
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
12,257 | 如何在 Ubuntu 中处理自动的无人值守升级 | https://itsfoss.com/auto-updates-ubuntu/ | 2020-05-27T23:40:53 | [
"Ubuntu",
"升级"
] | https://linux.cn/article-12257-1.html |
>
> 本教程教你如何处理无人值守的升级,即 Ubuntu Linux 的自动系统更新。
>
>
>

有时,当你尝试[关闭 Ubuntu 系统](https://itsfoss.com/schedule-shutdown-ubuntu/)时,可能看到这个阻止你关闭的页面:
>
> 关机过程中正在进行无人值守升级,请不要关闭计算机。
>
>
>

你可能会问这个“无人值守升级”是什么,怎么会在你不知情的情况下运行呢?
原因是 [Ubuntu](https://ubuntu.com/) 非常重视系统的安全性。默认情况下,它会每天自动检查系统更新,如果发现安全更新,它会下载这些更新并自行安装。对于正常的系统和应用更新,它会通过软件更新程序通知你。
由于所有这些都是在后台发生的,所以在你尝试关闭系统或尝试自行安装应用程序之前,你甚至不会意识到这一点。
在这些无人值守的升级过程中,尝试安装新软件,会导致著名的[无法获得锁定的错误](https://itsfoss.com/could-not-get-lock-error/)。

如你所见,自动更新带来了一些小麻烦。你可以选择禁用自动更新,但这意味着你必须一直手动检查并[更新你的 Ubuntu 系统](https://itsfoss.com/update-ubuntu/)。
>
> **你真的需要禁用自动更新吗?**
>
>
> 请注意,这是一项安全功能。Linux 实际上允许你禁用系统中的所有功能,甚至禁用这些安全功能。
>
>
> 但是我认为,作为普通用户,**你不应该禁用自动更新**。毕竟,它可以确保你的系统安全。
>
>
> 为了确保系统的安全性,你可以忍受自动更新所带来的小麻烦。
>
>
>
现在,你已经收到警告,还是觉得承担手动更新系统的额外任务更好,那么让我们看看如何处理自动更新。
与往常一样,有两种方法可以做到:GUI 和命令行。 我将向你展示两种方法。
我在这里使用 Ubuntu 20.04,但是这些步骤对 Ubuntu 18.04 和任何其他 Ubuntu 版本均有效。
### 方法 1:以图形方式禁用 Ubuntu 中的自动更新
进入菜单并查找“软件和更新”工具。

在此处,进入“更新”选项卡。查找“自动检查更新”。默认情况下,它设置为“每日”。
你可以将其更改为“从不”,你的系统将永远不会检查更新。如果不检查更新,它就不会找到要安装的新的更新。

如果这样做,那么必须不时手动更新系统。但是,这是额外的工作,你可能不会一直记得。
#### 在 Ubuntu 中处理自动更新的更好方法
就个人而言,我建议让它自己检查更新。如果你不希望它自动安装更新,那么可以更改该行为,以通知有关安全更新的可用性。
保持“自动检查更新”为“每日”,然后将“有安全更新时”选项更改为“立即显示”,而不是“自动下载并安装”。

这样,它会检查是否有更新,而不是在后台自动安装更新,软件更新程序会通知你有可用于系统的更新。而你的系统已经完成正常的系统和软件更新。

使用此设置,关闭系统时将不会看到“正在进行的无人值守升级”。但是,由于两个不同的进程无法同时使用 apt 包管理器,因此你仍然可能会遇到“无法锁定”错误。
我相信这是一个更好的解决方案,你不认为是么?
如我承诺的同时有 GUI 和命令行方法一样,让我向你展示如何在终端中禁用无人值守的升级。
### 如何在 Ubuntu 中使用命令行禁用自动更新
你可以在 `/etc/apt/apt.conf.d/20auto-upgrades` 中找到自动升级设置。Ubuntu 终端中的默认文本编辑器是 Nano,因此你可以使用以下命令来编辑此文件:
```
sudo nano /etc/apt/apt.conf.d/20auto-upgrades
```
现在,如果你不希望系统自动检查更新,那么可以将 `APT::Periodic::Update-Package-Lists` 的值更改为 `"0"`。
```
APT::Periodic::Update-Package-Lists "0";
APT::Periodic::Unattended-Upgrade "0";
```
如果你希望它检查更新但不自动安装无人值守的升级,那么可以选择将其设置为:
```
APT::Periodic::Update-Package-Lists "1";
APT::Periodic::Unattended-Upgrade "0";
```
### 最后
由于某种原因,启用了自动安全更新,建议你保持这种状态。这个小烦恼实际上并不值得冒险损害系统安全性。你怎么看?
---
via: <https://itsfoss.com/auto-updates-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: This tutorial teaches you how to handle the unattended upgrade i.e. the automatic system updates in Ubuntu Linux.**
Sometimes, when you try to [shutdown your Ubuntu system](https://itsfoss.com/schedule-shutdown-ubuntu/), you may come across this screen that stops you from shutting down:
**Unattended-upgrade in progress during shutdown, please don’t turn off the computer.**

You might wonder what is this “unattended upgrade” and how come it is running without your knowledge.
The reason is that [Ubuntu](https://ubuntu.com/) takes your system’s security very seriously. By default, it automatically checks for system updates daily and if it finds any security updates, it downloads those updates and install them on its own. For normal system and application updates, it notifies you via the Software Updater tool.
Since all this happens in the background, you don’t even realize it until you try to shutdown your system or try to install applications on your own.
Trying to install a new software when these unattended upgrades are in progress leads to the famous [could not get lock error](https://itsfoss.com/could-not-get-lock-error/).
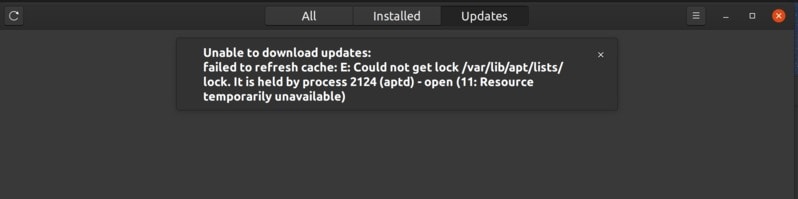
As you can see, the automatic updates present a couple of minor annoyance. You may choose to disable the auto updates but that would mean that you’ll have to check and [update your Ubuntu system](https://itsfoss.com/update-ubuntu/) manually all the time.
Do you really need to disable auto updates?
Please note that this is a security feature. Linux allows you to do practically everything in your system even disabling these security features.
But in my opinion, as a regular user, ** you should not disable the automatic updates**. It keeps your system safe after all.
For the sake of your system’s security, you may tolerate the minor annoyances that come with the automatic updates.
Now that you have been warned and you think it is better to take up the additional task of manually updating your system, let’s see how to handle the auto updates.
As always, there are two ways to do it: GUI and command line. I’ll show you both methods.
I have used Ubuntu 20.04 here but the steps are valid for Ubuntu 18.04 and any other Ubuntu version.
## Method 1: Disable automatic updates in Ubuntu graphically
Go to the menu and look for ‘software & updates’ tool.

In here, go to Updates tab. Now look for the “Automatically check for updates”. By default it is set to Daily.
You can change it to Never and your system will never check for updates on its own again. And if it won’t check for updates, it won’t find new updates to install.
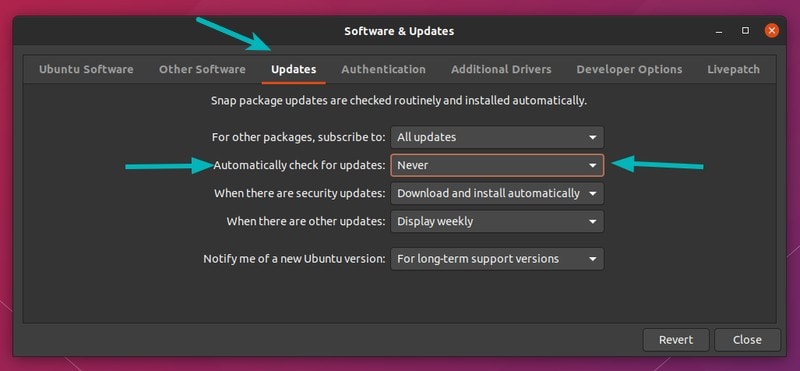
If you do this, you must manually update your system from time to time. But that’s an additional chore to do and you may not remember it all the time.
### Slightly better way to handle auto updates in Ubuntu
Personally, I would suggest to let it check for updates on its own. If you don’t want it installing the updates automatically, you can change that behavior to get notified about the availability of security updates.
Keep “Automatically check for updates” to Daily and change “When there are security updates” option to “Display immediately” instead of “Download and install automatically”.
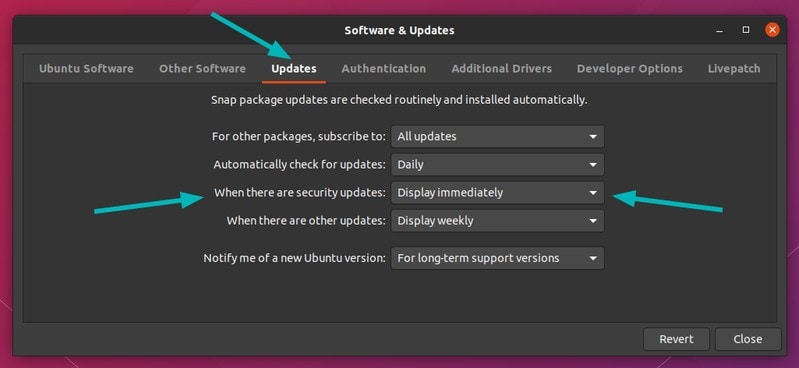
This way, it checks for updates and if there are updates, instead of installing them automatically in the background, the Software Updater tool notifies you that updates are available for your system. Your system already does that for normal system and software updates.
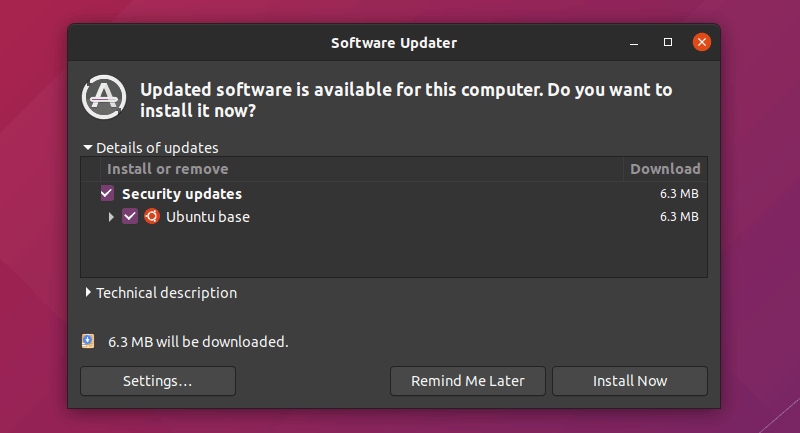
With this setup, you won’t see the “unattended upgrades in progress” when you shutdown your system However, you may still encounter the ‘could not get lock’ error because two separate processes cannot use apt package manager at the same time.
I believe this is a better solution, don’t you you think?
As I promised both GUI and command line methods, let me show you how to disable unattended upgrades in the terminal.
## How to disable automatic updates in Ubuntu using command line
You’ll find the auto-upgrades settings in the **/etc/apt/apt.conf.d/20auto-upgrades** file. The default text editor in Ubuntu terminal is Nano so you can use this command to edit this configuration file:
`sudo nano /etc/apt/apt.conf.d/20auto-upgrades`
Now, if you don’t want your system to check for updates automatically, you can change the value of APT::Periodic::Update-Package-Lists to 0.
```
APT::Periodic::Update-Package-Lists "0";
APT::Periodic::Unattended-Upgrade "0";
```
If you want it to check for updates but don’t install the unattended-upgrades automatically, you can choose to set it like this:
```
APT::Periodic::Update-Package-Lists "1";
APT::Periodic::Unattended-Upgrade "0";
```
**In the end…**
The automatic security updates are enabled automatically for a reason and I recommend you keep it like this. A couple of minor annoyances are not really worth risking the security of your system. What do you think? |
12,258 | 如何在 Arch Linux 上正确安装和设置 KDE Plasma? | https://itsfoss.com/install-kde-arch-linux/ | 2020-05-28T06:37:30 | [
"Arch",
"KDE"
] | https://linux.cn/article-12258-1.html | 我相信你是按照[这份很棒的指南安装来 Arch Linux](/article-9170-1.html) 的,这篇指南最后提到了 [GNOME 桌面](https://www.gnome.org/)的安装步骤。
但现在,不是每个人都是 GNOME 的粉丝,有几个读者要求我们向他们展示如何在 [Arch Linux](https://www.archlinux.org/) 上配置 [KDE 桌面](https://kde.org/plasma-desktop)。
因此,我创建了这个指南来演示如何在 Arch Linux 上正确安装和配置 KDE 桌面(也被称为 KDE Plasma桌面)的步骤。
### 如何在 Arch Linux 上安装和设置 KDE 桌面环境?

请记住,KDE 不允许直接以 root 身份登录。如果你已经安装了 Arch Linux 并以 root 身份使用,你应该创建一个新的用户,并给它以 root 身份运行命令的 sudo 权限。
如果你只是最小化安装了 Arch Linux,那么你可能是以 TTY 终端方式登录的。如果你使用的是其他桌面环境,步骤也是一样的。
让我们开始吧!
#### 步骤 1:创建一个 sudo 用户(如果你只有 root 用户)
你可以使用 [useradd 命令](https://linuxhandbook.com/useradd-command/)来创建一个新用户。我创建的用户名为 `dimitrios`(这是我的名字)。你可以使用与你的名字匹配的东西。
选项 `-m` 为新创建的用户创建一个主目录。
```
useradd -m dimitrios
```
你还应该为这个用户设置一个密码。使用此命令:
```
passwd dimitrios
```
现在你已经创建了用户,给它 sudo 权限。首先,安装 sudo 和一个像 [nano](https://www.nano-editor.org/) 这样的[命令行文本编辑器](https://itsfoss.com/command-line-text-editors-linux/)。
```
pacman -S sudo nano
```
sudo 的配置文件是 `/etc/sudoers`。该文件应该使用 `visudo` 来编辑,它会锁定 `sudoers` 文件,将编辑的内容保存到一个临时文件中,并在复制到 `/etc/sudoers` 之前检查该文件的语法。
要使用 `nano` 作为 `visudo` 编辑器,请这样设置:
```
EDITOR=nano visudo
```
像我的示例那样添加下面这一行,然后保存并退出。
```
dimitrios ALL=(ALL) ALL
```

保存你的更改,然后退出编辑器。你现在在 Arch Linux 上有了一个 sudo 用户。
#### 步骤 2 :安装 KDE Plasma 桌面
要运行 KDE 桌面,你需要以下软件包。
* [Xorg](https://wiki.archlinux.org/index.php/Xorg) 组
* [KDE Plasma](https://kde.org/plasma-desktop) 桌面环境
* [Wayland](https://wiki.archlinux.org/index.php/Wayland) KDE Plasma 的会话
* [KDE 应用程序](https://www.archlinux.org/groups/x86_64/kde-applications/)组(包括 KDE 特有的应用程序:Dolphin 管理器和其他有用的应用程序)。
你可以用下面的命令安装上述部分。
```
pacman -S xorg plasma plasma-wayland-session kde-applications
```
安装后,启用显示管理器和网络管理器服务。
```
systemctl enable sddm.service
systemctl enable NetworkManager.service
```
快完成了。关闭你的系统。
```
shutdown now
```
重新打开系统电源,你应该会看到 KDE 的登录界面。你还记得为你的 sudo 用户设置的密码吗?用它来登录。

#### 接下来?
你可能会想探索一下[基本的 pacman 命令](https://itsfoss.com/pacman-command/),了解一下 [Arch 用户资源库](/article-12107-1.html),了解一下 [AUR 助手](/article-12019-1.html)。
希望这篇教程对你在 Arch Linux 上安装 KDE 桌面有所帮助。如果你在安装过程中遇到任何障碍或困难,请在下面的评论中告诉我们。
你最喜欢的桌面环境或窗口管理器是什么?请告诉我们,别忘了在我们的社交媒体上订阅。
---
via: <https://itsfoss.com/install-kde-arch-linux/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I believe you followed the [fantastic It’s FOSS guide on installing Arch Linux](https://itsfoss.com/install-arch-linux/). The guide ends with steps mentioning the installation procedure for [GNOME desktop](https://www.gnome.org/?ref=itsfoss.com).
Now, not everyone is a GNOME fan and several readers requested that we show them how to configure the [KDE desktop](https://kde.org/plasma-desktop?ref=itsfoss.com) on [Arch Linux](https://www.archlinux.org/?ref=itsfoss.com).
And thus I created this guide to demonstrate the steps for properly installing and configuring the KDE desktop (also known as KDE Plasma desktop) on Arch Linux.
## How to install and setup KDE desktop environment on Arch Linux
Please keep in mind that KDE doesn’t allow login as root directly. If you have installed Arch Linux and using it as root, you should create a new user and give it sudo rights for running commands as root.
If you just have a bare minimum installation of Arch Linux, you probably are logging into a [TTY terminal](https://itsfoss.com/what-is-tty-in-linux/). If you are using some other desktop environment, steps remain the same.
Let’s go!
### Step 1: Create a sudo user (if you have only root user)
You can use the [useradd command](https://linuxhandbook.com/useradd-command/?ref=itsfoss.com) for creating a new user. I am creating user named dimitrios (that’s my name). You can use something that matches your name.
The option -m creates a home directory for the newly created user.
`useradd -m dimitrios`
You should also set a password for this user. Use this command:
`passwd dimitrios`
Now that you have created the user, give it sudo access. First, install sudo and a [command line text editor](https://itsfoss.com/command-line-text-editors-linux/) like [nano](https://www.nano-editor.org/?ref=itsfoss.com):
`pacman -S sudo nano`
The configuration file for sudo is /etc/sudoers. It should always be edited with the visudo command. visudo locks the sudoers file, saves edits to a temporary file, and checks that file’s grammar before copying it to /etc/sudoers.
To use nano as the visudo editor, use:
`EDITOR=nano visudo`
Add the following line like I do in the example, then save and exit.
`dimitrios ALL=(ALL) ALL`
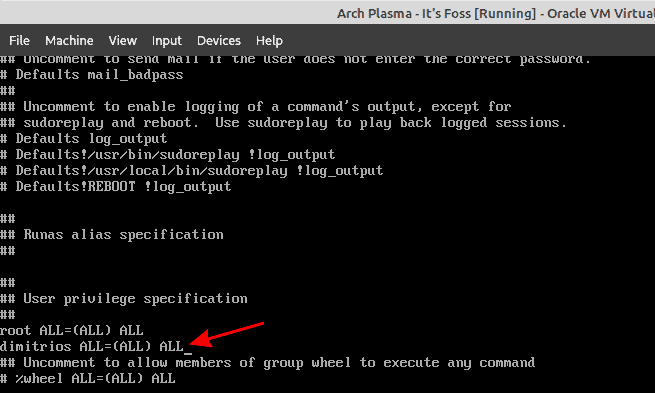
Save your changes and exit the editor. You now have a sudo user on Arch Linux.
### Step 2: Installing KDE Plasma desktop
To run KDE desktop, you need the following packages:
[Xorg](https://wiki.archlinux.org/index.php/Xorg?ref=itsfoss.com)group[KDE Plasma](https://kde.org/plasma-desktop?ref=itsfoss.com)Desktop Environment[Wayland](https://wiki.archlinux.org/index.php/Wayland?ref=itsfoss.com)session for KDE Plasma[KDE applications](https://www.archlinux.org/groups/x86_64/kde-applications/?ref=itsfoss.com)group (consists of KDE specific applications including the Dolphin manager and other useful apps)
You can install of the above using the following command:
`pacman -S xorg plasma plasma-wayland-session kde-applications `
Once installed, enable the [Display Manager](https://itsfoss.com/display-manager/) and Network Manager services:
```
systemctl enable sddm.service
systemctl enable NetworkManager.service
```
Almost there. Shutdown your system:
`shutdown now`
Power on your system and you should see the KDE login. Do you remember the password you set up for your sudo user? Use it to login.
### What next?
You may want to explore the [essential pacman commands](https://itsfoss.com/pacman-command/), to know what’s going on with the [Arch User Repository](https://itsfoss.com/aur-arch-linux/) and learn more about [AUR helpers](https://itsfoss.com/best-aur-helpers/).
I hope you found this tutorial helpful in installing KDE desktop on Arch Linux. Please let us know in the comments below if you encounter any obstacles or difficulties during the installation.
What’s your favourite Desktop environment or Window Manager? Let us know and don’t forget to subscribe on our social media. |
12,260 | 出于安全原因,OpenSSH 决定弃用 SHA-1 验证算法 | https://www.zdnet.com/article/openssh-to-deprecate-sha-1-logins-due-to-security-risk/ | 2020-05-28T17:57:07 | [
"OpenSSH",
"SHA-1"
] | https://linux.cn/article-12260-1.html |
>
> 破坏一个 SHA-1 生成的 SSH 验证密钥,现在的成本大约为 5 万美元,使得重要的远程服务器面临着被攻击的风险。
>
>
>

最受欢迎的连接和管理远程服务器的实用工具 OpenSSH 今天宣布,计划放弃对其 SHA-1 验证方案的支持。在这个宣布当中,OpenSSH 团队列举了 SHA-1 散列算法的安全问题,该算法目前被认为是不安全的。
SHA-1 算法在 2017 年 2 月的一次实际的、真实世界的攻击中被破解,当时谷歌密码学家披露的 [SHAttered](https://shattered.it/) 技术可以使两个不同的文件拥有相同的 SHA-1 文件签名(这称之为“碰撞”)。
在当时,创建一个 SHA-1 碰撞被认为需要非常昂贵的计算成本,谷歌的专家认为 SHA-1 在实际应用中至少还能用上五年,直到成本下降。
然而,随后在 2019 年 5 月和 2020 年 1 月发布的研究报告中,详细介绍了一种更新的方法,将 SHA-1 选择-前缀碰撞攻击chosen-prefix collision attack的成本分别降低到 [11 万美元](https://www.zdnet.com/article/sha-1-collision-attacks-are-now-actually-practical-and-a-looming-danger/)和 [5 万美元](https://eprint.iacr.org/2020/014.pdf)以下。
对于高级威胁攻击者,例如国家黑客和高端网络犯罪集团,如果他们能够生成一个 SSH 认证密钥,使他们能够远程不被发现地访问关键服务器,那么 5 万美元是一个很小的代价。
### OpenSSH 关闭 ssh-rsa 模式
“由于这个原因,我们将在不久的未来版本中默认禁用 ssh-rsa 公钥签名算法。”OpenSSH 开发者今天表示。
OpenSSH 应用程序使用 ssh-rsa 模式来[生成 SSH 验证密钥](https://www.ssh.com/ssh/public-key-authentication)。这些密钥中的一个存储在用户要登录的服务器上,另一个存储在用户的本地 OpenSSH 客户端中,这样用户就可以在每次登录时不需要输入密码就可以访问服务器,而是以本地认证密钥来代替。
在默认情况下,OpenSSH ssh-rsa 模式通过使用 SHA-1 哈希函数生成这些密钥,这意味着这些密钥容易受到 SHAterred 攻击,使攻击者能够生成重复的密钥。
“遗憾的是,尽管有更好的替代方案存在,但这种算法仍然被广泛使用,它是原始的 SSH RFC 规定的唯一剩下的公钥签名算法”,OpenSSH 的开发人员今天表示。
OpenSSH 团队现在要求服务器所有者检查他们的密钥是否已经使用默认的 ssh-rsa 模式生成,并使用不同的模式生成新的密钥。
OpenSSH 团队表示,推荐的模式是 rsa-sha2-256/512(从 OpenSSH 7.2 开始支持)、ssh-ed25519(从 OpenSSH 6.5 开始支持)或 ecdsa-sha2-nistp256/384/521(从 OpenSSH 5.7 开始支持)。
>
> 这里是最近公告中的最好的消息。让我们为所有的嵌入式系统和设备永远不会看到 OpenSSH 中废弃的 ssh-rsa SHA-1 密钥的升级而默哀一分钟。
>
>
> - Julio (@juliocesarfort) 2020 年 5 月 27 日
>
>
>
OpenSSH 项目将在未来(目前还未确定)的版本中默认禁用 ssh-rsa 模式,但是在此之前,他们还计划默认启用 UpdateHostKeys 功能,让服务器所有者可以轻松自动地从旧的 ssh-rsa 模式迁移到更好的验证算法。
依赖 OpenSSH 管理远程系统的服务器管理员可以在 [OpenSSH 8.3 的变更日志](http://www.openssh.com/txt/release-8.3)中找到更多关于如何测试他们的服务器是否有基于弱 SHA-1 的密钥的详细信息。
在之前的一个版本中,在 8.2 版本中,OpenSSH 团队还增加了对[基于 FIDO/U2F 的硬件安全密钥的支持](https://www.zdnet.com/article/openssh-adds-support-for-fidou2f-security-keys/),这也可以用来更安全地登录远程服务器。
---
via: <https://www.zdnet.com/article/openssh-to-deprecate-sha-1-logins-due-to-security-risk/>
作者:[Catalin Cimpanu](https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12257-1.html) 荣誉推出
| 200 | OK | # OpenSSH to deprecate SHA-1 logins due to security risk


OpenSSH, the most popular utility for connecting to and managing remote servers, has announced today plans to drop support for its SHA-1 authentication scheme.
The OpenSSH team cited security concerns with the SHA-1 hashing algorithm, currently considered insecure.
The algorithm was broken in a practical, real-world attack in February 2017, when Google cryptographers disclosed [SHAttered](https://shattered.it/), a technique that could make two different files appear as they had the same SHA-1 file signature.
At the time, creating an SHA-1 collision was considered computationally expensive, and Google experts thought SHA-1 could still be used in practice for at least half a decade until the cost would go down.
However, subsequent research released in May 2019 and in January 2020, detailed an updated methodology to cut down the cost of an SHA-1 chosen-prefix collision attack to [under $110,000](https://www.zdnet.com/article/sha-1-collision-attacks-are-now-actually-practical-and-a-looming-danger/) and [under $50,000](https://eprint.iacr.org/2020/014.pdf), respectively.
For advanced threat actors, such as nation-state and high-end cybercrime groups, $50,000 is a small price to pay if they could generate an SSH authentication key that grants them remote and undetected access to critical servers.
### OpenSSH to disable "ssh-rsa" mode
"For this reason, we will be disabling the 'ssh-rsa' public key signature algorithm by default in a near-future release," OpenSSH developers said today.
The OpenSSH app uses the "ssh-rsa" mode to generate [SSH authentication keys](https://www.ssh.com/ssh/public-key-authentication). One of these keys is stored on the server a user wants to log in, and the other is stored in the user's local OpenSSH client, allowing users to access servers without having to enter their passwords on every login, presenting the local authentication key instead.
By default, the OpenSSH ssh-rsa mode generates these keys by using the SHA-1 hashing function, meaning these keys are susceptible to SHAterred attacks, allowing threat actors to generate duplicate keys.
"This algorithm is unfortunately still used widely despite the existence of better alternatives, being the only remaining public key signature algorithm specified by the original SSH RFCs," OpenSSH devs said today.
The OpenSSH team is now asking server owners to check if their keys have been generated with the default ssh-rsa mode, and generate new ones using a different mode.
Recommended modes are rsa-sha2-256/512 (supported since OpenSSH 7.2), ssh-ed25519 (supported since OpenSSH 6.5) or ecdsa-sha2-nistp256/384/521 (supported since OpenSSH 5.7), the OpenSSH team said.
here's the best piece of the recent announcement. RIP & one minute silence to all embedded systems and appliances that will never see an upgrade for deprecating ssh-rsa SHA-1 based keys in OpenSSH.
— Julio (@juliocesarfort)[pic.twitter.com/zf5VewugC6][May 27, 2020]
The OpenSSH project will by disabling the ssh-rsa mode by default in a future (currently unspecified) release, however, before that, they also plan to enable the *UpdateHostKeys *feature by default, to allow server owners to easily and automatically migrate from the old ssh-rsa mode to better authentication algorithms.
Server owners who rely on OpenSSH to manage remote systems can find additional details on how to test their server for weak SHA-1-based keys in the [OpenSSH 8.3 changelog](http://www.openssh.com/txt/release-8.3).
In a previous release, in version 8.2, the OpenSSH team also added [support for FIDO/U2F-based hardware security keys](https://www.zdnet.com/article/openssh-adds-support-for-fidou2f-security-keys/), which can also be used to log into remote servers in even a safer manner.
#### What's in a name? These DevOps tools come with strange backstories
[Editorial standards](/editorial-guidelines/) |
12,261 | 攒一台“Linus Torvalds 牌”电脑 | https://www.zdnet.com/article/look-whats-inside-linus-torvalds-latest-linux-development-pc/ | 2020-05-28T22:46:00 | [
"Linus"
] | https://linux.cn/article-12261-1.html | 
前两天,Linus Torvalds 说他更新了其主力电脑,[据称编译内核时快了三倍](/article-12249-1.html)。虽然 Torvalds [用来编程时喜欢用戴尔 XPS 开发者版笔记本电脑](/article-7795-1.html),但他还有一台开发工作站,最近他将它升级为基于 AMD 锐龙 Threadripper 3970x 高速处理器。这是 Linus 15 年来第一次换用 AMD 的 CPU。
作为世界上最著名的程序员之一、Linux 操作系统之父以及 Git 的缔造者,他的一举一动都会引来开源社区的兴趣,因此大家对这台新电脑的配置也相当感兴趣。
### “Linus Torvalds 牌”电脑配置清单
Torvalds 是一个喜欢自己攒电脑的人。“我通常都是自己攒电脑。我会重新使用上一台机器的机箱或 SSD 之类的东西,但这一次是全新打造的。”
在这次攒机之前,他的机器是 i9-9900k。通常情况下,Torvalds 会直接去当地的 Fry's 商店直接购买一些比较基础的配件,但由于病毒的影响,这次都是从亚马逊买的。几周后就到货了(这年头电脑配件几天就发货了),最后两件是上周五到的。
以下列出这台电脑的具体配置,大家感兴趣的可以按图索骥。
#### CPU:AMD 锐龙 Threadripper 3970X

锐龙 Threadripper 3970X 并不便宜,而且它是目前最快的 CPU。AMD Threadripper 3970x 搭载了 32 个核心。它采用 AMD 的 7 纳米 Zen 2 核心架构,拥有 88 个 PCIe 4.0。AMD 声称它比竞争对手快了 90%。Phoronix 的独立测试发现,“[Threadripper 3970X 在性能上绝对占优势](https://www.phoronix.com/scan.php?page=article&item=amd-linux-3960x-3970x&num=1),超过了 Core i9 10980XE。”
“最初,我其实是计划用 AM4 主板和 Ryzen 3950X,这是比较主流的升级过程。” Torvalds 说,“Ryzen 3950X 是英特尔 i9-9900K 的升级版,但只是不多的升级。”
“通常情况下,我都会选择普通的消费级 CPU,因为它们往往是性价比最高的,而对于英特尔 CPU 来说,我其实喜欢它们只是因为集成了显卡。我不太在意 GPU,所以集成式的就好了,这样可以避免了挑选相匹配的 GPU,以及风扇不好的 GPU 可能产生的噪音。”
Torvalds 为此“来回折腾了好一阵子”,正如他所说的:“Threadripper 的功率让我担心噪音问题。但我决定做一次大升级,因为与传统的英特尔 Xeon 高核数平台不同,AMD 的 Threadripper 系列仍然属于‘物美价廉’的范畴。所以我咬咬牙就上了,到目前为止,我很满意。”
#### 主板:技嘉 Aorus TRX40 Master

对于顶级 CPU,你当然需要最好的主板:技嘉 Aorus RX40 Master。它使用的是 16+3 相英飞凌供电,考虑到新 CPU 恐怖的规格,技嘉还给主板的供电覆盖上了加强散热模块,模块以密集的散热鳍片热管为主。
在这里,Torvalds 主要关心的是:
“要有一块看起来不错的电源传输和风扇控制的主板。在我所攒的机器中,我希望的是最基本的东西都要可靠,没有什么比电源传输更基本的东西了。很久以前,我有几个系统因为电源断电而变得不可靠,现在我对这个问题已经变得很虔诚了。所以我就找一些适合超频的东西,然后**不超频**。”
简而言之,他要的是一台能承受高负载的 PC,但他不会把机器推到极限。话虽如此,Torvalds 很讨厌“这款主板的默认风扇设置(非常烦人的小高转速风扇,用于电压调节器模块 VRM 散热),但你可以通过 BIOS 设置调整得更好。另外请大家注意:这是一款 E-ATX 主板,所以在出现错误的情况下可能会很不方便。”
#### CPU 散热器和风扇:猫头鹰(Noctua) NF-A14 PWM、NH-U14S 和 NF-A15

高性能 CPU 的发热自然很高,因此 CPU 风扇也需要一台强劲的,但是,更重要的是,需要安静,Torvalds 以前就在用猫头鹰,感觉很好,这次依然用的是它。
Torvalds 使用了两款 CPU 散热器的风扇。其中 NH-U14S 是主打的,而多出的 NF-A15 风扇则是针对该散热器的推拉式配置。
既然他这么担心噪音问题,你问为什么不选择水冷呢?“我不喜欢水冷的。可靠性让我担心,而且我不觉得 AIO 系统会比好的风冷系统好。另外,定制那些系统太费劲了,我担心水泵和潺潺的噪音。” Torvalds 说。
Torvalds 说,“额外的风扇是因为我喜欢那种推拉式的设置,140mm 大的猫头鹰风扇低速运行,我不用担心噪音问题。即使是在负载下加速运行时,我也不觉得那些风扇的噪音很烦人。它更多的是一种舒缓的‘嗖嗖’的白噪音,没有劣质风扇所带来的恼人的呜呜声或嘎嘎声。”
#### 机箱:德商必酷(Be Quiet)Dark Base 700

显然程序员在工作时都想要安静,Torvalds 也不例外,那么德商必酷(Be Quiet)Dark Base 700 PC 机箱自然是首选。
其实 Torvalds 更喜欢猫头鹰,德商必酷只是第二选择,但是猫头鹰没有做机箱产品。
#### 附加风扇:德商必酷(Be Quiet)Silent Wings 3

高性能 PC 需要大量的电能,这又意味着它们会产生大量的热量。 自然,重视安静的 Torvalds 又选择了一块德商必酷(Be Quiet) Silent Wings 3 风扇。
为什么要多一个风扇?Torvalds 解释说:“多出一个风扇(机箱已经有两个)是因为我最初订购了这个机箱,然后在看的时候,我觉得前面的进气口看起来比后面的输出口更受限制(因为前面板的缘故),反正我在等其他配件到货,所以我决定多加一个进气口风扇会更有利于空气流通,希望能造成机箱的正压,减少灰尘的担心。”
最终,为了做一台安静强大的PC,所有的努力都是值得的。
“有了 BIOS 中正确的风扇控制设置(假设你选对了风扇头。主板的纸质手册上的图片太可怕了,而且我在第一次攒机的时候把 CPU 和系统风扇头弄错了),你的机器在空载的时候基本上是静音的,而且在满载的情况下没有任何恼人的呜呜声(但不是静音)。”
#### 电源:海韵(Seasonic)Focus GX-850

快速的 CPU 也需要大量的电能,海韵(Seasonal)Focus GX-850 可以提供澎湃的电能。
GX-850 并不是 Torvald 的首选,但在新冠期间只能选到它,不过“它应该是可靠的”,Torvalds 说。他对基础的电源传输非常在意:“我基本上会考虑机器的最高功率使用量是多少?然后挑选一个额定功率为 2 倍的电源,然后寻找评论和有信誉的品牌。”
#### 存储:1TB 三星 EVO 970 SSD

说到存储,Torvalds 说现在已经是固态硬盘(SSD)的天下:“到现在为止,我已经十几年没接触过旋转介质了,在过去的几代产品中,我尽量避免布线这些麻烦,只用 m.2 外形的固态硬盘。我用过几款三星的固态硬盘,它们一直都很好。几代以前有很多坏的固态硬盘,现在已经不是什么问题了,但我还是坚持用适合自己的东西。”
#### 内存:4 条 16GB DDR4-2666

在理想的情况下,当然是 64GB 的纠错码(ECC)内存更好,不过这次他只是选择了高质量的通用 DDR RAM。
事实证明,内存是 Torvalds 的一个痛点:“这其实是我攒的机器里面最不喜欢的部分 —— 它是个好内存,但我真的很想要 ECC(错误校正代码)内存。我很难在亚马逊上找到任何(价格合理)的东西,所以这个我觉得是暂时的‘够用了’,实际用起来起来还不错。”
此外,他继续说道:“其实我甚至不需要 64GB 内存,因为我做的东西往往都不太需要内存,但我想把四个内存通道都填满,而且内存很便宜。”
虽然游戏和人工智能和机器学习的开发者们都很关心图形,但视频和图像处理并不在 Torvalds 的兴趣范围之内。他用的是“随便选的蓝宝石 RX580 显卡。对于我所做的工作(台式机使用,不玩游戏)来说,这已经足够了。”
#### 操作系统:Linux Fedora 32

这没什么说的,Torvalds 肯定是用的 Linux ,他一直很喜欢用 Red Hat 的 Fedora 进行开发。当然,用的是最新版本的 Fedora 32。
“把它拼凑在一起,确保所有的风扇设置正确,然后在上面安装 Fedora 32,你就有了一个相当不错的工作站”,Torvalds 说。
除了这台工作站之外,Torvalds 日常使用笔记本电脑进行编程,他使用的是戴尔 XPS 13。
Torvalds 说,“通常情况下,我不会说出品牌,但对 XPS 13 我破例了,我实在太喜欢它了,以至于在我女儿上大学的时候,我还为她买了一台。”
### 羡慕吗?
要不要也攒一台呢,也就 3 万来块钱 :D
| 200 | OK | # Look what's inside Linus Torvalds' latest Linux development PC

In a [Linux Kernel Mailing List (LKML](https://lkml.org/)), Linus Torvalds, Linux's top developer, talked about the latest progress in the next version of Linux: [Linux 5.7-rc7](http://lkml.iu.edu/hypermail/linux/kernel/2005.3/00406.html). Along the way, he mentioned, "for the first time in about 15 years, my desktop isn't Intel-based." In his newest development box, he's "rocking an [AMD Threadripper 3970x](https://www.zdnet.com/article/amd-unveils-worlds-most-powerful-desktop-cpus/)." But a computer is more than just a processor no matter how speedy it is, so I talked with Torvalds to see exactly what's in his new box.
First, he's already impressed by its performance:
"My 'allmodconfig' test builds are now three times faster than they used to be, which doesn't matter so much right now during the calming down period, but I will most definitely notice the upgrade during the next merge window," said Torvalds.
The AMD Threadripper 3970x comes with 32 cores. It's built using AMD's 7-nanometer "Zen 2" core architecture, and it boasts 88 PCIe 4.0. AMD claims it's up to 90% faster than its competition. [Phoronix](https://www.phoronix.com/)'s independent tests found the "[Threadripper 3970X absolutely dominates in performance](https://www.phoronix.com/scan.php?page=article&item=amd-linux-3960x-3970x&num=1) and "outpaces the Core i9 10980XE."
Torvalds is a build-your-own box type of guy.
"I typically build all my own machines. Usually they are frankenboxes -- I'll re-use the case or the SSD from the previous machine or something like that. This time it was an all-new build," he said.
Why do it yourself?
"I don't like having others build my machine, partly because I have my own specs I care most about, but partly I get self-conscious about getting donations that I no longer really need," Torvalds said.
Before this latest build, his box was an [i9-9900k](https://www.zdnet.com/article/intel-9600k-9700k-and-9900k-cpu-specs/). Normally, Torvalds would just pop into the local Fry's to pick up some of the more basic stuff directly, but with the virus, this time it was all from Amazon. The pieces came in over a few weeks (no more two-day shipping of computer parts these days); the last two pieces came last Friday.
So, here's Torvald's annotated hardware list:
### CPU
**See it now:**[Ryzen Threadripper 3970X](https://www.amazon.com/AMD-Ryzen-Threadripper-3970X-64-Thread/dp/B0815JJQQ8/?tag=zdnet-deals-20)
"Initially, my plan was actually to do an AM4 board and just a Ryzen 3950X, which is the more mainstream upgrade," Torvalds said, but the "Ryzen 3950X would have been an upgrade over the Intel i9-9900K, but it would only have been an incremental one."
"Normally, I go for the regular consumer CPU's, since they tend to be the best bang for the buck, and in the case of Intel CPU's I actually like that they just have integrated graphics. I don't care about the GPU very much, so an integrated one is fine, and it avoids the worry about picking the right GPU and possible noise-levels from one with bad fans."
Torvalds went "back-and-forth about that for a while," because, as he said:
"The Threadripper power use made me worry about noise. But I decided to do a big upgrade because unlike the traditional Intel Xeon high-core-count platform, AMD's Threadripper series still falls in the 'good bang for the buck.' So I bit the bullet, and am so far quite pleased."
### Motherboard
**See it now: Gigabyte Aorus TRX40 Master**
Here, Torvald's main concern was:
"A board that had what looked like good power delivery and fan control. In the builds I do, I really want the basics to be solid, and there's little more basic than power delivery. Long long ago I had a couple of systems that were unreliable due to power brown-out, and I've gotten religious about this now. So I look for something that is good for overclocking, and then I do _not_ overclock things."
In short, he wants a PC that can handle a heavy load, but he's not going to push the machine to its limits. That said, Torvalds absolutely detests:
"The default fan settings of this motherboard (very whiny small high-RPM fan for VRM [Voltage Regulator Module] cooling), but you can tweak the BIOS settings to something much better. Also note to anybody else: This is an E-ATX board, so it can be inconvenient in the wrong case."
### Fan
**See it now:**[Noctua NF-A14 PWM, Premium Quiet Fan](https://www.amazon.com/Noctua-NF-A14-PWM-Premium-Cooling/dp/B00CP6QLY6/?tag=zdnet-deals-20)
As you can tell, noise is a big issue for Torvalds. He cares deeply about it:
"So I want good fans and coolers, and I've had good experiences with Noctua before," Torvalds said. "The extra fan is because I like that push-pull setup, and with a big 140mm Noctua fan running at low speed, I'm not worried about noise levels. Even when it ramps up under load, I don't find the noise of those fans annoying. It's more of a soothing 'whoosh" white noise sound, none of the annoying whining or rattling that you get with bad fans."
### CPU Cooler
**See it now:**[Noctua NH-U14S](https://www.amazon.com/Noctua-NH-U14S-Premium-Cooler-NF-A15/dp/B00C9FLSLY/?tag=zdnet-deals-20)and Noctua[NF-A15](https://www.amazon.com/Noctua-NF-A15-PWM-Premium-Cooling/dp/B00AED7XFI/?tag=zdnet-deals-20)
Torvalds uses two CPU cooler fans. The NH-U14S is the main one, while the extra NF-A15 fan is for the push-pull configuration of that cooler.
With all his concern about noise, why not water-cooling, you ask?
"I'm not a fan of water-cooling. Reliability worries me, and I'm not convinced the AIO systems are any better than a good air cooling system. And the custom ones are way too much effort, and I worry about the pump and gurgling noises," Torvalds said.
### Case
**See it now:**[Be Quiet Dark Base 700](https://www.amazon.com/Power-Modular-Platinum-fuente-alimentación/dp/B0773NWQNQ/?tag=zdnet-deals-20)
For the case, it's once again all about noise reduction.
"I like Noctua fans better than the Be Quiet ones for some reason. But Be Quiet would have been my second choice, and Noctua doesn't make cases," he said.
### Extra fan
**See it now:**[Silent Wings 3](https://www.amazon.com/quiet-BL066-SILENTWINGS-1450RPM-50-5CFM/dp/B01JMEDDYY/?tag=zdnet-deals-20)
Why an extra fan? Torvalds explained:
"The extra fan (the case comes with two already) is because I initially ordered the case, and then when looking at it I decided that it looks like the front intake looks more restricted than the back output (because of the front panel), and since I was waiting for other parts to be delivered anyway, I decided that an extra intake fan would be better for airflow, and hopefully cause positive case pressure and less worry about dust."
In the end, all the effort to make a quiet powerful PC was worth it.
"With the right fan control setup in the BIOS (and assuming you picked the right fan headers: The motherboard paper manual had horrible pictures and I got the CPU and system fan header the wrong way round for the first build), you have a machine that is basically silent when idling, and without any annoying whine (but not silent) under full load."
### Power Supply Unit
**See it now:**[Seasonic Focus GX-850](https://www.amazon.com/Seasonic-GX-850-Full-Modular-Application-SSR-850FX/dp/B07WVMDZMZ/?tag=zdnet-deals-20)
The GX-850 wasn't Torvald's first choice, but availability during the time of the coronavirus made it what it is, but "it should be solid," Torvalds said. He cares deeply about power delivery basics:
"I basically go 'what's the top power use of the machine?,' and then pick a power supply with a rating 2x that, and then look for reviews and reputable brands."
### Storage
**See it now:**[1TB Samsung EVO 970](https://www.amazon.com/Samsung-970-EVO-1TB-MZ-V7E1T0BW/dp/B07BN217QG/?tag=zdnet-deals-20)
When it comes to storage, Torvalds is solid-state drives (SSD) all the way:
"I've refused to touch spinning media for over a decade by now, and for the last several generations I've tried to avoid the hassle with cabling, etc., by just going with an m.2 form factor. I've had several of the Samsung SSD's, they've been fine. A few generations ago there were lots of bad SSD's, these days it's much less of an issue, but I've stuck with what works for me."
### Memory
**See it now:**[4x16GB DDR4-2666](https://www.amazon.com/s?k=4x16GB+DDR4-2666+memory&i=electronics&ref=nb_sb_noss&tag=zdnet-deals-20)
RAM proved to be a sore spot for Torvalds:
"This is actually the least favorite part of the build for me -- it's fine memory, but I really wanted ECC [Error-correcting code} memory. I had a hard time finding anything [priced sanely] on Amazon, so this I feel is a temporary 'good enough for now' thing that works fine in practice."
Besides, he continued:
"I don't actually even need 64GB of RAM, since the stuff I do doesn't tend to be all that memory-intensive, but I wanted to populate all four memory channels, and RAM is cheap."
While games and artificial intelligence and machine learning developers care deeply about graphics, video and image processing doesn't interest Torvalds much. He used:
"Some random Sapphire RX580 graphics card. It's overkill for what I do (desktop use, no games)."
### Linux
**See it now:**[Fedora 32](https://getfedora.org/)
That's it.
"Slap it all together, make sure you get all the fan settings right, and (in my case) install Fedora 32 on it, and you've got a fairly pleasant workstation," Torvalds said.
While for his main workstation, Torvalds builds his own, he also has cutting edge OEM PCs for "access to new technology that I might not otherwise have bought myself."
For his laptop, he uses a [Dell XPS 13](https://www.anrdoezrs.net/links/9041660/type/dlg/sid/zd-4db3425b61b14bbcb0560d6eee7de6e5--/https://www.dell.com/en-us/work/shop/overview/cp/linuxsystems).
"Normally, Torvalds said, "I wouldn't name names, but I'm making an exception for the XPS 13 just because I liked it so much that I also ended up buying one for my daughter when she went off to college.
#### Here's all the hardware and where to buy it
Torvalds concluded:
"If the above makes you go 'Linus has too much hardware,' you'd be right. Usually I have one main box, and usually it's something I built myself."
**Related Stories:**
[Editorial standards](/editorial-guidelines/) |
12,263 | 在 Linux 上检查 MySQL/MariaDB 数据库正常运行时间的三种方法 | https://www.2daygeek.com/check-mysql-mariadb-database-server-uptime-linux/ | 2020-05-29T21:10:38 | [
"MySQL",
"MariaDB"
] | https://linux.cn/article-12263-1.html | 
我们都知道在 Linux 中使用 `uptime` 命令的目的。它用于检查 [Linux 系统的正常运行时间](https://www.2daygeek.com/linux-system-server-uptime-check/)以及系统上次启动以来运行的时间。
而 Linux 管理员的工作是保持系统正常运行。
如果要检查 Linux 上的其他服务(例如 [Apache](https://www.2daygeek.com/check-find-apache-httpd-web-server-uptime-linux/)、MySQL、MariaDB、sftp 等)运行了多长时间,该怎么做?
每个服务都有自己的命令来检查服务的正常运行时间。但是你也可以为此使用其他命令。
### 方法 1:如何使用 ps 命令在 Linux 上检查 MySQL/MariaDB 数据库的正常运行时间
[ps 命令](https://www.2daygeek.com/linux-ps-command-find-running-process-monitoring/)的意思是<ruby> 进程状态 <rt> process status </rt></ruby>。这是最基本的命令之一,它显示了系统正在运行的进程的详细信息。
为此,你首先需要使用 [pidof 命令](https://www.2daygeek.com/check-find-parent-process-id-pid-ppid-linux/)查找 [MySQL](https://www.2daygeek.com/category/mysql/)/[MariaDB](https://www.2daygeek.com/category/mariadb/) 的 PID。
```
# pidof mysqld | cut -d" " -f1
2412
```
获取 MySQL/MariaDB 的 PID 后,请在 `ps` 命令中使用 `--etime` 选项获得正常运行时间。
* `--etime`:自进程启动以来经过的时间,形式为 `[[DD-]hh:]mm:ss`。
```
# ps -p 2412 -o etime
ELAPSED
2-08:49:30
```
或者,在 `ps` 命令中使用 `--lstart` 选项来获取指定 PID 的正常运行时间。
```
# ps -p 2412 -o lstart
STARTED
Sat May 2 03:02:15 2020
```
MySQL/MariaDB 进程已经运行了 2 天 03 小时 02 分 15 秒。
### 方法 2:如何使用 systemctl 命令在 Linux 上检查 MySQL/MariaDB 数据库的正常运行时间
[systemctl 命令](https://www.2daygeek.com/sysvinit-vs-systemd-cheatsheet-systemctl-command-usage/)用于控制 systemd 系统和服务管理器。
systemd 是新的初始化系统和系统管理器,现在大多数 Linux 发行版都淘汰了传统的 SysVinit 管理器而采用了 systemd。
```
# systemctl status mariadb
或者
# systemctl status mysql
● mariadb.service - MariaDB 10.1.44 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/mariadb.service.d
└─migrated-from-my.cnf-settings.conf
Active: active (running) since Sat 2020-05-02 03:02:18 UTC; 2 days ago
Docs: man:mysqld(8)
https://mariadb.com/kb/en/library/systemd/
Process: 2448 ExecStartPost=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
Process: 2388 ExecStartPre=/bin/sh -c [ ! -e /usr/bin/galera_recovery ] && VAR= || VAR=/usr/bin/galera_recovery; [ $? -eq 0 ] && systemctl set-environment _WSREP_START_POSITION=$VAR || exit 1 (code=exited, status=0/SUCCESS)
Process: 2386 ExecStartPre=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
Main PID: 2412 (mysqld)
Status: "Taking your SQL requests now…"
CGroup: /system.slice/mariadb.service
└─2412 /usr/sbin/mysqld
May 03 21:41:26 ns2.2daygeek.com mysqld[2412]: 2020-05-03 21:41:26 140328136861440 [Warning] Host name '1.1.1.1' could not be resolved: … not known
May 04 02:00:46 ns2.2daygeek.com mysqld[2412]: 2020-05-04 2:00:46 140328436418304 [Warning] IP address '1.1.1.1' has been resolved to the host name '2…ss itself.
May 04 03:01:31 ns2.2daygeek.com mysqld[2412]: 2020-05-04 3:01:31 140328436111104 [Warning] IP address '1.1.1.1' could not be resolved: Temporary fai…resolution
May 04 04:03:06 ns2.2daygeek.com mysqld[2412]: 2020-05-04 4:03:06 140328136861440 [Warning] IP address '1.1.1.1' could not be resolved: Name or ser… not known
May 04 07:23:54 ns2.2daygeek.com mysqld[2412]: 2020-05-04 7:23:54 140328435189504 [Warning] IP address '1.1.1.1' could not be resolved: Name or service not known
May 04 08:03:31 ns2.2daygeek.com mysqld[2412]: 2020-05-04 8:03:31 140328436418304 [Warning] IP address '1.1.1.1' could not be resolved: Name or service not known
May 04 08:25:56 ns2.2daygeek.com mysqld[2412]: 2020-05-04 8:25:56 140328135325440 [Warning] IP address '1.1.1.1' could not be resolved: Name or service not known
Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
Hint: Some lines were ellipsized, use -l to show in full.
```
### 方法 3:如何使用 MySQLAdmin 命令在 Linux 上检查 MySQL/MariaDB 数据库的正常运行时间
[MySQLAdmin](https://www.2daygeek.com/linux-mysqladmin-command-administrate-mysql-mariadb-server/) 是安装 MySQL 软件包时安装的 MySQL 服务器命令行程序。
MySQLAdmin 客户端允许你在 MySQL 服务器上执行一些基本的管理功能。
它用于创建数据库、删除数据库、设置 root 密码、更改 root 密码、检查 MySQL 状态、验证 MySQL 功能、监视 mysql 进程以及验证服务器的配置。
```
# mysqladmin -u root -pPassword version
mysqladmin Ver 8.42 Distrib 5.7.27, for Linux on x86_64
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Server version 5.7.27
Protocol version 10
Connection Localhost via UNIX socket
UNIX socket /var/lib/mysql/mysql.sock
Uptime: 1 day 10 hours 44 min 13 sec
```
---
via: <https://www.2daygeek.com/check-mysql-mariadb-database-server-uptime-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,264 | 怎样在树莓派上安装 TT-RSS | https://opensource.com/article/20/2/ttrss-raspberry-pi | 2020-05-29T23:04:19 | [
"RSS"
] | https://linux.cn/article-12264-1.html |
>
> 使用 Tiny Tiny RSS 来保护你阅读新闻馈送时的隐私。
>
>
>

[Tiny Tiny RSS](https://tt-rss.org/)(TT-RSS)是一个自由开源的基于 Web 的新闻<ruby> 馈送 <rt> feed </rt></ruby>(RSS/Atom)阅读器和聚合工具。它非常适合那些注重隐私,并且仍然依赖 RSS 来获取日常新闻的人。TT-RSS 是自行托管的软件,因此你可以 100% 的掌控你的服务器、数据以及你的全部隐私。它还支持大量的插件、扩展和主题。你喜欢黑暗模式的界面?没问题。想基于关键词过滤发来的消息?TT-RSS 也能让你得偿所愿。

现在你知道 TT-RSS 是什么了,那么为什么你可能会想用它。我会讲述要把它安装到树莓派或 Debian 10 服务器上你需要了解的所有的东西。
### 安装和配置 TT-RSS
要把 TT-RSS 安装到树莓派上,你还需要安装和配置最新版本的 PHP(本文撰写时 PHP 最新版本是 7.3)、后端数据库 PostgreSQL、Nginx web 服务器、Git,最后才是 TT-RSS。
#### 1、安装 PHP 7
安装 PHP 7 是整个过程中最复杂的部分。幸运的是,它并不像看起来那样困难。从安装下面的支持包开始:
```
$ sudo apt install -y ca-certificates apt-transport-https
```
现在,添加存储库 PGP 密钥:
```
$ wget -q https://packages.sury.org/php/apt.gpg -O- | sudo apt-key add -
```
下一步,把 PHP 库添加到你的 apt 源:
```
$ echo "deb https://packages.sury.org/php/ buster main" | sudo tee /etc/apt/sources.list.d/php.list
```
然后更新你的存储库索引:
```
$ sudo apt update
```
最后,安装 PHP 7.3(或最新版本)和一些通用组件:
```
$ sudo apt install -y php7.3 php7.3-cli php7.3-fpm php7.3-opcache php7.3-curl php7.3-mbstring php7.3-pgsql php7.3-zip php7.3-xml php7.3-gd php7.3-intl
```
上面的命令默认你使用的后端数据库是 PostgreSQL,会安装 `php7.3-pgsql`。如果你想用 MySQL 或 MariaDB,你可以把命令参数改为 `php7.3-mysql`。
下一步,确认 PHP 已安装并在你的树莓派上运行着:
```
$ php -v
```
现在是时候安装和配置 Web 服务器了。
#### 2、安装 Nginx
可以用下面的命令安装 Nginx:
```
$ sudo apt install -y nginx
```
修改默认的 Nginx 虚拟主机配置,这样 Web 服务器才能识别 PHP 文件以及知道如何处理它们。
```
$ sudo nano /etc/nginx/sites-available/default
```
你可以安全地删除原文件中的所有内容,用下面的内容替换:
```
server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html;
index index.html index.htm index.php;
server_name _;
location / {
try_files $uri $uri/ =404;
}
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/run/php/php7.3-fpm.sock;
}
}
```
按 `Ctrl+O` 保存修改后的配置文件,然后按 `Ctrl+X` 退出 Nano。你可以用下面的命令测试你的新配置文件:
```
$ nginx -t
```
如果没有报错,重启 Nginx 服务:
```
$ systemctl restart nginx
```
#### 3、安装 PostgreSQL
接下来是安装数据库服务器。在树莓派上安装 PostgreSQL 超级简单:
```
$ sudo apt install -y postgresql postgresql-client postgis
```
输入下面的命令看一下数据库服务器安装是否成功:
```
$ psql --version
```
#### 4、创建 Tiny Tiny RSS 数据库
在做其他事之前,你需要创建一个数数据库,用来给 TT-RSS 软件保存数据。首先,登录 PostgreSQL 服务器:
```
sudo -u postgres psql
```
下一步,新建一个用户,设置密码:
```
CREATE USER username WITH PASSWORD 'your_password' VALID UNTIL 'infinity';
```
然后创建一个给 TT-RSS 用的数据库:
```
CREATE DATABASE tinyrss;
```
最后,给新建的用户赋最高权限:
```
GRANT ALL PRIVILEGES ON DATABASE tinyrss to user_name;
```
这是安装数据库的步骤。你可以输入 `\q` 来退出 `psql` 程序。
#### 5、安装 Git
安装 TT-RSS 需要用 Git,所以输入下面的命令安装 Git:
```
$ sudo apt install git -y
```
现在,进入到 Nginx 服务器的根目录:
```
$ cd /var/www/html
```
下载 TT-RSS 最新源码:
```
$ git clone https://git.tt-rss.org/fox/tt-rss.git tt-rss
```
注意,这一步会创建一个 `tt-rss` 文件夹。
#### 6、安装和配置Tiny Tiny RSS
现在是安装和配置你的新 TT-RSS 服务器的最后时刻了。首先,确认下你在浏览器中能打开 `http://your.site/tt-rss/install/index.php`。如果浏览器显示 `403 Forbidden`,那么就证明 `/var/www/html` 文件夹的权限没有设置正确。下面的命令通常能解决这个问题:
```
$ chmod 755 /var/www/html/ -v
```
如果一切正常,你会看到 TT-RSS 安装页面,它会让你输入一些数据的信息。你只需要输入前面你创建的数据库用户名和密码;数据库名;主机名填 `localhost`;端口填 `5432`。
点击“Test Configuration”。如果一切正常,你会看到一个标记着“Initialize Database”的红色按钮。点击它来开始安装。结束后,你会看到一个配置文件,你可以把它复制到 TT-RSS 的目录,另存为 `config.php`。
安装过程结束后,浏览器输入 `http://yoursite/tt-rss/` 打开 TT-RSS,使用默认的凭证登录(用户名:`admin`,密码:`password`)。登录后系统会提示你修改密码。我强烈建议你尽快修改密码。
### 配置 TT-RSS
如果一切正常,你现在就可以开始使用 TT-RSS 了。建议你新建一个非管理员用户,使用新用户名登录,并开始导入你的馈送、订阅,按照你的意愿来配置它。
最后,并且是超级重要的事,不要忘了阅读 TT-RSS 维基上的 [Updating Feeds](https://tt-rss.org/wiki/UpdatingFeeds) 部分。它讲述了如何创建一个简单的 systemd 服务来更新馈送。如果你跳过了这一步,你的 RSS 馈送就不会自动更新。
### 总结
呵!工作量不小,但是你做完了!你现在有自己的 RSS 聚合服务器了。想了解 TT-RSS 更多的知识?我推荐你去看官方的 [FAQ](https://tt-rss.org/wiki/FAQ)、[支持](https://community.tt-rss.org/c/tiny-tiny-rss/support)论坛,和详细的[安装](https://tt-rss.org/wiki/InstallationNotes)笔记。如果你有任何问题,尽情地在下面评论吧。
---
via: <https://opensource.com/article/20/2/ttrss-raspberry-pi>
作者:[Patrick H. Mullins](https://opensource.com/users/pmullins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Tiny Tiny RSS](https://tt-rss.org/) (TT-RSS) is a free and open source web-based news feed (RSS/Atom) reader and aggregator. It's ideally suited to those who are privacy-focused and still rely on RSS for their daily news. Tiny Tiny RSS is self-hosted software, so you have 100% control of the server, your data, and your overall privacy. It also supports a wide range of plugins, add-ons, and themes, Want a dark mode interface? No problem. Want to filter your incoming news based on keywords? TT-RSS has you covered there, as well.
Now that you know what TT-RSS is and why you may want to use it, I'll explain everything you need to know about installing it on a Raspberry Pi or a Debian 10 server.
## Install and configure TT-RSS
To install TT-RSS on a Raspberry Pi, you must also install and configure the latest version of PHP (7.3 as of this writing), PostgreSQL for the database backend, the Nginx web server, Git, and finally, TT-RSS.
### 1. Install PHP 7
Installing PHP 7 is, by far, the most involved part of this process. Thankfully, it's not as difficult as it might appear. Start by installing the following support packages:
`$ sudo apt install -y ca-certificates apt-transport-https`
Now, add the repository PGP key:
`$ wget -q https://packages.sury.org/php/apt.gpg -O- | sudo apt-key add -`
Next, add the PHP repository to your apt sources:
`$ echo "deb https://packages.sury.org/php/ buster main" | sudo tee /etc/apt/sources.list.d/php.list`
Then update your repository index:
`$ sudo apt update`
Finally, install PHP 7.3 (or the latest version) and some common components:
`$ sudo apt install -y php7.3 php7.3-cli php7.3-fpm php7.3-opcache php7.3-curl php7.3-mbstring php7.3-pgsql php7.3-zip php7.3-xml php7.3-gd php7.3-intl`
The command above assumes you're using PostgreSQL as your database backend and installs **php7.3-pgsql**. If you'd rather use MySQL or MariaDB, you can easily change this to **php7.3-mysql**.
Next, verify that PHP is installed and running on your Raspberry Pi:
`$ php -v`
Now it's time to install and configure the webserver.
### 2. Install Nginx
Nginx can be installed via apt with:
`$ sudo apt install -y nginx`
Modify the default Nginx virtual host configuration so that the webserver will recognize PHP files and know what to do with them:
`$ sudo nano /etc/nginx/sites-available/default`
You can safely delete everything in the original file and replace it with:
```
server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html;
index index.html index.htm index.php;
server_name _;
location / {
try_files $uri $uri/ =404;
}
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/run/php/php7.3-fpm.sock;
}
}
```
Use **Ctrl+O** to save your new configuration file and then **Ctrl+X** to exit Nano. You can test your new configuration with:
`$ nginx -t`
If there are no errors, restart the Nginx service:
`$ systemctl restart nginx`
### 3. Install PostgreSQL
Next up is installing the database server. Installing PostgreSQL on the Raspberry Pi is super easy:
`$ sudo apt install -y postgresql postgresql-client postgis`
Check to see if the database server was successfully installed by entering:
`$ psql --version`
### 4. Create the Tiny Tiny RSS database
Before you can do anything else, you need to create a database that the TT-RSS software will use to store data. First, log into the PostgreSQL server:
`sudo -u postgres psql`
Next, create a new user and assign a password:
`CREATE USER username WITH PASSWORD 'your_password' VALID UNTIL 'infinity';`
Then create the database that will be used by TT-RSS:
`CREATE DATABASE tinyrss;`
Finally, grant full permissions to the new user:
`GRANT ALL PRIVILEGES ON DATABASE tinyrss to user_name;`
That's it for the database. You can exit the **psql** app by typing **\q**.
### 5. Install Git
Installing TT-RSS requires Git, so install Git with:
`$ sudo apt install git -y`
Now, change directory to wherever Nginx serves web pages:
`$ cd /var/www/html`
Then download the latest source for TT-RSS:
`$ git clone https://git.tt-rss.org/fox/tt-rss.git tt-rss`
Note that this process creates a new **tt-rss** folder.
### 6. Install and configure Tiny Tiny RSS
It's finally time to install and configure your new TT-RSS server. First, verify that you can open ** http://your.site/tt-rss/install/index.php** in a web browser. If you get a
**403 Forbidden**error, your permissions are not set properly on the
**/var/www/html**folder. The following will usually fix this issue:
`$ chmod 755 /var/www/html/ -v`
If everything goes as planned, you'll see the TT-RSS Installer page, and it will ask you for some database information. Just tell it the database username and password that you created earlier; the database name; **localhost** for the hostname; and **5432 **for the port.
Click **Test Configuration** to continue. If all went well, you should see a red button labeled **Initialize Database.** Click on it to begin the installation. Once finished, you'll have a configuration file that you can copy and save as **config.php** in the TT-RSS directory.
After finishing with the installer, open your TT-RSS installation at ** http://yoursite/tt-rss/** and log in with the default credentials (username:
**admin**, password:
**password**). The system will recommend that you change the admin password as soon as you log in. I highly recommend that you follow that advice and change it as soon as possible.
## Set up TT-RSS
If all went well, you can start using TT-RSS right away. It's recommended that you create a new non-admin user, log in as the new user, and start importing your feeds, subscribing, and configuring it as you see fit.
Finally, and this is super important, don't forget to read the [Updating Feeds](https://tt-rss.org/wiki/UpdatingFeeds) section on TT-RSS's wiki. It describes how to create a simple systemd service that will update your feeds. If you skip this step, your RSS feeds will not update automatically.
## Conclusion
Whew! That was a lot of work, but you did it! You now have your very own RSS aggregation server. Want to learn more about TT-RSS? I recommend checking out the official [FAQ](https://tt-rss.org/wiki/FAQ), the [support](https://community.tt-rss.org/c/tiny-tiny-rss/support) forum, and the detailed [installation](https://tt-rss.org/wiki/InstallationNotes) notes. Feel free to comment below if you have any questions or issues.
## Comments are closed. |
12,267 | 如何为开源软件写作文章 | https://opensource.com/article/20/5/write-about-open-source-software | 2020-05-31T11:51:23 | [
"写作",
"作者"
] | https://linux.cn/article-12267-1.html |
>
> 通过以下提示,成为一个更好的作者。
>
>
>

开始接触开源社区的一个方法就是写关于它的文章。你可以贡献技术文档,分享你如何使用软件,或者为我们社区写一篇文章。但是开始写作说起来容易做起来难。我听到的最常见的两个不写文章的借口是:“我没有什么新东西可写”和“我不是一个好的作者”。我在这里是为了打破这两个误区。
### 你应该写什么?
>
> “寻找那些经常被遗漏的故事。” 埃里克·拉尔森
>
>
>
对于某些人来说,写作的最大障碍是找到要写的想法或话题。很容易就落入了这样的思维陷阱:“这个话题已经写过了,何必再麻烦。”
我不是第一个写文章的人,也不会是最后一个。我带来的是我独特的视角和这些年来所学到的东西。曾经有人向我请教过一些关于写作入门的建议,或者是如何让自己的写作更上一层楼。我决定把这些建议变成一篇文章。
文如其人,没有人会以你的方式来述事,你的经验和观点可能正是别人所需要的。
这里有一些提示,可以帮助你想出一个主题:
* 你最近学到了什么东西?写出你是如何学习的,你学到了什么,或使你感到惊讶的事情。
* 你经常被问到的问题是什么?把答案写出来。
* 你最近是否在搜索一篇怎么做的文章,但在搜索结果中,你对排名靠前的文章不满意?请写出你要找的文章。
* 你是否参加过会议或研讨会?写一篇会后总结来说明你所学到的东西。
* 你开始使用新工具了吗?写一份操作指南或入门指南。
### 你写的是什么类型的文章?
有不同类型的文章,包括:
* 技术文档
* 操作指南
* 博客
* 白皮书或电子书
* 回顾性的文章
内容的类型会影响你的写作风格和语气。博客更加非正式和是对话式的。而技术文档更正式,更具有指导性。
### 你是为谁而写的?
每一篇文章都应该有一个单一的受众。受众是指你为之写作的对象是什么类型的人。在你开始写作之前,写下你的读者的一些特征是有助于写作的。重要的是要考虑到你要为谁写,以及你**不是为**谁写的 —— 确定你的目标受众将决定要包括哪些内容和不包括哪些内容。
例如,我在写这篇文章的时候,我设想的目标受众是这样的:
* 有基本的写作和语法知识
* 有兴趣提高写作能力
* 在技术领域担任开发人员、销售工程师、客户经理或类似职位的工作
* 不是经验丰富或资深的作者,可能在个人或工作博客上发表过几篇文章,想写更多的文章。
* 非虚构写作
如果你有针对多个受众的内容,可以考虑针对不同的受众将其分解成不同的内容。对你的受众要考虑的一些方面:
* 专业水平:新手、中级、高级
* 作用:管理人员、个人贡献者
* 目标:他们为什么要阅读这些?
### 言语很重要
你选择的言语会对读者产生影响。晦涩难懂的词汇会使文章更难理解,不常见的词汇会让读者觉得自己很笨,某些词汇可能会不小心冒犯读者。作为一个作者,你的目标是避免所有这些。下面是怎么做的:
#### 使用日常用语
不要把写作作为炫耀你的词汇量或你从“每日一字”台历上学到的单词的方式。写作是为了让读者能够理解。每一篇文章都有相关的阅读水平。如果你写的是技术文档,那么你的目标大约是初中的阅读水平。这并不意味着你的受众只有初中的教育水平。它意味着你的写作会更容易被人理解。你想让人们对这些言语过目不忘,还是想让他们觉得自己学到了什么?虽然你可以使用长而复杂的词汇,但并不意味着你应该这样做。使用简单的语言不一定意味着你的文章会很无聊。
使用 [Hemingway 应用](http://www.hemingwayapp.com/)等工具来检查你的作品的可读性(它不是开源的,但很优秀)。比如说,在初稿之后,这篇文章被评定为五年级的阅读水平。Hemingway 还提供了如何改进写作的建议 —— 找出难以理解的句子或需要改变选词的地方。
如果你想要找出替代的词汇,可以查看 [Plain English Campaign](http://www.plainenglish.co.uk/the-a-z-of-alternative-words.html) 的建议或 [Power Thesaurus](https://www.powerthesaurus.org/) 的众包建议。
#### 知道应该规避哪些词
>
> “每次你想写‘非常’的时候,就用‘该死的’代替;你的编辑会把它删掉,而作品就会如它应有的那样。” 马克·吐温
>
>
>
在写教程或指南的时候,这里有一些要避免的词,包括“<ruby> 简单 <rt> simple </rt></ruby>”、“<ruby> 容易 <rt> easy </rt></ruby>”和“<ruby> 就这样 <rt> just </rt></ruby>”。你是你所写的主题的专家,经过多年的实践,可能会觉得事情很简单。而初学者可能会觉得事情不“简单”,也不“容易”。你的读者可能会感到沮丧,因为他们觉得过程或解释并不简单。
你是否曾经因为无法理解作者的意思而不得不反复重读一个句子或段落?你有没有因为一篇文章对你来说没有意义而放弃过?我有过。
作为一个作者,你希望你的读者感到困惑或不理解吗?我希望不会。
在你的写作中要避免的其它词语:
* <ruby> 这件事 <rt> That </rt></ruby>
* <ruby> 真的 <rt> Really </rt></ruby>
* <ruby> 非常 <rt> Very </rt></ruby>
* <ruby> 所以 <rt> So </rt></ruby>
* <ruby> 为了 <rt> In order to </rt></ruby>
一般来说,这些词可以在不改变句子意思的情况下删除。
在我写完之后,我会在文档中搜索这些词。当我在这篇文章中搜索时,我发现了以下这句话:
>
> “这并不意味着你的受众只有初中的教育水平*这件事*,而意味着你的写作会更容易被理解*这件事*。”
>
>
>
这句话中出现了两个“<ruby> 这件事 <rt> That </rt></ruby>”的例子。它们并没有给句子增加价值。它们可以被删除而不改变其含义。删除这些词汇可以缩短句子,并且更短的句子更容易理解。而说到短句,我还把它改写成了两句话。
>
> “这并不意味着你的受众只有初中的教育水平。它意味着你的写作会更容易被人理解。”
>
>
>
#### 使用包容性语言
词语和短语的历史背景可能会导致人们感到被排斥或冒犯。在写作时,你要让读者感到被包容。当你使用包容性的语言时,会让读者感到被理解、被尊重,感觉被包容。我参考了 Buffer 中的这篇[关于使用包容性语言的指南](https://open.buffer.com/inclusive-language-tech/)。
### 修订和编辑
>
> “几乎所有好的写作都是从糟糕的第一次努力开始的。你需要从某个地方开始。” 安妮·拉莫特
>
>
>
写作是一个迭代的过程。如果你认为作者们坐在办公桌前,在一个小时内就能完成一篇文章准备发表,那么请你再想一想。有些文章需要我花几个星期的时间来完成。以下是我的标准流程:
* 写一个粗略的初稿。我说的粗略,我的意思是*粗陋*。写的时候不用担心语法问题。目的是让文字从我的脑海中浮现出来,写在纸上。这一步可能需要一个小时到几周的时间。
* 将草稿放一段时间。这可能需要几个小时到几天的时间,这取决于出版时间线。
* 审阅草稿。进行调整和编辑。
* 征求反馈意见,可以是同事或朋友的反馈意见。在这个阶段的反馈中,我的重点是明确性。是否有意义?是否有什么令人困惑的地方?有什么缺失的部分?
* 纳入反馈意见。无论你的写作经验有多丰富,让其他作者审阅你的作品,都会让你的作品变得更好。
在这个阶段,我有了一个相当扎实的草稿。现在到了我最不喜欢的写作部分 —— 编辑。我之前提到的 Hemingway 应用不仅能告诉你阅读水平,还能提供改进写作的建议。我还使用 Grammarly 来帮助编辑语法。关于 Grammarly 的开源替代工具,请查看[语言工具网站](https://languagetool.org/)或这篇文章中的[开源写作工具](https://opensource.com/article/20/3/open-source-writing-tools)。
我的写作挑战之一就是适当地使用逗号。Grammarly 可以帮助我找出我缺失或滥用逗号的地方。Grammarly 发现了 43 个这篇文章的最终草稿的正确性问题。其中大部分是逗号错误。

除了语法错误之外,该应用程序还提供了一些建议,以帮助提高清晰度、参与度和表达能力(其中一些功能可能在免费版中没有)。这包括单词选择和使用主动语气与被动语气等。有些建议我接受,有些则拒绝。在审查了所有的警报和建议后,Grammarly 会在各个方面进行反馈。

不要害怕寻求写作上的帮助。每一个好的作者背后都有一个好的编辑或好的编辑应用。
### 文体指南
文体指南为改善书面交流提供了标准。它们包括标点符号、语法和用词等方面。如果是为你的公司撰写文档,请检查一下公司是否有文体指南。如果没有文体指南,或者你是为自己写的,下面是一些常用的文体指南:
* [芝加哥文体手册](https://www.chicagomanualofstyle.org/home.html)
* [谷歌开发者文档指南](https://developers.google.com/style)
* [微软写作文体指南](https://docs.microsoft.com/en-us/style-guide/welcome/)
* [美联社文体手册](https://www.apstylebook.com/)
写作是一种与社区分享自己的思想和知识的方式。开始写作的唯一方法就是开始打字。用这些建议来微调你的写作。
---
via: <https://opensource.com/article/20/5/write-about-open-source-software>
作者:[Dawn Parzych](https://opensource.com/users/dawnparzych) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One way to get started with an open source community is to write about it. You can contribute to technical documentation, share how you use the software, or write an article for Opensource.com. But getting started writing is easier said than done. The two most common excuses I hear for not writing are: "I have nothing new to say" and "I'm not a good writer." I'm here to dispel both of those myths.
## What should you write about?
"Hunt for the stories that often get left out."
—Erik Larson
For some people, the biggest hurdle to writing is generating an idea or topic to write about. It's common to fall into the trap of thinking, "This topic has been written about, so why bother."
I'm not the first person to write an article on writing, and I won't be the last. What I bring is my unique perspective and things I've learned over the years. I've had people ask me for tips on getting started or how to get better at writing. I decided to turn those suggestions into an article.
Your writing is a reflection of you. Nobody will tell the story the way you do. Your experiences and perspective may be just what somebody else needs.
Here are some prompts to help you come up with a topic:
- What is something you've recently learned? Write about how you learned, what you learned, or what surprised you.
- What questions are you frequently asked? Write up the answer.
- Did you recently search for a how-to article and weren't satisfied with any of the top search results? Write the article you were looking for.
- Did you attend a conference or workshop? Write a post-event summary of what you learned.
- Did you start using a new tool? Write up a how-to or getting-started guide.
## What type of article are you writing?
There are different types of writing, including:
- Technical documentation
- How-to guide
- Blog
- White paper or eBook
- Retrospective
The type of content will influence your writing style and tone of voice. A blog is more informal and conversational. Technical documentation is more formal and instructional.
## Who are you writing for?
Each piece of writing should have a single audience. The audience is the type of person you are writing for. Before you begin writing, it helps to jot down a few characteristics of your reader. It's important to consider who you are writing for, as well as who you *aren't* writing for—identifying your target audience will shape what to include and what not to include.
For example, this is who I envisioned when writing this article:
- Has basic knowledge of writing and grammar
- Is interested in improving writing skills
- Works in technology as a developer, sales engineer, customer success manager, or similar role
- Is not an experienced or advanced writer, may have a couple of published articles on a personal or work blog, and wants to write more
- Is writing non-fiction
If you have content for multiple audiences, consider breaking it down into different pieces for the different audiences. Some areas to consider in your audience:
- Level of expertise: novice, intermediate, advanced
- Role: manager, individual contributor
- Goals: why are they reading?
## Words matter
The words you choose will have an impact on the reader. Difficult words can make an article harder to understand. Unfamiliar words can make the reader feel stupid. Certain words can accidentally offend a reader. Your goal as a writer is to avoid all of these. Here's how.
### Use everyday language
Don't write as a way to show off your vocabulary or the words you've learned from your "Word of the Day" calendar. Write so a reader can understand. There is a reading level associated with every piece of writing. If you're writing technical documentation, aim for about an eighth-grade reading level. This doesn't imply your audience has only an eighth-grade education. It means your writing will be more easily understood. Do you want people to get hung up on the language, or do you want them to walk away feeling like they learned something? Just because you can use big, complicated words doesn't mean you should. Using simple language does not necessarily mean your article will be boring.
Use tools like [Hemingway App](http://www.hemingwayapp.com/) to check the readability of your writing (it's not open source, but it's excellent). For example, after the first draft, this article was assessed at a fifth-grade reading level. Hemingway also provides suggestions on how to improve your writing—identifying hard-to-read sentences or places to alter word choice.
If you're struggling with coming up with alternative words, check out the suggestions at the [Plain English Campaign](http://www.plainenglish.co.uk/the-a-z-of-alternative-words.html) or the crowdsourced suggestions at [Power Thesaurus](https://www.powerthesaurus.org/).
### Know which words to avoid
"Substitute 'damn' every time you're inclined to write 'very'; your editor will delete it and the writing will be just as it should be."
—Mark Twain
When writing a tutorial or how-to guide, here are some words to avoid, including "simple," "easy," and "just." You, an expert on the topic you're writing about, may find things easy after years of practice. A beginner may not find things simple or easy. Your readers may get frustrated because they don't find the process or explanation simple.
Have you ever had to reread a sentence or paragraph multiple times because you couldn't figure out what the writer was saying? Have you ever given up on an article because it wasn't making sense to you? I have.
As a writer, do you want your readers to feel confused or unintelligent? I hope not.
Other words to avoid in your writing:
- That
- Really
- Very
- So
- In order to
Generally, these words can be deleted without changing the meaning of a sentence.
After I finish writing, I search a document for instances of those words. When I searched through this document, I found the following sentence:
"This doesn't imply that your audience only has an eighth-grade education, it means that your writing will be more easily understood."
Two instances of "that" appear in this sentence. They're not adding value to the sentence. They can be deleted without changing its meaning. Removing those instances shortens the sentence, and shorter sentences are easier to understand. And speaking of shorter sentences, I also re-wrote it as two sentences.
"This doesn't imply your audience has only an eighth-grade education. It means your writing will be more easily understood."
### Use inclusive language
The historical context of words and phrases can lead to people feeling excluded or offended. When writing, you want to make the reader feel included. When you use inclusive language, it makes your reader feel understood, respected, and like they belong. I refer to this [guide on using inclusive language](https://open.buffer.com/inclusive-language-tech/) from Buffer.
## Revising and editing
"Almost all good writing begins with terrible first efforts. You need to start somewhere."
—Anne Lamott
Writing is an iterative process. If you think writers sit down at their desk and, within an hour, have a completed article ready to be published, think again. Some articles take me weeks to complete. Here's a standard process for me:
- Write a rough first draft. By rough, I mean
*rough*. I write without worrying about grammar. The idea is to get words out of my head and onto paper. This step can take anywhere from an hour to a couple of weeks. - Put the draft away for some time. This can be anywhere from a couple of hours to a couple of days, depending on the publishing timeline.
- Review the draft. Make tweaks and edits.
- Ask for feedback, either from a coworker or a friend. During this phase of feedback, I focus on clarity. Does everything make sense? Is anything confusing, any missing sections?
- Incorporate feedback. No matter how experienced you are at writing, other writers reviewing your work will make it better.
At this stage, I have a pretty solid draft. Now comes my least favorite part of writing—editing. The Hemingway App I mentioned earlier not only tells you the reading level but also provides suggestions to improve your writing. I also use Grammarly to help with grammar edits. For open source alternatives to Grammarly, check out [Language Tool](https://languagetool.org/) or this article on [open source writing tools](https://opensource.com/article/20/3/open-source-writing-tools).
One of my writing challenges is using commas appropriately. Grammarly helps me figure out where I miss or misuse a comma. Grammarly identified 43 issues related to the correctness of this article's final draft. The majority were comma errors.
(Dawn Parzych, CC BY-SA 4.0)
In addition to grammatical errors, the app also provides suggestions to help with clarity, engagement, and delivery (some of these features may not be available in the free version). This includes things like word choice and using active vs. passive voice. Some suggestions I accept; others I reject. After reviewing all the alerts and suggestions, Grammarly reports back across all dimensions.
(Dawn Parzych, CC BY-SA 4.0)
Don't be afraid to ask for help with your writing. Behind every good writer is a good editor or a good editing app.
## Style guides
Style guides provide standards for improving communication in writing. They include aspects such as punctuation, grammar, and word usage. If writing a document for your company, check to see if it uses a style guide. If it doesn't have a style guide, or if you're writing for yourself, here are some common style guides to follow:
[Chicago Manual of Style](https://www.chicagomanualofstyle.org/home.html)[Google Developer Documentation Guide](https://developers.google.com/style)[Microsoft Writing Style Guide](https://docs.microsoft.com/en-us/style-guide/welcome/)[AP Stylebook](https://www.apstylebook.com/)
Writing is a way to share your thoughts and knowledge with the community. The only way to get started writing is to start typing. Use these suggestions to fine-tune your writing.
## 2 Comments |
12,268 | 如何使用 VTY Shell 配置路由器 | https://opensource.com/article/20/5/vty-shell | 2020-05-31T12:24:26 | [
"路由",
"FRR"
] | https://linux.cn/article-12268-1.html |
>
> FRR(free range routing)给了你实现多种协议的选择。本指南将帮助你入门。
>
>
>

最近,我写了一篇文章,解释了如何使用 [Quagga](/article-12199-1.html) 路由套件实现<ruby> 开放式最短路径优先 <rt> Open Shortest Path First </rt></ruby>(OSPF)。可以使用多个软件套件代替 Quagga 来实现不同的路由协议。其中一种是 FRR(free range routing)。
### FRR
[FRR](https://en.wikipedia.org/wiki/FRRouting) 是一个路由软件套件,它衍生自 Quagga,并在 GNU GPL2 许可下分发。与 Quagga 一样,它为类 Unix 平台提供了所有主要路由协议的实现,例如 OSPF、<ruby> 路由信息协议 <rt> Routing Information Protocol </rt></ruby>(RIP)、<ruby> 边界网关协议 <rt> Border Gateway Protocol </rt></ruby>(BGP) 和<ruby> 中间系统到中间系统 <rt> Intermediate system-to-intermediate system </rt></ruby> (IS-IS)。
开发了 Quagga 的一些公司,例如 Big Switch Networks、Cumulus、Open Source Routing 和 6wind,创建了 FRR 以在 Quagga 的良好基础上进行改善。
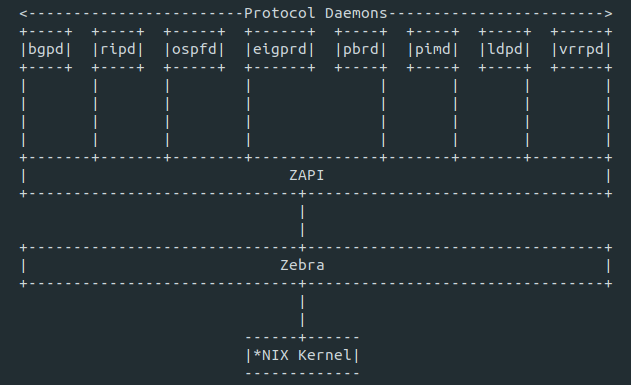
#### 体系结构
FRR 是一组守护进程,它们可以共同构建路由表。每个主协议都在其自己的守护进程中实现,并且这些守护进程与独立于协议的核心守护进程 Zebra 通信,后者提供内核路由表更新、接口查找以及不同路由协议之间路由的重新分配。每个特定协议的守护进程负责运行相关协议并根据交换的信息构建路由表。

### VTY shell
[VTYSH](http://docs.frrouting.org/projects/dev-guide/en/latest/vtysh.html) 是 FRR 路由引擎的集成 shell。它将每个守护进程中定义的所有 CLI 命令合并,并在单个 shell 中将它们呈现给用户。它提供了类似于 Cisco 的命令行模式,并且许多命令与 Cisco IOS 命令相似。CLI 有不同的模式,某些命令仅在特定模式下可用。
### 设置
在本教程中,我们将使用 FRR 配置动态路由来实现路由信息协议(RIP)。我们可以通过两种方式来做到这一点:在编辑器中编辑协议守护进程配置文件或使用 VTY Shell。在此例中,我们将使用 VTY shell。我们的设置包括两个名为 Alpha 和 Beta 的 CentOS 7.7 主机。这两台主机都有两个网络接口,并共享对 192.168.122.0/24 网络的访问。我们将广播 10.12.11.0/24 和 10.10.10.0/24 网络的路由。
对于主机 Alpha:
* eth0 IP:192.168.122.100/24
* 网关:192.168.122.1
* eth1 IP:10.10.10.12/24
对于主机 Beta:
* eth0 IP:192.168.122.50/24
* 网关:192.168.122.1
* eth1 IP:10.12.11.12/24
#### 安装软件包
首先,我们需要在两台主机上都安装 FRR 软件包。可以按照[官方 FRR 文档](http://docs.frrouting.org/projects/dev-guide/en/latest/building-frr-for-centos7.html)中的说明进行操作。
#### 启用 IP 转发
对于路由,我们需要在两台主机上都启用 IP 转发,因为这将由 Linux 内核执行:
```
sysctl -w net.ipv4.conf.all.forwarding = 1
sysctl -w net.ipv6.conf.all.forwarding = 1
sysctl -p
```
#### 启用 RIPD 守护进程
安装后,所有配置文件将保存在 `/etc/frr` 目录中。 必须通过编辑 `/etc/frr/daemons` 文件显式启用守护进程。该文件确定启动 FRR 服务时激活哪些守护进程。要启用特定的守护进程,只需将相应的 `no` 改为 `yes`。之后的服务重启将启动守护进程。

#### 防火墙配置
由于 RIP 协议使用 UDP 作为传输协议,并被分配了 520 端口,因此我们需要在 `firewalld` 配置中允许该端口。
```
firewall-cmd --add-port=520/udp –permanent
firewalld-cmd -reload
```
现在,我们可以使用以下命令启动 FRR 服务:
```
systemctl start frr
```
#### 使用 VTY 进行配置
现在,我们需要使用 VTY Shell 配置 RIP。
在主机 Alpha 上:
```
[root@alpha ~]# vtysh
Hello, this is FRRouting (version 7.2RPKI).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
alpha# configure terminal
alpha(config)# router rip
alpha(config-router)# network 192.168.122.0/24
alpha(config-router)# network 10.10.10.0/24
alpha(config-router)# route 10.10.10.5/24
alpha(config-router)# do write
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
alpha(config-router)# do write memory
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
alpha(config-router)# exit
```
类似地,在主机 Beta 上:
```
[root@beta ~]# vtysh
Hello, this is FRRouting (version 7.2RPKI).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
beta# configure terminal
beta(config)# router rip
beta(config-router)# network 192.168.122.0/24
beta(config-router)# network 10.12.11.0/24
beta(config-router)# do write
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/zebra.conf
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
beta(config-router)# do write memory
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/zebra.conf
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
beta(config-router)# exit
```
完成后,像下面这样检查两台主机路由:
```
[root@alpha ~]# ip route show
default via 192.168.122.1 dev eth0 proto static metric 100
10.10.10.0/24 dev eth1 proto kernel scope link src 10.10.10.12 metric 101
10.12.11.0/24 via 192.168.122.50 dev eth0 proto 189 metric 20
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.100 metric 100
```
我们可以看到 Alpha 上的路由表通过 `192.168.122.50` 包含了 `10.12.11.0/24` 的条目,它是通过 RIP 提供的。
类似地,在 Beta 上,该表通过 `192.168.122.100` 包含了 `10.10.10.0/24` 的条目。
```
[root@beta ~]# ip route show
default via 192.168.122.1 dev eth0 proto static metric 100
10.10.10.0/24 via 192.168.122.100 dev eth0 proto 189 metric 20
10.12.11.0/24 dev eth1 proto kernel scope link src 10.12.11.12 metric 101
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.50 metric 100
```
### 总结
如你所见,设置和配置相对简单。要增加复杂性,我们可以向路由器添加更多的网络接口,以为更多的网络提供路由。可以在编辑器中编辑配置文件来进行配置,但是使用 VTY Shell 在单个组合会话中为我们提供了所有 FRR 守护进程的前端。
---
via: <https://opensource.com/article/20/5/vty-shell>
作者:[M Umer](https://opensource.com/users/noisybotnet) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, I wrote an article explaining how we can implement Open Shortest Path First (OSPF) using the [Quagga](https://opensource.com/article/20/4/quagga-linux) routing suite. There are multiple software suites that can be used instead of Quagga to implement different routing protocols. One such option is free range routing (FRR).
## FRR
[FRR](https://en.wikipedia.org/wiki/FRRouting) is a routing software suite, which has been derived from Quagga and is distributed under GNU GPL2 license. Like Quagga, it provides implementations of all major routing protocols such as OSPF, Routing Information Protocol (RIP), Border Gateway Protocol (BGP), and Intermediate system-to-intermediate system (IS-IS) for Unix-like platforms.
Several companies, such as Big Switch Networks, Cumulus, Open Source Routing, and 6wind, who were behind the development of Quagga, created FRR to improve on Quagga's well-established foundations.
### Architecture
FRR is a suite of daemons that work together to build the routing table. Each major protocol is implemented in its own daemon, and these daemons talk to the core and protocol-independent daemon Zebra, which provides kernel routing table updates, interface lookups, and redistribution of routes between different routing protocols. Each protocol-specific daemon is responsible for running the relevant protocol and building the routing table based on the information exchanged.
## VTY shell
[VTYSH](http://docs.frrouting.org/projects/dev-guide/en/latest/vtysh.html) is an integrated shell for the FRR routing engine. It amalgamates all the CLI commands defined in each of the daemons and presents them to the user in a single shell. It provides a Cisco-like modal CLI, and many of the commands are similar to Cisco IOS commands. There are different modes to the CLI, and certain commands are only available within a specific mode.
## Setup
In this tutorial, we'll be implementing the routing information protocol (RIP) to configure dynamic routing using FRR. We can do this in two ways—either by editing the protocol daemon configuration file in an editor or by using the VTY shell. We'll be using the VTY shell in this example. Our setup includes two CentOS 7.7 hosts, named Alpha and Beta. Both hosts have two network interfaces and share access to the 192.168.122.0/24 network. We'll be advertising routes for 10.12.11.0/24 and 10.10.10.0/24 networks.
**For Host Alpha:**
- eth0 IP: 192.168.122.100/24
- Gateway: 192.168.122.1
- eth1 IP: 10.10.10.12/24
**For Host Beta:**
- eth0 IP: 192.168.122.50/24
- Gateway: 192.168.122.1
- eth1 IP: 10.12.11.12/24
### Installation of package
First, we need to install the FRR package on both hosts; this can be done by following the instructions in the [official FRR documentation](http://docs.frrouting.org/projects/dev-guide/en/latest/building-frr-for-centos7.html).
### Enable IP forwarding
For routing, we need to enable IP forwarding on both hosts since that will performed by the Linux kernel.
```
sysctl -w net.ipv4.conf.all.forwarding = 1
sysctl -w net.ipv6.conf.all.forwarding = 1
sysctl -p
```
### Enabling the RIPD daemon
Once installed, all the configuration files will be stored in the **/etc/frr** directory. The daemons must be explicitly enabled by editing the **/etc/frr/daemons** file. This file determines which daemons are activated when the FRR service is started. To enable a particular daemon, simply change the corresponding "no" to "yes." A subsequent service restart should start the daemon.
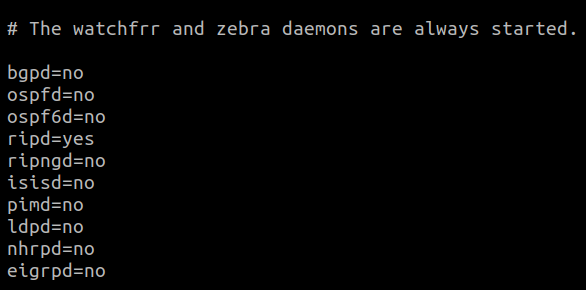
### Firewall configuration
Since RIP protocol uses UDP as its transport protocol and is assigned port 520, we need to allow this port in `firewalld`
configuration.
```
firewall-cmd --add-port=520/udp –permanent
firewalld-cmd -reload
```
We can now start the FRR service using:
`systemctl start frr`
### Configuration using VTY
Now, we need to configure RIP using the VTY shell.
On Host Alpha:
```
[root@alpha ~]# vtysh
Hello, this is FRRouting (version 7.2RPKI).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
alpha# configure terminal
alpha(config)# router rip
alpha(config-router)# network 192.168.122.0/24
alpha(config-router)# network 10.10.10.0/24
alpha(config-router)# route 10.10.10.5/24
alpha(config-router)# do write
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
alpha(config-router)# do write memory
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
alpha(config-router)# exit
```
Similarly, on Host Beta:
```
[root@beta ~]# vtysh
Hello, this is FRRouting (version 7.2RPKI).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
beta# configure terminal
beta(config)# router rip
beta(config-router)# network 192.168.122.0/24
beta(config-router)# network 10.12.11.0/24
beta(config-router)# do write
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/zebra.conf
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
beta(config-router)# do write memory
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Configuration saved to /etc/frr/zebra.conf
Configuration saved to /etc/frr/ripd.conf
Configuration saved to /etc/frr/staticd.conf
beta(config-router)# exit
```
Once done, check the routes on both hosts as follows:
```
[root@alpha ~]# ip route show
default via 192.168.122.1 dev eth0 proto static metric 100
10.10.10.0/24 dev eth1 proto kernel scope link src 10.10.10.12 metric 101
10.12.11.0/24 via 192.168.122.50 dev eth0 proto 189 metric 20
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.100 metric 100
```
We can see that the routing table on Alpha contains an entry of 10.12.11.0/24 via 192.168.122.50, which was offered through RIP. Similarly, on Beta, the table contains an entry of network 10.10.10.0/24 via 192.168.122.100.
```
[root@beta ~]# ip route show
default via 192.168.122.1 dev eth0 proto static metric 100
10.10.10.0/24 via 192.168.122.100 dev eth0 proto 189 metric 20
10.12.11.0/24 dev eth1 proto kernel scope link src 10.12.11.12 metric 101
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.50 metric 100
```
## Conclusion
As you can see, the setup and configuration are relatively simple. To add complexity, we can add more network interfaces to the router to provide routing for more networks. The configurations can be made by editing the configuration files in an editor, but using VTY shell provides us a frontend to all FRR daemons in a single, combined session.
## Comments are closed. |
12,270 | Linux 中软链接和硬链接的区别 | https://www.2daygeek.com/difference-between-soft-link-vs-hard-link-linux/ | 2020-06-01T08:28:03 | [
"链接",
"符号链接"
] | https://linux.cn/article-12270-1.html | 
<ruby> 链接 <rt> Link </rt></ruby>是一种快捷访问机制,它通过一个文件指向原始文件或目录的方式实现快捷访问,同时还记录了原始文件或目录的一些信息。
链接允许多个不同文件对同一个文件进行引用。
### 什么是软链接
<ruby> 符号链接 <rt> Symbolic Link </rt></ruby>(symlink),又称<ruby> 软链接 <rt> Soft Link </rt></ruby>,是一种特殊的文件,它指向 Linux 系统上的另一个文件或目录。
这和 Windows 系统中的快捷方式有点类似,链接文件中记录的只是原始文件的路径,并不记录原始文件的内容。
符号链接通常用于对库文件进行链接,也常用于链接日志文件和<ruby> 网络文件系统 <rt> Network File System </rt></ruby>(NFS)上共享的目录。
### 什么是硬链接
硬链接是原始文件的一个镜像副本。创建硬链接后,如果把原始文件删除,链接文件也不会受到影响,因为此时原始文件和链接文件互为镜像副本。
为什么要创建链接文件而不直接复制文件呢?
当你需要将同一个文件保存在多个不同位置,而且还要保持持续更新的时候,硬链接的重要性就体现出来了。
如果你只是单纯把文件复制到另一个位置,那么另一个位置的文件只会保存着复制那一刻的文件内容,后续也不会跟随着原始文件持续更新。
而使用硬链接时,各个镜像副本的文件内容都会同时更新。
### 软链接和硬链接的区别
下表列出了软链接和硬链接之间的区别。
| # | 软链接 | 硬链接 |
| --- | --- | --- |
| 1 | 软链接类似于 Windows 系统中的快捷方式 | 硬链接是原始文件的一个镜像副本 |
| 2 | 软链接又称符号链接 | 硬链接没有别名 |
| 3 | 链接中任何一个文件发生改变,都会同步到连接中的其它文件 | 和软链接一样 |
| 4 | 软链接可以跨文件系统进行创建 | 硬链接不可以跨文件系统进行创建 |
| 5 | 软链接可以指向文件或目录 | 硬链接只能指向文件 |
| 6 | 链接文件和原始文件之间的 inode 和文件权限不完全一致 | 链接文件和原始文件的 inode 和文件权限完全一致 |
| 7 | 链接文件只记录原始文件的路径,不记录原始文件的内容 | 链接文件记录了原始文件的内容 |
| 8 | 如果原始文件被移除,软链接就会因为指向不存在的文件而失效。这被称为“<ruby> 挂起链接 <rt> hanging link </rt></ruby>” | 即使原始文件被移除,链接文件也不受影响。 |
| 9 | 通过 `ln -s <原始文件> <链接文件>` 命令创建软链接 | 通过 `ln <原始文件> <链接文件>` 命令创建硬链接 |
| 10 | 软链接文件的文件权限中有一个特殊标记 `l` | 硬链接文件没有特殊标记 |
| 11 | 通过 `find / -type l` 命令可以查找软链接文件 | 通过 `find / -samefile <原始文件>` 命令可以查找硬链接文件 |
| 12 | 通过 `symlinks <目录>` 命令可以查找失效的软链接 | 硬链接不存在失效链接 |
---
via: <https://www.2daygeek.com/difference-between-soft-link-vs-hard-link-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,271 | 学习用 Git 变基来改变历史! | https://git-rebase.io/ | 2020-06-01T17:40:09 | [
"Git",
"变基"
] | https://linux.cn/article-12271-1.html | 
[Git](https://git-scm.com/) 核心的附加价值之一就是编辑历史记录的能力。与将历史记录视为神圣的记录的版本控制系统不同,在 Git 中,我们可以修改历史记录以适应我们的需要。这为我们提供了很多强大的工具,让我们可以像使用重构来维护良好的软件设计实践一样,编织良好的提交历史。这些工具对于新手甚至是有经验的 Git 用户来说可能会有些令人生畏,但本指南将帮助我们揭开强大的 git-rebase 的神秘面纱。
>
> 值得注意的是:一般建议不要修改公共分支、共享分支或稳定分支的历史记录。编辑特性分支和个人分支的历史记录是可以的,编辑还没有推送的提交也是可以的。在编辑完提交后,可以使用 `git push -f` 来强制推送你的修改到个人分支或特性分支。
>
>
>
尽管有这么可怕的警告,但值得一提的是,本指南中提到的一切都是非破坏性操作。实际上,在 Git 中永久丢失数据是相当困难的。本指南结尾介绍了在犯错误时进行纠正的方法。
### 设置沙盒
我们不想破坏你的任何实际的版本库,所以在整个指南中,我们将使用一个沙盒版本库。运行这些命令来开始工作。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup>
```
git init /tmp/rebase-sandbox
cd /tmp/rebase-sandbox
git commit --allow-empty -m"Initial commit"
```
如果你遇到麻烦,只需运行 `rm -rf /tmp/rebase-sandbox`,并重新运行这些步骤即可重新开始。本指南的每一步都可以在新的沙箱上运行,所以没有必要重做每个任务。
### 修正最近的提交
让我们从简单的事情开始:修复你最近的提交。让我们向沙盒中添加一个文件,并犯个错误。
```
echo "Hello wrold!" >greeting.txt
git add greeting.txt
git commit -m"Add greeting.txt"
```
修复这个错误是非常容易的。我们只需要编辑文件,然后用 `--amend` 提交就可以了,就像这样:
```
echo "Hello world!" >greeting.txt
git commit -a --amend
```
指定 `-a` 会自动将所有 Git 已经知道的文件进行暂存(例如 Git 添加的),而 `--amend` 会将更改的内容压扁到最近的提交中。保存并退出你的编辑器(如果需要,你现在可以修改提交信息)。你可以通过运行 `git show` 看到修复的提交。
```
commit f5f19fbf6d35b2db37dcac3a55289ff9602e4d00 (HEAD -> master)
Author: Drew DeVault
Date: Sun Apr 28 11:09:47 2019 -0400
Add greeting.txt
diff --git a/greeting.txt b/greeting.txt
new file mode 100644
index 0000000..cd08755
--- /dev/null
+++ b/greeting.txt
@@ -0,0 +1 @@
+Hello world!
```
### 修复较旧的提交
`--amend` 仅适用于最近的提交。如果你需要修正一个较旧的提交会怎么样?让我们从相应地设置沙盒开始:
```
echo "Hello!" >greeting.txt
git add greeting.txt
git commit -m"Add greeting.txt"
echo "Goodbye world!" >farewell.txt
git add farewell.txt
git commit -m"Add farewell.txt"
```
看起来 `greeting.txt` 像是丢失了 `"world"`。让我们正常地写个提交来解决这个问题:
```
echo "Hello world!" >greeting.txt
git commit -a -m"fixup greeting.txt"
```
现在文件看起来正确,但是我们的历史记录可以更好一点 —— 让我们使用新的提交来“修复”(`fixup`)最后一个提交。为此,我们需要引入一个新工具:交互式变基。我们将以这种方式编辑最后三个提交,因此我们将运行 `git rebase -i HEAD~3`(`-i` 代表交互式)。这样会打开文本编辑器,如下所示:
```
pick 8d3fc77 Add greeting.txt
pick 2a73a77 Add farewell.txt
pick 0b9d0bb fixup greeting.txt
# Rebase f5f19fb..0b9d0bb onto f5f19fb (3 commands)
#
# Commands:
# p, pick <commit> = use commit
# f, fixup <commit> = like "squash", but discard this commit's log message
```
这是变基计划,通过编辑此文件,你可以指导 Git 如何编辑历史记录。我已经将该摘要削减为仅与变基计划这一部分相关的细节,但是你可以在文本编辑器中浏览完整的摘要。
当我们保存并关闭编辑器时,Git 将从其历史记录中删除所有这些提交,然后一次执行一行。默认情况下,它将选取(`pick`)每个提交,将其从堆中召唤出来并添加到分支中。如果我们对此文件根本没有做任何编辑,则将直接回到起点,按原样选取每个提交。现在,我们将使用我最喜欢的功能之一:修复(`fixup`)。编辑第三行,将操作从 `pick` 更改为 `fixup`,并将其立即移至我们要“修复”的提交之后:
```
pick 8d3fc77 Add greeting.txt
fixup 0b9d0bb fixup greeting.txt
pick 2a73a77 Add farewell.txt
```
>
> **技巧**:我们也可以只用 `f` 来缩写它,以加快下次的速度。
>
>
>
保存并退出编辑器,Git 将运行这些命令。我们可以检查日志以验证结果:
```
$ git log -2 --oneline
fcff6ae (HEAD -> master) Add farewell.txt
a479e94 Add greeting.txt
```
### 将多个提交压扁为一个
在工作时,当你达到较小的里程碑或修复以前的提交中的错误时,你可能会发现写很多提交很有用。但是,在将你的工作合并到 `master` 分支之前,将这些提交“压扁”(`squash`)到一起以使历史记录更清晰可能很有用。为此,我们将使用“压扁”(`squash`)操作。让我们从编写一堆提交开始,如果要加快速度,只需复制并粘贴这些:
```
git checkout -b squash
for c in H e l l o , ' ' w o r l d; do
echo "$c" >>squash.txt
git add squash.txt
git commit -m"Add '$c' to squash.txt"
done
```
要制作出一个写着 “Hello,world” 的文件,要做很多事情!让我们开始另一个交互式变基,将它们压扁在一起。请注意,我们首先签出了一个分支来进行尝试。因此,因为我们使用 `git rebase -i master` 进行的分支,我们可以快速变基所有提交。结果:
```
pick 1e85199 Add 'H' to squash.txt
pick fff6631 Add 'e' to squash.txt
pick b354c74 Add 'l' to squash.txt
pick 04aaf74 Add 'l' to squash.txt
pick 9b0f720 Add 'o' to squash.txt
pick 66b114d Add ',' to squash.txt
pick dc158cd Add ' ' to squash.txt
pick dfcf9d6 Add 'w' to squash.txt
pick 7a85f34 Add 'o' to squash.txt
pick c275c27 Add 'r' to squash.txt
pick a513fd1 Add 'l' to squash.txt
pick 6b608ae Add 'd' to squash.txt
# Rebase 1af1b46..6b608ae onto 1af1b46 (12 commands)
#
# Commands:
# p, pick <commit> = use commit
# s, squash <commit> = use commit, but meld into previous commit
```
>
> **技巧**:你的本地 `master` 分支独立于远程 `master` 分支而发展,并且 Git 将远程分支存储为 `origin/master`。结合这种技巧,`git rebase -i origin/master` 通常是一种非常方便的方法,可以变基所有尚未合并到上游的提交!
>
>
>
我们将把所有这些更改压扁到第一个提交中。为此,将第一行除外的每个“选取”(`pick`)操作都更改为“压扁”(`squash`),如下所示:
```
pick 1e85199 Add 'H' to squash.txt
squash fff6631 Add 'e' to squash.txt
squash b354c74 Add 'l' to squash.txt
squash 04aaf74 Add 'l' to squash.txt
squash 9b0f720 Add 'o' to squash.txt
squash 66b114d Add ',' to squash.txt
squash dc158cd Add ' ' to squash.txt
squash dfcf9d6 Add 'w' to squash.txt
squash 7a85f34 Add 'o' to squash.txt
squash c275c27 Add 'r' to squash.txt
squash a513fd1 Add 'l' to squash.txt
squash 6b608ae Add 'd' to squash.txt
```
保存并关闭编辑器时,Git 会考虑片刻,然后再次打开编辑器以修改最终的提交消息。你会看到以下内容:
```
# This is a combination of 12 commits.
# This is the 1st commit message:
Add 'H' to squash.txt
# This is the commit message #2:
Add 'e' to squash.txt
# This is the commit message #3:
Add 'l' to squash.txt
# This is the commit message #4:
Add 'l' to squash.txt
# This is the commit message #5:
Add 'o' to squash.txt
# This is the commit message #6:
Add ',' to squash.txt
# This is the commit message #7:
Add ' ' to squash.txt
# This is the commit message #8:
Add 'w' to squash.txt
# This is the commit message #9:
Add 'o' to squash.txt
# This is the commit message #10:
Add 'r' to squash.txt
# This is the commit message #11:
Add 'l' to squash.txt
# This is the commit message #12:
Add 'd' to squash.txt
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# Date: Sun Apr 28 14:21:56 2019 -0400
#
# interactive rebase in progress; onto 1af1b46
# Last commands done (12 commands done):
# squash a513fd1 Add 'l' to squash.txt
# squash 6b608ae Add 'd' to squash.txt
# No commands remaining.
# You are currently rebasing branch 'squash' on '1af1b46'.
#
# Changes to be committed:
# new file: squash.txt
#
```
默认情况下,这是所有要压扁的提交的消息的组合,但是像这样将其保留肯定不是你想要的。不过,旧的提交消息在编写新的提交消息时可能很有用,所以放在这里以供参考。
>
> **提示**:你在上一节中了解的“修复”(`fixup`)命令也可以用于此目的,但它会丢弃压扁的提交的消息。
>
>
>
让我们删除所有内容,并用更好的提交消息替换它,如下所示:
```
Add squash.txt with contents "Hello, world"
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# Date: Sun Apr 28 14:21:56 2019 -0400
#
# interactive rebase in progress; onto 1af1b46
# Last commands done (12 commands done):
# squash a513fd1 Add 'l' to squash.txt
# squash 6b608ae Add 'd' to squash.txt
# No commands remaining.
# You are currently rebasing branch 'squash' on '1af1b46'.
#
# Changes to be committed:
# new file: squash.txt
#
```
保存并退出编辑器,然后检查你的 Git 日志,成功!
```
commit c785f476c7dff76f21ce2cad7c51cf2af00a44b6 (HEAD -> squash)
Author: Drew DeVault
Date: Sun Apr 28 14:21:56 2019 -0400
Add squash.txt with contents "Hello, world"
```
在继续之前,让我们将所做的更改拉入 `master` 分支中,并摆脱掉这一草稿。我们可以像使用 `git merge` 一样使用 `git rebase`,但是它避免了创建合并提交:
```
git checkout master
git rebase squash
git branch -D squash
```
除非我们实际上正在合并无关的历史记录,否则我们通常希望避免使用 `git merge`。如果你有两个不同的分支,则 `git merge` 对于记录它们合并的时间非常有用。在正常工作过程中,变基通常更为合适。
### 将一个提交拆分为多个
有时会发生相反的问题:一个提交太大了。让我们来看一看拆分它们。这次,让我们写一些实际的代码。从一个简单的 C 程序 <sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> 开始(你仍然可以将此代码段复制并粘贴到你的 shell 中以快速执行此操作):
```
cat <<EOF >main.c
int main(int argc, char *argv[]) {
return 0;
}
EOF
```
首先提交它:
```
git add main.c
git commit -m"Add C program skeleton"
```
然后把这个程序扩展一些:
```
cat <<EOF >main.c
#include <stdio.h>
const char *get_name() {
static char buf[128];
scanf("%s", buf);
return buf;
}
int main(int argc, char *argv[]) {
printf("What's your name? ");
const char *name = get_name();
printf("Hello, %s!\n", name);
return 0;
}
EOF
```
提交之后,我们就可以准备学习如何将其拆分:
```
git commit -a -m"Flesh out C program"
```
第一步是启动交互式变基。让我们用 `git rebase -i HEAD~2` 来变基这两个提交,给出的变基计划如下:
```
pick 237b246 Add C program skeleton
pick b3f188b Flesh out C program
# Rebase c785f47..b3f188b onto c785f47 (2 commands)
#
# Commands:
# p, pick <commit> = use commit
# e, edit <commit> = use commit, but stop for amending
```
将第二个提交的命令从 `pick` 更改为 `edit`,然后保存并关闭编辑器。Git 会考虑一秒钟,然后向你建议:
```
Stopped at b3f188b... Flesh out C program
You can amend the commit now, with
git commit --amend
Once you are satisfied with your changes, run
git rebase --continue
```
我们可以按照以下说明为提交*添加*新的更改,但我们可以通过运行 `git reset HEAD^` 来进行“软重置” <sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup>。如果在此之后运行 `git status`,你将看到它取消了提交最新的提交,并将其更改添加到工作树中:
```
Last commands done (2 commands done):
pick 237b246 Add C program skeleton
edit b3f188b Flesh out C program
No commands remaining.
You are currently splitting a commit while rebasing branch 'master' on 'c785f47'.
(Once your working directory is clean, run "git rebase --continue")
Changes not staged for commit:
(use "git add ..." to update what will be committed)
(use "git checkout -- ..." to discard changes in working directory)
modified: main.c
no changes added to commit (use "git add" and/or "git commit -a")
```
为了对此进行拆分,我们将进行*交互式提交*。这使我们能够选择性地仅提交工作树中的特定更改。运行 `git commit -p` 开始此过程,你将看到以下提示:
```
diff --git a/main.c b/main.c
index b1d9c2c..3463610 100644
--- a/main.c
+++ b/main.c
@@ -1,3 +1,14 @@
+#include <stdio.h>
+
+const char *get_name() {
+ static char buf[128];
+ scanf("%s", buf);
+ return buf;
+}
+
int main(int argc, char *argv[]) {
+ printf("What's your name? ");
+ const char *name = get_name();
+ printf("Hello, %s!\n", name);
return 0;
}
Stage this hunk [y,n,q,a,d,s,e,?]?
```
Git 仅向你提供了一个“大块”(即单个更改)以进行提交。不过,这太大了,让我们使用 `s` 命令将这个“大块”拆分成较小的部分。
```
Split into 2 hunks.
@@ -1 +1,9 @@
+#include <stdio.h>
+
+const char *get_name() {
+ static char buf[128];
+ scanf("%s", buf);
+ return buf;
+}
+
int main(int argc, char *argv[]) {
Stage this hunk [y,n,q,a,d,j,J,g,/,e,?]?
```
>
> **提示**:如果你对其他选项感到好奇,请按 `?` 汇总显示。
>
>
>
这个大块看起来更好:单一、独立的更改。让我们按 `y` 来回答问题(并暂存那个“大块”),然后按 `q` 以“退出”交互式会话并继续进行提交。会弹出编辑器,要求输入合适的提交消息。
```
Add get_name function to C program
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# interactive rebase in progress; onto c785f47
# Last commands done (2 commands done):
# pick 237b246 Add C program skeleton
# edit b3f188b Flesh out C program
# No commands remaining.
# You are currently splitting a commit while rebasing branch 'master' on 'c785f47'.
#
# Changes to be committed:
# modified: main.c
#
# Changes not staged for commit:
# modified: main.c
#
```
保存并关闭编辑器,然后我们进行第二次提交。我们可以执行另一次交互式提交,但是由于我们只想在此提交中包括其余更改,因此我们将执行以下操作:
```
git commit -a -m"Prompt user for their name"
git rebase --continue
```
最后一条命令告诉 Git 我们已经完成了此提交的编辑,并继续执行下一个变基命令。这样就行了!运行 `git log` 来查看你的劳动成果:
```
$ git log -3 --oneline
fe19cc3 (HEAD -> master) Prompt user for their name
659a489 Add get_name function to C program
237b246 Add C program skeleton
```
### 重新排序提交
这很简单。让我们从设置沙箱开始:
```
echo "Goodbye now!" >farewell.txt
git add farewell.txt
git commit -m"Add farewell.txt"
echo "Hello there!" >greeting.txt
git add greeting.txt
git commit -m"Add greeting.txt"
echo "How're you doing?" >inquiry.txt
git add inquiry.txt
git commit -m"Add inquiry.txt"
```
现在 `git log` 看起来应如下所示:
```
f03baa5 (HEAD -> master) Add inquiry.txt
a4cebf7 Add greeting.txt
90bb015 Add farewell.txt
```
显然,这都是乱序。让我们对过去的 3 个提交进行交互式变基来解决此问题。运行 `git rebase -i HEAD~3`,这个变基规划将出现:
```
pick 90bb015 Add farewell.txt
pick a4cebf7 Add greeting.txt
pick f03baa5 Add inquiry.txt
# Rebase fe19cc3..f03baa5 onto fe19cc3 (3 commands)
#
# Commands:
# p, pick <commit> = use commit
#
# These lines can be re-ordered; they are executed from top to bottom.
```
现在,解决方法很简单:只需按照你希望提交出现的顺序重新排列这些行。应该看起来像这样:
```
pick a4cebf7 Add greeting.txt
pick f03baa5 Add inquiry.txt
pick 90bb015 Add farewell.txt
```
保存并关闭你的编辑器,而 Git 将为你完成其余工作。请注意,在实践中这样做可能会导致冲突,参看下面章节以获取解决冲突的帮助。
### git pull –rebase
如果你一直在由上游更新的分支 `<branch>`(比如说原始远程)上做一些提交,通常 `git pull` 会创建一个合并提交。在这方面,`git pull` 的默认行为等同于:
```
git fetch origin <branch>
git merge origin/<branch>
```
假设本地分支 `<branch>` 配置为从原始远程跟踪 `<branch>` 分支,即:
```
$ git config branch.<branch>.remote
origin
$ git config branch.<branch>.merge
refs/heads/<branch>
```
还有另一种选择,它通常更有用,并且会让历史记录更清晰:`git pull --rebase`。与合并方式不同,这基本上 <sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> 等效于以下内容:
```
git fetch origin
git rebase origin/<branch>
```
合并方式更简单易懂,但是如果你了解如何使用 `git rebase`,那么变基方式几乎可以做到你想要做的任何事情。如果愿意,可以将其设置为默认行为,如下所示:
```
git config --global pull.rebase true
```
当你执行此操作时,从技术上讲,你在应用我们在下一节中讨论的过程……因此,让我们也解释一下故意执行此操作的含义。
### 使用 git rebase 来变基
具有讽刺意味的是,我最少使用的 Git 变基功能是它以之命名的功能:变基分支。假设你有以下分支:
```
A--B--C--D--> master
\--E--F--> feature-1
\--G--> feature-2
```
事实证明,`feature-2` 不依赖于 `feature-1` 的任何更改,它依赖于提交 E,因此你可以将其作为基础脱离 `master`。因此,解决方法是:
```
git rebase --onto master feature-1 feature-2
```
非交互式变基对所有牵连的提交都执行默认操作(`pick`)<sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> ,它只是简单地将不在 `feature-1` 中的 `feature-2` 中提交重放到 `master` 上。你的历史记录现在看起来像这样:
```
A--B--C--D--> master
| \--G--> feature-2
\--E--F--> feature-1
```
### 解决冲突
解决合并冲突的详细信息不在本指南的范围内,将来请你注意另一篇指南。假设你熟悉通常的解决冲突的方法,那么这里是专门适用于变基的部分。
有时,在进行变基时会遇到合并冲突,你可以像处理其他任何合并冲突一样处理该冲突。Git 将在受影响的文件中设置冲突标记,`git status` 将显示你需要解决的问题,并且你可以使用 `git add` 或 `git rm` 将文件标记为已解决。但是,在 `git rebase` 的上下文中,你应该注意两个选项。
首先是如何完成冲突解决。解决由于 `git merge` 引起的冲突时,与其使用 `git commit` 那样的命令,更适当的变基命令是 `git rebase --continue`。但是,还有一个可用的选项:`git rebase --skip`。 这将跳过你正在处理的提交,它不会包含在变基中。这在执行非交互性变基时最常见,这时 Git 不会意识到它从“其他”分支中提取的提交是与“我们”分支上冲突的提交的更新版本。
### 帮帮我! 我把它弄坏了!
毫无疑问,变基有时会很难。如果你犯了一个错误,并因此而丢失了所需的提交,那么可以使用 `git reflog` 来节省下一天的时间。运行此命令将向你显示更改一个引用(即分支和标记)的每个操作。每行显示你的旧引用所指向的内容,你可对你认为丢失的 Git 提交执行 `git cherry-pick`、`git checkout`、`git show` 或任何其他操作。
---
1. 我们添加了一个空的初始提交以简化本教程的其余部分,因为要对版本库的初始提交进行变基需要特殊的命令(即`git rebase --root`)。 [↩](#fnref1)
2. 如果要编译此程序,请运行 `cc -o main main.c`,然后运行 `./main` 查看结果。 [↩](#fnref2)
3. 实际上,这是“混合重置”。“软重置”(使用 `git reset --soft` 完成)将暂存更改,因此你无需再次 `git add` 添加它们,并且可以一次性提交所有更改。这不是我们想要的。我们希望选择性地暂存部分更改,以拆分提交。 [↩](#fnref3)
4. 实际上,这取决于上游分支本身是否已变基或删除/压扁了某些提交。`git pull --rebase` 尝试通过在 `git rebase` 和 `git merge-base` 中使用 “<ruby> 复刻点 <rt> fork-point </rt></ruby>” 机制来从这种情况中恢复,以避免变基非本地提交。 [↩](#fnref4)
5. 实际上,这取决于 Git 的版本。直到 2.26.0 版,默认的非交互行为以前与交互行为稍有不同,这种方式通常并不重要。 [↩](#fnref5)
---
via: <https://git-rebase.io/>
作者:[git-rebase](https://git-rebase.io/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## Amending your last commit
Let's start with something simple: fixing your most recent commit.
Let's add a file to our sandbox — and make a mistake:
echo "Hello wrold!" >greeting.txt
git add greeting.txt
git commit -m"Add greeting.txt"
Fixing this mistake is pretty easy. We can just edit the file and
commit with `--amend`
, like so:
echo "Hello world!" >greeting.txt
git commit -a --amend
Specifying `-a`
automatically stages (i.e. ```
git
add
```
's) all files that git already knows about, and
`--amend`
will *squash* the changes into the most
recent commit. Save and quit your editor (you have a chance to change
the commit message now if you'd like). You can see the fixed commit
by running `git show`
:
commit f5f19fbf6d35b2db37dcac3a55289ff9602e4d00 (HEAD -> master)
Author: Drew DeVault <[email protected]>
Date: Sun Apr 28 11:09:47 2019 -0400
Add greeting.txt
**diff --git a/greeting.txt b/greeting.txt
new file mode 100644
index 0000000..cd08755
--- /dev/null
+++ b/greeting.txt**
@@ -0,0 +1 @@
+Hello world!
## Fixing up older commits
Amending only works for the most recent commit. What happens if you
need to correct an older commit? Let's start by setting up our sandbox
accordingly:
echo "Hello!" >greeting.txt
git add greeting.txt
git commit -m"Add greeting.txt"
echo "Goodbye world!" >farewell.txt
git add farewell.txt
git commit -m"Add farewell.txt"
Looks like `greeting.txt`
is missing "world". Let's write a
commit normally which fixes that:
echo "Hello world!" >greeting.txt
git commit -a -m"fixup greeting.txt"
So now the files look correct, but our history could be better — let's
use the new commit to "fixup" the last one. For this, we need to
introduce a new tool: the interactive rebase. We're going to edit the
last three commits this way, so we'll run ```
git rebase -i
HEAD~3
```
(`-i`
for interactive). This'll open your
text editor with something like this:
pick 8d3fc77 Add greeting.txt
pick 2a73a77 Add farewell.txt
pick 0b9d0bb fixup greeting.txt
# Rebase f5f19fb..0b9d0bb onto f5f19fb (3 commands)
#
# Commands:
# p, pick <commit> = use commit
# f, fixup <commit> = like "squash", but discard this commit's log message
This is the rebase plan, and by editing this file you can instruct
git on how to edit history. I've trimmed the summary to just the
details relevant to this part of the rebase guide, but feel free to
skim the full summary in your text editor.
When we save and close our editor, git is going to remove all of these
commits from its history, then execute each line one at a time. By
default, it's going to *pick* each commit, summoning it from
the heap and adding it to the branch. If we don't edit this file at
all, we'll end up right back where we started, picking every commit
as-is. We're going to use one of my favorite features now: fixup. Edit
the third line to change the operation from "pick" to "fixup" and move
it to immediately after the commit we want to "fix up":
pick 8d3fc77 Add greeting.txt
fixup 0b9d0bb fixup greeting.txt
pick 2a73a77 Add farewell.txt
**Tip**: We can also abbreviate this with just "f" to
speed things up next time.
Save and quit your editor — git will run these commands. We can check
the log to verify the result:
$ git log -2 --oneline
fcff6ae (HEAD -> master) Add farewell.txt
a479e94 Add greeting.txt
## Using git rebase --autosquash
The steps described above can also be performed in a more automated
manner by taking advantage of the `--autosquash`
option
of `git rebase`
in combination with the
`--fixup`
option of `git commit`
:
git commit -a --fixup HEAD^
git rebase -i --autosquash HEAD~3
This will prepare the rebase plan with commits reordered and
actions set up:
pick 8d3fc77 Add greeting.txt
fixup 0b9d0bb fixup! Add greeting.txt
pick 2a73a77 Add farewell.txt
# Rebase f5f19fb..0b9d0bb onto f5f19fb (3 commands)
#
# Commands:
# p, pick <commit> = use commit
# f, fixup <commit> = like "squash", but discard this commit's log message
In addition to `--fixup`
, the `--squash`
option for `git commit`
also exists and will allow you to
edit the commit message.
Finally, the `--autosquash`
option can be omitted by
setting this behavior as the default through configuration:
git config --global rebase.autosquash true
## Squashing several commits into one
As you work, you may find it useful to write lots of commits as you
reach small milestones or fix bugs in previous commits. However, it
may be useful to "squash" these commits together, to make a cleaner
history before merging your work into master. For this, we'll use the
"squash" operation. Let's start by writing a bunch of commits — just
copy and paste this if you want to speed it up:
git checkout -b squash
for c in H e l l o , ' ' w o r l d; do
echo "$c" >>squash.txt
git add squash.txt
git commit -m"Add '$c' to squash.txt"
done
That's a lot of commits to make a file that says "Hello, world"! Let's
start another interactive rebase to squash them together. Note that we
checked out a branch to try this on, first. Because of that, we can
quickly rebase all of the commits since we branched by using ```
git
rebase -i master
```
. The result:
pick 1e85199 Add 'H' to squash.txt
pick fff6631 Add 'e' to squash.txt
pick b354c74 Add 'l' to squash.txt
pick 04aaf74 Add 'l' to squash.txt
pick 9b0f720 Add 'o' to squash.txt
pick 66b114d Add ',' to squash.txt
pick dc158cd Add ' ' to squash.txt
pick dfcf9d6 Add 'w' to squash.txt
pick 7a85f34 Add 'o' to squash.txt
pick c275c27 Add 'r' to squash.txt
pick a513fd1 Add 'l' to squash.txt
pick 6b608ae Add 'd' to squash.txt
# Rebase 1af1b46..6b608ae onto 1af1b46 (12 commands)
#
# Commands:
# p, pick <commit> = use commit
# s, squash <commit> = use commit, but meld into previous commit
**Tip**: your local master branch evolves independently
of the remote master branch, and git stores the remote branch as
`origin/master`
. Combined with this trick, ```
git
rebase -i origin/master
```
is often a very convenient way to
rebase all of the commits which haven't been merged upstream yet!
We're going to squash all of these changes into the first commit. To
do this, change every "pick" operation to "squash", except for the
first line, like so:
pick 1e85199 Add 'H' to squash.txt
squash fff6631 Add 'e' to squash.txt
squash b354c74 Add 'l' to squash.txt
squash 04aaf74 Add 'l' to squash.txt
squash 9b0f720 Add 'o' to squash.txt
squash 66b114d Add ',' to squash.txt
squash dc158cd Add ' ' to squash.txt
squash dfcf9d6 Add 'w' to squash.txt
squash 7a85f34 Add 'o' to squash.txt
squash c275c27 Add 'r' to squash.txt
squash a513fd1 Add 'l' to squash.txt
squash 6b608ae Add 'd' to squash.txt
When you save and close your editor, git will think about this for a
moment, then open your editor again to revise the final commit
message. You'll see something like this:
# This is a combination of 12 commits.
# This is the 1st commit message:
Add 'H' to squash.txt
# This is the commit message #2:
Add 'e' to squash.txt
# This is the commit message #3:
Add 'l' to squash.txt
# This is the commit message #4:
Add 'l' to squash.txt
# This is the commit message #5:
Add 'o' to squash.txt
# This is the commit message #6:
Add ',' to squash.txt
# This is the commit message #7:
Add ' ' to squash.txt
# This is the commit message #8:
Add 'w' to squash.txt
# This is the commit message #9:
Add 'o' to squash.txt
# This is the commit message #10:
Add 'r' to squash.txt
# This is the commit message #11:
Add 'l' to squash.txt
# This is the commit message #12:
Add 'd' to squash.txt
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# Date: Sun Apr 28 14:21:56 2019 -0400
#
# interactive rebase in progress; onto 1af1b46
# Last commands done (12 commands done):
# squash a513fd1 Add 'l' to squash.txt
# squash 6b608ae Add 'd' to squash.txt
# No commands remaining.
# You are currently rebasing branch 'squash' on '1af1b46'.
#
# Changes to be committed:
# new file: squash.txt
#
This defaults to a combination of all of the commit messages which
were squashed, but leaving it like this is almost always not what you
want. The old commit messages may be useful for reference when writing
the new one, though.
**Tip**: the "fixup" command you learned about in the
previous section can be used for this purpose, too — but it discards
the messages of the squashed commits.
Let's delete everything and replace it with a better commit message,
like this:
Add squash.txt with contents "Hello, world"
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# Date: Sun Apr 28 14:21:56 2019 -0400
#
# interactive rebase in progress; onto 1af1b46
# Last commands done (12 commands done):
# squash a513fd1 Add 'l' to squash.txt
# squash 6b608ae Add 'd' to squash.txt
# No commands remaining.
# You are currently rebasing branch 'squash' on '1af1b46'.
#
# Changes to be committed:
# new file: squash.txt
#
Save and quit your editor, then examine your git log — success!
commit c785f476c7dff76f21ce2cad7c51cf2af00a44b6 (HEAD -> squash)
Author: Drew DeVault <[email protected]>
Date: Sun Apr 28 14:21:56 2019 -0400
Add squash.txt with contents "Hello, world"
Before we move on, let's pull our changes into the master branch and
get rid of this scratch one. We can use `git rebase`
like
we use `git merge`
, but it avoids making a merge commit:
git checkout master
git rebase squash
git branch -D squash
We generally prefer to avoid using git merge unless we're actually
merging unrelated histories. If you have two divergent branches, a
git merge is useful to have a record of when they were... merged. In
the course of your normal work, rebase is often more appropriate.
## Splitting one commit into several
Sometimes the opposite problem happens — one commit is just too big.
Let's look into splitting it up. This time, let's write some actual
code. Start with a simple C program[2](#note-2) (you can still copy+paste this snippet into
your shell to do this quickly):
cat <<EOF >main.c
int **main**(int argc, char *argv[]) {
return 0;
}
EOF
We'll commit this first.
git add main.c
git commit -m"Add C program skeleton"
Next, let's extend the program a bit:
cat <<EOF >main.c
#include <stdio.h>
const char ***get_name**() {
static char buf[128];
scanf("%s", buf);
return buf;
}
int **main**(int argc, char *argv[]) {
printf("What's your name? ");
const char *name = get_name();
printf("Hello, %s!\n", name);
return 0;
}
EOF
After we commit this, we'll be ready to learn how to split it up.
git commit -a -m"Flesh out C program"
The first step is to start an interactive rebase. Let's rebase both
commits with `git rebase -i HEAD~2`
, giving us this rebase
plan:
pick 237b246 Add C program skeleton
pick b3f188b Flesh out C program
# Rebase c785f47..b3f188b onto c785f47 (2 commands)
#
# Commands:
# p, pick <commit> = use commit
# e, edit <commit> = use commit, but stop for amending
Change the second commit's command from "pick" to "edit", then save
and close your editor. Git will think about this for a second, then
present you with this:
Stopped at b3f188b... Flesh out C program
You can amend the commit now, with
git commit --amend
Once you are satisfied with your changes, run
git rebase --continue
We could follow these instructions to *add* new changes to the
commit, but instead let's do a "soft reset"[3](#note-3) by running ```
git
reset HEAD^
```
. If you run `git status`
after this,
you'll see that it un-commits the latest commit and adds its changes
to the working tree:
Last commands done (2 commands done):
pick 237b246 Add C program skeleton
edit b3f188b Flesh out C program
No commands remaining.
You are currently splitting a commit while rebasing branch 'master' on 'c785f47'.
(Once your working directory is clean, run "git rebase --continue")
Changes not staged for commit:
(use "git add ..." to update what will be committed)
(use "git restore ..." to discard changes in working directory)
modified: main.c
no changes added to commit (use "git add" and/or "git commit -a")
To split this up, we're going to do an *interactive commit*.
This allows us to selectively commit only specific changes from the
working tree. Run `git commit -p`
to start this process,
and you'll be presented with the following prompt:
**diff --git a/main.c b/main.c
index b1d9c2c..3463610 100644
--- a/main.c
+++ b/main.c**
@@ -1,3 +1,14 @@
+#include <stdio.h>
+
+const char *get_name() {
+ static char buf[128];
+ scanf("%s", buf);
+ return buf;
+}
+
int main(int argc, char *argv[]) {
+ printf("What's your name? ");
+ const char *name = get_name();
+ printf("Hello, %s!\n", name);
return 0;
}
**Stage this hunk [y,n,q,a,d,s,e,?]? **
Git has presented you with just one "hunk" (i.e. a single change) to
consider committing. This one is too big, though — let's use the "s"
command to "split" up the hunk into smaller parts.
**Split into 2 hunks.**
@@ -1 +1,9 @@
+#include <stdio.h>
+
+const char *get_name() {
+ static char buf[128];
+ scanf("%s", buf);
+ return buf;
+}
+
int main(int argc, char *argv[]) {
**Stage this hunk [y,n,q,a,d,j,J,g,/,e,?]? **
**Tip**: If you're curious about the other options, press
"?" to summarize them.
This hunk looks better — a single, self-contained change. Let's hit
"y" to answer the question (and stage that "hunk"), then "q" to "quit"
the interactive session and proceed with the commit. Your editor will
pop up to ask you to enter a suitable commit message.
Add get_name function to C program
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# interactive rebase in progress; onto c785f47
# Last commands done (2 commands done):
# pick 237b246 Add C program skeleton
# edit b3f188b Flesh out C program
# No commands remaining.
# You are currently splitting a commit while rebasing branch 'master' on 'c785f47'.
#
# Changes to be committed:
# modified: main.c
#
# Changes not staged for commit:
# modified: main.c
#
Save and close your editor, then we'll make the second commit. We
could do another interactive commit, but since we just want to include
the rest of the changes in this commit we'll just do this:
git commit -a -m"Prompt user for their name"
git rebase --continue
That last command tells git that we're done editing this commit, and
to continue to the next rebase command. That's it! Run ```
git
log
```
to see the fruits of your labor:
$ git log -3 --oneline
fe19cc3 (HEAD -> master) Prompt user for their name
659a489 Add get_name function to C program
237b246 Add C program skeleton
## Reordering commits
This one is pretty easy. Let's start by setting up our sandbox:
echo "Goodbye now!" >farewell.txt
git add farewell.txt
git commit -m"Add farewell.txt"
echo "Hello there!" >greeting.txt
git add greeting.txt
git commit -m"Add greeting.txt"
echo "How're you doing?" >inquiry.txt
git add inquiry.txt
git commit -m"Add inquiry.txt"
The git log should now look like this:
f03baa5 (HEAD -> master) Add inquiry.txt
a4cebf7 Add greeting.txt
90bb015 Add farewell.txt
Clearly, this is all out of order. Let's do an interactive rebase of
the past 3 commits to resolve this. Run ```
git rebase -i
HEAD~3
```
and this rebase plan will appear:
pick 90bb015 Add farewell.txt
pick a4cebf7 Add greeting.txt
pick f03baa5 Add inquiry.txt
# Rebase fe19cc3..f03baa5 onto fe19cc3 (3 commands)
#
# Commands:
# p, pick <commit> = use commit
#
# These lines can be re-ordered; they are executed from top to bottom.
The fix is now straightforward: just reorder these lines in the order
you wish for the commits to appear. Should look something like this:
pick a4cebf7 Add greeting.txt
pick f03baa5 Add inquiry.txt
pick 90bb015 Add farewell.txt
Save and close your editor and git will do the rest for you. Note that
it's possible to end up with conflicts when you do this in practice -
[click here for help resolving conflicts](#conflicts).
## git pull --rebase
If you've been writing some commits on a branch `<branch>`
which has been updated
upstream, say on remote `origin`
, normally `git pull`
will create a merge commit.
In this respect, `git pull`
's behavior by default is
equivalent to:
git fetch origin <branch>
git merge origin/<branch>
This assumes that the local branch `<branch>`
is configured to track the `<branch>`
branch
from the `origin`
remote, i.e.:
$ git config branch.<branch>.remote
origin
$ git config branch.<branch>.merge
refs/heads/<branch>
There's another option, which is often more useful and leads to a much
cleaner history: `git pull --rebase`
. Unlike the merge
approach, this is mostly[4](#note-4)
equivalent to the following:
git fetch origin
git rebase origin/<branch>
The merge approach is simpler and easier to understand, but the rebase
approach is almost always what you want to do if you understand how to
use git rebase. If you like, you can set it as the default behavior
like so:
git config --global pull.rebase true
When you do this, technically you're applying the procedure we
discuss in the next section... so let's explain what it means to do
that deliberately, too.
## Using git rebase to... rebase
Ironically, the feature of git rebase that I use the least is the one
it's named for: rebasing branches. Say you have the following
branches:
A--B--C--D--> master
\--E--F--> feature-1
\--G--> feature-2
It turns out feature-2 doesn't depend on any of the changes
in feature-1, that is, on commit E, so you can just base it
off of master. The fix is thus:
git rebase --onto master feature-1 feature-2
The non-interactive rebase does the default operation for all
implicated commits ("pick")[5](#note-5), which simply replays the
commits in feature-2 that are not in feature-1 on top of
master. Your history now looks like this:
A--B--C--D--> master
| \--G--> feature-2
\--E--F--> feature-1
## Resolving conflicts
The details on resolving merge conflicts are beyond the scope of
this guide — keep your eye out for another guide for this in the
future. Assuming you're familiar with resolving conflicts in general,
here are the specifics that apply to rebasing.
Sometimes you'll get a merge conflict when doing a rebase, which you
can handle just like any other merge conflict. Git will set up the
conflict markers in the affected files, `git status`
will
show you what you need to resolve, and you can mark files as resolved
with `git add`
or `git rm`
. However, in the
context of a git rebase, there are a few options you should be aware of.
The first is how you complete the conflict resolution. Rather than
`git commit`
like you'll use when addressing conflicts that
arise from `git merge`
, the appropriate command for
rebasing is `git rebase --continue`
. However, there's
another option available to you: `git rebase --skip`
. This
will skip the commit you're working on, and it won't be included in
the rebase. This is most common when doing a non-interactive rebase,
when git doesn't realize that a commit it's pulled from the "other"
branch is an updated version of the commit that it conflicts with on
"our" branch.
If you want to take a look at the diff of the commit that Git failed to
replay, and which resulted in a merge conflict, you can use
`git rebase --show-current-patch`
, or its
equivalent `git show REBASE_HEAD`
.
Finally, it's worth noting that when using `git checkout --ours`
or `--theirs`
to quickly resolve
conflicted paths by checking out a specific version from the index,
the meaning of those options is reversed compared to a regular `git merge`
merge conflict: during rebase, `--theirs`
refers to the changes
from the branch being rebased (`REBASE_HEAD`
), and `--ours`
refers to the changes from the branch onto which we are rebasing
(`HEAD`
)[6](#note-6).
## Help! I broke it!
No doubt about it — rebasing can be hard sometimes. If you've made a
mistake and in so doing lost commits which you needed, then ```
git
reflog
```
is here to save the day. Running this command will
show you every operation which changed a *ref*, or reference -
that is, branches and tags. Each line shows you what the old reference
pointed to, and you can `git cherry-pick`
, ```
git
checkout
```
, `git show`
, or use any other operation
on git commits once thought lost. |
12,273 | Drupal 中的 Gutenberg 编辑器入门 | https://opensource.com/article/20/3/gutenberg-editor-drupal | 2020-06-02T10:05:49 | [
"Drupal",
"WordPress",
"Gutenberg"
] | https://linux.cn/article-12273-1.html |
>
> 了解如何在 Drupal 中集成使用 WordPress 中流行的所见即所得编辑器。
>
>
>

自 2017 年以来,WordPress 的 [Gutenberg](https://wordpress.org/plugins/gutenberg/) 插件中的所见即所得编辑器就真的很不错。但是,Drupal 社区尚未就内容管理系统(CMS)编辑体验的最佳方法达成共识。但在社区的大量努力下,出现了一个强有力的新选择,将 [Gutenberg 与 Drupal 集成在一起](https://drupalgutenberg.org/)。
以前,Drupal 8 中有两种主要的内容创建方法:
* 在[基于段落的方法](https://www.droptica.com/blog/flexible-and-easy-content-creation-drupal-paragraphs-module/)中,内容是由称为段落的实体组合而成。目前,大约有 100,000 个网站使用“段落”(Paragraphs)模块(根据 Drupal 说法)。
* [Layout-Builder 方法](https://www.droptica.com/blog/layout-builder-building-drupal-8-layouts/)使用 Drupal 8.5 附带的编辑工具。它仍然在改进,但是它是下一个强有力的竞争者,因为它确实与 Drupal 内核很好地集成在一起。由于 Layout-Builder 是 Drupal 的一部分,因此无法获得使用情况的统计信息。
在 2018 年底,由 Fronkom(一家专注于开源解决方案的挪威数字机构)领导的 Drupal 社区将 WordPress Gutenberg 项目作为贡献模块移植到了 Drupal 中。让我们看一下 Gutenberg 在 Drupal 中的工作方式(包括一些很酷的 Drupal 特有的集成)。
### 安装
安装 [Gutenberg 模块](https://www.drupal.org/project/gutenberg)与安装任何 Drupal 模块一样简单,并且有良好的[安装文档](https://www.drupal.org/docs/8/extending-drupal-8/installing-drupal-8-modules)。
### 配置
Gutenberg 已集成到 Drupal 的默认内容实体创建工作流中。你可以将其用于你选择的任何内容类型,前提是内容类型至少有一个文本区域字段,它是 Gutenberg 编辑器输出的位置。
要在 Drupal 中的内容类型启用 Gutenberg 项目,你必须进入设置:“结构 -> 内容类型”,并且,从要你想使用 Gutenberg 的内容类型旁边的下拉框中单击“编辑”。

在出现的窗口中,向下滚动并选择左侧的“Gutenberg 体验”选项卡,你可以在其中找到下面描述的设置。选择“启用 Gutenberg 体验”。

#### 模板
这是 WordPress 开箱即用的很酷的功能之一。它能让你用 JSON 结构定义新页面模板。它将使用虚拟占位符内容预填充所有新创建的文章,这将有助于编辑者正确地构造内容。在上面的截图中,我添加了一个标题和一个段落。请注意,必须转义任何双引号。
#### 模板锁
此设置允许你定义是否允许用户删除占位符内容,添加新块或仅编辑现有的预填充内容。
#### 允许的 Gutenberg 和 Drupal 块
这是 Gutenberg Drupal 侧的另一个超酷功能。Drupal 允许用户创建各种类型的块来设计页面。例如,你可以创建一个块,其中包含五个最新博客的列表、最新评论或用于收集用户电子邮件的表单。
Gutenberg 与 Drupal 的深度集成允许用户在编辑时选择哪些 Drupal 块可供用户使用(例如,限制嵌入 YouTube),并将块用作内联内容。这是一个非常方便的功能,允许对用户体验进行精细控制。
在全新安装的 Drupal 中,没有太多的选择,但站点通常有许多提供各种功能的块。在下面的截图中,选择了“搜索表单”的 Drupal 块。

完成配置后,点击“保存内容类型”。
### 使用 Drupal Gutenberg 发布内容
启用 Gutenberg 内容类型后,它将接管大部分编辑体验。

在主窗口中,你可以看到我在上面的模板配置中添加的虚拟占位符内容。
#### 特定于 Drupal 的选项
在右侧,Drupal 提供了一些字段和设置。例如,“标题” 字段是 Drupal 中所需的单独字段,因此它不在主页面上。
在“标题”下面,根据在 Drupal 中安装的模块和设置的选项,其他设置可能有所不同。你可以看到“修订日志消息”、“菜单设置”、“评论设置”以及添加“URL 别名”。
通常,Drupal 内容类型由多个文本字段组成,如标记、类别、复选框、图像字段等。当你启用 Gutenberg 内容类型时,这些附加字段可在“更多设置”选项卡中提供。
你现在可以添加内容 —— 它的工作方式与 WordPress Gutenberg 中的相同,并有额外的添加 Drupal 块的选项。
在下面的截图中,你可以看到当我添加一些文本替换占位符文本、来自 Drupal 的搜索块、标题、标记和自定义 URL 别名后发生的情况。

点击“保存”后,你的内容将发布。

就是这样,它工作良好。
### 共同工作以获得更好的软件体验
Drupal 中的 Gutenberg 工作良好。这是一个可供选择的方式,允许编辑者控制网站的外观,直至最细微的细节。它的采用率正在增长,截至本文撰写时,已有 1,000 多个安装,每月有 50 个新安装。Drupal 集成添加了其他很酷的功能,如细粒度权限、占位符内容,以及内联包含 Drupal 块的功能,这些功能在 WordPress 插件中没有。
很高兴看到两个独立项目的社区共同努力实现为人们提供更好的软件的共同目标。
---
via: <https://opensource.com/article/20/3/gutenberg-editor-drupal>
作者:[MaciejLukianski](https://opensource.com/users/maciejlukianski) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Since 2017, WordPress has had a really great WYSIWYG editor in the [Gutenberg](https://wordpress.org/plugins/gutenberg/) plugin. But the Drupal community hasn't yet reached consensus on the best approach to the content management system's (CMS) editorial experience. But a strong new option appeared when, with a lot of community effort, [Gutenberg was integrated with Drupal](https://drupalgutenberg.org/).
Previously, there were two main approaches to content creation in Drupal 8:
- In the
, content is assembled out of entities called paragraphs. Currently, approximately 100,000 websites use the Paragraphs module (according to Drupal).**Paragraph-based approach** - The
uses an editorial tool shipped with Drupal 8.5. It is still undergoing improvements, but it is the next strong contender because it is really well integrated with the Drupal core. Stats on usage are not available since Layout Builder is part of Drupal.**Layout-Builder approach**
At the end of 2018, the Drupal community, lead by Frontkom (a Norwegian digital agency strongly focused on open source solutions), ported the WordPress Gutenberg project as a contributed module into Drupal. Let's take a look at how Gutenberg works in Drupal (including some cool Drupal-specific integrations).
## Installation
Installing the [Gutenberg module](https://www.drupal.org/project/gutenberg) is as straightforward as installing any Drupal module, and it has good [installation documentation](https://www.drupal.org/docs/8/extending-drupal-8/installing-drupal-8-modules).
## Configuration
Gutenberg is integrated into Drupal's default content-entity creation workflow. You can use it on any of the content types you choose, provided that the content type has at least one text area field, which is where the Gutenberg editor's output will be saved.
To enable the Gutenberg project on a content type in Drupal, you have to navigate to its settings: **Structure > Content types** and, from the dropdown next to the content type where you want to use Gutenberg, click **Edit**.
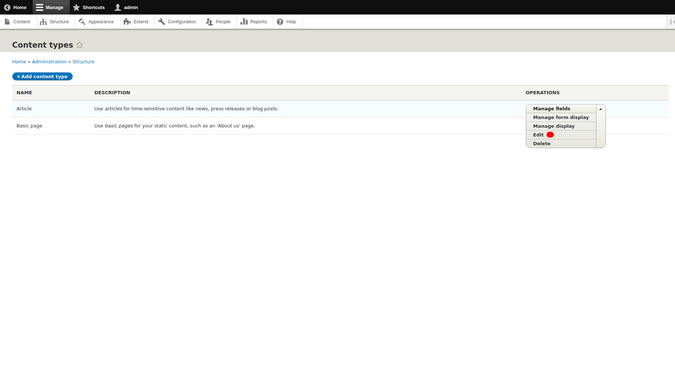
In the form that appears, scroll down and select the **Gutenberg experience** tab on the left, where you can find the settings described below. Select the **Enable Gutenberg experience** box.
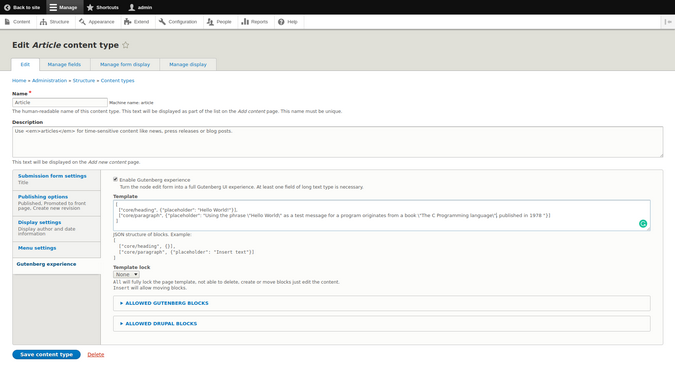
### Template
This is one of the cool features that is not available in WordPress out of the box. It enables you to define a template for a new page in a JSON structure. This will pre-populate all newly created articles with dummy placeholder content, which will help editors structure content correctly. In the screenshot above, I added a heading and a paragraph. Note that any double-quotes have to be escaped.
### Template lock
This setting allows you to define whether users are allowed to delete the placeholder content, add new blocks, or just edit the existing, pre-populated content.
### Allowed Gutenberg and Drupal blocks
This is another super-cool feature on the Drupal side of Gutenberg. Drupal allows users to create various types of blocks to design a page. For example, you could create a block with a list of the five latest blog posts, the most recent comments, or a form to collect users' emails.
Gutenberg's deep integration with Drupal allows users to select which Drupal blocks are available to users while they are editing (e.g., limit embeds to YouTube) and use blocks as inline content. This is a very handy feature that allows granular control of the user experience.
There's not much to choose from in a blank Drupal installation, but a live site usually has many blocks that provide various functionalities. In the screenshot below, the **Search form** Drupal block is selected.
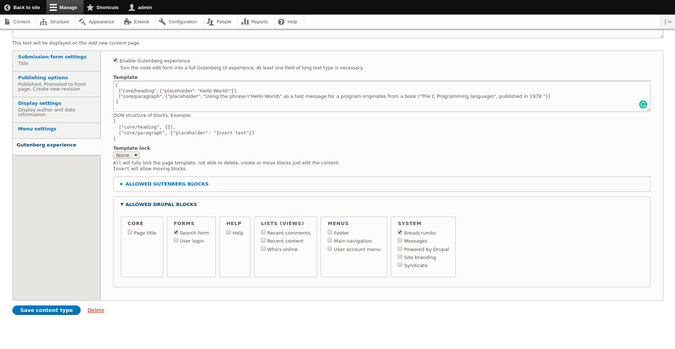
After you finish the configuration, hit **Save content type**.
## Publishing content with Drupal Gutenberg
When Gutenberg is enabled for a content type, it takes over most of the editorial experience.
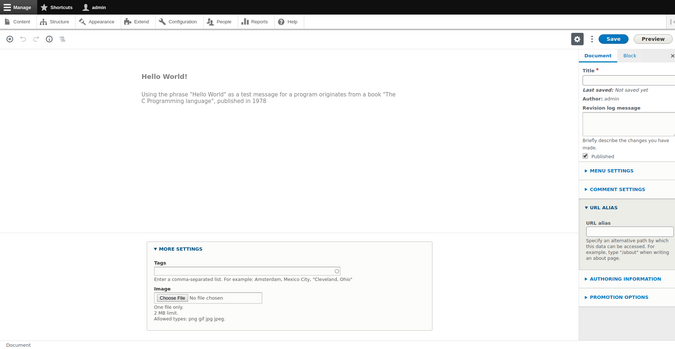
In the main window, you can see the dummy placeholder content I added in the Template configuration above.
### Drupal-specific options
On the right-hand side, there are a few fields and settings that Drupal provides. For example, the **Title **field is a required separate field in Drupal, and therefore it is not on the main Gutenberg screen.
Underneath the **Title**, there are additional settings that can vary, depending on the modules installed and options set up in Drupal. You can see **Revision log messages**, **Menu settings**, **Comment settings**, and a place to add a **URL alias**.
Typically, Drupal content types are composed of several text fields, such as tags, categories, checkboxes, image fields for teasers, etc. When you enable Gutenberg for a content type, these additional fields are available in the **More settings** tab.
You can now add your content—it works the same as it does in WordPress Gutenberg, with the additional option to add Drupal blocks.
In the screenshot below, you can see what happens when I add some text to replace the placeholder text, a search block from Drupal, a title, tags, and a custom URL alias.
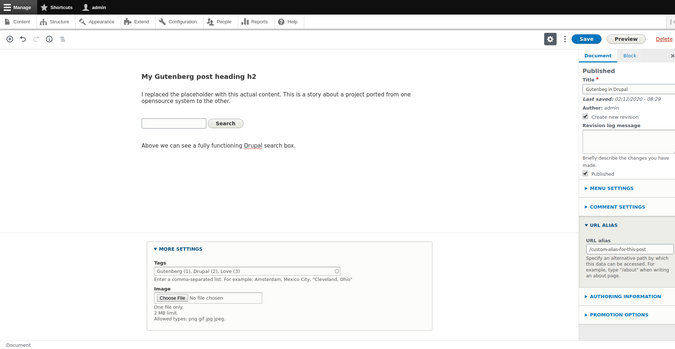
After you hit **Save**, your content will be published.
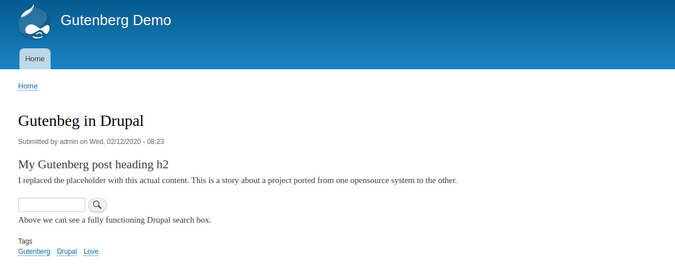
And that is it. It works like a charm!
## Working together for better software experiences
Gutenberg in Drupal works well. It is an alternative option that allows editors to control the look and feel of their websites down to the tiniest details. Adoption is growing well, with over 1,000 installations as of this writing and 50 new ones every month. The Drupal integration adds other cool features like fine-grained permissions, placeholder content, and the ability to include Drupal blocks inline, which aren't available in the WordPress plugin.
It is great to see the communities of two separate projects working together to achieve the common goal of giving people better software.
## 1 Comment |
12,274 | 20 个 Linux 终端下的生产力工具 | https://opensource.com/article/20/6/productivity-tools-linux-terminal | 2020-06-02T12:04:32 | [
"终端",
"生产力"
] | https://linux.cn/article-12274-1.html |
>
> 来试下这些开源工具。你的效率一定会提升。
>
>
>

诚然,很多人使用计算机来娱乐。但是一些人会用来工作,他们的理论是计算机应当能帮我们更快、更好、更有条理地做事。实际应用中,如果没有根据每个人的工作风格来做一些小小的手动配置,计算机也不会提升我们的效率。
[Kevin Sonney](https://opensource.com/users/ksonney) 喜欢设计系统,今年他在一个 20 篇文章的系列中介绍了 18 种不同的生产力工具,不仅涵盖了网络方面,也涉及了一些能提升他的工作效率的工具。Kevin 最喜欢的所有的工具都收集到了本文,下面概括介绍每种工具的用途。
### 文件同步

重要的文件应谨慎管理。
* [Syncthing](/article-11793-1.html) 能使不同设备上的文件彼此同步。*设备*可以是 Linux、Windows 或 Mac,也可以是服务器、Android 平板或手机,等等。文件可以是你期望在多台机器间同步的任意文件。Syncthing 是轻量级的点对点工具,因此你不需要支付服务费,你不需要第三方的服务器,而且它很快。
* 同步是一件事,但有时你还需要帮忙处理你拥有的文件。假设你想要一个应用程序在作为一个图形化应用和作为控制台应用时表现不同行为,你可以通过修改符号链接指向的不同的配置文件来达成,如 `.foo-gui` 和 `.foo-term`。这完全可以手动修改,但也可以用脚本处理,或者你可以试试 [GNU Stow](/article-11796-1.html)。
### 邮件管理

我们都依赖于邮件和收件箱,但似乎很少有人对自己管理邮件的方式满意。如果你喜欢用终端工作,为什么不在终端里管理邮件呢?在终端里收发邮件是一件事,但是要能在终端里组织你的邮件就更棒了。如果你的职业是打字员或是天生写脚本的人,试试这类工具吧。
* 我每天用 [OfflineIMAP](/article-11804-1.html) 把工作邮件同步到笔记本,以便用 Mutt 看邮件。它是很特别的工具,只做一件事:保证本地的邮件副本与远程的收件箱完全同步。配置和用 [cron](https://opensource.com/article/17/11/how-use-cron-linux) 调度它都相当简单,然后你就可以忘了它的存在。它相当简单,你与 IMAP 打交道的每一刻时间都应该用它。
* [Notmuch](/article-11807-1.html) 能为邮件消息建立索引、加标签以及搜索邮件。如果你的收件箱出了问题,它可以让你*不需要*花费很大精力去补救。
* [Vim](/article-11908-1.html) 可以收发邮件和管理你的日历。
* 当然,[Emacs](/article-11932-1.html) 可以收发邮件和管理你的日历。
### 日历和联系人

我用过的所有的 Linux 系统都预装了 `cal` 命令。这是一个在终端下用的便捷小日历,它也是个很好的速查工具。然而,它几乎不能被称为一个日历应用程序。[iCalendar](https://tools.ietf.org/html/rfc5545) 规范(与 Apple 的旧桌面日历无关)中提供了丰富的共享日历功能,虽然 `.ics` 的约会和事件是纯文本的,但没有在终端中管理它们的工作流。至少,在 khal 和 vdirsyncer 出现之前不存在。
* [Khal](/article-11812-1.html) 是基于控制台的读写 `.ics` 文件的日历工具。
* [Vdirsyncer](/article-11812-1.html) 是一个能把线上日历(和联系人)同步到本地的终端命令。Khal 在本地运行,vdirsyncer 在远程运行,这样远程的日历能与你管理的本地日历保持同步。
* 管理联系人可能会很难,但是如果你用了 [Khard](/article-11834-1.html) 这个可以读写 vCard 格式文件的终端命令,就会变得简单。反过来,这些文件可以使用 vdirsyncer(你可能已经在使用 khal 日历)同步到远程服务器上。这使得日历和联系人管理变得简单,而且[搭建个人信息管理(PIM)服务器](https://opensource.com/alternatives/google-calendar)也比以前容易得多。
### 待办清单

* 组织你每天的行程有很多种方式,但是最简单的一种是用 [todo.txt](/article-11835-1.html),一个简单、便携、易于理解的系统,即使设备上没有安装 todo.txt 也不会出现问题。todo.txt 能正常运行的原因是,它就是一个 Bash 脚本,能在几乎所有你能找到的的设备上运行。操作过程很简单:下载脚本,安装到家目录,用一个简单的命令开始调度任务。如果你的计算机上没有安装 `todo.sh` 命令,那么你的待办清单仍然可以作为纯文本文件来使用,你可以在需要时手动更新它。
* [Jrnl](/article-11846-1.html) 是一个能追踪的你的日常议程和活动的数字笔记本。如果你要摘抄桌面上的报纸的片段或者把随意的想法写下来,那么这就是你要找的程序。
### 保持联络

沟通是关键,然而现在似乎比以往更多的是聊天平台的问题。这不仅仅是几个客户端,而是几个独立的网络。你怎么管理它们?这里有两个方案。
* 如果你有很多的联系人分布在太多的聊天网络中,那么你应该试试 [BitlBee](/article-11856-1.html),使用这个单一的聊天客户端就可以关联其他所有的聊天网络。
* [Rainbow Stream](/article-11858-1.html) 是个推特客户端,能让你不被开放的网页浏览器分心,而又能紧跟时事。
### 消息通知

网页浏览器很好,但有时过犹不及。你希望能及时收到消息,但是你又不想全身心地陷入到互联网中。因为互联网是建立在开放的规范和大量的开源技术的基础上的,你不必在一个界面中做所有的事。对于不同的任务有不同的*客户端*,它们可以让你用自己喜欢的界面来获取你需要的信息。
* [Tuir](/article-11869-1.html) 是一个 Reddit 终端客户端。
* [Newsboat](/article-11876-1.html) 是一个 RSS 阅读器。
* [Wego](/article-11879-1.html) 是天气预报工具。
* [Vim](/article-11912-1.html) 可以帮助你登录 Reddit 和 Twitter。
* [Emacs](/article-11956-1.html) 能让你保持与 Reddit、Twitter 和聊天客户端的联系。
### 保持终端一直开启

如果你正在用终端工作,那么关闭它的意义是什么呢?摆脱 `exit` 和 `Ctrl+D` 的诱惑,让你的控制台一直开启着。
* [Tmux](/article-11900-1.html) 能分割你的终端,让一个终端窗口“分层"到另一个窗口之上,甚至从一台计算机离开到另一台计算机后,能保持相同的终端会话。
* [DESQview](/article-11892-1.html) 是另一种方式:它本质上是一个终端窗口管理器。
### 未完待续
本文列出的工具只是 Linux 终端的神奇生产力工具中的一小部分。这个清单会结束,但你自己的清单可以继续。找到你喜欢的工具,学习它们,并将其发挥出最大的优势。当然,一个好的工具不一定要提高你的生产力:有时你最喜欢的命令也可以是能让你最快乐的命令。你的工作是找到自己喜欢的命令,用它们来改变世界。
玩得愉快!
---
via: <https://opensource.com/article/20/6/productivity-tools-linux-terminal>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many of us, admittedly, only use computers because they're fun. But some people use computers to get stuff done, and their theory is computers are supposed to make things faster, better, and more organized. In practice, though, computers don't necessarily improve our lives without a little manual reconfiguration to match our individual work styles.
[Kevin Sonney](https://opensource.com/users/ksonney) likes to design systems, not just for networks but for improving his own workday, and this year he covered 18 different productivity tools in a series of 20 articles. This article gets all of Kevin's favorite tools in one place and provides a quick summary of what each one can do for you.
## File sync
Important files deserve to be managed carefully.
[Syncthing](https://opensource.com/article/20/1/sync-files-syncthing)is a way for you to keep files on different devices in sync with one another. A*device*can be a Linux, Windows, or Mac computer, a server, an Android tablet or phone, and so on, and the files can be any file you want to keep updated across many machines. Syncthing is lightweight and peer-to-peer, so you don't need to pay for a service, you don't need a third-party server, and it's fast.- Synchronization is one thing, but sometimes you also need help dealing with the files you have. Say you want an application to behave differently depending on whether it's being used as a graphical application or as a console application. You could change the config file between, say,
`.foo-gui`
and`.foo-term`
by changing which its symlink points to. Doing that manually is entirely possible, but it could be scripted, or you could just use[GNU Stow](https://opensource.com/article/20/1/configuration-management-stow)instead.
## Email management
We all depend on email and inboxes, but few of us seem to be comfortable with how we manage it. If you're inclined to working in the terminal, why not stay in the terminal for email? It's one thing to check and send email from a terminal, but it's even more exciting to organize your email that way. If you're a typist by trade and scripter by nature, check out some of these tools.
- I use
[OfflineIMAP](https://opensource.com/article/20/1/sync-email-offlineimap)every day to sync work email to my laptop for viewing in Mutt. It's a specific tool that does exactly one thing: it ensures that a local copy of your email inbox mirrors your remote inbox. It's relatively easy to set up and schedule with[cron](https://opensource.com/article/17/11/how-use-cron-linux), and then you can forget it exists. Easy and worth every minute you spend fighting with IMAP. [Notmuch](https://opensource.com/article/20/1/organize-email-notmuch)indexes, tags, and searches mail messages. If you have a problem with your inbox, it takes*not much*effort to remedy it.[Vim](https://opensource.com/article/20/1/vim-email-calendar)can check and send email and manage your calendar.[Emacs](https://opensource.com/article/20/1/emacs-mail-calendar), of course, also does email and calendaring.
## Calendars and contacts
Every Linux system I've ever used comes with the `cal`
command installed. This is a handy little calendar for the terminal, and it's a great quick reference. However, it's hardly what you'd call a calendaring application. The [iCalendar](https://tools.ietf.org/html/rfc5545) specification (no relation to Apple's old desktop calendar) provides rich shared calendaring functionality, and while `.ics`
appointments and events are plain text, the workflow for managing them in the terminal is basically non-existent. Or at least, it was non-existent until khal and vdirsyncer.
[Khal](https://opensource.com/article/20/1/open-source-calendar)is a console-based calendar that reads and writes`.ics`
files.[Vdirsyncer](https://opensource.com/article/20/1/open-source-calendar)is a terminal command that synchronizes online calendars (and contacts) to your local drive. Khal works locally and vdirsyncer works remotely, so your calendars online stay in sync with the calendar you're managing on your hard drive.- Contact management can be hard, but it gets easier if you use
[Khard](https://opensource.com/article/20/1/sync-contacts-locally), a terminal command that reads and writes files in the vCard format. This, in turn, can be synchronized to a remote server using vdirsyncer (which you may already be using for your khal calendar). This makes calendaring and contacts easy, and it's easier than ever to[run your own personal information management (PIM) server](https://opensource.com/alternatives/google-calendar).
## To-do lists
- There are many ways to organize your day, but one of the easiest is
[todo.txt](https://opensource.com/article/20/1/open-source-to-do-list), a simple, portable, understandable system that doesn't break down even if a device doesn't have todo.txt installed on it. The reason todo.txt works is because it's just a Bash shell script, which will run on nearly any computing device you can find. The process is simple: you download the script, install it to your home directory, and start scheduling tasks with a simple command. If you're on a computer that doesn't have the`todo.sh`
command installed, your to-do list is still useful as a plain-text file, which you can update manually as needed. [Jrnl](https://opensource.com/article/20/1/python-journal)is a digital notebook to keep track of your daily agenda and activities. This is the program you've been looking for if you compulsively jot notes on scraps of paper on your desk or echo idle thoughts into random text files.
## Keep in touch
Communication is key, and yet now more than ever, there seems to be a chat platform problem. There aren't just several clients, there are several isolated networks. How do you manage them all? Here are two ideas.
- If you've got lots of contacts spread across too many chat networks, you ought to try
[BitlBee](https://opensource.com/article/20/1/open-source-chat-tool), the singular chat client that lets you infiltrate all the others. [Rainbow Stream](https://opensource.com/article/20/1/tweet-terminal-rainbow-stream)is a Twitter client that can be awfully useful to keep you away from the distractions of an open web browser while still keeping you in touch with your adoring public.
## Keep informed
Web browsers are nice, but they can sometimes be overkill. You want to stay informed, but you don't want to give yourself entirely over to the internet. Because the internet is built upon open specifications and a lot of open source technology, you don't have to do everything through just one interface. There are *clients* for all kinds of tasks, and they give you access to the information you need, using the interface you prefer.
[Tuir](https://opensource.com/article/20/1/open-source-reddit-client)is a terminal client to Reddit.[Newsboat](https://opensource.com/article/20/1/open-source-rss-feed-reader)is an RSS feed reader.[Wego](https://opensource.com/article/20/1/open-source-weather-forecast)brings you a weather report.[Vim](https://opensource.com/article/20/1/vim-task-list-reddit-twitter)can help you check in with Reddit and Twitter.[Emacs](https://opensource.com/article/20/1/emacs-social-track-todo-list)can keep you connected with clients for Reddit, Twitter, chat, and much more.
## Keep that terminal open
If you're spending time in a terminal, what's the point in ever closing a terminal? Do away with the temptation of `exit`
or `Ctrl+D`
and keep your console open.
[Tmux](https://opensource.com/article/20/1/tmux-console)lets you split your terminal, "layer" one terminal window on top of another, and even walk away from one computer and continue the same terminal session from another computer.[DESQview](https://opensource.com/article/20/1/multiple-consoles-twin)takes a different approach: it's essentially a window manager for your terminal.
## Keep going
The tools in this article are but a subset of amazing productivity tools for your Linux terminal. This list must end, but your personal list can grow. Find the tools you love, learn them, and use them to your greatest advantage. Of course, a good tool doesn't always have to increase your productivity: sometimes your favorite command is the one that makes you happiest. Your job is to find the commands you love and to do amazing things with them.
Have fun!
## 6 Comments |
12,276 | 如何使用 firewall-cmd 管理网络服务 | https://fedoramagazine.org/how-to-manage-network-services-with-firewall-cmd/ | 2020-06-03T09:09:16 | [
"防火墙"
] | https://linux.cn/article-12276-1.html | 
在上一篇文章中,我们探讨了如何在 Fedora 中[用命令行控制防火墙](/article-12103-1.html)。
现在你将看到如何“添加”、“删除”和“列出”服务、协议和端口,以便“阻止”或“允许”它们。
### 简短回顾
首先,最好检查一下防火墙的*状态*,看它是否正在运行。如我们先前所学,你可以使用状态选项(`firewall-cmd ‐‐state`)来得到。
下一步是获取网络接口适用的<ruby> 域 <rt> zone </rt></ruby>。例如,我使用的桌面有两个网络接口:一个*物理*接口(`enp0s3`),代表我实际的*网卡*,和*虚拟*接口(`virbr0`),它由 KVM 等虚拟化软件使用。要查看哪些域处于活动状态,请运行 `firewall-cmd ‐‐get-active-zones`。
现在,你知道了你感兴趣的域,可以使用 `firewall-cmd ‐‐info-zone=FedoraWorkstation` 这样的命令列出该域的规则。
### 读取区域信息
要显示*特定域*的信息,请运行 `firewall-cmd ‐‐zone=ZoneName ‐‐list-all`,或使用以下命令显示默认域的信息:
```
[dan@localhost ~]$ firewall-cmd --list-all
FedoraWorkstation (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3
sources:
services: dhcpv6-client mdns samba-client ssh
ports: 1025-65535/udp 1025-65535/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
```
现在,让我们查看输出。第一行表明以下信息关联的域以及该域当前是否在使用中。
`target: default`:告诉我们这是默认域。可以通过 `‐‐set-default-zone=ZoneName` 和 `‐‐get-default-zone` 设置或获取。
`icmp-block-inversion` 表明是否阻止 [ICMP](https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol) 请求。例如,如果机器响应来自网络上其他机器的 ping 请求。
`interfaces` 字段显示接受此域的所有接口。
### 处理服务、端口和协议
现在,重点关注 `services`、`ports` 和 `protocols` 所在行。默认情况下,防火墙将阻止所有端口、服务和协议,而只允许列出的。
在这里,你可以看到允许的服务是非常基本的客户端服务。例如,访问网络上的共享文件夹(`samba-client`)、与 DNS 服务器通信或通过 SSH(`ssh` 服务)连接到计算机。你可以将 `service` 视为与端口组合的协议,例如 `ssh` 服务使用 SSH 协议,并且按照惯例使用 22 端口。通过允许 `ssh` 服务,你实际上所做的就是允许传入的连接在默认 22 端口上使用 SSH 协议。
请注意,根据经验,名称中带有 `client` 字样的服务是指传出连接,也就是你使用你的 IP 作为源对外部的*连接*,与之相反的是 `ssh` 服务,比如,它将接受传入连接(监听来自外部的连接)。
你可以在文件 `/etc/services` 中查找服务。例如,如果你想知道这些服务使用什么端口和协议:
```
[dan@localhost ~]$ cat /etc/services | grep ssh
ssh 22/tcp # The Secure Shell (SSH) Protocol
ssh 22/udp # The Secure Shell (SSH) Protocol
```
你可以看到 SSH 同时使用 TCP 和 UDP 的 22 端口。此外,如果你希望查看所有可用的服务,只需使用 `firewall-cmd --get-services`。
#### 打开端口
如果要阻止端口、服务或协议,请确保在此处未列出它们。展开来说,如果要允许服务,那么需要将它添加到列表中。
假设你要打开 `5000` 端口用于 TCP 连接。为此,请运行:
```
sudo firewall-cmd --zone=FedorwaWorkstation --permanent --add-port=5000/tcp
```
请注意,你需要指定规则适用的域。添加规则时,还需要如上指定它是 `tcp` 还是 `udp` 端口。`--permanent` 参数将规则设置为即使系统重启后也可以保留。
再次查看你所在区域的信息:
```
[dan@localhost ~]$ firewall-cmd --list-all
FedoraWorkstation (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3
sources:
services: dhcpv6-client mdns samba-client ssh
ports: 1025-65535/udp 1025-65535/tcp 5000/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
```
类似地,如果你想从列表删除该端口,请运行:
```
sudo firewall-cmd --zone=FedorwaWorkstation --permanent --remove-port=5000/tcp
```
相同的 `remove` (`‐‐remove-protocol`、`‐‐remove-service`) 和 `add`(`‐‐add-protocol`、`‐‐add-service`)选项同样适用于*服务*和*协议*。
---
via: <https://fedoramagazine.org/how-to-manage-network-services-with-firewall-cmd/>
作者:[dan01](https://fedoramagazine.org/author/dan01/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In a previous article, you explored how to [control the firewall at the command line](https://fedoramagazine.org/control-the-firewall-at-the-command-line/) in Fedora.
Now you are going to see how to see how *add*, *remove*, and *list* *services*, *protocols* and *ports* in order to *block* or *allow* them.
## A short recap
First, it’s a good idea to check the *status* of your firewall, see if it’s running or not. You do this, as we previously learned, by using the state option (*firewall-cmd *‐‐*state*).
The next step is to get the zone for the desired network interface. For example, I use a desktop that has two network interfaces: a *physical* interface (*enp0s3*), representing my actual *network card* and a *virtual* interface (*virbr0*) used by virtualization software like *KVM*. To see what zones are active, run *firewall-cmd ‐‐get-active-zones*.
Now that you know what zone you’re interested in, you can list the rules for the zone with *firewall-cmd ‐‐info-zone=FedoraWorkstation*.
## Reading zone information
To display information for a particular *zone*, run *firewall-cmd ‐‐zone=ZoneName ‐‐list-all*, or simply display information for the default zone with:
[dan@localhost ~]$ firewall-cmd --list-all
FedoraWorkstation (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3
sources:
services: dhcpv6-client mdns samba-client ssh
ports: 1025-65535/udp 1025-65535/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
Now, let’s explore the output. The first line is showing which *zone* the following information applies to and if that zone is currently in use.
The *target* : *default* simply tells us this is the default zone. This can be set or retrieved via the *‐‐set-default-zone=ZoneName* and *‐‐get-default-zone*.
*icmp-block-inversion*, indicates if [ICMP](https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol) requests are blocked. For example if the machine responds to *ping* requests from other machines on the network. The *interfaces* field shows all interfaces that adopt this zone.
## Handling services, ports, and protocols
Now focus on the *services*, *ports*, and *protocols* rows. By default, the firewall will block all ports, services and protocols. Only the listed ones will be allowed.
You can see the allowed services are very basic client services in this case. For example, accessing a shared folder on the network (*samba-client*), to talk to a *DNS* server or connect to a machine via SSH (the *ssh* service). You can think of a *service *as a protocol in combination to a port, for instance the ssh service is using the SSH protocol and, by convention, port 22. By allowing the ssh service, what you’re really doing is allowing incoming connections that use the ssh protocol at default port 22.
Notice, services that have the *client* word in their name, as a rule of thumb, refer to outgoing connections, i.e. *connections *that you make with your IP as source going to the outside, as opposed to the SSH* *service, for example, that will accept incoming connections (listening to connection coming from outside at you).
You can look up services in the file */etc/services*. For example if you wish to know what port and protocol these service uses:
[dan@localhost ~]$ cat /etc/services | grep ssh
ssh 22/tcp # The Secure Shell (SSH) Protocol
ssh 22/udp # The Secure Shell (SSH) Protocol
You can see SSH uses both TCP and UDP port 22. Also, if you wish to see all available services, just use *firewall-cmd ‐‐get-services*.
### Opening a port
If you want to block a port, service, or protocol, all you have to do if make sure it’s not listed here. By extension, if you want to allow a service, you need add it to your list.
Let’s say you want to open the port *5000* for *TCP*** **connection. To do this, run:
sudo firewall-cmd --zone=FedorwaWorkstation --permanent --add-port=5000/tcp
Notice that you need to specify the zone for which the rule applies. When you add the rule, you also need to specify if it is a *TCP* or *UDP* port via as indicated above. The *permanent* parameter sets the rule to persist even after a system reboot.
Look at the information for your zone again:
[dan@localhost ~]$ firewall-cmd --list-all FedoraWorkstation (active) target: default icmp-block-inversion: no interfaces: enp0s3 sources: services: dhcpv6-client mdns samba-client ssh ports: 1025-65535/udp 1025-65535/tcp 5000/tcp protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:
Similarly, if you wish to remove this port from the list, run:
sudo firewall-cmd --zone=FedorwaWorkstation --permanent --remove-port=5000/tcp
The very same *remove* (*‐‐remove-protocol*,* ‐‐remove-service*) and *add* (*‐‐add-protocol*,* ‐‐add-service*) options are also available for *services* and *protocols*.
## Jack
You seriously should delete this google+ button from top right corner 🙂
## Joao Rodrigues
If you use the –permanent, your rules won’t be applied until you do a firewall-cmd –reload or until you reboot.
Also, there’s a couple of typos.
It’s written fedorwa instead of fedora
## dan01
Good remark! And thanks for the observation, I’ll see what I can to correct that!
## Steven
Being able to create your own service definitions and applying those to specific zones and interfaces is also super useful.
## Jordan
Nice job, I need to learn more about this.
## dan01
Thank you! Means much to me! I know it’s a bit repetitive to what was written in part one, maybe should have covered also how to deal with custom services.
## Giovanni Fabbro
So I noticed that Fedora 33 is going to be using systemd-resolved by default too.
Great, but can we standardize on systemd-swap as well? Swap partitions seem to be wasteful and outdated at this point in time. Isn’t there security improvements having it as a file on an encrypted filesystem vs a standalone partition (does LUKS do this automatically?)? And shouldn’t it be more economical on resources with the EarlyOOM improvements?
## Muhammad Nabeel
Nice job, I need to learn more about this.Thank alot i hope you update upto time
## MF
One thing I have been missing in firewalld is the ability to add private services from e.g. rpm packages.
Assume that I have a exampled.rpm which contains a server listening on the “example” port, upon installation of that I would like to be able to register the “example” service in firewalld, how would I go about doing that?
## dan01
Good question! I think that by simply opening the correct port and protocol, it would become neutral or agnostic in regards to what you are running. In other words you could run http server X or server Y as long as they operate on same port/protocol and that’s set up in the firewall you can exchange them with no problem.
Now you could also create your custom service myHttpServer and deal with that level of abstractin if so wish.
Hope it helps
## Steven
You can easily create your own custom services by adding them at the command line with firewall-cmd and leverage the –new-service (I’d just inject all of the ports/description/etc, and then do a –runtime-to-permanent call).
Or you can write the file in your favorite text editor, and then call firewall-cmd –new-service-from-file.
Or you can write the definition straight to: /etc/firewalld/services/${YOUR_SERVICE}.xml, and then firewall-cmd –add-service=${YOUR_SERVICE}
## Joao Rodrigues
Let’s say your example service listens on ports 666/tcp and 999/udp:
Create a file called /etc/firewalld/services/example-service.xml with the contents:
Example Service
A longer description where you explain what the example service is and what it does
Then you can register the example service like this:
firewall-cmd –permanent –add-service=example-service
firewall-cmd –reload
## Joao Rodrigues
(Edit: Let’s see if this displays correctly – can we have a preview comment?)
Let’s say your example service listens on ports 666/tcp and 999/udp:
Create a file called /etc/firewalld/services/example-service.xml with the contents:
<service>
<short>Example Service</short>
<description>A longer description where you explain what the example service is and what it does</description>
<port protocol="tcp" port="666"/>
<port protocol="udp" port="999"/>
</service>
Then you can register the example service like this:
# firewall-cmd –permanent –add-service=example-service
# firewall-cmd –reload
## Ondrej
No it did not 😀
The default services are defined in:
/usr/lib/firewalld/services/*.xml
so you can always have a look and just copy paste them O:)
## itsmefma
Thanks for the article!
If there is another entry in this series I would like it to be about rich rules 😀
greets!
## Anonymous
A few tips and tricks for firewall-cmd I’ve learned over the years that are valuable when using Fedora on a multi-NIC system as firewall:
Get familiar with nmcli for managing the IP settings and configurations on your interfaces. Running nmcli without parameters will give you a quick overview of your current interfaces and their configuration. The nmcli commands aren’t difficult – nmcli connection edit ‘Connection Name’ drops you in, goto section lets you configure a section, print shows you the settings, back goes up a level, save, quit, etc. It’s all pretty self explanatory. Note it likes /CIDR notation (i.e. 123.45.67.89/24) for addresses, and it assumes when you got to set the address that you’re adding to an existing one, so you need to clear the existing address if it has one before adding a new one. At this point, I disable all IPv6 because I don’t know enough to secure it properly.
Next, you set up your zones using firewall-cmd independently of binding to them. I typically have an internal zone and two external zones – external_lockdown for when I don’t want any inbound connectivity, and external_normal that exposes my normal services to the Internet. For my external_lockdown zone, I even use –add-icmp-block for everything – I go completely icmp quiet.
On both of my external zones I have –add-masquerade – that’s how you get IPv4 NATing to work.
Finally, the tricky piece of the puzzle is that my experience is that firewall-cmd doesn’t bind zones to interfaces properly if the interface isn’t plugged in. Futher more, sometimes it seems like you can end up with multiple zones bound to a single interface, and that doesn’t seem helpful. So what I do now is do my zone binding from a console connection. Next, when I’m messing with zones on the external interface, I disconnect my external feed and just the cable from my internal network switch to whichever interface I’m binding. I unbind the current zone on that interface with –remove-interface, then add the interface to the new zone with –add-interface, then use –reload, then check everything with –get-active-zones.
Finally, I use GRC’s Shields Up to probe my machine from the Internet after doing any work as confirmation that the ports I expect to see are open and everything else is locked down tight.
## http://167.71.215.86
Hello to every one, for the reason that I am really keen of reading this
webpage’s post to be updated daily. It contains good data. |
12,277 | 修改磁盘镜像来创建基于树莓派的家庭实验室 | https://opensource.com/article/20/5/disk-image-raspberry-pi | 2020-06-03T12:34:48 | [
"树莓派",
"镜像"
] | https://linux.cn/article-12277-1.html |
>
> 使用树莓派或其它单板机创建一个“家庭私有云”。
>
>
>

构建一个[家庭实验室](https://opensource.com/article/19/3/home-lab)可以是一个有趣的方式,可以让你学习的新概念和实验新技术时还能自娱自乐。得益于以 [树莓派](https://opensource.com/resources/raspberry-pi) 为首的单板计算机(SBC)的流行,在舒适的家里就可以轻松构建一个多计算机实验室。比起试图在主流的云服务商建立的相同配置,创建一个“家庭私有云”以花更少的钱来体验到云原生技术,也是一个极好的方法。
这篇文章阐述如何修改树莓派或其它的单板机的磁盘镜像,预配置主机的 SSH,并禁用首次启动时强制竞选交互配置的服务。这是一个让你的设备“即启动,即运行”的极好方法,类似于云端实例。之后,你可以使用自动化的流程通过 SSH 连接来进行更专业和更深入的配置。
此外, 当向你的实验室添加更多的树莓派时,修改磁盘镜像可以来让你只需要将该镜像写到一个 SD 卡、放入树莓派中就可以了!

### 解压缩和挂载镜像
对于这个项目,你需要修改一个服务器磁盘镜像。在测试期间,我使用 [Fedora Server 31 ARM](https://arm.fedoraproject.org/)。在你下载该磁盘镜像并[验证其校验和](https://arm.fedoraproject.org/verify.html)之后,你需要将其解压缩并挂载其到宿主机的文件系统的某个位置上,以便你可以根据需要修改它。
你可以使用 [xz](https://tukaani.org/xz/) 命令通过 `--decompress` 参数来解压缩 Fedora 服务器镜像:
```
xz --decompress Fedora-Server-armhfp-X-y.z-sda.raw.xz
```
这会留下一个解压缩后的原始磁盘镜像(它会自动地替换 `.xz` 压缩文件)。这个原始磁盘镜像就像它听起来的那样:一个包含格式化后安装好的磁盘上的所有数据的文件。这包含分区信息、启动分区、root 分区以及其它分区。你需要挂载你打算在其中进行修改的分区,但是要做到这一点,你需要知道磁盘镜像中的分区起始位置和扇区大小,这样你才可以挂载该文件正确的扇区。
幸运的是,你可以在一个磁盘镜像上使用 [fdisk](https://en.wikipedia.org/wiki/Fdisk) 命令,就像在实际磁盘上使用一样容易。使用 `--list` 或 `-l` 参数来查看分区的列表和其信息:
```
# 使用 fdisk 来列出原始镜像文件的分区:
$ fdisk -l Fedora-Server-armhfp-31-1.9-sda.raw
Disk Fedora-Server-armhfp-X-y.z-sda.raw: 3.2 GiB, 3242196992 bytes, 6332416 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xdaad9f57
Device Boot Start End Sectors Size Id Type
Fedora-Server-armhfp-X-y.z-sda.raw1 8192 163839 155648 76M c W95 F
Fedora-Server-armhfp-X-y.z-sda.raw2 * 163840 1163263 999424 488M 83 Linux
Fedora-Server-armhfp-X-y.z-sda.raw3 1163264 6047743 4884480 2.3G 83 Linux
```
你需要的所有信息都可在上面的输出中获得。第 3 行表示扇区大小(包括逻辑和物理的):512 字节 / 512 字节。
设备列表显示的是原始磁盘镜像中的分区。第一个,`Fedora-Server-armhfp-X-y.z-sda.raw1` 毫无疑问是引导程序分区,因为它是第一个,很小(仅仅 76MB),而且类型被标识为 `c`,即 W95 FAT32(LBA),这是一个从 SD 卡启动的 FAT32 分区。
第二个分区也不是非常大,只有 488MB。这个分区是一个 Linux 原生类型分区(Id 83),它可能是包含内核和 [initramfs](https://wiki.debian.org/initramfs) 的 Linux 启动分区。
第三个分区可能是你需要的东西:它有 2.3GB 大小,所以在它其中应该有发行版的主要部分,并且它是一个 Linux 原生分区类型,这也是在预料之中的。这个分区应该包含了你需要修改的分区和数据。
第三个分区从扇区 1163264 开始(在 `fdisk` 的输出中被显示为 `Start` 列),所以你的挂载偏移量是 `595591168`,计算方法是将扇区大小(512)乘以起始扇区(1163264)(即 `512 * 1163264`)。这意味着你需要以偏移量 `595591168` 挂载该文件,才能挂载到正确位置。
装备了这些信息,现在你可以将第三个分区挂载到你的家目录中了:
```
$ mkdir ~/mnt
$ sudo mount -o loop,offset=595591168 Fedora-Server-armhfp-X-y.z-sda.raw ~/mnt
$ ls ~/mnt
```
### 直接在磁盘镜像中作业
在磁盘镜像被解压缩和被挂载到宿主机上的一个位置后,就可以修改镜像以符合你的需求。在我看来,对镜像进行更改的最简单的方法是使用 `chroot` 来将你会话的工作根目录更改为挂载镜像的工作根目录。不过,有点棘手。
在你改变了根目录后,你的会话将使用新的根目录下的二进制文件。除非你是在一个 ARM 系统做这些所有的操作,否则解压缩后的磁盘镜像的架构将与你正在使用的宿主机系统不同。即使在 chroot 环境中,宿主机系统也无法使用一个不同架构的二进制文件。至少,不能在本机使用。
幸运的是,这里有一个解决方案:qemu-user-static。来自 [Debian Wiki](https://wiki.debian.org/RaspberryPi/qemu-user-static) 的说明:
>
> “[qemu-user-static] 提供了用户模式的仿真二进制文件,是静态构建的。在这个模式中,QEMU 可以在一个 CPU 上启动为另一个 CPU 编译的 Linux 进程 …… 如果安装了 binfmt-support 软件包,qemu-user-static 软件包会注册提供的仿真器可以处理的二进制文件格式,以便其能够直接运行其他架构的二进制文件。”
>
>
>
这正是你需要在 chroot 环境中非本地架构中工作所需的。如果宿主机系统是 Fedora,使用 DNF 来安装 `qemu-user-static` 软件包,并重新启动 `systemd-binfmt.service`:
```
# 使用 DNF 启用非本地的 arch chroot 环境,添加新的二进制文件格式信息
# 输出镜像了精简
$ dnf install qemu-user-static
$ systemctl restart systemd-binfmt.service
```
使用这种方法,你一个能够更改根目录到挂载的磁盘镜像,运行 `uname` 命令来验证一切都在正常:
```
sudo chroot ~/mnt/ /usr/bin/uname -a -r
Linux marvin 5.5.16-200.fc31.x86_64 #1 SMP Wed Apr 8 16:43:33 UTC 2020 armv7l armv7l armv7l GNU/Linux
```
在 chroot 环境中运行 `uname` 将在输出中显示 `armv7l`,这个原始磁盘镜像的架构, 而不是宿主机的架构。一切如预期,可以继续修改镜像了。
### 修改磁盘镜像
现在你可以直接切换到这个基于 ARM 的磁盘镜像中,并在该环境中工作了,你可以对镜像自身镜像修改了。你需要设置该镜像,以便它能够启动并可立即访问,而不需要在树莓派上做任何额外的设置。为此,你需要安装并启用 sshd(OpenSSH 守护进程),并为 SSH 访问添加授权密码。
为了使其表现得更像一个云环境,实现在家里建立私有云的梦想,添加一个本地用户,给予该用户 `sudo` 权限,并(为了像云端的重度用户一样)允许该用户无需密码就可以使用 `sudo`。
所以,你将做的事情是:
* 安装并启用 SSHD(SSHD 已经在 Fedora ARM 镜像中安装并启用,但是你可能需要为你发行版手动执行这些工作)
* 设置一个本地用户
* 允许本地用户来使用 `sudo`(无需密码,可选)
* 添加授权密钥
* 允许 root 使用授权密码镜像 SSH(可选)
我使用 GitHub 功能,它允许你上传你的 SSH 公钥,并在 [https://github.com/.keys](https://github.com/%3Cyour_github_username%3E.keys) 处可访问。我发现这是一种很方便的分发公钥的方法,不过我生性多疑,我总是检查下载的密钥是否与我预期的匹配。如果你不想使用这种方法,你可以从你宿主机中复制你公钥到 chroot 环境中,或者你可以将公钥托管在你控制的 Web 服务器上以便使用相同的工作流。
要开始修改磁盘镜像,再次切换根目录到挂载的磁盘镜像中,这次启动一个 shell,以便可以运行多个命令:
```
# 为了简洁起见,省略了这些命令的输出(如果有的话)
$ sudo chroot ~/mnt /bin/bash
# 安装 openssh-server ,并启用它 (在 Fedora 上已经完成)
$ dnf install -y openssh-server
$ systemctl enable sshd.service
# 允许 root 使用授权密码访问 SSH
$ mkdir /root/.ssh
# 下载或者另外添加授权密码文件,你的公共密码
# 将 URL 替换为你自己公共密码的路径
$ curl <https://github.com/clcollins.keys> -o /root/.ssh/authorized_keys
$ chmod 700 /root/.ssh
$ chmod 600 /root/.ssh/authorized_keys
# 添加一个本地用户,并放置他们到 wheel 组中
# 将组和用户更改为您想要的一切
useradd -g chris -G wheel -m -u 1000 chris
# 下载并添加你的授权密码
# 像你上面所做的那样更改 home 目录和URL
mkdir /home/chris/.ssh
curl <https://github.com/clcollins.keys> -o /home/chris/.ssh/authorized_keys
chmod 700 /home/chris/.ssh
chmod 600 /home/chris/.ssh/authorized_keys
chown -R chris.chris /home/chris/.ssh/
# 允许 wheel 组( 使用你的本地用户) 不需要使用密码来使用 suso
echo "%wheel ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers.d/91-wheel-nopasswd
```
这就是树莓派或其它单板机在首次启动时需要完成设置 SSH 的全部工作。不过,每个发行版都有自己的特点。例如,Raspbian 已经包含一个本地用户:`pi`,并且不使用 `wheel` 组。因此对于 Raspbian 来说,最好使用现有用户,或者删除 `pi` 用户,并使用另一个用户来替换它。
在 Fedora ARM 的情况下,镜像会在首次引导启动时提示你完成设置。这会破坏你在上面所做的修改的目的,尤其是在设置完成之前,它会完全阻止启动。你的目标是使树莓派的功能类似于私有云的基础设施的一部分一样运行,而这个工作流程包括在主机启动时通过 SSH 远程设置主机。 禁用初始化设置,它由 `initial-setup.service` 控制:
```
# 对多用户和图形目标禁用 initial-setup.service
unlink /etc/systemd/system/multi-user.target.wants/initial-setup.service
unlink /etc/systemd/system/graphical.target.wants/initial-setup.service
```
当你在 chroot 环境时,你可以对你系统做任何你想做的其它更改,或者就放在那里,在第一次启动后,按照云原生的工作流通过 SSH 进行配置。
### 重新压缩并安装修改后的镜像
完成了这些更改后,剩下的就是重新压缩磁盘镜像,并将其安装其到你的树莓派的 SD 卡上。
确保退出 chroot 环境,然后卸载磁盘镜像:
```
$ sudo umount ~/mnt/
```
就像最初解压缩镜像一样,你可以再次使用 `xz` 命令来压缩镜像。通过使用 `--keep` 参数,`xz` 将保留原始的镜像,而不是清理掉它。虽然这会占用更多的磁盘空间,但保留下来的未压缩镜像将允许你对正在处理的镜像进行增量更改,而不需要每次都对其进行解压缩。这对于在测试和调整镜像时节省时间是非常好的。
```
# 压缩压缩磁盘镜像为一个 .xz 文件,但保留原始磁盘镜像
xz --compress Fedora-Server-armhfp-31-1.9-sda.raw --keep
```
压缩过程将花费一些时间,所以趁着这个时间站起来,舒展身体,让你的血液再次流动。
在压缩完成后,可以将新的、已修改过的磁盘镜像复制到 SD 卡上,以便与树莓派一起使用。标准的 `dd` 方法将镜像放置到 SD 卡上也很好用,但是我喜欢使用 Fedora 的 `arm-image-installer`,因为它因为它在处理未经编辑的镜像时提供了一些选项。它对编辑过的镜像也很好用,并且比 `dd` 命令更友好一些。
确保检查 SD 卡在哪个磁盘驱动器上,并用 `--media` 参数使用它:
```
# 使用 arm-image-installer 来复制已修改的磁盘镜像到 SD 卡上
arm-image-installer --image=Fedora-Server-armhfp-X-y.z-sda.raw.xz --target=rpi3 --media=/dev/sdc --norootpass --resizefs -y
```
现在,你已经为树莓派或其它单板机准备好了一个新的、已修改的 Fedora Server ARM 镜像,准备好启动并立即 SSH 到你的修改镜像中。这种方法也可以用来做其它的修改,并且你也可以使用其它发行版的原始磁盘镜像,如果你更喜欢它们,而不是 Fedora 的话。这是一个开始构建家庭实验室私有云的良好基础。在以后的文章中,我将指导你使用云技术和自动化建立一个家庭实验室。
### 延伸阅读
为了学习如何做这篇文章中的事情,我做了很多研究。以下是我找到的两个对学习如何定制磁盘映像和使用非原生架构最有帮助的资料。它们对我从“不知道自己在做什么”到“我能够完成它!”非常有帮助。
* [如何修改你的自定义 Linux 发行版的原始磁盘镜像](https://www.linux.com/news/how-modify-raw-disk-image-your-custom-linux-distro/)
* [使用 DNF 维基](https://wiki.mageia.org/en/Using_DNF#Setting_up_a_container_for_a_non-native_architectur)
---
via: <https://opensource.com/article/20/5/disk-image-raspberry-pi>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Building a [homelab](https://opensource.com/article/19/3/home-lab) can be a fun way to entertain yourself while learning new concepts and experimenting with new technologies. Thanks to the popularity of single-board computers (SBCs), led by the [Raspberry Pi](https://opensource.com/resources/raspberry-pi), it is easier than ever to build a multi-computer lab right from the comfort of your home. Creating a "private cloud at home" is also a great way to get exposure to cloud-native technologies for considerably less money than trying to replicate the same setup with a major cloud provider.
This article explains how to modify a disk image for the Raspberry Pi or another SBC, pre-configure the host for SSH (secure shell), and disable the service that forces interaction for configuration on first boot. This is a great way to make your devices "boot and go," similar to cloud instances. Later, you can do more specialized, in-depth configurations using automated processes over an SSH connection.
Also, as you add more Pis to your lab, modifying disk images lets you just write the image to an SD card, drop it into the Pi, and go!

## Decompress and mount the image
For this project, you need to modify a server disk image. I used the [Fedora Server 31 ARM](https://arm.fedoraproject.org/) image during testing. After you download the disk image and [verify its checksum](https://arm.fedoraproject.org/verify.html), you need to decompress and mount it to a location on the host computer's file system so you can modify it as needed.
You can use the ** xz** command to decompress the Fedora Server image by using the
**--decompress**argument:
`xz --decompress Fedora-Server-armhfp-X-y.z-sda.raw.xz`
This leaves you with a raw, decompressed disk image (which automatically replaces the **.xz** compressed file). This raw disk image is just what it sounds like: a file containing all the data that would be on a formatted and installed disk. That includes partition information, the boot partition, the root partition, and any other partitions. You need to mount the partition you intend to work in, but to do that, you need information about where that partition starts in the disk image and the size of the sectors on the disk, so you can mount the file at the right sector.
Luckily, you can use the [ fdisk](https://en.wikipedia.org/wiki/Fdisk) command on a disk image just as easily as on a real disk and use the
**--list**or
**-l**argument to view the list of partitions and their information:
```
# Use fdisk to list the partitions in the raw image:
$ fdisk -l Fedora-Server-armhfp-31-1.9-sda.raw
Disk Fedora-Server-armhfp-X-y.z-sda.raw: 3.2 GiB, 3242196992 bytes, 6332416 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xdaad9f57
Device Boot Start End Sectors Size Id Type
Fedora-Server-armhfp-X-y.z-sda.raw1 8192 163839 155648 76M c W95 F
Fedora-Server-armhfp-X-y.z-sda.raw2 * 163840 1163263 999424 488M 83 Linux
Fedora-Server-armhfp-X-y.z-sda.raw3 1163264 6047743 4884480 2.3G 83 Linux
```
All the information you need is available in this output. Line 3 indicates the sector size, both logical and physical: (512 bytes / 512 bytes).
The list of devices shows the partitions inside the raw disk image. The first one, **Fedora-Server-armhfp-X-y.z-sda.raw1** is no doubt the bootloader partition because it is the first, small (only 76MB), and type W95 FAT32 (LBA), as identified by the Id "c," a FAT32 partition for booting off the SD card.
The second partition is not very large either, just 488MB. This partition is a Linux native-type partition (Id 83), and it probably is the Linux boot partition containing the kernel and [initramfs](https://wiki.debian.org/initramfs).
The third partition is what you probably want: it is 2.3GB, so it should have the majority of the distribution on it, and it is a Linux-native partition type, which is expected. This should contain the partition and data you want to modify.
The third partition starts on sector 1163264 (indicated by the "Start" column in the output of **fdisk**), so your mount offset is **595591168**, calculated by multiplying the sector size (512) by the start sector (1163264) (i.e., **512 * 1163264**). This means you need to mount the file with an offset of 595591168 to be in the right place at the mount point.
ARMed (see what I did there?) with this information, you can now mount the third partition to a directory in your homedir:
```
$ mkdir ~/mnt
$ sudo mount -o loop,offset=595591168 Fedora-Server-armhfp-X-y.z-sda.raw ~/mnt
$ ls ~/mnt
```
## Work directly within the disk image
Once the disk image has been decompressed and mounted to a spot on the host computer, it is time to start modifying the image to suit your needs. In my opinion, the easiest way to make changes to the image is to use **chroot** to change the working root of your session to that of the mounted image. There's a tricky bit, though.
When you change root, your session will use the binaries from the new root. Unless you are doing all of this from an ARM system, the architecture of the decompressed disk image will not be the same as the host system you are using. Even inside the **chroot**, the host system will not be able to make use of binaries with a different architecture. At least, not natively.
Luckily, there is a solution: **qemu-user-static**. From the [Debian Wiki](https://wiki.debian.org/RaspberryPi/qemu-user-static):
"[qemu-user-static] provides the user mode emulation binaries, built statically. In this mode QEMU can launch Linux processes compiled for one CPU on another CPU… If binfmt-support package is installed, qemu-user-static package will register binary formats which the provided emulators can handle, so that it will be possible to run foreign binaries directly."
This is exactly what you need to be able to work in the non-native architecture inside your chroot. If the host system is Fedora, install the **qemu-user-static** package with DNF, and restart **systemd-binfmt.service**:
```
# Enable non-native arch chroot with DNF, adding new binary format information
# Output suppressed for brevity
$ dnf install qemu-user-static
$ systemctl restart systemd-binfmt.service
```
With this, you should be able to change root to the mounted disk image and run the **uname** command to verify that everything is working:
```
sudo chroot ~/mnt/ /usr/bin/uname -a -r
Linux marvin 5.5.16-200.fc31.x86_64 #1 SMP Wed Apr 8 16:43:33 UTC 2020 armv7l armv7l armv7l GNU/Linux
```
Running **uname** from within the changed root shows **armv7l** in the output—the architecture of the raw disk image—and not the host machine. Everything is working as expected, and you can continue on to modify the image.
## Modify the disk image
Now that you can change directly into the ARM-based disk image and work in that environment, you can begin to make changes to the image itself. You want to set up the image so it can be booted and immediately accessed without having to do any additional setup directly on the Raspberry Pi. To do this, you need to install and enable sshd (the OpenSSH daemon) and add the authorized keys for SSH access.
And to make this behave more like a cloud environment and realize the dream of a private cloud at home, add a local user, give that user **sudo** rights, and (to be just like the cloud heavyweights) allow that user to use **sudo** without a password.
So, your to-do list is:
- Install and enable SSHD (SSHD is already installed and enabled in the Fedora ARM image, but you may need to do this manually for your distribution)
- Set up a local user
- Allow the local user to use sudo (without a password, optional)
- Add authorized keys
- Allow root to SSH with the authorized keys (optional)
I use the GitHub feature that allows you to upload your public SSH keys and make them available at ** https://github.com/<your_github_username>.keys**. I find this to be a convenient way to distribute public keys, although I am paranoid enough that I always check that the downloaded keys match what I am expecting. If you don't want to use this method, you can copy your public keys into the
**chroot**directly from your host computer, or you can host your keys on a web server that you control in order to use the same workflow.
To start modifying the disk image, **chroot** into the mounted disk image again, this time starting a shell so multiple commands can be run:
```
# Output of these commands (if any) are omitted for brevity
$ sudo chroot ~/mnt /bin/bash
# Install openssh-server and enable it (already done on Fedora)
$ dnf install -y openssh-server
$ systemctl enable sshd.service
# Allow root to SSH with your authorized keys
$ mkdir /root/.ssh
# Download, or otherwise add to the authorized_keys file, your public keys
# Replace the URL with the path to your own public keys
$ curl https://github.com/clcollins.keys -o /root/.ssh/authorized_keys
$ chmod 700 /root/.ssh
$ chmod 600 /root/.ssh/authorized_keys
# Add a local user, and put them in the wheel group
# Change the group and user to whatever you desire
groupadd chris
useradd -g chris -G wheel -m -u 1000 chris
# Download or add your authorized keys
# Change the homedir and URL as you've done above
mkdir /home/chris/.ssh
curl https://github.com/clcollins.keys -o /home/chris/.ssh/authorized_keys
chmod 700 /home/chris/.ssh
chmod 600 /home/chris/.ssh/authorized_keys
chown -R chris.chris /home/chris/.ssh/
# Allow the wheel group (with your local user) to use suso without a password
echo "%wheel ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers.d/91-wheel-nopasswd
```
This is all that generally needs to be done to set up SSH into a Raspberry Pi or other single-board computer on first boot. However, each distribution has its own quirks. For example, Rasbian already includes a local user, **pi**, and does not use the **wheel** group. So for Raspbian, it may be better to use the existing user or to delete the **pi** user and replace it with another.
In the case of Fedora ARM, the image prompts you to finish setup on first boot. This defeats the purpose of the changes you made above, especially since it blocks startup entirely until setup is complete. Your goal is to make the Raspberry Pi function like part of a private cloud infrastructure, and that workflow includes setting up the host remotely via SSH when it starts up. Disable the initial setup, controlled by the service **initial-setup.service**:
```
# Disable the initial-setup.service for both the multi-user and graphical targets
unlink /etc/systemd/system/multi-user.target.wants/initial-setup.service
unlink /etc/systemd/system/graphical.target.wants/initial-setup.service
```
While you are in the change root, you can make any other changes you might want for your systems or just leave it at that and follow the cloud-native workflow of configuration over SSH after first boot.
## Recompress and install the modified image
With these changes to your system completed, all that is left is to recompress the disk image and install it on an SD card for your Raspberry Pi.
Make sure to exit the chroot, then unmount the disk image:
`$ sudo umount ~/mnt/`
Just as you decompressed the image initially, you can use the **xz** command again to compress the image. By using the **--keep** argument, **xz** will leave the raw image rather than cleaning it up. While this uses more disk space, leaving the uncompressed image allows you to make incremental changes to the images you are working with without needing to decompress them each time. This is great for saving time while testing and tweaking images to your liking:
```
# Compress the raw disk image to a .xz file, but keep the raw disk image
xz --compress Fedora-Server-armhfp-31-1.9-sda.raw --keep
```
The compression takes a while, so take this time to stand up, stretch, and get your blood flowing again.
Once the compression is done, the new, modified disk image can be copied to an SD card to use with a Raspberry Pi. The standard **dd** method to copy the image to the SD card works fine, but I like to use Fedora's **arm-image-installer** because of the options it provides when working with unedited images. It also works great for edited images and is a little more user-friendly than the **dd** command.
Make sure to check which disk the SD card is on and use that for the **--media** argument:
```
# Use arm-image-installer to copy the modified disk image to the SD card
arm-image-installer --image=Fedora-Server-armhfp-X-y.z-sda.raw.xz --target=rpi3 --media=/dev/sdc --norootpass --resizefs -y
```
Now you are all set with a new, modified Fedora Server ARM image for Raspberry Pis or other single board computers, ready to boot and immediately SSH into with your modifications. This method can also be used to make other changes, and you can use it with other distributions' raw disk images if you prefer them to Fedora. This is a good base to start building a private-cloud-at-home homelab. In future articles, I will guide you through setting up a homelab using cloud technologies and automation.
## Further reading
A lot of research went into learning how to do the things in this article. Two of the most helpful sources I found for learning how to customize disk images and work with non-native architectures are listed below. They were extremely helpful in rounding the corner from "I have no idea what I'm doing" to "OK, I can do this!"
## 4 Comments |
12,279 | 如何在重启或启动时执行命令或脚本 | https://www.2daygeek.com/execute-run-linux-scripts-command-at-reboot-startup/ | 2020-06-04T09:19:00 | [
"启动"
] | https://linux.cn/article-12279-1.html | 
众所周知 Linux 可以在启动时添加服务。例如,如果要在[启动时添加](https://www.2daygeek.com/enable-disable-services-on-boot-linux-chkconfig-systemctl-command/) Apache Httpd 服务,你可以在 `chkconfig` 和 `systemctl` 命令的帮助下完成此操作。
有时你需要在启动时添加自定义脚本、命令或服务,该怎么做?你可以使用以下三种方法来做到。
在本文中,我们将通过示例向你展示如何使用这些方法。
### 方法 1:如何使用 /etc/rc.d/rc.local 文件在重启或启动时运行脚本或命令
传统上,`/etc/rc.local` 文件是在切换到多用户运行级别的过程结束时,在所有正常的计算机服务启动之后执行的。
此方法也适用于 systemd 系统。
你需要将你的脚本位置添加到 `/etc/rc.d/rc.local` 文件中以在启动时运行。
确保该文件有运行权限:
```
# chmod +x /etc/rc.d/rc.local
```
作为演示,我们将创建一个简单的示例脚本。你可以根据需要创建任何脚本。
```
# vi /opt/scripts/run-script-on-boot.sh
#!/bin/bash
date > /root/on-boot-output.txt
hostname >> /root/on-boot-output.txt
```
脚本完成后,设置可执行权限:
```
# chmod +x /opt/scripts/run-script-on-boot.sh
```
最后,将该脚本添加到文件底部:
```
# vi /etc/rc.d/rc.local
/opt/scripts/run-script-on-boot.sh
```
[重启系统](https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/)进行检查:
```
# reboot
```
### 方法 2:如何使用 crontab 在重启或启动时执行命令或脚本
cron 在特定时间在后台自动执行计划的作业。可以在 [cron 任务](https://www.2daygeek.com/linux-crontab-cron-job-to-schedule-jobs-task/)中使用特殊的字符串 `@reboot` 来完成。`@reboot` 是一个特殊的字符串,它允许用户在启动时运行任何命令或脚本。
此示例在系统重启时运行 `/opt/scripts/run-script-on-boot.sh` 文件。我们将使用与上面相同的脚本。
为此,只需在 crontab 文件中添加以下条目:
```
# crontab -e
@reboot /opt/scripts/run-script-on-boot.sh
```
重启系统进行检查:
```
# reboot
```
### 方法 3:如何使用 systemd 服务单元在重启或启动时运行命令或脚本
此方法仅适用于 systemd 系统。该方法非常简单。
我们将使用上面相同的脚本进行演示。
为此,你需要创建一个 systemd 启动脚本并将其放在 `/etc/systemd/system/` 目录中。
这是我们的示例 systemd 启动单元脚本:
```
# vi sample-on-boot-script.service
[Unit]
Description=Run a Custom Script at Startup
After=default.target
[Service]
ExecStart=/opt/scripts/run-script-on-boot.sh
[Install]
WantedBy=default.target
```
将单元脚本放置在 systemd 所在位置后,运行以下命令更新 systemd 配置文件并启用服务:
```
# systemctl daemon-reload
# systemctl enable sample-on-boot-script.service
```
重启系统进行检查:
```
# reboot
```
### 额外提示
如果你想在后台运行脚本,你需要在最后加上 `&` 符号
```
/Path/To/My_Script &
```
如果你想以不同用户运行命令,使用以下格式:
```
su - $USER -c /Path/To/My_Script
```
---
via: <https://www.2daygeek.com/execute-run-linux-scripts-command-at-reboot-startup/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,280 | 使用 Python FastAPI 构建 Web 服务 | https://fedoramagazine.org/use-fastapi-to-build-web-services-in-python/ | 2020-06-04T11:00:04 | [
"FastAPI"
] | https://linux.cn/article-12280-1.html | 
[FastAPI](https://fastapi.tiangolo.com/) 是一个使用 Python 编写的 Web 框架,还应用了 Python asyncio 库中最新的优化。本文将会介绍如何搭建基于容器的开发环境,还会展示如何使用 FastAPI 实现一个小型 Web 服务。
### 起步
我们将使用 Fedora 作为基础镜像来搭建开发环境,并使用 Dockerfile 为镜像注入 FastAPI、[Uvicorn](https://www.uvicorn.org/) 和 [aiofiles](https://github.com/Tinche/aiofiles) 这几个包。
```
FROM fedora:32
RUN dnf install -y python-pip \
&& dnf clean all \
&& pip install fastapi uvicorn aiofiles
WORKDIR /srv
CMD ["uvicorn", "main:app", "--reload"]
```
在工作目录下保存 `Dockerfile` 之后,执行 `podman` 命令构建容器镜像。
```
$ podman build -t fastapi .
$ podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/fastapi latest 01e974cabe8b 18 seconds ago 326 MB
```
下面我们可以开始创建一个简单的 FastAPI 应用程序,并通过容器镜像运行。
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello Fedora Magazine!"}
```
将上面的代码保存到 `main.py` 文件中,然后执行以下命令开始运行:
```
$ podman run --rm -v $PWD:/srv:z -p 8000:8000 --name fastapi -d fastapi
$ curl http://127.0.0.1:8000
{"message":"Hello Fedora Magazine!"
```
这样,一个基于 FastAPI 的 Web 服务就跑起来了。由于指定了 `--reload` 参数,一旦 `main.py` 文件发生了改变,整个应用都会自动重新加载。你可以尝试将返回信息 `"Hello Fedora Magazine!"` 修改为其它内容,然后观察效果。
可以使用以下命令停止应用程序:
```
$ podman stop fastapi
```
### 构建一个小型 Web 服务
接下来我们会构建一个需要 I/O 操作的应用程序,通过这个应用程序,我们可以看到 FastAPI 自身的特点,以及它在性能上有什么优势(可以在[这里](https://www.techempower.com/benchmarks/#section=test&runid=7464e520-0dc2-473d-bd34-dbdfd7e85911&hw=ph&test=composite&l=z8kflr-v&a=2&f=jz8cg-0-3s-0-3k-6bo-0-0-18y74-8s5c-0)参考 FastAPI 和其它 Python Web 框架的对比)。为简单起见,我们直接使用 `dnf history` 命令的输出来作为这个应用程序使用的数据。
首先将 `dnf history` 命令的输出保存到文件。
```
$ dnf history | tail --lines=+3 > history.txt
```
在上面的命令中,我们使用 `tail` 去除了 `dnf history` 输出内容中无用的表头信息。剩余的每一条 `dnf` 事务都包括了以下信息:
* `id`:事务编号(每次运行一条新事务时该编号都会递增)
* `command`:事务中运行的 `dnf` 命令
* `date`:执行事务的日期和时间
然后修改 `main.py` 文件将相关的数据结构添加进去。
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class DnfTransaction(BaseModel):
id: int
command: str
date: str
```
FastAPI 自带的 [pydantic](https://pydantic-docs.helpmanual.io/) 库让你可以轻松定义一个数据类,其中的类型注释对数据的验证也提供了方便。
再增加一个函数,用于从 `history.txt` 文件中读取数据。
```
import aiofiles
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class DnfTransaction(BaseModel):
id: int
command: str
date: str
async def read_history():
transactions = []
async with aiofiles.open("history.txt") as f:
async for line in f:
transactions.append(DnfTransaction(
id=line.split("|")[0].strip(" "),
command=line.split("|")[1].strip(" "),
date=line.split("|")[2].strip(" ")))
return transactions
```
这个函数中使用了 `aiofiles` 库,这个库提供了一个异步 API 来处理 Python 中的文件,因此打开文件或读取文件的时候不会阻塞其它对服务器的请求。
最后,修改 `root` 函数,让它返回事务列表中的数据。
```
@app.get("/")
async def read_root():
return await read_history()
```
执行以下命令就可以看到应用程序的输出内容了。
```
$ curl http://127.0.0.1:8000 | python -m json.tool
[
{
"id": 103,
"command": "update",
"date": "2020-05-25 08:35"
},
{
"id": 102,
"command": "update",
"date": "2020-05-23 15:46"
},
{
"id": 101,
"command": "update",
"date": "2020-05-22 11:32"
},
....
]
```
### 总结
FastAPI 提供了一种使用 asyncio 构建 Web 服务的简单方法,因此它在 Python Web 框架的生态中日趋流行。要了解 FastAPI 的更多信息,欢迎查阅 [FastAPI 文档](https://fastapi.tiangolo.com/)。
本文中的代码可以在 [GitHub](https://github.com/cverna/fastapi_app) 上找到。
---
via: <https://fedoramagazine.org/use-fastapi-to-build-web-services-in-python/>
作者:[Clément Verna](https://fedoramagazine.org/author/cverna/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | * FastAPI* is a modern Python web framework that leverage the latest Python improvement in asyncio. In this article you will see how to set up a container based development environment and implement a small web service with FastAPI.
## Getting Started
The development environment can be set up using the Fedora container image. The following Dockerfile prepares the container image with FastAPI, [Uvicorn](https://www.uvicorn.org/) and [aiofiles](https://github.com/Tinche/aiofiles).
FROM fedora:32 RUN dnf install -y python-pip \ && dnf clean all \ && pip install fastapi uvicorn aiofiles WORKDIR /srv CMD ["uvicorn", "main:app", "--reload"]
After saving this Dockerfile in your working directory, build the container image using podman.
$ podman build -t fastapi . $ podman images REPOSITORY TAG IMAGE ID CREATED SIZE localhost/fastapi latest 01e974cabe8b 18 seconds ago 326 MB
Now let’s create a basic FastAPI program and run it using that container image.
from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello Fedora Magazine!"}
Save that source code in a *main.py* file and then run the following command to execute it:
$ podman run --rm -v $PWD:/srv:z -p 8000:8000 --name fastapi -d fastapi $ curl http://127.0.0.1:8000 {"message":"Hello Fedora Magazine!"
You now have a running web service using FastAPI. Any changes to *main.py* will be automatically reloaded. For example, try changing the “Hello Fedora Magazine!” message.
To stop the application, run the following command.
$ podman stop fastapi
## Building a small web service
To really see the benefits of FastAPI and the performance improvement it brings ([see comparison](https://www.techempower.com/benchmarks/#section=test&runid=7464e520-0dc2-473d-bd34-dbdfd7e85911&hw=ph&test=composite&l=z8kflr-v&a=2&f=jz8cg-0-3s-0-3k-6bo-0-0-18y74-8s5c-0) with other Python web frameworks), let’s build an application that manipulates some I/O. You can use the output of the *dnf history* command as data for that application.
First, save the output of that command in a file.
$ dnf history | tail --lines=+3 > history.txt
The command is using *tail* to remove the headers of *dnf history* which are not needed by the application. Each dnf transaction can be represented with the following information:
- id : number of the transaction (increments every time a new transaction is run)
- command : the dnf command run during the transaction
- date: the date and time the transaction happened
Next, modify the *main.py* file to add that data structure to the application.
from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class DnfTransaction(BaseModel): id: int command: str date: str
FastAPI comes with the [pydantic](https://pydantic-docs.helpmanual.io/) library which allow you to easily build data classes and benefit from type annotation to validate your data.
Now, continue building the application by adding a function that will read the data from the *history.txt * file.
import aiofiles from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class DnfTransaction(BaseModel): id: int command: str date: str async def read_history(): transactions = [] async with aiofiles.open("history.txt") as f: async for line in f: transactions.append(DnfTransaction( id=line.split("|")[0].strip(" "), command=line.split("|")[1].strip(" "), date=line.split("|")[2].strip(" "))) return transactions
This function makes use of the * aiofiles* library which provides an asyncio API to manipulate files in Python. This means that opening and reading the file will not block other requests made to the server.
Finally, change the root function to return the data stored in the transactions list.
@app.get("/") async def read_root(): return await read_history()
To see the output of the application, run the following command
$ curl http://127.0.0.1:8000 | python -m json.tool [ { "id": 103, "command": "update", "date": "2020-05-25 08:35" }, { "id": 102, "command": "update", "date": "2020-05-23 15:46" }, { "id": 101, "command": "update", "date": "2020-05-22 11:32" }, .... ]
## Conclusion
*FastAPI* is gaining a lot a popularity in the Python web framework ecosystem because it offers a simple way to build web services using asyncio. You can find more information about *FastAPI* in the [documentation](https://fastapi.tiangolo.com/).
The code of this article is available in [this GitHub repository](https://github.com/cverna/fastapi_app).
*Photo by Jan Kubita on Unsplash.*
## Mehdi
Does not work on local machine.
#ERROR: Error loading ASGI app. Could not import module “main”.
Command used is:
uvicorn main:app –reload
And I have installed everything:
pip3 install uvicorn fastapi aiofiles
## Mehdi
Turns out the file name has to be called main.py as mentioned in the post. I was using a different name. Solved.
## Eric L.
You probably haven’t created the
in the current directory.
## baoboa
Very useful, thanks for this post.
## pr0PM
Hi,
Got everything working until
which gives
## Vaclav
Awesome post! Thanks. It works fine without podman /docker container only.
Podman build fails at RUN:
“Error: error building at STEP “RUN dnf install -y python pip && dnf clean all && pip install fastapi uvicorn aiofiles”: error while running runtime: exit status 127
”
There could be a typo – check: dnf search python-pip
I suggest “python pip”
## Clément Verna
Yeah it looks like you are missing “-” in the RUN command which should be “RUN dnf install -y python-pip ….”
## tgfr
better way are using H2o https://h2o.examp1e.net/
## jan
Thanks for the introduction.
Today I was playing with this example on OSX and docker and I figured that one needs to rewrite the last line in the Dockerfile to make uvicorn accessible outside of the container, otherwise it’s only bounded to localhost inside the container and one can only curl within the container.
CMD [“uvicorn”, “main:app”, “–host”, “0.0.0.0”, “–reload”]
I thought this must be the same for podman but it’s not.
Any ideas why that is? |
12,281 | 适合在任何地方使用的 Linux:15 个小型 Linux 发行版 | https://www.zdnet.com/pictures/15-very-small-footprint-linux-distros/ | 2020-06-04T14:34:00 | [
"发行版",
"轻量级"
] | https://linux.cn/article-12281-1.html | 
如果你有一台老旧的 PC,或者是基于单板计算机的小型系统,你可能希望运行的是一个占用资源较少且易于下载的 Linux 版本。在这里,我们来看看占用资源非常小的 Linux 发行版。除了 Damn Small Linux 之外,这里列出的所有 Linux 发行版都是最近才更新的。每个发行版都可以在内存不足 1GB 的机器上运行,而且大多数发行版都可以在更小资源内运行。以下排列以字母排序。
### Alpine Linux

下载:130 MB
Alpine Linux 最初是针对虚拟服务器和设备的,它直接运行在内存中。它以安全为重点,面向最终用户的功能较少,但如果你需要的话,也可以支持桌面功能。上一次公开发布是在 2019 年 10 月。
### antiX Linux

下载:约 1GB
antiX 发行版声称完全不含 systemd —— 这是现代 Linux 发行版的基本构件。相反,antiX 提供了“antiX Magic”(我不确定那是什么)。我会告诉你,这个安装程序很复杂,有很多选项。这是一个基于 Debian 的构建版。最后一次更新是在去年 10 月份。
### ArchBang

下载:600 - 700MB
ArchBang 是一款受 CrunchBang 启发的发行版,其使用 Arch Linux 的 Openbox 窗口管理器。最近一次发布是在 2019 年 11 月。
### Bodhi Linux

下载:700MB
Bodhi 是一款基于 Ubuntu 的轻量级发行版,这款发行版采用的是 Moksha(一种基于 Enlightenment 的桌面)。它的模块化和可定制性很强,可以让用户构建非常简单或合理的系统。它最近刚刚更新过。
### BunsenLabs Helium

下载: 600MB 至 1.2GB
前有 CrunchBang 和 CrunchBang++,今有 BunsenLabs Helium 和 ArchBang,这两者都是在 CrunchBang++ 发行版的基础上构建的。Helium 基于 Debian,采用 Openbox 窗口管理器。最新的版本是在 2019 年 7 月发布的。
### Damn Small Linux

下载:50MB
Damn Small Linux 自 2008 年以来一直没有正式发布,虽然 2012 年曾经有过一个候选版本。如果你有旧的硬件,这应该没什么问题,但不要在互联网上多用,因为较新的漏洞还没有打补丁。其最轻量级的形式可以在 16MB 的内存中运行,完全加载也只需要 128MB 内存。
### Elive

下载:2.4GB
Elive 是一款即用版 Enlightenment 发行版,其中还包含了 Elpanel 控制面板。按照真正的 Linux 风格,它的口号是:“虽然 Elive 并不适合所有人,但你是例外吗?” 它只要 256MB 内存就能运行。Elive 最后一次更新是在 2019 年 10 月。
### Linux Lite

下载:1.4GB
Linux Lite 并不像一些微型发行版那样小,但它也不会让你感到多么庞大。它配备了你需要的所有组件,基于 Ubuntu,运行着一个令人感到愉快的 Linux 桌面环境。它可以在 768MB 内存中运行,但 1GB 内存更好。它最近刚刚更新。
### Lubuntu

下载:1.6GB
Lubuntu 名字的意思是“轻量级 Ubuntu”,顾名思义,你就知道这个发行版是怎么回事了。它是使用 LXQt 桌面环境构建的,你可以选择你想安装什么典型的 Ubuntu 软件包。它也是最近刚刚更新的。
### LXLE

下载:1.2GB
LXLE 基于 Ubuntu,有一个非常具体的口号:“重新唤醒那台老旧的 PC。”它的设计理念是拥有丰富的功能和应用,可以让你把一台老旧的 PC 变成一台可以工作的台式机,基本的 PC 使用所需的一切都有。最后一次公开发布是在 2019 年 9 月。
### Puppy Linux

下载:约 300MB
Linux 从来都不会让事情变得简单,Puppy Linux 也不例外。Puppy Linux 并不是一个发行版,而是有 11 个不同版本的 Puppy Linux。它不再像以前那样小,1GB 的内存运行的比较好。尽管如此,它是最早的轻量级发行版之一。它最后一次更新是在 2019 年 3 月。
### Raspberry Pi OS

下载:400MB 至 1.2GB
Raspberry Pi OS(以前叫 Raspbian)是一个适用于树莓派的 Debian 发行版。在这里列出的所有发行版中,Raspberry Pi OS 是我日常使用的一个。我在三台正在运行的树莓派服务器上运行着它,另外还有几台暂时不活跃的服务器也加载着它。我不使用 Linux 图形界面。相反,我连接到一个 OctoPi 网络界面,可以让我控制我的 3D 打印机。最近刚刚更新。
### SliTaz

下载:50MB
SliTaz 是一款完全运行在内存中的 Linux,可以通过 CD-ROM 或 USB 盘启动。它的体积很小,只有 50MB 左右,但具有强大的安全功能,可以只安装基础系统,或安装一个精简的 X 环境。最新的滚动发布是在 2018 年。
### SparkyLinux 基础版

下载:540MB
Sparky 是另一个基于 Debian 的发行版,它的设计是为了让家庭用户能有一个相对简单的开箱即用的 Enlightenment 体验,尽管它确实支持大约 20 个窗口管理器和桌面环境。它在 2019 年 11 月进行了更新。
### Tiny Core Linux

下载:11MB
有三个版本,最小的是 11MB 的下载。在没有图形界面的情况下,Tiny Core Linux 的运行内存为 64MB。最后一次更新是在 2019 年 1 月。
### 结语
就是这些了,你用过哪个轻量级发行版?如果有我们没有提及的轻量级发行版,也可以在下面留言。
| 200 | OK | # Linux that fits anywhere: 15 very small footprint distros


## Small-footprint Linux distros
If you have an older PC, or a small single board computer-based system, you probably want to run a version of Linux that's light on resources and easy to download. In this gallery, we look at very small footprint Linux distros. With the exception of Damn Small Linux, all have been updated relatively recently. Each distro can run on machines with less than 1GB of RAM and most can run in a much smaller footprint.
### Read more
## Alpine - 130 MB download
Originally intended for virtual servers and appliances, [Alpine Linux](https://www.alpinelinux.org/) will run directly from RAM. It's security-focused, with fewer end-user oriented features, but will still support desktop capabilities if you choose to enable them. The last public release was just last month in October 2019.
### Read more
## antiX Linux - about 1GB download
The [antiX distribution](https://antixlinux.com/) is a lean module that claims to be totally free of [systemd](https://en.wikipedia.org/wiki/Systemd), the code suite that provides the fundamental building blocks of Linux. Instead, antiX offers the "antiX Magic," (and no, I'm not entirely sure what that is). I will tell you the installer is complex, with a ton of options. This is a build based on Debian. It was last updated in October.
### Read more
## ArchBang - 600-700MB download
[ArchBang](http://archbang.org/) is a CrunchBang-inspired distro, this time also based on Arch Linux with the Openbox window manager. The most recent release was in November 2019.
### Read more
## Bodhi Linux - 700MB download
[Bodhi](https://www.bodhilinux.com/) is an Ubuntu-based light distribution, this one sporting Moksha (an Enlightenment-based desktop). It's very modular and customizable, allowing users to build very simple or reasonably capable systems. It has not been updated this year.
### Read more
## BunsenLabs Linux Helium - 600MB to 1.2GB download
Where once there was CrunchBang and CrunchBang++, there is now [BunsenLabs Helium](https://www.bunsenlabs.org/) and ArchBang. Both build off the CrunchBang++ distro. Helium is based on Debian and is an Openbox implementation. DistroWatch says the latest release was in July 2019.
**Update:***the maintainer of CrunchBang++ tells me it's definitely maintained and the last update was in July, corresponding with the Debian 10 release. See more **here**.*
### Read more
## Damn Small Linux - 50MB download
[Damn Small Linux](http://www.damnsmalllinux.org/) hasn't had a formal release since 2008, although there was a release candidate put out sometime in 2012. If you have old hardware, this shouldn't matter much, but don't use this actively on the Internet because newer exploits haven't been patched. It will run in its lightest form in 16MB of RAM or fully loaded in 128MB of RAM.
### Read more
## Elive - 2.4GB download
[Elive](https://www.elivecd.org/) is an Enlightenment live distribution that also includes the Elpanel control panel. In true Linux fashion, it's a bit off-putting, with its tagline being, "But Elive is not for everyone, are you the exception?" So, there's that. On the other hand, it'll run in as little as 256MB RAM. Elive was last updated in October 2019.
### Read more
## Linux Lite - 1.4GB download
[Linux Lite](https://www.linuxliteos.com/) isn't as small as some tiny distros, but it won't make you scream, either. It comes with all the components you'll need to run a pleasant desktop Linux environment, based on Ubuntu. It will run in 768MB of RAM, but it prefers 1GB. It was last updated in September 2019. Be careful: the main site for this distro is festooned with ads, some misleadingly seeming like links for the site itself.
### Read more
## Lubuntu - 1.6GB download
[Lubuntu](https://lubuntu.net/) essentially means "light Ubuntu," and that should tell you what this distro is all about. It's built using the LXQt desktop environment, and you're able to choose what typical Ubuntu packages you want to install. It was last updated last month, October 2019.
### Read more
## LXLE - 1.2GB download
[LXLE](https://www.lxle.net/) is based on Ubuntu and has a very specific tagline: "Revive that old PC." It's designed to have a broad selection of features and apps that will allow you to turn an older PC into a working desktop machine, with everything needed for basic PC use. The last public release was in September 2019.
### Read more
## Puppy Linux - around 300 MB download
Linux never makes things easy and [Puppy Linux](http://puppylinux.com/) is no exception. Puppy Linux isn't based on one distro. Instead, there 11 different versions of Puppy Linux. Because of course there are. It's not as small as it once was, liking 1GB of RAM. Still, it's one of the first. It was last updated in March 2019.
### Read more
## Raspbian - 400MB to 1.2GB download
[Raspbian](https://www.raspberrypi.org/downloads/raspbian/) is a Debian distribution for use on the Raspberry Pi. Of all the distributions listed in this gallery, Raspbian is the one I use on a day-to-day basis. I have it running on three live Pi servers and it's loaded on a few others that aren't active at the moment. I don't use a Linux GUI. Instead, I connect into an [OctoPi web interface](https://www.zdnet.com/article/how-to-add-a-smartphone-controlled-brain-to-your-3d-printer-for-about-fifty-bucks/) that lets me control my 3D printers. Latest public release was September 2019.
### Read more
## SliTaz - 50MB download
[SliTaz](http://www.slitaz.org/en/) is a full in-memory Linux designed to launch from CD-ROM or USB key. It's small, only about 50MB, but has the ability to provide strong security capabilities and can be installed in a base system or a stripped-down X environment. [DistroWatch says](https://distrowatch.com/table.php?distribution=slitaz) the latest rolling release was in 2018.
## SparkyLinux base edition - 540MB download
[Sparky](https://sparkylinux.org/) is another Debian-based distro, this time designed to let home users have a relatively simple out-of-the-box experience with Enlightenment, although it does support about 20 windowing managers and desktop environments. It was updated this month (November 2019).
## Tiny Core Linux — 11MB download
Comes in three versions, the smallest being an 11MB download. Without a GUI, [Tiny Core Linux](http://tinycorelinux.net/) will run in 64 MB. It was last updated in January 2019.
### Related Galleries
[Holiday wallpaper for your phone: Christmas, Hanukkah, New Year's, and winter scenes](/pictures/holiday-wallpaper-for-your-phone-christmas-hanukkah-new-years-and-winter-scenes/)
#### Related Galleries
### Holiday wallpaper for your phone: Christmas, Hanukkah, New Year's, and winter scenes
21 Photos[Winter backgrounds for your next virtual meeting](/pictures/winter-backgrounds-for-your-next-virtual-meeting/)
#### Related Galleries
### Winter backgrounds for your next virtual meeting
21 Photos[Holiday backgrounds for Zoom: Christmas cheer, New Year's Eve, Hanukkah and winter scenes](/pictures/free-holiday-backgrounds-for-zoom/)
#### Related Galleries
### Holiday backgrounds for Zoom: Christmas cheer, New Year's Eve, Hanukkah and winter scenes
21 Photos[Hyundai Ioniq 5 and Kia EV6: Electric vehicle extravaganza](/pictures/hyundai-ioniq-5-and-kia-ev6-electric-vehicle-extravaganza/)
#### Related Galleries
### Hyundai Ioniq 5 and Kia EV6: Electric vehicle extravaganza
26 Photos[A weekend with Google's Chrome OS Flex](/pictures/a-weekend-with-googles-chrome-os-flex/)
#### Related Galleries
### A weekend with Google's Chrome OS Flex
22 Photos[Cybersecurity flaws, customer experiences, smartphone losses, and more: ZDNet's research roundup](/pictures/cybersecurity-flaws-customer-experiences-smartphone-losses-and-more-zdnets-research-roundup/)
#### Related Galleries
### Cybersecurity flaws, customer experiences, smartphone losses, and more: ZDNet's research roundup
8 Photos[Inside a fake $20 '16TB external M.2 SSD'](/pictures/inside-a-fake-20-16tb-external-m-2-ssd/) |
12,283 | 现在你可以购买通过 Linux 认证的联想 ThinkPad 和 ThinkStation | https://itsfoss.com/lenovo-linux-certified/ | 2020-06-04T22:23:00 | [
"ThinkPad",
"联想"
] | https://linux.cn/article-12283-1.html | 曾经有一段时间,[ThinkPad](https://en.wikipedia.org/wiki/ThinkPad) 是 Linux 用户的首选系统。但那是在 ThinkPad 还是 [IBM](https://www.ibm.com/) 的产品的时候。当[联想在 2005 年收购了 IBM 的个人电脑业务](https://in.pcmag.com/laptops/38093/10-years-later-looking-back-at-the-ibm-lenovo-pc-deal)之后,(我觉得)事情开始发生了变化。
ThinkPad 曾经是一个令人惊叹的系列笔记本电脑,稳定可靠、值得信赖、坚如磐石,你只要问问 2010 年代以前用过它的人就知道了。
但在 2010 年前后,联想 ThinkPad 开始失去了它的魅力。它充满了一个又一个的问题,消费者们抱怨性能不佳。
而对于 Linux 用户来说,情况就更糟糕了。它的安全启动与 UEFI [给 Linux 用户带来了问题](https://www.phoronix.com/scan.php?page=news_item&px=mtiyotg)。[与 Linux 的争论](https://www.engadget.com/2016-09-21-lenovo-pc-linux-trouble.html)就这样没完没了。
我为什么要回忆起这些?因为联想似乎正在努力提高 Linux 的兼容性。对于 Linux 爱好者来说,联想的最新公告是一个极好的消息。
### 联想 ThinkPad 和 ThinkStation 全系产品将通过 Linux 认证

联想[宣布](https://news.lenovo.com/pressroom/press-releases/lenovo-brings-linux-certification-to-thinkpad-and-thinkstation-workstation-portfolio-easing-deployment-for-developers-data-scientists/),将对**全部工作站产品进行 Ubuntu 和红帽等顶级 Linux 发行版的认证**,这包括所有机型和配置。
作为 Linux 用户,这对你来说意味着什么?它意味着,如果你购买了联想电脑,你将获得**最好的开箱即用的 Linux 体验**。
等一下?不是可以随便在任何电脑上安装 Linux 吗,不管是联想还是幻想?当然,你可以。但是,当你把现有的(Windows)操作系统清除掉,自己安装 Linux 时,你可能会遇到硬件兼容性的问题,如没有声音、Wi-Fi 无法工作等。
开箱即用的体验很重要,因为并不是每个人都愿意花时间去修复声音、显卡、Wi-Fi 和蓝牙等问题,而不是专注于自己的实际工作,因为他们买电脑的目的就是为了这个。
来自 [Ubuntu](https://ubuntu.com/) 和 Red Hat 的开发人员会对联想系统的每一个硬件组件进行测试和验证,以确保联想系统的每一个硬件组件都能正常工作。
### Ubuntu、Red Hat 以及更多

为此,联想选择了两款顶级 Linux 发行版。Red Hat 是企业级 Linux 桌面和服务器的热门选择。而 Ubuntu 当然是普遍流行的。
这意味着,联想的计算机在使用 Ubuntu LTS 版本和 Red Hat Linux 时,会以最佳状态工作。联想甚至会在其中预装 Ubuntu 和 Red Hat 两种版本的系统。
但是,这还没有结束。Fedora 是 Red Hat 的一个社区项目,联想也会在 ThinkPad P53 和 P1 Gen 2 系统上预装 Fedora。
有很多基于 Ubuntu LTS 版本的 Linux 发行版。大多数情况下,这些发行版在外观、应用和其他图形化的东西上都不一样,但它们使用的是与 Ubuntu 相同的基础。
这应该意味着,基于 Ubuntu 的发行版,如 Linux Mint、Elementary OS 等也会与联想的设备有更好的硬件兼容性。
联想还将这些设备驱动直接发送给上游的 Linux 内核中,帮助它们的系统在整个生命周期内都保持稳定性和兼容性。这一点是非常棒的。
### 它能帮助增加 Linux 用户群吗?
开箱即用的体验很重要。它可以让你专注于系统上应该做的重要任务,而不是故障排除。
我有一台[预装了 Ubuntu 的戴尔 XPS 笔记本](https://itsfoss.com/dell-xps-13-ubuntu-review/)。这是唯一一台几乎不需要从我这一端进行硬件故障排除的设备,即使我手动安装了其它基于 Ubuntu 的发行版,也不需要进行硬件故障排除。
我很高兴看到联想为提高 Linux 的兼容性做出了更多努力。现在在[预装 Linux 的电脑列表](https://itsfoss.com/get-linux-laptops/)中有了更多的选择。
我不知道联想在其计算机产品中提供 Linux 是否有助于增加 Linux 用户群。大多数时候人们都会要 Windows,Linux 不会成为首要关注点。
但联想在设备上让自己的计算机产品更多的使用 Linux,这一点还是值得称赞的。我希望其他厂商也能这样做。希望没有什么坏处:)
---
via: <https://itsfoss.com/lenovo-linux-certified/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There was a time when [ThinkPad](https://en.wikipedia.org/wiki/ThinkPad) was the preferred system for Linux users.
But that was when ThinkPad was an [IBM](https://www.ibm.com/) product. When [Beijing-based Lenovo acquired New York-based IBM’s personal computer business in 2005](https://in.pcmag.com/laptops/38093/10-years-later-looking-back-at-the-ibm-lenovo-pc-deal), (I feel that) things started to change.
ThinkPad was/is an amazing series of laptops, reliable, trustworthy and rock solid. Just ask a person who used it before 2010s.
But around 2010, Lenovo ThinkPad started to lose its charm. It was filled with issues after issues and consumer complaints of poor performance.
Things were even worse for Linux users. Its secure boot with UEFI [created problems for Linux](https://www.phoronix.com/scan.php?page=news_item&px=mtiyotg) users. The [controversy with Linux](https://www.engadget.com/2016-09-21-lenovo-pc-linux-trouble.html) would just not end.
Why am I recalling all this? Because Lenovo seems to be working on improving Linux compatibility. The latest announcement from Lenovo is an excellent news for Linux lovers.
## Entire range of Lenovo ThinkPad and ThinkStation will be Linux certified

Lenovo [announced](https://news.lenovo.com/pressroom/press-releases/lenovo-brings-linux-certification-to-thinkpad-and-thinkstation-workstation-portfolio-easing-deployment-for-developers-data-scientists/) that it is going to **certify the full workstation portfolio for top Linux distributions from Ubuntu and Red Hat**. This is valid for all models and configuration.
What does it mean to you as a Linux users? It means that if you buy a Lenovo computer, you will have the **best possible out-of-the-box Linux experience**.
Wait? Can you not just install Linux on any computer be it Le-novo or The-novo? Of course, you can. But when you wipe out existing (Windows) operating system and install Linux on your own, you may encounter hardware compatibility issues like audio missing, Wi-Fi not working etc.
The out-of-the-box experience matters because not everyone would be willing to spend time in fixing sound, graphics card, Wi-Fi and Bluetooth issues instead of focusing on their real work for which they bought the computer.
The developers from [Ubuntu](https://ubuntu.com/) and Red Hat test and verify that each hardware component of Lenovo system works as intended.
## Ubuntu, Red Hat and more

Lenovo has chosen two of the top Linux distributions for this purpose. Red Hat is a popular choice for Linux desktop and servers in enterprises. Ubuntu is of course popular in general.
This means that Lenovo system would work the best with Ubuntu LTS versions and Red Hat Linux. Lenovo will even offer the choice of Ubuntu and Red Hat preinstalled on its systems.
But it just doesn’t end here. Fedora is a community project from Red Hat and Lenovo is going to offer Fedora preloaded on ThinkPad P53 and P1 Gen 2 systems.
There are so many Linux distributions based on Ubuntu LTS release. Most of the time, these distributions differ in looks, applications and other graphical stuff, but they use the same base as Ubuntu.
This should mean that the Ubuntu-based distributions like Linux Mint, elementary OS etc also better hardware compatibility with Lenovo devices.
Lenovo is also going to upstream device drivers directly to the Linux kernel, to help maintain stability and compatibility throughout the life of the workstation. That’s superb.
## Will it help increase the Linux user base?
Out of the box experience matters. It lets you focus on the important tasks that you are supposed to do on your system rather than troubleshooting.
I have a [Dell XPS laptop that came with Ubuntu preinstalled](https://itsfoss.com/dell-xps-13-ubuntu-review/). This is the only device that has required pretty much no hardware troubleshoot from my end even when I have installed Ubuntu-based distributions manually.
I am happy to see Lenovo doing the extra effort to improve Linux compatibility on its end. There is one more option in the [list of Linux preloaded computers](https://itsfoss.com/get-linux-laptops/) now.
I don’t know if Lenovo offering Linux on its systems will help increase the Linux user base. Most of the time Windows will be highlighted and Linux version won’t get the prime focus.
It is still commendable of Lenovo for their efforts to make their devices more Linux friendly. I hope other manufacturers do the same. There is no harm in hoping :)
[interaction id=”5ed76be4cfda7714a2e92eb9″] |
12,284 | 如何使用 Tmpwatch/Tmpreaper 删除旧文件 | https://www.2daygeek.com/how-to-remove-files-older-than-n-days-using-tmpwatch-tmpreaper-on-linux/ | 2020-06-05T09:18:22 | [
"删除"
] | https://linux.cn/article-12284-1.html | 
你可能忘记了删除计算机上某个目录中不再需要的文件的操作。这可能是“下载”或任何其他目录。它可能已经增长了一段时间。
即便有足够的存储空间,你也应该删除它们,因为这会在列出文件时降低系统速度。同样,当一个目录中有成千上万个文件时,它可能很会很臃肿。
当你不知道要检查的文件名时,很难在特定目录中找到文件。
我们可以通过结合使用 `find` 命令和一些组合来做到这一点,我们过去已经写过一篇文章。
* [使用 Bash 脚本在 Linux 中删除早于 “X” 天的文件/文件夹](/article-11490-1.html)
今天,我们将向你展示如何在 Linux 上使用 Tmpwatch 程序来实现这一目标。
### 什么是 tmpwatch
`tmpwatch` 会在指定目录中递归删除指定时间段内未被访问的文件。通常,它用于自动清除临时文件系统目录,例如 `/tmp` 和 `/var/tmp`。
它只会删除空目录、常规文件和符号链接。它不会切换到其他文件系统,并避开了属于根用户的 `lost+found` 目录。
默认情况下,`tmpwatch` 会根据文件的 atime(访问时间)而不是 mtime(修改时间)删除文件。
你可以在 `tmpwatch` 命令中添加其他参数来更改这些行为。
**警告:** 请不要在 `/` 中运行 `tmpwatch` 或 `tmpreaper`,因为该程序中没有防止这种情况的机制。
### 如何在 Linux 上安装 tmpwatch
可以在官方仓库中按以下方式安装 `tmpwatch`。
对于 RHEL/CentOS 6 系统,请使用 [yum 命令](https://www.2daygeek.com/linux-yum-command-examples-manage-packages-rhel-centos-systems/)安装 `tmpwatch`。
```
$ sudo yum install -y tmpwatch
```
对于 Debian 和 Ubuntu 系统,请使用 [apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 或 [apt-get 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 安装 `tmpreaper`。
```
$ sudo apt-get install tmpreaper
```
对于 openSUSE 系统,请使用 [zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 安装 `tmpwatch`。
```
$ sudo zypper install -y tmpwatch
```
对于 Fedora 系统,请使用 [dnf 命令](https://www.2daygeek.com/linux-dnf-command-examples-manage-packages-fedora-centos-rhel-systems/) 安装 `tmpwatch`。
```
$ sudo dnf install -y tmpwatch
```
**请注意:** 如果你使用的是基于 Debian 的系统,请使用 `tmpreaper` 而不是 `tmpwatch`。所有示例都可以如预期工作。
### 了解关键选项和参数
* `atime`(文件上次访问时间):显示命令或脚本等任意进程最后一次访问文件中数据的时间。
* `mtime`(文件上次修改时间):显示修改文件内容或保存文件的时间。除非是更改文件属性,否则大多数情况下 `ctime` 和 `mtime` 会相同。
* `ctime`(文件上次更改时间):显示文件元数据更改时间。这意味着更改文件属性的时间(如所有权或组等)。
* `dirmtime`(目录的上次修改时间):显示目录的上一次修改时间。
时间参数定义删除文件的阈值。
* `d` – 天
* `h` – 小时
* `m` – 分钟
* `s` – 秒
### 如何使用 tmpwatch 命令删除一段时间未访问的文件
正如我在本文开头所说,`tmpwatch` 默认根据文件访问时间(`atime`)来删除文件。另外,由于小时是默认参数,因此如果使用小时单位,那么无需在时间上添加后缀。
例如,运行以下命令以递归方式删除过去 5 个小时未访问的文件。
```
# tmpwatch 5 /tmp
```
运行以下命令删除最近 10 个小时未修改的文件。如果要使用修改时间(`mtime`)来删除文件,那么需要在 `tmpwatch` 命令中添加 `-m` 选项。
```
# tmpwatch -m 10 /home/daygeek/Downloads
```
### 如何使用 tmpwatch 命令删除超过 “X” 天未访问的文件
如果要使用天数删除文件,那么需要添加后缀 `d`。以下示例删除了 30 天以上的文件。
```
# tmpwatch 30d /home/daygeek/Downloads
```
### 如何使用 tmpwatch 命令删除一段时间内未访问的所有文件
以下命令将基于修改时间(`mtime`)删除所有类型的文件,而不仅仅是常规文件、符号链接和目录。
```
# tmpwatch -am 12 /tmp
```
### 如何在 tmpwatch 中排除目录
以下命令将删除过去 10 个小时未修改的所有文件,并排除目录。
```
# tmpwatch -am 10 --nodirs /home/daygeek/Downloads
```
### 如何在 tmpwatch 中排除特定路径
以下命令将删除过去 10 个小时未被修改的所有文件,除了下面排除的文件夹。
```
# tmpwatch -am 10 --exclude=/home/daygeek/Downloads/Movies /home/daygeek/Downloads
```
### 如何在 tmpwatch 中排除特定模式
以下命令将删除过去 10 小时未被修改的所有文件,除了满足下面列出的模式的文件。
```
# tmpwatch -am 10 --exclude-pattern='*.pdf' /home/daygeek/Downloads
```
### 如何让 tmpwatch 命令空运行
如果要空运行,请运行以下命令。
```
# tmpwatch -t 5h /home/daygeek/Downloads
```
### 如何设置 cronjob 来使用 tmpwatch 定期删除文件
默认情况下,它在 `/etc/cron.daily/tmpreaper` 目录下有一个 [cronjob](https://www.2daygeek.com/linux-crontab-cron-job-to-schedule-jobs-task/) 文件。该 cronjob 根据位于 `/etc/timereaper.conf` 中的配置文件工作。你可以根据需要自定义文件。
它每天运行一次,并删除 7 天之前的文件。
另外,如果你希望常规执行某项操作,那么可以根据需要手动添加一个 cronjob。
```
# crontab -e
0 10 * * * /usr/sbin/tmpwatch 15d /home/daygeek/Downloads
```
上面的 cronjob 将在每天上午 10 点删除早于 15 天的文件。
---
via: <https://www.2daygeek.com/how-to-remove-files-older-than-n-days-using-tmpwatch-tmpreaper-on-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,286 | 用 Python 解析命令行参数 | https://opensource.com/article/20/6/c-python-cli | 2020-06-05T23:16:19 | [
"Python",
"CLI",
"参数"
] | /article-12286-1.html |
>
> 借鉴 C 语言的历史,学习如何用 Python 编写有用的 CLI 程序。
>
>
>

本文的目标很简单:帮助新的 Python 开发者了解一些关于[命令行接口](https://en.wikipedia.org/wiki/Command-line_interface)(CLI)的历史和术语,并探讨如何在 Python 中编写这些有用的程序。
### 最初……
首先,从 [Unix](https://en.wikipedia.org/wiki/Unix) 的角度谈谈命令行界面设计。
Unix 是一种计算机操作系统,也是 Linux 和 macOS(以及许多其他操作系统)的祖先。在图形用户界面之前,用户通过命令行提示符与计算机进行交互(想想如今的 [Bash](https://www.gnu.org/software/bash/) 环境)。在 Unix 下开发这些程序的主要语言是 [C](https://en.wikipedia.org/wiki/C_(programming_language)),它的[功能](https://www.toptal.com/c/after-all-these-years-the-world-is-still-powered-by-c-programming)非常强大。
因此,我们至少应该了解 [C 程序](https://opensource.com/article/19/5/how-write-good-c-main-function)的基础知识。
假设你没有读过上面那个链接的内容,C 程序的基本架构是一个叫做 `main` 的函数,它的签名是这样的。
```
int main(int argc, char **argv)
{
...
}
```
对于 Python 程序员来说,这应该不会显得太奇怪。C 函数首先有一个返回类型、一个函数名,然后是括号内的类型化参数。最后,函数的主体位于大括号之间。函数名 `main` 是[运行时链接器](https://en.wikipedia.org/wiki/Dynamic_linker)(构造和运行程序的程序)如何决定从哪里开始执行你的程序。如果你写了一个 C 程序,而它没有包含一个名为 `main` 的函数,它将什么也做不了。伤心。
函数参数变量 `argc` 和 `argv` 共同描述了程序被调用时用户在命令行输入的字符串列表。在典型的 Unix 命名传统中,`argc` 的意思是“<ruby> 参数计数 <rt> argument count </rt></ruby>”,`argv` 的意思是“<ruby> 参数向量 <rt> argument vector </rt></ruby>”。向量听起来比列表更酷,而 `argl` 听起来就像一个要勒死的求救声。我们是 Unix 系统的程序员,我们不求救。我们让*其他人*哭着求救。
#### 再进一步
```
$ ./myprog foo bar -x baz
```
如果 `myprog` 是用 C 语言实现的,则 `argc` 的值是 5,而 `argv` 是一个有五个条目的字符指针数组。(不要担心,如果这听起来过于技术,那换句话说,这是一个由五个字符串组成的列表。)向量中的第一个条目 `argv[0]` 是程序的名称。`argv` 的其余部分包含参数。
```
argv[0] == "./myprog"
argv[1] == "foo"
argv[2] == "bar"
argv[3] == "-x"
argv[4] == "baz"
/* 注:不是有效的 C 代码 */
```
在 C 语言中,你有很多方法来处理 `argv` 中的字符串。你可以手动地循环处理数组 `argv`,并根据程序的需要解释每个字符串。这相对来说比较简单,但会导致程序的接口大相径庭,因为不同的程序员对什么是“好”有不同的想法。
```
include <stdio.h>
/* 一个打印 argv 内容的简单 C 程序。 */
int main(int argc, char **argv) {
int i;
for(i=0; i<argc; i++)
printf("%s\n", argv[i]);
}
```
#### 早期对命令行标准化的尝试
命令行武器库中的下一个武器是一个叫做 [getopt](http://man7.org/linux/man-pages/man3/getopt.3.html) 的 [C 标准库](https://en.wikipedia.org/wiki/C_standard_library)函数。这个函数允许程序员解析开关,即前面带破折号的参数(比如 `-x`),并且可以选择将后续参数与它们的开关配对。想想 `/bin/ls -alSh` 这样的命令调用,`getopt` 就是最初用来解析该参数串的函数。使用 `getopt` 使命令行的解析变得相当简单,并改善了用户体验(UX)。
```
include <stdio.h>
#include <getopt.h>
#define OPTSTR "b:f:"
extern char *optarg;
int main(int argc, char **argv) {
int opt;
char *bar = NULL;
char *foo = NULL;
while((opt=getopt(argc, argv, OPTSTR)) != EOF)
switch(opt) {
case 'b':
bar = optarg;
break;
case 'f':
foo = optarg;
break;
case 'h':
default':
fprintf(stderr, "Huh? try again.");
exit(-1);
/* NOTREACHED */
}
printf("%s\n", foo ? foo : "Empty foo");
printf("%s\n", bar ? bar : "Empty bar");
}
```
就个人而言,我*希望* Python 有*开关*,但这[永远](https://www.python.org/dev/peps/pep-0275/)、永远不会[发生](https://www.python.org/dev/peps/pep-3103/)。
#### GNU 时代
[GNU](https://www.gnu.org) 项目出现了,并为他们实现的传统 Unix 命令行工具引入了更长的格式参数,比如`--file-format foo`。当然,我们这些 Unix 程序员很讨厌这样,因为打字太麻烦了,但是就像我们这些旧时代的恐龙一样,我们输了,因为用户*喜欢*更长的选项。我从来没有写过任何使用 GNU 风格选项解析的代码,所以这里没有代码示例。
GNU 风格的参数也接受像 `-f foo` 这样的短名,也必须支持。所有这些选择都给程序员带来了更多的工作量,因为他们只想知道用户要求的是什么,然后继续进行下去。但用户得到了更一致的用户体验:长格式选项、短格式选项和自动生成的帮助,使用户不必再试图阅读臭名昭著的难以解析的[手册](https://en.wikipedia.org/wiki/Man_page)页面(参见 [ps](http://man7.org/linux/man-pages/man1/ps.1.html) 这个特别糟糕的例子)。
### 但我们正在讨论 Python?
你现在已经接触了足够多(太多?)的命令行的历史,对如何用我们最喜欢的语言来编写 CLI 有了一些背景知识。Python 在命令行解析方面给出了类似的几个选择:自己解析,<ruby> 自给自足 <rt> batteries-included </rt></ruby>的方式,以及大量的第三方方式。你选择哪一种取决于你的特定情况和需求。
#### 首先,自己解析
你可以从 [sys](https://docs.python.org/3/library/sys.html) 模块中获取程序的参数。
```
import sys
if __name__ == '__main__':
for value in sys.argv:
print(value)
```
#### 自给自足
在 Python 标准库中已经有几个参数解析模块的实现:[getopt](https://docs.python.org/2/library/getopt.html)、[optparse](https://docs.python.org/2/library/optparse.html),以及最近的 [argparse](https://docs.python.org/3/library/argparse.html)。`argparse` 允许程序员为用户提供一致的、有帮助的用户体验,但就像它的 GNU 前辈一样,它需要程序员做大量的工作和“[模板代码](https://en.wikipedia.org/wiki/Boilerplate_code)”才能使它“奏效”。
```
from argparse import ArgumentParser
if __name__ == "__main__":
argparser = ArgumentParser(description='My Cool Program')
argparser.add_argument("--foo", "-f", help="A user supplied foo")
argparser.add_argument("--bar", "-b", help="A user supplied bar")
results = argparser.parse_args()
print(results.foo, results.bar)
```
好处是当用户调用 `--help` 时,有自动生成的帮助。但是<ruby> <a href="https://www.python.org/dev/peps/pep-0206/"> 自给自足 </a> <rt> batteries included </rt></ruby>的优势呢?有时,你的项目情况决定了你对第三方库的访问是有限的,或者说是没有,你不得不用 Python 标准库来“凑合”。
#### CLI 的现代方法
然后是 [Click](https://click.palletsprojects.com/en/7.x/)。`Click` 框架使用[装饰器](https://wiki.python.org/moin/PythonDecorators)的方式来构建命令行解析。突然间,写一个丰富的命令行界面变得有趣而简单。在装饰器的酷炫和未来感的使用下,很多复杂的东西都消失了,用户惊叹于自动支持关键字补完以及上下文帮助。所有这些都比以前的解决方案写的代码更少。任何时候,只要你能写更少的代码,还能把事情做好,就是一种胜利。而我们都想要胜利。
```
import click
@click.command()
@click.option("-f", "--foo", default="foo", help="User supplied foo.")
@click.option("-b", "--bar", default="bar", help="User supplied bar.")
def echo(foo, bar):
"""My Cool Program
It does stuff. Here is the documentation for it.
"""
print(foo, bar)
if __name__ == "__main__":
echo()
```
你可以在 `@click.option` 装饰器中看到一些与 `argparse` 相同的模板代码。但是创建和管理参数分析器的“工作”已经被抽象化了。现在,命令行参数被解析,而值被赋给函数参数,从而函数 `echo` 被*魔法般地*调用。
在 `Click` 接口中添加参数就像在堆栈中添加另一个装饰符并将新的参数添加到函数定义中一样简单。
### 但是,等等,还有更多!
[Typer](https://typer.tiangolo.com) 建立在 `Click` 之上,是一个更新的 CLI 框架,它结合了 `Click` 的功能和现代 Python [类型提示](https://docs.python.org/3/library/typing.html)。使用 `Click` 的缺点之一是必须在函数中添加一堆装饰符。CLI 参数必须在两个地方指定:装饰符和函数参数列表。`Typer` [免去你造轮子](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself) 去写 CLI 规范,让代码更容易阅读和维护。
```
import typer
cli = typer.Typer()
@cli.command()
def echo(foo: str = "foo", bar: str = "bar"):
"""My Cool Program
It does stuff. Here is the documentation for it.
"""
print(foo, bar)
if __name__ == "__main__":
cli()
```
### 是时候开始写一些代码了
哪种方法是正确的?这取决于你的用例。你是在写一个只有你才会使用的快速而粗略的脚本吗?直接使用 `sys.argv` 然后继续编码。你需要更强大的命令行解析吗?也许 `argparse` 就够了。你是否有很多子命令和复杂的选项,你的团队是否会每天使用它?现在你一定要考虑一下 `Click` 或 `Typer`。作为一个程序员的乐趣之一就是魔改出替代实现,看看哪一个最适合你。
最后,在 Python 中有很多用于解析命令行参数的第三方软件包。我只介绍了我喜欢或使用过的那些。你喜欢和/或使用不同的包是完全可以的,也是我们所期望的。我的建议是先从这些包开始,然后看看你最终的结果。
去写一些很酷的东西吧。
---
via: <https://opensource.com/article/20/6/c-python-cli>
作者:[Erik O'Shaughnessy](https://opensource.com/users/jnyjny) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,287 | Linux Lite 5.0 发布,带有 UEFI 支持和其他重大改进 | https://itsfoss.com/linux-lite-5-release/ | 2020-06-06T07:02:00 | [] | https://linux.cn/article-12287-1.html | Linux Lite 是[适合 Windows 用户的最佳 Linux 发行版](https://itsfoss.com/windows-like-linux-distributions/)之一。 不仅限于此,它还是最受欢迎的[轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/)之一。
基于 Ubuntu 18.04 的 Linux Lite 4.x 系列虽然不错,但没有 [UEFI 支持](https://help.ubuntu.com/community/UEFI)。 但是现在基于 [Ubuntu 20.04](https://itsfoss.com/ubuntu-20-04-release-features/) 的 Linux Lite 5.0 终于来了,我很高兴看到这些变化!
在本文中,我们将介绍 Linux Lite 5.0 的新增功能。
### Linux Lite 5.0:关键变更

即使 Linux Lite 从 2.x 就开始支持 UEFI,但他们总是默认发布非 UEFI 的。
但是,在 Linux Lite 5.0 中,他们终于增加了开箱即用的 [UEFI](https://help.ubuntu.com/community/UEFI) 默认支持以及许多重大改进。让我们看看发生了什么变化:
#### UEFI 支持
Linux Lite 5.0 支持开箱即用的 UEFI。但是,他们建议禁用[安全启动](https://en.wikipedia.org/wiki/Hardware_restriction#Secure_boot),即使该功能可以工作。

你可以看看他们的[论坛文章](https://www.linuxliteos.com/forums/uefi-secure-boot/),以了解更多信息。此外,你还可以在新的内置**帮助手册**中找到有关此的更多信息。
#### 基于 Ubuntu 的发行版,没有隐藏的遥测
如果你正在寻找基于 Ubuntu 的 Linux 发行版,且没有任何隐藏的遥测功能,那么 Linux Lite 5.0 似乎是理想的选择。
在[发布公告](https://www.linuxliteos.com/forums/release-announcements/linux-lite-5-0-final-released/)中,他们在变更日志中提到了它,并提供了截图:

#### GUFW 防火墙替换为 firewalld
你可能已经读过[在 Linux 上使用 GUFW 设置防火墙](https://itsfoss.com/set-up-firewall-gufw/),但从 Linux Lite 5.0 开始,它已由 [firewalld](https://firewalld.org/) 取代。

似乎 [GUFW](http://gufw.org/) 不能像 firewalld 那样配置。因此,他们决定替换它。
默认情况下,它是禁用的。但是,你可以按照**帮助手册**中的教程选择启用它。
#### 新的 Whisker 菜单

[Whisker 菜单](https://gottcode.org/xfce4-whiskermenu-plugin/)已更新至最新可用的软件包(v2.4.4)。 除了更新之外,你还可以注意到**安装更新**现在被固定在收藏夹。
#### HiDPI 设置

如果需要,你会发现从**设置菜单**中设置 HiDPI 非常容易。
#### 已添加 XFCE 屏幕保护程序
在 Linux Lite 5.0 中,你还将注意到添加了 [XFCE 屏幕保护程序](https://docs.xfce.org/apps/screensaver/start),默认情况下它处于禁用状态。

这是一个简单的补充,对于一直想要屏幕保护程序并能够对其进行调整的用户而言,这将很有用。
### 其他重要改进
除了上面提到的关键要点外,还有其他一些改进对于 Linux Lite 5.0 用户而言应该是很方便的。我在这里列出其中一些:
* [Mousepad](https://salsa.debian.org/xfce-team/apps/mousepad) 替换 [Leafpad](https://tarot.freeshell.org/leafpad/)
* 新的更新通知
* 在即时启动时进行完整性检查
* 对**帮助手册**的重大改进
* Lite 软件中用 Chrome 取代了 Chromium
* 新的布局选项
* Lite 欢迎页面和 Lite 用户管理器现在更新到 GTK3 和 Python3。
* 欢迎页面添加了新的选择:**选择深色或浅色主题、UEFI 和安全启动、反馈**
* 改进的 Lite 小部件
如果你想进一步了解更改,可以在其[官方公告](https://www.linuxliteos.com/forums/release-announcements/linux-lite-5-0-final-released/)中找到详细的更改列表。
### 总结
我认为 Linux Lite 5.0 比以往任何时候要好,并且随着最近新增的功能,对于许多新 Linux 用户来说,它也是一个绝佳的选择。
你如何看待 Linux Lite 5.0?在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/linux-lite-5-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux Lite is one of the [best Linux distributions suitable for Windows users](https://itsfoss.com/windows-like-linux-distributions/). Not just limited to that, it’s also one of the most preferred [lightweight Linux distributions](https://itsfoss.com/lightweight-linux-beginners/) available.
Now that Linux Lite 5.0 has finally arrived based on [Ubuntu 20.04](https://itsfoss.com/ubuntu-20-04-release-features/) and I’m excited to see the changes!
In this article, we’ll take a look at what’s new in Linux Lite 5.0.
## Linux Lite 5.0: Key Changes

Even though Linux Lite supports UEFI since series 2.x, they always had their default release non-UEFI.
But, with Linux Lite 5.0, they have finally added the support for [UEFI](https://help.ubuntu.com/community/UEFI) out-of-the-box for the default release along with numerous significant improvements. Let’s take a brief look at what has changed:
### UEFI Support
Linux Lite 5.0 supports UEFI out-of-the-box. However, they recommend disabling the [Secure Boot](https://en.wikipedia.org/wiki/Hardware_restriction#Secure_boot) feature even though it should work with that.
You can take a look at one of their [forum threads](https://www.linuxliteos.com/forums/uefi-secure-boot/) to understand more about it. Not to mention, you can also find more information about it in the new inbuilt **Help Manual**.
### Ubuntu-based distro with no hidden telemetry
If you were looking for a Linux distribution that’s based on Ubuntu but without any hidden telemetry, Linux Lite 5.0 seems to be the perfect option.
In the [release announcement](https://www.linuxliteos.com/forums/release-announcements/linux-lite-5-0-final-released/), they mentioned it in the changelog along with a screenshot that you can see here:
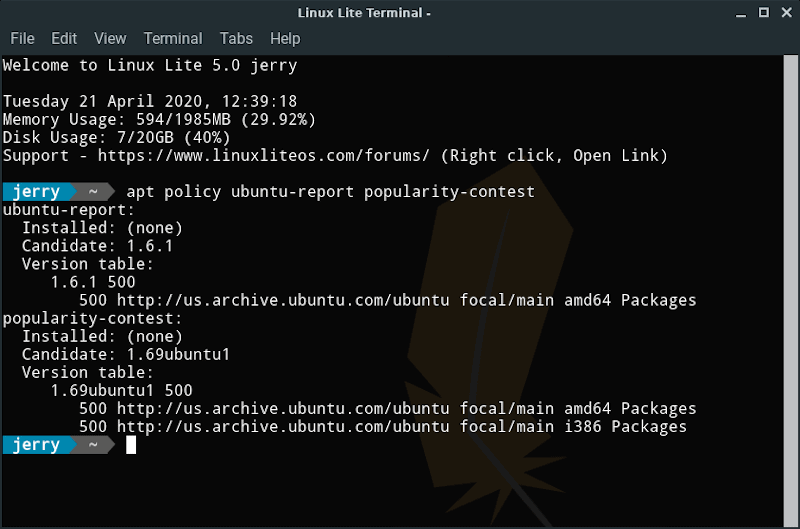
### GUFW Firewall replaced by firewallId
You might have read about [setting up a firewall using GUFW on Linux](https://itsfoss.com/set-up-firewall-gufw/) but starting with Linux Lite 5.0, it has been replaced by [firewallId](https://firewalld.org/).
It seems that [GUFW](http://gufw.org/) isn’t as configurable as firewallId. Hence, they decided to replace it.
By default, it is disabled. But, you can choose to enable it by following one of the tutorials in the **Help Manual**.
### Latest Whisker Menu
[Whisker Menu](https://gottcode.org/xfce4-whiskermenu-plugin/) has been updated to **v2.4.2**. In addition to the update, you can also notice that “**Install Updates**” is now pinned to the favorites section.
### HiDPI Settings
You will find it very easy to utilize the HiDPI settings from the **Settings menu** if you need it.
### XFCE Screensaver Added
With Linux Lite 5.0, you will also notice the addition of [XFCE screensaver](https://docs.xfce.org/apps/screensaver/start) program — which is disabled by default.
It’s a simple addition that should be useful for users who always wanted a screensaver app and the ability to tweak it.
## Other Important Improvements
In addition to the key highlights mentioned above, there are several other changes that should come in handy for Linux Lite 5.0 users. I’ve listed some of them here:
[Mousepad](https://salsa.debian.org/xfce-team/apps/mousepad)replaces[Leafpad](https://tarot.freeshell.org/leafpad/)- New update notification
- Integrity Check during live boot
- Major improvements to the
**Help Manual** - Chrome has replaced Chromium in Lite Software
- New Logout options
- Lite Welcome screen and Lite User Manager now updated to GTK3 and Python3.
- New options added to the Welcome screen:
**Select Dark or Light Theme, UEFI & Secure Boot, Feedback** - Improved Lite Widget
You can find a list of detailed changes in their [official announcement post](https://www.linuxliteos.com/forums/release-announcements/linux-lite-5-0-final-released/) if you want to explore more about it.
## Wrapping Up
I think Linux Lite 5.0 is better than ever and with all the recent additions it’s also going to be a fantastic option for a lot of new Linux users.
What do you think about Linux Lite 5.0? Let me know your thoughts in the comments down below. |
12,289 | 初级:如何在 GIMP 中制作 GIF | https://itsfoss.com/make-gif-in-gimp/ | 2020-06-06T22:16:59 | [
"GIMP",
"GIF"
] | https://linux.cn/article-12289-1.html | 制作一个 GIF 可能是一件很有趣的事,很多用户可能都想如何制作一个 GIF。你可以使用功能强大的开源图像编辑软件 [GIMP](https://www.gimp.org/) 创建一个非常简单的 GIF。
在这篇 GIMP 教程中,我将向你展示如何在 GIMP 中创建一个简单的 GIF。
### 在 GIMP 中制作一个 GIF

使用 GIMP 作为一个动画制作工具需要你把每个图层都看作动画的一帧。在这篇教程中,我将创建一个简单的基于我们的徽标的网页横幅。我将使用 2 个图像作为我的图层,但当你制作自己的 GIF 时,你可以随意添加更多的图像。
我在这里使用的方法叫做“组合法”,在这个方法中,新的帧被添加到先前的帧中。我的想法是制作一个“频闪”的网页横幅,来在对一些重要的事情引起注意。
我假设你已经 [在 Ubuntu 或其它使用的操作系统中安装了 GIMP](https://itsfoss.com/gimp-2-10-release/)。让我们开始制作 GIF 吧。
#### 步骤 1
从“文件”菜单中,单击“作为图层打开”,并选择你想包含在 GIF 中的所有图像。然后单击“打开”。

你可以排序图层标签页中的图像。GIF 的帧序列将从最下面的图层开始,从下到上运行每一层图层。

从主菜单中选择“滤镜”,接着选择“动画”,最后单击“优化(用于 GIF)”。

>
> “优化”做了什么?
>
>
> 优化会检查每一个图层,如果来自前一帧的信息在下一帧中没有改变,则重复使用这些信息。它只存储新更改的像素值,并清除任何重复的部分。
>
>
> 如果一帧与前一帧完全相同,那么它将完全删除这一幅帧,并且前一帧将恰当地在屏幕上停留更长时间。
>
>
>
要查看该 GIF,从主菜单中单击“滤镜”,接着单击“动画”和“回放”。

按下“回放”按钮来启动 GIF。要保存该 GIF,在文件菜单上选择“文件”,单击“导出为”。

命名你的 GIF,并选择你想将其保存到的文件夹。在“选择文件类型”时,选择 “GIF 图像”。

当提示时,选择“作为动画”、“反复循环”,设置期望的延迟值,并单击“上面输入的延迟用于所有帧”来生效。
最重要的选项是设置帧处理动作为“累积各图层(组合)”,以便为我们的横幅获取“频闪”效果。单击“导出”作为最后一个步骤。

你的 GIF 已经准备好了!

这是一个浅显易懂的示例,不过 GIMP 在动画创作方面有很多能力,需要大量的学习和实践才能掌握它。
---
via: <https://itsfoss.com/make-gif-in-gimp/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Making a GIF can be fun and many users would like to know how to make one. You can create a GIF very easily with [GIMP](https://www.gimp.org/?ref=itsfoss.com), the powerful open-source image editing software.
In this GIMP tutorial, I’ll show you how to create a simple GIF in GIMP.
## Making a GIF in GIMP
Using GIMP as an animation tool requires you to think of every layer as of an animation frame. In this tutorial, I will create a simple web banner based on It’s FOSS logo. I will use 2 images as my layers but you are welcome to add more when you make your own.
The method that I use here is called “the **combine** method”, in which the new frame is added to the previous frame. My idea is to make a “flashing” web banner, to draw the attention to something important.
I presume that you have [already installed GIMP in Ubuntu](https://itsfoss.com/gimp-2-10-release/) or whichever operating system you are using. Let’s start making the GIF.
### Step 1
From the File menu, click on **Open as Layers** and select all the images you want to include in the GIF. Then click **Open**.
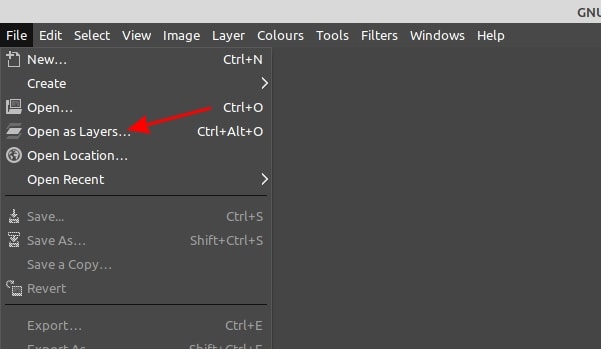
You can order your images in the layers tab. The GIF sequence will start with your bottom layer and run through each layer bottom to top.
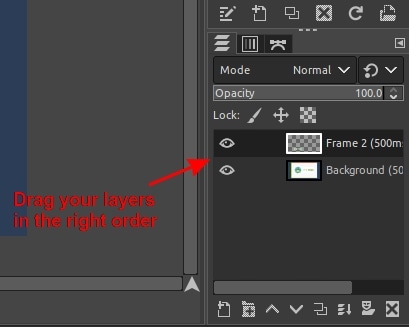
From the main menu select **Filters**, then **Animation** and finally click **Optimise (for GIF)**.
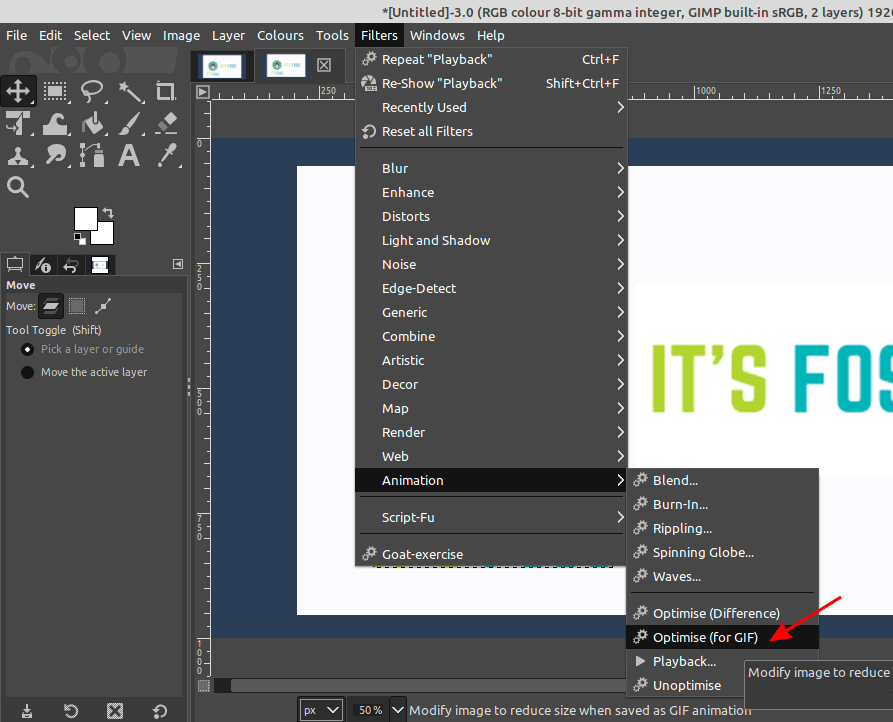
**What “Optimise” does?**
Optimise examines each layer, and reuses information from previous frames if they haven’t changed at the following frame. It only stores new values for pixels that change, and purges any duplicate parts.
If a frame is exactly the same as the previous one, it removes that frame completely and the previous frame just stays on the screen for longer.
To view GIF, from the main menu click on **Filter** then **Animation** and **Playback**.
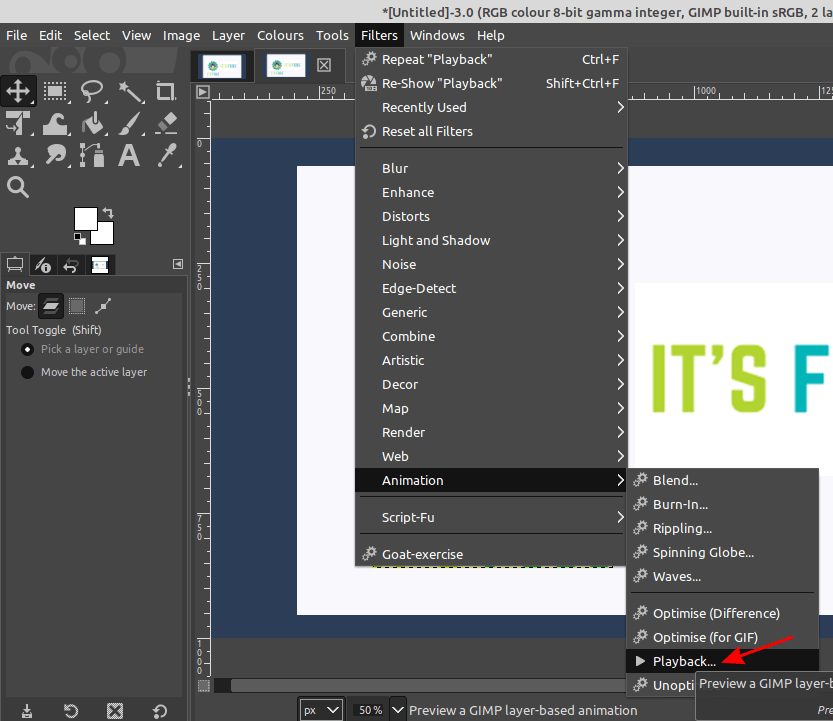
Press the **Playback** button to start GIF. To save GIF on the File Menu select **File**, click on **Export as**.
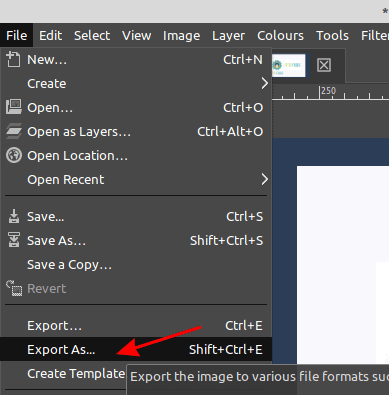
Name your GIF and choose the folder you want to save it in. On “**Select File Type**“, choose GIF Image.
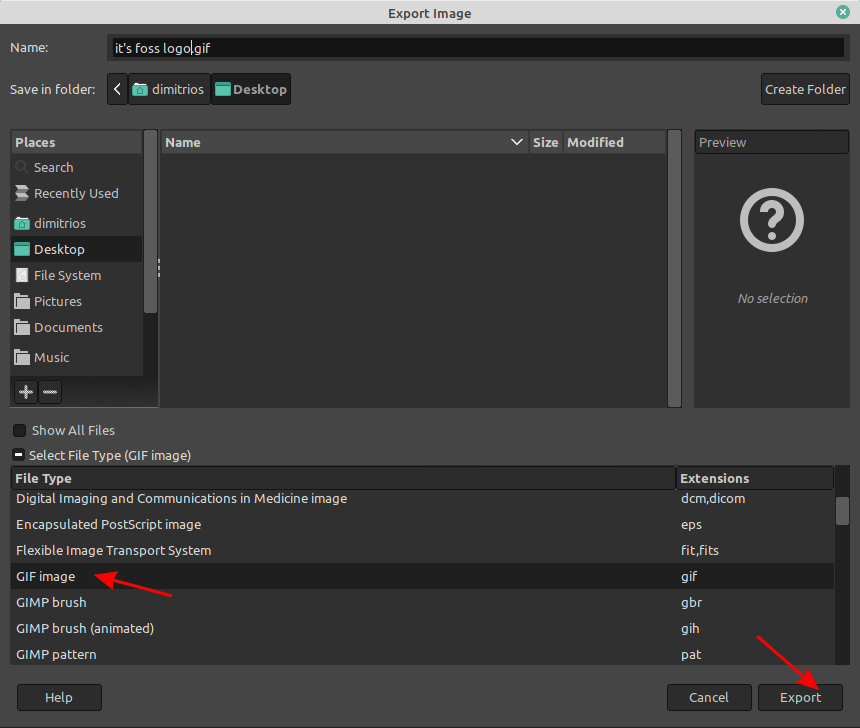
When prompted select ‘As Animation’, ‘Loop Forever’, set the desired delay value and to take effect click on “Use delay entered above for all frames”.
The most important option is to set the frame disposal action as “**Cumulative layers (combine)**” to get the “**flashing**” effect for our banner. Click Export as a final step.
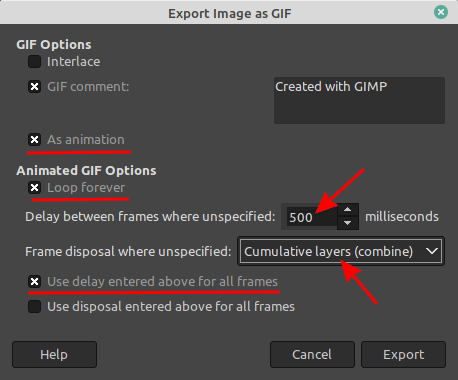
**Your GIF is ready!**

This was an easy-to-follow, simple example, although GIMP has a much greater depth in animation creating and requires a good amount of study and practice to master it.
If you are interested in more GIMP tutorials, you may[ read how to outline text in GIMP](https://itsfoss.com/gimp-text-outline/). Stay tuned at It’s FOSS for more such useful tips in the future. [Subscribing to the weekly newsletter](https://itsfoss.com/subscribe-to-newsletter/) is the best way to stay updated. Enjoy! |
12,290 | 如何使用 ethtool 命令管理以太网卡 | https://www.2daygeek.com/linux-ethtool-command-view-change-ethernet-adapter-settings-nic-card/ | 2020-06-06T22:34:00 | [
"网卡",
"ethtool"
] | https://linux.cn/article-12290-1.html | 
`ethtool` 用于查看和修改网络设备(尤其是有线以太网设备)的驱动参数和硬件设置。你可以根据需要更改以太网卡的参数,包括自动协商、速度、双工和局域网唤醒等参数。通过对以太网卡的配置,你的计算机可以通过网络有效地进行通信。该工具提供了许多关于接驳到你的 Linux 系统的以太网设备的信息。
在这篇文章中,我们将告诉你如何更改以下的参数以及如何查看这些参数。这篇文章将帮助你在 Linux 系统中排除与以太网卡相关的问题。
下面的信息将帮助你了解以太网卡的工作原理。
* **半双工**:半双工模式允许设备一次只能发送或接收数据包。
* **全双工**:全双工模式允许设备可以同时发送和接收数据包。
* **自动协商**:自动协商是一种机制,允许设备自动选择最佳网速和工作模式(全双工或半双工模式)。
* **速度**:默认情况下,它会使用最大速度,你可以根据自己的需要改变它。
* **链接检测**:链接检测可以显示网卡的状态。如果显示为 `no`,请尝试重启网卡。如果链路检测仍显示 `no`,则检查交换机与系统之间连接的线缆是否有问题。
### 如何在 Linux 上安装 ethtool
默认情况下,大多数系统上应该已经安装了 `ethtool`。如果没有,你可以从发行版的官方版本库中安装。
对于 RHEL/CentOS 6/7 系统,请使用 [yum 命令](https://www.2daygeek.com/linux-yum-command-examples-manage-packages-rhel-centos-systems/) 安装 `ethtool`:
```
$ sudo yum install -y ethtool
```
对于 RHEL/CentOS 8 和 Fedora 系统,请使用 [dnf 命令](https://www.2daygeek.com/linux-dnf-command-examples-manage-packages-fedora-centos-rhel-systems/) 安装 `ethtool`:
```
$ sudo dnf install -y ethtool
```
对于基于 Debian 的系统,请使用 [apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 或 [apt-get 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 安装 `ethtool`:
```
$ sudo apt-get install ethtool
```
对于 openSUSE 系统,使用 [zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 安装 `ethtool`:
```
$ sudo zypper install -y ethtool
```
对于 Arch Linux 系统,使用 [pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 安装 `ethtool`:
```
$ sudo pacman -S ethtool
```
### 如何检查 Linux 上的可用网络接口
你可以使用 [ip 命令](https://www.2daygeek.com/ip-command-configure-network-interface-usage-linux/)或 `ifconfig` 命令(在现代发行版中已被淘汰)来验证可用的、活动的网卡的名称和其他细节:
```
# ip a
或
# ifconfig
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:10:22:35:23:sf brd ff:ff:ff:ff:ff:ff
inet 192.164.23.100/24 brd 192.164.23.255 scope global eth0
valid_lft forever preferred_lft forever
```
### 如何检查 Linux 上的网卡(NIC)信息
掌握了以太网卡名称后,就可以使用 `ethtool` 命令轻松查看其详细信息,如下所示。
在 Linux 系统中,每个网卡(NIC)都被分配了唯一的名称,如 ethX、enpXXX 等。
* 旧的 Linux 发行版使用的是 `eth[X]` 格式。例如,RHEL 6 和它们的旧版本。
* 现代的 Linux 发行版使用 `enp[XXX]` 或 `ens[XXX]` 格式。例如,大多数现代 Linux 发行版都使用这种格式,包括 RHEL 7、Debian 10、Ubuntu 16.04 LTS。
```
# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 1000baseT/Full
10000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: No
Supported FEC modes: Not reported
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Advertised FEC modes: Not reported
Speed: 10000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: off
MDI-X: Unknown
Supports Wake-on: uag
Wake-on: d
Link detected: yes
```
### 如何检查以太网卡的驱动程序和固件版本
你可以使用 `ethtool` 命令的 `-i` 选项检查驱动程序版本、固件版本和总线的详细信息,如下所示:
```
# ethtool -i eth0
driver: vmxnet3
version: 1.4.16.0-k-NAPI
firmware-version:
expansion-rom-version:
bus-info: 0000:0b:00.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: yes
supports-priv-flags: no
```
### 如何检查网络使用情况统计
你可以使用 `ethtool` 命令中的 `-S` 选项来查看网络使用情况统计。它可以显示传输的字节数、接收的字节数、错误数等。
```
# ethtool -S eth0
NIC statistics:
Tx Queue#: 0
TSO pkts tx: 2053
TSO bytes tx: 7167572
ucast pkts tx: 4028081
ucast bytes tx: 399093197
mcast pkts tx: 0
mcast bytes tx: 0
bcast pkts tx: 0
bcast bytes tx: 0
pkts tx err: 0
pkts tx discard: 0
drv dropped tx total: 0
too many frags: 0
giant hdr: 0
hdr err: 0
tso: 0
ring full: 0
pkts linearized: 0
hdr cloned: 0
giant hdr: 0
Tx Queue#: 1
TSO pkts tx: 1955
TSO bytes tx: 6536945
ucast pkts tx: 3711838
ucast bytes tx: 346309662
mcast pkts tx: 0
mcast bytes tx: 0
bcast pkts tx: 1186
bcast bytes tx: 49812
pkts tx err: 0
pkts tx discard: 0
drv dropped tx total: 0
too many frags: 0
giant hdr: 0
hdr err: 0
tso: 0
ring full: 0
pkts linearized: 0
hdr cloned: 0
giant hdr: 0
Rx Queue#: 0
LRO pkts rx: 0
LRO byte rx: 0
ucast pkts rx: 5084776
ucast bytes rx: 4673133395
mcast pkts rx: 0
mcast bytes rx: 0
bcast pkts rx: 154143
bcast bytes rx: 45415676
pkts rx OOB: 0
pkts rx err: 0
drv dropped rx total: 0
err: 0
fcs: 0
rx buf alloc fail: 0
Rx Queue#: 1
LRO pkts rx: 0
LRO byte rx: 0
ucast pkts rx: 6346769
ucast bytes rx: 4835534292
mcast pkts rx: 0
mcast bytes rx: 0
bcast pkts rx: 3464
bcast bytes rx: 714646
pkts rx OOB: 0
pkts rx err: 0
drv dropped rx total: 0
err: 0
fcs: 0
rx buf alloc fail: 0
tx timeout count: 0
```
### 如何改变以太网设备的速度
你可以根据需要改变以太网的速度。当你进行此更改时,网卡将自动掉线,你需要使用 [ifup 命令](https://www.2daygeek.com/enable-disable-up-down-nic-network-interface-port-linux-using-ifconfig-ifdown-ifup-ip-nmcli-nmtui/) 或 `ip` 命令或 `nmcli` 命令将其重新上。
```
# ethtool -s eth0 speed 100
# ip link set eth0 up
```
### 如何在 Linux 上启用/禁用以太网卡的自动协商?
你可以使用 `ethtool` 命令中的 `autoneg` 选项启用或禁用自动协商,如下图所示:
```
# ethtool -s eth0 autoneg off
# ethtool -s eth0 autoneg on
```
### 如何同时更改多个参数
如果你想使用 `ethtool` 命令同时更改以太网卡的多个参数,请使用下面的格式:
```
Syntax:
ethtool –s [device_name] speed [10/100/1000] duplex [half/full] autoneg [on/off]
```
```
# ethtool –s eth0 speed 1000 duplex full autoneg off
```
### 如何检查特定网卡的自动协商、RX 和 TX
要查看关于特定以太网设备的自动协商等详细信息,请使用以下格式:
```
# ethtool -a eth0
```
### 如何从多个设备中识别出特定的网卡(闪烁网卡上的 LED)
如果你想识别一个特定的物理接口,这个选项非常有用。下面的 `ethtool` 命令会使 `eth0` 端口的 LED 灯闪烁:
```
# ethtool -p eth0
```
### 如何在 Linux 中永久设置这些参数
在系统重启后,你使用 `ethtool` 所做的更改将被默认恢复。
要使自定义设置永久化,你需要更新网络配置文件中的值。根据你的 Linux 发行版,你可能需要将此值更新到正确的文件中。
对于基于 RHEL 的系统。你必须使用 `ETHTOOL_OPTS` 变量:
```
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
ETHTOOL_OPTS="speed 1000 duplex full autoneg off"
```
对于基于 Debian 的系统:
```
# vi /etc/network/interfaces
post-up ethtool -s eth0 speed 1000 duplex full autoneg off
```
---
via: <https://www.2daygeek.com/linux-ethtool-command-view-change-ethernet-adapter-settings-nic-card/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,293 | OpenSSL 精粹:SSL 证书、私钥和 CSR | https://www.digitalocean.com/community/tutorials/openssl-essentials-working-with-ssl-certificates-private-keys-and-csrs | 2020-06-07T22:58:00 | [
"OpenSSL",
"证书"
] | https://linux.cn/article-12293-1.html | 
### 介绍
OpenSSL 是一个多功能的命令行工具,可以用于与<ruby> 公钥基础设施 <rp> ( </rp> <rt> Public Key Infrastructure </rt> <rp> ) </rp></ruby>(PKI)和 HTTPS(HTTP over TLS)相关的大量任务。这本小抄风格的指南提供了 OpenSSL 命令的快速参考,这些命令在常见的日常场景中非常有用。这包括生成私钥、<ruby> 证书签署请求 <rp> ( </rp> <rt> certificate signing request </rt> <rp> ) </rp></ruby>(CSR)和证书格式转换的 OpenSSL 示例,但它并没有涵盖 OpenSSL 的所有用途。
### 如何使用本指南
* 如果你不熟悉证书签署请求(CSR),请阅读第一部分。
* 除了第一部分,本指南采用了简单的小抄格式:自带了命令行代码片段。
* 跳到与你准备完成的任务相关的任何部分。
* 大多数命令都是单行的,为了清晰起见,已经扩展到多行(使用 `\` 符号)。
### 关于证书签署请求(CSR)
如果你想从<ruby> 证书颁发机构 <rp> ( </rp> <rt> certificate authority </rt> <rp> ) </rp></ruby>(CA)那里获得 SSL 证书,你必须生成一个<ruby> 证书签署请求 <rp> ( </rp> <rt> certificate signing request </rt> <rp> ) </rp></ruby>(CSR)。一个 CSR 主要是由一个密钥对的公钥和一些附加信息组成。当证书被签署时,这两部分都会被插入到证书中。
每当你生成一个 CSR 时,你会被提示提供有关证书的信息。这些信息被称为<ruby> 区分名称 <rp> ( </rp> <rt> Distinguised Name </rt> <rp> ) </rp></ruby>(DN)。DN 中的一个重要字段是<ruby> 通用名称 <rp> ( </rp> <rt> Common Name </rt> <rp> ) </rp></ruby>(CN),它应该是你打算使用证书的主机的<ruby> 完全合格域名 <rp> ( </rp> <rt> Fully Qualified Domain Name </rt> <rp> ) </rp></ruby>(FQDN)。当创建 CSR 时,也可以通过命令行或文件传递信息来跳过交互式提示。
DN 中的其他项目提供了有关你的业务或组织的附加信息。如果你是从证书机构购买 SSL 证书,通常要求这些附加字段(如“<ruby> 组织 <rp> ( </rp> <rt> Organization </rt> <rp> ) </rp></ruby>”)准确地反映你的组织的详细信息。
下面是一个 CSR 信息提示的例子:
```
---
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:New York
Locality Name (eg, city) []:Brooklyn
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Example Brooklyn Company
Organizational Unit Name (eg, section) []:Technology Division
Common Name (e.g. server FQDN or YOUR name) []:examplebrooklyn.com
Email Address []:
```
如果你想非交互式地回答 CSR 信息提示,你可以通过在任何请求 CSR 信息的 OpenSSL 命令中添加 `-subj` 选项来实现。这里是该选项的一个例子,使用上面代码块中显示的相同信息:
```
-subj "/C=US/ST=New York/L=Brooklyn/O=Example Brooklyn Company/CN=examplebrooklyn.com"
```
现在你已经了解了 CSR,可以自由跳转到本指南中涵盖你的 OpenSSL 需求的任何一节。
### 生成 CSR
本节介绍了与生成 CSR(以及私钥,如果它们还不存在的话)有关的 OpenSSL 命令。CSR 可以用来向证书颁发机构请求 SSL 证书。
请记住,你可以通过上一节中提到的 `-subj` 选项非交互式地添加 CSR 信息。
#### 生成一个私钥和一个 CSR
如果你想使用 HTTPS(HTTP over TLS)来保护你的 Apache HTTP 或 Nginx Web 服务器的安全,并且你想使用一个证书颁发机构(CA)来颁发 SSL 证书,那么就使用这个方法。生成的 CSR 可以发送给 CA,请求签发由 CA 签名的 SSL 证书。如果你的 CA 支持 SHA-2,请添加 `-sha256` 选项,用 SHA-2 签署 CSR。
这条命令从头开始创建一个 2048 位的私钥(`domain.key`)和一个 CSR(`domain.csr`):
```
openssl req \
-newkey rsa:2048 -nodes -keyout domain.key \
-out domain.csr
```
回答 CSR 信息提问,完成该过程。
选项 `-newkey rsa:2048` 指定密钥应该是 `2048` 位,使用 `RSA` 算法生成。选项 `-nodes` 指定私钥*没有*用密码加密。这里没有包含 `-new` 选项,而是隐含在其中,表示正在生成一个 CSR。
#### 从现有的私钥中生成一个 CSR
如果你已经有了私钥,并想用它向 CA 申请证书,请使用这个方法。
该命令基于现有的私钥(`domain.key`)创建一个新的 CSR(`domain.csr`):
```
openssl req \
-key domain.key \
-new -out domain.csr
```
回答 CSR 信息提问,完成该过程。
选项 `-key` 指定一个现有的私钥(`domain.key`),它将被用来生成一个新的 CSR。选项 `-new` 表示正在生成一个 CSR。
#### 从现有的证书和私钥生成 CSR
如果你想更新现有的证书,但由于某些原因,你或你的 CA 没有原始的 CSR,请使用这个方法。基本上可以省去重新输入 CSR 信息的麻烦,因为它是从现有证书中提取信息的。
该命令基于现有的证书(`domain.crt`)和私钥(`domain.key`)创建一个新的 CSR(`domain.csr`):
```
openssl x509 \
-in domain.crt \
-signkey domain.key \
-x509toreq -out domain.csr
```
选项 `-x509toreq` 指定你使用一个 X509 证书来制作 CSR。
### 生成 SSL 证书
如果你想使用 SSL 证书来确保服务的安全,但你不需要 CA 签名的证书,一个有效的(和免费的)解决方案是签署你自己的证书。
你可以自己签发的一种常见证书是<ruby> 自签证书 <rp> ( </rp> <rt> self-signed certificate </rt> <rp> ) </rp></ruby>。自签证书是用自己的私钥签署的证书。自签证书和 CA 签名证书一样可以用来加密数据,但是你的用户会显示一个警告,说这个证书不被他们的计算机或浏览器信任。因此,只有当你不需要向用户证明你的服务身份时,才可以使用自签名证书(例如非生产或非公开服务器)。
本节介绍与生成自签名证书相关的 OpenSSL 命令。
#### 生成自签证书
如果你想使用 HTTPS(HTTP over TLS)来保护你的 Apache HTTP 或 Nginx Web 服务器,并且你不需要你的证书由 CA 签名,那么就使用这个方法。
这个命令可以从头开始创建一个 2048 位的私钥(`domain.key`)和一个自签证书(`domain.crt`):
```
openssl req \
-newkey rsa:2048 -nodes -keyout domain.key \
-x509 -days 365 -out domain.crt
```
回答 CSR 信息提问,完成该过程。
选项 `-x509` 告诉 `req` 子命令创建一个自签名的证书。`-days 365` 选项指定证书的有效期为 `365` 天。它会生成一个临时的 CSR,以收集与证书相关的信息。
#### 从现有私钥生成自签名证书
如果你已经有了一个私钥,并且你想用它来生成一个自签证书,请使用这个方法。
这条命令可以从现有的私钥(`domain.key`)中创建一个自签证书(`domain.crt`):
```
openssl req \
-key domain.key \
-new \
-x509 -days 365 -out domain.crt
```
回答 CSR 信息提问,完成该过程。
选项 `-x509` 告诉 `req` 子命令创建一个自签证书。`-days 365` 选项指定证书的有效期为 `365` 天。选项 `-new` 启用 CSR 信息提问。
#### 从现有的私钥和 CSR 生成自签证书
如果你已经有了私钥和 CSR,并且你想用它们生成一个自签证书,请使用这个方法。
这条命令将从现有的私钥(`domain.key`)和(`domain.csr`)中创建一个自签证书(`domain.crt`)。
```
openssl x509 \
-signkey domain.key \
-in domain.csr \
-req -days 365 -out domain.crt
```
选项 `-days 365` 指定证书的有效期为 `365` 天。
### 查看证书
证书和 CSR 文件是以 PEM 格式编码的,不适合被人读取。
本节介绍的 OpenSSL 命令将输出 PEM 编码文件的实际条目。
#### 查看 CSR 条目
该命令允许你查看和验证纯文本的 CSR(`domain.csr`)的内容:
```
openssl req \
-text -noout -verify \
-in domain.csr
```
#### 查看证书条目
该命令允许你查看纯文本证书(`domain.crt`)的内容:
```
openssl x509 \
-text -noout \
-in domain.crt
```
#### 验证证书由 CA 签署
使用此命令验证证书(`domain.crt`)是否由特定的 CA 证书(`ca.crt`)签署:
```
openssl verify \
-verbose -CAFile ca.crt \
domain.crt
```
### 私钥
本节介绍了用于创建和验证私钥的 OpenSSL 命令。
#### 创建私钥
使用该命令创建一个受密码保护的 `2048` 位私钥(`domain.key`):
```
openssl genrsa \
-des3 -out domain.key 2048
```
在提示时输入密码以完成该过程。
#### 验证私钥
使用此命令检查私钥(`domain.key`)是否为有效密钥:
```
openssl rsa \
-check -in domain.key
```
如果你的私钥已经加密,系统会提示你输入它的密码,成功后,未加密的密钥会在终端上输出。
#### 验证私钥是否与证书和 CSR 匹配
使用这些命令来验证私钥(`domain.key`)是否匹配证书(`domain.crt`)和 CSR(`domain.csr`):
```
openssl rsa -noout -modulus -in domain.key | openssl md5
openssl x509 -noout -modulus -in domain.crt | openssl md5
openssl req -noout -modulus -in domain.csr | openssl md5
```
如果每条命令的输出都是相同的,那么私钥、证书和 CSR 就极有可能是相关的。
#### 加密私钥
这需要一个未加密的私钥(`unencrypted.key`),并输出它的加密版本(`encrypted.key`):
```
openssl rsa -des3 \
-in unencrypted.key \
-out encrypted.key
```
输入你所需的密码,以加密私钥。
#### 解密私钥
这需要一个加密的私钥(`encrypted.key`),并输出一个解密的版本(`decrypted.key`):
```
openssl rsa \
-in encrypted.key \
-out decrypted.key
```
在提示时,输入加密密钥的密码。
### 转换证书格式
我们一直在使用的所有证书都是 ASCII 码 PEM 编码的 X.509 证书。还有很多其他的证书编码和容器类型;一些应用程序喜欢某些格式而不是其他格式。此外,这些格式中的许多格式可以在一个文件中包含多个项目,如私钥、证书和 CA 证书。
OpenSSL 可以用来将证书在则西格式间转换。本节将介绍一些可能的转换。
#### 将 PEM 转换为 DER
如果要将 PEM 编码的证书(`domain.crt`)转换为 DER 编码的证书(`domain.der`),即二进制格式,请使用此命令:
```
openssl x509 \
-in domain.crt \
-outform der -out domain.der
```
DER 格式通常与 Java 一起使用。
#### 将 DER 转换为 PEM
如果要将 DER 编码的证书(`domain.der`)转换为 PEM 编码的证书(`domain.crt`),请使用此命令:
```
openssl x509 \
-inform der -in domain.der \
-out domain.crt
```
#### 将 PEM 转换为 PKCS7
如果你想把 PEM 证书(`domain.crt` 和 `ca-chain.crt`)添加到 PKCS7 文件(`domain.p7b`)中,请使用该命令:
```
openssl crl2pkcs7 -nocrl \
-certfile domain.crt \
-certfile ca-chain.crt \
-out domain.p7b
```
请注意,你可以使用一个或多个 `-certfile` 选项来指定要添加到 PKCS7 文件中的证书。
PKCS7 文件,也被称为 P7B,通常用于 Java Keystores 和 Microsoft IIS(Windows)。它们是 ASCII 文件,可以包含证书和 CA 证书。
#### 将 PKCS7 转换为 PEM
如果你想将 PKCS7 文件(`domain.p7b`)转换为 PEM 文件,请使用该命令:
```
openssl pkcs7 \
-in domain.p7b \
-print_certs -out domain.crt
```
请注意,如果你的 PKCS7 文件中有多个项目(如证书和 CA 中间证书),创建的 PEM 文件将包含其中的所有项目。
#### 将 PEM 转换为 PKCS12
如果你想使用私钥(`domain.key`)和证书(`domain.crt`),并将它们组合成一个 PKCS12 文件(`domain.pfx`),请使用这个命令:
```
openssl pkcs12 \
-inkey domain.key \
-in domain.crt \
-export -out domain.pfx
```
系统会提示你输入导出密码,你可以留空。请注意,在这种情况下,你可以通过将多个证书连接到一个 PEM 文件(`domain.crt`)中来添加一个证书链到 PKCS12 文件中。
PKCS12 文件,也被称为 PFX 文件,通常用于在 Micrsoft IIS(Windows)中导入和导出证书链。
#### 将 PKCS12 转换为 PEM
如果你想转换 PKCS12 文件(`domain.pfx`)并将其转换为 PEM 格式(`domain.combined.crt`),请使用此命令:
```
openssl pkcs12 \
-in domain.pfx \
-nodes -out domain.combined.crt
```
请注意,如果你的 PKCS12 文件中有多个项目(如证书和私钥),创建的 PEM 文件将包含其中的所有项目。
### OpenSSL 版本
`openssl version` 命令可以用来检查你正在运行的版本。你正在运行的 OpenSSL 版本,以及编译时使用的选项会影响到你可以使用的功能(有时也会影响到命令行选项)。
下面的命令显示了你正在运行的 OpenSSL 版本,以及它被编译时的所有选项:
```
openssl version -a
```
本指南是使用具有如下细节的 OpenSSL 二进制文件编写的(参见前面命令的输出):
```
OpenSSL 1.0.1f 6 Jan 2014
built on: Mon Apr 7 21:22:23 UTC 2014
platform: debian-amd64
options: bn(64,64) rc4(16x,int) des(idx,cisc,16,int) blowfish(idx)
compiler: cc -fPIC -DOPENSSL_PIC -DOPENSSL_THREADS -D_REENTRANT -DDSO_DLFCN -DHAVE_DLFCN_H -m64 -DL_ENDIAN -DTERMIO -g -O2 -fstack-protector --param=ssp-buffer-size=4 -Wformat -Werror=format-security -D_FORTIFY_SOURCE=2 -Wl,-Bsymbolic-functions -Wl,-z,relro -Wa,--noexecstack -Wall -DMD32_REG_T=int -DOPENSSL_IA32_SSE2 -DOPENSSL_BN_ASM_MONT -DOPENSSL_BN_ASM_MONT5 -DOPENSSL_BN_ASM_GF2m -DSHA1_ASM -DSHA256_ASM -DSHA512_ASM -DMD5_ASM -DAES_ASM -DVPAES_ASM -DBSAES_ASM -DWHIRLPOOL_ASM -DGHASH_ASM
OPENSSLDIR: "/usr/lib/ssl"
```
### 总结
这应该涵盖了大多数人如何使用 OpenSSL 来处理 SSL 证书的情况!它还有很多其他的用途,在这里没有介绍,所以请在评论中随时询问或建议其他用途。
如果你在使用这些命令时遇到了问题,请一定要评论(并附上你的 OpenSSL 版本输出)。
---
via: <https://www.digitalocean.com/community/tutorials/openssl-essentials-working-with-ssl-certificates-private-keys-and-csrs>
作者:[Mitchell Anicas](https://www.digitalocean.com/community/users/manicas) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12290-1.html) 荣誉推出
| 200 | OK | OpenSSL is a versatile command line tool that can be used for a large variety of tasks related to Public Key Infrastructure (PKI) and HTTPS (HTTP over TLS). This cheat sheet style guide provides a quick reference to OpenSSL commands that are useful in common, everyday scenarios. This includes OpenSSL examples for generating private keys, certificate signing requests, and certificate format conversion. It does not cover all of the uses of OpenSSL.
**How to Use This Guide:**
`\`
symbol) for clarityIf you would like to obtain an SSL certificate from a commercial certificate authority (CA), you must generate a certificate signing request (CSR). A CSR consists mainly of the public key of a key pair, and some additional information. Both of these components are inserted into the certificate when it is signed.
Whenever you generate a CSR, you will be prompted to provide information regarding the certificate. This information is known as a Distinguished Name (DN). An important field in the DN is the **Common Name** (CN), which should be the exact Fully Qualified Domain Name (FQDN) of the host that you intend to use the certificate with. It is also possible to skip the interactive prompts when creating a CSR by passing the information via command line or from a file.
The other items in a DN provide additional information about your business or organization. If you are purchasing an SSL certificate from a certificate authority, it is often required that these additional fields, such as “Organization”, accurately reflect your organization’s details.
Here is an example of what the CSR information prompt will look like:
```
---
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:New York
Locality Name (eg, city) []:Brooklyn
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Example Brooklyn Company
Organizational Unit Name (eg, section) []:Technology Division
Common Name (e.g. server FQDN or YOUR name) []:examplebrooklyn.com
Email Address []:
```
If you want to non-interactively answer the CSR information prompt, you can do so by adding the `-subj`
option to any OpenSSL commands that request CSR information. Here is an example of the option, using the same information displayed in the code block above:
```
-subj "/C=US/ST=New York/L=Brooklyn/O=Example Brooklyn Company/CN=examplebrooklyn.com"
```
Now that you understand CSRs, feel free to jump around to whichever section of this guide covers your OpenSSL needs.
This section covers OpenSSL commands that are related to generating CSRs (and private keys, if they do not already exist). CSRs can be used to request SSL certificates from a certificate authority.
Keep in mind that you may add the CSR information non-interactively with the `-subj`
option, mentioned in the previous section.
Use this method if you want to use HTTPS (HTTP over TLS) to secure your Apache HTTP or Nginx web server, and you want to use a Certificate Authority (CA) to issue the SSL certificate. The CSR that is generated can be sent to a CA to request the issuance of a CA-signed SSL certificate. If your CA supports SHA-2, add the `-sha256`
option to sign the CSR with SHA-2.
This command creates a 2048-bit private key (`domain.key`
) and a CSR (`domain.csr`
) from scratch:
- openssl req \
- -newkey rsa:2048 -nodes -keyout domain.key \
- -out domain.csr
Answer the CSR information prompt to complete the process.
The `-newkey rsa:2048`
option specifies that the key should be 2048-bit, generated using the RSA algorithm. The `-nodes`
option specifies that the private key should *not* be encrypted with a pass phrase. The `-new`
option, which is not included here but implied, indicates that a CSR is being generated.
Use this method if you already have a private key that you would like to use to request a certificate from a CA.
This command creates a new CSR (`domain.csr`
) based on an existing private key (`domain.key`
):
- openssl req \
- -key domain.key \
- -new -out domain.csr
Answer the CSR information prompt to complete the process.
The `-key`
option specifies an existing private key (`domain.key`
) that will be used to generate a new CSR. The `-new`
option indicates that a CSR is being generated.
Use this method if you want to renew an existing certificate but you or your CA do not have the original CSR for some reason. It basically saves you the trouble of re-entering the CSR information, as it extracts that information from the existing certificate.
This command creates a new CSR (`domain.csr`
) based on an existing certificate (`domain.crt`
) and private key (`domain.key`
):
- openssl x509 \
- -in domain.crt \
- -signkey domain.key \
- -x509toreq -out domain.csr
The `-x509toreq`
option specifies that you are using an X509 certificate to make a CSR.
If you would like to use an SSL certificate to secure a service but you do not require a CA-signed certificate, a valid (and free) solution is to sign your own certificates.
A common type of certificate that you can issue yourself is a *self-signed certificate*. A self-signed certificate is a certificate that is signed with its own private key. Self-signed certificates can be used to encrypt data just as well as CA-signed certificates, but your users will be displayed a warning that says that the certificate is not trusted by their computer or browser. Therefore, self-signed certificates should only be used if you do not need to prove your service’s identity to its users (e.g. non-production or non-public servers).
This section covers OpenSSL commands that are related to generating self-signed certificates.
Use this method if you want to use HTTPS (HTTP over TLS) to secure your Apache HTTP or Nginx web server, and you do not require that your certificate is signed by a CA.
This command creates a 2048-bit private key (`domain.key`
) and a self-signed certificate (`domain.crt`
) from scratch:
- openssl req \
- -newkey rsa:2048 -nodes -keyout domain.key \
- -x509 -days 365 -out domain.crt
Answer the CSR information prompt to complete the process.
The `-x509`
option tells `req`
to create a self-signed certificate. The `-days 365`
option specifies that the certificate will be valid for 365 days. A temporary CSR is generated to gather information to associate with the certificate.
Use this method if you already have a private key that you would like to generate a self-signed certificate with it.
This command creates a self-signed certificate (`domain.crt`
) from an existing private key (`domain.key`
):
- openssl req \
- -key domain.key \
- -new \
- -x509 -days 365 -out domain.crt
Answer the CSR information prompt to complete the process.
The `-x509`
option tells `req`
to create a self-signed certificate. The `-days 365`
option specifies that the certificate will be valid for 365 days. The `-new`
option enables the CSR information prompt.
Use this method if you already have a private key and CSR, and you want to generate a self-signed certificate with them.
This command creates a self-signed certificate (`domain.crt`
) from an existing private key (`domain.key`
) and (`domain.csr`
):
- openssl x509 \
- -signkey domain.key \
- -in domain.csr \
- -req -days 365 -out domain.crt
The `-days 365`
option specifies that the certificate will be valid for 365 days.
Certificate and CSR files are encoded in PEM format, which is not readily human-readable.
This section covers OpenSSL commands that will output the actual entries of PEM-encoded files.
This command allows you to view and verify the contents of a CSR (`domain.csr`
) in plain text:
- openssl req -text -noout -verify -in domain.csr
This command allows you to view the contents of a certificate (`domain.crt`
) in plain text:
- openssl x509 -text -noout -in domain.crt
Use this command to verify that a certificate (`domain.crt`
) was signed by a specific CA certificate (`ca.crt`
):
- openssl verify -verbose -CAFile ca.crt domain.crt
This section covers OpenSSL commands that are specific to creating and verifying private keys.
Use this command to create a password-protected, 2048-bit private key (`domain.key`
):
- openssl genrsa -des3 -out domain.key 2048
Enter a password when prompted to complete the process.
Use this command to check that a private key (`domain.key`
) is a valid key:
- openssl rsa -check -in domain.key
If your private key is encrypted, you will be prompted for its pass phrase. Upon success, the unencrypted key will be output on the terminal.
Use these commands to verify if a private key (`domain.key`
) matches a certificate (`domain.crt`
) and CSR (`domain.csr`
):
- openssl rsa -noout -modulus -in domain.key | openssl md5
- openssl x509 -noout -modulus -in domain.crt | openssl md5
- openssl req -noout -modulus -in domain.csr | openssl md5
If the output of each command is identical there is an extremely high probability that the private key, certificate, and CSR are related.
This takes an unencrypted private key (`unencrypted.key`
) and outputs an encrypted version of it (`encrypted.key`
):
- openssl rsa -des3 \
- -in unencrypted.key \
- -out encrypted.key
Enter your desired pass phrase, to encrypt the private key with.
This takes an encrypted private key (`encrypted.key`
) and outputs a decrypted version of it (`decrypted.key`
):
- openssl rsa \
- -in encrypted.key \
- -out decrypted.key
Enter the pass phrase for the encrypted key when prompted.
All of the certificates that we have been working with have been X.509 certificates that are ASCII PEM encoded. There are a variety of other certificate encoding and container types; some applications prefer certain formats over others. Also, many of these formats can contain multiple items, such as a private key, certificate, and CA certificate, in a single file.
OpenSSL can be used to convert certificates to and from a large variety of these formats. This section will cover a some of the possible conversions.
Use this command if you want to convert a PEM-encoded certificate (`domain.crt`
) to a DER-encoded certificate (`domain.der`
), a binary format:
- openssl x509 \
- -in domain.crt \
- -outform der -out domain.der
The DER format is typically used with Java.
Use this command if you want to convert a DER-encoded certificate (`domain.der`
) to a PEM-encoded certificate (`domain.crt`
):
- openssl x509 \
- -inform der -in domain.der \
- -out domain.crt
Use this command if you want to add PEM certificates (`domain.crt`
and `ca-chain.crt`
) to a PKCS7 file (`domain.p7b`
):
- openssl crl2pkcs7 -nocrl \
- -certfile domain.crt \
- -certfile ca-chain.crt \
- -out domain.p7b
Note that you can use one or more `-certfile`
options to specify which certificates to add to the PKCS7 file.
PKCS7 files, also known as P7B, are typically used in Java Keystores and Microsoft IIS (Windows). They are ASCII files which can contain certificates and CA certificates.
Use this command if you want to convert a PKCS7 file (`domain.p7b`
) to a PEM file:
- openssl pkcs7 \
- -in domain.p7b \
- -print_certs -out domain.crt
Note that if your PKCS7 file has multiple items in it (e.g. a certificate and a CA intermediate certificate), the PEM file that is created will contain all of the items in it.
Use this command if you want to take a private key (`domain.key`
) and a certificate (`domain.crt`
), and combine them into a PKCS12 file (`domain.pfx`
):
- openssl pkcs12 \
- -inkey domain.key \
- -in domain.crt \
- -export -out domain.pfx
You will be prompted for export passwords, which you may leave blank. Note that you may add a chain of certificates to the PKCS12 file by concatenating the certificates together in a single PEM file (`domain.crt`
) in this case.
PKCS12 files, also known as PFX files, are typically used for importing and exporting certificate chains in Microsoft IIS (Windows).
Use this command if you want to convert a PKCS12 file (`domain.pfx`
) and convert it to PEM format (`domain.combined.crt`
):
```
openssl pkcs12 \
-in domain.pfx \
-nodes -out domain.combined.crt
```
Note that if your PKCS12 file has multiple items in it (e.g. a certificate and private key), the PEM file that is created will contain all of the items in it.
The `openssl version`
command can be used to check which version you are running. The version of OpenSSL that you are running, and the options it was compiled with affect the capabilities (and sometimes the command line options) that are available to you.
The following command displays the OpenSSL version that you are running, and all of the options that it was compiled with:
```
openssl version -a
```
This guide was written using an OpenSSL binary with the following details (the output of the previous command):
```
OpenSSL 1.1.1 11 Sep 2018
built on: Mon Aug 23 17:02:39 2021 UTC
platform: debian-amd64
options: bn(64,64) rc4(16x,int) des(int) blowfish(ptr)
compiler: gcc -fPIC -pthread -m64 -Wa,--noexecstack -Wall -Wa,--noexecstack -g -O2 -fdebug-prefix-map=/build/openssl-Flav1L/openssl-1.1.1=. -fstack-protector-strong -Wformat -Werror=format-security -DOPENSSL_USE_NODELETE -DL_ENDIAN -DOPENSSL_PIC -DOPENSSL_CPUID_OBJ -DOPENSSL_IA32_SSE2 -DOPENSSL_BN_ASM_MONT -DOPENSSL_BN_ASM_MONT5 -DOPENSSL_BN_ASM_GF2m -DSHA1_ASM -DSHA256_ASM -DSHA512_ASM -DKECCAK1600_ASM -DRC4_ASM -DMD5_ASM -DAES_ASM -DVPAES_ASM -DBSAES_ASM -DGHASH_ASM -DECP_NISTZ256_ASM -DX25519_ASM -DPADLOCK_ASM -DPOLY1305_ASM -DNDEBUG -Wdate-time -D_FORTIFY_SOURCE=2
OPENSSLDIR: "/usr/lib/ssl"
ENGINESDIR: "/usr/lib/x86_64-linux-gnu/engines-1.1"
Seeding source: os-specific
```
That should cover how most people use OpenSSL to work with SSL certs. It has many other uses that were not covered here, so feel free to ask or suggest other uses in the comments.
If you are having issues with any of the commands, be sure to comment (and include your OpenSSL version output).
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
This textbox defaults to using **Markdown** to format your answer.
You can type **!ref** in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Sign up for Infrastructure as a Newsletter.
Working on improving health and education, reducing inequality, and spurring economic growth? We'd like to help.
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.
Great summary, was recently looking for exactly something like that. Thank you for the write up.
I recently stumbled across https://shaaaaaaaaaaaaa.com/ summarizing the soon to come retirement of SHA-1.
It may be of use also for this tutorial to add the option
to create the CSR.
I did that for a recent request from StartSSL and they offered a certificate accommodating the more secure requirements (passing also A+ on ssllabs.com)
Since you especially describe how to generate CSR for obtaining a certificate, it may be worth adding the option in order to be more future proof.
Best regards Sebastian
Should be
Mitchell - Fantastic post! Just one slight correction:
The option uses a lowercase “f”, as in:
Great article… Thanks for putting it together…
You can also create your own certificate authority and sign your own certificates, then trust your own certificate authority so you don’t get warnings.
https://www.mirthcorp.com/community/forums/showpost.php?p=22124&postcount=4
Hello, great article! I just want to ask you, maybe you know or you can give me a hint or suggestion. How can I create a CSR by passing the information from a json file, not with -subj? Thank you for your time.
How to enter into terminal:
openssl rsa -des3
-in unencrypted.key
-out encrypted.key
Total noob question sorry:
I’ve followed through and been able to create my rsa domain.key, domain.csr and domain.crt THANK YOU SO MUCH! :)
I’m using windows terminal to ssh into my Ubuntu droplet.
Once you started using multi-line commands which are indented I haven’t been able to run these. Can I have your advice please.
I’ve tried copying and pasting, typing, and I read the comment below regarding Ctrl+ins and Shift+ins from community/users/tiangolo with no success. I’ve tried stringing your command lines together into one line but I can’t get a result. I can’t encrypt my private.key for the same reason.
Thank you all in advance, NutAz
I have created a sample project using python to create and manage SSL certificates, if anyone interested can have a look at it. https://github.com/parthibann/shield
Great article. For https ,I had created client private key and certificate key. When i had tried connect the https server below logs were coming. But finally able to connect the server(Taking more time).
Verify requested for (Depth 2):
ceThis certificate has no flags
Verify requested for (Depth 1):
ceThis certificate has no flags
Verify requested for (Depth 0):
ceThis certificate has no flags
connected to server … I had used “openssl verify -verbose -CAFile ca.crt domain.crt” for to create the client certificate and "openssl genrsa -des3 -out domain.key 2048 " for to create privare key.
Could you please tell me if I missed something in my configuration of SSL?
Am i doing wrong?? any suggestions ??please
Great and concise guide. Saved a lot of my time, thanks for sharing! |
12,294 | 如何在 Linux 上将 USB 盘格式化为 exFAT | https://itsfoss.com/format-exfat-linux/ | 2020-06-08T10:35:43 | [
"exFAT",
"USB"
] | https://linux.cn/article-12294-1.html |
>
> 本教程教你如何在 Linux 系统上以 exFAT 格式格式化 USB 盘。同时包括 GUI 和命令行两种方法。
>
>
>
长期以来,[FAT](https://en.wikipedia.org/wiki/File_Allocation_Table) 是用于格式化磁盘文件系统的默认选择。它与几乎所有主要操作系统兼容。
FAT 文件系统的一个主要问题是你不能传输大于 4GB 的文件。这意味着即使你的 USB 盘有 32GB 的可用空间,如果你尝试传输 ISO 镜像或其他大于 4GB 的文件,传输也会失败。
这会[在 Linux 中创建 Windows 的可启动 USB 盘](https://itsfoss.com/bootable-windows-usb-linux/)的情况下造成问题。你不能使用 [NTFS](https://en.wikipedia.org/wiki/NTFS),并且 FAT 文件系统有 4GB 的大小限制。
为了克服 FAT 文件系统的限制,微软推出了 [exFAT 文件系统](https://en.wikipedia.org/wiki/ExFAT)。在本教程中,我将向你展示如何使用 exFAT 文件系统中格式化 USB 盘。
### 先决条件
从 [Linux kernel 5.4](https://itsfoss.com/linux-kernel-5-4/) 开始,Linux 内核本身中启用了 exFAT 文件系统支持。[检查正在运行的 Linux 内核版本](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/)。如果是内核 5.4 或更高版本,那么应该没问题。
不然,你必须[启用 exFAT 支持](https://itsfoss.com/mount-exfat/)。在基于 Ubuntu 的发行版中,你可以安装以下软件包:
```
sudo apt install exfat-fuse exfat-utils
```
### 方法 1:使用 GNOME 磁盘工具将磁盘格式化为 exFAT

使用 “[GNOME 磁盘](https://wiki.gnome.org/Apps/Disks)” 格式化驱动器是一项简单的工作。它预装在许多 Linux 发行版中。
插入外部 USB 盘。在菜单中查找 “Disk”,然后打开 “GNOME 磁盘” 应用。第一步,选择要格式化的驱动器,然后按照我的步骤操作。
**警告:请注意你要选择格式化的磁盘。请勿意外格式化主磁盘。**

诸如 Ext4、NTFS、FAT 之类的常用文件系统将首先出现。要使用 exFAT,请选择 “其它”,然后单击 “下一步”。

最后一步:在此页面上选择 exFAT 文件系统,然后单击 “创建”。完成了!

看到在 Linux 中以图形方式创建 exFAT 磁盘有多么容易了吧?现在,让我向你展示终端方法。
### 方法 2:在 Linux 命令行中将磁盘格式化为 exFAT(适用于高级用户)
[fdisk](https://www.tldp.org/HOWTO/Partition/fdisk_partitioning.html) 是一个交互式命令行程序,它可在硬盘上创建和操作分区表和分区。实际上,它被认为是 [Linux 最佳分区工具](https://itsfoss.com/partition-managers-linux/)之一。
插入外部硬盘,然后在终端中输入以下命令:
```
sudo fdisk -l
```

这将列出计算机中的所有硬盘和分区。识别出要在外部硬盘上格式化的分区。应该会提示磁盘大小。对我而言,USB 盘被标记为 `/dev/sdb1`。
识别出 USB 盘后,请使用以下命令将它格式化为 exfat。将 `/dev/sdXn` 替换为你的磁盘 ID。`LABEL` 是你要为磁盘命名的名称,例如 `Data`、`MyUSB` 等。
```
sudo mkfs.exfat -n LABEL /dev/sdXn
```

可选地,运行 `fsck` 检查,以确保格式化正确。
```
sudo fsck.exfat /dev/sdXn
```
就是这样。享受 exFAT 盘吧。
### 你是否成功创建了exFAT 盘?
我希望你觉得本教程足够简单,并建立坚实的分区知识基础的第一步。
从长远来看,有时简单易用的技巧将让你拥有一个更好的 Linux。
---
via: <https://itsfoss.com/format-exfat-linux/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

For a long time, [FAT](https://en.wikipedia.org/wiki/File_Allocation_Table?ref=itsfoss.com) has been the default choice of filesystem for formatting disks. It is compatible with pretty much all the major operating systems.
The one major problem with the FAT filesystem is that you cannot transfer a file larger than 4 GB. This means even if your USB disk has 32 GB of free space, if you try to transfer an ISO image or some other file greater than 4 GB in size, the transfer will fail.
This creates a problem in situations like when you are [creating a bootable USB of Windows in Linux](https://itsfoss.com/bootable-windows-usb-linux/). You cannot use [NTFS](https://en.wikipedia.org/wiki/NTFS?ref=itsfoss.com) and FAT filesystem has that 4 GB size restrictions.
To overcome the limitations of FAT filesystem, Microsoft came up with [exFAT filesystem](https://en.wikipedia.org/wiki/ExFAT?ref=itsfoss.com). In this tutorial, I’ll show you how to format a USB disk in exFAT filesystem.
## Prerequisites
Starting [Linux kernel 5.4](https://itsfoss.com/linux-kernel-5-4/), exFAT filesystem support is enabled in the Linux kernel itself. [Check which Linux kernel version you are running](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/). If it is kernel 5.4 or higher, you should be fine (mostly).
Otherwise, you can [enable exFAT support](https://itsfoss.com/mount-exfat/) explicitly.
In Ubuntu 20.04 and lower versions, you can use the following command:
`sudo apt install exfat-fuse exfat-utils`
For Ubuntu 22.04 and higher, you should use this command instead:
`sudo apt install exfat-fuse exfatprogs`
## Method 1: Format disk as exFAT using GNOME Disks tool
Formatting a drive using [GNOME Disks](https://wiki.gnome.org/Apps/Disks?ref=itsfoss.com) is a straightforward job. It comes preinstalled in a number of Linux distributions.
Plug in your external USB disk. Now, look for Disks in menu and open the GNOME Disks application. As a first step choose the drive that you want to format and follow the steps with me.
**Pay attention to the disk you are selecting to format. Don’t format your main disk accidentally.**
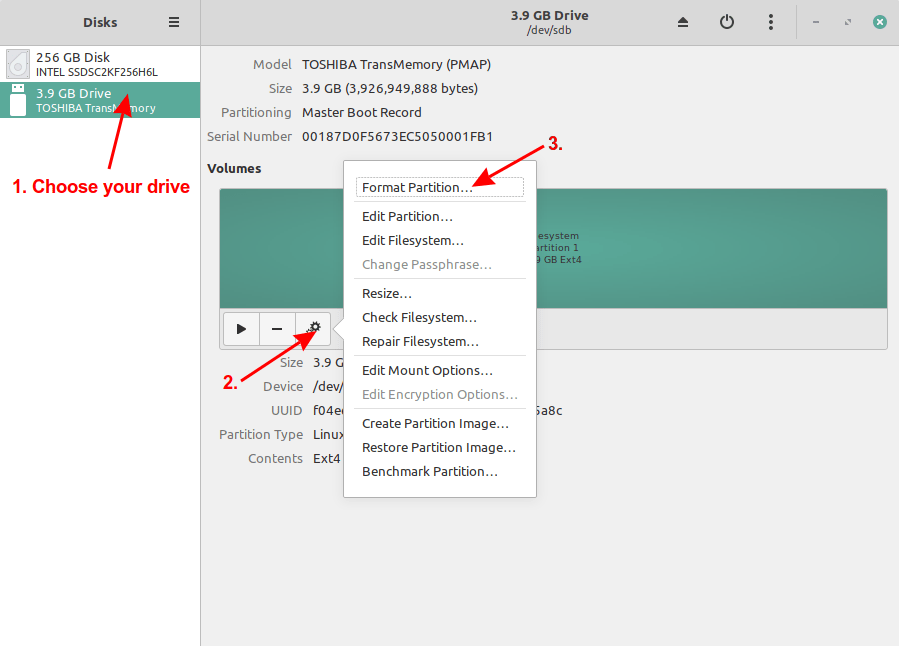
The commonly used file systems like Ext4, NTFS, FAT will appear first. To use exFAT, choose “**Other**” and then click on “**Next**“.
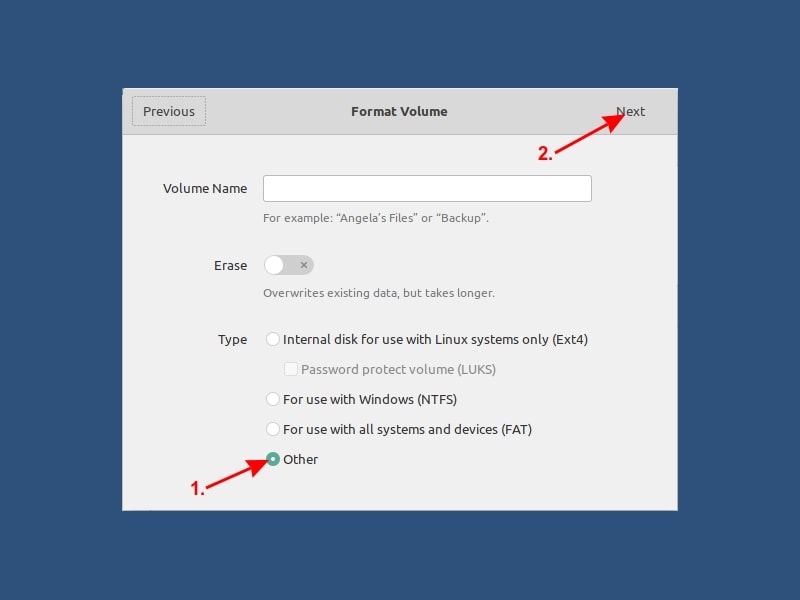
Final step: choose exFAT file system on this screen and then click **Create**. Job done!
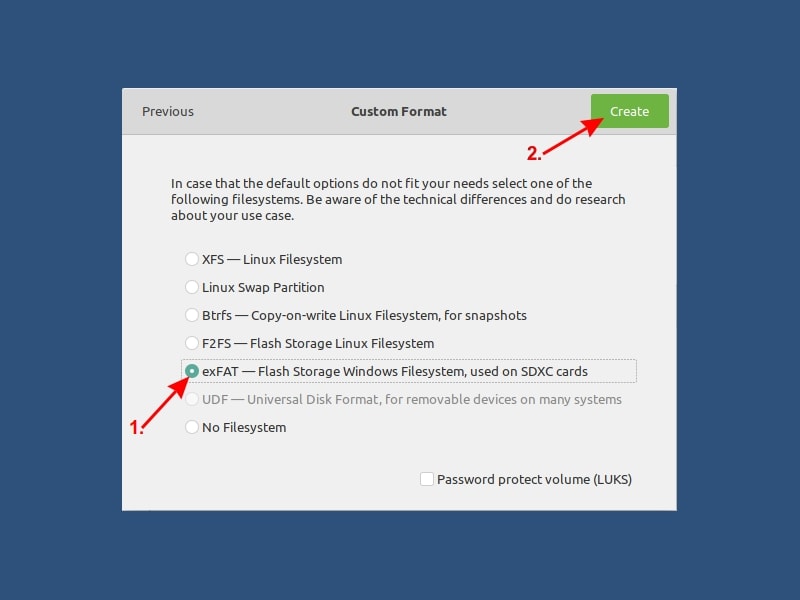
See how easy it was to create a exFAT disk in Linux graphically? Now, let me show you the terminal method as well.
## Method 2: Format disk as exFAT in Linux command line (for advanced users)
[fdisk](https://www.tldp.org/HOWTO/Partition/fdisk_partitioning.html?ref=itsfoss.com) is a dialogue-driven command-line utility that creates and manipulates partition tables and partitions on a hard disk. In fact, it is considered one of the [best partitioning tools for Linux](https://itsfoss.com/partition-managers-linux/).
Plug in your external hard disk then type the following command in the terminal:
`sudo fdisk -l`
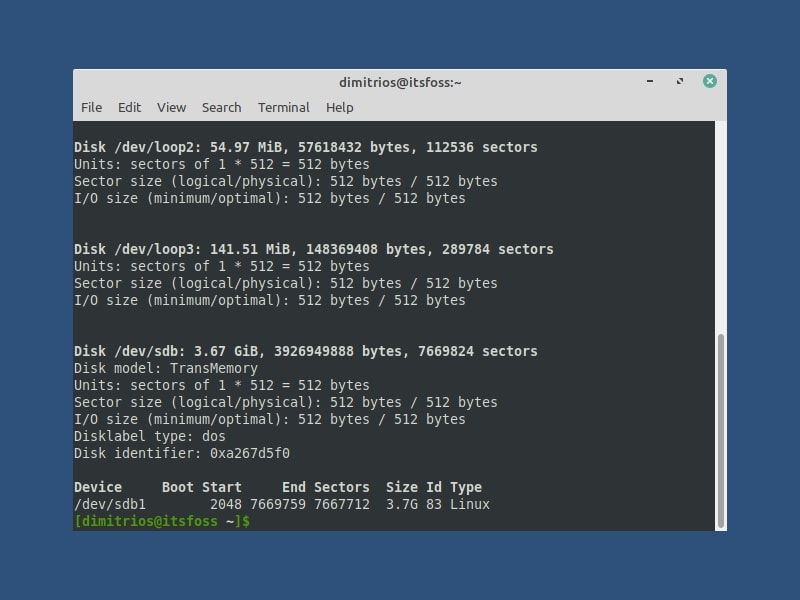
This will list down all the hard disks and partitions in your computer. Identify the partition that you want to format in your external hard disk. Size of the disks should give you a hint. For me, the USB disk was labelled as /dev/sdb1.
Once you have identified your USB disk, format it as exfat using the command below. Replace /dev/sdXn with your disk’s device ID. LABEL is basically the name you want to give to your disk like Data, MyUSB etc.
`sudo mkfs.exfat -n LABEL /dev/sdXn`
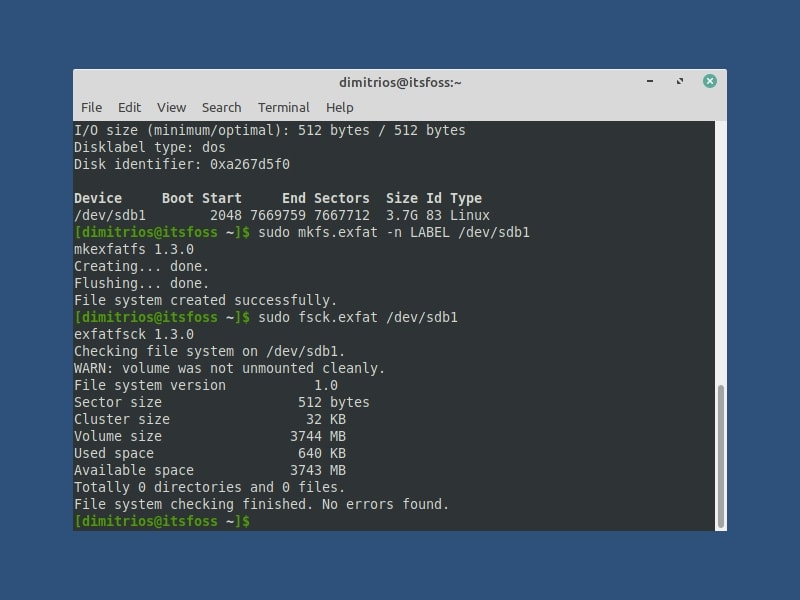
Optionally, [run fsck check](https://linuxhandbook.com/fsck-command/?ref=itsfoss.com) to make sure the formatting has been done properly.
`sudo fsck.exfat /dev/sdXn`
That’s it. Enjoy the exFAT disk.
## Did you succeed in creating exFAT disk?
I hope you find this tutorial simple enough and a step forward to build a solid partitioning knowledge foundation.
Sometimes, easy and simple tips and tricks will make you a better Linux in the long term. Our frequent readers know that first hand but if you discovered It’s FOSS recently, you may take the opportunity to explore our handy tutorials.
Don’t forget to subscribe and let me know your questions and suggestions in the comments below. |
12,297 | Linux Mint 20 发布前一窥 | https://itsfoss.com/linux-mint-20/ | 2020-06-08T23:00:24 | [
"Mint"
] | https://linux.cn/article-12297-1.html | [Ubuntu 20.04 LTS 版本发布了](https://itsfoss.com/ubuntu-20-04-release-features/)。这对 Linux Mint 用户来说也是一个好消息。一个新的 Ubuntu LTS 版本意味着新的 Linux Mint 主要版本也将很快随之出现。
为什么这么说呢?因为 Linux Mint 是基于 Ubuntu 的长期支持(LTS)版本的。Mint 18 系列是基于 Ubuntu 16.04 LTS,Mint 19 是基于 Ubuntu 18.04 LTS 等等。
与 Ubuntu 不同,Linux Mint 没有固定的发布时间表。根据以往的趋势,我可以做出一个明智的猜测,[Linux Mint](https://www.linuxmint.com/) 20 应该会在今年 6 月发布。
### Linux Mint 20 “Ulyana” 即将推出的新功能

让我们来看看代号为 Ulyana 的 Linux Mint 20 中提出的一些主要新功能和变化。
#### 1. 提高 Nemo 文件管理器的性能
Nemo 文件管理器计划中的性能改进之一是它处理缩略图的方式。你可能还没有意识到,但缩略图的生成需要相当多的系统资源(以及磁盘空间)。试着打开一个有几千张图片的文件夹,你会发现 CPU 的消耗会上升。
在 Linux Mint 20 中,其目标是优先考虑内容和导航,并尽可能地延迟缩略图的渲染。这意味着在缩略图渲染之前,文件夹的内容会以通用图标显示出来。这不会让人觉得赏心悦目,但你会注意到性能的改善。
#### 2. 两种焕然一新的颜色变体
默认情况下,Linux Mint 是绿色/薄荷色的风格。还有一些其它的颜色点缀。Linux Mint 20 新添加了两种可爱的的粉红色和青蓝色。
这里是新的粉红色风格:

以及新的青蓝色风格:

#### 3. 没有过度偏重于 Snap 包
Ubuntu 20.04 将 snap 包的优先级放在了通常的 apt 包之前。事实上,如果你在 Ubuntu 20.04 中使用 `apt` 命令安装 Chromium 浏览器时,它会自动安装 snap 版本。
Linux Mint 团队显然对此不满意,他们确认 Mint 20 将不会安装 snaps 或 snapd。它还将禁止 `apt` 使用 snapd。
你仍然可以自己手动安装 snap 包。只是不会由 `apt` 来安装它们。
#### 4. 有了这个新工具,跨网络共享文件变得很简单。
Linux Mint 20 将提供一个[新的 GUI 工具](https://blog.linuxmint.com/?p=3863),可以轻松地在本地网络上共享文件,而无需任何额外的配置。

#### 5. 更好地整合了 Electron 应用程序的桌面
[Electron](https://www.electronjs.org/) 是一个开源框架,它允许使用 Web 技术构建跨平台的桌面应用程序。有些人称它为懒惰的方法,因为应用程序运行在 Chromium 浏览器之上。然而,这可以让开发人员轻松地将他们的应用程序提供给 Linux(和 macOS)。[Linux 上的 Slack](https://itsfoss.com/slack-use-linux/) 就是众多这样的例子之一。
Linux Mint 20 将对 Electron 应用提供更好的支持,并改进系统托盘和桌面通知的集成。
#### 6. 改进的支持多显示器的比例缩放功能

一个提议的改变是在 Linux Mint 20 中加入支持多显示器的比例缩放功能。如果你有一个 HiDPI 和非 HiDPI 显示器的组合,你可以为它们每一个选择不同的分辨率、刷新率和不同的分数缩放。
在 Mint 20 的登录屏幕,可以让你跨多个显示器拉伸显示背景。
#### 7. 改进对 Nvidia Optimus 的支持
在 Mint 20 中,Nvidia prime 小程序会显示 GPU 渲染器。你也可以直接从系统托盘中的菜单中选择切换到哪块卡。

你也可以使用 Nvidia “On-Demand” 模式。在这种模式下,将使用英特尔卡来渲染会话。而如视频播放器或视频编辑器这样的兼容应用程序可以在应用程序菜单中打开时使用 Nvidia GPU。

#### 8. 不再支持 32 位
虽然 Ubuntu 18.04 在两年前就放弃了 32 位 ISO,但 Linux Mint 19 系列一直提供 32 位 ISO 的下载和安装。
这种情况在 Linux Mint 20 中有所改变。Linux Mint 20 已经没有 32 位版本了。这是因为 32 位支持从 Ubuntu 20.04 中完全消失了。
#### 还有什么?
Cinnamon 4.6 桌面版的发布带来了很多视觉上的变化。
在 Ubuntu 20.04 中,应该会有一些“引擎盖下”的变化,比如 Linux Kernel 5.4,取消了 Python 2 的支持,加入 [Wireguard VPN](https://itsfoss.com/wireguard/) 等。
随着开发的进展,我会在本文中更新更多的功能。敬请期待。
---
via: <https://itsfoss.com/linux-mint-20/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Linux Mint 20 is released. Check out all the new features it brings.*
Linux Mint is based on long-term support version of Ubuntu. Ubuntu 20.04 LTS was released in April this year. Almost two months later, Linux Mint 20 stable release is out now.
Excited about Linux Mint 20 release? Check out what’s new in it.
## New Features in Linux Mint 20 “Ulyana”
Let’s take a look at some of the main new features and changes in Linux Mint 20, code-named Ulyana.
### 1. Performance improvement to Nemo file manager
One of the performance improvements in the Nemo file manager is the way it handles the thumbnails. You might not have realized but thumbnail generations takes considerable system resources (and disk space as well). Try opening a folder with a few thousands images and you’ll notice that CPU consumption goes up.
In Linux Mint 20, the aim is to prioritize content and navigation and to delay thumbnails as much as possible. This means that the content of folders shows up with generic icons before the thumbnails are rendered. It won’t be pleasing to the eyes, but you’ll notice the improvement in performance.
### 2. Two refreshed color variants
By default Linux Mint has a green/mint accent. There are a few more color accents available. Linux Mint 20 refreshes the pink and blue colors in its kitty.
Here’s the new Aqua accent color:
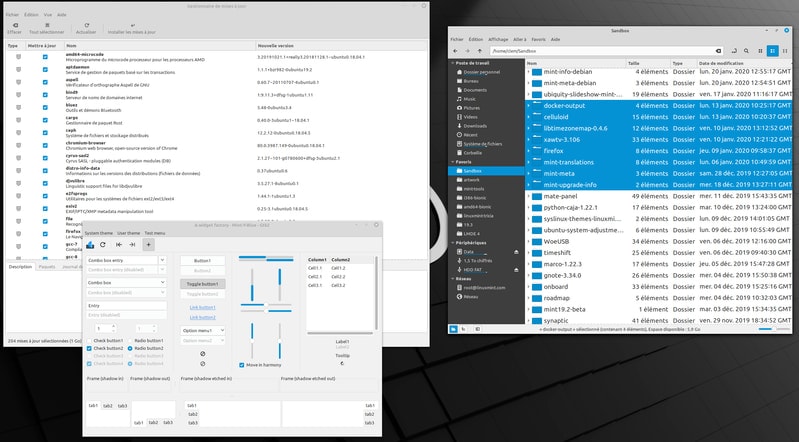
And the new Pink accent color:
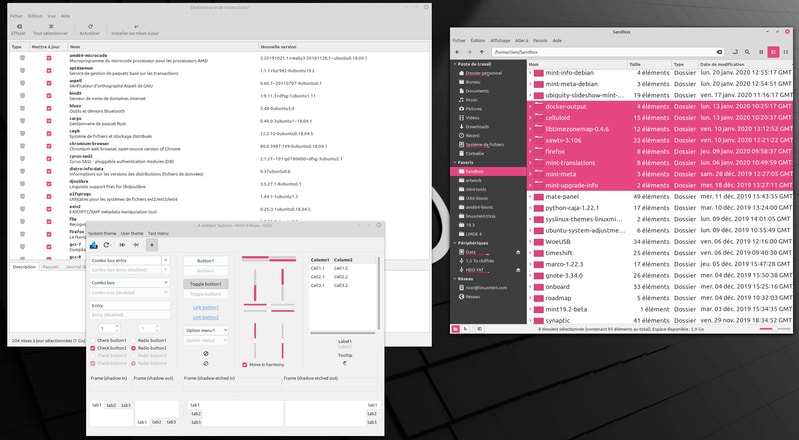
### 3. No undue preference to snap packages
Ubuntu 20.04 is putting snap packages before the usual apt packages. In fact, if you install Chromium browser in Ubuntu 20.04 using apt command, it installs a snap version automatically.
Linux Mint team is clearly not happy with it, and Mint 20 does not not ship with any snaps or snapd installed. It also forbids APT from installing snapd.
If you really need it, you can still do some [tweaking to enable snap support on Linux Mint 20](https://itsfoss.com/enable-snap-support-linux-mint/).
### 4. Sharing files across network becomes simple with this new tool
Linux Mint 20 features a [new GUI tool](https://blog.linuxmint.com/?p=3863) for easily sharing files on the local network without any additional configuration.
### 5. Better desktop integration for Electron apps
[Electron](https://www.electronjs.org/) is an open source framework that allows to build cross-platform desktop applications using web technologies. Some people call it the lazy approach because the application runs on top of Chromium web browser. However, this allows developers to easily make their applications available for Linux (and macOS). [Slack on Linux](https://itsfoss.com/slack-use-linux/) is one of many such examples.
Linux Mint 20 has better support for Electron applications with improved integration of system tray and desktop notifications.
### 6. Fractional scaling with improved multi-monitor support
Fractional scaling arrives in Linux Mint 20 that too with multi-monitor support. If you have a combination of HiDPI and non-HiDPI monitors, you should be able to select the different resolution, refresh rate and different fractional scaling for each of them.
The login screen lets you stretch the background across multiple monitors in Mint 20.
### 7. Improved Nvidia Optimus support
In Mint 20, the Nvidia prime applet shows the GPU renderer. You can also select which card to switch to straight from its menu in the system tray.
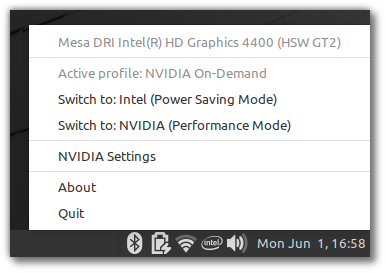
You can also use NVIDIA “On-Demand”. In this mode, the Intel card will be used to render the session. Compatible applications like video player or video editors can be opened using Nvidia GPU from the application menu.
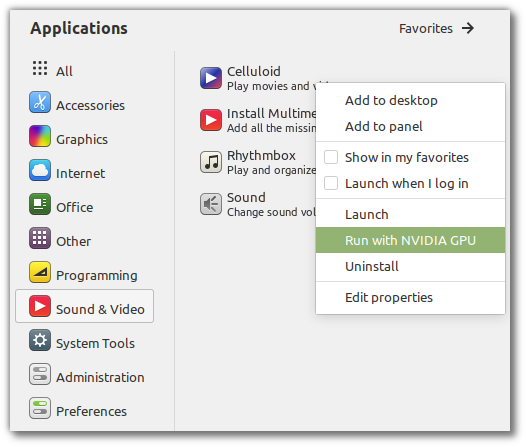
### 8. No more 32 bit
Though Ubuntu 18.04 dropped 32-bit ISO 2 years ago, Linux Mint 19 series kept on providing 32-bit ISO to download and install.
This changes in Linux Mint 20. There is no 32-bit version of Linux Mint 20 anymore. This is because 32-bit support completely disappears from Ubuntu 20.04.
### What else?
A lot of visual changes come with the release of Cinnamon 4.6 desktop version.
There are a few ‘under the hood’ changes coming from Ubuntu 20.04 such as Linux Kernel 5.4, removal of Python 2 support, inclusion of [Wireguard VPN](https://itsfoss.com/wireguard/) etc.
## System requirements for Linux Mint 20
The system requirements are same for Linux Mint 20 Cinnamon, Xfce and MATE versions:
- Minimum 1GB RAM (2GB recommended)
- 15GB of disk space (20GB recommended)
- Minimum 1024×768 resolution or higher
## Download Linux Mint
Linux Mint 20 ISO is available for download. You can find it on the link below and [install Linux Mint](https://itsfoss.com/install-linux-mint/) afresh:
If you are using Linux Mint 19.3 currently, you can [upgrade to Linux Mint 20 from Linux Mint 19.3](https://itsfoss.com/upgrade-linux-mint-version/).
**Are you looking forward to Linux Mint 20?**
Linux Mint 20 looks like an impressive upgrade to its predecessors. What do you think? Will you be installing it? |
12,298 | 如何在 Linux 上查找和删除损坏的符号链接 | https://www.networkworld.com/article/3546252/how-to-find-and-remove-broken-symlinks-on-linux.html | 2020-06-09T09:51:05 | [
"符号链接"
] | https://linux.cn/article-12298-1.html | 
>
> 符号链接是指向另一个文件的 Linux 文件。如果删除了被引用的文件,符号链接会保留,但不会显示有问题,除非你尝试使用它。以下是查找和删除指向文件已被删除的符号链接的简单方法。
>
>
>
<ruby> 符号链接 <rt> symbolic link </rt></ruby>在 Linux 系统上扮演了非常有用的角色。它们可以帮助你记住重要文件在系统上的位置,使你更容易访问这些文件,并让你不必为了更方便访问大文件而复制它们,从而节省了大量的空间。
### 什么是符号链接?
通常称它们为“符号链接”或“软链接”,符号链接是非常小的文件。实际上,符号链接真正包含的是它指向的文件的名称,通常包含路径(相对于当前位置或绝对路径)。如果有个名为 `ref1` 的文件指向名为 `/apps/refs/ref-2020` 的文件,那么 `ref1` 的长度将为 19 个字符,即使 `ref-202` 文件有 2TB。如果指向 `./ref-2020`,那么长度仅为 10 个字符。如果指向 `ref-2020`,那么只有 8 个字节。
如果你执行 `vi ref1` 之类的命令(其中 `ref1` 是符号链接的名称),你将编辑 `ref1` 指向的文件,而不是符号链接本身的内容。Linux 系统知道如何使用符号链接,并且可以做正确的事。同样,如果你使用诸如 `cat`、`more`、`head` 或 `tail` 之类的命令,那么将查看引用文件的内容。
另一方面,如果删除符号链接,你将删除该链接,而不是引用的文件。再说一次,Linux 知道怎么做。符号链接使得使用和共享文件更加容易,仅此而已。
#### 符号链接损坏时
当一个符号链接所指向的文件从系统中删除或重新命名时,符号链接将不再起作用。符号链接只不过是存储在某个特定目录中的引用而已,它不会随着指向它的文件发生变化而更新或删除。它一直指向被引用的文件,即使这个文件早已消失。
如果你尝试使用指向一个不存在的文件的符号链接,那么将出现如下错误:
```
$ tail whassup
tail: cannot open 'whassup' for reading: No such file or directory
```
如果你尝试访问指向自身的符号链接(是的,奇怪的事情发生了),你将看到类似以下的内容:
```
$ cat loopy
cat: loopy: Too many levels of symbolic links
$ ls -l loopy
lrwxrwxrwx 1 shs shs 5 May 28 18:07 loopy -> loopy
```
而且,如果(上面的)长列表的第一个字母没有引起你的注意,这表示该文件是符号链接。`rwxrwxrwx` 权限是标准权限,并不反映符号链接指向的文件的权限。
### 查找损坏的符号链接
`find` 命令有一个选项,能让你找到指向不再存在的文件的符号链接。此命令列出当前目录中的符号链接:
```
$ find . -type l
```
`l` (小写字母 `L`)告诉 `find` 命令查找符号链接。
另一方面,下面的命令在当前目录中查找指向*不存在*的文件的符号链接:
```
$ find . -xtype l
```
为了避免在该命令尝试查找你无权检查的文件或目录时发生错误,你可以将所有错误输出到 `/dev/null`,如下所示:
```
$ find . -xtype l 2>/dev/null
```
你也可以使用此命令找到损坏的符号链接。它比前面的更长,但做的是同样的事情:
```
$ find . -type l ! -exec test -e {} \; -print 2>/dev/null
```
### 如何处理损坏的符号链接
除非你知道符号链接引用的文件会被替换,否则最好的方法是直接删除损坏的链接。实际上,如果需要,你可以使用一条命令查找并删除损坏的符号链接,如:
```
$ find . -xtype l 2>/dev/null -exec rm {} \;
```
该命令的 `rm {}` 部分会变成“删除文件”的命令
如果你想将符号链接与不同的文件相关联,你必须先删除该符号链接,然后重新创建它,使其指向新文件。这是一个例子:
```
$ rm ref1
$ ln -s /apps/data/newfile ref1
```
### 总结
符号链接使引用的文件更易于查找和使用,但有时它会比那些宣传去年已经关闭的餐馆的路标还过分。`find` 命令可以帮助你摆脱损坏的符号链接,或者提醒你没有你可能仍然需要的文件。
---
via: <https://www.networkworld.com/article/3546252/how-to-find-and-remove-broken-symlinks-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,301 | 如何在 Fedora Linux 中安装 Nvidia 驱动 | https://itsfoss.com/install-nvidia-drivers-fedora/ | 2020-06-10T09:48:00 | [] | https://linux.cn/article-12301-1.html | 
与大多数 Linux 发行版一样,[Fedora](https://getfedora.org/ "https://getfedora.org/") 并未默认安装专有的 [Nvidia](https://www.nvidia.com/en-us/ "https://www.nvidia.com/en-us/") 驱动。
默认的开源 [Nouveau 驱动](https://en.wikipedia.org/wiki/Nouveau_(software) "https://en.wikipedia.org/wiki/Nouveau_(software)")在大多数情况下都可以使用,但是你可能会遇到屏幕撕裂等问题。

如果遇到此类图形/视频问题,那么可能需要在 Fedora 中安装官方专有的 Nvidia 驱动。让我告诉你如何安装。
### 在 Fedora 中安装 Nvidia 驱动
我在本教程中使用 [Fedora 32](https://itsfoss.com/fedora-32/ "https://itsfoss.com/fedora-32/"),但它应适用于其他 Fedora 版本。
#### 步骤 1
在做其他任何操作之前,请先确保你的系统是最新的。你可以使用软件中心,也可以在终端中使用以下命令:
```
`sudo dnf update`
```
#### 步骤 2
由于 Fedora 没有提供 Nvidia 驱动,因此你需要在系统中添加 [RPMFusion 仓库](https://rpmfusion.org/RPM%20Fusion "https://rpmfusion.org/RPM%20Fusion")。你可以在终端中使用以下命令:
```
`sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm https://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm`
```
>
> 不喜欢终端么?那使用 GUI 的方法添加 RPMFusion 仓库。
>
>
> 如果你使用 Firefox,那么还可以从浏览器添加 RPMFusion 仓库。进入这个[配置页面](https://rpmfusion.org/Configuration "https://rpmfusion.org/Configuration"),然后向下滚动到 “Graphical Setup via Firefox web browser”。单击自由和非自由仓库的链接。这将下载 .rpm 文件,并安装仓库。
>
>
> 
>
>
> 你可以双击下载的 RPM 文件进行安装。
>
>
> 
>
>
>
#### 步骤 3
现在,你需要确定 [Linux 系统中有哪些显卡(或芯片)](https://itsfoss.com/check-graphics-card-linux/ "https://itsfoss.com/check-graphics-card-linux/")。打开终端并输入以下命令:
```
`lspci -vnn | grep VGA`
```

接下来,你需要查找与该芯片对应的驱动。你可以在[此处](https://us.download.nvidia.com/XFree86/Linux-x86/367.57/README/supportedchips.html "https://us.download.nvidia.com/XFree86/Linux-x86/367.57/README/supportedchips.html")找到 Nvidia 芯片的列表。你也可以使用[此工具](https://www.nvidia.com/Download/index.aspx?lang=en-us "https://www.nvidia.com/Download/index.aspx?lang=en-us")搜索设备。
**注意**:请记住,即使 Nvidia 列表显示了更多驱动,但也只有三个驱动可以安装。Nvidia 驱动支持最新的显卡。nvidia-390 和 nvidia-340 驱动支持旧设备。
#### 步骤 4
要安装所需的驱动,请在终端中输入以下一个命令。下面的命令是用于我的显卡的命令。根据你的系统相应调整。
```
`sudo dnf install akmod-nvidia sudo dnf install xorg-x11-drv-nvidia-390xx akmod-nvidia-390xx sudo dnf install xorg-x11-drv-nvidia-340xx akmod-nvidia-340xx`
```

#### 步骤 5
要使更改生效,请重启系统。你的系统重启可能需要比较长的时间,因为它将 Nvidia 驱动注入到 Linux 内核中。
重启并登录系统后,你会看到更好的视觉效果,并且不会出现屏幕撕裂的情况。

### 额外的提示
这是可选步骤,但建议这样做。添加 RPMFusion 仓库时,你可以访问常规仓库中不可用的多媒体包。
此命令将为使用 [gstreamer](https://en.wikipedia.org/wiki/GStreamer "https://en.wikipedia.org/wiki/GStreamer") 的应用安装软件包:
```
`sudo dnf groupupdate multimedia --setop="install_weak_deps=False" --exclude=PackageKit-gstreamer-plugin`
```
此命令将安装声音和视频软件包所需的包:
```
`sudo dnf groupupdate sound-and-video`
```
希望本教程对在 Fedora 上安装 Nvidia 驱动很有用。
---
via: [https://itsfoss.com/install-nvidia-drivers-fedora/](https://itsfoss.com/install-nvidia-drivers-fedora/ "https://itsfoss.com/install-nvidia-drivers-fedora/")
作者:[John Paul](https://itsfoss.com/author/john/ "https://itsfoss.com/author/john/") 选题:[lujun9972](https://github.com/lujun9972 "https://github.com/lujun9972") 译者:[geekpi](https://github.com/geekpi "https://github.com/geekpi") 校对:[wxy](https://github.com/wxy "https://github.com/wxy")
本文由 [LCTT](https://github.com/LCTT/TranslateProject "https://github.com/LCTT/TranslateProject") 原创编译,[Linux中国](https://linux.cn/ "https://linux.cn/") 荣誉推出
| 200 | OK | 

Like most Linux distributions, [Fedora](https://getfedora.org/?ref=itsfoss.com) does not come with the proprietary [Nvidia](https://www.nvidia.com/en-us/?ref=itsfoss.com) drivers installed by default.
The default open source [Nouveau driver](https://en.wikipedia.org/wiki/Nouveau_(software)?ref=itsfoss.com) works in most situations, but you may encounter issues like screen tearing and some stutters.
If you encounter such graphics/video issues, you may want to install the official proprietary Nvidia drivers in Fedora. Let me show you how to do that.
## Installing Nvidia drivers in Fedora
I am using **Fedora 39** in this tutorial, but it should be applicable to other Fedora versions.
### Step 1
Before you do anything else, make sure that your system is up-to-date. You can either use the Software Center or use the following command in the terminal:
` sudo dnf update`
### Step 2
While Fedora does not ship with the Nvidia driver, you have the option to **enable third-party repositories** during its installation onboarding steps.
If you have not enabled it during setup, you can head to GNOME Software and head to manage the “**Software Repositories**”** **from the menu to proceed to enable the RPM Fusion repository for NVIDIA drivers.
Of course, you can manually [add the RPMFusion repos to your Fedora system](https://itsfoss.com/fedora-third-party-repos/) to install more programs like VLC or additional multimedia codecs as well.
For that, you can use the following command in the terminal:
`sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm https://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm`
### Step 3
Now you need to determine [what graphics card (or chip) you have in your Linux system](https://itsfoss.com/check-graphics-card-linux/). Pull up the terminal and enter the following command:
`lspci -vnn | grep VGA`
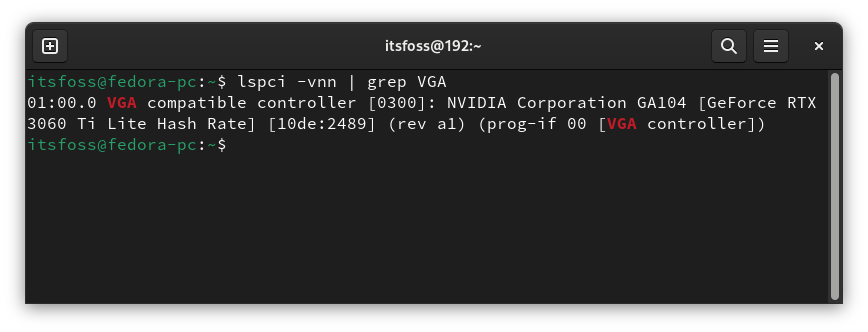
### Step 4
To proceed to install the latest NVIDIA graphics driver available in the RPM Fusion repo for the Fedora version you are using, enter the following command in the terminal:
`sudo dnf install akmod-nvidia`
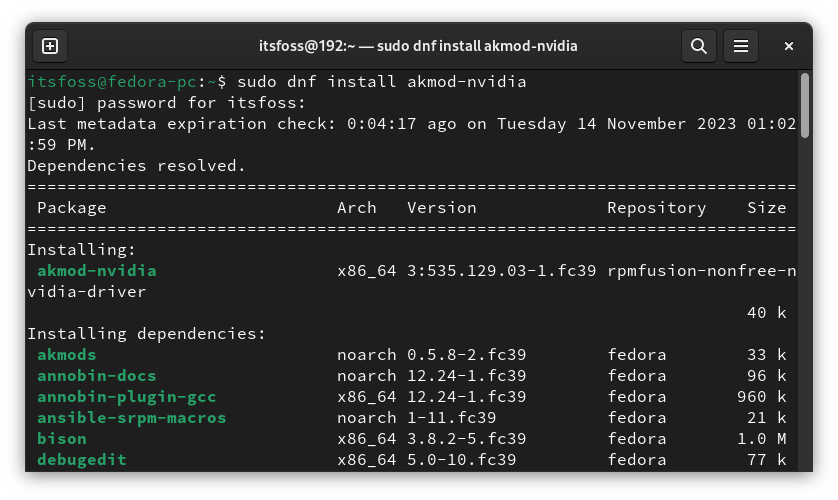
Once you confirm it by hitting "y", it will download the packages and again ask for another confirmation. Approve it to proceed installing.
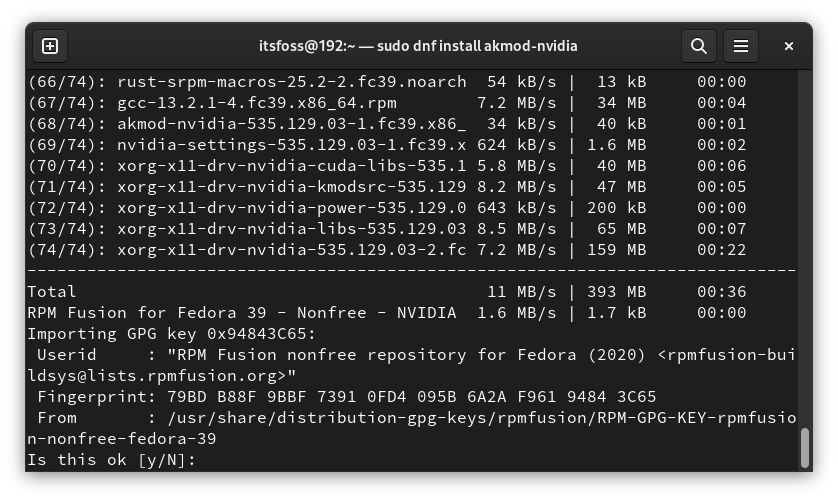
Optionally, you can enable CUDA support for the driver, which lets you check the stats for your NVIDIA card from the terminal using **nvidia-smi**:
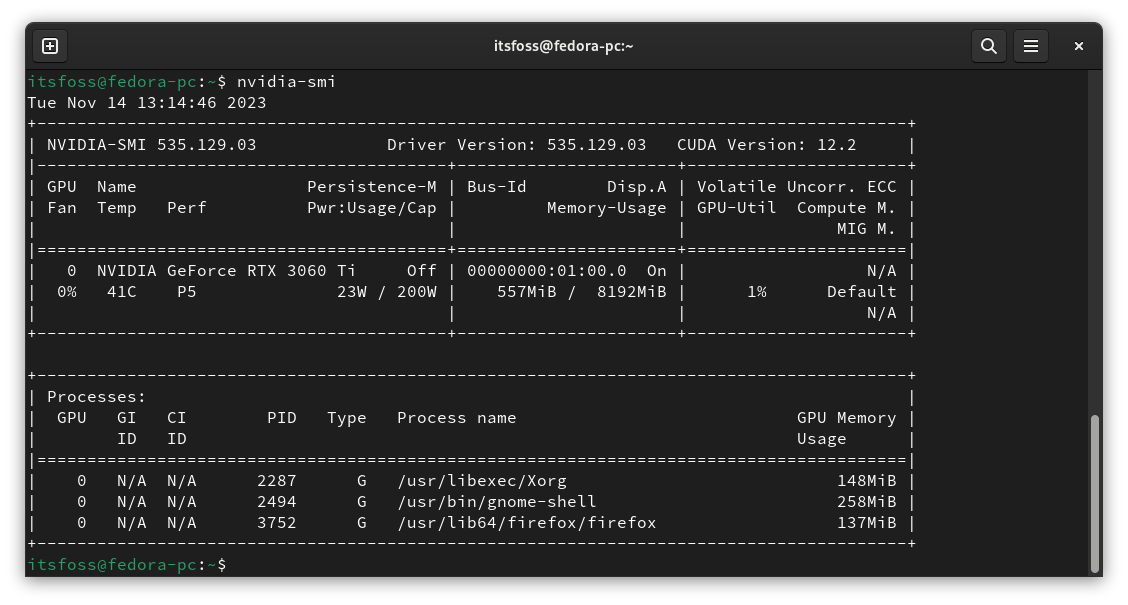
The command for it is:
```
sudo dnf install xorg-x11-drv-nvidia-cuda
```
### Step 5
To make the changes take effect, reboot your system and login.
## For Legacy Graphics Card
You can look up what driver corresponds to a specific chip. You can find a list of the Nvidia chips [here](https://us.download.nvidia.com/XFree86/Linux-x86/367.57/README/supportedchips.html?ref=itsfoss.com). Furthermore, you can also use [this tool](https://www.nvidia.com/Download/index.aspx?lang=en-us&ref=itsfoss.com) to search for your device.
To install the required driver, enter one of the commands into the terminal. The following command is the one I had to use for my card. Update as appropriate for your system.
`sudo dnf install akmod-nvidia sudo dnf install xorg-x11-drv-nvidia-390xx akmod-nvidia-390xx sudo dnf install xorg-x11-drv-nvidia-340xx akmod-nvidia-340xx`
## Bonus Tip
This is an optional step but it is recommended. When you add the RPMFusion repos, you get access to multimedia packages that are not available in the regular repos.
This command will install packages for applications that use [gstreamer](https://en.wikipedia.org/wiki/GStreamer?ref=itsfoss.com):
`sudo dnf groupupdate multimedia --setop="install_weak_deps=False" --exclude=PackageKit-gstreamer-plugin`
This command will install packages needed by sound and video packages:
`sudo dnf groupupdate sound-and-video`
Hopefully, you find this tutorial useful in installing Nvidia drivers on Fedora. What other Fedora tutorials would you like to see on It’s FOSS? |
12,302 | 使用 ActivityWatch 跟踪你在 Linux 中的屏幕使用时间 | https://itsfoss.com/activitywatch/ | 2020-06-10T10:52:00 | [
"时间"
] | https://linux.cn/article-12302-1.html | 
>
> ActivityWatch 是一款开源的隐私友好型应用程序,可追踪你在台式电脑或移动设备上的使用时间。
>
>
>
### ActivityWatch: 一个追踪你在哪个应用程序上花了多少时间的开源应用程序

[ActivityWatch](https://activitywatch.net/ "https://activitywatch.net/") 是一款跨平台的开源应用,可以帮助你追踪使用时间,衡量你的工作效率。它可以追踪你花在应用程序、浏览器上的时间,以及你是否 AFK(远离键盘)或系统处于休眠状态。
不只是追踪时间,它还提供了一堆有用的功能,通过可视化的方式帮助你轻松分析你是如何花费时间的,从而有可能提高你的生产力。

它是 [RescueTime](https://itsfoss.com/recommends/rescuetime/ "https://itsfoss.com/recommends/rescuetime/") 和 [ManicTime](https://www.manictime.com/ "https://www.manictime.com/") 等专有产品的绝佳替代品。
ActivityWatch 可用于 Linux、Windows、macOS 和 [Android](https://play.google.com/store/apps/details?id=net.activitywatch.android "https://play.google.com/store/apps/details?id=net.activitywatch.android")。它还提供了 Chrome 和 Firefox 的浏览器扩展。截至目前,App Store 上还没有它的 iOS 版应用。

它刚刚进入该领域,正在积极开发,以解决任何现有的问题并引入新的功能,如在多个设备上同步你的活动数据的能力。
**对于注重隐私的用户来说,我应该提到,收集的数据被存储在你本地的设备上。这是一件好事,因为你可以跟踪你的花费时间,而不会被别人跟踪。**
### ActivityWatch 的功能

基本上,ActivityWatch 可以让你监控你的活动,以分析不良的屏幕使用时间,或改善你在设备上工作的时间管理。
具体来说,它提供了几个有用的功能,主要有:
* 摘要你的日常活动及按使用时间排序的应用和程序列表。
* 追踪你的浏览器活动的时间,使用浏览器扩展来获得每个活动标签所花费时间的确切数据。
* 追踪 AFK 和非 AFK 时间。(AFK - “Away From Keyboard” 的缩写,即不在电脑前)
* 提供不同的可视化时间线,以监测你的活动。
* 能够使用 [watchers](https://docs.activitywatch.net/en/latest/watchers.html "https://docs.activitywatch.net/en/latest/watchers.html") 跟踪你在编辑器上写代码的时间。
* 记录你的活动,以分析你的生产力。
* 将花费的时间进行分类,可以帮助你详细分析。
* 可以添加更多的类别和调整时间轴的持续时长。
* 能够将数据导出/导入为 [JSON](https://en.wikipedia.org/wiki/JSON "https://en.wikipedia.org/wiki/JSON") 文件。
* 实验性的秒表功能。
* 本地存储数据,以尊重用户隐私。
### 在 Linux 上安装 ActivityWatch
>
> 注:如果你的 Linux 发行版不支持系统托盘图标,你需要遵循这个[文档](https://docs.activitywatch.net/en/latest/getting-started.html "https://docs.activitywatch.net/en/latest/getting-started.html")来解决这个问题。
>
>
>
不幸的是,你找不到 AppImage、Flatpak 或 Snap 软件包。然而,对于 Manjaro 或 Arch Linux 有可以安装的 [AUR](https://aur.archlinux.org/packages/activitywatch-bin/ "https://aur.archlinux.org/packages/activitywatch-bin/") 包。
对于所有其它的 Linux 发行版,你会得到一个 ZIP 文件,其中包括一个要运行的 `aw-qt` 应用程序。
要运行它,你需要[解压 zip 归档文件](https://itsfoss.com/unzip-linux/ "https://itsfoss.com/unzip-linux/"),然后通过双击 `aw-qt` 应用程序运行二进制文件来安装它。

你也可以使用终端:
```
`cd activitywatch-v0.9.2-linux-x86_64
sudo ./aw-qt`
```
解压文件夹的位置和文件名可能会有所不同 —— 所以请确保你导航到正确的目录,然后使用上面的命令。完成后,你可以从系统托盘图标访问 ActivityWatch,或者直接前往 [localhost:5600](https://itsfoss.com/activitywatch/5600 "https://itsfoss.com/activitywatch/5600") 访问它。
你也可以查看他们的 [GitHub 页面](https://github.com/ActivityWatch "https://github.com/ActivityWatch")或[官方网站](https://activitywatch.net/ "https://activitywatch.net/")来探索更多关于它的信息。
* [下载 ActivityWatch](https://activitywatch.net/ "https://activitywatch.net/")
顺便提一句,如果你计划经常使用 ActivityWatch,你应该将下载的文件移动到 `/opt` 目录下,并在 `/usr/share/bin` 目录下创建一个链接到 `aw-qt` 可执行文件符号链接。这样一来,该应用程序可以作为一个常规命令供系统上的所有用户使用。类似的方法在 [PopcornTime 安装教程](https://itsfoss.com/popcorn-time-ubuntu-linux/ "https://itsfoss.com/popcorn-time-ubuntu-linux/")中也有演示。
### 我对 ActivityWatch 的看法

在 [Pop!\_OS 20.04](https://itsfoss.com/pop-os-20-04-review/ "https://itsfoss.com/pop-os-20-04-review/") 上,时间跟踪功能可以完全正常地工作,也支持系统托盘图标。你可能会遇到一个错误,不能让你从系统托盘图标访问 ActivityWatch(这也是一个 [GitHub 上的已知问题](https://github.com/ActivityWatch/activitywatch/issues/208 "https://github.com/ActivityWatch/activitywatch/issues/208"))。在这种情况下,你需要通过 [localhost:5600](https://itsfoss.com/activitywatch/5600 "https://itsfoss.com/activitywatch/5600") 来访问它。
就个人而言,考虑到我在桌面上使用它,并且没有计划在智能手机上使用它,我对提供的功能相当满意。
我必须得向你推荐尝试这个不错的开源项目,并一路支持他们。如果你喜欢这个项目,请随时通过添加星标或赞助[他们的 GitHub 仓库](https://github.com/ActivityWatch/activitywatch "https://github.com/ActivityWatch/activitywatch")来表示你的赞赏。
欢迎在下面的评论中告诉我你的想法。
---
via: [https://itsfoss.com/activitywatch/](https://itsfoss.com/activitywatch/ "https://itsfoss.com/activitywatch/")
作者:[Ankush Das](https://itsfoss.com/author/ankush/ "https://itsfoss.com/author/ankush/") 选题:[lujun9972](https://github.com/lujun9972 "https://github.com/lujun9972") 译者:[wxy](https://github.com/wxy "https://github.com/wxy") 校对:[wxy](https://github.com/wxy "https://github.com/wxy")
本文由 [LCTT](https://github.com/LCTT/TranslateProject "https://github.com/LCTT/TranslateProject") 原创编译,[Linux中国](https://linux.cn/ "https://linux.cn/") 荣誉推出
| 200 | OK | 

[ActivityWatch](https://activitywatch.net/?ref=itsfoss.com) is a cross-platform open-source app that helps you track time to gauge your productivity. It lets you track the time you spent on applications, browsers, and if you were AFK (away from keyboard) or the system was hibernating. Sort of like [Traqq](https://traqq.com/) but for personal usage.
Not just limited to tracking time, but it offers a bunch of useful features with visualizations that help you easily analyze how you spent time to potentially improve your productivity.
It’s a great alternative to proprietary options like [RescueTime](https://itsfoss.com/recommends/rescuetime/) and [ManicTime](https://www.manictime.com/?ref=itsfoss.com).
ActivityWatch is available for Linux, Windows, macOS and [Android](https://play.google.com/store/apps/details?id=net.activitywatch.android&ref=itsfoss.com). It also offers browser extensions for both Chrome and Firefox. As of now, there’s no app available for iOS on the App Store.
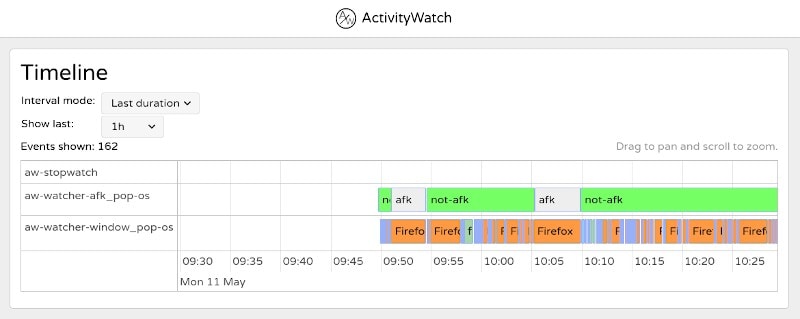
It’s fairly new to the scene and is being actively developed to address any existing issues and introduce new features like the ability to sync your activity data across multiple devices.
*For privacy-focused users, I should mention that the data collected is stored locally on your device. That’s a good thing as you can track your spent time without being tracked by someone else.*
## Features of ActivityWatch
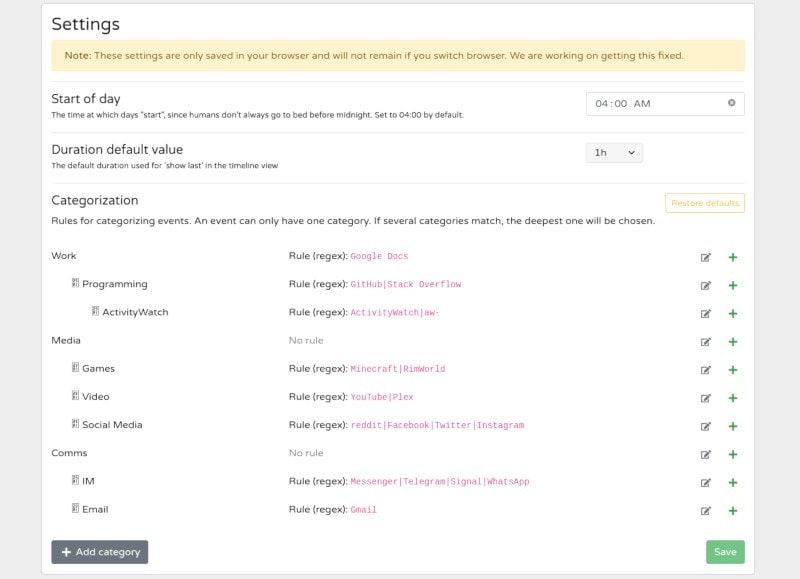
Basically, ActivityWatch lets you monitor your activity to analyze bad screen time or improve the time management for what you do on your device.
To break it down, it offers several useful options that I’d like to highlight here:
- Summary of your daily activity with apps/programs sorted as per the time spent using it.
- Track the time of your browser activity using the extension to get the exact data on time spent on every active tab.
- Tracks AFK and not-AFK time. (AFK — abbreviation for “Away From Keyboard” i.e. you’re not in front of your computer)
- Offers different visualizations of timelines to monitor your activity
- Ability to track the time you spend writing code on an editor using
[watchers](https://docs.activitywatch.net/en/latest/watchers.html?ref=itsfoss.com). - History of your activity to analyze your productivity
- Categorize the time spent to help you analyze in detail
- Lets you add more categories and tweak the duration of timeline.
- Ability to export/import your data as
[JSON](https://en.wikipedia.org/wiki/JSON?ref=itsfoss.com)file. - Experimental stopwatch feature
- Stores data locally to respect user privacy.
## Installing ActivityWatch on Linux
*Note:**If your Linux distribution does not support system tray icons, you will have to follow the* *documentation**for a workaround.*
Unfortunately, you won’t find an AppImage, Flatpak or Snap for it.
However, you do get an [AUR](https://aur.archlinux.org/packages/activitywatch-bin/?ref=itsfoss.com) package to install for Manjaro or Arch Linux.
For all other Linux distributions, you get a ZIP file which includes an **aw-qt** application to run.
To do that, you have to [extract the zip archive file](https://itsfoss.com/unzip-linux/) and then run the binary to install it by double-clicking on the aw-qt application.
You can also use the terminal as follows:
```
cd activitywatch-v0.9.2-linux-x86_64/activitywatch
./aw-qt
```
The location and filename of the extracted folder might differ – so make sure you navigate to the correct directory and then use the commands above. Once done, you can access ActivityWatch from the system tray icon or simply head to [localhost:5600](https://itsfoss.com/activitywatch/5600) to access it.
You can also check out their [GitHub page](https://github.com/ActivityWatch?ref=itsfoss.com) or the [official website](https://activitywatch.net/?ref=itsfoss.com) to explore more about it.
Just for your information, if you plan on using ActivityWatch regularly, you should move the downloaded files to the /opt directory and create a link to aw-qt executable in /usr/share/bin directory. This way, the application will be available as a regular command for all the users on the system. A similar method has been demonstrated in the [PopcornTime installation tutorial](https://itsfoss.com/popcorn-time-ubuntu-linux/).
## My Thoughts On ActivityWatch
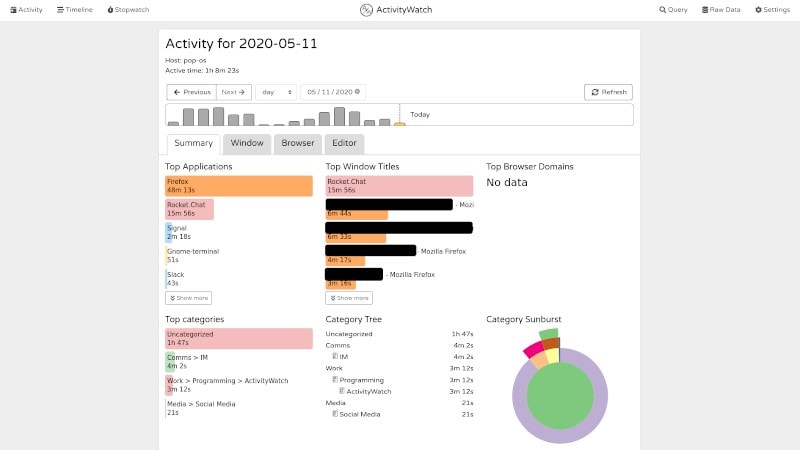
The time tracking works perfectly fine on [Pop!_OS 20.04](https://itsfoss.com/pop-os-20-04-review/) with the system tray icon support. You might encounter a bug that doesn’t let you access ActivityWatch from your system tray icon (which is also a [known issue on GitHub](https://github.com/ActivityWatch/activitywatch/issues/208?ref=itsfoss.com)). In that case, you need to access it through [localhost:5600](https://itsfoss.com/activitywatch/5600).
Personally, I’m quite satisfied with the features offered considering that I use it on my desktop and have no plans to use it on my smartphone.
I’d definitely recommend you try this nice open-source project and support them along the way. If you like the project, feel free to show your appreciation by adding a star or sponsoring [their GitHub repository](https://github.com/ActivityWatch/activitywatch?ref=itsfoss.com).
Feel free to let me know your thoughts in the comments below. |
12,307 | 9 款 Linux 上的最佳笔记应用 | https://itsfoss.com/note-taking-apps-linux/ | 2020-06-12T08:24:00 | [
"笔记",
"Joplin"
] | https://linux.cn/article-12307-1.html | 无论你做什么,做笔记总是一个好习惯。是的,有很多笔记应用可以帮助你实现这个目标。但是,Linux 上的开源笔记应用怎么样呢?
别担心,你不需要无休止地在互联网上搜索,就能找到 Linux 下最好的笔记应用。在这里,我挑选了一些最令人印象深刻的开源笔记应用。

请注意,此列表没有特定的排名顺序。
### 1、Joplin

主要功能:
* 支持 Markdown
* 支持附件
* 支持加密
* 跨平台,包括 Android 应用
[Joplin](https://joplinapp.org/ "https://joplinapp.org/") 是一款令人印象深刻的自由开源笔记应用,支持加密。凭借其提供的出色的功能,它也是目前[最好的 Evernote 替代品](https://itsfoss.com/5-evernote-alternatives-linux/ "https://itsfoss.com/5-evernote-alternatives-linux/")之一。事实上,我就是因为它提供的功能才从 Evernote 转移到 Joplin。
你可以选择添加待办事项列表、普通笔记,或者把它作为一个 Markdown 编辑器来写东西。它适用于 Linux、Windows、macOS、Android 和 iOS。你还可以选择使用 [Dropbox](https://www.dropbox.com/ "https://www.dropbox.com/")、OneDrive、[NextCloud](https://nextcloud.com/ "https://nextcloud.com/") 或 WebDAV 来同步你的笔记。
如果你好奇,可以阅读我们关于 [Joplin](/article-11896-1.html "/article-11896-1.html") 的详细文章来了解更多。
#### 如何安装?
你可以用一个 AppImage 文件来安装 Joplin。我已经在 Ubuntu 20.04 LTS 上试过了,和预期的一样没有问题。要找到该文件,你可以前往其官方网站或探索他们的 [GitHub 页面](https://github.com/laurent22/joplin "https://github.com/laurent22/joplin")。
如果你不知道如何安装它,请按照我们的[使用 AppImage 文件](https://itsfoss.com/use-appimage-linux/ "https://itsfoss.com/use-appimage-linux/")指南来开始。
另外,如果你想使用终端,你可以键入下面的命令,通过脚本来安装它(在这个过程中还会添加一个桌面图标)。
```
wget -O - https://raw.githubusercontent.com/laurent22/joplin/master/Joplin_install_and_update.sh | bash
```
### 2、Simplenote

主要功能:
* 支持 Markdown
* 简约的用户界面
* 通过你的 Simplenote 帐户轻松地进行同步
* 有 32 位软件包
* 跨平台,包括移动应用程序
顾名思义,它是一款简约的自由开源笔记应用。
由 [Automattic](https://automattic.com/ "https://automattic.com/")(WordPress 背后的公司)开发,[Simplenote](https://simplenote.com/ "https://simplenote.com") 可以让你在多个设备上无缝同步你的笔记。它支持 Android、iOS、Windows、Linux,以及 macOS。
与其它一些笔记应用不同的是,你会注意到它的界面非常简单,可能不会提供很多功能。但是,你可以为你的笔记添加标签。
#### 如何安装?
它提供了 .deb / .rpm 软件包以及一个 AppImage 文件。你可以在它的 [GitHub 发布部分](https://github.com/Automattic/simplenote-electron/releases/tag/v1.16.0 "https://github.com/Automattic/simplenote-electron/releases/tag/v1.16.0")中找到这些文件。
### 3、Laverna
注: 它已经不再积极开发了,但它仍然可以正常工作。

主要功能:
* 支持 Markdown
* 支持加密
* 支持同步
[Laverna](https://laverna.cc/ "https://laverna.cc") 是一个有趣的开源笔记应用程序,还提供加密(这是可选的)。
你可以把它作为一个基于 Web 的笔记应用,也可以作为电脑上的应用使用。它适用于 Linux、Mac 和 Windows。
虽然它除了支持加密外,还具有记事本应用的所有基本功能,但并没有一个可以使用的移动应用。所以,这是一个只有当你是一个桌面用户,并且在 Web 浏览器上完成大部分事情时才能使用的东西。
#### 如何安装?
它提供了一个压缩文件,可在其[官方网站](https://laverna.cc/ "https://laverna.cc")上获得。下载之后,你需要解压并启动可执行文件来开始。
### 4、Standard Notes

主要功能:
* 支持 Markdown
* 支持加密
* 支持同步
* 笔记的版本历史(付费计划)
* 跨平台,包括移动应用程序
* 提供了 32 位包。
* 提供付费选择
又一款开源笔记应用,为你的笔记和附件提供加密。
与 Laverna 不同,[Standard Notes](https://standardnotes.org/ "https://standardnotes.org") 正在积极开发中。虽然它提供了大量的功能,但其中一些功能以“扩展功能”或扩展插件仅提供给付费用户,这是偏昂贵的(每月订阅)。你也可以参考我们另外一篇关于 [Standard Notes](https://itsfoss.com/standard-notes/ "https://itsfoss.com/standard-notes/") 的文章来了解更多信息。
总的来说,你会得到 Markdown 支持、加密附件和笔记的能力、版本历史、备份支持(OneDrive、Google Drive 等)以及更多这样有用的功能。
#### 如何安装?
它提供了一个 AppImage 文件,可以在你的 Linux 发行版上安装它。你只需要前往它的[官方网站](https://standardnotes.org/ "https://standardnotes.org")下载即可。如果你不知道如何使用这个文件,可以参考我们的 [AppImage 指南](https://itsfoss.com/use-appimage-linux/ "https://itsfoss.com/use-appimage-linux/")。
对于其他可用的软件包或源代码,你可以参考他们的 [GitHub 页面](https://github.com/standardnotes "https://github.com/standardnotes")。
### 5、Boost Note

主要功能:
* 支持 Markdown
* 适用于开发者
* 跨平台
[Boost Note](https://itsfoss.com/boostnote-linux-review/ "https://itsfoss.com/boostnote-linux-review/") 是一款对使用 Linux 的程序员有用的笔记应用。你可以用它写你的代码,也可以用来写笔记、文档等等。
它提供了一个简洁直观的用户界面,并提供了 Linux 上笔记应用的所有基本功能。
#### 如何安装?
你可以选择其[官网](https://boostnote.io/ "https://boostnote.io/")上为 Ubuntu 提供的 .deb 文件。如果你想在其他 Linux 发行版上尝试,你还可以找到一个 AppImage 文件来开始使用。
如果你好奇,也可以查看他们的 [GitHub 页面](https://github.com/BoostIO/Boostnote "https://github.com/BoostIO/Boostnote")来探索更多关于它的内容或复刻它。
### 6、Tomboy Notes(新一代)

主要功能:
* 轻量级笔记应用
* 支持同步
* 跨平台
一款轻量级且极其简单的记事应用怎么样?
好吧,你可能知道旧版的 [Tomboy Notes](https://github.com/tomboy-notes/tomboy "https://github.com/tomboy-notes/tomboy") 已经不再开发了。幸运的是,有一个新一代的 [Tomboy Notes NG](https://github.com/tomboy-notes/tomboy-ng "https://github.com/tomboy-notes/tomboy-ng") 版本。你可以配置存储笔记的路径,并快速开始记笔记。
这款应用仅仅只有约 2MB 的下载量。所以,如果你正在寻找一个轻量级的解决方案 —— 那就是它。它可能无法用于智能手机,但你肯定可以在 Windows、Linux 和 MacOS 上使用它。
#### 如何安装?
你可以在他们的 [GitHub 发布部分](https://github.com/tomboy-notes/tomboy-ng/releases "https://github.com/tomboy-notes/tomboy-ng/releases")中找到 .deb / .rpm 和其他包。对于其他的 Linux 发行版,你可以关注他们 GitHub 页面的文档来了解更多。
### 7、RedNoteBook

主要功能
* 传统的日记式记事应用
* 有模板
* 离线使用
对于想要在 Linux 上使用离线笔记应用的用户来说,[RedNotebook](https://rednotebook.sourceforge.io/ "https://rednotebook.sourceforge.io") 应该是一个不错的选择。
是的,它不支持同步,如果你是一个不想要同步功能的人,RedNoteBook 应该是一款传统风格的记事应用,侧边栏为日历。
它主要是为喜欢离线日记的用户量身定做的。它还为你提供了几个模板,方便你创建某些笔记。
#### 如何安装?
如果你使用的是 Ubuntu(或者其他基于 Ubuntu 的发行版),你可以通过 PPA 来安装它。下面是你在终端中输入的安装方法:
```
sudo add-apt-repository ppa:rednotebook/stable
sudo apt-get update
sudo apt-get install rednotebook
```
对于其他的 Linux 发行版,你可以得到 [Flatpak 软件包](https://flathub.org/apps/details/app.rednotebook.RedNotebook "https://flathub.org/apps/details/app.rednotebook.RedNotebook")。
### 8、TagSpaces

主要特点:
* 丰富的用户界面
* 支持管理文件
* 支持同步
* 提供付费选择
[TagSpaces](https://www.tagspaces.org/ "https://www.tagspaces.org/") 是一款适用于 Linux 的精美笔记应用。不仅仅局限于创建笔记,你还可以管理照片和其他文档。
与其他一些可用的笔记应用不同,它不提供加密功能。所以,你可以尝试像 [Syncthing](https://itsfoss.com/syncthing/ "https://itsfoss.com/syncthing/") 这样支持 Dropbox 和 Nextcloud 的工具来安全地同步你的数据。
如果你想要特定的功能和支持,你也可以选择它的付费计划。
#### 如何安装?
你可以在他们的 [GitHub 发布区](https://github.com/tagspaces/tagspaces/releases/ "https://github.com/tagspaces/tagspaces/releases/")中找到 .deb 文件和一个 AppImage 文件来安装。无论哪种情况,你都可以把它也构建起来。
### 9、Trilium Notes

主要功能:
* 分层记事应用
* 支持加密
* 支持同步
[Trilium Notes](https://github.com/zadam/trilium/ "https://github.com/zadam/trilium/") 并不只是又一款笔记应用,它是一款专注于建立个人知识库的分层笔记应用。
是的,你也可以将它用于普通用途 —— 但它是为特定用户量身定制的,他们希望能够以分层方式管理笔记。
我个人还没有使用过 —— 除了测试。欢迎试用,多多探讨。
#### 如何安装?
只需前往其 [GitHub 发布区](https://github.com/zadam/trilium/releases "https://github.com/zadam/trilium/releases"),并抓取 [.deb 文件在 Ubuntu 上安装](https://itsfoss.com/install-deb-files-ubuntu/ "https://itsfoss.com/install-deb-files-ubuntu/")。如果你正在寻找其他 Linux 发行版上可用的软件包,你也可以从源代码构建它,或者下载并[解压缩文件](https://itsfoss.com/unzip-linux/ "https://itsfoss.com/unzip-linux/")。
### 总结
我对 Linux 上的笔记应用的推荐到此结束。我已经用过很多个,目前决定用 Simplenote 来做快速笔记,用 Joplin 来收集章节中的笔记。
你是否知道一些应该包括在这个列表中的其它 Linux 笔记应用程序?为什么不在评论区告诉我们呢?
你更喜欢哪个笔记应用程序?我很想知道你通常在 Linux 上寻找的最好的笔记应用程序是什么。
欢迎在下面的评论部分分享你的想法。
---
via: [https://itsfoss.com/note-taking-apps-linux/](https://itsfoss.com/note-taking-apps-linux/ "https://itsfoss.com/note-taking-apps-linux/")
作者:[Ankush Das](https://itsfoss.com/author/ankush/ "https://itsfoss.com/author/ankush/") 选题:[lujun9972](https://github.com/lujun9972 "https://github.com/lujun9972") 译者:[wxy](https://github.com/wxy "https://github.com/wxy") 校对:[wxy](https://github.com/wxy "https://github.com/wxy")
本文由 [LCTT](https://github.com/LCTT/TranslateProject "https://github.com/LCTT/TranslateProject") 原创编译,[Linux中国](https://linux.cn/ "https://linux.cn/") 荣誉推出
| 200 | OK | 

No matter what you do, taking notes is always a good habit. Yes, there are many note-taking apps that will help you achieve that. But, what about some good ones for Linux?
Fret not, you don’t need to endlessly search the Internet to find the best one for your Linux system. Here, I’ve picked some of the most impressive note-taking apps available.
## Best Note-Taking Apps for Linux

## 1. Joplin
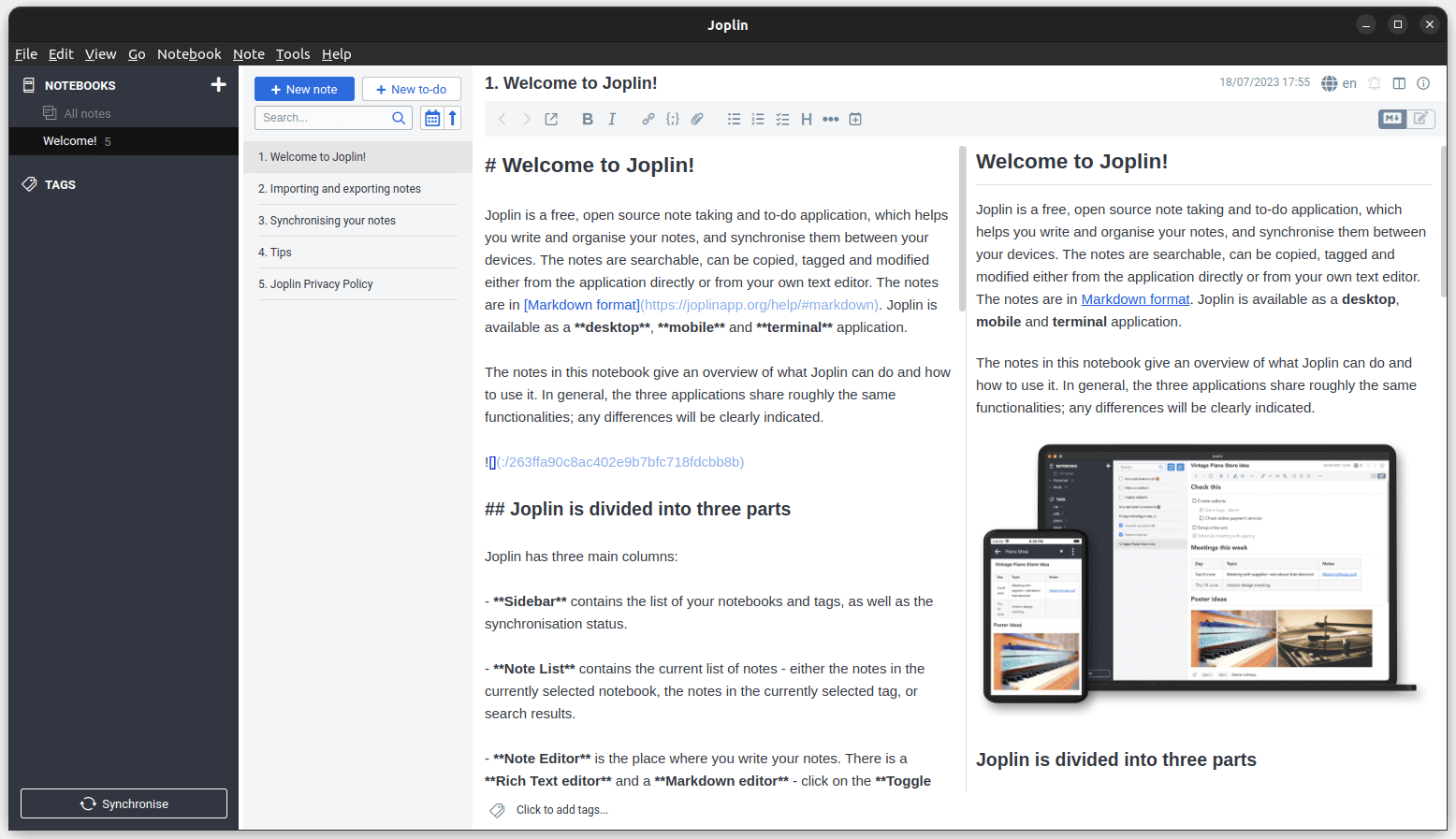
Joplin is an impressive free open-source note-taking app that supports encryption. With the features offered, it’s also one of the [best Evernote alternatives](https://itsfoss.com/5-evernote-alternatives-linux/) out there. In fact, I moved from Evernote to Joplin just because of the features offered.
You can choose to add to-do lists, plain notes, or use it as a markdown editor to write something. It’s available for **Linux**, **Windows**, **macOS**, **Android**, and **iOS**.
If you’re curious, you can read our detailed article on [Joplin](https://itsfoss.com/joplin/) to know more.
**Key Features:**
- Markdown support
- Encryption support
- Support for attachments
**How to install?**
You get an AppImage file to install Joplin. I’ve tried it on Ubuntu 22.04 LTS and it works as expected.
To look for the file, you can head to its [official website](https://joplinapp.org) or explore their [GitHub page](https://github.com/laurent22/joplin?ref=itsfoss.com), where you can find different packages.
In case you don’t know how to use the AppImage file, follow our guide on [using AppImage files](https://itsfoss.com/use-appimage-linux/) to get started.
## 2. cherrytree
cherrytree is a popular hierarchical note-taking application for power users. If you have many notes to manage or just want to store a variety of text, a hierarchical note-taking application like cherrytree can be the perfect choice.
**Key Features:**
- Hierarchical note-taking app.
- Rich text support.
- Cross-platform.
**How to install it?**
cherrytree should be available through the software center of your Linux distribution, or from the [official website](https://www.giuspen.net/cherrytree/).
You can also find** .deb/.rpm**, **Flatpaks**, **Snap **packages, and even the source code on its [GitHub repo](https://github.com/giuspen/cherrytree?ref=itsfoss.com).
## 3. Simplenote
As the name suggests, this is a simple, free and open-source note-taking app.
Developed by [Automattic](https://automattic.com/?ref=itsfoss.com) (the company behind WordPress), Simplenote lets you seamlessly sync your notes across multiple devices. It supports **Android**, **iOS**, **Windows**, **Linux**, and **macOS.**
Unlike other apps, you will notice that the interface is dead simple and very minimalistic in nature.
**Key Features:**
- Markdown support
- Simple user interface.
- 32-bit package available.
**How to install?**
It is offered in many package formats, including **.deb, .rpm**, **AppImage, tar.gz, **and more.** **You can find those in its [GitHub repo](https://github.com/Automattic/simplenote-electron) or the [official website](https://simplenote.com).
## 4. Notesnook
Notesnook is an interesting open-source note-taking app that **focuses on privacy** while providing a resemblance to the Evernote experience. You get end-to-end encryption by default and a private space for your note data.
We covered it during its [early days of launch](https://news.itsfoss.com/notesnook-goes-open-source/), and it impressed a bunch of our readers with what it offers. It is available for **Windows, macOS, Linux, Android, iOS, and the web**.
You can get started for free, and upgrade to its Pro edition for an affordable price (depends on your region).
**Key Features:**
- End-to-end encryption
- Web clipper
- Anonymous and secure note-sharing
- Markdown support
**How to install?**
You can download its AppImage file for PC or ARM device. If you prefer Flatpak and Snap, you will find both packages available for it, along with some more package manager support.
Head to its [download page](https://notesnook.com/downloads/) to get the package you need.
## 5. Gnote
Gnote is a minimal note-taking app that has been tailored for use with GNOME (not limited to). It allows you to link texts together using WikiWiki-style links, grouping them together in notebooks.
**Key Features:**
- Export notes as HTML documents.
- Support for sync.
- Tab support.
**How to install?**
You can get it from the [Flathub store](https://flathub.org/apps/org.gnome.Gnote), or you can head over to its [GitLab repo](https://gitlab.gnome.org/GNOME/gnote) to build it from source, or get access to alternative packages.
## 6. Logseq
[Logseq](https://logseq.com/) is a knowledge base focused note-taking app. You can visualize your ideas, and thoughts in a graph or use the whiteboard feature to organize them.
There are various ways to look at your notes, helping you keep track of your thoughts, and get back to them easily.
It presents a learning curve compared to others, but for some, it is well worth it.
**Key Features:**
- Graph view
- Whiteboard
- Flashcards
- Cross-platform sync
- Privacy-focused
**How to install it?**
It is available for Linux, Windows, macOS, iOS, and Android. For Linux, you can download the AppImage file.
You can refer to our [AppImage guide](https://itsfoss.com/use-appimage-linux/) for help.
## 7. Laverna
Laverna is an interesting open-source note-taking application that also offers optional encryption.
You can use it as a web-based note-taking app or locally on your computer. It is available for **Linux**, **Windows,** and **macOS**.
While it features all the basic functionalities found on a note-taking app, you don’t get a mobile app to go along with it.
**Key Features:**
- Markdown support
- Encryption support
- Sync support
**How to install?**
It is provided in a zip file which is available on the [official website](https://laverna.cc/?ref=itsfoss.com). Once you download it, you just need to extract it and launch the executable file to get started.
## 8. Standard Notes
Standard Notes is one of the best options as a note-taking app. While it offers a great deal of features, including end-to-end encryption, some of them are limited to paid subscribers as “extended features” or extensions, which could be on the expensive side (for a monthly subscription) as per your region.
Overall, you get markdown support, the ability to encrypt attachments/notes, version history, backup support (OneDrive, Google Drive, etc.) and more.
You can also refer to our article on Standard Notes to learn more.
**Key Features:**
- Markdown support (Paid)
- Cross-platform, including mobile apps.
- Version history of notes (Paid)
**How to install?**
It is offered as an AppImage file as well as a Snap for Linux, you can head over to the [official website](https://standardnotes.com/) to get the package of your choice.
For other available packages or source code, you can refer to its [GitHub page](https://github.com/standardnotes?ref=itsfoss.com).
## 9. Boost Note
Boost Note is a useful note-taking app for programmers using Linux. You can write code, and also use it to write notes, documentation, etc.
It offers a clean and intuitive user interface while offering all the basic features of a note-taking app.
**Key Features:**
- Markdown support
- Suitable for developers
- Cross-platform
**How to install it?**
You can opt for the **.deb** file available on its [official website](https://boostnote.io/?ref=itsfoss.com). You can also find other packages if you want to try it on other Linux distributions by heading to its [GitHub repo](https://github.com/BoostIO/BoostNote-App).
## 10. Tomboy Notes (Next Generation)
How about a lightweight and simple note-taking app?
Well, you might be aware of the old [Tomboy](https://github.com/tomboy-notes/tomboy?ref=itsfoss.com) note-taking app, which is no longer developed. Fortunately, there’s a next-generation version of it.
**Key Features:**
- Lightweight note-taking app
- Sync support
- Cross-platform
**How to install it?**
You can find .**deb, .rpm, .tgz, **and other packages in its [GitHub repo](https://github.com/tomboy-notes/tomboy-ng), as well as documentation and install instructions.
## 11. RedNoteBook
RedNoteBook should be a good choice for users who want an **offline note-taking app** for their Linux system.
Yes, it does not support online sync and if you’re someone who doesn’t want that, RedNoteBook is the one for you.
It is mostly tailored for users who like to have a journal, and also provides a couple of templates for a quick start.
**Key Features:**
- Traditional journal-style note-taking.
- Many templates available.
- It can be used offline.
**How to install it?**
If you’re using Ubuntu (or any other Ubuntu-based distro), you can install it via PPA. Otherwise, you can grab it from the [Flathub store](https://flathub.org/apps/app.rednotebook.RedNotebook).
For the PPA, here's what you have to type in the terminal to install it:
```
sudo add-apt-repository ppa:rednotebook/stable
sudo apt-get update
sudo apt-get install rednotebook
```
For other Linux distributions, you can get different packages from its [GitHub repo](https://github.com/jendrikseipp/rednotebook).
## 12. TagSpaces
TagSpaces is a beautiful note-taking app that is not just limited to creating notes, but you can manage photos and other documents as well.
Unlike other note-taking apps, it doesn’t offer encryption. So, you can try tools like [Syncthing](https://itsfoss.com/syncthing/) to sync your data safely.
You can also opt for its premium plans if you want special features and support.
**Key Features:**
- Rich user interface.
- Supports managing documents.
- Offers premium options.
**How to install it?**
You can find the AppImage file on the official website. For other packages, or source code, you can visit its [GitHub repo](https://github.com/tagspaces/tagspaces).
## 13. Trilium Notes
Trilium Notes is not just another note-taking app, it’s a hierarchical note-taking application with a focus on building large personal knowledge bases.
Yes, you can use it for common use as well, but it’s tailored for users who want the ability to manage the notes in a hierarchical manner.
**Key Features:**
- Hierarchical note-taking
- Encryption support
- Sync support
**How to install it?**
Simply head over to its [GitHub repo](https://github.com/zadam/trilium/?ref=itsfoss.com) or [Flathub store](https://flathub.org/apps/com.github.zadam.trilium) page to grab the packages of your choice. It is offered as a **.deb,** **Flatpak**, **.zip**, **.tar.xz**.
## 14. Notable
If you are looking for a simple note-taking app with a good UI while also having a GitHub-like Markdown experience, then Notable can be a good pick.
It does not support any specific cloud-storage integration, but it lets you choose a folder to store your notes. Unfortunately, it doesn’t offer encryption for the notes stored in that way.
**Key Features:**
- Markdown-based.
- Supports
[KaTeX](https://katex.org/?ref=itsfoss.com)expressions. - Cross-platform.
**How to install it?**
Notable is offered in a variety of package formats that include, **AppImage**, **.deb,** **pacman**, **.rpm,** and **Snap**. Head over to the official website to get it for **Linux**, **Windows**, **macOS**, and **iOS**.
## 15. QOwnNotes
QOwnNotes is yet another open-source note-taking app that supports Markdown. In addition to that, it also provides many advanced options to organize notes easily.
You can also use it as a [to-do list app](https://itsfoss.com/to-do-list-apps-linux/).
Its main highlight is that, it doesn’t rely on any cloud storage service. Instead, it supports Nextcloud / ownCloud integration.
**Key Features:**
- Supports markdown
- To-do list support
- Cross-platform
**How to install it?**
You can head over to the [official website](https://www.qownnotes.org) for installation instructions, and to the [GitHub repo](https://github.com/pbek/QOwnNotes) for the packages.
**Suggested Read 📖**
[7 Best To Do List Apps for Linux Desktop [2023]A good to-do list app helps you organize your work and be more productive by focusing on meaningful work. Here are the best to-do list apps for Linux desktop.](https://itsfoss.com/to-do-list-apps-linux/)

## 16. Zettlr
Zettlr is an impressive Markdown editor that can be used as a note-taking application. It features all the essential features found on a note app.
You can choose to store your files offline or sync the note folder with any of your [cloud storage services](https://itsfoss.com/cloud-services-linux/).
Personally, I like the user experience with a focused view of writing and managing things on Zettlr. In fact, we also have an article on [Zettlr](https://itsfoss.com/zettlr-markdown-editor/), if you’d like to get more details.
**Key Features:**
- Custom CSS support
- Easy tags management
[Zotero](https://www.zotero.org/?ref=itsfoss.com)integration
**How to install it?**
I tested it using the AppImage file and it worked great. You can head to its [official website](https://www.zettlr.com) to download the package you need.
Though, it is also offered in other packaging formats such as **.deb**, **.rpm**, **.dmg**, and more. You can check those out in its [GitHub repo](https://github.com/Zettlr/Zettlr).
## 17. Zim Wiki
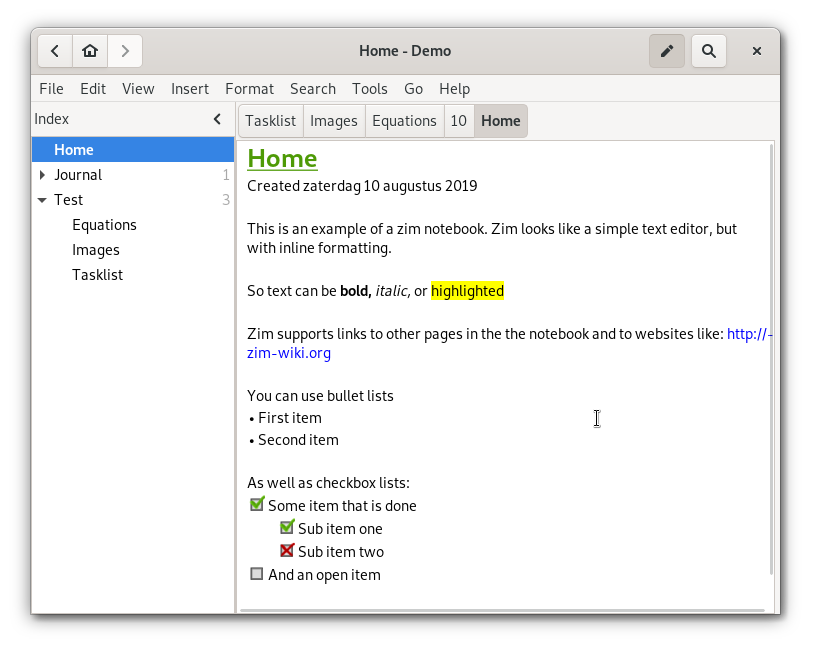
Zim is an interesting note-taking application in the form of a desktop wiki.
You can manage your notes or blog entries in the form of a collection of wiki pages, which is super efficient for many users.
Not just limited to that, but you can export your notes into the HTML format if you need to publish it as a web page.
On some Linux distributions, like [Linux Lite](https://www.linuxliteos.com/?ref=itsfoss.com), you might find it pre-installed.
**Key Features:**
- A concept of wiki pages on your desktop.
- Export your notes to HTML to create a webpage.
- Support for wiki syntax.
**How to install it?**
You can easily get it from the software center on your Linux distro. However, you may not find the latest version available.
So, in that case, you can head over to the [official website](https://zim-wiki.org/) to get started, and if you are interested in the source code for it, you can head over to its [GitHub repo](https://github.com/zim-desktop-wiki/zim-desktop-wiki).
## Wrapping Up
That concludes my recommendations for good note-taking apps on Linux. I have used most of them, and have currently settled with Standard Notes for quick notes and Joplin for collection of notes in chapters.
*💬 Do you know of any other notes apps available for Linux that you think should be included in this list? Please let us know in the comments below!* |
12,308 | 没有 systemd 的 Devuan Beowulf 3.0 发布 | https://itsfoss.com/devuan-3-release/ | 2020-06-12T11:25:48 | [
"Devuan",
"systemd"
] | https://linux.cn/article-12308-1.html | [Devuan GNU+Linux](https://devuan.org/) 是 [Debian](https://www.debian.org/) 的分支,它不含有 [systemd](https://en.wikipedia.org/wiki/Systemd)。如果你想知道 systemd 有什么问题,我们可以改天再讨论这个话题。
不过,如果你想要一个没有 systemd 的 Linux 发行版,那么 Devuan Beowulf 3.0 的发布对你来说应该是个好消息。
### Devuan Beowulf 3.0 有什么新增功能?

Devuan 通常因其提供了替代性的[初始化](https://en.wikipedia.org/wiki/Init)系统(如 [SysV](https://wiki.archlinux.org/index.php/SysVinit))而受到喜爱。
在本文中,我们将介绍 Devuan Beowulf 3.0 中的主要亮点。
#### 基于 Debian 10.4 Buster
[Debian 10 Buster](https://itsfoss.com/debian-10-buster/) 无疑是一款令人印象深刻的发行版系列,它的最新版本是 Debian 10.4。
而 Devuan Beowulf 3.0,是基于最新的 Debian 10.4 Buster 更新版本的。如果你不了解,可以查看 [Debian 10.4 Buster 的官方公告](https://www.debian.org/News/2020/20200509),以了解更多信息。
#### Linux Kernel 4.19
在它的最新版本中装有 [Linux Kernel 4.19 LTS](https://itsfoss.com/linux-kernel-4-19-lts-release/) 也是一个很好的加分项。
当然,这不是最新的内核,因为我们身处 “Debian 领域”,这里的事物并非总是最新的,但更加稳定。这个新内核应该可以解决以前版本中可能遇到的几个问题。
#### 支持 ppc64el 架构
对 [ppc64el](https://en.wikipedia.org/wiki/Ppc64) 的支持在大多数时候都不是大事,但支持 PowerPC 和 Power ISA 处理器是一个优势。
顺便提一句,Devuan GNU+Linux 已经支持 i386、amd64、armel、armhf 和 arm64 架构。
#### 添加 runit 和 OpenRC 作为可选项
想要更多替代的的初始化系统吗?现在最新版本中可选 [runit](https://en.wikipedia.org/wiki/Runit) 和 [openrc](https://en.wikipedia.org/wiki/OpenRC)。
#### 其他变化
除了上面的这样亮点外,你还可以发现它添加了独立守护进程 [eudev](https://wiki.gentoo.org/wiki/Eudev) 和 [elogind](https://wiki.gentoo.org/wiki/Elogind)。
启动页面、显示管理器和桌面主题也有了细微的变化。例如,启动菜单显示的是 “Debian” 而不是 “Devuan”。
如果你想了解有关 Devuan Beowulf 3.0.0 变更的更多技术详细信息,那么可以查看[官方发行说明](https://files.devuan.org/devuan_beowulf/Release_notes.txt)。
>
> 花絮
>
>
> Devuan 的发布版本以小行星命名。Beowulf 是一个[编号为 38086 的小行星](https://en.wikipedia.org/wiki/Meanings_of_minor_planet_names:_38001%E2%80%9339000#086)。
>
>
>
### 总结
最新稳定版本的 Devuan Beowulf 3.0 是提供无 systemd 的发行版的很好的进展。
如果你想支持 Devuan 项目,请[在财务上为他们的项目捐款](https://devuan.org/os/donate)或[通过其他方式](https://dev1galaxy.org/viewtopic.php?pid=1380#p1380)。
你觉得这个版本怎么样?请在下面评论让我知道你的想法!
---
via: <https://itsfoss.com/devuan-3-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Devuan GNU+Linux](https://devuan.org) is a fork of [Debian](https://www.debian.org) without [systemd](https://en.wikipedia.org/wiki/Systemd). If you are wondering what’s wrong with systemd — that’s a discussion for another day.
But, if you are someone who wanted a systemd-free Linux distribution, the release of Devuan Beowulf 3.0 should be good news for you.
## Devuan Beowulf 3.0: What’s New?
Devuan is normally appreciated for providing alternative [init](https://en.wikipedia.org/wiki/Init) software such as [SysV](https://wiki.archlinux.org/index.php/SysVinit).
In this article, we’ll take a look at the key highlights in Devuan Beowulf 3.0.
### Based on Debian 10.4 Buster
[Debian 10 Buster](https://itsfoss.com/debian-10-buster/) is undoubtedly an impressive series of releases while Debian 10.4 being the latest.
And, with Devuan Beowulf 3.0, you’ll be happy to know that the release is based on the latest Debian 10.4 Buster update.
In case you aren’t aware of it, you may check out the [official announcement post for Debian 10.4 Buster](https://www.debian.org/News/2020/20200509) release to know more about it.
### Linux Kernel 4.19
It’s also a great addition to have [Linux Kernel 4.19 LTS](https://itsfoss.com/linux-kernel-4-19-lts-release/) baked in the latest release.
Of course, not the latest because we are in ‘Debian land’ and things are not always latest here but more stable. The new kernel should fix several issues that you may have had with previous releases.
### Support For ppc64el Architecture
The support for [ppc64el](https://en.wikipedia.org/wiki/Ppc64) may not be a big deal for the most part — but having the support for PowerPC and Power ISA processors is a plus.
Not to forget, Devuan GNU+Linux already supports i386, amd64, armel, armhf and arm64 architectures.
### Added runit & OpenRC as optional alternative
To consider more init software alternatives, [runit](https://en.wikipedia.org/wiki/Runit) and [openrc](https://en.wikipedia.org/wiki/OpenRC) is now an option in the latest release.
### Other Changes
In addition to the key highlights mentioned above, you will also find the addition of standalone daemons [eudev](https://wiki.gentoo.org/wiki/Eudev) and [elogind](https://wiki.gentoo.org/wiki/Elogind).
The boot screen, the display manager and the desktop theming also includes subtle changes. For example, the boot menu says “**Debian**” instead of “**Devuan**“.
You might want to look the [official release notes](http://files.devuan.org/devuan_beowulf/Release_notes.txt) if you want more technical details on the changes with Devuan Beowulf 3.0.0.
Trivia
Devuan releases are named after minor planets. Beowulf is a [minor planet numbered 38086](https://en.wikipedia.org/wiki/Meanings_of_minor_planet_names:_38001%E2%80%9339000#086).
## Wrapping Up
The latest stable release of Devuan Beowulf 3.0 counts as good progress with systemd-free distributions available out there.
If you want to support Devuan project, please make some [contribution to their project either financially](https://devuan.org/os/donate) or [by other means](https://dev1galaxy.org/viewtopic.php?pid=1380#p1380).
What do you think about this release? Feel free to let me know what you think in the comments below! |
12,310 | 如何编写 VS Code 扩展 | https://opensource.com/article/20/6/vs-code-extension | 2020-06-13T10:54:57 | [
"VSCode",
"扩展"
] | https://linux.cn/article-12310-1.html |
>
> 通过为流行的代码编辑器编写自己的扩展来添加缺失的功能。
>
>
>

Visual Studio Code(VS Code)是微软为 Linux、Windows 和 macOS 创建的跨平台代码编辑器。遗憾的是,微软版本的 [VS Code](https://code.visualstudio.com/) 是在 [Microsoft Software License](https://code.visualstudio.com/license) 下发布的,这不是一个开源的许可证。然而,它的源代码是开源的,在 MIT 许可证下由 [VSCodium](https://vscodium.com/) 项目发布。
VSCodium 和 VS Code一样,支持扩展、内嵌式 Git 控制、GitHub 集成、语法高亮、调试、智能代码补完、代码片段等。换句话说,对于大多数用户来说,使用 VS Code 和 VSCodium 没有什么区别,而且后者是完全开源的!
### 什么是 VS Code 扩展?
<ruby> 扩展 <rt> extension </rt></ruby>可以让你为 VS Code 或 VSCodium 添加功能。你可以在 GUI 中或从终端安装扩展。
你也可以构建自己的扩展。有几个你可能想学习如何构建扩展的原因:
1. **想要添加一些功能:** 如果缺失你想要的功能,你可以创建一个扩展来添加它。
2. **为了乐趣和学习:** 扩展 API 允许你探索 VSCodium 是如何工作的,这是一件有趣的事情。
3. **为了提高您的技能:** 创建扩展可以提高你的编程技能。
4. **为了成名:** 创建一个对他人有用的扩展可以提高你的公众形象。
### 安装工具
在你开始之前,你必须已经安装了 [Node.js](https://nodejs.org/en/)、[npm](https://www.npmjs.com/) 和 VS Code 或 [VSCodium](https://vscodium.com/)。
要生成一个扩展,你还需要以下工具:[Yeoman](https://yeoman.io/),是一个开源的客户端脚手架工具,可以帮助你搭建新项目;以及 [vscode-generator-code](https://github.com/Microsoft/vscode-generator-code),是 VS Code 团队创建的 Yeoman 生成器。
### 构建一个扩展
在本教程中,你将构建一个扩展,它可以为应用程序初始化一个 Docker 镜像。
#### 生成一个扩展骨架
要在全局范围内安装并运行 Yeoman 生成器,请在命令提示符或终端中输入以下内容:
```
npm install -g yo generator-code
```
导航到要生成扩展的文件夹,键入以下命令,然后按回车:
```
yo code
```
根据提示,你必须回答一些关于你的扩展的问题:
* **你想创建什么类型的扩展?** 使用上下箭头选择其中一个选项。在本文中,我将只介绍第一个选项,`New Extension (TypeScript)`。
* **你的扩展名称是什么?** 输入你的扩展名称。我的叫 `initdockerapp`。(我相信你会有一个更好的名字。)
* **你的扩展的标识符是什么?** 请保持原样。
* **你的扩展的描述是什么?** 写一些关于你的扩展的内容(你可以现在填写或稍后编辑它)。
* **初始化 Git 仓库?** 这将初始化一个 Git 仓库,你可以稍后添加 `set-remote`。
* **使用哪个包管理器?** 你可以选择 `yarn` 或 `npm`;我使用 `npm`。
按回车键后,就会开始安装所需的依赖项。最后显示:
>
> "Your extension **initdockerapp** has been created!"
>
>
>
干的漂亮!
### 检查项目的结构
检查你生成的东西和项目结构。导航到新的文件夹,并在终端中键入 `cd initdockerapp`。
一旦你进入该目录,键入 `.code`。它将在你的编辑器中打开,看起来像这样。

(Hussain Ansari, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
最需要注意的两个文件是 `src` 文件夹内的 `package.json` 和 `extension.ts`。
#### package.json
首先来看看 `package.json`,它应该是这样的:
```
{
"name": "initdockerapp",
"displayName": "initdockerapp",
"description": "",
"version": "0.0.1",
"engines": {
"vscode": "^1.44.0"
},
"categories": [
"Other"
],
"activationEvents": [
"onCommand:initdockerapp.initialize"
],
"main": "./out/extension.js",
"contributes": {
"commands": [
{
"command": "initdockerapp.initialize",
"title": "Initialize A Docker Application"
}
]
},
"scripts": {
"vscode:prepublish": "npm run compile",
"compile": "tsc -p ./",
"lint": "eslint src --ext ts",
"watch": "tsc -watch -p ./",
"pretest": "npm run compile && npm run lint",
"test": "node ./out/test/runTest.js"
},
"devDependencies": {
"@types/vscode": "^1.44.0",
"@types/glob": "^7.1.1",
"@types/mocha": "^7.0.2",
"@types/node": "^13.11.0",
"eslint": "^6.8.0",
"@typescript-eslint/parser": "^2.26.0",
"@typescript-eslint/eslint-plugin": "^2.26.0",
"glob": "^7.1.6",
"mocha": "^7.1.1",
"typescript": "^3.8.3",
"vscode-test": "^1.3.0"
}
}
{
"name": "initdockerapp",
"displayName": "initdockerapp",
"description": "",
"version": "0.0.1",
"engines": {
"vscode": "^1.44.0"
},
"categories": [
"Other"
],
"activationEvents": [
"onCommand:initdockerapp.initialize"
],
"main": "./out/extension.js",
"contributes": {
"commands": [
{
"command": "initdockerapp.initialize",
"title": "Initialize A Docker Application"
}
]
},
"scripts": {
"vscode:prepublish": "npm run compile",
"compile": "tsc -p ./",
"lint": "eslint src --ext ts",
"watch": "tsc -watch -p ./",
"pretest": "npm run compile && npm run lint",
"test": "node ./out/test/runTest.js"
},
"devDependencies": {
"@types/vscode": "^1.44.0",
"@types/glob": "^7.1.1",
"@types/mocha": "^7.0.2",
"@types/node": "^13.11.0",
"eslint": "^6.8.0",
"@typescript-eslint/parser": "^2.26.0",
"@typescript-eslint/eslint-plugin": "^2.26.0",
"glob": "^7.1.6",
"mocha": "^7.1.1",
"typescript": "^3.8.3",
"vscode-test": "^1.3.0"
}
}
```
如果你是 Node.js 开发者,其中一些可能看起来很熟悉,因为 `name`、`description`、`version` 和 `scripts` 是 Node.js 项目的常见部分。
有几个部分是非常重要的:
* `engines`:说明该扩展将支持哪个版本的 VS Code / VSCodium。
* `categories`:设置扩展类型;你可以从 `Languages`、`Snippets`、`Linters`、`Themes`、`Debuggers`、`Formatters`、`Keymaps` 和 `Other`中选择。
* `contributes`:可用于与你的扩展一起运行的命令清单。
* `main`:扩展的入口点。
* `activationEvents`:指定激活事件发生的时间。具体来说,这决定了扩展何时会被加载到你的编辑器中。扩展是懒加载的,所以在激活事件触发之前,它们不会被激活。
#### src/extension.ts
接下来看看 `src/extension.ts`,它应该是这样的:
```
// The module 'vscode' contains the VSCodium extensibility API
// Import the module and reference it with the alias vscode in your code below
import * as vscode from "vscode";
const fs = require("fs");
const path = require("path");
// this method is called when your extension is activated
// your extension is activated the very first time the command is executed
export function activate(context: vscode.ExtensionContext) {
// Use the console to output diagnostic information (console.log) and errors (console.error)
// This line of code will only be executed once when your extension is activated
console.log('Congratulations, your extension "initdockerapp" is now active!');
// The command has been defined in the package.json file
// Now provide the implementation of the command with registerCommand
// The commandId parameter must match the command field in package.json
let disposable = vscode.commands.registerCommand('initdockerapp.initialize', () => {
// The code you place here will be executed every time your command is executed
let fileContent =`
FROM node:alpine
WORKDIR /usr/src/app
COPY package.json .
RUN npm install
COPY . .
EXPOSE 3000
CMD ["npm", "start"]
`;
fs.writeFile(path.join(vscode.workspace.rootPath, "Dockerfile"), fileContent, (err:any) => {
if (err) {
return vscode.window.showErrorMessage("Failed to initialize docker file!");
}
vscode.window.showInformationMessage("Dockerfile has been created!");
});
});
context.subscriptions.push(disposable);
}
// this method is called when your extension is deactivated
export function deactivate() {}
```
这是为你的扩展写代码的地方。已经有一些自动生成的代码了,我再来分析一下。
注意,`vscode.command.registerCommand` 里面的 `initdockerapp.initialize` 和 `package.json` 里面的命令是一样的。它需要两个参数。
1. 要注册的命令名称
2. 执行命令的功能
另一个需要注意的函数是 `fs.writeFile`,这是你写在 `vscode.command.registerCommand` 函数里面的。这将在你的项目根目录下创建一个 Dockerfile,并在其中附加代码来创建一个 Docker 镜像。
### 调试扩展
现在你已经写好了扩展,是时候调试它了。点击“Run”菜单,选择“Start Debugging”(或者直接按 `F5`)打开调试窗口。
在调试窗口里面点击“Add Folder”或“Clone Repository”按钮,打开该项目。
接下来,用 `Ctrl+Shift+P`(在 macOS 上,用 `Command` 键代替 `Ctrl`)打开命令面板,运行 `Initialize A Docker Application`。
* 第一次运行此命令时,自 VSCodium 启动后,激活函数尚未执行。因此,调用激活函数,并由激活 函数注册该命令。
* 如果命令已注册,那么它将被执行。
你会看到右下角有一条信息,上面写着:`Dockerfile has been created!`。这就创建了一个 Dockerfile,里面有一些预定义的代码,看起来是这样的:

(Hussain Ansari, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
### 总结
有许多有用的 API 可以帮助你创建你想要构建的扩展。VS Code 扩展 API 还有许多其他强大的方法可以使用。
你可以在 VS Code 扩展 API 文档中了解更多关于 VS Code API 的信息。
---
via: <https://opensource.com/article/20/6/vs-code-extension>
作者:[Ashique Hussain Ansari](https://opensource.com/users/uidoyen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Visual Studio Code (VS Code) is a cross-platform code editor created by Microsoft for Linux, Windows, and macOS. Unfortunately, Microsoft's version of [VS Code](https://code.visualstudio.com/) is released under the [Microsoft Software License](https://code.visualstudio.com/license), which is not an open source license. However, the source code is open source, released under the MIT license, with releases distributed by the [VSCodium](https://vscodium.com/) project.
VSCodium, like VS Code, has support for extensions, embedded Git control, GitHub integration, syntax highlighting, debugging, intelligent code completion, snippets, and more. In other words, for most users there's no difference between using VS Code and VSCodium, and the latter is completely open source!
## What are VS Code extensions?
Extensions allow you to add capabilities to VS Code or VSCodium. You can install extensions in the GUI or from a terminal.
You can also build your own extensions. There are several reasons you might want to learn to build an extension:
**To add something:**If a feature you want is missing, you can create an extension to add it.**For fun and learning:**The extension API allows you to explore how VSCodium works, which is a fun thing to do.**To improve your skills:**Creating an extension enhances your programming skills.**For fame:**Creating an extension that is useful to others can increase your public profile.
## Install the tools
Before you begin, you must already have [Node.js](https://nodejs.org/en/), [npm](https://www.npmjs.com/), and VS Code or [VSCodium](https://vscodium.com/) installed.
To generate an extension, you will also need the following tools: [Yeoman](https://yeoman.io/), an open source client-side scaffolding tool that helps you kickstart new projects, and [vscode-generator-code](https://github.com/Microsoft/vscode-generator-code), a Yeoman generator build created by the VS Code team.
## Build an extension
In this tutorial, you will build an extension that initializes a Docker image for an application.
### Generate an extension skeleton
To install and run the Yeoman generator globally, enter the following in a command prompt or terminal:
`npm install -g yo generator-code`
Navigate to the folder where you want to generate the extension, type the following command, and hit **Enter**:
`yo code`
At the prompt, you must answer some questions about your extension:
**What type of extension do you want to create?**Choose one of the options by using the Up and Down arrows. In this article, I will explain only the first one,**New Extension (TypeScript)**.**What's the name of your extension?**Enter the name of your extension. Mine is called**initdockerapp**. (I am sure you will have a better name.)**What's the identifier of your extension?**Leave this as it is.**What's the description of your extension?**Write something about your extension (you can fill this in or edit it later, too).**Initialize a Git repository?**This initializes a Git repository, and you can add`set-remote`
later.**Which package manager to use?**You can choose yarn or npm; I will use npm.
Hit the **Enter** key, and it will start installing the required dependencies. And finally:
"Your extension
initdockerapphas been created!"
Excellent!
## Check the project's structure
Examine what you generated and the project structure. Navigate to the new folder and type `cd initdockerapp`
in your terminal.
Once you are in, type `.code`
. It will open in your editor and look something like this:
(Hussain Ansari, CC BY-SA 4.0)
The two most important files to pay attention to are `package.json`
and `extension.ts`
inside the `src`
folder.
### package.json
First, look at `package.json`
, which should look something like this:
```
{
"name": "initdockerapp",
"displayName": "initdockerapp",
"description": "",
"version": "0.0.1",
"engines": {
"vscode": "^1.44.0"
},
"categories": [
"Other"
],
"activationEvents": [
"onCommand:initdockerapp.initialize"
],
"main": "./out/extension.js",
"contributes": {
"commands": [
{
"command": "initdockerapp.initialize",
"title": "Initialize A Docker Application"
}
]
},
"scripts": {
"vscode:prepublish": "npm run compile",
"compile": "tsc -p ./",
"lint": "eslint src --ext ts",
"watch": "tsc -watch -p ./",
"pretest": "npm run compile && npm run lint",
"test": "node ./out/test/runTest.js"
},
"devDependencies": {
"@types/vscode": "^1.44.0",
"@types/glob": "^7.1.1",
"@types/mocha": "^7.0.2",
"@types/node": "^13.11.0",
"eslint": "^6.8.0",
"@typescript-eslint/parser": "^2.26.0",
"@typescript-eslint/eslint-plugin": "^2.26.0",
"glob": "^7.1.6",
"mocha": "^7.1.1",
"typescript": "^3.8.3",
"vscode-test": "^1.3.0"
}
}
{
"name": "initdockerapp",
"displayName": "initdockerapp",
"description": "",
"version": "0.0.1",
"engines": {
"vscode": "^1.44.0"
},
"categories": [
"Other"
],
"activationEvents": [
"onCommand:initdockerapp.initialize"
],
"main": "./out/extension.js",
"contributes": {
"commands": [
{
"command": "initdockerapp.initialize",
"title": "Initialize A Docker Application"
}
]
},
"scripts": {
"vscode:prepublish": "npm run compile",
"compile": "tsc -p ./",
"lint": "eslint src --ext ts",
"watch": "tsc -watch -p ./",
"pretest": "npm run compile && npm run lint",
"test": "node ./out/test/runTest.js"
},
"devDependencies": {
"@types/vscode": "^1.44.0",
"@types/glob": "^7.1.1",
"@types/mocha": "^7.0.2",
"@types/node": "^13.11.0",
"eslint": "^6.8.0",
"@typescript-eslint/parser": "^2.26.0",
"@typescript-eslint/eslint-plugin": "^2.26.0",
"glob": "^7.1.6",
"mocha": "^7.1.1",
"typescript": "^3.8.3",
"vscode-test": "^1.3.0"
}
}
```
If you are a Node.js developer, some of this might look familiar since `name`
, `description`
, `version`
, and `scripts `
are common parts of a Node.js project.
There are a few sections that are very important.
`engines`
: States which version of VSCodium the extension will support`categories`
: Sets the extension type; you can choose from Languages, Snippets, Linters, Themes, Debuggers, Formatters, Keymaps, and Other`contributes`
: A list of commands that can be used to run with your extension`main`
: The entry point of your extension`activationEvents`
: Specifies when the activation event happens. Specifically, this dictates when the extension will be loaded into your editor. Extensions are lazy-loaded, so they aren't activated until an activation event occurs
### src/extension.ts
Next, look at `src/extension.ts`
, which should look something like this:
```
// The module 'vscode' contains the VSCodium extensibility API
// Import the module and reference it with the alias vscode in your code below
import * as vscode from "vscode";
const fs = require("fs");
const path = require("path");
// this method is called when your extension is activated
// your extension is activated the very first time the command is executed
export function activate(context: vscode.ExtensionContext) {
// Use the console to output diagnostic information (console.log) and errors (console.error)
// This line of code will only be executed once when your extension is activated
console.log('Congratulations, your extension "initdockerapp" is now active!');
// The command has been defined in the package.json file
// Now provide the implementation of the command with registerCommand
// The commandId parameter must match the command field in package.json
let disposable = vscode.commands.registerCommand('initdockerapp.initialize', () => {
// The code you place here will be executed every time your command is executed
let fileContent =`
FROM node:alpine
WORKDIR /usr/src/app
COPY package.json .
RUN npm install
COPY . .
EXPOSE 3000
CMD ["npm", "start"]
`;
fs.writeFile(path.join(vscode.workspace.rootPath, "Dockerfile"), fileContent, (err:any) => {
if (err) {
return vscode.window.showErrorMessage("Failed to initialize docker file!");
}
vscode.window.showInformationMessage("Dockerfile has been created!");
});
});
context.subscriptions.push(disposable);
}
// this method is called when your extension is deactivated
export function deactivate() {}
```
This is where you write the code for your extension. There's already some auto-generated code, which I'll break down.
Notice that the name `initdockerapp.initialize`
inside `vscode.command.registerCommand`
is the same as the command in `package.json`
. It takes two parameters:
- The name of the command to register
- A function to execute a command
The other function to note is `fs.writeFile`
, which you wrote inside the `vscode.command.registerCommand`
function. This creates a dockerfile inside your project root, and appends the code to create a Docker image.
## Debug the extension
Now that you've written the extension, its time to debug it. Click the **Run** menu and select **Start Debugging** (or just press **F5**) to open a debugging window.
Open the project inside the debugging window by clicking on either the **Add Folder** or the **Clone Repository** button.
Next, open a command panel with **Ctrl+Shift+P** (on macOS, substitute the Command key for Ctrl) and run **Initialize A Docker Application**.
- The first time you run this command, the activate function has not been executed since VSCodium was launched. Therefore, activate is called, and the activate function registers the command.
- If the command has already been registered, then it executes.
You'll see a message in the lower-right corner that says: "Dockerfile has been created!" This created a Dockerfile with some pre-defined code that looks something like this:
(Hussain Ansari, CC BY-SA 4.0)
## Summary
There are many helpful APIs that will help you create the extensions you want to build. The VS Code extension API has many other powerful methods you can use.
You can learn more about VS Code APIs in the VS Code Extension API documentation.
## Comments are closed. |
12,311 | 如何在 Ubuntu 20.04 中更改文件夹颜色 | https://itsfoss.com/folder-color-ubuntu/ | 2020-06-13T13:32:03 | [
"主题"
] | https://linux.cn/article-12311-1.html | 
[Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/) 中默认的 Yaru 主题赋予它优美、现代的外观。默认 Yaru 主题中的文件夹是紫色的外观,以与 Ubuntu 的品牌保持一致。
如果你不喜欢紫色,可以在 Ubuntu 中自由更改颜色主题。你可以更改 Ubuntu 的主题以使其有不同的颜色,但这将意味着放弃 Yaru 主题。
如果你只想在 Ubuntu 20.04 中更改文件夹的颜色,可以有两种方法:
* 为选定的文件夹赋予不同的颜色和标志(以便更好地组织文件和文件夹)
* 通过更改 Yaru 颜色主题来更改所有文件夹的颜色
让我向你展示两种方法。
### 更改所选文件和文件夹的颜色和标志

我知道有些人将他们的文件夹使用不同的颜色或放在不同的位置,来表示工作正在进行中还是待处理或已完成。
如果你也是这样的,那么可以使用 [Folder Color 工具](https://foldercolor.tuxfamily.org/)更改文件夹的颜色。你还可以在文件夹中添加标志(绿色的勾号表示完成,加号表示新的,感叹号表示重要等)。你可以在上一张图片中看到一些例子。
你还可以在文件上使用 “Folder Color” 工具。你不能更改文件图标的颜色,但可以添加标志。
如果你在 Ubuntu 20.04 中[使用 Yaru 主题](https://itsfoss.com/ubuntu-community-theme/),你可以使用[官方 PPA](https://launchpad.net/folder-color):
```
sudo add-apt-repository ppa:costales/yaru-colors-folder-color
```
现在,使用 Yaru 兼容包安装 Folder Color。
```
sudo apt install folder-color yaru-colors-folder-color
```
安装后,你必须使用 `nautilus -q` 命令重启 Nautilus 文件管理器。之后,你可以进入文件管理器,右键单击文件夹或文件。你会在上下文菜单中看到 Folder Color 的选项。你将在此处看到颜色和标志选项。

你还可以通过在菜单**通过选择“默认”恢复原始文件夹颜色**。
对于 Ubuntu 18.04 或更早版本,可以从软件中心安装 Folder Color。它还可用于 Linux Mint/Cinnamon 桌面的 Nemo 文件管理器和 MATE 桌面的 [Caja 文件管理器](https://github.com/mate-desktop/caja)。
#### 如何删除 Folder Color?
如果你不想使用 Folder Color,你可以删除应用并删除 PPA。首先删除该应用:
```
sudo apt remove folder-color yaru-colors-folder-color
```
现在[删除 PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/):
```
sudo add-apt-repository -r ppa:costales/yaru-colors-folder-color
```
### Yaru Colors 主题包更改 Yaru 主题颜色

如果你想继续使用 Yaru 主题但使用不同的颜色,那么需要[Yaru Colors 主题包](https://github.com/Jannomag/Yaru-Colors)。
Yaru Colors 由 12 种 Yaru 颜色变体组成。它们浅绿色、蓝色、棕色、深蓝色、绿色、灰色、MATE 绿、橙色、粉红色、紫色、红色和黄色。
主题包括 GTK 主题、图标、光标和 GNOME Shell 主题。
* 图标:更改文件夹的强调色
* GTK 主题:更改应用窗口的强调色
* 光标主题:向光标添加几乎可以忽略的色彩轮廓
* GNOME Shell 主题:更改消息托盘和系统托盘中的强调色
你可以从它的 GitHub 仓库下载 Yaru Colors 主题包:
#### 下载 Yaru Colors 主题包
在提取内容时,你会发现图标、主题文件夹,这两个文件夹都包含上述十二种颜色。你可以分别在 `~/.local/share/.icons` 和 `~/.local/share/themes` 文件夹中复制图标和主题文件夹。
如果你不想亲自复制,那么你可以在解压文件夹中找到 `install.sh` 脚本。你可以运行它来通过交互式终端会话安装全部或选定的几个主题。

要更改 GNOME Shell 主题,你必须[使用 GNOME Tweak 工具](https://itsfoss.com/gnome-tweak-tool/)。你也可以使用 GNOME Tweak 将图标和主题更改回默认。

享受为你的 Ubuntu 生活增色 ?
---
via: <https://itsfoss.com/folder-color-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The default Yaru theme in Ubuntu gives it a polished, modern look. The folders in the default Yaru theme have a purple-aubergine touch to keep in line with the branding of Ubuntu.
If you are not a fan of the purple shade, you have the freedom to change the color theme in Ubuntu.
You may change the theme of Ubuntu to give it a different color, but that would mean ditching Yaru theme.
If you just want to change the folder color in Ubuntu, there are two ways to do that:
- Give a different color and emblem to selected folders (for better organizing the files and folders)
- Change the colors for all folders by changing the Yaru color theme
Let me show you both methods.
## Change folder colors and emblem for selected files and folders
I know that some people keep their folders in different color/location to indicate whether a work is in progress or pending or completed.
If you are one of those people, you can use the Folder Color utility and change the color of the folders. You may also add emblem to the folders (the green tick sign for competition, + sign for new, exclamation mark for important etc.). You can see some examples in the previous image.
Furthermore, you can also use the Folder Color utility on files. You cannot change the color files icons, but you can add emblems to them.
If you are [using Yaru theme](https://itsfoss.com/ubuntu-community-theme/) in Ubuntu, you can use the official PPA:
```
sudo add-apt-repository ppa:costales/yaru-colors-folder-color
```
Now install Folder Color with Yaru compatibility package.
```
sudo apt update
sudo apt install folder-color yaru-colors-folder-color
```
Once installed, you’ll have to restart Nautilus file manager using `nautilus -q`
command. After that, you can go to the file manager, right-click on a folder or file. You’ll see a Folder’s Color option in the context menu. You’ll see the color and emblem options here.
Likewise, you can also restore the original folder color by choosing Default in the menu.
Folder Color is also available to install from the software center, but it won't keep the Yaru icon theme intact.
If you want that, install it using:
```
sudo apt install folder-color
```
The Folder Color utility is also available for Linux Mint/Cinnamon desktop’s [Nemo file manager](https://itsfoss.com/nemo-tweaks/) and MATE desktop’s [Caja file manager](https://github.com/mate-desktop/caja?ref=itsfoss.com).
### How to remove Folder Color tool?
If you don’t want to use Folder Color, you may remove the app and delete the PPA. First remove the app:
```
sudo apt purge folder-color yaru-colors-folder-color
sudo apt autoremove
```
Now [remove the PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/):
```
sudo add-apt-repository -r ppa:costales/yaru-colors-folder-color
```
## Change the color variant of Yaru theme
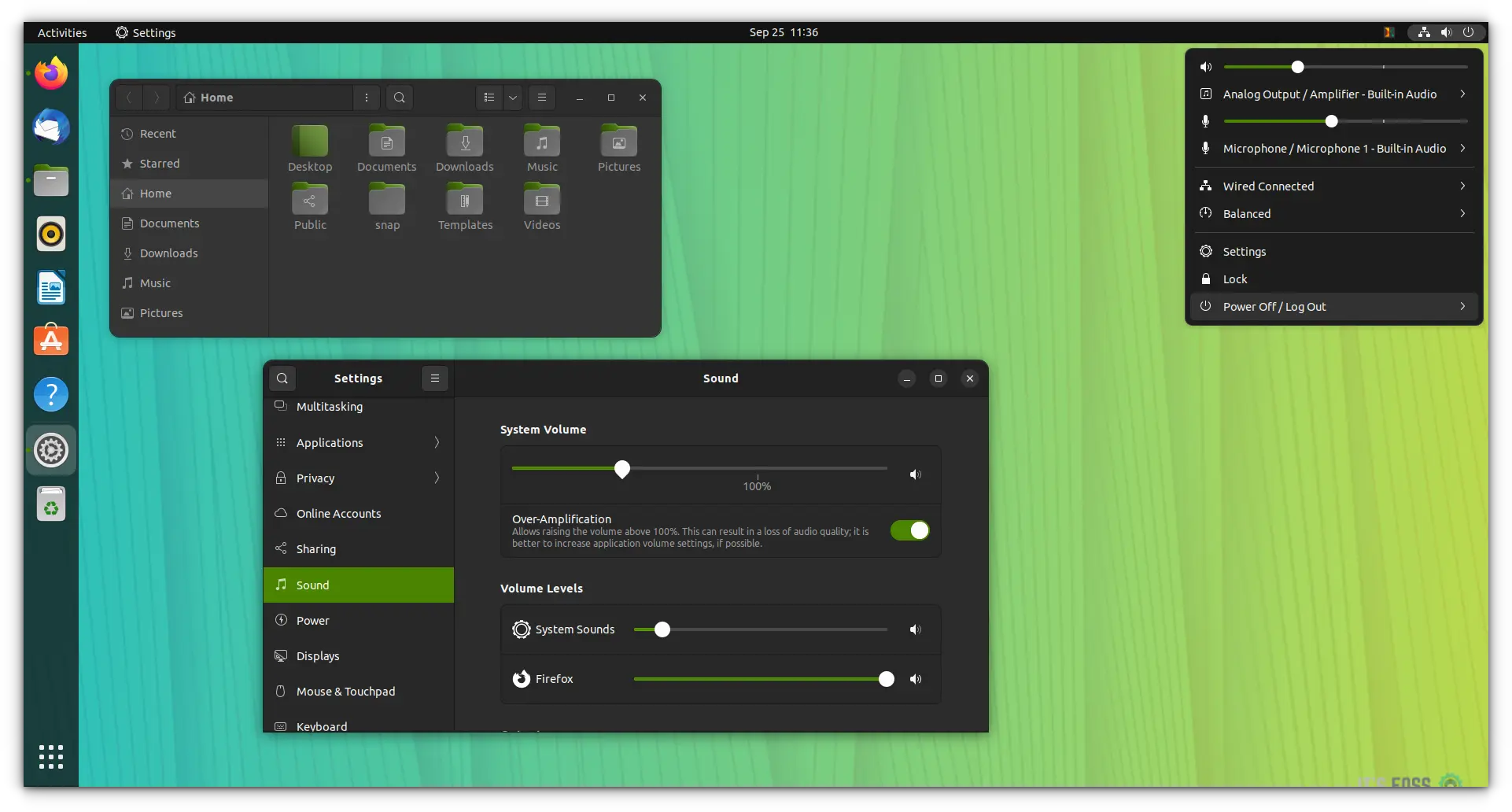
From Ubuntu 22.04, you can use the default Accent Color feature on system settings to use a different color variant of Yaru Icon theme.
You can select from 10 different accent colors, like Orange, Olive, Blue, Purple, Magenta, etc.
If you are doing it using system settings, open the Settings app and go to Appearance tab. From there, click on any of the accent color you want.
Or you can do the same with GNOME Tweaks. Open Tweaks and go to the Appearance Tab. You can change the following.
- Icons - Changes the accent color of folders
- Applications - Changes the application windows
- Cursor theme - Adds an almost negligible colored outline to the cursor
- GNOME Shell theme - Changes the accent color in the message tray and system tray
## Yaru Colors theme pack for Ubuntu 20.04 (and older)
If you want to keep on using Yaru theme but with a different color variant, [Yaru Colors theme pack](https://github.com/Jannomag/Yaru-Colors?ref=itsfoss.com) is what you need.
Yaru Colors consists of 12 color variants of Yaru. The colors are aqua, blue, brown, deep blue, green, gray, MATE green, orange, pink, purple, red and yellow.
You can download Yaru Colors theme pack from its GitHub repository:
When you extract the content you’ll find icons, Themes folders and both of these folders contains the twelve mentioned color variants. You can copy the icons and Themes folder in `~/.local/share/.icons`
and `~/.local/share/themes`
folders respectively.
If you are not comfortable doing it all by yourself, you’ll find the `install.sh`
shell script in the extracted folder. You can run it to install all or selected few themes via an interactive terminal session.
The installer will ask if you want to change the theme on the go or not.
You may also [use GNOME Tweak](https://itsfoss.com/gnome-tweak-tool/) to change the icons and themes back to the default ones.
Enjoy adding color to your Ubuntu life :) |
12,313 | 如何在 Fedora 上生成 EPUB 电子书 | https://fedoramagazine.org/how-to-generate-an-epub-file-on-fedora/ | 2020-06-14T13:21:25 | [
"电子书"
] | https://linux.cn/article-12313-1.html | 
在智能手机上阅读内容正在变得越来越流行。每一部手机都有它自己的电子书阅读器。可能你不知道,在 Fedora 创建你自己的电子书文件是非常容易的。
这篇文章展示了使用两种不同的方法来创建一个 [EPUB](https://en.wikipedia.org/wiki/EPUB) 文件。EPUB 格式是最流行的格式之一,并且被很多开源软件所支持。
绝大数的人们将会询问 “在很容易创建 PDF 文件的情况下,为什么要花费时间和精力来创建 EPUB 文件?” 答案是: “你曾经尝试看过每次只能看到一张纸的一小部分的吗?”为阅读一个 PDF 文件,你不得不经常缩放和移动文档,或者将其缩放到一个小尺寸来适合屏幕大小。在另一方面,EPUB 文件则被设计成可以适合很多不同的屏幕类型。
### 方法 1: ghostwriter 和 pandoc
第一种方法创建一个速成版的电子书文件。它使用一个名为 [ghostwriter](https://github.com/wereturtle/ghostwriter) 的 Markdown 编辑器,和一个名为 [pandoc](https://pandoc.org/) 的命令行文档转换工具。
你可以从软件中心搜查和安装它们,也可以从终端中安装它们。如果你使用终端来安装它们,运行这个命令:
```
sudo dnf install pandoc ghostwriter
```
对于那些不知道 [Markdown](https://fedoramagazine.org/applications-for-writing-markdown/) 是什么的人们来说,在这里有一个简要的解释:它是一个大约在 15 年前创建的简单的标记语言。它使用简单的语法来格式化纯文本。Markdown 文件可以随后转换成很多其它文档格式的文件。

对于工具,ghostwriter 是一个跨平台的易于使用的 Markdown 编辑器。pandoc 是一个非常易于使用的文档转换工具,可以处理数百种不同的格式。
要创建你的电子书,打开 ghostwriter,开始编写你的文档。如果你以前使用过 Markdown,你可能习惯于在文档的“标题 1”的前面放置一个 `#` 符号来作为标题。像这样: `# My Man Jeeves`。然而,pandoc 将不会识别其为标题,并将在你的电子书的顶部放置一个一个大的 “UNTITLED” 。相反地在你的标题前放置一个 `%` 来作为标题。例如,`% My Man Jeeves` 。章节应该被格式为“标题 2”,例如,`## Leave It to Jeeves`。如果你有子章节,使用“标题 3”(`###`)。

在你的文档完成后,单击“文件 -> 导出”(或按 `Ctrl+E` 键)。在对话框中,在几个 Markdown 转换器中进行选择。如果这是你第一次使用 ghostwriter ,默认选择的是 Sundown 转换器。从对话框中,选择 pandoc 。接下来单击“导出”。现在你的 EPUB 文件已经创建好了。

注意: 如果你得到一个与 pandoc 有关的错误,关闭“智能排版”,并再试一次。
### 方法 2: calibre
如果你想要一个更完美的电子书,那这就是你正在寻找的方法。它需要更多的步骤,但是是值得的。

首先,安装一个名为 [calibre](https://calibre-ebook.com/) 的应用程序。calibre 不仅仅是一个电子书阅读器,它也是一个电子书管理器系统。你可以从软件中心安装它,也可以从终端安装它:
```
sudo dnf install calibre
```
在这个方法中,你可以在 LibreOffice、ghostwriter,或者其它你选择的编辑器中编写你的文档。确保书籍的标题被格式为“标题 1”,章节被格式为“标题 2”,子章节被格式为“标题 3”。
接下来,导出你的文档为一个 HTML 文件。
现在添加该文件到 calibre 。打开 calibre ,并单击 “添加书籍”。calibre 会用几秒钟来添加文件。

在文件导入后,通过单击 “编辑元数据” 按钮来编辑文件的元数据。在这里你可以填写书的标题和作者的姓名。你也可以上传一个封面图片(如果你有的话),或者 calibre 将为你生成一个封面。

接下来,单击 “转换书籍” 按钮。在新的对话框中,选择 “界面与外观” 部分的 “布局” 标签页。勾选 “删除段间空行” 选项。这将更加严格地缩进每一段的内容。

现在,设置目录。选择 “内容目录” 部分。这里有三个需要注意的选项: “一级目录”、“二级目录” 和 “三级目录”。对于每一个选项点击其末尾处的魔法棒按钮。在新的对话框中,选择应用于目录表项的 HTML 标记。例如,为“一级目录”选择 “h1”。

接下来,告诉 calibre 包含内容目录。选择 “输出 EPUB” 部分并勾选 “插入内联目录”。单击“确定“ 创建 epub 文件。

现在,你有了一个看起来很专业的电子书文件。
---
via: <https://fedoramagazine.org/how-to-generate-an-epub-file-on-fedora/>
作者:[John Paul Wohlscheid](https://fedoramagazine.org/author/johnblood/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It is becoming more popular to read content on smartphones. Every phone comes with its own ebook reader. Believe or not, it is very easy to create your own ebook files on Fedora.
This article shows two different methods to create an [EPUB](https://en.wikipedia.org/wiki/EPUB). The epub format is one of the most popular formats and is supported by many open-source applications.
Most people will ask “Why bother creating an EPUB file when PDFs are so easy to create?” The answer is: “Have you ever tried reading a sheet of paper when you can only see a small section at a time?” In order to read a PDF you have to keep zooming and moving around the document or scale it down to a small size to fit the screen. An EPUB file, on the other hand, is designed to fit many different screen types.
## Method 1: ghostwriter and pandoc
This first method creates a quick ebook file. It uses a Markdown editor named [ghostwriter](https://github.com/wereturtle/ghostwriter) and a command-line document conversion tool named [pandoc](https://pandoc.org/).
You can either search for them and install them from the Software Center or you can install them from the terminal. If you are going to use the terminal to install them, run this command: *sudo dnf install pandoc ghostwriter*.
For those who are not aware of what [Markdown](https://fedoramagazine.org/applications-for-writing-markdown/) is, here is a quick explanation. It is a simple markup language created a little over 15 years ago. It uses simple syntax to format plain text. Markdown files can then be converted to a whole slew of other document formats.
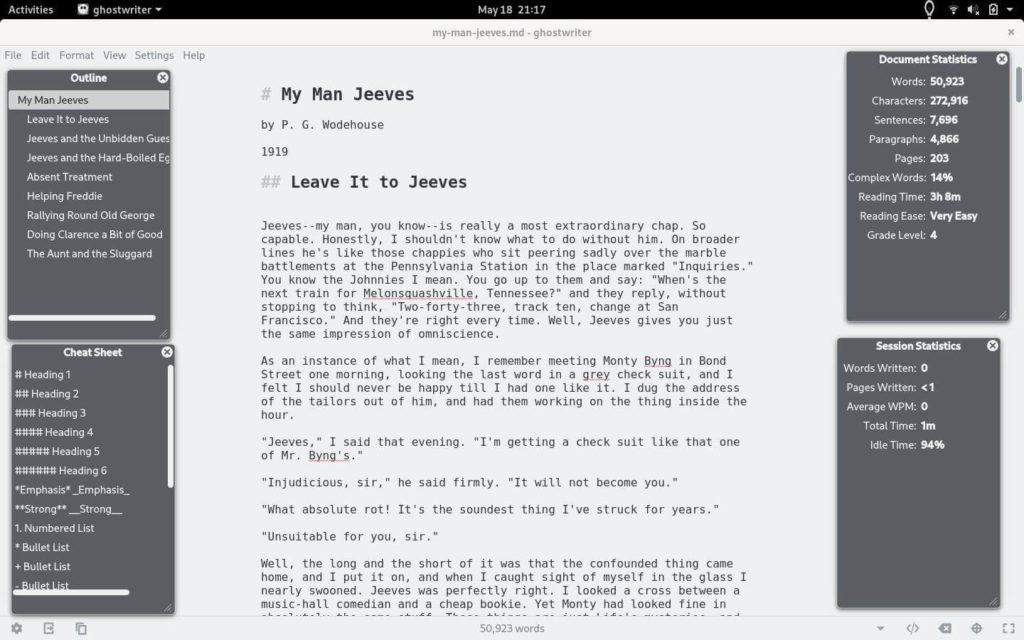
Now for the tools. ghostwriter is a cross-platform Markdown editor that is easy to use and does not get in the way. pandoc is a very handy document converting tool that can handle hundreds of different formats.
To create your ebook, open ghostwriter, and start writing your document. If you have used Markdown before, you may be used to making the title of your document Heading 1 by putting a pound sign in front of it. Like this: *# My Man Jeeves*. However, pandoc will not recognize that as the title and put a big UNTITLED at the top of your ebook. Instead put a *%* in front of your title. For example, *% My Man Jeeves*. Sections or chapters should be formatted as Heading 2, i.e.* ## Leave It to Jeeves*. If you have subsections, use Heading 3 (*###*).

Once your document is complete, click *File* -> *Export* (or press *Ctrl* + *E*). In the dialog box, select between several options for the Markdown converter. If this is the first time you have used ghostwriter, the Sundown converter will be picked by default. From the dialog box, select pandoc. Next click *Export*. Your EPUB file is now created.
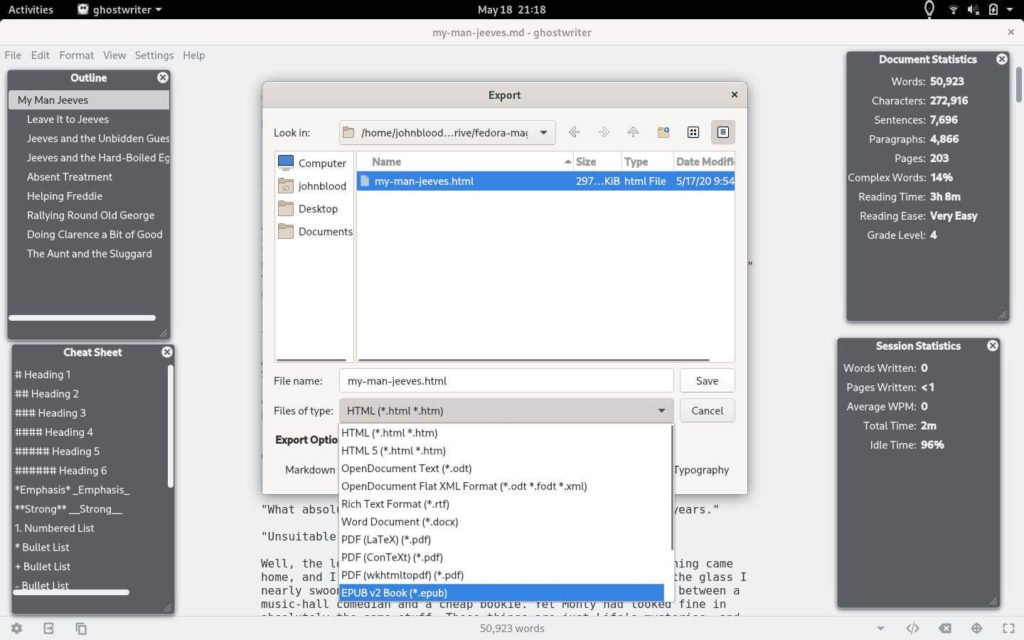
Note: If you get an error saying that there was an issue with pandoc, turn off *Smart Typography* and try again.
## Method 2: calibre
If you want a more polished ebook, this is the method that you are looking for. It takes a few more steps, but it’s worth it.
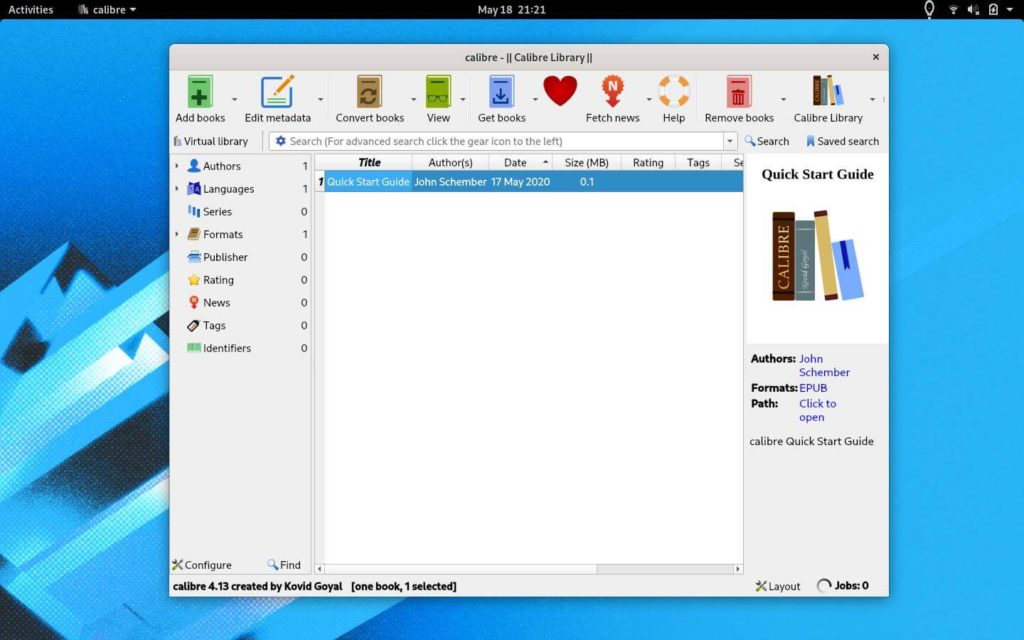
First, install an application named [calibre](https://calibre-ebook.com/). calibre is not just an ebook reader, it is an ebook management system. You can either install it from the Software Center or from the terminal via *sudo dnf install calibre*.
In this method, you can either write your document in LibreOffice, ghostwriter, or another editor of your choice. Make sure that the title of the book is formatted as Heading 1, chapters as Heading 2, and sub-sections as Heading 3.
Next, export your document as an HTML file.
Now add the file to calibre. Open calibre and click “*Add books*“. It will take calibre a couple of seconds to add the file.
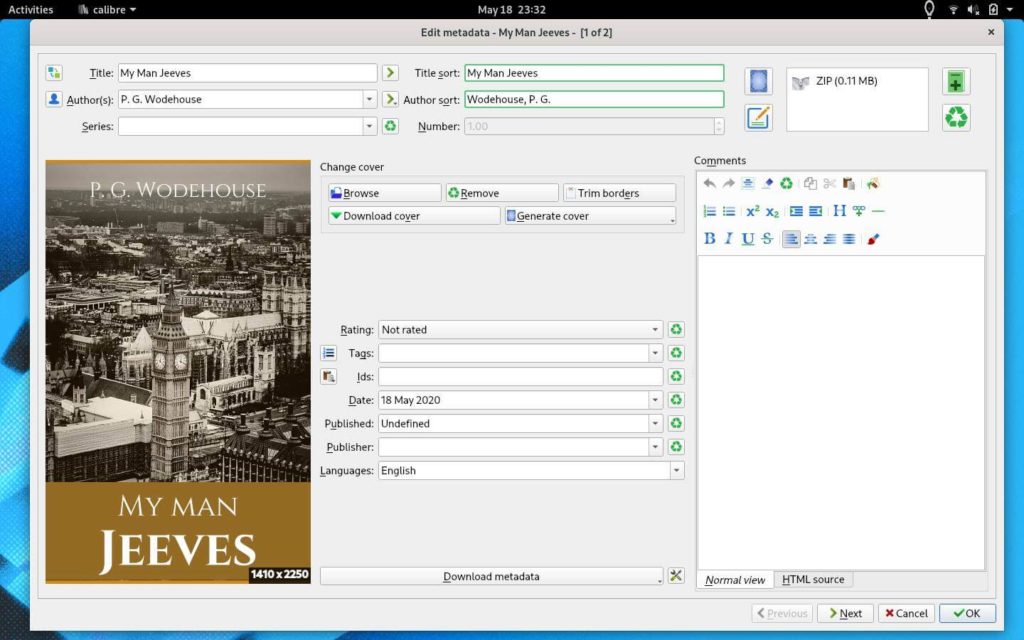
Once the file is imported, edit the file’s metadata by clicking on the “*Edit metadata*” button. Here you can fill out the title of the book and the author’s name. You can also upload a cover image (if you have one) or calibre will generate one for you.
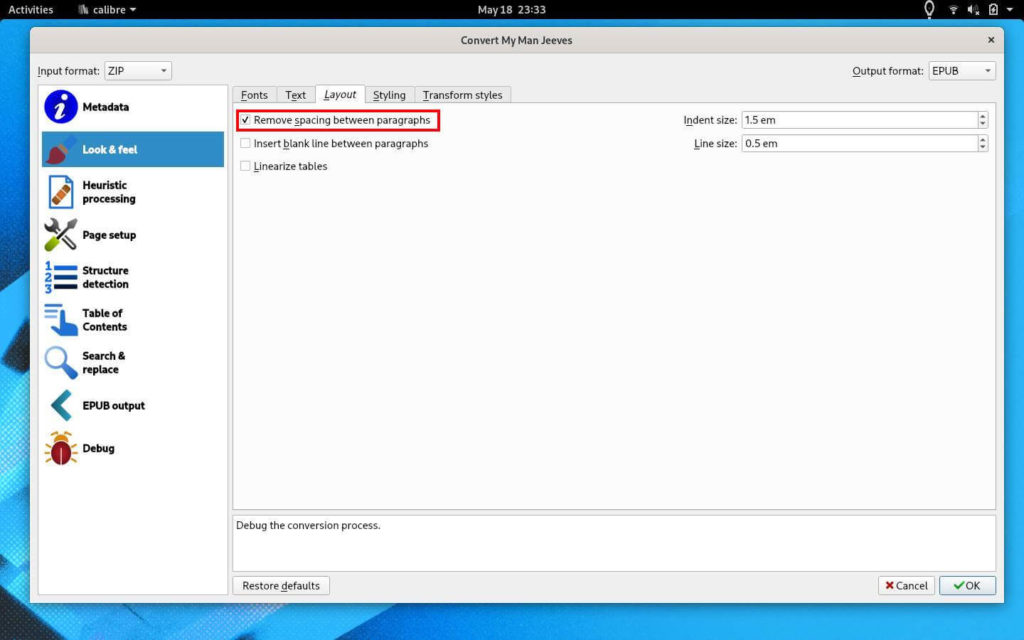
Next, click the “*Convert books*” button. In the new dialog box, select the “*Look & Feel*” section and the “*Layout*” tab. Check the “*Remove spacing between paragraphs*” option. This will tighten up the contents as indent each paragraph.
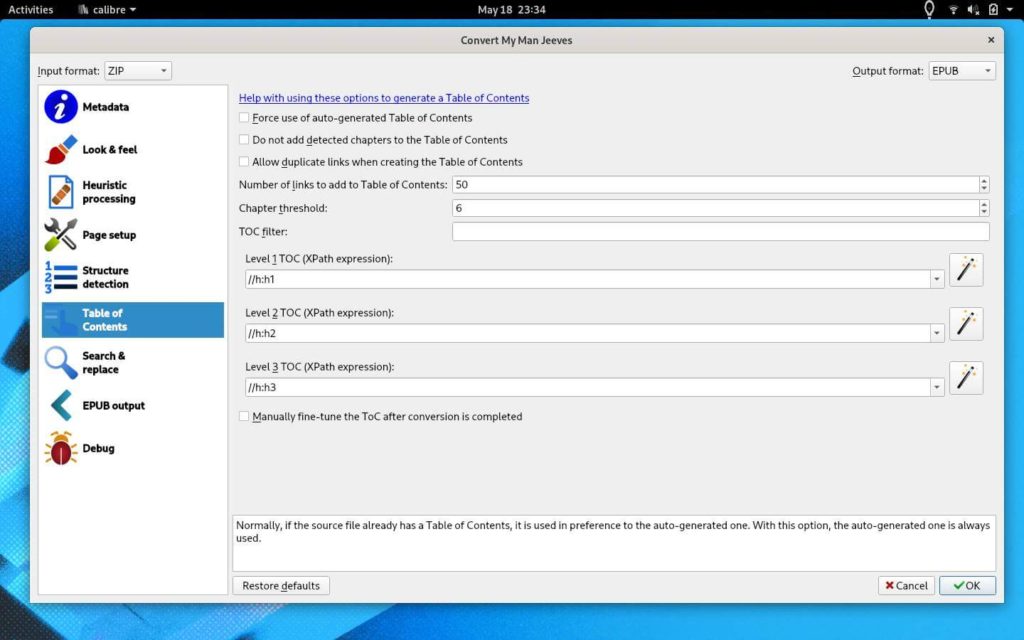
Now, set up the table of contents. Select the “*Table of Contents*” section. There are three options to focus on: Level 1 TOC, Level 2 TOC, and Level 3 TOC. For each, click the wand at the end. In this new dialog box, select the HTML tag that applies to the table of contents entry. For example, select *h1* for Level 1 TOC and so on.
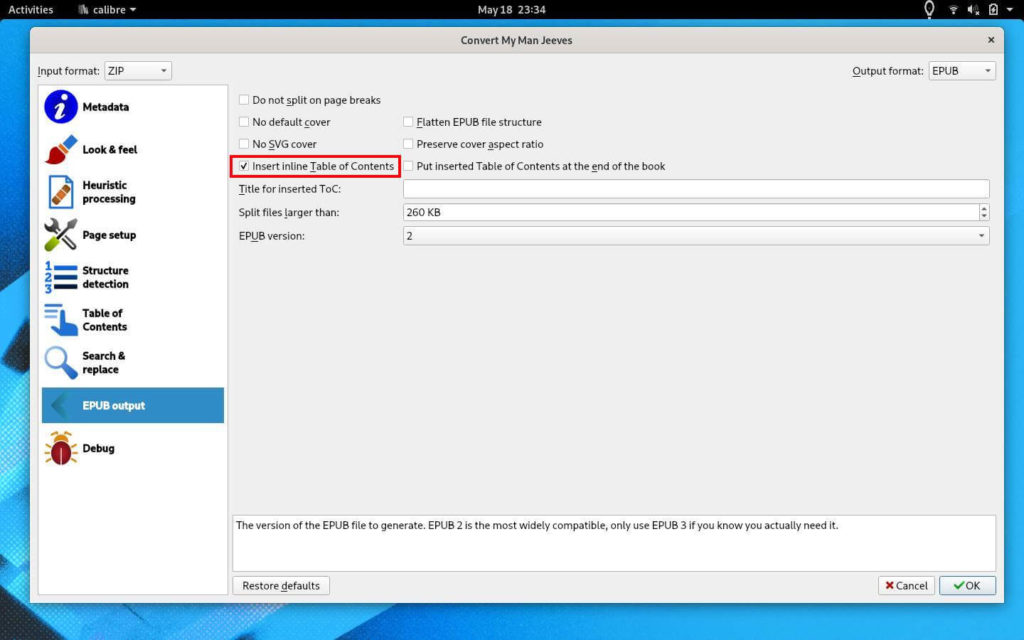
Next, tell calibre to include the table of contents. Select the “*EPUB output*” section and check the “*Insert Inline Table of Contents*“. To create the epub file, click “*OK*“.
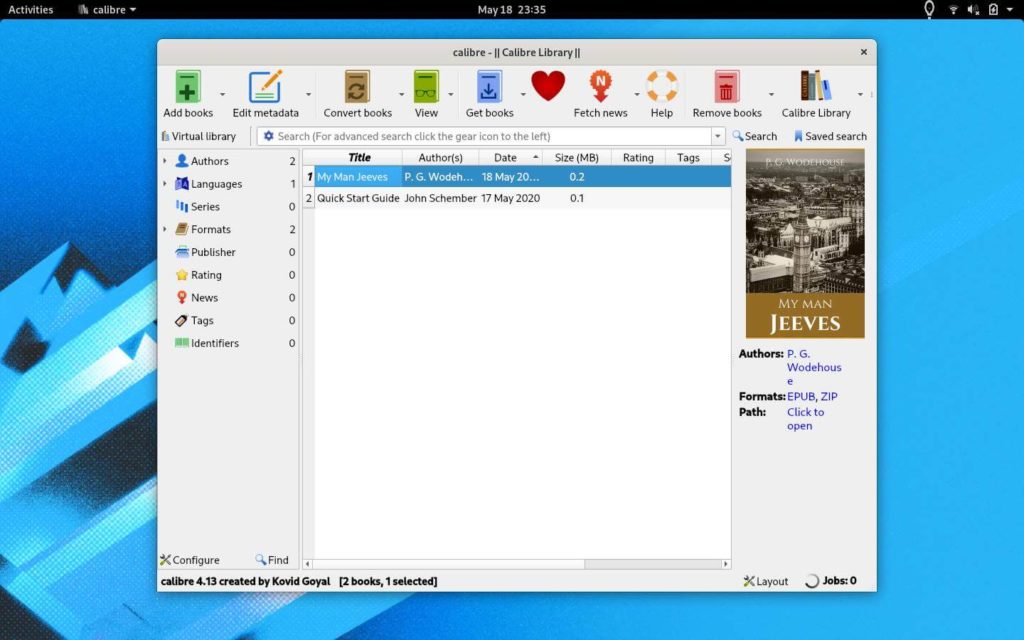
Now you have a professional-looking ebook file.
## Robert Keeney
There are a lot of command-line tools that come with Calibre one of these is ebook-convert.
## John Paul Wohlscheid
I was unaware of that. Thanks. I’ll look into it.
## dimwit
Cool, but where is the paragraph with some usage examples of the pandoc command line conversion tool?
Ok, as a seasoned Linux user I would study pandoc’s man page now.
## John Paul Wohlscheid
“where is the paragraph with some usage examples of the pandoc command line conversion tool?”
Unfortunately, I haven’t used pandoc from the command line. You don’t need to know those commands to make an epub file, but I’m sure it would help.
## Alper Orus
It’s simply $ pandoc -s -o output.docx file.md
## petersen
You can read the pandoc manual at https://pandoc.org/MANUAL.html or run
.
## Chris Moller
A more elaborate use of calibre, one I use in writing books, is to write the book using DocBook markups, an HTML-like schema.
DocBook sources can be spun in different ways, including directly to publication-quality PDF as well as to HTML, and then from there to EPUB using a CLI utility, called ebook-convert, that’s part of the calibre package. (I use a Makefile to run all that, so going from DocBook to EPUB is just a matter of pounding in “make epub” on the command line.)
The advantage of all this is that DocBook offers a lot of things like title page formatting, table-of-contents, bibliography, index, and glossary formatting, etc, and gives you access to most or all of the Unicode character set. You can also write the DocBook source using any text editor–I use emacs–that gives you a lot more control than WYSIWYG things like LibreOffice. (A plus of emacs is that you can customise it to, for example, have it insert things like pairs with a single keystroke.)
(DocBook is part of the “Authoring and Publishing” packages group.)
(Editor’s note: This comment was edited to remove artifacts of WordPress trying to treat the example as HTML)## John Paul Wohlscheid
I never heard of DocBook before. Thanks for mentioning it. I stopped using word processors about five years ago and now write exclusively in Markdown. I was writing in plain text, but I wanted to be able to add simple formating. I discovered Markdown and was hooked.
## John Paul Wohlscheid
Also, I’ve been meaning to get into the world of emacs, but haven’t had a chance to do so.
## Leslie Satenstein
My bit of fun for today.
This symbol # is called the octothorpe
and this one £ is the pound symbol.
I am not sure what to call ¤
And yes, I did find your article informative and I learned about
pandoc, ghostwriter and more.
Thanks
Leslie
## John Paul Wohlscheid
Thanks for setting me straight. I’ll fix it. By the way, was it named after a guy named Thorpe or a guy named Octo? 🙂
## leslie Satenstein
Hi John,
Actually, named after Thorpe. He was born missing the two pinky fingers from each hand.
No-one questioned him about his toes.
I also discovered that the ¤ on my Canadian French keyboard layout. I believe it represents currency, but the glyph has no name.
## Vernon Van Steenkist
In the Linux/Unix world, # is known as the pound, hash or number symbol – never the octothorpe symbol.
## Paul W. Frields
What Leslie means is that’s the actual name for the symbol itself. People also often call & an “and,” although the symbol is itself named the ampersand, because it’s clumsy to say “use ampersand ampersand for a logical AND” instead of “use ‘and and’ for a logical AND.” You’re right though, we usually refer to # as pound, hash, or number.
## robert pratersch
My E-Reader tolino doesnt work with linux/fedora. lsusb command list the device correctly but mounting did not work. So Fedora is unable to communicate with the device. What can i do?
## Ben Cotton
Robert, this sounds like a good question to post on Ask Fedora.
## Vernon Van Steenkist
What do you mean doesn’t work? Have you tried opening Calibre, connecting your tolino reader to your computer, and seeing if Calibre recognizes it?
## Rene Reichenbach
I am using Tolino shine 1 and 3 … both work flawless with fedora 32.
I fear your setup is slightly broken.
## Eduard Lucena
Quick fix: “Level 1 TOC, Level 3 TOC, and Level 3 TOC” should be “Level 1 TOC, Level 2 TOC, and Level 3 TOC”
## Ben Cotton
Fixed, thanks!
## Vernon Van Steenkist
A few comments.
Both LibreOffice and the web version of Google Docs, accessible through Firefox and Chromium will export into epub format directly. Not sure why you are exporting to HTML, importing into Calibre and then converting to epub.
Besides an epub editor, Calibre is also an e-book library. Epubs catalogued in the Calibre library can be transferred to an e-book reader by Calibre via USB. In addition, Calibre can act as a server. The Calibre Content Sharing button allows you to access your library through an HTML web browser (ex. http://fedorabox:8080) or an e-book reader supporting OPDS (ex. (ex. http://fedorabox:8080/opds). The Calibre server can be started through the menus or from the command line (calibre-server).
Reading e-books on your phone can cause eye problems since the screen is constantly refreshing and generating light. You are much better off reading e-books on an e-ink e-book reader. E-ink screens reflect light rather than emit light and the screen only refreshes when you turn the page. E-ink is like paper and will not wash out in direct sunlight. I personally use an Onyx Boox e-book reader model that supports WiFi and OPDS.
Finally, another way to generate epubs is to scan your paper book or printed page (scanimage), process the image with unpaper (unpaper) and then perform optical character recognition on the scanned image via tesseract. The resulting text file can be edited and converted into an epub via Calibre. You can also convert the scanned image to pdf using convert and then perform optical character recognition via the web version of Google Docs.
## John Paul Wohlscheid
Thanks for the input. I haven’t used LibreOffice or Google Docs in a while.
## Sergey
https://the-digital-reader.com/2018/02/01/libre-office-6-0-now-makes-epub-ebooks/
## Anthony
I have experimented with asciidoc, and with asciidoctor, using the output as html. Alternatively, if I specify the output as docbook, I can then use pandoc to send it to many different formats, such as epub, docx, or latex. Where I need precise PDF output, I’ve found writing latex the best method. I’ve wondered how to go from docbook to customised html (i.e. themed), but couldn’t wrap my head around xslt/saxon or whatever the mechanisms were to achieve that.
## John Paul Wohlscheid
I have experimented with LaTex, but it has more features than I need. I’ll have to look into asciidoc.
## Stefano Costa
LibreOffice Writer can export to EPUB as well. It’s perhaps a little less flexible than the tools described above but it is much more accessible. On my Fedora Workstation it’s in the “File – Export as …” menu.
## John Paul Wohlscheid
Cool. Thanks.
## Morten Juhl-Johansen Zölde-Fejér
I would write a piece on the excellent Sigil application, but I see that Fedora carries a rather older version of it.
## Marc Balmer
There is also AsciiDoctor, asciidoctor.org, which produces beautiful e-books in .epub format. |
12,314 | 6 个开源的奇妙清单(Wunderlist)替代品 | https://opensource.com/article/20/5/alternatives-list | 2020-06-14T14:28:00 | [
"清单"
] | https://linux.cn/article-12314-1.html |
>
> 喜欢列表?看看这个便捷的开源应用程序列表,以管理你所有的列表!
>
>
>

奇妙清单(Wunderlist)是一款清单应用,受到很多人的喜爱,但从 2020 年 5 月 6 日起,它就永远停止了。它的网站鼓励现有用户下载并使用“微软待办”来代替它。这很诱人,因为它可以轻松导入你多年来制作的所有这些列表。不过话又说回来,也许这是个机会,可以“近藤麻理惠”一下这些列表,并削减一些事务。(你真的需要 30 个列表吗?很显然,我觉得我需要,所以我不做评判。)
我有各种各样的清单,从“2020 年花园的植物”到“给丈夫的礼物”。有些是清单,有些是待办事项清单,有些是为了清单而清单。
对我和我丈夫来说,最有用的清单是我们共享的杂货清单。我们都有手机上的应用程序,我们都把东西添加到列表中,但在他去购物之前,我们分别在手机上审查它(是的,你没看错),他把东西放进购物车时,他就会勾掉它。这让整个过程变得出奇的高效,我想我们节省了一些钱,因为我们喜欢坚持按清单购物。
虽然奇妙清单的用户很喜欢它,但它并不是完全独一无二的。还有无数的列表应用。对于奇妙清单,我特别喜欢它将简洁性和设计感结合在一起,而且它成功实现了一些有用的功能,比如与他人分享和协作,列表的动态复选框,以及在移动和网页界面上的良好用户体验。我也很喜欢用它来做一个不“活跃”文档的列表:一个我不会每周都回顾或定期进展的列表,就像我用来进行头脑风暴的许多列表一样(包括我一直想写的小说...)。
从这些年来我们发表的许多精彩文章中,我整理了一系列奇妙清单的开源替代方案,从简单的任务管理和待办事项清单到复杂的笔记记录和流程管理,这些列表工具可能会满足你的需求。或者,如果你是那个在丢得到处都是的纸条和便签上书写任务和备注的人,这可能是尝试这些数字工具之一的好时机。
### Tasks:可与 OwnCloud 配合
Tasks 是一款自由开源的应用,你可以从 [F-droid](https://f-droid.org/en/packages/org.tasks/) 安装。Tasks 是一款只适用于手机的应用,但它可以同步到各种地方,非常灵活。你可以将你的列表保存到 NextCloud 或 OwnCloud、Google Tasks、Apple Reminders 以及几乎所有你有账户的 CalDAV 服务器上。
Tasks 的默认视图是每日视图,所以你输入的任何任务都被假定为从今天开始的任务。如果你像我一样,想维护几个不同的列表,你可以用标签来实现。当你创建一个标签时,你就为任务创建了一个类别。你可以为它指定一种颜色和一个图标,这样每个任务列表都是独一无二的。
这需要一点时间来适应,但标签有很多优点。因为所有的任务都是有标签的,你可以通过点击你想过滤的标签来查看任务组,但你也可以按天甚至按地点过滤。这意味着,当你去采购杂货时,你的杂货列表会成为活跃的默认列表,而当你回到家时,你的日常生活列表又会成为活跃的列表。
通过将你的数据同步到你的一个在线账户,你可以与亲人、合作者和同事分享列表。
另一个伟大的功能是,如果你每天早上上班时都有相同的任务,或者每周杂货清单中有 20 个相同的项目,你可以创建定期重复的任务。
评测者:Seth Kenlon

### OpenTasks:适于长列表
[OpenTasks](https://play.google.com/store/apps/details?id=org.dmfs.tasks) 是一款优秀的任务管理工具,可以创建带有各种设置的个人任务。它在创建任务时支持多种字段,从基本的东西,如名称和描述,到更复杂的项目,如选择任务是私人、公共还是机密。OpenTasks 与其他替代品最大的不同之处在于它在应用的主屏幕上使用了选项卡。这些选项卡可以让你快速看到到期的任务、即将开始的任务、按优先级排序的任务,以及按当前完成进度排序的任务。许多其他应用程序支持做这样的事情,但 OpenTasks 很快就能轻松访问这些列表。
[阅读完整的 OpenTasks 评测](https://opensource.com/article/17/1/task-management-time-tracking-android),作者:Joshua Allen Holm。

### Mirakel:嵌套列表的绝佳之选
[Mirakel](https://mirakel.azapps.de/) 是一款任务管理应用,它拥有现代化的用户界面,并支持你在这样一款程序中可能想要的几乎所有格式。Mirakel 在基础层面上支持多个被称为“元列表”的列表。创建一个单独的任务有大量的选项,有截止日期、提醒、进度跟踪、标签、备注、子任务和文件附件,所有这些都构成了任务条目的一部分。
[阅读完整的 Mirakel 评测](https://opensource.com/article/17/1/task-management-time-tracking-android),作者:Joshua Allen Holm。

### Todo:简单有效,随处可用
[Todo.txt](http://todotxt.org/) 是我不断反复推荐的两个待办事项和任务管理应用之一(另一个是 Org 模式)。而让我不断推荐的原因是,它简单、便携、易懂,而且有很多很棒的附加组件,即使一台机器有这个程序而其他机器上没有,也不会破坏它。而且由于它是一个 Bash shell 脚本,我从来没有发现不支持它的系统。阅读更多关于[如何安装和使用 Todo.txt](/article-11835-1.html)。
[阅读完整的 todo.txt 评测](/article-11835-1.html),作者:Kevin Sonney。

### Joplin:最佳私人列表
[Joplin](https://joplin.cozic.net/) 是一个 NodeJS 应用程序,它可以在本地运行和存储信息,允许你加密任务,并支持多种同步方法。Joplin 可以作为控制台或图形应用程序在 Windows、Mac 和 Linux 上运行。Joplin 还拥有 Android 和 iOS 的移动应用,这意味着你的笔记随处可用,而不需要大费周章。Joplin 甚至允许你用 Markdown、HTML 或纯文本来格式化你的笔记。
[阅读完整的 Joplin 评测](/article-10476-1.html),作者:Kevin Sonney。

### CherryTree:最好的 Evernote / OneNote / Keep 替代品
[CherryTree](https://www.giuspen.com/cherrytree/) 是一个 GPLv3 许可的应用程序,它以节点的形式组织信息。每个节点都可以有子节点,让你轻松组织你的列表和思想。而且,子节点可以有自己的子节点,具有独立的属性。
[阅读完整的 CherryTree 评测](https://opensource.com/article/19/5/cherrytree-notetaking),作者:Ben Cotton。

### 附赠:Wekan,给看板粉丝
<ruby> 看板 <rt> kanban </rt></ruby>是当今敏捷流程的主流。我们中的许多人(包括我自己)不仅用它们来组织我们的工作,还用它们来组织我们的个人生活。我认识一些艺术家,他们使用 Trello 这样的应用程序来跟踪他们的委托清单,以及正在进行和已经完成的工作。但这些应用往往与工作账户或商业服务挂钩。让我们看看 [Wekan](https://wekan.github.io/),这是一个开源的看板,你可以在本地或你选择的服务上运行。Wekan 提供了与其他看板应用相同的功能,比如创建面板、列表、泳道和卡片,在列表之间拖放,分配给用户,给卡片贴标签,以及做几乎所有你在现代看板中期待的事情。
[阅读完整的 Wekan 评测](/article-10454-1.html),作者:Kevin Sonney。

---
via: <https://opensource.com/article/20/5/alternatives-list>
作者:[Jen Wike Huger](https://opensource.com/users/jen-wike) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Wunderlist is an app for lists, loved by many, but gone for good as of May 6, 2020. The website encourages existing users to download and use Microsoft To Do in its place. That's tempting because it makes it easy to import all of those lists you've made over the years. Then again, maybe it's a chance to *Marie Kondo *those lists and pare things down. Do you really need 30 lists? (Apparently, I've decided that I do, so I won't judge.)
I have lists for all sorts of things, from "Plants for the garden 2020" to "Gifts for the husband." Some are checklists, some are To Do lists, and some are lists for list's sake.
For my husband and me, the most useful list is our shared grocery list. We both have the app on our phones, we both add things to the list, we review it together but separately on our phones before he goes shopping (yes, you read that correctly), and he checks things off as he puts them in the cart. It makes the whole thing surprisingly efficient, and I think we save some money because we're into sticking to THE LIST.
While its users loved it, Wunderlist isn't entirely unique. There are a gazillion list apps out there. With Wunderlist, I've specifically enjoyed its combination of simplicity and design, and that it managed to implement useful features like sharing and collaboration with others, dynamics checkboxes for lists, and a great user experience across both mobile and web interfaces. I've also enjoyed using it for a list that isn't an "active" document: a list I don't review weekly or make regular progress on—like my many lists I've used for brainstorming an idea (including that novel I've been meaning to write...).
From the many wonderful articles we've published over the years, I've curated a list of open source alternatives to Wunderlist that may work for your needs, from simple task management and to-do lists to complex note-taking and process management. Or, if you are that person scribbling tasks and notes on paper scraps and post-it notes that are lying... er, around somewhere and everywhere... this might be a good time to try one of these digital options out.
## Tasks—works with OwnCloud
Tasks is a free and open source app you can install from
[F-droid]. Tasks is a mobile-only application, but it's extremely flexible in what it can sync to. You can save your lists to NextCloud or OwnCloud, Google Tasks, Apple Reminders, and just about any CalDAV server you have an account on.The default view of Tasks is a daily view, so any task you enter is assumed to be a task from today onward. If you're like me and you want to maintain several unique lists, you can do that with Tags. When you create a tag, you create a category for tasks. You can assign a colour and an icon so each list of tasks is unique.
It takes a little getting used to, but tagging has many advantages. Because all tasks are tagged, you can view groups of tasks by clicking the tag you want to filter for, but you can also filter by day and even by place. That means that when you go grocery shopping, your grocery list becomes the active default list, and your everyday life list becomes active again when you return home.
By syncing your data to one of your online accounts, you can share lists with loved ones, collaborators, and colleagues.
Another great feature is that if you the same tasks every morning when you get to work, or the same 20 items in your weekly grocery list, you can create tasks that repeat on a regular basis.
Reviewed by Seth Kenlon
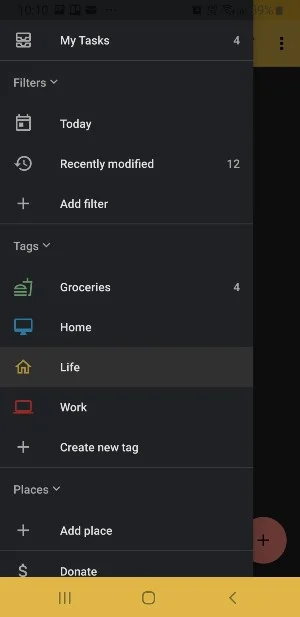
## OpenTasks—best for long lists
[OpenTasks]is an excellent task management tool for creating individual tasks with a wide variety of settings. It supports a wide range of fields when creating a task, ranging from basic things, such as name and description, to more complex items, such as choosing if the task is private, public, or confidential. The biggest thing that sets OpenTasks apart from the alternatives is its use of tabs on the app's main screen. These tabs quickly allow you to see the tasks due, tasks starting soon, tasks sorted by priority, and tasks sorted by current progress towards completion. Many of the other apps support doing things like these, but OpenTasks quickly easily accesses these lists.
[Read the full OpenTasks review](https://opensource.com/article/17/1/task-management-time-tracking-android) by Joshua Allen Holm
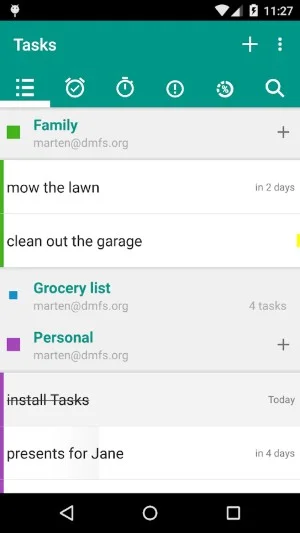
## Mirakel—great for nested lists
[Mirakel]is a task management app with a modern user interface and support for just about every format you might want in such a program. At Mirakel's basic level, it supports multiple lists, which are referred to as "meta lists." Creating an individual task has a plethora of options with deadlines, reminders, progress tracking, tags, notes, sub-tasks, and file attachments, all comprising a part of a task's entry.
[Read the full Mirakel review](https://opensource.com/article/17/1/task-management-time-tracking-android) by Joshua Allen Holm
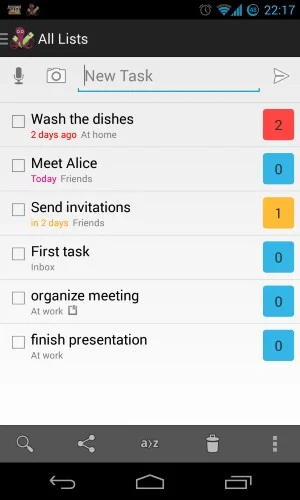
## Todo—simple and effective, works anywhere
[Todo.txt]is one of the two to-do list and task management apps that I keep coming back to over and over again (the other is Org mode). And what keeps me coming back is that it is simple, portable, understandable, and has many great add-ons that don't break it if one machine has them and the others don't. And since it is a Bash shell script, I have never found a system that cannot support it. Read more about[how to install and use Todo.txt].
[Read the full todo.txt review](https://opensource.com/article/20/1/open-source-to-do-list) by Kevin Sonney
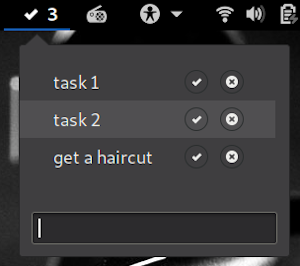
## Joplin—best for private lists
[Joplin]is a NodeJS application that runs and stores information locally, allows you to encrypt your tasks and supports multiple sync methods. Joplin can run as a console or graphical application on Windows, Mac, and Linux. Joplin also has mobile apps for Android and iOS, meaning you can take your notes with you without a major hassle. Joplin even allows you to format your notes with Markdown, HTML, or plain text.
[Read the full Joplin review](https://opensource.com/article/19/1/productivity-tool-joplin) by Kevin Sonney
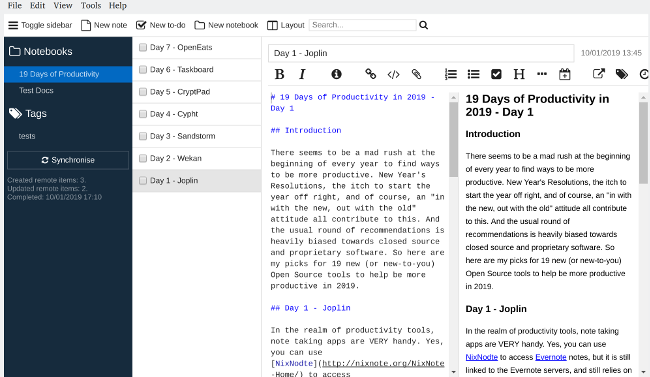
## CherryTree—great alternative to Evernote / OneNote / Keep
[CherryTree]is a GPLv3-licensed application that organizes information in nodes. Each node can have child nodes, allowing you to easily organize your lists and thoughts. And, child nodes can have their own children with independent properties.
[Read the full CherryTree review](https://opensource.com/article/19/5/cherrytree-notetaking) by Ben Cotton
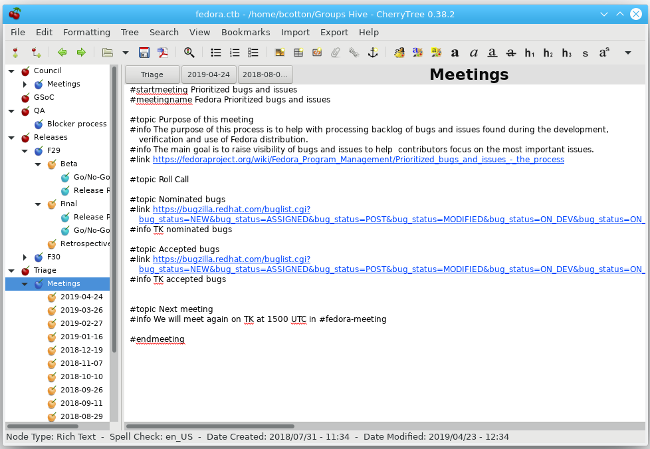
## Bonus: Wekan—for fans of Kanban
Kanban boards are a mainstay of today's agile processes. And many of us (myself included) use them to organize not just our work but also our personal lives. I know several artists who use apps like Trello to keep track of their commission lists as well as what's in progress and what's complete. But these apps are often linked to a work account or a commercial service. Enter
[Wekan], an open source kanban board you can run locally or on the service of your choice. Wekan offers much of the same functionality as other Kanban apps, such as creating boards, lists, swimlanes, and cards, dragging and dropping between lists, assigning to users, labeling cards, and doing pretty much everything else you'd expect in a modern kanban board.
[Read the full Wekan review](https://opensource.com/article/19/1/productivity-tool-wekan)* by Kevin Sonney*
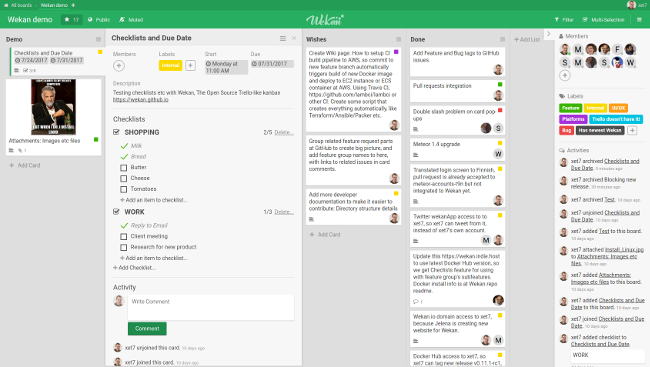
## 10 Comments |
12,316 | Ubuntu Remix Cinnamon 20.04 评测:Ubuntu 与 Cinnamon 的完美融合 | https://itsfoss.com/ubuntu-cinnamon-remix-review/ | 2020-06-15T11:32:49 | [
"Cinnamon",
"Ubuntu"
] | https://linux.cn/article-12316-1.html | 
推出于 2011 年的 GNOME 3,其 GNOME Shell 迎来了社区的赞扬的同时,也招致了一些人的反对。很多用户和开发者都很喜欢原来的 GNOME 界面,以至于有几个小组复刻了它,其中的一个小组 —— Linux Mint 团队创建了 [Cinnamon 桌面环境](https://en.wikipedia.org/wiki/Cinnamon_(desktop_environment))。
Cinnamon 桌面成为了 Linux Mint 的标志型产品。多年来,Cinnamon 一直是 [Linux Mint](https://www.linuxmint.com/) 的代名词。在过去的几年里,随着 Cinnamon 的普及,这种情况略有改变。现在其他发行版也开始提供 Cinnamon 桌面环境,[Manjaro](https://manjaro.org/) 就是这样一个例子。
几个月前,我们向大家介绍了一个[新 Ubuntu 变体](https://itsfoss.com/ubuntudde/),它提供了开箱即用的 Cinnamon 桌面体验,今天就让我们来深入了解一下 [Ubuntu Cinnamon Remix](https://ubuntucinnamon.org/)。
### 为什么是 Ubuntu Cinnamon Remix 而不是 Linux Mint?
的确,Linux Mint 是基于 Ubuntu 的,很多 Linux Mint 的用户都会有这样的疑问:既然 Linux Mint 已经如此成熟,而且用户体验也大致相同,那么换成 Ubuntu 有什么意义吗?
Ubuntu Cinnamon Remix 与 Linux Mint 有很多小的区别,但有一个关键的区别是 Linux 爱好者不能忽视的。
Linux Mint 是基于 “LTS”(长期支持)版本的 Ubuntu,这意味着它一直落后于 Canonical 的 6 个月的更新节奏。Ubuntu Cinnamon Remix 则可以得益于较新的内核以及其他 6 个月周期内的功能升级和较新的软件。
另一个关键的区别是,Ubuntu Cinnamon Remix 将 “继承” [Snap 支持](https://snapcraft.io/),而 Linux Mint 则拥抱 [FlatPak](https://flatpak.org/)。Ubuntu Cinnamon Remix 使用 Ubuntu 软件中心而不是 Mint 软件管理器。
我是 Cinnamon 的忠实粉丝,所以我选择了评测这款 Ubuntu 和 Cinnamon 的混合版,在这里我分享一下我的体验。
### 体验 Ubuntu Cinnamon Remix
只要有机会,我总会提到 [Calamares 安装程序](https://calamares.io/)有多快,感谢 Ubuntu Cinnamon Remix 团队如此选择。

新安装的 Ubuntu Cinnamon Remix 会消耗大约 750 MB 的内存。这与 Linux Mint Cinnamon 非常相似。

美丽的 [Kimmo 主题](https://github.com/Ubuntu-Cinnamon-Remix/kimmo-gtk-theme)和橙色调的 Ubuntu 壁纸也给我留下了深刻的印象,看来这是一个非常细致的努力的结果。

#### 足够让你开始的工具
和其他 Ubuntu 发行版一样,Ubuntu Cinnamon Remix 也包含了一些重要的生产力工具,下面是其中一些:
* 火狐浏览器
* Thunderbird - 电子邮件客户端
* LibreOffice套件
* Celluloid - 多媒体播放器
* [GIMP](https://itsfoss.com/gimp-2-10-release/) - 图像处理软件
* Synaptic 软件包管理器
* Gnome 软件中心
* [Gparted](https://itsfoss.com/gparted/) - 分区管理器
使用 Ubuntu Cinnamon Remix 作为我的主要平台已经有几天了,它满足了我的高期望。Ubuntu 稳定如磐石,速度非常快,在日常工作中我没有遇到任何问题。
#### 给 Linux Mint 爱好者的 Ubuntu
你是否热衷于 Ubuntu Cinnamon,却习惯了 Linux Mint 主题?点击下面的内容,看看如何获得一个完整的 Linux Mint 主题包,以及如何配置它来保持 Ubuntu 的传统。
给 Ubuntu Cinnamon Remix 以真正的 Mint 感受:
首先你必须下载并解压以下内容,通过终端很容易完成。
获取 Linux Mint-X 图标包:
```
wget http://packages.linuxmint.com/pool/main/m/mint-x-icons/mint-x-icons_1.5.5_all.deb
```
获取 Linux Mint-Y 图标包:
```
wget http://packages.linuxmint.com/pool/main/m/mint-y-icons/mint-y-icons_1.3.9_all.deb
```
获取 Linux Mint 主题:
```
wget http://packages.linuxmint.com/pool/main/m/mint-themes/mint-themes_1.8.4_all.deb
```
安装下载的软件包:
```
sudo dpkg -i ./mint-x-icons_1.5.5_all.deb ./mint-y-icons_1.3.9_all.deb ./mint-themes_1.8.4_all.deb
```
完成后,点击左下角的菜单按钮,输入 “themes”。你也可以在系统设置中找到“主题”功能。

打开后更换 kimmo 图标和主题,如下图所示。Linux Mint 默认的“绿色”是普通的 Mint-Y,而橙色是 Ubuntu 的最佳选择。

#### 为 Cinnamon 迷们准备的美食
让我们承认吧,审美很重要。Cinnamon 拥有简洁优雅的外观、易于阅读的字体和漂亮的色彩对比主题。Cinnamon 提供了一个整洁的桌面,只需进入系统设置下的桌面菜单,即可轻松配置桌面图标。你也可以选择桌面图标只显示在主显示器上、只显示在副显示器上,或者同时显示在两个显示器上。这也适用于超过两台显示器的设置。

桌面组件和小程序是一种小型的、单一用途的应用程序,可以分别添加到你的桌面或面板上。在众多的应用程序中,最常用的是 CPU 或资源监控器、天气小程序、便签和日历。
Cinnamon 控制中心集中提供许多桌面配置选项。通过访问 “主题” 部分,你可以选择桌面基本方案和图标、窗口边框、鼠标指针和控件外观。字体对桌面的整体外观有很大的影响,而 Cinnamon 让改变字体比以往任何时候都要容易。
Cinnamon 控制中心配置对新用户来说也足够简单,相比之下,KDE Plasma 会因为大量的配置选项而导致新用户感到困惑。

Cinnamon 面板包含用于启动程序的菜单、基本的系统托盘和应用程序选择器。面板的配置很简单,添加新的程序启动器只需在主菜单中找到你要添加的程序,右击图标,选择 “添加到面板” 即可。你也可以将启动程序图标添加到桌面,以及 Cinnamon 的 “收藏夹” 启动栏中。如果你不喜欢面板上图标的顺序,只需在面板栏上点击右键,进入面板的 “编辑” 模式,重新排列图标即可。
### 结论
无论你是决定给你的桌面 “加点料”,还是考虑从 [Windows 迁移到 Linux](https://itsfoss.com/windows-like-linux-distributions/),Cinnamon 社区都为你制作了大量的香料。
传统而又优雅,可定制而又简单,Ubuntu Cinnamon Remix 是一个有趣的项目,前途无量,对于喜欢 Ubuntu 的 Cinnamon 桌面爱好者来说,这可能是一个不二之选。
你觉得 Ubuntu Cinnamon Remix 怎么样?你已经使用过它了吗?
---
via: <https://itsfoss.com/ubuntu-cinnamon-remix-review/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | GNOME 3 was introduced in 2011, and the GNOME Shell immediately generated both positive and negative responses. Many users and developers liked the original GNOME interface enough that a few groups forked it and one of those, Linux Mint team, created the [Cinnamon desktop environment](https://en.wikipedia.org/wiki/Cinnamon_(desktop_environment)).
The Cinnamon desktop became the identity of Linux Mint. For years, Cinnamon has been synonymous to [Linux Mint](https://www.linuxmint.com/). It has changed slightly in the past few years as the popularity for Cinnamon grew. Now other distributions have also started offering Cinnamon desktop environment. [Manjaro](https://manjaro.org/) is one such example.
A few months back, we introduced you to a [new Ubuntu flavor that provides an out of the box Cinnamon desktop experience](https://itsfoss.com/ubuntudde/). let’s take a deeper look at [Ubuntu Cinnamon Remix](https://ubuntucinnamon.org/) today.
## Why Ubuntu Cinnamon Remix and not Linux Mint?
It is true that Linux Mint is based on Ubuntu. It is also true that you can [install Cinnamon desktop on Ubuntu](https://itsfoss.com/install-cinnamon-on-ubuntu/).
And Many Linux Mint users will have the question: Does it make any sense to switch over to Ubuntu as Linux Mint is such a mature project and the user experience will remain more or less the same?
Ubuntu Cinnamon Remix has a number of small differences from Linux Mint, but has has one key difference that a Linux enthusiast can’t ignore.
Linux Mint is based on “LTS” (Long-Term Support) versions of Ubuntu, meaning it stays behind the Canonical’s 6-month update cadence. Ubuntu Cinnamon Remix benefits from a newer kernel to other 6-month cycle feature upgrade and more recent software.
Another key difference is that Ubuntu Cinnamon Remix will “inherit” [Snap support](https://snapcraft.io/), and Linux Mint embraces [FlatPak](https://flatpak.org/). Ubuntu Cinnamon Remix uses Ubuntu Software Center instead of Mint Software Manager.
That said, I am a huge fan of Cinnamon. So I chose to review this mix of Ubuntu and Cinnamon and here I share my experience with it.
## Experiencing Ubuntu Cinnamon Remix
By any chance given, I will always mention how fast [Calamares installer](https://calamares.io/) is and thanks to Ubuntu Cinnamon Remix Team for choosing so.
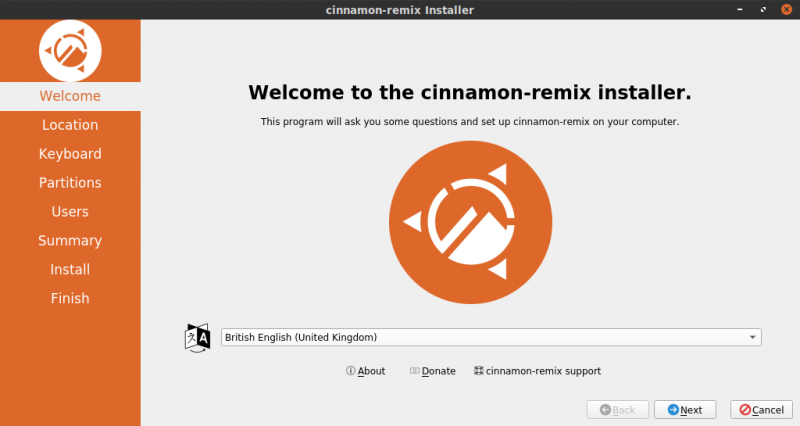
A fresh installation of Ubuntu Cinnamon Remix consumes approximately 750 MB of RAM. This is very similar to Linux Mint Cinnamon.
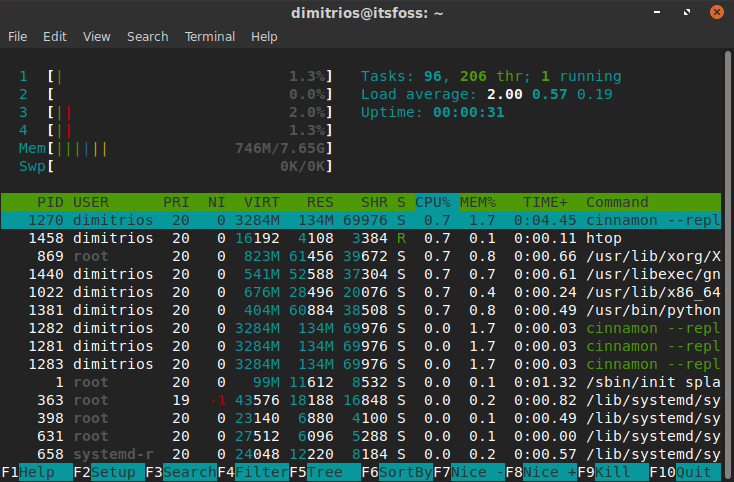
I was also impressed by the beautiful [Kimmo theme](https://github.com/Ubuntu-Cinnamon-Remix/kimmo-gtk-theme) and the orange toned Ubuntu wallpaper which seems to be a result of a very meticulous effort.
### Enough tools to get you started
As with any other Ubuntu distribution, Ubuntu Cinnamon Remix is packed with the essential productivity tools, to name a few:
- Firefox Web Browser
- Thunderbird – Email Client
- LibreOffice suite
- Celluloid – Multimedia player
[GIMP](https://itsfoss.com/gimp-2-10-release/)– Image processing software- Synaptic Package Manager
- Gnome Software Center
[Gparted](https://itsfoss.com/gparted/)– Partition Manager
Using Ubuntu Cinnamon Remix as my main runner for a few days, fulfilled my high expectations. Ubuntu is rock-solid stable, very fast and I didn’t face a single issue at my day to day tasks.
### Ubuntu for Linux Mint Lovers
Are you enthusiastic about Ubuntu Cinnamon but got used to Linux Mint theme? Click below to see how you can get a full Linux Mint theme pack and how to configure it to keep the Ubuntu heritage.
## Give Ubuntu Cinnamon Remix the real Mint touch
Firstly you have to download and unpack the following, easily done via terminal.
**Get the Linux Mint-X icon pack**
`wget http://packages.linuxmint.com/pool/main/m/mint-x-icons/mint-x-icons_1.5.5_all.deb`
**Get the Linux Mint-Y icon pack**
`wget http://packages.linuxmint.com/pool/main/m/mint-y-icons/mint-y-icons_1.3.9_all.deb`
**Get the Linux Mint Themes**
`wget http://packages.linuxmint.com/pool/main/m/mint-themes/mint-themes_1.8.4_all.deb`
**Install the downloaded content**
`sudo dpkg -i ./mint-x-icons_1.5.5_all.deb ./mint-y-icons_1.3.9_all.deb ./mint-themes_1.8.4_all.deb`
When done, click on the Menu button at the bottom left corner and type themes. You can also find themes in system settings.
Once opened replace the kimmo icons and theme as shown below. The Linux Mint default “Green” is the plain Mint-Y but the orange colour is a perfect selection for Ubuntu.
### A treat for Cinnamon fans
Let’s accept it, aesthetics are important. Cinnamon has a clean and elegant look, easy to read fonts and nice colour contrast themes. Cinnamon offers an uncluttered desktop with easily configured desktop icons simply by accessing the Desktop menu under System Settings. You can also choose the desktop icons to be shown only on the primary monitor, only on secondary monitor, or on both. This also applies to a beyond two monitor setup.
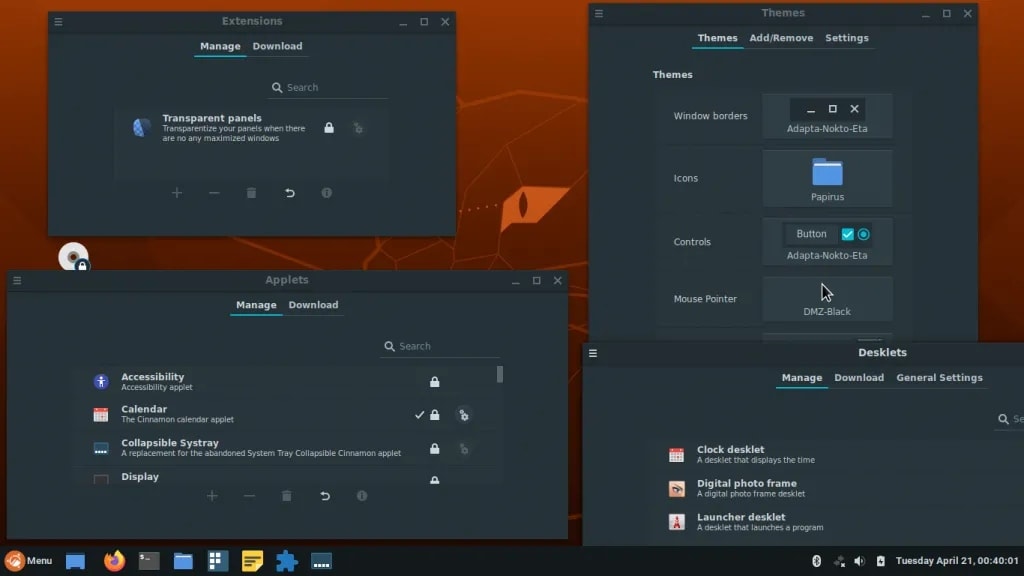
Desklets and applets are small, single-purpose applications that can be added to your desktop or your panel respectively. The most commonly used among the many you can choose are CPU or resources monitor, a weather applet, sticky notes, and calendar.
The Cinnamon Control Center provides centralized access to many of the desktop configuration options. By accessing the themes section you can choose the desktop basic scheme and icons, window borders, mouse pointers, and controls look. Fonts can have a great impact on the overall desktop look and cinnamon makes the change easier than ever.
The Cinnamon Control Center makes the configuration simple enough for a new user, compared to KDE Plasma that can lead a new user to confusion, due to the massive number of configuration options.
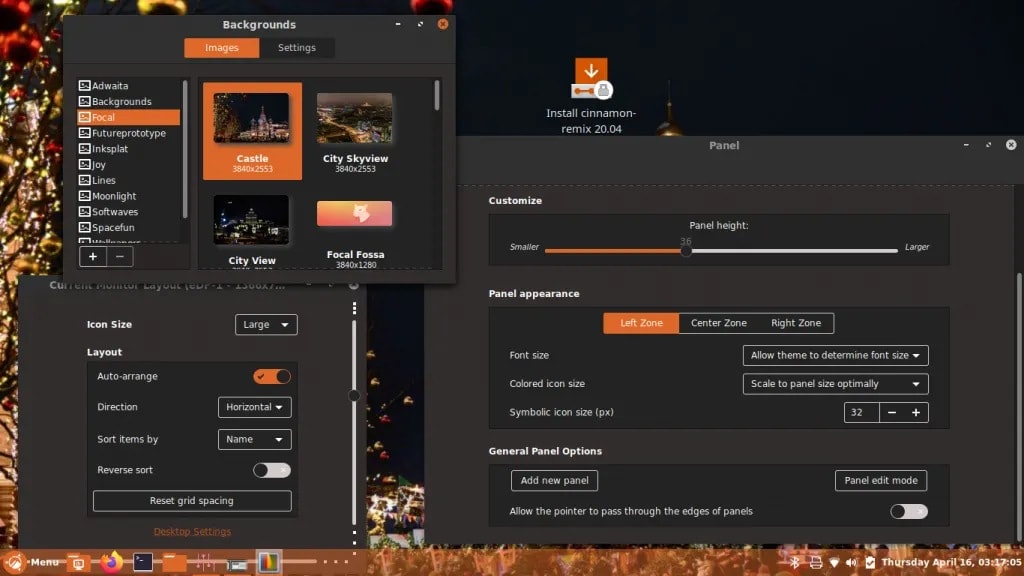
The Cinnamon Panel contains the menu used to launch programs, a basic system tray, and an application selector. The panel is easy to configure and adding new program launchers is simply done by locating the program you want to add in the main Menu, right click on the icon and select “Add to panel.” You can also add the launcher icon to the desktop, and to the Cinnamon “Favourites” launcher bar. If you don’t like the order of the icons at your panel, just right click at the panel bar, enter panel’s Edit mode and rearrange the icons.
**Conclusions**
Whether you decide to “spice” up your desktop or thinking to move from [Windows to Linux](https://itsfoss.com/windows-like-linux-distributions/), the Cinnamon Community has made plenty of spices for you.
Traditional yet elegant, customizable but simple, Ubuntu Cinnamon Remix is an interesting project with a promising future, and for existing fans of the Cinnamon Desktop who love Ubuntu, this is probably a no-brainer.
What do you think of Ubuntu Cinnamon Remix? Have you used it already? |
12,317 | 使用 AppImage 进行 Linux 软件包管理 | https://opensource.com/article/20/6/appimages | 2020-06-15T14:01:02 | [
"AppImage",
"软件包"
] | https://linux.cn/article-12317-1.html |
>
> AppImage 在自足的环境中分发应用, 它适用于任何 Linux 发行版。
>
>
>

管理 Linux 机器(尤其是远程机器)的一个重要分就是管理和安装软件。当本地应用程序出现问题时,或者文件系统上的某些文件损坏需要修复时,你通常会希望推送更新,而不必走很多路坐在物理屏幕前。正如我在 Pluralsight 课程《[Linux 系统维护和故障排除](https://pluralsight.pxf.io/VMKQj)》中所解释的那样,许多问题当然可以通过 Bash 脚本解决,但是仍有很多情况下,除了老式的二进制文件外,没有其他选择。
想象一下,你的某些远程系统需要安装新的应用程序,这样使用这些计算机的团队成员就能够执行某些业务。能够利用 Debian 或 RPM 之类的主要 Linux 仓库系统的集成和自动化,可以使你的管理任务变得更加容易。
正如 Linus Torvalds 永不厌倦地提醒我们的那样,太多的 Linux 软件管理系统的问题是 [Linux 软件管理系统太多了](https://itsfoss.com/desktop-linux-torvalds/)。多年来,应用开发甚至是 Linux 的采用都变得愈加复杂起来,因为你为了提供你的软件(比如,放到 Debian 仓库)而投入的所有时间和工作,对于你想让它们进入 RPM 系统并没有什么帮助,对于 SUSE 的 Zypper 管理器也一样,没有什么帮助。
解决软件孤岛问题的一种有前途的方案是分发具有自足环境的应用,它们可以在任何 Linux 发行版上运行。在这个年轻且不断发展的领域中,选择之一是 [AppImage](https://appimage.org/)。
### 使用 AppImage
我全面投入到了 AppImage。就像我提到的其他软件包管理系统一样,如果你需要的话,有很多复杂的功能可以使用。但是,从本质上讲,AppImage 非常简单。AppImage 不像大多数其他包管理器一样通过仓库工作,它使用单个、独立的文件,可以直接发送或通过网站共享。
下面是个展示它的美妙之处的例子。当我在用 AppImage 时,我在一个技术论坛上看到了一个很老的讨论,它让我找到了一个同样久远且废弃的 GitHub 项目以及相关的 YAML 和配方文件。它们旨在自动构建准备生成 AppImage 包所需的相当复杂的基础架构。尽管该基础架构全部是在 5 年前的 Ubuntu 版本上构建的,但是当我将它们放在一起并运行 `appimagetool` 命令时,它创建了一个 AppImage 文件,它可在我当前的桌面上无缝运行。我不认为有很多有五年历史的 GitHub 复杂项目可以使用其他技术运行,而无需认真重做。
但是这里我我不会介绍这个案例。相反,我将用一个简单的 Hello World 程序向你展示它是如何工作的。首先,请确保本地已安装 AppStream 包。
对于基于 Debian 的系统,运行:
```
$ sudo apt install appstream
```
对于 RPM 系统,请使用:
```
$ sudo dnf install appstream
```
克隆[这篇文章](https://www.booleanworld.com/creating-linux-apps-run-anywhere-appimage/)中提及的 Git 仓库,我会基于它示例:
```
$ git clone <https://github.com/boolean-world/appimage-resources>
$ cd appimage-resources
$ ls hello-world-appimage
```
接下来,使用 `cd` 进入 Git 新创建的目录。这里有两个目录。请使用 `hello-world-appimage`。另一个是更复杂的项目,你也应该考虑尝试一下。
Linux GUI 系统会读取 `helloworld.desktop` 文件来知道如何呈现桌面图标。事实证明,当前的这个文件会在以后给你带来点麻烦,因此请进行一些小修改:添加 `Categories=` 这行并为其赋予值 `GNOME`。不要忘记最后的分号:
```
$ nano hello-world-appimage/helloworld.desktop
add Categories=GNOME;
```
从 [AppImage GitHub 项目](https://github.com/AppImage/AppImageKit/releases)下载 `appimagetool` 预编译的二进制文件。访问 GitHub 的原因之一:那里有很多出色的文档和资源。下载二进制文件后,使文件可执行,并将 `hello-world-appimage` 目录传给它。但是首先,你需要告诉它你想要的架构。由于某些原因,一个名字以 x86\_64 结尾的工具都不能自行确定是否该使用 x86\_64 来构建应用程序(我不知道这是怎么回事)。
```
$ wget <https://github.com/AppImage/AppImageKit/releases/download/continuous/appimagetool-x86_64.AppImage>
$ chmod +x appimagetool-x86_64.AppImage
$ ARCH=x86_64 ./appimagetool-x86_64.AppImage hello-world-appimage
```
如果你没有看到任何错误消息,那么表示完成了,请运行:
```
$ ls
$ ./hello-world-appimage-x86_64.AppImage
```
### 总结
AppImage 是软件包管理的非常有效的选择。当你探索它时,我想你会发现它是 Linux 发行版默认软件包系统的很好的替代品。
---
via: <https://opensource.com/article/20/6/appimages>
作者:[David Clinton](https://opensource.com/users/dbclinton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A big part of administrating Linux machines—especially remote machines—is managing and installing software. When something goes wrong with a local application or when something on the filesystem breaks and needs fixing, you're often going to want to push updates without having to travel many miles to sit down in front of a physical screen. As I explain in my Pluralsight course [Linux system maintenance and troubleshooting](https://pluralsight.pxf.io/VMKQj), a lot of problems can be solved through Bash scripts of course, but there are still plenty of cases where there's no alternative to a good, old fashioned binary.
Imagine that some of your remote systems need new applications installed, so the team members using those computers will be able to perform some business function. Being able to leverage the integration and automation of one of the major Linux repository systems—like Debian or RPM—can make your administration tasks a whole lot easier.
As Linus Torvalds never tires of reminding us, the problem with many Linux software management systems is that there are [too many Linux software management systems](https://itsfoss.com/desktop-linux-torvalds/). Over the years, app development and even Linux adoption have been complicated by the fact that all the time and work you invest in preparing your software for, say, Debian repos, won't help you if you want to get them into RPM systems. And neither will help for SUSE's Zypper manager.
One promising solution to the software silo problem is to distribute applications with their own self-contained environments that'll work on any Linux distribution. One option of a standard in this young and growing field is [AppImage](https://appimage.org/).
## Working with AppImages
I'm all-in on AppImage. Like the other package management systems I've mentioned, there's plenty of complexity available should you want it. But, at its core, AppImages are actually quite straightforward. Rather than working through a repo like most other package managers, AppImages are single, standalone files that can be sent directly or shared through a website.
Here's an illustration of its beauty. While I was playing around with AppImages, I came across a very old discussion on a tech forum that led me to an equally old and abandoned GitHub project and associated YAML and recipe files. They were designed to automatically build the rather complex infrastructure required to prepare the archive needed to generate an AppImage package. Although that infrastructure was all built to run on a five-year-old release of Ubuntu, when I put it all together and ran the `appimagetool`
command against it, it created an AppImage file that worked seamlessly on my current desktop. I don't think there are too many five-year-old GitHub projects of that complexity that could run using other technologies without some serious reworking.
But I'm not going to go there. Instead, I'm going to show you how it works with a very simple Hello World application. First, make sure the AppStream package is installed locally.
For Debian-based system, run:
`$ sudo apt install appstream`
And for RPM systems, use:
`$ sudo dnf install appstream`
Clone the Git repo referenced in [this article](https://www.booleanworld.com/creating-linux-apps-run-anywhere-appimage/), which I based this example on:
```
$ git clone https://github.com/boolean-world/appimage-resources
$ cd appimage-resources
$ ls hello-world-appimage
```
Next, `cd`
into the new directory Git created, and take a look around. There are two directories here. Use `hello-world-appimage`
; the other one is a more complex project, and you should consider giving it a try, too.
The `helloworld.desktop`
file is what Linux GUI systems read to know how to handle the way they present a desktop icon. As it turns out, the way the file is currently written will give you trouble a bit later, so make one minor edit: add a `Categories=`
line and give it the value `GNOME`
. And don't forget the semicolon at the end:
```
$ nano hello-world-appimage/helloworld.desktop
add Categories=GNOME;
```
Download a precompiled copy of the `appimagetool`
binary from [the AppImage GitHub project](https://github.com/AppImage/AppImageKit/releases). Make a point of visiting the GitHub site—there's plenty of excellent documentation and resources there. Once the binary is downloaded, make the file executable and point it at the `hello-world-appimage`
directory. But first, you need to tell it what architecture you want. For some reason, a tool with a name that ends in `x86_64`
is all wobbly when it comes to choosing whether to build an application using x86_64 or not (I'm not sure what's going on there):
```
$ wget https://github.com/AppImage/AppImageKit/releases/download/continuous/appimagetool-x86_64.AppImage
$ chmod +x appimagetool-x86_64.AppImage
$ ARCH=x86_64 ./appimagetool-x86_64.AppImage hello-world-appimage
```
If you don't see any angry error messages, you're all set to give it a run:
```
$ ls
$ ./hello-world-appimage-x86_64.AppImage
```
## Conclusion
AppImage is an incredibly effective choice for package management. As you explore it, I think you'll find it's a great alternative to the defaults Linux distributions provide.
## 2 Comments |
12,319 | 给开源项目贡献代码时:先讨论,再编码 | https://dave.cheney.net/2019/02/18/talk-then-code | 2020-06-16T16:01:02 | [
"开发"
] | https://linux.cn/article-12319-1.html | 
我所参与的开源项目遵循的是一种这样的理念,我把它描述为 “先讨论,再编码”。我认为一般来说这是开发软件的好方法,我想花一点时间来谈谈这种方法的好处。
### 避免伤害感情
先讨论你想做的改变最重要的原因是避免伤害感情。我经常看到一个贡献者闭门造车地提交了一个 PR,却发现他的努力工作被拒绝了。这可能有一堆原因:PR 太大了,PR 没有遵循本地风格,PR 修复了一个对项目不重要的问题或者最近间接修复了的问题,等等。
这些问题的根本原因都是缺乏沟通。“先讨论,再编码” 理念的目标不是阻碍你或给你带来挫折,而是确保一个功能第一次就能正确落地,而不至于产生大量的维护债务。无论是改动的作者,还是审查者,当一个改动突然出现时,并暗示说 “好吧,我已经做完了,你要做的就是合并它,对吧?”,先讨论可以让他们不必背负伤害感情的情绪负担。
### 讨论应该如何进行?
每一个新功能或错误修复都应该在工作开始前与项目的维护者讨论。私下试验是可以的,但不要在没有讨论之前就发送修改。
对于简单的改动,“讨论” 的定义可以只是 GitHub 议题中的一个设计草图。如果你的 PR 修复了一个 bug,你应该链接到它修复的 bug。如果没有,你应该先提出一个 bug,等待维护者确认后再发送 PR。这可能看起来有点落后 —— 谁不希望一个 bug 被修复呢 —— 但考虑到这个 bug 可能是对软件工作方式的误解,也可能是一个更大问题的症状,这需要进一步调查。
对于比较复杂的改动,尤其是功能请求,我建议在发送代码之前,先分发一份设计文档并达成一致。这不一定是一个完整的文档,发一个议题,带个草图可能就足够了,但关键是在用代码搞定之前,先用文字达成一致。
在任何情况下,你都不应该继续发送你的代码,直到维护者同意你的方法是他们所满意的。拉取请求是日常生活,而不仅仅是为了赶着过节。
### 代码审查,而不是由委员会设计
代码审查不是争论设计的地方。这有两个原因。首先,大多数代码审查工具都不适合长长的评论会话,GitHub 的 PR 界面在这方面非常糟糕,Gerrit 比较好,但很少有管理员团队会维护 Gerrit 实例。更重要的是,在代码审查阶段就出现了分歧,说明大家对如何实现这个变化并没有达成一致。
---
讨论你想写的代码,然后再写你所讨论的代码。请不要反其道而行之。
---
via: <https://dave.cheney.net/2019/02/18/talk-then-code>
作者:[Dave Cheney](https://dave.cheney.net/author/davecheney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The open source projects that I contribute to follow a philosophy which I describe as *talk, then code*. I think this is generally a good way to develop software and I want to spend a little time talking about the benefits of this methodology.
### Avoiding hurt feelings
The most important reason for discussing the change you want to make is it avoids hurt feelings. Often I see a contributor work hard in isolation on a pull request only to find their work is rejected. This can be for a bunch of reasons; the PR is too large, the PR doesn’t follow the local style, the PR fixes an issue which wasn’t important to the project or was recently fixed indirectly, and many more.
The underlying cause of all these issues is a lack of communication. The goal of the *talk, then code* philosophy is not to impede or frustrate, but to ensure that a feature lands correctly the first time, without incurring significant maintenance debt, and neither the author of the change, or the reviewer, has to carry the emotional burden of dealing with hurt feelings when a change appears out of the blue with an implicit “well, I’ve done the work, all you have to do is merge it, right?”
### What does discussion look like?
Every new feature or bug fix should be discussed with the maintainer(s) of the project before work commences. It’s fine to experiment privately, but do not send a change without discussing it first.
The definition of *talk* for simple changes can be as little as a design sketch in a GitHub issue. If your PR fixes a bug, you should link to the bug it fixes. If there isn’t one, you should raise a bug and wait for the maintainers to acknowledge it before sending a PR. This might seem a little backward–who wouldn’t want a bug fixed–but consider the bug could be a misunderstanding in how the software works or it could be a symptom of a larger problem that needs further investigation.
For more complicated changes, especially feature requests, I recommend that a design document be circulated and agreed upon before sending code. This doesn’t have to be a full blown document, a sketch in an issue may be sufficient, but the key is to reach agreement using words, before locking it in stone with code.
In all cases you shouldn’t proceed to send code until there is a positive agreement from the maintainer that the approach is one they are happy with. A pull request is for life, not just for Christmas.
### Code review, not design by committee
A code review is not the place for arguments about design. This is for two reasons. First, most code review tools are not suitable for long comment threads, GitHub’s PR interface is very bad at this, Gerrit is better, but few have a team of admins to maintain a Gerrit instance. More importantly, disagreements at the code review stage suggests there wasn’t agreement on how the change should be implemented.
Talk about what you want to code, then code what you talked about. Please don’t do it the other way around. |
12,320 | 提升你 Kubernetes 技能的 5 种方式 | https://opensource.com/article/20/6/kubernetes-anniversary | 2020-06-16T19:10:33 | [
"Kubernetes"
] | https://linux.cn/article-12320-1.html |
>
> 值此周年纪念之际,来通过这些深度文章和实践项目了解下 Kubernetes。
>
>
>

在云原生的成长期,开发者们发现在一个小型的、原子化的、精简的 Linux 镜像里编写应用程序很方便,这些镜像与它们所运行的服务器共享资源。从技术上讲,这些基于内核命名空间的小环境定义被称为[容器](https://opensource.com/article/18/11/behind-scenes-linux-containers)。随着容器的激增,系统管理员们很快意识到,开发一个不仅能帮助他们管理容器,还能帮助他们管理下面的虚拟化基础设施的工具变得至关重要。于是,[Kubernetes](https://opensource.com/resources/what-is-kubernetes) 应运而生。
Kubernetes 是一个可扩展开源平台,用于管理容器。它可以帮助管理员和开发者们围绕容器管理工作负载、服务和进程。它促进了声明式配置,更容易实现自动化。在它相对较短的生命周期中,它已经催生了一个迅速成长的生态系统,其中包括来自大量公司和项目的服务、支持和工具。
如果你想对这项重要的云技术有更多的了解,这里有一些能帮忙你更深入学习的文章。还有 5 个项目可以帮你把学到的东西付诸实践。
### 遏制容器乱象
2016 年,我们发布了《[使用 Kubernetes 遏制容器乱象](https://opensource.com/life/16/9/containing-container-chaos-kubernetes)》,这是一篇由 Terry Ryan 写的关于 Kubernetes 的介绍性文章,讲述了 Kubernetes 如何帮助管理员和架构师们努力应对容器。如果你想找一篇从底层介绍容器是做什么的以及 Kubernetes 是如何实现容器管理的,那么你应该先读下本文。本文适合零基础的读者,解释了所有重要的概念,因此你能迅速了解相关技术。
如果想进阶了解内核层面发生的一些神奇的事情,请阅读 Jessica Cherry 对 [Kubernetes 命名空间](/article-11749-1.html)的解释。
延伸阅读:
* [一文了解 Kubernetes 是什么?](/article-8800-1.html)
* [Kubernetes 是什么?](/article-8858-1.html)
### Kubernetes:为什么它很重要?
Kubernetes 提供了<ruby> 基础设施即服务 <rt> Infrastructure-as-a-Service </rt></ruby>(IaaS)解决方案(类似 OpenStack)的便利和一个完整的<ruby> 平台即服务 <rt> Platform as a Service </rt></ruby>(PaaS)。它为你提供了管理基础设施的抽象能力,以及在裸金属基础层面进行故障排除所需的工具。如果你执着于使用单一的裸金属服务器,你可能需要阅读下 Tim Potter 写的《[你为什么需要 Kubernetes](/article-8902-1.html)》。他的文章对比了 IaaS 和 PaaS,解释了为什么 Kubernetes 如此广泛地被使用。你可能并不是一定需要 Kubernetes 或容器,但是重要的是知道什么情况下需要。
延伸阅读:
* [使用 Kubernetes 的 5 个理由](/article-10973-1.html)
* [你(多半)不需要 Kubernetes](/article-10469-1.html)
### 在树莓派上运行 Kubernetes
熟悉 Kubernetes 的最好方法莫过于自己运行它。不幸的是,不是每个人都有一个云服务基层设施(或者有足够的钱来租用一个)可供其支配。而幸运的是,Chris Collins 提供了《[在树莓派上运行 Kubernetes](/article-8499-1.html)》的教程。结合他的另外几篇关于《[Cloud-init](https://opensource.com/article/20/5/cloud-init-raspberry-pi-homelab)》和《[Cloud-init 服务](https://opensource.com/article/20/5/create-simple-cloud-init-service-your-homelab)》的教程(也是在树莓派上运行),你可以搭建任何你想要的家庭实验室,这样你就可以学习如何管理属于自己的开放混合云。
### Kubernetes 命令
一旦你运行起 Kubernetes 后,可以看看 Jessica Cherry 的文章和附带的备忘清单,这个清单列出了所有的[基本的 Kubernetes 命令](https://opensource.com/article/20/5/kubectl-cheat-sheet)。在她的文章中,她解释了 `kubectl` 命令的语法,简单讲述了每个命令和子命令是用来做什么的。
### 有趣的 Kubernetes 项目
没有什么比拥有技术却不知道该怎么用它更令人沮丧的了。例如,在你的办公桌上有一个树莓派是一回事,但是决定它的 CPU 应该用来做什么工作却完全是另一回事。我们发布了很多教程,来指导你完成你的 Kubernetes 之路的探索:
* [Helm](/article-12007-1.html) 是一个 Kubernetes 的包管理器。你可以在它的帮助下,很快熟悉 Kubernetes 环境。
* 学习下 [Operator SDK](https://opensource.com/article/20/3/kubernetes-operator-sdk) 的所有内容,来熟悉 Kubernetes 的对象和操作器。
* [在 Kubernetes 之上搭建网络文件系统(NFS)](https://opensource.com/article/20/6/kubernetes-nfs-client-provisioning)
* 学习如何使用 [Skipper](https://opensource.com/article/20/4/http-kubernetes-skipper) 或 [Traefik](https://opensource.com/article/20/3/kubernetes-traefik) 进行流量调度。
最重要的,花点时间来熟悉容器和 Kubernetes。不论你先把容器化的应用放到服务器、云上还是桌面,它们都是能帮助你理解的重要的范例,因为它们是一个强大的构造,可以让 Linux 的应用变得更好、更健壮、鲁棒性更好、更简单。一定要投入精力去学习它们,你不会后悔的。
---
via: <https://opensource.com/article/20/6/kubernetes-anniversary>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When the cloud was still in its formative years, developers discovered that it was convenient to write applications in small, atomic, minimal Linux images that shared resources with the server they ran on. Technically based on kernel namespaces, these small environment definitions came to be called [containers](https://opensource.com/article/18/11/behind-scenes-linux-containers). As containers proliferated, sysadmins quickly realized it was becoming essential to develop a tool that could help them manage not only containers but also the virtualized infrastructure underneath. And that's when [Kubernetes](https://opensource.com/resources/what-is-kubernetes) was born.
Kubernetes is an extensible open source platform for wrangling containers. It helps administrators and developers manage workloads, services, and processes around containers. It facilitates declarative configuration and easy automation. In its relatively short lifespan, it has fostered a rapidly growing ecosystem with services, support, and tools from many companies and projects.
If you're looking to get better acquainted with this important cloud technology, here are a few articles to help you dive deep and five projects to help you try out what you learn.
## Containing container chaos
In 2016, we published [Containing the container chaos with Kubernetes](https://opensource.com/life/16/9/containing-container-chaos-kubernetes), an introductory article by Terry Ryan about how Kubernetes is helping admins and architects grapple with containers. If you need a ground-level introduction to what containers do and how Kubernetes makes it easy, then this is the article to read first. It assumes no prior knowledge and explains all the most important concepts, so you can get up to speed fast.
For an advanced look into some of the magic happening at the kernel level, read Jessica Cherry's explanation of [Kubernetes namespaces](https://opensource.com/article/19/12/kubernetes-namespaces).
## Kubernetes: Why does it matter?
Kubernetes provides the benefits of an Infrastructure-as-a-Service (IaaS) solution (like OpenStack) and a full Platform as a Service (PaaS). It gives you abstractions for managing infrastructure and the tools you need to troubleshoot at the base level of bare metal. If you have the impulse to cling to a single bare-metal server, you might want to read Tim Potter's take on [why Kubernetes matters](https://opensource.com/article/17/6/introducing-kubernetes). His article compares IaaS and PaaS and gives his perspective on why Kubernetes has been so widely adopted. You don't always need Kubernetes or containers, but it's important to know when you do.
## Run it on a Raspberry Pi
There's no better way to get familiar with Kubernetes than to run it yourself. Unfortunately, not everyone has a cloud (nor the money to rent time on one) at their disposal. Luckily, Chris Collins has provided a guide for running [Kubernetes on a Pi](https://opensource.com/article/20/6/kubernetes-raspberry-pi). Combined with his equally elucidating tutorials about [Cloud-init](https://opensource.com/article/20/5/cloud-init-raspberry-pi-homelab) and [Cloud-init services](https://opensource.com/article/20/5/create-simple-cloud-init-service-your-homelab) (also on a Pi), you can build whatever kind of homelab you want so that you can learn how to manage your very own open hybrid cloud.
## Kubernetes commands
Once you have Kubernetes up and running, take a look at Jessica Cherry's article and accompanying cheat sheet that provides you with all the [essential Kubernetes commands](https://opensource.com/article/20/5/kubectl-cheat-sheet). In her article, she explains the syntax of `kubectl`
commands and provides an overview of what each command and subcommand is meant to do.
## Fun Kubernetes projects
Nothing's more frustrating than having access to technology but not knowing what to do with it. For instance, it's one thing to have a Raspberry Pi on your desk, but it's an entirely different matter to decide what it ought to spend its CPU cycles doing. We've published plenty of articles to give some guidance to your Kubernetes explorations:
[Helm](https://opensource.com/article/20/2/kubectl-helm-commands)is a package manager for Kubernetes. Exploring it is an easy way to get comfortable with living in Kubernetes.- Learn all about
[Operator SDK](https://opensource.com/article/20/3/kubernetes-operator-sdk)to get familiar with Kubernetes objects and operators. - Provide a
[network file system (NFS) on top of Kubernetes.](https://opensource.com/article/20/6/kubernetes-nfs-client-provisioning) - Learn how to route traffic with
[Skipper](https://opensource.com/article/20/4/http-kubernetes-skipper)or[Traefik.](https://opensource.com/article/20/3/kubernetes-traefik)
Most importantly, take the time to get comfortable with containers and Kubernetes. Whether you first embrace containerized apps on the server, cloud, or desktop, they're an important paradigm to understand, because they're a powerful construct that's made applications on Linux better, stronger, more robust, and easier. Invest time to learn more about them. You'll be glad you did.
## 1 Comment |
12,323 | 如何在 Bash 中编写函数 | https://opensource.com/article/20/6/bash-functions | 2020-06-17T12:59:54 | [
"函数"
] | https://linux.cn/article-12323-1.html | 
>
> 通过编写函数来减少代码的冗余和维护。
>
>
>
在编程时,实际上是在定义要由计算机执行的<ruby> 过程 <rt> procedure </rt></ruby>或<ruby> 例程 <rt> routine </rt></ruby>。一个简单的类比是将计算机编程与烤面包进行比较:你一次列出了要组建工作环境的配料,然后列出了烤面包所必须采取的步骤。在编程和烘烤中,必须以不同的间隔重复执行某些步骤。例如,在烤面包中,这可能是酵母培养的过程:
```
STIR=100
SNOOZE=86400
function feed_culture {
remove_from(pantry)
add(flour, water)
stir($STIR)
sleep($SNOOZE)
}
```
然后,揉面和醒发面团:
```
KNEAD=600
SNOOZE=7200
function process_dough {
remove_from(proofing_drawer)
knead($KNEAD)
return_to_drawer($SNOOZE)
}
```
在编程中,这些<ruby> 子例程 <rt> subroutines </rt></ruby>可以表示为<ruby> 函数 <rt> function </rt></ruby>。函数对程序员很重要,因为它们有助于减少代码中的冗余,从而减少了所需的维护量。例如,在以编程方式烤制面包的假想场景中,如果你需要更改面团醒发的用时,只要你之前使用函数,那么你只需更改一次用时,或使用变量(在示例代码中为 `SNOOZE`)或直接在处理面团的子程序中更改用时。这样可以节省你很多时间,因为你不必通过你的代码库遍历每个可能正在醒发的面团,更不用说担心错过一个。许多 bug 是由未更改的缺失的值或执行不正确的 `sed` 命令引起的,它们希望捕获所有可能而不必手动寻找。
在 [Bash](https://opensource.com/resources/what-bash) 中,无论是在编写的脚本或在独立的文件中,定义函数和使用它们一样简单。如果将函数保存到独立的文件中。那么可以将它 `source` 到脚本中,就像 `include` C 语言或 C++ 中的库或将模块 `import` 到 Python 中一样。要创建一个 Bash 函数,请使用关键字 `function`:
```
function foo {
# code here
}
```
这是一个如何在函数中使用参数的例子(有些人为设计,因此可能会更简单):
```
#!/usr/bin/env bash
ARG=$1
function mimic {
if [[ -z $ARG ]]; then
ARG='world'
fi
echo "hello $ARG"
}
mimic $ARG
```
结果如下:
```
$ ./mimic
hello world
$ ./mimic everybody
hello everybody
```
请注意脚本的最后一行,它会执行该函数。对于编写脚本的新手来说,这是一个普遍的困惑点:函数不会自动执行。它们作为*潜在的*例程存在,直到被调用。
如果没有调用该函数,那么函数只是被定义,并且永远不会运行。
如果你刚接触 Bash,请尝试在包含最后一行的情况下执行示例脚本一次,然后在注释掉最后一行的情况下再次执行示例脚本。
### 使用函数
即使对于简单的脚本,函数也是很重要的编程概念。你越适应函数,在面对一个不仅需要声明性的命令行,还需要更多动态的复杂问题时,你就会越容易。将通用函数保存在单独的文件中还可以节省一些工作,因为它将帮助你建立常用的程序,以便你可以在项目间重用它们。看看你的脚本习惯,看是否适合使用函数。
---
via: <https://opensource.com/article/20/6/bash-functions>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you're programming, you're literally defining a procedure, or a *routine*, you want the computer to perform. A simple analogy compares computer programming to baking bread: you list ingredients once to set up the work environment, then you list the steps you must take to end up with a loaf of bread. In both programming and baking, some steps must be repeated at different intervals. In baking bread, for instance, this could be the process of feeding a sourdough culture:
```
STIR=100
SNOOZE=86400
function feed_culture {
remove_from(pantry)
add(flour, water)
stir($STIR)
sleep($SNOOZE)
}
```
And later, kneading and proofing the dough:
```
KNEAD=600
SNOOZE=7200
function process_dough {
remove_from(proofing_drawer)
knead($KNEAD)
return_to_drawer($SNOOZE)
}
```
In programming, these subroutines can be expressed as *functions*. Functions are important for programmers because they help reduce redundancy in code, which in turn reduces the amount of maintenance required. For example, in the imaginary scenario of baking bread programmatically, if you need to change the amount of time the dough proofs, as long as you've used a function before, you merely have to change the value of the seconds once, either by using a variable (called **SNOOZE **in the sample code) or directly in the subroutine that processes dough. That can save you a lot of time, because you don't have to hunt through your codebase for every possible mention of rising dough, much less worry about missing one. Many a bug's been caused by a missed value that didn't get changed or by a poorly executed ** sed** command in hopes of catching every last match without having to hunt for them manually.
In [Bash](https://opensource.com/resources/what-bash), defining a function is as easy as setting it either in the script file you're writing or in a separate file. If you save functions to a dedicated file, you can `source`
it into your script as you would `include`
a library in C or C++ or `import`
a module into Python. To create a Bash function, use the keyword `function`
:
```
function foo {
# code here
}
```
Here's a simple (and somewhat contrived, as this could be made simpler) example of how a function works with arguments:
```
#!/usr/bin/env bash
ARG=$1
function mimic {
if [[ -z $ARG ]]; then
ARG='world'
fi
echo "hello $ARG"
}
mimic $ARG
```
Here are the results:
```
$ ./mimic
hello world
$ ./mimic everybody
hello everybody
```
Note the final line of the script, which executes the function. This is a common point of confusion for beginning scripters and programmers: functions don't get executed automatically. They exist as *potential* routines until they are called.
Without a line calling the function, the function would only be defined and would never run.
If you're new to Bash, try executing the sample script once with the last line included and again with the last line commented out.
## Using functions
Functions are vital programming concepts, even for simple scripts. The more comfortable you become with functions, the better off you'll be when you're faced with a complex problem that needs something more dynamic than just declarative lines of commands. Keeping general-purpose functions in separate files can also save you some work, as it'll help you build up routines you commonly use so that you can reuse them across projects. Look at your scripting habits and see where functions might fit.
## Comments are closed. |
12,324 | Cockpit 及其网页用户界面的演变 | https://fedoramagazine.org/cockpit-and-the-evolution-of-the-web-user-interface/ | 2020-06-17T15:46:00 | [
"Cockpit"
] | https://linux.cn/article-12324-1.html | 
3 年多以前,Fedora 杂志发表了一篇题为《[Cockpit 概览](https://fedoramagazine.org/cockpit-overview/)》的文章。从那时起,Cockit 的界面有了一些引人注目的变化。今天的 Cockpit 更加简洁,更大的字体更好地利用了屏幕的空间。
本文将介绍它的用户界面的一些变化。还将探讨一些在网页界面中可用的通用工具,以简化那些单调的系统管理员任务。
### Cockpit 驾驶舱安装
Cockpit 可以使用 `dnf install cockpit` 命令安装。这提供了一个最小的设置,提供了使用该界面所需的基本工具。
另一个选择是安装 “Headless Management” 组,这将安装用于扩展 Cockpit 功能的附加包。它包括用于 NetworkManager、软件包、磁盘和 SELinux 管理的扩展。
运行以下命令,在启动时启用 Web 服务并打开防火墙端口:
```
$ sudo systemctl enable --now cockpit.socket
Created symlink /etc/systemd/system/sockets.target.wants/cockpit.socket -> /usr/lib/systemd/system/cockpit.socket
$ sudo firewall-cmd --permanent --add-service cockpit
success
$ sudo firewall-cmd --reload
success
```
### 登录网页界面
要访问网页界面,打开你最喜欢的浏览器,在地址栏中输入该服务器的域名或 IP,然后输入服务端口(9090)。由于 Cockpit 使用 HTTPS,安装过程中会创建一个自签证书来加密密码和其他敏感数据。你可以安全地接受这个证书,或者向你的系统管理员或受信任的来源请求 CA 证书。
一旦证书被接受,就会出现新改进的登录屏幕。长期使用的用户会注意到用户名和密码字段已被移到顶部。此外,凭证字段后面的白色背景会立即吸引用户的注意力。

自上一篇文章后,登录界面增加了一个功能,就是用 `sudo` 权限登录 —— 如果你的账号是 `wheel` 组的成员。勾选 “对于特权任务,重用我的密码” 旁边的方框,就可以提升你的权限。
登录界面的另一个版本是连接到同样运行 Cockpit Web 服务的远程服务器的选项。点击 “其他选项” 并输入远程机器的主机名或 IP 地址,从本地浏览器管理它。
### 主屏幕视图
一开始,我们就会看到基本概述,带有常见的系统信息,这包括机器的品牌和型号、操作系统、系统是否是最新的,等等。

点击系统的品牌/型号会显示硬件信息,如 BIOS/固件。它还包括与 `lspci` 中可以看到的组件的详情。

点击任何一个选项,右边都会显示该设备的详细信息。例如,“CPU 核心百分比” 选项显示了用户和内核使用了多少 CPU 核心的详细信息。此外,“内存和交换” 图表显示了系统内存的使用量、缓存量和交换分区的活动量。“磁盘 I/O” 和 “网络流量” 图表连到了 Cockpit 的 “存储和网络” 部分。这些内容将在接下来详细探讨系统工具的一篇文章中重新探讨。
#### SSH 密钥和认证
由于安全是系统管理员的关键因素,Cockpit 现在有了查看机器 MD5 和 SHA256 密钥指纹的选项。点击 “显示指纹” 选项可以显示服务器的 ECDSA、ED25519 和 RSA 指纹密钥。

你也可以通过点击右上角的用户名,选择“验证”,添加自己的密钥。点击 “添加密钥”,可以在其他系统上验证该机器。你也可以通过点击右侧的 “X” 按钮,撤销你在 Cockpit Web 服务中的权限。

#### 更改主机名和加入域
更改主机名可以在主页上一键解决。单击当前显示的主机名,并在“更改主机名”框中输入新名称。最新的功能之一是提供了一个 “简称” 的选项。
Cockpit 增加的另一个功能是可以连接到目录服务器。点击 “加入域”,会出现一个弹窗,要求提供域地址或名称、组织单位(可选)和域管理员的凭证。“Domain Membership” 组提供了加入 LDAP 服务器所需的所有包,包括 FreeIPA,以及流行的 Active Directory。
要退出域,请点击域名,然后点击 “离开域”。将会出现一个警告,解释一旦系统不再在域上将会发生的变化。要确认,点击红色的 “离开域” 按钮。

#### 配置 NTP 和系统日期和时间
使用命令行和编辑配置文件绝对可以完成最大限度的调整。然而,有些时候,一些更直接的方法就足够了。通过 Cockpit,你可以选择手动设置或使用 NTP 自动设置系统的日期和时间。一旦同步,右边的信息图标就会由红色变成蓝色。如果你手动设置日期和时间,该图标将消失。
要更改时区,请输入洲,下面会弹出城市列表。

#### 关机和重启
你可以在 Cockpit 的主屏幕上轻松关闭和重启服务器。你也可以延迟关机/重启,并发送消息警告用户。

#### 设置性能配置文件
如果安装了 `tuned` 和 `tuned-utils` 包,可以在主屏幕上更改性能配置文件。默认情况下,它被设置为推荐的配置文件。然而,如果服务器的用途需要更多的性能,我们可以在 Cockpit 中更改配置文件以满足这些需求。

### 网页版终端控制台
一个 Linux 系统管理员的工具箱如果不能访问终端,将毫无用处。终端使得管理员可以对服务器进行微调,而不仅仅是 Cockpit 中的内容。随着主题功能的加入,管理员可以根据自己的喜好快速调整文字和背景颜色。
另外,如果你错输入了 `exit` 命令,点击右上角的 “重置” 按钮,会提供一个闪烁着光标的新屏幕。

### 添加远程服务器和仪表板布局
“Headless Management” 组包括了仪表盘模块(`cockpit-dashboard`)。它以实时图表的形式提供了 CPU、内存、网络和磁盘性能的概览。远程服务器也可以通过同一界面进行添加和管理。
例如,要在仪表盘中添加远程计算机,请单击 “+” 按钮。输入服务器的名称或 IP 地址,并选择你要的颜色。这有助于你在图中区分服务器的统计数据。要在服务器之间进行切换,请点击主机名称(如下面的屏幕动画所示)。要从列表中删除一个服务器,点击勾选标记图标,然后点击红色垃圾桶图标。下面的例子演示了 Cockpit 如何管理一台名为 `server02.local.lan` 的远程机器。

### 文档和寻找帮助
一如既往,手册页是查找文档的好地方。在命令行结果中进行简单搜索即可找到与使用和配置该 Web 服务的不同方面有关的页面。
```
$ man -k cockpit
cockpit (1) - Cockpit
cockpit-bridge (1) - Cockpit Host Bridge
cockpit-desktop (1) - Cockpit Desktop integration
cockpit-ws (8) - Cockpit web service
cockpit.conf (5) - Cockpit configuration file
```
Fedora 仓库中也有一个名为 `cockpit-doc` 的软件包。这个软件包的描述是最好的解释。
>
> 《Cockpit 部署和开发者指南》向系统管理员展示了如何在他们的机器上部署 Cockpit,并帮助开发者嵌入或扩展 Cockpit。
>
>
>
更多文档请访问 <https://cockpit-project.org/external/source/HACKING>。
### 结论
本文只涉及 Cockpit 中的一些主要功能。管理存储设备、网络、用户账户和软件控制将在下一篇文章中介绍。此外,可选的扩展,如 389 目录服务,以及用于处理 Fedora Silverblue 中的软件包的`cockpit-ostree` 模块。
随着越来越多的用户采用 Cockpit,可选的功能会继续增加。这个界面对于想要一个轻量级界面来控制服务器的管理员来说是非常理想的。
你对 Cockpit 有什么看法?在下面的评论中分享你的经验和想法。
---
via: <https://fedoramagazine.org/cockpit-and-the-evolution-of-the-web-user-interface/>
作者:[Shaun Assam](https://fedoramagazine.org/author/sassam/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Over 3 years ago the Fedora Magazine published an article entitled [Cockpit: an overview](https://fedoramagazine.org/cockpit-overview/). Since then, the interface has see some eye-catching changes. Today’s Cockpit is cleaner and the larger fonts makes better use of screen real-estate.
This article will go over some of the changes made to the UI. It will also explore some of the general tools available in the web interface to simplify those monotonous sysadmin tasks.
## Cockpit installation
Cockpit can be installed using the **dnf install cockpit** command. This provides a minimal setup providing the basic tools required to use the interface.
Another option is to install the Headless Management group. This will install additional packages used to extend the usability of Cockpit. It includes extensions for NetworkManager, software packages, disk, and SELinux management.
Run the following commands to enable the web service on boot and open the firewall port:
$sudo systemctl enable --now cockpit.socketCreated symlink /etc/systemd/system/sockets.target.wants/cockpit.socket -> /usr/lib/systemd/system/cockpit.socket $sudo firewall-cmd --permanent --add-service cockpitsuccess $sudo firewall-cmd --reloadsuccess
## Logging into the web interface
To access the web interface, open your favourite browser and enter the server’s domain name or IP in the address bar followed by the service port (9090). Because Cockpit uses HTTPS, the installation will create a self-signed certificate to encrypt passwords and other sensitive data. You can safely accept this certificate, or request a CA certificate from your sysadmin or a trusted source.
Once the certificate is accepted, the new and improved login screen will appear. Long-time users will notice the username and password fields have been moved to the top. In addition, the white background behind the credential fields immediately grabs the user’s attention.
A feature added to the login screen since the previous article is logging in with **sudo** privileges — if your account is a member of the wheel group. Check the box beside *Reuse my password for privileged tasks* to elevate your rights.
Another edition to the login screen is the option to connect to remote servers also running the Cockpit web service. Click *Other Options* and enter the host name or IP address of the remote machine to manage it from your local browser.
## Home view
Right off the bat we get a basic overview of common system information. This includes the make and model of the machine, the operating system, if the system is up-to-date, and more.
Clicking the make/model of the system displays hardware information such as the BIOS/Firmware. It also includes details about the components as seen with **lspci**.
Clicking on any of the options to the right will display the details of that device. For example, the *% of CPU cores* option reveals details on how much is used by the user and the kernel. In addition, the *Memory & Swap* graph displays how much of the system’s memory is used, how much is cached, and how much of the swap partition active. The *Disk I/O* and *Network Traffic* graphs are linked to the Storage and Networking sections of Cockpit. These topics will be revisited in an upcoming article that explores the system tools in detail.
### Secure Shell Keys and authentication
Because security is a key factor for sysadmins, Cockpit now has the option to view the machine’s MD5 and SHA256 key fingerprints. Clicking the **Show fingerprints** options reveals the server’s ECDSA, ED25519, and RSA fingerprint keys.
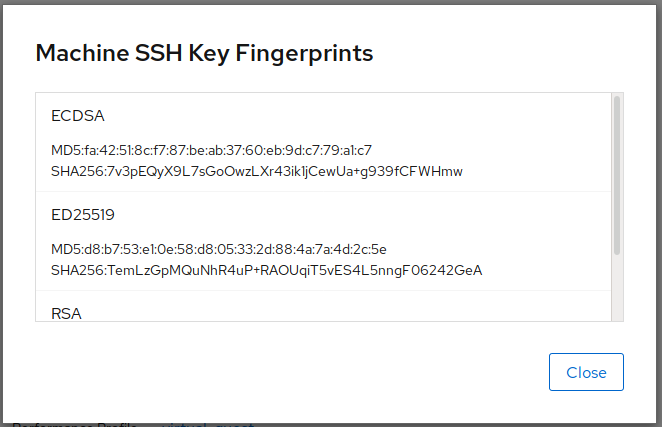
You can also add your own keys by clicking on your username in the top-right corner and selecting **Authentication**. Click on **Add keys** to validate the machine on other systems. You can also revoke your privileges in the Cockpit web service by clicking on the **X** button to the right.
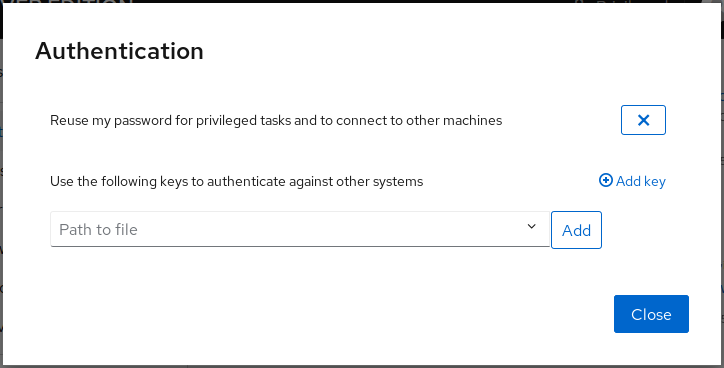
### Changing the host name and joining a domain
Changing the host name is a one-click solution from the home page. Click the host name currently displayed, and enter the new name in the *Change Host Name* box. One of the latest features is the option to provide a *Pretty name*.
Another feature added to Cockpit is the ability to connect to a directory server. Click *Join a domain* and a pop-up will appear requesting the domain address or name, organization unit (optional), and the domain admin’s credentials. The Domain Membership group provides all the packages required to join an LDAP server including FreeIPA, and the popular Active Directory.
To opt-out, click on the domain name followed by *Leave Domain*. A warning will appear explaining the changes that will occur once the system is no longer on the domain. To confirm click the red *Leave Domain* button.
### Configuring NTP and system date and time
Using the command-line and editing config files definitely takes the cake when it comes to maximum tweaking. However, there are times when something more straightforward would suffice. With Cockpit, you have the option to set the system’s date and time manually or automatically using NTP. Once synchronized, the information icon on the right turns from red to blue. The icon will disappear if you manually set the date and time.
To change the timezone, type the continent and a list of cities will populate beneath.
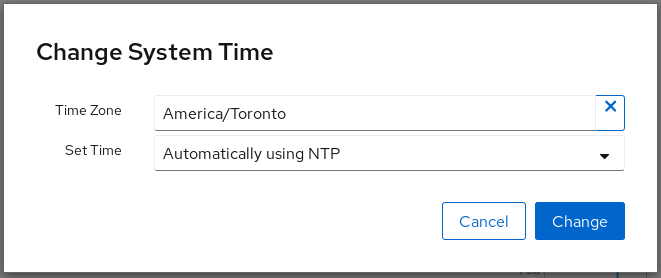
### Shutting down and restarting
You can easily shutdown and restart the server right from home screen in Cockpit. You can also delay the shutdown/reboot and send a message to warn users.
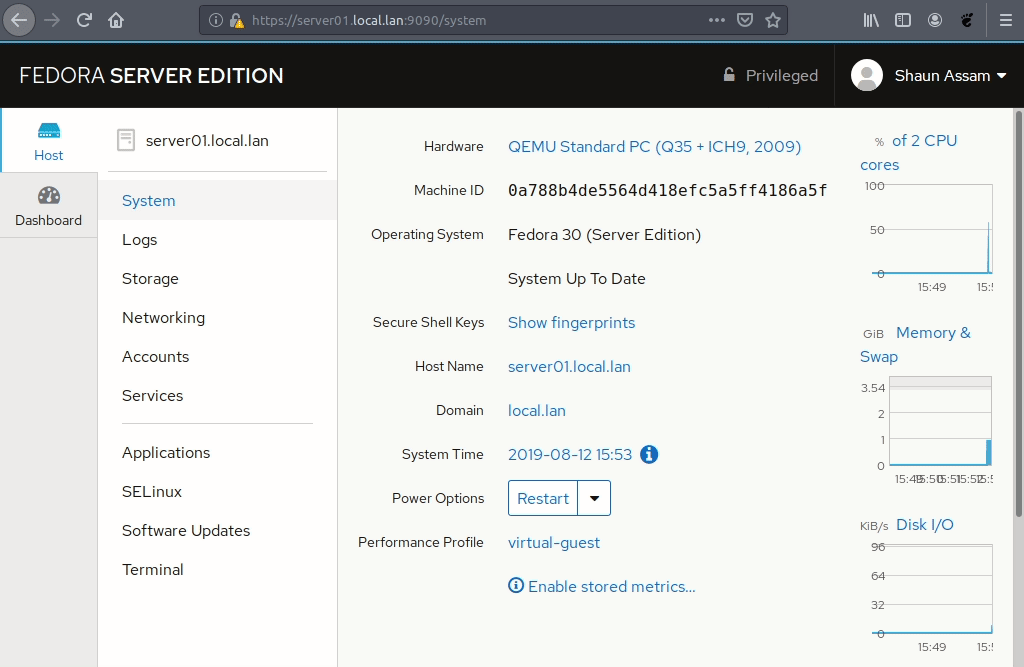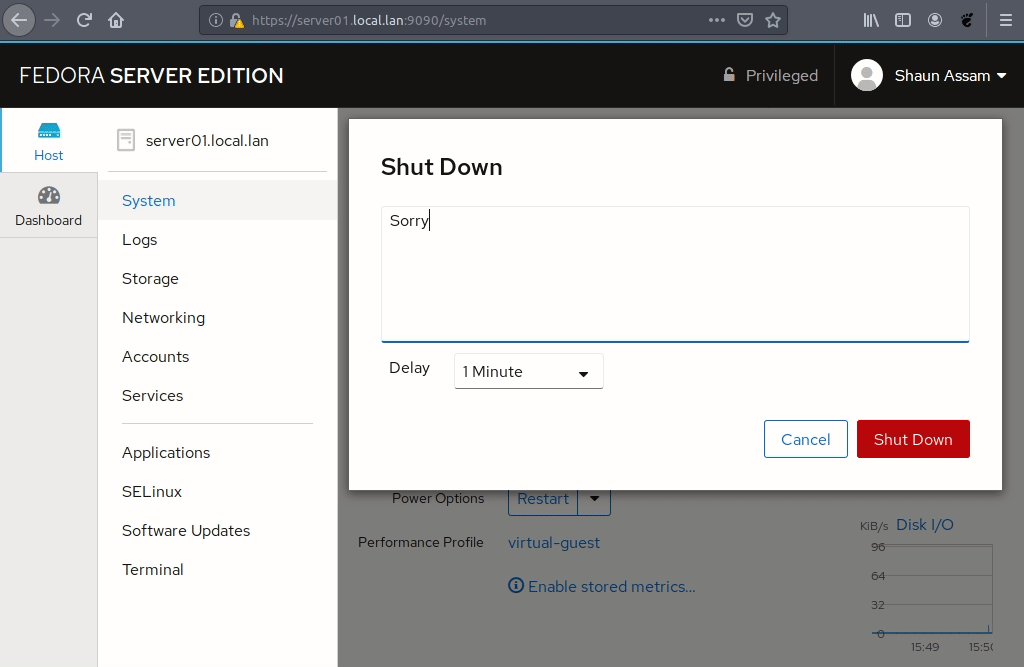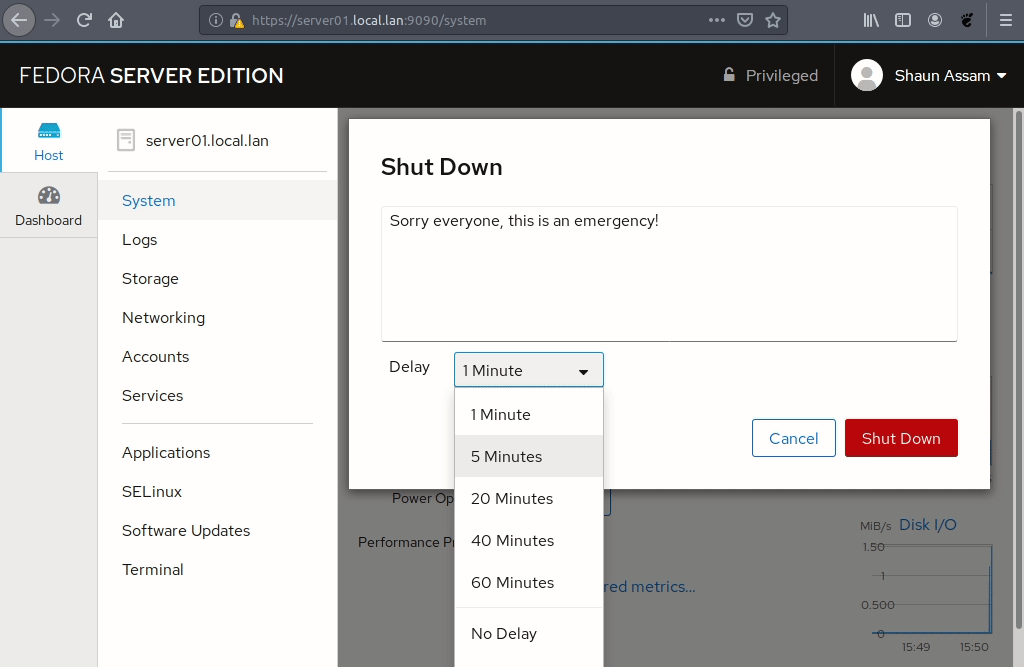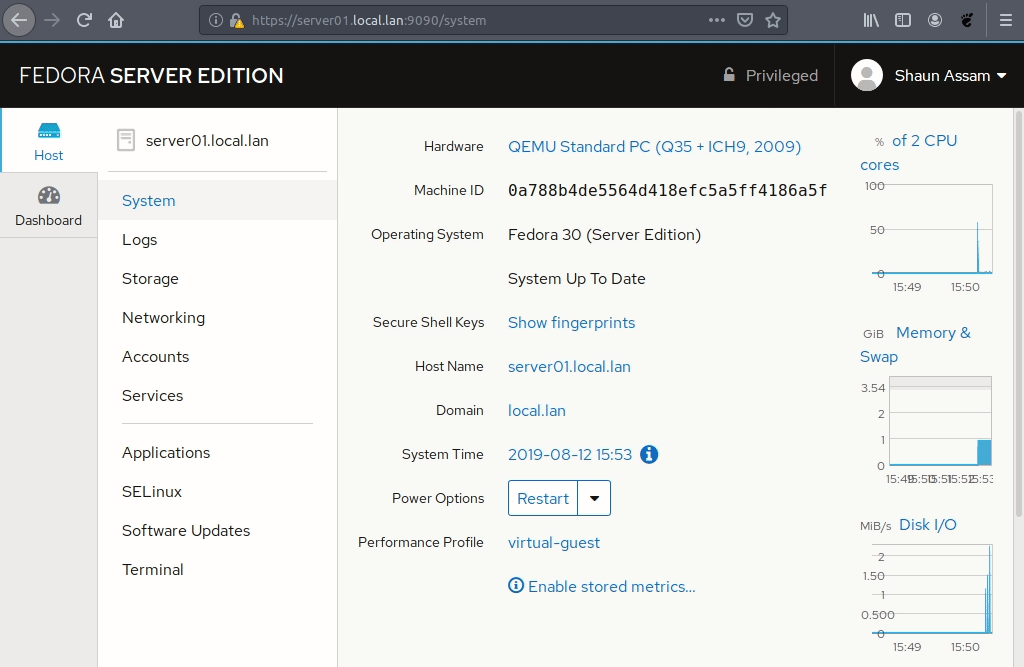
### Configuring the performance profile
If the *tuned* and *tuned-utils* packages are installed, performance profiles can be changed from the main screen. By default it is set to a recommended profile. However, if the purpose of the server requires more performance, we can change the profile from Cockpit to suit those needs.
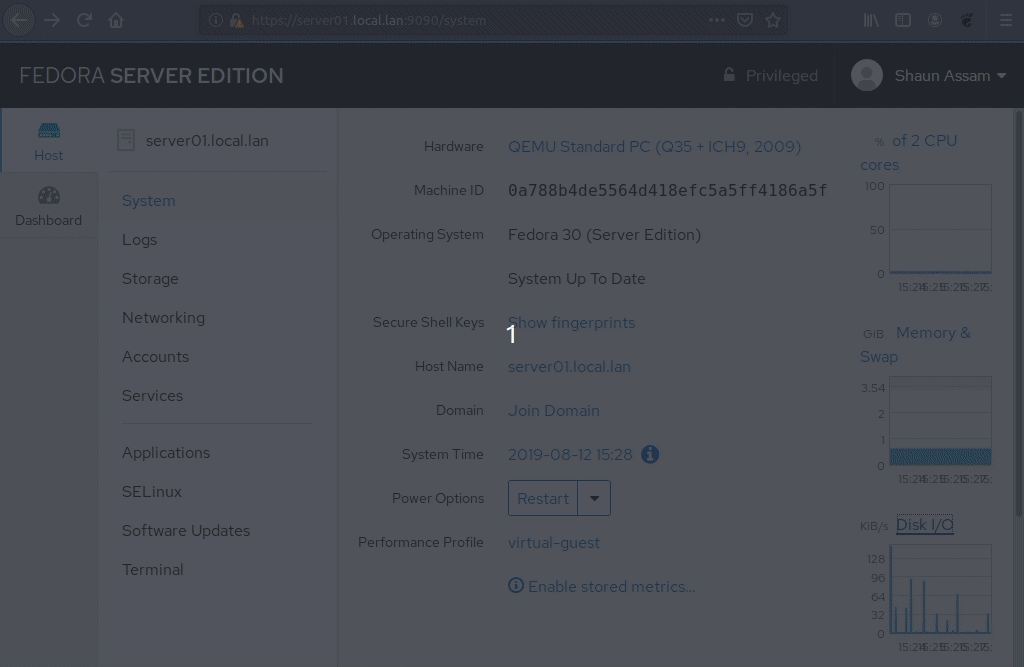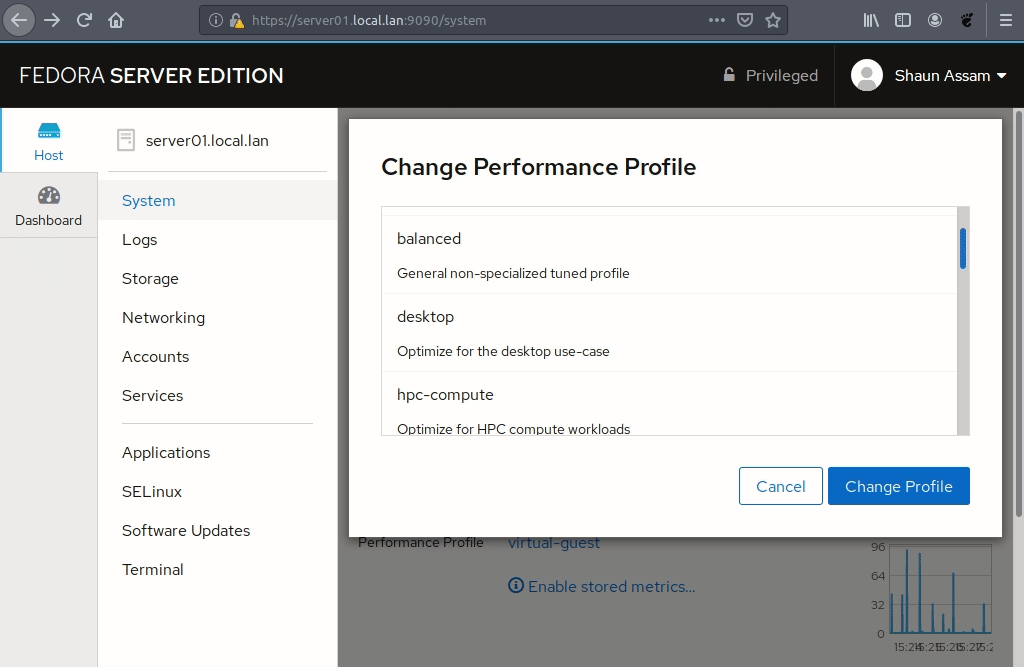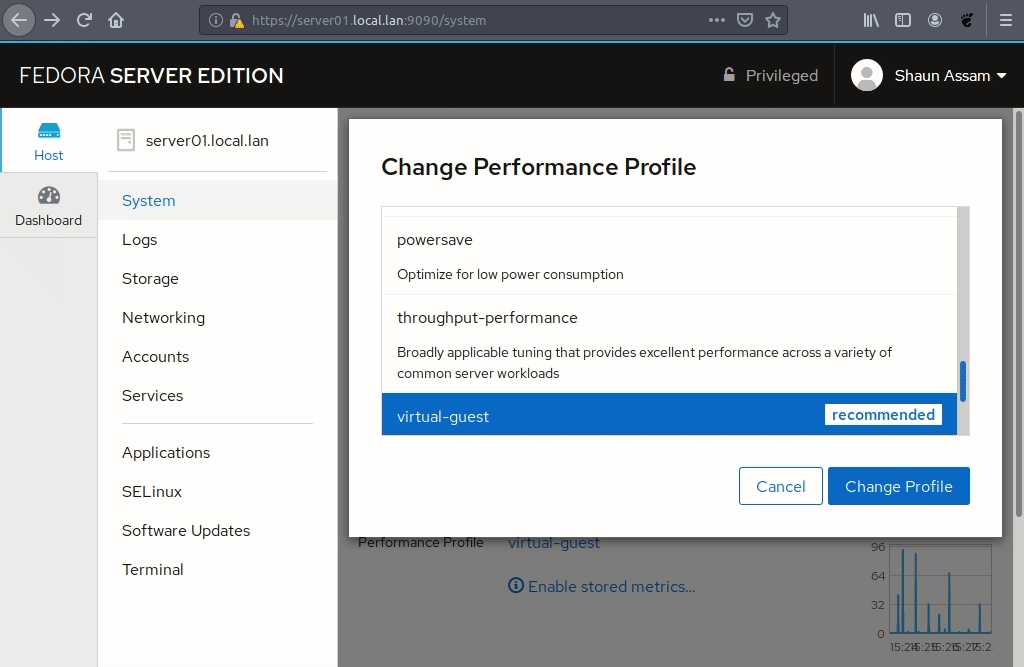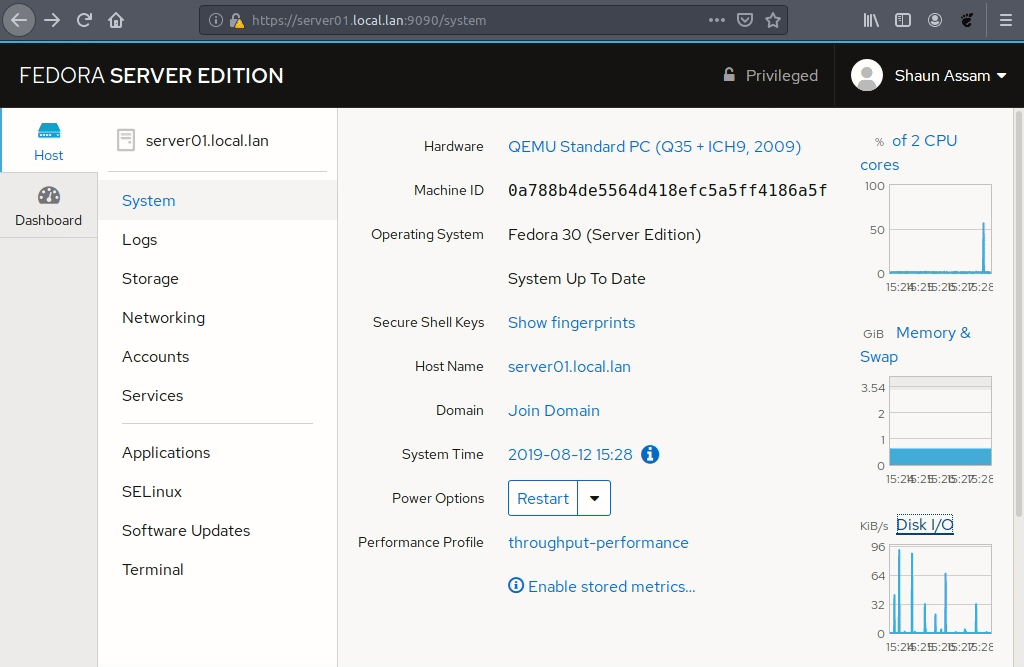
## Terminal web console
A Linux sysadmin’s toolbox would be useless without access to a terminal. This allows admins to fine-tune the server beyond what’s available in Cockpit. With the addition of themes, admins can quickly adjust the text and background colours to suit their preference.
Also, if you type **exit** by mistake, click the *Reset* button in the top-right corner*. *This will provide a fresh screen with a flashing cursor.
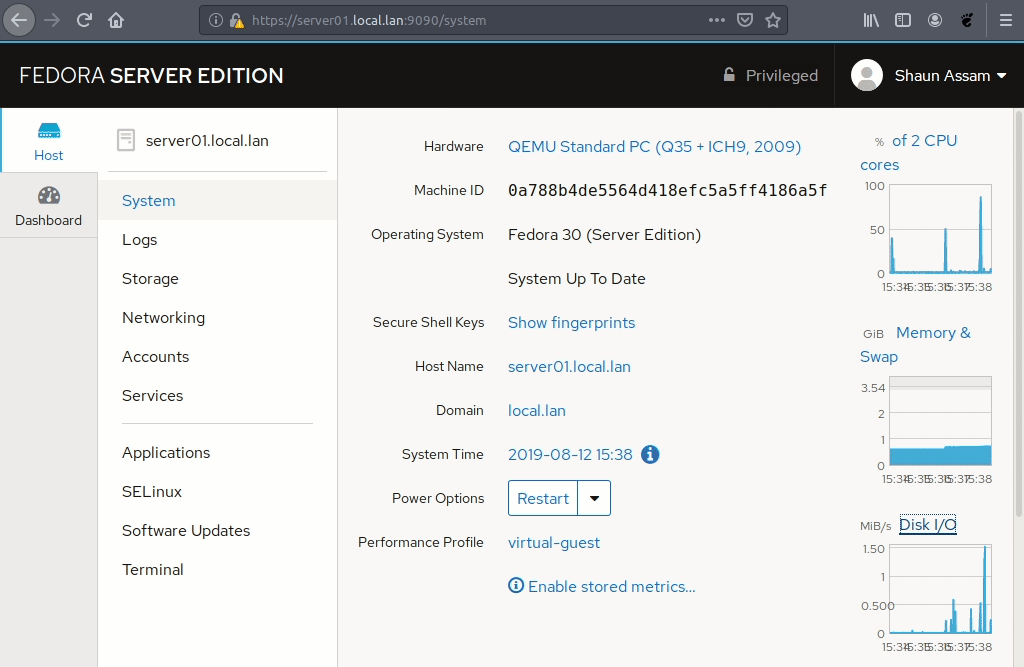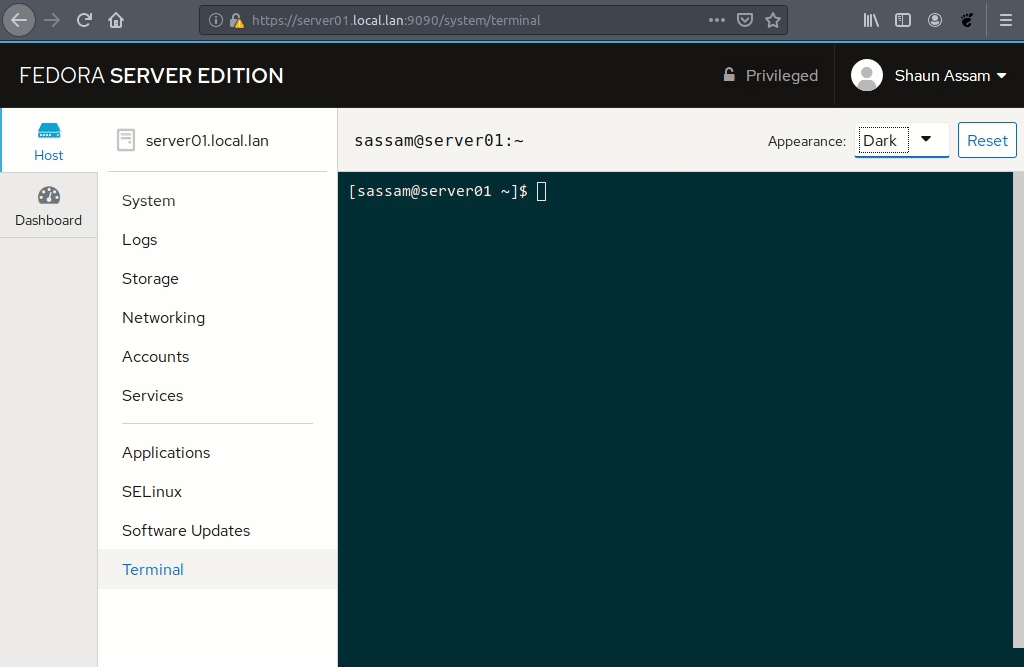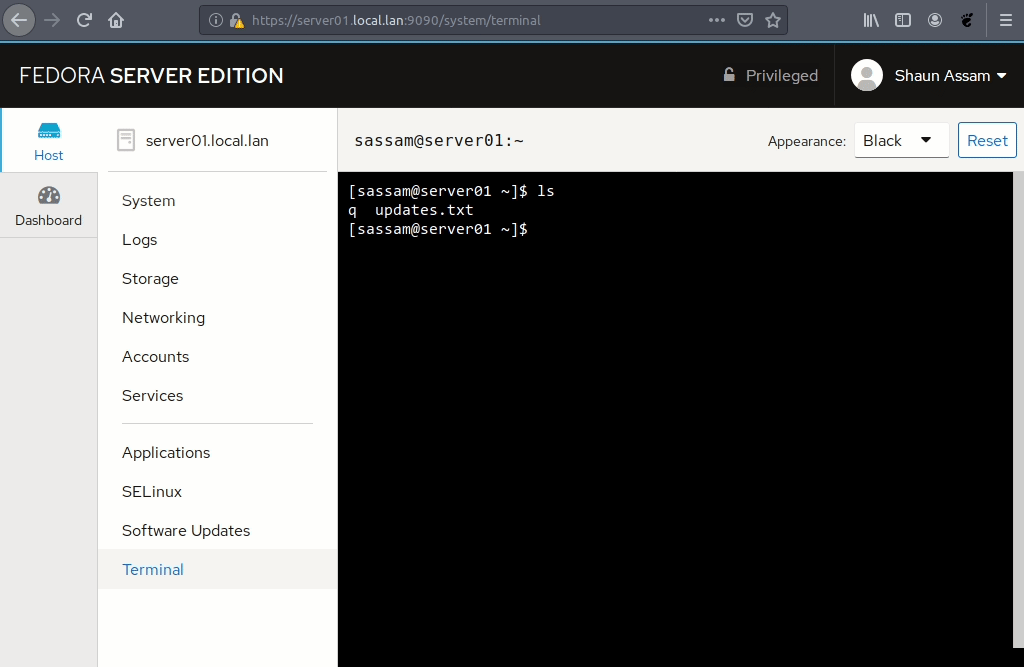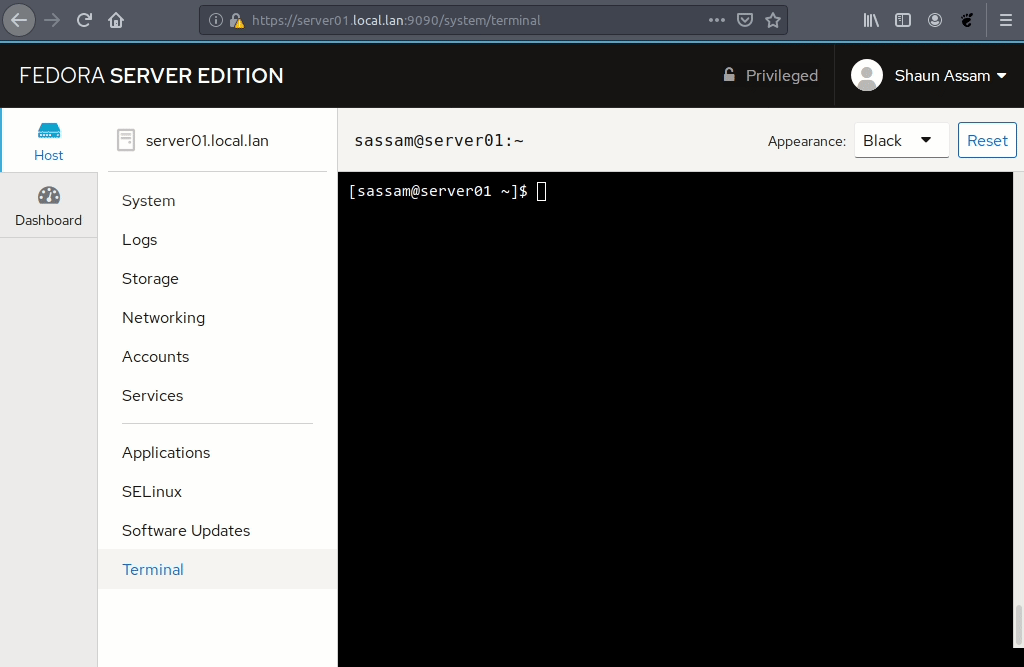
## Adding a remote server and the Dashboard overlay
The Headless Management group includes the Dashboard module (**cockpit-dashboard**). This provides an overview the of the CPU, memory, network, and disk performance in a real-time graph. Remote servers can also be added and managed through the same interface.
For example, to add a remote computer in Dashboard, click the **+** button. Enter the name or IP address of the server and select the colour of your choice. This helps to differentiate the stats of the servers in the graph. To switch between servers, click on the host name (as seen in the screen-cast below). To remove a server from the list, click the check-mark icon, then click the red trash icon. The example below demonstrates how Cockpit manages a remote machine named *server02.local.lan*.
## Documentation and finding help
As always, the *man* pages are a great place to find documentation. A simple search in the command-line results with pages pertaining to different aspects of using and configuring the web service.
$man -k cockpitcockpit (1) - Cockpit cockpit-bridge (1) - Cockpit Host Bridge cockpit-desktop (1) - Cockpit Desktop integration cockpit-ws (8) - Cockpit web service cockpit.conf (5) - Cockpit configuration file
The Fedora repository also has a package called **cockpit-doc**. The package’s description explains it best:
The Cockpit Deployment and Developer Guide shows sysadmins how to deploy Cockpit on their machines as well as helps developers who want to embed or extend Cockpit.
For more documentation visit [https://cockpit-project.org/external/source/HACKING](https://cockpit-project.org/external/source/HACKING)
## Conclusion
This article only touches upon some of the main functions available in Cockpit. Managing storage devices, networking, user account, and software control will be covered in an upcoming article. In addition, optional extensions such as the 389 directory service, and the *cockpit-ostree* module used to handle packages in Fedora Silverblue.
The options continue to grow as more users adopt Cockpit. The interface is ideal for admins who want a light-weight interface to control their server(s).
What do you think about Cockpit? Share your experience and ideas in the comments below.
## Ondrej Kolin
Thanks for sharing this! Cockpit looks great and I am looking forward to see the bright future with complex monitoring, mantaining system, which is simple, secure, and yet powerful!
So far we will stick to Icinga as we sysadmins are so conservative about techs and setups.
## Andreas P
I love Cockpit, I use it for my home computers and it works like a charm. Cockpit being so much developed right now makes it like christmas every update with new features and patches. A must have if you ask me!
## Eric Mesa
I’ve been using it for a few years now to manage my headless servers and I love it! It gives me a GUI for those times when I don’t want to remember all the commandline switches for a particular command. Also, I’m a visual person, so the graphs really help.
## Mark
Thanks for this, it has been a while since I looked at cockpit and it has certainly improved.
I’ve had another look at it after this post and what seems to be most useful (to me anyway) is the ability to add additional servers to the dashboard performance display; rather than having to logon to multiple servers to run iotop/iftop/top/sar to find a performance bottleneck the dashboard can at least give an indication of what is happening across all servers of interest to provide a starting point in hunting down active issues.
Hopefully in the future it will integrate into things like lm_sensors and virt-top to provide further useful graphs on the dashboard.
But as it currently exists it is already a useful tool.
## AsciiWolf
Nice article, thanks! Looking forward to similar article about Fleet Commander. 🙂
## Thomas
Nice article, thanks.
On the occasion of cockpit being talked about… maybe someone ’round here can shed some light: I still haven’t figured out what to do (and how) in order to make cockpit being available as a location in my nginx config.
See, I’d like to be able to serve cockpit under a path like {myserver}/console instead of {myserver}:9090. And although it should work in theory by following some sparse instructions available on the internet it actually does not.
Someone’s got a clue? Or even, whohoo, a working setup? TIA, Thomas
## Randy
I have a valid Let’s Encrypt Cert for my server. It works on every other service I use on my server. How do I make my LE Cert work with cockpit? It keeps telling me that the cert is invalid every time I go to https://my.domain:9090 I can just as easily accept the invalid cert, but I’d like it to use the valid cert already on the system, verified valid today with certbot.
I have never controlled the server with a GUI or WebUI before but I figured I’d give it a try with the new Cockpit.
## Ilias
You will need to symlink your LE certificate to the
directory. See https://cockpit-project.org/guide/149/https.html
## Thomas
Randy, I guess that varies a lot depending on which web server you are running… in my case it’s Nginx – and regarding how to make it play with cockpit, I found the following sites to be helpful.
( Well, let’s say “interesting” at least, since I wasn’t able to solve my issues. Maybe it helps you to gather more insight. )
https://github.com/cockpit-project/cockpit/wiki/Proxying-Cockpit-over-NGINX
https://cockpit-project.org/guide/latest/
HTH, Cheers, Thomas
## Thomas
Randy, me again. Check this:
https://github.com/cockpit-project/cockpit/wiki/Proxying-Cockpit-over-Apache-with-LetsEncrypt
And here’s a feature request from the cockpit wiki …that rather sounds like none of any currently availabe solutions works at all:
https://github.com/cockpit-project/cockpit/wiki/Feature:-Certificates
Cheers, Thomas |
12,326 | 微软称定制 Windows 10 是侵犯版权的行为 | https://news.softpedia.com/news/microsoft-claims-customizing-windows-10-is-a-copyright-violation-530284.shtml | 2020-06-18T10:34:00 | [
"Windows"
] | https://linux.cn/article-12326-1.html |
>
> 禁用“Windows 内置的恼人功能”也是如此。
>
>
>

自定义 Windows 10,禁用操作系统捆绑的一些功能,删除特定的应用,卸载一些组件,这些都是很多用户在安装微软操作系统后要做的事情。
然而,软件巨头微软却声称做这些其实是违反了 DMCA 的规定,虽然听起来很奇怪。
而 Ninjutsu OS 的开发者可能对此感受最深。

Ninjutsu 项目是专门以渗透测试为目的而打造的,它是一款 Windows 10 的重度定制版,配备了非常丰富的应用库,包括安全应用,用于帮助研究人员和专家进行各种测试和安全审计。
5 月 7 日发布的 Ninjutsu OS 声称要将 Windows 10 改造成一个渗透测试的强大堡垒,增加了大量针对安全专家的工具(约 800 个),还有一些针对普通用户的工具(例如 qBitTorrent),同时还删除了在这种环境下被认为不需要或不必要的功能。
它是基于 Windows 10 的,仍然需要微软操作系统的授权,所以从本质上来说,Ninjutsu OS 是 Windows 10 的定制版,它允许用户从一开始就预装一系列的应用,这样用户在安装操作系统后就不用再手动操作了。
但是,微软不喜欢这样,于是这个[托管在 GitHub 上的项目](https://github.com/ninjutsu-project/ninjutsu-project.github.io)遭到了商业软件联盟(BSA)代表微软发出的 [DMCA 投诉](https://github.com/github/dmca/blob/master/2020/06/2020-06-09-microsoft.md)。投诉中强调了 Ninjutsu OS 几项被指侵权的功能:
* 通过强大的调整和优化来定制 Windows 10。
* 通过调整和定制 Windows 10 来保护您的隐私。
* 禁用 Windows 内置的许多恼人的功能。
* 移除不需要的 Windows 组件。
* 删除/禁用许多 Windows 程序和服务。
根据投诉,Ninjutsu OS 在其 GitHub 页面上提到的上述行为提供了一个“绕过软件技术限制的工作”,这应该是违反了微软的软件许可条款。
乍一看,有些人可能会得出这样的结论:Ninjutsu OS 相当于一个经过大量修改却又盗版的 Windows 10。然而,[一段解释软件工作原理的视频](https://www.youtube.com/watch?v=asIlFqYXXxU)表明,用户实际上需要自己的正版 Windows 10 的授权才能让这些修改正常运行。
有趣的是,DMCA 投诉中提到的自定义和隐私功能其实是由其他第三方应用提供的,比如 [Win10-Initial-Setup-Script](https://github.com/Disassembler0/Win10-Initial-Setup-Script) 和 [O&O ShutUp10](https://www.oo-software.com/en/shutup10),它们仍然可以下载(后者没有托管在 GitHub 上)。
所以现在,在 DMCA 投诉之后,Ninjutsu OS 已经无法下载了,因为微软旗下的 GitHub 已经拿到了该操作系统镜像的链接。
对于这件事,你怎么看?
---
via: <https://news.softpedia.com/news/microsoft-claims-customizing-windows-10-is-a-copyright-violation-530284.shtml>
作者:[Bogdan Popa](https://news.softpedia.com/editors/browse/bogdan-popa "Editor profile and more articles by Bogdan Popa") 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12327-1.html) 荣誉推出
| 403 | Forbidden | null |
12,327 | 用 Python 绘制数据的7种最流行的方法 | https://opensource.com/article/20/4/plot-data-python | 2020-06-18T00:11:51 | [
"绘图"
] | https://linux.cn/article-12327-1.html | 
>
> 比较七个在 Python 中绘图的库和 API,看看哪个最能满足你的需求。
>
>
>
“如何在 Python 中绘图?”曾经这个问题有一个简单的答案:Matplotlib 是唯一的办法。如今,Python 作为数据科学的语言,有着更多的选择。你应该用什么呢?
本指南将帮助你决定。
它将向你展示如何使用四个最流行的 Python 绘图库:Matplotlib、Seaborn、Plotly 和 Bokeh,再加上两个值得考虑的优秀的后起之秀:Altair,拥有丰富的 API;Pygal,拥有漂亮的 SVG 输出。我还会看看 Pandas 提供的非常方便的绘图 API。
对于每一个库,我都包含了源代码片段,以及一个使用 [Anvil](https://anvil.works/) 的完整的基于 Web 的例子。Anvil 是我们的平台,除了 Python 之外,什么都不用做就可以构建网络应用。让我们一起来看看。
### 示例绘图
每个库都采取了稍微不同的方法来绘制数据。为了比较它们,我将用每个库绘制同样的图,并给你展示源代码。对于示例数据,我选择了这张 1966 年以来英国大选结果的分组柱状图。

我从维基百科上整理了[英国选举史的数据集](https://en.wikipedia.org/wiki/United_Kingdom_general_elections_overview):从 1966 年到 2019 年,保守党、工党和自由党(广义)在每次选举中赢得的英国议会席位数,加上“其他”赢得的席位数。你可以[以 CSV 文件格式下载它](https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv)。
### Matplotlib
[Matplotlib](https://matplotlib.org/) 是最古老的 Python 绘图库,现在仍然是最流行的。它创建于 2003 年,是 [SciPy Stack](https://www.scipy.org/about.html) 的一部分,SciPy Stack 是一个类似于 [Matlab](https://www.mathworks.com/products/matlab.html) 的开源科学计算库。
Matplotlib 为你提供了对绘制的精确控制。例如,你可以在你的条形图中定义每个条形图的单独的 X 位置。下面是绘制这个图表的代码(你可以在[这里](https://anvil.works/blog/plotting-in-matplotlib)运行):
```
import matplotlib.pyplot as plt
import numpy as np
from votes import wide as df
# Initialise a figure. subplots() with no args gives one plot.
fig, ax = plt.subplots()
# A little data preparation
years = df['year']
x = np.arange(len(years))
# Plot each bar plot. Note: manually calculating the 'dodges' of the bars
ax.bar(x - 3*width/2, df['conservative'], width, label='Conservative', color='#0343df')
ax.bar(x - width/2, df['labour'], width, label='Labour', color='#e50000')
ax.bar(x + width/2, df['liberal'], width, label='Liberal', color='#ffff14')
ax.bar(x + 3*width/2, df['others'], width, label='Others', color='#929591')
# Customise some display properties
ax.set_ylabel('Seats')
ax.set_title('UK election results')
ax.set_xticks(x) # This ensures we have one tick per year, otherwise we get fewer
ax.set_xticklabels(years.astype(str).values, rotation='vertical')
ax.legend()
# Ask Matplotlib to show the plot
plt.show()
```
这是用 Matplotlib 绘制的选举结果:

### Seaborn
[Seaborn](https://seaborn.pydata.org/) 是 Matplotlib 之上的一个抽象层;它提供了一个非常整洁的界面,让你可以非常容易地制作出各种类型的有用绘图。
不过,它并没有在能力上有所妥协!Seaborn 提供了访问底层 Matplotlib 对象的[逃生舱口](https://anvil.works/blog/escape-hatches-and-ejector-seats),所以你仍然可以进行完全控制。
Seaborn 的代码比原始的 Matplotlib 更简单(可在[此处](https://anvil.works/blog/plotting-in-seaborn)运行):
```
import seaborn as sns
from votes import long as df
# Some boilerplate to initialise things
sns.set()
plt.figure()
# This is where the actual plot gets made
ax = sns.barplot(data=df, x="year", y="seats", hue="party", palette=['blue', 'red', 'yellow', 'grey'], saturation=0.6)
# Customise some display properties
ax.set_title('UK election results')
ax.grid(color='#cccccc')
ax.set_ylabel('Seats')
ax.set_xlabel(None)
ax.set_xticklabels(df["year"].unique().astype(str), rotation='vertical')
# Ask Matplotlib to show it
plt.show()
```
并生成这样的图表:

### Plotly
[Plotly](https://plot.ly/) 是一个绘图生态系统,它包括一个 Python 绘图库。它有三个不同的接口:
1. 一个面向对象的接口。
2. 一个命令式接口,允许你使用类似 JSON 的数据结构来指定你的绘图。
3. 类似于 Seaborn 的高级接口,称为 Plotly Express。
Plotly 绘图被设计成嵌入到 Web 应用程序中。Plotly 的核心其实是一个 JavaScript 库!它使用 [D3](https://d3js.org/) 和 [stack.gl](http://stack.gl/) 来绘制图表。
你可以通过向该 JavaScript 库传递 JSON 来构建其他语言的 Plotly 库。官方的 Python 和 R 库就是这样做的。在 Anvil,我们将 Python Plotly API 移植到了 [Web 浏览器中运行](https://anvil.works/docs/client/components/plots)。
这是使用 Plotly 的源代码(你可以在这里[运行](https://anvil.works/blog/plotting-in-plotly)):
```
import plotly.graph_objects as go
from votes import wide as df
# Get a convenient list of x-values
years = df['year']
x = list(range(len(years)))
# Specify the plots
bar_plots = [
go.Bar(x=x, y=df['conservative'], name='Conservative', marker=go.bar.Marker(color='#0343df')),
go.Bar(x=x, y=df['labour'], name='Labour', marker=go.bar.Marker(color='#e50000')),
go.Bar(x=x, y=df['liberal'], name='Liberal', marker=go.bar.Marker(color='#ffff14')),
go.Bar(x=x, y=df['others'], name='Others', marker=go.bar.Marker(color='#929591')),
]
# Customise some display properties
layout = go.Layout(
title=go.layout.Title(text="Election results", x=0.5),
yaxis_title="Seats",
xaxis_tickmode="array",
xaxis_tickvals=list(range(27)),
xaxis_ticktext=tuple(df['year'].values),
)
# Make the multi-bar plot
fig = go.Figure(data=bar_plots, layout=layout)
# Tell Plotly to render it
fig.show()
```
选举结果图表:

### Bokeh
[Bokeh](https://docs.bokeh.org/en/latest/index.html)(发音为 “BOE-kay”)擅长构建交互式绘图,所以这个标准的例子并没有将其展现其最好的一面。和 Plotly 一样,Bokeh 的绘图也是为了嵌入到 Web 应用中,它以 HTML 文件的形式输出绘图。
下面是使用 Bokeh 的代码(你可以在[这里](https://anvil.works/blog/plotting-in-bokeh)运行):
```
from bokeh.io import show, output_file
from bokeh.models import ColumnDataSource, FactorRange, HoverTool
from bokeh.plotting import figure
from bokeh.transform import factor_cmap
from votes import long as df
# Specify a file to write the plot to
output_file("elections.html")
# Tuples of groups (year, party)
x = [(str(r[1]['year']), r[1]['party']) for r in df.iterrows()]
y = df['seats']
# Bokeh wraps your data in its own objects to support interactivity
source = ColumnDataSource(data=dict(x=x, y=y))
# Create a colourmap
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
fill_color = factor_cmap('x', palette=list(cmap.values()), factors=list(cmap.keys()), start=1, end=2)
# Make the plot
p = figure(x_range=FactorRange(*x), width=1200, title="Election results")
p.vbar(x='x', top='y', width=0.9, source=source, fill_color=fill_color, line_color=fill_color)
# Customise some display properties
p.y_range.start = 0
p.x_range.range_padding = 0.1
p.yaxis.axis_label = 'Seats'
p.xaxis.major_label_orientation = 1
p.xgrid.grid_line_color = None
```
图表如下:

### Altair
[Altair](https://altair-viz.github.io/) 是基于一种名为 [Vega](https://vega.github.io/vega/) 的声明式绘图语言(或“可视化语法”)。这意味着它具有经过深思熟虑的 API,可以很好地扩展复杂的绘图,使你不至于在嵌套循环的地狱中迷失方向。
与 Bokeh 一样,Altair 将其图形输出为 HTML 文件。这是代码(你可以在[这里](https://anvil.works/blog/plotting-in-altair)运行):
```
import altair as alt
from votes import long as df
# Set up the colourmap
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
# Cast years to strings
df['year'] = df['year'].astype(str)
# Here's where we make the plot
chart = alt.Chart(df).mark_bar().encode(
x=alt.X('party', title=None),
y='seats',
column=alt.Column('year', sort=list(df['year']), title=None),
color=alt.Color('party', scale=alt.Scale(domain=list(cmap.keys()), range=list(cmap.values())))
)
# Save it as an HTML file.
chart.save('altair-elections.html')
```
结果图表:

### Pygal
[Pygal](http://www.pygal.org/en/stable/) 专注于视觉外观。它默认生成 SVG 图,所以你可以无限放大它们或打印出来,而不会被像素化。Pygal 绘图还内置了一些很好的交互性功能,如果你想在 Web 应用中嵌入绘图,Pygal 是另一个被低估了的候选者。
代码是这样的(你可以在[这里](https://anvil.works/blog/plotting-in-pygal)运行它):
```
import pygal
from pygal.style import Style
from votes import wide as df
# Define the style
custom_style = Style(
colors=('#0343df', '#e50000', '#ffff14', '#929591')
font_family='Roboto,Helvetica,Arial,sans-serif',
background='transparent',
label_font_size=14,
)
# Set up the bar plot, ready for data
c = pygal.Bar(
title="UK Election Results",
style=custom_style,
y_title='Seats',
width=1200,
x_label_rotation=270,
)
# Add four data sets to the bar plot
c.add('Conservative', df['conservative'])
c.add('Labour', df['labour'])
c.add('Liberal', df['liberal'])
c.add('Others', df['others'])
# Define the X-labels
c.x_labels = df['year']
# Write this to an SVG file
c.render_to_file('pygal.svg')
```
绘制结果:

### Pandas
[Pandas](https://pandas.pydata.org/) 是 Python 的一个极其流行的数据科学库。它允许你做各种可扩展的数据处理,但它也有一个方便的绘图 API。因为它直接在数据帧上操作,所以 Pandas 的例子是本文中最简洁的代码片段,甚至比 Seaborn 的代码还要短!
Pandas API 是 Matplotlib 的一个封装器,所以你也可以使用底层的 Matplotlib API 来对你的绘图进行精细的控制。
这是 Pandas 中的选举结果图表。代码精美简洁!
```
from matplotlib.colors import ListedColormap
from votes import wide as df
cmap = ListedColormap(['#0343df', '#e50000', '#ffff14', '#929591'])
ax = df.plot.bar(x='year', colormap=cmap)
ax.set_xlabel(None)
ax.set_ylabel('Seats')
ax.set_title('UK election results')
plt.show()
```
绘图结果:

要运行这个例子,请看[这里](https://anvil.works/blog/plotting-in-pandas)。
### 以你的方式绘制
Python 提供了许多绘制数据的方法,无需太多的代码。虽然你可以通过这些方法快速开始创建你的绘图,但它们确实需要一些本地配置。如果需要,[Anvil](https://anvil.works/) 为 Python 开发提供了精美的 Web 体验。祝你绘制愉快!
---
via: <https://opensource.com/article/20/4/plot-data-python>
作者:[Shaun Taylor-Morgan](https://opensource.com/users/shaun-taylor-morgan "View user profile.") 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12324-1.html) 荣誉推出
| 200 | OK | "How do I make plots in Python?" used to have a simple answer: Matplotlib was the only way. Nowadays, Python is the language of [data science](https://opensource.com/resources/data-science), and there's a lot more choice. What should you use?
This guide will help you decide. It will show you how to use each of the four most popular Python plotting libraries—**Matplotlib**, **Seaborn**, **Plotly**, and **Bokeh**—plus a couple of great up-and-comers to consider: **Altair**, with its expressive API, and **Pygal**, with its beautiful SVG output. I'll also look at the very convenient plotting API provided by **pandas**.
For each library, I've included source code snippets, as well as a full web-based example using [Anvil](https://anvil.works/), our platform for building web apps with nothing but Python. Let's take a look.
## An example plot
Each library takes a slightly different approach to plotting data. To compare them, I'll make the same plot with each library and show you the source code. For my example data, I chose this grouped bar chart of British election results since 1966:
I compiled the [dataset of British election history](https://en.wikipedia.org/wiki/United_Kingdom_general_elections_overview) from Wikipedia: the number of seats in the UK parliament won by the Conservative, Labour, and Liberal parties (broadly defined) in each election from 1966 to 2019, plus the number of seats won by "others." You can [download it as a CSV file](https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv).
## Matplotlib
[Matplotlib](https://matplotlib.org/) is the oldest Python plotting library, and it's still the most popular. It was created in 2003 as part of the [SciPy Stack](https://www.scipy.org/about.html), an open source scientific computing library similar to [Matlab](https://www.mathworks.com/products/matlab.html).
Matplotlib gives you precise control over your plots—for example, you can define the individual x-position of each bar in your barplot. Here is the code to graph this (which you can run [here](https://anvil.works/blog/plotting-in-matplotlib)):
```
import matplotlib.pyplot as plt
import numpy as np
from votes import wide as df
# Initialise a figure. subplots() with no args gives one plot.
fig, ax = plt.subplots()
# A little data preparation
years = df['year']
x = np.arange(len(years))
# Plot each bar plot. Note: manually calculating the 'dodges' of the bars
ax.bar(x - 3*width/2, df['conservative'], width, label='Conservative', color='#0343df')
ax.bar(x - width/2, df['labour'], width, label='Labour', color='#e50000')
ax.bar(x + width/2, df['liberal'], width, label='Liberal', color='#ffff14')
ax.bar(x + 3*width/2, df['others'], width, label='Others', color='#929591')
# Customise some display properties
ax.set_ylabel('Seats')
ax.set_title('UK election results')
ax.set_xticks(x) # This ensures we have one tick per year, otherwise we get fewer
ax.set_xticklabels(years.astype(str).values, rotation='vertical')
ax.legend()
# Ask Matplotlib to show the plot
plt.show()
```
And here are the election results plotted in Matplotlib:
## Seaborn
[Seaborn](https://seaborn.pydata.org/) is an abstraction layer on top of Matplotlib; it gives you a really neat interface to make a wide range of useful plot types very easily.
It doesn't compromise on power, though! Seaborn gives [escape hatches](https://anvil.works/blog/escape-hatches-and-ejector-seats) to access the underlying Matplotlib objects, so you still have complete control.
Seaborn's code is simpler than the raw Matplotlib (runnable [here](https://anvil.works/blog/plotting-in-seaborn)):
```
import seaborn as sns
from votes import long as df
# Some boilerplate to initialise things
sns.set()
plt.figure()
# This is where the actual plot gets made
ax = sns.barplot(data=df, x="year", y="seats", hue="party", palette=['blue', 'red', 'yellow', 'grey'], saturation=0.6)
# Customise some display properties
ax.set_title('UK election results')
ax.grid(color='#cccccc')
ax.set_ylabel('Seats')
ax.set_xlabel(None)
ax.set_xticklabels(df["year"].unique().astype(str), rotation='vertical')
# Ask Matplotlib to show it
plt.show()
```
And produces this chart:
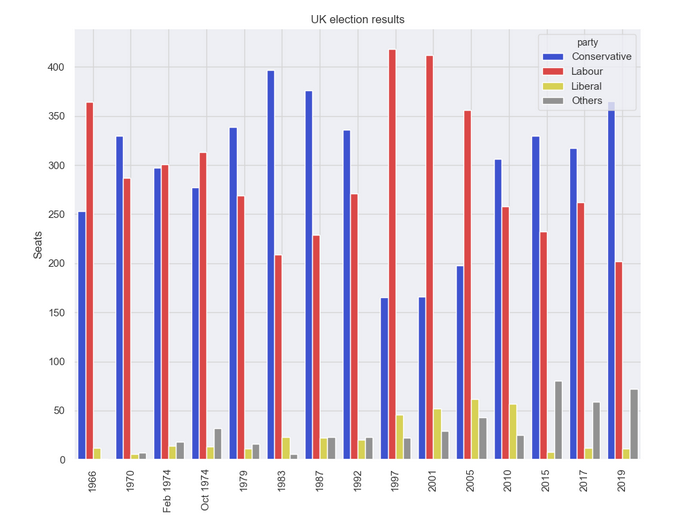
## Plotly
[Plotly](https://plot.ly/) is a plotting ecosystem that includes a Python plotting library. It has three different interfaces:
- An object-oriented interface
- An imperative interface that allows you to specify your plot using JSON-like data structures
- A high-level interface similar to Seaborn called Plotly Express
Plotly plots are designed to be embedded in web apps. At its core, Plotly is actually a JavaScript library! It uses [D3](https://d3js.org/) and [stack.gl](http://stack.gl/) to draw the plots.
You can build Plotly libraries in other languages by passing JSON to the JavaScript library. The official Python and R libraries do just that. At Anvil, we ported the Python Plotly API to [run in the web browser](https://anvil.works/docs/client/components/plots).
Here's the source code in Plotly (which you can run [here](https://anvil.works/blog/plotting-in-plotly)):
```
import plotly.graph_objects as go
from votes import wide as df
# Get a convenient list of x-values
years = df['year']
x = list(range(len(years)))
# Specify the plots
bar_plots = [
go.Bar(x=x, y=df['conservative'], name='Conservative', marker=go.bar.Marker(color='#0343df')),
go.Bar(x=x, y=df['labour'], name='Labour', marker=go.bar.Marker(color='#e50000')),
go.Bar(x=x, y=df['liberal'], name='Liberal', marker=go.bar.Marker(color='#ffff14')),
go.Bar(x=x, y=df['others'], name='Others', marker=go.bar.Marker(color='#929591')),
]
# Customise some display properties
layout = go.Layout(
title=go.layout.Title(text="Election results", x=0.5),
yaxis_title="Seats",
xaxis_tickmode="array",
xaxis_tickvals=list(range(27)),
xaxis_ticktext=tuple(df['year'].values),
)
# Make the multi-bar plot
fig = go.Figure(data=bar_plots, layout=layout)
# Tell Plotly to render it
fig.show()
```
And the election results plot:
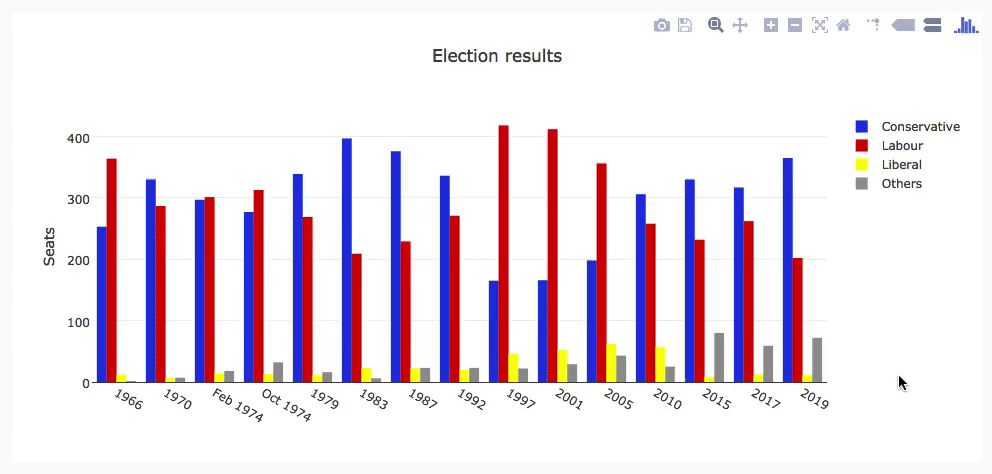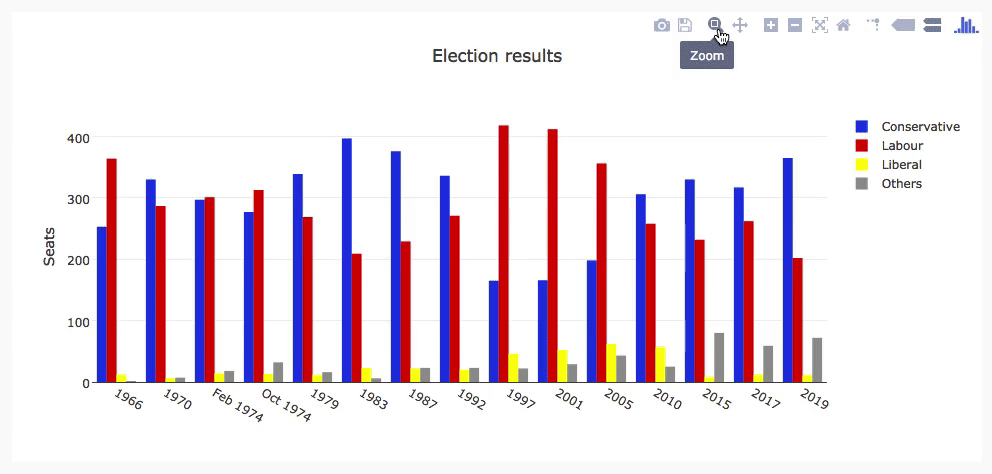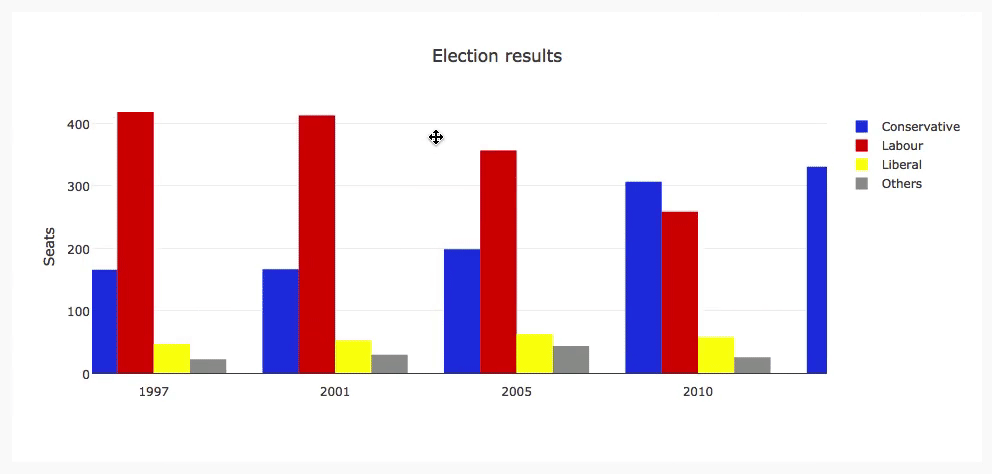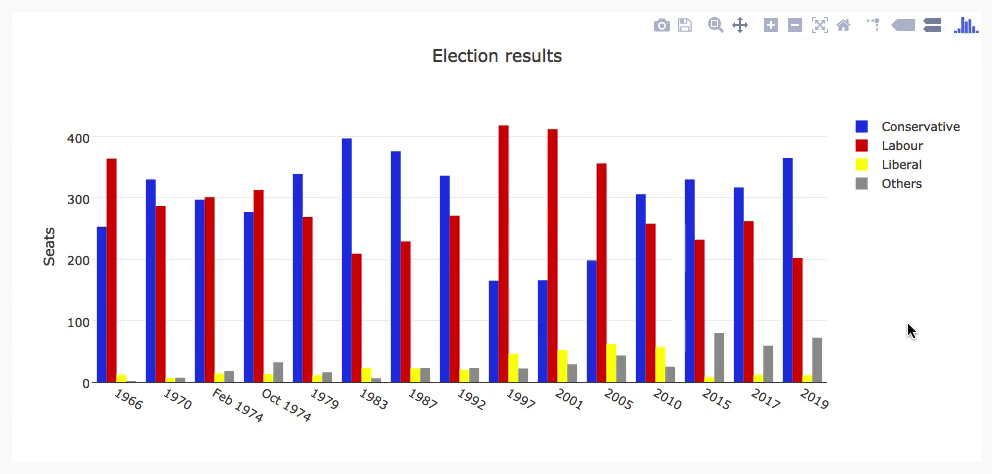
## Bokeh
[Bokeh](https://docs.bokeh.org/en/latest/index.html) (pronounced "BOE-kay") specializes in building interactive plots, so this standard example doesn't show it off to its best. Like Plotly, Bokeh's plots are designed to be embedded in web apps; it outputs its plots as HTML files.
Here is the code in Bokeh (which you can run [here](https://anvil.works/blog/plotting-in-bokeh))
```
from bokeh.io import show, output_file
from bokeh.models import ColumnDataSource, FactorRange, HoverTool
from bokeh.plotting import figure
from bokeh.transform import factor_cmap
from votes import long as df
# Specify a file to write the plot to
output_file("elections.html")
# Tuples of groups (year, party)
x = [(str(r[1]['year']), r[1]['party']) for r in df.iterrows()]
y = df['seats']
# Bokeh wraps your data in its own objects to support interactivity
source = ColumnDataSource(data=dict(x=x, y=y))
# Create a colourmap
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
fill_color = factor_cmap('x', palette=list(cmap.values()), factors=list(cmap.keys()), start=1, end=2)
# Make the plot
p = figure(x_range=FactorRange(*x), width=1200, title="Election results")
p.vbar(x='x', top='y', width=0.9, source=source, fill_color=fill_color, line_color=fill_color)
# Customise some display properties
p.y_range.start = 0
p.x_range.range_padding = 0.1
p.yaxis.axis_label = 'Seats'
p.xaxis.major_label_orientation = 1
p.xgrid.grid_line_color = None
```
And the plot:
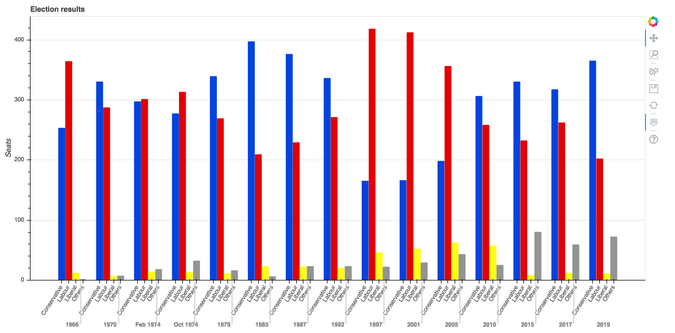
## Altair
[Altair](https://altair-viz.github.io/) is based on a declarative plotting language (or "visualization grammar") called [Vega](https://vega.github.io/vega/). This means it's a well-thought-through API that scales well for complex plots, saving you from getting lost in nested-for-loop hell.
As with Bokeh, Altair outputs its plots as HTML files. Here's the code (which you can run [here](https://anvil.works/blog/plotting-in-altair)):
```
import altair as alt
from votes import long as df
# Set up the colourmap
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
# Cast years to strings
df['year'] = df['year'].astype(str)
# Here's where we make the plot
chart = alt.Chart(df).mark_bar().encode(
x=alt.X('party', title=None),
y='seats',
column=alt.Column('year', sort=list(df['year']), title=None),
color=alt.Color('party', scale=alt.Scale(domain=list(cmap.keys()), range=list(cmap.values())))
)
# Save it as an HTML file.
chart.save('altair-elections.html')
```
And the resulting chart:
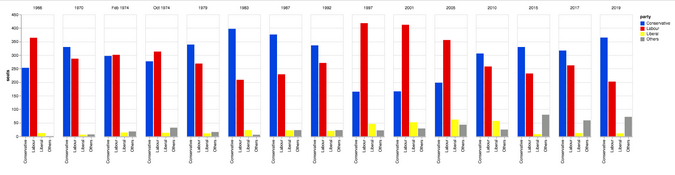
## Pygal
[Pygal](http://www.pygal.org/en/stable/) focuses on visual appearance. It produces SVG plots by default, so you can zoom them forever or print them out without them getting pixellated. Pygal plots also come with some good interactivity features built-in, making Pygal another underrated candidate if you're looking to embed plots in a web app.
The source code looks like this (and you can run it [here](https://anvil.works/blog/plotting-in-pygal)):
```
import pygal
from pygal.style import Style
from votes import wide as df
# Define the style
custom_style = Style(
colors=('#0343df', '#e50000', '#ffff14', '#929591')
font_family='Roboto,Helvetica,Arial,sans-serif',
background='transparent',
label_font_size=14,
)
# Set up the bar plot, ready for data
c = pygal.Bar(
title="UK Election Results",
style=custom_style,
y_title='Seats',
width=1200,
x_label_rotation=270,
)
# Add four data sets to the bar plot
c.add('Conservative', df['conservative'])
c.add('Labour', df['labour'])
c.add('Liberal', df['liberal'])
c.add('Others', df['others'])
# Define the X-labels
c.x_labels = df['year']
# Write this to an SVG file
c.render_to_file('pygal.svg')
```
And the chart:
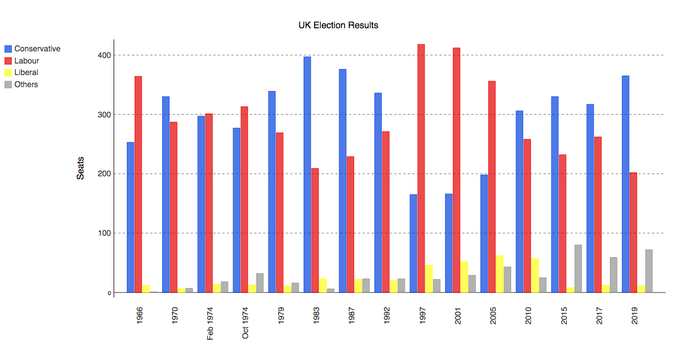
## Pandas
[Pandas](https://pandas.pydata.org/) is an extremely popular data science library for Python. It allows you to do all sorts of data manipulation scalably, but it also has a convenient plotting API. Because it operates directly on data frames, the pandas example is the most concise code snippet in this article—even shorter than the Seaborn code!
The pandas API is a wrapper around Matplotlib, so you can also use the underlying Matplotlib API to get fine-grained control of your plots.
Here's the election results plot in pandas. The code is beautifully concise!
```
from matplotlib.colors import ListedColormap
from votes import wide as df
cmap = ListedColormap(['#0343df', '#e50000', '#ffff14', '#929591'])
ax = df.plot.bar(x='year', colormap=cmap)
ax.set_xlabel(None)
ax.set_ylabel('Seats')
ax.set_title('UK election results')
plt.show()
```
And the resulting chart:
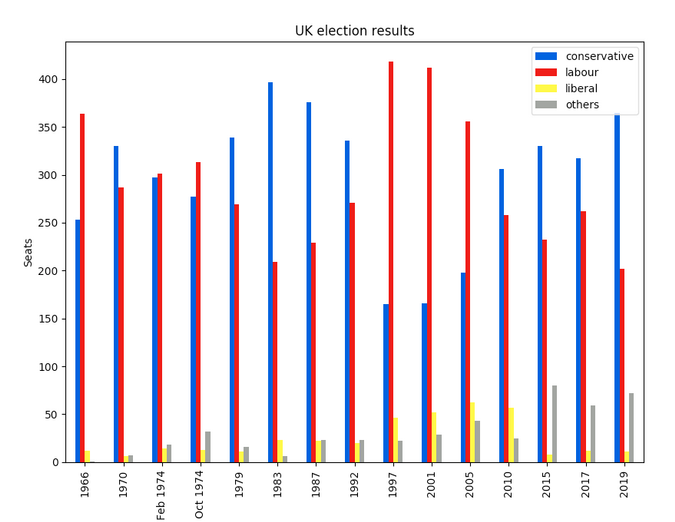
To run this example, check out [here](https://anvil.works/blog/plotting-in-pandas).
## Plot your way
Python offers many ways to plot the same data without much code. While you can get started quickly creating charts with any of these methods, they do take some local configuration. [Anvil](https://anvil.works/) offers a beautiful web-based experience for Python development if you're in need. Happy plotting!
*This article is based on Plotting in Python: comparing the options on Anvil's blog and is reused with permission.*
## 5 Comments |
12,329 | 使用 Bokeh 为你的 Python 绘图添加交互性 | https://opensource.com/article/20/5/bokeh-python | 2020-06-18T16:47:00 | [
"Python",
"绘图"
] | https://linux.cn/article-12329-1.html |
>
> 在 Bokeh 中绘图比其他一些绘图库要复杂一些,但付出额外的努力是有回报的。
>
>
>

在这一系列文章中,我通过在每个 Python 绘图库中制作相同的多条形绘图,来研究不同 Python 绘图库的特性。这次我重点介绍的是 [Bokeh](https://bokeh.org/)(读作 “BOE-kay”)。
Bokeh 中的绘图比[其它一些绘图库](/article-12327-1.html)要复杂一些,但付出的额外努力是有回报的。Bokeh 的设计既允许你在 Web 上创建自己的交互式绘图,又能让你详细控制交互性如何工作。我将通过给我在这个系列中一直使用的多条形图添加工具提示来展示这一点。它绘制了 1966 年到 2020 年之间英国选举结果的数据。

*绘图的放大视图(©2019 年 [Anvil](https://anvil.works/blog/plotting-in-bokeh))*
### 制作多条形图
在我们继续之前,请注意你可能需要调整你的 Python 环境来让这段代码运行,包括以下:
* 运行最新版本的 Python (在 [Linux](https://opensource.com/article/20/4/install-python-linux)、[Mac](https://opensource.com/article/19/5/python-3-default-mac) 和 [Windows](https://opensource.com/article/19/8/how-install-python-windows) 上的说明)
* 确认你运行的 Python 版本能与这些库一起工作。
数据可在线获得,可以用 Pandas 导入。
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
现在我们可以继续进行了。
为了做出多条形图,你需要对你的数据进行一下调整。
原始数据是这样的:
```
>> print(long)
year party seats
0 1966 Conservative 253
1 1970 Conservative 330
2 Feb 1974 Conservative 297
3 Oct 1974 Conservative 277
4 1979 Conservative 339
.. ... ... ...
103 2005 Others 30
104 2010 Others 29
105 2015 Others 80
106 2017 Others 59
107 2019 Others 72
[60 rows x 3 columns]
```
你可以把数据看成是每一个可能的 `(year, party)` 组合的一系列 `seats` 值。这正是 Bokeh 处理的方式。你需要做一个 `(year, party)` 元组的列表:
```
# 得到每种可能的 (year, party) 组合的元组
x = [(str(r[1]['year']), r[1]['party']) for r in df.iterrows()]
# This comes out as [('1922', 'Conservative'), ('1923', 'Conservative'), ... ('2019', 'Others')]
```
这些将是 `x` 值。`y` 值就是席位(`seats`)。
```
y = df['seats']
```
现在你的数据看起来应该像这样:
```
x y
('1966', 'Conservative') 253
('1970', 'Conservative') 330
('Feb 1974', 'Conservative') 297
('Oct 1974', 'Conservative') 277
('1979', 'Conservative') 339
... ... ...
('2005', 'Others') 30
('2010', 'Others') 29
('2015', 'Others') 80
('2017', 'Others') 59
('2019', 'Others') 72
```
Bokeh 需要你将数据封装在它提供的一些对象中,这样它就能给你提供交互功能。将你的 `x` 和 `y` 数据结构封装在一个 `ColumnDataSource` 对象中。
```
from bokeh.models import ColumnDataSource
source = ColumnDataSource(data={'x': x, 'y': y})
```
然后构造一个 `Figure` 对象,并传入你用 `FactorRange` 对象封装的 `x` 数据。
```
from bokeh.plotting import figure
from bokeh.models import FactorRange
p = figure(x_range=FactorRange(*x), width=2000, title="Election results")
```
你需要让 Bokeh 创建一个颜色表,这是一个特殊的 `DataSpec` 字典,它根据你给它的颜色映射生成。在这种情况下,颜色表是一个简单的党派名称和一个十六进制值之间的映射。
```
from bokeh.transform import factor_cmap
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
fill_color = factor_cmap('x', palette=list(cmap.values()), factors=list(cmap.keys()), start=1, end=2)
```
现在你可以创建条形图了:
```
p.vbar(x='x', top='y', width=0.9, source=source, fill_color=fill_color, line_color=fill_color)
```
Bokeh 图表上数据的可视化形式被称为“<ruby> 字形 <rt> glyphs </rt></ruby>”,因此你已经创建了一组条形字形。
调整图表的细节,让它看起来像你想要的样子。
```
p.y_range.start = 0
p.x_range.range_padding = 0.1
p.yaxis.axis_label = 'Seats'
p.xaxis.major_label_orientation = 1
p.xgrid.grid_line_color = None
```
最后,告诉 Bokeh 你现在想看你的绘图:
```
from bokeh.io import show
show(p)
```
这将绘图写入一个 HTML 文件,并在默认的 Web 浏览器中打开它。如下结果:

*Bokeh 中的多条形绘图(©2019年[Anvil](https://anvil.works/blog/plotting-in-bokeh))*
它已经有了一些互动功能,比如盒子缩放。

*Bokeh 内置的盒子缩放(©2019[Anvil](https://anvil.works/blog/plotting-in-bokeh))*
但 Bokeh 的厉害之处在于你可以添加自己的交互性。在下一节中,我们通过在条形图中添加工具提示来探索这个问题。
### 给条形图添加工具提示
要在条形图上添加工具提示,你只需要创建一个 `HoverTool` 对象并将其添加到你的绘图中。
```
h = HoverTool(tooltips=[
('Seats', '@y'),
('(Year, Party)', '(@x)')
])
p.add_tools(h)
```
参数定义了哪些数据会显示在工具提示上。变量 `@y` 和 `@x` 是指你传入 `ColumnDataSource` 的变量。你还可以使用一些其他的值。例如,光标在图上的位置由 `$x` 和 `$y` 给出(与 `@x` 和 `@y` 没有关系)。
下面是结果:

*选举图,现在带有工具提示(© 2019 [Anvil](https://anvil.works/blog/plotting-in-bokeh))*
借助 Bokeh 的 HTML 输出,将绘图嵌入到 Web 应用中时,你可以获得完整的交互体验。你可以在[这里](https://anvil.works/build#clone:CFRUWSM6PQ6JUUXH%3dSX4SACDSXBB4UOIVEVPWXH55%7cMYTOLCU2HM5WKJYM%3d6VJKGRSF74TCCVDG5CTVDOCS)把这个例子复制为 Anvil 应用(注:Anvil 需要注册才能使用)。
现在,你可以看到付出额外努力在 Bokeh 中将所有数据封装在 `ColumnDataSource` 等对象的原因了。作为回报,你可以相对轻松地添加交互性。
### 回归简单:Altair
Bokeh 是四大最流行的绘图库之一,本系列将研究[它们各自的特别之处](https://opensource.com/article/20/4/plot-data-python)。
我也在研究几个因其有趣的方法而脱颖而出的库。接下来,我将看看 [Altair](https://altair-viz.github.io/),它的声明式 API 意味着它可以做出非常复杂的绘图,而不会让你头疼。
---
via: <https://opensource.com/article/20/5/bokeh-python>
作者:[Shaun Taylor-Morgan](https://opensource.com/users/shaun-taylor-morgan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this series of articles, I'm looking at the characteristics of different Python plotting libraries by making the same multi-bar plot in each one. This time I'm focusing on [Bokeh](https://bokeh.org/) (pronounced "BOE-kay").
Plotting in Bokeh is a little more complicated than in some of the [other plotting libraries](https://opensource.com/article/20/4/plot-data-python), but there's a payoff for the extra effort. Bokeh is designed both to allow you to create your own interactive plots on the web *and* to give you detailed control over how the interactivity works. I'll show this by adding a tooltip to the multi-bar plot I've been using in this series. It plots data from UK election results between 1966 and 2020.
A zoomed-in view on the plot (© 2019 Anvil)
## Making the multi-bar plot
Before we go further, note that you may need to tune your Python environment to get this code to run, including the following.
- Running a recent version of Python (instructions for
[Linux](https://opensource.com/article/20/4/install-python-linux),[Mac](https://opensource.com/article/19/5/python-3-default-mac), and[Windows](https://opensource.com/article/19/8/how-install-python-windows)) - Verify you're running a version of Python that works with these libraries
The data is available online and can be imported using pandas:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
Now we're ready to go.
To make the multi-bar plot, you need to massage your data a little.
The original data looks like this:
```
>> print(long)
year party seats
0 1966 Conservative 253
1 1970 Conservative 330
2 Feb 1974 Conservative 297
3 Oct 1974 Conservative 277
4 1979 Conservative 339
.. ... ... ...
103 2005 Others 30
104 2010 Others 29
105 2015 Others 80
106 2017 Others 59
107 2019 Others 72
[60 rows x 3 columns]
```
You can think of the data as a series of `seats`
values for each possible `(year, party)`
combination. That's exactly how Bokeh thinks of it. You need to make a list of `(year, party)`
tuples:
```
# Get a tuple for each possible (year, party) combination
x = [(str(r[1]['year']), r[1]['party']) for r in df.iterrows()]
# This comes out as [('1922', 'Conservative'), ('1923', 'Conservative'), ... ('2019', 'Others')]
```
These will be the x-values. The y-values are simply the seats:
`y = df['seats']`
Now you have data that looks something like this:
```
x y
('1966', 'Conservative') 253
('1970', 'Conservative') 330
('Feb 1974', 'Conservative') 297
('Oct 1974', 'Conservative') 277
('1979', 'Conservative') 339
... ... ...
('2005', 'Others') 30
('2010', 'Others') 29
('2015', 'Others') 80
('2017', 'Others') 59
('2019', 'Others') 72
```
Bokeh needs you to wrap your data in some objects it provides, so it can give you the interactive functionality. Wrap your x and y data structures in a `ColumnDataSource`
object:
```
from bokeh.models import ColumnDataSource
source = ColumnDataSource(data={'x': x, 'y': y})
```
Then construct a `Figure`
object and pass in your x-data wrapped in a `FactorRange`
object:
```
from bokeh.plotting import figure
from bokeh.models import FactorRange
p = figure(x_range=FactorRange(*x), width=2000, title="Election results")
```
You need to get Bokeh to create a colormap—this is a special `DataSpec`
dictionary it produces from a color mapping you give it. In this case, the colormap is a simple mapping between the party name and a hex value:
```
from bokeh.transform import factor_cmap
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
fill_color = factor_cmap('x', palette=list(cmap.values()), factors=list(cmap.keys()), start=1, end=2)
```
Now you can create the bar chart:
` p.vbar(x='x', top='y', width=0.9, source=source, fill_color=fill_color, line_color=fill_color)`
Visual representations of data on Bokeh charts are referred to as glyphs, so you've created a set of bar glyphs.
Tweak the details of the graph to get it looking how you want:
```
p.y_range.start = 0
p.x_range.range_padding = 0.1
p.yaxis.axis_label = 'Seats'
p.xaxis.major_label_orientation = 1
p.xgrid.grid_line_color = None
```
And finally, tell Bokeh you'd like to see your plot now:
```
from bokeh.io import show
show(p)
```
This writes the plot to an HTML file and opens it in the default web browser. Here's the result:
A multi-bar plot in Bokeh (© 2019 Anvil)
This already has some interactive features, such as a box zoom:
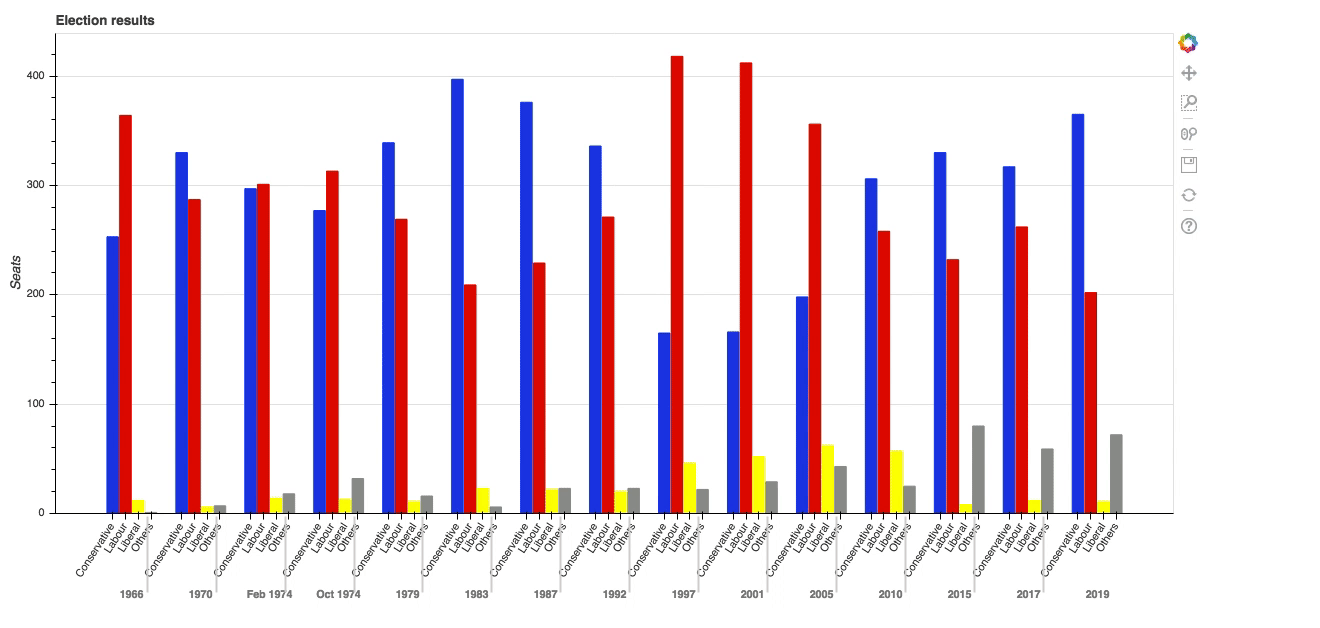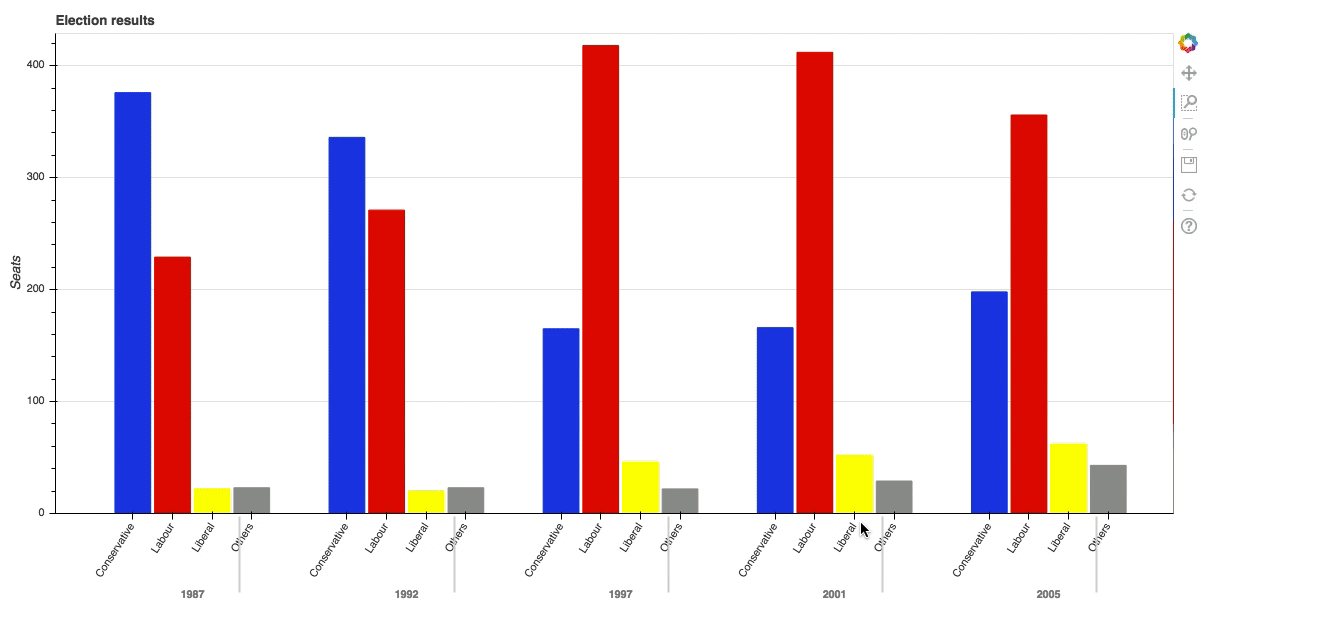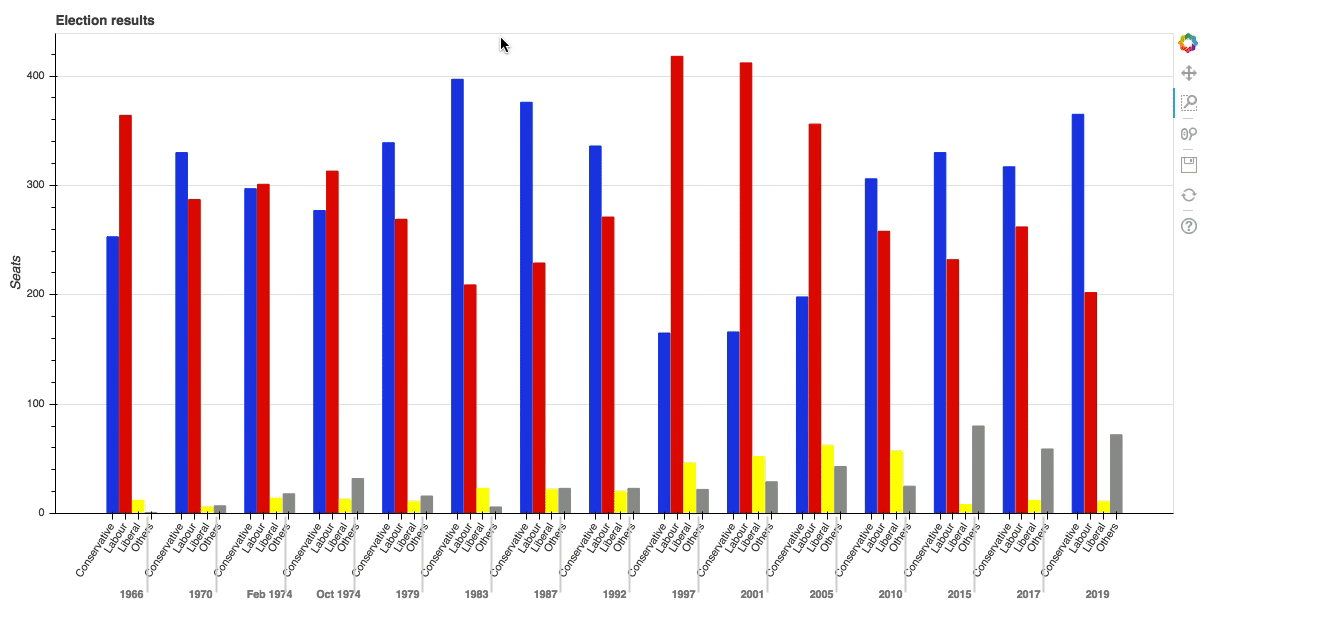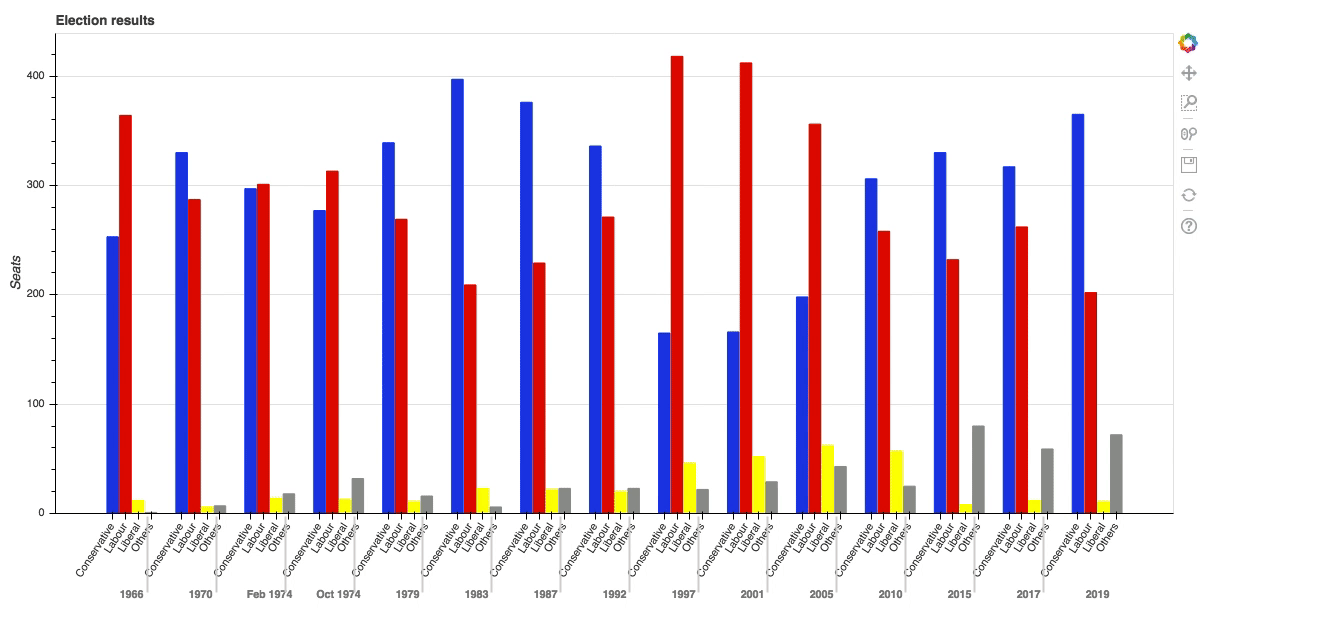
Bokeh's built-in box zoom (© 2019 Anvil)
But the great thing about Bokeh is how you can add your own interactivity. Explore that in the next section by adding tooltips to the bars.
## Adding tooltips to the bars
To add tooltips to the bars, you just need to create a `HoverTool`
object and add it to your figure:
```
h = HoverTool(tooltips=[
('Seats', '@y'),
('(Year, Party)', '(@x)')
])
p.add_tools(h)
```
The arguments define what data is displayed on the tooltips. The variables `@y`
and `@x`
refer to the variables you passed into the `ColumnDataSource`
. There are a few other values you could use; for example, the position of the cursor on the plot is given by `$x`
and `$y`
(no relation to `@x`
and `@y`
).
Here's the result:
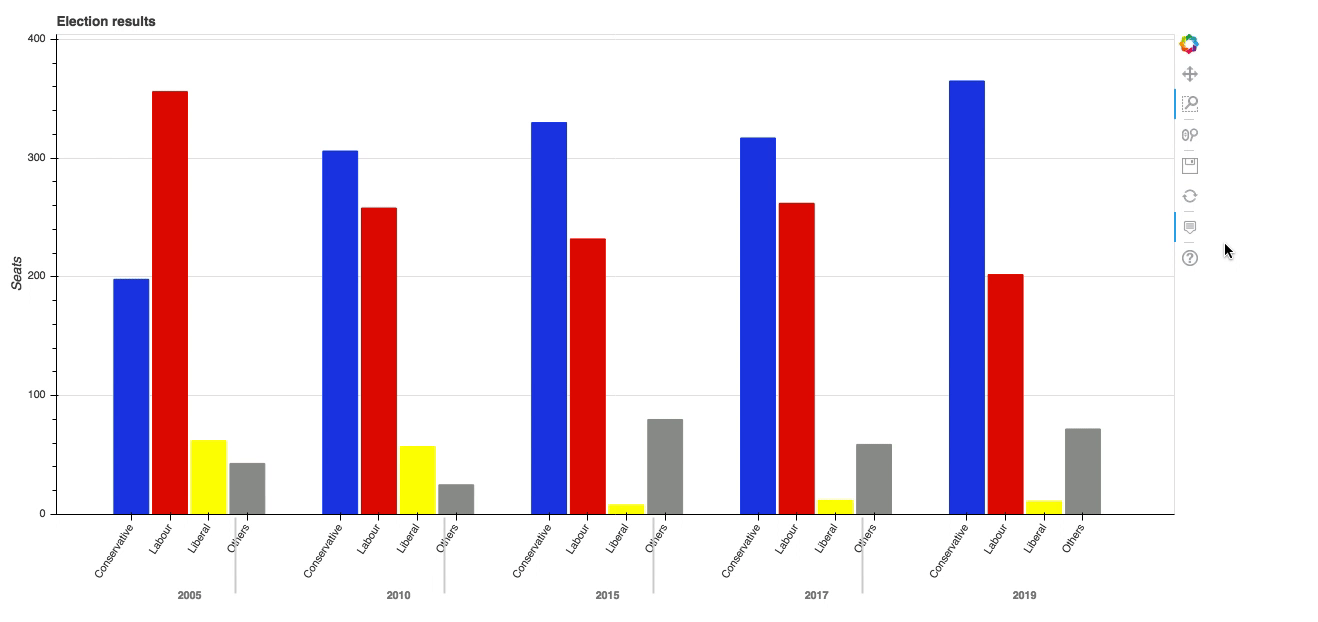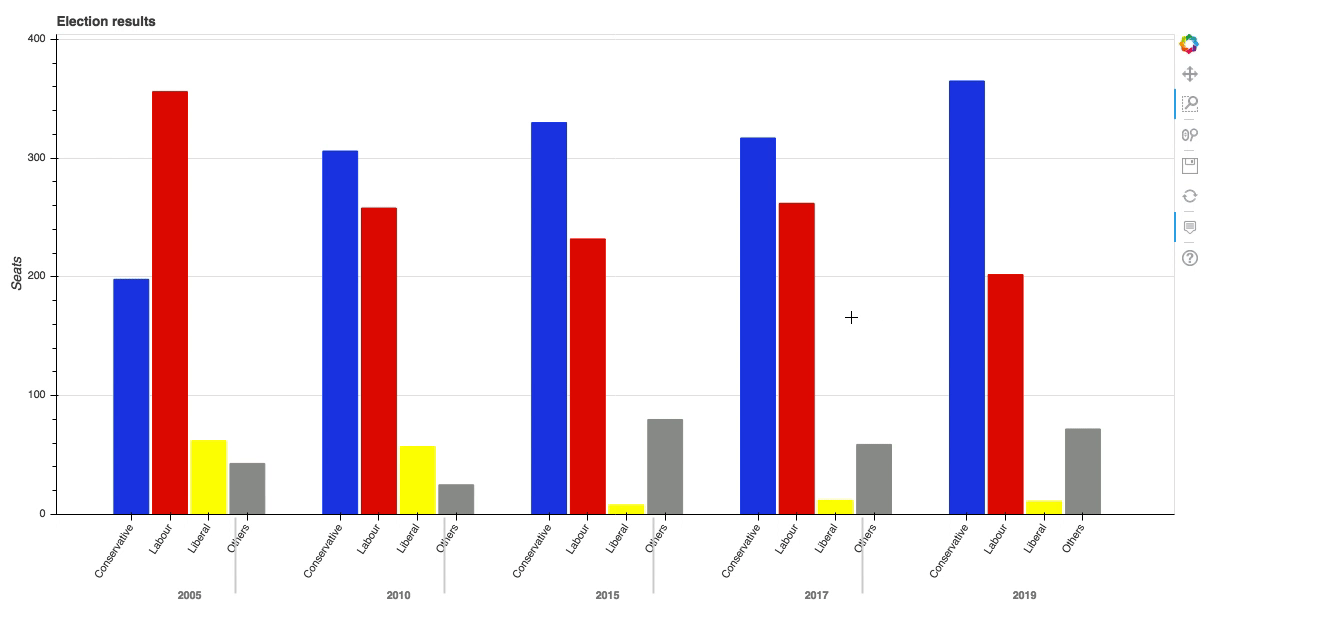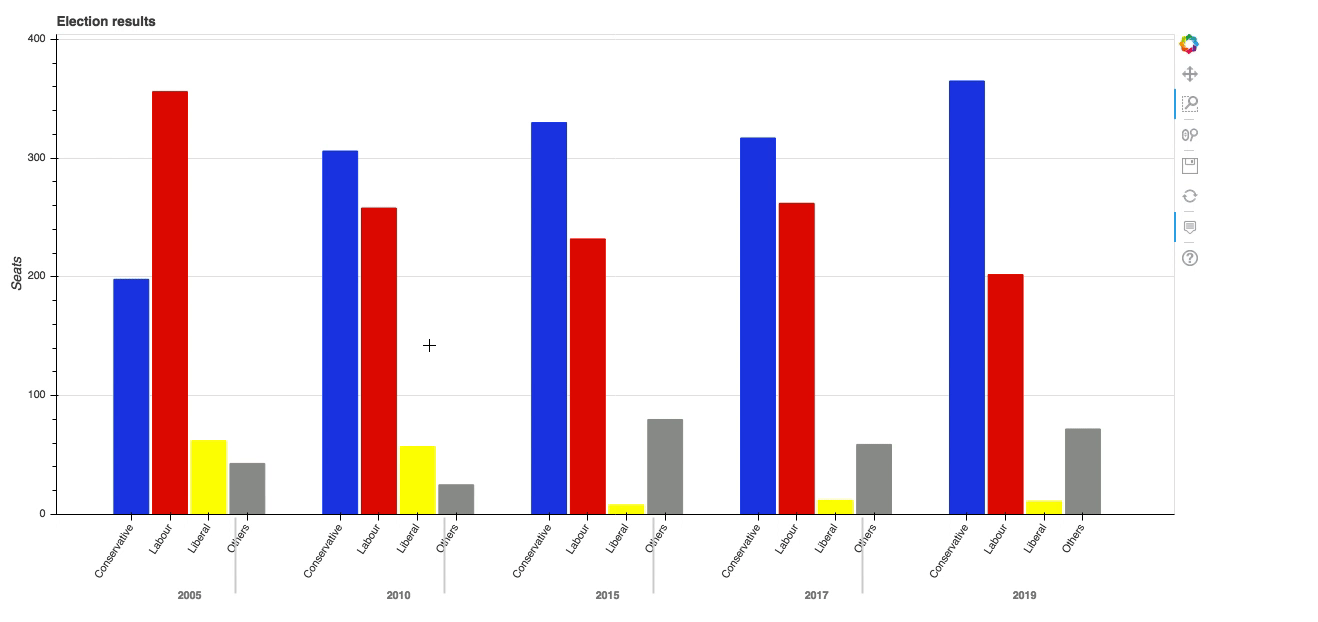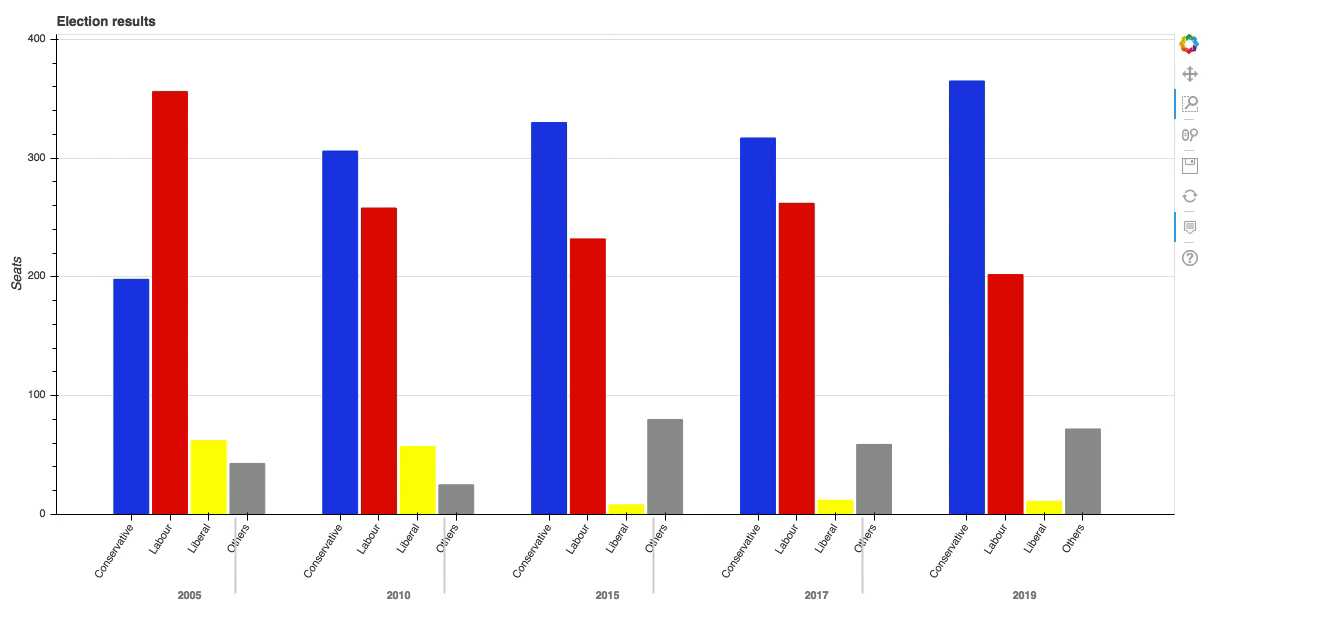
The election graph, now with tooltips (© 2019 Anvil)
Thanks to Bokeh's HTML output, you get the full interactive experience when you embed the plot in a web app. You can copy this example as an Anvil app [here](https://anvil.works/build#clone:CFRUWSM6PQ6JUUXH%3dSX4SACDSXBB4UOIVEVPWXH55%7cMYTOLCU2HM5WKJYM%3d6VJKGRSF74TCCVDG5CTVDOCS) (Note: Anvil requires registration to use).
Now you can see the reason for the extra effort of wrapping all your data in Bokeh in objects such as `ColumnDataSource`
. In return, you can add interactivity with relative ease.
## Back to simplicity: Altair
Bokeh is one of the four most popular plotting libraries, and this series is looking into [what makes each of them special](https://opensource.com/article/20/4/plot-data-python).
I'm also looking at a couple of libraries that stand out for their interesting approach. Next, I'll look at [Altair](https://altair-viz.github.io/), whose declarative API means it can make really complex plots without causing brain ache.
*This article is based on How to make plots using Bokeh on Anvil's blog and is reused with permission.*
## 2 Comments |
12,333 | 使用 Pandas 在 Python 中绘制数据 | https://opensource.com/article/20/6/pandas-python | 2020-06-19T23:19:08 | [
"Pandas"
] | https://linux.cn/article-12333-1.html |
>
> Pandas 是一个非常流行的 Python 数据操作库。学习怎样使用它的 API 绘制数据。
>
>
>

在有关基于 Python 的绘图库的系列文章中,我们将对使用 Pandas 这个非常流行的 Python 数据操作库进行绘图进行概念性的研究。Pandas 是 Python 中的标准工具,用于对进行数据可扩展的转换,它也已成为[从 CSV 和 Excel 格式导入和导出数据](https://anvil.works/docs/data-tables/csv-and-excel)的流行方法。
除此之外,它还包含一个非常好的绘图 API。这非常方便,你已将数据存储在 Pandas DataFrame 中,那么为什么不使用相同的库进行绘制呢?
在本系列中,我们将在每个库中制作相同的多条形柱状图,以便我们可以比较它们的工作方式。我们使用的数据是 1966 年至 2020 年的英国大选结果:

### 自行绘制的数据
在继续之前,请注意你可能需要调整 Python 环境来运行此代码,包括:
* 运行最新版本的 Python(用于 [Linux](https://opensource.com/article/20/4/install-python-linux)、[Mac](https://opensource.com/article/19/5/python-3-default-mac) 和 [Windows](https://opensource.com/article/19/8/how-install-python-windows) 的说明)
* 确认你运行的是与这些库兼容的 Python 版本
数据可在线获得,并可使用 Pandas 导入:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
现在我们已经准备好了。在本系列文章中,我们已经看到了一些令人印象深刻的简单 API,但是 Pandas 一定能夺冠。
要在 x 轴上绘制按年份和每个党派分组的柱状图,我只需要这样做:
```
import matplotlib.pyplot as plt
ax = df.plot.bar(x='year')
plt.show()
```
只有四行,这绝对是我们在本系列中创建的最棒的多条形柱状图。
我以[宽格式](https://anvil.works/blog/tidy-data)使用数据,这意味着每个党派都有一列:
```
year conservative labour liberal others
0 1966 253 364 12 1
1 1970 330 287 6 7
2 Feb 1974 297 301 14 18
.. ... ... ... ... ...
12 2015 330 232 8 80
13 2017 317 262 12 59
14 2019 365 202 11 72
```
这意味着 Pandas 会自动知道我希望如何分组,如果我希望进行不同的分组,Pandas 可以很容易地[重组 DataFrame](https://anvil.works/blog/tidy-data#converting-between-long-and-wide-data-in-pandas)。
与 [Seaborn](https://anvil.works/blog/plotting-in-seaborn) 一样,Pandas 的绘图功能是 Matplotlib 之上的抽象,这就是为什么要调用 Matplotlib 的 `plt.show()` 函数来实际生成绘图的原因。
看起来是这样的:

看起来很棒,特别是它又这么简单!让我们对它进行样式设置,使其看起来像 [Matplotlib](https://opensource.com/article/20/5/matplotlib-python) 的例子。
#### 调整样式
我们可以通过访问底层的 Matplotlib 方法轻松地调整样式。
首先,我们可以通过将 Matplotlib 颜色表传递到绘图函数来为柱状图着色:
```
from matplotlib.colors import ListedColormap
cmap = ListedColormap(['#0343df', '#e50000', '#ffff14', '#929591'])
ax = df.plot.bar(x='year', colormap=cmap)
```
我们可以使用绘图函数的返回值设置坐标轴标签和标题,它只是一个 [Matplotlib 的 Axis 对象](https://matplotlib.org/api/axis_api.html#axis-objects)。
```
ax.set_xlabel(None)
ax.set_ylabel('Seats')
ax.set_title('UK election results')
```
这是现在的样子:

这与上面的 Matplotlib 版本几乎相同,但是只用了 8 行代码而不是 16 行!我内心的[代码高手](https://en.wikipedia.org/wiki/Code_golf)非常高兴。
### 抽象必须是可转义的
与 Seaborn 一样,向下访问 Matplotlib API 进行细节调整的能力确实很有帮助。这是给出抽象[紧急出口](https://anvil.works/blog/escape-hatches-and-ejector-seats)使其既强大又简单的一个很好的例子。
---
via: <https://opensource.com/article/20/6/pandas-python>
作者:[Shaun Taylor-Morgan](https://opensource.com/users/shaun-taylor-morgan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this series of articles on Python-based plotting libraries, we're going to have a conceptual look at plots using pandas, the hugely popular Python data manipulation library. Pandas is a standard tool in Python for scalably transforming data, and it has also become a popular way to [import and export from CSV and Excel formats](https://anvil.works/docs/data-tables/csv-and-excel).
On top of all that, it also contains a very nice plotting API. This is extremely convenient—you already have your data in a pandas DataFrame, so why not use the same library to plot it?
In this series, we'll be making the same multi-bar plot in each library so we can compare how they work. The data we'll use is UK election results from 1966 to 2020:
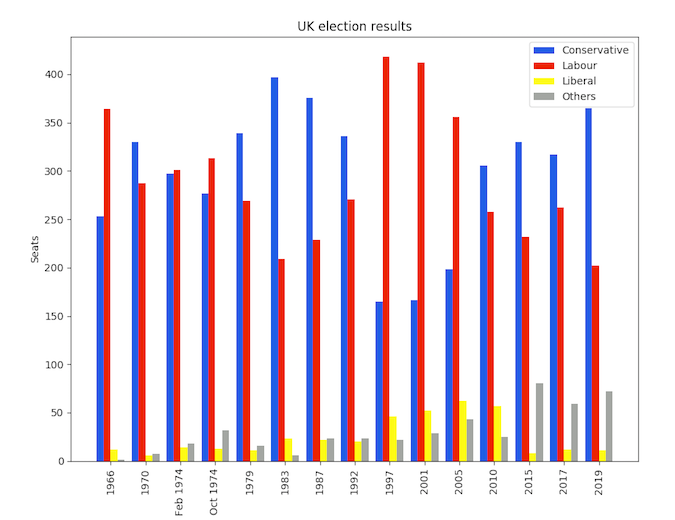
## Data that plots itself
Before we go further, note that you may need to tune your Python environment to get this code to run, including the following.
- Running a recent version of Python (instructions for
[Linux](https://opensource.com/article/20/4/install-python-linux),[Mac](https://opensource.com/article/19/5/python-3-default-mac), and[Windows](https://opensource.com/article/19/8/how-install-python-windows)) - Verify you're running a version of Python that works with these libraries
The data is available online and can be imported using pandas:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
Now we're ready to go. We've seen some impressively simple APIs in this series of articles, but pandas has to take the crown.
To plot a bar plot with a group for each party and `year`
on the x-axis, I simply need to do this:
```
import matplotlib.pyplot as plt
ax = df.plot.bar(x='year')
plt.show()
```
Four lines—definitely the tersest multi-bar plot we've created in this series.
I’m using my data in [wide form](https://anvil.works/blog/tidy-data), meaning there’s one column per political party:
```
year conservative labour liberal others
0 1966 253 364 12 1
1 1970 330 287 6 7
2 Feb 1974 297 301 14 18
.. ... ... ... ... ...
12 2015 330 232 8 80
13 2017 317 262 12 59
14 2019 365 202 11 72
```
This means pandas automatically knows how I want my bars grouped, and if I wanted them grouped differently, pandas makes it easy to [restructure my DataFrame](https://anvil.works/blog/tidy-data#converting-between-long-and-wide-data-in-pandas).
As with [Seaborn](https://anvil.works/blog/plotting-in-seaborn), pandas' plotting feature is an abstraction on top of Matplotlib, which is why you call Matplotlib's `plt.show()`
function to actually produce the plot.
Here's what it looks like:
Looks great, especially considering how easy it was! Let's style it to look just like the [Matplotlib](https://opensource.com/article/20/5/matplotlib-python) example.
### Styling it
We can easily tweak the styling by accessing the underlying Matplotlib methods.
Firstly, we can color our bars by passing a Matplotlib colormap into the plotting function:
```
from matplotlib.colors import ListedColormap
cmap = ListedColormap(['#0343df', '#e50000', '#ffff14', '#929591'])
ax = df.plot.bar(x='year', colormap=cmap)
```
And we can set up axis labels and titles using the return value of the plotting function—it's simply a [Matplotlib Axis object](https://matplotlib.org/api/axis_api.html#axis-objects).
```
ax.set_xlabel(None)
ax.set_ylabel('Seats')
ax.set_title('UK election results')
```
Here's what it looks like now:
That's pretty much identical to the Matplotlib version shown above but in 8 lines of code rather than 16! My inner [code golfer](https://en.wikipedia.org/wiki/Code_golf) is very pleased.
## Abstractions must be escapable
As with Seaborn, the ability to drop down and access Matplotlib APIs to do the detailed tweaking was really helpful. This is a great example of giving an abstraction [escape hatches](https://anvil.works/blog/escape-hatches-and-ejector-seats) to make it powerful as well as simple.
*This article is based on How to make plots using Pandas on Anvil's blog and is reused with permission.*
## Comments are closed. |
12,335 | 如何在 Windows 上安装 Python | https://opensource.com/article/19/8/how-install-python-windows | 2020-06-20T23:26:42 | [
"Python"
] | https://linux.cn/article-12335-1.html |
>
> 安装 Python,启动 IDE,然后你就可以在 Windows 系统下进行编程了。
>
>
>

你是否想学习编程呢?可以从 [Python](https://www.python.org/) 开始,它因为简洁的语法和面向对象的特性而非常受欢迎,是最常见的编程语言之一。而且 Python 是一门解释型语言,这意味着你无需知道如何把 Python 代码编译为机器语言 —— Python 会帮你做到这一点,从而使你能够在编写代码的同时立即进行测试。
但是你也不能仅仅因为 Python 学习起来简单而低估了它强大的潜能,无论是在[电影](https://github.com/edniemeyer/weta_python_db)[工作室](https://www.python.org/about/success/ilm/)、视频游戏工作室,还是在金融机构、IT 机构、制造业,都有 Python 的身影,甚至很多业余爱好者、[艺术家](https://opensource.com/article/19/7/rgb-cube-python-scribus)、教师和许多其他人都使用 Python。
另一方面,Python 也是一门严肃的编程语言,学习它需要付出和实践。还有,你什么都不需要马上做,就几乎可以在任何计算机平台上安装并尝试使用 Python ,因此,如果你使用的是 Windows 操作系统,那本文正适合你。
如果你使用的是开源的 Linux 操作系统,那你可以 [在 Linux 上安装](https://opensource.com/article/19/7/ways-get-started-linux) 并 [尝试使用 Python](https://opensource.com/article/17/10/python-101)。
### 如何获取 Python
你可以从 [Python 官方网站](https://www.python.org/downloads/) 上去下载 Python。在 Python 官方网站下载页,可以将鼠标悬停在 “Downloads” 按钮上,待菜单展开后,再将鼠标悬停在 “Windows” 选项,最后点击按钮就可以下载最新版的 Python 了。

或者你也可以直接点击 “Downloads” 按钮,然后在下载页中选择特定的版本去下载。
### 安装 Python
下载好安装包后,直接打开就可以启动安装程序了。
安装时,选择默认的安装路径比较好,最重要的是要将 Python 添加到搜索路径中,否则 Python 应用程序不知道它该从哪里找到 Python 必须的运行时环境;默认认安装时并没有选中这一项,需要手动勾选安装窗口的 “Add Python 3.7 to Path” ,然后点击继续。

由于 Windows 需要经过你的批准才会允许安装非微软官方发行的应用程序,因此你必须要在弹出 “User Account Control”(UAC) 系统提示窗口的时候 点击 “Yes” 来继续完成安装。

这时候你就需要耐心等待,系统会自动将 Python 软件包分发到合适的位置,等待过后,也就意味着你已经成功的安装了 Python ,你就可以愉快的与 Python 玩耍了!
### 安装一个 IDE
虽然说你仅需要一个文本编辑器,就可以开始编写 Python 代码了,但是我依然建议你使用 IDE(集成开发环境)来进行开发,这样开发起来就会变得方便很多。IDE 会将文本编辑器和一些好用的 Python 功能集成到一起,使用起来非常友好。你可以考虑选择 IDLE 3 或者 NINJA-IDE 来作为你的 IDE。
#### IDLE 3
Python 自带一款 IDE,名字叫 IDLE。虽然你可以使用任何文本编辑器编写 Python 代码,但 IDE 通常会提供 [Notepad++](https://notepad-plus-plus.org/) 之类的纯文本编辑器所没有的代码高亮、语法检测等功能,甚至在 IDE 里可以直接通过鼠标点击 “Run” 按钮就能快速运行 Python 代码。
想要启动 IDLE ,可以点击 Windows 的 “开始” (或者 “Windows”)按钮,然后输入 `python` 来进行搜索。这时候可能会搜索到多个选项,选择 IDLE 启动就好了。

如果在 “开始” 菜单中没有搜到,你也可以在 “开始” 菜单输入 `cmd` (或同时按下键盘 `win + R` 键) 来启动 Windows 命令提示符,然后输入下面命令来启动 IDLE :
```
C:\Windows\py.exe
```
如果还是无法启动的话,可是试着重新安装 Python ,安装时记得务必要在安装向导中选中 “Add Python to PATH”。详细说明,可以参考 [Python 官方文档](http://docs.python.org/3/using/windows.html) 。
#### Ninja-IDE
如果你已经有一些编程经验,而且你觉得 IDLE 对你来说有些简陋的话,你也可以试试 [Ninja-IDE](http://ninja-ide.org/)。 Ninja-IDE 是一款非常出色的 Python IDE,它具有代码高亮功能,并且它会自动帮你检测诸如拼写错误、引号或括号缺失以及其他语法错误。而且它还可以显示行号(调试的时候会非常有用)、缩进标记甚至可以直接通过点击 “Run” 按钮来运行你的代码。

如果要安装 Ninja-IDE ,你可以访问 Ninja-IDE 的官网 [下载 Windows 安装程序](http://ninja-ide.org/downloads/) 。步骤跟安装 Python 大同小异:下载安装包、允许 Windows 安装非微软官方的应用程序,然后等待完成安装即可。
Ninja-IDE 安装完成后,双击 Windows 桌面或开始菜单下的 Ninja-IDE 就可以启动了。
### 告诉 Python 怎么做
关键字能让 Python 知道你想要做什么。在 IDLE 或者 Ninja-IDE ,打开 “文件” 菜单,创建一个新文件。
在 Ninja-IDE 中,不要创建一个新项目,而是单独创建一个新文件就可以了。
在你用 IDLE 或者 Ninja-IDE 新建的文件中,输入以下代码:
```
print("Hello world.")
```
* 如果你使用的是 IDLE ,请点击 “运行” 菜单,选择 “运行模块” 选项来运行你的程序。
* 如果你使用的是 Ninja ,请单击左侧按钮栏中的 “运行文件” 按钮。

任何时间当你想要执行代码,IDE 都会提示你先保存当前正在处理的文件,然后再继续。
`print` 关键字会告诉 Python 打印出你在括号和引号中输入的所有文本。
但是别高兴地太早,Python 的核心库也就只能访问 `print` 和 `help` 之类的基本关键字、函数等。
如果想要使用更多的关键字和函数,你就需要使用 `import` 关键字去加载它们。好了,先在你的 IDLE 或者 Ninja 中新建一个文件,命名为 `pen.py` 。
**警告**:不要把你新建的文件命名为 `turtle.py` ,因为 `turtle.py` 是包含了你要控制的 turtle 程序的文件名称,使用 `turtle.py` 作为文件名会让 Python 感到困惑,因为它以为你想要引入你自己的文件。
在你新建的文件中输入一下代码,并运行:
```
import turtle
```
[Turtle](https://opensource.com/life/15/8/python-turtle-graphics) 是一个用起来非常有意思的模块. 把这段代码添加到你的文件内:
```
turtle.begin_fill()
turtle.forward(100)
turtle.left(90)
turtle.forward(100)
turtle.left(90)
turtle.forward(100)
turtle.left(90)
turtle.forward(100)
turtle.end_fill()
```
来看看你可以使用 turtle 模块来绘制出哪些图案。
想要清空 turtle 绘制的区域的话,你可以使用 `turtle.clear()` 函数。那你知道 `turtle.color("blue")` 是用来做什么的吗?
我们来试一下更复杂点的程序:
```
import turtle as t
import time
t.color("blue")
t.begin_fill()
counter = 0
while counter < 4:
t.forward(100)
t.left(90)
counter = counter+1
t.end_fill()
time.sleep(2)
```
给你个挑战,试试修改代码,让它得到下图所示的结果:

当你完成这段代码后,你就可以继续学习更多有意思的模块了。这个 [入门级骰子游戏](https://opensource.com/article/17/10/python-101#python-101-dice-game) 就是个不错的开始。
### 保持 Pythonic
Python 是一门非常有趣的语言,它的模块几乎能实现所有你想要实现的功能。正如你所看到的,Python 入门很容易,只要你对自己有耐心,很快就会发现自己在理解和编写 Python 时能像写汉字一样流畅。你可以多阅读关于 [Python 的文章](https://opensource.com/sitewide-search?search_api_views_fulltext=Python),试着自己编写一些小片段,然后看看 Python 会执行出什么结果。如果想要把 Python 真正融合到你实际工作中,你可以试试 Linux ,Linux 具有在本地可编写脚本的功能,而其他系统却没有。
祝你好运,记得保持 Pythonic。
---
via: <https://opensource.com/article/19/8/how-install-python-windows>
作者:[Seth Kenlon](https://opensource.com/users/sethhttps://opensource.com/users/greg-p) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LiuWenlong](https://github.com/011011100010110101101111) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So you want to learn to program? One of the most common languages to start with is [Python](https://www.python.org/), popular for its unique blend of [object-oriented](https://opensource.com/article/19/7/get-modular-python-classes) structure and simple syntax. Python is also an *interpreted* *language*, meaning you don't need to learn how to compile code into machine language: Python does that for you, allowing you to test your programs sometimes instantly and, in a way, while you write your code.
Just because Python is easy to learn doesn't mean you should underestimate its potential power. Python is used by [movie](https://github.com/edniemeyer/weta_python_db) [studios](https://www.python.org/about/success/ilm/), financial institutions, IT houses, video game studios, makers, hobbyists, [artists](https://opensource.com/article/19/7/rgb-cube-python-scribus), teachers, and many others.
On the other hand, Python is also a serious programming language, and learning it takes dedication and practice. Then again, you don't have to commit to anything just yet. You can install and try Python on nearly any computing platform, so if you're on Windows, this article is for you.
If you want to try Python on a completely open source operating system, you can [install Linux](https://opensource.com/article/19/7/ways-get-started-linux) and then [try Python](https://opensource.com/article/17/10/python-101).
## Get Python
Python is available from its website, [Python.org](https://www.python.org/downloads/). Once there, hover your mouse over the **Downloads** menu, then over the **Windows** option, and then click the button to download the latest release.
Alternatively, you can click the **Downloads** menu button and select a specific version from the downloads page.
## Install Python
Once the package is downloaded, open it to start the installer.
It is safe to accept the default install location, and it's vital to add Python to PATH. If you don't add Python to your PATH, then Python applications won't know where to find Python (which they require in order to run). This is *not* selected by default, so activate it at the bottom of the install window before continuing!

Before Windows allows you to install an application from a publisher other than Microsoft, you must give your approval. Click the **Yes** button when prompted by the **User Account Control** system.
Wait patiently for Windows to distribute the files from the Python package into the appropriate locations, and when it's finished, you're done installing Python.
Time to play.
## Install an IDE
To write programs in Python, all you really need is a text editor, but it's convenient to have an integrated development environment (IDE). An IDE integrates a text editor with some friendly and helpful Python features. IDLE 3 and Pycharm (Community Edition) are two great open source options to consider.
### IDLE 3
Python comes with an IDE called IDLE. You can write code in any text editor, but using an IDE provides you with keyword highlighting to help detect typos, a **Run** button to test code quickly and easily, and other code-specific features that a plain text editor like [Notepad++](https://notepad-plus-plus.org/) normally doesn't have.
To start IDLE, click the **Start** (or **Window**) menu and type **python** for matches. You may find a few matches, since Python provides more than one interface, so make sure you launch IDLE.
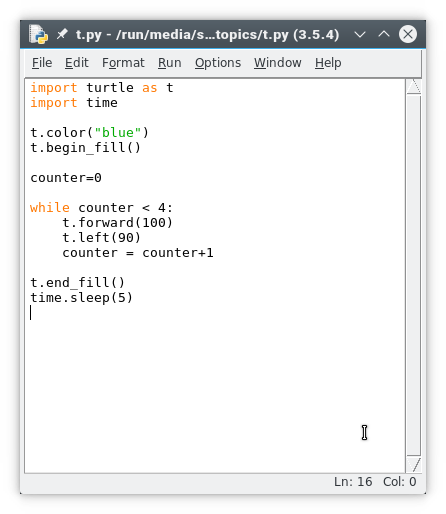
If you don't see Python in the Start menu, reinstall Python. Be sure to select **Add Python to PATH** in the install wizard. Refer to the [Python docs](http://docs.python.org/3/using/windows.html) for detailed instructions.
### PyCharm IDE
If you already have some coding experience and IDLE seems too simple for you, try [PyCharm (Community Edition)](https://www.jetbrains.com/pycharm/download/#section=windows), an open source IDE for Python. It has keyword highlighting to help detect typos, quotation and parenthesis completion to avoid syntax errors, line numbers (helpful when debugging), indentation markers, and a **Run** button to test code quickly and easily.
To install it, visit the PyCharm IDE website, download the installer, and run it. The process is the same as with Python: start the installer, allow Windows to install a non-Microsoft application, and wait for the installer to finish.
Once PyCharm is installed, double-click the PyCharm icon on your desktop or select it from the Start menu.
## Tell Python what to do
Keywords tell Python what you want it to do. In IDLE, go to the File menu and create a new file. In PyCharm, click the **New Project** button.
In your new, empty file, type this into IDLE or PyCharm:
`print("Hello world.")`
- If you are using IDLE, go to the Run menu and select the Run Module option.
- If you are using PyCharm, click the Run button in the top right corner of the window.
opensource.com
Any time you run code, your IDE prompts you to save the file you're working on. Do that before continuing.
The keyword **print** tells Python to print out whatever text you give it in parentheses and quotes.
That's not very exciting, though. At its core, Python has access to only basic keywords like **print** and **help**, basic math functions, and so on.
Use the **import** keyword to load more keywords. Start a new file and name it **pen.py**.
**Warning**: Do *not* call your file **turtle.py**, because **turtle.py** is the name of the file that contains the turtle program you are controlling. Naming your file **turtle.py** confuses Python because it thinks you want to import your own file.
[Turtle](https://opensource.com/life/15/8/python-turtle-graphics) is a fun module to use. Add this code to your file:
```
import turtle
turtle.begin_fill()
turtle.forward(100)
turtle.left(90)
turtle.forward(100)
turtle.left(90)
turtle.forward(100)
turtle.left(90)
turtle.forward(100)
turtle.end_fill()
```
See what shapes you can draw with the turtle module.
To clear your turtle drawing area, use the **turtle.clear()** keyword. What do you think the keyword **turtle.color("blue")** does?
Try more complex code:
```
import turtle as t
import time
t.color("blue")
t.begin_fill()
counter = 0
while counter < 4:
t.forward(100)
t.left(90)
counter = counter+1
t.end_fill()
time.sleep(2)
```
Notice that turtle, in this example code, has not only been imported, but it's also been given the shorter nickname **t**, which is quicker and easier to type. This is a convenience function in Python.
### Challenge
As a challenge, try changing your script to get this result:
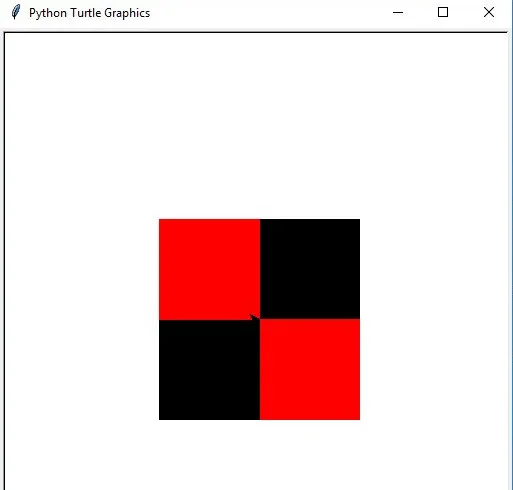
Once you complete that script, you're ready to move on to more exciting modules. A good place to start is this [introductory dice game](https://opensource.com/article/17/10/python-101#python-101-dice-game).
## Stay Pythonic
Python is a fun language with modules for practically anything you can think to do with it. As you can see, it's easy to get started with Python, and as long as you're patient with yourself, you may find yourself understanding and writing Python code with the same fluidity as you write your native language. Work through some [Python articles](https://opensource.com/sitewide-search?search_api_views_fulltext=Python) here on Opensource.com, try scripting some small tasks for yourself, and see where Python takes you. To really integrate Python with your daily workflow, you might even try Linux, which is natively scriptable in ways no other operating system is. You might find yourself, given enough time, using the applications you create!
Good luck, and stay Pythonic.
*This article was originally published in August 2019 and has been updated by the author.*
## 6 Comments |
12,337 | Mac 上的 Web 开发者最喜欢的编程工具 | https://www.zdnet.com/article/one-developers-favorite-mac-coding-tools-for-php-and-web-development/ | 2020-06-22T00:52:00 | [
"PHP",
"Mac"
] | https://linux.cn/article-12337-1.html | 
>
> 我在 Mac 上编写 WordPress 插件,这些是我的工具列表。
>
>
>
根据 [2020 年 Stack Overflow 开发者调查报告](https://insights.stackoverflow.com/survey/2020#technology-platforms-professional-developers5),在 Mac 上工作的编码者(27.5%)比在 Linux 上工作的编码者(26.6%)要多一点。相比之下,使用 Windows 作为开发机器的开发者数量几乎是其两倍(45.8%)。多年来,我在不同的平台之间跳来跳去,但我发现自己经常回到 Mac 上。
事实上,我从 Mac 专用的应用程序中获得了很多生产力,尤其是用于视频制作的 Final Cut Pro X。我喜欢能够在同一台机器上运行 Windows、Linux 和 Mac 应用程序,而这只有在 Mac 上才能实现(我将在下文中详谈)。虽然 Windows 也提供了一个强大的命令行环境,但我喜欢拥有一个完全是 Linux 风格的命令行,并且 Mac 上集成良好的图形工具对其进行了完整补充。
在本文中,我将向你展示我使用的工具。许多是跨平台的,而另一些是 Mac 专用的。虽然我过去曾开发过 Mac 应用和 iOS 应用,但我现在的开发工作完全是针对 Web 的。我维护了 10 个开源的 WordPress 插件,包括一个支持了 10000 多个非营利组织的捐款插件和一个支持了 20000 多个网站的网站隐私插件。
虽然我过去用过很多编程语言(也写过自己的编程语言),但我目前的项目主要涉及 PHP 和 JavaScript,并擅长 CSS、HTML 和 SQL(及一些框架)。为了创建和维护这些代码,我使用了下面所示的各种工具。在本篇中,我将向你展示我安装的工具。在以后的文章中,我将向你展示和深入介绍有助于完成工作的云服务。
就这样,让我们开始吧。
### 集成开发环境:PhpStorm

关于代码编辑和开发环境的话题,引发的宗教式的争论我都数不清了。有些程序员坚持走老路,只依靠命令行和 vi、emacs 等编辑器。有些程序员喜欢轻量级的文本编辑器,有些则喜欢可扩展性更强的编辑器,比如 vi 和 emacs。其他人则喜欢更加可扩展的编辑器,比如 Atom 和 Sublime Text。还有一些编码者,包括我自己,喜欢完整的集成开发环境,比如 PhpStorm、Visual Studio Code 和 Xcode(主要是它的 Mac 和 iOS 原生开发工具)。
我选择的武器一直是 [PhpStorm](https://www.jetbrains.com/phpstorm/)。我已经使用它多年了。它有一个优秀的集成调试环境,可以进行本地和远程调试。它还集成了我日常使用的各种功能,从它自带的终端窗口到文件同步,再到版本控制和逐行文件历史记录。另外,它还有丰富的插件可供选择,可以扩展和提升编码体验。
我最喜欢的一些插件包括:
* **Rainbow Brackets(彩虹括号)**:一个很棒的插件,它不仅能用行匹配括号,还能用颜色来匹配。它可以非常容易地看到哪些代码属于哪里。
* **String Manipulation(字符串操作)**:各种各样的字符串操作、大小写转换等等。
* **WordPress**:语法格式化和 WordPress 式的函数格式化,以及对 WordPress 挂钩的支持。对于任何一个 WordPress 插件的编码者来说都是必备的。
### 本地环境:Local

在做 Web 开发时,通常最好有一个本地开发栈。[Local](https://localwp.com/) 就是这样一个栈。它提供了 Nginx 或 Apache、MySQL、带有 Xdebug 的 PHP 安装包,以及其他一些资源,最重要的是它带有一个隧道,这样基于互联网的资源就可以访问本地环境进行编码和测试,内置了 SSL 集成,以及 MailHog —— 它可以拦截电子邮件,用于基于电子邮件的应用测试。哦,而且是免费的。
### 快速编辑:Sublime Text

我之前就提到过 [Sublime Text](https://www.sublimetext.com/),很多编码者都把它作为主要的开发环境。它几乎支持一系列传说中的插件和附加组件。当我想在 PhpStorm 固有的项目结构之外编辑项目文件时,我使用 Sublime Text 作为一个快速编辑器。它的速度快,反应灵敏,而且相当有特点。
### 提交文件到仓库:SmartSVN

WordPress 插件库(所有通过的插件都在这里提供给 WordPress 用户)不使用 Git 或 Github,而是使用 SVN 源码控制系统。我觉得 SVN 的命令行很烦人,所以我使用一个叫做 [SmartSVN](https://www.smartsvn.com/) 的图形化用户界面来将我的文件发送到仓库中。它大大降低了我在发布新版本时出错的几率。
### 潇洒的命令行:iTerm2

虽然在我的开发工具箱中,我更喜欢使用 GUI 界面来实现大部分功能,但我并不害怕在适当的时候使用命令行。虽然只使用标准的 MacOS 终端也是可以的,但我更喜欢 [iTerm2](https://www.iterm2.com/)。它提供了分屏、命令补全、粘贴历史等功能。它还可以根据你的心情和项目进行配置。
### 节省点击的每一秒:Shortcut Bar

这款 Mac App Store 的小宝贝是一款方便的工具,可以捕捉快速项目,并从 Mac 的菜单栏访问它们。我最大的用途是为我正在开发的各种网站创建管理页面和用户页面的[快捷方式](https://fiplab.com/apps/shortcut-bar-for-mac)。与其切换到浏览器窗口,然后调用书签,我只需进入菜单,选择我要去的地方,就会打开浏览器。
这似乎是一个小功能,但当每天在 IDE 和浏览器之间切换数千次时,这些节省下来的鼠标动作确实不少。因为快捷栏允许分组,所以我还将本地和远程服务器测试位置的链接进行了分组。
### Mac 上的 Windows 和 Linux:Parallels Desktop

因为我是做 Web 开发的,我必须在基于 Windows 的浏览器上检查我的代码,这意味着我需要启动 Windows 10 来测试新的 Edge、Chrome、Firefox 和 —— 请原谅我,还有 IE11。是的,还有用 IE11 的用户。
我在本文的介绍中提到了 [Parallels Desktop](https://www.anrdoezrs.net/links/9041660/type/dlg/sid/zd-14bdfb9dd2c448eda3bc07eae0b3691c---/https://www.parallels.com/products/desktop/)。我发现在同一台机器上运行 Windows、Mac 和 Linux 的能力在某些情况下是非常有用的。也就是说,我一直在[楼上办公室的 Mac](https://www.zdnet.com/article/5-reasons-im-not-sorry-i-bought-my-mac-mini-and-didnt-wait-for-the-new-mac-pro/) 上运行 Windows,它是我的速度和容量最大的一台机器。那台机器也是我用于视频制作的机器。
我的主要开发机器其实是在楼下,就在沙发旁边。这要追溯到我的狗狗还小的时候,我在办公室工作的时候,它经常会觉得孤独和害怕。现在,我在工作时,它趴在我的腿上是相当愉快的,我已经建立了一个完整的工作站,可以让我坐在客厅里,与键盘和狗共享我的膝盖。
那台机器是一台 [2013 年的 i7 iMac](https://www.zdnet.com/article/maxed-out-imac-just-how-far-can-we-push-this-thing/),内存 32GB。它是开发的理想之选,但它的速度实在不够快,无法满足多个 4K 视频流的需求。也不足以快到真正成功地托管 Windows 桌面。这让我想到了……
### 连接到远程机器:屏幕共享和微软远程桌面

尽管我的开发机器在楼下,而我的视频制作机器在楼上,但无论我在哪里,我都可以在其中任何一台机器上工作。我只需使用 MacOS 内置的“屏幕共享”应用来连接到远程机器。
当我想从楼下的开发机器连接到 Windows 时,我使用“[微软远程访问](https://apps.apple.com/us/app/microsoft-remote-desktop/id1295203466?mt=12)”。这是从 Mac OS 应用商店免费下载的,它提供了一个进入我的 Windows 10 机器的完整的远程界面。请注意,如果你打算使用“微软远程访问”,你需要运行 Windows 10 Pro。Windows Home 不支持远程访问。
哦,如果你想知道为什么这套环境似乎没有一个用于移动环境中,在咖啡店编程的组件,这很简单:如今的大流行病。一旦明确我所有的编码工作都将在家里完成,我就把我的开发工作整合到一台容量不错的固定机器上,并针对机器之间的千兆以太网进行了优化。如果我们还生活在之前的“旧常态”中,我就会有一个更以云为中心的实现。我很怀念咖啡店。
### 管理 MySQL 数据的整洁界面:Sequel Pro

我的代码要做大量的 SQL 操作。因此,我需要能够查看已经存储到数据库中的内容。对我来说,最简单、最快速的方法不是 PhpMyAdmin,而是一个叫 [Sequel Pro](https://www.sequelpro.com/) 的 Mac 本地应用(很奇妙,它的图标上把煎饼和数据存储混为一体)。
我最常用的方式是打开一个数据库表,搜索 “value contains” 或 “option\_name contains”,然后查找结果。它的速度很快,并且允许我在开发过程中对数据进行操作。我应该指出,PhpStorm 也有一个数据库浏览器,但我发现 Sequel Pro 对我来说更有效率。
### 一个不太复杂的 SFTP 客户端:Forklift

我花了很长时间才改掉了通过命令行和 SSH 隧道使用 SFTP 的习惯。而 [Forklift](https://binarynights.com/) 是一个很好的替代品。它保留了一个网站和登录信息的列表,支持加密,并提供了一个传统的拖放界面来批量移动文件。
### 强大的应用自动化:Keyboard Maestro

与 Final Cut Pro X 一样,[Keyboard Maestro](https://www.keyboardmaestro.com/main/) 是让我继续使用 Mac 的专用软件工具之一。我在 2011 年首次购买了 Keyboard Maestro,此后我一直使用它来制作各种专业脚本。
它是一个非常强大的跨应用脚本工具,也非常容易使用。我经常写一些特殊用途的脚本来运行一个原本需要很长时间的任务。我的一些脚本是非常强大的,可以跨多个应用程序。其他的脚本,比如截图中的 Stripe 填充测试,只做一件事,一遍又一遍。
我们来谈谈这个问题。在为我的捐赠插件开发 Stripe 支付网关时,我必须发起测试支付,大概有上千次。在我编码、测试和调试的过程中,我不得不用相同的测试数据填写相同的信用卡字段,一遍又一遍。Keyboard Maestro 中的一个简单的脚本为我完成了所有这些工作。我不需要为每一次测试手工填写数据,而是让 Keyboard Maestro 帮我完成。
### 特定用途的快速搜索:Alfred

[Alfred](https://www.alfredapp.com/) 是我的生产力家族的新成员。它会弹出一个命令栏,有点像 Spotlight,但增加了功能。你可以创建工作流来完成相对复杂的任务,但到目前为止,我的主要用处是四个自定义搜索。当我按下 `Alt-Space` 时,就会弹出 Alfred 的输入栏。
如果我键入 “codex”,它就会把后面的任何内容作为搜索字符串来在 WordPress 开发者文档站 codex 上搜索。输入 “plugin”,会搜索 WordPress 插件库。输入 “zdme”,会搜索 ZDNet 中我写过的带有要搜索的字符串的文章。我经常使用这个方法在文章中放置链接。现在,这些可能看起来很简单,你可以设置 Chrome 浏览器来进行自定义搜索,但同样,与快捷栏一样,这可以节省鼠标移动和按键。如果我需要查看 WordPress 函数的定义,只需轻点一下按键,就能得到它,而不需要动用鼠标。
### 你觉得怎么样?
那么,你看到了,这些是我的主要开发工具,可以帮助我完成工作。那你呢?你是编程人员吗?如果是的话,什么软件工具能帮助你提高工作效率?请在下面的评论中告诉我们。
---
via: https://www.zdnet.com/article/one-developers-favorite-mac-coding-tools-for-php-and-web-development/
作者:[David Gewirtz](https://www.zdnet.com/meet-the-team/us/david-gewirtz/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12326-1.html) 荣誉推出
| 200 | OK | 'ZDNET Recommends': What exactly does it mean?
ZDNET's recommendations are based on many hours of testing, research, and comparison shopping. We gather data from the best available sources, including vendor and retailer listings as well as other relevant and independent reviews sites. And we pore over customer reviews to find out what matters to real people who already own and use the products and services we’re assessing.
When you click through from our site to a retailer and buy a product or service, we may earn affiliate commissions. This helps support our work, but does not affect what we cover or how, and it does not affect the price you pay. Neither ZDNET nor the author are compensated for these independent reviews. Indeed, we follow strict guidelines that ensure our editorial content is never influenced by advertisers.
ZDNET's editorial team writes on behalf of you, our reader. Our goal is to deliver the most accurate information and the most knowledgeable advice possible in order to help you make smarter buying decisions on tech gear and a wide array of products and services. Our editors thoroughly review and fact-check every article to ensure that our content meets the highest standards. If we have made an error or published misleading information, we will correct or clarify the article. If you see inaccuracies in our content, please report the mistake via [this form](https://zdnet.zendesk.com/hc/en-us/requests/new).
[Close]
# One developer's favorite Mac coding tools for PHP and web development

According to the [2020 Stack Overflow Developer Survey](https://insights.stackoverflow.com/survey/2020#technology-platforms-professional-developers5), more coders work on Macs (27.5%) than on Linux (26.6%), but only by a very small margin. By contrast, nearly twice as many developers (45.8%) use Windows as their development machines. Over the years, I've jumped between platforms, but I find myself regularly returning to the Mac.
**Also: **[Best web hosting services](https://www.zdnet.com/article/best-web-hosting-service-provider/)
The fact is, I gain a lot of productivity from Mac-specific apps, particularly Final Cut Pro X for video production. I like being able to run Windows, Linux, and Mac applications on the same machine, which is only possible on a Mac (I'll talk more about that below). While Windows offers a robust command-line environment, I like having a full Linux-style command line as well as a complete complement of the Mac's well-integrated graphical tools.
In this article, I'm going to show you the tools I use. Many are cross-platform, while others are Mac-specific. While I [have coded Mac apps and iOS apps in the past](https://www.zdnet.com/article/true-confessions-of-a-former-iphone-developer/), my coding now is entirely for the web. I maintain 10 open-source WordPress plugins, including a donations plugin that supports more than 10,000 nonprofits and a site privacy plugin that supports more than 20,000 sites.
While I have programmed in many languages in the past (and written my own), my current projects involve coding primarily in PHP and JavaScript, with CSS, HTML, and SQL (as well as some frameworks) rounding out the mix. To create and maintain the code, I use the wide range of tools shown below. In this piece, I'm going to show you the installed tools. In a future piece, I'll dive back in and show you the cloud-based services that help get the job done.
And with that, let's get started.
The subject of code editing and developing environments has sparked more religious debates than I care to count. Some programmers swear by going old school, relying solely on the command line and editors like vi and emacs. Some coders prefer light-duty text editors. Others prefer more extendable editors like Atom and Sublime Text. And still other coders, myself included, prefer full-blown integrated development environments like PhpStorm, Visual Studio Code, and Xcode (mainly for its Mac and iOS native development tools).
My weapon of choice has been PhpStorm. I've been using it for years. It has an excellent integrated debugging environment that allows for both local and remote debugging. It also has a wide range of other integrated features I use daily, ranging from its own terminal window to file synchronization to version control and line-by-line file history. Plus, it has a rich selection of plugins that expand and enhance the coding experience.
Some of my favorite plugins include:
**Rainbow Brackets:**A wonderful plugin that matches brackets not only with lines but colors. It makes it very easy to see what code belongs to what other code.**String Manipulation:**All sorts of string tweaks, case conversions, and more.**WordPress:**Syntax and WordPress-aware function formatting, along with support for WordPress hooks. A must for any WordPress plugin coder.
When coding for the web, it's often best to have a local development stack. Local is one such stack. It provides Nginx or Apache, MySQL, a PHP install with Xdebug, and a number of other resources, most notably a tunnel so internet-based resources can access the local environment for coding and testing, a built-in SSL integration, and MailHog, which intercepts email for email-based application testing. Oh, and it's free.
I mentioned Sublime Text previously, and many coders use it as their primary development environment. It supports an almost legendary array of plugins and add-ons. I use Sublime as a quick editor when I want to edit project files outside of PhpStorm's intrinsic project structure. It's fast, responsive, and oh-so-geeky.
Rather than use Git or Github, the WordPress plugin repository (where all sanctioned plugins are made available to WordPress users) uses the SVN source code control system. I find command-line SVN annoying, so I use a graphical UI called SmartSVN to send my files into the repository. It substantially reduces the chances I'll make an error when posting a new build.
While I prefer using GUI interfaces for most functions in my development kit, I'm not one to fear dropping into the command line when it suits me. While it's possible to get by with just the standard MacOS terminal, I prefer iTerm2. It provides split screens, command completion, paste history, and quite a bit more. It's also configurable to fit both your mood and your project.
This little Mac App Store gem is a handy tool for capturing quick items and accessing them from the Mac's menubar. My biggest use is creating shortcuts to the admin and user pages of the various sites I'm working on. Rather than switching to a browser window and then invoking a bookmark, I just go to the menu, choose where I want to go, and the browser opens up.
This might seem like a minor feature, but when switching between IDE and browser thousands of times a day, those saved mouse movements really do add up. Because Shortcut Bar allows grouping, I also have links grouped for local and remote server testing locations.
Because I'm doing web development, I have to check my code on Windows-based browsers, which means I need to launch Windows 10 to test the new Edge, Chrome, Firefox, and -- forgive me, Father, for I have sinned -- IE11. Yeah, there are still IE11 users out there.
I mentioned [Parallels Desktop](https://www.zdnet.com/product/parallels-desktop-15-for-mac/) in my intro to this article. I find the ability to run Windows, Mac, and Linux on the same machine to be hugely helpful in certain circumstances. That said, I've been running Windows on [my upstairs office Mac](https://www.zdnet.com/article/5-reasons-im-not-sorry-i-bought-my-mac-mini-and-didnt-wait-for-the-new-mac-pro/), which is the one with the most speed and capacity. That machine is also the machine I use for video production.
My primary development machine is actually downstairs, next to the couch. This goes back to the days of when my dog was a pup, and he used to go through withdrawal when I worked in the office. Now, it's quite pleasant to work with him on my lap, and I've set up a full workstation that allows me to sit in the living room and share my lap with both the keyboard and the dog.
That machine is a [2013 i7 iMac with 32GB of RAM](https://www.zdnet.com/article/maxed-out-imac-just-how-far-can-we-push-this-thing/). It's ideal for development, but it's just not fast enough for multiple streams of 4K video. It's also no longer fast enough to really successfully host a Windows Desktop. Which brings me to...
Even though my dev machine is downstairs and my video production machine is upstairs, I can work on either, no matter where I happen to be. I simply use the built-in Screen Sharing app from MacOS to connect to the remote machine.
When I want to connect into Windows from the downstairs dev machine, I use Microsoft Remote Access. This is a free download from the Mac OS App store, and provides a full remote interface into my Windows 10 machine. Be aware that if you plan to use Microsoft Remote Access, you need to be running Windows 10 Pro. Windows Home does not support remote access.
Oh, and in case you're wondering why this setup doesn't seem to have a mobile, programming-in-a-coffee-shop component, it's simple: the pandemic. Once it became clear that all my coding work would be done at home, I consolidated my development onto a fixed machine with good capacity and optimized for gigabit Ethernet between the machines. If we were still living in the "old normal," I'd have a much more cloud-centric implementation. I miss coffee shops.
My code does a lot of SQL work. As such, I need to be able to look at what's been stored into the database. The easiest and fastest way for me to do that is not PhpMySQL, but a Mac-native app called Sequel Pro (which, wonderfully, conflates pancakes and data storage on its icon).
My most common use is to open a database table and search for "value contains" or "option_name contains" and look for the results. It's fast and allows me to manipulate the data as part of my development process. I should point out that PhpStorm also has a database browser, but I find Sequel Pro to be more efficient for my use.
It took me a long time to break my habit of using SFTP via the command line and SSH tunnels. But Forklift is a good substitute. It keeps a list of sites and logins, handles encryption, and provides a traditional drag-and-drop interface for moving batches of files.
Along with Final Cut Pro X, Keyboard Maestro is one of the Mac-only software tools that keeps me on a Mac. I first bought Keyboard Maestro in 2011, and I've been using it for a wide range of specialty scripts ever since.
It is an incredibly powerful cross-app scripting tool that's also very easy to use. I regularly spin up special-purpose scripts to run a task that would otherwise take a long time. Some of my scripts are very powerful and cross multiple applications. Others, like the Stripe Fill Test in the screenshot, does one thing, over and over.
Let's talk about that one. When developing the Stripe payment gateway for my donations plugin, I had to initiate a test payment, probably a thousand times. As I coded and tested and debugged, I had to fill in the same credit card fields with the same test data, over and over and over. A simple script in Keyboard Maestro did all that for me. Instead of hand-filling the data for every single pass, I just let Keyboard Maestro do it for me.
Alfred is the newest addition to my productivity family. It pops up a command bar sort of like Spotlight, but with added capabilities. You can create workflows to do relatively complex tasks, but my big use so far has been four custom searches. When I hit Alt-Space, Alfred's bar pops up.
If I type "codex," it will take whatever follows and use that as a search string to the WordPress developer codex. Typing "plugin," searches the WordPress plugin repository. Typing "zdme," searches* ZDNet* for articles I've written with the search string. I use this constantly for placing links into articles. Now, these may seem simple, and you can set up Chrome to do custom searches, but again, as with Shortcut Bar, this saves mouse moves and keystrokes. If I need to see the definition for a WordPress function, a tap gets it for me, without ever needing to go to the mouse.
### What about you?
So there you have it. Those are my main developer tools that help me get the job done. What about you? Are you coding? If so, what are the software tools that help you be the most productive? Let us know in the comments below.
*You can follow my day-to-day project updates on social media. Be sure to follow me on Twitter at @DavidGewirtz, on Facebook at Facebook.com/DavidGewirtz, on Instagram at Instagram.com/DavidGewirtz, and on YouTube at YouTube.com/DavidGewirtzTV.*
[Editorial standards](/editorial-guidelines/) |
12,338 | Homebrew :在 Mac 上无痛安装软件 | https://opensource.com/article/20/6/homebrew-mac | 2020-06-22T10:27:55 | [
"Homebrew",
"Mac"
] | https://linux.cn/article-12338-1.html |
>
> Homebrew 软件包管理器可以让你轻松地在 Mac 上安装和更新应用程序和实用程序。
>
>
>

在我追求“万物自动化”的过程中,我一直坚持走在用代码来管理我的 Mac 笔记本电脑的路上。与其用鼠标或触控板手动管理我的应用程序和实用程序,我更喜欢使用软件包管理软件来安装、更新和删除不需要的软件。
这对 Mac 用户来说是个挑战。Mac 的操作系统 macOS 始终落后于 Linux 的一个地方就是在包管理方面。Mac 用户没有默认的软件包管理器,而 Linux 用户则有很多选择 —— 从熟悉的 `yum` 和 `apt` 到现代的 [Flatpak](https://opensource.com/article/19/10/how-build-flatpak-packaging)。但 Mac 呢?
这就是 [Homebrew](https://brew.sh) 的作用。Homebrew(自酿)填补了 MacOS 事实上的软件包管理器的空白(它也是 Linux 上的又一个可选的包管理器)。它为任何熟悉命令行的人提供了令人难以置信的流畅而直接的体验,如果你是新手,它是学习命令行的好方法。
(LCTT 译注:Homebrew 系统中采用了大量针对自酿啤酒相关的比喻,大家在使用过程中会发现这些有趣的形容。)
如果你在 Mac 上还没有 Homebrew,你可以这样来安装:
```
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
```
该命令将执行 Homebrew 团队提供的安装程序脚本。如果你喜欢谨慎一点,可以 `curl` 下来这个文件,审核后再手动运行。
```
$ curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh --output homebrew_installer.sh
$ more homebrew_installer.sh # 审核该脚本,直到你觉得没问题了
$ bash homebrew_installer.sh
```
### 使用“酿造”来管理你的命令行实用程序
Homebrew 号称它“可以安装苹果(或你的 Linux 系统)默认没有安装的必需之物”。安装是通过 `brew`(酿造)命令进行的,它使我们能够访问成千上万的命令行实用程序,但不是更复杂的应用程序。
对于我们这些搞技术的人来说,符合“必需之物”类别的实用工具包括显示目录结构的方便的 `tree` 命令和我用来 [管理多个 Python 版本](https://opensource.com/article/20/4/pyenv) 的 `pyenv`。
你可以用 `search` 子命令看到 Homebrew 中所有的“<ruby> 秘方 <rt> formula </rt></ruby>”,我用 `wc` 命令显示有多少个“秘方”。
```
# -l 统计行数
$ brew search | wc -l
5013
```
有 5000 多个“秘方”,这是一个不可思议的软件数量。所以,在搜索那个庞大的清单之前,最好先对自己想要的东西有个概念。值得庆幸的是,浏览起来很方便。“秘方”被编入并集中存储到核心库中,核心库按操作系统划分(Mac 在 [Homebrew Core](https://github.com/Homebrew/homebrew-core),Linux 在 [Linux Core](https://github.com/Homebrew/linuxbrew-core))。它们也可以通过 Homebrew API 和[网站](https://formulae.brew.sh/formula/)列出。
口碑是另一个寻找实用工具的好方法。考虑到这一点,如果你正在寻找灵感,这里有一些我的最爱:
* `pyenv`、`rbenv` 和 `nodenv` 分别用于管理 Python、Ruby 和 Node.js 的版本
* `imagemagick` 用于可脚本化的图像编辑
* `pandoc` 用于可脚本化的文件转换(我经常从 .docx 切换到 .md 或 .html)
* `hub` 为 GitHub 用户提供了[更好的 Git 体验](https://opensource.com/article/20/3/github-hub)。
* `tldr` 提供了解如何使用命令行工具的例子
举个例子,看看 [tldr 页面](https://github.com/tldr-pages/tldr),这是一个用户友好的替代方式,可以滚动浏览应用程序的手册页。你可以通过再次运行 `search` 来确认它是否可用:
```
$ brew search tldr
==> Formulae
tldr ✔
```
成功了!这个对勾让你知道它是可用的。现在你可以安装它了:
```
$ brew install tldr
==> Downloading https://homebrew.bintray.com/bottles/tldr-1.3.0_2.catalina.bottle.tar.gz
Already downloaded: /Users/mbbroberg/Library/Caches/Homebrew/downloads/901bc14594a9283e9ab20aec942dc5a9a2befb7e96e1b0fcccb4e3257918813c--tldr-1.3.0_2.catalina.bottle.tar.gz
==> Installing tldr
==> Pouring tldr-1.3.0_2.catalina.bottle.tar.gz
? /usr/local/Cellar/tldr/1.3.0_2: 6 files, 35.5KB
```
值得庆幸的是,Homebrew 预先构建了二进制文件,所以你不必在本地机器上从源代码构建。这样就节省了很多时间,并免除了 CPU 风扇的噪音。我对 Homebrew 赞赏的另一件事是,你可以在不完全了解其含义的情况下欣赏此功能。
但如果你喜欢,看看复杂的东西也是很有趣的。对 `tldr` 运行 `info` 子命令,你可以看到所有的依赖管理、源代码,甚至公共分析。
```
$ brew info tldr
tldr: stable 1.3.0 (bottled), HEAD
Simplified and community-driven man pages
https://tldr.sh/
Conflicts with:
tealdeer (because both install `tldr` binaries)
/usr/local/Cellar/tldr/1.3.0_2 (6 files, 35.5KB) *
Poured from bottle on 2020-05-20 at 15:12:12
From: https://github.com/Homebrew/homebrew-core/blob/master/Formula/tldr.rb
==> Dependencies
Build: pkg-config ✔
Required: libzip ✔
==> Options
--HEAD
Install HEAD version
==> Analytics
install: 2,811 (30 days), 7,875 (90 days), 27,105 (365 days)
install-on-request: 2,806 (30 days), 7,860 (90 days), 27,080 (365 days)
build-error: 0 (30 days)
```
最后,和其他优秀的软件包管理器一样,Homebrew 的 `brew uninstall` 子命令可用于快速清理和删除未使用的实用程序。
### 用“酒桶”管理你的应用程序
命令行实用程序是一匹孤狼,但完整的应用程序呢?Homebrew 保持了其标准命令的简单性,只通过其默认的 `brew` 命令行界面安装单文件应用。而应用程序不符合这种结构。它们的目录层次比较复杂,比单一的二进制要复杂得多。
幸运的是,Mac 上的 Homebrew 包含了一个名为 `cask`(酒桶)的子命令,用于处理更复杂的多目录结构。特别好的是,`cask` 使用了与标准 `brew` 命令类似的命令结构,所以你可以使用类似的 `search`、`install` 和 `info` 子命令:
```
brew search --cask | wc -l
4772
```
哇,有近 5000 个应用程序,在 [Homebrew 的网站](https://formulae.brew.sh/cask/)上浏览更方便。
我将用我新喜欢的一款应用来引导你完成 `cask`。[Meld](https://meldmerge.org/)(我[在 Opensource.com 上读到的](https://opensource.com/article/20/3/meld))。这是一个功能丰富的编辑器,可以帮助管理合并冲突。在它的网站上有下载的链接,我可以运行安装程序,并将其拖放到我的应用程序文件夹中。但我不想再这样做了,我用的是 Homebrew。
首先,我可以通过稍微不同的语法确认它可以使用:
```
$ brew search --casks meld
==> Casks
meld
```
然后我使用 `cask` 子命令来安装它:
```
$ brew cask install meld
==> Downloading https://github.com/yousseb/meld/releases/download/osx-19/meldmerge.dmg
==> Downloading from https://github-production-release-asset-2e65be.s3.amazonaws.com/28624006/66cb25
######################################################################## 100.0%
==> Verifying SHA-256 checksum for Cask 'meld'.
==> Installing Cask meld
==> Moving App 'Meld.app' to '/Applications/Meld.app'.
==> Linking Binary 'meld.wrapper.sh' to '/usr/local/bin/meld'.
? meld was successfully installed!
```
Homebrew 不仅安装了应用程序,而且还在我当前的路径 `/usr/local/bin/` 下提供了它。现在,我可以从命令行运行 `meld` 或从应用程序文件夹中启动应用程序。
### 更新一切的“酿造升级”
我一直使用软件包管理器的主要原因是,我可以不断升级我的软件,以避免已知的安全漏洞,并确保我总是有最新的功能。如果我手工安装所有的东西,我必须关注每一个工具和应用程序,以了解它是否有自动更新程序,如果没有,就得自己拉回最新的版本。
升级功能是优秀的软件包管理的闪光点。由于我没有什么特殊的版本要求,所以我只需要运行一个命令就可以顺利更新一切:
```
$ brew upgrade
==> Upgrading 6 outdated packages:
helm 3.2.1 -> 3.2.2
[email protected] 3.8.2_4 -> 3.8.3
ipython 7.14.0 -> 7.15.0
go 1.14.2_1 -> 1.14.3
libzip 1.6.1 -> 1.6.1_1
sqlite 3.31.1 -> 3.32.1
```
如果你有更复杂的需求,或者想在安装升级前关注一下升级情况,有很多功能标志可供选择。例如,`-n` 提供了一个 “模拟运行”,列出了可用的升级,而不会进行安装。你也可以 “[钉](https://docs.brew.sh/FAQ#how-do-i-stop-certain-formulae-from-being-updated)” 住应用程序版本来防止它升级。
### 备份你的安装
当该工具允许你像其它[点文件的版本控制方案](https://opensource.com/article/19/3/move-your-dotfiles-version-control)一样备份你的安装环境时,命令行实用程序和应用程序的管理就跳到了一个全新的水平。Homebrew 就有这样的功能,可以在 `dump` 子命令下使用。它会生成一个 `Brewfile`,这是一个可重复使用的当前所有安装的工具的列表。要从你的安装的环境中生成一个,进入你的合适的文件夹并运行:
```
$ cd ~/Development/dotfiles # 这是我的点文件的文件夹
$ brew bundle dump
```
当我换了机器,想用 Homebrew 安装相同的应用程序时,我就会进入装有 `Brewfile` 的文件夹并运行。
```
$ brew bundle
```
它将在我的新机器上安装所有列出的“秘方”和“酒桶”。
### 用 Homebrew 进行软件包管理
Homebrew 是我常用的命令行工具和应用程序的管理器。它可以让我保持有条理和及时更新,它的设计在易用性和功能深度之间取得了美丽的平衡。Homebrew 将软件包管理的细节最小化到只需要你知道的程度,大多数用户都会从中受益。
如果你对 Linux 软件包管理器已经驾轻就熟,你可能会认为 Homebrew 太简单了,但不要误以为 Homebrew 的易用性是功能的缺乏。稍微深入一点看,就会发现很多高级选项,远远超出了我在这里向你展示的范围。将 `-h` 添加到任何 `brew` 子命令中,会显示可用来升级、删除、故障排除,甚至使用模板贡献新 “秘方” 的丰富功能。
总的来说,Homebrew 可以让一个重度命令行的 Mac 用户变得很开心。此外,它是开源的,所以如果你愿意,你可以[贡献代码](https://github.com/Homebrew/brew)。尝试一下它,让我知道你的想法,在下面留下评论。
---
via: <https://opensource.com/article/20/6/homebrew-mac>
作者:[Matthew Broberg](https://opensource.com/users/mbbroberg) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my quest to "automate all the things," I have been on a journey to manage my Mac laptop as the code it inherently is. Instead of pointing and clicking to manually manage my applications and utilities, I prefer to use package management software to install, update, and remove unneeded software.
That's a challenge for Mac users. One place where the Mac operating system, macOS, has always been behind Linux is in package management. There is no default package manager for Mac users, while Linux users have many options—from the familiar `yum`
and `apt`
to the modern choice of [Flatpak](https://opensource.com/article/19/10/how-build-flatpak-packaging). But what about us?
This is where [Homebrew](https://brew.sh) comes in. Homebrew fills the void as the de facto package manager for macOS (and as another option for Linux). It provides an incredibly smooth and straightforward experience for anyone familiar with the command line, and it's a good way to learn the command line if you're new to it.
If you're on a Mac and don't already have Homebrew, you can install it with:
`$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"`
This command executes the installer script provided by the Homebrew team. If you prefer to be more cautious, you can `curl`
the file, then run it manually after reviewing it:
```
$ curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh --output homebrew_installer.sh
$ more homebrew_installer.sh # review the script until you feel comfortable
$ bash homebrew_installer.sh
```
## Manage your command-line utilities with brew
Homebrew boasts that it "installs the stuff you need that Apple (or your Linux system) didn't" install by default. Installation happens with the `brew`
command, which gives us access to thousands of command-line utilities, but not more complex applications.
For us nerds, the utilities that fit into "the stuff you need" category include the handy `tree`
command that shows directory structures and `pyenv`
, which I use to [manage multiple versions of Python](https://opensource.com/article/20/4/pyenv).
You can see all the "formulae" that are available from Homebrew using the `search`
command, and I use the `wc`
command shows how many formulae there are:
```
# -l counts the number of lines
$ brew search | wc -l
5013
```
There are over 5,000 formulae, which is an incredible amount of software. So it's best to have an idea of what you want before searching that huge list. Thankfully, it is easy enough to browse. Formulae are codified and centralized into the core repositories that are split by operating system (Mac in [Homebrew Core](https://github.com/Homebrew/homebrew-core) and Linux in [Linux Core](https://github.com/Homebrew/linuxbrew-core)). They are also available through the Homebrew API and [listed on the website](https://formulae.brew.sh/formula/).
Word of mouth is another great method to find utilitites. With that in mind, here are some of my favorites if you're looking for inspiration:
`pyenv`
,`rbenv`
, and`nodenv`
to manage Python, Ruby, and Node.js versions (respectively)`imagemagick`
for scriptable image edits`pandoc`
for scriptable document conversions (I often switch from .docx to .md or .html)`hub`
for a[better Git experience](https://opensource.com/article/20/3/github-hub)for GitHub users`tldr`
for examples of how to use a command-line utility
As an example, take a look at [tldr pages](https://github.com/tldr-pages/tldr), a user-friendly alternative to scrolling through an application's man pages. You can confirm it's available by running `search`
again:
```
$ brew search tldr
==> Formulae
tldr ✔
```
Success! The checkmark lets you know it is available. Now you can install it:
```
$ brew install tldr
==> Downloading https://homebrew.bintray.com/bottles/tldr-1.3.0_2.catalina.bottle.tar.gz
Already downloaded: /Users/mbbroberg/Library/Caches/Homebrew/downloads/901bc14594a9283e9ab20aec942dc5a9a2befb7e96e1b0fcccb4e3257918813c--tldr-1.3.0_2.catalina.bottle.tar.gz
==> Installing tldr
==> Pouring tldr-1.3.0_2.catalina.bottle.tar.gz
? /usr/local/Cellar/tldr/1.3.0_2: 6 files, 35.5KB
```
Homebrew, thankfully, prebuilds the binaries, so you don't have to build from source code on your local machine. That saves a lot of time and CPU fan noise. Another thing I appreciate about Homebrew is that you can appreciate this feature without understanding exactly what it means.
But if you're into it, it can be fun to look at the complexity. Run `info`
on `tldr`
, and you can see all the dependency management, the source code, and even public analytics:
```
$ brew info tldr
tldr: stable 1.3.0 (bottled), HEAD
Simplified and community-driven man pages
https://tldr.sh/
Conflicts with:
tealdeer (because both install `tldr` binaries)
/usr/local/Cellar/tldr/1.3.0_2 (6 files, 35.5KB) *
Poured from bottle on 2020-05-20 at 15:12:12
From: https://github.com/Homebrew/homebrew-core/blob/master/Formula/tldr.rb
==> Dependencies
Build: pkg-config ✔
Required: libzip ✔
==> Options
--HEAD
Install HEAD version
==> Analytics
install: 2,811 (30 days), 7,875 (90 days), 27,105 (365 days)
install-on-request: 2,806 (30 days), 7,860 (90 days), 27,080 (365 days)
build-error: 0 (30 days)
```
Finally, as in any good package manager, Homebrew's `brew uninstall`
is available to quickly clean and remove unused utilities.
## Manage your applications with brew casks
Command-line utilities are a blast, but what about full-blown applications? Homebrew keeps its standard commands simple and installs only single-file applications through its default `brew`
command-line interface. Applications don't fit that structure. They have a more complex directory hierarchy that is much more than a single binary.
Fortunately, Homebrew on Mac includes a subcommand called "casks" for more complex multi-directory structures. What's especially nice is that `cask`
uses a similar command structure to the standard `brew`
commands, so you can use similar `search`
, `install`
, and `info`
steps:
```
brew search --cask | wc -l
4772
```
Wow, there are nearly 5,000 more applications to browse, which are easier to peruse on [Homebrew's website](https://formulae.brew.sh/cask/).
I'll walk you through `cask`
with one of my new favorite applications: [Meld](https://meldmerge.org/) (which I [read about on Opensource.com](https://opensource.com/article/20/3/meld)). It's a feature-rich editor that helps manage merge conflicts. There is a download on its website, and I could run through the installer and drag-and-drop it into my Applications folder, but I don't do that anymore. I use Homebrew.
First, I confirm it's available through a slightly different syntax:
```
$ brew search --casks meld
==> Casks
meld
```
Then I use the `cask`
sub-command to install it:
```
$ brew cask install meld
==> Downloading https://github.com/yousseb/meld/releases/download/osx-19/meldmerge.dmg
==> Downloading from https://github-production-release-asset-2e65be.s3.amazonaws.com/28624006/66cb25
######################################################################## 100.0%
==> Verifying SHA-256 checksum for Cask 'meld'.
==> Installing Cask meld
==> Moving App 'Meld.app' to '/Applications/Meld.app'.
==> Linking Binary 'meld.wrapper.sh' to '/usr/local/bin/meld'.
? meld was successfully installed!
```
Homebrew not only installs the application but also makes it available in my current path under `/usr/local/bin/`
. Now I can run `meld`
from the command line or launch the application from the Applications folder.
## Update everything with brew upgrade
The main reason I consistently use a package manager is so that I can consistently upgrade my software to avoid known security bugs and ensure I always have the latest features. If I install everything by hand, I have to keep an eye on each tool and application to know whether it has an auto-updater and, if not, pull down the latest releases myself.
Upgrades are where great package management shines. Since I don't have any special version requirements, I run only one command to update everything smoothly:
```
$ brew upgrade
==> Upgrading 6 outdated packages:
helm 3.2.1 -> 3.2.2
[email protected] 3.8.2_4 -> 3.8.3
ipython 7.14.0 -> 7.15.0
go 1.14.2_1 -> 1.14.3
libzip 1.6.1 -> 1.6.1_1
sqlite 3.31.1 -> 3.32.1
```
If you have more complex needs or want to keep an eye on upgrades before installing them, there are plenty of feature flags available. For instance, `-n`
offers a "dry run" that lists available upgrades without installing them. You can also ["pin"](https://docs.brew.sh/FAQ#how-do-i-stop-certain-formulae-from-being-updated) an application version to prevent upgrades.
## Back up your installation
The command-line utility and application management jumps to a whole new level when tools allow you to back up your installation like any other [dotfile in version control](https://opensource.com/article/19/3/move-your-dotfiles-version-control). Homebrew has that kind of functionality available to use under the `dump`
subcommand. It generates a `Brewfile`
, which is a reusable list of all the currently installed tools. To generate one from your installation, go into your preferred folder and run:
```
$ cd ~/Development/dotfiles # This is my dotfile folder
$ brew bundle dump
```
When I change machines and want to install the same applications with Homebrew, I go to the folder with the Brewfile and run:
`$ brew bundle `
It will install all the listed formulae and casks on my new machine.
## Go to Homebrew for package management
Homebrew is my go-to manager for command-line utilities and applications. It keeps me organized and up-to-date, and its design is a beautiful balance between ease of use and depth of functionality. Homebrew minimizes package management details to only what you need to know, and most users will benefit from that.
If you're already comfortable with Linux package managers, you may think Homebrew is too simple, but don't mistake Homebrew's ease of use for lack of features. Looking a little deeper reveals many advanced options that go far beyond what I showed you here. Adding `-h`
to any `brew`
subcommand shows the rich features available to upgrade, remove, troubleshoot, and even contribute new formulas using templates.
Overall, Homebrew makes being a command-line wielding Mac user a joy. In addition, it's open source, so you can [contribute back to the code](https://github.com/Homebrew/brew) if you're so inclined. Give it a try, and let me know what you think by leaving a comment below.
## 3 Comments |
12,340 | 在 Linux 上查看文件内容的 5 种方法 | https://www.networkworld.com/article/3561490/5-ways-to-examine-the-content-of-files-on-linux.html | 2020-06-23T12:11:37 | [
"文件",
"查看"
] | https://linux.cn/article-12340-1.html |
>
> 如何使用 cat、more、head 和 tail 命令查看 Linux 文件的内容,而不仅仅是文本文件。
>
>
>

Linux 提供了许多命令来查看文件的内容,包 括 `cat`、`more`、`head` 和 `tail`,但这只是一个开始。
一方面,即使是最显而易见的命令也有很多许多用户不会去使用的选项。还有一些普普通通的命令提供了一些独特的功能。在本文中,我们将介绍查看文件内容的命令,以及如何定制这些视图以更好地满足你的需求的选项。
### cat
`cat` 命令将文本文件的全部内容发送到终端窗口以供查看。实际上,如果你输入 `cat`,然后输入包含数千行内容的文件名,那么这些行将以极快的速度在你的窗口中滚动,你将无法看到除了最后一屏外的其他文本。对于 Linux 用户来说 `cat` 命令很熟悉,但即使是这个基本命令也提供了许多有用的选项,例如对输出中的行进行编号,这是我们许多人可能从未使用过的。更进一步,你不仅可以对行进行编号,还可以选择如何编号。
对每行进行编号就像这样:
```
$ cat -n msg
1 Hello --
2
3 I hope you are having a wonderful day!
4
5
6 That's it for ... now
7
8 bye!
9
10 s.
```
你也可以只对有内容的行编号。请注意,对于此命令,仅包含空格的行不被视为“空”,而是会被编号。
```
$ cat -b msg
1 Hello --
2 I hope you are having a wonderful day!
3 That's it for ... now
4 bye!
5 s.
```
`cat` 命令允许你使用 `-s` 选项忽略重复的空白行,但是要完全忽略空白行你必须添加另一个命令。
```
$ cat -s msg
Hello --
I hope you are having a wonderful day!
That's it for ... now
bye!
s.
```
要忽略所有空白行,只需如下将 `cat` 的输出通过管道传递给 `grep` 命令。 点(`.`)匹配包含任意字符的文本,因此它将显示任意非空的行,用于结束一行的回车换行做匹配(LCTT 译注:此处原文有误,径改)。
```
$ cat msg | grep .
Hello --
I hope you are having a wonderful day!
That's it for ... now
bye!
s.
```
`-E` 选项通过在每行末尾加 `$` 符提供视觉提示,来显示行尾是否还有多余的空格。
```
$ cat -E msg
Hello --$
$
I hope you are having a wonderful day! $
$
$
That's it for ... now$
$
bye!$
$
s.$
```
使用 `-A` 时,既可以在每行的末尾显示 `$` 字符,并且制表符会显示为 `^I` 而不是空白。
```
$ cat -A msg
Hello --$
$
I hope you are having a wonderful day!$
$
$
That’s it for ...^Inow$
$
bye!$
$
s.$
```
### 使用 head 和 tail 显示文件部分内容
`head` 和 `tail` 显示文件的头部或尾部,默认为十行。 你可以使用 `-3`(显示 3 行)或 `-11`(显示 11 行)之类的字符串来指定要查看的其它行数。`tail` 命令与 `head` 的工作方式相同,但是显示文件的尾部而不是头部。
```
$ head -3 msg
Hello --
I hope you are having a wonderful day!
$ tail -3 msg
bye!
s.
```
你还可以结合使用 `head` 和 `tail` 命令来查看文件中间的文本。你只需要选择起点和想要查看行数即可。在此例中,命令将在文件中显示第二个一百行,并在 `cat` 的帮助下为这些行编号。
```
$ cat -b mybigfile | head -200 | tail -100
101 Invoice #2020-06-07a sent to vendor
...
```
### 使用 more 或者 less 浏览一屏文本
`more` 命令是一次浏览一屏内容的自然之选,而 `less` 通过使用上下键盘箭头增加了在文件中上下移动的能力,这样你就可以遍历内容,然后在文件中回退。
### 使用 od 查看文本的两种方法
`od`(八进制转储)命令能够以常规文本和一系列 ASCII 值(即该文本在文件中的实际编码方式)的形式查看文件。在下面的例子中可以看到,带编号的行显示了 ASCII 数字值,而其他行则显示了文本和不可打印的字符。
```
$ od -bc msg
0000000 110 145 154 154 157 040 055 055 012 012 111 040 150 157 160 145
H e l l o - - \n \n I h o p e
0000020 040 171 157 165 040 141 162 145 040 150 141 166 151 156 147 040
y o u a r e h a v i n g
0000040 141 040 167 157 156 144 145 162 146 165 154 040 144 141 171 041
a w o n d e r f u l d a y !
0000060 012 012 012 124 150 141 164 047 163 040 151 164 040 146 157 162
\n \n \n T h a t ' s i t f o r
0000100 040 056 056 056 011 156 157 167 012 012 142 171 145 041 012 012
. . . \t n o w \n \n b y e ! \n \n
0000120 163 056 012
s . \n
```
请注意,换行符显示为 `\n`(八进制 `012`),而制表符显示为 `\t`(八进制 `011`)。
`od` 命令特别有用的用途之一是查看非文本文件以获取可以标识文件类型的信息。在这里,我们看到 `JFIF`(JPEG 文件交换格式)标签,该标签让 `file` 之类报告文件类型的命令将它标示为 jpg 文件。这里还有很多其他有用的信息,特别是如果你对这些文件的格式感到好奇的话。
在接下来的命令中,我们查看 jpg 文件的开始部分。
```
$ od -bc arrow.jpg | head -12
0000000 377 330 377 340 000 020 112 106 111 106 000 001 001 000 000 001
377 330 377 340 \0 020 J F I F \0 001 001 \0 \0 001
0000020 000 001 000 000 377 333 000 103 000 003 002 002 002 002 002 003
\0 001 \0 \0 377 333 \0 C \0 003 002 002 002 002 002 003
0000040 002 002 002 003 003 003 003 004 006 004 004 004 004 004 010 006
002 002 002 003 003 003 003 004 006 004 004 004 004 004 \b 006
0000060 006 005 006 011 010 012 012 011 010 011 011 012 014 017 014 012
006 005 006 \t \b \n \n \t \b \t \t \n \f 017 \f \n
0000100 013 016 013 011 011 015 021 015 016 017 020 020 021 020 012 014
\v 016 \v \t \t \r 021 \r 016 017 020 020 021 020 \n \f
0000120 022 023 022 020 023 017 020 020 020 377 333 000 103 001 003 003
022 023 022 020 023 017 020 020 020 377 333 \0 C 001 003 003
```
如果我们要 `file` 命令提供有关此图像的信息,我们可能会看到类似下面这样的信息。`file` 命令从文件开头的数据中提取了所有这些描述性信息:
```
$ file arrow.jpg
arrow.png: JPEG image data, JFIF standard 1.01, aspect ratio, density 1x1, segment length 16, baseline, precision 8, 500x375, components 3
```
### 使用 jp2a 将文件视为基于文本的图像
如果你只能在命令行工作,并且想了解特定图像包含的内容,那么可以使用 `jp2a`(jpeg to ascii)之类的工具提供字符渲染。图像在这种格式下的识别程度取决于文件。不要有太多期待,因为你将看到的图像版本是“低分辨率”下的测试!这是一只分辨率很低的帝王企鹅。(请离远点看)
```
$ jp2a Emperor_Penguin.jpg
MMMMMMMMWOdkNMMMMMMMMMMMMMMMMMMM
MMMXK0kc.... ,OKMMMMMMMMMMMMMMMM
MMNK0Ol... :Xx'dNMMMMMMMMMMMMM
MMMMMMMd;lx00Oo. ..xMMMMMMMMMMMM
MMMMMMK.OXMMMMMN,...lMMMMMMMMMMM
MMMMMMx'KXNNMMMMK....0MMMMMMMMMM
MMMMMMx:kkKNWWMMMl.. 'NMMMMMMMMM
MMMMMMddx0NNNWMMMK'...;NMMMMMMMM
MMMMMMck0NNWWWWWMMd ..lMMMMMMMM
MMMMMM.d0KXNWWWWMMo ...WMMMMMMM
MMMMMM.xOXNNWNMMMW. ....KMMMMMMM
MMMMMM'kKNKWXWMMMK ..'.0MMMMMMM
MMMMMMxckXNNNNMMMX .:..XMMMMMMM
MMMMMMW;xKNWWWMMMM. .;. NMMMMMMM
MMMMMMMok0NNWNWMMMx .l..MMMMMMMM
MMMMMMMkxOKXWXNMMMMl.:'dMMMMMMMM
MMMMMMM0dKOdKXXNMMMMNx,WMMMMMMMM
MMMMMMMWoKxldXKNNMMMMM;MMMMMMMMM
MMMMMMMMxxxxdNWNXNMMMM;MMMMMMMMM
MMMMMMMMxOcoo0XOOOOWMW,kMMMMMMMM
MMMMMMM0xK;.cO0dNX:0XXd;NMMMMMMM
MMMNkdd:,'ldXXO0xl;x0kx:;lKMMMMM
MMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMM
```
### 总结
Linux 上有很多命令可以通过各种方式查看文件的内容。其中一些选项在你需要处理文件内容时可能会非常有用。其它的只是……有趣。
---
via: <https://www.networkworld.com/article/3561490/5-ways-to-examine-the-content-of-files-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,341 | Ubuntu MATE 20.04 LTS:士别三日,当刮目相待 | https://itsfoss.com/ubuntu-mate-20-04-review/ | 2020-06-23T14:52:00 | [
"Ubuntu"
] | https://linux.cn/article-12341-1.html | Ubuntu MATE 20.04 LTS 无疑是最流行的 [Ubuntu 官方特色版本](https://itsfoss.com/which-ubuntu-install/)之一。
不仅仅是我,这份[Ubuntu 20.04 调查报告](https://ubuntu.com/blog/ubuntu-20-04-survey-results)也持同样观点。不过不管流行与否,它都是一个令人印象深刻的 Linux 发行版,尤其是用在较旧的硬件上时。事实上,它也是可用的[最轻量的 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/)之一。
所以,我想在一个虚拟机中尝试一下,为你提供一个概览,这样你可以了解其中有何值得期盼的变化,以及是否值得尝试。
### 在 Ubuntu MATE 20.04 LTS 中有什么新功能?
Ubuntu MATE 20.04 LTS 的主要亮点应该是增加了 MATE Desktop 1.24。
你可以期待 MATE Desktop 1.24 中的所有新特色都被打包到 Ubuntu MATE 20.04 中。除此之外,还有很多重要的变化、改进和增补。
这是 Ubuntu MATE 20.04 中变化的概述:
* 新增 MATE Desktop 1.24
* 大量视觉改进
* 数十处错误修复
* 基于 [Linux 内核 5.4](https://itsfoss.com/linux-kernel-5-4/) 系列
* 添加了实验性的 [ZFS](https://itsfoss.com/what-is-zfs/) 支持
* 添加了来自 [Feral Interactive](https://github.com/FeralInteractive/gamemode) 的 GameMode
* 一些软件包更新
现在,为了更好地了解 Ubuntu MATE 20.04,我将给你提供更多的细节。
### 用户体验改善

考虑到越来越多的用户倾向于在桌面上使用 Linux,而用户体验在桌面中起着至关重要的作用。
如果有一些易于使用和令人愉悦的东西,那么第一印象就会有很大不同。
对于 Ubuntu MATE 20.04 LTS,我没有感到失望。就我个人而言,我是最新的 [GNOME 3.36](https://itsfoss.com/gnome-3-36-release/) 的粉丝。我喜欢在我 [Pop!\_OS 20.04](/article-12175-1.html) 上使用它,但是随着 [MATE 1.24](https://mate-desktop.org/blog/2020-02-10-mate-1-24-released/) 的出现,使得 Ubuntu MATE 也同样具有很好的体验。
你会看到窗口管理器有一些重大更改,包括:增加了用于重新调整大小的隐形边框,HiDPI 图标渲染,重新设计了 `ALT+TAB` 工作区切换器的弹出窗口和一些其它的更改,这些是最新的 MATE 1.24 桌面环境的一部分。

此外, MATE Tweak 也得到了一些贴心的改进,即使你更改桌面的布局,也可以保留用户偏好。新的 MATE 欢迎屏幕也会告知用户更改桌面布局的能力,因此,用户无需不断摸索就能知道这个变化。
此外,我最喜欢的新增功能之一是可以预览最小化的应用程序。
例如,你已经最小化了一个应用程序,但是你想在拉起它之前看到它的预览 —— 现在你只需将鼠标悬停在任务栏上就可以做到这一点,如下图所示:

不过,我必须指出,并不是每个应用程序都可以如预期般的工作。因此,这个功能是有缺陷的,还需要改进。
### 应用程序新增或升级

在 MATE 20.04 中,你会注意到有一个新的固件更新器,它是 [fwupd](https://fwupd.org) 的 GTK 前端。你可以使用这个更新器来轻松地管理你的固件驱动。
这个版本也使用 Evolution 替换了 Thunderbird 电子邮件客户端。尽管 [Thunderbird](https://www.thunderbird.net/en-US/) 是一个非常流行的电子邮件客户端,但是 [Evolution](https://wiki.gnome.org/Apps/Evolution) 与 MATE 桌面集成得更好,并且证明它更有用。

考虑到我们已经搭载了 MATE 1.24,你也将发现一个新的时间和日期管理应用程序。不仅如此,如果你需要一个放大镜,Ubuntu MATE 20.04 还内置了 [Magnus](https://kryogenix.org/code/magnus/)。

Ubuntu MATE 20.04 也包括了众多预安装的软件包/应用程序的升级包。

尽管这些是小的增补,但却能在很大程度上帮助发行版变得更有用。
### Linux Kernel 5.4
Ubuntu MATE 20.04 带有 2019 年最后一个主要的稳定版内核,即 [Linux 内核 5.4](https://itsfoss.com/linux-kernel-5-4/)。
使用该内核,你可以获得原生的 [exFAT 支持](https://cloudblogs.microsoft.com/opensource/2019/08/28/exfat-linux-kernel/)、改进的硬件支持。更不用说,拥有 [WireGuard](https://wiki.ubuntu.com/WireGuard) VPN 的支持也是一件极好的事。
所以,你会注意到 Linux Kernel 5.4 的众多好处,包括内核锁定功能。如果你好奇,你可以阅读我们关于 [Linux Kernel 5.4](https://itsfoss.com/linux-kernel-5-4/) 的新闻报道来了解更多的细节。
### 增加了 Feral Interactive 的 GameMode
以将游戏带到 Linux 平台而闻名的 Feral Interactive 带来了一款实用的命令行工具,即 [GameMode](https://github.com/FeralInteractive/gamemode)。
它没有提供图形界面,但是在启动一个游戏前,你可以使用命令行请求临时性的系统优化。
虽然这可能不会给每个系统都带来很大的不同,而是给玩游戏提供了更多的资源,并且 GameMode 可以确保你获得必要的优化。
### 实验性的 ZFS 安装选项
你可以使用 ZFS 作为根文件系统了。值得注意的是,它是一个实验性的功能,如果你不确定自己在做什么,那么就不应该使用它。
要更好地了解 ZFS,我建议你阅读我们的一篇文章,[John Paul](https://itsfoss.com/author/john/) 所写的《[ZFS 是什么](https://itsfoss.com/what-is-zfs/)》的文章。
### 性能和其它的改进
Ubuntu MATE 是一款完美的轻量级发行版,同时也是一款适合现代台式机的发行版。

在这个评测中,我没有运行任何特殊的基准测试工具,以一个普通用户来说,我在虚拟机设置中没有发现任何性能问题。我在一台使用了一颗 i5-7400 处理器、配备 GTX 1050 显卡和 16 GB 内存的主机系统上进行了测试。并且,我将 7 GB 的内存 + 768 MB 的显存 + 2 个处理器核心分配给了虚拟机。

如果你要自己测试它,请随时告诉我你对它的感觉如何。
总的来说,除了所有主要的改进之外,还有一些细微的改变/修复/改进,使得 Ubuntu MATE 20.04 LTS 成为了一个很好的升级版本。
### 我应该升级吗?
如果你正在运行 Ubuntu MATE 19.10,你应该立即升级它,因为它的支持将在 2020 年 6 月结束。
对于 Ubuntu MATE 18.04 用户(支持到 2021 年 4 月)来说,这取决于你的需求。如果你需要最新发布版本的功能,你应该选择立即升级它。
但是,如果你不一定需要新的功能,你可以查看[现存的错误列表](https://bugs.launchpad.net/ubuntu-mate) 并加入 [Ubuntu MATE 社区](https://ubuntu-mate.community/) 来了解更多最新发布版本的问题。
在你做完必要的研究后,你可以继续升级你的系统到 Ubuntu MATE 20.04 LTS,它将支持到 2023 年 4 月。
你试过最新的 Ubuntu MATE 20.04 吗?你认为它怎么样?在评论中让我知道。
---
via: <https://itsfoss.com/ubuntu-mate-20-04-review/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ubuntu MATE 20.04 LTS is undoubtedly one of the most popular [official flavors of Ubuntu](https://itsfoss.com/which-ubuntu-install/).
It’s not just me, but [Ubuntu 20.04 survey results](https://ubuntu.com/blog/ubuntu-20-04-survey-results) also pointed out the same. Popular or not, it is indeed an impressive Linux distribution specially for older hardware. As a matter of fact, it is also one of the [best lightweight Linux distros](https://itsfoss.com/lightweight-linux-beginners/) available out there.
So, I thought of trying it out for a while in a virtual machine setting to provide you an overview of what you can expect out of it. And, whether it’s worth trying out.
## What’s New In Ubuntu MATE 20.04 LTS?
The primary highlight on Ubuntu MATE 20.04 LTS would be the addition of MATE Desktop 1.24.
You can expect all the new features of the MATE Desktop 1.24 to come packed in with Ubuntu MATE 20.04. In addition to that, there have been many significant changes, improvements, and additions.
Here’s an overview of what has changed in Ubuntu MATE 20.04:
- Addition of MATE Desktop 1.24
- Numerous visual improvements
- Dozens of bugs fixed
- Based on
[Linux Kernel 5.4](https://itsfoss.com/linux-kernel-5-4/)series - Addition of experimental
[ZFS](https://itsfoss.com/what-is-zfs/)support - Addition of GameMode from
[Feral Interactive](https://github.com/FeralInteractive/gamemode). - Several package updates
Now, to get a better idea on Ubuntu MATE 20.04, I’ll give you some more details.
## User Experience Improvements

Considering that more users are leaning towards Linux on Desktop, the user experience plays a vital role in that.
If it’s something easy to use and pleasant to look at that makes all the difference as the first impression.
With Ubuntu MATE 20.04 LTS, I wasn’t disappointed either. Personally, I’m a fan of the latest [GNOME 3.36](https://itsfoss.com/gnome-3-36-release/). I like it on my [Pop OS 20.04](https://itsfoss.com/pop-os-20-04-review/) but with the presence of [MATE 1.24](https://mate-desktop.org/blog/2020-02-10-mate-1-24-released/), it Ubuntu MATE was also a good experience.
You will see some significant changes to the window manager including the addition of **invisible resize borders**, **icons rendering in HiDPI**, **rework of ALT+TAB workspace switcher pop ups**, and a couple of other changes that comes as part of the latest MATE 1.24 desktop.
Also, **MATE Tweak** has got some sweet improvements where you get to preserve user preferences even if you change the layout of the desktop. The new **MATE Welcome screen** also informs the user about the ability to change the desktop layout, so they don’t have to fiddle around to know about it.
Among other things, one of my favorite additions would be the **minimized app preview feature**.
For instance, you have an app minimized but want to get a preview of it before launching it – now you can do that by simply hovering your mouse over the taskbar as shown in the image below.
Now, I must mention that it does not work as expected for every application. So, I’d still say **this feature is buggy and needs improvements**.
## App Additions or Upgrades
With MATE 20.04, you will notice a new **Firmware updater** which is a GTK frontend for [fwupd](https://fwupd.org). You can manage your drivers easily using the updater.
This release also **replaces** **Thunderbird with the Evolution** email client. While [Thunderbird](https://www.thunderbird.net/en-US/) is a quite popular desktop email client, [Evolution](https://wiki.gnome.org/Apps/Evolution) integrates better with the MATE desktop and proves to be more useful.
Considering that we have MATE 1.24 on board, you will also find a **new time and date manager app**. Not just that, if you need a magnifier, [Magnus](https://kryogenix.org/code/magnus/) comes baked in with Ubuntu MATE 20.04.
Ubuntu MATE 20.04 also includes upgrades to numerous packages/apps that come pre-installed.

While these are small additions – but help in a big way to make the distro more useful.
## Linux Kernel 5.4
Ubuntu MATE 20.04 ships with the last major stable kernel release of 2019 i.e [Linux Kernel 5.4](https://itsfoss.com/linux-kernel-5-4/).
With this, you will be getting the native [exFAT support](https://cloudblogs.microsoft.com/opensource/2019/08/28/exfat-linux-kernel/) and improved hardware support as well. Not to mention, the support for [WireGuard](https://wiki.ubuntu.com/WireGuard) VPN is also a nice thing to have.
So, you will be noticing [numerous benefits of Linux](https://itsfoss.com/advantages-linux/) Kernel 5.4 including the kernel lock down feature. In case you’re curious, you can read our coverage on [Linux Kernel 5.4](https://itsfoss.com/linux-kernel-5-4/) to get more details on it.
## Adding GameMode by Feral Interactive
Feral Interactive – popularly known for bringing games to Linux platform came up with a useful command-line tool i.e. [GameMode](https://github.com/FeralInteractive/gamemode).
You won’t get a GUI – but using the command-line you can apply temporary system optimizations before launching a game.
While this may not make a big difference for every system but it’s best to have more resources available for gaming and the GameMode ensures that you get the necessary optimizations.
## Experimental ZFS Install Option
You get the support for ZFS as your root file system. It is worth noting that it is an experimental feature and should not be used if you’re not sure what you’re doing.
To get a better idea of ZFS, I recommend you reading one of our articles on [What is ZFS](https://itsfoss.com/what-is-zfs/) by [John Paul](https://itsfoss.com/author/john/).
## Performance & Other Improvements
Ubuntu MATE is perfectly tailored as a lightweight distro and also something fit for modern desktops.
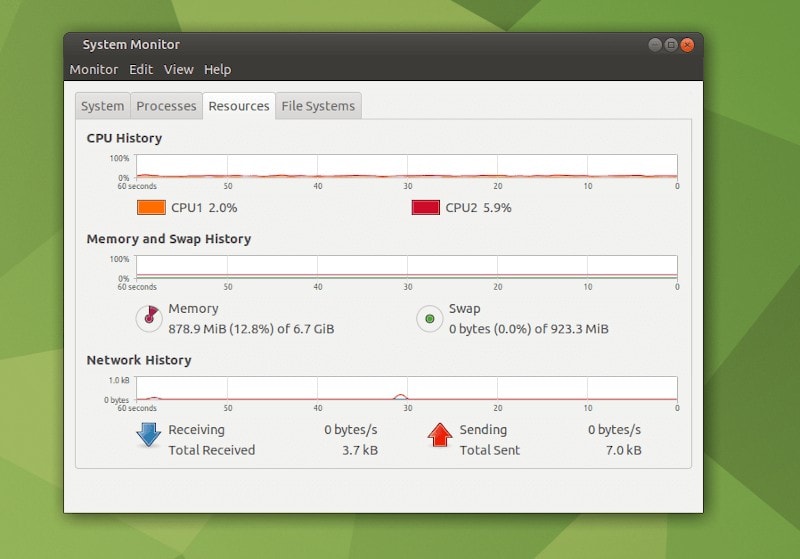
In this case, I didn’t run any specific benchmark tools- but for an average user, I didn’t find any performance issues in my virtual machine setting. If it helps, I tested this on a host system with an i5-7400 processor with a GTX 1050 graphics card coupled with 16 Gigs of RAM. And, 7 GB of RAM + 768 MB of graphics memory + 2 cores of my processor was allocated for the virtual machine.
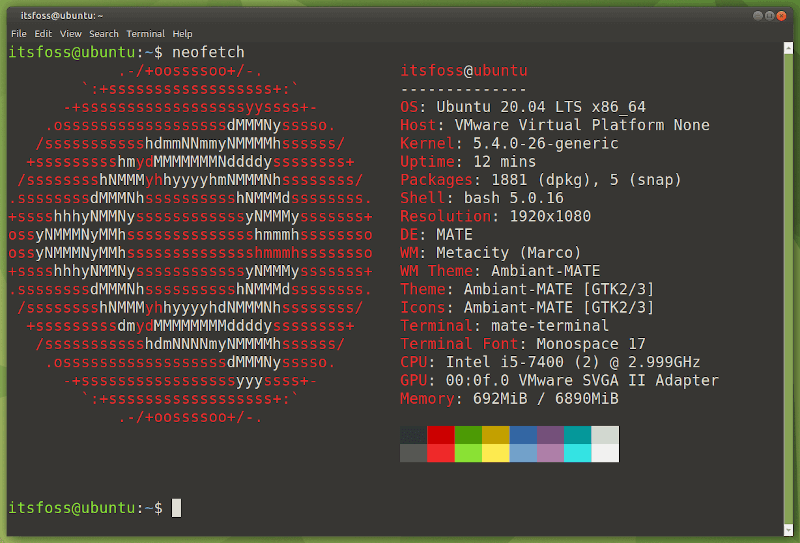
When you test it out yourself, feel free to let me know how it was for you.
Overall, along with all the major improvements, there are subtle changes/fixes/improvements here and there that makes Ubuntu MATE 20.04 LTS a good upgrade.
## Should You Upgrade?
If you are running Ubuntu MATE 19.10, you should proceed upgrading it immediately as the support for it ends in **June 2020.**
For Ubuntu MATE 18.04 users (**supported until April 2021**) – it depends on what works for you. If you need the features of the latest release, you should choose to upgrade it immediately.
But, if you don’t necessarily need the new stuff, you can look around for the [list of existing bugs](https://bugs.launchpad.net/ubuntu-mate) and join the [Ubuntu MATE community](https://ubuntu-mate.community/) to know more about the issues revolving the latest release.
Once you do the research needed, you can then proceed to upgrade your system to Ubuntu MATE 20.04 LTS which will be **supported until April 2023**.
**Have you tried the latest Ubuntu MATE 20.04 yet? What do you think about it? Let me know your thoughts in the comments.** |
12,343 | 新预装了 Ubuntu 20.04 LTS 的戴尔 XPS 13 开发者版笔记本上市 | https://www.omgubuntu.co.uk/2020/06/dell-xps-13-developer-edition-ubuntu-20-04 | 2020-06-23T23:49:00 | [
"笔记本",
"XPS",
"DELL"
] | https://linux.cn/article-12343-1.html | 
是否一直在等待预装 Ubuntu 20.04 LTS 的新戴尔 XPS 13 开发者版的消息?好吧,你很幸运,因为戴尔已经宣布了这个消息!
对于戴尔 XPS 13 开发者版,你可能不需要太多的介绍。这个笔记本电脑系列在许多方面都受到 Linux 开发人员的欢迎,就像 IBM 著名的 ThinkPad 系列(最近也[受到 Ubuntu 的青睐](/article-12283-1.html))一样。
戴尔开发者笔记本的最新迭代产品预装了 Ubuntu 20.04 LTS。该设备标榜了一个与 Ubuntu “兼容”的内置指纹识别器(开发人员正在向后移植新的[指纹登录改进功能](https://www.omgubuntu.co.uk/2020/04/ubuntu-fingerprint-scanner-login-desktop))以及其他一些功能。

在规格方面,这款笔记本的标准配置提供了一块 13.4 寸非触控的 InfinityEdge 显示屏(1920×1200,16:10)。可以将其换成同一面板的触控版本,也可以换成配备触控功能的像素组合版的 13.4″ UHD+(3840×2400)InfinityEdge 显示屏,不过这种替换会让价格上涨不少。
它的基本款宣传的是第十代英特尔酷睿 i5-1035G1 处理器,1.00 GHz(3.6 GHz 睿频加速)。再多花点钱,可以让你换成更气派的第十代英特尔酷睿 i7-1065G7 处理器,1.3GHz(3.9GHz 睿频加速)。这两款 CPU 都是四核。
其图形性能取决于你选择的处理器。i5 款配备了集成的英特尔 UHD 图形芯片,而第十代英特尔 i7 款则提供了集成的英特尔 Iris Plus 图形芯片。
这款笔记本标配 8GB 的 LPDDR4x 内存,但如果你想要的话,可以扩展到 16GB(是的,你可能确实想扩展一下,毕竟这东西运行 GNOME Shell)。
还有高达 2TB 的存储(M.2 PCIe NVMe 固态硬盘)、前面提到的指纹识别器和电池寿命 —— 注意这个 —— 戴尔说电池寿命高达 18 个小时。

在端口方面,它的连接方式很纤巧,只有两个 Thunderbolt 3 端口,用于视频和电源;一个普通的 3.5mm 耳机插孔;以及一个 microSD 闪存读卡器。主板上带有杀手级的 Wi-Fi 6 AX1650(2 x 2)和蓝牙 5.1,它们在 Ubuntu 20.04 中都可以“正常工作”。
在外观风格方面也没有什么变化。戴尔 XPS 13 开发者版有时尚的“铂银配黑色的碳纤维掌托”或更精致的“磨砂白配高山白的复合纤维掌托”(不过要多花 50 美元)。
“我们很高兴看到首批搭载 Ubuntu 20.04 LTS 的戴尔系统。企业们正越来越多地为他们的开发人员和工程师配备他们所选择的操作系统,以确保终端用户的高生产力。”Ubuntu 台式机负责人 Martin Wimpress 谈到这台新设备时说。
这款新近通过 Ubuntu 认证的机型在美国的定价为 1,099.99 美元起。价格将根据配置和地区的不同而有所不同。
戴尔的 Ubuntu 20.04 LTS 的 OEM 版本随附一些额外预装和预配置的东西,包括恢复工具、恢复分区、任何相关的驱动程序、戴尔 OEM 软件仓库,以及(可能不太受欢迎)谷歌 Chrome Web 浏览器。
有兴趣买一台?[前往戴尔网站了解更多信息](https://www.dell.com/en-us/work/shop/cty/pdp/spd/xps-13-9300-laptop/ctox13w10p1c2700u)(不过要注意的是,在写这篇文章时,规格仍然列出的是 Ubuntu 18.04 LTS)。
---
via: <https://www.omgubuntu.co.uk/2020/06/dell-xps-13-developer-edition-ubuntu-20-04>
作者:[Joey Sneddon](https://www.omgubuntu.co.uk/author/d0od "View all posts by Joey Sneddon") 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12338-1.html) 荣誉推出
| 200 | OK | **Been holding out for word on a new Dell XPS 13 Developer Edition preloaded with Ubuntu 20.04 LTS? Well you’re in in luck as Dell has announced one!**
You likely don’t need much in way of introduction to the Dell XPS 13 Developer Edition. This laptop series has, throughout its many incarnations, become as popular with Linux developers as IBM’s famed ThinkPad line (which was recently [blessed with Ubuntu](https://www.omgubuntu.co.uk/2020/06/ubuntu-on-lenovo-laptops) too).
The latest iteration of Dell’s developer laptop ships with Ubuntu 20.04 LTS pre-loaded. The device touts a built-in fingerprint reader that “just works” with Ubuntu (and devs are backporting newer [fingerprint login improvements](https://www.omgubuntu.co.uk/2020/04/ubuntu-fingerprint-scanner-login-desktop)) plus a bevvy of other features.
Specs wise this laptop offers a **13.4″ InfinityEdge display (1920×1200, 16:10)** (non-touch) in the standard config. This can be swapped out for a touch version of the same panel or replaced with a pixel-packed 13.4″ UHD+ (3840×2400) InfinityEdge display with touch, though this switch bumps the price up a fair bit.
The base model touts a **10th Gen Intel Core i5-1035G1 processor @ 1.00 GHz **(up to 3.6GHz turbo boost). A bit more money gets you a bit more oomph in the form of the 10th Gen Intel Core i7-1065G7 processor @ 1.3GHz (up to 3.9GHz turbo boost). Both CPUs are quad-core.
Graphics performance varies depending on the processor you opt for. The i5 config comes with **integrated Intel UHD graphics**, while the 10th Gen Intel i7 config offers integrated Intel Iris Plus graphics.
The laptop ships with **8GB of LPDDR4x RAM** as standard but this can be expanded to 32GB if you want (and yes, you probably do want — this thing runs GNOME Shell after all).
There’s also up to 2TB of storage (M.2 PCIe NVMe Solid State Drive), the aforementioned fingerprint reader, and a battery life which — get this — Dell say is good for up to 18 hours.
Ports-wise the connectivity options are svelte with **two Thunderbolt 3 ports **for video and power; a regular **3.5mm headphone jack**; and a flush **microSD card** reader. There’s Killer Wi-Fi 6 AX1650 (2 x 2) and Bluetooth 5.1 on board, both “just work” in Ubuntu 20.04.
Style isn’t compromised either. The Dell XPS 13 developer edition is available in a sleek ‘**platinum silver with black carbon fiber palmrest**‘ or a more refined ‘frost white with alpine white composite fiber palmrest’ (albeit for $50 more).
*“We’re delighted to see the first Dell systems ship with Ubuntu 20.04 LTS. Enterprises are increasingly equipping their developers and engineers with the operating system of their choice ensuring high end-user productivity,”* Martin Wimpress, Ubuntu desktop lead, says of the new unit.
Pricing for the newly Ubuntu certified model starts at $1,099.99 in the US. Price will vary depending on configuration and locale.
Dell’s OEM version of Ubuntu 20.04 LTS ships with a few extra things preinstalled and preconfigured including recovery tools, recovery partition, any relevant drivers, the Dell OEM repo, and (perhaps less welcome) the Google Chrome web browser.
Interested in getting one? Head [over the Dell website to learn more](https://www.dell.com/en-us/work/shop/cty/pdp/spd/xps-13-9300-laptop/ctox13w10p1c2700u). |
12,344 | 如何使用 Bash history 命令 | https://opensource.com/article/20/6/bash-history-commands | 2020-06-24T10:16:40 | [
"history",
"历史"
] | https://linux.cn/article-12344-1.html |
>
> Bash 的 history 命令在它提供的功能数量上超过了所有其他 Linux Shell 历史接口。
>
>
>

Bash 有丰富的历史。也就是说,它是一个古老的的 shell,还有一个更古老的 Shell (Bourne shell)的前辈,但是它还有一个很棒的 `history` 命令,它提供的功能数量超过了所有其他 shell 的历史接口。 [Bash](https://opensource.com/resources/what-bash) 版本的 `history` 可进行反向搜索、快速调用、重写历史记录等。
`history` 命令与许多其他命令不同。你可能习惯于将命令作为可执行文件放在常见的系统级位置,例如 `/usr/bin`、`/usr/local/bin` 或者 `~/bin`。 内置的 `history` 命令不在你的 `PATH` 中并且没有物理位置:
```
$ which history
which: no history in [PATH]
```
相反,`history` 是 shell 本身的内置函数:
```
$ type history
history is a shell builtin
$ help history
history: history [-c] [-d offset] [n] or
history -anrw [filename] or
history -ps arg [arg...]
Display or manipulate the history list.
[...]
```
出于这个原因,每个 shell 中的历史功能都是独特的,因此你在 Bash 中使用的功能可能无法在 Tcsh 或 Fish 或 Dash 中使用,而在这些 shell 中使用的功能可能也无法在 Bash 中使用。在某些情况下,了解 Bash 可以做什么可能会激发其他 shell 的用户创建有趣的改造来复制 Bash 行为,并且可能会解锁你从未知道的 Bash 功能。
### 查看你的 Bash 历史
`history` 命令最基本、最频繁的用法是查看 shell 会话的历史记录:
```
$ echo "hello"
hello
$ echo "world"
world
$ history
1 echo "hello"
2 echo "world"
3 history
```
### 事件指示器
<ruby> 事件指示器 <rt> Event designator </rt></ruby>按事件搜索你的历史记录。在这里,“事件”是指记录在历史中的命令,以换行符划定。换句话说,一行一个事件,以索引号来标记。
事件指示器大多以感叹号开头,有时也称为 “bang”(`!`)。
要从你的历史记录中重新运行命令,请使用感叹号,之后紧跟(之间没有空格)所需命令的索引号。例如,假设第 1 行包含命令 `echo "hello"`,你想要想再次运行它:
```
$ !1
echo "hello"
hello
```
你可以使用相对定位,提供基于你历史中当前位置向后的负数行号。例如,返回到历史中倒数第三个条目:
```
$ echo "foo"
foo
$ echo "bar"
bar
$ echo "baz"
baz
$ !-3
echo "foo"
foo
```
如果只想回去一行,那么可以使用速记 `!!` 代替 `!-1`。这节省了按键时间!
```
$ echo "foo"
$ !!
echo "foo"
foo
```
### 字符串搜索
你也可以对条目搜索特定的字符串,反过来搜索要运行命令。要搜索以指定字符串*开始*的命令,请使用感叹号,之后紧跟(没有空格)要搜索的字符串:
```
$ echo "foo"
$ true
$ false
$ !echo
echo "foo"
foo
```
你还可以在任意位置(不仅是开头)搜索包含该字符串的命令。为此,请像之前一样使用 `!` 加上要搜索的字符串,但在字符串的两端都用问号(`?`)围绕起来。如果你知道该字符串后紧跟一个换行符,那么可以省略最后的问号(就是在按*回车*之前输入的最后字符):
```
$ echo "foo"
$ true
$ false
$ !?foo?
echo "foo"
foo
```
### 字符串替换
类似于在行首搜索字符串,你可以搜索字符串并用新字符串替换它,以更改命令:
```
$ echo "hello"
hello
$ echo "world"
world
$ ^hello^foo
echo "foo"
foo
```
### 让 history 有用
在 Bash 中,`history` 命令的功能远远超过此处介绍的内容,但这是一个很好的开始, 可以让你习惯使用你的历史记录, 而不是仅仅把它当作一个参考。经常使用 `history` 命令,并试试无需输入命令即可执行的操作。你可能会感到惊讶!
---
via: <https://opensource.com/article/20/6/bash-history-commands>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Bash has a rich history. That is, it's an old shell with an even older ancestor (the Bourne shell), but it also has a great `history`
command that surpasses all other shell history interfaces based on its number of features. The [Bash](https://opensource.com/resources/what-bash) version of `history`
allows for reverse searches, quick recall, rewriting history, and more.
The `history`
command isn't like many other commands. You might be used to commands being executable files placed in common system-level locations like `/usr/bin`
, `/usr/local/bin`
, or `~/bin`
. The built-in `history`
command isn't in your `PATH`
and has no physical location:
```
$ which history
which: no history in [PATH]
```
Instead, `history`
is a built-in function of the shell itself:
```
$ type history
history is a shell builtin
$ help history
history: history [-c] [-d offset] [n] or
history -anrw [filename] or
history -ps arg [arg...]
Display or manipulate the history list.
[...]
```
For that reason, the history function in each shell is unique, so what you use in Bash may not work in Tcsh or Fish or Dash, and what you use in those may not work in Bash. In some cases, knowing what Bash can do may inspire users of other shells to create interesting hacks to clone Bash behavior, and it may unlock Bash features that you never knew existed.
## View your Bash history
The most basic and frequent use of the `history`
command is to view a history of your shell session:
```
$ echo "hello"
hello
$ echo "world"
world
$ history
1 echo "hello"
2 echo "world"
3 history
```
## Event designators
Event designators search through your history by event. An *event* in this context is a command logged in your history, delineated by a newline character. In other words, it's one line, marked by an index number for reference.
Event designators mostly start with an exclamation point, sometimes also called a *bang* (`!`
).
To rerun a command from your history, use the exclamation point followed immediately (no spaces) by the index number of the command you want. For instance, assume line 1 contains the command `echo "hello"`
, and you want to run it again:
```
$ !1
echo "hello"
hello
```
You can use relative positioning by providing a negative number of lines back from your current position in history. For example, to go back three entries in history:
```
$ echo "foo"
foo
$ echo "bar"
bar
$ echo "baz"
baz
$ !-3
echo "foo"
foo
```
If you're just going back one line, you can use the shorthand `!!`
instead of `!-1`
. That's a savings of one whole keystroke!
```
$ echo "foo"
$ !!
echo "foo"
foo
```
## String search
You can also search for a specific string through the entries, in reverse, for a command to run. To search for a command *starting* with a specific string, use an exclamation point followed immediately (no space) by the string you want to search for:
```
$ echo "foo"
$ true
$ false
$ !echo
echo "foo"
foo
```
You can also search for a command containing a string in any position (not just at the start). To do that, use `!`
plus the string you're searching for, as usual, but surround the string with question marks on either end. You may omit the trailing question mark if you know that the string is immediately followed by a newline character (meaning it's the last thing you typed before you pressed **Return**):
```
$ echo "foo"
$ true
$ false
$ !?foo?
echo "foo"
foo
```
## String substitution
Similar to searching for strings at the start of a line, you can search for a string and replace it with a new string, changing the command:
```
$ echo "hello"
hello
$ echo "world"
world
$ ^hello^foo
echo "foo"
foo
```
## Make history useful
In Bash, the history command is capable of much more than what's been covered here, but this is a good start for getting used to *using* your history instead of just treating it as a reference. Use the `history`
command often, and see how much you can do without having to type commands. You might surprise yourself!
## 1 Comment |
12,346 | 使用 source 命令将函数和变量导入 Bash | https://opensource.com/article/20/6/bash-source-command | 2020-06-24T23:55:00 | [
"source"
] | /article-12346-1.html |
>
> source 就像 Python 的 import 或者 Java 的 include。学习它来扩展你的 Bash 能力。
>
>
>

登录 Linux shell 时,你将继承特定的工作环境。对于 shell 而言,“<ruby> 环境 <rt> environment </rt></ruby>”意味着已经为你设置了某些变量,以确保你的命令可以按预期工作。例如,[PATH](https://opensource.com/article/17/6/set-path-linux) 环境变量定义 shell 从哪里查找命令。没有它,几乎在 Bash 中尝试执行的所有操作都会因“命令未发现” 错误而失败。在执行日常任务时,环境对你几乎是不可见的,但它很重要。
有多种方法可以影响你的 shell 环境。你可以在配置文件中进行修改,例如 `~/.bashrc` 和 `~/.profile`,你可以在启动时运行服务,还可以创建自己的自定义命令或编写自己的 [Bash 函数](https://opensource.com/article/20/6/how-write-functions-bash) 。
### 通过 source 添加到你的环境
Bash(以及其他一些 shell)有一个称为 `source` 的内置命令。这就是令人困惑的地方:`source` 执行与命令 `.` 相同的功能(是的,那只是一个点),而与 `Tcl` 命令的 `source` 不是同一个(如果你输入 `man source`,也许在屏幕上显示的是它)。实际上,内置的 `source` 命令根本不在你的 `PATH` 中。这是 Bash 附带的命令,要获取有关它的更多信息,可以输入 `help source`。
`.` 命令兼容 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains)。 但 `source` 命令不是 POSIX 定义的,但可以与 `.` 命令互换使用。
根据 Bash `help`,`source` 命令在你当前的 shell 中执行一个文件。 “在你当前的 shell 中” 这句很重要,因为它表示它不会启动子 shell。因此,用 `source` 执行的任何操作都发生在内部并影响*当前*环境。
在探讨 `source` 对环境的影响之前,请用 `source` 命令导入一个测试文件,以确保其按预期执行代码。首先,创建一个简单的 Bash 脚本并将其保存为 `hello.sh`:
```
#!/usr/bin/env bash
echo "hello world"
```
使用 `source`,即使该脚本不设置可执行也可以运行:
```
$ source hello.sh
hello world
```
你也可以使用内置的 `.` 命令获得相同的结果:
```
$ . hello.sh
hello world
```
`source` 和 `.` 命令成功地执行了测试文件的内容。
### 设置变量和导入函数
你可以使用 `source` 将文件 “导入” 到 shell 环境中,就像你可以在 C 或 C++ 中使用 `include` 关键字引用一个库,或者在 Python 中使用 `import` 关键字引入一个模块一样。这是 `source` 的最常见用法之一,它也是 `.bashrc` 中的一个默认包含方式,通过 `source` 导入 `.bash_aliases`,以便将任何你自定义的别名在登录时导入到你的环境。
这是导入 Bash 函数的示例。首先,在名为 `myfunctions` 的文件中创建一个函数。它将打印你的公共 IP 地址和本地 IP 地址:
```
function myip() {
curl <http://icanhazip.com>
ip addr | grep inet$IP | \
cut -d"/" -f 1 | \
grep -v 127\\.0 | \
grep -v \:\:1 | \
awk '{$1=$1};1'
}
```
将该函数导入你的 shell:
```
$ source myfunctions
```
测试新函数:
```
$ myip
93.184.216.34
inet 192.168.0.23
inet6 fbd4:e85f:49c:2121:ce12:ef79:0e77:59d1
inet 10.8.42.38
```
### source 的搜索
当你在 Bash 中使用 `source` 时,它将在当前目录中搜索你引用的文件。但并非所有 shell 都这样,因此,如果你不使用 Bash,请查看文档。
如果 Bash 找不到要执行的文件,它将搜索你的 `PATH`。同样,这并不是所有 shell 的默认设置,因此,如果你不使用 Bash,请查看文档。
这些都是 Bash 中不错的便利功能。这种出奇地强大,因为它允许你将常用函数保存在磁盘上的一个集中的位置,然后将你的环境视为集成开发环境 (IDE)。你不必担心函数的存储位置,因为你知道它们在你的本地位置等同于在 `/usr/include` 下,因此无论你在哪,当你导入它们时,Bash 都可以找到它们。
例如,你可以创建一个名为 `~/.local/include` 的目录作为常见函数存储区,然后将此代码块放入 `.bashrc` 文件中:
```
for i in $HOME/.local/include/*;
do source $i
done
```
这会将 `~/.local/include` 中所有包含自定义函数的文件“导入”到 shell 环境中。
当你使用 `source` 或 `.` 命令时,Bash 是唯一搜索当前目录和 `PATH` 的 shell。
### 将 source 用于开源
使用 `source` 或 `.` 来执行文件是影响环境同时保持变更模块化的一种便捷方法。在下次考虑将大量代码复制并粘贴到 `.bashrc` 文件中时,请考虑将相关函数或别名组放入专用文件中,然后使用 `source` 导入它们。
---
via: <https://opensource.com/article/20/6/bash-source-command>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,347 | 如何用 OBS 和 WebSockets 播放视频流 | https://opensource.com/article/20/6/obs-websockets-streaming | 2020-06-25T10:52:15 | [
"WebSockets",
"流媒体"
] | https://linux.cn/article-12347-1.html |
>
> 用这些简化了 WebSockets 的开源支持工具来控制你的流媒体。
>
>
>

[OBS](https://obsproject.com/) 是现在视频直播的主流之一。它是直播流媒体到 Twitch 的首选软件,Twitch 是近来最受欢迎的视频直播网站之一。有一些非常好的附加组件,可以让流媒体人从他们的手机或另一个屏幕上进行控制,而不影响正在运行的视频。事实证明,使用 [Node-RED](https://nodered.org/) 和 [obs-websockets](https://github.com/Palakis/obs-websocket) 插件来构建自己的控制面板真的很容易。

*我的 OBS 控制仪表盘*
我知道你们很多人在想什么 —— “他在同一句话中提到了 WebSockets 和简单?”很多人在设置和使用 WebSockets 时遇到了困难,WebSockets 允许通过 Web 服务器的单一连接进行双向通信。Node-RED 内置了对 WebSockets 的支持,是让这一切变得简单的原因之一,至少与编写自己的客户端/服务器相比是如此。
在开始之前,请确保你已经安装和配置了 OBS。首先下载并安装[最新稳定版的 obs-websockets](https://github.com/palakis/obs-websocket/releases)插件。对于本文来说,默认的设置就可以了,但我强烈建议你之后按照说明来保护 obs-websockets 的安全。
接下来,[下载并安装 Node-RED](https://nodered.org/docs/getting-started/),可以在同一个系统上,也可以在不同的系统上(比如树莓派)。同样,默认的安装对我们这篇文章来说是够了,但最好按照他们网站上的指示进行安全安装。
现在是有趣的部分。启动 Node-RED,打开网页界面(默认在 <http://localhost:1880>),你有了一个空白的画布。打开右边的“汉堡”菜单,选择“<ruby> 管理口味 <rt> Manage Palate </rt></ruby>”。然后点击“安装”标签,搜索 `node-red-contrib-dashboard` 和 `node-red-contrib-rbe` 模块。
安装好这些模块后,点击右侧列表,将以下模块拖拽到画布上。
* 1 Websocket Out
* 1 Websocket In
* 1 Debug
* 1 Inject
* 1 Switch
* 1 Change
* 2 JSON
* 1 Catch
以下列顺序连接它们:
```
Inject->Button->Change->JSON->Websocket Out
Websocket In->JSON->Switch->RBE->Debug
Catch->Debug
```

*基本流程*
当 “Button” 被按下时(或 “Inject” 节点发送一个时间戳),有效载荷通过 “change” 节点发送,从 JSON 对象转换为字符串,然后发送到 “WebSocket Out” 节点。当 “WebSocket In” 节点收到消息后,会将其转换为 JSON 对象,如果不是重复的,则发送到 “Debug” 节点进行输出。而 “Catch” 节点会捕捉到任何错误,并将其放入 “Debug” 面板中。
那有效载荷里有什么呢?让我们设置好一切,一探究竟。
首先,双击 “Button” 打开设置对话框。先使用下拉菜单将有效载荷改为 “JSON”。在该字段中,添加以下内容:
```
{"request-type":"GetVersion"}
```
启用 “If msg arrives on input, emulate a button click” 复选框,然后点击 “Done” 关闭 “Button” 配置。当消息从 “Inject” 节点传来时,或者 UI 中的 “Button” 被按下,它将把 JSON 有效载荷发送到下一个节点。

*设置 “Button”*
现在打开 “Change” 节点。我们要将 `msg.payload.message-id` 设置为 `msg._msgid`,方法是将第一个字段从 `payload`改为 `payload.message-id`,然后使用第二个字段的下拉菜单将类型从 `String` 改为 `msg.`,然后我们将 `_msgid` 放入该字段。这样就会把唯一的消息 ID 复制到 JSON 对象的有效载荷中,这样每个请求就有一个唯一的 ID 进行跟踪。
然后将其发送到 “JSON” 节点,以便将 JSON 对象转换为字符串,然后传递给 “Websocket Out” 节点。打开 “Websocket Out” 节点,配置到 OBS 的连接。首先,将 `Type` 更改为 `Connect to`,然后单击铅笔图标以创建新的连接 URL。将其设置为 `ws://OBSMachine:4444/`,然后关闭对话框进行保存。`OBSMachine` 是 OBS 和 obs-websocket 运行的机器名称。例如,如果 Node-RED 运行在同一台机器上,则为 `ws://localhost:4444`,如果是在名为 `luxuria.local` 的机器上,则为 `ws://luxuria.local:4444`。关闭并更新 “Websocket Out” 节点。这将向 OBS 中的 WebSocket 发送有效载荷文本字符串。

*“Websocket Out” 节点配置*
进入 “WebSocket In” 流程!打开 “WebSocket In” 节点,并对其设置 `Type` 为 `Connect to` 和我们之前定义的连接的 URL(应自动填充)。接下来是第二个 “JSON” 节点,我们可以不用管它。它接受 OBS 的输出,并将其转换为有效载荷对象。
接下来,我们将从中过滤出常规的心跳和状态更新。打开 “Switch”,将 `Property` 值设置为 `payload["update-type"]`。现在从它下面的下拉菜单中选择 `Is Not Null`。点击 `+` 添加第二个选项,并从下拉菜单中选择 `otherwise`。

*“Switch” 节点配置*
将 “Switch” 上的新输出直接连接到 “Debug” 节点的输入。
RBE 节点将过滤掉重复的内容,需要告诉它要观察什么字段。由于它应该连接到 “Switch” 的输出,而它只发送状态更新,所以这一点很重要,因为 obs-websocket 每隔几秒钟就会发送更新。默认情况下,RBE 会比较整个有效载荷对象,它将不断变化。打开 RBE 节点,将 `Property` 从 `payload` 改为 `payload.streaming`。如果 `payload` 的 `streaming`值发生了变化,那么就把消息传递过去,否则就丢弃。
最后一步是将 “Debug” 节点的输出从 `msg.payload` 改为完整的 `msg` 对象。这使我们能够看到整个对象,有时在 `payload` 之外还有有用的信息。
现在,单击 “Deploy” 以激活更改。希望 WebSocket 节点下面会有绿色的 `Connected` 消息。如果它们是红色或黄色的,则连接 URL 可能不正确,需要更新,或者连接被阻止。请确保远程机器上的 4444 端口是开放的、可用的,并且 OBS 正在运行!
如果没有 RBE 节点对 `streaming` 值的过滤,调试面板(点击画布右侧的“虫子”图标)大约现在就会被心跳消息填满。点击 “Inject” 节点左边的按钮,发送一个模拟按钮点击的信号。如果一切顺利,你应该会看到一个对象到达,它有一个 `obs-websocket` 可以做的所有事情的列表。

*对 “GetVersion” 的回应*
现在在另一个标签或窗口中打开 `http://localhost:1880/ui`。它应该显示一个单一的按钮。按下它! 调试面板应该会显示和之前一样的信息。
恭喜你!你已经发送了你的第一个(希望不是最后一个)WebSocket 消息!
这只是使用 obs-websockets 和 Node-RED 可以做的事情的起步。支持的完整文档记录在 obs-websockets 的 GitHub 仓库的 `protocol.md` 文件中。通过一点点的实验,你可以创建一个功能齐全的控制面板来启动和停止流媒体、改变场景,以及更多。如果你和我一样,在意识到之前,你就可以设置好各种控件了。

*如此多的能力让我有点疯*
---
via: <https://opensource.com/article/20/6/obs-websockets-streaming>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [OBS](https://obsproject.com/) is one of the staples of live streaming videos now. It is the preferred software for streaming to Twitch, one of the most popular live video sites around. There are some really nice add-ons to allow a streamer to control things from their phone or another screen without disrupting the running video. It turns out, it is really easy to build your own control panel using [Node-RED](https://nodered.org/) and the [obs-websockets](https://github.com/Palakis/obs-websocket) plugin.

My OBS control dashboard
I know what many of you are thinking—"He said WebSockets and easy in the same sentence?" Many people have had difficulty setting up and using WebSockets, which allow for bi-directional communication over a single connection via a web server. Node-RED has built-in support for WebSockets and is the part that makes this easy, at least compared to writing your own client/server.
Before starting, make sure you have OBS installed and configured. Start by downloading and installing the [latest stable release of the obs-websockets](https://github.com/palakis/obs-websocket/releases) plugin. For this article, the default settings are fine, but I strongly recommend following the instructions for securing obs-websockets in the future.
Next, [download and install Node-RED](https://nodered.org/docs/getting-started/), either on the same system or on a different one (like a Raspberry Pi). Again, the default installation is fine for our purposes, but it would be wise to secure the installation following the directions on their site.
Now for the fun parts. Start Node-RED and open up the web interface (by default at [http://localhost:1880](http://localhost:1880)), and you have a blank canvas. Open up the "hamburger" menu on the right and select "Manage Palate." Then click on the "Install" tab and search for the "node-red-contrib-dashboard" and "node-red-contrib-rbe" modules.
Once those are installed, click on the right-hand list and drag-and-drop the following blocks to the canvas:
- 1 Websocket Out
- 1 Websocket In
- 1 Debug
- 1 Inject
- 1 Switch
- 1 Change
- 2 JSON
- 1 Catch
Connect them in the following orders:
```
Inject->Button->Change->JSON->Websocket Out
Websocket In->JSON->Switch->RBE->Debug
Catch->Debug
```
The basic flows
When the button is pushed (or the Inject node sends a timestamp), a payload is sent through the change node, converted from a JSON object to a string, then sent to the WebSocket Out node. When a message is received by the WebSocket In node, it is converted to a JSON object, and if it is not a duplicate, sent to the Debug node for output. And the Catch node will catch any errors and put them into the debug panel.
What is in that payload? Let's set everything up and find out.
First, double click the `button`
to open the settings dialog. Start by changing the payload to "JSON" using the drop-down menu. In the field, add the following:
```
{"request-type":"GetVersion"}
```
Enable the checkbox for "If msg arrives on input, emulate a button click" and click Done to close the button config. When a message comes from the Inject node, or if the button is pressed in the UI, it will send the JSON payload to the next node.
Setting up the button
Now open up the Change node. We want to set `msg.payload.message-id`
to `msg._msgid`
by changing the first field from `payload`
to `payload.message-id`
and then using the drop-down on the second field to change the type from `String`
to `msg.,`
then we will put `_msgid`
in the field. This copies the unique message ID to the JSON object payload so that each request has a unique ID for tracking.
This is then sent to the JSON node to convert from a JSON object to a string, and then passed to the Websocket Out node. Open up the Websocket Out node to configure the connection to OBS. First, change the `Type`
to `Connect to`
and then click the pencil icon to create a new connection URL. Set that to `ws://OBSMachine:4444/`
and close the dialog to save. `OBSMachine`
is the name of the machine OBS and obs-websocket are running on. For example, if Node-RED is running on the same machine, this would be `ws://localhost:4444`
, and if it is on a machine named "luxuria.local" then it would be `ws://luxuria.local:4444`
. Close and update the Websocket Out node. This sends the payload text string to the WebSocket in OBS.
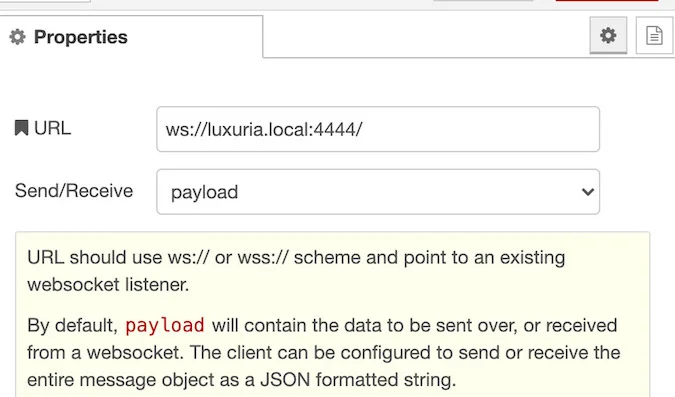
Websocket Out Node configuration
On to the WebSocket In flow! Open the WebSocket In node, and set it to a `Type`
of `Connect to`
and the URL to the connection we defined before (it should auto-fill). Next in line is the second JSON node, which we can leave alone. This accepts output from OBS and converts it into a payload object.
Next, we will filter the regular heartbeat and status updates from everything else. Open up the switch and set the "Property" value to `payload["update-type"]`
. Now select `Is Not Null`
from the drop-down below it. Click `+`
to add a second option and select `otherwise`
from the drop-down.
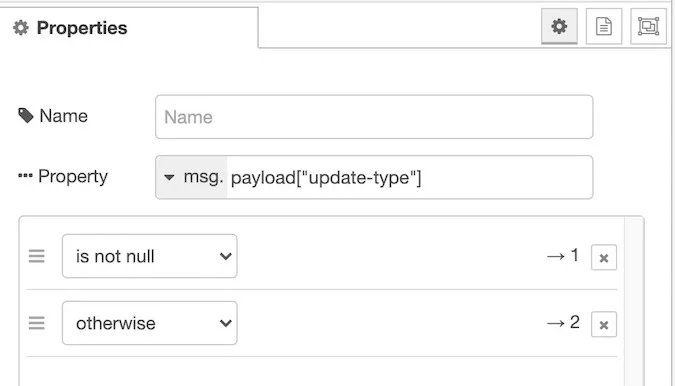
Switch Node configuration
Connect the new output on the switch directly to the Debug node input.
The RBE node, which will filter out duplicates, needs to be told what field to watch for. Since it should be connected to the output from the switch that sends nothing but status updates, this is important, as obs-websocket is sending updates every few seconds. By default, the RBE compares the entire payload object, which will constantly be changing. Open up the RBE Node, and change the `Property`
from `payload`
to `payload.streaming`
. If the `streaming`
value of the payload changes, then pass the message through; otherwise, discard it.
The final step is to change the Debug node output from `msg.payload`
to the complete msg object. This allows us to see the entire object, which sometimes has useful information outside the `payload`
.
Now, click `Deploy`
to activate the changes. Hopefully, the WebSocket nodes will have a green "Connected" message underneath them. If they are red or yellow, the connection URL is likely incorrect and needs to be updated, or the connection is being blocked. Make sure that port 4444 on the remote machine is open and available, and that OBS is running!
Without the RBE node filtering on the `streaming`
value, the debug panel (the bug icon on the right of the canvas) would be filling with Heartbeat messages about now. Click the button to the left of the Inject node to send a signal that will simulate a button click. If all is well, you should see an object arrive that has a listing of all the things `obs-websocket`
can do.
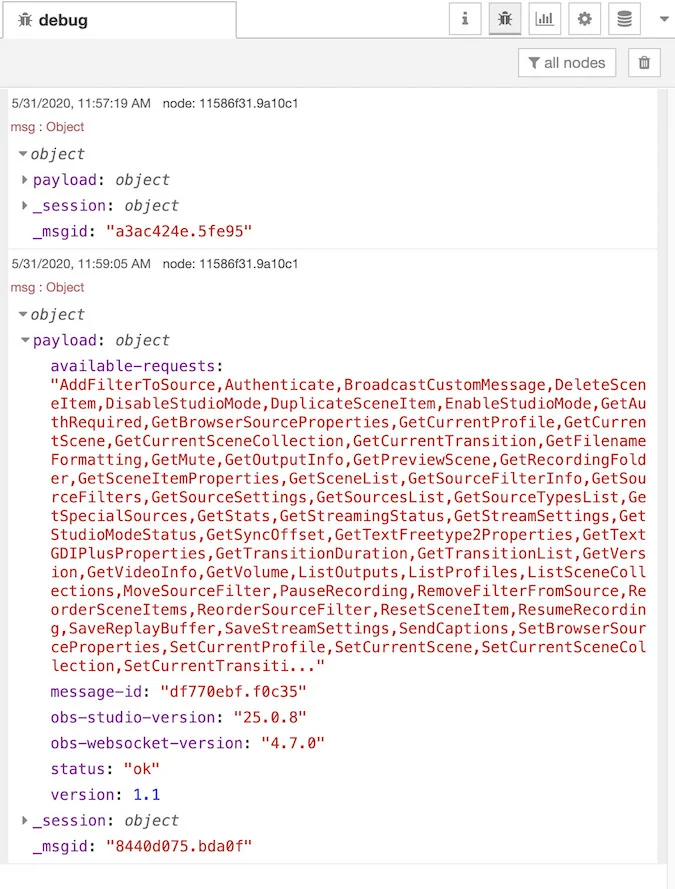
The response to "GetVersion"
Now open up `http://localhost:1880/ui`
in another tab or window. It should show a single button. Press it! The debug panel should show the same information as before.
Congrats! You have sent your first (and hopefully not last) WebSocket message to OBS!
This is just the beginning of what can be done with `obs-websockets`
and Node-RED. The complete documentation of what is supported is documented in the protocol.md file in the GitHub repository for obs-websockets. With a little experimentation, you can create a full-featured control panel to start and stop streaming, change scenes, and a whole lot more. If you are like me, you'll have all kinds of controls set up before you know it.
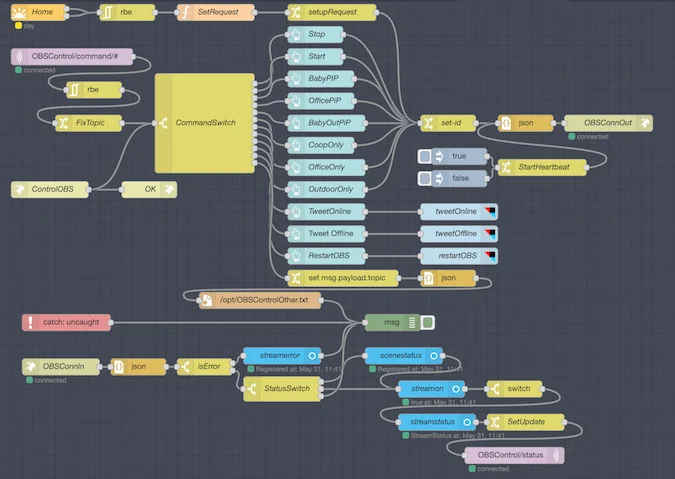
I may have gotten a little mad with power.
## Comments are closed. |
12,349 | Perl 继续前行,Perl 7 将是下一代(硬核老王点评版) | https://www.perl.com/article/announcing-perl-7/ | 2020-06-25T22:44:37 | [
"Perl"
] | https://linux.cn/article-12349-1.html | 
近日[召开的 Perl 大会是在云端举办的](https://perlconference.us/tpc-2020-cloud/),在会上 Sawyer X 宣布 Perl 有了新的前进计划。Perl 7 的开发工作已经在进行中,但不会有代码或语法上的巨大变化。它是默认带有现代行为的 Perl 5,将为以后更大的变化奠定基础。
>
> 硬核老王:在经历了 Perl 6 失败的巨大痛苦之后,Perl 社区终于从阴霾的心情中走出了。但是失去的黄金 20 年却是挽回不了了,否则别说 PHP,都不会有 Python 什么事。我认为,Perl 7 是一条自我救赎之路,应该,或许,会有新的 Perl 7、Perl 8 吧……
>
>
>
### Perl 7 基本上是 Perl 5.32
Perl 7.0 将会是 Perl 5 系列的 5.32,但会有不同的、更合理的、更现代的默认行为。你不需要启用大多数你已经设置过的默认行为,因为这些已经为你启用了。这个大版本跳跃为我们一直以来的工作方式和未来可以做的事情之间设定了一个界限。
>
> 硬核老王:可以理解为,Perl 是一个 Perl 5 兄弟们亲手打下的家族企业,而 Perl 6 是外面请来的职业经理人,结果经理人要对家族企业采用现代化管理,差点鸡飞蛋打。现在好了,Perl 6 分家出去单过了,亲儿子 Perl 7 准备重振家业。
>
>
>
请记住,Perl 是一门“按我的意思做”的语言,其默认行为可能就是你想要的。在 Perl 4 和 Perl 5 的早期,这很容易。但是,几十年过去了,现在的世界更加复杂了。我们不断地往其中添加编译指令,但由于 Perl 对向后兼容的承诺,我们不能改变其默认行为。现在,我们又回到了 C 语言的旧时代,在开始做一些事情之前,我们必须包含大量的例行模板:
```
use utf8;
use strict;
use warnings;
use open qw(:std :utf8);
no feature qw(indirect);
use feature qw(signatures);
no warnings qw(experimental::signatures);
```
这一点在 v5.12 及以后的版本中稍有好转,因为我们可以通过使用设置最低版本来免去设置 `strict` 指令:
```
use v5.32;
use utf8;
use warnings;
use open qw(:std :utf8);
no feature qw(indirect);
use feature qw(signatures);
no warnings qw(experimental::signatures);
```
>
> 硬核老王:不可否认,Perl 二十年前如日中天,那个时候,不说终端运行的脚本,就是互联网上主要的互动程序(CGI),也几乎全是用 Perl 写的。但是在风口时代它的主要精力都在折腾 Perl 6,而 Perl 5 系列不但很多地方显得老旧,历史包袱也过重。向前不能保持原有的精巧习惯,向后不能跟上现代的软工理念。
>
>
>
Perl 7 是一个新的机会,即使不指定版本,也可以把其中的一些行为变成默认行为。Perl 5 仍然有它的极度向后兼容的行为,但 Perl 7 将以最小的历史包袱获得现代实践的新生。我个人希望<ruby> 签名 <rp> ( </rp> <rt> signatures </rt> <rp> ) </rp></ruby>功能能够入选到新的版本,但要让 Unicode 成为默认行为还有很多工作要做,所以你可能需要保留其中的一些编译指令:
```
use utf8;
use open qw(:std :utf8);
```
你可能会丢掉一些你肯定不应该使用的垃圾功能,比如间接对象表示方式。Larry Wall 说他必须为 C++ 程序员做点什么。
```
my $cgi = new CGI; # 间接对象,但在 Perl 7 不这样用了
my $cgi = CGI->new; # 直接对象
```
但是,这个功能在 Perl 7 中并没有真正消失。它在 v5.32 中已经可以[通过设置关闭](https://www.effectiveperlprogramming.com/2020/06/turn-off-indirect-object-notation/)了,但现在有了不同的默认行为。
### Perl 5 怎么了?
没有人要把 Perl 5 从你身边夺走,它将进入长期维护模式 —— 比最新用户版本的两年滚动支持时间的两倍都要长得多。这可能要从现在支持到十年后了(或者说 Perl 5 已经人过中年了)。
>
> 硬核老王:这样挺好,旧时代的继续留在旧时代,新生代的轻装前行。
>
>
>
### 什么时候开始?
这项工作现在就在进行,但你不需要担心,大约六个月后,才会出现第一个候选版本。我们的目标是在明年发布 Perl 7.0 的用户版本,并在这期间发布一些候选版本。
这也是一个容易实现的承诺,因为 Perl 7 基本上就是 v5.32,默认行为不同而已。没有大的重写,也没新的功能,尽管目前一些实验性的功能可能会稳定下来(请把“签名”功能选入!)。
### CPAN 怎么办?
CPAN(<ruby> 综合 Perl 档案网 <rp> ( </rp> <rt> Comprehensive Perl Archive Network </rt> <rp> ) </rp></ruby>)有近 20 万个模块。人们正在使用的处于维护状态的模块应该还能用,对于其它的模块会有一个兼容模式。记住 Perl 7 主要是 v5.32,所以你应该不需要修改太多。
你可能不知道 [Perl5 Porters](https://lists.perl.org/list/perl5-porters.html) 几乎会针对所有的 CPAN 模块测试其新版本。这个用于检查更改可能对 Perl 社区产生影响的工具已有很长的历史了。作为一个模块的作者,我经常会收到来自不同人的消息,主要是 Andreas Koenig 或 Slaven Rezić,他们说我的模块中的一些奇怪的东西可能会在新的 Perl 版本中出问题。通常,我总是需要更新一些东西来解决这些问题。追踪现有代码中的问题已经不是问题了。修复代码应该不会那么繁琐,因为它仍然是 Perl 5,但有更好的实践。
>
> 硬核老王:知道当年 Perl 为什么强悍吗?有一个主要的原因是,Perl 有个无所不包的 CPAN 仓库。
>
>
>
会不会有一个单独的 Perl 7 的 CPAN?没有人说不能有,但是在跳转到 Perl 7 的过程中,开发人员不希望重做已经可以工作的东西。这个变化应该是可以控制的,尽量减少副作用。
另外,PAUSE(<ruby> Perl 作者上载服务器 <rp> ( </rp> <rt> Perl Authors Upload Server </rt> <rp> ) </rp></ruby>)在过去的几年里得到了不少人的喜爱。这使他们可以更容易适应未来的需要。从事这方面工作的人都是经验丰富、才华横溢的人,他们让代码库变得更加容易管理。
### 为什么要跳到大版本?
一个主要版本可以与用户订立不同的契约。跳转到一个主要版本可以用新的默认行为来改变这个契约,即使这与过去有冲突。如果你愿意的话,总会有办法将所有这些设置都重置为旧的 Perl 5 默认行为。不过在语法和行为上,Perl 7 的代码(大部分)仍然是 v5.32 的代码。
Sawyer 谈到了 Perl 用户的三个主要细分市场:
* 绝不会改变他们的代码的人
* 使用新功能的人
* 从零开始的人
Perl 5 的社会契约是<ruby> 极度后向兼容 <rp> ( </rp> <rt> extreme backward compatibility </rt> <rp> ) </rp></ruby>,并且在这方面取得了惊人的成功。问题是,极度后向兼容对那些不会更新代码的人有效,但对另外两部分人没有帮助。要使用新功能的人不得不在每个程序中加入挺长的例行模板部分,而从零开始的人们则想知道为什么他们创建一个程序就必须包含这么多,才能不让 StackOverflow 上的人因为少了那些编译指令而呵斥他们。
>
> 硬核老王:迎合新血才是最重要的,让旧代码和旧人们自己过吧。
>
>
>
### 为什么是 7,而不是 6?
这个答案分为两部分。 首先,“Perl 6” 已经被现在称为 [Raku](https://raku.org/) 的产品所采用。很久以前,我们认为这件非常雄心勃勃的重写工作将取代 v5.8。但最后,这件事并没有发生,Perl 语言依旧继续过着自己的生活。
因此,下一个可用数字为 7。如此而已。这只是序列中的下一个基数。版本跳跃这事情并不稀奇:PHP 直接从 5 升到了 7 —— 难道是我们从 PHP 社区偷学到的跳跃技能?看看一下历史上的其他奇怪的版本变化:
* 从 Solaris 2.6 到 Solaris 7
* 从 Java 1.4 至 Java 5
* 从以 Postgres 9.x 为主要版本变成了以 Postgres 10 为主要版本
* Windows 3.1 至 Windows 95(98、ME、2000、XP、Vista、7、8、10)
* TeX(每个新版本都更趋近于圆周率 π )
至少我们没跳到 Perl 34!
>
> 硬核老王:言外之意,你们跳得,我也跳得~而且,你们不觉得版本 6 这个数字有点不吉利么,而版本 7 这个数字就好多了。
>
>
>
### 有什么消失了么?
消失的东西不多。有些东西在默认情况下会被禁用,但同样,这本质上是调整旋钮和拨盘指向不同地方的 Perl 5.32。即使在 Perl 5 的土地上,有些东西你也应该学会不需要。以下这些都是第一轮变化的可能目标:
* 间接对象符号
* 裸词文件柄(标准文件柄除外)
* 伪多维数组和哈希值(老的 Perl 4 花招)
* Perl 4 风格的原型定义(使用 `:prototype()` 代替)
>
> 硬核老王:是该学会放弃了,又不是区块链,什么旧的都不能丢下。
>
>
>
### 增加了什么?
增加的也不多。Perl 7 主要是 Perl v5.32,但默认启用了所有的功能。你不需要做任何事情就可以获得大多数新功能,比如[postfix 解引用](https://www.effectiveperlprogramming.com/2014/09/use-postfix-dereferencing/),新的 [isa 操作符](https://www.effectiveperlprogramming.com/2020/01/use-the-infix-class-instance-operator/),或者其他一些功能。这就是一个主要版本可以提供的新社会契约的好处。这是一个硬边界,新功能可以在一边默认存在,而不干扰另一边。
>
> 硬核老王:多增加点新的编程语言技能吧!哪怕是语法糖。
>
>
>
### 那我现在应该做什么?
如果你需要一个旧版的 Perl 来运行你的代码,你继续好了。那些旧版本是不会消失的。就像 Perl 5.6 到现在仍然可以使用,如果那是你希望运行的版本的话。
如果你的代码在那些约束和警告下运行没有问题,而且你使用的是现代 Perl 风格,可能你大部分代码都不用动。如果你有一些裸词的文件柄,就开始转换这些,间接对象符号也一样。
如果你的代码比较凌乱,你也不是没有机会。在从 Perl 5 到 7 的过渡过程中,会有兼容模式来帮助你(但不是 Perl 5 到 8)。一个编译指令可以把那些旋钮和拨盘设置回旧的设置(但这最多也就是一个版本的事情)。
```
use compat::perl5; # 行为类似 Perl 5 的默认行为
```
对于模块来说,还有一些问题需要解决,但也会有一个兼容机制来解决这些问题。
>
> 硬核老王:代码实在写的烂(辩解:我这不是烂,是 Perl 的古怪传统),那没办法,只能给你一次机会。
>
>
>
好消息是,这些东西已经被主要的 Perl 利益相关者在生产环境中进行了测试。这不是纸上谈兵:我们已经在做了,一些粗陋的地方正在调整打磨。
而且,v5.32 中已经有了一些这些旋钮和拨盘,比如,你可以这样关闭间接对象表示:
```
no feature qw(indirect);
```
预期会有更多的旋钮或拨盘,或许像这样:
```
no multidimensional;
no bareword::filehandle;
```
我在《[为 Perl 7 做准备](https://leanpub.com/preparing_for_perl7)》一书中收集了所有这些信息,这是我通过 [Perl School](https://perlschool.com/) 和 LeanPub 提供的最新产品。
>
> 硬核老王:本文作者 brian d foy 也是《<ruby> 精通 Perl <rp> ( </rp> <rt> Mastering Perl </rt> <rp> ) </rp></ruby>》 的作者,我是这本书是中文译者之一。
>
>
>
### 一句话总结
Perl 7 是 v5.32,设置不同而已。你的代码如果不是乱七八糟的,应该可以用。预计一年内会有用户发布。
>
> 硬核老王:作为一个老 Perl 程序员,这个消息让我又动心了,认真考虑是不是再投回 Perl 的怀抱,哦不,是 Perl 7 的怀抱。
>
>
>
| 200 | OK | # Announcing Perl 7

*image credit: Darren Wood, “7”, on Flickr.*
This morning at [The Perl Conference in the Cloud](https://perlconference.us/tpc-2020-cloud/), Sawyer X announced that Perl has a new plan moving forward. Work on Perl 7 is already underway, but it’s not going to be a huge change in code or syntax. It’s Perl 5 with modern defaults and it sets the stage for bigger changes later. My latest book [Preparing for Perl 7](https://leanpub.com/preparing_for_perl7) goes into much more detail.
## Perl 7 is going to be Perl 5.32, mostly
Perl 7.0 is going to be v5.32 but with different, saner, more modern defaults. You won’t have to enable most of the things you are already doing because they are enabled for you. The major version jump sets the boundary between how we have been doing things and what we can do in the future.
Remember, Perl was the “Do what I mean” language where the defaults were probably what you wanted to do. In Perl 4 and the early days of Perl 5, that was easy. But, it’s been a couple of decades and the world is more complicated now. We kept adding pragmas, but with Perl’s commitment to backward compatibility, we can’t change the default settings. Now we’re back to the old days of C where we have to include lots of boilerplate before we start doing something:
```
use utf8;
use strict;
use warnings;
use open qw(:std :utf8);
no feature qw(indirect);
use feature qw(signatures);
no warnings qw(experimental::signatures);
```
This is slightly better with v5.12 and later because we get [ strict for free](https://www.effectiveperlprogramming.com/2010/08/implicitly-turn-on-strictures-with-perl-5-12/) by using setting a minimum version:
```
use v5.32;
use utf8;
use warnings;
use open qw(:std :utf8);
no feature qw(indirect);
use feature qw(signatures);
no warnings qw(experimental::signatures);
```
Perl 7 is a chance to make some of these the default even without specifying the version. Perl 5 still has Perl 5’s extreme backward compatibility behavior, but Perl 7 gets modern practice with minimal historical baggage. I’m personally hoping signatures makes the cut, but there’s still much to be done to make Unicode the default, so you’ll probably need to keep some of that:
```
use utf8;
use open qw(:std :utf8);
```
You might miss some seedier features that you shouldn’t be using anyway, such as the indirect object notation. Larry Wall said he had to do something for the C++ programmers:
```
my $cgi = new CGI; # indirect object, but not in Perl 7
my $cgi = CGI->new; # direct object
```
But, the feature doesn’t really disappear in Perl 7. It’s already [a setting in v5.32](https://www.effectiveperlprogramming.com/2020/06/turn-off-indirect-object-notation/), but now with a different default.
## What’s happening to Perl 5?
No one is taking Perl 5 away from you; it goes into long term maintenance mode—a lot longer than the two years of rolling support for the two latest user versions. That might be up to a decade from now (or half the time Perl 5 has already been around).
## When is this happening?
The work is happening now, but you won’t need to worry about it for about six months when the first release candidate should appear. The target for a user release of Perl 7.0 within the next year, with some release candidates along the way.
This is an easy promise to keep, too, since Perl 7 is mostly v5.32 with different defaults. There’s no big rewrite or new features, although some currently experimental features may stabilize (please choose signatures!).
## What about CPAN?
The Comprehensive Perl Archive Network, CPAN, has almost 200,000 modules. The maintained modules that people are using should still work, and for the rest there will be a compatibility mode. Remember Perl 7 is mostly v5.32 so you shouldn’t need to change much.
You may not know that the [Perl5 Porters](https://lists.perl.org/list/perl5-porters.html) tests new versions against almost all of CPAN. There’s a long history of tools to check the effect that changes may have on the Perl community. As a module author, I often get messages from various people, mostly Andreas Koenig or Slaven Rezić, about weird things in my modules that may break with new Perls. Usually, it’s something I need to update anyway. Tracking down problems with existing code is a solved problem. Fixing code shouldn’t be that onerous because it’s still Perl 5, but with better practices.
Will there be a separate CPAN for Perl 7? No one has said there can’t be, but in the jump to Perl 7, the developers don’t want to redo what’s already working. This change should be manageable with as few side quests as possible.
Also, PAUSE, the Perl Authors Upload Server, has received quite a bit of love in the past couple of years. That makes it easier for them to adapt to future needs. The people working on that are experienced and talented, and they’ve made the codebase much more tractable.
## Why the jump to a major version?
A major version can have a different contract with the user. A major version jump changes that contract with new default behavior, even if that conflicts with the past. There will be a way to reset all of those settings to the old Perl 5 default if you like. Perl 7 code will still be v5.32 code (mostly) in syntax and behavior though.
Sawyer speaks about three major market segments of Perl users:
- People who are never going to change their code
- People who use new features
- People starting from scratch
Perl 5’s social contract is extreme backward compatibility, and has been amazingly successful with that. The problem is that the extreme backward compatibility works for those who won’t update their code, but doesn’t help the two other segments. The new features crowd has to deal with a longer boilerplate section in every program, and newbies wonder why they have to include so much just to create a program so people on StackOverflow won’t hector them over missing pragmas.
## Why 7 and not 6?
There are two parts to this answer. First, “Perl 6” was already taken by what is now known as [Raku](https://raku.org). A long time ago, we thought that a very ambitious rewrite effort would replace v5.8. In short, that’s not what happened and the language has gone on to live a life of its own.
So, 7 was the next available number. That’s it. It’s just the next cardinal number in line. It’s not unheard of to make such a jump: PHP went directly from 5 to 7, and isn’t it time to steal something from that community? Consider these other weird jumps in history:
- Solaris 2.6 to Solaris 7
- Java 1.4 to Java 5
- Postgres 9.x as the major version to Postgres 10 as the major version
- Windows 3.1 to Windows 95 (98, ME, 2000, XP, Vista, 7, 8, 10)
- TeX (each new version more closely approximates π)
At least it’s not Perl 34.
## What’s disappearing?
Not much. Some things will be disabled by default, but again, this is essentially Perl 5.32 with the knobs and dials in different places. There are some things you should learn to live without, even in Perl 5 land. These are the likely candidates for the first round of changes:
- indirect object notation
- bareword filehandles (except maybe the standard filehandles)
- fake multidimensional arrays and hashes (old Perl 4 trick)
- Old-style prototype definitions (use
`:prototype()`
instead)
## What’s appearing?
Not much. Perl 7 is mostly Perl v5.32, but with all of the features enabled by default. You don’t have to do anything to get most new features, such as [postfix dereferencing](https://www.effectiveperlprogramming.com/2014/09/use-postfix-dereferencing/), the new [ isa operator](https://www.effectiveperlprogramming.com/2020/01/use-the-infix-class-instance-operator/), or several other features. That’s the benefit of the new social contract a major version provides. It’s a hard boundary where new features can exist by default on one side without disturbing the other side.
## What should I do right now?
If you need an older Perl to run your code, you are going to be fine. Those old versions are not going to disappear. Just like Perl 5.6 is still available, if that’s the version you wish to run.
If your code runs without a problem under strictures and warnings, and you are using modern Perl style, you’re probably mostly good. If you have some bareword filehandles, start converting those. Same with the indirect object notation.
With messy code, you aren’t out of luck. There will be compatibility modes to assist you in the transition from Perl 5 to 7 (but not Perl 5 to 8). A pragma will set the knobs and dials back to the old settings (but this is more of a one version thing):
`use compat::perl5; # act like Perl 5's defaults`
For modules, there are some issues to shake out, but there will be a compatibility mechanism for those too.
The good news is that these things are already being tested by major Perl stakeholders in production settings. This isn’t a paper plan: it’s already happening and the rough edges are being sanded out.
And, v5.32 has one of these knobs and dials in place already. You can [turn off the indirect object notation](https://www.effectiveperlprogramming.com/2020/06/turn-off-indirect-object-notation/):
`no feature qw(indirect);`
But expect two more knobs or dials, maybe like:
```
no multidimensional;
no bareword::filehandle;
```
I’m collecting all of this information in [Preparing for Perl 7](https://leanpub.com/preparing_for_perl7), my latest offering through [Perl School](https://perlschool.com) and LeanPub.
## The bottom line
Perl 7 is v5.32 with different settings. Your code should work if it’s not a mess. Expect a user release within a year.
**Tags**
### brian d foy
[brian d foy](http://www.pair.com/~comdog/) is a Perl trainer and writer, and a senior editor at Perl.com. He’s the author of [Mastering Perl](https://www.masteringperl.org), [Mojolicious Web Clients](https://leanpub.com/mojo_web_clients), [Learning Perl Exercises](https://leanpub.com/learning_perl_exercises), and co-author of [Programming Perl](https://www.programmingperl.org), [Learning Perl](https://www.learning-perl.com), [Intermediate Perl](https://www.intermediateperl.com) and [Effective Perl Programming](https://www.effectiveperlprogramming.com).
[Browse their articles](/authors/brian-d-foy/)
### Feedback
Something wrong with this article? Help us out by opening an issue or pull request on [GitHub](https://github.com/perladvent/perldotcom/blob/master/content/article/announcing-perl-7.md) |
12,350 | 在 Go 中如何转储一个方法的 GOSSAFUNC 图 | https://dave.cheney.net/2020/06/19/how-to-dump-the-gossafunc-graph-for-a-method | 2020-06-26T08:39:00 | [
"Go"
] | https://linux.cn/article-12350-1.html | 
Go 编译器的 SSA 后端包含一种工具,可以生成编译阶段的 HTML 调试输出。这篇文章介绍了如何为函数*和*方法打印 SSA 输出。
让我们从一个包含函数、值方法和指针方法的示例程序开始:
```
package main
import (
"fmt"
)
type Numbers struct {
vals []int
}
func (n *Numbers) Add(v int) {
n.vals = append(n.vals, v)
}
func (n Numbers) Average() float64 {
sum := 0.0
for _, num := range n.vals {
sum += float64(num)
}
return sum / float64(len(n.vals))
}
func main() {
var numbers Numbers
numbers.Add(200)
numbers.Add(43)
numbers.Add(-6)
fmt.Println(numbers.Average())
}
```
通过 `GOSSAFUNC` 环境变量控制 SSA 调试输出。此变量含有要转储的函数的名称。这*不是*函数的完全限定名。对于上面的 `func main`,函数名称为 `main` *而不是* `main.main`。
```
% env GOSSAFUNC=main go build
runtime
dumped SSA to ../../go/src/runtime/ssa.html
t
dumped SSA to ./ssa.html
```
在这个例子中,`GOSSAFUNC=main` 同时匹配了 `main.main` 和一个名为 `runtime.main` 的函数。<sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup>这有点不走运,但是实际上可能没什么大不了的,因为如果你要对代码进行性能调整,它就不会出现在 `func main` 中的巨大的意大利面块中。
你的代码更有可能在*方法*中,你可能已经看到这篇文章,并寻找能够转储方法的 SSA 输出。
要为指针方法 `func (n *Numbers) Add` 打印 SSA 调试,等效函数名为 `(*Numbers).Add`:<sup class="footnote-ref"> <a href="#fn2" id="fnref2"> [2] </a></sup>
```
% env "GOSSAFUNC=(*Numbers).Add" go build
t
dumped SSA to ./ssa.html
```
要为值方法 `func (n Numbers) Average` 打印 SSA 调试,等效函数名为 `(*Numbers).Average`,*即使这是一个值方法*:
```
% env "GOSSAFUNC=(*Numbers).Average" go build
t
dumped SSA to ./ssa.html
```
---
1. 如果你没有从源码构建 Go,那么 `runtime` 软件包的路径可能是只读的,并且可能会收到错误消息。请不要使用 `sudo` 来解决此问题。 [↩︎](#fnref1)
2. 请注意 shell 引用 [↩︎](#fnref2)
---
via: <https://dave.cheney.net/2020/06/19/how-to-dump-the-gossafunc-graph-for-a-method>
作者:[Dave Cheney](https://dave.cheney.net/author/davecheney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Go compiler’s SSA backend contains a facility to produce HTML debugging output of the compilation phases. This post covers how to print the SSA output for function *and* methods.
Let’s start with a sample program which contains a function, a value method, and a pointer method:
```
package main
import (
"fmt"
)
type Numbers struct {
vals []int
}
func (n *Numbers) Add(v int) {
n.vals = append(n.vals, v)
}
func (n Numbers) Average() float64 {
sum := 0.0
for _, num := range n.vals {
sum += float64(num)
}
return sum / float64(len(n.vals))
}
func main() {
var numbers Numbers
numbers.Add(200)
numbers.Add(43)
numbers.Add(-6)
fmt.Println(numbers.Average())
}
```
Control of the SSA debugging output is via the `GOSSAFUNC`
environment variable. This variable takes the name of the function to dump. This is *not* the functions fully qualified name. For `func main`
above the name of the function is `main`
*not* `main.main`
.
%env GOSSAFUNC=main go buildruntime dumped SSA to ../../go/src/runtime/ssa.html t dumped SSA to ./ssa.html
In this example `GOSSAFUNC=main`
matched both `main.main`
and a function called `runtime.main`
.[ 1](#easy-footnote-bottom-1-4188) This is a little unfortunate, but in practice probably not a big deal as, if you’re performance tuning your code, it won’t be in a giant spaghetti blob in
`func main`
. What is more likely is your code will be in a *method*, so you’ve probably landed on this post looking for the correct incantation to dump the SSA output for a method.
To print the SSA debug for the pointer method `func (n *Numbers) Add`
, the equivalent function name is`(*Numbers).Add`
:2
%env "GOSSAFUNC=(*Numbers).Add" go buildt dumped SSA to ./ssa.html
To print the SSA debug for a value method `func (n Numbers) Average`
, the equivalent function name is `(*Numbers).Average`
*even though this is a value method*:
%env "GOSSAFUNC=(*Numbers).Average" go buildt dumped SSA to ./ssa.html |
12,353 | 在 Ubuntu 中使用轻量的 Apt 软件包管理器 Synaptic | https://itsfoss.com/synaptic-package-manager/ | 2020-06-26T22:06:00 | [
"apt",
"Synaptic"
] | https://linux.cn/article-12353-1.html | 
这周推荐的开源软件是 Synaptic。学习这个经过时光积淀的软件包管理器能做哪些现代软件管理器做不到的事情。
### Synaptic 软件包管理器是什么?
[Synaptic](https://www.nongnu.org/synaptic/) 是一个轻量级的 [apt 软件包管理器系统](https://en.wikipedia.org/wiki/APT_(software))的 GUI 前端,使用在 Debian、Ubuntu、Linux Mint 以及其它很多基于 Debian/Ubuntu 发行版中。
总的来说,所有你可以 [在终端中使用 apt-get 命令](https://itsfoss.com/apt-get-linux-guide/) 来做的事,都可以通过 Synaptic 来实现。

曾几何时,Synaptic 几乎是所有基于 Debian Linux 发行版的默认图形化软件包管理器。它被认为是一种用户友好的、易于使用的管理应用程序的方法。
随着像 [GNOME “软件”](https://wiki.gnome.org/Apps/Software) 和 [KDE “发现”](https://userbase.kde.org/Discover) 等现代软件包管理器工具带来更现代和直观的图形用户界面,事情发生了变化。这些软件包管理器有更好的界面,以一种更友好的方式显示软件包信息,带有缩略图、评分和评论。
最后,Synaptic [的使用被局限于在大多数的轻量级 Linux 发行版](https://itsfoss.com/lightweight-alternative-applications-ubuntu/) 中。
#### 为什么你要使用像 Synaptic 软件包管理器这样的 “古老的” 软件?
当然,在多大数的情况下,你没有必要这样做。
但是,Synaptic 仍然比 GNOME “软件” 的功能要很多。记住,它基本上是 `apt` 的 GUI 前端,这意味着它(几乎)可以做任何你能够 [在终端中使用 apt 命令](https://itsfoss.com/apt-command-guide/) 所做的事。
例如,如果你想 [在 Ubuntu 中阻止特定的软件包更新](https://itsfoss.com/prevent-package-update-ubuntu/),你可以在 Synaptic 中做到这一点,但是你却不能 GNOME/Ubuntu 的软件中心中实现。

另外,我注意到 Ubuntu 20.04 的软件中心存在一些问题。它加载速度缓慢,它搜索软件包时缓慢,并且它充满了 snap 应用程序(不是每个人都喜欢)。
Synaptic 也是 [Ubuntu 中一个轻量级应用程序](https://itsfoss.com/lightweight-alternative-applications-ubuntu/),使用可以可以让你感觉你的系统快一点。
#### Synaptic 软件包管理器的功能
下面是对 Synaptic 的概况:
* 更新软件包缓存
* 升级整个系统
* 管理软件包包存储库
* 通过名称、描述、维护者、版本、依赖项等搜索软件包
* 通过组、状态(安装与否)、源或更多信息列出软件包
* 通过名称、状态、大小或版本排序软件包
* 获取与软件包相关的信息
* 锁定软件包版本
* 安装指定版本的软件包
还有很多功能,大家可以自己去探索。
### 如何在 Ubuntu 上安装 Synaptic 软件包管理器
Synaptic 软件包管理器可在 Ubuntu 的 Universe 存储库中获得。如果 Universe 存储库未启用,你可以在软件中心中找到Synaptic:

你也可以通过命令行来安装 Synaptic 。先确保启用 universe 存储库:
```
sudo add-apt-repository univers
```
然后更新缓存(在 Ubuntu 18.04 及更高版本中不需要):
```
sudo apt update
```
现在,使用下面的命令来安装 synaptic 软件包管理器:
```
sudo apt install synaptic
```
这就是所有的安装过程。
### 如何使用 Synaptic 软件包管理器
在安装后,你可以在菜单中开始搜索 Synaptic 并启动它:

可以看到,这个界面不是最好看的界面之一。注意复选框的颜色。白色意味着软件包未安装,绿色意味软件包已安装。

你可以搜索一个应用程序并单击复选框将标记其为安装。它也将(以绿色的形式)高亮将被作为依赖关系项目的软件包。单击应用来安装选择的软件包:

你可以使用 Synaptic [查看在 Ubuntu 中安装的所有软件包](https://itsfoss.com/list-installed-packages-ubuntu/) 。你也可以从这个视图中选择移除软件包。

你可以根据源显示各个存储库中可用的软件包。这是查看 [哪个 PPA 提供什么软件包](https://itsfoss.com/ppa-guide/)的好方法。你可以通过如上所述的方法来安装或移除软件包。

通常,当你更新 Ubuntu 时,所有的软件包都会同时更新。使用 Synaptic,你可以轻松地选择你需要更新/升级到较新版本的软件包。

你也可以锁定软件包的版本,以便它们就不会随着系统更新而被更新。

你也可以使用 Synaptic 搜索软件包。这类似于 [使用 apt-cache search 命令搜索软件包](https://itsfoss.com/apt-search-command/)。

如果你认为你做了错误的选择,你可以从“编辑”菜单中单击撤销。
你可以使用 Synaptic 做很多事,我无法涵盖所有可能的用法。我在这里已经涵盖了最常见的一些方法,如果你将要去使用 Synaptic 的话,我留给你去探索。
### Synaptic 并不适合所有的人
如果你不喜欢 Synaptic,你可以在软件中心中移除它,或在终端中使用这个命令:
```
sudo apt remove synaptic
```
Ubuntu 还有另一个被称为 [AppGrid](https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/) 的轻量级软件包管理器。据我所知,它已经有一段时间没有更新了。
Synaptic 当然并不适合所有的人。它列出了你在常规软件中心中看不到的库和包。如果你移除了一个你不知道的库,那么它可能会引起问题。
我认为 Synaptic 更适合于中高级用户,他们既想更好地控制软件包管理器又不想使用命令行方法。
你有什么要说的吗?你使用过 Synaptic 软件包管理器吗?你是使用软件中心还是你只在终端中探索?请在评论区中分享你的喜好。
---
via: <https://itsfoss.com/synaptic-package-manager/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.comrobsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

## What is Synaptic package manager?
[Synaptic](https://www.nongnu.org/synaptic/?ref=itsfoss.com) is a lightweight GUI front end to [apt package management system](https://en.wikipedia.org/wiki/APT_(software)?ref=itsfoss.com) used in Debian, Ubuntu, Linux Mint and many other Debian/Ubuntu based distributions.
Basically, everything that you can do [using the apt-get commands in the terminal](https://itsfoss.com/apt-get-linux-guide/) can be achieved with Synaptic.
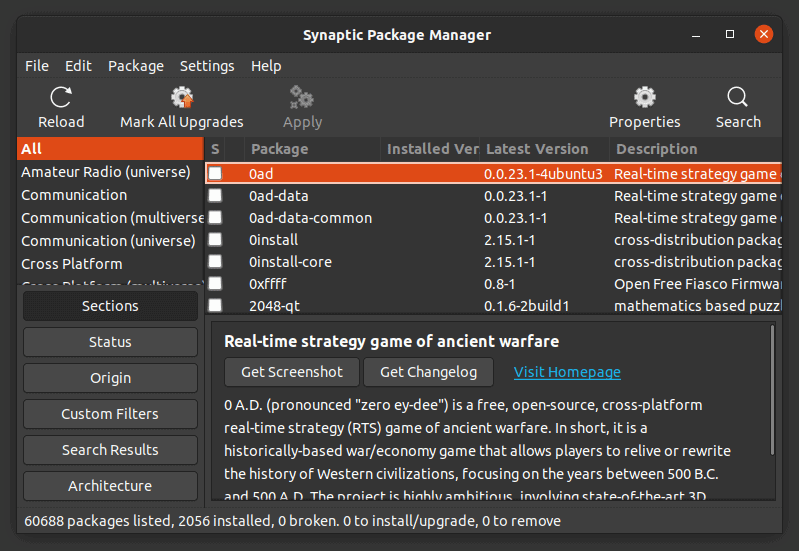
There was a time when Synaptic was the default graphical software manager on almost all Debian-based Linux distributions. It was considered to be a user-friendly, easy to use way of managing applications.
Things changed as modern software manager tools like [GNOME Software](https://wiki.gnome.org/Apps/Software?ref=itsfoss.com) and [KDE Discover](https://userbase.kde.org/Discover?ref=itsfoss.com) came up with more modern and intuitive UI. These software managers have better interface, display the package information in a more friendly way with thumbnails, ratings and reviews.
Eventually, Synaptic got [confined to mostly lightweight Linux distributions](https://itsfoss.com/lightweight-alternative-applications-ubuntu/).
### Why would you use an ‘ancient’ software like Synaptic package manager?
You don’t have to. Not most of the time, of course.
But Synaptic is still a lot versatile than the likes of GNOME Software. Remember, it is basically GUI front end to apt which means it can do (almost) everything you do with [apt commands in the terminal](https://itsfoss.com/apt-command-guide/).
For example, if you want to [prevent the update of a specific package in Ubuntu](https://itsfoss.com/prevent-package-update-ubuntu/), you can do that in Synaptic but not in GNOME/Ubuntu Software Center.
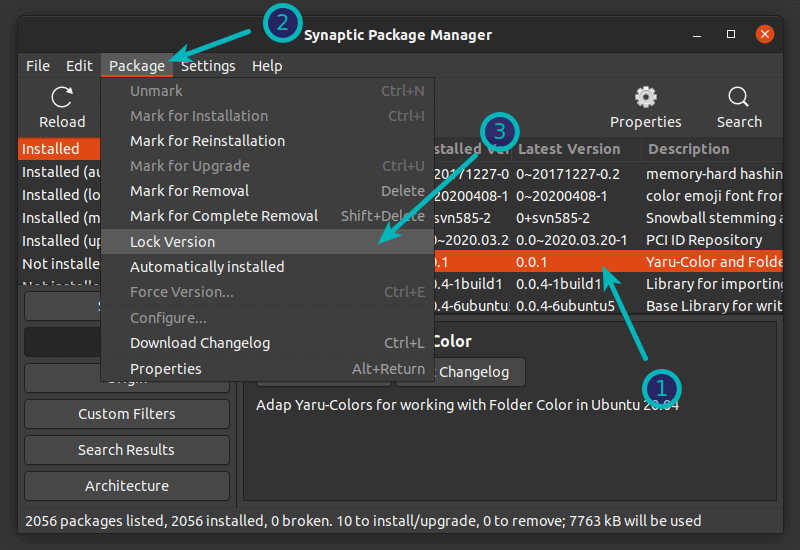
Also, I have noticed some issues with the Software Center in Ubuntu 20.04. It’s slow to load, it’s slow when searching for software and it is full of snap application (that not everyone prefers).
Synaptic is also [one of the lightweight applications you can use in Ubuntu](https://itsfoss.com/lightweight-alternative-applications-ubuntu/) to speed up your system a bit.
### Synaptic package manager features
Here is a summary of what you can do with Synaptic:
- Update the package cache
- Upgrade the entire system
- Manage package repositories
- Search for packages by name, description, maintainer, version, dependencies etc
- List packages by section, status (installed), origin or more
- Sort packages by name, status, size or version
- Get information related to a package
- Lock package version
- Install specific version of a package
There are more features that you may explore on your own.
## How to install Synaptic package manager on Ubuntu
Synaptic package manager is available in the Universe repository in Ubuntu. If it is enabled, you may find it in the Software Center:
You may also install Synaptic via command line. Make sure to enable universe repository first:
`sudo add-apt-repository universe`
And then update the cache (not required in Ubuntu 18.04 and higher versions):
`sudo apt update`
Now, use the command below to install synaptic package manager:
`sudo apt install synaptic`
That’s it.
## How to use Synaptic package manager
Once installed, you can search for Synaptic in the menu and start it from there:
You can see that the interface is not among the best-looking ones here. Note the color of the checkboxes. White means the package is not installed, green means it is installed.

You can search for an application and click on the checkbox to mark it for installation. It will also highlight packages (in green) that will be installed as dependencies. Hit apply to install the selected packages:
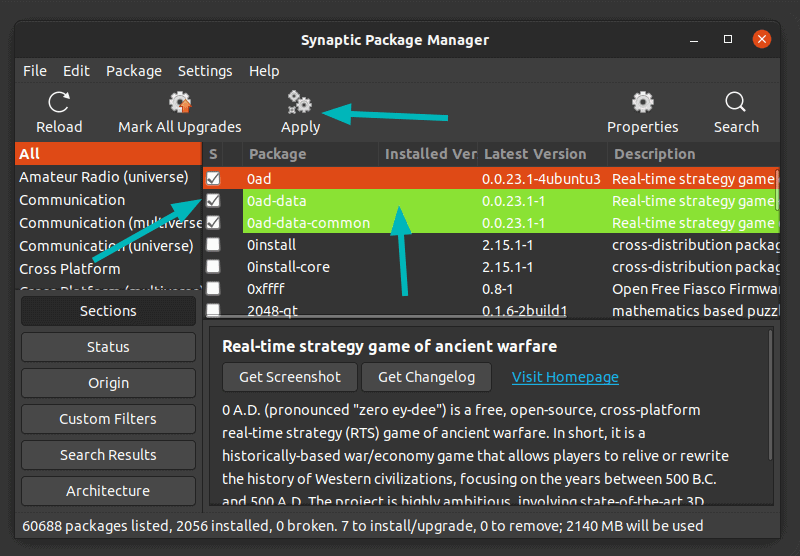
You can [see all the installed packages in Ubuntu](https://itsfoss.com/list-installed-packages-ubuntu/) using Synaptic. You can also choose to remove packages from this view.
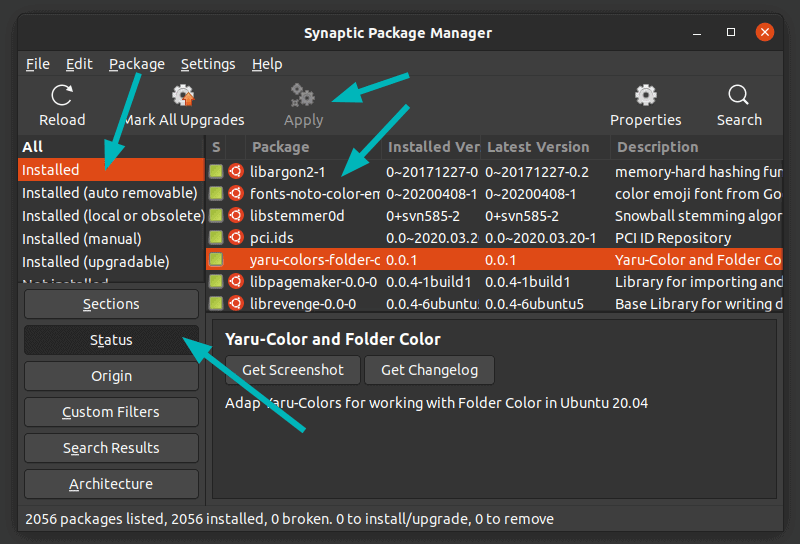
You can see packages available in individual repositories by displaying them based on Origin. Good way to see [which PPA offers what packages](https://itsfoss.com/ppa-guide/). You can install or remove packages as described above.
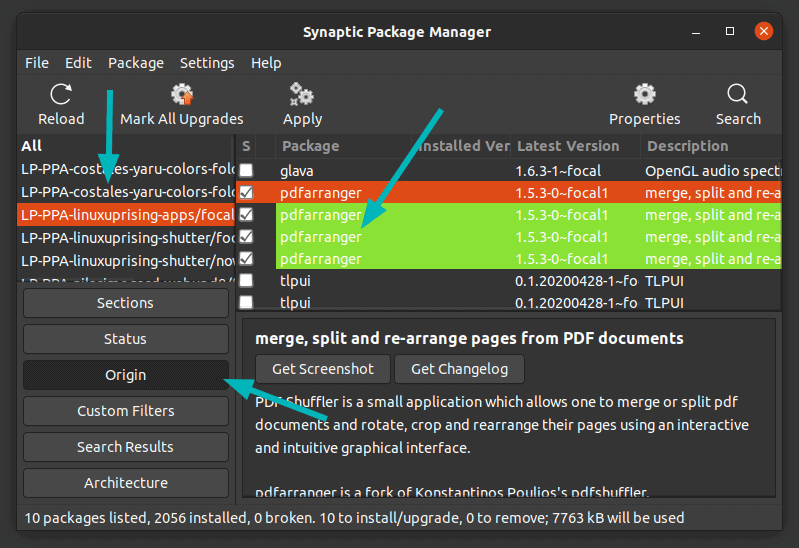
Usually, when you update Ubuntu, all the packages are updated at once. With Synaptic, you can easily choose which packages you want to update/upgrade to a newer version.
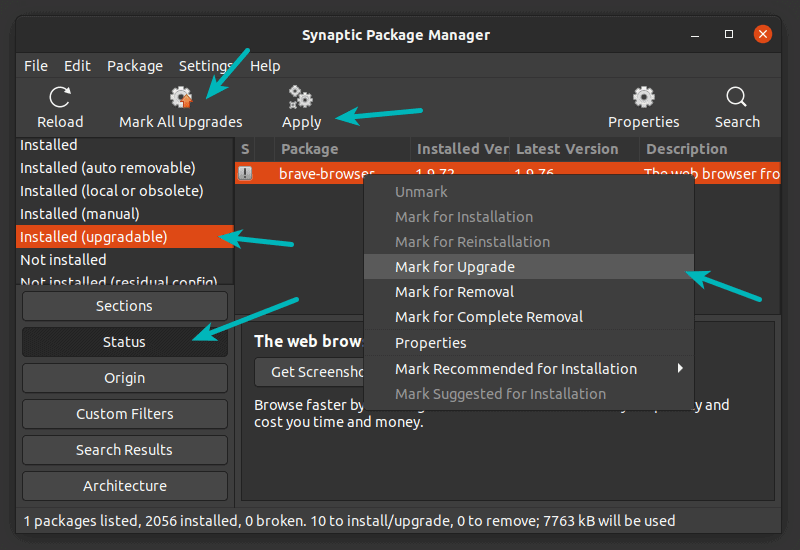
You can also lock the version of packages so that they don’t get updated along with the system updates.

You can also search for packages using Synaptic. This is like [searching for packages using apt-cache search command](https://itsfoss.com/apt-search-command/).
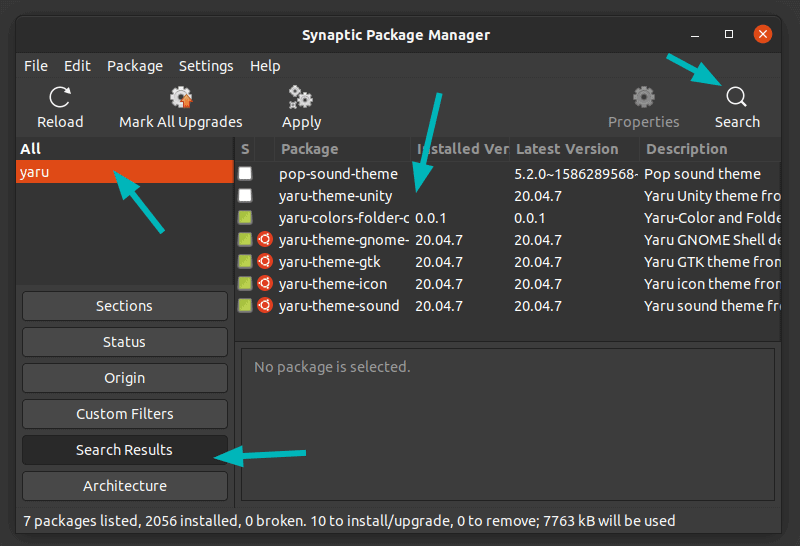
If you think you made the wrong selection, you can click Undo from the Edit menu.
There are plenty more you can do with Synaptic and I cannot cover all the possible usages. I have covered the most common ones here and I leave you to explore it, if you are going to use Synaptic.
[Understanding Ubuntu’s Repository System [Beginner’s Guide]Learn the underlying mechanism of the repository system in Ubuntu to better handle the package management and avoid common update errors.](https://itsfoss.com/ubuntu-repository-mechanism/)

## Synaptic is not for everyone
If you don’t like Synaptic, you can remove it from the Software Center or using this command in terminal:
`sudo apt remove synaptic`
There was another lightweight software manager for Ubuntu called [AppGrid](https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/). It hasn’t been updated in recent times as far as I know.
Synaptic is certainly not for everyone. It lists libraries and packages that you won’t otherwise see in the regular Software Center. If you removed a library that you were not aware of, it may cause issues.
I think that Synaptic is suitable for intermediate to advanced users who want better control over the package management without going the command line way.
What do you say? Have you ever used Synaptic for package management? Do you rely on software center or you just dive into the terminal? Do share your preference in the comment section. |
12,354 | Ubuntu Budgie 20.04 LTS:平滑、精致和丰富的变化 | https://itsfoss.com/ubuntu-budgie-20-04-review/ | 2020-06-27T10:12:00 | [] | https://linux.cn/article-12354-1.html | 正如我们向读者承诺的那样,我们将对 [Ubuntu 20.04 LTS 版本](https://itsfoss.com/download-ubuntu-20-04/)的所有主要特色版进行评测。在这个续篇中,我们将对 Ubuntu Budgie 进行评测。

顾名思义,[Ubuntu Budgie](https://ubuntubudgie.org/) 是使用 [Budgie 桌面环境](https://en.wikipedia.org/wiki/Budgie_)的 [Ubuntu 官方特色版](https://itsfoss.com/which-ubuntu-install/)。这个版本是 Ubuntu 家族中较新的一位成员。Ubuntu Budgie 的第一个版本是 16.04,它在 17.04 版本时被接受为官方特色版。
他们的[目标](https://ubuntubudgie.org/about-us/)是“结合 Budgie 界面的简洁和优雅,以生产具有现代范式的面向桌面的传统发行版。”
### Ubuntu Budgie 20.04 评测:哪些改变了,哪些没有!
[自 18.04 LTS 发布以来,Ubuntu Budgie](https://itsfoss.com/ubuntu-budgie-18-review/) 有了令人惊讶的更新和改进:
* 苹果风格的新菜单
* 默认采用基于 Budgie 的网络管理小程序
* 新的 Window Shuffler 允许你通过快捷键平铺应用程序
* 快速切换桌面布局的新工具
* 支持 4k 分辨率
* 新的默认应用程序:GNOME Firmware 和 Drawing
* 现在已经为 20.04 重构了向后移植包
* 默认浏览器是火狐
* 默认使用 Catfish 搜索文件和文本
* 在 Budgie 中集成了 Nemo 文件管理器
* 由于错误,系统托盘小程序被移除了
* 默认情况下,事件警报声被禁用
* 修复了键盘快捷键神秘失踪的问题
* 更好的锁屏样式
* 由于社区的需求,文件应用 Nautilus 已被 Nemo 取代
* Plank 坞站现在已经切换到屏幕底部,是透明的,并且默认有弹跳动画
* 快速笔记和热角小程序已从 Python 移植到 Vala,以提高速度
* Celluloid 取代了 MPV
* 更新了 GNOME 的依赖性

Ubuntu Budgie 现在随附了 Budgie 桌面环境的最新版本(10.5.1)。改进包括:
* 在 Budgie 桌面设置中新增 Raven 部分
* Raven 通知可以分组,通知可以关闭
* 重新打造了图标任务列表
* 能够设置虚拟桌面的数量
Ubuntu Budgie 自带了大量的 Budgie <ruby> 小程序 <rt> applet </rt></ruby>和<ruby> 微应用 <rt> min-app </rt></ruby>。它们可以通过 Ubuntu Budgie “欢迎”应用来安装。

* WeatherShow:显示未来五天的天气预报,每 3 小时更新一次
* Wallstreet:一个可以循环展示你的图像文件夹中的壁纸工具
* Visual-space:一个紧凑的工作区切换器
* Dropby:这个小程序可让你在面板上快速管理 U 盘
* Kangaroo:从面板上快速浏览文件夹
* 垃圾桶小程序:管理你的垃圾桶
* Fuzzyclock:以模糊的方式显示时间
* 工作区秒表:允许你跟踪在每个工作区花费的时间
完整的变更和更新列表,请访问[变更日志](https://ubuntubudgie.org/2020/04/21/ubuntu-budgie-20-04lts-release-notes-for-18-04-upgraders/)。
#### 系统要求
Ubuntu Budgie 20.04 更新了[系统要求](https://ubuntubudgie.org/downloads/):
* 4GB 或以上的内存
* 64 位的 Intel 和 AMD 处理器
* 在 CSM 模式下启动的 UEFI 电脑
* 基于英特尔的现代苹果电脑
如你所见,Budgie 并不是一个真正的轻量级选择。
#### 安装的应用

Ubuntu Budgie 中默认包含了以下有用的应用程序:
* AisleRiot Solitaire
* Geary
* Catfish 搜索工具
* Cheese 网络摄像头工具
* GNOME Drawing
* GNOME 2048
* GNOME Mahjongg
* GNOME Mines
* GNOME Sudoku
* Gthumb
* LibreOffice
* Maps
* Rhythmbox
* Tilix
* Ubuntu Budgie 欢迎应用
* Evince 文档查看器
* Plank
* Celluloid

### 安装
起初,我无法让 Ubuntu Budgie 进入<ruby> 即用 <rt> live </rt></ruby>环境来安装它。结果发现 Ubuntu Budgie 试图通过 EFI 来启动,我从 [Ubuntu Budgie 论坛](https://discourse.ubuntubudgie.org/t/cant-get-ub-to-boot/3397)得到了解决方案。
当出现紫色的闪屏时,我必须按下 `ESC` 键并选择 `legacy`。之后,它就如常启动了,安装也没有问题了。我只在 Ubuntu Budgie 上遇到过这个问题。我下载并尝试了 Ubuntu MATE 20.04 ISO,但没有遇到类似的问题。
### Ubuntu Budgie 20.04 的体验

除了这个安装上的小问题,我使用 Ubuntu Budgie 的体验非常愉快。自 [Ikey](https://itsfoss.com/ikey-doherty-serpent-interview/) 第一次创建 Budgie 桌面以来,Budgie 桌面已经进步了很多,并且已经成为一个非常成熟的选择。Ubuntu Budgie 的目标是“生产一个面向桌面的传统发行版”。它确实做到了极致。他们所做的所有改变都在不断地为他们的产品增添更多的光彩。
总的来说,Ubuntu Budgie 是一个非常漂亮的发行版。从默认的主题到壁纸选择,你可以看出他们付出了很多努力,视觉体验非常吸引人。
需要注意的是,Ubuntu Budgie 并不适合低配置的系统。我在戴尔 Latitude D630 上运行它。在没有打开任何应用程序的情况下,它使用了大约 700MB 的内存。
在 Ubuntu Budgie 中,让我喜欢的部分超乎我的预期,其中一个部分是 [Tilix 终端模拟器](https://gnunn1.github.io/tilix-web/)。Tilix 允许你在右侧或下方添加终端窗口。它有很多很多功能,我简直爱死了它,我打算在我的其他 Linux 系统上也安装它。
### 关于 Ubuntu Budgie 20.04 的最后感想
Ubuntu Budgie 是众多官方版本中一个很受欢迎的新版本。Budgie 给人的感觉非常流畅和精致。它不会让你觉得碍手碍脚,而是帮你完成工作。
如果你厌倦了当前的桌面环境,想体验一下新的东西,不妨来看看。如果你对当前的环境感到满意,那么就试试 Ubuntu Budgie 的即用 DVD。你可能会喜欢上它。

你是否已经尝试过 Ubuntu 20.04 Budgie?你对它的使用体验如何?如果没有用过,你现在使用的是哪个版本的 Ubuntu 20.04?
---
via: <https://itsfoss.com/ubuntu-budgie-20-04-review/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As we promised our readers, we’ll be reviewing all major flavors of [Ubuntu 20.04 LTS release](https://itsfoss.com/download-ubuntu-20-04/). In that continuation, here’s our take on the Ubuntu Budgie.
[Ubuntu Budgie](https://ubuntubudgie.org/), as the name implies, is an [official flavor of Ubuntu](https://itsfoss.com/which-ubuntu-install/) using the [Budgie desktop environment](https://en.wikipedia.org/wiki/Budgie_(desktop_environment). This flavor is a newer member of the Ubuntu family. Ubuntu Budgie’s first release was 16.04 and it was accepted as an official flavor with the 17.04 release.
Their [goal](https://ubuntubudgie.org/about-us/) is to “combine the simplicity and elegance of the Budgie interface to produce a traditional desktop orientated distro with a modern paradigm”.
## Ubuntu 20.04 Review: What has changed and what has not!
There have been a surprising number of updates and improvements to [Ubuntu Budgie since the 18.04 LTS release](https://itsfoss.com/ubuntu-budgie-18-review/).
- New stylish menu apple
- Budgie-based network manager applet as default
- New Window Shuffler allows you to tile applications from the keyboard
- New tool to quickly switch desktop layout
- 4k resolution support
- GNOME Firmware and Drawing are new default applications
- Backport packages have now been rebuilt for 20.04
- Firefox is the default browser.
- Catfish file and text search is now the default
- budgie-nemo integration
- System Tray applet removed due to bugs
- Event alerts sounds are disabled by default
- Fix for keyboard shortcuts mysteriously going missing
- Better lock screen styling
- Files (Nautilus) has been replaced with Files (Nemo) due to community demand
- Plank dock has now been switched to the bottom of the screen, is transparent and has the bounce animations by default
- The Quick Notes and Hot Corners applets have been ported from Python to Vala to improve speed
- Celluloid replaces MPV
- GNOME dependencies have been updated
Ubuntu Budgie now ships with the most recent release of the Budgie desktop environment (10.5.1). Improvements include:
- New Raven section in Budgie Desktop Settings
- Raven Notification grouping and the ability to turn off notifications
- Icon Task List has been revamped
- Ability to set number of virtual desktops
Ubuntu Budgie comes with a whole slew of Budgie applets and min-apps. They can be installed through Ubuntu Budgie Welcome.

- WeatherShow – shows the forecast for the next five days and updates every 3 hours
- Wallstreet – a wallpaper utility that allows you to cycle through a folder of images
- Visual-space – a compact workspace switcher
- Dropby – this applet allows you to quickly manage USB thumb drives from the panel
- Kangaroo – quickly browser folders from the panel
- Trash applet – manage your trash can
- Fuzzyclock – shows time in a fuzzy way
- Workspace stopwatch – allows you to keep track of the time spent in each workspace
For a complete list of changes and updates, visit the [changelog](https://ubuntubudgie.org/2020/04/21/ubuntu-budgie-20-04lts-release-notes-for-18-04-upgraders/).
### System Requirements
Ubuntu Budgie 20.04 has updated the [system requirements](https://ubuntubudgie.org/downloads/):
- 4GB or more of RAM
- 64-bit capable Intel and AMD processors
- UEFI PCs booting in CSM mode
- Modern Intel-based Apple Macs
As you can see, Budgie is not really a lightweight option here.
### Included Apps
The following useful applications are included in Ubuntu Budgie by default:
- AisleRiot Solitaire
- Geary
- Catfish search tool
- Cheese webcam tool
- GNOME Drawing
- GNOME 2048
- GNOME Mahjongg
- GNOME Mines
- GNOME Sudoku
- Gthumb
- LibreOffice
- Maps
- Rhythmbox
- Tilix
- Ubuntu Budgie Welcome
- Evince document viewer
- Plank
- Celluloid
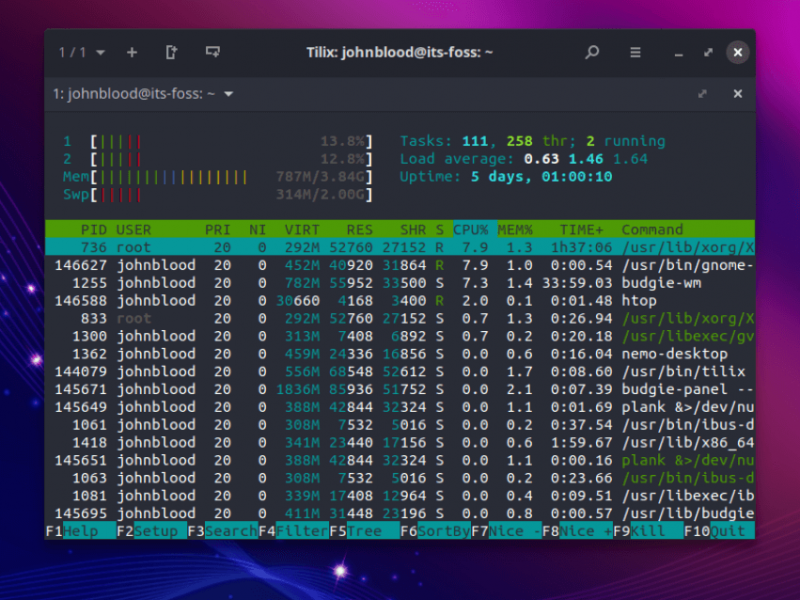
## Installation
Initially, I was unable to get Ubuntu Budgie to do into the live environment so that I could install it. It turned out that Ubuntu Budgie was trying to boot via EFI. I contacted the [Ubuntu Budgie forum](https://discourse.ubuntubudgie.org/t/cant-get-ub-to-boot/3397) and was able to get a solution.
Once the purple splash screen I had to hit ESC and select legacy. After that, it booted as normal and installed without issue. I have only run into this issue with Ubuntu Budgie. I downloaded and tried the Ubuntu MATE 20.04 ISO, but didn’t have a similar issue.
## Experience with Ubuntu Budgie 20.04
Other than the minor installation issue, my time with Ubuntu Budgie was very pleasant. The Budgie desktop has come a long way since [Ikey](https://itsfoss.com/ikey-doherty-serpent-interview/) first created it and it has become a very mature option. The goal of Ubuntu Budgie is to “produce a traditional desktop orientated distro”. It does that in spades. All the changes that they have made continually add more polish to their product.
Overall, Ubuntu Budgie is a very nice looking distro. From the default theme to wallpaper options, you can tell that a lot of effort was put into making the visual experience very appealing.
One thing to keep in mind is that Ubuntu Budgie is not intended for low spec systems. I’m running it on my Dell Latitude D630. Without any applications open, it used about 700 MB of RAM.
One part of Ubuntu Budgie that I enjoyed more than I should have, was the inclusion of the [Tilix terminal emulator](https://gnunn1.github.io/tilix-web/). Tilix allows you to add terminal windows to the right or below. It has a whole host of features and just loved using it. I’m planning to install on my other Linux systems.
## Final Thoughts on Ubuntu Budgie 20.04
Ubuntu Budgie is a welcome addition to the litany of official flavors. Budgie feels very smooth and polished. It gets out of your way and lets you get work done.
If you are tired of your current desktop environment and want to take a look at something new, check it out. If you’re happy with your current setup, check Ubuntu Budgie’s live DVD. You just might like it.
Have you already tried Ubuntu 20.04 Budgie? How’s your experience with it? If not, which Ubuntu 20.04 flavor are you using right now? |
12,356 | 使用 Plotly 来简化 Python 中的数据可视化 | https://opensource.com/article/20/5/plotly-python | 2020-06-27T21:55:00 | [] | https://linux.cn/article-12356-1.html |
>
> Plotly 是一个数据绘图库,具有整洁的接口,它旨在允许你构建自己的 API。
>
>
>

Plotly 是一个绘图生态系统,可以让你在 [Python](https://opensource.com/resources/python) 以及 JavaScript 和 R 中进行绘图。在本文中,我将重点介绍[使用 Python 库进行绘图](/article-12327-1.html)。
Plotly 有三种不同的 Python API,你可以选择不同的方法来使用它:
* 类似于 Matplotlib 的面向对象的 API
* 数据驱动的 API,通过构造类似 JSON 的数据结构来定义绘图
* 类似于 Seaborn 的高级绘图接口,称为 “Plotly Express” API
我将通过使用每个 API 来绘制相同的图来探索它们:英国大选结果的分组柱状图。
在我们进一步探讨之前,请注意,你可能需要调整你的 Python 环境来让这段代码运行,包括以下内容:
* 运行最新版本的Python([Linux](https://opensource.com/article/20/4/install-python-linux)、[Mac](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/thttps:/opensource.com/article/19/5/python-3-default-mac) 和 [Windows](https://opensource.com/article/19/8/how-install-python-windows) 的说明)
* 确认你运行的 Python 版本能与这些库一起工作
数据可在线获得,可以用 Pandas 导入。
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
现在我们可以继续进行了。
### 使用图对象来绘制图
Plotly 面向对象的 API 被称为 `graph_objects`,它有点类似于 [Matplotlib 的面向对象 API](https://opensource.com/article/20/5/matplotlib-python)。
要创建一个柱状图,你可以构造一个包含四个柱状图的对象:
```
# 导入 Plotly 和数据
import plotly.graph_objects as go
from votes import wide as df
# 得到 x 列表
years = df['year']
x = list(range(len(years)))
# 定义绘图
bar_plots = [
go.Bar(x=x, y=df['conservative'], name='Conservative', marker=go.bar.Marker(color='#0343df')),
go.Bar(x=x, y=df['labour'], name='Labour', marker=go.bar.Marker(color='#e50000')),
go.Bar(x=x, y=df['liberal'], name='Liberal', marker=go.bar.Marker(color='#ffff14')),
go.Bar(x=x, y=df['others'], name='Others', marker=go.bar.Marker(color='#929591')),
]
# 指定样式
layout = go.Layout(
title=go.layout.Title(text="Election results", x=0.5),
yaxis_title="Seats",
xaxis_tickmode="array",
xaxis_tickvals=list(range(27)),
xaxis_ticktext=tuple(df['year'].values),
)
# 绘制柱状图
fig = go.Figure(data=bar_plots, layout=layout)
# 告诉 Plotly 去渲染
fig.show()
```
与 Matplotlib 不同的是,你无需手动计算柱状图的 `x` 轴位置,Plotly 会帮你适配。
最终结果图:

*A multi-bar plot made using Graph Objects (© 2019 [Anvil](https://anvil.works/blog/plotting-in-plotly))*
### 使用 Python 数据结构来绘图
你还可以使用 Python 基本数据结构来定义绘图,它与面对对象 API 具有相同的结构。这直接对应于 Plotly 的 JavaScript 实现的 JSON API。
```
# 定义绘图数据
fig = {
'data': [
{'type': 'bar', 'x': x, 'y': df['conservative'], 'name': 'Conservative', 'marker': {'color': '#0343df'}},
{'type': 'bar', 'x': x, 'y': df['labour'], 'name': 'Labour', 'marker': {'color': '#e50000'}},
{'type': 'bar', 'x': x, 'y': df['liberal'], 'name': 'Liberal', 'marker': {'color': '#ffff14'}},
{'type': 'bar', 'x': x, 'y': df['others'], 'name': 'Others', 'marker': {'color': '#929591'}},
],
'layout': {
'title': {'text': 'Election results', 'x': 0.5},
'yaxis': {'title': 'Seats'},
'xaxis': {
'tickmode': 'array',
'tickvals': list(range(27)),
'ticktext': tuple(df['year'].values),
}
}
}
# 告诉 Plotly 去渲染它
pio.show(fig)
```
最终结果与上次完全相同:

*A multi-bar plot made using JSON-like data structures (© 2019 [Anvil](https://anvil.works/blog/plotting-in-plotly))*
#### 使用 Plotly Express 进行绘图
[Plotly Express](https://plot.ly/python/plotly-express/) 是对图对象进行封装的高级 API。
你可以使用一行代码来绘制柱状图:
```
# 导入 Plotly 和数据
import plotly.express as px
from votes import long as df
# 定义颜色字典获得自定义栏颜色
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
# 生成图
fig = px.bar(df, x="year", y="seats", color="party", barmode="group", color_discrete_map=cmap)
```
这里使用了<ruby> <a href="https://anvil.works/blog/tidy-data"> 长表 </a> <rt> Long Form </rt></ruby> 数据,也称为“整洁数据”。这些列代表年份、政党和席位,而不是按政党划分。这与在 [Seaborn](https://opensource.com/article/20/5/seaborn-visualization-python) 中制作柱状图非常相似。
```
>> print(long)
year party seats
0 1922 Conservative 344
1 1923 Conservative 258
2 1924 Conservative 412
3 1929 Conservative 260
4 1931 Conservative 470
.. ... ... ...
103 2005 Others 30
104 2010 Others 29
105 2015 Others 80
106 2017 Others 59
107 2019 Others 72
[108 rows x 3 columns]
```
你可以访问底层的图对象 API 进行详细调整。如添加标题和 `y` 轴标签:
```
# 使用图对象 API 来调整绘图
import plotly.graph_objects as go
fig.layout = go.Layout(
title=go.layout.Title(text="Election results", x=0.5),
yaxis_title="Seats",
)
```
最后,让 Plotly 渲染:
```
fig.show()
```
这将在未使用的端口上运行一个临时 Web 服务器,并打开默认的 Web 浏览器来查看图像(Web 服务器将会马上被关闭)。
不幸的是,结果并不完美。`x` 轴被视为整数,因此两组之间的距离很远且很小,这使得我们很难看到趋势。

*A multi-bar plot made using Plotly Express (© 2019 [Anvil](https://anvil.works/blog/plotting-in-plotly))*
你可能会尝试通过将 `x` 值转换为字符串来使 Plotly Express 将其视为字符串,这样它就会以均匀的间隔和词法顺序来绘制。不幸的是,它们的间隔还是很大,像在 `graph_objects`中那样设置 `xaxis_tickvals` 也不行。
与 [Seaborn](https://opensource.com/article/20/5/seaborn-visualization-python) 中的类似示例不同,在这种情况下,抽象似乎没有提供足够的[应急方案](https://anvil.works/blog/escape-hatches-and-ejector-seats)来提供你想要的东西,但是也许你可以编写*自己*的 API?
### 构建自己的 Plotly API
对 Plotly 的操作方式不满意?那就构建自己的 Plotly API!
Plotly 的核心是一个 JavaScript 库,它使用 [D3](https://d3js.org/) 和 [stack.gl](http://stack.gl/) 进行绘图。JavaScript 库的接口使用指定的 JSON 结构来绘图。因此,你只需要输出 JavaScript 库喜欢使用的 JSON 结构就好了。
Anvil 这样做是为了创建一个完全在浏览器中工作的 Python Plotly API。

*Plotly uses a JavaScript library to create plots, driven by libraries in other languages via JSON (© 2019 [Anvil](https://anvil.works/blog/plotting-in-plotly))*
在 Anvil 版本中,你可以同时使用图对象 API 和上面介绍的 Python 数据结构方法。运行完全相同的命令,将数据和布局分配给 Anvil 应用程序中的 [Plot 组件](https://anvil.works/docs/client/components/plots)。
这是用 Anvil 的客户端 Python API 绘制的多列柱状图:
```
# 导入 Anvil 库
from ._anvil_designer import EntrypointTemplate
from anvil import *
import anvil.server
# 导入客户端 Plotly
import plotly.graph_objs as go
# 这是一个 Anvil 表单
class Entrypoint(EntrypointTemplate):
def __init__(self, **properties):
# Set Form properties and Data Bindings.
self.init_components(**properties)
# 从服务器获取数据
data = anvil.server.call('get_election_data')
# 获取一个方便的 x 值列表
years = data['year']
x = list(range(len(years)))
# 定义绘图
bar_plots = [
go.Bar(x=x, y=data['conservative'], name='Conservative', marker=go.Marker(color='#0343df')),
go.Bar(x=x, y=data['labour'], name='Labour', marker=go.Marker(color='#e50000')),
go.Bar(x=x, y=data['liberal'], name='Liberal', marker=go.Marker(color='#ffff14')),
go.Bar(x=x, y=data['others'], name='Others', marker=go.Marker(color='#929591')),
]
# 规定布局
layout = {
'title': 'Election results',
'yaxis': {'title': 'Seats'},
'xaxis': {
'tickmode': 'array',
'tickvals': list(range(27)),
'ticktext': data['year'],
},
}
# 生成多列柱状图
self.plot_1.data = bar_plots
self.plot_1.layout = layout
```
绘图逻辑与上面相同,但是它完全在 Web 浏览器中运行,绘图是由用户计算机上的 Plotly JavaScript 库完成的!与本系列的所有其它 [Python 绘图库](/article-12327-1.html)相比,这是一个很大的优势。因为其它 Python 库都需要在服务器上运行。
这是在 Anvil 应用中运行的交互式 Plotly 图:

*The election plot on the web using Anvil's [client-side-Python](https://anvil.works/docs/client/python) Plotly library (© 2019 [Anvil](https://anvil.works/blog/plotting-in-plotly))*
你可以[复制此示例](https://anvil.works/login?app-name=Plotting%20in%20Plotly&app-author=shaun%40anvil.works)作为一个 Anvil 应用程序(注意:Anvil 需要注册才能使用)。
在前端运行 Plotly 还有另一个优势:它为自定义交互行为提供了更多选项。
### 在 Plotly 中自定义交互
Plotly 绘图不仅是动态的,你可以自定义它们的互动行为。例如,你可以在每个柱状图中使用 `hovertemplate` 自定义工具提示的格式:
```
go.Bar(
x=x,
y=df['others'],
name='others',
marker=go.bar.Marker(color='#929591'),
hovertemplate='Seats: <b>%{y}</b>',
),
```
当你把这个应用到每个柱状图时,你会看到以下结果:

*A multi-bar plot with custom tool-tips (© 2019 [Anvil](https://anvil.works/blog/plotting-in-plotly))*
这很有用,当你想要在某些事件发生时执行任何你想要的代码就更好了(例如,当用户将鼠标悬停在栏上,你想要显示一个相关选举的信息框)。在 Anvil 的 Plotly 库中,你可以将事件处理程序绑定到诸如悬停之类的事件,这使得复杂的交互成为可能。

*A multi-bar plot with a hover event handler (© 2019 [Anvil](https://anvil.works/blog/plotting-in-plotly))*
你可以通过将方法绑定到绘图的悬停事件来实现:
```
def plot_1_hover(self, points, **event_args):
"""This method is called when a data point is hovered."""
i = points[0]['point_number']
self.label_year.text = self.data['year'][i]
self.label_con.text = self.data['conservative'][i]
self.label_lab.text = self.data['labour'][i]
self.label_lib.text = self.data['liberal'][i]
self.label_oth.text = self.data['others'][i]
url = f"https://en.wikipedia.org/wiki/{self.data['year'][i]}_United_Kingdom_general_election"
self.link_more_info.text = url
self.link_more_info.url = url
```
这是一种相当极端的交互性,从开发人员的角度来看,也是一种极端的可定制性。这都要归功于 Plotly 的架构 —— 它有一个简洁的接口,明确的设计是为了让你建立自己的API。如果到处都能看到这种伟大的设计,那将会很有帮助!
### 使用 Bokeh 进行自定义交互
现在你已经了解了 Plotly 如何使用 JavaScript 来创建动态图,并且可以使用 Anvil 的客户端编写 Python 代码在浏览器中实时编辑它们。
Bokeh 是另一个 Python 绘图库,它可以输出可嵌入 Web 应用程序的 HTML 文档,并获得与 Plotly 提供的功能类似的动态功能(如果你想知道如何发音,那就是 “BOE-kay”)。
---
via: <https://opensource.com/article/20/5/plotly-python>
作者:[Shaun Taylor-Morgan](https://opensource.com/users/shaun-taylor-morgan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Plotly is a plotting ecosystem that allows you to make plots in [Python](https://opensource.com/resources/python), as well as JavaScript and R. In this series of articles, I'm focusing on [plotting with Python libraries](https://opensource.com/article/20/4/plot-data-python).
Plotly has three different Python APIs, giving you a choice of how to drive it:
- An
[object-oriented API](#GraphObjects)that feels similar to Matplotlib - A
[data-driven API](#DataDrivenAPI)that specifies plots by constructing dictionaries of JSON-like data - A
["Plotly Express" API](#PlotlyExpress)that gives you high-level plotting functions similar to Seaborn
I'll explore each of these APIs by making the same plot in each one: a grouped bar plot of historical UK election results.
Before we go further, note that you may need to tune your Python environment to get this code to run, including the following.
- Running a recent version of Python (instructions for
[Linux](https://opensource.com/article/20/4/install-python-linux),[Mac](https://opensource.com/article/19/5/python-3-default-mac), and[Windows](https://opensource.com/article/19/8/how-install-python-windows)) - Verify you're running a version of Python that works with these libraries
The data is available online and can be imported using pandas:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
Now we're ready to go.
Making plots using Graph Objects
Plotly's object-oriented API is named graph_objects. It's somewhat similar to [Matplotlib's object-oriented API](https://opensource.com/article/20/5/matplotlib-python).
To create a multi-bar plot, you can construct a figure object containing four bar plots:
```
# Import Plotly and our data
import plotly.graph_objects as go
# Get a convenient list of x-values
years = df['year']
x = list(range(len(years)))
# Specify the plots
bar_plots = [
go.Bar(x=x, y=df['conservative'], name='Conservative', marker=go.bar.Marker(color='#0343df')),
go.Bar(x=x, y=df['labour'], name='Labour', marker=go.bar.Marker(color='#e50000')),
go.Bar(x=x, y=df['liberal'], name='Liberal', marker=go.bar.Marker(color='#ffff14')),
go.Bar(x=x, y=df['others'], name='Others', marker=go.bar.Marker(color='#929591')),
]
# Specify the layout
layout = go.Layout(
title=go.layout.Title(text="Election results", x=0.5),
yaxis_title="Seats",
xaxis_tickmode="array",
xaxis_tickvals=list(range(27)),
xaxis_ticktext=tuple(df['year'].values),
)
# Make the multi-bar plot
fig = go.Figure(data=bar_plots, layout=layout)
# Tell Plotly to render it
fig.show()
```
Unlike in Matplotlib, there's no need to calculate the x-positions of the bars manually; Plotly takes care of that for you.
Here's the final plot:
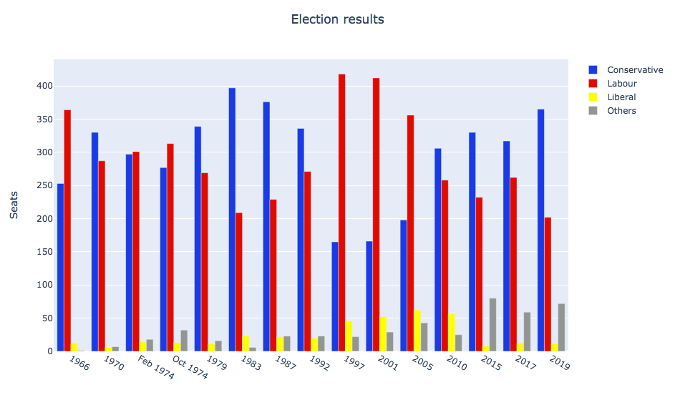
A multi-bar plot made using Graph Objects. (© 2019 Anvil)
Making plots using Python data structures
You can also specify your plot using basic Python data structures with the same structure as the object-oriented API. This corresponds directly to the JSON API for Plotly's JavaScript implementation.
```
# Specify the plots
fig = {
'data': [
{'type': 'bar', 'x': x, 'y': df['conservative'], 'name': 'Conservative', 'marker': {'color': '#0343df'}},
{'type': 'bar', 'x': x, 'y': df['labour'], 'name': 'Labour', 'marker': {'color': '#e50000'}},
{'type': 'bar', 'x': x, 'y': df['liberal'], 'name': 'Liberal', 'marker': {'color': '#ffff14'}},
{'type': 'bar', 'x': x, 'y': df['others'], 'name': 'Others', 'marker': {'color': '#929591'}},
],
'layout': {
'title': {'text': 'Election results', 'x': 0.5},
'yaxis': {'title': 'Seats'},
'xaxis': {
'tickmode': 'array',
'tickvals': list(range(27)),
'ticktext': tuple(df['year'].values),
}
}
}
# Tell Plotly to render it
pio.show(fig)
```
The final plot looks exactly the same as the previous plot:
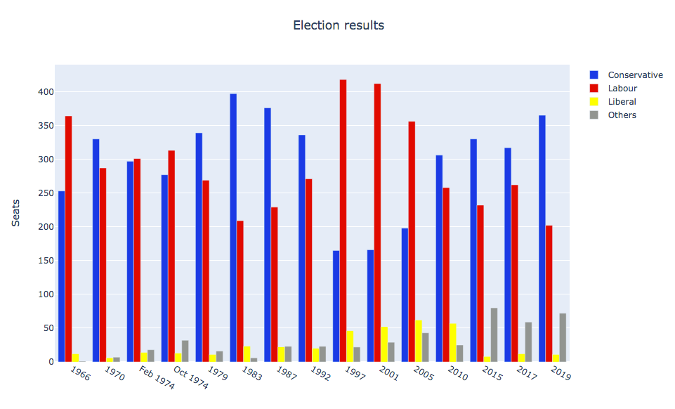
A multi-bar plot made using JSON-like data structures. (© 2019 Anvil)
Making plots using Plotly Express
[Plotly Express](https://plot.ly/python/plotly-express/) is a high-level API that wraps Graph Objects.
You can make a multi-bar plot in Plotly Express using (almost) a single line:
```
# Import Plotly and our data
import plotly.express as px
# Define the colourmap to get custom bar colours
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
# Make the plot!
fig = px.bar(df, x="year", y="seats", color="party", barmode="group", color_discrete_map=cmap)
```
This makes use of the data in [Long Form](https://anvil.works/blog/tidy-data), also known as "tidy data." The columns are year, party, and seats, rather than being split by party. It's very similar to making a multi-bar plot in [Seaborn](https://opensource.com/article/20/5/seaborn-visualization-python).
```
>> print(long)
year party seats
0 1922 Conservative 344
1 1923 Conservative 258
2 1924 Conservative 412
3 1929 Conservative 260
4 1931 Conservative 470
.. ... ... ...
103 2005 Others 30
104 2010 Others 29
105 2015 Others 80
106 2017 Others 59
107 2019 Others 72
[108 rows x 3 columns]
```
You can access the underlying Graph Objects API to make detailed tweaks. Add a title and a y-axis label:
```
# Use the Graph Objects API to tweak our plot
import plotly.graph_objects as go
fig.layout = go.Layout(
title=go.layout.Title(text="Election results", x=0.5),
yaxis_title="Seats",
)
```
And finally, ask Plotly to show it to you:
```
# Tell Plotly to render it
fig.show()
```
This runs a temporary web server on an unused port and opens the default web browser to view the plot (the webserver is immediately torn down).
Unfortunately, the result is not perfect. The x-axis is treated as an integer, so the groups are far apart and small. This makes it quite difficult to see trends.
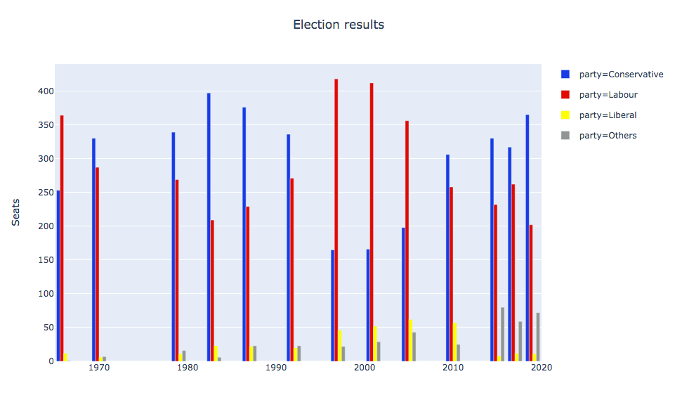
A multi-bar plot made using Plotly Express (© 2019 Anvil
You might try to encourage Plotly Express to treat the x-values as strings by casting them to strings. You might expect this to result in them being plotted with even spacing and lexical ordering. Unfortunately, you still get them helpfully spaced numerically. Setting the xaxis_tickvals does not work as it did in graph_objects, either.
Unlike the similar example in [Seaborn](https://opensource.com/article/20/5/seaborn-visualization-python), in this case, the abstraction does not appear to provide sufficient [escape hatches](https://anvil.works/blog/escape-hatches-and-ejector-seats) to provide things exactly how you want them. But perhaps you could write your *own* API?
## Building your own Plotly API
Not happy with how Plotly does something? Build your own Plotly API!
At its core, Plotly is a JavaScript library that makes plots using [D3](https://d3js.org/) and [stack.gl](http://stack.gl/). The JavaScript library has an interface that consumes JSON structures that specify plots. So you just need to output JSON structures that the JavaScript library likes to consume.
Anvil did that to create a Python Plotly API that works entirely in the browser.
Plotly uses a JavaScript library to create plots, driven by libraries in other languages via JSON (© 2019 Anvil)
In the Anvil version, you can use both the Graph Objects API and the Python data structure approach explained above. You run exactly the same commands, assigning the data and layout to a [Plot component](https://anvil.works/docs/client/components/plots) in your Anvil app.
Here's the multi-bar plot written in Anvil's client-side Python API:
```
# Import Anvil libraries
from ._anvil_designer import EntrypointTemplate
from anvil import *
import anvil.server
# Import client-side Plotly
import plotly.graph_objs as go
# This is an Anvil Form
class Entrypoint(EntrypointTemplate):
def __init__(self, **properties):
# Set Form properties and Data Bindings.
self.init_components(**properties)
# Fetch the data from the server
data = anvil.server.call('get_election_data')
# Get a convenient list of x-values
years = data['year']
x = list(range(len(years)))
# Specify the plots
bar_plots = [
go.Bar(x=x, y=data['conservative'], name='Conservative', marker=go.Marker(color='#0343df')),
go.Bar(x=x, y=data['labour'], name='Labour', marker=go.Marker(color='#e50000')),
go.Bar(x=x, y=data['liberal'], name='Liberal', marker=go.Marker(color='#ffff14')),
go.Bar(x=x, y=data['others'], name='Others', marker=go.Marker(color='#929591')),
]
# Specify the layout
layout = {
'title': 'Election results',
'yaxis': {'title': 'Seats'},
'xaxis': {
'tickmode': 'array',
'tickvals': list(range(27)),
'ticktext': data['year'],
},
}
# Make the multi-bar plot
self.plot_1.data = bar_plots
self.plot_1.layout = layout
```
The plotting logic is the same as above, but it's running *entirely in the web browser*—the plot is created by the Plotly JavaScript library on the user's machine! This is a big advantage over all the other [Python plotting libraries](https://opensource.com/article/20/4/plot-data-python) in this series. All the other Python libraries need to run on a server.
Here's the interactive Plotly plot running in an Anvil app:
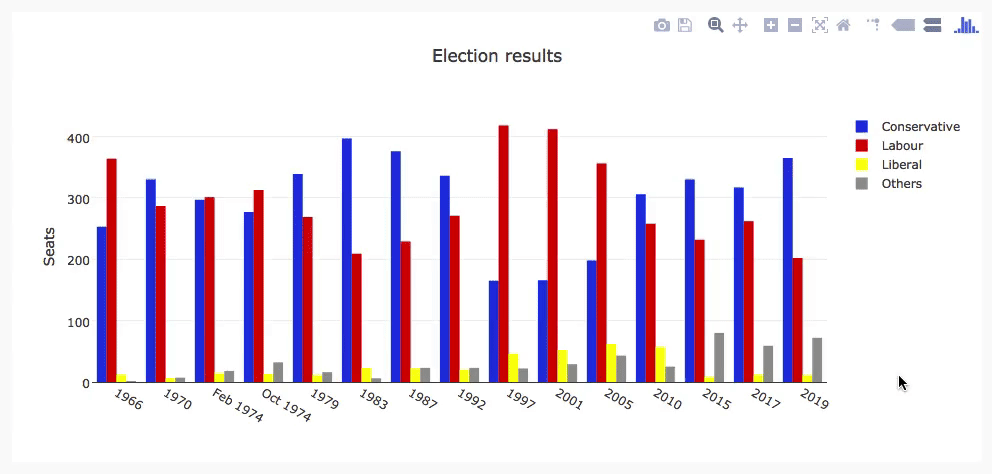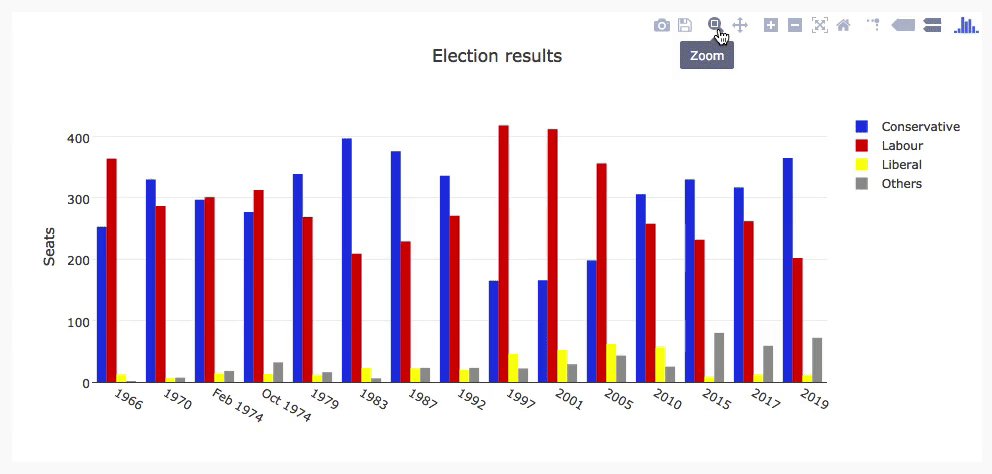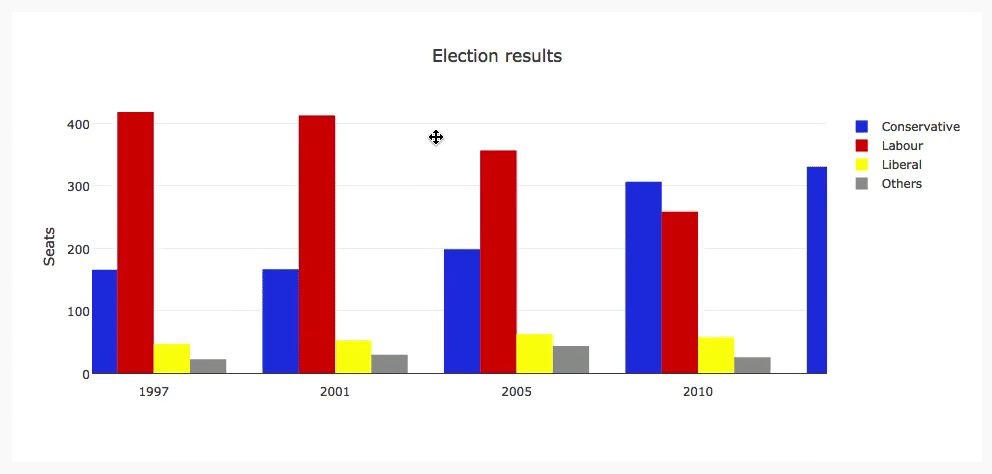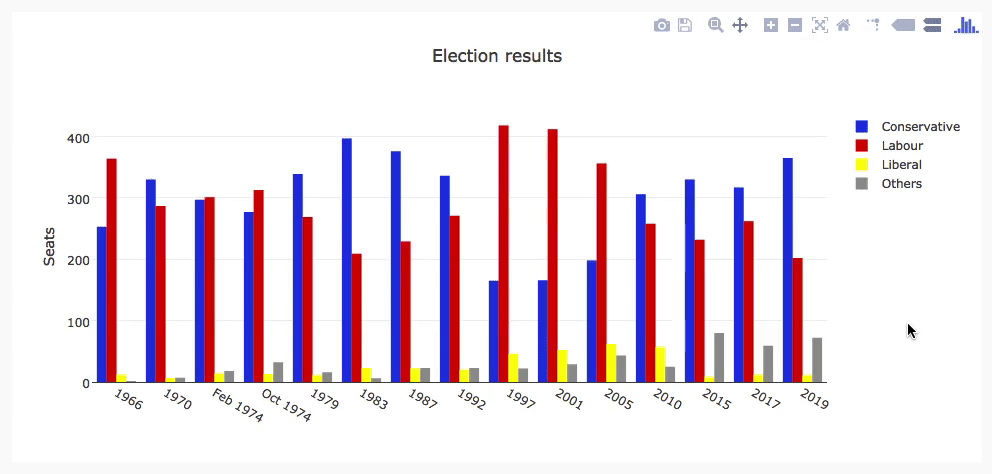
The election plot on the web using Anvil's client-side-Python Plotly library (© 2019 Anvil)
You can [copy this example](https://anvil.works/login?app-name=Plotting%20in%20Plotly&app-author=shaun%40anvil.works) as an Anvil app (Note: Anvil requires registration to use).
Running Plotly in the frontend has another advantage: it opens up many more options for customizing interactive behavior.
## Customizing interactivity in Plotly
Plotly plots aren't just dynamic; you can customize their interactive behavior. For example, you can customize the format of tool-tips using hovertemplate in each bar plot:
```
go.Bar(
x=x,
y=df['others'],
name='others',
marker=go.bar.Marker(color='#929591'),
hovertemplate='Seats: <b>%{y}</b>',
),
```
Here's what you get when you apply this to each bar plot:
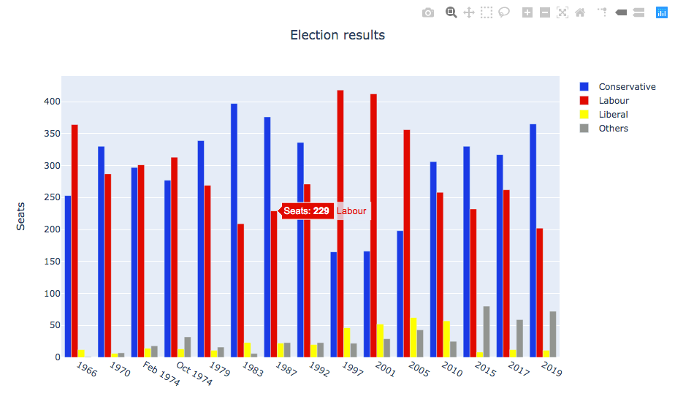
A multi-bar plot with custom tool-tips (© 2019 Anvil)
This is useful, but it would be even better if you could execute any code you want when certain events happen—like when a user hovers over the bar and you want to display an information box about the relevant election. In Anvil's Plotly library, you can bind event handlers to events such as hover, which makes that sort of complex interactivity possible!
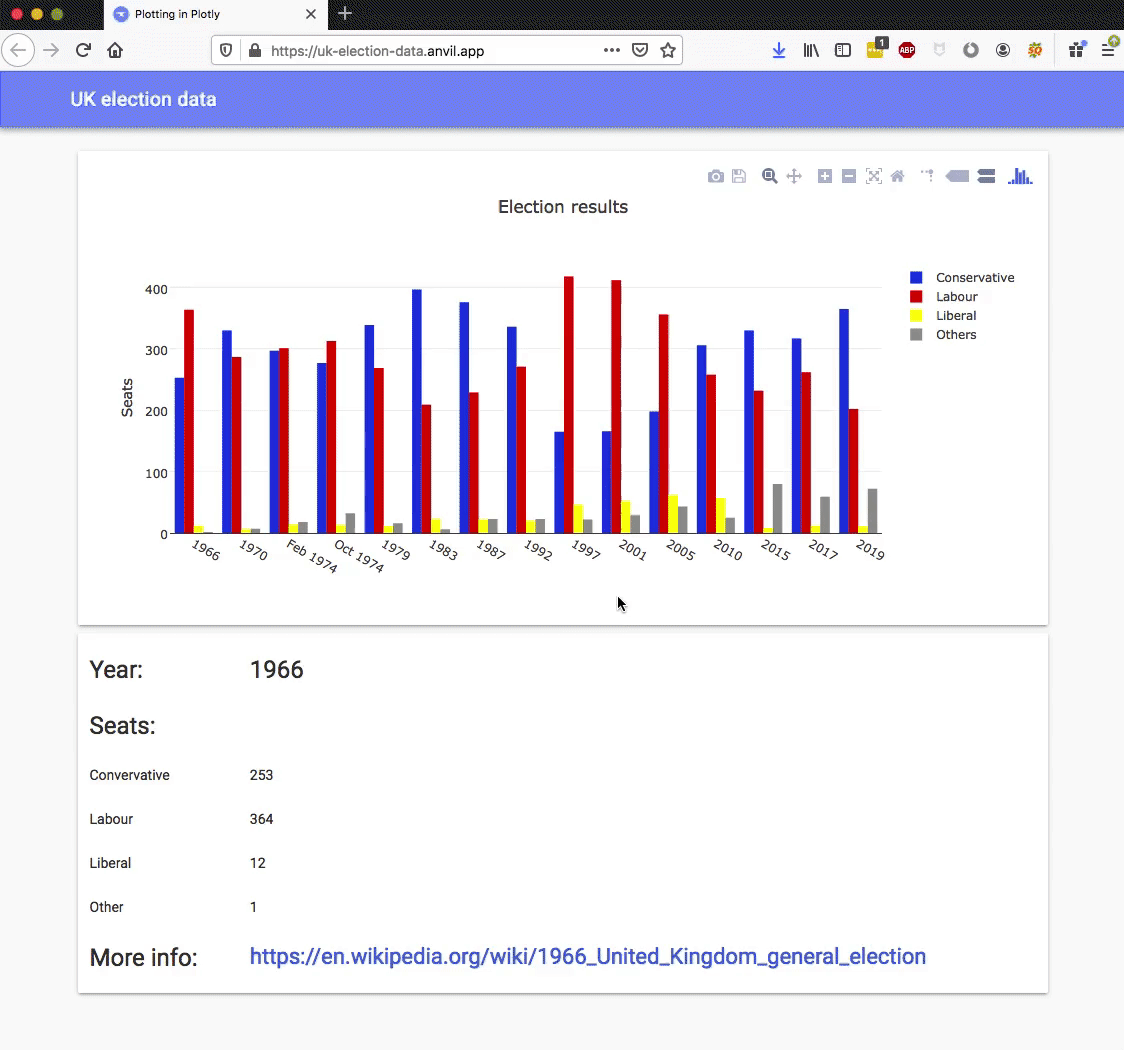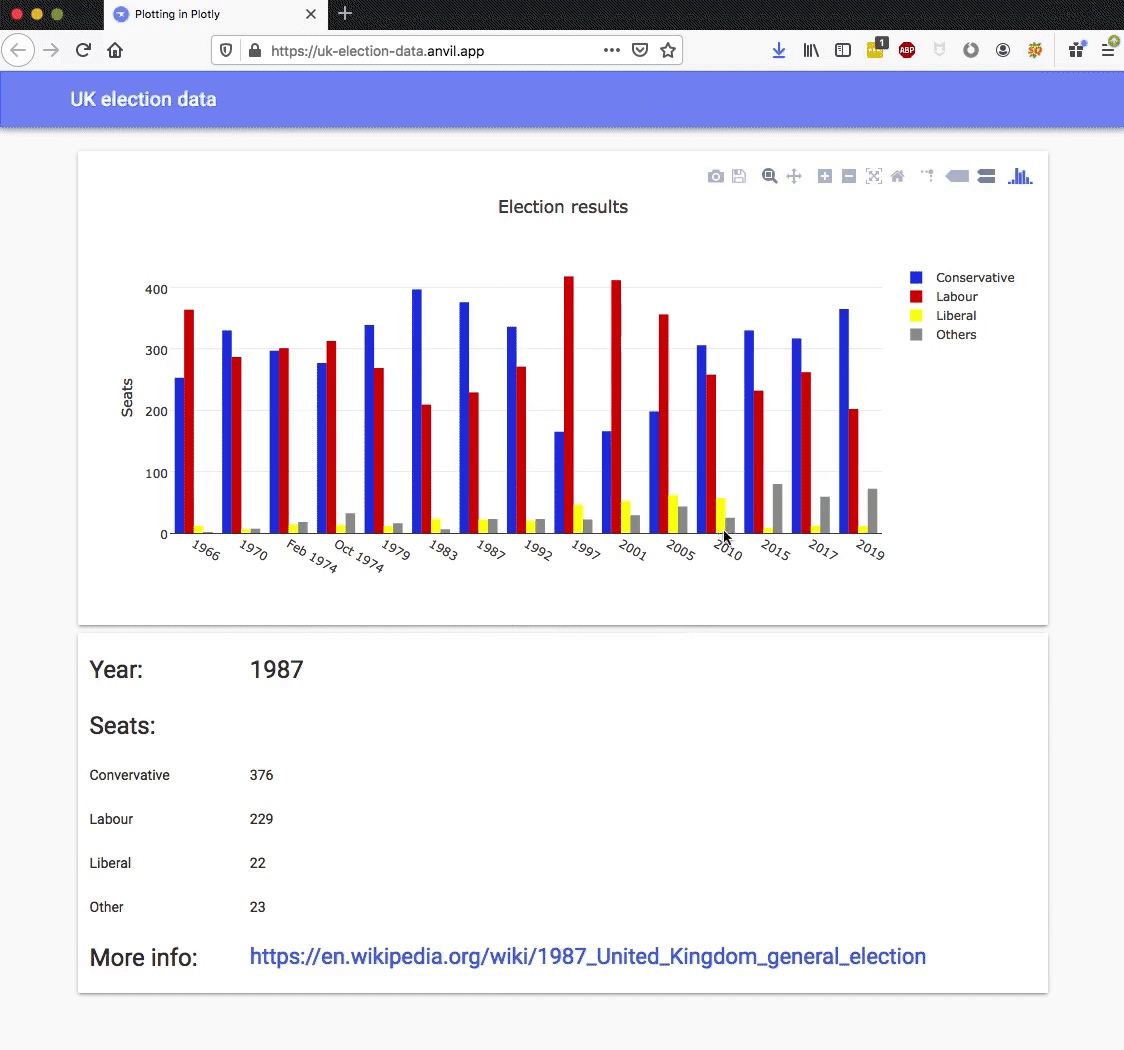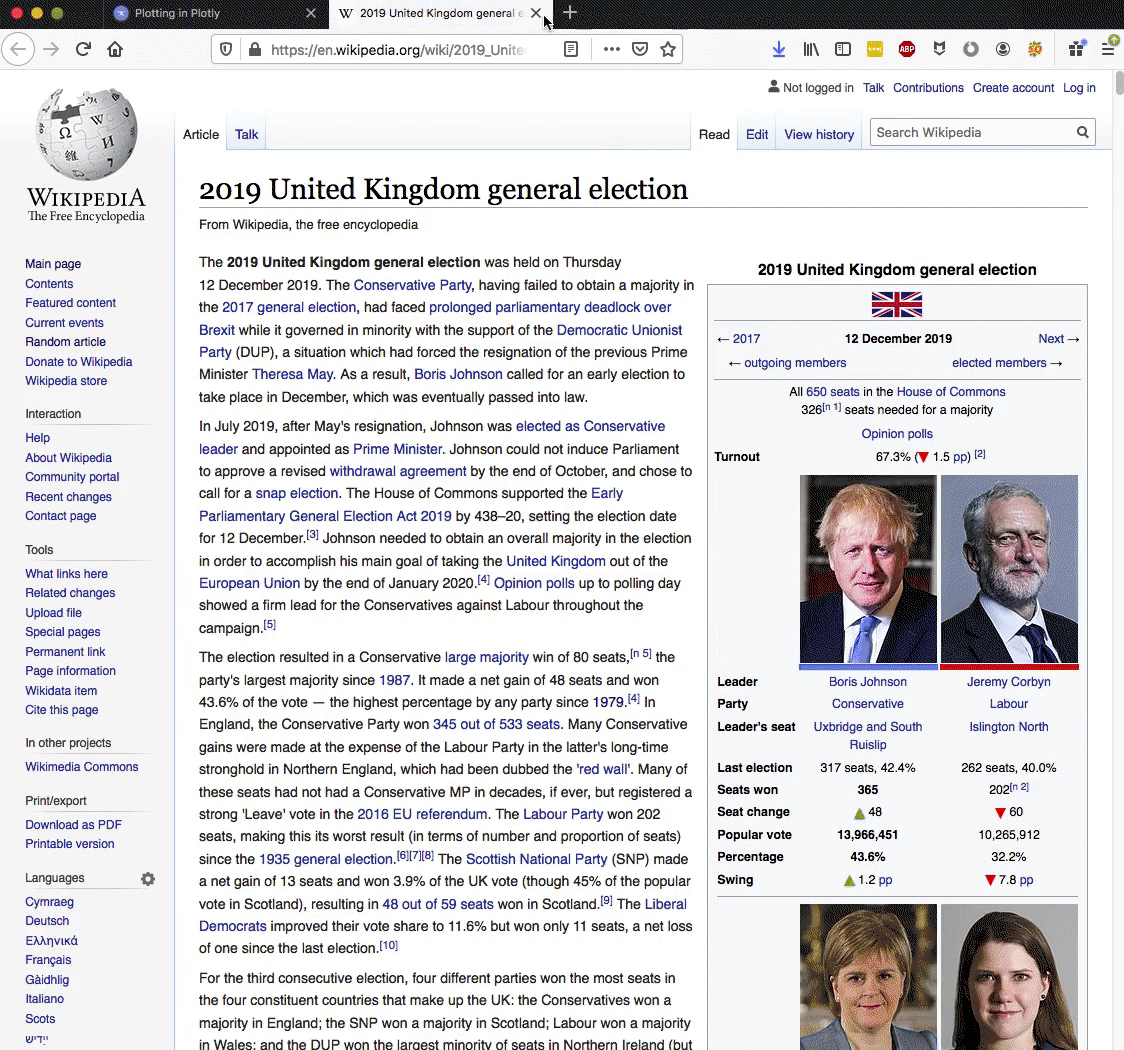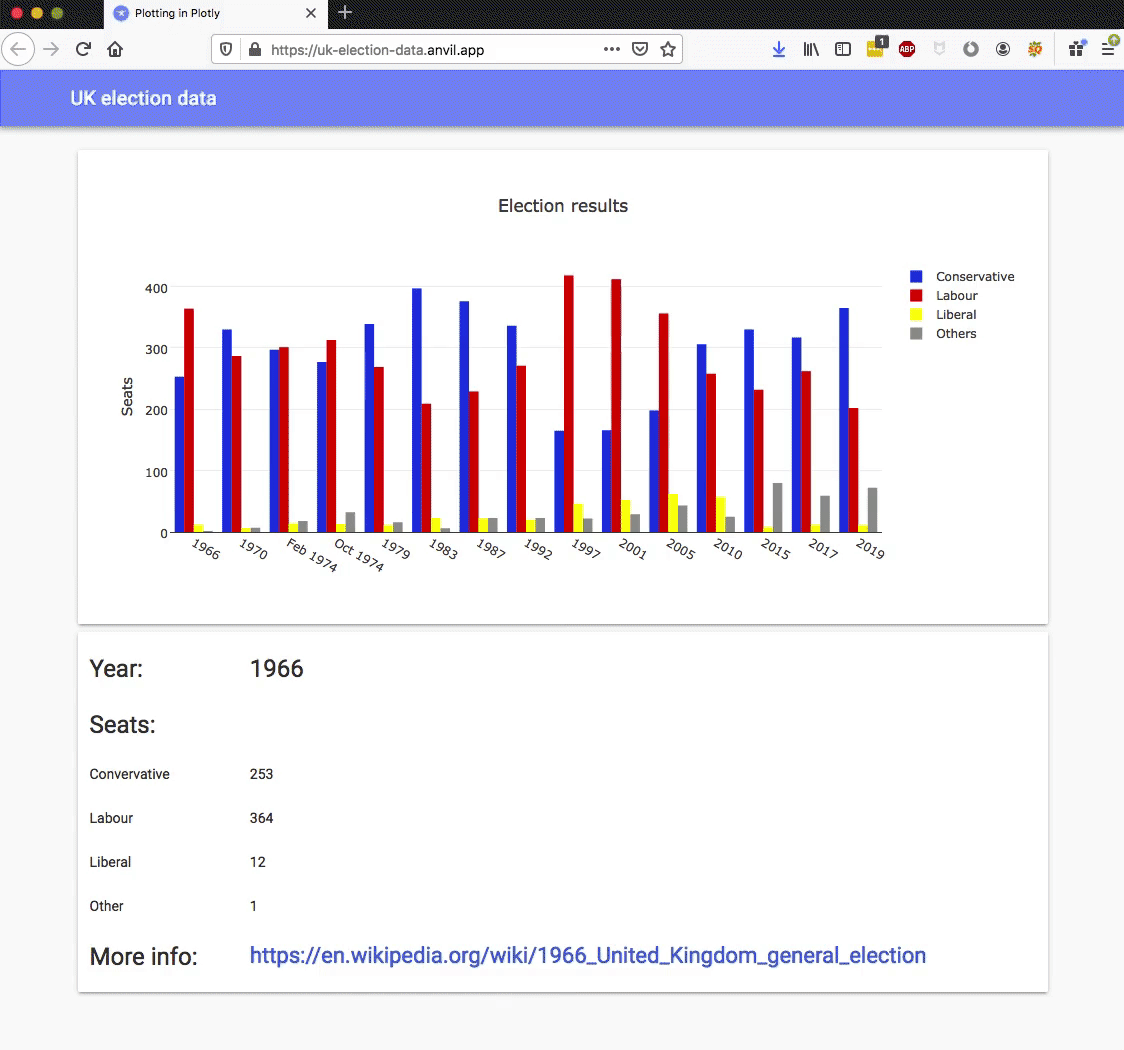
A multi-bar plot with a hover event handler (© 2019 Anvil)
You can achieve this by binding a method to the plot's hover event:
```
def plot_1_hover(self, points, **event_args):
"""This method is called when a data point is hovered."""
i = points[0]['point_number']
self.label_year.text = self.data['year'][i]
self.label_con.text = self.data['conservative'][i]
self.label_lab.text = self.data['labour'][i]
self.label_lib.text = self.data['liberal'][i]
self.label_oth.text = self.data['others'][i]
url = f"https://en.wikipedia.org/wiki/{self.data['year'][i]}_United_Kingdom_general_election"
self.link_more_info.text = url
self.link_more_info.url = url
```
This is a rather extreme level of interactivity, and from the developer's point of view, an extreme level of customizability. It's all thanks to Plotly's architecture—Plotly has a clean interface that is explicitly designed to allow you to build your own APIs. It would be helpful to see this kind of great design everywhere!
## Custom interactivity using Bokeh
You've seen how Plotly uses JavaScript to create dynamic plots, and you can edit them live in the browser using Anvil's client-side Python code.
Bokeh is another Python plotting library that outputs an HTML document you can embed in a web app and get similar dynamic features to those provided by Plotly. (That's "BOE-kay," if you're wondering how to pronounce it.)
Enjoy customizing charts and share tips and tricks in the comments below.
*This article is based on How to make plots using Plotly on Anvil's blog and is reused with permission.*
## Comments are closed. |
12,358 | Homebrew:让你从 Mac 切换到 Linux 更轻松 | https://opensource.com/article/20/6/homebrew-linux | 2020-06-28T09:12:07 | [
"Homebrew"
] | /article-12358-1.html |
>
> 不管你是想要更舒服地从 Mac 搬到 Linux,还是不满意常规的 Linux 包管理器,都可以试试 Homebrew。
>
>
>

[Homebrew](https://brew.sh/) 项目最初是为了给 Mac 用户提供一个非官方的 Linux 式的包管理器。用户很快就爱上了它友好的界面以及帮助性的提示,而且,它已经被移植到 Linux 系统 —— 这看起来像是一个奇怪的命运转折。
一开始,有两个分开的项目分别针对 macOS 和 Linux (Homebrew 与 Linuxbrew),但是现在是由 Homebrew 核心管理着这两个操作系统。由于我正 [从 Mac 切换到 Linux](https://opensource.com/article/19/10/why-switch-mac-linux),所以一直在研究我在 macOS 最常用的开源软件在 Linux 表现如何,最终,我很高兴地发现 Homebrew 对 Linux 的支持太赞了!
### 为什么要在 Linux 使用 Homebrew 呢?
长期使用 Linux 的用户对 Homebrew 的第一反应是:“为什么不直接使用……呢”,省略号代表他们喜欢的某个 Linux 包管理器。基于 Debian 的系统早就有了 `apt`,基于 Fedora 的系统则有 `dnf` 和 `yum`,并且像 Flatpak 跟 AppImage 这样的项目,在两种系统上都能流畅运行。我花了不少时间尝试这些技术,不得不说,它们都有其强大之处。
那我为什么还要 [坚持使用 Homebrew](https://opensource.com/article/20/6/homebrew-mac) 呢?首先,我对它非常熟悉。在为我过去使用的专有软件寻找开源替代品的过程中,我已经学会了许多使用方法,而保持一些熟悉的东西,比如 Homebrew,可以让我专注于一次学习一件事情,而不是被不同系统间的差异搞垮。
此外,我没有看到哪一个包管理器像 Homebrew 一样,对用户如此友好。正如默认的帮助命令一样,命令井然有序:
```
$ brew -h
Example usage:
brew search [TEXT|/REGEX/]
brew info [FORMULA...]
brew install FORMULA...
brew update
brew upgrade [FORMULA...]
brew uninstall FORMULA...
brew list [FORMULA...]
Troubleshooting:
brew config
brew doctor
brew install --verbose --debug FORMULA
Contributing:
brew create [URL [--no-fetch]]
brew edit [FORMULA...]
Further help:
brew commands
brew help [COMMAND]
man brew
<https://docs.brew.sh>
```
过于简短的输出可能会被误解为它功能局限,但是你简单看看每一个子命令,都有很丰富的功能。虽然上面的列表只有短短 23 行,但对高级用户来说,光是子命令 `install` 就包含整整 79 行的帮助信息:
```
$ brew --help | wc -l
23
$ brew install --help | wc -l
79
```
它可以选择忽略或者安装依赖关系,也可以选择用源代码编译以及用什么编译器来编译某个确切的上游 Git 提交,或者选择应用的官方 “灌装” 版。总而言之,Homebrew 即适合新手,也同样能满足老鸟。
### 开始在 Linux 使用 Homebrew
如果你想要试着使用 Homebrew,可以用这个单行脚本在 Mac 或者 Linux 上进行安装:
```
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
```
这条命令会立即开始安装 Homebrew。如果你比较谨慎,可以使用 `curl` 将该文件下载到本地,检查完毕之后再运行。
```
$ curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh --output homebrew_installer.sh
$ more homebrew_installer.sh # 审核该脚本,直到你觉得没问题了
$ bash homebrew_installer.sh
```
对 Linux 的安装步骤还包括如何配置点文件,对于 Debian 系统来说是 `~/.profile`,对于 Fedora 系统是 `~/.bash_profile`。
```
$ test -d /home/linuxbrew/.linuxbrew && eval $(/home/linuxbrew/.linuxbrew/bin/brew shellenv)
$ test -r ~/.bash_profile && echo "eval \$($(brew --prefix)/bin/brew shellenv)" >>~/.bash_profile
$ echo "eval \$($(brew --prefix)/bin/brew shellenv)" >>~/.profile
```
为了确认已经安装好,Homebrew 团队提供一个空的 `hello` “秘方” 供测试:
```
$ brew install hello
==> Downloading https://linuxbrew.bintray.com/bottles/hello-2.10.x86_64_linux.bottle.tar.gz
######################################################################## 100.0%
==> Pouring hello-2.10.x86_64_linux.bottle.tar.gz
? /home/linuxbrew/.linuxbrew/Cellar/hello/2.10: 52 files, 595.6KB
```
看起来安装毫无问题,让我来试试更多操作。
### 命令行工具 Brew
Homebrew 宣称自己是一款默认只 “安装你需要而 [Linux] 没有的东西”的应用程序。
你可以用 `brew` 命令安装任何打包在 Homebrew 中的命令行软件。这些包的定义文件叫做 “<ruby> 秘方 <rt> formula </rt></ruby>”,而且它们通过“<ruby> 瓶子 <rt> bottle </rt></ruby>”来编译并分享。在 Homebrew 的世界里,还有许多 “啤酒方面” 的术语,但这个包管理器主要目的是让软件便于使用。
都有些什么样的软件呢?对我这样的技术玩家(既然你已经在读这篇文章,估计你也是)来说最方便的东西。例如,便利的 `tree` 命令,可以展示目录结构,或者 `pyenv`,我用它来 [在 Mac 管理不同版本 Python](https://opensource.com/article/20/4/pyenv)。
你可以用 `search` 命令查看所有可以安装的“秘方”,在后面加上 `wc` 命令看看一共有多少:
```
# -l 选项统计行数
$ brew search | wc -l
5087
```
迄今为止,一共有 5000 多个 “秘方”,这囊括了很多软件。需要注意的是:并非所有 “秘方” 都能在 Linux 运行。在 `brew search --help` 输出中有一节提到可以按软件运行的操作系统来筛选软件。它会在浏览器打开用于每个操作系统的软件仓库。我运行的是 Fedora,所以我会用它来试一试:
```
$ brew search --fedora tree
```
浏览器打开了网址 `https://apps.fedoraproject.org/packages/s/tree`,向我展示了所有 Fedora 的可用选项。你也可以通过其它方法进行浏览。“秘方” 被集中整理到由操作系统划分的核心仓库当中(Mac 在 [Homebrew Core](https://github.com/Homebrew/homebrew-core),Linux 在 [Linux Core](https://github.com/Homebrew/linuxbrew-core))。同样也可以通过 Homebrew API [在网页显示](https://formulae.brew.sh/formula/)。
即使有这些选择,我还是通过其它用户的推荐找到很多新工具。我列出一些我最喜欢的工具,你可以在里面找点灵感:
* `pyenv`、`rbenv` 和 `nodenv` 用来管理(相应的) Python、Ruby 和 Node.js 版本
* `imagemagick` 用于脚本化编辑图片
* `pandoc` 用于脚本化转换文档格式(我通常将 .docx 文件转成 .md 或者 .html)
* `hub` 为 GitHub 用户提供 [更好的 Git 体验](https://opensource.com/article/20/3/github-hub)
* `tldr` 展示了命令工具的使用范例
想要深入了解 Homebrew,可以去 [trldr 页面](https://github.com/tldr-pages/tldr) 看看,比起应用的 man 页面,它要友好得多。使用 `search` 命令确认你可以安装:
```
$ brew search tldr
==> Formulae
tldr ✔
```
太好了!对勾说明你可以安装。那么继续吧:
```
$ brew install tldr
==> Downloading https://linuxbrew.bintray.com/bottles/tldr-1.3.0_2.x86_64_linux.bottle.1.tar.gz
######################################################################## 100.0%
==> Pouring tldr-1.3.0_2.x86_64_linux.bottle.1.tar.gz
? /home/linuxbrew/.linuxbrew/Cellar/tldr/1.3.0_2: 6 files, 63.2KB
```
Homebrew 提供了编译好的二进制文件,所以你不必在本地机器上从源码编译。这能节省很多时间,也不用听 CPU 风扇的噪声。我很欣赏 Homebrew 的另外一点是,你不完全理解每一个选项的含义也不会影响正常使用。若你想自己编译,可以在 `brew install` 命令后面加上 `-s` 或者 `--build-from-source` 标识,这样就能从源码编译 “秘方”(即便已经有一个 “瓶子” 存在)。
同样,软件底层的复杂性也很有意思。使用 `info` 可以查看 `tldr` 软件的依赖管理,“秘方” 的源代码存放在磁盘上的何处,甚至还能查看公开分析。
```
$ brew info tldr
tldr: stable 1.3.0 (bottled), HEAD
Simplified and community-driven man pages
https://tldr.sh/
Conflicts with:
tealdeer (because both install `tldr` binaries)
/home/linuxbrew/.linuxbrew/Cellar/tldr/1.3.0_2 (6 files, 63.2KB) *
Poured from bottle on 2020-06-08 at 15:56:15
From: https://github.com/Homebrew/linuxbrew-core/blob/master/Formula/tldr.rb
==> Dependencies
Build: pkg-config ✔
Required: libzip ✔, curl ✔
==> Options
--HEAD
Install HEAD version
==> Analytics
install: 197 (30 days), 647 (90 days), 1,546 (365 days)
install-on-request: 197 (30 days), 646 (90 days), 1,546 (365 days)
build-error: 0 (30 days)
```
### 从 Mac 到 Linux 的一点不足
在 macOS,Homebrew 的 `cask`(“酒桶”)子命令可以让用户使用命令行安装、管理整个应用软件。不幸的是,`cask`还不能在任何 Linux 发行版上使用。我在安装一个开源工具时发现了这点:
```
$ brew cask install tusk
Error: Installing casks is supported only on macOS
```
我在 [论坛上](https://discourse.brew.sh/t/add-linux-support-to-existing-cask/5766) 问了一下,很快得到其他用户的反馈。总结一下,方案如下:
* 复刻 Homebrew 项目,构建这个特性,然后像别人展示其价值
* 给该软件写一个 “秘方”,然后从源代码编译
* 为该软件创建一个第三方仓库
最后一个是我最感兴趣的。Homebrew 通过 [创建并维护 “<ruby> 水龙头 <rt> tap </rt></ruby>”](https://docs.brew.sh/How-to-Create-and-Maintain-a-Tap) (另一个受啤酒影响的术语)管理第三方仓库。随着你对系统越来越熟悉,并想加入生态系统, “水龙头” 是值得研究的。
### 备份 Homebrew 的安装记录
我最中意的 Homebrew 特性之一就是你可以像其它任何 [用版本控制工具来备份点文件](https://opensource.com/article/19/3/move-your-dotfiles-version-control) 一样备份你的安装记录。为了实现这个目的,Homebrew 提供 `bundle`(“捆扎”)子命令,它可以控制一个叫 `dump`(“倾倒”)的子命令生成一个 `Brewfile`。这个文件包含你目前所有安装的工具列表,可以重复使用。进入你想使用的目录然后运行命令,它会根据你所安装的软件生成 `Brewfile`:
```
$ cd ~/Development/dotfiles # This is my dotfile folder
$ brew bundle dump
$ ls Brewfile
Brewfile
```
当我换了一台机器,想要安装一样的软件时,进入含有 `Brewfile` 的文件夹,然后重新安装:
```
$ ls Brewfile
Brewfile
$ brew bundle
```
它会在我的新机器上安装所有列出的 “秘方”。
#### 在 Mac 和 Linux 同时管理 Brewfile
`Brewfile` 非常适合备份你目前的安装记录,但是如果某些在 Mac 上运行的软件无法运行在 Linux 呢?或者刚好相反?我发现不管是 Mac 还是 Linux,如果软件无法在当前操作系统运行,Homebrew 会优雅地忽略那一行。如果它遇到不兼容的请求(比如使用 `brew` 在 Linux 安装 “<ruby> 酒桶 <rt> cask </rt></ruby>” 时),它会选择跳过,继续安装过程:
```
$ brew bundle --file=Brewfile.example
Skipping cask licecap (on Linux)
Skipping cask macdown (on Linux)
Installing fish
Homebrew Bundle complete! 1 Brewfile dependency now installed.
```
为了保持配置文件的简洁,我在两个操作系统上使用同一份 `Brewfile`,因为它只安装与操作系统相关的版本,所以我一直没有遇到任何问题。
### 使用 Homebrew 管理软件包
Homebrew 已经成了我必备的命令行工具,由于我很熟悉它,所以在 Linux 上的体验也充满乐趣。Homebrew 让我的工具井然有序,并且时刻保持更新,我愈发欣赏它在实用性与功能上找到的平衡点。我更喜欢将软件包管理的细节保持在用户需要了解的最小程度,大多数人都会从中受益。如果你已经很熟悉 Linux 包管理器了,Homebrew 可能会让你觉得很基础,但稍微深入一点看,就会发现它的高级选项远远超过本文的内容。
对 Linux 用户来说,他们有很多包管理器可以选择。如果你来自 MacOS,Homebrew 会让你宾至如归。
---
via: <https://opensource.com/article/20/6/homebrew-linux>
作者:[Matthew Broberg](https://opensource.com/users/mbbroberg) 选题:[lujun9972](https://github.com/lujun9972) 译者:[nophDog](https://github.com/nophDog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,360 | 超过 75% 的开源软件安全漏洞存在于间接依赖中 | https://www.zdnet.com/article/more-than-75-of-all-vulnerabilities-reside-in-indirect-dependencies/ | 2020-06-28T16:53:00 | [
"安全",
"依赖"
] | https://linux.cn/article-12360-1.html | 
>
> JavaScript、Ruby 和 Java 是间接依赖中存在缺陷最多的生态系统。
>
>
>
开源项目中的绝大多数安全漏洞都存在于间接依赖关系中,而不是存在于直接加载的组件之中。
“汇总所有生态系统的数字后,我们发现间接依赖中存在的漏洞数量是直接依赖的三倍以上。”Snyk 的应用安全顾问 Alyssa Miller 在接受讨论 Snyk 的《[2020 年开源安全状况报告](https://info.snyk.io/sooss-report-2020)》的采访时说。
该报告研究了漏洞如何影响 JavaScript(npm)、Ruby(RubyGems)、Java(MavenCentral)、PHP(Packagist)和Python(PyPI)生态系统。
Snyk 表示,项目内部加载的主要组件所依赖的依赖库,受到了 86% 的 JavaScript 安全漏洞、81% 的 Ruby 漏洞和 74% 的 Java 漏洞的影响。

Snyk 认为,公司在扫描他们的主要依赖项是否存在安全问题时,如果不能探索其完整依赖树的多个层次,会导致发布或最终运行容易受到不可预见的缺陷影响的产品。
但是,虽然安全缺陷在 JavaScript、Ruby 和 Java 中普遍存在,但在 PHP 和 Python 中却不是这样,绝大多数缺陷都存在于直接依赖关系(主要组件)中。当然,这是有原因的。
“老实说,我发现这更多取决于生态系统内部本身的开发方法。”Miller 说。“尤其是 Java 和 Node.js 项目,似乎比其他生态系统更重地利用了依赖性。特别是,当你看到 Node.js 生态系统的庞大规模时,从其他包构建或利用关键功能的包是非常正常的。”
“询问任何 Node.js 开发人员,他们都可能会遇到这样的事,即在 npm 试图拉取所有必要的依赖关系时,等待很长时间才能打开一个项目,”Miller 补充说。“我们最喜欢的一个例子是一个 80 行的 Java 应用程序,指定了 7 个依赖关系。然而,当你走完整个依赖树时,你会发现有 59 个子依赖,突然间,80 行代码变成了 74 万行。”
“正如我们喜欢给它起的绰号,这种‘陌生人的危险’,是一些重大安全漏洞的根本原因,也是造成软件供应链安全复杂化的关键原因,”Miller说。
### 少量的缺陷会造成了巨大的影响
但 Snyk 团队并不只是看这些缺陷在开源生态系统中的位置,还看它们是什么类型的缺陷。
另一个有趣的发现是,2019 年发现的大部分新安全漏洞都是跨站脚本(XSS)缺陷,尽管数量很多,但这些缺陷只影响了一小部分实际运行的项目。
相反,在去年发现的所有缺陷中,有二十几个原型污染缺陷的影响最大,影响了超过 11.5 万个不同的开源项目,可能还有更多的私有项目也受影响。其中,jQuery 和 LoDash 的原型污染缺陷影响最大,因为这些框架是目前应用最广泛的 JavaScript 开发工具集。

但是,Snyk 团队在报告中还指出了另一个不寻常的地方,即“恶意软件包”被列为他们去年在项目中发现的第二大最常见的安全问题类型。这指的是故意出于恶意创建的开放源代码库,或者是开发人员帐户被黑并且代码中毒的库。
根据 Snyk 的说法,去年,被黑的或恶意的软件包是开源生态系统中第二大最常见的安全问题来源。“这些绝大多数(超过 87%)来自 npm (JavaScript)软件包,” Miller 说。
### 去年的安全问题不那么严重,但也不值得庆祝
此外,Snyk 还指出,他们在所扫描的所有五个生态系统中发现的缺陷数量下降了 20%。

“很难确定(它们因为什么下降),”Miller 说。“以我这种永久安全怀疑论者来说,这可能只是自然的退潮和流动的一部分。然而,在乐观的一面,我们确实看到了社区的一些关键变化,这可能意味着这不仅仅是这一年的异常值。”
“例如,我们看到所报告的跨站点脚本(XSS)漏洞比任何其他漏洞类型都多,它们只影响了我们当年扫描的总项目中的一小部分。这表明,XSS 可能不会影响到使用率更高因而更成熟的项目,这意味着人们可能更多关注安全编码技术方面。”
“此外,我们的调查显示,整个社区的态度开始将软件安全视为开发团队和安全团队(甚至在某种程度上是运营团队)之间的共同责任,”Miller 说。
“这种合作的改善无疑可以帮助推动围绕安全代码和安全使用开源包的更好的意识和战术措施。”
“我在安全领域工作了 15 年,我当然还没有准备好宣布某一年是事情出现转机的标志,但你可以认为这是一个趋势,我们将继续观察,看看未来几个月和整个 2020 年的情况如何。”
关于开源社区总体安全状况的其他见解,Snyk 的完整报告可在这里[下载](https://info.snyk.io/sooss-report-2020)。
---
via: <https://www.zdnet.com/article/more-than-75-of-all-vulnerabilities-reside-in-indirect-dependencies/>
作者:[Catalin Cimpanu](https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/) 译者:[wxy](https://github.com/wxy) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12361-1.html) 荣誉推出
| 200 | OK | # More than 75% of all vulnerabilities reside in indirect dependencies

The vast majority of security vulnerabilities in open-source projects reside in indirect dependencies rather than directly and first-hand loaded components.
"Aggregating the numbers from all ecosystems, we found more than three times as many vulnerabilities in indirect dependencies than we did direct dependencies," [Alyssa Miller](https://twitter.com/AlyssaM_InfoSec), Application Security Advocate at Snyk, told *ZDNet *in an interview discussing Snyk's State of Open Source Security for 2020 study.
The report looked at how vulnerabilities impacted the JavaScript (npm), Ruby (RubyGems), Java (MavenCentral), PHP (Packagist), and Python (PyPI) ecosystems.
Snyk said that 86% of the JavaScript security bugs, 81% of the Ruby bugs, and 74% of the Java ones impacted libraries that were dependencies of the primary components loaded inside a project.
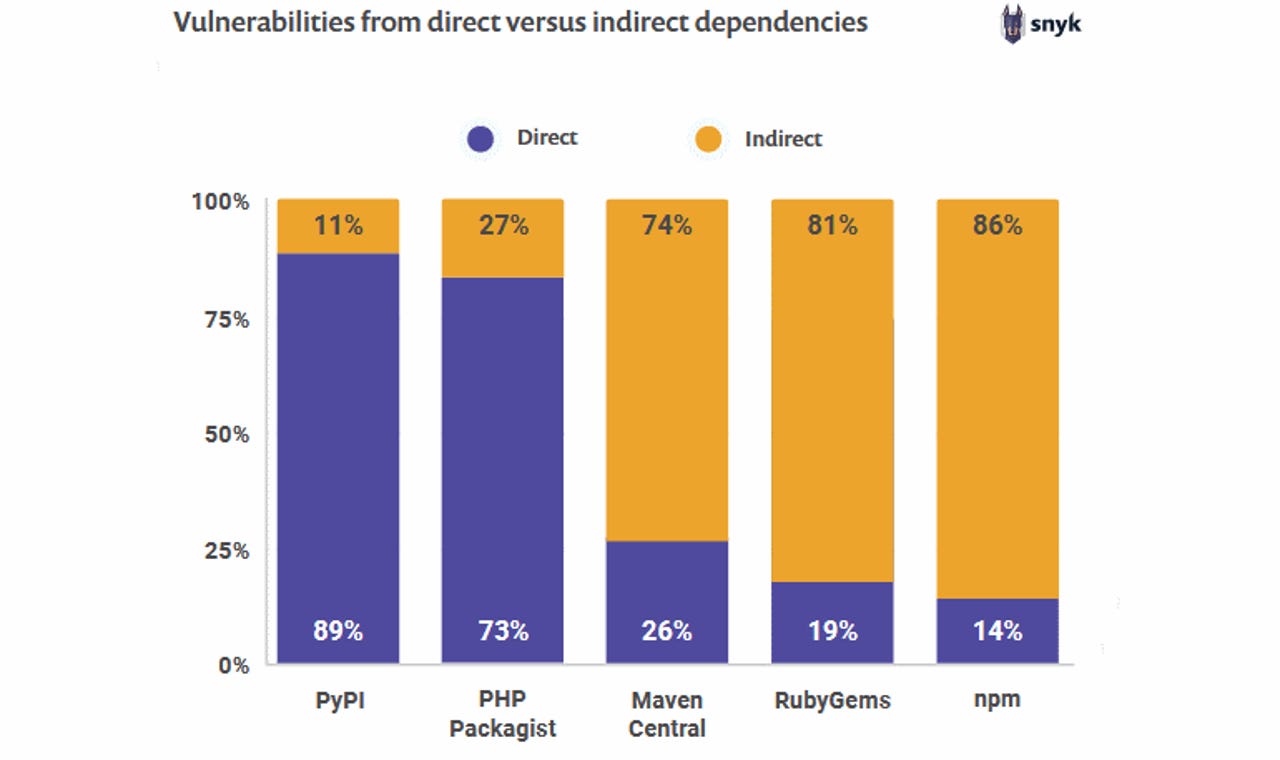
Snyk argues that companies scanning their primary dependencies for security issues without exploring their full dependency tree multiple levels down would release or end up running products that were vulnerable to unforeseen bugs.
But while security bugs were prevalent in JavaScript, Ruby, and Java, it was not in PHP and Python, where the vast majority of bugs were in the direct dependencies (primary components). However, there's a reason for that.
"I honestly find it's more a matter of the development approach within ecosystems themselves," Miller told *ZDNet*.
"Java and Node.js projects, in particular, seem to leverage dependencies a lot heavier than other ecosystems. In particular, when you look at the sheer size of the Node.js ecosystem, packages building off or leveraging key functionality from other packages is very much the norm.
"Ask any Node developer, and they probably have a story of waiting for long periods to open a project while npm is trying to pull all the necessary dependencies," Miller added. "One of our favorite examples is an 80 line Java application that specifies 7 dependencies. When you walk the entire dependency tree, however, you find 59 sub-dependencies, and suddenly, the 80 lines of code turns into 740,000 lines.
"That 'stranger danger,' as we like to nickname it, is at the heart of some high profile breaches and a key cause of complexity in terms of software supply chain security," Miller said.
### A few bugs had a large impact
But the Snyk team didn't just look at the location of these bugs in the open-source ecosystem, but also at what type of bugs they were.
Another interesting finding is that most of the new security flaws discovered in 2019 were cross-site scripting (XSS) bugs, but despite their high number, these impacted only a small portion of real-world projects.
Instead, two-dozen prototype pollution bugs had the biggest impact of all bugs discovered last year, affecting more than 115,000 different open source projects, and probably even more private ones.
Of these, the prototype pollution bugs in [jQuery](https://www.zdnet.com/article/popular-jquery-javascript-library-impacted-by-prototype-pollution-flaw/) and [LoDash](https://snyk.io/vuln/SNYK-JS-LODASH-450202) had the biggest impact, as these frameworks are some of the most widely employed JavaScript development toolsets today.
But the Snyk team also pointed to another quirck in their report, namely that "malicious packages" ranked as the second most common type of security issue they found in projects last year.
This refers to open-source libraries that have either been created to be malicious on purpose, or libraries where the developer account was hacked and the code poisoned.
According to Snyk, last year, hacked or malicious packages were the second most common source of security issues for the open-source ecosystem.
"The vast majority, over 87%, were from npm [JavaScript] packages," Miller told *ZDNet*.
### Fewer security bugs last year, but no reason to celebrate
Furthermore, Snyk also noted a 20% drop in the number of bugs they discovered across all the five ecosystems they scanned.
"It is hard to say for sure [why they dropped]," Miller said. "The perpetual security skeptic in me says this could just be part of the natural ebb and flow. However, on the optimistic side, we do see some key shifts in the community that could mean it's more than just a single year outlier.
"For instance, where we saw more Cross-Site Scripting (XSS) vulnerabilities reported than any other vulnerability type, they affected a small portion of the total projects we scanned for the year. That suggests that XSS is likely not impacting more heavily used and therefore matured projects meaning that we are potentially getting traction in secure coding techniques.
"Also, our survey showed that attitudes across the community are starting to see software security as a shared responsibility between developers and security teams (and even to some extent the operations teams)," Miller said.
"That improved cooperation could certainly be helping drive better awareness and tactical measures around secure code and secure use of open source packages.
"Having worked in security for 15 years, I'm certainly not ready to proclaim one year as a sign that things have taken a new direction, but you can bet it's a trend we'll continue to watch and see how things look over the coming months and the whole of 2020."
For additional insights into the general security state of the open-source community, Snyk's full report is available for download [here](https://info.snyk.io/sooss-report-2020).
#### What's in a name? These DevOps tools come with strange backstories
[Editorial standards](/editorial-guidelines/) |
12,361 | 5 个简单步骤使你的 Ubuntu 看起来像 macOS | https://itsfoss.com/make-ubuntu-look-like-macos/ | 2020-06-29T10:47:00 | [
"macOS"
] | https://linux.cn/article-12361-1.html | 定制是 [我为什么使用 Linux](https://itsfoss.com/why-use-linux/) 的一个主要原因。定制桌面 Linux 的道路是永无止境的。你可以更改图标、主题、字体、终端、添加屏幕小工具、[指示器小程序](https://itsfoss.com/best-indicator-applets-ubuntu/)、扩展等诸如此类的东西。
我们已经介绍了很多桌面环境定制的建议和技巧。在这篇文章中,我将向你展示如何使 Ubuntu 看起来像 macOS。
很多人使用 macOS,是因为它的简单和优雅的外观。你可能不同意这一点,但这仍然是一个流行的观点。甚至有的 Linux 发行版也有类似 macOS 外观和感觉。
一位读者要求我们展示如何使 Ubuntu 看起来像 macOS,因此我们写了这篇教程。事实上,这是一个用来展示桌面 Linux 定制能力的很好的示例。
不过,你没有必要为定制外观而安装一个新的发行版。你可以在你自己的系统上做一些调整来给予你一个类似 macOS 的外观。
### 如何给你的 Ubuntu Linux 进行 macOS 改造

尽管这篇文章是对 Ubuntu 的建议,但是你也可以在其它使用 GNOME 桌面环境的发行版中使用这些建议,几乎可以不做任何改动。请确保[检查一下你的桌面环境](/article-12124-1.html)。
说实话,即使你使用的是其它的桌面环境,你仍然可以得到一些关于要做哪些更改的提示。但是你必须确保使用你的桌面环境的工具按照步骤进行。
#### 必要条件: GNOME Tweaks 和 GNOME 扩展
请确保 [安装 GNOME Tweaks 工具](https://itsfoss.com/gnome-tweak-tool/)。你需要它来更改主题和图标。
你也需要 [启用 GNOME 扩展](/article-9447-1.html) 来更改 GNOME Shell 和添加重要的要点。
在你启用 GNOME 扩展后,你需要从 [GNOME 扩展](https://extensions.gnome.org/) 网站安装“用户主题” 扩展,或者只需要转到 [这个超链接](https://extensions.gnome.org/extension/19/user-themes/) ,并单击开关来将其打开。
我也希望你对 [在 Ubuntu 上安装主题](https://itsfoss.com/install-themes-ubuntu/) 有一定的了解。不过,我还是简单的谈了一下这个主题。
让我们依次看看每个步骤。
#### 步骤 1: 安装一个 macOS 风格的 GTK 主题
因为重点是使 GNOME 看起来像 macOS,所以你应该选择一个像 macOS 一样的主题。有很多主题都是像 macOS 一样的。
##### 下载一个你选择的主题
你可以转到 [Gnome-look](https://www.gnome-look.org/) 站点,并搜索关于 GTK3 的主题。如果你在 Gnome-look 网站上看到 “Pling” 字样,不用担心,它们都是来自同一个供应商。
你可以选择任何你想要的主题。下面是一些我认为你应该看看的macOS主题:
* [mcOS 11](https://www.pling.com/p/1220826)
* [McHigh Sierra](https://www.pling.com/p/1013714)
* [Catalina](https://www.pling.com/p/1226871)
* [McMojave](https://www.pling.com/p/1275087)
在这篇文章中,我将使用 “[McMojave](https://www.pling.com/p/1275087)”。你可以选择任何你想要的主题。你将在网站的右侧找到下拉式的下载按钮,单击它。

在这里你可以找到各种 “.tar.xz” 文件。这些不同的文件包含了相同的主题,但有一些小的差异。像在 “McMojave” 中,我们有像暗黑主题和明亮主题的变体。你可以尝试所有的主题,或者从之间随意选择一个你喜欢的。
##### 设置下载的主题
提取下载的主题,并复制这些提取的主题文件夹到 `.local/share/themes` 文件夹下。
打开 GNOME Tweak 工具,并更改应用程序和 Shell 的主题。在你更改主题的同时,你可以看到黄色、绿色和红色三个按钮,以及左上角的苹果标志。你也可以看到在面板项上的一些更改。

#### 步骤 2: 安装像 macOS 一样的图标
macOS 外观改造的下一步骤是使用像 macOS 一样的图标。
##### 下载图标集合
这里有一些我建议使用的图标集合,你可以从 Gnome-look 网站下载:
* [McMojave-circle](https://www.gnome-look.org/p/1305429/)
* [Mojave CT-icons](https://www.gnome-look.org/p/1210856/)
* [Cupertino icons](https://www.gnome-look.org/p/1102582/)
在这篇文章中,我将使用 “[McMojave-circle](https://www.gnome-look.org/p/1305429/)” ,你可以随意使用任何你喜欢的图标。
就像主题一样,你可以从右侧的下拉式的 “下载” 按钮下载图标集合。在这里你也可以找到同一种图标的不同版本。

##### 设置图标
现在设置下载的图标。为此,提取下载文件中的文件夹并复制它到你的家目录下的 `.icons` 文件夹。 查看这篇关于 [在 Ubuntu 中安装图标主题](https://itsfoss.com/install-themes-ubuntu/) 的文章。
这是这种图标看起来的样子:

#### 步骤 3: 添加类似 macOS 样子的坞站
没有类似 macOS 样子的<ruby> 坞站 <rt> dock </rt></ruby>,你的 Ubuntu 就看起来不像 macOS。在 Linux 上有很多可用的坞站。我喜欢 “[Dash to Dock](https://github.com/micheleg/dash-to-dock)”,我会在这里使用它。
“Dash to Dock” 是一个 GNOME 扩展。到现在为止,你已经熟悉 GNOME 扩展。只需要转到 [这个超链接](https://extensions.gnome.org/extension/307/dash-to-dock/) ,并单击切换按钮来安装它。你的原本的坞站将自动被 “Dash to Dock” 所替换。
你可以通过右键单击 “show applications” 按钮(最右边的菜单按钮)并选择 “Dash to dock settings” 来更改设置。

#### 步骤 4: 使用 macOS 壁纸
大多数复杂的东西已经完成。现在是时候设置 macOS 壁纸了。你可以从下面的超链接下载 macOS 默认壁纸:
* [下载 macOS 壁纸](https://oswallpapers.com/category/mac-os/)
##### 更改桌面背景
我将使用 “Mojave Day” 壁纸。右键单击已下载的的图像,并选择 “设置为壁纸” 选项来更改壁纸。
在设置这个壁纸后,这是我系统外观的样子:

##### 更改锁屏壁纸
锁屏壁纸选项已经从 [Ubuntu 20.04](https://itsfoss.com/ubuntu-20-04-release-features/) 的设置中移除。现在它使用一个模糊的桌面壁纸作为锁屏壁纸。
要设置一个自定义锁屏壁纸,你可以使用 “[Lock screen background](https://extensions.gnome.org/extension/1476/unlock-dialog-background/)” 扩展。
打开 “Lock screen background” 扩展设置,并设置锁屏壁纸。

这是锁屏现在的样子。如果你感到好奇话,这里是 [如何在 Ubuntu 中截图锁屏](https://itsfoss.com/screenshot-login-screen-ubuntu-linux/)。


#### 步骤 5: 更改系统字体
这几年,macOS 的主要系统字体是 “San Francisco” 。但是,这个字体并不是公共领域的,而是像苹果生态系统中的许多其他东西一样,是专有字体。基于这个原因,你不能使用这种字体。
你能做的就是使用一种看起来像 San Francisc 字体一样的开源字体。我建议使用 Google 的 [Roboto](https://fonts.google.com/specimen/Roboto?query=robot) 字体,或 Adobe 的 [Source Sans Pro](https://adobe-fonts.github.io/source-sans-pro/) 。
[在 Ubuntu 中安装字体是很简单的](https://itsfoss.com/install-fonts-ubuntu/) 。下载 字体的 zip 文件,只需要在提取出来的文件夹中双击 ttf 文件。它会给你一个选项来逐一安装字体。
如果你想节省时间并一次安装所有的字体,提取其中所有的字体到你的家目录(`~/.fonts`)下的 `.fonts` 目录中。

在你安装字体后,你可以使用 GNOME Tweaks 工具来更改系统字体。

#### 额外提示:Spotlight 式的应用程序启动器(如果你像更进一步的话)
如果你是 macOS Spotlight 启动器的粉丝,那么你在 Linux 上也能找到类似的东西。我最喜欢的这类启动器的软件包是 “[Albert](https://albertlauncher.github.io/)”。
你可以 [在 Albert 网站上找到它的安装说明](https://albertlauncher.github.io/docs/installing/) 。
安装完成后,打开 Albert 并设置快捷键(你想打开该启动器的组合键)就可以了。我想,在 macOS 中 `Command + Space` 键是来启动 Spotlight;在 Ubuntu 中,你可以设置 `Super+Space` [快捷键](https://itsfoss.com/ubuntu-shortcuts/)。
你会会得到很多内置的主题,在下面的图片中,我使用 “Spotlight dark” 主题。
Albert 不能直接启动应用程序,你必须授予它在哪里可以进行搜索的权限。

在设置后,这是它看起来的样子:

这是我的 Ubuntu 20.04 在完成所有定制后的样子。它看起来像 macOS 吗? 仁者见仁,智者见智。


如此,这就是你如何使你的 GNOME 桌面看起来像 macOS 一样的步骤。正如我在开始时所说的,这是一个很好的 Linux 桌面定制功能的示例。
如果你有新的注意或有任何疑问;评论区全是你的地盘。
本文由 Sumeet 编写,并由 Abhishek Prakash 提供补充输入信息。
---
via: <https://itsfoss.com/make-ubuntu-look-like-macos/>
作者:[Sumeet](https://itsfoss.com/author/itsfoss/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Customization is one of the main reasons [why I use Linux](https://itsfoss.com/why-use-linux/). There is no end to the kind of customization you can do to your desktop Linux. You can change icons, themes, change fonts, change terminals, add screenlets, [indicator applets](https://itsfoss.com/best-indicator-applets-ubuntu/), extensions and what not.
We have covered numerous desktop customization tips and tricks on It’s FOSS. In this one, I’ll show you how to make Ubuntu look like macOS.
Many people use macOS because of its simplistic and elegant look. You may disagree with it but it remains a popular opinion. Even there are [Linux distributions that have macOS like look](https://itsfoss.com/macos-like-linux-distros/) and feel.
**One of the readers requested us to show how to make Ubuntu look like macOS** and hence we’ve created this tutorial. In fact, this is a **good example to show the customization capability of desktop Linux**.
No, you don’t have to install a new distribution just for customizing the looks. You can do some tweaking on your own and give your system mac-like looks.
## How to give your Ubuntu Linux a macOS makeover
Although this article suggests it’s for Ubuntu, you can follow it for **other distributions with GNOME desktop** with little or no changes. Please make sure to [check your desktop environment](https://itsfoss.com/find-desktop-environment/).
To be honest, even if you are using some other [desktop environment](https://itsfoss.com/what-is-desktop-environment/), you can still take some hints about what changes to do. But you have to make sure to follow the steps using your DE’s tools.
### Prerequisites: GNOME Tweaks and GNOME Extensions
Please make sure to [install GNOME Tweaks tool](https://itsfoss.com/gnome-tweak-tool/). You’ll need it to change the themes and icons.
You’ll also need to [enable GNOME Extensions](https://itsfoss.com/gnome-shell-extensions/) for changing GNOME Shell and adding planks.
After you enable GNOME Extension, you need to install “user themes” extension from [Gnome extensions](https://extensions.gnome.org/) or just go to [this link](https://extensions.gnome.org/extension/19/user-themes/) and click on the switch to turn it on.
I also expect you to have some knowledge [about installing themes in Ubuntu](https://itsfoss.com/install-themes-ubuntu/). I’ll briefly touch on this subject, though.
Let’s see the steps one by one.
### Step 1: Install a macOS inspired GTK theme
Since the focus is on making GNOME look like macOS, you should choose a macOS like theme. There are plenty of themes which are macOS like.
**Download a theme of your choice**
You can go to [Gnome-look](https://www.gnome-look.org/) site, and look for themes for GTK3. Don’t worry if you see “Pling” written on the Gnome-look website, they both are from same providers.
You can choose any theme you want. Here are some macOS themes I think you should take a look at:
I shall be using “[McMojave](https://www.pling.com/p/1275087)” in this article. You can choose any theme you want. You will find dropdown download button on the right side of website, click on it.
Here you may find various “.tar.xz” files. These different files contain same theme with small differences. Like in “McMojave” we have variations like dark and light theme. You can try them all, or just pick anyone you like from the carousel given in middle.
**Set downloaded theme**
Extract the downloaded theme and copy this extracted theme folder to .local/share/themes folder.
Open GNOME Tweak tool and change the Application and Shell theme. As soon as you change the themes, you can see those three yellow, green and red buttons, and that Apple logo on upper left corner. You can also notice come changes on panel items.
### Step 2: Install macOS like icons
The next step in this macOS makeover is to use macOS like icons.
**Download icon set**
Here are some icon sets I suggest that you can download from Gnome-look website:
I shall be using “[McMojave-circle](https://www.gnome-look.org/p/1305429/)” in this article, feel free to use any icons you like.
Just like the theme, you can download it from “download” dropdown button from right side. Here you may also find various different versions of same icons.
**Set icon**
Now set the downloaded icon. For that extarct the download folder and copy it to .icons folder in your home directory. See this article on [installing icon](https://itsfoss.com/install-themes-ubuntu/)[ ](https://itsfoss.com/install-themes-ubuntu/)[themes in Ubuntu](https://itsfoss.com/install-themes-ubuntu/).
This is what this icon looks like:

### Step 3: Add macOS like dock
Without macOS like dock, your Ubuntu will not look like macOS. There are [various docks available for Linux](https://itsfoss.com/best-linux-docks/). I like [Dash to Dock](https://github.com/micheleg/dash-to-dock) and I am going to use it here.
Dash to Dock is a GNOME extension. By now you are familar with GNOME Extensions. Just go to [this link](https://extensions.gnome.org/extension/307/dash-to-dock/) and click on toggle button to install it. Your native dock will be automatically replaced with dash-to-dock.
You can change settings by right clicking on “show applications” button (rightmost menu button), and selecting “Dash to dock settings”.

### Step 4: Use macOS wallpaper
Most of the complicated stuff are done. Now it’s time to set macOS wallpaper. You can download macOS default wallpapers from the link below:
**Change the desktop background**
I shall be using “Mojave Day” wallpaper. Right click on the downloaded image and select ‘Set As Wallpaper’ option to change the wallpaper.
After setting this wallpaper, this is how my system looks like:
**Change the lock screen Wallpaper**
The lock screen background option is removed from the settings of [Ubuntu 20.04](https://itsfoss.com/ubuntu-20-04-release-features/). Now it uses blurred desktop wallpaper as the background of lock screen.
To set a custom lock screen wallpaper, you can use “[Lock screen background](https://extensions.gnome.org/extension/1476/unlock-dialog-background/)” extension.
Open “Lock screen background” extension setting, and set lock screen wallpaper.

This is how the lockscreen looks now. If you are wondering, here’s [how to take screenshot of lockscreen in Ubuntu](https://itsfoss.com/screenshot-login-screen-ubuntu-linux/).

### Step 5: Change system fonts
For several years, the primary system font in macOS is ‘San Francisco’. But this San Francisco font is not public domain but proprietary like so many other things in the Apple ecosystem. For this reason, you cannot use this font.
What you can do is to use an open source font that looks similar to the San Francisco fonts. I recommend using [Roboto](https://fonts.google.com/specimen/Roboto?query=robot) font by Google or [Source Sans Pro](https://adobe-fonts.github.io/source-sans-pro/) by Adobe.
[Installing fonts is straightforward in Ubuntu](https://itsfoss.com/install-fonts-ubuntu/). Download the zip files of the fonts and just double-click on the ttf files in the extracted folder. It will give you the option to install the fonts one by one.
If you want to save time and install all the fonts at once, extract all fonts in it to the “.fonts” directory in your home folder (~/.fonts).
Once you have installed the fonts, you can change the system wide font using GNOME Tweaks tool.
### Bonus Tip: Spotlight like app launcher (if you want to go the extra mile)
If you are a fan of macOS Spotlight launcher, you may have something similar on Linux also. My favorite package for getting this kind of launcher is “[Albert](https://albertlauncher.github.io/)“.
You can find the [installation instruction for Albert on its website](https://albertlauncher.github.io/docs/installing/).
After installing; open “Albert” and set hotkey (key combination you want for opening launcher) and you are good to go. I think in macOS, the Command+Space is to launch Spotlight. You may set Super+Space [keyboard shortcut in Ubuntu](https://itsfoss.com/ubuntu-shortcuts/).
You will get many themes in built, in picture below I’ve used “Spotlight dark”.
Albert won’t be able to launch apps directly, you have to give it permissions for where it can look for search results.
After setting up, this is how it looks:
This is how my Ubuntu 20.04 looks like after making all the customizations. Does it look like macOS? You be the judge.
So, this is how you can make your GNOME desktop look like macOS. As I said in the beginning, this is a good example of Linux desktop’s customization capability.
If you have any new ideas or have any queries; the comment section is all yours.
*Written by Sumeet with additional inputs from Abhishek Prakash.* |
12,364 | 使用 Pygal 在 Python 中设置数据图的样式 | https://opensource.com/article/20/6/pygal-python | 2020-06-30T12:07:53 | [
"Python",
"绘图"
] | https://linux.cn/article-12364-1.html |
>
> 介绍一种更时尚的 Python 绘图库。
>
>
>

[Python](https://opensource.com/article/20/4/plot-data-python) 有很多可以将数据可视化的库。其中一个互动性较强的库是 Pygal,我认为这个库适合喜欢漂亮事物的人。它可以生成用户可以与之交互的漂亮的 SVG(可缩放矢量图形)文件。SVG 是交互式图形的标准格式,仅使用几行 Python 就可以带来丰富的用户体验。
### 使用 Pygal 进行时尚的 Python 绘图
在本文中,我们要重新创建多柱状图,用来表示 1966 年至 2020 年英国大选的结果:

在继续之前,请注意你可能需要调整 Python 环境以使此代码运行,包括:
* 运行最新版本的 Python([Linux](https://opensource.com/article/20/4/install-python-linux)、[Mac](https://opensource.com/article/19/5/python-3-default-mac) 和 [Windows](https://opensource.com/article/19/8/how-install-python-windows) 的说明)
* 确认你运行的是与这些库兼容的 Python 版本
数据可在线获得,并可使用 pandas 导入:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
现在我们可以继续进行了。。数据如下所示:
```
year conservative labour liberal others
0 1966 253 364 12 1
1 1970 330 287 6 7
2 Feb 1974 297 301 14 18
.. ... ... ... ... ...
12 2015 330 232 8 80
13 2017 317 262 12 59
14 2019 365 202 11 72
```
在 Pygal 中进行绘制会以一种易于阅读的方式显示。首先,我们以一种简化柱状图定义的方式定义样式对象。然后我们将自定义样式以及其他元数据传递给 `Bar` 对象:
```
import pygal
from pygal.style import Style
custom_style = Style(
colors=('#0343df', '#e50000', '#ffff14', '#929591'),
font_family='Roboto,Helvetica,Arial,sans-serif',
background='transparent',
label_font_size=14,
)
c = pygal.Bar(
title="UK Election Results",
style=custom_style,
y_title='Seats',
width=1200,
x_label_rotation=270,
)
```
然后,我们将数据添加到 `Bar` 对象中:
```
c.add('Conservative', df['conservative'])
c.add('Labour', df['labour'])
c.add('Liberal', df['liberal'])
c.add('Others', df['others'])
c.x_labels = df['year']
```
最后,我们将图另存为 SVG 文件:
```
c.render_to_file('pygal.svg')
```
结果是一个交互式 SVG 图,你可以在此 gif 中看到:

精美简单,并且效果漂亮。
### 总结
Python 中的某些绘图工具需要非常详细地构建每个对象,而 Pygal 从一开始就为你提供这些。如果你手边有数据并且想做一个干净、漂亮、简单的交互式图表,请尝试一下 Pygal。
---
via: <https://opensource.com/article/20/6/pygal-python>
作者:[Shaun Taylor-Morgan](https://opensource.com/users/shaun-taylor-morgan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Python](https://opensource.com/article/20/4/plot-data-python) is full of libraries that can visualize data. One of the more interactive options comes from Pygal, which I consider the library for people who like things to look good. It generates beautiful SVG (Scalable Vector Graphics) files that users can interact with. SVG is a standard format for interactive graphics, and it can lead to rich user experiences with only a few lines of Python.
## Using Pygal for stylish Python plots
In this introduction, we want to recreate this multi-bar plot, which represents the UK election results from 1966 to 2020:
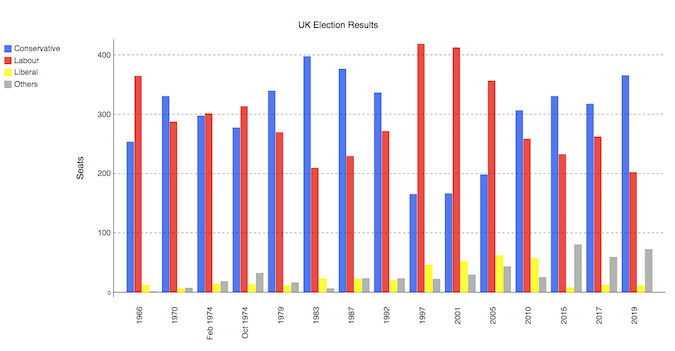
Before we go further, note that you may need to tune your Python environment to get this code to run, including the following.
- Running a recent version of Python (instructions for
[Linux](https://opensource.com/article/20/4/install-python-linux),[Mac](https://opensource.com/article/19/5/python-3-default-mac), and[Windows](https://opensource.com/article/19/8/how-install-python-windows)) - Verify you're running a version of Python that works with these libraries
The data is available online and can be imported using pandas:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
Now we're ready to go. The data looks like this:
```
year conservative labour liberal others
0 1966 253 364 12 1
1 1970 330 287 6 7
2 Feb 1974 297 301 14 18
.. ... ... ... ... ...
12 2015 330 232 8 80
13 2017 317 262 12 59
14 2019 365 202 11 72
```
Plotting this in Pygal builds up in a way that I find easy to read. First, we define the style object in a way that will simplify our bar chart definition. Then we pass the custom style along with other metadata to a `Bar`
object:
```
import pygal
from pygal.style import Style
custom_style = Style(
colors=('#0343df', '#e50000', '#ffff14', '#929591'),
font_family='Roboto,Helvetica,Arial,sans-serif',
background='transparent',
label_font_size=14,
)
c = pygal.Bar(
title="UK Election Results",
style=custom_style,
y_title='Seats',
width=1200,
x_label_rotation=270,
)
```
Then, we `add`
our data into the `Bar`
object:
```
c.add('Conservative', df['conservative'])
c.add('Labour', df['labour'])
c.add('Liberal', df['liberal'])
c.add('Others', df['others'])
c.x_labels = df['year']
```
Finally, we save the plot as an SVG file:
`c.render_to_file('pygal.svg')`
The result is an interactive SVG plot you can see in this gif:
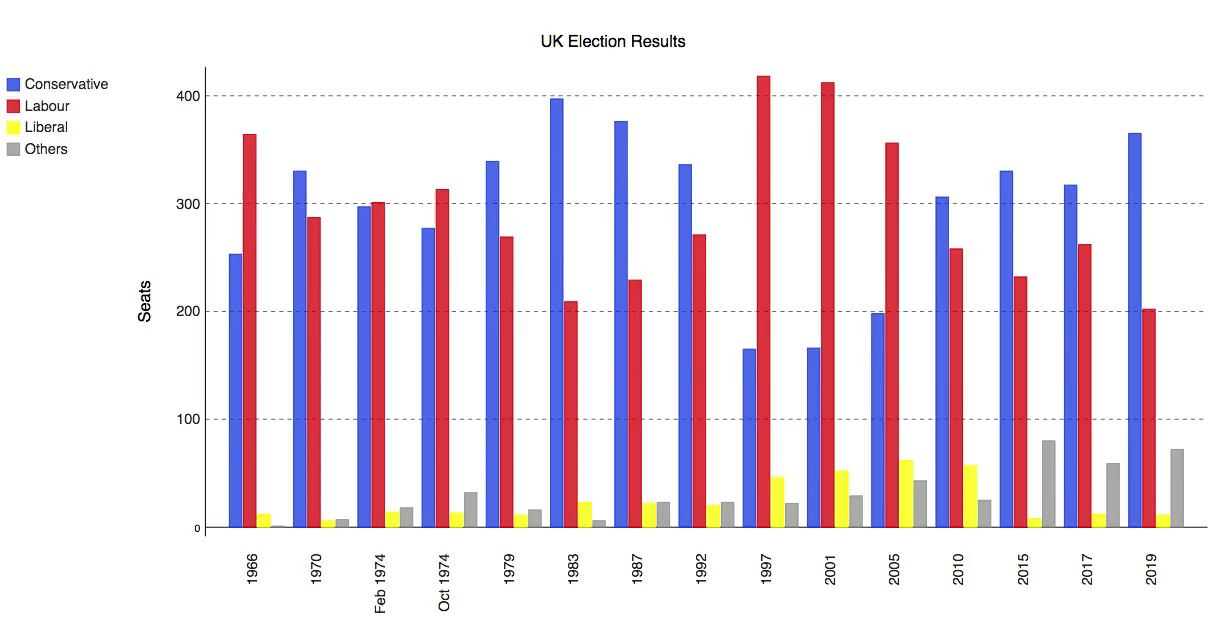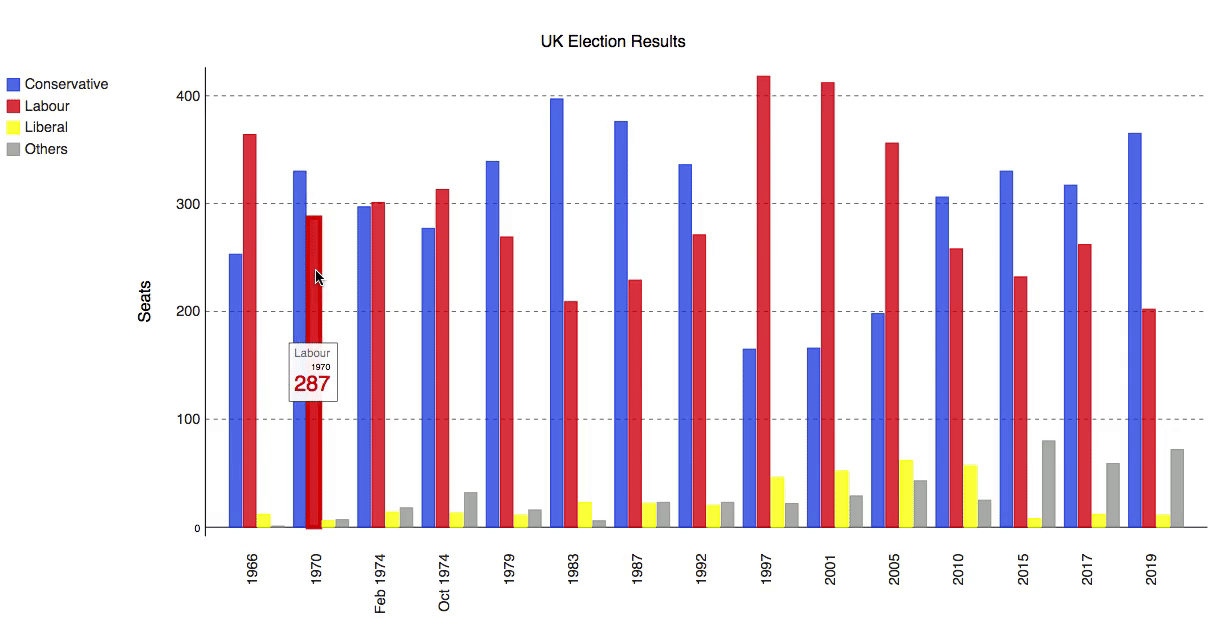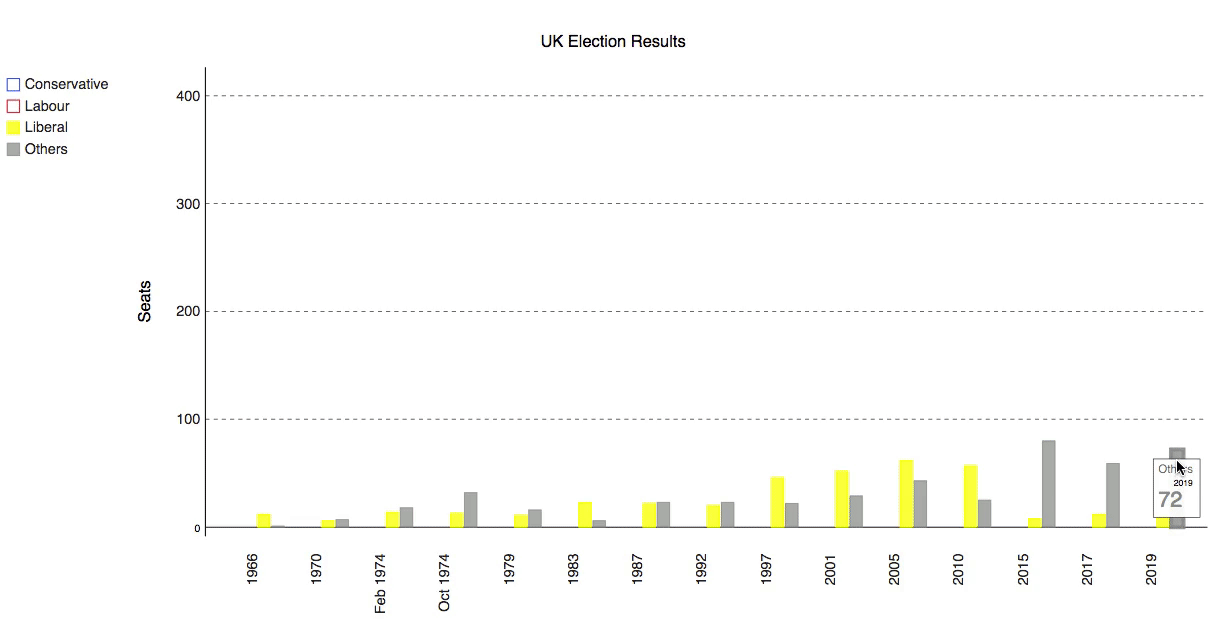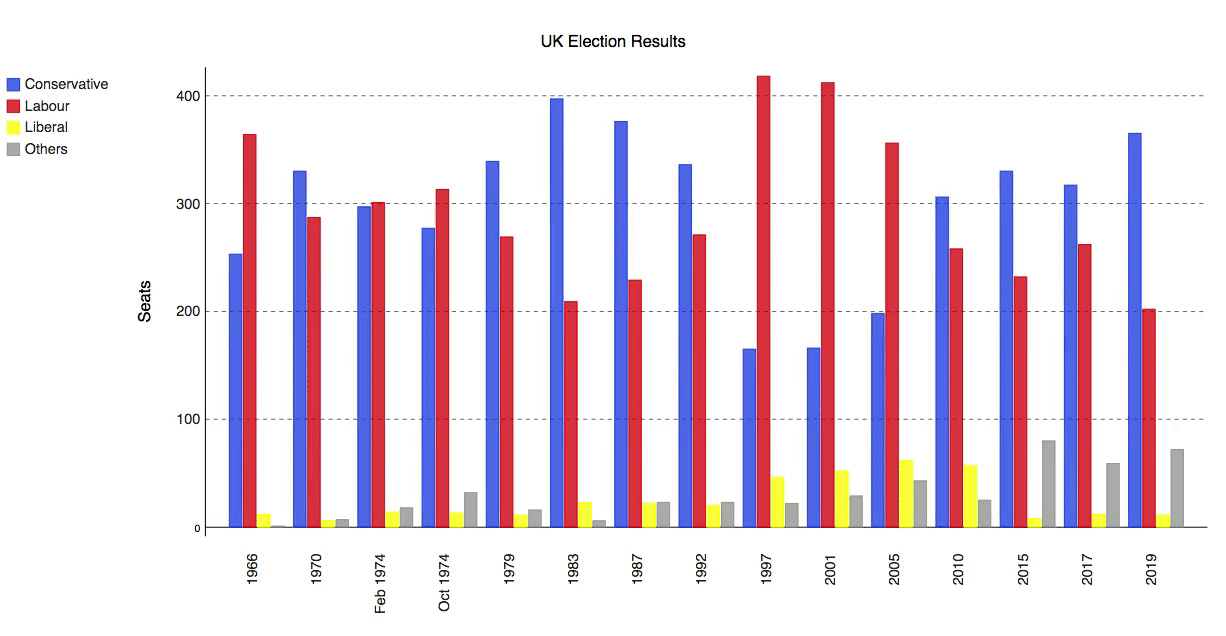
Beautifully simple, and with beautiful results.
## Conclusion
Some plotting options in Python require building every object in great detail, and Pygal gives you that functionality from the start. Give Pygal a go if you have data on hand and you want to make a clean, beautiful, and simple plot for user interaction. You can run this code [interactively on Anvil](https://anvil.works/blog/plotting-in-pygal) (with an account) or locally using [this open source runtime](https://github.com/anvil-works/anvil-runtime).
---
*This article is based on Plotting in Pygal on Anvil's blog and is reused with permission.*
## 1 Comment |
12,365 | 定制用于日常使用的树莓派系统 | https://opensource.com/article/20/6/custom-raspberry-pi | 2020-06-30T13:38:49 | [
"树莓派",
"精简"
] | https://linux.cn/article-12365-1.html |
>
> 安装精简版树莓派系统,让你的树莓派更加轻盈。
>
>
>

你有一个运行<ruby> <a href="https://www.raspberrypi.org/downloads/raspberry-pi-os/"> 树莓派系统 </a> <rt> Raspberry Pi OS </rt></ruby>(以前称为 Raspbian)操作系统的<ruby> 树莓派 <rt> Raspberry Pi </rt></ruby>,你肯定知道,它是一个非常棒的小型电脑,有一个很好的操作系统,对于初学者来说,它包括了你可能想要的一切。然而,一旦你熟悉了它,并且想用它干一些别的事情的时候,你可能不想要那个默认囊括了一切组件的操作系统。
在这种情况下,你两个选择:要么你可以绞尽脑汁地把所有你不需要的东西都删干净,要么你还可以用<ruby> 精简版树莓派系统 <rt> Raspberry Pi OS Lite </rt></ruby>来构建专门为你的需求而定制的轻量级操作系统。我的建议是,用第二种方法,既简便又节省时间。
### Raspberry Pi OS Lite
“<ruby> 精简版 <rt> Lite </rt></ruby>”的<ruby> 树莓派系统 <rt> Raspberry Pi OS </rt></ruby>其实没什么特别的,就是一个基于最新版本的 [Debian](https://www.debian.org/) 的最小化镜像。这个镜像仅包含了操作系统核心和启动到命令行的部分,而不会进入图形桌面。可以将这个作为你的定制树莓派系统的基础。这之后的所有东西都是建立在这个核心之上的。
前往树莓派基金会的网站上[下载](https://www.raspberrypi.org/downloads/raspberry-pi-os/)这个轻量级镜像。下载完成后,查看详细的[安装指南](https://www.raspberrypi.org/documentation/installation/installing-images/README.md),这里面介绍了在 Linux、Windows 或者 macOS 下如何烧制树莓派操作系统的 SD 卡。
如果你计划用树莓派作为一个极简系统来运行一些脚本和服务的话,差不多这么多就够了。如果你还想干更多事,那继续往下读。
### X Window
首先,如果偶尔需要通过图形用户界面(GUI)连接到你的树莓派,安装一个窗口系统还是不错的。
[X Window 系统](https://en.wikipedia.org/wiki/X_Window_System),有时候称为 X11,是 Unix 操作系统上一个常见的基本窗口系统。X11 提供了一套 GUI 桌面环境的基本框架。它可以让你通过窗口、鼠标和键盘与计算机交互。
#### 安装 X Window
下面这一行安装了能让 X11 运行的最少的包。
```
sudo apt install -y --no-install-recommends xserver-xorg-core xserver-xorg xfonts-base xinit
```
如果使用 `--no-install-recommends`,则只安装了主要的一些依赖(`Depends` 字段中的包)。这样可以节省很多空间,因为没有安装那些建议却不一定需要的包。
### 进阶:使用 Xfce 桌面环境
如果你愿意,可以就此停下了,然后开始使用 X Window 作为你的桌面。不过,我并不建议这么做。X Window 自带的这种最小化的窗口管理工具走的是极简主义风格,某种程度上让人感觉过时了。相反,我建议安装现代化的桌面环境,比如说像 Xfce、GNOME 或者 KDE。当用在微型计算机上时,我更倾向于 [Xfce](http://xfce.org) 而不是其他的,因为它就是为资源有限的系统设计的,而且你可以通过主题、图标或者其他东西对它进行定制。
#### 安装 Xfce
安装 Xfce 桌面环境相当简单。只需要:
```
sudo apt install -y --no-install-recommends xfce4 desktop-base lightdm
```
这就够了。你现在安装了 X Window(X11)和 Xfce 了。现在是时候来定制一下环境并且安装一些核心应用了。
### 核心应用
目前为止,你已经安装了 X Window(X11)、Xfce 桌面环境和 LightDM(一个 Xfce 自带的显示管理器)。现在,你已经有了一个可以启动并且正常使用的轻量级的完整系统。不过,在彻底完成之前,我还是喜欢装一些核心应用。
下面这条命令安装了一个终端程序、[Audacious](https://audacious-media-player.org/) 音频播放器、[Ristretto](https://docs.xfce.org/apps/ristretto/start) 图像浏览器、[Mousepad](https://github.com/codebrainz/mousepad) 文本编辑器、[File Roller](https://gitlab.gnome.org/GNOME/file-roller)存档管理器和 [Thunar](https://docs.xfce.org/xfce/thunar/thunar-volman) 容量管理器。
```
sudo apt install -y --no-install-recommends xfce4-terminal audacious ristretto
sudo apt install -y --no-install-recommends mousepad file-roller thunar-volman
```
#### 其他可选项
其他一些你可能想安装的东西,包括一个好的网络管理器、任务管理器、PDF 阅读器和通知工具,以及桌面背景管理器、截图工具、一些新的图标和光标主题。简单来说,如果树莓派是你的首选系统,这些都算是日常工作的一些补充。
```
sudo apt install -y --no-install-recommends network-manager xfce4-taskmanager xfce4-notifyd
sudo apt install -y --no-install-recommends xpdf gnome-icon-theme dmz-cursor-theme
```
### 下一步该做什么?
如果一切都正常工作的话,你现在就有一个基于 Xfce 和 Debian Lite 超轻量级操作系统的树莓派了。我建议现在你去 Xfce 网站上查看其它很酷的好东西,这些你都可以安装并使用。下一步做什么完全由你决定!
---
via: <https://opensource.com/article/20/6/custom-raspberry-pi>
作者:[Patrick H. Mullins](https://opensource.com/users/pmullins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you have a Raspberry Pi running [Raspberry Pi OS](https://www.raspberrypi.org/downloads/raspberry-pi-os/) (previously known as Raspbian) operating system, you know it's an awesome little computer with a great operating system for beginners that includes just about everything you could possibly want. However, once you become familiar with the Pi and want to start using it for other things, you might want an operating system (OS) that doesn't include everything in the default build.
When that happens, you have two choices: You can pull your hair out trying to uninstall all the cruft you don't want, or you can use Raspberry Pi OS Lite to build your own custom, lightweight operating system tailored to your exact specs. I suggest saving yourself some time and aggravation and going with the latter option.
## Raspberry Pi OS Lite
The "Lite" version of Raspberry Pi OS is really nothing more than a minimal image based on the latest version of [Debian](https://www.debian.org/). This image contains only the core operating system and boots to a command line instead of a desktop. Consider this the foundation of your custom Raspberry Pi OS. Everything from here on builds on this core.
Head over to the Raspberry Pi Foundation's website and [download](https://www.raspberrypi.org/downloads/raspberry-pi-os/) the Lite image. After that's complete, check out the detailed [installation guide](https://www.raspberrypi.org/documentation/installation/installing-images/README.md) covering how to burn a Raspberry Pi operating system image to an SD card using Linux, Windows, or macOS.
If you plan to use your Pi for a minimalist system to run scripts and services, you're pretty much done. If you want to do more, keep reading.
## X Windows
To start, it's good to have a windowing system for the occasional time you want to connect to a Raspberry Pi with a graphical user interface (GUI).
The [X Window System](https://en.wikipedia.org/wiki/X_Window_System), sometimes referred to as X11, is a basic windowing system common on Unix computer operating systems. X11 provides the basic framework for a GUI desktop environment. It is what allows you to interact with the computer using windows, a mouse, and a keyboard.
### Install X Windows
The following line will install the minimal set of packages needed to get X11 going:
`sudo apt install -y --no-install-recommends xserver-xorg-core xserver-xorg xfonts-base xinit`
With `--no-install-recommends`
, only the main dependencies (the packages in the depends field) are installed. This saves a ton of space because the other recommended—but not necessarily needed—packages are not installed.
## Go a step further with Xfce Desktop Environment
You could stop here and use X Windows as your desktop, if you want. However, I wouldn't recommend it. The windows manager that comes with X Windows is minimalist in a way that feels outdated. Instead, I recommend installing a modern desktop environment like Xfce, GNOME, or KDE. When it comes to microcomputers, I prefer [Xfce](http://xfce.org) over the others because it's designed to work well on systems with limited resources, and you can customize the way it looks via themes, icons, and more.
### Install Xfce
Installing the Xfce desktop environment is super easy. Just use:
`sudo apt install -y --no-install-recommends xfce4 desktop-base lightdm`
That's it! You now have X Windows (X11) and Xfce installed. Now it's time to customize the environment and install some essential applications.
## Essential applications
So far, you've installed X Windows (X11), the Xfce Desktop Environment, and LightDM (a display manager, added with Xfce). At this point, you have a complete, lightweight system that you can boot into and use normally. However, there are a few essential applications that I always like to install to round things out.
The following command installs a terminal app, the [Audacious](https://audacious-media-player.org/) audio player, the [Ristretto](https://docs.xfce.org/apps/ristretto/start) image viewer, the [Mousepad](https://github.com/codebrainz/mousepad) text editor, the [File Roller](https://gitlab.gnome.org/GNOME/file-roller) archive manager, and the [Thunar](https://docs.xfce.org/xfce/thunar/thunar-volman) volume manager:
```
sudo apt install -y --no-install-recommends xfce4-terminal audacious ristretto
sudo apt install -y --no-install-recommends mousepad file-roller thunar-volman
```
### Optional goodies
Some other goodies you might want to install are a good network manager, task manager, PDF viewer, and notification agent, as well as a wallpaper manager, screen-capture tool, some new icons, and new cursor themes. In short, these are practical additions for day-to-day usage if the Raspberry Pi will be your go-to system:
```
sudo apt install -y --no-install-recommends network-manager xfce4-taskmanager xfce4-notifyd
sudo apt install -y --no-install-recommends xpdf gnome-icon-theme dmz-cursor-theme
```
## Where to go from here?
If everything worked correctly, you now have a Raspberry Pi running a super-lightweight operating system based on Xfce 4 and Debian Lite. I suggest heading over to the Xfce website and checking out all the other cool [goodies](https://goodies.xfce.org/) you can install and use. Where you go from there is totally up to you!
## 6 Comments |
12,367 | 物联网将如何拯救航空业 | https://www.networkworld.com/article/3543318/how-iot-will-rescue-aviation.html | 2020-06-30T21:58:52 | [
"新冠病毒",
"IoT"
] | https://linux.cn/article-12367-1.html |
>
> 为防止感染新冠病毒的乘客登机,欧洲飞机制造商,空中客车公司正在研究能够识别病毒的物联网传感器。
>
>
>

一家开发传感器来探测飞机上和机场中的爆炸物和其他化学物品的生物技术公司正在和空中客车合作,一同开发一种可以检测已经感染新冠病毒乘客的传感器。
Koniku 的创始人兼首席执行管 Osh Agabi 在[一篇博文](https://www.linkedin.com/pulse/what-happens-when-airports-open-back-up-osh-agabi/?src=aff-lilpar&veh=aff_src.aff-lilpar_c.partners_pkw.10078_plc.Skimbit%20Ltd._pcrid.449670_learning&trk=aff_src.aff-lilpar_c.partners_pkw.10078_plc.Skimbit%20Ltd._pcrid.449670_learning&clickid=WNmzMlyalxyOUI7wUx0Mo34HUkiwwpy%3APQ3X1Y0&irgwc=1)中说,总部位于加州的 Konibu 公司和空中客车(Airbus)公司从 2017 年就开始合作共同开发能够探测出不同化学物质的非接触式设备。
他们希望通过识别从呼吸或者汗液中的气味来判断是否感染新冠病毒,因为这些气味可能是新冠病毒中化学物质的标记。“大多数感染和疾病都会或多或少的改变我们呼吸和汗液里的化学成分,也就会产生不同的气味,” Agabi 写道。“如果我们检测到这些气味,我们就可以检测是否存在感染。”
这两家公司希望能够识别这种新冠病毒的特异性标记,并且能找到一种可以检测这些标记的物联网(IoT)传感器,这些传感器配备有通过基因工程改造过的受体,从而对病毒进行探测。“那些受体会过滤空气中的分子,并且当它们接触到已经提前被编程检测的存在威胁或危险的分子化合物的时候,就会产生一个信号,”他写道。
他说,乘客将通过走过一个装有传感器的封闭通道来进行筛选。“通过对构成这些受体细胞中的 DNA 进行编程,使其对出现在感染者呼吸或者汗液中的化合物作出反应,我们相信,我们将能够迅速且可靠地筛查新冠病毒,并且确定一个人是否已经被感染,”他写道。
其他类型的非接触检测器已经在使用中了,包括<ruby> 皮肤温度升高 <rt> elevated-skin-temperature </rt></ruby>(EST)摄像头。
意大利的最主要的机场 Leonardo da Vinci 购置了三个热成像头盔来发现发烧的人。机场已经配备了固定的热感应扫描仪,并且订购了更多的这种设备。[根据当地媒体 Fiumicino Online 的报道](https://www.fiumicino-online.it/articoli/cronaca-2/fase-2-all-aeroporto-di-fiumicino-lo-smart-helmet-per-controllare-la-febbre-a-distanza),被发现潜在发烧的乘客被会要求做进一步的医学检查。
位于中国深圳制造这种头盔的 KC Wearable 公司表示,这种头盔可以由员工佩戴,并且可以与乘客保持一定的距离。
制造热感应摄像头的 FLIR Systems 公司在其本月的[财报](https://flir.gcs-web.com/news-releases/news-release-details/flir-systems-announces-first-quarter-2020-financial-results)中表示,对 EST 系统的需求正在持续增加。
“尽管这些热感应摄像头不能检测或者诊断任何医疗状况,但这些摄像头可以作为识别皮肤温度升高的有效工具。”报告说。
FLIR 公司 CEO Jim Cannon 在本月的收入电话会议上表示,“许多公司都在寻求在他们的设施中安装这种技术,以便解除<ruby> 就地避难 <rt> shelter-in-place </rt></ruby>法令”。[根据路透社报道](https://uk.reuters.com/article/us-flir-systems-gm/general-motors-taps-flir-systems-for-fever-check-cameras-at-factories-idUKKBN22J02B),通用汽车就是其中之一。
---
via: <https://www.networkworld.com/article/3543318/how-iot-will-rescue-aviation.html>
作者:[Patrick Nelson](https://www.networkworld.com/author/Patrick-Nelson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,368 | 如何在 Linux 的 bash 中永远循环 | https://www.networkworld.com/article/3562576/how-to-loop-forever-in-bash-on-linux.html | 2020-07-01T10:38:27 | [
"循环"
] | https://linux.cn/article-12368-1.html | 
在 Linux 中有很多永远循环(或直到你决定停止)的方法,你可以在命令行或脚本中执行此操作。
`for` 和 `while` 命令使这件事非常容易。关于相应的语法和策略,只有几件事要牢记。
### 使用 while
最简单的永远循环之一是使用 `while` 命令,后面跟上条件 `true`。 你不必使用诸如 `while [ 1 -eq 1 ]` 之类的逻辑或类似的测试。 `while true` 测试表示循环将一直运行,直到你使用 `CTRL-C` 停止循环、关闭终端窗口或注销为止。这是一个例子:
```
$ while true
> do
> echo Keep running
> sleep 3
> done
Keep running
Keep running
Keep running
^C
```
你也可以使用 `while :` 做同样的事情。这里的关键是 `:` 总是返回成功,因此就像 `while true` 一样,此测试永远不会失败,并且循环会继续运行:
```
$ while :
> do
> echo Keep running
> sleep 3
> done
Keep running
Keep running
^C
```
如果你在脚本中插入了无限循环,并想提醒使用它的人如何退出脚本,那么可以使用 `echo` 命令添加提示:
```
while :
do
echo Keep running
echo "Press CTRL+C to exit"
sleep 1
done
```
### 使用 for
`for` 命令还提供了一种永远循环的简便方法。虽然不如 `while true` 明显,但语法相当简单。你只需要在有界循环中替换参数即可,它通常类似于 “c 从等于 1 开始递增,直到 5”:
```
$ for (( c=1; c<=5; c++ ))
```
不指定任何参数的情况下:
```
$ for (( ; ; ))
```
没有起始值、增量或退出测试,此循环将永远运行或被强制停止:
```
$ for (( ; ; ))
> do
> echo Keep running
> echo “Press CTRL+C to exit”
> sleep 2
> done
Keep your spirits up
Keep your spirits up
Keep your spirits up
```
### 为什么要永远循环?
在现实中,你不会想永远循环下去,但一直运行直到想要回家、工作完成或者遇到问题才退出并不罕见。任何构造为无限循环的循环都可以设置为根据各种情况退出。
该脚本将一直处理数据直到下午 5 点,或者说检查发现第一次超过 5 点的时间:
```
#!/bin/bash
while true
do
if [ `date +%H` -ge 17 ]; then
exit # exit script
fi
echo keep running
~/bin/process_data # do some work
done
```
如果要退出循环而不是退出脚本,请使用 `break` 命令而不是 `exit`。
```
#!/bin/bash
while true
do
if [ `date +%H` -ge 17 ]; then
break # exit loop
fi
echo keep running
~/bin/process_data
done
… run other commands here …
```
#### 总结
永远循环很容易。指定要停止循环的条件却需要花费一些额外的精力。
---
via: <https://www.networkworld.com/article/3562576/how-to-loop-forever-in-bash-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,369 | 建立成功的 Python 环境的 4 个基本工具 | https://opensource.com/article/20/6/python-tools | 2020-07-01T12:30:19 | [
"Python"
] | https://linux.cn/article-12369-1.html |
>
> 选择的这些工具将简化你的 Python 环境,以实现顺畅和一致的开发实践。
>
>
>

Python 是一门出色的通用编程语言,经常作为第一门编程语言来教授。二十年来,我为它撰写了很多本书,而它仍然是[我的首选语言](https://opensource.com/article/19/10/why-love-python)。虽然通常来说这门语言是简洁明了的,但是(正如 [xkcd](https://xkcd.com/1987/) 讽刺的),从来没有人说过配置 Python 环境也是一样的简单。

*一个复杂的Python环境。 [xkcd](https://xkcd.com/1987/)*
在日常生活中有很多使用 Python 的方法。我将解释我是如何使用这些 Python 生态系统工具的。但坦诚的说,我仍在寻找更好的替代品。
### 使用 pyenv 来管理 Python 版本
我发现在机器上运行一个特定版本的 Python 的最好方法是使用 `pyenv`。这个软件可以在 Linux、Mac OS X 和 WSL2 上工作:这是我通常关心的三个 “类 UNIX” 环境。
安装 `pyenv` 本身有时会有点棘手。一种方法是使用专用的 [pyenv 安装程序](https://github.com/pyenv/pyenv-installer),它使用 `curl | bash` 方法来进行(详见其说明)。
如果你是在 Mac 上(或者你运行 Homebrew 的其他系统),你可以按照[这里](/article-12241-1.html)的说明来安装和使用 `pyenv`。
按照说明安装和设置了 `pyenv` 之后,你可以使用 `pyenv global` 来设置一个 “默认的” Python 版本。一般来说,你会选择你的 “首选” 版本。这通常是最新的稳定版本,但如果有其他考虑因素也可能做出不同的选择。
### 使用 virtualenvwrapper 让虚拟环境更简单
使用 `pyenv` 安装 Python 的一个好处是,你所有后继安装的 Python 解释器环境都是你自己的,而不是操作系统层面的。
虽然在 Python 本身内部安装东西通常不是最好的选择,但有一个例外:在上面选择的 “首选” Python 中,安装并配置 `virtualenvwrapper`。这样你就可以瞬间创建和切换到虚拟环境。
我在[这篇文章中](/article-11086-1.html)具体介绍了如何安装和使用 `virtualenvwrapper`。
这里我推荐一个独特的工作流程:你可以制作一个可以大量重复运行的虚拟环境,用来做<ruby> 运行器 <rt> runner </rt></ruby>。在这个环境中,可以安装你最喜欢的运行器 —— 也就是你会经常用来运行其他软件的软件。就目前而言,我的首选是 `tox`。
### 使用 tox 作为 Python 运行器
[tox](https://opensource.com/article/19/5/python-tox) 是一个很好的工具,可以让你的 Python 测试自动化。在每个 Python 环境中,我都会创建一个 `tox.ini` 文件。无论我使用什么系统做持续集成,都可以运行它,我可以用上面文章中描述的 `virtualenvwrapper` 的 `workon` 语法在本地运行同样的东西:
```
$ workon runner
$ tox
```
这个工作流程之所以重要,是因为我要在多个版本的 Python 和多个版本的依赖库中测试我的代码。这意味着在 `tox` 运行器中会有多个环境。一些会尝试在最新的依赖关系中运行,一些会尝试在冻结的依赖关系中运行(接下来会有更多的介绍),我也可能会用 `pip-compile` 在本地生成这些环境。
附注:我目前正在[研究使用 nox](https://nox.thea.codes/en/stable/) 作为 `tox` 的替代品。原因超出了本文的范畴,但值得一试。
### 使用 pip-compile 进行 Python 依赖性管理
Python 是一种动态编程语言,这意味着它在每次执行代码时都会加载其依赖关系。能否确切了解每个依赖项的具体运行版本可能意味着是平稳运行代码还是意外崩溃。这意味着我们必须考虑依赖管理工具。
对于每个新项目,我都会包含一个 `requirements.in` 文件,(通常)只有以下内容:
```
.
```
是的,没错。只有一个点的单行。我在 `setup.py` 文件中记录了 “宽松” 的依赖关系,比如 `Twisted>=17.5`。这与 `Twisted==18.1` 这样的确切依赖关系形成了鲜明对比,后者在需要一个特性或错误修复时,难以升级到新版本的库。
`.` 的意思是 “当前目录”,它使用当前目录下的 `setup.py` 作为依赖关系的来源。
这意味着使用 `pip-compile requirements.in > requirements.txt` 会创建一个冻结的依赖文件。你可以在 `virtualenvwrapper` 创建的虚拟环境中或者 `tox.ini` 中使用这个依赖文件。
有时,也可以从 `requirements-dev.in`(内容:`.[dev]`)生成 `requirements-dev.txt`,或从 `requirements-test.in`(内容:`.[test]`)生成 `requirements-test.txt`。
我正在研究在这个流程中是否应该用 [dephell](https://github.com/dephell/dephell) 代替 `pip-compile`。`dephell` 工具有许多有趣的功能,比如使用异步 HTTP 请求来下载依赖项。
### 结论
Python 的功能既强大又赏心悦目。为了编写这些代码,我依靠了一个对我来说很有效的特定工具链。工具 `pyenv`、`virtualenvwrapper`、`tox` 和 `pip-compile` 都是独立的。但是,它们各有各的作用,没有重叠,它们一起打造了一个强大的 Python 工作流。
---
via: <https://opensource.com/article/20/6/python-tools>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is a wonderful general-purpose programming language, often taught as a first programming language. Twenty years in, multiple books written, and it remains [my language of choice](https://opensource.com/article/19/10/why-love-python). While the language is often said to be straight-forward, configuring Python for development has not been described as such (as documented by [xkcd](https://xkcd.com/1987/)).
A complex Python environment: xkcd
There are many ways to use Python in your day-to-day life. I will explain how I use the Python ecosystem tools, and I will be honest where I am still looking for alternatives.
## Use pyenv to manage Python versions
The best way I have found to get a Python version working on your machine is `pyenv`
. This software will work on Linux, Mac OS X, and WSL2: the three "UNIX-like" environments that I usually care about.
Installing `pyenv`
itself can be a little tricky at times. One way is to use the dedicated [pyenv installer](https://github.com/pyenv/pyenv-installer), which uses a `curl | bash`
method to bootstrap (see the instructions for more details).
If you're on a Mac (or another system where you run Homebrew), you can follow instructions on how to install and use pyenv [here](https://opensource.com/article/20/4/pyenv).
Once you install and set up `pyenv`
per the directions, you can use `pyenv global `
to set a "default Python" version. In general, you will want to select your "favorite" version. This will usually be the latest stable, but other considerations can change that.
## Make virtual environments simpler with virtualenvwrapper
One advantage of using `pyenv`
to install Python is that all subsequent Python interpreter installations you care about are owned by you instead of the operating system you use.
Though installing things inside Python itself is usually not the best option, there is one exception: in your "favorite" Python chosen above, install and configure `virtualenvwrapper`
. This gives you the ability to create and switch to virtual environments at a moment's notice.
I walk through exactly how to install and use `virtualenvwrapper`
[in this article](https://opensource.com/article/19/6/python-virtual-environments-mac).
Here is where I recommend a unique workflow. There is one virtual environment that you will want to make so that you can reuse it a lot—`runner`
. In this environment, install your favorite `runner`
; that is, software that you will regularly use to run other software. As of today, my preference is `tox`
.
## Use tox as a Python runner
[tox](https://opensource.com/article/19/5/python-tox) is a great tool to automate your test runs of Python. In each Python environment, I create a `tox.ini`
file. Whatever system I use for continuous integration will run it, and I can run the same locally with `virtualenvwrapper`
's workon syntax described in the article above:
```
$ workon runner
$ tox
```
The reason this workflow is important is that I test my code against multiple versions of Python and multiple versions of the library dependencies. That means there are going to be multiple environments in the tox runner. Some will try running against the latest dependencies. Some will try running against frozen dependencies (more on that next), and I might also generate those locally with `pip-compile`
.
Side note: I am currently [looking at nox](https://nox.thea.codes/en/stable/) as a replacement for
`tox`
. The reasons are beyond the scope of this article, but it's worth taking a look at.## Use pip-compile for Python dependency management
Python is a dynamic programming language, which means it loads its dependencies on every execution of the code. Understanding exactly what version of each dependency is running could mean the difference between smoothly running code and an unexpected crash. That means we have to think about dependency management tooling.
For each new project, I include a `requirements.in`
file that is (usually) only the following:
`.`
Yes, that's right. A single line with a single dot. I document "loose" dependencies, such as `Twisted>=17.5`
in the `setup.py`
file. That is in contrast to exact dependencies like `Twisted==18.1`
, which make it harder to upgrade to new versions of the library when you need a feature or a bug fix.
The `.`
means "current directory," which uses the current directory's `setup.py `
as the source for dependencies.
This means that using `pip-compile requirements.in > requirements.txt `
will create a frozen dependencies file. You can use this dependencies file either in a virtual environment created by `virtualenvwrapper `
or in `tox.ini`
.
Sometimes it is useful to have `requirements-dev.txt`
, generated from `requirements-dev.in`
(contents: `.[dev]`
) or `requirements-test.txt`
, generated from `requirements-test.in`
(contents: `.[test]`
).
I am looking to see if `pip-compile`
should be replaced in this flow by [ dephell](https://github.com/dephell/dephell). The
`dephell `
tool has a bunch of interesting things about it, like the use of asynchronous HTTP requests to speak dependency downloads.## Conclusion
Python is as powerful as it is pleasing on the eyes. In order to write that code, I lean on a particular toolchain that has worked well for me. The tools `pyenv`
, `virtualenvwrapper`
, `tox`
, and `pip-compile `
are all separate. However, they each have their own role, with no overlaps, and together, they deliver a powerful Python workflow.
## 1 Comment |
12,371 | 在你的树莓派家庭实验室中使用 Cloud-init | https://opensource.com/article/20/5/cloud-init-raspberry-pi-homelab | 2020-07-01T20:38:02 | [
"云服务",
"树莓派"
] | https://linux.cn/article-12371-1.html |
>
> 了解了云行业的标准,该向你的家庭实验室自动添加新设备和用户了。
>
>
>

[Cloud-init](https://cloudinit.readthedocs.io/)(可以说)是一个标准,云提供商用它来为云实例提供初始化和配置数据。它最常用于新实例的首次启动,以自动完成网络设置、账户创建和 SSH 密钥安装等使新系统上线所需的任何事情,以便用户可以访问它。
在之前的一篇文章《[修改磁盘镜像来创建基于树莓派的家庭实验室](/article-12277-1.html)》中,我展示了如何为像树莓派这样的单板计算机定制操作系统镜像以实现类似的目标。有了 Cloud-init,就不需要向镜像中添加自定义数据。一旦在镜像中启用了它,你的虚拟机、物理服务器,甚至是小小的树莓派都可以表现得像你自己的 “家庭私有云” 中的云计算实例。新机器只需插入、打开,就可以自动成为你的[家庭实验室](https://opensource.com/article/19/3/home-lab)的一部分。
说实话,Cloud-init 的设计并没有考虑到家庭实验室。正如我所提到的,你可以很容易地修改给定的一套系统磁盘镜像,以启用 SSH 访问并在第一次启动后对它们进行配置。Cloud-init 是为大规模的云提供商设计的,这些提供商需要容纳许多客户,维护一组小的镜像,并为这些客户提供访问实例的机制,而无需为每个客户定制一个镜像。拥有单个管理员的家庭实验室则不会面临同样的挑战。
不过,Cloud-init 在家庭实验室中也不是没有可取之处。教育是我的家庭私有云项目的目标之一,而为你的家庭实验室设置 Cloud-init 是一个很好的方式,可以获得大大小小的云提供商大量使用的技术的经验。Cloud-init 也是其他初始配置选项的替代方案之一。与其为家庭实验室中的每台设备定制每个镜像、ISO 等,并在你要进行更改时面临繁琐的更新,不如直接启用 Cloud-init。这减少了技术债务 —— 还有什么比*个人*技术债务更糟糕的吗?最后,在你的家庭实验室中使用 Cloud-init 可以让你的私有云实例与你拥有的或将来可能拥有的任何公有云实例表现相同 —— 这是真正的[混合云](https://www.redhat.com/en/topics/cloud-computing/what-is-hybrid-cloud)。
### 关于 Cloud-init
当为 Cloud-init 配置的实例启动并且服务开始运行时(实际上是 systemd 中的四个服务,以处理启动过程中的依赖关系),它会检查其配置中的[数据源](https://cloudinit.readthedocs.io/en/latest/topics/datasources.html),以确定其运行在什么类型的云中。每个主要的云提供商都有一个数据源配置,告诉实例在哪里以及如何检索配置信息。然后,实例使用数据源信息检索云提供商提供的配置信息(如网络信息和实例识别信息)和客户提供的配置数据(如要复制的授权密钥、要创建的用户账户以及许多其他可能的任务)。
检索数据后,Cloud-init 再对实例进行配置:设置网络、复制授权密钥等,最后完成启动过程。然后,远程用户就可以访问它,准备好使用 [Ansible](https://www.ansible.com/) 或 [Puppet](https://puppet.com/) 等工具进行进一步的配置,或者准备好接收工作负载并开始分配任务。
### 配置数据
如上所述,Cloud-init 使用的配置数据来自两个潜在来源:云提供商和实例用户。在家庭实验室中,你扮演着这两种角色:作为云提供商提供网络和实例信息,作为用户提供配置信息。
#### 云提供商元数据文件
在你的云提供商角色中,你的家庭实验室数据源将为你的私有云实例提供一个元数据文件。这个[元数据](https://cloudinit.readthedocs.io/en/latest/topics/instancedata.html#)文件包含实例 ID、云类型、Python 版本(Cloud-init 用 Python 编写并使用 Python)或要分配给主机的 SSH 公钥等信息。如果你不使用 DHCP(或 Cloud-init 支持的其他机制,如镜像中的配置文件或内核参数),元数据文件还可能包含网络信息。
#### 用户提供的用户数据文件
Cloud-init 的真正价值在于用户数据文件。[用户数据](https://cloudinit.readthedocs.io/en/latest/topics/format.html)文件由用户提供给云提供商,并包含在数据源中,它将实例从一台普通的机器变成了用户舰队的一员。用户数据文件可以以可执行脚本的形式出现,与正常情况下脚本的工作方式相同;也可以以云服务配置 YAML 文件的形式出现,利用 [Cloud-init 的模块](https://cloudinit.readthedocs.io/en/latest/topics/modules.html) 来执行配置任务。
### 数据源
数据源是由云提供商提供的服务,它为实例提供了元数据和用户数据文件。实例镜像或 ISO 被配置为告知实例正在使用什么数据源。
例如,亚马逊 AWS 提供了一个 [link-local](https://en.wikipedia.org/wiki/Link-local_address) 文件,它将用实例的自定义数据来响应实例的 HTTP 请求。其他云提供商也有自己的机制。幸运的是,对于家庭私有云项目来说,也有 NoCloud 数据源。
[NoCloud](https://cloudinit.readthedocs.io/en/latest/topics/datasources/nocloud.html) 数据源允许通过内核命令以键值对的形式提供配置信息,或通过挂载的 ISO 文件系统以用户数据和元数据文件的形式提供。这些对于虚拟机来说很有用,尤其是与自动化搭配来创建虚拟机。
还有一个 NoCloudNet 数据源,它的行为类似于 AWS EC2 数据源,提供一个 IP 地址或 DNS 名称,通过 HTTP 从这里检索用户数据和元数据。这对于你的家庭实验室中的物理机器来说是最有帮助的,比如树莓派、[NUC](https://en.wikipedia.org/wiki/Next_Unit_of_Computing) 或多余的服务器设备。虽然 NoCloud 可以工作,但它需要更多的人工关注 —— 这是云实例的反模式。
### 家庭实验室的 Cloud-init
我希望这能让你了解到 Cloud-init 是什么,以及它对你的家庭实验室有何帮助。它是一个令人难以置信的工具,被主要的云提供商所接受,在家里使用它可以是为了教育和乐趣,并帮助你自动向实验室添加新的物理或虚拟服务器。之后的文章将详细介绍如何创建简单的静态和更复杂的动态 Cloud-init 服务,并指导你将它们纳入你的家庭私有云。
---
via: <https://opensource.com/article/20/5/cloud-init-raspberry-pi-homelab>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Cloud-init](https://cloudinit.readthedocs.io/) is a standard—it would not be a stretch to say it is *the* standard—that cloud providers use to provide initialization and configuration data to cloud instances. It is used most often on the first boot of a new instance to automate network setup, account creation, and SSH (secure shell) key installation—anything required to bring a new system online so that it is accessible by the user.
In a previous article, [ Modify a disk image to create a Raspberry Pi-based homelab](https://opensource.com/article/20/5/disk-image-raspberry-pi), I showed how to customize the operating system image for single-board computers like the Raspberry Pi to accomplish a similar goal. With Cloud-init, there is no need to add custom data to the image. Once it is enabled in your images, your virtual machines, physical servers, even tiny Raspberry Pis can behave like cloud instances in your own "private cloud at home." New machines can just be plugged in, turned on, and automatically become part of your
[homelab](https://opensource.com/article/19/3/home-lab).
To be honest, Cloud-init is not designed with homelabs in mind. As I mentioned, you can easily modify the disk image for a given set of systems to enable SSH access and configure them after the first boot. Cloud-init is designed for large-scale cloud providers that need to accommodate many customers, maintain a small set of images, and provide a mechanism for those customers to access instances without customizing an image for each of them. A homelab with a single administrator does not face the same challenges.
Cloud-init is not without merit in the homelab, though. Education is one of my goals for the private cloud at home project, and setting up Cloud-init for your homelab is a great way to gain experience with a technology used heavily by cloud providers, large and small. Cloud-init is also an alternative to other initial-configuration options. Rather than customizing each image, ISO, etc. for every device in your homelab and face tedious updates when you want to make changes, you can just enable Cloud-init. This reduces technical debt—and is there anything worse than *personal* technical debt? Finally, using Cloud-init in your homelab allows your private cloud instances to behave the same as any public cloud instances you have or may have in the future—a true [hybrid cloud](https://www.redhat.com/en/topics/cloud-computing/what-is-hybrid-cloud).
## About Cloud-init
When an instance configured for Cloud-init boots up and the service (actually, four services in systemd implementations to handle dependencies during the boot process) starts, it checks its configuration for a [datasource](https://cloudinit.readthedocs.io/en/latest/topics/datasources.html) to determine what type of cloud it is running in. Each major cloud provider has a datasource configuration that tells the instance where and how to retrieve configuration information. The instance then uses the datasource information to retrieve configuration information provided by the cloud provider, such as networking information and instance-identification information, and configuration data provided by the customer, such as authorized keys to be copied, user accounts to be created, and many other possible tasks.
After retrieving the data, Cloud-init then configures the instance: setting up networking, copying the authorized keys, etc., and finally completing the boot process. Then it is accessible to the remote user, ready for further configuration with tools like [Ansible](https://www.ansible.com/) or [Puppet](https://puppet.com/) or prepared to receive a workload and begin its assigned tasks.
## Configuration data
As mentioned above, the configuration data used by Cloud-init comes from two potential sources: the cloud provider and the instance user. In a homelab, you fill both roles: providing networking and instance information as the cloud provider and providing configuration information as the user.
### The cloud provider metadata file
In your cloud provider role, your homelab datasource will offer your private cloud instances a metadata file. The [metadata](https://cloudinit.readthedocs.io/en/latest/topics/instancedata.html#) file contains information such as the instance ID, cloud type, Python version (Cloud-init is written in and uses Python), or a public SSH key to be assigned to the host. The metadata file may also contain networking information if you're not using DHCP (or the other mechanisms Cloud-init supports, such as a config file in the image or kernel parameters).
### The user-provided user-data file
The real meat of Cloud-init's value is in the user-data file. Provided by the user to the cloud provider and included in the datasource, the [user-data](https://cloudinit.readthedocs.io/en/latest/topics/format.html) file is what turns an instance from a generic machine into a member of the user's fleet. The user-data file can come in the form of an executable script, working the same as the script would in normal circumstances, or as a cloud-config YAML file, which makes use of [Cloud-init's modules](https://cloudinit.readthedocs.io/en/latest/topics/modules.html) to perform configuration tasks.
## Datasource
The datasource is a service provided by the cloud provider that offers the metadata and user-data files to the instances. Instance images or ISOs are configured to tell the instance what datasource is being used.
For example, Amazon AWS provides a [link-local](https://en.wikipedia.org/wiki/Link-local_address) file that will respond to HTTP requests from an instance with the instance's custom data. Other cloud providers have their own mechanisms, as well. Luckily for the private cloud at home project, there are also NoCloud data sources.
[NoCloud](https://cloudinit.readthedocs.io/en/latest/topics/datasources/nocloud.html) datasources allow configuration information to be provided via the kernel command as key-value pairs or as user-data and metadata files provided as mounted ISO filesystems. These are useful for virtual machines, especially paired with automation to create the virtual machines.
There is also a NoCloudNet datasource that behaves similarly to the AWS EC2 datasource, providing an IP address or DNS name from which to retrieve user data and metadata via HTTP. This is most helpful for the physical machines in your homelab, such as Raspberry Pis, [NUCs](https://en.wikipedia.org/wiki/Next_Unit_of_Computing), or surplus server equipment. While NoCloud could work, it requires more manual attention—an anti-pattern for cloud instances.
## Cloud-init for the homelab
I hope this gives you an idea of what Cloud-init is and how it may be helpful in your homelab. It is an incredible tool that is embraced by major cloud providers, and using it at home can be educational and fun and help you automate adding new physical or virtual servers to your lab. Future articles will detail how to create both simple static and more complex dynamic Cloud-init services and guide you in incorporating them into your private cloud at home.
## 4 Comments |
12,373 | 在 Linux 上缺少 Photoshop?使用 PhotoGIMP 将 GIMP 变为 Photoshop | https://itsfoss.com/photogimp/ | 2020-07-02T11:11:51 | [
"GIMP",
"Photoshop"
] | https://linux.cn/article-12373-1.html | [Adobe Photoshop](https://www.adobe.com/in/products/photoshop.html) 不适用于桌面 Linux。GIMP 是 [Linux 上 Adobe Photoshop 的最佳替代品](https://itsfoss.com/open-source-photoshop-alternatives/)。
如果你使用过 Photoshop,那么你会注意到 [GIMP](https://www.gimp.org/) 和 Photoshop 相比有不同的设置、键盘快捷键和布局。
这没有错。毕竟,它们都是两种不同的软件,而且它们不必看起来相同。
但是,习惯了 Photoshop 的人们发现在切换到 GIMP 的时很难忘记他们反复学习的肌肉记忆。这可能会使某些人感到沮丧,因为使用新的界面意味着要学习大量的键盘快捷键,并花时间在查找工具位于何处。
为了帮助从 Photoshop 切换到 GIMP 的人,[Diolinux](https://diolinux.com.br/) 推出了一个在 GIMP 中模仿 Adobe Photoshop 的工具。
### PhotoGIMP:在 Linux 中为 GIMP 提供 Adobe Photoshop 的外观

[PhotoGIMP](https://github.com/Diolinux/PhotoGIMP) 不是独立的图形软件。它是 GIMP 2.10 的补丁。你需要在系统上安装 GIMP 才能使用 PhotoGIMP。
当你应用 PhotoGIMP 补丁时,它将更改 GIMP 布局以模仿 Adobe Photoshop。
* 默认安装数百种新字体
* 安装新的 Python 过滤器,例如 “heal selection”
* 添加新的启动画面
* 添加新的默认设置以最大化画布空间
* 添加类似于 Adobe Photoshop 的键盘快捷键
PhotoGIMP 还在自定义 `.desktop` 文件中添加新的图标和名称。让我们看看如何使用它。
### 在 Linux 上安装 PhotoGIMP (适合中级到专业用户)
PhotoGIMP 本质是一个补丁。在 Linux 中下载并[解压 zip 文件](https://itsfoss.com/unzip-linux/)。你将在解压的文件夹中找到以下隐藏的文件夹:
* `.icons`:其中包含新的 PhotoGIMP 图标
* `.local`:包含个性化的 `.desktop` 文件,以便你在系统菜单中看到的是 PhotoGIMP 而不是 GIMP
* `.var`:包含 GIMP 补丁的主文件夹
你应该[使用 Ctrl+H 快捷键在 Ubuntu 中显示隐藏文件](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/)。
警告:建议你备份 GIMP 配置文件,以便在不喜欢 PhotoGIMP 时可以还原。只需将 GIMP 配置文件复制到其他位置即可备份。
目前,PhotoGIMP 主要与通过 [Flatpak](https://flatpak.org/) 安装的 GIMP 兼容。如果你使用 Flatpak 安装了 GIMP,那么只需将这些隐藏的文件夹复制粘贴到家目录中,它将 GIMP 转换为 Adobe Photoshop 类似的设置。
但是,如果你通过 apt、snap 或发行版的包管理器安装了 GIMP,那么必须找到 GIMP 的配置文件夹,然后粘贴 PhotoGIMP 的 `.var` 目录的内容。当出现询问时,请选择合并选项并替换同名的现有文件。
我[使用 apt 在 Ubuntu 20.04 中安装了 GIMP](https://itsfoss.com/gimp-2-10-release/)。对我来说,GIMP 配置文件在 `~/.config/GIMP/2.10`。我复制了 `.var/app/org.gimp.GIMP/config/GIMP/2.10` 目录,并启动 GIMP 查看 PhotoGIMP 的启动页。
这是打了 PhotoGIMP 补丁后的 GIMP 界面:

我尝试了几个 Photoshop 快捷键来检查它所做的更改,一切似乎可以正常工作。
* [下载 PhotoGIMP](https://github.com/Diolinux/PhotoGIMP/releases)
我还找到了 [Snap 包形式的 PhotoGIMP](https://snapcraft.io/photogimp),但它是 2019 年的,我不确定它是否可以在所有地方使用,或者仅适用于 snap 安装。
### 总结
这不是类似的第一个项目。几年前,我们有一个类似的项目叫 Gimpshop。Gimpshop 项目在过去的几年中没有任何进展,可以肯定地认为该项目已经死亡。有一个名为 Gimpshop 的网站,但该网站来自冒名者试图以 Gimpshop 的名义获利。
我不是 Adobe Photoshop 用户。我甚至不是 GIMP 专家,这就是为什么我们的 [GIMP 教程](https://itsfoss.com/tag/gimp-tips/) 用 Dimitrios 的原因。
因此,我无法评论 PhotoGIMP 项目的实用性。如果你熟悉这两种软件,那么应该能够比我更好地进行判断。
如果你尝试使用 PhotoGIMP,请与他人分享你的经验,并告诉我们是否值得安装。
---
via: <https://itsfoss.com/photogimp/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Adobe Photoshop](https://www.adobe.com/in/products/photoshop.html?ref=itsfoss.com) is not available for desktop Linux. GIMP is the [best alternative to Adobe Photoshop on Linux](https://itsfoss.com/open-source-photoshop-alternatives/).
If you have used Photoshop for some time, you’ll notice that the [GIMP](https://www.gimp.org/?ref=itsfoss.com) has different settings, different keyboard shortcuts and layout than Photoshop.
And there is absolutely nothing wrong with it. After all, both are two different pieces of software, and they don’t have to look the same.
However, people who are used to Photoshop find it difficult to forget their hard learned muscle memory while switching to GIMP. This could frustrate some because using a new interface means learning numerous keyboard shortcuts and spending time on finding which tool is located where.
To help such Photoshop to GIMP switchers, [Diolinux](https://diolinux.com.br/?ref=itsfoss.com) has introduced a tool that mimics Adobe Photoshop in GIMP.
## PhotoGIMP: Give Adobe Photoshop like look and feel to GIMP in Linux
[PhotoGIMP](https://github.com/Diolinux/PhotoGIMP?ref=itsfoss.com) is not a standalone [graphics software](https://itsfoss.com/vector-graphics-editors-linux/). It is a patch for GIMP 2.10. You need to have [GIMP installed on your system](https://itsfoss.com/gimp-2-10-release/) to use PhotoGIMP.
Once GIMP is installed, open it and close it. This is to generate the default configurations in the required location. Later in this section, we will replace it. So, just back up a copy of this default config folder.
When you apply the PhotoGIMP patch, it changes the GIMP layout to mimic Adobe Photoshop.
- Installs new Python filters such as “heal selection”
- Adds new splash screen
- Adds new default settings to maximize space on the canvas
- Adds keyboard shortcuts similar to Adobe Photoshop
PhotoGIMP also adds a new icon and name from custom .desktop file. Let’s see how to use it.
## Installing PhotoGIMP on Linux [for intermediate to expert users]
PhotoGIMP is essentially a patch for GIMP 2.10+. You must have GIMP 2.10+ installed on your system. You download and [extract the zip file in Linux](https://itsfoss.com/unzip-linux/). You’ll find the following hidden folders in the extracted folder:
**.icons**: which have a new PhotoGIMP icon**.local**: which contains the personalized .desktop file so that you see PhotoGIMP instead of GIMP in the system menu**.var**: the main folder containing the patch for GIMP
You should [use Ctrl+H keyboard shortcut to show hidden files in Ubuntu](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/).
Usually, if you installed it from the Ubuntu repository, the location will be
`~/.config/GIMP`
.PhotoGIMP is mainly compatible with GIMP installed via [Flatpak](https://flatpak.org/?ref=itsfoss.com). If you installed GIMP using Flatpak, you can simply copy-paste these hidden folders in your home directory, and it will convert your GIMP into Adobe Photoshop like settings.
*and*
*.var**directories of the project to the respective folder in your home directory.*
*.icons*If you installed GIMP via apt or snap or your distribution’s package manager, you’ll have to find the GIMP config folder and paste the content of the `.var/app/org.gimp.GIMP/config/GIMP/2.10`
directory of PhotoGIMP.
I [installed GIMP in Ubuntu 24.04 using apt](https://itsfoss.com/gimp-2-10-release/). The location for the GIMP config file for me was `~/.config/GIMP/2.10`
. I copied the content of the `.var/app/org.gimp.GIMP/config/GIMP/2.10`
directory here and started GIMP to see the PhotoGIMP splash.

### PhotoGIMP with Flatpak
If you have installed the native package of GIMP on your system earlier, you should first remove the config files associated with that GIMP. For that, simply delete the GIMP directory in `~/.config`
directory.
Now you have to place the contents inside the extracted zip folder in the appropriate places of GIMP flatpak app. The folder for GIMP Flatpak app can be found at `/.var/app/`
.
So go inside the `~/.var/app`
directory and paste the `~/Downloads/PhotoGIMP/PhotoGIMP-master/.var/app/org.gimp.GIMP`
directory there.
When asked, opt for merge option.
It will then ask to replace some existing files of the same name. Accept it.
Now, copy the .desktop file from `.local/share/applications`
of extracted folder and paste it at `~/.local/share/applications`
.
### Getting PhotoGIMP desktop icon for GIMP installed through repo packages
By default, the desktop file of PhotoGIMP points to a Flatpak version. If you have installed the GIMP from your package manager, you should edit the *.desktop* (found at `.local/share/applications/`
inside the downloaded ZIP) file of PhotoGIMP to point to the actual GIMP.
First, check where does the GIMP actually points:
```
which gimp
```
This will tell you what is executed when you run `gimp`
. So, comment the `EXEC`
line in the default desktop file and paste the line just below:
```
Exec=/usr/bin/gimp
# Or whatever output, the which command tells.
```
Save the file and exit. You may need to log out and log back in some times to see the changes.
## Working with PhotoGIMP
If everything has been done correctly, you can now see the PhotoGIMP icon on the overview.

Here’s the interface of GIMP before and after being patched by PhotoGIMP:
Before and after the PhotoGIMP patch
I tried a couple of Photoshop keyboard shortcuts to check the changes it made, and it seemed to be working.
I also found [PhotoGIMP available as Snap package](https://snapcraft.io/photogimp?ref=itsfoss.com), but it's from 2020, and I am not sure if it works everywhere or just with snap install.
## Conclusion
This is not the first project of this kind. Some years ago, we had a similar project called Gimpshop. The Gimpshop project hasn’t seen any development in the past several years, and it is safe to assume that the project is dead. There is a website with the name of Gimpshop, but that’s from imposters trying to cash in on Gimpshop name.
I am not an Adobe Photoshop user. I am not even a GIMP expert, this is why the [GIMP tutorials](https://itsfoss.com/tag/gimp/) on It’s FOSS are covered by Dimitrios.
For this reason, I cannot comment on how useful the PhotoGIMP project is. If you are familiar with both software, you should be able to judge it better than me.
If you try PhotoGIMP, do share your experience with it and let us know whether it is worth the installation or not. |
12,375 | 你是否已经准备好从 Mac 切换到 Linux 了? | https://opensource.com/article/20/6/mac-to-linux | 2020-07-02T22:26:00 | [
"Mac"
] | /article-12375-1.html |
>
> 你几乎可以在 Linux 上做任何你在 Mac 上可以做的事情 —— 这是你拥有一个开源操作系统的自由。
>
>
>

我[从 Mac 转到 Linux](https://markosaric.com/linux/) 已经两年了。在使用 Linux 之前,我用的 Apple 的系统用了 15 年,而当我在 2018 年安装第一个 Linux 发行版时,还只是一个纯粹的新手。
这些日子以来,我只用 Linux,我可以用它完成任何任务。浏览网页、观看 Netflix 影片、写作以及编辑我的 Wordpress [博客](https://markosaric.com/how-start-blog/),甚至还在上面跑我的[开源网页分析项目](https://plausible.io/open-source-website-analytics)。
我甚至还不是一个开发者!Linux 被认为不适合日常使用,对非技术人员也不够友好的日子已经一去不返了。
最近有很多关于 Mac 的讨论,越来越多的人已经在考虑转到 Linux。我打算分享我的切换过程中的一些经验,帮助其它新手也能从容转移。
### 你该不该换?
在换系统之前,最好想清楚,因为有时候 Linux 可能跟你预期不一样。如果你仍希望跟 Apple Watch 无缝配对、可以用 FaceTime 给朋友打电话、或者你想打开 iMovie 看视频,那最好还是不要换了。这些都是 Apple 的专有产品,你只能在 Apple 的“围墙花园”里面使用。如果离不开 Apple 的生态系统,那么 Linux 可能不太适合你。
我对 Apple 生态没有太多挂念,我不用 iPhone,所以跟手机的协作没那么必要。我也不用 iCloud、FaceTime,当然也包括 Siri。我早就对开源充满兴趣,只是一直没有行动。
### 检查你的必备软件清单
我还在使用 Mac 的时候,就已经开始探索开源软件,我发现大部分在 Mac 上使用的软件,在 Linux 也可以运行。
很熟悉用火狐浏览网页吗?在 Linux 上它也可以运行。想用 VLC 看视频?它也有 Linux 版本。喜欢用 Audacity 录制、编辑音频?它正在 Linux 上等着你呢。你用 OBS Studio 直播?在 Linux 直接下载安装吧。一直用 Telegram 跟朋友和家人保持联系吗?Linux 上当然少不了它。
此外,Linux 不仅仅意味着开源软件。你最喜欢的大部分(也可能是所有)非 Apple 专有软件,都能在 Linux 见到它们的身影。Spotify、Slack、Zoom、Stream、Discord、Skype、Chrome 以及很多闭源软件,都可以使用。而且,在你 Mac 浏览器里面运行的任何东西,同样能够运行在 Linux 浏览器。
你能在 Linux 找到你的必备软件,或者更好的替代品吗?请再三确认,做到有备无患。用你最常用的搜索引擎,在网上检索一下。搜索“软件名 + Linux” 或者“软件名 + Linux 替代品”,然后再去 [Flathub](https://flathub.org/apps) 网站查看你能在 Linux 用 Flatpak 安装的专有软件有哪些。
### 请牢记:Linux 不等于 Mac
如果你希望能够从 Mac 轻松转移到 Linux,我相信有一点很重要,你需要保持包容的思想以及愿意学习新操作系统的心态。Linux 并不等于 Mac,所以你需要给自己一些时间去接触并了解它。
如果你想让 Linux 用起来、看起来跟你习惯的 macOS 一模一样,那么 Linux 可能也不适合你。尽管你可以通过各种方法[把 Linux 桌面环境打造得跟 macOS 相似](/article-12361-1.html),但我觉得要想成功转移到 Linux,最好的办法是从拥抱 Linux 开始。
试试新的工作流,该怎么用就怎么用。不要总想着把 Linux 变成其它东西。你会跟我一样,像享受 Mac 一样享受 Linux,甚至能有更好的体验感。
还记得你第一次使用 Mac 吧:你肯定花了不少时间去习惯它的用法。那么请给 Linux 同样多的时间和关怀。
### 选择一个 Linux 发行版
有别于 Windows 和 macOS,Linux 不止一个单一的操作系统。不同的 Linux 操作系统被称作发行版,开始使用 Linux 之后,我尝试过好几个不同的发行版。我也用过不同的桌面环境,或者图形界面。在美观度、易用性、工作流以及集成软件上,它们有很大差异。
尽管作为 Mac 的替代品,被提及最多的是 [ElementaryOS](https://opensource.com/article/20/2/macbook-linux-elementary) 和 [Pop!\_OS](https://support.system76.com/articles/pop-basics/),但我仍建议从 [Fedora 工作站](https://getfedora.org/) 开始,理由如下:
* 使用 [Fedora 介质写入器](https://getfedora.org/en/workstation/download/),容易安装
* 几乎可以支持你所有的硬件,开箱即用
* 支持最新的 Linux 软件
* 运行原生无改动的 GNOME 桌面环境
* 有一个大型开发团队以及一个庞大的社区在背后支持
在我看来,对从 macOS 过来的新手来说,[GNOME](https://www.gnome.org/) 是易用性、一致性、流畅性和用户体验最好的桌面环境。它拥有 Linux 世界中最多的开发资源和用户基数,所以你的使用体验会很好。
Fedora 可以为你打开一扇 Linux 的大门,当你适应之后,就可以开始进一步探索各个发行版、桌面环境,甚至窗口管理器之类的玩意了。
### 熟悉 GNOME
GNOME 是 Fedora 和许多其它 Linux 发行版的默认窗口管理器。它最近 [升级到 GNOME 3.36](https://www.gnome.org/news/2020/03/gnome-3-36-released/),带来了 Mac 用户会喜欢的现代设计。
一定要做好心理准备,Linux、Fedora 工作站和 GNOME 并不是 Apple 和 macOS。GNOME 非常干净、简约、现代、独创。它不会分散你的注意力,没有桌面图标,没有可见的坞站,窗口上甚至没有最小化和最大化按钮。但是不要慌张,如果你去尝试,它会证明这是你用过最好、最有生产力的操作系统。
GNOME 不会给你带来困扰。启动之后,你唯一能看到的东西只有顶栏和背景图片。顶栏由这几样东西组成,“活动”在左边,时间和日期在中间(这也是你的通知中心),右边是网络、蓝牙、VPN、声音、亮度、电池等托盘图标之类的东西。
#### 为什么 GNOME 像 Mac
你会注意到一些跟 macOS 的相似之处,例如窗口吸附、空格预览(用起来跟 “Quick Look” 一模一样)。
如果你把鼠标光标移动到左上角,点击顶栏的“活动”,或者按下键盘上超级键(`Super` 键,也就是 Mac 上的 `ஐ` 键),你会看到“活动概览”。它有点像 macOS 系统上“调度中心”和“聚焦搜索”的结合体。它会在屏幕中间展示已打开软件和窗口的概览。在左手边,你可以看到坞站,上面有你打开的软件和常用软件。所有打开的软件下面会有一个指示标志,在右手边,你可以看到不同的工作区。
在顶栏中间,有一个搜索框。只要你开始输入,焦点就会转移到搜索框。它能搜索你已经安装的软件和文件内容,可以在软件中心搜索指定的软件、进行计算、向你展示时间或者天气,当然它能做的还有很多。它就像“聚焦”一样。只需开始输入你要搜索的内容,按下回车就可以打开软件或者文件。
你也能看到一列安装好的软件(更像 Mac 上的“启动台”),点击坞站中的“显示应用”图标,或者按 `Super + A` 就行。
总体来说,Linux 是一个轻量级的系统,即使在很老的硬件上也能跑得很顺畅,跟 macOS 比起来仅仅占用很少的磁盘空间。并且不像 macOS,你可以删除任何你不想要或不需要的预装软件。
#### 自定义你的 GNOME 设置
浏览一下 GNOME 设置,熟悉它的选项,做一些更改,让它用起来更舒服。下面是一些我装好 GNOME 必做的事情。
* 在“鼠标和触摸板”中,我禁用“自然滚动”、启用“轻触点击”。
* 在“显示”中,我打开“夜光”功能,在晚上,屏幕会让颜色变暖,减少眼睛疲劳。
* 我也安装了 [GNOME 优化](https://wiki.gnome.org/Apps/Tweaks),因为它可以更改额外的设置选项。
* 在“GNOME 优化”中,我启用了 “Over-Amplification” 设置,这样就能获得更高的音量。
* 在“GNOME 优化”中,相比默认的亮色主题,我更喜欢 “Adwaita Dark” 主题。
#### 习惯使用键盘操作
GNOME 是以一个极度以键盘为中心的操作系统,所以尽量多使用键盘。在 GNOME 设置中的“键盘快捷键”部分,你可以找到各个快捷键。
你也可以根据自己的理想工作流程来设置键盘快捷键。我将我最常用的应用程序设置为使用超级键打开。比如说,`Super + B` 打开我的浏览器,`Super + F` 打开“文件”,`Super + T` 打开终端。我还把 `Ctrl + Q` 设置成关闭窗口。
我使用 `Super + Tab` 在打开的应用程序之间切换,`Super + H` 隐藏一个窗口,`F11` 全屏打开软件,`Super + Left` 把窗口吸附到屏幕左边,`Super + Right` 把窗口吸附到屏幕左边,等等。
### 在 Mac 上尝试 Linux 之后再做决定
在完全安装 Linux 之前,在你的 Mac 上先尝试 Fedora。从 [Fefora 官网](https://getfedora.org/en/workstation/download/)下载 ISO 镜像。使用 [Etcher](https://www.balena.io/etcher/) 将 ISO 镜像写入 USB 驱动器,然后在启动时点击 `Option` 键,这样你就可以在即用模式下尝试了。
现在您无需在 Mac 上安装任何东西就可以探索 Fedora 工作站了。试试各种东西,能否正常工作:能不能连接 WiFi?触控板是否正常?有没有声音?等等。
也记得花时间来尝试 GNOME。测试我上面提到的不同功能。打开一些安装好的软件。如果一切看起来都还不错,如果你喜欢这样的 Fedora 工作站和 GNOME,并且很肯定这就是你想要的,那么把它安装到你的 Mac 吧。
尽情探索 Linux 世界吧!
---
via: <https://opensource.com/article/20/6/mac-to-linux>
作者:[Marko Saric](https://opensource.com/users/markosaric) 选题:[lujun9972](https://github.com/lujun9972) 译者:[nophDog](https://github.com/nophDog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,376 | Linux Mint 20 正式发布了!你该升级吗? | https://itsfoss.com/linux-mint-20-download/ | 2020-07-03T08:42:35 | [
"Mint"
] | https://linux.cn/article-12376-1.html | 
Linux Mint 20 “Ulyana” 终于发布了,可以下载了。
Linux Mint 19 基于 Ubuntu 18.04 LTS,而 [Mint 20](/article-12297-1.html) 则基于 [Ubuntu 20.04 LTS](https://itsfoss.com/download-ubuntu-20-04/) —— 所以你会发现很多不同的地方、改进的地方,可能更棒了。
既然它来了,让我们来看看它的新功能,在哪里下载它,以及如何升级你的系统。
### Linux Mint 20:有什么新东西?
我们制作了一段关于 Linux Mint 20 的初步视觉印象的视频,让大家更好地了解。
说到 Linux Mint 20 的发布,有很多事情要谈。虽然我们已经介绍了 Linux Mint 20 的新的关键[功能](/article-12297-1.html),但我还是在这里提几点,让大家一目了然。
* Nemo 文件管理器在生成缩略图方面的性能提升
* 一些重新设计的颜色主题
* Linux Mint 20 将禁止 APT 使用 Snapd
* 一个新的图形用户界面工具,用于通过本地网络共享文件
* 改进对多显示器的支持
* 改进对笔记本电脑的混合图形支持
* 不再有 32 位版本
除了这些变化之外,你还会注意到 Cinnamon 4.6 桌面更新后的一些视觉变化。
以下是 Linux Mint 20 Cinnamon 版的一些截图。








### 升级到 Linux Mint 20:你需要知道什么?
如果你已经在使用 Linux Mint,你可以选择升级到 Linux Mint 20。
* 如果你使用的是 Linux Mint 20 测试版,你可以升级到 Mint 20 稳定版。
* 如果你正在使用 Linux Mint 19.3(这是 Mint 19 的最新迭代),你可以将系统升级到 Linux Mint 20,而不需要进行重新安装
* Linux Mint 20 没有 32 位版本。如果你**使用 32 位的 Mint 19 系列,你将无法升级到 Mint 20**
* 如果你使用的是 Linux Mint 18 系列,你必须先通过 Mint 19 系列升级。在我看来,重新安装 Mint 20 会比较省时省事
* 如果你使用的是 Linux Mint 17、16、15 或更低版本,你一定不要再使用它们了。这些版本已经不支持了
我们有一个详细的指南,展示了从 18.3 到 19 [升级 Linux Mint 版本](https://itsfoss.com/upgrade-linux-mint-version/)的步骤。我猜测 Mint 20 的步骤应该也是一样的。我们的团队会对 Mint 19.3 到 Mint 20 的升级做一些测试,并在适用的情况下更新这个指南。
在你继续升级之前,请确保备份你的数据和[使用 Timeshift 创建系统快照](https://itsfoss.com/backup-restore-linux-timeshift/)。
### 下载Linux Mint 20
你可以简单地前往其官方下载页面,为自己抓取最新的稳定 ISO。你会发现官方支持的桌面环境的 ISO,即 Cinnamon、MATE 和 Xfce。
此外,还为那些网络连接缓慢或不稳定的用户提供了 Torrent链接。
* [下载 Linux Mint 20](https://linuxmint.com/download.php)
如果你只是想在不更换主系统的情况下试一试,我建议先[在 VirtualBox 中安装 Linux Mint 20](https://itsfoss.com/install-linux-mint-in-virtualbox/),看看这是不是你喜欢的东西。
你试过 Linux Mint 20 了吗?你对这个版本有什么看法?请在下面的评论区告诉我你的想法。
---
via: <https://itsfoss.com/linux-mint-20-download/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux Mint 20 “Ulyana” is finally released and available to download.
Linux Mint 19 was based on Ubuntu 18.04 LTS and [Mint 20](https://itsfoss.com/linux-mint-20/) is based on [Ubuntu 20.04 LTS](https://itsfoss.com/download-ubuntu-20-04/) — so you will find a lot of things different, improved, and potentially better.
Now that it’s here, let’s take a look at its new features, where to download it, and how to upgrade your system.
## Linux Mint 20: What’s New?
We have made a video about the initial visual impressions on Linux Mint 20 to give you a better idea:
There’s a lot of things to talk about when it comes to Linux Mint 20 release. While we have already covered the new key [features in Linux Mint 20](https://itsfoss.com/linux-mint-20/), I’ll mention a few points here for a quick glance:
- Performance improvements in Nemo file manager for thumbnail generation
- Some re-worked color themes
- Linux Mint 20 will forbid APT from using Snapd
- A new GUI tool to share files using the local network
- Improved multi-monitor support
- Improved hybrid graphics support for laptops
- No 32-bit releases anymore
In addition to all these changes, you will also notice some visual changes with Cinnamon 4.6 desktop update.
Here are some screenshots of Linux Mint 20 Cinnamon edition. Click on the images to see in full screen.
Mint 20 Welcome Screen Mint 20 Color Themes Mint 20 Nemo File Manager Mint 20 Nemo File Manager Blue Color Theme Mint 20 Wallpapers Mint 20 Redesigned Gdebi Installer Mint 20 Warpinator Tool for Sharing Files on Local Network Mint 20 Terminal
## Upgrading to Linux Mint 20: What you need to know
If you are already using Linux Mint, you will have the option to upgrade to Linux Mint 20 in the first week of July.
- If you are using Linux Mint 20 beta version, you can upgrade to Mint 20 stable version.
- If you’re using Linux Mint 19.3 (which is the latest iteration of Mint 19), you can upgrade your system to Linux Mint 20 without needing to perform a clean installation.
- There is no 32-bit version of Linux Mint 20. If you are
**using 32-bit Mint 19 series, you won’t be able to upgrade to Mint 20**. - If you are using Linux Mint 18 series, you’ll have to upgrade through Mint 19 series first. A
[fresh install of Mint 20](https://itsfoss.com/install-linux-mint/)would be less time-consuming and troublesome in my opinion. - If you are using Linux Mint 17, 16, 15 or lower, you must not use them anymore. These versions are not supported anymore.
It’s FOSS has a detailed guide showing the steps to [upgrade Linux Mint version](https://itsfoss.com/upgrade-linux-mint-version/) from 19.3 to 20.
Before you go on upgrading make sure to backup your data and [create system snapshots using Timeshift](https://itsfoss.com/backup-restore-linux-timeshift/).
## Download Linux Mint 20
You can simply head on to its official download page and grab the latest stable ISO for yourself. You’ll find the ISO for the officially supported desktop environments, i.e. Cinnamon, MATE and Xfce.
Torrent links are also available for those who have slow or inconsistent internet connection.
If you just want to try it out without replacing your main system, I suggest [installing Linux Mint 20 in VirtualBox](https://itsfoss.com/install-linux-mint-in-virtualbox/) first and see if this is something you would like.
Have you tried Linux Mint 20 yet? What do you think about the release? Let me know your thoughts in the comments section below. |
12,379 | 学习 Shell 脚本编程的免费资源 | https://itsfoss.com/shell-scripting-resources/ | 2020-07-04T09:30:00 | [
"shell"
] | https://linux.cn/article-12379-1.html |
>
> 你想学习 shell 脚本编程吗?或者你想提升现有的 bash 知识?我收集了以下免费的资源来帮助你学习 shell 脚本编程。
>
>
>
(LCTT 译注:毫无疑问,这些都是英文的)
shell 是一个命令行解释器,它允许你输入命令并获得输出。当你在使用终端的时候,你就已经在看 shell 了。
是的,shell 是一个你可以和它进行交互的命令行界面,你可以通过它给操作系统某种指令。虽然有不同类型的 shell,但是 [bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell))(GNU Bourne-Again Shell)是在各 Linux 发行版中最流行的。
当谈到 shell 脚本编程的时候,也就意味着 —— 用户希望使用脚本来执行多条命令来获得一个输出。
也许你需要学习 shell 脚本编程作为你的课程或者工作的一部分。了解 shell 脚本编程也可以帮助你在 Linux 中自动化某些重复的任务。
不管出于什么原因学习 shell 脚本编程,都可以看看这些我给你展示的资源。
### 最好的免费学习 shell 脚本编程的资源

还没在你的系统上安装 Linux?不用担心。有很多种方法[在 Windows 上使用 Linux 终端](https://itsfoss.com/run-linux-commands-in-windows/)。你也可以在某些情况下[使用在线 Linux 终端](https://itsfoss.com/online-linux-terminals/)来练习 shell 脚本编程。
#### 1、学习 Shell —— 互动网站

如果你正在找一个互动网站来学习 shell 脚本编程,并且还可以在线试试,“[学习 Shell](https://www.learnshell.org/)” 是一个不错的起点。
它涵盖了基础知识,并且也提供了一些高级的练习。通常,内容还是简明扼要的 —— 因此,我建议你看看这个网站。
#### 2、Shell 脚本编程教程 —— 门户网站

“[Shell 脚本编程教程](https://www.shellscript.sh/)” 是一个完全专注于 shell 脚本编程的网站。你可以选择免费阅读其中的资源,也可以购买 PDF、实体书籍和电子书来支持他们。
当然,花钱买纸质的版本或者电子书不是强制的。但是,这些免费资源查看起来还是很方便的。
#### 3、Udemy:Shell 脚本 —— 免费视频课程

毫无疑问,[Udemy](https://www.udemy.com) 是最受欢迎的在线课程平台之一。而且,除了付费认证课程之外,它还提供了不包含证书的免费内容。
“[Shell 脚本](https://www.udemy.com/course/shell-scripting-i/)” 是 Udemy 上推荐度最高的免费课程之一。你不需要花费任何费用就可以注册这门课。
#### 4、Udemy:Bash Shell 脚本编程 —— 免费视频课程

Udemy 上另一个专注于 [bash shell 脚本编程](https://www.udemy.com/course/complete-bash-shell-scripting/)的有趣且免费的课程。与前面提到的课程相比,这个资源似乎更受欢迎。所以,你可以注册这门课,看看它都教些什么。
别忘了 Udemy 的免费课程不能提供证书。但是,它确实是一个让人印象深刻的免费 shell 脚本编程学习资源。
#### 5、Bash 研究院 —— 互动游戏在线门户

顾名思义,“[Bash 研究院](https://guide.bash.academy/)” 专注于向用户提供 bash shell 的教学。
尽管它没有很多的内容,它还是非常适合初学者和有一定经验的用户。不仅仅局限于指导 —— 它也可以提供交互式的游戏来练习,不过目前已经不能用了。
因此,如果这个足够有趣,你可以去看看这个 [Github 页面](https://github.com/lhunath/guide.bash.academy),并且如果你愿意的话,还可以复刻它并对现有资源进行改进。
#### 6、LinkedIn:学习 Bash 脚本编程 —— 免费视频课程

LinkedIn 提供了大量免费课程来帮助你提成技能,并且为更多工作做好准备。你还可以找到一些专注于 shell 脚本编程的课程,这些课程有助于重温基本技能或者这个过程中获得一些高级技能。
在这里,我提供一个 [学习 Bash 脚本编程](https://www.linkedin.com/learning/learning-bash-scripting) 的课程链接,你还可以发现其他类似的免费课程。
#### 7、高级 Bash 脚本编程指南 —— 免费 PDF 书籍

这是一个令人印象深刻的《[高级 Bash 脚本编程指南](http://tldp.org/LDP/abs/abs-guide.pdf)》,并且可以免费获得到它的 PDF 版本。这个 PDF 资源没有版权限制,在公开领域是完全免费的。
尽管这个资源主要是提供高级的知识,通过参考这个 PDF 并且开始学习 shell 脚本编程,它还是很适合初学者的。
#### 8、专业 Bash 笔记 —— 免费 PDF 书籍

如果你已经对 Bash Shell 脚本编程比较熟悉或者只是想快速总结一下,那这是一个很好的参考。
这个《[专业 Bash 笔记](https://goalkicker.com/BashBook/)》可以免费下载的书有 100 多页,通过简单的描述和例子,这本书涵盖了各种各样的主题。
#### 9、Tutorialspoint —— 门户网站

“[Tutorialspoint](https://www.tutorialspoint.com/unix/shell_scripting.htm)” 是一个非常流行的学习各种编程语言的门户网站。我想说这对于初学者学习基础知识非常好。
也许这不太适合作为一个详细的资源——但是它应该是不错的免费资源。
#### 10、旧金山城市学院:在线笔记 —— 门户网站

也许这不是最好的免费资源 —— 但是如果你已经为学习 shell 脚本编程做好了探索每种资源的准备,为什么不看看旧金山城市学院的 “[在线笔记](https://fog.ccsf.edu/~gboyd/cs160b/online/index.html)” 呢?
当我在网上随便搜索关于 shell 脚本编程的资源的时候,我偶然遇到到了这个资源。
同样需要注意的是,这个在线笔记可能会有点过时。但是,这应该还是一个值得探索的有趣资源。
#### 荣誉奖: Linux 手册

不要忘记,bash 手册也应该是一个相当不错的免费资源,可以用它来查看命令和使用方法。
尽管它不是专门为你掌握 shell 脚本编程而量身打造的,它依然是一个你可以免费使用的重要网络资源。你可以选择访问在线手册,或者直接打开终端然后输入以下命令:
```
man bash
```
### 总结
有很多很受欢迎的付费资源,比如这些[最好的 Linux 书籍](https://itsfoss.com/best-linux-books/)。从网络上的一些免费资源开始学习 shell 脚本编程还是很方便的。
除了我提到的这些,我敢肯定网上还有不计其数的资源可以帮助你学习 shell 脚本编程。
你喜欢换上面提到的资源吗?如果你知道我可能错过的非常棒的免费资源,记得在下面评论区告诉我。
---
via: <https://itsfoss.com/shell-scripting-resources/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

A shell is a command-line interpreter that lets you type in commands to get an output. You’re already looking at a shell when you’re using the terminal.
Yes, a shell is a command-line interface that you can interact with to give some type of instructions to the operating system. While there are different types of shells, [ bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)?ref=itsfoss.com) (GNU Bourne-Again Shell) is the popular one used by almost every Linux distro out there.
When talk about shell scripting, that means — a user wants to execute multiple commands to get an output using a script.
You may need to learn shell scripting as part of your course curriculum or as part of your job. Knowing shell scripting also helps you automate certain repeated tasks in Linux.
Whatever be the reason for learning shell scripting, let me show you the resources.
## Top Free Resources to Learn Shell Scripting

Don’t have Linux installed on your system? No, worries. There are various [ways of using Linux terminal on Windows](https://itsfoss.com/run-linux-commands-in-windows/). You may also [use online Linux terminals](https://itsfoss.com/online-linux-terminals/) in some cases to practice shell scripting.
### 1. Learn Shell [Interactive web portal]
If you’re looking for an interactive web portal to learn shell scripting and also try it online, Learn Shell is a great place to start.
It covers the basics and offers some advanced exercises as well. The content is usually brief and to the point – hence, I’d recommend you to check this out.
### 2. Bash Beginner Series from Linux Handbook [Web Portal]
An online tutorial series for bash beginners. The series is divided into chapters and each chapter has practice exercises.
[Bash Scripting Tutorial Series for Beginners [Free]Get started with Bash Shell script learning with practical examples. Also test your learning with practice exercises.](https://linuxhandbook.com/bash/)

### 3. Shell Scripting Tutorial [Web portal]

Shell scripting tutorial is web resource that’s completely dedicated for shell scripting. You can choose to read the resource for free or can opt to purchase the PDF, book, or the e-book to support it.
Of course, paying for the paperback edition or the e-book is optional. But, the resource should come in handy for free.
### 4. Shell Scripting – Udemy (Free video course)
[Udemy](https://www.udemy.com/?ref=itsfoss.com) is unquestionably one of the most popular platforms for online courses. And, in addition to the paid certified courses, it also offers some free stuff that does not include certifications.
Shell Scripting is one of the most recommended free course available on Udemy for free. You can enroll in it without spending anything.
### 5. Bash Shell Scripting – Udemy (Free video course)
Yet another interesting free course focused on bash shell scripting on Udemy. Compared to the previous one, this resource seems to be more popular. So, you can enroll in it and see what it has to offer.
Not to forget that the free Udemy course does not offer any certifications. But, it’s indeed an impressive free shell scripting learning resource.
### 6. Bash Academy [online portal with interactive game]

As the name suggests, the bash academy is completely focused on educating the users about bash shell.
It’s suitable for both beginners and experienced users even though it does not offer a lot of content. Not just limited to the guide — but it also used to offer an interactive game to practice which no longer works.
Hence, if this is interesting enough, you can also check out its [GitHub page](https://github.com/lhunath/guide.bash.academy?ref=itsfoss.com) and fork it to improve the existing resources if you want.
### 7. Bash Scripting LinkedIn Learning (Free video course)
LinkedIn offers a number of free courses to help you improve your skills and get ready for more job opportunities. You will also find a couple of courses focused on shell scripting to brush up some basic skills or gain some advanced knowledge in the process.
Here, I’ve linked a course for bash scripting, you can find some other similar courses for free as well.
[Bash Scripting (LinkedIn Learning)](https://www.linkedin.com/learning/learning-bash-scripting?ref=itsfoss.com)
### 8. Advanced Bash Scripting Guide [Free PDF book]

An impressive advanced bash scripting guide available in the form of PDF for free. This PDF resource does not enforce any copyrights and is completely free in the public domain.
Even though the resource is focused on providing advanced insights. It’s also suitable for beginners to refer this resource and start to learn shell scripting.
[Advanced Bash Scripting Guide [PDF]](http://tldp.org/LDP/abs/abs-guide.pdf?ref=itsfoss.com)
### 9. Bash Notes for Professionals [Free PDF book]

This is good reference guide if you are already familiar with Bash Shell scripting or if you just want a quick summary.
This free downloadable book runs over 100 pages and covers a wide variety of scripting topics with the help of brief description and quick examples.
[Download Bash Notes for Professional](https://goalkicker.com/BashBook/?ref=itsfoss.com)
### 10. Tutorialspoint [Web portal]

Tutorialspoint is a quite popular web portal to learn a variety of [programming languages](https://en.wikipedia.org/wiki/Programming_language?ref=itsfoss.com). I would say this is quite good for starters to learn the fundamentals and the basics.
This may not be suitable as a detailed resource — but it should be a useful one for free.
### 11. City College of San Francisco Online Notes [Web portal]

This may not be the best free resource there is — but if you’re ready to explore every type of resource to learn shell scripting, why not refer to the online notes of City College of San Francisco?
I came across this with a random search on the Internet about shell scripting resources.
Again, it’s important to note that the online notes could be a bit dated. But, it should be an interesting resource to explore.
[City College of San Francisco Notes](https://fog.ccsf.edu/~gboyd/cs160b/online/index.html?ref=itsfoss.com)
### Honorable mention: Linux Man Page
Not to forget, the man page for bash should also be a fantastic free resource to explore more about the commands and how it works.
Even if it’s not tailored as something that lets you master shell scripting, it is still an important web resource that you can use for free. You can either choose to visit the man page online or just head to the terminal and type the following command to get help:
`man bash`
### Wrapping Up
There are also a lot of popular paid resources just like some of the [best Linux books](https://itsfoss.com/best-linux-books/) available out there. It’s easy to start learning about shell scripting using some free resources available across the web.
In addition to the ones I’ve mentioned, I’m sure there must be numerous other resources available online to help you learn shell scripting.
Do you like the resources mentioned above? Also, if you’re aware of a fantastic free resource that I possibly missed, feel free to tell me about it in the comments below. |
12,381 | 这些技巧让 Bash 命令历史更加有用 | https://opensource.com/article/20/6/bash-history-control | 2020-07-05T09:12:00 | [
"历史",
"Bash"
] | /article-12381-1.html |
>
> 告诉 Bash 你想要它记住什么,甚至删除不需要的记录重写历史。
>
>
>

运行 [Bash](https://opensource.com/resources/what-bash) 的 Linux 终端有内置的历史记录,你可以用来跟踪最近的操作。要查看你的 Bash 会话的历史记录,请使用内置命令 `history`:
```
$ echo "foo"
foo
$ echo "bar"
bar
$ history
1 echo "foo"
2 echo "bar"
3 history
```
与大多数命令不一样,`history` 命令不是文件系统上的可执行文件,而是 Bash 的功能。你可以使用 `type` 命令来验证:
```
$ type history
history is a shell builtin
```
### 历史控制
shell 历史记录的行数上限由 `HISTSIZE` 变量定义。你可以在 `.bashrc` 文件中设置此变量。以下将你的历史记录设置为 3,000 行,之后将最早的行删除以为最新命令腾出空间,该命令位于列表的底部:
```
export HISTSIZE=3000
```
还有其他与历史相关的变量。 `HISTCONTROL` 变量控制哪些历史被记录。你可以在 `.bashrc` 中写入下面的行来强制 Bash 排除以空格开头的命令:
```
export HISTCONTROL=$HISTCONTROL:ignorespace
```
现在,如果你输入以空格开头的命令,那么它将不会记录在历史记录中:
```
$ echo "hello"
$ mysql -u bogus -h badpassword123 mydatabase
$ echo "world"
$ history
1 echo "hello"
2 echo "world"
3 history
```
你也可以避免重复的条目:
```
export HISTCONTROL=$HISTCONTROL:ignoredups
```
现在,如果你一个接着一个输入两个命令,历史记录中只会显示一个:
```
$ ls
$ ls
$ ls
$ history
1 ls
2 history
```
如果你喜欢这两个忽略功能,那么可以使用 `ignoreboth`:
```
export HISTCONTROL=$HISTCONTROL:ignoreboth
```
### 从历史记录中删除命令
有时你会犯一个错误,在 shell 中输入了一些敏感内容,或者你只是想清理历史记录,以便它更准确地表示让某件事正常工作所采取的步骤。如果要从 Bash 的历史记录中删除命令,请在要删除的项目的行号上使用 `-d` 选项:
```
$ echo "foo"
foo
$ echo "bar"
bar
$ history | tail
535 echo "foo"
536 echo "bar"
537 history | tail
$ history -d 536
$ history | tail
535 echo "foo"
536 history | tail
537 history -d 536
538 history | tail
```
要停止添加 `history` 条目,只要在 `HISTCONTROL` 环境变量中有 `ignorespace`,就可以在命令前添加空格:
```
$ history | tail
535 echo "foo"
536 echo "bar"
$ history -d 536
$ history | tail
535 echo "foo"
```
你可以使用 `-c` 选项清除所有会话历史记录:
```
$ history -c
$ history
$
```
### history 命令的经验教训
操纵历史通常没有听起来那么危险,尤其是当你有目标地管理它时。例如,如果你要记录一个复杂的问题,通常最好使用会话历史来记录命令,因为通过将命令插入历史记录,你能运行它们并从而测试过程。很多时候,不执行历史命令会导致忽略小的步骤或写错小细节。
按需使用历史会话,并明智地控制历史记录。享受历史修改吧!
---
via: <https://opensource.com/article/20/6/bash-history-control>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,382 | VS Code 的 7 个开源替代品 | https://opensource.com/article/20/6/open-source-alternatives-vs-code | 2020-07-05T11:24:14 | [
"VSCode",
"IDE",
"编辑器"
] | https://linux.cn/article-12382-1.html |
>
> 为了避免使用微软版本的 VS Code,我们需要另行选择一个开源的代码编辑器。
>
>
>

Visual Studio Code,也叫 VS Code,是一个跨平台代码编辑器,通用于 Linux、Windows 以及 macOS。它既能编辑简单文本,也能像集成开发环境(IDE)一样管理整个代码库。它可以通过插件进行扩展,并且已经被证明是一个可靠的文本编辑器,很轻松地就击败了非开源的强大竞品编辑器。
微软以开源的方式发布了 VS Code,但是你从微软下载的版本其实并不是开源的。然而,你仍有办法以开源的方式使用 VS Code,或者直接选择其它的开源替代品。
### 以开源的方式构建 VS Code
你可以在 [GitHub](https://github.com/microsoft/vscode) 获得 VS Code 的源代码。然而当你 [从微软](https://code.visualstudio.com/) 下载 VS Code 时,你会发现它是基于 [微软软件许可证](https://code.visualstudio.com/license) 授权的。这并不是一个开源许可证。其区别在于构建过程。
Chris Dias 是微软 VS Code 项目开发者之一,他对 VS Code [作了一个对比](https://github.com/Microsoft/vscode/issues/60#issuecomment-161792005),就像 Chrome 浏览器和其开源的“上游”项目 [Chromium](https://www.chromium.org/) 一样。VS Code 确实是基于开源代码库构建的。微软官方发布的版本带有一些与微软相关的功能,包括一项商标、一个插件库、一个 C# 调试器以及遥测。但如果你克隆仓库然后自行编译,这些东西都不会被加入,所以你会得到一个名为 Code - OSS 的“干净”版本(OSS 代表开源软件)。
实际上,VS Code 与 Code - OSS 之间的差异很小。最值得注意的是,VS Code 包含遥测功能,它会记录使用数据。微软不可能监控你的一举一动,而且目前越来越多软件都在收集使用数据。是否在乎 VS Code 的遥测功能,完全取决于你自己。如果你不希望它追踪你的使用情况,这里有一些很棒的 VS Code(开源)替代品。
### VSCodium

最简单的替代方案就是构建不带微软附属功能的 VS Code 版本。[VSCodium](https://vscodium.com/) 项目提供了可下载的 Code-OSS 可执行文件,它基于 VS Code 代码库编译,没有配置微软的 `product.json` 中的改变。VSCodium 的开发者还竭尽全力禁用了所有难以寻找的遥测选项,除非你自行编译,否则这已经是你能找到的最干净的 VS Code 版本了。
VSCodium 提醒说,VS Code 悄悄地包含了一些专有工具,这些工具无法与开源版本一起提供。这包括一个 C# 调试器和部分插件。如果你需要它们,可以在 [文档中] 找到解决办法。假如你依赖 VS Code 中某些特定的功能,你应该验证它在 VSCodium 中是否可以发挥功用。
此外,你还应该验证是否已禁用所有的遥测功能。
### Code - OSS
如果不想用 VSCodium 的版本,你可以自己 [从头编译 VS Code](https://github.com/Microsoft/vscode/wiki/How-to-Contribute#build-and-run),得到一样的版本。可执行文件叫做 `Code - OSS`,而不是 `VSCode`,适用于 VSCodium 的许可证限制也适用于你的构建,而工作方式也是一样。
如果通过编译源码构建应用,首次启动时你要确保 [所有遥测都已经被禁用]。
### Atom

[Atom](http://atom.io) 是一个类似于 IDE 的文本编辑器,当微软收购 Github 的同时也收购了它。和 VS Code 一样,你可以使用插件,扩展 Atom 编辑器,此外,你还能通过自己的工具和主题实现定制。它开源且与 Github 集成。简而言之,只要你能找到你想用的插件,或者你愿意自己动手写,那么 Atom 几乎可以满足你的一切需求。
跟 VS Code 一样,Atom 也 [默认包含遥测](https://discuss.atom.io/t/how-do-i-disable-the-metrics-or-tracking/24520)。你可以禁用这个功能,而且跟 VS Code 不同的是,使用插件不受任何限制,所以不必再因为隐私改变你的工作流。对写代码的人来说,毫无疑问 Atom 是很有用的工具,而对于 [使用电脑的任何人](https://opensource.com/article/19/4/write-git),它同样会是一个很赞的编辑器。如果你需要一个顺手的通用文本编辑器,请试试 Atom。
### GNOME Builder

为 GNOME 桌面而开发的 IDE,[GNOME Builder](https://wiki.gnome.org/Apps/Builder) 是一个 Linux 平台的代码编辑器,专门用于构建 GNOME 应用。如果你为 Linux 构建应用程序,希望轻松解决兼容性问题,那么 Builder 就是最简单的选择。从 [Flathub.org](https://flathub.org/apps/details/org.gnome.Builder) 安装 Builder;当你开启一个新项目,如果没有安装 GNOME SDK,它会提醒你。这意味着当维护你的应用时,你不必刻意关注 GNOME 的状态,因为 Builder 在替你做这件事。
然而,Builder 不仅能构建 GNOME 程序。它还支持各种各样的编程语言,包括 Python、Rust、C/C++、Java、Go、JavaScript、TypeScript、[VB.NET](http://VB.NET)、Markdown 和几种标记语言等等。它对部分语言有全面的支持,包括自动补全以及弹出式函数定义,但是其它语言仅仅含有一些比较方便的功能,例如语法高亮跟自动匹配括号。不管你是不是一个专门的程序员,或者你只想要一个给力的 HTML 和 CSS 编辑器,这个 IDE 都能让你舒心使用。
### Geany

[Geany](https://www.geany.org/) 是一个强大、稳定而轻量级的编辑器,它有很多有用的特性,能帮你写 Bash、Python、Lua、XML、HTML、LaTex,当然远不止这些。对 50 种各种编程及脚本语言、标记语言和各种文件类型(比如 .diff 和 .po),Geany 都有很好的支持。退一万步讲,Geany 还有括号匹配和语法高亮 —— 通常来说,它包含更多功能。
Geany 是一个小型编辑器,但是通过插件,你可以为它添加特性,例如项目视图面板、文件系统树、调试、终端等,直到它看起来像一个 IDE。当然,萝卜白菜各有所爱,你也可以尽量使它保持简洁易用。如果因为电脑 CPU 或者内存的限制而无法使用 VS Code,那么很明显 Geany 可以作为你的选择。它只占用少量内存,而且启动迅速。即便跟运行在终端里的 Vim 相比,Geany 稍显笨重,但就算在树莓派,它也能做到快速、灵活。
### Brackets

[Brackets](http://brackets.io/) 是一款面向网页开发者的文本编辑器和 IDE。对于 HTML、CSS、JavaScript、PHP 甚至 Python,它都有很强大的支持。而且跟 VS Code 一样,它也有一个很丰富的插件生态,所以你可以最大限度地扩展它,以适应你所有编程语言的工作。
有的插件用于辅助解析语言、运行脚本,甚至编译执行代码。Brackets 有一个传统的界面,不管你是否熟悉 IDE 或者像记事本一样简单的文本编辑器,都能驾轻就熟。如果稍微花点时间,添加几个相关插件,然后熟悉它们,你会发现 Brackets 真的是一个很精妙、很有用的编辑器,不管你输入什么,它都能通过自动补全、提示帮你避免低级错误。假如你是程序员,它能帮你加快测验和调试周期。
### Che

如果你喜欢新技术,那你应当尝试 [Che](https://www.eclipse.org/che/extend/) 编辑器。这是一个基于云的 IDE,所以它默认以软件即服务(SaaS)的形式运行,但它是完全开源的,如果你有 Kubernetes 实例,那就可以运行为*你自己的* SaaS。
Che 不仅是一个在线 IDE,而且是一个为云开发而构建的 IDE。在 Che 的概念里,用户无需查看本地文件系统。由于它在云端工作,所以你也可以这么做。事实上,如果你有一台 Git 服务器,那就可以直接把它当作你的文件系统,在它的仓库中完成你的项目。当然,你也可以下载所有文件做本地备份。
但 Che 的主要特点,也是云开发者最为兴奋的一点,它是一个功能全面、带有 Kubernetes 感知功能的开源 IDE。如果你正在为云构建应用、网站或容器(或三者的组合),那么 Che 是一个你需要尝试的编辑器。
### 那么你的选择是?
你有没有在使用这些 VS Code 替代品中的某一个呢?想不想挑一个试试呢?欢迎在评论中分享你的见解。
---
via: <https://opensource.com/article/20/6/open-source-alternatives-vs-code>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[nophDog](https://github.com/nophDog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Visual Studio Code, also known as VS Code, is a code editor for Linux, Windows, and macOS. It's the kind of editor that walks the line between editing text and managing your entire codebase, like an integrated development environment (IDE). It's extensible through plugins and has proven to be a reliable text editor that's easily beaten out formidable non-open rival editors.
Microsoft released VS Code as open source, but the version you download from Microsoft is not open source. However, you have several options for using VS Code as open source or selecting one of its open source alternatives.
## Building VS Code as open source
VS Code's source code is available [on GitHub](https://github.com/microsoft/vscode). Yet when you download the VS Code application [from Microsoft](https://code.visualstudio.com/), you'll find that your download is licensed under the [Microsoft Software License](https://code.visualstudio.com/license). This isn't an open source license. The difference is in the build process.
Chris Dias, a Microsoft developer on the VS Code project, [makes a comparison](https://github.com/Microsoft/vscode/issues/60#issuecomment-161792005) between VS Code and, for instance, the Chrome browser and its open source "upstream" project, [Chromium](https://www.chromium.org/). VS Code is indeed built upon an open source codebase. The official Microsoft-branded release is customized with Microsoft-specific functionality, including a trademark, an extensions gallery, a proprietary C# debugger, and telemetry. But when you clone and build the code yourself, none of these targets is configured, so you generate a "clean" version, which is called Code - OSS (OSS stands for open source software).
In practice, the differences between VS Code and Code - OSS are minimal. Most notably, VS Code includes telemetry, which is tracking software. It's unlikely that Microsoft is literally tracking your every move, and there's lots of software out there these days that gathers usage data. Whether or not you care about VS Code's telemetry is up to you. If you'd rather do without the usage tracking, here are some great (and open source) alternatives to VS Code.
## VSCodium
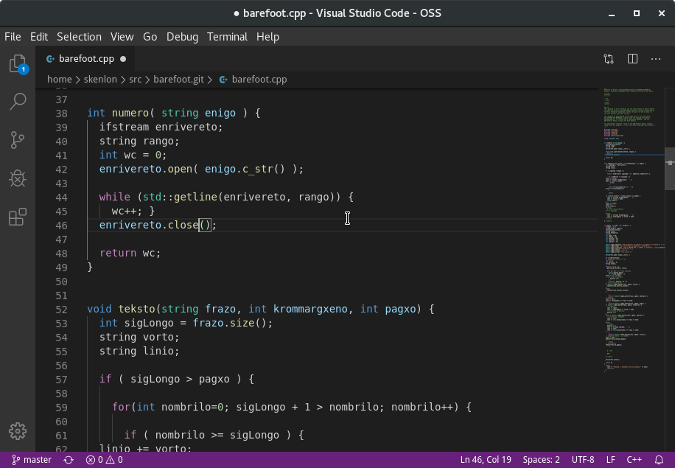
(Seth Kenlon, CC BY-SA 4.0)
The easiest alternative to VS Code is VS Code itself, built without Microsoft's proprietary additions. The [VSCodium](https://vscodium.com/) project provides downloadable executables of Code - OSS, built from the VS Code codebase without Microsoft's `product.json`
changes. The VSCodium developers also go to great length to deactivate all hard-to-find telemetry options, delivering the cleanest build of VS Code's source you can find without building it yourself.
VSCodium cautions that VS Code quietly includes some proprietary tools that cannot be shipped with an open source build. This includes a C# debugger and some gallery extensions. If you need them, there are [documented workarounds](https://github.com/VSCodium/vscodium/blob/master/DOCS.md) for these issues, but if you rely on something very specific in VS Code, you should verify that it functions in VSCodium.
You should also verify that all [telemetry is deactivated](https://code.visualstudio.com/docs/supporting/faq#_how-to-disable-telemetry-reporting).
## Code - OSS
If you don't want to use VSCodium's build, you can [compile VS Code from source](https://github.com/Microsoft/vscode/wiki/How-to-Contribute#build-and-run) yourself and end up with the same thing. The executable is called `Code - OSS`
rather than `VSCode`
, and the license restrictions that apply to VSCodium also apply to your build, but so do the workarounds.
If you build the application from source, you should verify that all [telemetry is deactivated](https://code.visualstudio.com/docs/supporting/faq#_how-to-disable-telemetry-reporting) when you first launch it.
## Atom
(Seth Kenlon, CC BY-SA 4.0)
[Atom](http://atom.io) is an open source IDE-like text editor that Microsoft acquired when it purchased GitHub. Like VS Code, you can extend the Atom editor with plugins and customize it with themes and your unique combination of tools. It is also cross-platform and has built-in GitHub integration. In short, Atom is potentially whatever you need it to be, so long as the extensions you need already exist or you're willing to write them.
Also like VS Code, Atom includes [metrics tracking by default](https://discuss.atom.io/t/how-do-i-disable-the-metrics-or-tracking/24520). This can be disabled, and unlike VS Code, there are no arbitrary restrictions on extensions, so you don't have to change up your workflow in exchange for your privacy. Atom is certainly a useful tool for coders, but it's also a pretty great editor for [anyone who uses a computer](https://opensource.com/article/19/4/write-git). If you're looking for a good general-purpose text editor, give Atom a try.
## GNOME Builder
(Seth Kenlon, CC BY-SA 4.0)
Developed as an IDE for the GNOME desktop, [GNOME Builder](https://wiki.gnome.org/Apps/Builder) is a code editor for Linux, specifically for building GNOME applications. If you're building applications for Linux and want an easy avenue to compatibility, Builder is the easy choice. Install Builder from [Flathub.org](https://flathub.org/apps/details/org.gnome.Builder); when you start a project, it'll even prompt you to install the GNOME SDK if you're missing it. This means you don't have to consciously track GNOME as you maintain your application because Builder does it for you.
However, you can use Builder for much more than just GNOME applications. It supports dozens of programming languages, including Python, Rust, C and C++, Java, Go, JavaScript, TypeScript, VB.NET, several markup and Markdown languages, and more. Some of these have full support with autocompletion and pop-up function definitions, while others only have simple conveniences such as syntax highlighting and auto-bracket matching. The IDE is a pleasure to work with, though, whether you consider yourself a serious programmer or you're just in need of a good HTML and CSS editor.
## Geany
(Seth Kenlon, CC BY-SA 4.0)
[Geany](https://www.geany.org/) is a powerful, stable, and lightweight editor with useful features to help you write good Bash, Python, Lua, XML, HTML, LaTeX, and more. There's plenty of support for 50 different programming and scripting languages, markup languages, and miscellaneous filetypes (such as .diff and .po). At the very least, Geany almost certainly provides bracket matching and syntax highlighting—and it usually offers quite a lot more.
Geany is a modest little editor, but through plugins, you can add features such as a panel for a project view, filesystem tree, debugging, a terminal, and so on until it looks and acts like an IDE. Or, if you prefer, you can keep it simple and understated. If you can't run VS Code on a computer due to limitations in CPU or RAM, Geany is the obvious alternative. It's quick to launch, and its memory footprint is negligible. While Geany is a little heftier than running Vim in a terminal, it's fast and snappy even on a Raspberry Pi.
## Brackets
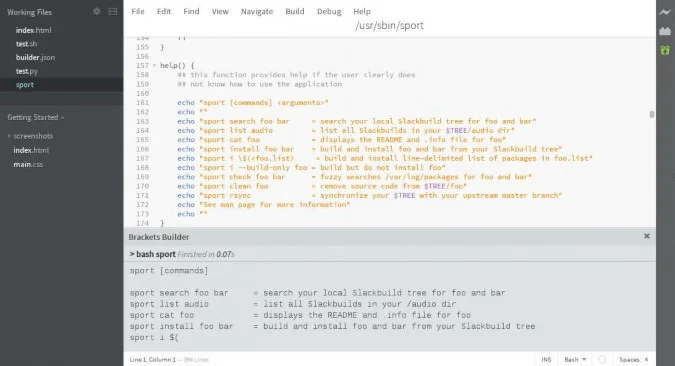
(Seth Kenlon, CC BY-SA 4.0)
[Brackets](http://brackets.io/) is a text editor and IDE aimed at web developers. It has strong support for HTML, CSS, JavaScript, PHP, and even Python. However, like VS Code, it has a rich ecosystem of extensions, so you can expand it to serve as your workbench for whatever language you work in the most.
There are extensions to help parse languages, to run scripts, and even to compile and execute code. Brackets has a traditional interface anyone can understand, whether or not you're familiar with an IDE or even a text editor beyond a simple notepad. If you spend a little time adding relevant extensions and getting to know them, you'll find Brackets a useful and subtle editor that helps you, through autocompletion and linting, avoid silly mistakes in whatever you're typing. And if you're writing code, it'll probably make your testing and debugging workflow faster.
## Che
(Seth Kenlon, CC BY-SA 4.0)
If you enjoy living on the cutting edge, [Che](https://www.eclipse.org/che/extend/) is an editor you need to try. It's a cloud-based IDE, so it runs by default as a Software as a Service (SaaS), but it's entirely open source, so it can be run as *your own* SaaS, provided you have a Kubernetes instance.
More than just being an online IDE, though, Che is an IDE built for cloud development. It makes no assumptions that you expect or want a view of your local filesystem. It lives and works in the cloud, so you can too. In fact, if you have a Git server, you can treat it as your filesystem and work on a project directly from its repository. Of course, you can also download any work you do, if you like to have a local backup copy.
But its main feature, and the one cloud developers are excited about, is that Che is a full-featured, Kubernetes-aware, open source IDE. If you're building apps, sites, or containers (or a combination of the three) for the cloud, then Che is an editor you need to try.
## What's your choice?
Are you using one of these alternatives to VS Code? Is there one you would like to try? Please share your feedback in the comments.
## 33 Comments |
12,384 | 一个可放大图像的开源的浏览器扩展 | https://opensource.com/article/20/6/hoverzoom | 2020-07-06T00:17:02 | [
"浏览器",
"扩展"
] | https://linux.cn/article-12384-1.html |
>
> 想细看网络图像并不总是那么简单,但是 Hover Zoom+ 让它像鼠标滑动一样容易。
>
>
>

你是否曾经在访问网站时希望查看更大的图像?我经常遇到这种情况,而要做到这点并不总是那么容易。
有时,我在源码中筛选,使用 `Ctrl + F` 搜索图像,复制图像源地址并将其粘贴到新窗口中,以便以全尺寸查看图像。或者,另一个选择是右键单击,复制图像地址,然后粘贴到新选项卡中。

Hover Zoom+ 让这个过程更加简单。Hover Zoom+ 是一个简单 Chrome 扩展程序,在 MIT 许可证下发布,可在 Chrome 商店中找到,它的源码可在 [GitHub](https://github.com/extesy/hoverzoom/) 上获得。它也适用于 Firefox。
这个应用使得该过程更加容易。只需将鼠标悬停在图像上,你将看到一个弹出窗口来显示该图像的全部内容,它会匹配你的浏览器窗口,无论图像是否被裁剪(或者图像尺寸适当,它看上去会是一样的)。这可能很有趣,因为有时可能会裁剪原始图像,以适应空间或聚焦于图像的特定部分。但是,你无法右键单击并直接从弹出窗口中保存图像。
根据加州圣何塞的开发人员 Oleg Anashkin 的说法,“这是原始 HoverZoom 扩展的开源版本,现已被恶意软件所占领,并被从商店中删除。在此版本中,所有间谍软件均已删除,许多 bug 已被修复,并添加了新功能。它默认不会收集任何统计信息。”
我在 Windows 10 笔记本上的 Chrome 中安装了此扩展,然后试用了一下。安装扩展后,我将鼠标悬停在图像上,它在弹出窗口中显示了比实际更大的图像。
但是,Hover Zoom+ 不适用于所有网站或所有图像。它适用于 Facebook 和 Twitter,但不适用于这些网站上的赞助内容。用户可以轻松切换该应用以针对特定站点启用或禁用它。使用 Hover Zoom+ 可以很容易地看到 Instagram 上的这只可爱小猫而无需实际阅读帖子(方便!):

---
via: <https://opensource.com/article/20/6/hoverzoom>
作者:[Jeff Macharyas](https://opensource.com/users/jeffmacharyas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Have you ever visited a website and wanted to see the images displayed larger? That happens to me all the time, and it isn't always easy to make that happen.
On occasion, I sift through the source code, use **Ctrl + F** to search for the image, copy the image source address and paste it into a new window in order to see the image at its full-size glory. Or, the other option is to right-click, copy the image address, and paste into a new tab.

Hover Zoom+ makes this a much simpler process. Issued under the MIT license, Hover Zoom+ is a simple Chrome extension available at the Chrome Store, and the source code is available on [GitHub.](https://github.com/extesy/hoverzoom/) It is also available for Firefox.
This app makes that process much easier. By simply hovering over an image, you will see a pop-up show the image in its entirety, fit to your browser window, whether it is cropped or not (or if the image was placed, sized to fit, it will look the same). This can be interesting, as sometimes, the original image may have been cropped, either to fit the space or to focus on a specific part of the image. You cannot right-click and save the image directly from the pop-up, however.
According to San Jose, California-based developer Oleg Anashkin, "This is an open source version of the original HoverZoom extension, which is now overrun by malware and deleted from the store. In this version, all spyware has been removed, many bugs were fixed, and new features were added. It doesn't collect any statistics by default."
I installed the extension in Chrome on my Windows 10 laptop and took it for a spin. With the extension installed, I simply hovered over an image, and it displayed larger-than-life in a pop-up window.
However, Hover Zoom+ does not work on all websites or for all images. It works great for Facebook and Twitter, but not for sponsored content on those sites. The user can easily toggle the app to enable or disable it for specific sites. It was easy to see the entire Instagram screenshot of this cute kitten by using Hover Zoom+ without having to actually read the post (convenient!):
## Comments are closed. |
12,385 | 通过重定向在 Linux 终端任意读写数据 | https://opensource.com/article/20/6/redirection-bash | 2020-07-06T00:54:00 | [
"重定向"
] | https://linux.cn/article-12385-1.html |
>
> 重定向是一种十分高效的数据流动方式,它能帮你减少很多鼠标和键盘上的操作。
>
>
>

对于任何编程或脚本语言,输入与输出重定向都是很自然的功能。严格来说,当你使用电脑时,数据自然而然地在发生着重定向。从 `stdin`(标准输入,通常是你的键盘或者鼠标)读取输入,输入则发往 `stdout`(标准输出,一段文本或者数据流),最后错误信息送至 `stderr`。如果你使用 [Bash](https://opensource.com/resources/what-bash) 或 [Zsh](https://opensource.com/article/19/9/getting-started-zsh) 之类的 shell,那么理解这些数据流能够让你更好地控制信息流向。
标准输入、标准输出以及标准错误输出都存在于 Linux 文件系统中。你可以在 `/dev` 查看:
```
$ ls /dev/std*
/dev/stderr@ /dev/stdin@ /dev/stdout@
```
你可能没法直接使用它们,但将它们想象成你能传递数据的元位置,会很有帮助。
重定向的基础很简单:用一些 `>` 符号重定向输出,然后用另外一些 `<` 符号重定向输入。
### 重定向输出
将 [ls](https://opensource.com/article/19/7/master-ls-command) 命令的输出写入一个文件:
```
$ ls > list.txt
```
你没法像平常那样看到 `ls` 的输出,因为它们并没有被发送到屏幕,而是被写入 `list.txt` 文件了,这个功能用处太多了,事实上,你甚至可以用它来将文件内容拷贝到另一个文件。不一定是文本文件,你也可以用将重定向用于二进制数据:
```
$ cat image.png > picture.png
```
(你可能会好奇为什么要这样做,有时候对于 [文件权限信息](https://opensource.com/article/19/8/linux-permissions-101) 而间接有用。)
### 重定向输入
你也能将输入重定向“到”一个命令。可以说,它没有重定向输出那么有用,因为许多命令已经被硬编码,只从你的参数中接收输入。但是,如果某个命令需要一系列参数,而且你把这些参数写在文件里,想要快速“复制粘贴”到终端的时候(除非你并不想复制粘贴),它就帮得上忙了。
```
$ sudo dnf install $(<package.list)
```
重定向输入得常规用法是<ruby> 嵌入文档 <rt> here-document </rt></ruby>(简写成 here-doc)和<ruby> 嵌入字符串 <rt> here-string </rt></ruby> 技巧。这种输入方法将一整块文本重定向至标准输入流,直到碰见一个特殊的文件结束标记(许多人习惯用 `EOF`,实际上你可以使用任何字符串,只要它是唯一的)。试着把这些(在第二个 `EOF` 标记之前)敲进你的终端:
```
$ echo << EOF
> foo
> bar
> baz
> EOF
```
输出结果:
```
foo
bar
baz
```
使用 [Bash](https://opensource.com/resources/what-bash) 编写脚本的人常常用这个技巧,将数行文本一次性写入文件或者打印到屏幕上。只要你别忘了末尾的文件结束标记,这会是一个帮你避免大量繁琐 `echo` 或 `printf` 语句的好办法。
嵌入字符串类似于嵌入文档,但是它只含有一个字符串(或者用引号包裹的几个字符串,同样会被当成一个字符串)
```
$ cat <<< "foo bar baz"
foo bar baz
```
### 重定向错误信息
错误信息流叫做 `stderr`,通过 `2>` 实现这个目的。下面这个命令把错误信息定向到 `output.log` 文件:
```
$ ls /nope 2> output.log
```
### 将数据送往 /dev/null
既然标准输入、标准输出和错误输出都有自己的位置,那么“空空如也”也应该在 Linux 文件系统占有一席之地。没错,它叫做 `null`,位于 `/dev`,频繁使用的人懒得说 “slash dev slash null”,于是索性叫它 “devnull”。
通过重定向,你可以把数据发送到 `/dev/null`。比如,`find` 命令常常会输出很多具体信息,而且在搜索文件遇到权限冲突时,会事无巨细地报告:
```
$ find ~ -type f
/home/seth/actual.file
find: `/home/seth/foggy': Permission denied
find: `/home/seth/groggy': Permission denied
find: `/home/seth/soggy': Permission denied
/home/seth/zzz.file
```
`find` 命令把那些当作错误,所以你可以只把错误信息重定向至 `/dev/null`:
```
$ find ~ -type f 2> /dev/null
/home/seth/actual.file
/home/seth/zzz.file
```
### 使用重定向
在 Bash 中,重定向是转移数据的有效方法。你可能不会频繁使用重定向,但是学会如何使用它,能帮你在打开文件、复制粘贴数据这类需要移动鼠标、大量按键操作上,节省很多不必要的时间。不要做如此浪费时间的事情。使用重定向,好好享受生活。
---
via: <https://opensource.com/article/20/6/redirection-bash>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[nophDog](https://github.com/nophDog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Redirection of input and output is a natural function of any programming or scripting language. Technically, it happens inherently whenever you interact with a computer. Input gets read from `stdin`
(standard input, usually your keyboard or mouse), output goes to `stdout`
(standard output, a text or data stream), and errors get sent to `stderr`
. Understanding that these data streams exist enables you to control where information goes when you're using a shell, such as [Bash](https://opensource.com/resources/what-bash) or [Zsh](https://opensource.com/article/19/9/getting-started-zsh).
Standard in, standard out, and standard error exist as filesystem locations on Linux. You can see them in `/dev`
:
```
$ ls /dev/std*
/dev/stderr@ /dev/stdin@ /dev/stdout@
```
You can't do much with them directly, but it's sometimes useful to think of them as meta-locations where you can send data.
The basics of redirection are simple: use some number of `>`
characters to redirect output, and some number of `<`
characters to redirect input.
## Redirecting output
To write the output of the [ls](https://opensource.com/article/19/7/master-ls-command) command to a file:
`$ ls > list.txt`
You don't see the output of `ls`
as you normally would, because the output is written to the `list.txt`
file instead of your screen. This is so versatile, in fact, that you can even use it to copy the contents of one file to another. It doesn't have to be a text file, either. You can use redirection for binary data:
`$ cat image.png > picture.png`
(In case you're wondering why you'd ever want to do that, it's for a sometimes-useful repercussion on [file permissions](https://opensource.com/article/19/8/linux-permissions-101).)
## Redirecting input
You can redirect input "into" a command, too. This is arguably less useful than redirecting output because many commands are already hard-coded to take input from an argument you provide. It can be useful, however, when a command expects a list of arguments, and you have those arguments in a file and want to quickly "copy and paste" them from the file into your terminal (except you don't actually want to copy and paste):
`$ sudo dnf install $(<package.list)`
Common uses of input redirection are the **here-document** (or just **here-doc** for short) and **here-string** techniques. This input method redirects a block of text into the standard input stream, up to a special end-of-file marker (most people use `EOF`
, but it can be any string you expect to be unique). Try typing this (up to the second instance of `EOF`
) into a terminal:
```
$ echo << EOF
> foo
> bar
> baz
> EOF
```
The expected result:
```
foo
bar
baz
```
A **here-doc** is a common trick used by [Bash](https://opensource.com/resources/what-bash) scripters to dump several lines of text into a file or onto the screen. As long as you don't forget to end the clause with your end-of-file marker, it's an effective way to avoid unwieldy lists of `echo`
or `printf`
statements.
A **here-string** is similar to a **here-doc**, but it consists of just one string (or several strings disguised as a single string with quotation marks):
```
$ cat <<< "foo bar baz"
foo bar baz
```
## Redirecting error messages
Error messages go to a stream called `stderr`
, designated as `2>`
for the purposes of redirection. This command directs error messages to a file called `output.log`
:
`$ ls /nope 2> output.log`
## Sending data to /dev/null
Just as there are locations for standard in, standard out, and error, there's also a location for *nowhere* on the Linux filesystem. It's called `null`
, and it's located in `/dev`
, so it's often pronounced "devnull" by people who use it too frequently to say "slash dev slash null."
You can send data to `/dev/null`
using redirection. For instance, the `find`
command tends to be verbose, and it often reports permission conflicts while searching through your files:
```
$ find ~ -type f
/home/seth/actual.file
find: `/home/seth/foggy': Permission denied
find: `/home/seth/groggy': Permission denied
find: `/home/seth/soggy': Permission denied
/home/seth/zzz.file
```
The `find`
command processes that as an error, so you can redirect just the error messages to `/dev/null`
:
```
$ find ~ -type f 2> /dev/null
/home/seth/actual.file
/home/seth/zzz.file
```
## Using redirection
Redirection is an efficient way to get data from one place to another in Bash. You may not use redirection all the time, but learning to use it when you need it can save you a lot of needless opening files and copying and pasting data, all of which generally require mouse movement and lots of key presses. Don't resort to such extremes. Live the good life and use redirection.
## 5 Comments |
12,386 | 统计数据显示,6 月份桌面 Linux 市场份额攀升至历史新高 | https://www.omgubuntu.co.uk/2020/07/linux-marketshare-june-2020 | 2020-07-06T11:27:00 | [
"Linux",
"市场份额"
] | https://linux.cn/article-12386-1.html | 
>
> 新的一个月,网络分析公司 NetMarketshare 也再次发布了新的 Linux 市场份额统计,它们显示 Linux 和 Ubuntu 的使用量连续第四个月上升。
>
>
>
该公司的技术监测到的桌面 Linux 的份额已经连续几个月持续不断地增长。[2020 年 6 月的数据](https://netmarketshare.com/operating-system-market-share.aspx?options=%7B%22filter%22%3A%7B%22%24and%22%3A%5B%7B%22deviceType%22%3A%7B%22%24in%22%3A%5B%22Desktop%2Flaptop%22%5D%7D%7D%5D%7D%2C%22dateLabel%22%3A%22Custom%22%2C%22attributes%22%3A%22share%22%2C%22group%22%3A%22platform%22%2C%22sort%22%3A%7B%22share%22%3A-1%7D%2C%22id%22%3A%22platformsDesktop%22%2C%22dateInterval%22%3A%22Monthly%22%2C%22dateStart%22%3A%222019-05%22%2C%22dateEnd%22%3A%222020-06%22%2C%22plotKeys%22%3A%5B%7B%22platform%22%3A%22Linux%22%7D%2C%7B%22platform%22%3A%22Mac%20OS%22%7D%2C%7B%22platform%22%3A%22Chrome%20OS%22%7D%5D%2C%22segments%22%3A%22-1000%22%7D)也没有例外,**Linux 从 2020 年 5 月的 3.17% 上升到 6 月的 3.61%。**

我想我们可以更有信心地说,现在的增长是一种趋势,而不是数据的畸变或随机错误([这不是第一次](https://www.omgubuntu.co.uk/2017/10/linux-marketshare-6-91-percent-september-2017))。或者换一种说法,如果它是一个错误,那就是一个一致的错误!
不过,如果对照 NetMarketShare 的桌面 Linux 历史数据来看(虽然只能追溯到 2016 年),这个数据代表了**桌面 Linux 的历史最高水平。**
和以前一样,这个波动的出现是由 Ubuntu 驱动的。根据这家公司的数据,正是基于 Ubuntu 的系统占据了桌面 Linux 的大部分市场份额。这个橙色的操作系统在所有桌面系统中的比例从 5 月份的 2.11% 上升到 6 月份的 2.57%。
作为参考,Linux Mint 也被单独跟踪。基于同样的统计,其目前的份额是 0.0%。

这是否意味着 Linux 市场占有率在增加,而且是大幅增加?不,它仍然是大海里的一条小鱼(更不是池塘)。但在这家公司的样本群中,Linux 用户的份额显然在增长(该公司称其追踪了数亿次对没有明确定义的但显然很受欢迎的网站的访问,所以这也是一个原因)。
不过,虽然这个趋势令人振奋,但我也必须指出,没有其它公司的报告可以互相印证。
以下是由网络分析公司 StatCounter 提供的数据,显示了 12 个月内桌面 Linux 的市场份额。

嗯。几乎没有任何动静 —— 当然也没有 4 月后的暴涨。
然而,这并不能“证明”什么都没有发生。分析公司的方法论和样本基础是不同的。他们会有不同的结果也是意料之中。B 公司的统计数据没有飙升,并不意味着 A 公司的统计数据没有飙升。
为什么会有增长(如果有的话)?
很遗憾,这就更难找到原因了!
这可能是因为更多的人在家工作(而他们自己的电脑也运行着 Linux)。也可能是他们的追踪软件现在更擅长识别 Linux。也可能是 *{在此插入你最喜欢的理论}*。
无论是哪种方式,即使没有什么其他的证据,这些统计数据都很有趣,并且即使不是普遍结论性的,也令人鼓舞。
我们永远不会知道 Linux 在桌面上的确切市场份额,但基于其他数据(如 Distrowatch 排名、ISO 下载量、Snap 应用安装量等),大多数人都会基于此有所估计。
---
via: <https://www.omgubuntu.co.uk/2020/07/linux-marketshare-june-2020>
作者:[Joey Sneddon](https://www.omgubuntu.co.uk/author/d0od "View all posts by Joey Sneddon") 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12382-1.html) 荣誉推出
| 200 | OK | **A new month means new Linux marketshare stats from net analytics company NetMarketshare and they show Linux and Ubuntu usage is up for the fourth consecutive month in a row.**
The share of Linux desktops monitored by the firm’s technology has grown consistently and continually for several months. The figures for June 2020 don’t prove the exception with Linux rising from 3.17 percent in May 2020 to 3.61 percent in June 2020:
I think we can more confidently say that increase **is** now a trend and not an aberration or random error in the data ([which wouldn’t be the first time](https://www.omgubuntu.co.uk/2017/10/linux-marketshare-6-91-percent-september-2017)). Or to put it another way, if its an error it’s a consistent one!
Still, when viewed against NetMarketShare’s historical data for desktop Linux (which only goes back as far as 2016, but still) **this figure represents an all-time high for desktop Linux**.
When viewed against historical data this figure represents an all-time high for Linux desktop share
As before the bump appears tone driven by Ubuntu. It’s Ubuntu-based systems that make up the bulk of Linux’s marketshare according to this company. The orange-tinged OS was up from 2.11 percent of all desktop Linux systems in May to 2.57 percent in June.
For reference, Linux Mint is tracked separately. Based on the same stats its current share sits on 0.0%.
Does this mean* *Linux marketshare is increasing, and increasing hugely? No; it’s still a small fish in the sea (much less a pond). But the share of Linux users is clearly growing among the sample base of *this* specific company (which says its tracks hundreds of millions of visits to a score of undefined but apparently popular websites, so counts for something).
But while the trend is exciting I must also point out that it is **not** **being reported elsewhere.**
Here is desktop Linux marketshare for the same 12 month period, this time furnished with [figures](https://gs.statcounter.com/os-market-share/desktop/worldwide) from web analytics company *StatCounter*:
Hmm. Virtually no movement at all — and certainly no post-April spike.
However, it’s not “proof” nothing is happening. Methodologies and sample bases of analytics company are different. It’s expected that they’d have different results. No spike in company B’s stats doesn’t mean there wasn’t a spike in company A’s.
Why is the increase happening (if it is happening)?
Sadly, that’s even more difficult to discern!
It *could* be because of more people working from home (and thus their own computers, which run Linux). It *could* simple be that their tracking software is now much better at identifying Linux. It *could* be {insert your favourite theory here}.
Either way, with little else to go on, these stats are interesting and encouraging if not universally conclusive.
We’ll never know the exact marketshare of Linux on the desktop but based on other data (like Distrowatch rankings, ISO downloads, Snap app installs, and other) it’s certainly north of most people’s assumptions.
*big thanks @fabidotsh* |
12,388 | 时间管理专家的 Linux 工具 | https://opensource.com/article/20/6/linux-time-management | 2020-07-07T08:50:25 | [
"生产力"
] | https://linux.cn/article-12388-1.html |
>
> 无论你是需要帮助来保持专注、保持及时性,还是为了找到避免重复的捷径,这些 Linux 工具能够帮助你。
>
>
>

生产力是一个主观术语,但从本质上讲,它是衡量特定任务完成效率的标准。每个人都有不同的方式来提高他们的生产力:有些人需要帮助专注于任务里、有些人需要特殊的工作环境、有些人需要警报和提醒以避免错过截止日期,还有些人需要协助处理重复的手工活。幸运的是,有多种工具和技术可为你提供所需的特定支持。特别地,如果你是 Linux 用户,有一些调整可以帮助你提高生产力。这是我经常使用的两个。
### 剪贴板指示器
你是否在日常使用中,在多个文档之间的大量使用复制和粘贴?如果是这样,那么 [剪贴板指示器](https://extensions.gnome.org/extension/779/clipboard-indicator/) 应该成为你的首选方案之一。将剪贴板指示器作为 GNOME 扩展安装到 Linux 发行版中。以我的经验,它对 GNOME Shell 的性能影响很小,至少比我尝试过的其他方案要小。
该工具添加了一个指示器菜单到顶部面板,并缓存剪贴板历史。你可以设置历史记录大小、要预览的字符数量。它可以在复制时显示通知,并充当保存任意复制内容的临时空间。

安装扩展程序和连接器的最简单方法是使用发行版的包管理器。
对于 Fedora、CentOS 或 RHEL,请使用:
```
$ sudo dnf install chrome-gnome-shell
```
在 Ubuntu 或 Debian 上,请改用 `apt install`。
安装完成后,进入 <https://extensions.gnome.org/> 并查看已安装的扩展。
如果你使用的是 Firefox,请使用 Firefox 浏览器附加组件并安装 “GNOME Shell integration”。你将在 Firefox 工具栏中看到一个很小的脚印图标,它将带你进入“扩展”页面。在该页面上,搜索 “Clipboard Indicator” 扩展并启用它。
现在,按照提示下载 GNOME 扩展并激活它。你可以查看 `~/.local/share/gnome-shell/extensions` 来浏览你的扩展。
好了!你将在 GNOME 桌面的右上角看到一个新图标。复制任意内容并尝试其设置。
也可以使用以下命令通过 Git 进行快速安装:将仓库克隆到本地的 gnome-shell 扩展目录中:
```
$ git clone https://github.com/Tudmotu/gnome-shell-extension-clipboard-indicator.git ~/.local/share/gnome-shell/extensions/[email protected]
```
进入 GNOME Tweaks 工具,然后从“扩展”页面激活它。
### 番茄计时器(Pomodoro)

Pomodoro 技术是一种时间管理理念,旨在为用户提供最大注意力。每个 25 分钟的工作时间称为“pomodoro”(意大利语的“番茄”);每个番茄之后,你需要休息五分钟。每四个番茄时间,即每 100 分钟,你就要休息 15 至 20 分钟。如果你有大量的待办事项,那么使用 Pomodoro 技术可以通过强迫你遵守严格的时间安排来帮助你更快地完成项目。
可以通过 GNOME Tweaks 网页 ([extensions.gnome.org](http://extensions.gnome.org))或通过命令行来管理安装过程。对于后者,请根据你的 Linux 发行版和版本,并使用以下命令进行安装:
```
$ sudo dnf install gnome-shell-extension-pomodoro
```
或者,如果你希望从源代码构建:
```
$ git clone -b gnome-3.34 https://github.com/codito/gnome-pomodoro.git
$ cd gnome-pomodoro
```
源码有许多依赖关系,其中许多可能已经安装。为了确保这点,请安装以下内容。
```
$ sudo dnf install autoconf-archive gettext vala vala-tools pkg-config desktop-file-utils glib2-devel gtk3-devel libappstream-glib-devel libappindicator-gtk3-devel libcanberra-devel libpeas-devel sqlite-devel gom-devel gobject-introspection-devel gsettings-desktop-schemas-devel gstreamer1-devel
```
在源代码的解压目录中,完成构建。
```
$ ./autogen.sh --prefix=/usr --datadir=/usr/share
$ make
$ sudo make install
```
不管是怎么安装的,请进入 GNOME Tweaks 并打开番茄计时器。如果你还没有 GNOME Tweaks,请通过包管理器或所选的软件安装程序进行安装。例如,在 Fedora 上:
```
$ sudo dnf install gnome-tweaks
```
在 Ubuntu 或 Debian上,请改用 `apt install`。
Pomodoro 桌面集成当前可在 GNOME Shell 中使用,并且它们计划在将来支持更多桌面。 查看 <https://gnomepomodoro.org/> 获取有关该项目的最新信息。同时,对于 KDE 用户,还有一个名为 [Fokus](https://store.kde.org/p/1308861/) 的替代品。
### Linux 上的生产力
生产力是个人的,但这是我们所有人都在以某种方式追求的东西。这些工具中的每一个要么节省了我的时间,要么使我的工作效率提高了,它们可以与 Linux 快速集成。
你是否有喜欢的生产力工具?请在评论中分享!
---
via: <https://opensource.com/article/20/6/linux-time-management>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Productivity is a subjective term, but essentially, it's a measurement of how efficiently a particular task is completed. Everyone has different things that keep them productive—some people need help staying on task, some people need a particular kind of work environment, some people need alerts and reminders to avoid missed deadlines, and some need assistance with repetitive, manual chores. Luckily, there are myriad tools and technologies available to provide you the specific support you need. In particular, if you are a Linux user, there are some tweaks that can help you increase your productivity; here are two that I use on a regular basis.
## Clipboard Indicator
Are you someone who uses a lot of copy and paste functions between several documents in your day to day usage? If so, then [Clipboard Indicator](https://extensions.gnome.org/extension/779/clipboard-indicator/) should become one of your go-to solutions. Install Clipboard Indicator as a GNOME extension to your Linux distribution. In my experience, it has a minimum performance impact on GNOME Shell—at least, less than other solutions I have tried.
This tool adds an indicator menu to the top panel and caches your clipboard history. You can set the history size, preview the number of characters you want to view. It shows notifications on copy and acts as a temporary space to store whatever you copy.
The easiest way to install the extension and connector is to use your distro's package manager.
For Fedora, CentOs, or RHEL, use:
`$ sudo dnf install chrome-gnome-shell`
On Ubuntu or Debian, use `apt install`
instead.
Once it's installed, go to [https://extensions.gnome.org/](https://extensions.gnome.org/) and check your installed extensions.
If you use Firefox, use the Firefox browser add-on and install the `GNOME Shell integration`
**.** You will see a small footprint icon in your Firefox toolbar, which will take you to the Extensions page. On that page, search for the Clipboard Indicator extension and toggle to enable it.
Now, follow the prompts to download the GNOME extension and activate it. You can check your `~/.local/share/gnome-shell/extensions`
location to view the extension.
Voila! You'll see a new icon in the top-right corner of your GNOME desktop. Copy anything and experiment with its settings.
A quick installation via Git can also be performed by cloning the repo into your local `gnome-shell extensions`
directory using the command:
`$ git clone https://github.com/Tudmotu/gnome-shell-extension-clipboard-indicator.git ~/.local/share/gnome-shell/extensions/[email protected]`
Go to the GNOME Tweak tool and activate it from the Extensions screen.
## Pomodoro
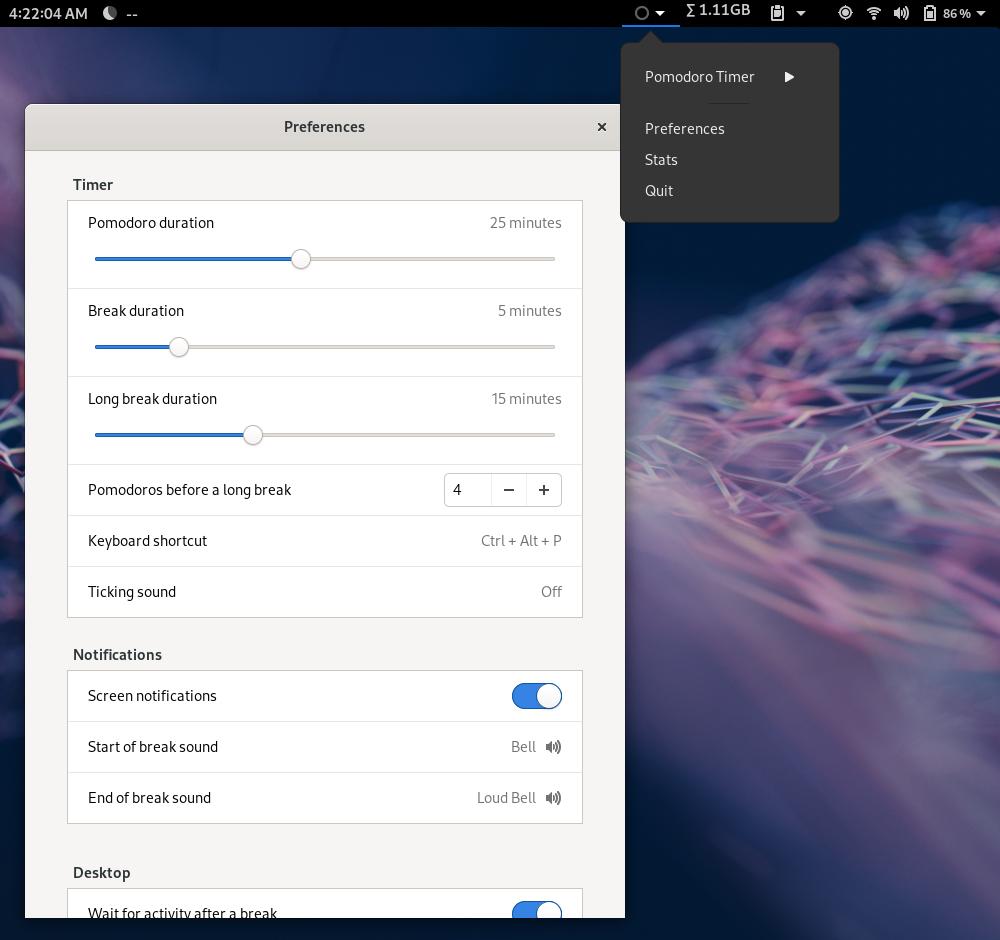
The Pomodoro Technique is a time management philosophy that aims to provide the user with maximum focus. Each 25-minute work period is called a "pomodoro," (Italian for tomato); after each pomodoro, you take a five-minute break. Every four pomodoros, or 100 minutes, you then take a 15 to 20-minute break. If you have a large and varied to-do list, using the Pomodoro Technique can help you crank through projects faster by forcing you to adhere to strict timing.
The installation procedure can be managed through the GNOME Tweaks webpage (extensions.gnome.org) or through the command line. For the latter, choose your distribution of Linux along with the release version and install using the following command:
`$ sudo dnf install gnome-shell-extension-pomodoro `
or if you wish to build from source:
```
$ git clone -b gnome-3.34 https://github.com/codito/gnome-pomodoro.git
$ cd gnome-pomodoro
```
The source code has a number of dependencies, many of which are likely already installed. To make sure of it, install of the following.
`$ sudo dnf install autoconf-archive gettext vala vala-tools pkg-config desktop-file-utils glib2-devel gtk3-devel libappstream-glib-devel libappindicator-gtk3-devel libcanberra-devel libpeas-devel sqlite-devel gom-devel gobject-introspection-devel gsettings-desktop-schemas-devel gstreamer1-devel `
Inside unpacked directory of the source code, complete the build.
```
$ ./autogen.sh --prefix=/usr --datadir=/usr/share
$ make
$ sudo make install
```
No matter how we install, go to GNOME Tweaks and turn on the pomodoro timer. If you don't already have GNOME Tweaks, installing it through your package manager or in your software installer of choice. For example, on Fedora:
`$ sudo dnf install gnome-tweaks `
On Ubuntu or Debian, use `apt install`
instead.
Pomodoro desktop integration is currently available for GNOME Shell, and they plan to support more desktops in the future. Check out [https://gnomepomodoro.org/](https://gnomepomodoro.org/) for the latest on the project. For KDE users in the meantime, there is an alternative called [Fokus](https://store.kde.org/p/1308861/).
## Productivity on Linux
Productivity is personal, but it's something we all are after in one way or another. Each of these tools has either saved me time or made my working time more productive, and they're a quick integration with Linux.
Do you have a favorite productivity tool? Share it in the comments!
## 1 Comment |
12,389 | 如何对你的 Linux 系统进行压力测试 | https://www.networkworld.com/article/3563334/how-to-stress-test-your-linux-system.html | 2020-07-07T10:34:10 | [
"压力测试"
] | https://linux.cn/article-12389-1.html |
>
> 如果你想了解 Linux 服务器在重压之下的运行情况,那么给 Linux 服务器施加压力是个不错的主意。在这篇文章中,我们将看一些工具,可以帮助你增加服务器压力并衡量结果。
>
>
>

为什么你会想给你的 Linux 系统施加压力呢?因为有时你可能想知道当一个系统由于大量运行的进程、繁重的网络流量、过多的内存使用等原因而承受很大的压力时,它的表现如何。这种压力测试可以帮助确保系统已经做好了 “上市” 的准备。
如果你需要预测应用程序可能需要多长时间才能做出反应,以及哪些(如果有的话)进程可能会在重负载下失败或运行缓慢,那么在前期进行压力测试是一个非常好的主意。
幸运的是,对于那些需要能够预测 Linux 系统在压力下的反应的人来说,你可以采用一些有用的技术和工具来使这个过程更容易。在这篇文章中,我们将研究其中的一些。
### 自己动手做个循环
第一种技术是在命令行上运行一些循环,观察它们对系统的影响。这种方式可以大大增加 CPU 的负荷。使用 `uptime` 或类似的命令可以很容易地看到结果。
在下面的命令中,我们启动了四个无尽循环。你可以通过添加数字或使用 bash 表达式,如 `{1...6}` 来代替 `1 2 3 4` 以增加循环次数:
```
for i in 1 2 3 4; do while : ; do : ; done & done
```
在命令行上输入后,将在后台启动四个无尽循环:
```
$ for i in 1 2 3 4; do while : ; do : ; done & done
[1] 205012
[2] 205013
[3] 205014
[4] 205015
```
在这种情况下,发起了作业 1-4,作业号和进程号会相应显示出来。
要观察对平均负载的影响,请使用如下所示的命令。在本例中,`uptime` 命令每 30 秒运行一次:
```
$ while true; do uptime; sleep 30; done
```
如果你打算定期运行这样的测试,你可以将循环命令放入脚本 `watch-it` 中。
```
#!/bin/bash
while true
do
uptime
sleep 30
done
```
在输出中,你可以看到平均负载是如何增加的,然后在循环结束后又开始下降。
```
11:25:34 up 5 days, 17:27, 2 users, load average: 0.15, 0.14, 0.08
11:26:04 up 5 days, 17:27, 2 users, load average: 0.09, 0.12, 0.08
11:26:34 up 5 days, 17:28, 2 users, load average: 1.42, 0.43, 0.18
11:27:04 up 5 days, 17:28, 2 users, load average: 2.50, 0.79, 0.31
11:27:34 up 5 days, 17:29, 2 users, load average: 3.09, 1.10, 0.43
11:28:04 up 5 days, 17:29, 2 users, load average: 3.45, 1.38, 0.54
11:28:34 up 5 days, 17:30, 2 users, load average: 3.67, 1.63, 0.66
11:29:04 up 5 days, 17:30, 2 users, load average: 3.80, 1.86, 0.76
11:29:34 up 5 days, 17:31, 2 users, load average: 3.88, 2.06, 0.87
11:30:04 up 5 days, 17:31, 2 users, load average: 3.93, 2.25, 0.97
11:30:34 up 5 days, 17:32, 2 users, load average: 3.64, 2.35, 1.04 <== 循环停止
11:31:04 up 5 days, 17:32, 2 users, load average: 2.20, 2.13, 1.01 11:31:34 up 5 days, 17:33, 2 users, load average: 1.40, 1.94, 0.98
```
因为所显示的负载分别代表了 1、5 和 15 分钟的平均值,所以这些值需要一段时间才能恢复到系统接近正常的状态。
要停止循环,请发出像下面这样的 `kill` 命令 —— 假设作业号是 1-4,就像本篇文章前面显示的那样。如果你不确定,可以使用 `jobs` 命令来确认作业号。
```
$ kill %1 %2 %3 %4
```
### 增加压力的专用工具
另一种方法是使用专门为你制造系统压力的工具。其中一种叫做 `stress`(压力),可以以多种方式对系统进行压力测试。`stress` 工具是一个工作负载生成器,提供 CPU、内存和磁盘 I/O 压力测试。
在使用 `--cpu` 选项时,`stress` 命令使用平方根函数强制 CPU 努力工作。指定的 CPU 数量越多,负载上升的速度就越快。
下面第二个脚本(`watch-it-2`)可以用来衡量对系统内存使用的影响。请注意,它使用 `free` 命令来查看加压的效果。
```
$ cat watch-it-2
#!/bin/bash
while true
do
free
sleep 30
done
```
发起任务并观察压力:
```
$ stress --cpu 2
$ ./watch-it
13:09:14 up 5 days, 19:10, 2 users, load average: 0.00, 0.00, 0.00
13:09:44 up 5 days, 19:11, 2 users, load average: 0.68, 0.16, 0.05
13:10:14 up 5 days, 19:11, 2 users, load average: 1.20, 0.34, 0.12
13:10:44 up 5 days, 19:12, 2 users, load average: 1.52, 0.50, 0.18
13:11:14 up 5 days, 19:12, 2 users, load average: 1.71, 0.64, 0.24
13:11:44 up 5 days, 19:13, 2 users, load average: 1.83, 0.77, 0.30
```
在命令行中指定的 CPU 越多,负载就增加的越快。
```
$ stress --cpu 4
$ ./watch-it
13:47:49 up 5 days, 19:49, 2 users, load average: 0.00, 0.00, 0.00
13:48:19 up 5 days, 19:49, 2 users, load average: 1.58, 0.38, 0.13
13:48:49 up 5 days, 19:50, 2 users, load average: 2.61, 0.75, 0.26
13:49:19 up 5 days, 19:50, 2 users, load average: 3.16, 1.06, 0.38
13:49:49 up 5 days, 19:51, 2 users, load average: 3.49, 1.34, 0.50
13:50:19 up 5 days, 19:51, 2 users, load average: 3.69, 1.60, 0.61
```
`stress` 命令也可以通过 `--io`(输入/输出)和 `--vm`(内存)选项增加 I/O 和内存的负载来给系统施加压力。
在接下来的这个例子中,运行这个增加内存压力的命令,然后启动 `watch-it-2` 脚本。
```
$ stress --vm 2
$ watch-it-2
total used free shared buff/cache available
Mem: 6087064 662160 2519164 8868 2905740 5117548
Swap: 2097148 0 2097148
total used free shared buff/cache available
Mem: 6087064 803464 2377832 8864 2905768 4976248
Swap: 2097148 0 2097148
total used free shared buff/cache available
Mem: 6087064 968512 2212772 8864 2905780 4811200
Swap: 2097148 0 2097148
```
`stress` 的另一个选项是使用 `--io` 选项为系统添加输入/输出活动。在这种情况下,你可以使用这样的命令:
```
$ stress --io 4
```
然后你可以使用 `iotop` 观察受压的 I/O。注意,运行 `iotop` 需要 root 权限。
之前:
```
$ sudo iotop -o
Total DISK READ: 0.00 B/s | Total DISK WRITE: 19.36 K/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 27.10 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
269308 be/4 root 0.00 B/s 0.00 B/s 0.00 % 1.24 % [kworker~fficient]
283 be/3 root 0.00 B/s 19.36 K/s 0.00 % 0.26 % [jbd2/sda1-8]
```
之后:
```
Total DISK READ: 0.00 B/s | Total DISK WRITE: 0.00 B/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
270983 be/4 shs 0.00 B/s 0.00 B/s 0.00 % 51.45 % stress --io 4
270984 be/4 shs 0.00 B/s 0.00 B/s 0.00 % 51.36 % stress --io 4
270985 be/4 shs 0.00 B/s 0.00 B/s 0.00 % 50.95 % stress --io 4
270982 be/4 shs 0.00 B/s 0.00 B/s 0.00 % 50.80 % stress --io 4
269308 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.09 % [kworker~fficient]
```
`stress` 只是给系统增加压力的若干工具之一。另一个较新的工具,`stress-ng`,将在以后的文章中介绍。
### 总结
用于系统压力测试的各种工具可以帮助你预测系统在真实世界的情况下如何响应,在这些情况下,它们受到增加的流量和计算需求。
虽然我们在文章中展示的是创建和测量各种类型的压力的方法,但最终的好处是压力如何帮助确定你的系统或应用程序对它的反应。
---
via: <https://www.networkworld.com/article/3563334/how-to-stress-test-your-linux-system.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,392 | 使用一条 CI/CD 流水线管理所有的产品 | https://opensource.com/article/19/7/cicd-pipeline-rule-them-all | 2020-07-07T22:48:18 | [
"流水线",
"CI",
"CD"
] | https://linux.cn/article-12392-1.html |
>
> 统一的持续集成与持续交付的流水线的构想是一种梦想吗?
>
>
>

当我加入 WorkSafeBC 负责云端运维和工程流程优化的云端运维团队时,我和大家分享了我的梦想,那就是一个工具化的流水线,每一个产品都可以持续集成和持续交付。
根据 Lukas Klose 的说法,<ruby> <a href="https://continuingstudies.sauder.ubc.ca/courses/agile-delivery-methods/ii861"> 流程 </a> <rt> flow </rt></ruby>(在软件工程的语境内)是“软件系统以稳定和可预测的速度创造价值的状态”。我认为这是最大的挑战和机遇之一,特别是在复杂的新兴解决方案领域。我力求通过一种持续、高效和优质的解决方案,提供一种持续交付模式,并且能够构建正确的事物让我们的用户感到满意。想办法把我们的系统分解成更小的碎片,这些碎片本身是有价值的,使团队能够渐进式地交付价值。这需要业务和工程部门改变思维方式。
### 持续集成和持续交付的(CI/CD)流水线
CI/CD 流水线是一种 DevOps 实践,用于更频繁、一致、可靠的地交付代码变更。它可以帮助敏捷开发团队提高**部署频率**,减少**变更准备时间**、**变更失败率**和关键绩效指标(KPI)的**平均恢复时间**,从而提高质量并且实现更快的交付。唯一的先决条件就是坚实的开发流程、对质量的心态和对需求从构想到废弃的责任心,以及一个全面的流水线(如下图所示)。

它简化了工程流程和产品,以稳定基础架构环境;优化工作流程;并创建一致的、可重复的、自动化的任务。正如 Dave Snowden 的 [Cynefin Sensemaking](https://en.wikipedia.org/wiki/Cynefin_framework) 模型所说的那样,这样就允许我们将复杂不可解决的任务变成了复杂可解决的任务,降低了维护成本,提高了质量和可靠性。
精简流程的一部分是将 <ruby> <a href="https://www.lean.org/lexicon/muda-mura-muri"> 浪费实践类型 </a> <rt> wasteful practice types </rt></ruby> Muri(过载)、Mura(变异)和 Muda(浪费)的浪费降低最低。
* **Muri(过载)**:避免过度工程化,避免与商业价值不相关的功能以及过多的文档。
* **Mura(变异)**:改善审批和验证流程(比如,安全签批);推动 <ruby> <a href="https://en.wikipedia.org/wiki/Shift_left_testing"> 左移提前 </a> <rt> shift-left </rt></ruby> 策略以推行单元测试、安全漏洞扫描与代码质量检查;并改进风险评定。
* **Muda(浪费)**:避免技术债、错误或前期的详细文档等浪费。
看起来 80% 的重点都集中在提供一种可以集成和协作的工程产品上,这些系统可以采用一个创意和计划、开发、测试和监控你的解决方案。然而,一个成功的转型和工程系统是由 5% 的产品、15% 的过程和 80% 的开发人员组成的。
我们可以使用的产品有很多。比如,Azure DevOps 为持续集成(CI)、持续交付(CD)和可扩展性提供了丰富支持,并与 Stryker、SonarQube、WhiteSource、Jenkins 和 Octopus 等开源集成和商用成品(COTS)软件即服务(SaaS)进行集成。对于工程师来说,关注产品总是一种诱惑,但请记住,它们只是我们旅程的 5%。

最大的挑战是打破数十年的规则、规定和已经步入舒适区的流程:“*我们一直都是这样做的;为什么需要改变呢?*”
开发和运维人员之间的摩擦导致了各种支离破碎的、重复的、不间断的集成和交付流水线。开发人员希望能访问所有东西,以便持续迭代,让用户使用起来和持续地快速发布。运维人员希望将所有东西锁起来,保护业务、用户和品质。这些矛盾在不经意间导致了很难做到一种自动化的流程,进而导致发布周期晚于预期。
让我们使用最近的一次白板讨论中的片段来探索流水线。
想要支持流水线的变化是一项困难并且花费巨大的工作;版本和可追溯性的不一致使得这个问题变得更加复杂,因此不断精简开发流程和流水线是一项挑战。

我主张一些原则使得每个产品都能使用通用流水线:
* 使一切可自动化的东西都自动化
* 一次构建
* 保持持续集成和持续交付
* 保持持续精简和改进
* 保持一个构建的定义
* 保持一个发布流水线的定义
* 尽早、频繁地扫描漏洞,并且*尽快失败*
* 尽早、频繁地进行测试,并且*尽快失败*
* 保持已发布版本的可追踪和监控
但是,如果我要打破这些,最重要的原则就是*保持简单*。如果你不能说明流水线化的原因(是什么、为什么)和过程(如何),你或许是不了解自己的软件过程的。我们大多数人想要的不是最好的、超现代的和具有革命意义的流水线 —— 我们仅仅是需要一个功能强大的、有价值的和能促进工程的流水线。首先需要解决的是那 80% —— 文化、人员和他们的心态。请你的 CI/CD 骑士们穿上闪亮的盔甲,在他们的盾牌上贴上 TLA(<ruby> 两个/三个字母的缩写 <rt> two/three-lettered acronym </rt></ruby>)符号,加入到实践和经验工程的力量中来。
### 统一流水线
让我们逐步完成我们的白板会议实践。

每个应用使用一套构建定义来定义一个 CI/CD 流水线,用来触发*拉取请求的预合并验证*与*持续集成*的构建。生成一个带有调试信息的*发布*的构建,并且将其上传到 [符号服务器](https://en.wikipedia.org/wiki/Microsoft_Symbol_Server)。这使开发人员可以在本地和远程生产环境进行调试,而在不用考虑需要加载哪个构建和符号,符号服务器为我们施展了这样的魔法。

在构建过程中进行尽可能多的验证(*左移提前*),这允许开发新特性的团队可以尽快失败,不断的提高整体的产品质量,并在拉取请求中为代码审核人员提供宝贵证据。你喜欢有大量提交的拉取请求吗?还是一个带有少数提交和提供了漏洞检查、测试覆盖率、代码质量检查和 [Stryker](https://stryker-mutator.io/) 突变残余等支持的拉取请求?就我个人而言,我投后者的票。

不要使用构建转换来生成多个特定环境的构建。通过一个构建实现*发布时转换*、*标记化*和 XML/JSON 的*值替换*。换句话说,*右移滞后*具体环境的配置。

安全存储发布配置数据,并且根据数据的*信任度*和*敏感度*,让开发和运维都能使用。使用开源的密钥管理工具、Azure 密钥保险库、AWS 密钥管理服务或者其他产品,记住你的工具箱中有很多方便的工具。

使用*用户组*而不是*用户*,将审批人管理从跨多个流水线的多个阶段移动到简单的组成员。

创建一条流水线并且对赋予特定的交付阶段的权限,而不是重复流水线让团队进入他们感兴趣的地方。

最后,但并非最不重要的是,拥抱拉取请求,以帮助提高对代码仓库的洞察力和透明度,增进整体质量、协作,并将预验证构建发布到选定的环境,比如,开发环境。
这是整个白板更正式的视图。

所以,你对 CI/CD 流水线有什么想法和经验?我的通过*一条流水线来管理它们*的这个梦想是空想吗?
---
via: <https://opensource.com/article/19/7/cicd-pipeline-rule-them-all>
作者:[Willy-Peter Schaub](https://opensource.com/users/wpschaub/users/bclaster/users/matt-micene/users/barkerd427) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chunibyo-wly](https://github.com/chunibyo-wly) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I joined the cloud ops team, responsible for cloud operations and engineering process streamlining, at WorkSafeBC, I shared my dream for one instrumented pipeline, with one continuous integration build and continuous deliveries for every product.
According to Lukas Klose, [flow](https://continuingstudies.sauder.ubc.ca/courses/agile-delivery-methods/ii861) (within the context of software engineering) is "the state of when a system produces value at a steady and predictable rate." I think it is one of the greatest challenges and opportunities, especially in the complex domain of emergent solutions. Strive towards a continuous and incremental delivery model with consistent, efficient, and quality solutions, building the right things and delighting our users. Find ways to break down our systems into smaller pieces that are valuable on their own, enabling teams to deliver value incrementally. This requires a change of mindset for both business and engineering.
## Continuous integration and delivery (CI/CD) pipeline
The CI/CD pipeline is a DevOps practice for delivering code changes more often, consistently, and reliably. It enables agile teams to increase *deployment frequency* and decrease *lead time for change*, *change-failure rate*, and *mean time to recovery* key performance indicators (KPIs), thereby improving *quality* and delivering *value* faster. The only prerequisites are a solid development process, a mindset for quality and accountability for features from ideation to deprecation, and a comprehensive pipeline (as illustrated below).
It streamlines the engineering process and products to stabilize infrastructure environments; optimize flow; and create consistent, repeatable, and automated tasks. This enables us to turn complex tasks into complicated tasks, as outlined by Dave Snowden's [Cynefin Sensemaking](https://en.wikipedia.org/wiki/Cynefin_framework) model, reducing maintenance costs and increasing quality and reliability.
Part of streamlining our flow is to minimize waste for the [wasteful practice types](https://www.lean.org/lexicon/muda-mura-muri) Muri (overloaded), Mura (variation), and Muda (waste).
**Muri:**avoid over-engineering, features that do not link to business value, and excessive documentation**Mura:**improve approval and validation processes (e.g., security signoffs); drive the[shift-left](https://en.wikipedia.org/wiki/Shift_left_testing)initiative to push unit testing, security vulnerability scanning, and code quality inspection; and improve risk assessment**Muda:**avoid waste such as technical debt, bugs, and upfront, detailed documentation
It appears that 80% of the focus and intention is on products that provide an integrated and collaborative engineering system that can take an idea and plan, develop, test, and monitor your solutions. However, a successful transformation and engineering system is only 5% about products, 15% about process, and 80% about people.
There are many products at our disposal. For example, Azure DevOps offers rich support for continuous integration (CI), continuous delivery (CD), extensibility, and integration with open source and commercial off-the-shelve (COTS) software as a service (SaaS) solutions such as Stryker, SonarQube, WhiteSource, Jenkins, and Octopus. For engineers, it is always a temptation to focus on products, but remember that they are only 5% of our journey.

The biggest challenge is breaking down a process based on decades of rules, regulations, and frustrating areas of comfort: "*It is how we have always done it; why change?*"
The friction between people in development and operation results in a variety of fragmented, duplicated, and incessant integration and delivery pipelines. Development wants access to everything, to iterate continuously, to enable users, and to release continuously and fast. Operations wants to lock down everything to protect the business and users and drive quality. This inadvertently and often entails processes and governance that are hard to automate, which results in slower-than-expected release cycles.
Let us explore the pipeline with snippets from a recent whiteboard discussion.
The variation of pipelines is difficult and costly to support; the inconsistency of versioning and traceability complicates live site incidents, and continuous streamlining of the development process and pipelines is a challenge.

I advocate a few principles that enable one universal pipeline per product:
- Automate everything automatable
- Build once
- Maintain continuous integration and delivery
- Maintain continuous streamlining and improvement
- Maintain one build definition
- Maintain one release pipeline definition
- Scan for vulnerabilities early and often, and
*fail fast* - Test early and often, and
*fail fast* - Maintain traceability and observability of releases
If I poke the hornet's nest, however, the most important principle is to *keep it simple*. If you cannot explain the reason (*what*, *why*) and the process (*how*) of your pipelines, you do not understand your engineering process. Most of us are not looking for the best, ultramodern, and revolutionary pipeline—we need one that is functional, valuable, and an enabler for engineering. Tackle the 80%—the culture, people, and their mindset—first. Ask your CI/CD knights in shining armor, with their TLA (two/three-lettered acronym) symbols on their shield, to join the might of practical and empirical engineering.
## Unified pipeline
Let us walk through one of our design practice whiteboard sessions.
Define one CI/CD pipeline with one build definition per application that is used to trigger *pull-request pre-merge validation* and *continuous integration* builds. Generate a *release* build with debug information and upload to the [Symbol Server](https://en.wikipedia.org/wiki/Microsoft_Symbol_Server).** **This enables developers to debug locally and remotely in production without having to worry which build and symbols they need to load—the symbol server performs that magic for us.
Perform as many validations as possible in the build—*shift left*—allowing feature teams to fail fast, continuously raise the overall product quality, and include invaluable evidence for the reviewers with every pull request. Do you prefer a pull request with a gazillion commits? Or a pull request with a couple of commits and supporting evidence such as security vulnerabilities, test coverage, code quality, and [Stryker](https://stryker-mutator.io/) mutant remnants? Personally, I vote for the latter.
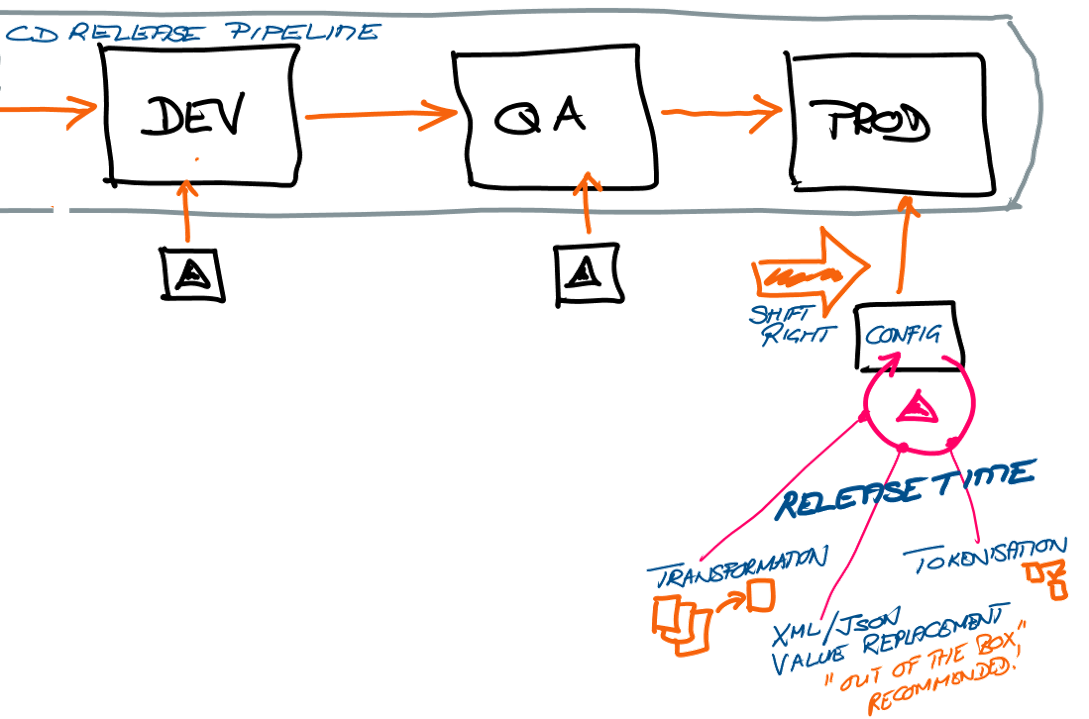
Do not use build transformation to generate multiple, environment-specific builds. Create one build and perform release-time *transformation*, *tokenization*, and/or XML/JSON *value replacement*. In other words, *shift-right* the environment-specific configuration.
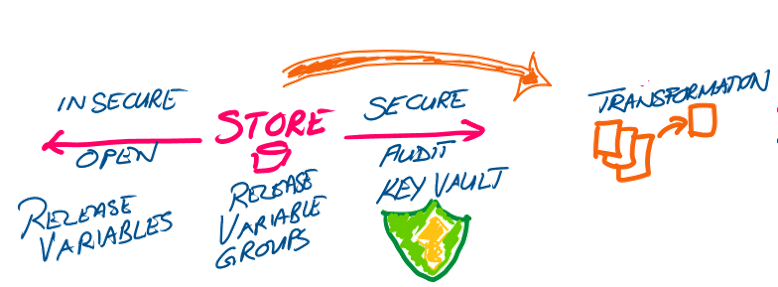
Securely store release configuration data and make it available to both Dev and Ops teams based on the level of *trust* and *sensitivity* of the data. Use the open source Key Manager, Azure Key Vault, AWS Key Management Service, or one of many other products—remember, there are many hammers in your toolkit!
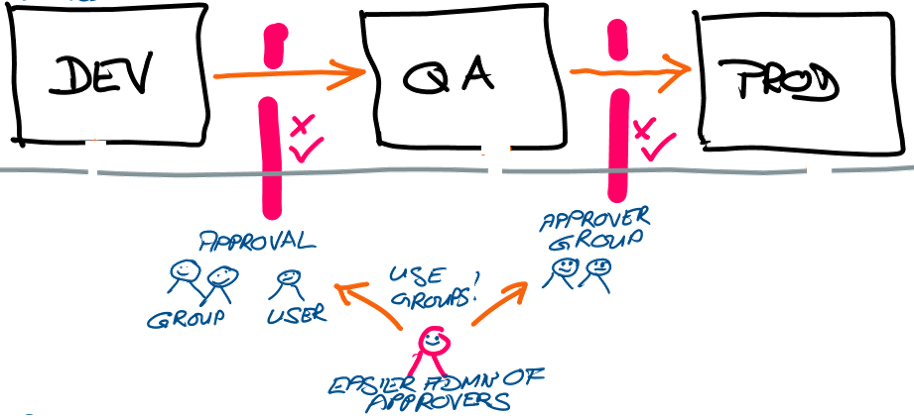
Use *groups* instead of *users* to move approver management from multiple stages across multiple pipelines to simple group membership.
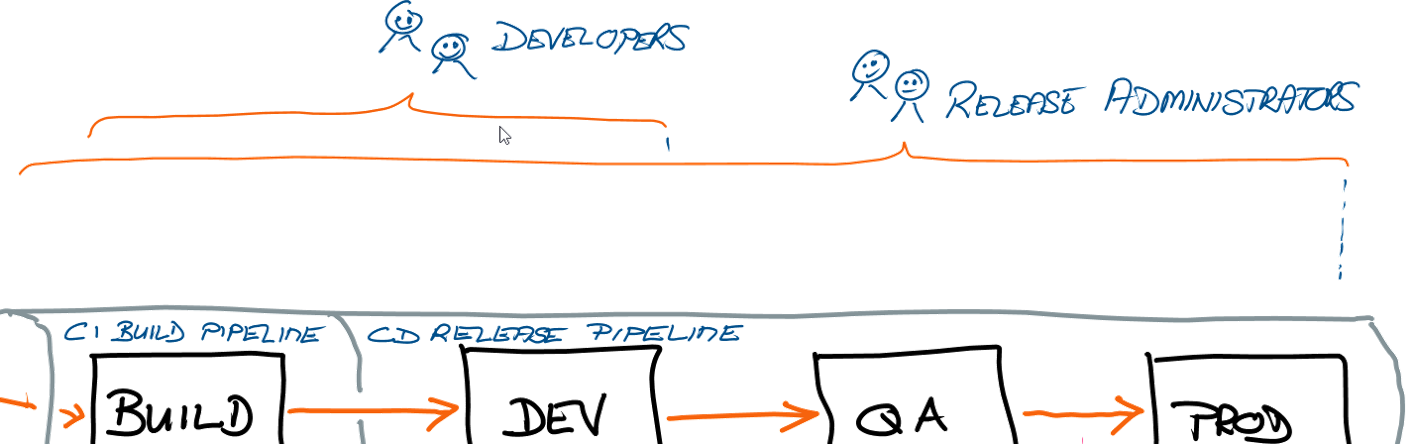
Instead of duplicating pipelines to give teams access to their *areas of interest*, create one pipeline and grant access to *specific stages* of the delivery environments.
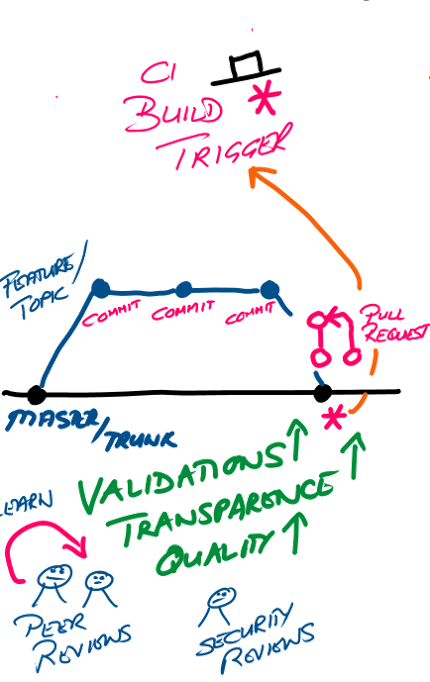
Last, but not least, embrace pull requests to help raise insight and transparency into your codebase, improve the overall quality, collaborate, and release pre-validation builds into selected environments; e.g., the Dev environment.
Here is a more formal view of the whole whiteboard sketch.
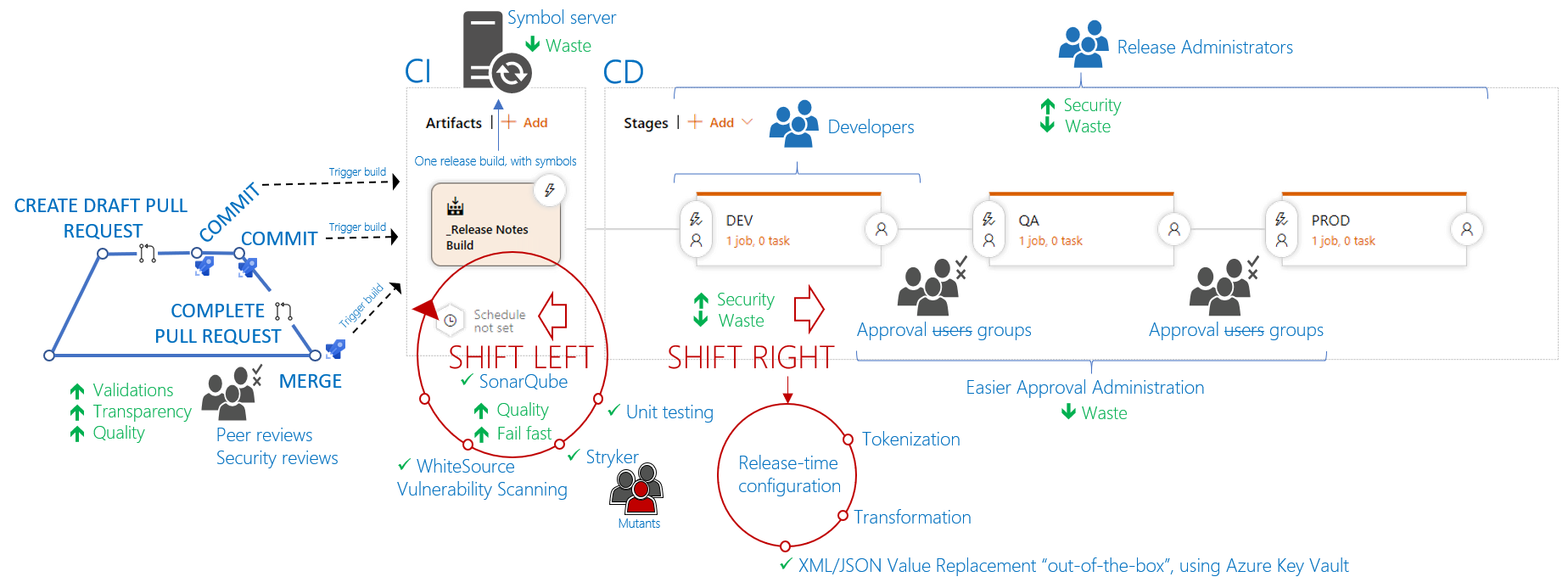
So, what are your thoughts and learnings with CI/CD pipelines? Is my dream of *one pipeline to rule them all* a pipe dream?
## 1 Comment |
12,393 | 如何在 Mac 上安装 Java | https://opensource.com/article/20/7/install-java-mac | 2020-07-08T12:33:47 | [
"Java",
"Mac"
] | https://linux.cn/article-12393-1.html |
>
> macOS 用户可以运行 Java 的开源版本,以及用于<ruby> 云原生 <rt> cloud native </rt></ruby>开发的新框架。
>
>
>

五月底,Java 庆祝了它的 25 周年纪念日,为了纪念这一时刻,世界各地的开发人员使用 [#MovedByJava](https://twitter.com/search?q=%23MovedByJava&src=typed_query) 这一标签分享他们使用这一编程语言的成就、记忆以及愿景。
>
> 我的时间线:
>
>
> * 1999 开始学习 Java
> * 2007 创建 [@grailsframework](https://twitter.com/grailsframework?ref_src=twsrc%5Etfw)
> * 2008 共同创建 G20ne
> * 2009 被 SpringSource 收购
> * 2015 加入 [@ObjectComputing](https://twitter.com/ObjectComputing?ref_src=twsrc%5Etfw)
> * 2018 创建 [@micronautfw](https://twitter.com/micronautfw?ref_src=twsrc%5Etfw) / 获得 [@groundbreakers](https://twitter.com/groundbreakers?ref_src=twsrc%5Etfw) 奖
> * 2019 成为 [@Java\_Champions](https://twitter.com/Java_Champions?ref_src=twsrc%5Etfw)
>
>
> 感谢你 [@java](https://twitter.com/java?ref_src=twsrc%5Etfw)
>
>
> — Graeme Rocher (@graemerocher) [2020年5月21日](https://twitter.com/graemerocher/status/1263484918157410304?ref_src=twsrc%5Etfw)
>
>
>
多年来,许多技术和趋势都促进了 Java 堆栈的开发、部署和在标准应用程序服务器上运行多个应用的能力。为 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 构建容器镜像使得 Java 开发者可以在多个云环境中打包和部署<ruby> <a href="https://opensource.com/resources/what-are-microservices"> 微服务 </a> <rt> microservices </rt></ruby>,而不是在虚拟机上运行几个应用程序服务器。

有了这些技术,Java 应用程序栈被优化为运行更大的堆和可以在运行时做出决策的高动态框架。然而不幸的是,这些努力还不足以使 Java 成为开发人员为<ruby> 无服务器 <rt> serverless </rt></ruby>和事件驱动平台开发<ruby> 云原生 <rt> cloud native </rt></ruby> Java 应用程序的首选编程语言。其他语言填补了这部分空缺,特别是 JavaScript、Python 和 Go,而 Rust 和 WebAssembly 也成了新的选择。
尽管存在这种竞争,<ruby> <a href="https://opensource.com/article/20/1/cloud-native-java"> 云原生 Java </a> <rt> cloud native Java </rt></ruby> 正在对以云为中心的软件开发产生影响。好在,新的 Java 框架(比如,[Quarkus](https://quarkus.io/)、[Micronaut](https://micronaut.io/) 和 [Helidon](https://helidon.io/#/))最近已经战胜了这些挑战,它们提供了编译速度更快而且更小的应用,同时它们在设计之初就将分布式系统考虑了进去。
### 如何在 macOS 上安装 Java
Java 开发的未来将从更多人安装和使用 Java 开始。因此,我将介绍如何在 macOS 上安装并开始使用 Java 开发环境。(如果你运行的是 Linux,请查看 Seth Kenlon 的文章《[如何在 Linux 上安装 Java](/article-11614-1.html)》)
#### 通过 Brew 仓库安装 OpenJDK
Homebrew 是 macOS 事实上的标准软件包管理器。如果你还没有安装的话,Matthew Broberg 的文章《[Homebrew 简介](/article-12338-1.html)》将带你完成这些步骤。
当你在 Mac 上安装好 Homebrew 后,使用 `brew` 命令安装 [OpenJDK](https://openjdk.java.net/),这是编写 Java 应用程序的开源方式:
```
$ brew cask install java
```
不到一分钟就能看到:
```
? java was successfully installed!
```
通过 `java -version` 命令确认 OpenJDK 已经正确安装:
```
$ java -version
openjdk version "14.0.1" 2020-04-14
OpenJDK Runtime Environment (build 14.0.1+7)
OpenJDK 64-Bit Server VM (build 14.0.1+7, mixed mode, sharing
```
从输出中可以确认 OpenJDK 14 (本文撰写时的最新版本)已经安装。
#### 从二进制文件安装 OpenJDK
如果你并不热衷于包管理器,并且更愿意自己来管理 Java 的话,那么你总是可以选择下载并且手动安装。
我在 OpenJDK 主页上找到了最新版本的下载链接。下载 OpenJDK 14 的二进制文件:
```
$ wget https://download.java.net/java/GA/jdk14.0.1/664493ef4a6946b186ff29eb326336a2/7/GPL/openjdk-14.0.1_osx-x64_bin.tar.gz
```
移动到你保存二进制文件的目录,然后解压:
```
$ tar -xf openjdk-14.0.1_osx-x64_bin.tar.gz
```
接下来,将 Java 加入到你的 PATH:
```
$ export PATH=$PWD/jdk-14.0.1.jdk/Contents/Home/bin:$PATH
```
同时,将这条命令加到你的点文件中,`.bash_profile` 还是 `.zshrc` 取决于你运行的 shell。你可以在《[如何在 Linux 中设置你的 PATH 变量][23]》一文中了解更多关于配置 `PATH变量][23]》一文中了解更多关于配置‘](https://opensource.com/article/17/6/set-path-linux)》一文中了解更多关于配置 `$PATH` 变量的内容。
最后,验证你安装的 OpenJDK 14:
```
$ java -version
openjdk version "14.0.1" 2020-04-14
OpenJDK Runtime Environment (build 14.0.1+7)
OpenJDK 64-Bit Server VM (build 14.0.1+7, mixed mode, sharing)
```
### 在 Mac 上编写你的第一个<ruby> <a href="https://opensource.com/resources/what-are-microservices"> 微服务 </a> <rt> microservices </rt></ruby>
现在,你已经准备好在 maxOS 上使用 OpenJDK 堆栈开发<ruby> 云原生 <rt> cloud native </rt></ruby> Java 应用程序了。在本教程中,你将在 [Quarkus](https://quarkus.io/) 上创建一个新的 Java 项目,这个项目使用<ruby> 依赖注入 <rt> dependency injection </rt></ruby>来公布 REST API。
你需要 [Maven](https://maven.apache.org/index.html) 启动,它是一个非常流行的 Java 依赖管理器。从 Maven 的网站[安装](https://maven.apache.org/install.html)它,或者通过 Homebrew 使用 `brew install maven` 命令。
执行以下 Maven 命令来配置 Quarkus 项目,并且创建一个简单的 web 应用:
```
$ mvn io.quarkus:quarkus-maven-plugin:1.5.1.Final:create \
-DprojectGroupId=com.example \
-DprojectArtifactId=getting-started \
-DclassName="com.example.GreetingResource" \
-Dpath="/hello"
cd getting-started
```
运行这个应用:
```
$ ./mvnw quarkus:dev
```
当应用程序运行的时候,你可以看到这个输出:
```
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
\--\\___\\_\\____/_/ |_/_/|_/_/|_|\\____/___/
2020-06-13 00:03:06,413 INFO [io.quarkus] (Quarkus Main Thread) getting-started 1.0-SNAPSHOT on JVM (powered by Quarkus 1.5.1.Final) started in 1.125s. Listening on: <http://0.0.0.0:8080>
2020-06-13 00:03:06,416 INFO [io.quarkus] (Quarkus Main Thread) Profile dev activated. Live Coding activated.
2020-06-13 00:03:06,416 INFO [io.quarkus] (Quarkus Main Thread) Installed features: [cdi, resteasy]
```
使用 `curl` 命令访问 REST 端点:
```
$ curl -w "\n" http://localhost:8080/hello
hello
```
恭喜!通过使用 Mavan 和 Quarkus,你很快从没有安装 Java 的环境里创建了第一个 web 应用。
### 接下来用 Java 做什么
Java 是一个成熟的编程语言,通过专门为<ruby> 云原生 <rt> cloud native </rt></ruby>应用程序开发设计的新框架,Java 的热度会一直持续下去。
如果你正走在这样构建未来应用的路上,你可能会对更多实用的 Quarkus 开发课程或其他现代化框架感兴趣。无论你在构建什么,下一步是配置你的文本编辑器。阅读我关于《[在 VS Code 用 Quarkus 编写 Java](https://opensource.com/article/20/4/java-quarkus-vs-code)》的教程,然后再看看你能做什么。
---
via: <https://opensource.com/article/20/7/install-java-mac>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In late May, [Java](https://opensource.com/resources/java) celebrated its 25th anniversary, and to commemorate the occasion, developers around the world used the hashtag [#MovedByJava](https://twitter.com/search?q=%23MovedByJava&src=typed_query) to share their achievements, memories, and insights with the programming language.
My timeline:
* 1999 Started learning Java
* 2007 Created[@grailsframework]
* 2008 Cofounded G2One
* 2009 Acquired by SpringSource
* 2015 Joined[@ObjectComputing]
* 2018 Created[@micronautfw]/ won[@groundbreakers]award
* 2019 Became[@Java_Champions]
Thank u[@java]![#MovedByJava]— Graeme Rocher (@graemerocher)
[May 21, 2020]
Over the years, many technologies and trends have contributed to the Java stack's development, deployment, and ability to run multiple applications on standard application servers. Building container images for [Kubernetes](https://opensource.com/resources/what-is-kubernetes) enables Java developers to package and deploy [microservices](https://opensource.com/resources/what-are-microservices) in multiple cloud environments rather than running several application servers on virtual machines.
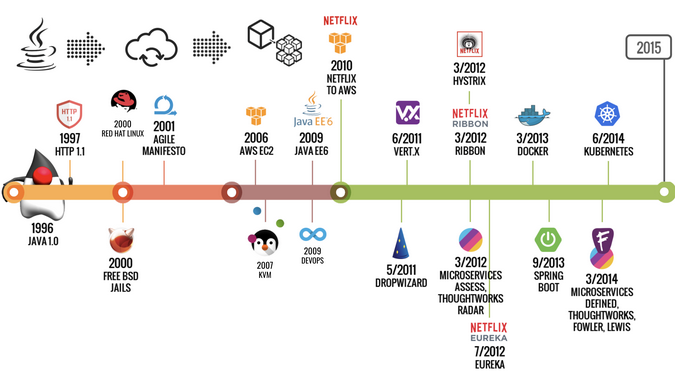
(Daniel Oh, CC BY-SA 4.0)
With these technologies, the Java application stack has been optimized to run larger heaps and highly dynamic frameworks that can make decisions at runtime. Unfortunately, those efforts weren't good enough to make Java the preferred programming language for developers to implement cloud-native Java applications for serverless and event-driven platforms. Other languages filled in the space, particularly JavaScript, Python, and Go, with Rust and WebAssembly offering new alternatives.
Despite this competition, [cloud-native Java](https://opensource.com/article/20/1/cloud-native-java) is making an impact on cloud-centric software development. Luckily, new Java frameworks (e.g., [Quarkus](https://quarkus.io/), [Micronaut](https://micronaut.io/), and [Helidon](https://helidon.io/#/)) have recently broken through the challenges by offering smaller applications that compile faster and are designed with distributed systems in mind.
## How to install Java on macOS
This future for Java development starts with more people installing and using Java. So I will walk through installing and getting started with the Java development environment on macOS. (If you are running Linux, please see Seth Kenlon's article [ How to install Java on Linux](https://opensource.com/article/19/11/install-java-linux).)
### Install OpenJDK from a Brew repository
Homebrew is the de-facto standard package manager for macOS. If you haven't installed it yet, Matthew Broberg's [ Introduction to Homebrew](https://opensource.com/article/20/6/homebrew-mac) walks you through the steps.
Once you have Homebrew on your Mac, use the `brew`
command to install [OpenJDK](https://openjdk.java.net/), which is the open source way to write Java applications:
`$ brew cask install java`
In just a few minutes, you will see:
`? java was successfully installed!`
Confirm that OpenJDK installed correctly with `$ java -version`
:
```
$ java -version
openjdk version "14.0.1" 2020-04-14
OpenJDK Runtime Environment (build 14.0.1+7)
OpenJDK 64-Bit Server VM (build 14.0.1+7, mixed mode, sharing
```
The output confirms OpenJDK 14 (the latest version, as of this writing) is installed.
### Install OpenJDK from a binary
If you are not a fan of package management and prefer managing Java yourself, there's always the option to download and install it manually.
I found a download link to the latest version on the OpenJDK homepage. Download the OpenJDK 14 binary:
`$ wget https://download.java.net/java/GA/jdk14.0.1/664493ef4a6946b186ff29eb326336a2/7/GPL/openjdk-14.0.1_osx-x64_bin.tar.gz`
Move to the directory where you downloaded the binary file and extract it:
`$ tar -xf openjdk-14.0.1_osx-x64_bin.tar.gz`
Next, add Java to your PATH:
`$ export PATH=$PWD/jdk-14.0.1.jdk/Contents/Home/bin:$PATH`
Also, add this to the path to your dotfiles, `.bash_profile`
or `.zshrc`
depending on what shell you are running. You can learn more about configuring the `$PATH`
variable in [ How to set your $PATH variable in Linux](https://opensource.com/article/17/6/set-path-linux).
Finally, verify your OpenJDK 14 installation:
```
$ java -version
openjdk version "14.0.1" 2020-04-14
OpenJDK Runtime Environment (build 14.0.1+7)
OpenJDK 64-Bit Server VM (build 14.0.1+7, mixed mode, sharing)
```
## Write your first Java microservice on a Mac
Now you are ready to develop a cloud-native Java application with OpenJDK stack on macOS. In this how-to, you'll create a new Java project on [Quarkus](https://quarkus.io/) that exposes a REST API using dependency injection.
You will need [Maven](https://maven.apache.org/index.html), a popular Java dependency manager, to start. [Install](https://maven.apache.org/install.html) it from Maven's website or using Homebrew with `brew install maven`
.
Execute the following Maven commands to configure a Quarkus project and create a simple web app:
```
$ mvn io.quarkus:quarkus-maven-plugin:1.5.1.Final:create \
-DprojectGroupId=com.example \
-DprojectArtifactId=getting-started \
-DclassName="com.example.GreetingResource" \
-Dpath="/hello"
cd getting-started
```
Run the application:
`$ ./mvnw quarkus:dev`
You will see this output when the application starts:
```
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2020-06-13 00:03:06,413 INFO [io.quarkus] (Quarkus Main Thread) getting-started 1.0-SNAPSHOT on JVM (powered by Quarkus 1.5.1.Final) started in 1.125s. Listening on: http://0.0.0.0:8080
2020-06-13 00:03:06,416 INFO [io.quarkus] (Quarkus Main Thread) Profile dev activated. Live Coding activated.
2020-06-13 00:03:06,416 INFO [io.quarkus] (Quarkus Main Thread) Installed features: [cdi, resteasy]
```
Access the REST endpoint using the `curl`
command:
```
$ curl -w "\n" http://localhost:8080/hello
hello
```
Congratulations! You have quickly gone from not even having Java installed to building your first web application using Maven and Quarkus.
## What to do next with Java
Java is a mature programming language that continues to grow in popularity through new frameworks designed for cloud-native application development.
If you are on the path toward building that future, you may be interested in more practical Quarkus development lessons or other modern frameworks. No matter what you're building, the next step is configuring your text editor. Read my tutorial on [ Writing Java with Quarkus in VS Code](https://opensource.com/article/20/4/java-quarkus-vs-code), then explore what else you can do.
## Comments are closed. |
12,396 | GIMP 教程:如何在 GIMP 中创建曲线文本 | https://itsfoss.com/curve-text-gimp/ | 2020-07-09T12:09:00 | [
"GIMP"
] | https://linux.cn/article-12396-1.html | 当你在 GIMP 中制作一个徽章、海报或其它任何作品时,你需要扭曲或弯曲一些文本。多功能的 [GIMP](https://www.gimp.org/) 工具提供了一些创建弯曲文本的方法。取决于你将如何使用它和你想给予文本的弧度,有一些适合不同情况的方法。
在本篇教程中,我将向你展示我最喜欢的创建曲线文本的方法。
### 如何在 GIMP 中创建曲线文本

请确保你已经在你的系统上安装了 GIMP。
#### 步骤 1: 创建一个你想要的匹配曲线的路径
创建一个新的图像或打开一个现有的图像。选择 “工具 -> 路径”,然后大致考虑曲线文本的位置,通过分别单击路径点的开始点和结束点来创建路径。

\*\*然后给你的路径一个曲率。\*\*首先向上或向下拖动中间的直线,然后通过移动调整点进行微调。这将给予它一个拱形结构。

#### 步骤 2: 创建你想弯曲的文本
当你对自己的曲线路径满意时,你可以移动到接下来的步骤,并 **创建你的文本**。
你可能想更改字体及其大小。我的选择只是为了演示用途。

#### 步骤 3: 创建一个新的图层
我强烈建议分割 GIMP 图像中的每个不同的元素到不同的图层中,以便很容易地控制它们,像移动,打开/关闭一个元素等等。
遵循这一规则,我们要弯曲的文本将被放置到一个新的图层中。建议使用像 “Curved Text” 一样的名字来命名你的新的图层,或者一些类似的东西来很容易地识别它。

#### 步骤 4: 弯曲文本
现在你需要在你的文本图层上单击,接下来在其上右击,并单击“文字对齐路径”来折弯你的文本。弯曲的文本将被放置到新创建的图层。

你把文本弯曲了!让我们使用颜色填充文本来使其更令人满意。
### 步骤 5: 最后的修饰和导出
单击弯曲的文本图层,然后转到路径选项卡来选择文本边界。

最后,选择油漆桶工具,选择一种颜色,并如下应用你的选择区。

随着最后一步的到来,打开不需要的层的可见性,只保留曲线文本。接下来,需要导出你的文件为你喜欢的图像格式。

#### 额外提示:创建阴影效果
我还有一个作为一次挑战的额外的步骤,如果你想更进一步的话。让我们在 [GIMP 中勾勒文本](https://itsfoss.com/gimp-text-outline/)以创建一个弯曲文本的阴影效果。
我将给予你一些提示:
* 重新启用所有图层
* 单击弯曲文本图层,并使用移动工具来到处移动文本
* 创建另一个图层,并使用黑色来重复油漆桶填充程序
* 以一种模拟一种阴影位置的方式覆盖图层(你可能需要更改图层顺序)
* 关闭辅助图层
最终结果:

让我在评论区知道你们对这篇 GIMP 教程的想法,以及有多少人尝试了这一额外的步骤。
---
via: <https://itsfoss.com/curve-text-gimp/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you are working on a badge, poster or any other composition in GIMP and you need to bend or curve some text. The versatile [GIMP](https://www.gimp.org/?ref=itsfoss.com) tool offers several ways to create curved text. Depending on how you will use it and the curvature you want to give to your text, some methods are better than others.
In this GIMP tutorial, I’ll show you my preferred way of creating curve texts.
## How to create curve text in GIMP
Please make sure that you have GIMP installed on your system already.
### Step 1: Create a path that matches the type of curve you want
Create a new image or open an existing one. Select the paths tool and then having in mind roughly the position of the curved text, create your path by clicking once for the start and then for the end of path point.
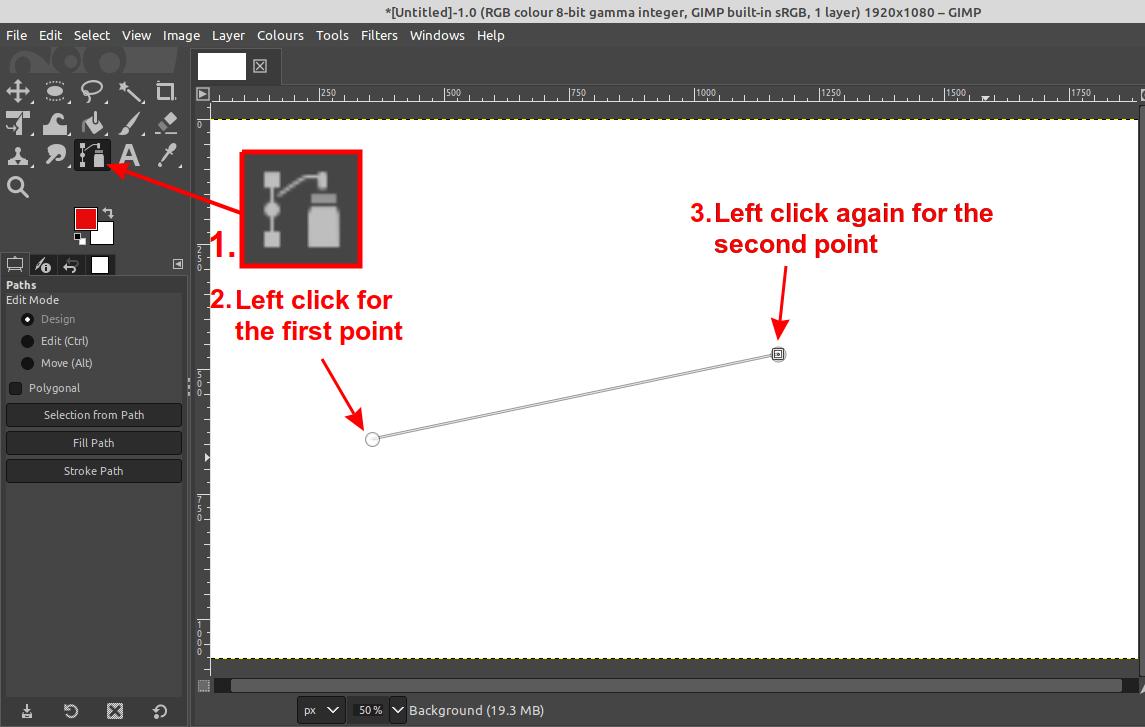
**Then give to your path a curvature. **First drag the line in the middle either up or down, and fine tune by moving the adjusting points. This will give it an arch.
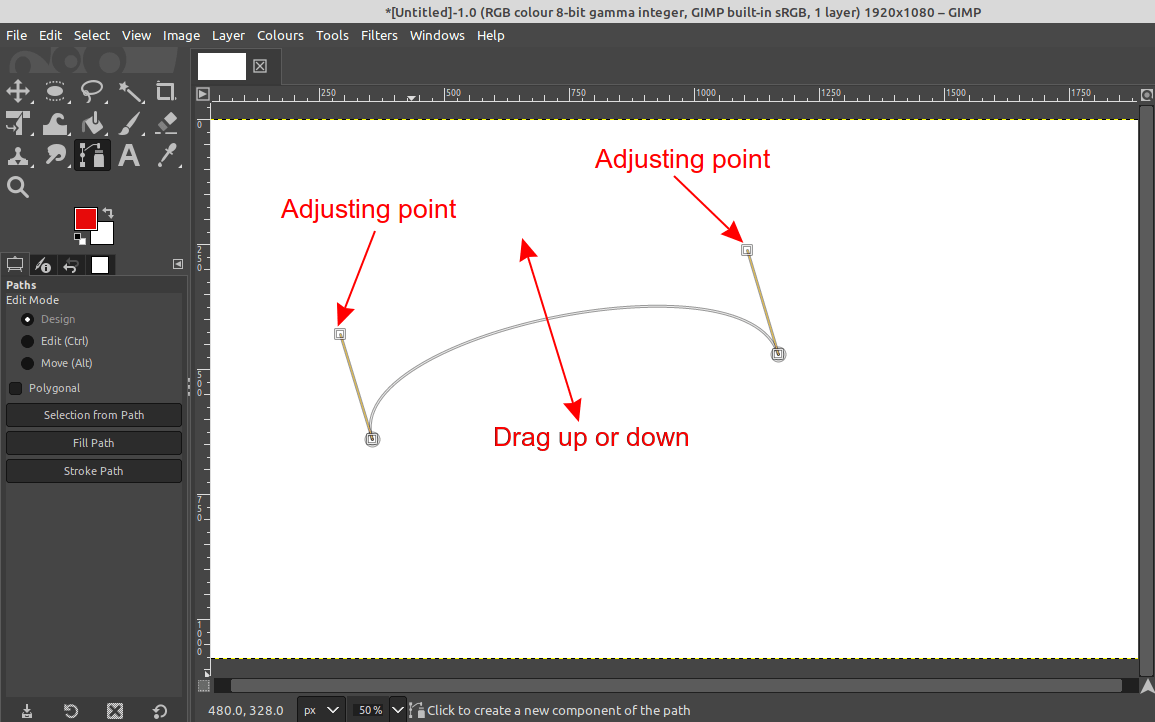
### Step 2: Create the text you want to curve
When you are satisfied with your curved path, you can move to the next step and **create your text**.
You may want to change the font and the font size. My selections are for demonstration purpose only.
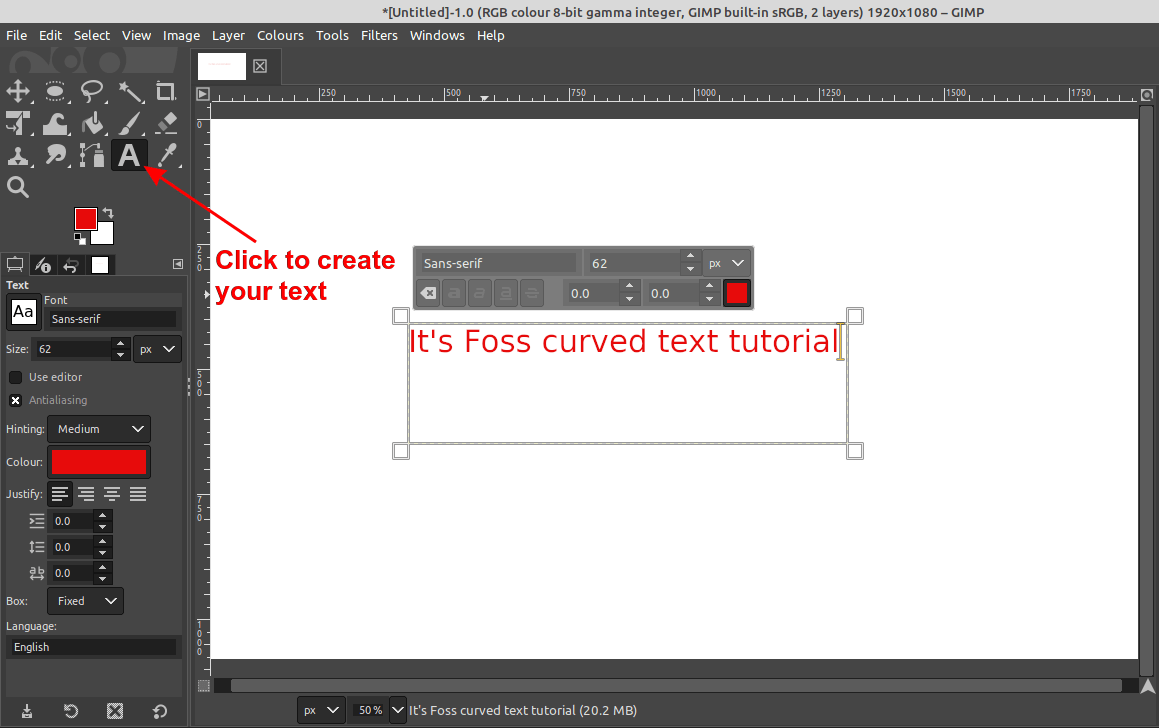
### Step 3: Create a new layer
I strongly suggest separating each different element of a GIMP image in different layers, in order to manipulate them easily like move, turn on/off an element etc.
Following this rule our curved text will be placed at a new layer. It is recommended to name your new layer like “Curved Text” or something similar to easily identify it.
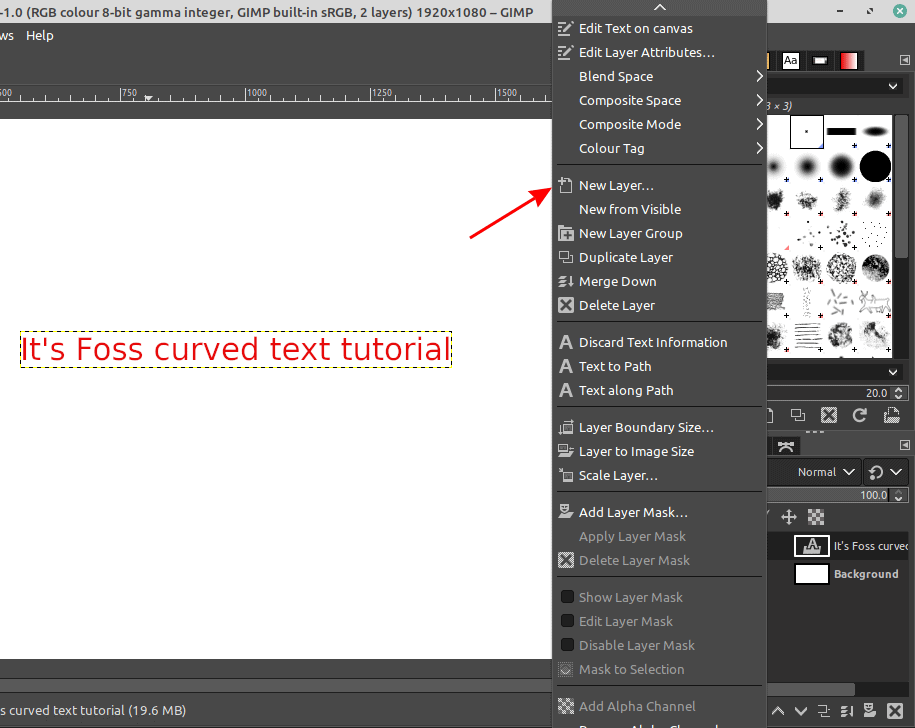
### Step 4: Curve the text
Now you need to click on the layer that your text is and right click on it and then click on “Text along path” to bend your text. The curved text will be placed at the newly created layer.
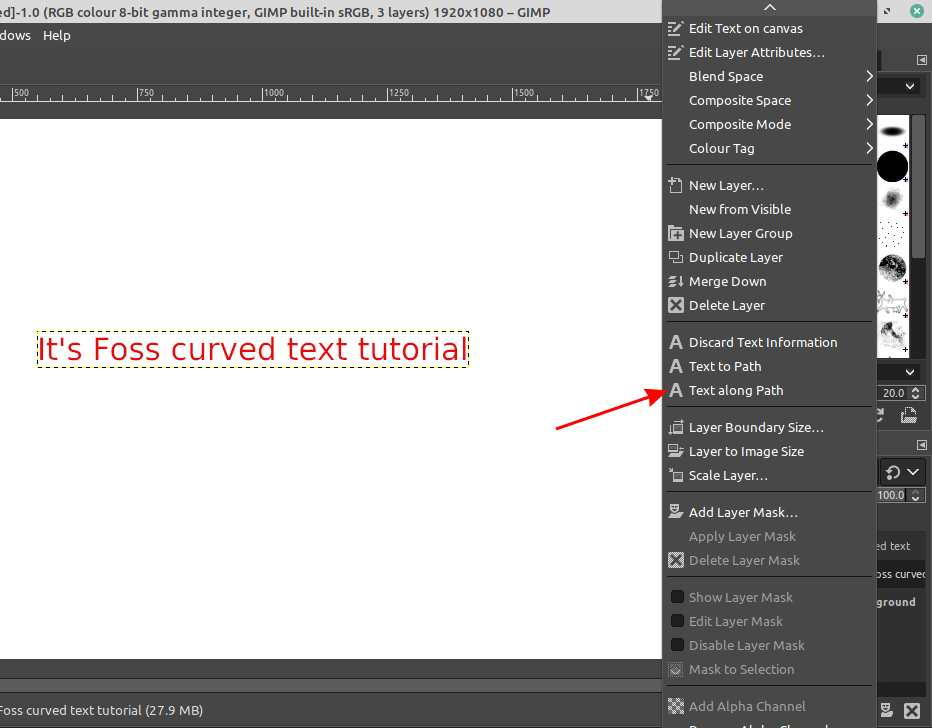
You just curved the text! Let’s make the text more presentable by filling it with colour.
## Step 5: Final touches and export
Click on the curved text layer and then go to the path tab to select the text boundaries.
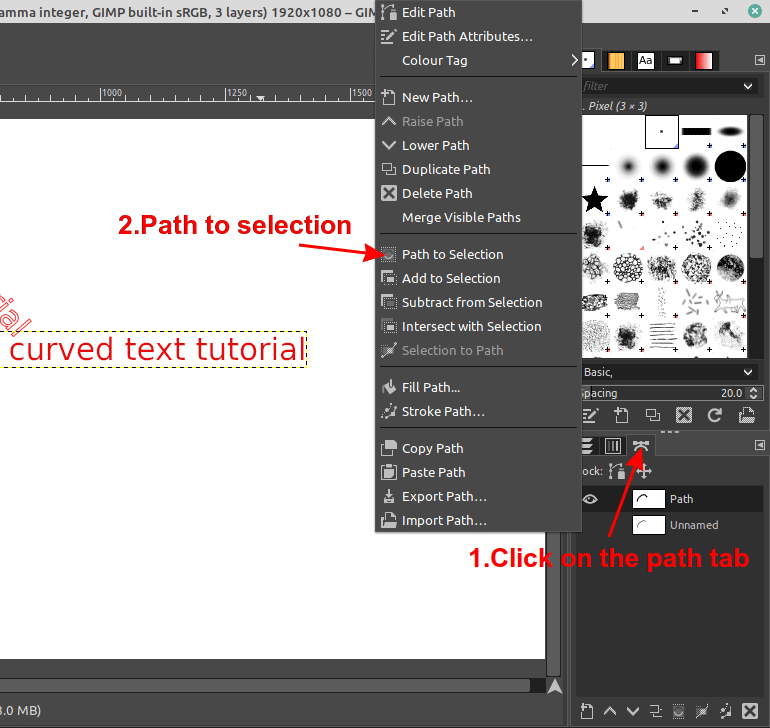
Finally, select the bucket tool, a color of your choice and apply your selection as per below.
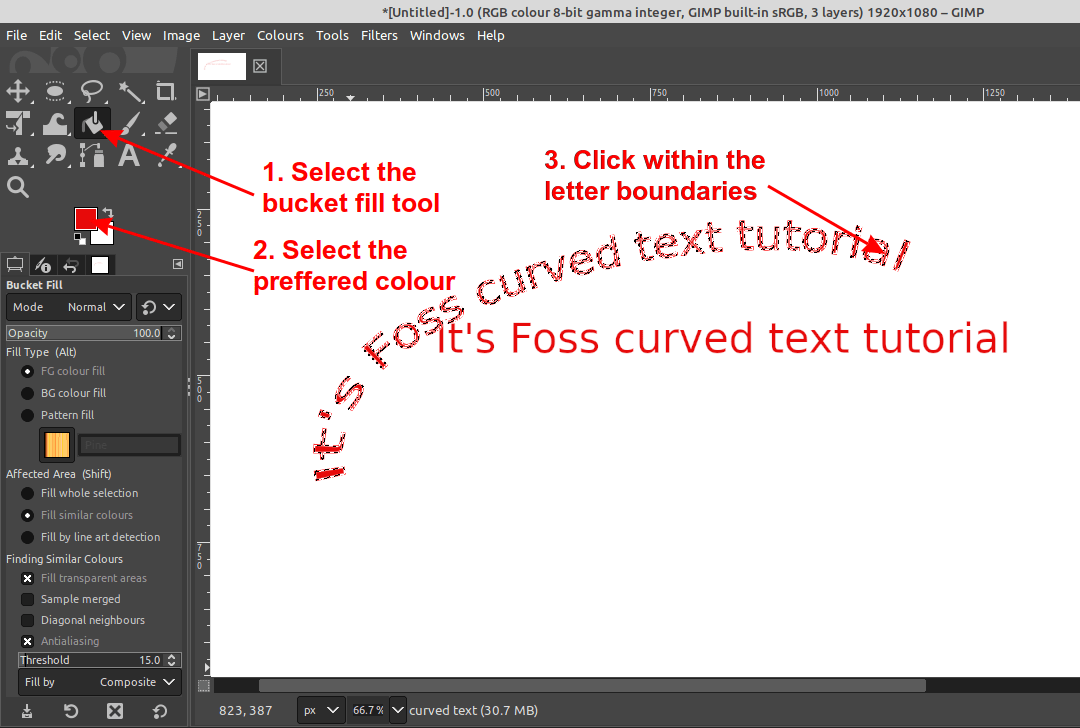
As the last step, turn the visibility of the layers that you don’t want and keep only the curved text. Then you are ready to export your file as your preferred image format.
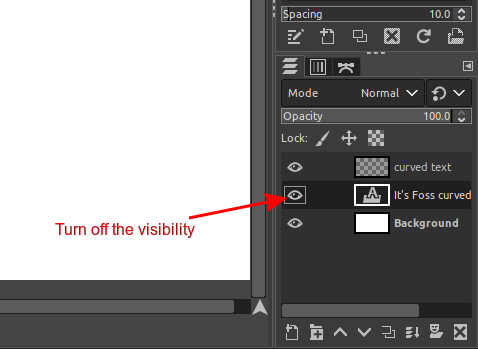
### Bonus Tip: Create shade effect
I have an additional step as an exercise/challenge if you want to go the extra mile. Let’s create a shade effect to the curved text by [outlining the text in GIMP](https://itsfoss.com/gimp-text-outline/).
I will give you some hints:
- Turn all the layers back on
- Click on the curved text layer and the use the move tool to move the text away
- Create another layer and repeat the bucket fill procedure with a black colour
- Overlay the layers in a way that they mimic a shaded position (you may need to change the layers order)
- Turn off the auxiliary layers
**The final result!**

Let me know in the comments below your thoughts about this GIMP tutorial and how many of you tried the bonus step.
Don’t forget to [subscribe to the newsletter](https://itsfoss.com/newsletter/) as It’s FOSS team has much more for you in the near future! |
12,399 | 开源代码广阔天地造福人类 | https://opensource.com/article/20/4/interview-Megan-Byrd-Sanicki | 2020-07-09T22:52:52 | [
"开源"
] | /article-12399-1.html |
>
> 了解 2020 年开源社区女性奖获得者 Megan Byrd-Sanicki 如何将人们聚集在一起。
>
>
>

“在成长的过程中,我曾经有点像陆军元帅,” 2020 年[开源社区女性奖获得者](https://www.redhat.com/en/about/women-in-open-source) Megan Byrd-Sanicki 笑着说。“我总是那个把同学们拉到一起的人。‘大家来吧,我们告诉你们规则。’我也会注意旁听,尝试找出没有被接纳进来的人,并把他们拉进圈子。”

这种将人们聚集在一起,并为他们建立一个组织,让他们表现出色的动力贯穿了她的大部分职业生涯和社区工作。“我回想起二年级体育课上的我,不得不承认,今天的我依然是这样的人。”
作为第一任 [Drupal 协会](https://www.drupal.org/association)执行主任,Megan 十年来活跃于开源社区,现在是谷歌开源项目办公室的研发和运营主管。“我很幸运能担任这个职位,因为它可以让我看到谷歌 2000 多个不同目标、不同治理结构、不同策略的开源项目。这个也是难得的学习机会。” Megan 最近被推选为 [开源代码促进会](https://opensource.org/)的董事会成员,她努力加强该组织为全球项目和企业提供的开源领导力。
### 从地下室台阶上学到的知识
Megan 原以为她会从商,远离循规的技术。坐在地下室台阶上,耳濡目染父亲的销售电话,到 16 岁时候就知道父亲的所有产品系列,也熟悉了其他知识。
“我从父亲学到了做生意就是解决问题和帮助别人” Megan 说。“在我的职业生涯这个信念我始终放在第一位。在某些角度看选择这条路我并不觉得奇怪;这是我个人选择的自然延伸,但它也把我带到了我从未梦想过的地方。”
开源事业对 Megan 不仅仅是一个职业;她在她的社区活动中也使用同样的理念。“现在,我正在与 [Covid Act Now](https://www.covidactnow.org/) 的一大群优秀的工程师、数据科学家以及流行病科学家合作。团队成员是义务提供他们的专业知识,公开合作,为政府公共人员提供数据建模,以便他们快速的做出有效的决策。”
她也活跃于 [FOSS Responders](https://fossresponders.com/),这是一个为受 COVID-19 事件影响的开源项目和社区成员点亮温暖的组织。“在疫情期间,项目很难得到他们需要的帮助。我们可以帮忙需要帮忙的组织和个人扩散他们的请求。”这个组织的一个重要的事务是管理 [FOSS Responders 基金](https://fossresponders.com/),这是一个寻求开源项目基金的融资需求的机制,避免社区衰亡。
### 在这不断变化的世界中一群可爱的人
影响 Megan 参与到社区的两个宗旨分别是对开源的明确承诺和把大家团结在一起的动力。“人们有梦想的时候,他们就积极的去实现它,这就造就了共同的信念和强烈的 ‘为什么’。人们很容易围绕着‘为什么’参与其中。我知道我是这样做的。” Megan 在被问到她这么努力时说到。
“不管是帮助 Drupal 基金会筹集资金的任务还是赋能开源项目可持续发展,都会对人类产生真正的影响。帮助人们达到他们的目标,实现他们的梦想和愿景,而我也实实在在感受到收获这种蝴蝶效应般的热情。”
开源技术在技术领域占的比重越来越大,Megan 对未来抱有很大希望。“令人兴奋的是故事还没有结束。作为一个社区,我们还在摸索,”她说:“关于开源,我们需要学习的东西太多了,我们的外部环境不断发生变化,它可以以多种方式发展,同时我们周围的环境也在变化。我们需要正确的对话,并找出如何共同发展的方法。确保每个人都有一席之地。”
用她的话说,这些都是经常从她的父亲生意电话里听到的感悟,做生意就是解决问题并帮助别人。“帮助更多的人学习如何使用和贡献开源来解决问题,的确是一件有益的事情。不管是推动创新,提升效率,还是实现业务目标,有很多方法可以从开源中获得价值。”
### 属于你的荣耀
当被问到对其他想参与到开源社区的女性有哪些建议时,Megan 兴奋的说:“请记住,在开源社区,所有人都有一席之地。这可能会让人望而生畏,但是从我的经验来看,人们都想帮忙。当你需要帮助的时候,就寻求帮助,但也要清楚你能在哪里做出贡献,如何做出贡献,以及你的需求是什么。”
她也认识到,在开源领域的所有声音中,有时会感觉到缺乏集中的领导力,但她提醒不要把它看成是一种只留给少数人的特权角色。“做你期望的领导者。当社区领导角色空缺时,每个个体可以自己填补空缺。每一个开源的贡献者都是领导者,不管是领导他人,领导社区,甚至领导自己。不要等待被动赋予属于你的权力和精彩。”
对 Megan 来说,开源之旅就如:一个前途不明朗的心路之旅。尽管如此,对风险和未来的不确定性她从不逃避。“我把生命看作一张你正在编织的美丽挂毯,日复一日,你仅仅看到后面的线头。如果你可以看到全貌,你将意识到,你只要每天尽自己最大的努力,就会以无数的方式为这个美好的作品做出贡献。”
---
via: <https://opensource.com/article/20/4/interview-Megan-Byrd-Sanicki>
作者:[Jay Barber](https://opensource.com/users/jaybarber) 选题:[lujun9972](https://github.com/lujun9972) 译者:[guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,400 | 使用 Delve 代替 Println 来调试 Go 程序 | https://opensource.com/article/20/6/debug-go-delve | 2020-07-09T23:44:18 | [
"Go",
"调试"
] | https://linux.cn/article-12400-1.html |
>
> Delve 是能让调试变成轻而易举的事的万能工具包。
>
>
>

你上次尝试去学习一种新的编程语言时什么时候?你有没有持之以恒,你是那些在新事物发布的第一时间就勇敢地去尝试的一员吗?不管怎样,学习一种新的语言也许非常有用,也会有很多乐趣。
你尝试着写简单的 “Hello, world!”,然后写一些示例代码并执行,继续做一些小的修改,之后继续前进。我敢保证我们都有过这个经历,不论我们使用哪种技术。假如你尝试用一段时间一种语言,并且你希望能够精通它,那么有一些事物能在你的进取之路上帮助你。
其中之一就是调试器。有些人喜欢在代码中用简单的 “print” 语句进行调试,这种方式很适合代码量少的简单程序;然而,如果你处理的是有多个开发者和几千行代码的大型项目,你应该使用调试器。
最近我开始学习 Go 编程语言了,在本文中,我们将探讨一种名为 Delve 的调试器。Delve 是专门用来调试 Go 程序的工具,我们会借助一些 Go 示例代码来了解下它的一些功能。不要担心这里展示的 Go 示例代码;即使你之前没有写过 Go 代码也能看懂。Go 的目标之一是简单,因此代码是始终如一的,理解和解释起来都很容易。
### Delve 介绍
Delve 是托管在 [GitHub](https://github.com/go-delve/delve) 上的一个开源项目。
它自己的文档中写道:
>
> Delve 是 Go 编程语言的调试器。该项目的目标是为 Go 提供一个简单、全功能的调试工具。Delve 应该是易于调用和易于使用的。当你使用调试器时,事情可能不会按你的思路运行。如果你这样想,那么你不适合用 Delve。
>
>
>
让我们来近距离看一下。
我的测试系统是运行着 Fedora Linux 的笔记本电脑,Go 编译器版本如下:
```
$ cat /etc/fedora-release
Fedora release 30 (Thirty)
$
$ go version
go version go1.12.17 linux/amd64
$
```
### Golang 安装
如果你没有安装 Go,你可以运行下面的命令,很轻松地就可以从配置的仓库中获取。
```
$ dnf install golang.x86_64
```
或者,你可以在[安装页面](https://golang.org/doc/install)找到适合你的操作系统的其他安装版本。
在开始之前,请先确认已经设置好了 Go 工具依赖的下列各个路径。如果这些路径没有设置,有些示例可能不能正常运行。你可以在 SHELL 的 RC 文件中轻松设置这些环境变量,我的机器上是在 `$HOME/bashrc` 文件中设置的。
```
$ go env | grep GOPATH
GOPATH="/home/user/go"
$
$ go env | grep GOBIN
GOBIN="/home/user/go/gobin"
$
```
### Delve 安装
你可以像下面那样,通过运行一个简单的 `go get` 命令来安装 Delve。`go get` 是 Golang 从外部源下载和安装需要的包的方式。如果你安装过程中遇到了问题,可以查看 [Delve 安装教程](https://github.com/go-delve/delve/blob/master/Documentation/installation/linux/install.md)。
```
$ go get -u github.com/go-delve/delve/cmd/dlv
$
```
运行上面的命令,就会把 Delve 下载到你的 `$GOPATH` 的位置,如果你没有把 `$GOPATH` 设置成其他值,那么默认情况下 `$GOPATH` 和 `$HOME/go` 是同一个路径。
你可以进入 `go/` 目录,你可以在 `bin/` 目录下看到 `dlv`。
```
$ ls -l $HOME/go
total 8
drwxrwxr-x. 2 user user 4096 May 25 19:11 bin
drwxrwxr-x. 4 user user 4096 May 25 19:21 src
$
$ ls -l ~/go/bin/
total 19596
-rwxrwxr-x. 1 user user 20062654 May 25 19:17 dlv
$
```
因为你把 Delve 安装到了 `$GOPATH`,所以你可以像运行普通的 shell 命令一样运行它,即每次运行时你不必先进入它所在的目录。你可以通过 `version` 选项来验证 `dlv` 是否正确安装。示例中安装的版本是 1.4.1。
```
$ which dlv
~/go/bin/dlv
$
$ dlv version
Delve Debugger
Version: 1.4.1
Build: $Id: bda606147ff48b58bde39e20b9e11378eaa4db46 $
$
```
现在,我们一起在 Go 程序中使用 Delve 来理解下它的功能以及如何使用它们。我们先来写一个 `hello.go`,简单地打印一条 `Hello, world!` 信息。
记着,我把这些示例程序放到了 `$GOBIN` 目录下。
```
$ pwd
/home/user/go/gobin
$
$ cat hello.go
package main
import "fmt"
func main() {
fmt.Println("Hello, world!")
}
$
```
运行 `build` 命令来编译一个 Go 程序,它的输入是 `.go` 后缀的文件。如果程序没有语法错误,Go 编译器把它编译成一个二进制可执行文件。这个文件可以被直接运行,运行后我们会在屏幕上看到 `Hello, world!` 信息。
```
$ go build hello.go
$
$ ls -l hello
-rwxrwxr-x. 1 user user 1997284 May 26 12:13 hello
$
$ ./hello
Hello, world!
$
```
### 在 Delve 中加载程序
把一个程序加载进 Delve 调试器有两种方式。
#### 在源码编译成二进制文件之前使用 debug 参数
第一种方式是在需要时对源码使用 `debug` 命令。Delve 会为你编译出一个名为 `__debug_bin` 的二进制文件,并把它加载进调试器。
在这个例子中,你可以进入 `hello.go` 所在的目录,然后运行 `dlv debug` 命令。如果目录中有多个源文件且每个文件都有自己的主函数,Delve 则可能抛出错误,它期望的是单个程序或从单个项目构建成单个二进制文件。如果出现了这种错误,那么你就应该用下面展示的第二种方式。
```
$ ls -l
total 4
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
$ dlv debug
Type 'help' for list of commands.
(dlv)
```
现在打开另一个终端,列出目录下的文件。你可以看到一个多出来的 `__debug_bin` 二进制文件,这个文件是由源码编译生成的,并会加载进调试器。你现在可以回到 `dlv` 提示框继续使用 Delve。
```
$ ls -l
total 2036
-rwxrwxr-x. 1 user user 2077085 Jun 4 11:48 __debug_bin
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
```
#### 使用 exec 参数
如果你已经有提前编译好的 Go 程序或者已经用 `go build` 命令编译完成了,不想再用 Delve 编译出 `__debug_bin` 二进制文件,那么第二种把程序加载进 Delve 的方法在这些情况下会很有用。在上述情况下,你可以使用 `exec` 命令来把整个目录加载进 Delve 调试器。
```
$ ls -l
total 4
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
$ go build hello.go
$
$ ls -l
total 1956
-rwxrwxr-x. 1 user user 1997284 Jun 4 11:54 hello
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
$ dlv exec ./hello
Type 'help' for list of commands.
(dlv)
```
### 查看 delve 帮助信息
在 `dlv` 提示符中,你可以运行 `help` 来查看 Delve 提供的多种帮助选项。命令列表相当长,这里我们只列举一些重要的功能。下面是 Delve 的功能概览。
```
(dlv) help
The following commands are available:
Running the program:
Manipulating breakpoints:
Viewing program variables and memory:
Listing and switching between threads and goroutines:
Viewing the call stack and selecting frames:
Other commands:
Type help followed by a command for full documentation.
(dlv)
```
#### 设置断点
现在我们已经把 hello.go 程序加载进了 Delve 调试器,我们在主函数处设置断点,稍后来确认它。在 Go 中,主程序从 `main.main` 处开始执行,因此你需要给这个名字提供个 `break` 命令。之后,我们可以用 `breakpoints` 命令来检查断点是否正确设置了。
不要忘了你还可以用命令简写,因此你可以用 `b main.main` 来代替 `break main.main`,两者效果相同,`bp` 和 `breakpoints` 同理。你可以通过运行 `help` 命令查看帮助信息来找到你想要的命令简写。
```
(dlv) break main.main
Breakpoint 1 set at 0x4a228f for main.main() ./hello.go:5
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42c410 for runtime.fatalthrow() /usr/lib/golang/src/runtime/panic.go:663 (0)
Breakpoint unrecovered-panic at 0x42c480 for runtime.fatalpanic() /usr/lib/golang/src/runtime/panic.go:690 (0)
print runtime.curg._panic.arg
Breakpoint 1 at 0x4a228f for main.main() ./hello.go:5 (0)
(dlv)
```
#### 程序继续执行
现在,我们用 `continue` 来继续运行程序。它会运行到断点处中止,在我们的例子中,会运行到主函数的 `main.main` 处中止。从这里开始,我们可以用 `next` 命令来逐行执行程序。请注意,当我们运行到 `fmt.Println("Hello, world!")` 处时,即使我们还在调试器里,我们也能看到打印到屏幕的 `Hello, world!`。
```
(dlv) continue
> main.main() ./hello.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a228f)
1: package main
2:
3: import "fmt"
4:
=> 5: func main() {
6: fmt.Println("Hello, world!")
7: }
(dlv) next
> main.main() ./hello.go:6 (PC: 0x4a229d)
1: package main
2:
3: import "fmt"
4:
5: func main() {
=> 6: fmt.Println("Hello, world!")
7: }
(dlv) next
Hello, world!
> main.main() ./hello.go:7 (PC: 0x4a22ff)
2:
3: import "fmt"
4:
5: func main() {
6: fmt.Println("Hello, world!")
=> 7: }
(dlv)
```
#### 退出 Delve
你随时可以运行 `quit` 命令来退出调试器,退出之后你会回到 shell 提示符。相当简单,对吗?
```
(dlv) quit
$
```
### Delve 的其他功能
我们用其他的 Go 程序来探索下 Delve 的其他功能。这次,我们从 [golang 教程](https://tour.golang.org/basics/4) 中找了一个程序。如果你要学习 Go 语言,那么 Golang 教程应该是你的第一站。
下面的程序,`functions.go` 中简单展示了 Go 程序中是怎样定义和调用函数的。这里,我们有一个简单的把两数相加并返回和值的 `add()` 函数。你可以像下面那样构建程序并运行它。
```
$ cat functions.go
package main
import "fmt"
func add(x int, y int) int {
return x + y
}
func main() {
fmt.Println(add(42, 13))
}
$
```
你可以像下面那样构建和运行程序。
```
$ go build functions.go && ./functions
55
$
```
#### 进入函数
跟前面展示的一样,我们用前面提到的一个选项来把二进制文件加载进 Delve 调试器,再一次在 `main.main` 处设置断点,继续运行程序直到断点处。然后执行 `next` 直到 `fmt.Println(add(42, 13))` 处;这里我们调用了 `add()` 函数。我们可以像下面展示的那样,用 Delve 的 `step` 命令从 `main` 函数进入 `add()` 函数。
```
$ dlv debug
Type 'help' for list of commands.
(dlv) break main.main
Breakpoint 1 set at 0x4a22b3 for main.main() ./functions.go:9
(dlv) c
> main.main() ./functions.go:9 (hits goroutine(1):1 total:1) (PC: 0x4a22b3)
4:
5: func add(x int, y int) int {
6: return x + y
7: }
8:
=> 9: func main() {
10: fmt.Println(add(42, 13))
11: }
(dlv) next
> main.main() ./functions.go:10 (PC: 0x4a22c1)
5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
=> 10: fmt.Println(add(42, 13))
11: }
(dlv) step
> main.add() ./functions.go:5 (PC: 0x4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv)
```
#### 使用`文件名:行号`来设置断点
上面的例子中,我们经过 `main` 函数进入了 `add()` 函数,但是你也可以在你想加断点的地方直接使用“文件名:行号”的组合。下面是在 `add()` 函数开始处加断点的另一种方式。
```
(dlv) break functions.go:5
Breakpoint 1 set at 0x4a2280 for main.add() ./functions.go:5
(dlv) continue
> main.add() ./functions.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv)
```
#### 查看当前的栈信息
现在我们运行到了 `add()` 函数,我们可以在 Delve 中用 `stack` 命令查看当前栈的内容。这里在 `0` 位置展示了栈顶的函数 `add()` ,紧接着在 `1` 位置展示了调用 `add()` 函数的 `main.main`。在 `main.main` 下面的函数属于 Go 运行时,是用来处理加载和执行该程序的。
```
(dlv) stack
0 0x00000000004a2280 in main.add
at ./functions.go:5
1 0x00000000004a22d7 in main.main
at ./functions.go:10
2 0x000000000042dd1f in runtime.main
at /usr/lib/golang/src/runtime/proc.go:200
3 0x0000000000458171 in runtime.goexit
at /usr/lib/golang/src/runtime/asm_amd64.s:1337
(dlv)
```
#### 在帧之间跳转
在 Delve 中我们可以用 `frame` 命令实现帧之间的跳转。在下面的例子中,我们用 `frame` 实现了从 `add()` 帧跳到 `main.main` 帧,以此类推。
```
(dlv) frame 0
> main.add() ./functions.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a2280)
Frame 0: ./functions.go:5 (PC: 4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv) frame 1
> main.add() ./functions.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a2280)
Frame 1: ./functions.go:10 (PC: 4a22d7)
5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
=> 10: fmt.Println(add(42, 13))
11: }
(dlv)
```
#### 打印函数参数
一个函数通常会接收多个参数。在 `add()` 函数中,它的入参是两个整型。Delve 有个便捷的 `args` 命令,它能打印出命令行传给函数的参数。
```
(dlv) args
x = 42
y = 13
~r2 = 824633786832
(dlv)
```
#### 查看反汇编码
由于我们是调试编译出的二进制文件,因此如果我们能查看编译器生成的汇编语言指令将会非常有用。Delve 提供了一个 `disassemble` 命令来查看这些指令。在下面的例子中,我们用它来查看 `add()` 函数的汇编指令。
```
(dlv) step
> main.add() ./functions.go:5 (PC: 0x4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv) disassemble
TEXT main.add(SB) /home/user/go/gobin/functions.go
=> functions.go:5 0x4a2280 48c744241800000000 mov qword ptr [rsp+0x18], 0x0
functions.go:6 0x4a2289 488b442408 mov rax, qword ptr [rsp+0x8]
functions.go:6 0x4a228e 4803442410 add rax, qword ptr [rsp+0x10]
functions.go:6 0x4a2293 4889442418 mov qword ptr [rsp+0x18], rax
functions.go:6 0x4a2298 c3 ret
(dlv)
```
#### 单步退出函数
另一个功能是 `stepout`,这个功能可以让我们跳回到函数被调用的地方。在我们的例子中,如果我们想回到 `main.main` 函数,我们只需要简单地运行 `stepout` 命令,它就会把我们带回去。在我们调试大型代码库时,这个功能会是一个非常便捷的工具。
```
(dlv) stepout
> main.main() ./functions.go:10 (PC: 0x4a22d7)
Values returned:
~r2: 55
5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
=> 10: fmt.Println(add(42, 13))
11: }
(dlv)
```
#### 打印变量信息
我们一起通过 [Go 教程](https://tour.golang.org/basics/9) 的另一个示例程序来看下 Delve 是怎么处理 Go 中的变量的。下面的示例程序定义和初始化了一些不同类型的变量。你可以构建和运行程序。
```
$ cat variables.go
package main
import "fmt"
var i, j int = 1, 2
func main() {
var c, python, java = true, false, "no!"
fmt.Println(i, j, c, python, java)
}
$
$ go build variables.go &&; ./variables
1 2 true false no!
$
```
像前面说过的那样,用 `delve debug` 在调试器中加载程序。你可以在 Delve 中用 `print` 命令通过变量名来展示他们当前的值。
```
(dlv) print c
true
(dlv) print java
"no!"
(dlv)
```
或者,你还可以用 `locals` 命令来打印函数内所有的局部变量。
```
(dlv) locals
python = false
c = true
java = "no!"
(dlv)
```
如果你不知道变量的类型,你可以用 `whatis` 命令来通过变量名来打印它的类型。
```
(dlv) whatis python
bool
(dlv) whatis c
bool
(dlv) whatis java
string
(dlv)
```
### 总结
现在我们只是了解了 Delve 所有功能的皮毛。你可以自己去查看帮助内容,尝试下其它的命令。你还可以把 Delve 绑定到运行中的 Go 程序上(守护进程!),如果你安装了 Go 源码库,你甚至可以用 Delve 导出 Golang 库内部的信息。勇敢去探索吧!
---
via: <https://opensource.com/article/20/6/debug-go-delve>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When was the last time you tried to learn a new programming language? Do you stick with your tried and true, or are you one of the brave souls who tries out a new one as soon as it is announced? Either way, learning a new language can be extremely useful, and a lot of fun.
You try out with a simple "Hello, world!" then move onto writing some sample code and executing it, making minor changes along the way and then moving on from there. I am sure we have all gone through this experience no matter which technology we've worked on. Though if you do manage to stay with a language for some time, and you wish to become proficient in it, there are a few things that can help you along the way.
One of those things is a debugger. Some people prefer debugging using simple "print" statements in code, and they are fine for a few simple line programs; however, if you are working on a large project with multiple developers and thousands of lines of code, it makes sense to invest in a debugger.
I've recently started learning the Go programming language, and in this article, we will explore a debugger called Delve. Delve is a special utility made to debug Go programs, and we will cover some of its features using some sample Go code. Don't worry about the Go code examples presented here; they are understandable even if you have never programmed in Go before. One of the goals of Go is simplicity, so the code is consistent, which can be easier to understand and interpret.
## Introduction to Delve
Delve is an open source project hosted at [GitHub](https://github.com/go-delve/delve).
In its own words:
*Delve is a debugger for the Go programming language. The goal of the project is to provide a simple, full-featured debugging tool for Go. Delve should be easy to invoke and easy to use. Chances are if you're using a debugger, things aren't going your way. With that in mind, Delve should stay out of your way as much as possible.*
Let's take a closer look.
My test system is a laptop running Fedora Linux along with the following Go compiler version:
```
$ cat /etc/fedora-release
Fedora release 30 (Thirty)
$
$ go version
go version go1.12.17 linux/amd64
$
```
## Golang installation
If you do not have Go installed, you can get it by simply running the following command to fetch it from your configured repositories.
`$ dnf install golang.x86_64`
Alternatively, you can visit the [install page](https://golang.org/doc/install) for other installation options suitable for your OS distribution.
Before we get started, please ensure that the following required PATHS are set, as required by Go tools. If these paths are not set, some of the examples might not work. These can be easily set as environment variables in your SHELL's RC file, like the `$HOME/bashrc`
file in my case.
```
$ go env | grep GOPATH
GOPATH="/home/user/go"
$
$ go env | grep GOBIN
GOBIN="/home/user/go/gobin"
$
```
## Delve installation
You can install Delve by running a simple `go get`
command, as shown below. `go get`
is the Golang way of downloading and installing required packages from external sources. If you do face any issues with installation, please refer to the install instructions for Delve [here](https://github.com/go-delve/delve/blob/master/Documentation/installation/linux/install.md).
```
$ go get -u github.com/go-delve/delve/cmd/dlv
$
```
Running the above command downloads Delve to your $GOPATH location, which, in the default case, happens to be $HOME/go. It will be different if you have set $GOPATH to something else.
You can move to the go/ directory, within which you will see `dlv`
under bin/ directory.
```
$ ls -l $HOME/go
total 8
drwxrwxr-x. 2 user user 4096 May 25 19:11 bin
drwxrwxr-x. 4 user user 4096 May 25 19:21 src
$
$ ls -l ~/go/bin/
total 19596
-rwxrwxr-x. 1 user user 20062654 May 25 19:17 dlv
$
```
Since you installed Delve under $GOPATH, it is also available as a regular shell command, so you do not have to move to the directory where it is installed every time. You can verify `dlv`
is correctly installed by running it with the `version`
option. The version it installed is 1.4.1.
```
$ which dlv
~/go/bin/dlv
$
$ dlv version
Delve Debugger
Version: 1.4.1
Build: $Id: bda606147ff48b58bde39e20b9e11378eaa4db46 $
$
```
Now, let's use Delve with some Go programs to understand its features and how to use them. As we do with all programs, let's start with a simple "Hello, world!" message, which, in Go, is called `hello.go`
.
Remember, I am placing these sample programs within the $GOBIN directory.
```
$ pwd
/home/user/go/gobin
$
$ cat hello.go
package main
import "fmt"
func main() {
fmt.Println("Hello, world!")
}
$
```
To build a Go program, you run the `build`
command and provide it with the source file using the .go extention. If the program is free of any syntax issues, the Go compiler compiles it and puts out a binary or executables file. This file can then be executed directly, and we see the "Hello, world!" message displayed onscreen.
```
$ go build hello.go
$
$ ls -l hello
-rwxrwxr-x. 1 user user 1997284 May 26 12:13 hello
$
$ ./hello
Hello, world!
$
```
## Loading a program in Delve
There are two ways to load a program into the Delve debugger.
**Using the debug argument when source code is not yet compiled to binary.**
The first way is to use the **debug** command when you simply need to source files. Delve compiles a binary for you named **__debug_bin**, and loads it into the debugger.
In this example, move to the directory where **hello.go** is present and run the **dlv debug** command. If there are multiple Go source files within a directory and each has its own main function, then Delve might throw an error, expecting a single program or a single project to build a binary from. Should that occur, you're better off using the second option, presented below.
```
$ ls -l
total 4
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
$ dlv debug
Type 'help' for list of commands.
(dlv)
```
Now open another terminal and list the contents of the same directory. You see an additional **__debug_bin** binary that was compiled from the source code and loaded into the debugger. You can now move to the **dlv** prompt to continue using Delve further.
```
$ ls -l
total 2036
-rwxrwxr-x. 1 user user 2077085 Jun 4 11:48 __debug_bin
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
```
**Using the exec argument **
The second method to load a program into Delve is useful when you have a pre-compiled Go binary, or one that you have already compiled using the **go build **command, and don't want Delve to compile it to a `__debug_bin` binary. In such cases, use the **exec** argument to load the binary directory into the Delve debugger.
```
$ ls -l
total 4
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
$ go build hello.go
$
$ ls -l
total 1956
-rwxrwxr-x. 1 user user 1997284 Jun 4 11:54 hello
-rw-rw-r--. 1 user user 74 Jun 4 11:48 hello.go
$
$ dlv exec ./hello
Type 'help' for list of commands.
(dlv)
```
## Getting help within Delve
At the **dlv** prompt, you can run `help`
to have a look at the various help options available in Delve. The command list is quite extensive, and we will cover some of the important features here. Following is an overview of Delve's functionality.
```
(dlv) help
The following commands are available:
Running the program:
Manipulating breakpoints:
Viewing program variables and memory:
Listing and switching between threads and goroutines:
Viewing the call stack and selecting frames:
Other commands:
Type help followed by a command for full documentation.
(dlv)
```
### Setting breakpoints
Now that we have loaded the hello.go program within the Delve debugger, let's set the breakpoint on our main function and then confirm it. Within Go, the main program starts with `main.main`
, so you need to provide this name to the `break command`
. Next, we will see if the breakpoint was set correctly using the `breakpoints`
command.
Also, remember you can use shorthands for commands, so instead of using `break main.main`
, you can also use `b main.main`
to the same effect, or `bp`
instead of `breakpoints`
. To find the exact shorthand for a command, please refer to the help section by running the `help`
command.
```
(dlv) break main.main
Breakpoint 1 set at 0x4a228f for main.main() ./hello.go:5
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42c410 for runtime.fatalthrow() /usr/lib/golang/src/runtime/panic.go:663 (0)
Breakpoint unrecovered-panic at 0x42c480 for runtime.fatalpanic() /usr/lib/golang/src/runtime/panic.go:690 (0)
print runtime.curg._panic.arg
Breakpoint 1 at 0x4a228f for main.main() ./hello.go:5 (0)
(dlv)
```
### Continue execution of the program
Now, let's continue running the program using "continue." It will run until it hits a breakpoint, which, in our case, is the `main.main`
or the main function. From there, we can use the `next`
command to execute the program line by line. Notice that, once we move ahead of `fmt.Println("Hello, world!")`
, we can see that `Hello, world!`
is printed to the screen while we are still within the debugger session.
```
(dlv) continue
> main.main() ./hello.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a228f)
1: package main
2:
3: import "fmt"
4:
=> 5: func main() {
6: fmt.Println("Hello, world!")
7: }
(dlv) next
> main.main() ./hello.go:6 (PC: 0x4a229d)
1: package main
2:
3: import "fmt"
4:
5: func main() {
=> 6: fmt.Println("Hello, world!")
7: }
(dlv) next
Hello, world!
> main.main() ./hello.go:7 (PC: 0x4a22ff)
2:
3: import "fmt"
4:
5: func main() {
6: fmt.Println("Hello, world!")
=> 7: }
(dlv)
```
### Quitting Delve
If you wish to quit the debugger at any time, you can run the `quit`
command, and you will be returned to the shell prompt. Pretty simple, right?
```
(dlv) quit
$
```
Let's use some other Go programs to explore some other Delve features. This time, we will pick a program from the [Golang tour](https://tour.golang.org/basics/4). If you are learning Go, the Golang tour should be your first stop.
The following program, `functions.go`
, simply displays how functions are defined and called in a Go program. Here, we have a simple `add()`
function that adds two numbers and returns their value. You can build the program and execute it, as shown below.
```
$ cat functions.go
package main
import "fmt"
func add(x int, y int) int {
return x + y
}
func main() {
fmt.Println(add(42, 13))
}
$
```
You can build the program and execute it as shown below.
```
$ go build functions.go && ./functions
55
$
```
### Stepping into functions
As shown earlier, let's load the binary into the Delve debugger using one of the options mentioned earlier, again setting a breakpoint at `main.main`
and continuing to run the program while we hit the breakpoint. Then hit `next`
until you reach `fmt.Println(add(42, 13))`
; here we make a call to the `add()`
function. We can use the Delve `step`
command to move from the `main`
function to the `add()`
function, as seen below.
```
$ dlv debug
Type 'help' for list of commands.
(dlv) break main.main
Breakpoint 1 set at 0x4a22b3 for main.main() ./functions.go:9
(dlv) c
> main.main() ./functions.go:9 (hits goroutine(1):1 total:1) (PC: 0x4a22b3)
4:
5: func add(x int, y int) int {
6: return x + y
7: }
8:
=> 9: func main() {
10: fmt.Println(add(42, 13))
11: }
(dlv) next
> main.main() ./functions.go:10 (PC: 0x4a22c1)
5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
=> 10: fmt.Println(add(42, 13))
11: }
(dlv) step
> main.add() ./functions.go:5 (PC: 0x4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv)
```
### Set breakpoint using filename: linenumber
Above, we went through `main`
and then moved to the `add()`
function, but you can also use the `filename:linenumber`
combination to set a breakpoint directly where we want it. Following is another way of setting a breakpoint at the start of the `add()`
function.
```
(dlv) break functions.go:5
Breakpoint 1 set at 0x4a2280 for main.add() ./functions.go:5
(dlv) continue
> main.add() ./functions.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv)
```
### View current stack details
Now that we are at the `add()`
function, we can view the current contents of the stack using the `stack`
command in Delve. This shows the topmost function `add()`
at 0 where we are, followed by `main.main`
at 1 from where the `add()`
function was called. Functions below `main.main`
belong to the Go runtime, which is responsible for loading and executing the program.
```
(dlv) stack
0 0x00000000004a2280 in main.add
at ./functions.go:5
1 0x00000000004a22d7 in main.main
at ./functions.go:10
2 0x000000000042dd1f in runtime.main
at /usr/lib/golang/src/runtime/proc.go:200
3 0x0000000000458171 in runtime.goexit
at /usr/lib/golang/src/runtime/asm_amd64.s:1337
(dlv)
```
### Move between frames
Using the `frame`
command in Delve, we can switch between the above frames at will. In the example below, using `frame 1`
switches us from within the `add()`
frame to the `main.main`
frame, and so on.
```
(dlv) frame 0
> main.add() ./functions.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a2280)
Frame 0: ./functions.go:5 (PC: 4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv) frame 1
> main.add() ./functions.go:5 (hits goroutine(1):1 total:1) (PC: 0x4a2280)
Frame 1: ./functions.go:10 (PC: 4a22d7)
5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
=> 10: fmt.Println(add(42, 13))
11: }
(dlv)
```
**Print function arguments**
A function often accepts multiple arguments to work on. In the case of the `add()`
function, it accepts two integers. Delve has a handy command called `args`
, which displays the command-line arguments passed to the function.
```
(dlv) args
x = 42
y = 13
~r2 = 824633786832
(dlv)
```
### View disassembly
Since we are dealing with compiled binaries, it is extremely helpful to be able to see the assembly language instructions produced by the compiler. Delve provides a `disassemble`
command to view these. In the example below, we use it to view the disassembly instructions for the `add()`
function.
```
(dlv) step
> main.add() ./functions.go:5 (PC: 0x4a2280)
1: package main
2:
3: import "fmt"
4:
=> 5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
10: fmt.Println(add(42, 13))
(dlv) disassemble
TEXT main.add(SB) /home/user/go/gobin/functions.go
=> functions.go:5 0x4a2280 48c744241800000000 mov qword ptr [rsp+0x18], 0x0
functions.go:6 0x4a2289 488b442408 mov rax, qword ptr [rsp+0x8]
functions.go:6 0x4a228e 4803442410 add rax, qword ptr [rsp+0x10]
functions.go:6 0x4a2293 4889442418 mov qword ptr [rsp+0x18], rax
functions.go:6 0x4a2298 c3 ret
(dlv)
```
### Stepout of functions
Another feature is `stepout`
, which allows us to return back to where the function was called from. In our example, if we wish to return to the `main.main`
function, we can simply run the `stepout`
command and it will take us back. This can be quite a handy tool to help you move around in a large codebase.
```
(dlv) stepout
> main.main() ./functions.go:10 (PC: 0x4a22d7)
Values returned:
~r2: 55
5: func add(x int, y int) int {
6: return x + y
7: }
8:
9: func main() {
=> 10: fmt.Println(add(42, 13))
11: }
(dlv)
```
Let's use another sample program from the [Go tour](https://tour.golang.org/basics/9) to see how Delve deals with variables in Go. The following sample program defines and initializes some variables of different types. You can build the program and execute it.
```
$ cat variables.go
package main
import "fmt"
var i, j int = 1, 2
func main() {
var c, python, java = true, false, "no!"
fmt.Println(i, j, c, python, java)
}
$
$ go build variables.go && ./variables
1 2 true false no!
$
```
### Print variable information
As stated earlier, use `delve debug`
to load the program in the debugger. You can use the `print`
command from within Delve along with the variable name to show their current values.
```
(dlv) print c
true
(dlv) print java
"no!"
(dlv)
```
Alternatively, you can use the `locals`
command to print all local variables within a function.
```
(dlv) locals
python = false
c = true
java = "no!"
(dlv)
```
If you are not aware of the type of the variable, you can use the `whatis`
command along with the variable name to print the type.
```
(dlv) whatis python
bool
(dlv) whatis c
bool
(dlv) whatis java
string
(dlv)
```
## Conclusion
So far, we have only scratched the surface of the features Delve offers. You can refer to the` help`
section and try out various other commands. Some of the other useful features include attaching Delve to running Go programs (daemons!) or even using Delve to explore some of the internals of Golang libraries, provided you have the Go source code package installed. Keep exploring!
## Comments are closed. |
12,401 | Solus Linux 创始人正在开发一个没有 GNU 的“真正现代”的 Linux 发行版 | https://itsfoss.com/serpent-os-announcement/ | 2020-07-10T10:04:00 | [
"Linux",
"GNU"
] | https://linux.cn/article-12401-1.html | 曾经创建独立 Linux 发行版 Solus 的开发人员 [Ikey Doherty](https://itsfoss.com/ikey-doherty-serpent-interview/) 宣布了他的新项目:Serpent OS。
[Serpent OS](https://www.serpentos.com/) 是一个**不想**被归类为“轻量级、用户友好、注重隐私的 Linux 桌面发行版”。
相反,Serpent OS 具有“与主流产品不同的目标”。具体怎么样?请继续阅读。
### Serpent OS:制作“真正现代”的 Linux 发行版

Serpent 采用发行版优先,兼容靠后的方法。这使他们可以做出一些非常大胆的决定。
Ikey 表示,这个项目不会对阻碍 Linux 的负面角色容忍。例如,不会容忍 NVIDIA 在其 GPU 上缺乏对 Wayland 加速的支持,并将 NVIDIA 专有驱动加入发行版黑名单。
这是 Serpent Linux 项目的拟议计划(摘自[其网站](https://www.serpentos.com/about/)):
* 不再分割 usrbin
* 100% clang 构建(包括内核)
* musl 作为 libc,依靠编译器优化而不是内联 asm
* 使用 libc++ 而不是 libstdc++
* LLVM 的 binutils 变体(lld、as 等)
* 混合源代码/二进制分发
* 从 x86\_64 通用基线转移到更新的 CPU,包括针对 Intel 和 AMD 的优化
* 包管理器中基于功能的订阅(硬件/用户选择等)
* 只支持 UEFI。不支持老式启动方式
* 完全开源,包括引导程序/重建脚本
* 针对高工作负载进行了认真的优化
* 第三方应用仅依赖于容器。没有兼容性修改
* 仅支持 Wayland。将调查通过容器的 X11 兼容性
* 完全无状态的管理工具和上游补丁
Ikey 大胆地宣称 Serpent Linux 不是 Serpent GNU/Linux,因为它不再依赖于 GNU 工具链或运行时。
Serpent OS 项目的开发将于 7 月底开始。没有确定最终稳定版本的时间表。
### 要求过高?但是 Ikey 过去做到了
你可能会怀疑 Serpent OS 是否会出现,是否能够兑现其所作的所有承诺。
但是 Ikey Doherty 过去已经做到了。如果我没记错的话,他首先基于 Debian 创建了 SolusOS。他于 2013 年停止了基于 [Debian 的 SolusOS](https://distrowatch.com/table.php?distribution=solusos) 的开发,甚至它还没有进入 Beta 阶段。
然后,他从头开始创建 [evolve OS](https://itsfoss.com/beta-evolve-os-released/),而不是使用其他发行版作为基础。由于某些命名版权问题,项目名称已更改为 Solus(是的,相同的旧名称)。[Ikey 在 2018 年退出了 Solus 项目](https://itsfoss.com/ikey-leaves-solus/),其他开发人员现在负责该项目。
Solus 是一个独立的 Linux 发行版,它为我们提供了漂亮的 Budgie 桌面环境。
Ikey 过去做到了(当然,在其他开发人员的帮助下)。他现在也应该能够做到。
### 看好还是不看好?
你如何看待这个 Serpent Linux?你是否认为是时候让开发人员采取大胆的立场,并着眼于未来开发操作系统,而不是坚持过去?请分享你的观点。
---
via: <https://itsfoss.com/serpent-os-announcement/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Ikey Doherty](https://itsfoss.com/ikey-doherty-serpent-interview/), the developer who once created the independent Linux distribution Solus has announced his new project: Serpent OS.
[Serpent OS](https://www.serpentos.com/) is a Linux distribution that DOES NOT want to be categorized as “lightweight, user-friendly, privacy-focused Linux desktop distribution”.
Instead, Serpent OS has “different goals from the mainstream offering”. How? Read on.
## Serpent OS: The making of a “truly modern” Linux distribution

Serpent takes distro-first, compatibility-later approach. This lets them take some really bold decisions.
Ikey says that it this project will not tolerate for negative actors holding Linux back. For example, NVIDIA’s lack of support for accelerated Wayland support on their GPUs will not be tolerated and NVIDIA proprietary drivers will be blocklisted from the distribution.
Here’s a proposed plan for the Serpent Linux project (taken from [their website](https://www.serpentos.com/about/)):
- No more usrbin split
- 100% clang-built throughout (including kernel)
- musl as libc, relying on compiler optimisations instead of inline asm
- libc++ instead of libstdc++
- LLVM’s binutils variants (lld, as, etc.)
- Mixed source/binary distribution
- Moving away from x86_64-generic baseline to newer CPUs, including Intel and AMD specific optimisations
- Capability based subscriptions in package manager (Hardware/ user choice / etc)
`UEFI`
only. No more legacy boot.- Completely open source, down to the bootstrap / rebuild scripts
- Seriously optimised for serious workloads.
- Third party applications reliant on containers only. No compat-hacks
- Wayland-only. X11 compatibility via containers will be investigated
- Fully stateless with management tools and upstreaming of patches
Ikey boldly claims that Serpent Linux is not Serpent GNU/Linux because it is not going to be dependent on a GNU toolchain or runtime.
The development for Serpent OS project starts by the end of July. There is no definite timeline of the final stable release.
## Too high claims? But Ikey has done it in the past
You may doubt if Serpent OS will see the light of the day and if it would be able to keep all the promises it made.
But Ikey Doherty has done it in the past. If I remember correctly, he first created SolusOS based on Debian. He discontinued the [Debian-based SolusOS](https://distrowatch.com/table.php?distribution=solusos) in 2013 before it even reached the beta stage.
He then went out to create [evolve OS](https://itsfoss.com/beta-evolve-os-released/) from scratch instead of using another distribution as base. Due to some naming copyright issues, the project name was changed to Solus (yes, the same old name). [Ikey quit the Solus projec](https://itsfoss.com/ikey-leaves-solus/)[t](https://itsfoss.com/ikey-leaves-solus/)[ in 2018](https://itsfoss.com/ikey-leaves-solus/) and other devs now handle the project.
Solus is an independent Linux distribution that gave us the beautiful Budgie desktop environment.
Ikey has done it in the past (with the help of other developers, of course). He should be able to pull this one off as well.
**Yay or Nay?**
What do you think of this Serpent Linux? Do you think it is time for developers to take a bold stand and develop the operating system with the future in the mind rather than holding on to the past? Do share your views. |
12,403 | entr:文件更改时重新运行构建 | https://jvns.ca/blog/2020/06/28/entr/ | 2020-07-11T09:42:44 | [
"文件监控",
"inotify"
] | https://linux.cn/article-12403-1.html | 
这是一篇简短的文章。我是最近才发现 [entr](http://eradman.com/entrproject/) 的,我很惊奇从来没有人告诉过我?!因此,如果你和我一样,那么我告诉你它是什么。
[entr 的网站](http://eradman.com/entrproject/)上对它已经有很好的解释,也有很多示例。
总结在其头部:`entr` 是一个命令行工具,当每次更改一组指定文件中的任何一个时,都能运行一个任意命令。你在标准输入给它传递要监控的文件列表,如下所示:
```
git ls-files | entr bash my-build-script.sh
```
或者
```
find . -name *.rs | entr cargo test
```
或者任何你希望的。
### 快速反馈很棒
就像世界上的每个程序员一样,我发现每次更改代码时都必须手动重新运行构建/测试非常烦人。
许多工具(例如 hugo 和 flask)都有一个内置的系统,可以在更改文件时自动重建,这很棒!
但是通常我会自己编写一些自定义的构建过程(例如 `bash build.sh`),而 `entr` 让我有了一种神奇的构建经验,我只用一行 bash 就能得到即时反馈,知道我的改变是否修复了那个奇怪的 bug。万岁!
### 重启服务器(entr -r)
但是如果你正在运行服务器,并且每次都需要重新启动服务器怎么办?如果你传递 `-r`,那么 `entr` 会帮你的
```
git ls-files | entr -r python my-server.py
```
### 清除屏幕(entr -c)
另一个简洁的标志是 `-c`,它让你可以在重新运行命令之前清除屏幕,以免被前面构建的输出分散注意力。
### 与 git ls-files 一起使用
通常,我要跟踪的文件集和我在 git 中的文件列表大致相同,因此将 `git ls-files` 传递给 `entr` 是很自然的事情。
我现在有一个项目,有时候我刚创建的文件还没有在 git 里。那么如果你想包含未被跟踪的文件怎么办呢?这些 `git` 命令行参数就可以做到(我是从一个读者的邮件中得到的,谢谢你!):
```
git ls-files -cdmo --exclude-standard | entr your-build-script
```
有人给我发了邮件,说他们做了一个 `git-entr` 命令,可以执行:
```
git ls-files -cdmo --exclude-standard | entr -d "$@"
```
我觉得这真是一个很棒的主意。
### 每次添加新文件时重启:entr -d
`git ls-files` 的另一个问题是有时候我添加一个新文件,当然它还没有在 git 中。`entr` 为此提供了一个很好的功能。如果你传递 `-d`,那么如果你在 `entr` 跟踪的任何目录中添加新文件,它就会退出。
我将它与一个 `while` 循环配合使用,它将重启 `entr` 来包括新文件,如下所示:
```
while true
do
{ git ls-files; git ls-files . --exclude-standard --others; } | entr -d your-build-scriot
done
```
### entr 在 Linux 上的工作方式:inotify
在 Linux 中,`entr` 使用 `inotify`(用于跟踪文件更改这样的文件系统事件的系统)工作。如果用 `strace` 跟踪它,那么你会看到每个监控文件的 `inotify_add_watch` 系统调用,如下所示:
```
inotify_add_watch(3, "static/stylesheets/screen.css", IN_ATTRIB|IN_CLOSE_WRITE|IN_CREATE|IN_DELETE_SELF|IN_MOVE_SELF) = 1152
```
### 就这样了
我希望这可以帮助一些人了解 `entr`!
---
via: <https://jvns.ca/blog/2020/06/28/entr/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is going to be a pretty quick post – I found out about [ entr](http://eradman.com/entrproject/) relatively
recently and I felt like WHY DID NOBODY TELL ME ABOUT THIS BEFORE?!?! So I’m
telling you about it in case you’re in the same boat as I was.
There’s a great explanation of the tool with lots of examples on [entr’s website](http://eradman.com/entrproject/).
The summary is in the headline: `entr`
is a command line tool that lets you run
an arbitrary command every time you change any of a set of specified files. You
pass it the list of files to watch on stdin, like this:
```
git ls-files | entr bash my-build-script.sh
```
or
```
find . -name *.rs | entr cargo test
```
or whatever you want really.
### quick feedback is amazing
Like possibly every single programmer in the universe, I find it Very Annoying to have to manually rerun my build / tests every time I make a change to my code.
A lot of tools (like hugo and flask) have a built in system to automatically rebuild when you change your files, which is great!
But often I have some hacked together custom build process that I wrote myself
(like `bash build.sh`
), and `entr`
lets me have a magical build experience
where I get instant feedback on whether my change fixed the weird bug with just
one line of bash. Hooray!
### restart a server (`entr -r`
)
Okay, but what if you’re running a server, and the server needs to be restarted
every time you change a file? entr’s got you – if you pass `-r`
, then
```
git ls-files | entr -r python my-server.py
```
### clear the screen (`entr -c`
)
Another neat flag is `-c`
, which lets you clear the screen before rerunning the
command, so that you don’t get distracted/confused by the previous build’s
output.
### use it with `git ls-files`
Usually the set of files I want to track is about the same list of files I have
in git, so `git ls-files`
is a natural thing to pipe to `entr`
.
I have a project right now where sometimes I have files that I’ve just created that aren’t in git just yet. So what if you want to include untracked files? These git command line arguments will do it (I got them from an email from a reader, thank you!):
```
git ls-files -cdmo --exclude-standard | entr your-build-script
```
Someone emailed me and said they have a `git-entr`
command that runs
```
git ls-files -cdmo --exclude-standard | entr -d "$@"
```
which I think is a great idea.
### restart every time a new file is added: `entr -d`
The other problem with this `git ls-files`
thing is that sometimes I add a new
file, and of course it’s not in git yet. entr has a nice feature for this – if
you pass `-d`
, then if you add a new file in any of the directories entr is
tracking, then it’ll exit.
I’m using this paired with a little while loop that will restart
`entr`
to include the new files, like this:
```
while true
do
{ git ls-files; git ls-files . --exclude-standard --others; } | entr -d your-build-script
done
```
### how entr works on Linux: inotify
On Linux, entr works using `inotify`
(a system for tracking filesystem events
like file changes) – if you strace it, you’ll see an `inotify_add_watch`
system call for each file you ask it to watch, like this:
```
inotify_add_watch(3, "static/stylesheets/screen.css", IN_ATTRIB|IN_CLOSE_WRITE|IN_CREATE|IN_DELETE_SELF|IN_MOVE_SELF) = 1152
```
### that’s all!
I hope this helps a few people learn about `entr`
! |
12,404 | 安装 Linux Mint 20 后需要做的 13 件事 | https://itsfoss.com/things-to-do-after-installing-linux-mint-20/ | 2020-07-11T11:37:02 | [
"Mint"
] | https://linux.cn/article-12404-1.html | 
Linux Mint 毫无疑问是 [最佳 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 之一,特别是考虑到 [Linux Mint 20](/article-12297-1.html) 的功能,我确信你也会同意这一说法。
假设你错过了我们的新闻报道,[Linux Mint 20 终于可以下载了](/article-12376-1.html)。
当然,如果你使用 Linux Mint 有一段时间了,你可能知道最好做一些什么。但是,对于新用户来说,在安装 Linux Mint 20 后,你需要做一些事,让你的体验更比以往任何时候都好。
### 在安装 Linux Mint 20 后建议做的事
在这篇文章中,我将列出其中一些要做的事来帮助你改善 Linux Mint 20 的用户体验。
#### 1、执行一次系统更新

安装后首先应该马上检查的是 —— 使用更新管理器进行系统更新,如上图所示。
为什么?因为你需要构建可用软件的本地缓存。更新所有软件包的更新也是一个好主意。
如果你喜欢使用终端,只需输入下面的命令来执行系统更新:
```
sudo apt update && sudo apt upgrade -y
```
#### 2、使用 Timeshift 来创建系统快照

如果你想在意外更改或错误更新后快速地恢复系统状态,有一个系统快照总是很有用的。
因此,如果你希望能够随时备份你的系统状态,那么使用 Timeshift 配置和创建系统快照是超级重要的。
如果你还不知道如何使用它的话,你可以遵循我们 [使用 Timeshift](/article-11619-1.html) 的详细指南。
#### 3、安装有用的软件
尽管在 Linux Mint 20 中已经安装有一些有用的预安装应用程序,你可能需要安装一些没有随之一起出炉的必不可少的应用程序。
你可以简单地使用软件包管理器或 synaptic 软件包管理器来查找和安装所需要的软件。
对于初学者来说,如果你想探索各种各样的工具,那么你可以遵循我们的 [必不可少的 Linux 应用程序](/article-10165-1.html) 的列表。
也参见:
* [75 个最常用的 Linux 应用程序(2018 年)](/article-10099-1.html)
* 100 个最佳 Ubuntu 应用([上](/article-11044-1.html)、[中](/article-11048-1.html)、[下](/article-11057-1.html))
这里是一个我最喜欢的软件包列表,我希望你也来尝试一下:
* [VLC 多媒体播放器](https://www.videolan.org/vlc/) 用于视频播放
* [FreeFileSync](https://itsfoss.com/freefilesync/) 用来同步文件
* [Flameshot](https://itsfoss.com/flameshot/) 用于截图
* [Stacer](https://itsfoss.com/optimize-ubuntu-stacer/) 用来优化和监控系统
* [ActivityWatch](https://itsfoss.com/activitywatch/) 用来跟踪你的屏幕时间并保持高效唤醒
#### 4、自定义主题和图标

当然,这在技术上不是必不可少的事,除非你想更改 Linux Mint 20 的外观和感觉。
但是,[在 Linux Mint 中更改主题和图标是非常容易的](https://itsfoss.com/install-icon-linux-mint/) ,而不需要安装任何额外的东西。
你会在欢迎屏幕中获得优化外观的选项。或者,你只需要进入 “主题”,并开始自定义主题。

为此,你可以搜索它或在系统设置中如上图所示找到它。
根据你正在使用的桌面环境,你也可以看看可用的 [最佳图标主题](https://itsfoss.com/best-icon-themes-ubuntu-16-04/)。
#### 5、启用 Redshift 来保护你的眼睛

你可以在 Linux Mint 上搜索 “[Redshift](https://itsfoss.com/install-redshift-linux-mint/)”,并启用它以在晚上保护你的眼睛。如你在上面的截图所见,它将根据时间自动地调整屏幕的色温。
你可能想启用自动启动选项,以便它在你重新启动计算机时自动启动。它可能与 [Ubuntu 20.04 LTS](https://itsfoss.com/ubuntu-20-04-release-features/) 的夜光功能不太一样,但是如果你不需要自定义时间表或微调色温的能力,那么它就足够好了。
#### 6、启用 snap(如果需要的话)
尽管 Ubuntu 比前所未有的更倾向于推崇使用 Snap,但是 Linux Mint 团队却反对使用它。因此,它禁止 APT 使用 snapd。
因此,你将无法获得 snap 开箱即用的支持。然而,你迟早会意识到一些软件包只以 Snap 的格式打包。在这种情况下,你将不得不在 Mint 上启用对 snap 的支持。
```
sudo apt install snapd
```
在你完成后,你可以遵循我们的指南来了解更多关于 [在 Linux 上安装和使用 snap](https://itsfoss.com/install-snap-linux/) 的信息。
#### 7、学习使用 Flatpak
默认情况下,Linux Mint 带有对 Flatpak 的支持。所以,不管你是讨厌使用 snap 或只是更喜欢使用 Flatpak,在系统中保留它是个好主意。
现在,你只需要遵循我们关于 [在 Linux 上使用 Flatpak](https://itsfoss.com/flatpak-guide/) 的指南来开始吧!
#### 8、清理或优化你的系统
优化或清理系统总是好的,以避免不必要的垃圾文件占用存储空间。
你可以通过在终端机上输入以下内容,快速删除系统中不需要的软件包:
```
sudo apt autoremove
```
除此之外,你也可以遵循我们 [在 Linux Mint 上释放空间的一些建议](https://itsfoss.com/free-up-space-ubuntu-linux/) 。
#### 9、使用 Warpinator 通过网络发送/接收文件
Warpinator 是 Linux Mint 20 的一个新功能,可以让你在连接到网络的多台电脑上共享文件。这里是它看起来的样子:

你只需要在菜单中搜索它就可以开始了!
#### 10、使用驱动程序管理器

如果你正在使用需要驱动程序的 Wi-Fi 设备、NVIDIA 显卡或 AMD 显卡,以及其它设备(如果适用的话)时,驱动程序管理器是一个重要的部分。
你只需要找到驱动程序管理器并启用它。它应该可以检测到正在使用的任何专有驱动程序,或者你也可以使用驱动程序管理器来利用 DVD 来安装驱动程序。
#### 11、设置防火墙

在大多数情况下,你可能已经保护了你的家庭网络。但是,如果你想在 Linux Mint 上有一些特殊的防火墙设置,你可以通过在菜单中搜索 “Firewall” 来实现。
正如你在上述截图中所看到的,你可以为家庭、企业和公共设置不同的配置文件。你只需要添加规则,并定义什么是允许访问互联网的,什么是不允许的。
你可以阅读我们关于 [使用 UFW 配置防火墙](https://itsfoss.com/set-up-firewall-gufw/) 的详细指南。
#### 12、学习管理启动应用程序
如果你是一个有经验的用户,你可能已经知道这一点了。但是,新用户经常忘记管理他们的启动应用程序,最终影响了系统启动时间。
你只需要从菜单中搜索 “Startup Applications” ,你可以启动它来查找像这样的东西:

你可以简单地切换你想要禁用的那些启动应用程序,添加一个延迟计时器,或从启动应用程序的列表中完全地移除它。
#### 13、安装必不可少的游戏应用程序
当然,如果你对游戏感兴趣,你可能想去阅读我们关于 [在 Linux 上的游戏](https://itsfoss.com/linux-gaming-guide/) 的文章来探索所有的选择。
但是,对于初学者来说,你可以尝试安装 [GameHub](https://itsfoss.com/gamehub/)、[Steam](https://store.steampowered.com) 和 [Lutris](https://lutris.net) 来玩一些游戏。
### 总结
就是这样,各位!在大多数情况下,如果你在安装 Linux Mint 20 后按照上面的要点进行操作,使其发挥出最好的效果,应该就可以了。
我确信你还能够做更多的事。我想知道你喜欢在安装 Linux Mint 20 后马上做了什么。在下面的评论中告诉我你的想法吧!
---
via: <https://itsfoss.com/things-to-do-after-installing-linux-mint-20/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Mint is easily one of the [best Linux distributions](https://itsfoss.com/best-linux-distributions/) out there and especially considering the features of [Linux Mint 20](https://itsfoss.com/linux-mint-20/), I’m sure you will agree with that.
In case you missed our coverage, [Linux Mint 20 is finally available to download](https://itsfoss.com/linux-mint-20-download/).
Of course, if you’ve been using Linux Mint for a while, you probably know what’s best for you. But, for new users, there are a few things that you need to do after installing Linux Mint 20 to make your experience better than ever.
## Recommended things to do after installing Linux Mint 20
In this article, I’m going to list some of them for to help you improve your Linux Mint 20 experience.
### 1. Perform a System Update
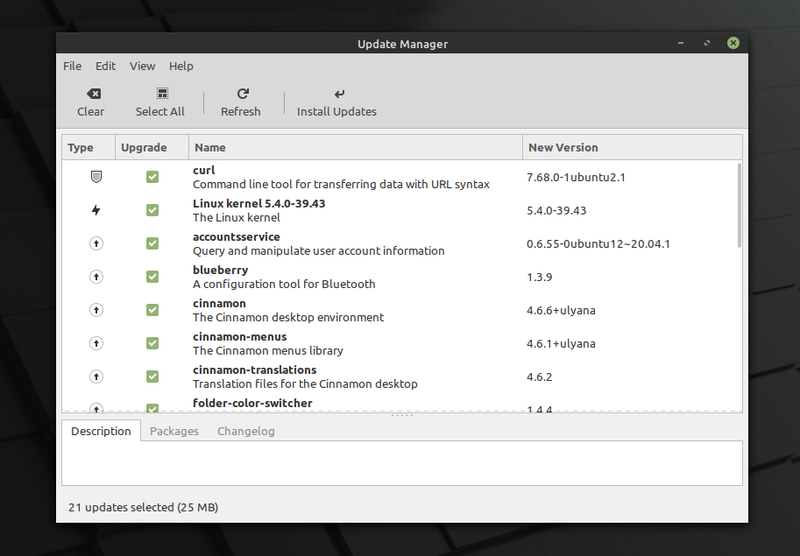
The first thing you should check right after installation is — system updates using the update manager as shown in the image above.
Why? Because you need to build the local cache of available software. It is also a good idea to update all the software updates.
If you prefer to use the terminal, simply type the following command to perform a system update:
`sudo apt update && sudo apt upgrade -y`
### 2. Use Timeshift to Create System Snapshots
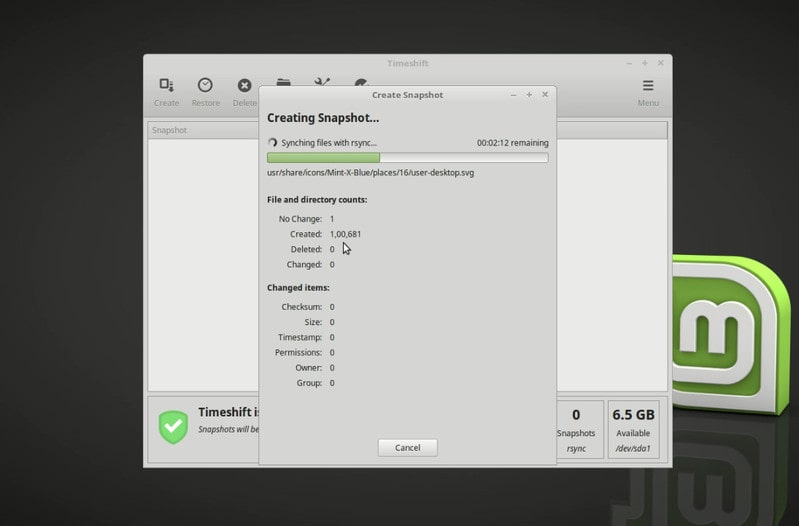
It’s always useful have system snapshots if you want to quickly restore your system state after an accidental change or maybe after a bad update.
Hence, it’s super important to configure and create system snapshots using Timeshift if you want the ability to have a backup of your system state from time to time.
You can follow our detailed guide on [using Timeshift](https://itsfoss.com/backup-restore-linux-timeshift/), if you didn’t know already.
### 3. Install Codecs
To make sure that you don’t have issues with playing a MP4 video file or any other file formats of media, you might want to install the media codecs to make sure that most of the media file formats work on your system.
You can just search for “**mint-meta-codecs**” on your software center or simply type in the following command in the terminal to install it:
`sudo apt install mint-meta-codecs`
### 4. Install Useful Software
Even though you have a bunch of useful pre-installed applications on Linux Mint 20, you probably need to install some essential apps that do not come baked in.
You can simply utilize the software manager or the [synaptic package manager](https://itsfoss.com/synaptic-package-manager/) to find and install software that you need.
For starters, you can follow our list of [essential Linux apps](https://itsfoss.com/essential-linux-applications/) if you want to explore a variety of tools.
Here’s a list of my favorite software that I’d want you to try:
[VLC media player](https://www.videolan.org/vlc/?ref=itsfoss.com)for video[FreeFileSync](https://itsfoss.com/freefilesync/)to sync files[Flameshot](https://itsfoss.com/flameshot/)for screenshots[Stacer](https://itsfoss.com/optimize-ubuntu-stacer/)to optimize and monitor system[ActivityWatch](https://itsfoss.com/activitywatch/)to track your screen time and stay productive
### 5. Customize the Themes and Icons
Of course, this isn’t something technically essential unless you want to change the look and feel of Linux Mint 20.
But, it’s very [easy to change the theme and icons in Linux Mint](https://itsfoss.com/install-icon-linux-mint/) 20 without installing anything extra.
You get the option to customize the look in the welcome screen itself. In either case, you just need to head on to “**Themes**” and start customizing.
To do that, you can search for it or find it inside the System Settings as shown in the screenshot above.
Depending on what desktop environment you are on, you can also take a look at some of the [best icon themes](https://itsfoss.com/best-icon-themes-ubuntu-16-04/) available.
### 6. Enable Redshift to protect your eyes
You can search for “[Redshift](https://itsfoss.com/install-redshift-linux-mint/)” on Linux Mint and launch it to start protecting your eyes at night. As you can see in the screenshot above, it will automatically adjust the color temperature of the screen depending on the time.
You may want to enable the autostart option so that it launches automatically when you restart the computer. It may not be the same as the night light feature on [Ubuntu 20.04 LTS](https://itsfoss.com/ubuntu-20-04-release-features/) but it’s good enough if you don’t need custom schedules or the ability to the tweak the color temperature.
### 7. Enable snap (if needed)
Even though Ubuntu is pushing to use Snap more than ever, the Linux Mint team is against it. Hence, it forbids APT to use snapd.
So, you won’t have the support for snap out-of-the-box. However, sooner or later, you’ll realize that some software is packaged only in Snap format. In such cases, you’ll have to [enable snap support on Linux Mint 20](https://itsfoss.com/enable-snap-support-linux-mint/).
Just because Linux Mint forbids the use of it, you will have to follow the commands below to successfully install snap:
```
sudo rm /etc/apt/preferences.d/nosnap.pref
sudo apt update
sudo apt install snapd
```
Once you do that, you can follow our guide to know more about [installing and using snaps on Linux](https://itsfoss.com/install-snap-linux/).
### 8. Learn to use Flatpak
By default, Linux Mint comes with the support for Flatpak. So, no matter whether you hate using snap or simply prefer to use Flatpak, it’s good to have it baked in.
Now, all you have to do is follow our guide on [using Flatpak on Linux](https://itsfoss.com/flatpak-guide/) to get started!
### 9. Clean or Optimize Your System
It’s always good to optimize or clean up your system to get rid of unnecessary junk files occupying storage space.
You can quickly remove unwanted packages from your system by typing this in your terminal:
`sudo apt autoremove`
In addition to this, you can also follow some of our [tips to free up space on Linux Mint](https://itsfoss.com/free-up-space-ubuntu-linux/).
### 10. Using Warpinator to send/receive files across the network
Warpinator is a new addition to Linux Mint 20 to give you the ability to share files across multiple computers connected to a network. Here’s how it looks:

You can just search for it in the menu and get started!
### 11. Using the driver manager
The driver manager is an important place to look for if you’re using Wi-Fi devices that needs a driver, NVIDIA graphics, or AMD graphics, and drivers for other devices if applicable.
You just need look for the driver manager and launch it. It should detect any proprietary drivers in use or you can also utilize a DVD to install the driver using the driver manager.
### 12. Set up a Firewall
For the most part, you might have already secured your home connection. But, if you want to have some specific firewall settings on Linux Mint, you can do that by searching for “Firewall” in the menu.
As you can observe the screenshot above, you get the ability to have different profiles for home, business, and public. You just need to add the rules and define what is allowed and what’s not allowed to access the Internet.
You may read our detailed guide on [using UFW for configuring a firewall](https://itsfoss.com/set-up-firewall-gufw/).
### 13. Learn to Manage Startup Apps
If you’re an experienced user, you probably know this already. But, new users often forget to manage their startup applications and eventually, the system boot time gets affected.
You just need to search for “**Startup Applications**” from the menu and you can launch it find something like this:
You can simply toggle the ones that you want to disable, add a delay timer, or remove it completely from the list of startup applications.
### 14. Install Essential Apps For Gaming
Of course, if you’re into gaming, you might want to read our article for [Gaming on Linux](https://itsfoss.com/linux-gaming-guide/) to explore all the options.
But, for starters, you can try installing [GameHub](https://itsfoss.com/gamehub/), [Steam](https://store.steampowered.com/?ref=itsfoss.com), and [Lutris](https://lutris.net/?ref=itsfoss.com) to play some games.
**Wrapping Up**
That’s it folks! For the most part, you should be good to go if you follow the points above after [installing Linux Mint 20](https://itsfoss.com/install-linux-mint/) to make the best out of it.
I’m sure there are more things you can do. I’d like to know what you prefer to do right after installing Linux Mint 20. Let me know your thoughts in the comments below! |
12,407 | 使用 Cloud-init 将节点添加到你的私有云中 | https://opensource.com/article/20/5/create-simple-cloud-init-service-your-homelab | 2020-07-12T10:09:52 | [
"家庭实验室",
"私有云"
] | https://linux.cn/article-12407-1.html |
>
> 像主流云提供商的处理方式一样,在家中添加机器到你的私有云。
>
>
>

[Cloud-init](https://cloudinit.readthedocs.io/) 是一种广泛使用的行业标准方法,用于初始化云实例。云提供商使用 Cloud-init 来定制实例的网络配置、实例信息,甚至用户提供的配置指令。它也是一个可以在你的“家庭私有云”中使用的很好的工具,可以为你的家庭实验室的虚拟机和物理机的初始设置和配置添加一点自动化 —— 并了解更多关于大型云提供商是如何工作的信息。关于更多的细节和背景,请看我之前的文章《[在你的树莓派家庭实验室中使用 Cloud-init](/article-12371-1.html)》。

*运行 Cloud-init 的 Linux 服务器的启动过程(Chris Collins,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
诚然,Cloud-init 对于为许多不同客户配置机器的云提供商来说,比对于由单个系统管理员运行的家庭实验室更有用,而且 Cloud-init 解决的许多问题对于家庭实验室来说可能有点多余。然而,设置它并了解它的工作原理是了解更多关于这种云技术的好方法,更不用说它是首次启动时配置设备的好方法。
本教程使用 Cloud-init 的 NoCloud 数据源,它允许 Cloud-init 在传统的云提供商环境之外使用。本文将向你展示如何在客户端设备上安装 Cloud-init,并设置一个运行 Web 服务的容器来响应客户端的请求。你还将学习如何审查客户端从 Web 服务中请求的内容,并修改 Web 服务的容器,以提供基本的、静态的 Cloud-init 服务。
### 在现有系统上设置 Cloud-init
Cloud-init 可能在新系统首次启动时最有用,它可以查询配置数据,并根据指令对系统进行定制。它可以[包含在树莓派和单板计算机的磁盘镜像中](/article-12277-1.html),也可以添加到用于<ruby> 配给 <rt> provision </rt></ruby>虚拟机的镜像中。对于测试用途来说,无论是在现有系统上安装并运行 Cloud-init,还是安装一个新系统,然后设置 Cloud-init,都是很容易的。
作为大多数云提供商使用的主要服务,大多数 Linux 发行版都支持 Cloud-init。在这个例子中,我将使用 Fedora 31 Server 来安装树莓派,但在 Raspbian、Ubuntu、CentOS 和大多数其他发行版上也可以用同样的方式来完成。
#### 安装并启用云计算初始服务
在你想作为 Cloud-init 客户端的系统上,安装 Cloud-init 包。如果你使用的是 Fedora:
```
# Install the cloud-init package
dnf install -y cloud-init
```
Cloud-init 实际上是四个不同的服务(至少在 systemd 下是这样),这些服务负责检索配置数据,并在启动过程的不同阶段进行配置更改,这使得可以做的事情更加灵活。虽然你不太可能直接与这些服务进行太多交互,但在你需要排除一些故障时,知道它们是什么还是很有用的。它们是:
* cloud-init-local.service
* cloud-init.service
* cloud-config.service
* cloud-final.service
启用所有四个服务:
```
# Enable the four cloud-init services
systemctl enable cloud-init-local.service
systemctl enable cloud-init.service
systemctl enable cloud-config.service
systemctl enable cloud-final.service
```
#### 配置数据源以查询
启用服务后,请配置数据源,客户端将从该数据源查询配置数据。有[许多数据源类型](https://cloudinit.readthedocs.io/en/latest/topics/datasources.html),而且大多数都是为特定的云提供商配置的。对于你的家庭实验室,请使用 NoCloud 数据源,(如上所述)它是为在没有云提供商的情况下使用 Cloud-init 而设计的。
NoCloud 允许以多种方式包含配置信息:以内核参数中的键/值对,用于在启动时挂载的 CD(或虚拟机中的虚拟 CD);包含在文件系统中的文件中;或者像本例中一样,通过 HTTP 从指定的 URL(“NoCloud Net” 选项)获取配置信息。
数据源配置可以通过内核参数提供,也可以在 Cloud-init 配置文件 `/etc/cloud/cloud.cfg` 中进行设置。该配置文件对于使用自定义磁盘镜像设置 Cloud-init 或在现有主机上进行测试非常方便。
Cloud-init 还会合并在 `/etc/cloud/cloud.cfg.d/` 中找到的任何 `*.cfg` 文件中的配置数据,因此为了保持整洁,请在 `/etc/cloud/cloud.cfg.d/10_datasource.cfg` 中配置数据源。Cloud-init 可以通过使用以下语法从 `seedfrom` 键指向的 HTTP 数据源中读取数据。
```
seedfrom: http://ip_address:port/
```
IP 地址和端口是你将在本文后面创建的 Web 服务。我使用了我的笔记本电脑的 IP 和 8080 端口。这也可以是 DNS 名称。
创建 `/etc/cloud/cloud.cfg.d/10_datasource.cfg` 文件:
```
# Add the datasource:
# /etc/cloud/cloud.cfg.d/10_datasource.cfg
# NOTE THE TRAILING SLASH HERE!
datasource:
NoCloud:
seedfrom: http://ip_address:port/
```
客户端设置就是这样。现在,重新启动客户端后,它将尝试从你在 `seedfrom` 键中输入的 URL 检索配置数据,并进行必要的任何配置更改。
下一步是设置一个 Web 服务器来侦听客户端请求,以便你确定需要提供的服务。
### 设置网络服务器以审查客户请求
你可以使用 [Podman](https://podman.io/) 或其他容器编排工具(如 Docker 或 Kubernetes)快速创建和运行 Web 服务器。这个例子使用的是 Podman,但同样的命令也适用于 Docker。
要开始,请使用 `fedora:31` 容器镜像并创建一个容器文件(对于 Docker 来说,这会是一个 Dockerfile)来安装和配置 Nginx。从该容器文件中,你可以构建一个自定义镜像,并在你希望提供 Cloud-init 服务的主机上运行它。
创建一个包含以下内容的容器文件:
```
FROM fedora:31
ENV NGINX_CONF_DIR "/etc/nginx/default.d"
ENV NGINX_LOG_DIR "/var/log/nginx"
ENV NGINX_CONF "/etc/nginx/nginx.conf"
ENV WWW_DIR "/usr/share/nginx/html"
# Install Nginx and clear the yum cache
RUN dnf install -y nginx \
&& dnf clean all \
&& rm -rf /var/cache/yum
# forward request and error logs to docker log collector
RUN ln -sf /dev/stdout ${NGINX_LOG_DIR}/access.log \
&& ln -sf /dev/stderr ${NGINX_LOG_DIR}/error.log
# Listen on port 8080, so root privileges are not required for podman
RUN sed -i -E 's/(listen)([[:space:]]*)(\[\:\:\]\:)?80;$/\1\2\38080 default_server;/' $NGINX_CONF
EXPOSE 8080
# Allow Nginx PID to be managed by non-root user
RUN sed -i '/user nginx;/d' $NGINX_CONF
RUN sed -i 's/pid \/run\/nginx.pid;/pid \/tmp\/nginx.pid;/' $NGINX_CONF
# Run as an unprivileged user
USER 1001
CMD ["nginx", "-g", "daemon off;"]
```
注:本例中使用的容器文件和其他文件可以在本项目的 [GitHub 仓库](https://github.com/clcollins/homelabCloudInit/tree/master/simpleCloudInitService/data)中找到。
上面容器文件中最重要的部分是改变日志存储方式的部分(写到 STDOUT 而不是文件),这样你就可以在容器日志中看到进入该服务器的请求。其他的一些改变使你可以在没有 root 权限的情况下使用 Podman 运行容器,也可以在没有 root 权限的情况下运行容器中的进程。
在 Web 服务器上的第一个测试并不提供任何 Cloud-init 数据;只是用它来查看 Cloud-init 客户端的请求。
创建容器文件后,使用 Podman 构建并运行 Web 服务器镜像:
```
# Build the container image
$ podman build -f Containerfile -t cloud-init:01 .
# Create a container from the new image, and run it
# It will listen on port 8080
$ podman run --rm -p 8080:8080 -it cloud-init:01
```
这会运行一个容器,让你的终端连接到一个伪 TTY。一开始看起来什么都没有发生,但是对主机 8080 端口的请求会被路由到容器内的 Nginx 服务器,并且在终端窗口中会出现一条日志信息。这一点可以用主机上的 `curl` 命令进行测试。
```
# Use curl to send an HTTP request to the Nginx container
$ curl http://localhost:8080
```
运行该 `curl` 命令后,你应该会在终端窗口中看到类似这样的日志信息:
```
127.0.0.1 - - [09/May/2020:19:25:10 +0000] "GET / HTTP/1.1" 200 5564 "-" "curl/7.66.0" "-"
```
现在,有趣的部分来了:重启 Cloud-init 客户端,并观察 Nginx 日志,看看当客户端启动时, Cloud-init 向 Web 服务器发出了什么请求。
当客户端完成其启动过程时,你应该会看到类似的日志消息。
```
2020/05/09 22:44:28 [error] 2#0: *4 open() "/usr/share/nginx/html/meta-data" failed (2: No such file or directory), client: 127.0.0.1, server: _, request: "GET /meta-data HTTP/1.1", host: "instance-data:8080"
127.0.0.1 - - [09/May/2020:22:44:28 +0000] "GET /meta-data HTTP/1.1" 404 3650 "-" "Cloud-Init/17.1" "-"
```
注:使用 `Ctrl+C` 停止正在运行的容器。
你可以看到请求是针对 `/meta-data` 路径的,即 `http://ip_address_of_the_webserver:8080/meta-data`。这只是一个 GET 请求 —— Cloud-init 并没有向 Web 服务器发送任何数据。它只是盲目地从数据源 URL 中请求文件,所以要由数据源来识别主机的要求。这个简单的例子只是向任何客户端发送通用数据,但一个更大的家庭实验室应该需要更复杂的服务。
在这里,Cloud-init 请求的是[实例元数据](https://cloudinit.readthedocs.io/en/latest/topics/instancedata.html#what-is-instance-data)信息。这个文件可以包含很多关于实例本身的信息,例如实例 ID、分配实例的主机名、云 ID,甚至网络信息。
创建一个包含实例 ID 和主机名的基本元数据文件,并尝试将其提供给 Cloud-init 客户端。
首先,创建一个可复制到容器镜像中的 `meta-data` 文件。
```
instance-id: iid-local01
local-hostname: raspberry
hostname: raspberry
```
实例 ID(`instance-id`)可以是任何东西。但是,如果你在 Cloud-init 运行后更改实例 ID,并且文件被送达客户端,就会触发 Cloud-init 再次运行。你可以使用这种机制来更新实例配置,但你应该意识到它是这种工作方式。
`local-hostname` 和 `hostname` 键正如其名,它们会在 Cloud-init 运行时为客户端设置主机名信息。
在容器文件中添加以下行以将 `meta-data` 文件复制到新镜像中。
```
# Copy the meta-data file into the image for Nginx to serve it
COPY meta-data ${WWW_DIR}/meta-data
```
现在,用元数据文件重建镜像(使用一个新的标签以方便故障排除),并用 Podman 创建并运行一个新的容器。
```
# Build a new image named cloud-init:02
podman build -f Containerfile -t cloud-init:02 .
# Run a new container with this new meta-data file
podman run --rm -p 8080:8080 -it cloud-init:02
```
新容器运行后,重启 Cloud-init 客户端,再次观察 Nginx 日志。
```
127.0.0.1 - - [09/May/2020:22:54:32 +0000] "GET /meta-data HTTP/1.1" 200 63 "-" "Cloud-Init/17.1" "-"
2020/05/09 22:54:32 [error] 2#0: *2 open() "/usr/share/nginx/html/user-data" failed (2: No such file or directory), client: 127.0.0.1, server: _, request: "GET /user-data HTTP/1.1", host: "instance-data:8080"
127.0.0.1 - - [09/May/2020:22:54:32 +0000] "GET /user-data HTTP/1.1" 404 3650 "-" "Cloud-Init/17.1" "-"
```
你看,这次 `/meta-data` 路径被提供给了客户端。成功了!
然而,客户端接着在 `/user-data` 路径上寻找第二个文件。该文件包含实例所有者提供的配置数据,而不是来自云提供商的数据。对于一个家庭实验室来说,这两个都是你自己提供的。
你可以使用[许多 user-data 模块](https://cloudinit.readthedocs.io/en/latest/topics/modules.html)来配置你的实例。对于这个例子,只需使用 `write_files` 模块在客户端创建一些测试文件,并验证 Cloud-init 是否工作。
创建一个包含以下内容的用户数据文件:
```
#cloud-config
# Create two files with example content using the write_files module
write_files:
- content: |
"Does cloud-init work?"
owner: root:root
permissions: '0644'
path: /srv/foo
- content: |
"IT SURE DOES!"
owner: root:root
permissions: '0644'
path: /srv/bar
```
除了使用 Cloud-init 提供的 `user-data` 模块制作 YAML 文件外,你还可以将其制作成一个可执行脚本供 Cloud-init 运行。
创建 `user-data` 文件后,在容器文件中添加以下行,以便在重建映像时将其复制到镜像中:
```
# Copy the user-data file into the container image
COPY user-data ${WWW_DIR}/user-data
```
重建镜像,并创建和运行一个新的容器,这次使用用户数据信息:
```
# Build a new image named cloud-init:03
podman build -f Containerfile -t cloud-init:03 .
# Run a new container with this new user-data file
podman run --rm -p 8080:8080 -it cloud-init:03
```
现在,重启 Cloud-init 客户端,观察 Web 服务器上的 Nginx 日志:
```
127.0.0.1 - - [09/May/2020:23:01:51 +0000] "GET /meta-data HTTP/1.1" 200 63 "-" "Cloud-Init/17.1" "-"
127.0.0.1 - - [09/May/2020:23:01:51 +0000] "GET /user-data HTTP/1.1" 200 298 "-" "Cloud-Init/17.1" "-
```
成功了!这一次,元数据和用户数据文件都被送到了 Cloud-init 客户端。
### 验证 Cloud-init 已运行
从上面的日志中,你知道 Cloud-init 在客户端主机上运行并请求元数据和用户数据文件,但它用它们做了什么?你可以在 `write_files` 部分验证 Cloud-init 是否写入了你在用户数据文件中添加的文件。
在 Cloud-init 客户端上,检查 `/srv/foo` 和 `/srv/bar` 文件的内容:
```
# cd /srv/ && ls
bar foo
# cat foo
"Does cloud-init work?"
# cat bar
"IT SURE DOES!"
```
成功了!文件已经写好了,并且有你期望的内容。
如上所述,还有很多其他模块可以用来配置主机。例如,用户数据文件可以配置成用 `apt` 添加包、复制 SSH 的 `authorized_keys`、创建用户和组、配置和运行配置管理工具等等。我在家里的私有云中使用它来复制我的 `authorized_keys`、创建一个本地用户和组,并设置 sudo 权限。
### 你接下来可以做什么
Cloud-init 在家庭实验室中很有用,尤其是专注于云技术的实验室。本文所演示的简单服务对于家庭实验室来说可能并不是超级有用,但现在你已经知道 Cloud-init 是如何工作的了,你可以继续创建一个动态服务,可以用自定义数据配置每台主机,让家里的私有云更类似于主流云提供商提供的服务。
在数据源稍显复杂的情况下,将新的物理(或虚拟)机器添加到家中的私有云中,可以像插入它们并打开它们一样简单。
---
via: <https://opensource.com/article/20/5/create-simple-cloud-init-service-your-homelab>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Cloud-init](https://cloudinit.readthedocs.io/) is a widely utilized industry-standard method for initializing cloud instances. Cloud providers use Cloud-init to customize instances with network configuration, instance information, and even user-provided configuration directives. It is also a great tool to use in your "private cloud at home" to add a little automation to the initial setup and configuration of your homelab's virtual and physical machines—and to learn more about how large cloud providers work. For a bit more detail and background, see my previous article on [Cloud-init and why it is useful](https://opensource.com/article/20/5/cloud-init-raspberry-pi-homelab).
Boot process for a Linux server running Cloud-init (Chris Collins, CC BY-SA 4.0)
Admittedly, Cloud-init is more useful for a cloud provider provisioning machines for many different clients than for a homelab run by a single sysadmin, and much of what Cloud-init solves might be a little superfluous for a homelab. However, getting it set up and learning how it works is a great way to learn more about this cloud technology, not to mention that it's a great way to configure your devices on first boot.
This tutorial uses Cloud-init's "NoCloud" datasource, which allows Cloud-init to be used outside a traditional cloud provider setting. This article will show you how to install Cloud-init on a client device and set up a container running a web service to respond to the client's requests. You will also learn to investigate what the client is requesting from the web service and modify the web service's container to serve a basic, static Cloud-init service.
## Set up Cloud-init on an existing system
Cloud-init probably is most useful on a new system's first boot to query for configuration data and make changes to customize the system as directed. It can be [included in a disk image for Raspberry Pis and single-board computers ](https://opensource.com/article/20/5/disk-image-raspberry-pi) or added to images used to provision virtual machines. For testing, it is easy to install and run Cloud-init on an existing system or to install a new system and then set up Cloud-init.
As a major service used by most cloud providers, Cloud-init is supported on most Linux distributions. For this example, I will be using Fedora 31 Server for the Raspberry Pi, but it can be done the same way on Raspbian, Ubuntu, CentOS, and most other distributions.
### Install and enable the cloud-init services
On a system that you want to be a Cloud-init client, install the Cloud-init package. If you're using Fedora:
```
# Install the cloud-init package
dnf install -y cloud-init
```
Cloud-init is actually four different services (at least with systemd), and each is in charge of retrieving config data and performing configuration changes during a different part of the boot process, allowing greater flexibility in what can be done. While it is unlikely you will interact much with these services directly, it is useful to know what they are in the event you need to troubleshoot something. They are:
- cloud-init-local.service
- cloud-init.service
- cloud-config.service
- cloud-final.service
Enable all four services:
```
# Enable the four cloud-init services
systemctl enable cloud-init-local.service
systemctl enable cloud-init.service
systemctl enable cloud-config.service
systemctl enable cloud-final.service
```
### Configure the datasource to query
Once the service is enabled, configure the datasource from which the client will query the config data. There are a [large number of datasource types](https://cloudinit.readthedocs.io/en/latest/topics/datasources.html), and most are configured for specific cloud providers. For your homelab, use the NoCloud datasource, which (as mentioned above) is designed for using Cloud-init without a cloud provider.
NoCloud allows configuration information to be included a number of ways: as key/value pairs in kernel parameters, for using a CD (or virtual CD, in the case of virtual machines) mounted at startup, in a file included on the filesystem, or, as in this example, via HTTP from a specified URL (the "NoCloud Net" option).
The datasource configuration can be provided via the kernel parameter or by setting it in the Cloud-init configuration file, `/etc/cloud/cloud.cfg`
. The configuration file works very well for setting up Cloud-init with customized disk images or for testing on existing hosts.
Cloud-init will also merge configuration data from any `*.cfg`
files found in `/etc/cloud/cloud.cfg.d/`
, so to keep things cleaner, configure the datasource in `/etc/cloud/cloud.cfg.d/10_datasource.cfg`
. Cloud-init can be told to read from an HTTP datasource with the seedfrom key by using the syntax:
`seedfrom: http://ip_address:port/`
The IP address and port are the web service you will create later in this article. I used the IP of my laptop and port 8080; this can also be a DNS name.
Create the `/etc/cloud/cloud.cfg.d/10_datasource.cfg`
file:
```
# Add the datasource:
# /etc/cloud/cloud.cfg.d/10_datasource.cfg
# NOTE THE TRAILING SLASH HERE!
datasource:
NoCloud:
seedfrom: http://ip_address:port/
```
That's it for the client setup. Now, when the client is rebooted, it will attempt to retrieve configuration data from the URL you entered in the seedfrom key and make any configuration changes that are necessary.
The next step is to set up a webserver to listen for client requests, so you can figure out what needs to be served.
## Set up a webserver to investigate client requests
You can create and run a webserver quickly with [Podman](https://podman.io/) or other container orchestration tools (like Docker or Kubernetes). This example uses Podman, but the same commands work with Docker.
To get started, use the Fedora:31 container image and create a Containerfile (for Docker, this would be a Dockerfile) that installs and configures Nginx. From that Containerfile, you can build a custom image and run it on the host you want to act as the Cloud-init service.
Create a Containerfile with the following contents:
```
FROM fedora:31
ENV NGINX_CONF_DIR "/etc/nginx/default.d"
ENV NGINX_LOG_DIR "/var/log/nginx"
ENV NGINX_CONF "/etc/nginx/nginx.conf"
ENV WWW_DIR "/usr/share/nginx/html"
# Install Nginx and clear the yum cache
RUN dnf install -y nginx \
&& dnf clean all \
&& rm -rf /var/cache/yum
# forward request and error logs to docker log collector
RUN ln -sf /dev/stdout ${NGINX_LOG_DIR}/access.log \
&& ln -sf /dev/stderr ${NGINX_LOG_DIR}/error.log
# Listen on port 8080, so root privileges are not required for podman
RUN sed -i -E 's/(listen)([[:space:]]*)(\[\:\:\]\:)?80;$/\1\2\38080 default_server;/' $NGINX_CONF
EXPOSE 8080
# Allow Nginx PID to be managed by non-root user
RUN sed -i '/user nginx;/d' $NGINX_CONF
RUN sed -i 's/pid \/run\/nginx.pid;/pid \/tmp\/nginx.pid;/' $NGINX_CONF
# Run as an unprivileged user
USER 1001
CMD ["nginx", "-g", "daemon off;"]
```
*Note: The example Containerfile and other files used in this example can be found in this project's GitHub repository.*
The most important part of the Containerfile above is the section that changes how the logs are stored (writing to STDOUT rather than a file), so you can see requests coming into the server in the container logs. A few other changes enable you to run the container with Podman without root privileges and to run processes in the container without root, as well.
This first pass at the webserver does not serve any Cloud-init data; just use this to see what the Cloud-init client is requesting from it.
With the Containerfile created, use Podman to build and run a webserver image:
```
# Build the container image
$ podman build -f Containerfile -t cloud-init:01 .
# Create a container from the new image, and run it
# It will listen on port 8080
$ podman run --rm -p 8080:8080 -it cloud-init:01
```
This will run the container, leaving your terminal attached and with a pseudo-TTY. It will appear that nothing is happening at first, but requests to port 8080 of the host machine will be routed to the Nginx server inside the container, and a log message will appear in the terminal window. This can be tested with a curl command from the host machine:
```
# Use curl to send an HTTP request to the Nginx container
$ curl http://localhost:8080
```
After running that curl command, you should see a log message similar to this in the terminal window:
`127.0.0.1 - - [09/May/2020:19:25:10 +0000] "GET / HTTP/1.1" 200 5564 "-" "curl/7.66.0" "-"`
Now comes the fun part: reboot the Cloud-init client and watch the Nginx logs to see what Cloud-init requests from the webserver when the client boots up.
As the client finishes its boot process, you should see log messages similar to:
```
2020/05/09 22:44:28 [error] 2#0: *4 open() "/usr/share/nginx/html/meta-data" failed (2: No such file or directory), client: 127.0.0.1, server: _, request: "GET /meta-data HTTP/1.1", host: "instance-data:8080"
127.0.0.1 - - [09/May/2020:22:44:28 +0000] "GET /meta-data HTTP/1.1" 404 3650 "-" "Cloud-Init/17.1" "-"
```
*Note: Use Ctrl+C to stop the running container.*
You can see the request is for the /meta-data path, i.e., `http://ip_address_of_the_webserver:8080/meta-data`
. This is just a GET request—Cloud-init is not POSTing (sending) any data to the webserver. It is just blindly requesting the files from the datasource URL, so it is up to the datasource to identify what the host is asking. This simple example is just sending generic data to any client, but a larger homelab will need a more sophisticated service.
Here, Cloud-init is requesting the [instance metadata](https://cloudinit.readthedocs.io/en/latest/topics/instancedata.html#what-is-instance-data) information. This file can include a lot of information about the instance itself, such as the instance ID, the hostname to assign the instance, the cloud ID—even networking information.
Create a basic metadata file with an instance ID and a hostname for the host, and try serving that to the Cloud-init client.
First, create a metadata file that can be copied into the container image:
```
instance-id: iid-local01
local-hostname: raspberry
hostname: raspberry
```
The instance ID can be anything. However, if you change the instance ID after Cloud-init runs and the file is served to the client, it will trigger Cloud-init to run again. You can use this mechanism to update instance configurations, but you should be aware that it works that way.
The local-hostname and hostname keys are just that; they set the hostname information for the client when Cloud-init runs.
Add the following line to the Containerfile to copy the metadata file into the new image:
```
# Copy the meta-data file into the image for Nginx to serve it
COPY meta-data ${WWW_DIR}/meta-data
```
Now, rebuild the image (use a new tag for easy troubleshooting) with the metadata file, and create and run a new container with Podman:
```
# Build a new image named cloud-init:02
podman build -f Containerfile -t cloud-init:02 .
# Run a new container with this new meta-data file
podman run --rm -p 8080:8080 -it cloud-init:02
```
With the new container running, reboot your Cloud-init client and watch the Nginx logs again:
```
127.0.0.1 - - [09/May/2020:22:54:32 +0000] "GET /meta-data HTTP/1.1" 200 63 "-" "Cloud-Init/17.1" "-"
2020/05/09 22:54:32 [error] 2#0: *2 open() "/usr/share/nginx/html/user-data" failed (2: No such file or directory), client: 127.0.0.1, server: _, request: "GET /user-data HTTP/1.1", host: "instance-data:8080"
127.0.0.1 - - [09/May/2020:22:54:32 +0000] "GET /user-data HTTP/1.1" 404 3650 "-" "Cloud-Init/17.1" "-"
```
You see that this time the /meta-data path was served to the client. Success!
However, the client is looking for a second file at the /user-data path. This file contains configuration data provided by the instance owner, as opposed to data from the cloud provider. For a homelab, both of these are you.
There are a [large number of user-data modules](https://cloudinit.readthedocs.io/en/latest/topics/modules.html) you can use to configure your instance. For this example, just use the write_files module to create some test files on the client and verify that Cloud-init is working.
Create a user-data file with the following content:
```
#cloud-config
# Create two files with example content using the write_files module
write_files:
- content: |
"Does cloud-init work?"
owner: root:root
permissions: '0644'
path: /srv/foo
- content: |
"IT SURE DOES!"
owner: root:root
permissions: '0644'
path: /srv/bar
```
In addition to a YAML file using the user-data modules provided by Cloud-init, you could also make this an executable script for Cloud-init to run.
After creating the user-data file, add the following line to the Containerfile to copy it into the image when the image is rebuilt:
```
# Copy the user-data file into the container image
COPY user-data ${WWW_DIR}/user-data
```
Rebuild the image and create and run a new container, this time with the user-data information:
```
# Build a new image named cloud-init:03
podman build -f Containerfile -t cloud-init:03 .
# Run a new container with this new user-data file
podman run --rm -p 8080:8080 -it cloud-init:03
```
Now, reboot your Cloud-init client, and watch the Nginx logs on the webserver:
```
127.0.0.1 - - [09/May/2020:23:01:51 +0000] "GET /meta-data HTTP/1.1" 200 63 "-" "Cloud-Init/17.1" "-"
127.0.0.1 - - [09/May/2020:23:01:51 +0000] "GET /user-data HTTP/1.1" 200 298 "-" "Cloud-Init/17.1" "-
```
Success! This time both the metadata and user-data files were served to the Cloud-init client.
## Validate that Cloud-init ran
From the logs above, you know that Cloud-init ran on the client host and requested the metadata and user-data files, but did it do anything with them? You can validate that Cloud-init wrote the files you added in the user-data file, in the write_files section.
On your Cloud-init client, check the contents of the `/srv/foo`
and `/srv/bar`
files:
```
# cd /srv/ && ls
bar foo
# cat foo
"Does cloud-init work?"
# cat bar
"IT SURE DOES!"
```
Success! The files were written and have the content you expect.
As mentioned above, there are plenty of other modules that can be used to configure the host. For example, the user-data file can be configured to add packages with apt, copy SSH authorized_keys, create users and groups, configure and run configuration-management tools, and many other things. I use it in my private cloud at home to copy my authorized_keys, create a local user and group, and set up sudo permissions.
## What you can do next
Cloud-init is useful in a homelab, especially a lab focusing on cloud technologies. The simple service demonstrated in this article may not be super useful for a homelab, but now that you know how Cloud-init works, you can move on to creating a dynamic service that can configure each host with custom data, making a private cloud at home more similar to the services provided by the major cloud providers.
With a slightly more complicated datasource, adding new physical (or virtual) machines to your private cloud at home can be as simple as plugging them in and turning them on.
## 1 Comment |
12,408 | 关于哈希(散列)函数你应该知道的东西 | https://opensource.com/article/20/7/hash-functions | 2020-07-12T14:58:14 | [
"哈希",
"散列",
"加密"
] | /article-12408-1.html |
>
> 从输出的哈希值反推回输入,这从计算的角度是不可行的。
>
>
>

无论安全从业人员用计算机做什么,有一种工具对他们每个人都很有用:加密<ruby> 哈希(散列) <rt> hash </rt></ruby>函数。这听起来很神秘、很专业,甚至可能有点乏味,但是, 在这里,关于什么是哈希函数以及它们为什么对你很重要,我会作出一个简洁的解释。
加密哈希函数,比如 SHA-256 或者 MD5,接受一组二进制数据(通常是字节)作为输入,并且对每个可能的输入集给出一个<ruby> 希望唯一 <rt> hopefully unique </rt></ruby>的输出。对于任意模式的输入,给定的哈希函数的输出(“哈希值”)的长度都是一样的(对于 SHA-256,是 32 字节或者 256 比特,这从名字中就能看出来)。最重要的是:从输出的哈希值反推回输入,这从计算的角度是<ruby> 不可行的 <rt> implausible </rt></ruby>(密码学家讨厌 “<ruby> 不可能 <rt> impossible </rt></ruby>” 这个词)。这就是为什么它们有时候被称作<ruby> 单向哈希函数 <rt> one-way hash function </rt></ruby>。
但是哈希函数是用来做什么的呢?为什么“唯一”的属性如此重要?
### 唯一的输出
在描述哈希函数的输出时,“<ruby> 希望唯一 <rt> hopefully unique </rt></ruby>”这个短语是至关重要的,因为哈希函数就是用来呈现完全唯一的输出。比如,哈希函数可以用于验证 *你* 下载的文件副本的每一个字节是否和 *我* 下载的文件一样。你下载一个 Linux 的 ISO 文件或者从 Linux 的仓库中下载软件时,你会看到使用这个验证过程。没有了唯一性,这个技术就没用了,至少就通常的目的而言是这样的。
如果两个不同的输入产生了相同的输出,那么这样的哈希过程就称作“<ruby> 碰撞 <rt> collision </rt></ruby>”。事实上,MD5 算法已经被弃用,因为虽然可能性微乎其微,但它现在可以用市面上的硬件和软件系统找到碰撞。
另外一个重要的特性是,消息中的一个微小变化,甚至只是改变一个比特位,都可能会在输出中产生一个明显的变化(这就是“<ruby> 雪崩效应 <rt> avalanche effect </rt></ruby>”)。
### 验证二进制数据
哈希函数的典型用途是当有人给你一段二进制数据,确保这些数据是你所期望的。无论是文本、可执行文件、视频、图像或者一个完整的数据库数据,在计算世界中,所有的数据都可以用二进制的形式进行描述,所以至少可以这么说,哈希是广泛适用的。直接比较二进制数据是非常缓慢的且计算量巨大,但是哈希函数在设计上非常快。给定两个大小为几 M 或者几 G 的文件,你可以事先生成它们的哈希值,然后在需要的时候再进行比较。
通常,对哈希值进行签名比对大型数据集本身进行签名更容易。这个特性太重要了,以至于密码学中对哈希值最常见的应用就是生成“数字”签名。
由于生成数据的哈希值很容易,所以通常不需要有两套数据。假设你想在你的电脑上运行一个可执行文件。但是在你运行之前,你需要检查这个文件就是你要的文件,没有被黑客篡改。你可以方便快捷的对文件生成哈希值,只要你有一个这个哈希值的副本,你就可以相当肯定这就是你想要的文件。
下面是一个简单的例子:
```
$ shasum -a256 ~/bin/fop
87227baf4e1e78f6499e4905e8640c1f36720ae5f2bd167de325fd0d4ebc791c /home/bob/bin/fop
```
如果我知道 `fop` 这个可执行文件的 SHA-256 校验和,这是由供应商(这个例子中是 Apache 基金会)提供的:
```
87227baf4e1e78f6499e4905e8640c1f36720ae5f2bd167de325fd0d4ebc791c
```
然后我就可以确信,我驱动器上的这个可执行文件和 Apache 基金会网站上发布的文件是一模一样的。这就是哈希函数难以发生碰撞(或者至少是 *很难通过计算得到碰撞*)这个性质的重要之处。如果黑客能将真实文件用哈希值相同的文件轻易的进行替换,那么这个验证过程就毫无用处。
事实上,这些性质还有更技术性的名称,我上面所描述的将三个重要的属性混在了一起。更准确地说,这些技术名称是:
1. <ruby> 抗原像性 <rt> pre-image resistance </rt></ruby>:给定一个哈希值,即使知道用了什么哈希函数,也很难得到用于创建它的消息。
2. <ruby> 抗次原像性 <rt> second pre-image resistance </rt> <ruby> :给定一个消息,很难找到另一个消息,使得这个消息可以产生相同的哈希值。 </ruby></ruby>
3. <ruby> 抗碰撞性 <rt> collision resistance </rt></ruby>:很难得到任意两个可以产生相同哈希值的消息。
*抗碰撞性* 和 *抗次原像性* 也许听上去是同样的性质,但它们具有细微而显著的不同。*抗次原像性* 说的是如果 *已经* 有了一个消息,你也很难得到另一个与之哈希值相匹配的消息。*抗碰撞性* 使你很难找到两个可以生成相同哈希值的消息,并且要在哈希函数中实现这一性质则更加困难。
让我回到黑客试图替换文件(可以通过哈希值进行校验)的场景。现在,要在“外面”使用加密哈希算法(除了使用那些在现实世界中由独角兽公司开发的完全无 Bug 且安全的实现之外),还有一些重要且困难的附加条件需要满足。认真的读者可能已经想到了其中一些,特别需要指出的是:
1. 你必须确保自己所拥有的哈希值副本也没有被篡改。
2. 你必须确保执行哈希算法的实体能够正确执行并报告了结果。
3. 你必须确保对比两个哈希值的实体确实报告了这个对比的正确结果。
确保你能满足这些条件绝对不是一件容易的事。这就是<ruby> 可信平台模块 <rt> Trusted Platform Modules </rt></ruby>(TPM)成为许多计算系统一部分的原因之一。它们扮演着信任的硬件基础,可以为验证重要二进制数据真实性的加密工具提供保证。TPM 对于现实中的系统来说是有用且重要的工具,我也打算将来写一篇关于 TPM 的文章。
---
via: <https://opensource.com/article/20/7/hash-functions>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,410 | Linux 上无痛文件提取 | https://www.networkworld.com/article/3564265/painless-file-extraction-on-linux.html | 2020-07-12T23:34:28 | [
"提取",
"解压"
] | https://linux.cn/article-12410-1.html | 
从 Linux 系统的存档中提取文件没有拔牙那么痛苦,但有时看起来更复杂。在这篇文章中,我们将看看如何轻松地从 Linux 系统中可能遇到的几乎所有类型的存档中提取文件。
它们有很多格式,从 .gz 到 .tbz2,这些文件的命名方式都各有一些不同。当然,你可以记住所有从存档中提取文件的各种命令以及它们的选项,但是你也可以将所有经验保存到脚本中,而不再担心细节。
在本文中,我们将一系列提取命令组合成一个脚本,它会调用适当的命令根据文档名提取文件的内容。该脚本首先以一些命令来验证是否已经提供了一个文件名作为参数,或要求运行脚本的人提供文件名。
```
#!/bin/bash
if [ $# -eq 0 ]; then
echo -n "filename> "
read filename
else
filename=$1
fi
if [ ! -f "$filename" ]; then
echo "No such file: $filename"
exit $?
fi
```
了解了么?如果未提供任何参数,脚本将提示输入文件名,如果存在则使用它。然后,它验证文件是否实际存在。如果不是,那么脚本退出。
下一步是使用 bash 的 `case` 语句根据存档文件的名称调用适当的提取命令。对于其中某些文件类型(例如 .bz2),也可以使用除 `tar` 之外的其它命令,但是对于每种文件命名约定,我们仅包含一个提取命令。因此,这是带有各种存档文件名的 `case` 语句:
```
case $filename in
*.tar) tar xf $filename;;
*.tar.bz2) tar xjf $filename;;
*.tbz) tar xjf $filename;;
*.tbz2) tar xjf $filename;;
*.tgz) tar xzf $filename;;
*.tar.gz) tar xzf $filename;;
*.gz) gunzip $filename;;
*.bz2) bunzip2 $filename;;
*.zip) unzip $filename;;
*.Z) uncompress $filename;;
*) echo "No extract option for $filename"
esac
```
如果提供给脚本的文件扩展名与脚本已知的扩展名都不匹配,那么会发出 “No extract option for $filename” 的消息。如果缺少你使用的任何存档类型,只需将它们与所需的提取命令一起添加即可。
将 bash 头添加到脚本顶部,使其可执行,然后就可以开始了。
```
#!/bin/bash
if [ $# -eq 0 ]; then
echo -n "filename> "
read filename
else
filename=$1
fi
if [ ! -f "$filename" ]; then
echo "No such file: $filename"
exit $?
fi
case $filename in
*.tar) tar xf $filename;;
*.tar.bz2) tar xjf $filename;;
*.tbz) tar xjf $filename;;
*.tbz2) tar xjf $filename;;
*.tgz) tar xzf $filename;;
*.tar.gz) tar xzf $filename;;
*.gz) gunzip $filename;;
*.bz2) bunzip2 $filename;;
*.zip) unzip $filename;;
*.Z) uncompress $filename;;
*.rar) rar x $filename ;;
*)
```
如果你希望脚本在提取文件时显示内容,请将详细选项(`-v`)添加到每个命令参数字符串中:
```
#!/bin/bash
if [ $# -eq 0 ]; then
echo -n "filename> "
read filename
else
filename=$1
fi
if [ ! -f "$filename" ]; then
echo "No such file: $filename"
exit $?
fi
case $filename in
*.tar) tar xvf $filename;;
*.tar.bz2) tar xvjf $filename;;
*.tbz) tar xvjf $filename;;
*.tbz2) tar xvjf $filename;;
*.tgz) tar xvzf $filename;;
*.tar.gz) tar xvzf $filename;;
*.gz) gunzip -v $filename;;
*.bz2) bunzip2 -v $filename;;
*.zip) unzip -v $filename;;
*.Z) uncompress -v $filename;;
*) echo "No extract option for $filename"
esac
```
### 总结
虽然可以为每个可能用到的提取命令创建别名,但是让脚本为遇到的每种文件类型提供命令要比自己停下来编写每个命令和选项容易。
---
via: <https://www.networkworld.com/article/3564265/painless-file-extraction-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,411 | 物联网(IoT)简介 | https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html | 2020-07-13T14:44:00 | [
"物联网",
"IoT"
] | https://linux.cn/article-12411-1.html |
>
> 物联网(IoT)是一个由智能设备连接起来的网络,并提供了丰富的数据,但是它也有可能是一场安全领域的噩梦。
>
>
>

<ruby> 物联网 <rt> Internet of Things </rt></ruby>(IoT)是一个统称,指的是越来越多不属于传统计算设备,但却连接到互联网接收或发送数据,或既接收也发送的电子设备组成的网络。
现在有数不胜数的东西可以归为这一类:可以联网的“智能”版传统设备,比如说电冰箱和灯泡;那些只能运行于有互联网环境的小设备,比如像 Alexa 之类的电子助手;与互联网连接的传感器,它们正在改变着工厂、医疗、运输、物流中心和农场。
### 什么是物联网?
物联网将互联网、数据处理和分析的能力带给了现实的实物世界。对于消费者来说,这就意味着不需要键盘和显示器这些东西,就能和这个全球信息网络进行互动;他们的日常用品当中,很多都可以通过该网络接受操作指令,而只需很少的人工干预。
互联网长期以来为知识工作提供了便利,在企业环境当中,物联网也能为制造和分销带来同样的效率。全球数以百万计甚至数十亿计的嵌入式具有互联网功能的传感器正在提供令人难以置信丰富的数据集,企业可以利用这些数据来保证他们运营的安全、跟踪资产和减少人工流程。研究人员也可以使用物联网来获取人们的喜好和行为数据,尽管这些行为可能会严重影响隐私和安全。
### 它有多大?
一句话:非常庞大。[Priceonomics 对此进行了分析](https://priceonomics.com/the-iot-data-explosion-how-big-is-the-iot-data/):在 2020 年的时候,有超过 50 亿的物联网设备,这些设备可以生成 4.4 <ruby> 泽字节 <rt> zettabyte </rt></ruby>(LCTT 译注:1 zettabyte = 10<sup> 9</sup> terabyte = 10<sup> 12</sup> gigabyte)的数据。相比较,物联网设备在 2013 年仅仅产生了 1000 亿<ruby> 千兆字节 <rt> gigabyte </rt></ruby>的数据。在物联网市场上可能挣到的钱也同样让人瞠目;到 2025 年,这块市场的价值可以达到 1.6 万亿美元到 14.4 万亿美元不等。
### 物联网的历史
一个联网设备和传感器无处不在的世界,是科幻小说中最经典的景象之一。物联网传说中将 1970 年 [卡耐基•梅隆大学的一台连接到 APRANET 的自动贩卖机](https://www.machinedesign.com/automation-iiot/article/21836968/iot-started-with-a-vending-machine) 称之为世界上第一个物联网设备,而且许多技术都被吹捧为可以实现 “智能” 的物联网式特征,使其颇具有未来主义的光彩。但是“物联网”这个词是由英国的技术专家 [Kevin Ashton](https://www.visioncritical.com/blog/kevin-ashton-internet-of-things) 于 1999 年提出来的。
一开始,技术是滞后于当时对未来的憧憬的。每个与互联网相连的设备都需要一个处理器和一种能和其他东西通信的方式,无线的最好,这些因素都增加了物联网大规模实际应用的成本和性能要求,这种情况至少一直持续到 21 世纪头十年中期,直到摩尔定律赶上来。
一个重要的里程碑是 [RFID 标签的大规模使用](https://www.networkworld.com/article/2319384/rfid-readers-route-tag-traffic.html),这种价格低廉的极简转发器可以被贴在任何物品上,然后这些物品就可以连接到更大的互联网上了。对于设计者来说,无处不在的 Wi-Fi 和 4G 让任何地方的无线连接都变得非常简单。而且,IPv6 的出现再也不用让人们担心把数十亿小设备连接到互联网上会将 IP 地址耗尽。(相关报道:[物联网网络可以促进 IPv6 的使用吗?](https://www.networkworld.com/article/3338106/can-iot-networking-drive-adoption-of-ipv6.html))
### 物联网是如何工作的?
物联网的基本元素是收集数据的设备。广义地说,它们是和互联网相连的设备,所以每一个设备都有 IP 地址。它们的复杂程度不一,这些设备涵盖了从工厂运输货物的自动驾驶车辆到监控建筑温度的简单传感器。这其中也包括每天统计步数的个人手环。为了让这些数据变得有意义,就需要对其收集、处理、过滤和分析,每一种数据都可以通过多种方式进行处理。
采集数据的方式是将数据从设备上传输到采集点。可以通过各种无线或者有线网络进行数据的转移。数据可以通过互联网发送到具有存储空间或者计算能力的数据中心或者云端,或者这些数据也可以分段进行传输,由中间设备汇总数据后再沿路径发送。
处理数据可以在数据中心或者云端进行,但是有时候这不太可行。对于一些非常重要的设备,比如说工业领域的关停设备,从设备上将数据发送到远程数据中心的延迟太大了。发送、处理、分析数据和返回指令(在管道爆炸之前关闭阀门)这些操作,来回一趟的时间可能要花费非常多的时间。在这种情况下,<ruby> 边缘计算 <rt> edge-computing </rt></ruby>就可以大显身手了,智能边缘设备可以汇总数据、分析数据,在需要的时候进行回应,所有这些都在相对较近的物理距离内进行,从而减少延迟。边缘设备可以有上游连接,这样数据就可以进一步被处理和储存。

*物联网是如何工作的。*
### 物联网设备的一些例子
本质上,任何可以搜集来自于真实世界数据,并且可以发送回去的设备都可以参与到物联网生态系统中。典型的例子包括智能家居设备、射频识别标签(RFID)和工业传感器。这些传感器可以监控一系列的因素,包括工业系统中的温度和压力、机器中关键设备的状态、患者身上与生命体征相关的信号、水电的使用情况,以及其它许许多多可能的东西。
整个工厂的机器人可以被认为是物联网设备,在工业环境和仓库中移动产品的自主车辆也是如此。
其他的例子包括可穿戴设备和家庭安防系统。还有一些其它更基础的设备,比如说[树莓派](https://www.networkworld.com/article/3176091/10-killer-raspberry-pi-projects-collection-1.html)和[Arduino](https://www.networkworld.com/article/3075360/arduino-targets-the-internet-of-things-with-primo-board.html),这些设备可以让你构建你自己的物联网终端节点。尽管你可能会认为你的智能手机是一台袖珍电脑,但它很可能也会以非常类似物联网的方式将你的位置和行为数据传送到后端服务。
#### 设备管理
为了能让这些设备一起工作,所有这些设备都需要进行验证、分配、配置和监控,并且在必要时进行修复和更新。很多时候,这些操作都会在一个单一的设备供应商的专有系统中进行;要么就完全不会进行这些操作,而这样也是最有风险的。但是整个业界正在向[标准化的设备管理模式](https://www.networkworld.com/article/3258812/the-future-of-iot-device-management.html)过渡,这使得物联网设备之间可以相互操作,并保证设备不会被孤立。
#### 物联网通信标准和协议
当物联网上的小设备和其他设备通信的时候,它们可以使用各种通信标准和协议,这其中许多都是为这些处理能力有限和电源功率不大的设备专门定制的。你一定听说过其中的一些,尽管有一些设备使用的是 Wi-Fi 或者蓝牙,但是更多的设备是使用了专门为物联网世界定制的标准。比如,ZigBee 就是一个低功耗、远距离传输的无线通信协议,而 MQTT(<ruby> 消息队列遥测传输 <rt> Message Queuing Telemetry Transport </rt></ruby>)是为连接在不可靠或者易发生延迟的网络上的设备定制的一个发布/订阅信息协议。(参考 Network World 的词汇表:[物联网标准和协议](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/talk/11)。)
物联网也会受益于 5G 为蜂窝网络带来的高速度和高带宽,尽管这种使用场景会[滞后于普通的手机](https://www.networkworld.com/article/3291778/what-s-so-special-about-5g-and-iot.html)。
### 物联网、边缘计算和云

*边缘计算如何使物联网成为可能。*
对于许多物联网系统来说,大量的数据会以极快的速度涌来,这种情况催生了一个新的科技领域,<ruby> <a href="https://www.networkworld.com/article/3224893/what-is-edge-computing-and-how-it-s-changing-the-network.html"> 边缘计算 </a> <rt> edge computing </rt></ruby>,它由放置在物联网设备附近的设备组成,处理来自那些设备的数据。这些机器对这些数据进行处理,只将相关的素材数据发送到一个更集中的系统系统进行分析。比如,想象一个由几十个物联网安防摄像头组成的网络,边缘计算会直接分析传入的视频,而且只有当其中一个摄像头检测到有物体移动的时候才向安全操作中心(SoC)发出警报,而不会是一下子将所有的在线数据流全部发送到建筑物的 SoC。
一旦这些数据已经被处理过了,它们又去哪里了呢?好吧,它也许会被送到你的数据中心,但是更多情况下,它最终会进入云。
对于物联网这种间歇或者不同步的数据来往场景来说,具有弹性的云计算是再适合不过的了。许多云计算巨头,包括[谷歌](https://cloud.google.com/solutions/iot)、[微软](https://azure.microsoft.com/en-us/overview/iot/)和[亚马逊](https://aws.amazon.com/iot/),都有物联网产品。
### 物联网平台
云计算巨头们正在尝试出售的,不仅仅是存放传感器搜集的数据的地方。他们正在提供一个可以协调物联网系统中各种元素的完整平台,平台会将很多功能捆绑在一起。本质上,物联网平台作为中间件,将物联网设备和边缘网关与你用来处理物联网数据的应用程序连接起来。也就是说,每一个平台的厂商看上去都会对物联网平台应该是什么这个问题有一些稍微不同的解释,以更好地[与其他竞争者拉开差距](https://www.networkworld.com/article/3336166/why-are-iot-platforms-so-darn-confusing.html)。
### 物联网和数据
正如前面所提到的,所有这些物联网设备收集了 ZB 级的数据,这些数据通过边缘网关被发送到平台上进行处理。在很多情况下,这些数据就是要部署物联网的首要原因。通过从现实世界中的传感器搜集来的数据,企业就可以实时的作出灵活的决定。
例如,Oracle 公司[假想了一个这样的场景](https://blogs.oracle.com/bigdata/how-big-data-powers-the-internet-of-things),当人们在主题公园的时候,会被鼓励下载一个可以提供公园信息的应用。同时,这个程序会将 GPS 信号发回到公园的管理部门来帮助他们预测排队时间。有了这些信息,公园就可以在短期内(比如通过增加员工数量来提升景点的一些容量)和长期内(通过了解哪些设施最受欢迎,那些最不受欢迎)采取行动。
这些决定可以在没有人工干预的情况作出。比如,从化工厂管道中的压力传感器收集的数据可以通过边缘设备的软件进行分析,从而发现管道破裂的威胁,这样的信息可以触发关闭阀门的信号,从而避免泄漏。
### 物联网和大数据分析
主题公园的例子可以让你很容易理解,但是和许多现实世界中物联网收集数据的操作相比,就显得小菜一碟了。许多大数据业务都会使用到来自物联网设备收集的信息,然后与其他数据关联,这样就可以分析预测到人类的行为。Software Advice 给出了[一些例子](https://www.softwareadvice.com/resources/iot-data-analytics-use-cases/),其中包括由 Birst 提供的一项服务,该服务将从联网的咖啡机中收集的咖啡冲泡的信息与社交媒体上发布的帖子进行匹配,看看顾客是否在网上谈论咖啡品牌。
另一个最近才发生的戏剧性的例子,X-Mode 发布了一张基于位置追踪数据的地图,地图上显示了在 2020 年 3 月春假的时候,正当新冠病毒在美国加速传播的时候,人们在<ruby> 劳德代尔堡 <rt> Ft. Lauderdale </rt></ruby>聚会完[最终都去了哪里](https://www.cnn.com/2020/04/04/tech/location-tracking-florida-coronavirus/index.html)。这张地图令人震撼,不仅仅是因为它显示出病毒可能的扩散方向,更是因为它说明了物联网设备是可以多么密切地追踪我们。(更多关于物联网和分析的信息,请点击[此处](https://www.networkworld.com/article/3311919/iot-analytics-guide-what-to-expect-from-internet-of-things-data.html)。)
### 物联网数据和 AI
物联网设备能够收集的数据量远远大于任何人类能够以有效的方式处理的数据量,而且这肯定也不是能实时处理的。我们已经看到,仅仅为了理解从物联网终端传来的原始数据,就需要边缘计算设备。此外,还需要检测和处理可能就是[完全错误的数据](https://www.networkworld.com/article/3396230/when-iot-systems-fail-the-risk-of-having-bad-iot-data.html)。
许多物联网供应商也同时提供机器学习和人工智能的功能,可以用来理解收集来的数据。比如,IBM 的 Jeopardy!-winning Watson 平台就可以在[物联网数据集上进行训练](https://www.networkworld.com/article/3449243/watson-iot-chief-ai-can-broaden-iot-services.html),这样就可以在预测性维护领域产生有用的结果 —— 比如说,分析来自无人机的数据,可以区分桥梁上轻微的损坏和需要重视的裂缝。同时,ARM 也在研发[低功耗芯片](https://www.networkworld.com/article/3532094/ai-everywhere-iot-chips-coming-from-arm.html),它可以在物联网终端上提供 AI 的能力。
### 物联网和商业
物联网的商业用途包括跟踪客户、库存和重要部件的状态。[IoT for All](https://www.iotforall.com/4-unlikely-industries-iot-changing/) 列举了四个已经被物联网改变的行业:
* **石油和天然气**:与人工干预相比,物联网传感器可以更好的检测孤立的钻井现场。
* **农业**:通过物联网传感器获得的田间作物的数据,可以用来提高产量。
* **采暖通风**:制造商可以监控全国各地的气候控制系统。
* **实体零售**:当顾客在商店的某些地方停留的时候,可以通过手机进行微目标定位,提供优惠信息。
更普遍的情况是,企业正在寻找能够在[四个领域](https://www.networkworld.com/article/3396128/the-state-of-enterprise-iot-companies-want-solutions-for-these-4-areas.html)上获得帮助的物联网解决方案:能源使用、资产跟踪、安全领域和客户体验。
---
via: <https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html>
作者:[Josh Fruhlinger](https://www.networkworld.com/author/Josh-Fruhlinger/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,413 | 把你的树莓派家庭实验室变成一个网络文件系统 | https://opensource.com/article/20/5/nfs-raspberry-pi | 2020-07-14T15:44:15 | [
"NFS"
] | /article-12413-1.html |
>
> 使用 NFS 服务器将共享文件系统添加到你的家庭实验室。
>
>
>

共享文件系统是为家庭实验室增加通用性和功能性的好方法。在实验室中为客户端共享一个集中的文件系统,使得组织数据、进行备份和共享数据变得相当容易。这对于在多个服务器上进行负载均衡的 Web 应用和 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 使用的持久化卷来说,尤其有用,因为它允许在任何数量的节点上用持久化数据来轮转 Pod。
无论你的家庭实验室是由普通计算机、多余的企业服务器,还是树莓派或其他单板计算机(SBC)组成,共享文件系统都是一种有用的资产,而网络文件系统(NFS)服务器是创建共享文件系统的好方法。
我之前写过关于[建立“家庭私有云”](/article-12277-1.html)的文章,这是一个由树莓派或其他 SBC 组成的家庭实验室,也许还有其他一些消费类硬件或台式 PC。NFS 服务器是这些组件之间共享数据的理想方式。由于大多数 SBC 的操作系统是通过 SD 卡运行的,所以存在一些挑战。尤其是在用作计算机的操作系统磁盘时,SD 卡的故障率会增加,它们并不是用来不断地读写的。你实际需要的是一个真正的硬盘:它们通常比 SD 卡的每 GB 价格便宜,特别是对于较大的磁盘,而且它们不太可能持续发生故障。树莓派 4 现在带有 USB 3.0 接口,而 USB 3.0 硬盘无处不在,价格也很实惠。这是一个完美的搭配。在这个项目中,我将使用一个 2TB 的 USB 3.0 外置硬盘插入到运行 NFS 服务器的树莓派 4 中。

### 安装 NFS 服务器软件
我在树莓派上运行 Fedora 服务器,但这个项目也可以在其他发行版上运行。要在 Fedora 上运行 NFS 服务器,你需要 `nfs-utils` 包,幸运的是它已经安装好了(至少在 Fedora 31 中是这样)。如果你打算运行 NFSv3 服务,你还需要 `rpcbind` 包,但它不是 NFSv4 的严格要求。
如果你的系统中还没有这些软件包,请使用 `dnf` 命令安装它们。
```
# 安装 nfs-utils 和 rpcbind
$ sudo dnf install nfs-utils rpcbind
```
Raspbian 是另一个与树莓派一起使用的流行操作系统,设置几乎完全相同。软件包名称不同而已,但这是唯一的主要区别。要在运行 Raspbian 的系统上安装 NFS 服务器,你需要以下软件包。
* `nfs-common`:这些文件是 NFS 服务器和客户端的通用文件。
* `nfs-kernel-server`:主要的 NFS 服务器软件包。
Raspbian 使用 `apt-get` 来管理软件包(而不是像 Fedora 那样使用 `dnf`),所以用它来安装软件包。
```
# 对于 Raspbian 系统,使用 apt-get 来安装 NFS 软件包
$ sudo apt-get install nfs-common nfs-kernel-server
```
### 准备一个 USB 硬盘作为存储设备
正如我上面提到的,USB 硬盘是为树莓派或其他 SBC 提供存储的好选择,尤其是用于操作系统磁盘镜像的 SD 卡并不适合这个用途。对于家庭私有云,你可以使用廉价的 USB 3.0 硬盘进行大规模存储。插入磁盘,使用 `fdisk` 找出分配给它的设备 ID,就可以使用它工作了。
```
# 使用 fdisk 找到你的硬盘
# 无关的硬盘信息已经省略
$ sudo fdisk -l
Disk /dev/sda: 1.84 TiB, 2000398933504 bytes, 3907029167 sectors
Disk model: BUP Slim BK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xe3345ae9
Device Boot Start End Sectors Size Id Type
/dev/sda1 2048 3907028991 3907026944 1.8T 83 Linux
```
为了清楚起见,在上面的例子输出中,除了我感兴趣的那个磁盘,我省略了所有其它磁盘的信息。你可以看到我想使用的 USB 磁盘被分配了设备 `/dev/sda`,你可以看到一些关于型号的信息(`Disk model: BUP Slim BK`),这有助于我识别正确的磁盘。该磁盘已经有了一个分区,它的大小也证实了它就是我要找的磁盘。
注意:请确保正确识别你的设备的磁盘和分区。它可能与上面的例子不同。
在驱动器上创建的每个分区都有一个特殊的通用唯一标识符(UUID)。计算机使用 UUID 来确保它使用 `/etc/fstab` 配置文件将正确的分区挂载到正确的位置。你可以使用 `blkid` 命令检索分区的 UUID。
```
# 获取该分区的块设备属性
# 确保你使用了合适的分区,它应该有所不同。
$ sudo blkid /dev/sda1
/dev/sda1: LABEL="backup" UUID="bd44867c-447c-4f85-8dbf-dc6b9bc65c91" TYPE="xfs" PARTUUID="e3345ae9-01"
```
在这里,`/dev/sda1` 的 UUID 是 `bd44867c-447c-4f85-8dbf-dc6b9bc65c91`。你的 UUID 会有所不同,所以要记下来。
### 配置树莓派在启动时挂载这个磁盘,然后挂载它
现在你已经确定了要使用的磁盘和分区,你需要告诉计算机如何挂载它,每次启动时都要这样做。现在就去挂载它。因为这是一个 USB 磁盘,可能会被拔掉,所以你还要配置树莓派在启动时如果磁盘没有插入或有其它不可用情况时不要等待。
在 Linux 中,通过将分区添加到 `/etc/fstab` 配置文件中,包括你希望它被挂载的位置和一些参数来告诉计算机如何处理它。这个例子将把分区挂载到 `/srv/nfs`,所以先创建这个路径:
```
# 创建该磁盘分区的挂载点
$ sudo mkdir -p /srv/nfs
```
接下来,使用以下语法格式修改 `/etc/fstab` 文件:
```
<disk id> <mountpoint> <filesystem type> <options> <fs_freq> <fs_passno>
```
使用你之前确定的 UUID 作为磁盘 ID。正如我在上一步提到的,挂载点是 `/srv/nfs`。对于文件系统类型,通常最好选择其实际的文件系统,但是因为这是一个 USB 磁盘,所以使用 `auto`。
对于选项值,使用 `nosuid,nodev,nofail`。
#### 关于手册页的一个旁白
其实,有*很多*可能的选项,手册页(`man`)是查看它们的最好方法。查看 `fstab` 的手册页是一个很好的开始。
```
# 打开 fstab 的手册页
$ man fstab
```
这将打开与 `fstab` 命令相关的手册/文档。在手册页中,每个选项都被分解成了不同的内容,以显示它的作用和常用的选择。例如,“第四个字段(fs\_mntopts)”给出了该字段中可用选项的一些基本信息,并引导你到 `man 8 mount` 中获取 `mount` 选项更深入的描述。这是有道理的,因为 `/etc/fstab` 文件,本质上是告诉计算机如何自动挂载磁盘,就像你手动使用 `mount` 命令一样。
你可以从 `mount` 的手册页中获得更多关于你将使用的选项的信息。数字 8 表示手册页的章节。在这里,第 8 章节是*系统管理工具和守护进程*。
你可以从 `man` 的手册页中得到标准章节的列表。
回到挂载磁盘,让我们看看 `man 8 mount`。
```
# 打开第 8 章节的 mount 手册页
$ man 8 mount
```
在这个手册页中,你可以查看上面列出的选项的作用。
* `nosuid`:不理会 suid/guid 位。不允许放在 U 盘上的任何文件以 root 身份执行。这是一个良好的安全实践。
* `nodev`:不识别文件系统中的字符或块特殊设备,即不理会在 U 盘上的任何设备节点。另一个良好的安全实践。
* `nofail`:如果设备不存在,不要记录任何错误。这是一个 U 盘,可能没有插入,所以在这种情况下,它将被忽略。
回到你正在添加到 `/etc/fstab` 文件的那一行,最后还有两个选项:`fs_freq` 和 `fs_passno`。它们的值与一些过时的选项有关,*大多数*现代系统对这两个选项都只用 `0`,特别是对 USB 磁盘上的文件系统而言。`fs_freq` 的值与 `dump` 命令和文件系统的转储有关。`fs_passno` 的值定义了启动时要 `fsck` 的文件系统及其顺序,如果设置了这个值,通常根分区是 `1`,其他文件系统是 `2`,将该值设置为 `0` 以跳过在该分区上使用 `fsck`。
在你喜欢的编辑器中,打开 `/etc/fstab` 文件,添加 U 盘上分区的条目,将这里的值替换成前面步骤中得到的值。
```
# With sudo, or as root, add the partition info to the /etc/fstab file
UUID="bd44867c-447c-4f85-8dbf-dc6b9bc65c91" /srv/nfs auto nosuid,nodev,nofail,noatime 0 0
```
### 启用并启动 NFS 服务器
安装好软件包,并将分区添加到你的 `/etc/fstab` 文件中,现在你可以开始启动 NFS 服务器了。在 Fedora 系统中,你需要启用和启动两个服务:`rpcbind` 和 `nfs-server`。使用 `systemctl` 命令来完成这项工作。
```
# 启动 NFS 服务器和 rpcbind
$ sudo systemctl enable rpcbind.service
$ sudo systemctl enable nfs-server.service
$ sudo systemctl start rpcbind.service
$ sudo systemctl start nfs-server.service
```
在 Raspbian 或其他基于 Debian 的发行版上,你只需要使用 `systemctl` 命令启用并启动 `nfs-kernel-server` 服务即可,方法同上。
#### RPCBind
rpcbind 工具用于将远程过程调用(RPC)服务映射到其监听的端口。根据 rpcbind 手册页:
>
> “当一个 RPC 服务启动时,它会告诉 rpcbind 它正在监听的地址,以及它准备服务的 RPC 程序号。当客户机想对给定的程序号进行 RPC 调用时,它首先与服务器机器上的 rpcbind 联系,以确定 RPC 请求应该发送到哪里的地址。”
>
>
>
在 NFS 服务器这个案例中,rpcbind 会将 NFS 的协议号映射到 NFS 服务器监听的端口上。但是,NFSv4 不需要使用 rpcbind。如果你*只*使用 NFSv4 (通过从配置中删除版本 2 和版本 3),则不需要使用 rpcbind。我把它放在这里是为了向后兼容 NFSv3。
### 导出挂载的文件系统
NFS 服务器根据另一个配置文件 `/etc/exports` 来决定与哪些远程客户端共享(导出)哪些文件系统。这个文件只是一个 IP(或子网)与要共享的文件系统的映射,以及一些选项(只读或读写、root 去除等)。该文件的格式是:
```
<目录> <主机>(选项)
```
在这个例子中,你将导出挂载到 `/srv/nfs` 的分区。这是“目录”部分。
第二部分,主机,包括你要导出这个分区的主机。这些主机可以是单个主机:使用具有完全限定域名(FQDN)或主机名、主机的 IP 地址来指定;也可以是一组主机:使用通配符字符来匹配域(如 \*.example.org)、IP 网络(如无类域间路由 CIDR 标识)或网组表示。
第三部分包括应用于该导出的选项。
* `ro/rw`:将文件系统导出为只读或读写。
* `wdelay`:如果即将进行另一次写入,则推迟对磁盘的写入,以提高性能(如果你使用的是固态 USB 磁盘,这*可能*没有那么有用)
* `root_squash`:防止客户机上的任何 root 用户在主机上有 root 权限,并将 root UID 设置为 `nfsnobody` 作为安全防范措施。
测试导出你挂载在 `/srv/nfs` 处的分区到一个客户端 —— 例如,一台笔记本电脑。确定你的客户机的 IP 地址(我的笔记本是 `192.168.2.64`,但你的可能会不同)。你可以把它共享到一个大的子网,但为了测试,请限制在单个 IP 地址上。这个 IP 的 CIDR 标识是 `192.168.2.64/32`,`/32` 子网代表一个 IP。
使用你喜欢的编辑器编辑 `/etc/exports` 文件,写上你的目录、主机 CIDR 以及 `rw` 和 `root_squash` 选项。
```
# 像这样编辑你的 /etc/exports 文件,替换为你的系统上的信息
/srv/nfs 192.168.2.64/32(rw,root_squash)
```
注:如果你从另一个地方复制了 `/etc/exports` 文件,或者用副本覆盖了原文件,你可能需要恢复该文件的 SELinux 上下文。你可以使用 `restorecon` 命令来恢复。
```
# 恢复 /etc/exports 文件的 SELinux 上下文
$ sudo restorecon /etc/exports
```
完成后,重新启动 NFS 服务器,以接收对 `/etc/exports` 文件的更改。
```
# 重新启动 NFS 服务器
$ sudo systemctl restart nfs-server.service
```
### 给 NFS 服务打开防火墙
有些系统,默认不运行[防火墙服务](https://opensource.com/article/18/9/linux-iptables-firewalld)。比如 Raspbian,默认是开放 iptables 规则,不同服务打开的端口在机器外部立即就可以使用。相比之下,Fedora 服务器默认运行的是 firewalld 服务,所以你必须为 NFS 服务器(以及 rpcbind,如果你将使用 NFSv3)打开端口。你可以通过 `firewall-cmd` 命令来实现。
检查 firewalld 使用的区域并获取默认区域。对于 Fedora 服务器,这是 `FedoraServer` 区域。
```
# 列出区域
# 出于简洁省略了部分输出
$ sudo firewall-cmd --list-all-zones
# R获取默认区域信息
# 记下默认区域
$ sudo firewall-cmd --get-default-zone
# 永久加入 nfs 服务到允许端口列表
$ sudo firewall-cmd --add-service=nfs --permanent
# 对于 NFSv3,我们需要再加一些端口: nfsv3、 rpc-mountd、 rpc-bind
$ sudo firewall-cmd --add-service=(nfs3,mountd,rpc-bind)
# 查看默认区域的服务,以你的系统中使用的默认区域相应替换
$ sudo firewall-cmd --list-services --zone=FedoraServer
# 如果一切正常,重载 firewalld
$ sudo firewall-cmd --reload
```
就这样,你已经成功地将 NFS 服务器与你挂载的 U 盘分区配置在一起,并将其导出到你的测试系统中进行共享。现在你可以在你添加到导出列表的系统上测试挂载它。
### 测试 NFS 导出
首先,从 NFS 服务器上,在 `/srv/nfs` 目录下创建一个文件来读取。
```
# 创建一个测试文件以共享
echo "Can you see this?" >> /srv/nfs/nfs_test
```
现在,在你添加到导出列表中的客户端系统上,首先确保 NFS 客户端包已经安装好。在 Fedora 系统上,它是 `nfs-utils` 包,可以用 `dnf` 安装。Raspbian 系统有 `libnfs-utils` 包,可以用 `apt-get` 安装。
安装 NFS 客户端包:
```
# 用 dnf 安装 nfs-utils 软件包
$ sudo dnf install nfs-utils
```
一旦安装了客户端包,你就可以测试 NFS 的导出了。同样在客户端,使用带有 NFS 服务器 IP 和导出路径的 `mount` 命令,并将其挂载到客户端的一个位置,在这个测试中是 `/mnt` 目录。在这个例子中,我的 NFS 服务器的 IP 是 `192.168.2.109`,但你的可能会有所不同。
```
# 挂载 NFS 服务器的输出到客户端主机
# 确保替换为你的主机的相应信息
$ sudo mount 192.168.2.109:/srv/nfs /mnt
# 查看 nfs_test 文件是不是可见
$ cat /mnt/nfs_test
Can you see this?
```
成功了!你现在已经有了一个可以工作的 NFS 服务器,可以与多个主机共享文件,允许多个读/写访问,并为你的数据提供集中存储和备份。家庭实验室的共享存储有很多选择,但 NFS 是一种古老的、高效的、可以添加到你的“家庭私有云”家庭实验室中的好选择。本系列未来的文章将扩展如何在客户端上自动挂载 NFS 共享,以及如何将 NFS 作为 Kubernetes 持久卷的存储类。
---
via: <https://opensource.com/article/20/5/nfs-raspberry-pi>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,414 | 如何在 Ubuntu 20.04 上禁用坞站(dock) | https://itsfoss.com/disable-ubuntu-dock/ | 2020-07-14T16:27:09 | [
"坞站",
"Dock"
] | https://linux.cn/article-12414-1.html | 左侧的启动器已成为 [Ubuntu](https://ubuntu.com/) 桌面的标识。它是在 [Unity 桌面](https://itsfoss.com/keeping-ubuntu-unity-alive/)中引入的,甚至在 [Ubuntu 切换到 GNOME](https://itsfoss.com/ubuntu-unity-shutdown/)时就有了,它复刻了 “Dash to Panel”,以在 [GNOME](https://www.gnome.org/) 上创建一个类似的<ruby> 坞站 <rt> dock </rt></ruby>。
就个人而言,我发现它对于快速访问常用应用非常方便,但并非所有人都希望它额外占用屏幕上的一些空间。
从 [Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/) 开始,你可以轻松禁用坞站。在本教程中,让我向你展示如何以图形和命令的方式执行此操作。

### 通过扩展应用禁用 Ubuntu Dock
[Ubuntu 20.04 的主要功能](https://itsfoss.com/ubuntu-20-04-release-features/)之一是引入“<ruby> 扩展 <rt> Extension </rt></ruby>”应用来管理系统上的 GNOME 扩展。只需在 GNOME 菜单中查找它(按下 Windows 键并输入):

>
> 没有找到扩展应用?
>
>
> 如果尚未安装,你应该启用 GNOME Shell 扩展,“扩展” GUI 是此软件包的一部分。
>
>
>
> ```
> sudo apt install gnome-shell-extensions
>
> ```
>
> 这仅对 [GNOME 3.36](https://itsfoss.com/gnome-3-36-release/) 或 Ubuntu 20.04(或更高版本) 中的更高版本有效。
>
>
>
启动“扩展”应用,你应该在“内置”扩展下看到 Ubuntu Dock。你只需要关闭即可禁用坞站。

更改是即时的,你会看到坞站立即消失。
你可以用相同的方式恢复。只需打开它,它就会立即显示。
在 Ubuntu 20.04 中非常容易隐藏坞站,不是吗?
### 替代方法:通过命令行禁用 Ubuntu 坞站
如果你是终端爱好者,并且喜欢在终端中做事,那么我有一个对你而言的好消息。你可以从命令行禁用 Ubuntu 坞站。
使用 `Ctrl+Alt+T` 打开终端。你可能已经知道 [Ubuntu 中的键盘快捷键](https://itsfoss.com/ubuntu-shortcuts/)。
在终端中,使用以下命令列出所有可用的 GNOME 扩展:
```
gnome-extensions list
```
这将显示类似于以下的输出:

默认的 Ubuntu 坞站扩展是 `[email protected]`。你可以使用以下命令将其禁用:
```
gnome-extensions disable [email protected]
```
屏幕上不会显示任何输出,但是你会注意到启动器(坞站)从左侧消失了。
如果需要,你可以使用与上面相同的命令再次启用它,但使用启用选项:
```
gnome-extensions enable [email protected]
```
### 总结
在 Ubuntu 18.04 中也有禁用坞站的方法。但是,如果你尝试在 18.04 中删除它,这可能会导致不想要的结果。删除此软件包也会删除 ubuntu-desktop 包,最终可能会导致系统崩溃,例如没有应用菜单。
这就是为什么我不建议在 Ubuntu 18.04 上删除它的原因。
好消息是 Ubuntu 20.04 提供了一种隐藏任务栏的方法。用户拥有更大的自由度和更多的屏幕空间。说到更多的屏幕空间,你是否知道可以[从 Firefox 移除顶部标题栏并获得更多的屏幕空间](https://itsfoss.com/remove-title-bar-firefox/)?
我想知道你喜欢怎样的 Ubuntu 桌面?要坞站,不要坞站,还是不要 GNOME?
---
via: <https://itsfoss.com/disable-ubuntu-dock/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The launcher on the left side has become the identity of [Ubuntu](https://ubuntu.com/) desktop. It was introduced with [Unity desktop](https://itsfoss.com/keeping-ubuntu-unity-alive/) and even [when Ubuntu switched to GNOME](https://itsfoss.com/ubuntu-unity-shutdown/), it forked Dash to Panel to create a [similar dock](https://itsfoss.com/best-linux-docks/) on [GNOME](https://www.gnome.org/) as well.
Personally, I find it handy for quickly accessing the frequently used applications. But not everyone wants it to take some extra space on the screen.
Starting with [Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/), you can easily disable this dock as part of [dock customization in Ubuntu](https://itsfoss.com/customize-ubuntu-dock/). Let me show you how to do that graphically and via command line in this quick tutorial.
## Disable Ubuntu dock with Extensions app
One of the [main features of Ubuntu 20.04](https://itsfoss.com/ubuntu-20-04-release-features/) was the introduction of Extensions to manage GNOME extensions on your system. Just look for it in the GNOME menu (press Windows key and start typing):
If you don’t have it installed already, you should enable GNOME Shell Extensions. The Extensions GUI app is part of this package.
This is only valid for [GNOME 3.36](https://itsfoss.com/gnome-3-36-release/) or higher versions available from Ubuntu 20.04.
`sudo apt install gnome-shell-extensions`
Start the extensions app and you should see Ubuntu Dock under the Built-in extensions section. You just have to toggle the button off to disable the dock.
The change is immediate and you’ll see that dock disappears immediately.
You can bring it back the same way. Just toggle it on and it will appear immediately.
So easy to hide the dock in Ubuntu 20.04, isn’t it?
## Alternative Method: Disable Ubuntu dock via command line
If you are a terminal enthusiast and prefer to do things in the terminal, I have good news for you. You can disable the Ubuntu dock from command line.
Open a terminal using Ctrl+Alt+T. You probably already know that [keyboard shortcut in Ubuntu](https://itsfoss.com/ubuntu-shortcuts/).
In the terminal, use the following command to list all the available GNOME extensions:
`gnome-extensions list`
This will show you an output similar to this:
The default Ubuntu dock extension is [[email protected]](/cdn-cgi/l/email-protection). You can disable it using this command:
`gnome-extensions disable `[[email protected]](/cdn-cgi/l/email-protection)
There will be no output message displayed on the screen but you’ll notice that the launcher or dock disappears from the left side.
If you want, you can enable it again using the same command as above but with enable option this time:
`gnome-extensions enable `[[email protected]](/cdn-cgi/l/email-protection)
## Conclusion
Docks are actually handy. Perhaps you disabled the dock to try something else? If that's the case, here are some suggestions.
[7 Docks to Customize Your Linux DesktopA dock has been an important part of the Linux desktop experience for decades. It provides a handy way of quickly accessing your favorite, frequently used applications. Unfortunately, the popular desktop environment GNOME doesn’t provide a dock. Fret not. You can always install a Docking applicati…](https://itsfoss.com/best-linux-docks/)

There are ways to disable the dock in Ubuntu 18.04 as well. However, it may lead to unwarranted situations if you try to remove it in 18.04. Removing this package also removes the ubuntu-desktop package and you may end up with a system with broken functionalities like no application menu.
This is the reason why I won’t recommend removing it on Ubuntu 18.04.
It’s good that Ubuntu 20.04 gives a way to hide the taskbar. Users have more freedom and more screen space. Speaking of more screen space, did you know that you can [remove the top title bar from Firefox and gain more screen space](https://itsfoss.com/remove-title-bar-firefox/)?
I am wondering how do you prefer your Ubuntu desktop. With the dock, without a dock or without GNOME? |
12,415 | 使用 Linux 实用程序 gPhoto2 备份手机存储 | https://opensource.com/article/20/7/gphoto2-linux | 2020-07-14T17:07:41 | [
"手机"
] | https://linux.cn/article-12415-1.html |
>
> 尽情地拍照吧,gphoto2 能够方便、快速地将照片从你的设备传输到 Linux 计算机上。
>
>
>

移动设备的最大缺点之一就是其将数据从设备传输到计算机很困难。移动设备在这一缺点上有着悠久的历史。早期的移动设备,如 Pilot 和掌上电脑 PDA 设备,需要使用特殊的同步软件来传输数据(你必须小心翼翼地做这件事,因为你的设备可能会因为电池耗尽而导致数据永久丢失);旧版 iPod 只提供特定平台的界面。现代移动设备默认将你的数据发送到在线帐户,以便你可以在计算机上再次下载。
好消息——如果你正在运行 Linux,你可以使用 `gphoto2` 命令与移动设备进行连接。`gphoto2` 最初是作为一种与数码相机通信的方式而开发的,那时的数码相机只有传统的相机功能,现在的 `gphoto2` 可以和许多不同种类的移动设备通讯。别让这个名字骗了你,它可以处理所有类型的文件,而不仅仅是照片。更棒的是,它可以编写脚本、很灵活、并且比大多数 GUI 界面功能强大得多。
如果你曾经为在计算机和移动设备之间同步数据而苦恼,请了解一下 `gphoto2`。
### 安装 gPhoto2
很可能你的 Linux 系统已经安装了 libgphoto2,因为它是与移动设备连接的一个关键库,但你可能还需要安装命令 `gphoto2`,该命令可能在你的存储库中。
在 Fedora 或 RHEL 上:
```
$ sudo dnf install gphoto2
```
在 Debian 或 Ubuntu 上:
```
$ sudo apt install gphoto2
```
### 验证兼容性
若要确认你的移动设备是否受支持,请使用 `--list-cameras`,通过管道传输到 `less`:
```
$ gPhoto2 --list-cameras | less
```
或者你可以通过管道把它传送到 `grep` 来搜索一个词。例如,如果你有三星 Galaxy,则使用 `grep`,并通过选项 `-i` 关闭区分大小写:
```
$ gphoto2 --list-cameras | grep -i galaxy
"Samsung Galaxy models (MTP)"
"Samsung Galaxy models (MTP+ADB)"
"Samsung Galaxy models Kies mode"
```
这证实了三星 Galaxy 设备支持通过 MTP 连接和通过 ADB 连接 MTP。
如果你没有在列表中找到自己的移动设备,你仍然可以尝试使用 `gphoto2`,可能你的设备在列表中使用了不同的称呼。
### 查找移动设备
要使用 gPhoto2,首先必须将移动设备插入计算机,设置为 MTP 模式,并且授予计算机与它交互的权限。这通常需要在你的移动设备上操作,往往是在屏幕上按下一个按钮,以允许其文件系统被刚刚连接的计算机访问。

如果你不授权电脑访问移动设备,那么 gPhoto2 可以检测到你的移动设备,但它不能与之交互。
要确保计算机检测到你连接的移动设备,请使用 `--auto-detect` 选项:
```
$ gphoto2 --auto-detect
Model Port
---------------------------------------
Samsung Galaxy models (MTP) usb:002,010
```
如果你的移动设备没有被检测到,请先检查数据线,然后检查你的设备是否配置为通过 MTP、ADB 或其它 gPhoto2 支持的协议连接,如 `--list-cameras` 所示。
### 查询你的设备支持的特性
对于现代设备,通常有过多的潜在功能,但并非所有移动设备都支持这些功能。你可以用 `--abilities` 选项来确定自己的移动设备支持哪些功能。我觉得结果看起来直观。
```
$ gphoto2 --abilities
Abilities for camera : Samsung Galaxy models (MTP)
Serial port support : no
USB support : yes
Capture choices : Capture not supported by driver
Configuration support : no
Delete selected files on camera : yes
Delete all files on camera : no
File preview (thumbnail) support: no
File upload support : yes
```
如果只连接一个设备,那么不需要指定查询的设备。但是,如果连接了多个 gPhoto2 可以与之交互的设备,则可以通过端口、相机型号或 usbid 指定设备。
### 与你的移动设备交互
如果你的设备支持拍摄功能,则可以从计算机调用你的摄像头来获取媒体。例如,要拍摄照片:
```
$ gphoto2 --capture-image
```
要拍摄照片并立即将其传输到连接的计算机:
```
$ gphoto2 --capture-image-and-download
```
你也可以录制视频和声音。如果连接了多个拍摄设备,可以按端口、相机型号或 usbid 指定要使用的设备:
```
$ gphoto2 --camera "Samsung Galaxy models (MTP)" \
--capture-image-and-download
```
### 文件和文件夹
要想更加智能地管理移动设备上的文件,你需要了解 gPhoto2 连接的文件系统的结构。
你可以使用 `--get-folders` 选项查看可用文件夹:
```
$ gphoto2 --list-folders
There are 2 folders in folder '/'.
- store_00010001
- store_00020002
There are 0 folders in folder '/store_00010001'.
There are 0 folders in folder '/store_00020002'.
```
每个文件夹代表设备上的一个存储单元。在本例中,`store_00010001` 是内部存储器,`store_00020002` 是 SD 卡,这可能与你的设备的结构不同。
### 获取文件
现在你知道了设备的文件夹布局,就可以从设备获取照片了。你可以使用许多不同的选项,具体取决于你想从设备中获取什么。
如果你知道绝对路径,则可以获取指定的文件:
```
$ gphoto2 --get-file IMG_0001.jpg --folder /store_00010001/myphotos
```
你可以同时获得所有的文件:
```
$ gphoto2 --get-all-files --folder /store_00010001/myfiles
```
你可以只获取音频文件:
```
gphoto2 --get-all-audio-data --folder /store_00010001/mysounds
```
gPhoto2 还有其他的选择,其中大多数取决于你连接的设备和使用协议是否支持。
### 上传文件
现在你知道了潜在的目标文件夹,就可以将文件从计算机上传到你的设备。例如,假设有一个名为 `example.epub` 的文件在当前目录中,你可以使用 `--upload-file` 选项和 `--folder` 选项将文件发送到设备并指定要上传到的目录:
```
$ gphoto2 --upload file example.epub \
--folder store_00010001
```
如果你希望将多个文件上传到同一个位置,你可以在设备上创建一个目录:
```
$ gphoto2 --mkdir books \
--folder store_00010001
$ gphoto2 --upload-file *.epub \
--folder store_00010001/books
```
### 列出文件
若要查看设备上的文件,请使用 `--list-files` 选项:
```
$ gphoto2 --list-files --folder /store_00010001
There is 1 file in folder '/store_00010001'
#1 example.epub 17713 KB application/x-unknown
$ gphoto2 --list-files --folder /store_00010001/books
There is 1 file in folder '/store_00010001'
#1 example0.epub 17713 KB application/x-unknown
#2 example1.epub 12264 KB application/x-unknown
[...]
```
### 探索你的使用方式
gPhoto2 的大部分功能取决于你的设备,因此不同用户的体验可能不尽相同。在 `gphoto2 --help` 中列出了许多操作供你探索。使用gPhoto2,再也不用费劲把文件从你的设备传输到电脑上了!
这些开源图片库能够帮助你组织文件,并让的图片看起来很棒。
---
via: <https://opensource.com/article/20/7/gphoto2-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[summer2233](https://github.com/summer2233) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the great failings of mobile devices is how difficult it can be to transfer data from your device to your computer. Mobile devices have a long history of this. Early mobiles, like Pilot and Handspring PDA devices, required special synchronization software (which you had to do religiously for fear of your device running out of batteries and losing all of your data forever). Old iPods required a platform-specific interface. Modern mobile devices default to sending your data to an online account so you can download it again on your computer.
Good news—if you're running Linux, you can probably interface with your mobile device using the `gphoto2`
command. Originally developed as a way to communicate with digital cameras back when a digital camera was just a camera, `gphoto2`
can talk to many different kinds of mobile devices now. Don't let the name fool you, either. It can handle all types of files, not just photos. Better yet, it's scriptable, flexible, and a lot more powerful than most GUI interfaces.
If you've ever struggled with finding a comfortable way to sync your data between your computer and mobile, take a look at `gphoto2`
.
## Install gPhoto2
Chances are your Linux system already has libgphoto2 installed, because it's a key library for interfacing with mobile devices. You may have to install the command `gphoto2`
, however, which is probably available from your repository.
On Fedora or RHEL:
```
$ sudo dnf install gphoto2
```
On Debian or Ubuntu:
```
$ sudo apt install gphoto2
```
## Verify compatibility
To verify that your mobile device is supported, use the `--list-cameras`
piped through `less`
:
`$ gPhoto2 --list-cameras | less `
Or you can pipe it through `grep`
to search for a term. For example, if you have a Samsung Galaxy, then use `grep`
with case sensitivity turned off with the `-i`
switch:
```
$ gphoto2 --list-cameras | grep -i galaxy
"Samsung Galaxy models (MTP)"
"Samsung Galaxy models (MTP+ADB)"
"Samsung Galaxy models Kies mode"
```
This confirms that Samsung Galaxy devices are supported through MTP and MTP with ADB.
If you can't find your device listed, you can still try using `gphoto2`
on the off chance that your device is actually something on the list masquerading as a different brand.
## Find your mobile device
To use gPhoto2, you first have to have a mobile device plugged into your computer, set to MTP mode, and you probably need to give your computer permission to interact with it. This usually requires physical interaction with your device, specifically pressing a button in the UI to permit its filesystem to be accessed by the computer it's just been attached to.
If you don't give your computer access to your mobile, then gPhoto2 detects your device, but it isn't unable to interact with it.
To ensure your computer detects the device you've attached, use the `--auto-detect`
option:
```
$ gphoto2 --auto-detect
Model Port
---------------------------------------
Samsung Galaxy models (MTP) usb:002,010
```
If your device isn't detected, check your cables first, and then check that your device is configured to interface over MTP or ADB, or whatever protocol gPhoto2 supports for your device, as shown in the output of `--list-cameras`
.
## Query your device for features
With modern devices, there's usually a plethora of potential features, but not all features are supported. You can find out for sure with the `--abilities`
option, which I find rather intuitive.
```
$ gphoto2 --abilities
Abilities for camera : Samsung Galaxy models (MTP)
Serial port support : no
USB support : yes
Capture choices : Capture not supported by driver
Configuration support : no
Delete selected files on camera : yes
Delete all files on camera : no
File preview (thumbnail) support: no
File upload support : yes
```
There's no need to specify what device you're querying as long as you only have one device attached. If you have attached more than one device that gPhoto2 can interact with, though, you can specify the device by port, camera model, or usbid.
## Interacting with your device
If your device supports capture, then you can grab media through your camera from your computer. For instance, to capture an image:
```
$ gphoto2 --capture-image
```
To capture an image and immediately transfer it to the computer you're on:
```
$ gphoto2 --capture-image-and-download
```
You can also capture video and sound. If you have more than one camera attached, you can specify which device you want to use by port, camera model, or usbid:
```
$ gphoto2 --camera "Samsung Galaxy models (MTP)" \
--capture-image-and-download
```
## Files and folders
To interact with files on your device intelligently, you need to understand the structure of the filesystem being exposed to gPhoto2.
You can view available folders with the `--get-folders`
option:
```
$ gphoto2 --list-folders
There are 2 folders in folder '/'.
- store_00010001
- store_00020002
There are 0 folders in folder '/store_00010001'.
There are 0 folders in folder '/store_00020002'.
```
Each of these folders represents a storage destination on the device. In this example, `store_00010001`
is the internal storage and `store_00020002`
is an SD card. Your device may be structured differently.
## Getting files
Now that you know the folder layout of your device, you can ingest photos from your device. There are many different options you can use, depending on what you want to take from the device.
You can get a specific file, providing you know the full path:
`$ gphoto2 --get-file IMG_0001.jpg --folder /store_00010001/myphotos`
You can get all files at once:
`$ gphoto2 --get-all-files --folder /store_00010001/myfiles`
You can get just audio files:
`gphoto2 --get-all-audio-data --folder /store_00010001/mysounds`
There are other options, too, and most of them depend on what your device, and the protocol you're using, support.
## Uploading files
Now that you know your potential target folders, you can upload files from your computer to your device. For example, assuming there's a file called `example.epub`
in your current directory, you can send the file to your device with the `--upload-file`
option combined with the `--folder`
option to specify which storage location you want to upload to:
```
$ gphoto2 --upload file example.epub \
--folder store_00010001
```
You can make a directory on your device, should you prefer to upload several files to a consolidated location:
```
$ gphoto2 --mkdir books \
--folder store_00010001
$ gphoto2 --upload-file *.epub \
--folder store_00010001/books
```
## Listing files
To see files uploaded to your device, use the `--list-files`
option:
```
$ gphoto2 --list-files --folder /store_00010001
There is 1 file in folder '/store_00010001'
#1 example.epub 17713 KB application/x-unknown
$ gphoto2 --list-files --folder /store_00010001/books
There is 1 file in folder '/store_00010001'
#1 example0.epub 17713 KB application/x-unknown
#2 example1.epub 12264 KB application/x-unknown
[...]
```
## Exploring your options
Much of gPhoto2's power depends on your device, so your experience will be different than anyone else's. There are many operations listed in `gphoto2 --help`
for you to explore. Use gPhoto2 and never struggle with transferring files from your device to your computer ever again!
## 6 Comments |
12,417 | 使用 fail2ban 和 FirewallD 黑名单保护你的系统 | https://fedoramagazine.org/protect-your-system-with-fail2ban-and-firewalld-blacklists/ | 2020-07-15T12:46:00 | [
"防火墙",
"fail2ban",
"FirewallD"
] | https://linux.cn/article-12417-1.html | 
如果你运行的服务器有面向公众的 SSH 访问,你可能遇到过恶意登录尝试。本文介绍了如何使用两个实用程序来防止入侵者进入我们的系统。
为了防止反复的 ssh 登录尝试,我们来看看 fail2ban。而且,如果你不经常旅行,基本上停留在一两个国家,你可以将 FirewallD 配置为只允许[从你选择的国家访问](https://www.linode.com/community/questions/11143/top-tip-firewalld-and-ipset-country-blacklist)。
首先,让我们为不熟悉这些应用程序的人员介绍一些术语,以完成这项工作:
**fail2ban**:一个守护进程,用于禁止发生多次认证错误的主机。fail2ban 将监控 SystemD 日志,以查找对任何已启用的“<ruby> 监狱 <rt> jail </rt></ruby>”的失败的验证尝试。在达到指定失败次数后,它将添加一个防火墙规则,在配置的时间内阻止该特定 IP 地址。
**FirewallD**:一个带有 D-Bus 接口的防火墙守护进程,提供动态防火墙。除非你另行决定使用传统的 iptables,否则你已经在所有支持的 Fedora 和 CentOS 上安装了 FirewallD。
### 假定前提
* 主机系统有一个互联网连接,并且要么是直接暴露在互联网上,要么是通过 DMZ(这两个都是非常糟糕的想法,除非你知道你在做什么),要么是有一个端口从路由器转发过来。
* 虽然大部分的内容可能适用于其他系统,但本文假设当前系统是 Fedora(31 及以上)或 RHEL/CentOS 8 版本。在 CentOS 上,你必须用 `sudo dnf install epel-release` 启用 Fedora EPEL 仓库。
### 安装与配置
#### Fail2Ban
很有可能已经有某个 Firewalld 区已经允许 SSH 访问,但 sshd 服务本身默认没有启用。要手动启动它,并且不在启动时永久启用它:
```
$ sudo systemctl start sshd
```
或者在系统启动时启用,并同时启动它:
```
$ sudo systemctl enable --now sshd
```
下一步就是安装、配置、启用 fail2ban。和往常一样,安装可以通过命令行完成:
```
$ sudo dnf install fail2ban
```
安装完毕后,下一步就是配置“监狱”(你要以设置的任何阈值监视并禁止的服务)。默认情况下,IP 会被禁止 1 小时(这其实不够长)。最好的做法是使用 `*.local` 文件覆盖系统默认值,而不是直接修改 `*.config` 文件。如果我们查看我的 `jail.local`,我们可以看到:
```
# cat /etc/fail2ban/jail.local
[DEFAULT]
# "bantime" is the number of seconds that a host is banned.
bantime = 1d
# A host is banned if it has generated "maxretry" during the last "findtime"
findtime = 1h
# "maxretry" is the number of failures before a host get banned.
maxretry = 5
```
换成通俗的语言讲,就是在过去一小时内尝试 5 次后,该 IP 将被封禁 1 天。对于多次被封的 IP,也可以选择增加封禁时间,但这是另一篇文章的主题。
下一步是配置“监狱”。在本教程中显示的是 `sshd`,但其他服务的步骤大致相同。在 `/etc/fail2ban/jail.d` 中创建一个配置文件。这是我的文件:
```
# cat /etc/fail2ban/jail.d/sshd.local
[sshd]
enabled = true
```
就这么简单! 很多配置已经在为 Fedora 构建的软件包中处理了(提示:我是当前的维护者)。接下来启用并启动 fail2ban 服务:
```
$ sudo systemctl enable --now fail2ban
```
希望没有立即出错,如果没有,请使用下面的命令检查 fail2ban 的状态:
```
$ sudo systemctl status fail2ban
```
如果它没有错误地启动,应该是这样的:
```
$ systemctl status fail2ban
● fail2ban.service - Fail2Ban Service
Loaded: loaded (/usr/lib/systemd/system/fail2ban.service; disabled; vendor preset: disabled)
Active: active (running) since Tue 2020-06-16 07:57:40 CDT; 5s ago
Docs: man:fail2ban(1)
Process: 11230 ExecStartPre=/bin/mkdir -p /run/fail2ban (code=exited, status=0/SUCCESS)
Main PID: 11235 (f2b/server)
Tasks: 5 (limit: 4630)
Memory: 12.7M
CPU: 109ms
CGroup: /system.slice/fail2ban.service
└─11235 /usr/bin/python3 -s /usr/bin/fail2ban-server -xf start
Jun 16 07:57:40 localhost.localdomain systemd[1]: Starting Fail2Ban Service…
Jun 16 07:57:40 localhost.localdomain systemd[1]: Started Fail2Ban Service.
Jun 16 07:57:41 localhost.localdomain fail2ban-server[11235]: Server ready
```
如果是刚刚启动的,fail2ban 不太可能显示任何有意思的信息,但要检查 fail2ban 的状态,并确保“监狱”被启用,请输入:
```
$ sudo fail2ban-client status
Status
|- Number of jail: 1
`- Jail list: sshd
```
sshd “监狱”的上级状态也会显示出来。如果启用了多个“监狱”,它们会在这里显示出来。
要查看一个“监狱”的详细状态,只需在前面的命令中添加“监狱”名称。下面是我的系统的输出,它已经运行了一段时间。我已经从输出中删除了被禁止的 IP:
```
$ sudo fail2ban-client status sshd
Status for the jail: sshd
|- Filter
| |- Currently failed: 8
| |- Total failed: 4399
| `- Journal matches: _SYSTEMD_UNIT=sshd.service + _COMM=sshd
`- Actions
|- Currently banned: 101
|- Total banned: 684
`- Banned IP list: ...
```
监控 fail2ban 日志文件是否有入侵尝试,可以通过“尾随”日志来实现:
```
$ sudo tail -f /var/log/fail2ban.log
```
`tail` 是一个很好的命令行工具,默认情况下,它可以显示一个文件的最后 10 行。添加 `-f` 告诉它尾随文件,这是个观察一个仍在被写入的文件的很好方式。
由于输出的内容中有真实的 IP,所以这里不会提供样本,但它的可读性很高。`INFO` 行通常是登录的尝试。如果从一个特定的 IP 地址进行了足够多的尝试,你会看到一个 `NOTICE` 行显示一个 IP 地址被禁止。在达到禁止时间后,你会看到一个 `NOTICE` 解禁行。
注意几个警告行。最常见的情况是,当添加了一个禁止后,fail2ban 发现该 IP 地址已经在其禁止数据库中,这意味着禁止可能无法正常工作。如果是最近安装的 fail2ban 包,它应该被设置为 FirewallD 的富规则。这个包在 fail2ban-0.11.1-6 版本时从 ipset 方式切换到了富规则方式,所以如果你的 fail2ban 安装时间较早,它可能还在尝试使用 ipset 方式,这种方式使用的是传统的 iptables,不是很可靠。
#### FirewallD 配置
##### 被动还是主动?
有两种策略可以分开或一起使用:**被动**地将单个 IP 地址或**主动**地根据来源国将子网永久列入黑名单。
对于被动方式,一旦 fail2ban 运行了一段时间,最好再运行 `sudo fail2ban-client status sshd` 来看看有哪些坏蛋。很可能会有很多被禁止的 IP 地址。选择一个,然后试着对它运行 `whois`。在输出结果中可能会有很多有趣的信息,但是对于这个方法来说,只有来源国是重要的。为了保持简单,让我们过滤掉除了国家以外的所有信息。
在这个例子中,我们将使用一些著名的域名:
```
$ whois google.com | grep -i country
Registrant Country: US
Admin Country: US
Tech Country: US
```
```
$ whois rpmfusion.org | grep -i country
Registrant Country: FR
```
```
$ whois aliexpress.com | grep -i country
Registrant Country: CN
```
使用 `grep -i` 的原因是为了使 `grep` 不区分大小写,而大多数条目都使用的是 “Country”,而有些条目则是全小写的 “country”,所以这种方法无论如何都能匹配。
现在知道了尝试入侵的来源国,问题是,“是否有来自这个国家的人有合法的理由连接到这台计算机?”如果答案是否定的,那么封锁整个国家应该是可以接受的。
从功能上看,主动式方法它与被动式方法没有太大区别,然而,来自有些国家的入侵企图是非常普遍的。如果你的系统既不放在这些国家里,也没有任何源自这些国家的客户,那么为什么不现在就把它们加入黑名单而是等待呢?(LCTT 译注:我的经验是,动辄以国家的范畴而列入黑名单有些过于武断。建议可以将该 IP 所属的 WHOIS 网段放入到黑名单,因为这些网段往往具有相同的使用性质,如都用于用户接入或 IDC 托管,其安全状况也大致相同,因此,如果有来自该网段的某个 IP 的恶意尝试,可以预期该网段内的其它 IP 也可能被利用来做这样的尝试。)
##### 黑名单脚本和配置
那么如何做到这一点呢?用 FirewallD ipset。我开发了下面的脚本来尽可能地自动化这个过程:
```
#!/bin/bash
# Based on the below article
# https://www.linode.com/community/questions/11143/top-tip-firewalld-and-ipset-country-blacklist
# Source the blacklisted countries from the configuration file
. /etc/blacklist-by-country
# Create a temporary working directory
ipdeny_tmp_dir=$(mktemp -d -t blacklist-XXXXXXXXXX)
pushd $ipdeny_tmp_dir
# Download the latest network addresses by country file
curl -LO http://www.ipdeny.com/ipblocks/data/countries/all-zones.tar.gz
tar xf all-zones.tar.gz
# For updates, remove the ipset blacklist and recreate
if firewall-cmd -q --zone=drop --query-source=ipset:blacklist; then
firewall-cmd -q --permanent --delete-ipset=blacklist
fi
# Create the ipset blacklist which accepts both IP addresses and networks
firewall-cmd -q --permanent --new-ipset=blacklist --type=hash:net \
--option=family=inet --option=hashsize=4096 --option=maxelem=200000 \
--set-description="An ipset list of networks or ips to be dropped."
# Add the address ranges by country per ipdeny.com to the blacklist
for country in $countries; do
firewall-cmd -q --permanent --ipset=blacklist \
--add-entries-from-file=./$country.zone && \
echo "Added $country to blacklist ipset."
done
# Block individual IPs if the configuration file exists and is not empty
if [ -s "/etc/blacklist-by-ip" ]; then
echo "Adding IPs blacklists."
firewall-cmd -q --permanent --ipset=blacklist \
--add-entries-from-file=/etc/blacklist-by-ip && \
echo "Added IPs to blacklist ipset."
fi
# Add the blacklist ipset to the drop zone if not already setup
if firewall-cmd -q --zone=drop --query-source=ipset:blacklist; then
echo "Blacklist already in firewalld drop zone."
else
echo "Adding ipset blacklist to firewalld drop zone."
firewall-cmd --permanent --zone=drop --add-source=ipset:blacklist
fi
firewall-cmd -q --reload
popd
rm -rf $ipdeny_tmp_dir
```
这个应该安装到 `/usr/local/sbin`,不要忘了让它可执行!
```
$ sudo chmod +x /usr/local/sbin/firewalld-blacklist
```
然后创建一个配置文件 `/etc/blacklist-by-country`:
```
# Which countries should be blocked?
# Use the two letter designation separated by a space.
countries=""
```
而另一个配置文件 `/etc/blacklist-by-ip`,每行只有一个 IP,没有任何额外的格式化。
在这个例子中,从 ipdeny 的区文件中随机选择了 10 个国家:
```
# ls | shuf -n 10 | sed "s/\.zone//g" | tr '\n' ' '
nl ee ie pk is sv na om gp bn
```
现在只要在配置文件中加入至少一个国家,就可以运行了!
```
$ sudo firewalld-blacklist
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 142 100 142 0 0 1014 0 --:--:-- --:--:-- --:--:-- 1014
100 662k 100 662k 0 0 989k 0 --:--:-- --:--:-- --:--:-- 989k
Added nl to blacklist ipset.
Added ee to blacklist ipset.
Added ie to blacklist ipset.
Added pk to blacklist ipset.
Added is to blacklist ipset.
Added sv to blacklist ipset.
Added na to blacklist ipset.
Added om to blacklist ipset.
Added gp to blacklist ipset.
Added bn to blacklist ipset.
Adding ipset blacklist to firewalld drop zone.
success
```
要验证 FirewallD 黑名单是否成功,请检查 `drop` 区和 `blacklist` ipset。
```
$ sudo firewall-cmd --info-zone=drop
drop (active)
target: DROP
icmp-block-inversion: no
interfaces:
sources: ipset:blacklist
services:
ports:
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
$ sudo firewall-cmd --info-ipset=blacklist | less
blacklist
type: hash:net
options: family=inet hashsize=4096 maxelem=200000
entries:
```
第二条命令将输出所有的子网,这些子网是基于被封杀的国家而添加的,可能会相当长。
### 那么现在我该怎么做?
虽然在开始的时候,监控的频率会比较高,但随着时间的推移,入侵尝试的次数应该会随着黑名单的增加而减少。那么目标应该是维护而不是主动监控。
为此,我创建了一个 SystemD 服务文件和定时器,这样每月都会刷新由 ipdeny 维护的每个国家的子网。事实上,这里讨论的所有内容都可以从我的 [pagure.io](https://pagure.io/firewalld-blacklist) 项目中下载。
是不是很高兴你看完了整篇文章?现在只要把服务文件和定时器下载到 `/etc/systemd/system/`,并启用定时器就行了:
```
$ sudo systemctl daemon-reload
$ sudo systemctl enable --now firewalld-blacklist.timer
```
---
via: <https://fedoramagazine.org/protect-your-system-with-fail2ban-and-firewalld-blacklists/>
作者:[hobbes1069](https://fedoramagazine.org/author/hobbes1069/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you run a server with a public-facing SSH access, you might have experienced malicious login attempts. This article shows how to use two utilities to keep the intruder out of our systems.
To protect against repeated ssh login attempts, we’ll look at *fail2ban*. And if you don’t travel much, and perhaps stay in one or two countries, you can configure *firewalld* to only [allow access from the countries you choose](https://www.linode.com/community/questions/11143/top-tip-firewalld-and-ipset-country-blacklist).
First let’s work through a little terminology for those not familiar with the various applications we’ll need to make this work:
**fail2ban:** Daemon to ban hosts that cause multiple authentication errors.
fail2ban will monitor the SystemD journal to look for failed authentication attempts for whichever jails have been enabled. After the number of failed attempts specified it will add a firewall rule to block that specific IP address for an amount of time configured.
**firewalld:** A firewall daemon with D-Bus interface providing a dynamic firewall.
Unless you’ve manually decided to use traditional iptables, you’re already using firewalld on all supported releases of Fedora and CentOS.
## Assumptions
- The host system has an internet connection and is either fully exposed directly, through a DMZ (both REALLY bad ideas unless you know what you’re doing), or has a port being forwarded to it from a router.
- While most of this might apply to other systems, this article assumes a current version of Fedora (31 and up) or RHEL/CentOS 8. On CentOS you must enable the Fedora EPEL repo with
sudo dnf install epel-release
## Install & Configuration
### Fail2Ban
More than likely whichever FirewallD zone is set already allows SSH access but the sshd service itself is not enabled by default. To start it manually and without permanently enabling on boot:
$ sudo systemctl start sshd
Or to start and enable on boot:
$ sudo systemctl enable --now sshd
The next step is to install, configure, and enable fail2ban. As usual the install can be done from the command line:
$ sudo dnf install fail2ban
Once installed the next step is to configure a jail (a service you want to monitor and ban at whatever thresholds you’ve set). By default IPs are banned for 1 hour (which is not near long enough). The best practice is to override the system defaults using *.local files instead of directly modifying the *.config files. If we look at my jail.local we see:
# cat /etc/fail2ban/jail.local [DEFAULT] # "bantime" is the number of seconds that a host is banned. bantime = 1d # A host is banned if it has generated "maxretry" during the last "findtime" findtime = 1h # "maxretry" is the number of failures before a host get banned. maxretry = 5
Turning this into plain language, after 5 attempts within the last hour the IP will be blocked for 1 day. There’s also options for increasing the ban time for IPs that get banned multiple times, but that’s the subject for another article.
The next step is to configure a jail. In this tutorial sshd is shown but the steps are more or less the same for other services. Create a configuration file inside */etc/fail2ban/jail.d*. Here’s mine:
# cat /etc/fail2ban/jail.d/sshd.local [sshd] enabled = true
It’s that simple! A lot of the configuration is already handled within the package built for Fedora (Hint: I’m the current maintainer). Next enable and start the fail2ban service.
$ sudo systemctl enable --now fail2ban
Hopefully there were not any immediate errors, if not, check the status of fail2ban using the following command:
$ sudo systemctl status fail2ban
If it started without errors it should look something like this:
$ systemctl status fail2ban ● fail2ban.service - Fail2Ban Service Loaded: loaded (/usr/lib/systemd/system/fail2ban.service; disabled; vendor preset: disabled) Active: active (running) since Tue 2020-06-16 07:57:40 CDT; 5s ago Docs: man:fail2ban(1) Process: 11230 ExecStartPre=/bin/mkdir -p /run/fail2ban (code=exited, status=0/SUCCESS) Main PID: 11235 (f2b/server) Tasks: 5 (limit: 4630) Memory: 12.7M CPU: 109ms CGroup: /system.slice/fail2ban.service └─11235 /usr/bin/python3 -s /usr/bin/fail2ban-server -xf start Jun 16 07:57:40 localhost.localdomain systemd[1]: Starting Fail2Ban Service… Jun 16 07:57:40 localhost.localdomain systemd[1]: Started Fail2Ban Service. Jun 16 07:57:41 localhost.localdomain fail2ban-server[11235]: Server ready
If recently started, fail2ban is unlikely to show anything interesting going on just yet but to check the status of fail2ban and make sure the jail is enabled enter:
$ sudo fail2ban-client status Status |- Number of jail: 1 `- Jail list: sshd
And the high level status of the sshd jail is shown. If multiple jails were enabled they would show up here.
To check the detailed status a jail, just add the jail to the previous command. Here’s the output from my system which has been running for a while. I have removed the banned IPs from the output:
$ sudo fail2ban-client status sshd Status for the jail: sshd |- Filter | |- Currently failed: 8 | |- Total failed: 4399 | `- Journal matches: _SYSTEMD_UNIT=sshd.service + _COMM=sshd `- Actions |- Currently banned: 101 |- Total banned: 684 `- Banned IP list: ...
Monitoring the fail2ban log file for intrusion attempts can be achieved by “tailing” the log:
$ sudo tail -f /var/log/fail2ban.log
Tail is a nice little command line utility which by default shows the last 10 lines of a file. Adding the “-f” tells it to follow the file which is a great way to watch a file that’s still being written to.
Since the output has real IPs in it, a sample won’t be provided but it’s pretty human readable. The INFO lines will usually be attempts at a login. If enough attempts are made from a specific IP address you will see a NOTICE line showing an IP address was banned. After the ban time has been reached you will see an NOTICE unban line.
Lookout for several WARNING lines. Most often this happens when a ban is added but fail2ban finds the IP address already in its ban database, which means banning may not be working correctly. If recently installed the fail2ban package it should be setup for FirewallD rich rules. The package was only switched from “ipset” to “rich rules” as of *fail2ban-0.11.1-6* so if you have an older install of fail2ban it may still be trying to use the ipset method which utilizes legacy iptables and is not very reliable.
### FirewallD Configuration
#### Reactive or Proactive?
There are two strategies that can be used either separately or together. Reactive or proactive permanent blacklisting of individual IP address or subnets based on country of origin.
For the reactive approach once fail2ban has been running for a while it’s a good idea to take a look at how “bad is bad” by running *sudo fail2ban-client status sshd* again. There most likely will be many banned IP addresses. Just pick one and try running *whois* on it. There can be quite a bit of interesting information in the output but for this method, only the country of origin is of importance. To keep things simple, let’s filter out everything but the country.
For this example a few well known domain names will be used:
$ whois google.com | grep -i country
Registrant Country: US
Admin Country: US
Tech Country: US
$ whois rpmfusion.org | grep -i country
Registrant Country: FR
$ whois aliexpress.com | grep -i country
Registrant Country: CN
The reason for the *grep -i* is to make grep non-case sensitive while most entries use “Country”, some are in all lower case so this method matches regardless.
Now that the country of origin of an intrusion attempt is known the question is, “Does anyone from that country have a legitimate reason to connect to this computer?” If the answer is NO, then it should be acceptable to block the entire country.
Functionally the proactive approach it not very different from the reactive approach, however, there are countries from which intrusion attempts are very common. If the system neither resides in one of those countries, nor has any customers originating from them, then why not add them to the blacklist now rather than waiting?
#### Blacklisting Script and Configuration
So how do you do that? With FirewallD ipsets. I developed the following script to automate the process as much as possible:
#!/bin/bash # Based on the below article # https://www.linode.com/community/questions/11143/top-tip-firewalld-and-ipset-country-blacklist # Source the blacklisted countries from the configuration file . /etc/blacklist-by-country # Create a temporary working directory ipdeny_tmp_dir=$(mktemp -d -t blacklist-XXXXXXXXXX) pushd $ipdeny_tmp_dir # Download the latest network addresses by country file curl -LO http://www.ipdeny.com/ipblocks/data/countries/all-zones.tar.gz tar xf all-zones.tar.gz # For updates, remove the ipset blacklist and recreate if firewall-cmd -q --zone=drop --query-source=ipset:blacklist; then firewall-cmd -q --permanent --delete-ipset=blacklist fi # Create the ipset blacklist which accepts both IP addresses and networks firewall-cmd -q --permanent --new-ipset=blacklist --type=hash:net \ --option=family=inet --option=hashsize=4096 --option=maxelem=200000 \ --set-description="An ipset list of networks or ips to be dropped." # Add the address ranges by country per ipdeny.com to the blacklist for country in $countries; do firewall-cmd -q --permanent --ipset=blacklist \ --add-entries-from-file=./$country.zone && \ echo "Added $country to blacklist ipset." done # Block individual IPs if the configuration file exists and is not empty if [ -s "/etc/blacklist-by-ip" ]; then echo "Adding IPs blacklists." firewall-cmd -q --permanent --ipset=blacklist \ --add-entries-from-file=/etc/blacklist-by-ip && \ echo "Added IPs to blacklist ipset." fi # Add the blacklist ipset to the drop zone if not already setup if firewall-cmd -q --zone=drop --query-source=ipset:blacklist; then echo "Blacklist already in firewalld drop zone." else echo "Adding ipset blacklist to firewalld drop zone." firewall-cmd --permanent --zone=drop --add-source=ipset:blacklist fi firewall-cmd -q --reload popd rm -rf $ipdeny_tmp_dir
This should be installed to */usr/local/sbin* and don’t forget to make it executable!
$ sudo chmod +x /usr/local/sbin/firewalld-blacklist
Then create a configure file: */etc/blacklist-by-country*:
# Which countries should be blocked? # Use the two letter designation separated by a space. countries=""
And another configuration file */etc/blacklist-by-ip*, which is just one IP per line without any additional formatting.
For this example 10 random countries were selected from the ipdeny zones:
# ls | shuf -n 10 | sed "s/\.zone//g" | tr '\n' ' ' nl ee ie pk is sv na om gp bn
Now as long as at least one country has been added to the config file it’s ready to run!
$ sudo firewalld-blacklist % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 142 100 142 0 0 1014 0 --:--:-- --:--:-- --:--:-- 1014 100 662k 100 662k 0 0 989k 0 --:--:-- --:--:-- --:--:-- 989k Added nl to blacklist ipset. Added ee to blacklist ipset. Added ie to blacklist ipset. Added pk to blacklist ipset. Added is to blacklist ipset. Added sv to blacklist ipset. Added na to blacklist ipset. Added om to blacklist ipset. Added gp to blacklist ipset. Added bn to blacklist ipset. Adding ipset blacklist to firewalld drop zone. success
To verify that the firewalld blacklist was successful, check the drop zone and blacklist ipset:
$ sudo firewall-cmd --info-zone=drop drop (active) target: DROP icmp-block-inversion: no interfaces: sources: ipset:blacklist services: ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: $ sudo firewall-cmd --info-ipset=blacklist | less blacklist type: hash:net options: family=inet hashsize=4096 maxelem=200000 entries:
The second command will output all of the subnets that were added based on the countries blocked and can be quite lengthy.
#### So now what do I do?
While it will be a good idea to monitor things more frequently at the beginning, over time the number of intrusion attempts should decline as the blacklist grows. Then the goal should be maintenance rather than active monitoring.
To this end I created a SystemD service file and timer so that on a monthly basis the by country subnets maintained by ipdeny are refreshed. In fact everything discussed here can be downloaded from my pagure.io project:
[https://pagure.io/firewalld-blacklist](https://pagure.io/firewalld-blacklist)
Aren’t you glad you read the whole article? Now just download the service file and timer to */etc/systemd/system/ *and enable the timer:
$ sudo systemctl daemon-reload $ sudo systemctl enable --now firewalld-blacklist.timer
## K. de Jong
“If you run a server with a public-facing SST access”, do you mean SSH? If not, please add the acronym in full or a hyperlink for more info.
## Pieter
Thank you for this great article and the firewalld-blacklist repo!
## Ron Olson
Great article! FYI If you’re doing this from CentOS, you need to first run
sudo dnf install epel-release
to get the packages.
## Stephen Snow
Thanks Ron,
Good catch!
## Leo L. B.
fail2ban doesnt protect against distributed bruteforce attacks coming from several hosts at the same time, which is what the bruteforce attempts you get over SSH are when you run a public facing server.
Maybe you could talk about Port Knocking and how it can stop port scanning and therefore these distributed bruteforce attacks completely?
Good article nonetheless!
## Joao Rodrigues
If you really want to stop worrying about brute force attacks, the only way is to completely disable password authentication and rely on public keys or client certificate authentication.
## Elio Qoshi
Bonus points if you could change ‘Blacklist’ to a less discriminatory term, such as “Blocklist” or ‘Deny List’ 🙂
## Till Maas
Thank you for highlighting this. This is currently tracked/discussed at https://lists.fedoraproject.org/archives/list/[email protected]/thread/TJUHPD2ANXHYNAKVXYRYNHDLCPPAKNYI/
## Paul W. Frields
Although this article was planned and written some time before publication, and before people were starting to have discussions in IT about the use of these terms, that doesn’t make it any less of an issue. The editors are aware of the concern, and are having a discussion currently about new guidelines for standard usage, including using “allowlist/denylist.” Work is already underway on those guidelines. One thing to note in that discussion — there is plenty of input from many quarters already, but much of the input is not coming from editors. As with other open source communities, the people who do the work get to make the decisions on what to do here, and the editors seem to be largely in agreement about fixing this.
## Randy
BLOCKlists 🙄 c’mon
## Luya Tshimbalanga
Small correction. “Systemd” instead of “SystemD”.
## sieukeo.com
Glad to bе one of many visitants on tһis awing site
:D.
## francesco
Suddenly it looks like fail2ban doesn’t support IPv6 (I’m a Debian user, so I’m not sure about Fedora…)
Here you can find more info:
https://github.com/fail2ban/fail2ban/issues/39
That’s why I uncomment the line:
ListenAddress 0.0.0.0
in the sshd config file (/etc/ssh/sshd_config on my system).
sshd will then listen only on IPv4.
## francesco
I’m sorry, I didn’t notice that the issue was closed a few years ago… so fail2ban supports IPv6 too, now.
## Brooks Kelley
Thank you for posting this article. How timely too!
I had just upgraded from Fedora 29 to 32 ( yes, I know, big leap ).
I have been used to using IPTABLES to exclude countries from accessing my SSH server. I was not looking forward to the learning curve for NFTABLES to do what I used to do for my SSH server with IPTABLES. I finally gave up and just secured my SSH server to not being accessible from the cloud when I saw this article posted.
I have limited now my access to the US and CN. I also set the failure rate to 3 instead of 5. In addition, I extended the attempts time to two hours and the ban to two days.
After installing the script and running it, I VPNed into France and tried to access my SSH server using my FQDN. No response! 😎
Before adding the country blacklist though, I just ran fail2bain for a couple of days. I had somewhere around 345 bans in effect by the time I installed your scripts for firewalld and ipsets.
What I would love to see is the article you promised following up on how if someone shows up again on the BAN list, you can extend their BANTIME even further or even permanently.
I would really love to know how to do that. My server is a private server and I don’t mind making it as hard as possible to gain access via SSH. I have turned off direct root access. Of course, I could go further with keys and may do so. But, I would rather install some sort of two factor authentication over the use of keys.
Thank you again for posting this!
## Marcwa
I cam across this and in the first shot it was not working for me using Fedora 32.
I noticed, that i added the Country-Lists with uppercase characters in /etc/blacklist-by-country.
So i adjusted the Code of firewalld-blacklist a little bit, that it converts the country code to lowercase characters.
To do so, just change on line from:
“–add-entries-from-file=./$country.zone && \”
to
“–add-entries-from-file=./${country,,}.zone && \”
Now it is working perfectly! Thank you very much for this guide.
## Brooks Kelley
Last night, I had to shut down my server. It’s okay. It is just a toy I use to learn on trying out server software. Our home network’s LAN was experiencing a data storm and devices weren’t working. Afterwards, things returned to normal on the network. I went into the cable router and shutdown port forwarding to my server.
Upon examining the fail2ban.log file this morning, I found the fail2ban service restarted around 9 in the morning, which is odd since I was leaving the system alone. Twenty-five minutes later everything shut down in the log file for the remainder of the day. Of course, this left my system vulnerable for the rest of the day to a brute force attack. By the evening, my network was in disarray. I suspect a vulnerability of fail2ban has been found.
I went to their website and was shocked to find that it hasn’t been updated since 2015.
The worse part is that fail2ban shuts down logging on ‘secure’ so I couldn’t see what was going on with my ssh server independently of my fail2ban service after it failed.
This is the last of my fail2ban log file. The abuser is from China. …
2020-07-04 09:25:30,175 fail2ban.actions [767]: NOTICE [sshd] Restore Ban 106.12.88.165
2020-07-04 09:26:30,212 fail2ban.utils [767]: ERROR 7f974829f630 — exec: ports=”ssh”; for p in $(echo $ports | tr “, ” ” “); do firewall-cmd –add-rich-rule=”rule family=’ipv4′ source address=’106.12.88.165′ port port=’$p’ protocol=’tcp’ reject type=’icmp-port-unreachable'”; done
2020-07-04 09:26:30,213 fail2ban.utils [767]: ERROR 7f974829f630 — timed out after 60 seconds.
2020-07-04 09:26:30,413 fail2ban.utils [767]: ERROR ports=”ssh”; for p in $(echo $ports | tr “, ” ” “); do firewall-cmd –add-rich-rule=”rule family=’ipv4′ source address=’106.12.88.165′ port port=’$p’ protocol=’tcp’ reject type=’icmp-port-unreachable'”; done — failed with [Errno 3] No such process
2020-07-04 09:26:30,413 fail2ban.utils [767]: ERROR 7f974829f630 — stderr: ‘ERROR:dbus.proxies:Introspect error on :1.7:/org/fedoraproject/FirewallD1: dbus.exceptions.DBusException: org.freedesktop.DBus.Error.NoReply: Did not receive a reply. Possible causes include: the remote application did not send a reply, the message bus security policy blocked the reply, the reply timeout expired, or the network connection was broken.’
2020-07-04 09:26:30,413 fail2ban.utils [767]: ERROR 7f974829f630 — killed with SIGTERM (return code: -15)
2020-07-04 09:26:30,414 fail2ban.actions [767]: ERROR Failed to execute ban jail ‘sshd’ action ‘firewallcmd-rich-rules’ info ‘ActionInfo({‘ip’: ‘106.12.88.165’, ‘family’: ‘inet4’, ‘fid’: <function Actions.ActionInfo. at 0x7f9748fcfe50>, ‘raw-ticket’: <function Actions.ActionInfo. at 0x7f9748fd0550>})’: Error banning 106.12.88.165
## Tim
If you want to block visitors by country using ipset, you can find the instructions in https://blog.ip2location.com/knowledge-base/how-to-block-ip-addresses-from-a-country-using-ipset/ |
12,418 | 如何解密 Linux 版本信息 | https://www.networkworld.com/article/3565432/how-to-decipher-linux-release-info.html | 2020-07-15T13:31:09 | [
"版本",
"内核"
] | https://linux.cn/article-12418-1.html |
>
> 显示和解释有关 Linux 版本的信息比看起来要复杂一些。
>
>
>

与引用一个简单的版本号不同,识别 Linux 版本有很多种方法。即使只是快速查看一下 `uname` 命令的输出,也可以告诉你一些信息。这些信息是什么,它告诉你什么?
在本文中,我们将认真研究 `uname` 命令的输出以及其他一些命令和文件提供的版本说明。
### 使用 uname
每当在 Linux 系统终端窗口中执行命令 `uname -a` 时,都会显示很多信息。那是因为这个小小的 `a` 告诉 `uname` 命令你想查看该命令能提供的*全部*输出。结果显示的内容将告诉你许多有关该系统的各种信息。实际上,显示的每一块信息都会告诉你一些关于系统的不同信息。
例如,`uname -a` 输出看起来像这样:
```
$ uname -a
Linux dragonfly 5.4.0-37-generic #41-Ubuntu SMP Wed Jun 3 18:57:02 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
```
尽管这可能不太重要,但你可以使用一个按适当的顺序包含 `uname` 所有选项来显示相同的信息:
```
$ uname -snmrvpio
Linux dragonfly 5.4.0-37-generic #41-Ubuntu SMP Wed Jun 3 18:57:02 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
```
要将这一长串信息分解为单独的块,可以使用类似这样的 `for` 循环来遍历每个选项:
```
$ for option in s n m r v p i o; do echo -n "$option: "; uname -$option; done
s: Linux
n: dragonfly
m: x86_64
r: 5.4.0-37-generic
v: #41-Ubuntu SMP Wed Jun 3 18:57:02 UTC 2020
p: x86_64
i: x86_64
o: GNU/Linux
```
该循环显示了该选项提供了哪些信息。`uname` 手册页提供了每个选项的描述。以下是清单:
* Linux –- 内核名称(选项 `s`)
* dragonfly –- 节点名(选项 `n`)
* x86\_64 –- 机器硬件名(选项 `m`)
* 5.4.0-37-generic –- 内核发布版本(选项 `r`)
* #41-Ubuntu SMP Wed Jun 3 18:57:02 UTC 2020 -- 内核版本(选项 `v`)
* x86\_64 –- 处理器(选项 `p`)
* x86\_64 –- 硬件平台(选项 `i`)
* GNU/Linux –- 操作系统(选项 `o`)
要更深入地研究显示的信息,请认真查看显示的内核发行数据。第四行中的 `5.4.0-37` 不仅仅是一串任意数字。每个数字都很重要。
* `5` 表示内核版本
* `4` 表示主要版本
* `0` 表示次要版本
* `37` 表示最新补丁
此外,在上面的循环中输出的第 5 行(内核版本)中的 `#41` 表示此发布版本已编译 41 次。
如果你只想显示所有信息中的一项,那么单个选项可能很有用。例如,命令 `uname -n` 可以仅告诉你系统名称,而 `uname -r` 仅可以告诉你内核发布版本。在盘点服务器或构建脚本时,这些和其他选项可能很有用。
在 Red Hat 系统时,`uname -a` 命令将提供相同种类的信息。这是一个例子:
```
$ uname -a
Linux fruitfly 4.18.0-107.el8.x86_64 #1 SMP Fri Jun 14 13:46:34 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
```
### 发行版信息
如果你需要了解运行的发行版是什么,那么 `uname` 的输出不会对你有太大帮助。毕竟,内核版本与发行版不同。关于这个信息,你可以在 Ubuntu 和其他基于 Debian 的系统上使用 `lsb_release -r` 命令,而在 Red Hat 上可以显示 `/etc/redhat-release` 文件的内容。
对于 Debian 系统:
```
$ lsb_release -r
Release: 20.04
```
对于 Red Hat 及相关系统:
```
$ cat /etc/redhat-release
Red Hat Enterprise Linux release 8.1 Beta (Ootpa)
```
### 使用 /proc/version
`/proc/version` 文件还可以提供有关 Linux 版本的信息。该文件中提供的信息与 `uname -a` 输出有很多共同点。以下是例子。
在 Ubuntu 上:
```
$ cat /proc/version
Linux version 5.4.0-37-generic (buildd@lcy01-amd64-001) (gcc version 9.3.0 (Ubuntu 9.3.0-10ubuntu2)) #41-Ubuntu SMP Wed Jun 3 18:57:02 UTC 2020
```
在 RedHat 上:
```
$ cat /proc/version
Linux version 4.18.0-107.el8.x86_64 ([email protected]) (gcc version 8.3.1 20190507 (Red Hat 8.3.1-4) (GCC)) #1 SMP Fri Jun 14 13:46:34 UTC 2019
```
### 总结
Linux 系统提供了很多关于内核和发行版安装的信息。你只需要知道在哪里或如何寻找并理解它的含义。
---
via: <https://www.networkworld.com/article/3565432/how-to-decipher-linux-release-info.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,421 | 用树莓派构建 Kubernetes 集群 | https://opensource.com/article/20/6/kubernetes-raspberry-pi | 2020-07-15T23:43:26 | [
"Kubernetes"
] | https://linux.cn/article-12421-1.html |
>
> 将 Kubernetes 安装在多个树莓派上,实现自己的“家庭私有云”容器服务。
>
>
>

[Kubernetes](https://opensource.com/resources/what-is-kubernetes) 从一开始就被设计为云原生的企业级容器编排系统。它已经成长为事实上的云容器平台,并由于接受了容器原生虚拟化和无服务器计算等新技术而继续发展。
从微型的边缘计算到大规模的容器环境,无论是公有云还是私有云环境,Kubernetes 都可以管理其中的容器。它是“家庭私有云”项目的理想选择,既提供了强大的容器编排,又让你有机会了解一项这样的技术 —— 它的需求如此之大,与云计算结合得如此彻底,以至于它的名字几乎就是“云计算”的代名词。
没有什么比 Kubernetes 更懂“云”,也没有什么能比树莓派更合适“集群起来”!在廉价的树莓派硬件上运行本地的 Kubernetes 集群是获得在真正的云技术巨头上进行管理和开发的经验的好方法。
### 在树莓派上安装 Kubernetes 集群
本练习将在三个或更多运行 Ubuntu 20.04 的树莓派 4 上安装 Kubernetes 1.18.2 集群。Ubuntu 20.04(Focal Fossa)提供了针对 64 位 ARM(ARM64)的树莓派镜像(64 位内核和用户空间)。由于目标是使用这些树莓派来运行 Kubernetes 集群,因此运行 AArch64 容器镜像的能力非常重要:很难找到 32 位的通用软件镜像乃至于标准基础镜像。借助 Ubuntu 20.04 的 ARM64 镜像,可以让你在 Kubernetes 上使用 64 位容器镜像。
#### AArch64 vs. ARM64;32 位 vs. 64 位;ARM vs. x86
请注意,AArch64 和 ARM64 实际上是同一种东西。不同的名称源于它们在不同社区中的使用。许多容器镜像都标为 AArch64,并能在标为 ARM64 的系统上正常运行。采用 AArch64/ARM64 架构的系统也能够运行 32 位的 ARM 镜像,但反之则不然:32 位的 ARM 系统无法运行 64 位的容器镜像。这就是 Ubuntu 20.04 ARM64 镜像如此有用的原因。
这里不会太深入地解释不同的架构类型,值得注意的是,ARM64/AArch64 和 x86\_64 架构是不同的,运行在 64 位 ARM 架构上的 Kubernetes 节点无法运行为 x86\_64 构建的容器镜像。在实践中,你会发现有些镜像没有为两种架构构建,这些镜像可能无法在你的集群中使用。你还需要在基于 Arch64 的系统上构建自己的镜像,或者跳过一些限制以让你的常规的 x86\_64 系统构建 Arch64 镜像。在“家庭私有云”项目的后续文章中,我将介绍如何在常规系统上构建 AArch64 镜像。
为了达到两全其美的效果,在本教程中设置好 Kubernetes 集群后,你可以在以后向其中添加 x86\_64 节点。你可以通过使用 [Kubernetes 的<ruby> 污点 <rt> taint </rt></ruby> 和<ruby> 容忍 <rt> toleration </rt></ruby>](https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/) 能力,由 Kubernetes 的调度器将给定架构的镜像调度到相应的节点上运行。
关于架构和镜像的内容就不多说了。是时候安装 Kubernetes 了,开始吧!
#### 前置需求
这个练习的要求很低。你将需要:
* 三台(或更多)树莓派 4(最好是 4GB 内存的型号)。
* 在全部树莓派上安装 Ubuntu 20.04 ARM64。
为了简化初始设置,请阅读《[修改磁盘镜像来创建基于树莓派的家庭实验室](/article-12277-1.html)》,在将 Ubuntu 镜像写入 SD 卡并安装在树莓派上之前,添加一个用户和 SSH 授权密钥(`authorized_keys`)。
### 配置主机
在 Ubuntu 被安装在树莓派上,并且可以通过 SSH 访问后,你需要在安装 Kubernetes 之前做一些修改。
#### 安装和配置 Docker
截至目前,Ubuntu 20.04 在 base 软件库中提供了最新版本的 Docker,即 v19.03,可以直接使用 `apt` 命令安装它。请注意,包名是 `docker.io`。请在所有的树莓派上安装 Docker:
```
# 安装 docker.io 软件包
$ sudo apt install -y docker.io
```
安装好软件包后,你需要做一些修改来启用 [cgroup](https://en.wikipedia.org/wiki/Cgroups)(控制组)。cgroup 允许 Linux 内核限制和隔离资源。实际上,这可以让 Kubernetes 更好地管理其运行的容器所使用的资源,并通过让容器彼此隔离来增加安全性。
在对所有树莓派进行以下修改之前,请检查 `docker info` 的输出:
```
# 检查 `docker info`
# 省略了某些输出
$ sudo docker info
(...)
Cgroup Driver: cgroups
(...)
WARNING: No memory limit support
WARNING: No swap limit support
WARNING: No kernel memory limit support
WARNING: No kernel memory TCP limit support
WARNING: No oom kill disable support
```
上面的输出突出显示了需要修改的部分:cgroup 驱动和限制支持。
首先,将 Docker 使用的默认 cgroup 驱动从 `cgroups` 改为 `systemd`,让 systemd 充当 cgroup 管理器,确保只有一个 cgroup 管理器在使用。这有助于系统的稳定性,这也是 Kubernetes 所推荐的。要做到这一点,请创建 `/etc/docker/daemon.json` 文件或将内容替换为:
```
# 创建或替换 /etc/docker/daemon.json 以启用 cgroup 的 systemd 驱动
$ sudo cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
```
#### 启用 cgroup 限制支持
接下来,启用限制支持,如上面的 `docker info` 输出中的警告所示。你需要修改内核命令行以在引导时启用这些选项。对于树莓派 4,将以下内容添加到 `/boot/firmware/cmdline.txt` 文件中:
```
cgroup_enable=cpuset
cgroup_enable=memory
cgroup_memory=1
swapaccount=1
```
确保它们被添加到 `cmdline.txt` 文件的行末。这可以通过使用 `sed` 在一行中完成。
```
# 将 cgroup 和交换选项添加到内核命令行中
# 请注意 "cgroup_enable=cpuset" 前的空格,以便在该行的最后一个项目后添加一个空格
$ sudo sed -i '$ s/$/ cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1 swapaccount=1/' /boot/firmware/cmdline.txt
```
`sed` 命令匹配该行的终止符(由第一个 `$` 代表),用列出的选项代替它(它实际上是将选项附加到该行)。
有了这些改变,Docker 和内核应该按照 Kubernetes 的需要配置好了。重新启动树莓派,当它们重新启动后,再次检查 `docker info` 的输出。现在,`Cgroups driver` 变成了 `systemd`,警告也消失了。
#### 允许 iptables 查看桥接流量
根据文档,Kubernetes 需要配置 iptables 来查看桥接网络流量。你可以通过修改 `sysctl` 配置来实现。
```
# 启用 net.bridge.bridge-nf-call-iptables 和 -iptables6
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
$ sudo sysctl --system
```
#### 安装 Ubuntu 的 Kubernetes 包
由于你使用的是 Ubuntu,你可以从 [Kubernetes.io](http://Kubernetes.io) 的 apt 仓库中安装 Kubernetes 软件包。目前没有 Ubuntu 20.04(Focal)的仓库,但最近的 Ubuntu LTS 仓库 Ubuntu 18.04(Xenial) 中有 Kubernetes 1.18.2。最新的 Kubernetes 软件包可以从那里安装。
将 Kubernetes 软件库添加到 Ubuntu 的源列表之中:
```
# 添加 packages.cloud.google.com 的 atp 密钥
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
# 添加 Kubernetes 软件库
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
```
当 Kubernetes 添加了 Ubuntu 20.04(Focal)仓库时 —— 也许是在下一个 Kubernetes 版本发布时 —— 请确保切换到它。
将仓库添加到源列表后,安装三个必要的 Kubernetes 包:kubelet、kubeadm 和 kubectl:
```
# 更新 apt 缓存并安装 kubelet、kubeadm kubectl
# (输出略)
$ sudo apt update && sudo apt install -y kubelet kubeadm kubectl
```
最后,使用 `apt-mark hold` 命令禁用这三个包的定期更新。升级到 Kubernetes 需要比一般的更新过程更多的手工操作,需要人工关注。
```
# 禁止(标记为保持)Kubernetes 软件包的更新
$ sudo apt-mark hold kubelet kubeadm kubectl
kubelet set on hold.
kubeadm set on hold.
kubectl set on hold.
```
主机配置就到这里了! 现在你可以继续设置 Kubernetes 本身了。
### 创建 Kubernetes 集群
在安装了 Kubernetes 软件包之后,你现在可以继续创建集群了。在开始之前,你需要做一些决定。首先,其中一个树莓派需要被指定为控制平面节点(即主节点)。其余的节点将被指定为计算节点。
你还需要选择一个 [CIDR](https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing)(无类别域间路由)地址用于 Kubernetes 集群中的 Pod。在集群创建过程中设置 `pod-network-cidr` 可以确保设置了 `podCIDR` 值,它以后可以被<ruby> 容器网络接口 <rt> Container Network Interface </rt></ruby>(CNI)加载项使用。本练习使用的是 [Flannel](https://github.com/coreos/flannel)CNI。你选择的 CIDR 不应该与你的家庭网络中当前使用的任何 CIDR 重叠,也不应该与你的路由器或 DHCP 服务器管理的 CIDR 重叠。确保使用一个比你预期需要的更大的子网:**总是**有比你最初计划的更多的 Pod!在这个例子中,我将使用 CIDR 地址 `10.244.0.0/16`,但你可以选择一个适合你的。
有了这些决定,你就可以初始化控制平面节点了。用 SSH 或其他方式登录到你为控制平面指定的节点。
#### 初始化控制平面
Kubernetes 使用一个引导令牌来验证被加入集群的节点。当初始化控制平面节点时,需要将此令牌传递给 `kubeadm init` 命令。用 `kubeadm token generate` 命令生成一个令牌:
```
# 生成一个引导令牌来验证加入集群的节点
$ TOKEN=$(sudo kubeadm token generate)
$ echo $TOKEN
d584xg.xupvwv7wllcpmwjy
```
现在你可以使用 `kubeadm init` 命令来初始化控制平面了:
```
# 初始化控制平面
#(输出略)
$ sudo kubeadm init --token=${TOKEN} --kubernetes-version=v1.18.2 --pod-network-cidr=10.244.0.0/16
```
如果一切顺利,你应该在输出的最后看到类似这样的东西:
```
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
```
注意两点:第一,Kubernetes 的 `kubectl` 连接信息已经写入到 `/etc/kubernetes/admin.conf`。这个 kubeconfig 文件可以复制到用户的 `~/.kube/config` 中,可以是主节点上的 root 用户或普通用户,也可以是远程机器。这样你就可以用 `kubectl` 命令来控制你的集群。
其次,输出中以 `kubernetes join` 开头的最后一行是你可以运行的命令,你可以运行这些命令加入更多的节点到集群中。
将新的 kubeconfig 复制到你的用户可以使用的地方后,你可以用 `kubectl get nodes` 命令来验证控制平面是否已经安装:
```
# 显示 Kubernetes 集群中的节点
# 你的节点名称会有所不同
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
elderberry Ready master 7m32s v1.18.2
```
#### 安装 CNI 加载项
CNI 加载项负责 Pod 网络的配置和清理。如前所述,这个练习使用的是 Flannel CNI 加载项,在已经设置好 `podCIDR` 值的情况下,你只需下载 Flannel YAML 并使用 `kubectl apply` 将其安装到集群中。这可以用 `kubectl apply -f -` 从标准输入中获取数据,用一行命令完成。这将创建管理 Pod 网络所需的 ClusterRoles、ServiceAccounts 和 DaemonSets 等。
下载并应用 Flannel YAML 数据到集群中:
```
# 下载 Flannel YAML 数据并应用它
# (输出略)
$ curl -sSL https://raw.githubusercontent.com/coreos/flannel/v0.12.0/Documentation/kube-flannel.yml | kubectl apply -f -
```
#### 将计算节点加入到集群中
有了 CNI 加载项,现在是时候将计算节点添加到集群中了。加入计算节点只需运行 `kube init` 命令末尾提供的 `kubeadm join` 命令来初始化控制平面节点。对于你想加入集群的其他树莓派,登录主机,运行命令即可:
```
# 加入节点到集群,你的令牌和 ca-cert-hash 应各有不同
$ sudo kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
```
一旦你完成了每个节点的加入,你应该能够在 `kubectl get nodes` 的输出中看到新节点:
```
# 显示 Kubernetes 集群中的节点
# 你的节点名称会有所不同
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
elderberry Ready master 7m32s v1.18.2
gooseberry Ready <none> 2m39s v1.18.2
huckleberry Ready <none> 17s v1.18.2
```
#### 验证集群
此时,你已经拥有了一个完全正常工作的 Kubernetes 集群。你可以运行 Pod、创建部署和作业等。你可以使用[服务](https://kubernetes.io/docs/concepts/services-networking/service/)从集群中的任何一个节点访问集群中运行的应用程序。你可以通过 NodePort 服务或入口控制器实现外部访问。
要验证集群正在运行,请创建一个新的命名空间、部署和服务,并检查在部署中运行的 Pod 是否按预期响应。此部署使用 `quay.io/clcollins/kube-verify:01` 镜像,这是一个监听请求的 Nginx 容器(实际上,与文章《[使用 Cloud-init 将节点添加到你的私有云](/article-12407-1.html)》中使用的镜像相同)。你可以在[这里](https://github.com/clcollins/homelabCloudInit/blob/master/simpleCloudInitService/data/Containerfile)查看镜像的容器文件。
为部署创建一个名为 `kube-verify` 的命名空间:
```
# 创建一个新的命名空间
$ kubectl create namespace kube-verify
# 列出命名空间
$ kubectl get namespaces
NAME STATUS AGE
default Active 63m
kube-node-lease Active 63m
kube-public Active 63m
kube-system Active 63m
kube-verify Active 19s
```
现在,在新的命名空间创建一个部署:
```
# 创建一个新的部署
$ cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-verify
namespace: kube-verify
labels:
app: kube-verify
spec:
replicas: 3
selector:
matchLabels:
app: kube-verify
template:
metadata:
labels:
app: kube-verify
spec:
containers:
- name: nginx
image: quay.io/clcollins/kube-verify:01
ports:
- containerPort: 8080
EOF
deployment.apps/kube-verify created
```
Kubernetes 现在将开始创建部署,它由三个 Pod 组成,每个 Pod 都运行 `quay.io/clcollins/kube-verify:01` 镜像。一分钟左右后,新的 Pod 应该运行了,你可以用 `kubectl get all -n kube-verify` 来查看它们,以列出新命名空间中创建的所有资源:
```
# 检查由该部署创建的资源
$ kubectl get all -n kube-verify
NAME READY STATUS RESTARTS AGE
pod/kube-verify-5f976b5474-25p5r 0/1 Running 0 46s
pod/kube-verify-5f976b5474-sc7zd 1/1 Running 0 46s
pod/kube-verify-5f976b5474-tvl7w 1/1 Running 0 46s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-verify 3/3 3 3 47s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-verify-5f976b5474 3 3 3 47s
```
你可以看到新的部署、由部署创建的复制子集,以及由复制子集创建的三个 Pod,以满足部署中的 `replicas: 3` 的要求。你可以看到 Kubernetes 内部工作正常。
现在,创建一个服务来暴露在三个 Pod 中运行的 Nginx “应用程序”(在本例中是“欢迎”页面)。这将作为一个单一端点,你可以通过它连接到 Pod:
```
# 为该部署创建服务
$ cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Service
metadata:
name: kube-verify
namespace: kube-verify
spec:
selector:
app: kube-verify
ports:
- protocol: TCP
port: 80
targetPort: 8080
EOF
service/kube-verify created
```
创建服务后,你可以对其进行检查并获取新服务的 IP 地址:
```
# 检查新服务
$ kubectl get -n kube-verify service/kube-verify
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-verify ClusterIP 10.98.188.200 <none> 80/TCP 30s
```
你可以看到 `kube-verify` 服务已经被分配了一个 ClusterIP(仅对集群内部)`10.98.188.200`。这个 IP 可以从你的任何节点到达,但不能从集群外部到达。你可以通过在这个 IP 上连接到部署内部的容器来验证它们是否在工作:
```
# 使用 curl 连接到 ClusterIP:
# (简洁期间,输出有删节)
$ curl 10.98.188.200
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
```
成功了!你的服务正在运行,容器内的 Nginx 正在响应你的请求。你的服务正在运行,容器内的 Nginx 正在响应你的请求。
此时,你的树莓派上有一个正在运行的 Kubernetes 集群,安装了一个 CNI 加载项(Flannel),并有一个运行 Nginx Web 服务器的测试部署和服务。在大型公有云中,Kubernetes 有不同的入口控制器来与不同的解决方案交互,比如最近报道的 [Skipper](https://opensource.com/article/20/4/http-kubernetes-skipper) 项目。同样,私有云也有与硬件负载均衡器设备(如 F5 Networks 的负载均衡器)交互的入口控制器,或用于处理进入节点的流量的 Nginx 和 HAProxy 控制器。
在以后的文章中,我将通过安装自己的入口控制器来解决将集群中的服务暴露给外界的问题。我还将研究动态存储供应器和 StorageClasses,以便为应用程序分配持久性存储,包括利用你在上一篇文章《[将树莓派家庭实验室变成网络文件系统](/article-12413-1.html)》中设置的 NFS 服务器来为你的 Pod 创建按需存储。
### 去吧,Kubernetes
“Kubernetes”(κυβερνήτης)在希腊语中是飞行员的意思 —— 但这是否意味着驾驶船只以及引导船只的人?诶,不是。“Kubernan”(κυβερνάω)是希腊语“驾驶”或“引导”的意思,因此,去吧,Kubernan,如果你在会议上或其它什么活动上看到我,请试着给我一个动词或名词的通行证,以另一种语言 —— 我不会说的语言。
免责声明:如前所述,我不会读也不会讲希腊语,尤其是古希腊语,所以我选择相信我在网上读到的东西。你知道那是怎么一回事。我对此有所保留,放过我吧,因为我没有开“对我来说都是希腊语”这种玩笑。然而,只是提一下,虽然我可以开玩笑,但是实际上没有,所以我要么偷偷摸摸,要么聪明,要么两者兼而有之。或者,两者都不是。我并没有说这是个好笑话。
所以,去吧,像专业人员一样在你的家庭私有云中用自己的 Kubernetes 容器服务来试运行你的容器吧!当你越来越得心应手时,你可以修改你的 Kubernetes 集群,尝试不同的选项,比如前面提到的入口控制器和用于持久卷的动态 StorageClasses。
这种持续学习是 [DevOps](https://opensource.com/tags/devops) 的核心,持续集成和新服务交付反映了敏捷方法论,当我们学会了处理云实现的大规模扩容,并发现我们的传统做法无法跟上步伐时,我们就接受了这两种方法论。
你看,技术、策略、哲学、一小段希腊语和一个可怕的原始笑话,都汇聚在一篇文章当中。
---
via: <https://opensource.com/article/20/6/kubernetes-raspberry-pi>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Kubernetes](https://opensource.com/resources/what-is-kubernetes) is an enterprise-grade container-orchestration system designed from the start to be cloud-native. It has grown to be the de-facto cloud container platform, continuing to expand as it has embraced new technologies, including container-native virtualization and serverless computing.
Kubernetes manages containers and more, from micro-scale at the edge to massive scale, in both public and private cloud environments. It is a perfect choice for a "private cloud at home" project, providing both robust container orchestration and the opportunity to learn about a technology in such demand and so thoroughly integrated into the cloud that its name is practically synonymous with "cloud computing."
Nothing says "cloud" quite like Kubernetes, and nothing screams "cluster me!" quite like Raspberry Pis. Running a local Kubernetes cluster on cheap Raspberry Pi hardware is a great way to gain experience managing and developing on a true cloud technology giant.
## Install a Kubernetes cluster on Raspberry Pis
This exercise will install a Kubernetes 1.18.2 cluster on three or more Raspberry Pi 4s running Ubuntu 20.04. Ubuntu 20.04 (Focal Fossa) offers a Raspberry Pi-focused 64-bit ARM (ARM64) image with both a 64-bit kernel and userspace. Since the goal is to use these Raspberry Pis for running a Kubernetes cluster, the ability to run AArch64 container images is important: it can be difficult to find 32-bit images for common software or even standard base images. With its ARM64 image, Ubuntu 20.04 allows you to use 64-bit container images with Kubernetes.
### AArch64 vs. ARM64; 32-bit vs. 64-bit; ARM vs. x86
Note that AArch64 and ARM64 are effectively the same thing. The different names arise from their use within different communities. Many container images are labeled AArch64 and will run fine on systems labeled ARM64. Systems with AArch64/ARM64 architecture are capable of running 32-bit ARM images, but the opposite is not true: a 32-bit ARM system cannot run 64-bit container images. This is why the Ubuntu 20.04 ARM64 image is so useful.
Without getting too deep in the woods explaining different architecture types, it is worth noting that ARM64/AArch64 and x86_64 architectures differ, and Kubernetes nodes running on 64-bit ARM architecture cannot run container images built for x86_64. In practice, you will find some images that are not built for both architectures and may not be usable in your cluster. You will also need to build your own images on an AArch64-based system or jump through some hoops to allow your regular x86_64 systems to build AArch64 images. In a future article in the "private cloud at home" project, I will cover how to build AArch64 images on your regular system.
For the best of both worlds, after you set up the Kubernetes cluster in this tutorial, you can add x86_64 nodes to it later. You can schedule images of a given architecture to run on the appropriate nodes by Kubernetes' scheduler through the use of [Kubernetes taints and tolerations](https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/).
Enough about architectures and [images](https://www.kubernetesbyexample.com/en/learning-paths/container-fundamentals/container-images/introduction). It's time to install Kubernetes, so get to it!
### Requirements
The requirements for this exercise are minimal. You will need:
- Three (or more) Raspberry Pi 4s (preferably the 4GB RAM models)
- Install Ubuntu 20.04 ARM64 on all the Raspberry Pis
To simplify the initial setup, read [ Modify a disk image to create a Raspberry Pi-based homelab](https://opensource.com/article/20/5/disk-image-raspberry-pi) to add a user and SSH authorized_keys to the Ubuntu image before writing it to an SD card and installing on the Raspberry Pi.
## Configure the hosts
Once Ubuntu is installed on the Raspberry Pis and they are accessible via SSH, you need to make a few changes before you can install Kubernetes.
### Install and configure Docker
As of this writing, Ubuntu 20.04 ships the most recent version of Docker, v19.03, in the base repositories and can be installed directly using the `apt`
command. Note that the package name is `docker.io`
. Install Docker on all of the Raspberry Pis:
```
# Install the docker.io package
$ sudo apt install -y docker.io
```
After the package is installed, you need to make some changes to enable [cgroups](https://en.wikipedia.org/wiki/Cgroups) (Control Groups). Cgroups allow the Linux kernel to limit and isolate resources. Practically speaking, this allows Kubernetes to better manage resources used by the containers it runs and increases security by isolating containers from one another.
Check the output of `docker info`
before making the following changes on all of the RPis:
```
# Check `docker info`
# Some output omitted
$ sudo docker info
(...)
Cgroup Driver: cgroups
(...)
WARNING: No memory limit support
WARNING: No swap limit support
WARNING: No kernel memory limit support
WARNING: No kernel memory TCP limit support
WARNING: No oom kill disable support
```
The output above highlights the bits that need to be changed: the cgroup driver and limit support.
First, change the default cgroups driver Docker uses from `cgroups`
to `systemd`
to allow systemd to act as the cgroups manager and ensure there is only one cgroup manager in use. This helps with system stability and is recommended by Kubernetes. To do this, create or replace the `/etc/docker/daemon.json`
file with:
```
# Create or replace the contents of /etc/docker/daemon.json to enable the systemd cgroup driver
$ sudo cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
```
### Enable cgroups limit support
Next, enable limit support, as shown by the warnings in the `docker info`
output above. You need to modify the kernel command line to enable these options at boot. For the Raspberry Pi 4, add the following to the `/boot/firmware/cmdline.txt`
file:
`cgroup_enable=cpuset`
`cgroup_enable=memory`
`cgroup_memory=1`
`swapaccount=1`
Make sure they are added to the end of the line in the `cmdline.txt`
file. This can be accomplished in one line using `sed`
:
```
# Append the cgroups and swap options to the kernel command line
# Note the space before "cgroup_enable=cpuset", to add a space after the last existing item on the line
$ sudo sed -i '$ s/$/ cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1 swapaccount=1/' /boot/firmware/cmdline.txt
```
The **sed** command matches the termination of the line (represented by the first `$`
), replacing it with the options listed (it effectively appends the options to the line).
With these changes, Docker and the kernel should be configured as needed for Kubernetes. Reboot the Raspberry Pis, and when they come back up, check the output of `docker info`
again. The `Cgroups driver`
is now `systemd`
, and the warnings are gone.
### Allow iptables to see bridged traffic
According to the documentation, Kubernetes needs iptables to be configured to see bridged network traffic. You can do this by changing the `sysctl `
config:
```
# Enable net.bridge.bridge-nf-call-iptables and -iptables6
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
$ sudo sysctl --system
```
### Install the Kubernetes packages for Ubuntu
Since you are using Ubuntu, you can install the Kubernetes packages from the Kubernetes.io Apt repository. There is not currently a repository for Ubuntu 20.04 (Focal), but Kubernetes 1.18.2 is available in the last Ubuntu LTS repository: Ubuntu 18.04 (Xenial). The latest Kubernetes packages can be installed from there.
Add the Kubernetes repo to Ubuntu's sources:
```
# Add the packages.cloud.google.com atp key
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
# Add the Kubernetes repo
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
```
When Kubernetes adds a Focal repository—perhaps when the next Kubernetes version is released—make sure to switch to it.
With the repository added to the sources list, install the three required Kubernetes packages: kubelet, kubeadm, and kubectl:
```
# Update the apt cache and install kubelet, kubeadm, and kubectl
# (Output omitted)
$ sudo apt update && sudo apt install -y kubelet kubeadm kubectl
```
Finally, use the `apt-mark hold`
command to disable regular updates for these three packages. Upgrades to Kubernetes need more hand-holding than is possible with the general update process and will require manual attention:
```
# Disable (mark as held) updates for the Kubernetes packages
$ sudo apt-mark hold kubelet kubeadm kubectl
kubelet set on hold.
kubeadm set on hold.
kubectl set on hold.
```
That is it for the host configuration! Now you can move on to setting up Kubernetes itself.
## Create a Kubernetes cluster
With the Kubernetes packages installed, you can continue on with creating a cluster. Before getting started, you need to make some decisions. First, one of the Raspberry Pis needs to be designated the Control Plane (i.e., primary) node. The remaining nodes will be designated as compute nodes.
You also need to pick a network [CIDR](https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing) to use for the pods in the Kubernetes cluster. Setting the `pod-network-cidr`
during the cluster creation ensures that the `podCIDR`
value is set and can be used by the Container Network Interface (CNI) add-on later. This exercise uses the [Flannel](https://github.com/coreos/flannel) CNI. The CIDR you pick should not overlap with any CIDR currently used within your home network nor one managed by your router or DHCP server. Make sure to use a subnet that is larger than you expect to need: there are ALWAYS more pods than you initially plan for! In this example, I will use 10.244.0.0/16, but pick one that works for you.
With those decisions out of the way, you can initialize the Control Plane node. SSH or otherwise log into the node you have designated for the Control Plane.
### Initialize the Control Plane
Kubernetes uses a bootstrap token to authenticate nodes being joined to the cluster. This token needs to be passed to the `kubeadm init`
command when initializing the Control Plane node. Generate a token to use with the `kubeadm token generate`
command:
```
# Generate a bootstrap token to authenticate nodes joining the cluster
$ TOKEN=$(sudo kubeadm token generate)
$ echo $TOKEN
d584xg.xupvwv7wllcpmwjy
```
You are now ready to initialize the Control Plane, using the `kubeadm init`
command:
```
# Initialize the Control Plane
# (output omitted)
$ sudo kubeadm init --token=${TOKEN} --kubernetes-version=v1.18.2 --pod-network-cidr=10.244.0.0/16
```
If everything is successful, you should see something similar to this at the end of the output:
```
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
```
Make a note of two things: first, the Kubernetes `kubectl`
connection information has been written to `/etc/kubernetes/admin.conf`
. This kubeconfig file can be copied to `~/.kube/config`
, either for root or a normal user on the master node or to a remote machine. This will allow you to control your cluster with the `kubectl`
command.
Second, the last line of the output starting with `kubernetes join`
is a command you can run to join more nodes to the cluster.
After copying the new kubeconfig to somewhere your user can use it, you can validate that the Control Plane has been installed with the `kubectl get nodes`
command:
```
# Show the nodes in the Kubernetes cluster
# Your node name will vary
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
elderberry Ready master 7m32s v1.18.2
```
### Install a CNI add-on
A CNI add-on handles configuration and cleanup of the pod networks. As mentioned, this exercise uses the Flannel CNI add-on. With the `podCIDR`
value already set, you can just download the Flannel YAML and use `kubectl apply`
to install it into the cluster. This can be done on one line using `kubectl apply -f -`
to take the data from standard input. This will create the ClusterRoles, ServiceAccounts, and DaemonSets (etc.) necessary to manage the pod networking.
Download and apply the Flannel YAML data to the cluster:
```
# Download the Flannel YAML data and apply it
# (output omitted)
$ curl -sSL https://raw.githubusercontent.com/coreos/flannel/v0.12.0/Documentation/kube-flannel.yml | kubectl apply -f -
```
### Join the compute nodes to the cluster
With the CNI add-on in place, it is now time to add compute nodes to the cluster. Joining the compute nodes is just a matter of running the `kubeadm join`
command provided at the end of the `kube init`
command run to initialize the Control Plane node. For the other Raspberry Pis you want to join your cluster, log into the host, and run the command:
```
# Join a node to the cluster - your tokens and ca-cert-hash will vary
$ sudo kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
```
Once you have completed the join process on each node, you should be able to see the new nodes in the output of `kubectl get nodes`
:
```
# Show the nodes in the Kubernetes cluster
# Your node name will vary
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
elderberry Ready master 7m32s v1.18.2
gooseberry Ready <none> 2m39s v1.18.2
huckleberry Ready <none> 17s v1.18.2
```
### Validate the cluster
At this point, you have a fully working Kubernetes cluster. You can run pods, create deployments and jobs, etc. You can access applications running in the cluster from any of the nodes in the cluster using [Services](https://kubernetes.io/docs/concepts/services-networking/service/). You can achieve external access with a NodePort service or ingress controllers.
To validate that the cluster is running, create a new namespace, deployment, and service, and check that the pods running in the deployment respond as expected. This deployment uses the `quay.io/clcollins/kube-verify:01`
image—an Nginx container listening for requests (actually, the same image used in the article [ Add nodes to your private cloud using Cloud-init](https://opensource.com/article/20/5/create-simple-cloud-init-service-your-homelab)). You can view the image Containerfile
[here](https://github.com/clcollins/homelabCloudInit/blob/master/simpleCloudInitService/data/Containerfile).
Create a namespace named `kube-verify`
for the deployment:
```
# Create a new namespace
$ kubectl create namespace kube-verify
# List the namespaces
$ kubectl get namespaces
NAME STATUS AGE
default Active 63m
kube-node-lease Active 63m
kube-public Active 63m
kube-system Active 63m
kube-verify Active 19s
```
Now, create a deployment in the new namespace:
```
# Create a new deployment
$ cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-verify
namespace: kube-verify
labels:
app: kube-verify
spec:
replicas: 3
selector:
matchLabels:
app: kube-verify
template:
metadata:
labels:
app: kube-verify
spec:
containers:
- name: nginx
image: quay.io/clcollins/kube-verify:01
ports:
- containerPort: 8080
EOF
deployment.apps/kube-verify created
```
Kubernetes will now start creating the deployment, consisting of three pods, each running the `quay.io/clcollins/kube-verify:01`
image. After a minute or so, the new pods should be running, and you can view them with `kubectl get all -n kube-verify`
to list all the resources created in the new namespace:
```
# Check the resources that were created by the deployment
$ kubectl get all -n kube-verify
NAME READY STATUS RESTARTS AGE
pod/kube-verify-5f976b5474-25p5r 0/1 Running 0 46s
pod/kube-verify-5f976b5474-sc7zd 1/1 Running 0 46s
pod/kube-verify-5f976b5474-tvl7w 1/1 Running 0 46s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-verify 3/3 3 3 47s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-verify-5f976b5474 3 3 3 47s
```
You can see the new deployment, a replicaset created by the deployment, and three pods created by the replicaset to fulfill the `replicas: 3`
request in the deployment. You can see the internals of Kubernetes are working.
Now, create a Service to expose the Nginx "application" (or, in this case, the Welcome page) running in the three pods. This will act as a single endpoint through which you can connect to the pods:
```
# Create a service for the deployment
$ cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Service
metadata:
name: kube-verify
namespace: kube-verify
spec:
selector:
app: kube-verify
ports:
- protocol: TCP
port: 80
targetPort: 8080
EOF
service/kube-verify created
```
With the service created, you can examine it and get the IP address for your new service:
```
# Examine the new service
$ kubectl get -n kube-verify service/kube-verify
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-verify ClusterIP 10.98.188.200 <none> 80/TCP 30s
```
You can see that the `kube-verify`
service has been assigned a ClusterIP (internal to the cluster only) of `10.98.188.200`
. This IP is reachable from any of your nodes, but not from outside of the cluster. You can verify the containers inside your deployment are working by connecting to them at this IP:
```
# Use curl to connect to the ClusterIP:
# (output truncated for brevity)
$ curl 10.98.188.200
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
```
Success! Your service is running and Nginx inside the containers is responding to your requests.
At this point, you have a running Kubernetes cluster on your Raspberry Pis with a CNI add-on (Flannel) installed and a test deployment and service running an Nginx webserver. In the large public clouds, Kubernetes has different ingress controllers to interact with different solutions, such as the recently-covered [Skipper](https://opensource.com/article/20/4/http-kubernetes-skipper) project. Similarly, private clouds have ingress controllers for interacting with hardware load balancer appliances (like F5 Networks' load balancers) or Nginx and HAProxy controllers for handling traffic coming into the nodes.
In a future article, I will tackle exposing services in the cluster to the outside world by installing your own ingress controller. I will also look at dynamic storage provisioners and StorageClasses for allocating persistent storage for applications, including making use of the NFS server you set up in a previous article, [ Turn your Raspberry Pi homelab into a network filesystem](https://opensource.com/article/20/5/nfs-raspberry-pi), to create on-demand storage for your pods.
## Go forth, and Kubernetes
"Kubernetes" (κυβερνήτης) is Greek for pilot—but does that mean the individual who steers a ship as well as the action of guiding the ship? Eh, no. "Kubernan" (κυβερνάω) is Greek for "to pilot" or "to steer," so go forth and Kubernan, and if you see me out at a conference or something, give me a pass for trying to verb a noun. From another language. That I don't speak.
Disclaimer: As mentioned, I don't read or speak Greek, especially the ancient variety, so I'm choosing to believe something I read on the internet. You know how that goes. Take it with a grain of salt, and give me a little break since I didn't make an "It's all Greek to me" joke. However, just mentioning it, I, therefore, was able to make the joke without actually making it, so I'm either sneaky or clever or both. Or, neither. I didn't claim it was a *good* joke.
So, go forth and pilot your containers like a pro with your own Kubernetes container service in your private cloud at home! As you become more comfortable, you can modify your Kubernetes cluster to try different options, like the aforementioned ingress controllers and dynamic StorageClasses for persistent volumes.
This continuous learning is at the heart of [DevOps](https://opensource.com/tags/devops), and the continuous integration and delivery of new services mirrors the agile methodology, both of which we have embraced as we've learned to deal with the massive scale enabled by the cloud and discovered our traditional practices were unable to keep pace.
Look at that! Technology, policy, philosophy, a *tiny* bit of Greek, and a terrible meta-joke, all in one article!
## 25 Comments |
12,423 | OpenStack,开源云十年 | https://www.zdnet.com/article/openstack-the-open-source-cloud-at-10/ | 2020-07-16T17:02:00 | [
"OpenStack"
] | https://linux.cn/article-12423-1.html |
>
> 到了 2010 年,“云”和“开源软件”都成为主流,但它们还没有结合起来。后来,美国宇航局和 Rackspace 联手发布了第一个开源云 OpenStack,世界从此改变。
>
>
>

在 2010 年的时候。[甲骨文(Oracle)的拉里·埃里森可能还认为云“完全是胡说八道”](https://www.cnet.com/news/oracles-ellison-nails-cloud-computing/),而有些人则坚持认为“云只是别人的电脑”,但精明的人更清楚。在[美国宇航局(NASA)艾姆斯研究中心](https://www.nasa.gov/ames)和 [Rackspace](https://www.rackspace.com/),两组开发者决定,接近云的最佳方式是用开源软件构建出一朵云:[OpenStack](https://www.openstack.org/)。
当时,[亚马逊网络服务(AWS)](https://aws.amazon.com/)的祖先[亚马逊弹性计算云](https://aws.amazon.com/ec2/)已经出现,微软在 2010 年 2 月推出了 [Azure](https://azure.microsoft.com/en-us/)。但尽管他们已经在运行 Linux 和其他开源程序,但这些都是私人控制的专有平台。艾姆斯团队希望[美国宇航局(NASA)能够托管和管理自己的计算和数据资源](https://www.nasa.gov/directorates/spacetech/spinoff/in-cloud-computing-open-source-becomes-big-business)。
艾姆斯的答案是创建 [Nebula](https://www.nasa.gov/open/nebula.html),这是一个早期的基础设施即服务(IaaS)云。但是,正如[红帽公司](https://www.redhat.com/en)产品战略高级总监 Brian Gracely 所指出的那样,“NASA 没有人员来构建整个事情并长期维护它”。所以,艾姆斯走了开源路线。第一个主要的构件 [Nova](https://docs.openstack.org/nova/latest/#:~:text=Nova%20is%20the%20OpenStack%20project,limited%20support%20for%20system%20containers.&text=Keystone%3A%20This%20provides%20identity%20and%20authentication%20for%20all%20OpenStack%20services.),至今仍然是 OpenStack 的一部分。不过当时,正如一位开发者所说的那样,“它是有生命力的,它有 bug,它是个测试版。来看看吧”。
Rackspace 正是这么做的。两个月后,Rackspace 和 NASA 团队合作,发布了第一个版本的 OpenStack。
几年内,OpenStack 的人气就爆发了。惠普、IBM、红帽、VMware 等众多科技大佬都对 OpenStack 给予了支持。正如当时 Rackspace 的战略和企业发展高级副总裁 Jim Curry 所解释的那样:“有几件事是相辅相成的。首先,云技术及其形式因素正遭遇到一个临界点。几年后, AWS 刚刚进入主流,人们不仅仅想寻找它的开源替代品,而且是想寻找任何 AWS 的替代品。”
而现在,它已经远不止是 AWS 的替代品。OpenStack 拥有超过 8000 名程序员,目前旗下有 32 个不同的项目。这些项目,如云配给系统 [Airship](https://wiki.openstack.org/wiki/Airship)、轻量级的类似容器的虚拟机 [Kata Containers](https://katacontainers.io/)、边缘基础设施软件栈 [StarlingX](https://www.starlingx.io/) 以及 Netflix 的网络网关 [Zuul](https://github.com/Netflix/zuul) 等,涵盖了各种云和相关服务。这些服务包括在单一网络上编排裸机、虚拟机和容器资源的 API。如今的 OpenStack 还能满足高性能计算(HPC)、AI 和机器学习等用例的需求。
OpenStack 自诞生以来,从 Austin 到 Ussuri,已经有 21 个按时发布。展望未来,[451 Research](https://451research.com/) 预计到 2023 年,OpenStack 市场规模将达到 77 亿美元。其增长大部分发生在亚洲(36%)、拉丁美洲(27%)、欧洲(22%)和北美(17%)。
OpenStack 也已经成为电信企业的首选云。这些公司,如 AT&T 和英国电信正在使用 OpenStack 作为其 5G 计划的基础。
最后要说的是,OpenStack 仍然是私有云、混合云和公共云中最受欢迎的开源云。虽然它的一些早期支持者,[如 SUSE,已经放弃了 OpenStack](https://www.zdnet.com/article/suse-drops-openstacks/),但其他一些人,[如红帽,仍然是 OpenStack 的坚定支持者](https://www.redhat.com/en/blog/openstack-10-red-hats-take-decade-customer-defined-clouds-and-update-red-hat-openstack-platform)。红帽很快就会发布下一个 OpenStack 版本- ——Red Hat OpenStack Platform 16.1。红帽不会是唯一一个站在 OpenStack 一边的公司。它的未来仍然是光明的。
---
via: <https://www.zdnet.com/article/openstack-the-open-source-cloud-at-10/>
作者:[Steven J. Vaughan-Nichols](https://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12418-1.html) 荣誉推出
| 200 | OK | # OpenStack, the open-source cloud at 10

In 2010. [Oracle's Larry Ellison may still have thought that the cloud was "complete gibberish,"](https://www.cnet.com/news/oracles-ellison-nails-cloud-computing/) while some people were insisting that the "cloud was just someone else's computer," but savvy folks knew better. At [NASA Ames Research Center](https://www.nasa.gov/ames) and [Rackspace](https://www.rackspace.com/), two groups of developers decided that the best way to approach a cloud was to build one out from open-source software: [OpenStack](https://www.openstack.org/).
The [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/), [Amazon Web Services'](https://aws.amazon.com/) ancestor was already around and Microsoft had launched [Azure](https://click.linksynergy.com/deeplink?id=IokOf8qagZo&mid=24542&murl=https%3A%2F%2Fazure.microsoft.com%2Fen-us%2F&u1=zd-0b1a1f3e77ff4265a892f1b643ee55d2--) in February 2010. But even though they were already running Linux and other open-source programs, these were privately held, proprietary platforms. The Ames team wanted [NASA to host and manage its own computing and data resources](https://www.nasa.gov/directorates/spacetech/spinoff/in-cloud-computing-open-source-becomes-big-business).
### Cloud
Ames' answer was to create [Nebula](https://www.nasa.gov/open/nebula.html), an early Infrastructure-as-a-Service (IaaS) cloud. But, as Brian Gracely, [Red Hat](https://www.redhat.com/en)'s senior director of product strategy, pointed out, "NASA didn't have the staff to build the whole thing and maintain it long-term." So, Ames went the open-source route. The first major building block, [Nova](https://docs.openstack.org/nova/latest/#:~:text=Nova%20is%20the%20OpenStack%20project,limited%20support%20for%20system%20containers.&text=Keystone%3A%20This%20provides%20identity%20and%20authentication%20for%20all%20OpenStack%20services.), is still part of OpenStack today. At the time, though, as one developer put it, "It's live, it's buggy, it's beta. Check it out."
That's exactly what Rackspace did. Two months later, the Rackspace and NASA teams were working together and released the very first version of OpenStack.
Within a few years, OpenStack's popularity exploded. HP, IBM, Red Hat, VMware, and numerous other tech powers threw their support behind OpenStack. As Jim Curry, then Rackspace's SVP of Strategy and Corporate Development, explained, "A couple of things came together. First, cloud technology and its form factor was hitting an infraction point. After several years, Amazon Web Services was just moving into the mainstream and people were looking not just for an open-source alternative, but for any AWS alternative."
It's become far more than an AWS alternative. With over 8,000 programmers, OpenStack now has 32 different projects under its umbrella. These projects, such as [Airship](https://wiki.openstack.org/wiki/Airship), a cloud-provisioning system; [Kata Containers](https://katacontainers.io/), lightweight, container-like virtual machines (VMs); [StarlingX](https://www.starlingx.io/), an edge infrastructure software stack; and [Zuul](https://zuul-ci.org/docs/zuul/), a continuous integration/delivery (CI/CD) program, cover a wide variety of cloud and related services. These include APIs to orchestrate bare metal, VMs, and container resources on a single network. Today's OpenStack can also meet the demands of such use cases as high-performance computing (HPC), AI, and [machine learning](https://www.zdnet.com/article/what-is-machine-learning-everything-you-need-to-know/).
Since its origins OpenStack has had 21 on-time releases, from "Austin" to "Ussuri." Looking ahead, [451 Research](https://451research.com/) projects a $7.7 billion USD OpenStack market by 2023. Most of its growth is happening in Asia (36%), Latin America (27%), Europe (22%), and North America (17%).
OpenStack has also become the cloud of choice for telecoms. These companies, such as AT&T and BT are using OpenStack as the foundation for their [5G ](https://www.zdnet.com/article/what-is-5g-the-business-guide-to-next-generation-wireless-technology/)initiatives.
Last, but not least, OpenStack remains the most popular open-source cloud for private, hybrid, and public clouds. While some of its early proponents, such as [SUSE, have abandoned OpenStack](https://www.zdnet.com/article/suse-drops-openstacks/), others like [Red Hat, remain staunch OpenStack supporters](https://www.redhat.com/en/blog/openstack-10-red-hats-take-decade-customer-defined-clouds-and-update-red-hat-openstack-platform). Red Hat will soon be releasing its next OpenStack release, Red Hat OpenStack Platform 16.1. Red Hat won't be the only one standing by OpenStack. Its future still looks bright.
**Related Stories:**
[Editorial standards](/editorial-guidelines/) |
12,424 | Ubuntu 将不再跟踪用户安装的软件包 | https://www.omgubuntu.co.uk/2020/07/ubuntu-popularity-contest-removed | 2020-07-16T17:37:25 | [
"Ubuntu"
] | https://linux.cn/article-12424-1.html | 
>
> Ubuntu 表示,它将不再跟踪桌面用户从存档中安装的软件包。
>
>
>
这个“人气竞赛”(`popularity-contest`)工具,[从该发行版早期](https://fslog.com/2006/07/30/ubuntu-popularity-contest/)开始就作为 Ubuntu 标准安装包的一部分,正在被移除。
但是这个软件是做什么的呢?引用 [Ubuntu 帮助页面](https://help.ubuntu.com/community/UbuntuPopularityContest)上的一句话:
>
> Ubuntu 人气竞赛 …… 收集统计数据,以确定哪些软件包在 Ubuntu 用户中最受欢迎。人气竞赛软件包会每周一次向中央服务器提交数据。
>
>
>
它收集到的统计数据用于帮助“改进 Ubuntu 的未来版本,使最受欢迎的软件包成为新用户自动安装的软件包”。不过 Ubuntu 已经很久没有在默认安装中添加或删除应用了(几年前它选择添加 GNOME To Do 应用时,并不是因为“受欢迎”)。
而另外一方面,随着 Snap、Flatpak、PPA 和其它途径给开发者提供了更直接的触达用户的方式(也就无法更准确地统计有多少人在使用他们的软件了),“仓库中流行的东西”的相对优点……嗯,有点不切实际。
所以未来 Ubuntu 桌面的安装将不再默认包含这个人气竞赛软件包。
事实证明,这也是好事,因为这东西根本就不能用!
[Canonical 的 Michael Hudson Doyle 说](https://discourse.ubuntu.com/t/popcon-to-be-removed-from-the-standard-seed/17238?u=d0od):“……从 18.04 LTS 开始,这个包和后台都损坏了,但好像也没少啥。”
虽然听起来有点让人担心,但所有的这些跟踪都是匿名的,其数据结果可以在 [popcon.ubuntu.com](https://popcon.ubuntu.com/) 网站上公开查看。
“Ubuntu 删除了这个[不能用](https://bugs.launchpad.net/ubuntu/+source/popularity-contest/+bug/1754847)又没人用的东西”是头条新闻吗?不是,但这是一个相当值得注意的删除,因为它跟上了 Linux 软件包分发和获取的变化。
从现有的 Ubuntu 安装中删除 Ubuntu 人气竞赛也是可以的。只要启动终端窗口并运行:
```
sudo apt remove popularity-contest
```
输入密码后按 `y` 键允许。这个过程也会删除 `ubuntu-standard` 包。这是一个元包,它告诉 Ubuntu 在“标准”安装中要引入哪些包。虽然它不应该被删除(一般来说),但这是完全删除这个包的唯一方法。
---
via: <https://www.omgubuntu.co.uk/2020/07/ubuntu-popularity-contest-removed>
作者: [Joey Sneddon](https://www.omgubuntu.co.uk/author/d0od "View all posts by Joey Sneddon") 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-12418-1.html) 荣誉推出
| 200 | OK | **Ubuntu will no longer be able to track which packages desktop users install from the archives**.
The “popularity-contest” tool that has shipped as part of the standard Ubuntu install [since the distro’s early days](https://fslog.com/2006/07/30/ubuntu-popularity-contest/) is being decoupled from the install image.
But what does `popcon`
do? Well, to quote the [Ubuntu help page for it](https://help.ubuntu.com/community/UbuntuPopularityContest):
The Ubuntu Popularity Contest […] gathers statistics determining which packages are the most popular with Ubuntu users. Once a week, the popularity-contest package submits data to a central server.
The stats `popcon`
gathers were apparently used to help *“improve future versions of Ubuntu so that the most popular packages are the ones which are installed automatically for new users.”*
Except, er, it’s been a long time since Ubuntu added or removed an app to its default install. And when it did choose to add the GNOME To Do app a few years back it wasn’t because of “popularity”.
[
Privacy Conscious?
This is the data Ubuntu collects about your PC
](https://www.omgubuntu.co.uk/2018/05/this-is-the-data-ubuntu-collects-about-your-system)
Plus *Snaps*, *Flatpaks,* *PPAs* and other app distribution avenues give developers a more direct way to market to users, and more accurate numbers on how many people use their software. Thus the relative merits of *“what’s popular in the repos”* is …Well, a touch moot.
So future installs of Ubuntu desktop will **no longer **include the popularity contest package by default.
Which it turns out is just as well because the thing doesn’t work!
[Canonical’s Michael Hudson Doyle says](https://discourse.ubuntu.com/t/popcon-to-be-removed-from-the-standard-seed/17238?u=d0od) *“…the package and backend have both been broken since 18.04 LTS without being much missed.”*
Though creepy sounding, all the tracking the package does is kept anonymous. The results of data is viewable publicly on the [popcon.ubuntu.com](https://popcon.ubuntu.com) website.
Is *“Ubuntu removes thing which doesn’t work and no-one uses”* front page news? No, but it’s a notable removal that keeps pace with the changing nature of Linux package distribution and procurement.
It is possible to remove Ubuntu popularity contest from an *existing* Ubuntu install. Just launch a *Terminal* window and run:
sudo apt remove popularity-contest
Enter your password and hit `y`
to approve. The process will also remove the `ubuntu-standard`
package. This is a meta-package that tells Ubuntu which packages to pull in as part of a ‘standard’ install. While it shouldn’t (generally speaking) be removed it’s the only way to remove popcon fully.
Unless you don’t mind its broken rump end being parked on your system of course! |
12,425 | openSUSE Leap 15.2 发布:重点关注容器、AI 和加密 | https://itsfoss.com/opensuse-leap-15-2-release/ | 2020-07-16T23:06:24 | [
"openSUSE"
] | https://linux.cn/article-12425-1.html | 
[openSUSE](https://www.opensuse.org/) Leap 15.2 最终带来了一些有用的变化和改进。
同时,我想到 SUSE 这篇让人激动的公告《[消除 Leap 差异](https://www.suse.com/c/sle-15-sp2-schedule-and-closing-the-opensuse-leap-gap/)》,openSUSE Leap 15.2 的发布使我们下一步将 SLE([SUSE Linux Enterprise](https://www.suse.com/))二进制文件集成到 openSUSE Leap 15.3 更加近了一步。
让我们看一下 openSUSE Leap 15.2 中发生了哪些变化和改进。
### openSUSE Leap 15.2:关键变化

总体而言,openSUSE Leap 15.2 发行版涉及安全更新、新的主要软件包、bug 修复以及其他改进。
该项目的开发人员 Marco Varlese 在新闻稿中提到:
>
> “ Leap 15.2 代表了人工智能领域的巨大进步,我很高兴 openSUSE 用户现在终于可以通过我们的仓库使用机器学习/深度学习框架和应用,以享受稳定和最新的生态系统。”
>
>
>
尽管这暗示了可能涉及的一些变化,以下是 openSUSE Leap 15.2 中的新功能:
#### 添加人工智能(AI)和机器学习包
毫无疑问,人工智能(AI)和机器学习是最具颠覆性的技术。
为了向用户提供便利,openSUSE Leap 15.2 为新的开源技术添加了许多重要的软件包:
* [Tensorflow](https://www.tensorflow.org)
* [PyTorch](https://pytorch.org)
* [ONNX](https://onnx.ai)
* [Grafana](https://grafana.com)
* [Prometheus](https://prometheus.io/docs/introduction/overview/)
#### 引入实时内核

在 openSUSE Leap 15.2 中,将引入实时内核来管理[微处理器](https://en.wikipedia.org/wiki/Microprocessor)的时序,以有效处理时间关键的事件。
实时内核的添加对于现实意义重大。项目委员会主席 Gerald Pfeifer 的讲话如下:
>
> “将实时内核添加到 openSUSE Leap 开启了新的可能性。想想边缘计算、嵌入式设备、数据抓取,所有这些都在飞速发展。从历史上看,其中很多都是专有领域。现在,openSUSE 为有兴趣测试实时功能的开发者、研究人员和公司甚至贡献者将打开了通道。这是另一个开源帮助开放的领域!”
>
>
>
#### 纳入容器技术
在最新版本中,你会注意到 [Kubernetes](https://kubernetes.io) 作为官方包而纳入其中。这让用户可以轻松地自动化部署、扩展和管理容器化的应用。
[Helm](https://helm.sh)(Kubernetes 的包管理器)也是内置的。不仅于此,你还可以在此找到其他一些附加功能,从而可以更轻松地保护和部署容器化应用。
#### 更新的 openSUSE 安装程序

openSUSE 的安装程序已经非常不错。但是,在最新的 Leap 15.2 版本中,它们添加了更多信息,兼容从右至左语言(如阿拉伯语)以及一些小的更改,从而在安装时更容易选择。
#### YaST 改进
尽管 [YaST](https://yast.opensuse.org/) 已经是一个非常强大的安装和配置工具,但是此发行版增加了创建和管理 Btrfs 文件系统以及实施高级加密技术的能力。
当然,你肯定知道 [openSUSE 在 WSL](https://itsfoss.com/opensuse-bash-on-windows/) 的可用性。因此,根据 Leap 15.2 的发行说明,YaST 与 WSL 的兼容性得到了改善。
#### 桌面环境改进

可用的桌面环境已更新为最新版本,包括 [KDE Plasma 5.18 LTS](https://itsfoss.com/kde-plasma-5-18-release/) 和 [GNOME 3.34](https://itsfoss.com/gnome-3-34-release/)。
你还能发现更新的 [XFCE 4.14](https://www.xfce.org/about/news/?post=1565568000) 桌面在 openSUSE Leap 15.2 上也是可用的。
如果你想知道最新版本的所有详细信息,可以参考[官方发布公告](https://en.opensuse.org/Release_announcement_15.2)。
### 下载和可用性
目前,你可以找到 Leap 15.2 的 Linode 云镜像。另外,你会注意到其他云托管服务(如 AWS、Azure 和其他服务)也提供了它。
你还可以从官方网站获取 DVD ISO 或网络镜像文件。
要升级你当前的安装,我建议按照[官方说明](https://en.opensuse.org/SDB:System_upgrade)操作。
* [openSUSE Leap 15.2](https://software.opensuse.org/distributions/leap)
你尝试过 openSUSE Leap 15.2 了么?请随时让我知道你的想法!
---
via: <https://itsfoss.com/opensuse-leap-15-2-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.