heavy. The data that is imprinted in them once they're baked can't be changed. All of these features of how information was processed, stored, transferred, created has changed, right?
**04:04** - *Saron Yitbarek*
Changed big time. Around the year 1450, you get the first information revolution with the invention of the printing press. And today, we have our own revolution.
**04:16** - *Kenneth Cukier*
It's lightweight. It can be changed super simply because we can just use the delete key and change the instantiation of the information that we have in whether it's the magnetic tape or in the transition of the electronic transistors and the processors that we have. We can transport it at the speed of light, unlike say a clay disk that you have to carry.
**04:37** - *Saron Yitbarek*
The printing press levelled up our understanding of things with the 15th-century flood of data that ushered in the enlightenment.
**04:45** - *Saron Yitbarek*
Today, big data can level us up again. But only if we figure out how to take advantage of all that data. Only if we build the dams and the turbines that will put the flood to work.
**05:00** - *Kenneth Cukier*
There is a huge gap between what is possible and what companies and individuals and organizations are doing. That's really important because we could already see that there's this latent value in the data and that the cost of collecting, storing, and processing the data has really dropped down considerably to where it was, of course, a hundred years ago but even just ten years ago.
**05:22** - *Kenneth Cukier*
That's really exciting. But the problem is that, culturally, and in our organizational processes and even in the budgets that our CFOs and our CIOs allot to data, we're not there yet.
**05:35** - *Saron Yitbarek*
Super frustrating when you think about it. Enlightenment knocking at the door and nobody's answering. Part of the reason we're not answering though is that, well, who's actually behind the door? What's all this data gonna deliver?
**05:51** - *Saron Yitbarek*
Kenneth figures the newness of big data keeps some companies from taking that leap.
**05:56** - *Kenneth Cukier*
What is the value of the data once you collect a lot of it? The most honest answer is if you think you know, you're a fool. Because you can never identify today all the ways with which we're going to put the data to uses tomorrow.
**06:12** - *Kenneth Cukier*
The most important thing is to have the data and to have an open mind in all the ways that it can be used.
**06:18** - *Saron Yitbarek*
What Kenneth’s envisioning if we get big data right, is a wholesale transformation of our attitudes towards what's possible. A world where everybody, not just data scientists, can see the potential and gain insight.
**06:33** - *Kenneth Cukier*
By understanding that the world is one in which we can collect empirical evidence about it in order to understand it, and in order to change it, and improve it, and that improvements can happen in an automated fashion, we will see the world in a different way, and I think that's the really interesting change that's happening now culturally or psychologically around the world with policy makers and business people and Starbucks baristas.
**07:00** - *Kenneth Cukier*
Everyone in all walks of life sort of have the data gene. They got it. They've sort of gotten the inoculation and now, everywhere they look, they think in a data mindset.
**07:15** - *Saron Yitbarek*
Kenneth Cukier told us a quick story to illustrate the power of that new data mindset. Some researchers at Microsoft began thinking about pancreatic cancer.
**07:27** - *Saron Yitbarek*
People often find out about pancreatic cancer too late and early detection could save lives. So, the researchers began asking before these patients start searching for information on pancreatic cancer, what were they searching for in the previous few months? And in the previous years.
**07:46** - *Saron Yitbarek*
They began looking for clues buried inside all that search data. They began looking for patterns.
**07:54** - *Kenneth Cukier*
They struck pay dirt. They saw that they can identify patterns in the search terms leading up to the moment where people started searching for pancreatic cancer that predicted very accurately that people had pancreatic cancer.
**08:09** - *Kenneth Cukier*
The lesson here is that by using their imagination in terms of the latent knowledge inside of data, they can save lives. All they need now to do is to find a way to instrument through policy this finding, so that when people are searching for these terms, they can intervene in a subtle way to say, "You might wanna go to a healthcare clinic and get this checked out."
**08:29** - *Kenneth Cukier*
If they start doing that, people's lives will be saved.
**08:37** - *Saron Yitbarek*
What the researchers stumbled upon is a new form of cancer screening, a process that could alert patients month earlier. Making use of data isn't just a question of maximizing profits or efficiency.
**08:52** - *Saron Yitbarek*
It's about so much more than that. Hiding in all that data are real, enormous positives for humankind. If we don't use that data, we could be cheating ourselves. It's that epic struggle to put data to work that we're focusing on next.
**09:18** - *Saron Yitbarek*
Boston Children's Hospital at Harvard Medical School performed more than 26,000 surgeries last year. Kids walk through their doors for about a quarter million radiological exams.
**09:31** - *Saron Yitbarek*
The staff is doing incredible work, but there's a huge roadblock standing in their way.
**09:37** - *Ellen Grant*
A lot of the problems that we have in a hospital environment, especially as a physician, is how to get access to the data.
**09:45** - *Saron Yitbarek*
That's Dr. Ellen Grant. She's a pediatric neuroradiologist at Boston Children's and she depends on accessing data and analyzing medical images.
**09:56** - *Ellen Grant*
It's not simple to get access into say a pax archive where the images are stored to do additional data analysis unless you set up an environment. That's not easy to do when you're in a reading room where there are just standard hospital PCs provided.
**10:14** - *Ellen Grant*
There's a barrier to actually get to the data.
**10:17** - *Saron Yitbarek*
Hospitals actually dump a lot of their data because they can't afford to store it. So, that data's just lost. Radiologists like Dr. Grant may have been the first group of doctors to feel the frustration of data overload.
**10:33** - *Saron Yitbarek*
When they went digital, they began creating enormous amounts of data and that quickly became impossible to handle.
**10:41** - *Ellen Grant*
I, as a clinician, in the reading room wanted to be able to do all the fancy analysis that could be done in a research environment. But there's no way to easily get images off of the packs and get them to some place where the analysis could be done and get them back into my hands.
**10:59** - *Saron Yitbarek*
Packs by the way are what hospitals call the data banks that store their images. Dr. Grant knew there were tools that could make those packs of images more functional, but costs were prohibitive.
**11:12** - *Ellen Grant*
As we're entering into this era of machine learning and AI, there's more of that gonna happen that we need these larger computational resources to really start to do the large database analysis we wanna do.
**11:27** - *Saron Yitbarek*
The data's been piling up, but not so much the processing. On premise data processing would be out of reach. And elaborate, expensive supercomputers aren't an option for hospitals.
**11:41** - *Saron Yitbarek*
Dr. Grant became deeply frustrated.
**11:44** - *Ellen Grant*
Can't we figure out a better way for me to just get data over here, analyze it, get it back so I can do it at the console where I'm interpreting clinical images cause I wanna have that data there and analyzed there quickly.
**11:56** - *Ellen Grant*
I don't wanna have to move to different computers and memorize all this line code when that's not my job. My job is trying to understand very complex medical diseases and keep all those facts in my head.
**12:10** - *Ellen Grant*
I wanted to keep my focus on where my skill set was but exploit what is emerging in the computational side without having to dive that deep into it.
**12:21** - *Saron Yitbarek*
What Dr. Grant and radiologists around the world needed was a way to click on imagery, run detailed analysis, and have it all happen on the cloud so the hospital didn't have to build their own server farm and didn't have to turn the medical staff into programmers.
**12:40** - *Saron Yitbarek*
They needed a way to make their data save all the lives it could and so, that's exactly what Dr. Grant and a few command line heroes decided to build.
**12:55** - *Saron Yitbarek*
Dr. Grant's team at Boston Children's Hospital worked with Red Hat and the Massachusetts Open Cloud (MOC). More on the MOC a little later. First though, here's Rudolph Pienaar, a biomedical engineer at the hospital describing their solution. It's an open source, container-based imaging platform.
**13:15** - *Saron Yitbarek*
It's all run on the cloud, too. So you're not limited by the computing power at the hospital itself. They call their creation ChRIS.
**13:24** - *Rudolph Pienaar*
There's a backend database that's a Django Python machine really and that keeps track of users. It keeps track of the data they've processed. It keeps track of results.
**13:35** - *Rudolph Pienaar*
Then there are a whole bunch of constellation of services around this database that all exist as their own instances in containers. These deal with communicating with hospital resources like databases. They deal with the intricacies of pulling data from these resources and then pushing them out to other services that exist on a cloud or another lab or whatever it might be. On the place where data is computed, there's all these services like Kubernetes, the schedule, the actual analysis of the data that you want to be doing. Then, pulling it back again.
**14:11** - *Saron Yitbarek*
For Dr. Grant, the ChRIS imaging platform is a way to make data come to life. More than that, it's a way for data to make her a better doctor.
**14:21** - *Ellen Grant*
What makes a person a good physician is the experience they've had over a lifetime of practicing. But if I can kind of embody that into the data analysis and access more of that information, we just all know more and can combine the information better.
**14:39** - *Ellen Grant*
For example, I have a perception of what a certain pattern of injury looks like in a certain patient population built on my Gestalt understanding from the memories that I have.
**14:52** - *Ellen Grant*
I can now actually create probability maps of their distributions and inform everybody based on real data, or I can look for similar patients who had similar patterns and say what works best with them when they were treated to try to get closer to precision medicine.
**15:10** - *Ellen Grant*
Integrating the large amount of data and trying to exploit our past knowledge and to best inform how to treat any individual the best you can.
**15:21** - *Saron Yitbarek*
What does that mean for the children that are brought to the hospital? Dr. Grant says the ChRIS platform delivers more targeted diagnoses and more individualized care.
**15:31** - *Ellen Grant*
If we have more complex databases, we can understand complex interactions better and hopefully guide individual patients better. I think of ChRIS basically as my portal into multiple accessory lobes so I can be a lot smarter than I can on my own, ‘cause I cannot keep all this data in my brain at one time.
**15:53** - *Saron Yitbarek*
When the stakes are this high, we wanna push past the limits of the human brain. Here's Máirín Duffy. She's a designer on the Red Hat team that makes ChRIS happen and she knows from personal experience what's at stake.
**16:15** - *Máirín Duffy*
My father had a stroke, so I've been there sort of in the patient's family side of waiting for medical technology, ‘cause when someone has a stroke, they bring you in the hospital and they have to figure out what type of stroke it is. Based on the type, there's different treatments.
**16:31** - *Máirín Duffy*
If you give the wrong treatment, then really bad things can happen. So, the faster you can get the patient in for an MRI, the faster you can interpret the results in that situation. The faster you can potentially save their life.
**16:43** - *Máirín Duffy*
Just think about just the fact of getting that image processing pushed out of the cloud, parallelized, make it so much faster. So instead of being hours or days, it's minutes.
**16:55** - *Saron Yitbarek*
Medicine may be arriving at a new inflection point. One not driven by pharmacology, but by computer science. Also, think about the scalability of something like ChRIS.
**17:08** - *Saron Yitbarek*
You could have doctors in developing countries benefiting from the expertise and data sets at Boston Children's Hospital. Anybody with cell service could access web-based computing and data that might save lives.
**17:24** - *Saron Yitbarek*
Besides medicine, lots of other fields could be witnessing a similar inflection point. But only if they figure out how to make their data collections sing. To do that, they need to discover a whole new territory of computing.
**17:46** - *Saron Yitbarek*
All around the world, we're learning to make use of our data. Diverting those data floods towards our own goals, like at Boston Children's Hospital.
**17:56** - *Saron Yitbarek*
In other words, we're processing that data. But we can only do that because a new generation of cloud-based computing makes the processing possible.
**18:11** - *Saron Yitbarek*
For platforms like ChRIS, a key ingredient is that cloud-based computing is a new kind of storage. Remember that lots of hospitals throw out the data they gather because they literally can't hold it all.
**18:25** - *Saron Yitbarek*
That's what I wanna focus on as a last piece of the data flood puzzle. The storage solution. For ChRIS, the storage solution came in the form of an open source project called Ceph. The Massachusetts Open Cloud, which ChRIS uses, depends on Ceph.
**18:45** - *Saron Yitbarek*
So, I got chatting with its creator, Sage Weil, to learn more about how places like Boston Children's can process enormous amounts of data in lightning time. Here's my conversation with Sage. I think a great first question is what is Ceph and what does it do?
**19:05** - *Sage Weil*
Sure. Ceph is a software-defined storage system that allows you to provide a reliable storage service, providing various protocols across unreliable hardware.
**19:14** - *Sage Weil*
It's designed from the ground up to be scalable, so you can have very, very large storage systems, very large data sets and you can make them available and tolerate hardware failures and network failures and so on without compromising availability.
**19:29** - *Saron Yitbarek*
Nowadays, there's just so much data.
**19:31** - *Sage Weil*
Yes.
**19:33** - *Saron Yitbarek*
So much consumption. There's just so much to get a handle on. Do you feel like the timing of it was part of the need for the solution?
**19:39** - *Sage Weil*
Yes, definitely. At the time, it just seemed painfully obvious that there's this huge gap in the industry. There was no open source solution that would address the scalable storage problem. So it was obvious that we needed to build something.
**19:53** - *Saron Yitbarek*
When we're thinking about the amount of data we're dealing with on a daily basis and the fact that it's only growing, it's only getting bigger and harder to manage, what do you see that's being worked on today that will maybe address this growing need?
**20:09** - *Sage Weil*
I think there are sort of several pieces of it. The first thing is that there's incredible amount of data being generated, of course, so you need scalable systems that can scale not just in the amount of hardware and data that you're storing but also have a sort of fixed or nearly fixed operational overhead.
**20:25** - *Saron Yitbarek*
Mm-hmm (affirmative).
**20:26** - *Sage Weil*
You don't wanna pay another person per 10 petabytes or something like that. They have to be operationally scalable, I guess would be the way to put it.
**20:33** - *Saron Yitbarek*
Yeah.
**20:35** - *Sage Weil*
That's part of it. I think also the way that people interact with storage is changing as well. In the beginning, it was all file storage and then we have block storage for VMs, object storage is sort of, I think, a critical trend in the industry.
**20:51** - *Sage Weil*
I think really the next phase of this is not so much around just providing an object storage endpoint and being able to store data in one cluster, but really taking this sort of the level up and having clusters of clusters, geographically distributed mesh of cloud footprints or private datacenter footprints where data is stored and being able to manage the data that's distributed across those.
**21:13** - *Sage Weil*
Maybe you write the data today in one location, you tier it off to somewhere else over time because it's cheaper, or it's closer, or the data's older, and you need to move it to a lower-performance, higher-capacity tier for pricing reasons.
**21:27** - *Sage Weil*
Dealing with things like compliance so that when you ingest data in one, in Europe, it has to stay within certain political boundaries in order to comply with regulation.
**21:39** - *Sage Weil*
In certain industries, you have things like HIPAA that restricts the way that data's moved around. I think as modern IT organizations are increasingly spread across lots of different datacenters and lots of public clouds and their own private cloud infrastructure, being able to manage all this data and automate that management is becoming increasingly important.
**21:58** - *Saron Yitbarek*
When you think about how we're going to manage and store data in the future, and process data in the future, how does open source play a role in that? You mentioned that you wanted to create an open source solution because of your personal philosophy and your strong feelings on free and open software.
**22:16** - *Saron Yitbarek*
How do you see open source affecting other solutions in the future?
**22:21** - *Sage Weil*
I think that, particularly in the infrastructure space, solutions are converging towards open source. I think the reason for that is there are high cost pressures in the infrastructure space and particularly for people building software-as-a-service or cloud services, it's important that they keep their infrastructure very cheap and open source is obviously a very good way to do that from their perspective.
**22:48** - *Sage Weil*
I think the second reason is more of a, I think, a social reason and that it's such a fast-moving field where you have new tools, new frameworks, new protocols, new ways of thinking about data and there's so much innovation and change happening in that space and so many different products and projects that are interacting, that it's very hard to do that in a way that is sort of based on the traditional model, where you have different companies having partnership agreements and co-development or whatever.
**23:20** - *Sage Weil*
Open source removes all of that friction.
**23:28** - *Saron Yitbarek*
Sage Weil is a senior consulting engineer at Red Hat and the Ceph project lead. I'm gonna circle back to Kenneth Cukier from The Economist so we can zoom out a bit, because I want us to remember that vision he had about our relationship with data and how we've progressed from clay tablets to the printing press to cloud-based wonders like the one Sage built.
**23:55** - *Kenneth Cukier*
This is about human progress and it is about how we can understand the world and the empirical evidence of the world better to improve the world. It is the same mission of progress that humans have always been on.
**24:08** - *Saron Yitbarek*
The mission never ends. But, in the meantime, learning to process the data we've gathered and put that flood to work, that's an open source mission for a whole generation. We're ending our data journey with a quick stop at the Oak Ridge National Laboratory in Tennessee. It's home to Summit, the world's fastest supercomputer or at least fastest as of 2018.
**24:43** - *Saron Yitbarek*
This machine processes 200,000 trillion calculations per second. That's 200 petaflops, if you're counting. Processing speed like that isn't practical for hospitals or banks or all the thousands of organizations that benefit from high high performance computing today.
**25:04** - *Saron Yitbarek*
Supercomputers like Summit are reserved more for Hadron Collider territory. But then again, we were once recording just a hundred bytes of info on clay tablets.
**25:16** - *Saron Yitbarek*
The story of data storage and data processing is one where extraordinary feats keep becoming the new normal. One day, we might all have Summit-sized supercomputers in our pockets. Think of the answers we'll be able to search for then.
**25:42** - *Saron Yitbarek*
Next episode, we're going serverless. Or are we? Episode 7 is all about our evolving relationship with cloud-based development. We're figuring out how much of our work we can abstract and what we might be giving up in the process.
**25:58** - *Saron Yitbarek*
Meantime, if you wanna dive deeper into the ChRIS story, visit [redhat.com/chris](https://www.redhat.com/chris) to learn more about how it was built and how you can contribute to the project itself.
**26:12** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Listen for free on Apple Podcasts, Google Podcasts, or wherever you do your thing.
**26:24** - *Saron Yitbarek*
I'm Saron Yitbarek. Until next time, keep on coding.
### Keep going
### Why our big data questions require scalable, open answers
Data use is too universal for closed source solutions
### Creating ChRIS
Boston Children's Hospital needed better access to their data. So they teamed up with Red Hat and the Mass Open Cloud.
### File, block, or object storage?
We can store worlds of data—and how we do that matters.
### Featured in this episode
### Also in this episode
### Red Hat legal and privacy links
[About Red Hat](/en/about/company)[Jobs](/en/jobs)[Events](/en/events)[Locations](/en/about/office-locations)[Contact Red Hat](/en/contact)[Red Hat Blog](/en/blog)[Diversity, equity, and inclusion](/en/about/our-culture/diversity-equity-inclusion)[Cool Stuff Store](https://coolstuff.redhat.com/)[Red Hat Summit](https://www.redhat.com/en/summit) |
12,650 | Wi-Fi 6E:它何时到来,又有何作用? | https://www.networkworld.com/article/3563832/wi-fi-6e-when-its-coming-and-what-its-good-for.html | 2020-09-25T09:50:28 | [
"Wi-Fi"
] | https://linux.cn/article-12650-1.html |
>
> Extreme Networks 的一位高管表示,近来专用于 Wi-Fi 的新无线频谱可以提供更多的信道和更高的密度部署,但是要支持它的设备要到 2020 年才能得到广泛部署。
>
>
>

今年开春 [FCC 在 6GHz 频段内开辟了一系列新的未授权的无线频谱](https://www.networkworld.com/article/3540288/how-wi-fi-6e-boosts-wireless-spectrum-five-fold.html),该频谱旨在用于 Wi-Fi,以提供更低的延迟和更快的数据速率。新频谱的范围更短,与已经专用于 Wi-Fi 的频段相比支持的信道也更多,因此适合在体育场馆等高密度区域部署。
为了进一步了解什么是 Wi-Fi 6E 以及它与 Wi-Fi 6 有何不同,我最近与网络解决方案提供商 Extreme Networks 的产品管理总监 Perry Correll 进行了交谈。
**了解更多关于 5G 和 WiFi 6 的信息**
* [什么是 5G?相较于 4G 它更好吗?](https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html)
* [如何确定 WiFi 6 是否适合你?](https://www.networkworld.com/article/3356838/how-to-determine-if-wi-fi-6-is-right-for-you.html)
* [什么是 MU-MIMO?为什么它在你的无线路由器中不可或缺?](https://www.networkworld.com/article/3250268/what-is-mu-mimo-and-why-you-need-it-in-your-wireless-routers.html)
* [何时使用 5G?何时使用 WiFi 6?](https://www.networkworld.com/article/3402316/when-to-use-5g-when-to-use-wi-fi-6.html)
* [企业如何为5G网络做准备呢?](https://www.networkworld.com/article/3306720/mobile-wireless/how-enterprises-can-prep-for-5g.html)
**Kerravala: Wi-Fi 6 似乎得到了许多热捧,而 Wi-Fi 6E 却没有。为什么?**
**Correll:** 所有这些带 666 的数字会混乱得会吓死你。我们已经有了 Wi-Fi 6、Wi-Fi 6E,之后,Wi-Fi 6 还有其它的增强功能,比如多用户多入多出(多用户 MIMO)功能。还有就是 6GHz 频谱,但这并不是 Wi-Fi 6 的名称的由来:它是第六代 Wi-Fi。最重要的是,我们刚刚掌握了 5G,并且已经在谈论 6G —— 认真的讲,这更容易搞混了。
**Kerravala: 为什么我们需要 Wi-Fi 6E 和普通的 Wi-Fi 6?**
**Correll:** 上一次我们在 UNII-2 和 UNII-2 扩展中得到提升是在 15 年前,而在当时智能手机甚至还没有兴起。现在能够获得 1.2GHz 的频谱已经非常大了。使用 Wi-Fi 6E,我们不是将 Wi-Fi 空间增加一倍,事实上,我们将可用空间增加了三倍。根据你所处的地点,频谱的数量要多三倍、四倍或五倍。此外,你不必担心 DFS(<ruby> 动态频率选择 <rt> dynamic frequency selection </rt></ruby>),尤其是在室内。
Wi-Fi 6E 不会比 Wi-Fi 6 更快,也不会添加增强的技术功能。最妙的是运行 6GHz 需要 Wi-Fi 6 或以上的客户端。所以,我们不会有任何缓慢的客户端,也不会有很多噪声。我们将在更干净的环境中使用更快的设备来得到高性能。
**Kerravala: 也能用更宽的信道吗**
**Correll:** 没错,那是一件很酷的事情。如果你处于一个典型的企业环境中,20 和 40MHz 基本上就是你需要的。在体育馆这种高密度环境中,想要使用 80 或 160MHz 的带宽就会变得很困难了。更宽的信道将会真正有助于像虚拟现实这类应用,它可以利用这些信道占用频谱中剩余的部分。这可能是最大的用例了。
在未来的三四年里,如果你想在体育场做数字标识牌或者边缘屏幕处理,则可以使用 160MHz 的 80% 带宽,而不会受到其他任何影响。已经有传言说 Wi-Fi 7 将会有 320MHz 宽的频道。
**Kerravala: 这将主要是对大多数 Wi-Fi 策略的增强吗?**
**Correll:** 短期内肯定会处于先锐领域。首批产品大概会在今年底发布,它们将是消费类产品。对于企业来说,支持 6GHz 的产品将会在明年亮相。在 2022 年之前,你不会真正看到它密集出现——所以,短期内不会。对于智能手机公司来说,Wi-Fi 并不是什么大事,他们更愿意关注其他功能。
但它仍是一个巨大的机会。6GHz 与 CBRS(公民宽带无线电服务)或 5G 相比,最棒的一点是(许多人)宁愿坚持使用 Wi-Fi,也不愿迁移到不同的架构。这些用户将推动驱动部件制造商转向物联网设备或机器人或任何需要 6GHz 的设备。这是一个干净的频谱,可能比普通的 Wi-Fi 6 还要便宜也更节能。
**Kerravala: 有人说 5G 会替代 Wi-Fi 6。但这有什么实际意义呢?**
**Correll:** 现实中,你不可能在每个设备中插入 SIM 卡。但是其中一个大问题是数据所有权,因为运营商将拥有你的数据,而不是你。如果你想使用你的数据进行任何类型的业务分析,运营商是否会以一定价格将数据返还给你?这是一个可怕的想法。
Wi-Fi 不会消失有太多的理由。当具备 Wi-Fi 6 和 5G 功能的设备问世时,其他只有 Wi-Fi 功能的笔记本电脑、平板电脑和物联网设备将会发生什么呢?要么是只支持 Wi-Fi 的设备,要么是支持 Wi-Fi 和 5G 的设备,但 5G 不会完全取代 Wi-Fi。如果你看看 5G 无线网络的骨干网,Wi-Fi 就是其中的一个组成部分。这是一个幸福的大家庭。这些技术是为了共存而设计的。
---
via: <https://www.networkworld.com/article/3563832/wi-fi-6e-when-its-coming-and-what-its-good-for.html>
作者:[Zeus Kerravala](https://www.networkworld.com/author/Zeus-Kerravala/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,653 | 使用 Btrfs 快照进行增量备份 | https://fedoramagazine.org/btrfs-snapshots-backup-incremental/ | 2020-09-26T11:26:58 | [
"快照",
"Btrfs",
"备份"
] | https://linux.cn/article-12653-1.html | 
<ruby> 快照 <rt> snapshot </rt></ruby>是 Btrfs 的一个有趣的功能。快照是一个子卷的副本。生成快照是立即的。然而,生成快照与执行 `rsync` 或 `cp` 不同,快照并不是一创建就会占用空间。
>
> 编者注:来自 [BTRFS Wiki](https://btrfs.wiki.kernel.org/index.php/SysadminGuide#Snapshots):快照简单的来说就是一个子卷,它使用 Btrfs 的 COW 功能与其他子卷共享其数据(和元数据)。
>
>
>
占用的空间将随着原始子卷或快照本身(如果它是可写的)的数据变化而增加。子卷中已添加/修改的文件和已删除的文件仍然存在于快照中。这是一种方便的备份方式。
### 使用快照进行备份
快照驻留在子卷所在的同一磁盘上。你可以像浏览普通目录一样浏览它,并按照生成快照时的状态恢复文件的副本。顺便说一下,在快照子卷的同一磁盘上生成快照并不是一个理想的备份策略:如果硬盘坏了,快照也会丢失。快照的一个有趣的功能是可以将快照发送到另一个位置。快照可以被发送到外部硬盘或通过 SSH 发送到远程系统(目标文件系统也需要格式化为 Btrfs)。要实现这个,需要使用命令 `btrfs send` 和 `btrfs receive`。
### 生成快照
要使用 `btrfs send` 和 `btrfs receive` 命令,重要的是要将快照创建为只读,而快照默认是可写的。
下面的命令将对 `/home` 子卷进行快照。请注意 `-r` 标志代表只读。
```
sudo btrfs subvolume snapshot -r /home /.snapshots/home-day1
```
快照的名称可以是当前日期,而不是 `day1`,比如 `home-$(date +%Y%m%d)`。快照看起来像普通的子目录。你可以把它们放在任何你喜欢的地方。目录 `/.snapshots` 可能是一个不错的选择,以保持它们的整洁和避免混淆。
>
> 编者注:快照不会对自己进行递归快照。如果你创建了一个子卷的快照,子卷所包含的每一个子卷或快照都会被映射到快照里面的一个同名的空目录。
>
>
>
### 使用 btrfs send 进行备份
在本例中,U 盘中的目标 Btrfs 卷被挂载为 `/run/media/user/mydisk/bk`。发送快照到目标卷的命令是:
```
sudo btrfs send /.snapshots/home-day1 | sudo btrfs receive /run/media/user/mydisk/bk
```
这被称为初始启动,它相当于一个完整的备份。这个任务需要一些时间,取决于 `/home` 目录的大小。显然,后续的增量发送只需要更短的时间。
### 增量备份
快照的另一个有用的功能是能够以增量的方式执行发送任务。让我们再来生成一个快照。
```
sudo btrfs subvolume snapshot -r /home /.snapshots/home-day2
```
为了执行增量发送任务,需要指定上一个快照作为基础,并且这个快照必须存在于源文件和目标文件中。请注意 `-p` 选项。
```
sudo btrfs send -p /.snapshot/home-day1 /.snapshot/home-day2 | sudo btrfs receive /run/media/user/mydisk/bk
```
再来一次(一天之后):
```
sudo btrfs subvolume snapshot -r /home /.snapshots/home-day3
sudo btrfs send -p /.snapshot/home-day2 /.snapshot/home-day3 | sudo btrfs receive /run/media/user/mydisk/bk
```
### 清理
操作完成后,你可以保留快照。但如果你每天都执行这些操作,你可能最终会有很多快照。这可能会导致混乱,并可能会在你的磁盘上使用大量的空间。因此,如果你认为你不再需要一些快照,删除它们是一个很好的建议。
请记住,为了执行增量发送,你至少需要最后一个快照。这个快照必须存在于源文件和目标文件中。
```
sudo btrfs subvolume delete /.snapshot/home-day1
sudo btrfs subvolume delete /.snapshot/home-day2
sudo btrfs subvolume delete /run/media/user/mydisk/bk/home-day1
sudo btrfs subvolume delete /run/media/user/mydisk/bk/home-day2
```
注意:第 3 天的快照被保存在源文件和目标文件中。这样,明天(第 4 天),你就可以执行新的增量 `btrfs send`。
最后的建议是,如果 U 盘的空间很大,可以考虑在目标盘中保留多个快照,而在源盘中只保留最后一个快照。
---
via: <https://fedoramagazine.org/btrfs-snapshots-backup-incremental/>
作者:[Alessio](https://fedoramagazine.org/author/alciregi/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Snapshots are an interesting feature of Btrfs. A snapshot is a copy of a subvolume. Taking a snapshot is immediate. However, taking a snapshot is not like performing a *rsync* or a *cp*, and a snapshot doesn’t occupy space as soon as it is created.
Editors note: From the [BTRFS Wiki](https://btrfs.wiki.kernel.org/index.php/SysadminGuide#Snapshots) – A snapshot is simply a subvolume that shares its data (and metadata) with some other subvolume, using Btrfs’s COW capabilities.
Occupied space will increase alongside the data changes in the original subvolume or in the snapshot itself, if it is writeable. Added/modified files, and deleted files in the subvolume still reside in the snapshots. This is a convenient way to perform backups.
## Using snapshots for backups
A snapshot resides on the same disk where the subvolume is located. You can browse it like a regular directory and recover a copy of a file as it was when the snapshot was performed. By the way, a snapshot on the same disk of the snapshotted subvolume is not an ideal backup strategy: if the hard disk broke, snapshots will be lost as well. An interesting feature of snapshots is the ability to send them to another location. The snapshot can be sent to an external hard drive or to a remote system via SSH (the destination filesystems need to be formatted as Btrfs as well). To do this, the commands *btrfs send* and *btrfs receive* are used.
## Taking a snapshot
In order to use the *send* and the *receive* commands, it is important to create the snapshot as read-only, and snapshots are writeable by default.
The following command will take a snapshot of the */home* subvolume. Note the *-r* flag for readonly.
Instead of day1, the snapshot name can be the current date, like *home-$(date +%Y%m%d)*. Snapshots look like regular subdirectories. You can place them wherever you like. The directory */.snapshots* could be a good choice to keep them neat and to avoid confusion.
Editors note: Snapshots will not take recursive snapshots of themselves. If you create a snapshot of a subvolume, every subvolume or snapshot that the subvolume contains is mapped to an empty directory of the same name inside the snapshot.
## Backup using btrfs send
In this example the destination Btrfs volume in the USB drive is mounted as */run/media/user/mydisk/bk* . The command to send the snapshot to the destination is:
*/home*directory. Obviously, subsequent incremental sends will take a shorter time.
## Incremental backup
Another useful feature of snapshots is the ability to perform the send task in an incremental way. Let’s take another snapshot.
In order to perform the send task incrementally, you need to specify the previous snapshot as a base and this snapshot has to exist in the source and in the destination. Please note the *-p* option.
## Cleanup
Once the operation is complete, you can keep the snapshot. But if you perform these operations on a daily basis, you could end up with a lot of them. This could lead to confusion and potentially a lot of used space on your disks. So it is a good advice to delete some snapshots if you think you don’t need them anymore.
Keep in mind that in order to perform an incremental send you need at least the last snapshot. This snapshot must be present in the source and in the destination.
Note: the day 3 snapshot was preserved in the source and in the destination. In this way, tomorrow (day 4), you can perform a new incremental *btrfs send*.
As some final advice, if the USB drive has a bunch of space, you could consider maintaining multiple snapshots in the destination, while in the source disk you would keep only the last one.
## Brad Smith
Thanks for the information. Very useful and much appreciated. I am a long time Fedora user but not really a linux sysadmin. I have been using ext3 and ext4 along with LVM for quite a while. It would be nice if there were an article with links to information on safely migrating from EXT4/LVM (and an LVM raid) for /home) to btrfs for Fedora users.
thanks!
## Sebastiaan Franken
As far as I know the only “safe” way of migrating from ext4 + LLVM to BTRFS is to reinstall your OS, since changing your underlying filesystem (and it’s layout) is quite a big deal, plumbing wise. There is
nosafe way of doing that with a running system, as far as I know.## Horniger Glücksbärchi
Actually you would be surprised.
It doesnt really matter which filesystem the files are on as long as you dont change the mount tree.
Exceptions:
If you forget to copy extended attributes (selinux labels) then you need to relabel.
If you forget to copy with preserve then you lose file permissions and dates…
But this whiles it uses filesystem features, doesnt depend on a particular filesystem.
So any fs that has the feature can contain your system files + metadata.
Notes:
Bringup of logical devices is managed by the kernel cmdline. To port plain to lvm you need to bringup lvm there if it doesnt autodetect your vgs.
Porting to luks encryption, same deal.
All that stuff is autogenerated by bootloader rebuild if you have fstab and crypttab populated.
BTRFS Snapshots trees arent directly (integrated to some preinstalled copying solution) portable to other schemes.
So copy btrfs tree to plain ext4 volume -> you get the same layout as in btrfs without subvolumes.
Conversion of btrfs tree to linked lvm volumes, is possible but I dont know a tool that does it.
## pctux982
Full backup of entire system is possible using rsync, taking care of preserving extended attributes.
Once you have performed a backup, create btrfs partition and eventually subvolumes within, mount it and redo rsync of backup on new system root.
Once terminated, chroot into new root and regenerate initramfs, therefore reconfigure grub, and you’re done.
Check arch wiki for information about full system backup
## Andrew
I’ve used these steps to migrate systems:
1: Research what changes you’ll need to make to the fstab file, kernel command line, boot loader, and/or initramfs.
2: Install any tools needed for the new file system. Btrfs tools in this case.
3: Boot from an SD card.
4: Dd the whole hard drive to a file on an external drive.
5: If the drive is encrypted, decrypt it and dd the decrypted hard drive to another file on the external drive.
6: Reformat the drive.
7: Mount your decrypted dd image via a loopback device.
8: Rsync the dd filesystem to the drive.
9: Apply the changes you identified in step 1.
If you get stuck, you can dd the image from step 4 back to the hard drive.
## Nick Avem
Will the new F33 LVM layout be (preferably out of the box) compatible with snapper?
## Kyle
Second snapper.io to help mange the snapshots. Very handy.
## Vernon Van Steenkist
rdiff-backup has had this capability for over 20 years and works great on many different file systems and even remote machines. What is the advantage of using btrfs?
## Chris Murphy
Perhaps the most significant difference is how difference is computed. Whether cp, rsync, or rdiff-backup, both the source and the destination need to be scanned and compared to know how they differ and what to copy.
Btrfs snapshots, the difference is a function of copy-on-write, and what changes have happened between two “generations”. Each snapshot has a unique generation. Deep traversal isn’t required. For example, I have a 1TB subvolume, and 1M of difference between two of its subvolume snapshots. The incremental send takes only a few seconds. Also, the difference is a function of changed blocks, and btrfs send will only send changed blocks (depending on how the owning application updates files).
Send+receive is well suited for backup, but it’s primarily a replication scheme. So you don’t see options for filtering (excludes or includes), or whether to preserve dates, times, permissions, or labels. These things are always preserved. A related feature is the possibility of creating a file out of the send stream, whether it’s a full or incremental send. This can come in handy for replicating containers or even a full file system root to many machines, physical or virtual.
Like anything, there are tradeoffs. But no matter what, backups are better than no backups!
## Vernon Van Steenkist
“Whether cp, rsync, or rdiff-backup, both the source and the destination need to be scanned and compared to know how they differ and what to copy.”
No. rdiff-backup is not like cp or rsync. Unlike cp and rsync, rdiff-backup has its own meta-data directory where it stores sha1 checksums on every file. rdiff-backup only needs to compare these checksums to see if an incremental delta backup needs to occur which makes rdiff-backup extremely fast. More information is below
https://current.workingdirectory.net/posts/2018/rsyncvsrdiff/
In addition, unlike cp and rsync, rdiff-backup creates delta snapshots each time it runs where only the deltas ares stored like a version manager ala CVS.
“Send+receive is well suited for backup, but it’s primarily a replication scheme. So you don’t see options for filtering (excludes or includes), or whether to preserve dates, times, permissions, or labels.”
No, rdiff-backup does have filtering and does preserve dates, times, permissions etc.
More information is below:
https://linux.die.net/man/1/rdiff-backup
## satai
It still needs to go through files, count SHAs and so on.
Snapshots don’t do it, their existence is just a side effect of CoW.
## Vernon Van Steenkist
“It still needs to go through files, count SHAs and so on. Snapshots don’t do it, their existence is just a side effect of CoW.”
Yes. Which is why it is non-trivial to restore a deleted file with btrfs if you don’t know when (how many snapshots ago) it was last on the disk. You can think of rdiff-backup as a version control system for your files whereas btrfs snapshots are like dd with a delta feature.
I certainly agree that btrfs can create snapshots quicker than rdiff-backup can create snapshots. However, the trade-offs are backup and restore inflexibility (doesn’t natively support different filesystems, network backups, file backup history), higher cpu loads, slower filesystem performance and filesystem instability (as opposed to ext4) making this article prescient for btrfs users who should take backup snapshots often 🙂
## Chris Murphy
rdiff-backup doesn’t have to read every file on the target, but it does have to read every file on the source. It computes a new sha1sum for each file, comparing to its own metadata directory, to know what’s changed.
Btrfs send doesn’t need to read a single file, source or target, to know what’s changed, and what to send. It doesn’t even have to read all of the metadata for the snapshots being sent, because the nodes contain a generation value for each referenced leaf. If a leaf is too old or new (compared to the generations of the two snapshots) it doesn’t need to be read.
## Sergey
I join in the question. If you’re looking at the future of SilverBlue with its update system, what’s the point of the subject then?
## Robert Redziak
Main difference is that you can, for example, quiesce/freeze and sync do to disks your database or application, take a snapshot, bring back your app to normal work and take backup your data from snapshot in consistent state. Which is not possible with tools, which work on file level.
## Duncan Ball
Nice article, but of ou are going to write an something describing a backup mechanism, it would be helpful to provide at least one example of how to recover from that backup Is there an efficient way to apply just the delta from the snapshot copy to roll back the filesystem to that point in time?
## Thomas Klein
Definitely – I second the request for a brief “how-to” regarding restoring the backed-up dtat.
If possible, could you elaborate on two cases please: “restoring a running system to a specific point in time / snapshot” and “restoring everything in a desaster recovery scenario” ?
While the above may sound a bit demanding, be assured that your article is MUCH appreciated! Thanks a ton, this adds a new twist to the btrfs discussions 😉
## laolux
Thanks for the article, will use that once f33 is out.
Now it would be great if you could elaborate on the ssh option a bit. How would I do that? And do I need to be root on the receiving machine?
## Juan Orti
Yes, you need root in both the source and target machine.
## Alex Corf
How about the backup size? The file compressed on destination or left as is?
## Juan Orti
If the source is using compression, the sender decompress the data and sends it to the receiver that will re-compress or no depending of the target compress options.
There’s ongoing work to optimize this process and allow to send the compressed stream directly, but that’s still in development.
## Chris Murphy
I’m using ssh pki, so only keys. On the remote, I create /etc/sudoers.d/1chris containing:
chris ALL = NOPASSWD: /usr/sbin/btrfs
Then from the local computer:
sudo btrfs send -p gits.20200830 gits.20200905 | ssh [email protected] “sudo btrfs receive .”
## svsv sarma
I think backup and snapshot are entirely different. While the former refers to documents, the later refers to the entire system including virus if any. I prefer the former to the later in a different devise. But I do only manual backup as it is easy for me to install fedora any time and start the documents from the backup. Perhaps this btrfs article is for developers and software engineers. Thanks for a very nice article prompting a debate.
## bbrot
Are there any cloud storage providers that support btrfs send/receive via SSH for backups? That would be super helpful!
## Lucas
Nice article. Snapshots in btrfs have already saved my workday.
## Shy
Blivet 2.2.0-1 supports creating Timeshift-compatible btrfs volume labels (@ for the rootfs subvol and @home for the /home subvol. That version of blivet was submitted in bodhi for testing on fc33 Feb 12, 2020. See BZ 1859963 for the bug report with the bodhi link.
I’m not sure if it will make it onto the distribution media for Fedora 33 or not. I don’t think that those btrfs volume labels can be easily applied after installation.
Timeshift is a GUI that can take btrfs snapshots.
## Nik
I’m using btrbk which automates this in a really nice way for quite a while on Arch. When switching to Fedora later this year i think i’ll stay with btrbk (or snapper).
## Nik
btrbk – https://github.com/digint/btrbk
## Juan Orti
I personally use the btrbk utility that it’s very handy to manage to all my snapshots and send-receive backups. I recommend it.
## Lockheed
Thanks for this article. Never had much to do with the file system things aside the real basics to go along as a simple user. I really love examples and how this is introduced and – as I am going to have a NAS finally soon finally rather than an external drive – I look forward to utilize. Will need a bit practice though but I hope I’ll do fine having then a real backup solution. Thanks again a lot for warming up users for btrfs! Very welcomed!
## Folkert M.
It may not be the right place, but the right time to post “Farewell Fedora and take care of yourself”. Our friendship ends here after 11 years. I’m still using 86ed hardware and I’m not convinced by the current x64 hardware offerings, either too expensive, as in the case of Apple, or the hardware feels useless even when playing. I am now friends with Debian.
## Michael
Great article, can’t wait to try it out.
## leslie Satenstein
In brfs terms, what is a volume and what is a sub-volume.
In my system, I have separate partitions for boot/efi,
/boot, /, /var /home and swap.
Leaving out swap, and /boot/efi, do I create a single partition for /, /var, /boot, /home and on boot of the new system, they become sub-volumes?
Do I just change type=ext4 to type=btrfs, when declaring the partitions for the /, /var, /boot and /home?
If I think about volumes and sub-volumes as an encyclopaedia,
then the individual books are sub-volumes, and they are individually bound items. Drawing from encyclopaedia to Linux partitioning, am I wrong to think of a sub-volume as a partition?
## Andrew Holden
Btrfs subvolumes are somewhere between directories and partitions. Many btrfs systems would have 2 or 3 partitions:
1: /boot, probably fat32.
2: swap (optional, or you can make it a file in btrfs is many circumstances–read the docs if you want to try).
3: The btrfs volume. More about mounting it below.
If you have multiple drives, then you can make a single partition on the remaining drives and list them all along with partition #3 above then you run mkfs.btrfs. This will group all the partitions into a single volume. By default, btrfs will mirror metadata and stripe data.
Now, it’s time to plan subvolumes. There are several schemes to choose from:
* Ignore subvolumes and just mount the volume as /.
* Mount the volume as /, but make a subvolume for any folders that you want to snapshot independently. Just name the subvolumes after their path, and they’ll automatically mount. For example, a subvolume named “home” would contain the home folder, or a subvolume named “var/log” would contain the log folder.
* Full manual. Make subvolumes for root, home, and whatever else you want and list them all in fstab.
Don’t try to format the subvolumes. They’re not block devices.
## Magnus Asbjørn
I found an old comment linking to btrfs’ bugtracker, compared to other filesystems it seems to have way more open issues. Understandable since they have so many features. But some of the reports are years old like corruption, with no reply.
Any comments about that?
## Per F
I am also concerned about this. Maybe it has gotten better and more stable over the years, but btrfs still have that bad reputation of loosing entire file systems to corruption.
What I don’t get is why Fedora is now making btrfs the default file system when RedHat officially dumped all future support of btrfs back in 2017?
Well for me it’s ok to have btrfs as an available option (for the adventurous ones), but as the default fs?? I don’t think so!
## Mike G
Honestly, what is the point of btrfs? I’ve been using zfs for years on mac, linux, and BSD. Aside from getting around some kind of nebulous legal problem, is anything actually better about btr? If the intellectual property laws force people to spend years reinventing the wheel, maybe things were better before we had all of this software licensing nonsense. |
12,654 | 使用 Mu 编辑器教授 Python | https://opensource.com/article/20/9/teach-python-mu | 2020-09-26T11:51:03 | [
"Python"
] | /article-12654-1.html |
>
> Mu 让你轻松学会如何编写 Python 代码。
>
>
>

在学校里,教孩子们编程是非常流行的。很多年前,在 Apple II 和 [Logo](https://en.wikipedia.org/wiki/Logo_(programming_language)) 编程的年代,我学会了创建<ruby> 乌龟 <rt> turtle </rt></ruby>绘图。我很喜欢学习如何对虚拟乌龟进行编程,后来也帮助学生进行编程。
大约五年前,我了解了 [Python 的 turtle 模块](https://docs.python.org/3/library/turtle.html),这是我 Python 之旅的转折点。很快,我开始使用 `turtle` 模块来教学生 Python 编程基础,包括使用它来创建有趣的图形。
### 开始使用 Python 的 turtle 模块
在 Linux 或 macOS 电脑上,你只需打开一个终端,输入 `python`,你就会看到 Python shell。
如果你使用的是 Windows 电脑,则需要先安装 Python,到 Python 网站上[下载](https://www.python.org/downloads/windows/)最新的稳定版。
接下来,用 `import turtle` 或 `import turtle as t` 将 `turtle` 模块导入 Python 中。然后你就可以开始享受创建乌龟绘图的乐趣了。
### 认识一下 Mu
在我的 Python 冒险的早期,我使用了 [IDLE](https://docs.python.org/3/library/idle.html),它是 Python 的集成开发环境。它比在 Python shell 中输入命令要容易得多,而且我可以编写和保存程序供以后使用。我参加了一些在线课程,阅读了许多关于 Python 编程的优秀书籍。我教老师和学生如何使用 IDLE 创建乌龟绘图。
IDLE 是一个很大的改进,但在克利夫兰的 PyConUS 2019 上,我看到了 [Nicholas Tollervey](https://ntoll.org/)的演讲,这改变了我学习和教授 Python 的方式。Nick 是一位教育家,他创建了 [Mu](https://codewith.mu/en/download),一个专门为年轻程序员(甚至像我这样的老程序员)设计的 Python 编辑器。Mu 可以安装在 Linux、macOS 和 Windows 上。它很容易使用,并且附带了优秀的[文档](https://codewith.mu/en/howto/)和[教程](https://codewith.mu/en/tutorials/)。
在 Linux 上,你可以通过命令行安装 Mu。
在 Ubuntu 或 Debian 上:
```
$ sudo apt install mu-editor
```
在 Fedora 或类似的地方:
```
$ sudo dnf install mu
```
或者,你可以使用 Python 来进行安装。首先,确保你已经安装了 Python 3:
```
$ python --version
```
如果失败了,就试试:
```
$ python3 --version
```
假设你有 Python 3 或更高版本,使用 Python 包管理器 `pip` 安装 Mu。
```
$ python -m pip install mu-editor --user
```
然后你可以从命令行运行 Mu,或者创建一个快捷方式:
```
$ python -m pip install shortcut mu-editor --user
```
[树莓派](https://www.raspberrypi.org/blog/mu-python-ide/)上默认安装了 Mu,这是一个很大的优点。在过去的几年里,我已经向学生介绍了使用树莓派和 Mu 编辑器的 Python 编程。
### 如何用 Mu 教授 Python
Mu 是向学生展示 Python 入门的好方法。下面是我如何教学生开始使用它。
1. 打开 Mu 编辑器。

2. 输入 `import turtle` 导入 `turtle` 模块,就可以让乌龟动起来了。我的第一课是用 Python 代码画一个简单的正方形。

3. 保存这个程序,确保文件名以 .py 结尾。

4. 运行程序。哪怕是运行这样一个简单的程序都会让人兴奋,看到你写的程序的图形输出是很有趣的。

### 超越基础知识
在上完这节简单的课后,我讲解了有一些方法可以简化和扩展学生所学的基础知识。一是创建一个更简单的 `turtle` 对象,`import turtle as t`。然后我介绍了一个 `for` 循环,用另外一种 `turtle` 方法画一个正方形。

接下来,我将展示如何创建一个 `my_square` 函数,作为另一种绘制正方形的方法。

后来,我通过介绍其他 `turtle` 模块方法,包括 `penup`、`pendown` 和 `pencolor` 来扩展这个概念。很快,我的学生们就开始开发更复杂的程序,并对其进行迭代。

我一直渴望学习,我很想知道你在学校或家里是如何教授 Python 的。请在评论中分享你的经验。
---
via: <https://opensource.com/article/20/9/teach-python-mu>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,655 | eDEX-UI:一款科幻风格的酷炫 Linux 终端仿真器 | https://itsfoss.com/edex-ui-sci-fi-terminal/ | 2020-09-26T22:02:00 | [
"终端"
] | https://linux.cn/article-12655-1.html |
>
> eDEX-UI 是一个很酷的科幻电影式的终端仿真器,看起来很酷,有大量包括系统监控在内的选项。让我们来快速看看它提供了什么。
>
>
>
你可能已经知道了[大量有趣的 Linux 命令](https://itsfoss.com/funny-linux-commands/)。但你知道当谈到 Linux 命令行时,还有什么有趣的东西吗?那就是终端本身。
是的,终端仿真器(俗称终端)也可以很有趣。还记得 80 年代和 90 年代初的[酷炫复古的终端,给你一个复古的终端](https://itsfoss.com/cool-retro-term/)吗?
那一款深受 《<ruby> <a href="https://www.imdb.com/title/tt1104001/"> 创:战纪 </a> <rt> TRON Legacy </rt></ruby>》 电影特效启发的养眼终端感觉怎么样?
在本文中,让我们来看看一款神奇的跨平台终端模拟器,注意口水!
### eDEX-UI: 一个很酷的终端仿真器
[eDEX-UI](https://github.com/GitSquared/edex-ui) 是一款开源的跨平台终端仿真器,它为你呈现了一个科幻风格的外观和一些有用的功能。
它最初的灵感来自于 [DEX UI](https://github.com/seenaburns/dex-ui) 项目,但该项目已经不再维护。
尽管 eDEX-UI 的重点是外观和未来主义主题的终端,但它也可以作为一个 [Linux 系统监控工具](https://itsfoss.com/linux-system-monitoring-tools/)。怎么说呢?因为当你在终端中工作时,它可以在侧边栏中显示系统的统计信息。事实上,其开发者提到,他的目标是将其改进为一个可用的系统管理工具。
让我们来看看它还提供了什么,以及如何让它安装到你的电脑上。
### eDEX-UI 的特点

eDEX-UI 本质上是一个终端仿真器。你可以像普通终端一样使用它来运行命令和其他任何你可以在终端中做的事情。
它以全屏方式运行,侧边栏和底部面板可以监控系统和网络的统计信息。此外,还有一个用于触摸设备的虚拟键盘。
我做了一个简短的视频,我建议你观看这个视频,看看这个很酷的终端模拟器运行起来是什么样子。**播放视频时要打开声音**(相信我)。
eDEX-UI 的特点:
* 多标签
* 对 curses 的支持
* 目录查看器,显示当前工作目录的内容
* 显示系统信息,包括主板信息、网络状态、IP、网络带宽使用情况、CPU 使用情况、CPU 温度、RAM 使用情况等
* 自定义选项,以改变主题、键盘布局、CSS 注入
* 可选的声音效果,让你有一种黑客的感觉
* 跨平台支持(Windows、macOS 和 Linux)
### 在 Linux 上安装 eDEX

如前所述,它支持所有主要平台,包括 Windows、macOS,当然还有 Linux。
要在 Linux 发行版上安装它,你可以从它的 [GitHub 发布部分](https://github.com/GitSquared/edex-ui/releases)中抓取 AppImage 文件,或者在包括 [AUR](https://itsfoss.com/aur-arch-linux/) 在内的[可用资源库](https://repology.org/project/edex-ui/versions)中找到它。如果你不知道,我建议你去看一下我们关于[在 Linux 中使用 AppImage](https://itsfoss.com/use-appimage-linux/) 的指南。
你可以访问它的 GitHub 页面,如果你喜欢它,可以随时星标他们的仓库。
* [eDEX-UI](https://github.com/GitSquared/edex-ui)
### 我对 eDEX-UI 的体验
因为它的科幻风格的外观,我喜欢这个终端仿真器。但是,我发现它对系统资源的消耗相当大。我没有[检查我的 Linux 系统的 CPU 温度](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/),但 CPU 消耗肯定很高。
所以,如果你需要它运行在后台或单独的工作空间中(像我这样),你可能要注意这一点。除此以外,它是一个令人印象深刻的工具,拥有目录查看器和系统资源监控等有用的选项。
顺便说一句,如果你想模拟黑客来娱乐一下客人和孩子们,[那么可以试试好莱坞工具](https://itsfoss.com/hollywood-hacker-screen/)。
你觉得 eDEX-UI 怎么样?你是想试一试,还是觉得太幼稚/过于复杂?
---
via: <https://itsfoss.com/edex-ui-sci-fi-terminal/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You probably already know [plenty of fun Linux commands](https://itsfoss.com/funny-linux-commands/). You know what else can be fun when it comes to Linux command line? The terminal itself.
Yes, the terminal emulator (commonly known as terminal) can be pretty amusing as well. Remember the [Cool Retro Term terminal that gives you a vintage terminal](https://itsfoss.com/cool-retro-term/) of 80s and early 90s?
How about an eye candy terminal that is heavily inspired from the [TRON Legacy](https://www.imdb.com/title/tt1104001/?ref=itsfoss.com) movie effects?
In this article, let’s take a look at a [fantastic terminal emulator](https://itsfoss.com/linux-terminal-emulators/) that can keep you drooling over your terminal!
## eDEX-UI: A Cool Terminal Emulator

[eDEX-UI](https://github.com/GitSquared/edex-ui?ref=itsfoss.com) is an open-source cross-platform terminal emulator that presents you with a Sci-Fi inspired look along with useful some features as well.
It was originally inspired from the [DEX UI](https://github.com/seenaburns/dex-ui?ref=itsfoss.com) project. It is also worth noting that eDEX-UI is in maintenance mode but it hasn’t been completely abandoned. You can learn more about the current status of the project [here](https://github.com/GitSquared/edex-ui/issues/769?ref=itsfoss.com).
Even though eDEX-UI is more about the looks and the futuristic theme for a terminal, it could double up as a [system monitoring tool for Linux](https://itsfoss.com/linux-system-monitoring-tools/) in the future if the development resumes or if someone else forks it. How? Because it shows system stats in the sidebar while you work in the terminal.
Let’s take a look at what else it offers and how to get it installed on your computer.
## Features of eDEX-UI
eDEX-UI is essentially a terminal emulator. You can use it like your regular terminal for running commands and whatever else you do in the terminal.
It runs in full screen with sidebars and bottom panels to monitor system and networks stats. There is also a virtual keyboard for touch devices.
I made a short video and I suggest watching this video to see this cool terminal emulator in action. **Play the video with sound** for the complete effect (trust me on this).
eDEX-UI has a directory viewer on the left bottom side.
- Multiple tabs
- Support for curses
- Directory viewer to show the contents of the current working directory
- Displays system information that includes Motherboard info, Network status, IP, network bandwidth used, CPU usage, temperature of the CPU, RAM usage, and so on
- Customization options to change the theme, keyboard layout, CSS injection
- Optional sound effect to give you a hacking vibe
- Cross-platform support (Windows, macOS, and Linux)
## Installing eDEX on Linux
As mentioned, it supports all the major platforms that includes Windows, macOS, and of course, Linux.
To install it on any Linux distribution, you can either grab the AppImage file from its [GitHub releases section](https://github.com/GitSquared/edex-ui/releases?ref=itsfoss.com) or find it in one of the [available repositories](https://repology.org/project/edex-ui/versions?ref=itsfoss.com) that include [AUR](https://itsfoss.com/aur-arch-linux/) as well.
In case you didn’t know, I’d recommend going through our guide on [using AppImage in Linux](https://itsfoss.com/use-appimage-linux/).
You can visit the project on its GitHub page and if you like it, feel free to star their repository.
## My experience with eDEX-UI
I liked this terminal emulator because of the sci-fi inspired look. However, I found it pretty heavy on the system resources. I didn’t [check the CPU temperature on my Linux system](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/) but the CPU consumption was surely high.
So, you might have to take care about that if you need it running it in the background or in a separate workspace (like I do). Apart from that, it’s an impressive tool with useful options like directory viewer and system resource monitoring.
By the way, if you just want to entertain guests and children with a [hacking simulation, try Hollywood tool](https://itsfoss.com/hollywood-hacker-screen/).
What do you think about eDEX-UI? Is it something you would like to give a try or is too kiddish/overwhelming for you? |
12,656 | Nextcloud 如何简化去中心化的注册流程? | https://opensource.com/article/20/9/decentralization-signup | 2020-09-27T10:04:23 | [
"Nextcloud",
"注册"
] | https://linux.cn/article-12656-1.html |
>
> Nextcloud 是开源软件,我们不提供托管服务,但我们却能从根本上简化注册体验。
>
>
>

我们一直有个列表,上面有几十个 Nextcloud 提供商,然而我听到的最常见的问题,即使是我的技术方面的朋友,也是:
>
> ”嗨,Jan,你推荐哪个 Nextcloud 提供商?”
>
>
>
当然,这也是可以理解的。如果你有一长串的供应商,你怎么选择?托管商在附近?名字可爱?标志最大?
每一个使用服务器的去中心化开源解决方案都在努力解决这些:
* Mastodon 有 [joinmastodon.org](https://joinmastodon.org/) 来选择社区,但很明显主实例是 mastodon.social。
* Diaspora 有[joindiaspora.com](https://joindiaspora.com),它也是主实例。
* Matrix 有 [matrix.to](https://matrix.to),还有一个在 [Element.io](http://Element.io) 的应用(多平台)。
* WordPress 有 [wordpress.com](https://wordpress.com)。我不确定是否有提供商能接近它的知名度。
* PeerTube 有一堆实例,都有不同的技术细节。
* Pixelfed 在[beta.joinpixelfed.org](http://beta.joinpixelfed.org) 有一个早期版本的实例选择器,以及在 [pixelfed.social](http://pixelfed.social) 有一个大型实例。
* 还有更多的去中心化开源应用的例子,这里列出了如何通过终端访问它、设置 Rust 实现、或使其在网络打印机上运行。
这就导致了一些问题:
* ? 人们不知道该选哪个,有<ruby> 错失恐惧症 <rt> Fear Of Missing Out </rt></ruby>(FOMO),然后根本不选。这就是选择的悖论!
* ? 网络并不是真正的去中心化,因为大多数人都在少数服务器上,或者主要是只有一台服务器。
Nextcloud 不存在这些问题。
### 我们的解决方案:简单注册
这是它是如何工作的:
当你下载我们的手机或桌面应用时,你首先看到的是“登录”或“使用供应商注册”的选择。这是任何专有应用都会做的事情:

选择“注册”可打开应用中的[简易注册页面](https://nextcloud.com/signup)。

你输入你的电子邮件地址,然后点击“注册”。
输入密码,就可以了! ?
>
> ”等一下,这怎么这么简单?“
>
>
>
我知道,对吧?✨
事实上,它甚至比很多集中式的应用更简单,在那里你需要输入你的全名和电话号码,然后点击谷歌的验证码。
这基本上可以归结为:
### 我们为你选择
而不是面对一个无法判断什么适合你供应商的名单,我们只向你展示一个选择。就好像我是你的朋友一样,我回答了那个关于我推荐哪家供应商的问题。
很好!?
澄清一下:你可以修改供应商,但默认的应该很适合你。目前,它只是地理位置上离你最近的提供商。
除此之外,我们对通过简单注册列出的提供商有一些要求,以确保无论你选择哪一个提供商都能获得良好的用户体验:
* ? 2 GB 的免费存储空间,而且不仅仅是试用期。
* ? 一套核心应用。文件、日历、联系人、邮件、通话、任务、笔记。有些供应商甚至提供更多。
* ? 最新版本,让你始终保持最新的功能、修复和安全更新。
除此之外,我们还提出了一个尊重隐私的流程。当你点击“注册”时,你的邮件不会发送给我们,而是直接发送给你选择的供应商,这将无缝过渡到他们的设置步骤,在那里你选择一个密码。这意味着在 Nextcloud 不会有任何数据泄露给我们,我们甚至不知道你选择的是哪家提供商!
因此,虽然我们提供这项服务,而且它超级容易使用,但我们只做绝对最低限度的数据处理,以连接你与你的理想供应商。
### 去中心化项目需要简单的注册方式
很多开源软件项目可以从简单注册这样的体验中受益。我们[在最初发布的时候写过有关它的文章](https://nextcloud.com/blog/introducing-simple-signup-you-can-now-get-started-with-nextcloud-in-2-steps/),我们希望这篇文章能澄清使它成功的设计决策,以便它能被更多项目采用。
去中心化是赋能,但只有当人们即使不知道服务器是什么也能简单注册时,才是真正的革命。
当然,现在也还不完美。比如,如果你已经在 Nextcloud 实例上有了账户,任何一个应用的登录过程都会要求你输入一个服务器地址,而很多人根本不知道那是什么。比如在很多邮件应用中,在这一步会有一个最受欢迎的供应商列表,底部有一个“自定义服务器”的条目。这也可能是一种可能性,但同样带来了系统过于集中的风险,或者让人们对选择什么感到困惑。
所以,我们不断尝试为所有 Nextcloud 桌面和移动应用改进这一点,比如 Nextcloud Talk 或者所有优秀的社区开发的应用。在 Android 上,我们与 DAVx5(Android 上的日历和联系人同步)紧密集成,而且,对于其他 Android 应用,还有一个[单点登录库](https://github.com/nextcloud/Android-SingleSignOn)。不幸的是,在 iOS 上,就没有那么容易了,因为应用必须来自同一个开发者才能共享凭证。
如果你想合作解决类似这些有趣的挑战,[来加入我们的 Nextcloud 设计团队吧](https://nextcloud.com/design)!
---
via: <https://opensource.com/article/20/9/decentralization-signup>
作者:[Jan C. Borchardt](https://opensource.com/users/jancborchardt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We always had a nice list of dozens of Nextcloud providers, yet the most common question I heard, even from technically apt friends of mine, was:
"Hi, Jan, umm…so, which Nextcloud provider do you recommend?"
Which is, of course, understandable. If you have a long list of providers, how do you choose? Hosted nearby? Cute name? Biggest logo?
Every decentralized open source solution using servers struggles with this:
- Mastodon has
[joinmastodon.org](https://joinmastodon.org/)for choosing a community, but clearly a main instance with mastodon.social. - Diaspora has
[joindiaspora.com](https://joindiaspora.com), which is also the main instance. - Matrix has
[matrix.to](https://matrix.to)and an app (for multiple platforms) at[Element.io](http://Element.io). - WordPress has
[wordpress.com](https://wordpress.com)—and I'm not sure any provider comes close to its popularity. - PeerTube has a bunch of instances, all with different technical details.
- Pixelfed has an early version of an instance picker at
[beta.joinpixelfed.org](http://beta.joinpixelfed.org), as well as a large instance at[pixelfed.social](http://pixelfed.social) - … lots more examples of decentralized open source apps, which list how you can access it via the terminal, set up the Rust implementation, or make it run on your networked printer.
This leads to problems:
- ? People don't know which one to pick, have FOMO (Fear Of Missing Out), and then don't pick at all. It's the paradox of choice!
- ? The network is not really decentralized because the majority of people are on a handful of servers, or mainly just a single one.
Nextcloud does not have any of these problems.
## Our solution: Simple Signup
How it works:
When you download the mobile or desktop app, the first thing you see is a choice for "Log in" or "Sign up with a provider." This is what any proprietary app does:
Choosing "Sign up" opens [the Simple Signup page](https://nextcloud.com/signup) in the app.
You put in your email address and click "sign up."
Enter a password, and you're done! ?
"Wait a second; how is this so simple?"
I know, right? ✨
In fact, it's even simpler than lots of centralized apps where you need to put in your full name and phone number and then click on pictures of fire hydrants for Google.
It basically boils down to this:
## We choose for you
Instead of being faced with a list of providers where you could not possibly judge what works for you, we only show you one option. It's as if I'm your friend, and I answer that question about which provider I recommend.
Neat! ?
Just to clarify: You do have the ability to change the provider, but the default should suit you fine. For now, it's simply the provider geographically closest to you.
On top of that, we have some requirements for the providers which are listed through Simple Signup to ensure a good user experience no matter which one you get:
- ? 2 GB of free storage minimum, and not only for a trial period.
- ? A core set of apps: Files, Calendar, Contacts, Mail, Talk, Tasks, Notes. Some providers offer even more.
- ? The latest version, so you are always up to date with the latest features, fixes, and security updates.
Beyond that, we came up with a privacy respecting process. When you click "sign up," your email is not sent to us but directly to the provider you chose, which seamlessly transitions you to their setup step where you choose a password. This means no data leaks to us at Nextcloud—we don't even know which provider you picked!
So, while we offer this service, and while it is super easy to use, we only do the absolute minimum in terms of data handling to connect you with your ideal provider.
## Decentralized projects need simple signup
A lot of open source software projects could benefit from an onboarding experience like Simple Signup. We [wrote about it when we initially released it](https://nextcloud.com/blog/introducing-simple-signup-you-can-now-get-started-with-nextcloud-in-2-steps/), and we hope this post clarifies the design decisions that make it successful so it can be adopted by more projects.
Decentralization is empowering, but only truly revolutionary when people can simply sign up even if they don't know what a server is.
Of course, it's not perfect just yet, either. For example, if you already have an account on a Nextcloud instance, the login process in any of the apps asks you to put in a server address, and a lot of people have no idea what that even is. In lots of email apps, for example, there is a list of the most popular providers at this step, with a "custom server" entry on the bottom. This could be a possibility as well, but again brings the risk of centralizing the system too much or leaving people confused as to what to pick.
So, we constantly try to improve this for any of the Nextcloud desktop and mobile apps, like Nextcloud Talk or all of the great community-developed apps. On Android, we have tight integration with DAVx5 (Calendar and Contact sync on Android), and, for other Android apps, there is a [single sign-on library](https://github.com/nextcloud/Android-SingleSignOn). On iOS, it is, unfortunately, not so easy, since apps have to be from the same developer to share credentials.
If you want to collaborate on solving interesting challenges like these, [come join our Nextcloud design team](https://nextcloud.com/design)!
## Comments are closed. |
12,658 | 通过两个简单的教程来提高你的 awk 技能 | https://opensource.com/article/19/10/advanced-awk | 2020-09-28T15:47:19 | [
"awk"
] | https://linux.cn/article-12658-1.html |
>
> 超越单行的 awk 脚本,学习如何做邮件合并和字数统计。
>
>
>

`awk` 是 Unix 和 Linux 用户工具箱中最古老的工具之一。`awk` 由 Alfred Aho、Peter Weinberger 和 Brian Kernighan(即工具名称中的 A、W 和 K)在 20 世纪 70 年代创建,用于复杂的文本流处理。它是流编辑器 `sed` 的配套工具,后者是为逐行处理文本文件而设计的。`awk` 支持更复杂的结构化程序,是一门完整的编程语言。
本文将介绍如何使用 `awk` 完成更多结构化的复杂任务,包括一个简单的邮件合并程序。
### awk 的程序结构
`awk` 脚本是由 `{}`(大括号)包围的功能块组成,其中有两个特殊的功能块,`BEGIN` 和 `END`,它们在处理第一行输入流之前和最后一行处理之后执行。在这两者之间,块的格式为:
```
模式 { 动作语句 }
```
当输入缓冲区中的行与模式匹配时,每个块都会执行。如果没有包含模式,则函数块在输入流的每一行都会执行。
另外,以下语法可以用于在 `awk` 中定义可以从任何块中调用的函数。
```
function 函数名(参数列表) { 语句 }
```
这种模式匹配块和函数的组合允许开发者结构化的 `awk` 程序,以便重用和提高可读性。
### awk 如何处理文本流
`awk` 每次从输入文件或流中一行一行地读取文本,并使用字段分隔符将其解析成若干字段。在 `awk` 的术语中,当前的缓冲区是一个*记录*。有一些特殊的变量会影响 `awk` 读取和处理文件的方式:
* `FS`(<ruby> 字段分隔符 <rt> field separator </rt></ruby>)。默认情况下,这是任何空格字符(空格或制表符)。
* `RS`(<ruby> 记录分隔符 <rt> record separator </rt></ruby>)。默认情况下是一个新行(`n`)。
* `NF`(<ruby> 字段数 <rt> number of fields </rt></ruby>)。当 `awk` 解析一行时,这个变量被设置为被解析出字段数。
* `$0:` 当前记录。
* `$1`、`$2`、`$3` 等:当前记录的第一、第二、第三等字段。
* `NR`(<ruby> 记录数 <rt> number of records </rt></ruby>)。迄今已被 `awk` 脚本解析的记录数。
影响 `awk` 行为的变量还有很多,但知道这些已经足够开始了。
### 单行 awk 脚本
对于一个如此强大的工具来说,有趣的是,`awk` 的大部分用法都是基本的单行脚本。也许最常见的 `awk` 程序是打印 CSV 文件、日志文件等输入行中的选定字段。例如,下面的单行脚本从 `/etc/passwd` 中打印出一个用户名列表:
```
awk -F":" '{print $1 }' /etc/passwd
```
如上所述,`$1` 是当前记录中的第一个字段。`-F` 选项将 `FS` 变量设置为字符 `:`。
字段分隔符也可以在 `BEGIN` 函数块中设置:
```
awk 'BEGIN { FS=":" } {print $1 }' /etc/passwd
```
在下面的例子中,每一个 shell 不是 `/sbin/nologin` 的用户都可以通过在该块前面加上匹配模式来打印出来:
```
awk 'BEGIN { FS=":" } ! /\/sbin\/nologin/ {print $1 }' /etc/passwd
```
### awk 进阶:邮件合并
现在你已经掌握了一些基础知识,尝试用一个更具有结构化的例子来深入了解 `awk`:创建邮件合并。
邮件合并使用两个文件,其中一个文件(在本例中称为 `email_template.txt`)包含了你要发送的电子邮件的模板:
```
From: Program committee <[email protected]>
To: {firstname} {lastname} <{email}>
Subject: Your presentation proposal
Dear {firstname},
Thank you for your presentation proposal:
{title}
We are pleased to inform you that your proposal has been successful! We
will contact you shortly with further information about the event
schedule.
Thank you,
The Program Committee
```
而另一个则是一个 CSV 文件(名为 `proposals.csv`),里面有你要发送邮件的人:
```
firstname,lastname,email,title
Harry,Potter,[email protected],"Defeating your nemesis in 3 easy steps"
Jack,Reacher,[email protected],"Hand-to-hand combat for beginners"
Mickey,Mouse,[email protected],"Surviving public speaking with a squeaky voice"
Santa,Claus,[email protected],"Efficient list-making"
```
你要读取 CSV 文件,替换第一个文件中的相关字段(跳过第一行),然后把结果写到一个叫 `acceptanceN.txt` 的文件中,每解析一行就递增文件名中的 `N`。
把 `awk` 程序写在一个叫 `mail_merge.awk` 的文件中。在 `awk` 脚本中的语句用 `;` 分隔。第一个任务是设置字段分隔符变量和其他几个脚本需要的变量。你还需要读取并丢弃 CSV 中的第一行,否则会创建一个以 `Dear firstname` 开头的文件。要做到这一点,请使用特殊函数 `getline`,并在读取后将记录计数器重置为 0。
```
BEGIN {
FS=",";
template="email_template.txt";
output="acceptance";
getline;
NR=0;
}
```
主要功能非常简单:每处理一行,就为各种字段设置一个变量 —— `firstname`、`lastname`、`email` 和 `title`。模板文件被逐行读取,并使用函数 `sub` 将任何出现的特殊字符序列替换为相关变量的值。然后将该行以及所做的任何替换输出到输出文件中。
由于每行都要处理模板文件和不同的输出文件,所以在处理下一条记录之前,需要清理和关闭这些文件的文件句柄。
```
{
# 从输入文件中读取关联字段
firstname=$1;
lastname=$2;
email=$3;
title=$4;
# 设置输出文件名
outfile=(output NR ".txt");
# 从模板中读取一行,替换特定字段,
# 并打印结果到输出文件。
while ( (getline ln < template) > 0 )
{
sub(/{firstname}/,firstname,ln);
sub(/{lastname}/,lastname,ln);
sub(/{email}/,email,ln);
sub(/{title}/,title,ln);
print(ln) > outfile;
}
# 关闭模板和输出文件,继续下一条记录
close(outfile);
close(template);
}
```
你已经完成了! 在命令行上运行该脚本:
```
awk -f mail_merge.awk proposals.csv
```
或
```
awk -f mail_merge.awk < proposals.csv
```
你会在当前目录下发现生成的文本文件。
### awk 进阶:字频计数
`awk` 中最强大的功能之一是关联数组,在大多数编程语言中,数组条目通常由数字索引,但在 `awk` 中,数组由一个键字符串进行引用。你可以从上一节的文件 `proposals.txt` 中存储一个条目。例如,在一个单一的关联数组中,像这样:
```
proposer["firstname"]=$1;
proposer["lastname"]=$2;
proposer["email"]=$3;
proposer["title"]=$4;
```
这使得文本处理变得非常容易。一个使用了这个概念的简单的程序就是词频计数器。你可以解析一个文件,在每一行中分解出单词(忽略标点符号),对行中的每个单词进行递增计数器,然后输出文本中出现的前 20 个单词。
首先,在一个名为 `wordcount.awk` 的文件中,将字段分隔符设置为包含空格和标点符号的正则表达式:
```
BEGIN {
# ignore 1 or more consecutive occurrences of the characters
# in the character group below
FS="[ .,:;()<>{}@!\"'\t]+";
}
```
接下来,主循环函数将遍历每个字段,忽略任何空字段(如果行末有标点符号,则会出现这种情况),并递增行中单词数:
```
{
for (i = 1; i <= NF; i++) {
if ($i != "") {
words[$i]++;
}
}
}
```
最后,处理完文本后,使用 `END` 函数打印数组的内容,然后利用 `awk` 的能力,将输出的内容用管道输入 shell 命令,进行数字排序,并打印出 20 个最常出现的单词。
```
END {
sort_head = "sort -k2 -nr | head -n 20";
for (word in words) {
printf "%s\t%d\n", word, words[word] | sort_head;
}
close (sort_head);
}
```
在这篇文章的早期草稿上运行这个脚本,会产生这样的输出:
```
[[email protected]]$ awk -f wordcount.awk < awk_article.txt
the 79
awk 41
a 39
and 33
of 32
in 27
to 26
is 25
line 23
for 23
will 22
file 21
we 16
We 15
with 12
which 12
by 12
this 11
output 11
function 11
```
### 下一步是什么?
如果你想了解更多关于 `awk` 编程的知识,我强烈推荐 Dale Dougherty 和 Arnold Robbins 所著的《[Sed 和 awk](https://www.amazon.com/sed-awk-Dale-Dougherty/dp/1565922255/book)》这本书。
`awk` 编程进阶的关键之一是掌握“扩展正则表达式”。`awk` 为你可能已经熟悉的 sed [正则表达式](https://en.wikibooks.org/wiki/Regular_Expressions/POSIX-Extended_Regular_Expressions)语法提供了几个强大的补充。
另一个学习 `awk` 的好资源是 [GNU awk 用户指南](https://www.gnu.org/software/gawk/manual/gawk.html)。它有一个完整的 `awk` 内置函数库的参考资料,以及很多简单和复杂的 `awk` 脚本的例子。
---
via: <https://opensource.com/article/19/10/advanced-awk>
作者:[Dave Neary](https://opensource.com/users/dneary) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Awk is one of the oldest tools in the Unix and Linux user's toolbox. Created in the 1970s by Alfred Aho, Peter Weinberger, and Brian Kernighan (the A, W, and K of the tool's name), awk was created for complex processing of text streams. It is a companion tool to sed, the stream editor, which is designed for line-by-line processing of text files. Awk allows more complex structured programs and is a complete programming language.
This article will explain how to use awk for more structured and complex tasks, including a simple mail merge application.
## Awk program structure
An awk script is made up of functional blocks surrounded by **{}** (curly brackets). There are two special function blocks, **BEGIN **and **END**, that execute before processing the first line of the input stream and after the last line is processed. In between, blocks have the format:
`pattern { action statements }`
Each block executes when the line in the input buffer matches the pattern. If no pattern is included, the function block executes on every line of the input stream.
Also, the following syntax can be used to define functions in awk that can be called from any block:
`function name(parameter list) { statements }`
This combination of pattern-matching blocks and functions allows the developer to structure awk programs for reuse and readability.
## How awk processes text streams
Awk reads text from its input file or stream one line at a time and uses a field separator to parse it into a number of fields. In awk terminology, the current buffer is a *record*. There are a number of special variables that affect how awk reads and processes a file:
**FS**(field separator): By default, this is any whitespace (spaces or tabs)**RS**(record separator): By default, a newline (**\n**)**NF**(number of fields): When awk parses a line, this variable is set to the number of fields that have been parsed**$0:**The current record**$1, $2, $3, etc.:**The first, second, third, etc. field from the current record**NR**(number of records): The number of records that have been parsed so far by the awk script
There are many other variables that affect awk's behavior, but this is enough to start with.
## Awk one-liners
For a tool so powerful, it's interesting that most of awk's usage is basic one-liners. Perhaps the most common awk program prints selected fields from an input line from a CSV file, a log file, etc. For example, the following one-liner prints a list of usernames from **/etc/passwd**:
`awk -F":" '{print $1 }' /etc/passwd`
As mentioned above, **$1** is the first field in the current record. The **-F** option sets the FS variable to the character **:**.
The field separator can also be set in a BEGIN function block:
`awk 'BEGIN { FS=":" } {print $1 }' /etc/passwd`
In the following example, every user whose shell is not **/sbin/nologin** can be printed by preceding the block with a pattern match:
`awk 'BEGIN { FS=":" } ! /\/sbin\/nologin/ {print $1 }' /etc/passwd`
## Advanced awk: Mail merge
Now that you have some of the basics, try delving deeper into awk with a more structured example: creating a mail merge.
A mail merge uses two files, one (called in this example **email_template.txt**) containing a template for an email you want to send:
```
From: Program committee <[email protected]>
To: {firstname} {lastname} <{email}>
Subject: Your presentation proposal
Dear {firstname},
Thank you for your presentation proposal:
{title}
We are pleased to inform you that your proposal has been successful! We
will contact you shortly with further information about the event
schedule.
Thank you,
The Program Committee
```
And the other is a CSV file (called **proposals.csv**) with the people you want to send the email to:
```
firstname,lastname,email,title
Harry,Potter,[email protected],"Defeating your nemesis in 3 easy steps"
Jack,Reacher,[email protected],"Hand-to-hand combat for beginners"
Mickey,Mouse,[email protected],"Surviving public speaking with a squeaky voice"
Santa,Claus,[email protected],"Efficient list-making"
```
You want to read the CSV file, replace the relevant fields in the first file (skipping the first line), then write the result to a file called **acceptanceN.txt**, incrementing **N** for each line you parse.
Write the awk program in a file called **mail_merge.awk**. Statements are separated by **;** in awk scripts. The first task is to set the field separator variable and a couple of other variables the script needs. You also need to read and discard the first line in the CSV, or a file will be created starting with *Dear firstname*. To do this, use the special function **getline** and reset the record counter to 0 after reading it.
```
BEGIN {
FS=",";
template="email_template.txt";
output="acceptance";
getline;
NR=0;
}
```
The main function is very straightforward: for each line processed, a variable is set for the various fields—**firstname**, **lastname**, **email**, and **title**. The template file is read line by line, and the function **sub** is used to substitute any occurrence of the special character sequences with the value of the relevant variable. Then the line, with any substitutions made, is output to the output file.
Since you are dealing with the template file and a different output file for each line, you need to clean up and close the file handles for these files before processing the next record.
```
{
# Read relevant fields from input file
firstname=$1;
lastname=$2;
email=$3;
title=$4;
# Set output filename
outfile=(output NR ".txt");
# Read a line from template, replace special fields, and
# print result to output file
while ( (getline ln < template) > 0 )
{
sub(/{firstname}/,firstname,ln);
sub(/{lastname}/,lastname,ln);
sub(/{email}/,email,ln);
sub(/{title}/,title,ln);
print(ln) > outfile;
}
# Close template and output file in advance of next record
close(outfile);
close(template);
}
```
You're done! Run the script on the command line with:
`awk -f mail_merge.awk proposals.csv`
or
`awk -f mail_merge.awk < proposals.csv`
and you will find text files generated in the current directory.
## Advanced awk: Word frequency count
One of the most powerful features in awk is the associative array. In most programming languages, array entries are typically indexed by a number, but in awk, arrays are referenced by a key string. You could store an entry from the file *proposals.txt* from the previous section. For example, in a single associative array, like this:
```
proposer["firstname"]=$1;
proposer["lastname"]=$2;
proposer["email"]=$3;
proposer["title"]=$4;
```
This makes text processing very easy. A simple program that uses this concept is the idea of a word frequency counter. You can parse a file, break out words (ignoring punctuation) in each line, increment the counter for each word in the line, then output the top 20 words that occur in the text.
First, in a file called **wordcount.awk**, set the field separator to a regular expression that includes whitespace and punctuation:
```
BEGIN {
# ignore 1 or more consecutive occurrences of the characters
# in the character group below
FS="[ .,:;()<>{}@!\"'\t]+";
}
```
Next, the main loop function will iterate over each field, ignoring any empty fields (which happens if there is punctuation at the end of a line), and increment the word count for the words in the line.
```
{
for (i = 1; i <= NF; i++) {
if ($i != "") {
words[$i]++;
}
}
}
```
Finally, after the text is processed, use the END function to print the contents of the array, then use awk's capability of piping output into a shell command to do a numerical sort and print the 20 most frequently occurring words:
```
END {
sort_head = "sort -k2 -nr | head -n 20";
for (word in words) {
printf "%s\t%d\n", word, words[word] | sort_head;
}
close (sort_head);
}
```
Running this script on an earlier draft of this article produced this output:
```
[[email protected]]$ awk -f wordcount.awk < awk_article.txt
the 79
awk 41
a 39
and 33
of 32
in 27
to 26
is 25
line 23
for 23
will 22
file 21
we 16
We 15
with 12
which 12
by 12
this 11
output 11
function 11
```
## What's next?
If you want to learn more about awk programming, I strongly recommend the book [ Sed and awk](https://www.amazon.com/sed-awk-Dale-Dougherty/dp/1565922255/book) by Dale Dougherty and Arnold Robbins.
One of the keys to progressing in awk programming is mastering "extended regular expressions." Awk offers several powerful additions to the sed [regular expression](https://en.wikibooks.org/wiki/Regular_Expressions/POSIX-Extended_Regular_Expressions) syntax you may already be familiar with.
Another great resource for learning awk is the [GNU awk user guide](https://www.gnu.org/software/gawk/manual/gawk.html). It has a full reference for awk's built-in function library, as well as lots of examples of simple and complex awk scripts.
## Comments are closed. |
12,659 | 对华为的禁令可能使 5G 部署复杂化 | https://www.networkworld.com/article/3575408/huawei-ban-could-complicate-5g-deployment.html | 2020-09-28T16:28:12 | [
"5G"
] | https://linux.cn/article-12659-1.html |
>
> 对华为、中兴的禁令意味着无线运营商建设 5G 服务的选择减少了。
>
>
>

随着运营商竞相建设他们的 5G 网络,由于美国联邦政府的压力,在美国购买所需设备的选择比其他国家少,这可能会减缓部署。
在 2018 年的《国防授权法案》中,总部位于中国的华为和中兴通讯都被禁止向美国政府提供设备,此后不久又全面禁止进口。这极大地改变了竞争格局,并引发了美国 5G 的形态可能因此而改变的问题。
Gartner 的分析师 Michael Porowski 表示,虽然还不完全清楚,但运营商可以在哪里购买 5G 设备的限制有可能会减缓部署速度。
他说:”供应商数量仍然很多:爱立信、诺基亚、三星。中兴和华为都是更经济的选择。如果它们可用,你可能会看到更快的采用速度。”
451 Research 的研究总监 Christian Renaud 表示,业界普遍认为,华为设备既成熟又价格低廉,而在没有华为的情况下,运营商也没有明确的替代方案。
他说:“目前,会有采用诺基亚或爱立信标准的运营商。(而且)现在判断谁最成熟还为时过早,因为部署是如此有限。”
这种争论在运营商本身的覆盖地图上可以得到证实。虽然他们很快就大肆宣传 5G 服务在美国的许多市场上已经有了,但实际的地理覆盖范围大多局限于大城市核心区的公共场所。简而言之,大部分地区的 5G 部署还没有到来。
部署缓慢是有充分理由的。5G 接入点的部署密度要远高于上一代的无线技术,这使得该过程更加复杂且耗时。还有一个问题是,目前可用的 5G 用户设备数量还很少。
Renaud 说:“这就好比说,在有人发明汽车之前,说‘我已经有了这条八车道的高速公路’。”
设备供应商目前的部分目标是通过私有部署来展示 5G 的潜力,这些部署将该技术用做<ruby> 信号隧道 <rt> backhaul </rt></ruby>,用于支持[物联网](https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html)和其他针对单个企业的链接场景。
Renaud 说:“(设备供应商)都在大力推动私有部署这一块,然后他们可以利用这一点说:你看,我可以用在布鲁克林造船厂或某个私有部署的 5G 网络中,所以,如果可以的话……,它可以用于支持人们观看 YouTube。”
对中国的禁令的一个不幸结果可能是供应商为满足 5G 要求而遵循的规范的分裂。Renaud 称,如果非中国供应商必须为允许华为和中兴的市场制作一个版本,而为不允许华为和中兴的地方制作不同的版本,这可能会给他们带来新的麻烦。
他说:“这将把成本负担转移到设备制造商身上,来试图支持不同的运营商实施。我们会造成非技术性的壁垒。”而这些,反过来又会导致客户体验受到影响。
但是,5G 已经通过[开放无线接入网技术](https://www.networkworld.com/article/3574977/carriers-vendors-work-to-promote-5g-network-flexibility-with-open-standards.html)拥抱了更高的互操作性的趋势,它将 5G 栈各层之间的软件接口标准化。运营商和设备商都接受了这一推动,使得互操作性更有可能,这可能会在未来吸引更多的参与者。
当然,即便是普遍的互操作性,设备制造商仍然会试图建立客户依赖性。他说“在试图锁定客户的供应商和试图保持供应商中立的客户之间,总是会有一场拉锯战。这不会有很大的改变。(但是)我们显然已经看到了试图更加开放的动向。”
---
via: <https://www.networkworld.com/article/3575408/huawei-ban-could-complicate-5g-deployment.html>
作者:[Jon Gold](https://www.networkworld.com/author/Jon-Gold/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,662 | 如何寻找可行之路?开源律师如是说 | https://opensource.com/article/20/9/advice-open-source-lawyer | 2020-09-28T21:03:00 | [
"律师"
] | /article-12662-1.html |
>
> 开源法规对成功有不同寻常的要求。一起来了解开源组织的律师如何帮助其雇主找到可行路径。
>
>
>

正如我在这个分为两部分的系列文章的[第一部分](/article-12585-1.html)中所分享的那样,我是<ruby> 红帽公司 <rp> ( </rp> <rt> Red Hat </rt> <rp> ) </rp></ruby>的一名开源律师。我工作中的一个重要部分是向其他公司(包括其内部法律顾问)提供有关红帽公司如何采用完全开源的开发模式来构建企业级产品的信息,并回答他们有关开源许可的一般问题。在听了红帽公司的成功经验之后,这些律师与我对话的话题常常转变为其所在组织如何发展成为更具开源意识和能力的组织,他们也经常询问我如何改善他们的做法,以便更熟练地为其组织的雇员提供开源法律咨询。在这两篇文章中,我将分享我通常在这些主题上告诉内部法律顾问的那些内容。
### 总是要找到一条可行路径
我的雇主红帽公司在使用开源软件方面的独特之处在于,我们的开发模式始于具有数千名贡献者的开源社区,并产生了经受过尝试、测试和信任的最终产品。更具体地说,通过我们独特的开发模式,我们从社区创建的开源软件开始,并在每个项目的基础上加强安全性,修复错误,修补漏洞并添加新功能。然后,我们将这些改进回馈给每个项目,以便使整个开源社区受益。此方法的效用非常重要,包括:
1. 通过内部团队与组织外部其他人之间的协作来利用外部创新;
2. 当现有或潜在的社区与您在同一问题上开展工作而且能够合作时,可以避免您自己开发和维护开源解决方案的成本和效率低下的问题;
3. 通过与合作伙伴和上游项目社区的富有成效的合作,能够避免维护主项目下游分支的昂贵代价。
* 一些公司发现创建上游代码的非公共分支很诱人,因为它是解决特定<ruby> 用例 <rt> use case </rt></ruby>的快速方法,或者因为它们不愿意在社区中进行协作。然而,由于增加的开发成本、互操作性损失和其他原因,这种分支的长期维护负担可能是令人望而却步的。相比之下,将开发集中在原始上游社区中,可以在所有参与者之间分担开发成本。
除少数例外(例如红帽公司)外,大多数使用开源软件的组织可能都拥有专有软件许可模式(或与 SaaS 等效的概念),并在其业务中对专有软件进行许可。这些组织认为他们拥有可以提供某些竞争优势的软件组件,并且不希望看到这些组件在开源条款下对其他人可用。这是可以理解的。但是,我会鼓励任何咨询此类问题的开源律师来敦促其客户采用开源开发模式,尤其是对于所有无差异且通用的软件。
例如,如果您的公司开发了用于手机的应用程序,并且您需要一个软件模块来读取和写入 PNG 图像文件,那么使用 GitHub 上流行的开源 PNG 软件模块之一将便宜得多。对于您的业务而言,对 PNG 图像进行编码和解码可能是无差别的,那么为什么要花费宝贵的工程时间来编写自己的版本?此外,为此功能编写自己的模块也可能会导致与使用常用开源模块的其他软件的兼容性问题。这是为什么呢?尽管您的模块和开源模块可能已被编写为对已发布的 PNG 规范进行编码和解码,但有时对规范的解释可能会有所不同,也可能会出现实施错误。使用同一模块执行此功能的每个人都可以确保大多数用户的兼容性,并降低开发和维护成本。
还必须意识到,您可能需要某些软件来保持专有性,并且不受开源条款的约束。取决于您系统的软件体系架构和所使用的开源许可证,除非采取某些措施(超出本文的范围),否则打算保留专有权的软件代码可能会受到开源许可证条款的约束。在这里向客户提供一些有关许可证选择和体系架构的咨询服务将变得很有用。
### 寻找灵活的解决方案
之前主要许可专有软件的组织逐渐增加了对开源软件的使用,但审核和批准的要求可能会增长(以我的经验甚至成倍增长)。由于资源限制,这样的组织可能会陷入困境。下面介绍了一些可以采用的灵活的解决方案。
#### 授权并委托他人
律师不能也不应成为看门人。那样效率低下,并且肯定会导致开发和发布时间出现瓶颈,从而产生挫败感和收入损失。相反,应将审批权限授予产品或项目管理和工程领域有能力的个人。这可以让组织有效地保持灵活性。对客户进行教育(请参阅下一节)对于成功实现这一点至关重要。
我采用的一种方法是为整个工程组织提供开源培训,以便他们可以进行基本的许可模式和体系架构选择,同时为软件开发人员提供更专业的培训,以使他们能够提供更复杂的指导和决策。也要考虑在每个级别上对权限进行明确限制,包括哪些类型的问题和决定必须上报给作为他们开源律师的您。您组织的特定授权级别将取决于您团队在开源方面的经验以及对某些开源问题的敏感性。
#### 教育客户
我发现培训是将您的组织迁移到更具开源意识组织的最有效工具之一。培训您的软件工程师和产品经理至关重要。让我详细说明。
尽管您的软件工程师处在最前沿,并且通常可能对开源问题和软件许可非常了解,但是基于您组织的特定要求对他们进行培训仍然很重要。例如,您的公司可能只允许使用宽松的开源许可证,并且可能对其版权声明和源代码可用性有某些要求。为避免开发中出现随后必须纠正的问题(一种昂贵且耗时的实践),最好培训工程师最大程度地减少不当行为的可能性,尤其是在所有开发过程的开始时(请参阅下一节)。
产品经理也必须接受培训。在许多公司中,产品经理负责营销的经典四个环节(产品、价格、定位和促销),并负责产品从生到死的整个生命周期。产品经理工作的方方面面可能会受到使用开源软件的影响。出于上述相同的原因,了解使用开源软件的要求对他们很有用。此外,更重要的是,产品经理在组织中的重要影响,意味着他们通常能够对流程和政策进行必要的更改。产品经理可能会成为您针对“开放”进行流程变更的最强有力的拥护者之一。
#### 早期发现
在开发过程快要结束时解决开源许可问题非常困难且成本很高。随着软件的发布日期临近,体系架构和开源软件模块都是已经选定且难以更改了。如果检测到问题,例如专有软件模块中嵌入的“左版”(copyleft)软件(当该专有模块无意受开源条款约束时),则在该开发阶段修改体系架构或模块可能非常困难且成本昂贵。相反,应该在开发过程中尽早进行架构分析和开源模块选择的过程,以便可以进行成本更低且更有效的更正。
### 开源法规的“奖励”
实践开源法规是一项有益的职业,因为它具有影响组织朝着“开放”方向发展的能力,这具有很大的好处。是否成功取决于您随着组织的成长和成熟而找到具备可行性和灵活性的解决方案的能力。
---
作者简介:Jeffrey R. Kaufman 是全球领先的开源软件解决方案供应商<ruby> 红帽公司 <rp> ( </rp> <rt> Red Hat </rt> <rp> ) </rp></ruby>开源法务团队的资深商务法律顾问,还担任<ruby> 北卡罗来纳大学 <rp> ( </rp> <rt> University of North Carolina </rt> <rp> ) </rp></ruby>的兼职法律教授。在任职红帽公司之前,Jeffrey 曾担任<ruby> 高通公司 <rp> ( </rp> <rt> Qualcomm </rt> <rp> ) </rp></ruby>的专利和开源法律顾问。
译者简介:薛亮,集慧智佳知识产权咨询公司互联网事业部总监,擅长专利分析、专利布局、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,663 | 11 年后重新打造的 rdiff-backup 2.0 有什么新功能? | https://opensource.com/article/20/9/rdiff-backup-linux | 2020-09-29T09:49:19 | [
"备份"
] | /article-12663-1.html |
>
> 这个老牌 Linux 备份方案迁移到了 Python 3 提供了添加许多新功能的机会。
>
>
>

2020 年 3 月,[rdiff-backup](https://rdiff-backup.net/) 升级到了 2.0 版,这距离上一个主要版本已经过去了 11 年。2020 年初 Python 2 的废弃是这次更新的动力,但它为开发团队提供了整合其他功能和优势的机会。
大约二十年来,`rdiff-backup` 帮助 Linux 用户在本地或远程维护他们的数据的完整备份,而无需无谓地消耗资源。这是因为这个开源解决方案可以进行反向增量备份,只备份从上一次备份中改变的文件。
这次改版(或者说,重生)得益于一个新的、自组织的开发团队(由来自 [IKUS Software](https://www.ikus-soft.com/en/) 的 Eric Zolf 和 Patrik Dufresne,以及来自 [Seravo](https://seravo.fi/english) 的 Otto Kekäläinen 共同领导)的努力,为了所有 `rdiff-backup` 用户的利益,他们齐心协力。
### rdiff-backup 的新功能
在 Eric 的带领下,随着向 Python 3 的迁移,项目被迁移到了一个新的、不受企业限制的[仓库](https://github.com/rdiff-backup/rdiff-backup),以欢迎贡献。团队还整合了多年来提交的所有补丁,包括对稀疏文件的支持和对硬链接的修复。
#### 用 Travis CI 实现自动化
另一个巨大的改进是增加了一个使用开源 [Travis CI](https://en.wikipedia.org/wiki/Travis_CI) 的持续集成/持续交付(CI/CD)管道。这允许在各种环境下测试 `rdiff-backup`,从而确保变化不会影响方案的稳定性。CI/CD 管道包括集成所有主要平台的构建和二进制发布。
#### 使用 yum 和 apt 轻松安装
新的 `rdiff-backup` 解决方案可以运行在所有主流的 Linux 发行版上,包括 Fedora、Red Hat、Elementary、Debian 等。Frank 和 Otto 付出了艰辛的努力,提供了开放的仓库以方便访问和安装。你可以使用你的软件包管理器安装 `rdiff-backup`,或者按照 GitHub 项目页面上的[分步说明](https://github.com/rdiff-backup/rdiff-backup#installation)进行安装。
#### 新的主页
团队将网站从 Savannah 迁移到了 GitHub Pages,并对 [rdiff-backup.net](https://rdiff-backup.net/) 官网进行了改版,加入了新的内容,让外观和感觉更加到位。
### 如何使用 rdiff-backup
如果你是 `rdiff-backup` 的新手,你可能会对它的易用性感到惊讶。备份方案应该让你对备份和恢复过程感到舒适,而不是吓人。
#### 开始备份
要开始备份到本地驱动器,例如通过 USB 连接的驱动器,输入 `rdiff-backup` 命令,然后输入要备份的驱动器和要存储文件的目标目录。
例如,要备份到名为 `my_backup_drive` 的本地驱动器,请输入:
```
$ rdiff-backup /home/tux/ /run/media/tux/my_backup_drive/
```
要将数据备份到异地存储,请使用远程服务器的位置,并在 `::` 后面指向备份驱动器的挂载点:
```
$ rdiff-backup /home/tux/ [email protected]::/my_backup_drive/
```
你可能需要[设置 SSH 密钥](https://opensource.com/article/20/8/how-ssh)来使这个过程更轻松。
#### 还原文件
做备份的原因是有时文件会丢失。为了使恢复尽可能简单,你甚至不需要 `rdiff-backup` 来恢复文件(虽然使用 `rdiff-backup` 命令提供了一些方便)。
如果你需要从备份驱动器中获取一个文件,你可以使用 `cp` 将其从备份驱动器复制到本地系统,或者对于远程驱动器使用 `scp` 命令。
对于本地驱动器,使用:
```
$ cp _run_media/tux/my_backup_drive/Documents/example.txt ~/Documents
```
或者用于远程驱动器:
```
$ scp [email protected]::/my_backup_drive/Documents/example.txt ~/Documents
```
然而,使用 `rdiff-backup` 命令提供了其他选项,包括 `--restore-as-of`。这允许你指定你要恢复的文件的哪个版本。
例如,假设你想恢复一个文件在四天前的版本:
```
$ rdiff-backup --restore-as-of 4D /run/media/tux/foo.txt ~/foo_4D.txt
```
你也可以用 `rdiff-backup` 来获取最新版本:
```
$ rdiff-backup --restore-as-of now /run/media/tux/foo.txt ~/foo_4D.txt`
```
就是这么简单。另外,`rdiff-backup` 还有很多其他选项,例如,你可以从列表中排除文件,从一个远程备份到另一个远程等等,这些你可以在[文档](https://rdiff-backup.net/docs/examples.html)中了解。
### 总结
我们的开发团队希望用户能够喜欢这个改版后的开源 `rdiff-backup` 方案,这是我们不断努力的结晶。我们也感谢我们的贡献者,他们真正展示了开源的力量。
---
via: <https://opensource.com/article/20/9/rdiff-backup-linux>
作者:[Patrik Dufresne](https://opensource.com/users/patrik-dufresne) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,666 | 如何修复 Ubuntu Linux 中的 “Release file is not valid yet” 错误 | https://itsfoss.com/fix-repository-not-valid-yet-error-ubuntu/ | 2020-09-29T22:56:00 | [
"Ubuntu"
] | https://linux.cn/article-12666-1.html | 我最近[在我的树莓派上安装了 Ubuntu 服务器](https://itsfoss.com/install-ubuntu-server-raspberry-pi/)。我[在 Ubuntu 终端连接上了 Wi-Fi](https://itsfoss.com/connect-wifi-terminal-ubuntu/),然后做了我在安装任何 Linux 系统后都会做的事情,那就是更新系统。
当我使用 `sudo apt update` 命令时,它给了一个对我而言特别的错误。它报出仓库的发布文件在某个时间段内无效。
>
> E: Release file for <http://ports.ubuntu.com/ubuntu-ports/dists/focal-security/InRelease> is not valid yet (invalid for another 159d 15h 20min 52s). Updates for this repository will not be applied.\*\*
>
>
>
下面是完整输出:
```
ubuntu@ubuntu:~$ sudo apt update
Hit:1 http://ports.ubuntu.com/ubuntu-ports focal InRelease
Get:2 http://ports.ubuntu.com/ubuntu-ports focal-updates InRelease [111 kB]
Get:3 http://ports.ubuntu.com/ubuntu-ports focal-backports InRelease [98.3 kB]
Get:4 http://ports.ubuntu.com/ubuntu-ports focal-security InRelease [107 kB]
Reading package lists... Done
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal/InRelease is not valid yet (invalid for another 21d 23h 17min 25s). Updates for this repository will not be applied.
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal-updates/InRelease is not valid yet (invalid for another 159d 15h 21min 2s). Updates for this repository will not be applied.
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal-backports/InRelease is not valid yet (invalid for another 159d 15h 21min 32s). Updates for this repository will not be applied.
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal-security/InRelease is not valid yet (invalid for another 159d 15h 20min 52s). Updates for this repository will not be applied.
```
### 修复 Ubuntu 和其他 Linux 发行版中 “Release file is not valid yet” 的错误。

错误的原因是系统上的时间和现实世界的时间不同。
你看,每个仓库文件都是在某个日期签名的,你可以通过查看发布文件信息了解:
```
sudo head /var/lib/apt/lists/ports.ubuntu.com_ubuntu_dists_focal_InRelease
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA512
Origin: Ubuntu
Label: Ubuntu
Suite: focal
Version: 20.04
Codename: focal
Date: Thu, 23 Apr 2020 17:33:17 UTC
Architectures: amd64 arm64 armhf i386 ppc64el riscv64 s390x
```
现在,由于某些原因,我的 Ubuntu 服务器上的时间是过去时间,这也是为什么 Ubuntu 报出发布文件已经无效 X 天的原因。
如果你连接到了互联网,你可以**等待几分钟让系统同步时间**。
如果不行,你可以强制系统使用本地时间作为实时时钟(硬件时钟):
```
sudo timedatectl set-local-rtc 1
```
`timedatectl` 命令可以让你在 Linux 上配置时间、日期和[更改时区](https://itsfoss.com/change-timezone-ubuntu/)。
你应该不需要重新启动。它可以立即工作,你可以通过[更新你的 Ubuntu 系统](https://itsfoss.com/update-ubuntu/)再次验证它。
如果问题解决了,你可以将[实时时钟](https://www.computerhope.com/jargon/r/rtc.htm)设置为使用 UTC(Ubuntu 推荐的)。
```
sudo timedatectl set-local-rtc 0
```
**是否为你解决了这个问题?**
我希望这个提示能帮助你解决这个错误。如果你仍然遇到这个问题,请在评论栏告诉我,我会尽力帮助你。
---
via: <https://itsfoss.com/fix-repository-not-valid-yet-error-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently [installed Ubuntu server on my Raspberry Pi](https://itsfoss.com/install-ubuntu-server-raspberry-pi/). I [connected it to the Wi-Fi from Ubuntu terminal](https://itsfoss.com/connect-wifi-terminal-ubuntu/) and went about doing what I do after installing any Linux system which is to update the system.
When I used the ‘sudo apt update’ command, it gave me an error which was kind of unique to me. It complained that release file for the repository was invalid for a certain time period.
**E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal-security/InRelease is not valid yet (invalid for another 159d 15h 20min 52s). Updates for this repository will not be applied.**
Here’s the complete output:
```
ubuntu@ubuntu:~$ sudo apt update
Hit:1 http://ports.ubuntu.com/ubuntu-ports focal InRelease
Get:2 http://ports.ubuntu.com/ubuntu-ports focal-updates InRelease [111 kB]
Get:3 http://ports.ubuntu.com/ubuntu-ports focal-backports InRelease [98.3 kB]
Get:4 http://ports.ubuntu.com/ubuntu-ports focal-security InRelease [107 kB]
Reading package lists... Done
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal/InRelease is not valid yet (invalid for another 21d 23h 17min 25s). Updates for this repository will not be applied.
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal-updates/InRelease is not valid yet (invalid for another 159d 15h 21min 2s). Updates for this repository will not be applied.
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal-backports/InRelease is not valid yet (invalid for another 159d 15h 21min 32s). Updates for this repository will not be applied.
E: Release file for http://ports.ubuntu.com/ubuntu-ports/dists/focal-security/InRelease is not valid yet (invalid for another 159d 15h 20min 52s). Updates for this repository will not be applied.
```
## Fixing “release file is not valid yet” error in Ubuntu and other Linux distributions

The reason for the error is the difference in the time on the system and the time in real world.
You see, every repository file is signed on some date and you can see this information by viewing the release file:
```
sudo head /var/lib/apt/lists/ports.ubuntu.com_ubuntu_dists_focal_InRelease
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA512
Origin: Ubuntu
Label: Ubuntu
Suite: focal
Version: 20.04
Codename: focal
Date: Thu, 23 Apr 2020 17:33:17 UTC
Architectures: amd64 arm64 armhf i386 ppc64el riscv64 s390x
```
Now, for some reasons, the time on my Ubuntu server was in the past and this is why Ubuntu complained that the release file is not valid yet for X many days.
If you are connected to the internet, you may** wait a few minutes for your system to synchronize the time**.
If it doesn’t work, you may force the system to use local time as real time clock (hardware clock):
`sudo timedatectl set-local-rtc 1`
The timedatectl command enables you to configure time, date and [change timezone on Linux](https://itsfoss.com/change-timezone-ubuntu/).
You shouldn’t need to restart. It works immediately and you can verify it by [updating your Ubuntu system](https://itsfoss.com/update-ubuntu/) again.
If the problem is solved, you may set the [real time clock](https://www.computerhope.com/jargon/r/rtc.htm) to use UTC (as recommended by Ubuntu).
`sudo timedatectl set-local-rtc 0`
**Did it fix the issue for you?**
I hope this quick tip helped you to fix this error. If you are still facing the issue, let me know in the comment section and I’ll try to help you out. |
12,667 | 使用 RT-Thread 的 FinSH 对硬件进行编程 | https://opensource.com/article/20/9/hardware-command-line | 2020-09-29T23:31:42 | [
"硬件",
"RT-Thread"
] | https://linux.cn/article-12667-1.html |
>
> 由于物联网(IoT)的兴起,对硬件进行编程变得越来越普遍。RT-Thread 可以让你可以用 FinSH 从 Linux 命令行与设备进行沟通、
>
>
>

RT-Thread 是一个开源的[实时操作系统](https://opensource.com/article/20/6/open-source-rtos),用于对物联网(IoT)设备进行编程。FinSH 是 [RT-Thread](https://github.com/RT-Thread/rt-thread) 的命令行组件,它提供了一套操作界面,使用户可以从命令行与设备进行沟通。它主要用于调试或查看系统信息。
通常情况下,开发调试使用硬件调试器和 `printf` 日志来显示。但在某些情况下,这两种方法并不是很有用,因为它是从运行的内容中抽象出来的,而且它们可能很难解析。不过 RT-Thread 是一个多线程系统,当你想知道一个正在运行的线程的状态,或者手动控制系统的当前状态时,这很有帮助。因为它是多线程的,所以你能够拥有一个交互式的 shell,你可以直接在设备上输入命令、调用函数来获取你需要的信息,或者控制程序的行为。如果你只习惯于 Linux 或 BSD 等现代操作系统,这在你看来可能很普通,但对于硬件黑客来说,这是极其奢侈的,远超将串行电缆直接连线到电路板上以获取一丝错误的做法。
FinSH 有两种模式。
* C 语言解释器模式,称为 c-style。
* 传统的命令行模式,称为 msh(模块 shell)。
在 C 语言解释器模式下,FinSH 可以解析执行大部分 C 语言的表达式,并使用函数调用访问系统上的函数和全局变量。它还可以从命令行创建变量。
在 msh 模式下,FinSH 的操作与 Bash 等传统 shell 类似。
### GNU 命令标准
当我们在开发 FinSH 时,我们了解到,在编写命令行应用程序之前,你需要熟悉 GNU 命令行标准。这个标准实践的框架有助于给界面带入熟悉感,这有助于开发人员在使用时感到舒适和高效。
一个完整的 GNU 命令主要由四个部分组成。
1. 命令名(可执行文件):命令行程序的名称;
2. 子命令:命令程序的子函数名称。
3. 选项:子命令函数的配置选项。
4. 参数:子命令函数配置选项的相应参数。
你可以在任何命令中看到这一点。以 Git 为例:
```
git reset --hard HEAD~1
```
这一点可以分解为:

可执行的命令是 `git`,子命令是 `reset`,使用的选项是 `--head`,参数是 `HEAD~1`。
再举个例子:
```
systemctl enable --now firewalld
```
可执行的命令是 `systemctl`,子命令是 `enable`,选项是 `--now`,参数是 `firewalld`。
想象一下,你想用 RT-Thread 编写一个符合 GNU 标准的命令行程序。FinSH 拥有你所需要的一切,并且会按照预期运行你的代码。更棒的是,你可以依靠这种合规性,让你可以自信地移植你最喜欢的 Linux 程序。
### 编写一个优雅的命令行程序
下面是一个 RT-Thread 运行命令的例子,RT-Thread 开发人员每天都在使用这个命令:
```
usage: env.py package [-h] [--force-update] [--update] [--list] [--wizard]
[--upgrade] [--printenv]
optional arguments:
-h, --help show this help message and exit
--force-update force update and clean packages, install or remove the
packages by your settings in menuconfig
--update update packages, install or remove the packages by your
settings in menuconfig
--list list target packages
--wizard create a new package with wizard
--upgrade upgrade local packages list and ENV scripts from git repo
--printenv print environmental variables to check
```
正如你所看到的那样,它看起来很熟悉,行为就像你可能已经在 Linux 或 BSD 上运行的大多数 POSIX 应用程序一样。当使用不正确或不充分的语法时,它会提供帮助,它支持长选项和短选项。这种通用的用户界面对于任何使用过 Unix 终端的人来说都是熟悉的。
### 选项种类
选项的种类很多,按长短可分为两大类。
1. 短选项:由一个连字符加一个字母组成,如 `pkgs -h` 中的 `-h` 选项。
2. 长选项:由两个连字符加上单词或字母组成,例如,`scons- --target-mdk5` 中的 `--target` 选项。
你可以把这些选项分为三类,由它们是否有参数来决定。
1. 没有参数:该选项后面不能有参数。
2. 参数必选:选项后面必须有参数。
3. 参数可选:选项后可以有参数,但不是必需的。
正如你对大多数 Linux 命令的期望,FinSH 的选项解析非常灵活。它可以根据空格或等号作为定界符来区分一个选项和一个参数,或者仅仅通过提取选项本身并假设后面的内容是参数(换句话说,完全没有定界符)。
* `wavplay -v 50`
* `wavplay -v50`
* `wavplay --vol=50`
### 使用 optparse
如果你曾经写过命令行程序,你可能会知道,一般来说,你所选择的语言有一个叫做 optparse 的库或模块。它是提供给程序员的,所以作为命令的一部分输入的选项(比如 `-v` 或 `--verbose`)可以与命令的其他部分进行*解析*。这可以帮助你的代码从一个子命令或参数中获取一个选项。
当为 FinSH 编写一个命令时,`optparse` 包希望使用这种格式:
```
MSH_CMD_EXPORT_ALIAS(pkgs, pkgs, this is test cmd.);
```
你可以使用长形式或短形式,或者同时使用两种形式来实现选项。例如:
```
static struct optparse_long long_opts[] =
{
{"help" , 'h', OPTPARSE_NONE}, // Long command: help, corresponding to short command h, without arguments.
{"force-update", 0 , OPTPARSE_NONE}, // Long comman: force-update, without arguments
{"update" , 0 , OPTPARSE_NONE},
{"list" , 0 , OPTPARSE_NONE},
{"wizard" , 0 , OPTPARSE_NONE},
{"upgrade" , 0 , OPTPARSE_NONE},
{"printenv" , 0 , OPTPARSE_NONE},
{ NULL , 0 , OPTPARSE_NONE}
};
```
创建完选项后,写出每个选项及其参数的命令和说明:
```
static void usage(void)
{
rt_kprintf("usage: env.py package [-h] [--force-update] [--update] [--list] [--wizard]\n");
rt_kprintf(" [--upgrade] [--printenv]\n\n");
rt_kprintf("optional arguments:\n");
rt_kprintf(" -h, --help show this help message and exit\n");
rt_kprintf(" --force-update force update and clean packages, install or remove the\n");
rt_kprintf(" packages by your settings in menuconfig\n");
rt_kprintf(" --update update packages, install or remove the packages by your\n");
rt_kprintf(" settings in menuconfig\n");
rt_kprintf(" --list list target packages\n");
rt_kprintf(" --wizard create a new package with wizard\n");
rt_kprintf(" --upgrade upgrade local packages list and ENV scripts from git repo\n");
rt_kprintf(" --printenv print environmental variables to check\n");
}
```
下一步是解析。虽然你还没有实现它的功能,但解析后的代码框架是一样的:
```
int pkgs(int argc, char **argv)
{
int ch;
int option_index;
struct optparse options;
if(argc == 1)
{
usage();
return RT_EOK;
}
optparse_init(&options, argv);
while((ch = optparse_long(&options, long_opts, &option_index)) != -1)
{
ch = ch;
rt_kprintf("\n");
rt_kprintf("optopt = %c\n", options.optopt);
rt_kprintf("optarg = %s\n", options.optarg);
rt_kprintf("optind = %d\n", options.optind);
rt_kprintf("option_index = %d\n", option_index);
}
rt_kprintf("\n");
return RT_EOK;
}
```
这里是函数头文件:
```
#include "optparse.h"
#include "finsh.h"
```
然后,编译并下载到设备上。

### 硬件黑客
对硬件进行编程似乎很吓人,但随着物联网的发展,它变得越来越普遍。并不是所有的东西都可以或者应该在树莓派上运行,但在 RT-Thread,FinSH 可以让你保持熟悉的 Linux 感觉。
如果你对在裸机上编码感到好奇,不妨试试 RT-Thread。
---
via: <https://opensource.com/article/20/9/hardware-command-line>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | RT-Thread is an open source [real-time operating system](https://opensource.com/article/20/6/open-source-rtos) used for programming Internet of Things (IoT) devices. FinSH is [RT-Thread](https://github.com/RT-Thread/rt-thread)'s command-line component, and it provides a set of operation interfaces enabling users to contact a device from the command line. It's mainly used to debug or view system information.
Usually, development debugging is displayed using hardware debuggers and `printf`
logs. In some cases, however, these two methods are not very useful because it's abstracted from what's running, and they can be difficult to parse. RT-Thread is a multi-thread system, though, which is helpful when you want to know the state of a running thread, or the current state of a manual control system. Because it's multi-threaded, you're able to have an interactive shell, so you can enter commands, call a function directly on the device to get the information you need, or control the program's behavior. This may seem ordinary to you if you're only used to modern operating systems such as Linux or BSD, but for hardware hackers this is a profound luxury, and a far cry from wiring serial cables directly onto boards to get glimpses of errors.
FinSH has two modes:
- A C-language interpreter mode, known as c-style
- A traditional command-line mode, known as
`msh`
(module shell)
In the C-language interpretation mode, FinSH can parse expressions that execute most of the C language and access functions and global variables on the system using function calls. It can also create variables from the command line.
In `msh`
mode, FinSH operates similarly to traditional shells such as Bash.
## The GNU command standard
When we were developing FinSH, we learned that before you can write a command-line application, you need to become familiar with GNU command-line standards. This framework of standard practices helps bring familiarity to an interface, which helps developers feel comfortable and productive when using it.
A complete GNU command consists of four main parts:
**Command name (executable):**The name of the command line program**Sub-command:**The sub-function name of the command program**Options:**Configuration options for the sub-command function**Arguments:**The corresponding arguments for the configuration options of the sub-command function
You can see this in action with any command. Taking Git as an example:
`git reset --hard HEAD~1`
Which breaks down as:

(Cathy, CC BY-SA 4.0)
The executable command is **git**, the sub-command is **reset**, the option used is **--head**, and the argument is **HEAD~1**.
Another example:
`systemctl enable --now firewalld`
The executable command is **systemctl**, the sub-command is **enable**, the option is **--now**, and the argument is **firewalld**.
Imagine you want to write a command-line program that complies with the GNU standards using RT-Thread. FinSH has everything you need, and will run your code as expected. Better still, you can rely on this compliance so you can confidently port your favorite Linux programs.
## Write an elegant command-line program
Here's an example of RT-Thread running a command that RT-Thread developers use every day.
```
usage: env.py package [-h] [--force-update] [--update] [--list] [--wizard]
[--upgrade] [--printenv]
optional arguments:
-h, --help show this help message and exit
--force-update force update and clean packages, install or remove the
packages by your settings in menuconfig
--update update packages, install or remove the packages by your
settings in menuconfig
--list list target packages
--wizard create a new package with wizard
--upgrade upgrade local packages list and ENV scripts from git repo
--printenv print environmental variables to check
```
As you can tell, it looks familiar and acts like most POSIX applications that you might already run on Linux or BSD. Help is provided when incorrect or insufficient syntax is used, both long and short options are supported, and the general user interface is familiar to anyone who's used a Unix terminal.
## Kinds of options
There are many different kinds of options, and they can be divided into two main categories by length:
**Short options:**Consist of one hyphen plus a single letter, e.g., the`-h`
option in`pkgs -h`
**Long options:**Consist of two hyphens plus words or letters, e.g., the`--target`
option in`scons- --target-mdk5`
You can divide these options into three categories, determined by whether they have arguments:
**No arguments:**The option cannot be followed by arguments**Arguments must be included:**The option must be followed by arguments**Arguments optional:**Arguments after the option are allowed but not required
As you'd expect from most Linux commands, FinSH option parsing is pretty flexible. It can distinguish an option from an argument based on a space or equal sign as delimiter, or just by extracting the option itself and assuming that whatever follows is the argument (in other words, no delimiter at all):
`wavplay -v 50`
`wavplay -v50`
`wavplay --vol=50`
## Using optparse
If you've ever written a command-line application, you may know there's generally a library or module for your language of choice called optparse. It's provided to programmers so that options (such as **-v **or **--verbose**) entered as part of a command can be *parsed* in relation to the rest of the command. It's what helps your code know an option from a sub-command or argument.
When writing a command for FinSH, the `optparse`
package expects this format:
`MSH_CMD_EXPORT_ALIAS(pkgs, pkgs, this is test cmd.);`
You can implement options using the long or short form, or both. For example:
```
static struct optparse_long long_opts[] =
{
{"help" , 'h', OPTPARSE_NONE}, // Long command: help, corresponding to short command h, without arguments.
{"force-update", 0 , OPTPARSE_NONE}, // Long comman: force-update, without arguments
{"update" , 0 , OPTPARSE_NONE},
{"list" , 0 , OPTPARSE_NONE},
{"wizard" , 0 , OPTPARSE_NONE},
{"upgrade" , 0 , OPTPARSE_NONE},
{"printenv" , 0 , OPTPARSE_NONE},
{ NULL , 0 , OPTPARSE_NONE}
};
```
After the options are created, write the command and instructions for each option and its arguments:
```
static void usage(void)
{
rt_kprintf("usage: env.py package [-h] [--force-update] [--update] [--list] [--wizard]\n");
rt_kprintf(" [--upgrade] [--printenv]\n\n");
rt_kprintf("optional arguments:\n");
rt_kprintf(" -h, --help show this help message and exit\n");
rt_kprintf(" --force-update force update and clean packages, install or remove the\n");
rt_kprintf(" packages by your settings in menuconfig\n");
rt_kprintf(" --update update packages, install or remove the packages by your\n");
rt_kprintf(" settings in menuconfig\n");
rt_kprintf(" --list list target packages\n");
rt_kprintf(" --wizard create a new package with wizard\n");
rt_kprintf(" --upgrade upgrade local packages list and ENV scripts from git repo\n");
rt_kprintf(" --printenv print environmental variables to check\n");
}
```
The next step is parsing. While you can't implement its functions yet, the framework of the parsed code is the same:
```
int pkgs(int argc, char **argv)
{
int ch;
int option_index;
struct optparse options;
if(argc == 1)
{
usage();
return RT_EOK;
}
optparse_init(&options, argv);
while((ch = optparse_long(&options, long_opts, &option_index)) != -1)
{
ch = ch;
rt_kprintf("\n");
rt_kprintf("optopt = %c\n", options.optopt);
rt_kprintf("optarg = %s\n", options.optarg);
rt_kprintf("optind = %d\n", options.optind);
rt_kprintf("option_index = %d\n", option_index);
}
rt_kprintf("\n");
return RT_EOK;
}
```
Here is the function head file:
```
#include "optparse.h"
#include "finsh.h"
```
Then, compile and download onto a device.
Cathy, CC BY-SA 4.0)
## Hardware hacking
Programming hardware can seem intimidating, but with IoT it's becoming more and more common. Not everything can or should be run on a Raspberry Pi, but with RT-Thread you can maintain a familiar Linux feel, thanks to FinSH.
If you're curious about coding on bare metal, give RT-Thread a try.
## 1 Comment |
12,670 | 如何在 Linux 中创建/配置 LVM(逻辑卷管理) | https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/ | 2020-10-01T11:12:00 | [
"LVM"
] | https://linux.cn/article-12670-1.html | 
<ruby> 逻辑卷管理 <rt> Logical Volume Management </rt></ruby>(LVM)在 Linux 系统中扮演着重要的角色,它可以提高可用性、磁盘 I/O、性能和磁盘管理的能力。
LVM 是一种被广泛使用的技术,对于磁盘管理来说,它是非常灵活的。
它在物理磁盘和文件系统之间增加了一个额外的层,允许你创建一个逻辑卷而不是物理磁盘。
LVM 允许你在需要的时候轻松地调整、扩展和减少逻辑卷的大小。

### 如何创建 LVM 物理卷?
你可以使用任何磁盘、RAID 阵列、SAN 磁盘或分区作为 LVM <ruby> 物理卷 <rt> Physical Volume </rt></ruby>(PV)。
让我们想象一下,你已经添加了三个磁盘,它们是 `/dev/sdb`、`/dev/sdc` 和 `/dev/sdd`。
运行以下命令来[发现 Linux 中新添加的 LUN 或磁盘](https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/):
```
# ls /sys/class/scsi_host
host0
```
```
# echo "- - -" > /sys/class/scsi_host/host0/scan
```
```
# fdisk -l
```
**创建物理卷 (`pvcreate`) 的一般语法:**
```
pvcreate [物理卷名]
```
当在系统中检测到磁盘,使用 `pvcreate` 命令初始化 LVM PV:
```
# pvcreate /dev/sdb /dev/sdc /dev/sdd
Physical volume "/dev/sdb" successfully created
Physical volume "/dev/sdc" successfully created
Physical volume "/dev/sdd" successfully created
```
**请注意:**
* 上面的命令将删除给定磁盘 `/dev/sdb`、`/dev/sdc` 和 `/dev/sdd` 上的所有数据。
* 物理磁盘可以直接添加到 LVM PV 中,而不必是磁盘分区。
使用 `pvdisplay` 和 `pvs` 命令来显示你创建的 PV。`pvs` 命令显示的是摘要输出,`pvdisplay` 显示的是 PV 的详细输出:
```
# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb lvm2 a-- 15.00g 15.00g
/dev/sdc lvm2 a-- 15.00g 15.00g
/dev/sdd lvm2 a-- 15.00g 15.00g
```
```
# pvdisplay
"/dev/sdb" is a new physical volume of "15.00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdb
VG Name
PV Size 15.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 69d9dd18-36be-4631-9ebb-78f05fe3217f
"/dev/sdc" is a new physical volume of "15.00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdc
VG Name
PV Size 15.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID a2092b92-af29-4760-8e68-7a201922573b
"/dev/sdd" is a new physical volume of "15.00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdd
VG Name
PV Size 15.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID d92fa769-e00f-4fd7-b6ed-ecf7224af7faS
```
### 如何创建一个卷组
<ruby> 卷组 <rt> Volume Group </rt></ruby>(VG)是 LVM 结构中的另一层。基本上,卷组由你创建的 LVM 物理卷组成,你可以将物理卷添加到现有的卷组中,或者根据需要为物理卷创建新的卷组。
**创建卷组 (`vgcreate`) 的一般语法:**
```
vgcreate [卷组名] [物理卷名]
```
使用以下命令将一个新的物理卷添加到新的卷组中:
```
# vgcreate vg01 /dev/sdb /dev/sdc /dev/sdd
Volume group "vg01" successfully created
```
**请注意:**默认情况下,它使用 4MB 的<ruby> 物理范围 <rt> Physical Extent </rt></ruby>(PE),但你可以根据你的需要改变它。
使用 `vgs` 和 `vgdisplay` 命令来显示你创建的 VG 的信息:
```
# vgs vg01
VG #PV #LV #SN Attr VSize VFree
vg01 3 0 0 wz--n- 44.99g 44.99g
```
```
# vgdisplay vg01
--- Volume group ---
VG Name vg01
System ID
Format lvm2
Metadata Areas 3
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 3
Act PV 3
VG Size 44.99 GiB
PE Size 4.00 MiB
Total PE 11511
Alloc PE / Size 0 / 0
Free PE / Size 11511 / 44.99 GiB
VG UUID d17e3c31-e2c9-4f11-809c-94a549bc43b7
```
### 如何扩展卷组
如果 VG 没有空间,请使用以下命令将新的物理卷添加到现有卷组中。
**卷组扩展 (`vgextend`)的一般语法:**
```
vgextend [已有卷组名] [物理卷名]
```
```
# vgextend vg01 /dev/sde
Volume group "vg01" successfully extended
```
### 如何以 GB 为单位创建逻辑卷?
<ruby> 逻辑卷 <rt> Logical Volume </rt></ruby>(LV)是 LVM 结构中的顶层。逻辑卷是由卷组创建的块设备。它作为一个虚拟磁盘分区,可以使用 LVM 命令轻松管理。
你可以使用 `lvcreate` 命令创建一个新的逻辑卷。
**创建逻辑卷(`lvcreate`) 的一般语法:**
```
lvcreate –n [逻辑卷名] –L [逻辑卷大小] [要创建的 LV 所在的卷组名称]
```
运行下面的命令,创建一个大小为 10GB 的逻辑卷 `lv001`:
```
# lvcreate -n lv001 -L 10G vg01
Logical volume "lv001" created
```
使用 `lvs` 和 `lvdisplay` 命令来显示你所创建的 LV 的信息:
```
# lvs /dev/vg01/lvol01
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
lv001 vg01 mwi-a-m-- 10.00g lv001_mlog 100.00
```
```
# lvdisplay /dev/vg01/lv001
--- Logical volume ---
LV Path /dev/vg01/lv001
LV Name lv001
VG Name vg01
LV UUID ca307aa4-0866-49b1-8184-004025789e63
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2020-09-10 11:43:05 -0700
LV Status available
# open 0
LV Size 10.00 GiB
Current LE 2560
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:4
```
### 如何以 PE 大小创建逻辑卷?
或者,你可以使用物理范围(PE)大小创建逻辑卷。
### 如何计算 PE 值?
很简单,例如,如果你有一个 10GB 的卷组,那么 PE 大小是多少?
默认情况下,它使用 4MB 的物理范围,但可以通过运行 `vgdisplay` 命令来检查正确的 PE 大小,因为这可以根据需求进行更改。
```
10GB = 10240MB / 4MB (PE 大小) = 2560 PE
```
**用 PE 大小创建逻辑卷 (`lvcreate`) 的一般语法:**
```
lvcreate –n [逻辑卷名] –l [物理扩展 (PE) 大小] [要创建的 LV 所在的卷组名称]
```
要使用 PE 大小创建 10GB 的逻辑卷,命令如下:
```
# lvcreate -n lv001 -l 2560 vg01
```
### 如何创建文件系统
在创建有效的文件系统之前,你不能使用逻辑卷。
**创建文件系统的一般语法:**
```
mkfs –t [文件系统类型] /dev/[LV 所在的卷组名称]/[LV 名称]
```
使用以下命令将逻辑卷 `lv001` 格式化为 ext4 文件系统:
```
# mkfs -t ext4 /dev/vg01/lv001
```
对于 xfs 文件系统:
```
# mkfs -t xfs /dev/vg01/lv001
```
### 挂载逻辑卷
最后,你需要挂载逻辑卷来使用它。确保在 `/etc/fstab` 中添加一个条目,以便系统启动时自动加载。
创建一个目录来挂载逻辑卷:
```
# mkdir /lvmtest
```
使用挂载命令[挂载逻辑卷](https://www.2daygeek.com/mount-unmount-file-system-partition-in-linux/):
```
# mount /dev/vg01/lv001 /lvmtest
```
在 [/etc/fstab 文件](https://www.2daygeek.com/understanding-linux-etc-fstab-file/)中添加新的逻辑卷详细信息,以便系统启动时自动挂载:
```
# vi /etc/fstab
/dev/vg01/lv001 /lvmtest xfs defaults 0 0
```
使用 [df 命令](https://www.2daygeek.com/linux-check-disk-space-usage-df-command/)检查新挂载的卷:
```
# df -h /lvmtest
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg01-lv001 15360M 34M 15326M 4% /lvmtest
```
---
via: <https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,671 | 10 大静态网站生成工具 | https://itsfoss.com/open-source-static-site-generators/ | 2020-10-01T12:39:00 | [
"静态网站"
] | https://linux.cn/article-12671-1.html | 
>
> 在寻找部署静态网页的方法吗?这几个开源的静态网站生成工具可以帮你迅速部署界面优美、功能强大的静态网站,无需掌握复杂的 HTML 和 CSS 技能。
>
>
>
### 静态网站是什么?
技术上来讲,静态网站是指网页不是由服务器动态生成的。HTML、CSS 和 JavaScript 文件就静静地躺在服务器的某个路径下,它们的内容与终端用户接收到的版本是一样的。原始的源码文件已经提前编译好了,源码在每次请求后都不会变化。
[Linux.CN](http://Linux.CN) 是一个依赖多个数据库的动态网站,当有浏览器的请求时,网页就会生成并提供服务。大部分网站是动态的,你与这些网站互动时,大量的内容会经常改变。
静态网站有一些好处,比如加载时间更短,请求的服务器资源更少、更安全(值得商榷)。
传统上,静态网站更适合于创建只有少量网页、内容变化不频繁的小网站。
然而,随着静态网站生成工具出现后,静态网站的适用范围越来越大。你还可以使用这些工具搭建博客网站。
我整理了几个开源的静态网站生成工具,这些工具可以帮你搭建界面优美的网站。
### 最好的开源静态网站生成工具
请注意,静态网站不会提供很复杂的功能。如果你需要复杂的功能,那么你可以参考适用于动态网站的[最佳开源 CMS](https://itsfoss.com/open-source-cms/)列表。
#### 1、Jekyll

Jekyll 是用 [Ruby](https://www.ruby-lang.org/en/) 写的最受欢迎的开源静态生成工具之一。实际上,Jekyll 是 [GitHub 页面](https://pages.github.com/) 的引擎,它可以让你免费用 GitHub 托管网站。
你可以很轻松地跨平台配置 Jekyll,包括 Ubuntu。它利用 [Markdown](https://github.com/Shopify/liquid/wiki)、[Liquid](https://github.com/Shopify/liquid/wiki)(模板语言)、HTML 和 CSS 来生成静态的网页文件。如果你要搭建一个没有广告或推广自己工具或服务的产品页的博客网站,它是个不错的选择。
它还支持从常见的 CMS(<ruby> 内容管理系统 <rt> Content management system </rt></ruby>)如 Ghost、WordPress、Drupal 7 迁移你的博客。你可以管理永久链接、类别、页面、文章,还可以自定义布局,这些功能都很强大。因此,即使你已经有了一个网站,如果你想转成静态网站,Jekyll 会是一个完美的解决方案。你可以参考[官方文档](https://jekyllrb.com/docs/)或 [GitHub 页面](https://github.com/jekyll/jekyll)了解更多内容。
* [Jekyll](https://jekyllrb.com/)
#### 2、Hugo

Hugo 是另一个很受欢迎的用于搭建静态网站的开源框架。它是用 [Go 语言](https://golang.org/)写的。
它运行速度快、使用简单、可靠性高。如果你需要,它也可以提供更高级的主题。它还提供了一些有用的快捷方式来帮助你轻松完成任务。无论是组合展示网站还是博客网站,Hogo 都有能力管理大量的内容类型。
如果你想使用 Hugo,你可以参照它的[官方文档](https://gohugo.io/getting-started/)或它的 [GitHub 页面](https://github.com/gohugoio/hugo)来安装以及了解更多相关的使用方法。如果需要的话,你还可以将 Hugo 部署在 GitHub 页面或任何 CDN 上。
* [Hugo](https://gohugo.io/)
#### 3、Hexo

Hexo 是一个有趣的开源框架,基于 [Node.js](https://nodejs.org/en/)。像其他的工具一样,你可以用它搭建相当快速的网站,不仅如此,它还提供了丰富的主题和插件。
它还根据用户的每个需求提供了强大的 API 来扩展功能。如果你已经有一个网站,你可以用它的[迁移](https://hexo.io/api/migrator.html)扩展轻松完成迁移工作。
你可以参照[官方文档](https://hexo.io/docs/)或 [GitHub 页面](https://github.com/hexojs/hexo) 来使用 Hexo。
* [Hexo](https://hexo.io/)
#### 4、Gatsby

Gatsby 是一个越来越流行的开源网站生成框架。它使用 [React.js](https://reactjs.org/) 来生成快速、界面优美的网站。
几年前在一个实验性的项目中,我曾经非常想尝试一下这个工具,它提供的成千上万的新插件和主题的能力让我印象深刻。与其他静态网站生成工具不同的是,你可以使用 Gatsby 生成一个网站,并在不损失任何功能的情况下获得静态网站的好处。
它提供了与很多流行的服务的整合功能。当然,你可以不使用它的复杂的功能,或将其与你选择的流行 CMS 配合使用,这也会很有趣。你可以查看他们的[官方文档](https://www.gatsbyjs.com/docs/)或它的 [GitHub 页面](https://github.com/gatsbyjs/gatsby)了解更多内容。
* [Gatsby](https://www.gatsbyjs.com/)
#### 5、VuePress

VuePress 是由 [Vue.js](https://vuejs.org/) 支持的静态网站生成工具,而 Vue.js 是一个开源的渐进式 JavaScript 框架。
如果你了解 HTML、CSS 和 JavaScript,那么你可以无压力地使用 VuePress。你应该可以找到几个有用的插件和主题来为你的网站建设开个头。此外,看起来 Vue.js 的更新一直很活跃,很多开发者都在关注 Vue.js,这是一件好事。
你可以参照他们的[官方文档](https://vuepress.vuejs.org/guide/)和 [GitHub 页面](https://github.com/vuejs/vuepress)了解更多。
* [VuePress](https://vuepress.vuejs.org/)
#### 6、Nuxt.js

Nuxt.js 使用了 Vue.js 和 Node.js,但它致力于模块化,并且有能力依赖服务端而非客户端。不仅如此,它的目标是为开发者提供直观的体验,并提供描述性错误,以及详细的文档等。
正如它声称的那样,在你用来搭建静态网站的所有工具中,Nuxt.js 可以做到功能和灵活性两全其美。他们还提供了一个 [Nuxt 线上沙盒](https://template.nuxtjs.org/),让你不费吹灰之力就能直接测试它。
你可以查看它的 [GitHub 页面](https://github.com/nuxt/nuxt.js)和[官方网站](https://nuxtjs.org/)了解更多。
* [Nuxt.js](https://nuxtjs.org/)
#### 7、Docusaurus

Docusaurus 是一个有趣的开源静态网站生成工具,为搭建文档类网站量身定制。它还是 [Facebook 开源计划](https://opensource.facebook.com/)的一个项目。
Docusaurus 是用 React 构建的。你可以使用所有的基本功能,像文档版本管理、文档搜索和翻译大多是预先配置的。如果你想为你的产品或服务搭建一个文档网站,那么可以试试 Docusaurus。
你可以从它的 [GitHub 页面](https://github.com/facebook/docusaurus)和它的[官网](https://docusaurus.io/)获取更多信息。
* [Docusaurus](https://docusaurus.io/)
#### 8、Eleventy

Eleventy 自称是 Jekyll 的替代品,旨在以更简单的方法来制作更快的静态网站。
它似乎很容易上手,而且它还提供了适当的文档来帮助你。如果你想找一个简单的静态网站生成工具,Eleventy 似乎会是一个有趣的选择。
你可以参照它的 [GitHub 页面](https://github.com/11ty/eleventy/)和[官网](https://www.11ty.dev/)来了解更多的细节。
* [Eleventy](https://www.11ty.dev/)
#### 9、Publii

Publii 是一个令人印象深刻的开源 CMS,它能使生成一个静态网站变得很容易。它是用 [Electron](https://www.electronjs.org) 和 Vue.js 构建的。如果有需要,你也可以把你的文章从 WorkPress 网站迁移过来。此外,它还提供了与 GitHub 页面、Netlify 及其它类似服务的一键同步功能。
如果你利用 Publii 生成一个静态网站,你还可以得到一个所见即所得的编辑器。你可以从[官网](https://getpublii.com/)下载它,或者从它的 [GitHub 页面](https://github.com/GetPublii/Publii)了解更多信息。
* [Publii](https://getpublii.com/)
#### 10、Primo

一个有趣的开源静态网站生成工具,目前开发工作仍很活跃。虽然与其他的静态生成工具相比,它还不是一个成熟的解决方案,有些功能还不完善,但它是一个独特的项目。
Primo 旨在使用可视化的构建器帮你构建和搭建网站,这样你就可以轻松编辑和部署到任意主机上。
你可以参照[官网](https://primo.af/)或查看它的 [GitHub 页面](https://github.com/primo-app/primo-desktop)了解更多信息。
* [Primo](https://primo.af/)
### 结语
还有很多文章中没有列出的网站生成工具。然而,我试图提到最好的静态生成器,为您提供最快的加载时间,最好的安全性和令人印象深刻的灵活性。
列表中没有你最喜欢的工具?在下面的评论中告诉我。
---
via: <https://itsfoss.com/open-source-static-site-generators/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Looking to deploy a static web-page? No need to fiddle with HTML and CSS. These open source static website generators will help you deploy beautiful, functional static websites in no time.*
## What is a static website?
Technically, a static website means the webpages are not generated on the server dynamically. The HTML, CSS, JavaScript lie on the server in the version the end user receives it. The raw source code files are already prebuilt, the source code doesn’t change with the next server request.
It’s FOSS is a dynamic website which depends on several databases and the web pages are generated and served when there’s a request from your browser. Majority of the web is powered by dynamic sites where you interact with the websites and there are plenty of content that often change.
Static websites give you a few benefits like faster loading times, less server resource requirements, and better security (debatable?).
Traditionally, static websites are more suitable for creating small websites with only a few pages and where the content doesn’t change too often.
This, however, is changing thanks to static website generator tools and you can use them to create blogs as well.
I have compiled a list of open source static site generators that can help you build a beautiful website.
## Best Open Source Static Site Generators
It’s worth noting that you will not get complex functionality on a static website. In that case, you might want to check out our list of [best open source CMS](https://itsfoss.com/open-source-cms/) for dynamic websites.
### 1. Jekyll
Jekyll is one of the most popular open source static generator built using [Ruby](https://www.ruby-lang.org/en/). In fact, Jekyll is the engine behind [GitHub pages](https://pages.github.com/) which lets you host websites using GitHub for free.
Setting up Jekyll is easy across multiple platforms which includes Ubuntu as well. It utilizes [Markdown](https://github.com/Shopify/liquid/wiki), [Liquid](https://github.com/Shopify/liquid/wiki) (for template), HTML, and CSS to generate the static site files. It is also a pretty good option if you want to build a blog without advertisements or a product page to promote your tool or service.
Also, it supports migrating your blog from popular CMSs like Ghost, WordPress, Drupal 7, and more. You get to manage permalinks, categories, pages, posts, and custom layouts, which is nice. So, even if you already have an existing website that you want to convert to a static site, Jekyll should be a perfect solution. You can learn more about it by exploring the [official documentation](https://jekyllrb.com/docs/) or its [GitHub page](https://github.com/jekyll/jekyll).
### 2. Hugo

Hugo is yet another popular open source framework for building static sites. It’s built using the [Go programming language](https://golang.org/).
It is fast, simple, and reliable. You also get some advanced theming support if you need it. It also offers some useful shortcuts to help you get things done easily. No matter whether it’s a portfolio site or a blog, Hugo is capable enough to manage a variety of content types.
To get started, you can follow its [official documentation](https://gohugo.io/getting-started/) or go through its [GitHub page](https://github.com/gohugoio/hugo) to install it and learn more about its usage. You can also deploy Hugo on GitHub pages or any CDN if required.
### 3. Hexo
Hexo is an interesting open-source framework powered by [Node.js](https://nodejs.org/en/). Similar to others, you will end up creating blazing fast websites but you will also get a good collection of themes and plugins.
You do get a powerful API here to extend functionality as per your requirements as well. If you already have a website, you can simply use its [Migrator](https://hexo.io/api/migrator.html) extension as well.
To get started, you can go through the [official documentation](https://hexo.io/docs/) or just explore their [GitHub page](https://github.com/hexojs/hexo).
### 4. Gatsby

Gatsby is an increasingly open-source popular site generator framework. It utilizes [React.js](https://reactjs.org/) for creating fast and beautiful websites.
I was quite interested to give this a try for some experimental projects a few years back and it is impressive to see the availability thousands of new plugins and themes. Unlike other static site generators, you can use Gatsby to generate a site and get the benefits of static sites without losing any features.
It offers a lot of useful integrations from popular services. Of course, you can keep it simple or use it coupled with a popular CMS of your choice, which should be interesting. You can take a look at their [official documentation](https://www.gatsbyjs.com/docs/) and its [GitHub page](https://github.com/gatsbyjs/gatsby) to find out more on it.
### 5. VuePress

VuePress is a static site generator powered by [Vue.js](https://vuejs.org/) which happens to be an open-source progressive JavaScript framework.
If you know HTML, CSS, and JavaScript, you can easily get started using VuePress. You should find several useful plugins and themes to get a head start on building your site. Also, it seems like Vue.js is being actively improved and has the attention of more developers, which is a good thing.
You can learn more about it through their [official guide](https://vuepress.vuejs.org/guide/) and the [GitHub page](https://github.com/vuejs/vuepress).
### 6. Nuxt.js
Nuxt.js utilizes Vue.js and Node.js but it focuses on providing modularity and has the ability to rely on the server-side instead of the client-side. Not just that, it aims to provide an intuitive experience to the developers with descriptive errors, and detailed documentations among other things.
As it claims, Nuxt.js should be the best of both world with all of its features and flexibility that you get to build a static website. They also offer a [Nuxt Online sandbox](https://template.nuxtjs.org/) to let you directly test it without a lot of effort.
You can explore its [GitHub page](https://github.com/nuxt/nuxt.js) or visit the [official](https://nuxtjs.org/)[ ](https://nuxtjs.org/)[site](https://nuxtjs.org/) to get more details.
### 7. Docusaurus

Docusaurus is an interesting open-source static site generator tailored for building documentation websites. It happens to be a part of [Facebook’s open source initiative](https://opensource.facebook.com/).
It is built using React. You get all the essential features like document versioning, document search, and translation mostly pre-configured. If you’re planning to build a documentation website for any of your products/services, this should be a good start.
You can learn more about it on its [GitHub page](https://github.com/facebook/docusaurus) and its [official website](https://docusaurus.io/).
### 8. Eleventy

Eleventy describes itself as an alternative to Jekyll and aims for a simpler approach to make faster static websites.
It seems easy to get started and it also offers proper documentation to help you out. If you want a simple static site generator that gets the job done, Eleventy seems to be an interesting choice.
You can explore more about it on its [GitHub page](https://github.com/11ty/eleventy/) and visit the [official website](https://www.11ty.dev/) for more details.
### 9. Publii
Publii is an impressive open-source CMS that makes it easy to generate a static site. It’s built using [Electron](https://www.electronjs.org) and Vue.js. You can also migrate your posts from a WordPress site if needed. In addition to that, it offers several one-click synchronizations with GitHub Pages, Netlify, and similar services.
You also get a WYSIWYG editor if you utilize Publii to generate a static site. To get started, visit the [official website](https://getpublii.com/) to download it or explore its [GitHub page](https://github.com/GetPublii/Publii) for more information.
### 10. Primo
An interesting open-source static site generator which is still in active development. Even though it’s not a full-fledged solution with all the features compared to other static generators, it is a unique project.
Primo aims to help you build and develop a site using a visual builder which can be easily edited and deployed to any host of your choice.
You can visit the [official website](https://primo.af/) or explore its [GitHub page](https://github.com/primo-app/primo-desktop) for more information.
## Wrapping Up
There are a lot of other site generators available out there. However, I’ve tried to mention the best static generators that gives you the fastest loading times, the best security, and an impressive flexibility.
Did I miss any of your favorites? Let me know in the comments below. |
12,673 | 如何在 Linux 中扩展/增加 LVM 大小(逻辑卷调整) | https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux/ | 2020-10-01T23:41:59 | [
"LVM"
] | https://linux.cn/article-12673-1.html | 
扩展逻辑卷非常简单,只需要很少的步骤,而且不需要卸载某个逻辑卷就可以在线完成。
LVM 的主要目的是灵活的磁盘管理,当你需要的时候,可以很方便地调整、扩展和缩小逻辑卷的大小。
如果你是逻辑卷管理(LVM) 新手,我建议你从我们之前的文章开始学习。
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)](/article-12670-1.html)**

扩展逻辑卷涉及到以下步骤:
* 检查逻辑卷(LV)所在的卷组中是否有足够的未分配磁盘空间
* 如果有,你可以使用这些空间来扩展逻辑卷
* 如果没有,请向系统中添加新的磁盘或 LUN
* 将物理磁盘转换为物理卷(PV)
* 扩展卷组
* 增加逻辑卷大小
* 扩大文件系统
* 检查扩展的文件系统大小
### 如何创建 LVM 物理卷?
使用 `pvcreate` 命令创建 LVM 物理卷。
当在操作系统中检测到磁盘,使用 `pvcreate` 命令初始化 LVM 物理卷:
```
# pvcreate /dev/sdc
Physical volume "/dev/sdc" successfully created
```
**请注意:**
* 上面的命令将删除磁盘 `/dev/sdc` 上的所有数据。
* 物理磁盘可以直接添加到 LVM 物理卷中,而不是磁盘分区。
使用 `pvdisplay` 命令来显示你所创建的物理卷:
```
# pvdisplay /dev/sdc
"/dev/sdc" is a new physical volume of "10.00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdc
VG Name
PV Size 10.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 69d9dd18-36be-4631-9ebb-78f05fe3217f
```
### 如何扩展卷组
使用以下命令在现有的卷组(VG)中添加一个新的物理卷:
```
# vgextend vg01 /dev/sdc
Volume group "vg01" successfully extended
```
使用 `vgdisplay` 命令来显示你所创建的物理卷:
```
# vgdisplay vg01
--- Volume group ---
VG Name vg01
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 14.99 GiB
PE Size 4.00 MiB
Total PE 3840
Alloc PE / Size 1280 / 4.99
Free PE / Size 2560 / 9.99 GiB
VG UUID d17e3c31-e2c9-4f11-809c-94a549bc43b7
```
### 如何扩展逻辑卷?
使用以下命令增加现有逻辑卷大小。
**逻辑卷扩展(`lvextend`)的常用语法:**
```
lvextend [要增加的额外空间] [现有逻辑卷名称]
```
使用下面的命令将现有的逻辑卷增加 10GB:
```
# lvextend -L +10G /dev/mapper/vg01-lv002
Rounding size to boundary between physical extents: 5.90 GiB
Size of logical volume vg01/lv002 changed from 5.00 GiB (1280 extents) to 15.00 GiB (3840 extents).
Logical volume var successfully resized
```
使用 PE 大小来扩展逻辑卷:
```
# lvextend -l +2560 /dev/mapper/vg01-lv002
```
要使用百分比(%)扩展逻辑卷,请使用以下命令:
```
# lvextend -l +40%FREE /dev/mapper/vg01-lv002
```
现在,逻辑卷已经扩展,你需要调整文件系统的大小以扩展逻辑卷内的空间:
对于基于 ext3 和 ext4 的文件系统,运行以下命令:
```
# resize2fs /dev/mapper/vg01-lv002
```
对于 xfs 文件系统,使用以下命令:
```
# xfs_growfs /dev/mapper/vg01-lv002
```
使用 [df 命令](https://www.2daygeek.com/linux-check-disk-space-usage-df-command/)查看文件系统大小:
```
# df -h /lvmtest1
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg01-lv002 15360M 34M 15326M 4% /lvmtest1
```
---
via: <https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,674 | 用 testdisk 恢复 Linux 上已删除的文件 | https://www.networkworld.com/article/3575524/recovering-deleted-files-on-linux-with-testdisk.html | 2020-10-02T00:39:15 | [
"testdisk",
"删除"
] | https://linux.cn/article-12674-1.html |
>
> 这篇文章介绍了 testdisk,这是恢复最近删除的文件(以及用其他方式修复分区)的工具之一,非常方便。
>
>
>

当你在 Linux 系统上删除一个文件时,它不一定会永远消失,特别是当你最近才刚刚删除了它的时候。
除非你用 `shred` 等工具把它擦掉,否则数据仍然会放在你的磁盘上 —— 而恢复已删除文件的最佳工具之一 `testdisk` 可以帮助你拯救它。虽然 `testdisk` 具有广泛的功能,包括恢复丢失或损坏的分区和使不能启动磁盘可以重新启动,但它也经常被用来恢复被误删的文件。
在本篇文章中,我们就来看看如何使用 `testdisk` 恢复已删除的文件,以及该过程中的每一步是怎样的。由于这个过程需要不少的步骤,所以当你做了几次之后,你可能会觉得操作起来会更加得心应手。
### 安装 testdisk
可以使用 `apt install testdisk` 或 `yum install testdisk` 等命令安装 `testdisk`。有趣的是,它不仅是一个 Linux 工具,而且还适用于 MacOS、Solaris 和 Windows。
文档可在 [cgsecurity.org](https://www.cgsecurity.org/testdisk.pdf) 中找到。
### 恢复文件
首先,你必须以 `root` 身份登录,或者有 `sudo` 权限才能使用 `testdisk`。如果你没有 `sudo` 访问权限,你会在这个过程一开始就被踢出,而如果你选择创建了一个日志文件的话,最终会有这样的消息:
```
TestDisk exited normally.
jdoe is not in the sudoers file. This incident will be reported.
```
当你用 `testdisk` 恢复被删除的文件时,你最终会将恢复的文件放在你启动该工具的目录下,而这些文件会属于 `root`。出于这个原因,我喜欢在 `/home/recovery` 这样的目录下启动。一旦文件被成功地还原和验证,就可以将它们移回它们的所属位置,并将它们的所有权也恢复。
在你可以写入的选定目录下开始:
```
$ cd /home/recovery
$ testdisk
```
`testdisk` 提供的第一页信息描述了该工具并显示了一些选项。至少在刚开始,创建个日志文件是个好主意,因为它提供的信息可能会被证明是有用的。下面是如何做的:
```
Use arrow keys to select, then press Enter key:
>[ Create ] Create a new log file
[ Append ] Append information to log file
[ No Log ] Don’t record anything
```
左边的 `>` 以及你看到的反转的字体和背景颜色指出了你按下回车键后将使用的选项。在这个例子中,我们选择了创建日志文件。
然后会提示你输入密码(除非你最近使用过 `sudo`)。
下一步是选择被删除文件所存储的磁盘分区(如果没有高亮显示的话)。根据需要使用上下箭头移动到它。然后点两次右箭头,当 “Proceed” 高亮显示时按回车键。
```
Select a media (use Arrow keys, then press Enter):
Disk /dev/sda - 120 GB / 111 GiB - SSD2SC120G1CS1754D117-551
>Disk /dev/sdb - 500 GB / 465 GiB - SAMSUNG HE502HJ
Disk /dev/loop0 - 13 MB / 13 MiB (RO)
Disk /dev/loop1 - 101 MB / 96 MiB (RO)
Disk /dev/loop10 - 148 MB / 141 MiB (RO)
Disk /dev/loop11 - 36 MB / 35 MiB (RO)
Disk /dev/loop12 - 52 MB / 49 MiB (RO)
Disk /dev/loop13 - 78 MB / 75 MiB (RO)
Disk /dev/loop14 - 173 MB / 165 MiB (RO)
Disk /dev/loop15 - 169 MB / 161 MiB (RO)
>[Previous] [ Next ] [Proceed ] [ Quit ]
```
在这个例子中,被删除的文件在 `/dev/sdb` 的主目录下。
此时,`testdisk` 应该已经选择了合适的分区类型。
```
Disk /dev/sdb - 500 GB / 465 GiB - SAMSUNG HE502HJ
Please select the partition table type, press Enter when done.
[Intel ] Intel/PC partition
>[EFI GPT] EFI GPT partition map (Mac i386, some x86_64...)
[Humax ] Humax partition table
[Mac ] Apple partition map (legacy)
[None ] Non partitioned media
[Sun ] Sun Solaris partition
[XBox ] XBox partition
[Return ] Return to disk selection
```
在下一步中,按向下箭头指向 “[ Advanced ] Filesystem Utils”。
```
[ Analyse ] Analyse current partition structure and search for lost partitions
>[ Advanced ] Filesystem Utils
[ Geometry ] Change disk geometry
[ Options ] Modify options
[ Quit ] Return to disk selection
```
接下来,查看选定的分区。
```
Partition Start End Size in sectors
> 1 P Linux filesys. data 2048 910155775 910153728 [drive2]
```
然后按右箭头选择底部的 “[ List ]”,按回车键。
```
[ Type ] [Superblock] >[ List ] [Image Creation] [ Quit ]
```
请注意,它看起来就像我们从根目录 `/` 开始,但实际上这是我们正在工作的文件系统的基点。在这个例子中,就是 `/home`。
```
Directory / <== 开始点
>drwxr-xr-x 0 0 4096 23-Sep-2020 17:46 .
drwxr-xr-x 0 0 4096 23-Sep-2020 17:46 ..
drwx——— 0 0 16384 22-Sep-2020 11:30 lost+found
drwxr-xr-x 1008 1008 4096 9-Jul-2019 14:10 dorothy
drwxr-xr-x 1001 1001 4096 22-Sep-2020 12:12 nemo
drwxr-xr-x 1005 1005 4096 19-Jan-2020 11:49 eel
drwxrwxrwx 0 0 4096 25-Sep-2020 08:08 recovery
...
```
接下来,我们按箭头指向具体的主目录。
```
drwxr-xr-x 1016 1016 4096 17-Feb-2020 16:40 gino
>drwxr-xr-x 1000 1000 20480 25-Sep-2020 08:00 shs
```
按回车键移动到该目录,然后根据需要向下箭头移动到子目录。注意,如果选错了,可以选择列表顶部附近的 `..` 返回。
如果找不到文件,可以按 `/`(就像在 `vi` 中开始搜索时一样),提示你输入文件名或其中的一部分。
```
Directory /shs <== current location
Previous
...
-rw-rw-r— 1000 1000 426 8-Apr-2019 19:09 2-min-topics
>-rw-rw-r— 1000 1000 24667 8-Feb-2019 08:57 Up_on_the_Roof.pdf
```
一旦你找到需要恢复的文件,按 `c` 选择它。
注意:你会在屏幕底部看到有用的说明:
```
Use Left arrow to go back, Right to change directory, h to hide deleted files
q to quit, : to select the current file, a to select all files
C to copy the selected files, c to copy the current file <==
```
这时,你就可以在起始目录内选择恢复该文件的位置了(参见前面的说明,在将文件移回原点之前,先在一个合适的地方进行检查)。在这种情况下,`/home/recovery` 目录没有子目录,所以这就是我们的恢复点。
注意:你会在屏幕底部看到有用的说明:
```
Please select a destination where /shs/Up_on_the_Roof.pdf will be copied.
Keys: Arrow keys to select another directory
C when the destination is correct
Q to quit
Directory /home/recovery <== 恢复位置
```
一旦你看到 “Copy done! 1 ok, 0 failed” 的绿色字样,你就会知道文件已经恢复了。
在这种情况下,文件被留在 `/home/recovery/shs` 下(起始目录,附加所选目录)。
在将文件移回原来的位置之前,你可能应该先验证恢复的文件看起来是否正确。确保你也恢复了原来的所有者和组,因为此时文件由 root 拥有。
**注意:** 对于文件恢复过程中的很多步骤,你可以使用退出(按 `q` 或“[ Quit ]”)来返回上一步。如果你愿意,可以选择退出选项一直回到该过程中的第一步,也可以选择按下 `^c` 立即退出。
#### 恢复训练
使用 `testdisk` 恢复文件相对来说没有痛苦,但有些复杂。在恐慌时间到来之前,最好先练习一下恢复文件,让自己有机会熟悉这个过程。
---
via: <https://www.networkworld.com/article/3575524/recovering-deleted-files-on-linux-with-testdisk.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,676 | 使用 qemu-kvm 安装和运行 Vagrant | https://fedoramagazine.org/vagrant-qemukvm-fedora-devops-sysadmin/ | 2020-10-03T09:46:49 | [
"Vagrant"
] | https://linux.cn/article-12676-1.html | 
Vagrant 是一个出色的工具,DevOps 专业人员、程序员、系统管理员和普通极客来使用它来建立可重复的基础架构来进行开发和测试。引用自它的网站:
>
> Vagrant 是用于在单工作流程中构建和管理虚拟机环境的工具。凭借简单易用的工作流程并专注于自动化,Vagrant 降低了开发环境的设置时间,提高了生产效率,并使“在我的机器上可以工作”的借口成为过去。
>
>
> 如果你已经熟悉 Vagrant 的基础知识,那么该文档为所有的功能和内部结构提供了更好的参考。
>
>
> Vagrant 提供了基于行业标准技术构建的、易于配置、可复制、可移植的工作环境,并由一个一致的工作流程控制,帮助你和你的团队最大限度地提高生产力和灵活性。
>
>
> <https://www.vagrantup.com/intro>
>
>
>
本指南将逐步介绍使 Vagrant 在基于 Fedora 的计算机上工作所需的步骤。
我从最小化安装 Fedora 服务器开始,因为这样可以减少宿主机操作系统的内存占用,但如果你已经有一台可以使用的 Fedora 机器,无论是服务器还是工作站版本,那么也没问题。
### 检查机器是否支持虚拟化
```
$ sudo lscpu | grep Virtualization
```
```
Virtualization: VT-x
Virtualization type: full
```
### 安装 qemu-kvm
```
sudo dnf install qemu-kvm libvirt libguestfs-tools virt-install rsync
```
### 启用并启动 libvirt 守护进程
```
sudo systemctl enable --now libvirtd
```
### 安装 Vagrant
```
sudo dnf install vagrant
```
### 安装 Vagrant libvirtd 插件
```
sudo vagrant plugin install vagrant-libvirt
```
### 添加一个 box
```
vagrant box add fedora/32-cloud-base --provider=libvirt
```
(LCTT 译注:以防你不知道,box 是 Vagrant 中的一种包格式,Vagrant 支持的任何平台上的任何人都可以使用盒子来建立相同的工作环境。)
### 创建一个最小化的 Vagrantfile 来测试
```
$ mkdir vagrant-test
$ cd vagrant-test
$ vi Vagrantfile
```
```
Vagrant.configure("2") do |config|
config.vm.box = "fedora/32-cloud-base"
end
```
**注意文件名和文件内容的大小写。**
### 检查文件
```
vagrant status
```
```
Current machine states:
default not created (libvirt)
The Libvirt domain is not created. Run 'vagrant up' to create it.
```
### 启动 box
```
vagrant up
```
### 连接到你的新机器
```
vagrant ssh
```
完成了。现在你的 Fedora 机器上 Vagrant 可以工作了。
要停止该机器,请使用 `vagrant halt`。这只是简单地停止机器,但保留虚拟机和磁盘。 要关闭并删除它,请使用 `vagrant destroy`。这将删除整个机器和你在其中所做的任何更改。
### 接下来的步骤
在运行 `vagrant up` 命令之前,你不需要下载 box。你可以直接在 Vagrantfile 中指定 box 和提供者,如果还没有的话,Vagrant 会下载它。下面是一个例子,它还设置了内存量和 CPU 数量:
```
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.box = "fedora/32-cloud-base"
config.vm.provider :libvirt do |libvirt|
libvirt.cpus = 1
libvirt.memory = 1024
end
end
```
关于使用 Vagrant、创建你自己的机器和使用不同 box 的更多信息,请参见官方文档 <https://www.vagrantup.com/docs>。
有一个庞大的仓库,你可以随时下载使用这些 box,它们的的官方仓库是 Vagrant Cloud - <https://app.vagrantup.com/boxes/search>。这里有些是基本的操作系统,有些提供完整的功能,如数据库、网络服务器等。
---
via: <https://fedoramagazine.org/vagrant-qemukvm-fedora-devops-sysadmin/>
作者:[Andy Mott](https://fedoramagazine.org/author/amott/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Vagrant is a brilliant tool, used by DevOps professionals, coders, sysadmins and regular geeks to stand up repeatable infrastructure for development and testing. From their website:
Vagrant is a tool for building and managing virtual machine environments in a single workflow. With an easy-to-use workflow and focus on automation, Vagrant lowers development environment setup time, increases production parity, and makes the “works on my machine” excuse a relic of the past.
https://www.vagrantup.com/intro
If you are already familiar with the basics of Vagrant, the documentation provides a better reference build for all available features and internals.
Vagrant provides easy to configure, reproducible, and portable work environments built on top of industry-standard technology and controlled by a single consistent workflow to help maximize the productivity and flexibility of you and your team.
This guide will walk through the steps necessary to get Vagrant working on a Fedora-based machine.
I started with a minimal install of Fedora Server as this reduces the memory footprint of the host OS, but if you already have a working Fedora machine, either Server or Workstation, then this should still work.
#### Check the machine supports virtualisation:
$
sudo lscpu | grep VirtualizationVirtualization: VT-x Virtualization type: full
#### Install qemu-kvm:
sudo dnf install qemu-kvm libvirt libguestfs-tools virt-install rsync
#### Enable and start the libvirt daemon:
sudo systemctl enable --now libvirtd
#### Install Vagrant:
sudo dnf install vagrant
#### Install the Vagrant libvirtd plugin:
sudo vagrant plugin install vagrant-libvirt
#### Add a box
vagrant box add fedora/32-cloud-base --provider=libvirt
#### Create a minimal Vagrantfile to test
$
Vagrant.configure("2") do |config| config.vm.box = "fedora/32-cloud-base" endmkdir vagrant-test$cd vagrant-test$vi Vagrantfile
**Note the capitalisation of the file name and in the file itself.**
#### Check the file:
Current machine states: default not created (libvirt) The Libvirt domain is not created. Run 'vagrant up' to create it.
vagrant status
#### Start the box:
vagrant up
#### Connect to your new machine:
vagrant ssh
That’s it – you now have Vagrant working on your Fedora machine.
To stop the machine, use *vagrant halt*. This simply halts the machine but leaves the VM and disk in place.
To shut it down and delete it use *vagrant destroy*. This will remove the whole machine and any changes you’ve made in it.
### Next steps
You don’t need to download boxes before issuing the *vagrant up* command – you can specify the box and the provider in the Vagrantfile directly and Vagrant will download it if it’s not already there. Below is an example which also sets the amount memory and number of CPUs:
# -*- mode: ruby -*- # vi: set ft=ruby : Vagrant.configure("2") do |config| config.vm.box = "fedora/32-cloud-base" config.vm.provider :libvirt do |libvirt| libvirt.cpus = 1 libvirt.memory = 1024 end end
For more information on using Vagrant, creating your own machines and using different boxes, see the official documentation at [https://www.vagrantup.com/docs](https://www.vagrantup.com/docs)
There is a huge repository of boxes ready to download and use, and the official location for these is Vagrant Cloud – [https://app.vagrantup.com/boxes/search](https://app.vagrantup.com/boxes/search). Some are basic operating systems and some offer complete functionality such as databases, web servers etc.
## Lucas
Very useful. I will test with qemu-kvm. I’ve had problems with vagrant and vbox, so I stopped using it.
## Sergey
I understand the use of Vagrant for Virtual Box, etc., but why use it for KVM ?
We have a virsh and ansible.
## Andy Mott
As with anything Unix/Linux there are many ways to get the job done!
While virsh commands and Ansible would also work, the simplicity of finding a suitable Vagrant box and getting it up and running quickly reduces the learning curve for anyone new to automated provisioning as it takes away a number of the steps required. I believe this makes it a fantastic tool for quickly creating machines for testing or other lab work.
## Dominique
Andy could you do a Virsh and Ansible tutorial ?
## Sandra
With KVM you would have to set up all the networking and partitioning and so on you self, and Vagrant have to handy builtin commands, which should make many taskes easier.
There would however be 2 good reasons to go with KVM over Vagrant:
you can use snapshots with KVM, so you can make a snapshot between each of your virsh commands and that way simulate the layers in Docker/Podman that speeds up building the box/image. Vagrant can’t do this for some strange reason.
All commands in a Vagrant file are executed as an non-privileged user, so you can’t copy a file directly to e.g. /etc. You first have to copy the file to /tmp and then write a script that copies the file from /tmp to /etc and then execute it. With virsh that is a one-liner.
## Serge Meeuwsen
Hi,
Thanks for providing this write up! This works fine with Linux based boxes but unfortunately it seems to be broken for Windows based boxes.
I have tried several and always get the “kernel_require.rb:83:in `require’: cannot load such file — winrm (LoadError)” error.
According to the hashicorp site you need to install vagrant 2.2.10 but then I had problems installing the vagrant-libvirt plugin… It is probably a dependency issue but I couldn’t figure it out.
## Mike Rosile
You may need the “vagrant-winrm” plugin. It can be installed using the following command:
vagrant plugin install vagrant-winrm
## tsyang
Serge,
It is the Fedora libssh binding issue. Please see this site for solution:
https://github.com/hashicorp/vagrant/issues/11020
## Mehdi
Thank you for the article. Didn’t get a chance to work with Vagrant before. Seems like some Docker projects can be done with Vagrant.
Btw, does Vagrant anything to do with Gnome Boxes?
## MattPie
@Mehdi,
Vagrant doesn’t really have much to do with Gnome Boxes, other than Gnome Boxes manages KVM VMs so you may be able to see the VMs Vagrant spins up in there.
And FWIW, Fedora (32, at least) comes with podman install, which is CLI-compatible with docker so many of the same commands will work. Like:
piechota@localhost Downloads]$ podman run -it ubuntu bash
…
Trying to pull docker.io/library/ubuntu…
Getting image source signatures
Copying blob 990916bd23bb done
Copying blob 534a5505201d done
Copying blob e6ca3592b144 done
Copying config bb0eaf4eee done
Writing manifest to image destination
Storing signatures
root@223636bf41b2:/# more /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=20.04
DISTRIB_CODENAME=focal
DISTRIB_DESCRIPTION=”Ubuntu 20.04.1 LTS”
root@223636bf41b2:/# exit
exit
## Sandra
Why do you install vagrant-libvirt from Vagrant and not
?
## tsyang
Sandra,
The reason is stated in Peru’s Windows 10 box page:
https://app.vagrantup.com/peru/boxes/windows-10-enterprise-x64-eval
## Josef
Why not to mention the developer guide from Fedora Developer [0]? You would also see that we have vagrant-libvirt directly packaged in Fedora.
[0] https://developer.fedoraproject.org/tools/vagrant/vagrant-libvirt.html
## Sandra
Ok, so it makes a lot of sense for Windows boxes. So why still do it, when the box is Fedora/Linux?
## Eric L.
I also don’t install
because I know that I need more Vagrant plugins than are packaged as RPM, and, if you dare mixing up RPM-packaged and “native” Vagrant-plugins, it
alwaysgo wrong at some point in time. I even blockallvagrant plugins to avoid any issue with Ruby dependencies:[main]
excludepkgs=vagrant-*
It still goes wrong from time to time when the Vagrant-RPM is upgraded, but then you follow
allthe recommendations from the Vagrant-CLI (clean-up/rebuild/update the plug-ins) and it fixes the issue.To be honest, I’d like to get rid of Vagrant and replace it fully with Ansible. It’s technically possible but, as someone else wrote, the Vagrant library of prepared images is just too comfortable.
## Jeff Pettorino
So this does not work with Fedora 33 beta, nor Fedora 32. I tried both, a couple of times.
The problem comes from an old and well established bug:
https://bugzilla.redhat.com/show_bug.cgi?id=1835308
So what did you do to overcome this, and can you update the article to include the steps?
I’ve tried both the vagrant plugin installer and the RPM package vagrant-libvirtd. Same problems with racc-1.5.0 in both cases.
## Andy Mott
Hi Jeff
I just built a new F32 VM to test this on, and everything worked as expected. This is a vanilla build using Fedora 32 Server. No updates installed, just right out of the box. The only thing I did in the OS install was add my user account to the wheel group so I could use sudo.
$ libvirtd –version
libvirtd (libvirt) 6.1.0
$ vagrant –version
Vagrant 2.2.9
$ sudo vagrant plugin install vagrant-libvirt
Installing the ‘vagrant-libvirt’ plugin. This can take a few minutes…
Installed the plugin ‘vagrant-libvirt (0.0.45)’!
I copied and pasted commands from this article and saw no errors. Sorry I can’t offer more advice, but the steps above do work.
## Jeff Pettorino
Hi Andy, I double checked and found an error, I was deploying F33-Beta for all of my tests. I can confirm as well that on a (properly) installed F32 the article instructions work fine.
Thanks for being patient. 🙂
## Andy Mott
Hi Jeff
Glad you got it sorted! 🙂
I’m always happy to help if people have questions about my articles, so no worries about asking.
## Josef
I have Fedora 32 and Vagrant installed as vagrant-libvirt RPM package. I don’t use any non packaged plugins, perhaps this is why it works for me?
## Tom Christopher
The only way I found around this is to install toolbox on the system. Then run toolbox create -c libvirt -r f29 to create a Fedora 29 container. Then I run the installation as documented on the vagrant-libvirt github page. I also run terraform-libvirt from this same container. |
12,677 | 微软帮我在 Windows 10 电脑上安装了 Ubuntu Linux | https://www.zdnet.com/article/microsoft-helped-me-install-ubuntu-linux-on-my-windows-10-pc-and-its-actually-pretty-good/ | 2020-10-03T11:12:00 | [
"Linux",
"微软"
] | https://linux.cn/article-12677-1.html | 
>
> 很多读过我们的技术文章评论的人都知道,每个技术问题的答案都是“切换到 Linux”。而如果你对 Linux 是什么以及它是如何工作的感到好奇,微软可以提供帮助。
>
>
>
如果你曾经经历过痛苦的 Windows 更新,或者不敢置信地看着你的 MacBook 慢到像爬行,并将其风扇切换到巨型喷气式飞机起飞模式,你知道有一个也只有一个答案来解决你的困境:“切换到 Linux”。
当然,我是开玩笑的,但如果你浏览一下这些技术评论,你会发现这个建议是认真的,有一支开源布道者大军定期宣讲圣莱纳斯的福音,以回应关于其他平台的哪怕是最模糊的相关新闻。
你知道吗?我认为那些评论者的观点是合理的。任何有志于了解现代计算环境的人都应该对他们经常使用的操作系统平台以外的平台有一些经验,因为今天你在 Windows、MacOS 和 Linux 中看到的很多东西都来自于相同的 DNA。
为了跟上 Linux 的新动向,我自己每隔一两年就会进行一次这样的练习。所以,想象一下我的惊讶吧,今年我能够在几分钟内搭建一个功能完善的 Ubuntu Linux 机器,而不干扰我当前的 Windows 10 设置。更令人惊讶的是,微软为此做了大部分的工作。
使这一切成为可能的魔法是每台运行 Windows 10 专业版或企业版的 PC 所包含的 Hyper-V 虚拟化软件。(对不起,Windows 10 家庭用户,如果你想玩这些,你得先升级)。用 Hyper-V 的“快速创建”陈列栏,只需点击几下就可以建立一个新的虚拟机,其中包括了独立的 Ubuntu 镜像,而且不是一个而是三个,包括新的 Ubuntu 20.04 版本。

*Hyper-V 快速创建工具包括了三个 Ubuntu Linux 版本*
最重要的是,这些自定义镜像能够在 Hyper-V 增强会话中运行,这意味着你可以选择自定义的显示分辨率,或者在全屏中运行,甚至跨越多个显示器,其性能接近于在裸机上运行的性能。在增强型会话中,你的虚拟机可以共享主机上的 Windows 剪贴板、本地存储和音频硬件。
一旦你把一切都弄好了,你就可以在全屏模式下启动 Ubuntu 虚拟机,并与它一起工作,就像 Windows 10 宿主机不存在一样。
唉,关于所有东西都能正常工作的那部分话并不是说说而已。好消息是,两年前的 Ubuntu 18.04.3 长期支持(LTS)版本工作得很完美,不需要任何操作。但两个较新的版本却让我欲哭无泪。我需要手动编辑一个受保护的 Linux 配置文件,然后才能让增强的会话在最新的 Ubuntu 版本(20.04)中工作,19.10 版本的虚拟机挂了好几次,至少需要重启十几次(包括几次硬重置)才能如期工作。
不过,在一切都结束后,我还是有了三个可以工作的虚拟机,让我对 Ubuntu Linux 中的新功能有了一个相当不错的印象。
* 补充更新,2020 年 6 月 5 日。[通过 Twitter](https://twitter.com/unixterminal/status/1268918077141528579),@Canonical 的 Ubuntu on WSL 和 Hyper-V 的开发布道师 Hayden Barnes 说,“我们知道 19.10 和 20.04 中的 xrdp bug。20.04 镜像将在即将到来的 20.04.1 LTS 更新中进行修补。19.10 已经接近 EOL,将被放弃。"
* 补充更新 2,2020 年 10 月 1 日。20.04.1 LTS 桌面 Ubuntu 镜像于 2020 年 7 月 31 日发布,但截至 10 月 1 日,它还没有被整合到 Hyper-V 中的快速创建镜像中。
另外,正如我的同事 Mary Branscombe 所指出的那样,包括 Home 在内的所有版本的 Windows 10 都提供了对 Windows Subsystem for Linux(WSL)的访问,该系统在轻量级虚拟机中运行 Linux 内核,并且从 Windows 10 的 2004 版本开始,该系统已经全新升级为 WSL2。正如 WSL2 文档中明确指出的那样,这并不是传统的虚拟机体验,它最适合那些希望获得命令行体验并能够运行 Bash shell 脚本和 GNU/Linux 命令行应用程序的开发者。在 WSL2 环境中运行图形应用程序的能力已列入微软的路线图,应该会在 2020 年底或 2021 年初由 Windows Insiders 进行测试。
如果你想尝试在 Windows 10 中设置一个或多个 Ubuntu 虚拟机进行自己的实验,请看我的另外一篇文章。
---
via: <https://www.zdnet.com/article/microsoft-helped-me-install-ubuntu-linux-on-my-windows-10-pc-and-its-actually-pretty-good/>
作者:[Ed Bott](https://www.zdnet.com/meet-the-team/us/ed-bott/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12674-1.html) 荣誉推出
| 200 | OK | # Microsoft helped me install Ubuntu Linux on my Windows 10 PC, and it's actually pretty good

If you've ever suffered through a painful Windows update or watched in disbelief as your MacBook decided to slow to a crawl and switch its fan into jumbo-jet-at-takeoff mode, you know that there's one and only one answer to your woes: "Switch to Linux."
I kid, of course, but you'll find that advice offered in earnest if you scroll through the comments here at *ZDNet*, where an army of open source evangelists regularly preaches the Gospel of Saint Linus in response to even the most vaguely related bit of news about other platforms.
**Also: ****Open source's Eric Raymond: Windows 10 will soon be just an emulation layer on Linux kernel**** **
And you know what? I think those commenters have a legitimate point. Anyone who aspires to understand the modern computing landscape should have some experience with platforms other than the one they use regularly because a lot of what you see in Windows, MacOS, and Linux today comes from the same DNA.
In the interest of keeping up with what's new in Linux, I go through this exercise myself every year or two. So, imagine my surprise when this year I was able to build a functional Ubuntu Linux machine in minutes, without disturbing my current Windows 10 setup. Even more surprising: Microsoft did most of the work.
The magic that made all this possible is the Hyper-V virtualization software included with every PC running Windows 10 Pro or Enterprise. (Sorry, Windows 10 Home users, you're going to have to upgrade if you want to play along.) Hyper-V's Quick Create gallery, which can build a new virtual machine in just a few clicks, includes not one but three separate Ubuntu images, including the new Ubuntu 20.04 version.
The Hyper-V Quick Create utility includes three Ubunutu Linux versions
Best of all, these custom images are capable of running in a Hyper-V *enhanced session*, which means you can choose a custom display resolution or run in a full screen, even spanning multiple monitors, with a performance that's close to what you'd get running on bare metal. In an enhanced session, your virtual machine can share the Windows Clipboard, local storage, and audio hardware on the host machine.
Once you get everything working, you can fire up that Ubuntu VM in full-screen mode and work with it just as if the Windows 10 host machine weren't there.
**Must read:**
[Microsoft: Linux GUI apps coming to Windows 10 WSL along with GPU access](https://www.zdnet.com/article/microsoft-linux-gui-apps-coming-to-windows-10-wsl-along-with-gpu-access/)[Desktop Linux: Why open source is heading for a new breakthrough](https://www.techrepublic.com/article/desktop-linux-why-open-source-is-heading-for-a-new-breakthrough/)**TechRepublic**[Linux-based Windows makes perfect sense](https://www.zdnet.com/article/linux-based-windows-makes-perfect-sense/)
Alas, that part about getting everything working isn't just a figure of speech. The good news is that the two-year-old [Ubuntu 18.04.3 Long Term Support (LTS)](https://www.zdnet.com/article/linux-on-windows-10-running-ubuntu-vms-just-got-a-lot-easier-says-microsoft/) version worked perfectly, with no futzing required. But the two newer releases had me tearing my hair out. I needed to manually edit a protected Linux configuration file before I could get an enhanced session to work in the latest [Ubuntu release (20.04), ](https://www.zdnet.com/article/ubuntu-20-04-arrives-with-linux-5-4-kernel-and-wireguard-vpn/)and the version 19.10 VM hung several times and required at least a dozen restarts (including a few hard resets) before it worked as expected.
Still, after all was said and done, I had three working virtual machines, giving me a pretty decent overview of what's new in Ubuntu Linux.
*Update, June 5, 2020: Via Twitter, Hayden Barnes, Developer Advocate for Ubuntu on WSL and Hyper-V at @Canonical, says, "We know about the xrdp bug in 19.10 and 20.04. The 20.04 image will be patched in the upcoming 20.04.1 LTS update. 19.10 is nearing EOL and will be dropped."*
*Update 2, October 1, 2020: The 20.04.1 LTS desktop Ubuntu image was released on July 31, 2020, but as of October 1 it has not yet been integrated into the Quick Create image in Hyper-V. *
*Also, as my colleague Mary Branscombe notes, all editions of Windows 10, including Home, offer access to the Windows Subsystem for Linux, which runs the Linux kernel in a lightweight virtual machine and has been freshly updated to WSL2 as of Windows 10 version 2004. As the WSL2 documentation makes clear, this is not a traditional VM experience and it's best suited for developers who want a command line experience and the ability to run Bash shell scripts and GNU/Linux command-line applications. The ability to run graphical apps in the WSL2 environment is on Microsoft's roadmap and should be available for testing by Windows Insiders in late 2020 or early 2021.*
If you'd like to try setting up one or more Ubuntu VMs in Windows 10 for your own experimentation, follow these steps.
### 1. Enable the Hyper-V Platform
This hypervisor is built into all 64-bit Windows 10 Pro, Enterprise, and Education editions, but it's not enabled by default. You might need to turn on some firmware options on older PCs before you can enable the feature. For full instructions, see ["Windows 10: How to enable Hyper-V and create virtual machines."](https://www.zdnet.com/article/windows-10-tip-how-to-enable-hyper-v-and-create-virtual-machines/)
### 2. Use Quick Create to download and install the Ubuntu VM
Hyper-V offers two ways to create a new virtual machine. The old fashioned way is to click your way through a tedious multi-step wizard. The much easier solution is to use the Hyper-V Quick Create utility. You'll find a shortcut in the right pane in Hyper-V Manager, or you can open it directly using the Vmcreate.exe command in the Windows 10 search box.
Choose an Ubuntu version from the gallery on the left, then click the Create Virtual Machine button. That kicks off a download of between 1.6GB (18.04.3 LTS) and 2GB (more recent versions). After the download is complete, the Quick Create utility extracts the image, configures the VM, and then displays a dialog box telling you your virtual machine was created successfully.
I recommend you edit a few settings before running the VN for the first time.
### 3. Tweak a few settings
Although you can get started immediately by clicking Connect, if you have sufficient resources on your Windows 10 host machine, I recommend that you click Edit Settings instead, so you can make a few adjustments first.
Choose Memory from the hardware list for your new VM, and then change the assigned RAM from its default value of 2048 to 4096, which should result in better performance. You can also disable dynamic memory if you want a fixed amount of virtual RAM. You might also want to increase the size of the system disk from its default 12GB. Click Hard Drive, then click Edit, and follow the prompts till you reach the Expand command.
Feel free to tweak the memory assigned to your Linux VM
Finally, under the Management heading, click Checkpoints and then clear the Use Automatic Checkpoints box. (You can always create a checkpoint manually if you want the ability to roll back changes.)
With those adjustments out of the way, you can close the Settings dialog box and open the VM for the first time.
### 4. Set up your user account
Run through the system configuration for Ubuntu, choosing your default language, time zone, and so on. When you get to the screen where you create your login credentials, leave the default setting at **Require my password to log in**.
Although it sounds convenient, do not enable the auto-login feature. If you choose this option, you won't be able to sign in using an enhanced session, and your VM will be forced to run in a relatively small window with a default resolution that you can't easily change.
This is also a good time to run the Software Updater app and get the latest Ubuntu updates. (Click the waffle icon in the lower-left corner and use the search box to find the app.)
### 5. Sign in using an enhanced session
You'll know you've started an enhanced session if you see this dialog box in the VM Connect window.
Move that slider to the far right to run your VM in a full screen
Slide the switch to choose your display resolution. I prefer to move the slider to the right, to the Full Screen position. If you have multiple monitors and you want your VM to span across them, select the Use All My Monitors checkbox. Click Connect to continue, which opens the Xrdp sign-in dialog box, shown here.
Sign in to Xrdp to launch your enhanced Hyper-V session
Enter the username and password you set up when creating your Ubuntu Linux account and click OK. Assuming the gods are not angry, you'll sign in to your VM and can get to work. You might have to enter your password a second time if you're not already signed in on the session that you're connecting to. (If you get a black screen, try pressing Enter.)
All of that should work just fine if you started with an 18.04.3 LTS VM. If you're using Ubuntu 19.10, you might have to go through the same frustrating sequence of restarts that I did before everything works properly.
### Linux
For Ubuntu 20.04, everything worked just fine in a basic session, but the option to run an enhanced session wasn't available until I edited the Xrdp.ini file in /etc/xrdp. This is a protected location, so I had to open an editor with an administrator's credentials, a task which is neither intuitive nor easy.
I had to change two lines in that ini file. First, change port=3389 to port=vsock://-1:3389. Then change use_vsock=true to use_vsock=false. Close the Vmconnect window and connect to the VM again and you should be able to start an enhanced session. But you might also be required to invoke some minor deities and burn some incense. It's Linux, after all.
(As I noted earlier, the Canonical/Microsoft team will have a fix for that image with the 20.04.1 update, so the xrdp.ini file won't require editing.)
And you're now on your own. You'll have to find productivity software that allows you to get actual work done. If you're like me and use mostly Microsoft services, prepare for a heaping helping of frustration.
Microsoft doesn't currently have any Office apps for Linux, so you'll need to access your files from a web browser. (Yes, there are Office clones for Linux, including the LibreOffice suite, which is a faithful clone of Microsoft Office 2007. It's... barely adequate.)
**Must read:**
[Look what's inside Linus Torvalds' latest Linux development PC](https://www.zdnet.com/article/look-whats-inside-linus-torvalds-latest-linux-development-pc/)[New fuzzing tool finds 26 USB bugs in Linux, Windows, macOS, and FreeBSD](https://www.zdnet.com/article/new-fuzzing-tool-finds-26-usb-bugs-in-linux-windows-macos-and-freebsd/)[Microsoft's Windows Package Manager: This command-line tool can install all your apps](https://www.zdnet.com/article/microsofts-windows-package-manager-this-command-line-tool-can-install-all-your-apps/)
In Ubuntu Linux 20.04, I was able to connect Google Drive directly, so that those cloud-backed files appeared directly in the Files app. An easy-to-install Dropbox app was also available. But OneDrive? Not so much. There's an open source third-party sync client, but the installation required more than a half-dozen dependent packages, and I didn't have the patience or the confidence to complete the process.
The default browser in Ubuntu Linux is Mozilla Firefox, which worked well enough on the 18.04.3 LTS version but was jerky in the 20.04 release. Microsoft says it plans to release its new Chromium-based Edge for Linux, but so far that's just a pipe dream. On the plus side, there's a very well done [Microsoft Teams client](https://www.zdnet.com/article/microsoft-teams-for-linux-now-available-in-public-preview/) that installs as a native .deb package.
Although the overall experience is surprisingly smooth, there were too many moments when running Linux felt slightly janky for me. In the 20.04 release, for example, Firefox downloads package files to a temp folder, where they won't open properly. Once I figured out that I had to move those files to the Downloads directory, everything was fine. (Note that Google Chrome downloads go to the correct location by default.)
If, on the other hand, your workday is spent in the Google ecosystem, Linux will probably feel very comfortable. After installing Chrome and setting up G Suite, this VM is basically a slightly snooty Chromebook.
Am I going to switch to Linux as my primary operating system? Uh, no. But I will keep these VMs in service and check in regularly. Because you never know...
#### Windows
[Editorial standards](/editorial-guidelines/) |
12,678 | 如何在 Windows 10 中设置 Ubuntu 虚拟机 | https://www.zdnet.com/article/microsoft-helped-me-install-ubuntu-linux-on-my-windows-10-pc-and-its-actually-pretty-good/ | 2020-10-03T12:01:00 | [
"Linux",
"Windows",
"Hyper-V"
] | https://linux.cn/article-12678-1.html | 
如果你想尝试在 Windows 10 中设置一个或多个 Ubuntu 虚拟机进行自己的实验,请按照以下步骤进行。
### 1、启用 Hyper-V 平台
所有 64 位 Windows 10 专业版、企业版和教育版都内置了这个<ruby> 管理程序 <rp> ( </rp> <rt> hypervisor </rt> <rp> ) </rp></ruby>,但默认情况下并没有启用。在在旧电脑上启用该功能之前,你可能需要打开一些固件选项。有关完整说明,请参阅“[Windows 10:如何启用 Hyper-V 并创建虚拟机](https://www.zdnet.com/article/windows-10-tip-how-to-enable-hyper-v-and-create-virtual-machines/)”。
### 2、使用快速创建工具来下载并安装 Ubuntu 虚拟机
Hyper-V 提供了两种创建新虚拟机的方法。老式的方法是通过一个繁琐的多步骤向导来点击。更简单的解决方案是使用 Hyper-V 的“快速创建”工具。你可以在 Hyper-V 管理器的右侧窗格中找到一个快捷方式,或者你可以直接在 Windows 10 搜索框搜索 `Vmcreate.exe` 命令打开它。
从左侧的陈列栏中选择一个 Ubuntu 版本,然后点击“创建虚拟机”按钮。这将需要下载 1.6GB(18.04.3 LTS)到 2GB(更近的版本)。下载完成后,该“快速创建”功能会提取镜像、配置虚拟机,然后显示一个对话框,告诉你虚拟机已成功创建。
### 3、调整一些设置
虽然你可以通过点击“连接”立即开始,但如果你的 Windows 10 主机上有足够的资源,我建议你点击“编辑设置”,以便你可以先进行一些调整。

*我建议你在第一次运行虚拟机之前编辑一些设置*
从新虚拟机的硬件列表中选择“内存”,然后将分配的 RAM 从其默认值 2048 改为 4096,这应该会带来更好的性能。如果你想要一个固定数量的虚拟内存,你也可以禁用动态内存。你可能还希望将系统磁盘的大小从其默认的 12GB 提升到更多。单击“硬盘驱动器”,然后单击“编辑”,并按照提示操作,直到进行到“扩展”命令那一步。

*根据需要调整分配给你的 Linux 虚拟机的内存*
最后,在“管理”标题下,单击“检查点”,然后清除“使用自动检查点”框。(如果你希望能够回滚更改,可以随时手动创建检查点。)
这些调整完毕后,可以关闭“设置”对话框,并首次打开虚拟机。
### 4、设置你的用户账户
运行 Ubuntu 的系统配置,选择你的默认语言、时区等。当你进入创建登录凭证的界面时,将默认设置保留在“需要我的密码才能登录”。
虽然听起来很方便,但不要启用自动登录功能。如果你选择此选项,将无法使用增强型会话登录,并且你的虚拟机将被迫在一个相对较小的窗口中运行,其默认分辨率无法轻松更改。
这也是运行“系统更新管理器”应用程序并获取最新 Ubuntu 更新的好时机。(点击左下角的 Ubuntu 图标,使用搜索框找到该应用。)
### 5、使用增强版会话登录
如果你在“虚拟机连接”窗口中看到这个对话框,你就会知道已经启动了一个增强的会话:

*将该滑块移至最右侧,以全屏方式运行虚拟机*
滑动开关来选择你的显示分辨率。我喜欢将滑块向右移动,到全屏位置。如果你有多个显示器,并希望虚拟机跨越它们,请选择 “使用所有我的显示器”复选框。单击“连接”继续,打开 Xrdp 登录对话框,如图所示:

*登录到 Xrdp 以启动增强型 Hyper-V 会话*
输入你在创建 Ubuntu Linux 账户时设置的用户名和密码,然后点击“确定”。假设大神们没有生气,你就会登录到你的虚拟机上,可以开始工作了。如果你还没有在你要连接的会话上登录,可能需要第二次输入密码。(如果你得到一个黑屏,尝试按回车键。)
如果你使用 18.04.3 LTS 虚拟机,所有这些都应该可以正常工作。如果你使用的是 Ubuntu 19.10,你可能要经历我所做的同样令人沮丧的一次次重启,然后一切才能正常工作。
对于 Ubuntu 20.04 来说,在基本会话中一切都很正常,但是在我编辑 `/etc/xrdp` 中的 `Xrdp.ini` 文件之前,运行增强会话的选项是不可用的。这是一个受保护的位置,所以我不得不用管理员的凭证打开一个编辑器,这个任务既不直观也不容易。
我必须修改 ini 文件中的两行内容。首先,把 `port=3389` 改为 `port=vsock://-1:3389`。然后把 `use_vsock=true` 改为 `use_vsock=false`。关闭虚拟机连接窗口并再次连接到虚拟机,你应该可以启动增强型会话。但你可能还需要召唤一些小神灵,烧一些香。毕竟,这是 Linux。
(正如我之前所提到的,Canonical/微软团队将在 20.04.1 更新中对该镜像进行修复,所以到时候 xrdp.ini 文件不需要编辑了。)
而你现在就只能靠自己了。你必须找到能让你完成实际工作的生产力软件。如果你像我一样,主要使用微软的服务,准备好接受一大堆的挫折吧。
微软目前没有任何适用于 Linux 的 Office 应用程序,所以你需要从 Web 浏览器访问你的文件。(是的,有 Linux 的 Office 克 隆版,包括 LibreOffice 套件,它是微软 Office 2007 的忠实克隆版。它……勉强够用。)
在 Ubuntu Linux 20.04 中,我可以直接连接 Google Drive,这样那些云端备份的文件就直接出现在文件应用中。还可以使用一个易于安装的 Dropbox 应用。但是 OneDrive 呢?那就不一定了。有一个开源的第三方同步客户端,但安装时需要半打以上的依赖包,我没有耐心也没有信心完成这个过程。
Ubuntu Linux 中的默认浏览器是 Mozilla Firefox,它在 18.04.3 LTS 版本上工作得足够好,但在 20.04 版本中却很卡顿。微软表示,它计划为 Linux 发布基于 Chromium 的新 Edge,但到目前为止,这还只是一个排期。从好的方面来看,有一个做得非常好的微软 Teams 客户端,它可以提供一个原生的 .deb 包来安装。
虽然整体体验出乎意料的流畅,但有太多的时刻,运行 Linux 对我来说感觉略显磕磕绊绊。比如在 20.04 版本中,Firefox 会将包文件下载到一个临时文件夹,在那里无法正常打开。当我弄清楚我必须把这些文件移到下载目录下,一切都好了。(请注意, Google Chrome 浏览器的下载会默认到正确的位置。)
另一方面,如果你的工作日是在谷歌生态系统中度过的,Linux 可能会感到非常舒适。在安装 Chrome 浏览器和设置 G Suite 之后,这个虚拟机基本上就是一个略显廉价的 Chromebook。
我是不是要改用 Linux 作为主要操作系统?呃,不会。但我会让这些虚拟机继续服务,并定期检查。因为你永远不知道会……
---
via: <https://www.zdnet.com/article/microsoft-helped-me-install-ubuntu-linux-on-my-windows-10-pc-and-its-actually-pretty-good/>
作者:[Ed Bott](https://www.zdnet.com/meet-the-team/us/ed-bott/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12677-1.html) 荣誉推出
| 200 | OK | # Microsoft helped me install Ubuntu Linux on my Windows 10 PC, and it's actually pretty good

If you've ever suffered through a painful Windows update or watched in disbelief as your MacBook decided to slow to a crawl and switch its fan into jumbo-jet-at-takeoff mode, you know that there's one and only one answer to your woes: "Switch to Linux."
I kid, of course, but you'll find that advice offered in earnest if you scroll through the comments here at *ZDNet*, where an army of open source evangelists regularly preaches the Gospel of Saint Linus in response to even the most vaguely related bit of news about other platforms.
**Also: ****Open source's Eric Raymond: Windows 10 will soon be just an emulation layer on Linux kernel**** **
And you know what? I think those commenters have a legitimate point. Anyone who aspires to understand the modern computing landscape should have some experience with platforms other than the one they use regularly because a lot of what you see in Windows, MacOS, and Linux today comes from the same DNA.
In the interest of keeping up with what's new in Linux, I go through this exercise myself every year or two. So, imagine my surprise when this year I was able to build a functional Ubuntu Linux machine in minutes, without disturbing my current Windows 10 setup. Even more surprising: Microsoft did most of the work.
The magic that made all this possible is the Hyper-V virtualization software included with every PC running Windows 10 Pro or Enterprise. (Sorry, Windows 10 Home users, you're going to have to upgrade if you want to play along.) Hyper-V's Quick Create gallery, which can build a new virtual machine in just a few clicks, includes not one but three separate Ubuntu images, including the new Ubuntu 20.04 version.
The Hyper-V Quick Create utility includes three Ubunutu Linux versions
Best of all, these custom images are capable of running in a Hyper-V *enhanced session*, which means you can choose a custom display resolution or run in a full screen, even spanning multiple monitors, with a performance that's close to what you'd get running on bare metal. In an enhanced session, your virtual machine can share the Windows Clipboard, local storage, and audio hardware on the host machine.
Once you get everything working, you can fire up that Ubuntu VM in full-screen mode and work with it just as if the Windows 10 host machine weren't there.
**Must read:**
[Microsoft: Linux GUI apps coming to Windows 10 WSL along with GPU access](https://www.zdnet.com/article/microsoft-linux-gui-apps-coming-to-windows-10-wsl-along-with-gpu-access/)[Desktop Linux: Why open source is heading for a new breakthrough](https://www.techrepublic.com/article/desktop-linux-why-open-source-is-heading-for-a-new-breakthrough/)**TechRepublic**[Linux-based Windows makes perfect sense](https://www.zdnet.com/article/linux-based-windows-makes-perfect-sense/)
Alas, that part about getting everything working isn't just a figure of speech. The good news is that the two-year-old [Ubuntu 18.04.3 Long Term Support (LTS)](https://www.zdnet.com/article/linux-on-windows-10-running-ubuntu-vms-just-got-a-lot-easier-says-microsoft/) version worked perfectly, with no futzing required. But the two newer releases had me tearing my hair out. I needed to manually edit a protected Linux configuration file before I could get an enhanced session to work in the latest [Ubuntu release (20.04), ](https://www.zdnet.com/article/ubuntu-20-04-arrives-with-linux-5-4-kernel-and-wireguard-vpn/)and the version 19.10 VM hung several times and required at least a dozen restarts (including a few hard resets) before it worked as expected.
Still, after all was said and done, I had three working virtual machines, giving me a pretty decent overview of what's new in Ubuntu Linux.
*Update, June 5, 2020: Via Twitter, Hayden Barnes, Developer Advocate for Ubuntu on WSL and Hyper-V at @Canonical, says, "We know about the xrdp bug in 19.10 and 20.04. The 20.04 image will be patched in the upcoming 20.04.1 LTS update. 19.10 is nearing EOL and will be dropped."*
*Update 2, October 1, 2020: The 20.04.1 LTS desktop Ubuntu image was released on July 31, 2020, but as of October 1 it has not yet been integrated into the Quick Create image in Hyper-V. *
*Also, as my colleague Mary Branscombe notes, all editions of Windows 10, including Home, offer access to the Windows Subsystem for Linux, which runs the Linux kernel in a lightweight virtual machine and has been freshly updated to WSL2 as of Windows 10 version 2004. As the WSL2 documentation makes clear, this is not a traditional VM experience and it's best suited for developers who want a command line experience and the ability to run Bash shell scripts and GNU/Linux command-line applications. The ability to run graphical apps in the WSL2 environment is on Microsoft's roadmap and should be available for testing by Windows Insiders in late 2020 or early 2021.*
If you'd like to try setting up one or more Ubuntu VMs in Windows 10 for your own experimentation, follow these steps.
### 1. Enable the Hyper-V Platform
This hypervisor is built into all 64-bit Windows 10 Pro, Enterprise, and Education editions, but it's not enabled by default. You might need to turn on some firmware options on older PCs before you can enable the feature. For full instructions, see ["Windows 10: How to enable Hyper-V and create virtual machines."](https://www.zdnet.com/article/windows-10-tip-how-to-enable-hyper-v-and-create-virtual-machines/)
### 2. Use Quick Create to download and install the Ubuntu VM
Hyper-V offers two ways to create a new virtual machine. The old fashioned way is to click your way through a tedious multi-step wizard. The much easier solution is to use the Hyper-V Quick Create utility. You'll find a shortcut in the right pane in Hyper-V Manager, or you can open it directly using the Vmcreate.exe command in the Windows 10 search box.
Choose an Ubuntu version from the gallery on the left, then click the Create Virtual Machine button. That kicks off a download of between 1.6GB (18.04.3 LTS) and 2GB (more recent versions). After the download is complete, the Quick Create utility extracts the image, configures the VM, and then displays a dialog box telling you your virtual machine was created successfully.
I recommend you edit a few settings before running the VN for the first time.
### 3. Tweak a few settings
Although you can get started immediately by clicking Connect, if you have sufficient resources on your Windows 10 host machine, I recommend that you click Edit Settings instead, so you can make a few adjustments first.
Choose Memory from the hardware list for your new VM, and then change the assigned RAM from its default value of 2048 to 4096, which should result in better performance. You can also disable dynamic memory if you want a fixed amount of virtual RAM. You might also want to increase the size of the system disk from its default 12GB. Click Hard Drive, then click Edit, and follow the prompts till you reach the Expand command.
Feel free to tweak the memory assigned to your Linux VM
Finally, under the Management heading, click Checkpoints and then clear the Use Automatic Checkpoints box. (You can always create a checkpoint manually if you want the ability to roll back changes.)
With those adjustments out of the way, you can close the Settings dialog box and open the VM for the first time.
### 4. Set up your user account
Run through the system configuration for Ubuntu, choosing your default language, time zone, and so on. When you get to the screen where you create your login credentials, leave the default setting at **Require my password to log in**.
Although it sounds convenient, do not enable the auto-login feature. If you choose this option, you won't be able to sign in using an enhanced session, and your VM will be forced to run in a relatively small window with a default resolution that you can't easily change.
This is also a good time to run the Software Updater app and get the latest Ubuntu updates. (Click the waffle icon in the lower-left corner and use the search box to find the app.)
### 5. Sign in using an enhanced session
You'll know you've started an enhanced session if you see this dialog box in the VM Connect window.
Move that slider to the far right to run your VM in a full screen
Slide the switch to choose your display resolution. I prefer to move the slider to the right, to the Full Screen position. If you have multiple monitors and you want your VM to span across them, select the Use All My Monitors checkbox. Click Connect to continue, which opens the Xrdp sign-in dialog box, shown here.
Sign in to Xrdp to launch your enhanced Hyper-V session
Enter the username and password you set up when creating your Ubuntu Linux account and click OK. Assuming the gods are not angry, you'll sign in to your VM and can get to work. You might have to enter your password a second time if you're not already signed in on the session that you're connecting to. (If you get a black screen, try pressing Enter.)
All of that should work just fine if you started with an 18.04.3 LTS VM. If you're using Ubuntu 19.10, you might have to go through the same frustrating sequence of restarts that I did before everything works properly.
### Linux
For Ubuntu 20.04, everything worked just fine in a basic session, but the option to run an enhanced session wasn't available until I edited the Xrdp.ini file in /etc/xrdp. This is a protected location, so I had to open an editor with an administrator's credentials, a task which is neither intuitive nor easy.
I had to change two lines in that ini file. First, change port=3389 to port=vsock://-1:3389. Then change use_vsock=true to use_vsock=false. Close the Vmconnect window and connect to the VM again and you should be able to start an enhanced session. But you might also be required to invoke some minor deities and burn some incense. It's Linux, after all.
(As I noted earlier, the Canonical/Microsoft team will have a fix for that image with the 20.04.1 update, so the xrdp.ini file won't require editing.)
And you're now on your own. You'll have to find productivity software that allows you to get actual work done. If you're like me and use mostly Microsoft services, prepare for a heaping helping of frustration.
Microsoft doesn't currently have any Office apps for Linux, so you'll need to access your files from a web browser. (Yes, there are Office clones for Linux, including the LibreOffice suite, which is a faithful clone of Microsoft Office 2007. It's... barely adequate.)
**Must read:**
[Look what's inside Linus Torvalds' latest Linux development PC](https://www.zdnet.com/article/look-whats-inside-linus-torvalds-latest-linux-development-pc/)[New fuzzing tool finds 26 USB bugs in Linux, Windows, macOS, and FreeBSD](https://www.zdnet.com/article/new-fuzzing-tool-finds-26-usb-bugs-in-linux-windows-macos-and-freebsd/)[Microsoft's Windows Package Manager: This command-line tool can install all your apps](https://www.zdnet.com/article/microsofts-windows-package-manager-this-command-line-tool-can-install-all-your-apps/)
In Ubuntu Linux 20.04, I was able to connect Google Drive directly, so that those cloud-backed files appeared directly in the Files app. An easy-to-install Dropbox app was also available. But OneDrive? Not so much. There's an open source third-party sync client, but the installation required more than a half-dozen dependent packages, and I didn't have the patience or the confidence to complete the process.
The default browser in Ubuntu Linux is Mozilla Firefox, which worked well enough on the 18.04.3 LTS version but was jerky in the 20.04 release. Microsoft says it plans to release its new Chromium-based Edge for Linux, but so far that's just a pipe dream. On the plus side, there's a very well done [Microsoft Teams client](https://www.zdnet.com/article/microsoft-teams-for-linux-now-available-in-public-preview/) that installs as a native .deb package.
Although the overall experience is surprisingly smooth, there were too many moments when running Linux felt slightly janky for me. In the 20.04 release, for example, Firefox downloads package files to a temp folder, where they won't open properly. Once I figured out that I had to move those files to the Downloads directory, everything was fine. (Note that Google Chrome downloads go to the correct location by default.)
If, on the other hand, your workday is spent in the Google ecosystem, Linux will probably feel very comfortable. After installing Chrome and setting up G Suite, this VM is basically a slightly snooty Chromebook.
Am I going to switch to Linux as my primary operating system? Uh, no. But I will keep these VMs in service and check in regularly. Because you never know...
#### Windows
[Editorial standards](/editorial-guidelines/) |
12,680 | 构建一个即时消息应用(四):消息 | https://nicolasparada.netlify.com/posts/go-messenger-messages/ | 2020-10-04T11:45:50 | [
"即时消息"
] | https://linux.cn/article-12680-1.html | 
本文是该系列的第四篇。
* [第一篇: 模式](/article-11396-1.html)
* [第二篇: OAuth](/article-11510-1.html)
* [第三篇: 对话](/article-12056-1.html)
在这篇文章中,我们将对端点进行编码,以创建一条消息并列出它们,同时还将编写一个端点以更新参与者上次阅读消息的时间。 首先在 `main()` 函数中添加这些路由。
```
router.HandleFunc("POST", "/api/conversations/:conversationID/messages", requireJSON(guard(createMessage)))
router.HandleFunc("GET", "/api/conversations/:conversationID/messages", guard(getMessages))
router.HandleFunc("POST", "/api/conversations/:conversationID/read_messages", guard(readMessages))
```
消息会进入对话,因此端点包含对话 ID。
### 创建消息
该端点处理对 `/api/conversations/{conversationID}/messages` 的 POST 请求,其 JSON 主体仅包含消息内容,并返回新创建的消息。它有两个副作用:更新对话 `last_message_id` 以及更新参与者 `messages_read_at`。
```
func createMessage(w http.ResponseWriter, r *http.Request) {
var input struct {
Content string `json:"content"`
}
defer r.Body.Close()
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
errs := make(map[string]string)
input.Content = removeSpaces(input.Content)
if input.Content == "" {
errs["content"] = "Message content required"
} else if len([]rune(input.Content)) > 480 {
errs["content"] = "Message too long. 480 max"
}
if len(errs) != 0 {
respond(w, Errors{errs}, http.StatusUnprocessableEntity)
return
}
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
conversationID := way.Param(ctx, "conversationID")
tx, err := db.BeginTx(ctx, nil)
if err != nil {
respondError(w, fmt.Errorf("could not begin tx: %v", err))
return
}
defer tx.Rollback()
isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
if err != nil {
respondError(w, fmt.Errorf("could not query participant existance: %v", err))
return
}
if !isParticipant {
http.Error(w, "Conversation not found", http.StatusNotFound)
return
}
var message Message
if err := tx.QueryRowContext(ctx, `
INSERT INTO messages (content, user_id, conversation_id) VALUES
($1, $2, $3)
RETURNING id, created_at
`, input.Content, authUserID, conversationID).Scan(
&message.ID,
&message.CreatedAt,
); err != nil {
respondError(w, fmt.Errorf("could not insert message: %v", err))
return
}
if _, err := tx.ExecContext(ctx, `
UPDATE conversations SET last_message_id = $1
WHERE id = $2
`, message.ID, conversationID); err != nil {
respondError(w, fmt.Errorf("could not update conversation last message ID: %v", err))
return
}
if err = tx.Commit(); err != nil {
respondError(w, fmt.Errorf("could not commit tx to create a message: %v", err))
return
}
go func() {
if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
log.Printf("could not update messages read at: %v\n", err)
}
}()
message.Content = input.Content
message.UserID = authUserID
message.ConversationID = conversationID
// TODO: notify about new message.
message.Mine = true
respond(w, message, http.StatusCreated)
}
```
首先,它将请求正文解码为包含消息内容的结构。然后,它验证内容不为空并且少于 480 个字符。
```
var rxSpaces = regexp.MustCompile("\\s+")
func removeSpaces(s string) string {
if s == "" {
return s
}
lines := make([]string, 0)
for _, line := range strings.Split(s, "\n") {
line = rxSpaces.ReplaceAllLiteralString(line, " ")
line = strings.TrimSpace(line)
if line != "" {
lines = append(lines, line)
}
}
return strings.Join(lines, "\n")
}
```
这是删除空格的函数。它遍历每一行,删除两个以上的连续空格,然后回非空行。
验证之后,它将启动一个 SQL 事务。首先,它查询对话中的参与者是否存在。
```
func queryParticipantExistance(ctx context.Context, tx *sql.Tx, userID, conversationID string) (bool, error) {
if ctx == nil {
ctx = context.Background()
}
var exists bool
if err := tx.QueryRowContext(ctx, `SELECT EXISTS (
SELECT 1 FROM participants
WHERE user_id = $1 AND conversation_id = $2
)`, userID, conversationID).Scan(&exists); err != nil {
return false, err
}
return exists, nil
}
```
我将其提取到一个函数中,因为稍后可以重用。
如果用户不是对话参与者,我们将返回一个 `404 NOT Found` 错误。
然后,它插入消息并更新对话 `last_message_id`。从这时起,由于我们不允许删除消息,因此 `last_message_id` 不能为 `NULL`。
接下来提交事务,并在 goroutine 中更新参与者 `messages_read_at`。
```
func updateMessagesReadAt(ctx context.Context, userID, conversationID string) error {
if ctx == nil {
ctx = context.Background()
}
if _, err := db.ExecContext(ctx, `
UPDATE participants SET messages_read_at = now()
WHERE user_id = $1 AND conversation_id = $2
`, userID, conversationID); err != nil {
return err
}
return nil
}
```
在回复这条新消息之前,我们必须通知一下。这是我们将要在下一篇文章中编写的实时部分,因此我在那里留一了个注释。
### 获取消息
这个端点处理对 `/api/conversations/{conversationID}/messages` 的 GET 请求。 它用一个包含会话中所有消息的 JSON 数组进行响应。它还具有更新参与者 `messages_read_at` 的副作用。
```
func getMessages(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
conversationID := way.Param(ctx, "conversationID")
tx, err := db.BeginTx(ctx, &sql.TxOptions{ReadOnly: true})
if err != nil {
respondError(w, fmt.Errorf("could not begin tx: %v", err))
return
}
defer tx.Rollback()
isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
if err != nil {
respondError(w, fmt.Errorf("could not query participant existance: %v", err))
return
}
if !isParticipant {
http.Error(w, "Conversation not found", http.StatusNotFound)
return
}
rows, err := tx.QueryContext(ctx, `
SELECT
id,
content,
created_at,
user_id = $1 AS mine
FROM messages
WHERE messages.conversation_id = $2
ORDER BY messages.created_at DESC
`, authUserID, conversationID)
if err != nil {
respondError(w, fmt.Errorf("could not query messages: %v", err))
return
}
defer rows.Close()
messages := make([]Message, 0)
for rows.Next() {
var message Message
if err = rows.Scan(
&message.ID,
&message.Content,
&message.CreatedAt,
&message.Mine,
); err != nil {
respondError(w, fmt.Errorf("could not scan message: %v", err))
return
}
messages = append(messages, message)
}
if err = rows.Err(); err != nil {
respondError(w, fmt.Errorf("could not iterate over messages: %v", err))
return
}
if err = tx.Commit(); err != nil {
respondError(w, fmt.Errorf("could not commit tx to get messages: %v", err))
return
}
go func() {
if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
log.Printf("could not update messages read at: %v\n", err)
}
}()
respond(w, messages, http.StatusOK)
}
```
首先,它以只读模式开始一个 SQL 事务。检查参与者是否存在,并查询所有消息。在每条消息中,我们使用当前经过身份验证的用户 ID 来了解用户是否拥有该消息(`mine`)。 然后,它提交事务,在 goroutine 中更新参与者 `messages_read_at` 并以消息响应。
### 读取消息
该端点处理对 `/api/conversations/{conversationID}/read_messages` 的 POST 请求。 没有任何请求或响应主体。 在前端,每次有新消息到达实时流时,我们都会发出此请求。
```
func readMessages(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
conversationID := way.Param(ctx, "conversationID")
if err := updateMessagesReadAt(ctx, authUserID, conversationID); err != nil {
respondError(w, fmt.Errorf("could not update messages read at: %v", err))
return
}
w.WriteHeader(http.StatusNoContent)
}
```
它使用了与更新参与者 `messages_read_at` 相同的函数。
---
到此为止。实时消息是后台仅剩的部分了。请等待下一篇文章。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-messages/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,681 | 使用 gosec 检查 Go 代码中的安全问题 | https://opensource.com/article/20/9/gosec | 2020-10-04T12:51:53 | [
"Golang",
"安全"
] | https://linux.cn/article-12681-1.html |
>
> 来学习下 Go 语言的安全检查工具 gosec。
>
>
>

[Go 语言](https://golang.org/)写的代码越来越常见,尤其是在容器、Kubernetes 或云生态相关的开发中。Docker 是最早采用 Golang 的项目之一,随后是 Kubernetes,之后大量的新项目在众多编程语言中选择了 Go。
像其他语言一样,Go 也有它的长处和短处(如安全缺陷)。这些缺陷可能会因为语言本身的缺陷加上程序员编码不当而产生,例如,C 代码中的内存安全问题。
无论它们出现的原因是什么,安全问题都应该在开发过程的早期修复,以免在封装好的软件中出现。幸运的是,静态分析工具可以帮你以更可重复的方式处理这些问题。静态分析工具通过解析用某种编程语言写的代码来找到问题。
这类工具中很多被称为 linter。传统意义上,linter 更注重的是检查代码中编码问题、bug、代码风格之类的问题,它们可能不会发现代码中的安全问题。例如,[Coverity](https://www.synopsys.com/software-integrity/security-testing/static-analysis-sast.html) 是一个很流行的工具,它可以帮助寻找 C/C++ 代码中的问题。然而,也有一些工具专门用来检查源码中的安全问题。例如,[Bandit](https://pypi.org/project/bandit/) 可以检查 Python 代码中的安全缺陷。而 [gosec](https://github.com/securego/gosec) 则用来搜寻 Go 源码中的安全缺陷。`gosec` 通过扫描 Go 的 AST(<ruby> 抽象语法树 <rt> abstract syntax tree </rt></ruby>)来检查源码中的安全问题。
### 开始使用 gosec
在开始学习和使用 `gosec` 之前,你需要准备一个 Go 语言写的项目。有这么多开源软件,我相信这不是问题。你可以在 GitHub 的 [热门 Golang 仓库](https://github.com/trending/go)中找一个。
本文中,我随机选了 [Docker CE](https://github.com/docker/docker-ce) 项目,但你可以选择任意的 Go 项目。
#### 安装 Go 和 gosec
如果你还没安装 Go,你可以先从仓库中拉取下来。如果你用的是 Fedora 或其他基于 RPM 的 Linux 发行版本:
```
$ dnf install golang.x86_64
```
如果你用的是其他操作系统,请参照 [Golang 安装](https://golang.org/doc/install)页面。
使用 `version` 参数来验证 Go 是否安装成功:
```
$ go version
go version go1.14.6 linux/amd64
```
运行 `go get` 命令就可以轻松地安装 `gosec`:
```
$ go get github.com/securego/gosec/cmd/gosec
```
上面这行命令会从 GitHub 下载 `gosec` 的源码,编译并安装到指定位置。在仓库的 `README` 中你还可以看到[安装该工具的其他方法](https://github.com/securego/gosec#install)。
`gosec` 的源码会被下载到 `$GOPATH` 的位置,编译出的二进制文件会被安装到你系统上设置的 `bin` 目录下。你可以运行下面的命令来查看 `$GOPATH` 和 `$GOBIN` 目录:
```
$ go env | grep GOBIN
GOBIN="/root/go/gobin"
$ go env | grep GOPATH
GOPATH="/root/go"
```
如果 `go get` 命令执行成功,那么 `gosec` 二进制应该就可以使用了:
```
$ ls -l ~/go/bin/
total 9260
-rwxr-xr-x. 1 root root 9482175 Aug 20 04:17 gosec
```
你可以把 `$GOPATH` 下的 `bin` 目录添加到 `$PATH` 中。这样你就可以像使用系统上的其他命令一样来使用 `gosec` 命令行工具(CLI)了。
```
$ which gosec
/root/go/bin/gosec
$
```
使用 `gosec` 命令行工具的 `-help` 选项来看看运行是否符合预期:
```
$ gosec -help
gosec - Golang security checker
gosec analyzes Go source code to look for common programming mistakes that
can lead to security problems.
VERSION: dev
GIT TAG:
BUILD DATE:
USAGE:
```
之后,创建一个目录,把源码下载到这个目录作为实例项目(本例中,我用的是 Docker CE):
```
$ mkdir gosec-demo
$ cd gosec-demo/
$ pwd
/root/gosec-demo
$ git clone https://github.com/docker/docker-ce.git
Cloning into 'docker-ce'...
remote: Enumerating objects: 1271, done.
remote: Counting objects: 100% (1271/1271), done.
remote: Compressing objects: 100% (722/722), done.
remote: Total 431003 (delta 384), reused 981 (delta 318), pack-reused 429732
Receiving objects: 100% (431003/431003), 166.84 MiB | 28.94 MiB/s, done.
Resolving deltas: 100% (221338/221338), done.
Updating files: 100% (10861/10861), done.
```
代码统计工具(本例中用的是 `cloc`)显示这个项目大部分是用 Go 写的,恰好迎合了 `gosec` 的功能。
```
$ ./cloc /root/gosec-demo/docker-ce/
10771 text files.
8724 unique files.
2560 files ignored.
-----------------------------------------------------------------------------------
Language files blank comment code
-----------------------------------------------------------------------------------
Go 7222 190785 230478 1574580
YAML 37 4831 817 156762
Markdown 529 21422 0 67893
Protocol Buffers 149 5014 16562 10071
```
### 使用默认选项运行 gosec
在 Docker CE 项目中使用默认选项运行 `gosec`,执行 `gosec ./...` 命令。屏幕上会有很多输出内容。在末尾你会看到一个简短的 “Summary”,列出了浏览的文件数、所有文件的总行数,以及源码中发现的问题数。
```
$ pwd
/root/gosec-demo/docker-ce
$ time gosec ./...
[gosec] 2020/08/20 04:44:15 Including rules: default
[gosec] 2020/08/20 04:44:15 Excluding rules: default
[gosec] 2020/08/20 04:44:15 Import directory: /root/gosec-demo/docker-ce/components/engine/opts
[gosec] 2020/08/20 04:44:17 Checking package: opts
[gosec] 2020/08/20 04:44:17 Checking file: /root/gosec-demo/docker-ce/components/engine/opts/address_pools.go
[gosec] 2020/08/20 04:44:17 Checking file: /root/gosec-demo/docker-ce/components/engine/opts/env.go
[gosec] 2020/08/20 04:44:17 Checking file: /root/gosec-demo/docker-ce/components/engine/opts/hosts.go
# End of gosec run
Summary:
Files: 1278
Lines: 173979
Nosec: 4
Issues: 644
real 0m52.019s
user 0m37.284s
sys 0m12.734s
$
```
滚动屏幕你会看到不同颜色高亮的行:红色表示需要尽快查看的高优先级问题,黄色表示中优先级的问题。
#### 关于误判
在开始检查代码之前,我想先分享几条基本原则。默认情况下,静态检查工具会基于一系列的规则对测试代码进行分析,并报告出它们发现的*所有*问题。这是否意味着工具报出来的每一个问题都需要修复?非也。这个问题最好的解答者是设计和开发这个软件的人。他们最熟悉代码,更重要的是,他们了解软件会在什么环境下部署以及会被怎样使用。
这个知识点对于判定工具标记出来的某段代码到底是不是安全缺陷至关重要。随着工作时间和经验的积累,你会慢慢学会怎样让静态分析工具忽略非安全缺陷,使报告内容的可执行性更高。因此,要判定 `gosec` 报出来的某个问题是否需要修复,让一名有经验的开发者对源码做人工审计会是比较好的办法。
#### 高优先级问题
从输出内容看,`gosec` 发现了 Docker CE 的一个高优先级问题,它使用的是低版本的 TLS(<ruby> 传输层安全 <rt> Transport Layer Security </rt> <rt> </rt></ruby>)。无论什么时候,使用软件和库的最新版本都是确保它更新及时、没有安全问题的最好的方法。
```
[/root/gosec-demo/docker-ce/components/engine/daemon/logger/splunk/splunk.go:173] - G402 (CWE-295): TLS MinVersion too low. (Confidence: HIGH, Severity: HIGH)
172:
> 173: tlsConfig := &tls.Config{}
174:
```
它还发现了一个弱随机数生成器。它是不是一个安全缺陷,取决于生成的随机数的使用方式。
```
[/root/gosec-demo/docker-ce/components/engine/pkg/namesgenerator/names-generator.go:843] - G404 (CWE-338): Use of weak random number generator (math/rand instead of crypto/rand) (Confidence: MEDIUM, Severity: HIGH)
842: begin:
> 843: name := fmt.Sprintf("%s_%s", left[rand.Intn(len(left))], right[rand.Intn(len(right))])
844: if name == "boring_wozniak" /* Steve Wozniak is not boring */ {
```
#### 中优先级问题
这个工具还发现了一些中优先级问题。它标记了一个通过与 `tar` 相关的解压炸弹这种方式实现的潜在的 DoS 威胁,这种方式可能会被恶意的攻击者利用。
```
[/root/gosec-demo/docker-ce/components/engine/pkg/archive/copy.go:357] - G110 (CWE-409): Potential DoS vulnerability via decompression bomb (Confidence: MEDIUM, Severity: MEDIUM)
356:
> 357: if _, err = io.Copy(rebasedTar, srcTar); err != nil {
358: w.CloseWithError(err)
```
它还发现了一个通过变量访问文件的问题。如果恶意使用者能访问这个变量,那么他们就可以改变变量的值去读其他文件。
```
[/root/gosec-demo/docker-ce/components/cli/cli/context/tlsdata.go:80] - G304 (CWE-22): Potential file inclusion via variable (Confidence: HIGH, Severity: MEDIUM)
79: if caPath != "" {
> 80: if ca, err = ioutil.ReadFile(caPath); err != nil {
81: return nil, err
```
文件和目录通常是操作系统安全的最基础的元素。这里,`gosec` 报出了一个可能需要你检查目录的权限是否安全的问题。
```
[/root/gosec-demo/docker-ce/components/engine/contrib/apparmor/main.go:41] - G301 (CWE-276): Expect directory permissions to be 0750 or less (Confidence: HIGH, Severity: MEDIUM)
40: // make sure /etc/apparmor.d exists
> 41: if err := os.MkdirAll(path.Dir(apparmorProfilePath), 0755); err != nil {
42: log.Fatal(err)
```
你经常需要在源码中启动命令行工具。Go 使用内建的 exec 库来实现。仔细地分析用来调用这些工具的变量,就能发现安全缺陷。
```
[/root/gosec-demo/docker-ce/components/engine/testutil/fakestorage/fixtures.go:59] - G204 (CWE-78): Subprocess launched with variable (Confidence: HIGH, Severity: MEDIUM)
58:
> 59: cmd := exec.Command(goCmd, "build", "-o", filepath.Join(tmp, "httpserver"), "github.com/docker/docker/contrib/httpserver")
60: cmd.Env = append(os.Environ(), []string{
```
#### 低优先级问题
在这个输出中,gosec 报出了一个 `unsafe` 调用相关的低优先级问题,这个调用会绕开 Go 提供的内存保护。再仔细分析下你调用 `unsafe` 的方式,看看是否有被别人利用的可能性。
```
[/root/gosec-demo/docker-ce/components/engine/pkg/archive/changes_linux.go:264] - G103 (CWE-242): Use of unsafe calls should be audited (Confidence: HIGH, Severity: LOW)
263: for len(buf) > 0 {
> 264: dirent := (*unix.Dirent)(unsafe.Pointer(&buf[0]))
265: buf = buf[dirent.Reclen:]
[/root/gosec-demo/docker-ce/components/engine/pkg/devicemapper/devmapper_wrapper.go:88] - G103 (CWE-242): Use of unsafe calls should be audited (Confidence: HIGH, Severity: LOW)
87: func free(p *C.char) {
> 88: C.free(unsafe.Pointer(p))
89: }
```
它还标记了源码中未处理的错误。源码中出现的错误你都应该处理。
```
[/root/gosec-demo/docker-ce/components/cli/cli/command/image/build/context.go:172] - G104 (CWE-703): Errors unhandled. (Confidence: HIGH, Severity: LOW)
171: err := tar.Close()
> 172: os.RemoveAll(dockerfileDir)
173: return err
```
### 自定义 gosec 扫描
使用 `gosec` 的默认选项会带来很多的问题。然而,经过人工审计,随着时间推移你会掌握哪些问题是不需要标记的。你可以自己指定排除和包含哪些测试。
我上面提到过,`gosec` 是基于一系列的规则从 Go 源码中查找问题的。下面是它使用的完整的[规则](https://github.com/securego/gosec#available-rules)列表:
* G101:查找硬编码凭证
* G102:绑定到所有接口
* G103:审计 `unsafe` 块的使用
* G104:审计未检查的错误
* G106:审计 `ssh.InsecureIgnoreHostKey` 的使用
* G107: 提供给 HTTP 请求的 url 作为污点输入
* G108: `/debug/pprof` 上自动暴露的剖析端点
* G109: `strconv.Atoi` 转换到 int16 或 int32 时潜在的整数溢出
* G110: 潜在的通过解压炸弹实现的 DoS
* G201:SQL 查询构造使用格式字符串
* G202:SQL 查询构造使用字符串连接
* G203:在 HTML 模板中使用未转义的数据
* G204:审计命令执行情况
* G301:创建目录时文件权限分配不合理
* G302:使用 `chmod` 时文件权限分配不合理
* G303:使用可预测的路径创建临时文件
* G304:通过污点输入提供的文件路径
* G305:提取 zip/tar 文档时遍历文件
* G306: 写到新文件时文件权限分配不合理
* G307: 把返回错误的函数放到 `defer` 内
* G401:检测 DES、RC4、MD5 或 SHA1 的使用
* G402:查找错误的 TLS 连接设置
* G403:确保最小 RSA 密钥长度为 2048 位
* G404:不安全的随机数源(`rand`)
* G501:导入黑名单列表:crypto/md5
* G502:导入黑名单列表:crypto/des
* G503:导入黑名单列表:crypto/rc4
* G504:导入黑名单列表:net/http/cgi
* G505:导入黑名单列表:crypto/sha1
* G601: 在 `range` 语句中使用隐式的元素别名
#### 排除指定的测试
你可以自定义 `gosec` 来避免对已知为安全的问题进行扫描和报告。你可以使用 `-exclude` 选项和上面的规则编号来忽略指定的问题。
例如,如果你不想让 `gosec` 检查源码中硬编码凭证相关的未处理的错误,那么你可以运行下面的命令来忽略这些错误:
```
$ gosec -exclude=G104 ./...
$ gosec -exclude=G104,G101 ./...
```
有时候你知道某段代码是安全的,但是 `gosec` 还是会报出问题。然而,你又不想完全排除掉整个检查,因为你想让 `gosec` 检查新增的代码。通过在你已知为安全的代码块添加 `#nosec` 标记可以避免 `gosec` 扫描。这样 `gosec` 会继续扫描新增代码,而忽略掉 `#nosec` 标记的代码块。
#### 运行指定的检查
另一方面,如果你只想检查指定的问题,你可以通过 `-include` 选项和规则编号来告诉 `gosec` 运行哪些检查:
```
$ gosec -include=G201,G202 ./...
```
#### 扫描测试文件
Go 语言自带对测试的支持,通过单元测试来检验一个元素是否符合预期。在默认模式下,`gosec` 会忽略测试文件,你可以使用 `-tests` 选项把它们包含进来:
```
gosec -tests ./...
```
#### 修改输出的格式
找出问题只是它的一半功能;另一半功能是把它检查到的问题以用户友好同时又方便工具处理的方式报告出来。幸运的是,`gosec` 可以用不同的方式输出。例如,如果你想看 JSON 格式的报告,那么就使用 `-fmt` 选项指定 JSON 格式并把结果保存到 `results.json` 文件中:
```
$ gosec -fmt=json -out=results.json ./...
$ ls -l results.json
-rw-r--r--. 1 root root 748098 Aug 20 05:06 results.json
$
{
"severity": "LOW",
"confidence": "HIGH",
"cwe": {
"ID": "242",
"URL": "https://cwe.mitre.org/data/definitions/242.html"
},
"rule_id": "G103",
"details": "Use of unsafe calls should be audited",
"file": "/root/gosec-demo/docker-ce/components/engine/daemon/graphdriver/graphtest/graphtest_unix.go",
"code": "304: \t// Cast to []byte\n305: \theader := *(*reflect.SliceHeader)(unsafe.Pointer(\u0026buf))\n306: \theader. Len *= 8\n",
"line": "305",
"column": "36"
},
```
### 用 gosec 检查容易被发现的问题
静态检查工具不能完全代替人工代码审计。然而,当代码量变大、有众多开发者时,这样的工具往往有助于以可重复的方式找出容易被发现的问题。它对于帮助新开发者识别和在编码时避免引入这些安全缺陷很有用。
---
via: <https://opensource.com/article/20/9/gosec>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbowlf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's extremely common now to encounter code written in the [Go programming language](https://golang.org/), especially if you are working with containers, Kubernetes, or a cloud ecosystem. Docker was one of the first projects to adopt Golang, Kubernetes followed, and many new projects select Go over other programming languages.
Like any other language, Go has its share of strengths and weaknesses, which include security flaws. These can arise due to issues in the programming language itself coupled with insecure coding practices, such as memory safety issues in C code, for example.
Regardless of why they occur, security issues need to be fixed early in development to prevent them from creeping into shipped software. Fortunately, static analysis tools are available to help you tackle these issues in a more repeatable manner. Static analysis tools work by parsing source code written in a programming language and looking for issues.
Many of these tools are called linters. Traditionally, linters are more focused on finding programming issues, bugs, code style issues, and the like, and they may not find security issues in code. For example, [Coverity](https://www.synopsys.com/software-integrity/security-testing/static-analysis-sast.html) is a popular tool that helps find issues in C/C++ code. However, there are tools that specifically seek out security issues in source code. For example, [Bandit](https://pypi.org/project/bandit/) looks for security flaws in Python code. And [gosec](https://github.com/securego/gosec) searches for security flaws in Go source code. Gosec scans the Go abstract syntax tree (AST) to inspect source code for security problems.
## Get started with gosec
To play around with gosec and learn how it works, you need a project written in Go. With a wide variety of open source software available, this shouldn't be a problem. You can find one by looking at the [trending Golang repositorties](https://github.com/trending/go) on GitHub.
For this tutorial, I randomly chose the [Docker CE](https://github.com/docker/docker-ce) project, but you can choose any Go project you want.
### Install Go and gosec
If you do not already have Go installed, you can fetch it from your repository. If you use Fedora or another RPM-based Linux distribution:
`$ dnf install golang.x86_64`
Or you can visit the [Golang install](https://golang.org/doc/install) page for other options for your operating system.
Verify that Go is installed on your system using the `version`
argument:
```
$ go version
go version go1.14.6 linux/amd64
$
```
Installing gosec is simply a matter of running the `go get`
command:
```
$ go get github.com/securego/gosec/cmd/gosec
$
```
This downloads gosec's source code from GitHub, compiles it, and installs it in a specific location. You can find [other ways of installing the tools](https://github.com/securego/gosec#install) in the repo's README.
Gosec's source code should be downloaded to the location set by `$GOPATH`
, and the compiled binary will be installed in the `bin`
directory you set for your system. To find out what `$GOPATH`
and `$GOBIN`
point to, run:
```
$ go env | grep GOBIN
GOBIN="/root/go/gobin"
$
$ go env | grep GOPATH
GOPATH="/root/go"
$
```
If the `go get`
command worked, then the gosec binary should be available:
```
$
$ ls -l ~/go/bin/
total 9260
-rwxr-xr-x. 1 root root 9482175 Aug 20 04:17 gosec
$
```
You can add the `bin`
directory in `$GOPATH`
to the `$PATH`
variable in your shell. This makes the gosec command-line interface (CLI) available just like any other command line on your system:
```
$ which gosec
/root/go/bin/gosec
$
```
Try running the gosec CLI with the `-help`
option to see if it is working as expected:
```
$ gosec -help
gosec - Golang security checker
gosec analyzes Go source code to look for common programming mistakes that
can lead to security problems.
VERSION: dev
GIT TAG:
BUILD DATE:
USAGE:
```
Next, create a directory and get the source code for the demo project (Docker CE, in this case) using:
```
$ mkdir gosec-demo
$
$ cd gosec-demo/
$
$ pwd
/root/gosec-demo
$
$ git clone https://github.com/docker/docker-ce.git
Cloning into 'docker-ce'...
remote: Enumerating objects: 1271, done.
remote: Counting objects: 100% (1271/1271), done.
remote: Compressing objects: 100% (722/722), done.
remote: Total 431003 (delta 384), reused 981 (delta 318), pack-reused 429732
Receiving objects: 100% (431003/431003), 166.84 MiB | 28.94 MiB/s, done.
Resolving deltas: 100% (221338/221338), done.
Updating files: 100% (10861/10861), done.
$
```
A quick look at the source code shows that most of the project is written in Go—just what you need to tinker with gosec's features:
```
$ ./cloc /root/gosec-demo/docker-ce/
10771 text files.
8724 unique files.
2560 files ignored.
-----------------------------------------------------------------------------------
Language files blank comment code
-----------------------------------------------------------------------------------
Go 7222 190785 230478 1574580
YAML 37 4831 817 156762
Markdown 529 21422 0 67893
Protocol Buffers 149 5014 16562 10071
```
## Run gosec with the default options
Run gosec on the Docker CE project using the default options by running `gosec ./...`
from within the Git repo you just cloned. A lot of output will be shown on the screen. Towards the end, you should see a short `Summary`
showing the number of files scanned, the number of lines in those files, and the issues it found in the source code:
```
$ pwd
/root/gosec-demo/docker-ce
$
$ time gosec ./...
[gosec] 2020/08/20 04:44:15 Including rules: default
[gosec] 2020/08/20 04:44:15 Excluding rules: default
[gosec] 2020/08/20 04:44:15 Import directory: /root/gosec-demo/docker-ce/components/engine/opts
[gosec] 2020/08/20 04:44:17 Checking package: opts
[gosec] 2020/08/20 04:44:17 Checking file: /root/gosec-demo/docker-ce/components/engine/opts/address_pools.go
[gosec] 2020/08/20 04:44:17 Checking file: /root/gosec-demo/docker-ce/components/engine/opts/env.go
[gosec] 2020/08/20 04:44:17 Checking file: /root/gosec-demo/docker-ce/components/engine/opts/hosts.go
# End of gosec run
Summary:
Files: 1278
Lines: 173979
Nosec: 4
Issues: 644
real 0m52.019s
user 0m37.284s
sys 0m12.734s
$
```
If you scroll through the output on the screen, you should see some lines highlighted in various colors: red indicates high-priority issues that need to be looked into first, and yellow indicates medium-priority issues.
### About false positives
Before getting into the findings, I want to share some ground rules. By default, static analysis tools report *everything* that they find to be an issue based on a set of rules that the tool compares against the code being tested. Does this mean that everything reported by the tool is an issue that needs to be fixed? Well, it depends. The best authorities on this question are the developers who designed and developed the software. They understand the code much better than anybody else, and more importantly, they understand the environment where the software will be deployed and how it will be used.
This knowledge is critical when deciding whether a piece of code flagged by a tool is actually a security flaw. Over time and with more experience, you will learn to tweak static analysis tools to ignore issues that are not security flaws and make the reports more actionable. So, an experienced developer doing a manual audit of the source code would be in a better position to decide whether an issue reported by gosec warrants attention or not.
### High-priority issues
According to the output, gosec found a high-priority issue that Docker CE is using an old Transport Layer Security (TLS) version. Whenever possible, it's best to use the latest version of a software or library to ensure it is up to date and has no security issues.
```
[/root/gosec-demo/docker-ce/components/engine/daemon/logger/splunk/splunk.go:173] - G402 (CWE-295): TLS MinVersion too low. (Confidence: HIGH, Severity: HIGH)
172:
> 173: tlsConfig := &tls.Config{}
174:
```
It also found a weak random number generator. Depending on how the generated random number is used, you can decide whether or not this is a security flaw.
```
[/root/gosec-demo/docker-ce/components/engine/pkg/namesgenerator/names-generator.go:843] - G404 (CWE-338): Use of weak random number generator (math/rand instead of crypto/rand) (Confidence: MEDIUM, Severity: HIGH)
842: begin:
> 843: name := fmt.Sprintf("%s_%s", left[rand.Intn(len(left))], right[rand.Intn(len(right))])
844: if name == "boring_wozniak" /* Steve Wozniak is not boring */ {
```
### Medium-priority issues
The tool also found some medium-priority issues. It flagged a potential denial of service (DoS) vulnerability by way of a decompression bomb related to a tar that could possibly be exploited by a malicious actor.
```
[/root/gosec-demo/docker-ce/components/engine/pkg/archive/copy.go:357] - G110 (CWE-409): Potential DoS vulnerability via decompression bomb (Confidence: MEDIUM, Severity: MEDIUM)
356:
> 357: if _, err = io.Copy(rebasedTar, srcTar); err != nil {
358: w.CloseWithError(err)
```
It also found an issue related to a file that is included by way of a variable. If malicious users take control of this variable, they could change its contents to read a different file.
```
[/root/gosec-demo/docker-ce/components/cli/cli/context/tlsdata.go:80] - G304 (CWE-22): Potential file inclusion via variable (Confidence: HIGH, Severity: MEDIUM)
79: if caPath != "" {
> 80: if ca, err = ioutil.ReadFile(caPath); err != nil {
81: return nil, err
```
File and directory permissions are often the basic building blocks of security on an operating system. Here, gosec identified an issue where you might need to check whether the permissions for a directory are secure or not.
```
[/root/gosec-demo/docker-ce/components/engine/contrib/apparmor/main.go:41] - G301 (CWE-276): Expect directory permissions to be 0750 or less (Confidence: HIGH, Severity: MEDIUM)
40: // make sure /etc/apparmor.d exists
> 41: if err := os.MkdirAll(path.Dir(apparmorProfilePath), 0755); err != nil {
42: log.Fatal(err)
```
Often, you need to launch command-line utilities from source code. Go uses the built-in exec library to do this task. Carefully analyzing the variable used to spawn such utilities can uncover security flaws.
```
[/root/gosec-demo/docker-ce/components/engine/testutil/fakestorage/fixtures.go:59] - G204 (CWE-78): Subprocess launched with variable (Confidence: HIGH, Severity: MEDIUM)
58:
> 59: cmd := exec.Command(goCmd, "build", "-o", filepath.Join(tmp, "httpserver"), "github.com/docker/docker/contrib/httpserver")
60: cmd.Env = append(os.Environ(), []string{
```
### Low-severity issues
In this output, gosec identified low-severity issues related to "unsafe" calls, which typically bypass all the memory protections that Go provides. Closely analyze your use of "unsafe" calls to see if they can be exploited in any way possible.
```
[/root/gosec-demo/docker-ce/components/engine/pkg/archive/changes_linux.go:264] - G103 (CWE-242): Use of unsafe calls should be audited (Confidence: HIGH, Severity: LOW)
263: for len(buf) > 0 {
> 264: dirent := (*unix.Dirent)(unsafe.Pointer(&buf[0]))
265: buf = buf[dirent.Reclen:]
[/root/gosec-demo/docker-ce/components/engine/pkg/devicemapper/devmapper_wrapper.go:88] - G103 (CWE-242): Use of unsafe calls should be audited (Confidence: HIGH, Severity: LOW)
87: func free(p *C.char) {
> 88: C.free(unsafe.Pointer(p))
89: }
```
It also flagged unhandled errors in the source codebase. You are expected to handle cases where errors could arise in the source code.
```
[/root/gosec-demo/docker-ce/components/cli/cli/command/image/build/context.go:172] - G104 (CWE-703): Errors unhandled. (Confidence: HIGH, Severity: LOW)
171: err := tar.Close()
> 172: os.RemoveAll(dockerfileDir)
173: return err
```
## Customize gosec scans
Using gosec with its defaults brings up many kinds of issues. However, with manual auditing and over time, you learn which issues don't need to be flagged. You can customize gosec to exclude or include certain tests.
As I mentioned above, gosec uses a set of rules to find problems in Go source code. Here is a complete list of the [rules](https://github.com/securego/gosec#available-rules) it uses:
- G101: Look for hard coded credentials
- G102: Bind to all interfaces
- G103: Audit the use of unsafe block
- G104: Audit errors not checked
- G106: Audit the use of ssh.InsecureIgnoreHostKey
- G107: Url provided to HTTP request as taint input
- G108: Profiling endpoint automatically exposed on /debug/pprof
- G109: Potential Integer overflow made by strconv.Atoi result conversion to int16/32
- G110: Potential DoS vulnerability via decompression bomb
- G201: SQL query construction using format string
- G202: SQL query construction using string concatenation
- G203: Use of unescaped data in HTML templates
- G204: Audit use of command execution
- G301: Poor file permissions used when creating a directory
- G302: Poor file permissions used with chmod
- G303: Creating tempfile using a predictable path
- G304: File path provided as taint input
- G305: File traversal when extracting zip/tar archive
- G306: Poor file permissions used when writing to a new file
- G307: Deferring a method which returns an error
- G401: Detect the usage of DES, RC4, MD5 or SHA1
- G402: Look for bad TLS connection settings
- G403: Ensure minimum RSA key length of 2048 bits
- G404: Insecure random number source (rand)
- G501: Import blocklist: crypto/md5
- G502: Import blocklist: crypto/des
- G503: Import blocklist: crypto/rc4
- G504: Import blocklist: net/http/cgi
- G505: Import blocklist: crypto/sha1
- G601: Implicit memory aliasing of items from a range statement
### Exclude specific tests
You can customize gosec to prevent it from looking for and reporting on issues that are safe. To ignore specific issues, you can use the `-exclude`
flag with the rule codes above.
For example, if you don't want gosec to find unhandled errors related to hardcoding credentials in source code, you can ignore them by running:
```
$ gosec -exclude=G104 ./...
$ gosec -exclude=G104,G101 ./...
```
Sometimes, you know an area of source code is safe, but gosec keeps reporting it as an issue. However, you don't want to exclude that check completely because you want gosec to scan new code added to the codebase. To prevent gosec from scanning the area you know is safe, add a `#nosec`
flag to that part of the source code. This ensures gosec continues to scan new code for an issue but ignores the area flagged with `#nosec`
.
### Run specific checks
On the other hand, if you need to focus on specific issues, you can use tell gosec to run those checks by using the `-include`
option with the rule codes:
`$ gosec -include=G201,G202 ./...`
### Scan test files
The Go language has built-in support for testing that uses unit tests to verify whether a component works as expected. In default mode, gosec ignores test files, but if you want them included in the scan, use the `-tests`
flag:
`gosec -tests ./...`
### Change the output format
Finding issues is only part of the picture; the other part is reporting what it finds in a way that is easy for humans and tools to consume. Fortunately, gosec can output results in a variety of ways. For example, if you want to get reports in JSON format, use the `-fmt`
option to specify JSON and save the results in a `results.json`
file:
```
$ gosec -fmt=json -out=results.json ./...
$ ls -l results.json
-rw-r--r--. 1 root root 748098 Aug 20 05:06 results.json
$
{
"severity": "LOW",
"confidence": "HIGH",
"cwe": {
"ID": "242",
"URL": "https://cwe.mitre.org/data/definitions/242.html"
},
"rule_id": "G103",
"details": "Use of unsafe calls should be audited",
"file": "/root/gosec-demo/docker-ce/components/engine/daemon/graphdriver/graphtest/graphtest_unix.go",
"code": "304: \t// Cast to []byte\n305: \theader := *(*reflect.SliceHeader)(unsafe.Pointer(\u0026buf))\n306: \theader. Len *= 8\n",
"line": "305",
"column": "36"
},
```
## Find low-hanging fruit with gosec
A static analysis tool is not a replacement for manual code audits. However, when a codebase is large with many people contributing to it, such a tool often helps find low-hanging fruit in a repeatable way. It is also useful for helping new developers identify and avoid writing code that introduces these security flaws.
## Comments are closed. |
12,683 | Windows 的 Linux 子系统(WSL)即将带来图形化应用 | https://www.zdnet.com/article/linux-graphical-apps-coming-to-windows-subsystem-for-linux/ | 2020-10-04T22:47:03 | [
"WSL"
] | https://linux.cn/article-12683-1.html |
>
> Windows 上的 Linux 正在继续发展,功能越来越强大。现在,图形化的 Linux 程序正在被整合到 WSL 中。
>
>
>

在微软 Build 2020 虚拟开发者大会上,微软 CEO 萨提亚·纳德拉宣布 Windows 的 Linux 子系统(WSL)2.0 [即将支持 Linux GUI 和应用程序](https://www.zdnet.com/article/microsoft-linux-gui-apps-coming-to-windows-10-wsl-along-with-gpu-access/)。现在这一天比以往任何时候都要近。在最近的 X.Org 开发者大会(XDC)上,微软合作伙伴开发者负责人 Steve Pronovost 透露,微软已经可以在 WSL 中运行图形化的 Linux 应用。
一直以来,虽然都可以在 WSL 上运行 [GIMP 图形编辑器](https://www.gimp.org/)、[Evolution 电子邮件客户端](https://wiki.gnome.org/Apps/Evolution)和 [LibreOffice](https://www.libreoffice.org/) 等 Linux 图形程序,但这并不容易。你必须安装一个第三方 X Window 显示服务器,比如 Windows 10 中的 [VcXsrv Windows X Server](https://sourceforge.net/projects/vcxsrv/),然后[对 Windows 和 Linux 做一些调整,让它们顺利地一起工作](https://techcommunity.microsoft.com/t5/windows-dev-appconsult/running-wsl-gui-apps-on-windows-10/ba-p/1493242)。[X Window 系统](http://www.opengroup.org/tech/desktop/x-window-system/)几乎是所有 Linux 图形用户界面的基础。
现在,微软已经将 [Wayland 显示服务器](https://www.linux-magazine.com/Online/Features/Is-Wayland-the-New-X)移植到 WSL 中。Wayland 是最流行的 X Window 兼容的显示服务器。在 WSL2 中,它通过远程桌面协议(RDP)连接将图形化的 Linux 应用程序连接到主 Windows 显示器上。这意味着你可以在同一个桌面屏幕上同时运行 Linux 和 Windows GUI 应用程序。
Pronovost 解释道:
>
> WSL 本质上是在 Windows 托管的虚拟机里面运行 Linux,我们将应用程序(控制台程序,现在还有 GUI 程序)整合回你的 Windows 桌面,这样你就可以在统一的体验里面同时运行 Win32 和 Linux 应用程序。由于 Linux 是在虚拟机中运行,我们不能运行期望直接访问 GPU 的原生 GPU 驱动程序(除非我们做一些类似于离散设备分配的事情,并将其中一个宿主机 GPU 分配给虚拟机......但那样宿主机将失去对该 GPU 的访问!)。有了[GPU-PV(GPU 准虚拟化)](https://petri.com/microsoft-announces-gpu-hardware-acceleration-and-gui-app-support-for-wsl-2-at-build-2020),我们基本上可以在 Linux 中投射宿主机 GPU,让 Linux 和 Windows 进程共享同一个物理 GPU,而不需要固定的资源分区。
>
>
>
微软 WSL 项目经理 Craig Loewen 在 Twitter 上补充道,使用第三方 X 服务器和内置 Wayland 服务器的关键区别在于。“[你不需要启动显示服务器](https://twitter.com/craigaloewen/status/1308452901266751488),我们会为你处理。”此外,它还带有“与 Windows 的完美集成”,例如投影和 Linux 图标支持。
Loewen 还表示,你可以在其中运行 Linux Web 浏览器。“我们还没有用完整的桌面环境(DE)对它进行充分测试,因为我们想先专注于运行经常被问及的应用,主要是 IDE(集成开发环境),这样你就可以在一个完整的 Linux 环境中运行这些应用,”他说。
不过,先别太兴奋。Loewen 继续说道:“我们还没有制定测试通道的时间表,不过,这项工作通常会在接下来几个月内提供给 Insiders 试用。”
[微软将 Linux 整合到 Windows 中](https://www.zdnet.com/article/2020-will-be-the-year-of-linux-on-the-windows-desktop/)已经有一段时间了。四年前,微软推出了 WSL,[将 Linux Bash shell 带到了 Windows 10 中](https://www.zdnet.com/article/microsoft-to-show-bash-on-linux-running-on-windows-10/)。通过 Bash 和 WSL,你可以运行大多数 [Linux shell 工具](http://blog.dustinkirkland.com/2016/03/ubuntu-on-windows.html)和流行的 Linux 编程语言。
随着时间的推移,Linux 更成为 Windows 桌面上的一等公民。多个 Linux 发行版,从 Ubuntu 开始,随后是红帽 Fedora 和 SUSE Linux 企业桌面版(SLED) 都进入了 Windows 商店。随后,微软用 WSL 2 取代了将 Linux 内核调用转换为 Windows 调用的 WSL 翻译层。这一更新是在精简版 Hyper-V 管理程序上运行的[微软自己的 Linux 内核](https://www.zdnet.com/article/hell-freezing-over-microsoft-releases-its-own-linux-for-windows/)附带的。
最近,[从 Windows 10 Insider Preview build 20211 开始,Windows 用户可以访问 Linux 文件系统](https://devblogs.microsoft.com/commandline/access-linux-filesystems-in-windows-and-wsl-2/)。这包括访问 Windows 本身不支持的 Linux 文件系统,例如 ext4。这也意味着,如果你用不同的磁盘双启动 Windows 和 Linux,现在可以从 Windows 访问 Linux 文件。有了这个功能,你可以通过管理权限从 Windows 文件资源管理器和 PowerShell 窗口访问 Linux 文件。
按照现在的发展速度,我对 [Windows 11 可能会运行在 Linux 之上](https://www.computerworld.com/article/3438856/call-me-crazy-but-windows-11-could-run-on-linux.html)的“疯狂”预测,也许会成为现实!
| 200 | OK | # Linux graphical apps coming to Windows Subsystem for Linux

At the Microsoft Build 2020 virtual developers' conference, CEO Satya Nadella announced that Windows Subsystem for Linux (WSL) 2.0 would [soon support Linux GUIs and applications](https://www.zdnet.com/article/microsoft-linux-gui-apps-coming-to-windows-10-wsl-along-with-gpu-access/). That day is closer now than ever before. At the recent [X.Org Developers Conference (XDC)](https://xdc2020.x.org/), Microsoft partner developer lead Steve Pronovost revealed that Microsoft has made it possible to run graphical Linux applications within WSL.
### Windows
It's always been possible to run Linux graphical programs such as the [GIMP graphics editor](https://www.gimp.org/), [Evolution e-mail client](https://wiki.gnome.org/Apps/Evolution), and [LibreOffice](https://www.libreoffice.org/) on WSL. But it wasn't easy. You had to install a third-party X Window display server, such as the [VcXsrv Windows X Server ](https://sourceforge.net/projects/vcxsrv/)in Windows 10, and then do some [tuning with both Windows and Linux to get them to work together smoothly.](https://techcommunity.microsoft.com/t5/windows-dev-appconsult/running-wsl-gui-apps-on-windows-10/ba-p/1493242) The [X Window System](http://www.opengroup.org/tech/desktop/x-window-system/) underlies almost all Linux graphical user interfaces.
Now, Microsoft has ported a [Wayland display server](https://www.linux-magazine.com/Online/Features/Is-Wayland-the-New-X) to WSL. Wayland is the most popular X Window compatible server. In WSL2, it connects the graphical Linux applications via a Remote Desktop Protocol (RDP) connection to the main Windows display. This means you can run Linux and Windows GUI applications simultaneously on the same desktop screen.
Pronovost explained:
WSL essentially runs Linux inside of a Virtual Machine hosted by Windows and we integrate applications (console, and now GUI) back onto your Windows desktop so you can run both Win32 and Linux applications inside of a unified experience. Because Linux is running in VM, we can't run the native GPU driver that expects direct access to the GPU (unless we were to do something like discrete device assignment and assign one of the host GPU to the VM... but then the host would lose access to that GPU!). With
[GPU-PV [GPU Paravirtualization]]we can essentially project the host GPU in Linux and have both Linux and Windows processes share the same physical GPU without the need for fixed resource partitioning.
Craig Loewen, Microsoft WSL Program Manager, added in a Twitter thread that the key differences between using a third-party X server and the built-in Wayland server is that: "[You don't need to start up or start the server,](https://twitter.com/craigaloewen/status/1308452901266751488) we'll handle that for you." In addition, it comes with "Lovely integration with Windows," such as drop shadows and Linux icon support.
Loewen also said you can run a Linux web browser in it. "We haven't tested it extensively with a full desktop environment yet, as we want to focus on running often asked for apps first, and primarily IDEs [integrated development environment] so you can run those in a full Linux environment," he said.
Don't get too excited about it just yet, though. Loewen continued, "We don't yet have an ETA for the beta channel, however, this work will be available in general for Insiders to try within the next couple of months."
[Microsoft's integration of Linux into Windows](https://www.zdnet.com/article/2020-will-be-the-year-of-linux-on-the-windows-desktop/) has been coming for some time. Four years ago, Microsoft introduced WSL, which brought the [Linux Bash shell to Windows 10](https://www.zdnet.com/article/microsoft-to-show-bash-on-linux-running-on-windows-10/). With Bash and WSL, you can run most [Linux shell tools](http://blog.dustinkirkland.com/2016/03/ubuntu-on-windows.html) and popular Linux programming languages.
As time went on, Linux became more of a first-class citizen on the Windows desktop. Multiple Linux distros, starting with [Ubuntu](https://ubuntu.com/), were followed by [Red Hat Fedora](https://getfedora.org/) and [SUSE Linux Enterprise Desktop (SLED)](https://www.suse.com/products/desktop/). Then, Microsoft replaced its WSL translation layer, which converted Linux kernel calls into Windows calls, with WSL 2. This update came with [Microsoft's own Linux kernel](https://www.zdnet.com/article/hell-freezing-over-microsoft-releases-its-own-linux-for-windows/) running on a thin version of the Hyper-V hypervisor.
More recently, starting with the [Windows 10 Insider Preview build 20211, Windows users can access Linux file systems](https://devblogs.microsoft.com/commandline/access-linux-filesystems-in-windows-and-wsl-2/). This includes access to Linux file systems, such as ext4, which Windows doesn't natively support. It also means, if you dual-boot Windows and Linux with different disks, you can now access Linux files from Windows. With this, you can access Linux files from both the Windows File Explorer and PowerShell window with administrative privilege.
At the rate things are going, my "crazy" prediction that [Windows 11 might run on top of Linux](https://www.computerworld.com/article/3438856/call-me-crazy-but-windows-11-could-run-on-linux.html) may yet come true!
**Related Stories:**
[Editorial standards](/editorial-guidelines/) |
12,685 | 构建一个即时消息应用(五):实时消息 | https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/ | 2020-10-05T09:17:27 | [
"即时消息"
] | https://linux.cn/article-12685-1.html | 
本文是该系列的第五篇。
* [第一篇: 模式](/article-11396-1.html)
* [第二篇: OAuth](/article-11510-1.html)
* [第三篇: 对话](/article-12056-1.html)
* [第四篇: 消息](/article-12680-1.html)
对于实时消息,我们将使用 <ruby> <a href="https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events"> 服务器发送事件 </a> <rt> Server-Sent Events </rt></ruby>。这是一个打开的连接,我们可以在其中传输数据流。我们会有个端点,用户会在其中订阅发送给他的所有消息。
### 消息户端
在 HTTP 部分之前,让我们先编写一个<ruby> 映射 <rt> map </rt></ruby> ,让所有客户端都监听消息。 像这样全局初始化:
```
type MessageClient struct {
Messages chan Message
UserID string
}
var messageClients sync.Map
```
### 已创建的新消息
还记得在 [上一篇文章](/article-12680-1.html) 中,当我们创建这条消息时,我们留下了一个 “TODO” 注释。在那里,我们将使用这个函数来调度一个 goroutine。
```
go messageCreated(message)
```
把这行代码插入到我们留注释的位置。
```
func messageCreated(message Message) error {
if err := db.QueryRow(`
SELECT user\_id FROM participants
WHERE user\_id != $1 and conversation\_id = $2
`, message.UserID, message.ConversationID).
Scan(&message.ReceiverID); err != nil {
return err
}
go broadcastMessage(message)
return nil
}
func broadcastMessage(message Message) {
messageClients.Range(func(key, \_ interface{}) bool {
client := key.(\*MessageClient)
if client.UserID == message.ReceiverID {
client.Messages <- message
}
return true
})
}
```
该函数查询接收者 ID(其他参与者 ID),并将消息发送给所有客户端。
### 订阅消息
让我们转到 `main()` 函数并添加以下路由:
```
router.HandleFunc("GET", "/api/messages", guard(subscribeToMessages))
```
此端点处理 `/api/messages` 上的 GET 请求。请求应该是一个 [EventSource](https://developer.mozilla.org/en-US/docs/Web/API/EventSource) 连接。它用一个事件流响应,其中的数据是 JSON 格式的。
```
func subscribeToMessages(w http.ResponseWriter, r \*http.Request) {
if a := r.Header.Get("Accept"); !strings.Contains(a, "text/event-stream") {
http.Error(w, "This endpoint requires an EventSource connection", http.StatusNotAcceptable)
return
}
f, ok := w.(http.Flusher)
if !ok {
respondError(w, errors.New("streaming unsupported"))
return
}
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
h := w.Header()
h.Set("Cache-Control", "no-cache")
h.Set("Connection", "keep-alive")
h.Set("Content-Type", "text/event-stream")
messages := make(chan Message)
defer close(messages)
client := &MessageClient{Messages: messages, UserID: authUserID}
messageClients.Store(client, nil)
defer messageClients.Delete(client)
for {
select {
case <-ctx.Done():
return
case message := <-messages:
if b, err := json.Marshal(message); err != nil {
log.Printf("could not marshall message: %v\n", err)
fmt.Fprintf(w, "event: error\ndata: %v\n\n", err)
} else {
fmt.Fprintf(w, "data: %s\n\n", b)
}
f.Flush()
}
}
}
```
首先,它检查请求头是否正确,并检查服务器是否支持流式传输。我们创建一个消息通道,用它来构建一个客户端,并将其存储在客户端映射中。每当创建新消息时,它都会进入这个通道,因此我们可以通过 `for-select` 循环从中读取。
<ruby> 服务器发送事件 <rt> Server-Sent Events </rt></ruby>使用以下格式发送数据:
```
data: some data here\n\n
```
我们以 JSON 格式发送:
```
data: {"foo":"bar"}\n\n
```
我们使用 `fmt.Fprintf()` 以这种格式写入响应<ruby> 写入器 <rt> writter </rt></ruby>,并在循环的每次迭代中刷新数据。
这个循环会一直运行,直到使用请求上下文关闭连接为止。我们延迟了通道的关闭和客户端的删除,因此,当循环结束时,通道将被关闭,客户端不会收到更多的消息。
注意,<ruby> 服务器发送事件 <rt> Server-Sent Events </rt></ruby>(EventSource)的 JavaScript API 不支持设置自定义请求头?,所以我们不能设置 `Authorization: Bearer <token>`。这就是为什么 `guard()` 中间件也会从 URL 查询字符串中读取令牌的原因。
---
实时消息部分到此结束。我想说的是,这就是后端的全部内容。但是为了编写前端代码,我将再增加一个登录端点:一个仅用于开发的登录。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,686 | awk 实用学习指南 | https://opensource.com/article/20/9/awk-ebook | 2020-10-05T10:07:07 | [
"awk"
] | https://linux.cn/article-12686-1.html |
>
> 下载我们的电子书,学习如何更好地使用 `awk`。
>
>
>

在众多 [Linux](https://opensource.com/resources/linux) 命令中,`sed`、`awk` 和 `grep` 恐怕是其中最经典的三个命令了。它们引人注目或许是由于名字发音与众不同,也可能是它们无处不在,甚至是因为它们存在已久,但无论如何,如果要问哪些命令很有 Linux 风格,这三个命令是当之无愧的。其中 `sed` 和 `grep` 已经有很多简洁的标准用法了,但 `awk` 的使用难度却相对突出。
在日常使用中,通过 `sed` 实现字符串替换、通过 `grep` 实现过滤,这些都是司空见惯的操作了,但 `awk` 命令相对来说是用得比较少的。在我看来,可能的原因是大多数人都只使用 `sed` 或者 `grep` 的一些变化实现某些功能,例如:
```
$ sed -e 's/foo/bar/g' file.txt
$ grep foo file.txt
```
因此,尽管你可能会觉得 `sed` 和 `grep` 使用起来更加顺手,但实际上它们还有更多更强大的作用没有发挥出来。当然,我们没有必要在这两个命令上钻研得很深入,但我有时会好奇自己“学习”命令的方式。很多时候我会记住一整串命令“咒语”,而不会去了解其中的运作过程,这就让我产生了一种很熟悉命令的错觉,我可以随口说出某个命令的好几个选项参数,但这些参数具体有什么作用,以及它们的相关语法,我都并不明确。
这大概就是很多人对 `awk` 缺乏了解的原因了。
### 为使用而学习 awk
`awk` 并不深奥。它是一种相对基础的编程语言,因此你可以把它当成一门新的编程语言来学习:使用一些基本命令来熟悉语法、了解语言中的关键字并实现更复杂的功能,然后再多加练习就可以了。
### awk 是如何解析输入内容的
`awk` 的本质是将输入的内容看作是一个数组。当 `awk` 扫描一个文本文件时,会把每一行作为一条<ruby> 记录 <rt> record </rt></ruby>,每一条记录中又分割为多个<ruby> 字段 <rt> field </rt></ruby>。`awk` 记录了各条记录各个字段的信息,并通过内置变量 `NR`(记录数) 和 `NF`(字段数) 来调用相关信息。例如一下这个命令可以查看文件的行数:
```
$ awk 'END { print NR;}' example.txt
36
```
从上面的命令可以看出 `awk` 的基本语法,无论是一个单行命令还是一整个脚本,语法都是这样的:
```
模式或关键字 { 操作 }
```
在上面的例子中,`END` 是一个关键字而不是模式,与此类似的另一个关键字是 `BEGIN`。使用 `BEGIN` 或 `END` 可以让 `awk` 在解析内容前或解析内容后执行大括号中指定的操作。
你可以使用<ruby> 模式 <rt> pattern </rt></ruby>作为过滤器或限定符,这样 `awk` 只会对匹配模式的对应记录执行指定的操作。以下这个例子就是使用 `awk` 实现 `grep` 命令在文件中查找“Linux”字符串的功能:
```
$ awk '/Linux/ { print $0; }' os.txt
OS: CentOS Linux (10.1.1.8)
OS: CentOS Linux (10.1.1.9)
OS: Red Hat Enterprise Linux (RHEL) (10.1.1.11)
OS: Elementary Linux (10.1.2.4)
OS: Elementary Linux (10.1.2.5)
OS: Elementary Linux (10.1.2.6)
```
`awk` 会将文件中的每一行作为一条记录,将一条记录中的每个单词作为一个字段,默认情况下会以空格作为<ruby> 字段分隔符 <rt> field separator </rt></ruby>(`FS`)切割出记录中的字段。如果想要使用其它内容作为分隔符,可以使用 `--field-separator` 选项指定分隔符:
```
$ awk --field-separator ':' '/Linux/ { print $2; }' os.txt
CentOS Linux (10.1.1.8)
CentOS Linux (10.1.1.9)
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
Elementary Linux (10.1.2.4)
Elementary Linux (10.1.2.5)
Elementary Linux (10.1.2.6)
```
在上面的例子中,可以看到在 `awk` 处理后每一行的行首都有一个空格,那是因为在源文件中每个冒号(`:`)后面都带有一个空格。和 `cut` 有所不同的是,`awk` 可以指定一个字符串作为分隔符,就像这样:
```
$ awk --field-separator ': ' '/Linux/ { print $2; }' os.txt
CentOS Linux (10.1.1.8)
CentOS Linux (10.1.1.9)
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
Elementary Linux (10.1.2.4)
Elementary Linux (10.1.2.5)
Elementary Linux (10.1.2.6)
```
### awk 中的函数
可以通过这样的语法在 `awk` 中自定义函数:
```
函数名称(参数) { 操作 }
```
函数的好处在于只需要编写一次就可以多次复用,因此函数在脚本中起到的作用会比在构造单行命令时大。同时 `awk` 自身也带有很多预定义的函数,并且工作原理和其它编程语言或电子表格一样。你只需要了解函数需要接受什么参数,就可以放心使用了。
`awk` 中提供了数学运算和字符串处理的相关函数。数学运算函数通常比较简单,传入一个数字,它就会传出一个结果:
```
$ awk 'BEGIN { print sqrt(1764); }'
42
```
而字符串处理函数则稍微复杂一点,但 [GNU awk 手册](https://www.gnu.org/software/gawk/manual/gawk.html)中也有充足的文档。例如 `split()` 函数需要传入一个待分割的单一字段、一个用于存放分割结果的数组,以及用于分割的<ruby> 定界符 <rt> delimiter </rt></ruby>。
例如前面示例中的输出内容,每条记录的末尾都包含了一个 IP 地址。由于变量 `NF` 代表的是每条记录的字段数量,刚好对应的是每条记录中最后一个字段的序号,因此可以通过引用 `NF` 将每条记录的最后一个字段传入 `split()` 函数:
```
$ awk --field-separator ': ' '/Linux/ { split($NF, IP, "."); print "subnet: " IP[3]; }' os.txt
subnet: 1
subnet: 1
subnet: 1
subnet: 2
subnet: 2
subnet: 2
```
还有更多的函数,没有理由将自己限制在每个 `awk` 代码块中。你可以在终端中使用 `awk` 构建复杂的管道,也可以编写 `awk` 脚本来定义和使用你自己的函数。
### 下载电子书
使用 `awk` 本身就是一个学习 `awk` 的过程,即使某些操作使用 `sed`、`grep`、`cut`、`tr` 命令已经完全足够了,也可以尝试使用 `awk` 来实现。只要熟悉了 `awk`,就可以在 Bash 中自定义一些 `awk` 函数,进而解析复杂的数据。
[下载我们的这本电子书](https://opensource.com/downloads/awk-ebook)(需注册)学习并开始使用 `awk` 吧!
---
via: <https://opensource.com/article/20/9/awk-ebook>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/hankchow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Of all the [Linux](https://opensource.com/resources/linux) commands out there (and there are many), the three most quintessential seem to be `sed`
, `awk`
, and `grep`
. Maybe it's the arcane sound of their names, or the breadth of their potential use, or just their age, but when someone's giving an example of a "Linuxy" command, it's usually one of those three. And while `sed`
and `grep`
have several simple one-line standards, the less prestigious `awk`
remains persistently prominent for being particularly puzzling.
You're likely to use `sed`
for a quick string replacement or `grep`
to filter for a pattern on a daily basis. You're far less likely to compose an `awk`
command. I often wonder why this is, and I attribute it to a few things. First of all, many of us barely use `sed`
and `grep`
for anything but some variation upon these two commands:
```
$ sed -e 's/foo/bar/g' file.txt
$ grep foo file.txt
```
So, even though you might feel more comfortable with `sed`
and `grep`
, you may not use their full potential. Of course, there's no obligation to learn more about `sed`
or `grep`
, but I sometimes wonder about the way I "learn" commands. Instead of learning *how* a command works, I often learn a specific incantation that includes a command. As a result, I often feel a false familiarity with the command. I think I know a command because I can name three or four options off the top of my head, even though I don't know what the options do and can't quite put my finger on the syntax.
And that's the problem, I believe, that many people face when confronted with the power and flexibility of `awk`
.
## Learning awk to use awk
The basics of `awk`
are surprisingly simple. It's often noted that `awk`
is a programming language, and although it's a relatively basic one, it's true. This means you can learn `awk`
the same way you learn a new coding language: learn its syntax using some basic commands, learn its vocabulary so you can build up to complex actions, and then practice, practice, practice.
## How awk parses input
`Awk`
sees input, essentially, as an array. When `awk`
scans over a text file, it treats each line, individually and in succession, as a *record*. Each record is broken into *fields*. Of course, `awk`
must keep track of this information, and you can see that data using the `NR`
(number of records) and `NF`
(number of fields) built-in variables. For example, this gives you the line count of a file:
```
$ awk 'END { print NR;}' example.txt
36
```
This also reveals something about `awk`
syntax. Whether you're writing `awk`
as a one-liner or as a self-contained script, the structure of an `awk`
instruction is:
`pattern or keyword { actions }`
In this example, the word `END`
is a special, reserved keyword rather than a pattern. A similar keyword is `BEGIN`
. With both of these keywords, `awk`
just executes the action in braces at the start or end of parsing data.
You can use a *pattern* as a filter or qualifier so that `awk`
only executes a given action when it is able to match your pattern to the current record. For instance, suppose you want to use `awk`
, much as you would `grep`
, to find the word *Linux* in a file of text:
```
$ awk '/Linux/ { print $0; }' os.txt
OS: CentOS Linux (10.1.1.8)
OS: CentOS Linux (10.1.1.9)
OS: Red Hat Enterprise Linux (RHEL) (10.1.1.11)
OS: Elementary Linux (10.1.2.4)
OS: Elementary Linux (10.1.2.5)
OS: Elementary Linux (10.1.2.6)
```
For `awk`
, each line in the file is a record, and each word in a record is a field. By default, fields are separated by a space. You can change that with the `--field-separator`
option, which sets the `FS`
(field separator) variable to whatever you want it to be:
```
$ awk --field-separator ':' '/Linux/ { print $2; }' os.txt
CentOS Linux (10.1.1.8)
CentOS Linux (10.1.1.9)
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
Elementary Linux (10.1.2.4)
Elementary Linux (10.1.2.5)
Elementary Linux (10.1.2.6)
```
In this sample, there's an empty space before each listing because there's a blank space after each colon (`:`
) in the source text. This isn't `cut`
, though, so the field separator needn't be limited to one character:
```
$ awk --field-separator ': ' '/Linux/ { print $2; }' os.txt
CentOS Linux (10.1.1.8)
CentOS Linux (10.1.1.9)
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
Elementary Linux (10.1.2.4)
Elementary Linux (10.1.2.5)
Elementary Linux (10.1.2.6)
```
## Functions in awk
You can build your own functions in `awk`
using this syntax:
`name(parameters) { actions }`
Functions are important because they allow you to write code once and reuse it throughout your work. When constructing one-liners, custom functions are a little less useful than they are in scripts, but `awk`
defines many functions for you already. They work basically the same as any function in any other language or spreadsheet: You learn the order that the function needs information from you, and you can feed it whatever you want to get the results.
There are functions to perform mathematical operations and string processing. The math ones are often fairly straightforward. You provide a number, and it crunches it:
```
$ awk 'BEGIN { print sqrt(1764); }'
42
```
String functions can be more complex but are well documented in the [GNU awk manual](https://www.gnu.org/software/gawk/manual/gawk.html). For example, the `split`
function takes an entity that `awk`
views as a single field and splits it into different parts. It requires a field, a variable to use as an array containing each part of the split, and the character you want to use as the delimiter.
Using the output of the previous examples, I know that there's an IP address at the very end of each record. In this case, I can send just the last field of a record to the `split`
function by referencing the variable `NF`
because it contains the number of fields (and the final field must be the highest number):
```
$ awk --field-separator ': ' '/Linux/ { split($NF, IP, "."); print "subnet: " IP[3]; }' os.txt
subnet: 1
subnet: 1
subnet: 1
subnet: 2
subnet: 2
subnet: 2
```
There are many more functions, and there's no reason to limit yourself to one per block of `awk`
code. You can construct complex pipelines with `awk`
in your terminal, or you can write `awk`
scripts to define and utilize your own functions.
## Download the eBook
Learning `awk`
is mostly a matter of using `awk`
. Use it even if it means duplicating functionality you already have with `sed`
or `grep`
or `cut`
or `tr`
or any other perfectly valid commands. Once you get comfortable with it, you can write Bash functions that invoke your custom `awk`
commands for easier use. And eventually, you'll be able to write scripts to parse complex datasets.
[Download our ](https://opensource.com/downloads/awk-ebook)** eBook **to learn everything you need to know about
`awk`
, and start using it today.
## 1 Comment |
12,688 | 什么是 IPv6,为什么我们还未普及? | https://www.networkworld.com/article/3254575/what-is-ipv6-and-why-aren-t-we-there-yet.html | 2020-10-05T17:44:33 | [
"IPv6"
] | https://linux.cn/article-12688-1.html |
>
> 自 1998 年以来,IPv6 一直在努力解决 IPv4 可用 IP 地址的不足的问题,然而尽管 IPv6 在效率和安全方面具有优势,但其采用速度仍然缓慢。
>
>
>

在大多数情况下,已经没有人一再对互联网地址耗尽的可怕境况发出警告,因为,从互联网协议版本 4(IPv4)的世界到 IPv6 的迁移,虽然缓慢,但已经坚定地开始了,并且相关软件已经到位,以防止许多人预测的地址耗竭。
但在我们看到 IPv6 的现状和发展方向之前,让我们先回到互联网寻址的早期。
### 什么是 IPv6,为什么它很重要?
IPv6 是最新版本的<ruby> 互联网协议 <rt> Internet Protocol </rt></ruby>(IP),它可以跨互联网识别设备,从而确定它们的位置。每一个使用互联网的设备都要通过自己的 IP 地址来识别,以便可以通过互联网通信。在这方面,它就像你需要知道街道地址和邮政编码一样,以便邮寄信件。
之前的版本 IPv4 采用 32 位寻址方案,可以支持 43 亿台设备,本以为已经足够。然而,互联网、个人电脑、智能手机以及现在物联网设备的发展证明,这个世界需要更多的地址。
幸运的是,<ruby> 互联网工程任务组 <rt> Internet Engineering Task Force </rt></ruby>(IETF)在 20 年前就认识到了这一点。1998 年,它创建了 IPv6,使用 128 位寻址方式来支持大约 340 <ruby> 亿亿亿 <rt> trillion trillion </rt></ruby>(或者 2 的 128 次幂,如果你喜欢用这种表示方式的话)。IPv4 的地址可表示为四组一至三位十进制数,IPv6 则使用八组四位十六进制数字,用冒号隔开。
### IPv6 的好处是什么?
IETF 在其工作中为 IPv6 加入了对 IPv4 增强的功能。IPv6 协议可以更有效地处理数据包,提高性能和增加安全性。它使互联网服务提供商(ISP)能够通过使他们的路由表更有层次性来减少其大小。
### 网络地址转换(NAT)和 IPv6
IPv6 的采用被推迟,部分原因是<ruby> 网络地址转换 <rt> network address translation </rt></ruby>(NAT)导致的,NAT 可以将私有 IP 地址转化为公共 IP 地址。这样一来,拥有私有 IP 地址的企业的机器就可以向位于私有网络之外拥有公共 IP 地址的机器发送和接收数据包。
如果没有 NAT,拥有数千台或数万台计算机的大公司如果要与外界通信,就会吞噬大量的公有 IPv4 地址。但是这些 IPv4 地址是有限的,而且接近枯竭,以至于不得不限制分配。
NAT 有助于缓解这个问题。有了 NAT,成千上万的私有地址计算机可以通过防火墙或路由器等 NAT 设备呈现在公共互联网上。
NAT 的工作方式是,当一台拥有私有 IP 地址的企业计算机向企业网络外的公共 IP 地址发送数据包时,首先会进入 NAT 设备。NAT 在翻译表中记下数据包的源地址和目的地址。NAT 将数据包的源地址改为 NAT 设备面向公众的地址,并将数据包一起发送到外部目的地。当数据包回复时,NAT 将目的地址翻译成发起通信的计算机的私有 IP 地址。这样一来,一个公网 IP 地址可以代表多台私有地址的计算机。
### 谁在部署 IPv6?
运营商网络和互联网服务供应商是最早开始在其网络上部署 IPv6 的群体,其中移动网络处于领先地位。例如,T-Mobile USA 有超过 90% 的流量通过 IPv6,Verizon Wireless 紧随其后,占 82.25%。根据行业组织 [World Ipv6 Launch](http://www.worldipv6launch.org/measurements/) 的数据,Comcast 和 AT&T 的网络分别为 63% 和 65%。
主要网站则排在其后 —— World IPv6 Launch 称,目前 Alexa 前 1000 的网站中只有不到 30% 可以通过 IPv6 到达。
企业在部署方面比较落后,根据<ruby> 互联网协会 <rt> Internet Society </rt></ruby>的[《2017年 IPv6 部署状况》报告](https://www.internetsociety.org/resources/doc/2017/state-of-ipv6-deployment-2017/),只有不到四分之一的企业宣传其 IPv6 前缀。复杂性、成本和完成迁移所需时间都是他们给出的理由。此外,一些项目由于软件兼容性的问题而被推迟。例如,一份 [2017 年 1 月的报告](https://www.theregister.co.uk/2017/01/19/windows_10_bug_undercuts_ipv6_rollout/https://www.theregister.co.uk/2017/01/19/windows_10_bug_undercuts_ipv6_rollout/)称,Windows 10 中的一个 bug “破坏了微软在其西雅图总部推出纯 IPv6 网络的努力”。
### 何时会有更多部署?
互联网协会表示,IPv4 地址的价格将在 2018 年达到顶峰,然后在 IPv6 部署通过 50% 大关后,价格会下降。目前,[根据 Google](https://www.google.com/intl/en/ipv6/statistics.html),全球的 IPv6 采用率为 20% 到 22%,但在美国约为 32%。
随着 IPv4 地址的价格开始下降,互联网协会建议企业出售现有的 IPv4 地址,以帮助资助其 IPv6 的部署。根据[一个发布在 GitHub 上的说明](https://gist.github.com/simonster/e22e50cd52b7dffcf5a4db2b8ea4cce0),麻省理工学院已经这样做了。这所大学得出的结论是,其有 800 万个 IPv4 地址是“过剩”的,可以在不影响当前或未来需求的情况下出售,因为它还持有 20 个<ruby> 非亿级 <rt> nonillion </rt></ruby> IPv6 地址。(非亿级地址是指数字 1 后面跟着 30 个零)。
此外,随着部署的增多,更多的公司将开始对 IPv4 地址的使用收费,而免费提供 IPv6 服务。[英国的 ISP Mythic Beasts](https://www.mythic-beasts.com/sales/ipv6) 表示,“IPv6 连接是标配”,而 “IPv4 连接是可选的额外服务”。
### IPv4 何时会被“关闭”?
在 2011 年至 2018 年期间,世界上大部分地区[“用完”了新的 IPv4 地址](https://ipv4.potaroo.net/) —— 但我们不会完全没有 IPv4 地址,因为 IPv4 地址会被出售和重新使用(如前所述),而剩余的地址将用于 IPv6 过渡。
目前还没有正式的 IPv4 关闭日期,所以人们不用担心有一天他们的互联网接入会突然消失。随着越来越多的网络过渡,越来越多的内容网站支持 IPv6,以及越来越多的终端用户为 IPv6 功能升级设备,世界将慢慢远离 IPv4。
### 为什么没有 IPv5?
曾经有一个 IPv5,也被称为<ruby> 互联网流协议 <rt> Internet Stream Protocol </rt></ruby>,简称 ST。它被设计用于跨 IP 网络的面向连接的通信,目的是支持语音和视频。
它在这个任务上是成功的,并被实验性地使用。它的一个缺点是它的 32 位地址方案 —— 与 IPv4 使用的方案相同,从而影响了它的普及。因此,它存在着与 IPv4 相同的问题 —— 可用的 IP 地址数量有限。这导致了发展出了 IPv6 并和最终得到采用。尽管 IPv5 从未被公开采用,但它已经用掉了 IPv5 这个名字。
---
via: <https://www.networkworld.com/article/3254575/what-is-ipv6-and-why-aren-t-we-there-yet.html>
作者:[Keith Shaw](https://www.networkworld.com/author/Keith-Shaw/),[Josh Fruhlinger](https://www.networkworld.com/author/Josh-Fruhlinger/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,689 | 如何在 Ubuntu Linux 上禁用 IPv6 | https://itsfoss.com/disable-ipv6-ubuntu-linux/ | 2020-10-05T20:34:00 | [
"IPv6"
] | https://linux.cn/article-12689-1.html | 想知道怎样在 Ubuntu 上**禁用 IPv6** 吗?我会在这篇文章中介绍一些方法,以及为什么你应该考虑这一选择;以防改变主意,我也会提到如何**启用,或者说重新启用 IPv6**。
### 什么是 IPv6?为什么会想要禁用它?
<ruby> <a href="https://en.wikipedia.org/wiki/IPv6"> 互联网协议第 6 版 </a> <rt> Internet Protocol version 6 </rt></ruby>(IPv6)是互联网协议(IP)的最新版本。互联网协议是一种通信协议,它为网络上的计算机提供识别和定位系统,并在互联网上进行通信路由。IPv6 于 1998 年设计,以取代 IPv4 协议。
**IPv6** 意在提高安全性与性能的同时保证地址不被用尽;它可以在全球范围内为每台设备分配唯一的以 **128 位比特**存储的地址,而 IPv4 只使用了 32 位比特。

尽管 IPv6 的目标是取代 IPv4,但目前还有很长的路要走;互联网上只有不到 **30%** 的网站支持 IPv6([这里](https://www.google.com/intl/en/ipv6/statistics.html) 是谷歌的统计),IPv6 有时也给 [一些应用带来问题](https://whatismyipaddress.com/ipv6-issues)。
由于 IPv6 使用全球(唯一分配的)路由地址,以及(仍然)有<ruby> 互联网服务供应商 <rt> Internet Service Provider </rt></ruby>(ISP)不提供 IPv6 支持的事实,IPv6 这一功能在提供全球服务的<ruby> <strong> 虚拟私人网络 </strong> <rt> Virtual Private Network </rt></ruby>(VPN)供应商的优先级列表中处于较低的位置,这样一来,他们就可以专注于对 VPN 用户最重要的事情:安全。
不想让自己暴露在各种威胁之下可能是另一个让你想在系统上禁用 IPv6 的原因。虽然 IPv6 本身比 IPv4 更安全,但我所指的风险是另一种性质上的。如果你不实际使用 IPv6 及其功能,那么[启用 IPv6 后,你会很容易受到各种攻击](https://www.internetsociety.org/blog/2015/01/ipv6-security-myth-1-im-not-running-ipv6-so-i-dont-have-to-worry/),因而为黑客提供另一种可能的利用工具。
同样,只配置基本的网络规则是不够的;你必须像对 IPv4 一样,对调整 IPv6 的配置给予同样的关注,这可能会是一件相当麻烦的事情(维护也是)。并且随着 IPv6 而来的将会是一套不同于 IPv4 的问题(鉴于这个协议的年龄,许多问题已经可以在网上找到了),这又会使你的系统多了一层复杂性。
据观察,在某些情况下,禁用 IPv6 有助于提高 Ubuntu 的 WiFi 速度。
### 在 Ubuntu 上禁用 IPv6 [高级用户]
在本节中,我会详述如何在 Ubuntu 上禁用 IPv6 协议,请打开终端(默认快捷键:`CTRL+ALT+T`),让我们开始吧!
**注意:**接下来大部分输入终端的命令都需要 root 权限(`sudo`)。
>
> 警告!
>
>
> 如果你是一个普通 Linux 桌面用户,并且偏好稳定的工作系统,请避开本教程,接下来的部分是为那些知道自己在做什么以及为什么要这么做的用户准备的。
>
>
>
#### 1、使用 sysctl 禁用 IPv6
首先,可以执行以下命令来**检查** IPv6 是否已经启用:
```
ip a
```
如果启用了,你应该会看到一个 IPv6 地址(网卡的名字可能会与图中有所不同)

在教程《[在 Ubuntu 中重启网络](/article-10804-1.html)》(LCTT 译注:其实这篇文章并没有提到使用 sysctl 的方法……)中,你已经见过 `sysctl` 命令了,在这里我们也同样会用到它。要**禁用 IPv6**,只需要输入三条命令:
```
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=1
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=1
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=1
```
检查命令是否生效:
```
ip a
```
如果命令生效,你应该会发现 IPv6 的条目消失了:

然而这种方法只能**临时禁用 IPv6**,因此在下次系统启动的时候,IPv6 仍然会被启用。
(LCTT 译注:这里的临时禁用是指这次所做的改变直到此次关机之前都有效,因为相关的参数是存储在内存中的,可以改变值,但是在内存断电后就会丢失;这种意义上来讲,下文所述的两种方法都是临时的,只不过改变参数值的时机是在系统启动的早期,并且每次系统启动时都有应用而已。那么如何完成这种意义上的永久改变?答案是在编译内核的时候禁用相关功能,然后要后悔就只能重新编译内核了(悲)。)
一种让选项持续生效的方式是修改文件 `/etc/sysctl.conf`,在这里我用 `vim` 来编辑文件,不过你可以使用任何你想使用的编辑器,以及请确保你拥有**管理员权限**(用 `sudo`):

将下面这几行(和之前使用的参数相同)加入到文件中:
```
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default.disable_ipv6=1
net.ipv6.conf.lo.disable_ipv6=1
```
执行以下命令应用设置:
```
sudo sysctl -p
```
如果在重启之后 IPv6 仍然被启用了,而你还想继续这种方法的话,那么你必须(使用 root 权限)创建文件 `/etc/rc.local` 并加入以下内容:
```
#!/bin/bash
# /etc/rc.local
/etc/sysctl.d
/etc/init.d/procps restart
exit 0
```
接着使用 [chmod 命令](https://linuxhandbook.com/chmod-command/) 来更改文件权限,使其可执行:
```
sudo chmod 755 /etc/rc.local
```
这会让系统(在启动的时候)从之前编辑过的 sysctl 配置文件中读取内核参数。
#### 2、使用 GRUB 禁用 IPv6
另外一种方法是配置 **GRUB**,它会在系统启动时向内核传递参数。这样做需要编辑文件 `/etc/default/grub`(请确保拥有管理员权限)。

现在需要修改文件中分别以 `GRUB_CMDLINE_LINUX_DEFAULT` 和 `GRUB_CMDLINE_LINUX` 开头的两行来在启动时禁用 IPv6:
```
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ipv6.disable=1"
GRUB_CMDLINE_LINUX="ipv6.disable=1"
```
(LCTT 译注:这里是指在上述两行内增加参数 `ipv6.disable=1`,不同的系统中这两行的默认值可能有所不同。)
保存文件,然后执行命令:
```
sudo update-grub
```
(LCTT 译注:该命令用以更新 GRUB 的配置文件,在没有 `update-grub` 命令的系统中需要使用 `sudo grub-mkconfig -o /boot/grub/grub.cfg` )
设置会在重启后生效。
### 在 Ubuntu 上重新启用 IPv6
要想重新启用 IPv6,你需要撤销之前的所有修改。不过只是想临时启用 IPv6 的话,可以执行以下命令:
```
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=0
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=0
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=0
```
否则想要持续启用的话,看看是否修改过 `/etc/sysctl.conf`,可以删除掉之前增加的部分,也可以将它们改为以下值(两种方法等效):
```
net.ipv6.conf.all.disable_ipv6=0
net.ipv6.conf.default.disable_ipv6=0
net.ipv6.conf.lo.disable_ipv6=0
```
然后应用设置(可选):
```
sudo sysctl -p
```
(LCTT 译注:这里可选的意思可能是如果之前临时启用了 IPv6 就没必要再重新加载配置文件了)
这样应该可以再次看到 IPv6 地址了:

另外,你也可以删除之前创建的文件 `/etc/rc.local`(可选):
```
sudo rm /etc/rc.local
```
如果修改了文件 `/etc/default/grub`,回去删掉你所增加的参数:
```
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
GRUB_CMDLINE_LINUX=""
```
然后更新 GRUB 配置文件:
```
sudo update-grub
```
### 尾声
在这篇文章中,我介绍了在 Linux 上**禁用 IPv6** 的方法,并简述了什么是 IPv6 以及可能想要禁用掉它的原因。
那么,这篇文章对你有用吗?你有禁用掉 IPv6 连接吗?让我们评论区见吧~
---
via: <https://itsfoss.com/disable-ipv6-ubuntu-linux/>
作者:[Sergiu](https://itsfoss.com/author/sergiu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rakino](https://github.com/rakino) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Are you looking for a way to **disable IPv6** connections on your Ubuntu machine? In this article, I’ll teach you exactly how to do it and why you would consider this option. I’ll also show you how to **enable or re-enable IPv6** in case you change your mind.
## What is IPv6 and why would you want to disable IPv6 on Ubuntu?
**Internet Protocol version 6**[ (](https://en.wikipedia.org/wiki/IPv6?ref=itsfoss.com)**IPv6**[)](https://en.wikipedia.org/wiki/IPv6?ref=itsfoss.com) is the most recent version of the Internet Protocol (IP), the communications protocol that provides an identification and location system for computers on networks and routes traffic across the Internet. It was developed in 1998 to replace the **IPv4** protocol.
**IPv6** aims to improve security and performance, while also making sure we don’t run out of addresses. It assigns unique addresses globally to every device, storing them in **128-bits**, compared to just 32-bits used by IPv4.
Although the goal is for IPv4 to be replaced by IPv6, there is still a long way to go. Less than **30%** of the sites on the Internet makes IPv6 connectivity available to users (tracked by Google [here](https://www.google.com/intl/en/ipv6/statistics.html?ref=itsfoss.com)). IPv6 can also cause [problems with some applications at time](https://whatismyipaddress.com/ipv6-issues?ref=itsfoss.com).
Since **VPNs **provide global services, the fact that IPv6 uses globally routed addresses (uniquely assigned) and that there (still) are ISPs that don’t offer IPv6 support shifts this feature lower down their priority list. This way, they can focus on what matters the most for VPN users: security.
Another possible reason you might want to disable IPv6 on your system is not wanting to expose yourself to various threats. Although IPv6 itself is safer than IPv4, the risks I am referring to are of another nature. If you aren’t actively using IPv6 and its features, [having IPv6 enabled leaves you vulnerable to various attacks](https://www.internetsociety.org/blog/2015/01/ipv6-security-myth-1-im-not-running-ipv6-so-i-dont-have-to-worry/?ref=itsfoss.com), offering the hacker another possible exploitable tool.
On the same note, configuring basic network rules is not enough. You have to pay the same level of attention to tweaking your IPv6 configuration as you do for IPv4. This can prove to be quite a hassle to do (and also to maintain). With IPv6 comes a suite of problems different to those of IPv4 (many of which can be referenced online, given the age of this protocol), giving your system another layer of complexity.
It has also been observed that disabling IPv6 helps to [improve WiFi speed in Ubuntu](https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/) in some cases.
## Disabling IPv6 on Ubuntu [For Advanced Users Only]
In this section, I’ll be covering how you can disable IPv6 protocol on your Ubuntu machine. Open up a terminal (**default:** CTRL+ALT+T) and let’s get to it!
**Note:** *For most of the commands you are going to input in the terminal,* *you are going to need root privileges ( sudo).*
### 1. Disable IPv6 using Sysctl
First of all, you need to make sure that you have IPv6 enabled on your system. [Check your IP address in Ubuntu](https://itsfoss.com/check-ip-address-ubuntu/) with this command:
`ip a`
You should see an IPv6 address if it is enabled (the name of your internet card might be different):
You have see the sysctl command in the tutorial about [restarting network in Ubuntu](https://itsfoss.com/restart-network-ubuntu/). We are going to use it here as well. To **disable IPv6** you only have to input 3 commands:
```
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=1
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=1
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=1
```
You can check if it worked using:
`ip a`
You should see no IPv6 entry:
However, this only **temporarily disables IPv6**. The next time your system boots, IPv6 will be enabled again.
One method to make this option persist is modifying **/etc/sysctl.conf**. I’ll be using vim to edit the file, but you can use any editor you like. Make sure you have **administrator rights** (use **sudo**):
Add the following lines to the file:
```
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default.disable_ipv6=1
net.ipv6.conf.lo.disable_ipv6=1
```
For the settings to take effect use:
`sudo sysctl -p`
If IPv6 is still enabled after rebooting, you must create (with root privileges) the file **/etc/rc.local** and fill it with:
```
#!/bin/bash
# /etc/rc.local
/etc/sysctl.d
/etc/init.d/procps restart
exit 0
```
Now use [chmod command](https://linuxhandbook.com/chmod-command/?ref=itsfoss.com) to make the file executable:
`sudo chmod 755 /etc/rc.local`
What this will do is manually read (during the boot time) the kernel parameters from your sysctl configuration file.
### 2. Disable IPv6 using GRUB
An alternative method is to configure **GRUB** to pass kernel parameters at boot time. You’ll have to edit **/etc/default/grub**. Once again, make sure you have administrator privileges:
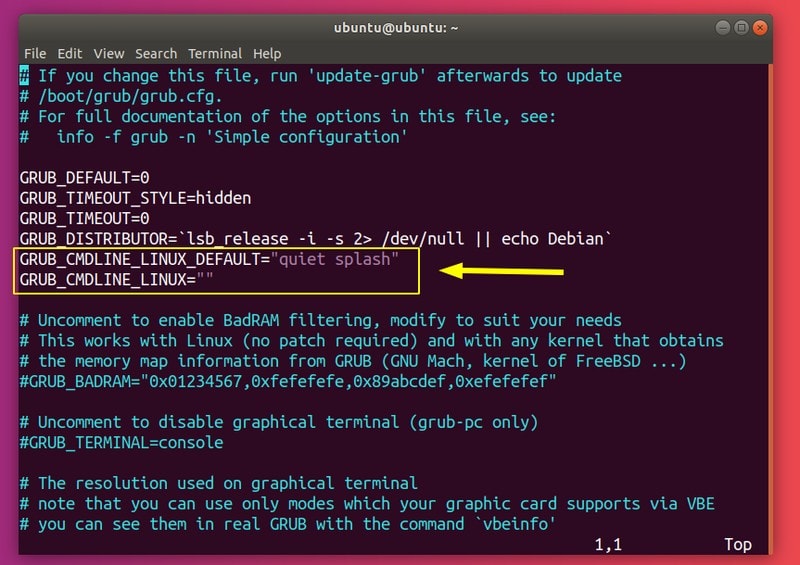
Now you need to modify **GRUB_CMDLINE_LINUX_DEFAULT** and **GRUB_CMDLINE_LINUX** to disable IPv6 on boot:
```
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ipv6.disable=1"
GRUB_CMDLINE_LINUX="ipv6.disable=1"
```
Save the file and run the [update-grub command](https://itsfoss.com/update-grub/):
`sudo update-grub`
The settings should now persist on reboot.
## Re-enabling IPv6 on Ubuntu
To re-enable IPv6, you’ll have to undo the changes you made. To enable IPv6 until reboot, enter:
```
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=0
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=0
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=0
```
Otherwise, if you modified **/etc/sysctl.conf** you can either remove the lines you added or change them to:
```
net.ipv6.conf.all.disable_ipv6=0
net.ipv6.conf.default.disable_ipv6=0
net.ipv6.conf.lo.disable_ipv6=0
```
You can optionally reload these values:
`sudo sysctl -p`
You should once again see a IPv6 address:
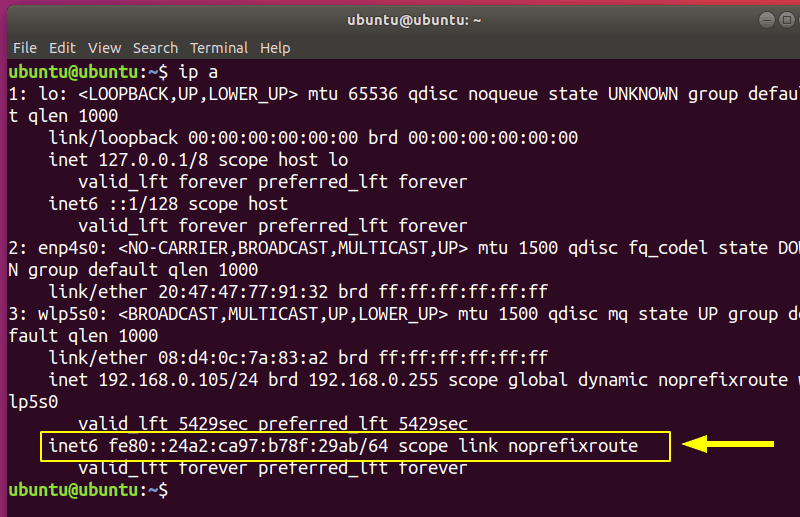
Optionally, you can remove **/etc/rc.local**:
`sudo rm /etc/rc.local`
If you modified the kernel parameters in **/etc/default/grub**, go ahead and delete the added options:
```
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
GRUB_CMDLINE_LINUX=""
```
Now do:
`sudo update-grub`
## Wrapping Up
In this guide I provided you ways in which you can **disable IPv6** on Linux, as well as giving you an idea about what IPv6 is and why you would want to disable it.
Did you find this article useful? Do you disable IPv6 connectivity? Let us know in the comment section! |
12,691 | 编写项目文档时要问自己的 5 个问题 | https://opensource.com/article/20/9/project-documentation | 2020-10-06T22:32:10 | [
"文档"
] | https://linux.cn/article-12691-1.html |
>
> 使用有效沟通的一些基本原则可以帮助你创建与你的品牌一致的、编写良好、内容丰富的项目文档。
>
>
>

在开始实际撰写又一个开源项目的文档之前,甚至在采访专家之前,最好回答一些有关新文档的高级问题。
著名的传播理论家 Harold Lasswell 在他 1948 年的文章《<ruby> 社会中的传播结构和功能 <rt> The Structure and Function of Communication in Society </rt></ruby>》中写道:
>
> (一种)描述沟通行为的方便方法是回答以下问题:
>
>
> * 谁
> * 说什么
> * 在哪个渠道
> * 对谁
> * 有什么效果?
>
>
>
作为一名技术交流者,你可以运用 Lasswell 的理论,回答关于你文档的类似问题,以更好地传达你的信息,达到预期的效果。
### 谁:谁是文档的所有者?
或者说,文档背后是什么公司?它想向受众传达什么品牌形象?这个问题的答案将极大地影响你的写作风格。公司可能有自己的风格指南,或者至少有正式的使命声明,在这种情况下,你应该从这开始。
如果公司刚刚起步,你可以向文件的主人提出上述问题。作为作者,将你为公司创造的声音和角色与你自己的世界观和信念结合起来是很重要的。这将使你的写作看起来更自然,而不像公司的行话。
### 说什么:文件类型是什么?
你需要传达什么信息?它是什么类型的文档:用户指南、API 参考、发布说明等?许多文档类型有模板或普遍认可的结构,这些结构为你提供一个开始的地方,并帮助确保包括所有必要的信息。
### 在哪个渠道:文档的格式是什么?
对于技术文档,沟通的渠道通常会告诉你文档的最终格式,也就是 PDF、HTML、文本文件等。这很可能也决定了你应该使用什么工具来编写你的文档。
### 对谁:目标受众是谁?
谁会阅读这份文档?他们的知识水平如何?他们的工作职责和主要挑战是什么?这些问题将帮助你确定你应该覆盖什么内容,是否应该应该涉及细节,是否可以使用特定的术语,等等。在某些情况下,这些问题的答案甚至可以影响你使用的语法的复杂性。
### 有什么效果:文档的目的是什么?
在这里,你应该定义这个文档要为它的潜在读者解决什么问题,或者它应该为他们回答什么问题。例如,你的文档的目的可以是教你的客户如何使用你的产品。
这时,你可以参考 [Divio](https://documentation.divio.com/) 建议的方法。根据这种方法,你可以根据文档的总体方向,将任何文档分为四种类型之一:学习、解决问题、理解或获取信息。
在这个阶段,另一个很好的问题是,这个文档要解决什么业务问题(例如,如何削减支持成本)。带着业务问题,你可能会看到你写作的一个重要角度。
### 总结
上面的问题旨在帮助你形成有效沟通的基础,并确保你的文件涵盖了所有应该涵盖的内容。你可以把它们分解成你自己的问题清单,并把它们放在身边,以便在你有文件要创建的时候使用。当你面对空白页无从着笔时,这份清单也可能会派上用场。希望它能激发你的灵感,帮助你产生想法。
---
via: <https://opensource.com/article/20/9/project-documentation>
作者:[Alexei Leontief](https://opensource.com/users/alexeileontief) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Before getting down to the actual writing part of documenting another one of your open source projects, and even before interviewing the experts, it's a good idea to answer some high-level questions about your new document.
Renowned communication theorist Harold Lasswell wrote in his 1948 article, *The Structure and Function of Communication in Society*:
[A] convenient way to describe an act of communication is to answer the following questions:
- Who
- Says what
- In which channel
- To whom
- With what effect?
As a technical communicator, you can apply Lasswell's theory and answer similar questions about your document to communicate your message better and with the desired effect.
## Who—Who is the document owner?
Or, what company is behind the document? What brand identity does it want to convey to its audience? The answer to this question will significantly influence your writing style. The company may also have its own style guide or at least a formal mission statement, in which case, you should start there.
If the company is just starting out, you may ask the questions above to the document's owner. As the writer, it's important to integrate the voice and persona you create for the company with your own worldview and beliefs. This will make your writing sound more natural and less like company jargon.
## Says what—What is the document type?
What information do you need to communicate? What type of document is it: a user guide, API reference, release notes, etc.? Many document types will have templates or generally agreed-upon structures that will give you a place to start and help ensure you include all the necessary information.
## In which channel—What is the format of the document?
With technical documents, the channel of communication often informs the final format of your doc, i.e., whether it's going to be a PDF, HTML, a text file, etc. This will, most likely, also determine the tools you should use to write your document.
## To whom—Who is the target audience?
Who will read this document? What is their level of knowledge? What are their job responsibilities and their main challenges? These questions will help you determine what you should cover, whether or not you should go into details, whether you can use any specific terms, etc. In some cases, the answers to these questions can even influence the complexity of syntax that you should use.
## With what effect—What is the purpose of the document?
This is where you should define what problem(s) this document is expected to solve for its prospective readers, or what questions it should answer for them. For example, the purpose of your document can be to teach your customers to work with your product.
At this point, you may refer to the approach suggested by [Divio](https://documentation.divio.com/). According to this approach, you can assign any document one of four types, depending on the document's general orientation: learning, solving a problem, understanding, or getting information.
Another good question to ask at this stage is what business problem this document is meant to solve (for example, how to cut down support costs.) With a business problem in mind, you may see an important angle for your writing.
## Conclusion
The questions above are designed to help you form the basis for effective communication and ensure your document covers everything it should. You can break them down into your own checklist of questions and keep them around for whenever you have a document to create. This checklist may also come in handy when you become stuck, confronted with a blank page. It will hopefully inspire you and help you generate ideas.
## Comments are closed. |
12,692 | 构建一个即时消息应用(六):仅用于开发的登录 | https://nicolasparada.netlify.com/posts/go-messenger-dev-login/ | 2020-10-07T10:15:00 | [
"即时消息"
] | https://linux.cn/article-12692-1.html | 
本文是该系列的第六篇。
* [第一篇: 模式](/article-11396-1.html)
* [第二篇: OAuth](/article-11510-1.html)
* [第三篇: 对话](/article-12056-1.html)
* [第四篇: 消息](/article-12680-1.html)
* [第五篇: 实时消息](/article-12685-1.html)
我们已经实现了通过 GitHub 登录,但是如果想把玩一下这个 app,我们需要几个用户来测试它。在这篇文章中,我们将添加一个为任何用户提供登录的端点,只需提供用户名即可。该端点仅用于开发。
首先在 `main()` 函数中添加此路由。
```
router.HandleFunc("POST", "/api/login", requireJSON(login))
```
### 登录
此函数处理对 `/api/login` 的 POST 请求,其中 JSON body 只包含用户名,并以 JSON 格式返回通过认证的用户、令牌和过期日期。
```
func login(w http.ResponseWriter, r \*http.Request) {
if origin.Hostname() != "localhost" {
http.NotFound(w, r)
return
}
var input struct {
Username string `json:"username"`
}
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
defer r.Body.Close()
var user User
if err := db.QueryRowContext(r.Context(), `
SELECT id, avatar\_url
FROM users
WHERE username = $1
`, input.Username).Scan(
&user.ID,
&user.AvatarURL,
); err == sql.ErrNoRows {
http.Error(w, "User not found", http.StatusNotFound)
return
} else if err != nil {
respondError(w, fmt.Errorf("could not query user: %v", err))
return
}
user.Username = input.Username
exp := time.Now().Add(jwtLifetime)
token, err := issueToken(user.ID, exp)
if err != nil {
respondError(w, fmt.Errorf("could not create token: %v", err))
return
}
respond(w, map[string]interface{}{
"authUser": user,
"token": token,
"expiresAt": exp,
}, http.StatusOK)
}
```
首先,它检查我们是否在本地主机上,或者响应为 `404 Not Found`。它解码主体跳过验证,因为这只是为了开发。然后在数据库中查询给定用户名的用户,如果没有,则返回 `404 NOT Found`。然后,它使用用户 ID 作为主题发布一个新的 JSON Web 令牌。
```
func issueToken(subject string, exp time.Time) (string, error) {
token, err := jwtSigner.Encode(jwt.Claims{
Subject: subject,
Expiration: json.Number(strconv.FormatInt(exp.Unix(), 10)),
})
if err != nil {
return "", err
}
return string(token), nil
}
```
该函数执行的操作与 [前文](/article-11510-1.html) 相同。我只是将其移过来以重用代码。
创建令牌后,它将使用用户、令牌和到期日期进行响应。
### 种子用户
现在,你可以将要操作的用户添加到数据库中。
```
INSERT INTO users (id, username) VALUES
(1, 'john'),
(2, 'jane');
```
你可以将其保存到文件中,并通过管道将其传送到 Cockroach CLI。
```
cat seed_users.sql | cockroach sql --insecure -d messenger
```
---
就是这样。一旦将代码部署到生产环境并使用自己的域后,该登录功能将不可用。
本文也结束了所有的后端开发部分。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-dev-login/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,693 | 使用 Flutter 创建 App | https://opensource.com/article/20/9/mobile-app-flutter | 2020-10-07T11:30:27 | [
"Flutter"
] | https://linux.cn/article-12693-1.html |
>
> 使用流行的 Flutter 框架开始你的跨平台开发之旅。
>
>
>

[Flutter](https://flutter.dev/) 是一个深受全球移动开发者欢迎的项目。该框架有一个庞大的、友好的爱好者社区,随着 Flutter 帮助程序员将他们的项目带入移动领域,这个社区还在继续增长。
本教程旨在帮助你开始使用 Flutter 进行移动开发。阅读之后,你将了解如何快速安装和设置框架,以便开始为智能手机、平板电脑和其他平台开发。
本操作指南假定你已在计算机上安装了 [Android Studio](https://developer.android.com/studio),并且具有一定的使用经验。
### 什么是 Flutter ?
Flutter 使得开发人员能够为多个平台构建应用程序,包括:
* Android
* iOS
* Web(测试版)
* macOS(正在开发中)
* Linux(正在开发中)
对 macOS 和 Linux 的支持还处于早期开发阶段,而 Web 支持预计很快就会发布。这意味着你可以立即试用其功能(如下所述)。
### 安装 Flutter
我使用的是 Ubuntu 18.04,但其他 Linux 发行版安装过程与之类似,比如 Arch 或 Mint。
#### 使用 snapd 安装
要使用 [Snapd](https://snapcraft.io/docs/getting-started) 在 Ubuntu 或类似发行版上安装 Flutter,请在终端中输入以下内容:
```
$ sudo snap install flutter --classic
$ sudo snap install flutter –classic
flutter 0+git.142868f from flutter Team/ installed
```
然后使用 `flutter` 命令启动它。 首次启动时,该框架会下载到你的计算机上:
```
$ flutter
Initializing Flutter
Downloading https://storage.googleapis.com/flutter_infra[...]
```
下载完成后,你会看到一条消息,告诉你 Flutter 已初始化:

#### 手动安装
如果你没有安装 Snapd,或者你的发行版不是 Ubuntu,那么安装过程会略有不同。在这种情况下,请[下载](https://flutter.dev/docs/get-started/install/linux) 为你的操作系统推荐的 Flutter 版本。

然后将其解压缩到你的主目录。
在你喜欢的文本编辑器中打开主目录中的 `.bashrc` 文件(如果你使用 [Z shell](https://opensource.com/article/19/9/getting-started-zsh),则打开 `.zshc`)。因为它是隐藏文件,所以你必须首先在文件管理器中启用显示隐藏文件,或者使用以下命令从终端打开它:
```
$ gedit ~/.bashrc &
```
将以下行添加到文件末尾:
```
export PATH="$PATH:~/flutter/bin"
```
保存并关闭文件。 请记住,如果在你的主目录之外的其他位置解压 Flutter,则 [Flutter SDK 的路径](https://opensource.com/article/17/6/set-path-linux) 将有所不同。
关闭你的终端,然后再次打开,以便加载新配置。 或者,你可以通过以下命令使配置立即生效:
```
$ . ~/.bashrc
```
如果你没有看到错误,那说明一切都是正常的。
这种安装方法比使用 `snap` 命令稍微困难一些,但是它非常通用,可以让你在几乎所有的发行版上安装该框架。
#### 检查安装结果
要检查安装结果,请在终端中输入以下内容:
```
flutter doctor -v
```
你将看到有关已安装组件的信息。 如果看到错误,请不要担心。 你尚未安装任何用于 Flutter SDK 的 IDE 插件。

### 安装 IDE 插件
你应该在你的 [集成开发环境(IDE)](https://www.redhat.com/en/topics/middleware/what-is-ide) 中安装插件,以帮助它与 Flutter SDK 接口、与设备交互并构建代码。
Flutter 开发中常用的三个主要 IDE 工具是 IntelliJ IDEA(社区版)、Android Studio 和 VS Code(或 [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code))。我在本教程中使用的是 Android Studio,但步骤与它们在 IntelliJ Idea(社区版)上的工作方式相似,因为它们构建在相同的平台上。
首先,启动 Android Studio。打开 “Settings”,进入 “Plugins” 窗格,选择 “Marketplace” 选项卡。在搜索行中输入 “Flutter”,然后单击 “Install”。

你可能会看到一个安装 “Dart” 插件的选项;同意它。如果看不到 Dart 选项,请通过重复上述步骤手动安装它。我还建议使用 “Rainbow Brackets” 插件,它可以让代码导航更简单。
就这样!你已经安装了所需的所有插件。你可以在终端中输入一个熟悉的命令进行检查:
```
flutter doctor -v
```

### 构建你的 “Hello World” 应用程序
要启动新项目,请创建一个 Flutter 项目:
1、选择 “New -> New Flutter project”。

2、在窗口中,选择所需的项目类型。 在这种情况下,你需要选择 “Flutter Application”。
3、命名你的项目为 `hello_world`。 请注意,你应该使用合并的名称,因此请使用下划线而不是空格。 你可能还需要指定 SDK 的路径。

4、输入软件包名称。
你已经创建了一个项目!现在,你可以在设备上或使用模拟器启动它。

选择你想要的设备,然后按 “Run”。稍后,你将看到结果。

现在你可以在一个 [中间项目](https://opensource.com/article/18/6/flutter) 上开始工作了。
### 尝试 Flutter for web
在安装 Flutter 的 Web 组件之前,你应该知道 Flutter 目前对 Web 应用程序的支持还很原始。 因此,将其用于复杂的项目并不是一个好主意。
默认情况下,基本 SDK 中不启用 “Flutter for web”。 要打开它,请转到 beta 通道。 为此,请在终端中输入以下命令:
```
flutter channel beta
```

接下来,使用以下命令根据 beta 分支升级 Flutter:
```
flutter upgrade
```

要使 “Flutter for web” 工作,请输入:
```
flutter config --enable-web
```
重新启动 IDE;这有助于 Android Studio 索引新的 IDE 并重新加载设备列表。你应该会看到几个新设备:

选择 “Chrome” 会在浏览器中启动一个应用程序, “Web Server” 会提供指向你的 Web 应用程序的链接,你可以在任何浏览器中打开它。
不过,现在还不是急于开发的时候,因为你当前的项目不支持 Web。要改进它,请打开项目根目录下的终端,然后输入:
```
flutter create
```
此命令重新创建项目,并添加 Web 支持。 现有代码不会被删除。
请注意,目录树已更改,现在有了一个 `web` 目录:

现在你可以开始工作了。 选择 “Chrome”,然后按 “Run”。 稍后,你会看到带有应用程序的浏览器窗口。

恭喜你! 你刚刚为浏览器启动了一个项目,并且可以像其他任何网站一样继续使用它。
所有这些都来自同一代码库,因为 Flutter 使得几乎无需更改就可以为移动平台和 Web 编写代码。
### 用 Flutter 做更多的事情
Flutter 是用于移动开发的强大工具,而且它也是迈向跨平台开发的重要一步。 了解它,使用它,并将你的应用程序交付到所有平台!
---
via: <https://opensource.com/article/20/9/mobile-app-flutter>
作者:[Vitaly Kuprenko](https://opensource.com/users/kooper) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Flutter](https://flutter.dev/) is a popular project among mobile developers around the world. The framework has a massive, friendly community of enthusiasts, which continues to grow as Flutter helps programmers take their projects into the mobile space.
This tutorial is meant to help you start doing mobile development with Flutter. After reading it, you'll know how to quickly install and set up the framework to start coding for smartphones, tablets, and other platforms.
This how-to assumes you have [Android Studio](https://developer.android.com/studio) installed on your computer and some experience working with it.
## What is Flutter?
Flutter enables developers to build apps for several platforms, including:
- Android
- iOS
- Web (in beta)
- macOS (in development)
- Linux (in development)
Support for macOS and Linux is in early development, while web support is expected to be released soon. This means that you can try out its capabilities now (as I'll describe below).
## Install Flutter
I'm using Ubuntu 18.04, but the installation process is similar with other Linux distributions, such as Arch or Mint.
### Install with snapd
To install Flutter on Ubuntu or similar distributions using [snapd](https://snapcraft.io/docs/getting-started), enter this in a terminal:
```
$ sudo snap install flutter --classic
$ sudo snap install flutter –classic
flutter 0+git.142868f from flutter Team/ installed
```
Then launch it using the `flutter`
command. Upon the first launch, the framework downloads to your computer:
```
$ flutter
Initializing Flutter
Downloading https://storage.googleapis.com/flutter_infra[...]
```
Once the download is finished, you'll see a message telling you that Flutter is initialized:
(Vitaly Kuprenko, CC BY-SA 4.0)
### Install manually
If you don't have snapd or your distribution isn't Ubuntu, the installation process will be a little bit different. In that case, [download](https://flutter.dev/docs/get-started/install/linux) the version of Flutter recommended for your operating system.
(Vitaly Kuprenko, CC BY-SA 4.0)
Then extract it to your home directory.
Open the `.bashrc`
file in your home directory (or `.zshrc`
if you use the [Z shell](https://opensource.com/article/19/9/getting-started-zsh)) in your favorite text editor. Because it's a hidden file, you must first enable showing hidden files in your file manager or open it from a terminal with:
`$ gedit ~/.bashrc &`
Add the following line to the end of the file:
`export PATH="$PATH:~/flutter/bin"`
Save and close the file. Keep in mind that if you extracted Flutter somewhere other than your home directory, the [path to Flutter SDK](https://opensource.com/article/17/6/set-path-linux) will be different.
Close your terminal and then open it again so that your new configuration loads. Alternatively, you can source the configuration with:
`$ . ~/.bashrc`
If you don't see an error, then everything is fine.
This installation method is a little bit harder than using the `snap`
command, but it's pretty versatile and lets you install the framework on almost any distribution.
### Check the installation
To check the result, enter the following in the terminal:
`flutter doctor -v`
You'll see information about installed components. Don't worry if you see errors. You haven't installed any IDE plugins for working with Flutter SDK yet.
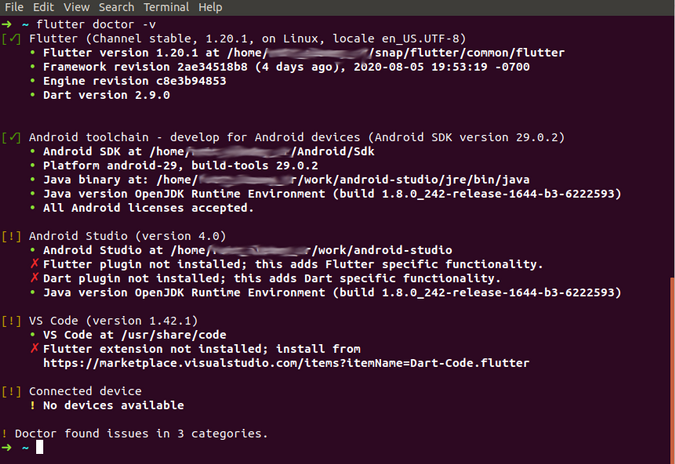
(Vitaly Kuprenko, CC BY-SA 4.0)
## Install IDE plugins
You should install plugins in your [integrated development environment (IDE)](https://www.redhat.com/en/topics/middleware/what-is-ide) to help it interface with the Flutter SDK, interact with devices, and build code.
The three main IDE tools that are commonly used for Flutter development are IntelliJ IDEA (Community Edition), Android Studio, and VS Code (or [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code)). I'm using Android Studio in this tutorial, but the steps are similar to how they work on IntelliJ IDEA (Community Edition) since they're built on the same platform.
First, launch **Android Studio**. Open **Settings** and go to the **Plugins** pane, and select the **Marketplace** tab. Enter **Flutter** in the search line and click **Install**.
(Vitaly Kuprenko, CC BY-SA 4.0)
You'll probably see an option to install the **Dart** plugin; agree to it. If you don't see the Dart option, then install it manually by repeating the steps above. I also recommend using the **Rainbow Brackets** plugin, which makes code navigation easier.
That's it! You've installed all the plugins you need. You can check by entering a familiar command in the terminal:
`flutter doctor -v`
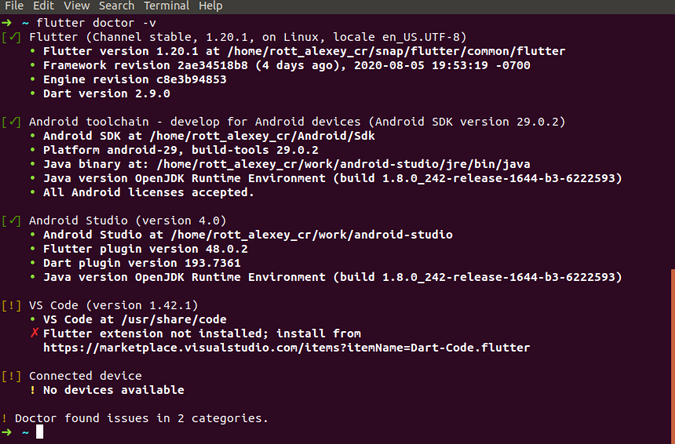
(Vitaly Kuprenko, CC BY-SA 4.0)
## Build your "Hello World" application
To start a new project, create a Flutter project:
- Select
**New -> New Flutter project**.
(Vitaly Kuprenko,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - In the window, choose the type of project you want. In this case, you need
**Flutter Application**. - Name your project
**hello_world**. Note that you should use a merged name, so use an underscore instead of a space. You may also need to specify the path to the SDK.
(Vitaly Kuprenko,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - Enter the package name.
You've created a project! Now you can launch it on a device or by using an emulator.
(Vitaly Kuprenko, CC BY-SA 4.0)
Select the device you want and press **Run**. In a moment, you will see the result.
(Vitaly Kuprenko, CC BY-SA 4.0)
Now you can start working on an [intermediate project](https://opensource.com/article/18/6/flutter).
## Try Flutter for web
Before you install Flutter components for the web, you should know that Flutter's support for web apps is pretty raw at the moment. So it's not a good idea to use it for complicated projects yet.
Flutter for web is not active in the basic SDK by default. To switch it on, go to the beta channel. To do this, enter the following command in the terminal:
`flutter channel beta`
(Vitaly Kuprenko, CC BY-SA 4.0)
Next, upgrade Flutter according to the beta branch by using the command:
`flutter upgrade`
(Vitaly Kuprenko, CC BY-SA 4.0)
To make Flutter for web work, enter:
`flutter config --enable-web`
Restart your IDE; this helps Android Studio index the new IDE and reload the list of devices. You should see several new devices:
(Vitaly Kuprenko, CC BY-SA 4.0)
Selecting **Chrome** launches an app in the browser, while **Web Server** gives you the link to your web app, which you can open in any browser.
Still, it's not time to rush into development because your current project doesn't support the web. To improve it, open the terminal in the project's root and enter:
`flutter create`
This command recreates the project, adding web support. The existing code won't be deleted.
Note that the tree has changed and now has a "web" directory:
(Vitaly Kuprenko, CC BY-SA 4.0)
Now you can get to work. Select **Chrome** and press **Run**. In a moment, you'll see the browser window with your app.
(Vitaly Kuprenko, CC BY-SA 4.0)
Congratulations! You've just launched a project for the browser and can continue working with it as with any other website.
All of this comes from the same codebase because Flutter makes it possible to write code for both mobile platforms and the web with little to no changes.
## Do more with Flutter
Flutter is a powerful tool for mobile development, and moreover, it's an important evolutionary step toward cross-platform development. Learn it, use it, and deliver your apps to all the platforms!
## Comments are closed. |
12,696 | 使用 Lynis 扫描 Linux 安全性 | https://opensource.com/article/20/5/linux-security-lynis | 2020-10-08T09:55:50 | [
"Lynis",
"安全"
] | https://linux.cn/article-12696-1.html |
>
> 使用这个全面的开源安全审计工具检查你的 Linux 机器的安全性。
>
>
>

你有没有想过你的 Linux 机器到底安全不安全?Linux 发行版众多,每个发行版都有自己的默认设置,你在上面运行着几十个版本各异的软件包,还有众多的服务在后台运行,而我们几乎不知道或不关心这些。
要想确定安全态势(指你的 Linux 机器上运行的软件、网络和服务的整体安全状态),你可以运行几个命令,得到一些零碎的相关信息,但你需要解析的数据量是巨大的。
如果能运行一个工具,生成一份关于机器安全状况的报告,那就好得多了。而幸运的是,有一个这样的软件:[Lynis](https://github.com/CISOfy/lynis)。它是一个非常流行的开源安全审计工具,可以帮助强化基于 Linux 和 Unix 的系统。根据该项目的介绍:
>
> “它运行在系统本身,可以进行深入的安全扫描。主要目标是测试安全防御措施,并提供进一步强化系统的提示。它还将扫描一般系统信息、易受攻击的软件包和可能的配置问题。Lynis 常被系统管理员和审计人员用来评估其系统的安全防御。”
>
>
>
### 安装 Lynis
你的 Linux 软件仓库中可能有 Lynis。如果有的话,你可以用以下方法安装它:
```
dnf install lynis
```
或
```
apt install lynis
```
然而,如果你的仓库中的版本不是最新的,你最好从 GitHub 上安装它。(我使用的是 Red Hat Linux 系统,但你可以在任何 Linux 发行版上运行它)。就像所有的工具一样,先在虚拟机上试一试是有意义的。要从 GitHub 上安装它:
```
$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.8 (Maipo)
$
$ uname -r
3.10.0-1127.el7.x86_64
$
$ git clone https://github.com/CISOfy/lynis.git
Cloning into 'lynis'...
remote: Enumerating objects: 30, done.
remote: Counting objects: 100% (30/30), done.
remote: Compressing objects: 100% (30/30), done.
remote: Total 12566 (delta 15), reused 8 (delta 0), pack-reused 12536
Receiving objects: 100% (12566/12566), 6.36 MiB | 911.00 KiB/s, done.
Resolving deltas: 100% (9264/9264), done.
$
```
一旦你克隆了这个版本库,那么进入该目录,看看里面有什么可用的。主要的工具在一个叫 `lynis` 的文件里。它实际上是一个 shell 脚本,所以你可以打开它看看它在做什么。事实上,Lynis 主要是用 shell 脚本来实现的:
```
$ cd lynis/
$ ls
CHANGELOG.md CONTRIBUTING.md db developer.prf FAQ include LICENSE lynis.8 README SECURITY.md
CODE_OF_CONDUCT.md CONTRIBUTORS.md default.prf extras HAPPY_USERS.md INSTALL lynis plugins README.md
$
$ file lynis
lynis: POSIX shell script, ASCII text executable, with very long lines
$
```
### 运行 Lynis
通过给 Lynis 一个 `-h` 选项来查看帮助部分,以便有个大概了解:
```
$ ./lynis -h
```
你会看到一个简短的信息屏幕,然后是 Lynis 支持的所有子命令。
接下来,尝试一些测试命令以大致熟悉一下。要查看你正在使用的 Lynis 版本,请运行:
```
$ ./lynis show version
3.0.0
$
```
要查看 Lynis 中所有可用的命令:
```
$ ./lynis show commands
Commands:
lynis audit
lynis configure
lynis generate
lynis show
lynis update
lynis upload-only
$
```
### 审计 Linux 系统
要审计你的系统的安全态势,运行以下命令:
```
$ ./lynis audit system
```
这个命令运行得很快,并会返回一份详细的报告,输出结果可能一开始看起来很吓人,但我将在下面引导你来阅读它。这个命令的输出也会被保存到一个日志文件中,所以你可以随时回过头来检查任何可能感兴趣的东西。
Lynis 将日志保存在这里:
```
Files:
- Test and debug information : /var/log/lynis.log
- Report data : /var/log/lynis-report.dat
```
你可以验证是否创建了日志文件。它确实创建了:
```
$ ls -l /var/log/lynis.log
-rw-r-----. 1 root root 341489 Apr 30 05:52 /var/log/lynis.log
$
$ ls -l /var/log/lynis-report.dat
-rw-r-----. 1 root root 638 Apr 30 05:55 /var/log/lynis-report.dat
$
```
### 探索报告
Lynis 提供了相当全面的报告,所以我将介绍一些重要的部分。作为初始化的一部分,Lynis 做的第一件事就是找出机器上运行的操作系统的完整信息。之后是检查是否安装了什么系统工具和插件:
```
[+] Initializing program
------------------------------------
- Detecting OS... [ DONE ]
- Checking profiles... [ DONE ]
---------------------------------------------------
Program version: 3.0.0
Operating system: Linux
Operating system name: Red Hat Enterprise Linux Server 7.8 (Maipo)
Operating system version: 7.8
Kernel version: 3.10.0
Hardware platform: x86_64
Hostname: example
---------------------------------------------------
<<截断>>
[+] System Tools
------------------------------------
- Scanning available tools...
- Checking system binaries...
[+] Plugins (phase 1)
------------------------------------
Note: plugins have more extensive tests and may take several minutes to complete
- Plugin: pam
[..]
- Plugin: systemd
[................]
```
接下来,该报告被分为不同的部分,每个部分都以 `[+]` 符号开头。下面可以看到部分章节。(哇,要审核的地方有这么多,Lynis 是最合适的工具!)
```
[+] Boot and services
[+] Kernel
[+] Memory and Processes
[+] Users, Groups and Authentication
[+] Shells
[+] File systems
[+] USB Devices
[+] Storage
[+] NFS
[+] Name services
[+] Ports and packages
[+] Networking
[+] Printers and Spools
[+] Software: e-mail and messaging
[+] Software: firewalls
[+] Software: webserver
[+] SSH Support
[+] SNMP Support
[+] Databases
[+] LDAP Services
[+] PHP
[+] Squid Support
[+] Logging and files
[+] Insecure services
[+] Banners and identification
[+] Scheduled tasks
[+] Accounting
[+] Time and Synchronization
[+] Cryptography
[+] Virtualization
[+] Containers
[+] Security frameworks
[+] Software: file integrity
[+] Software: System tooling
[+] Software: Malware
[+] File Permissions
[+] Home directories
[+] Kernel Hardening
[+] Hardening
[+] Custom tests
```
Lynis 使用颜色编码使报告更容易解读。
* 绿色。一切正常
* 黄色。跳过、未找到,可能有个建议
* 红色。你可能需要仔细看看这个
在我的案例中,大部分的红色标记都是在 “Kernel Hardening” 部分找到的。内核有各种可调整的设置,它们定义了内核的功能,其中一些可调整的设置可能有其安全场景。发行版可能因为各种原因没有默认设置这些,但是你应该检查每一项,看看你是否需要根据你的安全态势来改变它的值:
```
[+] Kernel Hardening
------------------------------------
- Comparing sysctl key pairs with scan profile
- fs.protected_hardlinks (exp: 1) [ OK ]
- fs.protected_symlinks (exp: 1) [ OK ]
- fs.suid_dumpable (exp: 0) [ OK ]
- kernel.core_uses_pid (exp: 1) [ OK ]
- kernel.ctrl-alt-del (exp: 0) [ OK ]
- kernel.dmesg_restrict (exp: 1) [ DIFFERENT ]
- kernel.kptr_restrict (exp: 2) [ DIFFERENT ]
- kernel.randomize_va_space (exp: 2) [ OK ]
- kernel.sysrq (exp: 0) [ DIFFERENT ]
- kernel.yama.ptrace_scope (exp: 1 2 3) [ DIFFERENT ]
- net.ipv4.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv4.conf.all.bootp_relay (exp: 0) [ OK ]
- net.ipv4.conf.all.forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.conf.all.mc_forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.proxy_arp (exp: 0) [ OK ]
- net.ipv4.conf.all.rp_filter (exp: 1) [ OK ]
- net.ipv4.conf.all.send_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_source_route (exp: 0) [ OK ]
- net.ipv4.conf.default.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.icmp_echo_ignore_broadcasts (exp: 1) [ OK ]
- net.ipv4.icmp_ignore_bogus_error_responses (exp: 1) [ OK ]
- net.ipv4.tcp_syncookies (exp: 1) [ OK ]
- net.ipv4.tcp_timestamps (exp: 0 1) [ OK ]
- net.ipv6.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv6.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.default.accept_source_route (exp: 0) [ OK ]
```
看看 SSH 这个例子,因为它是一个需要保证安全的关键领域。这里没有什么红色的东西,但是 Lynis 对我的环境给出了很多强化 SSH 服务的建议:
```
[+] SSH Support
------------------------------------
- Checking running SSH daemon [ FOUND ]
- Searching SSH configuration [ FOUND ]
- OpenSSH option: AllowTcpForwarding [ SUGGESTION ]
- OpenSSH option: ClientAliveCountMax [ SUGGESTION ]
- OpenSSH option: ClientAliveInterval [ OK ]
- OpenSSH option: Compression [ SUGGESTION ]
- OpenSSH option: FingerprintHash [ OK ]
- OpenSSH option: GatewayPorts [ OK ]
- OpenSSH option: IgnoreRhosts [ OK ]
- OpenSSH option: LoginGraceTime [ OK ]
- OpenSSH option: LogLevel [ SUGGESTION ]
- OpenSSH option: MaxAuthTries [ SUGGESTION ]
- OpenSSH option: MaxSessions [ SUGGESTION ]
- OpenSSH option: PermitRootLogin [ SUGGESTION ]
- OpenSSH option: PermitUserEnvironment [ OK ]
- OpenSSH option: PermitTunnel [ OK ]
- OpenSSH option: Port [ SUGGESTION ]
- OpenSSH option: PrintLastLog [ OK ]
- OpenSSH option: StrictModes [ OK ]
- OpenSSH option: TCPKeepAlive [ SUGGESTION ]
- OpenSSH option: UseDNS [ SUGGESTION ]
- OpenSSH option: X11Forwarding [ SUGGESTION ]
- OpenSSH option: AllowAgentForwarding [ SUGGESTION ]
- OpenSSH option: UsePrivilegeSeparation [ OK ]
- OpenSSH option: AllowUsers [ NOT FOUND ]
- OpenSSH option: AllowGroups [ NOT FOUND ]
```
我的系统上没有运行虚拟机或容器,所以这些显示的结果是空的:
```
[+] Virtualization
------------------------------------
[+] Containers
------------------------------------
```
Lynis 会检查一些从安全角度看很重要的文件的文件权限:
```
[+] File Permissions
------------------------------------
- Starting file permissions check
File: /boot/grub2/grub.cfg [ SUGGESTION ]
File: /etc/cron.deny [ OK ]
File: /etc/crontab [ SUGGESTION ]
File: /etc/group [ OK ]
File: /etc/group- [ OK ]
File: /etc/hosts.allow [ OK ]
File: /etc/hosts.deny [ OK ]
File: /etc/issue [ OK ]
File: /etc/issue.net [ OK ]
File: /etc/motd [ OK ]
File: /etc/passwd [ OK ]
File: /etc/passwd- [ OK ]
File: /etc/ssh/sshd_config [ OK ]
Directory: /root/.ssh [ SUGGESTION ]
Directory: /etc/cron.d [ SUGGESTION ]
Directory: /etc/cron.daily [ SUGGESTION ]
Directory: /etc/cron.hourly [ SUGGESTION ]
Directory: /etc/cron.weekly [ SUGGESTION ]
Directory: /etc/cron.monthly [ SUGGESTION ]
```
在报告的底部,Lynis 根据报告的发现提出了建议。每项建议后面都有一个 “TEST-ID”(为了下一部分方便,请将其保存起来)。
```
Suggestions (47):
----------------------------
* If not required, consider explicit disabling of core dump in /etc/security/limits.conf file [KRNL-5820]
https://cisofy.com/lynis/controls/KRNL-5820/
* Check PAM configuration, add rounds if applicable and expire passwords to encrypt with new values [AUTH-9229]
https://cisofy.com/lynis/controls/AUTH-9229/
```
Lynis 提供了一个选项来查找关于每个建议的更多信息,你可以使用 `show details` 命令和 TEST-ID 号来访问:
```
./lynis show details TEST-ID
```
这将显示该测试的其他信息。例如,我检查了 SSH-7408 的详细信息:
```
$ ./lynis show details SSH-7408
2020-04-30 05:52:23 Performing test ID SSH-7408 (Check SSH specific defined options)
2020-04-30 05:52:23 Test: Checking specific defined options in /tmp/lynis.k8JwazmKc6
2020-04-30 05:52:23 Result: added additional options for OpenSSH < 7.5
2020-04-30 05:52:23 Test: Checking AllowTcpForwarding in /tmp/lynis.k8JwazmKc6
2020-04-30 05:52:23 Result: Option AllowTcpForwarding found
2020-04-30 05:52:23 Result: Option AllowTcpForwarding value is YES
2020-04-30 05:52:23 Result: OpenSSH option AllowTcpForwarding is in a weak configuration state and should be fixed
2020-04-30 05:52:23 Suggestion: Consider hardening SSH configuration [test:SSH-7408] [details:AllowTcpForwarding (set YES to NO)] [solution:-]
```
### 试试吧
如果你想更多地了解你的 Linux 机器的安全性,请试试 Lynis。如果你想了解 Lynis 是如何工作的,可以研究一下它的 shell 脚本,看看它是如何收集这些信息的。
---
via: <https://opensource.com/article/20/5/linux-security-lynis>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Have you ever thought about how secure your Linux machine really is? There are numerous Linux distros, each with its own default settings, on which you run dozens of software packages with different version numbers, and numerous services running in the background, which we hardly know or care about.
To find the security posture—the overall security status of the software, network, and services running on your Linux machine—you could run a few commands and get bits and pieces of relevant information, but the amount of data you need to parse is huge.
It would be so much better if you could just run a tool that generates a report on a machine's security posture. And luckily there is one: [Lynis](https://github.com/CISOfy/lynis). It is an extremely popular open source security auditing tool that helps with hardening Linux- and Unix-based systems. According to the project:
"It performs an in-depth security scan and runs on the system itself. The primary goal is to test security defenses and provide tips for further system hardening. It will also scan for general system information, vulnerable software packages, and possible configuration issues. Lynis [is] commonly used by system administrators and auditors to assess the security defenses of their systems."
## Install Lynis
Lynis might be available in your Linux software repository. If so, you can install it using:
`dnf install lynis`
or
`apt install lynis`
However, if the version in your repo isn't the latest one, you are better off installing it from GitHub. (I am using a Red Hat Linux system, but you can run it on any Linux distribution.) As with all tools, it makes sense to try it out on a virtual machine first. To install it from GitHub:
```
$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.8 (Maipo)
$
$ uname -r
3.10.0-1127.el7.x86_64
$
$ git clone https://github.com/CISOfy/lynis.git
Cloning into 'lynis'...
remote: Enumerating objects: 30, done.
remote: Counting objects: 100% (30/30), done.
remote: Compressing objects: 100% (30/30), done.
remote: Total 12566 (delta 15), reused 8 (delta 0), pack-reused 12536
Receiving objects: 100% (12566/12566), 6.36 MiB | 911.00 KiB/s, done.
Resolving deltas: 100% (9264/9264), done.
$
```
Once you have cloned the repository, move into it and see what is available. The main tool is in a file called **lynis**. It's actually a shell script, so you can open it and read what it is doing. In fact, Lynis is mainly implemented using shell scripts:
```
$ cd lynis/
$ ls
CHANGELOG.md CONTRIBUTING.md db developer.prf FAQ include LICENSE lynis.8 README SECURITY.md
CODE_OF_CONDUCT.md CONTRIBUTORS.md default.prf extras HAPPY_USERS.md INSTALL lynis plugins README.md
$
$ file lynis
lynis: POSIX shell script, ASCII text executable, with very long lines
$
```
## Run Lynis
Take Lynis out for a spin by giving it a **-h** option to see the Help section:
`$ ./lynis -h`
You'll see a short information screen followed by all the commands that Lynis supports.
Next, try out some test commands to get a feel for things and get comfortable. To see which version of Lynis you are working with, run:
```
$ ./lynis show version
3.0.0
$
```
To see all the commands available in Lynis:
```
$ ./lynis show commands
Commands:
lynis audit
lynis configure
lynis generate
lynis show
lynis update
lynis upload-only
$
```
## Audit a Linux system
To audit your system's security posture, run the following command:
`$ ./lynis audit system`
This runs quickly and returns a detailed report—the output might seem intimidating at first, but I'll walk you through it below. The command's output is also saved to a log file, so you can always go back later and check anything that might be of interest.
Lynis saves the logs here:
```
Files:
- Test and debug information : /var/log/lynis.log
- Report data : /var/log/lynis-report.dat
```
You can verify whether the log files were created, and indeed they were:
```
$ ls -l /var/log/lynis.log
-rw-r-----. 1 root root 341489 Apr 30 05:52 /var/log/lynis.log
$
$ ls -l /var/log/lynis-report.dat
-rw-r-----. 1 root root 638 Apr 30 05:55 /var/log/lynis-report.dat
$
```
## Explore the reports
Lynis provides pretty comprehensive reports, so I will cover some of the important sections. The very first thing that Lynis does as part of initialization is to find out complete information about the operating system running on the machine. This is followed by checks to see what system tools and plugins are installed:
```
[+] Initializing program
------------------------------------
- Detecting OS... [ DONE ]
- Checking profiles... [ DONE ]
---------------------------------------------------
Program version: 3.0.0
Operating system: Linux
Operating system name: Red Hat Enterprise Linux Server 7.8 (Maipo)
Operating system version: 7.8
Kernel version: 3.10.0
Hardware platform: x86_64
Hostname: example
---------------------------------------------------
<<snip>>
[+] System Tools
------------------------------------
- Scanning available tools...
- Checking system binaries...
[+] Plugins (phase 1)
------------------------------------
Note: plugins have more extensive tests and may take several minutes to complete
- Plugin: pam
[..]
- Plugin: systemd
[................]
```
Next, the report is divided into various sections, and each section starts with a **[+]** symbol. Some of the sections can be seen below. (Wow, there are so many areas to audit, and Lynis is the right tool for the job!)
```
[+] Boot and services
[+] Kernel
[+] Memory and Processes
[+] Users, Groups and Authentication
[+] Shells
[+] File systems
[+] USB Devices
[+] Storage
[+] NFS
[+] Name services
[+] Ports and packages
[+] Networking
[+] Printers and Spools
[+] Software: e-mail and messaging
[+] Software: firewalls
[+] Software: webserver
[+] SSH Support
[+] SNMP Support
[+] Databases
[+] LDAP Services
[+] PHP
[+] Squid Support
[+] Logging and files
[+] Insecure services
[+] Banners and identification
[+] Scheduled tasks
[+] Accounting
[+] Time and Synchronization
[+] Cryptography
[+] Virtualization
[+] Containers
[+] Security frameworks
[+] Software: file integrity
[+] Software: System tooling
[+] Software: Malware
[+] File Permissions
[+] Home directories
[+] Kernel Hardening
[+] Hardening
[+] Custom tests
```
Lynis uses color-coding to make the report easier to parse:
- Green: All good
- Yellow: Skipped, not found, or it may have a suggestion
- Red: You might need to give this a closer look
In my case, most of the red marks were found in the Kernel Hardening section. The kernel has various tunable settings that define how the kernel functions, and some of these tunables may have a security context. The distro may not be setting these by default for various reasons, but you should examine each and see if you need to change its value based on your security posture:
```
[+] Kernel Hardening
------------------------------------
- Comparing sysctl key pairs with scan profile
- fs.protected_hardlinks (exp: 1) [ OK ]
- fs.protected_symlinks (exp: 1) [ OK ]
- fs.suid_dumpable (exp: 0) [ OK ]
- kernel.core_uses_pid (exp: 1) [ OK ]
- kernel.ctrl-alt-del (exp: 0) [ OK ]
- kernel.dmesg_restrict (exp: 1) [ DIFFERENT ]
- kernel.kptr_restrict (exp: 2) [ DIFFERENT ]
- kernel.randomize_va_space (exp: 2) [ OK ]
- kernel.sysrq (exp: 0) [ DIFFERENT ]
- kernel.yama.ptrace_scope (exp: 1 2 3) [ DIFFERENT ]
- net.ipv4.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv4.conf.all.bootp_relay (exp: 0) [ OK ]
- net.ipv4.conf.all.forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.conf.all.mc_forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.proxy_arp (exp: 0) [ OK ]
- net.ipv4.conf.all.rp_filter (exp: 1) [ OK ]
- net.ipv4.conf.all.send_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_source_route (exp: 0) [ OK ]
- net.ipv4.conf.default.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.icmp_echo_ignore_broadcasts (exp: 1) [ OK ]
- net.ipv4.icmp_ignore_bogus_error_responses (exp: 1) [ OK ]
- net.ipv4.tcp_syncookies (exp: 1) [ OK ]
- net.ipv4.tcp_timestamps (exp: 0 1) [ OK ]
- net.ipv6.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv6.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.default.accept_source_route (exp: 0) [ OK ]
```
Look at SSH, an example, since it is a key area and needs to be secured. There's nothing in red here, but Lynis has a lot of suggestions about hardening the SSH service on my setup:
```
[+] SSH Support
------------------------------------
- Checking running SSH daemon [ FOUND ]
- Searching SSH configuration [ FOUND ]
- OpenSSH option: AllowTcpForwarding [ SUGGESTION ]
- OpenSSH option: ClientAliveCountMax [ SUGGESTION ]
- OpenSSH option: ClientAliveInterval [ OK ]
- OpenSSH option: Compression [ SUGGESTION ]
- OpenSSH option: FingerprintHash [ OK ]
- OpenSSH option: GatewayPorts [ OK ]
- OpenSSH option: IgnoreRhosts [ OK ]
- OpenSSH option: LoginGraceTime [ OK ]
- OpenSSH option: LogLevel [ SUGGESTION ]
- OpenSSH option: MaxAuthTries [ SUGGESTION ]
- OpenSSH option: MaxSessions [ SUGGESTION ]
- OpenSSH option: PermitRootLogin [ SUGGESTION ]
- OpenSSH option: PermitUserEnvironment [ OK ]
- OpenSSH option: PermitTunnel [ OK ]
- OpenSSH option: Port [ SUGGESTION ]
- OpenSSH option: PrintLastLog [ OK ]
- OpenSSH option: StrictModes [ OK ]
- OpenSSH option: TCPKeepAlive [ SUGGESTION ]
- OpenSSH option: UseDNS [ SUGGESTION ]
- OpenSSH option: X11Forwarding [ SUGGESTION ]
- OpenSSH option: AllowAgentForwarding [ SUGGESTION ]
- OpenSSH option: UsePrivilegeSeparation [ OK ]
- OpenSSH option: AllowUsers [ NOT FOUND ]
- OpenSSH option: AllowGroups [ NOT FOUND ]
```
I do not have virtual machines or containers running on my system, so they show empty results:
```
[+] Virtualization
------------------------------------
[+] Containers
------------------------------------
```
Lynis checks file permissions on some files that are important from a security standpoint:
```
[+] File Permissions
------------------------------------
- Starting file permissions check
File: /boot/grub2/grub.cfg [ SUGGESTION ]
File: /etc/cron.deny [ OK ]
File: /etc/crontab [ SUGGESTION ]
File: /etc/group [ OK ]
File: /etc/group- [ OK ]
File: /etc/hosts.allow [ OK ]
File: /etc/hosts.deny [ OK ]
File: /etc/issue [ OK ]
File: /etc/issue.net [ OK ]
File: /etc/motd [ OK ]
File: /etc/passwd [ OK ]
File: /etc/passwd- [ OK ]
File: /etc/ssh/sshd_config [ OK ]
Directory: /root/.ssh [ SUGGESTION ]
Directory: /etc/cron.d [ SUGGESTION ]
Directory: /etc/cron.daily [ SUGGESTION ]
Directory: /etc/cron.hourly [ SUGGESTION ]
Directory: /etc/cron.weekly [ SUGGESTION ]
Directory: /etc/cron.monthly [ SUGGESTION ]
```
Towards the bottom of the report, Lynis offers suggestions based on the report's findings. Each suggestion is followed by a **TEST-ID** (keep this handy for the next part):
```
Suggestions (47):
----------------------------
* If not required, consider explicit disabling of core dump in /etc/security/limits.conf file [KRNL-5820]
https://cisofy.com/lynis/controls/KRNL-5820/
* Check PAM configuration, add rounds if applicable and expire passwords to encrypt with new values [AUTH-9229]
https://cisofy.com/lynis/controls/AUTH-9229/
```
Lynis provides an option to find more information about each suggestion, which you can access using the **show details** command followed by the test ID number:
`./lynis show details TEST-ID`
This will show additional information about that test. For example, I checked the details of SSH-7408:
```
$ ./lynis show details SSH-7408
2020-04-30 05:52:23 Performing test ID SSH-7408 (Check SSH specific defined options)
2020-04-30 05:52:23 Test: Checking specific defined options in /tmp/lynis.k8JwazmKc6
2020-04-30 05:52:23 Result: added additional options for OpenSSH < 7.5
2020-04-30 05:52:23 Test: Checking AllowTcpForwarding in /tmp/lynis.k8JwazmKc6
2020-04-30 05:52:23 Result: Option AllowTcpForwarding found
2020-04-30 05:52:23 Result: Option AllowTcpForwarding value is YES
2020-04-30 05:52:23 Result: OpenSSH option AllowTcpForwarding is in a weak configuration state and should be fixed
2020-04-30 05:52:23 Suggestion: Consider hardening SSH configuration [test:SSH-7408] [details:AllowTcpForwarding (set YES to NO)] [solution:-]
```
## Give it a try
If you want to learn more about the security of your Linux machine, check out Lynis. And, if you want to learn how Lynis works, dig into its shell scripts to see how it gathers all this information.
## 3 Comments |
12,697 | 如何阅读 Lynis 报告提高 Linux 安全性 | https://opensource.com/article/20/8/linux-lynis-security | 2020-10-08T10:24:19 | [
"Lynis",
"安全"
] | https://linux.cn/article-12697-1.html |
>
> 使用 Lynis 的扫描和报告来发现和修复 Linux 安全问题。
>
>
>

当我读到 Gaurav Kamathe 的文章《[使用 Lynis 扫描 Linux 安全性](/article-12696-1.html)》时,让我想起了我在美国劳工部担任系统管理员的日子。我那时的职责之一是保证我们的 Unix 服务器的安全。每个季度,都会有一个独立的核查员来审查我们服务器的安全状态。每次在核查员预定到达的那一天,我都会运行 Security Readiness Review(SRR),这是一个扫描工具,它使用一大套脚本来识别和报告任何安全线索。SRR 是开源的,因此我可以查看所有源码脚本及其功能。这使我能够查看其代码,确定具体是什么问题,并迅速修复它发现的每个问题。
### 什么是 Lynis?
[Lynis](https://github.com/CISOfy/lynis) 是一个开源的安全审计工具,它的工作原理和 SRR 很像,它会扫描 Linux 系统,并提供它发现的任何弱点的详细报告。同样和 SRR 一样,它也是由一大套脚本组成的,每个脚本都会检查一个特定的项目,例如,最小和最大密码时间要求。
运行 Lynis 后,你可以使用它的报告来定位每个项目的脚本,并了解 Lynis 是如何检查和报告每个问题的。你也可以使用相同的脚本代码来创建新的代码来自动解决。
### 如何阅读 Lynis 报告
由于 Gaurav 的文章介绍了 Lynis 的安装和使用,在本文中,我将展示一些如何阅读和使用其报告的例子。
请从运行一次审计开始:
```
# lynis audit system --quick
```
完成后,完整的报告将显示在你的屏幕上。在底部,“Suggestions” 部分列出了所有可能需要修复以更好地加固系统的项目,以及每个项目的 TEST-ID。
要想加固系统并减少列表的大小,请开始解决每个项目。在 “Suggestions” 部分的描述可能包含了你需要采取的全部行动。如果没有,你可以使用 `show details` 命令。
```
# lynis show details TEST-ID
```
例如,在我的系统中,有一条建议是:
>
> 找不到 `locate` 所需的数据库,运行 `updatedb` 或 `locate.updatedb` 来创建这个文件。[FILE-6410]
>
>
>
看起来我只需要运行 `updatedb` 命令就行,但如果我想确定一下,我可以使用 Lynis 的 `show details` 选项。
```
# lynis show details FILE-6410
2020-06-16 20:54:33 Performing test ID FILE-6410 (Checking Locate database)
2020-06-16 20:54:33 Test: Checking locate database
2020-06-16 20:54:33 Result: file /var/lib/mlocate/mlocate.db not found
2020-06-16 20:54:33 Result: file /var/lib/locate/locatedb not found
2020-06-16 20:54:33 Result: file /var/lib/locatedb not found
2020-06-16 20:54:33 Result: file /var/lib/slocate/slocate.db not found
2020-06-16 20:54:33 Result: file /var/cache/locate/locatedb not found
2020-06-16 20:54:33 Result: file /var/db/locate.database not found
2020-06-16 20:54:33 Result: database not found
2020-06-16 20:54:33 Suggestion: The database required for 'locate' could not be found. Run 'updatedb' or 'locate.updatedb' to create this file. [test:FILE-6410] [details:-] [solution:-]
2020-06-16 20:54:33 ====
```
这些细节表明 Lynis 无法找到各种文件。这个情况描述的非常清楚。我可以运行 `updatedb` 命令,然后重新检查这个测试。
```
# updatedb
# lynis --tests FILE-6410
```
重新检查细节时,会显示它发现哪个文件满足了测试:
```
# lynis show details FILE-6410
2020-06-16 21:38:40 Performing test ID FILE-6410 (Checking Locate database)
2020-06-16 21:38:40 Test: Checking locate database
2020-06-16 21:38:40 Result: locate database found (/var/lib/mlocate/mlocate.db)
2020-06-16 21:38:40 Result: file /var/lib/locate/locatedb not found
2020-06-16 21:38:40 Result: file /var/lib/locatedb not found
2020-06-16 21:38:40 Result: file /var/lib/slocate/slocate.db not found
2020-06-16 21:38:40 Result: file /var/cache/locate/locatedb not found
2020-06-16 21:38:40 Result: file /var/db/locate.database not found
2020-06-16 21:38:40 ====
```
### 深入挖掘
Lynis 的许多建议并不像这个建议那样直接。如果你不确定某个发现或建议指的是什么,就很难知道如何解决问题。假设你在一个新的 Linux 服务器上运行 Lynis,有几项与 SSH 守护进程有关的内容,其中一项是关于 `MaxAuthTries` 的设置:
```
* Consider hardening SSH configuration [SSH-7408]
- Details : MaxAuthTries (6 --> 3)
https://cisofy.com/lynis/controls/SSH-7408/
```
要解决这个问题,你需要知道 SSH 配置文件的位置。一个经验丰富的 Linux 管理员可能已经知道在哪里找到它们,但如果你不知道,有一个方法可以看到 Lynis 在哪里找到它们。
#### 定位 Lynis 测试脚本
Lynis 支持多种操作系统,因此你的安装位置可能有所不同。在 Red Hat Enterprise Linux 或 Fedora Linux 系统中,使用 `rpm` 命令来查找测试文件:
```
# rpm -ql lynis
```
这将列出所有测试文件,并报告它们在 `lynis/include` 目录下的位置。在这个目录下搜索你想知道的 TEST-ID(本例中为 SSH-7408):
```
# grep SSH-7408 /usr/share/lynis/include/*
/usr/share/lynis/include/tests_ssh: # Test : SSH-7408
```
#### 查找 SSH 问题
名为 `tests_ssh` 的文件中包含了 TEST-ID,在这里可以找到与 SSH 相关的扫描函数。看看这个文件,就可以看到 Lynis 扫描器调用的各种函数。第一部分在一个名为 `SSH_DAEMON_CONFIG_LOCS` 的变量中定义了一个目录列表。下面几节负责检查 SSH 守护进程的状态、定位它的配置文件,并识别它的版本。我在 SSH-7404 测试中找到了查找配置文件的代码,描述为 “确定 SSH 守护进程配置文件位置”。这段代码包含一个 `for` 循环,在列表中的项目中搜索一个名为 `sshd_config` 的文件。我可以用这个逻辑来自己进行搜索:
```
# find /etc /etc/ssh /usr/local/etc/ssh /opt/csw/etc/ssh -name sshd_config
/etc/ssh/sshd_config
/etc/ssh/sshd_config
find: ‘/usr/local/etc/ssh’: No such file or directory
find: ‘/opt/csw/etc/ssh’: No such file or directory
```
进一步探索这个文件,就会看到寻找 SSH-7408 的相关代码。这个测试涵盖了 `MaxAuthTries` 和其他一些设置。现在我可以在 SSH 配置文件中找到该变量:
```
# grep MaxAuthTries /etc/ssh/sshd_config
#MaxAuthTries 6
```
#### 修复法律横幅问题
Lynis 还报告了一个与登录系统时显示的法律横幅有关的发现。在我的家庭桌面系统上(我并不希望有很多其他人登录),我没有去改变默认的 `issue` 文件。企业或政府的系统很可能被要求包含一个法律横幅,以警告用户他们的登录和活动可能被记录和监控。Lynis 用 BANN-7126 测试和 BANN-7130 测试报告了这一点:
```
* Add a legal banner to /etc/issue, to warn unauthorized users [BANN-7126]
https://cisofy.com/lynis/controls/BANN-7126/
* Add legal banner to /etc/issue.net, to warn unauthorized users [BANN-7130]
https://cisofy.com/lynis/controls/BANN-7130/
```
我在运行 Fedora 32 工作站的系统上没有发现什么:
```
# cat /etc/issue /etc/issue.net
\S
Kernel \r on an \m (\l)
\S
Kernel \r on an \m (\l)
```
我可以添加一些诸如 “keep out” 或 “don't break anything” 之类的内容,但测试的描述并没有提供足够的信息来解决这个问题,所以我又看了看 Lynis 的脚本。我注意到 `include` 目录下有一个叫 `tests_banners` 的文件;这似乎是一个很好的地方。在 `grep` 的帮助下,我看到了相关的测试:
```
# grep -E 'BANN-7126|BANN-7130' /usr/share/lynis/include/tests_banners
# Test : BANN-7126
Register --test-no BANN-7126 --preqs-met ${PREQS_MET} --weight L --network NO --category security --description "Check issue banner file contents"
# Test : BANN-7130
Register --test-no BANN-7130 --preqs-met ${PREQS_MET} --weight L --network NO --category security --description "Check issue.net banner file contents"
```
在检查了测试文件中的相关代码后,我发现这两个测试都是通过一个 `for` 循环来迭代一些预定义的法律术语:
```
for ITEM in ${LEGAL_BANNER_STRINGS}; do
```
这些法律术语存储在文件顶部定义的变量 `LEGAL_BANNER_STRINGS` 中。向后滚动到顶部可以看到完整的清单:
```
LEGAL_BANNER_STRINGS="audit access authori condition connect consent continu criminal enforce evidence forbidden intrusion law legal legislat log monitor owner penal policy policies privacy private prohibited record restricted secure subject system terms warning"
```
我最初的建议(“keep out” 或 “don't break anything”)不会满足这个测试,因为它们不包含这个列表中的任何单词。
下面这条横幅信息包含了几个必要的词,因此,它将满足这个测试,并防止 Lynis 报告它:
>
> Attention, by continuing to connect to this system, you consent to the owner storing a log of all activity. Unauthorized access is prohibited.
>
>
>
请注意,这条信息必须被添加到 `/etc/issue` 和 `/etc/issue.net` 中。
### 使其可重复
你可以手动进行这些编辑,但你可能要考虑自动化。例如,可能有许多设置需要更改,或者你可能需要在许多服务器上定期进行这些编辑。创建一个加固脚本将是简化这个过程的好方法。对于 SSH 配置,在你的加固脚本中的一些 `sed` 命令可以解决这些发现。或者,你可以使用 `echo` 语句来添加合法的横幅。
```
sed -i '/MaxAuthTries/s/#MaxAuthTries 6/MaxAuthTries 3/' /etc/ssh/sshd_config
echo "Legal Banner" | tee -a /etc/issue /etc/issue.net
```
自动化使你能够创建一个可重复的脚本,可以在你的基础设施中保存和管理。你也可以在你的初始服务器配置中加入这个脚本。
### 加固你的系统
这种类型的练习可以提高你的脚本技能,既可以跟着现有的代码走,也可以写自己的脚本。因为 Lynis 是开源的,所以你可以很容易地看到你的系统是如何被检查的,以及它的报告意味着什么。最终的结果将是一个完善的系统,你可以在审计人员来的时候随时向他们炫耀。
---
via: <https://opensource.com/article/20/8/linux-lynis-security>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I read Gaurav Kamathe's article * Scan your Linux security with Lynis*, it reminded me of my time as a systems administrator for the US Department of Labor. One of my duties was to keep our Unix servers hardened. Each quarter, an independent verifier came in to review our servers' security status. Each time on the day the verifier was scheduled to arrive, I ran Security Readiness Review (SRR), a scanning tool that used a large set of scripts to identify and report any security findings. SRR was open source, so I could view all the source scripts and their functions. This enabled me to look into the code, determine what specifically was wrong, and quickly fix each problem it found.
## What is Lynis?
[Lynis](https://github.com/CISOfy/lynis) is an open source security-auditing tool that works much like SRR by scanning a Linux system and providing detailed reports on any weaknesses it finds. Also like SRR, it is made up of a large set of scripts, and each script checks for a specific item, e.g., minimum and maximum password age requirements.
After running Lynis, you can use its report to locate each item's script and learn exactly how Lynis checked for and reported each problem. You can also use the same script code to create new code to automate a resolution.
## How to read Lynis reports
Since Gaurav's article covered Lynis' installation and usage, in this article, I'll show some examples of how you can read and use its reports.
To get started, run an audit:
`# lynis audit system --quick`
After it completes, the full report will be displayed on your screen. Towards the bottom, the **Suggestions** section lists all the items that may need to be triaged to better harden the system, as well as a TEST-ID for each.
To harden the system and reduce the size of the list, start chasing each item. The description in the **Suggestions** section may be everything you need to know what action to take. If it doesn't, you can use the `show details`
command:
`# lynis show details TEST-ID`
For instance, one of the suggestions on my system is:
The database required for
`locate`
could not be found. Run`updatedb`
or`locate.updatedb`
to create this file. [FILE-6410]
It looks like I just need to run the command `updatedb`
, but if I want to be sure, I can use Lynis' `show details`
option:
```
# lynis show details FILE-6410
2020-06-16 20:54:33 Performing test ID FILE-6410 (Checking Locate database)
2020-06-16 20:54:33 Test: Checking locate database
2020-06-16 20:54:33 Result: file /var/lib/mlocate/mlocate.db not found
2020-06-16 20:54:33 Result: file /var/lib/locate/locatedb not found
2020-06-16 20:54:33 Result: file /var/lib/locatedb not found
2020-06-16 20:54:33 Result: file /var/lib/slocate/slocate.db not found
2020-06-16 20:54:33 Result: file /var/cache/locate/locatedb not found
2020-06-16 20:54:33 Result: file /var/db/locate.database not found
2020-06-16 20:54:33 Result: database not found
2020-06-16 20:54:33 Suggestion: The database required for 'locate' could not be found. Run 'updatedb' or 'locate.updatedb' to create this file. [test:FILE-6410] [details:-] [solution:-]
2020-06-16 20:54:33 ====
```
These details indicate Lynis was unable to find various files. This case is very clear-cut. I can run the `updatedb`
command and recheck this test:
```
# updatedb
# lynis --tests FILE-6410
```
Furthermore, rechecking the details shows which file it found that satisfied the test:
```
# lynis show details FILE-6410
2020-06-16 21:38:40 Performing test ID FILE-6410 (Checking Locate database)
2020-06-16 21:38:40 Test: Checking locate database
2020-06-16 21:38:40 Result: locate database found (/var/lib/mlocate/mlocate.db)
2020-06-16 21:38:40 Result: file /var/lib/locate/locatedb not found
2020-06-16 21:38:40 Result: file /var/lib/locatedb not found
2020-06-16 21:38:40 Result: file /var/lib/slocate/slocate.db not found
2020-06-16 21:38:40 Result: file /var/cache/locate/locatedb not found
2020-06-16 21:38:40 Result: file /var/db/locate.database not found
2020-06-16 21:38:40 ====
```
## Diving deeper
Many of Lynis' suggestions are not as straightforward as this one. If you aren't sure what a finding or a suggestion refers to, it can be difficult to know how to fix the problem. Suppose you run Lynis against a new Linux server, and there are several items pertaining to the secure shell (SSH) daemon, one of which refers to the `MaxAuthTries`
setting:
```
* Consider hardening SSH configuration [SSH-7408]
- Details : MaxAuthTries (6 --> 3)
https://cisofy.com/lynis/controls/SSH-7408/
```
To resolve this, you need to know the location of the SSH configuration files. A seasoned Linux administrator may already know where to find them, but if you don't, there is a way to see where Lynis found them.
### Locate Lynis test scripts
Lynis supports many operating systems; therefore, your installation location might vary. On a Red Hat Enterprise Linux or Fedora Linux system, use `rpm`
to find the test files:
`# rpm -ql lynis`
This lists all the test files and reports their location in the `lynis/include`
directory. Search this directory for the TEST-ID you want to know about (SSH-7408 in this case):
```
# grep SSH-7408 /usr/share/lynis/include/*
/usr/share/lynis/include/tests_ssh: # Test : SSH-7408
```
### Find SSH issues
The file named `tests_ssh`
contains the TEST-ID, and this is where you can find the scan functions related to SSH. Take a look at this file to see the various functions called by the Lynis scanner. The first section defines a list of directories in a variable called `SSH_DAEMON_CONFIG_LOCS`
. The following few sections are responsible for checking the SSH daemon status, locating its configuration file, and identifying its version. I found the code that looks for the configuration file in the section for Test SSH-7404, described as "Determine SSH daemon configuration file location". This code contains a ** for** loop that searches the items in the list for a file called
`sshd_config`
. I can use this logic to do my own search:```
# find /etc /etc/ssh /usr/local/etc/ssh /opt/csw/etc/ssh -name sshd_config
/etc/ssh/sshd_config
/etc/ssh/sshd_config
find: ‘/usr/local/etc/ssh’: No such file or directory
find: ‘/opt/csw/etc/ssh’: No such file or directory
```
Further exploring this file reveals the code related to finding SSH-7408. This test covers `MaxAuthTries`
and several other settings. Now I can find the variable in the SSH configuration file:
```
# grep MaxAuthTries /etc/ssh/sshd_config
#MaxAuthTries 6
```
### Fix legal banner problems
Lynis also reported a finding pertaining to the legal banners shown when you log into a system. On my home desktop system (where I don't expect many other people to log in), I haven't bothered to change the default `issue`
files. A corporate or government system is likely required to include a legal banner to warn users that their logins and activity may be recorded and monitored. Lynis reports this with tests BANN-7126 and BANN-7130:
```
* Add a legal banner to /etc/issue, to warn unauthorized users [BANN-7126]
https://cisofy.com/lynis/controls/BANN-7126/
* Add legal banner to /etc/issue.net, to warn unauthorized users [BANN-7130]
https://cisofy.com/lynis/controls/BANN-7130/
```
I don't find much on my system running Fedora 32 Workstation:
```
# cat /etc/issue /etc/issue.net
\S
Kernel \r on an \m (\l)
\S
Kernel \r on an \m (\l)
```
I could add something like "Keep out" or "Don't break anything," but the test's description doesn't provide enough information to resolve the issue, so I took another look at the Lynis scripts. I noticed that the `include`
directory contained a file called `tests_banners`
; this seemed like a good place to look. With some help from `grep`
, I saw the associated tests:
```
# grep -E 'BANN-7126|BANN-7130' /usr/share/lynis/include/tests_banners
# Test : BANN-7126
Register --test-no BANN-7126 --preqs-met ${PREQS_MET} --weight L --network NO --category security --description "Check issue banner file contents"
# Test : BANN-7130
Register --test-no BANN-7130 --preqs-met ${PREQS_MET} --weight L --network NO --category security --description "Check issue.net banner file contents"
```
After examining the associated code in the file for the test, I found out that both of these tests are iterating through some predefined legal terms with a `for`
loop:
`for ITEM in ${LEGAL_BANNER_STRINGS}; do`
These legal terms are stored in the variable `LEGAL_BANNER_STRINGS`
defined at the top of the file. Scrolling back to the top shows the full list:
`LEGAL_BANNER_STRINGS="audit access authori condition connect consent continu criminal enforce evidence forbidden intrusion law legal legislat log monitor owner penal policy policies privacy private prohibited record restricted secure subject system terms warning"`
My initial suggestions ("keep out" and "don't break anything") wouldn't have satisfied the test, because they don't contain any words from this list.
This banner message contains several of the required words, and therefore, it will satisfy this test and prevent Lynis from reporting it:
Attention, by continuing to connect to this system, you consent to the owner storing a log of all activity. Unauthorized access is prohibited.
Note that this message must be added to both `/etc/issue`
and `/etc/issue.net`
.
## Making it repeatable
You could make these edits manually, but you may instead want to consider automation. For example, there may be many settings that need to be changed, or you might need to do these edits on a regular basis on many servers. Creating a hardening script would be a great way to streamline this process. For SSH configurations, some `sed`
commands in your hardening script will resolve those findings. Or, you might use an echo statement to add the legal banners:
```
sed -i '/MaxAuthTries/s/#MaxAuthTries 6/MaxAuthTries 3/' /etc/ssh/sshd_config
echo "Legal Banner" | tee -a /etc/issue /etc/issue.net
```
Automation enables you to create a repeatable script that can be saved and managed across your infrastructure. You could also incorporate this script in your initial server provisioning.
## Harden your system
This type of exercise can improve your scripting skills both by following along with existing code and by writing your own scripts. Because it is open source, Lynis makes it easy to see under the hood how your system is checked and what its reports mean. The end result will be a well-hardened system that you can show off anytime those auditors come around.
## Comments are closed. |
12,699 | 在 GNOME 中创建文档模板 | https://opensource.com/article/20/9/gnome-templates | 2020-10-08T21:53:45 | [
"模板"
] | https://linux.cn/article-12699-1.html |
>
> 制作模板可以让你更快地开始写作新的文档。
>
>
>

我只是偶然发现了 [GNOME](https://www.gnome.org/) 的一个新功能(对我来说是的):创建文档模版。<ruby> 模版 <rt> template </rt></ruby>也被称作<ruby> 样版文件 <rt> boilerplate </rt></ruby>,一般是有着特定格式的空文档,例如律师事务所的信笺,在其顶部有着律所的名称和地址;另一个例子是银行以及保险公司的保函,在其底部页脚包含着某些免责声明。由于这类信息很少改变,你可以把它们添加到空文档中作为模板使用。
一天,在浏览我的 Linux 系统文件的时候,我点击了<ruby> 模板 <rt> Templates </rt></ruby>文件夹,然后刚好发现窗口的上方有一条消息写着:“将文件放入此文件夹并用作新文档的模板”,以及一个“获取详情……” 的链接,打开了模板的 [GNOME 帮助页面](https://help.gnome.org/users/gnome-help/stable/files-templates.html.en)。

### 创建模板
在 GNOME 中创建模板非常简单。有几种方法可以把文件放进模板文件夹里:你既可以通过图形用户界面(GUI)或是命令行界面(CLI)从另一个位置复制或移动文件,也可以创建一个全新的文件;我选择了后者,实际上,我创建了两个文件。

我的第一份模板是为 [Opensource.com](http://Opensource.com) 的文章准备的,它有一个输入标题的位置以及关于我的名字和文章使用的许可证的几行。我的文章使用 Markdown 格式,所以我将模板创建为了一个新的 Markdown 文档——`Opensource.com Article.md`:
```
# Title
```
An article for Opensource.com
by: Alan Formy-Duval
Creative Commons BY-SA 4.0
```
```
我将这份文档保存在了 `/home/alan/Templates` 文件夹内,现在 GNOME 就可以将这个文件识别为模板,并在我要创建新文档的时候提供建议了。
### 使用模板
每当我有了新文章的灵感的时候,我只需要在我计划用来组织内容的文件夹里单击右键,然后从<ruby> 新建文档 <rt> New Document </rt></ruby>列表中选择我想要的模板就可以开始了。

你可以为各种文档或文件制作模板。我写这篇文章时使用了我为 [Opensource.com](http://Opensource.com) 的文章创建的模板。程序员可能会把模板用于软件代码,这样的话也许你想要只包含 `main()` 的模板。
GNOME 桌面环境为 Linux 及相关操作系统的用户提供了一个非常实用、功能丰富的界面。你最喜欢的 GNOME 功能是什么,你又是怎样使用它们的呢?请在评论中分享~
---
via: <https://opensource.com/article/20/9/gnome-templates>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rakino](https://github.com/rakino) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I just stumbled onto a new (to me) feature of the [GNOME](https://www.gnome.org/) desktop that enables you to create a document template. A template is generally an empty shell of a document with certain things configured and is often referred to as boilerplate. An example might be a letterhead for a law firm, with its corporate title and address at the top. Another might be a bank or insurance carrier letter that contains certain disclaimers in the footer at the bottom of the document. Since this sort of information rarely changes, you can add it to an empty document to use as a template.
I was browsing through files on my Linux system one day and clicked on the **Templates** directory. I just happened to notice a message at the top of the window that stated, "Put files in this folder to use them as templates for new documents." There was also a link to **Learn more…** that opens the [GNOME help](https://help.gnome.org/users/gnome-help/stable/files-templates.html.en) for templates.

(Alan Formy-Duval, CC BY-SA 4.0)
## Create a template
Creating a template for the GNOME desktop is quite simple. There are several ways you can place a file into this folder: You can copy or move a file from another location through either the graphical user interface (GUI) or the command-line interface (CLI), or you can create an entirely new file. I chose the latter; actually, I created two files.
(Alan Formy-Duval, CC BY-SA 4.0)
The first template I created is for an Opensource.com article. It provides a place to enter a title and several lines for my name and the license terms under which I am providing the content of the article. I use the Markdown document format for my articles, so I create the template as a new Markdown document—**Opensource.com Article.md**:
```
# Title
```
An article for Opensource.com
by: Alan Formy-Duval
Creative Commons BY-SA 4.0
```
```
I saved this document as a file in `/home/alan/Templates`
. Now GNOME recognizes this file as a template and suggests it whenever I want to create a new document.
## Use a template
Whenever I get a spark or epiphany for a new article, I can just right-click in the folder where I plan to organize my content and select the template from the **New Document** list.
(Alan Formy-Duval, CC BY-SA 4.0)
You can make a template for all sorts of documents or files. I am writing this article using a template I created for my Opensource.com articles. Programmers might use templates for software code; perhaps you want a template that just contains `main()`
.
The GNOME desktop environment provides a very useful, feature-rich user interface for users of Linux and related operating systems. What are your favorite GNOME desktop features, and how do you use them? Please share in the comments!
## 3 Comments |
12,700 | 使用这个 Python 工具对网站 SEO 问题进行自动化测试 | https://opensource.com/article/20/7/seodeploy | 2020-10-09T19:49:00 | [
"SEO"
] | /article-12700-1.html |
>
> SEODeploy 可以帮助我们在网站部署之前识别出 SEO 问题。
>
>
>

作为一个技术性搜索引擎优化开发者,我经常被请来协助做网站迁移、新网站发布、分析实施和其他一些影响网站在线可见性和测量等领域,以控制风险。许多公司每月经常性收入的很大一部分来自用户通过搜索引擎找到他们的产品和服务。虽然搜索引擎已经能妥善地处理没有被良好格式化的代码,但在开发过程中还是会出问题,对搜索引擎如何索引和为用户显示页面产生不利影响。
我曾经也尝试通过评审各阶段会破坏 SEO(<ruby> 搜索引擎优化 <rt> search engine optimization </rt></ruby>)的问题来手动降低这种风险。我的团队最终审查到的结果,决定了该项目是否可以上线。但这个过程通常很低效,只能用于有限的页面,而且很有可能出现人为错误。
长期以来,这个行业一直在寻找可用且值得信赖的方式来自动化这一过程,同时还能让开发人员和搜索引擎优化人员在必须测试的内容上获得有意义的发言权。这是非常重要的,因为这些团队在开发冲刺中优先级通常会发生冲突,搜索引擎优化者需要推动变化,而开发人员需要控制退化和预期之外的情况。
### 常见的破坏 SEO 的问题
我合作过的很多网站有成千上万的页面,甚至上百万。实在令人费解,为什么一个开发过程中的改动能影响这么多页面。在 SEO 的世界中,Google 或其他搜索引擎展示你的页面时,一个非常微小和看起来无关紧要的修改也可能导致全网站范围的变化。在部署到生产环境之前,必须要处理这类错误。
下面是我去年见过的几个例子。
#### 偶发的 noindex
在部署到生产环境之后,我们用的一个专用的第三方 SEO 监控工具 [ContentKing](https://www.contentkingapp.com/) 马上发现了这个问题。这个错误很隐蔽,因为它在 HTML 中是不可见的,确切地说,它隐藏在服务器响应头里,但它能很快导致搜索不可见。
```
HTTP/1.1 200 OK
Date: Tue May 25 2010 21:12:42 GMT
[...]
X-Robots-Tag: noindex
[...]
```
#### canonical 小写
上线时错误地把整个网站的 [canonical 链接元素](https://en.wikipedia.org/wiki/Canonical_link_element)全改成小写了。这个改动影响了接近 30000 个 URL。在修改之前,所有的 URL 大小写都正常(例如 `URL-Path` 这样)。这之所以是个问题是因为 `canonical` 链接元素是用来给 Google 提示一个网页真实的规范 URL 版本的。这个改动导致很多 URL 被从 Google 的索引中移除并用小写的版本(`/url-path`)重新建立索引。影响范围是流量损失了 10% 到 15%,也污染了未来几个星期的网页监控数据。
#### 源站退化
有个网站的 React 实现复杂而奇特,它有个神奇的问题,`origin.domain.com` URL 退化显示为 CDN 服务器的源站。它会在网站元数据(如 `canonical` 链接元素、URL 和 Open Graph 链接)中间歇性地显示原始的主机而不是 CDN 边缘主机。这个问题在原始的 HTML 和渲染后的 HTML 中都存在。这个问题影响搜索的可见性和在社交媒体上的分享质量。
### SEODeploy 介绍
SEO 通常使用差异测试工具来检测渲染后和原始的 HTML 的差异。差异测试是很理想的,因为它避免了肉眼测试的不确定性。你希望检查 Google 对你的页面的渲染过程的差异,而不是检查用户对你页面的渲染。你希望查看下原始的 HTML 是什么样的,而不是渲染后的 HTML,因为 Google 的渲染过程是有独立的两个阶段的。
这促使我和我的同事创造了 [SEODeploy](https://github.com/locomotive-agency/SEODeploy) 这个“在部署流水线中用于自动化 SEO 测试的 Python 库。”我们的使命是:
>
> 开发一个工具,让开发者能提供若干 URL 路径,并允许这些 URL 在生产环境和预演环境的主机上进行差异测试,尤其是对 SEO 相关数据的非预期的退化。
>
>
>
SEODeploy 的机制很简单:提供一个每行内容都是 URL 路径的文本文件,SEODeploy 对那些路径运行一系列模块,对比<ruby> 生产环境 <rt> production </rt></ruby>和<ruby> 预演环境 <rt> staging </rt></ruby>的 URL,把检测到的所有的错误和改动信息报告出来。

这个工具及其模块可以用一个 YAML 文件来配置,可以根据预期的变化进行定制。

最初的发布版本包含下面的的核心功能和概念:
1. **开源**:我们坚信分享代码可以被大家批评、改进、扩展、分享和复用。
2. **模块化**:Web 开发中有许多不同的堆栈和边缘案例。SEODeploy 工具在概念上很简单,因此采用模块化用来控制复杂性。我们提供了两个建好的模块和一个实例模块来简述基本结构。
3. **URL 抽样**:由于它不是对所有 URL 都是可行和有效的,因此我们引入了一种随机抽取 XML 网站地图 URL 或被 ContentKing 监控的 URL 作为样本的方法。
4. **灵活的差异检测**:Web 数据是凌乱的。无论被检测的数据是什么类型(如 ext、数组或列表、JSON 对象或字典、整数、浮点数等等),差异检测功能都会尝试将这些数据转换为差异信息。
5. **自动化**: 你可以在命令行来调用抽样和运行方法,将 SEODeploy 融合到已有的流水线也很简单。
### 模块
虽然核心功能很简单,但在设计上,SEODeploy 的强大功能和复杂度体现在模块上。模块用来处理更难的任务:获取、清理和组织预演服务器和生产服务器上的数据来作对比。
#### Headless 模块
[Headless 模块](https://locomotive-agency.github.io/SEODeploy/modules/headless/) 是为那些从库里获取数据时不想为第三方服务付费的开发者准备的。它可以运行任意版本的 Chrome,会从每组用来比较的 URL 中提取渲染的数据。
Headless 模块会提取下面的核心数据用来比较:
1. SEO 内容,如标题、H1-H6、链接等等。
2. 从 Chrome <ruby> 计时器 <rt> Timings </rt></ruby>和 CDP(<ruby> Chrome 开发工具协议 <rt> Chrome DevTools Protocol </rt></ruby>)性能 API 中提取性能数据
3. 计算出的性能指标,包括 CLS(<ruby> 累积布局偏移 <rt> Cumulative Layout Shift </rt></ruby>),这是 Google 最近发布的一个很受欢迎的 [Web 核心数据](https://web.dev/vitals/)
4. 从上述 CDP 的覆盖率 API 获取的 CSS 和 JavaScript 的覆盖率数据
这个模块引入了处理预演环境、网络速度预设(为了让对比更规范化)等功能,也引入了一个处理在预演对比数据中替换预演主机的方法。开发者也能很容易地扩展这个模块,以收集他们想要在每个页面上进行比较的任何其他数据。
#### 其他模块
我们为开发者创建了一个[示例模块](https://locomotive-agency.github.io/SEODeploy/modules/creating/),开发者可以参照它来使用框架创建一个自定义的提取模块。另一个示例模块是与 ContentKing 结合的。ContentKing 模块需要有 ContentKing 订阅,而 Headless 可以在所有能运行 Chrome 的机器上运行。
### 需要解决的问题
我们有扩展和强化工具库的[计划](https://locomotive-agency.github.io/SEODeploy/todo/),但正在寻求开发人员的[反馈](https://locomotive-agency.github.io/SEODeploy/about/#contact),了解哪些是可行的,哪些是不符合他们的需求。我们正在解决的问题和条目有:
1. 对于某些对比元素(尤其是 schema),动态时间戳会产生误报。
2. 把测试数据保存到数据库,以便查看部署历史以及与上次的预演推送进行差异测试。
3. 通过云基础设施的渲染,强化提取的规模和速度。
4. 把测试覆盖率从现在的 46% 提高到 99% 以上。
5. 目前,我们依赖 [Poetry](https://python-poetry.org/) 进行部署管理,但我们希望发布一个 PyPl 库,这样就可以用 `pip install` 轻松安装。
6. 我们还在关注更多使用时的问题和相关数据。
### 开始使用
这个项目在 [GitHub](https://github.com/locomotive-agency/SEODeploy) 上,我们对大部分功能都提供了 [文档](https://locomotive-agency.github.io/SEODeploy/)。
我们希望你能克隆 SEODeploy 并试试它。我们的目标是通过这个由技术性搜索引擎优化开发者开发的、经过开发者和工程师们验证的工具来支持开源社区。我们都见过验证复杂的预演问题需要多长时间,也都见过大量 URL 的微小改动能有什么样的业务影响。我们认为这个库可以为开发团队节省时间、降低部署过程中的风险。
如果你有问题或者想提交代码,请查看项目的[关于](https://locomotive-agency.github.io/SEODeploy/about/)页面。
---
via: <https://opensource.com/article/20/7/seodeploy>
作者:[JR Oakes](https://opensource.com/users/jroakes) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,702 | 如何使用 lshw 查看 Linux 设备信息 | https://www.networkworld.com/article/3583598/how-to-view-information-on-your-linux-devices-with-lshw.html | 2020-10-10T08:55:34 | [
"lshw",
"硬件"
] | https://linux.cn/article-12702-1.html |
>
> Linux 系统上的 lshw 命令提供的系统设备信息比我们大多数人想象的要多得多。
>
>
>

虽然 `lshw` 命令(<ruby> 列出硬件 <rt> list hardware </rt></ruby>,读作 “ls hardware”)远不是每个人最先学会的 50 个 Linux 命令之一,但它可以提供很多系统硬件的有用信息。
它以一种相当易于理解的格式提取出可能比你知道的更多的信息。在看到描述、(设备)逻辑名称、大小等以后,你可能会理解到自己能获得多少信息。
这篇文章会研究 `lshw` 给出的信息,但侧重于磁盘及相关硬件。下面是 `lshw` 的输出示例:
```
$ sudo lshw -C disk
*-disk:0
description: SCSI Disk
product: Card Reader-1
vendor: JIE LI
physical id: 0.0.0
bus info: scsi@4:0.0.0
logical name: /dev/sdc
version: 1.00
capabilities: removable
configuration: logicalsectorsize=512 sectorsize=512
*-medium
physical id: 0
logical name: /dev/sdc
```
请注意,你需要使用 `sudo` 运行 `lshw` 命令以确保能得到所有可用的信息。
虽然我们在上面的命令中要求了输出“磁盘(`disk`)”(上面只包含了原始输出里五个条目中的一个),这里的输出却不是一个硬盘,而是读卡器——磁盘的一种。注意系统将这个设备命名为了 `/dev/sdc`。
系统的主磁盘上也有相似的信息:
```
*-disk
description: ATA Disk
product: SSD2SC120G1CS175
physical id: 0
bus info: scsi@0:0.0.0
logical name: /dev/sda <==这里
version: 1101
serial: PNY20150000778410606
size: 111GiB (120GB)
capabilities: partitioned partitioned:dos
configuration: ansiversion=5 logicalsectorsize=512 sectorsize=512 signature=
f63b5929
```
这块硬盘是 `/dev/sda`。这个系统上的硬盘都显示为 `ATA` 磁盘,`ATA` 是一种把控制器与盘体集成在一起的磁盘驱动器实现。
要获得“磁盘”类设备的简略列表,可以运行下面这条命令。注意其中有两个设备被列出了两次,所以我们看到的仍然是五个磁盘设备。
```
$ sudo lshw -short -C disk
H/W path Device Class Description
=============================================================
/0/100/1d/1/1/0.0.0 /dev/sdc disk Card Reader-1
/0/100/1d/1/1/0.0.0/0 /dev/sdc disk
/0/100/1d/1/1/0.0.1 /dev/sdd disk 2
/0/100/1d/1/1/0.0.1/0 /dev/sdd disk
/0/100/1f.2/0 /dev/sda disk 120GB SSD2SC120G1CS175
/0/100/1f.2/1 /dev/cdrom disk DVD+-RW GSA-H73N
/0/100/1f.5/0.0.0 /dev/sdb disk 500GB SAMSUNG HE502HJ
```
如果你决定要查看系统上的 **所有** 设备,请坐稳了;你会得到一个包含的东西比你通常认为的“设备”要多得多的列表,下面是一个例子,这是一个“简短(`short`)”(信息很少)的列表:
```
$ sudo lshw -short
[sudo] password for shs:
H/W path Device Class Description
=============================================================
system Inspiron 530s
/0 bus 0RY007
/0/0 memory 128KiB BIOS
/0/4 processor Intel(R) Core(TM)2 Duo CPU
/0/4/a memory 32KiB L1 cache
/0/4/b memory 6MiB L2 cache
/0/24 memory 6GiB System Memory
/0/24/0 memory 2GiB DIMM DDR2 Synchronous 667
/0/24/1 memory 1GiB DIMM DDR2 Synchronous 667
/0/24/2 memory 2GiB DIMM DDR2 Synchronous 667
/0/24/3 memory 1GiB DIMM DDR2 Synchronous 667
/0/1 generic
/0/10 generic
/0/11 generic
/0/12 generic
/0/13 generic
/0/14 generic
/0/15 generic
/0/17 generic
/0/18 generic
/0/19 generic
/0/2 generic
/0/20 generic
/0/100 bridge 82G33/G31/P35/P31 Express DRAM
/0/100/1 bridge 82G33/G31/P35/P31 Express PCI
/0/100/1/0 display Caicos [Radeon HD 6450/7450/84
/0/100/1/0.1 multimedia Caicos HDMI Audio [Radeon HD 6
/0/100/19 enp0s25 network 82562V-2 10/100 Network Connec
/0/100/1a bus 82801I (ICH9 Family) USB UHCI
/0/100/1a/1 usb3 bus UHCI Host Controller
/0/100/1a.1 bus 82801I (ICH9 Family) USB UHCI
/0/100/1a.1/1 usb4 bus UHCI Host Controller
/0/100/1a.1/1/2 input Rock Candy Wireless Keyboard
/0/100/1a.2 bus 82801I (ICH9 Family) USB UHCI
/0/100/1a.2/1 usb5 bus UHCI Host Controller
/0/100/1a.2/1/2 input USB OPTICAL MOUSE
/0/100/1a.7 bus 82801I (ICH9 Family) USB2 EHCI
/0/100/1a.7/1 usb1 bus EHCI Host Controller
/0/100/1b multimedia 82801I (ICH9 Family) HD Audio
/0/100/1d bus 82801I (ICH9 Family) USB UHCI
/0/100/1d/1 usb6 bus UHCI Host Controller
/0/100/1d/1/1 scsi4 storage CD04
/0/100/1d/1/1/0.0.0 /dev/sdc disk Card Reader-1
/0/100/1d/1/1/0.0.0/0 /dev/sdc disk
/0/100/1d/1/1/0.0.1 /dev/sdd disk 2
/0/100/1d/1/1/0.0.1/0 /dev/sdd disk
/0/100/1d.1 bus 82801I (ICH9 Family) USB UHCI
/0/100/1d.1/1 usb7 bus UHCI Host Controller
/0/100/1d.2 bus 82801I (ICH9 Family) USB UHCI
/0/100/1d.2/1 usb8 bus UHCI Host Controller
/0/100/1d.7 bus 82801I (ICH9 Family) USB2 EHCI
/0/100/1d.7/1 usb2 bus EHCI Host Controller
/0/100/1d.7/1/2 multimedia USB Live camera
/0/100/1e bridge 82801 PCI Bridge
/0/100/1e/1 communication HSF 56k Data/Fax Modem
/0/100/1f bridge 82801IR (ICH9R) LPC Interface
/0/100/1f.2 scsi0 storage 82801IR/IO/IH (ICH9R/DO/DH) 4
/0/100/1f.2/0 /dev/sda disk 120GB SSD2SC120G1CS175
/0/100/1f.2/0/1 /dev/sda1 volume 111GiB EXT4 volume
/0/100/1f.2/1 /dev/cdrom disk DVD+-RW GSA-H73N
/0/100/1f.3 bus 82801I (ICH9 Family) SMBus Con
/0/100/1f.5 scsi3 storage 82801I (ICH9 Family) 2 port SA
/0/100/1f.5/0.0.0 /dev/sdb disk 500GB SAMSUNG HE502HJ
/0/100/1f.5/0.0.0/1 /dev/sdb1 volume 433GiB EXT4 volume
/0/3 system PnP device PNP0c02
/0/5 system PnP device PNP0b00
/0/6 storage PnP device PNP0700
/0/7 system PnP device PNP0c02
/0/8 system PnP device PNP0c02
/0/9 system PnP device PNP0c01
```
运行下面的命令来列出设备类别,并统计每个类别中的设备数量。
```
$ sudo lshw -short | awk ‘{print substr($0,36,13)}’ | tail -n +3 | sort | uniq -c
4 bridge
18 bus
1 communication
7 disk
1 display
12 generic
2 input
8 memory
3 multimedia
1 network
1 processor
4 storage
6 system
2 volume
```
**注意:** 上面使用 `awk` 命令从 `lshw` 的输出中选择 Class(类别)栏是这样实现的:使用 `$0`(选取完整行),但只取从正确位置(第 36 个字符)开始的子串,而因为“类别”中并没有条目的长度超过 13 个字符,所以子串就在那里结束。命令中 `tail -n +3` 的部分移除了标题和下面的`=====`,所以最终的列表中只包含了那 14 种设备类型。
(LCTT 译注:上面的命令中 `awk` 的部分在选取子串时是从第 36 个字符开始的,这个数字基本上取决于最长的设备逻辑名称的长度,因而在不同的系统环境中可能有所不同,一个例子是,当你的系统上有 NVMe SSD 时,可能需要将其改为 41。)
你会发现在没有使用 `-short` 选项的时候,每一个磁盘类设备都会有大约 12 行的输出,包括像是 `/dev/sda` 这样的逻辑名称,磁盘大小和种类等等。
```
$ sudo lshw -C disk
[sudo] password for shs:
*-disk:0
description: SCSI Disk
product: Card Reader-1 <== 读卡器?
vendor: JIE LI
physical id: 0.0.0
bus info: scsi@4:0.0.0
logical name: /dev/sdc
version: 1.00
capabilities: removable
configuration: logicalsectorsize=512 sectorsize=512
*-medium
physical id: 0
logical name: /dev/sdc
*-disk:1
description: SCSI Disk
product: 2
vendor: AC4100 -
physical id: 0.0.1
bus info: scsi@4:0.0.1
logical name: /dev/sdd
capabilities: removable
configuration: logicalsectorsize=512 sectorsize=512
*-medium
physical id: 0
logical name: /dev/sdd
*-disk
description: ATA Disk
product: SSD2SC120G1CS175
physical id: 0
bus info: scsi@0:0.0.0
logical name: /dev/sda <== 主要磁盘
version: 1101
serial: PNY20150000778410606
size: 111GiB (120GB)
capabilities: partitioned partitioned:dos
configuration: ansiversion=5 logicalsectorsize=512 sectorsize=512 signature=f63b5929
*-cdrom <== 也叫 /dev/sr0
description: DVD writer
product: DVD+-RW GSA-H73N
vendor: HL-DT-ST
physical id: 1
bus info: scsi@1:0.0.0
logical name: /dev/cdrom
logical name: /dev/cdrw
logical name: /dev/dvd
logical name: /dev/dvdrw
logical name: /dev/sr0
version: B103
serial: [
capabilities: removable audio cd-r cd-rw dvd dvd-r
configuration: ansiversion=5 status=nodisc
*-disk
description: ATA Disk
product: SAMSUNG HE502HJ
physical id: 0.0.0
bus info: scsi@3:0.0.0
logical name: /dev/sdb <== 次要磁盘
version: 0002
serial: S2B6J90B501053
size: 465GiB (500GB)
capabilities: partitioned partitioned:dos
configuration: ansiversion=5 logicalsectorsize=512 sectorsize=512 signature=7e67ccf3
```
### 总结
`lshw` 命令提供了一些我们许多人通常不会处理的信息,不过即使你只用了其中的一部分,知道有多少信息可用还是很不错的。
---
via: <https://www.networkworld.com/article/3583598/how-to-view-information-on-your-linux-devices-with-lshw.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rakino](https://github.com/rakino) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,703 | 如何使用 Ansible 安装软件 | https://opensource.com/article/20/9/install-packages-ansible | 2020-10-10T09:51:00 | [
"Ansible"
] | https://linux.cn/article-12703-1.html |
>
> 使用 Ansible 剧本自动安装和更新设备上的软件。
>
>
>

Ansible 是系统管理员和开发人员用来保持计算机系统处于最佳状态的一种流行的自动化工具。与可扩展框架一样,[Ansible](https://opensource.com/resources/what-ansible) 本身功能有限,它真正的功能体现在许多模块中。在某种程度上,Ansible 模块就是 [Linux](https://opensource.com/resources/linux) 系统的命令。它们针对特定问题提供解决方案,而维护计算机时的一项常见任务是使所有计算机的更新和一致。
我曾经使用软件包的文本列表来保持系统或多或少的同步:我会列出笔记本电脑上安装的软件包,然后将其与台式机或另一台服务器之间进行交叉参考,手动弥补差异。当然,在 Linux 机器上安装和维护应用程序是 Ansible 的一项基本功能,这意味着你可以在自己关心的计算机上列出所需的内容。
### 寻找正确的 Ansible 模块
Ansible 模块的数量非常庞大,如何找到能完成你任务的模块?在 Linux 中,你可以在应用程序菜单或 `/usr/bin` 中查找要运行的应用程序。使用 Ansible 时,你可以参考 [Ansible 模块索引](https://docs.ansible.com/ansible/latest/modules/modules_by_category.html)。
这个索引按照类别列出。稍加搜索,你就很可能找到所需的模块。对于包管理,[Packaging 模块](https://docs.ansible.com/ansible/latest/modules/list_of_packaging_modules.html)几乎适用于所有带包管理器的系统。
### 动手写一个 Ansible 剧本
首先,选择本地计算机上的包管理器。例如,如果你打算在运行 Fedora 的笔记本电脑上编写 Ansible 指令(在 Ansible 中称为“<ruby> 剧本 <rt> playbook </rt></ruby>”),那么从 `dnf` 模块开始。如果你在 Elementary OS 上编写,使用 `apt` 模块,以此类推。这样你就可以开始进行测试和验证,并可以在以后扩展到其它计算机。
第一步是创建一个代表你的剧本的目录。这不是绝对必要的,但这是一个好习惯。Ansible 只需要一个配置文件就可以运行在 YAML 中,但是如果你以后想要扩展剧本,你就可以通过改变目录和文件的方式来控制 Ansible。现在,只需创建一个名为 `install_packages` 或类似的目录:
```
$ mkdir ~/install_packages
```
你可以根据自己的喜好来命名 Ansible 的剧本,但通常将其命名为 `site.yml`:
```
$ touch ~/install_packages/site.yml
```
在你最喜欢的文本编辑器中打开 `site.yml`,添加以下内容:
```
---
- hosts: localhost
tasks:
- name: install packages
become: true
become_user: root
dnf:
state: present
name:
- tcsh
- htop
```
你必须调整使用的模块名称以匹配你使用的发行版。在此示例中,我使用 `dnf` 是因为我在 Fedora Linux 上编写剧本。
就像 Linux 终端中的命令一样,知道 **如何** 来调用 Ansible 模块就已经成功了一半。这个示例剧本遵循标准剧本格式:
* `hosts` 是一台或多台计算机。在本示例中,目标计算机是 `localhost`,即你当前正在使用的计算机(而不是你希望 Ansible 连接的远程系统)。
* `tasks` 是你要在主机上执行的任务列表。
+ `name` 是任务的人性化名称。在这种情况下,我使用 `install packages`,因为这就是该任务正在做的事情。
+ `become` 允许 Ansible 更改运行此任务的用户。
+ `become_user` 允许 Ansible 成为 `root` 用户来运行此任务。这是必须的,因为只有 root 用户才能使用 `dnf` 安装应用程序。
+ `dnf` 是模块名称,你可以在 Ansible 网站上的模块索引中找到。
`dnf` 下的节点是 `dnf` 模块专用的。这是模块文档的关键所在。就像 Linux 命令的手册页一样,模块文档会告诉你可用的选项和所需的参数。

安装软件包是一个相对简单的任务,仅需要两个元素。`state` 选项指示 Ansible 检查系统上是否存在 **软件包**,而 `name` 选项列出要查找的软件包。Ansible 会针对机器的 **状态** 进行调整,因此模块指令始终意味着更改。假如 Ansible 扫描了系统状态,发现剧本里描述的系统(在本例中,`tcsh` 和 `htop` 存在)与实际状态存在冲突,那么 Ansible 的任务是进行必要的更改来使系统与剧本匹配。Ansible 可以通过 `dnf`(或 `apt` 或者其它任何包管理器)模块进行更改。
每个模块可能都有一组不同的选项,所以在编写剧本时,要经常参考模块文档。除非你对模块非常熟悉,否则这是期望模块完成工作的唯一合理方法。
### 验证 YAML
剧本是用 YAML 编写的。因为 YAML 遵循严格的语法,所以安装 `yamllint` 来检查剧本是很有帮助的。更妙的是,有一个专门针对 Ansible 的检查工具称为 `ansible-lint`,它专门为剧本而生。在继续之前,安装它。
在 Fedora 或 CentOs 上:
```
$ sudo dnf ins tall yamllint python3-ansible-lint
```
在 Debian、Elementary 或 Ubuntu 上,同样的:
```
$ sudo apt install yamllint ansible-lint
```
使用 `ansible-link` 来验证你的剧本。如果你无法使用 `ansible-lint`,你可以使用 `yamllint`。
```
$ ansible-lint ~/install_packages/site.yml
```
成功则不返回任何内容,但如果文件中有错误,则必须先修复它们,然后再继续。复制和粘贴过程中的常见错误包括在最后一行的末尾省略换行符、使用制表符而不是空格来缩进。在文本编辑器中修复它们,重新运行 `ansible-llint`,重复这个过程,直到 `ansible-lint` 或 `yamllint` 没有返回为止。
### 使用 Ansible 安装一个应用
现在你有了一个可验证的有效剧本,你终于可以在本地计算机上运行它了,因为你碰巧知道该剧本定义的任务需要 root 权限,所以在调用 Ansible 时必须使用 `--ask-become-pass` 选项,因此系统会提示你输入管理员密码。
开始安装:
```
$ ansible-playbook --ask-become-pass ~/install_packages/site.yml
BECOME password:
PLAY [localhost] ******************************
TASK [Gathering Facts] ******************************
ok: [localhost]
TASK [install packages] ******************************
ok: [localhost]
PLAY RECAP ******************************
localhost: ok=0 changed=2 unreachable=0 failed=0 [...]
```
这些命令被执行后,目标系统将处于与剧本中描述的相同的状态。
### 在远程系统上安装应用程序
通过这么多操作来替换一个简单的命令可能会适得其反,但是 Ansible 的优势是它可以在你的所有系统中实现自动化。你可以使用条件语句使 Ansible 在不同的系统上使用特定的模块,但是现在,假定所有计算机都使用相同的包管理器。
要连接到远程系统,你必须在 `/etc/ansible/hosts` 文件中定义远程系统,该文件与 Ansible 是一起安装的,所以它已经存在了,但它可能是空的,除了一些解释性注释之外。使用 `sudo` 在你喜欢的文本编辑器中打开它。
你可以通过其 IP 地址或主机名(只要主机名可以解析)定义主机。例如,如果你已经在 `/etc/hosts` 中定义了 `liavara` 并可以成功 `ping` 通,那么你可以在 `/etc/ansible/hosts` 中将 `liavara` 设置为主机。或者,如果你正在运行一个域名服务器或 Avahi 服务器并且可以 `ping` 通 `liavara`,那么你就可以在 `/etc/ansible/hosts` 中定义它。否则,你必须使用它的 IP 地址。
你还必须成功地建立与目标主机的安全 shell(SSH)连接。最简单的方法是使用 `ssh-copy-id` 命令,但是如果你以前从未与主机建立 SSH 连接,[阅读我关于如何创建自动 SSH 连接的文章](https://opensource.com/article/20/8/how-ssh)。
一旦你在 `/etc/ansible/hosts` 文件中输入了主机名或 IP 地址后,你就可以在剧本中更改 `hosts` 定义:
```
---
- hosts: all
tasks:
- name: install packages
become: true
become_user: root
dnf:
state: present
name:
- tcsh
- htop
```
再次运行 `ansible-playbook`:
```
$ ansible-playbook --ask-become-pass ~/install_packages/site.yml
```
这次,剧本会在你的远程系统上运行。
如果你添加更多主机,则有许多方法可以过滤哪个主机执行哪个任务。例如,你可以创建主机组(服务器的 `webserves`,台式机的 `workstations`等)。
### 适用于混合环境的 Ansible
到目前为止,我们一直假定 Ansible 配置的所有主机都运行相同的操作系统(都是是使用 `dnf` 命令进行程序包管理的操作系统)。那么,如果你要管理不同发行版的主机,例如 Ubuntu(使用 `apt`)或 Arch(使用 `pacman`),或者其它的操作系统时,该怎么办?
只要目标操作系统具有程序包管理器([MacOs 有 Homebrew](https://opensource.com/article/20/6/homebrew-mac),[Windows 有 Chocolatey](https://opensource.com/article/20/3/chocolatey)),Ansible 就能派上用场。
这就是 Ansible 优势最明显的地方。在 shell 脚本中,你必须检查目标主机上有哪些可用的包管理器,即使使用纯 Python,也必须检查操作系统。Ansible 不仅内置了这些功能,而且还具有在剧本中使用命令结果的机制。你可以使用 `action` 关键字来执行由 Ansible 事实收集子系统提供的变量定义的任务,而不是使用 `dnf` 模块。
```
---
- hosts: all
tasks:
- name: install packages
become: true
become_user: root
action: >
{{ ansible_pkg_mgr }} name=htop,transmission state=present update_cache=yes
```
`action` 关键字会加载目标插件。在本例中,它使用了 `ansible_pkg_mgr` 变量,该变量由 Ansible 在初始 **收集信息** 期间填充。你不需要告诉 Ansible 收集有关其运行操作系统的事实,所以很容易忽略这一点,但是当你运行一个剧本时,你会在默认输出中看到它:
```
TASK [Gathering Facts] *****************************************
ok: [localhost]
```
`action` 插件使用来自这个探针的信息,使用相关的包管理器命令填充 `ansible_pkg_mgr`,以安装在 `name` 参数之后列出的程序包。使用 8 行代码,你可以克服在其它脚本选项中很少允许的复杂跨平台难题。
### 使用 Ansible
现在是 21 世纪,我们都希望我们的计算机设备能够互联并且相对一致。无论你维护的是两台还是 200 台计算机,你都不必一次又一次地执行相同的维护任务。使用 Ansible 来同步生活中的计算机设备,看看 Ansible 还能为你做些什么。
---
via: <https://opensource.com/article/20/9/install-packages-ansible>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ansible is a popular automation tool used by sysadmins and developers to keep their computer systems in prime condition. As is often the case with extensible frameworks, [Ansible](https://opensource.com/resources/what-ansible) has limited use on its own, with its real power dwelling in its many modules. Ansible modules are, in a way, what commands are to a [Linux](https://opensource.com/resources/linux) computer. They provide solutions to specific problems, and one common task when maintaining computers is keeping all the ones you use updated and consistent.
I used to use a text list of packages to keep my systems more or less synchronized: I'd list the packages installed on my laptop and then cross-reference that with my desktop, or between one server and another server, making up for any difference manually. Of course, installing and maintaining applications on a Linux machine is a basic task for Ansible, and it means you can list what you want across all computers under your care.
## Finding the right Ansible module
The number of Ansible modules can be overwhelming. How do you find the one you need for a given task? In Linux, you might look in your Applications menu or in `/usr/bin`
to discover new applications to run. When you're using Ansible, you refer to the [Ansible module index](https://docs.ansible.com/ansible/latest/modules/modules_by_category.html).
The index is listed primarily by category. With a little searching, you're very likely to find a module for whatever you need. For package management, the [Packaging modules](https://docs.ansible.com/ansible/latest/modules/list_of_packaging_modules.html) section contains a module for nearly any system with a package manager.
## Writing an Ansible playbook
To begin, choose the package manager on your local computer. For instance, if you're going to write your Ansible instructions (a "playbook," as it's called in Ansible) on a laptop running Fedora, start with the `dnf`
module. If you're writing on Elementary OS, use the `apt`
module, and so on. This gets you started with something you can test and verify as you go, and you can expand your work for your other computers later.
The first step is to create a directory representing your playbook. This isn't strictly necessary, but it's a good idea to establish the habit. Ansible can run with just a configuration file written in YAML, but if you want to expand your playbook later, you can control Ansible by how you lay out your directories and files. For now, just create a directory called `install_packages`
or similar:
```
````$ mkdir ~/install_packages`
The file that serves as the Ansible playbook can be named anything you like, but it's traditional to name it `site.yml`
:
```
````$ touch ~/install_packages/site.yml`
Open `site.yml`
in your favorite text editor, and add this:
```
``````
---
- hosts: localhost
tasks:
- name: install packages
become: true
become_user: root
dnf:
state: present
name:
- tcsh
- htop
```
You must adjust the module name you use to match the distribution you're using. In this example, I used `dnf`
because I wrote the playbook on Fedora Linux.
Like with a command in a Linux terminal, knowing *how* to invoke an Ansible module is half the battle. This playbook example follows the standard playbook format:
`hosts`
targets a computer or computers. In this case, the computer being targeted is`localhost`
, which is the computer you're using right now (as opposed to a remote system you want Ansible to connect with).`tasks`
opens a list of tasks you want to be performed on the hosts.`name`
is a human-friendly title for a task. In this case, I'm using`install packages`
because that's what this task is doing.`become`
permits Ansible to change which user is running this task.`become_user`
permits Ansible to become the`root`
user to run this task. This is necessary because only the root user can install new applications using`dnf`
.`dnf`
is the name of the module, which you discovered from the module index on the Ansible website.
The items under the `dnf`
item are specific to the `dnf`
module. This is where the module documentation is essential. Like a man page for a Linux command, the module documentation tells you what options are available and what kinds of arguments are required.

(Seth Kenlon, CC BY-SA 4.0)
Package installation is a relatively simple task and only requires two elements. The `state`
option instructs Ansible to check whether or not *some package* is present on the system, and the `name`
option lists which packages to look for. Ansible deals in machine *state*, so module instructions always imply change. Should Ansible scan a system and find a conflict between how a playbook describes a system (in this case, that the commands `tcsh`
and `htop`
are present) and what the system state actually is (in this example, `tcsh`
and `htop`
are not present), then Ansible's task is to make whatever changes are necessary for the system to match the playbook. Ansible can make those changes because of the `dnf`
(or `apt`
or whatever your package manager is) module.
Each module is likely to have a different set of options, so when you're writing playbooks, anticipate referring to the module documentation often. Until you're very familiar with a module, it's the only reasonable way to expect a module to do what you need it to do.
## Verifying YAML
Playbooks are written in YAML. Because YAML adheres to a strict syntax, it's helpful to install the `yamllint`
command to check (or "lint," in computer terminology) your work. Better still, there's a linter specific to Ansible called `ansible-lint`
created specifically for playbooks. Install these before continuing.
On Fedora or CentOS:
```
````$ sudo dnf install yamllint python3-ansible-lint`
On Debian, Elementary, Ubuntu, or similar:
```
````$ sudo apt install yamllint ansible-lint`
Verify your playbook with `ansible-lint`
. If you don't have access to `ansible-lint`
, you can use `yamllint`
.
```
````$ ansible-lint ~/install_packages/site.yml`
Success returns nothing, but if there are errors in your file, you must fix them before continuing. Common errors from copying and pasting include omitting a newline character at the end of the final line and using tabs instead of spaces for indentation. Fix them in a text editor, rerun the linter, and repeat this process until you get no feedback from `ansible-lint`
or `yamllint`
.
**[ Advance your automation expertise. Get the Ansible checklist: 5 reasons to migrate to Red Hat Ansible Automation Platform 2 ]**
## Installing an application with Ansible
Now that you have a verifiably valid playbook, you can finally run it on your local machine. Because you happen to know that the task defined by the playbook requires root permissions, you must use the `--ask-become-pass`
option when invoking Ansible, so you will be prompted for your administrative password.
Start the installation:
```
``````
$ ansible-playbook --ask-become-pass ~/install_packages/site.yml
BECOME password:
PLAY [localhost] ******************************
TASK [Gathering Facts] ******************************
ok: [localhost]
TASK [install packages] ******************************
ok: [localhost]
PLAY RECAP ******************************
localhost: ok=0 changed=2 unreachable=0 failed=0 [...]
```
The commands are installed, leaving the target system in an identical state to the one described by the playbook.
## Installing an application on remote systems
Going through all of that to replace one simple command would be counterproductive, but Ansible's advantage is that it can be automated across all of your systems. You can use conditional statements to cause Ansible to use a specific module on different systems, but for now, assume all your computers use the same package manager.
To connect to a remote system, you must define the remote system in the `/etc/ansible/hosts`
file. This file was installed along with Ansible, so it already exists, but it's probably empty, aside from explanatory comments. Use `sudo`
to open the file in your favorite text editor.
You can define a host by its IP address or hostname, as long as the hostname can be resolved. For instance, if you've already defined `liavara`
in `/etc/hosts`
and can successfully ping it, then you can set `liavara`
as a host in `/etc/ansible/hosts`
. Alternately, if you're running a domain name server or Avahi server and can ping `liavara`
, then you can set it as a host in `/etc/ansible/hosts`
. Otherwise, you must use its internet protocol address.
You also must have set up a successful secure shell (SSH) connection to your target hosts. The easiest way to do that is with the `ssh-copy-id`
command, but if you've never set up an SSH connection with a host before, [read my article on how to create an automated SSH connection](https://opensource.com/article/20/8/how-ssh).
Once you've entered the hostname or IP address in the `/etc/ansible/hosts`
file, change the `hosts`
definition in your playbook:
```
``````
---
- hosts: all
tasks:
- name: install packages
become: true
become_user: root
dnf:
state: present
name:
- tcsh
- htop
```
Run `ansible-playbook`
again:
```
````$ ansible-playbook --ask-become-pass ~/install_packages/site.yml`
This time, the playbook runs on your remote system.
Should you add more hosts, there are many ways to filter which host performs which task. For instance, you can create groups of hosts (`webservers`
for servers, `workstations`
for desktop machines, and so on).
## Ansible for mixed environments
The logic used in the solution so far assumes that all hosts being configured by Ansible run the same OS (specifically, one that uses the **dnf** command for package management). So what do you do if you're managing hosts running a different distribution, such as Ubuntu (which uses **apt**) or Arch (using **pacman**), or even different operating systems?
As long as the targeted OS has a package manager (and these days even [MacOS has Homebrew](https://opensource.com/article/20/6/homebrew-mac) and [Windows has Chocolatey](https://opensource.com/article/20/3/chocolatey)), Ansible can help.
This is where Ansible's advantage becomes most apparent. In a shell script, you'd have to check for what package manager is available on the target host, and even with pure Python you'd have to check for the OS. Ansible not only has those checks built in, but it also has mechanisms to use the results in your playbook. Instead of using the **dnf** module, you can use the **action** keyword to perform tasks defined by variables provided by Ansible's fact gathering subsystem.
```
``````
---
- hosts: all
tasks:
- name: install packages
become: true
become_user: root
action: >
{{ ansible_pkg_mgr }} name=htop,transmission state=present update_cache=yes
```
The **action** keyword loads action plugins. In this example, it's using the **ansible_pkg_mgr** variable, which is populated by Ansible during the initial **Gathering Facts** task. You don't have to tell Ansible to gather facts about the OS it's running on, so it's easy to overlook it, but when you run a playbook, you see it listed in the default output:
```
``````
TASK [Gathering Facts] *****************************************
ok: [localhost]
```
The **action** plugin uses information from this probe to populate **ansible_pkg_mgr** with the relevant package manager command to install the packages listed after the **name** argument. With 8 lines of code, you can overcome a complex cross-platform quandary that few other scripting options allow.
## Use Ansible
It's the 21st century, and we all expect our computing devices to be connected and relatively consistent. Whether you maintain two or 200 computers, you shouldn't have to perform the same maintenance tasks over and over again. Use Ansible to synchronize the computers in your life, then see what else Ansible can do for you.
## 3 Comments |
12,704 | 构建一个即时消息应用(七):Access 页面 | https://nicolasparada.netlify.com/posts/go-messenger-access-page/ | 2020-10-10T10:15:00 | [
"即时消息"
] | https://linux.cn/article-12704-1.html | 
本文是该系列的第七篇。
* [第一篇: 模式](/article-11396-1.html)
* [第二篇: OAuth](/article-11510-1.html)
* [第三篇: 对话](/article-12056-1.html)
* [第四篇: 消息](/article-12680-1.html)
* [第五篇: 实时消息](/article-12685-1.html)
* [第六篇: 仅用于开发的登录](/article-12692-1.html)
现在我们已经完成了后端,让我们转到前端。 我将采用单页应用程序方案。
首先,我们创建一个 `static/index.html` 文件,内容如下。
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Messenger</title>
<link rel="shortcut icon" href="data:,">
<link rel="stylesheet" href="/styles.css">
<script src="/main.js" type="module"></script>
</head>
<body></body>
</html>
```
这个 HTML 文件必须为每个 URL 提供服务,并且使用 JavaScript 负责呈现正确的页面。
因此,让我们将注意力转到 `main.go` 片刻,然后在 `main()` 函数中添加以下路由:
```
router.Handle("GET", "/...", http.FileServer(SPAFileSystem{http.Dir("static")}))
type SPAFileSystem struct {
fs http.FileSystem
}
func (spa SPAFileSystem) Open(name string) (http.File, error) {
f, err := spa.fs.Open(name)
if err != nil {
return spa.fs.Open("index.html")
}
return f, nil
}
```
我们使用一个自定义的文件系统,因此它不是为未知的 URL 返回 `404 Not Found`,而是转到 `index.html`。
### 路由器
在 `index.html` 中我们加载了两个文件:`styles.css` 和 `main.js`。我把样式留给你自由发挥。
让我们移动到 `main.js`。 创建一个包含以下内容的 `static/main.js` 文件:
```
import { guard } from './auth.js'
import Router from './router.js'
let currentPage
const disconnect = new CustomEvent('disconnect')
const router = new Router()
router.handle('/', guard(view('home'), view('access')))
router.handle('/callback', view('callback'))
router.handle(/^\/conversations\/([^\/]+)$/, guard(view('conversation'), view('access')))
router.handle(/^\//, view('not-found'))
router.install(async result => {
document.body.innerHTML = ''
if (currentPage instanceof Node) {
currentPage.dispatchEvent(disconnect)
}
currentPage = await result
if (currentPage instanceof Node) {
document.body.appendChild(currentPage)
}
})
function view(pageName) {
return (...args) => import(`/pages/${pageName}-page.js`)
.then(m => m.default(...args))
}
```
如果你是这个博客的关注者,你已经知道它是如何工作的了。 该路由器就是在 [这里](https://nicolasparada.netlify.com/posts/js-router/) 显示的那个。 只需从 [@nicolasparada/router](https://unpkg.com/@nicolasparada/router) 下载并保存到 `static/router.js` 即可。
我们注册了四条路由。 在根路由 `/` 处,我们展示 `home` 或 `access` 页面,无论用户是否通过身份验证。 在 `/callback` 中,我们展示 `callback` 页面。 在 `/conversations/{conversationID}` 上,我们展示对话或 `access` 页面,无论用户是否通过验证,对于其他 URL,我们展示一个 `not-found` 页面。
我们告诉路由器将结果渲染为文档主体,并在离开之前向每个页面调度一个 `disconnect` 事件。
我们将每个页面放在不同的文件中,并使用新的动态 `import()` 函数导入它们。
### 身份验证
`guard()` 是一个函数,给它两个函数作为参数,如果用户通过了身份验证,则执行第一个函数,否则执行第二个。它来自 `auth.js`,所以我们创建一个包含以下内容的 `static/auth.js` 文件:
```
export function isAuthenticated() {
const token = localStorage.getItem('token')
const expiresAtItem = localStorage.getItem('expires\_at')
if (token === null || expiresAtItem === null) {
return false
}
const expiresAt = new Date(expiresAtItem)
if (isNaN(expiresAt.valueOf()) || expiresAt <= new Date()) {
return false
}
return true
}
export function guard(fn1, fn2) {
return (...args) => isAuthenticated()
? fn1(...args)
: fn2(...args)
}
export function getAuthUser() {
if (!isAuthenticated()) {
return null
}
const authUser = localStorage.getItem('auth\_user')
if (authUser === null) {
return null
}
try {
return JSON.parse(authUser)
} catch (_) {
return null
}
}
```
`isAuthenticated()` 检查 `localStorage` 中的 `token` 和 `expires_at`,以判断用户是否已通过身份验证。`getAuthUser()` 从 `localStorage` 中获取经过身份验证的用户。
当我们登录时,我们会将所有的数据保存到 `localStorage`,这样才有意义。
### Access 页面

让我们从 `access` 页面开始。 创建一个包含以下内容的文件 `static/pages/access-page.js`:
```
const template = document.createElement('template')
template.innerHTML = `
<h1>Messenger</h1>
<a href="/api/oauth/github" onclick="event.stopPropagation()">Access with GitHub</a>
`
export default function accessPage() {
return template.content
}
```
因为路由器会拦截所有链接点击来进行导航,所以我们必须特别阻止此链接的事件传播。
单击该链接会将我们重定向到后端,然后重定向到 GitHub,再重定向到后端,然后再次重定向到前端; 到 `callback` 页面。
### Callback 页面
创建包括以下内容的 `static/pages/callback-page.js` 文件:
```
import http from '../http.js'
import { navigate } from '../router.js'
export default async function callbackPage() {
const url = new URL(location.toString())
const token = url.searchParams.get('token')
const expiresAt = url.searchParams.get('expires\_at')
try {
if (token === null || expiresAt === null) {
throw new Error('Invalid URL')
}
const authUser = await getAuthUser(token)
localStorage.setItem('auth\_user', JSON.stringify(authUser))
localStorage.setItem('token', token)
localStorage.setItem('expires\_at', expiresAt)
} catch (err) {
alert(err.message)
} finally {
navigate('/', true)
}
}
function getAuthUser(token) {
return http.get('/api/auth\_user', { authorization: `Bearer ${token}` })
}
```
`callback` 页面不呈现任何内容。这是一个异步函数,它使用 URL 查询字符串中的 token 向 `/api/auth_user` 发出 GET 请求,并将所有数据保存到 `localStorage`。 然后重定向到 `/`。
### HTTP
这里是一个 HTTP 模块。 创建一个包含以下内容的 `static/http.js` 文件:
```
import { isAuthenticated } from './auth.js'
async function handleResponse(res) {
const body = await res.clone().json().catch(() => res.text())
if (res.status === 401) {
localStorage.removeItem('auth\_user')
localStorage.removeItem('token')
localStorage.removeItem('expires\_at')
}
if (!res.ok) {
const message = typeof body === 'object' && body !== null && 'message' in body
? body.message
: typeof body === 'string' && body !== ''
? body
: res.statusText
throw Object.assign(new Error(message), {
url: res.url,
statusCode: res.status,
statusText: res.statusText,
headers: res.headers,
body,
})
}
return body
}
function getAuthHeader() {
return isAuthenticated()
? { authorization: `Bearer ${localStorage.getItem('token')}` }
: {}
}
export default {
get(url, headers) {
return fetch(url, {
headers: Object.assign(getAuthHeader(), headers),
}).then(handleResponse)
},
post(url, body, headers) {
const init = {
method: 'POST',
headers: getAuthHeader(),
}
if (typeof body === 'object' && body !== null) {
init.body = JSON.stringify(body)
init.headers['content-type'] = 'application/json; charset=utf-8'
}
Object.assign(init.headers, headers)
return fetch(url, init).then(handleResponse)
},
subscribe(url, callback) {
const urlWithToken = new URL(url, location.origin)
if (isAuthenticated()) {
urlWithToken.searchParams.set('token', localStorage.getItem('token'))
}
const eventSource = new EventSource(urlWithToken.toString())
eventSource.onmessage = ev => {
let data
try {
data = JSON.parse(ev.data)
} catch (err) {
console.error('could not parse message data as JSON:', err)
return
}
callback(data)
}
const unsubscribe = () => {
eventSource.close()
}
return unsubscribe
},
}
```
这个模块是 [fetch](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API) 和 [EventSource](https://developer.mozilla.org/en-US/docs/Web/API/EventSource) API 的包装器。最重要的部分是它将 JSON web 令牌添加到请求中。
### Home 页面

因此,当用户登录时,将显示 `home` 页。 创建一个具有以下内容的 `static/pages/home-page.js` 文件:
```
import { getAuthUser } from '../auth.js'
import { avatar } from '../shared.js'
export default function homePage() {
const authUser = getAuthUser()
const template = document.createElement('template')
template.innerHTML = `
<div>
<div>
${avatar(authUser)}
<span>${authUser.username}</span>
</div>
<button id="logout-button">Logout</button>
</div>
<!-- conversation form here -->
<!-- conversation list here -->
`
const page = template.content
page.getElementById('logout-button').onclick = onLogoutClick
return page
}
function onLogoutClick() {
localStorage.clear()
location.reload()
}
```
对于这篇文章,这是我们在 `home` 页上呈现的唯一内容。我们显示当前经过身份验证的用户和注销按钮。
当用户单击注销时,我们清除 `localStorage` 中的所有内容并重新加载页面。
### Avatar
那个 `avatar()` 函数用于显示用户的头像。 由于已在多个地方使用,因此我将它移到 `shared.js` 文件中。 创建具有以下内容的文件 `static/shared.js`:
```
export function avatar(user) {
return user.avatarUrl === null
? `<figure class="avatar" data-initial="${user.username[0]}"></figure>`
: `<img class="avatar" src="${user.avatarUrl}" alt="${user.username}'s avatar">`
}
```
如果头像网址为 `null`,我们将使用用户的姓名首字母作为初始头像。
你可以使用 `attr()` 函数显示带有少量 CSS 样式的首字母。
```
.avatar[data-initial]::after {
content: attr(data-initial);
}
```
### 仅开发使用的登录

在上一篇文章中,我们为编写了一个登录代码。让我们在 `access` 页面中为此添加一个表单。 进入 `static/ages/access-page.js`,稍微修改一下。
```
import http from '../http.js'
const template = document.createElement('template')
template.innerHTML = `
<h1>Messenger</h1>
<form id="login-form">
<input type="text" placeholder="Username" required>
<button>Login</button>
</form>
<a href="/api/oauth/github" onclick="event.stopPropagation()">Access with GitHub</a>
`
export default function accessPage() {
const page = template.content.cloneNode(true)
page.getElementById('login-form').onsubmit = onLoginSubmit
return page
}
async function onLoginSubmit(ev) {
ev.preventDefault()
const form = ev.currentTarget
const input = form.querySelector('input')
const submitButton = form.querySelector('button')
input.disabled = true
submitButton.disabled = true
try {
const payload = await login(input.value)
input.value = ''
localStorage.setItem('auth\_user', JSON.stringify(payload.authUser))
localStorage.setItem('token', payload.token)
localStorage.setItem('expires\_at', payload.expiresAt)
location.reload()
} catch (err) {
alert(err.message)
setTimeout(() => {
input.focus()
}, 0)
} finally {
input.disabled = false
submitButton.disabled = false
}
}
function login(username) {
return http.post('/api/login', { username })
}
```
我添加了一个登录表单。当用户提交表单时。它使用用户名对 `/api/login` 进行 POST 请求。将所有数据保存到 `localStorage` 并重新加载页面。
记住在前端完成后删除此表单。
---
这就是这篇文章的全部内容。在下一篇文章中,我们将继续使用主页添加一个表单来开始对话,并显示包含最新对话的列表。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-access-page/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,706 | 你所不知的 GNU Readline | https://twobithistory.org/2019/08/22/readline.html | 2020-10-10T22:29:01 | [
"Readline"
] | https://linux.cn/article-12706-1.html | 
有时我会觉得自己的计算机是一栋非常大的房子,我每天都会访问这栋房子,也对一楼的大部分房间都了如指掌,但仍然还是有我没有去过的卧室,有我没有打开过的衣柜,有我没有探索过的犄角旮旯。我感到有必要更多地了解我的计算机了,就像任何人都会觉得有必要看看自己家里从未去过的房间一样。
GNU Readline 是个不起眼的小软件库,我依赖了它多年却没有意识到它的存在,也许有成千上万的人每天都在不经意间使用它。如果你用 Bash shell 的话,每当你自动补全一个文件名,或者在输入的一行文本中移动光标,以及搜索之前命令的历史记录时,你都在使用 GNU Readline;当你在 Postgres(`psql`)或是 Ruby REPL(`irb`)的命令行界面中进行同样的操作时,你依然在使用 GNU Readline。很多软件都依赖 GNU Readline 库来实现用户所期望的功能,不过这些功能是如此的辅助与不显眼,以至于在我看来很少有人会停下来去想它是从哪里来的。
GNU Readline 最初是自由软件基金会在 20 世纪 80 年代创建的,如今作为每个人的基础计算设施的重要的、甚至看不见的组成部分的它,由一位志愿者维护。
### 充满特色
GNU Readline 库的存在,主要是为了增强各种命令行界面,它提供了一组通用的按键,使你可以在一个单行输入中移动和编辑。例如,在 Bash 提示符中按下 `Ctrl-A`,你的光标会跳到行首,而按下 `Ctrl-E` 则会跳到行末;另一个有用的命令是 `Ctrl-U`,它会删除该行中光标之前的所有内容。
有很长一段时间,我通过反复敲击方向键来在命令行上移动,如今看来这十分尴尬,也不知道为什么,当时的我从来没有想过可以有一种更快的方法。当然了,没有哪一个熟悉 Vim 或 Emacs 这种文本编辑器的程序员愿意长时间地击打方向键,所以像 Readline 这样的东西必然会被创造出来。在 Readline 上可以做的绝非仅仅跳来跳去,你可以像使用文本编辑器那样编辑单行文本——这里有删除单词、单词换位、大写单词、复制和粘贴字符等命令。Readline 的大部分按键/快捷键都是基于 Emacs 的,它基本上就是一个单行文本版的 Emacs 了,甚至还有录制和重放宏的功能。
我从来没有用过 Emacs,所以很难记住所有不同的 Readline 命令。不过 Readline 有着很巧妙的一点,那就是能够切换到基于 Vim 的模式,在 Bash 中可以使用内置的 `set` 命令来这样做。下面会让 Readline 在当前的 shell 中使用 Vim 风格的命令:
```
$ set -o vi
```
该选项启用后,就可以使用 `dw` 等命令来删除单词了,此时相当于 Emacs 模式下的 `Ctrl-U` 的命令是 `d0`。
我第一次知道有这个功能的时候很兴奋地想尝试一下,但它对我来说并不是那么好用。我很高兴知道有这种对 Vim 用户的让步,在使用这个功能上你可能会比我更幸运,尤其是你还没有使用 Readline 的默认按键的话;我的问题在于,我听说有基于 Vim 的界面时已经学会了几种默认按键,因此即使启用了 Vim 的选项,也一直在错误地用着默认的按键;另外因为没有某种指示器,所以 Vim 的模态设计在这里会很尴尬——你很容易就忘记了自己处于哪个模式,就因为这样,我卡在了一种虽然使用 Vim 作为文本编辑器,但却在 Readline 上用着 Emacs 风格的命令的情况里,我猜其他很多人也是这样的。
如果你觉得 Vim 和 Emacs 的键盘命令系统诡异而神秘(这并不是没有道理的),你可以按照喜欢的方式自定义 Readline 的键绑定。Readline 在启动时会读取文件 `~/.inputrc`,它可以用来配置各种选项与键绑定,我做的一件事是重新配置了 `Ctrl-K`:通常情况下该命令会从光标处删除到行末,但我很少这样做,所以我在 `~/.inputrc` 中添加了以下内容,把它绑定为直接删除整行:
```
Control-k: kill-whole-line
```
每个 Readline 命令(文档中称它们为 “函数” )都有一个名称,你可以用这种方式将其与一个键序列联系起来。如果你在 Vim 中编辑 `~/.inputrc`,就会发现 Vim 知道这种文件类型,还会帮你高亮显示有效的函数名,而不高亮无效的函数名。
`~/.inputrc` 可以做的另一件事是通过将键序列映射到输入字符串上来创建预制宏。[Readline 手册](https://tiswww.case.edu/php/chet/readline/readline.html)给出了一个我认为特别有用的例子:我经常想把一个程序的输出保存到文件中,这意味着我得经常在 Bash 命令中追加类似 `> output.txt` 这样的东西,为了节省时间,可以把它做成一个 Readline 宏:
```
Control-o: "> output.txt"
```
这样每当你按下 `Ctrl-O` 时,你都会看到 `> output.txt` 被添加到了命令行光标的后面,这样很不错!
不过你可以用宏做的可不仅仅是为文本串创建快捷方式;在 `~/.inputrc` 中使用以下条目意味着每次按下 `Ctrl-J` 时,行内已有的文本都会被 `$(` 和 `)` 包裹住。该宏先用 `Ctrl-A` 移动到行首,添加 `$(` ,然后再用 `Ctrl-E` 移动到行尾,添加 `)`:
```
Control-j: "\C-a$(\C-e)"
```
如果你经常需要像下面这样把一个命令的输出用于另一个命令的话,这个宏可能会对你有帮助:
```
$ cd $(brew --prefix)
```
`~/.inputrc` 文件也允许你为 Readline 手册中所谓的 “变量” 设置不同的值,这些变量会启用或禁用某些 Readline 行为,你也可以使用这些变量来改变 Readline 中像是自动补全或者历史搜索这些行为的工作方式。我建议开启的一个变量是 `revert-all-at-newline`,它是默认关闭的,当这个变量关闭时,如果你使用反向搜索功能从命令历史记录中提取一行并编辑,但随后又决定搜索另一行,那么你所做的编辑会被保存在历史记录中。我觉得这样会很混乱,因为这会导致你的 Bash 命令历史中出现从未运行过的行。所以在你的 `~/.inputrc` 中加入这个:
```
set revert-all-at-newline on
```
在你用 `~/.inputrc` 设置了选项或键绑定以后,它们会适用于任何使用 Readline 库的地方,显然 Bash 也包括在内,不过你也会在其它像是 `irb` 和 `psql` 这样的程序中受益。如果你经常使用关系型数据库的命令行界面,一个用于插入 `SELECT * FROM` 的 Readline 宏可能会很有用。
### Chet Ramey
GNU Readline 如今由凯斯西储大学的高级技术架构师 Chet Ramey 维护,Ramey 同时还负责维护 Bash shell;这两个项目都是由一位名叫 Brian Fox 的自由软件基金会员工在 1988 年开始编写的,但从 1994 年左右开始,Ramey 一直是它们唯一的维护者。
Ramey 通过电子邮件告诉我,Readline 远非一个原创的想法,它是为了实现 POSIX 规范所规定的功能而被创建的,而 POSIX 规范又是在 20 世纪 80 年代末被制定的。许多早期的 shell,包括 Korn shell 和至少一个版本的 Unix System V shell,都包含行编辑功能。1988 年版的 Korn shell(`ksh88`)提供了 Emacs 风格和 Vi/Vim 风格的编辑模式。据我从[手册页](https://web.archive.org/web/20151105130220/http://www2.research.att.com/sw/download/man/man1/ksh88.html)中得知,Korn shell 会通过查看 `VISUAL` 和 `EDITOR` 环境变量来决定你使用的模式,这一点非常巧妙。POSIX 中指定 shell 功能的部分近似于 `ksh88` 的实现,所以 GNU Bash 也要实现一个类似的灵活的行编辑系统来保持兼容,因此就有了 Readline。
Ramey 第一次参与 Bash 开发时,Readline 还是 Bash 项目目录下的一个单一的源文件,它其实只是 Bash 的一部分;随着时间的推移,Readline 文件慢慢地成为了独立的项目,不过直到 1994 年(Readline 2.0 版本发布),Readline 才完全成为了一个独立的库。
Readline 与 Bash 密切相关,Ramey 也通常把 Readline 与 Bash 的发布配对,但正如我上面提到的,Readline 是一个可以被任何有命令行界面的软件使用的库,而且它真的很容易使用。下面是一个例子,虽然简单,但这就是在 C 程序中使用 Readline 的方法。向 `readline()` 函数传递的字符串参数就是你希望 Readline 向用户显示的提示符:
```
#include <stdio.h>
#include <stdlib.h>
#include "readline/readline.h"
int main(int argc, char** argv)
{
char* line = readline("my-rl-example> ");
printf("You entered: \"%s\"\n", line);
free(line);
return 0;
}
```
你的程序会把控制权交给 Readline,它会负责从用户那里获得一行输入(以这样的方式让用户可以做所有花哨的行编辑工作),一旦用户真正提交了这一行,Readline 就会把它返回给你。在我的库搜索路径中有 Readline 库,所以我可以通过调用以下内容来链接 Readline 库,从而编译上面的内容:
```
$ gcc main.c -lreadline
```
当然,Readline 的 API 比起那个单一的函数要丰富得多,任何使用它的人都可以对库的行为进行各种调整,库的用户(开发者)甚至可以添加新的函数,来让最终用户可以通过 `~/.inputrc` 来配置它们,这意味着 Readline 非常容易扩展。但是据我所知,即使是 Bash ,虽然事先有很多配置,最终也会像上面的例子一样调用简单的 `readline()` 函数来获取输入。(参见 GNU Bash 源代码中的[这一行](https://github.com/bminor/bash/blob/9f597fd10993313262cab400bf3c46ffb3f6fd1e/parse.y#L1487),Bash 似乎在这里将获取输入的责任交给了 Readline)。
Ramey 现在已经在 Bash 和 Readline 上工作了二十多年,但他的工作却从来没有得到过报酬 —— 他一直都是一名志愿者。Bash 和 Readline 仍然在积极开发中,尽管 Ramey 说 Readline 的变化比 Bash 慢得多。我问 Ramey 作为这么多人使用的软件唯一的维护者是什么感觉,他说可能有几百万人在不知不觉中使用 Bash(因为每个苹果设备都运行 Bash),这让他担心一个破坏性的变化会造成多大的混乱,不过他已经慢慢习惯了所有这些人的想法。他还说他会继续在 Bash 和 Readline 上工作,因为在这一点上他已经深深地投入了,而且他也只是单纯地喜欢把有用的软件提供给世界。
*你可以在 [Chet Ramey 的网站](https://tiswww.case.edu/php/chet/)上找到更多关于他的信息。*
*喜欢这篇文章吗?我会每四周写出一篇像这样的文章。关注推特帐号 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或者[订阅 RSS](https://twobithistory.org/feed.xml) 来获取更新吧!*
---
via: <https://twobithistory.org/2019/08/22/readline.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rakino](https://github.com/rakino) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I sometimes think of my computer as a very large house. I visit this house every day and know most of the rooms on the ground floor, but there are bedrooms I’ve never been in, closets I haven’t opened, nooks and crannies that I’ve never explored. I feel compelled to learn more about my computer the same way anyone would feel compelled to see a room they had never visited in their own home.
GNU Readline is an unassuming little software library that I relied on for
years without realizing that it was there. Tens of thousands of people probably
use it every day without thinking about it. If you use the Bash shell, every
time you auto-complete a filename, or move the cursor around within a single
line of input text, or search through the history of your previous commands,
you are using GNU Readline. When you do those same things while using the
command-line interface to Postgres (`psql`
), say, or the Ruby REPL
(`irb`
), you are again using GNU Readline. Lots of software depends on the GNU
Readline library to implement functionality that users expect, but the
functionality is so auxiliary and unobtrusive that I imagine few people stop to
wonder where it comes from.
GNU Readline was originally created in the 1980s by the Free Software Foundation. Today, it is an important if invisible part of everyone’s computing infrastructure, maintained by a single volunteer.
## Feature Replete
The GNU Readline library exists primarily to augment any command-line interface
with a common set of keystrokes that allow you to move around within and edit a
single line of input. If you press `Ctrl-A`
at a Bash prompt, for example, that
will jump your cursor to the very beginning of the line, while pressing
`Ctrl-E`
will jump it to the end. Another useful command is `Ctrl-U`
, which
will delete everything in the line before the cursor.
For an embarrassingly long time, I moved around on the command line by repeatedly tapping arrow keys. For some reason, I never imagined that there was a faster way to do it. Of course, no programmer familiar with a text editor like Vim or Emacs would deign to punch arrow keys for long, so something like Readline was bound to be created. Using Readline, you can do much more than just jump around—you can edit your single line of text as if you were using a text editor. There are commands to delete words, transpose words, upcase words, copy and paste characters, etc. In fact, most of Readline’s keystrokes/shortcuts are based on Emacs. Readline is essentially Emacs for a single line of text. You can even record and replay macros.
I have never used Emacs, so I find it hard to remember what all the
different Readline commands are. But one thing about Readline that is really
neat is that you can switch to using a Vim-based mode instead. To do this for
Bash, you can use the `set`
builtin. The following will tell Readline
to use Vim-style commands for the current shell:
```
$ set -o vi
```
With this option enabled, you can delete words using `dw`
and so on. The
equivalent to `Ctrl-U`
in the Emacs mode would be `d0`
.
I was excited to try this when I first learned about it, but I’ve found that it doesn’t work so well for me. I’m happy that this concession to Vim users exists, and you might have more luck with it than me, particularly if you haven’t already used Readline’s default command keystrokes. My problem is that, by the time I heard about the Vim-based interface, I had already learned several Readline keystrokes. Even with the Vim option enabled, I keep using the default keystrokes by mistake. Also, without some sort of indicator, Vim’s modal design is awkward here—it’s very easy to forget which mode you’re in. So I’m stuck at a local maximum using Vim as my text editor but Emacs-style Readline commands. I suspect a lot of other people are in the same position.
If you feel, not unreasonably, that both Vim and Emacs’ keyboard command
systems are bizarre and arcane, you can customize Readline’s key bindings and
make them whatever you like. This is not hard to do. Readline reads a
`~/.inputrc`
file on startup that can be used to configure various options and
key bindings. One thing I’ve done is reconfigured `Ctrl-K`
. Normally it deletes
from the cursor to the end of the line, but I rarely do that. So I’ve instead
bound it so that pressing `Ctrl-K`
deletes the whole line, regardless of where
the cursor is. I’ve done that by adding the following to `~/.inputrc`
:
```
Control-k: kill-whole-line
```
Each Readline command (the documentation refers to them as *functions*) has a
name that you can associate with a key sequence this way. If you edit
`~/.inputrc`
in Vim, it turns out that Vim knows the filetype and will
help you by highlighting valid function names but not invalid ones!
Another thing you can do with `~/.inputrc`
is create canned macros by mapping
key sequences to input strings. [The Readline
manual](https://tiswww.case.edu/php/chet/readline/readline.html) gives one
example that I think is especially useful. I often find myself wanting to save
the output of a program to a file, which means that I often append something
like `> output.txt`
to Bash commands. To save some time, you could make this a
Readline macro:
```
Control-o: "> output.txt"
```
Now, whenever you press `Ctrl-O`
, you’ll see that `> output.txt`
gets added
after your cursor on the command line. Neat!
But with macros you can do more than just create shortcuts for
strings of text. The following entry in `~/.inputrc`
means that, every time I
press `Ctrl-J`
, any text I already have on the line is surrounded by `$(`
and
`)`
. The macro moves to the beginning of the line with `Ctrl-A`
, adds `$(`
,
then moves to the end of the line with `Ctrl-E`
and adds `)`
:
```
Control-j: "\C-a$(\C-e)"
```
This might be useful if you often need the output of one command to use for another, such as in:
```
$ cd $(brew --prefix)
```
The `~/.inputrc`
file also allows you to set different values for what the
Readline manual calls *variables*. These enable or disable certain Readline
behaviors. You can use these variables to change, for example, how Readline
auto-completion works or how the Readline history search works. One variable
I’d recommend turning on is the `revert-all-at-newline`
variable, which by
default is off. When the variable is off, if you pull a line from your command
history using the reverse search feature, edit it, but then decide to search
instead for another line, the edit you made is preserved in the history. I find
this confusing because it leads to lines showing up in your Bash command
history that you never actually ran. So add this to your `~/.inputrc`
:
```
set revert-all-at-newline on
```
When you set options or key bindings using `~/.inputrc`
, they apply wherever
the Readline library is used. This includes Bash most obviously, but you’ll
also get the benefit of your changes in other programs like `irb`
and `psql`
too! A Readline macro that inserts `SELECT * FROM`
could be useful if you often
use command-line interfaces to relational databases.
## Chet Ramey
GNU Readline is today maintained by Chet Ramey, a Senior Technology Architect at Case Western Reserve University. Ramey also maintains the Bash shell. Both projects were first authored by a Free Software Foundation employee named Brian Fox beginning in 1988. But Ramey has been the sole maintainer since around 1994.
Ramey told me via email that Readline, far from being an original idea, was
created to implement functionality prescribed by the POSIX specification, which
in the late 1980s had just been created. Many earlier shells, including the
Korn shell and at least one version of the Unix System V shell, included line
editing functionality. The 1988 version of the Korn shell (`ksh88`
) provided
both Emacs-style and Vi/Vim-style editing modes. As far as I can tell from [the
manual
page](https://web.archive.org/web/20151105130220/http://www2.research.att.com/sw/download/man/man1/ksh88.html),
the Korn shell would decide which mode you wanted to use by looking at the
`VISUAL`
and `EDITOR`
environment variables, which is pretty neat. The parts of
POSIX that specified shell functionality were closely modeled on `ksh88`
, so
GNU Bash was going to have to implement a similarly flexible line-editing
system to stay compliant. Hence Readline.
When Ramey first got involved in Bash development, Readline was a single source file in the Bash project directory. It was really just a part of Bash. Over time, the Readline file slowly moved toward becoming an independent project, though it was not until 1994 (with the 2.0 release of Readline) that Readline became a separate library entirely.
Readline is closely associated with Bash, and Ramey usually pairs Readline
releases with Bash releases. But as I mentioned above, Readline is a library
that can be used by any software implementing a command-line interface. And
it’s really easy to use. This is a simple example, but here’s how you would you
use Readline in your own C program. The string argument to the `readline()`
function is the prompt that you want Readline to display to the user:
```
#include <stdio.h>
#include <stdlib.h>
#include "readline/readline.h"
int main(int argc, char** argv)
{
char* line = readline("my-rl-example> ");
printf("You entered: \"%s\"\n", line);
free(line);
return 0;
}
```
Your program hands off control to Readline, which is responsible for getting a line of input from the user (in such a way that allows the user to do all the fancy line-editing things). Once the user has actually submitted the line, Readline returns it to you. I was able to compile the above by linking against the Readline library, which I apparently have somewhere in my library search path, by invoking the following:
```
$ gcc main.c -lreadline
```
The Readline API is much more extensive than that single function of course,
and anyone using it can tweak all sorts of things about the library’s behavior.
Library users can even add new functions that end users can configure via
`~/.inputrc`
, meaning that Readline is very easy to extend. But, as far as I
can tell, even Bash ultimately calls the simple `readline()`
function to get
input just as in the example above, though there is a lot of configuration
beforehand. (See [this
line](https://github.com/bminor/bash/blob/9f597fd10993313262cab400bf3c46ffb3f6fd1e/parse.y#L1487)
in the source for GNU Bash, which seems to be where Bash hands off
responsibility for getting input to Readline.)
Ramey has now worked on Bash and Readline for well over a decade. He has never once been compensated for his work—he is and has always been a volunteer. Bash and Readline continue to be actively developed, though Ramey said that Readline changes much more slowly than Bash does. I asked Ramey what it was like being the sole maintainer of software that so many people use. He said that millions of people probably use Bash without realizing it (because every Apple device runs Bash), which makes him worry about how much disruption a breaking change might cause. But he’s slowly gotten used to the idea of all those people out there. He said that he continues to work on Bash and Readline because at this point he is deeply invested and because he simply likes to make useful software available to the world.
*You can find more information about Chet Ramey at his
website.*
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
Please enjoy my long overdue new post, in which I use the story of the BBC Micro and the Computer Literacy Project as a springboard to complain about Codecademy.
— TwoBitHistory (@TwoBitHistory)[https://t.co/PiWlKljDjK][March 31, 2019] |
12,708 | 如何使用 Firefox 任务管理器 | https://itsfoss.com/firefox-task-manager/ | 2020-10-11T10:32:21 | [
"Firefox"
] | https://linux.cn/article-12708-1.html | 
>
> 查找并杀死占用内存和 CPU 的标签页和扩展程序
>
>
>
Firefox 在 Linux 用户中很受欢迎。它是几个 Linux 发行版上的默认 Web 浏览器。
在它所提供的许多功能之中,Firefox 也提供了一个自己的任务管理器。
不过,在 Linux 中既然你有[任务管理器](https://itsfoss.com/task-manager-linux/)这种形式的[系统监控工具](https://itsfoss.com/linux-system-monitoring-tools/),为什么还要使用 Firefox 的呢?这里有个很好的理由。
假设你的系统占用了太多的内存或 CPU。如果你使用 `top` 或其他一些系统[资源监控工具,如 Glances](https://itsfoss.com/glances/),你会发现这些工具无法区分是哪个打开的标签或扩展占用了资源。
通常情况下,每个 Firefox 标签页都显示为 “<ruby> Web 内容 <rt> Web Content </rt></ruby>”。你可以看到是某个 Firefox 进程导致了这个问题,但这无法准确判断是哪个标签页或扩展。
这时你可以使用 Firefox 任务管理器。让我来告诉你怎么做!
### Firefox 任务管理器
有了 Firefox 任务管理器,你就可以列出所有消耗系统资源的标签页、跟踪器和附加组件。

正如你在上面的截图中所看到的,你会看到标签页的名称、类型(标签或附加组件)、能源影响和消耗的内存。
其它的都不言自明,但\*\*“能源影响”指的是 CPU 的使用\*\*,如果你使用的是笔记本电脑,它是一个很好的指标,可以告诉你什么东西会更快耗尽电池电量。
#### 在 Firefox 中访问任务管理器
令人意外的是,任务管理器没有 [Firefox 键盘快捷键](https://itsfoss.com/firefox-keyboard-shortcuts/)。
要快速启动 Firefox 任务管理器,可以在地址栏中输入 `about:performance`,如下图所示。

另外,你也可以点击“菜单”图标,然后进入“更多”选项,如下截图所示。

接下来,你会发现选择“任务管理器”的选项,只需点击它就行。

#### 使用 Firefox 任务管理器
到这后,你可以检查资源的使用情况,展开标签页来查看跟踪器和它的使用情况,也可以选择关闭标签,如下截图高亮所示。

以下是你应该知道的:
* “能源影响”指的是 CPU 消耗。
* 子框架或子任务通常是与需要在后台运行的标签相关联的跟踪器/脚本。
通过这个任务管理器,你可以发现网站上的流氓脚本,以及它是否导致你的浏览器变慢。
这并不是什么 高科技,但并不是所有人都知道 Firefox 任务管理器。现在你知道了,它应该很方便,你觉得呢?
---
via: <https://itsfoss.com/firefox-task-manager/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Firefox is popular among Linux users. It is the default web browser on several Linux distributions.
Among many other features, Firefox provides a task manager of its own.
Now, why would you use it when you have [task manager in Linux](https://itsfoss.com/task-manager-linux/) in the form of [system monitoring tools](https://itsfoss.com/linux-system-monitoring-tools/)? There is a good reason for that.
Suppose your system is taking too much of RAM or CPU. If you use top or some other system [resource monitoring tool like Glances](https://itsfoss.com/glances/), you’ll notice that these tools cannot distinguish the opened tabs or extensions.
Usually, each Firefox tab is displayed as **Web Content**. You can see that some Firefox process is causing the issue but that’s no way to accurately determine which tab or extension it is.
This is where you can use the Firefox task manager. Let me show you how!
## Firefox Task Manager
With Firefox Task Manager, you will be able to list all the tabs, trackers, and add-ons consuming system resources.
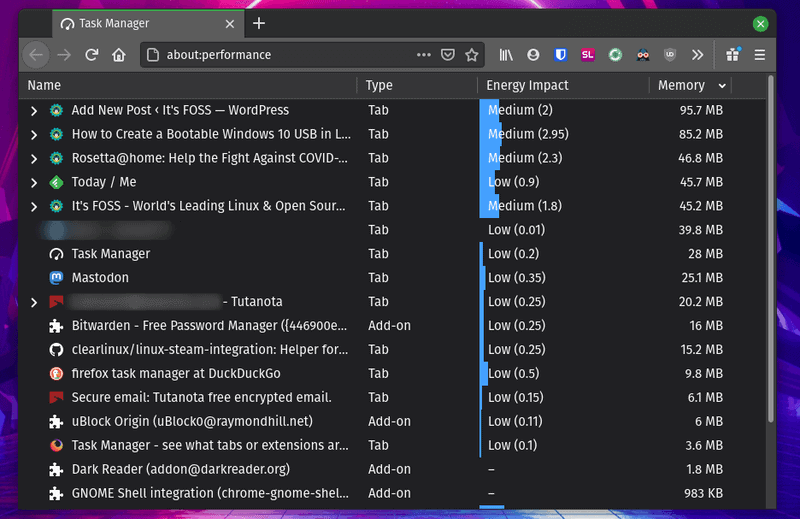
As you can see in the screenshot above, you get the name of the tab, the type (tab or add-on), the energy impact, and the memory consumed.
While everything is self-explanatory, the **energy impact refers to the CPU usage** and if you are using a Laptop, it is a good indicator to show you what will drain the battery quicker.
### Access Task Manager in Firefox
Surprisingly, there is no [Firefox keyboard shortcut](https://itsfoss.com/firefox-keyboard-shortcuts/) for the task manager.
To quickly launch Firefox Task Manager, you can type “**about:performance**” in the address bar as shown in the screenshot below.
Alternatively, you can click on the **menu** icon and then head on to “**More**” options as shown in the screenshot below.
Next, you will find the option to select “**Task Manager**” — so just click on it.
### Using Firefox task manager
Once there, you can check for the resource usage, expand the tabs to see the trackers and its usage, and also choose to close the tabs right there as highlighted in the screenshot below.
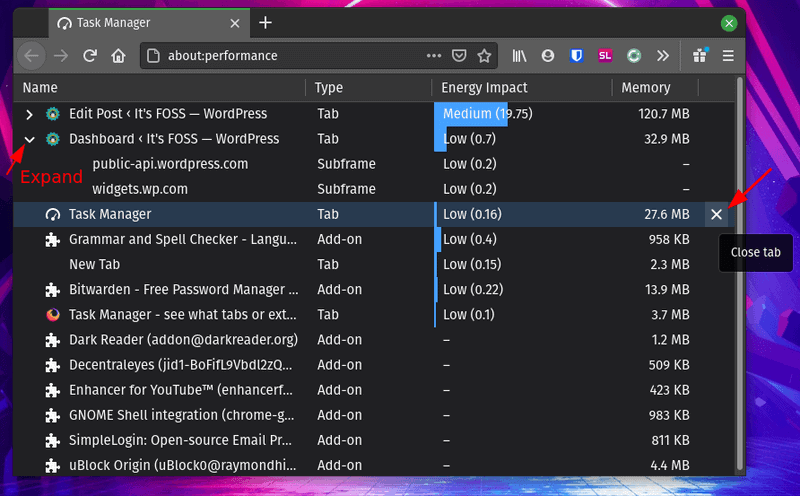
Here’s what you should know:
- Energy impact means CPU consumption.
- The subframes or the subtasks are usually the trackers/scripts associated with a tab that needs to run in the background.
With this task manager, you can spot a rogue script on a site as well whether it’s causing your browser to slow down. It would have been better if there was a dedicated keyboard shortcut for it.
This isn’t rocket-science but not many people are aware of Firefox task manager. Now that you know it, this should come in pretty handy, don’t you think? |
12,710 | TCP 窗口缩放、时间戳和 SACK | https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/ | 2020-10-12T11:41:13 | [
"TCP"
] | https://linux.cn/article-12710-1.html | 
Linux TCP 协议栈具有无数个可以更改其行为的 `sysctl` 旋钮。 这包括可用于接收或发送操作的内存量、套接字的最大数量、可选的特性和协议扩展。
有很多文章出于各种“性能调优”或“安全性”原因,建议禁用 TCP 扩展,比如时间戳或<ruby> 选择性确认 <rt> Selective ACKnowledgments </rt></ruby>(SACK)。
本文提供了这些扩展功能的背景,为什么会默认启用,它们之间是如何关联的,以及为什么通常情况下将它们关闭是个坏主意。
### TCP 窗口缩放
TCP 可以承受的数据传输速率受到几个因素的限制。其中包括:
* <ruby> 往返时间 <rt> Round trip time </rt></ruby>(RTT)。
这是数据包到达目的地并返回回复所花费的时间。越低越好。
* 所涉及的网络路径的最低链路速度。
* 丢包频率。
* 新数据可用于传输的速度。
例如,CPU 需要能够以足够快的速度将数据传递到网络适配器。如果 CPU 需要首先加密数据,则适配器可能必须等待新数据。同样地,如果磁盘存储不能足够快地读取数据,则磁盘存储可能会成为瓶颈。
* TCP 接收窗口的最大可能大小。
接收窗口决定了 TCP 在必须等待接收方报告接收到该数据之前可以传输多少数据(以字节为单位)。这是由接收方宣布的。接收方将在读取并确认接收到传入数据时不断更新此值。接收窗口的当前值包含在 [TCP 报头](https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure) 中,它是 TCP 发送的每个数据段的一部分。因此,只要发送方接收到来自对等方的确认,它就知道当前的接收窗口。这意味着往返时间(RTT)越长,发送方获得接收窗口更新所需的时间就越长。
TCP 的未确认(正在传输)数据被限制为最多 64KB。在大多数网络场景中,这甚至还不足以维持一个像样的数据速率。让我们看看一些例子。
**理论数据速率**
在往返时间(RTT)为 100 毫秒的情况下,TCP 每秒最多可以传输 640KB。在延迟为 1 秒的情况下,最大理论数据速率降至只有 64KB/s。
这是因为接收窗口的原因。一旦发送了 64KB 的数据,接收窗口就已经满了。发送方必须等待,直到对等方通知它应用程序已经读取了至少一部分数据。
发送的第一个段会把 TCP 窗口缩减去该段的大小。在接收窗口值的更新信息可用之前,需要往返一次。当更新以 1 秒的延迟到达时,即使链路有足够的可用带宽,也会导致 64KB 的限制。
为了充分利用一个具有几毫秒延迟的快速网络,必须有一个比传统 TCP 支持的窗口更大的窗口。“64KB 限制”是协议规范的产物:TCP 头只为接收窗口大小保留了 16 个位。这允许接收窗口最大为 64KB。在 TCP 协议最初设计时,这个大小并没有被视为一个限制。
不幸的是,想通过仅仅更改 TCP 头来支持更大的最大窗口值是不可能的。如果这样做就意味着 TCP 的所有实现都必须同时更新,否则它们将无法相互理解。为了解决这个问题,我们改变了对接收窗口值的解释。
“窗口缩放选项”允许你改变这个解释,同时保持与现有实现的兼容性。
#### TCP 选项:向后兼容的协议扩展
TCP 支持可选扩展。这允许使用新特性增强协议,而无需立即更新所有实现。当 TCP 发起方连接到对等方时,它还会发送一个支持的扩展列表。所有扩展都遵循相同的格式:一个唯一的选项号,后跟选项的长度以及选项数据本身。
TCP 响应方检查连接请求中包含的所有选项号。如果它遇到一个不能理解的选项号,则会跳过 该选项号附带的“长度”字节的数据,并检查下一个选项号。响应方忽略了从答复中无法理解的内容。这使发送方和接收方都够理解所支持的公共选项集。
使用窗口缩放时,选项数据总是由单个数字组成。
### 窗口缩放选项
```
Window Scale option (WSopt): Kind: 3, Length: 3
+---------+---------+---------+
| Kind=3 |Length=3 |shift.cnt|
+---------+---------+---------+
1 1 1
```
[窗口缩放](https://www.rfc-editor.org/info/rfc7323) 选项告诉对等方,应该使用给定的数字缩放 TCP 标头中的接收窗口值,以获取实际大小。
例如,一个宣告窗口缩放因子为 7 的 TCP 发起方试图指示响应方,任何将来携带接收窗口值为 512 的数据包实际上都会宣告 65536 字节的窗口。增加了 128 倍(2^7)。这将允许最大为 8MB 的 TCP 窗口。
不能理解此选项的 TCP 响应方将会忽略它,为响应连接请求而发送的 TCP 数据包(SYN-ACK)不会包含该窗口缩放选项。在这种情况下,双方只能使用 64k 的窗口大小。幸运的是,默认情况下,几乎每个 TCP 栈都支持并默认启用了此选项,包括 Linux。
响应方包括了它自己所需的缩放因子。两个对等方可以使用不同的因子。宣布缩放因子为 0 也是合法的。这意味着对等方应该如实处理它接收到的接收窗口值,但它允许应答方向上的缩放值,然后接收方可以使用更大的接收窗口。
与 SACK 或 TCP 时间戳不同,窗口缩放选项仅出现在 TCP 连接的前两个数据包中,之后无法更改。也不可能通过查看不包含初始连接三次握手的连接的数据包捕获来确定缩放因子。
支持的最大缩放因子为 14。这将允许 TCP 窗口的大小高达 1GB。
**窗口缩放的缺点**
在非常特殊的情况下,它可能导致数据损坏。但在你禁用该选项之前,要知道通常情况下是不可能损坏的。还有一种解决方案可以防止这种情况。不幸的是,有些人在没有意识到它与窗口缩放的关系的情况下禁用了该解决方案。首先,让我们看一下需要解决的实际问题。想象以下事件序列:
1. 发送方发送段:s\_1、s\_2、s\_3、... s\_n。
2. 接收方看到:s\_1、s\_3、... s\_n,并发送对 s\_1 的确认。
3. 发送方认为 s\_2 丢失,然后再次发送。它还发送了段 s\_n+1 中包含的新数据。
4. 接收方然后看到:s\_2、s\_n+1,s\_2:数据包 s\_2 被接收两次。
当发送方过早触发重新传输时,可能会发生这种情况。在正常情况下,即使使用窗口缩放,这种错误的重传也绝不会成为问题。接收方将只丢弃重复项。
#### 从旧数据到新数据
TCP 序列号最多可以为 4GB。如果它变得大于此值,则该序列会回绕到 0,然后再次增加。这本身不是问题,但是如果这种问题发生得足够快,则上述情况可能会造成歧义。
如果在正确的时刻发生回绕,则序列号 s\_2(重新发送的数据包)可能已经大于 s\_n+1。因此,在最后的步骤(4)中,接收方可以将其解释为:s\_2、s\_n+1、s\_n+m,即它可以将 “旧” 数据包 s\_2 视为包含新数据。
通常,这不会发生,因为即使在高带宽链接上,“回绕”也只会每隔几秒钟或几分钟发生一次。原始数据包和不需要的重传的数据包之间的间隔将小得多。
例如,对于 50MB/s 的传输速度,重复项要迟到一分钟以上才会成为问题。序列号的回绕速度没有快到让小的延迟会导致这个问题。
一旦 TCP 达到 “GB/s” 的吞吐率,序列号的回绕速度就会非常快,以至于即使只有几毫秒的延迟也可能会造成 TCP 无法检测出的重复项。通过解决接收窗口太小的问题,TCP 现在可以用于以前无法实现的网络速度,这会产生一个新的,尽管很少见的问题。为了在 RTT 非常低的环境中安全使用 GB/s 的速度,接收方必须能够检测到这些旧的重复项,而不必仅依赖序列号。
### TCP 时间戳
#### 最佳截止日期
用最简单的术语来说,[TCP 时间戳](https://www.rfc-editor.org/info/rfc7323)只是在数据包上添加时间戳,以解决由非常快速的序列号回绕引起的歧义。如果一个段看起来包含新数据,但其时间戳早于上一个在接收窗口内的数据包,则该序列号已被重新回绕,而“新”数据包实际上是一个较旧的重复项。这解决了即使在极端情况下重传的歧义。
但是,该扩展不仅仅是检测旧数据包。TCP 时间戳的另一个主要功能是更精确的往返时间测量(RTTm)。
#### 需要准确的 RTT 估算
当两个对等方都支持时间戳时,每个 TCP 段都携带两个附加数字:时间戳值和回显时间戳。
```
TCP Timestamp option (TSopt): Kind: 8, Length: 10
+-------+----+----------------+-----------------+
|Kind=8 | 10 |TS Value (TSval)|EchoReply (TSecr)|
+-------+----+----------------+-----------------+
1 1 4 4
```
准确的 RTT 估算对于 TCP 性能至关重要。TCP 会自动重新发送未确认的数据。重传由计时器触发:如果超时,则 TCP 会将尚未收到确认的一个或多个数据包视为丢失。然后再发送一次。
但是,“尚未得到确认” 并不意味着该段已丢失。也有可能是接收方到目前为止没有发送确认,或者确认仍在传输中。这就造成了一个两难的困境:TCP 必须等待足够长的时间,才能让这种轻微的延迟变得无关紧要,但它也不能等待太久。
**低网络延迟 VS 高网络延迟**
在延迟较高的网络中,如果计时器触发过快,TCP 经常会将时间和带宽浪费在不必要的重发上。
然而,在延迟较低的网络中,等待太长时间会导致真正发生数据包丢失时吞吐量降低。因此,在低延迟网络中,计时器应该比高延迟网络中更早到期。所以,TCP 重传超时不能使用固定常量值作为超时。它需要根据其在网络中所经历的延迟来调整该值。
**往返时间的测量**
TCP 选择基于预期的往返时间(RTT)的重传超时。RTT 事先是未知的。它是通过测量发送的段与 TCP 接收到该段所承载数据的确认之间的增量来估算的。
由于多种因素使其而变得复杂。
* 出于性能原因,TCP 不会为收到的每个数据包生成新的确认。它等待的时间非常短:如果有更多的数据段到达,则可以通过单个 ACK 数据包确认其接收。这称为<ruby> “累积确认” <rt> cumulative ACK </rt></ruby>。
* 往返时间并不恒定。这是有多种因素造成的。例如,客户端可能是一部移动电话,随其移动而切换到不同的基站。也可能是当链路或 CPU 的利用率提高时,数据包交换花费了更长的时间。
* 必须重新发送的数据包在计算过程中必须被忽略。这是因为发送方无法判断重传数据段的 ACK 是在确认原来的传输数据(毕竟已到达)还是在确认重传数据。
最后一点很重要:当 TCP 忙于从丢失中恢复时,它可能仅接收到重传段的 ACK。这样,它就无法在此恢复阶段测量(更新)RTT。所以,它无法调整重传超时,然后超时将以指数级增长。那是一种非常具体的情况(它假设其他机制,如快速重传或 SACK 不起作用)。但是,使用 TCP 时间戳,即使在这种情况下也会进行 RTT 评估。
如果使用了扩展,则对等方将从 TCP 段的扩展空间中读取时间戳值并将其存储在本地。然后,它将该值作为 “回显时间戳” 放入发回的所有数据段中。
因此,该选项带有两个时间戳:它的发送方自己的时间戳和它从对等方收到的最新时间戳。原始发送方使用 “回显时间戳” 来计算 RTT。它是当前时间戳时钟与 “回显时间戳” 中所反映的值之间的增量。
**时间戳的其他用途**
TCP 时间戳甚至还有除 PAWS(<ruby> 防止序列号回绕 <rt> Protection Against Wrapped Sequences </rt></ruby>) 和 RTT 测量以外的其他用途。例如,可以检测是否不需要重发。如果该确认携带较旧的回显时间戳,则该确认针对的是初始数据包,而不是重新发送的数据包。
TCP 时间戳的另一个更晦涩的用例与 TCP [syn cookie](https://en.wikipedia.org/wiki/SYN_cookies) 功能有关。
**在服务器端建立 TCP 连接**
当连接请求到达的速度快于服务器应用程序可以接受新的传入连接的速度时,连接积压最终将达到其极限。这可能是由于系统配置错误或应用程序中的错误引起的。当一个或多个客户端发送连接请求而不对 “SYN ACK” 响应做出反应时,也会发生这种情况。这将用不完整的连接填充连接队列。这些条目需要几秒钟才会超时。这被称为<ruby> “同步泛洪攻击” <rt> syn flood attack </rt></ruby>。
**TCP 时间戳和 TCP Syn Cookie**
即使队列已满,某些 TCP 协议栈也允许继续接受新连接。发生这种情况时,Linux 内核将在系统日志中打印一条突出的消息:
>
> 端口 P 上可能发生 SYN 泛洪。正在发送 Cookie。检查 SNMP 计数器。
>
>
>
此机制将完全绕过连接队列。通常存储在连接队列中的信息被编码到 SYN/ACK 响应 TCP 序列号中。当 ACK 返回时,可以根据序列号重建队列条目。
序列号只有有限的空间来存储信息。因此,使用 “TCP Syn Cookie” 机制建立的连接不能支持 TCP 选项。
但是,对两个对等点都通用的 TCP 选项可以存储在时间戳中。ACK 数据包在回显时间戳字段中反映了该值,这也允许恢复已达成共识的 TCP 选项。否则,cookie 连接受标准的 64KB 接收窗口限制。
**常见误区 —— 时间戳不利于性能**
不幸的是,一些指南建议禁用 TCP 时间戳,以减少内核访问时间戳时钟来获取当前时间所需的次数。这是不正确的。如前所述,RTT 估算是 TCP 的必要部分。因此,内核在接收/发送数据包时总是采用微秒级的时间戳。
在包处理步骤的其余部分中,Linux 会重用 RTT 估算所需的时钟时间戳。这还避免了将时间戳添加到传出 TCP 数据包的额外时钟访问。
整个时间戳选项在每个数据包中仅需要 10 个字节的 TCP 选项空间,这不会显著减少可用于数据包有效负载的空间。
**常见误区 —— 时间戳是个安全问题**
一些安全审计工具和(较旧的)博客文章建议禁用 TCP 时间戳,因为据称它们泄露了系统正常运行时间:这样一来,便可以估算系统/内核的补丁级别。这在过去是正确的:时间戳时钟基于不断增加的值,该值在每次系统引导时都以固定值开始。时间戳值可以估计机器已经运行了多长时间(正常运行时间 `uptime`)。
从 Linux 4.12 开始,TCP 时间戳不再显示正常运行时间。发送的所有时间戳值都使用对等设备特定的偏移量。时间戳值也每 49 天回绕一次。
换句话说,从地址 “A” 出发,或者终到地址 “A” 的连接看到的时间戳与到远程地址 “B” 的连接看到的时间戳不同。
运行 `sysctl net.ipv4.tcp_timeamp=2` 以禁用随机化偏移。这使得分析由诸如 `wireshark` 或 `tcpdump` 之类的工具记录的数据包跟踪变得更容易 —— 从主机发送的数据包在其 TCP 选项时间戳中都具有相同的时钟基准。因此,对于正常操作,默认设置应保持不变。
### 选择性确认
如果同一数据窗口中的多个数据包丢失了,TCP 将会出现问题。这是因为 TCP 确认是累积的,但仅适用于按顺序到达的数据包。例如:
* 发送方发送段 s\_1、s\_2、s\_3、... s\_n
* 发送方收到 s\_2 的 ACK
* 这意味着 s\_1 和 s\_2 都已收到,并且发送方不再需要保留这些段。
* s\_3 是否应该重新发送? s\_4 呢? s\_n?
发送方等待 “重传超时” 或 “重复 ACK” 以使 s\_2 到达。如果发生重传超时或到达了 s\_2 的多个重复 ACK,则发送方再次发送 s\_3。
如果发送方收到对 s\_n 的确认,则 s\_3 是唯一丢失的数据包。这是理想的情况。仅发送单个丢失的数据包。
如果发送方收到的确认段小于 s\_n,例如 s\_4,则意味着丢失了多个数据包。发送方也需要重传下一个数据段。
**重传策略**
可能只是重复相同的序列:重新发送下一个数据包,直到接收方指示它已处理了直至 s\_n 的所有数据包为止。这种方法的问题在于,它需要一个 RTT,直到发送方知道接下来必须重新发送的数据包为止。尽管这种策略可以避免不必要的重传,但要等到 TCP 重新发送整个数据窗口后,它可能要花几秒钟甚至更长的时间。
另一种方法是一次重新发送几个数据包。当丢失了几个数据包时,此方法可使 TCP 恢复更快。在上面的示例中,TCP 重新发送了 s\_3、s\_4、s\_5、...,但是只能确保已丢失 s\_3。
从延迟的角度来看,这两种策略都不是最佳的。如果只有一个数据包需要重新发送,第一种策略是快速的,但是当多个数据包丢失时,它花费的时间太长。
即使必须重新发送多个数据包,第二个也是快速的,但是以浪费带宽为代价。此外,这样的 TCP 发送方在进行不必要的重传时可能已经发送了新数据。
通过可用信息,TCP 无法知道丢失了哪些数据包。这就是 TCP [选择性确认](https://www.rfc-editor.org/info/rfc2018)(SACK)的用武之地了。就像窗口缩放和时间戳一样,它是另一个可选的但非常有用的 TCP 特性。
**SACK 选项**
```
TCP Sack-Permitted Option: Kind: 4, Length 2
+---------+---------+
| Kind=4 | Length=2|
+---------+---------+
```
支持此扩展的发送方在连接请求中包括 “允许 SACK” 选项。如果两个端点都支持该扩展,则检测到数据流中丢失数据包的对等方可以将此信息通知发送方。
```
TCP SACK Option: Kind: 5, Length: Variable
+--------+--------+
| Kind=5 | Length |
+--------+--------+--------+--------+
| Left Edge of 1st Block |
+--------+--------+--------+--------+
| Right Edge of 1st Block |
+--------+--------+--------+--------+
| |
/ . . . /
| |
+--------+--------+--------+--------+
| Left Edge of nth Block |
+--------+--------+--------+--------+
| Right Edge of nth Block |
+--------+--------+--------+--------+
```
接收方遇到 s\_2 后跟 s\_5 ... s\_n,则在发送对 s\_2 的确认时将包括一个 SACK 块:
```
+--------+-------+
| Kind=5 | 10 |
+--------+------+--------+-------+
| Left edge: s_5 |
+--------+--------+-------+------+
| Right edge: s_n |
+--------+-------+-------+-------+
```
这告诉发送方到 s\_2 的段都是按顺序到达的,但也让发送方知道段 s\_5 至 s\_n 也已收到。然后,发送方可以重新发送那两个数据包(s\_3、s\_4),并继续发送新数据。
**神话般的无损网络**
从理论上讲,如果连接不会丢包,那么 SACK 就没有任何优势。或者连接具有如此低的延迟,甚至等待一个完整的 RTT 都无关紧要。
在实践中,无损行为几乎是不可能保证的。即使网络及其所有交换机和路由器具有足够的带宽和缓冲区空间,数据包仍然可能丢失:
* 主机操作系统可能面临内存压力并丢弃数据包。请记住,一台主机可能同时处理数万个数据包流。
* CPU 可能无法足够快地消耗掉来自网络接口的传入数据包。这会导致网络适配器本身中的数据包丢失。
* 如果 TCP 时间戳不可用,即使一个非常小的 RTT 的连接也可能在丢失恢复期间暂时停止。
使用 SACK 不会增加 TCP 数据包的大小,除非连接遇到数据包丢失。因此,几乎没有理由禁用此功能。几乎所有的 TCP 协议栈都支持 SACK —— 它通常只在不进行 TCP 批量数据传输的低功耗 IOT 类的设备上才不存在。
当 Linux 系统接受来自此类设备的连接时,TCP 会自动为受影响的连接禁用 SACK。
### 总结
本文中研究的三个 TCP 扩展都与 TCP 性能有关,最好都保留其默认设置:启用。
TCP 握手可确保仅使用双方都可以理解的扩展,因此,永远不需因为对等方可能不支持而全局禁用该扩展。
关闭这些扩展会导致严重的性能损失,尤其是 TCP 窗口缩放和 SACK。可以禁用 TCP 时间戳而不会立即造成不利影响,但是现在没有令人信服的理由这样做了。启用它们还可以支持 TCP 选项,即使在 SYN cookie 生效时也是如此。
---
via: <https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/>
作者:[Florian Westphal](https://fedoramagazine.org/author/strlen/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Linux TCP stack has a myriad of *sysctl* knobs that allow to change its behavior. This includes the amount of memory that can be used for receive or transmit operations, the maximum number of sockets and optional features and protocol extensions.
There are multiple articles that recommend to disable TCP extensions, such as timestamps or selective acknowledgments (SACK) for various “performance tuning” or “security” reasons.
This article provides background on what these extensions do, why they
are enabled by default, how they relate to one another and why it is normally a bad idea to turn them off.
## TCP Window scaling
The data transmission rate that TCP can sustain is limited by several factors. Some of these are:
- Round trip time (RTT). This is the time it takes for a packet to get to the destination and a reply to come back. Lower is better.
- lowest link speed of the network paths involved
- frequency of packet loss
- the speed at which new data can be made available for transmission
For example, the CPU needs to be able to pass data to the network adapter fast enough. If the CPU needs to encrypt the data first, the adapter might have to wait for new data. In similar fashion disk storage can be a bottleneck if it can’t read the data fast enough. - The maximum possible size of the TCP receive window. The receive window determines how much data (in bytes) TCP can transmit before it has to wait for the receiver to report reception of that data. This is announced by the receiver. The receiver will constantly update this value as it reads and acknowledges reception of the incoming data. The receive windows current value is contained in the
[TCP header](https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure)that is part of every segment sent by TCP. The sender is thus aware of the current receive window whenever it receives an acknowledgment from the peer. This means that the higher the round-trip time, the longer it takes for sender to get receive window updates.
TCP is limited to at most 64 kilobytes of unacknowledged (in-flight) data. This is not even close to what is needed to sustain a decent data rate in most networking scenarios. Let us look at some examples.
#### Theoretical data rate
With a round-trip-time of 100 milliseconds, TCP can transfer at most 640 kilobytes per second. With a 1 second delay, the maximum theoretical data rate drops down to only 64 kilobytes per second.
This is because of the receive window. Once 64kbyte of data have been sent the receive window is already full. The sender must wait until the peer informs it that at least some of the data has been read by the application.
The first segment sent reduces the TCP window by the size of that segment. It takes one round-trip before an update of the receive window value will become available. When updates arrive with a 1 second delay, this results in a 64 kilobyte limit even if the link has plenty of bandwidth available.
In order to fully utilize a fast network with several milliseconds of delay, a window size larger than what classic TCP supports is a must. The ’64 kilobyte limit’ is an artifact of the protocols specification: The TCP header reserves only 16bits for the receive window size. This allows receive windows of up to 64KByte. When the TCP protocol was originally designed, this size was not seen as a limit.
Unfortunately, its not possible to just change the TCP header to support a larger maximum window value. Doing so would mean all implementations of TCP would have to be updated simultaneously or they wouldn’t understand one another anymore. To solve this, the interpretation of the receive window value is changed instead.
The ‘window scaling option’ allows to do this while keeping compatibility to existing implementations.
### TCP Options: Backwards-compatible protocol extensions
TCP supports optional extensions. This allows to enhance the protocol with new features without the need to update all implementations at once. When a TCP initiator connects to the peer, it also send a list of supported extensions. All extensions follow the same format: an unique option number followed by the length of the option and the option data itself.
The TCP responder checks all the option numbers contained in the connection request. If it does not understand an option number it skips
‘length’ bytes of data and checks the next option number. The responder omits those it did not understand from the reply. This allows both the sender and receiver to learn the common set of supported options.
With window scaling, the option data always consist of a single number.
## The window scaling option
Window Scale option (WSopt): Kind: 3, Length: 3
+---------+---------+---------+
| Kind=3 |Length=3 |shift.cnt|
+---------+---------+---------+
1 1 1
The [window scaling](https://www.rfc-editor.org/info/rfc7323) option tells the peer that the receive window value found in the TCP header should be scaled by the given number to get the real size.
For example, a TCP initiator that announces a window scaling factor of 7 tries to instruct the responder that any future packets that carry a receive window value of 512 really announce a window of 65536 byte. This is an increase by a factor of 128. This would allow a maximum TCP Window of 8 Megabytes.
A TCP responder that does not understand this option ignores it. The TCP packet sent in reply to the connection request (the syn-ack) then does not contain the window scale option. In this case both sides can only use a 64k window size. Fortunately, almost every TCP stack supports and enables this option by default, including Linux.
The responder includes its own desired scaling factor. Both peers can use a different number. Its also legitimate to announce a scaling factor of 0. This means the peer should treat the receive window value it receives verbatim, but it allows scaled values in the reply direction — the recipient can then use a larger receive window.
Unlike SACK or TCP timestamps, the window scaling option only appears in the first two packets of a TCP connection, it cannot be changed afterwards. It is also not possible to determine the scaling factor by looking at a packet capture of a connection that does not contain the initial connection three-way handshake.
The largest supported scaling factor is 14. This allows TCP window sizes
of up to one Gigabyte.
#### Window scaling downsides
It can cause data corruption in very special cases. Before you disable the option – it is impossible under normal circumstances. There is also a solution in place that prevents this. Unfortunately, some people disable this solution without realizing the relationship with window scaling. First, let’s have a look at the actual problem that needs to be addressed. Imagine the following sequence of events:
- The sender transmits segments: s_1, s_2, s_3, … s_n
- The receiver sees: s_1, s_3, .. s_n and sends an acknowledgment for s_1.
- The sender considers s_2 lost and sends it a second time. It also sends new data contained in segment s_n+1.
- The receiver then sees: s_2, s_n+1, s_2: the packet s_2 is received twice.
This can happen for example when a sender triggers re-transmission too early. Such erroneous re-transmits are never a problem in normal cases, even with window scaling. The receiver will just discard the duplicate.
### Old data to new data
The TCP sequence number can be at most 4 Gigabyte. If it becomes larger than this, the sequence wraps back to 0 and then increases again. This is not a problem in itself, but if this occur fast enough then the above scenario can create an ambiguity.
If a wrap-around occurs at the right moment, the sequence number s_2 (the re-transmitted packet) can already be larger than s_n+1. Thus, in the last step (4), the receiver may interpret this as: s_2, s_n+1, s_n+m, i.e. it could view the ‘old’ packet s_2 as containing new data.
Normally, this won’t happen because a ‘wrap around’ occurs only every couple of seconds or minutes even on high bandwidth links. The interval between the original and a unneeded re-transmit will be a lot smaller.
For example,with a transmit speed of 50 Megabytes per second, a
duplicate needs to arrive more than one minute late for this to become a problem. The sequence numbers do not wrap fast enough for small delays to induce this problem.
Once TCP approaches ‘Gigabyte per second’ throughput rates, the sequence numbers can wrap so fast that even a delay by only a few milliseconds can create duplicates that TCP cannot detect anymore. By solving the problem of the too small receive window, TCP can now be used for network speeds that were impossible before – and that creates a new, albeit rare problem. To safely use Gigabytes/s speed in environments with very low RTT receivers must be able to detect such old duplicates without relying on the sequence number alone.
## TCP time stamps
### A best-before date
In the most simple terms, [TCP timestamps](https://www.rfc-editor.org/info/rfc7323) just add a time stamp to the packets to resolve the ambiguity caused by very fast sequence number wrap around. If a segment appears to contain new data, but its timestamp is older than the last in-window packet, then the sequence number has wrapped and the ”new” packet is actually an older duplicate. This resolves the ambiguity of re-transmits even for extreme corner cases.
But this extension allows for more than just detection of old packets. The other major feature made possible by TCP timestamps are more precise round-trip time measurements (RTTm).
### A need for precise round-trip-time estimation
When both peers support timestamps, every TCP segment carries two additional numbers: a timestamp value and a timestamp echo.
TCP Timestamp option (TSopt): Kind: 8, Length: 10
+-------+----+----------------+-----------------+
|Kind=8 | 10 |TS Value (TSval)|EchoReply (TSecr)|
+-------+----+----------------+-----------------+
1 1 4 4
An accurate RTT estimate is crucial for TCP performance. TCP automatically re-sends data that was not acknowledged. Re-transmission is triggered by a timer: If it expires, TCP considers one or more packets that it has not yet received an acknowledgment for to be lost. They are then sent again.
But “has not been acknowledged” does not mean the segment was lost. It is also possible that the receiver did not send an acknowledgment so far or that the acknowledgment is still in flight. This creates a dilemma: TCP must wait long enough for such slight delays to not matter, but it can’t wait for too long either.
#### Low versus high network delay
In networks with a high delay, if the timer fires too fast, TCP frequently wastes time and bandwidth with unneeded re-sends.
In networks with a low delay however, waiting for too long causes reduced throughput when a real packet loss occurs. Therefore, the timer should expire sooner in low-delay networks than in those with a high delay. The tcp retransmit timeout therefore cannot use a fixed constant value as a timeout. It needs to adapt the value based on the delay that it experiences in the network.
#### Round-trip time measurement
TCP picks a retransmit timeout that is based on the expected round-trip time (RTT). The RTT is not known in advance. RTT is estimated by measuring the delta between the time a segment is sent and the time TCP receives an acknowledgment for the data carried by that segment.
This is complicated by several factors.
- For performance reasons, TCP does not generate a new acknowledgment for every packet it receives. It waits for a very small amount of time: If more segments arrive, their reception can be acknowledged with a single ACK packet. This is called “cumulative ACK”.
- The round-trip-time is not constant. This is because of a myriad of factors. For example, a client might be a mobile phone switching to different base stations as its moved around. Its also possible that packet switching takes longer when link or CPU utilization increases.
- a packet that had to be re-sent must be ignored during computation. This is because the sender cannot tell if the ACK for the re-transmitted segment is acknowledging the original transmission (that arrived after all) or the re-transmission.
This last point is significant: When TCP is busy recovering from a loss, it may only receives ACKs for re-transmitted segments. It then can’t measure (update) the RTT during this recovery phase. As a consequence it can’t adjust the re-transmission timeout, which then keeps growing exponentially. That’s a pretty specific case (it assumes that other mechanisms such as fast retransmit or SACK did not help). Nevertheless, with TCP timestamps, RTT evaluation is done even in this case.
If the extension is used, the peer reads the timestamp value from the TCP segments extension space and stores it locally. It then places this value in all the segments it sends back as the “timestamp echo”.
Therefore the option carries two timestamps: Its senders own timestamp and the most recent timestamp it received from the peer. The “echo timestamp” is used by the original sender to compute the RTT. Its the delta between its current timestamp clock and what was reflected in the “timestamp echo”.
#### Other timestamp uses
TCP timestamps even have other uses beyond PAWS and RTT measurements. For example it becomes possible to detect if a retransmission was unnecessary. If the acknowledgment carries an older timestamp echo, the acknowledgment was for the initial packet, not the re-transmitted one.
Another, more obscure use case for TCP timestamps is related to the TCP [syn cookie](https://en.wikipedia.org/wiki/SYN_cookies) feature.
#### TCP connection establishment on server side
When connection requests arrive faster than a server application can accept the new incoming connection, the connection backlog will eventually reach its limit. This can occur because of a mis-configuration of the system or a bug in the application. It also happens when one or more clients send connection requests without reacting to the ‘syn ack’ response. This fills the connection queue with incomplete connections. It takes several seconds for these entries to time out. This is called a “syn flood attack”.
#### TCP timestamps and TCP syn cookies
Some TCP stacks allow to accept new connections even if the queue is full. When this happens, the Linux kernel will print a prominent message to the system log:
Possible SYN flooding on port P. Sending Cookies. Check SNMP counters.
This mechanism bypasses the connection queue entirely. The information that is normally stored in the connection queue is encoded into the SYN/ACK responses TCP sequence number. When the ACK comes back, the queue entry can be rebuilt from the sequence number.
The sequence number only has limited space to store information. Connections established using the ‘TCP syn cookie’ mechanism can not support TCP options for this reason.
The TCP options that are common to both peers can be stored in the timestamp, however. The ACK packet reflects the value back in the timestamp echo field which allows to recover the agreed-upon TCP options as well. Else, cookie-connections are restricted by the standard 64 kbyte receive window.
#### Common myths – timestamps are bad for performance
Unfortunately some guides recommend disabling TCP timestamps to reduce the number of times the kernel needs to access the timestamp clock to get the current time. This is not correct. As explained before, RTT estimation is a necessary part of TCP. For this reason, the kernel always takes a microsecond-resolution time stamp when a packet is received/sent.
Linux re-uses the clock timestamp taken for the RTT estimation for the remainder of the packet processing step. This also avoids the extra clock access to add a timestamp to an outgoing TCP packet.
The entire timestamp option only requires 10 bytes of TCP option space in each packet, this is not a significant decrease in space available for packet payload.
#### common myths – timestamps are a security problem
Some security audit tools and (older) blog posts recommend to disable TCP
timestamps because they allegedly leak system uptime: This would then allow to estimate the patch level of the system/kernel. This was true in the past: The timestamp clock is based on a constantly increasing value that starts at a fixed value on each system boot. A timestamp value would give a estimate as to how long the machine has been running (uptime).
As of Linux 4.12 TCP timestamps do not reveal the uptime anymore. All timestamp values sent use a peer-specific offset. Timestamp values also wrap every 49 days.
In other words, connections from or to address “A” see a different timestamp than connections to the remote address “B”.
Run *sysctl net.ipv4.tcp_timestamps=2 *to disable the randomization offset. This makes analyzing packet traces recorded by tools like *wireshark* or *tcpdump* easier – packets sent from the host then all have the same clock base in their TCP option timestamp. For normal operation the default setting should be left as-is.
## Selective Acknowledgments
TCP has problems if several packets in the same window of data are lost. This is because TCP Acknowledgments are cumulative, but only for packets
that arrived in-sequence. Example:
- Sender transmits segments s_1, s_2, s_3, … s_n
- Sender receives ACK for s_2
- This means that both s_1 and s_2 were received and the
sender no longer needs to keep these segments around. - Should s_3 be re-transmitted? What about s_4? s_n?
The sender waits for a “retransmission timeout” or ‘duplicate ACKs’ for s_2 to arrive. If a retransmit timeout occurs or several duplicate ACKs for s_2 arrive, the sender transmits s_3 again.
If the sender receives an acknowledgment for s_n, s_3 was the only missing packet. This is the ideal case. Only the single lost packet was re-sent.
If the sender receives an acknowledged segment that is smaller than s_n, for example s_4, that means that more than one packet was lost. The
sender needs to re-transmit the next segment as well.
#### Re-transmit strategies
Its possible to just repeat the same sequence: re-send the next packet until the receiver indicates it has processed all packet up to s_n. The problem with this approach is that it requires one RTT until the sender knows which packet it has to re-send next. While such strategy avoids unnecessary re-transmissions, it can take several seconds and more until TCP has re-sent the entire window of data.
The alternative is to re-send several packets at once. This approach allows TCP to recover more quickly when several packets have been lost. In the above example TCP re-send s_3, s_4, s_5, .. while it can only be sure that s_3 has been lost.
From a latency point of view, neither strategy is optimal. The first strategy is fast if only a single packet has to be re-sent, but takes too long when multiple packets were lost.
The second one is fast even if multiple packet have to be re-sent, but at the cost of wasting bandwidth. In addition, such a TCP sender could have transmitted new data already while it was doing the unneeded re-transmissions.
With the available information TCP cannot know which packets were lost. This is where TCP [Selective Acknowledgments](https://www.rfc-editor.org/info/rfc2018) (SACK) come in. Just like window scaling and timestamps, it is another optional, yet very useful TCP feature.
#### The SACK option
TCP Sack-Permitted Option: Kind: 4, Length 2
+---------+---------+
| Kind=4 | Length=2|
+---------+---------+
A sender that supports this extension includes the “Sack Permitted” option in the connection request. If both endpoints support the extension, then a peer that detects a packet is missing in the data stream can inform the sender about this.
TCP SACK Option: Kind: 5, Length: Variable
+--------+--------+
| Kind=5 | Length |
+--------+--------+--------+--------+
| Left Edge of 1st Block |
+--------+--------+--------+--------+
| Right Edge of 1st Block |
+--------+--------+--------+--------+
| |
/ . . . /
| |
+--------+--------+--------+--------+
| Left Edge of nth Block |
+--------+--------+--------+--------+
| Right Edge of nth Block |
+--------+--------+--------+--------+
A receiver that encounters segment_s2 followed by s_5…s_n, it will include a SACK block when it sends the acknowledgment for s_2:
+--------+-------+
| Kind=5 | 10 |
+--------+------+--------+-------+
| Left edge: s_5 |
+--------+--------+-------+------+
| Right edge: s_n |
+--------+-------+-------+-------+
This tells the sender that segments up to s_2 arrived in-sequence, but it also lets the sender know that the segments s_5 to s_n were also received. The sender can then re-transmit these two packets and proceed to send new data.
#### The mythical lossless network
In theory SACK provides no advantage if the connection cannot experience packet loss. Or the connection has such a low latency that even waiting one full RTT does not matter.
In practice lossless behavior is virtually impossible to ensure.
Even if the network and all its switches and routers have ample bandwidth and buffer space packets can still be lost:
- The host operating system might be under memory pressure and drop
packets. Remember that a host might be handling tens of thousands of packet streams simultaneously. - The CPU might not be able to drain incoming packets from the network interface fast enough. This causes packet drops in the network adapter itself.
- If TCP timestamps are not available even a connection with a very small RTT can stall momentarily during loss recovery.
Use of SACK does not increase the size of TCP packets unless a connection experiences packet loss. Because of this, there is hardly a reason to disable this feature. Almost all TCP stacks support SACK – it is typically only absent on low-power IOT-alike devices that are not doing TCP bulk data transfers.
When a Linux system accepts a connection from such a device, TCP automatically disables SACK for the affected connection.
## Summary
The three TCP extensions examined in this post are all related to TCP performance and should best be left to the default setting: enabled.
The TCP handshake ensures that only extensions that are understood by both parties are used, so there is never a need to disable an extension globally just because a peer might not support it.
Turning these extensions off results in severe performance penalties, especially in case of TCP Window Scaling and SACK. TCP timestamps can be disabled without an immediate disadvantage, however there is no compelling reason to do so anymore. Keeping them enabled also makes it possible to support TCP options even when SYN cookies come into effect.
## idanka
Thx, article!
Fedora default settings, perfect?
## Vernon Van steenkist
Excellent, well written and informative article. Thanks for the information.
## DoubleM
Amazing article!
I remember that when old Cisco FWSM were in place I had to disable seqnumber randomization on firewall side because they used not to rewrite seq numbers on packets congaing sack correctly, this was entirely a Cisco issue. Anyway even with more recent firewalls I had a couple of cases in which performance issues were solved disabling SACK on server side, but I was never able to understand where the effective issue lay.
## Ernest Bass
Great article, just right depth of explanation.
One minor irritation. The text of the article was not written by a native English speaker or someone with limited education in writing a technical article or machine generated.
I would be happy to serve as a proof-reader. Spent years performing that service at IBM.
## Stephen Snow
Hello Ernest,
Thank you for offering to write articles. If you follow https://docs.fedoraproject.org/en-US/fedora-magazine/ you can see how to become a writer for the magazine, and editor as well. As the editor of the week, I had rush edited this article to get it out for the writer, it should have been published Monday. So there are very likely things I should have spent more time on. FWIW, this is an article, not a technical manual, the two are quite different. I do create technical manuals in my “day job.” Magazine articles have next to nothing in common with a technical reference manual.
## FeRD (Frank Dana)
Ernest’s criticisms seem a little harsh, I certainly see NOTHING that leads me to conclude, “The text of the article was not written by a native English speaker or someone with limited education in writing a technical article or machine generated.” That’s an insane leap.
There are some minor issues of copy editing and flow, easily attributable to the rush to get the article published — and probably things that you’re aware of (or would pick up on) yourself. A couple that come to mind off the top of my head (IOW, the stuff that I can’t help noticing, no matter how hard I try!):
• There are at least a half-dozen “its”-es that should be “it’s”-es, including the very first word in “Re-transmit strategies”. (That’s actually kind of refreshing, normally I see it the other way around.) Apostrophes are not being rationed!
• There’s only one small issue with the sentence, “TCP timestamps even have other uses beyond PAWS and RTT measurements.”: It’s the very first time “PAWS” is mentioned in the entire article. (…The ONLY time, now that I look.) Yet it’s thrown out there as though the reader is supposed to be familiar with it already — in fact, it’s thrown out there as if it’s already been covered.
## Paul W. Frields
@Ernest: We welcome new contributors, and because we have many non-native speakers contributing in English, proofreading would be a great help. You can learn more here: https://docs.fedoraproject.org/en-US/fedora-magazine/
## Stuart Gathman
The information flow in this article was perfect. I would have to re-read in “proof reader” mode to see whatever flaw another commenter noted. I did not even see the word. I was in the middle of a mental animation of packets traveling over wires a la “Tron” with stop and examine features for the header fields.
It brought to mind implementing a protocol similar to TCP over full-duplex bisync (SOCOMM) for the Air Force. The spec I received has cumulative Acks. When I went to install in the field, I discovered that the reality was selective acks. There were no option fields in the spec to switch between the two.
## FeRD (Frank Dana)
“I would have to re-read in “proof reader” mode to see whatever flaw another commenter noted.”
Wait. You mean… You Can. Turn. That. Mode. OFF!!!???!! 🙀
Jealous…Showoff. 😖## Mohammed El-Afifi
An excellent article with clear-cut explanation. An enjoyable dive into some TCP options. My only wish would be to split the article so that every option might have its own article.
## Bruno
Really great article ! You could have cut it in pieces to make a series.
Why not add the “Protection Against Wrapped Sequences (PAWS)” to the article now?
Also the multiple “if …” in “Selective Acknowledgments” chapter are a bit confusing, I had to re-read to get it.
Overall excellent job, useful way beyond Fedora |
12,712 | Drawing:一款开源的类似微软画图的 Linux 桌面应用 | https://itsfoss.com/drawing-app/ | 2020-10-12T23:18:05 | [
"画图"
] | https://linux.cn/article-12712-1.html | 
>
> Drawing 是一个基本的图像编辑器,就像微软画图一样。有了这个开源的应用,你可以画箭头、线条、几何图形、添加颜色和其他你期望在普通绘图应用程序中做的事情。
>
>
>
### Drawing: 一个简单的 Linux 绘图应用

对于从 Windows XP (或更早版本)开始使用电脑的人来说,微软<ruby> 画图 <rt> Paint </rt></ruby>是一个有趣的应用,是个可以随便画一些草图的应用。在这个被 Photoshop 和 GIMP 主导的世界里,画图应用仍然具有一定的现实意义。
有几个[可用于 Linux 的绘画应用](https://itsfoss.com/open-source-paint-apps/),我打算在这个列表中再添加一个。
这款应用不出意外地叫做 [Drawing](https://maoschanz.github.io/drawing/),你可以在 Linux 桌面和 Linux 智能手机上使用它。
### Drawing 应用的功能

Drawing 拥有你所期待的绘图应用的所有功能。你可以:
* 从头开始创建新的绘图
* 编辑现有的 PNG、JPEG 或 BMP 图像文件
* 添加几何图形、线条、箭头等
* 虚线
* 使用铅笔工具进行自由手绘
* 使用曲线和形状工具
* 裁剪图像
* 缩放图像到不同的像素大小
* 添加文本
* 选择图像的一部分(矩形、自由选择和颜色选择)
* 旋转图像
* 添加复制到剪贴板的图像
* 可在偏好中使用橡皮擦、荧光笔、油漆桶、颜色选择、颜色选择器工具
* 无限撤销
* 滤镜可以增加模糊、像素化、透明度等
### 我使用 Drawing 的经验

这个应用是新出现的,并且有不错的用户界面。它具有你期望在标准的绘画应用中找到的所有基本功能。
它有一些额外的工具,如颜色选择和拾色器,但在使用时可能会混淆。没有什么文档描述这些工具的使用,要全靠你自己摸索。
它的体验很流畅,作为图像编辑工具,我觉得这个工具很有潜力取代 Shutter (是的,我[用 Shutter 编辑截图](https://itsfoss.com/install-shutter-ubuntu/))。
我觉得最麻烦的是,添加元素后无法编辑/修改。你有撤消和重做选项,但如果你想修改一个你在 12 步前添加的文本,你就必须重做所有的步骤。这是未来的版本中开发者可能要做的一些改进。
### 在 Linux 上安装 Drawing
这是一款 Linux 专属应用。它也适用于基于 Linux 的智能手机,如 [PinePhone](https://itsfoss.com/pinephone/)。
有多种方式可以安装 Drawing。它在许多主要的 Linux 发行版的仓库中都有。
#### 基于 Ubuntu 的发行版
Drawing 包含在 Ubuntu 的 universe 仓库中,这意味着你可以从 Ubuntu 软件中心安装它。
但是,如果你想要最新的版本,有一个 [PPA](https://launchpad.net/~cartes/+archive/ubuntu/drawing) 可以轻松地在 Ubuntu、Linux Mint 和其他基于 Ubuntu 的发行版上安装 Drawing。
使用下面的命令:
```
sudo add-apt-repository ppa:cartes/drawing
sudo apt update
sudo apt install drawing
```
如果你想删除它,你可以使用以下命令:
```
sudo apt remove drawing
sudo add-apt-repository -r ppa:cartes/drawing
```
#### 其他 Linux 发行版
检查你的发行版的包管理器中是否有 Drawing,然后在那里安装。如果你想要最新的版本,你可以使用 Flatpak 版本的应用。
* [Drawing Flatpak](https://flathub.org/apps/details/com.github.maoschanz.drawing)
### 总结
你还在用画图应用么?你用的是哪一款?如果你已经尝试过 Drawing,你的体验如何?
---
via: <https://itsfoss.com/drawing-app/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

For people introduced to computers with Windows XP (or earlier version), MS Paint was an amusing application from sketching random stuff. In a world dominated with Photoshop and GIMP, the paint applications still hold some relevance.
There are several [painting applications available for Linux](https://itsfoss.com/open-source-paint-apps/), and I am going to add one more to this list.
The app is unsurprisingly called [Drawing](https://maoschanz.github.io/drawing/?ref=itsfoss.com) and you can use it on both Linux desktop and Linux smartphones.
## Features of Drawing app

Drawing has all the features you expect from a drawing application. You can
- Create new drawings from scratch
- Edit an existing image in PNG, JPEG or BMP file
- Add geometrical shapes, lines, arrows etc
- Dashed
- Use pencil tool for free-hand drawing
- Use curve and shape tool
- Crop image canvas (not the image itself)
- Scale images to different pixel size
- Add text
- Select part of image (rectangle, freehand and color selection)
- Rotate images
- Add images copied to clipboard
- Eraser, Highlighter, Paint, Color Selection, Color Picker tools are available in preferences
- Unlimited undo
- Filters to add blur, pixelisation, transparency etc
## My experience with Drawing
The application is new and has a decent user interface. It comes with the basic features you expect to find in a standard paint app.
It has some additional tools like color selection and color picker but it might be confusing to use them. There is no documentation available to describe the use of these tools to you are on your own here.
The crop tool is misleading because it just resizes the image to a smaller scale. There is also a separate scale tool to increase the canvas size and this is why crop makes no sense here.
The experience is smooth and I feel that this tool has good potential to replace Shutter as image editing tool (yes, I [use Shutter for editing screenshots](https://itsfoss.com/install-shutter-ubuntu/)) if it could improve a few things.
The thing that I find most bothersome is that it is not possible to edit/modify an element after adding it. You have the undo and redo options but if you want to modify a text you added 12 steps back, you’ll have to redo all the steps. This is something the developer may look into it in the future releases.
## Installing Drawing on Linux
This is a Linux exclusive app. It is also available for Linux-based smartphones like [PinePhone](https://itsfoss.com/pinephone/).
There are various ways you can install Drawing app. It is available in the repositories of many major Linux distributions.
### Ubuntu-based distributions
Drawing is included in the universe repository in Ubuntu. Which means you can install it from the Ubuntu Software Center.
However, if you want the latest version, there is a [PPA available](https://launchpad.net/~cartes/+archive/ubuntu/drawing?ref=itsfoss.com) for easily installing Drawing on Ubuntu. Linux Mint and other Ubuntu-based distributions.
Use the following command:
```
sudo add-apt-repository ppa:cartes/drawing
sudo apt update
sudo apt install drawing
```
If you want to remove it, you can use the following commands:
```
sudo apt remove drawing
sudo add-apt-repository -r ppa:cartes/drawing
```
### Other Linux distributions
Check your distribution’s package manager for Drawing and install it from there. If you want the latest version, you may use the Flatpak version of the app.
**Conclusion**
Do you still use a paint application? Which one do you use? If you have tried Drawing app already, how is your experience with it? |
12,713 | Linux 黑话解释:什么是包管理器?它是如何工作的? | https://itsfoss.com/package-manager/ | 2020-10-13T09:49:18 | [
"包管理器"
] | https://linux.cn/article-12713-1.html | 
[Linux 发行版之间有什么不同](https://itsfoss.com/what-is-linux/)的要点之一是包管理。在这篇 Linux 黑话解释中,你将了解 Linux 中的打包和包管理器。你将了解什么是包,什么是包管理器,它们是如何工作的,以及有什么包管理器。
### 什么是包管理器?
简单来说,“<ruby> 包管理器 <rt> package manager </rt></ruby>”(或“软件包管理器”)是一种工具,它允许用户在操作系统上安装、删除、升级、配置和管理软件包。软件包管理器可以是像“软件中心”这样的图形化应用,也可以是像 [apt-get](https://itsfoss.com/apt-vs-apt-get-difference/) 或 [pacman](https://itsfoss.com/pacman-command/) 这样的命令行工具。
你会发现我经常在教程和文章中使用“包”这个词。要了解包管理器,你必须了解什么是包。
### 什么是包?
一个“<ruby> 包 <rt> package </rt></ruby>”(或“软件包”)通常指的是一个应用程序,它可以是一个 GUI 应用程序、命令行工具或(其他软件程序需要的)软件库。包本质上是一个存档文件,包含二进制可执行文件、配置文件,有时还包含依赖关系的信息。
在旧时代,[软件曾经是从它的源代码安装的](https://itsfoss.com/install-software-from-source-code/)。你会参考一个文件(通常命名为 `README`),看看它需要什么软件组件、二进制文件的位置。它通常包括一个配置脚本或 `Makefile`。你必须自己编译该软件或自己处理所有的依赖关系(有些软件需要安装其他软件)。
为了摆脱这种复杂性,Linux 发行版创建了自己的打包格式,为终端用户提供随时可用的二进制文件(预编译软件),以便安装软件,同时提供一些[元数据](https://www.computerhope.com/jargon/m/metadata.htm)(版本号、描述)和依赖关系。
这就像烤蛋糕与买蛋糕一样。

大约在上世纪 90 年代中期,Debian 创建了 DEB 打包格式(`.deb`),Red Hat Linux 创建了 RPM(Red Hat Package Manager 的缩写)打包系统(`.rpm`)。编译源代码的方式仍然存在,但现在是可选的。
要与打包系统交互或使用打包系统,你需要一个包管理器。
### 包管理器是如何工作的?
请记住,包管理器是一个通用的概念,它并不是 Linux 独有的。你会经常发现各种软件或编程语言的包管理器。有[只是针对 Python 包的 PIP 包管理器](https://itsfoss.com/install-pip-ubuntu/)。甚至 [Atom 编辑器也有自己的包管理器](https://itsfoss.com/install-packages-in-atom/)。
由于本文的重点是 Linux,所以我会从 Linux 的角度出发。不过,这里的大部分解释也可以应用于一般的包管理器。
我创建了这个图(基于 SUSE Wiki),这样你就可以很容易理解包管理器是如何工作的。

几乎所有的 Linux 发行版都有“<ruby> 软件仓库 <rt> software repository </rt></ruby>”,它基本上是软件包的集合。是的,可以有不止一个软件库。软件库包含不同种类的软件包。
软件仓库也有元数据文件,其中包含了软件包的信息,如软件包的名称、版本号、软件包的描述和软件仓库名称等。这就是你在 Ubuntu/Debian 中使用 [apt show 命令](https://itsfoss.com/apt-search-command/)所看到的。
你的系统上的包管理器首先会与元数据进行交互。包管理器在你的系统上创建了一个元数据的本地缓存。当你运行包管理器的更新选项(例如 `apt update`)时,它会通过引用仓库中的元数据来更新本地元数据缓存。
当你运行软件包管理器的安装命令(例如 `apt install package_name`)时,软件包管理器会引用这个缓存。如果它在缓存中找到了包的信息,它就会使用互联网连接到相应的仓库,并在你的系统上安装之前先下载包。
一个包可能有依赖关系。意思是说,它可能需要安装其他软件包。软件包管理器通常会处理这些依赖关系,并将其与你正在安装的软件包一起自动安装。

同样,当你使用包管理器删除一个包时,它要么自动删除,要么通知你系统有未使用的包可以清理。
除了安装、删除这些显而易见的任务外,你还可以使用包管理器对包进行配置,并根据自己的需要进行管理。例如,你可以在常规的系统更新中[防止升级某个包的版本](https://itsfoss.com/prevent-package-update-ubuntu/)。你的包管理器可能还能做很多事情。
### 不同种类的包管理器
包管理器因打包系统而异,但同一打包系统却可能有多个包管理器。
例如,RPM 有 [Yum](https://fedoraproject.org/wiki/Yum) 和 [DNF](https://fedoraproject.org/wiki/DNF) 包管理器。对于 DEB,你有 `apt-get`、[aptitude](https://wiki.debian.org/Aptitude) 等基于命令行的包管理器。

软件包管理器不一定是基于命令行的,也有图形化的软件包管理工具,比如 [Synaptic](https://itsfoss.com/synaptic-package-manager/)。你的发行版的“软件中心”也是一个软件包管理器,即使它在底层运行的是 `apt-get` 或 DNF。
### 结论
我不想进一步详细介绍这个话题,虽然我可以继续说下去,但这将偏离本主题的目标 —— 即让你对 Linux 中的包管理器有一个基本的了解。
我暂时忽略了新的通用打包格式,比如 Snap 和 Flatpak。
我希望你对 Linux 中的包管理系统有更好的理解。如果你还有困惑,或者你对这个主题有一些问题,请发表评论。我会尽量回答你的问题,如果需要的话,我会在本文中更新新的内容。
---
via: <https://itsfoss.com/package-manager/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

One of the main points [how Linux distributions differ from each other](https://itsfoss.com/what-is-linux/) is the package management. In this part of the Linux jargon buster series, you’ll learn about packaging and package managers in Linux. You’ll learn what are packages, what are package managers and how do they work and what kind of package managers available.
## What is a package manager in Linux?
In simpler words, a package manager is a tool that allows users to install, remove, upgrade, configure and manage software packages on an operating system. The package manager can be a graphical application like a software center or a command line tool like [apt-get](https://itsfoss.com/apt-vs-apt-get-difference/) or [pacman](https://itsfoss.com/pacman-command/).
You’ll often find me using the term ‘package’ in tutorials and articles on It’s FOSS. To understand package manager, you must understand what a package is.
## What is a package?
A package is usually referred to an application but it could be a GUI application, command line tool or a software library (required by other software programs). A package is essentially an archive file containing the binary executable, configuration file and sometimes information about the dependencies.
In older days, [software used to installed from its source code](https://itsfoss.com/install-software-from-source-code/). You would refer to a file (usually named readme) and see what software components it needs, location of binaries. A configure script or makefile is often included. You will have to compile the software or on your own along with handling all the dependencies (some software require installation of other software) on your own.
To get rid of this complexity, Linux distributions created their own packaging format to provide the end users ready-to-use binary files (precompiled software) for installing software along with some [metadata](https://www.computerhope.com/jargon/m/metadata.htm?ref=itsfoss.com) (version number, description) and dependencies.
It is like baking a cake versus buying a cake.

Around mid 90s, Debian created .deb or DEB packaging format and Red Hat Linux created .rpm or RPM (short for Red Hat Package Manager) packaging system. Compiling source code still exists but it is optional now.
To interact with or use the packaging systems, you need a package manager.
## How does the package manager work?
Please keep in mind that package manager is a generic concept and it’s not exclusive to Linux. You’ll often find package manager for different software or programming languages. There is [PIP package manager just for Python packages](https://itsfoss.com/install-pip-ubuntu/). Even [Atom editor has its own package manager](https://itsfoss.com/install-packages-in-atom/).
Since the focus in this article is on Linux, I’ll take things from Linux’s perspective. However, most of the explanation here could be applied to package manager in general as well.
I have created this diagram (based on SUSE Wiki) so that you can easily understand how a package manager works.
Almost all Linux distributions have software repositories which is basically collection of software packages. Yes, there could be more than one repository. The repositories contain software packages of different kind.
Repositories also have metadata files that contain information about the packages such as the name of the package, version number, description of package and the repository name etc. This is what you see if you use the [apt show command](https://itsfoss.com/apt-search-command/) in Ubuntu/Debian.
Your system’s package manager first interacts with the metadata. The package manager creates a local cache of metadata on your system. When you run the update option of the package manager (for example apt update), it updates this local cache of metadata by referring to metadata from the repository.
When you run the installation command of your package manager (for example apt install package_name), the package manager refers to this cache. If it finds the package information in the cache, it uses the internet connection to connect to the appropriate repository and downloads the package first before installing on your system.
A package may have dependencies. Meaning that it may require other packages to be installed. The package manager often takes care of the dependencies and installs it automatically along with the package you are installing.
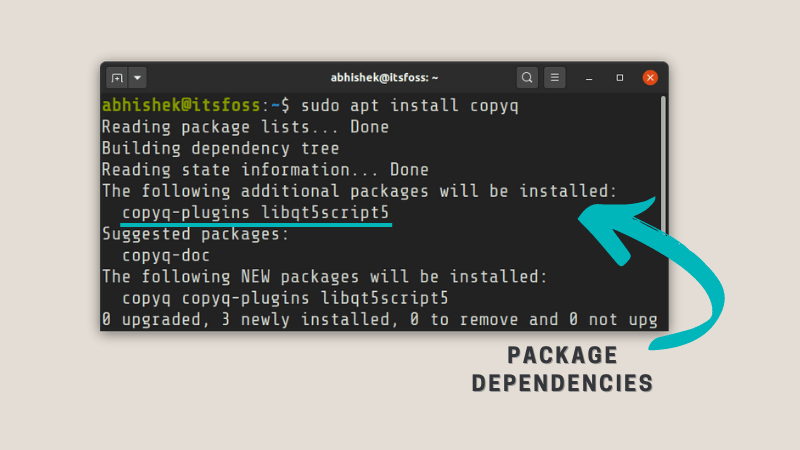
Similarly, when you remove a package using the package manager, it either automatically removes or informs you that your system has unused packages that can be cleaned.
Apart from the obvious tasks of installing, removing, you can use the package manager to configure the packages and manage them as per your need. For example, you can [prevent the upgrade of a package version](https://itsfoss.com/prevent-package-update-ubuntu/) from the regular system updates. There are many more things your package manager might be capable of.
## Different kinds of package managers
Package Managers differ based on packaging system but same packaging system may have more than one package manager.
For example, RPM has [Yum](https://fedoraproject.org/wiki/Yum?ref=itsfoss.com) and [DNF](https://fedoraproject.org/wiki/DNF?ref=itsfoss.com) package managers. For DEB, you have apt-get, [aptitude](https://wiki.debian.org/Aptitude?ref=itsfoss.com) command line based package managers.
Package managers are not necessarily command line based. You have graphical package managing tools like [Synaptic](https://itsfoss.com/synaptic-package-manager/). Your distribution’s software center is also a package manager even if it runs apt-get or DNF underneath.
## Conclusion
I don’t want to go in further detail on this topic because I can go on and on. But it will deviate from the objective of the topic which is to give you a basic understanding of package manager in Linux.
I have omitted the new universal packaging formats like Snap and Flatpak for now.
I do hope that you have a bit better understanding of the package management system in Linux. If you are still confused or if you have some questions on this topic, please use the comment system. I’ll try to answer your questions and if required, update this article with new points. |
12,715 | 在脚本中使用 Bash 信号捕获 | https://opensource.com/article/20/6/bash-trap | 2020-10-13T18:22:31 | [
"信号",
"脚本"
] | https://linux.cn/article-12715-1.html |
>
> 无论你的脚本是否成功运行,<ruby> 信号捕获 <rt> trap </rt></ruby>都能让它平稳结束。
>
>
>

Shell 脚本的启动并不难被检测到,但 Shell 脚本的终止检测却并不容易,因为我们无法确定脚本会按照预期地正常结束,还是由于意外的错误导致失败。当脚本执行失败时,将正在处理的内容记录下来是非常有用的做法,但有时候这样做起来并不方便。而 [Bash](https://opensource.com/resources/what-bash) 中 `trap` 命令的存在正是为了解决这个问题,它可以捕获到脚本的终止信号,并以某种预设的方式作出应对。
### 响应失败
如果出现了一个错误,可能导致发生一连串错误。下面示例脚本中,首先在 `/tmp` 中创建一个临时目录,这样可以在临时目录中执行解包、文件处理等操作,然后再以另一种压缩格式进行打包:
```
#!/usr/bin/env bash
CWD=`pwd`
TMP=${TMP:-/tmp/tmpdir}
## create tmp dir
mkdir "${TMP}"
## extract files to tmp
tar xf "${1}" --directory "${TMP}"
## move to tmpdir and run commands
pushd "${TMP}"
for IMG in *.jpg; do
mogrify -verbose -flip -flop "${IMG}"
done
tar --create --file "${1%.*}".tar *.jpg
## move back to origin
popd
## bundle with bzip2
bzip2 --compress "${TMP}"/"${1%.*}".tar \
--stdout > "${1%.*}".tbz
## clean up
/usr/bin/rm -r /tmp/tmpdir
```
一般情况下,这个脚本都可以按照预期执行。但如果归档文件中的文件是 PNG 文件而不是期望的 JPEG 文件,脚本就会在中途失败,这时候另一个问题就出现了:最后一步删除临时目录的操作没有被正常执行。如果你手动把临时目录删掉,倒是不会造成什么影响,但是如果没有手动把临时目录删掉,在下一次执行这个脚本的时候,它必须处理一个现有的临时目录,里面充满了不可预知的剩余文件。
其中一个解决方案是在脚本开头增加一个预防性删除逻辑用来处理这种情况。但这种做法显得有些暴力,而我们更应该从结构上解决这个问题。使用 `trap` 是一个优雅的方法。
### 使用 trap 捕获信号
我们可以通过 `trap` 捕捉程序运行时的信号。如果你使用过 `kill` 或者 `killall` 命令,那你就已经使用过名为 `SIGTERM` 的信号了。除此以外,还可以执行 `trap -l` 或 `trap --list` 命令列出其它更多的信号:
```
$ trap --list
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
```
可以被 `trap` 识别的信号除了以上这些,还包括:
* `EXIT`:进程退出时发出的信号
* `ERR`:进程以非 0 状态码退出时发出的信号
* `DEBUG`:表示调试模式的布尔值
如果要在 Bash 中实现信号捕获,只需要在 `trap` 后加上需要执行的命令,再加上需要捕获的信号列表就可以了。
例如,下面的这行语句可以捕获到在进程运行时用户按下 `Ctrl + C` 组合键发出的 `SIGINT` 信号:
```
trap "{ echo 'Terminated with Ctrl+C'; }" SIGINT
```
因此,上文中脚本的缺陷可以通过使用 `trap` 捕获 `SIGINT`、`SIGTERM`、进程错误退出、进程正常退出等信号,并正确处理临时目录的方式来修复:
```
#!/usr/bin/env bash
CWD=`pwd`
TMP=${TMP:-/tmp/tmpdir}
trap \
"{ /usr/bin/rm -r "${TMP}" ; exit 255; }" \
SIGINT SIGTERM ERR EXIT
## create tmp dir
mkdir "${TMP}"
tar xf "${1}" --directory "${TMP}"
## move to tmp and run commands
pushd "${TMP}"
for IMG in *.jpg; do
mogrify -verbose -flip -flop "${IMG}"
done
tar --create --file "${1%.*}".tar *.jpg
## move back to origin
popd
## zip tar
bzip2 --compress $TMP/"${1%.*}".tar \
--stdout > "${1%.*}".tbz
```
对于更复杂的功能,还可以用 [Bash 函数](https://opensource.com/article/20/6/how-write-functions-bash)来简化 `trap` 语句。
### Bash 中的信号捕获
信号捕获可以让脚本在无论是否成功执行所有任务的情况下都能够正确完成清理工作,能让你的脚本更加可靠,这是一个很好的习惯。尽管尝试把信号捕获加入到你的脚本里看看能够起到什么作用吧。
---
via: <https://opensource.com/article/20/6/bash-trap>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's easy to detect when a shell script starts, but it's not always easy to know when it stops. A script might end normally, just as its author intends it to end, but it could also fail due to an unexpected fatal error. Sometimes it's beneficial to preserve the remnants of whatever was in progress when a script failed, and other times it's inconvenient. Either way, detecting the end of a script and reacting to it in some pre-calculated manner is why the [Bash](https://opensource.com/resources/what-bash) `trap`
directive exists.
## Responding to failure
Here's an example of how one failure in a script can lead to future failures. Say you have written a program that creates a temporary directory in `/tmp`
so that it can unarchive and process files before bundling them back together in a different format:
```
#!/usr/bin/env bash
CWD=`pwd`
TMP=${TMP:-/tmp/tmpdir}
## create tmp dir
mkdir "${TMP}"
## extract files to tmp
tar xf "${1}" --directory "${TMP}"
## move to tmpdir and run commands
pushd "${TMP}"
for IMG in *.jpg; do
mogrify -verbose -flip -flop "${IMG}"
done
tar --create --file "${1%.*}".tar *.jpg
## move back to origin
popd
## bundle with bzip2
bzip2 --compress "${TMP}"/"${1%.*}".tar \
--stdout > "${1%.*}".tbz
## clean up
/usr/bin/rm -r /tmp/tmpdir
```
Most of the time, the script works as expected. However, if you accidentally run it on an archive filled with PNG files instead of the expected JPEG files, it fails halfway through. One failure leads to another, and eventually, the script exits without reaching its final directive to remove the temporary directory. As long as you manually remove the directory, you can recover quickly, but if you aren't around to do that, then the next time the script runs, it has to deal with an existing temporary directory full of unpredictable leftover files.
One way to combat this is to reverse and double-up on the logic by adding a precautionary removal to the start of the script. While valid, that relies on brute force instead of structure. A more elegant solution is `trap`
.
## Catching signals with trap
The `trap`
keyword catches *signals* that may happen during execution. You've used one of these signals if you've ever used the `kill`
or `killall`
commands, which call `SIGTERM`
by default. There are many other signals that shells respond to, and you can see most of them with `trap -l `
(as in "list"):
```
$ trap --list
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
```
Any of these signals may be anticipated with `trap`
. In addition to these, `trap`
recognizes:
`EXIT`
: Occurs when the shell process itself exits`ERR`
: Occurs when a command (such as**tar**or**mkdir**) or a built-in command (such as**pushd**or**cd**) completes with a non-zero status`DEBUG`
: A Boolean representing debug mode
To set a trap in Bash, use `trap`
followed by a list of commands you want to be executed, followed by a list of signals to trigger it.
For instance, this trap detects a `SIGINT`
, the signal sent when a user presses **Ctrl+C** while a process is running:
`trap "{ echo 'Terminated with Ctrl+C'; }" SIGINT`
The example script with temporary directory problems can be fixed with a trap detecting `SIGINT`
, errors, and successful exits:
```
#!/usr/bin/env bash
CWD=`pwd`
TMP=${TMP:-/tmp/tmpdir}
trap \
"{ /usr/bin/rm -r "${TMP}" ; exit 255; }" \
SIGINT SIGTERM ERR EXIT
## create tmp dir
mkdir "${TMP}"
tar xf "${1}" --directory "${TMP}"
## move to tmp and run commands
pushd "${TMP}"
for IMG in *.jpg; do
mogrify -verbose -flip -flop "${IMG}"
done
tar --create --file "${1%.*}".tar *.jpg
## move back to origin
popd
## zip tar
bzip2 --compress $TMP/"${1%.*}".tar \
--stdout > "${1%.*}".tbz
```
For complex actions, you can simplify `trap`
statements with [Bash functions](https://opensource.com/article/20/6/how-write-functions-bash).
## Traps in Bash
Traps are useful to ensure that your scripts end cleanly, whether they run successfully or not. It's never safe to rely completely on automated garbage collection, so this is a good habit to get into in general. Try using them in your scripts, and see what they can do!
## 13 Comments |
12,717 | 《代码英雄》第二季(7):无服务器 | https://www.redhat.com/en/command-line-heroes/season-2/at-your-serverless | 2020-10-14T12:09:06 | [
"代码英雄"
] | https://linux.cn/article-12717-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(7):无服务器](https://www.redhat.com/en/command-line-heroes/season-2/at-your-serverless)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/aebc2c45.mp3)脚本。
>
> 导语:<ruby> 无服务器Serverless</ruby>到底意味着什么?当然,总得有服务器存在 —— 构建网络的基本架构不会改变。不过在将服务器交给一小部分人运维之后,开发者们会发生什么变化呢?
>
>
> 无服务器编程让初学者们可以更加轻松简单地部署自己的应用程序,让工作更有效率,这是它的优点。Andrea Passwater 跟我们分享了抽象底层架构会给我们带来多大的便利。不过凡事必有代价,无服务器化也有很多问题。Rodric Rabbah 解释了无服务器意味着你将部署和回应问题的能力拱手献出 —— 这就是为什么他帮助创建了 Apache OpenWhisk,这是一个开源的无服务环境框架,同时 Himanshu Pant 也来分享了他对于何时应该使用无服务器服务的观点。
>
>
> 无服务器编程应该是为开发者们<ruby> 赋能授权 <rt> empowerment </rt></ruby>的。我们也应该对于全局场景保持关注 —— 尽管我们精简了我们的工具箱。
>
>
>
>
> **00:00:03 - Al Gore 档案**:
>
>
> 现如今,当然了,在全美乃至全世界,互联网正在彻头彻尾地改变着我们的生活。
>
>
>
**00:00:13 - Saron Yitbarek**:
那是 1998 年。 Google 才刚刚雇佣了它的第一名员工,副总统 Al Gore 在接受媒体采访。
>
> **00:00:22 - Al Gore 档案**:
>
>
> 这项技术还处于起步阶段。当我和<ruby> 比尔·克林顿 <rt> Bill Clinton </rt></ruby>总统入主白宫时,只有 50 个网站。现在看看,我在生日那天收到了一束虚拟鲜花。
>
>
>
**00:00:37 - Saron Yitbarek**:
好的。我已经感觉到你的眉毛皱起了。为什么我要向你展现某些 20 年前的互联网史?这是因为我想要提醒你,互联网的基础仍然是相同的。
**00:00:51**:
当然,现在有不止 50 个站点了,我知道。但是,我们仍然在发送虚拟鲜花。从开发人员的角度来看,如果你将我们所有的惊人进步剥离开来,你得到的仍然是相同的“<ruby> 客户端 - 服务器 <rt> client-server </rt></ruby>”(C/S)模型,这就是一切的开始。一个提供了分布式网络的客户端 - 服务器模型。
**00:01:16**:
如今,开发人员谈论了很多有关<ruby> 无服务器 <rt> Serverless </rt></ruby>的问题,这听起来像是 Al Gore 谈到的客户端 - 服务器模型被废弃了。而且,如果我们不小心,我们能够抽象出太多的基础架构,以至于忘记了仍然有服务器在那里做着它们的工作。
**00:01:37**:
但是,无服务器真的意味着没有服务器吗?真的吗?还是开发人员与服务器之间的关系正在变化?在这一集中,我们将与来自世界各地的人们交谈,以探索这种被称为“<ruby> 无服务器 <rt> serverless </rt></ruby>”的东西。
**00:01:54**:
我是 Saron Yitbarek,这里是《代码英雄》,一档来自红帽的原创播客节目。
**00:02:03 - Andrea Passwater**:
你知道无线网络在某些地方还有线缆吗?
**00:02:06 - Saron Yitbarek**:
Andrea Passwater 在一家名为 …… 嗯…… “无服务器” 的公司工作。他们创建了一款流行的开源框架来开发无服务器应用程序。Andrea 注意到了各个组织是多么渴望抽象化基础架构的方法,而这正是神奇的“无服务器”一词始终给予人希望的地方。
**00:02:28 - Andrea Passwater**:
我认为这一术语主要是为了传达这样一个事实,即如果你是从事无服务器应用方面工作的开发人员,你不必考虑那些服务器。你只需要写代码并将代码部署到云提供商即可,而不必担心管理。这就是无服务器的真正含义。
**00:02:49 - Saron Yitbarek**:
对于 Andrea 来说,无服务器的吸引力很明显。
**00:02:53 - Andrea Passwater**:
倘若你以无服务器的方式开发应用程序,则可以不必去考虑部署和维护该应用程序的日常工作。这意味着你可以专注于它的商业价值,你可以专注于发挥创造力。
**00:03:12 - Saron Yitbarek**:
而无服务器的另一大好处是,你不太可能发现自己在重复造轮子。
**00:03:18 - Andrea Passwater**:
当有像 Auth0 这样可以直接使用的服务存在时,为什么要创建自己的身份验证方法呢?归根结底,无服务器就是为开发人员提供机会,使得他们能够更加轻松快速地构建起能把他们脑子里的所有的主意带到世界上的程序。
**00:03:41 - Saron Yitbarek**:
我明白了!
**00:02:27**:
想象一下,你拿了满手的东西,正跌跌撞撞地走向一扇门。这扇门滑开了,以简单、友好……
**00:03:50**:
(让我来说)
**00:03:51**:
……的方式。这就是无服务器。它为你打开了大门,使得开发工作不再那么繁琐。事实上,随着各个组织趋向于混合云环境,以及无服务器运动的发展,开发的障碍正在消失。
**00:04:09**:
Andrea 听说过很多有关非开发人员进行开发的话题。
**00:04:15 - Andrea Passwater**:
这是传统上认为自己写不了代码,而现如今由于无服务器而得以投身于软件工程的人的故事,并且能够开发这些使得他们自己的工作流程和类似的东西自动化的工具。这与你你做什么工作都没关系。
**00:04:31**:
你在工作中要做的一些事情是如此的呆板无聊,比如你每天都在做的例行事情,和那些你会想“难道计算机不能为我做这件事吗?”的事情。我开始有了这种感觉的时候,我碰巧在一家名为“无服务器”的公司工作,他们像这样:“你意识到我们制作的产品可以为你提供帮助,对吗?”
**00:04:50 - Saron Yitbarek**:
Andrea 认为,不久之后,许多从未将自己视为开发人员的人将意识到他们能够自己构建简单的应用程序,基本上免费。
**00:05:02 - Andrea Passwater**:
借助 Lambda,我从不需要为自己制作的任何小型应用程序付费。我可以让这些机器人为我做一部分工作,是的,我可以提高工作效率。但是,我也不必再做这些无聊的工作了。我可以做些更有趣的事情。
**00:05:17 - Saron Yitbarek**:
即使是对于专业开发人员来说,这种自动门效果在满手杂物的世界里也是很诱人的。
**00:05:25 - Andrea Passwater**:
我认为人们对于能够让一两个人的团队,在短时间内就让原型工作起来很感兴趣。在几天时间内,他们就可以启动并运行原型。我认为这使得人们开始意识到,他们可以专注于驱动他们的应用、产品和公司中的商业价值的部分。这非常让人兴奋,他们可以专注于商业价值。
**00:05:54 - Saron Yitbarek**:
我要再抛出一个术语给你。准备好了吗?<ruby> 功能即服务 <rt> Functions-as-a-service </rt></ruby>(FaaS)。就像是 AWS Lambda 或 Apache OpenWhisk 之类的无服务器产品。“功能即服务”意味着,只有在被触发时程序才会执行某个功能,这效率更高。
**00:06:15**:
此外,这让我对计算能力和运行时间的担心少了很多。最终,无服务器可能会成为一个相当不错的基础配置。事实上,有些人甚至开始怀疑,我们是否要完全使用无服务器?它可以替代容器吗?
**00:06:34 - Michael Hausenblas**:
我理解这这种想法。
**00:06:35 - Saron Yitbarek**:
Michael Hausenblas 是 Red Hat OpenShift 团队的开发倡导者。
**00:06:41 - Michael Hausenblas**:
如果你看一下我们现在拥有的这些东西,包括 OpenShift 和 Cloud Foundry 和一些其他东西,你实质上就拥有了抽象化。基本上,Heroku 或多或少地倾向于向这个想法。对吗?这是非常简单的方式,无需担心程序会如何运行,无需担心它是什么样的。只需要给我们代码,我们来处理剩下的工作。
**00:07:03 - Saron Yitbarek**:
是的。听起来相当不错。这听起来有点儿像是梦想中的“<ruby> 无运维 <rt> no-ops </rt></ruby>”环境,一切都自动化并且抽象化了,就像是开发者版本的极简主义室内设计。很棒、很干净的界面。
**00:07:21**:
但是, Michael 想要让你了解你一些现实情况。
**00:07:25 - Michael Hausenblas**:
没有运维!是吗?你知道,它只是神奇地以某种方式消失。你可以在 HackerNews 和 Twitter 以及其他任何地方看到这些笑话。无服务器?当然有服务器!我知道,当然有。而且也肯定有运维。
**00:07:39**:
总得有人去做这些,总得有人去架设服务器、给操作系统打补丁、去创建容器镜像,因为,你猜猜这些功能会在哪里执行?当然是在某种计算机上。
**00:07:54 - Saron Yitbarek**:
这不是零和博弈。功能即服务无法直接取代容器,而是在工具箱中增加了一个工具。我还有更多的事情要告诉你。通过使用这种新工具,转变成无服务器并不只是意味着运维就是其他人的事情,你仍然需要自己考虑自己的运维。
**00:08:14 - Michael Hausenblas**:
你会看到在基础架构侧有一点运维工作。但是,也有一点是开发人员的事情。如果你处在一个极端情况之下,比如说使用 Lambda,那么你是没有任何任何类型的管理员权限的,对吧?
**00:08:29**:
你不能简单地致电或是短信给一名基础架构管理员。显然,你组织之中的某一个人就必须得做这件事。但是,我担心许多组织只看到了它是如此简单而便宜。我们无需动这个,还有这个、这个,然后忘记了谁在待命,谁是真正地在待命?你对此有什么策略吗?
**00:08:52**:
如果没有的话,那么你可能会想要在进行之前,先制定一个策略。
**00:09:00 - Saron Yitbarek**:
需要有人处于待命状态。即使选择了“无服务器”,你仍然需要在头脑中萦绕更大的场景,你仍然需要让你的运维有序进行。
**00:09:24**:
在我早先时候抛出那个“功能即服务”术语时,你是不是有过些许畏缩?过去,基于云的开发为我们带来了大量的 “xx 即服务”的术语。我们有基础架构即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)、数据即服务(DaaS)、数据库即服务(DBaaS) …… 等等。
**00:09:48**:
如果你难以理解它们的不同,那你并不孤单。这就是我们找来了 Himanshu Pant 的原因。他是位于印度德里的苏格兰皇家银行的技术主管。他花了多年时间来分析其中的差异。
**00:10:04 - Himanshu Pant**:
这些其他的计算范例在名称上和无服务器听起来是如此的相似,以至于人们往往会忘记,或者困惑于为什么没有将它们称之为无服务器,或者为什么这个被称为无服务器。
**00:10:20 - Saron Yitbarek**:
因此,无服务器与容器不同,无服务器也不是平台即服务。但是 Himanshu 希望将其明确一下。功能即服务能够提供什么?又不能提供什么?
**00:10:35**:
他与我们分享了两件轶事,有两次他弄清楚了什么时候该使用无服务器,什么时候应该放弃。第一次来自一个 24 小时黑客马拉松。 Himanshu 当时正试图开发一个聊天机器人。
**00:10:49 - Himanshu Pant**:
有各种各样的指标会影响它的选择。例如逻辑覆盖率、可能产生的成本以及可伸缩性。而我选择在无服务器环境下完成这项工作。
**00:11:04**:
当我在开发它的时候,我意识到成本是一个层面,而这确实是我所青睐的技能。因此,即使其他所有的参与者都有更好的……我想说的是,覆盖率,或者说是逻辑覆盖率。这里讲的是 NLP 语境或其场景。
**00:11:19**:
但是,就成本和可伸缩性而言,我是手操胜券的,因为借助无服务器,这完全取决于人们在该聊天机器人上所进行调用的次数,并相应的触发该功能。这是一个我十分乐意采用无服务器的用例,因为成本 —— 没有成本。以及更快的开发时间,而且老实说,当时还并不完全是生产规模级别的工作负载。
**00:11:45**:
我可以使用平台上的某些新兴工具。这对我而言是一次胜利。
**00:11:52 - Saron Yitbarek**:
很好。那时无服务器才有了意义。但是,在 Himanshu 目前供职的银行里,人们正在将他们的系统从旧版迁移到云端。而这提出了不同的目标。
**00:12:07 - Himanshu Pant**:
我们正在尝试查看哪些工作负载适用于哪些范例。比如 IaaS、BaaS、FaaS,这显然是属于企业领域的。你要看到这些方面,比如说第一,可靠的供应商难以寻找,以及第二,该技术应该得到广泛的验证。这对于像是银行业这样的规避风险的行业而言更是如此。
**00:12:30**:
这就是平台即服务(PaaS),但是仍然需要更好的证明、更好的功能,以及它们比传统工具更优越的地方。
**00:12:40 - Saron Yitbarek**:
Himanshu 正在研究自己的需求以及他自己的舒适区,并且研究哪些工作负载在哪种云计算规范中是有意义的。
**00:12:49 - Himanshu Pant**:
假设某个听众在一家贸易商店工作,他想构建某种东西,比如说一个入口。对于他或者她来说,无服务器可能并不是真正合适的选择,因为在那种在特定机器的应用程序中,延迟可能是不该出现的。
**00:13:05 - Saron Yitbarek**:
归根结底,这是一种有节制的做法,而不是将所有东西都丢进一个桶里。当我们思索哪一种基于云的架构是真正我们所想要做的工作时,还有一件事情需要考虑。所有这些抽象的东西,所有解放你双手的东西,最终如何改变的不仅仅是我们的工作方式,还改变了完成工作本身。
**00:13:31**:
抽象掉一部分工作负载可能意味着更少的自定义选项。想象一下你购买的一辆车。它能工作,它能开。但是接着想象一下你自己组装的一辆车,这辆车会按照你决定的方式工作。
**00:13:48 - Rania Khalaf**:
这是有代价的。
**00:13:50 - Saron Yitbarek**:
Rania Khalaf 是 IBM 研究部门的 AI 工程总监。
**00:13:56 - Rania Khalaf**:
在使用这些无服务器应用程序的过程中,你可能无法完全控制所有正在发生的事情。你无法控制全盘计划,或是程序何时何地运行。
**00:14:06 - Saron Yitbarek**:
这是一种权衡,对吗?当你使用无服务器时,细粒度控制可能会失误。
**00:14:13 - Rania Khalaf**:
它对于终端用户而言,抽象化了如此之多的东西,以至于你想要拥有更多的控制权、不同的规划、更多的检查与平衡、功能可以运行多长时间的不同值,等等等等。那么,如果你真的希望能够进入系统并修补,也许你可以创建你自己的部署环境。
**00:14:32 - Saron Yitbarek**:
不过,这将需要一些新东西,一类新的无服务器环境,开源社区已经在为自己打造了它。Rania 和她的 IBM 团队参与了该运动。
**00:14:44 - Rania Khalaf**:
我们首先研究是一种语言……它基本上是 JavaScript 的扩展,可以让你创建这些多线程交互服务的组合,以此作为起点,为你提供一种更加轻量级服务的方式。大约在同一时间,云和微服务以及平台即服务开始真正兴起。
**00:15:08**:
仅仅是将这两种趋势结合起来,就可以用可能来自于你,也可能来自其他人的许多小部件,构建更加高阶的功能。
**00:15:18 - Saron Yitbarek**:
Rania 和她的团队正在构建 Apache OpenWhisk,一款开源的功能平台。
**00:15:23 - Rania Khalaf**:
对于 OpenWhisk,我们从一开始就开源了。其中很大的原因是,为了让社区和我们一起参与进来。但是同时也是为了揭掉外包装,将控制权交给想要运行自己的无服务器计算环境的人们,以便他们能够根据自己的需求对其进行自定义,也许将它们置身于自己的控制之中,看看它实际上是如何运行的,以对其进行更好的控制。
**00:15:54**:
而且,我们还可以提供更加精细的控制,如果仅仅是普通服务,人们就不会有这种控制。
**00:16:03 - Saron Yitbarek**:
将控制权交还给想要运行自己的无服务器运行环境的人。这是下一阶段的无服务器。加入 OpenWhisk,你将获得像是 Fission 和 Gestalt 之类的其它开源平台。我们开始看到无服务器领域正在演变得比原先更具适应性,而且功能更为强大。
**00:16:31**:
为了真正了解为什么开源版的无服务器很重要,我与 OpenWhisk 的创始人之一进行了谈话。
**00:16:39**:
嗨,Rodric。最近好吗?
**00:16:40 - Rodric Rabbah**:
很好。你好吗?谢谢你邀请我参与节目。
**00:16:42 - Saron Yitbarek**:
Rodric Rabbah 是构思并创立 OpenWhisk 的三位开发者之一。以下是我们的谈话。
**00:16:54 - Rodric Rabbah**:
别人可能会很困惑,也可能会窃笑,因为人们可能会想:“倘若没有服务器,你要怎么做计算呢?”
**00:17:02 - Saron Yitbarek**:
是的。服务器就在某处,只是我不必去费心考虑它。
**00:17:05 - Rodric Rabbah**:
完全正确。这就是这个模式的真正美妙之处。当你开始以无服务器的方式进行开发时,你就再也不想回到过去了。你知道的,如今我已经置身其中接近 4 年了,并且已经开发了一些达到生产质量的应用程序。
**00:17:19**:
这是我如今惟一的开发方式。如果你告诉我必须要配置一台计算机并且安装操作系统,这对我而言完完全全是陌生的。我甚至都不确定我是不是还知道该怎么做。
**00:17:29 - Saron Yitbarek**:
是的。当你这样说的时候,听起来像是减轻了很大的负担。你知道吗?当最初听说无服务器时,至少我会想:“伙计,我必须要去学习的事又多了一件。”
**00:17:38**:
但是,当你这样说的时候,听起来不错。
**00:17:41 - Rodric Rabbah**:
这确实听起来很棒。然而,你应该已经意识到你必须要从这幻想的气泡中抽出一点儿空气。它不是万能药。
**00:17:50 - Saron Yitbarek**:
有哪些令人惊讶的风险或问题是人们在起步时可能没有看到或意识到的呢?
**00:17:58 - Rodric Rabbah**:
我认为缺乏透明度可能是最大的问题。这有点儿让我想起了新语言问世时出现的,那些提高了计算机抽象水平的技术。在当今的无服务器环境中,这是一种类似的令人震惊的效果。
**00:18:16**:
在这个过程中,你通常会写一个功能,然后只需部署这个功能即可。它可以立即运行,比如在 web 上作为 APIN 点。它可以大规模伸缩。我的意思是你无需自己做任何工作即可运行数千个实例。
**00:18:32**:
但是,倘若哪里出了问题,那应该如何调试呢?或者我实际上是想要检查我的功能失败的上下文环境。通常,这些功能在进程内运行,与你隔离 —— 你甚至无法登录计算机查看你的代码在何处运行。它们可能在封闭的容器环境之中运行,你不知道里面有什么。
**00:18:53**:
获得一点儿透明度对你而言变得很困难。这是工具最终将提供帮助的地方。但是,工具的缺乏某种程度上会让人们陷入一个相当大的陷阱。
**00:19:05 - Saron Yitbarek**:
这真的很好。那么让我们回到 OpenWhisk。请给我说说关于它的事情。
**00:19:11 - Rodric Rabbah**:
该项目在 Amazon Lambda 宣布推出产品的那一刻就开始了,这实际上是无服务器开始成为术语,并且开始在该领域获得关注的时刻。当我们看到 Lambda 时,我们开始思索:“这里有许多技术需要开发。不仅仅是在新的云计算的基础层上,而且在置于其上的编程模型之上,这实际上都使得它更易于被程序员访问。”你知道,由于出自 IBM 研究所,我们拥有相当强大的技术,不只是编程语言设计、编译器专业知识以及运行时的专业知识的技能。
**00:19:54**:
我们的一个小团队,基本上三个人……
**00:19:57 - Saron Yitbarek**:
哇。
**00:19:57 - Rodric Rabbah**
……聚集在一起,做了最初的开发和原型,最终成为 OpenWhisk,带有命令行工具,这是现如今无服务器实际上的编程接口。编程模型概念,然后是它必须支持的实际架构,本质上,是服务器模型的这个功能,提供了无服务器所支持的所有好处。
**00:20:22**:
请注意,真正的起源是 Amazon Lambda 的出现,并可以说这是一种新的计算模型。
**00:20:28 - Saron Yitbarek**:
那么花了多长时间?或者说是第一个版本什么时候出现的。
**00:20:30 - Rodric Rabbah**:
实际上很快。事实上,当 IBM 宣布……好吧,那时还是 IBM OpenWhisk。从我们第一次提交到现在才一年。
**00:20:39 - Saron Yitbarek**:
哇。我的天哪。
**00:20:41 - Rodric Rabbah**:
这着实令人激动。
**00:20:43 - Saron Yitbarek**:
这确实很令人印象深刻。事实上,当它第一次启动时,它不叫 OpenWhisk,而是 Whisk。对吗?
**00:20:49 - Rodric Rabbah**:
Whisk 是内部名称,没错。我取的这个名字。这个名字背后的意思是迅速而又灵活地行动。
**00:21:00 - Saron Yitbarek**:
很好。
**00:21:01 - Rodric Rabbah**:
你“搅拌”了一个功能,就可以了。你可以将其放入烤箱中烘焙。
**00:21:07 - Saron Yitbarek**:
太好了,因为当我看到它,我肯定想的是鸡蛋。我在想,让我们“<ruby> 搅拌 <rt> whisk </rt></ruby>”一些鸡蛋。
**00:21:12 - Rodric Rabbah**:
对。我们对该名称进行了一些正面和负面的评价。当我们开源一项技术,并将其放到 GitHub 上时,我们会在上面加上 open 前缀,以强调该技术与开源一样开放,可以自由使用、自由下载、自由贡献。
**00:21:32 - Saron Yitbarek**:
是的。
**00:21:33 - Rodric Rabbah**:
我们将其开源的目的,实际上是一定程度上提升可以在当今无服务器平台上执行标准。对我们来说,重要的是要建立一个平台,不仅可以用于生产环境,还可以与全世界共享,而且还可用于学术研究或一般性研究。也许因为出自 IBM 的研究机构,我们有点儿在意这个。
**00:22:00**:
但是,这是有所回报的,我知道一些大学 —— 从 Princeton 到 Cornell —— 在他们的研究中使用 OpenWhisk。我去过 Brown、 Williams College、 MIT、 CMU 等几所大学,并且进行了一些讲座,目的是鼓励学生真正地去研究围绕无服务器以及服务器功能的问题、工具、编程模型,并且使他们对技术感兴趣。
**00:22:26**:
向他们显示,如果他们真的为开源项目做出了贡献,那么有一条路可以让 IBM 的云功能接受它并在生产环境中运行,通常在一周之内。
**00:22:34 - Saron Yitbarek**:
哇。这么快。
**00:22:36 - Rodric Rabbah**:
这让一些人感到惊讶。
**00:22:38 - Saron Yitbarek**:
这是一个非常高效的过程。
**00:22:41 - Rodric Rabbah**:
这确实证明了我们是如何在开源环境下开发许许多多技术的。这不是一个开放核心模式,有些组件有所保留。实际上在 IBM 云之中所运行的就是 Apache OpenWhisk 项目。
**00:22:56 - Saron Yitbarek**:
当你思索无服务器的未来,以及我们所选择的前进道路时,你觉得它们将是不可避免地奔向开源吗?
**00:23:08**:
我认为最近对于开源的价值存在一场激烈的争议,尤其是在云计算领域。
**00:23:13 - Saron Yitbarek**:
是的,没错。
**00:23:15 - Rodric Rabbah**:
如果你在思考为什么人们会转向云计算,或者为什么他们可能会厌恶投身于云计算领域,这就是供应商锁定的问题……丧失透明度。开源在一定程度上缓解这些问题,发挥了重要的作用。然后再看看类似 Kubernetes 的服务,它只是在容器和系统管理方面吞噬了云,就那么的成功!
**00:23:41 - Rodric Rabbah**:
如果你正在做的事情接触到了容器,鉴于它的主导地位,保持闭源与否还值得讨论吗?我倾向于认为开放性是有帮助的,从开发人员的角度来看,这很有吸引力。
**00:23:57 - Saron Yitbarek**:
当你考虑未来的无服务器生态及其工具、项目以及服务时,你看到了什么呢?对你来说,无服务器的未来是什么样的?
**00:24:08 - Rodric Rabbah**:
我认为,你会开始越来越少思考底层技术,而变得越来越多地考虑编程体验以及围绕它的工具:用于调试的、用于部署管理的、用于性能分析的、用于安全性。
**00:24:26**:
我认为,所有这些都非常重要。你如何运行你的功能的底层机制 —— 无论它们是在容器中还是在一些未来的技术下运行,也无论你是将它们运行在一个云上或是多个云上 —— 我认为,它们都不重要。有点儿像是 Kubernetes 在容器以及容器管理方面所做的事情。
**00:24:46**:
类似的还有一层要放在上面,就是服务分层的功能,可以实现那种无服务器概念。然后,它实际上的表现取决于你在其中安放的中间件。你如何赋能授权给开发者,让他们真正利用这款新的云端计算机,以及你要在它周围投入的辛劳,让他们的体验愉快。
**00:25:07 - Saron Yitbarek**:
是的。这种赋能授权看起来怎么样?
**00:25:13 - Rodric Rabbah**:
一言以蔽之,就是高效。这是一种能力,可以只专注于对于我,作为一名开发人员而言有价值的东西,或者如果我在公司工作的话,对于我公司的价值。这样能够更快地规避问题,因为你释放了你的脑细胞,而不用去考虑基础设施和如何伸缩,以及在硬件层面如何保障事物的安全性。
**00:25:38**:
现在,你可以真正地创新,将脑力重新投入到更快的创新中去,从而为你的终端用户带来更多的价值。我想把这一切都归结于更高的效率。
**00:25:55 - Saron Yitbarek**:
Rodric Rabbah 是 OpenWhisk 的一位创始人。还记得我在这一期节目开始的时候所说的吗?互联网所基于的那种老旧的客户端 - 服务器模型并不会消失。改变的是,我是说彻底改变的是我们对服务器的思考方式。
**00:26:19**:
在所谓的无服务器世界之中,希望我们专注于代码本身,而不用担心基础架构。但是,我们所选择的抽象等级,以及如何保持对于未被抽象的工作的控制,才是使得无服务器世界变得真正有趣的地方。
**00:26:40**:
无服务器最终应当是为开发人员赋能授权的。免于打补丁、进行扩展和管理基础设施。但是,与此同时,即使我们抽象化了一些任务,依然必须对整体如何工作保持关注。我们会问,我要放弃的是哪些控制权,而我要收回的又是哪些控制权?
**00:27:07**:
下一集是我们史诗般的第二季的大结局,《代码英雄》将要前往火星。我们将会了解 NASA 的火星探测器如何开始自己的开源革命。并且我们将与 NASA 喷气推进实验室的 CTO 进行交流,了解开源是如何塑造太空探索的未来的。
**00:27:39 - Saron Yitbarek**:
与此同时,如果你想要更加深入地研究无服务器开发的问题,或是在这一季里我们所探索过的任何主题,请访问 [redhat.com/commandlineheroes](vscode-webview-resource://1aa00f58-b48b-4835-90e5-2e2fd87998ef/file///Users/xingyuwang/develop/LCRH-wxy/translated/redhat.com/commandlineheroes),查看免费资源。当你在那里时,你甚至可以为我们自己的代码英雄游戏作出贡献。
**00:28:00 - Saron Yitbarek**:
我是 Saron Yitbarek。感谢收听,编程不已。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/at-your-serverless>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | What does serverless really mean? Of course there are still servers—the basics of the internet aren't changing. But what can developers accomplish when someone else handles the servers?
Serverless computing makes it easy for beginners to deploy applications and makes work more efficient for the pros. Andrea Passwater shares how convenient it can be to abstract away (or remove from view) the infrastructure components of development. But as with any convenience, going serverless has tradeoffs. Rodric Rabbah explains that going serverless can mean giving up control of your deployment and restricts your ability to respond to problems—which is why he helped create Apache OpenWhisk, an open source serverless environment framework. And Himanshu Pant considers when to use serverless services.
Serverless computing should be about developer empowerment. But we have to stay curious about the big picture—even as we simplify our toolbox.
**00:03** - *Archival Al Gore*
But now, of course, all over the United States of America and all over the world the internet is revolutionizing our lives.
**00:13** - *Saron Yitbarek*
It's 1998. Google just hired its first employee, and Vice President Al Gore is talking to the press.
**00:22** - *Archival Al Gore*
This technology is still in its infancy. When president Bill Clinton and I came into the White House there were only 50 sites. And look at it now. I got a bouquet of virtual flowers on my birthday.
**00:37** - *Saron Yitbarek*
Okay. I can sense your eyebrow arching already. Why am I playing you some bit of 20-year-old internet history? It's because I want to remind you that the basics of the internet are still the same.
**00:51** - *Saron Yitbarek*
Sure, there are more than 50 sites now. I get it. But, we're still sending virtual flowers. And from a developer's perspective, if you strip away all our incredible advances, you've still got that same client-server model that started it all. A client-server model that allows for a distributed network.
**01:16** - *Saron Yitbarek*
Today, developers talk a lot about going serverless, which sounds like Al Gore's client-server internet just got trashed. And if we're not careful, we can abstract away so much infrastructure that we forget there are still servers out there doing their server thing.
**01:37** - *Saron Yitbarek*
But does serverless literally mean no servers? Really? Or is the developer's relationship with servers just evolving? In this episode, we are talking with people from around the world to explore this thing called serverless.
**01:54** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes. An original podcast from Red Hat.
**02:03** - *Andrea Passwater*
Did you know wireless internet has wires somewhere?
**02:06** - *Saron Yitbarek*
Andrea Passwater works for a company called ... Wait for it, Serverless. They created a popular, open source framework for developing serverless applications. Andrea is noticing how organizations are hungry for ways to abstract away infrastructure, which is what that magical word serverless is always promising.
**02:28** - *Andrea Passwater*
I think the term is mostly just supposed to convey the fact that as a developer who works in serverless applications, that's abstracted for you. You don't have to worry about those servers. You just get to code and deploy that code up to a cloud provider and not have to worry about the administration. That's really what serverless means.
**02:49** - *Saron Yitbarek*
For Andrea, the attractions of serverless are pretty obvious.
**02:53** - *Andrea Passwater*
If you develop applications in a serverless way, it gives you the ability to not have to think about the mundane parts of deploying that application and maintaining that application. It just means that you can focus on business value. You can focus on being creative.
**03:12** - *Saron Yitbarek*
And another big serverless bonus is you're less likely to find yourself reinventing the wheel.
**03:18** - *Andrea Passwater*
Why would you create your own way to handle authentication when services like Auth0 exist that you can just use and tap into? At the end of the day, serverless is about giving developers the opportunity to be able to more easily and more rapidly build all of these ideas in their heads that they want to get out into the world.
**03:41** - *Saron Yitbarek*
I did it!
**02:27** - *Saron Yitbarek*
Imagine you've got your arms full of groceries, and you're stumbling toward a door. The door slides open in a simple, friendly-
**03:50** - *Saron Yitbarek*
Allow me.
**03:51** - *Saron Yitbarek*
... kind of way. That's serverless. It's opening the door for you, making development a lot less cumbersome. In fact, as organizations flock toward hybrid cloud setups and the serverless movement gets underway, the barriers toward development are vanishing.
**04:09** - *Saron Yitbarek*
Andrea has been hearing a lot of talk about non-developer development.
**04:15** - *Andrea Passwater*
Sort of stories from people who traditionally thought they couldn't code, and who are now actually able to get into the software engineering game because of serverless. And able to make these tools that automate their own workflows and stuff like that. It doesn't matter what job you do.
**04:31** - *Andrea Passwater*
There's something you do on your job that is so rote, like you do it every single day and it's this thing that you're like, "You know, couldn't a computer do this for me?" I started to feel that way. I happened to work at this company called Serverless and they were like, "You realize that the product we make can help you with that. Right?"
**04:50** - *Saron Yitbarek*
Andrea figures that pretty soon a lot of people who never considered themselves developers are going to realize they can build simple apps themselves. At essentially no cost.
**05:02** - *Andrea Passwater*
With Lambda, I've never had to pay for any of these small applications that I've made. I can make these bots that do part of my job for me, and I can become more efficient at my job, yes. But, I also don't have to do that boring stuff anymore. I can do something that's more fun.
**05:17** - *Saron Yitbarek*
Even for pro developers, that automatic door effect is pretty tempting in an arms-full-of-groceries kind of world.
**05:25** - *Andrea Passwater*
I think people are very attracted to the idea that they can get prototypes working with a one- or two-person team in a very short amount of time. Like, a handful of days. They can get a prototype up and running. I think it makes it very exciting for people to start realizing that they get to just focus on what drives business value in their application, or for their product, for their company. They get to focus on that business value.
**05:54** - *Saron Yitbarek*
I'm going to throw another term at you. Ready? Functions-as-a-service. That's the offering at serverless places like AWS Lambda, or Apache OpenWhisk. Functions-as-a-service means a single function can be executed on demand, only when triggered. And that's a lot more efficient.
**06:15** - *Saron Yitbarek*
Plus, I'm way less worried about compute capacity and run time. End of the day, that serverless deal can be a pretty sweet setup. In fact, some folks have even started wondering, are we going all in on serverless? Does it maybe replace containers?
**06:34** - *Michael Hausenblas*
I see the point.
**06:35** - *Saron Yitbarek*
Michael Hausenblas is the developer advocate for the OpenShift® team over at Red Hat.
**06:41** - *Michael Hausenblas*
If you look at all of these things we have here, OpenShift and Cloud Foundry and what not, you have essentially these abstractions. This idea that the Heroku, essentially, bent it more or less. Right? This very simple way of, don't worry about how the execution will run, don't worry about what it looks like. Just give us the code and we take care of the rest.
**07:03** - *Saron Yitbarek*
Yeah. That sounds pretty good. It kind of sounds like that dream of a “noops”environment. Where everything is automated and abstracted away. It's like the developer's version of minimalist interior design. Nice, clean surfaces.
**07:21** - *Saron Yitbarek*
But, Michael wants to give you a little reality check.
**07:25** - *Michael Hausenblas*
No ops! Right? You know, it magically just will somehow go away. You see these jokes on HackerNews and Twitter, and wherever. Serverless, of course there are servers! I know, of course there are. There's operations.
**07:39** - *Michael Hausenblas*
Someone has to do that, someone has to rack the servers. Someone has to patch the operating system. Someone has to create container images, because guess where these functions are executing? Of course, in some kind of computer.
**07:54** - *Saron Yitbarek*
It's not a zero-sum game. Functions-as-a-service don't outright replace containers. Instead, they add a tool to the tool box. And I've got some more news for you. Using that new tool, going serverless doesn't just mean the ops is somebody else's problem. You've still got ops of your own to think about.
**08:14** - *Michael Hausenblas*
You see there is operations bits on the infrastructure side. But, also with the developers. If you're in an extreme case, using let's say Lambda, then you have zero access to any kind of administrators. Right?
**08:29** - *Michael Hausenblas*
You cannot simply call or page an infrastructure administrator. Obviously, someone in your organization has to do it. But, I fear that many organizations only see it's so simple and cheap. We don't need to move this, and this, and this. Then forget about who is on call, and who really is on call? Do you have a strategy for that?
**08:52** - *Michael Hausenblas*
If no, then you might want to come up with a strategy first before you go all in there.
**09:00** - *Saron Yitbarek*
Someone needs to be on call. Even if you do go "serverless,." you still need to have your head wrapped around that bigger picture. You still need to get your operations in order.
**09:24** - *Saron Yitbarek*
When I threw out that term earlier, functions-as-a-service, did you cringe a little? Over the last while cloud-based development has brought us an army of “as-a-service” terms. We've got infrastructure-as-a-service, we've got platform-as-a-service, we've got software-as-a-service, data-as-a-service. Database-as-a-service. You get the idea.
**09:48** - *Saron Yitbarek*
If you're having trouble keeping the differences straight, you're not alone. That's why we tracked down Himanshu Pant. He's a tech lead at the Royal Bank of Scotland, over in Delhi, India. He spent years parsing out the differences here.
**10:04** - *Himanshu Pant*
These other computing paradigms are so similar sounding in name to serverless that one tends to forget, or tends to get confused as to why, this is not being called serverless. Or why this is being called a serverless.
**10:20** - *Saron Yitbarek*
So, serverless is not the same as containers. Serverless is not platform-as-a-service. But Himanshu wanted to nail it down. What can functions-as-a-service provide, exactly? And what can't it?
**10:35** - *Saron Yitbarek*
He shared two anecdotes with us, two times when he figured out when to go with serverless and when to forgo. The first moment came during a 24-hour hackathon. Himanshu was trying to make a chat bot.
**10:49** - *Himanshu Pant*
There were various vectors on which this was going to be a sales. For example, that coverage of logic, the cost which would be incurred and the scalability. I sat down to do this work in serverless.
**11:04** - *Himanshu Pant*
As I did, I realized that cost aspect was one aspect, which kind of really tipped the scale in my favor. So even though all the other participants, they had a much better ... I would say coverage, or maybe coverage of logic. The NLP situations or their scenarios.
**11:19** - *Himanshu Pant*
But, as far as cost is concerned, and scalability, I was going hands down to win over there because with serverless it all depended on how many invocations people are doing on that chat bot. Accordingly, the functions will be triggered. This was one use case when I was very much happy to do serverless, because of the cost—there was no cost. Faster development time, and to be honest, it was not exactly a production-scale workload at that moment.
**11:45** - *Himanshu Pant*
I could make do with the somewhat infant tooling of the platform. It was a win for me.
**11:52** - *Saron Yitbarek*
Nice. That was a time when serverless made sense. But at the bank Himanshu is working in right now, they're migrating their systems from legacy to cloud. And that's bringing up different kinds of goals.
**12:07** - *Himanshu Pant*
We are trying to see which workload can go on to which paradigm. I should just go into IS, BAS, FAS, obviously the ones who come down to enterprise space. You need to see that there are no aspects, like number one, let’s say vendor lock-in. And number two, that technology should be proven, extensively. More so for a risk-averse industry like, you know, the banking sector.
**12:30** - *Himanshu Pant*
This is where a platform-as-a-service, but still has a better proving, and a better capability, and a better tooling kind of takes the upper hand.
**12:40** - *Saron Yitbarek*
Himanshu is looking at his own needs, and his own comfort levels, and curating which workloads make sense in which cloud computing paradigm.
**12:49** - *Himanshu Pant*
Let's say a listener is working on a trading shop, and he wants to build something, which is event-driven. For him or her, serverless may not really be apt because the latency may not really be desirable in that kind of a mission-critical application.
**13:05** - *Saron Yitbarek*
End of the day, it's a measured approach. Instead of throwing everything into one bucket. When we're thinking about which cloud-based architecture is actually right for the work we want to do, there's one more thing to consider. How all that abstracting, all that taking things off your hands, can end up changing not just our work lives, but the finished work itself.
**13:31** - *Saron Yitbarek*
Abstracting away part of our workload can mean less ability to customize. Think of a car you bought off the lot. It works. It drives. But then, think of a car you built on your own. That one works the way you decided it would work.
**13:48** - *Rania Khalaf*
It comes at a cost.
**13:50** - *Saron Yitbarek*
Rania Khalaf is the director of AI Engineering at IBM research.
**13:56** - *Rania Khalaf*
In using these serverless applications, you may not have full control of everything that's going on. You don't have control of scheduling, or when they'll run, or where.
**14:06** - *Saron Yitbarek*
There's a trade off taking place, right? Fine-grain control may slip when you're using serverless.
**14:13** - *Rania Khalaf*
It abstracts so much away from the end-user that if you do want to have more control, different scheduling, more checks and balances, different values on how long a function can run for. So on and so forth. Then you really want to be able to get in there and tinker, and maybe create your own deployments.
**14:32** - *Saron Yitbarek*
That would require something new, though. A new kind of serverless that open source communities are already building for themselves. Rania and her team of IBMers are part of that movement.
**14:44** - *Rania Khalaf*
We first worked on a language that was ... It’s basically JavaScript extensions to let you create these multi-threaded interactive service compositions as a starting point to give you a lighter-weight way. That was around the same time that cloud and microservices and platform-as-a-service were really picking up.
**15:08** - *Rania Khalaf*
Just combining these two trends and saying, there is this idea of being able to build higher order function for many small pieces that may or may not come from you.
**15:18** - *Saron Yitbarek*
Rania and her team were building Apache OpenWhisk. An open source functions platform.
**15:23** - *Rania Khalaf*
With OpenWhisk, from the beginning, we made it open source. A big part of that was to really enable the community to participate with us. But also to peel away the covers. And give control to the people that are wanting to operate their own serverless computing environments, so that they can customize it to their needs. Maybe put in their own controls, see how it really works, and control it better.
**15:54** - *Rania Khalaf*
But, also provide the kind of finer-grain control that people wouldn't have with it if it was only offered as a service.
**16:03** - *Saron Yitbarek*
Giving control back to anyone who wants to operate their own serverless environment. It's next-stage serverless. Joining OpenWhisk, you've got other open source platforms like Fission and Gestalt. We start to see the serverless arena evolving into something more adaptable, and more powerful than before.
**16:31** - *Saron Yitbarek*
To really get why an open source version of serverless matters, I got chatting with one of the founders of OpenWhisk.
**16:39** - *Saron Yitbarek*
Hi, Rodric. How is it going?
**16:40** - *Rodric Rabbah*
Good. How are you? Thanks for having me on.
**16:42** - *Saron Yitbarek*
Rodric Rabbah was one of the three developers who conceived of, and founded, OpenWhisk. Here is our conversation.
**16:54** - *Rodric Rabbah*
It tends to be confusing for others or tends to get snickers, because people tend to think, “How could you possibly compute without servers?”
**17:02** - *Saron Yitbarek*
Right. Server is there somewhere, it's just I don't have to worry about it.
**17:05** - *Rodric Rabbah*
Exactly. That's really the beauty of this model. When you start developing in a serverless style, you never really want to go back. You know, I've been in it for close to four years now, and I've developed some production-quality applications.
**17:19** - *Rodric Rabbah*
This is the only way I develop now. If you tell me I have to provision a machine and install an OS, it's completely foreign to me. I'm not even sure I'd know how to do it anymore.
**17:29** - *Saron Yitbarek*
Yeah. When you put it like that, it sounds like a huge load off, you know? Because when you initially hear of serverless, at least I think, "Man, it's yet another thing I have to learn."
**17:38** - *Saron Yitbarek*
But, when you put it that way it sounds nice.
**17:41** - *Rodric Rabbah*
It does sound nice. Then you have to realize that you have to take a little bit of air out of the bubble. It's not a silver bullet.
**17:50** - *Saron Yitbarek*
What are some of the surprising risks or issues that people may not see or be aware of when they get started?
**17:58** - *Rodric Rabbah*
I think the lack of transparency is possibly the biggest one. It's sort of reminiscent to me of sort of the technology that came about when new languages came about and raised a level of abstraction relative to the computer. It's a similar kind of, sort of, startling effect in serverless today.
**18:16** - *Rodric Rabbah*
In that you write, typically a function, then you just deploy that function. It's instantaneously available to run, say on the web as an APIN point. It scales massively. I mean, you can run thousands of instances without any work on your part.
**18:32** - *Rodric Rabbah*
But, if something goes wrong, it's like, how do I debug this? Or I actually want to inspect the context within which my function failed. Typically, these functions run within processes, are isolated from you—you can't even log into the machine to see where your code is running. They might run in container environments that are closed off. You don't know what's in them.
**18:53** - *Rodric Rabbah*
It becomes hard for you to get that little bit of transparency. This is where tools will eventually help. But, the lack of tools sort of makes that pretty significant pitfall for people to get their heads around.
**19:05** - *Saron Yitbarek*
That was really good. Okay. Let's go back to OpenWhisk, alright? Tell me about that.
**19:11** - *Rodric Rabbah*
The project started right around the time Amazon Lambda announced their offering, which was really where serverless started to get into the nomenclature and started to gain mindshare in the space. When we saw Lambda, we started thinking, “There is a lot of technology here that has to be developed. Not just at the base layer in terms of a new cloud computer, but really in terms of your programming model that you put on top of it to make it more easily accessible to programmers.” You know, coming out of IBM research, we had pretty strong ... Instead of skills around programming language design, compiler expertise, and run time expertise.
**19:54** - *Rodric Rabbah*
A small team of us, basically three people-
**19:57** - *Saron Yitbarek*
Wow.
**19:57** - *Rodric Rabbah*
... got together to essentially do the initial development and prototyped what became, eventually, OpenWhisk, with respect to the command line tools, which is really the programming interface for serverless today. The programming model concepts, and then the actual architecture that it has to support, essentially, this function of the service model and give you all the benefits that serverless espouses.
**20:22** - *Rodric Rabbah*
The genesis was really Amazon Lambda coming on the scene and saying there's this new model of computing. Pay attention.
**20:28** - *Saron Yitbarek*
How long did it take? Or the first version anyway.
**20:30** - *Rodric Rabbah*
It happened quite fast. In fact, when IBM announced ... Well, it was at the time IBM OpenWhisk. It was one year to the date from our first commit.
**20:39** - *Saron Yitbarek*
Wow. Oh my goodness.
**20:41** - *Rodric Rabbah*
That was quite exciting.
**20:43** - *Saron Yitbarek*
That's really impressive. Actually, when it first started, it wasn't OpenWhisk, it was just Whisk. Right?
**20:49** - *Rodric Rabbah*
Whisk was the internal name, that's right. I'm responsible for the name. The idea behind the name was to move quickly and nimbly.
**21:00** - *Saron Yitbarek*
Nice.
**21:01** - *Rodric Rabbah*
You whip up a function and there it is. You can put it in the oven and bake it.
**21:07** - *Saron Yitbarek*
That's wonderful, because I was definitely thinking eggs when I saw that. I was thinking, let's whisk some eggs.
**21:12** - *Rodric Rabbah*
Right. We've done some positives and some negatives on the name. When we open source a technology, and sort of put it out on GitHub, we put the open prefix on it to sort of emphasize that this is open as in open source and free to use, free to download, free to contribute to.
**21:32** - *Saron Yitbarek*
Yeah.
**21:33** - *Rodric Rabbah*
And our goal in putting it on open source was really to sort of raise the bar in terms of what's available to execute these days as a serverless platform. It was important to us to sort of build a platform that is not only production-ready, and share it with the world, but also to make it possible for academic research or research in general. Maybe coming out of IBM research, we cared about that a little too much.
**22:00** - *Rodric Rabbah*
But, it sort of paid off in that I know of universities that actually use OpenWhisk for their own research—from Cornell to Princeton. I've gone to several universities like Brown, Williams College, MIT, CMU, and I've given talks with the purpose of encouraging students to really look at the problems around serverless and functions of the service. The tooling, the programming model, and get them excited about the technology.
**22:26** - *Rodric Rabbah*
Showing them that there's a path to where if they actually contribute to the open source project, it's picked up by IBM cloud functions and run in production, usually within a week.
**22:34** - *Saron Yitbarek*
Wow. That's so fast.
**22:36** - *Rodric Rabbah*
That's been surprising to some people.
**22:38** - *Saron Yitbarek*
That's a super-efficient process.
**22:41** - *Rodric Rabbah*
It's really a testament to how we develop a lot of technology in the open. It's not an open core model where there are some components that have been held back. What's running in the IBM cloud is really what's in the Apache OpenWhisk project.
**22:56** - *Saron Yitbarek*
When you think about the future of serverless and the options we may have moving forward, do you feel like they will inevitably be open?
**23:08** - *Rodric Rabbah*
I think there's a raging debate these days about the value of open source, especially in the cloud.
**23:13** - *Saron Yitbarek*
Right, yeah.
**23:15** - *Rodric Rabbah*
If you consider why people go to the cloud, or why they might have aversions to go into the cloud, it's this whole concept of vendor lock-in being ... losing transparency. Open source has played an important role in sort of alleviating some of these issues. Then you look at efforts like Kubernetes, which is just gobbling up the cloud in terms of a container and management system. How successful that's been.
**23:41** - *Rodric Rabbah*
If you're doing something that even touches containers, does it even warrant having a discussion about keeping it closed source, given how dominant it is? I tend to think that openness helps. It's compelling from developers’ perspectives.
**23:57** - *Saron Yitbarek*
When you think about the future of the serverless ecosystem and tools, and projects, and services that we're going to see, what does that look like? What does the future of serverless look like for you?
**24:08** - *Rodric Rabbah*
I think you start to think less and less about the underlying technology, and it becomes more and more about the programming experience, and the tooling around it. The tooling for debugging, the tooling for deployment management, the tooling for performance analysis, the tooling for security.
**24:26** - *Rodric Rabbah*
All of these are sort of fundamentally important, I think. The underlying mechanics of how you run your function, whether they run in a container or some future technology, whether you can run them on one cloud, or multi-cloud, I think fades into the background. Kind of like what Kubernetes did for containers and container management.
**24:46** - *Rodric Rabbah*
In a similar way there's a layer that's going to come on top, which is the function of the service layering to give you that kind of serverless notion. Then it's really about what's the new middleware that you're putting on top of it. How are you empowering developers to really take advantage of this new cloud computer and the tooling that you're going to put around it to make their experience pleasant.
**25:07** - *Saron Yitbarek*
Yeah. What does that empowerment look like?
**25:13** - *Rodric Rabbah*
Efficiency, to put it in one word. It's the ability to just focus on the things that are of value to me as a developer, or the value to my company if I'm working at a corporation. It's more rapid innovation that, then, you beget out of that, because you freed up your brain cells to not think about infrastructure and how things scale, and how things are secured at the hardware level.
**25:38** - *Rodric Rabbah*
Now you can really innovate in terms of rededicating that brain power to just innovating more rapidly, delivering more value to your end-users. I'd lump that all into just better efficiency.
**25:55** - *Saron Yitbarek*
Rodric Rabbah is a founder of OpenWhisk. Remember what I said at the top of the show? That old client-server model that the internet is based on really isn't going anywhere. What's changing, and I mean radically changing, is the way we think about those servers.
**26:19** - *Saron Yitbarek*
In a so-called serverless world, the hope is that we concentrate on the code itself and don't have to worry about infrastructure. But the level of abstraction we select, and how we maintain control over work we don't abstract away, are where that serverless world gets interesting.
**26:40** - *Saron Yitbarek*
Serverless should, ultimately, be about developer empowerment. The freedom from patching, scaling, and infrastructure management. But, at the same time, we have to stay curious about how that big picture works even as we abstract some tasks away. We're going to be asking, what controls am I giving up and what controls do I want to take back?
**27:07** - *Saron Yitbarek*
Next episode it's our epic season two finale. Command Line Heroes is taking a journey to Mars. We're learning how NASA's Martian rover is kicking off an open source revolution of its own. And we're hanging out with the CTO at NASA's Jet Propulsion Laboratory. No biggie. To learn how open source is shaping the future of space exploration.
**27:39** - *Saron Yitbarek*
Meantime, if you want to dive deeper into the question of serverless development, or any of the subjects we've explored this season, check out the free resources waiting for you at redhat.com/commandlineheroes. While you're there, you can even contribute to our very own Command Line Heroes game.
**28:00** - *Saron Yitbarek*
I'm Saron Yitbarek. Thanks for listening, and keep on coding.
### Keep going
### Functions-as-a-Service with OpenWhisk and OpenShift
FaaS can help launch applications quickly. Get started with some open source tools and a quick tutorial.
### 3 implications of serverless
Serverless infrastructure is changing how people develop software. Find out how and what to consider before going serverless.
### Is serverless the next phase of cloud-native application development?
Serverless computing is getting popular? OpenWhisk provides an open source platform to get started.
### Red Hat legal and privacy links
[About Red Hat](/en/about/company)[Jobs](/en/jobs)[Events](/en/events)[Locations](/en/about/office-locations)[Contact Red Hat](/en/contact)[Red Hat Blog](/en/blog)[Diversity, equity, and inclusion](/en/about/our-culture/diversity-equity-inclusion)[Cool Stuff Store](https://coolstuff.redhat.com/)[Red Hat Summit](https://www.redhat.com/en/summit) |
12,718 | 微软能否放弃 Windows 转向 Linux? | https://www.techrepublic.com/article/could-microsoft-be-en-route-to-dumping-windows-in-favor-of-linux/ | 2020-10-14T23:23:32 | [
"微软",
"Linux"
] | https://linux.cn/article-12718-1.html |
>
> Jack Wallen 认为,Microsoft Linux 是 Microsoft 桌面操作系统的下一个演进方向。他解释了为什么这将是一个对 Microsoft、IT 专业人士、用户和 Linux 社区的双赢。
>
>
>

我尊敬的同事 Steven J. Vaughan-Nichols 在姊妹网站 ZDNet 上发表了一篇出色的文章,名为《[基于 Linux 的 Windows 非常有意义](https://www.zdnet.com/article/linux-based-windows-makes-perfect-sense/)》,他在文中讨论了 Eric S. Raymond 的[观点](/article-12664-1.html),即我们正接近桌面战争的最后阶段。Vaughan-Nichols 猜测,下一个合乎逻辑的步骤是在 Linux 内核上运行的 Windows 界面。
这是有道理的,尤其是考虑到微软在 [Windows 的 Linux 子系统(WSL)](https://www.techrepublic.com/article/microsoft-older-windows-10-versions-now-get-to-run-windows-subsystem-for-linux-2/) 上的努力。然而,从我过去几年所目睹的一切来看,我认为可以得出一个对微软更有意义的结论。
### Microsoft Linux: 为什么它是最好的解决方案
一度,微软的最大摇钱树是软件,确切地说是 Windows 和 Microsoft Office。但是,就像科技行业中的所有事物一样,进化也在发生,而拒绝进化的科技公司失败了。
微软明白这一点,并且它已经进化了。一个恰当的例子是:[Microsoft Azure](https://www.techrepublic.com/article/microsoft-azure-the-smart-persons-guide/)。微软的云计算服务,以及 [AWS](https://www.techrepublic.com/article/amazon-web-services-the-smart-persons-guide/) 和 [Google Cloud](https://www.techrepublic.com/article/google-cloud-platform-the-smart-persons-guide/) 已经成为这个不断变化的行业的巨大推动力。Azure 已成为微软新世界的摇钱树 —— 多到以至于这家在桌面电脑市场上享有垄断地位的公司已经开始意识到,或许还有更好的方式来利用桌面计算机。
这种优势很容易通过 Linux 来实现,但不是你可能想到的 Linux。Vaughan-Nichols 所建议的 Microsoft Linux 对于微软来说可能是一个很好的垫脚石,但我相信该公司需要做出一个更大的飞跃。我说的是登月规模的飞跃 —— 这将使所有参与者的生活变得更加轻松。
我说的是深入 Linux 领域。忘掉在 Linux 内核上运行 [Windows 10](https://www.techrepublic.com/article/windows-10-the-smart-persons-guide/) 界面的桌面版本吧,最后承认 Microsoft Linux 可能是当今世界的最佳解决方案。
微软发布一个完整的 Linux 发行版将对所有参与者来说意味着更少的挫败感。微软可以将其在 Windows 10 桌面系统上的开发工作转移到一个更稳定、更可靠、更灵活、更经考验的桌面系统上来。微软可以从任意数量的桌面系统中选择自己的官方风格:GNOME、KDE、Pantheon、Xfce、Mint、Cinnamon... 不胜枚举。微软可以按原样使用桌面,也可以为它们做出贡献,创造一些更符合用户习惯的东西。
### 开发:微软并没有摆脱困境
这并不意味着微软在开发方面将摆脱困境。微软也希望对 Wine 做出重大贡献,以确保其所有产品均可在兼容层上顺畅运行,并且默认集成到操作系统中,这样最终用户就不必为安装 Windows 应用程序做任何额外的工作。
### Windows 用户需要 Defender
微软开发团队也希望将 Windows Defender 移植到这个新的发行版中。等一等。什么?我真的是在暗示 Microsoft Linux 需要 Windows Defender 吗?是的,我确定。为什么?
最终用户仍然需要防范 <ruby> <a href="https://www.techrepublic.com/article/phishing-and-spearphishing-a-cheat-sheet/"> 网络钓鱼 </a> 诈骗 <rt> phishing scams </rt></ruby>、恶意 URL 和其他类型的攻击。普通的 Windows 用户可能不会意识到,Linux 和安全使用实践的结合远比 Windows 10 和 Windows Defender 要安全得多。所以,是的,将 Windows Defender 移植到 Microsoft Linux 将是保持用户基础舒适的一个很好的步骤。
这些用户将很快了解在台式计算机上工作的感觉,而不必处理 Windows 操作系统带来的日常困扰。更新更流畅、更值得信赖、更安全,桌面更有意义。
### 微软、用户和 IT 专业人士的双赢
微软一直在尽其所能将用户从标准的基于客户端的软件迁移到云和其他托管解决方案,并且其软件摇钱树已经变成了以网络为中心和基于订阅的软件。所有这些 Linux 用户仍然可以使用 [Microsoft 365](https://www.techrepublic.com/article/microsoft-365-a-cheat-sheet/) 和它必须提供的任何其他 <ruby> <a href="https://www.techrepublic.com/article/software-as-a-service-saas-a-cheat-sheet/"> 软件即服务 </a> <rt> Software as a Service </rt></ruby>(SaaS)解决方案——所有这些都来自于 Linux 操作系统的舒适性和安全性。
这对微软和消费者而言是双赢的,因为这样 Windows 没有那么多令人头疼的事情要处理(通过捕获漏洞和对其专有解决方案进行安全补丁),消费者可以得到一个更可靠的解决方案而不会错过任何东西。 如果微软打对了牌,他们可以对 KDE 或几乎任何 Linux 桌面环境重新设置主题,使其与 Windows 10 界面没有太大区别。
如果布局得当,消费者甚至可能都不知道其中的区别——“Windows 11” 将仅仅是 Microsoft 桌面操作系统的下一个演进版本。
说到胜利,IT 专业人员将花费更少的时间来处理病毒、恶意软件和操作系统问题,而把更多的时间用于保持网络(以及为该网络供动力的服务器)的运行和安全上。
### 大卖场怎么办?
这是个关键的地方。为了让这一做法真正发挥作用,微软将不得不完全放弃 Windows,转而使用自己风格的 Linux。基于同样的思路,微软需要确保大卖场里的 PC 都安装了 Microsoft Linux 系统。没有半途而废的余地——微软必须全力以赴,以确保这次转型的成功。
一旦大卖场开始销售安装了 Microsoft Linux 的 PC 和笔记本电脑,我预测这一举措对所有相关人员来说将会是一个巨大的成功。微软会被视为终于推出了一款值得消费者信赖的操作系统;消费者将拥有一个这样的桌面操作系统,它不会带来太多令人头疼的事情,而会带来真正的生产力和乐趣;Linux 社区最终将主导桌面计算机。
### Microsoft Linux:时机已到
你可能会认为这个想法很疯狂,但如果你真的仔细想想,微软 Windows 的演进就是朝着这个方向发展的。为什么不绕过这个时间线的中途部分,而直接跳到一个为所有参与者带来成功的终极游戏呢? Microsoft Linux 正当其时。
---
via: <https://www.techrepublic.com/article/could-microsoft-be-en-route-to-dumping-windows-in-favor-of-linux/>
作者:[jack-wallen](https://www.techrepublic.com/meet-the-team/us/jack-wallen/) 选题:[wxy](https://github.com/wxy) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,719 | 在 Linux 终端中展示幻灯片 | https://itsfoss.com/presentation-linux-terminal/ | 2020-10-15T00:03:00 | [
"演示文稿",
"终端"
] | https://linux.cn/article-12719-1.html | 
演示文稿往往是枯燥的。这就是为什么有些人会添加动画或漫画/meme 来增加一些幽默和风格来打破单调。
如果你需要在你的大学或公司的演示文稿中加入一些独特的风格,那么使用 Linux 终端怎么样?想象一下,这将是多么酷的事情啊!
### Present:Linux 终端中进行演示
在终端中可以做很多[有趣好玩的事情](https://itsfoss.com/funny-linux-commands/)。制作和展示幻灯片只是其中之一。
这个基于 Python 的应用名为 [Present](https://github.com/vinayak-mehta/present),它可以让你创建基于 Markdown 和 YML 的幻灯片,你可以在你的大学或公司里演讲,并以真正的极客风格取悦人们。
我制作了一个视频,展示了在 Linux 终端中用 Present 演示一些东西的样子。
#### Present 的功能
你可以用 Present 做以下事情:
* 使用 Markdown 语法在幻灯片中添加文本
* 用箭头或 `PgUp`/`Down` 键控制幻灯片
* 改变前景和背景颜色
* 在幻灯片中添加图像
* 增加代码块
* 播放模拟代码,并用 codio YML 文件输出
#### 在 Linux 上安装 Present
Present 是一个基于 Python 的工具,你可以使用 PIP 来安装它。你应该确保用这个命令[在 Ubuntu 上安装 Pip](https://itsfoss.com/install-pip-ubuntu/):
```
sudo apt install python3-pip
```
如果你使用的是其他发行版,请检查你的包管理器来安装 PIP3。
安装 PIP 后,你就可以以这种方式全局安装 Present:
```
sudo pip3 install present
```
你也可以只为当前用户安装,但你也必须将 `~/.local/bin` 添加到你的 `PATH` 环境变量。
#### 在 Linux 终端中使用 Present 来创建和展示幻灯片

由于 Present 使用了 Markdown 语法,你应该用它来创建自己的幻灯片。在这里使用 [Markdown 编辑器](https://itsfoss.com/best-markdown-editors-linux/)会有帮助。
Present 需要一个 Markdown 文件来读取和播放幻灯片。你可以[下载这个示例幻灯片](https://github.com/vinayak-mehta/present/blob/master/examples/sample.md),但你需要单独下载嵌入的图像,并将它放在图像文件夹内。
* 在 Markdown 文件中使用 `—` 来分隔幻灯片。
* 使用 Markdown 语法在幻灯片中添加文本。
* 使用以下语法添加图片 `![RC] (images/name.png)`。
* 通过添加像 `<!– fg=white bg=red –>` 这样的语法来改变幻灯片的颜色。
* 使用像 `<!– effect=fireworks –>` 这样的语法来添加带有效果的幻灯片。
* 使用 [codio 语法](https://present.readthedocs.io/en/latest/codio.html) 添加代码运行模拟。
* 使用 `q` 退出演示,并用左/右箭头或 `PgUp`/`Down` 键控制幻灯片。
请记住,在演示时调整终端窗口的大小会把东西搞乱,按回车键也是如此。
### 总结
如果你熟悉 Markdown 和终端,使用 Present 对你来说并不困难。
你不能把它和常规的用 Impress、MS Office 等制作的幻灯片相比,但偶尔使用,它是一个很酷的工具。如果你是计算机科学/网络专业的学生,或者是开发人员或系统管理员,你的同事一定会觉得很有趣。
---
via: <https://itsfoss.com/presentation-linux-terminal/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Presentations are often boring. This is why some people add animation or comics/meme to add some humor and style to break the monotony.
If you have to add some unique style to your college or company presentation, how about using the Linux terminal? Imagine how cool it would be!
## Present: Do Your Presentation in Linux Terminal
There are so many amusing and [fun stuff you can do in the terminal](https://itsfoss.com/funny-linux-commands/). Making and presenting slides is just one of them.
Python based application named [Present](https://github.com/vinayak-mehta/present) lets you create markdown and YML based slides that you can present in your college or company and amuse people in the true geek style.
I have made a video showing what it would look like to present something in the Linux terminal with Present.
### Features of Present
You can do the following things with Present:
- Use markdown syntax for adding text to the slides
- Control the slides with arrow or PgUp/Down keys
- Change the foreground and background colors
- Add images to the slides
- Add code blocks
- Play a simulation of code and output with codio YML files
### Installing Present on Linux
Present is a Python based tool and you can use PIP to install it. You should make sure to [install Pip on Ubuntu](https://itsfoss.com/install-pip-ubuntu/) with this command:
`sudo apt install python3-pip`
If you are using some other distributions, please check your package manager to install PIP3.
Once you have PIP installed, you can install Present system wide in this manner:
`sudo pip3 install present`
You may also install it for only the current user but then you’ll also have to add ~/.local/bin to your PATH.
### Using Present to create and present slides in Linux terminal
Since Present utilizes markdown syntax, you should be aware of it to create your own slides. Using a [markdown editor](https://itsfoss.com/best-markdown-editors-linux/) will be helpful here.
Present needs a markdown file to read and play the slides. You may [download this sample slide](https://github.com/vinayak-mehta/present/blob/master/examples/sample.md) but you need to download the embed image separately and put it inside image folder.
- Separate slides using — in your markdown file.
- Use markdown syntax for adding text to the slides.
- Add images with this syntax: ![RC] (images/name.png).
- Change slide colors by adding syntax like <!– fg=white bg=red –>.
- Add a slide with effects using syntax like <!– effect=fireworks –>.
- Use
[codio syntax](https://present.readthedocs.io/en/latest/codio.html)to add a code running simulation. - Quit the presentation using q and control the slides with left/right arrow or PgUp/Down keys.
Keep in mind that resizing the terminal window while running the presentation will mess things up and so does pressing enter key.
**Conclusion**
If you are familiar with Markdown and the terminal, using Present won’t be difficult for you.
You cannot compare it to regular presentation slides made with Impress, MS Office etc but it is a cool tool to occasionally use it. If you are a computer science/networking student or work as a developer or sysadmin, your colleagues will surely find this amusing. |
12,721 | 安装 Manjaro Linux 后必做的 6 件事 | https://itsfoss.com/things-to-do-after-installing-manjaro/ | 2020-10-15T20:50:00 | [
"Manjaro"
] | https://linux.cn/article-12721-1.html | 你刚刚[全新安装了 Manjaro Linux](https://itsfoss.com/install-manjaro-linux/),那么现在该做什么呢?
下面是我推荐你在安装后进行的一些必不可少的步骤。
不过说实话,这些都是我在安装 Manjaro 后喜欢做的事,根据你的需求,步骤可能会有所不同。
### 推荐在安装完 Manjaro Linux 后去做的事

我使用的是 Xfce 版的 Manjaro,但这些步骤也适用于 [Manjaro](https://manjaro.org) 的其它桌面环境版本。
#### 1、设置最快的镜像
在更新系统之前,我建议先整理一下镜像列表。在刷新 Manjaro 系统和从软件仓库下载软件包的时候,优化后的镜像列表会对系统的性能产生明显的影响。
打开终端模拟器并输入以下命令:
```
sudo pacman-mirrors --fasttrack
```

#### 2、更新系统
保持系统更新可以降低安全漏洞的发生机率,在安装新的软件之前也建议刷新一下系统的软件仓库。
你可以用下面的命令来[更新 Manjaro 系统](https://itsfoss.com/update-arch-linux/):
```
sudo pacman -Syu
```

#### 3、启用 AUR、Snap 以及 Flatpak 支持
[<ruby> Arch 用户仓库 <rt> Arch User Repository </rt></ruby>(AUR)](https://itsfoss.com/aur-arch-linux/)是用户选择[基于 Arch Linux 的系统](https://itsfoss.com/arch-based-linux-distros/)的一个主要理由。你可以在 AUR 中访问到大量的附加软件。
(LCTT 译注:AUR 中的 PKGBUILD 均为用户上传且未经审核,使用者需要自负责任,在构建软件包前请注意检查其中内容是否合理。)
作为可选项,你可以直接在 Pacman 图形化软件包管理器中启用对 [Snap](https://itsfoss.com/use-snap-packages-ubuntu-16-04/) 以及 [Flatpak](https://itsfoss.com/flatpak-guide/) 的支持。

#### 启用 TRIM(仅 SSD)
如果你的根分区已经安装在了 SSD 上,启用 [TRIM](https://en.wikipedia.org/wiki/Trim_(computing)) 会是你在安装 Manjaro 后需要做的一件事。TRIM 会帮助清理 SSD 中的块,从而延长 SSD 的使用寿命。
要在 Manjaro 中启用 TRIM,请在终端中输入以下命令:
```
sudo systemctl enable fstrim.timer
```

#### 5、安装内核(高级用户)
我在 [Manjaro 评测](https://itsfoss.com/manjaro-linux-review/)中提到的一个话题就是,你可以在图形界面中轻易地更换内核。
喜欢使用命令行?你也可以在终端中列出系统中已安装的内核以及安装新的内核。
列出已安装的内核:
```
mhwd-kernel -li
```
安装新内核(以最新的 5.8 版本内核为例):
```
sudo mhwd-kernel -i linux58
```

#### 6、安装微软 TrueType 字体(如果需要)
我经常在个人电脑上编辑工作文件,因此我需要 Times New Roman 或 Arial 等微软字体。
如果你也需要使用微软字体,可以从 [AUR](https://itsfoss.com/aur-arch-linux/) 中取得这个[软件包](https://aur.archlinux.org/packages/ttf-ms-fonts)。如果你想要在命令行中管理 AUR 软件包,可以选择安装一个 [AUR 助手](https://itsfoss.com/best-aur-helpers/)。

### 结论
如果你想在一个预配置、为桌面优化的发行版上享受 Arch Linux 的优点,[Manjaro 是一个很好的发行版](https://itsfoss.com/why-use-manjaro-linux/)。虽然它预置了很多东西,但由于每个人设置和需求的不同,有几个步骤是不能提前完成的。
除开已经提到的步骤,还有哪一步对你来说是必不可少的?请在下面的评论中告诉我们。
---
via: <https://itsfoss.com/things-to-do-after-installing-manjaro/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rakino](https://github.com/rakino) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So, you just did a [fresh installation of Manjaro Linux](https://itsfoss.com/install-manjaro-linux/). Now what?
Here are a few essential post installation steps I recommend you to follow.
Quite honestly, these are the things I prefer to do after installing Manjaro. Yours could differ depending on your need.
## Recommended Things To Do After Installing Manjaro Linux

I am using Manjaro Xfce edition but the steps are applicable to other desktop variants of [Manjaro](https://manjaro.org) as well.
### 1. Set the fastest mirror
Before even updating your system, I suggest to sort out your mirror list first. When refreshing the Manjaro system and downloading software from repositories, an optimized mirror list can have noticeable performance impact to the system.
Open the Terminal emulator and type the following command:
`sudo pacman-mirrors --fasttrack`
### 2. Update your system
Keeping your system up-to-date reduces the chances of security vulnerabilities. Refreshing your system repository is also a recommended thing to do before installing new software.
You can [update your Manjaro system](https://itsfoss.com/update-arch-linux/) by running the following command.
`sudo pacman -Syu`
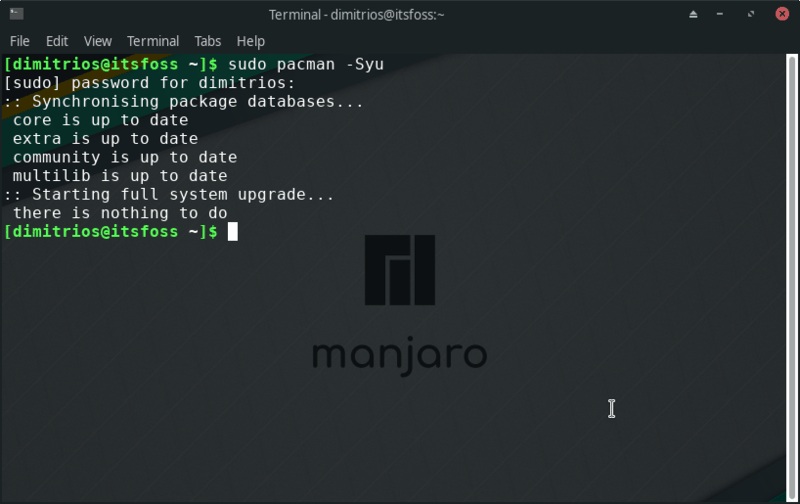
### 3. Enable AUR, Snap or Flatpak support
[Arch User Repository (AUR)](https://itsfoss.com/aur-arch-linux/) is one of the main reasons that a user chooses an [Arch-based system](https://itsfoss.com/arch-based-linux-distros/). It gives you access to a huge number of additional software.
Optionally, you can also enable support for [Snaps](https://itsfoss.com/use-snap-packages-ubuntu-16-04/) and [Flatpaks](https://itsfoss.com/flatpak-guide/) directly from Pamac GUI package manager.
### 4. Enable TRIM (SSD only)
If your root partition has been installed on SSD, enabling [TRIM](https://en.wikipedia.org/wiki/Trim_(computing)) is one thing you need to do after installing Manjaro. TRIM helps to clean blocks in your SSD and extend the lifespan of your SSD.
To enable TRIM on Manjaro, run the following command in a terminal:
`sudo systemctl enable fstrim.timer`
### 5. Installing a kernel of your choice (advanced users)
One of the topics that I covered in my [Manjaro Linux review](https://itsfoss.com/manjaro-linux-review/), is how easily you can switch kernels through a graphical interface.
Do you prefer to use the command line? You can list the installed kernel(s) on your system and install a kernel using your terminal.
To list the installed kernels:
`mhwd-kernel -li`
**To install a new kernel **(the latest to date 5.8 kernel for example)**:**
`sudo mhwd-kernel -i linux58`
### 6. Install Microsoft true type fonts (if you need it)
I have to often edit the work documents on my personal computer and hence I need the Microsoft fonts like Times New Roman or Arial.
If you also need to use Microsoft fonts, you can access the [package](https://aur.archlinux.org/packages/ttf-ms-fonts) from [AUR](https://itsfoss.com/aur-arch-linux/). If you want to use the command line for AUR packages, you can install an [AUR helper](https://itsfoss.com/best-aur-helpers/).
### Conclusion
[Manjaro is a great distribution](https://itsfoss.com/why-use-manjaro-linux/) if you want to use the benefits of Arch Linux on a pre-configured, desktop optimized distribution. Though it comes pre-configured with many essentials, there are a few steps that cannot be done in advance, as everyone has a different setup and different needs.
Please let us know in the comments below, which step apart from the already mentioned is the essential for you. |
12,722 | 构建一个即时消息应用(八):Home 页面 | https://nicolasparada.netlify.com/posts/go-messenger-home-page/ | 2020-10-15T21:32:00 | [
"即时消息"
] | https://linux.cn/article-12722-1.html | 
本文是该系列的第八篇。
* [第一篇: 模式](/article-11396-1.html)
* [第二篇: OAuth](/article-11510-1.html)
* [第三篇: 对话](/article-12056-1.html)
* [第四篇: 消息](/article-12680-1.html)
* [第五篇: 实时消息](/article-12685-1.html)
* [第六篇: 仅用于开发的登录](/article-12692-1.html)
* [第七篇: Access 页面](/article-12704-1.html)
继续前端部分,让我们在本文中完成 `home` 页面的开发。 我们将添加一个开始对话的表单和一个包含最新对话的列表。
### 对话表单

转到 `static/ages/home-page.js` 文件,在 HTML 视图中添加一些标记。
```
<form id="conversation-form">
<input type="search" placeholder="Start conversation with..." required>
</form>
```
将该表单添加到我们显示 “auth user” 和 “logout” 按钮部分的下方。
```
page.getElementById('conversation-form').onsubmit = onConversationSubmit
```
现在我们可以监听 “submit” 事件来创建对话了。
```
import http from '../http.js'
import { navigate } from '../router.js'
async function onConversationSubmit(ev) {
ev.preventDefault()
const form = ev.currentTarget
const input = form.querySelector('input')
input.disabled = true
try {
const conversation = await createConversation(input.value)
input.value = ''
navigate('/conversations/' + conversation.id)
} catch (err) {
if (err.statusCode === 422) {
input.setCustomValidity(err.body.errors.username)
} else {
alert(err.message)
}
setTimeout(() => {
input.focus()
}, 0)
} finally {
input.disabled = false
}
}
function createConversation(username) {
return http.post('/api/conversations', { username })
}
```
在提交时,我们使用用户名对 `/api/conversations` 进行 POST 请求,并重定向到 `conversation` 页面(用于下一篇文章)。
### 对话列表

还是在这个文件中,我们将创建 `homePage()` 函数用来先异步加载对话。
```
export default async function homePage() {
const conversations = await getConversations().catch(err => {
console.error(err)
return []
})
/\*...\*/
}
function getConversations() {
return http.get('/api/conversations')
}
```
然后,在标记中添加一个列表来渲染对话。
```
<ol id="conversations"></ol>
```
将其添加到当前标记的正下方。
```
const conversationsOList = page.getElementById('conversations')
for (const conversation of conversations) {
conversationsOList.appendChild(renderConversation(conversation))
}
```
因此,我们可以将每个对话添加到这个列表中。
```
import { avatar, escapeHTML } from '../shared.js'
function renderConversation(conversation) {
const messageContent = escapeHTML(conversation.lastMessage.content)
const messageDate = new Date(conversation.lastMessage.createdAt).toLocaleString()
const li = document.createElement('li')
li.dataset['id'] = conversation.id
if (conversation.hasUnreadMessages) {
li.classList.add('has-unread-messages')
}
li.innerHTML = `
<a href="/conversations/${conversation.id}">
<div>
${avatar(conversation.otherParticipant)}
<span>${conversation.otherParticipant.username}</span>
</div>
<div>
<p>${messageContent}</p>
<time>${messageDate}</time>
</div>
</a>
`
return li
}
```
每个对话条目都包含一个指向对话页面的链接,并显示其他参与者信息和最后一条消息的预览。另外,您可以使用 `.hasUnreadMessages` 向该条目添加一个类,并使用 CSS 进行一些样式设置。也许是粗体字体或强调颜色。
请注意,我们需要转义信息的内容。该函数来自于 `static/shared.js` 文件:
```
export function escapeHTML(str) {
return str
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/"/g, '"')
.replace(/'/g, ''')
}
```
这会阻止将用户编写的消息显示为 HTML。如果用户碰巧编写了类似以下内容的代码:
```
<script>alert('lololo')</script>
```
这将非常烦人,因为该脚本将被执行?。所以,永远记住要转义来自不可信来源的内容。
### 消息订阅
最后但并非最不重要的一点,我想在这里订阅消息流。
```
const unsubscribe = subscribeToMessages(onMessageArrive)
page.addEventListener('disconnect', unsubscribe)
```
在 `homePage()` 函数中添加这一行。
```
function subscribeToMessages(cb) {
return http.subscribe('/api/messages', cb)
}
```
函数 `subscribe()` 返回一个函数,该函数一旦调用就会关闭底层连接。这就是为什么我把它传递给 <ruby> “断开连接” <rt> disconnect </rt></ruby>事件的原因;因此,当用户离开页面时,事件流将被关闭。
```
async function onMessageArrive(message) {
const conversationLI = document.querySelector(`li[data-id="${message.conversationID}"]`)
if (conversationLI !== null) {
conversationLI.classList.add('has-unread-messages')
conversationLI.querySelector('a > div > p').textContent = message.content
conversationLI.querySelector('a > div > time').textContent = new Date(message.createdAt).toLocaleString()
return
}
let conversation
try {
conversation = await getConversation(message.conversationID)
conversation.lastMessage = message
} catch (err) {
console.error(err)
return
}
const conversationsOList = document.getElementById('conversations')
if (conversationsOList === null) {
return
}
conversationsOList.insertAdjacentElement('afterbegin', renderConversation(conversation))
}
function getConversation(id) {
return http.get('/api/conversations/' + id)
}
```
每次有新消息到达时,我们都会在 DOM 中查询会话条目。如果找到,我们会将 `has-unread-messages` 类添加到该条目中,并更新视图。如果未找到,则表示该消息来自刚刚创建的新对话。我们去做一个对 `/api/conversations/{conversationID}` 的 GET 请求,以获取在其中创建消息的对话,并将其放在对话列表的前面。
---
以上这些涵盖了主页的所有内容 ?。 在下一篇文章中,我们将对 conversation 页面进行编码。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-home-page/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,723 | 构建一个即时消息应用(九):Conversation 页面 | https://nicolasparada.netlify.com/posts/go-messenger-conversation-page/ | 2020-10-18T22:02:00 | [
"即时消息"
] | https://linux.cn/article-12723-1.html | 
本文是该系列的第九篇,也是最后一篇。
* [第一篇: 模式](/article-11396-1.html)
* [第二篇: OAuth](/article-11510-1.html)
* [第三篇: 对话](/article-12056-1.html)
* [第四篇: 消息](/article-12680-1.html)
* [第五篇: 实时消息](/article-12685-1.html)
* [第六篇: 仅用于开发的登录](/article-12692-1.html)
* [第七篇: Access 页面](/article-12704-1.html)
* [第八篇: Home 页面](/article-12722-1.html)
在这篇文章中,我们将对<ruby> 对话 <rt> conversation </rt></ruby>页面进行编码。此页面是两个用户之间的聊天室。在顶部我们将显示其他参与者的信息,下面接着的是最新消息列表,以及底部的消息表单。
### 聊天标题

让我们从创建 `static/pages/conversation-page.js` 文件开始,它包含以下内容:
```
import http from '../http.js'
import { navigate } from '../router.js'
import { avatar, escapeHTML } from '../shared.js'
export default async function conversationPage(conversationID) {
let conversation
try {
conversation = await getConversation(conversationID)
} catch (err) {
alert(err.message)
navigate('/', true)
return
}
const template = document.createElement('template')
template.innerHTML = `
<div>
<a href="/">← Back</a>
${avatar(conversation.otherParticipant)}
<span>${conversation.otherParticipant.username}</span>
</div>
<!-- message list here -->
<!-- message form here -->
`
const page = template.content
return page
}
function getConversation(id) {
return http.get('/api/conversations/' + id)
}
```
此页面接收路由从 URL 中提取的会话 ID。
首先,它向 `/api/ conversations/{conversationID}` 发起一个 GET 请求,以获取有关对话的信息。 如果出现错误,我们会将其显示,并重定向回 `/`。然后我们呈现有关其他参与者的信息。
### 对话列表

我们也会获取最新的消息并显示它们。
```
let conversation, messages
try {
[conversation, messages] = await Promise.all([
getConversation(conversationID),
getMessages(conversationID),
])
}
```
更新 `conversationPage()` 函数以获取消息。我们使用 `Promise.all()` 同时执行这两个请求。
```
function getMessages(conversationID) {
return http.get(`/api/conversations/${conversationID}/messages`)
}
```
发起对 `/api/conversations/{conversationID}/messages` 的 GET 请求可以获取对话中的最新消息。
```
<ol id="messages"></ol>
```
现在,将该列表添加到标记中。
```
const messagesOList = page.getElementById('messages')
for (const message of messages.reverse()) {
messagesOList.appendChild(renderMessage(message))
}
```
这样我们就可以将消息附加到列表中了。我们以时间倒序来显示它们。
```
function renderMessage(message) {
const messageContent = escapeHTML(message.content)
const messageDate = new Date(message.createdAt).toLocaleString()
const li = document.createElement('li')
if (message.mine) {
li.classList.add('owned')
}
li.innerHTML = `
<p>${messageContent}</p>
<time>${messageDate}</time>
`
return li
}
```
每个消息条目显示消息内容本身及其时间戳。使用 `.mine`,我们可以将不同的 css 类附加到条目,这样您就可以将消息显示在右侧。
### 消息表单

```
<form id="message-form">
<input type="text" placeholder="Type something" maxlength="480" required>
<button>Send</button>
</form>
```
将该表单添加到当前标记中。
```
page.getElementById('message-form').onsubmit = messageSubmitter(conversationID)
```
将事件监听器附加到 “submit” 事件。
```
function messageSubmitter(conversationID) {
return async ev => {
ev.preventDefault()
const form = ev.currentTarget
const input = form.querySelector('input')
const submitButton = form.querySelector('button')
input.disabled = true
submitButton.disabled = true
try {
const message = await createMessage(input.value, conversationID)
input.value = ''
const messagesOList = document.getElementById('messages')
if (messagesOList === null) {
return
}
messagesOList.appendChild(renderMessage(message))
} catch (err) {
if (err.statusCode === 422) {
input.setCustomValidity(err.body.errors.content)
} else {
alert(err.message)
}
} finally {
input.disabled = false
submitButton.disabled = false
setTimeout(() => {
input.focus()
}, 0)
}
}
}
function createMessage(content, conversationID) {
return http.post(`/api/conversations/${conversationID}/messages`, { content })
}
```
我们利用 [partial application](https://en.wikipedia.org/wiki/Partial_application) 在 “submit” 事件处理程序中获取对话 ID。它 从输入中获取消息内容,并用它对 `/api/conversations/{conversationID}/messages` 发出 POST 请求。 然后将新创建的消息添加到列表中。
### 消息订阅
为了实现实时,我们还将订阅此页面中的消息流。
```
page.addEventListener('disconnect', subscribeToMessages(messageArriver(conversationID)))
```
将该行添加到 `conversationPage()` 函数中。
```
function subscribeToMessages(cb) {
return http.subscribe('/api/messages', cb)
}
function messageArriver(conversationID) {
return message => {
if (message.conversationID !== conversationID) {
return
}
const messagesOList = document.getElementById('messages')
if (messagesOList === null) {
return
}
messagesOList.appendChild(renderMessage(message))
readMessages(message.conversationID)
}
}
function readMessages(conversationID) {
return http.post(`/api/conversations/${conversationID}/read\_messages`)
}
```
在这里我们仍然使用这个应用的部分来获取会话 ID。 当新消息到达时,我们首先检查它是否来自此对话。如果是,我们会将消息条目预先添加到列表中,并向 `/api/conversations/{conversationID}/read_messages` 发起 POST 一个请求,以更新参与者上次阅读消息的时间。
---
本系列到此结束。 消息应用现在可以运行了。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
* [演示](https://go-messenger-demo.herokuapp.com/)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-conversation-page/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,724 | 如何在 Ubuntu 20.04 LTS 上安装深度(Deepin)桌面环境 | https://itsfoss.com/install-deepin-ubuntu/ | 2020-10-16T20:00:00 | [
"深度"
] | https://linux.cn/article-12724-1.html |
>
> 本教程向你展示在 Ubuntu 上安装深度(Deepin)桌面环境的正确步骤。还提到了移除步骤。
>
>
>

毫无疑问,深度操作系统(Deepin OS)是一个 [漂亮的 Linux 发行版](https://itsfoss.com/beautiful-linux-distributions/)。最近发布的 [深度操作系统 V20](https://itsfoss.com/deepin-20-review/) 就更加美观了。
[深度操作系统](https://www.deepin.org/en/) 是基于 [Debian](https://www.debian.org/) 的,默认的存储库镜像太慢了。如果你更愿意使用 Ubuntu,可以选择 [UbuntuDDE Linux 发行版](https://itsfoss.com/ubuntudde/) 形式的 Ubuntu 的深度操作系统的变体。它还不是 [官方的 Ubuntu 风格](https://itsfoss.com/which-ubuntu-install/) 之一。
[重新安装新的发行版](https://itsfoss.com/reinstall-ubuntu/) 是一个麻烦,因为你会丢失数据,你将不得不在新安装的 UbuntuDDE 上重新安装你的应用程序。
一个更简单的选择是在现有的 Ubuntu 系统上安装深度桌面环境(DDE)。毕竟,你可以轻松地在一个系统中安装多个[桌面环境](https://itsfoss.com/what-is-desktop-environment/)。
不要烦恼,这很容易做到,如果你不喜欢,也可以恢复这些更改。让我来告诉你怎么做。
### 在 Ubuntu 20.04 上安装深度桌面环境
UbuntuDDE 团队已为他们的发行版创建了一个 PPA,你可以使用相同的 PPA 在 Ubuntu 20.04 上安装深度桌面环境。请记住,此 PPA 仅适用于 Ubuntu 20.04。请阅读有关 [在 Ubuntu 中使用 PPA](https://itsfoss.com/ppa-guide/)。
>
> 没有深度桌面环境 V20
>
>
> 你将在此处使用 PPA 安装的深度桌面环境还不是新的 V20。它可能会在 Ubuntu 20.10 发布后出现,但是我们不能担保。
>
>
>
以下是你需要遵循的步骤:
**步骤 1**:你需要首先在终端上输入以下内容,来添加 [Ubuntu DDE Remix 团队的官方 PPA](https://launchpad.net/~ubuntudde-dev/+archive/ubuntu/stable):
```
sudo add-apt-repository ppa:ubuntudde-dev/stable
```
**步骤 2**:添加存储库以后,继而安装深度桌面环境。
```
sudo apt install ubuntudde-dde
```

现在,安装将启动,一段时间后,将要求你选择<ruby> 显示管理器 <rt> display manager </rt></ruby>。

如果需要深度桌面主题的锁屏,则需要选择 “lightdm”。如果不需要,你可以将其设置为 “gdm3”。
如果你看不到此选项,可以通过键入以下命令来获得它,然后选择你首选的显示管理器:
```
sudo dpkg-reconfigure lightdm
```
**步骤 3**: 完成后,你必须退出并通过选择 “Deepin” 会话再次登录,或者重新启动系统。

就是这样。马上在你的 Ubuntu 20.04 LTS 系统上享受深度桌面环境体验吧!

### 从 Ubuntu 20.04 删除深度桌面
如果你不喜欢这种体验,或者由于某些原因它有 bug,可以按照以下步骤将其删除。
**步骤 1**: 如果你已将 “lightdm” 设置为显示管理器,则需要在卸载深度桌面环境之前将显示管理器设置为 “gdm3”。为此,请键入以下命令:
```
sudo dpkg-reconfigure lightdm
```

然后,选择 “gdm3” 继续。
完成此操作后,你只需输入以下命令即可完全删除深度桌面环境:
```
sudo apt remove startdde ubuntudde-dde
```
你只需重启即可回到原来的 Ubuntu 桌面环境。如果图标没有响应,只需打开终端(`CTRL + ALT + T`)并输入:
```
reboot
```
### 总结
有不同的 [桌面环境选择](https://itsfoss.com/best-linux-desktop-environments/) 是件好事。如果你真的喜欢深度桌面环境的界面,那么这可能是在 Ubuntu 上体验深度操作系统的一种方式。
如果你有任何疑问或遇到任何问题,请在评论中告诉我。
---
via: <https://itsfoss.com/install-deepin-ubuntu/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Deepin is undoubtedly a [beautiful Linux distribution](https://itsfoss.com/beautiful-linux-distributions/). It is based on [Debian](https://www.debian.org/?ref=itsfoss.com) and the default repository mirrors are too slow. If you would rather stay with Ubuntu, you have the Deepin variant of Ubuntu in the form [UbuntuDDE Linux distribution](https://itsfoss.com/ubuntudde/). It is one of the [official Ubuntu flavors](https://itsfoss.com/which-ubuntu-install/) yet.
[Reinstalling a new distribution](https://itsfoss.com/reinstall-ubuntu/) is a bit of an annoyance for you would lose the data, and you’ll have to reinstall your applications on the newly installed UbuntuDDE.
A simpler option is to install the Deepin desktop environment on your existing Ubuntu system. After all, you can easily install more than one [desktop environment](https://itsfoss.com/what-is-desktop-environment/) in one system.
Fret not, it is easy to do it, and you can also revert the changes if you do not like it. Let me show you how to do that.
## Installing Deepin Desktop on Ubuntu
The UbuntuDDE team has created a PPA for their distribution, and you can use the same PPA to install Deepin desktop on supported Ubuntu releases, which is currently up to Ubuntu 23.04 Lunar Lobster. Please read about [using PPA in Ubuntu](https://itsfoss.com/ppa-guide/).
Here are the steps that you need to follow:
**Step 1**: You need to first add the [official PPA by Ubuntu DDE Remix team](https://launchpad.net/~ubuntudde-dev/+archive/ubuntu/stable?ref=itsfoss.com) by typing this on the terminal:
`sudo add-apt-repository ppa:ubuntudde-dev/stable`
**Step 2**: Once you have added the repository, proceed with installing the Deepin desktop.
`sudo apt install ubuntudde-dde`
Now, the installation will start and after a while, you will be asked to choose the [display manager](https://itsfoss.com/display-manager/).
You need to select “**lightdm**” if you want Deepin desktop themed lock screen. If not, you can set it as “**gdm3**” or any other display manager you are using.
In case you don’t see this option, you can get it by typing the following command and then selecting your preferred display manager:
`sudo dpkg-reconfigure lightdm`
**Step 3:** Once done, you have to log out and log in again by choosing the “**Deepin**” session or just reboot the system.
And, that is it. Enjoy the Deepin experience on your Ubuntu 20.04 LTS system in no time!
## Removing Deepin desktop from Ubuntu
In case you don’t like the experience or if it is buggy for some reason, you can remove it by following the steps below.
**Step 1: **If you’ve set “lightdm” as your display manager, you need to [change the display manager to GDM](https://itsfoss.com/switch-gdm-and-lightdm-in-ubuntu-14-04/) before uninstalling Deepin. To do that, type in the following command:
`sudo dpkg-reconfigure lightdm`
And select **gdm3** to proceed.
Once you’re done with that, you can enter the following command to remove Deepin completely:
`sudo apt remove startdde ubuntudde-dde`
To also remove related dependencies and other leftover packages, you can type in:
`sudo apt autoremove`
You can just [reboot to get back to your original Ubuntu desktop](https://itsfoss.com/schedule-shutdown-ubuntu/). If the icons become unresponsive, open the terminal (**CTRL + ALT + T**) and type in:
`reboot`
You can also remove the PPA from your system by entering:
```
sudo add-apt-repository --remove ppa:ubuntudde-dev/stable
sudo apt update
```
[LightDM](https://en.wikipedia.org/wiki/LightDM?ref=itsfoss.com), but for some reason, the Deepin Desktop login screen does not work with it. You will get the Deepin Desktop environment after logging in, but the lock screen stays the same as on Mint.
## Wrapping Up
It is good to have different [choices of desktop environments](https://itsfoss.com/best-linux-desktop-environments/). If you really like Deepin desktop interface, this could be a way to experience Deepin on Ubuntu.
By the way, there are several official Ubuntu flavors available and you may experiment with their looks.
[Explained: Which Ubuntu Version Should I Use?Confused about Ubuntu vs Xubuntu vs Lubuntu vs Kubuntu?? Want to know which Ubuntu flavor you should use? This beginner’s guide helps you decide which Ubuntu should you choose.](https://itsfoss.com/which-ubuntu-install/)

You may also customize Ubuntu to get a better experience with it.
[15 Simple Tips to Customize Ubuntu GNOMESome basic and interesting GNOME customization tips for enriching your experience and getting more out of your Ubuntu desktop.](https://itsfoss.com/gnome-tricks-ubuntu/)

If you have questions or if you face any issues, please let me know in the comments. |
12,726 | GNOME 3.38:可定制应用程序网格、性能改善 | https://itsfoss.com/gnome-3-38-release/ | 2020-10-16T20:58:00 | [
"GNOME"
] | https://linux.cn/article-12726-1.html | 
[GNOME 3.36](https://itsfoss.com/gnome-3-36-release/) 带来大量亟需的改进,同时也带来性能的重大提升。现在,在 6 个月后,我们终于引来了 GNOME 3.38,并带来了一系列重大的变化。
### GNOME 3.38 主要特色
这里是 GNOME 3.38 (代码名称:Orbis) 的主要亮点:
#### 可定制应用程序菜单
作为 GNOME 3.38 重大更改中的一部分,应用程序网格(或称应用菜单)现在是可以可定制的。
现在,你可以通过拖拽每个应用程序图标来创建文件夹,将它们移到文件夹,或移出文件夹并将其设置回应用网格。你也可以在应用网格中随心所欲地调整图标的位置。

此外,这些变化是一些即将到来的设计更改的基本组成部分,因此,看到我们可以期待的东西会很令人兴奋。
#### 日历菜单更新

随着最近一次的 GNOME 更新,通知区整洁了很多,但是现在随着 GNOME 3.38 的到来,你终于可以通过日历区域的正下方访问日历事件,使事情变得方便且容易访问。
它不是一个重大的视觉改造,但也是一些改善。
#### 家长控制改善
作为 GNOME 3.38 一部分,你将会注意家长控制服务。它支持与桌面、shell、设置以及其它各种各样组件的集成,来帮助你限制用户可以访问的内容。
#### 重新启动按钮
一些细微的改善导致了巨大的变化,重新启动按钮正是其中的一个变化。先单击 “关闭电源” / “关机” 按钮,再单击 “重新启动” 按钮的操作来重新启动系统总是让人很烦。
因此,随着 GNOME 3.38 的到来,你将最终会注意到一个作为单独按钮的 “重新启动” ,这将节省你的单击次数,平复你烦闷的心情。
#### 屏幕录制改善
[GNOME shell 内置的屏幕录制](https://itsfoss.com/gnome-screen-recorder/) 现在是一项独立的系统服务,这可能会使录制屏幕成为一种平滑流畅的体验。
另外,窗口截屏也有一些改善,并修复了一些错误:
#### GNOME 应用程序更新
GNOME 计算器也收到很多的错误修复。除此之外,你也将发现 [epiphany GNOME 浏览器](https://en.wikipedia.org/wiki/GNOME_Web) 的一些重大改变。
GNOME Boxes 现在允许你从一个操作系统列表中选择将要运行的操作系统,GNOME 地图也有一些图像用户界面上的更改。
当然,不仅限于这些,你页将注意到 GNOME 控制中心、联系人、照片、Nautilus,以及其它一些软件包的细微更新和修复。
#### 性能和多显示器支持改善
这里有一大堆底层的改进来全面地改善 GNOME 3.38 。例如,[Mutter](https://en.wikipedia.org/wiki/Mutter_(software)) 有一些重要的修正,它现在允许在两个显示器中使用不同的刷新频率。

先前,如果一台显示器的刷新频率为 60 Hz,而另一台的刷新频率为 144 Hz ,那么刷新频率较慢的显示器将限制另外一台显示器的刷新频率。但是,随着在 GNOME 3.38 中的改善,它将能够处理多个显示器,而不会使显示器相互限制。
另外,[Phoronix](https://www.phoronix.com/scan.php?page=news_item&px=GNOME-3.38-Last-Min-Mutter) 报告的一些更改指出,在一些情况下,缩短大约 10% 的渲染时间。因此,这绝对是一个很棒的性能优化。
#### 各种各样的其它更改
* 电池百分比指示器
* 电源菜单中的重新启动选项
* 新的欢迎指引
* 指纹登录
* 二维码扫描以共享 Wi-Fi 热点
* GNOME 浏览器的隐私和其它改善
* GNOME 地图现在反应敏捷并能根据屏幕大小改变其大小
* 重新修订的图标
你可以在它们的官方 [更改日志](https://help.gnome.org/misc/release-notes/3.38) 中找到一个详细的更改列表。
### 总结
GNOME 3.38 确实是一个令人赞叹的更新,它改善了 GNOME 用户体验。尽管 GNOME 3.36 带来了性能的很大改善,但是针对 GNOME 3.38 的更多优化仍然是一件非常好的事.
GNOME 3.38 将在 Ubuntu 20.10 和 [Fedora 33](https://itsfoss.com/fedora-33/) 中可用。Arch 和 Manjaro 用户应该很快就能获得。
我认为有很多变化是朝着正确的方向发展的。你觉得呢?
---
via: <https://itsfoss.com/gnome-3-38-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [GNOME 3.36](https://itsfoss.com/gnome-3-36-release/) brought some much-needed improvements along with a major performance boost. Now, after 6 months, we’re finally here with GNOME 3.38 with a big set of changes.
## GNOME 3.38 Key Features
Here are the main highlight of GNOME 3.38 codenamed Orbis:
### Customizable App Menu
The app grid or the app menu will now be customizable as part of a big change in GNOME 3.38.
Now, you can create folders by dragging application icons over each other and move them to/from folders and set it right back in the app grid. You can also just reposition the icons as you want in the app grid.
Also, these changes are some basic building blocks for upcoming design changes planned for future updates — so it’ll be exciting to see what we can expect.
### Calendar Menu Updates
The notification area is a lot cleaner with the recent GNOME updates but now with GNOME 3.38, you can finally access calendar events right below the calendar area to make things convenient and easy to access.
It’s not a major visual overhaul, but there’s a few improvements to it.
### Parental Controls Improvement
You will observe a parental control service as a part of GNOME 3.38. It supports integration with various components of the desktop, the shell, the settings, and others to help you limit what a user can access.
### The Restart Button
Some subtle improvements lead to massive changes and this is exactly one of those changes. It’s always annoying to click on the “Power Off” / “Shut down” button first and then hit the “Restart” button to reboot the system.
So, with GNOME 3.38, you will finally notice a “Restart” entry as a separate button which will save you click and give you a peace of mind.
### Screen Recording Improvements
[GNOME shell’s built-in screen record](https://itsfoss.com/gnome-screen-recorder/) is now a separate system service which should potentially make recording the screen a smooth experience.
Also, window screencasting had several improvements to it along with some bug fixes:
### GNOME apps Updates
The GNOME calculator has received a lot of bug fixes. In addition to that, you will also find some major changes to the [epiphany GNOME browser](https://en.wikipedia.org/wiki/GNOME_Web).
GNOME Boxes now lets you pick the OS from a list of operating systems and GNOME Maps was updated with some UI changes as well.
Not just limited to these, you will also find subtle updates and fixes to GNOME control center, Contacts, Photos, Nautilus, and some other packages.
### Performance & multi-monitor support improvements
There’s a bunch of under-the-hood improvements to improve GNOME 3.38 across the board. For instance, there were some serious fixes to [Mutter](https://en.wikipedia.org/wiki/Mutter_(software)) which now lets two monitors run at different refresh rates.

Previously, if you had one monitor with a 60 Hz refresh rate and another with 144 Hz, the one with the slower rate will limit the second monitor. But, with the improvements in GNOME 3.38, it will handle multi-monitors without limiting any of them.
Also, some changes reported by [Phoronix](https://www.phoronix.com/scan.php?page=news_item&px=GNOME-3.38-Last-Min-Mutter) pointed out around 10% lower render time in some cases. So, that’s definitely a great performance optimization.
### Miscellaneous other changes
- Battery percentage indicator
- Restart option in the power menu
- New welcome tour
- Fingerprint login
- QR code scanning for sharing Wi-Fi hotspot
- Privacy and other improvements to GNOME Browser
- GNOME Maps is now responsive and changes its size based on the screen
- Revised icons
You can find a details list of changes in their official [changelog](https://help.gnome.org/misc/release-notes/3.38).
## Wrapping Up
GNOME 3.38 is indeed an impressive update to improve the GNOME experience. Even though the performance was greatly improved with GNOME 3.36, more optimizations is a very good thing for GNOME 3.38.
GNOME 3.38 will be available in Ubuntu 20.10 and [Fedora 33](https://itsfoss.com/fedora-33/). Arch and Manjaro users should be getting it soon.
I think there are plenty of changes in right direction. What do you think? |
12,729 | 如何在 Linux 上安装微软 Windows 计算器 | https://betanews.com/2020/10/15/how-to-install-windows-calculator-linux/ | 2020-10-17T21:36:00 | [
"微软",
"计算器"
] | https://linux.cn/article-12729-1.html | 
微软不再是 Linux 或开源社区的敌人。不管你信不信,Windows 的制造商现在是一个盟友。我知道这很令人震惊,但完全是事实。多亏了 WSL,Linux 现在已经内置于 Windows 中,而微软也有几款应用可供 Linux 使用。
该公司甚至将一些应用程序也开源了。例如,早在 2019 年,微软就[在 GitHub 上发布了 Windows 计算器的源代码](https://betanews.com/2019/03/06/microsoft-windows-calculator-open-source-github/)。而现在,该计算器应用已经被 Uno Platform 移植到 Linux 上。最重要的是,它的安装超简单,因为它是以 Snap 格式打包的。
“Uno Platform 社区的好人们已经将开源的 Windows 计算器移植到了 Linux 上。而且做得比微软把他们的浏览器带到 Linux 上还快。这个计算器发布在 Snap 商店中,可以马上下载。”Canonical 产品经理 Rhys Davies [解释](https://snapcraft.io/blog/the-windows-calculator-on-linux-with-uno-platform)道。
Davies 进一步解释说:“在 UnoConf 2020 期间,Uno Platform 将他们的支持带到了 Linux。Uno Platform 允许你使用 C# 和 XAML 从单一代码库中构建本地移动、桌面和 WebAssembly 应用程序。你可以使用 Visual Studio 和 Ubuntu 在 WSL 上使用 Uno Platform 构建 Linux 应用程序。你可以在 Snap 商店中抓取它们,然后在从 Linux 桌面到树莓派等各种系统上运行你的应用程序。”
那么,在 Linux 上安装 Windows 计算器有多容易呢?如果你有一个现代的操作系统,内置 Snap 支持,比如 Ubuntu 20.04,你可以从[这里的 Snap 商店](https://snapcraft.io/uno-calculator)安装它。喜欢使用命令行吗?只需在终端中输入 `snap install uno-calculator` 即可。
请注意:如果你的发行版没有原生的 Snap 支持,你可以按照[这里的说明](https://snapcraft.io/docs/installing-snapd)进行设置。
当然,你可能想知道为什么你应该在 Linux 上安装 Windows 计算器。嗯……只是因为你可以,当然!但说真的,它实际上是一个设计得非常好的应用程序,你可能会发现它比其他计算器程序更优秀 —— 包括任何预装在你的操作系统上的程序。试试吧,伙计们 —— 你可能会喜欢它。
---
via: <https://betanews.com/2020/10/15/how-to-install-windows-calculator-linux/>
作者:[Brian Fagioli](https://betanews.com/author/brianfagioli/) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12726-1.html) 荣誉推出
| 200 | OK | # How to install Microsoft Windows Calculator on Linux

Microsoft is no longer an enemy of the Linux or Open Source communities. Believe it or not, the Windows-maker is an ally these days. Shocking, I know, but totally true. Linux is now built into Windows thanks to WSL, and Microsoft has several apps available for Linux.
The company has even made some of its apps open source as well. For instance, back in 2019, Microsoft [released the source for Windows Calculator on GitHub](https://betanews.com/2019/03/06/microsoft-windows-calculator-open-source-github/). And now, that calculator app has been ported to Linux by [Uno Platform](https://platform.uno/). Best of all, its insanely easy to install as it is packaged in Snap format.
**ALSO READ:** [Ubuntu Linux 20.10 'Groovy Gorilla' Beta available for download](https://betanews.com/2020/10/02/ubuntu-linux-2010-groovy-gorilla-beta/)
"The good folks in the Uno Platform community have ported the open-source Windows Calculator to Linux. And they’ve done it quicker than Microsoft could bring their browser to Linux. The calculator is published in the snapstore and can be downloaded right away," [explains](https://snapcraft.io/blog/the-windows-calculator-on-linux-with-uno-platform) Rhys Davies, Product Manager, Canonical.
Davies further explains, "The Uno Platform brought their support to Linux during UnoConf 2020. Uno Plaform allows you to build native mobile, desktop, and WebAssembly apps with C# and XAML from a single code base. You can build Linux applications with Uno Platform using Visual Studio and Ubuntu on WSL. You can snap them up in the snap store and then run your apps on anything from the Linux desktop to a Raspberry Pi."
So, how easy is it to install Windows Calculator on Linux? If you have a modern operating system with baked-in Snap support, such as Ubuntu 20.04, you can install it from the Snap store [here](https://snapcraft.io/uno-calculator). Prefer to use the command line? Just enter **snap install uno-calculator** into terminal.
**Please note:** If your distro doesn't have native Snap support, you can follow instructions [here](https://snapcraft.io/docs/installing-snapd) to set it up.
Of course, you are probably wondering *why *you should install the Windows Calculator on Linux. Well... because you can, of course! But seriously, it is actually a very well-designed app that you may find to be superior to other calculator programs -- including whatever came pre-installed with your operating system. Give it a try, folks -- you just might like it. |
12,732 | C 语言简单编程速成 | https://opensource.com/article/20/8/c-programming-cheat-sheet | 2020-10-18T21:37:03 | [
"C语言"
] | https://linux.cn/article-12732-1.html |
>
> 我们将所有的 C 语言要素放置到一份易读的备忘录上。
>
>
>

1972 年,<ruby> 丹尼斯·里奇 <rt> Dennis Ritchie </rt></ruby>任职于<ruby> 贝尔实验室 <rt> Bell Labs </rt></ruby>,在几年前,他和他的团队成员发明了 Unix 。在创建了一个经久不衰的操作系统(至今仍在使用)之后,他需要一种好的方法来对这些 Unix 计算机编程,以便它们可用执行新的任务。在现在看来,这很奇怪,但在当时,编程语言相对较少,Fortran、Lisp、[Algol](https://opensource.com/article/20/6/algol68) 以及 B 语言都很流行,但是,对于贝尔实验室的研究员们想要做的事情来说,它们还是远远不够的。丹尼斯·里奇表现出一种后来被称为程序员的主要特征的特质:创造了他自己的解决方案。他称之为 C 语言,并且在近 50 年后,它仍在广泛的使用。
### 为什么你应该学习 C 语言
今天,有很多语言为程序员提供了比 C 语言更多的特性。最明显的是 C++ 语言,这是一种以相当露骨的方式命名的语言,它构建在 C 语言之上,创建了一种很好的面向对象语言。不过,许多其它语言的存在是有充分理由的。计算机擅长一致的重复,因此任何可预见的东西都可以构建在编程语言中,对程序员来说这意味着更少的工作量。为什么在 C++ 语言中用一行语句就可以将一个 `int` 转换为一个 `long` 时(`long x = long(n);`),还要在 C 语言用两行语句呢?
然而,C 语言在今天仍然有用。
首先,C 语言是一种相当简约和直接的语言。除了编程的基础知识之外,并没有很高级的概念,这很大程度上是因为 C 语言实际上就是现代编程语言的基础之一。例如,C 语言的特性之一是数组,但是它不提供字典(除非你自己写一个)。当你学习 C 语言时,你会学习编程的基础组成部分,它可以帮助你认识到如今的编程语言的改进及其的精心设计。
因为 C 语言是一种最小化的编程语言,你的应用程序很可能会获得性能上的提升,这在其它许多编程语言中是看不到的。当你考虑你的代码可以执行多快的时候,很容易陷入锱铢必较的境地,因此,重要的是要问清楚你是否*需要*为某一特定任务提供更多的速度。与 Python 或 Java 相比,使用 C 语言,你在每行代码中需要纠结的地方更少。C 语言程序运行很快。这是 Linux 内核使用 C 语言编写的一个很好的理由。
最后,C 语言很容易入门,特别是,如果你正在运行 Linux,就已经能运行 C 语言代码了,因为 Linux 系统包含 GNU C 库(`glibc`)。为了编写和构建 C 语言程序,你需要做的全部工作就是安装一个编译器,打开一个文本编辑器,开始编码。
### 开始学习 C 语言
如果你正在运行 Linux ,你可以使用你的软件包管理器安装一个 C 编译器。在 Fedora 或 RHEL 上:
```
$ sudo dnf install gcc
```
在 Debian 及其衍生系统上:
```
$ sudo apt install build-essential
```
在 macOS 上,你可以 [安装 Homebrew](https://opensource.com/article/20/6/homebrew-mac) ,并使用它来安装 [GCC](https://gcc.gnu.org/):
```
$ brew install gcc
```
在 Windows 上, 你可以使用 [MinGW](https://opensource.com/article/20/8/gnu-windows-mingw) 安装一套最小的包含 GCC 的 GNU 实用程序集。
在 Linux 或 macOS 上验证你已经安装的 GCC:
```
$ gcc --version
gcc (GCC) x.y.z
Copyright (C) 20XX Free Software Foundation, Inc.
```
在 Windows 上,提供 EXE 文件的完整路径:
```
PS> C:\MinGW\bin\gcc.exe --version
gcc.exe (MinGW.org GCC Build-2) x.y.z
Copyright (C) 20XX Free Software Foundation, Inc.
```
### C 语法
C 语言不是一种脚本语言。它是一种编译型语言,这意味着它由 C 编译器处理来产生一个二进制可执行文件。这不同于脚本语言(如 [Bash](https://opensource.com/resources/what-bash))或混合型语言(如 [Python](https://opensource.com/resources/python))。
在 C 语言中,你可以创建*函数*来执行你希望做到的任务。默认情况下,执行的是一个名为 `main` 的函数。
这里是一个使用 C 语言写的简单的 “hello world” 程序:
```
#include <stdio.h>
int main() {
printf("Hello world");
return 0;
}
```
第一行包含一个被称为 `stdio.h`(标准输入和输出)的 *头文件*,它基本上是自由使用的、非常初级的 C 语言代码,你可以在你自己的程序中重复使用它。然后创建了一个由一条基本的输出语句构成的名为 `main` 的函数。保存这些文本到一个被称为 `hello.c` 的文件中,然后使用 GCC 编译它:
```
$ gcc hello.c --output hello
```
尝试运行你的 C 语言程序:
```
$ ./hello
Hello world$
```
#### 返回值
这是 Unix 哲学的一部分,一个函数在执行后“返回”一些东西:在成功时不返回任何东西,在失败时返回其它的一些东西(例如,一个错误信息)。这些返回的内容通常使用数字(确切地说是整数)表示:`0` 表示没有错误,任何大于 `0` 的数字都表示一些不成功的状态。
Unix 和 Linux 被设计成在运行成功时保持沉默是很明智的。这是为了让你在执行一系列命令时,假设没有任何错误或警告会妨碍你的工作,从而可以始终为成功执行做准备。类似地,在 C 语言中的函数在设计上也预期不出现错误。
你可以通过一个小的修改,让你的程序看起来是失败的,就可以看到这一点:
```
include <stdio.h>
int main() {
printf("Hello world");
return 1;
}
```
编译它:
```
$ gcc hello.c --output failer
```
现在使用一个内置的 Linux 测试方式来运行它。仅在*成功*时,`&&` 操作符才会执行一个命令的第二部分。例如:
```
$ echo "success" && echo "it worked"
success
it worked
```
在*失败*时,`||` 测试会执行一个命令的第二部分。
```
$ ls blah || echo "it did not work"
ls: cannot access 'blah': No such file or directory
it did not work
```
现在,尝试你的程序,在成功时,它*不*返回 `0`;而是返回 `1`:
```
$ ./failer && echo "it worked"
String is: hello
```
这个程序成功地执行了,但是没有触发第二个命令。
#### 变量和类型
在一些语言中,你可以创建变量而不具体指定变量所包含的数据的*类型*。这些语言如此设计使得解释器需要对一个变量运行一些测试来视图发现变量是什么样的数据类型。例如,`var=1` 定义了一个整型数,当你创建一个表达式将 `var` 与某些东西相加时,Python 知道显然它是一个整型数。它同样知道当你连接 `hello` 和 `world` 时,单词 `world` 是一个字符串。
C 语言不会为你做任何这些识别和调查;你必须自己定义你的变量类型。这里有几种变量类型,包括整型(`int`),字符型(`char`),浮点型(`float`),布尔型(`boolean`)。
你可能也注意到这里没有字符串类型。与 Python 和 Java 和 Lua 以及其它的编程语言不同,C 语言没有字符串类型,而是将字符串看作一个字符数组。
这里是一些简单的代码,它建立了一个 `char` 数组变量,然后使用 [printf](https://opensource.com/article/20/8/printf) 将数组变量和一段简单的信息打印到你的屏幕上:
```
#include <stdio.h>
int main() {
char var[6] = "hello";
printf("Your string is: %s\r\n",var);
}
```
你可能会注意到,这个代码示例向一个由五个字母组成的单词提供了六个字符的空间。这是因为在字符串的结尾有处一个隐藏的终止符,它占用了数组中的一个字节。你可以通过编译和执行代码来运行它:
```
$ gcc hello.c --output hello
$ ./hello
hello
```
### 函数
和其它的编程语言一样,C 函数也接受可选的参数。你可以通过定义你希望函数接受的数据类型,来将参数从一个函数传递到另一个函数:
```
#include <stdio.h>
int printmsg(char a[]) {
printf("String is: %s\r\n",a);
}
int main() {
char a[6] = "hello";
printmsg(a);
return 0;
}
```
简单地将一个函数分解为两个函数的这种方法并不是非常有用,但是它演示了默认运行 `main` 函数以及如何在函数之间传递数据。
### 条件语句
在真实的编程中,你通常希望你的代码根据数据做出判断。这是使用*条件*语句完成的,`if` 语句是其中最基础的一个语句。
为了使这个示例程序更具动态性,你可以包含 `string.h` 头文件,顾名思义,它包含用于检查字符串的代码。尝试使用来自 `string.h` 文件中的 `strlen` 函数测试传递给 `printmsg` 函数的字符串是否大于 `0`:
```
#include <stdio.h>
#include <string.h>
int printmsg(char a[]) {
size_t len = strlen(a);
if ( len > 0) {
printf("String is: %s\r\n",a);
}
}
int main() {
char a[6] = "hello";
printmsg(a);
return 1;
}
```
正如在这个示例中所实现的,该条件永远都不会是非真的,因为所提供的字符串总是 `hello`,它的长度总是大于 `0`。这个不够认真的重新实现的 `echo` 命令的最后一点要做是接受来自用户的输入。
### 命令参数
`stdio.h` 文件包含的代码在每次程序启动时提供了两个参数: 一个是命令中包含多少项的计数(`argc`),一个是包含每个项的数组(`argv`)。例如, 假设你发出这个虚构的命令:
```
$ foo -i bar
```
`argc` 是 `3`,`argv` 的内容是:
* `argv[0] = foo`
* `argv[1] = -i`
* `argv[2] = bar`
你可以修改示例 C 语言程序来以字符串方式接受 `argv[2]`,而不是默认的 `hello` 吗?
### 命令式编程语言
C 语言是一种命令式编程语言。它不是面向对象的,也没有类结构。使用 C 语言的经验可以教你很多关于如何处理数据,以及如何更好地管理你的代码运行时生成的数据。多使用 C 语言,你最后能够编写出其它语言(例如 Python 和 Lua)可以使用的库。
想要了解更多关于 C 的知识,你需要使用它。在 `/usr/include/` 中查找有用的 C 语言头文件,并且看看你可以做什么小任务来使 C 语言对你有用。在学习的过程中,使用来自 FreeDOS 的 [Jim Hall](https://opensource.com/users/jim-hall) 编写的 [C 语言忘备录](https://opensource.com/downloads/c-programming-cheat-sheet)。它在一张双面纸忘备录上放置了所有的基本要素,所以在你练习时,可以立即访问 C 语言语法的所有要素。
---
via: <https://opensource.com/article/20/8/c-programming-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 1972, Dennis Ritchie was at Bell Labs, where a few years earlier, he and his fellow team members invented Unix. After creating an enduring OS (still in use today), he needed a good way to program those Unix computers so that they could perform new tasks. It seems strange now, but at the time, there were relatively few programming languages; Fortran, Lisp, [Algol](https://opensource.com/article/20/6/algol68), and B were popular but insufficient for what the Bell Labs researchers wanted to do. Demonstrating a trait that would become known as a primary characteristic of programmers, Dennis Ritchie created his own solution. He called it C, and nearly 50 years later, it's still in widespread use.
## Why you should learn C
Today, there are many languages that provide programmers more features than C. The most obvious one is C++, a rather blatantly named language that built upon C to create a nice object-oriented language. There are many others, though, and there's a good reason they exist. Computers are good at consistent repetition, so anything predictable enough to be built into a language means less work for programmers. Why spend two lines recasting an `int`
to a `long`
in C when one line of C++ (`long x = long(n);`
) can do the same?
And yet C is still useful today.
First of all, C is a fairly minimal and straightforward language. There aren't very advanced concepts beyond the basics of programming, largely because C is literally one of the foundations of modern programming languages. For instance, C features arrays, but it doesn't offer a dictionary (unless you write it yourself). When you learn C, you learn the building blocks of programming that can help you recognize the improved and elaborate designs of recent languages.
Because C is a minimal language, your applications are likely to get a boost in performance that they wouldn't see with many other languages. It's easy to get caught up in the race to the bottom when you're thinking about how fast your code executes, so it's important to ask whether you *need* more speed for a specific task. And with C, you have less to obsess over in each line of code, compared to, say, Python or Java. C is fast. There's a good reason the Linux kernel is written in C.
Finally, C is easy to get started with, especially if you're running Linux. You can already run C code because Linux systems include the GNU C library (`glibc`
). To write and build it, all you need to do is install a compiler, open a text editor, and start coding.
## Getting started with C
If you're running Linux, you can install a C compiler using your package manager. On Fedora or RHEL:
`$ sudo dnf install gcc`
On Debian and similar:
`$ sudo apt install build-essential `
On macOS, you can [install Homebrew](https://opensource.com/article/20/6/homebrew-mac) and use it to install [GCC](https://gcc.gnu.org/):
`$ brew install gcc`
On Windows, you can install a minimal set of GNU utilities, GCC included, with [MinGW](https://opensource.com/article/20/8/gnu-windows-mingw).
Verify you've installed GCC on Linux or macOS:
```
$ gcc --version
gcc (GCC) x.y.z
Copyright (C) 20XX Free Software Foundation, Inc.
```
On Windows, provide the full path to the EXE file:
```
PS> C:\MinGW\bin\gcc.exe --version
gcc.exe (MinGW.org GCC Build-2) x.y.z
Copyright (C) 20XX Free Software Foundation, Inc.
```
## C syntax
C isn't a scripting language. It's compiled, meaning that it gets processed by a C compiler to produce a binary executable file. This is different from a scripting language like [Bash](https://opensource.com/resources/what-bash) or a hybrid language like [Python](https://opensource.com/resources/python).
In C, you create *functions* to carry out your desired task. A function named `main`
is executed by default.
Here's a simple "hello world" program written in C:
```
#include <stdio.h>
int main() {
printf("Hello world");
return 0;
}
```
The first line includes a *header file*, essentially free and very low-level C code that you can reuse in your own programs, called `stdio.h`
(standard input and output). A function called `main`
is created and populated with a rudimentary print statement. Save this text to a file called `hello.c`
, then compile it with GCC:
`$ gcc hello.c --output hello`
Try running your C program:
```
$ ./hello
Hello world$
```
### Return values
It's part of the Unix philosophy that a function "returns" something to you after it executes: nothing upon success and something else (an error message, for example) upon failure. These return codes are often represented with numbers (integers, to be precise): 0 represents nothing, and any number higher than 0 represents some non-successful state.
There's a good reason Unix and Linux are designed to expect silence upon success. It's so that you can always plan for success by assuming no errors nor warnings will get in your way when executing a series of commands. Similarly, functions in C expect no errors by design.
You can see this for yourself with one small modification to make your program appear to fail:
```
include <stdio.h>
int main() {
printf("Hello world");
return 1;
}
```
Compile it:
`$ gcc hello.c --output failer`
Now run it using a built-in Linux test for success. The `&&`
operator executes the second half of a command only upon success. For example:
```
$ echo "success" && echo "it worked"
success
it worked
```
The `||`
test executes the second half of a command upon *failure*.
```
$ ls blah || echo "it did not work"
ls: cannot access 'blah': No such file or directory
it did not work
```
Now try your program, which does *not* return 0 upon success; it returns 1 instead:
```
$ ./failer && echo "it worked"
String is: hello
```
The program executed successfully, yet did not trigger the second command.
### Variables and types
In some languages, you can create variables without specifying what *type* of data they contain. Those languages have been designed such that the interpreter runs some tests against a variable in an attempt to discover what kind of data it contains. For instance, Python knows that `var=1`
defines an integer when you create an expression that adds `var`
to something that is obviously an integer. It similarly knows that the word `world`
is a string when you concatenate `hello`
and `world`
.
C doesn't do any of these investigations for you; you must define your variable type. There are several types of variables, including integers (int), characters (char), float, and Boolean.
You may also notice there's no string type. Unlike Python and Java and Lua and many others, C doesn't have a string type and instead sees strings as an array of characters.
Here's some simple code that establishes a `char`
array variable, and then prints it to your screen using [printf](https://opensource.com/article/20/8/printf) along with a short message:
```
#include <stdio.h>
int main() {
char var[6] = "hello";
printf("Your string is: %s\r\n",var);
```
You may notice that this code sample allows six characters for a five-letter word. This is because there's a hidden terminator at the end of the string, which takes up one byte in the array. You can run the code by compiling and executing it:
```
$ gcc hello.c --output hello
$ ./hello
hello
```
## Functions
As with other languages, C functions take optional parameters. You can pass parameters from one function to another by defining the type of data you want a function to accept:
```
#include <stdio.h>
int printmsg(char a[]) {
printf("String is: %s\r\n",a);
}
int main() {
char a[6] = "hello";
printmsg(a);
return 0;
}
```
The way this code sample breaks one function into two isn't very useful, but it demonstrates that `main`
runs by default and how to pass data between functions.
## Conditionals
In real-world programming, you usually want your code to make decisions based on data. This is done with *conditional* statements, and the `if`
statement is one of the most basic of them.
To make this example program more dynamic, you can include the `string.h`
header file, which contains code to examine (as the name implies) strings. Try testing whether the string passed to the `printmsg`
function is greater than 0 by using the `strlen`
function from the `string.h`
file:
```
#include <stdio.h>
#include <string.h>
int printmsg(char a[]) {
size_t len = strlen(a);
if ( len > 0) {
printf("String is: %s\r\n",a);
}
}
int main() {
char a[6] = "hello";
printmsg(a);
return 1;
}
```
As implemented in this example, the sample condition will never be untrue because the string provided is always "hello," the length of which is always greater than 0. The final touch to this humble re-implementation of the `echo`
command is to accept input from the user.
## Command arguments
The `stdio.h`
file contains code that provides two arguments each time a program is launched: a count of how many items are contained in the command (`argc`
) and an array containing each item (`argv`
). For example, suppose you issue this imaginary command:
`$ foo -i bar`
The `argc`
is three, and the contents of `argv`
are:
`argv[0] = foo`
`argv[1] = -i`
`argv[2] = bar`
Can you modify the example C program to accept `argv[2]`
as the string instead of defaulting to `hello`
?
## Imperative programming
C is an imperative programming language. It isn't object-oriented, and it has no class structure. Using C can teach you a lot about how data is processed and how to better manage the data you generate as your code runs. Use C enough, and you'll eventually be able to write libraries that other languages, such as Python and Lua, can use.
To learn more about C, you need to use it. Look in `/usr/include/`
for useful C header files, and see what small tasks you can do to make C useful to you. As you learn, use our [C cheat sheet](https://opensource.com/downloads/c-programming-cheat-sheet) by [Jim Hall](https://opensource.com/users/jim-hall) of FreeDOS. It's got all the basics on one double-sided sheet, so you can immediately access all the essentials of C syntax while you practice.
## 5 Comments |
12,733 | 将你的日历与 Ansible 集成,以避免与日程冲突 | https://opensource.com/article/20/10/calendar-ansible | 2020-10-18T22:11:22 | [
"Ansible",
"日历"
] | https://linux.cn/article-12733-1.html |
>
> 通过将日历应用集成到 Ansible 中,确保你的自动化工作流计划不会与其他东西冲突。
>
>
>

“随时”是执行自动化工作流的好时机吗?出于不同的原因,答案可能是否定的。
如果要避免同时进行更改,以最大限度地减少对关键业务流程的影响,并降低意外服务中断的风险,则在你的自动化运行的同时,其他任何人都不应该试图进行更改。
在某些情况下,可能存在一个正在进行的计划维护窗口。或者,可能有大型事件即将来临、一个关键的业务时间、或者假期(你或许不想在星期五晚上进行更改)。

无论出于什么原因,你都希望将此信息发送到你的自动化平台,以防止在特定时间段内执行周期性或临时任务。用变更管理的行话,我说的是当变更活动不应该发生时,指定封锁窗口。
### Ansible 中的日历集成
如何在 [Ansible](https://docs.ansible.com/ansible/latest/index.html) 中实现这个功能?虽然它本身没有日历功能,但 Ansible 的可扩展性将允许它与任何具有 API 的日历应用集成。
目标是这样的:在执行任何自动化或变更活动之前,你要执行一个 `pre-task` ,它会检查日历中是否已经安排了某些事情(目前或最近),并确认你没有在一个阻塞的时间段中。
想象一下,你有一个名为 `calendar` 的虚构模块,它可以连接到一个远程日历,比如 Google 日历,以确定你指定的时间是否已经以其他方式被标记为繁忙。你可以写一个类似这样的剧本:
```
- name: Check if timeslot is taken
calendar:
time: "{{ ansible_date_time.iso8601 }}"
register: output
```
Ansible 实际会给出 `ansible_date_time`,将其传递给 `calendar` 模块,以验证时间的可用性,以便它可以注册响应 (`output`),用于后续任务。
如果你的日历是这样的:

那么这个任务的输出就会指明这个时间段被占用的事实 (`busy: true`):
```
ok: [localhost] => {
"output": {
"busy": true,
"changed": false,
"failed": false,
"msg": "The timeslot 2020-09-02T17:53:43Z is busy: true"
}
}
```
### 阻止任务运行
接下来,[Ansible Conditionals](https://docs.ansible.com/ansible/latest/user_guide/playbooks_conditionals.html) 将帮助阻止所有之后任务的执行。一个简单的例子,你可以在下一个任务上使用 `when` 语句来强制它只有当上一个输出中的 `busy` 字段不是 `true` 时,它才会运行:
```
tasks:
- shell: echo "Run this only when not busy!"
when: not output.busy
```
### 总结
在[上一篇文章](https://medium.com/swlh/python-and-ansible-to-automate-a-network-security-workflow-28b9a44660c6)中,我说过 Ansible 是一个将事物连接在一起的框架,将不同的组成部分相互连接,以协调端到端自动化工作流。
这篇文章探讨了 Ansible 剧本如何与日历应用集成以检查可用性。然而,我只做了一些表面工作!例如,你的任务也可以阻止日历中的一个时间段,这里的发挥空间很大。
在我的下一篇文章中,我将深入 `calendar` 模块是如何构建的,以及其他编程语言如何与 Ansible 一起使用。如果你和我一样是 [Go](https://golang.org/) 的粉丝,请继续关注!
---
*这篇文章最初发表在 Medium 上,名为 [Ansible and Google Calendar integration for change management](https://medium.com/swlh/ansible-and-google-calendar-integration-for-change-management-7c00553b3d5a),采用 CC BY-SA 4.0 许可,经许可后转载。*
---
via: <https://opensource.com/article/20/10/calendar-ansible>
作者:[Nicolas Leiva](https://opensource.com/users/nicolas-leiva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Is "anytime" a good time to execute your automation workflow? The answer is probably no, for different reasons.
If you want to avoid simultaneous changes to minimize the impact on critical business processes and reduce the risk of unintended service disruptions, then no one else should be attempting to make changes at the same time your automation is running.
In some scenarios, there could be an ongoing scheduled maintenance window. Or maybe there is a big event coming up, a critical business time, or a holiday—or maybe you prefer not to make changes on a Friday night.

Whatever the reason, you want to signal this information to your automation platform and prevent the execution of periodic or ad-hoc tasks during specific time slots. In change management jargon, I am talking about specifying blackout windows when change activity should not occur.
## Calendar integration in Ansible
How can you accomplish this in [Ansible](https://docs.ansible.com/ansible/latest/index.html)? While it has no calendar function per se, Ansible's extensibility will allow it to integrate with any calendar application that has an API.
The goal is this: Before you execute any automation or change activity, you execute a `pre-task`
that checks whether something is already scheduled in the calendar (now or soon enough) and confirms you are not in the middle of a blocked timeslot.
Imagine you have a fictitious module named `calendar`
, and it can connect to a remote calendar, like Google Calendar, to determine if the time you specify has otherwise been marked as busy. You could write a playbook that looks like this:
```
- name: Check if timeslot is taken
calendar:
time: "{{ ansible_date_time.iso8601 }}"
register: output
```
Ansible facts will give `ansible_date_time`
, which is passed to the `calendar`
module to verify the time availability so that it can register the response (`output`
) to use in subsequent tasks.
If your calendar looks like this:
(Nicolas Leiva, CC BY-SA 4.0)
Then the output of this task would highlight the fact this timeslot is taken (`busy: true`
):
```
ok: [localhost] => {
"output": {
"busy": true,
"changed": false,
"failed": false,
"msg": "The timeslot 2020-09-02T17:53:43Z is busy: true"
}
}
```
## Prevent tasks from running
Next, [Ansible Conditionals](https://docs.ansible.com/ansible/latest/user_guide/playbooks_conditionals.html) will help prevent the execution of any further tasks. As a simple example, you could use a `when`
statement on the next task to enforce that it runs only when the field `busy`
in the previous output is not `true`
:
```
tasks:
- shell: echo "Run this only when not busy!"
when: not output.busy
```
## Conclusion
In a [previous article](https://medium.com/swlh/python-and-ansible-to-automate-a-network-security-workflow-28b9a44660c6), I said Ansible is a framework to wire things together, interconnecting different building blocks to orchestrate an end-to-end automation workflow.
This article looked at how playbooks can integrate or talk to a calendar application to check availability. However, I am just scratching the surface! For example, your tasks could also block a timeslot in the calendar… the sky is the limit.
In my next article, I will dig into how the `calendar`
module is built and how other programming languages can be used with Ansible. Stay tuned if you are a [Go](https://golang.org/) fan like me!
*This originally appeared on Medium as Ansible and Google Calendar integration for change management under a CC BY-SA 4.0 license and is republished with permission.*
## Comments are closed. |
12,735 | 近场通信 vs. 低功耗蓝牙:如何抉择 | https://www.networkworld.com/article/3574932/nfc-vs-bluetooth-le-when-to-use-which.html | 2020-10-19T20:17:22 | [
"NFC",
"BLE",
"蓝牙"
] | https://linux.cn/article-12735-1.html |
>
> 近场通信(NFC)和低功耗蓝牙(BLE)是适合企业不同用途的低功耗无线技术。
>
>
>

在低功率、相对短距离连接的众多选择中,有两种技术脱颖而出——近场通信(NFC)和低功耗蓝牙(BLE)。两者都具有相对低廉的部署成本且易于使用。
NFC 作为许多现代智能卡片的背后技术而为大众所熟知。NFC 芯片必须十分接近(在几厘米内)读卡器来实现连接,但这是它主要企业用例(安全性和访问控制)的一个优势。
BLE 是主要蓝牙标准的低功耗衍生品,以较低的潜在吞吐量换来了能耗的显著降低,从而能够适应更广泛的潜在用例。
接下来,我们将对每种技术及其主要用例进行更深入的描述。
### NFC 的未来
NFC 在近距离接触范围内工作(设备间必须靠近到几厘米范围内来进行连接),一个可读的无源 NFC “标签”根本不需要任何独立电源,它会从读卡器的信号中汲取能量,工作频率约为 13.5MHz,在主动读取芯片时需要 100-700µA 的电量。
“短距离实际上是它的优势。”Gartner 研究高级总监兼分析师说, “NFC 的一大优点是它不仅仅是无线电,还内置了一个庞大的安全协议。”也就是说,潜在的不良行为者必须非常接近——使用专用设备、在几米的范围内——才能检测到正在发生的 NFC 连接。NFC 还可以施行在 SSL 技术上面一层以提高安全性。
考虑到 NFC 本就起源于非接触式支付技术,这不足为奇。它在这一领域的根基在于对零售商的吸引力,零售商可以利用 NFC 让客户在购买商品前获取相关的信息、获得优惠券或者向店员寻求帮助,只需将手机接触到 NFC 热点即可。
尽管 NFC 只能在一个很近的范围内使用,这限制了使用 NFC 技术用例场景,但它不仅仅是为了开门和买一杯拿铁。NFC 可以用于引导连接,便于设备间轻松快速的配对,因此用户只需在会议室中将手机贴近配备好的投影仪,即可创建一个 NFC 连接,并验证智能手机是否是一个可连接的授权设备,并进行演示。演示文稿或者视频数据本身不会通过 NFC 来传输,但是 NFC 握手可作为另外的无线协议(例如 Wi-Fi 网络或者任何其他更高带宽可以传输数据的网络)间的验证,从而无需用户登录。
### BLE 的特点
相较之下,BLE 的工作距离要远的多(长达几十米),其最大带宽 :1 Mbit/s 约为 NFC 连接的两倍。它是著名的蓝牙技术的产物,相较于主线标准的更低功耗,它为机器到机器的连接做了优化。在连接两端的耗电量均小于 15 mA,实用范围约为 10米,可通过 AES 加密保护连接。
然而,根据 Forrester 首席分析师 Andre Kindness 的说法,它远非 NFC 的替代品。
他说:“从信息传递角度来看, [NFC] 比 BLE 快得多。”BLE 通常需要几分之一秒或更长时间的验证并安全连接,而 NFC 几乎在瞬间完成连接。
不过,根据 IDC 高级研究分析师 Patrick Filkins 的说法,相较于 NFC,BLE 由于范围更广而有着更多的通用性。
他说:“我认为 BLE 比较适合企业”。而类似于资产追踪、室内导航和目标广告的用例只是冰山一角。
对于企业,结果是相当直接的——NFC 用例大多与公司使用蓝牙的用例是分开的,对于少有的可以选择的重叠,相对的优势和劣势显而易见。NFC 距离很短、价格便宜、可即时连接以及数据转换率较低。BLE 的工作距离更远、传输速率更高,成本也更高,连接时还需要一点时间来进行“握手”。
---
via: <https://www.networkworld.com/article/3574932/nfc-vs-bluetooth-le-when-to-use-which.html>
作者:[Jon Gold](https://www.networkworld.com/author/Jon-Gold/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,737 | 在 Ubuntu 和其他 Linux 发行版上使用 Yarn | https://itsfoss.com/install-yarn-ubuntu | 2020-10-20T23:52:00 | [
"npm",
"Yarn"
] | https://linux.cn/article-12737-1.html |
>
> 本速成教程向你展示了在 Ubuntu 和 Debian Linux 上安装 Yarn 包管理器的官方方法。你还将学习到一些基本的 Yarn 命令以及彻底删除 Yarn 的步骤。
>
>
>

[Yarn](https://yarnpkg.com/lang/en/) 是 Facebook 开发的开源 JavaScript 包管理器。它是流行的 npm 包管理器的一个替代品,或者应该说是改进。 [Facebook 开发团队](https://code.fb.com/) 创建 Yarn 是为了克服 [npm](https://www.npmjs.com/) 的缺点。 Facebook 声称 Yarn 比 npm 更快、更可靠、更安全。
与 npm 一样,Yarn 为你提供一种自动安装、更新、配置和删除从全局注册库中检索到的程序包的方法。
Yarn 的优点是它更快,因为它可以缓存已下载的每个包,所以无需再次下载。它还将操作并行化,以最大化资源利用率。在执行每个已安装的包代码之前,Yarn 还使用 [校验和来验证完整性](https://itsfoss.com/checksum-tools-guide-linux/)。 Yarn 还保证可以在一个系统上运行的安装,在任何其他系统上都会以完全相同地方式工作。
如果你正 [在 Ubuntu 上使用 node.js](https://itsfoss.com/install-nodejs-ubuntu/),那么你的系统上可能已经安装了 npm。在这种情况下,你可以使用 npm 通过以下方式全局安装 Yarn:
```
sudo npm install yarn -g
```
不过,我推荐使用官方方式在 Ubuntu/Debian 上安装 Yarn。
### 在 Ubuntu 和 Debian 上安装 Yarn [官方方式]
这里提到的说明应该适用于所有版本的 Ubuntu,例如 Ubuntu 18.04、16.04 等。同样的一组说明也适用于 Debian 和其他基于 Debian 的发行版。
由于本教程使用 `curl` 来添加 Yarn 项目的 GPG 密钥,所以最好验证一下你是否已经安装了 `curl`。
```
sudo apt install curl
```
如果 `curl` 尚未安装,则上面的命令将安装它。既然有了 `curl`,你就可以使用它以如下方式添加 Yarn 项目的 GPG 密钥:
```
curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
```
在此之后,将存储库添加到源列表中,以便将来可以轻松地升级 Yarn 包,并进行其余系统更新:
```
sudo sh -c 'echo "deb https://dl.yarnpkg.com/debian/ stable main" >> /etc/apt/sources.list.d/yarn.list'
```
你现在可以继续了。[更新 Ubuntu](https://itsfoss.com/update-ubuntu/) 或 Debian 系统,以刷新可用软件包列表,然后安装 Yarn:
```
sudo apt update
sudo apt install yarn
```
这将一起安装 Yarn 和 node.js。该过程完成后,请验证是否已成功安装 Yarn。 你可以通过检查 Yarn 版本来做到这一点。
```
yarn --version
```
对我来说,它显示了这样的输出:
```
yarn --version
1.12.3
```
这意味着我的系统上安装了 Yarn 版本 1.12.3。
### 使用 Yarn
我假设你对 JavaScript 编程以及依赖项的工作原理有一些基本的了解。我在这里不做详细介绍。我将向你展示一些基本的 Yarn 命令,这些命令将帮助你入门。
#### 使用 Yarn 创建一个新项目
与 `npm` 一样,Yarn 也可以使用 `package.json` 文件。在这里添加依赖项。所有依赖包都缓存在项目根目录下的 `node_modules` 目录中。
在项目的根目录中,运行以下命令以生成新的 `package.json` 文件:
它会问你一些问题。你可以按回车键跳过或使用默认值。
```
yarn init
yarn init v1.12.3
question name (test_yarn): test_yarn_proect
question version (1.0.0): 0.1
question description: Test Yarn
question entry point (index.js):
question repository url:
question author: abhishek
question license (MIT):
question private:
success Saved package.json
Done in 82.42s.
```
这样,你就得到了一个如下的 `package.json` 文件:
```
{
"name": "test_yarn_proect",
"version": "0.1",
"description": "Test Yarn",
"main": "index.js",
"author": "abhishek",
"license": "MIT"
}
```
现在你有了 `package.json`,你可以手动编辑它以添加或删除包依赖项,也可以使用 Yarn 命令(首选)。
#### 使用 Yarn 添加依赖项
你可以通过以下方式添加对特定包的依赖关系:
```
yarn add <包名>
```
例如,如果你想在项目中使用 [Lodash](https://lodash.com/),则可以使用 Yarn 添加它,如下所示:
```
yarn add lodash
yarn add v1.12.3
info No lockfile found.
[1/4] Resolving packages…
[2/4] Fetching packages…
[3/4] Linking dependencies…
[4/4] Building fresh packages…
success Saved lockfile.
success Saved 1 new dependency.
info Direct dependencies
└─ [email protected]
info All dependencies
└─ [email protected]
Done in 2.67s.
```
你可以看到,此依赖项已自动添加到 `package.json` 文件中:
```
{
"name": "test_yarn_proect",
"version": "0.1",
"description": "Test Yarn",
"main": "index.js",
"author": "abhishek",
"license": "MIT",
"dependencies": {
"lodash": "^4.17.11"
}
}
```
默认情况下,Yarn 将在依赖项中添加最新版本的包。如果要使用特定版本,可以在添加时指定。
```
yarn add package@version-or-tag
```
像往常一样,你也可以手动更新 `package.json` 文件。
#### 使用 Yarn 升级依赖项
你可以使用以下命令将特定依赖项升级到其最新版本:
```
yarn upgrade <包名>
```
它将查看所涉及的包是否具有较新的版本,并且会相应地对其进行更新。
你还可以通过以下方式更改已添加的依赖项的版本:
```
yarn upgrade package_name@version_or_tag
```
你还可以使用一个命令将项目的所有依赖项升级到它们的最新版本:
```
yarn upgrade
```
它将检查所有依赖项的版本,如果有任何较新的版本,则会更新它们。
#### 使用 Yarn 删除依赖项
你可以通过以下方式从项目的依赖项中删除包:
```
yarn remove <包名>
```
#### 安装所有项目依赖项
如果对你 `project.json` 文件进行了任何更改,则应该运行:
```
yarn
```
或者,
```
yarn install
```
一次安装所有依赖项。
### 如何从 Ubuntu 或 Debian 中删除 Yarn
我将通过介绍从系统中删除 Yarn 的步骤来完成本教程,如果你使用上述步骤安装 Yarn 的话。如果你意识到不再需要 Yarn 了,则可以将它删除。
使用以下命令删除 Yarn 及其依赖项。
```
sudo apt purge yarn
```
你也应该从源列表中把存储库信息一并删除掉:
```
sudo rm /etc/apt/sources.list.d/yarn.list
```
下一步删除已添加到受信任密钥的 GPG 密钥是可选的。但要做到这一点,你需要知道密钥。你可以使用 `apt-key` 命令获得它:
```
Warning: apt-key output should not be parsed (stdout is not a terminal) pub rsa4096 2016-10-05 [SC] 72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310 uid [ unknown] Yarn Packaging [email protected] sub rsa4096 2016-10-05 [E] sub rsa4096 2019-01-02 [S] [expires: 2020-02-02]
```
这里的密钥是以 `pub` 开始的行中 GPG 密钥指纹的最后 8 个字符。
因此,对于我来说,密钥是 `86E50310`,我将使用以下命令将其删除:
```
sudo apt-key del 86E50310
```
你会在输出中看到 `OK`,并且 Yarn 包的 GPG 密钥将从系统信任的 GPG 密钥列表中删除。
我希望本教程可以帮助你在 Ubuntu、Debian、Linux Mint、 elementary OS 等操作系统上安装 Yarn。 我提供了一些基本的 Yarn 命令,以帮助你入门,并完成了从系统中删除 Yarn 的完整步骤。
希望你喜欢本教程,如果有任何疑问或建议,请随时在下面留言。
---
via: <https://itsfoss.com/install-yarn-ubuntu>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,738 | 使用互联网协议替代方案 Gemini 简化你的 Web 体验 | https://opensource.com/article/20/10/gemini-internet-protocol | 2020-10-21T07:10:33 | [
"Gemini",
"Gopher"
] | /article-12738-1.html |
>
> 用 Gemini 协议发现更安静、更简单的互联网新角落。
>
>
>

如果你很久以前就已经上网了,或者是知识非常丰富,你可能还记得一个早期的文本共享协议,叫做 [Gopher](https://en.wikipedia.org/wiki/Gopher_%28protocol%29)。Gopher 最终被 HTTP 协议所取代,当然,HTTP 协议是现代万维网的基础。对于很多人来说,“<ruby> 互联网 <rt> internet </rt></ruby>”和“<ruby> 万维网 <rt> World Wide Web </rt></ruby>”是一回事,因为很多人没有意识到在网上进行了*非* www 子域下的任何操作。
但一直以来,都有各种网络协议在互联网络上共享信息:Telnet、FTP、SSH、Torrent、GNUnet 等等。最近,在这一系列的替代品中又多了一个,它叫 [Gemini](https://gemini.circumlunar.space/)。
Gemini(双子座)协议,以“水星计划”和“阿波罗计划”的基础实验之间的太空任务命名,旨在和平地处在 Gopher 和 HTTP 之间。无论如何,它的目的并不是要取代现代 Web,但它确实试图创造一个简化的网络和一个现代化的 Gopher。
它的发展历史虽然可能很年轻,但意义重大,原因有很多。当然,人们会因为技术和哲学上的原因而对现代 Web 表示质疑,但它只是一般的臃肿。当你真正想要的是一个非常具体的问题的可靠答案时,那么无数次点击谷歌搜索的结果让人感觉过头了。
许多人使用 Gopher 就是因为这个原因:它的规模小到可以让小众的兴趣很容易找到。然而,Gopher 是一个旧的协议,它对编程、网络和浏览做出了一些假设,但这些假设已经不再适用了。 Gemini 的目标是将最好的网络带入一种类似于 Gopher 但易于编程的格式。一个简单的 Gemini 浏览器可以用几百行代码写成,并且有一个非常好的浏览器用 1600 行左右写成。这对于程序员、学生和极简主义者来说都是一个强大的功能。
### 如何浏览 Gemini
就像早期的网络一样,Gemini 的规模很小,所以有一个列表列出了运行 Gemini 网站的已知服务器。就像浏览 HTTP 站点需要一个网页浏览器一样,访问 Gemini 站点也需要一个 Gemini 浏览器。在 [Gemini 网站](https://gemini.circumlunar.space/clients.html)上列出了有几个可用的浏览器。
最简单的一个是 [AV-98](https://tildegit.org/solderpunk/AV-98) 客户端。它是用 Python 编写的,在终端中运行。要想试试的话,请下载它:
```
$ git clone https://tildegit.org/solderpunk/AV-98.git
```
进入下载目录,运行 AV-98:
```
$ cd AV-98.git
$ python3 ./main.py
```
客户端是一个交互式的提示符。它有有限的几个命令,主要的命令是简单的 `go`,后面跟着一个 Gemini 服务器地址。在已知的 [Gemini 服务器](https://portal.mozz.us/gemini/gemini.circumlunar.space/servers)列表中选择一个看起来很有趣的服务器,然后尝试访问它:
```
AV-98> go gemini://example.club
Welcome to the example.club Gemini server!
Here are some folders of ASCII art:
[1] Penguins
[2] Wildebeests
[3] Demons
```
导航是按照编号的链接来进行的。例如,要进入 `Penguins` 目录,输入 `1` 然后按回车键:
```
AV-98> 1
[1] Gentoo
[2] Emperor
[3] Little Blue
```
要返回,输入 `back` 并按回车键:
```
AV-98> back
```
更多命令,请输入 `help`。
### 用 Gemini 作为你的 web 替代
Gemini 协议非常简单,初级和中级程序员都可以为其编写客户端,而且它是在互联网上分享内容的一种简单快捷的方式。虽然万维网的无处不在对广泛传播是有利的,但总有替代方案的空间。看看 Gemini,发现更安静、更简单的互联网的新角落。
---
via: <https://opensource.com/article/20/10/gemini-internet-protocol>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,740 | 如何在 Linux 中减少/缩小 LVM 大小(逻辑卷调整) | https://www.2daygeek.com/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux/ | 2020-10-21T21:07:00 | [
"LVM"
] | https://linux.cn/article-12740-1.html | 
减少/缩小逻辑卷是数据损坏的最高风险。
所以,如果可能的话,尽量避免这种情况,但如果没有其他选择的话,那就继续。
缩减 LVM 之前,建议先做一个备份。
当你在 LVM 中的磁盘空间耗尽时,你可以通过缩小现有的没有使用全部空间的 LVM,而不是增加一个新的物理磁盘,在卷组上腾出一些空闲空间。
**需要注意的是:** 在 GFS2 或者 XFS 文件系统上不支持缩小。
如果你是逻辑卷管理 (LVM) 的新手,我建议你从我们之前的文章开始学习。
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)](/article-12670-1.html)**
* **第二部分:[如何在 Linux 中扩展/增加 LVM(逻辑卷调整)](/article-12673-1.html)**

减少逻辑卷涉及以下步骤:
* 卸载文件系统
* 检查文件系统是否有任何错误
* 缩小文件系统的大小
* 缩小逻辑卷的大小
* 重新检查文件系统是否存在错误(可选)
* 挂载文件系统
* 检查减少后的文件系统大小
**比如:** 你有一个 **100GB** 的没有使用全部空间的 LVM,你想把它减少到 **80GB**,这样 **20GB** 可以用于其他用途。
```
# df -h /testlvm1
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg01-lv002 100G 15G 85G 12% /testlvm1
```
### 卸载文件系统
使用 `umount` 命令卸载文件系统:
```
# umount /testlvm1
```
### 检查文件系统是否有任何错误
使用 `e2fsck` 命令检查文件系统是否有错误:
```
# e2fsck -f /dev/mapper/vg01-lv002
e2fsck 1.42.9 (28-Dec-2013)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/mapper/vg01-lv002: 13/6553600 files (0.0% non-contiguous), 12231854/26212352 blocks
```
### 缩小文件系统
下面的命令将把 `testlvm1` 文件系统从 **100GB** 缩小到 **80GB**。
**文件系统大小调整的常用语法(`resize2fs`)**:
```
resize2fs [现有逻辑卷名] [新的文件系统大小]
```
实际命令如下:
```
# resize2fs /dev/mapper/vg01-lv002 80G
resize2fs 1.42.9 (28-Dec-2013)
Resizing the filesystem on /dev/mapper/vg01-lv002 to 28321400 (4k) blocks.
The filesystem on /dev/mapper/vg01-lv002 is now 28321400 blocks long.
```
### 减少逻辑卷 (LVM) 容量
现在使用 `lvreduce` 命令缩小逻辑卷(LVM) 的大小。通过下面的命令, `/dev/mapper/vg01-lv002` 将把逻辑卷 (LVM) 从 100GB 缩小到 80GB。
**LVM 缩减 (`lvreduce`) 的常用语法**:
```
lvreduce [新的 LVM 大小] [现有逻辑卷名称]
```
实际命令如下:
```
# lvreduce -L 80G /dev/mapper/vg01-lv002
WARNING: Reducing active logical volume to 80.00 GiB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce lv002? [y/n]: y
Reducing logical volume lv002 to 80.00 GiB
Logical volume lv002 successfully resized
```
### 可选:检查文件系统是否有错误
缩减 LVM 后再次检查文件系统是否有错误:
```
# e2fsck -f /dev/mapper/vg01-lv002
e2fsck 1.42.9 (28-Dec-2013)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/mapper/vg01-lv002: 13/4853600 files (0.0% non-contiguous), 1023185/2021235 blocks
```
### 挂载文件系统并检查缩小后的大小
最后挂载文件系统,并检查缩小后的文件系统大小。
使用 `mount` 命令[挂载逻辑卷](https://www.2daygeek.com/mount-unmount-file-system-partition-in-linux/):
```
# mount /testlvm1
```
使用 [df 命令](https://www.2daygeek.com/linux-check-disk-space-usage-df-command/)检查挂载的卷。
```
# df -h /testlvm1
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg01-lv002 80G 15G 65G 18% /testlvm1
```
---
via: <https://www.2daygeek.com/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,743 | 在 Linux 上安装 MariaDB 或 MySQL | https://opensource.com/article/20/10/mariadb-mysql-linux | 2020-10-22T14:41:56 | [
"MySQL"
] | https://linux.cn/article-12743-1.html |
>
> 开始在 Linux 系统上使用开源的 SQL 数据库吧。
>
>
>

[MariaDB](https://mariadb.org/) 和 [MySQL](https://www.mysql.com/) 都是使用 SQL 的开源数据库,并且共享相同的初始代码库。MariaDB 是 MySQL 的替代品,你可以使用相同的命令(`mysql`)与 MySQL 和 MariaDB 数据库进行交互。因此,本文同时适用于 MariaDB 和 MySQL。
### 安装 MariaDB
你可以使用你的 Linux 发行版的包管理器安装 MariaDB。在大多数发行版上,MariaDB 分为服务器包和客户端包。服务器包提供了数据库“引擎”,即 MariaDB 在后台运行(通常在物理服务器上)的部分,它监听数据输入或数据输出请求。客户端包提供了 `mysql` 命令,你可以用它来与服务器通信。
在 RHEL、Fedora、CentOS 或类似的发行版上:
```
$ sudo dnf install mariadb mariadb-server
```
在 Debian、Ubuntu、Elementary 或类似的发行版上:
```
$ sudo apt install mariadb-client mariadb-server
```
其他操作系统可能会以不同的打包系统封装 MariaDB,所以你可能需要搜索你的软件仓库来了解你的发行版的维护者是如何提供它的。
### 启动 MariaDB
因为 MariaDB 被设计为部分作为数据库服务器,它可以在一台计算机上运行,并从另一台计算机上进行管理。只要你能访问运行它的计算机,你就可以使用 `mysql` 命令来管理数据库。在写这篇文章时,我在本地计算机上运行了 MariaDB,但你同样可与远程系统上托管的 MariaDB 数据库进行交互。
在启动 MariaDB 之前,你必须创建一个初始数据库。在初始化其文件结构时,你应该定义你希望 MariaDB 使用的用户。默认情况下,MariaDB 使用当前用户,但你可能希望它使用一个专用的用户帐户。你的包管理器可能为你配置了一个系统用户和组。使用 `grep` 查找是否有一个 `mysql` 组:
```
$ grep mysql /etc/group
mysql:x:27:
```
你也可以在 `/etc/passwd` 中寻找这个专门的用户,但通常情况下,有组就会有用户。如果没有专门的 `mysql` 用户和组,可以在 `/etc/group` 中寻找一个明显的替代品(比如 `mariadb`)。如果没有,请阅读你的发行版文档来了解 MariaDB 是如何运行的。
假设你的安装使用 `mysql`,初始化数据库环境:
```
$ sudo mysql_install_db --user=mysql
Installing MariaDB/MySQL system tables in '/var/lib/mysql'...
OK
[...]
```
这一步的结果显示了接下来你必须执行的配置 MariaDB 的任务:
```
PLEASE REMEMBER TO SET A PASSWORD FOR THE MariaDB root USER !
To do so, start the server, then issue the following commands:
'/usr/bin/mysqladmin' -u root password 'new-password'
'/usr/bin/mysqladmin' -u root -h $(hostname) password 'new-password'
Alternatively you can run:
'/usr/bin/mysql_secure_installation'
which will also give you the option of removing the test
databases and anonymous user created by default. This is
strongly recommended for production servers.
```
使用你的发行版的初始化系统启动 MariaDB:
```
$ sudo systemctl start mariadb
```
在启动时启用 MariaDB 服务器:
```
$ sudo systemctl enable --now mariadb
```
现在你已经有了一个 MariaDB 服务器,为它设置一个密码:
```
mysqladmin -u root password 'myreallysecurepassphrase'
mysqladmin -u root -h $(hostname) password 'myreallysecurepassphrase'
```
最后,如果你打算在生产服务器上使用它,请在上线前运行 `mysql_secure_installation` 命令。
---
via: <https://opensource.com/article/20/10/mariadb-mysql-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Both [MariaDB](https://mariadb.org/) and [MySQL](https://www.mysql.com/) are open source databases that use SQL and share the same original codebase. MariaDB is a drop-in replacement for MySQL, so much so that you use the same command (`mysql`
) to interact with MySQL and MariaDB databases. This article, therefore, applies equally to MariaDB and MySQL.
## Install MariaDB
You can install MariaDB using your Linux distribution's package manager. On most distributions, MariaDB is split into a server package and a client package. The server package provides the database "engine," the part of MariaDB that runs (usually on a physical server) in the background, listening for data input or requests for data output. The client package provides the command `mysql`
, which you can use to communicate with the server.
On RHEL, Fedora, CentOS, or similar:
`$ sudo dnf install mariadb mariadb-server`
On Debian, Ubuntu, Elementary, or similar:
`$ sudo apt install mariadb-client mariadb-server`
Other systems may package MariaDB differently systems, so you may need to search your software repository to learn how your distribution's maintainers provide it.
## Start MariaDB
Because MariaDB is designed to function, in part, as a database server, it can run on one computer and be administered from another. As long as you have access to the computer running it, you can use the `mysql`
command to administer the database. I ran MariaDB on my local computer when writing this article, but it's just as likely that you'll interact with a MariaDB database hosted on a remote system.
Before starting MariaDB, you must create an initial database. You should define the user you want MariaDB to use when initializing its file structure. By default, MariaDB uses the current user, but you probably want it to use a dedicated user account. Your package manager probably configured a system user and group for you. Use `grep`
to find out whether there's a `mysql`
group:
```
$ grep mysql /etc/group
mysql:x:27:
```
You can also look in `/etc/passwd`
for a dedicated user, but usually, where there's a group, there's also a user. If there isn't a dedicated `mysql`
user and group, look through `/etc/group`
for an obvious alternative (such as `mariadb`
). Failing that, read your distribution's documentation to learn how MariaDB runs.
Assuming your install uses `mysql`
, initialize the database environment:
```
$ sudo mysql_install_db --user=mysql
Installing MariaDB/MySQL system tables in '/var/lib/mysql'...
OK
[...]
```
The result of this step reveals the next tasks you must perform to configure MariaDB:
```
PLEASE REMEMBER TO SET A PASSWORD FOR THE MariaDB root USER !
To do so, start the server, then issue the following commands:
'/usr/bin/mysqladmin' -u root password 'new-password'
'/usr/bin/mysqladmin' -u root -h $(hostname) password 'new-password'
Alternatively you can run:
'/usr/bin/mysql_secure_installation'
which will also give you the option of removing the test
databases and anonymous user created by default. This is
strongly recommended for production servers.
```
Start MariaDB using your distribution's init system:
`$ sudo systemctl start mariadb`
To enable the MariaDB server to start upon boot:
`$ sudo systemctl enable --now mariadb`
Now that you have a MariaDB server to communicate with, set a password for it:
```
mysqladmin -u root password 'myreallysecurepassphrase'
mysqladmin -u root -h $(hostname) password 'myreallysecurepassphrase'
```
Finally, if you intend to use this installation on a production server, run the `mysql_secure_installation`
command before going live.
## Comments are closed. |
12,744 | 《代码英雄》第二季(8):开源好奇号 | https://www.redhat.com/en/command-line-heroes/season-2/open-curiosity | 2020-10-23T00:23:33 | [
"代码英雄"
] | https://linux.cn/article-12744-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(8):开源好奇号](https://www.redhat.com/en/command-line-heroes/season-2/open-curiosity)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/1ebfa28a.mp3)脚本。
>
> 导语:那些最棒的、最聪明的人用袖珍计算器的计算能力把我们带到了月球。现在他们要带我们走得更远 —— 而且是用我们整季播客都在谈论的技术来实现。开源将带我们去火星。
>
>
> 第二季的结局是将我们带到美国宇航局(NASA)的<ruby> 喷气推进实验室 <rt> Jet Propulsion Laboratory </rt></ruby>(JPL)。Tom Soderstrom 分享了 JPL 通过拥抱开源获得了多少好处。Hila Lifshitz-Assaf 解释说,NASA 正在用开源软件和众包解决一些最大的问题。Dan Wachspress 介绍了与 NASA 合作意味着专有商业需要做出一些牺牲 —— 但他们可以参与到世界上最具创新性的项目中。
>
>
> 远疆的探索者们选择在开放的环境中工作 —— 火星是他们的目的地。那么下一步呢?
>
>
>
**00:00:12 - Saron Yitbarek**:
2012 年 8 月 6 日,一枚汽车大小的<ruby> 漫游车 <rt> rover </rt></ruby>,<ruby> 好奇号 <rt> Curiosity </rt></ruby>,从火星大气的顶层降落到了这颗星球的地表。降落花了 7 分钟,下降的过程仿佛永无止境。漫游车携带着贵重的货物:500,000 行代码,76 台尖端科学仪器,以及另一些工具,用以开展一些前所未有的实验。先是超音速降落伞展开,接着是隔热护盾分离,然后,反冲发动机启动,甚至在半空中部署天车——最终,好奇号平稳着陆。
**00:00:59 - NASA 工程师**:
现在,是时候看看“好奇号”会将我们带向何方了。
**00:01:13 - Saron Yitbarek**:
听见那声音了吗?那就是火星车成功着陆后,满屋子工程师的欢呼声。几天后,他们将收到来自贝拉克·奥巴马总统的贺电。但现在是只属于他们的时刻。这群人一同完成的这件事,是他们中的任何一人永远都无法独自做到的。
**00:01:39**:
我是 Saron Yitbarek,这里是代码英雄,来自红帽的一档播客节目。本季以来,我们见证了开源技术对我们工作方式的重塑,及其对人们能力的拓展。作为线索,社区这个要素贯穿了整季节目。这些故事告诉我们该怎么团队协作,该怎么向行家学习,以及,如何在这同时学会听取新人的意见 —— 一言以蔽之,如何更好地与人交流。
**00:02:11**:
在第二季的终章,我们在记住所有这些道理的同时,我们将探索开源是如何为那些伟大的项目赋能的。你也许在去年的十一月观看了 NASA 的<ruby> 洞察号 <rt> insight </rt></ruby>登陆器抵达火星地表。彼时四周皆是欢呼与拥抱。事实证明,这项向星星 —— 这颗红色的星球发射漫游车的任务,只有把宝押在众人合作上才能实现。
**00:02:45**:
我刚才说过了吗?那台火星车有它自己的推特账号。它还有 4 百万粉丝呢。这还不算什么。最近它给地球人发送了一条推文,是一封邀请函,邀请人们使用 NASA 喷气动力实验室开源的说明和代码,建造一辆属于自己的漫游车。我们跟踪采访了一个民间的组织,叫 SGVHAK 小组,他们是第一批自己建造漫游车的人。
**00:03:13 - SGVHAK 小组**:
现在我要试试从坎上开过去。
**00:03:15**:
看看她(LCTT 译注:指漫游车)这样能不能行。
**00:03:15**:
上来了——不,不行。
**00:03:15**:
不行。
**00:03:20**:
她以前很容易就能开过去的。不过我们现在对轮子做了一些改动,她就有点不乐意了。
**00:03:27 - Saron Yitbarek**:
这个小组的成员包括 Roger Cheng、Dave Flynn、Emily Velasco 以及 Lan Dang。
**00:03:34 - SGVHAK 小组**:
Dave 包揽了所有机械设计,我想我应该算是负责组装的。Roger 是我们的程序员,Dave 是机械设计师,Lan 是我们无畏的领导。
**00:03:45**:
你也是一个,你是队里的机械制造专家。
**00:03:49**:
大概吧,应该算是。
**00:03:51**:
跟他们讲讲伺服电机架子的事。
**00:03:53**:
噢,好的。
**00:03:54**:
是你把电机凑起来的,现在可以让它运行,演示一下——
**00:03:58**:
我们现在就拿——
**00:04:00 - Saron Yitbarek**:
打造这样一部漫游车可不是玩乐高玩具。它需要真正的火箭科学家花 200 小时来完成。所以,让我们给这些家伙几分钟的准备时间,稍后再回来。
**00:04:19**:
与此同时,我想了解更多关于为什么一开始 NASA 要将漫游车的技术和代码向全世界开源。我刚刚找到了回答这个问题的最佳人选。
**00:04:29 - Tom Soderstrom**:
我叫 Tom Soderstorm,我是 NASA <ruby> 喷气推进实验室 <rt> Jet Propulsion Laboratory </rt></ruby>(JPL)的 IT 部门的<ruby> 首席技术与创新官 <rt> technology and innovation officer </rt></ruby>。
**00:04:37 - Saron Yitbarek**:
JPL 总共有大约 6000 人。它是 NASA 的研究中心之一,由联邦政府提供资金,专注于研究如何用无人机械进行太空探索。
**00:04:48 - Tom Soderstrom**:
我们寻找地外生命,我们也探究宇宙的起源和未来。除此之外,考虑到可能的星际移民需求,我们也在寻找地球 2.0。也就是具有类似地球的环境的、另一个适宜人类居住的行星。
**00:05:33 - Saron Yitbarek**:
是的,他们肩负着伟大的使命。不过,事情是这样的。Tom 的团队并不是一群秘密进行研究、与外界全然不接触的工程师。他们与下一代的科学家们有着深厚的联系。他们常常采用全新的方式激发大众的创造性思维。事实上,这是他们工作中至关重要的一部分。漫游车开源计划释放出了部分设计,这样一来,NASA 之外的民间组织就能组建他们自己的漫游车了。这是 NASA 促进创新的宏观战略的一部分。很自然地,Tom 从开源漫游车开始,向我讲述了为何开源 NASA 的成果是如此重要。
**00:05:46**:
有很多人可能像我一样;发现这个网站时,我想,天啊,也许我可以自己打造一个漫游车呢。这真是太激动人心了。这太令人神往了。
**00:05:55 - Tom Soderstrom**:
我们打造这个开源网站,是为了能让公众和学校能够从中学习。而且我们发现,围绕漫游车开源形成的社区是非常优秀的实验平台。所以当我们想测试新鲜事物的时候,这里就是最佳的演练场,非常简单,非常快速,我们能很快就把想要的技术应用到真正的漫游车上。所以我们希望人们能够把像太阳能面板、加速度传感器、科学实验仪器,以及先进的人工智能程序等结合起来,我们只是希望这些经验能够扩散,在这些方面感兴趣的人最终也能对太空感兴趣。因为太空真的是太酷了。
**00:06:32 - Saron Yitbarek**:
所以除了刚才提到的这些之外,人们在这个项目中还做过什么让你印象深刻的,或者是让你觉得激动的事儿?
**00:06:42 - Tom Soderstrom**:
降价是一项非常令人印象深刻的工作,而现在有一堆人在试着用人工智能干这个事儿。这是目前我见到的最有趣的事情之一,我很想看到有人能为其添加一个机械臂。
**00:06:55 - Saron Yitbarek**:
真是太酷了。
**00:06:55 - Tom Soderstrom**:
也是我们正在思考的问题。
**00:06:58 - Saron Yitbarek**:
这个项目是全方位开放的吗?我是指,对于硬件部分,你们给出了一份推荐的零部件清单,但参与者如果愿意,也能自行替换,换成更便宜的,或者换成更贵的;而软件部分就完全是开源的了。这中间有任何非开源的部分吗?
**00:07:17 - Tom Soderstrom**:
没有,完全是开源的。
**00:07:19 - Saron Yitbarek**:
如果你告诉我高中生都能通过这个项目自行制作漫游车,我会觉得非常震惊。那听起来太难了;你知道吗,听起来太高大上了,高到只有 NASA 才会去做的那种。对吧?真正地组装火星车会是件容易的事吗?
**00:07:36 - Tom Soderstrom**:
我们并不想将这做成一个玩具。这个项目是货真价实的,能给参与者带来实际的经验。加利福尼亚州的几所学校已经将其纳入他们的科学、工程与编程课程中,比如所谓的<ruby> 机械电子学 <rt> Mechatronics </rt></ruby>,就是上述几方面的结合体。这让我们非常高兴,因为这样,在不久的将来就能有一批训练有素的专业人才来到 NASA。
**00:08:04 - Saron Yitbarek**
但这似乎不仅有利于未来的 NASA 工程师、未来的科学家,也有利于你们(LCTT 译注:指目前在 NASA 工作的科学家、工程师)。跟我多说说这方面吧。
**00:08:14 - Tom Soderstrom**:
嗯……突然间,我们就有了一个非常简单易用的实验平台。我能想象到开源的漫游车在 JPL 附近行驶,还向人问好。在于艰苦环境中验证某些技术之前,我们能在后院里对它们快速地进行试验。它成为了我们可以实验的移动平台。话又说回来,我认为人工智能会是这些技术中非常有趣的一样,因为它发展得太快了,而且,向它加入新的机器人部件也很容易。
**00:08:50 - Saron Yitbarek**:
所以,理论上来说,你们也可以创建一个你们自己的移动试验场,可以进行试验,也不用将其开源,对吧?它本来可以成为一个内部项目。但它现在是开源的。这能让你们多学到什么呢?
**00:09:08 - Tom Soderstrom**:
嗯,这是一个好问题。为什么要开源?对我们来说,开源才是更困难的选择,不过那也是挑战所在。我们希望,通过将其开源,学校以及其他民间组织能够用上代码,并且将漫游车造出来。编写一本不是机器人学专家的人也能看懂的手册带来了大量额外的工作。但起码,当我们最终将一些东西真正开源的时候,它变得更整洁、更紧凑、文档更完善了;因为我们知道,其他人会来使用这些东西,所以也必须要具备一定的可扩展性。因此,项目的质量提高了。我曾经和 Netflix 的人谈过,他们也有同样的感觉,被开源的代码普遍更加整洁、质量更好。
**00:09:54 - Saron Yitbarek**:
你是怎样看待开源漫游车的?五年,十年,甚至将来的二十多年后,你觉得它们能做什么,而人们能够创造出什么?你认为这些能为身处地球的我们带来什么潜在利好?
**00:10:11 - Tom Soderstrom**:
能带来多方面的利好。现在的漫游车被设计成使用轮子行驶。我可以说,它其实也可以被设计成采用步行,也可以对它进行扩展,加上跳跃的功能。我们已经送了一架直升飞机上火星,它现在还在飞着。所以说,这些漫游车并不仅仅局限于现在我们所说的漫游车。有了全世界各地人们的实验,我们能走得更快,更远,不断探寻可能性的上限,并提出一些坦率地说我们可能没有想到的想法。未来到底会是什么样的?我迫切地想了解,不过我不知道。
**00:10:49 - Saron Yitbarek**:
通过创造这个平台,你们已经为许多人提供了打造自己的“玩具”的机会。接下来就让我们拭目以待吧。
**00:10:57 - Tom Soderstrom**:
是的,这是很重要的一点。因为我发现,我能想到的主意都已经有人做过了。但我们需要找到这些人。无论我们最开始做的是什么,一旦到最终用户手上,他们就能以我们无法想象的方式将其改进十倍。所以,向大众开放一些这样的“玩具”,任他们自由发挥,他们会因此而得到锻炼,这对将来使用更先进技术的任务也大有益处。
**00:11:23 - Saron Yitbarek**:
这真是太棒了。
**00:11:29**:
如果你想了解开源漫游车项目,你可以访问 [opensourcerover.jpl.nasa.gov](http://opensourcerover.jpl.nasa.gov) 。你能在那儿玩个尽兴。我们稍后再与 Tom Soderstrom 进行更多讨论。但首先,让我们来更深入地挖掘 NASA 与开源之间的关系。
**00:11:51 - Hila Lifshitz-Assaf**:
大家好,我是 Hila Lifshitz-Assaf,纽约大学商学院的教授。
**00:11:57 - Saron Yitbarek**:
Hila 正在研究 NASA 是如何打破知识壁垒的。
**00:12:02 - Hila Lifshitz-Assaf**:
如果你能够回到过去,回到 15 世纪,看看那些孤独的发明家,像莱昂纳多·达芬奇和其他人,他们某种程度上只在自己所在的本地社区活动。之后,有了工业革命,有了实验室。此后的两百多年里,人们都在实验室里工作。最大的变化发生在 21 世纪,数字革命之后我们有了开源的概念,而它打破了之前这类组织结构的边界。
**00:12:34 - Saron Yitbarek**:
在 NASA 工作的日子里,Hila 见证了这种巨大变革的典型例子。
**00:12:39 - Hila Lifshitz-Assaf**:
NASA 最吸引我的一点在于,他们就某种意义上来说是最勇敢的,因为他们勇于接受战略性的<ruby> 研究与开发 <rt> research and development </rt></ruby>(R&D)事业中的挑战,他们的科学家、工程师,最优秀的一批人才为此而努力工作,并使这些挑战向大众开放。而且,我必须说,直到现在,很多其他的组织在做开源科学或是众包的时候,他们不会把最核心的、战略性的难题交给社区,而是只开放一些次要的任务。无论成功还是失败,这都不会让他们的组织蒙受多大损失。而 NASA 做的事情,一旦成功了,就真的改变了一切。
**00:13:14 - Saron Yitbarek**:
自 2009 年起,NASA 就开始使用像 Innocentive 和 Topcoder 这样的开源创新平台。而且,他们不是闹着玩的。就像 Hila 所提到的,他们甚至把他们核心的 R&D 难题都放了上去。
**00:13:29 - Hila Lifshitz-Assaf**:
这些问题上传之后,甚至没过一年,我们就已经陆续开始看到来自众包平台的解决方案。
**00:13:34 - Saron Yitbarek**:
这确实很快。我将在此举出一项研究成果,它是 NASA 开源科研的诸多喜人硕果之一。Hila 向我们将讲述,他们是如何将太阳耀斑的预测技术提升一个台阶的。
**00:13:46 - Hila Lifshitz-Assaf**:
嗯……太阳耀斑的预测是学术界研究了数十年的一项非常困难的太阳物理学问题。总的来说,他们已经完成初步的构想,以便更多的人可以参与这方面的研究。而且他们非常在意这一点。这让我觉得很惊奇,因为他们确确实实地希望能从太阳物理学圈子外的人那里找到解决方案。Bruce Kragan,一名来自新罕布什尔州乡村的、半退休的无线电工程师,只花了三个月,就给我们带来了太阳耀斑的预测方法。当 NASA 验证模型时,他们发现,这种预测方法的准确率有 80%。用传统方式需要花费数百万美元及数年时间才能获取的成果,在三个月内就被收获了,花费大概在三万和四五万美元之间。
**00:14:36 - Saron Yitbarek**:
你也许已经猜到了,这样的变化需要 NASA 内部的文化作出改变。
**00:14:44 - Hila Lifshitz-Assaf**:
他们中的有些人选择邀请外来的解决方案提供者进入项目组,还有一些选择提供实习或合作机会;他们采用了很多有意思的方法来交流知识,使其不至于淤塞。
**00:14:59 - Saron Yitbarek**:
仔细想想,这其实是很美好的。就如我们所知,很多组织仍然抵制开源活动,不愿放弃专有软件。但在这里,你可以找到这个星球上最具创新性,愿景宏大的一群科学家;而他们说,嗨,我们一起来。这样的态度有绝大的影响力。
**00:15:22 - Hila Lifshitz-Assaf**:
我们已经看到了开源给软件行业带来的变革。我们目前尚未在科学与技术方面见到太多改变,不过,我认为,现在就是最好的时机。计算物理学、计算生物学越是崛起,这就越有可能实现。我认为,像这样,就有更多人能够参与到科研中,协助处理不同的任务。以这种方式,科学技术的发展速度或许甚至能够超过应用开发。
**00:15:53 - Saron Yitbarek**:
Hila Lifshitz-Assaf 是一位来自纽约大学斯特恩商学院的教授。
**00:16:00**:
NASA 在开放他们的研究课题的道路上受益良多,但他们也通过<ruby> 中小企业创新资助计划 <rt> Small Business Innovation Grant Program </rt></ruby>——这个项目鼓励私营经济中的创新——打造了另一种社区。所有<ruby> 大胆的计划 <rt> blue sky projects </rt> <rt> </rt></ruby>都有风险,可能付出代价,但有时回报也尤其丰厚。
**00:16:22 - Dan Wachspress**:
大家好,我叫 Dan Wachspress,我是一名航空工程师,在 Continuum Dynamics 集团工作。
**00:16:28 - Saron Yitbarek**:
Dan 的公司专注于研究与开发旋翼飞行器,也就是直升机、旋翼飞机这类的飞行器。这可以说从是字面上看就很“<ruby> 蓝天 <rt> blue sky </rt></ruby>”(LCTT 译注:此处呼应之前提到的 blue sky projects)了。他们一直与 NASA 合作,致力于解决垂直升降的问题,让飞行器能变得像是 Jetson 的“空中出租车”(LCTT 译注:典出《The Jetsons》,一部始播于 1962 年的系列动画,这里的 Jetson 指动画主角 George Jetson)那样。
**00:16:50 - Dan Wachspress**:
总体的构思是,只要用电动机代替车辆上的燃气涡轮发动机,你就可以安装更多推进器。它们会比现有的更安静、更安全,直升机所有恼人的问题统统消失,而我们可能会得到这样的未来:你打个的就能从达拉斯去到沃斯堡(LCTT 译注:均为美国得克萨斯州的城市),而那是一辆准乘 5 人、无人驾驶的电动飞的,而非一辆汽车,在汽车里面你还得跟堵车较劲。这就是我们的愿景。
**00:17:22 - Saron Yitbarek**:
有很多公司,比如 Uber,对这种空中出租车的设想非常感兴趣。而 NASA 在这之中扮演的角色是伟大的:它打破了不同公司本要各自为营死磕研究的壁垒。
**00:17:38 - Dan Wachspress**:
那些公司必定不想走漏风声,他们想保持商业机密,不愿共享成果。NASA 的目标就是把尽可能多的研究成果送到他们手里,让他们尽可能地获得能力。而且我敢说你如果去问他们任何一家公司,他们肯定会说,没有 NASA 长久以来的技术支持,他们没法做到这么快地开发。
**00:18:13 - Saron Yitbarek**:
我想这并不影响 NASA 拥有一些非常棒的风洞。从火星漫游车到飞行汽车,你有感觉了吗?我们谈论的是创新,天穹尚且不是我们的极限。而且这一切都归功于我们全地球级别的合作,而正是开源观念让这一切成为可能。
**00:18:41 - Saron Yitbarek**:
我们再回来和 NASA 的 Tom Soderstrom 聊聊。Tom 认为,我们两季以来探讨的开源的“魔力”已经形成了一股巨大的推动力。他称之为第四次工业革命。
**00:18:59 - Tom Soderstrom**:
创新总是与科技的潮流挂钩。当今,有好几波科技浪潮同时袭来,它们的合流将引起巨大的海啸。它们逼近得越来越快,所有事物都会为之改变,因此,我称其为第四次工业革命。
**00:19:21 - Saron Yitbarek**:
我将简单几句带过那些浪潮,虽然就它们中的每一样都可以独立讲一期节目。Tom 所说的“即将到冲击我们生活的潮流”包括了大规模的网络安全问题、量子计算之类,也包括了各类“<ruby> 软件定义的 <rt> software-defined </rt></ruby>”东西。但这些只是其中的一小部分。他还提到了<ruby> 普适计算 <rt> ubiquitous computing </rt></ruby>、<ruby> 自然用户界面 <rt> natural interfaces </rt></ruby>和物联网。
**00:19:49 - Tom Soderstrom**:
这些技术都将是那场海啸的一部分,生活将因为无处不在的<ruby> 内置智能 <rt> built-in intelligence </rt></ruby>而大为改观。
**00:19:54 - Saron Yitbarek**:
想象一下,如果这些技术合流,产生了 1+1 大于 2 的效应,“海啸”发生,情况会变成什么样?
**00:20:04 - Tom Soderstrom**:
我不认为这种变化会是突然发生的;不会有像是一个人站起来感叹“你看这个”这样的情况。就如我刚才所说,内置智能会渗透进生活的各个方面。“智能”,对吧?比如智能电视,或者智能会议室。我们生活中的事物会变得越来越智能,越来越聪明。对于企业来说,它意味着,你可以对着一个房间提出问题,然后程序会为你在数千种不同的数据源、好几 PB 的数据里找出答案。而这背后,就是自然语言处理、深度学习、机器学习这样的技术;而我们不会突然说,“哇,我们已经发展到这种地步了”。不会的,这是一个循序渐进、潜移默化的过程。
**00:20:49 - Saron Yitbarek**:
这第四次工业革命,又会如何影响你在 JPL 的工作呢?
**00:20:57 - Tom Soderstrom**:
我认为首先是实验,下一场工业革命可以帮助我们更快地完成实验,并且利用更好的组件,包括软件和硬件,也许我们不需要把所有的东西都造出来,但是我们可以更智能地使用它。然后是开源。开源真是一项颠覆我们工作方式和工作内容的事业。
**00:21:23 - Saron Yitbarek**:
此话怎讲?
**00:21:24 - Tom Soderstrom**:
说到开源这东西,我的资历足够老,我当年也经历过开源战争。当时开源还只是个玩笑。那时的开源很糟糕,开源软件似乎比商业软件低一等似的。不过,那些都已经是过去了,至少在喷气动力实验室是这样的。现在,开源的方式更适合我们。开源的研究与开发更加经济划算,也可以更快地做实验验证。另外,因为开源软件的存在,现在我们再也不用全部从头造轮子了。我们可以自己开发;在此之后,如果我们选择将之开源,就能从社区获得帮助,对成果进行改进。开源的软件和科研也能为我们招贤纳士。这就很有趣了。
**00:22:05 - Saron Yitbarek**:
确实很有意思。
**00:22:07 - Tom Soderstrom**:
我认为现在的人们,特别是新一代,可以将他们的项目开源,以此获得更多的影响力,得到尽可能多的星标。你可以看见他们的简历上写着,我开发的软件得到了多少星标。
**00:22:21 - Saron Yitbarek**:
对你来说,让你们的工作方式和内容发生变化的开源,并不是什么新鲜事物,对吧?这点让我很感兴趣。你说你经历过开源战争。你也见证了开源在这么多年来的发展。那么,当今的开源有哪些优势是十年、十五年、二十年前没有的呢?
**00:22:47 - Tom Soderstrom**:
有两点。一个就是云计算。我们不用签署一份大合同,购买一堆软件然后使用许多年。我们可以在云端简单地做个实验。这点相当重要。还有另外一点,就是开源并不比闭源的安全性差。这早就不是 —— 请原谅我的用词 —— 一个<ruby> 信仰 <rt> religious </rt></ruby>的问题了。这更多地只是一个实用性和经济性的问题。
**00:23:15 - Saron Yitbarek**:
开源显然在你的工作当中扮演了一个重要的角色;尤其是当你谈及喷气动力实验室的未来,以及你期望它以怎样的方式前行的时候,开源似乎仍将是故事的重要组成部分。说到开源社区式的合作开发,你认为这种方式在最理想的情况下能够导向怎么样的成果?而对于人类,它的意义又是什么?
**00:23:42 - Tom Soderstrom**:
好问题。我认为你刚刚已经说出了正确答案——“人类”。它的理想结果是能让每个人都参与到这份工作中来,而它的意义也在于此。你知道,总有一天我们会把人送上火星。我们要探索更广袤的深空,去寻找地球 2.0。我们还要再开展一次载人登月。这些都需要来自世界各地的人们积极参与。
**00:24:15 - Saron Yitbarek**:
我被这场变革深深的吸引了。Tom Soderstrom 是 NASA 喷气动力实验室的首席技术与创新官。
**00:24:29**:
从地球 2.0 的话题,回到地球 1.0。我们应当铭记,“第四次工业革命”的起源,也是艰苦朴素的。开源项目固然可以变得宏大无比,但千里之行毕竟始于足下;一项伟大的事业,在其伊始,或许只是几名极客试图让漫游车正常工作。
**00:24:47 - SGVHAK 小组**:
我们再看看这样它能不能跑起来。我们会——再加一样东西,方便它从坎上过去。过去了!耶!
**00:24:59 - Saron Yitbarek**:
耶。
**00:25:02 - SGVHAK 小组**:
啊呀,我下不来了,它被卡在花坛里了。
**00:25:14**:
我们把它抬出来就行了。
**00:25:16**:
这又不是在火星。你可以直接走过去,把它拿起来。
**00:25:20 - Saron Yitbarek**:
我觉得他们有所进步。
**00:25:25**:
让我们和这些代码英雄说再见吧,他们要继续学习、探索、投入他们的工作了。他们会知道,通过开源,我们总有一天可以到达天空之外的高度。
**00:25:40**:
如果你想让你自己的开源游戏项目上一个台阶,不要忘了我们正在开发《代码英雄》游戏,开发已经持续了一整季的时间,现在你仍然可以贡献代码。
**00:25:52 - Michael Clayton**:
嗨,我是 Michael。
**00:25:52 - Jared Sprague**:
嗨,我是 Jared。我们是《代码英雄》游戏的开发人员。
**00:25:58 - Saron Yitbarek**:
我们请来了红帽的 Jared Sprague 和 Michael Clayton,看看情况怎么样。
\*\*00:26:03 - Michael Clayton\_
我有点惊讶于我们这么快就引来了这么多的感兴趣的人。反响非常好,提交的拉取请求蹭蹭上涨。
**00:26:17 - Saron Yitbarek**:
你认为是什么让大家这么激动?
**00:26:18 - Michael Clayton**:
我认为我们播客的许多听众都受到了鼓励,因此他们看到这个开源项目就迫不及待地想试试看。尤其是自从我们开始征求不限类型的贡献,让任何想要贡献的创意人员、任何类型的工程师都能够参与项目后,听众就找到事儿做了。
**00:26:39 - Saron Yitbarek**:
那么接下来希望社区能给大家带来什么?这游戏还在开发中。你最想见到什么?
**00:26:47 - Jared Sprague**:
我个人非常享受开发过程中的进入节奏的感觉,我们让大家贡献美术素材和音乐以及音频效果、故事线、代码,所有这些东西都可以并行不悖。一旦每个人都进入节奏,我们可以一起开发,共同看着游戏被开发出来,那真是太美妙了。
**00:27:14 - Saron Yitbarek**:
顺带一提,我们的游戏的公测版将会在今年的五月七日到九日,在波士顿开办的红帽峰会发布。届时,数千名像你一样的代码英雄会前来进行为期三天的创新与教育之旅。访问 [redhat.com/summit](http://redhat.com/summit) 以查看详情。
**00:27:34**:
最后一件事,这或许是第二季的最终章,但这不是真正的告别。第三季已经在筹备中!与此同时,我们也会为大家带来一期彩蛋。我们开展了一次圆桌会议,与你们最喜爱的思想家们探讨开源的未来。请锁定一月份。别忘了,如果你不想错过最新一期节目,记得点关注哦。就点一下,点一下又不会怎么样,这样你才能在第一时间收到新内容的通知哦。
**00:28:09**:
我是 Saron Yitbarek,感谢你聆听本季节目,生命不止,编码不休。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/open-curiosity>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[Colin-XKL](https://github.com/Colin-XKL) 校对:[Northurland](https://github.com/Northurland), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The best and brightest took us to the moon with the computing power of pocket calculators. Now they're taking us farther—and they're doing it with the tech we've been talking about all season. Open source is taking us to Mars.
The Season 2 finale takes us to NASA's Jet Propulsion Laboratory (JPL). Tom Soderstrom shares how much JPL has gained by embracing open source. Hila Lifshitz-Assaf explains that NASA is solving some of their greatest problems with open software and crowdsourcing. And Dan Wachspress describes how working with NASA means proprietary companies need to make some sacrifices—but they get to work on the most innovative projects in the world.
The explorers of the final frontier are choosing to work in the open—and Mars is their destination. What's next?
**00:12** - *Saron Yitbarek*
On August 6, 2012, a car-size rover called Curiosity fell from the top of the Martian atmosphere to the planet's surface. The fall took seven minutes. Down, down. The rover carried a precious cargo, 500,000 lines of code, 76 pyrotechnic devices, and a series of tools for conducting never-before-possible experiments. After releasing a supersonic parachute, after heat shield separation, after power descent, and even a sky crane deployment in mid-air, Curiosity at last touched down.
**00:59** - *NASA engineers*
Time to see where Curiosity will take us.
**01:13** -*Saron Yitbarek*
Hear that sound? That's what it sounds like when a room full of engineers land a rover on Mars. In a few days, they'll be getting a congrats phone call from President Barack Obama. But for now it's all about the team. A room full of people who know they've just accomplished something together that they could never have accomplished on their own.
**01:39** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat. All season long, we've seen how open source technology remakes the way we work and what we're capable of accomplishing. The through-line for me has always been community. It's always about discovering better ways to work together, better ways to learn from the pros, while listening to fresh voices, too. Better ways to connect.
**02:11** - *Saron Yitbarek*
For our season two finale, we're holding on to all those lessons, while we discover how open source powers some of our grandest projects. You might've been watching last November when NASA's InSight Lander touched down on the surface of Mars. Hugs all around. Well, it turns out that shooting for the stars or the red planet only works when you bet everything on collaboration.
**02:45** - *Saron Yitbarek*
Did I mention that rover on Mars has its own Twitter account? Four million followers. No big deal. And it recently tweeted a message to earthlings, an invitation to build a rover of their own, complete with open source instructions and code, courtesy of NASA's Jet Propulsion Lab. We caught up with some folks called the SGVHAK Group. They're one of the first to build their own rover.
**03:13** - *SGVHAK Group*
I'm gonna try and drive over that curb.
**03:15** - *SGVHAK Group*
Let's see what she can do.
**03:15** - *SGVHAK Group*
Going up. Nope.
**03:15** - *SGVHAK Group*
No.
**03:20** - *SGVHAK Group*
She used to be able to go over pretty easily, but with the changes we've made to the wheels, she's a little reluctant now.
**03:27** - *Saron Yitbarek*
The group includes Roger Cheng, Dave Flynn, Emily Velasco, and Lan Dang.
**03:34** - *SGVHAK Group*
Dave designs all the mechanical stuff, and I guess I put things together. Roger's our software guy, Dave's design, Lan is our fearless leader, so.
**03:45** - *SGVHAK Group*
You are the one, you're the mechanical fabrication expert on the team.
**03:49** - *SGVHAK Group*
I guess. I guess so.
**03:51** - *SGVHAK Group*
Tell people about the serval bracket.
**03:53** - *SGVHAK Group*
Oh right.
**03:54** - *SGVHAK Group*
You're the one that built the servo kludge that, run it, the show.
**03:58** - *SGVHAK Group*
We were gonna take-
**04:00** - *Saron Yitbarek*
Building one of these rovers isn't exactly a Lego project. It takes actual rocket scientists about 200 hours to complete. So yeah, let's give these guys a few minutes to get their act together. We'll check in with them later.
**04:19** - *Saron Yitbarek*
Meanwhile, I wanted to learn more about why NASA gave the world an open source rover in the first place. And I found just the person to ask.
**04:29** - *Tom Soderstrom*
My name is Tom Soderstrom. I am chief technology and innovation officer for IT at NASA's Jet Propulsion Laboratory.
**04:37** - *Saron Yitbarek*
JPL is a group of about 6,000 people. It's NASA's federally-funded research center, and they focus on robotic exploration in space.
**04:48** - *Tom Soderstrom*
We look for is there life out there? How did the universe originate, where is it going? And in addition to that, should we ever need to export humanity, we're trying to find Earth 2.0. The earth-like planets that one day we could inhabit.
**05:33** - *Saron Yitbarek*
Yeah, it's the big leagues. But here's the thing. Tom's team isn't some siloed group of engineers. They're deeply committed to connecting with the next generation of scientists. They're constantly trying to find new ways to spark original thinking. In fact, it's a crucial part of their job. The open source rover project gives away those designs, so teams of non-NASA folk can try building their own rover. That was part of NASA's larger strategy to promote innovation. Tom and I got talking about why open sourcing NASA's work is so important. Starting naturally with that open source rover.
**05:46** - *Saron Yitbarek*
A lot of people are, but when I found this site, I'm like, oh man, maybe I can make a rover. It's really exciting. It's really engaging.
**05:55** - *Tom Soderstrom*
We built it for the public and schools to learn, and we're realizing that as we did, it's becoming a wonderful experimentation platform for us. So as we try new things, it's the best place to try it, very easy, very quick, and then we can put it on the real rovers. So we're hoping that people will incorporate things like solar panels, accelerometers, the science payloads, very advanced artificial intelligence programming, and we just want the experiences to proliferate and the people get interested in this and eventually interested in space. Because space is way cool.
**06:32** - *Saron Yitbarek*
So besides the ideas that you have listed, things that people can do, what have people done with it that you were really excited about or impressed by?
**06:42** - *Tom Soderstrom*
The price reduction was one really impressive thing and right now, there's a lot of artificial intelligence (AI) going on. So that's one of the most interesting things I see coming. I would love to see somebody add a robot arm to it.
**06:55** - *Saron Yitbarek*
Really cool.
**06:55** - *Tom Soderstrom*
And something we're thinking about.
**06:58** - *Saron Yitbarek*
So it sounds like this project is open on all angles, right? I mean the hardware is a list of parts that are suggested and it sounds like you can use your own thing, make it cheaper, make it more expensive also, I guess if you wanted to. The software is completely open. Is there any part of this that isn't open?
**07:17** - *Tom Soderstrom*
No, it's all completely open.
**07:19** - *Saron Yitbarek*
So what's really amazing about this is if you told me that high school students could build their own rovers, that would just sound too difficult, you know, that sounds so advanced. It sounds like something that only NASA would do. Right? How simple is it really to put together?
**07:36** - *Tom Soderstrom*
So it's not meant to be a toy. It's meant to be something real, that really gives them the real experience. So several schools in California have already adopted it, to put it into their science and engineering and programming program. Something called Mechatronics, for instance, where it combines all of them. And that makes us very happy, because then we will get better trained people coming into NASA at one point.
**08:04** - *Saron Yitbarek*
But it sounds like at this point it's not only benefiting these future NASA people, these future scientists, but it's also benefiting you. Tell me a little bit more about that.
**08:14** - *Tom Soderstrom*
So all of a sudden, we have now a very simple platform to experiment with. So I can envision the open source rover driving around JPL and saying hello to people. So we can experiment very quickly in our own backyard on things that we would later on need to take to much more difficult places. So, it becomes a mobile platform that we can experiment with. And again, I think AI is going to be the interesting one, because it's exploding so quickly, and the simplicity of adding new robotics parts to it is another factor.
**08:50** - *Saron Yitbarek*
So, theoretically you could have created your own mobile playground, a place to experiment and not made it open source, right? It could have just been like an internal thing. How has the fact that it's been open source affected what you've been able to learn?
**09:08** - *Tom Soderstrom*
So, that's a really good question. Why open source? For us, it was more difficult to make it open source, but that's kind of the challenge. So we wanted to make it open source so that other schools and all that could adopt it and build it. It created a lot more work to create a manual that other people could use who are not already robotics experts. But the bottom line is, I think when we release something into open source, it's cleaner, it's tighter, it's better-documented, because people know other people are going to reuse this, and it has to be built to be extended. So the quality is higher. I talked to Netflix, and they had found the same thing, that the code, once it was released open source, was cleaner. It was better.
**09:54** - *Saron Yitbarek*
When you think about these open source rovers, 5-, 10-, maybe even 20-plus years from now, how do you see the things that they're able to do and what people have been able to create? How do you see that possibly benefiting us here on earth?
**10:11** - *Tom Soderstrom*
In many, many ways. So, today this rover is built to roll. I can see that it could be built to walk. It could be extended to hop. We're already sending a helicopter to Mars, it's flying right now. So these rovers are not just rovers of today. Having people worldwide experiment with it can help us move much, much faster to see what's possible, and come up with ideas that frankly we might not have thought of. So what will it look like? I can't wait to see. I don't know.
**10:49** - *Saron Yitbarek*
By creating this platform, you've kind of enabled and empowered a lot of people to make a lot of toys, and then we'll see what turns up.
**10:57** - *Tom Soderstrom*
Yes, and that's actually a very strong point, because what I have noticed is if I can even think of something, somebody is already doing it. It's a matter of finding them, and whatever we came up with to start, once the end users get their hands on it, they're gonna improve it tenfold, in ways that we never even imagined. So giving them toys to play with makes for a much stronger and better place with more advanced missions in the future.
**11:23** - *Saron Yitbarek*
Beautiful.
**11:29** - *Saron Yitbarek*
f you feel like getting in on the open source rover mission, you can find out how at opensourcerover.jpl.nasa.gov. There is so much fun to be had there. We'll return for more with Tom Soderstrom. But first, I want us to dig a bit deeper into NASA's relationship with open source.
**11:51** - *Hila Lifshitz-Assaf*
Hi, I'm Hila Lifshitz-Assaf. I'm a professor at Stern School of Business, NYU.
**11:57** - *Saron Yitbarek*
Hila's been studying how NASA breaks down knowledge barriers.
**12:02** - *Hila Lifshitz-Assaf*
If you go back, even to 15th century, and you think about lone inventors, like Leonardo da Vinci and others, they were kind of connected only in their local communities. And then, we had the industrial revolution and the birth of the lab. And ever since, for 200 years or more, people have been working in their labs. And the big change that's happened in the 21st century with the digital revolution that we're experiencing has brought up things like open source, which are debunking the need for those organizational boundaries that we had.
**12:34** - *Saron Yitbarek*
In NASA's work, Hila sees a prime example of that massive change.
**12:39** - *Hila Lifshitz-Assaf*
One of the things that attracted me about NASA was that they were the bravest in the sense that they really took strategic research and development (R&D) challenges, that their scientists and engineers and top brains were working at the same time and opened them to the crowd. And I have to say that still to today, many other organizations, when they do open source science or crowdsourcing, they do not take their core strategic challenges. They take something that is on the side, that doesn't risk their organization too much, whether it succeeds or fails, and NASA did something that really changed things, once it succeeded.
**13:14** - *Saron Yitbarek*
Starting back in 2009, NASA began using open innovation platforms, like Innocentive and Topcoder. And they weren't playing around. Like Hila mentioned, they were putting their top R &D challenges on those platforms.
**13:29** - *Hila Lifshitz-Assaf*
It didn't even took a full year to see solutions starting to come from crowdsourcing platforms.
**13:34** - *Saron Yitbarek*
Real quick, I want to give you just one of the home runs they got from opening up their research. Hila's gonna describe how they were able to level-up their solar flare prediction.
**13:46** - *Hila Lifshitz-Assaf*
So, predicting solar storms is a hard heliophysics problem that people have been working on it for more than a decade. And basically they formulated it in a way that was able to be solved by a wide area of people. And they were very intentional about it. That's the amazing thing that I found that they were trying to get solutions from people outside of heliophysics. They were really looking for an innovative solution. And indeed, Bruce Kragan, a semi-retired radio engineer from rural New Hampshire, in 3 months brought us solutions that predicted solar flares. And when the NASA folks ran it, they actually saw that he predicted at 80%. So basically, something that in the traditional model will take years and millions of dollars happened in 3 months in something around $30,000 to $40,000, $50,000.
**14:36** - *Saron Yitbarek*
You might have already guessed, this kind of change required some culture shifts over at NASA.
**14:44** - *Hila Lifshitz-Assaf*
So, some of them invited those external solvers to come to their organizations, other created internships or collaboration, all types of interesting ways to bring that knowledge in, and not to keep it kind of buffered.
**14:59** - *Saron Yitbarek*
There's something kind of beautiful there when you think about it. A lot of organizations still resist open source development and don't like giving up proprietary software, but here you've got the most innovative, biggest-picture group of scientists on the planet, and they're saying, yeah, you know what? Let's do this together. That's a powerful thing.
**15:22** - *Hila Lifshitz-Assaf*
We've seen that revolution in software . We have not yet fully seen it in science and technology, and I think it is prime time to go through it. The more we see the rise of computational physics, computational biology, the more this will become possible. I think much more of the population can participate and help in different type of tasks, and maybe this way, science and technology can really make progress beyond developing a new app.
**15:53** - *Saron Yitbarek*
Hila Lifshitz-Assaf is a professor at the Stern School of business at NYU.
**16:00** - *Saron Yitbarek*
NASA benefits massively from opening up their research challenges, but another way they build community is via the Small Business Innovation Grant program, which supports innovative work in the private sector. All those blue sky projects that are risky but might pay off big time.
**16:22** - *Dan Wachspress*
Hi, my name is Dan Wachspress. I'm an aeronautical engineer working at Continuum Dynamics Incorporated.
**16:28** - *Saron Yitbarek*
Dan's company, CDI, does R&D related to the rotorcraft industry. So that's helicopters, gyrocopters—anything that uses wings or blades to fly, literally blue sky. They've been working with NASA researching vertical takeoff. Think Jetson-style air taxis.
**16:50** - *Dan Wachspress*
The whole idea is, once you have electric motors instead of gas turbine engines on your vehicles, you can have many more propulsors. They could be much quieter, safer, and all issues with helicopters that annoy people could go away, and we might have a world where you call up a taxi that takes you from Dallas to Fort Worth, let's say, in an electric-powered air taxi with 4 other passengers and no pilot, as opposed to getting in a car and trying to battle through the traffic. That's the vision.
**17:22** - *Saron Yitbarek*
A lot of companies, including Uber, are very interested in the potential of air taxis. And the great thing about NASA's role here is that it breaks down barriers that would exist if each of those companies were slogging through the research on their own.
**17:38** - *Dan Wachspress*
Companies do not want to divulge information necessarily. They want to keep trade secrets, and they won't share knowledge . NASA's goal is to put as much knowledge and have as much capability as possible out there in their hands. And I think if you talk to any of these companies, they'll agree that they're just, they wouldn't be able to do what they're doing as fast as they're doing if they weren't supported by NASA and the technology NASA is pushing on today and has pushed on in the past.
**18:13** - *Saron Yitbarek*
I'm guessing it doesn't hurt that NASA has already got some pretty killer wind tunnels, too. From Mars Rovers to flying cars, are you getting a certain vibe here? We're talking about innovation, where the sky is not even the limit. And it's all because of the planet-sized collaboration that the open source mindset makes possible.
**18:41** - *Saron Yitbarek*
I promise we'd come back to NASA's Tom Soderstrom. Tom figures that all the open source magic we've been exploring for the past 2 seasons is building up into a massive shift point that he calls the Fourth Industrial Revolution.
**18:59** - *Tom Soderstrom*
When you look at how innovation happens, it's really about technology waves. And there's a lot of technology waves that are coming right now, and they're all building to a giant tsunami. They're coming faster and faster, and they're all going to change everything, so that's why we call it the Fourth Industrial Revolution.
**19:21** - *Saron Yitbarek*
I'm just going to break down what's in those waves super fast, even though each one of them could be an episode in itself. When Tom talks about those waves that are hitting us, he's talking about things like cybersecurity challenges at scale, quantum computing, and software-defined everything. But wait, there's more. He's also talking about ubiquitous computing, natural interfaces, and the internet of things.
**19:49** - *Tom Soderstrom*
These all build to the giant tsunami, which is built-in intelligence everywhere.
**19:54** - *Saron Yitbarek*
When you imagine this tsunami, this moment when it all comes together and creates something bigger than its individual parts, what does that look like?
**20:04** - *Tom Soderstrom*
I think it's not gonna be like one day somebody stands up and says, look at this. I am now announcing built-in intelligence everywhere. It's creeping into everything that we do. We say smart, right? The smart TV, a smart conference room. That's really where we will start realizing that it's becoming smarter and smarter and smarter, and for the enterprise it means you can just ask a question by speaking to the room and it searches through petabytes of data in thousands of different data sources and gets you the answer. So it's natural language processing. It's deep learning, it's machine learning, and we're not gonna say all of a sudden, wow we're here. It's just going keep morphing and getting better and better.
**20:49** - *Saron Yitbarek*
Thinking about this Fourth Industrial Revolution , how does that influence the way you do work at the Jet PropulsionLab?
**20:57** - *Tom Soderstrom*
I think the experimentation, this next industrial revolution is really helping us experiment quicker and to take advantage of much better components, both software and hardware, that perhaps we don't have to build all of it, but we can just be more intelligent about using it. And then open source. Open source is really what's changing a lot of how we work and what we do.
**21:23** - *Saron Yitbarek*
How so? Tell me more about that.
**21:24** - *Tom Soderstrom*
I think the open source, I'm old enough to have gone through the open source wars, where the open source was a toy. It was bad, it was inferior to commercial. All of that has kind of gone away, at least at JPL. Now it's what's most appropriate for the problem at hand. It's more economical. It's much faster to experiment. Another one is... in open source is, we don't have to develop everything ourselves anymore. We can develop it, and then if we can release it open source, we can get help to make it better. And then it helps us retain and attract talent. This one is interesting.
**22:05** - *Saron Yitbarek*
Oh, that is interesting.
**22:07** - *Tom Soderstrom*
I think people, the new generation especially, get their street creds from submitting to open source and getting as many stars as possible. So that's what you'll see on the resume. My software got x stars.
**22:21** - *Saron Yitbarek*
What's really interesting about how much open source has affected and helped the work that you're doing is the fact that open source isn't new, right? You mentioned yourself that you've lived through the open source wars. You've seen it progress over the years. What is it about open source today that allows you to really take advantage of it in a way that maybe you couldn't 10, 15, 20 years ago?
**22:47** - *Tom Soderstrom*
There's a couple. One of them is simply cloud computing. We don't have to do the big bet and buy a bunch of software and own it for many years. We can just experiment. So that's been a big one. The other one is the realization that open source is no less secure than commercial source. It's no longer, forgive the expression, a religious argument. It's just more of an economical and practical discussion.
**23:15** - *Saron Yitbarek*
Open source has clearly played a big part in what you all are doing, especially when you think about the future of JPL and what you hope to accomplish moving forward. It sounds like open source will probably continue to be a big part of that story. When you think about the most exciting or the most ideal outcome of that collaboration, that participation, what might that look like and what do you think it will mean for humankind?
**23:42** - *Tom Soderstrom*
That's a great question. I think that the real answer is you just said it, humankind. It's getting everybody more involved in what we do. You know, one day we're going to put humans on Mars. We're going to explore even further to find Earth 2.0. We're going to put humans on the moon again. All of that will require a lot more involvement from the world.
**24:15** - *Saron Yitbarek*
I'm into that revolution. Tom Soderstrom is the chief technology and innovation officer for IT at NASA's Jet Propulsion Laboratory.
**24:29** - *Saron Yitbarek*
From Earth 2.0, back to Earth 1.0. It's time to remember the humble origins of that Fourth Industrial Revolution. As grand as open source projects can get, it all starts with a group of hackers just trying to make their rover work.
**24:47** - *SGVHAK Group*
So we're gonna see if it'll run. We're gonna, we put down another thing to help it get over the curb. It made it. Yay.
**24:59** - *Saron Yitbarek*
Yay.
**25:02** - *SGVHAK Group*
Uh-oh. Now I can't get down. It's stuck in the flower bed.
**25:14** - *SGVHAK Group*
We're just going to have to lift it out.
**25:16** - *SGVHAK Group*
It's not on Mars. You can just go over and pick it up.
**25:20** - *Saron Yitbarek*
I think they're making progress.
**25:25** - *Saron Yitbarek*
We're going to leave those command line heroes just the way we found them, exploring, learning, diving into their work, and knowing that, through open source, the sky's not even the limit.
**25:40** - *Saron Yitbarek*
If you're ready to level up your own open source game, don't forget, we've been building Command Line Heroes: The Game, all season long and you can still contribute.
**25:52** - *Michael Clayton*
Hi, I'm Michael.
**25:52** - *Jared Sprague*
Hi, I'm Jared. And we're the developers of Command Line Heroes: The Game.
**25:58** - *Saron Yitbarek*
We checked in with Jared Sprague and Michael Clayton from Red Hat to find out how it's going.
**26:03** - *Michael Clayton*
I was a little surprised at how much interest we got so quickly. The response was just phenomenal, and the pull requests started flowing.
**26:17** - *Saron Yitbarek*
What do you think it is that got people so excited?
**26:18** - *Michael Clayton*
I think this just was for a lot of people listening to the podcast, kind of a catalyst for them to try it out, especially since we put out a call for all types of contributions, any type of creative person that wants to contribute or an engineer of any type, there's something that they can do on it.
**26:39** - *Saron Yitbarek*
So what do you hope to see next from the community? The game is still in development. What do you hope to see?
**26:47** - *Jared Sprague*
I would personally really like to get into the groove of development, where we have people contributing art assets and music and sound effects, storyline, coding, and all of these things can all work in parallel, and once we get everyone into that groove, and we're all just building a game and we can see it coming together, that's going to be a great time.
**27:14** - *Saron Yitbarek*
By the way, we'll have a beta of the game on display at this year's Red Hat Summit—in Boston, May 7-9—thousands of command line heroes just like you are coming together for 3 days of innovation and education. Check out the details at redhat.com/summit.
**27:34** - *Saron Yitbarek*
And one final announcement. This may be the end of season 2, but it's not really goodbye. Season 3 is already in the works! And in the meantime, we've got a bonus episode coming your way. We're hosting a roundtable with some of our favorite thinkers—getting them talking about what's next for open source. Look for that one in January. And remember, if you don't want to worry about missing new episodes, just subscribe. It's one click, it's free, and you'll be the first to know when new content drops.
**28:09** - *Saron Yitbarek*
I'm Saron Yitbarek. Thanks for listening all season long and keep on coding. |
12,747 | Go 语言在极小硬件上的运用(二) | https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html | 2020-10-24T09:01:41 | [
"Go",
"极小硬件"
] | https://linux.cn/article-12747-1.html | 
在本文的 [第一部分](/article-11383-1.html) 的结尾,我承诺要写关于接口的内容。我不想在这里写有关接口或完整或简短的讲义。相反,我将展示一个简单的示例,来说明如何定义和使用接口,以及如何利用无处不在的 `io.Writer` 接口。还有一些关于<ruby> 反射 <rt> reflection </rt></ruby>和<ruby> 半主机 <rt> semihosting </rt></ruby>的内容。
]
接口是 Go 语言的重要组成部分。如果你想了解更多有关它们的信息,我建议你阅读《[高效的 Go 编程](https://golang.org/doc/effective_go.html#interfaces)》 和 [Russ Cox 的文章](https://research.swtch.com/interfaces)。
### 并发 Blinky – 回顾
当你阅读前面示例的代码时,你可能会注意到一中打开或关闭 LED 的反直觉方式。 `Set` 方法用于关闭 LED,`Clear` 方法用于打开 LED。这是由于在 <ruby> 漏极开路配置 <rt> open-drain configuration </rt></ruby> 下驱动了 LED。我们可以做些什么来减少代码的混乱?让我们用 `On` 和 `Off` 方法来定义 `LED` 类型:
```
type LED struct {
pin gpio.Pin
}
func (led LED) On() {
led.pin.Clear()
}
func (led LED) Off() {
led.pin.Set()
}
```
现在我们可以简单地调用 `led.On()` 和 `led.Off()`,这不会再引起任何疑惑了。
在前面的所有示例中,我都尝试使用相同的 <ruby> 漏极开路配置 <rt> open-drain configuration </rt></ruby>来避免代码复杂化。但是在最后一个示例中,对于我来说,将第三个 LED 连接到 GND 和 PA3 引脚之间并将 PA3 配置为<ruby> 推挽模式 <rt> push-pull mode </rt></ruby>会更容易。下一个示例将使用以此方式连接的 LED。
但是我们的新 `LED` 类型不支持推挽配置,实际上,我们应该将其称为 `OpenDrainLED`,并定义另一个类型 `PushPullLED`:
```
type PushPullLED struct {
pin gpio.Pin
}
func (led PushPullLED) On() {
led.pin.Set()
}
func (led PushPullLED) Off() {
led.pin.Clear()
}
```
请注意,这两种类型都具有相同的方法,它们的工作方式也相同。如果在 LED 上运行的代码可以同时使用这两种类型,而不必注意当前使用的是哪种类型,那就太好了。 接口类型可以提供帮助:
```
package main
import (
"delay"
"stm32/hal/gpio"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
)
type LED interface {
On()
Off()
}
type PushPullLED struct{ pin gpio.Pin }
func (led PushPullLED) On() {
led.pin.Set()
}
func (led PushPullLED) Off() {
led.pin.Clear()
}
func MakePushPullLED(pin gpio.Pin) PushPullLED {
pin.Setup(&gpio.Config{Mode: gpio.Out, Driver: gpio.PushPull})
return PushPullLED{pin}
}
type OpenDrainLED struct{ pin gpio.Pin }
func (led OpenDrainLED) On() {
led.pin.Clear()
}
func (led OpenDrainLED) Off() {
led.pin.Set()
}
func MakeOpenDrainLED(pin gpio.Pin) OpenDrainLED {
pin.Setup(&gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain})
return OpenDrainLED{pin}
}
var led1, led2 LED
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(false)
led1 = MakeOpenDrainLED(gpio.A.Pin(4))
led2 = MakePushPullLED(gpio.A.Pin(3))
}
func blinky(led LED, period int) {
for {
led.On()
delay.Millisec(100)
led.Off()
delay.Millisec(period - 100)
}
}
func main() {
go blinky(led1, 500)
blinky(led2, 1000)
}
```
我们定义了 `LED` 接口,它有两个方法: `On` 和 `Off`。 `PushPullLED` 和 `OpenDrainLED` 类型代表两种驱动 LED 的方式。我们还定义了两个用作构造函数的 `Make*LED` 函数。这两种类型都实现了 `LED` 接口,因此可以将这些类型的值赋给 `LED` 类型的变量:
```
led1 = MakeOpenDrainLED(gpio.A.Pin(4))
led2 = MakePushPullLED(gpio.A.Pin(3))
```
在这种情况下,<ruby> 可赋值性 <rt> assignability </rt></ruby>在编译时检查。赋值后,`led1` 变量包含一个 `OpenDrainLED{gpio.A.Pin(4)}`,以及一个指向 `OpenDrainLED` 类型的方法集的指针。 `led1.On()` 调用大致对应于以下 C 代码:
```
led1.methods->On(led1.value)
```
如你所见,如果仅考虑函数调用的开销,这是相当廉价的抽象。
但是,对接口的任何赋值都会导致包含有关已赋值类型的大量信息。对于由许多其他类型组成的复杂类型,可能会有很多信息:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
10356 196 212 10764 2a0c cortexm0.elf
```
如果我们不使用 [反射](https://blog.golang.org/laws-of-reflection),可以通过避免包含类型和结构字段的名称来节省一些字节:
```
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
10312 196 212 10720 29e0 cortexm0.elf
```
生成的二进制文件仍然包含一些有关类型的必要信息和关于所有导出方法(带有名称)的完整信息。在运行时,主要是当你将存储在接口变量中的一个值赋值给任何其他变量时,需要此信息来检查可赋值性。
我们还可以通过重新编译所导入的包来删除它们的类型和字段名称:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
10272 196 212 10680 29b8 cortexm0.elf
```
让我们加载这个程序,看看它是否按预期工作。这一次我们将使用 [st-flash](https://github.com/texane/stlink) 命令:
```
$ arm-none-eabi-objcopy -O binary cortexm0.elf cortexm0.bin
$ st-flash write cortexm0.bin 0x8000000
st-flash 1.4.0-33-gd76e3c7
2018-04-10T22:04:34 INFO usb.c: -- exit_dfu_mode
2018-04-10T22:04:34 INFO common.c: Loading device parameters....
2018-04-10T22:04:34 INFO common.c: Device connected is: F0 small device, id 0x10006444
2018-04-10T22:04:34 INFO common.c: SRAM size: 0x1000 bytes (4 KiB), Flash: 0x4000 bytes (16 KiB) in pages of 1024 bytes
2018-04-10T22:04:34 INFO common.c: Attempting to write 10468 (0x28e4) bytes to stm32 address: 134217728 (0x8000000)
Flash page at addr: 0x08002800 erased
2018-04-10T22:04:34 INFO common.c: Finished erasing 11 pages of 1024 (0x400) bytes
2018-04-10T22:04:34 INFO common.c: Starting Flash write for VL/F0/F3/F1_XL core id
2018-04-10T22:04:34 INFO flash_loader.c: Successfully loaded flash loader in sram
11/11 pages written
2018-04-10T22:04:35 INFO common.c: Starting verification of write complete
2018-04-10T22:04:35 INFO common.c: Flash written and verified! jolly good!
```
我没有将 NRST 信号连接到编程器,因此无法使用 `-reset` 选项,必须按下复位按钮才能运行程序。

看来,`st-flash` 与此板配合使用有点不可靠(通常需要复位 ST-LINK 加密狗)。此外,当前版本不会通过 SWD 发出复位命令(仅使用 NRST 信号)。软件复位是不现实的,但是它通常是有效的,缺少它会将会带来不便。对于<ruby> 板卡程序员 <rt> board-programmer </rt></ruby> 来说 OpenOCD 工作得更好。
### UART
UART(<ruby> 通用异步收发传输器 <rt> Universal Aynchronous Receiver-Transmitter </rt></ruby>)仍然是当今微控制器最重要的外设之一。它的优点是以下属性的独特组合:
* 相对较高的速度,
* 仅两条信号线(在 <ruby> 半双工 <rt> half-duplex </rt></ruby> 通信的情况下甚至一条),
* 角色对称,
* 关于新数据的 <ruby> 同步带内信令 <rt> synchronous in-band signaling </rt></ruby>(起始位),
* 在传输 <ruby> 字 <rt> words </rt></ruby> 内的精确计时。
这使得最初用于传输由 7-9 位的字组成的异步消息的 UART,也被用于有效地实现各种其他物理协议,例如被 [WS28xx LEDs](http://www.world-semi.com/solution/list-4-1.html) 或 [1-wire](https://en.wikipedia.org/wiki/1-Wire) 设备使用的协议。
但是,我们将以其通常的角色使用 UART:从程序中打印文本消息。
```
package main
import (
"io"
"rtos"
"stm32/hal/dma"
"stm32/hal/gpio"
"stm32/hal/irq"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
"stm32/hal/usart"
)
var tts *usart.Driver
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(true)
tx := gpio.A.Pin(9)
tx.Setup(&gpio.Config{Mode: gpio.Alt})
tx.SetAltFunc(gpio.USART1_AF1)
d := dma.DMA1
d.EnableClock(true)
tts = usart.NewDriver(usart.USART1, d.Channel(2, 0), nil, nil)
tts.Periph().EnableClock(true)
tts.Periph().SetBaudRate(115200)
tts.Periph().Enable()
tts.EnableTx()
rtos.IRQ(irq.USART1).Enable()
rtos.IRQ(irq.DMA1_Channel2_3).Enable()
}
func main() {
io.WriteString(tts, "Hello, World!\r\n")
}
func ttsISR() {
tts.ISR()
}
func ttsDMAISR() {
tts.TxDMAISR()
}
//c:__attribute__((section(".ISRs")))
var ISRs = [...]func(){
irq.USART1: ttsISR,
irq.DMA1_Channel2_3: ttsDMAISR,
}
```
你会发现此代码可能有些复杂,但目前 STM32 HAL 中没有更简单的 UART 驱动程序(在某些情况下,简单的轮询驱动程序可能会很有用)。 `usart.Driver` 是使用 DMA 和中断来减轻 CPU 负担的高效驱动程序。
STM32 USART 外设提供传统的 UART 及其同步版本。要将其用作输出,我们必须将其 Tx 信号连接到正确的 GPIO 引脚:
```
tx.Setup(&gpio.Config{Mode: gpio.Alt})
tx.SetAltFunc(gpio.USART1_AF1)
```
在 Tx-only 模式下配置 `usart.Driver` (rxdma 和 rxbuf 设置为 nil):
```
tts = usart.NewDriver(usart.USART1, d.Channel(2, 0), nil, nil)
```
我们使用它的 `WriteString` 方法来打印这句名言。让我们清理所有内容并编译该程序:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
12728 236 176 13140 3354 cortexm0.elf
```
要查看某些内容,你需要在 PC 中使用 UART 外设。
**请勿使用 RS232 端口或 USB 转 RS232 转换器!**
STM32 系列使用 3.3V 逻辑,但是 RS232 可以产生 -15 V ~ +15 V 的电压,这可能会损坏你的 MCU。你需要使用 3.3V 逻辑的 USB 转 UART 转换器。流行的转换器基于 FT232 或 CP2102 芯片。

你还需要一些终端仿真程序(我更喜欢 [picocom](https://github.com/npat-efault/picocom))。刷新新图像,运行终端仿真器,然后按几次复位按钮:
```
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; reset run; exit'
Open On-Chip Debugger 0.10.0+dev-00319-g8f1f912a (2018-03-07-19:20)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
debug_level: 0
adapter speed: 1000 kHz
adapter_nsrst_delay: 100
none separate
adapter speed: 950 kHz
target halted due to debug-request, current mode: Thread
xPSR: 0xc1000000 pc: 0x080016f4 msp: 0x20000a20
adapter speed: 4000 kHz
** Programming Started **
auto erase enabled
target halted due to breakpoint, current mode: Thread
xPSR: 0x61000000 pc: 0x2000003a msp: 0x20000a20
wrote 13312 bytes from file cortexm0.elf in 1.020185s (12.743 KiB/s)
** Programming Finished **
adapter speed: 950 kHz
$
$ picocom -b 115200 /dev/ttyUSB0
picocom v3.1
port is : /dev/ttyUSB0
flowcontrol : none
baudrate is : 115200
parity is : none
databits are : 8
stopbits are : 1
escape is : C-a
local echo is : no
noinit is : no
noreset is : no
hangup is : no
nolock is : no
send_cmd is : sz -vv
receive_cmd is : rz -vv -E
imap is :
omap is :
emap is : crcrlf,delbs,
logfile is : none
initstring : none
exit_after is : not set
exit is : no
Type [C-a] [C-h] to see available commands
Terminal ready
Hello, World!
Hello, World!
Hello, World!
```
每次按下复位按钮都会产生新的 “Hello,World!”行。一切都在按预期进行。
要查看此 MCU 的 <ruby> 双向 <rt> bi-directional </rt></ruby> UART 代码,请查看 [此示例](https://github.com/ziutek/emgo/blob/master/egpath/src/stm32/examples/f030-demo-board/usart/main.go)。
### io.Writer 接口
`io.Writer` 接口可能是 Go 中第二种最常用的接口类型,仅次于 `error` 接口。其定义如下所示:
```
type Writer interface {
Write(p []byte) (n int, err error)
}
```
`usart.Driver` 实现了 `io.Writer`,因此我们可以替换:
```
tts.WriteString("Hello, World!\r\n")
```
为
```
io.WriteString(tts, "Hello, World!\r\n")
```
此外,你需要将 `io` 包添加到 `import` 部分。
`io.WriteString` 函数的声明如下所示:
```
func WriteString(w Writer, s string) (n int, err error)
```
如你所见,`io.WriteString` 允许使用实现了 `io.Writer` 接口的任何类型来编写字符串。在内部,它检查基础类型是否具有 `WriteString` 方法,并使用该方法代替 `Write`(如果可用)。
让我们编译修改后的程序:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15456 320 248 16024 3e98 cortexm0.elf
```
如你所见,`io.WriteString` 导致二进制文件的大小显着增加:15776-12964 = 2812 字节。 Flash 上没有太多空间了。是什么引起了这么大规模的增长?
使用这个命令:
```
arm-none-eabi-nm --print-size --size-sort --radix=d cortexm0.elf
```
我们可以打印两种情况下按其大小排序的所有符号。通过过滤和分析获得的数据(`awk`,`diff`),我们可以找到大约 80 个新符号。最大的十个如下所示:
```
> 00000062 T stm32$hal$usart$Driver$DisableRx
> 00000072 T stm32$hal$usart$Driver$RxDMAISR
> 00000076 T internal$Type$Implements
> 00000080 T stm32$hal$usart$Driver$EnableRx
> 00000084 t errors$New
> 00000096 R $8$stm32$hal$usart$Driver$$
> 00000100 T stm32$hal$usart$Error$Error
> 00000360 T io$WriteString
> 00000660 T stm32$hal$usart$Driver$Read
```
因此,即使我们不使用 `usart.Driver.Read` 方法,但它被编译进来了,与 `DisableRx`、`RxDMAISR`、`EnableRx` 以及上面未提及的其他方法一样。不幸的是,如果你为接口赋值了一些内容,就需要它的完整方法集(包含所有依赖项)。对于使用大多数方法的大型程序来说,这不是问题。但是对于我们这种极简的情况而言,这是一个巨大的负担。
我们已经接近 MCU 的极限,但让我们尝试打印一些数字(你需要在 `import` 部分中用 `strconv` 替换 `io` 包):
```
func main() {
a := 12
b := -123
tts.WriteString("a = ")
strconv.WriteInt(tts, a, 10, 0, 0)
tts.WriteString("\r\n")
tts.WriteString("b = ")
strconv.WriteInt(tts, b, 10, 0, 0)
tts.WriteString("\r\n")
tts.WriteString("hex(a) = ")
strconv.WriteInt(tts, a, 16, 0, 0)
tts.WriteString("\r\n")
tts.WriteString("hex(b) = ")
strconv.WriteInt(tts, b, 16, 0, 0)
tts.WriteString("\r\n")
}
```
与使用 `io.WriteString` 函数的情况一样,`strconv.WriteInt` 的第一个参数的类型为 `io.Writer`。
```
$ egc
/usr/local/arm/bin/arm-none-eabi-ld: /home/michal/firstemgo/cortexm0.elf section `.rodata' will not fit in region `Flash'
/usr/local/arm/bin/arm-none-eabi-ld: region `Flash' overflowed by 692 bytes
exit status 1
```
这一次我们的空间超出的不多。让我们试着精简一下有关类型的信息:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15876 316 320 16512 4080 cortexm0.elf
```
很接近,但很合适。让我们加载并运行此代码:
```
a = 12
b = -123
hex(a) = c
hex(b) = -7b
```
Emgo 中的 `strconv` 包与 Go 中的原型有很大的不同。它旨在直接用于写入格式化的数字,并且在许多情况下可以替换沉重的 `fmt` 包。 这就是为什么函数名称以 `Write` 而不是 `Format` 开头,并具有额外的两个参数的原因。 以下是其用法示例:
```
func main() {
b := -123
strconv.WriteInt(tts, b, 10, 0, 0)
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, 6, ' ')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, 6, '0')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, 6, '.')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, -6, ' ')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, -6, '0')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, -6, '.')
tts.WriteString("\r\n")
}
```
下面是它的输出:
```
-123
-123
-00123
..-123
-123
-123
-123..
```
### Unix 流 和 <ruby> 莫尔斯电码 <rt> Morse code </rt></ruby>
由于大多数写入的函数都使用 `io.Writer` 而不是具体类型(例如 C 中的 `FILE` ),因此我们获得了类似于 Unix <ruby> 流 <rt> stream </rt></ruby> 的功能。在 Unix 中,我们可以轻松地组合简单的命令来执行更大的任务。例如,我们可以通过以下方式将文本写入文件:
```
echo "Hello, World!" > file.txt
```
`>` 操作符将前面命令的输出流写入文件。还有 `|` 操作符,用于连接相邻命令的输出流和输入流。
多亏了流,我们可以轻松地转换/过滤任何命令的输出。例如,要将所有字母转换为大写,我们可以通过 `tr` 命令过滤 `echo` 的输出:
```
echo "Hello, World!" | tr a-z A-Z > file.txt
```
为了显示 `io.Writer` 和 Unix 流之间的类比,让我们编写以下代码:
```
io.WriteString(tts, "Hello, World!\r\n")
```
采用以下伪 unix 形式:
```
io.WriteString "Hello, World!" | usart.Driver usart.USART1
```
下一个示例将显示如何执行此操作:
```
io.WriteString "Hello, World!" | MorseWriter | usart.Driver usart.USART1
```
让我们来创建一个简单的编码器,它使用莫尔斯电码对写入的文本进行编码:
```
type MorseWriter struct {
W io.Writer
}
func (w *MorseWriter) Write(s []byte) (int, error) {
var buf [8]byte
for n, c := range s {
switch {
case c == '\n':
c = ' ' // Replace new lines with spaces.
case 'a' <= c && c <= 'z':
c -= 'a' - 'A' // Convert to upper case.
}
if c < ' ' || 'Z' < c {
continue // c is outside ASCII [' ', 'Z']
}
var symbol morseSymbol
if c == ' ' {
symbol.length = 1
buf[0] = ' '
} else {
symbol = morseSymbols[c-'!']
for i := uint(0); i < uint(symbol.length); i++ {
if (symbol.code>>i)&1 != 0 {
buf[i] = '-'
} else {
buf[i] = '.'
}
}
}
buf[symbol.length] = ' '
if _, err := w.W.Write(buf[:symbol.length+1]); err != nil {
return n, err
}
}
return len(s), nil
}
type morseSymbol struct {
code, length byte
}
//emgo:const
var morseSymbols = [...]morseSymbol{
{1<<0 | 1<<1 | 1<<2, 4}, // ! ---.
{1<<1 | 1<<4, 6}, // " .-..-.
{}, // #
{1<<3 | 1<<6, 7}, // $ ...-..-
// Some code omitted...
{1<<0 | 1<<3, 4}, // X -..-
{1<<0 | 1<<2 | 1<<3, 4}, // Y -.--
{1<<0 | 1<<1, 4}, // Z --..
}
```
你可以在 [这里](https://github.com/ziutek/emgo/blob/master/egpath/src/stm32/examples/f030-demo-board/morseuart/main.go) 找到完整的 `morseSymbols` 数组。 `//emgo:const` 指令确保 `morseSymbols` 数组不会被复制到 RAM 中。
现在我们可以通过两种方式打印句子:
```
func main() {
s := "Hello, World!\r\n"
mw := &MorseWriter{tts}
io.WriteString(tts, s)
io.WriteString(mw, s)
}
```
我们使用指向 `MorseWriter` `&MorseWriter{tts}` 的指针而不是简单的 `MorseWriter{tts}` 值,因为 `MorseWriter` 太大,不适合接口变量。
与 Go 不同,Emgo 不会为存储在接口变量中的值动态分配内存。接口类型的大小受限制,相当于三个指针(适合 `slice` )或两个 `float64`(适合 `complex128`)的大小,以较大者为准。它可以直接存储所有基本类型和小型 “结构体/数组” 的值,但是对于较大的值,你必须使用指针。
让我们编译此代码并查看其输出:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15152 324 248 15724 3d6c cortexm0.elf
```
```
Hello, World!
.... . .-.. .-.. --- --..-- .-- --- .-. .-.. -.. ---.
```
### 终极闪烁
Blinky 是等效于 “Hello,World!” 程序的硬件。一旦有了摩尔斯编码器,我们就可以轻松地将两者结合起来以获得终极闪烁程序:
```
package main
import (
"delay"
"io"
"stm32/hal/gpio"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
)
var led gpio.Pin
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(false)
led = gpio.A.Pin(4)
cfg := gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain, Speed: gpio.Low}
led.Setup(&cfg)
}
type Telegraph struct {
Pin gpio.Pin
Dotms int // Dot length [ms]
}
func (t Telegraph) Write(s []byte) (int, error) {
for _, c := range s {
switch c {
case '.':
t.Pin.Clear()
delay.Millisec(t.Dotms)
t.Pin.Set()
delay.Millisec(t.Dotms)
case '-':
t.Pin.Clear()
delay.Millisec(3 * t.Dotms)
t.Pin.Set()
delay.Millisec(t.Dotms)
case ' ':
delay.Millisec(3 * t.Dotms)
}
}
return len(s), nil
}
func main() {
telegraph := &MorseWriter{Telegraph{led, 100}}
for {
io.WriteString(telegraph, "Hello, World! ")
}
}
// Some code omitted...
```
在上面的示例中,我省略了 `MorseWriter` 类型的定义,因为它已在前面展示过。完整版可通过 [这里](https://github.com/ziutek/emgo/blob/master/egpath/src/stm32/examples/f030-demo-board/morseled/main.go) 获取。让我们编译它并运行:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
11772 244 244 12260 2fe4 cortexm0.elf
```

### 反射
是的,Emgo 支持 [反射](https://blog.golang.org/laws-of-reflection)。`reflect` 包尚未完成,但是已完成的部分足以实现 `fmt.Print` 函数族了。来看看我们可以在小型 MCU 上做什么。
为了减少内存使用,我们将使用 <ruby> <a href="http://infocenter.arm.com/help/topic/com.arm.doc.dui0471g/Bgbjjgij.html"> 半主机 </a> <rt> semihosting </rt></ruby> 作为标准输出。为了方便起见,我们还编写了简单的 `println` 函数,它在某种程度上类似于 `fmt.Println`。
```
package main
import (
"debug/semihosting"
"reflect"
"strconv"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
)
var stdout semihosting.File
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
var err error
stdout, err = semihosting.OpenFile(":tt", semihosting.W)
for err != nil {
}
}
type stringer interface {
String() string
}
func println(args ...interface{}) {
for i, a := range args {
if i > 0 {
stdout.WriteString(" ")
}
switch v := a.(type) {
case string:
stdout.WriteString(v)
case int:
strconv.WriteInt(stdout, v, 10, 0, 0)
case bool:
strconv.WriteBool(stdout, v, 't', 0, 0)
case stringer:
stdout.WriteString(v.String())
default:
stdout.WriteString("%unknown")
}
}
stdout.WriteString("\r\n")
}
type S struct {
A int
B bool
}
func main() {
p := &S{-123, true}
v := reflect.ValueOf(p)
println("kind(p) =", v.Kind())
println("kind(*p) =", v.Elem().Kind())
println("type(*p) =", v.Elem().Type())
v = v.Elem()
println("*p = {")
for i := 0; i < v.NumField(); i++ {
ft := v.Type().Field(i)
fv := v.Field(i)
println(" ", ft.Name(), ":", fv.Interface())
}
println("}")
}
```
`semihosting.OpenFile` 函数允许在主机端打开/创建文件。特殊路径 `:tt` 对应于主机的标准输出。
`println` 函数接受任意数量的参数,每个参数的类型都是任意的:
```
func println(args ...interface{})
```
可能是因为任何类型都实现了空接口 `interface{}`。 `println` 使用 [类型开关](https://golang.org/doc/effective_go.html#type_switch) 打印字符串,整数和布尔值:
```
switch v := a.(type) {
case string:
stdout.WriteString(v)
case int:
strconv.WriteInt(stdout, v, 10, 0, 0)
case bool:
strconv.WriteBool(stdout, v, 't', 0, 0)
case stringer:
stdout.WriteString(v.String())
default:
stdout.WriteString("%unknown")
}
```
此外,它还支持任何实现了 `stringer` 接口的类型,即任何具有 `String()` 方法的类型。在任何 `case` 子句中,`v` 变量具有正确的类型,与 `case` 关键字后列出的类型相同。
`reflect.ValueOf(p)` 函数通过允许以编程的方式分析其类型和内容的形式返回 `p`。如你所见,我们甚至可以使用 `v.Elem()` 取消引用指针,并打印所有结构体及其名称。
让我们尝试编译这段代码。现在让我们看看如果编译时没有类型和字段名,会有什么结果:
```
$ egc -nt -nf
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
16028 216 312 16556 40ac cortexm0.elf
```
闪存上只剩下 140 个可用字节。让我们使用启用了半主机的 OpenOCD 加载它:
```
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; arm semihosting enable; reset run'
Open On-Chip Debugger 0.10.0+dev-00319-g8f1f912a (2018-03-07-19:20)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
debug_level: 0
adapter speed: 1000 kHz
adapter_nsrst_delay: 100
none separate
adapter speed: 950 kHz
target halted due to debug-request, current mode: Thread
xPSR: 0xc1000000 pc: 0x08002338 msp: 0x20000a20
adapter speed: 4000 kHz
** Programming Started **
auto erase enabled
target halted due to breakpoint, current mode: Thread
xPSR: 0x61000000 pc: 0x2000003a msp: 0x20000a20
wrote 16384 bytes from file cortexm0.elf in 0.700133s (22.853 KiB/s)
** Programming Finished **
semihosting is enabled
adapter speed: 950 kHz
kind(p) = ptr
kind(*p) = struct
type(*p) =
*p = {
X. : -123
X. : true
}
```
如果你实际运行此代码,则会注意到半主机运行缓慢,尤其是在逐字节写入时(缓冲很有用)。
如你所见,`*p` 没有类型名称,并且所有结构字段都具有相同的 `X.` 名称。让我们再次编译该程序,这次不带 `-nt -nf` 选项:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
16052 216 312 16580 40c4 cortexm0.elf
```
现在已经包括了类型和字段名称,但仅在 ~~*main.go* 文件中~~ `main` 包中定义了它们。该程序的输出如下所示:
```
kind(p) = ptr
kind(*p) = struct
type(*p) = S
*p = {
A : -123
B : true
}
```
反射是任何易于使用的序列化库的关键部分,而像 [JSON](https://en.wikipedia.org/wiki/JSON) 这样的序列化 ~~算法~~ 在<ruby> 物联网 <rt> IoT </rt></ruby>时代也越来越重要。
这些就是我完成的本文的第二部分。我认为有机会进行第三部分,更具娱乐性的部分,在那里我们将各种有趣的设备连接到这块板上。如果这块板装不下,我们就换一块大一点的。
---
via: <https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html>
作者:[Michał Derkacz](https://ziutek.github.io/) 译者:[gxlct008](https://github.com/gxlct008) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Go on very small hardware (Part 2)
At the end of the [first part](/2018/03/30/go_on_very_small_hardware.html) of this article I promised to write something about *interfaces*. I don’t want to write here a complete or even brief lecture about the interfaces. Instead, I’ll show a simple example how to define and use an interface, and then, how to take advantage of ubiquitous *io.Writer* interface. There will also be a few words about *reflection* and *semihosting*.
Interfaces are a crucial part of Go language. If you want to learn more about them, I suggest to read [Effective Go](https://golang.org/doc/effective_go.html#interfaces) and [Russ Cox article](https://research.swtch.com/interfaces).
## Concurrent Blinky – revisited
When you read the code of previous examples you probably noticed a counterintuitive way to turn the LED on or off. The *Set* method was used to turn the LED off and the *Clear* method was used to turn the LED on. This is due to driving the LEDs in open-drain configuration. What we can do to make the code less confusing? Let’s define the *LED* type with *On* and *Off* methods:
```
type LED struct {
pin gpio.Pin
}
func (led LED) On() {
led.pin.Clear()
}
func (led LED) Off() {
led.pin.Set()
}
```
Now we can simply call `led.On()`
and `led.Off()`
which no longer raises any doubts.
In all previous examples I tried to use the same open-drain configuration to don’t complicate the code. But in the last example, it would be easier for me to connect the third LED between GND and PA3 pins and configure PA3 in push-pull mode. The next example will use a LED connected this way.
But our new *LED* type doesn’t support the push-pull configuration. In fact, we should call it *OpenDrainLED* and define another *PushPullLED* type:
```
type PushPullLED struct {
pin gpio.Pin
}
func (led PushPullLED) On() {
led.pin.Set()
}
func (led PushPullLED) Off() {
led.pin.Clear()
}
```
Note, that both types have the same methods that work the same. It would be nice if the code that operates on LEDs could use both types, without paying attention to which one it uses at the moment. The *interface type* comes to help:
```
package main
import (
"delay"
"stm32/hal/gpio"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
)
type LED interface {
On()
Off()
}
type PushPullLED struct{ pin gpio.Pin }
func (led PushPullLED) On() {
led.pin.Set()
}
func (led PushPullLED) Off() {
led.pin.Clear()
}
func MakePushPullLED(pin gpio.Pin) PushPullLED {
pin.Setup(&gpio.Config{Mode: gpio.Out, Driver: gpio.PushPull})
return PushPullLED{pin}
}
type OpenDrainLED struct{ pin gpio.Pin }
func (led OpenDrainLED) On() {
led.pin.Clear()
}
func (led OpenDrainLED) Off() {
led.pin.Set()
}
func MakeOpenDrainLED(pin gpio.Pin) OpenDrainLED {
pin.Setup(&gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain})
return OpenDrainLED{pin}
}
var led1, led2 LED
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(false)
led1 = MakeOpenDrainLED(gpio.A.Pin(4))
led2 = MakePushPullLED(gpio.A.Pin(3))
}
func blinky(led LED, period int) {
for {
led.On()
delay.Millisec(100)
led.Off()
delay.Millisec(period - 100)
}
}
func main() {
go blinky(led1, 500)
blinky(led2, 1000)
}
```
We’ve defined *LED* interface that has two methods: *On* and *Off*. The *PushPullLED* and *OpenDrainLED* types represent two ways of driving LEDs. We also defined two *Make***LED* functions which act as constructors. Both types implement the *LED* interface, so the values of these types can be assigned to the variables of type *LED*:
```
led1 = MakeOpenDrainLED(gpio.A.Pin(4))
led2 = MakePushPullLED(gpio.A.Pin(3))
```
In this case the assignability is checked at compile time. After the assignment the *led1* variable contains `OpenDrainLED{gpio.A.Pin(4)}`
and a pointer to the method set of the *OpenDrainLED* type. The `led1.On()`
call roughly corresponds to the following C code:
```
led1.methods->On(led1.value)
```
As you can see, this is quite inexpensive abstraction if only consider the function call overhead.
But any assigment to an interface causes to include a lot of information about the assigned type. There can be a lot information in case of complex type which consists of many other types:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
10356 196 212 10764 2a0c cortexm0.elf
```
If we don’t use [reflection](https://blog.golang.org/laws-of-reflection) we can save some bytes by avoid to include the names of types and struct fields:
```
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
10312 196 212 10720 29e0 cortexm0.elf
```
The resulted binary still contains some necessary information about types and full information about all exported methods (with names). This information is need for checking assignability at runtime, mainly when you assign one value stored in the interface variable to any other variable.
We can also remove type and field names from imported packages by recompiling them all:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
10272 196 212 10680 29b8 cortexm0.elf
```
Let’s load this program to see does it work as expected. This time we’ll use the [st-flash](https://github.com/texane/stlink) command:
```
$ arm-none-eabi-objcopy -O binary cortexm0.elf cortexm0.bin
$ st-flash write cortexm0.bin 0x8000000
st-flash 1.4.0-33-gd76e3c7
2018-04-10T22:04:34 INFO usb.c: -- exit_dfu_mode
2018-04-10T22:04:34 INFO common.c: Loading device parameters....
2018-04-10T22:04:34 INFO common.c: Device connected is: F0 small device, id 0x10006444
2018-04-10T22:04:34 INFO common.c: SRAM size: 0x1000 bytes (4 KiB), Flash: 0x4000 bytes (16 KiB) in pages of 1024 bytes
2018-04-10T22:04:34 INFO common.c: Attempting to write 10468 (0x28e4) bytes to stm32 address: 134217728 (0x8000000)
Flash page at addr: 0x08002800 erased
2018-04-10T22:04:34 INFO common.c: Finished erasing 11 pages of 1024 (0x400) bytes
2018-04-10T22:04:34 INFO common.c: Starting Flash write for VL/F0/F3/F1_XL core id
2018-04-10T22:04:34 INFO flash_loader.c: Successfully loaded flash loader in sram
11/11 pages written
2018-04-10T22:04:35 INFO common.c: Starting verification of write complete
2018-04-10T22:04:35 INFO common.c: Flash written and verified! jolly good!
```
I didn’t connected the NRST signal to the programmer so the *—reset* option can’t be used and the reset button have to be pressed to run the program.
It seems that the *st-flash* works a bit unreliably with this board (often requires reseting the ST-LINK dongle). Additionally, the current version doesn’t issue the reset command over SWD (uses only NRST signal). The software reset isn’t realiable however it usually works and lack of it introduces inconvenience. For this board-programmer pair the *OpenOCD* works much better.
[UART](#uart)
UART (Universal Aynchronous Receiver-Transmitter) is still one of the most important peripherals of today’s microcontrollers. Its advantage is unique combination of the following properties:
- relatively high speed,
- only two signal lines (even one in case of half-duplex communication),
- symmetry of roles,
- synchronous in-band signaling about new data (start bit),
- accurate timing inside transmitted word.
This causes that UART, originally intedned to transmit asynchronous messages consisting of 7-9 bit words, is also used to efficiently implement various other phisical protocols such as used by [WS28xx LEDs](http://www.world-semi.com/solution/list-4-1.html) or [1-wire](https://en.wikipedia.org/wiki/1-Wire) devices.
However, we will use the UART in its usual role: to printing text messages from our program.
```
package main
import (
"rtos"
"stm32/hal/dma"
"stm32/hal/gpio"
"stm32/hal/irq"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
"stm32/hal/usart"
)
var tts *usart.Driver
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(true)
tx := gpio.A.Pin(9)
tx.Setup(&gpio.Config{Mode: gpio.Alt})
tx.SetAltFunc(gpio.USART1_AF1)
d := dma.DMA1
d.EnableClock(true)
tts = usart.NewDriver(usart.USART1, d.Channel(2, 0), nil, nil)
tts.Periph().EnableClock(true)
tts.Periph().SetBaudRate(115200)
tts.Periph().Enable()
tts.EnableTx()
rtos.IRQ(irq.USART1).Enable()
rtos.IRQ(irq.DMA1_Channel2_3).Enable()
}
func main() {
tts.WriteString("Hello, World!\r\n")
}
func ttsISR() {
tts.ISR()
}
func ttsDMAISR() {
tts.TxDMAISR()
}
//c:__attribute__((section(".ISRs")))
var ISRs = [...]func(){
irq.USART1: ttsISR,
irq.DMA1_Channel2_3: ttsDMAISR,
}
```
You can find this code slightly complicated but for now there is no simpler UART driver in STM32 HAL (simple polling driver will be probably useful in some cases). The *usart.Driver* is efficient driver that uses DMA and interrupts to ofload the CPU.
STM32 USART peripheral provides traditional UART and its synchronous version. To use it as output we have to connect its Tx signal to the right GPIO pin:
```
tx.Setup(&gpio.Config{Mode: gpio.Alt})
tx.SetAltFunc(gpio.USART1_AF1)
```
The *usart.Driver* is configured in Tx-only mode (rxdma and rxbuf are set to nil):
```
tts = usart.NewDriver(usart.USART1, d.Channel(2, 0), nil, nil)
```
We use its *WriteString* method to print the famous sentence. Let’s clean everything and compile this program:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
12728 236 176 13140 3354 cortexm0.elf
```
To see something you need an UART peripheral in your PC.
**Do not use RS232 port or USB to RS232 converter!**
The STM32 family uses 3.3 V logic but RS232 can produce from -15 V to +15 V which will probably demage your MCU. You need USB to UART converter that uses 3.3 V logic. Popular converters are based on FT232 or CP2102 chips.
You also need some terminal emulator program (I prefer [picocom](https://github.com/npat-efault/picocom)). Flash the new image, run the terminal emulator and press the reset button a few times:
```
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; reset run; exit'
Open On-Chip Debugger 0.10.0+dev-00319-g8f1f912a (2018-03-07-19:20)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
debug_level: 0
adapter speed: 1000 kHz
adapter_nsrst_delay: 100
none separate
adapter speed: 950 kHz
target halted due to debug-request, current mode: Thread
xPSR: 0xc1000000 pc: 0x080016f4 msp: 0x20000a20
adapter speed: 4000 kHz
** Programming Started **
auto erase enabled
target halted due to breakpoint, current mode: Thread
xPSR: 0x61000000 pc: 0x2000003a msp: 0x20000a20
wrote 13312 bytes from file cortexm0.elf in 1.020185s (12.743 KiB/s)
** Programming Finished **
adapter speed: 950 kHz
$
$ picocom -b 115200 /dev/ttyUSB0
picocom v3.1
port is : /dev/ttyUSB0
flowcontrol : none
baudrate is : 115200
parity is : none
databits are : 8
stopbits are : 1
escape is : C-a
local echo is : no
noinit is : no
noreset is : no
hangup is : no
nolock is : no
send_cmd is : sz -vv
receive_cmd is : rz -vv -E
imap is :
omap is :
emap is : crcrlf,delbs,
logfile is : none
initstring : none
exit_after is : not set
exit is : no
Type [C-a] [C-h] to see available commands
Terminal ready
Hello, World!
Hello, World!
Hello, World!
```
Every press of the reset button produces new “Hello, World!” line. Everything works as expected.
To see bi-directional UART code for this MCU check out [this example](https://github.com/ziutek/emgo/blob/master/egpath/src/stm32/examples/f030-demo-board/usart/main.go).
## io.Writer
The *io.Writer* interface is probably the second most commonly used interface type in Go, right after the *error* interface. Its definition looks like this:
```
type Writer interface {
Write(p []byte) (n int, err error)
}
```
*usart.Driver* implements *io.Writer* so we can replace:
```
tts.WriteString("Hello, World!\r\n")
```
with
```
io.WriteString(tts, "Hello, World!\r\n")
```
Additionally you need to add the *io* package to the *import* section.
The declaration of *io.WriteString* function looks as follows:
```
func WriteString(w Writer, s string) (n int, err error)
```
As you can see, the *io.WriteString* allows to write strings using any type that implements *io.Writer* interface. Internally it check does the underlying type has *WriteString* method and uses it instead of *Write* if available.
Let’s compile the modified program:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15456 320 248 16024 3e98 cortexm0.elf
```
As you can see, *io.WriteString* causes a significant increase in the size of the binary: 15776 - 12964 = 2812 bytes. There isn’t too much space left on the Flash. What caused such a drastic increase in size?
Using the command:
```
arm-none-eabi-nm --print-size --size-sort --radix=d cortexm0.elf
```
we can print all symbols ordered by its size for both cases. By filtering and analyzing the obtained data (awk, diff) we can find about 80 new symbols. The ten largest are:
```
> 00000062 T stm32$hal$usart$Driver$DisableRx
> 00000072 T stm32$hal$usart$Driver$RxDMAISR
> 00000076 T internal$Type$Implements
> 00000080 T stm32$hal$usart$Driver$EnableRx
> 00000084 t errors$New
> 00000096 R $8$stm32$hal$usart$Driver$$
> 00000100 T stm32$hal$usart$Error$Error
> 00000360 T io$WriteString
> 00000660 T stm32$hal$usart$Driver$Read
```
So, even though we don’t use the *usart.Driver.Read* method it was compiled in, same as *DisableRx*, *RxDMAISR*, *EnableRx* and other not mentioned above. Unfortunately, if you assign something to the interface, its full method set is required (with all dependences). This isn’t a problem for a large programs that use most of the methods anyway. But for our simple one it’s a huge burden.
We’re already close to the limits of our MCU but let’s try to print some numbers (you need to replace *io* package with *strconv* in *import* section):
```
func main() {
a := 12
b := -123
tts.WriteString("a = ")
strconv.WriteInt(tts, a, 10, 0, 0)
tts.WriteString("\r\n")
tts.WriteString("b = ")
strconv.WriteInt(tts, b, 10, 0, 0)
tts.WriteString("\r\n")
tts.WriteString("hex(a) = ")
strconv.WriteInt(tts, a, 16, 0, 0)
tts.WriteString("\r\n")
tts.WriteString("hex(b) = ")
strconv.WriteInt(tts, b, 16, 0, 0)
tts.WriteString("\r\n")
}
```
As in the case of *io.WriteString* function, the first argument of the *strconv.WriteInt* is of type *io.Writer*.
```
$ egc
/usr/local/arm/bin/arm-none-eabi-ld: /home/michal/firstemgo/cortexm0.elf section `.rodata' will not fit in region `Flash'
/usr/local/arm/bin/arm-none-eabi-ld: region `Flash' overflowed by 692 bytes
exit status 1
```
This time we’ve run out of space. Let’s try to slim down the information about types:
```
$ cd $HOME/emgo
$ ./clean.sh
$ cd $HOME/firstemgo
$ egc -nf -nt
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15876 316 320 16512 4080 cortexm0.elf
```
It was close, but we fit. Let’s load and run this code:
```
a = 12
b = -123
hex(a) = c
hex(b) = -7b
```
The *strconv* package in Emgo is quite different from its archetype in Go. It is intended for direct use to write formatted numbers and in many cases can replace heavy *fmt* package. That’s why the function names start with *Write* instead of *Format* and have additional two parameters. Below is an example of their use:
```
func main() {
b := -123
strconv.WriteInt(tts, b, 10, 0, 0)
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, 6, ' ')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, 6, '0')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, 6, '.')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, -6, ' ')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, -6, '0')
tts.WriteString("\r\n")
strconv.WriteInt(tts, b, 10, -6, '.')
tts.WriteString("\r\n")
}
```
There is its output:
```
-123
-123
-00123
..-123
-123
-123
-123..
```
## Unix streams and Morse code
Thanks to the fact that most of the functions that write something use *io.Writer* instead of concrete type (eg. *FILE* in C) we get a functionality similar to *Unix streams*. In Unix we can easily combine simple commands to perform larger tasks. For example, we can write text to the file this way:
```
echo "Hello, World!" > file.txt
```
The `>`
operator writes the output stream of the preceding command to the file. There is also `|`
operator that connects output and input streams of adjacent commands.
Thanks to the streams we can easily convert/filter output of any command. For example, to convert all letters to uppercase we can filter the echo’s output through *tr* command:
```
echo "Hello, World!" | tr a-z A-Z > file.txt
```
To show the analogy between *io.Writer* and Unix streams let’s write our:
```
io.WriteString(tts, "Hello, World!\r\n")
```
in the following pseudo-unix form:
```
io.WriteString "Hello, World!" | usart.Driver usart.USART1
```
The next example will show how to do this:
```
io.WriteString "Hello, World!" | MorseWriter | usart.Driver usart.USART1
```
Let’s create a simple encoder that encodes the text written to it using Morse coding:
```
type MorseWriter struct {
W io.Writer
}
func (w *MorseWriter) Write(s []byte) (int, error) {
var buf [8]byte
for n, c := range s {
switch {
case c == '\n':
c = ' ' // Replace new lines with spaces.
case 'a' <= c && c <= 'z':
c -= 'a' - 'A' // Convert to upper case.
}
if c < ' ' || 'Z' < c {
continue // c is outside ASCII [' ', 'Z']
}
var symbol morseSymbol
if c == ' ' {
symbol.length = 1
buf[0] = ' '
} else {
symbol = morseSymbols[c-'!']
for i := uint(0); i < uint(symbol.length); i++ {
if (symbol.code>>i)&1 != 0 {
buf[i] = '-'
} else {
buf[i] = '.'
}
}
}
buf[symbol.length] = ' '
if _, err := w.W.Write(buf[:symbol.length+1]); err != nil {
return n, err
}
}
return len(s), nil
}
type morseSymbol struct {
code, length byte
}
//emgo:const
var morseSymbols = [...]morseSymbol{
{1<<0 | 1<<1 | 1<<2, 4}, // ! ---.
{1<<1 | 1<<4, 6}, // " .-..-.
{}, // #
{1<<3 | 1<<6, 7}, // $ ...-..-
// Some code omitted...
{1<<0 | 1<<3, 4}, // X -..-
{1<<0 | 1<<2 | 1<<3, 4}, // Y -.--
{1<<0 | 1<<1, 4}, // Z --..
}
```
You can find the full *morseSymbols* array [here](https://github.com/ziutek/emgo/blob/master/egpath/src/stm32/examples/f030-demo-board/morseuart/main.go). The `//emgo:const`
directive ensures that *morseSymbols* array won’t be copied to the RAM.
Now we can print our sentence in two ways:
```
func main() {
s := "Hello, World!\r\n"
mw := &MorseWriter{tts}
io.WriteString(tts, s)
io.WriteString(mw, s)
}
```
We use the pointer to the *MorseWriter* `&MorseWriter{tts}`
instead os simple `MorseWriter{tts}`
value beacuse the *MorseWriter* is to big to fit into an interface variable.
Emgo, unlike Go, doesn’t dynamically allocate memory for value stored in interface variable. The interface type has limited size, equal to the size of three pointers (to fit *slice*) or two *float64* (to fit *complex128*), what is bigger. It can directly store values of all basic types and small structs/arrays but for bigger values you must use pointers.
Let’s compile this code and see its output:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
15152 324 248 15724 3d6c cortexm0.elf
```
```
Hello, World!
.... . .-.. .-.. --- --..-- .-- --- .-. .-.. -.. ---.
```
### The Ultimate Blinky
The *Blinky* is hardware equivalent of *Hello, World!* program. Once we have a Morse encoder we can easly combine both to obtain the *Ultimate Blinky* program:
```
package main
import (
"delay"
"io"
"stm32/hal/gpio"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
)
var led gpio.Pin
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
gpio.A.EnableClock(false)
led = gpio.A.Pin(4)
cfg := gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain, Speed: gpio.Low}
led.Setup(&cfg)
}
type Telegraph struct {
Pin gpio.Pin
Dotms int // Dot length [ms]
}
func (t Telegraph) Write(s []byte) (int, error) {
for _, c := range s {
switch c {
case '.':
t.Pin.Clear()
delay.Millisec(t.Dotms)
t.Pin.Set()
delay.Millisec(t.Dotms)
case '-':
t.Pin.Clear()
delay.Millisec(3 * t.Dotms)
t.Pin.Set()
delay.Millisec(t.Dotms)
case ' ':
delay.Millisec(3 * t.Dotms)
}
}
return len(s), nil
}
func main() {
telegraph := &MorseWriter{Telegraph{led, 100}}
for {
io.WriteString(telegraph, "Hello, World! ")
}
}
// Some code omitted...
```
In the above example I omitted the definition of *MorseWriter* type because it was shown earlier. The full version is available [here](https://github.com/ziutek/emgo/blob/master/egpath/src/stm32/examples/f030-demo-board/morseled/main.go). Let’s compile it and run:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
11772 244 244 12260 2fe4 cortexm0.elf
```
## Reflection
Yes, Emgo supports [reflection](https://blog.golang.org/laws-of-reflection). The *reflect* package isn’t complete yet but that what is done is enough to implement *fmt.Print* family of functions. Let’s see what can we do on our small MCU.
To reduce memory usage we will use [semihosting](http://infocenter.arm.com/help/topic/com.arm.doc.dui0471g/Bgbjjgij.html) as standard output. For convenience, we also write simple *println* function which to some extent mimics *fmt.Println*.
```
package main
import (
"debug/semihosting"
"reflect"
"strconv"
"stm32/hal/system"
"stm32/hal/system/timer/systick"
)
var stdout semihosting.File
func init() {
system.SetupPLL(8, 1, 48/8)
systick.Setup(2e6)
var err error
stdout, err = semihosting.OpenFile(":tt", semihosting.W)
for err != nil {
}
}
type stringer interface {
String() string
}
func println(args ...interface{}) {
for i, a := range args {
if i > 0 {
stdout.WriteString(" ")
}
switch v := a.(type) {
case string:
stdout.WriteString(v)
case int:
strconv.WriteInt(stdout, v, 10, 0, 0)
case bool:
strconv.WriteBool(stdout, v, 't', 0, 0)
case stringer:
stdout.WriteString(v.String())
default:
stdout.WriteString("%unknown")
}
}
stdout.WriteString("\r\n")
}
type S struct {
A int
B bool
}
func main() {
p := &S{-123, true}
v := reflect.ValueOf(p)
println("kind(p) =", v.Kind())
println("kind(*p) =", v.Elem().Kind())
println("type(*p) =", v.Elem().Type())
v = v.Elem()
println("*p = {")
for i := 0; i < v.NumField(); i++ {
ft := v.Type().Field(i)
fv := v.Field(i)
println(" ", ft.Name(), ":", fv.Interface())
}
println("}")
}
```
The *semihosting.OpenFile* function allows to open/create file on the host side. The special path *:tt* corresponds to host’s standard output.
The *println* function accepts arbitrary number of arguments, each of arbitrary type:
```
func println(args ...interface{})
```
It’s possible because any type implements the empty interface *interface{}*. The *println* uses [type switch](https://golang.org/doc/effective_go.html#type_switch) to print strings, integers and booleans:
```
switch v := a.(type) {
case string:
stdout.WriteString(v)
case int:
strconv.WriteInt(stdout, v, 10, 0, 0)
case bool:
strconv.WriteBool(stdout, v, 't', 0, 0)
case stringer:
stdout.WriteString(v.String())
default:
stdout.WriteString("%unknown")
}
```
Additionally it supports any type that implements *stringer* interface, that is, any type that has *String()* method. In any *case* clause the *v* variable has the right type, same as listed after *case* keyword.
The `reflect.ValueOf(p)`
returns *p* in the form that allows to analyze its type and content programmatically. As you can see, we can even dereference pointers using `v.Elem()`
and print all struct fields with their names.
Let’s try to compile this code. For now let’s see what will come out if compiled without type and field names:
```
$ egc -nt -nf
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
16028 216 312 16556 40ac cortexm0.elf
```
Only 140 free bytes left on the Flash. Let’s load it using OpenOCD with semihosting enabled:
```
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; arm semihosting enable; reset run'
Open On-Chip Debugger 0.10.0+dev-00319-g8f1f912a (2018-03-07-19:20)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
debug_level: 0
adapter speed: 1000 kHz
adapter_nsrst_delay: 100
none separate
adapter speed: 950 kHz
target halted due to debug-request, current mode: Thread
xPSR: 0xc1000000 pc: 0x08002338 msp: 0x20000a20
adapter speed: 4000 kHz
** Programming Started **
auto erase enabled
target halted due to breakpoint, current mode: Thread
xPSR: 0x61000000 pc: 0x2000003a msp: 0x20000a20
wrote 16384 bytes from file cortexm0.elf in 0.700133s (22.853 KiB/s)
** Programming Finished **
semihosting is enabled
adapter speed: 950 kHz
kind(p) = ptr
kind(*p) = struct
type(*p) =
*p = {
X. : -123
X. : true
}
```
If you’ve actually run this code, you noticed that semihosting is slow, especially if you write a byte after byte (buffering helps).
As you can see, there is no type name for `*p`
and all struct fields have the same *X.* name. Let’s compile this program again, this time without *-nt -nf* options:
```
$ egc
$ arm-none-eabi-size cortexm0.elf
text data bss dec hex filename
16052 216 312 16580 40c4 cortexm0.elf
```
Now the type and field names have been included but only these defined in *main.go* file*main* package. The output of our program looks as follows:
```
kind(p) = ptr
kind(*p) = struct
type(*p) = S
*p = {
A : -123
B : true
}
```
Reflection is a crucial part of any easy to use serialization library and serialization ~~algorithms~~ like [JSON](https://en.wikipedia.org/wiki/JSON) gain in importance in the IOT era.
This is where I finish the second part of this article. I think there is a chance for the [third part](/2018/05/03/go_on_very_small_hardware3.html), more entertaining, where we connect to this board various interesting devices. If this board won’t carry them, we replace it with something a little bigger. |
12,748 | Linux 黑话解释:什么是 FOSS(自由和开源软件)?什么是开源? | https://itsfoss.com/what-is-foss/ | 2020-10-24T11:42:00 | [
"开源",
"FOSS",
"黑话解释"
] | https://linux.cn/article-12748-1.html | 
什么是 FOSS?
在过去,我曾多次被问到这个问题,现在是时候解释一下什么是 Linux 和软件世界中的 FOSS 了。
这个区别很重要,因为 FOSS 是一个通用的词汇,它可以根据上下文的不同而有不同的含义。在这里,我讨论的是软件中的 FOSS 原则。
### 什么是 FOSS?
FOSS 是指<ruby> 自由和开放源码软件 <rt> Free and Open Source Software </rt></ruby>。这并不意味着软件是免费的。它意味着软件的源代码是开放的,任何人都可以自由使用、研究和修改代码。这个原则允许人们像一个社区一样为软件的开发和改进做出贡献。
#### FOSS 的起源
在上世纪 60、70 年代,计算机以硬件为主,硬件价格昂贵。它们主要由大学的学者或实验室的研究人员使用。以前有限的软件都是免费的,或者是带有它们的源代码,用户可以根据自己的需要修改源代码。
在上世纪 70 年代末和 80 年代初,制造商为了不让自己的软件在竞争对手的计算机上运行,停止了分发源代码。
这种限制性的许可导致了那些习惯和喜欢修改软件的人的不便和不喜。上世纪 80 年代中期,Richard Stallman 发起了<ruby> 自由软件运动 <rt> Free Software Movement </rt></ruby>。
[Stallman 指明了一个软件要成为 FOSS 的四个基本自由](https://www.gnu.org/philosophy/free-sw.html)。

为了便于理解,我将它们重新表述:
* 任何用户应能为任何目的运行软件。
* 用户应能自由查看软件的源代码,如有需要,应允许用户修改代码。
* 用户应能自由地将软件的副本分发给他人。
* 如果用户修改了代码,她/他应该可以自由地将修改后的代码发布给他人。修改后的代码必须开放源代码。
如果有兴趣,我建议阅读这篇关于 [FOSS 的历史](https://itsfoss.com/history-of-foss/)的文章。
### FOSS 中的 “Free” 并不意味着免费

你可能已经注意到了,自由和开源软件中的 “Free” 并不意味着它是免费的,它意味着运行、修改和分发软件的“自由”。
人们经常错误地认为,FOSS 或开源软件不能有价格标签。这是不正确的。
大多数 FOSS 都是免费提供的,原因有很多:
* 源代码已经向公众开放,所以一些开发者认为没有必要在下载软件时贴上价格标签。
* 有些项目是由一些志愿者免费提供的。因此,主要的开发者认为对这么多人免费贡献的东西收费是不道德的。
* 有些项目是由较大的企业或非营利组织支持和/或开发的,这些组织会雇佣开发人员在他们的开源项目上工作。
* 有些开发者创建开源项目是出于兴趣,或者出于他们对用代码为世界做贡献的热情。对他们来说,下载量、贡献和感谢的话比金钱更重要。
为了避免强调 “免费”,有些人使用了 FLOSS 这个词(LCTT 译注:有时候也写作 F/LOSS)。FLOSS 是<ruby> 自由和开源软件 <rt> Free/Libre Open Source Software </rt></ruby>的缩写。单词 Libre(意为自由)与 gartuit/gratis(免费)不同。
>
> “Free” 是言论自由的自由,而不是免费啤酒的免费。
>
>
>
### FOSS 项目如何赚钱?
开源项目不赚钱是一个神话。红帽是第一个达到 10 亿美元大关的开源公司。[IBM 以 340 亿美元收购了红帽](https://itsfoss.com/ibm-red-hat-acquisition/)。这样的例子有很多。
许多开源项目,特别是企业领域的项目,都会提供收费的支持和面向企业的功能。这是红帽、SUSE Linux 和更多此类项目的主要商业模式。
一些开源项目,如 Discourse、WordPress 等,则提供其软件的托管实例,并收取一定的费用。
许多开源项目,特别是桌面应用程序,依靠捐赠。VLC、GIMP、Inkscape 等这类开源软件就属于这一类。有[资助开源项目的方法](https://itsfoss.com/open-source-funding-platforms/),但通常,你会在项目网站上找到捐赠链接。
利用开源软件赚钱可能很难,但也不是完全不可能。
### 但我不是程序员,我为什么要关心一个软件是否开源?
这是一个合理的问题。你不是一个软件开发者,只是一个普通的计算机用户。即使软件的源代码是可用的,你也不会理解程序的工作原理。
这很好。你不会明白,但有必要技能的人就会明白,这才是最重要的。
你可以这样想。也许你不会理解一份复杂的法律文件。但如果你有看文件的自由,并保留一份副本,你就可以咨询某个人,他可以检查文件中的法律陷阱。
换句话说,开源软件具有透明度。
### FOSS 与开源之间的区别是什么?
你会经常遇到 FOSS 和<ruby> 开源 <rt> Open Source </rt></ruby>的术语。它们经常被互换使用。
它们是同一件事吗?这很难用“是”和“不是”来回答。
你看,FOSS 中的“Free”一词让很多人感到困惑,因为人们错误地认为它是免费的。企业高管、高层和决策者往往会关注自由和开源中的“免费”。由于他们是商业人士,专注于为他们的公司赚钱,“自由”一词在采用 FOSS 原则时起到了威慑作用。
这就是为什么在上世纪 90 年代中期创立了一个名为<ruby> <a href="https://opensource.org/"> 开源促进会 </a> <rt> Open Source Initiative </rt></ruby>的新组织。他们从自由和开放源码软件中去掉了“自由”一词,并创建了自己的[开放源码的定义](https://opensource.org/osd),以及自己的一套许可证。
“<ruby> 开源 <rt> Open Source </rt></ruby>”一词在软件行业特别流行。高管们对开源更加适应。开源软件的采用迅速增长,我相信 “免费”一词的删除确实起到了作用。
### 有问题吗?
这正如我在[什么是 Linux 发行版](https://itsfoss.com/what-is-linux-distribution/)一文中所解释的那样,FOSS/开源的概念在 Linux 的发展和普及中起到了很大的作用。
我试图在这篇黑话解释文章中用更简单的语言解释 FOSS 和开源的概念,而试图避免在细节或技术精度上做过多的阐述。
我希望你现在对这个话题有了更好的理解。如果你有问题或建议,欢迎留言并继续讨论。
---
via: <https://itsfoss.com/what-is-foss/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

What does FOSS in It’s FOSS mean? What is FOSS?
I have been asked this question numerous times in the past. It was about time that I explained what is FOSS in Linux and the software world.
The distinction is important because FOSS is a generic world and it could mean different depending on the context. Here, I am discussing the FOSS principle in software.
## What is FOSS?
FOSS means Free and Open Source Software. It doesn’t mean the software is free of cost. It means that the software's source code is open for all and anyone is free to use, study and modify the code. This principle allows others to contribute to developing and improving a software like a community.
### The origin of FOSS
In the 60s and 70s, computers were hardware focused and the hardware was expensive. They were mainly used by academics in universities or researchers in labs. The limited amount of software used to come for free or with their source code and the users were allowed to modify the source code to suit their needs.
In the late 70s and early 80s, the manufacturer’s stopped distributing source code in an attempt to not let their software run on their competitor’s computers.
This restrictive licensing led to the inconvenience and dislike of people who were used to and fond of modifying software. In the mid-80s, Richard Stallman started the Free Software Movement.
[Stallman specified four essential fundamental freedom](https://www.gnu.org/philosophy/free-sw.html) for software to be Free and Open Source Software.

I am rephrasing them for easier understanding:
- Any user should be able to run the software for any purpose.
- Users should be free to see the source code of the software and if need be, users should be allowed to modify the code as well.
- Users should be free to distribute copies of the software to others.
- If a user modifies the code, she/he should be free to distribute the modified code to others. The modified code must have the source code open.
If interested, I would advise reading this article on the [history of FOSS](https://itsfoss.com/history-of-foss/).
[A Brief History of FOSS PracticesA little peek into some facts from FOSS History.](https://itsfoss.com/history-of-foss/)

## Free in Free and Open Source Software DOES NOT mean free of cost

As you may have noticed, the ‘free’ in Free and Open Source Software doesn’t mean it is free of cost. It means freedom to run, modify and distribute the software.
People often wrongly think that FOSS or Open Source software cannot have a price tag. This is not correct.
Most Free and Open Source Software are available free of cost because of several reasons:
- The source code is already available to the public so some developers see no point in putting a price tag on the downloads.
- Some projects are contributed by a number of volunteers for free. So, the main developer(s) find it unethical to charge for something that has been contributed freely by so many people.
- Some projects are supported and/or developed by bigger corporate or non-profit organizations that employ developers to work on their open source projects.
- Some developers create open source projects as hobby or out of their passion for contributing to the world with their code. Things like the number of downloads, contributions, and words of appreciation matter more than money for them.
To avoid the emphasis on ‘free’ some people use the term FLOSS. FLOSS stands for Free and Libre Open Source Software. The world libre (freedom) is different from gratuit/gratis (free of cost).
Free as in free speech, not free as in free beer.
## How do FOSS projects make money?
It is a myth that open source projects don’t make money. Red Hat was the first open source company to reach the billion dollars mark. [IBM bought Red Hat for $34 billion](https://itsfoss.com/ibm-red-hat-acquisition/). There are many such examples.
Many open source projects, especially the ones in the enterprise sectors, offer support and enterprise-oriented features for a fee. This is main business model for Red Hat, SUSE Linux and more such projects.
Some open source projects like Discourse, and WordPress offer hosted instances of their software for a premium fee.
Many open source projects, especially desktop applications, rely on donations. VLC, GIMP, Inkscape and other such open source software fell in this category. There are [ways to fund open-source programs](https://itsfoss.com/open-source-funding-platforms/) but usually, you’ll find donation links on project websites.
Making money with open source software may be difficult but it is not entirely impossible.
## But I am not a programmer. Why should I care if software is open source or not?
This is a valid question. You are not a software developer, just a regular computer user. Even if the source code of the software is available, you won’t understand how the program works.
That’s fine. You won’t understand it but someone with the necessary skill sets will and that’s what matters.
Think of it this way. Perhaps you won’t understand a complicated legal document. But if you have the freedom to look at the document and keep a copy of it, you can consult someone who can check it for legal pitfalls.
In other words, open source software has transparency.
## What is the difference between FOSS and Open Source?

You’ll often come across the terms FOSS and open source. They are often used interchangeably.
Are they the same thing? It is difficult to answer yes and no.
The term ‘free’ in FOSS is confusing for many as people incorrectly assume that it as free of cost. Enterprise executives, higher-ups and decision makers tend to focus on ‘free’ in Free and Open Source. Since they are business people focused on making money for their company, the term ‘free’ works as deterrence in adopting the FOSS principles.
This is why a new organization named [Open Source Initiative](https://opensource.org/) was created in the mid 90s. They removed the ‘Free’ from Free and Open Source Software and created their own [definition of open source](https://opensource.org/osd). and their own set of licenses.
The term ‘open source’ got quite popular specially in the software industry. The executives are more comfortable with Open Source. The adoption of open source snowballed and I believe the removal of the ‘free’ term did play a role here.
## Got questions?
As I explained in the article, [what is Linux Distribution](https://itsfoss.com/what-is-linux-distribution/), the FOSS/open source concept played a big role in the development and popularity of Linux.
I explained the concept of FOSS and open source more straightforwardly in this jargon buster article. I have tried to avoid going into too much in detail or technical accuracies.
*💬 I do hope you have a better understanding of this topic now. If you have questions or suggestions, feel free to comment and continue the discussion there.* |
12,750 | 如何从 LVM 的卷组中删除物理卷? | https://www.2daygeek.com/linux-remove-delete-physical-volume-pv-from-volume-group-vg-in-lvm/ | 2020-10-25T10:16:26 | [
"LVM"
] | https://linux.cn/article-12750-1.html | 
如果你的 LVM 不再需要使用某个设备,你可以使用 `vgreduce` 命令从卷组中删除物理卷。
`vgreduce` 命令可以通过删除物理卷来缩小卷组的容量。但要确保该物理卷没有被任何逻辑卷使用,请使用 `pvdisplay` 命令查看。如果物理卷仍在使用,你必须使用 `pvmove` 命令将数据转移到另一个物理卷。
数据转移后,它就可以从卷组中删除。
最后使用 `pvremove` 命令删除空物理卷上的 LVM 标签和 LVM 元数据。
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)](/article-12670-1.html)**
* **第二部分:[如何在 Linux 中扩展/增加 LVM 大小(逻辑卷调整)](/article-12673-1.html)**
* **第三部分:[如何在 Linux 中减少/缩小 LVM 大小(逻辑卷调整)](/article-12740-1.html)**

### 将扩展块移动到现有物理卷上
使用 `pvs` 命令检查是否使用了所需的物理卷(我们计划删除 LVM 中的 `/dev/sdc` 磁盘)。
```
# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda myvg lvm2 a- 75.00G 14.00G 61.00G
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
/dev/sdc myvg lvm2 a- 17.15G 12.15G 5.00G
```
如果使用了,请检查卷组中的其他物理卷是否有足够的空闲<ruby> 扩展块 <rt> extent </rt></ruby>。
如果有的话,你可以在需要删除的设备上运行 `pvmove` 命令。扩展块将被分配到其他设备上。
```
# pvmove /dev/sdc
/dev/sdc: Moved: 2.0%
…
/dev/sdc: Moved: 79.2%
…
/dev/sdc: Moved: 100.0%
```
当 `pvmove` 命令完成后。再次使用 `pvs` 命令检查物理卷是否有空闲。
```
# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda myvg lvm2 a- 75.00G 1.85G 73.15G
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
/dev/sdc myvg lvm2 a- 17.15G 17.15G 0
```
如果它是空闲的,使用 `vgreduce` 命令从卷组中删除物理卷 `/dev/sdc`。
```
# vgreduce myvg /dev/sdc
Removed "/dev/sdc" from volume group "vg01"
```
最后,运行 `pvremove` 命令从 LVM 配置中删除磁盘。现在,磁盘已经完全从 LVM 中移除,可以用于其他用途。
```
# pvremove /dev/sdc
Labels on physical volume "/dev/sdc" successfully wiped.
```
### 移动扩展块到新磁盘
如果你在卷组中的其他物理卷上没有足够的可用扩展。使用以下步骤添加新的物理卷。
向存储组申请新的 LUN。分配完毕后,运行以下命令来[在 Linux 中发现新添加的 LUN 或磁盘](https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/)。
```
# ls /sys/class/scsi_host
host0
```
```
# echo "- - -" > /sys/class/scsi_host/host0/scan
```
```
# fdisk -l
```
操作系统中检测到磁盘后,使用 `pvcreate` 命令创建物理卷。
```
# pvcreate /dev/sdd
Physical volume "/dev/sdd" successfully created
```
使用以下命令将新的物理卷 `/dev/sdd` 添加到现有卷组 `vg01` 中。
```
# vgextend vg01 /dev/sdd
Volume group "vg01" successfully extended
```
现在,使用 `pvs` 命令查看你添加的新磁盘 `/dev/sdd`。
```
# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda myvg lvm2 a- 75.00G 14.00G 61.00G
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
/dev/sdc myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdd myvg lvm2 a- 60.00G 60.00G 0
```
使用 `pvmove` 命令将数据从 `/dev/sdc` 移动到 `/dev/sdd`。
```
# pvmove /dev/sdc /dev/sdd
/dev/sdc: Moved: 10.0%
…
/dev/sdc: Moved: 79.7%
…
/dev/sdc: Moved: 100.0%
```
数据移动到新磁盘后。再次使用 `pvs` 命令检查物理卷是否空闲。
```
# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda myvg lvm2 a- 75.00G 14.00G 61.00G
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
/dev/sdc myvg lvm2 a- 17.15G 17.15G 0
/dev/sdd myvg lvm2 a- 60.00G 47.85G 12.15G
```
如果空闲,使用 `vgreduce` 命令从卷组中删除物理卷 `/dev/sdc`。
```
# vgreduce myvg /dev/sdc
Removed "/dev/sdc" from volume group "vg01"
```
最后,运行 `pvremove` 命令从 LVM 配置中删除磁盘。现在,磁盘已经完全从 LVM 中移除,可以用于其他用途。
```
# pvremove /dev/sdc
Labels on physical volume "/dev/sdc" successfully wiped.
```
---
via: <https://www.2daygeek.com/linux-remove-delete-physical-volume-pv-from-volume-group-vg-in-lvm/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,752 | 2 种从 Linux 终端下载文件的方法 | https://itsfoss.com/download-files-from-linux-terminal/ | 2020-10-25T11:23:00 | [
"下载"
] | https://linux.cn/article-12752-1.html | 如果你被困在 Linux 终端,比如说在服务器上,如何从终端下载文件?
在 Linux 中是没有 `download` 命令的,但是有几个 Linux 命令可用于下载文件。
在这篇终端技巧中,你将学习两种在 Linux 中使用命令行下载文件的方法。
我在这里使用的是 Ubuntu,但除了安装,其余的命令同样适用于所有其他 Linux 发行版。
### 使用 wget 命令从 Linux 终端下载文件

[wget](https://www.gnu.org/software/wget/) 也许是 Linux 和类 UNIX 系统中使用最多的命令行下载管理器。你可以使用 `wget` 下载一个文件、多个文件、整个目录甚至整个网站。
`wget` 是非交互式的,可以轻松地在后台工作。这意味着你可以很容易地在脚本中使用它,甚至构建像 [uGet 下载管理器](https://itsfoss.com/install-latest-uget-ubuntu-linux-mint/)这样的工具。
让我们看看如何使用 `wget` 从终端下载文件。
#### 安装 wget
大多数 Linux 发行版都预装了 `wget`。它也可以在大多数发行版的仓库中找到,你可以使用发行版的包管理器轻松安装它。
在基于 Ubuntu 和 Debian 的发行版上,你可以使用 [apt 包管理器](https://itsfoss.com/apt-command-guide/)命令:
```
sudo apt install wget
```
#### 使用 wget 下载文件或网页
你只需要提供文件或网页的 URL。它将在你所在的目录下以原始名下载该文件。
```
wget URL
```

要下载多个文件,你必须将它们的 URL 保存在一个文本文件中,并将该文件作为输入提供给 `wget`,就像这样:
```
wget -i download_files.txt
```
#### 用 wget 下载不同名字的文件
你会注意到,网页在 `wget` 中几乎总是以 `index.html` 的形式保存。为下载的文件提供自定义名称是个好主意。
你可以在下载时使用 `-O` (大写字母 `O`) 选项来提供输出文件名:
```
wget -O filename URL
```

#### 用 wget 下载一个文件夹
假设你正在浏览一个 FTP 服务器,你需要下载整个目录,你可以使用递归选项 `-r`:
```
wget -r ftp://server-address.com/directory
```
#### 使用 wget 下载整个网站
是的,你完全可以做到这一点。你可以用 `wget` 镜像整个网站。我说的下载整个网站是指整个面向公众的网站结构。
虽然你可以直接使用镜像选项 `-m`,但最好加上:
* `–convert-links`:链接将被转换,使内部链接指向下载的资源,而不是网站。
* `–page-requisites`:下载额外的东西,如样式表,使页面在离线状态下看起来更好。
```
wget -m --convert-links --page-requisites website_address
```

#### 额外提示:恢复未完成的下载
如果你因为某些原因按 `CTRL-C` 键中止了下载,你可以用选项 `-c` 恢复之前的下载:
```
wget -c
```
### 使用 curl 在 Linux 命令行中下载文件
和 `wget` 一样,[curl](https://curl.haxx.se/) 也是 Linux 终端中最常用的下载文件的命令之一。[使用 curl](https://linuxhandbook.com/curl-command-examples/) 的方法有很多,但我在这里只关注简单的下载。
#### 安装 curl
虽然 `curl` 并不是预装的,但在大多数发行版的官方仓库中都有。你可以使用你的发行版的包管理器来安装它。
要[在 Ubuntu](https://itsfoss.com/install-curl-ubuntu/) 和其他基于 Debian 的发行版上安装 `curl`,请使用以下命令:
```
sudo apt install curl
```
#### 使用 curl 下载文件或网页
如果你在使用 `curl` 命令时没有在 URL 中带任何选项,它就会读取文件并打印在终端上。
要在 Linux 终端中使用 `curl` 命令下载文件,你必须使用 `-O`(大写字母 `O`)选项:
```
curl -O URL
```

在 Linux 中,用 `curl` 下载多个文件是比较简单的。你只需要指定多个 URL 即可:
```
curl -O URL1 URL2 URL3
```
请记住,`curl` 不像 `wget` 那么简单。`wget` 可以将网页保存为 `index.html`,`curl` 却会抱怨远程文件没有网页的名字。你必须按照下一节的描述用一个自定义的名字来保存它。
#### 用不同的名字下载文件
这可能会让人感到困惑,但如果要为下载的文件提供一个自定义的名称(而不是原始名称),你必须使用 `-o`(小写 `O`)选项:
```
curl -o filename URL
```

有些时候,`curl` 并不能像你期望的那样下载文件,你必须使用选项 `-L`(代表位置)来正确下载。这是因为有些时候,链接会重定向到其他链接,而使用选项 `-L`,它就会跟随最终的链接。
#### 用 curl 暂停和恢复下载
和 `wget` 一样,你也可以用 `curl` 的 `-c` 选项恢复暂停的下载:
```
curl -c URL
```
### 总结
和以往一样,在 Linux 中做同一件事有多种方法。从终端下载文件也不例外。
`wget` 和 `curl` 只是 Linux 中最流行的两个下载文件的命令。还有更多这样的命令行工具。基于终端的网络浏览器,如 [elinks](http://elinks.or.cz/)、[w3m](http://w3m.sourceforge.net/) 等也可以用于在命令行下载文件。
就个人而言,对于一个简单的下载,我更喜欢使用 `wget` 而不是 `curl`。它更简单,也不会让你感到困惑,因为你可能很难理解为什么 `curl` 不能以预期的格式下载文件。
欢迎你的反馈和建议。
---
via: <https://itsfoss.com/download-files-from-linux-terminal/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you are stuck to the Linux terminal, say on a server, how do you download a file from the terminal?
There is no download command in Linux but there are a couple of Linux commands for downloading file.
In this terminal trick, you’ll learn two ways to download files using the command line in Linux.
I am using Ubuntu here but apart from the installation, the rest of the commands are equally valid for all other Linux distributions.
## Download files from Linux terminal using wget command
[wget](https://www.gnu.org/software/wget/?ref=itsfoss.com) is perhaps the most used command line [download manager for Linux](https://itsfoss.com/32-bit-linux-distributions/) and UNIX-like systems. You can download a single file, multiple files, an entire directory, or even an entire website using wget.
wget is non-interactive and can easily work in the background. This means you can easily use it in scripts or even build tools like [uGet download manager](https://itsfoss.com/install-latest-uget-ubuntu-linux-mint/).
Let’s see how to use wget to download files from terminal.
### Installing wget
Most Linux distributions come with wget preinstalled. It is also available in the repository of most distributions and you can easily install it using your distribution’s package manager.
On Ubuntu and Debian based distributions, you can use the [apt package manager](https://itsfoss.com/apt-command-guide/) command:
`sudo apt install wget`
### Download a file or webpage using wget
You just need to provide the URL of the file or webpage. It will download the file with its original name in the directory you are in.
`wget URL`
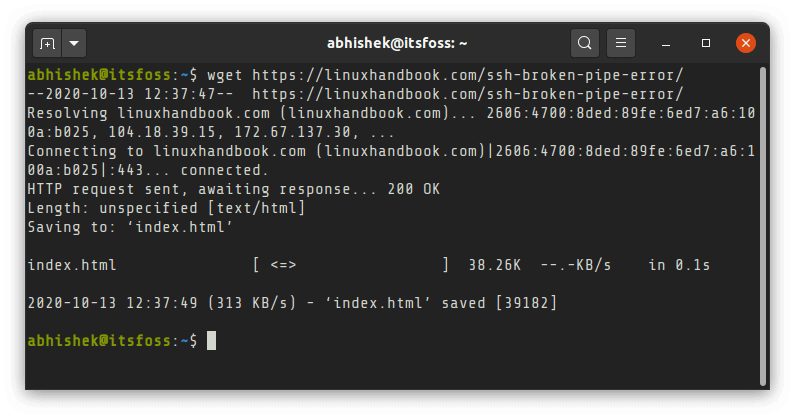
To download multiple files, you’ll have to save their URLs in a text file and provide that text file as input to wget like this:
`wget -i download_files.txt`
### Download files with a different name using wget
You’ll notice that a webpage is almost always saved as index.html with wget. It will be a good idea to provide custom name to downloaded file.
You can use the -O (uppercase O) option to provide the output filename while downloading.
`wget -O filename URL`
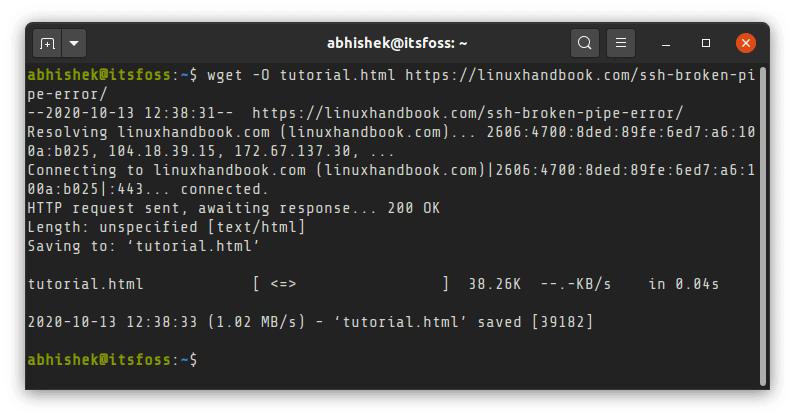
### Download a folder using wget
Suppose you are browsing an FTP server and you need to download an entire directory, you can use the recursive option
`wget -r ftp://server-address.com/directory`
### Download an entire website using wget
Yes, you can totally do that. You can mirror an entire website with wget. By downloading an entire website I mean the entire public facing website structure.
While you can use the mirror option -m directly, it will be a good idea add:
- –convert-links : links are converted so that internal links are pointed to downloaded resource instead of web
- –page-requisites: downloads additional things like style sheets so that the pages look better offline
`wget -m --convert-links --page-requisites website_address`
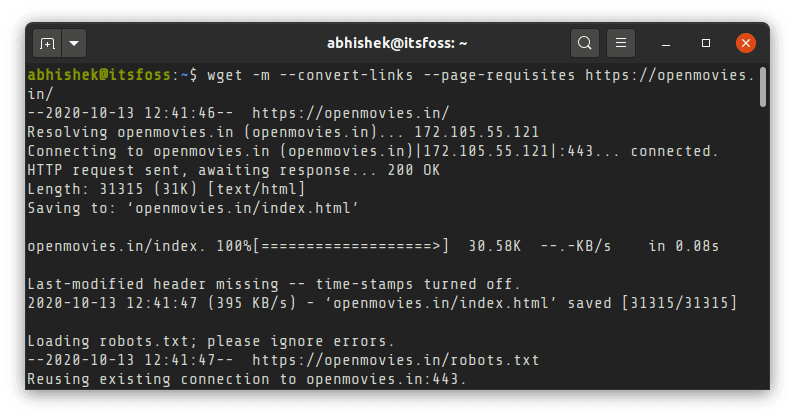
### Bonus Tip: Resume incomplete downloads
If you aborted the download by pressing C for some reasons, you can resume the previous download with option -c.
`wget -c `
## Download files from Linux command line using curl
Like wget, [curl](https://curl.haxx.se/?ref=itsfoss.com) is also one of the most popular commands to download files in Linux terminal. There are so many ways to [use curl extensively](https://linuxhandbook.com/curl-command-examples/?ref=itsfoss.com) but I’ll focus on only the simple downloading here.
### Installing curl
Though curl doesn’t come preinstalled, it is available in the official repositories of most distributions. You can use your distribution’s package manager to install it.
To [install curl on Ubuntu](https://itsfoss.com/install-curl-ubuntu/) and other Debian based distributions, use the following command:
`sudo apt install curl`
### Download files or webpage using curl
If you use curl without any option with a URL, it will read the file and print it on the terminal screen.
To download a file using curl command in Linux terminal, you’ll have to use the -O (uppercase O) option:
`curl -O URL`
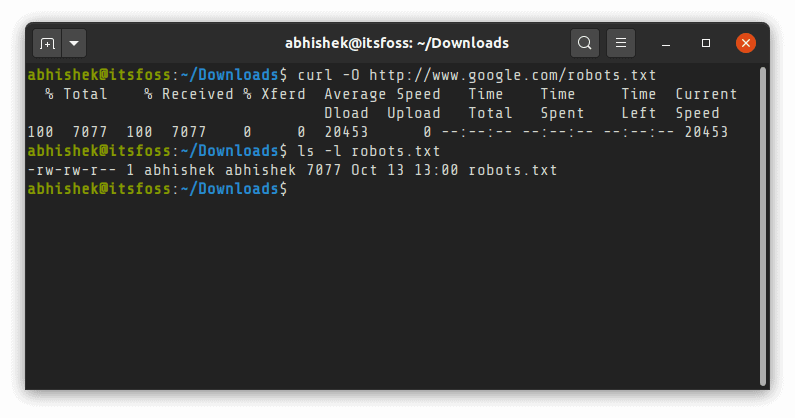
It is simpler to download multiple files in Linux with curl. You just have to specify multiple URLs:
`curl -O URL1 URL2 URL3`
Keep in mind that curl is not as simple as wget. While wget saves webpages as index.html, curl will complain of remote file not having a name for webpages. You’ll have to save it with a custom name as described in the next section.
### Download files with a different name
It could be confusing but to provide a custom name for the downloaded file (instead of the original source name), you’ll have to use -o (lowercase O) option:
`curl -o filename URL`
Some times, curl wouldn’t just download the file as you expect it to. You’ll have to use option -L (for location) to download it correctly. This is because some times the links redirect to some other link and with option -L, it follows the final link.
### Pause and resume download with curl
Like wget, you can also resume a paused download using curl with option -c:
`curl -C URL`
**Conclusion**
As always, there are multiple ways to do the same thing in Linux. Downloading files from the terminal is no different.
wget and curl are just two of the most popular commands for downloading files in Linux. There are more such command line tools. [Terminal based web-browsers](https://itsfoss.com/terminal-web-browsers/) like [elinks](http://elinks.or.cz/?ref=itsfoss.com), [w3m](http://w3m.sourceforge.net/?ref=itsfoss.com) etc can also be used for downloading files in command line.
Personally, for a simple download, I prefer using wget over curl. It is simpler and less confusing because you may have a difficult time figuring out why curl could not download a file in the expected format.
Your feedback and suggestions are welcome. |
12,754 | 在 Linux 上使用 yum 设置 ZFS | https://opensource.com/article/20/10/zfs-dnf | 2020-10-26T10:30:39 | [
"ZFS",
"yum"
] | /article-12754-1.html |
>
> 在 Fedora 上使用 yum 仓库来获取最新的 ZFS 特性。
>
>
>

我是一名 Fedora Linux 用户,我每天都会运行 `yum upgrade`。虽然这个习惯使我能够运行所有最新的软件([Fedora 的四个基础](https://docs.fedoraproject.org/en-US/project/#_what_is_fedora_all_about)之一的 “First” ,它也做到了),但它也会提醒 [ZFS](https://zfsonlinux.org/) 存储平台和新内核之间的不兼容性。
作为一名开发者,有时我需要最新的 ZFS 分支的新特性。例如,ZFS 2.0.0 包含了一个令人兴奋的新功能,它大大[提高了 ZVOL 同步性能](https://www.phoronix.com/scan.php?page=news_item&px=OpenZFS-3x-Boost-Sync-ZVOL),这对我这个 KVM 用户来说至关重要。但这意味着,如果我想使用 2.0.0 分支,我必须自己构建 ZFS。
起初,我只是在每次内核更新后从它的 Git 仓库中手动编译 ZFS。如果我忘记了,ZFS 就会在下次启动时无法被识别。幸运的是,我很快就学会了如何为 ZFS 设置动态内核模块支持 ([DKMS](https://www.linuxjournal.com/article/6896))。然而,这个解决方案并不完美。首先,它没有利用强大的 [yum](https://en.wikipedia.org/wiki/Yum_%28software%29) 系统,而这个系统可以帮助解决依赖关系和升级。此外,使用 `yum` 在你自己的包和上游包之间进行切换是非常容易的。
在本文中,我将演示如何设置 `yum` 仓库来打包 ZFS。这个方案有两个步骤:
1. 从 ZFS 的 Git 仓库中创建 RPM 包。
2. 建立一个 `yum` 仓库来托管这些包。
### 创建 RPM 包
要创建 RPM 包,你需要安装 RPM 工具链。`yum` 提供了一个组来捆绑安装这些工具:
```
sudo dnf group install 'C Development Tools and Libraries' 'RPM Development Tools'
```
安装完这些之后,你必须从 ZFS Git 仓库中安装构建 ZFS 所需的所有包。这些包属于三个组:
1. [Autotools](https://opensource.com/article/19/7/introduction-gnu-autotools),用于从平台配置中生成构建文件。
2. 用于构建 ZFS 内核和用户态工具的库。
3. 构建 RPM 包的库。
```
sudo dnf install libtool autoconf automake gettext createrepo \
libuuid-devel libblkid-devel openssl-devel libtirpc-devel \
lz4-devel libzstd-devel zlib-devel \
kernel-devel elfutils-libelf-devel \
libaio-devel libattr-devel libudev-devel \
python3-devel libffi-devel
```
现在你已经准备好创建你自己的包了。
### 构建 OpenZFS
[OpenZFS](https://openzfs.org/wiki/Main_Page) 提供了优秀的基础设施。要构建它:
1. 用 `git` 克隆仓库,并切换到你希望使用的分支/标签。
2. 运行 Autotools 生成一个 makefile。
3. 运行 `make rpm`,如果一切正常,RPM 文件将被放置在 `build` 文件夹中。
```
$ git clone --branch=zfs-2.0.0-rc3 <https://github.com/openzfs/zfs.git> zfs
$ cd zfs
$ ./autogen.sh
$ ./configure
$ make rpm
```
### 建立一个 yum 仓库
在 `yum` 中,仓库是一个服务器或本地路径,包括元数据和 RPM 文件。用户设置一个 INI 配置文件,`yum` 命令会自动解析元数据并下载相应的软件包。
Fedora 提供了 `createrepo` 工具来设置 `yum` 仓库。首先,创建仓库,并将 ZFS 文件夹中的所有 RPM 文件复制到仓库中。然后运行 `createrepo --update` 将所有的包加入到元数据中。
```
$ sudo mkdir -p /var/lib/zfs.repo
$ sudo createrepo /var/lib/zfs.repo
$ sudo cp *.rpm /var/lib/zfs.repo/
$ sudo createrepo --update /var/lib/zfs.repo
```
在 `/etc/yum.repos.d` 中创建一个新的配置文件来包含仓库路径:
```
$ echo \
"[zfs-local]\\nname=ZFS Local\\nbaseurl=file:///var/lib/zfs.repo\\nenabled=1\\ngpgcheck=0" |\
sudo tee /etc/yum.repos.d/zfs-local.repo
$ sudo dnf --repo=zfs-local list available --refresh
```
终于完成了!你已经有了一个可以使用的 `yum` 仓库和 ZFS 包。现在你只需要安装它们。
```
$ sudo dnf install zfs
$ sudo /sbin/modprobe zfs
```
运行 `sudo zfs version` 来查看你的用户态和内核工具的版本。恭喜!你拥有了 [Fedora 中的 ZFS](https://openzfs.github.io/openzfs-docs/Getting%20Started/Fedora.html)。
---
via: <https://opensource.com/article/20/10/zfs-dnf>
作者:[Sheng Mao](https://opensource.com/users/ivzhh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,759 | MellowPlayer:一款用于各种流媒体音乐服务的桌面应用 | https://itsfoss.com/mellow-player/ | 2020-10-26T23:35:00 | [
"流媒体"
] | https://linux.cn/article-12759-1.html |
>
> MellowPlayer 是一个自由开源的桌面应用,可以让你在 Linux 和 Windows 上整合基于网络的音乐流媒体服务。
>
>
>

毋庸置疑,很多用户都喜欢使用流媒体服务来收听自己喜欢的音乐,而不是从商店购买单首音乐或者下载收藏。
当然,流媒体服务可以让你探索新的音乐,帮助艺术家轻松传播到更多的听众。但是,由于有许多的音乐流媒体服务([Soundcloud](https://soundcloud.com)、[Spotify](https://www.spotify.com)、[YouTube Music](https://music.youtube.com)、[Amazon Music](https://music.amazon.com/home) 等),因此当在使用电脑时,要有效地使用它们往往会变得很麻烦。
你可以[在 Linux 上安装 Spotify](https://itsfoss.com/install-spotify-ubuntu-linux/),但没有 Amazon Music 的桌面应用,所以,有可能你无法从单一门户管理流媒体服务。
如果一个桌面应用可以让你同时在 Windows 和 Linux 上免费整合流媒体服务呢?在本文中,我将介绍这样一款应用:[MellowPlayer](https://colinduquesnoy.gitlab.io/MellowPlayer/)。
### MellowPlayer: 集成各种流媒体音乐服务的开源应用

MellowPlayer 是一款自由开源的跨平台桌面应用,它可以让你整合多个流媒体服务,并在一个界面上管理它们。
你可以整合多个支持的流媒体服务。你还可以从每个服务中获得一定程度的控制权,来调整你的体验。例如,你可以设置在 YouTube 上自动跳过或静音广告。
对 Windows 和 Linux 的跨平台支持绝对是一个加分项。
除了能够管理流媒体服务外,它还将播放器与系统托盘整合在一起来轻松控制音乐。这意味着你可以使用键盘上的媒体键来控制音乐播放器。
另外值得一提的是,你只要在应用内自己创建一个插件,就可以添加一个官方不支持的新服务。为了让你对它有更多的了解,下面就让我重点介绍一下所有的主要特点。
### MellowPlayer 的特点
* 跨平台 (Windows 和 Linux)
* 自由且开源
* 基于插件的应用,让你可以通过创建一个插件来添加新的服务
* 将服务作为本地桌面应用与系统托盘整合
* 支持热键
* 支持通知
* 收听历史
### 在 Linux 上安装 MellowPlayer

MellowPlayer 是以 [Flatpak 包](https://flathub.org/apps/details/com.gitlab.ColinDuquesnoy.MellowPlayer)的形式提供的。我知道这让一些人很失望,但它在 Linux 中只有 Flaptak,Windows 中只有一个可执行文件。如果你不知道,请按照我们的[在 Linux 上使用 Flatpak](https://itsfoss.com/flatpak-guide/) 指南来开始使用。
* [下载 MellowPlayer](https://colinduquesnoy.gitlab.io/MellowPlayer/#features)
### 总结
MellowPlayer 是一款方便的桌面应用,适合经常涉猎多种流媒体音乐服务的用户使用。尽管根据我的测试,它在 SoundCloud、YouTube 和 Spotify 上都能正常工作,但我确实注意到,当我试图重新调整窗口大小时,应用会崩溃,只是在此提醒一下。你可以在它的 [GitLab 页面](https://gitlab.com/ColinDuquesnoy/MellowPlayer)上了解更多关于它的内容。
还有两个类似的应用,可以让你播放多个流媒体音乐服务。[Nuvola](https://itsfoss.com/nuvola-music-player/) 和 [Nuclear Music Player](https://itsfoss.com/nuclear-music-player-linux/)。你可能会想看看它们。
你试过 MellowPlayer 吗?欢迎在下方评论中分享你的想法。
---
via: <https://itsfoss.com/mellow-player/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: MellowPlayer is a free and open-source desktop that lets you integrate web-based music streaming services on Linux and Windows.*
Undoubtedly, a lot of users prefer tuning in to streaming services to listen to their favorite music instead of purchasing individual music from stores or downloading them for a collection.
Of course, streaming services let you explore new music and help artists reach out to a wider audience easily. But, with so much music streaming services available ([Soundcloud](https://soundcloud.com), [Spotify](https://www.spotify.com), [YouTube Music](https://music.youtube.com), [Amazon Music](https://music.amazon.com/home), etc) it often becomes annoying to utilize them effectively while using your computer.
You may [install Spotify on Linux](https://itsfoss.com/install-spotify-ubuntu-linux/) but there is no desktop app for Amazon Music. So, potentially you cannot manage the streaming service from a single portal.
What if a desktop app lets you integrate streaming services on both Windows and Linux for free? In this article, I will talk about such an app — ‘[MellowPlayer](https://colinduquesnoy.gitlab.io/MellowPlayer/)‘.
## MellowPlayer: Open Source App to Integrate Various Streaming Music Services
MellowPlayer is a free and open-source cross-platform desktop app that lets you integrate multiple streaming services and manage them all from one interface.
There are several supported streaming services that you can integrate. You also get a certain level of control to tweak your experience from each individual service. For instance, you can set to automatically skip ads or mute them on YouTube.
The cross-platform support for both Windows and Linux is definitely a plus point.
Apart from the ability to manage the streaming services, it also integrates the player with your system tray to easily control the music. This means that you can use media keys on your keyboard to control the music player.
It is also worth noting that you can add a new service that is not officially supported by just creating a plugin for it yourself within the app. To let you know more about it, let me highlight all the key features below.
## Features of MellowPlayer
- Cross-platform (Windows & Linux)
- Free & Open-Source
- Plugin-based Application to let you add new service by creating a plugin
- Integrates the services as a native desktop app with the system tray
- Supports hot keys
- Notifications support
- Listening history
## Installing MellowPlayer on Linux
MellowPlayer is available as a [Flatpak package](https://flathub.org/apps/details/com.gitlab.ColinDuquesnoy.MellowPlayer). I know it’s disappointing for some but it’s just Flatpak for Linux and an executable file for Windows. In case you didn’t know, follow our guide on [using Flatpak on Linux](https://itsfoss.com/flatpak-guide/) to get started.
## Wrapping Up
MellowPlayer is a handy desktop app for users who often dabble with multiple streaming services for music. Even though it works fine as per my test with SoundCloud, YouTube, and Spotify, I did notice that the app crashed when trying to re-size the window, just a heads up on that. You can explore more about it on its [GitLab page](https://gitlab.com/ColinDuquesnoy/MellowPlayer).
There are two similar applications that allow you to play multiple streaming music services: [Nuvola](https://itsfoss.com/nuvola-music-player/) and [Nuclear Music Player](https://itsfoss.com/nuclear-music-player-linux/). You may want to check them out.
Have you tried MellowPlayer? Feel free to share your thoughts in the comments below. |
12,762 | Linux 5.10 终于抛弃了造成了安全隐患的老函数 | https://www.zdnet.com/article/linux-5-10-finally-ditches-decades-old-tool-that-caused-security-bugs/ | 2020-10-27T21:50:00 | [
"Linux",
"内核"
] | https://linux.cn/article-12762-1.html |
>
> 多年来,set\_fs() 一直是众所周知的麻烦,现在它终于消失了。
>
>
>

Linus Torvalds 开启了 Linux 内核的又一个开发周期,宣布 5.10-rc1 发布了,而且这一次还有一个历史性的转折:新内核标志着一个几十年前的函数的落幕,这个函数在被发现会导致安全漏洞后早已成为多余的函数。
随着长达两周的,每一次新的 Linux 内核迭代发布前的合并窗口的关闭,Torvalds 在 Linux 内核邮件列表上分享了他的感想,他认为“事情似乎相当顺利”。
“合并窗口”是 Linux 新内核发布过程中的一个关键部分,在此窗口期间,每天有多达 1000 个由开发者社区提交的补丁被合并到 Torvalds 管理的主线仓库中。而审查过程会确保每个补丁都能实现理想的变化。
这一次,Torvalds 提请大家注意移除了一个叫 `set_fs()` 的寻址函数,这个函数可以追溯到 Linux 的最初版本。“对我来说,这是最有趣的变化,`set_fs()` 被移除了,”他写道,“这不是一个巨大的变化,但很有趣,因为 `set_fs()` 指定用户空间副本是否真正进入用户空间或内核空间的这个模式,几乎可以追溯到 Linux 的最初版本。”
正如 Torvalds 所解释的那样,`set_fs()` 函数可以通过取消用户空间和内核空间之间的分界来覆盖地址空间。该函数在管理英特尔早期 x86 处理器时被广泛使用,以控制非特权代码可以访问的虚拟地址范围。
然而,2010 年,“[常见漏洞和暴露](Common%20Vulnerabilities and Exposures)”(CVE)详细披露了 `set_fs()` 带来的安全问题。通过绕过某些访问限制,证实该函数能够“覆盖任意内核内存位置”和“获得特权” —— 在某些情况下,这可以让用户空间覆盖内核数据。
鉴于该工具的安全缺陷,包括 x86、PowerPC、s390 和 RISC-V 在内的一些架构已经取消了地址空间覆盖功能。但是,正如 Torvalds 写道:“我们仍然留着 `set_fs()`,因为并不是每个架构都已经转换为新的世界秩序。”
除了这个久违的历史补救之外,5.10-rc1 版本和大多数内核版本一样,还伴随着无数的变化。Torvalds 统计了近 1700 人的近 1.4 万次提交,改动范围从支持自动驾驶汽车和机器人的 Nvidia SOC 芯片到支持任天堂 Switch 控制器。
统计结果表明。大约新增了 70.4 万行代码和删除了 41.9 万行代码,这使得 5.10-rc1 的大小与 Linux 有史以来最大的内核 5.8 相当。“这看起来是一个比我预期的更大的版本,虽然合并窗口比 5.8 的窗口小,但也小不了多少,”Torvalds 说,“而 5.8 是我们有史以来最大的版本。”
按照 Linux 典型的时间表,5.10-rc1 之后将有几个星期时间来提交修复问题的补丁,在预计 12 月发布稳定内核之前,将发布几个候选版本。
---
via: <https://www.zdnet.com/article/linux-5-10-finally-ditches-decades-old-tool-that-caused-security-bugs/>
作者:[Daphne Leprince-ringuet](https://www.zdnet.com/meet-the-team/uk/daphne+leprince-ringuet/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Linux 5.10 finally ditches decades-old tool that caused security bugs

Linus Torvalds has kicked off yet another development cycle for the Linux kernel, announcing the release of 5.10-rc1, and this time with an historical twist. The new version of the kernel effectively marks the end of a decade-old feature that has long been made redundant after it was found to cause security bugs.
With the closing of the two-week-long merge window, which precedes the release of every new iteration of the Linux kernel, Torvalds shared his reflections [on the Linux kernel mailing list](http://lkml.iu.edu/hypermail/linux/kernel/2010.3/00552.html), maintaining that "things seem to have gone fairly smoothly".
### Linux
The merging window is a key part of any new kernel release process, during which up to 1,000 patches submitted by the developer community are merged every day into the mainline repository managed by Torvalds. A review process ensures that each patch implements a desirable change.
**SEE: ****Diversity and Inclusion policy**** (TechRepublic Premium)**
This time around, Torvalds drew attention to the removal of an addressing tool, called set_fs(), which goes back to the original release of Linux. "The most interesting -- to me -- change here is Christoph's set_fs() removal," he wrote. "It's not a huge change, but it's interesting because the whole model of set_fs() to specify whether a userspace copy actually goes to user space or kernel space goes back to pretty much the original release of Linux."
As Torvalds explained, the set_fs() function could be used to override address spaces, by nullifying the split between user space and kernel space. The tool was widely used when managing Intel's early x86 processors, to control the range of virtual addresses that could be accessed by unprivileged code.
However, in 2010 the Common Vulnerabilities and Exposures (CVE) dictionary [detailed the security issues](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2010-4258) posed by set_fs(). By bypassing certain access restrictions, the function was shown to be able to "overwrite arbitrary kernel memory locations" and "gain privileges" -- in some cases, to let user space overwrite kernel data.
Given the security shortcomings of the tool, some architectures including x86, powerpc, s390 and RISC-V have already removed address space overrides. But, as Torvalds wrote: "We still do have 'set_fs()' around, and not every architecture has been converted to the new world order."
On top of this long-overdue historical remediation, the 5.10-rc1 version, like most kernel releases, comes with innumerably more changes. Torvalds counted almost 14,000 commits by close to 1,700 people, with changes that range from support for Nvidia's SOCs for self-driving cars and robots to Nintendo Switch controller support.
**SEE: ****Windows 10: This is what your new 'Meet Now' taskbar button does, explains Microsoft**
Reports have [counted](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.10-rc1-Released) around 704,000 lines of new code and 419,000 lines deleted, making 5.10-rc1 comparable in size to Linux's biggest kernel ever -- 5.8. "This looks to be a bigger release than I expected, and while the merge window is smaller than the one for 5.8 was, it's not a lot smaller," said Torvalds. "And 5.8 was our biggest release ever."
As per Linux's typical schedule, 5.10-rc1 will be followed by several weeks' worth of problem-fixing patches, with several candidate versions to be released before the stable kernel release expected in December.
[Editorial standards](/editorial-guidelines/) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.