
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
11,934 | 不喜欢 IDE?试试看 grepgitvi | https://opensource.com/article/20/2/no-ide-script | 2020-02-26T11:49:00 | [
"IDE"
] | https://linux.cn/article-11934-1.html |
>
> 一个简单又原始的脚本来用 Vim 打开你选择的文件。
>
>
>

像大多数开发者一样,我整天都在搜索和阅读源码。就我个人而言,我从来没有习惯过集成开发环境 (IDE),多年来,我主要使用 `grep` (找到文件),并复制/粘贴文件名来打开 Vi(m)。
最终,我写了这个脚本,并根据需要缓慢地对其进行了完善。
它依赖 [Vim](https://www.vim.org/) 和 [rlwrap](https://linux.die.net/man/1/rlwrap),并使用 Apache 2.0 许可证开源。要使用该脚本,请[将它放到 PATH 中](https://opensource.com/article/17/6/set-path-linux),然后在文本目录下运行:
```
grepgitvi <grep options> <grep/vim search pattern>
```
它将返回搜索结果的编号列表,并提示你输入结果编号并打开 Vim。退出 Vim 后,它将再次显示列表,直到你输入除结果编号以外的任何内容。你也可以使用向上和向下箭头键选择一个文件。(这对我来说)更容易找到我已经看过的结果。
与现代 IDE 甚至与 Vim 的更复杂的用法相比,它简单而原始,但它对我有用。
### 脚本
```
#!/bin/bash
# grepgitvi - grep source files, interactively open vim on results
# Doesnt really have to do much with git, other than ignoring .git
#
# Copyright Yedidyah Bar David 2019
#
# SPDX-License-Identifier: Apache-2.0
#
# Requires vim and rlwrap
#
# Usage: grepgitvi <grep options> <grep/vim pattern>
#
TMPD=$(mktemp -d /tmp/grepgitvi.XXXXXX)
UNCOLORED=${TMPD}/uncolored
COLORED=${TMPD}/colored
RLHIST=${TMPD}/readline-history
[ -z "${DIRS}" ] && DIRS=.
cleanup() {
rm -rf "${TMPD}"
}
trap cleanup 0
find ${DIRS} -iname .git -prune -o \! -iname "*.min.css*" -type f -print0 > ${TMPD}/allfiles
cat ${TMPD}/allfiles | xargs -0 grep --color=always -n -H "$@" > $COLORED
cat ${TMPD}/allfiles | xargs -0 grep -n -H "$@" > $UNCOLORED
max=`cat $UNCOLORED | wc -l`
pat="${@: -1}"
inp=''
while true; do
echo "============================ grep results ==============================="
cat $COLORED | nl
echo "============================ grep results ==============================="
prompt="Enter a number between 1 and $max or anything else to quit: "
inp=$(rlwrap -H $RLHIST bash -c "read -p \"$prompt\" inp; echo \$inp")
if ! echo "$inp" | grep -q '^[0-9][0-9]*$' || [ "$inp" -gt "$max" ]; then
break
fi
filename=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $1}')
linenum=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $2-1}')
vim +:"$linenum" +"norm zz" +/"${pat}" "$filename"
done
```
---
via: <https://opensource.com/article/20/2/no-ide-script>
作者:[Yedidyah Bar David](https://opensource.com/users/didib) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Like most developers, I search and read source code all day long. Personally, I've never gotten used to integrated development environments (IDEs), and for years, I mainly used **grep** and copy/pasted file names to open Vi(m).
Eventually, I came up with this script, slowly refining it as needed.
Its dependencies are [Vim](https://www.vim.org/) and [rlwrap](https://linux.die.net/man/1/rlwrap), and it is open source under the Apache 2.0 license. To use the script,[ put it in your PATH](https://opensource.com/article/17/6/set-path-linux), and run it inside a directory of text files with:
`grepgitvi <grep options> <grep/vim search pattern>`
It will return a numbered list of search results, prompt you for the number of the result you want to use, and open Vim with that result. After you exit Vim, it will show the list again in a loop until you enter anything other than a result number. You can also use the Up and Down arrow keys to select a file; this makes it easier (for me) to find which results I've already looked at.
It's simple and primitive compared to modern IDEs, or even to more sophisticated uses of Vim, but that's what does the job for me.
## The script
```
#!/bin/bash
# grepgitvi - grep source files, interactively open vim on results
# Doesn't really have to do much with git, other than ignoring .git
#
# Copyright Yedidyah Bar David 2019
#
# SPDX-License-Identifier: Apache-2.0
#
# Requires vim and rlwrap
#
# Usage: grepgitvi <grep options> <grep/vim pattern>
#
TMPD=$(mktemp -d /tmp/grepgitvi.XXXXXX)
UNCOLORED=${TMPD}/uncolored
COLORED=${TMPD}/colored
RLHIST=${TMPD}/readline-history
[ -z "${DIRS}" ] && DIRS=.
cleanup() {
rm -rf "${TMPD}"
}
trap cleanup 0
find ${DIRS} -iname .git -prune -o \! -iname "*.min.css*" -type f -print0 > ${TMPD}/allfiles
cat ${TMPD}/allfiles | xargs -0 grep --color=always -n -H "$@" > $COLORED
cat ${TMPD}/allfiles | xargs -0 grep -n -H "$@" > $UNCOLORED
max=`cat $UNCOLORED | wc -l`
pat="${@: -1}"
inp=''
while true; do
echo "============================ grep results ==============================="
cat $COLORED | nl
echo "============================ grep results ==============================="
prompt="Enter a number between 1 and $max or anything else to quit: "
inp=$(rlwrap -H $RLHIST bash -c "read -p \"$prompt\" inp; echo \$inp")
if ! echo "$inp" | grep -q '^[0-9][0-9]*$' || [ "$inp" -gt "$max" ]; then
break
fi
filename=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $1}')
linenum=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $2-1}')
vim +:"$linenum" +"norm zz" +/"${pat}" "$filename"
done
```
## 2 Comments |
11,935 | 如何组织构建多文件 C 语言程序(一) | https://opensource.com/article/19/7/structure-multi-file-c-part-1 | 2020-02-26T21:45:34 | [
"编程"
] | https://linux.cn/article-11935-1.html |
>
> 准备好你喜欢的饮料、编辑器和编译器,放一些音乐,然后开始构建一个由多个文件组成的 C 语言程序。
>
>
>

大家常说计算机编程的艺术部分是处理复杂性,部分是命名某些事物。此外,我认为“有时需要添加绘图”是在很大程度上是正确的。
在这篇文章里,我会编写一个小型 C 程序,命名一些东西,同时处理一些复杂性。该程序的结构大致基于我在 《[如何写一个好的 C 语言 main 函数](/article-10949-1.html)》 文中讨论的。但是,这次做一些不同的事。准备好你喜欢的饮料、编辑器和编译器,放一些音乐,让我们一起编写一个有趣的 C 语言程序。
### 优秀 Unix 程序哲学
首先,你要知道这个 C 程序是一个 [Unix](https://en.wikipedia.org/wiki/Unix) 命令行工具。这意味着它运行在(或者可被移植到)那些提供 Unix C 运行环境的操作系统中。当贝尔实验室发明 Unix 后,它从一开始便充满了[设计哲学](http://harmful.cat-v.org/cat-v/)。用我自己的话来说就是:程序只做一件事,并做好它,并且对文件进行一些操作。虽然“只做一件事,并做好它”是有意义的,但是“对文件进行一些操作”的部分似乎有点儿不合适。
事实证明,Unix 中抽象的 “文件” 非常强大。一个 Unix 文件是以文件结束符(EOF)标志为结尾的字节流。仅此而已。文件中任何其它结构均由应用程序所施加而非操作系统。操作系统提供了系统调用,使得程序能够对文件执行一套标准的操作:打开、读取、写入、寻址和关闭(还有其他,但说起来那就复杂了)。对于文件的标准化访问使得不同的程序共用相同的抽象,而且可以一同工作,即使它们是不同的人用不同语言编写的程序。
具有共享的文件接口使得构建*可组合的*的程序成为可能。一个程序的输出可以作为另一个程序的输入。Unix 家族的操作系统默认在执行程序时提供了三个文件:标准输入(`stdin`)、标准输出(`stdout`)和标准错误(`stderr`)。其中两个文件是只写的:`stdout` 和 `stderr`。而 `stdin` 是只读的。当我们在常见的 Shell 比如 Bash 中使用文件重定向时,可以看到其效果。
```
$ ls | grep foo | sed -e 's/bar/baz/g' > ack
```
这条指令可以被简要地描述为:`ls` 的结果被写入标准输出,它重定向到 `grep` 的标准输入,`grep` 的标准输出重定向到 `sed` 的标准输入,`sed` 的标准输出重定向到当前目录下文件名为 `ack` 的文件中。
我们希望我们的程序在这个灵活又出色的生态系统中运作良好,因此让我们编写一个可以读写文件的程序。
### 喵呜喵呜:流编码器/解码器概念
当我还是一个露着豁牙的孩子懵懵懂懂地学习计算机科学时,学过很多编码方案。它们中的有些用于压缩文件,有些用于打包文件,另一些毫无用处因此显得十分愚蠢。列举最后这种情况的一个例子:[哞哞编码方案](http://www.jabberwocky.com/software/moomooencode.html)。
为了让我们的程序有个用途,我为它更新了一个 [21 世纪](https://giphy.com/gifs/nyan-cat-sIIhZliB2McAo) 的概念,并且实现了一个名为“喵呜喵呜” 的编码方案的概念(毕竟网上大家都喜欢猫)。这里的基本的思路是获取文件并且使用文本 “meow” 对每个半字节(半个字节)进行编码。小写字母代表 0,大写字母代表 1。因为它会将 4 个比特替换为 32 个比特,因此会扩大文件的大小。没错,这毫无意义。但是想象一下人们看到经过这样编码后的惊讶表情。
```
$ cat /home/your_sibling/.super_secret_journal_of_my_innermost_thoughts
MeOWmeOWmeowMEoW...
```
这非常棒。
### 最终的实现
完整的源代码可以在 [GitHub](https://github.com/JnyJny/meowmeow) 上面找到,但是我会写下我在编写程序时的思考。目的是说明如何组织构建多文件 C 语言程序。
既然已经确定了要编写一个编码和解码“喵呜喵呜”格式的文件的程序时,我在 Shell 中执行了以下的命令 :
```
$ mkdir meowmeow
$ cd meowmeow
$ git init
$ touch Makefile # 编译程序的方法
$ touch main.c # 处理命令行选项
$ touch main.h # “全局”常量和定义
$ touch mmencode.c # 实现对喵呜喵呜文件的编码
$ touch mmencode.h # 描述编码 API
$ touch mmdecode.c # 实现对喵呜喵呜文件的解码
$ touch mmdecode.h # 描述解码 API
$ touch table.h # 定义编码查找表
$ touch .gitignore # 这个文件中的文件名会被 git 忽略
$ git add .
$ git commit -m "initial commit of empty files"
```
简单的说,我创建了一个目录,里面全是空文件,并且提交到 git。
即使这些文件中没有内容,你依旧可以从它的文件名推断每个文件的用途。为了避免万一你无法理解,我在每条 `touch` 命令后面进行了简单描述。
通常,程序从一个简单 `main.c` 文件开始,只有两三个解决问题的函数。然后程序员轻率地向自己的朋友或者老板展示了该程序,然后为了支持所有新的“功能”和“需求”,文件中的函数数量就迅速爆开了。“程序俱乐部”的第一条规则便是不要谈论“程序俱乐部”,第二条规则是尽量减少单个文件中的函数。
老实说,C 编译器并不关心程序中的所有函数是否都在一个文件中。但是我们并不是为计算机或编译器写程序,我们是为其他人(有时也包括我们)去写程序的。我知道这可能有些奇怪,但这就是事实。程序体现了计算机解决问题所采用的一组算法,当问题的参数发生了意料之外的变化时,保证人们可以理解它们是非常重要的。当在人们修改程序时,发现一个文件中有 2049 函数时他们会诅咒你的。
因此,优秀的程序员会将函数分隔开,将相似的函数分组到不同的文件中。这里我用了三个文件 `main.c`、`mmencode.c` 和 `mmdecode.c`。对于这样小的程序,也许看起来有些过头了。但是小的程序很难保证一直小下去,因此哥忒拓展做好计划是一个“好主意”。
但是那些 `.h` 文件呢?我会在后面解释一般的术语,简单地说,它们被称为头文件,同时它们可以包含 C 语言类型定义和 C 预处理指令。头文件中不应该包含任何函数。你可以认为头文件是提供了应用程序接口(API)的定义的一种 `.c` 文件,可以供其它 `.c` 文件使用。
### 但是 Makefile 是什么呢?
我知道下一个轰动一时的应用都是你们这些好孩子们用 “终极代码粉碎者 3000” 集成开发环境来编写的,而构建项目是用 Ctrl-Meta-Shift-Alt-Super-B 等一系列复杂的按键混搭出来的。但是如今(也就是今天),使用 `Makefile` 文件可以在构建 C 程序时帮助做很多有用的工作。`Makefile` 是一个包含如何处理文件的方式的文本文件,程序员可以使用其自动地从源代码构建二进制程序(以及其它东西!)
以下面这个小东西为例:
```
00 # Makefile
01 TARGET= my_sweet_program
02 $(TARGET): main.c
03 cc -o my_sweet_program main.c
```
`#` 符号后面的文本是注释,例如 00 行。
01 行是一个变量赋值,将 `TARGET` 变量赋值为字符串 `my_sweet_program`。按照惯例,也是我的习惯,所有 `Makefile` 变量均使用大写字母并用下划线分隔单词。
02 行包含该<ruby> 步骤 <rt> recipe </rt></ruby>要创建的文件名和其依赖的文件。在本例中,构建<ruby> 目标 <rt> target </rt></ruby>是 `my_sweet_program`,其依赖是 `main.c`。
最后的 03 行使用了一个制表符号(`tab`)而不是四个空格。这是将要执行创建目标的命令。在本例中,我们使用 <ruby> C 编译器 <rt> C compiler </rt></ruby>前端 `cc` 以编译链接为 `my_sweet_program`。
使用 `Makefile` 是非常简单的。
```
$ make
cc -o my_sweet_program main.c
$ ls
Makefile main.c my_sweet_program
```
构建我们喵呜喵呜编码器/解码器的 [Makefile](https://github.com/JnyJny/meowmeow/blob/master/Makefile) 比上面的例子要复杂,但其基本结构是相同的。我将在另一篇文章中将其分解为 Barney 风格。
### 形式伴随着功能
我的想法是程序从一个文件中读取、转换它,并将转换后的结果存储到另一个文件中。以下是我想象使用程序命令行交互时的情况:
```
$ meow < clear.txt > clear.meow
$ unmeow < clear.meow > meow.tx
$ diff clear.txt meow.tx
$
```
我们需要编写代码以进行命令行解析和处理输入/输出流。我们需要一个函数对流进行编码并将结果写到另一个流中。最后,我们需要一个函数对流进行解码并将结果写到另一个流中。等一下,我们在讨论如何写一个程序,但是在上面的例子中,我调用了两个指令:`meow` 和 `unmeow`?我知道你可能会认为这会导致越变越复杂。
### 次要内容:argv[0] 和 ln 指令
回想一下,C 语言 main 函数的结构如下:
```
int main(int argc, char *argv[])
```
其中 `argc` 是命令行参数的数量,`argv` 是字符指针(字符串)的列表。`argv[0]` 是包含正在执行的程序的文件路径。在 Unix 系统中许多互补功能的程序(比如:压缩和解压缩)看起来像两个命令,但事实上,它们是在文件系统中拥有两个名称的一个程序。这个技巧是通过使用 `ln` 命令创建文件系统链接来实现两个名称的。
在我笔记本电脑中 `/usr/bin` 的一个例子如下:
```
$ ls -li /usr/bin/git*
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git-receive-pack
...
```
这里 `git` 和 `git-receive-pack` 是同一个文件但是拥有不同的名字。我们说它们是相同的文件因为它们具有相同的 inode 值(第一列)。inode 是 Unix 文件系统的一个特点,对它的介绍超越了本文的内容范畴。
优秀或懒惰的程序可以通过 Unix 文件系统的这个特点达到写更少的代码但是交付双倍的程序。首先,我们编写一个基于其 `argv[0]` 的值而作出相应改变的程序,然后我们确保为导致该行为的名称创建链接。
在我们的 `Makefile` 中,`unmeow` 链接通过以下的方式来创建:
```
# Makefile
...
$(DECODER): $(ENCODER)
$(LN) -f $< $@
...
```
我倾向于在 `Makefile` 中将所有内容参数化,很少使用 “裸” 字符串。我将所有的定义都放置在 `Makefile` 文件顶部,以便可以简单地找到并改变它们。当你尝试将程序移植到新的平台上时,需要将 `cc` 改变为某个 `cc` 时,这会很方便。
除了两个内置变量 `$@` 和 `$<` 之外,该<ruby> 步骤 <rt> recipe </rt></ruby>看起来相对简单。第一个便是该步骤的目标的快捷方式,在本例中是 `$(DECODER)`(我能记得这个是因为 `@` 符号看起来像是一个目标)。第二个,`$<` 是规则依赖项,在本例中,它解析为 `$(ENCODER)`。
事情肯定会变得复杂,但它还在管理之中。
---
via: <https://opensource.com/article/19/7/structure-multi-file-c-part-1>
作者:[Erik O'Shaughnessy](https://opensource.com/users/jnyjnyhttps://opensource.com/users/jnyjnyhttps://opensource.com/users/jim-salterhttps://opensource.com/users/cldxsolutions) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It has often been said that the art of computer programming is part managing complexity and part naming things. I contend that this is largely true with the addition of "and sometimes it requires drawing boxes."
In this article, I'll name some things and manage some complexity while writing a small C program that is loosely based on the program structure I discussed in "[How to write a good C main function](https://opensource.com/article/19/5/how-write-good-c-main-function)"—but different. This one will do something. Grab your favorite beverage, editor, and compiler, crank up some tunes, and let's write a mildly interesting C program together.
## Philosophy of a good Unix program
The first thing to know about this C program is that it's a [Unix](https://en.wikipedia.org/wiki/Unix) command-line tool. This means that it runs on (or can be ported to) operating systems that provide a Unix C runtime environment. When Unix was invented at Bell Labs, it was imbued from the beginning with a [design philosophy](http://harmful.cat-v.org/cat-v/). In my own words: *programs do one thing, do it well, and act on files*. While it makes sense to do one thing and do it well, the part about "acting on files" seems a little out of place.
It turns out that the Unix abstraction of a "file" is very powerful. A Unix file is a stream of bytes that ends with an end-of-file (EOF) marker. That's it. Any other structure in a file is imposed by the application and not the operating system. The operating system provides system calls that allow a program to perform a set of standard operations on files: open, read, write, seek, and close (there are others, but those are the biggies). Standardizing access to files allows different programs to share a common abstraction and work together even when different people implement them in different programming languages.
Having a shared file interface makes it possible to build programs that are *composable*. The output of one program can be the input of another program. The Unix family of operating systems provides three files by default whenever a program is executed: standard in (**stdin**), standard out (**stdout**), and standard error (**stderr**). Two of these files are opened in write-only mode: **stdout** and **stderr**, while **stdin** is opened read-only. We see this in action whenever we use file redirection in a command shell like Bash:
`$ ls | grep foo | sed -e 's/bar/baz/g' > ack`
This construction can be described briefly as: the output of **ls** is written to stdout, which is redirected to the stdin of **grep**, whose stdout is redirected to **sed**, whose stdout is redirected to write to a file called **ack** in the current directory.
We want our program to play well in this ecosystem of equally flexible and awesome programs, so let's write a program that reads and writes files.
## MeowMeow: A stream encoder/decoder concept
When I was a dewy-eyed kid studying computer science in the <mumbles>s, there were a plethora of encoding schemes. Some of them were for compressing files, some were for packaging files together, and others had no purpose but to be excruciatingly silly. An example of the last is the [MooMoo encoding scheme](http://www.jabberwocky.com/software/moomooencode.html).
To give our program a purpose, I'll update this concept for the [2000s](https://giphy.com/gifs/nyan-cat-sIIhZliB2McAo) and implement a concept called MeowMeow encoding (since the internet loves cats). The basic idea here is to take files and encode each nibble (half of a byte) with the text "meow." A lower-case letter indicates a zero, and an upper-case indicates a one. Yes, it will balloon the size of a file since we are trading 4 bits for 32 bits. Yes, it's pointless. But imagine the surprise on someone's face when this happens:
```
$ cat /home/your_sibling/.super_secret_journal_of_my_innermost_thoughts
MeOWmeOWmeowMEoW...
```
This is going to be awesome.
## Implementation, finally
The full source for this can be found on [GitHub](https://github.com/JnyJny/meowmeow), but I'll talk through my thought process while writing it. The object is to illustrate how to structure a C program composed of multiple files.
Having already established that I want to write a program that encodes and decodes files in MeowMeow format, I fired up a shell and issued the following commands:
```
$ mkdir meowmeow
$ cd meowmeow
$ git init
$ touch Makefile # recipes for compiling the program
$ touch main.c # handles command-line options
$ touch main.h # "global" constants and definitions
$ touch mmencode.c # implements encoding a MeowMeow file
$ touch mmencode.h # describes the encoding API
$ touch mmdecode.c # implements decoding a MeowMeow file
$ touch mmdecode.h # describes the decoding API
$ touch table.h # defines encoding lookup table values
$ touch .gitignore # names in this file are ignored by git
$ git add .
$ git commit -m "initial commit of empty files"
```
In short, I created a directory full of empty files and committed them to git.
Even though the files are empty, you can infer the purpose of each from its name. Just in case you can't, I annotated each **touch** with a brief description.
Usually, a program starts as a single, simple **main.c** file, with only two or three functions that solve the problem. And then the programmer rashly shows that program to a friend or her boss, and suddenly the number of functions in the file balloons to support all the new "features" and "requirements" that pop up. The first rule of "Program Club" is don't talk about "Program Club." The second rule is to minimize the number of functions in one file.
To be honest, the C compiler does not care one little bit if every function in your program is in one file. But we don't write programs for computers or compilers; we write them for other people (who are sometimes us). I know that is probably a surprise, but it's true. A program embodies a set of algorithms that solve a problem with a computer, and it's important that people understand it when the parameters of the problem change in unanticipated ways. People will have to modify the program, and they will curse your name if you have all 2,049 functions in one file.
So we good and true programmers break functions out, grouping similar functions into separate files. Here I've got files **main.c**, **mmencode.c**, and **mmdecode.c**. For small programs like this, it may seem like overkill. But small programs rarely stay small, so planning for expansion is a "Good Idea."
But what about those **.h** files? I'll explain them in general terms later, but in brief, those are called *header* files, and they can contain C language type definitions and C preprocessor directives. Header files should *not* have any functions in them. You can think of headers as a definition of the application programming interface (API) offered by the **.c** flavored file that is used by other **.c** files.
## But what the heck is a Makefile?
I know all you cool kids are using the "Ultra CodeShredder 3000" integrated development environment to write the next blockbuster app, and building your project consists of mashing on Ctrl-Meta-Shift-Alt-Super-B. But back in my day (and also today), lots of useful work got done by C programs built with Makefiles. A Makefile is a text file that contains recipes for working with files, and programmers use it to automate building their program binaries from source (and other stuff too!).
Take, for instance, this little gem:
```
00 # Makefile
01 TARGET= my_sweet_program
02 $(TARGET): main.c
03 cc -o my_sweet_program main.c
```
Text after an octothorpe/pound/hash is a comment, like in line 00.
Line 01 is a variable assignment where the variable **TARGET** takes on the string value **my_sweet_program**. By convention, OK, my preference, all Makefile variables are capitalized and use underscores to separate words.
Line 02 consists of the name of the file that the recipe creates and the files it depends on. In this case, the target is **my_sweet_program**,** **and the dependency is **main.c**.
The final line, 03, is indented with a tab and not four spaces. This is the command that will be executed to create the target. In this case, we call **cc** the C compiler frontend to compile and link **my_sweet_program**.
Using a Makefile is simple:
```
$ make
cc -o my_sweet_program main.c
$ ls
Makefile main.c my_sweet_program
```
The [Makefile](https://github.com/JnyJny/meowmeow/blob/master/Makefile) that will build our MeowMeow encoder/decoder is considerably more sophisticated than this example, but the basic structure is the same. I'll break it down Barney-style in another article.
## Form follows function
My idea here is to write a program that reads a file, transforms it, and writes the transformed data to another file. The following fabricated command-line interaction is how I imagine using the program:
```
$ meow < clear.txt > clear.meow
$ unmeow < clear.meow > meow.tx
$ diff clear.txt meow.tx
$
```
We need to write code to handle command-line parsing and managing the input and output streams. We need a function to encode a stream and write it to another stream. And finally, we need a function to decode a stream and write it to another stream. Wait a second, I've only been talking about writing one program, but in the example above, I invoke two commands: **meow** and **unmeow**? I know you are probably thinking that this is getting complex as heck.
## Minor sidetrack: argv[0] and the ln command
If you recall, the signature of a C main function is:
`int main(int argc, char *argv[])`
where **argc** is the number of command-line arguments, and **argv** is a list of character pointers (strings). The value of **argv[0]** is the path of the file containing the program being executed. Many Unix utility programs with complementary functions (e.g., compress and uncompress) look like two programs, but in fact, they are one program with two names in the filesystem. The two-name trick is accomplished by creating a filesystem "link" using the **ln** command.
An example from **/usr/bin** on my laptop is:
```
$ ls -li /usr/bin/git*
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git-receive-pack
...
```
Here **git** and **git-receive-pack** are the same file with different names. We can tell it's the same file because they have the same inode number (the first column). An inode is a feature of the Unix filesystem and is super outside the scope of this article.
Good and/or lazy programmers can use this feature of the Unix filesystem to write less code but double the number of programs they deliver. First, we write a program that changes its behavior based on the value of **argv[0]**, then we make sure to create links with the names that cause the behavior.
In our Makefile, the **unmeow** link is created using this recipe:
```
# Makefile
...
$(DECODER): $(ENCODER)
$(LN) -f $< $@
...
```
I tend to parameterize everything in my Makefiles, rarely using a "bare" string. I group all the definitions at the top of the Makefile, which makes it easy to find and change them. This makes a big difference when you are trying to port software to a new platform and you need to change all your rules to use **xcc** instead of **cc**.
The recipe should appear relatively straightforward except for the two built-in variables **$@** and **$<**. The first is a shortcut for the target of the recipe; in this case, **$(DECODER)**. (I remember this because the at-sign looks like a target to me.) The second, **$<** is the rule dependency; in this case, it resolves to **$(ENCODER)**.
Things are getting complex for sure, but it's managed.
## 2 Comments |
11,936 | 使用 KRAWL 扫描 Kubernetes 错误 | https://opensource.com/article/20/2/kubernetes-scanner | 2020-02-27T10:29:43 | [
"Kubernetes"
] | https://linux.cn/article-11936-1.html |
>
> 用 KRAWL 脚本来识别 Kubernetes Pod 和容器中的错误。
>
>
>

当你使用 Kubernetes 运行容器时,你通常会发现它们堆积在一起。这是设计使然。它是容器的优点之一:每当需要新的容器时,它们启动成本都很低。你可以使用前端工具(如 OpenShift 或 OKD)来管理 Pod 和容器。这些工具使可视化设置变得容易,并且它具有一组丰富的用于快速交互的命令。
如果管理容器的平台不符合你的要求,你也可以仅使用 Kubernetes 工具链获取这些信息,但这需要大量命令才能全面了解复杂环境。出于这个原因,我编写了 [KRAWL](https://github.com/abhiTamrakar/kube-plugins/tree/master/krawl),这是一个简单的脚本,可用于扫描 Kubernetes 集群命名空间下的 Pod 和容器,并在发现任何事件时,显示事件的输出。它也可用作为 Kubernetes 插件使用。这是获取大量有用信息的快速简便方法。
### 先决条件
* 必须安装 `kubectl`。
* 集群的 kubeconfig 配置必须在它的默认位置(`$HOME/.kube/config`)或已被导出到环境变量(`KUBECONFIG=/path/to/kubeconfig`)。
### 使用
```
$ ./krawl
```

### 脚本
```
#!/bin/bash
# AUTHOR: Abhishek Tamrakar
# EMAIL: [email protected]
# LICENSE: Copyright (C) 2018 Abhishek Tamrakar
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
#define the variables
KUBE_LOC=~/.kube/config
#define variables
KUBECTL=$(which kubectl)
GET=$(which egrep)
AWK=$(which awk)
red=$(tput setaf 1)
normal=$(tput sgr0)
# define functions
# wrapper for printing info messages
info()
{
printf '\n\e[34m%s\e[m: %s\n' "INFO" "$@"
}
# cleanup when all done
cleanup()
{
rm -f results.csv
}
# just check if the command we are about to call is available
checkcmd()
{
#check if command exists
local cmd=$1
if [ -z "${!cmd}" ]
then
printf '\n\e[31m%s\e[m: %s\n' "ERROR" "check if $1 is installed !!!"
exit 1
fi
}
get_namespaces()
{
#get namespaces
namespaces=( \
$($KUBECTL get namespaces --ignore-not-found=true | \
$AWK '/Active/ {print $1}' \
ORS=" ") \
)
#exit if namespaces are not found
if [ ${#namespaces[@]} -eq 0 ]
then
printf '\n\e[31m%s\e[m: %s\n' "ERROR" "No namespaces found!!"
exit 1
fi
}
#get events for pods in errored state
get_pod_events()
{
printf '\n'
if [ ${#ERRORED[@]} -ne 0 ]
then
info "${#ERRORED[@]} errored pods found."
for CULPRIT in ${ERRORED[@]}
do
info "POD: $CULPRIT"
info
$KUBECTL get events \
--field-selector=involvedObject.name=$CULPRIT \
-ocustom-columns=LASTSEEN:.lastTimestamp,REASON:.reason,MESSAGE:.message \
--all-namespaces \
--ignore-not-found=true
done
else
info "0 pods with errored events found."
fi
}
#define the logic
get_pod_errors()
{
printf "%s %s %s\n" "NAMESPACE,POD_NAME,CONTAINER_NAME,ERRORS" > results.csv
printf "%s %s %s\n" "---------,--------,--------------,------" >> results.csv
for NAMESPACE in ${namespaces[@]}
do
while IFS=' ' read -r POD CONTAINERS
do
for CONTAINER in ${CONTAINERS//,/ }
do
COUNT=$($KUBECTL logs --since=1h --tail=20 $POD -c $CONTAINER -n $NAMESPACE 2>/dev/null| \
$GET -c '^error|Error|ERROR|Warn|WARN')
if [ $COUNT -gt 0 ]
then
STATE=("${STATE[@]}" "$NAMESPACE,$POD,$CONTAINER,$COUNT")
else
#catch pods in errored state
ERRORED=($($KUBECTL get pods -n $NAMESPACE --no-headers=true | \
awk '!/Running/ {print $1}' ORS=" ") \
)
fi
done
done< <($KUBECTL get pods -n $NAMESPACE --ignore-not-found=true -o=custom-columns=NAME:.metadata.name,CONTAINERS:.spec.containers[*].name --no-headers=true)
done
printf "%s\n" ${STATE[@]:-None} >> results.csv
STATE=()
}
#define usage for seprate run
usage()
{
cat << EOF
USAGE: "${0##*/} </path/to/kube-config>(optional)"
This program is a free software under the terms of Apache 2.0 License.
COPYRIGHT (C) 2018 Abhishek Tamrakar
EOF
exit 0
}
#check if basic commands are found
trap cleanup EXIT
checkcmd KUBECTL
#
#set the ground
if [ $# -lt 1 ]; then
if [ ! -e ${KUBE_LOC} -a ! -s ${KUBE_LOC} ]
then
info "A readable kube config location is required!!"
usage
fi
elif [ $# -eq 1 ]
then
export KUBECONFIG=$1
elif [ $# -gt 1 ]
then
usage
fi
#play
get_namespaces
get_pod_errors
printf '\n%40s\n' 'KRAWL'
printf '%s\n' '---------------------------------------------------------------------------------'
printf '%s\n' ' Krawl is a command line utility to scan pods and prints name of errored pods '
printf '%s\n\n' ' +and containers within. To use it as kubernetes plugin, please check their page '
printf '%s\n' '================================================================================='
cat results.csv | sed 's/,/,|/g'| column -s ',' -t
get_pod_events
```
此文最初发布在 [KRAWL 的 GitHub 仓库](https://github.com/abhiTamrakar/kube-plugins/tree/master/krawl)下的 README 中,并被或许重用。
---
via: <https://opensource.com/article/20/2/kubernetes-scanner>
作者:[Abhishek Tamrakar](https://opensource.com/users/tamrakar) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you're running containers with Kubernetes, you often find that they pile up. This is by design. It's one of the advantages of containers: they're cheap to start whenever a new one is needed. You can use a front-end like OpenShift or OKD to manage pods and containers. Those make it easy to visualize what you have set up, and have a rich set of commands for quick interactions.
If a platform to manage containers doesn't fit your requirements, though, you can also get that information using only a Kubernetes toolchain, but there are a lot of commands you need for a full overview of a complex environment. For that reason, I wrote [KRAWL](https://github.com/abhiTamrakar/kube-plugins/tree/master/krawl), a simple script that scans pods and containers under the namespaces on Kubernetes clusters and displays the output of events, if any are found. It can also be used as Kubernetes plugin for the same purpose. It's a quick and easy way to get a lot of useful information.
## Prerequisites
- You must have kubectl installed.
- Your cluster's kubeconfig must be either in its default location ($HOME/.kube/config) or exported (KUBECONFIG=/path/to/kubeconfig).
## Usage
`$ ./krawl`
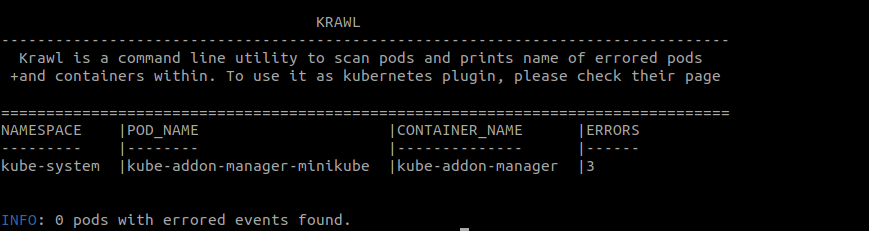
## The script
```
#!/bin/bash
# AUTHOR: Abhishek Tamrakar
# EMAIL: [email protected]
# LICENSE: Copyright (C) 2018 Abhishek Tamrakar
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
#define the variables
KUBE_LOC=~/.kube/config
#define variables
KUBECTL=$(which kubectl)
GET=$(which egrep)
AWK=$(which awk)
red=$(tput setaf 1)
normal=$(tput sgr0)
# define functions
# wrapper for printing info messages
info()
{
printf '\n\e[34m%s\e[m: %s\n' "INFO" "$@"
}
# cleanup when all done
cleanup()
{
rm -f results.csv
}
# just check if the command we are about to call is available
checkcmd()
{
#check if command exists
local cmd=$1
if [ -z "${!cmd}" ]
then
printf '\n\e[31m%s\e[m: %s\n' "ERROR" "check if $1 is installed !!!"
exit 1
fi
}
get_namespaces()
{
#get namespaces
namespaces=( \
$($KUBECTL get namespaces --ignore-not-found=true | \
$AWK '/Active/ {print $1}' \
ORS=" ") \
)
#exit if namespaces are not found
if [ ${#namespaces[@]} -eq 0 ]
then
printf '\n\e[31m%s\e[m: %s\n' "ERROR" "No namespaces found!!"
exit 1
fi
}
#get events for pods in errored state
get_pod_events()
{
printf '\n'
if [ ${#ERRORED[@]} -ne 0 ]
then
info "${#ERRORED[@]} errored pods found."
for CULPRIT in ${ERRORED[@]}
do
info "POD: $CULPRIT"
info
$KUBECTL get events \
--field-selector=involvedObject.name=$CULPRIT \
-ocustom-columns=LASTSEEN:.lastTimestamp,REASON:.reason,MESSAGE:.message \
--all-namespaces \
--ignore-not-found=true
done
else
info "0 pods with errored events found."
fi
}
#define the logic
get_pod_errors()
{
printf "%s %s %s\n" "NAMESPACE,POD_NAME,CONTAINER_NAME,ERRORS" > results.csv
printf "%s %s %s\n" "---------,--------,--------------,------" >> results.csv
for NAMESPACE in ${namespaces[@]}
do
while IFS=' ' read -r POD CONTAINERS
do
for CONTAINER in ${CONTAINERS//,/ }
do
COUNT=$($KUBECTL logs --since=1h --tail=20 $POD -c $CONTAINER -n $NAMESPACE 2>/dev/null| \
$GET -c '^error|Error|ERROR|Warn|WARN')
if [ $COUNT -gt 0 ]
then
STATE=("${STATE[@]}" "$NAMESPACE,$POD,$CONTAINER,$COUNT")
else
#catch pods in errored state
ERRORED=($($KUBECTL get pods -n $NAMESPACE --no-headers=true | \
awk '!/Running/ {print $1}' ORS=" ") \
)
fi
done
done< <($KUBECTL get pods -n $NAMESPACE --ignore-not-found=true -o=custom-columns=NAME:.metadata.name,CONTAINERS:.spec.containers[*].name --no-headers=true)
done
printf "%s\n" ${STATE[@]:-None} >> results.csv
STATE=()
}
#define usage for seprate run
usage()
{
cat << EOF
USAGE: "${0##*/} </path/to/kube-config>(optional)"
This program is a free software under the terms of Apache 2.0 License.
COPYRIGHT (C) 2018 Abhishek Tamrakar
EOF
exit 0
}
#check if basic commands are found
trap cleanup EXIT
checkcmd KUBECTL
#
#set the ground
if [ $# -lt 1 ]; then
if [ ! -e ${KUBE_LOC} -a ! -s ${KUBE_LOC} ]
then
info "A readable kube config location is required!!"
usage
fi
elif [ $# -eq 1 ]
then
export KUBECONFIG=$1
elif [ $# -gt 1 ]
then
usage
fi
#play
get_namespaces
get_pod_errors
printf '\n%40s\n' 'KRAWL'
printf '%s\n' '---------------------------------------------------------------------------------'
printf '%s\n' ' Krawl is a command line utility to scan pods and prints name of errored pods '
printf '%s\n\n' ' +and containers within. To use it as kubernetes plugin, please check their page '
printf '%s\n' '================================================================================='
cat results.csv | sed 's/,/,|/g'| column -s ',' -t
get_pod_events
```
*This was originally published as the README in KRAWL's GitHub repository and is reused with permission.*
## 2 Comments |
11,938 | 如何让 Emacs 俄罗斯方块变得更难 | https://nickdrozd.github.io/2019/01/14/tetris.html | 2020-02-27T12:06:11 | [
"Emacs",
"俄罗斯方块"
] | https://linux.cn/article-11938-1.html | 
你知道吗,Emacs 捆绑了一个俄罗斯方块的实现?只需要输入 `M-x tetris` 就行了。

在对文本编辑器的讨论中,Emacs 鼓吹者经常提到这一点。“没错,但是你那个编辑器能运行俄罗斯方块吗?”我很好奇,这会让大家相信 Emacs 更优秀吗?比如,为什么有人会关心他们是否可以在文本编辑器中玩游戏呢?“没错,但是你那台吸尘器能播放 mp3 吗?”
有人说,俄罗斯方块总是很有趣的。像 Emacs 中的所有东西一样,它的源代码是开放的,易于检查和修改,因此 **我们可以使它变得更加有趣**。所谓更加有趣,我的意思是更难。
让游戏变得更难的一个最简单的方法就是“隐藏下一个块预览”。你无法在知道下一个块会填满空间的情况下有意地将 S/Z 块放在一个危险的位置——你必须碰碰运气,希望出现最好的情况。下面是没有预览的情况(如你所见,没有预览,我做出的某些选择带来了“可怕的后果”):

预览框由一个名为 `tetris-draw-next-shape` <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> 的函数设置:
```
(defun tetris-draw-next-shape ()
(dotimes (x 4)
(dotimes (y 4)
(gamegrid-set-cell (+ tetris-next-x x)
(+ tetris-next-y y)
tetris-blank)))
(dotimes (i 4)
(let ((tetris-shape tetris-next-shape)
(tetris-rot 0))
(gamegrid-set-cell (+ tetris-next-x
(aref (tetris-get-shape-cell i) 0))
(+ tetris-next-y
(aref (tetris-get-shape-cell i) 1))
tetris-shape))))
```
首先,我们引入一个标志,决定是否允许显示下一个预览块 <sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>:
```
(defvar tetris-preview-next-shape nil
"When non-nil, show the next block the preview box.")
```
现在的问题是,我们如何才能让 `tetris-draw-next-shape` 遵从这个标志?最明显的方法是重新定义它:
```
(defun tetris-draw-next-shape ()
(when tetris-preview-next-shape
;; existing tetris-draw-next-shape logic
))
```
但这不是理想的解决方案。同一个函数有两个定义,这很容易引起混淆,如果上游版本发生变化,我们必须维护修改后的定义。
一个更好的方法是使用 **advice**。Emacs 的 advice 类似于 **Python 装饰器**,但是更加灵活,因为 advice 可以从任何地方添加到函数中。这意味着我们可以修改函数而不影响原始的源文件。
有很多不同的方法使用 Emacs advice([查看手册](https://www.gnu.org/software/emacs/manual/html_node/elisp/Advising-Functions.html)),但是这里我们只使用 `advice-add` 函数和 `:around` 标志。advice 函数将原始函数作为参数,原始函数可能执行也可能不执行。我们这里,我们让原始函数只有在预览标志是非空的情况下才能执行:
```
(defun tetris-maybe-draw-next-shape (tetris-draw-next-shape)
(when tetris-preview-next-shape
(funcall tetris-draw-next-shape)))
(advice-add 'tetris-draw-next-shape :around #'tetris-maybe-draw-next-shape)
```
这段代码将修改 `tetris-draw-next-shape` 的行为,而且它可以存储在配置文件中,与实际的俄罗斯方块代码分离。
去掉预览框是一个简单的改变。一个更激烈的变化是,**让块随机停止在空中**:

本图中,红色的 I 和绿色的 T 部分没有掉下来,它们被固定下来了。这会让游戏变得 **极其困难**,但却很容易实现。
和前面一样,我们首先定义一个标志:
```
(defvar tetris-stop-midair t
"If non-nil, pieces will sometimes stop in the air.")
```
目前,**Emacs 俄罗斯方块的工作方式** 类似这样子:活动部件有 x 和 y 坐标。在每个时钟滴答声中,y 坐标递增(块向下移动一行),然后检查是否有与现存的块重叠。如果检测到重叠,则将该块回退(其 y 坐标递减)并设置该活动块到位。为了让一个块在半空中停下来,我们所要做的就是破解检测函数 `tetris-test-shape`。
**这个函数内部做什么并不重要** —— 重要的是它是一个返回布尔值的无参数函数。我们需要它在正常情况下返回布尔值 true(否则我们将出现奇怪的重叠情况),但在其他时候也需要它返回 true。我相信有很多方法可以做到这一点,以下是我的方法的:
```
(defun tetris-test-shape-random (tetris-test-shape)
(or (and
tetris-stop-midair
;; Don't stop on the first shape.
(< 1 tetris-n-shapes )
;; Stop every INTERVAL pieces.
(let ((interval 7))
(zerop (mod tetris-n-shapes interval)))
;; Don't stop too early (it makes the game unplayable).
(let ((upper-limit 8))
(< upper-limit tetris-pos-y))
;; Don't stop at the same place every time.
(zerop (mod (random 7) 10)))
(funcall tetris-test-shape)))
(advice-add 'tetris-test-shape :around #'tetris-test-shape-random)
```
这里的硬编码参数使游戏变得更困难,但仍然可玩。当时我在飞机上喝醉了,所以它们可能需要进一步调整。
顺便说一下,根据我的 `tetris-scores` 文件,我的 **最高分** 是:
```
01389 Wed Dec 5 15:32:19 2018
```
该文件中列出的分数默认最多为五位数,因此这个分数看起来不是很好。
### 给读者的练习
1. 使用 advice 修改 Emacs 俄罗斯方块,使得每当方块下移动时就闪烁显示讯息 “OH SHIT”。消息的大小与块堆的高度成比例(当没有块时,消息应该很小的或不存在的,当最高块接近天花板时,消息应该很大)。
2. 在这里给出的 `tetris-test-shape-random` 版本中,每隔七格就有一个半空中停止。一个玩家有可能能计算出时间间隔,并利用它来获得优势。修改它,使间隔随机在一些合理的范围内(例如,每 5 到 10 格)。
3. 另一个对使用 Tetris 使用 advise 的场景,你可以试试 [autotetris-mode](https://nullprogram.com/blog/2014/10/19/)。
4. 想出一个有趣的方法来打乱块的旋转机制,然后使用 advice 来实现它。
---
1. Emacs 只有一个巨大的全局命名空间,因此函数和变量名一般以包名做前缀以避免冲突。 [↩](#fnref1)
2. 很多人会说你不应该使用已有的命名空间前缀而且应该将自己定义的所有东西都放在一个预留的命名空间中,比如像这样 `my/tetris-preview-next-shape`,然而这样很难看而且没什么意义,因此我不会这么干。 [↩](#fnref2)
---
via: <https://nickdrozd.github.io/2019/01/14/tetris.html>
作者:[nickdrozd](https://nickdrozd.github.io) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Some Advice for How to Make Emacs Tetris Harder
Did you know that **Emacs** comes bundled with an implementation of **Tetris**? Just hit `M-x tetris`
and there it is:
This is often mentioned by Emacs advocates in text editor discussions. “Yeah, but can *that other editor* run Tetris?” I wonder, is that supposed to convince anyone that Emacs is superior? Like, why would anyone care that they could play games in their text editor? “Yeah, but can *that other vacuum* play mp3s?”
That said, **Tetris is always fun**. Like everything in Emacs, the source code is open for easy inspection and modifcation, so **it’s possible to make it even more fun**. And by *more fun*, I mean *harder*.
One of the simplest ways to make the game harder is to **get rid of the next-block preview**. No more sitting that S/Z block in a precarious position knowing that you can fill in the space with the next piece – you have to chance it and hope for the best. Here’s what it looks like with no preview (as you can see, without the preview I made some choices that turned out to have **dire consequences**):
The preview box is set with a function called `tetris-draw-next-shape`
1:
```
(defun tetris-draw-next-shape ()
(dotimes (x 4)
(dotimes (y 4)
(gamegrid-set-cell (+ tetris-next-x x)
(+ tetris-next-y y)
tetris-blank)))
(dotimes (i 4)
(let ((tetris-shape tetris-next-shape)
(tetris-rot 0))
(gamegrid-set-cell (+ tetris-next-x
(aref (tetris-get-shape-cell i) 0))
(+ tetris-next-y
(aref (tetris-get-shape-cell i) 1))
tetris-shape))))
```
First, we’ll introduce a flag to allow configuring next-preview 2:
```
(defvar tetris-preview-next-shape nil
"When non-nil, show the next block the preview box.")
```
Now the question is, how can we make `tetris-draw-next-shape`
obey this flag? The obvious way would be to redefine it:
```
(defun tetris-draw-next-shape ()
(when tetris-preview-next-shape
;; existing tetris-draw-next-shape logic
))
```
This is not an ideal solution. There will be two definitions of the same function floating around, which is confusing, and we’ll have to maintain our modified definition in case the upstream version changes.
A better approach is to use **advice**. Emacs advice is like a **Python decorator**, but even more flexible, since advice can be added to a function from anywhere. This means that we can modify the function without disturbing the original source file at all.
There are a lot of different ways to use Emacs advice ([check the manual](https://www.gnu.org/software/emacs/manual/html_node/elisp/Advising-Functions.html)), but for now we’ll just stick with the `advice-add`
function with the `:around`
flag. The advising function takes the original function as an argument, and it might or might not execute it. In this case, we’ll say that the original should be executed only if the preview flag is non-nil:
```
(defun tetris-maybe-draw-next-shape (tetris-draw-next-shape)
(when tetris-preview-next-shape
(funcall tetris-draw-next-shape)))
(advice-add 'tetris-draw-next-shape :around #'tetris-maybe-draw-next-shape)
```
This code will modify the behavior of `tetris-draw-next-shape`
, but it can be stored in your config files, safely away from the actual Tetris code.
Getting rid of the preview box is a simple change. A more drastic change is to make it so that **blocks randomly stop in the air**:
In that picture, the red I and green T pieces are not falling, they’re set in place. This can make the game almost **unplayably hard**, but it’s easy to implement.
As before, we’ll first define a flag:
```
(defvar tetris-stop-midair t
"If non-nil, pieces will sometimes stop in the air.")
```
Now, **the way Emacs Tetris works** is something like this. The active piece has x- and y-coordinates. On each clock tick, the y-coordinate is incremented (the piece moves down one row), and then a check is made for collisions. If a collision is detected, the piece is backed out (its y-coordinate is decremented) and set in place. In order to make a piece stop in the air, all we have to do is hack the detection function, `tetris-test-shape`
.
**It doesn’t matter what this function does internally** – what matters is that it’s a function of no arguments that returns a boolean value. We need it to return true whenever it normally would (otherwise we risk weird collisions) but also at other times. I’m sure there are a variety of ways this could be done, but here is what I came up with:
```
(defun tetris-test-shape-random (tetris-test-shape)
(or (and
tetris-stop-midair
;; Don't stop on the first shape.
(< 1 tetris-n-shapes )
;; Stop every INTERVAL pieces.
(let ((interval 7))
(zerop (mod tetris-n-shapes interval)))
;; Don't stop too early (it makes the game unplayable).
(let ((upper-limit 8))
(< upper-limit tetris-pos-y))
;; Don't stop at the same place every time.
(zerop (mod (random 7) 10)))
(funcall tetris-test-shape)))
(advice-add 'tetris-test-shape :around #'tetris-test-shape-random)
```
The hardcoded parameters here were chosen to make the game harder but still playable. I was **drunk on an airplane** when I decided on them though, so they might need some further tweaking.
By the way, according to my `tetris-scores`
file, my **top score** is
`01389 Wed Dec 5 15:32:19 2018`
The scores in that file are listed up to five digits by default, so that doesn’t seem very good.
**Exercises for the reader**
-
Using advice, modify Emacs Tetris so that it flashes the messsage “OH SHIT” under the scoreboard every time the block moves down. Make the size of the message proportional to the height of the block stack (when there are no blocks, the message should be small or nonexistent, and when the highest block is close to the ceiling, the message should be large).
-
The version of
`tetris-test-shape-random`
given here has every seventh piece stop midair. A player could potentially figure out the interval and use it to their advantage. Modify it to make the interval random in some reasonable range (say, every five to ten pieces). -
For a different take on advising Tetris, try out
.`autotetris-mode`
-
Come up with an interesting way to mess with the piece-rotation mechanics and then implement it with advice.
# Footnotes
1 Emacs has just one big global namespace, so function and variable names are typically prefixed with their package name in order to avoid collisions.
2 A lot of people will tell you that you shouldn’t use an existing namespace prefix and that you should reserve a namespace prefix for anything you define yourself, e.g.
`my/tetris-preview-next-shape`
. This is ugly and usually pointless, so I don’t do it. |
11,939 | elementary OS 正在构建一个可以买应用的开源应用商店 | https://itsfoss.com/appcenter-for-everyone/ | 2020-02-27T23:36:01 | [
"应用中心"
] | https://linux.cn/article-11939-1.html |
>
> elementary OS 正在构建一个应用中心生态系统,你可以在其中购买用于 Linux 发行版的开源应用程序。
>
>
>
### 众筹构建一个开源应用中心

[elementary OS](https://elementary.io/) 最近宣布,它正在[众筹举办一个构建应用中心的活动](https://www.indiegogo.com/projects/appcenter-for-everyone/),你可以从这个应用中心购买开源应用程序。应用中心中的应用程序将为 Flatpak 格式。
尽管这是 elementary OS 发起的活动,但这个新的应用中心也将适用于其他发行版。
该活动旨在资助在美国科罗拉多州丹佛市进行的一项一周个人开发冲刺活动,其中包括来自 elementary OS、[Endless](https://itsfoss.com/endless-linux-computers/)、[Flathub](https://flathub.org/) 和 [GNOME](https://www.gnome.org/) 的开发人员。
众筹活动已经超过了筹集 1 万美元的目标(LCTT 译注:截止至本译文发布,已近 15000 美金)。但你仍然可以为其提供资金,因为其他资金将用于开发 elementary OS。
### 这个应用中心将带来什么功能
其重点是提供“安全”应用程序,因此使用 [Flatpak](https://flatpak.org/) 应用来提供受限的应用程序。在这种格式下,默认情况下将会限制应用程序访问系统或个人文件,并在技术层面上将它们与其他应用程序隔离。
仅当你明确表示同意时,应用程序才能访问操作系统和个人文件。
除了安全性,[Flatpak](https://itsfoss.com/flatpak-guide/) 还捆绑了所有依赖项。这样,即使当前 Linux 发行版中不提供这些依赖项,应用程序开发人员也可以利用这种最先进的技术使用它。
AppCenter 还具有钱包功能,可以保存你的信用卡详细信息。这样,你无需每次输入卡的详细信息即可快速为应用付费。

这个新的开源“应用中心”也将适用于其他 Linux 发行版。
### 受到了 elementary OS 自己的“按需付费”应用中心模型成功的启发
几年前,elementary OS 推出了自己的应用中心。应用中心的“按需付费”方法很受欢迎。开发人员可以为其开源应用设置最低金额,而用户可以选择支付等于或高于最低金额的金额。

这帮助了几位独立开发人员可以对其开源应用程序接受付款。该应用中心现在拥有约 160 个原生应用程序,elementary OS 表示已通过应用中心向开发人员支付了数千美元。
受到此应用中心实验在 elementary OS 中的成功的启发,他们现在也希望将此应用中心的方法也引入其他发行版。
### 如果应用程序是开源的,你怎么为此付费?
某些人仍然对 FOSS(自由而开源)的概念感到困惑。在这里,该软件的“源代码”是“开源的”,任何人都可以“自由”进行修改和重新分发。
但这并不意味着开源软件必须免费。一些开发者依靠捐赠,而另一些则收取支持费用。
获得开源应用程序的报酬可能会鼓励开发人员创建 [Linux 应用程序](https://itsfoss.com/essential-linux-applications/)。
### 让我们拭目以待

就个人而言,我不是 Flatpak 或 Snap 包格式的忠实拥护者。它们确实有其优点,但是它们花费了相对更多的时间来启动,并且它们的包大小很大。如果安装了多个此类 Snap 或 Flatpak 软件包,磁盘空间就会慢慢耗尽。
也需要对这个新的应用程序生态系统中的假冒和欺诈开发者保持警惕。想象一下,如果某些骗子开始创建冷门的开源应用程序的 Flatpak 程序包,并将其放在应用中心上?我希望开发人员采用某种机制来淘汰此类应用程序。
我确实希望这个新的应用中心能够复制在 elementary OS 中已经看到的成功。对于桌面 Linux 的开源应用程序,我们绝对需要更好的生态系统。
你对此有何看法?这是正确的方法吗?你对改进应用中心有什么建议?
---
via: <https://itsfoss.com/appcenter-for-everyone/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: elementary OS is building an app center ecosystem where you can buy open source applications for your Linux distribution.*
## Crowdfunding to build an open source AppCenter for everyone

[elementary OS](https://elementary.io/) recently announced that it is [crowdfunding a campaign to build an app center](https://www.indiegogo.com/projects/appcenter-for-everyone/) from where you can buy open source applications. The applications in the app center will be in Flatpak format.
Though it’s an initiative taken by elementary OS, this new app center will be available for other distributions as well.
The campaign aims to fund a week of in-person development sprint in Denver, Colorado (USA) featuring developers from elementary OS, [Endless](https://itsfoss.com/endless-linux-computers/), [Flathub](https://flathub.org/) and [GNOME](https://www.gnome.org/).
The crowdfunding campaign has already crossed its goal of raising $10,000. You can still fund it as additional funds will be used for the development of elementary OS.
## What features this AppCenter brings
The focus is on providing ‘secure’ applications and hence [Flatpak](https://flatpak.org/) apps are used to provide confined applications. In this format, apps will be restricted from accessing system or personal files and will be isolated from other apps on a technical level by default.
Apps will have access to operating system and personal files only if you explicitly provide your consent for it.
Apart from security, [Flatpak](https://itsfoss.com/flatpak-guide/) also bundles all the dependencies. This way, app developers can utilize the cutting edge technologies even if it is not available on the current Linux distribution.
AppCenter will also have the wallet feature to save your card details. This enables you to quickly pay for apps without entering the card details each time.
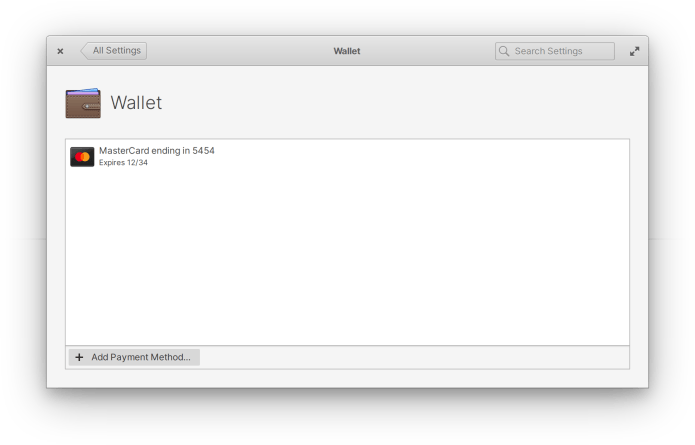
This new open source ‘app center’ will be available for other Linux distributions as well.
## Inspired by the success of elementary OS’s own ‘Pay What You Want’ app center model
A couple of years ago, elementary OS launched its own app center. The ‘pay what you want’ approach for the app center was quite a hit. The developers can put a minimum amount for their open source apps and the users can choose to pay an amount equal to or more than the minimum amount.
This helped several indie developers get paid for their open source applications. The app store now has around 160 native applications and elementary OS says that thousands of dollars have been paid to the developers through the app center.
Inspired by the success of this app center experiment in elementary OS, they now want to bring this app center approach to other distributions as well.
## If the applications are open source, how can you charge money for it?
Some people still get confused with the idea of FOSS (free and open source). Here, the **source** code of the software is **open** and anyone is **free** to modify it and redistribute it.
It doesn’t mean that open source software has to be free of cost. Some developers rely on donations while some charge a fee for support.
Getting paid for the open source apps may encourage developers to create [applications for Linux](https://itsfoss.com/essential-linux-applications/).
## Let’s see if it could work

Personally, I am not a huge fan of Flatpak or Snap packaging formats. They do have their benefits but they take relatively more time to start and they are huge in size. If you install several such Snaps or Flatpaks, your disk space may start running out of free space.
There is also a need to be vigilant about the fake and scam developers in this new app ecosystem. Imagine if some scammers starts creating Flatpak package of obscure open source applications and put it on the app center? I hope the developers put some sort of mechanism to weed out such apps.
I do hope that this new AppCenter replicates the success it has seen in elementary OS. We definitely need a better ecosystem for open source apps for desktop Linux.
[interaction id=”5e424f49045794547eb59117″]
What are your views on it? Is it the right approach? What suggestions do you have for the improvement of the AppCenter? |
11,940 | Kubernetes 如何成为计算资源的标准 | https://www.linux.com/articles/how-kubernetes-became-the-standard-for-compute-resources/ | 2020-02-28T13:17:46 | [
"Kubernetes"
] | https://linux.cn/article-11940-1.html | 
对于原生云生态系统来说,2019 年是改变游戏规则的一年。有大的[并购](https://www.cloudfoundry.org/blog/2019-is-the-year-of-consolidation-why-ibms-deal-with-red-hat-is-a-harbinger-of-things-to-come/),如 Red Hat Docker 和 Pivotal,并出现其他的玩家,如 Rancher Labs 和 Mirantis。
Rancher Labs (一家为采用容器的团队提供完整软件栈的公司)的联合创始人兼首席执行官盛亮表示:“所有这些整合和并购,都表明这一领域的市场成熟的速度很快。”
传统上,像 Kubernetes 和 Docker 这样的新兴技术吸引着开发者和像脸书和谷歌这样的超级用户。除了这群人之外则没什么兴趣。然而,这两种技术都在企业层面得到了广泛采用。突然间,出现了一个巨大的市场,有着巨大的机会。几乎每个人都跳了进去。有人带来了创新的解决方案,也有人试图赶上其他人。它很快变得非常拥挤和热闹起来。
它也改变了创新的方式。[早期采用者通常是精通技术的公司](https://www.packet.com/blog/open-source-season-on-the-kubernetes-highway/)。现在,几乎每个人都在使用它,即使是在不被认为是 Kubernetes 地盘的地方。它改变了市场动态,像 Rancher Labs 这样的公司见证了独特的用例。
盛亮补充道,“我从来没有经历过像 Kubernete 这样快速、动态的市场或技术演变。当我们五年前开始的时候,这是一个非常拥挤的空间。随着时间的推移,我们大多数的友商因为这样或那样的原因消失了。他们要么无法适应变化,要么选择不适应某些变化。”
在 Kubernetes 的早期,最明显的机会是建立 Kubernetes 发行版本和 Kubernetes 业务。这是新技术。众所周知,它的安装、升级和操作相当的复杂。
当谷歌、AWS 和微软进入市场时,一切都变了。当时,一群供应商蜂拥而至,为平台提供解决方案。盛亮表示:“一旦像谷歌这样的云提供商决定将 Kubernetes 作为一项服务,并免费提供亏本出售的商品,以推动基础设施消费;我们就知道,运营和支持 Kubernetes 业务的优势将非常有限了。”
对谷歌之外的其它玩家来说,并非一切都不好。由于云供应商通过将它作为服务来提供,消除了 Kubernetes 带来的所有复杂性,这意味着更广泛地采用该技术,即使是那些由于运营成本而不愿使用该技术的人也是如此。这意味着 Kubernetes 将变得无处不在,并将成为一个行业标准。
“Rancher Labs 是极少数将此视为机遇并比其他公司看得更远的公司之一。我们意识到 Kubernetes 将成为新的计算标准,就像 TCP/IP 成为网络标准一样,”盛亮说。
CNCF 在围绕 Kubernetes 构建一个充满活力的生态系统方面发挥着至关重要的作用,创建了一个庞大的社区来构建、培育和商业化原生云开源技术。
---
via: <https://www.linux.com/articles/how-kubernetes-became-the-standard-for-compute-resources/>
作者:[Swapnil Bhartiya](https://www.linux.com/author/swapnil/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,942 | 如何在 Fedora 上安装 MongoDB 服务器 | https://fedoramagazine.org/how-to-get-mongodb-server-on-fedora/ | 2020-02-28T14:27:44 | [
"MongoDB"
] | https://linux.cn/article-11942-1.html | 
Mongo(来自 “humongous” —— 巨大的)是一个高性能、开源、无模式的、面向文档的数据库,它是最受欢迎的 [NoSQL](https://en.wikipedia.org/wiki/NoSQL) 数据库之一。它使用 JSON 作为文档格式,并且可以在多个服务器节点之间进行扩展和复制。
### 有关许可证更改的故事
MongoDB 上游决定更改服务器代码的许可证已经一年多了。先前的许可证是 GNU Affero General Public License v3(AGPLv3)。但是,上游公司写了一个新许可证,旨在使运行 MongoDB 即服务的公司可以回馈社区。新许可证称为 Server Side Public License(SSPLv1),关于这个举措及其解释的更多说明,请参见 [MongoDB SSPL FAQ](https://www.mongodb.com/licensing/server-side-public-license/faq)。
Fedora 一直只包含自由软件。当 SSPL 发布后,Fedora [确定](https://lists.fedoraproject.org/archives/list/[email protected]/thread/IQIOBOGWJ247JGKX2WD6N27TZNZZNM6C/)它并不是自由软件许可证。许可证更改日期(2018 年 10 月)之前发布的所有 MongoDB 版本都可保留在 Fedora 中,但之后再也不更新的软件包会带来安全问题。因此,从 Fedora 30 开始,Fedora 社区决定完全[移除 MongoDB 服务器](https://fedoraproject.org/wiki/Changes/MongoDB_Removal)。
### 开发人员还有哪些选择?
是的,还有替代方案,例如 PostgreSQL 在最新版本中也支持 JSON,它可以在无法再使用 MongoDB 的情况下使用它。使用 JSONB 类型,索引在 PostgreSQL 中可以很好地工作,其性能可与 MongoDB 媲美,甚至不会受到 ACID 的影响。
开发人员可能选择 MongoDB 的技术原因并未随许可证而改变,因此许多人仍想使用它。重要的是要意识到,SSPL 许可证仅更改仅针对 MongoDB 服务器。MongoDB 上游还开发了其他项目,例如 MongoDB 工具、C 和 C++ 客户端库以及用于各种动态语言的连接器,这些项目在客户端使用(通过网络与服务器通信的应用中)。由于这些包的许可证人保持自由(主要是 Apache 许可证),因此它们保留在 Fedora 仓库中,因此用户可以将其用于应用开发。
唯一的变化实际是服务器软件包本身,它已从 Fedora 仓库中完全删除。让我们看看 Fedora 用户可以如何获取非自由的包。
### 如何从上游安装 MongoDB 服务器
当 Fedora 用户想要安装 MongoDB 服务器时,他们需要直接向上游获取 MongoDB。但是,上游不为 Fedora 提供 RPM 包。相反,MongoDB 服务器可以获取源码 tarball,用户需要自己进行编译(这需要一些开发知识),或者 Fedora 用户可以使用一些兼容的包。在兼容的选项中,最好的选择是 RHEL-8 RPM。以下步骤描述了如何安装它们以及如何启动守护进程。
#### 1、使用上游 RPM 创建仓库(RHEL-8 构建)
```
$ sudo cat > /etc/yum.repos.d/mongodb.repo >>EOF
[mongodb-upstream]
name=MongoDB Upstream Repository
baseurl=https://repo.mongodb.org/yum/redhat/8Server/mongodb-org/4.2/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.2.asc
EOF
```
#### 2、安装元软件包,来拉取服务器和工具包
```
$ sudo dnf install mongodb-org
......
Installed:
mongodb-org-4.2.3-1.el8.x86_64 mongodb-org-mongos-4.2.3-1.el8.x86_64
mongodb-org-server-4.2.3-1.el8.x86_64 mongodb-org-shell-4.2.3-1.el8.x86_64
mongodb-org-tools-4.2.3-1.el8.x86_64
Complete!
```
#### 3、启动 MongoDB 守护进程
```
$ sudo systemctl status mongod
● mongod.service - MongoDB Database Server
Loaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2020-02-08 12:33:45 EST; 2s ago
Docs: https://docs.mongodb.org/manual
Process: 15768 ExecStartPre=/usr/bin/mkdir -p /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 15769 ExecStartPre=/usr/bin/chown mongod:mongod /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 15770 ExecStartPre=/usr/bin/chmod 0755 /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 15771 ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 15773 (mongod)
Memory: 70.4M
CPU: 611ms
CGroup: /system.slice/mongod.service
```
#### 4、通过 mongo shell 连接服务器来验证是否运行
```
$ mongo
MongoDB shell version v4.2.3
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("20b6e61f-c7cc-4e9b-a25e-5e306d60482f") }
MongoDB server version: 4.2.3
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
---
```
就是这样了。如你所见,RHEL-8 包完美兼容,只要 Fedora 包还与 RHEL-8 兼容,它就应该会一直兼容。请注意,在使用时必须遵守 SSPLv1 许可证。
---
via: <https://fedoramagazine.org/how-to-get-mongodb-server-on-fedora/>
作者:[Honza Horak](https://fedoramagazine.org/author/hhorak/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mongo (from “humongous”) is a high-performance, open source, schema-free document-oriented database, which is one of the most favorite so-called [NoSQL](https://en.wikipedia.org/wiki/NoSQL) databases. It uses JSON as a document format, and it is designed to be scalable and replicable across multiple server nodes.
## Story about license change
It’s been more than a year when the upstream MongoDB decided to change the license of the Server code. The previous license was GNU Affero General Public License v3 (AGPLv3). However, upstream wrote a new license designed to make companies running MongoDB as a service contribute back to the community. The new license is called Server Side Public License (SSPLv1) and more about this step and its rationale can be found at [MongoDB SSPL FAQ](https://www.mongodb.com/licensing/server-side-public-license/faq).
Fedora has always included only free (as in “freedom”) software. When SSPL was released, Fedora [determined](https://lists.fedoraproject.org/archives/list/[email protected]/thread/IQIOBOGWJ247JGKX2WD6N27TZNZZNM6C/) that it is not a free software license in this meaning. All versions of MongoDB released before the license change date (October 2018) could be potentially kept in Fedora, but never updating the packages in the future would bring security issues. Hence the Fedora community decided to [remove the MongoDB server](https://fedoraproject.org/wiki/Changes/MongoDB_Removal) entirely, starting Fedora 30.
## What options are left to developers?
Well, alternatives exist, for example PostgreSQL also supports JSON in the recent versions, and it can be used in cases when MongoDB cannot be used any more. With JSONB type, indexing works very well in PostgreSQL with performance comparable with MongoDB, and even without any compromises from ACID.
The technical reasons that a developer may have chosen MongoDB did not change with the license, so many still want to use it. What is important to realize is that the SSPL license was only changed to the MongoDB server. There are other projects that MongoDB upstream develops, like MongoDB tools, C and C++ client libraries and connectors for various dynamic languages, that are used on the client side (in applications that want to communicate with the server over the network). Since the license is kept free (Apache License mostly) for those packages, they are staying in Fedora repositories, so users can use them for the application development.
The only change is really the server package itself, which was removed entirely from Fedora repos. Let’s see what a Fedora user can do to get the non-free packages.
## How to install MongoDB server from the upstream
When Fedora users want to install a MongoDB server, they need to approach MongoDB upstream directly. However, the upstream does not ship RPM packages for Fedora itself. Instead, the MongoDB server is either available as the source tarball, that users need to compile themselves (which requires some developer knowledge), or Fedora user can use some compatible packages. From the compatible options, the best choice is the RHEL-8 RPMs at this point. The following steps describe, how to install them and how to start the daemon.
### 1. Create a repository with upstream RPMs (RHEL-8 builds)
$ sudo cat > /etc/yum.repos.d/mongodb.repo <<EOF
[mongodb-upstream]
name=MongoDB Upstream Repository
baseurl=https://repo.mongodb.org/yum/redhat/8Server/mongodb-org/4.2/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.2.asc
EOF
### 2. Install the meta-package, that pulls the server and tools packages
$ sudo dnf install mongodb-org
<snipped>
Installed:
mongodb-org-4.2.3-1.el8.x86_64 mongodb-org-mongos-4.2.3-1.el8.x86_64
mongodb-org-server-4.2.3-1.el8.x86_64 mongodb-org-shell-4.2.3-1.el8.x86_64
mongodb-org-tools-4.2.3-1.el8.x86_64
Complete!
### 3. Start the MongoDB daemon
$ sudo systemctl status mongod
● mongod.service - MongoDB Database Server
Loaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2020-02-08 12:33:45 EST; 2s ago
Docs: https://docs.mongodb.org/manual
Process: 15768 ExecStartPre=/usr/bin/mkdir -p /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 15769 ExecStartPre=/usr/bin/chown mongod:mongod /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 15770 ExecStartPre=/usr/bin/chmod 0755 /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 15771 ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 15773 (mongod)
Memory: 70.4M
CPU: 611ms
CGroup: /system.slice/mongod.service
└─15773 /usr/bin/mongod -f /etc/mongod.conf
### 4. Verify that the server runs by connecting to it from the mongo shell
$ mongo
MongoDB shell version v4.2.3
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("20b6e61f-c7cc-4e9b-a25e-5e306d60482f") }
MongoDB server version: 4.2.3
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
---
> _
That’s all. As you see, the RHEL-8 packages are pretty compatible and it should stay that way for as long as the Fedora packages remain compatible with what’s in RHEL-8. Just be careful that you comply with the SSPLv1 license in your use.
## Alberto Patino
I used to build mongodb from source. It is not that difficult by the way (http://albertopatino.com.mx/?p=21)
Thanks
## Peter Kumaschow
Alternatively you could run it in docker https://hub.docker.com/_/mongo
## Simon
That’d be my option too… not just for mongodb, but for any server component that I might need as a developer. Using container images (docker / podman) is just so convenient.
## kwizart
Is it possible to build the official mongodb RPM from src.rpm ?
## Gaboury arnaud
Why not run the app with it’s docker file?
## Gaboury arnaud
Why not run the app as a container using the amazing podman command?
## David Frantz
Why run the database at all?
Seriously they changed the license in the hopes that they can get users to contribute back. It is foolish in my mind to try to create a license that forces anybody to do anything with free software. Doing so really turns free software into slave ware.
Now in an ideal world users would contribute back. However we are not in an ideal world and frankly you wouldn’t want a lot of the user base trying to contribute. It is far better to have capable people contributing because they have a personal desire to do so. Frankly I think the new Mongo license is nuts.
## Nathan
“It uses JSON as a document format,….” Not quite. It uses BSON actually https://en.wikipedia.org/wiki/BSON. |
11,943 | 使用 Python 和 GNU Octave 绘制数据 | https://opensource.com/article/20/2/python-gnu-octave-data-science | 2020-02-29T11:48:00 | [
"数据科学"
] | https://linux.cn/article-11943-1.html |
>
> 了解如何使用 Python 和 GNU Octave 完成一项常见的数据科学任务。
>
>
>

数据科学是跨越编程语言的知识领域。有些语言以解决这一领域的问题而闻名,而另一些则鲜为人知。这篇文章将帮助你熟悉用一些流行的语言完成数据科学的工作。
### 选择 Python 和 GNU Octave 做数据科学工作
我经常尝试学习一种新的编程语言。为什么?这既有对旧方式的厌倦,也有对新方式的好奇。当我开始学习编程时,我唯一知道的语言是 C 语言。那些年的编程生涯既艰难又危险,因为我必须手动分配内存、管理指针、并记得释放内存。
后来一个朋友建议我试试 Python,现在我的编程生活变得轻松多了。虽然程序运行变得慢多了,但我不必通过编写分析软件来受苦了。然而,我很快就意识到每种语言都有比其它语言更适合自己的应用场景。后来我学习了一些其它语言,每种语言都给我带来了一些新的启发。发现新的编程风格让我可以将一些解决方案移植到其他语言中,这样一切都变得有趣多了。
为了对一种新的编程语言(及其文档)有所了解,我总是从编写一些执行我熟悉的任务的示例程序开始。为此,我将解释如何用 Python 和 GNU Octave 编写一个程序来完成一个你可以归类为数据科学的特殊任务。如果你已经熟悉其中一种语言,从它开始,然后通过其他语言寻找相似之处和不同之处。这篇文章并不是对编程语言的详尽比较,只是一个小小的展示。
所有的程序都应该在[命令行](https://en.wikipedia.org/wiki/Command-line_interface)上运行,而不是用[图形用户界面](https://en.wikipedia.org/wiki/Graphical_user_interface)(GUI)。完整的例子可以在 [polyglot\_fit 存储库](https://gitlab.com/cristiano.fontana/polyglot_fit)中找到。
### 编程任务
你将在本系列中编写的程序:
* 从 [CSV 文件](https://en.wikipedia.org/wiki/Comma-separated_values)中读取数据
* 用直线插入数据(例如 `f(x)=m ⋅ x + q`)
* 将结果生成图像文件
这是许多数据科学家遇到的常见情况。示例数据是 [Anscombe 的四重奏](https://en.wikipedia.org/wiki/Anscombe%27s_quartet)的第一组,如下表所示。这是一组人工构建的数据,当用直线拟合时会给出相同的结果,但是它们的曲线非常不同。数据文件是一个文本文件,以制表符作为列分隔符,开头几行作为标题。此任务将仅使用第一组(即前两列)。

### Python 方式
[Python](https://www.python.org/) 是一种通用编程语言,是当今最流行的语言之一(依据 [TIOBE 指数](https://www.tiobe.com/tiobe-index/)、[RedMonk 编程语言排名](https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/)、[编程语言流行指数](http://pypl.github.io/PYPL.html)、[GitHub Octoverse 状态](https://octoverse.github.com/)和其他来源的调查结果)。它是一种[解释型语言](https://en.wikipedia.org/wiki/Interpreted_language);因此,源代码由执行该指令的程序读取和评估。它有一个全面的[标准库](https://docs.python.org/3/library/)并且总体上非常好用(我对这最后一句话没有证据;这只是我的拙见)。
#### 安装
要使用 Python 开发,你需要解释器和一些库。最低要求是:
* [NumPy](https://numpy.org/) 用于简化数组和矩阵的操作
* [SciPy](https://www.scipy.org/) 用于数据科学
* [Matplotlib](https://matplotlib.org/) 用于绘图
在 [Fedora](https://getfedora.org/) 安装它们是很容易的:
```
sudo dnf install python3 python3-numpy python3-scipy python3-matplotlib
```
#### 代码注释
在 Python中,[注释](https://en.wikipedia.org/wiki/Comment_(computer_programming))是通过在行首添加一个 `#` 来实现的,该行的其余部分将被解释器丢弃:
```
# 这是被解释器忽略的注释。
```
[fitting\_python.py](https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_python.py) 示例使用注释在源代码中插入许可证信息,第一行是[特殊注释](https://en.wikipedia.org/wiki/Shebang_(Unix)),它允许该脚本在命令行上执行:
```
#!/usr/bin/env python3
```
这一行通知命令行解释器,该脚本需要由程序 `python3` 执行。
#### 需要的库
在 Python 中,库和模块可以作为一个对象导入(如示例中的第一行),其中包含库的所有函数和成员。可以通过使用 `as` 方式用自定义标签重命名它们:
```
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
```
你也可以决定只导入一个子模块(如第二行和第三行)。语法有两个(基本上)等效的方式:`import module.submodule` 和 `from module import submodule`。
#### 定义变量
Python 的变量是在第一次赋值时被声明的:
```
input_file_name = "anscombe.csv"
delimiter = "\t"
skip_header = 3
column_x = 0
column_y = 1
```
变量类型由分配给变量的值推断。没有具有常量值的变量,除非它们在模块中声明并且只能被读取。习惯上,不应被修改的变量应该用大写字母命名。
#### 打印输出
通过命令行运行程序意味着输出只能打印在终端上。Python 有 [print()](https://docs.python.org/3/library/functions.html#print) 函数,默认情况下,该函数打印其参数,并在输出的末尾添加一个换行符:
```
print("#### Anscombe's first set with Python ####")
```
在 Python 中,可以将 `print()` 函数与[字符串类](https://docs.python.org/3/library/string.html)的[格式化能力](https://docs.python.org/3/library/string.html#string-formatting)相结合。字符串具有`format` 方法,可用于向字符串本身添加一些格式化文本。例如,可以添加格式化的浮点数,例如:
```
print("Slope: {:f}".format(slope))
```
#### 读取数据
使用 NumPy 和函数 [genfromtxt()](https://docs.scipy.org/doc/numpy/reference/generated/numpy.genfromtxt.html) 读取 CSV 文件非常容易,该函数生成 [NumPy 数组](https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html):
```
data = np.genfromtxt(input_file_name, delimiter = delimiter, skip_header = skip_header)
```
在 Python 中,一个函数可以有数量可变的参数,你可以通过指定所需的参数来传递一个参数的子集。数组是非常强大的矩阵状对象,可以很容易地分割成更小的数组:
```
x = data[:, column_x]
y = data[:, column_y]
```
冒号选择整个范围,也可以用来选择子范围。例如,要选择数组的前两行,可以使用:
```
first_two_rows = data[0:1, :]
```
#### 拟合数据
SciPy 提供了方便的数据拟合功能,例如 [linregress()](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.linregress.html) 功能。该函数提供了一些与拟合相关的重要值,如斜率、截距和两个数据集的相关系数:
```
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
print("Slope: {:f}".format(slope))
print("Intercept: {:f}".format(intercept))
print("Correlation coefficient: {:f}".format(r_value))
```
因为 `linregress()` 提供了几条信息,所以结果可以同时保存到几个变量中。
#### 绘图
Matplotlib 库仅仅绘制数据点,因此,你应该定义要绘制的点的坐标。已经定义了 `x` 和 `y` 数组,所以你可以直接绘制它们,但是你还需要代表直线的数据点。
```
fit_x = np.linspace(x.min() - 1, x.max() + 1, 100)
```
[linspace()](https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html) 函数可以方便地在两个值之间生成一组等距值。利用强大的 NumPy 数组可以轻松计算纵坐标,该数组可以像普通数值变量一样在公式中使用:
```
fit_y = slope * fit_x + intercept
```
该公式在数组中逐元素应用;因此,结果在初始数组中具有相同数量的条目。
要绘图,首先,定义一个包含所有图形的[图形对象](https://matplotlib.org/api/_as_gen/matplotlib.figure.Figure.html#matplotlib.figure.Figure):
```
fig_width = 7 #inch
fig_height = fig_width / 16 * 9 #inch
fig_dpi = 100
fig = plt.figure(figsize = (fig_width, fig_height), dpi = fig_dpi)
```
一个图形可以画几个图;在 Matplotlib 中,这些图被称为[轴](https://matplotlib.org/api/axes_api.html#matplotlib.axes.Axes)。本示例定义一个单轴对象来绘制数据点:
```
ax = fig.add_subplot(111)
ax.plot(fit_x, fit_y, label = "Fit", linestyle = '-')
ax.plot(x, y, label = "Data", marker = '.', linestyle = '')
ax.legend()
ax.set_xlim(min(x) - 1, max(x) + 1)
ax.set_ylim(min(y) - 1, max(y) + 1)
ax.set_xlabel('x')
ax.set_ylabel('y')
```
将该图保存到 [PNG 图形文件](https://en.wikipedia.org/wiki/Portable_Network_Graphics)中,有:
```
fig.savefig('fit_python.png')
```
如果要显示(而不是保存)该绘图,请调用:
```
plt.show()
```
此示例引用了绘图部分中使用的所有对象:它定义了对象 `fig` 和对象 `ax`。这在技术上是不必要的,因为 `plt` 对象可以直接用于绘制数据集。《[Matplotlib 教程](https://matplotlib.org/tutorials/introductory/pyplot.html#sphx-glr-tutorials-introductory-pyplot-py)》展示了这样一个接口:
```
plt.plot(fit_x, fit_y)
```
坦率地说,我不喜欢这种方法,因为它隐藏了各种对象之间发生的重要交互。不幸的是,有时[官方的例子](https://matplotlib.org/gallery/index.html)有点令人困惑,因为他们倾向于使用不同的方法。在这个简单的例子中,引用图形对象是不必要的,但是在更复杂的例子中(例如在图形用户界面中嵌入图形时),引用图形对象就变得很重要了。
#### 结果
命令行输入:
```
#### Anscombe's first set with Python ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421
```
这是 Matplotlib 产生的图像:

### GNU Octave 方式
[GNU Octave](https://www.gnu.org/software/octave/) 语言主要用于数值计算。它提供了一个简单的操作向量和矩阵的语法,并且有一些强大的绘图工具。这是一种像 Python 一样的解释语言。由于 Octave 的语法[几乎兼容](https://wiki.octave.org/FAQ#Differences_between_Octave_and_Matlab) [MATLAB](https://en.wikipedia.org/wiki/MATLAB),它经常被描述为一个替代 MATLAB 的免费方案。Octave 没有被列为最流行的编程语言,而 MATLAB 则是,所以 Octave 在某种意义上是相当流行的。MATLAB 早于 NumPy,我觉得它是受到了前者的启发。当你看这个例子时,你会看到相似之处。
#### 安装
[fitting\_octave.m](https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_octave.m) 的例子只需要基本的 Octave 包,在 Fedora 中安装相当简单:
```
sudo dnf install octave
```
#### 代码注释
在 Octave 中,你可以用百分比符号(`%`)为代码添加注释,如果不需要与 MATLAB 兼容,你也可以使用 `#`。使用 `#` 的选项允许你编写像 Python 示例一样的特殊注释行,以便直接在命令行上执行脚本。
#### 必要的库
本例中使用的所有内容都包含在基本包中,因此你不需要加载任何新的库。如果你需要一个库,[语法](https://octave.org/doc/v5.1.0/Using-Packages.html#Using-Packages)是 `pkg load module`。该命令将模块的功能添加到可用功能列表中。在这方面,Python 具有更大的灵活性。
#### 定义变量
变量的定义与 Python 的语法基本相同:
```
input_file_name = "anscombe.csv";
delimiter = "\t";
skip_header = 3;
column_x = 1;
column_y = 2;
```
请注意,行尾有一个分号;这不是必需的,但是它会抑制该行结果的输出。如果没有分号,解释器将打印表达式的结果:
```
octave:1> input_file_name = "anscombe.csv"
input_file_name = anscombe.csv
octave:2> sqrt(2)
ans = 1.4142
```
#### 打印输出结果
强大的函数 [printf()](https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFprintf) 是用来在终端上打印的。与 Python 不同,`printf()` 函数不会自动在打印字符串的末尾添加换行,因此你必须添加它。第一个参数是一个字符串,可以包含要传递给函数的其他参数的格式信息,例如:
```
printf("Slope: %f\n", slope);
```
在 Python 中,格式是内置在字符串本身中的,但是在 Octave 中,它是特定于 `printf()` 函数。
#### 读取数据
[dlmread()](https://octave.org/doc/v5.1.0/Simple-File-I_002fO.html#XREFdlmread) 函数可以读取类似 CSV 文件的文本内容:
```
data = dlmread(input_file_name, delimiter, skip_header, 0);
```
结果是一个[矩阵](https://octave.org/doc/v5.1.0/Matrices.html)对象,这是 Octave 中的基本数据类型之一。矩阵可以用类似于 Python 的语法进行切片:
```
x = data(:, column_x);
y = data(:, column_y);
```
根本的区别是索引从 1 开始,而不是从 0 开始。因此,在该示例中,`x` 列是第一列。
#### 拟合数据
要用直线拟合数据,可以使用 [polyfit()](https://octave.org/doc/v5.1.0/Polynomial-Interpolation.html) 函数。它用一个多项式拟合输入数据,所以你只需要使用一阶多项式:
```
p = polyfit(x, y, 1);
slope = p(1);
intercept = p(2);
```
结果是具有多项式系数的矩阵;因此,它选择前两个索引。要确定相关系数,请使用 [corr()](https://octave.org/doc/v5.1.0/Correlation-and-Regression-Analysis.html#XREFcorr) 函数:
```
r_value = corr(x, y);
```
最后,使用 `printf()` 函数打印结果:
```
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);
```
#### 绘图
与 Matplotlib 示例一样,首先需要创建一个表示拟合直线的数据集:
```
fit_x = linspace(min(x) - 1, max(x) + 1, 100);
fit_y = slope * fit_x + intercept;
```
与 NumPy 的相似性也很明显,因为它使用了 [linspace()](https://octave.sourceforge.io/octave/function/linspace.html) 函数,其行为就像 Python 的等效版本一样。
同样,与 Matplotlib 一样,首先创建一个[图](https://octave.org/doc/v5.1.0/Multiple-Plot-Windows.html)对象,然后创建一个[轴](https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFaxes)对象来保存这些图:
```
fig_width = 7; %inch
fig_height = fig_width / 16 * 9; %inch
fig_dpi = 100;
fig = figure("units", "inches",
"position", [1, 1, fig_width, fig_height]);
ax = axes("parent", fig);
set(ax, "fontsize", 14);
set(ax, "linewidth", 2);
```
要设置轴对象的属性,请使用 [set()](https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFset) 函数。然而,该接口相当混乱,因为该函数需要一个逗号分隔的属性和值对列表。这些对只是代表属性名的一个字符串和代表该属性值的第二个对象的连续。还有其他设置各种属性的函数:
```
xlim(ax, [min(x) - 1, max(x) + 1]);
ylim(ax, [min(y) - 1, max(y) + 1]);
xlabel(ax, 'x');
ylabel(ax, 'y');
```
绘图是用 [plot()](https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#XREFplot) 功能实现的。默认行为是每次调用都会重置坐标轴,因此需要使用函数 [hold()](https://octave.org/doc/v5.1.0/Manipulation-of-Plot-Windows.html#XREFhold)。
```
hold(ax, "on");
plot(ax, fit_x, fit_y,
"marker", "none",
"linestyle", "-",
"linewidth", 2);
plot(ax, x, y,
"marker", ".",
"markersize", 20,
"linestyle", "none");
hold(ax, "off");
```
此外,还可以在 `plot()` 函数中添加属性和值对。[legend](https://octave.org/doc/v5.1.0/Plot-Annotations.html#XREFlegend) 必须单独创建,标签应手动声明:
```
lg = legend(ax, "Fit", "Data");
set(lg, "location", "northwest");
```
最后,将输出保存到 PNG 图像:
```
image_size = sprintf("-S%f,%f", fig_width * fig_dpi, fig_height * fig_dpi);
image_resolution = sprintf("-r%f,%f", fig_dpi);
print(fig, 'fit_octave.png',
'-dpng',
image_size,
image_resolution);
```
令人困惑的是,在这种情况下,选项被作为一个字符串传递,带有属性名和值。因为在 Octave 字符串中没有 Python 的格式化工具,所以必须使用 [sprintf()](https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFsprintf) 函数。它的行为就像 `printf()` 函数,但是它的结果不是打印出来的,而是作为字符串返回的。
在这个例子中,就像在 Python 中一样,图形对象很明显被引用以保持它们之间的交互。如果说 Python 在这方面的文档有点混乱,那么 [Octave 的文档](https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#Two_002dDimensional-Plots)就更糟糕了。我发现的大多数例子都不关心引用对象;相反,它们依赖于绘图命令作用于当前活动图形。全局[根图形对象](https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFgroot)跟踪现有的图形和轴。
#### 结果
命令行上的结果输出是:
```
#### Anscombe's first set with Octave ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421
```
它显示了用 Octave 生成的结果图像。

### 接下来
Python 和 GNU Octave 都可以绘制出相同的信息,尽管它们的实现方式不同。如果你想探索其他语言来完成类似的任务,我强烈建议你看看 [Rosetta Code](http://www.rosettacode.org/)。这是一个了不起的资源,可以看到如何用多种语言解决同样的问题。
你喜欢用什么语言绘制数据?在评论中分享你的想法。
---
via: <https://opensource.com/article/20/2/python-gnu-octave-data-science>
作者:[Cristiano L. Fontana](https://opensource.com/users/cristianofontana) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Data science is a domain of knowledge that spans programming languages. Some are well-known for solving problems in this space, while others are lesser-known. This article will help you become familiar with doing data science with some popular languages.
## Choosing Python and GNU Octave for data science
Every so often, I try to learn a new programming language. Why? It is mostly a combination of boredom with the old ways and curiosity about the new ways. When I started programming, the only language I knew was C. Life was hard and dangerous in those years, as I had to manually allocate memory, manage pointers, and remember to free memory.
Then a friend suggested I try Python, and life became much easier. Programs became much slower, but I did not have to suffer through writing analysis software. However, I soon realized that each language was more suitable than others for some applications. I later studied some other languages, and each one brought some new bit of enlightenment. Discovering new programming styles let me backport some solutions to other languages, and everything became much more interesting.
To get a feeling for a new programming language (and its documentation), I always start by writing some example programs that perform a task I know well. To that ends, I will explain how to write a program in Python and GNU Octave for a particular task you could classify as data science. If you are already familiar with one of the languages, start with that one and go through the others to look for similarities and differences. It is not intended to be an exhaustive comparison of the languages, just a little showcase.
All of the programs are meant to be run on the [command line](https://en.wikipedia.org/wiki/Command-line_interface), not with a [graphical user interface](https://en.wikipedia.org/wiki/Graphical_user_interface) (GUI). The full examples are available in the [polyglot_fit repository](https://gitlab.com/cristiano.fontana/polyglot_fit).
## The programming task
The program you will write in this series:
- Reads data from a
[CSV file](https://en.wikipedia.org/wiki/Comma-separated_values) - Interpolates the data with a straight line (i.e.,
*f(x)=m ⋅ x + q*) - Plots the result to an image file
This is a common situation that many data scientists have encountered. The example data is the first set of [Anscombe's quartet](https://en.wikipedia.org/wiki/Anscombe%27s_quartet), shown in the table below. This is a set of artificially constructed data that gives the same results when fitted with a straight line, but their plots are very different. The data file is a text file with tabs as column separators and a few lines as a header. This task will use only the first set (i.e., the first two columns).
I | II | III | IV | ||||
---|---|---|---|---|---|---|---|
x | y | x | y | x | y | x | y |
10.0 | 8.04 | 10.0 | 9.14 | 10.0 | 7.46 | 8.0 | 6.58 |
8.0 | 6.95 | 8.0 | 8.14 | 8.0 | 6.77 | 8.0 | 5.76 |
13.0 | 7.58 | 13.0 | 8.74 | 13.0 | 12.74 | 8.0 | 7.71 |
9.0 | 8.81 | 9.0 | 8.77 | 9.0 | 7.11 | 8.0 | 8.84 |
11.0 | 8.33 | 11.0 | 9.26 | 11.0 | 7.81 | 8.0 | 8.47 |
14.0 | 9.96 | 14.0 | 8.10 | 14.0 | 8.84 | 8.0 | 7.04 |
6.0 | 7.24 | 6.0 | 6.13 | 6.0 | 6.08 | 8.0 | 5.25 |
4.0 | 4.26 | 4.0 | 3.10 | 4.0 | 5.39 | 19.0 | 12.50 |
12.0 | 10.84 | 12.0 | 9.13 | 12.0 | 8.15 | 8.0 | 5.56 |
7.0 | 4.82 | 7.0 | 7.26 | 7.0 | 6.42 | 8.0 | 7.91 |
5.0 | 5.68 | 5.0 | 4.74 | 5.0 | 5.73 | 8.0 | 6.89 |
## The Python way
[Python](https://www.python.org/) is a general-purpose programming language that is among the most popular languages in use today (as evidenced by findings from the [TIOBE index](https://www.tiobe.com/tiobe-index/), [RedMonk Programming Language Rankings](https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/), [Popularity of Programming Language Index](http://pypl.github.io/PYPL.html), [State of the Octoverse of GitHub](https://octoverse.github.com/), and other sources). It is an [interpreted language](https://en.wikipedia.org/wiki/Interpreted_language); therefore, the source code is read and evaluated by a program that executes the instructions. It has a comprehensive [standard library](https://docs.python.org/3/library/) and is generally very pleasant to use (I have no reference for this last statement; it is just my humble opinion).
### Installation
To develop with Python, you need the interpreter and a few libraries. The minimum requirements are:
[NumPy](https://numpy.org/)for convenient array and matrices manipulation[SciPy](https://www.scipy.org/)for scientific calculations[Matplotlib](https://matplotlib.org/)for plotting
Installing them in [Fedora](https://getfedora.org/) is easy:
`sudo dnf install python3 python3-numpy python3-scipy python3-matplotlib`
### Commenting code
In Python, [comments](https://en.wikipedia.org/wiki/Comment_(computer_programming)) are achieved by putting a **#** at the beginning of the line, and the rest of the line will be discarded by the interpreter:
`# This is a comment ignored by the interpreter.`
The [fitting_python.py](https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_python.py) example uses comments to insert licensing information in the source code, and the first line is a [special comment](https://en.wikipedia.org/wiki/Shebang_(Unix)) that enables the script to be executed on the command line:
`#! /usr/bin/env python3`
This line informs the command-line interpreter that the script needs to be executed by the program **python3**.
### Required libraries
Libraries and modules can be imported in Python as an object (as in the first line in the example) with all the functions and members of the library. There is a convenient option to rename them with a custom label by using the **as** specification:
```
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
```
You may also decide to import only a submodule (as in the second and third lines). The syntax has two (more or less) equivalent options: **import module.submodule** and **from module import submodule**.
### Defining variables
Python's variables are declared the first time a value is assigned to them:
```
input_file_name = "anscombe.csv"
delimiter = "\t"
skip_header = 3
column_x = 0
column_y = 1
```
The variable types are inferred by the value that is assigned to the variable. There are no variables with constant values unless they are declared in a module and can only be read. Idiomatically, variables that should not be modified should be named in uppercase.
### Printing output
Running the programs through the command line means that the output is just printed on the terminal. Python has the [ print()](https://docs.python.org/3/library/functions.html#print) function that, by default, prints its argument and adds a newline at the end of the output:
`print("#### Anscombe's first set with Python ####")`
It is possible to combine the **print()** function with the [formatting power](https://docs.python.org/3/library/string.html#string-formatting) of the [string class](https://docs.python.org/3/library/string.html) in Python. Strings have the **format** method that can be used to add some formatted text to the string itself. For instance, it is possible to add a formatted float number, e.g.:
`print("Slope: {:f}".format(slope))`
### Reading data
Reading CSV files is very easy with NumPy and the function [ genfromtxt()](https://docs.scipy.org/doc/numpy/reference/generated/numpy.genfromtxt.html), which generates a
[NumPy array](https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html):
`data = np.genfromtxt(input_file_name, delimiter = delimiter, skip_header = skip_header)`
In Python, a function can have a variable number of arguments, and you can have it pass a subset by specifying the desired ones. Arrays are very powerful matrix-like objects that can be easily sliced into smaller arrays:
```
x = data[:, column_x]
y = data[:, column_y]
```
The colons select the whole range, and they can also be used to select a subrange. For instance, to select the first two rows of the array, you would use:
`first_two_rows = data[0:1, :]`
### Fitting data
SciPy provides convenient functions for data fitting, such as the [ linregress()](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.linregress.html) function. This function provides some significant values related to the fit, such as the slope, intercept, and the correlation coefficient of the two datasets:
```
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
print("Slope: {:f}".format(slope))
print("Intercept: {:f}".format(intercept))
print("Correlation coefficient: {:f}".format(r_value))
```
Since **linregress()** provides several pieces of information, the result can be saved to several variables at the same time.
### Plotting
The Matplotlib library plots only data points; therefore, you should define the points you want to plot. The **x** and **y** arrays were already defined, so you can directly plot them, but you also need data points that will represent the straight line.
`fit_x = np.linspace(x.min() - 1, x.max() + 1, 100)`
The [ linspace()](https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html) function conveniently generates a set of equally spaced values between two values. The ordinates can be easily calculated by exploiting the powerful NumPy arrays, which can be used in a formula as if they were ordinary numeric variables:
`fit_y = slope * fit_x + intercept`
The formula is applied element-by-element on the array; therefore, the result has the same number of entries in the initial array.
To create the plot, first, define a [figure object](https://matplotlib.org/api/_as_gen/matplotlib.figure.Figure.html#matplotlib.figure.Figure) that will contain all the graphics:
```
fig_width = 7 #inch
fig_height = fig_width / 16 * 9 #inch
fig_dpi = 100
fig = plt.figure(figsize = (fig_width, fig_height), dpi = fig_dpi)
```
Several plots can be drawn on a figure; in Matplotlib, the plots are called [axes](https://matplotlib.org/api/axes_api.html#matplotlib.axes.Axes). This example defines a single axis object to plot the data points:
```
ax = fig.add_subplot(111)
ax.plot(fit_x, fit_y, label = "Fit", linestyle = '-')
ax.plot(x, y, label = "Data", marker = '.', linestyle = '')
ax.legend()
ax.set_xlim(min(x) - 1, max(x) + 1)
ax.set_ylim(min(y) - 1, max(y) + 1)
ax.set_xlabel('x')
ax.set_ylabel('y')
```
Save the figure to a [PNG image file](https://en.wikipedia.org/wiki/Portable_Network_Graphics) with:
`fig.savefig('fit_python.png')`
If you want to display (instead of saving) the plot, call:
`plt.show()`
This example references all the objects used in the plotting section: it defines the object **fig** and the object **ax**. This technicality is not necessary, as the **plt** object can be used directly to plot the datasets. The [Matplotlib tutorial](https://matplotlib.org/tutorials/introductory/pyplot.html#sphx-glr-tutorials-introductory-pyplot-py) shows an interface such as:
`plt.plot(fit_x, fit_y)`
Frankly, I do not like this approach because it hides the non-trivial interactions that happen between the various objects. Unfortunately, sometimes the [official examples](https://matplotlib.org/gallery/index.html) are a bit confusing because they tend to use different approaches. Referencing graphical objects is not necessary in this simple example, but it becomes important in more complex ones (such as when embedding plots in GUIs).
### Results
The output on the command line is:
```
#### Anscombe's first set with Python ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421
```
Here is the image Matplotlib generates.
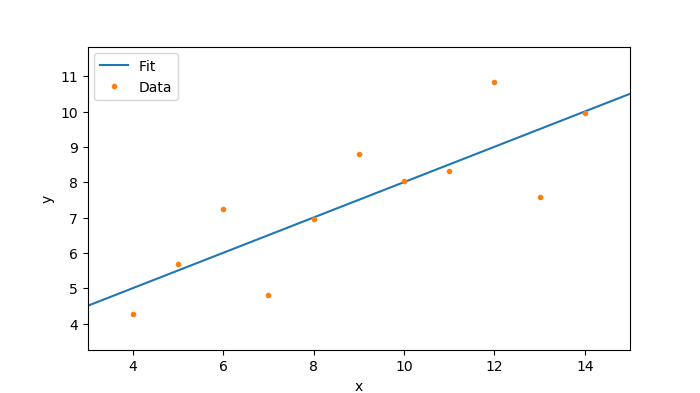
## The GNU Octave way
The [GNU Octave](https://www.gnu.org/software/octave/) language is primarily intended for numerical computations. It offers a simple syntax for manipulating vectors and matrices and has some powerful plotting facilities. It is an interpreted language like Python. Since Octave's syntax is [mostly compatible](https://wiki.octave.org/FAQ#Differences_between_Octave_and_Matlab) with [MATLAB](https://en.wikipedia.org/wiki/MATLAB), it is often described as a free alternative to MATLAB. Octave is not listed among the most popular programming languages, but MATLAB is, so Octave is rather popular in a sense. MATLAB predates NumPy, and I have the feeling that it was inspired by the former. While you go through the example, you will see the analogies.
### Installation
The [fitting_octave.m](https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_octave.m) example only needs the basic Octave package, making the installation in Fedora rather simple:
`sudo dnf install octave`
### Commenting code
In Octave, you can add comments to code with the percent symbol (**%**), and you can also use **#** if MATLAB compatibility is not needed. The option to use **#** allows you to write the same special comment line from the Python example to execute the script directly on the command line.
### Necessary libraries
Everything used in this example is contained in the basic package, so you do not need to load any new libraries. If you need a library, the [syntax](https://octave.org/doc/v5.1.0/Using-Packages.html#Using-Packages) is **pkg load module**. This command adds the module's functions to the list of available functions. In this regard, Python has more flexibility.
### Defining variables
Variables are defined with pretty much the same syntax as Python:
```
input_file_name = "anscombe.csv";
delimiter = "\t";
skip_header = 3;
column_x = 1;
column_y = 2;
```
Note that the end of the line has a semicolon; this is not necessary, but it suppresses the output of the results of the line. Without a semicolon, the interpreter would print the result of the expression:
```
octave:1> input_file_name = "anscombe.csv"
input_file_name = anscombe.csv
octave:2> sqrt(2)
ans = 1.4142
```
### Printing output
The powerful function [ printf()](https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFprintf) is used to print on the terminal. Unlike in Python, the
**printf()**function does not automatically add a newline at the end of the printed string, so you have to add it. The first argument is a string that can contain format information for the other arguments to be passed to the function, such as:
`printf("Slope: %f\n", slope);`
In Python, the formatting is built into the string itself, but in Octave, it is specific to the **printf()** function.
### Reading data
The [ dlmread()](https://octave.org/doc/v5.1.0/Simple-File-I_002fO.html#XREFdlmread) function can read text files structured like CSV files:
`data = dlmread(input_file_name, delimiter, skip_header, 0);`
The result is a [matrix](https://octave.org/doc/v5.1.0/Matrices.html) object, which is one of the fundamental data types in Octave. Matrices may be sliced with a syntax similar to Python:
```
x = data(:, column_x);
y = data(:, column_y);
```
The fundamental difference is that the indexes start at one instead of zero. Therefore, in the example, the
*x* column is column number one.
### Fitting data
To fit the data with a straight line, you can use the [ polyfit()](https://octave.org/doc/v5.1.0/Polynomial-Interpolation.html) function. It fits the input data with a polynomial, so you just need to use a polynomial of order one:
```
p = polyfit(x, y, 1);
slope = p(1);
intercept = p(2);
```
The result is a matrix with the polynomial coefficients; therefore, it selects the first two indexes. To determine the correlation coefficient, use the [ corr()](https://octave.org/doc/v5.1.0/Correlation-and-Regression-Analysis.html#XREFcorr) function:
`r_value = corr(x, y);`
Finally, print the results with the **printf()** function:
```
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);
```
### Plotting
As in the Matplotlib example, you first need to create a dataset that represents the fitted line:
```
fit_x = linspace(min(x) - 1, max(x) + 1, 100);
fit_y = slope * fit_x + intercept;
```
The analogy with NumPy is also evident here, as it uses the [ linspace()](https://octave.sourceforge.io/octave/function/linspace.html) function that behaves just like the Python's equivalent version.
Again, as with Matplotlib, create a [figure](https://octave.org/doc/v5.1.0/Multiple-Plot-Windows.html) object first, then create an [axes](https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFaxes) object to hold the plots:
```
fig_width = 7; %inch
fig_height = fig_width / 16 * 9; %inch
fig_dpi = 100;
fig = figure("units", "inches",
"position", [1, 1, fig_width, fig_height]);
ax = axes("parent", fig);
set(ax, "fontsize", 14);
set(ax, "linewidth", 2);
```
To set properties of the axes object, use the [ set()](https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFset) function. The interface is rather confusing, though, as the function expects a comma-separated list of property and value pairs. These pairs are just a succession of a string representing the property name and a second object representing the value for that property. There are also other functions to set various properties:
```
xlim(ax, [min(x) - 1, max(x) + 1]);
ylim(ax, [min(y) - 1, max(y) + 1]);
xlabel(ax, 'x');
ylabel(ax, 'y');
```
Plotting is achieved with the [ plot()](https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#XREFplot) function. The default behavior is that each call resets the axes, so you need to use the function
[.](https://octave.org/doc/v5.1.0/Manipulation-of-Plot-Windows.html#XREFhold)
**hold()**```
hold(ax, "on");
plot(ax, fit_x, fit_y,
"marker", "none",
"linestyle", "-",
"linewidth", 2);
plot(ax, x, y,
"marker", ".",
"markersize", 20,
"linestyle", "none");
hold(ax, "off");
```
Also, it is possible in the **plot()** function to add the property and value pairs. The [legend](https://octave.org/doc/v5.1.0/Plot-Annotations.html#XREFlegend) must be created separately, and the labels should be stated manually:
```
lg = legend(ax, "Fit", "Data");
set(lg, "location", "northwest");
```
Finally, save the output to a PNG image:
```
image_size = sprintf("-S%f,%f", fig_width * fig_dpi, fig_height * fig_dpi);
image_resolution = sprintf("-r%f,%f", fig_dpi);
print(fig, 'fit_octave.png',
'-dpng',
image_size,
image_resolution);
```
Confusingly, in this case, the options are passed as a single string with the property name and the value. Since in Octave strings do not have the formatting facilities of Python, you must use the [ sprintf()](https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFsprintf) function. It behaves just like the
**printf()**function, but its result is not printed, rather it is returned as a string.
In this example, as in the Python one, the graphical objects are referenced to keep their interactions evident. If Python's documentation in this regard is a little bit confusing, [Octave's documentation](https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#Two_002dDimensional-Plots) is even worse. Most of the examples I found did not care about referencing the objects; instead, they rely on the fact that the plotting commands act on the currently active figure. A global [root graphics object](https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFgroot) keeps track of the existing figures and axes.
### Results
The resulting output on the command line is:
```
#### Anscombe's first set with Octave ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421
```
And this shows the resulting image generated with Octave.
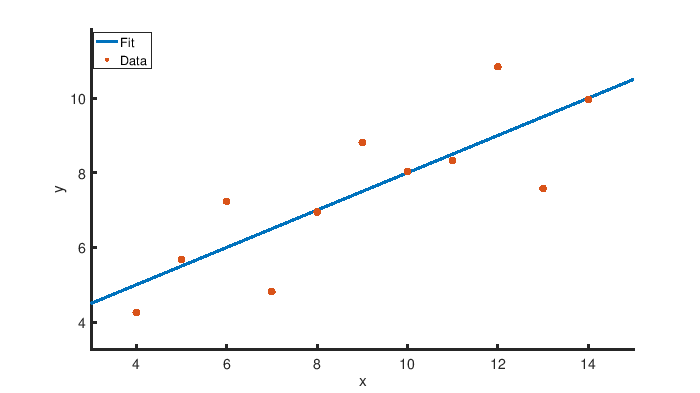
## Next up
Both Python and GNU Octave can plot the same information, though they differ in how they get there. If you're looking to explore other languages to complete similar tasks, I highly recommend looking at [Rosetta Code](http://www.rosettacode.org/). It's a marvelous resource to see how to solve the same problems in many languages.
What language do you like to plot data in? Share your thoughts in the comments.
## 2 Comments |
11,944 | 如何使用 byobu 复用 SSH 会话 | https://opensource.com/article/20/2/byobu-ssh | 2020-02-29T12:50:50 | [
"SSH"
] | https://linux.cn/article-11944-1.html |
>
> Byobu 能让你在保持会话活跃的情况下维护多个终端窗口,通过 SSH 连接、断开、重连以及共享访问。
>
>
>
[Byobu](https://byobu.org/) 是基于文本的窗口管理器和终端多路复用器。它类似于 [GNU Screen](http://www.gnu.org/software/screen/),但更现代、更直观。它还适用于大多数 Linux、BSD 和 Mac 发行版。
Byobu 能让你在保持会话活跃的情况下维护多个终端窗口、通过 SSH(secure shell)连接、断开、重连,甚至让其他人访问。
比如,你 SSH 进入树莓派或服务器,并运行(比如) `sudo apt update && sudo apt upgrade`,然后你在它运行的时候失去了互联网连接,你的命令会丢失无效。然而,如果你首先启动 byobu 会话,那么它会继续运行,在你重连后,你会发现它仍在继续运行。

Byobu 名称来自于日语的装饰性多面板屏风,它可作为折叠式隔断,我认为这很合适。
要在 Debian/Raspbian/Ubuntu 上安装 byobu:
```
sudo apt install byobu
```
接着启用它:
```
byobu-enable
```
现在,请退出 SSH 会话并重新登录,你将会在 byobu 会话中登录。运行类似 `sudo apt update` 命令并关闭窗口(或输入转义序列([Enter + ~ + .](https://www.google.com/search?client=ubuntu&channel=fs&q=Enter-tilde-dot&ie=utf-8&oe=utf-8))并重新登录。你将看到更新命令在你离开后还在运行。
有*很多*我不常使用的功能。我通常使用的是:
* `F2` – 新窗口
* `F3/F4` – 在窗口间导航
* `Ctrl`+`F2` – 垂直拆分窗格
* `Shift`+`F2` – 水平拆分窗格
* `Shift`+`左箭头/Shift`+`右箭头` – 在拆分窗格间导航
* `Shift`+`F11` – 放大(或缩小)拆分窗格
### 我们如何使用 byobu
Byobu 对于维护 [piwheels](https://opensource.com/article/20/1/piwheels)(一个用于树莓派的方便的,预编译 Python 包)很好用。我水平拆分了窗格,在上半部分显示了 piwheels 监视器,在下半部分实时显示了 syslog 条目。接着,如果我们想要做其他事情,我们可以切换到另外一个窗口。当我们进行协作分析时,这特别方便,因为当我在 IRC 中聊天时,我可以看到我的同事 Dave 输入了什么(并纠正他的错字)。
我在家庭和办公服务器上启用了 byobu,因此,当我登录到任何一台计算机时,一切都与我离开时一样。它正在运行多个作业、在特定目录中保留一个窗口,以另一个用户身份运行进程等。

Byobu 对于在树莓派上进行开发也很方便。你可以在桌面上启动它,运行命令,然后 SSH 进入,并连接到该命令运行所在的会话。请注意,启用 byobu 不会更改终端启动器的功能。只需运行 `byobu` 即可启动它。
本文最初发表在 Ben Nuttall 的 [Tooling blog](https://tooling.bennuttall.com/byobu/) 中,并获许重用。
---
via: <https://opensource.com/article/20/2/byobu-ssh>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Byobu](https://byobu.org/) is a text-based window manager and terminal multiplexer. It's similar to [GNU Screen](http://www.gnu.org/software/screen/) but more modern and more intuitive. It also works on most Linux, BSD, and Mac distributions.
Byobu allows you to maintain multiple terminal windows, connect via SSH (secure shell), disconnect, reconnect, and even let other people access it, all while keeping the session alive.
For example, if you are SSH'd into a Raspberry Pi or server and run (for example) **sudo apt update && sudo apt upgrade**—and lose your internet connection while it is running, your command will be lost to the void. However, if you start a byobu session first, it will continue running and, when you reconnect, you will find it's been running happily without your eyes on it.
Byobu is named for a Japanese term for decorative, multi-panel screens that serve as folding room dividers, which I think is quite fitting.
To install byobu on Debian/Raspbian/Ubuntu:
**sudo apt install byobu**
Then enable it:
**byobu-enable**
Now drop out of your SSH session and log back in—you'll land in a byobu session. Run a command like **sudo apt update** and close the window (or enter the escape sequence ([ Enter+~+.](https://www.google.com/search?client=ubuntu&channel=fs&q=Enter-tilde-dot&ie=utf-8&oe=utf-8)) and log back in. You'll see the update running just as you left it.
There are a *lot* of features I don't use regularly or at all. The most common ones I use are:
**F2**– New window**F3/F4**– Navigate between windows**Ctrl**+**F2**– Split pane vertically**Shift**+**F2**– Split pane horizontally**Shift**+**Left arrow/Shift**+**Right arrow**– Navigate between splits**Shift**+**F11**– Zoom in (or out) on a split
You can learn more by watching this video:
## How we're using byobu
Byobu has been great for the maintenance of [piwheels](https://opensource.com/article/20/1/piwheels), the convenient, pre-compiled Python packages for Raspberry Pi. We have a horizontal split showing the piwheels monitor in the top half and the syslog entries scrolled in real time on the bottom half. Then, if we want to do something else, we switch to another window. It's particularly handy when we're investigating something collaboratively, as I can see what my colleague Dave types (and correct his typos) while we chat in IRC.
I have byobu enabled on my home and work servers, so when I log into either machine, everything is as I left it—multiple jobs running, a window left in a particular directory, running a process as another user, that kind of thing.
Byobu is handy for development on Raspberry Pis, too. You can launch it on the desktop, run a command, then SSH in and attach yourself to the session where that command is running. Just note that enabling byobu won't change what the terminal launcher does. Just run **byobu** to launch it.
*This article originally appeared on Ben Nuttall's Tooling blog and is reused with permission.*
## 2 Comments |
11,946 | 如何在 Linux 中编辑字幕 | https://itsfoss.com/editing-subtitles | 2020-03-01T11:33:00 | [
"字幕"
] | https://linux.cn/article-11946-1.html | 我作为一位世界电影和地区电影爱好者已经几十年了。这期间字幕是一个必不可少的工具,它可以使我享受来自不同国家不同语言的优秀电影。
如果你喜欢观看带有字幕的电影,你可能会注意到有时字幕并不同步或者说并不正确。
你知道你可以自己编写字幕并使得它们更完美吗?让我们向你展示一些 Linux 中的基本字幕编辑吧。

### 从闭路字幕数据中提取字幕
大概在 2012、2013 年我开始了解到有一款叫做 [CCEextractor](https://www.ccextractor.org/) 的工具。随着时间的推移,它已经成为我必不可少的工具之一,尤其是当我偶然发现一份内含有字幕的媒体文件。
CCExtractor 负责解析视频文件以及从<ruby> 闭路字幕 <rt> closed captions </rt></ruby>数据中产生独立的字幕文件。
CCExtractor 是一个跨平台的、自由开源工具。自它形成的那年起该工具已经成熟了不少而如今已成为 [GSOC](https://itsfoss.com/best-open-source-internships/) 和谷歌编码输入的一部分。
简单来说,这个工具基本上是一系列脚本,这些脚本以一种顺序方式一个接着一个地给你提供提取到的字幕。
你可以按照[本页](https://github.com/CCExtractor/ccextractor/wiki/Installation)的 CCExtractor 安装指南进行操作。
若安装后你想从媒体文件中提取字幕,请按以下步骤操作:
```
ccextractor <path_to_video_file>
```
该命令将会输出以下内容:
```
$ ccextractor $something.mkv
CCExtractor 0.87, Carlos Fernandez Sanz, Volker Quetschke.
Teletext portions taken from Petr Kutalek's telxcc
--------------------------------------------------------------------------
Input: $something.mkv
[Extract: 1] [Stream mode: Autodetect]
[Program : Auto ] [Hauppage mode: No] [Use MythTV code: Auto]
[Timing mode: Auto] [Debug: No] [Buffer input: No]
[Use pic_order_cnt_lsb for H.264: No] [Print CC decoder traces: No]
[Target format: .srt] [Encoding: UTF-8] [Delay: 0] [Trim lines: No]
[Add font color data: Yes] [Add font typesetting: Yes]
[Convert case: No] [Video-edit join: No]
[Extraction start time: not set (from start)]
[Extraction end time: not set (to end)]
[Live stream: No] [Clock frequency: 90000]
[Teletext page: Autodetect]
[Start credits text: None]
[Quantisation-mode: CCExtractor's internal function]
-----------------------------------------------------------------
Opening file: $something.mkv
File seems to be a Matroska/WebM container
Analyzing data in Matroska mode
Document type: matroska
Timecode scale: 1000000
Muxing app: libebml v1.3.1 + libmatroska v1.4.2
Writing app: mkvmerge v8.2.0 ('World of Adventure') 64bit
Title: $something
Track entry:
Track number: 1
UID: 1
Type: video
Codec ID: V_MPEG4/ISO/AVC
Language: mal
Name: $something
Track entry:
Track number: 2
UID: 2
Type: audio
Codec ID: A_MPEG/L3
Language: mal
Name: $something
Track entry:
Track number: 3
UID: somenumber
Type: subtitle
Codec ID: S_TEXT/UTF8
Name: $something
99% | 144:34
100% | 144:34
Output file: $something_eng.srt
Done, processing time = 6 seconds
Issues? Open a ticket here
https://github.com/CCExtractor/ccextractor/issues
```
它会大致浏览媒体文件。在这个例子中,它发现该媒体文件是马拉雅拉姆语言(mal)并且格式是 [.mkv](https://en.wikipedia.org/wiki/Matroska)。之后它将字幕文件提取出来,命名为源文件名并添加“\_eng”后缀。
CCExtractor 是一款用来增强字幕功能和字幕编辑的优秀工具,我将在下一部分对它进行介绍。
>
> 趣味阅读:在 [vicaps](https://www.vicaps.com/blog/history-of-silent-movies-and-subtitles/) 有一份有趣的字幕提要,它讲解和分享为何字幕对我们如此重要。对于那些对这类话题感兴趣的人来说,这里面也有许多电影制作的细节。
>
>
>
### 用 SubtitleEditor 工具编辑字幕
你大概意识到大多数的字幕都是 [.srt 格式](https://en.wikipedia.org/wiki/SubRip#SubRip_text_file_format) 的。这种格式的优点在于你可以将它加载到文本编辑器中并对它进行少量的修改。
当进入一个简单的文本编辑器时,一个 srt 文件看起来会是这个样子:
```
1
00:00:00,959 --> 00:00:13,744
"THE CABINET
OF DR. CALIGARI"
2
00:00:40,084 --> 00:01:02,088
A TALE of the modern re-appearance of an 11th Century Myth
involting the strange and mysterious influence
of a mountebank monk over a somnambulist.
```
我分享的节选字幕来自于一部非常老的德国电影《[卡里加里博士的小屋](https://www.imdb.com/title/tt0010323/)》(1920)。
Subtitleeditor 是一款非常棒的字幕编辑软件。字幕编辑器可以用来设置字幕持续时间、与多媒体文件同步的字幕帧率以及字幕间隔时间等等。接下来我将在这分享一些基本的字幕编辑。

首先,以安装 ccextractor 工具同样的方式安装 subtitleeditor 工具,使用你自己喜爱的安装方式。在 Debian 中,你可以使用命令:
```
sudo apt install subtitleeditor
```
当你安装完成后,让我们来看一下在你编辑字幕时一些常见的场景。
#### 调整帧率使其媒体文件同步
如果你发现字幕与视频不同步,一个原因可能是视频文件的帧率与字幕文件的帧率并不一致。
你如何得知这些文件的帧率呢,然后呢?为了获取视频文件的帧率,你可以使用 `mediainfo` 工具。首先你可能需要发行版的包管理器来安装它。
使用 `mediainfo` 非常简单:
```
$ mediainfo somefile.mkv | grep Frame
Format settings : CABAC / 4 Ref Frames
Format settings, ReFrames : 4 frames
Frame rate mode : Constant
Frame rate : 25.000 FPS
Bits/(Pixel*Frame) : 0.082
Frame rate : 46.875 FPS (1024 SPF)
```
现在你可以看到视频文件的帧率是 25.000 FPS 。我们看到的另一个帧率则是音频文件的帧率。虽然我可以分享为何在视频解码和音频解码等地方会使用特定的 fps,但这将会是一个不同的主题,与它相关的历史信息有很多。
下一个问题是解决字幕文件的帧率,这个稍微有点复杂。
通常情况下,大多数字幕都是压缩格式的。将.zip 归档文件和字幕文件(以 XXX.srt 结尾)一起解压缩。除此之外,通常还会有一个同名的 .info 文件,该文件可能包含字幕的帧率。
如果不是,那么通常最好去某个站点并从具有该帧速率信息的站点下载字幕。对于这个特定的德文文件,我使用 [Opensubtitle.org](https://www.opensubtitles.org/en/search/sublanguageid-eng/idmovie-4105) 来找到它。
正如你在链接中所看到的,字幕的帧率是 23.976 FPS 。很明显,它不能与帧率为 25.000 FPS 的视频文件一起很好地播放。
在这种情况下,你可以使用字幕编辑工具来改变字幕文件的帧率。
按下 `CTRL+A` 选择字幕文件中的全部内容。点击 “Timings -> Change Framerate” ,将 23.976 fps 改为 25.000 fps 或者你想要的其他帧率,保存已更改的文件。

#### 改变字幕文件的起点
有时以上的方法就足够解决问题了,但有时候以上方法并不足够解决问题。
在帧率相同时,你可能会发现字幕文件的开头与电影或媒体文件中起点并不相同。
在这种情况下,请按以下步骤进行操作:
按下 `CTRL+A` 键选中字幕文件的全部内容。点击 “Timings -> Select Move Subtitle” 。

设定字幕文件的新起点,保存已更改的文件。

如果你想要时间更精确一点,那么可以使用 [mpv](https://itsfoss.com/mpv-video-player/) 来查看电影或者媒体文件并点击进度条(可以显示电影或者媒体文件的播放进度),它也会显示微秒。
通常我喜欢精准无误的操作,因此我会试着尽可能地仔细调节。相较于人类的反应时间来说,MPV 中的反应时间很精确。如果我想要极其精确的时间,那么我可以使用像 [Audacity](https://www.audacityteam.org/) 之类的东西,但是那是另一种工具,你可以在上面做更多的事情。那也将会是我未来博客中将要探讨的东西。
#### 调整字幕间隔时间
有时,两种方法都采用了还不够,甚至你可能需要缩短或增加间隔时间以使其与媒体文件同步。这是较为繁琐的工作之一,因为你必须单独确定每个句子的间隔时间。尤其是在媒体文件中帧率可变的情况下(现已很少见,但你仍然会得到此类文件)
在这种设想下,你可能因为无法实现自动编辑而不得不手动的修改间隔时间。最好的方式是修改视频文件(会降低视频质量)或者换另一个更高质量的片源,用你喜欢的设置对它进行[转码](https://en.wikipedia.org/wiki/Transcoding) 。这又是一重大任务,以后我会在我的一些博客文章上阐明。
### 总结
以上我分享的内容或多或少是对现有字幕文件的改进。如果从头开始,你需要花费大量的时间。我完全没有分享这一点,因为一部电影或一个小时内的任何视频材料都可以轻易地花费 4-6 个小时,甚至更多的时间,这取决于字幕员的技巧、耐心、上下文、行话、口音、是否是以英语为母语的人、翻译等,所有的这些都会对字幕的质量产生影响。
我希望自此以后你会觉得这件事很有趣,并将你的字幕处理的更好一点。如果你有其他想要补充的问题,请在下方留言。
---
via: <https://itsfoss.com/editing-subtitles>
作者:[Shirish](https://itsfoss.com/author/shirish/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,947 | SSH 密钥管理工具 | https://opensource.com/article/20/2/ssh-tools | 2020-03-01T12:23:55 | [
"SSH"
] | https://linux.cn/article-11947-1.html |
>
> 常用开源工具的省时快捷方式。
>
>
>

我经常使用 SSH。我发现自己每天都要登录多个服务器和树莓派(与我位于同一房间,并接入互联网)。我有许多设备需要访问,并且获得访问权限的要求也不同,因此,除了使用各种 `ssh` / `scp` 命令选项之外,我还必须维护一个包含所有连接详细信息的配置文件。
随着时间的推移,我发现了一些省时的技巧和工具,你可能也会发现它们有用。
### SSH 密钥
SSH 密钥是一种在不使用密码的情况下认证 SSH 连接的方法,可以用来加快访问速度或作为一种安全措施(如果你关闭了密码访问权限并确保仅允许授权的密钥)。要创建 SSH 密钥,请运行以下命令:
```
$ ssh-keygen
```
这将在 `~/.ssh/` 中创建一个密钥对(公钥和私钥)。将私钥(`id_rsa`)保留在 PC 上,切勿共享。你可以与其他人共享公钥(`id_rsa.pub`)或将其放置在其他服务器上。
### ssh-copy-id
如果我在家中或公司工作时使用树莓派,则倾向于将 SSH 设置保留为默认设置,因为我不担心内部信任网络上的安全性,并且通常将 SSH 密钥(公钥)复制到树莓派上,以避免每次都使用密码进行身份验证。为此,我使用 `ssh-copy-id` 命令将其复制到树莓派。这会自动将你的密钥(公钥)添加到树莓派:
```
$ ssh-copy-id [email protected]
```
在生产服务器上,我倾向于关闭密码身份验证,仅允许授权的 SSH 密钥登录。
### ssh-import-id
另一个类似的工具是 `ssh-import-id`。你可以使用此方法通过从 GitHub 导入密钥来授予你自己(或其他人)对计算机或服务器的访问权限。例如,我已经在我的 GitHub 帐户中注册了各个 SSH 密钥,因此无需密码即可推送到 GitHub。这些公钥是有效的,因此 `ssh-import-id` 可以使用它们在我的任何计算机上授权我:
```
$ ssh-import-id gh:bennuttall
```
我还可以使用它来授予其他人访问服务器的权限,而无需询问他们的密钥:
```
$ ssh-import-id gh:waveform80
```
### storm
我还使用了名为 Storm 的工具,该工具可帮助你将 SSH 连接添加到 SSH 配置中,因此你不必记住这些连接细节信息。你可以使用 `pip` 安装它:
```
$ sudo pip3 install stormssh
```
然后,你可以使用以下命令将 SSH 连接信息添加到配置中:
```
$ storm add pi3 [email protected]
```
然后,你可以只使用 `ssh pi3` 来获得访问权限。类似的还有 `scp file.txt pi3:` 或 `sshfs pi pi3:`。
你还可以使用更多的 SSH 选项,例如端口号:
```
$ storm add pi3 [email protected]:2000
```
你可以参考 Storm 的[文档](https://stormssh.readthedocs.io/en/stable/usage.html)轻松列出、搜索和编辑已保存的连接。Storm 实际所做的只是管理 SSH 配置文件 `~/.ssh/config` 中的项目。一旦了解了它们是如何存储的,你就可以选择手动编辑它们。配置中的示例连接如下所示:
```
Host pi3
user pi
hostname 192.168.1.20
port 22
```
### 结论
从树莓派到大型的云基础设施,SSH 是系统管理的重要工具。熟悉密钥管理会很方便。你还有其他 SSH 技巧要添加吗?我希望你在评论中分享他们。
---
via: <https://opensource.com/article/20/2/ssh-tools>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I use SSH constantly. Every day I find myself logged in to multiple servers and Pis (both in the same room as me and over the internet). I have many devices I need access to, and different requirements for gaining access, so in addition to using various SSH/SCP command options, I have to maintain a config file with all the connection details.
Over time I’ve come up with a few time-saving tips and tools that you might find useful, too.
## SSH keys
SSH keys are a way to authenticate SSH connections without using a password, either to speed up your access or as a security measure, if you turn password access off and ensure only authorized keys are permitted. To create an SSH key, run the command:
`$ ssh-keygen`
This will create a key-pair (a public and private key) in **~/.ssh/**. Keep the private key (id_rsa) on the PC and never share it. You can share the public key (id_rsa.pub) with others or place it on other servers.
## ssh-copy-id
If I’m working on a Pi at home or work, I tend to leave SSH settings at their default, as I’m not concerned with security on an internal trusted network, and I usually copy my SSH key to the Pi to avoid having to authenticate with a password every time. To do this, I use the **ssh-copy-id** command to copy it to the Pi. This automatically adds your key to the Pi:
`$ ssh-copy-id [email protected]`
On production servers, I tend to turn off password authentication and only allow authorized SSH keys.
## ssh-import-id
Another similar tool is ssh-import-id. You can use this to give yourself (or others) access to a computer or server by importing their keys from GitHub. For example, I have registered my various SSH keys with my GitHub account, so I can push to GitHub without a password. These public keys are made available, so ssh-import-id can use them to authorize me from any of my computers:
`$ ssh-import-id gh:bennuttall`
I can also use this to give someone else access to a server without asking them for their keys:
`$ ssh-import-id gh:waveform80`
## storm
I also use a tool called Storm, which helps you add SSH connections to your SSH config, so you don’t have to remember them all. You can install it with pip:
`$ sudo pip3 install stormssh`
Then you can add an SSH connection to your config with the following command:
`$ storm add pi3 [email protected]`
Then you can just use **ssh pi3** to gain access. Similarly, **scp file.txt pi3:** or **sshfs pi pi3:**
You can also use more SSH options, such as the port number:
```
$ storm add pi3 [email protected]:2000
```
You can list, search, and edit saved connections easily using Storm’s [documentation](https://stormssh.readthedocs.io/en/stable/usage.html). All Storm actually does is manage items in your ssh config file at **~/.ssh/config**. Once you see how these are stored, you might choose to edit them manually. An example connection in config looks like this:
```
Host pi3
user pi
hostname 192.168.1.20
port 22
```
## Conclusion
SSH is an important tool for system administration, from Raspberry Pi to the largest cloud infrastructures. Familiarizing yourself with key management will forever be handy. Do you have other SSH tricks to add? I would love to have you share them in the comments.
## 3 Comments |
11,949 | “Emacs 游戏机”完全指南 | https://www.masteringemacs.org/article/fun-games-in-emacs | 2020-03-02T09:36:00 | [
"游戏",
"Emacs"
] | https://linux.cn/article-11949-1.html | 
又是周一,你正在为你的老板 Lumbergh (LCTT 译注:《上班一条虫》中的副总裁)努力倒腾那些 [无聊之极的文档](https://en.wikipedia.org/wiki/Office_Space)。为什么不玩玩 Emacs 中类似 zork 的文字冒险游戏来让你的大脑从单调的工作中解脱出来呢?
但说真的,Emacs 中既有游戏,也有古怪的玩物。有些你可能有所耳闻。这些玩意唯一的共同点就是,它们大多是很久以前就添加到 Emacs 中的:有些东西真的是相当古怪(如你将在下面看到的),而另一些则显然是由无聊的员工或学生们编写的。它们全有一个共同点,都带着一种奇思妙想和随意性,这在今天的 Emacs 中很少见。Emacs 现在变得十分严肃,在某种程度上,它已经与 20 世纪 80 年代那些游戏被编写出来的时候大不一样。
### 汉诺塔
[汉诺塔](https://en.wikipedia.org/wiki/Tower_of_Hanoi) 是一款古老的数学解密游戏,有些人可能对它很熟悉,因为它的递归和迭代解决方案经常被用于计算机科学教学辅助。

Emacs 中有三个命令可以运行汉诺塔:`M-x hanoi` 默认为 3 个碟子; `M-x hanoi-unix` 和 `M-x hanoi-unix-64` 使用 unix 时间戳的位数(32 位或 64 位)作为默认盘子的个数,并且每秒钟自动移动一次,两者不同之处在于后者假装使用 64 位时钟(因此有 64 个碟子)。
Emacs 中汉诺塔的实现可以追溯到 20 世纪 80 年代中期——确实是久得可怕。它有一些自定义选项(`M-x customize-group RET hanoi RET`),如启用彩色碟子等。当你离开汉诺塔缓冲区或输入一个字符,你会收到一个讽刺的告别信息(见上图)。
### 5x5

5x5 的游戏是一个逻辑解密游戏:你有一个 5x5 的网格,中间的十字被填满;你的目标是通过按正确的顺序切换它们的空满状态来填充所有的单元格,从而获得胜利。这并不像听起来那么容易!
输入 `M-x 5x5` 就可以开始玩了,使用可选的数字参数可以改变网格的大小。这款游戏的有趣之处在于它能向你建议下一步行动并尝试找到该游戏网格的解法。它用到了 Emacs 自己的一款非常酷的符号 RPN 计算器 `M-x calc`(在《[Emacs 快乐计算](https://www.masteringemacs.org/article/fun-emacs-calc)》这篇文章中,我使用它来解决了一个简单的问题)。
所以我喜欢这个游戏的原因是它提供了一个非常复杂的解题器——真的,你应该通过 `M-x find-library RET 5x5` 来阅读其源代码——这是一个试图通过暴力破解游戏解法的“破解器”。
创建一个更大的游戏网格,例如输入 `M-10 M-x 5x5`,然后运行下面某个 `crack` 命令。破解器将尝试通过迭代获得最佳解决方案。它会实时运行该游戏,观看起来非常有趣:
* `M-x 5x5-crack-mutating-best`: 试图通过变异最佳解决方案来破解 5x5。
* `M-x 5x5-crack-mutating-current`: 试图通过变异当前解决方案来破解 5x5。
* `M-x 5x5-crack-random`: 尝试使用随机方案解破解 5x5。
* `M-x 5x5-crack-xor-mutate`: 尝试通过将当前方案和最佳方案进行异或运算来破解 5x5。
### 文本动画
你可以通过运行 `M-x animation-birthday-present` 并给出你的名字来显示一个奇特的生日礼物动画。它看起来很酷!

这里用的 `animate` 包也用在了 `M-x butterfly` 命令中,这是一个向上面的 [XKCD](http://www.xkcd.com) 漫画致敬而添加到 Emacs 中的命令。当然,漫画中的 Emacs 命令在技术上是无效的,但它的幽默足以弥补这一点。
### 黑箱
我将逐字引用这款游戏的目标:
>
> 游戏的目标是通过向黑盒子发射光线来找到四个隐藏的球。有四种可能: 1) 射线将通过盒子不受干扰; 2) 它将击中一个球并被吸收; 3) 它将偏转并退出盒子,或 4) 立即偏转,甚至不能进入盒子。
>
>
>
所以,这有点像我们小时候玩的[战舰游戏](https://en.wikipedia.org/wiki/Battleship_(game)),但是……是专为物理专业高学历的人准备的吧?
这是另一款添加于 20 世纪 80 年代的游戏。我建议你输入 `C-h f blackbox` 来阅读玩法说明(文档巨大)。
### 泡泡

`M-x bubble` 游戏相当简单:你必须用尽可能少移动清除尽可能多的“泡泡”。当你移除气泡时,其他气泡会掉落并粘在一起。这是一款有趣的游戏,此外如果你使用 Emacs 的图形用户界面,它还支持图像显示。而且它还支持鼠标。
你可以通过调用 `M-x bubbles-set-game-<difficulty>` 来设置难度,其中 `<difficulty>` 可以是这些之一:`easy`、`medium`、`difficult`、`hard` 或 `userdefined`。此外,你可以使用:`M-x custom-group bubbles` 来更改图形、网格大小和颜色。
由于它即简单又有趣,这是 Emacs 中我最喜欢的游戏之一。
### 幸运饼干
我喜欢 `fortune` 命令。每当我启动一个新 shell 时,这些与文学片段、谜语相结合的刻薄、无益、常常带有讽刺意味的“建议”就会点亮我的一天。
令人困惑的是,Emacs 中有两个包或多或少地做着类似的事情:`fortune` 和 `cookie`。前者主要用于在电子邮件签名中添加幸运饼干消息,而后者只是一个简单的 fortune 格式阅读器。
不管怎样,使用 Emacs 的 `cookie` 包前,你首先需要通过 `customize-option RET cookie RET` 来自定义变量 `cookie-file` 告诉它从哪找到 fortune 文件。
如果你的操作系统是 Ubuntu,那么你先安装 `fortune` 软件包,然后就能在 `/usr/share/games/fortune/` 目录中找到这些文件了。
之后你就可以调用 `M-x cookie` 随机显示 fortune 内容,或者,如果你想的话,也可以调用 `M-x cookie-apropos` 查找所有匹配的饼干。
### 破译器
这个包完美地抓住了 Emacs 的功利本质:这个包为你破解简单的替换密码(如“密码谜题”)提供了一个很有用的界面。你知道,二十多年前,有些人确实迫切需要破解很多基本的密码。正是像这个模块这样的小玩意让我非常高兴地用起 Emacs 来:一个只对少数人有用的模块,但是,如果你突然需要它了,那么它就在那里等着你。
那么如何使用它呢?让我们假设使用 “rot13” 密码:在 26 个字符的字母表中,将字符旋转 13 个位置。 通过 `M-x ielm` (Emacs 用于 [运行 Elisp](https://www.masteringemacs.org/article/evaluating-elisp-emacs) 的 REPL 环境)可以很容易在 Emacs 中进行尝试:
```
*** Welcome to IELM *** Type (describe-mode) for help.
ELISP> (rot13 "Hello, World")
"Uryyb, Jbeyq"
ELISP> (rot13 "Uryyb, Jbeyq")
"Hello, World"
ELISP>
```
简而言之,你将明文旋转了 13 个位置,就得到了密文。你又旋转了一次 13 个位置,就返回了最初的明文。 这就是这个包可以帮助你解决的问题。
那么,decipher 模块又是如何帮助我们的呢?让我们创建一个新的缓冲区 `test-cipher` 并输入你的密文(在我的例子中是 `Uryyb,Jbeyq`)。
你现在面对的是一个相当复杂的界面。现在把光标放在紫色行的密文的任意字符上,并猜测这个字符可能是什么:Emacs 将根据你的选择更新其他明文的猜测结果,并告诉你目前为止字母表中的字符是如何分配的。
你现在可以用下面各种助手命令来关闭选项,以帮助推断密码字符可能对应的明文字符:
* `D`: 列出示意图(该加密算法中双字符对)及其频率
* `F`: 表示每个密文字母的频率
* `N`: 显示字符的邻近信息。我不确定这是干啥的。
* `M` 和 `R`: 保存和恢复一个检查点,允许你对工作进行分支以探索破解密码的不同方法。
总而言之,对于这样一个深奥的任务,这个包是相当令人印象深刻的!如果你经常破解密码,也许这个程序包能帮上忙?
### 医生

啊,Emacs 医生。其基于最初的 [ELIZA](https://en.wikipedia.org/wiki/ELIZA),“医生”试图对你说的话进行心理分析,并试图把问题复述给你。体验几分钟,相当有趣,它也是 Emacs 中最著名的古怪玩意之一。你可以使用 `M-x doctor` 来运行它。
### Dunnet
Emacs 自己特有的类 Zork 文字冒险游戏。输入 `M-x dunnet` 就能玩了。这是一款相当不错的游戏,简单的说,它是另一款非常著名的 Emacs 游戏,很少有人真正玩到通关。
如果你发现自己能在无聊的文档工作之间空出时间来,那么这是一个超级棒的游戏,内置“老板屏幕”,因为它是纯文本的。
哦,还有,不要想着吃掉那块 CPU 卡 :)
### 五子棋

另一款写于 20 世纪 80 年代的游戏。你必须将 5 个方块连成一条线,井字棋风格。你可以运行 `M-x gomoku` 来与 Emacs 对抗。游戏还支持鼠标,非常方便。你也可以自定义 `gomoku` 组来调整网格的大小。
### 生命游戏
[康威的生命游戏](https://en.wikipedia.org/wiki/Conway's_Game_of_Life) 是细胞自动机的一个著名例子。Emacs 版本提供了一些启动模式,你可以(通过 elisp 编程)调整 `life-patterns` 变量来更改这些模式。
你可以用 `M-x life` 触发生命游戏。事实上,所有的东西,包括显示代码、注释等等一切,总共不到 300 行,这也让人印象深刻。
### 乒乓,贪吃蛇和俄罗斯方块

这些经典游戏都是使用 Emacs 包 `gamegrid` 实现的,这是一个用于构建网格游戏(如俄罗斯方块和贪吃蛇)的通用框架。gamegrid 包的伟大之处在于它同时兼容图形化和终端 Emacs:如果你在 GUI 中运行 Emacs,你会得到精美的图形;如果你没有,你看到简单的 ASCII 艺术。
你可以通过输入 `M-x pong`、`M-x snake`、`M-x tetris` 来运行这些游戏。
特别是俄罗斯方块游戏实现的非常到位,会逐渐增加速度并且能够滑块。而且既然你已经有了源代码,你完全可以移除那个讨厌的 Z 形块,没人喜欢它!
### Solitaire

可惜,这不是纸牌游戏,而是一个基于“钉子”的游戏,你可以选择一块石头(`o`)并“跳过”相邻的石头进入洞中(`.`),并在这个过程中去掉你跳过的石头,最终只能在棋盘上留下一块石头,重复该过程直到棋盘被请空(只保留一个石头)。
如果你卡住了,有一个内置的解题器名为 `M-x solitire-solve`。
### Zone
我的另一个最爱。这是一个屏幕保护程序——或者更确切地说,是一系列的屏幕保护程序。
输入 `M-x zone`,然后看看屏幕上发生了什么!
你可以通过运行 `M-x zone-when-idle`(或从 elisp 调用它)来配置屏幕保护程序的空闲时间,时间以秒为单位。你也可以通过 `M-x zone-leave-me-alone` 来关闭它。
如果在你的同事看着的时候启动它,你的同事肯定会抓狂的。
### 乘法解谜

这是另一个脑筋急转弯的益智游戏。当你运行 `M-x mpuz` 时,将看到一个乘法解谜题,你必须将字母替换为对应的数字,并确保数字相加(相乘?)符合结果。
如果遇到难题,可以运行 `M-x mpuz-show-solution` 来解决。
### 杂项
还有更多好玩的东西,但它们就不如刚才那些那么好玩好用了:
* 你可以通过 `M-x morse-region` 和 `M-x unmorse-region` 将一个区域翻译成莫尔斯电码。
* Dissociated Press 是一个非常简单的命令,它将一个类似随机穿行的马尔可夫链生成器应用到缓冲区中的文本中,并以此生成无意义的文本。试一下 `M-x dissociated-press`。
* `gametree` 软件包是一个通过电子邮件记录和跟踪国际象棋游戏的复杂方法。
* `M-x spook` 命令插入随机单词(通常是到电子邮件中),目的是混淆/超载 “NSA 拖网渔船” —— 记住,这个模块可以追溯到 20 世纪 80 年代和 90 年代,那时应该有间谍们在监听各种单词。当然,即使是在十年前,这样做也会显得非常偏执和古怪,不过现在看来已经不那么奇怪了……
### 总结
我喜欢 Emacs 附带的游戏和玩具。它们大多来自于,嗯,我们姑且称之为一个不同的时代:一个允许或甚至鼓励奇思妙想的时代。有些玩意非常经典(如俄罗斯方块和汉诺塔),有些对经典游戏进行了有趣的变种(如黑盒)——但我很高兴这么多年后它们依然存在于 Emacs 中。我想知道时至今日,类似这些的玩意是否还会再纳入 Emacs 的代码库中;嗯,它们很可能不会——它们将被归入包管理仓库中,而在这个干净而无菌的世界中,它们无疑属于包管理仓库。
Emacs 要求将对 Emacs 体验不重要的内容转移到包管理仓库 ELPA 中。我的意思是,作为一个开发者,这是有道理的,但是……对于每一个被移出并流放到 ELPA 的包,我们是不是在蚕食 Emacs 的精髓?
---
via: <https://www.masteringemacs.org/article/fun-games-in-emacs>
作者:[Mickey Petersen](https://www.masteringemacs.org/about) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It’s yet another Monday and you’re hard at work on those [TPS reports](https://en.wikipedia.org/wiki/Office_Space) for your boss, Lumbergh. Why not play Emacs’s Zork-like text adventure game to take your mind off the tedium of work?
But seriously, yes, there are both games and quirky playthings in Emacs. Some you have probably heard of or played before. The only thing they have in common is that most of them were added a *long* time ago: some are rather odd inclusions (as you’ll see below) and others were clearly written by bored employees or graduate students. What they all have in common is a whimsy and a casualness that I rarely see in Emacs today. Emacs is Serious Business now in a way that it probably wasn’t back in the 1980s when some of these games were written.
## Tower of Hanoi
The [Tower of Hanoi](https://en.wikipedia.org/wiki/Tower_of_Hanoi) is an ancient mathematical puzzle game and one that is probably familiar to some of us as it is often used in Computer Science as a teaching aid because of its recursive and iterative solutions.
In Emacs there are three commands you can run to trigger the Tower of Hanoi puzzle: `M-x hanoi`
with a default of 3 discs; `M-x hanoi-unix`
and `M-x hanoi-unix-64`
uses the unix timestamp, making a move each second in line with the clock, and with the latter pretending it uses a 64-bit clock.
The Tower of Hanoi implementation in Emacs dates from the mid 1980s — an awful long time ago indeed. There are a few *Customize* options (`M-x customize-group RET hanoi RET`
) such as enabling colorized discs. And when you exit the Hanoi buffer or type a character you are treated to a sarcastic goodbye message (see above.)
## 5x5
The 5x5 game is a logic puzzle: you are given a 5x5 grid with a central cross already filled-in; your goal is to fill all the cells by toggling them on and off in the right order to win. It’s not as easy as it sounds!
To play, type `M-x 5x5`
, and with an optional digit argument you can change the size of the grid. What makes this game interesting is its rather complex ability to suggest the next move and attempt to solve the game grid. It uses Emacs’s very own, and very cool, symbolic RPN calculator `M-x calc`
(and in [Fun with Emacs Calc](/article/fun-emacs-calc) I use it to solve a simple problem.)
So what I like about this game is that it comes with a very complex solver – really, you should read the source code with `M-x find-library RET 5x5`
– and a “cracker” that attempts to brute force solutions to the game.
Try creating a bigger game grid, such as `M-10 M-x 5x5`
, and then run one of the `crack`
commands below. The crackers will attempt to iterate their way to the best solution. This runs in real time and is fun to watch:
`M-x 5x5-crack-mutating-best`
Attempt to crack 5x5 by mutating the best solution.
`M-x 5x5-crack-mutating-current`
Attempt to crack 5x5 by mutating the current solution.
`M-x 5x5-crack-randomly`
Attempt to crack 5x5 using random solutions.
`M-x 5x5-crack-xor-mutate`
Attempt to crack 5x5 by xoring the current and best solution.
## Text Animation
You can display a fancy birthday present animation by running `M-x animate-birthday-present`
and giving it your name. It looks rather cool!
The `animate`
package is also used by the `M-x butterfly`
command, a command added to Emacs as an homage to the [XKCD](http://www.xkcd.com) strip above. Of course the Emacs command in the strip is *teeechnically* not valid but the humor more than makes up for it.
## Blackbox
The objective of this game I am going to quote literally:
The object of the game is to find four hidden balls by shooting rays into the black box. There are four possibilities: 1) the ray will pass thru the box undisturbed, 2) it will hit a ball and be absorbed, 3) it will be deflected and exit the box, or 4) be deflected immediately, not even being allowed entry into the box.
So, it’s a bit like the [Battleship](https://en.wikipedia.org/wiki/Battleship_(game)) game most of us played as kids but… for people with advanced degrees in physics?
It’s another game that was added back in the 1980s. I suggest you read the extensive documentation on how to play by typing `C-h f blackbox`
.
## Bubbles
The `M-x bubbles`
game is rather simple: you must clear out as many “bubbles” as you can in as few moves as possible. When you remove bubbles the other bubbles drop and stick together. It’s a fun game that, as an added bonus, comes with graphics if you use Emacs’s GUI. It also works with your mouse.
You can configure the difficulty of the game by calling `M-x bubbles-set-game-<difficulty>`
where `<difficulty>`
is one of: `easy`
, `medium`
, `difficult`
, `hard`
, or `userdefined`
. Furthermore, you can alter the graphics, grid size and colors using Customize: `M-x customize-group bubbles`
.
For its simplicity and fun factor, this ranks as one of my favorite games in Emacs.
## Fortune & Cookie
I like the `fortune`
command. Snarky, unhelpful and often sarcastic “advice” mixed in with literature and riddles brightens up my day whenever I launch a new shell.
Rather confusingly there are two packages in Emacs that does more-or-less the same thing: `fortune`
and `cookie1`
. The former is geared towards putting fortune cookie messages in email signatures and the latter is just a simple reader for the fortune format.
Anyway, to use Emacs’s `cookie1`
package you must first tell it where to find the file by customizing the variable `cookie-file`
with `customize-option RET cookie RET`
.
If you’re on Ubuntu you will have to install the `fortune`
package first. The files are found in the `/usr/share/games/fortunes/`
directory.
You can then call `M-x cookie`
or, should you want to do this, find all matching cookies with `M-x cookie-apropos`
. Yes, that’s right: Emacs has a self-documenting *apropos* command to help you find the right fortune cookie message!
## Decipher: Breaking Cryptograms
This package perfectly captures the utilitarian nature of Emacs: it’s a package to help you break simple substitution ciphers (like cryptogram puzzles) using a helpful user interface. You just know that – more than twenty years ago – someone *really* had a dire need to break a lot of basic ciphers. It’s little things like this module that makes me overjoyed to use Emacs: a module of scant importance to all but a few people and, yet, should you need it – there it is.
So how do you use it then? Well, let’s consider the “rot13” cipher: rotating characters by 13 places in a 26-character alphabet. It’s an easy thing to try out in Emacs with `M-x ielm`
, Emacs’s REPL for [Evaluating Elisp](/article/evaluating-elisp-emacs):
```
*** Welcome to IELM *** Type (describe-mode) for help.
ELISP> (rot13 "Hello, World")
"Uryyb, Jbeyq"
ELISP> (rot13 "Uryyb, Jbeyq")
"Hello, World"
ELISP>
```
Simply put, you rotate your plaintext 13 places and you get your ciphertext; you rotate it another 13 and you end up where you started. This is the sort of thing this package can help you solve.
So how can the decipher module help us here? Well, create a new buffer `test-cipher`
and type in your cipher text (in my case `Uryyb, Jbeyq`
) and then start deciphering with `M-x decipher`
.
You’re now presented with a rather complex interface. You can now place the point on any of the characters in the ciphertext on the purple line and guess what the character might be: Emacs will update the rest of the plaintext guess with your choices and tell you how the characters in the alphabet have been allocated thus far.
You can then start winnowing down the options using various helper commands to help infer which cipher characters might correspond to the correct plaintext character:
`D`
Shows a list of digrams (two-character combinations from the cipher) and their frequency
`F`
Shows the frequency of each ciphertext letter
`N`
Shows adjacency of characters. I am not entirely sure how this works.
`M`
and`R`
Save and restore a checkpoint, allowing you to branch your work and explore different ways of cracking the cipher.
All in all, for such an esoteric task, this package is rather impressive! If you regularly solve cryptograms maybe this package can help?
## Doctor
Ah, the Emacs doctor. Based on the original [ELIZA](https://en.wikipedia.org/wiki/ELIZA) the “Doctor” tries to psychoanalyze what you say. Rather fun, for a few minutes, and one of the more famous Emacs oddities. You can run it with `M-x doctor`
.
## Yow! Zippy the Pinhead
Back in the day, you could call `M-x yow`
and get a Zippy the Pinhead quote. Sadly Emacs no longer proffers the wisdom of Zippy due to legal restrictions. The module’s still there, so if you can source a `yow.lines`
file from an older Emacs (pre Emacs 22) you can still enjoy his zany sayings.
There is, naturally, a `M-x apropos-zippy`
command also for when you absolutely need to find the right Zippy quote.
More amusingly, there’s `M-x psychoanalyze-pinhead`
so you can pit the good `M-x doctor`
against Zippy in a battle of wits.
## Dunnet
Emacs’s very own Zork-like text adventure game. To play it, type `M-x dunnet`
. It’s rather good, if short, but it’s another rather famous Emacs game that too few have actually played through to the end.
If you find yourself with time to kill between your TPS reports then it’s a great game with a built-in “boss screen” as it’s text-only.
Oh, and, don’t try to eat the CPU card :)
## Gomoku
Another game written in the 1980s. You have to connect 5 squares, tic-tac-toe style. You can play against Emacs with `M-x gomoku`
. The game also supports the mouse, which is rather handy. You can customize the group `gomoku`
to adjust the size of the grid.
## Game of Life
[Conway’s Game of Life](https://en.wikipedia.org/wiki/Conway's_Game_of_Life) is a famous example of cellular automata. The Emacs version comes with a handful of starting patterns that you can (programmatically with elisp) alter by adjusting the `life-patterns`
variable.
You can trigger a game of life with `M-x life`
. The fact that the whole thing, display code, comments and all, come in at less than 300 characters is also rather impressive.
## Pong, Snake and Tetris
These classic games are all implemented using the Emacs package `gamegrid`
, a generic framework for building grid-based games like Tetris and Snake. The great thing about the gamegrid package is its compatibility with both graphical and terminal Emacs: if you run Emacs in a GUI you get fancy graphics; if you don’t, you get simple ASCII art.
You can run the games by typing `M-x pong`
, `M-x snake`
, or `M-x tetris`
.
The Tetris game in particular is rather faithfully implemented, having both gradual speed increase and the ability to slide blocks into place. And because you have the source code you can finally remove that annoying `Z`
-shaped piece no one likes!
## Solitaire
This is *not* the card game, unfortunately. But a peg-based game where you have to end up with just one stone on the board, by taking a stone (the `o`
) and “jumping” over an adjacent stone into the hole (the `.`
), removing the stone you jumped over in the process. Rinse and repeat until the board is empty.
There is a handy solver built in called `M-x solitaire-solve`
if you get stuck.
## Zone
Another of my favorites. This time’s it’s a *screensaver* – or rather, a series of screensavers.
Type `M-x zone`
and watch what happens to your screen!
You can configure a screensaver idle time by running `M-x zone-when-idle`
(or calling it from elisp) with an idle time in seconds. You can turn it off with `M-x zone-leave-me-alone`
.
This one’s *guaranteed* to make your coworkers freak out if it kicks off while they are looking.
## Multiplication Puzzle
This is another brain-twisting puzzle game. When you run `M-x mpuz`
you are given a multiplication puzzle where you have to replace the letters with numbers and ensure the numbers add (multiply?) up.
You can run `M-x mpuz-show-solution`
to solve the puzzle if you get stuck.
## Miscellaneous
There are more, but they’re not the most useful or interesting:
- You can translate a region into morse code with
`M-x morse-region`
and`M-x unmorse-region`
. - The
*Dissociated Press*is a very simple command that applies something like a random walk markov-chain generator to a body of text in a buffer and generates nonsensical text from the source body. Try it with`M-x dissociated-press`
. - The
*Gamegrid*package is a generic framework for building grid-based games. So far only Tetris, Pong and Snake use it. It’s called`gamegrid`
. - The
`gametree`
package is a complex way of notating and tracking chess games played via email. - The
`M-x spook`
command inserts random words (usually into emails) designed to confuse/overload the “NSA trunk trawler” – and keep in mind this module dates from the 1980s and 1990s – with various words the spooks are supposedly listening for. Of course, even fifteen years ago that would’ve seemed awfully paranoid and quaint but not so much any more…
## Conclusion
I *love* the games and playthings that ship with Emacs. A lot of them date from, well, let’s just call a different era: an era where whimsy was allowed or perhaps even encouraged. Some are known classics (like Tetris and Tower of Hanoi) and some of the others are fun variations on classics (like *blackbox*) — and yet I love that they ship with Emacs after all these years. I wonder if any of these would make it into Emacs’s codebase today; well, they probably wouldn’t — they’d be relegated to the package manager where, in a clean and sterile world, they no doubt belong.
There’s a mandate in Emacs to move things not essential to the Emacs experience to ELPA, the package manager. I mean, as a developer myself, that does make sense, but… surely for every package removed and exiled to ELPA we chip away the essence of what defines Emacs? |
11,950 | 在数据科学中使用 C 和 C++ | https://opensource.com/article/20/2/c-data-science | 2020-03-02T10:19:43 | [
"数据科学"
] | https://linux.cn/article-11950-1.html |
>
> 让我们使用 C99 和 C++11 完成常见的数据科学任务。
>
>
>

虽然 [Python](https://opensource.com/article/18/9/top-3-python-libraries-data-science) 和 [R](https://opensource.com/article/19/5/learn-python-r-data-science) 之类的语言在数据科学中越来越受欢迎,但是 C 和 C++ 对于高效的数据科学来说是一个不错的选择。在本文中,我们将使用 [C99](https://en.wikipedia.org/wiki/C99) 和 [C++11](https://en.wikipedia.org/wiki/C%2B%2B11) 编写一个程序,该程序使用 [Anscombe 的四重奏](https://en.wikipedia.org/wiki/Anscombe%27s_quartet)数据集,下面将对其进行解释。
我在一篇涉及 [Python 和 GNU Octave](/article-11943-1.html) 的文章中写了我不断学习编程语言的动机,值得大家回顾。这里所有的程序都需要在[命令行](https://en.wikipedia.org/wiki/Command-line_interface)上运行,而不是在[图形用户界面(GUI)](https://en.wikipedia.org/wiki/Graphical_user_interface)上运行。完整的示例可在 [polyglot\_fit 存储库](https://gitlab.com/cristiano.fontana/polyglot_fit)中找到。
### 编程任务
你将在本系列中编写的程序:
* 从 [CSV 文件](https://en.wikipedia.org/wiki/Comma-separated_values)中读取数据
* 用直线插值数据(即 `f(x)=m ⋅ x + q`)
* 将结果绘制到图像文件
这是许多数据科学家遇到的普遍情况。示例数据是 [Anscombe 的四重奏](https://en.wikipedia.org/wiki/Anscombe%27s_quartet)的第一组,如下表所示。这是一组人工构建的数据,当拟合直线时可以提供相同的结果,但是它们的曲线非常不同。数据文件是一个文本文件,其中的制表符用作列分隔符,前几行作为标题。该任务将仅使用第一组(即前两列)。

### C 语言的方式
[C](https://en.wikipedia.org/wiki/C_%28programming_language%29) 语言是通用编程语言,是当今使用最广泛的语言之一(依据 [TIOBE 指数](https://www.tiobe.com/tiobe-index/)、[RedMonk 编程语言排名](https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/)、[编程语言流行度指数](http://pypl.github.io/PYPL.html)和 [GitHub Octoverse 状态](https://octoverse.github.com/) 得来)。这是一种相当古老的语言(大约诞生在 1973 年),并且用它编写了许多成功的程序(例如 Linux 内核和 Git 仅是其中的两个例子)。它也是最接近计算机内部运行机制的语言之一,因为它直接用于操作内存。它是一种[编译语言](https://en.wikipedia.org/wiki/Compiled_language);因此,源代码必须由[编译器](https://en.wikipedia.org/wiki/Compiler)转换为[机器代码](https://en.wikipedia.org/wiki/Machine_code)。它的[标准库](https://en.wikipedia.org/wiki/C_standard_library)很小,功能也不多,因此人们开发了其它库来提供缺少的功能。
我最常在[数字运算](https://en.wiktionary.org/wiki/number-crunching)中使用该语言,主要是因为其性能。我觉得使用起来很繁琐,因为它需要很多[样板代码](https://en.wikipedia.org/wiki/Boilerplate_code),但是它在各种环境中都得到了很好的支持。C99 标准是最新版本,增加了一些漂亮的功能,并且得到了编译器的良好支持。
我将一路介绍 C 和 C++ 编程的必要背景,以便初学者和高级用户都可以继续学习。
#### 安装
要使用 C99 进行开发,你需要一个编译器。我通常使用 [Clang](https://clang.llvm.org/),不过 [GCC](https://gcc.gnu.org/) 是另一个有效的开源编译器。对于线性拟合,我选择使用 [GNU 科学库](https://www.gnu.org/software/gsl/)。对于绘图,我找不到任何明智的库,因此该程序依赖于外部程序:[Gnuplot](http://www.gnuplot.info/)。该示例还使用动态数据结构来存储数据,该结构在[伯克利软件分发版(BSD)](https://en.wikipedia.org/wiki/Berkeley_Software_Distribution)中定义。
在 [Fedora](https://getfedora.org/) 中安装很容易:
```
sudo dnf install clang gnuplot gsl gsl-devel
```
#### 代码注释
在 C99 中,[注释](https://en.wikipedia.org/wiki/Comment_(computer_programming))的格式是在行的开头放置 `//`,行的其它部分将被解释器丢弃。另外,`/*` 和 `*/` 之间的任何内容也将被丢弃。
```
// 这是一个注释,会被解释器忽略
/* 这也被忽略 */
```
#### 必要的库
库由两部分组成:
* [头文件](https://en.wikipedia.org/wiki/Include_directive),其中包含函数说明
* 包含函数定义的源文件
头文件包含在源文件中,而库文件的源文件则[链接](https://en.wikipedia.org/wiki/Linker_%28computing%29)到可执行文件。因此,此示例所需的头文件是:
```
// 输入/输出功能
#include <stdio.h>
// 标准库
#include <stdlib.h>
// 字符串操作功能
#include <string.h>
// BSD 队列
#include <sys/queue.h>
// GSL 科学功能
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
```
#### 主函数
在 C 语言中,程序必须位于称为主函数 [main()](https://en.wikipedia.org/wiki/Entry_point#C_and_C++) 的特殊函数内:
```
int main(void) {
...
}
```
这与上一教程中介绍的 Python 不同,后者将运行在源文件中找到的所有代码。
#### 定义变量
在 C 语言中,变量必须在使用前声明,并且必须与类型关联。每当你要使用变量时,都必须决定要在其中存储哪种数据。你也可以指定是否打算将变量用作常量值,这不是必需的,但是编译器可以从此信息中受益。 以下来自存储库中的 [fitting\_C99.c 程序](https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_C99.c):
```
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;
```
C 语言中的数组不是动态的,从某种意义上说,数组的长度必须事先确定(即,在编译之前):
```
int data_array[1024];
```
由于你通常不知道文件中有多少个数据点,因此请使用[单链列表](https://en.wikipedia.org/wiki/Linked_list#Singly_linked_list)。这是一个动态数据结构,可以无限增长。幸运的是,BSD [提供了链表](http://man7.org/linux/man-pages/man3/queue.3.html)。这是一个示例定义:
```
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);
```
该示例定义了一个由结构化值组成的 `data_point` 列表,该结构化值同时包含 `x` 值和 `y` 值。语法相当复杂,但是很直观,详细描述它就会太冗长了。
#### 打印输出
要在终端上打印,可以使用 [printf()](https://en.wikipedia.org/wiki/Printf_format_string) 函数,其功能类似于 Octave 的 `printf()` 函数(在第一篇文章中介绍):
```
printf("#### Anscombe's first set with C99 ####\n");
```
`printf()` 函数不会在打印字符串的末尾自动添加换行符,因此你必须添加换行符。第一个参数是一个字符串,可以包含传递给函数的其他参数的格式信息,例如:
```
printf("Slope: %f\n", slope);
```
#### 读取数据
现在来到了困难的部分……有一些用 C 语言解析 CSV 文件的库,但是似乎没有一个库足够稳定或流行到可以放入到 Fedora 软件包存储库中。我没有为本教程添加依赖项,而是决定自己编写此部分。同样,讨论这些细节太啰嗦了,所以我只会解释大致的思路。为了简洁起见,将忽略源代码中的某些行,但是你可以在存储库中找到完整的示例代码。
首先,打开输入文件:
```
FILE* input_file = fopen(input_file_name, "r");
```
然后逐行读取文件,直到出现错误或文件结束:
```
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}
```
[getline()](http://man7.org/linux/man-pages/man3/getline.3.html) 函数是 [POSIX.1-2008 标准](https://en.wikipedia.org/wiki/POSIX)新增的一个不错的函数。它可以读取文件中的整行,并负责分配必要的内存。然后使用 [strtok()](http://man7.org/linux/man-pages/man3/strtok.3.html) 函数将每一行分成<ruby> <a href="https://en.wikipedia.org/wiki/Lexical_analysis#Token"> 字元 </a> <rt> token </rt></ruby>。遍历字元,选择所需的列:
```
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}
```
最后,当选择了 `x` 和 `y` 值时,将新数据点插入链表中:
```
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);
```
[malloc()](http://man7.org/linux/man-pages/man3/malloc.3.html) 函数为新数据点动态分配(保留)一些持久性内存。
#### 拟合数据
GSL 线性拟合函数 [gslfitlinear()](https://www.gnu.org/software/gsl/doc/html/lls.html) 期望其输入为简单数组。因此,由于你将不知道要创建的数组的大小,因此必须手动分配它们的内存:
```
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);
```
然后,遍历链表以将相关数据保存到数组:
```
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}
```
现在你已经处理完了链表,请清理它。要**总是**释放已手动分配的内存,以防止[内存泄漏](https://en.wikipedia.org/wiki/Memory_leak)。内存泄漏是糟糕的、糟糕的、糟糕的(重要的话说三遍)。每次内存没有释放时,花园侏儒都会找不到自己的头:
```
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}
```
终于,终于!你可以拟合你的数据了:
```
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);
```
#### 绘图
你必须使用外部程序进行绘图。因此,将拟合数据保存到外部文件:
```
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}
```
用于绘制两个文件的 Gnuplot 命令是:
```
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'
```
#### 结果
在运行程序之前,你必须编译它:
```
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99
```
这个命令告诉编译器使用 C99 标准、读取 `fitting_C99.c` 文件、加载 `gsl` 和 `gslcblas` 库、并将结果保存到 `fitting_C99`。命令行上的结果输出为:
```
#### Anscombe's first set with C99 ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421
```
这是用 Gnuplot 生成的结果图像:

### C++11 方式
[C++](https://en.wikipedia.org/wiki/C%2B%2B) 语言是一种通用编程语言,也是当今使用的最受欢迎的语言之一。它是作为 [C 的继承人](http://www.cplusplus.com/info/history/)创建的(诞生于 1983 年),重点是[面向对象程序设计(OOP)](https://en.wikipedia.org/wiki/Object-oriented_programming)。C++ 通常被视为 C 的超集,因此 C 程序应该能够使用 C++ 编译器进行编译。这并非完全正确,因为在某些极端情况下它们的行为有所不同。 根据我的经验,C++ 与 C 相比需要更少的样板代码,但是如果要进行面向对象开发,语法会更困难。C++11 标准是最新版本,增加了一些漂亮的功能,并且基本上得到了编译器的支持。
由于 C++ 在很大程度上与 C 兼容,因此我将仅强调两者之间的区别。我在本部分中没有涵盖的任何部分,则意味着它与 C 中的相同。
#### 安装
这个 C++ 示例的依赖项与 C 示例相同。 在 Fedora 上,运行:
```
sudo dnf install clang gnuplot gsl gsl-devel
```
#### 必要的库
库的工作方式与 C 语言相同,但是 `include` 指令略有不同:
```
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}
```
由于 GSL 库是用 C 编写的,因此你必须将这个特殊情况告知编译器。
#### 定义变量
与 C 语言相比,C++ 支持更多的数据类型(类),例如,与其 C 语言版本相比,`string` 类型具有更多的功能。相应地更新变量的定义:
```
const std::string input_file_name("anscombe.csv");
```
对于字符串之类的结构化对象,你可以定义变量而无需使用 `=` 符号。
#### 打印输出
你可以使用 `printf()` 函数,但是 `cout` 对象更惯用。使用运算符 `<<` 来指示要使用 `cout` 打印的字符串(或对象):
```
std::cout << "#### Anscombe's first set with C++11 ####" << std::endl;
...
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;
```
#### 读取数据
该方案与以前相同。将打开文件并逐行读取文件,但语法不同:
```
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}
```
使用与 C99 示例相同的功能提取行字元。代替使用标准的 C 数组,而是使用两个[向量](https://en.wikipedia.org/wiki/Sequence_container_%28C%2B%2B%29#Vector)。向量是 [C++ 标准库](https://en.wikipedia.org/wiki/C%2B%2B_Standard_Library)中对 C 数组的扩展,它允许动态管理内存而无需显式调用 `malloc()`:
```
std::vector<double> x;
std::vector<double> y;
// Adding an element to x and y:
x.emplace_back(value);
y.emplace_back(value);
```
#### 拟合数据
要在 C++ 中拟合,你不必遍历列表,因为向量可以保证具有连续的内存。你可以将向量缓冲区的指针直接传递给拟合函数:
```
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;
```
#### 绘图
使用与以前相同的方法进行绘图。 写入文件:
```
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();
```
然后使用 Gnuplot 进行绘图。
#### 结果
在运行程序之前,必须使用类似的命令对其进行编译:
```
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11
```
命令行上的结果输出为:
```
#### Anscombe's first set with C++11 ####
Slope: 0.500091
Intercept: 3.00009
Correlation coefficient: 0.816421
```
这就是用 Gnuplot 生成的结果图像:

### 结论
本文提供了用 C99 和 C++11 编写的数据拟合和绘图任务的示例。由于 C++ 在很大程度上与 C 兼容,因此本文利用了它们的相似性来编写了第二个示例。在某些方面,C++ 更易于使用,因为它部分减轻了显式管理内存的负担。但是其语法更加复杂,因为它引入了为 OOP 编写类的可能性。但是,仍然可以用 C 使用 OOP 方法编写软件。由于 OOP 是一种编程风格,因此可以在任何语言中使用。在 C 中有一些很好的 OOP 示例,例如 [GObject](https://en.wikipedia.org/wiki/GObject) 和 [Jansson](http://www.digip.org/jansson/)库。
对于数字运算,我更喜欢在 C99 中进行,因为它的语法更简单并且得到了广泛的支持。直到最近,C++11 还没有得到广泛的支持,我倾向于避免使用先前版本中的粗糙不足之处。对于更复杂的软件,C++ 可能是一个不错的选择。
你是否也将 C 或 C++ 用于数据科学?在评论中分享你的经验。
---
via: <https://opensource.com/article/20/2/c-data-science>
作者:[Cristiano L. Fontana](https://opensource.com/users/cristianofontana) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While languages like [Python](https://opensource.com/article/18/9/top-3-python-libraries-data-science) and [R](https://opensource.com/article/19/5/learn-python-r-data-science) are increasingly popular for data science, C and C++ can be a strong choice for efficient and effective data science. In this article, we will use [C99](https://en.wikipedia.org/wiki/C99) and [C++11](https://en.wikipedia.org/wiki/C%2B%2B11) to write a program that uses the [Anscombe’s quartet](https://en.wikipedia.org/wiki/Anscombe%27s_quartet) dataset, which I'll explain about next.
I wrote about my motivation for continually learning languages in an article covering [Python and GNU Octave](https://opensource.com/article/20/2/python-gnu-octave-data-science), which is worth reviewing. All of the programs are meant to be run on the [command line](https://en.wikipedia.org/wiki/Command-line_interface), not with a [graphical user interface](https://en.wikipedia.org/wiki/Graphical_user_interface) (GUI). The full examples are available in the [polyglot_fit repository](https://gitlab.com/cristiano.fontana/polyglot_fit).
## The programming task
The program you will write in this series:
- Reads data from a
[CSV file](https://en.wikipedia.org/wiki/Comma-separated_values) - Interpolates the data with a straight line (i.e.,
*f(x)=m ⋅ x + q*) - Plots the result to an image file
This is a common situation that many data scientists have encountered. The example data is the first set of [Anscombe's quartet](https://en.wikipedia.org/wiki/Anscombe%27s_quartet), shown in the table below. This is a set of artificially constructed data that gives the same results when fitted with a straight line, but their plots are very different. The data file is a text file with tabs as column separators and a few lines as a header. This task will use only the first set (i.e., the first two columns).
I | II | III | IV | ||||
---|---|---|---|---|---|---|---|
x | y | x | y | x | y | x | y |
10.0 | 8.04 | 10.0 | 9.14 | 10.0 | 7.46 | 8.0 | 6.58 |
8.0 | 6.95 | 8.0 | 8.14 | 8.0 | 6.77 | 8.0 | 5.76 |
13.0 | 7.58 | 13.0 | 8.74 | 13.0 | 12.74 | 8.0 | 7.71 |
9.0 | 8.81 | 9.0 | 8.77 | 9.0 | 7.11 | 8.0 | 8.84 |
11.0 | 8.33 | 11.0 | 9.26 | 11.0 | 7.81 | 8.0 | 8.47 |
14.0 | 9.96 | 14.0 | 8.10 | 14.0 | 8.84 | 8.0 | 7.04 |
6.0 | 7.24 | 6.0 | 6.13 | 6.0 | 6.08 | 8.0 | 5.25 |
4.0 | 4.26 | 4.0 | 3.10 | 4.0 | 5.39 | 19.0 | 12.50 |
12.0 | 10.84 | 12.0 | 9.13 | 12.0 | 8.15 | 8.0 | 5.56 |
7.0 | 4.82 | 7.0 | 7.26 | 7.0 | 6.42 | 8.0 | 7.91 |
5.0 | 5.68 | 5.0 | 4.74 | 5.0 | 5.73 | 8.0 | 6.89 |
## The C way
[C](https://en.wikipedia.org/wiki/C_%28programming_language%29) is a general-purpose programming language that is among the most popular languages in use today (according to data from the [TIOBE Index](https://www.tiobe.com/tiobe-index/), [RedMonk Programming Language Rankings](https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/), [Popularity of Programming Language Index](http://pypl.github.io/PYPL.html), and [State of the Octoverse of GitHub](https://octoverse.github.com/)). It is a quite old language (circa 1973), and many successful programs were written in it (e.g., the Linux kernel and Git to name just two). It is also one of the closest languages to the inner workings of the computer, as it is used to manipulate memory directly. It is a [compiled language](https://en.wikipedia.org/wiki/Compiled_language); therefore, the source code has to be translated by a [compiler](https://en.wikipedia.org/wiki/Compiler) into [machine code](https://en.wikipedia.org/wiki/Machine_code). Its [standard library](https://en.wikipedia.org/wiki/C_standard_library) is small and light on features, so other libraries have been developed to provide missing functionalities.
It is the language I use the most for [number crunching](https://en.wiktionary.org/wiki/number-crunching), mostly because of its performance. I find it rather tedious to use, as it needs a lot of [boilerplate code](https://en.wikipedia.org/wiki/Boilerplate_code), but it is well supported in various environments. The C99 standard is a recent revision that adds some nifty features and is well supported by compilers.
I will cover the necessary background of C and C++ programming along the way so both beginners and advanced users can follow along.
### Installation
To develop with C99, you need a compiler. I normally use [Clang](https://clang.llvm.org/), but [GCC](https://gcc.gnu.org/) is another valid open source compiler. For linear fitting, I chose to use the [GNU Scientific Library](https://www.gnu.org/software/gsl/). For plotting, I could not find any sensible library, and therefore this program relies on an external program: [Gnuplot](http://www.gnuplot.info/). The example also uses a dynamic data structure to store data, which is defined in the [Berkeley Software Distribution](https://en.wikipedia.org/wiki/Berkeley_Software_Distribution) (BSD).
Installing in [Fedora](https://getfedora.org/) is as easy as running:
`sudo dnf install clang gnuplot gsl gsl-devel`
### Commenting code
In C99, [comments](https://en.wikipedia.org/wiki/Comment_(computer_programming)) are formatted by putting **//** at the beginning of the line, and the rest of the line will be discarded by the interpreter. Alternatively, anything between **/*** and ***/** is discarded, as well.
```
// This is a comment ignored by the interpreter.
/* Also this is ignored */
```
### Necessary libraries
Libraries are composed of two parts:
- A
[header file](https://en.wikipedia.org/wiki/Include_directive)that contains a description of the functions - A source file that contains the functions' definitions
Header files are included in the source, while the libraries' sources are [linked](https://en.wikipedia.org/wiki/Linker_%28computing%29) against the executable. Therefore, the header files needed for this example are:
```
// Input/Output utilities
#include <stdio.h>
// The standard library
#include <stdlib.h>
// String manipulation utilities
#include <string.h>
// BSD queue
#include <sys/queue.h>
// GSL scientific utilities
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
```
### Main function
In C, the program must be inside a special function called [main()](https://en.wikipedia.org/wiki/Entry_point#C_and_C++):
```
int main(void) {
...
}
```
This differs from Python, as covered in the last tutorial, which will run whatever code it finds in the source files.
### Defining variables
In C, variables have to be declared before they are used, and they have to be associated with a type. Whenever you want to use a variable, you have to decide what kind of data to store in it. You can also specify if you intend to use a variable as a constant value, which is not necessary, but the compiler can benefit from this information. From the [fitting_C99.c program](https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_C99.c) in the repository:
```
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;
```
Arrays in C are not dynamic, in the sense that their length has to be decided in advance (i.e., before compilation):
`int data_array[1024];`
Since you normally do not know how many data points are in a file, use a [singly linked list](https://en.wikipedia.org/wiki/Linked_list#Singly_linked_list). This is a dynamic data structure that can grow indefinitely. Luckily, the BSD [provides linked lists](http://man7.org/linux/man-pages/man3/queue.3.html). Here is an example definition:
```
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);
```
This example defines a **data_point** list comprised of structured values that contain both an **x** value and a **y** value. The syntax is rather complicated but intuitive, and describing it in detail would be too wordy.
### Printing output
To print on the terminal, you can use the [ printf()](https://en.wikipedia.org/wiki/Printf_format_string) function, which works like Octave's
**printf()**function (described in the first article):
`printf("#### Anscombe's first set with C99 ####\n");`
The **printf()** function does not automatically add a newline at the end of the printed string, so you have to add it. The first argument is a string that can contain format information for the other arguments that can be passed to the function, such as:
`printf("Slope: %f\n", slope);`
### Reading data
Now comes the hard part… There are some libraries for CSV file parsing in C, but none seemed stable or popular enough to be in the Fedora packages repository. Instead of adding a dependency for this tutorial, I decided to write this part on my own. Again, going into details would be too wordy, so I will only explain the general idea. Some lines in the source will be ignored for the sake of brevity, but you can find the complete example in the repository.
First, open the input file:
`FILE* input_file = fopen(input_file_name, "r");`
Then read the file line-by-line until there is an error or the file ends:
```
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}
```
The [ getline()](http://man7.org/linux/man-pages/man3/getline.3.html) function is a nice recent addition from the
[POSIX.1-2008 standard](https://en.wikipedia.org/wiki/POSIX). It can read a whole line in a file and take care of allocating the necessary memory. Each line is then split into
[tokens](https://en.wikipedia.org/wiki/Lexical_analysis#Token)with the
[function. Looping over the token, select the columns that you want:](http://man7.org/linux/man-pages/man3/strtok.3.html)
**strtok()**```
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}
```
Finally, when the **x** and **y** values are selected, insert the new data point in the linked list:
```
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);
```
The [ malloc()](http://man7.org/linux/man-pages/man3/malloc.3.html) function dynamically allocates (reserves) some persistent memory for the new data point.
### Fitting data
The GSL linear fitting function [ gsl_fit_linear()](https://www.gnu.org/software/gsl/doc/html/lls.html) expects simple arrays for its input. Therefore, since you won't know in advance the size of the arrays you create, you must manually allocate their memory:
```
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);
```
Then, loop over the linked list to save the relevant data to the arrays:
```
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}
```
Now that you are done with the linked list, clean it up. *Always* release the memory that has been manually allocated to prevent a [memory leak](https://en.wikipedia.org/wiki/Memory_leak). Memory leaks are bad, bad, bad. Every time memory is not released, a garden gnome loses its head:
```
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}
```
Finally, finally(!), you can fit your data:
```
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);
```
### Plotting
You must use an external program for the plotting. Therefore, save the fitting function to an external file:
```
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}
```
The Gnuplot command for plotting both files is:
`plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'`
### Results
Before running the program, you must compile it:
`clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99`
This command tells the compiler to use the C99 standard, read the **fitting_C99.c** file, load the libraries **gsl** and **gslcblas**, and save the result to **fitting_C99**. The resulting output on the command line is:
```
#### Anscombe's first set with C99 ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421
```
Here is the resulting image generated with Gnuplot.
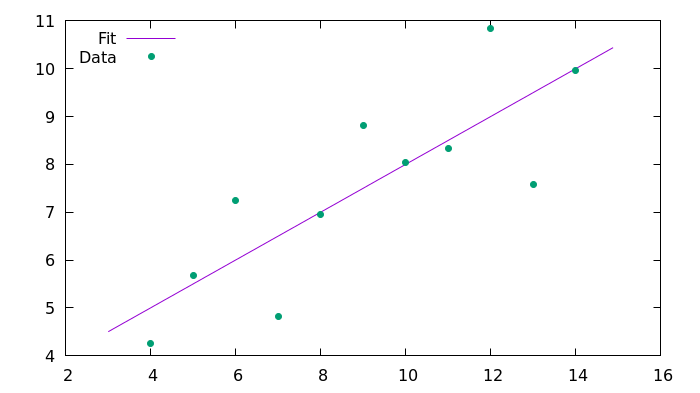
## The C++11 way
[C++](https://en.wikipedia.org/wiki/C%2B%2B) is a general-purpose programming language that is also among the most popular languages in use today. It was created as a [successor of C](http://www.cplusplus.com/info/history/) (in 1983) with an emphasis on [object-oriented programming](https://en.wikipedia.org/wiki/Object-oriented_programming) (OOP). C++ is commonly regarded as a superset of C, so a C program should be able to be compiled with a C++ compiler. This is not exactly true, as there are some corner cases where they behave differently. In my experience, C++ needs less boilerplate than C, but the syntax is more difficult if you want to develop objects. The C++11 standard is a recent revision that adds some nifty features and is more or less supported by compilers.
Since C++ is largely compatible with C, I will just highlight the differences between the two. If I do not cover a section in this part, it means that it is the same as in C.
### Installation
The dependencies for the C++ example are the same as the C example. On Fedora, run:
`sudo dnf install clang gnuplot gsl gsl-devel`
### Necessary libraries
Libraries work in the same way as in C, but the **include** directives are slightly different:
```
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}
```
Since the GSL libraries are written in C, you must inform the compiler about this peculiarity.
### Defining variables
C++ supports more data types (classes) than C, such as a **string** type that has many more features than its C counterpart. Update the definition of the variables accordingly:
`const std::string input_file_name("anscombe.csv");`
For structured objects like strings, you can define the variable without using the **=** sign.
### Printing output
You can use the **printf()** function, but the **cout** object is more idiomatic. Use the operator **<<** to indicate the string (or objects) that you want to print with **cout**:
```
std::cout << "#### Anscombe's first set with C++11 ####" << std::endl;
...
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;
```
### Reading data
The scheme is the same as before. The file is opened and read line-by-line, but with a different syntax:
```
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}
```
The line tokens are extracted with the same function as in the C99 example. Instead of using standard C arrays, use two [vectors](https://en.wikipedia.org/wiki/Sequence_container_%28C%2B%2B%29#Vector). Vectors are an extension of C arrays in the [C++ standard library](https://en.wikipedia.org/wiki/C%2B%2B_Standard_Library) that allows dynamic management of memory without explicitly calling **malloc()**:
```
std::vector<double> x;
std::vector<double> y;
// Adding an element to x and y:
x.emplace_back(value);
y.emplace_back(value);
```
### Fitting data
For fitting in C++, you do not have to loop over the list, as vectors are guaranteed to have contiguous memory. You can directly pass to the fitting function the pointers to the vectors buffers:
```
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;
```
### Plotting
Plotting is done with the same approach as before. Write to a file:
```
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();
```
And then use Gnuplot for the plotting.
### Results
Before running the program, it must be compiled with a similar command:
`clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11`
The resulting output on the command line is:
```
#### Anscombe's first set with C++11 ####
Slope: 0.500091
Intercept: 3.00009
Correlation coefficient: 0.816421
```
And this is the resulting image generated with Gnuplot.
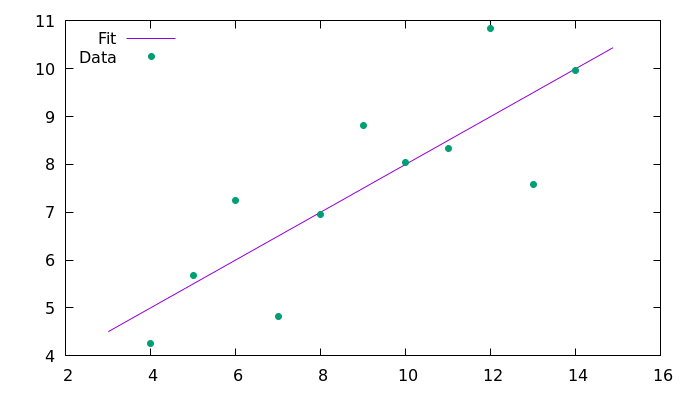
## Conclusion
This article provides examples for a data fitting and plotting task in C99 and C++11. Since C++ is largely compatible with C, this article exploited their similarities for writing the second example. In some aspects, C++ is easier to use because it partially relieves the burden of explicitly managing memory. But the syntax is more complex because it introduces the possibility of writing classes for OOP. However, it is still possible to write software in C with the OOP approach. Since OOP is a style of programming, it can be used in any language. There are some great examples of OOP in C, such as the [GObject](https://en.wikipedia.org/wiki/GObject) and [Jansson](http://www.digip.org/jansson/) libraries.
For number crunching, I prefer working in C99 due to its simpler syntax and widespread support. Until recently, C++11 was not as widely supported, and I tended to avoid the rough edges in the previous versions. For more complex software, C++ could be a good choice.
Do you use C or C++ for data science as well? Share your experiences in the comments.
## 14 Comments |
11,953 | Linux 硬件故障排除指南 | https://opensource.com/article/18/12/troubleshooting-hardware-problems-linux | 2020-03-03T10:13:22 | [
"硬件"
] | https://linux.cn/article-11953-1.html |
>
> 了解是什么原因导致你的 Linux 硬件发生故障,以便你可以将其恢复并快速运行。
>
>
>

[Linux 服务器](https://opensource.com/article/18/5/what-linux-server)在物理机、虚拟化、私有云、公共云和混合云等许多不同种类的基础设施中运行着关键的业务应用程序。对于 Linux 系统管理员来说,了解如何管理 Linux 硬件基础设施(包括与 [网络](https://opensource.com/article/18/11/intro-software-defined-networking)、存储、Linux 容器相关的软件定义功能)和 Linux 服务器上的多种工具非常重要。
在 Linux 上进行排除和解决与硬件相关的问题可能需要一些时间。即使是经验丰富的系统管理员,有时也会花费数小时来解决神秘的硬件和软件差异。
以下提示可以使你更快、更轻松地对 Linux 中的硬件进行故障排除。许多不同的事情都可能导致 Linux 硬件出现问题。在开始诊断它们之前,明智的做法是了解最常见的问题以及最有可能找到问题的地方。
### 快速诊断设备、模块和驱动程序
故障排除的第一步通常是显示 Linux 服务器上安装的硬件的列表。你可以使用诸如 [lspci](https://linux.die.net/man/8/lspci)、[lsblk](https://linux.die.net/man/8/lsblk)、[lscpu](https://linux.die.net/man/1/lscpu) 和 [lsscsi](https://linux.die.net/man/8/lsscsi) 之类的列出命令获取有关硬件的详细信息。例如,这是 `lsblk` 命令的输出:
```
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 50G 0 disk
├─xvda1 202:1 0 1M 0 part
└─xvda2 202:2 0 50G 0 part /
xvdb 202:16 0 20G 0 disk
└─xvdb1 202:17 0 20G 0 part
```
如果这些列出命令没有显示任何错误,请使用初始化系统(例如 systemd)查看 Linux 服务器的工作方式。 systemd 是最流行的初始化系统,用于启动用户空间并控制多个系统进程。例如,这是 `systemctl status` 命令的输出:
```
# systemctl status
● bastion.f347.internal
State: running
Jobs: 0 queued
Failed: 0 units
Since: Wed 2018-11-28 01:29:05 UTC; 2 days ago
CGroup: /
├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
├─kubepods.slice
│ ├─kubepods-pod3881728a_f2af_11e8_af77_06af52f87498.slice
│ │ ├─docker-88b27385f4bae77bba834fbd60a61d19026bae13d18eb147783ae27819c34967.scope
│ │ │ └─23860 /opt/bridge/bin/bridge --public-dir=/opt/bridge/static --config=/var/console-config/console-c
│ │ └─docker-a4433f0d523c7e5bc772ee4db1861e4fa56c4e63a2d48f6bc831458c2ce9fd2d.scope
│ │ └─23639 /usr/bin/pod
....
```
### 深入到各个日志当中
使用 `dmesg` 可以找出内核最新消息中的错误和警告。例如,这是 `dmesg | more` 命令的输出:
```
# dmesg | more
....
[ 1539.027419] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 1539.042726] IPv6: ADDRCONF(NETDEV_UP): veth61f37018: link is not ready
[ 1539.048706] IPv6: ADDRCONF(NETDEV_CHANGE): veth61f37018: link becomes ready
[ 1539.055034] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
[ 1539.098550] device veth61f37018 entered promiscuous mode
[ 1541.450207] device veth61f37018 left promiscuous mode
[ 1542.493266] SELinux: mount invalid. Same superblock, different security settings for (dev mqueue, type mqueue)
[ 9965.292788] SELinux: mount invalid. Same superblock, different security settings for (dev mqueue, type mqueue)
[ 9965.449401] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 9965.462738] IPv6: ADDRCONF(NETDEV_UP): vetheacc333c: link is not ready
[ 9965.468942] IPv6: ADDRCONF(NETDEV_CHANGE): vetheacc333c: link becomes ready
....
```
你还可以在 `/var/log/messages` 文件中查看所有 Linux 系统日志,在该文件中你可以找到与特定问题相关的错误。当你对硬件进行修改(例如安装额外的磁盘或添加以太网网卡)时,通过 `tail` 命令实时监视消息是值得的。例如,这是 `tail -f /var/log/messages` 命令的输出:
```
# tail -f /var/log/messages
Dec 1 13:20:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain in-addr.arpa
Dec 1 13:20:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain cluster.local
Dec 1 13:21:03 bastion dnsmasq[30201]: setting upstream servers from DBus
Dec 1 13:21:03 bastion dnsmasq[30201]: using nameserver 192.199.0.2#53
Dec 1 13:21:03 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain in-addr.arpa
Dec 1 13:21:03 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain cluster.local
Dec 1 13:21:33 bastion dnsmasq[30201]: setting upstream servers from DBus
Dec 1 13:21:33 bastion dnsmasq[30201]: using nameserver 192.199.0.2#53
Dec 1 13:21:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain in-addr.arpa
Dec 1 13:21:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain cluster.local
```
### 分析网络功能
你可能有成千上万的云原生应用程序在一个复杂的网络环境中为业务提供服务,其中可能包括虚拟化、多云和混合云。这意味着,作为故障排除的一部分,你应该分析网络连接是否正常工作。弄清 Linux 服务器中网络功能的有用命令包括:`ip addr`、`traceroute`、`nslookup`、`dig` 和 `ping` 等。例如,这是 `ip addr show` 命令的输出:
```
# ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 06:af:52:f8:74:98 brd ff:ff:ff:ff:ff:ff
inet 192.199.0.169/24 brd 192.199.0.255 scope global noprefixroute dynamic eth0
valid_lft 3096sec preferred_lft 3096sec
inet6 fe80::4af:52ff:fef8:7498/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:67:fb:1a:a2 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:67ff:fefb:1aa2/64 scope link
valid_lft forever preferred_lft forever
....
```
### 总结
对 Linux 硬件进行故障排除需要大量的知识,包括如何使用功能强大的命令行工具以及找出系统日志记录。 你还应该知道如何诊断内核空间,在那里你可以找到许多硬件问题的根本原因。请记住,Linux 中的硬件问题可能来自许多不同的来源,包括设备、模块、驱动程序、BIOS、网络,甚至是普通的旧硬件故障。
---
via: <https://opensource.com/article/18/12/troubleshooting-hardware-problems-linux>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Linux servers](https://opensource.com/article/18/5/what-linux-server) run mission-critical business applications in many different types of infrastructures including physical machines, virtualization, private cloud, public cloud, and hybrid cloud. It's important for Linux sysadmins to understand how to manage Linux hardware infrastructure—including software-defined functionalities related to [networking](https://opensource.com/article/18/11/intro-software-defined-networking), storage, Linux containers, and multiple tools on Linux servers.
It can take some time to troubleshoot and solve hardware-related issues on Linux. Even highly experienced sysadmins sometimes spend hours working to solve mysterious hardware and software discrepancies.
The following tips should make it quicker and easier to troubleshoot hardware in Linux. Many different things can cause problems with Linux hardware; before you start trying to diagnose them, it's smart to learn about the most common issues and where you're most likely to find them.
## Quick-diagnosing devices, modules, and drivers
The first step in troubleshooting usually is to display a list of the hardware installed on your Linux server. You can obtain detailed information on the hardware using **ls** commands such as ** lspci**,
**,**
[lsblk](https://linux.die.net/man/8/lsblk)**, and**
[lscpu](https://linux.die.net/man/1/lscpu)**. For example, here is output of the**
[lsscsi](https://linux.die.net/man/8/lsscsi)**lsblk**command:
```
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 50G 0 disk
├─xvda1 202:1 0 1M 0 part
└─xvda2 202:2 0 50G 0 part /
xvdb 202:16 0 20G 0 disk
└─xvdb1 202:17 0 20G 0 part
```
If the **ls** commands don't reveal any errors, use init processes (e.g., **systemd**) to see how the Linux server is working. **systemd** is the most popular init process for bootstrapping user spaces and controlling multiple system processes. For example, here is output of the **systemctl status** command:
```
# systemctl status
● bastion.f347.internal
State: running
Jobs: 0 queued
Failed: 0 units
Since: Wed 2018-11-28 01:29:05 UTC; 2 days ago
CGroup: /
├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
├─kubepods.slice
│ ├─kubepods-pod3881728a_f2af_11e8_af77_06af52f87498.slice
│ │ ├─docker-88b27385f4bae77bba834fbd60a61d19026bae13d18eb147783ae27819c34967.scope
│ │ │ └─23860 /opt/bridge/bin/bridge --public-dir=/opt/bridge/static --config=/var/console-config/console-c
│ │ └─docker-a4433f0d523c7e5bc772ee4db1861e4fa56c4e63a2d48f6bc831458c2ce9fd2d.scope
│ │ └─23639 /usr/bin/pod
....
```
## Digging into multiple loggings
**Dmesg** allows you to figure out errors and warnings in the kernel's latest messages. For example, here is output of the **dmesg | more** command:
```
# dmesg | more
....
[ 1539.027419] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 1539.042726] IPv6: ADDRCONF(NETDEV_UP): veth61f37018: link is not ready
[ 1539.048706] IPv6: ADDRCONF(NETDEV_CHANGE): veth61f37018: link becomes ready
[ 1539.055034] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
[ 1539.098550] device veth61f37018 entered promiscuous mode
[ 1541.450207] device veth61f37018 left promiscuous mode
[ 1542.493266] SELinux: mount invalid. Same superblock, different security settings for (dev mqueue, type mqueue)
[ 9965.292788] SELinux: mount invalid. Same superblock, different security settings for (dev mqueue, type mqueue)
[ 9965.449401] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 9965.462738] IPv6: ADDRCONF(NETDEV_UP): vetheacc333c: link is not ready
[ 9965.468942] IPv6: ADDRCONF(NETDEV_CHANGE): vetheacc333c: link becomes ready
....
```
You can also look at all Linux system logs in the **/var/log/messages** file, which is where you'll find errors related to specific issues. It's worthwhile to monitor the messages via the **tail** command in real time when you make modifications to your hardware, such as mounting an extra disk or adding an Ethernet network interface. For example, here is output of the **tail -f /var/log/messages** command:
```
# tail -f /var/log/messages
Dec 1 13:20:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain in-addr.arpa
Dec 1 13:20:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain cluster.local
Dec 1 13:21:03 bastion dnsmasq[30201]: setting upstream servers from DBus
Dec 1 13:21:03 bastion dnsmasq[30201]: using nameserver 192.199.0.2#53
Dec 1 13:21:03 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain in-addr.arpa
Dec 1 13:21:03 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain cluster.local
Dec 1 13:21:33 bastion dnsmasq[30201]: setting upstream servers from DBus
Dec 1 13:21:33 bastion dnsmasq[30201]: using nameserver 192.199.0.2#53
Dec 1 13:21:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain in-addr.arpa
Dec 1 13:21:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domain cluster.local
```
## Analyzing networking functions
You may have hundreds of thousands of cloud-native applications to serve business services in a complex networking environment; these may include virtualization, multiple cloud, and hybrid cloud. This means you should analyze whether networking connectivity is working correctly as part of your troubleshooting. Useful commands to figure out networking functions in the Linux server include **ip addr**, **traceroute**, **nslookup**, **dig**, and **ping**, among others. For example, here is output of the **ip addr show** command:
```
# ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 06:af:52:f8:74:98 brd ff:ff:ff:ff:ff:ff
inet 192.199.0.169/24 brd 192.199.0.255 scope global noprefixroute dynamic eth0
valid_lft 3096sec preferred_lft 3096sec
inet6 fe80::4af:52ff:fef8:7498/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:67:fb:1a:a2 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:67ff:fefb:1aa2/64 scope link
valid_lft forever preferred_lft forever
....
```
## In conclusion
Troubleshooting Linux hardware requires considerable knowledge, including how to use powerful command-line tools and figure out system loggings. You should also know how to diagnose the kernel space, which is where you can find the root cause of many hardware problems. Keep in mind that hardware issues in Linux may come from many different sources, including devices, modules, drivers, BIOS, networking, and even plain old hardware malfunctions.
## 7 Comments |
11,954 | 开源软件许可出毛病了? | https://opensource.com/article/20/2/open-source-licensing | 2020-03-03T17:18:26 | [
"许可证"
] | https://linux.cn/article-11954-1.html |
>
> 对于让开源软件变得如此出色的协作开发来说,开源软件许可以其不同于常规软件许可的方式提供了诸多支持。
>
>
>

人们在使用常规软件许可时产生的实践和期望,也许会让他们在面对开源软件时感到沮丧。“请给我看下许可证”这种简单的要求,可能得不到令人满意的答复。尽管有的时候这种答复非常简单,但开源软件的许可信息通常更为复杂,达不到常规软件许可所设定的那种期望。
这是怎么回事儿呢?开源软件许可是否出毛病了?然而并没有。许可条款类型以及软件开发方式的差异,都会导致软件许可信息的传送方式不同。律师便利性和开发人员便利性之间的折衷是造成这种状况的部分原因。
如果只是说开源软件可以“协作”开发,那还没有弄清楚开源开发活动与常规许可软件之间可能存在的差别程度。尽管有像常规许可软件一样由一个人或一个固定的小团体来维护的开源项目,但是在开源项目上的协作可能会在广泛的潜在贡献者之间进行。例如,根据 GitHub 的“[2019 年 Octoverse 报告](https://octoverse.github.com/#dependencies-overview)” ,有超过 35 万人对前 1000 个项目做出了贡献。但是,开源软件开发与常规许可软件开发的不同之处不仅仅是贡献者数量。除了被发现对该开源项目拥有某些共同兴趣,为开源项目做出贡献的人们之间可能没有任何联系。人们的参与情况可能会随着时间的推移而变化。原始开发人员可能会离开,留下其他人继续进行项目开发。所有这一切都可能在没有规划或总体治理组织的情况下发生。
除了遵循规范性的治理规则,开源协作活动还是轻量级的,而且可以比常规许可软件更加灵敏地响应。有关开源许可信息的实践与这种协作开发方式相适应。
1. 针对二进制文件以及源代码,开源许可中的条款通过提供所需的权限(包括复制、修改和分发)促进了协作开发。事实证明,<ruby> “开源定义” <rp> ( </rp> <rt> Open Source Definition </rt> <rp> ) </rp></ruby>(OSD)有助于将注意力集中在满足其要求的许可上。
2. 开源软件的许可信息嵌入在源代码中。当获得源代码时,就会接收到相应的许可信息。想象一下每年以百万计的贡献规模,单独的许可管理是否完全可行呢?同样,通过将许可信息嵌入源代码中,可以反映与许可相关的详细信息,而这些细节在某些单独管理的许可流程中不可行。例如,将许可信息嵌入源代码,使得指示哪些许可条款适用于软件的哪些部分变得切实可行。
为了说明开源许可实践所能实现的效果,请考虑以下示例性软件项目:
该项目始于 5 年前;到目前为止,已有 50 位贡献者做出了贡献;通过改编其他项目中的部分软件,增加了一些功能;原始代码的开发者在三年后离开;几家商业企业已经在其内部或一部分产品中依赖该软件;如果考虑到其他软件和计算机世界方面相关的变化,则该软件未来可能还会有 5-10 年的发展。
在开源项目中现有和常用的表示许可信息的方法,很容易适应这样一个项目的过程。没有预先规划,贡献者可以从项目中来来去去;项目的各个部分遵循不同的许可条款;如果与其他公司的合作破裂,商业企业可以继续以很少的管理开销成本分担软件维护工作,同时保持完全独立开发其软件分支的能力。
相反,传统的软件许可方法将如何支持这种开发呢?甚至这样的合作有可能发生吗?我们是否将拥有一个完整的许可基础结构来跟踪数千个“主软件开发和分发协议”的适用性?我们是否要通过让某些公司控制一切来简化许可?
让我们回到“是什么许可?”这个问题。我谈论开源开发特征的目的,是说明存在重要的影响开源许可信息如何表示的非法律因素。开源软件中许可信息的表示形式通常不符合常规软件许可的期望。但是,存在差异并不代表系统出毛病了。相反,对于支持过去二十年中已被证明有效的大规模协作开发这种软件构建方法来说,差异的作用非常强大。
### 开源许可信息是什么样的呢?
通常,人们会考虑每个“软件组件”的许可条款。软件组件可能作为应用程序对用户可见,或者对于用户来说可能不那么明显,例如与大型程序结合使用时可提供某些功能的库。
对于许多软件组件而言,许可很简单:组件中的所有软件适用数十种最常见的开源许可证中的一种。除了最常见的许可证之外,还有很多文本有所变动的不经常使用的许可证。但是,在“开源定义”的指导下,开源许可条款中的权限和限制仍保持在一定范围内。
如果要进行将开源软件集成到其他软件中的软件开发,那么你需要了解适用于所集成软件的所有<ruby> “左版” <rp> ( </rp> <rt> Copyleft </rt> <rp> ) </rp></ruby>条款(例如著名的 GPL 系列许可证)。
由于从我对开源软件开发方式的讨论中揭示的显而易见的原因,许可信息可能比单个许可证更为复杂。
1. 尽管一个软件组件可能有一个主要的“项目许可”,但可能有一部分软件遵循其他许可证。这可能会导致在源代码的各个部分中出现不同的许可声明。
2. 一些项目的做法是在每个源文件中放置版权声明。其他项目主要依靠放置包含许可文本的一个或多个文件。
3. 版权声明指示谁可能是该软件部分的版权拥有者(但是,鉴于版权声明实践的多样性,该指示的作用可能微不足道)。
4. 用来构建软件组件的源代码可以包括未反映在所得组件中的软件,例如与测试或构建相关的文件。这对于使用无 GPL 规则(项目中可能包含遵循 GPL 许可证的文件,但用于生成可执行程序的文件不得包含遵循GPL许可证的文件)的人可能很重要。
因为许多细节都与某些许可信息涉及的软件部分有关,这种细粒度的许可信息在源代码中最有效地进行了传达。在最详细的级别上,[源代码即许可证](https://opensource.com/article/17/12/source-code-license)。当许可信息在源代码中时,可以用与源代码相同的方式(例如在版本控制系统中)来维护该许可信息,并且该信息固有地可用于获得源代码的任何人。
从源代码中提取许可信息并创建许可条款概要似乎很简单。但是,对于一个人或一个公司来说足够了的摘要,可能对于另一个人或公司是不足的。不同的人可能关注不同的许可信息细节。一些人可能想确切地知道该软件的哪些组件遵循“左版”条款。其他人可能并不关心所有组件的许可条款概要。还有的人可能需要包括每个不同的版权声明在内的所有许可声明。
你想查看哪些许可信息的细节呢?在软件开发中有大量的工具可以使用。扫描、提取和报告现有许可信息的工具是持续开发的活跃主题。现在,“是什么许可?”可能会改写为“向我显示许可信息报告”,该报告可能包括一系列程度不同的详细信息,具体取决于对请求报告的人的重要性。在最详细的级别上,源代码即许可证。
因为软件可以采用不同的方式构建出来,常规软件许可和开源软件许可分别适用于不同的领域。两者之间可能存在差异,对于这一点要做好准备。
---
作者简介:Scott Peterson 是红帽公司法律团队成员。很久以前,一位工程师就一个叫做 GPL 的奇怪文件向 Scott 征询法律建议,这个致命的问题让 Scott 走上了探索包括技术标准和开源软件在内的协同开发法律问题的纠结之路。
译者简介:薛亮,集慧智佳知识产权咨询公司互联网事业部总监,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | Practices and expectations that one may have developed in working with conventional software licensing may lead to frustration when confronting open source software. The modest request, "Please, just show me the license" may be met with an unsatisfying response. While sometimes the response is very simple, often, the license information for open source software is more complicated and does not match the expectations set by conventional software licensing.
What's up? Is open source software licensing broken? No. Differences, not just in the type of license terms, but in how the software is developed, lead to differences in how software license information is conveyed. In part, this results from tradeoffs between lawyer convenience and developer convenience.
To say that open source software can be developed 'collaboratively' does not begin to capture the extent to which open source development activities may differ from those for conventionally-licensed software. While there are open source projects that, like conventionally-licensed software, are maintained by a single person or by a small, fixed group, collaboration on open source projects can take occur between a wide range of potential contributors. For example, [GitHub's](https://octoverse.github.com/#dependencies-overview)[ annual Octoverse report for 2019](https://octoverse.github.com/#dependencies-overview) says that over 350,000 people contributed to the top 1,000 projects). But it is not just the number of contributors that sets this apart from the development of conventionally licensed software. The people contributing to an open source project may have no connection among themselves other than having discovered some shared interest in that software project. Participation may evolve over time. The original developer(s) may move on and leave others to continue the development of the project. All this may take place without planning or an overarching governance organization.
Rather than following prescriptive governance rules, open source collaborative activities can be not merely lightweight, but much more responsively ad hoc than would be expected for conventionally licensed software. Practices concerning open source license information are adapted to such collaborative development.
- The terms in open source licenses facilitate collaborative development by providing the needed permissions—copy, modify, distribute—not just for binaries, but for source, too. The Open Source Definition has proven to be a valuable aid in focusing attention on licenses that meet its requirements.
- License information for open source software is embedded in the source code. When one obtains the source code, one receives the corresponding license information. Imagine, at the scale of millions of contributions each year, could separate license management be at all workable? Also, by embedding the license information in the source code, that license information can reflect license-related details that would be impractical to represent in some separately managed license process. For example, embedding in the source code makes it practical to indicate which license terms apply to which portions of the software.
To illustrate what open source license practices accomplish, consider the following example software project: it began five years ago; 50 contributors have contributed so far; several features have been added by adapting portions of software from other projects; the developer of the original code moved on after three years; several commercial enterprises have come to depend on this software, either in one of their products or in-house; this software could have a future of 5-10 more years if updated to take into account changes in other software and relevant aspects of the computing world.
The course of such a project is readily accommodated by existing, commonly used approaches to representing license information in open source projects. With no advance planning, contributors can come and go from the project; portions of the project have different license terms; commercial enterprises can continue to share the work of maintaining the software with little governance overhead cost, and while retaining the ability to go completely independent with their fork of the software, if cooperation with others falls apart.
In contrast, how would conventional approaches to software licensing have operated to support this development? Would this collaboration even have been possible? Are we going to have a whole license infrastructure to keep track of the applicability of thousands of "master software development and distribution agreements?" Are we going to simplify licensing by having a few companies control everything?
Let's return to the question, "What is the license?" My purpose in talking about the characteristics of open source development is to illustrate that there are important non-legal considerations that contribute to how open source license information is represented. The representation of license information in open source software often does not match the expectations of conventional licensing. But, the differences are not a sign of a broken system. Rather, these are differences that support large scale collaborative development of software, an approach to building software that has proven, over the last two decades, to be remarkably powerful.
## What does open source license information look like?
In general, one considers the license terms for each "software component." A software component might be visible to users as an application program, or it might be something less apparent to users, like a library that provides certain functionality when combined with larger programs.
For many software components, the license is simple: one of a dozen of the most common open source licenses applies to all of the software in the component. Beyond those most common licenses, there is a long tail of licenses with text variations that are not frequently used. But, with the guidance of the Open Source Definition, the permissions and restrictions in open source license terms stay within certain bounds.
If you are going to do software development that integrates open source software into other software, then one needs to understand any copyleft terms (such as in the famous GPL family of licenses) that apply to the software being integrated.
For reasons that may be apparent from my discussion of how open source software is developed, license information can be more complicated than a single license.
- While there may be one main "project license" for a software component, there may be portions of the software licensed under other licenses. This may result in different license notices in various parts of the source code.
- Some projects have a practice of putting copyright notices in each source file. Others primarily rely on the presence of one or more files that contain license text.
- Copyright notices give an indication of who might be copyright owners of portions of the software (however, given the variability of copyright notice practices, that indication may be weak).
- The source code from which a software component is built may include software that is not reflected in the resulting component, such as tests or build-related files. This might matter to someone who is using a no-GPL rule (a project might include GPL-licensed files, but not in the files from which the executable program is built).
This fine-grained license information is most efficiently conveyed in the source code, as much of the detail concerns which portions of software certain license information relates to. At the most detailed level, the [source code is the license](https://opensource.com/article/17/12/source-code-license). When the license information is in the source code, that license information can be maintained in the same way as the source code, such as in a version control system, and the information is inherently available to anyone who obtains the source code.
It might seem straightforward to extract the license information from the source code and create a summary of the license terms. However, what might be a good summary for one person or company might be inadequate for another. Different people may focus on different license details. One might want to know exactly which components of the software are under copyleft terms. Someone else might not be concerned about a component-by-component summary. Someone else might want all of the license notices, including every different copyright notice.
What license information details do you want to see? Software development is rich with tools. Tools that scan and extract and report license information exist are an active subject of continuing development. Now, "What is the license?" might be reframed as, "Show me a report of the license information," where that report might include a range of different details depending on what matters to the person requesting the report. At the most detailed level, the source code is the license.
Conventional software licensing and open source software licensing address different worlds—software being built in different ways. Be prepared. Have different expectations.
## Comments are closed. |
11,956 | 使用 Emacs 进行社交并跟踪你的待办事项列表 | https://opensource.com/article/20/1/emacs-social-track-todo-list | 2020-03-04T10:09:26 | [
"Emacs"
] | https://linux.cn/article-11956-1.html |
>
> 在 2020 年用开源实现更高生产力的二十种方式的第十九篇文章中,访问 Twitter、Reddit、 交谈、电子邮件 、RSS 和你的待办事项列表。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 Emacs 做(几乎)所有的事情,第 2 部分
[昨天](/article-11932-1.html),我谈到了如何在 Emacs 中读取电子邮件、访问电子邮件地址和显示日历。Emacs 功能繁多,你还可以将它用于 Twitter、交谈、待办事项列表等等!

要完成所有这些,你需要安装一些 Emacs 包。和昨天一样,用 `Meta+x package-manager` 打开 Emacs 包管理器(Meta 键在大多数键盘上是 `Alt`,在 MacOS 上是 `Option`)。然后通过 `i` 选择以下带有的软件包,然后输入 `x` 进行安装:
```
nnreddit
todotxt
twittering-mode
```
安装之后,按下 `Ctrl+x ctrl+f` 打开 `~/.emacs.d/init.el`,并在 `(custom-set-variables` 行前加上:
```
;; Todo.txt
(require 'todotxt)
(setq todotxt-file (expand-file-name "~/.todo/todo.txt"))
;; Twitter
(require 'twittering-mode)
(setq twittering-use-master-password t)
(setq twittering-icon-mode t)
;; Python3 for nnreddit
(setq elpy-rpc-python-command "python3")
```
按下 `Ctrl+x Ctrl+s` 保存文件,使用 `Ctrl+x Ctrl+c` 退出 Emacs,然后重启 Emacs。
#### 使用 twittering-mode 在 Emacs 中发推

[Twittering-mode](https://github.com/hayamiz/twittering-mode) 是 Twitter 最好的 Emacs 接口之一。它几乎支持 Twitter 的所有功能,并且键盘快捷键也易于使用。
首先,输入 `Meta+x twit` 来启动 twittering-mode。它会提供一个 URL 并提示你启动浏览器来访问它,你登录该 URL 后就能获得授权令牌。将令牌复制并粘贴到 Emacs 中,你的 Twitter 时间线就会加载了。你可以使用箭头键滚动,使用 `Tab` 从一个项目移动到另一个项目,并按回车访问光标所在的 URL。如果光标在用户名上,按回车将在 web 浏览器中打开时间轴。如果你在一条推文的文本上,按回车将回复该推文。你可以用 `u` 创建一个新的推文,用 `Ctrl+c+Enter` 转发一些内容,然后用 `d` 发送一条即时消息——它打开的对话框中有关于如何发送、取消和缩短 URL 的说明。
按 `V` 会打开一个提示让你跳转到其他时间线。输入 `:mentions` 打开你的提及。输入 `:home` 打开你的主时间线,输入用户名将进入该用户的时间线。最后,按 `q` 会退出 twittering-mode 并关闭窗口。
twitter-mode 还有更多功能,我鼓励你阅读它 GitHub 页面上的[完整功能列表](https://github.com/hayamiz/twittering-mode#features)。
#### 在 Emacs 上使用 Todotxt.el 追踪你的待办事项

[Todotxt.el](https://github.com/rpdillon/todotxt.el) 是一个很棒的 [todo.txt](http://todotxt.org/) 待办列表管理器接口。它的快捷键几乎无所不包。
输入 `Meta+x todotxt` 启动它将加载 `todotxt-file` 变量中指定的 `todo.txt` 文件(本文的第一部分中设置了该文件)。在 `todo.txt` 的缓冲区(窗口),你可以按 `a` 添加新任务并和按 `c` 标记它已被完成。你还可以使用 `r` 设置优先级,并使用 `t` 添加项目和上下文。完成事项后只需要按下 `A` 即可将任务移如 `done.txt`。你可以使用 `/` 过滤列表,也可以使用 `l` 刷新完整列表。同样,你可以按 `q` 退出。
#### 在 Emacs 中使用 ERC 进行交谈

Vim 的缺点之一是很难用它与人交谈。另一方面,Emacs 则将 [ERC](https://www.gnu.org/software/emacs/manual/html_mono/erc.html) 客户端内置到默认发行版中。使用 `Meta+x ERC` 启动 ERC,系统将提示你输入服务器、用户名和密码。你可以使用几天前介绍设置 [BitlBee](/article-11856-1.html) 时使用的相同信息:服务器为 `localhost`,端口为 `6667`,相同用户名,无需密码。
ERC 使用起来与其他 IRC 客户端一样。每个频道单独一个缓冲区(窗口),你可以使用 `Ctrl+x ctrl+b` 进行频道间切换,这也可以在 Emacs 中的其他缓冲区之间进行切换。`/quit` 命令将退出 ERC。
#### 使用 Gnus 阅读电子邮件,Reddit 和 RSS

我相信昨天在我提及在 Emacs 中阅读邮件时,许多 Emacs 的老用户会问,“怎么没有 [Gnus](https://www.gnus.org/) 呢?”
这个疑问很合理。Gnus 是一个内置在 Emacs 中的邮件和新闻阅读器,尽管它这个邮件阅读器不支持以 [Notmuch](/article-11807-1.html) 作为搜索引擎。但是,如果你将其配置来阅读 Reddit 和 RSS feed(稍后你将这样做),那么同时使用它来阅读邮件是个聪明的选择。
Gnus 是为阅读 Usenet 新闻而创建的,并从此发展而来。因此,它的很多外观和感觉(以及术语)看起来很像 Usenet 的新闻阅读器。
Gnus 以 `~/.gnus` 作为自己的配置文件。(该配置也可以包含在 `~/.emacs.d/init.el` 中)。使用 `Ctrl+x Ctrl+f` 打开 `~/.gnus`,并添加以下内容:
```
;; Required packages
(require 'nnir)
(require 'nnrss)
;; Primary Mailbox
(setq gnus-select-method
'(nnmaildir "Local"
(directory "~/Maildir")
(nnir-search-engine notmuch)
))
(add-to-list 'gnus-secondary-select-methods
'(nnreddit ""))
```
用 `Ctrl+x Ctrl+s` 保存文件。这分配置告诉 Gnus 从 `~/Maildir` 这个本地邮箱中读取邮件作为主源(参见 `gnus-select-method` 变量),并使用 [nnreddit](https://github.com/dickmao/nnreddit) 插件添加辅源(`gnus-secondary-select-methods` 变量)。你还可以定义多个辅助源,包括 Usenet 新闻(nntp)、IMAP (nnimap)、mbox(nnmbox)和虚拟集合(nnvirtual)。你可以在 [Gnus 手册](https://www.gnus.org/manual/gnus.html) 中了解更多有关所有选项的信息。
保存文件后,使用 `Meta+x Gnus` 启动 Gnus。第一次运行将在 Python 虚拟环境中安装 [Reddit 终端查看器](https://pypi.org/project/rtv/),Gnus 通过它获取 Reddit 上的文章。然后它会启动浏览器来登录 Reddit。之后,它会扫描并加载你订阅的 Reddit 群组。你会看到一个有新邮件的邮件夹列表和一个有新内容的看板列表。在任一列表上按回车将加载该组中的消息列表。你可以使用箭头键导航并按回车加载和读取消息。在查看消息列表时,按 `q` 将返回到前一个视图,从主窗口按 `q` 将退出 Gnus。在阅读 Reddit 群组时,`a` 会创建一条新消息;在邮件组中,`m` 创建一个新的电子邮件;并且在任何一个视图中按 `r` 回复邮件。
你还可以向 Gnus 接口中添加 RSS 流,并像阅读邮件和新闻组一样阅读它们。要添加 RSS 流,输入 `G+R` 并填写 RSS 流的 URL。会有提示让你输入 RSS 的标题和描述,这些信息可以从流中提取出来并填充进去。现在输入 `g` 来检查新消息(这将检查所有组中的新消息)。阅读 RSS 流 就像阅读 Reddit 群组和邮件一样,它们使用相同的快捷键。
Gnus 中有*很多*功能,还有大量的键组合。[Gnus 参考卡](https://www.gnu.org/software/emacs/refcards/pdf/gnus-refcard.pdf)为每个视图列出了所有这些键组合(以非常小的字体显示在 5 页纸上)。
#### 使用 nyan-mode 查看位置
最后,你可能会一些截屏底部注意到 [Nyan cat](http://www.nyan.cat/)。这是 [nyan-mode](https://github.com/TeMPOraL/nyan-mode),它指示了你在缓冲区中的位置,因此当你接近文档或缓冲区的底部时,它会变长。你可以使用包管理器安装它,并在 `~/.emacs.d/init.el` 中使用以下代码进行设置:
```
;; Nyan Cat
(setq nyan-wavy-trail t)
(setq nyan-bar-length 20)
(nyan-mode)
```
### Emacs 的基本功能
这只是 Emacs 所有功能的皮毛。Emacs *非常*强大,是我用来提高工作效率的必要工具之一,无论我是在追踪待办事项、阅读和回复邮件、编辑文本,还是与朋友和同事交流我都用它。这需要一点时间来适应,但是一旦你习惯了,它就会成为你桌面上最有用的工具之一。
---
via: <https://opensource.com/article/20/1/emacs-social-track-todo-list>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Doing (almost) all the things with Emacs, part 2
[Yesterday](https://opensource.com/article/20/1/emacs-mail-calendar), I talked about how to read email, access your addresses, and show calendars in Emacs. Emacs has tons and tons of functionality, and you can also use it for Twitter, chatting, to-do lists, and more!
To do all of this, you need to install some Emacs packages. As you did yesterday, open the Emacs package manager with **Meta**+**x package-manager** (Meta is **Alt** on most keyboards or **Option** on MacOS). Now select the following packages with **i**, then install them by typing **x**:
```
nnreddit
todotxt
twittering-mode
```
Once they are installed, open **~/.emacs.d/init.el** with **Ctrl**+**x Ctrl**+**x**, and add the following before the **(custom-set-variables** line:
```
;; Todo.txt
(require 'todotxt)
(setq todotxt-file (expand-file-name "~/.todo/todo.txt"))
;; Twitter
(require 'twittering-mode)
(setq twittering-use-master-password t)
(setq twittering-icon-mode t)
;; Python3 for nnreddit
(setq elpy-rpc-python-command "python3")
```
Save the file with **Ctrl**+**x Ctrl**+**a**, exit Emacs with **Ctrl**+**x Ctrl**+**c**, then restart Emacs.
### Tweet from Emacs with twittering-mode
[Twittering-mode](https://github.com/hayamiz/twittering-mode) is one of the best Emacs interfaces for Twitter. It supports almost all the features of Twitter and has some easy-to-use keyboard shortcuts.
To get started, type **Meta**+**x twit** to launch twittering-mode. It will give a URL to open—and prompt you to launch a browser with it if you want—so you can log in and get an authorization token. Copy and paste the token into Emacs, and your Twitter timeline should load. You can scroll with the **Arrow** keys, use **Tab** to move from item to item, and press **Enter** to view the URL the cursor is on. If the cursor is on a username, pressing **Enter** will open that timeline in a web browser. If you are on a tweet's text, pressing **Enter** will reply to that tweet. You can create a new tweet with **u**, retweet something with **Ctrl**+**c**+**Enter**, and send a direct message with **d**—the dialog it opens has instructions on how to send, cancel, and shorten URLs.
Pressing **V** will open a prompt to get to other timelines. To open your mentions, type **:mentions**. The home timeline is **:home**, and typing a username will take you to that user's timeline. Finally, pressing **q** will quit twittering-mode and close the window.
There is a lot more functionality available in twittering-mode, and I encourage you to read the [full list](https://github.com/hayamiz/twittering-mode#features) on its GitHub page.
### Track your to-do's in Emacs with Todotxt.el
[Todotxt.el](https://github.com/rpdillon/todotxt.el) is a nice interface for the [todo.txt](http://todotxt.org/) to-do list manager. It has hotkeys for just about everything.
To start it up, type **Meta**+**x todotxt**, and it will load the todo.txt file you specified in the **todotxt-file** variable (which you set in the first part of this article). Inside the buffer (window) for todo.txt, you can press **a** to add a new task and **c** to mark it complete. You can set priorities with **r**, and add projects and context to an item with **t**. When you are ready to move everything to **done.txt**, just press **A**. And you can filter the list with **/** or refresh back to the full list with **l**. And again, you can press **q** to exit.
### Chat in Emacs with ERC
One of Vim's shortcomings is that trying to use chat with it is difficult (at best). Emacs, on the other hand, has the [ERC](https://www.gnu.org/software/emacs/manual/html_mono/erc.html) client built into the default distribution. Start ERC with **Meta**+**x erc**, and you will be prompted for a server name, username, and password. You can use the same information you used a few days ago when you set up [BitlBee](https://opensource.com/article/20/1/open-source-chat-tool): server **localhost**, port **6667**, and the same username with no password. It should be the same as using almost any other IRC client. Each channel will be split into a new buffer (window), and you can switch between them with **Ctrl**+**x Ctrl**+**b**, which also switches between other buffers in Emacs. The **/quit** command will exit ERC.
### Read email, Reddit, and RSS feeds with Gnus
I'm sure many long-time Emacs users were asking, "but what about [Gnus](https://www.gnus.org/)?" yesterday when I was talking about reading mail in Emacs. And it's a valid question. Gnus is a mail and newsreader built into Emacs, although it doesn't support [Notmuch](https://opensource.com/article/20/1/organize-email-notmuch) as a mail reader, just as a search engine. However, if you are configuring it for Reddit and RSS feeds (as you'll do in a moment), it's smart to add in mail functionality as well.
Gnus was created for reading Usenet News and grew from there. So, a lot of its look and feel (and terminology) seem a lot like a Usenet newsreader.
Gnus has its own configuration file in **~/.gnus** (the configuration can also be included in the main **~/.emacs.d/init.el**). Open **~/.gnus** with **Ctrl**+**x Ctrl**+**f** and add the following:
```
;; Required packages
(require 'nnir)
(require 'nnrss)
;; Primary Mailbox
(setq gnus-select-method
'(nnmaildir "Local"
(directory "~/Maildir")
(nnir-search-engine notmuch)
))
(add-to-list 'gnus-secondary-select-methods
'(nnreddit ""))
```
Save the file with **Ctrl**+**x Ctrl**+**s**. This tells Gnus to read mail from the local mailbox in **~/Maildir** as the primary source (**gnus-select-method**) and add a second source (**gnus-secondary-select-methods**) using the [nnreddit](https://github.com/dickmao/nnreddit) plugin. You can also define multiple secondary sources, including Usenet News (nntp), IMAP (nnimap), mbox (nnmbox), and virtual collections (nnvirtual). You can learn more about all the options in the [Gnus manual](https://www.gnus.org/manual/gnus.html).
Once you save the file, start Gnus with **Meta**+**x gnus**. The first run will install [Reddit Terminal Viewer](https://pypi.org/project/rtv/) in a Python virtual environment, which is how it gets Reddit articles. It will then launch your browser to log into Reddit. After that, it will scan and load your subscribed Reddit groups. You will see a list of email folders with new mail and the list of subreddits with new content. Pressing **Enter** on any of them will load the list of messages for the group. You can navigate with the **Arrow** keys and press **Enter** to load and read a message. Pressing **q** will go back to the prior view when viewing message lists, and pressing **q** from the main window will exit Gnus. When reading a Reddit group, **a** creates a new message; in a mail group, **m** creates a new email; and **r** replies to messages in either view.
You can also add RSS feeds to the Gnus interface and read them like mail and newsgroups. To add an RSS feed, type **G**+**R** and fill in the RSS feed's URL. You will be prompted for the title and description of the feed, which should be auto-filled from the feed. Now type **g** to check for new messages (this checks for new messages in all groups). Reading a feed is like reading Reddit groups and mail, so it uses the same keys.
There is a *lot* of functionality in Gnus, and there are a whole lot more key combinations. The [Gnus Reference Card](https://www.gnu.org/software/emacs/refcards/pdf/gnus-refcard.pdf) lists all of them for each view (on five pages in very small type).
### See your position with nyan-mode
As a final note, you might notice [Nyan cat](http://www.nyan.cat/) at the bottom of some of my screenshots. This is [nyan-mode](https://github.com/TeMPOraL/nyan-mode), which indicates where you are in a buffer, so it gets longer as you get closer to the bottom of a document or buffer. You can install it with the package manager and set it up with the following code in **~/.emacs.d/init.el**:
```
;; Nyan Cat
(setq nyan-wavy-trail t)
(setq nyan-bar-length 20)
(nyan-mode)
```
## Scratching Emacs' surface
This is just scratching the surface of all the things you can do with Emacs. It is *very* powerful, and it is one of my go-to tools for being productive whether I'm tracking to-dos, reading and responding to mail, editing text, or chatting with my friends and co-workers. It takes a bit of getting used to, but once you do, it can become one of the most useful tools on your desktop.
## 1 Comment |
11,957 | 开发者需要了解的领域特定语言(DSL) | https://opensource.com/article/20/2/domain-specific-languages | 2020-03-04T11:22:00 | [
"DSL"
] | https://linux.cn/article-11957-1.html |
>
> 领域特定语言是在特定领域下用于特定上下文的语言。作为开发者,很有必要了解领域特定语言的含义,以及为什么要使用特定领域语言。
>
>
>

<ruby> 领域特定语言 <rt> domain-specific language </rt></ruby>(DSL)是一种旨在特定领域下的上下文的语言。这里的领域是指某种商业上的(例如银行业、保险业等)上下文,也可以指某种应用程序的(例如 Web 应用、数据库等)上下文。与之相比的另一个概念是<ruby> 通用语言 <rt> general-purpose language </rt></ruby>(GPL,LCTT 译注:注意不要和 GPL 许可证混淆),通用语言则可以广泛应用于各种商业或应用问题当中。
DSL 并不具备很强的普适性,它是仅为某个适用的领域而设计的,但它也足以用于表示这个领域中的问题以及构建对应的解决方案。HTML 是 DSL 的一个典型,它是在 Web 应用上使用的语言,尽管 HTML 无法进行数字运算,但也不影响它在这方面的广泛应用。
而 GPL 则没有特定针对的领域,这种语言的设计者不可能知道这种语言会在什么领域被使用,更不清楚用户打算解决的问题是什么,因此 GPL 会被设计成可用于解决任何一种问题、适合任何一种业务、满足任何一种需求。例如 Java 就属于 GPL,它可以在 PC 或移动设备上运行,嵌入到银行、金融、保险、制造业等各种行业的应用中去。
### DSL 的类别
从使用方式的角度,语言可以划分出以下两类:
* DSL:使用 DSL 形式编写或表示的语言
* <ruby> 宿主语言 <rt> host language </rt></ruby>:用于执行或处理 DSL 的语言
由不同的语言编写并由另一种宿主语言处理的 DSL 被称为<ruby> 外部 <rt> external </rt></ruby> DSL。
以下就是可以在宿主语言中处理的 SQL 形式的 DSL:
```
SELECT account
FROM accounts
WHERE account = '123' AND branch = 'abc' AND amount >= 1000
```
因此,只要在规定了词汇和语法的情况下,DSL 也可以直接使用英语来编写,并使用诸如 ANTLR 这样的<ruby> 解析器生成器 <rt> parser generator </rt></ruby>以另一种宿主语言来处理 DSL:
```
if smokes then increase premium by 10%
```
如果 DSL 和宿主语言是同一种语言,这种 DSL 称为<ruby> 内部 <rt> internal </rt></ruby>DSL,其中 DSL 由以同一种语义的宿主语言编写和处理,因此又称为<ruby> 嵌入式 <rt> embedded </rt></ruby> DSL。以下是两个例子:
* Bash 形式的 DSL 可以由 Bash 解释器执行:
```
if today_is_christmas; then apply_christmas_discount; fi
```
同时这也是一段看起来符合英语语法的 Bash。
* 使用类似 Java 语法编写的 DSL:
```
orderValue = orderValue
.applyFestivalDiscount()
.applyCustomerLoyalityDiscount()
.applyCustomerAgeDiscount();
```
这一段的可读性也相当强。
实际上,DSL 和 GPL 之间并没有非常明确的界限。
### DSL 家族
以下这些语言都可以作为 DSL 使用:
* Web 应用:HTML
* Shell:用于类 Unix 系统的 sh、Bash、CSH 等;用于 Windows 系统的 MS-DOS、Windows Terminal、PowerShell 等
* 标记语言:XML
* 建模:UML
* 数据处理:SQL 及其变体
* 业务规则管理:Drools
* 硬件:Verilog、VHD
* 构建工具:Maven、Gradle
* 数值计算和模拟:MATLAB(商业)、GNU Octave、Scilab
* 解析器和生成器:Lex、YACC、GNU Bison、ANTLR
### 为什么要使用 DSL?
DSL 的目的是在某个领域中记录一些需求和行为,在某些方面(例如金融商品交易)中,DSL 的适用场景可能更加狭窄。业务团队和技术团队能通过 DSL 有效地协同工作,因此 DSL 除了在业务用途上有所发挥,还可以让设计人员和开发人员用于设计和开发应用程序。
DSL 还可以用于生成一些用于解决特定问题的代码,但生成代码并不是 DSL 的重点并不在此,而是对专业领域知识的结合。当然,代码生成在领域工程中是一个巨大的优势。
### DSL 的优点和缺点
DSL 的优点是,它对于领域的特征捕捉得非常好,同时它不像 GPL 那样包罗万有,学习和使用起来相对比较简单。因此,它在专业人员之间、专业人员和开发人员之间都提供了一个沟通的桥梁。
而 DSL 最显著的缺点就在于它只能用于一个特定的领域和目标。尽管学习起来不算太难,但学习成本仍然存在。如果使用到 DSL 相关的工具,即使对工作效率有所提升,但开发或配置这些工具也会增加一定的工作负担。另外,如果要设计一款 DSL,设计者必须具备专业领域知识和语言开发知识,而同时具备这两种知识的人却少之又少。
### DSL 相关软件
开源的 DSL 软件包括:
* Xtext:Xtext 可以与 Eclipse 集成,并支持 DSL 开发。它能够实现代码生成,因此一些开源和商业产品都用它来提供特定的功能。用于农业活动建模分析的<ruby> 多用途农业数据系统 <rt> Multipurpose Agricultural Data System </rt></ruby>(MADS)就是基于 Xtext 实现的一个项目,可惜的是这个项目现在已经不太活跃了。
* JetBrains MPS:JetBrains MPS 是一个可供开发 DSL 的<ruby> 集成开发环境 <rt> Integrated Development Environment </rt></ruby>,它将文档在底层存储为一个抽象树结构(Microsoft Word 也使用了这一概念),因此它也自称为一个<ruby> 投影编辑器 <rt> projectional editor </rt></ruby>。JetBrains MPS 支持 Java、C、JavaScript 和 XML 的代码生成。
### DSL 的最佳实践
如果你想使用 DSL,记住以下几点:
* DSL 不同于 GPL,DSL 只能用于解决特定领域中有限范围内的问题。
* 不必动辄建立自己的 DSL,可以首先尝试寻找已有的 DSL。例如 [DSLFIN](http://www.dslfin.org/resources.html) 这个网站就提供了很多金融方面的 DSL。在实在找不到合适的 DSL 的情况下,才需要建立自己的 DSL。
* DSL 最好像平常的语言一样具有可读性。
* 尽管代码生成不是一项必需的工作,但它确实会大大提高工作效率。
* 虽然 DSL 被称为语言,但 DSL 不需要像 GPL 一样可以被执行,可执行性并不是 DSL 需要达到的目的。
* DSL 可以使用文本编辑器编写,但专门的 DSL 编辑器可以更轻松地完成 DSL 的语法和语义检查。
如果你正在使用或将要使用 DSL,欢迎在评论区留言。
---
via: <https://opensource.com/article/20/2/domain-specific-languages>
作者:[Girish Managoli](https://opensource.com/users/gammay) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A [domain-specific language](https://en.wikipedia.org/wiki/Domain-specific_language) (DSL) is a language meant for use in the context of a particular domain. A domain could be a business context (e.g., banking, insurance, etc.) or an application context (e.g., a web application, database, etc.) In contrast, a general-purpose language (GPL) can be used for a wide range of business problems and applications.
A DSL does not attempt to please all. Instead, it is created for a limited sphere of applicability and use, but it's powerful enough to represent and address the problems and solutions in that sphere. A good example of a DSL is HTML. It is a language for the web application domain. It can't be used for, say, number crunching, but it is clear how widely used HTML is on the web.
A GPL creator does not know where the language might be used or the problems the user intends to solve with it. So, a GPL is created with generic constructs that potentially are usable for any problem, solution, business, or need. Java is a GPL, as it's used on desktops and mobile devices, embedded in the web across banking, finance, insurance, manufacturing, etc., and more.
## Classifying DSLs
In the DSL world, there are two types of languages:
**Domain-specific language (DSL):**The language in which a DSL is written or presented**Host language:**The language in which a DSL is executed or processed
A DSL written in a distinct language and processed by another host language is called an **external** DSL.
This is a DSL in SQL that can be processed in a host language:
```
SELECT account
FROM accounts
WHERE account = '123' AND branch = 'abc' AND amount >= 1000
```
For that matter, a DSL could be written in English with a defined vocabulary and form that can be processed in another host language using a parser generator like ANTLR:
`if smokes then increase premium by 10%`
If the DSL and host language are the same, then the DSL type is **internal**, where the DSL is written in the language's semantics and processed by it. These are also referred to as **embedded** DSLs. Here are two examples.
- A Bash DSL that can be executed in a Bash engine:
`if today_is_christmas; then apply_christmas_discount; fi`
This is valid Bash that is written like English.
- A DSL written in a GPL like Java:
`orderValue = orderValue .applyFestivalDiscount() .applyCustomerLoyalityDiscount() .applyCustomerAgeDiscount();`
This uses a fluent style and is readable like English.
Yes, the boundaries between DSL and GPL sometimes blur.
## DSL examples
Some languages used for DSLs include:
- Web: HTML
- Shell: sh, Bash, CSH, and the likes for *nix; MS-DOS, Windows Terminal, PowerShell for Windows
- Markup languages: XML
- Modeling: UML
- Data management: SQL and its variants
- Business rules: Drools
- Hardware: Verilog, VHD
- Build tools: Maven, Gradle
- Numerical computation and simulation: MATLAB (commercial), GNU Octave, Scilab
- Various types of parsers and generators: Lex, YACC, GNU Bison, ANTLR
## Why DSL?
The purpose of a DSL is to capture or document the requirements and behavior of one domain. A DSL's usage might be even narrower for particular aspects within the domain (e.g., commodities trading in finance). DSLs bring business and technical teams together. This does not imply a DSL is for business use alone. For example, designers and developers can use a DSL to represent or design an application.
A DSL can also be used to generate source code for an addressed domain or problem. However, code generation from a DSL is not considered mandatory, as its primary purpose is domain knowledge. However, when it is used, code generation is a serious advantage in domain engineering.
## DSL pros and cons
On the plus side, DSLs are powerful for capturing a domain's attributes. Also, since DSLs are small, they are easy to learn and use. Finally, a DSL offers a language for domain experts and between domain experts and developers.
On the downside, a DSL is narrowly used within the intended domain and purpose. Also, a DSL has a learning curve, although it may not be very high. Additionally, although there may be advantages to using tools for DSL capture, they are not essential, and the development or configuration of such tools is an added effort. Finally, DSL creators need domain knowledge as well as language-development knowledge, and individuals rarely have both.
## DSL software options
Open source DSL software options include:
**Xtext:**Xtext enables the development of DSLs and is integrated with Eclipse. It makes code generation possible and has been used by several open source and commercial products to provide specific functions.[MADS](http://mads.sourceforge.net/)(Multipurpose Agricultural Data System) is an interesting idea based on Xtext for "modeling and analysis of agricultural activities" (however, the project seems to be no longer active).**JetBrains MPS:**JetBrains MPS is an integrated development environment (IDE) to create DSLs. It calls itself a projectional editor that stores a document as its underlying abstract tree structure. (This concept is also used by programs such as Microsoft Word.) JetBrains MPS also supports code generation to Java, C, JavaScript, or XML.
## DSL best practices
Want to use a DSL? Here are a few tips:
- DSLs are not GPLs. Try to address limited ranges of problems in the definitive domain.
- You do not need to define your own DSL. That would be tedious. Look for an existing DSL that solves your need on sites like
[DSLFIN](http://www.dslfin.org/resources.html), which lists DSLs for the finance domain. If you are unable to find a suitable DSL, you could define your own. - It is better to make DSLs "like English" rather than too technical.
- Code generation from a DSL is not mandatory, but it offers significant and productive advantages when it is done.
- DSLs are called languages but, unlike GPLs, they need not be executable. Being executable is not the intent of a DSL.
- DSLs can be written with word processors. However, using a DSL editor makes syntax and semantics checks easier.
If you are using DSL now or plan to do so in the future, please share your experience in the comments.
## Comments are closed. |
11,959 | 在 Linux 下使用 fstrim 延长 SSD 驱动器的寿命 | https://opensource.com/article/20/2/trim-solid-state-storage-linux | 2020-03-04T12:16:58 | [
"SSD"
] | https://linux.cn/article-11959-1.html |
>
> 这个新的系统服务可以使你的生活更轻松。
>
>
>

在过去的十年中,固态驱动器(SSD)带来了一种管理存储的新方法。与上一代的转盘产品相比,SSD 具有无声、更冷却的操作和更快的接口规格等优点。当然,新技术带来了新的维护和管理方法。SSD 具有一种称为 TRIM 的功能。从本质上讲,这是一种用于回收设备上未使用的块的方法,该块可能先前已被写入,但不再包含有效数据,因此可以返回到通用存储池以供重用。Opensource.com 的 Don Watkins 首先在其 2017 年的文章《[Linux 固态驱动器:为 SSD 启用 TRIM](/article-8177-1.html)》中介绍过 TRIM 的内容。
如果你一直在 Linux 系统上使用此功能,则你可能熟悉下面描述的两种方法。
### 老的方式
#### 丢弃选项
我最初使用 `mount` 命令的 `discard` 选项启用了此功能。每个文件系统的配置都放在 `/etc/fstab` 文件中。
```
# cat /etc/fstab
UUID=3453g54-6628-2346-8123435f /home xfs defaults,discard 0 0
```
丢弃选项可启用自动的在线 TRIM。由于可能会对性能造成负面影响,最近关于这是否是最佳方法一直存在争议。使用此选项会在每次将新数据写入驱动器时启动 TRIM。这可能会引入其他磁盘活动,从而影响存储性能。
#### Cron 作业
我从 `fstab` 文件中删除了丢弃选项。然后,我创建了一个 cron 作业来按计划调用该命令。
```
# crontab -l
@midnight /usr/bin/trim
```
这是我最近在 Ubuntu Linux 系统上使用的方法,直到我了解到另一种方法。
### 一个新的 TRIM 服务
我最近发现有一个用于 TRIM 的 systemd 服务。Fedora 在版本 30 中将其[引入](https://fedoraproject.org/wiki/Changes/EnableFSTrimTimer "Fedora Project WIKI: Changes/EnableFSTrimTimer"),尽管默认情况下在版本 30 和 31 中未启用它,但计划在版本 32 中使用它。如果你使用的是 Fedora 工作站 31,并且你想要开始使用此功能,可以非常轻松地启用它。我还将在下面向你展示如何对其进行测试。该服务并非 Fedora 独有的服务。它是否存在及其地位将因发行版而异。
#### 测试
我喜欢先进行测试,以更好地了解幕后情况。我通过打开终端并发出配置服务调用的命令来执行此操作。
```
/usr/sbin/fstrim --fstab --verbose --quiet
```
`fstrim` 的 `-help` 参数将描述这些信息和其他参数。
```
$ sudo /usr/sbin/fstrim --help
Usage:
fstrim [options] <mount point>
Discard unused blocks on a mounted filesystem.
Options:
-a, --all trim all supported mounted filesystems
-A, --fstab trim all supported mounted filesystems from /etc/fstab
-o, --offset <num> the offset in bytes to start discarding from
-l, --length <num> the number of bytes to discard
-m, --minimum <num> the minimum extent length to discard
-v, --verbose print number of discarded bytes
--quiet suppress error messages
-n, --dry-run does everything, but trim
-h, --help display this help
-V, --version display version
```
因此,现在我可以看到这个 systemd 服务已配置为在我的 `/etc/fstab` 文件中的所有受支持的挂载文件系统上运行该修剪操作(`-fstab`),并打印出所丢弃的字节数(`-verbose`),但是抑制了任何可能会发生的错误消息(`–quiet`)。了解这些选项对测试很有帮助。例如,我可以从最安全的方法开始,即空运行。我还将去掉 `-quiet` 参数,以便确定驱动器设置是否发生任何错误。
```
$ sudo /usr/sbin/fstrim --fstab --verbose --dry-run
```
这就会显示 `fstrim` 命令根据在 `/etc/fstab` 文件中找到的文件系统要执行的操作。
```
$ sudo /usr/sbin/fstrim --fstab --verbose
```
现在,这会将 TRIM 操作发送到驱动器,并报告每个文件系统中丢弃的字节数。以下是我最近在新的 NVME SSD 上全新安装 Fedora 之后的示例。
```
/home: 291.5 GiB (313011310592 bytes) trimmed on /dev/mapper/wkst-home
/boot/efi: 579.2 MiB (607301632 bytes) trimmed on /dev/nvme0n1p1
/boot: 787.5 MiB (825778176 bytes) trimmed on /dev/nvme0n1p2
/: 60.7 GiB (65154805760 bytes) trimmed on /dev/mapper/wkst-root
```
#### 启用
Fedora Linux 实现了一个计划每周运行它的 systemd 计时器服务。要检查其是否存在及当前状态,请运行 `systemctl status`。
```
$ sudo systemctl status fstrim.timer
```
现在,启用该服务。
```
$ sudo systemctl enable fstrim.timer
```
#### 验证
然后,你可以通过列出所有计时器来验证该计时器是否已启用。
```
$ sudo systemctl list-timers --all
```
会显示出下列行,表明 `fstrim.timer` 存在。注意,该计时器实际上激活了 `fstrim.service` 服务。这是实际调用 `fstrim` 的地方。与时间相关的字段显示为 `n/a`,因为该服务已启用且尚未运行。
```
NEXT LEFT LAST PASSED UNIT ACTIVATES
n/a n/a n/a n/a fstrim.timer fstrim.service
```
### 结论
该服务似乎是在驱动器上运行 TRIM 的最佳方法。这比必须创建自己的 crontab 条目来调用 `fstrim` 命令要简单得多。不必编辑 `fstab` 文件也更安全。观察固态存储技术的发展很有趣,并且我很高兴看到 Linux 似乎正在朝着标准且安全的方向实现它。
在本文中,学习了固态驱动器与传统硬盘驱动器有何不同以及它的含义…
---
via: <https://opensource.com/article/20/2/trim-solid-state-storage-linux>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Over the past decade, solid-state drives (SSD) have brought about a new way of managing storage. SSDs have benefits like silent and cooler operation and a faster interface spec, compared to their elder spinning ancestors. Of course, new technology brings with it new methods of maintenance and management. SSDs have a feature called TRIM. This is essentially a method for reclaiming unused blocks on the device, which may have been previously written, but no longer contain valid data and therefore, can be returned to the general storage pool for reuse. Opensource.com’s Don Watkins first wrote about TRIM in his 2017 article ["Solid-state drives in Linux: Enabling TRIM for SSDs."](https://opensource.com/article/17/1/solid-state-drives-linux-enabling-trim-ssds)
If you have been using this feature on your Linux system, then you are probably familiar with the two methods described below.
## The old ways
### Discard
I initially enabled this with the discard option to the mount command. The configuration is placed into the **/etc/fstab** file for each file system.
```
# cat /etc/fstab
UUID=3453g54-6628-2346-8123435f /home xfs defaults,discard 0 0
```
The discard option enables automatic online TRIM. There has recently been debate on whether this is the best method due to possible negative performance impacts. Using this option causes a TRIM to be initiated every time new data is written to the drive. This may introduce additional activity that interferes with storage performance.
### Cron
I removed the discard option from the **fstab** file. Then I created a cron job to call the command on a scheduled basis.
```
# crontab -l
@midnight /usr/bin/trim
```
This is the method I used most recently on my Ubuntu Linux systems until I learned about another way.
## A new TRIM service
I recently discovered that a systemd service for TRIM exists. Fedora [introduced](https://fedoraproject.org/wiki/Changes/EnableFSTrimTimer) this into their distribution in version 30, and, although it is not enabled by default in versions 30 and 31, it is planned to be in version 32. If you’re working on Fedora Workstation 31 and you want to begin using this feature, you can enable it very easily. I’ll also show you how to test it below. This service is not unique to Fedora. The existence and status will depend on an individual distribution basis.
### Test
I like to test first, to better understand what is happening behind the scenes. I do this by opening a terminal and issuing the command that the service is configured to call.
`/usr/sbin/fstrim --fstab --verbose --quiet`
The **–help** argument to **fstrim** will describe these and other arguments.
```
$ sudo /usr/sbin/fstrim --help
Usage:
fstrim [options] <mount point>
Discard unused blocks on a mounted filesystem.
Options:
-a, --all trim all supported mounted filesystems
-A, --fstab trim all supported mounted filesystems from /etc/fstab
-o, --offset <num> the offset in bytes to start discarding from
-l, --length <num> the number of bytes to discard
-m, --minimum <num> the minimum extent length to discard
-v, --verbose print number of discarded bytes
--quiet suppress error messages
-n, --dry-run does everything, but trim
-h, --help display this help
-V, --version display version
```
So, now I can see that the systemd service is configured to run the trim on all supported mounted filesystems in my **/etc/fstab** file **–fstab** and print the number of discarded bytes **–verbose** but suppress any error messages that might occur **–quiet**. Knowing these options is helpful for testing. For instance, I can start with the safest one, which is the dry run. I’ll also leave off the quiet argument so I can determine if any errors will occur with my drive setup.
`$ sudo /usr/sbin/fstrim --fstab --verbose --dry-run`
This will simply show what the **fstrim** command will do based on the file systems that it finds configured in your **/etc/fstab** file.
`$ sudo /usr/sbin/fstrim --fstab --verbose`
This will now send the TRIM operation to the drive and report on the number of discarded bytes from each file system. Below is an example after my recent fresh install of Fedora on a new NVME SSD.
```
/home: 291.5 GiB (313011310592 bytes) trimmed on /dev/mapper/wkst-home
/boot/efi: 579.2 MiB (607301632 bytes) trimmed on /dev/nvme0n1p1
/boot: 787.5 MiB (825778176 bytes) trimmed on /dev/nvme0n1p2
/: 60.7 GiB (65154805760 bytes) trimmed on /dev/mapper/wkst-root
```
### Enable
Fedora Linux implements systemd timer service, scheduled to run on a weekly basis. To check the existence and current status, run **systemctl status**.
`$ sudo systemctl status fstrim.timer`
Now, enable the service.
`$ sudo systemctl enable fstrim.timer`
### Verify
Then you can verify that the timer is enabled by listing all of the timers.
`$ sudo systemctl list-timers --all`
The following line referring to the **fstrim.timer** will appear. Notice that the timer actually activates **fstrim.service**. This is from where the actual **fstrim** is called. The time-related fields show **n/a** because the service has just been enabled and has not run yet.
```
NEXT LEFT LAST PASSED UNIT ACTIVATES
n/a n/a n/a n/a fstrim.timer fstrim.service
```
## Conclusion
This service seems like the best way to run TRIM on your drives. It is much simpler than having to create your own crontab entry to call the **fstrim** command. It is also safer not having to edit the **fstab** file. It has been interesting to watch the evolution of solid-state storage technology and nice to know that it appears Linux is moving toward a standard and safe way to implement it.
## 5 Comments |
11,960 | Syncthing:开源 P2P 文件同步工具 | https://itsfoss.com/syncthing/ | 2020-03-05T09:42:29 | [
"Syncthing"
] | https://linux.cn/article-11960-1.html |
>
> Syncthing 是一个开源的 P2P 文件同步工具,可用于在多个设备(包括 Android 手机)之间同步文件。
>
>
>

通常,我们有 [MEGA](https://itsfoss.com/install-mega-cloud-storage-linux/) 或 Dropbox 之类的云同步解决方案,以便在云上备份我们的文件,同时更易于共享。但是,如果要跨多个设备同步文件而不将其存储在云中怎么办?
这就是 [Syncthing](https://syncthing.net/) 派上用场的地方了。
### Syncthing:一个跨设备同步文件的开源工具

Syncthing 可让你跨多个设备同步文件(包括对 Android 智能手机的支持)。它主要通过 Linux 上的 Web UI 进行工作,但也提供了 GUI(需要单独安装)。
然而,Syncthing 完全没有利用云,它是 [P2P](https://en.wikipedia.org/wiki/Peer-to-peer) 文件同步工具。你的数据不会被发送到中央服务器。而是会在所有设备之间同步。因此,它并不能真正取代 [Linux 上的典型云存储服务](https://itsfoss.com/cloud-services-linux/)。
要添加远程设备,你只需要设备 ID(或直接扫描二维码),而无需 IP 地址。
如果你想要远程备份文件,那么你可能应该依靠云。

考虑到所有因素,Syncthing 可以在很多方面派上用场。从技术上讲,你可以安全、私密地在多个系统上访问重要文件,而不必担心有人监视你的数据。
例如,你可能不想在云上存储一些敏感文件,因此你可以添加其他受信任的设备来同步并保留这些文件的副本。
即使我对它的描述很简单,但它并不像看到的那么简单。如果你感兴趣的话,我建议你阅读[官方 FAQ](https://docs.syncthing.net/users/faq.html) 来了解它如何工作的。
### Syncthing 的特性
你可能不希望同步工具中有很多选项。它要可靠地同步文件,应该非常简单。
Syncthing 确实非常简单且易于理解。即使这样,如果你想使用它的所有功能,那么也建议你阅读它的[文档](https://docs.syncthing.net/users/index.html)。
在这里,我将重点介绍 Syncthing 的一些有用特性:
#### 跨平台支持

作为开源解决方案,它支持 Windows、Linux 和 macOS。
除此之外,它还支持 Android 智能手机。如果你使用的是 iOS 设备,那么你会感到失望。到目前为止,它还没有支持 iOS 的计划。
#### 文件版本控制

如果替换或删除了旧文件,那么 Syncthing 会利用各种[文件版本控制方法](https://docs.syncthing.net/users/versioning.html)来存档旧文件。
默认情况下,你不会发现它启用。但是,当你创建一个要同步的文件夹时,你将找到将文件版本控制切换为首选方法的选项。
#### 易于使用
作为 P2P 文件同步工具,它无需高级调整即可使用。
但是,它允许你在需要时配置高级设置。
#### 安全和隐私
即使你不与任何云服务提供商共享数据,仍会有一些连接可能会引起窃听者的注意。因此,Syncthing 使用 TLS 保护通信。
此外,它还有可靠的身份验证方法,以确保仅授予只有你允许的设备/连接能够取得同步/读取数据的权限。
对于 Android 智能手机,如果你使用 [Orbot 应用](https://play.google.com/store/apps/details?id=org.torproject.android&hl=en_IN),你还可以强制将流量通过 Tor。在 Android 中你还有几个不同选择。
#### 其他功能

当你探索这个工具时,你会注意到可以同步的文件夹数和可同步的设备数没有限制。
因此,作为一个有着丰富有用特性的自由开源解决方案,对于在寻找 P2P 同步客户端的 Linux 用户而言是一个令人印象深刻的选择。
### 在 Linux 上安装 Syncthing
你可能无法在官网上找到 .deb 或者 .AppImage 文件。但是,你可在 [Snap 商店](https://snapcraft.io/syncthing)中找到 snap 包。如果你好奇,你可以阅读在 Linux 上[使用 snap 应用](https://itsfoss.com/install-snap-linux/)的文章来开始使用。
你可能无法在软件中心找到它(如果你找到了,那它可能不是最新版本)。
**注意:**如果你需要一个 GUI 应用而不是浏览器来管理它,它还有一个 [Syncthing-GTK](https://github.com/syncthing/syncthing-gtk/releases/latest)。
* [Syncthing](https://syncthing.net/)
如果你有基于 Debian 的发行版,你也可以利用终端来安装它,这些说明位于[官方下载页面](https://syncthing.net/downloads/)上。
### 我在 Syncthing 方面的体验
就个人而言,我把它安装在 Pop!\_OS 19.10 上,并在写这篇文章之前用了一会儿。
我尝试同步文件夹、删除它们、添加重复文件以查看文件版本控制是否工作,等等。它工作良好。
然而,当我尝试同步它到手机(安卓),同步启动有点晚,它不是很快。因此,如果我们可以选择显式强制同步,那会有所帮助。或者,我错过了什么选项吗?如果是的话,请在评论中让我知道。
从技术上讲,它使用系统资源来工作,因此,如果你连接了多个设备进行同步,这可能会提高同步速度(上传/下载)。
总体而言,它工作良好,但我必须说,你不应该依赖它作为唯一的数据备份方案。
### 总结
你试过 Syncthing 了吗?如果有的话,你的体验如何?欢迎在下面的评论中分享。
此外,如果你知道一些不错的替代品,也请让我知道。
---
via: <https://itsfoss.com/syncthing/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Syncthing is an open-source peer-to-peer file synchronization tool that you can use for syncing files between multiple devices (including an Android phone).*
Usually, we have a cloud sync solution like [MEGA](https://itsfoss.com/install-mega-cloud-storage-linux/) or Dropbox to have a backup of our files on the cloud while making it easier to share it.
But, what do you do if you want to sync your files across multiple devices without storing them on the cloud?
That is where [Syncthing](https://syncthing.net/) comes to the rescue.
## Syncthing: An open source tool to synchronize files across devices
Syncthing lets you sync your files across multiple devices (including the support for Android smartphones). It primarily works through a web UI on Linux but also offers a GUI (to separately install).
However, Syncthing does not utilize the cloud at all – it is a [peer-to-peer](https://en.wikipedia.org/wiki/Peer-to-peer) file synchronization tool. Your data doesn’t go to a central server. Instead, the data is synced with all the devices between them. So, it does not really replace the [typical cloud storage services on Linux](https://itsfoss.com/cloud-services-linux/).
To add remote devices, you just need the device ID (or simply scan the QR code), no IP addresses involved.
If you want a remote backup of your files – you should probably rely on the cloud.
All things considered, Syncthing can come in handy for a lot of things. Technically, you can have your important files accessible on multiple systems securely and privately without worrying about anyone spying on your data.
For instance, you may not want to store some of the sensitive files on the cloud – so you can add other trusted devices to sync and keep a copy of those files.
Even though I described it briefly, there’s more to it and than meets the eye. I’d also recommend reading the [official FAQ](https://docs.syncthing.net/users/faq.html) to clear some confusion on how it works – if you’re interested.
## Features of Syncthing
You probably do not want a lot of options in a synchronization tool – it should be dead simple to work reliably to sync your files.
Syncthing is indeed quite simple and easy to understand – even though it is recommended that you should go through the [documentation](https://docs.syncthing.net/users/index.html) if you want to use every bit of its functionality.
Here, I’ll highlight a few useful features of Syncthing:
### Cross-Platform Support
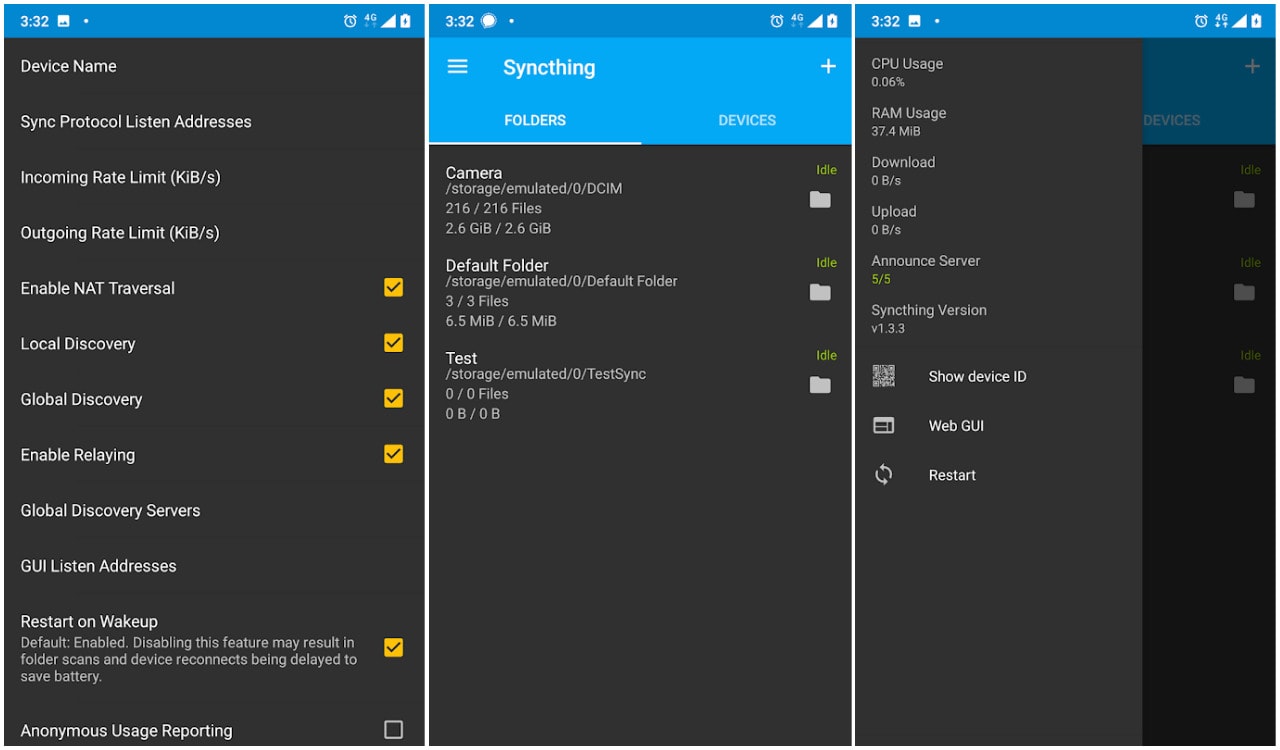
Being an open-source solution, it does support Windows, Linux, and macOS.
In addition to that, it also supports Android smartphones. You’ll be disappointed if you have an iOS device – so far, no plans for iOS support.
### File Versioning
Syncthing utilizes a variety of [File Versioning methods](https://docs.syncthing.net/users/versioning.html) to archive the old files if they are replaced or deleted.
By default, you won’t find it enabled. But, when you create a folder to sync, that’s when you will find the option to toggle the file versioning to your preferred method.
### Easy To Use
While being a peer-to-peer file synchronization tool, it just works out of the box with no advanced tweaks.
However, it does let you configure advanced settings when needed.
### Security & Privacy
Even though you do not share your data with any cloud service providers, there are still some connections made that might gain the attention of an eavesdropper. So, Syncthing makes sure the communication is secured using TLS.
In addition to that, there are solid authentication methods to ensure that only the devices/connections you allow explicitly will be granted access to sync/read data.
For Android smartphones, you can also force the traffic through Tor if you’re using the [Orbot app](https://play.google.com/store/apps/details?id=org.torproject.android&hl=en_IN). You’ll find several other options for Android as well.
### Other Functionalities
When exploring the tool yourself, you will notice that there are no limits to how many folders you can sync and the number of devices that you can sync.
So, being a free and open-source solution with lots of useful features makes it an impressive choice for Linux users looking to have a peer-to-peer sync client.
## Installing Syncthing on Linux
You may not observe a .deb file or an .AppImage file for it on its official download webpage. But, you do get a snap package on the [Snap store](https://snapcraft.io/syncthing) – if you’re curious you can read about [using snap apps](https://itsfoss.com/install-snap-linux/) on Linux to get started.
You may not find it in the software center (if you do – it may not be the latest version).
**Note:** *There’s also a Syncthing-GTK available if you want a GUI to manage that – instead of a browser.*
You can also utilize the terminal to get it installed if you have a Debian-based distro – the instructions are on the [official download page](https://syncthing.net/downloads/).
## My experience with Syncthing
Personally, I got it installed on Pop!_OS 19.10 and used it for a while before writing this up.
I tried syncing folders, removing them, adding duplicate files to see how the file versioning works, and so on. It worked just fine.
However, when I tried syncing it to a phone (Android) – the sync started a bit late, it wasn’t very quick. So, if we could have an option to explicitly force sync, that could help. Or, did I miss the option? Let me know in the comments if I did.
Technically, it uses the resources of your system to work – so if you have a number of devices connected to sync, it should potentially improve the sync speed (upload/download).
Overall, it works quite well – but I must say that you shouldn’t rely on it as the only backup solution to your data.
**Wrapping Up**
Have you tried Syncthing yet? If yes, how was your experience with it? Feel free to share it in the comments below.
Also, if you know about some awesome alternatives to this – let me know about it as well. |
11,961 | 我的愿望清单上的 4 种开源生产力工具 | https://opensource.com/article/20/1/open-source-productivity-tools | 2020-03-05T10:17:00 | [
"生产力"
] | https://linux.cn/article-11961-1.html |
>
> 在 2020 年用开源实现更高生产力的二十种方式的最后一篇文章中,了解开源世界还需要什么。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 然而…
在搜索生产力应用程序时,我找不到想要的所有应用,而且几乎总是会丢失一些读者与我分享的精彩内容。 因此,当我结束本系列文章时,是时候[再次](https://opensource.com/article/19/1/productivity-tool-wish-list)谈论我在本年度系列文章中未能涵盖的一些主题。

#### 在 Vim 中聊天
我试过了。我真的非常、非常想能够在 Vim 中聊天,但我做不到。我找到的一个软件包 [VimIRC.vim](https://github.com/vim-scripts/VimIRC.vim) 一直就工作不起来,我试了几天也没用。我探索的另一个选项是 [Irc it](https://tools.suckless.org/ii/),这需要我付出更多的[努力去设置](https://www.reddit.com/r/vim/comments/48t7ws/vim_ii_irc_client_xpost_runixporn/d0macnl/),超过了我正常可以付出的耐心或时间。我尝试过了,也确实做到了,但对于同处于相同境地的 Vim 用户,对不起,我无法帮到你。
#### Org 模式

我喜欢 [Org 模式](https://orgmode.org/),并且每天都使用它。关于 Org 模式我可以滔滔不绝的说上几天。它提供了基本的[任务跟踪](https://opensource.com/article/20/1/open-source-to-do-list);谷歌[日历](https://opensource.com/article/20/1/open-source-calendar)同步和 [CalFW](https://github.com/kiwanami/emacs-calfw) 集成;富文本文档、网站和演示文稿;链接到任何事物;等等、等等……
我希望你会在 2020 年从我这里收到更多有关 Org 模式的信息,因为它真的很酷。
#### 图形用户界面程序
在 2019 年的生产力系列中,我共享了很多图形用户界面程序,而今年几乎都是命令行应用程序。有一些很棒的图形程序可以帮助解决我今年谈论的一些问题,例如可以使用 Maildir 邮箱的[邮件](https://opensource.com/article/20/1/organize-email-notmuch)程序、用于读取本地日历文件的日历程序、[天气](https://opensource.com/article/20/1/open-source-weather-forecast)应用程序等等。我甚至尝试了几项对我而言新奇的事物,看它们是否适合这个主题。除了 [twin](https://github.com/cosmos72/twin) 之外,我没有感觉到有什么图形用户界面程序是新颖的(对我而言)或值得注意的(同样对我而言)是今年要写的。至于……
#### 移动应用程序
越来越多的人将平板电脑(有时与笔记本电脑结合使用)作为主要设备。我将手机用于大多数社交媒体和即时消息传递,并且经常使用平板电脑(好的,老实说,好几个平板电脑)来阅读或浏览网络。可以肯定的是,并不是没有开源移动应用程序,但是它们与我今年的主题不符。开源和移动应用程序正在发生很多变化,我正在仔细地寻找可以帮助我在手机和平板电脑上提高工作效率的事物。
### 该你了
非常感谢你阅读今年的系列文章。请你发表评论,告诉我错过的或需要在 2021 年看到的内容。正如我在 [Productivity Alchemy](https://productivityalchemy.com) 播客上所说:“哥们,记着:要保持生产力!”
### 本系列汇总
1. [使用 Syncthing 在多个设备间同步文件](/article-11793-1.html)
2. [使用 Stow 管理多台机器配置](/article-11796-1.html)
3. [使用 OfflineIMAP 同步邮件](/article-11804-1.html)
4. [使用 Notmuch 组织你的邮件](/article-11807-1.html)
5. [使用 khal 和 vdirsyncer 组织和同步你的日历](/article-11812-1.html)
6. [用于联系人管理的三个开源工具](/article-11834-1.html)
7. [开始使用开源待办事项清单管理器](/article-11835-1.html)
8. [使用这个 Python 程序记录你的活动](/article-11846-1.html)
9. [一个通过 IRC 管理所有聊天的开源聊天工具](/article-11856-1.html)
10. [使用这个 Twitter 客户端在 Linux 终端中发推特](/article-11858-1.html)
11. [在 Linux 终端中阅读 Reddit](/article-11869-1.html)
12. [使用此开源工具在一起收取你的 RSS 订阅源和播客](/article-11876-1.html)
13. [使用这个开源工具获取本地天气预报](/article-11879-1.html)
14. [使用此开源窗口环境一次运行多个控制台](/article-11892-1.html)
15. [使用 tmux 创建你的梦想主控台](/article-11900-1.html)
16. [使用 Vim 发送邮件和检查日历](/article-11908-1.html)
17. [使用 Vim 管理任务列表和访问 Reddit 和 Twitter](/article-11912-1.html)
18. [使用 Emacs 发送电子邮件和检查日历](/article-11932-1.html)
19. [使用 Emacs 进行社交并跟踪你的待办事项列表](/article-11956-1.html)
20. [我的愿望清单上的 4 种开源生产力工具](/article-11961-1.html)
---
via: <https://opensource.com/article/20/1/open-source-productivity-tools>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## But what about…
When searching for productivity apps, I never find everything I want, and I almost always miss something great that my readers share with me. So, as I bring this series to a close, it's time [again](https://opensource.com/article/19/1/productivity-tool-wish-list) to talk about some of the topics I failed to cover in this year's series.
### Chatting in Vim
I tried. I really, *really* tried to get chat to work in Vim, but it was not to be. The one package I was able to find, [VimIRC.vim](https://github.com/vim-scripts/VimIRC.vim), never did work for me, and I tried for a few days to no avail. The other option I explored was [Irc it](https://tools.suckless.org/ii/), which requires a lot more [effort to set up](https://www.reddit.com/r/vim/comments/48t7ws/vim_ii_irc_client_xpost_runixporn/d0macnl/) than I could fit into my available space or time. I tried, I really did, and for the Vim users out there, I'm sorry I wasn't able to get something workable for you.
### Org mode
I love [Org Mode](https://orgmode.org/), and I use it daily. I could spend several days *just* talking about Org. It provides basic [task tracking](https://opensource.com/article/20/1/open-source-to-do-list); Google [calendar](https://opensource.com/article/20/1/open-source-calendar) sync and [CalFW](https://github.com/kiwanami/emacs-calfw) integration; rich text documents, websites, and presentations; linking to all the things; and; and; and…
I expect you will hear more from me about Org in 2020 because it really is pretty cool.
### GUI programs
In 2019's productivity series, I shared a lot of programs with a graphical user interface (GUI), and this year almost all are command-line applications. There are some great graphical programs to help with some of the things I talked about this year—[mail](https://opensource.com/article/20/1/organize-email-notmuch) programs to talk to Maildir mailboxes, calendar programs to read local calendar files, [weather](https://opensource.com/article/20/1/open-source-weather-forecast) apps, and so on. I even tried several new-to-me things to see if they would fit with the overall theme. With the exception of [twin](https://github.com/cosmos72/twin), I didn't feel that there were any GUI programs that were new (to me) or notable (again, to me) to write about this year. And that brings me to…
### Mobile
More and more people are using tablets (sometimes in conjunction with a laptop) as their primary device. I use my phone for most of my social media and instant messaging, and, more often than not, I use my tablet (OK, let's be honest, *tablets*) to read or browse the web. It isn't that open source mobile apps aren't out there, that's for sure, but they didn't fit with my themes this year. There is a lot going on with open source and mobile apps, and I'm watching carefully for things that can help me be more productive on my phone and tablet.
## Your turn
Thank you very much for reading the series this year. Please comment with what you think I missed or need to look at for 2021. And as I say on the [Productivity Alchemy](https://productivityalchemy.com) podcast: "Remember folks: Stay productive!"
## Comments are closed. |
11,964 | 使用 Fedora 31 和 Nextcloud 服务器构建自己的云 | https://fedoramagazine.org/build-your-own-cloud-with-fedora-31-and-nextcloud-server/ | 2020-03-06T09:32:41 | [
"Nextcloud"
] | https://linux.cn/article-11964-1.html | 
[Nextcloud](https://nextcloud.com/) 是用于跨多个设备存储和同步数据的软件套件。你可以从 [https://github.com/nextcloud/server](https://github.com/nextcloud/server#nextcloud-server-) 了解有关 Nextcloud 服务器的更多特性信息。
本文通过几个简单的步骤演示了如何使用 Fedora 和 Nextcloud 构建个人云。对于本教程,你将需要一台独立计算机或运行 Fedora 31 服务器版的虚拟机,还需要互联网连接。
### 步骤 1:预先安装条件
在安装和配置 Nextcloud 之前,必须满足一些预先条件。
首先,安装 Apache Web 服务器:
```
# dnf install httpd
```
接下来,安装 PHP 和一些其他模块。确保所安装的 PHP 版本符合 [Nextcloud 的要求](https://docs.nextcloud.com/server/17/admin_manual/installation/system_requirements.html#server):
```
# dnf install php php-gd php-mbstring php-intl php-pecl-apcu php-mysqlnd php-pecl-redis php-opcache php-imagick php-zip php-process
```
安装 PHP 后,启用并启动 Apache Web 服务器:
```
# systemctl enable --now httpd
```
接下来,允许 HTTP 流量穿过防火墙:
```
# firewall-cmd --permanent --add-service=http
# firewall-cmd --reload
```
接下来,安装 MariaDB 服务器和客户端:
```
# dnf install mariadb mariadb-server
```
然后启用并启动 MariaDB 服务器
```
# systemctl enable --now mariadb
```
现在,MariaDB 正在运行,你可以运行 `mysql_secure_installation` 命令来保护它:
```
# mysql_secure_installation
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL
MariaDB SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP
CAREFULLY!
In order to log into MariaDB to secure it, we'll need the
current password for the root user. If you've just installed
MariaDB, and you haven't set the root password yet, the password
will be blank, so you should just press enter here.
Enter current password for root (enter for none): <ENTER>
OK, successfully used password, moving on...
Setting the root password ensures that nobody can log into
the MariaDB root user without the proper authorization.
Set root password? [Y/n] <ENTER>
New password: Your_Password_Here
Re-enter new password: Your_Password_Here
Password updated successfully!
Reloading privilege tables...
... Success!
By default, a MariaDB installation has an anonymous user,
allowing anyone to log into MariaDB without having to have
a user account created for them. This is intended only for
testing, and to make the installation go a bit smoother. You
should remove them before moving into a production environment.
Remove anonymous users? [Y/n] <ENTER>
... Success!
Normally, root should only be allowed to connect from
'localhost'. This ensures that someone cannot guess at the
root password from the network.
Disallow root login remotely? [Y/n] <ENTER>
... Success!
By default, MariaDB comes with a database named 'test' that
anyone can access. This is also intended only for testing, and
should be removed before moving into a production environment.
Remove test database and access to it? [Y/n] <ENTER>
- Dropping test database...
... Success!
- Removing privileges on test database...
... Success!
Reloading the privilege tables will ensure that all changes
made so far will take effect immediately.
Reload privilege tables now? [Y/n] <ENTER>
... Success!
Cleaning up...
All done! If you've completed all of the above steps, your
MariaDB installation should now be secure.
Thanks for using MariaDB!
```
接下来,为你的 Nextcloud 实例创建独立的用户和数据库:
```
# mysql -p
> create database nextcloud;
> create user 'nc_admin'@'localhost' identified by 'SeCrEt';
> grant all privileges on nextcloud.* to 'nc_admin'@'localhost';
> flush privileges;
> exit;
```
### 步骤 2:安装 Nextcloud 服务器
现在,你已满足 Nextcloud 安装的预先条件,请下载并解压 [Nextcloud 压缩包](https://nextcloud.com/install/#instructions-server):
```
# wget https://download.nextcloud.com/server/releases/nextcloud-17.0.2.zip
# unzip nextcloud-17.0.2.zip -d /var/www/html/
```
接下来,创建一个数据文件夹,并授予 Apache 对 `nextcloud` 目录树的读写访问权限:
```
# mkdir /var/www/html/nextcloud/data
# chown -R apache:apache /var/www/html/nextcloud
```
SELinux 必须配置为可与 Nextcloud 一起使用。基本命令如下所示,但在 nexcloud 安装中还有很多其他的命令,发布在这里:[Nextcloud SELinux 配置](https://docs.nextcloud.com/server/17/admin_manual/installation/selinux_configuration.html)。
```
# semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/config(/.*)?'
# semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/apps(/.*)?'
# semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/data(/.*)?'
# semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/.user.ini'
# semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/3rdparty/aws/aws-sdk-php/src/data/logs(/.*)?'
# restorecon -Rv '/var/www/html/nextcloud/'
```
### 步骤 3:配置 Nextcloud
可以使用它的 Web 界面或在命令行配置 Nextcloud。
#### 使用 Web 界面
在你喜欢的浏览器中,访问 <http://your_server_ip/nextcloud> 并输入字段:

#### 使用命令行
在命令行中,只需输入以下内容,使用你之前在 MariaDB 中创建的独立 Nextcloud 用户替换相应的值:
```
# sudo -u apache php occ maintenance:install --data-dir /var/www/html/nextcloud/data/ --database "mysql" --database-name "nextcloud" --database-user "nc_admin" --database-pass "DB_SeCuRe_PaSsWoRd" --admin-user "admin" --admin-pass "Admin_SeCuRe_PaSsWoRd"
```
### 最后几点
* 我使用的是 http 协议,但是 Nextcloud 也可以在 https 上运行。我可能会在以后的文章中写一篇有关保护 Nextcloud 的文章。
* 我禁用了 SELinux,但是如果配置它,你的服务器将更加安全。
* Nextcloud 的建议 PHP 内存限制为 512M。要更改它,请编辑 `/etc/php.ini` 配置文件中的 `memory_limit` 变量,然后重新启动 httpd 服务。
* 默认情况下,只能使用 <http://localhost/> URL 访问 Web 界面。如果要允许使用其他域名访问,[你可编辑 /var/www/html/nextcloud/config/config.php 来进行此操作](https://help.nextcloud.com/t/adding-a-new-trusted-domain/26)。`*` 字符可用于绕过域名限制,并允许任何解析为服务器 IP 的 URL 访问。
```
'trusted_domains' =>
array (
0 => 'localhost',
1 => '*',
),
```
---
via: <https://fedoramagazine.org/build-your-own-cloud-with-fedora-31-and-nextcloud-server/>
作者:[storyteller](https://fedoramagazine.org/author/storyteller/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Nextcloud](https://nextcloud.com/) is a software suite for storing and syncing your data across multiple devices. You can learn more about Nextcloud Server’s features from [https://github.com/nextcloud/server](https://github.com/nextcloud/server#nextcloud-server-).
This article demonstrates how to build a personal cloud using Fedora and Nextcloud in a few simple steps. For this tutorial you will need a dedicated computer or a virtual machine running Fedora 31 server edition and an internet connection.
## Step 1: Install the prerequisites
Before installing and configuring Nextcloud, a few prerequisites must be satisfied.
First, install Apache web server:
# dnf install httpd
Next, install PHP and some additional modules. Make sure that the PHP version being installed meets [Nextcloud’s requirements](https://docs.nextcloud.com/server/17/admin_manual/installation/system_requirements.html#server):
# dnf install php php-gd php-mbstring php-intl php-pecl-apcu php-mysqlnd php-pecl-redis php-opcache php-imagick php-zip php-process
After PHP is installed enable and start the Apache web server:
# systemctl enable --now httpd
Next, allow *HTTP* traffic through the firewall:
# firewall-cmd --permanent --add-service=http
# firewall-cmd --reload
Next, install the MariaDB server and client:
# dnf install mariadb mariadb-server
Then enable and start the MariaDB server:
# systemctl enable --now mariadb
Now that MariaDB is running on your server, you can run the *mysql_secure_installation* command to secure it:
# mysql_secure_installation NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY! In order to log into MariaDB to secure it, we'll need the current password for the root user. If you've just installed MariaDB, and you haven't set the root password yet, the password will be blank, so you should just press enter here. Enter current password for root (enter for none):<ENTER>OK, successfully used password, moving on... Setting the root password ensures that nobody can log into the MariaDB root user without the proper authorization. Set root password? [Y/n]<ENTER>New password:Your_Password_HereRe-enter new password:Your_Password_HerePassword updated successfully! Reloading privilege tables... ... Success! By default, a MariaDB installation has an anonymous user, allowing anyone to log into MariaDB without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? [Y/n]<ENTER>... Success! Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? [Y/n]<ENTER>... Success! By default, MariaDB comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? [Y/n]<ENTER>- Dropping test database... ... Success! - Removing privileges on test database... ... Success! Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? [Y/n]<ENTER>... Success! Cleaning up... All done! If you've completed all of the above steps, your MariaDB installation should now be secure. Thanks for using MariaDB!
Next, create a dedicated user and database for your Nextcloud instance:
# mysql -p > create database nextcloud; > create user 'nc_admin'@'localhost' identified by 'SeCrEt'; > grant all privileges on nextcloud.* to 'nc_admin'@'localhost'; > flush privileges; > exit;
## Step 2: Install Nextcloud Server
Now that the prerequisites for your Nextcloud installation have been satisfied, download and unzip [the Nextcloud archive](https://nextcloud.com/install/#instructions-server):
# wget https://download.nextcloud.com/server/releases/nextcloud-17.0.2.zip # unzip nextcloud-17.0.2.zip -d /var/www/html/
Next, create a data folder and grant Apache read and write access to the *nextcloud* directory tree:
# mkdir /var/www/html/nextcloud/data # chown -R apache:apache /var/www/html/nextcloud
SELinux must be configured to work with Nextcloud. The basic commands are those bellow, but a lot more, by features used on nexcloud installation, are posted here: [Nextcloud SELinux configuration](https://docs.nextcloud.com/server/17/admin_manual/installation/selinux_configuration.html)
# semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/config(/.*)?' # semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/apps(/.*)?' # semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/data(/.*)?' # semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/.user.ini' # semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/3rdparty/aws/aws-sdk-php/src/data/logs(/.*)?' # restorecon -Rv '/var/www/html/nextcloud/'
## Step 3: Configure N**extclou**d
Nextcloud can be configured using its web interface or from the command line.
### Using the web interface
From your favorite browser, access *http://your_server_ip/nextcloud* and fill the fields:
### Using the command line
From the command line, just enter the following, substituting the values you used when you created a dedicated Nextcloud user in MariaDB earlier:
# sudo -u apache php occ maintenance:install --data-dir /var/www/html/nextcloud/data/ --database "mysql" --database-name "nextcloud" --database-user "nc_admin" --database-pass "DB_SeCuRe_PaSsWoRd" --admin-user "admin" --admin-pass "Admin_SeCuRe_PaSsWoRd"
## Final Notes
- I used the
*http*protocol, but Nextcloud also works over*https*. I might write a follow-up about securing Nextcloud in a future article. - I disabled SELinux, but your server will be more secure if you configure it.
- The recommend PHP memory limit for Nextcloud is 512M. To change it, edit the
*memory_limit*variable in the*/etc/php.ini*configuration file and restart your*httpd*service. - By default, the web interface can only be accessed using the
*http://localhost/*URL. If you want to allow access using other domain names,[you can do so by editing the](https://help.nextcloud.com/t/adding-a-new-trusted-domain/26). The * character can be used to bypass the domain name restriction and allow the use of any URL that resolves to one of your server’s IP addresses.*/var/www/html/nextcloud/config/config.php*file
'trusted_domains' => array ( 0 => 'localhost', 1 => '*', ),
*— Updated on January 28th, 2020 to include SELinux configuration —*
## Markus
Ok there’s a little thing I take issue with here. It is never acceptable to disable SELinux.
Please update this guide (which seems to be slightly edited copypasta) to actually include the very few very simple steps to ensure functionality with SELinux enabled.
There’s a big problem on the internet that many guides starts with disabling SELinux and I think Fedora Magazine should be part of educating people on good practices instead of being part of the problem.
## Ahmed
Absolutely right! Security should be number one priority.
## Tijmen
Agreed!
## Robin Lee
Nextcloud is great. I already run my own instance. But the problem is connecting to it. I have NC running on a server at home and only reachable by the world as a hidden service i.e. through an .onion-address. I can access my own NC from my laptop anywhere in the world with the Tor browser. Unfortunately Gnome desktop is really bad at handling .onion-addresses though. Wish that would improve
## Jan
Great to see Nextcloud get some attention! It is a great project and has all the features you could ever want from a personal cloud.
I have been a bit disappointed with the Nextcloud hosting providers, so I might use this guide in the future.
If you are going to continue with a writeup, could you elaborate on how to install HTTPS certificates on the server, for best security?
## qoheniac
There is also this cool project that adds some convenience tools around Nextcloud and ships everything as a Docker container: https://ownyourbits.com/2017/11/15/nextcloudpi-dockers-for-x86-and-arm/
## Damien Dye
I recommend usign php-fpm rather than mod_php in apache.
php-fpm is much better at resource control that impact both ram and CPU performace.
## Stuart D Gathman
What is the advantage of nextcloud over owncloud (which is already packaged for Fedora)? Is there a Fedora packaging effort underway for nextcloud?
## Rhea
Nextcloud can not be repackaged (it is packaged in fact) with latest version due to no upgrade path to it. It’s stuck, it’s been stuck for a few years now with many discussions how to solve it, so far without a result. Nextcloud is developed by the original authors of Owncloud but with less business-only features and restrictions and better licensing – see their presentation at FOSDEM 2018: https://archive.fosdem.org/2018/schedule/event/nextcloud
Forther note that Owncloud is also out of date in Fedora with packaged version 9.1 (.fc28!!) and latest 10.8
Do not take either from Fedora repositories or you will lose your data when you will decide to upgrade to the latest. There is no upgrade path for either.
## Eric Nicholls
Owncloud is like Open Office in the Linux world. The project was acquired by a for profit company, so even the original developer moved to a more community friendly environment.
So nextcloud is more like LibreOffice.
## Rohit
Stop disabling SELinux D: —
http://tag1consulting.com/blog/stop-disabling-selinux
## Curt Warfield
Hi,
It’s not a good idea to disable SELinux and our recommended practice is to always have it in enforcing mode.
## Pete Thorsen Jr
First, let me say this, I could be wrong but in my humble opinion it’s wrong to have folks disable SELinux and use the http protocol instead of the https protocol.
Wouldn’t it have been better to include those and make the article better from a security aspect? I know it would have made it longer also but I am not aware of any kind of article length restriction. Of is there?
I’m just saying …
## Héctor Louzao
There is a discussion in fedora devel-list about that:
https://lists.fedoraproject.org/archives/list/[email protected]/thread/R2DBDLZAUSV7S6PBQS5GX44SNC7S3GPL/
Regards.,
## Scott Trakker
Great article!
This is definitely something I want to do in the future!
My ideal setup would be:
Fedora CoreOS
NextCloud Hub
LibreOffice Online
This way we have the perfect modern open source home server!!
Could you (in the future) also write an article with Fedora CoreOS?
## Joe Fidler
Thank you very much for documenting this setup. I rely on both Fedora and NextCloud, so I see needing this in my future.
## Astor D
Thanks for writing this article. It is very useful. An “https” follow-up would be greatly appreciated.
## Stan
I cant accept the fact that disabling SELinux is a step of the article? I see the link of how to configure it, but I think it should be the other way – the article should have the steps, how to configure it and a link, how to disable it. I never disable SELinux and take the extra 15 minutes to configure it and I believe that should be the recommended way to install anything on Fedora/CentOS/etc
## David Juran
Both NextCloud and OwnCloud
arepackaged in Fedora but unfortunately both are more or less abandoned. A volunteer to help out maintaining those would be much appreciated## Narcis
Maybe this link will answer few questions:
https://civihosting.com/blog/nextcloud-vs-owncloud/
## Mario
Does it, in 2020, make sense to make tutorials like these for installing software on a box rather than just using Docker (or Podman for that matter)?
NextCloud has an official image: https://github.com/nextcloud/docker
Note, this is not so much criticism as it is a question 🙂
## D
I totally agree with Mario.
Especially in the case of nextcloud it would be very helpful to have a documented away to configure the various containers required on Fedora with podman.
It’s a non-trivial task if you don’t compromise on security and actually set up CA signed SSL certificates with a reverse proxy
## Mark
I Use OwnCloud currently, although thanks to the link posted by Narcis I will look into NextCloud. However…
OwnCloud client files are still usable in F31, although it is smart enough to irritatingly notify that updates are available.
The OwnCloud server component (owncloud-files) also works on F31, if you use rpm to remove all the ones installed from the Fedora repositories and download the packages the supported location https://download.owncloud.org/download/repositories/production/owncloud/ so there is an update path; if you keep away from the fedora repos; as mentioned by Rhea in an earlier reply the packages in the fedora repos do not work.
I would argue against packaging NextCloud in Fedora repositories for the same reason the OwnCloud server component does not work correctly from Fedora repositories; package maintainers have no reason to keep up with the fast pace of changes in Fedora; if a build works on ubuntu/mint/bsd/fedora and a change in fedora breaks it on fedora why would any developer risk changing a working code base because fedora changed the rules (remember they are not being paid by fedora users to support this free software, if it works on the majority of linux OS’s they are not going to change it because a change in fedora breaks it). Packages disappear from (or simply stop working from) the Fedora repos with every Fedora update so the reply earlier that the version of owncloud in the fedora repos does not work is to be expected rather than a surprise.
Apart from that, I mentioned the OwnCloud client packaged with the Fedora31 repos still worked and it slots nicely into the gnome file manager so I have a big green tick on owncloud and dropbox folders when seen from the file manager; in fact I use the Fedora client to sync files between a combination of F30 and F31 desktops via my local owncloud server.
The point of the above paragraph is that this post is about setting up the server side of NextCloud. Nice but totally useless to have a server side without integrated client software.
It would be useful if a followup up post (or addition to this post) on what desktop clients are available to use with NextCloud for those like me that have never heard of it.
For example as it is based on OwnCloud will the existing OwnCloud clients in the Fedora repos be able to sync files in the background via a NextCloud server or are there separate clients readers of the post need to be aware of.
On the many comments on the preference to never disable SELinux I agree. If it was a package in a repo I would expect a SELinux policy to be available and installed as part of the package if it was needed for the application to work; absence of a policy for any application (writing a policy is simple) implies they are not quite sure how it works.
## Rhea
Maybe there is upgrade path for Owncloud for now, but not for long. You can’t upgrade cross-major versions. That was what I meant, Nextcloud in Fedora is several major versions behind. Owncloud will get to the same situation sooner or later – it wasn’t updated in something like two years now.
## Mark
Thanks Rhea for clarifying.
You are also correct on OwnCloud not being updated for a few years, and it simply not working on any OS with an up-to-date version of php for over a year before they got around to updating the app which was a major pain for me.
An interesting observation you made that the NextCloud packages available in the repositories are also a few major versions behind, which I guess is why the article downloads them directly from the nextcloud site. For users that may do a ‘dnf search nextcloud’ note Rheas comment above and don’t use the packages but follow the instructions in the article instead.
With any app sourced from other than the Fedora repo you cannot guarantee it will keep working with Fedora which is to be expected; as long as users expect that installing packages like NextCloud as discussed in this article should be embraced by users for the short term functionality gained, as long as they do not rely on it.
Although it always supprises me the number of packages in the Fedora repos that just do not work on Fedora anymore.
## K. de Jong
Why isn’t my comment approved? I also think it’s not acceptable for Fedora to publish a guide which starts with disabling SELinux.
## Thomas Klein
Thanks for including the steps regading SELinux! I remember that was a bit on the trick side (even with the help of NC readmes) when I had to find out how to do this for running NC on my Fedora Server. Disabling SELinux, like most of us have agreed here, is not an option. Certainly not for a server 🙂
Regarding SSL certificates, I have this up and running with let’s encrypt certbot, deployed on nginx, serving NC and WordPress. And it was a PITA to get this working for someone like me who still feels like a “newbie” on Linux and with web servers.
I was about to write an article here about the whole shebang, but am still reluctant to do so, as I still feel I’m not a savvy linux user who knows what he’s doing and who should tell more experienced people how to setup somthing 😉
Anyways, to whom it may concern, here’s how to run NC with letsencrypt certificates. Your mileage may vary as it is based on nginx running on ubuntu. Sigh.
https://draculaservers.com/tutorials/install-nextcloud-nginx-ubuntu/
You probably are lucky with searching on Google for a combination of keywords that suits your intended setup like “apache letsencrypt fedora” etc. Cheers, Thomas
## J.Goutin
Nextcloud works well on Fedora. have been using it daily for and that I am very happy with it.
Concerning the setup, I personally use Ansible to deploy and fully configure Nextcloud.
I have an Ansible role here if somebody is interested (Part of a larger collection for Fedora): https://github.com/JGoutin/ansible_home/tree/master/roles/nextcloud
## Vic
Hi,
After you edit the article to use SELinux, you let this line:
“I disabled SELinux, but your server will be more secure if you configure it.”
Thanks for the article !
## dffr
this is not cloud, this is web serwer with some functionality
cloud are morre, more
diskless machine, etc
## Felix Calderon
Please help with:
Could not open input file: occ
## P-Kay
I prefer docker-compose. There are some official examples on https://github.com/nextcloud/docker/tree/master/.examples (insecure or with nginx proxy). Works fine, also with LDAPS (LDAP SSL). Just take not the alpine nextcloud image and copy the certs via bash. |
11,966 | 通过 find 命令找到你要找的东西 | https://www.networkworld.com/article/3527420/how-to-find-what-you-re-looking-for-on-linux-with-find.html | 2020-03-06T11:39:37 | [
"find",
"查找"
] | https://linux.cn/article-11966-1.html |
>
> find 命令有巨多的选项可以帮助你准确定位你在 Linux 系统上需要寻找的文件。这篇文章讨论了一系列非常有用的选项。
>
>
>

在 Linux 系统上有许多用于查找文件的命令,而你在使用它们时也有巨多的选项可以使用。
例如,你不仅可以通过文件的名称来查找文件,还可以通过文件的所有者或者组、它们的创建时间、大小、分配的权限、最后一次访问它们的时间、关联的信息节点,甚至是文件是否属于系统上不再存在的帐户或组等等来查找文件。
你还可以指定搜索从哪里开始,搜索应该深入到文件系统的什么位置,以及搜索结果将告诉你它所找到的文件的数量。
而所有这些要求都可以通过 `find` 命令来处理。
下面提供了根据这些要求查找文件的示例。在某些命令中,错误(例如试图列出你没有读取权限的文件)输出将被发送到 `/dev/null`,以便我们不必查看它。或者,我们可以简单地以 root 身份运行以避免这个问题。
请记住,还有更多的其他选项。这篇文章涵盖了很多内容,但并不是 `find` 命令帮助你定位查找文件的所有方式。
### 选择起点
使用 `find`,你可以选择一个起点或从你所在的位置开始。要选择的搜索的起点,请在单词 `find` 后输入它。例如,`find /usr` 或 `find ./bin` 将在 `/usr` 目录或当前位置下的 `bin` 目录开始搜索,而 `find ~` 将在你的主目录中开始搜索,即使你当前位于当前文件系统中的其他位置。
### 选择你要找的
最常用的搜索策略之一是按名称搜索文件。这需要使用 `-name` 选项。
默认情况下,`find` 会显示找到的文件的完整路径。如果你在命令中添加 `-print`,你会看到同样的结果。如果你想查看与文件相关的详细信息—-例如:文件的长度、权限等,你需要在你的 `find` 命令的末尾添加 `-ls` 参数。
```
$ find ~/bin -name tryme
/home/shs/bin/tryme
$ find ~/bin -name tryme -print
/home/shs/bin/tryme
$ find ~/bin -name tryme -ls
917528 4 -rwx------ 1 shs shs 139 Apr 8 2019 /home/shs/bin/tryme
```
你也可以使用子字符串来查找文件。例如,如果你将上面示例中的 `tryme` 替换为 `try*`,你将会找到所有名称以 `try` 开头的文件。(LCTT 译注:如果要使用通配符 `*` ,请将搜索字符串放到单引号或双引号内,以避免通配符被 shell 所解释)
按名称查找文件可能是 `find` 命令最典型的用法,不过还有很多其他的方式来查找文件,并且有这样做的需要。下面的部分展示了如何使用其他可用的方式。
此外,当按文件大小、组、索引节点等条件来搜索文件时,你需要确认找到的文件与你要查找的文件是否相匹配。使用 `-ls` 选项来显示细节是非常有用。
### 通过大小查找文件
按大小查找文件需要使用 `-size` 选项并且对相应规范使用一点技巧。例如,如果你指定 `-size 189b`,你将找到 189 个块大小的文件,而不是 189 个字节。(LCTT 译注:如果不跟上单位,默认单位是 `b`。一个块是 512 个字节大小,不足或正好 512 个字节将占据一个块。)对于字节,你需要使用 `--size 189c`(字符)。而且,如果你指定 `--size 200w` ,你将会找到 200 个“<ruby> 字 <rt> word </rt></ruby>”的文件——以“双字节增量”为单位的字,而不是“我们互相谈论的那些事情”中的单词。你还可以通过以千字节(`k`)、兆字节(`M`)和千兆字节(`G`)为单位提供大小来查找文件。(LCTT 译注:乃至还有 `T`、`P`)
大多数情况下,Linux 用户会搜索比选定大小要大的文件。例如,要查找大于 1 千兆字节的文件,你可以使用这样的命令,其中 `+1G` 表示“大于 1 千兆字节”:
```
$ find -size +1G -ls 2>/dev/null
787715 1053976 -rw-rw-r-- 1 shs shs 1079263432 Dec 21 2018 ./backup.zip
801834 1052556 -rw-rw-r-- 1 shs shs 1077809525 Dec 21 2018 ./2019/hold.zip
```
### 通过索引节点号查找文件
你可以通过用于维护文件元数据(即除文件内容和文件名之外的所有内容)的索引节点来查找文件。
```
$ find -inum 919674 -ls 2>/dev/null
919674 4 -rw-rw-r-- 1 shs shs 512 Dec 27 15:25 ./bin/my.log
```
### 查找具有特定文件所有者或组的文件
按所有者或组查找文件也非常简单。这里我们使用 `sudo` 来解决权限问题。
```
$ sudo find /home -user nemo -name "*.png" -ls
1705219 4 drwxr-xr-x 2 nemo nemo 4096 Jan 28 08:50 /home/nemo/Pictures/me.png
```
在下面这个命令中,我们寻找一个被称为 `admins` 的多用户组拥有的文件。
```
# find /tmp -group admins -ls
262199 4 -rwxr-x--- 1 dory admins 27 Feb 16 18:57 /tmp/testscript
```
### 查找没有所有者或组的文件
你可以使用如下命令所示的 `-nouser` 选项来查找不属于当前系统上的任何用户的文件。
```
# find /tmp -nouser -ls
262204 4 -rwx------ 1 1016 1016 17 Feb 17 16:42 /tmp/hello
```
请注意,该列表显示了旧用户的 UID 和 GID,这清楚地表明该用户未在系统上定义。这种命令将查找帐户已从系统中删除的用户创建在主目录之外的文件,或者在用户帐户被删除后而未被删除的主目录中创建的文件。类似地,`-nogroup` 选项也会找到这样的文件,尤其是当这些用户是相关组的唯一成员时。
### 按上次更新时间查找文件
在此命令中,我们在特定用户的主目录中查找过去 24 小时内更新过的文件。`sudo` 用于搜索另一个用户的主目录。
```
$ sudo find /home/nemo -mtime -1
/home/nemo
/home/nemo/snap/cheat
/home/nemo/tryme
```
### 按上次更改权限的时间查找文件
`-ctime` 选项可以帮助你查找在某个参考时间范围内状态(如权限)发生更改的文件。以下是查找在最后一天内权限发生更改的文件的示例:
```
$ find . -ctime -1 -ls
787987 4 -rwxr-xr-x 1 shs shs 189 Feb 11 07:31 ./tryme
```
请记住,显示的日期和时间只反映了对文件内容进行的最后更新。你需要使用像 `stat` 这样的命令来查看与文件相关联的三个状态(文件创建、修改和状态更改)。
### 按上次访问的时间查找文件
在这个命令中,我们使用 `-atime` 选项查找在过去两天内访问过的本地 pdf 文件。
```
$ find -name "*.pdf" -atime -2
./Wingding_Invites.pdf
```
### 根据文件相对于另一个文件的时间来查找文件
你可以使用 `-newer` 选项来查找比其他文件更新的文件。
```
$ find . -newer dig1 -ls
786434 68 drwxr-xr-x 67 shs shs 69632 Feb 16 19:05 .
1064442 4 drwxr-xr-x 5 shs shs 4096 Feb 16 11:06 ./snap/cheat
791846 4 -rw-rw-r-- 1 shs shs 649 Feb 13 14:26 ./dig
```
没有相应的 `-older` 选项,但是你可以用 `! -newer` (即更旧)得到类似的结果,它们基本上一样。
### 按类型查找文件
通过文件类型找到一个文件,你有很多选项——常规文件、目录、块和字符文件等等。以下是文件类型选项列表:
```
b 块特殊文件(缓冲的)
c 字符特殊文件(无缓冲的)
d 目录
p 命名管道(FIFO)
f 常规文件
l 符号链接
s 套接字
```
这里有一个寻找符号链接的例子:
```
$ find . -type l -ls
805717 0 lrwxrwxrwx 1 shs shs 11 Apr 10 2019 ./volcano -> volcano.pdf
918552 0 lrwxrwxrwx 1 shs shs 1 Jun 16 2018 ./letter -> pers/letter2mom
```
### 限制查找的深度
`-mindepth` 和 `-maxdepth` 选项控制在文件系统中搜索的深度(从当前位置或起始点开始)。
```
$ find -maxdepth 3 -name "*loop"
./bin/save/oldloop
./bin/long-loop
./private/loop
```
### 查找空文件
在这个命令中,我们寻找空文件,但不进入目录及其子目录。
```
$ find . -maxdepth 2 -empty -type f -ls
917517 0 -rw-rw-r-- 1 shs shs 0 Sep 23 11:00 ./complaints/newfile
792050 0 -rw-rw-r-- 1 shs shs 0 Oct 4 19:02 ./junk
```
### 按权限查找文件
你可以使用 `-perm` 选项查找具有特定权限集的文件。在下面的示例中,我们只查找常规文件(`-type f`),以避免看到符号链接,默认情况下符号链接被赋予了这种权限,即使它们所引用的文件是受限的。
```
$ find -perm 777 -type f -ls
find: ‘./.dbus’: Permission denied
798748 4 -rwxrwxrwx 1 shs shs 15 Mar 28 2019 ./runme
```
### 使用查找来帮助你删除文件
如果使用如下命令,你可以使用 `find` 命令定位并删除文件:
```
$ find . -name runme -exec rm {} \;
```
`{}` 代表根据搜索条件找到的每个文件的名称。
一个非常有用的选项是将 `-exec` 替换为 `-ok`。当你这样做时,`find` 会在删除任何文件之前要求确认。
```
$ find . -name runme -ok rm -rf {} \;
< rm ... ./bin/runme > ?
```
删除文件并不是 `-ok` 和 `-exec` 能为你做的唯一事情。例如,你可以复制、重命名或移动文件。
确实有很多选择可以有效地使用 `find` 命令,毫无疑问还有一些在本文中没有涉及到。我希望你已经找到一些新的,特别有帮助的。
---
via: <https://www.networkworld.com/article/3527420/how-to-find-what-you-re-looking-for-on-linux-with-find.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,967 | 使用 Eclipse 在 Fedora 上进行 PHP 开发 | https://fedoramagazine.org/php-development-on-fedora-with-eclipse/ | 2020-03-06T23:24:37 | [
"PHP",
"Eclipse"
] | https://linux.cn/article-11967-1.html | 
[Eclipse](https://projects.eclipse.org/projects/eclipse) 是由 Eclipse 基金会开发的功能全面的自由开源 IDE。它诞生于 2001 年。你可以在此 IDE 中编写各种程序,从 C/C++ 和 Java 到 PHP,乃至于 Python、HTML、JavaScript、Kotlin 等等。
### 安装
该软件可从 Fedora 的官方仓库中获得。要安装它,请用:
```
sudo dnf install eclipse
```
这将安装基本的 IDE 和 Eclipse 平台,能让你开发 Java 应用。为了将 PHP 开发支持添加到 IDE,请运行以下命令:
```
sudo dnf install eclipse-pdt
```
这将安装 PHP 开发工具,如 PHP 项目向导、PHP 服务器配置,composer 支持等。
### 功能
该 IDE 有许多使 PHP 开发更加容易的功能。例如,它有全面的项目向导(你可以在其中为新项目配置许多选项)。它还有如 composer 支持、调试支持、浏览器、终端等内置功能。
### 示例项目
现在已经安装了 IDE,让我们创建一个简单的 PHP 项目。进入 “File →New → Project”。在出现的对话框中,选择 “PHP project”。输入项目的名称。你可能还需要更改其他一些选项,例如更改项目的默认位置,启用 JavaScript 以及更改 PHP 版本。请看以下截图。

你可以单击 “Finish” 按钮创建项目,或按 “Next” 配置其他选项,例如添加包含和构建路径。在大多数情况下,你无需更改这些设置。
创建项目后,右键单击项目文件夹,然后选择 “New→PHP File” 将新的 PHP 文件添加到项目。在本教程中,我将其命名为 `index.php`,这是每个 PHP 项目中公认的默认文件。

接着在新文件中添加代码。

在上面的例子中,我在同一页面上使用了 CSS、JavaScript 和 PHP 标记,主要是为了展示 IDE 能够支持所有这些标记。
页面完成后,你可以将文件移至 Web 服务器文档根目录或在项目目录中创建一个 PHP 开发服务器来查看输出。
借助 Eclipse 中的内置终端,我们可以直接在 IDE 中启动 PHP 开发服务器。只需单击工具栏上的终端图标,然后单击 “OK”。在新终端中,进入项目目录,然后运行以下命令:
```
php -S localhost:8080 -t . index.php
```

现在,打开浏览器并进入 <http://localhost:8080>。如果按照说明正确完成了所有操作,并且代码没有错误,那么你将在浏览器中看到 PHP 脚本的输出。

---
via: <https://fedoramagazine.org/php-development-on-fedora-with-eclipse/>
作者:[Mehdi Haghgoo](https://fedoramagazine.org/author/powergame/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Eclipse](https://projects.eclipse.org/projects/eclipse) is a full-featured free and open source IDE developed by the Eclipse Foundation. It has been around since 2001. You can write anything from C/C++ and Java to PHP, Python, HTML, JavaScript, Kotlin, and more in this IDE.
## Installation
The software is available from Fedora’s official repository. To install it, invoke:
sudo dnf install eclipse
This will install the base IDE and Eclipse platform, which enables you to develop Java applications. In order to add PHP development support to the IDE, run this command:
sudo dnf install eclipse-pdt
This will install PHP development tools like PHP project wizard, PHP server configurations, composer support, etc.
## Features
This IDE has many features that make PHP development easier. For example, it has a comprehensive project wizard (where you can configure many options for your new projects). It also has built-in features like composer support, debugging support, a browser,a terminal, and more.
## Sample project
Now that the IDE is installed, let’s create a simple PHP project. Go to *File →New → Project*. From the resulting dialog, select *PHP project*. Enter a name for your project. There are some other options you might want to change, like changing the project’s default location, enabling JavaScript, and changing PHP version. See the following screenshot.
You can click the *Finish* button to create the project or press *Next* to configure other options like adding include and build paths. You don’t need to change those in most cases.
Once the project is created, right click on the project folder and select *New → PHP File* to add a new PHP file to the project. For this tutorial I named it *index.php*, the conventionally-recognized default file in every PHP project.
Then add the your code to the new file.
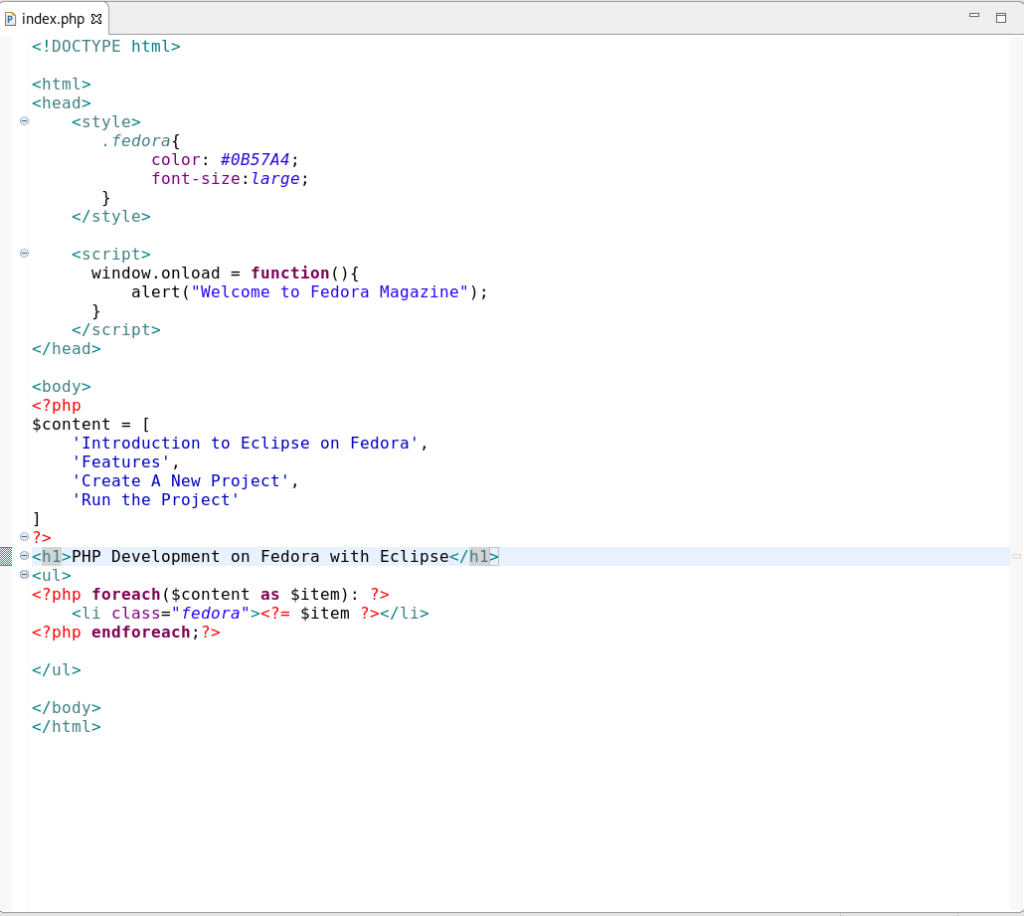
In the example above, I used CSS, JavaScript, and PHP tags on the same page mainly to show that the IDE is capable of supporting all of them together.
Once your page is ready, you can see the result output by moving the file to your web server document root or by creating a development PHP server in the project directory.
Thanks to the built-in terminal in Eclipse, we can launch a PHP development server right from within the IDE. Simply click the terminal icon on the toolbar () and click
*OK*. In the new terminal, change to the project directory and run the following command:
php -S localhost:8080 -t . index.php
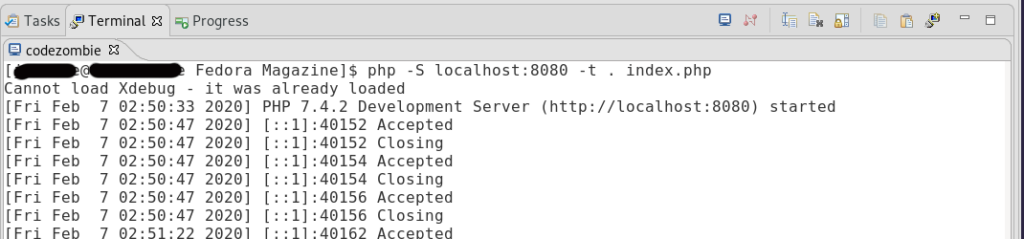
Now, open a browser and head over to http://localhost:8080. If everything has been done correctly per instructions and your code is error-free, you will see the output of your PHP script in the browser.
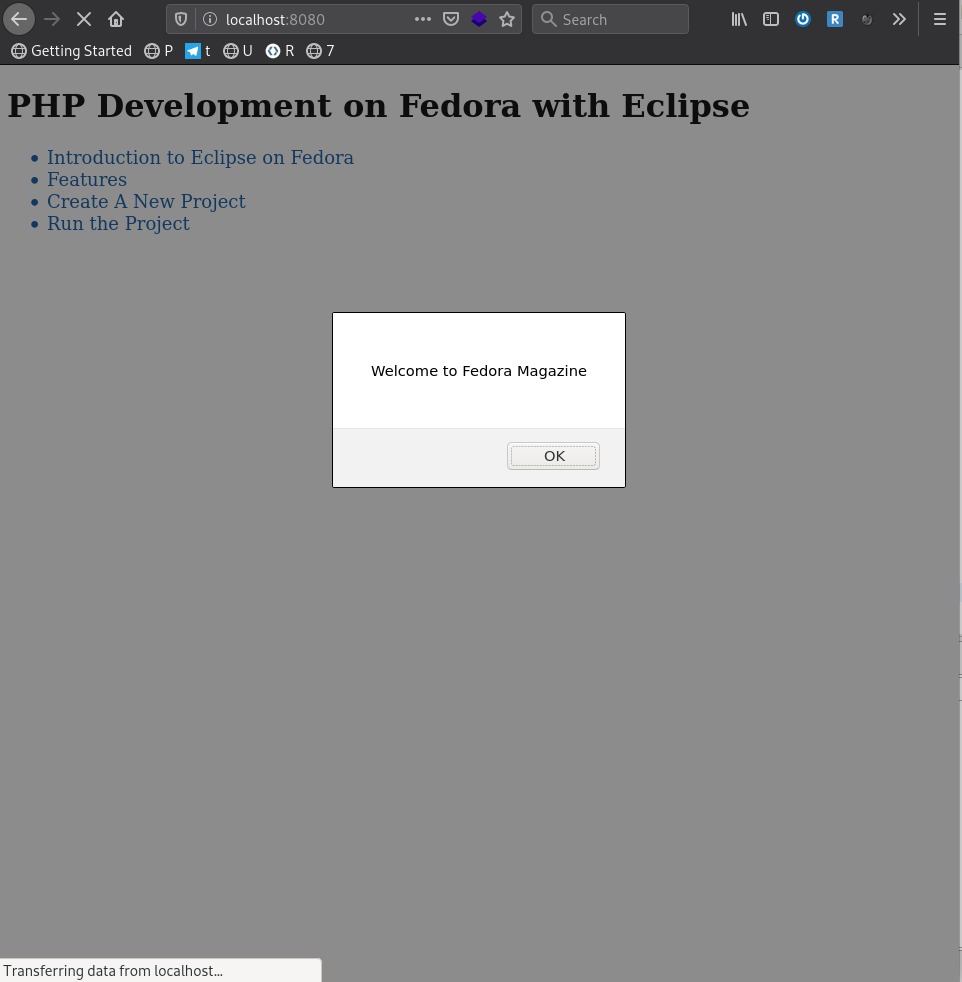
## Truls Gulbrandsen
Unfortunately eclipse seems to be broken:
[root@localhost ~]# dnf install eclipse –skip-broken
Last metadata expiration check: 0:50:05 ago on fr. 14. feb. 2020 kl. 10.33 +0100.
Dependencies resolved.
Problem: package eclipse-jdt-1:4.14-5.fc31.noarch requires eclipse-platform = 1:4.14-5.fc31, but none of the providers can be installed
– package eclipse-platform-1:4.14-5.fc31.x86_64 requires glassfish-el >= 3.0.1, but none of the providers can be installed
– cannot install the best candidate for the job
– package glassfish-el-3.0.1-0.12.b08.module_f31+6519+12cd0b27.noarch is filtered out by modular filtering
– package glassfish-el-3.0.1-0.12.b08.module_f31+6793+1c93c38e.noarch is filtered out by modular filtering
– package glassfish-el-3.0.1-0.11.b08.fc31.noarch is filtered out by modular filtering
Package Architecture Version Repository Size
Skipping packages with broken dependencies:
eclipse-jdt noarch 1:4.14-5.fc31 updates 31 M
eclipse-platform x86_64 1:4.14-5.fc31 updates 40 M
Transaction Summary
Skip 2 Packages
Nothing to do.
Complete!
## Alexander Borro
Download it from the eclipse website and install that way, that usually worked for me. While I do not use it any more eclipse installations have been broken/problematic since forever in Fedora as I recall. I wonder how the author just got it to work.
Also, it has proven to be a pain in any case braking with Java open SDK updates and third party dependencies. I was often fixing things manually with updates.
Today I would not recommend this IDE. I switched to vscode on Fedora a long time ago and everything “just works” once you know what you are doing. Pardon the NVidia ray-tracing quote 🙂
## Mehdi Haghgoo
I have had my problems with Eclipse, mostly in terms of its complexity and very intricate configurations, but I don’t remember seeing its packages broken, at least during the last 4-5 releases I can recall.
## Jeremie Barnes
I was able to install by doing “sudo dnf module enable eclipse:latest”
## Mark LaDoux
That should have been in the article. This fixed mine, I couldn’t install without enabling the module that the article fails to mention. Seeing as the module isn’t enabled by default, it should have been mentioned.
## pgar
true !
## qbl
Thanks, agree it should be in article
## Alexander Yurchenko
I prefer netbeans 😉
netbeans.apache.org
## Mehdi Haghgoo
There was a discussion in Fedora mailing lists to include NetBeans in Fedora. I hope that succeeds. I like NetBeans too.
## Raphael Groner
https://www.quora.com/How-does-PHP-in-the-context-of-Laravel-compare-with-Node-js-for-realtime-web-applications-in-terms-of-real-world-performance-and-development-experience
## Maciej
Yes you can do that, but first add another 32GB of RAM to your PC or you can just use VScode…
## Ben Knobi
… then let the language server consume the 32G of RAM with a few projects open.
## Fedora lover
No one gonna make development like that in 2020 with PHP
Why you make pointless articles about software development. But not making articles directly related with the OS.
## Gregory Bartholomew
“Fedora lover”:
Eclipse is used by millions of developers. Also, the Fedora Project is not
justabout creating an operating system. The Fedora Project’s main goal is actually to “advance free software“.## Bill Chatfield
I think people just like VSCode because it has a black theme. If they actually explored the functionality differences between VSCode and Eclipse, they would not bother with VSCode because it is just a toy compared to Eclipse.
## Kevin
Jetbrains best! |
11,968 | 如何建立自己的快速、私有的开源网状网络(mesh) | https://opensource.com/article/20/2/mesh-network-freemesh | 2020-03-06T23:49:18 | [
"Mesh"
] | https://linux.cn/article-11968-1.html |
>
> 只需要不到 10 分钟的安装时间,就可以用 FreeMesh 搭建一个经济实惠、性能卓越、尊重隐私的网格系统。
>
>
>

[FreeMesh](https://freemeshwireless.com/) 系统有望为大众带来完全开源的<ruby> 网状网络 <rt> mesh network </rt></ruby>(LCTT 译注:也称之为“多跳网络”)。我最近有机会对它进行了测试;它安装迅速,性能非常好 —— 特别是相对它的价格而言。
### 为什么要网格化和开源?
使用开源的原因很简单:隐私。有了 FreeMesh,你的数据就是你自己的。它不会跟踪或收集数据。不相信吗?毕竟,你可以轻松检查 —— 它是开源的!而其它大型高科技企业集团提供的一些流行的网状网络解决方案,你是否相信它们会保护你的数据?
另一个重要因素:更新。FreeMesh 表示,它将致力于定期发布安全性和性能更新。从现在起到 10 年后呢?使用开源解决方案,你可以根据需要自由地更新产品。
那么为什么要用网状网络呢?在网状网络中,多个无线路由器一起工作以广播单个超大型的无线网络。网状网络中的每个路由器都可与其他路由器智能地通信,以便为你的数据提供最佳的“路径”。FreeMesh 网站上的以下图片突出显示了使用单个无线路由器和网状网络之间的区别。红色网络表示单个无线路由器,绿色网络是网状网络。


### 采购设备
要开始使用 FreeMesh,请[订购套件](https://freemeshwireless.com/#pricing)。它提供两种套件:标准套件和 4G LTE。
顾名思义,4G LTE 套件支持蜂窝数据连接。此功能在消费级网络领域非常罕见,但对某些人来说非常有用。你可以在提供电源和电池的任何地方建立具有完整的快速故障转移功能的便携式网状网络。
FreeMesh 套件带有一个主路由器和两个节点。路由器和节点使用 802.11ac、802.11r 和 802.11s 标准。随附的固件运行定制版本的 [OpenWrt](https://openwrt.org/),这是嵌入式设备的 Linux 发行版。
FreeMesh 路由器的一些规格非常好:
* CPU:双核 880MHz MediaTek MT7621AT(双核/四线程!)
* 内存:DDR3 512MB
* 接口:1 个 GbE WAN、4 个 GbE LAN、1 个 USB 2.0 端口、1 个 microSD 卡插槽、1 个 SIM 插槽
* 天线:2 个 5dBi 2.4GHz、2 个 5dBi 5GHz、2 个 3dBi 3G/4G(内置)
* 4G LTE 调制解调器:LTE 4 类模块,下行 150Mbps/上行 50Mbps
### 设置
设置很容易,FreeMesh 的 [README](https://gitlab.com/slthomason/freemesh/-/blob/master/README.md) 提供了简单的说明和图表。首先首先设置主路由器。然后按照以下简单步骤操作:
1、将第一个节点(蓝色 WAN 端口)连接到主路由器(黄色 LAN 端口)。

2、等待约 30 至 60 秒。设置完成后,节点的 LED 将会闪烁。

3、将节点移到另一个位置。
仅此而已!节点不需要手动设置。你只需将它们插入主路由器,其余的工作就完成了。你可以以相同的方式添加更多节点;只需重复上述步骤即可。
### 功能
FreeMesh 是开箱即用的,它由 OpenWRT 和 LuCI 组合而成。它具有你期望路由器提供的所有功能。是否要安装新功能或软件包?SSH 连入并开始魔改!



### 性能如何
设置完 FreeMesh 系统后,我将节点移动到了房屋周围的各个地方。我使用 [iPerf](https://opensource.com/article/20/1/internet-speed-tests) 测试带宽,它达到了约 150Mbps。WiFi 可能会受到许多环境变量的影响,因此你的结果可能会有所不同。节点与主路由器之间的距离在带宽中也有很大的影响。
但是,网状网络的真正优势不是高峰速度,而是整个空间的平均速度要好得多。即使在我家很远的地方,我仍然能够用流媒体播放视频并正常工作。我甚至可以在后院工作。在出门之前,我只是将一个节点重新放在窗口前面而已。
### 结论
FreeMesh 确实令人信服。它以简单、开源的形式为你提供高性价比和隐私。
以我的经验,设置非常容易,而且足够快。覆盖范围非常好,远远超过了任何单路由器环境。你可以随意魔改和定制 FreeMesh 设置,但是我觉得没有必要。它提供了我需要的一切。
如果你正在寻找价格可承受、性能良好且尊重隐私的网格系统,且该系统可以在不到 10 分钟的时间内安装完毕,你可以考虑一下 FreeMesh。
---
via: <https://opensource.com/article/20/2/mesh-network-freemesh>
作者:[Spencer Thomason](https://opensource.com/users/spencerthomason) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [FreeMesh](https://freemeshwireless.com/) system promises to bring fully open source mesh networking to the masses. I recently had a chance to test it; it installed quickly, and the performance was great—especially for the price.
## Why mesh and open source?
The reason to use open source is simple: privacy. With FreeMesh, your data is your own. It doesn't track or collect data. Don't trust it? You can easily check—it's open source, after all! With some other popular mesh solutions, say those provided by very large tech conglomerates, would you trust them with your data?
Another important factor: updates. FreeMesh says it is committed to pushing out security and performance updates regularly. What about 10 years from now? With an open source solution, you are free to update the product for as long as you want.
So why mesh? In a mesh network, multiple wireless routers work together to broadcast a single, very large wireless network. Each router in a mesh network intelligently communicates with the other(s) to provide the best "path" for your data. The following images from FreeMesh's website highlight the difference between using a single wireless router and a mesh network. The red network represents a single wireless router, and the green is a mesh network.
![]() |
![]() |
## Get the equipment
To get started with FreeMesh, [order a kit](https://freemeshwireless.com/#pricing). Two kits are available: standard and 4G LTE.
The 4G LTE kit, as the name suggests, supports cellular data connections. This feature is a rarity in the consumer networking space, and it will be *very* useful to some folks. You can set up a portable mesh network anywhere with power and cell service with full fast-failover capability.
The FreeMesh kits come with a primary router and two nodes. The router and nodes use 802.11ac, 802.11r, and 802.11s standards. The included firmware runs a customized version of [OpenWrt](https://openwrt.org/), a Linux distro for embedded devices.
The FreeMesh router has some really good specs:
**CPU:**Dual-core 880MHz MediaTek MT7621AT (two cores/four threads!)**RAM:**DDR3 512MB**Interfaces:**1x GbE WAN, 4x GbE LAN, 1x USB 2.0 ports, 1x microSD card slot, 1x SIM slot**Antenna:**2x 5dBi 2.4GHz, 2x 5dBi 5GHz, 2x 3dBi 3G/4G (built-in)**4G LTE modem:**LTE category 4 module, 150Mbps downlink and 50Mbps uplink
## Setup
Setup is easy, and FreeMesh's [README](https://gitlab.com/slthomason/freemesh/-/blob/master/README.md) offers simple instructions and diagrams. Start by setting up the primary router first. Then follow these simple steps:
- Connect the first node (blue WAN port) to the primary router (yellow LAN port).
- Wait about 30 to 60 seconds. The node will flash its LEDs when the setup is complete.
- Move the node to another location.
That's it! There is no manual setup required for the nodes; you simply plug them into the primary router, and it does the rest. You can add more nodes the same way; just repeat the steps above.
## Features
Out of the box, FreeMesh runs a combination of OpenWRT and LuCI. It has all the features you'd expect from a router. Want to install new features or packages? SSH in and start hacking!
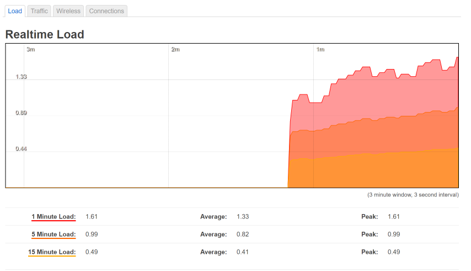
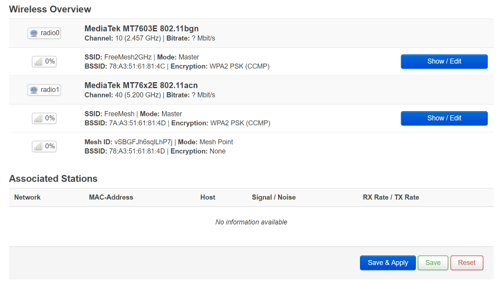
## Performance
After setting up the FreeMesh system, I moved the nodes to various places around my house. I used [iPerf](https://opensource.com/article/20/1/internet-speed-tests) to test the bandwidth and was getting around 150Mbps. WiFi can be affected by any number of environmental variables, so your mileage may vary. Distance between the nodes and the primary router also plays a large factor in bandwidth.
However, the real advantage of a mesh network isn't its top-end speed but much better average speed across a space. Even at the far reaches of my home, I was still able to stream videos and work without interruption. I was even able to work in my backyard. I simply repositioned one of the nodes in front of a window before heading outside.
## Conclusion
FreeMesh is really compelling; it offers performance, privacy, and price, all in a simple, open source package.
In my experience, setup is a breeze, and it is more than fast enough. The range is excellent and far exceeds any single-router setup. You are free to hack and customize your FreeMesh setup, but I didn't feel the need to. It has everything I need out of the box.
If you are looking for an affordable, performant, privacy-respecting mesh system that installs in less than 10 minutes, you might want to consider FreeMesh.
## 4 Comments |
11,970 | 使用 logzero 在 Python 中进行简单日志记录 | https://opensource.com/article/20/2/logzero-python | 2020-03-07T12:24:59 | [] | https://linux.cn/article-11970-1.html |
>
> 快速了解一个方便的日志库,来帮助你掌握这个重要的编程概念。
>
>
>

logzero 库使日志记录就像打印语句一样容易,是简单性的杰出代表。我不确定 logzero 的名称是否要与 pygame-zero、GPIO Zero 和 guizero 这样的 “zero 样板库”契合,但是肯定属于该类别。它是一个 Python 库,可以使日志记录变得简单明了。
你可以使用它基本的记录到标准输出的日志记录,就像你可以使用 print 来获得信息和调试一样,学习它的更高级日志记录(例如记录到文件)的学习曲线也很平滑。
首先,使用 pip 安装 logzero:
```
$ sudo pip3 install logzero
```
在 Python 文件中,导入 logger 并尝试以下一个或所有日志实例:
```
from logzero import logger
logger.debug("hello")
logger.info("info")
logger.warning("warning")
logger.error("error")
```
输出以易于阅读的方式自动着色:

因此现在不要再使用 `print` 来了解发生了什么,而应使用有相关日志级别的日志器。
### 在 Python 中将日志写入文件
如果你阅读至此,并会在你写代码时做一点改变,这对我就足够了。如果你要了解更多,请继续阅读!
写到标准输出对于测试新程序不错,但是仅当你登录到运行脚本的计算机时才有用。在很多时候,你需要远程执行代码并在事后查看错误。这种情况下,记录到文件很有帮助。让我们尝试一下:
```
from logzero import logger, logfile
logfile('/home/pi/test.log')
```
现在,你的日志条目将记录到文件 `test.log` 中。记住确保[脚本有权限](https://opensource.com/article/19/6/understanding-linux-permissions)写入该文件及其目录结构。
你也可以指定更多选项:
```
logfile('/home/pi/test.log', maxBytes=1e6, backupCount=3)
```
现在,当提供给 `test.log` 文件的数据达到 1MB(10<sup> 6</sup> 字节)时,它将通过 `test.log.1`、`test.log.2` 等文件轮替写入。这种行为可以避免系统打开和关闭大量 I/O 密集的日志文件,以至于系统无法打开和关闭。更专业一点,你或许还要记录到 `/var/log`。假设你使用的是 Linux,那么创建一个目录并将用户设为所有者,以便可以写入该目录:
```
$ sudo mkdir /var/log/test
$ sudo chown pi /var/log/test
```
然后在你的 Python 代码中,更改 `logfile` 路径:
```
logfile('/var/log/test/test.log', maxBytes=1e6, backupCount=3)
```
当要在 `logfile` 中捕获异常时,可以使用 `logging.exception`:
```
try:
c = a / b
except Exception as e:
logger.exception(e)
```
这将输出(在 `b` 为零的情况下):
```
[E 190422 23:41:59 test:9] division by zero
Traceback (most recent call last):
File "test.py", line 7, in
c = a / b
ZeroDivisionError: division by zero
```
你会得到日志,还有完整回溯。另外,你可以使用 `logging.error` 并隐藏回溯:
```
try:
c = a / b
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
```
现在,将产生更简洁的结果:
```
[E 190423 00:04:16 test:9] ZeroDivisionError: division by zero
```

你可以在 [logzero.readthedocs.io](https://logzero.readthedocs.io/en/latest/) 中阅读更多选项。
### logzero 为教育而生
对于新手程序员来说,日志记录可能是一个具有挑战性的概念。大多数框架依赖于流控制和大量变量操作来生成有意义的日志,但是 logzero 不同。由于它的语法类似于 `print` 语句,因此它在教育上很成功,因为它无需解释其他概念。在你的下个项目中试试它。
此文章最初发布在[我的博客](https://tooling.bennuttall.com/logzero/)上,经许可重新发布。
---
via: <https://opensource.com/article/20/2/logzero-python>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The logzero library makes logging as easy as a print statement, which is quite a feat of simplicity. I'm not sure whether logzero took its name to fit in with the series of "zero boilerplate" libraries like pygame-zero, GPIO Zero, and guizero, but it's certainly in that category. It's a Python library that makes logging straightforward.
You can just use its basic logging to stdout the same way you might use print for information and debugging purposes, and it has a smooth learning curve towards more advanced logging, like logging to a file.
To start, install logzero with pip:
`$ sudo pip3 install logzero`
Now in a Python file, import logger and try one or all of these logging examples:
```
from logzero import logger
logger.debug("hello")
logger.info("info")
logger.warning("warning")
logger.error("error")
```
The output is automatically colored in an easy-to-read way:
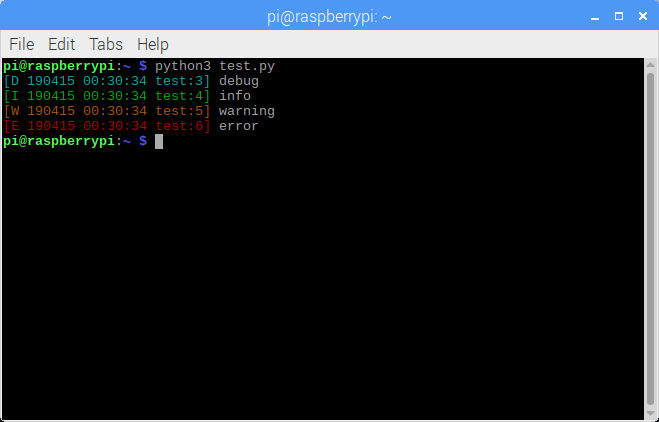
So now, instead of using **print** to figure out what's going on, use logger instead, with the relevant log level.
## Writing logs to a file in Python
If you only read this far and make that one change in the way you write code, that's good enough for me. If you want to go further, read on!
Writing to **stdout** is fun for testing a new program, but it is only useful if you are logged into the computer where the script is running. Many times when using an application you'll want to execute the code remotely and review errors after the fact. That's when it's helpful to log to a file instead. Let's try it:
```
from logzero import logger, logfile
logfile('/home/pi/test.log')
```
Now your log entries will be logged into the file **test.log**. Remember to make sure that the [script has permission](https://opensource.com/article/19/6/understanding-linux-permissions) to write to that file and its directory structure.
You can specify some more options too:
`logfile(’/home/pi/test.log’, maxBytes=1e6, backupCount=3)`
Now when the file provided to **logfile** reaches 1MB (1×106 bytes), it will rotate entries through **test.log.1**, **test.log.2**, and so on. This behavior is nice to avoid generating a massive log file that is I/O intensive for the system to open and close. You might also want to log to **/var/log** like a pro. Assuming you're on Linux, you a directory and make your user the owner so they can write to it:
```
$ sudo mkdir /var/log/test
$ sudo chown pi /var/log/test
```
Then in your Python code, change the **logfile** path:
`logfile(’/var/log/test/test.log’, maxBytes=1e6, backupCount=3)`
When it comes to catching exceptions in your **logfile**, you can either use **logging.exception:**
```
try:
c = a / b
except Exception as e:
logger.exception(e)
```
This will produce the following (in the case that b is zero):
```
[E 190422 23:41:59 test:9] division by zero
Traceback (most recent call last):
File "test.py", line 7, in
c = a / b
ZeroDivisionError: division by zero
```
You get the log entry, followed by the full traceback. Alternatively, you could use **logging.error** and hide the traceback:
```
try:
c = a / b
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
```
Now this will produce the more succinct:
`[E 190423 00:04:16 test:9] ZeroDivisionError: division by zero`
There are plenty more options which you can read in the docs at [logzero.readthedocs.io](https://logzero.readthedocs.io/en/latest/).
## logzero shines for education
Logging can be a challenging concept for a new programmer. Most frameworks depend on flow control and lots of variable manipulation to make a meaningful log, but logzero is different. With its syntax being similar to a print statement, it is a big win for education as it saves from explaining another concept. Give it a try on your next project.
--
*This article was originally written on my blog and is republished with permission.*
## 3 Comments |
11,971 | 在 Windows 上安装 GNU Emacs | https://opensource.com/article/20/3/emacs-windows | 2020-03-08T09:49:56 | [
"Emacs"
] | /article-11971-1.html |
>
> 即使你的操作系统是闭源的,你仍然可以使用这个流行的开源文本编辑器。
>
>
>

GNU Emacs 是一个专为各种程序员设计的流行的文本编辑器。因为它是在 Unix 上开发的,并在 Linux(macOS 中也有)上得到了广泛使用,所以人们有时没有意识到它也可用于微软 Windows 上。你也无需成为有经验的或专职的程序员即可使用 Emacs。只需单击几下就可以下载并安装 Emacs,本文向你展示了如何进行。
你可以手动安装 Windows,也可以使用包管理器安装,例如 [Chocolatey](https://github.com/chocolatey/choco)。
### 7-zip
如果还没在 Windows 中安装 7-zip,那么就先安装它。[7-zip](https://www.7-zip.org/) 是一个开源的归档程序,能够创建和解压 ZIP、7z、TAR、XZ、BZIP2 和 GZIP(以及更多)文件。对于 Windows 用户来说,这是一个宝贵的工具。
安装 7-zip 后,在 Windows 资源管理器中浏览文件时,右键单击菜单中就有新的 7-zip 归档选项。
### Powershell 和 Chocolatey
要在 Windows 上使用 Chocolatey 安装 GNU Emacs :
```
PS> choco install emacs-full
```
安装后,在 Powershell 中启动 Emacs:
```
PS> emacs
```

### 下载适用于 Windows 的 GNU Emacs
要在 Windows 上手动安装 GNU Emacs,你必须[下载 Emacs](https://www.gnu.org/software/emacs/download.html)。

它会打开连接到离你最近的服务器,并展示所有可用的 Emacs 版本。找到发行版本号最高的目录,然后单击进入。Windows 有许多不同的 Emacs 构建,但是最通用的版本只是被命名为 `emacs-VERSION-ARCHITECTURE.zip`。`VERSION` 取决于你要下载的版本,而 `ARCHITECTURE` 取决于你使用的是 32 位还是 64 位计算机。大多数现代计算机都是 64 位的,但是如果你有疑问,可以下载 32 位版本,它可在两者上运行。
如果要下载 64 位计算机的 Emacs v26,你应该点击 `emacs-26.2-x86_64.zip` 的链接。有较小的下载包(例如 “no-deps” 等),但是你必须熟悉如何从源码构建 Emacs,知道它需要哪些库以及你的计算机上已经拥有哪些库。通常,获取较大版本的 Emacs 最容易,因为它包含了在计算机上运行所需的一切。
### 解压 Emacs
接下来,解压下载的 ZIP 文件。要解压缩,请右键单击 Emacs ZIP 文件,然后从 7-zip 子菜单中选择 “Extract to Emacs-VERSION”。这是一个很大的压缩包,因此解压可能需要一段时间,但是完成后,你将拥有一个新目录,其中包含与 Emacs 一起分发的所有文件。例如,在此例中,下载了 `emacs-26.2-x86_64.zip`,因此解压后的目录为 `emacs-26.2-x86_64`。
### 启动 Emacs
在 Emacs 目录中,找到 `bin` 目录。此文件夹存储随 Emacs 一起分发的所有二进制可执行文件(EXE 文件)。双击 `emacs.exe` 文件启动应用。

你可以在桌面上创建 `emacs.exe` 的快捷方式,以便于访问。
### 学习 Emacs
Emacs 并不像传闻那样难用。它具有自己的传统和惯例,但是当你其中输入文本时,你可以像在记事本或者网站的文本框中那样使用它。
重要的区别是在你*编辑*输入的文本时。
但是,学习的唯一方法是开始使用它,因此,使 Emacs 成为完成简单任务的首选文本编辑器。当你通常打开记事本、Word 或 Evernote 或其他工具来做快速笔记或临时记录时,请启动 Emacs。
Emacs 以基于终端的应用而闻名,但它显然有 GUI,因此请像使用其他程序一样经常使用它的 GUI。从菜单而不是使用键盘复制、剪切和粘贴(paste)(或用 Emacs 的术语 “yank”),然后从菜单或工具栏打开和保存文件。从头开始,并根据应用本身来学习它,而不是根据你以往对其他编辑器的经验就认为它应该是怎样。
* 下载[速查表](https://opensource.com/downloads/emacs-cheat-sheet)!
感谢 Matthias Pfuetzner 和 Stephen Smoogen。
---
via: <https://opensource.com/article/20/3/emacs-windows>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,972 | Drauger OS Linux 旨在为台式机带来主机游戏体验 | https://itsfoss.com/drauger-os/ | 2020-03-08T10:10:00 | [
"游戏"
] | https://linux.cn/article-11972-1.html | 多年来(或数十年),人们抱怨不[使用Linux](https://itsfoss.com/why-use-linux/) 的原因之一是它缺乏主流游戏。[Linux 上的游戏](/article-7316-1.html)在最近几年有了显著改进,特别是 [Steam Proton](/article-10054-1.html) 项目的引入使你可以[在 Linux 上玩很多 Windows 专用的游戏](https://itsfoss.com/steam-play/)。
这也鼓励了一些[以游戏为中心的 Linux发行版](https://itsfoss.com/linux-gaming-distributions/)。以 [Lakka](http://www.lakka.tv/) 为例,你可以[借助 Lakka Linux 将旧计算机变成复古的街机游戏机](https://itsfoss.com/lakka-retrogaming-linux/)。
另一个以游戏为中心的 Linux 发行版是 [Draguer OS](https://draugeros.org/go/),我们今天将对其进行研究。
### Drauger OS
根据[该项目的网站](https://www.draugeros.org/go/about/),“Drauger OS 是 Linux 桌面游戏操作系统。它旨在为游戏玩家提供一个平台,使他们可以在不牺牲安全性的情况下获得出色的性能。此外,它旨在使任何人都可以轻松玩游戏,无论他们使用键盘和鼠标还是某种控制器。”
他们强调 Drauger OS 并非供日常使用。因此,大多数其他发行版附带的许多生产力工具都不在 Drauger OS 中。

Drauger OS [基于](https://www.draugeros.org/go/about/) Ubuntu 之上。当前版本(7.4.1 Jiangshi)使用 “[Liquorix](https://liquorix.net/) 低延迟Linux 内核,这是一种预编译的 ZEN 内核,设计时考虑了延迟和吞吐量之间的平衡”。但是,这将在下一版本中更改。他们只有一个桌面环境可供选择,即一个修改版本的 [Xfce](https://www.xfce.org/)。
Drauger OS 开箱即用地安装了多个应用程序和工具,以改善游戏体验。这些包括:
* [PlayOnLinux](https://www.playonlinux.com/en/)
* WINE
* [Lutris](https://lutris.net/)
* Steam
* [DXVK](https://github.com/doitsujin/dxvk)
它还具有一组与游戏无关的有趣工具。[Drauger 安装器](https://github.com/drauger-os-development/drauger-installer)是 .deb 安装程序,是 Gdebi 的替代品。[多软件库应用安装器](https://github.com/drauger-os-development/mrai)(mrai)是“用于基于 Debian 的 Linux 操作系统的类似于 AUR-helper 的脚本”。Mrai 旨在与 apt、snap、flatpaks 配合使用,并且可以从 GitHub 安装应用程序。
有趣的是,Drauger OS 的名称是一个错误。开发负责人 [Thomas Castleman](https://github.com/Batcastle)(即 batcastle)曾打算为其发行版命名为 Draugr,但是却打错了名字。在 Drauger OS 播客的[第 23 集](https://anchor.fm/drauger-os/episodes/Episode-23-eapu47)中,Castleman 说会保留这个拼写错误的名称,因为要对其进行更正需要大量工作。根据 [Wikipedia](https://en.wikipedia.org/wiki/Draugr) 的描述,Draugr 是“来自北欧神话中的不死生物”。
是的,你没看错。Drauger OS 是仅有的几个具有自己的[播客](https://anchor.fm/drauger-os)的发行版之一。当被问到这个问题时,Castleman 告诉我:“无论他们的情况如何,我都希望确保我们的社区拥有最大的透明度。”多数情况下,播客是 Drauger OS 博客的音频版本,但有时他们会在没有时间撰写博客文章时使用它来发布公告。
### Drauger OS 的未来

Druager OS 背后的开发人员正在开发其下一个主要版本:7.5.1。此版本将基于 Ubuntu 19.10。将有三个主要变化。首先,将使用“我们内部构建的内核” [替换](https://www.draugeros.org/go/2020/01/20/major-changes-in-drauger-os-7-5-1/) Liquorix 内核。该内核将基于 Linux 内核 GitHub 存储库,“因此,它会变得越来越原汁原味”。
新版本的第二个主要变化将是为其桌面提供新布局。根据用户的反馈,他们决定将其更改为看起来更类似于 GNOME 的样子。
第三,他们放弃了 SystemBack 作为其备份工具和安装程序。相反,他们从头开始编写了新的[安装程序](https://github.com/drauger-os-development/system-installer)。
开发团队也正在研究 Drauger OS 的 [ARM 版本](https://www.draugeros.org/go/system-requirements/)。他们希望在 2022 年的某个时候发布它。
### 系统要求
Drauger OS [系统要求](https://www.draugeros.org/go/system-requirements/)非常适中。请记住,Drauger OS 仅在 64 位系统上运行。
#### 最低系统要求
* CPU:双核、1.8GHz、64 位处理器
* RAM:1 GB
* 储存空间:16 GB
* 图形处理器:集成
* 屏幕分辨率:60Hz 时为 1024×768
* 外部端口:1 个用于显示的端口(HDMI/DisplayPort/VGA/DVI),2 个用于安装 USB 驱动器和键盘的 USB 端口(鼠标可选,但建议使用)
#### 推荐系统要求
* CPU:四核、2.2Ghz、64 位处理器
* RAM:4 GB
* 储存空间:128 GB
* 图形处理器:NVIDIA GTX 1050、AMD RX 460 或同等显卡
* 屏幕分辨率:60Hz 时为 1080p
* 外部端口:1 个用于显示的端口(HDMI/DisplayPort/VGA/DVI),3 个用于安装 USB 驱动器、键盘和鼠标的 USB 端口,1 个音频输出端口
### 如何为Drauger OS提供帮助
如果你有兴趣,可以通过多种方法来帮助 Drauger OS。他们一直在寻找[财政支持](https://www.draugeros.org/go/contribute/)以保持发展。
如果你想贡献代码,他们正在寻找具有 BASH、C++ 和 Python 经验的人员。他们所有的代码都在 [GitHub](https://github.com/drauger-os-development) 上。你也可以在社交媒体上[联系](https://www.draugeros.org/go/contact-us/)他们。
### 结语
Drauger OS 只是这类项目之一。我还见过其他[面向游戏的发行版](https://itsfoss.com/manjaro-gaming-linux/),但 Drauger OS 在专注于游戏方面一心一意。由于我更喜欢休闲游戏,因此该发行版对我个人而言并不具有吸引力。但是,我可以看到它如何吸引游戏爱好者使用 Linux。祝他们在以后的发行中好运。
你对这个仅限于游戏的发行版有何想法?你最喜欢的 Linux 游戏解决方案是什么?请在下面的评论中告诉我们。
---
via: <https://itsfoss.com/drauger-os/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For years (or decades) people complained that one of the reasons to not [use Linux](https://itsfoss.com/why-use-linux/) is lack of mainstream games. [Gaming on Linux](https://itsfoss.com/linux-gaming-guide/) has improved drastically in last few years specially with the [introduction of Steam Proton](https://itsfoss.com/steam-play-proton/) project that enables you to [play a lot of Windows-only games on Linux](https://itsfoss.com/steam-play/).
This also has encourages several [Linux distributions centered around gaming](https://itsfoss.com/linux-gaming-distributions/). Take [Lakka](http://www.lakka.tv/) for example. You can [turn your old computer into a retro gaming console thanks to Lakka Linux](https://itsfoss.com/lakka-retrogaming-linux/).
Another such gaming focused Linux distribution is [Drauger OS](https://draugeros.org/go/) and we are going to take a look at it today.
## What is Drauger OS?
Accord to [the project’s website](https://www.draugeros.org/go/about/), “Drauger OS is a Linux desktop gaming operating system. It aims to provide a platform for gamers to use where they can get great performance without sacrificing their security. Furthermore, it aims to make it easy for anyone to game, whether they use a keyboard and mouse, or some sort of controller.”
They stress that Drauger OS is not for everyday use. As such, many of the productivity tools that most other distros come with are not in Drauger OS.
Drauger OS is [based](https://www.draugeros.org/go/about/) on the Ubuntu. The current version (7.4.1 Jiangshi) uses “[Liquorix](https://liquorix.net/) low latency Linux kernel, a pre-compiled ZEN kernel designed with a balance between latency and throughput in mind”. However, that will be changing in the next release. They only have one desktop environment choice, a modified version of [Xfce](https://www.xfce.org/).
Drauger OS has several applications and tools installed out of the box to improve the gaming experience. These include:
[PlayOnLinux](https://www.playonlinux.com/en/)- WINE
[Lutris](https://lutris.net/)- Steam
[DXVK](https://github.com/doitsujin/dxvk)
It also has an interesting set of tools that are not gaming related. [Drauger Installer](https://github.com/drauger-os-development/drauger-installer) is a .deb installer and alternative to Gdebi. [Multiple Repository App Installer](https://github.com/drauger-os-development/mrai) (mrai) is “an AUR-helper-like script for Debian-based Linux Operating Systems”. Mrai is designed to work with apt, snaps, flatpaks, and can install apps from GitHub.
Interestingly, Drauger OS’ name is an error. Lead dev [Thomas Castleman](https://github.com/Batcastle) (aka batcastle) has intended to name his distro Draugr, but had mistyped the name. In [episode 23](https://anchor.fm/drauger-os/episodes/Episode-23-eapu47) of the Drauger OS podcast, Castleman said the name will stay misspelled because it would be a lot of work to correct it. According to [Wikipedia](https://en.wikipedia.org/wiki/Draugr), a draugr is “an undead creature from Norse mythology”.
Yes, you read that correctly. Drauger OS is one of only a few distros that have its own [podcast](https://anchor.fm/drauger-os). When asked about it, Castleman told me that “I wanted to ensure that we had the maximum transparency possible with our community, no matter their circumstances.” Most of the time, the podcast is an audio version of the Drauger OS blog, but sometimes they use it to make an announcement when they don’t have time to write a blog post.
## The Future for Drauger OS
The developers behind Druager OS are working on their next major release: 7.5.1. This release will be based on Ubuntu 20.04. There will be three major changes. First, the Liquorix kernel will be [replaced](https://www.draugeros.org/go/2020/01/20/major-changes-in-drauger-os-7-5-1/) with “a kernel we are building in-house.” This kernel will be based on the Linux Kernel GitHub repository, “so it’s about as vanilla as it gets”.
The second major change in the new release will a new layout for their desktop. Based on user feedback, they have decided to change it to something that looks more GNOME-like.
Thirdly, they are dropping SystemBack as their backup tool and installer. They have instead written a new [installer](https://github.com/drauger-os-development/system-installer) from scratch.
The Dev team is also working on an [ARM version](https://www.draugeros.org/go/system-requirements/) of Drauger OS. They hope to release it sometime in 2022.
## System requirements for Drauger OS
The Drauger OS [system requirements](https://www.draugeros.org/go/system-requirements/) are pretty modest. Keep in mind that Drauger OS will only run on 64-bit systems.
### Minimum system requirements
- CPU: Dual-Core, 1.8GHz, 64-bit processor
- RAM: 1 GB
- Storage: 16 GB
- Graphics Processor: Integrated
- Screen Resolution: 1024×768 at 60Hz
- External Ports: 1 Port for Display (HDMI / DisplayPort / VGA / DVI), 2 USB Ports for Installation USB Drive and Keyboard (Mouse optional, but recommended)
### Recommended system requirements
- CPU: Quad-Core, 2.2Ghz, 64-bit processor
- RAM: 4 GB
- Storage: 128 GB
- Graphics Processor: NVIDIA GTX 1050, AMD RX 460, or equivalent card
- Screen Resolution: 1080p at 60Hz
- External Ports: 1 Port for Display (HDMI / DisplayPort / VGA / DVI), 3 USB Ports for Installation USB Drive, Keyboard, and Mouse, 1 Audio Out Port
## How you can help out Drauger OS
There are several ways that you can help out the Drauger OS if you are interestedin doing so. They are always looking for [financial support](https://www.draugeros.org/go/contribute/) to keep development going.
If you want to contribute code, they are looking for people with experience in BASH, C++, and Python. All of their code is up on [GitHub](https://github.com/drauger-os-development). You can also [contact](https://www.draugeros.org/go/contact-us/) them on social media.
## Final Thoughts
Drauger OS is quite a project. I’ve seen a couple of other [gaming-oriented distributions](https://itsfoss.com/manjaro-gaming-linux/), but Drauger OS is single-minded in its focus on gaming. Since I am more of a casual gamer, this distro doesn’t appeal to me personally. But, I can see how it could lure gaming enthusiasts to Linux. I wish them good luck in their future releases.
What are your thoughts on this gaming-only distro? What is your favorite Linux gaming solution? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
11,974 | 探索自由而开放的 Web 字体 | https://opensource.com/article/18/3/webfonts | 2020-03-08T17:49:45 | [
"字体",
"OTF"
] | https://linux.cn/article-11974-1.html |
>
> 谷歌字体和开放字体库中的免费 Web 字体已经改变了游戏规则,但仅在有限的范围内。
>
>
>

毫无疑问,近些年来互联网的面貌已经被开源字体所改变。早在 2010 年之前,你在 Web 浏览器上几乎只能看到微软制作的通常“Web 安全”的[核心字体](https://en.wikipedia.org/wiki/Core_fonts_for_the_Web)。但这一年(2010)正好是好几轮技术革新开始的见证之年:<ruby> <a href="https://en.wikipedia.org/wiki/Web_Open_Font_Format"> Web 开放字体格式 </a> <rt> Web Open Font Format </rt></ruby>(WOFF)的引入为通过 HTTP 有效地传输字体文件提供了一个开放的标准,以及像[谷歌字体](https://fonts.google.com/)和<ruby> <a href="https://fontlibrary.org/"> 开放字体库 </a> <rt> Open Font Library </rt></ruby>这样的 Web 字体服务的推出,使得 Web 内容发布者可以在开源许可证之下免费使用海量的字体库。
这些事件对 Web 排版的积极影响再夸大都不过分。但是要将 Web 开放字体的成功与整个开源排版等同起来,并得到结论——挑战已经远离了我们,困难悉数被解决了——却很容易。然而事实并非如此,如果你很关注字体,那么好消息是你有好多机会参与到对这些字体的改进工作当中去。
对新手来说,至关重要的是必须要意识到谷歌字体和开放字体库提供了专用的服务(为网页提供字体),而没有为其他使用情况制定字体解决方案。这不是服务方面的缺点,这只是意味着我们必须去开发其它的解决方案。
需要解决的问题还非常多。可能最明显的例子就是给 Linux 桌面计算机的其他软件安装字体所遇到的尴尬情况。你可以通过任何一种服务下载任何一种 Web 字体,但是你得到的只是一个最普通的压缩包文件,里面有一些 TTF 或 OTF 二进制文件和一个普通文本文件的许可证。接下来会发生什么完完全全需要你去猜。
大部分用户很快学会了“正确”的步骤就是手动地复制这些字体二进制文件到他们硬盘里几个特殊文件夹里的某一个里。但是这样做只能使这个文件对操作系统可见。它并不能为用户体验带来什么提升。再强调一遍,这不是 Web 字体服务的缺陷,相反它佐证了对于关于服务到哪里停止和需要在其他方面做更多工作的观点。
在用户视角来说,一个巨大的提升可能就是在“只是下载”这个阶段,操作系统或者桌面环境变得更智能。系统或桌面环境不仅会把字体文件安装到正确的位置上,更重要的是,当用户选择要在一个项目中使用的字体时,它会自己添加用户所需要的重要的元数据。
这些附加信息包含的内容与它如何呈现给用户与另一个挑战有关:与其它操作系统相比,在 Linux 环境管理一个字体库显然不那么令人满意。字体管理器总是时不时的出现一下(例如 [GTK+ 字体管理器](https://fontmanager.github.io/),这是最近的一个例子),但是它们很少变得流行起来。我一直在思考一大堆这些软件让人失望的方面。一个核心的原因是它们把自己局限于只展示内嵌在二进制字体文件内的信息:基本字符集的覆盖、粗细/宽度和斜率的设定,内置的许可证和版权说明等等。
但是除了这些内嵌数据中的内容,在选择字体的过程中还涉及很多决策。严肃的字体用户,像信息设计者、杂志文章作者,或者书籍美工设计者,他们的字体选择是根据每一份文件的要求和需求做出的。这当然包含了许可证信息,但它还包含了更多,像关于设计师和厂商的信息、潮流风格的趋势,或者字体在使用中的细节。
举个例子,如果你的文档包含了英语和阿拉伯文,你多半想要拉丁文和阿拉伯文的字体由同时熟悉这两种<ruby> 字母系统 <rt> script </rt></ruby>的设计师所设计。否则,你将浪费一大堆时间来微调字体大小和行间距来使两种字母系统良好地结合在一起。你可能从经验中学到,某些设计师或字体厂商比其他人更善于多种字母系统设计。或许和你职业相关的是今天的时尚杂志几乎无一例外的采用 “[Didone](https://en.wikipedia.org/wiki/Didone_(typography))”风格的字体,“[Didone](https://en.wikipedia.org/wiki/Didone_(typography))”是指一种两百多年前最先被 [Firmin Didot](https://en.wikipedia.org/wiki/Firmin_Didot) 和 [Giambattista Bodoni](https://en.wikipedia.org/wiki/Giambattista_Bodoni) 设计出来的超高反差的字体风格。这种字体恰好就是现在的潮流。
但是像 Didone、Didot 或 Bodoni 这些术语都不可能会出现在二进制文件的内置数据当中,你也不容易判断拉丁文和阿拉伯文是否相得益彰或其它关于字体的历史背景。这些信息有可能出现在补充的材料中,类似某种字形样本或字体文件中,如果这些东西存在的话。
<ruby> 字形样本 <rt> specimen </rt></ruby>是一份设计好的文档(一般是 PDF),它展示了这种字体的使用情况,而且包括了背景信息。字形样本经常在挑选字体时充当市场营销和外观样例的双重角色。一份精心设计的样本展示了字体在实际应用中的情况和在自动生成的字符表中所不能体现的风格。字形样本文件也有可能包含了一些其他重要信息,比如怎样激活字体的 OpenType 特性、提供的数学表达式或古体字,或者它在支持的多种语言上的风格变化。在字体管理应用程序中向用户提供此类材料,对于帮助用户找到适合其项目需求的字体将大有帮助。
当然,如果我们希望一个字体管理软件能够处理文件和样本问题,我们也必须仔细观察一下各种发行版提供的字体包所随附的内容。Linux 的用户刚开始只有自动安装的那几种字体,并且发行版存储库提供的包是大部分用户除了下载通用的压缩包档案之外的唯一字体来源。这些包往往非常的“简陋”。商业字体总的来说都包含了样本、文档,还有其他的支持项目,然而开源字体往往没有这些配套文件。
也有一些优秀的开放字体提供了高质量的样本和文档(例如 [SIL Gentium](https://software.sil.org/gentium/) 和 [Bungee](https://djr.com/bungee/) 是两种差异明显但是都有效的方案),但是它们几乎不涉足下游的打包工作链。我们显然可以做的更好一些。
要在系统的字体交互方面提供更丰富的用户体验上面还存在一些技术问题。一方面,[AppStream](https://www.freedesktop.org/wiki/Distributions/AppStream/) 的元数据标准定义了一些字体文件特有的参数,但是到现在为止,这些参数没有包含样本、设计师/厂商和其他相关细节的任何信息。另外一个例子,[SPDX](https://spdx.org/)(<ruby> 软件包数据交换 <rt> Software Package Data Exchange </rt></ruby>)格式也没有包含太多用于分发字体的软件许可证(及许可证变体)。
最后,就像任何一个唱片爱好者都会告诉你的,一个不允许你编辑和完善你的 MP3 曲库中的 ID3 信息的音乐播放器很快就会变得令人失望(LCTT 译注:ID3 信息是 MP3 文件头部的元信息,用于存储歌曲信息)。你想要处理标签里的错误、想要添加注释和专辑封面之类的信息,本质上,这就是完善你的音乐库。同样,你可能也想要让你的本地字体库也保持在一个方便使用的状态。
但是改动字体文件的内置数据一直有所忌讳,因为字体往往是被内置或附加到其他文件里的。如果你随意改变了字体二进制文件中的字段,然后将其与你的演示文稿一起重新分发,那么下载这些演示文稿的任何人最终都会得到错误的元数据,但这个错误不是他们自己造成的。所以任何一个要改善字体管理体验的人都要想明白如何从策略上解决对内置或外置的字体元数据的重复修改。
除了技术角度之外,丰富的字体管理经验也是一项设计挑战。就像我在前面说的一样,有几种开放字体也带了良好的样本和精心编写的文档。但是更多的字体包这两者都没有,还有大量的更老的字体包已经没有人维护了。这很可能意味着大部分开放字体包想要获得样本和证明文件的唯一办法就是让社区去创建它们。
也许这是一个很高的要求。但是开源设计社区现在比以往任何时候都要庞大,它是整个自由开源软件运动中的一个高度活跃的组成部分。所以谁知道呢,也许明年这个时候会发现,在 Linux 桌面系统查找、下载和使用字体会变成一种完全不同的体验。
在这一连串关于现代 Linux 用户的文字设计上的挑战的思考中包含了打包、文档设计,甚至有可能需要在桌面环境加入不少新的软件部分。此外还有其他一系列的东西也需要考虑。其共通性就是在 Web 字体服务不可及的地方,事情就会变得更加困难。
从我的视角来看,最好的消息是现在比起以前有更多的人对这个话题感兴趣。我认为我们要感谢像谷歌字体和开放字体库这样的 Web 字体服务巨头让开放字体得到了更高的关注。
---
via: <https://opensource.com/article/18/3/webfonts>
作者:[Nathan Willis](https://opensource.com/users/n8willis) 译者:[Fisherman110](https://github.com/Fisherman110) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There is no question that the face of the web has been transformed in recent years by open source fonts. Prior to 2010, the only typefaces you were likely to see in a web browser were the generic "web safe" [core fonts](https://en.wikipedia.org/wiki/Core_fonts_for_the_Web) from Microsoft. But that year saw the start of several revolutions: the introduction of the Web Open Font Format ([WOFF](https://en.wikipedia.org/wiki/Web_Open_Font_Format)), which offered an open standard for efficiently delivering font files over HTTP, and the launch of web-font services like [Google Fonts](https://fonts.google.com/) and the [Open Font Library](https://fontlibrary.org/)—both of which offered web publishers access to a large collection of fonts, for free, available under open licenses.
It is hard to overstate the positive impact of these events on web typography. But it can be all too easy to equate the successes of open web fonts with open source typography as a whole and conclude that the challenges are behind us, the puzzles solved. That is not the case, so if you care about type, the good news is there are a lot of opportunities to get involved in improvement.
For starters, it's critical to understand that Google Fonts and Open Font Library offer a specialized service—delivering fonts in web pages—and they don't implement solutions for other use cases. That is not a shortcoming on the services' side; it simply means that we have to develop other solutions.
There are a number of problems to solve. Probably the most obvious example is the awkwardness of installing fonts on a desktop Linux machine for use in other applications. You can download any of the web fonts offered by either service, but all you will get is a generic ZIP file with some TTF or OTF binaries inside and a plaintext license file. What happens next is up to you to guess.
Most users learn quickly that the "right" step is to manually copy those font binaries into any one of a handful of special directories on their hard drive. But that just makes the files visible to the operating system; it doesn't offer much in the way of a user experience. Again, this is not a flaw with the web-font service; rather it's evidence of the point where the service stops and more work needs to be done on the other side.
A big improvement from the user's perspective would be for the OS or the desktop environment to be smarter at this "just downloaded" stage. Not only would it install the font files to the right location but, more importantly, it could add important metadata that the user will want to access when selecting a font to use in a project.
What this additional information consists of and how it is presented to the user is tied to another challenge: Managing a font collection on Linux is noticeably less pleasant than on other operating systems. Periodically, font manager applications appear (see [GTK+ Font Manager](https://fontmanager.github.io/) for one of the most recent examples), but they rarely catch on. I've been thinking a lot about where I think they come up short; one core factor is they have limited themselves to displaying only the information embedded in the font binary: basic character-set coverage, weight/width/slope settings, embedded license and copyright statements, etc.
But a lot of decisions go into the process of selecting a font for a job besides what's in this embedded data. Serious font users—like information designers, journal article authors, or book designers—make their font-selection decisions in the context of each document's requirements and needs. That includes license information, naturally, but it includes much more, like information about the designer and the foundry, stylistic trends, or details about how the font works in use.
For example, if your document includes both English and Arabic text, you probably want a font where the Latin and Arabic glyphs were designed together by someone experienced with the two scripts. Otherwise, you'll waste a ton of time making tiny adjustments to the font sizes and line spacing trying to get the two languages to mix well. You may have learned from experience that certain designers or vendors are better at multi-script design than others. Or it might be relevant to your project that today's fashion magazines almost exclusively use "[Didone](https://en.wikipedia.org/wiki/Didone_(typography))"-style typefaces, a name that refers to super-high-contrast styles pioneered by [Firmin Didot](https://en.wikipedia.org/wiki/Firmin_Didot) and [Giambattista Bodoni](https://en.wikipedia.org/wiki/Giambattista_Bodoni) around 200 years ago. It just happens to be the trend.
But none of those terms (Didone, Didot, or Bodoni) are likely to show up in the binary's embedded data, nor is easy to tell whether the Latin and Arabic fit together or anything else about the typeface's back history. That information might appear in supplementary material like a type specimen or font documentation—if any exists.
A specimen is a designed document (often a PDF) that shows the font in use and includes background information; it frequently serves a dual role as a marketing piece and a sample to look at when choosing a font. The considered design of a specimen showcases how the font functions in practice and in a manner that an automatically generated character table simply cannot. Documentation may include some other vital information, like how to activate the font's OpenType features, what mathematical or archaic forms it provides, or how it varies stylistically across supported languages. Making this sort of material available to the user in the font-management application would go a long way towards helping users find the fonts that fit their projects' needs.
Of course, if we're going to consider a font manager that can handle documentation and specimens, we also have to take a hard look at what comes with the font packages provided by distributions. Linux users start with a few fonts automatically installed, and repository-provided packages are the only font source most users have besides downloading the generic ZIP archive. Those packages tend to be pretty bare-bones. Commercial fonts generally include specimens, documentation, and other support items, whereas open source fonts usually do not.
There are some excellent examples of open fonts that *do* provide quality specimens and documentation (see [SIL Gentium](https://software.sil.org/gentium/) and [Bungee](https://djr.com/bungee/) for two distinctly different but valid approaches), but they rarely (if ever) make their way into the downstream packaging chain. We plainly can do better.
There are some technical obstacles to offering a richer user experience for interacting with the fonts on your system. For one thing, the [AppStream](https://www.freedesktop.org/wiki/Distributions/AppStream/) metadata standard defines a few [parameters](https://www.freedesktop.org/software/appstream/docs/sect-Metadata-Fonts.html) specific to font files, but so far includes nothing that would cover specimens, designer and foundry information, and other relevant details. For another, the [SPDX](https://spdx.org/) (Software Package Data Exchange) format does not cover many of the software licenses (and license variants) used to distribute fonts.
Finally, as any audiophile will tell you, a music player that does not let you edit and augment the ID3 tags in your MP3 collection is going to get frustrating quickly. You want to fix errors in the tags, you want to add things like notes and album art—essentially, you want to polish your library. You would want to do the same to keep your local font library in a pleasant-to-use state.
But editing the embedded data in a font file has been taboo because fonts tend to get embedded and attached to other documents. If you monkey with the fields in a font binary, then redistribute it with your presentation slides, anyone who downloads those slides can end up with bad metadata through no fault of their own. So anyone making improvements to the font-management experience will have to figure out how to strategically wrangle repeated changes to the embedded and external font metadata.
In addition to the technical angle, enriching the font-management experience is also a design challenge. As I said above, good specimens and well-written documentation exist for several open fonts. But there are many more packages missing both, and there are a lot of older font packages that are no longer being maintained. That probably means the only way that most open font packages are going to get specimens or documentation is for the community to create them.
Perhaps that's a tall order. But the open source design community is bigger than it has ever been, and it is a highly motivated segment of the overall free and open source software movement. So who knows; maybe this time next year finding, downloading, and using fonts on a desktop Linux system will be an entirely different experience.
One train of thought on the typography challenges of modern Linux users includes packaging, document design, and maybe even a few new software components for desktop environments. There are other trains to consider, too. The commonality is that where the web-font service ends, matters get more difficult.
The best news, from my perspective, is that there are more people interested in this topic than ever before. For that, I think we have the higher profile that open fonts have received from big web-font services like Google Fonts and Open Font Library to thank.
*Nathan Willis** will be presenting *[So we have free web fonts; now what?](https://www.socallinuxexpo.org/scale/16x/presentations/so-we-have-free-web-fonts-now-what) *at SCaLE16x this year, March 8-11 in Pasadena, California. To attend and get 50% of your ticket, register using promo code OSDC.*
## 4 Comments |
11,975 | 快速技巧:如何在 GIMP 中添加新画笔 | https://itsfoss.com/add-brushes-gimp/ | 2020-03-09T09:15:00 | [
"GIMP"
] | https://linux.cn/article-11975-1.html | [GIMP](https://www.gimp.org/) 是最流行的自由开源的图像编辑器,它也许是 Linux 上最好的 [Adobe Photoshop 替代品](https://itsfoss.com/open-source-photoshop-alternatives/)。
当你[在 Ubuntu 或其他任何操作系统上安装了 GIMP 后](https://itsfoss.com/gimp-2-10-release/),你会发现已经安装了一些用于基本图像编辑的画笔。如果你需要更具体的画笔,你可以随时在 GIMP 中添加新画笔。
怎么样?让我在这个快速教程中向你展示。
### 如何在 GIMP 中添加画笔

在 GIMP 中安装新画笔需要三个步骤:
* 获取新画笔
* 将其放入指定的文件夹中
* 刷新 GIMP 中的画笔
#### 步骤 1:下载新的 GIMP 画笔
第一步是获取新的 GIMP 画笔。你从哪里获取?当然是从互联网上。
你可以在 Google 或[如 Duck Duck Go 这种隐私搜索引擎](https://itsfoss.com/privacy-search-engines/)来搜索 “GIMP brushes”,并从网站下载一个你喜欢的。
GIMP 画笔通常以 .gbr 和 .gih 文件格式提供。.gbr 文件用于常规画笔,而 .gih 用于动画画笔。
>
> 你知道吗?
>
>
> 从 2.4 版本起,GIMP 使安装和使用 Photoshop 画笔(.abr 文件)非常简单。你只需将 Photoshop 画笔文件放在正确的文件夹中。
>
>
> 请记住,最新的 Photoshop 画笔可能无法完美地在 GIMP 中使用。
>
>
>
#### 步骤 2:将新画笔复制到它的位置
获取画笔文件后,下一步是复制该文件并将其粘贴到 GIMP 配置目录中所在的文件夹。
>
> 在微软 Windows 上,你必须进入类似 `C:\Documents and Settings\myusername.gimp-2.10\brushes` 这样的文件夹。
>
>
>
我将展示 Linux 上的详细步骤,因为我们是一个专注于 Linux 的网站。
选择画笔文件后,在家目录中按下 `Ctrl+h` [查看 Linux 中的隐藏文件](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/)。

你应该进入 `.config/GIMP/2.10/brushes` 文件夹(如果你使用的是 GIMP 2.10)。如果使用其他版本,那么应在 `.config/GIMP` 下看到相应文件夹。

将画笔文件粘贴到此文件夹中。可选地,你可以通过再次按 `Ctrl+h` 来隐藏隐藏的文件。
#### 步骤 3:刷新画笔(避免重启 GIMP)
GIMP 将在启动时自动加载画笔。如果已在运行,并且不想关闭它,你可以刷新画笔。
在 GIMP 的主菜单中找到 “Windows->Dockable Dialogues->Brushes”。

在右侧栏的 Brushes 对话框中找到“refresh”图标。

如果你的画笔没有出现,那么你可以试试重启 GIMP。
>
> 额外的技巧!
>
>
> 在 [GIMP 中添加新画笔还能让你轻松给图片添加水印](https://itsfoss.com/add-watermark-gimp-linux/)。只需将 logo 用作画笔,并点击一下就可添加到图片中。
>
>
>
我希望你喜欢这个快速 GIMP 技巧。敬请期待更多。
---
via: <https://itsfoss.com/add-brushes-gimp/>
作者:[Community](https://itsfoss.com/author/itsfoss/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[GIMP](https://www.gimp.org/?ref=itsfoss.com), is the most popular free and open-source image editor and perhaps the best[ Adobe Photoshop alternative](https://itsfoss.com/open-source-photoshop-alternatives/) on Linux.
When you [install GIMP on Ubuntu](https://itsfoss.com/gimp-2-10-release/) or any other operating system, you’ll find a few brushes already installed for basic image editing. If you need something more specific, you can always add new brushes in GIMP.
How? Let me show you that in this quick tutorial.
## How to add brushes in GIMP
There are three steps involved in installing new brushes in GIMP:
- Get new brush
- Put it in the designated folder
- Refresh the brushes in GIMP
### Step 1: Download new GIMP brushes
The first step is to get new brushes for GIMP. Where do you get it from? From the internet, of course.
You can search on Google or [alternative private search engines like Duck Duck Go](https://itsfoss.com/privacy-search-engines/) for ‘GIMP brushes’ and download the ones you like from a reputed website.
GIMP brushes are usually available in .gbr and .gih file formats. The .gbr file is for regular brushes while .gih is used for animated brushes.
### Step 2: Copy the new brushes into its location
After you get your brush file, the next step is to copy and paste it to the right folder in GIMP configuration directory.
On **Windows**, you’ll have to go to a folder like “**C:\Documents and Settings\myusername.gimp-2.10\brushes**“.
I’ll show detailed steps for **Linux** because It’s FOSS is a Linux-focused website.
After selecting the brush files press **Ctrl+h** in your **Home** folder to [see hidden files in Linux](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/).
You should go to **.config/GIMP/2.10/brushes** folder (if you are using GIMP version 2.10). If you are using some other version, you should see an equivalent folder under .config/GIMP.
Paste the brush files in this folder. Optionally, you can hide the hidden files by pressing **Ctrl+h** again.
### Step 3: Refresh the brushes (to avoid restarting GIMP)
GIMP will automatically load brushes when it’s launched. If you are already running it and don’t want to close it, you can refresh the brushes.
In GIMP go to **Windows**->**Dockable Dialogues**->**Brushes** in the main menu.
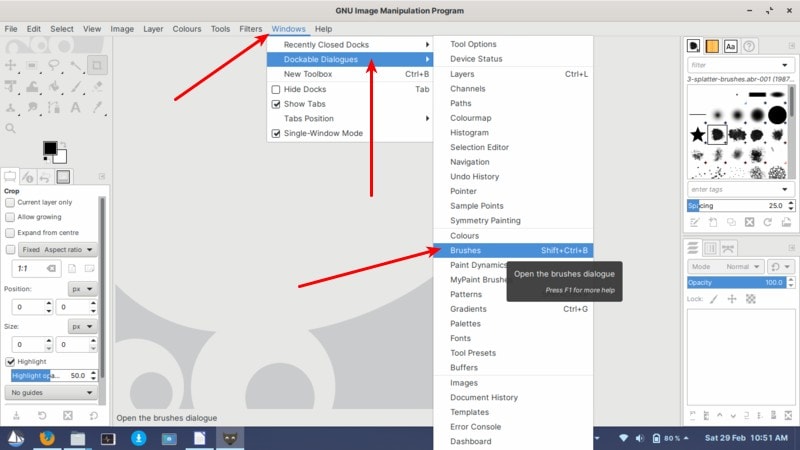
Refresh GIMP Brushes by going go to Windows->Dockable Dialogues-> Brushes
Locate the **refresh** icon in the **Brushes** dialog on the right side bar.
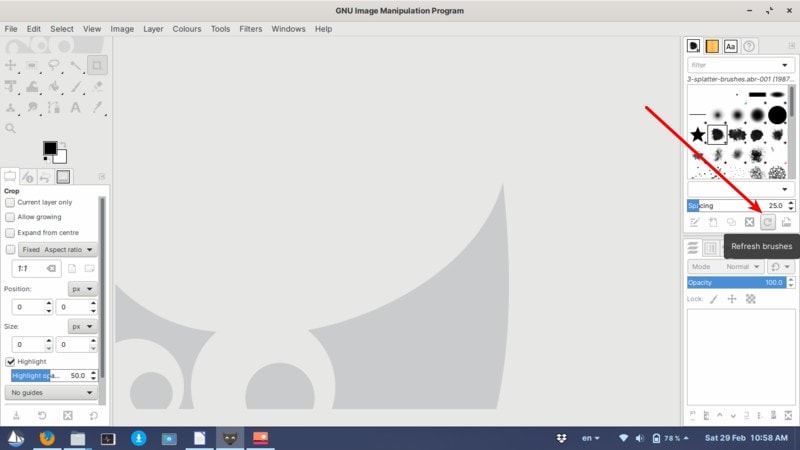
If your brushes are not present, you can always try to restart GIMP.
[GIMP also allows you easily watermark images](https://itsfoss.com/add-watermark-gimp-linux/). Just use your logo as a brush and add it to the images in a single click.
I hope you enjoyed this quick GIMP tip. Stay tuned for more. |
11,977 | Rust 包管理器 Cargo 入门 | https://opensource.com/article/20/3/rust-cargo | 2020-03-09T10:49:18 | [
"Rust",
"Cargo"
] | https://linux.cn/article-11977-1.html |
>
> 了解 Rust 的软件包管理器和构建工具。
>
>
>

[Rust](https://www.rust-lang.org/) 是一种现代编程语言,可提供高性能、可靠性和生产力。几年来,它一直被 StackOverflow 调查评为[最受欢迎的语言](https://insights.stackoverflow.com/survey/2019#technology-_-most-loved-dreaded-and-wanted-languages)。
除了是一种出色的编程语言之外,Rust 还具有一个称为 Cargo 的构建系统和软件包管理器。Cargo 处理许多任务,例如构建代码、下载库或依赖项等等。这两者捆绑在一起,因此在安装 Rust 时会得到 Cargo。
### 安装 Rust 和 Cargo
在开始之前,你需要安装 Rust 和 Cargo。Rust 项目提供了一个可下载的脚本来处理安装。要获取该脚本,请打开浏览器以访问 [https://sh.rustup.rs](https://sh.rustup.rs/) 并保存该文件。阅读该脚本以确保你对它的具体行为有所了解,然后再运行它:
```
$ sh ./rustup.rs
```
你也可以参考这个[安装 Rust](https://www.rust-lang.org/tools/install) 的网页以获取更多信息。
安装 Rust 和 Cargo 之后,你必须<ruby> 获取 <rt> source </rt></ruby> `env` 文件中的配置:
```
$ source $HOME/.cargo/env
```
更好的办法是,将所需目录添加到 `PATH` 环境变量中:
```
export PATH=$PATH:~/.cargo/bin
```
如果你更喜欢使用软件包管理器(例如 Linux 上的 DNF 或 Apt),请在发行版本的存储库中查找 Rust 和 Cargo 软件包,并进行相应的安装。 例如:
```
$ dnf install rust cargo
```
安装并设置它们后,请验证你拥有的 Rust 和 Cargo 版本:
```
$ rustc --version
rustc 1.41.0 (5e1a79984 2020-01-27)
$ cargo --version
cargo 1.41.0 (626f0f40e 2019-12-03)
```
### 手动构建和运行 Rust
从在屏幕上打印“Hello, world!”的简单程序开始。打开你喜欢的文本编辑器,然后键入以下程序:
```
$ cat hello.rs
fn main() {
println!("Hello, world!");
}
```
以扩展名 `.rs` 保存文件,以将其标识为 Rust 源代码文件。
使用 Rust 编译器 `rustc` 编译程序:
```
$ rustc hello.rs
```
编译后,你将拥有一个与源程序同名的二进制文件:
```
$ ls -l
total 2592
-rwxr-xr-x. 1 user group 2647944 Feb 13 14:14 hello
-rw-r--r--. 1 user group 45 Feb 13 14:14 hello.rs
$
```
执行程序以验证其是否按预期运行:
```
$ ./hello
Hello, world!
```
这些步骤对于较小的程序或任何你想快速测试的东西就足够了。但是,在进行涉及到多人的大型程序时,Cargo 是前进的最佳之路。
### 使用 Cargo 创建新包
Cargo 是 Rust 的构建系统和包管理器。它可以帮助开发人员下载和管理依赖项,并帮助创建 Rust 包。在 Rust 社区中,Rust 中的“包”通常被称为“crate”(板条箱),但是在本文中,这两个词是可以互换的。请参阅 Rust 社区提供的 Cargo [FAQ](https://doc.rust-lang.org/cargo/faq.html) 来区分。
如果你需要有关 Cargo 命令行实用程序的任何帮助,请使用 `--help` 或 `-h` 命令行参数:
```
$ cargo –help
```
要创建一个新的包,请使用关键字 `new`,跟上包名称。在这个例子中,使用 `hello_opensource` 作为新的包名称。运行该命令后,你将看到一条消息,确认 Cargo 已创建具有给定名称的二进制包:
```
$ cargo new hello_opensource
Created binary (application) `hello_opensource` package
```
运行 `tree` 命令以查看目录结构,它会报告已创建了一些文件和目录。首先,它创建一个带有包名称的目录,并且在该目录内有一个存放你的源代码文件的 `src` 目录:
```
$ tree .
.
└── hello_opensource
├── Cargo.toml
└── src
└── main.rs
2 directories, 2 files
```
Cargo 不仅可以创建包,它也创建了一个简单的 “Hello, world” 程序。打开 `main.rs` 文件看看:
```
$ cat hello_opensource/src/main.rs
fn main() {
println!("Hello, world!");
}
```
下一个要处理的文件是 `Cargo.toml`,这是你的包的配置文件。它包含有关包的信息,例如其名称、版本、作者信息和 Rust 版本信息。
程序通常依赖于外部库或依赖项来运行,这使你可以编写应用程序来执行不知道如何编码或不想花时间编码的任务。你所有的依赖项都将在此文件中列出。此时,你的新程序还没有任何依赖关系。打开 `Cargo.toml` 文件并查看其内容:
```
$ cat hello_opensource/Cargo.toml
[package]
name = "hello_opensource"
version = "0.1.0"
authors = ["user <[email protected]>"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
```
### 使用 Cargo 构建程序
到目前为止,一切都很顺利。现在你已经有了一个包,可构建一个二进制文件(也称为可执行文件)。在此之前,进入包目录:
```
$ cd hello_opensource/
```
你可以使用 Cargo 的 `build` 命令来构建包。注意消息说它正在“编译”你的程序:
```
$ cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.38s
```
运行 `build` 命令后,检查项目目录发生了什么:
```
$ tree .
.
├── Cargo.lock
├── Cargo.toml
├── src
│ └── main.rs
└── target
└── debug
├── build
├── deps
│ ├── hello_opensource-147b8a0f466515dd
│ └── hello_opensource-147b8a0f466515dd.d
├── examples
├── hello_opensource
├── hello_opensource.d
└── incremental
└── hello_opensource-3pouh4i8ttpvz
├── s-fkmhjmt8tj-x962ep-1hivstog8wvf
│ ├── 1r37g6m45p8rx66m.o
│ ├── 2469ykny0eqo592v.o
│ ├── 2g5i2x8ie8zed30i.o
│ ├── 2yrvd7azhgjog6zy.o
│ ├── 3g9rrdr4hyk76jtd.o
│ ├── dep-graph.bin
│ ├── query-cache.bin
│ ├── work-products.bin
│ └── wqif2s56aj0qtct.o
└── s-fkmhjmt8tj-x962ep.lock
9 directories, 17 files
```
哇!编译过程产生了许多中间文件。另外,你的二进制文件将以与软件包相同的名称保存在 `./target/debug` 目录中。
### 使用 Cargo 运行你的应用程序
现在你的二进制文件已经构建好了,使用 Cargo 的 `run` 命令运行它。如预期的那样,它将在屏幕上打印 `Hello, world!`。
```
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/hello_opensource`
Hello, world!
```
或者,你可以直接运行二进制文件,该文件位于:
```
$ ls -l ./target/debug/hello_opensource
-rwxr-xr-x. 2 root root 2655552 Feb 13 14:19 ./target/debug/hello_opensource
```
如预期的那样,它产生相同的结果:
```
$ ./target/debug/hello_opensource
Hello, world!
```
假设你需要重建包,并丢弃早期编译过程创建的所有二进制文件和中间文件。Cargo 提供了一个方便的`clean` 选项来删除所有中间文件,但源代码和其他必需文件除外:
```
$ cargo clean
$ tree .
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
1 directory, 3 files
```
对程序进行一些更改,然后再次运行以查看其工作方式。例如,下面这个较小的更改将 `Opensource` 添加到 `Hello, world!` 字符串中:
```
$ cat src/main.rs
fn main() {
println!("Hello, Opensource world!");
}
```
现在,构建该程序并再次运行它。这次,你会在屏幕上看到 `Hello, Opensource world!`:
```
$ cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.39s
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/hello_opensource`
Hello, Opensource world!
```
### 使用 Cargo 添加依赖项
Cargo 允许你添加程序需要运行的依赖项。使用 Cargo 添加依赖项非常容易。每个 Rust 包都包含一个 `Cargo.toml` 文件,其中包含一个依赖关系列表(默认为空)。用你喜欢的文本编辑器打开该文件,找到 `[dependencies]` 部分,然后添加要包含在包中的库。例如,将 `rand` 库添加为依赖项:
```
$ cat Cargo.toml
[package]
name = "hello_opensource"
version = "0.1.0"
authors = ["test user <[email protected]>"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
rand = "0.3.14"
```
试试构建你的包,看看会发生什么。
```
$ cargo build
Updating crates.io index
Compiling libc v0.2.66
Compiling rand v0.4.6
Compiling rand v0.3.23
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 4.48s
```
现在,Cargo 会联系 [Crates.io](http://crates.io)(这是 Rust 用于存储 crate(或包)的中央仓库),并下载和编译 `rand`。但是,等等 —— `libc` 包是怎么回事?你没有要安装 libc 啊。是的,`rand` 包依赖于 `libc` 包;因此,Cargo 也会下载并编译 `libc`。
库的新版本会不断涌现,而 Cargo 提供了一种使用 `update` 命令更新其所有依赖关系的简便方法:
```
cargo update
```
你还可以选择使用 `-p` 标志跟上包名称来更新特定的库:
```
cargo update -p rand
```
### 使用单个命令进行编译和运行
到目前为止,每当对程序进行更改时,都先使用了 `build` 之后是 `run`。有一个更简单的方法:你可以直接使用 `run` 命令,该命令会在内部进行编译并运行该程序。要查看其工作原理,请首先清理你的软件包目录:
```
$ cargo clean
$ tree .
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
1 directory, 3 files
```
现在执行 `run`。输出信息表明它已进行编译,然后运行了该程序,这意味着你不需要每次都显式地运行 `build`:
```
$ cargo run
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello_opensource`
Hello, world!
```
### 在开发过程中检查代码
在开发程序时,你经常会经历多次迭代。你需要确保你的程序没有编码错误并且可以正常编译。你不需要负担在每次编译时生成二进制文件的开销。Cargo 为你提供了一个 `check` 选项,该选项可以编译代码,但跳过了生成可执行文件的最后一步。首先在包目录中运行 `cargo clean`:
```
$ tree .
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
1 directory, 3 files
```
现在运行 `check` 命令,查看对目录进行了哪些更改:
```
$ cargo check
Checking hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.18s
```
该输出显示,即使在编译过程中创建了中间文件,但没有创建最终的二进制文件或可执行文件。这样可以节省一些时间,如果该包包含了数千行代码,这非常重要:
```
$ tree .
.
├── Cargo.lock
├── Cargo.toml
├── src
│ └── main.rs
└── target
└── debug
├── build
├── deps
│ ├── hello_opensource-842d9a06b2b6a19b.d
│ └── libhello_opensource-842d9a06b2b6a19b.rmeta
├── examples
└── incremental
└── hello_opensource-1m3f8arxhgo1u
├── s-fkmhw18fjk-542o8d-18nukzzq7hpxe
│ ├── dep-graph.bin
│ ├── query-cache.bin
│ └── work-products.bin
└── s-fkmhw18fjk-542o8d.lock
9 directories, 9 files
```
要查看你是否真的节省了时间,请对 `build` 和 `check` 命令进行计时并进行比较。首先,计时 `build` 命令:
```
$ time cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.40s
real 0m0.416s
user 0m0.251s
sys 0m0.199s
```
在运行 `check` 命令之前清理目录:
```
$ cargo clean
```
计时 `check` 命令:
```
$ time cargo check
Checking hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.15s
real 0m0.166s
user 0m0.086s
sys 0m0.081s
```
显然,`check` 命令要快得多。
### 建立外部 Rust 包
到目前为止,你所做的这些都可以应用于你从互联网上获得的任何 Rust crate。你只需要下载或克隆存储库,移至包文件夹,然后运行 `build` 命令,就可以了:
```
git clone <github-like-url>
cd <package-folder>
cargo build
```
### 使用 Cargo 构建优化的 Rust 程序
到目前为止,你已经多次运行 `build`,但是你注意到它的输出了吗?不用担心,再次构建它并密切注意:
```
$ cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.36s
```
看到了每次编译后的 `[unoptimized + debuginfo]` 文本了吗?这意味着 Cargo 生成的二进制文件包含大量调试信息,并且未针对执行进行优化。开发人员经常经历开发的多次迭代,并且需要此调试信息进行分析。同样,性能并不是开发软件时的近期目标。因此,对于现在而言是没问题的。
但是,一旦准备好发布软件,就不再需要这些调试信息。而是需要对其进行优化以获得最佳性能。在开发的最后阶段,可以将 `--release` 标志与 `build` 一起使用。仔细看,编译后,你应该会看到 `[optimized]` 文本:
```
$ cargo build --release
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished release [optimized] target(s) in 0.29s
```
如果愿意,你可以通过这种练习来了解运行优化软件与未优化软件时节省的时间。
### 使用 Cargo 创建库还是二进制文件
任何软件程序都可以粗略地分类为独立二进制文件或库。一个独立二进制文件也许即使是当做外部库使用的,自身也是可以运行的。但是,作为一个库,是可以被另一个独立二进制文件所利用的。到目前为止,你在本教程中构建的所有程序都是独立二进制文件,因为这是 Cargo 的默认设置。 要创建一个**库**,请添加 `--lib` 选项:
```
$ cargo new --lib libhello
Created library `libhello` package
```
这次,Cargo 不会创建 `main.rs` 文件,而是创建一个 `lib.rs` 文件。 你的库的代码应该是这样的:
```
$ tree .
.
└── libhello
├── Cargo.toml
└── src
└── lib.rs
2 directories, 2 files
```
Cargo 就是这样的,不要奇怪,它在你的新库文件中添加了一些代码。通过移至包目录并查看文件来查找添加的内容。默认情况下,Cargo 在库文件中放置一个测试函数。
### 使用 Cargo 运行测试
Rust 为单元测试和集成测试提供了一流的支持,而 Cargo 允许你执行以下任何测试:
```
$ cd libhello/
$ cat src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
}
```
Cargo 有一个方便的 `test` 命令,可以运行代码中存在的任何测试。尝试默认运行 Cargo 在库代码中放入的测试:
```
$ cargo test
Compiling libhello v0.1.0 (/opensource/libhello)
Finished test [unoptimized + debuginfo] target(s) in 0.55s
Running target/debug/deps/libhello-d52e35bb47939653
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests libhello
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
```
### 深入了解 Cargo 内部
你可能有兴趣了解在运行一个 Cargo 命令时它底下发生了什么。毕竟,在许多方面,Cargo 只是个封装器。要了解它在做什么,你可以将 `-v` 选项与任何 Cargo 命令一起使用,以将详细信息输出到屏幕。
这是使用 `-v` 选项运行 `build` 和 `clean` 的几个例子。
在 `build` 命令中,你可以看到这些给定的命令行选项触发了底层的 `rustc`(Rust 编译器):
```
$ cargo build -v
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Running `rustc --edition=2018 --crate-name hello_opensource src/main.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type bin --emit=dep-info,link -C debuginfo=2 -C metadata=147b8a0f466515dd -C extra-filename=-147b8a0f466515dd --out-dir /opensource/hello_opensource/target/debug/deps -C incremental=/opensource/hello_opensource/target/debug/incremental -L dependency=/opensource/hello_opensource/target/debug/deps`
Finished dev [unoptimized + debuginfo] target(s) in 0.36s
```
而 `clean` 命令表明它只是删除了包含中间文件和二进制文件的目录:
```
$ cargo clean -v
Removing /opensource/hello_opensource/target
```
### 不要让你的技能生锈
要扩展你的技能,请尝试使用 Rust 和 Cargo 编写并运行一个稍微复杂的程序。很简单就可以做到:例如,尝试列出当前目录中的所有文件(可以用 9 行代码完成),或者尝试自己回显输入。小型的实践应用程序可帮助你熟悉语法以及编写和测试代码的过程。
本文为刚起步的 Rust 程序员提供了大量信息,以使他们可以开始入门 Cargo。但是,当你开始处理更大、更复杂的程序时,你需要对 Cargo 有更深入的了解。当你准备好迎接更多内容时,请下载并阅读 Rust 团队编写的开源的《[Cargo 手册](https://doc.rust-lang.org/cargo)》,看看你可以创造什么!
---
via: <https://opensource.com/article/20/3/rust-cargo>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Rust](https://www.rust-lang.org/) is a modern programming language that provides performance, reliability, and productivity. It has consistently been voted as the [most-loved language](https://insights.stackoverflow.com/survey/2019#technology-_-most-loved-dreaded-and-wanted-languages) on StackOverflow surveys for a few years now.
In addition to being a great programming language, Rust also features a build system and package manager called Cargo. Cargo handles a lot of tasks, like building code, downloading libraries or dependencies, and so on. The two are bundled together, so you get Cargo when you install Rust.
## Installing Rust and Cargo
Before getting started, you need to install Rust and Cargo. The Rust project provides a downloadable script to handle the installation. To get the script, open a browser to [https://sh.rustup.rs](https://sh.rustup.rs/) and save the file. Read the script to make sure you're happy with what it intends to do, and then run it:
`$ sh ./rustup.rs `
You can also refer to the [Install Rust](https://www.rust-lang.org/tools/install) webpage for more information.
After installing Rust and Cargo, you must source the env file:
`$ source $HOME/.cargo/env`
Better yet, add the required directory to your PATH variable:
`$ source $HOME/.cargo/env`
If you prefer to use your package manager (such as DNF or Apt on Linux), look for Rust and Cargo packages in your distribution's repositories and install accordingly. For example:
`$ dnf install rust cargo`
Once they're installed and set up, verify which versions of Rust and Cargo you have:
```
$ rustc --version
rustc 1.41.0 (5e1a79984 2020-01-27)
$ cargo --version
cargo 1.41.0 (626f0f40e 2019-12-03)
```
## Building and running Rust by hand
Start with a simple program that prints "Hello, world!" on the screen. Open your favorite text editor and type the following program:
```
$ cat hello.rs
fn main() {
println!("Hello, world!");
}
```
Save the file with an **.rs** extension to identify it as a Rust source code file.
Compile your program using the Rust compiler, **rustc**:
`$ rustc hello.rs`
After compilation, you will have a binary that has the same name as the source program:
```
$ ls -l
total 2592
-rwxr-xr-x. 1 user group 2647944 Feb 13 14:14 hello
-rw-r--r--. 1 user group 45 Feb 13 14:14 hello.rs
$
```
Execute your program to verify that it runs as expected:
```
$ ./hello
Hello, world!
```
These steps are sufficient for smaller programs or whenever you want to test out something quickly. However, when working on bigger programs involving multiple people, Cargo is the best way forward.
## Creating a new package using Cargo
Cargo is a build system and package manager for Rust. It helps developers download and manage dependencies and assists in creating Rust packages. Packages in Rust are often called "crates" in the Rust community, but in this article, the two words are interchangeable. Refer to the Cargo [FAQ](https://doc.rust-lang.org/cargo/faq.html) provided by the Rust community for clarification.
If you need any help with Cargo's command-line utility, use the **--help** or **-h** command-line argument:
`$ cargo –help`
To create a new package, use the **new** keyword, followed by the package name. For this example, use **hello_opensource** as your new package name. After running the command, you will see a message confirming that Cargo has created a binary package with the given name:
```
$ cargo new hello_opensource
Created binary (application) `hello_opensource` package
```
Running a **tree** command to see the directory structure reports that some files and directories were created. First, it creates a directory with the name of the package, and within that directory is an **src** directory for your source code files:
```
$ tree .
.
└── hello_opensource
├── Cargo.toml
└── src
└── main.rs
2 directories, 2 files
```
Cargo not only creates a package, but it also creates a simple **Hello, world!** program. Open the **main.rs** file and have a look:
```
$ cat hello_opensource/src/main.rs
fn main() {
println!("Hello, world!");
}
```
The next file to work with is **Cargo.toml**, which is a configuration file for your package. It contains information about the package, such as its name, version, author information, and Rust edition information.
A program often depends on external libraries or dependencies to run, which enables you to write applications that perform tasks that you don't know how to code or you don't want to spend time coding. All your dependencies will be listed in this file. At this point, you do not have any dependencies for your new program. Open the **Cargo.toml** file and view its contents:
```
$ cat hello_opensource/Cargo.toml
[package]
name = "hello_opensource"
version = "0.1.0"
authors = ["user <[email protected]>"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
```
## Building the program using Cargo
So far, so good. Now that you have a package in place, build a binary (also called an executable). Before doing that, move into the package directory:
`$ cd hello_opensource/`
You can use Cargo's **build** command to build the package. Notice the messages that say it is **Compiling** your program:
```
$ cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.38s
```
Check what happens to your project directory after you run the **build** command:
```
$ tree .
.
├── Cargo.lock
├── Cargo.toml
├── src
│ └── main.rs
└── target
└── debug
├── build
├── deps
│ ├── hello_opensource-147b8a0f466515dd
│ └── hello_opensource-147b8a0f466515dd.d
├── examples
├── hello_opensource
├── hello_opensource.d
└── incremental
└── hello_opensource-3pouh4i8ttpvz
├── s-fkmhjmt8tj-x962ep-1hivstog8wvf
│ ├── 1r37g6m45p8rx66m.o
│ ├── 2469ykny0eqo592v.o
│ ├── 2g5i2x8ie8zed30i.o
│ ├── 2yrvd7azhgjog6zy.o
│ ├── 3g9rrdr4hyk76jtd.o
│ ├── dep-graph.bin
│ ├── query-cache.bin
│ ├── work-products.bin
│ └── wqif2s56aj0qtct.o
└── s-fkmhjmt8tj-x962ep.lock
9 directories, 17 files
```
Wow! The compilations process produced a lot of intermediate files. Your binary, though, is saved in the **./target/debug** directory with the same name as your package.
## Running your application using Cargo
Now that your binary is built, run it using Cargo's **run** command. As expected, it prints **Hello, world!** on the screen.
```
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/hello_opensource`
Hello, world!
```
Alternatively, you can run the binary directly, which is located at:
```
$ ls -l ./target/debug/hello_opensource
-rwxr-xr-x. 2 root root 2655552 Feb 13 14:19 ./target/debug/hello_opensource
```
As expected, it produces the same results:
```
$ ./target/debug/hello_opensource
Hello, world!
```
Say you need to rebuild your package and get rid of all the binaries and the intermediate files created by the earlier compilation process. Cargo provides a handy **clean** option to remove all intermediate files except the source code and other required files:
```
$ cargo clean
$ tree .
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
1 directory, 3 files
```
Make some changes to the program and run it again to see how it works. For example, this minor change adds **Opensource** to the **Hello, world!** string:
```
$ cat src/main.rs
fn main() {
println!("Hello, Opensource world!");
}
```
Now, build the program and run it again. This time you see **Hello, Opensource world!** displayed on the screen:
```
$ cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.39s
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/hello_opensource`
Hello, Opensource world!
```
## Adding dependencies using Cargo
Cargo allows you to add dependencies that your program needs to run. Adding a dependency is extremely easy with Cargo. Every Rust package includes a **Cargo.toml** file, which contains a list (empty by default) of dependencies. Open the file in your favorite text editor, find the **[dependencies]** section, and add the library you want to include in your package. For example, to add the **rand** library as your dependency:
```
$ cat Cargo.toml
[package]
name = "hello_opensource"
version = "0.1.0"
authors = ["test user <[email protected]>"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
rand = "0.3.14"
```
Try building your package to see what happens.
```
$ cargo build
Updating crates.io index
Compiling libc v0.2.66
Compiling rand v0.4.6
Compiling rand v0.3.23
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 4.48s
```
Cargo is now reaching out to [Crates.io](http://crates.io), which is Rust's central repository for crates (or packages) and downloading and compiling **rand**. But wait—what about the **libc** package? You did not ask for **libc** to be installed. Well, the **rand** package is dependent on the **libc** package; hence, Cargo downloads and compiles **libc** as well.
New versions of libraries keep coming, and Cargo provides an easy way to update all of their dependencies using the **update** command:
`cargo update`
You can also choose to update specific libraries using the **-p** flag followed by the package name:
`cargo update -p rand`
## Compiling and running with a single command
So far, you have used **build** followed by **run** whenever you make changes to your program. There is an easier way: you can simply use the **run** command, which internally compiles and runs the program. To see how it works, first clean up your package directory:
```
$ cargo clean
$ tree .
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
1 directory, 3 files
```
Now execute **run**. The output states that it compiled and then ran the program, and this means you don't need to explicitly run **build** each time:
```
$ cargo run
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello_opensource`
Hello, world!
```
## Checking your code in development
You often go through multiple iterations when developing a program. You need to ensure that your program has no coding errors and compiles fine. You don't need the overhead of generating the binary on each compilation. Cargo has you covered with a **check** option that compiles your code but skips the final step of generating an executable.
Start by running **cargo clean** within your package directory:
```
$ tree .
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
1 directory, 3 files
```
Now run the **check** command and see what changes were made to the directory:
```
$ cargo check
Checking hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.18s
```
The output shows that, even though intermediate files were created as part of the compilation process, the final binary or executable was not created. This saves some time, which matters a lot if the package is huge with thousands of lines of code:
```
$ tree .
.
├── Cargo.lock
├── Cargo.toml
├── src
│ └── main.rs
└── target
└── debug
├── build
├── deps
│ ├── hello_opensource-842d9a06b2b6a19b.d
│ └── libhello_opensource-842d9a06b2b6a19b.rmeta
├── examples
└── incremental
└── hello_opensource-1m3f8arxhgo1u
├── s-fkmhw18fjk-542o8d-18nukzzq7hpxe
│ ├── dep-graph.bin
│ ├── query-cache.bin
│ └── work-products.bin
└── s-fkmhw18fjk-542o8d.lock
9 directories, 9 files
```
To see if you are really saving time, time the **build** and **check** commands and compare them.
First, the **build** command:
```
$ time cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.40s
real 0m0.416s
user 0m0.251s
sys 0m0.199s
```
Clean the directory before running the **check** command:
`$ cargo clean`
The **check** command:
```
$ time cargo check
Checking hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.15s
real 0m0.166s
user 0m0.086s
sys 0m0.081s
```
Clearly, the **check** command is much faster.
## Building external Rust packages
Everything you've done so far will apply to any Rust crate you get from the internet. You simply need to download or clone the repository, move to the package folder, and run the **build** command, and you are good to go:
```
git clone <github-like-url>
cd <package-folder>
cargo build
```
## Building optimized Rust programs using Cargo
You've run **build** multiple times so far, but did you notice its output? No worries, build it again and watch closely:
```
$ cargo build
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished dev [unoptimized + debuginfo] target(s) in 0.36s
```
See the **[unoptimized + debuginfo]** text after each compilation? This means that the binary generated by Cargo includes a lot of debugging information and is not optimized for execution. Developers often go through multiple iterations of development and need this debugging information for analysis. Also, performance is not the immediate goal while developing software. Therefore, this is OK for now.
However, once the software is ready for release, it doesn't need to have the debugging information anymore. But it does need to be optimized for best performance. In the final stages of development, you can use the **--release** flag with **build**. Watch closely; you should see the **[optimized]** text after compilation:
```
$ cargo build --release
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Finished release [optimized] target(s) in 0.29s
```
If you want to, you can go through the exercise to find out your time savings when running optimized vs. unoptimized software.
## Creating a library vs. a binary using Cargo
Any software program can be roughly categorized as either a standalone binary or a library. A standalone binary can be run as it is, even though it might make use of external libraries. A library, however, is utilized by another standalone binary. All the programs you've built so far in this tutorial are standalone binaries since that is Cargo's default. To create a **library**, add the **--lib** option:
```
$ cargo new --lib libhello
Created library `libhello` package
```
This time, Cargo does not create a **main.rs** file; instead, it creates a **lib.rs** file. The code for your library should go here:
```
$ tree .
.
└── libhello
├── Cargo.toml
└── src
└── lib.rs
2 directories, 2 files
```
Knowing Cargo, don't be surprised that it put some code in your new library file. Find out what it added by moving to the package directory and viewing the file. By default, Cargo puts a test function within library files.
## Running tests using Cargo
Rust provides first-class support for unit and integration testing, and Cargo allows you to execute any of these tests:
```
$ cd libhello/
$ cat src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
}
```
Cargo has a handy **test** option to run any test that is present in your code. Try running the tests that Cargo put in the library code by default:
```
$ cargo test
Compiling libhello v0.1.0 (/opensource/libhello)
Finished test [unoptimized + debuginfo] target(s) in 0.55s
Running target/debug/deps/libhello-d52e35bb47939653
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests libhello
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
```
## Looking under Cargo's hood
You may be interested in knowing what Cargo does under the hood when you run a command. After all, Cargo is, in many ways, a wrapper. To find out what it's doing, you can use the **-v** option with any Cargo command to output verbose information to the screen.
Here are a couple of examples that run **build** and **clean** using the **-v** option.
In the **build** command, you can see that the underlying **rustc** (Rust compiler) fired with the given command-line options:
```
$ cargo build -v
Compiling hello_opensource v0.1.0 (/opensource/hello_opensource)
Running `rustc --edition=2018 --crate-name hello_opensource src/main.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type bin --emit=dep-info,link -C debuginfo=2 -C metadata=147b8a0f466515dd -C extra-filename=-147b8a0f466515dd --out-dir /opensource/hello_opensource/target/debug/deps -C incremental=/opensource/hello_opensource/target/debug/incremental -L dependency=/opensource/hello_opensource/target/debug/deps`
Finished dev [unoptimized + debuginfo] target(s) in 0.36s
```
Whereas the **clean** command shows that it is simply removing the directory that contains the intermediate files and the binary:
```
$ cargo clean -v
Removing /opensource/hello_opensource/target
```
## Don't let your skills get rusty
To expand your skills, try writing and running a slightly more complex program using Rust and Cargo. Something simple will do: for instance, try listing all files in the current directory (it can be done in nine lines of code), or try echoing input back out at yourself. Small practice applications help you get comfortable with the syntax and the process of writing and testing code.
This article offers plenty of information for budding Rust programmers to get started with Cargo. However, as you begin working on larger and more complicated programs, you'll need a more advanced understanding of Cargo. When you're ready for more, download and read the open source [Cargo Book](https://doc.rust-lang.org/cargo) written by the Rust team, and see what you can create!
## Comments are closed. |
11,978 | 九种用开源拯救地球的方法 | https://opensource.com/article/19/4/save-planet | 2020-03-10T00:40:00 | [
"环保"
] | https://linux.cn/article-11978-1.html |
>
> 这些主意都用到了有关的开源技巧。
>
>
>

人们可以做些什么来拯救地球?这个问题可能会让人感到压抑,因为有时我们感觉个人可以做的贡献太少了。但是作为地球公民,我们从来不是一个人。所以,我向我们的作家社区征集了一些开源软件或硬件可以帮助改变现状的方法。以下是他们的回复。
### 九种利用开源的方法来拯救地球的方式
##### 1、在你的终端禁用闪烁的光标
这听起来可能有点傻,但是那个无关紧要的闪烁的光标可能导致[每小时两瓦特的额外电力开销](https://www.redhat.com/archives/fedora-devel-list/2009-January/msg02406.html)。如果要禁用光标闪烁,可以通过更改终端设置:<ruby> 编辑 <rt> Edit </rt></ruby> > <ruby> 偏好设置 <rt> Preferences </rt></ruby> > <ruby> 光标 <rt> Cursor </rt></ruby> > <ruby> 光标闪烁 <rt> Cursor blinking </rt></ruby> > <ruby> 禁用 <rt> Disabled </rt></ruby>。
*由 Mars Toktonaliev 推荐*
##### 2、减少有关动物产品和加工食物的消费
这样做的一种方法是在你的手机中添加这些开源的 App:Daily Dozen、OpenFoodFacts、OpenVegeMap 和 Food Restrictions。这些 App 可以帮助你准备一份健康的素食饮食计划,为你找到素食主义者和严格素食主义者可以就餐的餐厅,还可以帮助你把你的饮食需求告诉别人,即使他们不和你讲同一种语言。如果想要了解更多有关这些的 App 的信息,你可以阅读《[4 款“吃草”的开源应用](/article-10926-1.html)》。
*由 Joshua Allen Holm 推荐*
##### 3、让旧电脑重焕新生
怎么做?当然是用 Linux。通过给那些自己得不到新电脑的人创造一台新电脑来传递爱心,同时也可以避免让这台电脑进到垃圾填埋场。可以在 [The Asian Penguins](https://opensource.com/article/19/2/asian-penguins-close-digital-divide) 看看我们是怎么做的。
*由 Stu Keroff 推荐*
##### 4、在你不使用设备时关闭它们
你可以使用带有主插座和控制插座的“智能插座板”。把你的电脑连接到主插座上,这样的话当你打开电脑时所有你连接到控制插座上的设备如显示器,打印机等也都会打开。一个更简单的、技术含量更低的方法是使用一个带有计时器的插座板。我在家里就是用的这个。你可以用计时器上的开关设定一个定时开关电源的时间表。这样可以在没有人在家时自动关闭网络打印机。或者以我的用了六年的笔记本电脑为例,我通过一个交替使用外接电源(插座打开)和使用电脑电池(插座关闭)的电源计划延长了电脑电池的寿命。
*由 Jim Hall 推荐*
##### 5、减少供暖通风系统(HVAC)的使用
在夏天,透过窗户的阳光可以为室内提供很多热量。使用 Home Assistant 可以[基于一天中的时间的](https://www.home-assistant.io/components/cover/),甚至是基于太阳高度角[自动调节](https://www.home-assistant.io/docs/automation/trigger/#sun-trigger)窗帘和遮阳棚。
*由 Michael Hrivnak 推荐*
##### 6、出门就把恒温器关闭或调低
如果你的家用恒温器具有“离开”功能,你很容易忘记在出门时启用它。借助自动化,任何连接到网络的恒温器都可以在你不在家时自动节省能量。[Stataway](https://github.com/mhrivnak/stataway) 就是一个这样项目。它通过调用你的手机的 GPS 坐标来决定是将你的恒温器设置为“在家”还是“离开”。
*由 Michael Hrivnak 推荐*
##### 7、为未来储蓄算力
我有一个主意:创建一个可以读取可选的能量阵列(如风能或太阳能)的输出的脚本。这个脚本应该将计算集群中的服务器从睡眠模式更改为激活模式,直到过量的电能(超出可以储存的部分)被用尽。然后在高产能时段使用这些过量的电能来进行需要大量计算的项目,比如渲染。这个过程本质应该是免费的,因为使用的能量无法被储存起来挪作它用。我相信现有的监控、能量管理和服务器阵列工具一定可以实现这个功能。那么剩下的只是一些整合上的问题,就可以让整个系统工作起来。
*由 Terry Hancock 推荐*
##### 8、关掉你的灯
根据<ruby> <a href="http://advances.sciencemag.org/content/2/6/e1600377"> 人工夜空亮度图集 </a> <rt> World Atlas of Artificial Night Sky Brightness </rt></ruby>的说法,光污染影响了全世界超过 80% 的人口。这一结论在 2016 年(遵循 CC-NC 4.0 协议)发表在公开访问的期刊《<ruby> 科学进展 <rt> Science Advances </rt></ruby>》上。关闭外部照明是一个可以使野生生物、人类健康受益并让我们享受夜晚的天空的快速途径,而且可以减少能量消耗。访问 [darksky.org](http://darksky.org/) 来查看更多减少外部照明影响的方法。
*由 Michael Hrivnak 推荐*
##### 9、减少你的 CPU 数量
就我个人而言,我记得我以前有很多在地下室运行的电脑作为我的 IT 游乐场/实验室。我现在对于能源消耗更加注意了,所以确实大大地减少了我的 CPU 数量。我现在更喜欢利用虚拟机、区域和容器等技术。另外,我很高兴有小型电脑和 SoC 电脑这种东西,比如树莓派,因为我可以用一台这样的电脑做很多事情,比如运行一个 DNS 或者 Web 服务器,而无需使整个屋子变热并积累昂贵的电费账单。
P.S. 这些电脑都运行于 Linux、FreeBSD,或者 Raspbian 系统!
*由 Alan Formy-Duvall 推荐*
---
via: <https://opensource.com/article/19/4/save-planet>
作者:[Jen Wike Huger](https://opensource.com/users/jen-wike/users/alanfdoss/users/jmpearce) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MFGJT](https://github.com/MFGJT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | What can be done to help save the planet? The question can seem depressing at a time when it feels like an individual's contribution isn't enough. But, who are we Earth dwellers if not for a collection of individuals? So, I asked our writer community to share ways that open source software or hardware can be used to make a difference. Here's what I heard back.
## 9 ways to save the planet with an open source twist
**1. ****Disable the blinking cursor in your terminal.**
It might sound silly, but the trivial, blinking cursor can cause up to [2 watts per hour of extra power consumption](https://www.redhat.com/archives/fedora-devel-list/2009-January/msg02406.html). To disable it, go to Terminal Settings: Edit > Preferences > Cursor > Cursor blinking > Disabled.
*Recommended by Mars Toktonaliev*
**2. Reduce your consumption of animal products and processed foods.**
One way to do this is to add these open source apps to your phone: Daily Dozen, OpenFoodFacts, OpenVegeMap, and Food Restrictions. These apps will help you eat a healthy, plant-based diet, find vegan- and vegetarian-friendly restaurants, and communicate your dietary needs to others, even if they do not speak the same language. To learn more about these apps read [ 4 open source apps to support eating a plant-based diet](https://opensource.com/article/19/4/apps-plant-based-diets).
*Recommendation by Joshua Allen Holm*
**3. Recycle old computers.**
How? With Linux, of course. Pay it forward by giving creating a new computer for someone who can't one and keep a computer out of the landfill. Here's how we do it at [The Asian Penguins](https://opensource.com/article/19/2/asian-penguins-close-digital-divide).
*Recommendation by Stu Keroff*
**4. Turn off devices when you're not using them.**
Use "smart power strips" that have a "master" outlet and several "controlled" outlets. Plug your PC into the master outlet, and when you turn on the computer, your monitor, printer, and anything else plugged into the controlled outlets turns on too. A simpler, low-tech solution is a power strip with a timer. That's what I use at home. You can use switches on the timer to set a handy schedule to turn the power on and off at specific times. Automatically turn off your network printer when no one is at home. Or for my six-year-old laptop, extend the life of the battery with a schedule to alternate when it's running from wall power (outlet is on) and when it's running from the battery (outlet is off).
*Recommended by Jim Hall*
**5. Reduce the use of your HVAC system.**
Sunlight shining through windows adds a lot of heat to your home during the summer. Use Home Assistant to [automatically adjust](https://www.home-assistant.io/docs/automation/trigger/#sun-trigger) window blinds and awnings [based on the time of day](https://www.home-assistant.io/components/cover/), or even based on the angle of the sun.
*Recommended by Michael Hrivnak*
**6. Turn your thermostat off or to a lower setting while you're away.**
If your home thermostat has an "Away" feature, activating it on your way out the door is easy to forget. With a touch of automation, any connected thermostat can begin automatically saving energy while you're not home. [Stataway](https://github.com/mhrivnak/stataway) is one such project that uses your phone's GPS coordinates to determine when it should set your thermostat to "Home" or "Away".
*Recommended by Michael Hrivnak*
**7. Save computing power for later.**
I have an idea: Create a script that can read the power output from an alternative energy array (wind and solar) and begin turning on servers (taking them from a power-saving sleep mode to an active mode) in a computing cluster until the overload power is used (whatever excess is produced beyond what can be stored/buffered for later use). Then use the overload power during high-production times for compute-intensive projects like rendering. This process would be essentially free of cost because the power can't be buffered for other uses. I'm sure the monitoring, power management, and server array tools must exist to do this. Then, it's just an integration problem, making it all work together.
*Recommended by Terry Hancock*
**8. Turn off exterior lights.**
Light pollution affects more than 80% of the world's population, according to the [World Atlas of Artificial Night Sky Brightness](http://advances.sciencemag.org/content/2/6/e1600377), published (Creative Commons Attribution-NonCommercial 4.0) in 2016 in the open access journal *Science Advances*. Turning off exterior lights is a quick way to benefit wildlife, human health, our ability to enjoy the night sky, and of course energy consumption. Visit [darksky.org](http://darksky.org/) for more ideas on how to reduce the impact of your exterior lighting.
*Recommended by Michael Hrivnak*
**9. Reduce your CPU count.**
For me, I remember I used to have a whole bunch of computers running in my basement as my IT playground/lab. I've become more conscious now of power consumption and so have really drastically reduced my CPU count. I like to take advantage of VMs, zones, containers... that type of technology a lot more these days. Also, I'm really glad that small form factor and SoC computers, such as the Raspberry Pi, exist because I can do a lot with one, such as run a DNS or Web server, without heating the room and running up my electricity bill.
P.S. All of these computers are running Linux, FreeBSD, or Raspbian!
*Recommended by Alan Formy-Duvall*
## 3 Comments |
11,981 | Calculator N+:一款智能手机上的开源科学计算器 | https://opensource.com/article/19/11/calculator-n-mobile | 2020-03-10T11:36:00 | [
"计算器"
] | https://linux.cn/article-11981-1.html |
>
> 这个 Android 应用可在掌中计算许多高级数学函数。
>
>
>

移动电话每天都在变得越来越强大,因此毫不奇怪它们可以击败不太久前的大多数计算机。这也意味着移动手机上的工具每天都在变得越来越强大。
之前,我写过一篇 [两款 Linux 桌面端可用的科学计算器](/article-9643-1.html),我接着将介绍 [Calculator N+](https://github.com/tranleduy2000/ncalc),这是一款很棒的适用于 Android 设备的计算机代数系统(CAS)应用,采用 GPL v3.0 许可证下。
Calculator N+ 被认为是“适用于 Android 的强大计算器”,但这是一个谦虚的说法。它不仅可以以任意精度工作,还可以显示根数和分数等*很多*功能。
寻找多项式根?可以。分解因数?可以。导数、积分和极限?可以。数论(模算术、组合学、素因数分解)?可以。
你还可以求解方程系统、简化表达式(包括三角函数)、转换单位,只要你想到的,它都能做!

其结果以 LaTeX 输出。左上方的菜单提供了许多强大的功能,只需触摸一下即可使用。同样在该菜单中,你将找到该应用所有功能的帮助文件。在屏幕的右上角,你可以在精确表示法和十进制表示法之间切换。最后,点击屏幕底部的蓝色栏,即可访问应用中的所有函数库。不过要小心!如果你不是数学家、物理学家或工程师,那么这么长的列表会看上去很吓人。
所有这些功能都来自 [Symja 库](https://github.com/axkr/symja_android_library),这是另一个出色的 GPL 3 项目。
这两个项目都处于积极开发中,并且每个版本都在不断完善。特别是,Calculator N+ 的 v3.4.6 在用户界面(UI)品质方面取得了重大飞跃。虽然还是存在一些不够好的地方,但是要在智能手机的小巧的用户界面中发挥如此强大的功能是一项艰巨的任务,我认为应用开发人员正在很好地解决其剩余的问题。对他们表示敬意!
如果你是老师、学生或在理工科领域工作,请试试 Calculator N+。它是免费、无广告、开源的,并可以满足你所有的数学需求。(当然,除了数学考试期间,为防止作弊绝对不允许使用智能手机。)
可以在 [Google Play 商店](https://play.google.com/store/apps/details?id=com.duy.calculator.free)找到 Calculator N+,也可以使用 GitHub 页面上的说明[从源代码构建](https://github.com/tranleduy2000/ncalc/blob/master/README.md)。
如果你知道用于科学或工程的其他有用的开源应用,请在评论中告知我们。
---
via: <https://opensource.com/article/19/11/calculator-n-mobile>
作者:[Ricardo Berlasso](https://opensource.com/users/rgb-es) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mobile phones are becoming more powerful every day, so it is no surprise that they can beat most computers from the not-so-distant past. This also means the tools available on them are getting more powerful every day.
Previously, I wrote about [scientific calculators for the Linux desktop](https://opensource.com/article/18/1/scientific-calculators-linux), and I'm following that up here with information about [Calculator N+](https://github.com/tranleduy2000/ncalc), an awesome GPL v3.0-licensed computer algebra system (CAS) app for Android devices.
Calculator N+ is presented as a "powerful calculator for Android," but that's a humble statement; the app not only works with arbitrary precision, displaying results with roots and fractions in all their glory, it does a *lot* more.
Finding polynomial roots? Check. Factorization? Check. Symbolic derivatives, integrals, and limits? Check. Number theory (modular arithmetic, combinatorics, prime factorization)? Check.
You can also solve systems of equations, simplify expressions (including trigonometric ones), convert units… you name it!
Results are output in LaTeX. The menu in the top-left provides many powerful functions ready to use with a simple touch. Also in that menu, you'll find Help files for all of the app's functions. At the top-right of the screen, you can toggle between exact and decimal representation. Finally, tapping the blue bar at the bottom of the screen gives you access to the whole library of functions available in the app. But be careful! If you are not a mathematician, physicist, or engineer, such a long list may seem overwhelming.
All of this power comes from the [Symja library](https://github.com/axkr/symja_android_library), another great GPL 3 project.
Both projects are under active development, and they are getting better with each version. In particular, version 3.4.6 of Calculator N+ gets a major leap in user interface (UI) quality. And yes, there are still some rough corners here and there, but taming this much power in the tiny UI of a smartphone is a difficult task, and I think the app developers are solving its remaining issues quite well. Kudos to them!
If you are a teacher, a student, or work on a STEM field, check out Calculator N+. It's free, no ads, open source, and covers all your math needs. (Except, of course, during math exams, where smartphones should never be allowed to prevent cheating.)
Calculator N+ is available in the [Google Play Store](https://play.google.com/store/apps/details?id=com.duy.calculator.free), or you can [build it from source code](https://github.com/tranleduy2000/ncalc/blob/master/README.md) using the instructions on the GitHub page.
If you know any other useful open source apps for science or engineering, let us know in the comments.
## Comments are closed. |
11,982 | Session:一款不需要电话号码的开源通信应用 | https://itsfoss.com/session-messenger/ | 2020-03-10T17:29:00 | [
"Signal",
"Session"
] | https://linux.cn/article-11982-1.html | 
Signal 作为一款私人通信应用,正在变得愈发流行。而我们下面要介绍开源应用 Session 则是 Signal 的一个<ruby> 复刻 <rt> fork </rt></ruby>,它的一大亮点是并不需要提供手机号码即可以开始使用。
### Session:一款真正意义上的私人通信应用

对于私人通信服务来说,有没有既能保护通信安全性,又尊重用户跨平台隐私的集大成者呢?很多注重个人隐私的用户似乎都在寻找这个问题的答案。
最近,我留意到 [Loki 基金会](https://loki.foundation/)开发的一款叫做 [Session](https://getsession.org/) 的开源通信应用。从技术上来说,Session 是另一款[开源、加密的通信应用 Signal](/article-11764-1.html) 的一个复刻。
在本文中,我会讲述我自己使用 Session 的体验,以及 Session 的一些主要功能。
Session 在这个领域中算是一款比较新的应用了,因此我还会在文章的最后提到它的一些不足之处。
### Session 的一些主要功能
接下来我会重点介绍 Session 的主要功能,可以供你参考这款应用是否值得使用。
#### Session 的使用过程中不需要提供手机号码

在 Signal 或者其它类似的通信应用中,用户都需要提供手机号码才得以成功注册。注重隐私的用户们都认为这样的做法会潜藏着巨大的安全隐患。
而使用 Session 则简单得多。在 PC 或手机上安装应用之后,只需要点击“<ruby> 创建账号 <rt> Create Account </rt></ruby>”,无须提供手机号码,它就会生成一个类似 05652245af9a8bfee4f5a8138fd5c….. 这样的随机且唯一的 Session ID。
此后,把 Session ID 分享给想要添加的联系人就可以了。Session 还支持二维码,其他人可以通过扫描二维码添加你的 Session ID 为好友。
#### Session 使用了区块链等加密技术

对[区块链](https://en.wikipedia.org/wiki/Blockchain)有所了解的用户都很期待区块链能为普罗大众做出什么有实际意义的应用,而 Session 可以算得上其中一个。尽管 Session 的核心是基于区块链的,但普通用户在使用时并不需要真正弄懂区块链。
如果你好奇它的工作原理,可以参考这篇[官方的博客文章](https://getsession.org/how-session-protects-your-anonymity-with-blockchain-and-crypto/),里面有相关的解释。
#### 跨平台支持

这样严格保护隐私的应用,是否能在不同平台上使用?
答案是肯定的。首先,它支持 Linux 和 Android 平台,同时也支持 Windows/Mac/iOS 平台。因此跨平台、跨设备的消息同步是没有问题的。
#### 包含基本隐私选项

毫无疑问,基本的隐私功能是必须有的,这是作为一个以安全为卖点的应用所必备的体验。
最基本的选项包括:
* **消息有效期**:你可以控制一条消息在接收者阅读前的保留时长
* **已读回执**:消息发送者可以知晓你已经阅读该消息
#### Session 使用去中心化网络保护你的元数据
尽管 Session 不使用<ruby> 端对端 <rt> peer-to-peer </rt></ruby>技术,但它也不使用中心化的服务器。
Session 采用了去中心化的架构实现消息的传输和路由。如果你不熟悉这方面的内容,可以关注 Session 的官方博客,尝试了解[中心化网络和去中心化网络的区别](https://getsession.org/centralisation-vs-decentralisation-in-private-messaging/),以及它的实际工作原理。
同时,这样的网络架构还有助于保护诸如与 IP 地址相关的信息等元数据。
#### 其它功能
除了专注于隐私之外,Session 也支持群聊、语音消息、发送附件等通信应用的基本功能。
### 在 Linux 上安装 Session
在[官方下载页面](https://getsession.org/download/)中可以下载到对应的 .AppImage 文件。如果你不了解这个文件的使用方法,可以查阅我们的[相关文章](https://itsfoss.com/use-appimage-linux/)。
另外,你也可以在它的 [Github 发布页面](https://github.com/loki-project/session-desktop/releases) 获取到对应的 .deb 安装文件。
* [下载 Session](https://getsession.org/download/)
### 我使用 Session 的体验
我在各种平台上都试用过 Session,其中在 PC 上我使用了 Pop!\_OS 19.10 的 .AppImage 文件运行这个应用。
总的来说,使用的体验很不错,用户界面也没有出现问题。
在设置中备份了密码(也称为<ruby> 种子 <rt> seed </rt></ruby>)后,可以很方便地恢复账号。

当然,我也发现了一些需要改进的地方:
* 在接受好友请求时会出现延迟
* 设备间连接的方式不太直观
* 当你在不同的设备上使用同一个 Session ID 向同一个人回复消息时,对方会收到两个不同的对话
### 总结
当然,最完美的事物是不存在的。我也会一直使用 Session 并考虑它发展的方向,这是一个注重隐私的用户应该做的事情。
欢迎在评论区发表你的看法。
---
via: <https://itsfoss.com/session-messenger/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Our open source software highlight of the week is Session. It is a fork of another increasingly popular private messenger Signal. Session doesn’t even need your phone number to operate.*
## Session: A private messenger in true sense
Privacy concerned people are always in the search of an ultimate service that lets you communicate securely while respecting our privacy across multiple platforms.
Recently, I came across an interesting open-source messaging app “[Session](https://getsession.org/)” by [Loki Foundation](https://loki.foundation/), which is technically a fork of another [open source encrypted messenger Signal](https://itsfoss.com/signal-messaging-app/).
In this article, I’ll be sharing my experience with the Session app while highlighting the features it offers.
Session is fairly new to the scene – I’ve mentioned some of the bugs that I encountered at the bottom of the article.
## Features of Session Messenger
I’ll highlight the key features of Session that will help you decide if it’s good enough for you to try.
### Session does not require a phone number
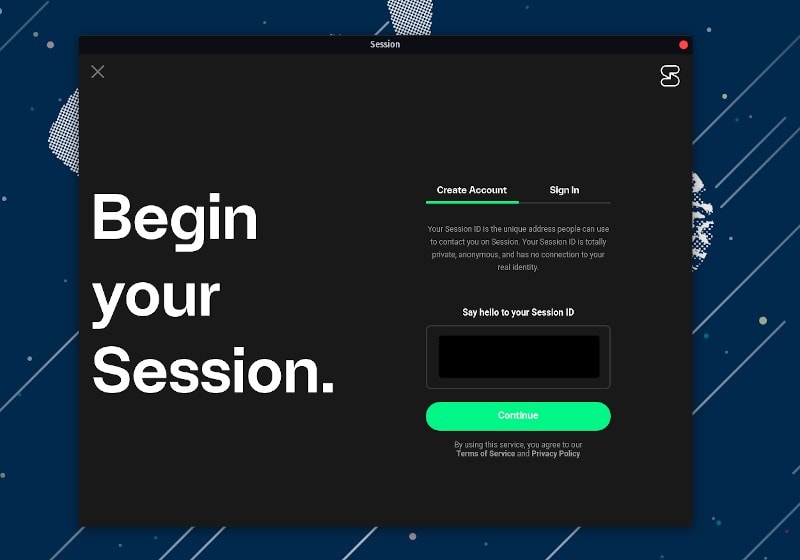
For privacy-enthusiasts, registering the phone number with Signal or other such applications is a potential risk.
But, with Session, you do not need a phone number, simply click on “**Create Account**” after you install it on your desktop or phone and it will simply generate a random (unique) **Session ID**.
It’ll look something like this: **05652245af9a8bfee4f5a8138fd5c……..**
So, you just have to share your Session ID with the contact you want to add. Or, you can also opt to get the **QR Code** after account creation which you can share with your friends to add you back.
### Session uses blockchain (and other crypto tech)
For the users who’re aware of what a [blockchain](https://en.wikipedia.org/wiki/Blockchain) is – they’ve been waiting for real-world applications that an average user can utilize. Session is one such example that utilizes blockchain at its core and you don’t need to know it’s there.
If you’re curious about how it works, you can take a look at their [official blog post](https://getsession.org/how-session-protects-your-anonymity-with-blockchain-and-crypto/) explaining it.
### Cross-Platform Support
For something strictly privacy-focused, you’d also want it to be available across multiple platforms.
Of course, primarily, I’d focus on the Linux and Android support but it also supports Windows/Mac/iOS. So, you can easily sync between multiple devices cross-platform.
### Includes Essential Privacy Options
Undoubtedly, it offers some essential privacy-focused features that will help make the experience more secure.
For starters, you have the following options:
**Message TTL**: This lets you control how long the message exists before the recipient sees the message.**Read Receipts**: Let others know that you’ve seen the message or if your message has been read.
### Session uses a decentralized network and protects your metadata
Even though Session isn’t a peer-to-peer technology, it does not have a central server for the network.
It takes a decentralized approach to how the messages are transmitted (or routed). If you’ve no idea what I’m talking about, you can follow Session’s official blog post to know the [difference between centralization and decentralization](https://getsession.org/centralisation-vs-decentralisation-in-private-messaging/) and explore how it potentially works.
And, this approach of network helps them to protect the metadata (the information associated with a message like IP address).
### Other Features
Not just limited to the latest/greatest privacy-friendly features, but it also supports group chats, voice messages, and also allows you to send attachments.
## Installing Session on Linux
If you head to the [official download page](https://getsession.org/download/), you will be able to download an .**AppImage** file. In case you have no clue how it works, you should take a look at our article on [how to use AppImage](https://itsfoss.com/use-appimage-linux/).
In either case, you can also head to their [GitHub releases page](https://github.com/loki-project/session-desktop/releases) and grab the **.deb** file.
## My Experience On Using Session App
I’ve managed to try it on multiple platforms. For the desktop, I utilized the .AppImage file on **Pop!_OS 19.10** to run Session.
Overall, the user experience was impressive and had no UI glitches.
It’s also easy to recover your account once you’ve backed up your secret code (which is known as **seed**) from the settings.
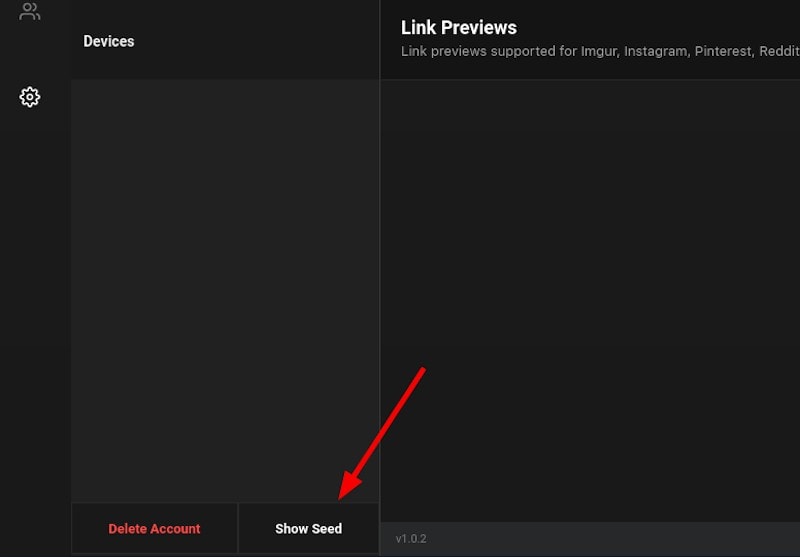
But, I also noticed a couple of issues- which can be fixed/improved:
- Delay in accepting a friend request
- The way of linking devices is not intuitive
- Sometimes when you reply from two separate devices (using the same ID), the receiver gets two different conversations.
**Conclusion**
Of course, nothing’s ever perfect. For now, I’m thinking of keeping it installed and considering Session’s features, it is definitely something a privacy-focused user should try.
What do you think about it? Feel free to let me know your thoughts in the comments below. |
11,983 | 在 Linux 命令行中转换大小写 | https://www.networkworld.com/article/3529409/converting-between-uppercase-and-lowercase-on-the-linux-command-line.html | 2020-03-11T10:00:00 | [
"大小写"
] | https://linux.cn/article-11983-1.html |
>
> 转换文本的大小写可能非常繁琐,尤其是当你要避免无意间的拼写错误时。幸运的是,Linux 提供了一些命令,可以使工作变得非常容易。
>
>
>

有很多方法可以在 Linux 命令行中将文本从小写更改为大写,反之亦然。实际上,有一组这样的命令可以选择。这篇文章检验了一些最佳的命令来完成这项工作,以及你该如何让它们正常工作。
### 使用 tr
`tr`(translate)命令是在命令行或脚本中最容易使用的命令之一。如果你要确定要一串大写字符串,你只需将它传给 `tr`,如下所示:
```
$ echo Hello There | tr [:lower:] [:upper:]
HELLO THERE
```
下面是一个在脚本中使用这个命令的例子,当你要确保添加到文件中的所有文本都使用大写形式以保持一致性时(LCTT 译注:这里输入部门名称作为示例):
```
#!/bin/bash
echo -n "Enter department name: "
read dept
echo $dept | tr [:lower:] [:upper:] >> depts
```
将顺序切换为 `[:upper:] [:lower:]` 会产生相反的效果,将所有大写的部门名称都转换为小写:
```
echo $dept | tr [:upper:] [:lower:] >> depts
```
同样,你可以使用 `sed` 命令的 `A-Z` 和 `a-z` 字符串完成相同的操作:
```
echo $dept | tr a-z A-Z >> depts
```
毫无疑问,反转 `a-z` 和 `A-Z` 字符串的顺序将产生相反的效果,将文本全部变为小写。
### 使用 awk
`awk` 命令可让你使用它的 `toupper` 和 `tolower` 选项执行相同的操作。上例脚本中的命令可以用这种方式代替:
```
echo $dept | awk '{print toupper($0)}' >> depts
```
相反操作(切换为小写)如下所示:
```
echo $dept | awk '{print tolower($0)}' >> depts
```
### 使用 sed
`sed`(stream editor)命令也可用于切换大小写。它与上面显示的两个命令中的第一个具有相同的效果。
```
echo $dept | sed 's/[a-z]/\U&/g' >> depts
```
从大写字母切换到小写字母只需将行尾附近的 `U` 替换为 `L`。
```
echo $dept | sed 's/[A-Z]/\L&/g' >> depts
```
### 操作文件中的文本
`awk` 和 `sed` 都能更改整个文件的文本大小写。因此,你发现你的老板需要所有部门名称的小写么?没问题。只需带上文件名运行以下命令:
```
$ awk '{print tolower($0)}' depts
finance
billing
bookkeeping
```
如果要覆盖 `depts` 文件,而不仅仅是以小写形式显示,则需要执行以下操作:
```
$ awk '{print tolower($0)}' depts > depts-
$ mv depts- depts
```
但是,使用 `sed` 进行更改,你可以避免最后一步,因为 `sed` 可以“原地”编辑文件,如下所示,文件完整,但文本全部小写:
```
$ sed 's/[A-Z]/\L&/g' depts
```
### 仅将首字母转换为大写
要仅将字符串中单词的首字母转换为大写,那么可以执行以下操作:
```
$ echo design \& engineering| sed -e "s/\b\(.\)/\u\1/g"
Design & Engineering
```
该命令将确保首字母大写,但不会更改其余字母。
### 确保只有首字母大写
当要更改文本以使只有首字母大写时,这更具挑战性。假设你正在处理一个工作人员姓名列表,并且希望以正常的“名 姓”方式对其格式化。
#### 使用 sed
你可以使用更复杂的 `sed` 命令来确保以下结果:
```
$ echo design \& ENGINEERING | sed 's/\b\([[:alpha:]]\)\([[:alpha:]]*\)\b/\u\1\L\2/g'
Design & Engineering
```
#### 使用 Python
如果你已安装 Python,你可以运行这样的命令,它还可以设置文本格式,以便每个单词只有首字母大写,并且它可能比上面显示的 `sed` 命令更易于解析:
```
$ echo -n "design & engineering" | python3 -c "import sys; print(sys.stdin.read().title())"
Design & Engineering
```
有多种方法可以在大小写之间更改文本格式。哪种方法效果最好取决于你要处理的是单个字符串还是整个文件,以及想要的最终结果。
---
via: <https://www.networkworld.com/article/3529409/converting-between-uppercase-and-lowercase-on-the-linux-command-line.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,986 | 在 Python 调试过程中设置不中断的断点 | https://opensource.com/article/19/8/debug-python | 2020-03-12T10:45:00 | [
"Python",
"调试器"
] | https://linux.cn/article-11986-1.html |
>
> 你对如何让调试器变得更快产生过兴趣吗?本文将分享我们在为 Python 构建调试器时得到的一些经验。
>
>
>

整段故事讲的是我们在 [Rookout](https://rookout.com/) 公司的团队为 Python 调试器开发不中断断点的经历,以及开发过程中得到的经验。我将在本月于旧金山举办的 [PyBay 2019](https://pybay.com/) 上介绍有关 Python 调试过程的更多细节,但现在就让我们立刻开始这段故事。
### Python 调试器的心脏:sys.set\_trace
在诸多可选的 Python 调试器中,使用最广泛的三个是:
* pdb,它是 Python 标准库的一部分
* PyDev,它是内嵌在 Eclipse 和 Pycharm 等 IDE 中的调试器
* ipdb,它是 IPython 的调试器
Python 调试器的选择虽多,但它们几乎都基于同一个函数:`sys.settrace`。 值得一提的是, [sys.settrace](https://docs.python.org/3/library/sys.html#sys.settrace) 可能也是 Python 标准库中最复杂的函数。

简单来讲,`settrace` 的作用是为解释器注册一个跟踪函数,它在下列四种情形发生时被调用:
* 函数调用
* 语句执行
* 函数返回
* 异常抛出
一个简单的跟踪函数看上去大概是这样:
```
def simple_tracer(frame, event, arg):
co = frame.f_code
func_name = co.co_name
line_no = frame.f_lineno
print("{e} {f} {l}".format(
e=event, f=func_name, l=line_no))
return simple_tracer
```
在分析函数时我们首先关注的是参数和返回值,该跟踪函数的参数分别是:
* `frame`,当前堆栈帧,它是包含当前函数执行时解释器里完整状态的对象
* `event`,事件,它是一个值可能为 `call`、`line`、`return` 或 `exception` 的字符串
* `arg`,参数,它的取值基于 `event` 的类型,是一个可选项
该跟踪函数的返回值是它自身,这是由于解释器需要持续跟踪两类跟踪函数:
* **全局跟踪函数(每线程)**:该跟踪函数由当前线程调用 `sys.settrace` 来设置,并在解释器创建一个新的堆栈帧时被调用(即代码中发生函数调用时)。虽然没有现成的方式来为不同的线程设置跟踪函数,但你可以调用 `threading.settrace` 来为所有新创建的 `threading` 模块线程设置跟踪函数。
* **局部跟踪函数(每一帧)**:解释器将该跟踪函数的值设置为全局跟踪函数创建帧时的返回值。同样也没有现成的方法能够在帧被创建时自动设置局部跟踪函数。
该机制的目的是让调试器对被跟踪的帧有更精确的把握,以减少对性能的影响。
### 简单三步构建调试器 (我们最初的设想)
仅仅依靠上文提到的内容,用自制的跟踪函数来构建一个真正的调试器似乎有些不切实际。幸运的是,Python 的标准调试器 pdb 是基于 Bdb 构建的,后者是 Python 标准库中专门用于构建调试器的基类。
基于 Bdb 的简易断点调试器看上去是这样的:
```
import bdb
import inspect
class Debugger(bdb.Bdb):
def __init__(self):
Bdb.__init__(self)
self.breakpoints = dict()
self.set_trace()
def set_breakpoint(self, filename, lineno, method):
self.set_break(filename, lineno)
try :
self.breakpoints[(filename, lineno)].add(method)
except KeyError:
self.breakpoints[(filename, lineno)] = [method]
def user_line(self, frame):
if not self.break_here(frame):
return
# Get filename and lineno from frame
(filename, lineno, _, _, _) = inspect.getframeinfo(frame)
methods = self.breakpoints[(filename, lineno)]
for method in methods:
method(frame)
```
这个调试器类的全部构成是:
1. 继承 `Bdb`,定义一个简单的构造函数来初始化基类,并开始跟踪。
2. 添加 `set_breakpoint` 方法,它使用 `Bdb` 来设置断点,并跟踪这些断点。
3. 重载 `Bdb` 在当前用户行调用的 `user_line` 方法,该方法一定被一个断点调用,之后获取该断点的源位置,并调用已注册的断点。
### 这个简易的 Bdb 调试器效率如何呢?
Rookout 的目标是在生产级性能的使用场景下提供接近普通调试器的使用体验。那么,让我们来看看先前构建出来的简易调试器表现的如何。
为了衡量调试器的整体性能开销,我们使用如下两个简单的函数来进行测试,它们分别在不同的情景下执行了 1600 万次。请注意,在所有情景下断点都不会被执行。
```
def empty_method():
pass
def simple_method():
a = 1
b = 2
c = 3
d = 4
e = 5
f = 6
g = 7
h = 8
i = 9
j = 10
```
在使用调试器的情况下需要大量的时间才能完成测试。糟糕的结果指明了,这个简陋 `Bdb` 调试器的性能还远不足以在生产环境中使用。

### 对调试器进行优化
降低调试器的额外开销主要有三种方法:
1. **尽可能的限制局部跟踪**:由于每一行代码都可能包含大量事件,局部跟踪比全局跟踪的开销要大得多。
2. **优化 `call` 事件并尽快将控制权还给解释器**:在 `call` 事件发生时调试器的主要工作是判断是否需要对该事件进行跟踪。
3. **优化 `line` 事件并尽快将控制权还给解释器**:在 `line` 事件发生时调试器的主要工作是判断我们在此处是否需要设置一个断点。
于是我们复刻了 `Bdb` 项目,精简特征、简化代码,针对使用场景进行优化。这些工作虽然得到了一些效果,但仍无法满足我们的需求。因此我们又继续进行了其它的尝试,将代码优化并迁移至 `.pyx` 使用 [Cython](https://cython.org/) 进行编译,可惜结果(如下图所示)依旧不够理想。最终,我们在深入了解 CPython 源码之后意识到,让跟踪过程快到满足生产需求是不可能的。

### 放弃 Bdb 转而尝试字节码操作
熬过先前对标准调试方法进行的试验-失败-再试验循环所带来的失望,我们将目光转向另一种选择:字节码操作。
Python 解释器的工作主要分为两个阶段:
1. **将 Python 源码编译成 Python 字节码**:这种(对人类而言)不可读的格式专为执行的效率而优化,它们通常缓存在我们熟知的 `.pyc` 文件当中。
2. **遍历 解释器循环中的字节码**: 在这一步中解释器会逐条的执行指令。
我们选择的模式是:使用**字节码操作**来设置没有全局额外开销的**不中断断点**。这种方式的实现首先需要在内存中的字节码里找到我们感兴趣的部分,然后在该部分的相关机器指令前插入一个函数调用。如此一来,解释器无需任何额外的工作即可实现我们的不中断断点。
这种方法并不依靠魔法来实现,让我们简要地举个例子。
首先定义一个简单的函数:
```
def multiply(a, b):
result = a * b
return result
```
在 [inspect](https://docs.python.org/2/library/inspect.html) 模块(其包含了许多实用的单元)的文档里,我们得知可以通过访问 `multiply.func_code.co_code` 来获取函数的字节码:
```
'|\x00\x00|\x01\x00\x14}\x02\x00|\x02\x00S'
```
使用 Python 标准库中的 [dis](https://docs.python.org/2/library/dis.html) 模块可以翻译这些不可读的字符串。调用 `dis.dis(multiply.func_code.co_code)` 之后,我们就可以得到:
```
4 0 LOAD_FAST 0 (a)
3 LOAD_FAST 1 (b)
6 BINARY_MULTIPLY
7 STORE_FAST 2 (result)
5 10 LOAD_FAST 2 (result)
13 RETURN_VALUE
```
与直截了当的解决方案相比,这种方法让我们更靠近发生在调试器背后的事情。可惜 Python 并没有提供在解释器中修改函数字节码的方法。我们可以对函数对象进行重写,不过那样做的效率满足不了大多数实际的调试场景。最后我们不得不采用一种迂回的方式来使用原生拓展才能完成这一任务。
### 总结
在构建一个新工具时,总会学到许多事情的工作原理。这种刨根问底的过程能够使你的思路跳出桎梏,从而得到意料之外的解决方案。
在 Rookout 团队中构建不中断断点的这段时间里,我学到了许多有关编译器、调试器、服务器框架、并发模型等等领域的知识。如果你希望更深入的了解字节码操作,谷歌的开源项目 [cloud-debug-python](https://github.com/GoogleCloudPlatform/cloud-debug-python) 为编辑字节码提供了一些工具。
---
via: <https://opensource.com/article/19/8/debug-python>
作者:[Liran Haimovitch](https://opensource.com/users/liranhaimovitch) 选题:[lujun9972](https://github.com/lujun9972) 译者:[caiichenr](https://github.com/caiichenr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the story of how our team at [Rookout](https://rookout.com/) built non-breaking breakpoints for Python and some of the lessons we learned along the way. I'll be presenting all about the nuts and bolts of debugging in Python at [PyBay 2019](https://pybay.com/) in San Francisco this month. Let's dig in.
## The heart of Python debugging: sys.set_trace
There are many Python debuggers out there. Some of the more popular include:
**pdb**, part of the Python standard library**PyDev**, the debugger behind the Eclipse and PyCharm IDEs**ipdb**, the IPython debugger
Despite the range of choices, almost every Python debugger is based on just one function: **sys.set_trace**. And let me tell you, ** sys.settrace** might just be the most complex function in the Python standard library.

In simpler terms, **settrace** registers a trace function for the interpreter, which may be called in any of the following cases:
- Function call
- Line execution
- Function return
- Exception raised
A simple trace function might look like this:
```
def simple_tracer(frame, event, arg):
co = frame.f_code
func_name = co.co_name
line_no = frame.f_lineno
print("{e} {f} {l}".format(
e=event, f=func_name, l=line_no))
return simple_tracer
```
When looking at this function, the first things that come to mind are its arguments and return values. The trace function arguments are:
**frame**object, which is the full state of the interpreter at the point of the function's execution**event**string, which can be**call**,**line**,**return**, or**exception****arg**object, which is optional and depends on the event type
The trace function returns itself because the interpreter keeps track of two kinds of trace functions:
**Global trace function (per thread):**This trace function is set for the current thread by**sys.settrace**and is invoked whenever a new**frame**is created by the interpreter (essentially on every function call). While there's no documented way to set the trace function for a different thread, you can call**threading.settrace**to set the trace function for all newly created**threading**module threads.**Local trace function (per frame):**This trace function is set by the interpreter to the value returned by the global trace function upon frame creation. There's no documented way to set the local trace function once the frame has been created.
This mechanism is designed to allow the debugger to have more granular control over which frames are traced to reduce performance impact.
## Building our debugger in three easy steps (or so we thought)
With all that background, writing your own debugger using a custom trace function looks like a daunting task. Luckily, **pdb**, the standard Python debugger, is built on top of **Bdb**, a base class for building debuggers.
A naive breakpoints debugger based on **Bdb** might look like this:
```
import bdb
import inspect
class Debugger(bdb.Bdb):
def __init__(self):
Bdb.__init__(self)
self.breakpoints = dict()
self.set_trace()
def set_breakpoint(self, filename, lineno, method):
self.set_break(filename, lineno)
try :
self.breakpoints[(filename, lineno)].add(method)
except KeyError:
self.breakpoints[(filename, lineno)] = [method]
def user_line(self, frame):
if not self.break_here(frame):
return
# Get filename and lineno from frame
(filename, lineno, _, _, _) = inspect.getframeinfo(frame)
methods = self.breakpoints[(filename, lineno)]
for method in methods:
method(frame)
```
All this does is:
- Inherits from
**Bdb**and write a simple constructor initializing the base class and tracing. - Adds a
**set_breakpoint**method that uses**Bdb**to set the breakpoint and keeps track of our breakpoints. - Overrides the
**user_line**method that is called by**Bdb**on certain user lines. The function makes sure it is being called for a breakpoint, gets the source location, and invokes the registered breakpoints
## How well did the simple Bdb debugger work?
Rookout is about bringing a debugger-like user experience to production-grade performance and use cases. So, how well did our naive breakpoint debugger perform?
To test it and measure the global performance overhead, we wrote two simple test methods and executed each of them 16 million times under multiple scenarios. Keep in mind that no breakpoint was executed in any of the cases.
```
def empty_method():
pass
def simple_method():
a = 1
b = 2
c = 3
d = 4
e = 5
f = 6
g = 7
h = 8
i = 9
j = 10
```
Using the debugger takes a shocking amount of time to complete. The bad results make it clear that our naive **Bdb** debugger is not yet production-ready.
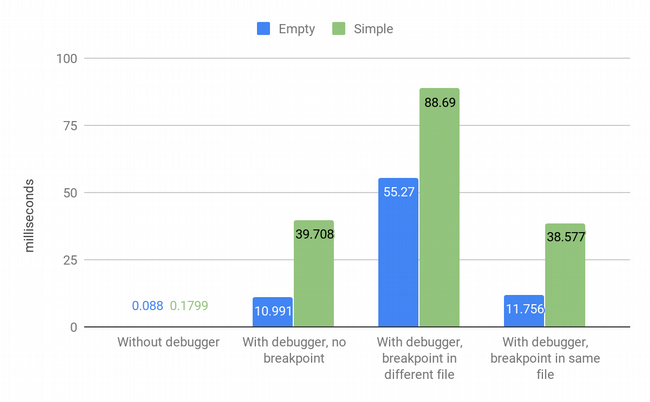
## Optimizing the debugger
There are three main ways to reduce debugger overhead:
**Limit local tracing as much as possible:**Local tracing is very costly compared to global tracing due to the much larger number of events per line of code.**Optimize "call" events and return control to the interpreter faster:**The main work in**call**events is deciding whether or not to trace.**Optimize "line" events and return control to the interpreter faster:**The main work in**line**events is deciding whether or not we hit a breakpoint.
So we forked **Bdb**, reduced the feature set, simplified the code, optimized for hot code paths, and got impressive results. However, we were still not satisfied. So, we took another stab at it, migrated and optimized our code to **.pyx**, and compiled it using [Cython](https://cython.org/). The final results (as you can see below) were still not good enough. So, we ended up diving into CPython's source code and realizing we could not make tracing fast enough for production use.
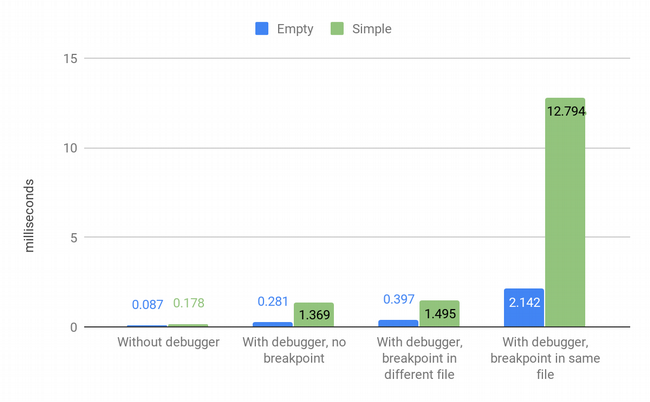
## Rejecting Bdb in favor of bytecode manipulation
After our initial disappointment from the trial-and-error cycles of standard debugging methods, we decided to look into a less obvious option: bytecode manipulation.
The Python interpreter works in two main stages:
**Compiling Python source code into Python bytecode:**This unreadable (for humans) format is optimized for efficient execution and is often cached in those**.pyc**files we have all come to love.
**Iterating through the bytecode in the**This executes one instruction at a time.*interpreter loop*:
This is the pattern we chose: use **bytecode manipulation** to set **non-breaking breakpoints** with no global overhead. This is done by finding the bytecode in memory that represents the source line we are interested in and inserting a function call just before the relevant instruction. This way, the interpreter does not have to do any extra work to support our breakpoints.
This approach is not magic. Here's a quick example.
We start with a very simple function:
```
def multiply(a, b):
result = a * b
return result
```
In documentation hidden in the ** inspect** module (which has several useful utilities), we learn we can get the function's bytecode by accessing
**multiply.func_code.co_code**:
`'|\x00\x00|\x01\x00\x14}\x02\x00|\x02\x00S'`
This unreadable string can be improved using the ** dis** module in the Python standard library. By calling
**dis.dis(multiply.func_code.co_code)**, we get:
```
4 0 LOAD_FAST 0 (a)
3 LOAD_FAST 1 (b)
6 BINARY_MULTIPLY
7 STORE_FAST 2 (result)
5 10 LOAD_FAST 2 (result)
13 RETURN_VALUE
```
This gets us closer to understanding what happens behind the scenes of debugging but not to a straightforward solution. Unfortunately, Python does not offer a method for changing a function's bytecode from within the interpreter. You can overwrite the function object, but that's not good enough for the majority of real-world debugging scenarios. You have to go about it in a roundabout way using a native extension.
## Conclusion
When building a new tool, you invariably end up learning a lot about how stuff works. It also makes you think out of the box and keep your mind open to unexpected solutions.
Working on non-breaking breakpoints for Rookout has taught me a lot about compilers, debuggers, server frameworks, concurrency models, and much much more. If you are interested in learning more about bytecode manipulation, Google's open source ** cloud-debug-python** has tools for editing bytecode.
*Liran Haimovitch will present " Understanding Python’s Debugging Internals" at PyBay, which will be held August 17-18 in San Francisco. Use code OpenSource35 for a discount when you purchase your ticket to let them know you found out about the event from our community.*
## Comments are closed. |
11,987 | Ubuntu 上 Wireshark 的安装与使用 | https://itsfoss.com/install-wireshark-ubuntu/ | 2020-03-12T11:55:00 | [
"嗅探",
"Wireshark"
] | https://linux.cn/article-11987-1.html |
>
> 在本教程中,你将学习如何在 Ubuntu 和其它基于 Ubuntu 的发行版上安装最新的 Wireshark。同时你也将学习如何在没有 sudo 的情况下来运行 Wireshark,以及如何设置它来进行数据包嗅探。
>
>
>
[Wireshark](https://www.wireshark.org/) 是一款自由开源的网络协议分析器,它在全球被广泛使用。
通过使用 Wireshark,你可以实时捕获网络的传入和传出数据包,并将其用于网络故障排除、数据包分析、软件和通信协议开发等。
它适用于所有主流的桌面操作系统,如 Windows、Linux、macOS、BSD 等。
在本教程中,我将指导你在 Ubuntu 和其他基于 Ubuntu 的发行版上安装 Wireshark 。我还将介绍如何设置和配置 Wireshark 来捕获数据包。
### 在基于 Ubuntu 的 Linux 发行版上安装 Wireshark

Wireshark 适用于所有主流 Linux 发行版。你应该查看[官方安装说明](https://www.wireshark.org/docs/wsug_html_chunked/ChBuildInstallUnixInstallBins.html)。因为在本教程中,我将着重在仅基于 Ubuntu 的发行版上安装最新版本的 Wireshark 。
Wireshark 可以在 Ubuntu 的 Universe 存储库中找到。你可以[启用 universe 存储库](https://itsfoss.com/ubuntu-repositories/),然后按如下方式安装:
```
sudo add-apt-repository universe
sudo apt install wireshark
```
这种方法的一个小问题是,你可能并不总是得到最新版本的 Wireshark 。
例如,在 Ubuntu 18.04 中,如果你使用 [apt](https://itsfoss.com/apt-command-guide/) 命令检查 Wireshark 的可用版本,可用版本会显示是 2.6 。
```
abhishek@nuc:~$ apt show wireshark
Package: wireshark
Version: 2.6.10-1~ubuntu18.04.0
Priority: optional
Section: universe/net
Origin: Ubuntu
Maintainer: Balint Reczey <[email protected]>
```
然而, [Wireshark 3.2 稳定版](https://www.wireshark.org/news/20191218.html)已经在几个月前发布了。当然,新版本拥有新的特性。
那么在这种情况下,你应该怎么办呢?谢天谢地, Wireshark 开发者提供了一种官方 PPA 方式,你可以使用它在 Ubuntu 和其它基于 Ubuntu 的发行版上安装最新稳定版本的 Wireshark.
我希望你熟悉 PPA。如果没有,请[阅读我们关于 PPA 的优秀指南,以便完全理解它](https://itsfoss.com/ppa-guide/)。
打开终端并逐个使用以下命令:
```
sudo add-apt-repository ppa:wireshark-dev/stable
sudo apt update
sudo apt install wireshark
```
即使安装了旧版本的 Wireshark ,它也将更新为新版本。
安装时,系统将询问你是否允许非超级用户捕获数据包。选择“Yes”允许,选择“No”限制非超级用户捕获数据包,最后完成安装。
### 不使用 sudo 运行 Wireshark
如果在上一次安装中选择了“No”,则以 root 用户身份运行以下命令:
```
sudo dpkg-reconfigure wireshark-common
```
然后按 `tab` 键并使用回车键选择“No”:

由于你允许非超级用户捕获数据包,因此你必须将该用户添加到 `wireshark` 组。使用 [usermod](https://linuxhandbook.com/usermod-command/) 命令将自己添加到 `wireshark` 组。
```
sudo usermod -aG wireshark $(whoami)
```
最后,[重启你的 Ubuntu 系统](https://itsfoss.com/schedule-shutdown-ubuntu/)对你的系统进行必要的修改。
>
> 冷知识
>
>
> Wireshark 于 1998 年首次发布,最初被称为 Ethereal 。2006 年,由于商标问题,开发商不得不将其名称改为 Wireshark 。
>
>
>
### 启动 Wireshark
你可以从应用程序启动器或者命令行启动 Wireshark 应用。
如果从命令行启动,只需要在你的控制台中输入 `wireshark`:
```
wireshark
```
要是从**图形化界面**启动,需要在搜索栏搜索 Wireshark 应用,并按回车键。

现在,让我们来玩玩 Wireshark 吧。
### 使用 Wireshark 捕获数据包
当你启动 Wireshark 的时候,你会看到一个接口列表,你可以使用它来捕获这个接口接收和发送的数据包。
你可以使用 Wireshark 监视许多类型的接口,例如,有线、外部设备等。根据你的偏好,你可以从下图中的标记区域选择在欢迎屏幕中显示特定类型的接口。

例如,我只列出了**有线**网络接口。

接下来,要开始捕获数据包,你必须选择接口(在我的示例中是 `ens33` ),然后单击“Start capturing packets”图标,如下图所示。

你还可以同时从多个接口捕获数据包。只需按住 `CTRL` 按钮,同时单击要捕获的接口,然后点击“Start capturing packets”图标,如下图所示。

接下来,我尝试在终端中使用 `ping google.com` 命令,如你所见,捕获了许多数据包。

现在你可以选择任何数据包来检查该特定数据包。在点击一个特定的包之后,你可以看到与它相关的 TCP/IP 协议的不同层的信息。

你还可以在底部看到该特定数据包的原始数据,如下图所示。

>
> 这就是为什么端到端加密很重要。
>
>
> 假设你正在登录一个不使用 HTTPS 的网站。与你在同一网络上的任何人都可以嗅探数据包,并在原始数据中看到用户名和密码。
>
>
> 这就是为什么现在大多数聊天应用程序使用端到端加密,而大多数网站使用 https (而不是 http)。
>
>
>
#### 在 Wireshark 中停止数据包捕获
你可以点击如图所示的红色图标停止捕获数据包。

#### 将捕获的数据包保存成文件
你可以单击下图中标记的图标,将捕获的数据包保存到文件中以备将来使用。

**注意**:输出可以导出为 XML、PostScript、CSV 或纯文本。
接下来,选择一个目标文件夹,键入文件名并单击“Save”。
然后选择文件并单击“Open”。

现在你可以随时打开和分析保存的数据包。要打开文件,请按 `\+o`,或从 Wireshark 转到 “File > Open”。
捕获的数据包将从文件中加载。

### 结语
Wireshark 支持许多不同的通信协议。有许多选项和功能,使你能够以独特的方式捕获和分析网络数据包。你可以从 Wireshark 的[官方文档](https://www.wireshark.org/docs/https://www.wireshark.org/docs/)了解更多关于 Wireshark 的信息。
我希望这个教程能帮助你在 Ubuntu 上安装 Wireshark 。请让我知道你的问题和建议。
---
via: <https://itsfoss.com/install-wireshark-ubuntu/>
作者:[Community](https://itsfoss.com/author/itsfoss/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qianmigntian](https://github.com/qianmigntian) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Wireshark](https://www.wireshark.org/?ref=itsfoss.com) is a free and open-source network protocol analyzer widely used around the globe.
With Wireshark, you can capture incoming and outgoing packets of a network in real time and use it for network troubleshooting, packet analysis, software and communication protocol development, and many more.
It is available on all major desktop operating systems like Windows, Linux, macOS, BSD and more.
In this tutorial, I will guide you to install Wireshark on Ubuntu and other Ubuntu-based distributions. I’ll also show a little about setting up and configuring Wireshark to capture packets.
# Installing Wireshark on Ubuntu based Linux distributions
Wireshark is available on all major Linux distributions. You should check out the [official installation instructions](https://www.wireshark.org/docs/wsug_html_chunked/ChBuildInstallUnixInstallBins.html?ref=itsfoss.com). In this tutorial, I’ll focus on installing the latest Wireshark version on Ubuntu-based distributions only.
Wireshark is available in the Universe repository of Ubuntu, which is usually enabled by default. If not, you can [enable universe repository](https://itsfoss.com/ubuntu-repositories/) and then install it by running:
`sudo apt install wireshark`
One slight problem with this approach is that you might not always get the latest version of Wireshark.
[use the apt command](https://itsfoss.com/apt-command-guide/)to check the available version of Wireshark, it is 3.6. However,
[Wireshark 4.0.0 stable version](https://www.wireshark.org/news/20221004.html)was released a few months ago. The new release brings new features, of course.
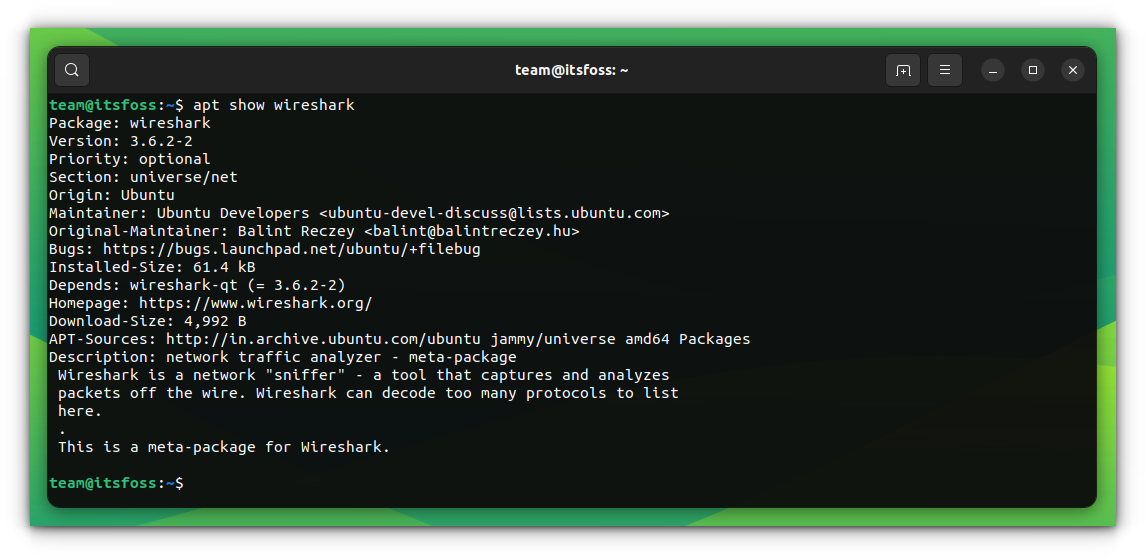
So, what do you do in such a case? Thankfully, Wireshark developers provide an official PPA that you can use to install the latest stable version of Wireshark on Ubuntu and other Ubuntu-based distributions.
I hope you are acquainted with PPA. If not, please [read our excellent guide on PPA to understand it completely](https://itsfoss.com/ppa-guide/).
Open a terminal and use the following commands one by one:
```
sudo add-apt-repository ppa:wireshark-dev/stable
sudo apt update
sudo apt install wireshark
```
Even if you have an older version of Wireshark installed, it will be updated to the newer version.
While installing, you will be asked whether to allow non-superusers to capture packets. Select Yes to allow and No to restrict non-superusers from capturing packets & finish the installation.
### Running Wireshark without sudo
If you have selected **No** in the previous installation, then run the following command as root:
`sudo dpkg-reconfigure wireshark-common`
And select **Yes** by pressing the tab key and then using the enter key:
Since you have allowed the non-superuser to capture packets, you have to add the user to Wireshark group. Use the [usermod command](https://linuxhandbook.com/usermod-command/?ref=itsfoss.com) to add yourself to the Wireshark group.
`sudo usermod -aG wireshark $(whoami)`
Finally, [restart your Ubuntu system](https://itsfoss.com/schedule-shutdown-ubuntu/) to make the necessary changes to your system.
**Trivia:**First released in 1998, Wireshark was initially known as Ethereal. Developers had to change its name to Wireshark in 2006 due to trademark issues.
### Starting Wireshark
Launching Wireshark application can be done from the application launcher or the CLI.
To start from CLI, just type **Wireshark** on your console:
`wireshark`
From GUI, search for Wireshark application on the search bar and hit enter.
Now let’s play with Wireshark.
## Using Wireshark
Wireshark provides a wide range of functions like capturing packets, stop packet capture, save packets etc., with a lot of additional information.
### Capturing packets using Wireshark
When you start Wireshark, you will see a list of interfaces that you can use to capture packets to and from.
There are many types of interfaces available which you can monitor using Wireshark such as, Wired, External devices, etc. According to your preference, you can choose to show specific types of interfaces in the welcome screen from the marked area in the given image below.
For instance, I listed only the **Wired** network interfaces.
Next, to start capturing packets, you have to select the interface (which in my case is enp1s0) and click on the Start capturing packets icon as marked in the image below.
You can also capture packets to and from multiple interfaces at the same time. Just press and hold the **CTRL** button while clicking on the interfaces that you want to capture to and from, and then hit the **Start capturing packets** icon as marked in the image below.
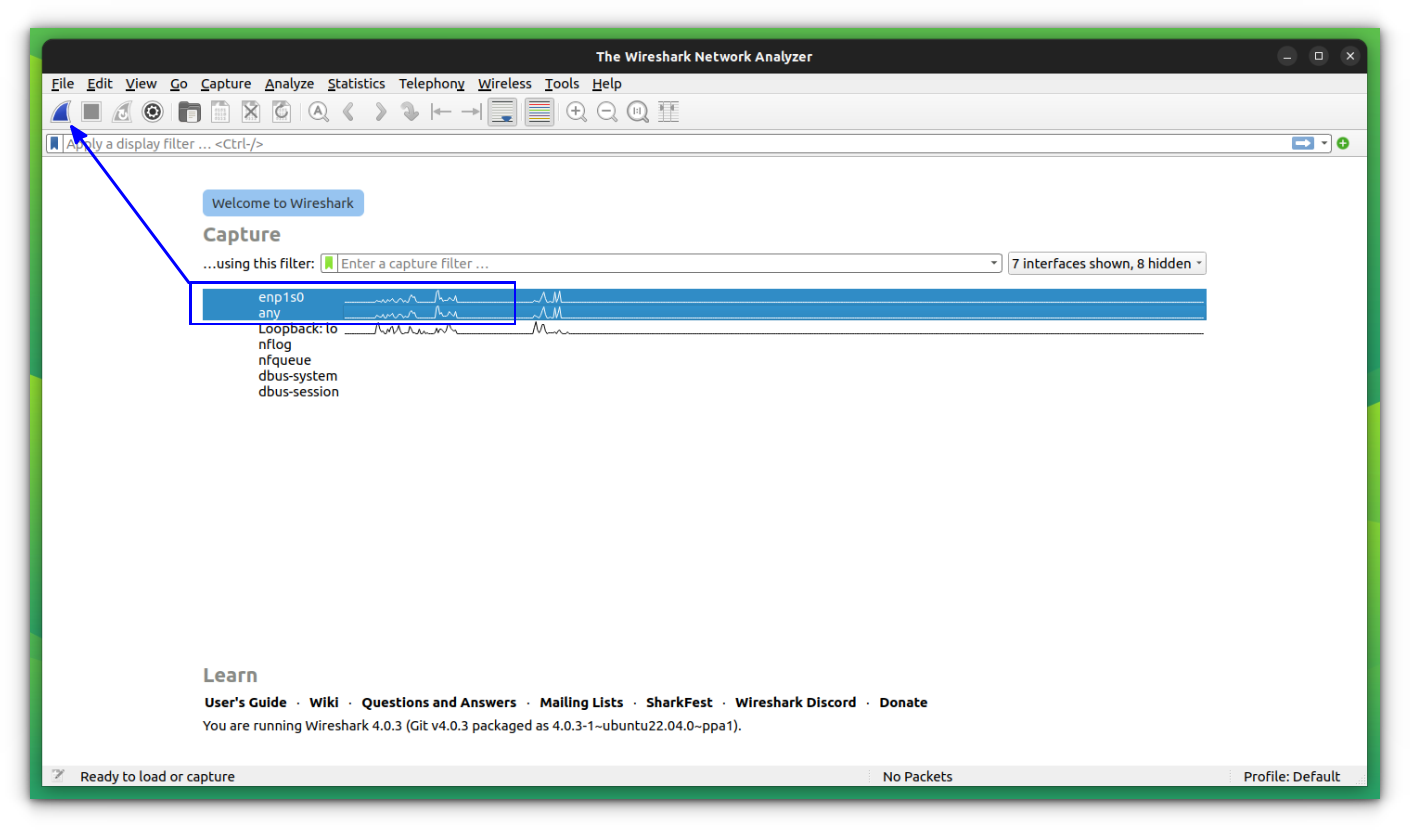
### Viewing Packets with details
Next, I tried using `ping google.com`
command in the terminal and as you can see, many packets were captured.
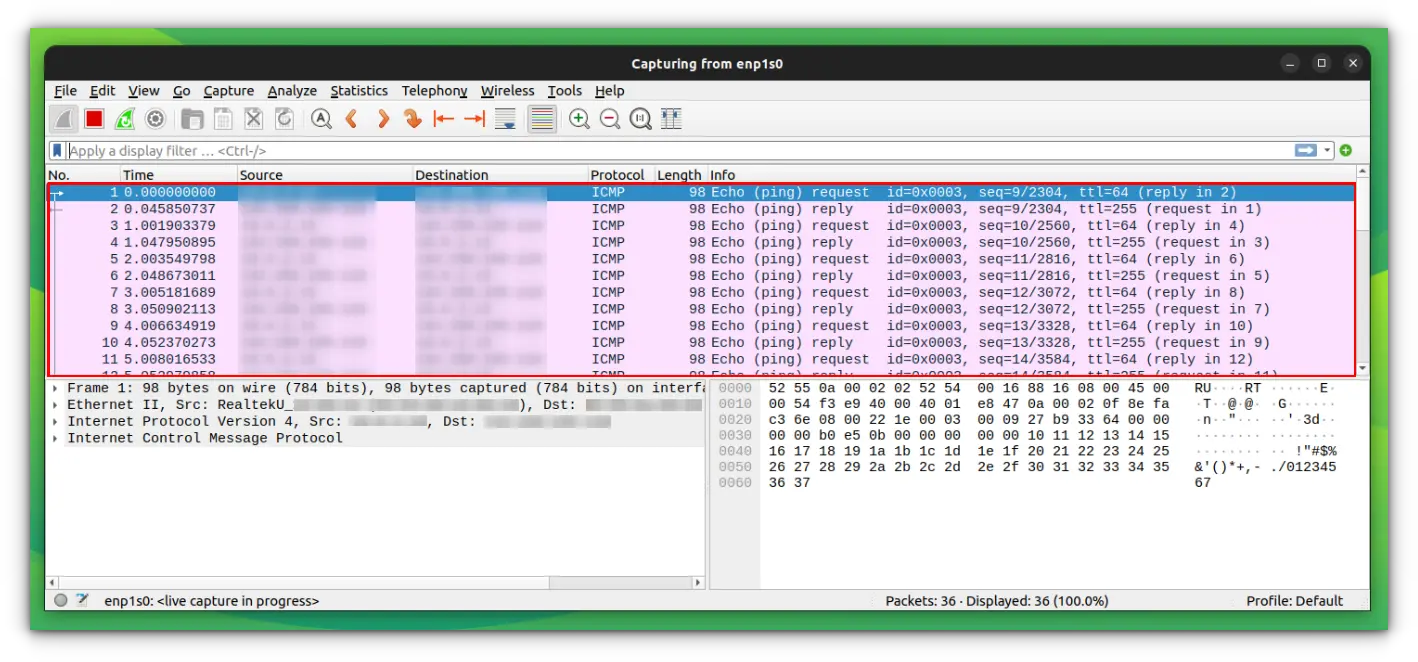
Now you can select on any packet to check that particular packet. After clicking on a particular packet, you can see the information about different layers of TCP/IP Protocol associated with it. You can also see the RAW data of that particular packet at the bottom as shown in the image below.
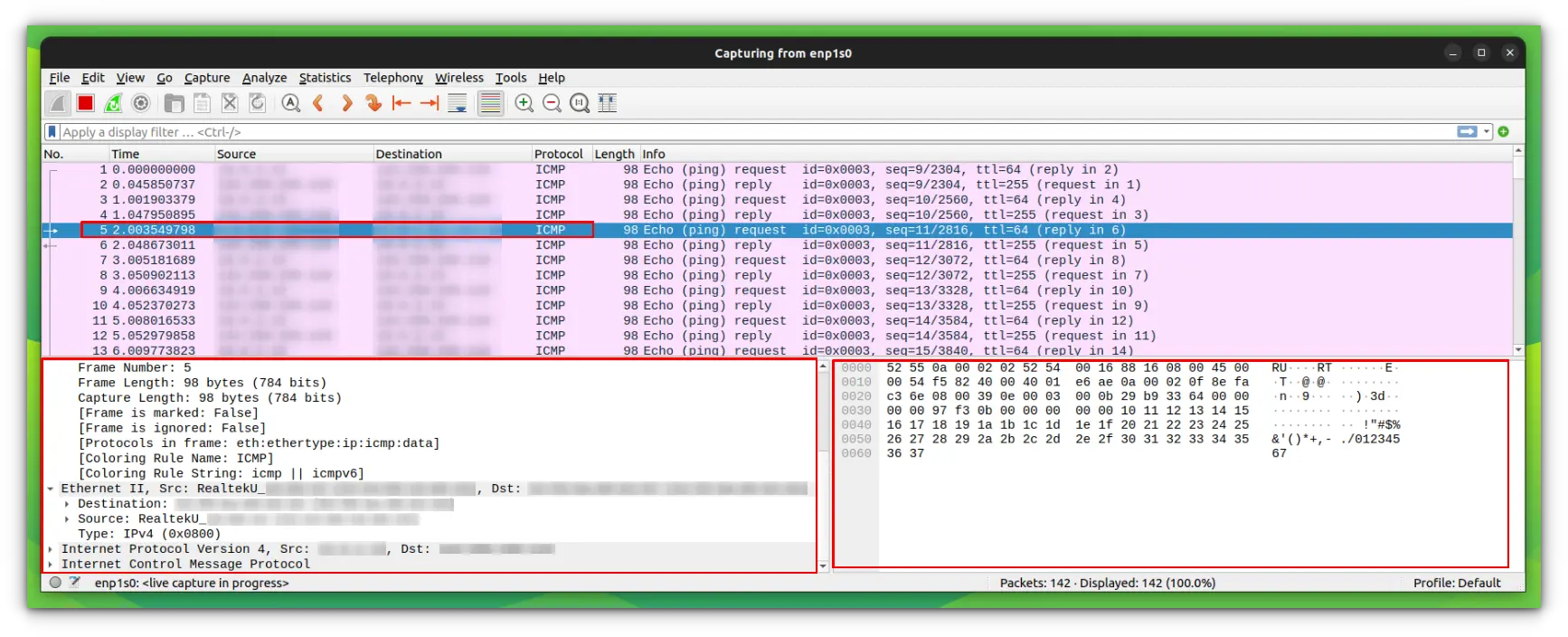
**This is why end-to-end encryption is important**
Imagine you are logging into a website that doesn’t use HTTPS. Anyone on the same network as you can sniff the packets and see the username and password in the RAW data. This is why most chat applications use end-to-end encryption and most websites these days use HTTPS (instead of HTTP).
### Stopping packet capture in Wireshark
You can click on the red icon as marked in the given image to stop capturing Wireshark packets.
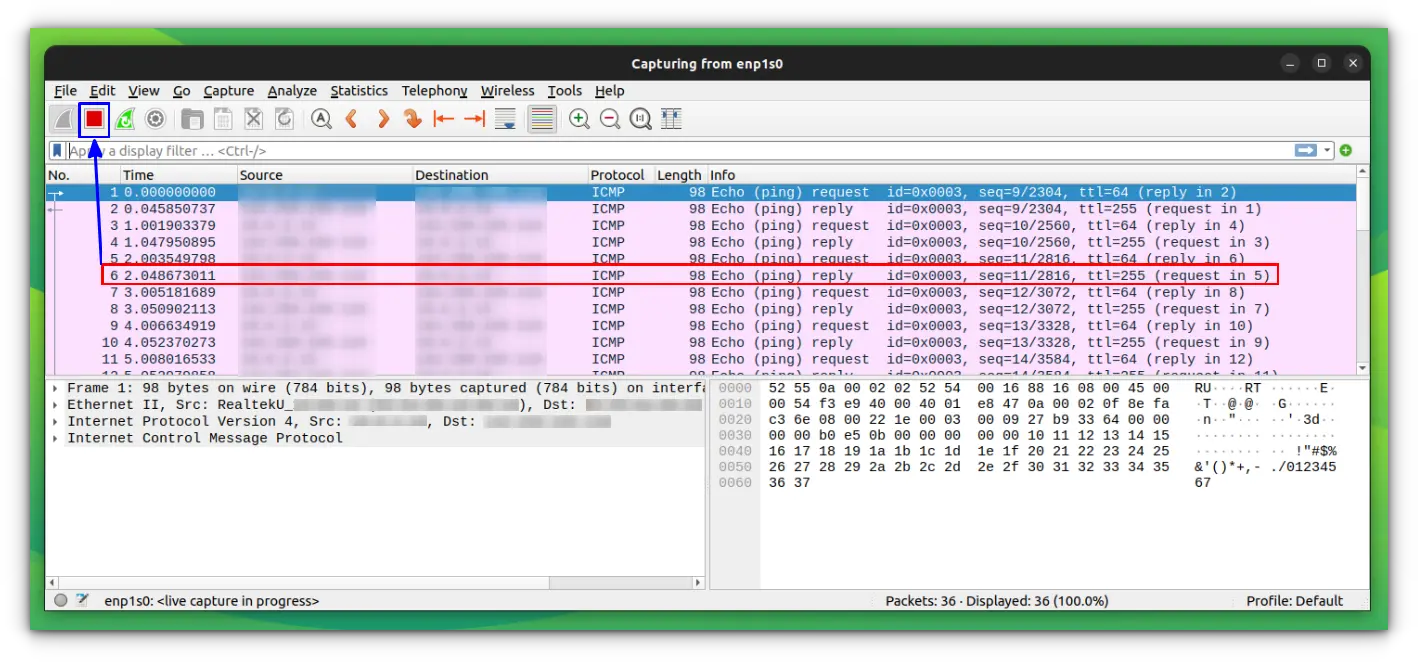
### Save captured packets to a file
You can click on the marked icon in the image below to save captured packets to a file for future use.
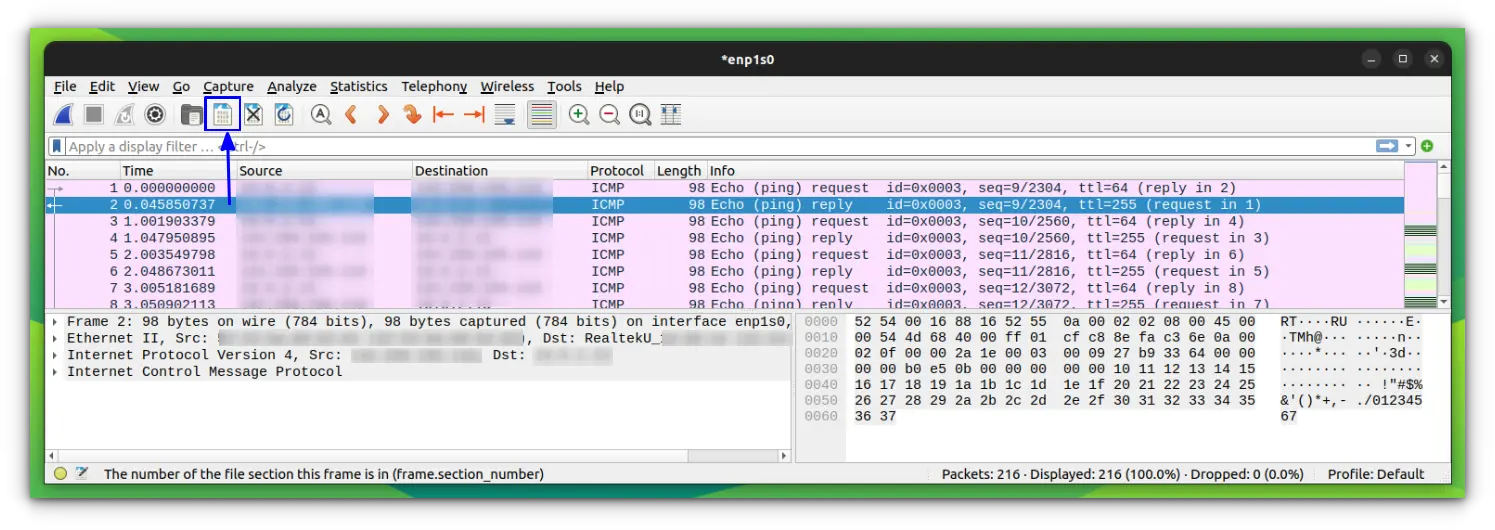
Next, select a destination folder, and type the file name and click on Save.
Now you can open and analyze the saved packets anytime. To open the file, press **CTRL + o** or go to **File > Open** from Wireshark.
The captured packets should be loaded from the file.
## More on networking...
Get insights into your network activity and connected devices.
[Monitor Linux Network Usage And Devices With NuttySee what devices are on your network and other network usage with this GUI tool.](https://itsfoss.com/nutty-network-monitoring-tool/)

Stay on top of your network bandwidth and speed.
[Monitoring Network Bandwidth and Speed in LinuxBrief: In this article, we list some open source utilities to monitor the network traffic, bandwidth and internet speed in Linux. Monitoring internet speed can be a crucial step in understanding your connection and it can help you find possible problems. It will also help you troubleshoot any c…](https://itsfoss.com/network-speed-monitor-linux/)

Master Linux networking with these essential commands.
[21 Basic Linux Networking Commands You Should KnowA list of basic Linux networking commands that will help you troubleshoot network issues, monitor packets, connect devices, and much more.](https://itsfoss.com/basic-linux-networking-commands/)

Wireshark supports many communication protocols. There are many options and features that provide you the power to capture and analyze the network packets uniquely. You can learn more about Wireshark from their [official documentation](https://www.wireshark.org/docs/https://www.wireshark.org/docs/?ref=itsfoss.com).
I hope this tutorial helped you to install Wireshark on Ubuntu. Please let me know your questions and suggestions. |
11,990 | 可在 Linux 桌面使用的 3 个电子书阅读器应用 | https://opensource.com/article/20/2/linux-ebook-readers | 2020-03-13T08:55:28 | [
"电子书",
"Calibre"
] | https://linux.cn/article-11990-1.html |
>
> 任意一个开源电子书应用都能使你在大屏设备上的阅读体验得到提升。
>
>
>

我通常使用手机或 Kobo 阅读器阅读电子书,总是没有在大屏设备上阅读书籍那么爽。很多人经常在自己的笔记本或桌面电脑上阅读电子书,如果你有这种需求(或者你认为以后会遇到这种情况),我想向你介绍三种 Linux 桌面下的电子书阅读器。
### Bookworm(书虫)
[Bookworm](https://babluboy.github.io/bookworm/) 意在成为一个“简洁、专注的电子书阅读器”。事实证明它也确实做到了。Bookworm 内置一系列基础功能,有人抱怨它太过*简单*,缺少*功能性*(虽然这词显然有点指意不明)。Bookworm 起到了应有的作用而没有无关的花哨功能。
该应用的界面整洁干净。

你可通过以下方式查看书籍:
* 空格键前往下一页
* 上下方向键按行移动
* 左右方向键跳转至前后章节
你也可以通过添加注释或书签跳转至特定页面。

Bookworm 没有太多设置选项。你能调整书籍字体大小及间距,开启双页模式或夜间模式。在应用中添加新文件夹后,Bookworm 会自动扫描文件夹中的电子书。

Bookworm 支持常用的电子书格式:EPUB、PDF、MOBI、[FB2](https://en.wikipedia.org/wiki/FictionBook),你还能用它阅读 [CBR](https://en.wikipedia.org/wiki/Comic_book_archive) 和 CBZ 格式的数字版漫画。我只在 Bookworm 上测试了前三种格式,PDF 倒是能打开,但加载速度很慢,格式也很难看。
### Foliate
单从功能上来说,[Foliate](https://johnfactotum.github.io/foliate/) 确实比 Bookworm 强上一些。Foliate 不仅功能更强,它还有更多设置选项。这个功能多样、简单干净的应用满足了所有要求。

在 Foliate 中可以通过空格、方向键、向上或向下翻页键浏览电子书,这里没什么特别的。
你还可以在书籍中添加注释、查找以及翻译字句、查询字词含义。如果你电脑上安装了智能语音应用, Foliate 还能将文本朗读出来。

Foliate 与 Bookworm 相比有更多自定义选项。你能在应用中修改字体类型及大小、行间距、电子书页边距,也可以调高或降低屏幕亮度,从应用内置的四个主题中选择一个等。

你可以在 Foliate 上阅读 EPUB、MOBI、AZW、AZW3 格式的电子书。如果你不了解,我可以提前告诉你,后三种格式是亚马逊 Kindle 阅读器上架的书籍的闭源格式。
### Calibre 电子书阅读器
这个[电子书阅读器](https://calibre-ebook.com/about)是 [Calibre](https://opensourcemusings.com/managing-your-ebooks-with-calibre) 电子书管理工具的一个组件,就像它的前代一样,电子书阅读器这部分并不是软件整体最棒的部分。

不过别被上面的话吓到,它也的确是个桌面电子书阅读器。
在 Calibre 电子书阅读器中,你可以通过方向键、向上/向下翻页键以及空格浏览书籍,还能在在线字典中查找词语含义,添加书签。这一阅读器没有注释功能,但内置的搜索引擎却很好用,你还能将书籍保存为 PDF 格式(虽然我不太明白你为什么要这么做)。
不过参数设置这里确是它出彩的地方,它的可选设置比 Bookworm 和 Foliate 加起来都多,从字体到文本布局,页面分割方式你都能改。除此之外,你还能自定义应用按键设置,将你喜欢的词典网站添加进来,方便阅读查找。

Calibre 电子书阅读器一个很有用的功能,就是把自行设置的 CSS 配置文件效果应用到电子书上。赘言一句,CSS 是一种调整网页格式的方法(这类文件就是许多电子书的一个组成部分)。如果你是使用 CSS 的高手,你可以将自己的 CSS 文件复制粘贴到配置窗口的 “User stylesheet” 部分,这就是个性化的究极办法。
据开发者描述,这一电子书阅读器“能支持所有主流电子书格式”。如果你想知道具体支持格式是什么,[这是列表链接](https://manual.calibre-ebook.com/faq.html#what-formats-does-calibre-support-conversion-to-from)。我测试了列表中的一小部分格式,没有发现问题。
### 留在最后的话
不管你只是单纯想找个电子书阅读器,还是有个更多复杂功能的应用,上文提到的三个选择都很不错,而且它们都能提升你在大屏设备上的阅读体验。
---
via: <https://opensource.com/article/20/2/linux-ebook-readers>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wenwensnow](https://github.com/wenwensnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I usually read eBooks on my phone or with my Kobo eReader. I've never been comfortable reading books on larger screens. However, many people regularly read books on their laptops or desktops. If you are one of them (or think you might be), I'd like to introduce you to three eBook readers for the Linux desktop.
## Bookworm
[Bookworm](https://babluboy.github.io/bookworm/) is billed as a "simple, focused eBook reader." And it is. Bookworm has a basic set of features, which some people will complain about being *too basic* or lacking *functionality* (whatever that word means). Bookworm does one thing and does it well without unnecessary frills.
The application's interface is very clean and uncluttered.

You navigate through a book by pressing:
- The space bar to move down a page
- The Down and Up arrow keys to move down and up a single line
- The Right and Left arrow keys to jump to the next or previous chapter
You can also annotate portions of a book and insert bookmarks to jump back to a page.
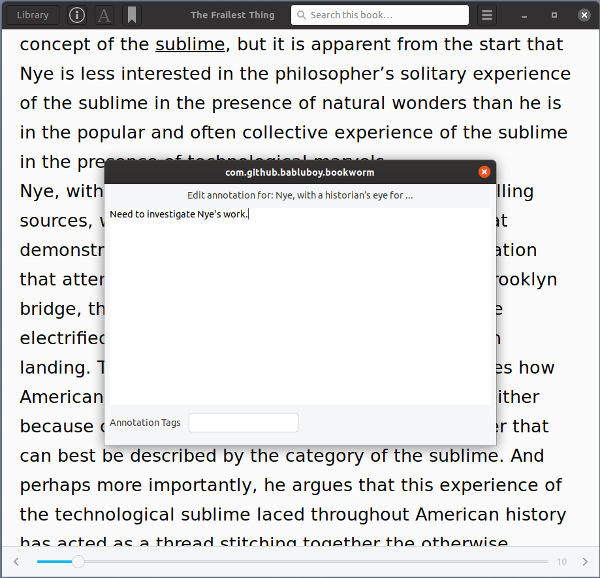
Bookworm doesn't have many configuration options. You can change the size and spacing of a book's font, enable a two-page reading view or dark mode, and add folders that Bookworm will scan to find new eBooks.
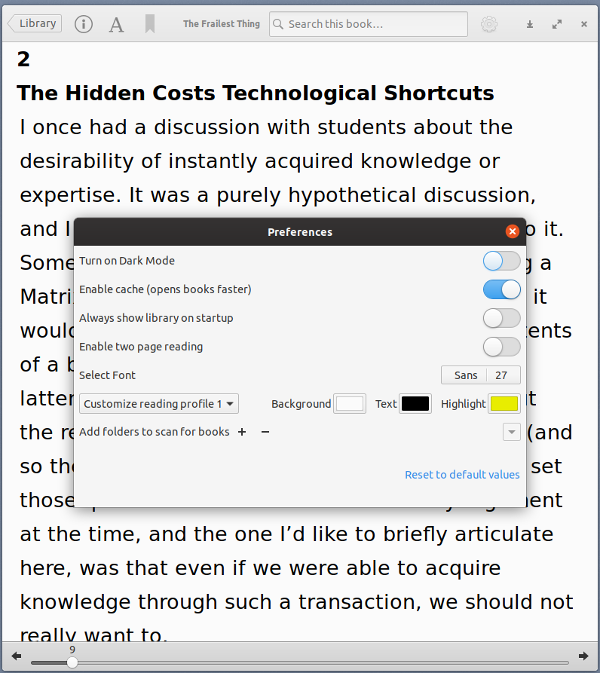
Bookworm supports the most widely used eBook formats: EPUB, PDF, MOBI, and [FB2](https://en.wikipedia.org/wiki/FictionBook). You can also use Bookworm to read popular digital comic book formats [CBR](https://en.wikipedia.org/wiki/Comic_book_archive) and CBZ. I've tested Bookworm with only the first three formats. PDF files are readable, but they load slowly and the formatting can be rather ugly.
## Foliate
As far as features go, [Foliate](https://johnfactotum.github.io/foliate/) is a step or two above Bookworm. Not only does it have several more features, but it also has more configuration options. You get all of that in a zippy, clean, and uncluttered package.

You can navigate through an eBook in Foliate using the space bar, arrow keys, or PgUp and PgDn keys. There's nothing unique there.
You can also annotate text, look up and translate words and phrases, and look up the meanings of words. If you have a text-to-speech application installed on your computer, Foliate can use it to read books aloud.
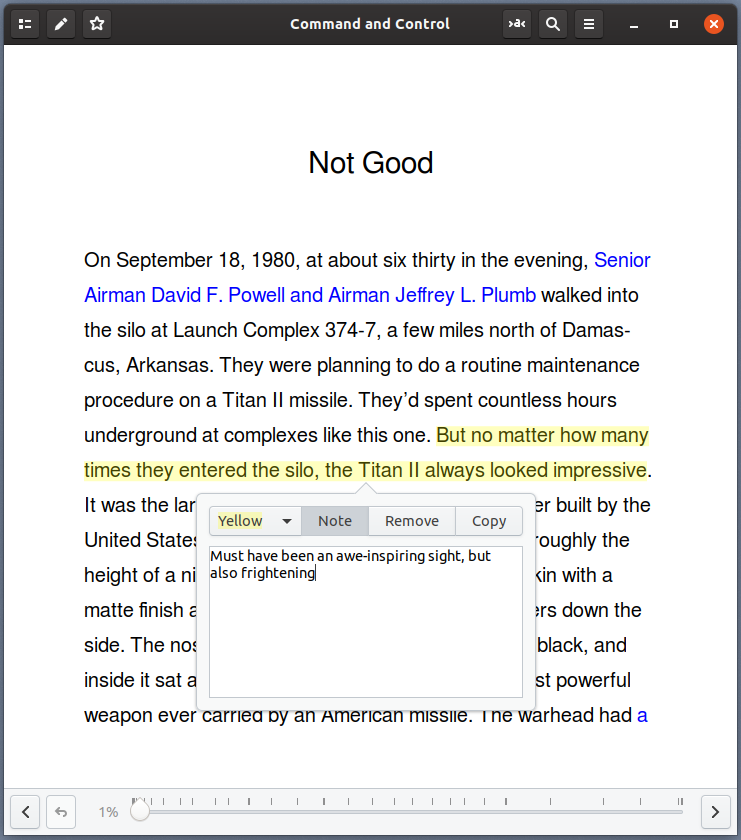
opensource.com
Foliate has a few more customization options than Bookworm. You can change a book's font and its size, the spacing of lines, and the size of a book's margins. You can also increase or decrease the brightness and select one of four built-in themes.
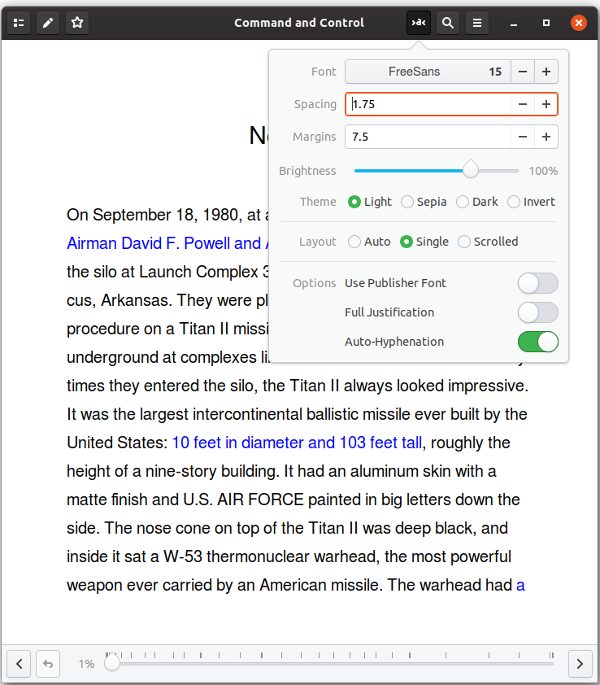
You can read books in the EPUB, MOBI, AZW, and AZW3 formats using Foliate. In case you're wondering, the latter three are closed formats used with books published for Amazon's Kindle eReader
## Calibre's eBook viewer
[eBook viewer](https://calibre-ebook.com/about) is a component of the [Calibre](https://opensourcemusings.com/managing-your-ebooks-with-calibre) eBook management tool. Like its parent, the eBook viewer feature isn't the prettiest piece of software out there.
Don't let that put you off, though. It's a solid desktop eBook reader.
You navigate through an eBook in Calibre's e-book viewer using the arrow and PgUp/PgDn keys or by pressing the space bar. You can also look up words in an online dictionary and add bookmarks throughout a book. E-book viewer lacks an annotation function, but its built-in search engine is solid, and you can save books as PDFs (though I'm not sure why you'd want to).
Configuration options are an area where this eBook viewer shines. It has far more of them than both Bookworm and Foliate combined. You can change everything from fonts to the layout of text to how text is broken up into pages. On top of that, you can customize the keyboard shortcuts for using the application and add your favorite dictionary website or sites to help you look up words in a book you're reading.
One useful feature of Calibre's eBook viewer is the ability to apply your own CSS file to your e-books. CSS, in case you're wondering, is a way to format web pages (which is what many e-books are made of). If you're a master with CSS, you can copy and paste your CSS file into the **User stylesheet** tab in eBook viewer's Preferences window. That's the ultimate in customization.
eBook viewer, according to its developer, "can display all the major e-book formats." If you're wondering what those formats are, [here's a list](https://manual.calibre-ebook.com/faq.html#what-formats-does-calibre-support-conversion-to-from). I've tested it with just a few of those formats and have had no problems with them.
## Final thought
Whether you're looking for a simple eBook reader or one with bells and whistles and whatever else, the three applications in this article are good choices. Any of them can make reading an eBook on a larger screen easier.
*This article is based on an article published on Open Source Musings and appears here via a CC BY-SA 4.0 license.*
## 4 Comments |
11,992 | 从 apt 升级中排除/保留/阻止特定软件包的三种方法 | https://www.2daygeek.com/debian-ubuntu-exclude-hold-prevent-packages-from-apt-get-upgrade/ | 2020-03-13T10:40:07 | [
"更新",
"软件包",
"apt"
] | https://linux.cn/article-11992-1.html | 
有时,由于某些应用依赖性,你可能会意外更新不想更新的软件包。这在全系统更新或自动包升级时经常会发生。如果发生这种情况,可能会破坏应用的功能。这会造成严重的问题,你需要花费大量时间来解决问题。
如何避免这种情况?如何从 `apt-get` 更新中排除软件包?
>
> 如果你要[从 Yum Update 中排除特定软件包](https://www.2daygeek.com/redhat-centos-yum-update-exclude-specific-packages/),请参考这篇。
>
>
>
是的,可以在 Debian 和 Ubuntu 系统上使用以下三种方法来完成。
* [apt-mark 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/)
* [dpkg 命令](https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/)
* aptitude 命令
我们将分别详细展示。
### 方法 1:如何使用 apt-mark 命令排除 Debian/Ubuntu 系统上的软件包更新
`apt-mark` 用于将软件包标记/取消标记为自动安装。
`hold` 选项用于将软件包标记为保留,以防止软件包被自动安装、升级或删除。
`unhold` 选项用于取消先前面的设置,以允许重复执行所有操作。
运行以下命令以使用 `apt-mark` 命令保留指定的软件包。
```
$ sudo apt-mark hold nano
nano set on hold.
```
保留软件包后,请运行以下 `apt-mark` 命令查看它们。
```
$ sudo apt-mark showhold
nano
```
这表明在执行完整的系统更新时,不会升级 nano 包。
```
$ sudo apt update
Reading package lists… Done
Building dependency tree
Reading state information… Done
Calculating upgrade… Done
The following packages have been kept back:
nano
0 upgraded, 0 newly installed, 0 to remove and 1 not upgraded.
```
运行以下命令,使用 `apt-mark` 命令取消保留 nano 包。
```
$ sudo apt-mark unhold nano
Canceled hold on nano.
```
### 方法 2:如何使用 dpkg 命令在 Debian/Ubuntu 系统上排除软件包更新
`dpkg` 命令是一个 CLI 工具,用于安装、构建、删除和管理 Debian 软件包。`dpkg` 的主要且更用户友好的前端是 `aptitude`。
运行以下命令使用 `dpkg` 命令阻止给定的软件包。
语法:
```
$ echo "package_name hold" | sudo dpkg --set-selections
```
运行以下 `dpkg` 命令以保留 apache2 包。
```
$ echo "apache2 hold" | sudo dpkg --set-selections
```
保留软件包后,请运行以下命令查看它们。
```
$ sudo dpkg --get-selections | grep "hold"
apache2 hold
```
它会显示在执行完整的系统更新时,不会升级 apache2包。
```
$ sudo apt update
Reading package lists… Done
Building dependency tree
Reading state information… Done
Calculating upgrade… Done
The following packages have been kept back:
apache2
0 upgraded, 0 newly installed, 0 to remove and 1 not upgraded.
```
运行以下命令,使用 `dpkg` 命令取消对指定软件包的保留。
语法:
```
$ echo "package_name install" | sudo dpkg --set-selections
```
运行以下命令,使用 `dpkg` 命令取消保留 apache2 包。
```
$ echo "apache2 install" | sudo dpkg --set-selections
```
### 方法 3:如何使用 aptitude 命令排除 Debian/Ubuntu 系统上的软件包更新
`aptitude` 命令是 Debian 及其衍生版本的基于文本的软件包管理界面。
它允许用户查看软件包列表并执行软件包管理任务,例如安装、升级和删除软件包。它可以从可视界面或命令行执行操作。
运行以下命令,使用 `aptitude` 命令保留指定的软件包。
```
$ sudo aptitude hold python3
```
保留某些软件包后,请运行以下命令查看它们。
```
$ sudo dpkg --get-selections | grep "hold"
或者
$ sudo apt-mark showhold
python3
```
这表明在执行完整的系统更新时,不会升级 python3 软件包。
```
$ sudo apt update
Reading package lists… Done
Building dependency tree
Reading state information… Done
Calculating upgrade… Done
The following packages have been kept back:
python3
0 upgraded, 0 newly installed, 0 to remove and 1 not upgraded.
```
使用 `aptitude` 命令运行以下命令以解除对 python3 软件包的保留。
```
$ sudo aptitude unhold python3
```
---
via: <https://www.2daygeek.com/debian-ubuntu-exclude-hold-prevent-packages-from-apt-get-upgrade/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,993 | 安装 pip 轻松管理 PyPI 软件包 | https://opensource.com/article/20/3/pip-linux-mac-windows | 2020-03-14T10:25:52 | [
"pip",
"Python"
] | https://linux.cn/article-11993-1.html |
>
> 在 Linux、Mac 或 Windows 上为旧版 Python 安装 pip。
>
>
>

Python 是一种功能强大、流行广泛的编程语言,在常规编程、数据科学等很多方面它都有丰富的软件包可供使用。但这些软件包通常都不会在 Python 安装时自动附带,而是需要由用户自行下载、安装和管理。所有的这些软件包(包括库和框架)都存放在一个名叫 [PyPI](https://pypi.org/)(也就是 <ruby> Python 软件包索引 <rt> Python Package Index </rt></ruby>)的中央存储库当中,而 `pip`(也就是<ruby> 首选安装程序 <rt> Preferred Installer Program </rt></ruby>)则是管理这个中央存储库的工具。
在安装 `pip` 之后,管理 PyPI 的软件包就变得很方便了。大部分的软件包都可以通过在终端或者命令行界面执行 `python -m pip install <软件包名>` 这样的命令来完成安装。
较新版本的 Python 3(3.4 或以上)和 Python 2(2.7.9 或以上)都已经预装了 `pip`,旧版本的 Python 没有自带 `pip`,但可以另外安装。
在这篇文章中,我将会介绍 `pip` 在 Linux、Mac 和 Windows 系统上的安装过程。想要了解更多详细信息,可以参考 [pip.pypa](https://pip.pypa.io/en/stable/installing/) 的文档。
### 首先需要安装 Python
首先你的系统中需要安装好 Python,否则 `pip` 安装器无法理解任何相关的命令。你可以在命令行界面、Bash 或终端执行 `python` 命令确认系统中是否已经安装 Python,如果系统无法识别 `python` 命令,请先[下载 Python](https://www.python.org/downloads/) 并安装。安装完成后,你就可以看到一些引导你安装 `pip` 的提示语了。
### 在 Linux 上安装 pip
在不同发行版的 Linux 上,安装 `pip` 的命令也有所不同。
在 Fedora、RHEL 或 CentOS 上,执行以下命令安装:
```
$ sudo dnf install python3
```
在 Debian 或 Ubuntu 上,使用 `apt` 包管理工具安装:
```
$ sudo apt install python3-pip
```
其它的发行版可能还会有不同的包管理工具,比如 Arch Linux 使用的是 `pacman`:
```
$ sudo pacman -S python-pip
```
执行 `pip --version` 命令就可以确认 `pip` 是否已经正确安装。
在 Linux 系统上安装 `pip` 就是这样简单,你可以直接跳到“使用 pip”部分继续阅读。
### 在 Mac 上安装 pip
MacOS 已经预装了 Python,但 Python 版本一般是比较旧的。如果你要使用 Python 的话,建议[另外安装 Python 3](https://opensource.com/article/19/5/python-3-default-mac)。
在 Mac 上可以使用 [homebrew](https://brew.sh) 安装 Python 3:
```
$ brew update && brew upgrade python
```
如果你安装的是以上提到的新版本 Python 3,它会自带 `pip` 工具。你可以使用以下命令验证:
```
$ python3 -m pip --version
```
如果你使用的是 Mac,安装过程也到此结束,可以从“使用 pip”部分继续阅读。
### 在 Windows 上安装 pip
以下 `pip` 安装过程是针对 Windows 8 和 Windows 10 的。下面文章中的截图是 Windows 10 环境下的截图,但对 Windows 8 同样适用。
首先确认 [Python 已经安装完成](https://opensource.com/article/19/8/how-install-python-windows)。
如果你想在 Windows 系统上像 Linux 一样使用包管理工具,[Chocolatey](https://opensource.com/article/20/3/chocolatey) 是一个不错的选择,它可以让 Python 的调用和更新变得更加方便。Chocolatey 在 PowerShell 中就可以运行,只需要简单的命令,Python 就可以顺利安装。
```
PS> choco install python
```
接下来就可以使用 `pip` 安装所需的软件包了。
### 使用 pip
在 Linux、BSD、Windows 和 Mac 上,`pip` 都是以同样的方式使用的。
例如安装某个库:
```
python3 -m pip install foo --user
```
卸载某个已安装的库:
```
python3 -m pip uninstall foo
```
按照名称查找软件包:
```
python3 -m pip search foo
```
将 `pip` 更新到一个新版本:
```
$ sudo pip install --upgrade pip
```
需要注意的是,在 Windows 系统中不需要在前面加上 `sudo` 命令,这是因为 Windows 通过独有的方式管理用户权限,对应的做法是[创建一个执行策略例外](https://opensource.com/article/20/3/chocolatey#admin)。
```
python -m pip install --upgrade pip
```
希望本文介绍的的方法能对你有所帮助,欢迎在评论区分享你的经验。
---
via: <https://opensource.com/article/20/3/pip-linux-mac-windows>
作者:[Vijay Singh Khatri](https://opensource.com/users/vijaytechnicalauthor) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python is a powerful and popular programming language with many packages that are useful for general programming, data science, and many other things. These packages are not included with the Python installation, so you have to download, install, and manage them separately. All of these packages (libraries and frameworks) are stored in a central repository called the Python Package Index, or [PyPI](https://pypi.org/) for short. This is where pip (short for Preferred Installer Program), Python's package manager, comes into the picture.
Installing Python pip on your system allows you to manage PyPI packages easily. Many of these packages can be installed just by typing **python -m pip install <package-name>** into a terminal or command-line.
Newer versions of Python 3 (3.4 and higher) and Python 2 (2.7.9 and higher) come preloaded with pip. Older versions of Python didn't include pip, but it can be installed retroactively.
In this article, I explain how to install pip on Linux, Mac, and Windows computers. You can also check the [pip.pypa](https://pip.pypa.io/en/stable/installing/) documentation for more information.
## Make sure Python is installed
If you don't already have Python installed on your system, do that first; otherwise, the pip installer won't understand any commands. To check whether you have Python, enter **python** in your command line, Bash, or terminal window and see what happens. If the command is not recognized, then you need to [download Python](https://www.python.org/downloads/). If you have Python installed, you will see a lot of commands and other stuff that will indicate you can install pip.
## Install Python pip on Linux
The command you use to install pip on Linux depends on the distribution you use.
On Fedora, RHEL, and CentOS:
`$ sudo dnf install python3`
For Debian or Ubuntu, use the Apt package:
`$ sudo apt install python3-pip`
Other distributions may have their own package manager. For example, Arch Linux uses pacman:
`$ sudo pacman -S python-pip`
To find out whether pip is installed properly, check the version using the **--version** option.
That's all you need. You can skip down to the [using pip](#usage) section of this article.
## Install Python pip on Mac
MacOS comes with Python installed by default, but the version provided by Apple is almost always outdated, even right an OS release. If you're working with Python, you should [use a custom install of Python 3](https://opensource.com/article/19/5/python-3-default-mac).
To install Python 3 on a Mac, use [homebrew](https://brew.sh):
`$ brew update && brew upgrade python `
Because you've installed a recent version of Python3, pip is also installed.** **You can verify it with:
`$ python3 -m pip --version`
That's all you need. You can skip down to the [using pip](#usage) section of this article.
## Install Python pip on Windows
To install pip, you must have Windows 8 or 10. The screenshots below are from Windows 10 (but the same commands work for Windows 8).
Once you confirm you have [Python installed](https://opensource.com/article/19/8/how-install-python-windows).
If you want the same luxuries as Linux users have with a package manager, you can use the [Chocolatey](https://opensource.com/article/20/3/chocolatey) package manager for Windows. This provides easy access to Python but also easy updates. You can use it in the open source PowerShell application to make amazing things happen in just a few commands.
`PS> choco install python`
That's it! You can now use pip to install any package you need.
## Using Python pip
Python pip works exactly the same way on each platform: Linux, BSD, Windows, Mac, and so on.
To install the imaginary library **foo**, use:
`python3 -m pip install foo --user`
To uninstall it:
`python3 -m pip uninstall foo`
To search for a package:
`python3 -m pip search foo`
To upgrade to a new version of pip:
`$ sudo pip install --upgrade pip`
On Windows, omit the **sudo** command (Windows has its own method of privilege management, so you may need to [create an exception to your execution policy](https://opensource.com/article/20/3/chocolatey#admin)).
`python -m pip install --upgrade pip`
I hope you tried the installation methods described in this article and that they helped you. Please share your experience in the comments.
## 4 Comments |
11,994 | Emacs 调试秘籍之 GUD 调试器 | https://opensourceforu.com/2019/09/debugging-in-emacs-the-grand-unified-debugger/ | 2020-03-14T12:31:00 | [
"GUD",
"Emacs",
"GDB"
] | https://linux.cn/article-11994-1.html | 
>
> 本文简短地对 Emacs 的调试工具 GUD 的特性进行了探索。
>
>
>
如果你是一个 C 或 C++ 开发者,你很可能已经使用过 GDB(GNU 调试器),毫无疑问,它是现今最强大、最无可匹敌的调试器之一。它唯一的缺点就是它基于命令行,虽然仍能提供许多强大的功能,但有时也会具有一些局限性。这也就是为什么聪明的人们开始追求整合了编辑器和调试器的<ruby> 图形化 <rt> GUI </rt></ruby><ruby> 集成开发环境 <rt> Integrated Development Environment </rt></ruby>。仍有些开发者坚信使用鼠标会降低工作效率,在 GUI 上用鼠标点~点~点~是来自恶魔的诱惑。
因为 Emacs 是现今最酷的文本编辑器之一,我将为你展示如何在不碰鼠标且不离开 Emacs 的情况下,实现写代码、编译代码、调试代码的过程。
GUD(LCTT 译注:全称<ruby> 大统一调试器 <rt> Grand Unified Debugger </rt></ruby>,鉴于其缩写形式更为人熟知,以下全文将使用缩写替代此全称)是 Emacs 下的一个<ruby> 模式 <rt> mode </rt></ruby>,用于在 Emacs 中运行 GDB。它向 GDB 提供了 Emacs 的所有特性,使用户无需离开编辑器就可以对代码进行调试。
### 使用 GUD 的前期准备
如果你正在使用一个 Linux 机器,很可能你已经安装了 GDB 和 gcc,接下来就是要确保已经安装了 Emacs。以下的内容我将假设读者熟悉 GDB 并且至少用它做过基本的调试。如果你未曾接触过 GDB,你可以做个快速入门,这些资料在网上随处可得。
对于那些 Emacs 新手,我将向你介绍一些基本术语。纵览整篇文章,你将看到诸如 `C-c M-x` 等快捷键。此处 `C` 代表 `Ctrl` 键,`M` 代表 `Alt` 键。`C-c` 代表 `Ctrl` 键和 `c` 键被同时按下。如果你看到 `C-c c`,它代表同时按下 `Ctrl` 键和 `c` 键,释放后紧接着按下 `c` 键。在 Emacs 中,编辑文本的主要区域被称为<ruby> 主缓冲区 <rt> main buffer </rt></ruby>,而在 Emacs 窗口下方用于输入命令的区域被称为<ruby> 迷你缓冲区 <rt> mini buffer </rt></ruby>。
启动 Emacs,并按下 `C-x C-f` 来创建一个新文件。Emacs 将提示你输入一个文件名,此处让我们将文件命名为 `buggyFactorial.cpp`。一旦文件打开,输入如下代码:
```
#include<iostream>
#include <assert.h>
int factorial(int num) {
int product = 1;
while(num--) {
product *= num;
}
return product;
}
int main() {
int result = factorial(5);
assert(result == 120);
}
```
使用 `C-x C-s` 快捷键保存文件。文件保存完毕,是时候进行编译了。按下 `M-x`,在弹出的<ruby> 提示符 <rt> prompt </rt></ruby>后输入 `compile` 并点击回车。然后在提示符后,将内容替换为 `g++ -g buggyFactorial.cpp` 并再次点击回车。

这将在 Emacs 中开启另一个缓冲区,显示编译的状态。如果你的代码输入没有错误,你将预期得到如图 2 所示的缓冲区。

要想隐藏编译缓冲区,首先确保你的光标在编译缓冲区中(你可以不使用鼠标,而是通过 `C-x o` 快捷键将光标从一个缓冲区移动到另一个),然后按下 `C-x 0`。下一步就是运行代码,并观察是否运行良好。按下 `M-!` 快捷键并在迷你缓冲区的提示符后面输入 `./a.out`。

你可以看到迷你缓冲区中显示断言失败。很明显代码中有错误,因为 5 的阶乘是 120。那么让我们现在开始调试吧。
### 使用 GUD 调式代码
现在,我们的代码已经编译完成,是时候看看到底哪里出错了。按下 `M-x` 快捷键并在提示符后输入 `gdb`。在接下来的提示符后,输入 `gdb -i=mi a.out`。如果一切顺利,GDB 会在 Emacs 缓冲区中启动,你会看到如图 4 所示的窗口。

在 `gdb` 提示符后,输入 `break main` 来设置断点,并输入 `r` 来运行程序。程序会开始运行并停在 `main()` 函数处。
一旦 GDB 到达了 `main` 处设置的断点,就会弹出一个新的缓冲区显示你正在调试的代码。注意左侧的红点,正是你设置断点的位置,同时会有一个小的标志提示你当前代码运行到了哪一行。当前,该标志就在断点处(如图 5)。

为了调试 `factorial` 函数,我们需要单步运行。想要达到此目的,你可以在 GBD 提示符使用 GDB 命令 `step`,或者使用 Emacs 快捷键 `C-c C-s`。还有其它一些快捷键,但我更喜欢 GDB 命令。因此我将在本文的后续部分使用它们。
单步运行时让我们注意一下局部变量中的阶乘值。参考图 6 来设置在 Emacs 帧中显示局部变量值。

在 GDB 提示符中进行单步运行并观察局部变量值的变化。在循环的第一次迭代中,我们发现了一个问题。此处乘法的结果应该是 5 而不是 4。
本文到这里也差不多结束了,读者可以自行探索发现 GUD 模式这片新大陆。GDB 中的所有命令都可以在 GUD 模式中运行。我将此代码的修复留给读者作为一个练习。看看你在调试的过程中,可以做哪一些定制化,来使你的工作流更加简单和高效。
---
via: <https://opensourceforu.com/2019/09/debugging-in-emacs-the-grand-unified-debugger/>
作者:[Vineeth Kartha](https://opensourceforu.com/author/vineeth-kartha/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,997 | 如何使用 bind 设置 DNS 服务器 | https://fedoramagazine.org/how-to-setup-a-dns-server-with-bind/ | 2020-03-15T10:44:29 | [
"DNS",
"BIND"
] | https://linux.cn/article-11997-1.html | 
<ruby> 域名系统 <rt> Domain Name System </rt></ruby>,我们更通常称为 DNS 的系统,可以将域名翻译或转换为与该域关联的 IP 地址。DNS 是能够让你通过名称找到自己喜欢的网站而不是在浏览器中输入 IP 地址的原因。本指南将向你展示如何配置一个主 DNS 系统以及客户端。
以下是本文示例中使用的系统细节:
```
dns01.fedora.local (192.168.1.160)- 主 DNS 服务器
client.fedora.local (192.168.1.136)- 客户端
```
### DNS 服务器配置
使用 `sudo` 安装 bind 包:
```
$ sudo dnf install bind bind-utils -y
```
bind 包提供了 `/etc/named.conf` 配置文件,来供你配置 DNS 服务器。
编辑 `/etc/named.conf` 文件:
```
sudo vi /etc/named.conf
```
查找以下行:
```
listen-on port 53 { 127.0.0.1; };
```
添加主 DNS 服务器的 IP 地址,如下所示:
```
listen-on port 53 { 127.0.0.1; 192.168.1.160; };
```
查找以下行:
```
allow-query { localhost; };
```
添加本地网络范围。该示例系统使用的 IP 地址在 192.168.1.X 的范围内。指定如下:
```
allow-query { localhost; 192.168.1.0/24; };
```
指定转发和反向区域。<ruby> 区域文件 <rt> Zone file </rt></ruby>就是具有系统上 DNS 信息(例如 IP 地址和主机名)的文本文件。<ruby> 转发区域文件 <rt> forward zone file </rt></ruby>使得将主机名转换为 IP 地址成为可能。<ruby> 反向区域文件 <rt> reverse zone file </rt></ruby>则相反。它允许远程系统将 IP 地址转换为主机名。
在 `/etc/named.conf` 文件的底部查找以下行:
```
include "/etc/named.rfc1912.zones";
```
在此处,你将在**该行的正上方**指定区域文件信息,如下所示:
```
zone "dns01.fedora.local" IN {
type master;
file "forward.fedora.local";
allow-update { none; };
};
zone "1.168.192.in-addr.arpa" IN {
type master;
file "reverse.fedora.local";
allow-update { none; };
};
```
`forward.fedora.local` 和 `reverse.fedora.local` 文件是要创建的区域文件的名称。它们可以是任意名字。
保存并退出。
#### 创建区域文件
创建你在 `/etc/named.conf` 文件中指定的转发和反向区域文件:
```
$ sudo vi /var/named/forward.fedora.local
```
添加以下行:
```
$TTL 86400
@ IN SOA dns01.fedora.local. root.fedora.local. (
2011071001 ;Serial
3600 ;Refresh
1800 ;Retry
604800 ;Expire
86400 ;Minimum TTL
)
@ IN NS dns01.fedora.local.
@ IN A 192.168.1.160
dns01 IN A 192.168.1.160
client IN A 192.168.1.136
```
所有**粗体**(LCTT 译注:本译文中无法呈现粗体)内容都特定于你的环境。保存文件并退出。接下来,编辑 `reverse.fedora.local` 文件:
```
$ sudo vi /var/named/reverse.fedora.local
```
添加以下行:
```
$TTL 86400
@ IN SOA dns01.fedora.local. root.fedora.local. (
2011071001 ;Serial
3600 ;Refresh
1800 ;Retry
604800 ;Expire
86400 ;Minimum TTL
)
@ IN NS dns01.fedora.local.
@ IN PTR fedora.local.
dns01 IN A 192.168.1.160
client IN A 192.168.1.136
160 IN PTR dns01.fedora.local.
136 IN PTR client.fedora.local.
```
所有**粗体**(LCTT 译注:本译文中无法呈现粗体)内容都特定于你的环境。保存文件并退出。
你还需要配置 SELinux 并为配置文件添加正确的所有权。
```
sudo chgrp named -R /var/named
sudo chown -v root:named /etc/named.conf
sudo restorecon -rv /var/named
sudo restorecon /etc/named.conf
```
配置防火墙:
```
sudo firewall-cmd --add-service=dns --perm
sudo firewall-cmd --reload
```
#### 检查配置是否存在语法错误
```
sudo named-checkconf /etc/named.conf
```
如果没有输出或返回错误,那么你的配置有效。
检查转发和反向区域文件。
```
$ sudo named-checkzone forward.fedora.local /var/named/forward.fedora.local
$ sudo named-checkzone reverse.fedora.local /var/named/reverse.fedora.local
```
你应该看到 “OK” 的响应:
```
zone forward.fedora.local/IN: loaded serial 2011071001
OK
zone reverse.fedora.local/IN: loaded serial 2011071001
OK
```
#### 启用并启动 DNS 服务
```
$ sudo systemctl enable named
$ sudo systemctl start named
```
#### 配置 resolv.conf 文件
编辑 `/etc/resolv.conf` 文件:
```
$ sudo vi /etc/resolv.conf
```
查找你当前的 `nameserver` 行。在示例系统上,使用调制解调器/路由器充当名称服务器,因此当前看起来像这样:
```
nameserver 192.168.1.1
```
这需要更改为主 DNS 服务器的 IP 地址:
```
nameserver 192.168.1.160
```
保存更改并退出。
不幸的是需要注意一点。如果系统重启或网络重启,那么 NetworkManager 会覆盖 `/etc/resolv.conf` 文件。这意味着你将丢失所做的所有更改。
为了防止这种情况发生,请将 `/etc/resolv.conf` 设为不可变:
```
$ sudo chattr +i /etc/resolv.conf
```
如果要重新设置,就需要允许其再次被覆盖:
```
$ sudo chattr -i /etc/resolv.conf
```
#### 测试 DNS 服务器
```
$ dig fedoramagazine.org
```
```
; <<>> DiG 9.11.13-RedHat-9.11.13-2.fc30 <<>> fedoramagazine.org
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8391
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 6
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: c7350d07f8efaa1286c670ab5e13482d600f82274871195a (good)
;; QUESTION SECTION:
;fedoramagazine.org. IN A
;; ANSWER SECTION:
fedoramagazine.org. 50 IN A 35.197.52.145
;; AUTHORITY SECTION:
fedoramagazine.org. 86150 IN NS ns05.fedoraproject.org.
fedoramagazine.org. 86150 IN NS ns02.fedoraproject.org.
fedoramagazine.org. 86150 IN NS ns04.fedoraproject.org.
;; ADDITIONAL SECTION:
ns02.fedoraproject.org. 86150 IN A 152.19.134.139
ns04.fedoraproject.org. 86150 IN A 209.132.181.17
ns05.fedoraproject.org. 86150 IN A 85.236.55.10
ns02.fedoraproject.org. 86150 IN AAAA 2610:28:3090:3001:dead:beef:cafe:fed5
ns05.fedoraproject.org. 86150 IN AAAA 2001:4178:2:1269:dead:beef:cafe:fed5
;; Query time: 830 msec
;; SERVER: 192.168.1.160#53(192.168.1.160)
;; WHEN: Mon Jan 06 08:46:05 CST 2020
;; MSG SIZE rcvd: 266
```
需要检查几件事以验证 DNS 服务器是否正常运行。显然,取得结果很重要,但这本身并不意味着 DNS 服务器实际上正常工作。
顶部的 `QUERY`、`ANSWER` 和 `AUTHORITY` 字段应显示为非零,如我们的示例所示:
```
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 6
```
并且 `SERVER` 字段应有你的 DNS 服务器的 IP 地址:
```
;; SERVER: 192.168.1.160#53(192.168.1.160)
```
如果这是你第一次运行 `dig` 命令,请注意完成查询要花费 830 毫秒的时间:
```
;; Query time: 830 msec
```
如果再次运行它,查询将会更快:
```
$ dig fedoramagazine.org
```
```
;; Query time: 0 msec
;; SERVER: 192.168.1.160#53(192.168.1.160)
```
### 客户端配置
客户端配置将简单得多。
安装 bind 程序:
```
$ sudo dnf install bind-utils -y
```
编辑 `/etc/resolv.conf` 文件,并将主 DNS 配置为唯一的名称服务器:
```
$ sudo vi /etc/resolv.conf
```
它看起来像这样:
```
nameserver 192.168.1.160
```
保存更改并退出。然后,使 `/etc/resolv.conf` 文件不可变,防止其被覆盖并变回默认设置:
```
$ sudo chattr +i /etc/resolv.conf
```
#### 测试客户端
你应该获得与 DNS 服务器相同的结果:
```
$ dig fedoramagazine.org
```
```
; <<>> DiG 9.11.13-RedHat-9.11.13-2.fc30 <<>> fedoramagazine.org
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8391
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 6
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: c7350d07f8efaa1286c670ab5e13482d600f82274871195a (good)
;; QUESTION SECTION:
;fedoramagazine.org. IN A
;; ANSWER SECTION:
fedoramagazine.org. 50 IN A 35.197.52.145
;; AUTHORITY SECTION:
fedoramagazine.org. 86150 IN NS ns05.fedoraproject.org.
fedoramagazine.org. 86150 IN NS ns02.fedoraproject.org.
fedoramagazine.org. 86150 IN NS ns04.fedoraproject.org.
;; ADDITIONAL SECTION:
ns02.fedoraproject.org. 86150 IN A 152.19.134.139
ns04.fedoraproject.org. 86150 IN A 209.132.181.17
ns05.fedoraproject.org. 86150 IN A 85.236.55.10
ns02.fedoraproject.org. 86150 IN AAAA 2610:28:3090:3001:dead:beef:cafe:fed5
ns05.fedoraproject.org. 86150 IN AAAA 2001:4178:2:1269:dead:beef:cafe:fed5
;; Query time: 1 msec
;; SERVER: 192.168.1.160#53(192.168.1.160)
;; WHEN: Mon Jan 06 08:46:05 CST 2020
;; MSG SIZE rcvd: 266
```
确保 `SERVER` 输出的是你 DNS 服务器的 IP 地址。
你的 DNS 服务器设置完成了,现在所有来自客户端的请求都会经过你的 DNS 服务器了!
---
via: <https://fedoramagazine.org/how-to-setup-a-dns-server-with-bind/>
作者:[Curt Warfield](https://fedoramagazine.org/author/rcurtiswarfield/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Domain Name System, or DNS, as it’s more commonly known, translates or converts domain names into the IP addresses associated with that domain. DNS is the reason you are able to find your favorite website by name instead of typing an IP address into your browser. This guide shows you how to configure a Master DNS system and one client.
Here are system details for the example used in this article:
dns01.fedora.local (192.168.1.160 ) - Master DNS server client.fedora.local (192.168.1.136 ) - Client
## DNS server configuration
Install the bind packages using sudo:
$ sudo dnf install bind bind-utils -y
The */etc/named.conf* configuration file is provided by the *bind* package to allow you to configure the DNS server.
Edit the */etc/named.conf* file:
sudo vi /etc/named.conf
Look for the following line:
listen-on port 53 { 127.0.0.1; };
Add the IP address of your Master DNS server as follows:
listen-on port 53 { 127.0.0.1; 192.168.1.160; };
Look for the next line:
allow-query { localhost; };
Add your local network range. The example system uses IP addresses in the 192.168.1.X range. This is specified as follows:
allow-query { localhost; 192.168.1.0/24; };
Specify a forward and reverse zone. Zone files are simply text files that have the DNS information, such as IP addresses and host-names, on your system. The forward zone file makes it possible for the translation of a host-name to its IP address. The reverse zone file does the opposite. It allows a remote system to translate an IP address to the host name.
Look for the following line at the bottom of the /etc/named.conf file:
include "/etc/named.rfc1912.zones";
Here, you’ll specify the zone file information ** directly above that line** as follows:
zone "dns01.fedora.local" IN { type master; file "forward.fedora.local"; allow-update { none; }; }; zone "1.168.192.in-addr.arpa" IN { type master; file "reverse.fedora.local"; allow-update { none; }; };
The *forward.fedora.local* and the file *reverse.fedora.local* are just the names of the zone files you will be creating. They can be called anything you like.
Save and exit.
### Create the zone files
Create the forward and reverse zone files you specified in the /etc/named.conf file:
$ sudo vi /var/named/forward.fedora.local
Add the following lines:
$TTL 86400 @ IN SOAdns01.fedora.local.root.fedora.local.( 2011071001 ;Serial 3600 ;Refresh 1800 ;Retry 604800 ;Expire 86400 ;Minimum TTL ) @ IN NSdns01.fedora.local.@ IN A192.168.1.160dns01IN A192.168.1.160clientIN A192.168.1.136
Everything in ** bold** is specific to your environment. Save the file and exit. Next, edit the
*reverse.fedora.local*file:
$ sudo vi /var/named/reverse.fedora.local
Add the following lines:
$TTL 86400 @ IN SOAdns01.fedora.local.root.fedora.local.( 2011071001 ;Serial 3600 ;Refresh 1800 ;Retry 604800 ;Expire 86400 ;Minimum TTL ) @ IN NSdns01.fedora.local.@ IN PTRfedora.local.dns01IN A192.168.1.160clientIN A192.168.1.136160IN PTRdns01.fedora.local.136IN PTRclient.fedora.local.
Everything in ** bold** is also specific to your environment. Save the file and exit.
You’ll also need to configure SELinux and add the correct ownership for the configuration files.
sudo chgrp named -R /var/named sudo chown -v root:named /etc/named.conf sudo restorecon -rv /var/named sudo restorecon /etc/named.conf
Configure the firewall:
sudo firewall-cmd --add-service=dns --perm sudo firewall-cmd --reload
### Check the configuration for any syntax errors
sudo named-checkconf /etc/named.conf
Your configuration is valid if no output or errors are returned.
Check the forward and reverse zone files.
$ sudo named-checkzone forward.fedora.local /var/named/forward.fedora.local $ sudo named-checkzone reverse.fedora.local /var/named/reverse.fedora.local
You should see a response of OK:
zone forward.fedora.local/IN: loaded serial 2011071001 OK zone reverse.fedora.local/IN: loaded serial 2011071001 OK
### Enable and start the DNS service
$ sudo systemctl enable named $ sudo systemctl start named
### Configuring the resolv.conf file
Edit the */etc/resolv.conf* file:
$ sudo vi /etc/resolv.conf
Look for your current name server line or lines. On the example system, a cable modem/router is serving as the name server and so it currently looks like this:
nameserver 192.168.1.1
This needs to be changed to the IP address of the Master DNS server:
nameserver 192.168.1.160
Save your changes and exit.
Unfortunately there is one caveat to be aware of. NetworkManager overwrites the */etc/resolv.conf* file if the system is rebooted or networking gets restarted. This means you will lose all of the changes that you made.
To prevent this from happening, make */etc/resolv.conf* immutable:
$ sudo chattr +i /etc/resolv.conf
If you want to set it back and allow it to be overwritten again:
$ sudo chattr -i /etc/resolv.conf
### Testing the DNS server
$ dig fedoramagazine.org
; <<>> DiG 9.11.13-RedHat-9.11.13-2.fc30 <<>> fedoramagazine.org ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8391 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 6 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: c7350d07f8efaa1286c670ab5e13482d600f82274871195a (good) ;; QUESTION SECTION: ;fedoramagazine.org. IN A ;; ANSWER SECTION: fedoramagazine.org. 50 IN A 35.197.52.145 ;; AUTHORITY SECTION: fedoramagazine.org. 86150 IN NS ns05.fedoraproject.org. fedoramagazine.org. 86150 IN NS ns02.fedoraproject.org. fedoramagazine.org. 86150 IN NS ns04.fedoraproject.org. ;; ADDITIONAL SECTION: ns02.fedoraproject.org. 86150 IN A 152.19.134.139 ns04.fedoraproject.org. 86150 IN A 209.132.181.17 ns05.fedoraproject.org. 86150 IN A 85.236.55.10 ns02.fedoraproject.org. 86150 IN AAAA 2610:28:3090:3001:dead:beef:cafe:fed5 ns05.fedoraproject.org. 86150 IN AAAA 2001:4178:2:1269:dead:beef:cafe:fed5 ;; Query time: 830 msec ;; SERVER: 192.168.1.160#53(192.168.1.160) ;; WHEN: Mon Jan 06 08:46:05 CST 2020 ;; MSG SIZE rcvd: 266
There are a few things to look at to verify that the DNS server is working correctly. Obviously getting the results back are important, but that by itself doesn’t mean the DNS server is actually doing the work.
The QUERY, ANSWER, and AUTHORITY fields at the top should show non-zero as it in does in our example:
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 6
And the SERVER field should have the IP address of your DNS server:
;; SERVER: 192.168.1.160#53(192.168.1.160)
In case this is the first time you’ve run the *dig* command, notice how it took 830 milliseconds for the query to complete:
;; Query time: 830 msec
If you run it again, the query will run much quicker:
$ dig fedoramagazine.org
;; Query time: 0 msec ;; SERVER: 192.168.1.160#53(192.168.1.160)
## Client configuration
The client configuration will be a lot simpler.
Install the bind utilities:
$ sudo dnf install bind-utils -y
Edit the /etc/resolv.conf file and configure the Master DNS as the only name server:
$ sudo vi /etc/resolv.conf
This is how it should look:
nameserver 192.168.1.160
Save your changes and exit. Then, make the */etc/resolv.conf* file immutable to prevent it from be overwritten and going back to its default settings:
$ sudo chattr +i /etc/resolv.conf
### Testing the client
You should get the same results as you did from the DNS server:
$ dig fedoramagazine.org
; <<>> DiG 9.11.13-RedHat-9.11.13-2.fc30 <<>> fedoramagazine.org ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8391 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 6 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: c7350d07f8efaa1286c670ab5e13482d600f82274871195a (good) ;; QUESTION SECTION: ;fedoramagazine.org. IN A ;; ANSWER SECTION: fedoramagazine.org. 50 IN A 35.197.52.145 ;; AUTHORITY SECTION: fedoramagazine.org. 86150 IN NS ns05.fedoraproject.org. fedoramagazine.org. 86150 IN NS ns02.fedoraproject.org. fedoramagazine.org. 86150 IN NS ns04.fedoraproject.org. ;; ADDITIONAL SECTION: ns02.fedoraproject.org. 86150 IN A 152.19.134.139 ns04.fedoraproject.org. 86150 IN A 209.132.181.17 ns05.fedoraproject.org. 86150 IN A 85.236.55.10 ns02.fedoraproject.org. 86150 IN AAAA 2610:28:3090:3001:dead:beef:cafe:fed5 ns05.fedoraproject.org. 86150 IN AAAA 2001:4178:2:1269:dead:beef:cafe:fed5 ;; Query time: 1 msec ;; SERVER: 192.168.1.160#53(192.168.1.160) ;; WHEN: Mon Jan 06 08:46:05 CST 2020 ;; MSG SIZE rcvd: 266
Make sure the SERVER output has the IP Address of your DNS server.
Your DNS server is now ready to use and all requests from the client should be going through your DNS server now!
## AquaL1te
Nice! But I prefer NSD 🙂
## Dirk
I think the TLD .local is not a good example because it’s mainly used for Zeroconf environments (ala DNS-SD / MDNS) as referenced by RFC 6762. This could cause strange behavior in Networks where both name resolving mechanisms are used.
However, this is a good article describing rudimentary setup of a local DNS server with a domain for an internal network.
## Mark
For a home network dnsmasq is easier to use to provide local dns servers as the only file that has to be edited to provide hostname/ipaddr mappings is the /etc/hosts file on the machine to be used as the dns server which dnsmasq reads on startup and is immediately able to be a dns resolver to clients for any host in that file, and the resolv.conf for the example used in the post would simply be
nameserver 192.168.1.160
nameserver 192.168.1.1
to resolve local hosts from the local dns and anything not in the local dns resolved as per normal.
For a home network dnsmasq is easier as there is only one file to edit, and users with home networks not already using a local dns are already familar with editing /etc/hosts.
Also it is probably better to reconfigure the network nameserver settings in NetworkManager (or network) rather than manually edit resolv.conf.
A good clear article however.
Could a follow-up article on changes needed to configure DNS services for IPV6 be produced as Fedora ships with ipv6 enabled by default and ipv6 is where most headaches come from.
## Amos
Can you share an example of 2 servers with scheduled zone tranfers?
## Göran Uddeborg
Good article!
May I suggest a little section at the end actually using the local domain configured? For example, to run “ping dns01.fedora.local” on the client and see how it works using the name?
(I would second Dirk’s suggestion using different TLD than “local”. Personally, I use my last name. There doesn’t seem to be any optimal solution, see e.g. https://serverfault.com/questions/17255/top-level-domain-domain-suffix-for-private-network But “local” is probably a less good choice.)
## Chris
everyone has their personal favorite for DNS server software, dnsmasq was mentioned above, can i throw unbound into the hat of DNS server software? I currently like unbound as it allows for randomization of addresses queried to |
11,999 | 简单是 Python 编程的第一要则 | https://opensource.com/article/19/12/zen-python-simplicity-complexity | 2020-03-15T12:42:00 | [
"Python"
] | https://linux.cn/article-11999-1.html |
>
> 本文是 Python 之禅特别系列的第二篇,我们将要关注其中第三与第四条原则:简单与复杂。
>
>
>

>
> Il semble que la perfection soit atteinte non quand il n'y a plus rien à ajouter, mais quand il n'y plus rien à retrancher.
>
>
> It seems that perfection is finally attained not when there is no longer anything to add, but when there is no longer anything to take away.
>
>
> “完美并非无可增,而是不可减。”
>
>
> —Antoine de Saint-Exupéry, [Terre des Hommes](https://en.wikipedia.org/wiki/Wind,_Sand_and_Stars), 1939
>
>
>
编程时最常有的考量是与复杂性的斗争,只想写出让旁人无从下手的繁杂代码,对每个程序员来讲都算不上难事。倘若未能触及代码的简繁取舍,那么 《[Python 之禅](https://www.python.org/dev/peps/pep-0020/)》 就有了一角残缺。
### <ruby> 简单胜过复杂 <rt> Simple is better than complex </rt></ruby>
尚有选择余地时,应该选简单的方案。Python 少有*不可为*之事,这意味着设计出巴洛克风格(LCTT 译注:即夸张和不理性)的程序只为解决浅显的问题不仅有可能,甚至很简单。
正因如此,编程时应当谨记,代码的简单性是最易丢失,却最难复得的。
这意味着,在可以选用函数来表达时不要去引入额外的类;避免使用强力的第三方库往往有助于你针对迫切的问题场景设计更妥当的简短函数。不过其根本的意图,旨在让你减少对将来的盘算,而去着重解决手头的问题。
以简单和优美作为指导原则的代码相比那些想要囊括将来一切变数的,在日后要容易修改得多。
### <ruby> 复杂胜过错综复杂 <rt> Complex is better than complicated </rt></ruby>
把握用词的精确含义对于理解这条令人费解的原则是至关重要的。形容某事<ruby> 复杂 <rt> complex </rt></ruby>,是说它由许多部分组成,着重组成成分之多;而形容某事<ruby> 错综复杂 <rt> complicated </rt></ruby>,则是指其包含着差异巨大、难以预料的行为,强调的是各组成部分之间的杂乱联系。
解决困难问题时,往往没有可行的简单方案。此时,最 Python 化的策略是“<ruby> 自底向上 <rt> bottom-up </rt></ruby>”地构建出简单的工具,之后将其组合用以解决该问题。
这正是<ruby> 对象组合 <rt> object composition </rt></ruby>这类技术的闪耀之处,它避免了错综复杂的继承体系,转而由独立的对象把一些方法调用传递给别的独立对象。这些对象都能独立地测试与部署,最终却可以组成一体。
“自底建造” 的另一例即是<ruby> <a href="https://opensource.com/article/19/5/python-singledispatch"> 单分派泛函数 </a> <rt> singledispatch </rt></ruby>的使用,抛弃了错综复杂的对象之后,我们得到是简单、几乎无行为的对象以及独立的行为。
---
via: <https://opensource.com/article/19/12/zen-python-simplicity-complexity>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[caiichenr](https://github.com/caiichenr) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | "Il semble que la perfection soit atteinte non quand il n'y a plus rien à ajouter, mais quand il n'y plus rien à retrancher."
"It seems that perfection is finally attained not when there is no longer anything to add, but when there is no longer anything to take away."
—Antoine de Saint-Exupéry,, 1939[Terre des Hommes]
A common concern in programming is the struggle with complexity. It is easy for any programmer to make a program so complicated no expert can debug it or modify it. The [Zen of Python](https://www.python.org/dev/peps/pep-0020/) would not be complete if it did not touch on this.
## Simple is better than complex.
When it is possible to choose at all, choose the simple solution. Python is rarely in the business of *disallowing* things. This means it is possible, and even straightforward, to design baroque programs to solve straightforward problems.
It is worthwhile to remember at each point that simplicity is one of the easiest things to lose and the hardest to regain when writing code.
This can mean choosing to write something as a function, rather than introducing an extraneous class. This can mean avoiding a robust third-party library in favor of writing a two-line function that is perfect for the immediate use-case. Most often, it means avoiding predicting the future in favor of solving the problem at hand.
It is much easier to change the program later, especially if simplicity and beauty were among its guiding principles than to load the code down with all possible future variations.
## Complex is better than complicated.
This is possibly the most misunderstood principle because understanding the precise meanings of the words is crucial. Something is *complex* when it is composed of multiple parts. Something is *complicated* when it has a lot of different, often hard to predict, behaviors.
When solving a hard problem, it is often the case that no simple solution will do. In that case, the most Pythonic strategy is to go "bottom-up." Build simple tools and combine them to solve the problem.
This is where techniques like *object composition* shine. Instead of having a complicated inheritance hierarchy, have objects that forward some method calls to a separate object. Each of those can be tested and developed separately and then finally put together.
Another example of "building up" is using [singledispatch](https://opensource.com/article/19/5/python-singledispatch), so that instead of one complicated object, we have a simple, mostly behavior-less object and separate behaviors.
## Comments are closed. |
12,000 | 如何组织构建多文件 C 语言程序(二) | https://opensource.com/article/19/7/structure-multi-file-c-part-2 | 2020-03-16T12:30:00 | [
"C语言"
] | https://linux.cn/article-12000-1.html |
>
> 我将在本系列的第二篇中深入研究由多个文件组成的 C 程序的结构。
>
>
>

在[第一篇](/article-11935-1.html)中,我设计了一个名为[喵呜喵呜](https://github.com/jnyjny/MeowMeow.git)的多文件 C 程序,该程序实现了一个玩具[编解码器](https://en.wikipedia.org/wiki/Codec)。我也提到了程序设计中的 Unix 哲学,即在一开始创建多个空文件,并建立一个好的结构。最后,我创建了一个 `Makefile` 文件夹并阐述了它的作用。在本文中将另一个方向展开:现在我将介绍简单但具有指导性的喵呜喵呜编解码器的实现。
当读过我的《[如何写一个好的 C 语言 main 函数](/article-10949-1.html)》后,你会觉得喵呜喵呜编解码器的 `main.c` 文件的结构很熟悉,其主体结构如下:
```
/* main.c - 喵呜喵呜流式编解码器 */
/* 00 系统包含文件 */
/* 01 项目包含文件 */
/* 02 外部声明 */
/* 03 定义 */
/* 04 类型定义 */
/* 05 全局变量声明(不要用)*/
/* 06 附加的函数原型 */
int main(int argc, char *argv[])
{
/* 07 变量声明 */
/* 08 检查 argv[0] 以查看该程序是被如何调用的 */
/* 09 处理来自用户的命令行选项 */
/* 10 做点有用的事情 */
}
/* 11 其它辅助函数 */
```
### 包含项目头文件
位于第二部分中的 `/* 01 项目包含文件 */` 的源代码如下:
```
/* main.c - 喵呜喵呜流式编解码器 */
...
/* 01 项目包含文件 */
#include "main.h"
#include "mmecode.h"
#include "mmdecode.h"
```
`#include` 是 C 语言的预处理命令,它会将该文件名的文件内容拷贝到当前文件中。如果程序员在头文件名称周围使用双引号(`""`),编译器将会在当前目录寻找该文件。如果文件被尖括号包围(`<>`),编译器将在一组预定义的目录中查找该文件。
[main.h](https://github.com/JnyJny/meowmeow/blob/master/main.h) 文件中包含了 [main.c](https://github.com/JnyJny/meowmeow/blob/master/main.c) 文件中用到的定义和类型定义。我喜欢尽可能多将声明放在头文件里,以便我在我的程序的其他位置使用这些定义。
头文件 [mmencode.h](https://github.com/JnyJny/meowmeow/blob/master/mmencode.h) 和 [mmdecode.h](https://github.com/JnyJny/meowmeow/blob/master/mmdecode.h) 几乎相同,因此我以 `mmencode.h` 为例来分析。
```
/* mmencode.h - 喵呜喵呜流编解码器 */
#ifndef _MMENCODE_H
#define _MMENCODE_H
#include <stdio.h>
int mm_encode(FILE *src, FILE *dst);
#endif /* _MMENCODE_H */
```
`#ifdef`、`#define`、`#endif` 指令统称为 “防护” 指令。其可以防止 C 编译器在一个文件中多次包含同一文件。如果编译器在一个文件中发现多个定义/原型/声明,它将会产生警告。因此这些防护措施是必要的。
在这些防护内部,只有两个东西:`#include` 指令和函数原型声明。我在这里包含了 `stdio.h` 头文件,以便于能在函数原型中使用 `FILE` 定义。函数原型也可以被包含在其他 C 文件中,以便于在文件的命名空间中创建它。你可以将每个文件视为一个独立的命名空间,其中的变量和函数不能被另一个文件中的函数或者变量使用。
编写头文件很复杂,并且在大型项目中很难管理它。不要忘记使用防护。
### 喵呜喵呜编码的最终实现
该程序的功能是按照字节进行 `MeowMeow` 字符串的编解码,事实上这是该项目中最简单的部分。截止目前我所做的工作便是支持允许在适当的位置调用此函数:解析命令行,确定要使用的操作,并打开将要操作的文件。下面的循环是编码的过程:
```
/* mmencode.c - 喵呜喵呜流式编解码器 */
...
while (!feof(src)) {
if (!fgets(buf, sizeof(buf), src))
break;
for(i=0; i<strlen(buf); i++) {
lo = (buf[i] & 0x000f);
hi = (buf[i] & 0x00f0) >> 4;
fputs(tbl[hi], dst);
fputs(tbl[lo], dst);
}
}
```
简单的说,当文件中还有数据块时( `feof(3)` ),该循环读取(`feof(3)` )文件中的一个数据块。然后将读入的内容的每个字节分成两个 `hi` 和 `lo` 的<ruby> 半字节 <rt> nibble </rt></ruby>。半字节是半个字节,即 4 个位。这里的奥妙之处在于可以用 4 个位来编码 16 个值。我将 `hi` 和 `lo` 用作 16 个字符串查找表 `tbl` 的索引,表中包含了用半字节编码的 `MeowMeow` 字符串。这些字符串使用 `fputs(3)` 函数写入目标 `FILE` 流,然后我们继续处理缓存区的下一个字节。
该表使用 [table.h](https://github.com/JnyJny/meowmeow/blob/master/table.h) 中的宏定义进行初始化,在没有特殊原因(比如:要展示包含了另一个项目的本地头文件)时,我喜欢使用宏来进行初始化。我将在未来的文章中进一步探讨原因。
### 喵呜喵呜解码的实现
我承认在开始工作前花了一些时间。解码的循环与编码类似:读取 `MeowMeow` 字符串到缓冲区,将编码从字符串转换为字节
```
/* mmdecode.c - 喵呜喵呜流式编解码器 */
...
int mm_decode(FILE *src, FILE *dst)
{
if (!src || !dst) {
errno = EINVAL;
return -1;
}
return stupid_decode(src, dst);
}
```
这不符合你的期望吗?
在这里,我通过外部公开的 `mm_decode()` 函数公开了 `stupid_decode()` 函数细节。我上面所说的“外部”是指在这个文件之外。因为 `stupid_decode()` 函数不在该头文件中,因此无法在其他文件中调用它。
当我们想发布一个可靠的公共接口时,有时候会这样做,但是我们还没有完全使用函数解决问题。在本例中,我编写了一个 I/O 密集型函数,该函数每次从源中读取 8 个字节,然后解码获得 1 个字节写入目标流中。较好的实现是一次处理多于 8 个字节的缓冲区。更好的实现还可以通过缓冲区输出字节,进而减少目标流中单字节的写入次数。
```
/* mmdecode.c - 喵呜喵呜流式编解码器 */
...
int stupid_decode(FILE *src, FILE *dst)
{
char buf[9];
decoded_byte_t byte;
int i;
while (!feof(src)) {
if (!fgets(buf, sizeof(buf), src))
break;
byte.field.f0 = isupper(buf[0]);
byte.field.f1 = isupper(buf[1]);
byte.field.f2 = isupper(buf[2]);
byte.field.f3 = isupper(buf[3]);
byte.field.f4 = isupper(buf[4]);
byte.field.f5 = isupper(buf[5]);
byte.field.f6 = isupper(buf[6]);
byte.field.f7 = isupper(buf[7]);
fputc(byte.value, dst);
}
return 0;
}
```
我并没有使用编码器中使用的位移方法,而是创建了一个名为 `decoded_byte_t` 的自定义数据结构。
```
/* mmdecode.c - 喵呜喵呜流式编解码器 */
...
typedef struct {
unsigned char f7:1;
unsigned char f6:1;
unsigned char f5:1;
unsigned char f4:1;
unsigned char f3:1;
unsigned char f2:1;
unsigned char f1:1;
unsigned char f0:1;
} fields_t;
typedef union {
fields_t field;
unsigned char value;
} decoded_byte_t;
```
初次看到代码时可能会感到有点儿复杂,但不要放弃。`decoded_byte_t` 被定义为 `fields_t` 和 `unsigned char` 的 **联合**。可以将联合中的命名成员看作同一内存区域的别名。在这种情况下,`value` 和 `field` 指向相同的 8 位内存区域。将 `field.f0` 设置为 `1` 也将会设置 `value` 中的最低有效位。
虽然 `unsigned char` 并不神秘,但是对 `fields_t` 的类型定义(`typedef`)也许看起来有些陌生。现代 C 编译器允许程序员在结构体中指定单个位字段的值。字段所在的类型是一个无符号整数类型,并在成员标识符后紧跟一个冒号和一个整数,该整数指定了位字段的长度。
这种数据结构使得按字段名称访问字节中的每个位变得简单,并可以通过联合中的 `value` 字段访问组合后的值。我们依赖编译器生成正确的移位指令来访问字段,这可以在调试时为你节省不少时间。
最后,因为 `stupid_decode()` 函数一次仅从源 `FILE` 流中读取 8 个字节,所以它效率并不高。通常我们尝试最小化读写次数,以提高性能和降低调用系统调用的开销。请记住:少量的读取/写入大的块比大量的读取/写入小的块好得多。
### 总结
用 C 语言编写一个多文件程序需要程序员要比只是是一个 `main.c` 做更多的规划。但是当你添加功能或者重构时,只需要多花费一点儿努力便可以节省大量时间以及避免让你头痛的问题。
回顾一下,我更喜欢这样做:多个文件,每个文件仅有简单功能;通过头文件公开那些文件中的小部分功能;把数字常量和字符串常量保存在头文件中;使用 `Makefile` 而不是 Bash 脚本来自动化处理事务;使用 `main()` 函数来处理命令行参数解析并作为程序主要功能的框架。
我知道我只是蜻蜓点水般介绍了这个简单的程序,并且我很高兴知道哪些事情对你有所帮助,以及哪些主题需要详细的解释。请在评论中分享你的想法,让我知道。
---
via: <https://opensource.com/article/19/7/structure-multi-file-c-part-2>
作者:[Erik O'Shaughnessy](https://opensource.com/users/jnyjny) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In [Part 1](https://opensource.com/article/19/7/how-structure-multi-file-c-program-part-1), I laid out the structure for a multi-file C program called [MeowMeow](https://github.com/jnyjny/MeowMeow.git) that implements a toy [codec](https://en.wikipedia.org/wiki/Codec). I also talked about the Unix philosophy of program design, laying out a number of empty files to start with a good structure from the very beginning. Lastly, I touched on what a Makefile is and what it can do for you. This article picks up where the other one left off and now I'll get to the actual implementation of our silly (but instructional) MeowMeow codec.
The structure of the **main.c** file for **meow**/**unmeow** should be familiar to anyone who's read my article "[How to write a good C main function](https://opensource.com/article/19/5/how-write-good-c-main-function)." It has the following general outline:
```
/* main.c - MeowMeow, a stream encoder/decoder */
/* 00 system includes */
/* 01 project includes */
/* 02 externs */
/* 03 defines */
/* 04 typedefs */
/* 05 globals (but don't)*/
/* 06 ancillary function prototypes if any */
int main(int argc, char *argv[])
{
/* 07 variable declarations */
/* 08 check argv[0] to see how the program was invoked */
/* 09 process the command line options from the user */
/* 10 do the needful */
}
/* 11 ancillary functions if any */
```
## Including project header files
The second section, **/* 01 project includes /***, reads like this from the source:
```
/* main.c - MeowMeow, a stream encoder/decoder */
...
/* 01 project includes */
#include "main.h"
#include "mmecode.h"
#include "mmdecode.h"
```
The **#include** directive is a C preprocessor command that causes the contents of the named file to be "included" at this point in the file. If the programmer uses double-quotes around the name of the header file, the compiler will look for that file in the current directory. If the file is enclosed in <>, it will look for the file in a set of predefined directories.
The file [ main.h](https://github.com/JnyJny/meowmeow/blob/master/main.h) contains the definitions and typedefs used in
[. I like to collect these things here in case I want to use those definitions elsewhere in my program.](https://github.com/JnyJny/meowmeow/blob/master/main.c)
**main.c**The files [ mmencode.h](https://github.com/JnyJny/meowmeow/blob/master/mmencode.h) and
[are nearly identical, so I'll break down](https://github.com/JnyJny/meowmeow/blob/master/mmdecode.h)
**mmdecode.h****mmencode.h**.
```
/* mmencode.h - MeowMeow, a stream encoder/decoder */
#ifndef _MMENCODE_H
#define _MMENCODE_H
#include <stdio.h>
int mm_encode(FILE *src, FILE *dst);
#endif /* _MMENCODE_H */
```
The **#ifdef, #define, #endif** construction is collectively known as a "guard." This keeps the C compiler from including this file more than once per file. The compiler will complain if it finds multiple definitions/prototypes/declarations, so the guard is a *must-have* for header files.
Inside the guard, there are only two things: an **#include** directive and a function prototype declaration. I include **stdio.h** here to bring in the definition of **FILE** that is used in the function prototype. The function prototype can be included by other C files to establish that function in the file's namespace. You can think of each file as a separate *namespace*, which means variables and functions in one file are not usable by functions or variables in another file.
Writing header files is complex, and it is tough to manage in larger projects. Use guards.
## MeowMeow encoding, finally
The meat and potatoes of this program—encoding and decoding bytes into/out of **MeowMeow** strings—is actually the easy part of this project. All of our activities until now have been putting the scaffolding in place to support calling this function: parsing the command line, determining which operation to use, and opening the files that we'll operate on. Here is the encoding loop:
```
/* mmencode.c - MeowMeow, a stream encoder/decoder */
...
while (!feof(src)) {
if (!fgets(buf, sizeof(buf), src))
break;
for(i=0; i<strlen(buf); i++) {
lo = (buf[i] & 0x000f);
hi = (buf[i] & 0x00f0) >> 4;
fputs(tbl[hi], dst);
fputs(tbl[lo], dst);
}
}
```
In plain English, this loop reads in a chunk of the file while there are chunks left to read (**feof(3)** and **fgets(3)**). Then it splits each byte in the chunk into **hi** and **lo** nibbles. Remember, a nibble is half of a byte, or 4 bits. The real magic here is realizing that 4 bits can encode 16 values. I use **hi** and **lo** as indices into a 16-string lookup table, **tbl**, that contains the **MeowMeow** strings that encode each nibble. Those strings are written to the destination **FILE** stream using **fputs(3)**, then we move on to the next byte in the buffer.
The table is initialized with a macro defined in [ table.h](https://github.com/JnyJny/meowmeow/blob/master/table.h) for no particular reason except to demonstrate including another project local header file, and I like initialization macros. We will go further into why a future article.
## MeowMeow decoding
Alright, I'll admit it took me a couple of runs at this before I got it working. The decode loop is similar: read a buffer full of **MeowMeow** strings and reverse the encoding from strings to bytes.
```
/* mmdecode.c - MeowMeow, a stream decoder/decoder */
...
int mm_decode(FILE *src, FILE *dst)
{
if (!src || !dst) {
errno = EINVAL;
return -1;
}
return stupid_decode(src, dst);
}
```
Not what you were expecting?
Here, I'm exposing the function **stupid_decode()** via the externally visible **mm_decode()** function. When I say "externally," I mean outside this file. Since **stupid_decode()** isn't in the header file, it isn't available to be called in other files.
Sometimes we do this when we want to publish a solid public interface, but we aren't quite done noodling around with functions to solve a problem. In my case, I've written an I/O-intensive function that reads 8 bytes at a time from the source stream to decode 1 byte to write to the destination stream. A better implementation would work on a buffer bigger than 8 bytes at a time. A *much* better implementation would also buffer the output bytes to reduce the number of single-byte writes to the destination stream.
```
/* mmdecode.c - MeowMeow, a stream decoder/decoder */
...
int stupid_decode(FILE *src, FILE *dst)
{
char buf[9];
decoded_byte_t byte;
int i;
while (!feof(src)) {
if (!fgets(buf, sizeof(buf), src))
break;
byte.field.f0 = isupper(buf[0]);
byte.field.f1 = isupper(buf[1]);
byte.field.f2 = isupper(buf[2]);
byte.field.f3 = isupper(buf[3]);
byte.field.f4 = isupper(buf[4]);
byte.field.f5 = isupper(buf[5]);
byte.field.f6 = isupper(buf[6]);
byte.field.f7 = isupper(buf[7]);
fputc(byte.value, dst);
}
return 0;
}
```
Instead of using the bit-shifting technique I used in the encoder, I elected to create a custom data structure called **decoded_byte_t**.
```
/* mmdecode.c - MeowMeow, a stream decoder/decoder */
...
typedef struct {
unsigned char f7:1;
unsigned char f6:1;
unsigned char f5:1;
unsigned char f4:1;
unsigned char f3:1;
unsigned char f2:1;
unsigned char f1:1;
unsigned char f0:1;
} fields_t;
typedef union {
fields_t field;
unsigned char value;
} decoded_byte_t;
```
It's a little complex when viewed all at once, but hang tight. The **decoded_byte_t** is defined as a **union** of a **fields_t** and an **unsigned char**. The named members of a union can be thought of as aliases for the same region of memory. In this case, **value** and **field** refer to the same 8-bit region of memory. Setting **field.f0** to 1 would also set the least significant bit in **value**.
While **unsigned char** shouldn't be a mystery, the **typedef** for **fields_t** might look a little unfamiliar. Modern C compilers allow programmers to specify "bit fields" in a **struct**. The field type needs to be an unsigned integral type, and the member identifier is followed by a colon and an integer that specifies the length of the bit field.
This data structure makes it simple to access each bit in the byte by field name and then access the assembled value via the **value** field of the union. We depend on the compiler to generate the correct bit-shifting instructions to access the fields, which can save you a lot of heartburn when you are debugging.
Lastly, **stupid_decode()** is *stupid* because it only reads 8 bytes at a time from the source **FILE** stream. Usually, we try to minimize the number of reads and writes to improve performance and reduce our cost of system calls. Remember that reading or writing a bigger chunk less often is much better than reading/writing a lot of smaller chunks more frequently.
## The wrap-up
Writing a multi-file program in C requires a little more planning on behalf of the programmer than just a single **main.c**. But just a little effort up front can save a lot of time and headache when you refactor as you add functionality.
To recap, I like to have a lot of files with a few short functions in them. I like to expose a small subset of the functions in those files via header files. I like to keep my constants in header files, both numeric and string constants. I *love* Makefiles and use them instead of Bash scripts to automate all sorts of things. I like my **main()** function to handle command-line argument parsing and act as a scaffold for the primary functionality of the program.
I know I've only touched the surface of what's going on in this simple program, and I'm excited to learn what things were helpful to you and which topics need better explanations. Share your thoughts in the comments to let me know.
## Comments are closed. |
12,001 | Basilisk:一个有着经典的外观和扩展的 Firefox 复刻 | https://itsfoss.com/basilisk-browser/ | 2020-03-16T13:00:00 | [
"浏览器",
"Firefox"
] | https://linux.cn/article-12001-1.html |
>
> Basilisk 是一个 Firefox 复刻,它支持旧版的扩展等更多功能。在这里,我们看一下它的功能并尝试一下。
>
>
>

### Basilisk:基于 XUL 的开源 Web 浏览器
尽管最好使用 Linux 上的常规浏览器(如 Firefox 或 Chromium),但了解其他浏览器也没坏处。最近,我偶然发现了一个 Firefox 复刻:[Basilisk](https://www.basilisk-browser.org/) 浏览器,它有经典的 Firefox 用户界面以及对旧版扩展的支持(就像 [Waterfox](https://itsfoss.com/waterfox-browser/) 一样)。

如果你迫切需要使用旧版扩展程序或怀念 Firefox 的经典外观,Basilisk 浏览器可以帮到你。这个浏览器是由 [Pale Moon](https://www.palemoon.org) 浏览器背后的团队维护(这是我接下来要介绍的另一个 Firefox 复刻)。
如果你正在寻找开源 [Chrome 替代品](https://itsfoss.com/open-source-browsers-linux/),那么你可以快速了解一下 Basilisk 提供的功能。
**注意:**Basilisk 是开发中软件。即使我在使用时没有遇到重大的可用性问题,但你也不应依赖它作为唯一使用的浏览器。
### Basilisk 浏览器的特性

Basilisk 开箱即用。但是,在考虑使用之前,可能需要先看一下以下这些特性:
* 基于 [XUL](https://developer.mozilla.org/en-US/docs/Archive/Mozilla/XUL) 的 Web 浏览器
* 它具有 “Australis” Firefox 界面,这在 v29–v56 的 Firefox 版本中非常流行。
* 支持 [NPAPI](https://wiki.mozilla.org/NPAPI) 插件(Flash、Unity、Java 等)
* 支持 XUL/Overlay Mozilla 形式的扩展。
* 使用 [Goanna](https://en.wikipedia.org/wiki/Goanna_(software)) 开源浏览器引擎,它是 Mozilla [Gecko](https://developer.mozilla.org/en-US/docs/Mozilla/Gecko) 的复刻
* 不使用 Rust 或 Photon 用户界面
* 仅支持 64 位系统
### 在 Linux 上安装 Basilisk
你可能没有在软件中心中找到它。因此,你必须前往其官方[下载页面](https://www.basilisk-browser.org/download.shtml)获得 tarball(tar.xz)文件。
下载后,只需将其解压缩并进入文件夹。接下来,你将在其中找到一个 `Basilisk` 可执行文件。你只需双击或右键单击并选择 “运行” 即可运行它。
你可以查看它的 [GitHub 页面](https://github.com/MoonchildProductions/Basilisk)获取更多信息。

你也可以按照下面的步骤使用终端进入下载的文件夹,并运行文件:
```
cd basilisk-latest.linux64
cd basilisk
./basilisk
```
* [下载 Basilisk](https://www.basilisk-browser.org/)
### 使用 Basilisk 浏览器

如果你想要支持旧版扩展,Basilisk 是不错的 Firefox 复刻。它是由 Pale Moon 背后的团队积极开发的,对于希望获得 Mozilla Firefox(在 Quantum 更新之前)经典外观,且不包括现代 Web 支持的用户而言,它可能是一个不错的选择。
浏览网页没有任何问题。但是,我注意到 YouTube 将其检测为过时的浏览器,并警告说它将很快停止支持它。
**因此,我不确定 Basilisk 是否适合所有现有的 Web 服务 —— 但是,如果你确实需要使用 Firefox 较早版本中的扩展,那这是一个解决方案。**
### 总结
你认为这个 Firefox 复刻值得尝试吗?你喜欢哪个?在下面的评论中分享你的想法。
---
via: <https://itsfoss.com/basilisk-browser/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Basilisk is a Firefox fork that supports legacy extensions and much more. Here, we take a look at its features and try it out.*
## Basilisk: Open Source XUL-Based Web Browser
Even though it is better to stick with the regular web browsers like Firefox or Chromium available for Linux – it doesn’t hurt to know about other browsers. Recently, I stumbled upon a Firefox fork, [Basilisk](https://www.basilisk-browser.org/) web browser that features the classic Firefox user interface along with legacy add-ons support (just like [Waterfox](https://itsfoss.com/waterfox-browser/)).
If you are in the dire need of using a legacy extensions or miss the classic look and feel of Firefox, the Basilisk web browser can save your day. The web browser is being maintained by the team behind [Pale Moon](https://www.palemoon.org) browser (which is another Firefox fork I will be looking at next).
If you’re looking for open-source [Chrome alternatives](https://itsfoss.com/open-source-browsers-linux/), you may have a quick look at what Basilisk offers.
**Note:** *Basilisk is a development software. Even though I didn’t have any major usability issues for the time I used, you should not rely on it as the only browser to use.*
## Features of Basilisk web browser
Basilisk works out of the box. However, here are some features you might want to take a look before considering to use it:
[XUL](https://developer.mozilla.org/en-US/docs/Archive/Mozilla/XUL)-based web browser- It features the ‘Australis’ Firefox interface, which was quite popular back in the time of v29 – v56 Firefox version.
[NPAPI](https://wiki.mozilla.org/NPAPI)plugins supported (Flash, Unity, Java, etc.)- Support for XUL/Overlay Mozilla-style extensions.
- Uses
[Goanna](https://en.wikipedia.org/wiki/Goanna_(software))open-source browser engine which is a fork of Mozilla’s[Gecko](https://developer.mozilla.org/en-US/docs/Mozilla/Gecko) - Does not use Rust or the Photon user interface
- Supports 64-bit systems only
## Installing Basilisk on Linux
You may not find it listed in your Software Center. So, you will have to head to its official [download page](https://www.basilisk-browser.org/download.shtml) to get the tarball (tar.xz) file.
Once you download it, simply extract it and head inside the folders. Next, you will find a “**Basilisk**” executable file in it. You need to simply run it by double-clicking on it or performing a right-click and selecting “**Run**“.
You may check out its [GitHub page](https://github.com/MoonchildProductions/Basilisk) for more information.
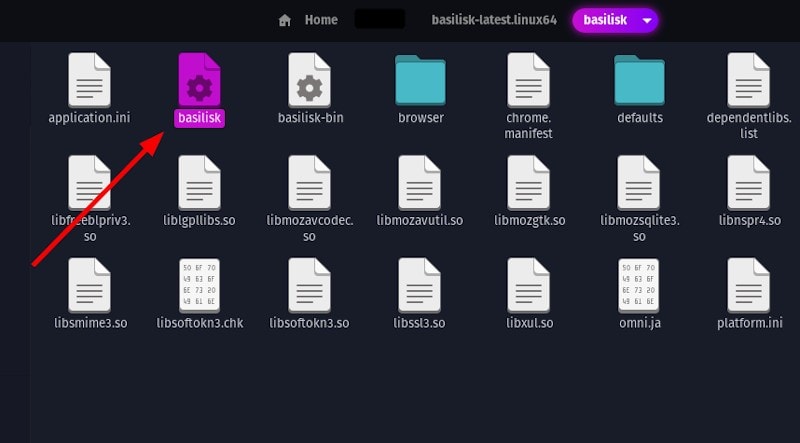
You can also use the terminal and run the file by following the steps below while navigating to the directory you downloaded it to:
```
cd basilisk-latest.linux64
cd basilisk
./basilisk
```
## Using Basilisk browser
Basilisk is a decent Firefox fork if you want the legacy extensions support. It is being actively developed by the team behind Pale Moon and is potentially a great option for users who want the classic look and feel of Mozilla’s Firefox (before the Quantum update) without comprising on the modern web support.
I didn’t have any issues with browsing webpages. However, I did notice that “**YouTube**” detects this as an obsolete browser and warns that it will stop supporting it soon enough.
*So, I’m not sure if Basilisk will be a fit for every web service out there – but if you really need the archived legacy extensions that you used on Firefox’s older releases, this could be a solution for your problem.*
**Wrapping Up**
Do you think a Firefox fork is worth trying out? What do you prefer? Share your thoughts in the comments below. |
12,003 | 你所不知道的用 less 查看文件的高级用法 | https://opensource.com/article/18/5/advanced-use-less-text-file-viewer | 2020-03-16T15:38:00 | [
"more",
"less"
] | /article-12003-1.html |
>
> 使用 less 文件查看器的一些技巧。
>
>
>

最近,我正在拜读 Scott Nesbitt 的文章《[在 Linux 命令行中使用 less 来查看文本文件](http://opensource.com/article/18/4/using-less-view-text-files-command-line)》,并受到了一些启发,所以我想分享一些使用 `less` 命令的技巧。
### LESS 环境变量
如果你定义了环境变量 `LESS`(例如在 `.bashrc` 中),那么 `less` 会将其视为一个选项列表,就像在命令行中传递给它一样。
我这样定义:
```
LESS='-C -M -I -j 10 -# 4'
```
它的意思是:
* `-C` – 通过不从底部滚动来加快全屏打印速度。
* `-M` – 在最后一行(状态行)显示更多信息。你可以使用 `-PM` 来自定义显示的信息,但我通常只用 `-M`。
* `-I` – 忽略搜索中的大小写。
* `-j 10` – 在终端的第 10 行而不是第一行显示搜索结果。这样,每次按 `n` 或(`N`) 跳到下一个(或上一个)匹配项时,就会有 10 条上下文。
* `-# 4` – 当按下向右或向左的箭头时,会向右或向左跳四个字符。默认情况时跳转半个屏幕,我觉得太多了。一般来说,`less` 似乎(至少部分)是按最初开发它时的环境优化的,那时使用慢速调制解调器和低带宽的互联网连接,所以跳过半个屏幕是有意义的。
### PAGER 环境变量
许多程序使用在 `PAGER` 环境变量中的命令来显示信息。因此,你可以在 `.bashrc` 中设置 `PAGER=less`,然后让程序运行 `less`。查看手册页(`man 7 environ`)中是否有其它此类变量。
### -S
`-S` 告诉 `less` 将长行切断而不是将它们换行。除非我在(或我要)查看文件,否则我很少需要这样做。幸运的是,你可以在 `less` 中输入所有命令行选项,就像它们是键盘命令一样。因此,如果我想在文件已经打开的情况下隔断长行,我可以简单地输入 `-S`。(LCTT 译注:注意大写 `S` ,并按回车)
这是我经常使用的一个例子:
```
su - postgres
export PAGER=less # 因为我不用在所有的机器上编辑 postgres 的 .bashrc
psql
```
有时当我查看一个 `SELECT` 命令的输出非常宽时,我会输入 `-S` 以便将其格式化的漂亮一些。如果当我按下右箭头想查看更多内容时它跳得太远(因为我没有设置 `-#`),则可以输入 `-#8`,那么每次按下右箭头都会向右移动八个字符。
有时在多次输入 `-S` 之后,我会退出 psql 并设置环境变量后再次运行它:
```
export LESS=-S
```
### F
命令 `F` 可以使 `less` 像 `tail -f` 一样工作,等待更多的数据被添加到文件后再显示它们。与 `tail -f` 相比,它的一个优点是,高亮显示搜索匹配仍然有效。因此,你可以输入 `less /var/log/logfile`,搜索某些内容时,它将高亮显示所有出现的内容(除非你使用了 `-g`),然后按下 `F` 键,当更多数据写入到日志时,`less` 将显示它并高亮新的匹配项。
按下 `F` 后,可以按 `Ctrl+C` 来停止其查找新数据(这不会干掉它),这样你可以返回文件查看旧内容,搜索其它内容等,然后再次按 `F` 键来查看更多新数据。
### 搜索
搜索使用系统的正则表达式库,这通常意味着你可以使用扩展正则表达式。特别是,搜索 `one|two|three` 可以找到并高亮所有的 one、two 或 three。
我经常使用的另一种模式是 `.*someting.*`,特别是对于一些很长的日志行(例如,跨越多个终端宽度的行),它会高亮整行。这种模式使查看一行的起始和结束位置变得更加容易。我还会结合其它内容,例如 `.*one thing.*|.*another thing.*`,或者使用 `key: .*|.*marker.*` 来查看 `key` 的内容。例如,一个日志文件中包含一些字典/哈希的转储。它会高亮相关的标记行,这样我就看到上下文了,甚至,如果我知道这个值被引号引起来的话,就可以:
```
key: '[^']*'|.*marker.*
```
`less` 会保留你的搜索项的历史纪录,并将其保存到磁盘中以备将来调用。当你按下 `/` 或 `?` 时,可以使用向上或向下箭头浏览历史记录(以及进行基本的行编辑)。
在撰写本文时,我无意间看了下 `less` 手册页,发现了一个非常有用的功能:使用 `&!pattern` 跳过无关的行。例如,当我在 `/var/log/messages` 中寻找内容时,经常会一个个迭代使用以下命令:
```
cat /var/log/messages | egrep -v 'systemd: Started Session' | less
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session' | less
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session|User Slice' | less
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session|User Slice|dbus' | less
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session|User Slice|dbus|PackageKit Daemon' | less
```
但是现在我知道如何在 `less` 中做同样的事情。例如,我可以输入 `&!systemd: Started Session`,然后想要隐藏 `systemd: Starting Session`,所以我输入 `&!`,并使用向上箭头从历史记录中获得上一次搜索的结果。然后我接着输入 `|systemd: Starting Session` 并按下回车,继续以相同的方式添加更多条目,直到我过滤掉足够多的条目,看到更有趣的内容。
### =
命令 `=` 显示有关文件和位置的更多信息,甚至比 `-M` 更多。如果文件非常大,计算 `=` 花费的时间太长,可以按下 `Ctrl+C`,它将停止尝试计算。
如果你正在查看的内容来自管道而不是文件,则 `=`(和 `-M`)不会显示未知内容,包括文件中的行数和字节数。要查看这些数据,如果你知道管道命令将很快结束,则可以使用 `G` 跳到最后,然后 `less` 将开始显示这些信息。
如果按下 `G` 并且写入管道的命令花费的时间比预期的长,你可以按下 `Ctrl+C`,该命令将被终止。即使你没有按 `G`,`Ctrl+C` 键也会杀死它。因此,如果你不想终止命令,请不要意外按下 `Ctrl+C`。出于这个原因,如果命令执行了某些操作(不仅是显示信息),通常更安全的做法是将其输出写入文件并在单独的终端中查看文件,而不是使用管道。
### 为什么你需要 less
`less` 是一个非常强大的程序,与该领域中较新的竞争者(例如 `most` 和 `more`)不同,你可能会在几乎所有的系统上找到它,就像 `vi` 一样。因此,即使你使用 GUI 查看器或编辑器,花一些时间浏览 `less` 手册页也是值得的,至少可以了解一下它的用处。这样,当你需要做一些已有的功能可能提供的工作时,就会知道如何要搜索手册页或互联网来找到所需的内容。
有关更多信息,访问 [less 主页](http://www.greenwoodsoftware.com/less/)。该网站有一个不错的常见问题解答,其中包含更多提示和技巧。
---
via: <https://opensource.com/article/18/5/advanced-use-less-text-file-viewer>
作者:[Yedidyah Bar David](https://opensource.com/users/didib) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,004 | 6 件你应该用 Emacs 做的事 | https://opensource.com/article/20/1/emacs-cheat-sheet | 2020-03-17T13:37:00 | [
"Emacs"
] | https://linux.cn/article-12004-1.html |
>
> 下面六件事情你可能都没有意识到可以在 Emacs 下完成。此外还有我们的新备忘单,拿去,充分利用 Emacs 的功能吧。
>
>
>

想象一下使用 Python 的 IDLE 界面来编辑文本。你可以将文件加载到内存中,编辑它们,并保存更改。但是你执行的每个操作都由 Python 函数定义。例如,调用 `upper()` 来让一个单词全部大写,调用 `open` 打开文件,等等。文本文档中的所有内容都是 Python 对象,可以进行相应的操作。从用户的角度来看,这与其他文本编辑器的体验一致。对于 Python 开发人员来说,这是一个丰富的 Python 环境,只需在配置文件中添加几个自定义函数就可以对其进行更改和开发。
这就是 [Emacs](https://www.gnu.org/software/emacs/) 对 1958 年的编程语言 [Lisp](https://en.wikipedia.org/wiki/Lisp_(programming_language)) 所做的事情。在 Emacs 中,运行应用程序的 Lisp 引擎与输入文本之间无缝结合。对 Emacs 来说,一切都是 Lisp 数据,因此一切都可以通过编程进行分析和操作。
这造就了一个强大的用户界面(UI)。但是,如果你是 Emacs 的普通用户,你可能对它的能力知之甚少。下面是你可能没有意识到 Emacs 可以做的六件事。
### 使用 Tramp 模式进行云端编辑
Emacs 早在网络流行化之前就实现了透明的网络编辑能力了,而且时至今日,它仍然提供了最流畅的远程编辑体验。Emacs 中的 [Tramp 模式](https://www.gnu.org/software/tramp/)(以前称为 RPC 模式)代表着 “<ruby> 透明的远程(文件)访问,多协议 <rt> Transparent Remote (file) Access,Multiple Protocol </rt></ruby>”,这准确说明了它提供的功能:通过最流行的网络协议轻松访问你希望编辑的远程文件。目前最流行、最安全的能用于远程编辑的协议是 [OpenSSH](https://www.openssh.com/),因此 Tramp 使用它作为默认的协议。
在 Emacs 22.1 或更高版本中已经包含了 Tramp,因此要使用 Tramp,只需使用 Tramp 语法打开一个文件。在 Emacs 的 “File” 菜单中,选择 “Open File”。当在 Emacs 窗口底部的小缓冲区中出现提示时,使用以下语法输入文件名:
```
/ssh:[email protected]:/path/to/file
```
如果需要交互式登录,Tramp 会提示你输入密码。但是,Tramp 直接使用 OpenSSH,所以为了避免交互提示,你可以将主机名、用户名和 SSH 密钥路径添加到你的 `~/.ssh/config` 文件。与 Git 一样,Emacs 首先使用你的 SSH 配置,只有在出现错误时才会停下来询问更多信息。
Tramp 非常适合编辑并没有放在你的计算机上的文件,它的用户体验与编辑本地文件没有明显的区别。下次,当你 SSH 到服务器启动 Vim 或 Emacs 会话时,请尝试使用 Tramp。
### 日历
如果你喜欢文本多过图形界面,那么你一定会很高兴地知道,可以使用 Emacs 以纯文本的方式安排你的日程(或生活),而且你依然可以在移动设备上使用开源的 [Org 模式](https://orgmode.org/)查看器来获得华丽的通知。
这个过程需要一些配置,以创建一个方便的方式来与移动设备同步你的日程(我使用 Git,但你可以调用蓝牙、KDE Connect、Nextcloud,或其他文件同步工具),此外你必须在移动设备上安装一个 Org 模式查看器(如 [Orgzly](https://f-droid.org/en/packages/com.orgzly/))以及 Git 客户程序。但是,一旦你搭建好了这些基础,该流程就会与你常用的(或正在完善的,如果你是新用户)Emacs 工作流完美地集成在一起。你可以在 Emacs 中方便地查阅日程、更新日程,并专注于任务上。议程上的变化将会反映在移动设备上,因此即使在 Emacs 不可用的时候,你也可以保持井然有序。

感兴趣了?阅读我的关于[使用 Org mode 和 Git 进行日程安排](/article-11320-1.html)的逐步指南。
### 访问终端
有[许多终端模拟器](/article-11814-1.html)可用。尽管 Emacs 中的 Elisp 终端仿真器不是最强大的通用仿真器,但是它有两个显著的优点:
1. **打开在 Emacs 缓冲区之中**:我使用 Emacs 的 Elisp shell,因为它在 Emacs 窗口中打开很方便,我经常全屏运行该窗口。这是一个小而重要的优势,只需要输入 `Ctrl+x+o`(或用 Emacs 符号来表示就是 `C-x o`)就能使用终端了,而且它还有一个特别好的地方在于当运行漫长的作业时能够一瞥它的状态报告。
2. **在没有系统剪贴板的情况下复制和粘贴特别方便**:无论是因为懒惰不愿将手从键盘移动到鼠标,还是因为在远程控制台运行 Emacs 而无法使用鼠标,在 Emacs 中运行终端有时意味着可以从 Emacs 缓冲区中很快地传输数据到 Bash。
要尝试 Emacs 终端,输入 `Alt+x`(用 Emacs 符号表示就是 `M-x`),然后输入 `shell`,然后按回车。
### 使用 Racket 模式
[Racket](http://racket-lang.org/) 是一种激动人心的新兴 Lisp 方言,拥有动态编程环境、GUI 工具包和充满激情的社区。学习 Racket 的默认编辑器是 DrRacket,它的顶部是定义面板,底部是交互面板。使用该设置,用户可以编写影响 Racket 运行时环境的定义。就像旧的 [Logo Turtle](https://en.wikipedia.org/wiki/Logo_(programming_language)#Turtle_and_graphics) 程序,但是有一个终端而不是仅仅一个海龟。

*由 PLT 提供的 LGPL 示例代码*
基于 Lisp 的 Emacs 为资深 Racket 编程人员提供了一个很好的集成开发环境(IDE)。它尚未附带 [Racket 模式](https://www.racket-mode.com/),但你可以使用 Emacs 包安装程序安装 Racket 模式和辅助扩展。要安装它,按下 `Alt+X`(用 Emacs 符号表示就是 `M-x`),键入 `package-install`,然后按回车。接着输入要安装的包 `racet-mode`,按回车。
使用 `M-x racket-mode` 进入 Racket 模式。如果你是 Racket 新手,而对 Lisp 或 Emacs 比较熟悉,可以从这份优秀的[图解 Racket](https://docs.racket-lang.org/quick/index.html) 入手。
### 脚本
你可能知道,Bash 脚本在自动化和增强 Linux 或 Unix 体验方面很流行。你可能听说过 Python 在这方面也做得很好。但是你知道 Lisp 脚本可以用同样的方式运行吗?有时人们会对 Lisp 到底有多有用感到困惑,因为许多人是通过 Emacs 来了解 Lisp 的,因此有一种潜在的印象,即在 21 世纪运行 Lisp 的惟一方法是在 Emacs 中运行。幸运的是,事实并非如此,Emacs 是一个很好的 IDE,它支持将 Lisp 脚本作为一般的系统可执行文件来运行。
除了 Elisp 之外,还有两种流行的现代 Lisp 可以很容易地用来作为独立脚本运行。
1. **Racket**:你可以通过在系统上运行 Racket 来提供运行 Racket 脚本所需的运行时支持,或者你可以使用 `raco exe` 产生一个可执行文件。`raco exe` 命令将代码和运行时支持文件一起打包,以创建可执行文件。然后,`raco distribution` 命令将可执行文件打包成可以在其他机器上工作的发行版。Emacs 有许多 Racket 工具,因此在 Emacs 中创建 Racket 文件既简单又有效。
2. **GNU Guile**:[GNU Guile](https://www.gnu.org/software/guile/)(<ruby> GNU 通用智能语言扩展 <rt> GNU Ubiquitous Intelligent Language for Extensions </rt></ruby> 的缩写)是 [Scheme](https://en.wikipedia.org/wiki/Scheme_(programming_language)) 编程语言的一个实现,它可以用于为桌面、互联网、终端等创建应用程序和游戏。Emacs 中的 Scheme 扩展众多,使用任何一个扩展来编写 Scheme 都很容易。例如,这里有一个用 Guile 编写的 “Hello world” 脚本:
```
#!/usr/bin/guile -s
!#
(display "hello world")
(newline)
```
用 `guile` 编译并允许它:
```
$ guile ./hello.scheme
;;; compiling /home/seth/./hello.scheme
;;; compiled [...]/hello.scheme.go
hello world
$ guile ./hello.scheme
hello world
```
### 无需 Emacs 允许 Elisp
Emacs 可以作为 Elisp 的运行环境,但是你无需按照传统印象中的必须打开 Emacs 来运行 Elisp。`--script` 选项可以让你使用 Emacs 作为引擎来执行 Elisp 脚本,而无需运行 Emacs 图形界面(甚至也无需使用终端)。下面这个例子中,`-Q` 选项让 Emacs 忽略 `.emacs` 文件,从而避免由于执行 Elisp 脚本时产生延迟(若你的脚本依赖于 Emacs 配置中的内容,那么请忽略该选项)。
```
emacs -Q --script ~/path/to/script.el
```
### 下载 Emacs 备忘录
Emacs 许多重要功能都不是只能通过 Emacs 来实现的;Org 模式是 Emacs 扩展也是一种格式标准,流行的 Lisp 方言大多不依赖于具体的应用,我们甚至可以在没有可见或可交互式 Emacs 实例的情况下编写和运行 Elisp。然后若你对为什么模糊代码和数据之间的界限能够引发创新和效率感到好奇的话,那么 Emacs 是一个很棒的工具。
幸运的是,现在是 21 世纪,Emacs 有了带有传统菜单的图形界面以及大量的文档,因此学习曲线不再像以前那样。然而,要最大化 Emacs 对你的好处,你需要学习它的快捷键。由于 Emacs 支持的每个任务都是一个 Elisp 函数,Emacs 中的任何功能都可以对应一个快捷键,因此要描述所有这些快捷键是不可能完成的任务。你只要学习使用频率 10 倍于不常用功能的那些快捷键即可。
我们汇聚了最常用的 Emacs 快捷键成为一份 Emacs 备忘录以便你查询。将它挂在屏幕附近或办公室墙上,把它作为鼠标垫也行。让它触手可及经常翻阅一下。每次翻两下可以让你获得十倍的学习效率。而且一旦开始编写自己的函数,你一定不会后悔获取了这个免费的备忘录副本的!
* [这里下载 Emacs 备忘录(需注册)](https://opensource.com/downloads/emacs-cheat-sheet)
---
via: <https://opensource.com/article/20/1/emacs-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Imagine using Python's IDLE interface to edit text. You would be able to load files into memory, edit them, and save changes. But every action you perform would be defined by a Python function. Making a word all capitals, for instance, calls **upper()**, opening a file calls **open**, and so on. Everything in your text document is a Python object and can be manipulated accordingly. From the user's perspective, it's the same experience as any text editor. For a Python developer, it's a rich Python environment that can be changed and developed with just a few custom functions in a config file.
This is what [Emacs](https://www.gnu.org/software/emacs/) does for the 1958 programming language [Lisp](https://en.wikipedia.org/wiki/Lisp_(programming_language)). In Emacs, there's no separation between the Lisp engine running the application and the arbitrary text you type into it. To Emacs, everything is Lisp data, so everything can be analyzed and manipulated programmatically.
That makes for a powerful user interface (UI). But if you're a casual Emacs user, you may only be scratching the surface of what it can do for you. Here are six things you may not have realized you could do with Emacs.
## Use Tramp mode for cloud editing
Emacs has been network-transparent for a lot longer than has been trendy, and today it still provides one of the smoothest remote editor experiences available. The [Tramp mode](https://www.gnu.org/software/tramp/) in Emacs (formerly known as RPC mode) stands for "Transparent Remote (file) Access, Multiple Protocol," which spells out exactly what it offers: easy access to remote files you want to edit over most popular network protocols. The most popular and safest protocol for remote editing these days is [OpenSSH](https://www.openssh.com/), so that's the default.
Tramp is already included in Emacs 22.1 or greater, so to use Tramp, you just open a file in the Tramp syntax. In the **File** menu of Emacs, select **Open File**. When prompted in the mini-buffer at the bottom of the Emacs window, enter the file name using this syntax:
`/ssh:[email protected]:/path/to/file`
If you are required to log in interactively, Tramp prompts you for your password. However, Tramp uses OpenSSH directly, so to avoid interactive prompts, you can also add your hostname, username, and SSH key path to your **~/.ssh/config** file. Like Git, Emacs uses your SSH config first and only stops to ask for more information in the event of an error.
Tramp is great for editing files that don't exist on your computer, and the user experience is not noticeably any different from editing a local file. The next time you start to SSH into a server just to launch a Vim or Emacs session, try Tramp instead.
## Calendaring
If you parse text better than you parse graphical interfaces, you'll be happy to know that you can schedule your day (or life) in plain text with Emacs but still get fancy notifications on your mobile device with open source [Org mode](https://orgmode.org/) viewers.
The process takes a little setup to create a convenient way to sync your agenda with your mobile device (I use Git, but you could invoke Bluetooth, KDE Connect, Nextcloud, or your file synchronization tool of choice), and you have to install an Org mode viewer (such as [Orgzly](https://f-droid.org/en/packages/com.orgzly/)) and a Git client app on your mobile. Once you've got your infrastructure sorted, though, the process is inherently perfectly integrated with your usual (or developing, if you're a new user) Emacs workflow. You can refer to your agenda easily in Emacs, make updates to your schedule, and generally stay on task. Pushing changes to your agenda is reflected on your mobile, so you can stay organized even when Emacs isn't available.
Intrigued? Read my step-by-step guide about [calendaring with Org mode and Git](https://opensource.com/article/19/4/calendar-git).
## Access the terminal
There are [lots of terminal emulators](https://opensource.com/article/19/12/favorite-terminal-emulator) available. Although the Elisp terminal emulator in Emacs isn't the greatest general-purpose one, it's got two notable advantages.
**Opens in an Emacs buffer:**I use Emacs' Elisp shell because it's conveniently located in my Emacs window, which I often run in fullscreen. It's a small but significant advantage to have a terminal just a**Ctrl+x+o**(or C-x o in Emacs notation) away, and it's especially nice to be able to glance over at it for status reports when it's running a lengthy job.**Easy copying and pasting if no system clipboard is available:**Whether I'm too lazy to move my hand from the keys to the mouse, or I don't have mouse functionality because I'm running Emacs in a remote console, having a terminal in Emacs can sometimes mean a quick transfer of data from my Emacs buffer to Bash.
To try the Emacs terminal, type **Alt**+**x** (**M-x** in Emacs notation), then type **shell**, and press **Return**.
## Use Racket mode
[Racket](http://racket-lang.org) is an exciting emerging Lisp dialect with a dynamic programming environment, a GUI toolkit, and a passionate community. The default editor when learning Racket is DrRacket, which has a Definitions panel at the top and an Interactions panel at the bottom. Using this setup, the user writes definitions that affect the Racket runtime. Imagine the old [Logo Turtle](https://en.wikipedia.org/wiki/Logo_(programming_language)#Turtle_and_graphics) program, but with a terminal instead of just a turtle.
LGPL sample code by PLT
Emacs, being based on Lisp, makes a great integrated development environment (IDE) for advanced Racket coders. It doesn't ship with [Racket mode](https://www.racket-mode.com/) (yet), but you can install Racket mode and several other helper extensions using the Emacs package installer. To install it, press **Alt**+**X** (**M-x** in Emacs notation), type **package-install**, and press **Return**. Then enter the package you want to install (**racket-mode**), and press **Return**.
Enter Racket mode with **M-x racket-mode**. If you're new to Racket but not to Lisp or Emacs, start with the excellent [Quick introduction to Racket with pictures](https://docs.racket-lang.org/quick/index.html).
## Scripting
You might know that Bash scripts are popular for automating and enhancing your Linux or Unix experience. You may have heard that Python does a pretty good job of that, too. But did you know that Lisp scripts can be run in much the same way? There's sometimes confusion about just how useful Lisp really is because many people are introduced to Lisp through Emacs, so there's the latent impression that the only way to run Lisp in the 21st century is to open an Emacs window. Luckily, that's not the case at all, and Emacs is a great IDE for the tools that enable you to run Lisp scripts as general system executables.
There are two popular modern Lisps, aside from Elisp, that are easy to run as standalone scripts.
**Racket:**You can run Racket scripts relying on your system's Racket install to provide runtime support, or you can use**raco exe**to produce an executable. The**raco exe**command packages your code together with runtime support files to create an executable. The**raco distribute**command then packages that executable into a distribution that works on other machines. Emacs has many Racket-specific tools, so creating Racket files in Emacs is easy and efficient.**GNU Guile:**[GNU Guile](https://www.gnu.org/software/guile/)(short for "GNU Ubiquitous Intelligent Language for Extensions") is an implementation of the[Scheme](https://en.wikipedia.org/wiki/Scheme_(programming_language))programming language that's used for creating applications and games for the desktop, internet, terminal, and more. Writing Scheme is easy, using any one of the many Scheme extensions in Emacs. For example, here's a "Hello world" script in Guile:
`#!/usr/bin/guile -s !# (display "hello world") (newline)`
Compile and run it with the
**guile**command:`$ guile ./hello.scheme ;;; compiling /home/seth/./hello.scheme ;;; compiled [...]/hello.scheme.go hello world $ guile ./hello.scheme hello world`
## Run Elisp without Emacs
Emacs can serve as an Elisp runtime, but you don't have to "open" Emacs in the traditional sense. The **--script** option allows you to run Elisp scripts using Emacs as the engine but without launching the Emacs GUI (not even its terminal-based one). In this example, the **-Q** option causes Emacs to ignore your **.emacs** file to avoid any delays in executing the Elisp script (if your script relies upon something in your Emacs configuration, omit this option).
`emacs -Q --script ~/path/to/script.el`
## Download the Emacs cheat sheet
Many of the greatest parts of Emacs can happen without Emacs; Org mode is a format just as much as it is an Emacs extension, popular Lisp dialects are languages mostly independent of any specific application, and even Elips can be written and run without a visible or interactive instance of Emacs. However, Emacs is an amazing tool for anyone curious about how blurring the line between code and data can lead to greater innovation and heightened efficiency.
Luckily, it's the 21st century, and Emacs has a GUI with traditional menus and plenty of documentation, so the learning curve isn't what it used to be. To maximize the way Emacs can benefit you, though, you're going to want to learn its keyboard shortcuts. Because every task that Emacs is capable of is an Elisp function, *anything and everything* in Emacs can be mapped to a keyboard shortcut, so it's impractical to try to describe them all. The essential key combinations to learn are the ones you use 10 times as often as the obscure ones.
We've gathered the most common Emacs key bindings into an [Emacs cheat sheet](https://opensource.com/downloads/emacs-cheat-sheet) for your reference. Hang it near your monitor or on your office wall, or use it as a mousepad. Keep it handy, and refer to it often. You'll get all the time you spend learning the commands back tenfold once you start getting twice as much done in one sitting. And once you start writing your own functions, it's fair to say you won't regret having grabbed a copy of this free cheat sheet!
## Comments are closed. |
12,005 | 6 个可以尝试的树莓派教程 | https://opensource.com/article/20/3/raspberry-pi-tutorials | 2020-03-17T14:26:32 | [
"树莓派"
] | https://linux.cn/article-12005-1.html |
>
> 这些树莓派项目均旨在简化你的生活并提高生产力。
>
>
>

没有什么比体验树莓派创作结果更令人兴奋了。经过数小时的编程、测试和徒手构建,你的项目终于开始成形,你不禁大喊 “哇哦!”树莓派可以带给日常生活的可能性让我着迷。无论你是想学习新知识、尝试提高效率还是只是乐在其中,本文总有一个树莓派项目适合你。
### 设置 VPN 服务器
本[教程](https://opensource.com/article/19/6/raspberry-pi-vpn-server)教你如何使用树莓派添加一个网络安全层。这个项目不仅有实际好处,而且还能为你带来很多乐趣。额外的安全性使你可以放心地做其它项目,例如下面列出的项目。
### 创建一个物体跟踪摄像机
树莓派之所以具有吸引力,是因为它提供了较低的入门门槛来学习机器学习等新技术。这份[分步指南](https://opensource.com/article/20/1/object-tracking-camera-raspberry-pi)提供了详尽的说明,说明了如何构建一个全景摄像头,以便使用 TensorFlow 和树莓派跟踪运动。
### 使用照片幻灯片展示你最喜欢的回忆
你是否曾经问过自己:“我应该怎么处理这些数码照片?”。如果你像我一样这样想过,那么答案是“是”。在朋友和家人圈子中,我被公认为摄像爱好者。这就是为什么我喜欢这个树莓派项目。在[本教程](https://opensource.com/article/19/2/wifi-picture-frame-raspberry-pi)中,你将学习如何设置照片幻灯片,以便轻松地在家里展示自己喜欢的回忆,而无需打印机!
### 玩复古电子游戏
如果你对复古游戏系统怀有怀旧之情,那么可以尝试[本教程](https://opensource.com/article/19/3/amiga-raspberry-pi)。了解包括树莓派在内的哪些设备可以运行 Amiga 模拟器。完成设置后,你将可在树莓派上玩自己喜欢的 Amiga 游戏。
### 为你的娱乐中心搭建时钟
在过去的十年中,家庭娱乐中心发生了很大的变化。我的家人完全依靠流媒体服务来观看节目和电影。我之所以爱它是因为我可以通过移动设备或语音助手控制电视。但是,当你不再能一眼看到时钟时,便会失去一定程度的便利!请遵循[这些步骤](https://opensource.com/article/17/7/raspberry-pi-clock),使用树莓派从头开始搭建自己的时钟显示。
### 扩大自制啤酒的生产规模
在[本教程](https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi)中,经验丰富的家庭酿酒师分享了他建立电动啤酒酿造系统的经验。该项目需要在硬件和零件上进行更多的前期投资,但由此产生的效率和一致性让这些值得。为此祝贺!
如果你是像我这样的树莓派新手,那么我建议你阅读我们这些可下载的树莓派指南。我们的[单页速查表](https://opensource.com/downloads/getting-started-raspberry-pi-cheat-sheet)提供了入门指南。有关更多技巧和教程,我们的[综合指南](https://opensource.com/downloads/raspberry-pi-guide)涵盖了一些主题,例如选择树莓派、保持更新、为社区做出贡献等。
你会尝试哪个树莓派项目?让我们在评论中知道。
---
via: <https://opensource.com/article/20/3/raspberry-pi-tutorials>
作者:[Lauren Pritchett](https://opensource.com/users/lauren-pritchett) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There's nothing like the thrill of experiencing the result of your Raspberry Pi creation. After hours of coding, testing, and building with your bare hands, your project starts to finally take shape and you can’t help but yell "woohoo!." I’m fascinated by the possibilities of what the Raspberry Pi can bring to daily life. Whether you are looking to learn something new, try a productivity hack, or just have fun, there is a Raspberry Pi project for you in this round-up.
## Set up a VPN server
This [tutorial](https://opensource.com/article/19/6/raspberry-pi-vpn-server) teaches you how to use the Raspberry Pi to add a layer of network security. Not only does this project have practical advantages, but it also sets you up for lots of fun to be had. The extra security will give you peace of mind to play around with other projects, like the ones listed below.
## Create an object-tracking camera
The Raspberry Pi is appealing because it offers a low barrier of entry to learn about new technologies like machine learning. This [step-by-step guide](https://opensource.com/article/20/1/object-tracking-camera-raspberry-pi) gives thorough instructions on how to build a camera that pans and tilts in order to track movement with TensorFlow and your Raspberry Pi.
## Display your favorite memories using a photo slideshow
Have you ever asked yourself: "What should I do with all of these digital photos?." If you are like me, then the answer is **yes**. I am definitely known as the picture-taker in my circle of friends and family. That’s why I love this Raspberry Pi project. In [this tutorial](https://opensource.com/article/19/2/wifi-picture-frame-raspberry-pi), you’ll learn how to set up a photo slideshow so you can display your favorite memories in your home with ease. No printer necessary!
## Play retro video games
If you feel nostalgic about retro gaming systems, you’ll want to try [this tutorial](https://opensource.com/article/19/3/amiga-raspberry-pi). Learn what kind of devices work for running an Amiga emulator including the Raspberry Pi. After going through the set-up instructions, you’ll be playing your favorite Amiga games on your Raspberry Pi.
## Build a clock for your entertainment center
Home entertainment centers have evolved so much in the last decade. My family relies solely on streaming services for watching shows and movies. I love this because I can control my TV from my mobile device or voice assistant. However, there’s a level of convenience that’s missing when you no longer can glance at a clock! Follow [these quick steps](https://opensource.com/article/17/7/raspberry-pi-clock) to build your own clock display from scratching using your Raspberry Pi.
## Scale your homebrewed beer operation
In [this tutorial](https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi), a seasoned homebrewer shares his experience with setting up an electric beer-brewing system. This project requires more of an investment in hardware and parts upfront, but the resulting efficiency and consistency make it all worth it. Cheers to that!
If you are a Raspberry Pi newb like me, then I recommend checking out our downloadable Raspberry Pi guides. Our [one-page cheat sheet](https://opensource.com/downloads/getting-started-raspberry-pi-cheat-sheet) offers step-by-step instructions for how to get started. For more tips and tutorials, our [comprehensive guide](https://opensource.com/downloads/raspberry-pi-guide) covers topics like choosing a Raspberry Pi, keeping it updated, contributing to the community and everything in between.
Which Raspberry Pi project will you try? Let us know in the comments.
## 5 Comments |
12,007 | 适用于初学者的基本 kubectl 和 Helm 命令 | https://opensource.com/article/20/2/kubectl-helm-commands | 2020-03-18T11:31:33 | [
"Kubernetes",
"kubectl"
] | https://linux.cn/article-12007-1.html |
>
> 去杂货店“采购”这些命令,你需要用这些 Kubernetes 工具来入门。
>
>
>

最近,我丈夫告诉我他即将要去参加一个工作面试,面试时他需要在计算机上运行一些基本命令。他对这场面试感到焦虑,但是对于他来说,学习和记住事情的最好方法是将不了解的事物比喻为非常熟悉的事物。因为我们的谈话是在我逛杂货店试图决定当晚要烹饪的食物之后进行的,所以这启发我用一次去杂货店的行程来介绍 `kubectl` 和 `helm` 命令。
[Helm](https://helm.sh/)(“舵轮”)是在 Kubernetes(来自希腊语,意思是“舵手” 或 “领航员”)中管理应用程序的工具。你可以轻松地使用你的应用程序信息来部署“<ruby> 海图 <rt> chart </rt></ruby>”,从而可以在你的 Kubernetes 环境中几分钟之内让它们就绪并预配置好。在学习新知识时,查看示例的“海图”以了解其用法总是很有帮助的,因此,如果有时间,请查看这些成型的“[海图](https://github.com/helm/charts/tree/master/stable)”。(LCTT 译注:Kubernetes 生态中大量使用了和航海有关的比喻,因此本文在翻译时也采用了这些比喻)
[kubectl](https://kubernetes.io/docs/reference/kubectl/kubectl/) 是与 Kubernetes 环境交互的命令行界面,允许你配置和管理集群。它需要一些配置才能在环境中工作,因此请仔细阅读其[文档](https://kubernetes.io/docs/reference/kubectl/overview/)以了解你需要做什么。
我会在示例中使用命名空间,你可以在我的文章《[Kubernetes 命名空间入门](/article-11749-1.html)》中了解它。
现在我们已经准备好了,让我们开始 `kubectl`和 `helm` 基本命令的购物之旅!
### 用 Helm 列出清单
你去商店之前要做的第一件事是什么?好吧,如果你做事有条理,会创建一个“清单”。同样,这是我将解释的第一个基本的 Helm 命令。
在一个用 Helm 部署的应用程序中,`list` 命令提供有关应用程序当前版本的详细信息。在此示例中,我有一个已部署的应用程序:Jenkins CI/CD 应用程序。运行基本的 `list` 命令总是会显示默认的命名空间。由于我没有在默认的命名空间中部署任何内容,因此不会显示任何内容:
```
$helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
```
但是,如果运行带有额外标志的命令,则会显示我的应用程序和信息:
```
$helm list --all-namespaces
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
jenkins jenkins 1 2020-01-18 16:18:07 EST deployed jenkins-1.9.4 lts
```
最后,我可以指示 `list` 命令只检查我想从中获取信息的命名空间:
```
$helm list --namespace jenkins
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
jenkins jenkins 1 2020-01-18 16:18:07 EST deployed jenkins-1.9.4 lts
```
现在我有了一个清单,并且知道该清单上有什么,我可以使用 `get` 命令来“获取”我的物品!我会从 Kubernetes 集群开始,看看我能从中获取到什么?
### 用 Kubectl 获取物品
`kubectl get` 命令提供了有关 Kubernetes 中许多事物的信息,包括“<ruby> 吊舱 <rt> Pod </rt></ruby>”、节点和命名空间。同样,如果没有指定命名空间标志,就会使用默认的命名空间。首先,我获取集群中的命名空间以查看正在运行的命名空间:
```
$kubectl get namespaces
NAME STATUS AGE
default Active 53m
jenkins Active 44m
kube-node-lease Active 53m
kube-public Active 53m
kube-system Active 53m
```
现在我已经知道了在我的环境中运行的有哪些命名空间了,接下来获取节点并查看有多少个节点正在运行:
```
$kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 55m v1.16.2
```
我有一个节点正在运行,这主要是因为我的 Minikube 运行在一台小型服务器上。要得到在我的这一个节点上运行的“吊舱”可以这样:
```
$kubectl get pods
No resources found in default namespace.
```
啊哦,它是空的。我将通过以下方式获取 Jenkins 命名空间中的内容:
```
$kubectl get pods --namespace jenkins
NAME READY STATUS RESTARTS AGE
jenkins-7fc688c874-mh7gv 1/1 Running 0 40m
```
好消息!这里发现了一个“吊舱”,它还没有重新启动过,已运行了 40 分钟了。好的,如今我知道“吊舱”已经装好,所以我想看看用 Helm 命令可以得到什么。
### 用 Helm 获取信息
`helm get` 命令稍微复杂一点,因为这个“获取”命令所需要的不仅仅是一个应用程序名称,而且你可以从应用程序中请求多个内容。我会从获取用于制作该应用程序的值开始,然后展示“获取全部”的操作结果的片段,该操作将提供与该应用程序相关的所有数据。
```
$helm get values jenkins -n jenkins
USER-SUPPLIED VALUES:
null
```
由于我只安装了最小限度的稳定版,因此配置没有更改。如果我运行“获取全部”命令,我将得到所有的“海图”:
```
$helm get all jenkins -n jenkins
```

这会产生大量数据,因此我始终建议保留一份 Helm “海图”的副本,以便你可以查看“海图”中的模板。我还创建自己的值来了解自己所拥有的。
现在,我把所有的商品都放在购物车中了,我会检查一下“描述”它们包含什么的标签。这些示例仅与 `kubectl` 命令有关,它们描述了我通过 Helm 部署的内容。
### 用 kubectl 查看描述
正如我使用“获取”命令(该命令可以描述 Kubernetes 中的几乎所有内容)所做的那样,我将示例限定到命名空间、“吊舱”和节点上。由于我知道它们每一个是什么,因此这很容易。
```
$kubectl describe ns jenkins
Name: jenkins
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
No resource limits.
```
我可以看到我的命名空间的名称,并且它是活动的,没有资源或限额限制。
`describe pods` 命令会产生大量信息,因此我这里提供的是一小段输出。如果你在不使用“吊舱”名称的情况下运行该命令,它将返回名称空间中所有“吊舱”的信息,这可能会很麻烦。因此,请确保在此命令中始终包含“吊舱”名称。例如:
```
$kubectl describe pods jenkins-7fc688c874-mh7gv --namespace jenkins
```

这会提供容器的状态、管理方式、标签以及“吊舱”中所使用的镜像(还有很多其它信息)。没有在这个简化过的输出中包括的数据有:在 Helm 配置值文件中应用的各种条件下的资源请求和限制、初始化容器和存储卷信息。如果你的应用程序由于资源不足而崩溃,或者是一个需要运行前置脚本进行配置的初始配置容器,或者生成不应该存储于纯文本 YAML 文件中的隐藏密码,则此数据很有用。
最后,我将使用 `describe node` 命令,当然,它是用来描述节点的。由于本示例只有一个名为 Minikube 的示例,因此我将使用这个名字。如果你的环境中有多个节点,则必须包含你想查找的的节点名称。
与“吊舱”一样,这个节点的命令会产生大量数据,因此我将仅包括输出片段。
```
$kubectl describe node minikube
```

注意,`describe node` 是更重要的基本命令之一。如此图所示,该命令返回统计信息,该信息指示节点何时资源用尽,并且该数据非常适合在需要扩展时(如果你的环境中没有自动扩展)向你发出警报。此输出片段中未包含的其它内容包括:对所有资源和限制的请求所占的百分比,以及资源的使用期限和分配(例如,对于我的应用程序而言)。
### 买单
使用这些命令,我完成了“购物”并得到了我想要的一切。希望这些基本命令也能在你使用 Kubernetes 的日常工作中提供帮助。
我鼓励你经常使用命令行并学习“帮助”部分中的速记标志,你可以通过运行以下命令来查看这些标志:
```
$helm --help
```
或
```
$kubectl -h
```
### 花生酱和果冻
有些东西像花生酱和果冻一样混在一起。Helm 和 `kubectl` 就有点像那样交错在一起。
我经常在自己的环境中使用这些工具。因为它们在很多地方都有很多相似之处,所以在使用其中一个之后,我通常需要跟进另一个。例如,我可以进行 Helm 部署,并使用 `kubectl` 观察它是否失败。一起试试它们,看看它们能为你做什么。
---
via: <https://opensource.com/article/20/2/kubectl-helm-commands>
作者:[Jessica Cherry](https://opensource.com/users/jrepka) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, my husband was telling me about an upcoming job interview where he would have to run through some basic commands on a computer. He was anxious about the interview, but the best way for him to learn and remember things has always been to equate the thing he doesn't know to something very familiar to him. Because our conversation happened right after I was roaming the grocery store trying to decide what to cook that evening, it inspired me to write about kubectl and Helm commands by equating them to an ordinary trip to the grocer.
[Helm](https://helm.sh/) is a tool to manage applications within Kubernetes. You can easily deploy charts with your application information, allowing them to be up and preconfigured in minutes within your Kubernetes environment. When you're learning something new, it's always helpful to look at chart examples to see how they are used, so if you have time, take a look at these stable [charts](https://github.com/helm/charts/tree/master/stable).
[Kubectl](https://kubernetes.io/docs/reference/kubectl/kubectl/) is a command line that interfaces with Kubernetes environments, allowing you to configure and manage your cluster. It does require some configuration to work within environments, so take a look through the [documentation](https://kubernetes.io/docs/reference/kubectl/overview/) to see what you need to do.
I'll use namespaces in the examples, which you can learn about in my article [ Kubernetes namespaces for beginners](https://opensource.com/article/19/12/kubernetes-namespaces).
Now that we have that settled, let's start shopping for basic kubectl and Helm commands!
## Helm list
What is the first thing you do before you go to the store? Well, if you're organized, you make a **list**. LIkewise, this is the first basic Helm command I will explain.
In a Helm-deployed application, **list** provides details about an application's current release. In this example, I have one deployed application—the Jenkins CI/CD application. Running the basic **list** command always brings up the default namespace. Since I don't have anything deployed in the default namespace, nothing shows up:
```
$ helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
```
However, if I run the command with an extra flag, my application and information appear:
```
$ helm list --all-namespaces
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
jenkins jenkins 1 2020-01-18 16:18:07 EST deployed jenkins-1.9.4 lts
```
Finally, I can direct the **list** command to check only the namespace I want information from:
```
$ helm list --namespace jenkins
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
jenkins jenkins 1 2020-01-18 16:18:07 EST deployed jenkins-1.9.4 lts
```
Now that I have a list and know what is on it, I can go and get my items with **get** commands! I'll start with the Kubernetes cluster; what can I get from it?
## Kubectl get
The **kubectl get** command gives information about many things in Kubernetes, including pods, nodes, and namespaces. Again, without a namespace flag, you'll always land in the default. First, I'll get the namespaces in the cluster to see what's running:
```
$ kubectl get namespaces
NAME STATUS AGE
default Active 53m
jenkins Active 44m
kube-node-lease Active 53m
kube-public Active 53m
kube-system Active 53m
```
Now that I have the namespaces running in my environment, I'll get the nodes and see how many are running:
```
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 55m v1.16.2
```
I have one node up and running, mainly because my Minikube is running on one small server. To get the pods running on my one node:
```
$ kubectl get pods
No resources found in default namespace.
```
Oops, it's empty. I'll get what's in my Jenkins namespace with:
```
$ kubectl get pods --namespace jenkins
NAME READY STATUS RESTARTS AGE
jenkins-7fc688c874-mh7gv 1/1 Running 0 40m
```
Good news! There's one pod, it hasn't restarted, and it has been running for 40 minutes. Well, since I know the pod is up, I want to see what I can get from Helm.
## Helm get
**Helm get** is a little more complicated because this **get** command requires more than an application name, and you can request multiple things from applications. I'll begin by getting the values used to make the application, and then I'll show a snip of the **get all** action, which provides all the data related to the application.
```
$ helm get values jenkins -n jenkins
USER-SUPPLIED VALUES:
null
```
Since I did a very minimal stable-only install, the configuration didn't change. If I run the **all** command, I get everything out of the chart:
`$ helm get all jenkins -n jenkins`
This produces a ton of data, so I always recommend keeping a copy of a Helm chart so you can look over the templates in the chart. I also create my own values to see what I have in place.
Now that I have all my goodies in my shopping cart, I'll check the labels that **describe** what's in them. These examples pertain only to kubectl, and they describe what I've deployed through Helm.
## Kubectl describe
As I did with the **get** command, which can describe just about anything in Kubernetes, I'll limit my examples to namespaces, pods, and nodes. Since I know I'm working with one of each, this will be easy.
```
$ kubectl describe ns jenkins
Name: jenkins
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
No resource limits.
```
I can see my namespace's name and that it is active and has no resource nor quote limits.
The **describe pods** command produces a large amount of information, so I'll provide a small snip of the output. If you run the command without the pod name, it will return information for all of the pods in the namespace, which can be overwhelming. So, be sure you always include the pod name with this command. For example:
`$ kubectl describe pods jenkins-7fc688c874-mh7gv --namespace jenkins`
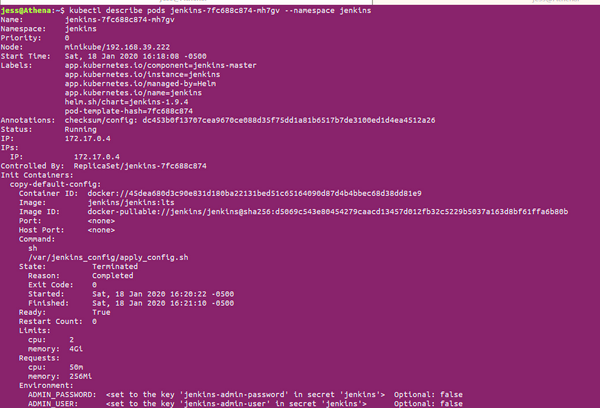
This provides (among many other things) the status of the container, how the container is managed, the label, and the image used in the pod. The data not in this abbreviated output includes resource requests and limits along with any conditions, init containers, and storage volume information applied in a Helm values file. This data is useful if your application is crashing due to inadequate resources, a configured init container that runs a prescript for configuration, or generated hidden passwords that shouldn't be in a plain text YAML file.
Finally, I'll use **describe node**, which (of course) describes the node. Since this example has just one, named Minikube, that is what I'll use; if you have multiple nodes in your environment, you must include the node name of interest.
As with pods, the node command produces an abundance of data, so I'll include just a snip of the output.
`$ kubectl describe node minikube`
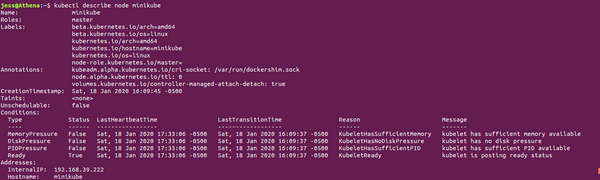
Note that **describe node** is one of the more important basic commands. As this image shows, the command returns statistics that indicate when the node is running out of resources, and this data is excellent for alerting you when you need to scale up (if you do not have autoscaling in your environment). Other things not in this snippet of output include the percentages of requests made for all resources and limits, as well as the age and allocation of resources (e.g., for my application).
## Checking out
With these commands, I've finished my shopping and gotten everything I was looking for. Hopefully, these basic commands can help you, too, in your day-to-day with Kubernetes.
I urge you to work with the command line often and learn the shorthand flags available in the Help sections, which you can access by running these commands:
`$ helm --help`
and
`$ kubectl -h`
## Peanut butter and jelly
Some things just go together like peanut butter and jelly. Helm and kubectl are a little like that.
I often use these tools in my environment. Because they have many similarities in a ton of places, after using one, I usually need to follow up with the other. For example, I can do a Helm deployment and watch it fail using kubectl. Try them together, and see what they can do for you.
## Comments are closed. |
12,008 | 如何在 Linux 中更改 MAC 地址 | https://itsfoss.com/change-mac-address-linux/ | 2020-03-18T12:05:00 | [
"MAC地址"
] | https://linux.cn/article-12008-1.html | 在向你展示如何在 Linux 中更改 MAC 地址之前,让我们首先讨论为什么要更改它。
可能有几个原因。也许你不希望在公共网络上公开你的实际 [MAC 地址](https://en.wikipedia.org/wiki/MAC_address)(也称为物理地址)?还有可能是网络管理员可能已在路由器或防火墙中阻止了特定的 MAC 地址。
一个实用的“好处”是某些公共网络(例如机场 WiFi)允许在有限的时间内免费上网。如果你还想继续使用,那么伪造 Mac 地址可能会欺骗网络,让它认为是一台新设备。这也是一个有名的原因。

我将展示更改 MAC 地址(也称为欺骗/伪造 MAC 地址)的步骤。
### 在 Linux 中更改 MAC 地址
让我们一步步来:
#### 查找你的 MAC 地址和网络接口
让我们找出一些[关于 Linux 中网卡的细节](https://itsfoss.com/find-network-adapter-ubuntu-linux/)。使用此命令获取网络接口详细信息:
```
ip link show
```
在输出中,你将看到一些详细信息以及 MAC 地址:
```
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eno1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
link/ether 94:c6:f8:a7:d7:30 brd ff:ff:ff:ff:ff:ff
3: enp0s31f6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DORMANT group default qlen 1000
link/ether 38:42:f8:8b:a7:68 brd ff:ff:ff:ff:ff:ff
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 42:02:07:8f:a7:38 brd ff:ff:ff:ff:ff:ff
```
如你所见,在这里,我的网络接口称为 `enp0s31f6`,MAC 地址为 `38:42:f8:8b:a7:68`。
你可能需要在安全的地方记录下来,以便稍后还原到该原始 MAC 地址。
现在你可以继续更改 MAC 地址。
注意!
如果在当前使用的网络接口上执行此操作,那么可能会中断你的网络连接。因此,请在其他网卡上尝试使用此方法,或者准备重启网络。
#### 方法 1:使用 Macchanger 更改 MAC 地址

[Macchanger](https://github.com/alobbs/macchanger) 是查看、修改和操作网卡 MAC 地址的简单程序。它几乎在所有 GNU/Linux 操作系统中都可用,你可以使用发行版的包安装程序进行安装。
在 Arch Linux 或 Manjaro 上:
```
sudo pacman -S macchanger
```
在 Fedora、CentOS 和 RHEL 上:
```
sudo dnf install macchanger
```
在 Debian、Ubuntu、Linux Mint、Kali Linux 上:
```
sudo apt install macchanger
```
**重要!**系统会要求你选择是否应将 `macchanger` 设置为在每次启动或关闭网络设备时自动运行。每当你接到网线或重启 WiFi 时,它都会提供一个新的 MAC 地址。

我建议不要自动运行它,除非你确实需要每次更改 MAC 地址。因此,选择“No”(按 `Tab` 键),然后按回车键继续。
**如何使用 Macchanger 更改 MAC 地址**
你还记得网络接口名称吗?你在前面的步骤中获得了它。
现在,要将随机 MAC 地址分配给该网卡,请使用:
```
sudo macchanger -r enp0s31f6
```
更改 MAC 后,使用以下命令进行验证:
```
ip addr
```
现在你将看到已经伪造 MAC。
要将 MAC 地址更改为特定值,请使用以下命令指定自定义 MAC 地址:
```
macchanger --mac=XX:XX:XX:XX:XX:XX
```
其中 XX:XX:XX:XX:XX:XX 是你要更改的新 MAC。
最后,要将 MAC 地址恢复为其原始硬件值,请运行以下命令:
```
macchanger -p enp0s31f6
```
但是,你不必如此。重启系统后,更改将自动丢失,并且实际的 MAC 地址将再次恢复。
你可以随时查看手册页以获取更多详细信息。
#### 方法 2:使用 iproute2 更改 Mac 地址(中级知识)
我建议你使用 macchanger,但如果你不想使用它,那么可以使用另一种方法在 Linux 中更改 MAC 地址。
首先,使用以下命令关闭网卡:
```
sudo ip link set dev enp0s31f6 down
```
接下来,使用以下命令设置新的 MAC:
```
sudo ip link set dev enp0s31f6 address XX:XX:XX:XX:XX:XX
```
最后,使用以下命令重新打开网络:
```
sudo ip link set dev enp0s31f6 up
```
现在,验证新的 MAC 地址:
```
ip link show enp0s31f6
```
就是这些了。你已经成功地在 Linux 中修改了 MAC 地址。敬请期待 FOSS 更多有关 Linux 教程和技巧的文章。
---
via: <https://itsfoss.com/change-mac-address-linux/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/itsfoss/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Before I show you how to change the MAC address in Linux, let’s first discuss why you would change it in the first place.
You may have several reasons. Maybe you don’t want your actual [MAC address](https://en.wikipedia.org/wiki/MAC_address?ref=itsfoss.com) (also called physical address) to be exposed on a public network? Other cases can be that the network administrator might have blocked a particular MAC address in the router or firewall.
One practical ‘benefit’ is that some public network (like Airport WiFi) allows free internet for a limited time. If you want to use the internet beyond that, spoofing your Mac address may trick the network into believing that it’s a new device. It’s a famous meme as well.

I am going to show the steps for changing MAC address (also called spoofing/faking MAC address). Let’s go through each step:
## Step 1: Find your MAC address and network interface
Let’s find out some [details about the network card in Linux](https://itsfoss.com/find-network-adapter-ubuntu-linux/). Use this command to get the network interface details:
`ip link show`
In the output, you’ll [see your IP address](https://itsfoss.com/check-ip-address-ubuntu/), MAC address and other details:
```
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eno1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
link/ether 94:c6:f8:a7:d7:30 brd ff:ff:ff:ff:ff:ff
3: enp0s31f6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DORMANT group default qlen 1000
link/ether 38:42:f8:8b:a7:68 brd ff:ff:ff:ff:ff:ff
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 42:02:07:8f:a7:38 brd ff:ff:ff:ff:ff:ff
```
Output of `ip link show`
As you can see, in this case, my network interface is called ** enp0s31f6** and its MAC address is
**.**
**38:42:f8:8b:a7:68**
You may want to note it down in a secure place to revert to this original MAC address later on.
Now you may proceed to change the MAC address.
**! If you do this on a network interface that is currently in use, probably your network connection will be terminated. So either try this method on an additional card or**
**Attention***.*
*be prepared to restart your network*## Step 2: Changing MAC address in Linux
There's a popular tool dedicated to changing MAC addresses (`macchanger`
), or you could use the `ip`
command as well. We'll go through both of them.
If you say `ifconfig`
, remember that you're officially living in the past, since it's now one of the [deprecated Linux commands](https://itsfoss.com/deprecated-linux-commands?ref=itsfoss.com). Adieu, * net-tools*!
### Method 1: Change MAC address using Macchanger
[Macchanger](https://github.com/alobbs/macchanger?ref=itsfoss.com) is a simple utility to view, modify, and manipulate MAC addresses for your Network interface cards. It is available in almost all GNU/Linux operating systems and you can install it using the package installer of your distribution.
On Arch Linux or Manjaro:
`sudo pacman -S macchanger`
On Fedora, CentOS, RHEL:
`sudo dnf install macchanger`
On Debian, Ubuntu, Linux Mint, and Kali Linux:
`sudo apt install macchanger`
**You’ll be asked to specify whether macchanger should be set up to run automatically every time a network device is brought up or down. This gives a new MAC address whenever you attach an Ethernet cable or re-enable WiFi.**
**Important!**
**)**
**Not a good idea to run it automatically**I recommend not running it automatically unless you really need to change your MAC address every time. So, choose No (by pressing the tab key) and hit Enter key to continue.
#### How to Use Macchanger to change MAC address
Do you remember your network interface name? You got it in Step 1 earlier.
Now, to assign any random MAC address to this network card, use:
`sudo macchanger -r enp0s31f6`
After changing the MAC id, verify it using the command:
`ip addr`
You will now see that MAC has been spoofed.
To change the MAC address to a specific value, specify any custom MAC address using the command:
`macchanger --mac=XX:XX:XX:XX:XX:XX `
where `XX:XX:XX:XX:XX:XX`
is the new MAC id that you want to change.
Finally, to revert the MAC address to its original hardware value, run the following command (where `-p`
tag refers to the permanent/original MAC address of the hardware):
`macchanger -p enp0s31f6`
However, you don’t have to do this. Once you reboot the system, the changes will be automatically lost, and the actual MAC address will be restored again.
You can always check the [man page of macchanger](https://manpages.ubuntu.com/manpages/jammy/man1/macchanger.1.html) for more details.
### Method 2: Changing Mac address using iproute2 [intermediate knowledge]
I would recommend using Macchanger but if you don’t want to use it, there is another way to change the [MAC address in Linux](https://itsfoss.com/find-mac-address-linux/).
First, turn off the network card using the command (this was the warning, you're manually restarting the network here):
`sudo ip link set dev enp0s31f6 down`
Next, set the new MAC for the network card using the command:
`sudo ip link set dev enp0s31f6 address XX:XX:XX:XX:XX:XX`
Finally, turn the network back on with this command:
`sudo ip link set dev enp0s31f6 up`
Now, verify the new MAC address:
`ip link show enp0s31f6`
That’s it. You have successfully changed the MAC address in true Linux style. Interested in Linux networking? Check out these commands.
[21 Basic Linux Networking Commands You Should KnowA list of basic Linux networking commands that will help you troubleshoot network issues, monitor packets, connect devices, and much more.](https://itsfoss.com/basic-linux-networking-commands/)

Stay tuned with It’s FOSS for more Linux tutorials and tips. |
12,011 | 10 篇对初学者和专家都有用的 Linux 命令教程 | https://opensource.com/article/19/12/linux-commands | 2020-03-19T09:59:58 | [
"Linux",
"命令"
] | https://linux.cn/article-12011-1.html |
>
> 在这有关 Linux 命令的十大文章中,了解如何使 Linux 发挥所需的作用。
>
>
>

**很好地**使用 Linux 意味着了解有哪些命令以及它们可以为你执行的功能。
### 《在 Linux 命令行下使用“原力”》
<ruby> 原力 <rt> force </rt></ruby>有光明的一面和黑暗的一面。正确理解这个对于真正掌握它至关重要。Alan Formy-Duval 在他的文章《[在 Linux 命令行下使用“原力”](/article-10881-1.html)》中,解释了一些流行的、有时是危险的命令的 `-f` 选项(也称为 `--force`)。
### 《Linux useradd 命令介绍》
共享帐户是一个坏主意。相反,请使用典型的 `useradd` 命令为不同的人(甚至是不同的角色)分配单独的帐户。作为其经典的 Linux 管理基础系列的一部分,Alan Formy-Duval 提供了《[Linux useradd 命令介绍](/article-11756-1.html)》,并且像往常一样,他用**朴实明白的语言**对其进行了解释,以便新老管理员都可以理解。
### 《用 Linux 命令显示硬件信息》
机器**里面**是什么?有时不使用螺丝刀检查硬件很有用。无论是你正在使用的计算机,还是在商店购买前进行测试的计算机、或者是正在尝试维修的计算机,在《[用 Linux 命令显示硬件信息](/article-11422-1.html)》中,Howard Fosdick 提供了或流行或晦涩难懂的命令,以帮助你深入了解计算机的硬件信息。
### 《如何在 Linux 上使用 gocryptfs 加密文件》
从社会保险号到个人信件再到亲人,我们的文件中包含了许多私人数据。在《[如何在 Linux 上使用 gocryptfs 加密文件](https://opensource.com/article/19/8/how-encrypt-files-gocryptfs)》中,Brian Bex Exelbierd 解释了如何保持\**隐私*的私密性。此外,他展示了一种加密文件的方式,这种方式对你现有的工作流程几乎没有影响。这不是复杂的 PGP 风格的密钥管理和后台密钥代理的难题,这是快速、无缝和安全的文件加密。
### 《如何使用 rsync 的高级用法进行大型备份》
在新的一年中,许多人会下定决心要更加努力地进行备份。Alan Formy-Duval 早在几年前就已经做出了解决方案,因为在《[如何使用 rsync 的高级用法进行大型备份](/article-10865-1.html)》中,他表现出对文件同步命令的极其熟悉。你可能不会马上记住所有语法,但其思路是读取和处理选项、构造备份命令,然后使其自动化。这是使用 `rsync` 的明智方法,也是可靠地执行备份的**唯一**方法。
### 《在 Linux 命令行使用 more 查看文本文件》
在 Scott Nesbitt 的文章《[在 Linux 命令行使用 more 查看文本文件](/article-10531-1.html)》中,古老而良好的默认分页器 `more` 引起了人们的关注。许多人安装和使用 `less`,因为它比 `more` 更灵活。但是,随着越来越多的系统在新出现的容器中实现,有时甚至不存在像 `less` 或 `most` 之类的新颖的豪华工具。了解和使用`more` 很简单,这是常见的默认设置,并且是生产系统最后的调试工具。
### 《关于 sudo 你可能不知道的》
`sudo` 命令因其过失而闻名。人们知道 `sudo` 一词,我们大多数人认为我们知道它的作用。我们的观点是正确的,但是正如 Peter Czanik 在他的文章《[关于 sudo 你可能不知道的](/article-11595-1.html)》中所揭示的那样,该命令所包含的不仅仅是“<ruby> 西蒙说的 <rt> Simon says </rt></ruby>”(LCTT 译注:国外的一个儿童游戏)。就像这个经典的童年游戏一样,`sudo` 命令功能强大,也容易犯愚蠢的错误 —— 有更多的可能产生可怕都后果,而这是你绝不想遇上的事情!
### 《怎样用 Bash 编程:语法和工具》
如果你是 Linux、BSD 或 Mac(以及近来的 Windows)用户,你也许使用过交互式 Bash shell。它是快速的、一次性命令的绝佳 shell,这就是为什么这么多 Linux 用户喜欢将其用作主要用户界面的原因。但是,Bash 不仅仅是个命令提示符。它也是一种编程语言,如果你已经在使用 Bash 命令,那么自动化的道路从未如此简单过。在 David Both 的出色作品《[怎样用 Bash 编程:语法和工具](/article-11552-1.html)》中对其进行全面了解。
### 《精通 Linux 的 ls 命令》
`ls` 命令是那些两个字母的命令之一。单字母命令是针对慢速终端的优化,因为慢速终端的输入的每个字母都会导致明显的延迟,而这对于懒惰的打字员来说也是不错的奖励。一如既往地,Seth Kenlon 清晰实用地解释了你可以怎样《[精通 Linux 的 ls 命令](/article-11159-1.html)》。最重要的是,在“一切都是文件”的系统中,列出文件至关重要。
### 《Linux cat 命令入门》
`cat` 命令(con*cat*enate 的缩写)看似简单。无论是使用它来快速查看文件的内容还是将内容通过管道传输到另一个命令,你都可能没有充分利用 `cat` 的功能。Alan Formy-Duval 的《[Linux cat 命令入门](https://opensource.com/article/19/2/getting-started-cat-command)》提供了一些新思路,可以使你没有打开文件的感觉就可以看到文件内容。另外,了解各种有关 `zcat` 的知识,这样你就可以无需解压缩就可以得到压缩文件的内容!这是一件小而简单的事情,但是**这**是使 Linux 很棒的原因。
### 继续旅程
不要让这些关于 Linux 命令的 10 篇最佳文章成为你的旅程终点。关于 Linux 及其多才多艺的提示符,还有更多值得去发现,因此,请继续关注以获取更多知识。而且,如果你想让我们介绍一个 Linux 命令,请在评论中告诉我们。
---
via: <https://opensource.com/article/19/12/linux-commands>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Using Linux *well* means understanding what commands are available and what they're capable of doing for you. We have covered a lot of them on Opensource.com during 2019, and here are 10 favorites from the bunch.
## Using the force at the Linux command line
The Force has a light side and a dark side. Properly understanding that is crucial to true mastery. In his article [ Using the force at the Linux command line](https://opensource.com/article/19/5/may-the-force-linux), Alan Formy-Duval explains the
**-f**option (also known as
**--force**) for several popular and sometimes dangerous commands.
## Intro to the Linux useradd command
Sharing accounts is a bad idea. Instead, give separate accounts to different people (and even different roles) with the quintessential **useradd** command. Part of his venerable series on basic Linux administration, Alan Formy-Duval provides an [ Intro to the Linux useradd command](https://opensource.com/article/19/10/linux-useradd-command), and, as usual, he explains it in
*plain English*so that both new and experienced admins can understand it.
## Linux commands to display your hardware information
What's *inside* the box? Sometimes it's useful to inspect your hardware without using a screwdriver. In [ Linux commands to display your hardware information](https://opensource.com/article/19/9/linux-commands-hardware-information), Howard Fosdick provides both popular and obscure commands to help you dig deep into the computer you're using, the computer you're testing at the store before buying, or the computer you're trying to repair.
## How to encrypt files with gocryptfs on Linux
Our files hold lots of private data, from social security numbers to personal letters to loved ones. In [ How to encrypt files with gocryptfs on Linux](https://opensource.com/article/19/8/how-encrypt-files-gocryptfs), Brian "Bex" Exelbierd explains how to keep
*private*what's meant to be private. As a bonus, he demonstrates encrypting files in a way that has little to no impact on your existing workflow. This isn't a complex PGP-style puzzle of key management and background key agents; this is quick, seamless, and secure file encryption.
## How to use advanced rsync for large Linux backups
In the New Year, many people will resolve to be more diligent about making backups. Alan Formy-Duval must have made that resolution years ago, because in [ How to use advanced rsync for large Linux backups](https://opensource.com/article/19/5/advanced-rsync), he displays remarkable familiarity with the file synchronization command. You might not remember all the syntax right away, but the idea is to read and process the options, construct your backup command, and then automate it. That's the smart way to use
**rsync**, and it's the
*only*way to do backups reliably.
## Using more to view text files at the Linux command line
In Scott Nesbitt's article [ Using more to view text files at the Linux command line](https://opensource.com/article/19/1/more-text-files-linux), the good old default pager
**more**finally gets the spotlight. Many people install and use
**less**, because it's more flexible than
**more**. However, with more and more systems being implemented in the sparsest of containers, the luxury of fancy new tools like
**less**or
**most**sometimes just doesn't exist. Knowing and using
**more**is simple, it's a common default, and it's the production system's debugging tool of last resort.
## What you probably didn't know about sudo
The **sudo** command is famous to a fault. People know the **sudo** term, and most of us believe we know what it does. And we're a little bit correct, but as Peter Czanik reveals in his article [ What you probably didn't know about sudo](https://opensource.com/article/19/10/know-about-sudo), there's a lot more to the command than just "Simon says." Like that classic childhood game, the
**sudo**command is powerful and also prone to silly mistakes—only with greater potential for horrible consequences. This is one game you do not want to lose!
## How to program with Bash: Syntax and tools
If you're a Linux, BSD, or Mac (and lately, Windows) user, you may have used the Bash shell interactively. It's a great shell for quick, one-off commands, which is why so many Linux users love to use it as their primary user interface. However, Bash is much more than just a command prompt. It's also a programming language, and if you're already using Bash commands, then the path to automation has never been more straightforward. Learn all about it in David Both's excellent [ How to program with Bash: Syntax and tools](https://opensource.com/article/19/10/programming-bash-syntax-tools).
## Master the Linux ls command
The **ls** command is one of those commands that merits a two-letter name; one-letter commands are an optimization for slow terminals where each letter causes a significant delay and also a nice bonus for lazy typists. Seth Kenlon explains how you can [ Master the Linux ls command](https://opensource.com/article/19/7/master-ls-command) and he does so with his usual clarity and pragmatism. Most significantly, in a system where "everything is a file," being able to list the files is crucial.
## Getting started with the Linux cat command
The **cat** command (short for con*cat*enate) is deceptively simple. Whether you use it to quickly see the contents of a file or to pipe the contents to another command, you may not be using **cat** to its full potential. Alan Formy-Duval's elucidating [ Getting started with the Linux cat command](https://opensource.com/article/19/2/getting-started-cat-command) offers new ideas to take advantage of a command that lets you open a file without feeling like you've opened it. As a bonus, learn all about
**zcat**so you can decompress files without all the trouble of decompression! It's a small and simple thing, but
*this*is what makes Linux great.
## Continue the journey
Don't let Opensource.com's 10 best articles about Linux commands of 2019 be the end of your journey. There's much more to discover about Linux and its versatile prompt, so stay tuned in 2020 for more insights. And, if there's a Linux command you want us to know about, please tell us about it in the comments, or share your knowledge with Opensource.com readers by [submitting an article](https://opensource.com/how-submit-article) about your favorite Linux command.
## 1 Comment |
12,012 | 共享、免费还是公有?开源软件的真正定义 | https://opensource.com/article/19/10/shareware-vs-open-source | 2020-03-19T10:48:48 | [
"开源软件",
"许可证",
"免费"
] | https://linux.cn/article-12012-1.html |
>
> 如果你认为开源软件是共享软件、免费软件和公有领域软件的代名词,那么你并不是唯一有这种看法的人。
>
>
>

当你听到“<ruby> 开源软件 <rp> ( </rp> <rt> open source </rt> <rp> ) </rp></ruby>”一词时,你是否认为它与诸如<ruby> 共享软件 <rp> ( </rp> <rt> shareware </rt> <rp> ) </rp></ruby>、<ruby> 免费软件 <rp> ( </rp> <rt> freeware </rt> <rp> ) </rp></ruby>或<ruby> 公有领域软件 <rp> ( </rp> <rt> public domain </rt> <rp> ) </rp></ruby>之类的术语同义? 如果是这样的话,你并不是唯一有这种看法的人。在软件行业内外的许多人都认为这些术语是一样的。本文说明了这些术语的不同之处,认为开源是一种变革性的许可和开发模式。分享我与以上几种软件打交道的经验,可能是探究差异的最佳方法。
### 共享软件和免费软件
早在 1982 年,当我在 Apple II Plus 上用 BASIC 编写代码时,我就开始从事计算机程序员的工作。我回想起去家乡当地的计算机商店,并在塑料袋中找到看起来价格高昂的装有游戏和实用程序软件的软盘。请记住,这是从一个中学生的角度来看的。
但是,有一些软件可以免费或以最低价格获得。依据具体许可模式,它被称为共享软件或免费软件。在共享软件模式下,你只能在一定时间内使用该软件,如果你发现它有用,则要求你将支票寄给该软件的作者。
但是,某些共享软件实际上也鼓励你复制并提供给你的朋友。这种模式通常称为免费软件。也就是说,共享软件和免费软件确切定义之间的差异十分微小,因此很容易将两者简单地统称为“共享软件”。我虽不能肯定,但是我不记得我是否向任何软件作者提供过使用共享软件的费用,主要是因为我在十几岁的时候就没有钱,但是我肯定喜欢使用这些软件程序,并且从中学到了很多有关计算机的知识。
回顾过去,我现在意识到,如果该软件是根据开源许可条款而非共享软件条款提供的,那么作为一名新兴的程序员,我本可以在成长中学到很多东西,并且可以取得更多成就。这是因为几乎没有共享软件会提供源代码(即,人类可读的软件形式)。共享软件还包含许可限制,禁止接收者试图泄露其源代码。如果无法访问源代码,则很难了解该软件的实际工作方式,从而很难扩展或更改其功能。这使得最终用户完全依赖共享软件原始作者进行任何更改或改进。
使用共享软件模式,任何开发人员社区几乎都不可能对代码施加影响,并进一步围绕代码进行创新。再分发和商业使用也可能受到进一步的限制。尽管共享软件可能在价格方面是免费的(至少在最初是免费的),但它在自由权利方面并不是免费的,并且不允许你通过探索代码的内部原理来学习和创新。
这就引出了一个大问题:*它与开源软件有何不同?*
### 开源许可的基础
首先,我们需要了解“开源”是指许可模式和软件开发模式,两者与共享软件都有很大不同。在一种称为非<ruby> “左版” <rp> ( </rp> <rt> copyleft </rt> <rp> ) </rp></ruby>开源许可的开源形式下,向用户提供了关键的自由权利,例如对访问源代码没有限制;可以出于任何目的出售、使用或赠送该软件;可以修改软件。
这种形式的许可也不需要支付任何使用费或许可费。因为许可是高度宽松的,不需要谈判就可以使用,这种许可模式的一个惊人结果是它具有独特的能力,可以使无数软件开发人员协作起来对代码进行新的、有用的更改和创新。尽管从技术上讲,在这种许可模式下不需要提供源代码,但是几乎所有人都可以使用它来查看、学习、修改和分发给他人。
非“左版”开源许可的另一个方面是,此类软件的任何接收者都可以添加其他许可限制。这意味着以这种许可形式对代码进行许可的初始作者,无法阻止接收者可能依据限制性更强的条款不再进一步许可给其他人。例如:
>
> 假设作者 Noah 编写了一些软件,并根据非“左版”开源许可将其分发给了接收者 Aviva。然后,Aviva 修改并改进了 Noah 的软件,她有权根据非“左版”开源许可条款使用该软件。然后,Aviva 可以决定对可能限制该软件使用的任何接收者施加进一步的限制,例如在何处或如何使用它(例如,Aviva 可以增加一项限制,规定该软件只能在以下地区使用:加利福尼亚,并且不允许在任何核电厂中使用)。 即使 Aviva 可以访问源代码,也可以选择永远不将修改后的源代码发布给他人。
>
>
>
不幸的是,有无数的专有软件公司以上述方式使用非“左版”开源许可软件。实际上,共享软件程序可以通过添加共享软件类型限制(例如,无法访问源代码或排除商业用途)来使用非“左版”开源许可软件,从而将非“左版”开源许可代码转换为共享软件许可模式。
幸运的是,许多使用非“左版”开源许可软件的专有软件公司都看到了发布源代码的好处。这些组织一般通过诸如 GitHub 之类的软件存储平台向其接收者或更广泛的开源社区提供修改后的源代码,从而继续保持开源模式的持久性,实现创新的良性循环。这并不是完全出于慈善目的(或者至少通常不是这样):这些公司希望鼓励社区创新和进一步改进,从而使他们也一并受益。
同时,许多专有软件公司不选择这样做,这也完全符合非“左版”开源许可证条款的规定。
### “左版”许可的开源软件
1989 年,一种新的被称为 GNU 通用公共许可证(也称为 GPL 许可证)的开源许可证被开发出来,其目的是确保软件“生来自由”(如同言论自由),并且能始终保持这种自由,这与非“左版”开源许可软件有时会发生的情况不同。作为版权法的独特适用,只要遵守这些规则(稍后会再介绍),GPL 许可证能够确保持续的软件自由。版权的这种独特适用称为<ruby> “左版” <rp> ( </rp> <rt> copyleft </rt> <rp> ) </rp></ruby>。
与非“左版”开源软件一样,“左版”许可证允许接收者不受限制地使用该软件、检查源代码、修改软件,以及将原始或经修改的软件进一步分发给其他接收者。与非“左版”开源许可证不同,“左版”开源许可证要求所有接收者必须也具有这些相同的自由权利。除非不遵守规则,否则这些自由权利决不能被收回。
使“左版”开源许可证能够强制执行,并促使人们遵守法规的原因是版权法的适用。如果“左版”代码的接收者不遵守许可条款(例如,对软件使用添加任何其他限制或不提供源代码),则其许可将被终止,并且由于他不再享有使用该软件的法律许可,他将成为版权侵犯者。因此,该“左版”许可软件任何下游接收者的自由权利得以保障。
### 超越基础:其他软件许可模式
我在前面提到了公有领域软件,尽管它通常与开源软件混为一谈,但是这种模式有所不同。公有领域软件是指已采取步骤查看后获知没有与该软件相对应的版权存在,最常见的情况是软件版权到期或被作者放弃。(在许多国家/地区,版权保护机制尚不明确,这就是为什么某些公有领域软件可能选择开源许可模式作为备选方案的原因。)使用公有领域软件无需许可证。尽管如果源代码可获取的话,许多人会认为公有领域软件是开源软件的一种形式,但无需许可证是否让公有领域软件成为“开源软件”,是存在很多争论的主题。
有趣的是,有许多开源项目利用公有领域软件的小模块来实现某些功能。甚至还有声称整个程序属于公有领域的软件,例如实现了 SQL 数据库引擎并在许多应用程序和设备中使用的 SQLite。没有许可条款的软件也是很常见的。
许多人错误地认为这种未经许可的软件是开源软件,属于公有领域,或者不受限制地免费使用。在大多数国家(包括美国),软件的版权在其创建时就已存在。这意味着不以许可证的形式许可就不能使用它,除非它以某种方式放弃版权,并将其放置在公有领域。此通用规则存在一些例外情况,例如法律层面的默示许可或合理使用。但是在如何将它们应用于特定状况方面,情况非常复杂。在意图让其遵守开源许可条款的情况下,我不建议提供没有许可条款的软件,因为这会导致混乱和潜在的滥用。
### 开源软件的好处
就像我之前说的那样,开源是高效的软件开发模式,并具有推动创新的巨大能力。但这到底意味着什么?
开源许可模式的好处之一是大大减少了创新方面的摩擦,尤其是原始作者以外的其他用户所进行的创新。这种摩擦是有限的,因为使用开源软件通常不需要协商许可条款,从而大大简化并降低了使用成本。反过来,这创建了一种开源生态系统,它鼓励快速修改和组合现有技术以形成新的事物。这些修改通常能回馈到开源生态系统中,从而构造了一个创新循环。
驱动大量事物(从你的烤面包机到火星飞行器)运转的无数种软件,正是这种轻松地将各种程序组合在一起的能力的直接结果——开源开发模式让所有这些软件得以成为现实。
---
作者简介:Jeffrey R. Kaufman 是全球领先的开源软件解决方案供应商<ruby> 红帽公司 <rp> ( </rp> <rt> Red Hat </rt> <rp> ) </rp></ruby>开源法务团队的资深商务法律顾问,还担任<ruby> 北卡罗来纳大学 <rp> ( </rp> <rt> University of North Carolina </rt> <rp> ) </rp></ruby>的兼职法律教授。在任职红帽公司之前,Jeffrey曾担任<ruby> 高通公司 <rp> ( </rp> <rt> Qualcomm </rt> <rp> ) </rp></ruby>的专利和开源法律顾问。
译者简介:薛亮,集慧智佳知识产权咨询公司互联网事业部总监,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | When you hear the term open source, do you think this is synonymous with terms such as shareware, freeware, or public domain? If so, you are not alone. Many people, both within and without the technology industry, think of these terms as one and the same. This article illustrates how these terms are different and how open source is a transformative licensing and development model. Perhaps the best way to explore the differences will be to share my experience with software provided under one of the above models.
## Shareware and freeware
My early years as a computer programmer started when I began to code in BASIC on my Apple II Plus in 1982. I recall going to the local computer store in my hometown and finding floppy diskettes in plastic bags containing software games and utilities for what seemed to be extraordinarily high prices. Keep in mind, this was from the perspective of a middle-schooler.
There was, however, some software that was available for free or at a minimal price; this was referred to as shareware or freeware, depending on the exact licensing model. Under the shareware model, you could use the software for only a certain amount of time, and/or if you found it useful, then there was a request that you send in a check to the author of that software.
Some shareware software, however, actually encouraged you to also make a copy and give it to your friends. This model is often referred to as freeware. That said, the exact definitions and differences between shareware and freeware are a bit soft, so it's collectively easiest to refer to both simply as "shareware." I cannot say for certain, but I doubt I ever provided money to any of the software authors for using their shareware, mainly because I had no money as an early teenager, but I sure enjoyed using these software programs and learned a lot about computers along the way.
In retrospect, I realize now that I could have learned and accomplished so much more in my growth as a budding programmer if the software had been provided under open source license terms instead of shareware terms. This is because the source code (i.e., the human-readable form of software) is almost never provided with shareware. Shareware also contains licensing restrictions that prohibit the recipient from attempting to reveal the source code. Without access to the source code, it is extraordinarily difficult to learn how the software actually works, making it very difficult to expand or change its functionality. This leaves the end user completely dependent on the original shareware author for any changes or improvements.
With the shareware model, it is practically impossible to enable any community of developers to leverage and further innovate around the code. There can also be further restrictions on redistribution and commercial usage. Although the shareware may be free in terms of price (at least initially), *it is not free in terms of freedom* and does not allow you to learn and innovate by exploring the inner workings of the code.
Which leads me to the big question: *How is this different from open source software?*
## The basics of open source licensing
First, we need to understand that "open source" refers to a *licensing *and a *software development model* that are both significantly different than shareware. Under one form of open source called non-copyleft open source licensing, the user is provided key freedoms such as no restrictions on accessing source code; selling, using, or giving away the software for any purpose; or modifying the software.
This form of license also does not require payment of any fee or royalty for use. One amazing outcome of this licensing model is its unique ability to enable countless software developers to collaborate on new and useful changes and innovations to the code because the license is highly permissive, requiring no negotiations for use. Although the source code is technically not required to be provided under such a license, it is almost always available for everyone to view, learn from, modify, and distribute to others.
Another aspect of non-copyleft open source licensing is that any recipient of such software may add additional license restrictions. This means that the initial author that licensed the code under this form of license has no assurances that the recipient may not further license to others under more restrictive terms. For example:
Let us assume an author, Noah, wrote some software and distributed it under a non-copyleft open source license to a recipient, Aviva. Aviva then modifies and improves Noah's software, which she is entitled to do under the non-copyleft open source license terms. Aviva could then decide to add further restrictions to any recipients of her software that could limit its use, such as where or how it may be used (e.g., Aviva could add in a restriction that the software may only be used within the geographical boundaries of California and never in any nuclear power plant). Aviva could also opt to never release the modified source code to others even though she had access to the source code.
Sadly, there are countless proprietary software companies that use non-copyleft open source licensed software in the way described immediately above. In fact, a shareware program could use non-copyleft open source licensed software by adding shareware-type restrictions (e.g., no access to source code or excluding commercial use) thereby converting non-copyleft open source licensed code to a shareware licensing model.
Fortunately, many proprietary companies using non-copyleft open source licensed software see the benefits of releasing source code. These organizations often continue to perpetuate the open source model by providing their modified source code to their recipients or the broader open source community via software repositories like GitHub to enable a virtuous cycle of innovation. This isn't entirely out of benevolence (or at least it normally isn't): These companies want to encourage community innovation and further enhancements, which can benefit them further.
At the same time, many proprietary companies do not opt to do this, which is well within the terms of non-copyleft open source licenses.
## Copyleft-licensed open source software
In 1989, a new open source license named the GNU General Public License, also known commonly as the GPL license, was developed with the objective to ensure that software should be inherently free (as in free speech) and that that these freedoms must always persist, unlike what sometimes happens with non-copyleft open source licensed software. In a unique application of copyright law, the GPL uses copyright law to ensure perpetual software freedoms, so long as the rules are followed (more on that later). This unique use of copyright is called copy**left**.
Like non-copyleft open source software, this license allows recipients to use the software without restriction, examine the source code, change the software, and make further distributions of the original or modified software to other recipients. *Unlike* a non-copyleft open source license, the copyleft open source license absolutely requires that any recipients are also provided these same freedoms. They can never be taken away unless the rules are not followed.
What makes the copyleft open source license enforceable and an incentive for compliance is the application of copyright law. If one of the recipients of copyleft code does not comply with the license terms (e.g., by adding any additional restrictions on the use of the software or not providing the source code), then their license terminates, and they become a copyright infringer because they no longer have legal permission to use the software. In this way, the software freedoms are ensured for any downstream recipients of that copyleft software.
## Beyond the basics: Other software license models
I mentioned public domain earlier—while it's commonly conflated with open source, this model is a bit different. Public domain means that steps have been taken to see that there are no applicable copyright rights associated with the software, which most often happens when the software copyright expires or is disclaimed by the author. (In many countries, the mechanism to disclaim copyright is unclear, which is why some public domain software may provide an option to obtain an open source-type license as a fallback.) No license is required to use public domain software; whether this makes it "open source" or not is the subject of much debate, though many would consider public domain a form of open source if the source code were made available.
Interestingly, there are a significant number of open source projects that make use of small modules of public domain software for certain functions. There are even entire programs that claim to be in the public domain, such as SQLite, which implements a SQL database engine and is used in many applications and devices. It is also common to see software with no license terms.
Many people incorrectly assume that such unlicensed software is open source, in the public domain, or otherwise free to use without restriction. In most countries, including the United States, copyright in software exists when it is created. This means that it cannot be used without permission in the form of a license, unless the copyright is somehow disclaimed, rendering it in the public domain. Some exceptions exist to this general rule, like the laws of implied licenses or fair use, but these are quite complex in how they may apply to a specific situation. I do not recommend providing software with no license terms when the intention is for it to be under open source license terms as this leads to confusion and potential misuse.
## Benefits of open source software
As I said previously, open source enables an efficient software development model with enormous ability to drive innovation. But what does this really mean?
One of the benefits of the open source licensing model is a significant reduction in the friction around innovation, especially innovation done by other users beyond the original creator. This friction is limited because using open source code generally does not require the negotiation of license terms, thereby greatly simplifying and lowering any cost burden for use. In turn, this creates a type of open source ecosystem that encourages rapid modification and combination of existing technologies to form something new. These changes are often provided back into this open source ecosystem, creating a cycle of innovation.
There is an innumerable number of software programs that run everything from your toaster to Mars-going spacecraft that are the direct result of this effortless ability to combine various programs together… all enabled by the open source development model.
## 2 Comments |
12,014 | 在家工作的十大开源工具 | https://opensource.com/article/20/3/open-source-working-home | 2020-03-20T10:38:33 | [
"在家工作"
] | https://linux.cn/article-12014-1.html |
>
> 无论你是在家工作的资深人士还是远程工作的新手,这些工具都可以使交流和协作变得轻而易举。
>
>
>

如果你<ruby> 在家工作 <rt> work from home </rt></ruby>(WFH),你就会知道拥有一系列实用的工具是很重要的,这些工具可以让你远离烦恼,专注于重要的事情。在工作期间工作越努力,工作日结束后,你就越容易放松。
我已经在家工作多年了,这是我精选的远程工作者必备的最佳开源工具。
### 视频会议:Jitsi

当你不在同事身边时,每周保持连接几次非常重要,甚至只是这样也可以保持人与人之间的联系,否则你就会变得孤独。市场上有很多视频会议系统,但以我的经验,最简单、最好的是开源的 [Jitsi](http://meet.jit.si)。
通过易于记忆的 URL([meet.jit.si](http://meet.jit.si))和按需会议室,Jitsi 使得召开即席会议非常简单。而且更好的是,无需注册。你只需进入 [meet.jit.si](http://meet.jit.si),找到一个带有友好的、随机生成的 URL(此处没有字母和数字的随机组合) 的会议室,你就可以立即开始聊天。如果你选择注册,那么还可以与几种日历进行集成。
在现实生活中,我参加了许多来自新西兰最偏远地区的会议,而 Jitsi 无疑是我迄今为止拥有的最好的视频聊天体验。不需要浪费一半的会议时间在迷宫般的虚拟会议室中寻找彼此,也不用在尴尬的滞后时间中坐着发呆,更不用努力地为聊天应用程序安装更新。使用开源和符合标准的 webRTC 协议的 Jitsi 可以让你有个愉悦的开会体验。
### 白板:Drawpile

有时,白板非常适合解释事情、跟踪想法或只是散布一下疯狂的想法。白板是办公室会议室的常见物品,但在数字世界中却很难获得。幸运的是,有了 [Drawpile](https://drawpile.net/),这是一个实时协作的绘图应用程序。你可以在自己的计算机上托管绘图会话并邀请其他用户,也可以在 Drawpile 的服务器上托管会话。
它易于使用,足够精简、直观而功能强大,当你的粗略想法开始逐渐成型时,它是使其成为可行的作品的应用程序。
### 看板:Taiga

想要保持有序并与你的部门保持同步吗?你应该试试 [Taiga](http://taiga.io),这是一个虚拟的“便利贴”面板,可以帮助团队跟踪各个任务。这种组织和项目计划方法被称为<ruby> 看板 <rt> kanban </rt></ruby>,在软件开发中很流行,而它也流行于从假期规划到家庭装修项目的所有计划之中。
Taiga 的优点是它是一个在线共享空间。与你进行协作或与之合作的任何人都可以把任务放到面板上,并且随着每个人的进展,他们将任务从左列(起点)移到右边(终点线)。Taiga 具有令人愉悦的图形化和交互性,没有什么比从一列移动到另一列的拖放任务令人感到舒适的了。
如果你的团队有 Taiga 无法满足的特定需求,那么你应该看看[我们挑选的最佳开源看板](https://opensource.com/alternatives/trello)。
### 个人笔记本:Joplin

我在办公桌旁放着一个纸质笔记本,这样我就可以随时记下思考或想法了。想要捕捉这种简单动作的感受和便利是很棘手的,但 Joplin 却做的很好。
你可以在 Joplin 中创建虚拟笔记本,每个笔记本可以有任意数量的条目。这些条目可以是简单的文本,也可以是带有图形、任务列表、超链接等的复杂的动态文档。最重要的是,你可以将 Joplin 与所有的在线存储服务同步,包括开源的 Nextcloud 服务,这样你可以在任何计算机和任何设备上使用笔记本。这是使你的工作日井井有条、专心致志并保持活动顺畅的好方法。
如果 Joplin 不太满足你的要求,请查看一些我们最喜欢的[笔记本应用](https://opensource.com/alternatives/evernote)。
### 群聊:Riot

并非所有内容都需要视频聊天或语音通话,但是有些事情比电子邮件更紧急。这就是团队聊天发挥作用的地方。一个好的群聊应用程序应该具有这些功能:即时消息传递、支持表情符号、支持 GIF 和图像,按需聊天室或“频道”、广泛的兼容性和隐私性。[Matrix](http://matrix.org) 是一个用于实时通信的开放标准和轻量级协议,如果你厌烦于键入大段消息,则可以使用相同的协议快速切换到 VOIP。你将获得世界上最好的群聊体验。
Matrix 是一种协议,并且有许多应用程序可以接驳到它(就像使用 Internet 协议一样,Firefox 是使人类可以访问的应用程序)。最受欢迎的客户端之一是 [Riot.im](http://riot.im)。你可以为你的计算机和手机下载 Riot,并且只是短时间使用的话,可以通过 Web 浏览器连接到 Riot。你的团队总是会近在咫尺,但永远不会近到让你感到不舒服。
### 共享文档:Etherpad

如果你想与他人协作处理文档或与开会,则仅需 Etherpad 就行。Etherpad 是一个实时共享的文字处理器。可以邀请一个或多个人访问文档,并在每个人进行添加和编辑时进行观察。这是一种快速有效的方法,可将想法记入“纸上”并一起迭代修订。
有几种使用 Etherpad 的方法。如果你拥有良好的 IT 支持,则可以要求你的 IT 部门为你的组织托管一个 Etherpad 实例。否则,将有来自开源支持者的在线公共实例,例如 [Riseup](https://pad.riseup.net/) 和 [Etherpad](https://beta.etherpad.org) 本身所提供的。
### 共享电子表格:Ethercalc

与 Etherpad 相似,在线 [Ethercalc](https://ethercalc.org) 编辑器允许多个用户同时在同一屏幕上远程地在电子表格上工作。Ethercalc 甚至可以从现有电子表格和定界文本文件中导入数据。你可能会也可能不会丢失大部分格式,具体取决于要导入的内容的复杂性,但是我从来没有弄坏过我的数据,因此导入文件总是一个好的开始。 下次需要复杂公式的帮助时,或者需要在最新预算中输入收据时,或者只是需要某人在格子上的输入时,请将其输入到 Ethercalc。
### 共享存储与日历:Nextcloud

[Nextcloud](http://nextcloud.com) 是一个心存远志的应用程序。顾名思义,它是你自己的个人云。它最明显的切入点是在线共享存储,它可以与台式机和移动设备上的文件夹同步。将文件放入文件中,文件会上传到存储空间,然后当一切内容都同步后,它们会出现在所有设备上。为组织中的每个人提供一个帐户,你马上便拥有了共享的存储空间,可以通过单击鼠标单击以共享带有或不带有密码的文件和文件夹。
但是,除了充当共享数据的保管箱之外,Nextcloud 还有很多其他功能。由于其插件式结构,你可以将无数的 Web 应用程序安装到 Nextcloud 中,例如聊天客户端、电子邮件客户端、视频聊天等等。并非所有插件都是“官方的”,因此其支持服务各不相同,但是有几个非常好的官方插件。值得注意的是,有一个官方的日历应用程序,你和你的同事可以用它安排会议并跟踪即将发生的重要事件。该日历使用 CalDAV 协议,因此你所做的一切都可以与任何 CalDAV 客户端兼容。
### LibreOffice

如果你习惯于每天一整天都在办公室里工作,那么你也可能习惯整天在办公套件里工作。包含所有常用功能的面面俱到的应用程序会令人感到某种程度的舒适,而在开源办公世界中的这样的应用程序就是 [LibreOffice](http://libreoffice.org)。它具有办公套件所应有的一切:文字处理器、电子表格和幻灯片演示。它还具有超出预期的功能,例如基于矢量的绘图应用程序,它还可以编辑 PDF 文件,还有一个带有图形界面构建器的关系型数据库。如果你正在寻找一个好的办公应用程序,那么 LibreOffice 是你应该首先看一看的,因为一旦你使用它,你就再也不用看别的了。
### Linux

如果你不熟悉远程工作,而可能是由于某种原因而正在经历一场重大变革。对于某些人来说,变革的时光是一个极好的动力,它可以一劳永逸地改变一切。如果你是其中的一员,那么可能是时候更改一下整个操作系统了。Windows 和 Mac 可能在过去为你提供了很好的服务,但是如果你希望从非开源软件转向开源软件,为什么不换一下运行所有这些应用程序的平台呢?
有许多出色的 Linux 发行版可以让你认真地工作、认真地自我管理和认真地进阶。获取一份 Linux 副本,不论是 [Fedora](https://getfedora.org/)、[Elementary](https://elementary.io) 还是 [Red Hat Enterprise Linux](https://www.redhat.com/en/store/red-hat-enterprise-linux-workstation) 的长期支持订购,去尝试使用自由的开源操作系统吧。等你熟悉了远程人的生活时,你最终将成为一名 Linux 专家!
---
via: <https://opensource.com/article/20/3/open-source-working-home>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you work from home, you know how important it is to have a great set of tools that stay out of your way and let you focus on what matters. The harder you work during work hours, the more easily you can relax once the workday is through.
I've been working from home for years, and here are my top picks for the best tools open source has to offer the remote worker.
## Jitsi video conferencing

When you're away from your colleagues, it's vital to connect a few times a week, even if it's just so you have a human connection as you otherwise toil away in solitude. There are lots of video conferencing systems on the market, but in my experience, the simplest and the best happens to be the open source [Jitsi](http://meet.jit.si).
With an URL that's easy to remember ([meet.jit.si](http://meet.jit.si)) and on-demand conference rooms, Jitsi makes it shockingly simple to start an impromptu meeting. And better yet, there's no registration required. You just go to [meet.jit.si](http://meet.jit.si), grab a conference room with a human-friendly, randomly generated URL (no random assortment of letters and numbers here), and you're chatting in no time. If you do choose to register, there are several calendar integrations available, too.
In real life, I attend a lot of meetings from the remotest regions of New Zealand, and Jitsi is easily the best video chat experience I've had yet. Don't waste half your meeting trying to find each other in a maze of virtual meeting rooms, or sitting through awkward lagtime, or struggling to install updates to your chat app. Just get Jitsi, using open source and standards-compliant webRTC protocols, and have a great meeting.
## Drawpile whiteboard
Sometimes it's easiest to explain things, or to track ideas, or just hash out crazy ideas, on a whiteboard. While whiteboards are staples of office conference rooms, they're harder to come by in the digital world. Luckily, there's [Drawpile](https://drawpile.net/), the real-time collaborative drawing application. You can host drawing sessions on your own computer and invite other users, or you can host a session on Drawpile's servers.
It's easy to use—minimal enough to be intuitive, but powerful enough to make it a viable artistic application in the event that your rough ideas start to develop into something important.
## Kanban board for project management
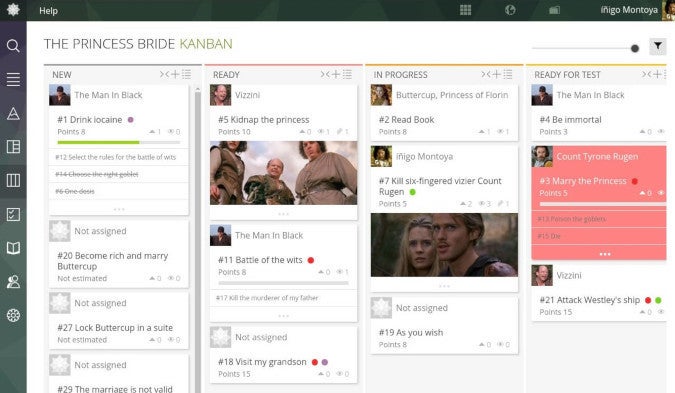
Trying to stay organized and synchronized with your department? You should try [Taiga](http://taiga.io), a virtual "post-it note" board to help teams keep track of individual tasks. This method of organization and project planning is called kanban and is popular in software development, but it's a popular method for planning everything from holidays to home improvement projects.
The advantage of Taiga is that it's an online shared space. Anyone you collaborate or work with can keep tasks on the board, and as each person makes progress, they move their tasks from the left column (the starting line) to the right (the finish line). Taiga is pleasantly graphical and interactive, and there's nothing quite as satisfying as dragging-and-dropping tasks from one column to the next.
If your team has specific needs that Taiga doesn't meet, then you should take a look at [our pick of the best open source Kanban boards](https://opensource.com/alternatives/trello).
## Joplin personal notes
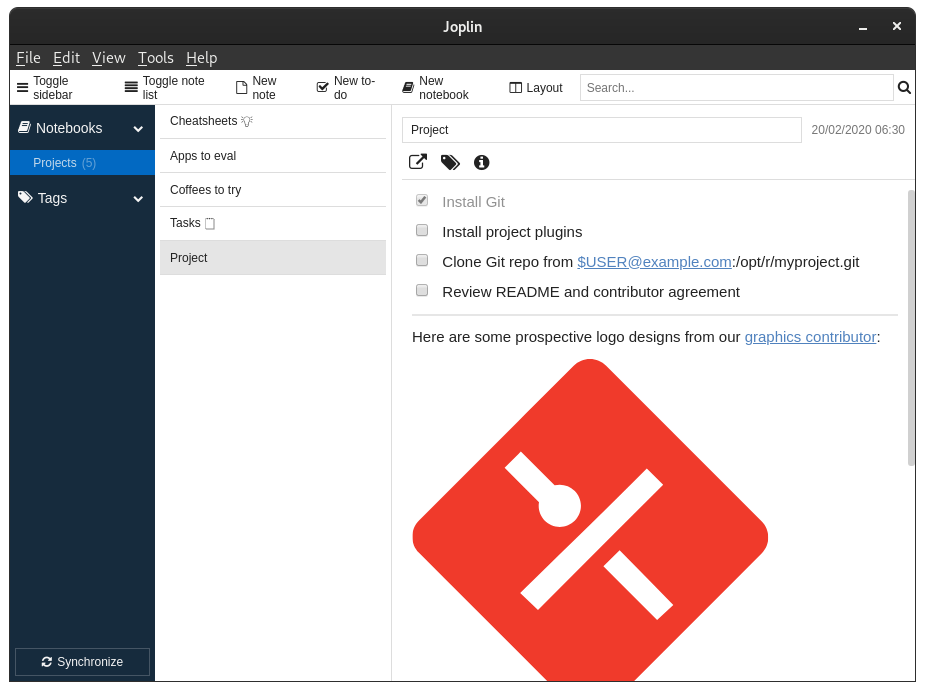
I keep a paper notebook at my desk so I can jot down thoughts or ideas. Capturing the feel and convenience of this simple act is tricky, but Joplin comes close.
You can create virtual notebooks within Joplin, and each notebook can have any number of entries. The entries can be simple text, or they can be complex, dynamic documents with graphics, a to-do list, hyperlinks, and much more. Best of all, you can synchronize Joplin to all kinds of online storage services, including the open source Nextcloud service, so that your notebooks are available to you on any computer and any device. It's a great way to keep your workday organized, your mind focused, and your activities on track.
If you Joplin doesn't quite meet your requirements, take a look at some of our favorite [notebook applications](https://opensource.com/alternatives/evernote).
## Riot team chat
Not everything requires a video chat or a voice call, and yet some things are more urgent than an email. That's where team chat comes into play. A good group chat application has all the features: instant messaging, emoji support, GIF and image support, on-demand chat rooms or "channels," widespread compatibility, and privacy. [Matrix](http://matrix.org) is an open standard and lightweight protocol for real-time communication, and if you run into problems typing your messages, you can switch over to VOIP quickly using the same protocol. You get the best of all worlds.
**[Read next: 10 must-read books for better collaboration]**
Matrix is the protocol, and there are many applications that hook into it (the same way that there's an Internet protocol, with Firefox being an application that makes it accessible to humans). One of the most popular clients is [Riot.im](http://riot.im). You can download Riot for your computer and your mobile, and in a pinch, you can just connect to it through a web browser. Your team will always be close at hand, but never so close that it gets uncomfortable.
## Etherpad shared documents
If you're looking to collaborate on a document or work on meeting notes with someone, you need look no further than Etherpad. Etherpad is a real-time shared word processor. Invite one or more people to a document, and watch as you each make your additions and edits. It's a fast and efficient way to get ideas down on "paper" and to iterate on revisions together.
There are a few ways to use Etherpad. If you have good IT support, you can ask your IT department to host an instance of Etherpad for your organization. Otherwise, there are public instances online from open source supporters such as [Riseup](https://pad.riseup.net/) and [Etherpad](https://beta.etherpad.org) itself.
## Ethercalc shared spreadsheets
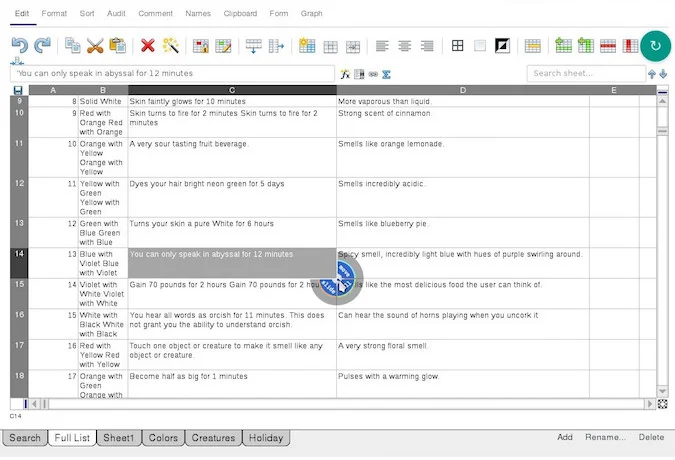
Similar to Etherpad, the online [Ethercalc](https://ethercalc.org) editor lets multiple users work on a spreadsheet, at the same time, on the same screen, remotely. Ethercalc can even import data from existing spreadsheets and delimited text files. You may or may not lose most of your formatting, depending on the complexity of what you're importing, but I've never had my data get munged, so importing has always been a good start. The next time you need help on a complex formula, or you need receipts entered into the latest budget, or you just need someone's input on layout, take it to Ethercalc.
## Nextcloud shared storage and calendar
[Nextcloud](http://nextcloud.com) is a humble giant of an application. As its name implies, it's your own personal cloud. Its most obvious entry point is as online shared storage that syncs itself with a folder on your desktop and mobile device. You put files in, the files get uploaded to your storage space, and then they appear on all of your devices because everything's synchronized. Give everyone in your organization an account, and suddenly you have shared storage space with the ability to point-and-click to share files and folders with or without passwords.
But there's so much more to Nextcloud than just acting as a dropbox for shared data. Thanks to its plug-in structure, there are countless web apps you can install into Nextcloud, like chat clients, email clients, video chat, and much more. Not all plug-ins are "official," so support varies, but there are several official plug-ins that are very good. Notably, there's an official calendaring app, so you and your colleagues can schedule meetings and keep track of important upcoming events. The calendar uses the CalDAV protocol, so everything you do is compatible with any CalDAV client.
## LibreOffice
If you're used to working in an office all day every day, you may also be used to working in an office suite all day. There's something comforting about an all-inclusive application with all the usual bells and whistles, and that application in the open source office world is [LibreOffice](http://libreoffice.org). It's got everything you'd expect from an office suite: a word processor, spreadsheet, and slide presentation. It also has more than might expect, such as a vector-based drawing application that can also edit PDF files, and a relational database complete with a graphical interface builder. If you're looking for a good office application, LibreOffice is where you need to look first, because you'll look no further once you do.
## Linux
If you're new to remote work, then you might be undergoing a major upheaval for one reason or another. A time of change, for some, is a great impetus to go for broke and change everything all in one go. If you're one of those people, then it might be time for a change of your whole operating system. Windows and Mac may have served you well in the past, but if you're looking to make the switch from non-open software to open source, why not change the platform upon which all those apps run?
There are many excellent Linux distributions built for serious work, serious autonomy, and serious advancement of skill. Grab a copy of Linux, whether it's [Fedora](https://getfedora.org/), [Elementary](https://elementary.io), or a long-term support subscription of [Red Hat Enterprise Linux](https://www.redhat.com/en/store/red-hat-enterprise-linux-workstation), and give a free and open source OS a try. By the time you get comfortable with life as a remotee, you'll be a Linux pro at last!
## 16 Comments |
12,015 | 每周开源点评:容器 vs 虚拟机、生产环境中的 Istio 等 | https://opensource.com/article/20/3/survey-istio-industry-news | 2020-03-20T11:37:48 | [
"开源",
"容器"
] | /article-12015-1.html |
>
> 本文是最近一周开源社区的新闻和行业进展。
>
>
>

我在一家采用开源软件开发模型的企业软件公司任高级产品营销经理,我的一部分职责是为产品营销人员,经理和其他相关人定期发布有关开源社区,市场和业界发展趋势的更新。以下是该更新中我和他们最喜欢的五篇文章。
### 云原生应用采用的技术:容器等
* [文章链接](https://thenewstack.io/cncf-survey-snapshot-tech-adoption-in-the-cloud-native-world/)
>
> * 在生产环境中采用容器的比例从 2018 年的 73% 上升到 2019 年的 84%。其中,运行了至少 250 个容器的比例从 2018 年的 46% 上升到 2019 年的 58%。2017 到 2019 年间, 环境中拥有 50 台以上计算机(物理或虚拟)的受访者人数从 2017 年的 77% 上升到 2019 年的 81%。
> * 表明: 容器的引入似乎缓解了需要管理的 VM 的快速增长。但是,请警惕要管理的原始机器数量会减少的说法。
>
>
>
**分析**:从直觉上看,随着容器使用的增长,虚拟机的增长将放缓;有许多容器被部署在虚拟机内部,从而充分利用了两者的优势特性,而且许多应用不会很快被容器化(留意下你所在企业的传统单体式应用)。
### 在生产环境中运行Istio的经验
* [文章链接](https://engineering.hellofresh.com/everything-we-learned-running-istio-in-production-part-1-51efec69df65)
>
> 在 HelloFresh,我们将团队分为小队和团伙。每个团伙都有自己的 Kubernetes 命名空间。如上所述,我们先按命名空间启用 sidecar 注入,然后再逐个对应用启用。在将应用添加到 Istio 之前,我们举办了研讨会,以使小队了解其应用发生的变化。由于我们采用“您构建,您维护”的模型,团队可以在故障定位时了解应用的进出流量。不仅如此,它还提升了公司内部的知识量。我们还创建了 Istio 相关的 [OKR](https://en.wikipedia.org/wiki/OKR) ,来跟踪我们的进度并达成我们引入Istio的目的。
>
>
>
**分析**:引入或是不引入技术,要由自己决定,同时要自行承担相应的后果。
### Aether: 首个开源的边缘云平台
* [文章链接](https://www.sdxcentral.com/articles/news/onf-projects-coalesce-for-enterprise-edge-cloud/2020/03/)
>
> ONF 的营销副主席 Sloane 这样解释 Aether: 它将多个正在自己的沙箱中开发和运行的项目聚集到一起,ONF 试图在该框架下将多种边缘服务在一个融合平台上支持起来。ONF 的各个项目将保持独立并可继续单独使用,但是 Aether 试图将多个能力绑定到一起来简化企业的私有边缘云运营。
>
>
> 他说:“我们认为我们正在创造一个新的合作空间,工业界和社区可以携手帮助推动通用平台背后的整合和关键工作,然后可以帮助这些边缘云中的通用功能不断发展”。
>
>
>
**分析**:当今,使用技术解决的问题过于复杂,无法通过单一技术解决。比技术更重要的是要解决的业务问题需要聚焦于真正增值的部分。将两者结合起来,就是企业之间需要在他们共同的需求上找到合作的方法,并在它们特有的方面进行竞争。除了开源,你找不到比这更好的方法了。
### 与云相关职业的女性正在改变现状
* [文章链接](https://www.cloudpro.co.uk/leadership/cloud-essentials/8446/how-women-in-cloud-are-challenging-the-narrative)
>
> Yordanova 说:“由于云是一种相对较新的技术,我的[成为一名“科技女性”](https://www.itpro.co.uk/business-strategy/33301/diversity-not-a-company-priority-claim-nearly-half-of-women-in-tech)的经验可能并不典型,因为云行业极为多样化”。“实际上,我的团队中性别比例相当,成员由随着云技术而成长的不同个性、文化和优势的具体人员组成。“
>
>
>
**分析**:我想考虑的一件事就是跨越式的演进思路。你可能可以跳过演进过程中的某个步骤或阶段,因为原先导致其存在的条件已不再适用。云技术时代没有形成“谁发明的以及它是为谁而生”的固有说法,所以也许它所承载的某些前代的技术负担更少?
### StarlingX 如何在中国开源项目的星空中闪耀
* [文章链接](https://superuser.openstack.org/articles/starlingx-community-interview-how-starlingx-shines-in-the-starry-sky-of-open-source-projects-in-china/)
>
> 我们的团队在中国,因此我们的任务之一是帮助中国的社区开发软件、贡献代码、文档等。大多数 StarlingX 项目会议是在中国的深夜举行,因此华人社区成员的出席和参与颇具挑战。为了克服这些障碍,我们与中国的其他社区成员(例如 99cloud 的朋友)一起采取了一些措施,例如和其他社区成员一起聚会,一起参加动手实践研讨会和中文的特设技术会议,将一些文档翻译成中文,并在微信小组中不断进行互动(就像每个人都可以享受的 24/7 通话服务一样)
>
>
>
**分析**:随着中国对开源项目的贡献不断增长,这种情况似乎有可能逆转或至少相当。“学习英语”根本不是参与开源项目开发的先决条件。
希望你喜欢这个列表,下周再见。
---
via: <https://opensource.com/article/20/3/survey-istio-industry-news>
作者:[Tim Hildred](https://opensource.com/users/thildred) 选题:[lujun9972](https://github.com/lujun9972) 译者:[messon007](https://github.com/messon007) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,017 | 如何在 Ubuntu 和其他 Linux 上安装 Netbeans | https://itsfoss.com/install-netbeans-ubuntu/ | 2020-03-20T12:21:08 | [
"Netbeans"
] | https://linux.cn/article-12017-1.html |
>
> 在本教程中,你将学习在 Ubuntu 和其他 Linux 发行版上安装 Netbeans IDE 的各种方法。
>
>
>
[NetBeans](https://netbeans.org/) 是一个开源集成开发环境,具有良好的跨平台支持。此工具已被 Java 和 C/C++ 开发社区广泛认可。

开发环境相当灵活。你可以配置它以支持各种开发。实际上,你可以用它来开发 Web、桌面和移动应用,而无需离开此平台。这太神奇了,不是吗?除此之外,用户可以添加许多已知语言,如 [PHP](https://www.php.net/)、C、C++、HTML、[Ajax](https://en.wikipedia.org/wiki/Ajax_(programming))、JavaScript、JSP、Ruby on Rails 等。
如果你正在了解如何在 Linux 上安装 Netbeans,那么有几种方法可以做到。我编写本教程主要是为了 Ubuntu,但一些安装方法也适用于其他发行版。
* [使用 apt 在 Ubuntu 上安装 Netbeans](tmp.ZNFNEC210y#apt):适用于 Ubuntu 和基于 Ubuntu 的发行版,但通常**它是旧版的 Netbeans**
* [使用 Snap 在 Ubuntu 上安装 Netbeans](tmp.ZNFNEC210y#snap):适用于已启用 Snap 包支持的任何 Linux 发行版
* [使用 Flatpak 安装 Netbeans](tmp.ZNFNEC210y#flatpak):适用于所有支持 Flatpak 包的 Linux 发行版
### 使用 Apt 包管理器在 Ubuntu 上安装 Netbeans IDE
如果在 Ubuntu 软件中心搜索 Netbeans,你将找到两个版本的 Netbeans。Apache Netbeans 是 snap 版本,大小较大,但提供了最新的 Netbeans。
只需单击一下即可安装它。无需打开终端。是最简单的方法。

你也可以选择使用 `apt` 命令,但使用 `apt` 时,你无法获得最新的 Netbeans。例如,在编写本教程时,Ubuntu 18.04 中 Apt 提供 Netbeans 10,而 Snap 有最新的 Netbeans 11。
如果你是 [apt 或 apt-get](https://itsfoss.com/apt-vs-apt-get-difference/) 的粉丝,那么可以[启用 universe 仓库](https://itsfoss.com/ubuntu-repositories/),并在终端中使用此命令安装 Netbeans:
```
sudo apt install netbeans
```
### 使用 Snap 在任何 Linux 发行版上安装 Netbeans IDE
Snap 是一个通用包管理器,如果[发行版上启用了 Snap](https://itsfoss.com/install-snap-linux/),那么可以使用以下命令安装它:
```
sudo snap install netbeans --classic
```
此过程可能需要一些时间才能完成,因为总下载大小约为 1 GB。完成后,你将在应用程序启动器中看到它。
你不仅可以通过 Snap 获取最新的 Netbeans,已安装的版本将自动更新到较新版本。
### 使用 Flatpak 安装 Netbeans
[Flatpak](https://flatpak.org/) 是另一个类似 Snap 的包安装器。默认情况下,某些发行版支持 Flatpak,在其他发行版上你可以[启用 Flatpak 支持](https://itsfoss.com/flatpak-guide/)。
发行版支持 Flatpak 后,你可以使用以下命令安装 Netbeans:
```
flatpak install flathub org.apache.netbeans
```
另外,你可以下载源码并自己编译。
* [下载 Netbeans](https://netbeans.apache.org/download/index.html)
希望你使用了上面其中一个方法在你的 Ubuntu 上安装了 Netbeans。但你使用的是哪个方法?有遇到问题么?让我们知道。
---
via: <https://itsfoss.com/install-netbeans-ubuntu/>
作者:[Srimanta Koley](https://itsfoss.com/author/itsfoss/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *In this tutorial, you’ll learn various ways to install Netbeans IDE on Ubuntu and other Linux distributions.*
[NetBeans](https://netbeans.org/) is an open source integrated development environment that comes with good cross-platform support. This tool has been recognized by the Java and C/C++ development community widely.
The development environment is quite flexible. You can configure this tool to support a wide array of development objectives. Practically, you can develop Web, Desktop and Mobile Applications without leaving this platform. It’s amazing, isn’t it? Besides this, the user can add a wide array of known languages such as [PHP](https://www.php.net/), C, C++, HTML, [Ajax](https://en.wikipedia.org/wiki/Ajax_(programming)), JavaScript, JSP, Ruby on Rails and the list goes on and on!
If you are looking to install Netbeans on Linux, you have several ways to do that. I have written this tutorial primarily for Ubuntu but some installation methods are applicable to other distributions as well.
[Installing Netbeans on Ubuntu using apt](#apt): for Ubuntu and Ubuntu-based distributions but usually**it has older version of Netbeans**[Installing Netbeans on Ubuntu using Snap](#snap): for any Linux distribution that has Snap packaging support enabled[Installing Netbeans using Flatpak](#flatpak): for any Linux distribution with Flatpak package support
## Installing Netbeans IDE on Ubuntu using Apt package manager
If you search for Netbeans in Ubuntu Software Center, you’ll find two Netbeans available. The Apache Netbeans is the snap version which is bigger in download size but gives you the latest Netbeans.
You can install it in one click. No need to open terminal. Easiest way.
You may also opt for using the apt command but with apt version, you won’t get the latest Netbeans. For example, at the time of writing this tutorial, Ubuntu 18.04 has Netbeans version 10 available via Apt while Snap has the latest Netbeans 11.
If you are a fan of [apt or apt-get](https://itsfoss.com/apt-vs-apt-get-difference/), you can [enable the universe repository](https://itsfoss.com/ubuntu-repositories/) and install Netbeans using this command in the terminal:
`sudo apt install netbeans`
## Installing Netbeans IDE on any Linux distribution using Snap

Snap is a universal package manager and if [you have enabled Snap on your distribution](https://itsfoss.com/install-snap-linux/), you can install it using the following command:
`sudo snap install netbeans --classic`
The process might take some time to complete because the total download size is around 1 GB. Once done, you will see the app in the application launcher.
Not only you’ll get the latest Netbeans with Snap, the installed version will be automatically updated to the newer version.
## Installing Netbeans using Flatpak
[Flatpak](https://flatpak.org/) is another universal packaging like Snap. Some distributions support Flatpak by default while you can [enable Flatpak support](https://itsfoss.com/flatpak-guide/) on others.
Once you have the Flatpak support on your distribution, you can use the following command to install Netbeans:
`flatpak install flathub org.apache.netbeans`
Alernatively, you can always download the source code of this open source software and compile it yourself.
Hopefully, you selected one of the above methods to install Netbeans on your Ubuntu Linux system. But which one did you use? Did you face any issues? Do let us know.

## Srimanta Koley
Srimanta is a passionate writer, a distrohopper & open source enthusiast. He is extremely fond of everything related to technology. He loves to read books and has an unhealthy addiction to the 90s! |
12,018 | 来自 Amazon 的容器专用 Linux 发行版“瓶装火箭” | https://itsfoss.com/bottlerocket-linux/ | 2020-03-21T07:50:00 | [
"容器",
"AWS"
] | https://linux.cn/article-12018-1.html | 
Amazon 已经[推出](https://aws.amazon.com/blogs/aws/bottlerocket-open-source-os-for-container-hosting/)了自己的基于 Linux 的开源操作系统 Bottlerocket(“瓶装火箭”)。但在你兴奋地想要尝试安装和运行它之前,我必须告诉你,它不是常规的如 Ubuntu、Fedora 或 Debian 这样的 Linux 发行版。那它是什么?
### Bottlerocket:来自 Amazon 的 Linux 发行版,用于运行容器

如果你不了解 Linux 容器,建议你阅读 Red Hat 的[这篇文章](https://www.redhat.com/en/topics/containers/whats-a-linux-container)。
自从首次提出云计算一词以来,IT 行业发生了许多变化。得益于 Amazon AWS、Google、Linode、Digital Ocean 等云服务器提供商,部署 Linux 服务器(通常在虚拟机中运行)只需几秒钟。最重要的是,你可以借助 Docker 和 Kubernetes 之类的工具在这些服务器上以容器形式部署应用和服务。
问题是,当你唯一目的是在 Linux 系统上运行容器时,并不总是需要完整的 Linux 发行版。这就是为什么容器专用 Linux 仅提供必要软件包的原因。这将大大减少操作系统的大小,从而进一步减少部署时间。
[Bottlerocket](https://aws.amazon.com/bottlerocket/) Linux 由 Amazon Web Services(AWS)专门构建,用于在虚拟机或裸机上运行容器。它支持 docker 镜像和其他遵循 [OCI 镜像](https://www.opencontainers.org/)格式的镜像。
### Bottlerocket Linux 的特性

这是来自 Amazon 的新 Linux 发行版提供的特性:
#### 没有逐包更新
传统的 Linux 发行版更新过程由更新单个软件包组成。Bottlerocket 改用基于镜像的更新。
由于采用了这种方法,可以避免冲突和破坏,并可以进行快速而完整的回滚(如有必要)。
#### 只读文件系统
Bottlerocket 还使用了只读主文件系统。在启动时通过 dm-verity 检查其完整性。在其他安全措施上,也不建议使用 SSH 访问,并且只能通过[管理容器](https://github.com/bottlerocket-os/bottlerocket-admin-container)(附加机制)使用。
AWS 已经统治了云世界。
#### 自动更新
你可以使用 Amazon EKS 之类的编排服务来自动执行 Bottlerocket 更新。
Amazon 还声称,与通用 Linux 发行版相比,仅包含运行容器的基本软件可以减少攻击面。
### 你怎么看?
Amazon 并不是第一个创建“容器专用 Linux” 的公司。我认为 CoreOS 是最早的此类发行版之一。[CoreOS 被 Red Hat 收购](https://itsfoss.com/red-hat-acquires-coreos/),Red Hat 又被 [IBM 收购](https://itsfoss.com/ibm-red-hat-acquisition/)。Red Hat 公司最近停用了 CoreOS,并用 [Fedora CoreOS](https://getfedora.org/en/coreos/) 代替了它。
云服务器是一个巨大的行业,它将继续发展壮大。像 Amazon 这样的巨头将竭尽所能与它竞争对手保持一致或领先。我认为,Bottlerocket 是对 IBM Fedora CoreOS(目前)的应答。
尽管 [Bottlerocket 仓库可在 GitHub 上找到](https://github.com/bottlerocket-os/bottlerocket),但我还没发现就绪的镜像(LCTT 译注:源代码已经提供)。在撰写本文时,它仅[可在 AWS 上预览](https://aws.amazon.com/bottlerocket/)。
你对此有何看法?Amazon 会从 Bottlerocket 获得什么?如果你以前使用过 CoreOS 之类的软件,你会切换到 Bottlerocket 么?
---
via: <https://itsfoss.com/bottlerocket-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Amazon has [launched](https://aws.amazon.com/blogs/aws/bottlerocket-open-source-os-for-container-hosting/) its own Linux-based open source operating system, Bottlerocket.
Before you get too excited and try to install and run it, I must tell you that it’s not your regular Linux distribution like Ubuntu, Fedora or Debian. What is it then?
## Bottlerocket: Linux distribution from Amazon for running containers
If you are not aware of containers in Linux, I recommend reading [this article](https://www.redhat.com/en/topics/containers/whats-a-linux-container) from Red Hat.
A lot has changed in the IT industry since the term cloud computing was first coined. It takes few seconds to deploy a Linux server (usually running in a VM) thanks to cloud server providers like Amazon AWS, Google, [Linode](https://www.linode.com/), Digital Ocean etc. On top of that, you can deploy applications and services on these servers in form of containers thanks to tools like Docker and Kubernetes.
The thing is that when your sole purpose is to run containers on a Linux system, a full-fledged Linux distribution is not always required. This is why there are container specific Linux that provide only the necessary packages. This reduces the size of the operating system drastically which further reduces the deployment time.
** Bottlerocket Linux is purpose-built by Amazon Web Services for running containers on virtual machines or bare metal hosts. **It supports docker images and other images that follow the
[OCI image](https://www.opencontainers.org/)format.
## Features of Bottlerocket Linux

Here’s what this new Linux distribution from Amazon offers:
### No package-by-package updates
The traditional Linux distribution update procedure is composed of updating individual packages. Bottlerocket uses image-based updates instead.
Thanks to this approach, conflicts and breakage are avoided with the possibility of a rapid and complete rollback (if necessary).
### Read-only file system
Bottlerocket also uses a primarily read-only file system. Its integrity is checked at boot time via dm-verity. For additional security measures, SSH access is also discouraged and is only available through the [admin container](https://github.com/bottlerocket-os/bottlerocket-admin-container) (additional mechanism).
AWS already rules the cloud world and with it
### Automated updates
You can automate updates to Bottlerocket by using an orchestration service like Amazon EKS.
Amazon also claims that including only the essential software to run containers reduces the attack surface compared to general purpose Linux distributions.
## Getting Started with Bottlerocket
You can find [Bottlerocket repositories on GitHub](https://github.com/bottlerocket-os/bottlerocket) and also the [public roadmap](https://github.com/orgs/bottlerocket-os/projects/1). As of now, it’s only available for AWS EKS Kubernetes clusters and Amazon ECS clusters as a host OS. Simply, utilize AWS-provided Bottlerocket AMIs with Amazon EKS or ECS.
You will have to build your own images using the instructions in their GitHub page, if you’re wondering.
In addition to all that, you should also check out the [announcement post for Bottlerocket’s general availability](https://aws.amazon.com/blogs/opensource/announcing-the-general-availability-of-bottlerocket-an-open-source-linux-distribution-purpose-built-to-run-containers/) and their GitHub page for all the necessary instructions.
## What do you think?
Amazon is not the first to create a ‘container specific Linux’. I think CoreOS was among the first such distributions. [CoreOS was acquired by Red Hat](https://itsfoss.com/red-hat-acquires-coreos/) which itself was [sold to IBM](https://itsfoss.com/ibm-red-hat-acquisition/). Red Hat recently discontinued CoreOS and replaced it with [Fedora CoreOS](https://getfedora.org/en/coreos/).
Cloud server is a big industry that will continue to grow bigger. A giant like Amazon will do everything to stay at par or ahead with its competitors. In my opinion, Bottlerocket is an answer to (now) IBM’s Fedora CoreOS.
What are your views on it? What does Amazon gain with Bottlerocket? If you used something like CoreOS before, will you switch to Bottlerocket? |
12,019 | 6 个用于 Arch Linux 的最佳 AUR 助手 | https://www.2daygeek.com/best-aur-arch-user-repository-helpers-arch-linux-manjaro/ | 2020-03-21T08:30:11 | [
"Arch",
"AUR"
] | https://linux.cn/article-12019-1.html | 
Arch Linux 是一款 Linux 发行版,主要由针对 x86-64 微处理器计算机的二进制软件包组成。Arch Linux 使用的是滚动发布模型,这种模式会频繁的给应用程序交付更新。它使用名为 [pacman](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 的软件包管理器,可以用来安装、删除和更新软件包。
由于 Arch Linux 是为有经验的用户构建的,建议新手在使用过其他 Linux 后再来尝试。
### 什么是 AUR(Arch 用户软件仓库)?
[Arch 用户软件仓库](https://wiki.archlinux.org/index.php/Arch_User_Repository) 通常称为 AUR,是给 Arch 用户的基于社区的软件存储库。
根据软件包在 AUR 社区的流行程度,用户编译的软件包会进入到 Arch 的官方存储库。
### 什么是 AUR 助手?
[AUR 助手](https://wiki.archlinux.org/index.php/AUR_helpers)是一个包装程序,允许用户从 AUR 存储库安装软件包,而无需手动干预。
很多用例实现了自动化,比如包搜索、解决依赖关系、检索和构建 AUR 包、Web 内容检索和 AUR 包提交之类。
以下列出了 6 种最佳的 AUR 助手:
* Yay(Yet another Yogurt)
* Pakku
* Pacaur
* Pikaur
* Trizen
* Aura
### 1)Yay(Yet another Yogurt)
[Yay](https://github.com/Jguer/yay) 是 Arch Linux 下基于 CLI 的最佳 AUR 助手,使用 Go 语言编写。Yay 是基于 yaourt、apacman 和 pacaur 设计的。
这是最合适推荐给新手的 AUR 助手。类似于 Pacman,其使用方法和 `pacman` 中的命令和选项很相似,可以让用户在搜索过程中找到匹配的软件包提供程序,并进行选择。
#### 如何安装 yay
依次运行以下命令以在 Arch Linux 系统上安装。
```
$ sudo pacman -S git go base-devel
$ git clone https://aur.archlinux.org/yay.git
$ cd yay
$ makepkg -si
```
#### 如何使用 yay
`yay` 语法与 `pacman` 相同,使用以下命令安装软件包。
```
$ yay -s arch-wiki-man
```
### 2)Pakku
[Pakku](https://github.com/kitsunyan/pakku) 可以被视为一个初始阶段的 Pacman。它是一个包装程序,可以让用户从 AUR 中搜索或安装软件包。
它在删除依赖项方面做得不错,并且还允许通过克隆 PKGBUILD 来安装软件包。
#### 如何安装 Pakku
要在 Arch Linux 的系统上安装 Pakku,请依次运行以下命令。
```
$ sudo pacman -S git base-devel
$ git clone https://aur.archlinux.org/pakku.git
$ cd pakku
$ makepkg -si
```
#### 如何使用 Pakku
`pakku` 语法与 `pacman` 相同,使用以下命令安装软件包。
```
$ pakku -s dropbox
```
### 3)Pacaur
另一个基于 CLI 的 AUR 助手,可帮助减少用户与提示符的交互。
[Pacaur](https://github.com/E5ten/pacaur) 专为倾向于自动化重复任务的高级用户而设计。用户需要熟悉 `makepkg` 及其配置的 AUR 手动构建过程。
#### 如何安装 Pacaur
要在 Arch Linux 的系统上安装 Pakku,请依次运行以下命令。
```
$ sudo pacman -S git base-devel
$ git clone https://aur.archlinux.org/pacaur.git
$ cd pacaur
$ makepkg -si
```
#### 如何使用 Pacaur
`pacaur` 语法与 `pacman` 相同,使用以下命令安装软件包。
```
$ pacaur -s spotify
```
### 4)Pikaur
[Pikaur](https://github.com/actionless/pikaur) 是具有最小依赖性的 AUR 助手,可以一次查看所有 PKGBUILD,无需用户交互即可全部构建。
Pikaur 将通过控制 `pacman` 命令来告知 Pacman 要执行的下一个步骤。
#### 如何安装 Pikaur
要在 Arch Linux 的系统上安装 Pakku,请依次运行以下命令。
```
$ sudo pacman -S git base-devel
$ git clone https://aur.archlinux.org/pikaur.git
$ cd pikaur
$ makepkg -fsri
```
#### 如何使用 Pikaur
`pikaur` 语法与 `pacman` 相同,使用以下命令安装软件包。
```
$ pacaur -s spotify
```
### 5)Trizen
[Trizen](https://github.com/trizen/trizen) 是用 Perl 编写的基于命令行的 AUR 轻量级包装器。这个面向速度的 AUR 助手,它允许用户搜索、安装软件包,还允许阅读 AUR 软件包注释。
支持编辑文本文件,并且输入/输出使用 UTF-8。内置与 `pacman` 的交互功能。
#### 如何安装 Trizen
要在 Arch Linux 的系统上安装 Trizen,请依次运行以下命令。
```
$ sudo pacman -S git base-devel
$ git clone https://aur.archlinux.org/trizen.git
$ cd trizen
$ makepkg -si
```
#### 如何使用 Trizen
`trizen` 语法与 `pacman` 相同,使用以下命令安装软件包。
```
$ pacaur -s google-chrome
```
### 6)Aura
[Aura](https://github.com/fosskers/aura) 是用 Haskell 编写的,是用于 Arch Linux 和 AUR 的安全的多语言包管理器。它支持许多Pacman 操作和子选项,可轻松进行开发并编写精美的代码。
它可以自动从 AUR 安装软件包。使用 Aura 时,用户通常会在系统升级方面遇到一些困难。
#### 如何安装 Aura
要在 Arch Linux 的系统上安装 Pakku,请依次运行以下命令。
```
$ sudo pacman -S git base-devel
$ git clone https://aur.archlinux.org/aura.git
$ cd aura
$ makepkg -si
```
#### 如何使用 Aura
`aura` 语法与 `pacman` 相同,使用以下命令安装软件包。
```
$ pacaur -s android-sdk
```
### 结论
用户可以凭借这些分析在上述 6 个 AUR 助手中进行选择。
---
via: <https://www.2daygeek.com/best-aur-arch-user-repository-helpers-arch-linux-manjaro/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hkurj](https://github.com/hkurj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,020 | 撰写有效的技术简历的 7 个技巧 | https://opensource.com/article/20/2/technical-resume-writing | 2020-03-21T09:23:12 | [
"简历",
"求职"
] | https://linux.cn/article-12020-1.html |
>
> 遵循以下这些要点,把自己最好的一面呈现给潜在雇主。
>
>
>

如果你是一名软件工程师或技术领域的经理,那么创建或更新简历可能是一项艰巨的任务。要考虑的重点是什么?应该怎么把控格式、内容以及求职目标或摘要?哪些工作经验相关?如何确保自动化招聘工具不会过滤掉你的简历?
在过去的七年中,作为一名招聘经理,我看到了各种各样的简历;尽管有些令人印象深刻,但还有很多人写的很糟糕。
在编写或更新简历时,请遵循以下七个简单原则。
### 1、概述
简历顶部的简短段落应简洁明了、目的明确,避免过度使用形容词和副词。诸如“令人印象深刻”、“广泛”和“卓越”之类的词,这些词不会增加你的招聘机会;相反,它们看起来和感觉上像是过度使用的填充词。 关于你的求职目标,问自己一个重要的问题:**它是否告诉招聘经理我正在寻找什么样的工作以及如何为他们提供价值?** 如果不是,请加强并简化它以回答该问题,或者将其完全排除在外。
### 2、工作经验
数字、数字、数字——重要的事情说三遍。用确凿的事实传达观点远比一般的陈述,例如“帮助构建、管理、交付许多对客户利润有贡献的项目”更能对你有帮助。你的表达中应包括统计数据,例如“直接影响了 5 个顶级银行的项目,这些项目将其上市时间缩短了 40%”,你提交了多少行代码或管理了几个团队。数据比修饰语更能有效地展示你的能力和价值。
如果你经验不足,没有什么工作经验可展示,那些无关的经验,如暑期兼职工作,就不要写了。相反,将相关经验的细节以及你所学到的知识的详细信息写进简历,这些可以使你成为一个更好的候选人。
### 3、搜索术语和行话
随着技术在招聘过程中发挥如此巨大的作用,确保简历被标记为正确的职位非常重要,但不要在简历上过分吹嘘自己。如果你提到敏捷技能但不知道看板是什么,请三思。如果你提到自己精通 Java,但是已经有五年都没有使用过 Java 了,请小心。如果存在你熟悉但不一定是当前在用的语言和框架,请创建其他类别或将你的经验分为“精通”和“熟悉”。
### 4、教育
如果你不是应届大学毕业生,那就没必要再写你的 GPA 或你参加过的俱乐部或兄弟会,除非你计划将它们用作谈话要点以在面试中赢得信任。确保将你发表的或获取过专利的东西包括在内,即使它与该工作无关。如果你没有大学学位,请添加一个证书部分代替教育背景部分。如果你是军人,请包括现役和预备役时间。
### 5、资质证书
除非你想重新进入之前离开的领域,否则不要写过期的证书,例如,如果你曾经是一名人事经理,而现在正寻求动手编程的工作。如果你拥有与该领域不再相关的认证,就不要写这些认证,因为这些可能会分散招聘者的注意力,使你的简历失去吸引力。利用你的 LinkedIn 个人资料为简历添加更多色彩,因为大多数人在面试之前都会阅读你的简历和 LinkedIn 个人资料。
### 6、拼写和语法
让其他人帮忙对你的简历校对一下。很多时候,我在简历中看到过拼写错误的单词,或者错误用词,如“他们的”、“他们是”、“那些”。这些可以避免和修复的错误会产生负面影响。理想情况下,你的简历应用主动语态,但是如果这样会使你感到不舒服,那么就用过去时书写 —— 最重要的是要始终保持一致。不正确的拼写和语法会传递你要么不是很在乎所申请的工作,要么没有足够注意细节。
### 7、格式
确保你的简历是最新的并且富有吸引力,这是留下良好第一印象的简便方法。确保格式一致,例如相同的页边距,相同的间距、大写字母和颜色(将调色板保持在最低限度,不要花花绿绿)是简历写作中最基本的部分,但有必要表明你对工作感到自豪,并重视自己的价值和未来的雇主。在适当的地方使用表格,以视觉吸引人的方式分配信息。如果支持的话,以 .pdf 和 .docx 格式上传简历,然后用 Google Docs 导出为 .odt 格式,这样可以在 LibreOffice 中轻松打开。这里有一个我推荐的简单的 Google 文档[简历模板](https://docs.google.com/document/d/1ARVyybC5qQEiCzUOLElwAdPpKOK0Qf88srr682eHdCQ/edit)。 你还可以支付少量费用(不到 10 美元)从一些设计公司购买模板。
### 定期更新
如果你需要(或希望)申请一份工作,定期更新简历可以最大程度地减少压力,也可以帮助你创建和维护更准确的简历版本。撰写简历时,要有远见,确保至少让另外三个人对你的简历内容、拼写和语法进行检查。即使你是由公司招募或其他人推荐给公司的,面试官也可能只能通过简历来认识你,因此请确保它为你带来良好的第一印象。
你还有其他提示要添加吗?
---
via: <https://opensource.com/article/20/2/technical-resume-writing>
作者:[Emily Brand](https://opensource.com/users/emily-brand) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're a software engineer or a manager in the technology sector, creating or updating your resume can be a daunting task. What is most important to consider? How should you handle the formatting, the content, and your objective or summary? What work experience is relevant? How can you make sure automated recruitment tools don't filter out your resume?
As a hiring manager over the last seven years, I have seen a wide range of resumes and CVs; while some have been impressive, many more have been terribly written.
When writing or updating your resume, here are seven easy rules to follow.
## 1. Summary statement
The short paragraph at the top of your resume should be clean and concise, have a clear purpose, and avoid excessive use of adjectives and adverbs. Words such as "impressive," "extensive," and "excellent" do not improve your hiring chances; instead, they look and feel like overused filler words. An important question to ask yourself regarding your objective is: **Does it tell the hiring manager what kind of job I'm looking for and how I can provide value to them?** If not, either strengthen and streamline it to answer that question or leave it out altogether.
## 2. Work experience
Numbers, numbers, numbers. Hard facts help you convey your point far more than general statements such as "Helped build, manage, deliver many projects that directly contributed to my customers' bottom line." Your wording should include statistics such as "Directly impacted five projects with top banks that accelerated their time to market by 40%," how many lines of code you committed, or how many teams you managed. Data is far more effective than frilly language to showcase your abilities and value.
If you are less-experienced and have fewer jobs to showcase, do not include irrelevant experience like part-time summer jobs. Instead, add detail about the specifics of your relevant experience and what you learned that would make you a better employee for the organization you are applying for.
## 3. Search terms and jargon
With technology playing such a huge role in the hiring process, it is extremely important to make sure your resume gets flagged for the right positions—but do not oversell yourself on your resume. If you mention agile skills but do not know what kanban is, think twice. If you mention that you are skilled in Java but haven't used it in five years, beware. If there are languages and frameworks you are familiar with but not necessarily current in, create a different category or divide your experience into "proficient in" and "familiar with."
## 4. Education
If you are not a recent college graduate, there is no need to include your GPA or the clubs or fraternities you participated in, unless you plan on using them as talking points to gain trust during an interview. Be sure that anything you have published or patented is included, even if it is not relevant to the job. If you do not have a college degree, add a certification section in place of education. If you were in the military, include your active duty and reserve time.
## 5. Certifications
Do not include expired certifications unless you are trying to re-enter a field you have left, such as if you were a people manager and are now looking to get back into hands-on programming. If you have certifications that are no longer relevant to the field, do not include them since it can be distracting and unappealing. Leverage your LinkedIn profile to add more color to your resume, as most people will read your resume and your LinkedIn profile before they interview you.
## 6. Spelling and grammar
Ask others to proofread your resume. So often, I have seen misspelled words in a resume or mistaken uses of words like their, they're, and there. These are avoidable and fixable errors that will create a negative impression. Ideally, your resume will be in active tense, but if that makes you uncomfortable, write it in past tense—the most important thing is to maintain a consistent tense throughout. Improper spelling and grammar will convey that you either do not really care about the job you are applying for or do not have the level of attention to detail necessary for the job.
## 7. Formatting
Ensuring your resume looks up-to-date and appealing is an easy way to make a good first impression. Ensuring consistent formatting, e.g., similar margins, similar spacing, capitalization, and colors (but keep color palettes to a minimum) is the most mundane part of resume writing, but it's necessary to show that you take pride in your work and value yourself and your future employer. Use tables where appropriate to space information in a visually appealing way. If given the option, upload your resume in .pdf and .docx formats, and Google Docs exports to the .odt format, which can be opened easily in LibreOffice. Here is an easy Google Docs [resume template](https://docs.google.com/document/d/1ARVyybC5qQEiCzUOLElwAdPpKOK0Qf88srr682eHdCQ/edit) that I recommend. You can also purchase templates from companies that do attractive designs for a small fee (under $10).
## Update regularly
Updating your resume regularly will minimize your stress if you're asked to (or want to) apply for a job, and it will help you create and maintain a more accurate version of yourself. When working on your resume, be forward-thinking and be sure to ask at least three other people to review it for content, spelling, and grammar. Even if you are recruited by or referred to a company, your interviewers may know you only by your resume, so ensure that it creates a positive first impression of you.
*Do you have additional tips to add?*
## 4 Comments |
12,022 | 学习 Linux 是我们的爱情语言 | https://opensource.com/article/20/2/linux-love-language | 2020-03-22T16:38:58 | [
"学习"
] | https://linux.cn/article-12022-1.html |
>
> 当一个妻子教丈夫一些新技能的时候,他们都学到了比期待更多的东西。
>
>
>

2019 年是我们 Cherry 家学习的一年。我是一个喜欢学习新技术的高级软件工程师,并把学到的内容一起教给了我的丈夫 Chris。通过教给他一些我学到的东西,并让他全程经历我的技术演练文章,我帮助 Chris 学习到了新技术,使他能够将自己的职业生涯更深入地转向技术领域。而我学习到了新的方法,使我的演练和培训材料更易于让读者理解。
在这篇文章中,我们来讨论一下我们各自和彼此学习到了什么东西,然后探讨这对于我们的未来有何影响。
### 向学生的提问
**Jess:** Chris,是什么导致你想深入学习我的领域的技能呢?
**Chris:** 主要目的是为了让我事业更进一步。作为一个网络工程师的经历告诉我,现在的网络专家已经不像以前一样有价值了,我必须掌握更多的知识。由于网络经常被认为是造成这些天程序中断或出错的原因,我想从开发人员的角度了解更多关于编写应用程序的知识,以便于了解它们如何依赖网络资源。
**Jess:** 我首先教你什么内容?你从中学到什么?
**Chris:** 首先是从学习除此安装 Linux 系统开始的,之后又安装了 [Ansible](https://opensource.com/resources/what-ansible)。只要硬件兼容,我用过的每一个 Linux 发行版都很容易安装,但可能会出现个别不兼容的情况。这就意味着我有时候第一手学习到的是如何解决系统安装过程的最初 5 分钟出现的问题了(这个我最喜欢了)。Ansible 给了一个我学习使用软件管理器来安装程序的理由。当程序安装完成后,通过查看 yum 安装的程序,我快速了解了程序管理器是如何处理程序的依赖项的,因此,用 Python 编写的 Ansible 能够在我的系统运行。自此之后,我开始使用 Ansible 来安装各种各样的程序。
**Jessica:** 你喜欢我这种教学方式不?
**Chris:** 我们一开始有过争吵,直到我们弄清楚了我喜欢的学习方式,你也知道了应该怎样为我提供最好的学习方式。在一开始的时候,我很难跟上你讲的内容。例如,当你说“一个码头工人集装箱”的时候,我完全不知道你在讲什么。比较早的时候,我的回答就是“这是一个集装箱”,然而当时这对我来说,完全没有意义。当你对这些内容进行一些更深入的讲解后,才让学习更有趣。
**Jess:** 老实说,这对我来说也是一个重要的教训。在你之前,我从来没有教过在这个技术领域知识比我少的人,所以你帮助我认识到我需要解释更多细节。我也得说声谢谢。
当你通过这几个学习步骤的时候,你觉得我的这篇测试文章怎样呢?
**Chris:** 就我个人而言,我认为这很容易,但我错了。在我主要学习的内容中,比如你[介绍的Vagrant](https://opensource.com/resources/vagrant),它在不同的 Linux 发行版间的变化比我想像的要多。操作系统的变化会影响设置的方式、运行都要求和特定的命令。这看起来比我用的网络设备变化更大。这让我花费更多的精力去查看这些说明是对应我的系统还是其它的系统(有时候很难知道)。在这学习路上,我似乎碰到很多问题。
**Jess:** 我每天都会遇到各种各样的问题,所以对我来说日常就是用各种方法解决各种问题。
### 向老师的提问
**Chris:** Jess,你将来教我的方式会有所改变吗?
**Jess:** 我想让你像我一样读多一些书。通过翻阅书籍来学习新技术。每天起床后一小时和睡觉前一小时我都会看书,花费一个星期左右我就能看一到两本书。我也会创建为期两周的任务计划来实践我从书本中学习到的技能。这是除了我一天中第一个小时在喝大量咖啡时读到的科技文章之外的。当我考虑到你的职业发展目标的时候,我认为除了我们谈到的优秀博客文章和文章之外,书籍是一个重要的元素。我觉得我的阅读量使我保持进步,如果你也这么做了,你也会很快赶上我的。
**Chris:** 那么学生有没有教过老师呢?
**Jess:** 我在你那里学习到耐心。举个例子,当你完成了安装 Ansible 的时候,我问你下一步要怎样操作的时候。你直接回复我,“不知道”,这不是我想让你学习到的内容。所以我改变了策略,现在在逐步安装任何组件之前,我们将详细讨论你想要实现的目标。当我们在写 Vagrant 文章的时候,我们一起进行相应的演示操作,我以创建它时就牢记目标,因此我们就有一些需要马上实现的目标。
这实际上对我在工作中的培训方式产生了巨大的改变。现在我在大家学习的过程中会问更多问题,并更多地进行手把手讲解。我更愿意坐下来仔细检查,确保有人明白我在说什么和我们在做什么。这是我之前从来没有做过的。
### 我们一起学到了什么
做为一对夫妇,在这一年的技术合作中我们的技术都有所增长。
**Chris:** 我对自己学到的东西感到震惊。通过一年课程学习,我认识了新操作系统、如何使用 API、使用 Ansible 部署 Web 应用和使用 Vagrant 启动虚拟机器。我还学习到了文档可以让生活变得更好,所以我也会尝试去写一写。然而,在这个工作领域,操作并不总是被记录在案,所以我学会了准备好处理棘手的问题,并记录如何解决它们。
**Jess:** 除了我在教你中学到的知识外,我还专注于学习 Kubernetes 在云环境中的应用知识。这包括部署策略、Kubernetes API 的复杂度、创建我自己的容器,并对环境进行加密处理。我还节省了探索的时间:研究了 serverless 的代码、AI 模型、Python 和以图形方式显示热图。对于我来说,这一年也很充足。
我们下一个目标是什么?现在还不知道,但我可以向你保证,我们将会继续进行分享它。
---
via: <https://opensource.com/article/20/2/linux-love-language>
作者:[Christopher Cherry](https://opensource.com/users/chcherry) 选题:[lujun9972](https://github.com/lujun9972) 译者:[sndnvaps](https://github.com/sndnvaps) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 2019 was a year of learning in the Cherry household. I am a senior software engineer who set out to learn new skills and, along the way, I taught my husband, Chris. By teaching him some of the things I learned and asking him to work through my technology walkthrough articles, I helped Chris learn new skills that enabled him to pivot his career deeper into the technology field. And I learned new ways to make my walkthroughs and training materials more accessible for readers to digest.
In this article, we talk about what we learned individually and from each other, then we explore what it means for their future.
## Questions for the student
**Jess:** Chris, what made you want to learn more about my field?
**Chris:** It was primarily to further my career. Being in network engineering has shown me that being an expert only on networks is not as valuable as it once was, and I have to know a little bit of everything. Since the network is often blamed for outages or application challenges these days, I wanted to understand more from a developer's perspective on writing applications so I could see how they depend on the network as a resource.
**Jess:** What did I teach you first, and what did you learn from it?
**Chris:** It all started with installing Linux for the first time, then adding [Ansible](https://opensource.com/resources/what-ansible). Each Linux distribution I worked with was easy enough to install, as long as the hardware was compatible, but compatibility wasn't always clear. That meant sometimes I learned first-hand how to troubleshoot Linux within the first five minutes of running an installation (and I liked it). Ansible gave me a reason to learn Linux package managers to install the software. Once it was installed, I quickly learned how package management handles dependencies as I looked at the files that yum installed, so Ansible, which is written in Python, can run on my system. From there, I started to install all kinds of applications with Ansible.
**Jessica:** Do you like the way I taught you?
**Chris:** We had our struggles at first, until we ironed out how I like to learn and how you should present the best way for me to learn. In the beginning, it was hard to follow what you meant. For instance, when you said things like "a Docker container," I had no reference to what you were talking about. Early on, the response was, "well, it's a container," which meant nothing to me at the time. Once I got you to explain it in more detail, it became a lot more fun to learn.
**Jess:** To be fair, this was a big lesson for me as well. I hadn't trained anyone with less knowledge on this technology than me before you, so you helped me realize that I needed to be clearer with my explanations. Thanks for that.
How did you feel about testing my articles, the ones where I had you run through the steps?
**Chris:** Personally, I thought it would be easy, and boy, was I wrong. One of the main things I learned from these, like your [introduction to Vagrant](https://opensource.com/resources/vagrant), was how each Linux distribution varies more than I realized. The operating system (OS) changes how you set it up, the requirements to run, and the specific commands. It seems like a lot more variability than there is with the network gear I've worked on. So I started to pay a lot more attention to the instructions and whether they were written for my OS or another one (and how difficult it can be to know sometimes). I seemed to break a lot of things along the way.
**Jess:** I break stuff all day, so different paths for different problems are daily occurrences for me.
## Questions for the teacher
**Chris:** Jess, would you change anything with the way you taught me so far?
**Jess:** I'd have liked to make you read more, as I do. Learning new technology has me churning through books. I read a book and a half, if not two books, a week, and that's with spending one hour in the morning and one hour before bed every day. I also pick one project to run through for two weeks for about an hour a day to reinforce the book skills. And that's in addition to the tech articles I read for the first hour of my day while taking in an immense amount of coffee. When I think about your goal to grow your career, I think books are an important element alongside the great blog posts and articles we talk about. I feel my reading regiment has kept me up to speed, and if you did the same, you would catch up to me pretty quickly.
**Chris:** So did the student teach the teacher in any way?
**Jess:** I learned a great deal about being patient from you. For instance, after walking through an installation of Ansible, I asked what you wanted to do next. Your first answer was, "I don't know," which was hard for me because I want you to learn what you want to learn. So I changed my approach, and now we talk more about what you want to achieve before walking through installing anything. When we moved on to the Vagrant article we worked on together, I created it with an end goal in mind, so we had something to achieve right away.
This actually made a massive change in how I do training at work. Now I ask more questions on how people learn and work hand-in-hand more often than I did before. I am more likely to sit and go through and make sure someone understands what I'm saying and what we're doing. I wasn't really before.
## What we learned together
As a couple, we both grew from collaborating on technology over the last year.
**Chris:** I'm blown away at how much I learned. Over the course of a year, I understand new operating systems, how to use an API, web application deployment with Ansible, and standing up virtual machines with Vagrant. I also learned how documentation makes life better, so it's worth the time it takes to write some. In this field of work, however, behavior isn't always documented, so I've learned to be ready to work through tough issues and document how I fix them.
**Jess:** Beyond what I learned from teaching you, I've focused on learning a good deal about Kubernetes in cloud environments. That includes deployment strategies, the complexity of the Kubernetes API, building my own containers, and securing these environments. I've also saved time to dabble: toying around with serverless code, AI models, Python, and graphically displaying heat maps. It's been a good year.
What's next for us? It's yet to be seen, but I can assure you that we're going to share it here on Opensource.com.
**Who did you mentor in 2019, or who are you mentoring in 2020? Tell us about it in the comments.**
## 2 Comments |
12,023 | 使用 Linux 命令行与其他用户进行通信 | https://www.networkworld.com/article/3530343/communicating-with-other-users-on-the-linux-command-line.html | 2020-03-22T17:11:46 | [
"Linux",
"wall"
] | https://linux.cn/article-12023-1.html | 
使用 Linux 命令行向其他用户发送消息或许非常容易,这里有一些相关的命令你可以考虑使用。在这篇文章中,我们会考察 4 个这样的命令,看看它们是怎么工作的。
### wall
`wall`(“Write ALL” 的简称)命令允许你向所有系统中已登录的用户发送一条信息。这里我们假设用户都使用命令行在同一台服务器上工作。虽然 `wall` 命令最常被系统管理员用于向用户发布公告和传递信息(比如说,服务器即将因维护而关闭),但它可以被任何用户使用。
系统管理员可能会用类似下面的方式发送信息:
```
$ wall The system will be going down in 15 minutes to address a serious problem
```
而所有登录的用户都将看到类似这样的信息:
```
Broadcast message from admin@dragonfly (pts/0) (Thu Mar 5 08:56:42 2020):
The system is going down in 15 minutes to address a serious problem
```
如果希望在消息中使用单引号,你可以像这样将信息用双引号括起来:
```
$ wall "Don't forget to save your work before logging off"
```
最外层的双引号不会出现在发出的消息中,但是如果没有它们,`wall` 会停下并等待输入一个配对的单引号。
### mesg
如果出于某种理由你不想接收来自另一个用户的消息,你可以使用 `mesg` 命令来屏蔽这些消息。这个命令可以接受一个 `n` 作为参数来拒绝某用户的消息,或者接收一个 `y` 作为参数来接收用户发来的消息。
```
$ mesg n doug
$ mesg y doug
```
被屏蔽的用户不会被告知这一事实。你也可以像这样使用 `mesg` 来屏蔽或者接收所有消息:
```
$ mesg y
$ mesg n
```
### write
另一个在不使用电子邮件的情况下发送文本的命令是 `write`,这个命令可以用来和一个特定的用户通信。
```
$ write nemo
Are you still at your desk?
I need to talk with you right away.
^C
```
输入你的信息后用 `ctrl-c` 退出,这样就完成了通信。这个命令允许你发送文本,但并不会建立一个双向的通话。它只是将文本发送过去而已。如果目标用户在多个终端上登录,你可以指定你想将消息发送到哪一个终端,否则系统会选择空闲时间最短的那个终端。
```
$ write nemo#1
```
如果你试图向一个将消息屏蔽了的用户发送信息,你应该会看到这样的输出:
```
$ write nemo
write: nemo has messages disabled
```
### talk/ytalk
`talk` 和 `ytalk` 命令让你可以和一个或多个用户进行交互式的聊天。它们会展示一个有上下两个子窗口的界面,每个用户向显示在他们屏幕上方的窗口内输入内容,并在下方的窗口看到回复信息。要回复一个`talk` 请求,接收方可以输入 `talk`,在后面加上请求方的用户名。
```
Message from Talk_Daemon@dragonfly at 10:10 ...
talk: connection requested by [email protected].
talk: respond with: talk [email protected]
$ talk dory
```
如果使用的是 `ytalk`,那么窗口中可以包含多于两个参与者。正如下面的例子所展示的(这是上面 `talk dory` 命令的结果),`talk` 通常指向 `ytalk`。
```
----------------------------= YTalk version 3.3.0 =--------------------------
Is the report ready?
-------------------------------= nemo@dragonfly =----------------------------
Just finished it
```
如上所述,在通话的另一侧,`talk`会话界面的窗口是相反的:
```
----------------------------= YTalk version 3.3.0 =--------------------------
Just finished it
-------------------------------= dory@dragonfly =----------------------------
Is the report ready?
```
同样的,使用 `ctrl-c` 来退出。
如果要和非本机的用户通讯,你需要加上 `-h` 选项和目标主机名或IP地址,就像这样:
```
$ talk -h 192.168.0.11 nemo
```
### 总结
Linux 上有若干基本的命令可以用来向其他登录的用户发送消息。如果你需要向所有用户快速发送信息或是需要便捷的电话替代品,又或是希望能简单地开始一个多用户快速通讯会话,这些命令会十分实用。
一些命令如 `wall` 允许广播消息但却不是交互式的。另外的一些命令如 `talk` 允许多用户进行长时间通讯,当你只需要非常快速地交换一些信息,它们可以你你避免建立一个电话会议。
---
via: <https://www.networkworld.com/article/3530343/communicating-with-other-users-on-the-linux-command-line.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[linusboyle](https://github.com/linusboyle) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,025 | 针对大型文件系统可以试试此 Bash 脚本 | https://opensource.com/article/20/2/script-large-files | 2020-03-23T09:51:32 | [
"脚本",
"Bash"
] | https://linux.cn/article-12025-1.html |
>
> 一个可以列出文件、目录、可执行文件和链接的简单脚本。
>
>
>

你是否曾经想列出目录中的所有文件,但仅列出文件,而不列出其它的。仅列出目录呢?如果有这种需求的话,那么下面的脚本可能正是你一直在寻找的,它在 GPLv3 下开源。
当然,你可以使用 `find` 命令:
```
find . -maxdepth 1 -type f -print
```
但这键入起来很麻烦,输出也不友好,并且缺少 `ls` 命令拥有的一些改进。你还可以结合使用 `ls` 和 `grep` 来达到相同的结果:
```
ls -F . | grep -v /
```
但是,这又有点笨拙。下面这个脚本提供了一种简单的替代方法。
### 用法
该脚本提供了四个主要功能,具体取决于你调用它的名称:`lsf` 列出文件,`lsd` 列出目录,`lsx` 列出可执行文件以及 `lsl` 列出链接。
通过符号链接无需安装该脚本的多个副本。这样可以节省空间并使脚本更新更容易。
该脚本通过使用 `find` 命令进行搜索,然后在找到的每个项目上运行 `ls`。这样做的好处是,任何给脚本的参数都将传递给 `ls` 命令。因此,例如,这可以列出所有文件,甚至包括以点开头的文件:
```
lsf -a
```
要以长格式列出目录,请使用 `lsd` 命令:
```
lsd -l
```
你可以提供多个参数,以及文件和目录路径。
下面提供了当前目录的父目录和 `/usr/bin` 目录中所有文件的长分类列表:
```
lsf -F -l .. /usr/bin
```
目前该脚本不处理递归,仅列出当前目录中的文件。
```
lsf -R
```
该脚本不会深入子目录,这个不足有一天可能会进行修复。
### 内部
该脚本采用自上而下的方式编写,其初始化功能位于脚本的开头,而工作主体则接近结尾。脚本中只有两个真正重要的功能。函数 `parse_args()` 会仔细分析命令行,将选项与路径名分开,并处理脚本中的 `ls` 命令行选项中的特定选项。
`list_things_in_dir()` 函数以目录名作为参数并在其上运行 `find` 命令。找到的每个项目都传递给 `ls` 命令进行显示。
### 总结
这是一个可以完成简单功能的简单脚本。它节省了时间,并且在使用大型文件系统时可能会非常有用。
### 脚本
```
#!/bin/bash
# Script to list:
# directories (if called "lsd")
# files (if called "lsf")
# links (if called "lsl")
# or executables (if called "lsx")
# but not any other type of filesystem object.
# FIXME: add lsp (list pipes)
#
# Usage:
# <command_name> [switches valid for ls command] [dirname...]
#
# Works with names that includes spaces and that start with a hyphen.
#
# Created by Nick Clifton.
# Version 1.4
# Copyright (c) 2006, 2007 Red Hat.
#
# This is free software; you can redistribute it and/or modify it
# under the terms of the GNU General Public License as published
# by the Free Software Foundation; either version 3, or (at your
# option) any later version.
# It is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
# ToDo:
# Handle recursion, eg: lsl -R
# Handle switches that take arguments, eg --block-size
# Handle --almost-all, --ignore-backups, --format and --ignore
main ()
{
init
parse_args ${1+"$@"}
list_objects
exit 0
}
report ()
{
echo $prog": " ${1+"$@"}
}
fail ()
{
report " Internal error: " ${1+"$@"}
exit 1
}
# Initialise global variables.
init ()
{
# Default to listing things in the current directory.
dirs[0]=".";
# num_dirs is the number of directories to be listed minus one.
# This is because we are indexing the dirs[] array from zero.
num_dirs=0;
# Default to ignoring things that start with a period.
no_dots=1
# Note - the global variables 'type' and 'opts' are initialised in
# parse_args function.
}
# Parse our command line
parse_args ()
{
local no_more_args
no_more_args=0 ;
prog=`basename $0` ;
# Decide if we are listing files or directories.
case $prog in
lsf | lsf.sh)
type=f
opts="";
;;
lsd | lsd.sh)
type=d
# The -d switch to "ls" is presumed when listing directories.
opts="-d";
;;
lsl | lsl.sh)
type=l
# Use -d to prevent the listed links from being followed.
opts="-d";
;;
lsx | lsx.sh)
type=f
find_extras="-perm /111"
;;
*)
fail "Unrecognised program name: '$prog', expected either 'lsd', 'lsf', 'lsl' or 'lsx'"
;;
esac
# Locate any additional command line switches for ls and accumulate them.
# Likewise accumulate non-switches to the directories list.
while [ $# -gt 0 ]
do
case "$1" in
# FIXME: Handle switches that take arguments, eg --block-size
# FIXME: Properly handle --almost-all, --ignore-backups, --format
# FIXME: and --ignore
# FIXME: Properly handle --recursive
-a | -A | --all | --almost-all)
no_dots=0;
;;
--version)
report "version 1.2"
exit 0
;;
--help)
case $type in
d) report "a version of 'ls' that lists only directories" ;;
l) report "a version of 'ls' that lists only links" ;;
f) if [ "x$find_extras" = "x" ] ; then
report "a version of 'ls' that lists only files" ;
else
report "a version of 'ls' that lists only executables";
fi ;;
esac
exit 0
;;
--)
# A switch to say that all further items on the command line are
# arguments and not switches.
no_more_args=1 ;
;;
-*)
if [ "x$no_more_args" = "x1" ] ;
then
dirs[$num_dirs]="$1";
let "num_dirs++"
else
# Check for a switch that just uses a single dash, not a double
# dash. This could actually be multiple switches combined into
# one word, eg "lsd -alF". In this case, scan for the -a switch.
# XXX: FIXME: The use of =~ requires bash v3.0+.
if [[ "x${1:1:1}" != "x-" && "x$1" =~ "x-.*a.*" ]] ;
then
no_dots=0;
fi
opts="$opts $1";
fi
;;
*)
dirs[$num_dirs]="$1";
let "num_dirs++"
;;
esac
shift
done
# Remember that we are counting from zero not one.
if [ $num_dirs -gt 0 ] ;
then
let "num_dirs--"
fi
}
list_things_in_dir ()
{
local dir
# Paranoia checks - the user should never encounter these.
if test "x$1" = "x" ;
then
fail "list_things_in_dir called without an argument"
fi
if test "x$2" != "x" ;
then
fail "list_things_in_dir called with too many arguments"
fi
# Use quotes when accessing $dir in order to preserve
# any spaces that might be in the directory name.
dir="${dirs[$1]}";
# Catch directory names that start with a dash - they
# confuse pushd.
if test "x${dir:0:1}" = "x-" ;
then
dir="./$dir"
fi
if [ -d "$dir" ]
then
if [ $num_dirs -gt 0 ]
then
echo " $dir:"
fi
# Use pushd rather passing the directory name to find so that the
# names that find passes on to xargs do not have any paths prepended.
pushd "$dir" > /dev/null
if [ $no_dots -ne 0 ] ; then
find . -maxdepth 1 -type $type $find_extras -not -name ".*" -printf "%f\000" \
| xargs --null --no-run-if-empty ls $opts -- ;
else
find . -maxdepth 1 -type $type $find_extras -printf "%f\000" \
| xargs --null --no-run-if-empty ls $opts -- ;
fi
popd > /dev/null
else
report "directory '$dir' could not be found"
fi
}
list_objects ()
{
local i
i=0;
while [ $i -le $num_dirs ]
do
list_things_in_dir i
let "i++"
done
}
# Invoke main
main ${1+"$@"}
```
---
via: <https://opensource.com/article/20/2/script-large-files>
作者:[Nick Clifton](https://opensource.com/users/nickclifton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Have you ever wanted to list all the files in a directory, but just the files, nothing else? How about just the directories? If you have, then the following script, which is open source under GPLv3, could be what you have been looking for.
Of course, you could use the **find** command:
`find . -maxdepth 1 -type f -print`
But this is cumbersome to type, produces unfriendly output, and lacks some of the refinement of the **ls** command. You could also combine **ls** and **grep** to achieve the same result:
`ls -F . | grep -v /`
But again, this is clunky. This script provides a simple alternative.
## Usage
The script provides four main functions, which depend upon which name you call: **lsf** lists files, **lsd** lists directories, **lsx** lists executables, and **lsl** lists links.
There is no need to install multiple copies of the script, as symbolic links work. This saves space and makes updating the script easier.
The script works by using the **find** command to do the searching, and then it runs **ls** on each item it finds. The nice thing about this is that any arguments given to the script are passed to the **ls** command. So, for example, this lists all files, even those that start with a dot:
`lsf -a`
To list directories in long format, use the **lsd** command:
`lsd -l`
You can provide multiple arguments, and also file and directory paths.
This provides a long classified listing of all of files in the current directory's parent directory, and in the **/usr/bin** directory:
`lsf -F -l .. /usr/bin`
One thing that the script does not currently handle, however, is recursion. This command lists only the files in the current directory.
`lsf -R`
The script does not descend into any subdirectories. This is something that may be fixed one day.
## Internals
The script is written in a top-down fashion with the initial functions at the start of the script and the body of the work performed near the end. There are only two functions that really matter in the script. The **parse_args() **function peruses the command line, separates options from pathnames, and scripts specific options from the **ls** command-line options.
The **list_things_in_dir()** function takes a directory name as an argument and runs the **find** command on it. Each item found is passed to the **ls** command for display.
## Conclusion
This is a simple script to accomplish a simple function. It is a time saver and can be surprisingly useful when working with large filesystems.
## The script
```
#!/bin/bash
# Script to list:
# directories (if called "lsd")
# files (if called "lsf")
# links (if called "lsl")
# or executables (if called "lsx")
# but not any other type of filesystem object.
# FIXME: add lsp (list pipes)
#
# Usage:
# <command_name> [switches valid for ls command] [dirname...]
#
# Works with names that includes spaces and that start with a hyphen.
#
# Created by Nick Clifton.
# Version 1.4
# Copyright (c) 2006, 2007 Red Hat.
#
# This is free software; you can redistribute it and/or modify it
# under the terms of the GNU General Public License as published
# by the Free Software Foundation; either version 3, or (at your
# option) any later version.
# It is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
# ToDo:
# Handle recursion, eg: lsl -R
# Handle switches that take arguments, eg --block-size
# Handle --almost-all, --ignore-backups, --format and --ignore
main ()
{
init
parse_args ${1+"$@"}
list_objects
exit 0
}
report ()
{
echo $prog": " ${1+"$@"}
}
fail ()
{
report " Internal error: " ${1+"$@"}
exit 1
}
# Initialise global variables.
init ()
{
# Default to listing things in the current directory.
dirs[0]=".";
# num_dirs is the number of directories to be listed minus one.
# This is because we are indexing the dirs[] array from zero.
num_dirs=0;
# Default to ignoring things that start with a period.
no_dots=1
# Note - the global variables 'type' and 'opts' are initialised in
# parse_args function.
}
# Parse our command line
parse_args ()
{
local no_more_args
no_more_args=0 ;
prog=`basename $0` ;
# Decide if we are listing files or directories.
case $prog in
lsf | lsf.sh)
type=f
opts="";
;;
lsd | lsd.sh)
type=d
# The -d switch to "ls" is presumed when listing directories.
opts="-d";
;;
lsl | lsl.sh)
type=l
# Use -d to prevent the listed links from being followed.
opts="-d";
;;
lsx | lsx.sh)
type=f
find_extras="-perm /111"
;;
*)
fail "Unrecognised program name: '$prog', expected either 'lsd', 'lsf', 'lsl' or 'lsx'"
;;
esac
# Locate any additional command line switches for ls and accumulate them.
# Likewise accumulate non-switches to the directories list.
while [ $# -gt 0 ]
do
case "$1" in
# FIXME: Handle switches that take arguments, eg --block-size
# FIXME: Properly handle --almost-all, --ignore-backups, --format
# FIXME: and --ignore
# FIXME: Properly handle --recursive
-a | -A | --all | --almost-all)
no_dots=0;
;;
--version)
report "version 1.2"
exit 0
;;
--help)
case $type in
d) report "a version of 'ls' that lists only directories" ;;
l) report "a version of 'ls' that lists only links" ;;
f) if [ "x$find_extras" = "x" ] ; then
report "a version of 'ls' that lists only files" ;
else
report "a version of 'ls' that lists only executables";
fi ;;
esac
exit 0
;;
--)
# A switch to say that all further items on the command line are
# arguments and not switches.
no_more_args=1 ;
;;
-*)
if [ "x$no_more_args" = "x1" ] ;
then
dirs[$num_dirs]="$1";
let "num_dirs++"
else
# Check for a switch that just uses a single dash, not a double
# dash. This could actually be multiple switches combined into
# one word, eg "lsd -alF". In this case, scan for the -a switch.
# XXX: FIXME: The use of =~ requires bash v3.0+.
if [[ "x${1:1:1}" != "x-" && "x$1" =~ "x-.*a.*" ]] ;
then
no_dots=0;
fi
opts="$opts $1";
fi
;;
*)
dirs[$num_dirs]="$1";
let "num_dirs++"
;;
esac
shift
done
# Remember that we are counting from zero not one.
if [ $num_dirs -gt 0 ] ;
then
let "num_dirs--"
fi
}
list_things_in_dir ()
{
local dir
# Paranoia checks - the user should never encounter these.
if test "x$1" = "x" ;
then
fail "list_things_in_dir called without an argument"
fi
if test "x$2" != "x" ;
then
fail "list_things_in_dir called with too many arguments"
fi
# Use quotes when accessing $dir in order to preserve
# any spaces that might be in the directory name.
dir="${dirs[$1]}";
# Catch directory names that start with a dash - they
# confuse pushd.
if test "x${dir:0:1}" = "x-" ;
then
dir="./$dir"
fi
if [ -d "$dir" ]
then
if [ $num_dirs -gt 0 ]
then
echo " $dir:"
fi
# Use pushd rather passing the directory name to find so that the
# names that find passes on to xargs do not have any paths prepended.
pushd "$dir" > /dev/null
if [ $no_dots -ne 0 ] ; then
find . -maxdepth 1 -type $type $find_extras -not -name ".*" -printf "%f\000" \
| xargs --null --no-run-if-empty ls $opts -- ;
else
find . -maxdepth 1 -type $type $find_extras -printf "%f\000" \
| xargs --null --no-run-if-empty ls $opts -- ;
fi
popd > /dev/null
else
report "directory '$dir' could not be found"
fi
}
list_objects ()
{
local i
i=0;
while [ $i -le $num_dirs ]
do
list_things_in_dir i
let "i++"
done
}
# Invoke main
main ${1+"$@"}
```
## 7 Comments |
12,027 | 如何在 Linux 上为特定的用户或用户组启用或禁用 SSH? | https://www.2daygeek.com/allow-deny-enable-disable-ssh-access-user-group-in-linux/ | 2020-03-23T10:59:29 | [
"SSH"
] | https://linux.cn/article-12027-1.html | 
由于你的公司标准规定,你可能只能允许部分人访问 Linux 系统。或者你可能只能够允许几个用户组中的用户访问 Linux 系统。那么如何实现这样的要求呢?最好的方法是什么呢?如何使用一个简单的方法去实现呢?
是的,我们会有很多种方法去实现它。但是我们应该使用简单轻松的方法。为了简单轻松的完成目的,我们可以通过对 `/etc/ssh/sshd_config` 文件做必要的修改来实现。在这篇文章中我们将会向你展示实现要求的详细步骤。
为什么我们要这样做呢?是出于安全的原因。你可以访问[这个链接](https://www.2daygeek.com/category/ssh-tutorials/)来获取更多关于 openSSH 的使用方法。
### 什么是 SSH ?
openssh 全称为 OpenBSD Secure Shell。Secure Shell(ssh)是一个自由开源的网络工具,它能让我们在一个不安全的网络中通过使用 Secure Shell(SSH)协议来安全访问远程主机。
它采用了客户端-服务器架构(C/S),拥有用户身份认证、加密、在计算机和隧道之间传输文件等功能。
我们也可以用 `telnet` 或 `rcp` 等传统工具来完成,但是这些工具都不安全,因为它们在执行任何动作时都会使用明文来传输密码。
### 如何在 Linux 中允许用户使用 SSH?
通过以下内容,我们可以为指定的用户或用户列表启用 `ssh` 访问。如果你想要允许多个用户,那么你可以在添加用户时在同一行中用空格来隔开他们。
为了达到目的只需要将下面的值追加到 `/etc/ssh/sshd_config` 文件中去。 在这个例子中, 我们将会允许用户 `user3` 使用 ssh。
```
# echo "AllowUsers user3" >> /etc/ssh/sshd_config
```
你可以运行下列命令再次检查是否添加成功。
```
# cat /etc/ssh/sshd_config | grep -i allowusers
AllowUsers user3
```
这样就行了, 现在只需要重启 `ssh` 服务和见证奇迹了。(下面这两条命令效果相同, 请根据你的服务管理方式选择一条执行即可)
```
# systemctl restart sshd
或
# service restart sshd
```
接下来很简单,只需打开一个新的终端或者会话尝试用不同的用户身份访问 Linux 系统。是的,这里 `user2` 用户是不被允许使用 SSH 登录的并且会得到如下所示的错误信息。
```
# ssh [email protected]
[email protected]'s password:
Permission denied, please try again.
```
输出:
```
Mar 29 02:00:35 CentOS7 sshd[4900]: User user2 from 192.168.1.6 not allowed because not listed in AllowUsers
Mar 29 02:00:35 CentOS7 sshd[4900]: input_userauth_request: invalid user user2 [preauth]
Mar 29 02:00:40 CentOS7 unix_chkpwd[4902]: password check failed for user (user2)
Mar 29 02:00:40 CentOS7 sshd[4900]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=192.168.1.6 user=user2
Mar 29 02:00:43 CentOS7 sshd[4900]: Failed password for invalid user user2 from 192.168.1.6 port 42568 ssh2
```
与此同时用户 `user3` 被允许登入系统因为他在被允许的用户列表中。
```
# ssh [email protected]
[email protected]'s password:
[user3@CentOS7 ~]$
```
输出:
```
Mar 29 02:01:13 CentOS7 sshd[4939]: Accepted password for user3 from 192.168.1.6 port 42590 ssh2
Mar 29 02:01:13 CentOS7 sshd[4939]: pam_unix(sshd:session): session opened for user user3 by (uid=0)
```
### 如何在 Linux 中阻止用户使用 SSH ?
通过以下内容,我们可以配置指定的用户或用户列表禁用 `ssh`。如果你想要禁用多个用户,那么你可以在添加用户时在同一行中用空格来隔开他们。
为了达到目的只需要将以下值追加到 `/etc/ssh/sshd_config` 文件中去。 在这个例子中, 我们将禁用用户 `user1` 使用 `ssh`。
```
# echo "DenyUsers user1" >> /etc/ssh/sshd_config
```
你可以运行下列命令再次检查是否添加成功。
```
# cat /etc/ssh/sshd_config | grep -i denyusers
DenyUsers user1
```
这样就行了, 现在只需要重启 `ssh` 服务和见证奇迹了。
```
# systemctl restart sshd
活
# service restart sshd
```
接下来很简单,只需打开一个新的终端或者会话,尝试使用被禁用的用户身份被访问 Linux 系统。是的,这里 `user1` 用户在禁用名单中。所以,当你尝试登录时,你将会得到如下所示的错误信息。
```
# ssh [email protected]
[email protected]'s password:
Permission denied, please try again.
```
输出:
```
Mar 29 01:53:42 CentOS7 sshd[4753]: User user1 from 192.168.1.6 not allowed because listed in DenyUsers
Mar 29 01:53:42 CentOS7 sshd[4753]: input_userauth_request: invalid user user1 [preauth]
Mar 29 01:53:46 CentOS7 unix_chkpwd[4755]: password check failed for user (user1)
Mar 29 01:53:46 CentOS7 sshd[4753]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=192.168.1.6 user=user1
Mar 29 01:53:48 CentOS7 sshd[4753]: Failed password for invalid user user1 from 192.168.1.6 port 42522 ssh2
```
### 如何在 Linux 中允许用户组使用 SSH?
通过以下内容,我们可以允许一个指定的组或多个组使用 `ssh`。
如果你想要允许多个组使用 `ssh` 那么你在添加用户组时需要在同一行中使用空格来隔开他们。
为了达到目的只需将以下值追加到 `/etc/ssh/sshd_config` 文件中去。在这个例子中,我们将允许 `2g-admin` 组使用 ssh。
```
# echo "AllowGroups 2g-admin" >> /etc/ssh/sshd_config
```
你可以运行下列命令再次检查是否添加成功。
```
# cat /etc/ssh/sshd_config | grep -i allowgroups
AllowGroups 2g-admin
```
运行下列命令查看属于该用户组的用户有哪些。
```
# getent group 2g-admin
2g-admin:x:1005:user1,user2,user3
```
这样就行了, 现在只需要重启 `ssh` 服务和见证奇迹了。
```
# systemctl restart sshd
或
# service restart sshd
```
是的, `user1` 被允许登入系统因为用户 `user1` 属于 `2g-admin` 组。
```
# ssh [email protected]
[email protected]'s password:
[user1@CentOS7 ~]$
```
输出:
```
Mar 29 02:10:21 CentOS7 sshd[5165]: Accepted password for user1 from 192.168.1.6 port 42640 ssh2
Mar 29 02:10:22 CentOS7 sshd[5165]: pam_unix(sshd:session): session opened for user user1 by (uid=0)
```
是的, `user2` 被允许登入系统因为用户 `user2` 同样属于 `2g-admin` 组。
```
# ssh [email protected]
[email protected]'s password:
[user2@CentOS7 ~]$
```
输出:
```
Mar 29 02:10:38 CentOS7 sshd[5225]: Accepted password for user2 from 192.168.1.6 port 42642 ssh2
Mar 29 02:10:38 CentOS7 sshd[5225]: pam_unix(sshd:session): session opened for user user2 by (uid=0)
```
当你尝试使用其他不在被允许的组中的用户去登入系统时, 你将会得到如下所示的错误信息。
```
# ssh [email protected]
[email protected]'s password:
Permission denied, please try again.
```
输出:
```
Mar 29 02:12:36 CentOS7 sshd[5306]: User ladmin from 192.168.1.6 not allowed because none of user's groups are listed in AllowGroups
Mar 29 02:12:36 CentOS7 sshd[5306]: input_userauth_request: invalid user ladmin [preauth]
Mar 29 02:12:56 CentOS7 unix_chkpwd[5310]: password check failed for user (ladmin)
Mar 29 02:12:56 CentOS7 sshd[5306]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=192.168.1.6 user=ladmin
Mar 29 02:12:58 CentOS7 sshd[5306]: Failed password for invalid user ladmin from 192.168.1.6 port 42674 ssh2
```
### 如何在 Linux 中阻止用户组使用 SSH?
通过以下内容,我们可以禁用指定的组或多个组使用 `ssh`。
如果你想要禁用多个用户组使用 `ssh`,那么你需要在添加用户组时在同一行中使用空格来隔开他们。
为了达到目的只需要将下面的值追加到 `/etc/ssh/sshd_config` 文件中去。
```
# echo "DenyGroups 2g-admin" >> /etc/ssh/sshd_config
```
你可以运行下列命令再次检查是否添加成功。
```
# # cat /etc/ssh/sshd_config | grep -i denygroups
DenyGroups 2g-admin
# getent group 2g-admin
2g-admin:x:1005:user1,user2,user3
```
这样就行了, 现在只需要重启 `ssh` 服务和见证奇迹了。
```
# systemctl restart sshd
或
# service restart sshd
```
是的 `user1` 不被允许登入系统,因为他是 `2g-admin` 用户组中的一员。他属于被禁用 `ssh` 的组中。
```
# ssh [email protected]
[email protected]'s password:
Permission denied, please try again.
```
输出:
```
Mar 29 02:17:32 CentOS7 sshd[5400]: User user1 from 192.168.1.6 not allowed because a group is listed in DenyGroups
Mar 29 02:17:32 CentOS7 sshd[5400]: input_userauth_request: invalid user user1 [preauth]
Mar 29 02:17:38 CentOS7 unix_chkpwd[5402]: password check failed for user (user1)
Mar 29 02:17:38 CentOS7 sshd[5400]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=192.168.1.6 user=user1
Mar 29 02:17:41 CentOS7 sshd[5400]: Failed password for invalid user user1 from 192.168.1.6 port 42710 ssh2
```
除了 `2g-admin` 用户组之外的用户都可以使用 ssh 登入系统。 例如,`ladmin` 等用户就允许登入系统。
```
# ssh [email protected]
[email protected]'s password:
[ladmin@CentOS7 ~]$
```
输出:
```
Mar 29 02:19:13 CentOS7 sshd[5432]: Accepted password for ladmin from 192.168.1.6 port 42716 ssh2
Mar 29 02:19:13 CentOS7 sshd[5432]: pam_unix(sshd:session): session opened for user ladmin by (uid=0)
```
---
via: <https://www.2daygeek.com/allow-deny-enable-disable-ssh-access-user-group-in-linux/>
作者:[2daygeek](http://www.2daygeek.com/author/2daygeek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[way-ww](https://github.com/way-ww) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,029 | Linus Torvalds 关于在冠状病毒禁足期间在家工作的建议 | https://itsfoss.com/torvalds-remote-work-advice/ | 2020-03-23T11:40:49 | [
"冠状病毒"
] | https://linux.cn/article-12029-1.html | 
在冠状病毒爆发期间,我们中的许多人都在室内自我隔离。[ZDNet](https://www.zdnet.com/article/pet-the-cat-own-the-bathrobe-linus-torvalds-on-working-from-home/) 特此与 Linus Torvalds 进行了专题采访,讨论了他对冠状病毒禁足期间在家工作的看法或想法。
如果你还不知道(怎么可能不知道),[Linus Torvalds](https://en.wikipedia.org/wiki/Linus_Torvalds) 是 Linux 的创建者,也是 [Git](https://git-scm.com/) 的创建者,而所有这一切都是他在家里工作时做的。这是 2016 年的视频,Torvalds 展示了他的家庭办公室:
因此,在本文中,我将分享我关注的一些主要要点,以及来自 Linus Torvalds 接受 ZDNet [Steven J. Vaughan-Nichols](https://twitter.com/sjvn) 采访互动时的回应。
### 消除对人际交往缺失的恐惧
Linus 提到,几年前刚开始在家工作时,他担心过缺少人与人之间的互动,包括去办公室、与人互动或哪怕只是出去吃个午餐。
有趣的是,他似乎并没有错过任何东西,他更喜欢在家中没有人际交往的时间。
当然,将自己与人际互动隔离开并不是最好的事情 ,但在目前看来,这是一件好事。
### 利用在家工作的优势
就像我们是完全远程操作一样,你可以做很多事情,而无需实际在办公室。
不要忘记,你可以随心所欲地养猫,我有 6 只猫,我知道这很困难(*哈哈*)。
而且,正如 Linus 所提到的,远程工作的真正优势在于“灵活性”。你不一定需要朝九晚五甚至更长的时间坐在办公桌前。从技术上讲,你可以在工作中自由休息,并在家中做你想做的任何事情。
换句话说,Linus 建议**不要在你的家中重新搞一个办公室**,这比去办公室还差。
### 高效沟通是关键

虽然你可以在一天之中召开几次会议(视频会议或音频呼叫),但这真的有必要吗?
对于某些人来说,这可能很重要,但是你应该通过简化和整理内容来尽量减少会议花费的时间。
或者,按照 Linus 的建议,最好有个电子邮件列表来记录事情,以确保一切各司其职,这就是 [Linux 内核](https://en.wikipedia.org/wiki/Linux_kernel) 的运行方式。
James Bottomley 是 [IBM 研究院](https://www.research.ibm.com/)的杰出工程师,也是资深 Linux 内核开发人员,他也建议你重新阅读你的文字以确保发送的准确信息不会被人不小心跳过。
就个人而言,出于同样的原因,我更喜欢文本而不是语音。实际上,它可以节省你的时间。
但是,请记住,你需要只以适当的方式传达必要的信息,而不要使通过文本/电子邮件发送的信息过载。
### 追踪你的时间
灵活性并不一定意味着你可以减少工作量并泡在社交媒体平台上,除非那就是你的工作。
因此,你需要确保充分利用自己的时间。为此,你可以使用多种工具来跟踪你的时间用在什么地方,以及在计算机上花费的时间。
你甚至可以将其记录在便签上,以确保你可以将时间高效地分配于工作上。你可以选择使用 [RescueTime](https://www.rescuetime.com/) 或 [ActivityWatch](https://activitywatch.net/) 来跟踪你在计算机或智能手机上花费的时间。
### 和猫(宠物)一起玩

不歧视其他宠物,但这就是 Linus Torvalds 提到的。
正因为你在家中,你在安排工作或尝试有效利用时间时要做的事情有很多。
Linus 坚持认为,每当你感到无聊时,可以在必要时出门获取必需品,也可以与猫(或你的其它宠物)一起玩。
### 结语
虽然 Linus 还提到了当你在家时没人会评判你,但他的建议似乎是正确的,对于那些在家工作的人来说可能很有用。
不仅是因为冠状病毒的爆发,而且如果你打算一直在家工作,应该牢记这些。
你如何看待 Linus 的看法呢?你同意他的观点吗?
---
via: <https://itsfoss.com/torvalds-remote-work-advice/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While many of us are self-isolating indoors amidst the coronavirus outbreak. [ZDNet](https://www.zdnet.com/article/pet-the-cat-own-the-bathrobe-linus-torvalds-on-working-from-home/) had a special feature discussion with Linus Torvalds on his opinions or thoughts on working from home during the Coronavirus lockdown.
If you didn’t know already (how could you not?), [Linus Torvalds](https://en.wikipedia.org/wiki/Linus_Torvalds) is the creator of Linux and [Git](https://git-scm.com/) as well. And, he did all that while working from home. Here’s a video from 2016 where Torvalds shows his home office:
So, in this article, I’m going to share some of my key takeaways along with his responses from [Steven J. Vaughan-Nichols](https://twitter.com/sjvn)‘ interaction with Linus Torvalds for ZDNet.
## Discard the fear of missing human interaction
Torvalds mentioned that when he first started working from home years ago, he was worried about missing human interaction that included going to the office, interacting with people, or simply going out for lunch.
Interestingly, he did not seem to miss any of that anymore- he preferred his time at home without human interaction.
Of course, isolating yourself from human interacting isn’t the best thing – but it looks like that is a good thing for now.
## Take advantage of working from home

Just like we at It’s FOSS operate completely remote, you can do a lot of stuff without actually being at an office.
Not to forget – you can pet your cat as much as you want and I have 6 of them, I know it’s difficult (*giggles*).
And, as Linus Torvalds mentioned, the real advantage of remote work is “flexibility”. You do not necessarily need to sit in front of your desk working from 9-5 or more. Technically, you are free to take breaks in between and do whatever you wish at home.
In other words, ** Linus suggests avoiding re-creating an office at your home** – which is worse than going to an office.
## Efficient communication is the key

You can choose to have several meetings (video conferences or audio calls) in a day – but is it really necessary?
For some, it might be a big deal – but you should try to minimize the time spent on a meeting by clearing things up in brief.
Or, as Linus recommends, it’s best to have email lists to keep things on point and that’s how [Linux kernel](https://en.wikipedia.org/wiki/Linux_kernel) runs.
**James Bottomley**, Distinguished Engineer at [IBM Research](https://www.research.ibm.com/), and a senior Linux kernel developer, also adds a suggestion that you should re-read your text to make sure that you’re sending precise information that no one will potentially skim through.
Personally, I prefer texts over voice for the very same reason. It saves you time, fact.
But, keep in mind, that you need to convey only the necessary information in a proper manner without overloading the information that you send via texts/email.
## Track your time
Flexibility doesn’t necessarily mean that you can work less and lurk on social media platforms, unless that’s your job.
So, you need to make sure that you are making the most out of your time. To do that, you can use several tools to track your time on what you use and the duration of it on your computer.
You can even write it down on a sticky note to make sure you reach your goal of spending the allocated time for work efficiently. You can opt to utilize [RescueTime](https://www.rescuetime.com/) or [ActivityWatch](https://itsfoss.com/activitywatch/) to track the time you spend on your computer or smartphone.
## Play with your cat (pets)

Not to discriminate against other pets, but that’s what Linus Torvalds mentioned.
Just because you are at your home – you have a lot to do while you schedule your work or try to efficiently utilize the time.
Linus insists that whenever you’re bored, you can head out to get essentials if necessary or simply play with the cat (or your pet).
## Wrapping Up
While Linus Torvalds also mentioned that no one will be judging you when you’re at home, his suggestions seem to be on point and could be very useful for people who struggle with working from home.
Not just for the coronavirus outbreak – but if you are planning to work from home permanently, you should keep these things in mind.
What do you think about Linus Torvalds thoughts here? Do you agree with him? |
12,030 | GNOME 3.36 发布,对视觉和性能进行了改进 | https://itsfoss.com/gnome-3-36-release/ | 2020-03-23T15:19:31 | [
"GNOME"
] | https://linux.cn/article-12030-1.html | 
在 [GNOME 3.34](https://itsfoss.com/gnome-3-34-release/) 发布 6 个月后,最新版本的 GNOME 3.36 代号为 “Gresik” 也最终发布了。不仅是添加了功能,GNOME 3.36 还改进了许多我们需要的功能。
在本文中,我将重点介绍 GNOME 新版本的主要更改。
### GNOME 3.36 的关键改进
如果你想快速了解发生了什么变化,可以看以下官方视频:
现在,让我分别重点介绍最新版本中的更改:
#### GNOME Shell 扩展应用
你可以通过专门的“扩展”程序轻松管理 GNOME Shell 的扩展。

因此,你可以使用该程序更新、配置、删除或禁用现有扩展。
#### 切换到请勿打扰(DND)

你可能已经在 Pop!\_OS 或其他 Linux 发行版中注意到了它。
但是,GNOME 3.36 现在在通知弹出区域中实现了 DND 切换。除非你将其关闭,否则不会收到任何通知。
#### 锁屏改进

在新版本中,锁定屏幕在输入凭据之前没有额外的动画。取而代之会在登录屏幕直接打招呼。
另外,为了提升一致性,锁屏背景将是墙纸的模糊版本。
总的来说,对锁屏的改进旨在使之更易于访问,同时改善其外观/感觉。
#### 视觉变化

包含了一些明显的新增,这些设计更改改善了 GNOME 3.36 的总体外观。
从图标的重新设计到文件夹和系统对话框,进行了许多小的改进以增强 GNOME 3.36 的用户体验。
此外,设置应用已进行了调整,通过微小的界面重新设计,使得选项访问更加容易。
#### 主要性能改进
GNOME 声称,此更新还提升了 GNOME 桌面的性能。
当使用装有 GNOME 3.36 的发行版时,你会注意到在性能上有明显的不同。无论是动画、重新设计还是微小的调整,对于 GNOME 3.36 所做的一切都会对用户的性能产生积极影响。
#### 其他更改
除了上述关键更改之外,还有很多其他改进,例如:
* 时钟重新设计
* 用户文档更新
* GNOME 安装助手改进
还有许多其他更改。你可以查看[官方发布说明](https://help.gnome.org/misc/release-notes/3.36/)了解更多信息。
### 如何获取 GNOME 3.36?
即使 GNOME 3.36 已正式发布。Linux 发行版可能需要一段时间才能让你轻松升级 GNOME 体验。
[Ubuntu 20.04 LTS](https://itsfoss.com/ubuntu-20-04-release-features/) 将提供最新版本 GNOME。你可以等待。
其他[流行的 Linux 发行版](https://itsfoss.com/best-linux-distributions/),如 Fedora、OpenSuse、Pop!\_OS,应该会很快包含 GNOME 3.36。[Arch Linux](https://www.archlinux.org/) 已升级到 GNOME 3.36。
我建议你耐心等待,直到获得发行版本的更新。不过,你可以查看[源代码](https://gitlab.gnome.org/GNOME)或尝试即将发布的流行发行版的开发版本,这些发行版可能有 GNOME 3.36。
你如何看待 GNOME 3.36?在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/gnome-3-36-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The latest version GNOME 3.36 also codenamed as “Gresik” has finally landed after 6 months of [GNOME 3.34](https://itsfoss.com/gnome-3-34-release/) release.
Not just limited to the feature additions, but GNOME 3.36 improves on a lot of things that we needed.
In this article, I’ll highlight the key changes with GNOME’s new release.
## GNOME 3.36 Key Improvements
If you want a quick look at what has changed, you can take a look at the official video below:
Now, let me highlight the changes in the latest release separately:
### GNOME Shell Extensions App
You can easily manage your GNOME shell extensions right through a dedicated “Extensions” app.
So, you can update, configure, delete or disable the existing extension using the app.
### Do Not Disturb Toggle
You might have already noticed this on Pop!_OS or other Linux distros.
However, GNOME 3.36 now implements a DND toggle in the notifications pop-over area out of the box. You won’t be notified of anything unless you turn it off.
### Lock Screen Improvements
With the new version, the lock screen won’t need an additional slide (or animation) before entering the credentials. Instead, you will be directly greeted by the login screen.
Also, to improve consistency, the background image of the lockscreen will be a blurred out version of your wallpaper.
So, overall, the improvements to the lock screen aim to make it easier to access while improving the look/feel of it.
### Visual Changes
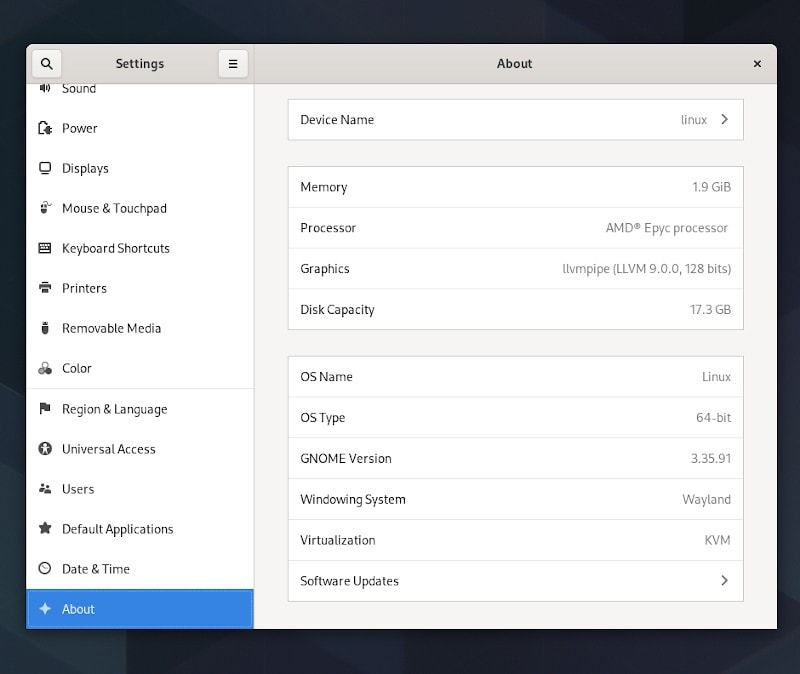
Including the obvious new additions – there are several design changes that have improved the overall look and feel of GNOME 3.36.
Ranging from the icon redesign to the folders and system dialogues, a lot of minor improvements are in place to enhance the user experience on GNOME 3.36.
Also, the settings app has been tweaked to make the options easier to access along with minor interface re-designs.
### Major Performance Improvement
GNOME claims that this update also brings in performance improvement for the GNOME desktop.
You will have a noticeable difference in the performance when using a distribution with GNOME 3.36 on board. Be it an animation, a redesign, or a minor tweak, everything that has been done for GNOME 3.36 positively impacts the performance for the users.
### Other Changes
In addition to all the key changes mentioned above, there’s a bunch of other improvements like:
- Clock redesign
- User documentation update
- GNOME Setup assistant improvements
And, a lot of stuff here and there. You can take a look at the [official release notes](https://help.gnome.org/misc/release-notes/3.36/) to learn more about it.
## How to get GNOME 3.36?
Even though GNOME 3.36 has officially released. It will take a while for the Linux distributions to let you easily upgrade your GNOME experience.
[Ubuntu 20.04 LTS](https://itsfoss.com/ubuntu-20-04-release-features/) release will include the latest version out of the box. You can wait for it.
Other [popular Linux distributions](https://itsfoss.com/best-linux-distributions/) like Fedora, OpenSuse, Pop!_OS should soon include GNOME 3.36 soon enough. [Arch Linux](https://www.archlinux.org/) has already upgraded to GNOME 3.36.
I’ll advise you to wait it out till you get an update for your distribution. Nevertheless, you can take a look at the [source code](https://gitlab.gnome.org/GNOME) or try the upcoming development editions of popular distros that could potentially feature GNOME 3.36.
What do you think about GNOME 3.36? Let me know your thoughts in the comments below. |
12,031 | DevOps 和敏捷:究竟有什么区别? | https://opensource.com/article/20/2/devops-vs-agile | 2020-03-23T20:06:40 | [
"敏捷",
"DevOps"
] | https://linux.cn/article-12031-1.html |
>
> 两者之间的区别在于开发完毕之后发生的事情。
>
>
>

早期,软件开发并没有特定的管理流程。随后出现了<ruby> <a href="http://www.agilenutshell.com/agile_vs_waterfall"> 瀑布开发流程 </a> <rt> Waterfall </rt></ruby>,它提出软件开发活动可以用开发和构建应用所耗费的时间来定义。
那时候,由于在开发流程中没有审查环节和权衡考虑,常常需要花费很长的时间来开发、测试和部署软件。交付的软件也是带有缺陷和 Bug 的质量较差的软件,而且交付时间也不满足要求。那时候软件项目管理的重点是长期而拖沓的计划。
瀑布流程与<ruby> <a href="https://en.wikipedia.org/wiki/Project_management_triangle"> 三重约束模型 </a> <rt> triple constraint model </rt></ruby>相关,三重约束模型也称为<ruby> 项目管理三角形 <rt> project management triangle </rt></ruby>。三角形的每一个边代表项目管理三要素的一个要素: **范围、时间和成本**。正如 [Angelo Baretta 写到](https://www.pmi.org/learning/library/triple-constraint-erroneous-useless-value-8024),三重约束模型“认为成本是时间和范围的函数,这三个约束以一种确定的、可预测的方式相互作用。……如果我们想缩短时间表(时间),就必须增加成本。如果我们想增加范围,就必须增加成本或时间。”
### 从瀑布流程过渡到敏捷开发
瀑布流程来源于生产和工程领域,这些领域适合线性化的流程:正如房屋封顶之前需要先盖好支撑墙。相似地,软件开发问题被认为可以通过提前做好计划来解决。从头到尾,开发流程均由路线图清晰地定义,沿着路线图就可以得到最终交付的产品。
最终,瀑布模型被认为对软件开发是不利的而且违反人的直觉,因为通常直到开发流程的最后才能体现出项目的价值,这导致许多项目最终都以失败告终。而且,在项目结束前客户看不到任何可以工作的软件。
<ruby> 敏捷 <rt> Agile </rt></ruby>采用了一种不同的方法,它抛弃了规划整个项目,承诺估计的时间点,简单的遵循计划。与瀑布流程相反,它假设和拥抱不确定性。它的理念是以响应变化代替讨论过去,它认为变更是客户需求的一部分。
### 敏捷价值观
敏捷由<ruby> 敏捷宣言 <rt> Agile Manifesto </rt></ruby>代言,敏捷宣言定义了 [12 条原则](http://agilemanifesto.org/principles.html)(LCTT 译注:此处没有采用本文原本的简略句式,而是摘录了来自敏捷软件开发宣言官方的[中文译本](http://agilemanifesto.org/iso/zhchs/principles.html)):
1. 我们最重要的目标,是通过持续不断地及早交付有价值的软件使客户满意。
2. 欣然面对需求变化,即使在开发后期也一样。
3. 经常交付可工作的软件,相隔几星期或一两个月,倾向于采取较短的周期。
4. 业务人员和开发人员必须相互合作,项目中的每一天都不例外。
5. 激发个体的斗志,以他们为核心搭建项目。提供所需的环境和支援,辅以信任,从而达成目标。
6. 面对面沟通是传递信息的最佳的也是效率最高的方法。
7. 可工作的软件是进度的首要度量标准。
8. 敏捷流程倡导可持续的开发,责任人、开发人员和用户要能够共同维持其步调稳定延续。
9. 坚持不懈地追求技术卓越和良好设计,敏捷能力由此增强。
10. 以简洁为本,它是极力减少不必要工作量的艺术。
11. 最好的架构,需求和设计出自自组织团队
12. 团队定期地反思如何能提高成效,并依此调整自身的举止表现。
敏捷的四个[核心价值观](https://agilemanifesto.org/)是(LCTT 译注:[此处译文](http://agilemanifesto.org/iso/zhchs/manifesto.html)同样来自敏捷软件开发宣言官方):
* **个体和互动** 高于流程和工具
* **工作的软件** 高于详尽的文档
* **客户合作** 高于合同谈判
* **响应变化** 高于遵循计划
这与瀑布流程死板的计划风格相反。在敏捷流程中,客户是开发团队的一员,而不仅仅是在项目开始时参与项目需求的定义,在项目结束时验收最终的产品。客户帮忙团队完成[验收标准](https://www.productplan.com/glossary/acceptance-criteria/),并在整个过程中保持投入。另外,敏捷需要整个组织的变化和持续的改进。开发团队和其他团队一起合作,包括项目管理团队和测试团队。做什么和计划什么时候做由指定的角色领导,并由整个团队同意。
### 敏捷软件开发
敏捷软件开发需要自适应的规划、演进式的开发和交付。许多软件开发方法、框架和实践遵从敏捷的理念,包括:
* Scrum
* <ruby> 看板 <rt> Kanban </rt></ruby>(可视化工作流)
* <ruby> 极限编程 <rt> Xtreme Programming </rt></ruby>(XP)
* <ruby> 精益方法 <rt> Lean </rt></ruby>
* DevOps
* <ruby> 特性驱动开发 <rt> Feature-Driven Development </rt></ruby>(FDD)
* <ruby> 测试驱动开发 <rt> Test-Driven Development </rt></ruby>(TDD)
* <ruby> 水晶方法 <rt> Crystal </rt></ruby>
* <ruby> 动态系统开发方法 <rt> Dynamic Systems Development Method </rt></ruby>(DSDM)
* <ruby> 自适应软件开发 <rt> Adaptive Software Development </rt></ruby>(ASD)
所有这些已经被单独用于或一起用于开发和部署软件。最常用的是 [Scrum](https://opensource.com/article/19/8/scrum-vs-kanban)、看板(或 Scrumban)和 DevOps。
[Scrum](https://www.scrum.org/) 是一个框架,采用该框架的团队通常由一个 Scrum 教练、产品经理和开发人员组成,该团队以跨职能、自主的工作方式运作,能够加快软件交付速度从而给客户带来巨大的商业价值。其关注点是[较小增量](https://www.scrum.org/resources/what-is-an-increment)的快速迭代。
[看板](https://www.atlassian.com/agile/kanban) 是一个敏捷框架,有时也叫工作流管理系统,它能帮助团队可视化他们的工作从而最大化效率(因而变得敏捷)。看板通常由数字或物理展示板来呈现。团队的工作在展示板上随着进度而移动,例如从未启动到进行中,一直到测试中、已完成。看板使得每个团队成员可以随时查看到所有工作的状态。
### DevOps 价值观
DevOps 是一种文化,是一种思维状态,是一种软件开发的方式或者基础设施的方式,也是一种构建和部署软件和应用的方式。它假设开发和运维之间没有隔阂,他们一起合作,没有矛盾。
DevOps 基于其它两个领域的实践: 精益和敏捷。DevOps 不是一个公司内的岗位或角色;它是一个组织或团队对持续交付、持续部署和持续集成的坚持不懈的追求。[Gene Kim](https://itrevolution.com/the-unicorn-project/)(Phoenix 项目和 Unicorn 项目的作者)认为,有三种方式定义 DevOps 的理念:
* 第一种: 流程原则
* 第二种: 反馈原则
* 第三种: 持续学习原则
### DevOps 软件开发
DevOps 不会凭空产生;它是一种灵活的实践,它的本质是一种关于软件开发和 IT 或基础设施实施的共享文化和思维方式。
当你想到自动化、云、微服务时,你会想到 DevOps。在一次[访谈](https://www.infoq.com/articles/book-review-accelerate/)中,《加速构建和扩张高性能技术组织》的作者 Nicol Forsgren、Jez Humble 和 Gene Kim 这样解释到:
>
> * 软件交付能力很重要,它极大地影响到组织的成果,例如利润、市场份额、质量、客户满意度以及组织战略目标的达成。
> * 优秀的团队能达到很高的交付量、稳定性和质量;他们并没有为了获得这些属性而进行取舍。
> * 你可以通过实施精益、敏捷和 DevOps 中的实践来提升能力。
> * 实施这些实践和能力也会影响你的组织文化,并且会进一步对你的软件交付能力和组织能力产生有益的提升。
> * 懂得怎样改进能力需要做很多工作。
>
>
>
### DevOps 和敏捷的对比
DevOps 和敏捷有相似性,但是它们不完全相同,一些人认为 DevOps 比敏捷更好。为了避免造成混淆,深入地了解它们是很重要的。
#### 相似之处
* 毫无疑问,两者都是软件开发技术。
* 敏捷已经存在了 20 多年,DevOps 是最近才出现的。
* 两者都追求软件的快速开发,它们的理念都基于怎样在不伤害客户或运维利益的情况下快速开发出软件。
#### 不同之处
* 两者的差异在于软件开发完成后发生的事情。
+ 在 DevOps 和敏捷中,都有软件开发、测试和部署的阶段。然而,敏捷流程在这三个阶段之后会终止。相反,DevOps 包括后续持续的运维。因此,DevOps 会持续的监控软件运行情况和进行持续的开发。
* 敏捷中,不同的人负责软件的开发、测试和部署。而 DevOps 工程角色负责所有活动,开发即运维,运维即开发。
* DevOps 更关注于削减成本,而敏捷则是精益和减少浪费的代名词,侧重于像敏捷项目会计和最小可行产品的概念。
* 敏捷专注于并体现了经验主义(适应、透明和检查),而不是预测性措施。
| 敏捷 | DevOps |
| --- | --- |
| 从客户得到反馈 | 从自己得到反馈 |
| 较小的发布周期 | 较小的发布周期,立即反馈 |
| 聚焦于速度 | 聚焦于速度和自动化 |
| 对业务不是最好 | 对业务最好 |
### 总结
敏捷和 DevOps 是截然不同的,尽管它们的相似之处使人们认为它们是相同的。这对敏捷和 DevOps 都是一种伤害。
根据我作为一名敏捷专家的经验,我发现对于组织和团队从高层次上了解敏捷和 DevOps 是什么,以及它们如何帮助团队更高效地工作,更快地交付高质量产品从而提高客户满意度非常有价值。
敏捷和 DevOps 绝不是对抗性的(或至少没有这个意图)。在敏捷革命中,它们更像是盟友而不是敌人。敏捷和 DevOps 可以相互协作一致对外,因此可以在相同的场合共存。
---
via: <https://opensource.com/article/20/2/devops-vs-agile>
作者:[Taz Brown](https://opensource.com/users/heronthecli) 选题:[lujun9972](https://github.com/lujun9972) 译者:[messon007](https://github.com/messon007) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Early on, software development didn't really fit under a particular management umbrella. Then along came [waterfall](http://www.agilenutshell.com/agile_vs_waterfall), which spoke to the idea that software development could be defined by the length of time an application took to create or build.
Back then, it often took long periods of time to create, test, and deploy software because there were no checks and balances during the development process. The results were poor software quality with defects and bugs and unmet timelines. The focus was on long, drawn-out plans for software projects.
Waterfall projects have been associated with the [triple constraint](https://en.wikipedia.org/wiki/Project_management_triangle) model, which is also called the project management triangle. Each side of the triangle represents a component of the triple constraints of project management: **scope**, **time**, and **cost**. As [Angelo Baretta writes](https://www.pmi.org/learning/library/triple-constraint-erroneous-useless-value-8024), the triple constraint model "says that cost is a function of time and scope, that these three factors are related in a defined and predictable way… [I]f we want to shorten the schedule (time), we must increase cost. It says that if we want to increase scope, we must increase cost or schedule."
## Transitioning from waterfall to agile
Waterfall came from manufacturing and engineering, where a linear process makes sense; you build the wall before you build the roof. Similarly, software development problems were viewed as something that could be solved with planning. From beginning to end, the development process was clearly defined by a roadmap that would lead to the final delivery of a product.
Eventually, waterfall was recognized as detrimental and counterintuitive to software development because, often, the value could not be determined until the very end of the project cycle, and in many cases, the projects failed. Also, the customer didn't get to see any working software until the end of the project.
Agile takes a different approach that moves away from planning the entire project, committing to estimated dates, and being accountable to a plan. Rather, agile assumes and embraces uncertainty. It is built around the idea of responding to change instead of charging past it or ignoring the need for it. Instead, change is considered as a way to fulfill the needs of the customer.
## Agile values
Agile is governed by the Agile Manifesto, which defines [12 principles](https://agilemanifesto.org/principles.html):
- Satisfying the customer is the top priority
- Welcome changing requirements, even late in development
- Deliver working software frequently
- Development and business must work together
- Build projects around motivated people
- Face-to-face communication is the most efficient and effective method of conveying information
- The primary measure of success is working software
- Agile processes promote sustainable development
- Maintain continuous attention to technical excellence and good design
- Simplicity is essential
- The best architectures, requirements, and designs emerge from self-organizing teams
- Regularly reflect on work, then tune and adjust behavior
Agile's four [core values](https://agilemanifesto.org/) are:
**Individuals and interactions**over processes and tools**Working software**over comprehensive documentation**Customer collaboration**over contract negotiation**Responding to change**over following a plan
This contrasts with waterfall's rigid planning style. In agile, the customer is a member of the development team rather than engaging only at the beginning, when setting business requirements, and at the end, when reviewing the final product (as in waterfall). The customer helps the team write the [acceptance criteria](https://www.productplan.com/glossary/acceptance-criteria/) and remains engaged throughout the process. In addition, agile requires changes and continuous improvement throughout the organization. The development team works with other teams, including the project management office and the testers. What gets done and when are led by a designated role and agreed to by the team as a whole.
## Agile software development
Agile software development requires adaptive planning, evolutionary development, and delivery. Many software development methodologies, frameworks, and practices fall under the umbrella of being agile, including:
- Scrum
- Kanban (visual workflow)
- XP (eXtreme Programming)
- Lean
- DevOps
- Feature-driven development (FDD)
- Test-driven development (TDD)
- Crystal
- Dynamic systems development method (DSDM)
- Adaptive software development (ASD)
All of these have been used on their own or in combination for developing and deploying software. The most common are [scrum, kanban](https://opensource.com/article/19/8/scrum-vs-kanban) (or the combination called scrumban), and DevOps.
[Scrum](https://www.scrum.org/) is a framework under which a team, generally consisting of a scrum master, product owner, and developers, operates cross-functionally and in a self-directed manner to increase the speed of software delivery and
to bring greater business value to the customer. The focus is on faster iterations with smaller [increments](https://www.scrum.org/resources/what-is-an-increment).
[Kanban](https://www.atlassian.com/agile/kanban) is an agile framework, sometimes called a workflow management system, that helps teams visualize their work and maximize efficiency (thus being agile). Kanban is usually represented by a digital or physical board. A team's work moves across the board, for example, from not started, to in progress, testing, and finished, as it progresses. Kanban allows each team member to see the state of all work at any time.
## DevOps values
DevOps is a culture, a state of mind, a way that software development or infrastructure is, and a way that software and applications are built and deployed. There is no wall between development and operations; they work simultaneously and without silos.
DevOps is based on two other practice areas: lean and agile. DevOps is not a title or role within a company; it's really a commitment that an organization or team makes to continuous delivery, deployment, and integration. According to [Gene Kim](https://itrevolution.com/the-unicorn-project/), author of *The Phoenix Project* and *The Unicorn Project*, there are three "ways" that define the principles of DevOps:
- The First Way: Principles of flow
- The Second Way: Principles of feedback
- The Third Way: Principles of continuous learning
## DevOps software development
DevOps does not happen in a vacuum; it is a flexible practice that, in its truest form, is a shared culture and mindset around software development and IT or infrastructure implementation.
When you think of automation, cloud, microservices, you think of DevOps. In an [interview](https://www.infoq.com/articles/book-review-accelerate/), *Accelerate: Building and Scaling High Performing Technology Organizations* authors Nicole Forsgren, Jez Humble, and Gene Kim explained:
- Software delivery performance matters, and it has a significant impact on organizational outcomes such as profitability, market share, quality, customer satisfaction, and achieving organizational and mission goals.
- High performers achieve levels of throughput, stability, and quality; they're not trading off to achieve these attributes.
- You can improve your performance by implementing practices from the lean, agile, and DevOps playbooks.
- Implementing these practices and capabilities also has an impact on your organizational culture, which in turn has an impact on both your software delivery performance and organizational performance.
- There's still lots of work to do to understand how to improve performance.
## DevOps vs. agile
Despite their similarities, DevOps and agile are not the same, and some argue that DevOps is better than agile. To eliminate the confusion, it's important to get down to the nuts and bolts.
### Similarities
- Both are software development methodologies; there is no disputing this.
- Agile has been around for over 20 years, and DevOps came into the picture fairly recently.
- Both believe in fast software development, and their principles are based on how fast software can be developed without causing harm to the customer or operations.
### Differences
**The difference between the two**is what happens after development.- Software development, testing, and deployment happen in both DevOps and agile. However, pure agile tends to stop after these three stages. In contrast, DevOps includes operations, which happen continually. Therefore, monitoring and software development are also continuous.
- In agile, separate people are responsible for developing, testing, and deploying the software. In DevOps, the DevOps engineering role is are responsible for everything; development is operations, and operations is development.
- DevOps is more associated with cost-cutting, and agile is more synonymous with lean and reducing waste, and concepts like agile project accounting and minimum viable product (MVP) are relevant.
- Agile focuses on and embodies empiricism (
**adaptation**,**transparency**, and**inspection**) instead of predictive measures.
Agile | DevOps |
---|---|
Feedback from customer | Feedback from self |
Smaller release cycles | Smaller release cycles, immediate feedback |
Focus on speed | Focus on speed and automation |
Not the best for business | Best for business |
## Wrapping up
Agile and DevOps are distinct, although their similarities lead people to think they are one and the same. This does both agile and DevOps a disservice.
In my experience as an agilist, I have found it valuable for organizations and teams to understand—from a high level—what agile and DevOps are and how they aid teams in working faster and more efficiently, delivering quality faster, and improving customer satisfaction.
Agile and DevOps are not adversarial in any way (or at least the intent is not there). They are more allies than enemies in the agile revolution. Agile and DevOps can operate exclusively and inclusively, which allows both to exist in the same space.
## 3 Comments |
12,033 | 水狐:一个支持旧版扩展的火狐复刻版 | https://itsfoss.com/waterfox-browser/ | 2020-03-24T20:24:41 | [
"Firefox",
"浏览器"
] | https://linux.cn/article-12033-1.html |
>
> 在本周的开源软件推荐中,我们将介绍一个基于 Firefox 的浏览器,该浏览器支持 Firefox 如今已不再支持的旧版扩展,同时尽可能地提供了快速的用户体验。
>
>
>
在 Web 浏览器方面,虽然谷歌浏览器已经占据了最大的市场份额,但 [Mozilla Firefox 仍然是关切隐私的主流 Web 浏览器的一面大旗](https://itsfoss.com/why-firefox/)。
Firefox 最近有了很多改进,这些改进的副作用之一是它删除了旧版<ruby> 扩展附件 <rt> add-on </rt></ruby>的支持。如果你最喜欢的扩展附件在最近几个月/几年内消失了,那么你可以以 Witerfox 的形式再次拥有它们。
>
> 注意!
>
>
> 我们注意到,Waterfox 已被 System1 收购。该公司还收购了注重隐私的搜索引擎 Startpage。尽管 System1 声称他们提供注重隐私的产品,因为“这是刚需”,但我们不能对此担保。换句话说,这要取决于你是否信任 System1 和 Waterfox。
>
>
>
### Waterfox:一个基于 Firefox 的浏览器

[Waterfox](https://www.waterfox.net/) 是基于 Firefox 构建的一个好用的开源浏览器,它注重隐私并支持旧版扩展。它没有将自己定位为偏执于隐私的浏览器,但确实尊重这个基本的认知。
你可以得到两个单独的 Waterfox 浏览器版本。当前版旨在提供现代体验,而经典版则旨在支持 [NPAPI 插件](https://en.wikipedia.org/wiki/NPAPI) 和 [bootstrap 扩展](https://wiki.mozilla.org/Extension_Manager:Bootstrapped_Extensions)。

如果你不需要使用 bootstrap 扩展程序,而是需要 [WebExtensions](https://wiki.mozilla.org/WebExtensions),则应该选择 Waterfox 当前版。
而如果你需要设置一个需要大量 NPAPI 插件或 Bootstrap 扩展的浏览器,则 Waterfox 经典版将非常适合你。
因此,如果你喜欢 Firefox,但想在同一阵营内尝试一些不同的体验,那么这个 Firefox 替代选择就是为此而生的。
### Waterfox 的功能

当然,从技术上讲,你应该能够做 Mozilla Firefox 支持的许多操作。
因此,我将在此处的列表中突出显示 Waterfox 的所有重要功能。
* 支持 NPAPI 插件
* 支持 Bootstrap 扩展
* 分别提供了支持旧版本扩展和现代的 WebExtension 两个版本。
* 跨平台支持(Windows、Linux 和 macOS)
* 主题定制
* 支持已经归档的扩展
### 在 Ubuntu/Linux 上安装 Waterfox
与其他流行的浏览器不同,它没有可以安装的软件包。因此,你将必须从其[官方下载页面](https://www.waterfox.net/download/)下载归档包。

根据你想要的版本(当前版/经典版),只需下载该文件,它是以 .tar.bz2 为扩展名的文件。
下载后,只需解压缩文件即可。
接下来,转到解压缩的文件夹并查找 `Waterfox` 文件。你只需双击它即可运行以启动浏览器。
如果这不起作用,则可以使用终端并导航到提取的 `Waterfox` 文件夹。到达那里后,你只需使用一个命令即可运行它。看起来如下:
```
cd waterfox-classic
./waterfox
```
无论是哪种情况,你都可以访问其 [GitHub 页面](https://github.com/MrAlex94/Waterfox)以了解将其安装在系统上的更多方式。
* [下载 Waterfox](https://www.waterfox.net/)
### 总结
我在我的 Pop!\_OS 19.10 系统中启动了它,在我这里工作的很好。尽管我不准备从 Firefox 切换到 Waterfox,因为我没有使用任何旧版扩展附件。但对于某些用户来说,它可能是一个重要选择。
你可以尝试一下,在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/waterfox-browser/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When it comes to web browsers, Google Chrome leads the market share. [Mozilla Firefox is there still providing hopes for a mainstream web browser that respects your privacy](https://itsfoss.com/why-firefox/).
Firefox has improved a lot lately and one of the side effects of the improvements is the removal of add-ons. If your favorite add-on disappeared in the last few months/years, you have good news in the form of Waterfox.
[privacy-focused search engine](https://itsfoss.com/privacy-search-engines/)Startpage. While System1 claims that they are providing privacy focused products because ‘there is a demand’, we cannot vouch for their claim. In other words, it’s up to you to trust System1 and Waterfox.
## Waterfox: A Firefox-based Browser

[Waterfox](https://www.waterfox.net/?ref=itsfoss.com) is a useful open-source browser built on top of Firefox that focuses on privacy and supports legacy extensions. It doesn’t pitch itself as a privacy-paranoid browser but it does respect the basics.
You get two separate Waterfox browser versions. The current edition aims to provide a modern experience and the classic version focuses to support [NPAPI plugins](https://en.wikipedia.org/wiki/NPAPI?ref=itsfoss.com) and [bootstrap extensions](https://wiki.mozilla.org/Extension_Manager:Bootstrapped_Extensions?ref=itsfoss.com).
If you do not need to utilize bootstrap extensions but rely on [WebExtensions](https://wiki.mozilla.org/WebExtensions?ref=itsfoss.com), Waterfox Current is the one you should go for.
And, if you need to set up a browser that needs NPAPI plugins or bootstrap extensions extensively, the Waterfox Classic version will be suitable for you.
So, if you like Firefox but want to try something different on the same line, this is a Firefox alternative for the job.
## Features of Waterfox
Of course, technically, you should be able to do a lot of things that Mozilla Firefox supports.
So, I’ll just highlight all the important features of Waterfox in a list here.
- Supports NPAPI Plugins
- Supports Bootstrap Extensions
- Offers separate editions for legacy extension support and modern WebExtension support.
- Cross-platform support (Windows, Linux, and macOS)
- Theme customization
- Archived Add-ons supported
## Installing Waterfox on Ubuntu/Linux
Unlike other popular browsers, you don’t get a package to install. So, you will have to download the archived package from its [official download page](https://www.waterfox.net/download/?ref=itsfoss.com).
Depending on what edition (Current/Classic) you want – just download the file, which will be **.tar.bz2** extension file.
Once downloaded, simply extract the file.
Next, head on to the extracted folder and look for the “**Waterfox**” file. You can simply double-click on it to run start up the browser.
If that doesn’t work, you can utilize the terminal and navigate to the extracted **Waterfox** folder. Once there, you can simply run it with a single command. Here’s what it looks like:
```
cd waterfox-classic
./waterfox
```
In either case, you can also head to its [GitHub page](https://github.com/MrAlex94/Waterfox?ref=itsfoss.com) and explore more options to get it installed on your system.
## More browsing options
Want a more unique browsing experience? Here's something you'll love if you like using keyboard shortcuts.
[Nyxt Browser is a Keyboard-oriented Web Browser Inspired by Emacs and VimYou get plenty of web browsers available for Linux. Not just limited to Chrome-based options, but Chrome alternatives as well. Most of the options available focus on a pretty user experience while offering privacy features. However, Nyxt browser may not be built for the best user experienc…](https://itsfoss.com/nyxt-browser/)

Or explore some [lightweight web browsers](https://itsfoss.com/lightweight-web-browsers-linux/).
[10 Open Source Lightweight Web Browsers for LinuxThere are plenty of web browsers available for Linux. A lot of them are based on Chromium but we also have a list of browsers that are not based on Chromium. Recently, a reader asked for a lightweight web browsers recommendation and hence I took the responsibility of doing some](https://itsfoss.com/lightweight-web-browsers-linux/)

I fired it up on my Pop!_OS 19.10 installation and it worked really well for me. Though I don’t think I could switch from Firefox to Waterfox because I am not using any legacy add-on. It could still be an impressive option for certain users.
You could give it a try and let me know your thoughts in the comments below. |
12,034 | 2020 年将是 SD-WAN 的回顾之年 | https://www.networkworld.com/article/3531315/2020-will-be-a-year-of-hindsight-for-sd-wan.html | 2020-03-24T21:49:25 | [
"SD-WAN",
"WAN"
] | https://linux.cn/article-12034-1.html | 
对于软件定义的广域网(SD-WAN),“过去看起来困难的选择,知道了这些选择的结果后,现在看起来就很清晰了” 这一说法再合适不过了。总结过去的几年:云计算和数字化转型促使公司重新评估传统的 WAN 技术,该技术不再能够满足其不断增长的业务需求。从那时起,SD-WAN 成为一种有前途的新技术。
SD-WAN 旨在解决物理设备的流量管理问题,并支持从云进行基于软件的配置。许多最初的 SD-WAN 部署都因希望取代昂贵的多协议标签交换 (MPLS) 而得到推动。公司希望它可以神奇地解决他们所有的网络问题。但是在实践中,基本的 SD-WAN 解决方案远没有实现这一愿景。
快速发展到现在,围绕 SD-WAN 的炒作已经尘埃落定,并且早期的实施工作已经过去。现在是时候回顾一下我们在 2019 年学到的东西以及在 2020 年要改进的地方。所以,让我们开始吧。
### 1、这与节省成本无关
大多数公司选择 SD-WAN 作为 MPLS 的替代品,因为它可以降低 WAN 成本。但是,[节省的成本](https://blog.silver-peak.com/to-maximize-the-value-of-sd-wan-look-past-hardware-savings)会因 SD-WAN 的不同而异,因此不应将其用作部署该技术的主要驱动力。无论公司需要什么,公司都应该专注于提高网络敏捷性,例如实现更快的站点部署和减少配置时间。SD-WAN 的主要驱动力是使网络更高效。如果成功实现那么成本也会随之降低。
### 2、WAN 优化是必要的
说到效率,[WAN 优化](https://blog.silver-peak.com/sd-wan-vs-wan-optimization)提高了应用程序和数据流量的性能。通过应用协议加速、重复数据消除、压缩和缓存等技术,WAN 优化可以增加带宽、减少延迟并减轻数据包丢失。最初的想法是 SD-WAN 可以完成对 WAN 优化的需求,但是我们现在知道某些应用程序需要更多的性能支持。这些技术相互补充,而不是相互替代。它们应该用来解决不同的问题。
### 3、安全性不应该事后考虑
SD-WAN 具有许多优点,其中之一就是使用宽带互联网快速发送企业应用程序流量。但是这种方法也带来了安全风险,因为它使用户及其本地网络暴露于不受信任的公共互联网中。从一开始,安全性就应该成为 SD-WAN 实施的一部分,而不是在事后。公司可以通过使用[安全的云托管](https://blog.silver-peak.com/sd-wans-enable-scalable-local-internet-breakout-but-pose-security-risk)之类的服务,将安全性放在分支机构附近,从而实现所需的应用程序性能和保护。
### 4、可见性对于 SD-WAN 成功至关重要
在应用程序和数据流量中具有[可见性](https://blog.silver-peak.com/know-the-true-business-drivers-for-sd-wan),这使网络管理不再需要猜测。最好的起点是部署前阶段,在此阶段,公司可以在实施 SD-WAN 之前评估其现有功能以及缺少的功能。可见性以日常监控和警报的形式在部署后继续发挥重要作用。了解网络中正在发生的情况的公司会更好地准备应对性能问题,并可以利用这些知识来避免将来出现问题。
### 5、无线广域网尚未准备就绪
SD-WAN 可通过包括宽带和 4G/LTE 无线在内的任何传输将用户连接到应用程序。这就是[移动互联](https://blog.silver-peak.com/mobility-and-sd-wan-part-1-sd-wan-with-4g-lte-is-a-reality)越来越多地集成到 SD-WAN 解决方案中的原因。尽管公司渴望将 4G 用作潜在的传输替代方案(尤其是在偏远地区),但由此带来的按使用付费 4G 服务成本却很高。此外,由于延迟和带宽限制,4G 可能会出现问题。最好的方法是等待服务提供商部署具有更好的价格选择的 5G。今年我们将看到 5G 的推出,并更加关注无线 SD-WAN。
请务必观看以下 SD-WAN 视频系列:[你应该知道的所有关于 SD-WAN 的知识](https://www.silver-peak.com/everything-you-need-to-know-about-sd-wan)。
---
via: <https://www.networkworld.com/article/3531315/2020-will-be-a-year-of-hindsight-for-sd-wan.html>
作者:[Zeus Kerravala](https://www.networkworld.com/author/Zeus-Kerravala/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hkurj](https://github.com/hkurj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,035 | 10 篇关于 Linux 的好文章 | https://opensource.com/article/19/12/learn-linux | 2020-03-25T11:55:17 | [
"Linux"
] | https://linux.cn/article-12035-1.html |
>
> 2019 年对于 Linux 来说是个好年份,让我们一起来回顾一下这十篇关于 Linux 的好文章。
>
>
>

2019 年对于 Linux 来说是个好年份,显然这里的 “Linux” 一词有更多含义: 内核? 桌面? 或是生态? 在此次回顾年度 Linux 好文中,我在选择十大好文时有意采取了更开放的视角。下面就是十大好文(无先后次序之分)。
### 《Linux 权限入门指南》
Bryant Son 的《[Linux 权限入门指南](/article-11056-1.html)》向新用户介绍了文件权限的概念,通过图形和图表的方式来说明每个要点。通常很难以视觉的方式来解释纯粹基于文本的概念,而本文则对可视方式学习的人非常友好。 Bryant 在讲述时也很专注主题。关于文件权限的任何阐述都可能引出几个相关主题(例如所有权和访问控制列表等),但是本文致力于解释一件事并很好地解释它。
### 《为什么我从 Mac 换到了 Linux》
Matthew Broberg 在《[为什么我从 Mac 换到了 Linux](/article-11586-1.html)》中清楚而客观的介绍了他从 MacOS 切换到 Linux 的经历。通常切换平台是很困难的,因此记录决定切换的背后考虑非常重要。我认为 Matt 的文章带有几个目的,但对我来说最重要的两个目的是:通过解答他的问题并提供潜在的解决方案,他请 Linux 社区的人们来支持他;这对于其他正在考虑采用 Linux 的人来说是一个很好的参考。
### 《在 Linux 上定位 WiFi 速度慢的问题》
《[在 Linux 上定位 WiFi 速度慢的问题](http://opensource.com/article/19/4/troubleshooting-wifi-linux)》这篇文章中,David Clinton 对每个人都可能遇到的问题进行了分析,并提供了怎么样一步步解决的思路。这是“偶然的 Linux”技巧的一个很好的例子,但它不仅可以帮助经常遇到问题的人,而且可以向非 Linux 用户展示如何在其他平台上进行问题定位。
### 《一个非技术人员对 GNOME 项目使用 GitLab 的感受》
Molly de Blanc 所写的《[一个非技术人员对 GNOME 项目使用 GitLab 的感受](/article-11806-1.html)》深层次地揭示了开源界的一个典范(GNOME 桌面)如何使用开源界的另一个典范(Git)进行开发。听到一个开放源代码项目对于任何需要做的事情默认为开放源代码解决方案,这总是让我感到振奋。无论如何,这种情况并不常见,然而对于 GNOME 来说,这是项目本身的重要且受欢迎的部分。
### 《详解 Linux 中的虚拟文件系统》
Alison Chaiken 在《[详解 Linux 中的虚拟文件系统](/article-10884-1.html)》中巧妙地解释了对许多用户来说都很难理解的东西。理解文件系统是什么、虚拟文件系统和真实的文件系统是一回事,但从定义上讲,*虚拟的*其实并不是真正的文件系统。Linux 以一种普通用户也能从中受益的方式提供了它们,Alison 的文章以一种易于理解的方式对其进行了阐述。另外,Alison 在文章的后半部分更深入地介绍了如何使用 `bcc` 脚本查看她刚刚讲的虚拟文件系统的相关内容。
### 《理解文件路径并学会使用它们》
我认为《[理解文件路径并学会使用它们](https://opensource.com/article/19/8/understanding-file-paths-linux)》很重要,因为这是大多数用户(在任何平台上)似乎都没有学过的概念。这是一个奇怪的现象,因为现在比以往任何时候,人们都越来越多地看到*文件路徑*:几乎所有的互联网网址都包含一个文件路径,该路径告诉你你在域中的确切位置。我常常在想为什么计算机教育不是从互联网开始的,互联网是目前最熟悉的应用程序,并且可以说是使用最频繁的超级计算机,完全可以用它来解释我们每天使用的设备。(我想如果这些设备运行 Linux 会有所帮助,但是我们正在努力。)
### 《Linux 下的进程间通信:共享存储》
Marty Kalin 的《[Linux 下的进程间通信:共享存储](/article-10826-1.html)》从 Linux 的开发者视角解释了 IPC 以及如何在代码中使用它。虽然我只是列入了这篇文章,不过它实际上是一个三篇文章的系列,而它是同类文章中阐述的最好的。很少有文档能够解释 Linux 怎样处理 IPC,更不用说 IPC 是什么,为什么它很重要,或者在编程时该如何使用它。通常这是你在大学读书时关注的话题。现在,你可以在这里阅读所有内容。
### 《在 Linux 上用 strace 来理解系统调用》
Gaurav Kamathe 的《[在 Linux 上用 strace 来理解系统调用](/article-11545-1.html)》具有很强的技术性,我希望我所见过的有关 `strace` 的每次会议演讲都是如此。这是对一个复杂但非常有用的命令的清晰演示。令我惊讶的是,我读了本文才发现自己一直使用的命令不是这个命令,而是 `ltrace`(可以用来查看命令调用了哪些函数)。本文包含了丰富的信息,是开发人员和测试人员的快捷参考手册。
### 《Linux 桌面发展旅程》
Jim Hall 的《[Linux 桌面发展旅程](https://opensource.com/article/19/8/how-linux-desktop-grown)》是对 Linux 桌面历史的一次视觉之旅。从 [TWM](https://github.com/freedesktop/twm) 开始,经历了 [FVWM](http://www.fvwm.org/)、[GNOME](http://gnome.org)、[KDE](http://kde.org) 等薪火相传。如果你是 Linux 的新手,那么这将是一个出自那个年代的人的有趣的历史课(有截图可以证明这一点)。如果你已经使用 Linux 多年,那么这肯定会唤醒你的记忆。最后,可以肯定的是:仍然可以找到 20 年前屏幕快照的人都是神一样的数据档案管理员。
### 《用 Linux 创建你自己的视频流服务器》
Aaron J. Prisk 的 《[用 Linux 创建你自己的视频流服务器](https://opensource.com/article/19/1/basic-live-video-streaming-server)》消除了大多数人对我们视为理所当然的服务的误解。由于 YouTube 和 Twitch 之类服务的存在,许多人认为这是向世界广播视频的唯一方式。当然,人们过去常常以为 Windows 和 Mac 是计算机的唯一入口,值得庆幸的是,最终证明这是严重的误解。在本文中,Aaron 建立了一个视频流服务器,甚至还顺便讨论了一下 [OBS](https://opensource.com/life/15/12/real-time-linux-video-editing-with-obs-studio),以便你可以创建视频。这是一个有趣的周末项目还是新职业的开始?你自己决定。
### 《塑造 Linux 历史的 10 个时刻》
Alan Formy-Duval 撰写的《[塑造 Linux 历史的 10 个时刻](https://opensource.com/article/19/4/top-moments-linux-history)》试图完成一项艰巨的任务,即从 Linux 的历史中选出 10 件有代表性的事情。当然,这是很难的,因为有如此多重要的时刻,所以我想看看 Alan 是如何通过自己的经历来选择它。例如,什么时候开始意识到 Linux 必然可以发展下去?—— 当 Alan 意识到他维护的所有系统都在运行 Linux 时。用这种方式来解释历史是很美的,因为每个人的重要时刻都会有所不同。 关于 Linux 没有权威性列表,关于 Linux 的文章也没有,关于开源也没有。你可以创建你自己的列表,也可以使你自己成为列表的一部分。
(LCTT 译注:这里推荐了 11 篇,我数了好几遍,没眼花……)
### 你想从何学起?
你还想知道 Linux 的什么内容?请在评论区告诉我们或来文讲述你的 Linux 经验。
---
via: <https://opensource.com/article/19/12/learn-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[messon007](https://github.com/messon007) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The year 2019 has been good for Linux with Opensource.com readers. Obviously, the term "Linux" itself is weighted: Does it refer to the kernel or the desktop or the ecosystem? In this look back at the top Linux articles of the year, I've intentionally taken a broad view in defining the top 10 Linux articles (for some definition of "top" and some definition of "Linux"). Here they are, offered in no particular order.
## A beginner's guide to Linux permissions
[ A beginner's guide to Linux permissions](https://opensource.com/article/19/6/understanding-linux-permissions) by Bryant Son introduces new users to the concept of file permissions with graphics and charts to illustrate each point. It can be hard to come up with visuals for concepts that are, at their core, purely text-based, and this article is friendly for the visual learners out there. I also like how Bryant stays focused. Any discussion of file permissions can lead to several related topics (like ownership and access control lists and so on), but this article is dedicated to explaining one thing and explaining it well.
## Why I made the switch from Mac to Linux
Matthew Broberg offers an insightful and honest look at his migration to Linux from MacOS in [ Why I made the switch from Mac to Linux](https://opensource.com/article/19/10/why-switch-mac-linux). Changing platforms is always tough, and it's important to record what's behind the decision to switch. Matt's article, I think, serves several purposes, but the two most important for me: it's an invitation for the Linux community to support him by answering questions and offering potential solutions, and it's a good data point for others who are considering Linux adoption.
## Troubleshooting slow WiFi on Linux
In [ Troubleshooting slow WiFi on Linux](http://opensource.com/article/19/4/troubleshooting-wifi-linux), David Clinton provides a useful analysis of a problem everyone has on every platform—and has tips on how to solve it. It's a good example of an "incidentally Linux" tip that not only helps everyday people with everyday problems but also shows non-Linux users how approachable troubleshooting (on any platform) is.
## How GNOME uses Git
[ How GNOME uses Git](https://opensource.com/article/19/10/how-gnome-uses-git) by Molly de Blanc takes a look behind the scenes, revealing how one of the paragons of open source software (the GNOME desktop) uses one of the other paragons of open source (Git) for development. It's always heartening to me to hear about an open source project that defaults to an open source solution for whatever needs to be done. Believe it or not, this isn't always the case, but for GNOME, it's an important and welcoming part of the project's identity.
## Virtual filesystems in Linux: Why we need them and how they work
Alison Chaiken masterfully explains what is considered incomprehensible to many users in [ Virtual filesystems in Linux: Why we need them and how they work](https://opensource.com/article/19/3/virtual-filesystems-linux). Understanding what a filesystem is and what it does is one thing, but
*virtual*ones aren't even, by definition, real. And yet Linux delivers them in a way that even casual users can benefit from, and Alison's article explains it in a way that anyone can understand. As a bonus, Alison goes even deeper in the second half of the article and demonstrates how to use bcc scripts to monitor everything she just taught you.
## Understanding file paths and how to use them
I thought [ Understanding file paths and how to use them](https://opensource.com/article/19/8/understanding-file-paths-linux) was important to write about because it's a concept most users (on any platform) don't seem to be taught. It's a strange phenomenon, because now, more than ever, the
*file path*is something people see literally on a daily basis: Nearly all internet URLs contain a file path telling you exactly where within the domain you are. I often wonder why computer education doesn't start with the internet, the most familiar app of all and arguably the most heavily used supercomputer in existence, and use it to explain the appliances we interface with each day. (I guess it would help if those appliances were running Linux, but we're working on that.)
## Inter-process communication in Linux
[ Inter-process communication in Linux: Shared storage](https://opensource.com/article/19/4/interprocess-communication-linux-storage) by Marty Kalin delves into the developer side of Linux, explaining IPC and how to interact with it in your code. I'm cheating by including this article because it's actually a three-part series, but it's the best explanation of its kind. There is very little documentation that manages to explain how Linux handles IPC, much less what IPC is, why it's important, or how to take advantage of it when programming. It's normally a topic you work your way up to in university. Now you can read all about it here instead.
## Understanding system calls on Linux with strace
[ Understanding system calls on Linux with strace](https://opensource.com/article/19/10/strace) by Gaurav Kamathe is highly technical in ways I wish that every conference talk I've ever seen about
**strace**was. This is a clear and helpful demonstration of a complex but amazingly useful command. To my surprise, the command I've found myself using since this article isn't the titular command, but
**ltrace**(to see which functions are called by a command). Obviously, this article's packed with information and is a handy reference for developers and QA testers.
## How the Linux desktop has grown
[ How the Linux desktop has grown](https://opensource.com/article/19/8/how-linux-desktop-grown) by Jim Hall is a visual journey through the history of the Linux desktop. It starts with
[TWM](https://github.com/freedesktop/twm)and passes by
[FVWM](http://www.fvwm.org/),
[GNOME](http://gnome.org),
[KDE](http://kde.org), and others. If you're new to Linux, this is a fascinating history lesson from someone who was there (and has the screenshots to prove it). If you've been with Linux for many years, then this will definitely bring back memories. In the end, though, one thing is certain: Anyone who can still locate screenshots from 20 years ago is a superhuman data archivist.
## Create your own video streaming server with Linux
[ Create your own video streaming server with Linux](https://opensource.com/article/19/1/basic-live-video-streaming-server) by Aaron J. Prisk breaks down more than just a few preconceptions most of us have about the services we take for granted. Because services like YouTube and Twitch exist, many people assume that those are the only gateways to broadcasting video to the world. Of course, people used to think that Windows and Mac were the only gateways into computing, and that, thankfully, turned out to be a gross miscalculation. In this article, Aaron sets up a video-streaming server and even manages to find space to talk about
[OBS](https://opensource.com/life/15/12/real-time-linux-video-editing-with-obs-studio)in so you can create videos to stream. Is it a fun weekend project or the start of a new career? You decide.
## 10 moments that shaped Linux history
[ 10 moments that shaped Linux history](https://opensource.com/article/19/4/top-moments-linux-history) by Alan Formy-Duval attempts the formidable task of choosing just 10 things to highlight in the history of Linux. It's an exercise in futility, of course, because there have been so many important moments, so I love how Alan filters it through his own experience. For example, when was it obvious that Linux was going to last? When Alan realized that all the systems he maintained at work were running Linux. There's a beauty to interpreting history this way because the moments of importance will differ for each person. There's no definitive list for Linux, or articles about Linux, or for open source. You make your own list, and you make yourself a part of it.
## What do you want to learn?
What else do you want to know about Linux? Please tell us about it in the comments, or [write an article](https://opensource.com/how-submit-article) for Opensource.com about your experience with Linux.
## Comments are closed. |
12,037 | 将你的 Google Drive 连接到 Fedora 工作站 | https://fedoramagazine.org/connect-your-google-drive-to-fedora-workstation/ | 2020-03-25T21:57:09 | [
"Google",
"云存储"
] | https://linux.cn/article-12037-1.html | 
有大量的云服务可用于存储重要文档。Google Drive 无疑是最受欢迎的之一。它提供了一组相应的应用程序,例如文档,表格和幻灯片来创建内容。但是,你也可以在 Google Drive 中存储任意内容。本文向你展示如何将其连接到 [Fedora 工作站](https://getfedora.org/workstation)。
### 添加帐户
Fedora 工作站可在安装后首次启动或者之后的任何时候添加一个帐户。要在首次启动期间添加帐户,请按照提示进行操作。其中包括选择添加一个帐户:

选择 Google,然后会出现一个登录提示,请使用你的 Google 帐户信息登录。

请注意,此信息仅传输给 Google,而不传输给 GNOME 项目。下一个页面要求你授予访问权限,这是必需的,以便系统桌面可以与 Google 进行交互。向下滚动查看访问请求,然后选择“允许”继续。
你会在移动设备和 Gmail 中收到有关新设备(系统)访问 Google 帐户的通知。这是正常现象。

如果你在初次启动时没有执行此操作,或者需要重新添加帐户,请打开“设置”,然后选择“在线账户”来添加帐户。可以通过顶部栏右侧的下拉菜单(“齿轮”图标)或打开“概览”并输入“settings”来使用它。接着和上面一样。
### 在 Google Drive 中使用“文件”应用
打开“文件”应用(以前称为 “nautilus”)。“文件”应用可以通过左侧栏访问。在列表中找到你的 Google 帐户。
当你选择帐户后,“文件”应用会显示你的 Google Drive 的内容。你可以使用 Fedora 工作站的本地应用打开某些文件,例如声音文件或 [LibreOffice](https://fedoramagazine.org/discover-hidden-gems-libreoffice/) 兼容文件(包括 Microsoft Office 文档)。其他文件(例如 Google 文档、表格和幻灯片等 Google 应用文件)将使用浏览器和相应的应用打开。
请记住,如果文件很大,将需要一些时间才能通过网络接收文件,你才可以打开它。
你还可以复制粘贴 Google Drive 中的文件到连接到 Fedora 工作站的其他存储,或者反之。你还可以使用内置功能来重命名文件、创建文件夹并组织它们。对于共享和其他高级选项,请和平常一样在浏览器中使用 Google Drive。
请注意,“文件”应用程序不会实时刷新内容。如果你从其他连接 Google 的设备(例如手机或平板电脑)添加或删除文件,那么可能需要按 `Ctrl+R` 刷新“文件”应用。
---
via: <https://fedoramagazine.org/connect-your-google-drive-to-fedora-workstation/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are plenty of cloud services available where you can store important documents. Google Drive is undoubtedly one of the most popular. It offers a matching set of applications like Docs, Sheets, and Slides to create content. But you can also store arbitrary content in your Google Drive. This article shows you how to connect it to your [Fedora Workstation](https://getfedora.org/workstation).
## Adding an account
Fedora Workstation lets you add an account either after installation during first startup, or at any time afterward. To add your account during first startup, follow the prompts. Among them is a choice of accounts you can add:
Select Google and a login prompt appears for you to login, so use your Google account information.
Be aware this information is only transmitted to Google, not to the GNOME project. The next screen asks you to grant access, which is required so your system’s desktop can interact with Google. Scroll down to review the access requests, and choose *Allow* to proceed.
You can expect to receive notifications on mobile devices and Gmail that a new device — your system — accessed your Google account. This is normal and expected.
If you didn’t do this at first startup, or you need to re-add your account, open the *Settings* tool, and select *Online Accounts* to add the account. The *Settings* tool is available through the dropdown at right side of the Top Bar (the “gear” icon), or by opening the Overview and typing *settings*. Then proceed as described above.
## Using the Files app with Google Drive
Open the *Files* app (formerly known as *nautilus*). Locations the Files app can access appear on the left side. Locate your Google account in the list.
When you select this account, the Files app shows the contents of your Google drive. Some files can be opened using your Fedora Workstation local apps, such as sound files or [LibreOffice](https://fedoramagazine.org/discover-hidden-gems-libreoffice/)-compatible files (including Microsoft Office docs). Other files, such as Google app files like Docs, Sheets, and Slides, open using your web browser and the corresponding app.
Remember that if the file is large, it will take some time to receive over the network so you can open it.
You can also copy and paste files in your Google Drive storage from or to other storage connected to your Fedora Workstation. You can also use the built in functions to rename files, create folders, and organize them. For sharing and other advanced options, use Drive from your browser per normal.
Be aware that the Files app does not refresh contents in real time. If you add or remove files from other Google connected devices like your mobile phone or tablet, you may need to hit **Ctrl+R** to refresh the Files app view.
*Photo by Beatriz Pérez Moya on Unsplash.*
## Vernon Van Steenkist
So, is this a VFS feature of the GNOME File manager or is your Google Drive actually being mounted? This technical detail would have been helpful, especially for people like me who do not use GNOME. If your Google Drive is not actually being mounted to a mount point, google-drive-ocamlfuse is a much better choice since your Google Drive is actually being mounted via FUSE which means you can access all you Google Drive files with any application – including command line.
https://github.com/astrada/google-drive-ocamlfuse
## Paul W. Frields
The mount is performed via GVFS and can also be found via
/run/user/$UID/gvfs/. This article is written for the audience of Fedora Workstation users, for whom GNOME is provided.## Frank L
Are you sure? When I tried to use a terminal window to access /user/$UID/ I didn’t find anything.
## Paul W. Frields
Yes, I’m sure. It’s /run/user/$UID/gvfs as stated earlier.
## Roland Müller
I am using XFCE as DE and find it a bit strange that the article did not even bother to mention that its content is Gnome-only. Linux is for many a matter of having a choice.
## Paul W. Frields
It’s not strange at all; the article title itself specifically says “Fedora Workstation,” which uses the GNOME desktop environment.
## Roland Müller
https://en.wikipedia.org/wiki/Fedora_(operating_system)#Editions
“Fedora Workstation – It targets users who want a reliable, user-friendly, and powerful operating system for their laptop or desktop computer. It comes with GNOME by default but other desktops can be installed or can be directly installed as Spins.”
## Paul W. Frields
Wikipedia doesn’t speak for the Fedora Workstation group and their intent to have a cohesive, modern desktop environment. Also, when the Magazine produces articles for Workstation, they’re intended to feature the edition as it ships out of the box, not altered with other window managers or environments. Articles for other environments will be so titled. Thanks for writing, let’s move on. 🙂
## K. de Jong
It’s nice indeed! However, it doesn’t work when using 2FA exclusively with e.g. a Yubikey. For that Chrome/Chromium is needed.
## Paul W. Frields
Actually, it will still work if you’re using Google’s 2FA method that attaches to your mobile device. When I sign in, even after I provide a correct passphrase, I receive a notification on my phone that I have to approve to allow the access. However, for some other types of custom 2FA you may not be able to attach this way.
## K. de Jong
Not if you enrolled into the Advanced Protection Program of Google. That’s when you exclusive have to use a YubiKey. Unsafe 2FA is blocked. Then you need Chrome/Chromium, which is not used in GNOME online accounts.
## Paul W. Frields
Right, my point was about the standard 2FA method specifically, which suffices for most users. You already made the exception of APP clear. 🙂
## Mario Castellano
Hi, is there something similar for Microsoft Onedrive?
## Paul W. Frields
The GNOME Online Accounts system doesn’t support OneDrive. There should be other ways to sync to OneDrive using Fedora, though, that are searchable online.
## Mario Castellano
Sure, right now I’m using Rclone Browser, but nautilus integration was a more interesting and practical option.
Thank you.
## Colin Wu
I use rclone script in a bash script that run at startup. It mounts my OneDrive under my home and can access it from any GUI file manager. Have a look at rclone.org
## Mario Castellano
Done, I already had the software installed and the config done because of Rclone Browser, I only had to launch the rclone mount command and everything is done.
Thank you very very very very very very very very very very much!!
## Danny Voisine
How does one use this feature if they use xfce?
## Paul W. Frields
You’ll need to use some other method — this feature is part of GNOME, and you can use it with Fedora Workstation. Some other commenters have already mentioned alternatives, so feel free to try one of those.
## Harish Ketheeswaran
i like fedora very much. I Like the polished gnome design than windows 10 start.KEEP IT UP FEDORA
## Silvia
Is there a way to do this but in KDE or XFCE?
## Paul W. Frields
Asked and answered earlier.
## Bruno
If the remote access does not work well for your workflow, there is also RClone https://rclone.org/drive/ (it has a nice GUI too).
If your workflow is even more demanding, you can add on top : https://github.com/cjnaz/rclonesync-V2 RCloneSync a two way sync Python script.
But still it would be nice to have an optimized two-way sync client.
## Vd
What about LXDE ?
## hammerhead corvette
Although the title is Explicit in stating “Fedora Workstation” which has Gnome by default, there are other Fedora spins and the title leaves toomuch to the assumption of “Fedora”. The title should be changed to “Connect your Google Drive with Gnome”
## ewrgfergf
i3wm have any program?
or terminal? I’m not using gnome
## Gregory Bartholomew
If you still have GNOME installed on your workstation, you can use it to do a one-time setup/initialization of the online account. Once the online account exists, nautilus can access it; even when run under i3wm. When you change your Google password, you can use the “Passwords and Keys” (aka seahorse) application to update the password that is stored in your keyring.
FYI & YMMV
## Patrick O'Callaghan
Not sure if it’s appropriate to mention this here but as several people are asking, there is a commercial program called Insync which does a fairly good job of syncing with Google Drive (and OneDrive). I’ve used it for several years. There is a one-off license fee and they have an RPM package that’s updated frequently. I only mention this because of Google’s perennial reluctance to release a Linux equivalent to their Windows and MacOS offerings.
There are also a number of free software alternatives which can be found by searching for “google drive linux” but those I’ve seen don’t seem quite as slick or regularly maintained.
## Tobias
As Bruno said rclone works really well. It can mount google drive to your filesystem so you do not have to start the sync process manually. It feels a little bit slow sometimes but overall it works fine. And it’s open-source (unlike insync) and it is, in contrast what Patrick said, pretty well maintained.
## sonu sahu
Sorry to ask but what is the additional benefit of connecting google drive to fedora workstation
## Vernon Van Steenkisy
If I am working remotely with only my Iphone and its HDMI dongle and I accidentally left my pdf presentation file on my fedora workstation, I can ssh into my fedora workstation from my Iphone and use the cp or mc command to copy the pdf to the fedora workstation google drive mount point which my Iphone can then easily access through the google drive app. There are many similar such use cases.
Another pro tip. if you use the bash shell, type the command
set -o vi
after sshing into your workstation. This will give your command line vi key bindings instead of the default emacs key bindings. One of the many advantages is that you can now use the hjkl keys as arrow keys which is nice because the Iphone and Ipad keyboards don’t have arrow keys. |
12,038 | 在 Linux 系统中手动滚动日志 | https://www.networkworld.com/article/3531969/manually-rotating-log-files-on-linux.html | 2020-03-25T22:40:13 | [
"日志",
"logrotate"
] | https://linux.cn/article-12038-1.html | 
<ruby> 日志滚动 <rt> log rotation </rt></ruby>在 Linux 系统上是再常见不过的一个功能了,它为系统监控和故障排查保留必要的日志内容,同时又防止过多的日志造成单个日志文件太大。
日志滚动的过程是这样的:在一组日志文件之中,编号最大的(最旧的)一个日志文件会被删除,其余的日志文件编号则依次增大并取代较旧的日志文件,而较新的文件则取代它作为当前的日志文件。这一个过程很容易就可以实现自动化,在细节上还能按需作出微调。
使用 `logrotate` 命令可以手动执行日志滚动的操作。本文将要介绍的就是手动进行日志滚动的方法,以及预期产生的结果。
文中出现的示例适用于 Ubuntu 等 Linux 系统,对于其它类型的系统,日志文件和配置文件可能会有所不同,但日志滚动的过程是大同小异的。
### 为什么需要滚动日志
一般情况下,无需手动旋转日志文件。Linux 系统会每隔一天(或间隔更长的时间)或根据日志文件的大小自动进行一次日志滚动。如果你需要滚动日志以释放存储空间,又或者将某一部分日志从当前的活动中分割出来,这很容易做到,具体要取决于文件滚动规则。
### 一点背景介绍
在 Linux 系统安装完成后就已经有很多日志文件被纳入到日志滚动的范围内了。另外,一些应用程序在安装时也会为自己产生的日志文件设置滚动规则。一般来说,日志滚动的配置文件会放置在 `/etc/logrotate.d`。如果你想了解日志滚动的详细实现,可以参考[这篇以前的文章](https://www.networkworld.com/article/3218728/how-log-rotation-works-with-logrotate.html)。
在日志滚动的过程中,活动日志会以一个新名称命名,例如 `log.1`,之前被命名为 `log.1` 的文件则会被重命名为 `log.2`,依此类推。在这一组文件中,最旧的日志文件(假如名为 `log.7`)会从系统中删除。日志滚动时文件的命名方式、保留日志文件的数量等参数是由 `/etc/logrotate.d` 目录中的配置文件决定的,因此你可能会看到有些日志文件只保留少数几次滚动,而有些日志文件的滚动次数会到 7 次或更多。
例如 `syslog` 在经过日志滚动之后可能会如下所示(注意,行尾的注释部分只是说明滚动过程是如何对文件名产生影响的):
```
$ ls -l /var/log/syslog*
-rw-r----- 1 syslog adm 128674 Mar 10 08:00 /var/log/syslog <== 新文件
-rw-r----- 1 syslog adm 2405968 Mar 9 16:09 /var/log/syslog.1 <== 之前的 syslog
-rw-r----- 1 syslog adm 206451 Mar 9 00:00 /var/log/syslog.2.gz <== 之前的 syslog.1
-rw-r----- 1 syslog adm 216852 Mar 8 00:00 /var/log/syslog.3.gz <== 之前的 syslog.2.gz
-rw-r----- 1 syslog adm 212889 Mar 7 00:00 /var/log/syslog.4.gz <== 之前的 syslog.3.gz
-rw-r----- 1 syslog adm 219106 Mar 6 00:00 /var/log/syslog.5.gz <== 之前的 syslog.4.gz
-rw-r----- 1 syslog adm 218596 Mar 5 00:00 /var/log/syslog.6.gz <== 之前的 syslog.5.gz
-rw-r----- 1 syslog adm 211074 Mar 4 00:00 /var/log/syslog.7.gz <== 之前的 syslog.6.gz
```
你可能会发现,除了当前活动的日志和最新一次滚动的日志文件之外,其余的文件都已经被压缩以节省存储空间。这样设计的原因是大部分系统管理员都只需要查阅最新的日志文件,其余的日志文件压缩起来,需要的时候可以解压查阅,这是一个很好的折中方案。
### 手动日志滚动
你可以这样执行 `logrotate` 命令进行手动日志滚动:
```
$ sudo logrotate -f /etc/logrotate.d/rsyslog
```
值得一提的是,`logrotate` 命令使用 `/etc/logrotate.d/rsyslog` 这个配置文件,并通过了 `-f` 参数实行“强制滚动”。因此,整个过程将会是:
* 删除 `syslog.7.gz`,
* 将原来的 `syslog.6.gz` 命名为 `syslog.7.gz`,
* 将原来的 `syslog.5.gz` 命名为 `syslog.6.gz`,
* 将原来的 `syslog.4.gz` 命名为 `syslog.5.gz`,
* 将原来的 `syslog.3.gz` 命名为 `syslog.4.gz`,
* 将原来的 `syslog.2.gz` 命名为 `syslog.3.gz`,
* 将原来的 `syslog.1.gz` 命名为 `syslog.2.gz`,
* 但新的 `syslog` 文件不一定必须创建。
你可以按照下面的几条命令执行操作,以确保文件的属主和权限正确:
```
$ sudo touch /var/log/syslog
$ sudo chown syslog:adm /var/log/syslog
$ sudo chmod 640 /var/log/syslog
```
你也可以把以下这一行内容添加到 `/etc/logrotate.d/rsyslog` 当中,由 `logrotate` 来帮你完成上面三条命令的操作:
```
create 0640 syslog adm
```
整个配置文件的内容是这样的:
```
/var/log/syslog
{
rotate 7
daily
missingok
notifempty
create 0640 syslog adm <==
delaycompress
compress
postrotate
/usr/lib/rsyslog/rsyslog-rotate
endscript
}
```
下面是手动滚动记录用户登录信息的 `wtmp` 日志的示例。由于 `/etc/logrotate.d/wtmp` 中有 `rotate 2` 的配置,因此系统中只保留了两份 `wtmp` 日志文件。
滚动前:
```
$ ls -l wtmp*
-rw-r----- 1 root utmp 1152 Mar 12 11:49 wtmp
-rw-r----- 1 root utmp 768 Mar 11 17:04 wtmp.1
```
执行滚动命令:
```
$ sudo logrotate -f /etc/logrotate.d/wtmp
```
滚动后:
```
$ ls -l /var/log/wtmp*
-rw-r----- 1 root utmp 0 Mar 12 11:52 /var/log/wtmp
-rw-r----- 1 root utmp 1152 Mar 12 11:49 /var/log/wtmp.1
-rw-r----- 1 root adm 99726 Feb 21 07:46 /var/log/wtmp.report
```
需要知道的是,无论发生的日志滚动是自动滚动还是手动滚动,最近一次的滚动时间都会记录在 `logrorate` 的状态文件中。
```
$ grep wtmp /var/lib/logrotate/status
"/var/log/wtmp" 2020-3-12-11:52:57
```
---
via: <https://www.networkworld.com/article/3531969/manually-rotating-log-files-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,039 | 新型冠状病毒对远程网络的影响 | https://www.networkworld.com/article/3532440/coronavirus-challenges-remote-networking.html | 2020-03-26T10:56:00 | [
"网络",
"新冠病毒"
] | https://linux.cn/article-12039-1.html |
>
> 由于 COVID-19 的肆虐,IBM、谷歌、亚马逊、AT&T、思科、苹果等公司都争先恐后地为远程办公提供了技术上的支持,这为远程网络带来了不少的压力。
>
>
>

在新型冠状病毒广泛传播的大环境下,很多公司都要求员工留在家中远程办公,远程网络技术因此承受了更大的压力,一些带宽和安全方面的问题也接踵而至。
在过去的几十年当中,由于企业的蓬勃发展,远程办公的人数估计增加了 400 多万。而当前疫情流行的背景下,远程办公的需求激增,有望达到一个新的高峰。
一家<ruby> 虚拟私有网络 <rt> Virtual Private Network </rt></ruby>(缩写:???)提供商 [Atlas](https://atlasvpn.com/blog/vpn-usage-in-italy-rockets-by-112-and-53-in-the-us-amidst-coronavirus-outbreak/) 的一份研究表明,在今年 3 月 9 日到 3 月 15 日之间,美国的虚拟私有网络使用量增加了 53%,并且还会继续提高。而在意大利这个疫情爆发比美国早两周的国家,过去一周内的虚拟私有网络使用量甚至增加了 112%。Atlas 虚拟私有网络的首席执行官 Rachel Welch 在一份声明中称,美国的虚拟私有网络使用量在 3 月底预估会达到 150% 的增幅。
部分企业正在尝试通过<ruby> 一日测试 <rt> one-day test </rt></ruby>来评估远程办公的可行性。据《[芝加哥论坛报](https://www.chicagotribune.com/coronavirus/ct-coronavirus-work-from-home-20200312-bscm4ifjvne7dlugjn34sksrz4-story.html)》的报道,摩根大通、晨星以及一家数据分析方面的初创公司 Arity 已经通过让员工在家办公一天来测试整个办公系统的稳定性。
在政府方面,[美国国家海洋与大气管理局](https://federalnewsnetwork.com/workforce/2020/03/agencies-ramp-up-coronavirus-preparations-as-noaa-plans-large-scale-telework-test/)和 NASA 都已经进行或计划进行网络方面的压力测试,评估是否有足够的网络容量足以让上千名工作人员远程办公,以及远程办公可能造成的影响。而放眼整个美国,供职于美国政府部门的员工数量在 [200 万](https://fas.org/sgp/crs/misc/R43590.pdf)左右。
为了避免蜂窝数据网络发生拥堵,美国[联邦通信委员会](https://www.fcc.gov/coronavirus)已批准 T-mobile 临时访问已分配给其它运营商的 600MHz 频段,T-mobile 表示“将使用这个频段让美国人更方便地享受远程医疗、参与远程工作和学习,同时在保持‘物理距离’的情况下保持联系”。
但也有一些业内人士指出,在一些对蜂窝网络有较强依赖的的场景下,“最后一英里”的网络访问会变得非常拥堵。
网络情报公司 ThousandEyes 的主要产品是局域网和广域网性能分析的软件,该公司的产品经理 Alex Cruz Farmer 表示,网络瓶颈在于一些较为偏远的农村地区,因为那些地区的网络基础设施较为薄弱,主要通过微波或蜂窝网络来访问互联网。最大的挑战在于现有的解决方案所能提供的带宽远远不足。
Alex Cruz Farmer 还补充道,尽管持续时间不长,但现在的确已经出现一些由于运营商问题或网络负载增加导致的故障现象。
AT&T 表示目前已经留意到蜂窝网络使用量的变化,但网络容量并没有作出提高。
[AT&T 在一份声明中称](https://about.att.com/pages/COVID-19.html),在新冠病毒传播最严重的城市中,由于越来越多的人留在了家中远程办公,减少了通勤和人群聚集,很多特定位置和特定时段的蜂窝网络使用量峰值都明显降低了。他们还使用了一些工具对网络带宽进行了统计和监控,通过这些工具,他们可以更直观地了解网络使用情况的趋势,同时获取网络性能和网络容量方面的报告,进而管理整个通信网络。
Verison 表示,自从新型冠状病毒疫情爆发以来,尽管在家办公的用户数量大增,但使用的数据量并没有明显的上升。他们在一份声明中称:“Verison 的网络是为满足未来的需求设计建造的,面对各种需求量的增加或使用方式的改变,我们都有充分的准备。虽然这是一次前所未有的社会事件,整个局面也在不断发生改变,但随着不断了解实际需求的变化情况,我们随时可以对网络资源作出调整”。
Verison 一直在关注受影响最严重的地区的网络使用情况,并承诺将会与医院、医护人员、政府机构合作,制定网络资源使用的优先级,以满足他们的需求。Verison 还宣布计划在 2020 年将支出在 170 亿至 180 亿美元的基础上再提高 5 亿美元,以实现“加快 Verison 向 5G 过渡并在困难时期帮助支撑经济”的目标。
### 企业虚拟私有网络安全问题
对于企业来说,数据中心与远程用户之间的网络和安全问题解决起来绝非易事,尤其是使用虚拟私有网络进行远程访问时,来自用户所在住宅网络的访问几乎无法由企业控制。CIMI 公司总裁 Tom Nolle 认为,IT 部门有必要验证这些连接是否符合企业的标准(关于 Tom Nolle 更多关于在家办公的看法,可以查阅[这里](https://blog.cimicorp.com/?p=4055))。
Tom Nolle 认为像 ISP、DNS 和 Wi-Fi 这些常见的家用网络要素都应该作为适合远程办公网络业务认证的一部分。他发现 Google 的 DNS 服务比 ISP 提供的服务更能承受压力,OpenDNS 也是一个很好的选择,这说明用户可以考虑使用其中一种。
Tom Nolle 还说,家庭 Wi-Fi 网络的安全性也是一个问题,IT 部门应该要求远程办公的员工提交 Wi-Fi 配置的屏幕截图,以保证使用了正确的加密方式。之所以有这样的想法,是因为他觉得很多远程办公的员工都会绕过企业预设的一些安全措施。
DNS 软件公司 BlueCat 的首席战略官 Andrew Wertkin 表示,对一些刚刚开始在家远程办公的员工来说,适当提供相关指导是很有必要的。大部分员工从来没有尝试过在家远程办公,他们或许并不了解安全的重要性。如果员工访问公司网络的时候使用的是个人设备而不是公司设备,就更有可能出现问题。
而使用[虚拟私有网络](https://www.networkworld.com/article/3268744/understanding-virtual-private-networks-and-why-vpns-are-important-to-sd-wan.html)远程办公的人数激增也会为企业带来成本上的挑战。
“虚拟私有网络设备并不便宜,如果考虑到计算资源的成本和每个人的均摊成本,迁移到云上的虚拟环境会带来一笔不小的开支,这还不包括每个虚拟私有网络许可证价格的上升”,Alex Cruz Farmer 坦言。
在容量方面,随着远程访问量的增加,用于分配 IP 地址的 DHCP 服务也会承受巨大的压力。Andrew Wertkin 指出,如果进行远程连接的设备无法获取到网络地址,则是否具有足够的虚拟私有网络许可证并不重要。企业内部必须对这些风险进行测试,了解其中存在瓶颈的部分,并制定规避这些风险的策略。
按照这个思路,企业甚至需要验证数据中心可以用于公开的 SSL 套接字数量,否则也会面临数量不足的风险。
微软 Office 365 产品团队的高级程序经理 Paul Collinge 也表达了类似的担忧。他在一篇关于优化 Office 365 员工远程办公流量的[博客](https://techcommunity.microsoft.com/t5/office-365-blog/how-to-quickly-optimize-office-365-traffic-for-remote-staff-amp/ba-p/1214571)中写道,当大量员工在同时接入企业网络时,会对诸如虚拟私有网络集中器、中央网络出口设备(例如代理、DLP)、中央互联网带宽、回程 MPLS 和 NAT 等网络要素产生巨大的压力。最终导致的结果是低下的性能、低下的生产力,以及员工们低下的使用体验。
Alex Cruz Farmer 提出,企业很可能需要增加网络上虚拟私有网络集中器的数量,这样就可以让远程用户分布在多个不同的虚拟私有网络端点上,避免产生拥堵。退而求其次,只能在防火墙上把某些端口放开,允许特定应用程序的公开访问,尽管这样有助于提高工作效率,但却降低了整体的安全性。
### 虚拟私有网络隧道分割技术有效吗?
业内人士对<ruby> 隧道分割 <rt> tunneling split </rt></ruby>有不同的看法。
BlueCat 的 Andrew Wertkin 认为,虚拟私有网络可以使用隧道分割技术,使得仅有需要访问企业内部网络的流量才通过虚拟私有网络隧道访问,其余流量则直接进入互联网。这意味着会有部分流量不受隧道和企业网络内部的安全控制,用户的计算机会暴露在互联网当中,进而导致企业的数据和网络面临安全风险。
尽管如此,微软在上周还是建议 IT 管理员使用隧道分割技术以缓解 Office 365 由于大量远程用户涌入导致的拥堵问题。微软在[建议](https://techcommunity.microsoft.com/t5/office-365-blog/how-to-quickly-optimize-office-365-traffic-for-remote-staff-amp/ba-p/1214571)中提供了相关接入点的 URL 和 IP 地址列表,并引导 IT 人员如何按照这个方式将流量路由到 Office 365。
按照 Paul Collinge 的说法,虚拟私有网络客户端需要经过配置,才能将流量路由到已标识的 URL/IP/ 端口上,进而为全球的用户提供高性能的服务。
Alex Cruz Farmer 认为,在虚拟私有网络使用率上升之后,企业很有必要对网络安全进行一个全面的审查。对于仍然在使用传统网络安全架构的企业来说,应该开始考虑基于云端的网络安全方案了,这不仅可以提升远程办公的性能,还能减少企业对于广域网的使用量。
其它相关情况:
* [FCC](https://www.fcc.gov/document/commissioner-starks-statement-fccs-response-covid-19) 呼吁,宽带提供商应该适当放宽数据传输的限制,电话运营商应该适当免除用户的长途电话费,远程教育提供商应该合作为社会提供远程学习的机会,网络运营商应该优先考虑医院或医疗机构的网络连接需求。对此,AT&T 已经作出了相关的回应和行动。
* [美国参议员 Mark R. Warner (D-VA)](https://www.warner.senate.gov/public/_cache/files/2/3/239084db-83bd-4641-bf59-371cb829937a/A99E41ACD1BA92FB37BDE54E14A97BFA.letter-to-isps-on-covid-19-final-v2.-signed.pdf) 和其他 17 名参议员致信了 AT&T、CenturyLink、Charter Communications、Comcast、Cox Communications、Sprint、T-Mobile、Verizon 这八家主要 ISP 的首席执行官,呼吁这些公司应该采取措施应对远程办公、在线教育、远程医疗、远程支持服务等方面需求激增带来的压力。这些参议员在信中呼吁,各公司应该降低可能对远程服务产生影响的限制和费用,同时还应该为受到疫情影响的学生提供免费或收费的宽带服务,否则学生在疫情期间无法接入网络进行在线学习。
* [思科](https://blogs.cisco.com/collaboration/cisco-announces-work-from-home-webex-contact-center-quick-deployment)、微软、[谷歌](https://cloud.google.com/blog/products/g-suite/helping-businesses-and-schools-stay-connected-in-response-to-coronavirus)、[LogMeIn](https://www.gotomeeting.com/work-remote?clickid=RFlSQF3DBxyOTSr0MKVSfWfHUknShrScK0%3AhTY0&irgwc=1&cid=g2m_noam_ir_aff_cm_pl_ct)、[Spectrum](https://www.multichannel.com/news/charter-opening-wi-fi-hotspots-in-face-of-covid-19) 等供应商都提供了一些免费工具,帮助用户在疫情爆发期间正常进行安全通信。
---
via: <https://www.networkworld.com/article/3532440/coronavirus-challenges-remote-networking.html>
作者:[Michael Cooney](https://www.networkworld.com/author/Michael-Cooney/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,041 | 在 Linux 上查看和配置密码时效 | https://www.networkworld.com/article/3532815/viewing-and-configuring-password-aging-on-linux.html | 2020-03-27T10:21:34 | [
"密码",
"passwd",
"chage"
] | https://linux.cn/article-12041-1.html |
>
> 使用正确的设置,可以强制 Linux 用户定期更改密码。以下是查看密码时效以及如何更改其中设置的方法。
>
>
>

可以将 Linux 系统上的用户密码配置为永久或设置过期时间,以让人们必须定期重置它们。出于安全原因,通常认为定期更改密码是一种好习惯,但默认并未配置。
要查看和修改密码时效,你需要熟悉几个重要的命令:`chage` 命令及其 `-l` 选项,以及 `passwd` 命令及其 `-S` 选项。本文会介绍这些命令,还有其他一些 `chage` 命令选项来配置密码时效。
### 查看密码时效设置
确定某个特定帐户是否已设置密码时效的方法是使用如下 `chage` 命令。请注意,除了你自己的帐户以外,其他任何帐户都需要 root 权限。请注意下面的密码到期日期。
```
$ sudo chage -l dory
Last password change : Mar 15, 2020
Password expires : Jun 13, 2020 <==
Password inactive : never
Account expires : never
Minimum number of days between password change : 10
Maximum number of days between password change : 90
Number of days of warning before password expires : 14
```
如果未应用密码时效,那么帐户信息将如下所示:
```
$ sudo chage -l nemo
Last password change : Jan 14, 2019
Password expires : never <==
Password inactive : never
Account expires : Mar 26, 2706989
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7
```
你也可以使用 `passwd -S` 命令查看某些信息,但是你需要知道输出中的每个字段代表什么:
```
dory$ passwd -S
dory P 03/15/2020 10 90 14 -1
```
这里的七个字段代表:
* 1 – 用户名
* 2 - 帐户状态(`L` = 锁定,`NP` = 无密码,`P` = 可用密码)
* 3 – 上次密码更改的日期
* 4 – 可更改最低时效(如果没有这么多天,则不能更改密码)
* 5 – 最长时效(这些天后,密码必须更改)
* 6 – 密码过期前提前警告的天数
* 7 – 密码过期后锁定之前的天数(设为无效)
需要注意的一件事是,`chage` 命令不会显示帐户是否被锁定;它仅显示密码时效设置。另一方面,`passwd -S` 命令将告诉你密码被锁定的时间。在此例中,请注意帐户状态为 `L`:
```
$ sudo passwd -S dorothy
dorothy L 07/09/2019 0 99999 7 10
```
通过将 `/etc/shadow` 文件中通常包含密码的“哈希”字段变为 `!`,从而达成锁定的效果。
```
$ sudo grep dorothy /etc/shadow
dorothy:!:18086:0:99999:7:10:: <==
```
帐户被锁定的事实在 `chage` 输出中并不明显:
```
$ sudo chage -l dorothy
Last password change : Jul 09, 2019
Password expires : never
Password inactive : never
Account expires : never
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7
```
### 密码时效的一些选项
最常用的设置是最短和最长的天数。它们经常结合使用。例如,你可以配置一个密码,使其最长不能使用超过 90 天(最大),然后添加一个有效期为一周或 10 天(最小)的密码。这样可以确保用户不会在需要更改密码后马上改回以前的密码。
```
$ sudo chage -M 90 -m 10 shark
$ sudo chage -l shark
Last password change : Mar 16, 2020
Password expires : Jun 14, 2020
Password inactive : never
Account expires : never
Minimum number of days between password change : 10 <==
Maximum number of days between password change : 90 <==
Number of days of warning before password expires : 7
```
你还可以使用 `-E` 选项为帐户设置特定的到期日期。
```
$ sudo chage -E 2020-11-11 tadpole
$ sudo chage -l tadpole
Last password change : Oct 15, 2019
Password expires : never
Password inactive : never
Account expires : Nov 11, 2020 <==
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7
```
密码时效可能是一个重要的选择,只要它不鼓励用户使用过于简单的密码或以不安全的方式写下来即可。有关控制密码字符(例如,大小写字母、数字等的组合)的更多信息,请参考这篇关于[密码复杂度](/article-11709-1.html)的文章。
---
via: <https://www.networkworld.com/article/3532815/viewing-and-configuring-password-aging-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,042 | Purism Librem Mini:隐私为重的基于 Linux 的微型个人电脑 | https://itsfoss.com/purism-librem-mini/ | 2020-03-27T11:09:56 | [
"隐私",
"微型电脑"
] | https://linux.cn/article-12042-1.html |
>
> Purism 推出了一款外形小巧的微型个人电脑 “Librem Mini”,旨在提供隐私和安全性。让我们来看看它的细节。
>
>
>
[Purism](https://puri.sm/) 以专注于增强用户的数字隐私和安全性的服务或产品而闻名。
Purism 自诩为“<ruby> <a href="https://puri.sm/about/social-purpose/"> 社会目地公司 </a> <rt> Social Purpose Company </rt></ruby>”,旨在为社会造福,并在这方面提供了多种服务和产品。
你可能听说过它的 Librem 系列 [Linux 笔记本电脑](https://itsfoss.com/get-linux-laptops/)、[Librem One](https://itsfoss.com/librem-one/)(加密服务)、[PureOS Linux](https://itsfoss.com/pureos-convergence/) 和 [Librem 5 Linux 智能手机](https://itsfoss.com/librem-linux-phone/)。现在,他们已经针对想要掌控自己的隐私和安全性的用户推出了小尺寸微型个人电脑。
### Librem Mini: Purism 的微型个人电脑

[Purism](https://puri.sm/) 的 [Librem Mini](https://puri.sm/products/librem-mini/) 旨在成为小型、轻便且功能强大的微型个人电脑。
当然,已经有很多[基于 Linux 的微型个人电脑](https://itsfoss.com/linux-based-mini-pc/)了,但是 Librem Mini 专门关注于其用户的隐私和安全性。它随附了 [PureOS](https://itsfoss.com/pureos-convergence/)、[Pureboot](https://docs.puri.sm/PureBoot.html) 和 [Librem Key](https://puri.sm/products/librem-key/) 支持。
基本配置将以 699 美元的价格提供。这比大多数其他微型个人电脑要贵。但是,与大多数其他产品不同,Librem Mini 并不是又一个 [Intel NUC](https://itsfoss.com/intel-nuc-essential-accessories/)。 那么,它提供了什么呢?
### Librem Mini 的规格

这是它的规格表:
* Intel Core i7-8565U(Whiskey Lake),主动(风扇)冷却,4 核 8 线程最高频率 4.6GHz
* Intel UHD Graphics 620
* RAM: 最多 64 GB DDR4 2400 MHz(2 个 SO-DIMM 插槽)
* 1 SATA III 6GB/s SSD/HDD(7mm)
* 1 M.2 SSD(SATA III/NVMe x4)
* 1 HDMI 2.0 4K @ 60Hz
* 1 DisplayPort 1.2 4K @ 60Hz
* 4 x USB 3.0
* 2 x USB 2.0
* 1 x Type-C 3.1
* 3.5mm 音频插孔(麦克风输入和耳机插孔合一)
* 1 RJ45 Gigabit Ethernet LAN
* WiFi 802.11n(2.4/5.0 GHz),可选 Atheros ATH9k 模块
* 包括在 WiFi 模块的蓝牙 4.0(可选)
* 重量:1 公斤(2.2 磅)
* 尺寸:12.8 厘米(5.0 英寸) x 12.8 厘米(5.0 英寸) x 3.8 厘米(1.5 英寸)
我不知道他们为什么决定采用 Intel 的 8 代处理器,而市场上已经出现了 10 代处理器。也许是因为 Whiskey Lake 是第 8 代处理器的最新产品。
是的,他们已禁用并中止了 Intel 的管理引擎,所以仍然可以采用这个产品。
除此之外,你还应该记住,这款微型个人电脑在提供全盘加密的同时具有检测硬件和软件篡改的功能。
而且,当然,用的是 Linux。
### 价格和供应

具有 8 Gigs RAM 和 256 GB SSD 的基本配置将需要花费 $699。而且,如果你想要最强大的配置,其价格轻松就升高到 $3000。
他们的预定销售额目标是 $50,000,并且他们计划在达到预定目标后一个月内开始发货。
因此,如果你要是现在[预订](https://shop.puri.sm/shop/librem-mini/)的话,不要指望很快就会开始发货。因此,我建议你关注 [Librem Mini 产品页面](https://puri.sm/products/librem-mini/)的预定目标。
### 总结
如果你正在寻找一台微型个人电脑(不是专门为隐私和安全而设计的),则可以看看我们的[基于 Linux 的最佳微型个人电脑](https://itsfoss.com/linux-based-mini-pc/)列表,以获取更多建议。
对于普通消费者而言,Librem Mini 绝对听起来很昂贵。对于隐私发烧友来说,它仍然是一个不错的选择。
你怎么看?让我知道你的想法!
---
via: <https://itsfoss.com/purism-librem-mini/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Purism launched a mini PC, “Librem Mini” tailored to provide privacy and security while offering a small form-factor. Here, we talk about the details. *
[Purism](https://puri.sm/) is usually known for services or products that focus on enhancing the digital privacy and security of the user.
Purism flaunts itself as “[Social Purpose Company](https://puri.sm/about/social-purpose/)” aiming to do good for society and they have several services and products to offer in this regard.
While you might be aware of its Librem series of [Linux laptops](https://itsfoss.com/get-linux-laptops/), [Librem One](https://itsfoss.com/librem-one/) (encrypted services), [PureOS Linux](https://itsfoss.com/pureos-convergence/), and the [Librem 5 Linux smartphone](https://itsfoss.com/librem-linux-phone/). Now, they have come up with a small-factor mini PC targeted at the users who want to take control of their privacy and security.
## Librem Mini: Purism’s Mini PC

[Purism](https://puri.sm/)‘s [Librem Mini](https://puri.sm/products/librem-mini/) is intended to be a small, light, and powerful mini computer.
Of course, there are a bunch of [Linux-based mini PCs](https://itsfoss.com/linux-based-mini-pc/) out there – but Librem Mini specifically focuses on the privacy and security of its users. It comes included with [PureOS](https://itsfoss.com/pureos-convergence/), [Pureboot](https://docs.puri.sm/PureBoot.html), and [Librem Key](https://puri.sm/products/librem-key/) support.
The base configuration will be **available for $699**. Which is expensive than most other mini PCs. But unlike most others, Librem Mini is not a re-branding of [Intel NUC](https://itsfoss.com/intel-nuc-essential-accessories/). So, what does it offers then?
## Specifications of Librem Mini

Here’s the spec sheet:
- Intel Core i7-8565U (Whiskey Lake), Active (fan) Cooling
4 Cores, 8 Threads, up to 4.6GHz - Intel UHD Graphics 620
- RAM: Upto 64 GB DDR4 2400 MHz (2 SO-DIMM Slots)
- 1 SATA III 6GB/s SSD/HDD (7mm)
- 1 M.2 SSD (SATA III/NVMe x4)
- 1 HDMI 2.0 4K @ 60Hz
- 1 DisplayPort 1.2 4K @ 60Hz
- 4 x USB 3.0
- 2 x USB 2.0
- 1 x Type-C 3.1
- 3.5mm audio jack (Mic-in & headphone out combo)
- 1 RJ45 Gigabit Ethernet LAN
- WiFi 802.11n (2.4/5.0 GHz) via Atheros ATH9k module (optional)
- Bluetooth 4.0 included in WiFi module (optional)
- Weight: 1 kg (2.2 lbs)
- Dimensions: 12.8cm (5.0 inches) x 12.8cm (5.0 inches) x 3.8cm (1.5 inches)
I don’t know why they decided for going with Intel’s 8th gen processor considering that 10th gen processor is already in the market. Perhaps because Whiskey Lake is also the latest refresh on the 8th gen processor.
But, yes, just because they have disabled and neutralized Intel’s Management Engine on it – it could be still a viable option to go with.
In addition to that, you should also keep in mind that this mini PC features the ability to detect hardware and software tampering while providing full disk encryption.
And, of course, Linux powers it up.
## Pricing and Availability

The base configuration with **8 Gigs of RAM** and a **256 GB SSD** will cost you **$699**. And, if you want the most powerful configuration available, it will cost you about** $3000** easily.
They have a pre-order goal of **$50,000** and they plan to start shipping the units **a month** after reaching the pre-order goal.
So, if you’re going to pre-order now, you should not expect the shipping to start anytime soon. Hence, I recommend you to keep an eye on the pre-order goal on their [Librem Mini product page](https://puri.sm/products/librem-mini/).
**Wrapping Up**
If you’re looking for a mini PC (not specifically tailored for privacy and security), you can have a look at our list of [best Linux based mini PCs](https://itsfoss.com/linux-based-mini-pc/) to get more ideas.
Librem Mini is definitely going to sound expensive for an average consumer. It is still a decent choice for privacy enthusiasts.
What do you think about it? Let me know your thoughts! |
12,044 | Fedora 32 发布日期、新功能和其它信息 | https://itsfoss.com/fedora-32/ | 2020-03-27T22:23:37 | [
"Fedora",
"发行版"
] | https://linux.cn/article-12044-1.html | Fedora 32 应该和 [Ubuntu 20.04 LTS](https://itsfoss.com/ubuntu-20-04-release-features/) 一样都在 4 月底发布。
由于我们详细介绍了 Ubuntu 20.04,因此我们考虑在这里为 Fedora 粉丝做同样的事情。
在本文中,我将重点介绍 Fedora 32 的新功能。随着开发的进行,我将对本文进行更新。
### Fedora 32 的新功能

#### 启用了 EarlyOOM
在此版本中,默认启用 [EarlyOOM](https://fedoraproject.org/wiki/Changes/EnableEarlyoom#Enable_EarlyOOM)。提供一下背景知识,EarlyOOM 可以让用户在大量进行[交换](https://itsfoss.com/swap-size/)时轻松地摆脱内存不足状况恢复其系统。
值得注意的是,它适用于 Fedora 32 Beta 工作站版本。
#### 添加了 GNOME 3.36
新的 Fedora 32 工作站版也包含了新的 [GNOME 3.36](https://itsfoss.com/gnome-3-36-release/)。不仅限于 Fedora 32 Beta 工作站版,[Ubuntu 20.04 LTS](https://itsfoss.com/ubuntu-20-04-release-features/) 的每日构建版中也添加了它。
当然,GNOME 3.36 中的改进也进入了 Fedora 的最新版本,总体上提供了更快,更好的体验。因此,你将获得新的锁定屏幕、请勿打扰功能以及 GNOME 3.36 附带的所有其他功能。
#### 软件包更新
Fedora 32 版本还更新了许多重要的软件包,包括 Ruby、Perl 和 Python。它还有 [GNU 编译器集合(GCC)](https://gcc.gnu.org/)的最新版本 10。
#### 其他更改
除了主要亮点之外,还有很多更改、改进或修复。你可以详细查看它的[更新日志](https://fedoraproject.org/wiki/Releases/32/ChangeSet)来了解有关更多信息。
### 下载Fedora 32(开发版)
Fedora 32 仍在开发中。Beta 版已经发布,你可以在空闲系统或虚拟机上对其进行测试。**我不建议你在最终版本之前在主系统上使用它**。当前版本有一个官方的[已知 bug 列表](https://fedoraproject.org/wiki/Common_F32_bugs),你也可以参考。
在[官方公告](https://fedoramagazine.org/announcing-the-release-of-fedora-32-beta/)中,他们提到了 **Fedora 32 beta 工作站版**和**服务器版**以及其他流行版本的可用性。
要获取工作站和服务器版本,你必须访问 [Fedora 工作站](https://getfedora.org/workstation/download/)和 [Fedora 服务器](https://getfedora.org/server/download/)的官方下载页面(取决于你的需求)。

打开后,你只需查找如上图所示的标记为 “**Beta!**” 的发行版,然后开始下载。对于其他变体版本,请单击下面的链接以转到各自的下载页面:
* [Fedora 32 Beta Spins](https://spins.fedoraproject.org/prerelease)
* [Fedora 32 Beta Labs](https://labs.fedoraproject.org/prerelease)
* [Fedora 32 Beta ARM](https://arm.fedoraproject.org/prerelease)
你是否注意到 Fedora 32 中的其他新功能?你想在这里看到哪些功能?请随时在下面发表评论。
---
via: <https://itsfoss.com/fedora-32/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora 32 has finally arrived! Just a few days after [Ubuntu 20.04 LTS release](https://itsfoss.com/download-ubuntu-20-04/), fedora fans can get their hands on the latest Fedora 32 as well!
In this article, I am going to highlight the new features available on Fedora 32.
## What’s new in Fedora 32?

### EarlyOOM Enabled
With this release, [EarlyOOM](https://fedoraproject.org/wiki/Changes/EnableEarlyoom#Enable_EarlyOOM) comes enabled by default. To give you a background, EarlyOOM lets users to easily recover their systems from a low-memory situation with heavy [swap](https://itsfoss.com/swap-size/) usage.
It is worth noting that it is applicable to the Fedora 32 Workstation edition.
### GNOME 3.36 Added
The new Fedora 32 Workstation also comes included with the new [GNOME 3.36](https://itsfoss.com/gnome-3-36-release/).
Not just limited to Fedora 32 Workstation – but you’ll find it on Ubuntu 20.04 LTS as well.
Of course, the improvements in GNOME 3.36 translates to Fedora’s latest release as well – providing a faster and better experience, overall.
So, with that being said, you get some of the following visual highlights:
#### Re-designed Lock Screen
The lockscreen is completely something new with a focus on better and faster user experience.
#### Supports The New Extensions App
You no longer need to utilize the GNOME Tweaks tool to separately install/manage extensions. Fedora 32 features the new extension app which lets you manage GNOME extensions directly.
However, you won’t find it pre-installed. You will have to look through the software center to get it installed or simply type in the following command:
`sudo dnf install gnome-extensions-app`
#### Revamped Settings Menu
As part of the new GNOME 3.36, you will find the Settings app to be re-organized and more useful than ever before. You can get more information about your system and access the options easily.
#### Notifications Area Redesign With Do Not Disturb Toggle
The best thing about GNOME 3.36 is the notification area or the calendar pop-over redesign. And, Fedora 32 has it nicely set up as well in addition to the **Do Not Disturb **mode toggle if needed.
#### Redesigned Clock App
Fedora 32 also includes an overhaul to the design of the clock app. The latest design also fits well with smaller windows.
### Package Updates
Fedora 32 release also updates a lot of important packages that include Ruby 2.7, Perl, and Python 3.8. It also features the latest version 10 of the [GNU Compiler Collection](https://gcc.gnu.org/) (GCC).
### Other Changes
In addition to the key highlights, there’s a lot of things that have changed, improved, or fixed. You can take a detailed look at its [changelog](https://fedoraproject.org/wiki/Releases/32/ChangeSet) to know more about what has changed.
## Upgrade Fedora 31 to Fedora 32
You can simply head to the software center to find the latest update available or head to the terminal to upgrade your system from Fedora 31 to Fedora 32.
If you need help with that, we have an article on [how to upgrade a Fedora version](https://itsfoss.com/upgrade-fedora-version/) to assist you.
## Download Fedora 32
Now that Fedora 32 has finally landed. You can get started downloading it.
However, before you give it a try, I’d also suggest taking a look at the official [list of know bugs](https://fedoraproject.org/wiki/Common_F32_bugs) for the current release.
In the [official announcement](https://fedoramagazine.org/announcing-fedora-32/), they mentioned the availability of both **Fedora 32 workstation** and the **server** along with other popular variants.
To get the Workstation and the Server edition, you have to visit the official download page for [Fedora Workstation](https://getfedora.org/workstation/download/) and [Fedora Server](https://getfedora.org/server/download/) (depending on what you want).
For other variants, click on the links below to head to their respective download pages:
Have you noticed any other new feature in Fedora 32? Feel free to leave a comment below. |
12,046 | 我眼中的 2020 年最漂亮的 Linux 发行版 | https://itsfoss.com/beautiful-linux-distributions/ | 2020-03-28T10:39:54 | [
"Linux",
"发行版"
] | https://linux.cn/article-12046-1.html | 
以我的观点,每个人都该有一个 Linux 发行版,不管他们喜欢的是哪种,或者想用来做什么。
要是你刚刚开始使用 Linux,你可以使用这些[最适合于初学者的 Linux 发行版](/article-11145-1.html);要是你是从 Windows 投奔过来的,你可以使用这些[看起来像 Windows 一样的 Linux 发行版](/article-8311-1.html);要是你有台旧电脑想让它发挥余热,你可以使用这些[轻量级 Linux 发行版](/article-11040-1.html)。当然,无论你是在[企业](/article-9553-1.html)还是 [SOHO](/article-10490-1.html),Linux 还可以用于[个人工作](/article-11028-1.html)、[开发](/article-10534-1.html),以及作为[服务器](/article-7813-1.html)或[嵌入式系统](/article-9324-1.html)的操作系统,它可以用于[各种用途](/article-8628-1.html)。
但在这个列表中,我们只关注最漂亮的 Linux 发行版。
### 7 款最漂亮的 Linux 发行版
等一下!Linux 发行版有漂亮这个分类吗?显然,你可以自己定制任何发行版的外观,并使用[主题](https://itsfoss.com/best-gtk-themes/)和[图标](https://itsfoss.com/best-icon-themes-ubuntu-16-04/)之类的来使其看起来更漂亮。
你说得对。但是在这里,我所说的是指不需要用户进行任何调整和自定义工作就看起来很漂亮的发行版。这些发行版提供友好的顺滑、流畅、开箱即用的桌面体验。
**注意:** 以下列表排名不分前后,名单纯属个人喜好,请使劲喷你的观点。
#### 1、elementary OS

首先踏上 T 台的 elementary OS 是最漂亮的 Linux 发行版(如果非得说的话,可以是“之一”)。它靠着一种类似 macOS 的外观,而为 Linux 用户提供了出色的体验。如果你已经适应了 macOS,那么你在使用 elementary OS 时就不会有任何不适感。
此外,elementary OS 是基于 Ubuntu 的,因此,你可以很容易地找到大量的可以满足你的需要的应用程序。
不仅仅是外观和感受,elementary OS 总是努力地引入一些重要的变化。因此,你可以期待用户体验会随着每次更新而获得提升。
* [elementary OS](https://elementary.io/)
#### 2、深度 Linux

深度 Linux(或许现在该叫统信 UOS?)是另外一个漂亮的 Linux 发行版,它起源于 Debian 的稳定版分支。对于某些人来说,其动画效果(外观和感受)可能有点过度了,虽然它看起来很漂亮。
它有它自己特色的 Deepin 桌面环境(DDE),蕴藏了多种基本功能,从而提供尽可能好的用户体验。它可能不像其它发行版的用户界面,但你很容易就可以习惯。
我个人对深度中的控制中心和特色配色方案印象深刻。你可以自己尝试一下,我觉得值得一试。
* [深度](https://www.deepin.org/en/)
#### 3、Pop!\_OS

Pop!\_OS 在提供了纯净的 [GNOME](https://www.gnome.org/) 体验的同事,也成功地在 Ubuntu 之上打造出了一个出色的用户界面。
这正是我的最爱,我使用它作为我的主要桌面系统。Pop!\_OS 既不浮华,也没有一些花哨的动画。然而,它通过图标和主题的完美组合做到了最好,同时从技术角度提升了用户体验。
我不想发起一场 [Ubuntu 和 Pop!\_OS](https://itsfoss.com/pop-os-vs-ubuntu/) 之间的争论,但是如果你已经习惯了 Ubuntu,Pop!\_OS 可能是一个可能更好的用户体验的绝佳选择。
* [Pop!\_OS](https://system76.com/pop)
#### 4、Manjaro Linux

Manjaro Linux 是一个基于 [Arch](https://en.wikipedia.org/wiki/Arch) 的 Linux 发行版。虽然[安装 Arch Linux](https://itsfoss.com/install-arch-linux/) 是一件稍微复杂的工作,而 Manjaro 则提供了一种更舒适、更流畅的 Arch 体验。
它提供各种各样的[桌面环境版本](https://itsfoss.com/best-linux-desktop-environments/),在下载时可供选择。不管你选择哪一个,你都仍然有足够的选择权来自定义外观和感觉或布局。
对我来说,这样一个开箱即用的、基于 Arch 的发行版看起来棒极了,你值得拥有!
* [Manjaro Linux](https://manjaro.org/download/)
#### 5、KDE Neon

[KDE Neon](https://itsfoss.com/kde-neon-unveiled/) 是为那些想要采用简化的设计方案而仍可以得到丰富体验的用户所准备的。
它是一个基于 Ubuntu 的轻量级 Linux 发行版。顾名思义,它采用 KDE Plasma 桌面,看起来精美绝伦。
KDE Neon 给予你最新的、最好的 KDE Plasma 桌面及 KDE 应用程序。不像 [Kubuntu](https://kubuntu.org/) 或其它基于 KDE 的发行版,你不需要等待数月来获取新的 [KDE 软件](https://kde.org/)。
你可以在 KDE 桌面中获取很多内置的自定义选项,请按你的心意摆弄它!
* [KDE Neon](https://neon.kde.org/)
#### 6、Zorin OS

毫无疑问,Zorin OS 是一款令人印象深刻的 Linux 发行版,它努力提供了良好的用户体验,即便是它的精简版也是如此。
你可以尝试完整版或精简版(使用 [Xfce 桌面](https://www.xfce.org/))。这个用户界面是专门为习惯于 Windows 和 macOS 的用户定制的。虽然它是基于 Ubuntu 的,但它仍然提供了出色的用户体验。
如果你开始喜欢上了它的用户界面,那你也可以尝试使用 [Zorin Grid](https://itsfoss.com/zorin-grid/) 来管理运行在工作区/家庭中的 Zorin OS 计算机。而使用其终极版,你还可以控制桌面布局(如上图所示)。
* [Zorin OS](https://zorinos.com/)
#### 7、Nitrux OS

[Nitrux OS](https://itsfoss.com/nitrux-linux-overview/) 在 Linux 发行版里算是个另类,它某种程度上基于 Ubuntu,但是不完全基于 Ubuntu 。
对于那些正在寻找在 Linux 发行版上使用全新方式的独特设计语言的用户来说,它专注于为他们提供一种良好的用户体验。它使用基于 KDE 的 Nomad 桌面。
Nitrux 鼓励使用 [AppImage](https://itsfoss.com/use-appimage-linux/) 应用程序。但是在这个基于 Ubuntu 的 Nitrux 中你也可以使用 Arch Linux 的 pacman 软件包管理器。真令人惊叹!
如果它不是你安装过(或尚未安装过)的完美的操作系统,但它确实看起来很漂亮,并且对大多数基本任务来说已经足够了。你可以阅读我们的 [Nitrux 创始人的采访](https://itsfoss.com/nitrux-linux/),可以更多地了解它。
这是一个稍微过时的 Nitrux 视频,但是它仍然看起来很好:
* [Nitrux OS](https://nxos.org/)
#### 赠品:eXtern OS (处于‘停滞’开发阶段)

如果你想尝试一个实验性的 Linux 发行版,extern OS 是非常漂亮的。
它没有积极维护,因此不应该用于生产系统。但是,它提供独特的用户体验,尽管还不够完美无缺。
如果只是想尝试一个好看的 Linux 发行版,你可以试试。
* [eXtern OS](https://externos.io/)
### 总结
俗话说,情人眼里出西施。所以这份来自我眼中的最漂亮 Linux 发行版列表。你可以随意提出不同的意见 (当然要礼貌一点),并提出你最喜欢的 Linux 发行版。
---
via: <https://itsfoss.com/beautiful-linux-distributions/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It’s a no-brainer that there’s a Linux distribution for every user — regardless of what they prefer or what they want to do.
Starting out with Linux? You can go with the [Linux distributions for beginners](https://itsfoss.com/best-linux-beginners/). Switching from Windows? You have [Windows-like Linux distributions](https://itsfoss.com/windows-like-linux-distributions/). Have an old computer? You can [use lightweight Linux distros](https://itsfoss.com/lightweight-linux-beginners/).
In this list, I’m going to focus only on the most beautiful Linux distros out there.
## Best Beautiful Linux Distributions
Wait! Is there a thing called a beautiful Linux distribution? Is it not redundant considering the fact that you can customize the look of any distribution and make it look better with [themes](https://itsfoss.com/best-gtk-themes/) and [icons](https://itsfoss.com/best-icon-themes-ubuntu-16-04/)?
For instance, [customize the theme of a KDE Plasma desktop](https://itsfoss.com/properly-theme-kde-plasma/).
You are right about that. But here, we focus on the distributions that look great without any tweaks and customization effort from the user’s end. These distros provide a seamless, pleasant desktop experience right out of the box.
*The list is in no particular order of ranking.*## 1. Exodia OS
Exodia OS is a fairly new distro tailored for a specific group of users, i.e., cybersecurity enthusiasts.
At its core, it is a customized Arch-based distro. While we may not recommend this to replace your daily driver, it packs in an aesthetic look out of the box.
You can choose your edition based on your purpose of use, and pick a window manager among the two BSPWM and DWM.
**Suggested Read 📖**
[8 Best Window Managers for LinuxWant to organize your windows and use all the screen space you have? These window managers for Linux should come in handy!](https://itsfoss.com/best-window-managers/)

## 2. Zorin OS
Undoubtedly, Zorin OS is an aesthetically pleasing Linux distro that manages to provide a good user experience—even with its lite edition.
You can try either the full version or the lite edition (with [Xfce desktop](https://www.xfce.org/?ref=itsfoss.com)). The UI is tailored for Windows and macOS users to get used to. While based on Ubuntu, it provides a great user experience with what it has to offer.
The paid edition (or the pro version) includes different types of layouts. So, if you want access to those along with a curated collection of wallpapers, you should opt for the pro edition and support the Zorin OS team financially.
You might want to go through the [features of Zorin OS 16](https://news.itsfoss.com/zorin-os-16-features/?ref=itsfoss.com) (based on Ubuntu 20.04 LTS) to explore more about it.
## 3. Deepin

Deepin is yet another beautiful Linux distro originally based on Debian’s stable branch. The animations (look and feel) could be too overwhelming for some — but it looks pretty.
It features Deepin Desktop Environment that involves a mix of essential features for the best user experience possible. It may not exactly resemble the UI of any other distribution, but it is effortless to get used to.
Deepin Linux includes a variety of pre-installed tools that blend in with the desktop environment and should be useful.
My personal attention would go to the control center and the color scheme. If you do not trust the distribution, but want the desktop environment for the look, you can try [UbuntuDDE](https://itsfoss.com/ubuntudde/) as well.
## 4. Feren OS
Feren OS is an Ubuntu-based distro that features KDE desktop. It presents a clean and functional user interface.
It does not have numerous things going on, but if you want a simple, and unique KDE experience, Feren OS can be a good-looking choice.
## 5. Pop!_OS

Pop!_OS manages to offer a great UI on top of Ubuntu while offering a customized [GNOME](https://www.gnome.org/?ref=itsfoss.com) experience.
The distribution also happens to be my personal favorite, which I utilize as my primary desktop OS. Pop!_OS isn’t flashy—nor involves any fancy animations. However, they’ve managed to get things right by having a perfect combo of icon/themes—while polishing the user experience from a technical perspective.
With the introduction of their new [COSMIC desktop environment](https://news.itsfoss.com/system76-cosmic-panel/?ref=itsfoss.com) (still a work in progress at the time of updating this), this can potentially improve.
I want to avoid initiating an [Ubuntu vs Pop OS](https://itsfoss.com/pop-os-vs-ubuntu/) debate, but if you’re used to Ubuntu, Pop!_OS can be a great alternative for a potentially better user experience.
## 6. Manjaro Linux
Manjaro Linux is an [Arch](https://en.wikipedia.org/wiki/Arch?ref=itsfoss.com)-based Linux distribution. While [installing Arch Linux](https://itsfoss.com/install-arch-linux/) is a slightly complicated job, Manjaro provides an easier and smoother Arch experience.
It offers a variety of [desktop environment editions](https://itsfoss.com/best-linux-desktop-environments/) to choose from while downloading. No matter what you pick, you still get enough options to customize the look and feel or the layout.
To me, it looks quite fantastic for an Arch-based distribution that works out of the box and easy to use– you can give it a try!
**Suggested Read 📖**
[I Ditched Ubuntu for Manjaro: Here’s What I Think After a WeekPrimarily, I rely on Ubuntu-based distributions like Pop!_OS, Zorin OS, Linux Mint, or Ubuntu itself for work. They get out of the way when I work on something, along with seamless software updates. Not to forget, they get along well with my Intel-Nvidia-powered system. Everything (can be…](https://news.itsfoss.com/manjaro-linux-experience/)

## 7. Garuda Linux
Yet another [Arch-based distribution](https://itsfoss.com/arch-based-linux-distros/) in the list. This is fairly new, but it offers an impressive experience out of the box.
It offers both [KDE and GNOME desktop environment](https://itsfoss.com/kde-vs-gnome/) editions along with a variety of spins with different tiling window managers out of the box.
You can watch the video above to know more about it. Things might have changed with the latest version upgrades, so you should also check out its official website.
**Suggested Read 📖**
[Top 10 User-friendly Arch-Based Linux Distributions [2023]Want to experience Arch Linux without the hassle of the complicated installation and setup? Here are a few user-friendly Arch-based Linux distributions.](https://itsfoss.com/arch-based-linux-distros/)

## 8. KDE Neon
[KDE Neon](https://itsfoss.com/kde-neon-unveiled/) is for the users who want a simplified approach to the design language, but still get the latest and greatest user experience.
It is an interesting Linux distro which is based on Ubuntu and focuses on providing the latest KDE packages. You may not find it the most suitable desktop OS, but if you want the latest and greatest from KDE, there’s no other alternative to KDE Neon.
Unlike [Kubuntu](https://kubuntu.org/?ref=itsfoss.com) or other KDE-based distributions, you don’t have to wait for months to get the new [KDE software](https://kde.org/?ref=itsfoss.com).
You get a lot of customization options built-in with the KDE desktop—so feel free to try it out!
## 9. elementary OS
elementary OS is one of the most beautiful Linux distros out there. It leans on a macOS-ish look while providing a great user experience for Linux users. If you’re already comfortable with macOS — you will have no problem using the elementary OS.
Furthermore, elementary OS is based on Ubuntu – so you can easily find plenty of applications to get things done.
Not just limited to the look and feel – but the elementary OS is always hard at work to introduce meaningful changes. So, you can expect the user experience to improve with every update you get.
## 10. Nitrux OS
[Nitrux OS](https://itsfoss.com/nitrux-linux-overview/) is a unique take on a Linux distribution which is based on Debian. It was initially based on Ubuntu, but [Nitrux ditched Ubuntu base](https://news.itsfoss.com/nitrux-linux-debian/?ref=itsfoss.com).
It focuses on providing a good user experience to the users who are looking for a unique design language with a fresh take on a Linux distro. Likewise, it uses Nomad desktop, which is based on KDE.
Nitrux encourages using of [AppImage](https://itsfoss.com/use-appimage-linux/) for applications. But you can also use Arch Linux’s [pacman package manager](https://itsfoss.com/pacman-command/) in Nitrux. Awesome, isn’t it?
It certainly looks pretty and good enough for most of the basic tasks. You can also know more about it when you read our [interview with Nitrux’s founder](https://itsfoss.com/nitrux-linux/).
## 11. Linux Mint

Linux Mint has been making progress improving its user interface and the overall look/feel with rounded corners.
The classic themes are available, but the updated themes/icons look great out of the box. While it may not be as attractive compared to some other options in this list, it is a decent choice in terms of simplicity with a blend of modern desktop experience.
Furthermore, [Linux Mint does a few things better than Ubuntu](https://itsfoss.com/linux-mint-vs-ubuntu/), which might make it a solid desktop OS for your use-case.
## 12. Solus Budgie

Want a Linux distro that’s not based on Arch/Ubuntu? Solus with its original Budgie desktop should give you a refreshing user experience.
It takes queues from various other desktop environments and provides a clean/comfortable user interface.

You can also find other desktop editions, but the Budgie desktop edition should stand out among others.
## 13. XeroLinux
XeroLinux is yet another Arch-based distribution that offers a nice look by default.
It is a community-maintained distribution with KDE Plasma desktop as its flagship edition. You can find spins with other desktop environments.
The customized look out of the box is aesthetically pleasing. You can give it a try if you are interested in joining the Arch family.
## Wrapping Up
Now, as the saying goes, beauty lies in the eyes of the beholder. So this list of beautiful Linux distributions is from my point of view.
*💬 You are welcome to disagree (politely, of course) and mention your favorites.* |
12,047 | 应对新冠病毒的 7 个开源硬件项目 | https://opensource.com/article/20/3/open-hardware-covid19 | 2020-03-29T10:39:00 | [
"开源硬件",
"新冠病毒"
] | https://linux.cn/article-12047-1.html |
>
> 开源硬件解决方案可以为抵御新型冠状病毒的传播和痛苦做出贡献。
>
>
>

开源[硬件](https://opensource.com/resources/what-open-hardware)运动长期以来一直主张维修权的重要性,完全拥有所购买的技术,并能够像音乐一样重新组合和复制部件。因此,在这个充满挑战的时期内,开源硬件为由冠状病毒大流行引起的一些问题提供了一些答案。
### 背景概述
首先,全球的硬件开发人员正在努力使用开源解决供应链中的弱点,在过去 30 年中,这种理念推动了新软件技术的大量涌现。过去在硬件运动方面的成功,如 [RepRap Project](https://reprap.org/wiki/RepRap)、[Open Source Ecology](https://www.opensourceecology.org/) 和 [Open Source Beehives](https://www.osbeehives.com/),证明了这一点是可以做到的。
对于使用 3D 打印和其他技术按需生产安全设备和按需制造它的替换零件,创客们的兴趣日益增加。例如,香港理工大学实验室为医院工作人员提供 [3D 打印面罩](https://www.scmp.com/news/hong-kong/health-environment/article/3052135/polytechnic-university-lab-3d-printing-face)。意大利初创公司 Isinnova 与米兰 FabLab 合作,为受重灾的意大利北部提供用于呼吸机的 [3D 打印替换阀](https://www.3dprintingmedia.network/covid-19-3d-printed-valve-for-reanimation-device/)。公司们还发布了设计以适应我们的物理接触需求,例如 Materialise 的 [3D 打印免提开门器](https://www.3dprintingmedia.network/materialise-shows-3d-printed-door-opener-for-coronavirus-containment-efforts/)。这些更换零件和解决问题的示例是一个很好的起点,为挽救生命做出了努力。
另一种传统的硬件技术正在加速发展:缝纫。法新社报道说,全球急需口罩,来自世界卫生组织的指导也指明了其重要性。随着一次性口罩要优先供给于医护人员,捷克共和国的人们[开始缝制自己的口罩](https://news.yahoo.com/stitch-time-czechs-sew-combat-virus-mask-shortage-205213804.html)。(重复使用的口罩确实会带来细菌问题。)Facebook 小组“捷克缝制口罩”开始在他们的国家解决这个问题,成千上万的成员开始用起了他们的家用缝纫机。
开源硬件设备和机械项目也越来越受欢迎。首先,有一些测试性设备具备高精度且功能强大。其次,在没有其他选择方案的情况下,有一些医疗设备(顶多)可以归类为现场级。这些项目将在下面详细概述。
为了解更多信息,我与总部位于芝加哥的 [Tapster Robotics](http://tapster.io/) 的创始人兼首席执行官 Jason Huggins 进行了交谈。Tapster Robotics 使用 3D 打印、计算机数控(CNC)加工和 [Arduino](https://opensource.com/life/15/5/arduino-or-raspberry-pi) 等开源电子产品设计和制造台式机器人。他兼具技术知识和工业能力,具有很高的影响力。他想投入自己公司的资源来帮助这场斗争。
“基本上,我们现在正处于第二次世界大战的动员时刻。即使我不是医生,我们仍然应该遵循希波克拉底誓言。无论我做什么,我都不想让问题变得更糟”,Huggins 解释,他认为:“作为对策,世卫组织执行主任 Michael Ryan 博士发表了这样的评论:‘速度胜过完美’。”
>
> 哇!
>
>
> 这个人是疾病传播的全球权威。如果您是领导者(无论以何种身份),请注意。如果不是,也请注意。
>
>
> [pic.twitter.com/bFogaekehM](https://t.co/bFogaekehM)
>
>
> — Jim RichardsSh?wgram(@JIMrichards1010)[2020 年 3 月 15 日](https://twitter.com/JIMrichards1010/status/1239140710558969857?ref_src=twsrc%5Etfw)
>
>
>
Huggins 在应需提供方面具有丰富的经验。他的努力有助于 [Healthcare.gov](http://Healthcare.gov) 在挑战性的最初启动后得以扩展。他还创建了软件行业标准的测试框架 Selenium 和 Appium。有了这一经验,他的建议非常值得考虑。
我还与 [Tyson Law](https://www.marktysonlaw.com/) 的西雅图律师 Mark Tyson 进行了交谈,他的合作对象是初创公司和小型企业。他在快速发展的行业中与敏捷公司合作有着直接的经验。在阐述整个问题时,Tyson 说到:
>
> 《<ruby> 善良的撒玛利亚人法 <rt> Good Samaritan law </rt></ruby>》保护志愿者(即“好撒玛利亚人”)免于因其在紧急情况下提供援助的决定而承担责任。尽管这些法律的具体内容因州而异,但它们具有共同的公共政策依据:即鼓励旁观者帮助遇到紧急情况的其他人。可以想象,除了传统的把车祸的受害者从伤害中拉出来之外,这种理论依据可以证明在不太传统的环境中应用这类法律的合理性。
>
>
>
对于这种特定情况,Tyson 指出:
>
> “在采取行动之前,创客们明智的做法是与律师沟通一下,以针对特定的州进行风险评估。还应谨慎地要求大型机构(例如医院或保险公司)通过合同接受潜在的责任风险,例如,通过使用赔偿协议,使医院或其保险人同意赔偿创客们的责任。”
>
>
>
Tyson 明白情况的紧迫性和严重性。使用合同的这种选择并不意味着障碍。相反,这可能是一种帮助其大规模采用的方法,以更快地产生更大的变化。这取决于你或你的机构。
综上所述,让我们探索正在使用或正在开发中的项目(可能很快就可以部署)。
### 7 个与新冠病毒对抗的开源硬件项目
#### Opentrons
[Opentrons](https://opentrons.com/) 的开源实验室自动化平台由一套开源硬件、经过验证的实验室器具、消耗品、试剂和工作站组成。Opentrons 表示,其产品可以“在下订单后几天内每天自动进行多达 2400 个测试”的系统,可以极大地帮助提高[新冠病毒测试规模](https://blog.opentrons.com/testing-for-covid-19-with-opentrons/)。它计划在 7 月 1 日之前提升到多达 100 万个测试样本。

*来自 Opentrons [网站](https://blog.opentrons.com/testing-for-covid-19-with-opentrons/),版权所有*
该公司已经在与联邦和地方政府机构合作,以确定其系统是否可以在[紧急使用授权](https://www.fda.gov/regulatory-information/search-fda-guidance-documents/policy-diagnostics-testing-laboratories-certified-perform-high-complexity-testing-under-clia-prior)下用于临床诊断。 Opentrons 在 [Apache 2.0 许可证](https://github.com/Opentrons/opentrons/blob/edge/LICENSE)下共享。我最初是从与该项目有联系的生物学家 Kristin Ellis 那里得知它的。
#### Chai 的 Open qPCR
Chai 的 [Open qPCR](https://www.chaibio.com/openqpcr) 设备使用[聚合酶链反应](https://en.wikipedia.org/wiki/Polymerase_chain_reaction)(PCR)快速检测物品表面(例如,门把手和电梯按钮)上的拭子,以查看是否存在新型冠状病毒。这种在 [Apache 2.0 许可证](https://github.com/chaibio/chaipcr)下共享的开源硬件使用 [BeagleBone](https://beagleboard.org/bone) 低功耗 Linux 计算机。Chai 的 Open qPCR 提供的数据可以使公共卫生、公民和企业领导者做出有关清洁、缓解、关闭设施、接触追踪和测试的更明智的决策。
#### OpenPCR
[OpenPCR](https://openpcr.org/) 是 Chai Open qPCR 的创建者 Josh Perfetto 和 Jessie Ho 的 PCR 测试设备套件。与他们的前一个项目相比,这更像是一种 DIY 开源设备,但它具有相同的使用场景:使用环境测试来识别野外冠状病毒。正如该项目页面所指出的那样,“能够检测这些病原体的传统实时 PCR 设备通常花费超过 30,000 美元,而且不适合在现场使用。”由于 OpenPCR 是用户构建的工具包,并且在 [GPLv3.0 许可证](https://github.com/jperfetto/OpenPCR/blob/master/license.txt)下共享,因此该设备旨在使分子诊断的访问大众化。

*来自 OpenPCR [网站](https://openpcr.org/),版权所有*
而且,就像任何优秀的开源项目一样,它也有一个衍生产品!瑞士的 [Gaudi Labs](http://www.gaudi.ch/GaudiLabs/?page_id=328) 推出的 [WildOpenPCR](https://github.com/GenericLab/WildOpenPCR) 也以 [GPLv3.0 许可证](https://github.com/GenericLab/WildOpenPCR/blob/master/license.txt)共享。
#### PocketPCR
Gaudi Labs 的 [PocketPCR](http://gaudi.ch/PocketPCR/) 热循环仪可通过升高和降低小试管中液体的温度来激活生物反应。它可以通过简单的 USB 电源适配器供电,该适配器可以绑定到设备上,也可以单独使用,不使用计算机或智能手机时可使用预设参数。

*来自 PocketPCR [网站](http://gaudi.ch/PocketPCR/),版权所有*
与本文所述的其他 PCR 产品一样,此设备可能有助于对冠状病毒进行环境测试,尽管其项目页面并未明确说明。PocketPCR 在 [GPLv3.0 许可证](https://github.com/GaudiLabs/PocketPCR/blob/master/LICENSE)下共享。
#### Open Lung 低资源呼吸机
[Open Lung 低资源呼吸机](https://gitlab.com/TrevorSmale/low-resource-ambu-bag-ventilor)是一种快速部署的呼吸机,它以[气囊阀罩](https://en.wikipedia.org/wiki/Bag_valve_mask)(BVM)(也称为 Ambu 气囊)为核心组件。Ambu 气囊已批量生产,经过认证,体积小,机械简单,并且适用于侵入性导管和口罩。 Open Lung 呼吸机使用微电子技术来感测和控制气压和流量,以实现半自主运行。

*Open Lung,[GitLab](https://gitlab.com/TrevorSmale/low-resource-ambu-bag-ventilor/-/blob/master/images/CONCEPT_1_MECH.png)*
这个早期项目拥有一支由数百名贡献者组成的大型团队,领导者包括:Colin Keogh、David Pollard、Connall Laverty 和 Gui Calavanti。它是以 [GPLv3.0 许可证](https://gitlab.com/TrevorSmale/low-resource-ambu-bag-ventilor/-/blob/master/LICENSE)共享的。
#### Pandemic 呼吸机
[Pandemic 呼吸机](https://www.instructables.com/id/The-Pandemic-Ventilator/)是 DIY 呼吸机的原型。像 RepRap 项目一样,它在设计中使用了常用的硬件组件。该项目已由用户 Panvent 于 10 多年前上传到 Instructables,并且有六个主要的生产步骤。该项目是以 [CC BY-NC-SA 许可证](https://www.instructables.com/id/The-Pandemic-Ventilator/)共享的。
#### Folding at Home
[Folding at Home](https://foldingathome.org/) 是一个分布式计算项目,用于模拟蛋白质动力学,包括蛋白质折叠的过程以及与多种疾病有关的蛋白质运动。这是一个面向公民科学家、研究人员和志愿者的行动呼吁,类似于退役的 [SETI@Home 项目](https://setiathome.ssl.berkeley.edu/)使用家中的计算机来运行解码计算。如果你是具备强大计算机硬件功能的技术人员,那么这个项目适合你。

*Vincent Voelz,CC BY-SA 3.0*
Folding at Home 项目使用马尔可夫状态模型(如上所示)来建模蛋白质可能采取的形状和折叠途径,以寻找新的治疗机会。你可以在华盛顿大学生物物理学家 Greg Bowman 的帖子《[它是如何运作的以及如何提供帮助](https://foldingathome.org/2020/03/15/coronavirus-what-were-doing-and-how-you-can-help-in-simple-terms/)》中找到有关该项目的更多信息。
该项目涉及来自许多国家和地区(包括香港、克罗地亚、瑞典和美国)的财团的学术实验室、贡献者和公司赞助者。 在 [GitHub](https://github.com/FoldingAtHome) 上,[在混合了 GPL 和专有许可证](https://en.wikipedia.org/wiki/Folding@home)下共享,并且可以在 Windows、macOS 和 GNU/Linux(例如 Debian、Ubuntu、Mint、RHEL、CentOS、Fedora)。
### 许多其他有趣的项目
这些项目只是在开源硬件领域中解决或治疗新冠病毒活动中的一小部分。在研究本文时,我发现了其他值得探索的项目,例如:
* Coronavirus Tech Handbook 提供的[开源呼吸机、氧气浓缩器等](https://coronavirustechhandbook.com/hardware)
* 来自 ProjectOpenAir 的 [有用的工程](https://app.jogl.io/project/121#about)
* Hackaday 上的[开源呼吸机黑客马拉松](https://hackaday.com/2020/03/12/ultimate-medical-hackathon-how-fast-can-we-design-and-deploy-an-open-source-ventilator/)
* 约翰·霍普金斯急诊医学住院医师 Julian Botta 的[简单开源机械呼吸机规范](https://docs.google.com/document/d/1FNPwrQjB1qW1330s5-S_-VB0vDHajMWKieJRjINCNeE/edit?fbclid=IwAR3ugu1SGMsacwKi6ycAKJFOMduInSO4WVM8rgmC4CgMJY6cKaGBNR14mpM)
* [与冠状病毒有关的网络钓鱼、恶意软件和随机软件正在增加](https://www.youtube.com/watch?v=dmQ1twpPpXA),作者:Shannon Morse
* [将低成本的 CPAP 鼓风机转换为基本呼吸机](https://github.com/jcl5m1/ventilator),作者: jcl5m1
* [A.I.R.E. 论坛上关于开源呼吸器和风扇的讨论](https://foro.coronavirusmakers.org/)(西班牙语)
* [关于新冠病毒的开源医疗硬件的特殊问题](https://www.journals.elsevier.com/hardwarex/call-for-papers/special-issue-on-open-source-covid19-medical-hardware),作者:Elsevier HardwareX
这些项目遍布全球,而这种全球合作正是我们所需要的,因为病毒无视国界。新冠病毒大流行在不同时期以不同方式影响国家,因此我们需要一种分布式方法。
正如我和同事 Steven Abadie 在 [OSHdata 2020 报告](https://oshdata.com/2020-report)中所写的那样,开源硬件运动是全球性运动。参与该认证项目的个人和组织遍布全球 35 个国家地区和每个半球。

*OSHdata,CC BY-SA 4.0 国际版*
如果你有兴趣加入这场与全球开源硬件开发人员的对话,请加入[开源硬件峰会的 Discord](https://discord.gg/duAtG5h) 服务器,并通过专用渠道进行有关新冠病毒的讨论。你在这里可以找到机器人专家、设计师、艺术家、固件和机械工程师、学生、研究人员以及其他共同为这场战争而战的人。希望可以看到你。
---
via: <https://opensource.com/article/20/3/open-hardware-covid19>
作者:[Harris Kenny](https://opensource.com/users/harriskenny) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The open source [hardware](https://opensource.com/resources/what-open-hardware) movement has long championed the importance of the right to repair, fully own the technology you buy, and be able to remix and reproduce gadgets, just like you can with music. And so, during this challenging time, open hardware is providing some answers to some of the problems created by the coronavirus pandemic.
## An overview of what's happening
For one, hardware developers around the world are working to resolve supply chain weaknesses using open source, the same philosophy that has driven a proliferation of new software technologies over the last 30 years. The hardware movement's past successes include the [RepRap Project](https://reprap.org/wiki/RepRap), [Open Source Ecology](https://www.opensourceecology.org/), and [Open Source Beehives](https://www.osbeehives.com/), proving this can be done.
There has been increasing interest in creators using 3D printing and other technologies to create replacement parts for and manufacturing of safety equipment on demand. For example, the Polytechnic University lab in Hong Kong [3D printed face shields](https://www.scmp.com/news/hong-kong/health-environment/article/3052135/polytechnic-university-lab-3d-printing-face) for hospital workers. And Italian startup Isinnova partnered with the FabLab in Milan to [3D-print replacement valves](https://www.3dprintingmedia.network/covid-19-3d-printed-valve-for-reanimation-device/) for reanimation devices in hard-hit Northern Italy. Companies are also releasing designs to adapt our physical interactions, like this [3D printed hands-free door opener](https://www.3dprintingmedia.network/materialise-shows-3d-printed-door-opener-for-coronavirus-containment-efforts/) from Materialise. These examples of replacing parts and solving problems are an excellent start and appear to be saving lives.
Another traditional hardware technique is picking up steam: sewing. The AFP reports that there is an acute need for face masks around the world and guidance from the World Health Organization about their importance. With single-use, disposable masks being prioritized for healthcare workers, in the Czech Republic people are [taking to sewing to make their own masks](https://news.yahoo.com/stitch-time-czechs-sew-combat-virus-mask-shortage-205213804.html). (Repeat-use masks do introduce sterility concerns.) The Facebook group "Czechia sews face masks" started to address this problem in their country, with tens of thousands of members using their at-home sewing machines.
Open source hardware equipment and machinery projects are also gaining traction. First, there is testing equipment that is sophisticated and highly capable. Next, there is medical equipment that can be categorized as field-grade (at best) for scenarios with no other option. These projects are outlined in detail below.
To learn more, I spoke with Jason Huggins, founder and CEO of Chicago-based [Tapster Robotics](http://tapster.io/). Tapster Robotics designs and manufactures desktop robots using 3D printing, computer numerical control (CNC) machining, and open electronics like [Arduino](https://opensource.com/life/15/5/arduino-or-raspberry-pi). He has both the technical know-how and the industrial capacity to make an impact. And he wants to commit his company's resources to help in this fight.
"Basically, we're in a World War II mobilization moment right now. Even though I'm not a doctor, we should still all follow the Hippocratic Oath. Whatever I do, I don't want to make the problem worse," Huggins explains. "As a counterpoint, there is WHO executive director Dr. Michael Ryan's comment: 'Speed trumps perfection,'" Huggins argues.
Wow.
This man is the global authority on the spread of disease. If you are a leader (in any capacity) watch this. If you are not, watch it too.[pic.twitter.com/bFogaekehM]— Jim Richards Sh?wgram (@JIMrichards1010)
[March 15, 2020]
Huggins has extensive experience with delivering during times of need. His efforts were instrumental in helping [Healthcare.gov](http://Healthcare.gov) scale after its challenging initial launch. He also created the software industry-standard testing frameworks Selenium and Appium. With this experience, his advice is well worth considering.
I also spoke with Seattle-based attorney Mark Tyson of [Tyson Law](https://www.marktysonlaw.com/), who works with startups and small businesses. He has direct experience working with nimble companies in rapidly evolving industries. In framing the overall question, Tyson begins:
Good Samaritan laws protect volunteers—i.e., “Good Samaritans”—from being held liable as a result of their decision to give aid during an emergency. While the specifics of these laws vary by state, they share a common public policy rationale: namely, encouraging bystanders to help others facing an emergency. Conceivably, this rationale could justify application of these types of laws in less traditional settings than, say, pulling the victim of a car accident out of harm’s way.
Applying this specific situation, Tyson notes:
"Before taking action, creators would be wise to speak with an attorney to conduct a state-specific risk assessment. It would also be prudent to ask larger institutions, like hospitals or insurers, to accept potential liability exposure via contract—for instance, through the use of indemnification agreements, whereby the hospital or its insurer agrees to indemnify the creator for liability."
Tyson understands the urgency and gravity of the situation. This option to use contracts is not meant to be a roadblock; instead, it may be a way to help adoption happen at scale to make a bigger difference faster. It is up to you or your organization to make this determination.
With all that said, let's explore the projects that are in use or in development (and may be available for deployment soon).
## 7 open hardware projects fighting COVID-19
### Opentrons
[Opentrons](https://opentrons.com/)' open source lab automation platform is comprised of a suite of open source hardware, verified labware, consumables, reagents, and workstations. Opentrons says its products can help dramatically [scale-up COVID-19 testing](https://blog.opentrons.com/testing-for-covid-19-with-opentrons/) with systems that can "automate up to 2,400 tests per day within days of an order being placed." It plans to ramp up to 1 million tested samples by July 1.
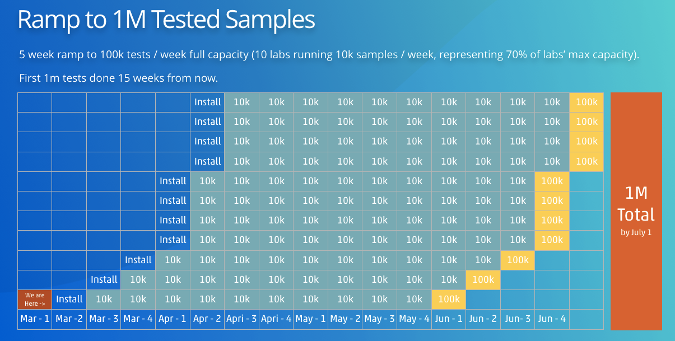
The company is already working with federal and local government agencies to determine if its systems can be used for clinical diagnosis under an [emergency use authorization](https://www.fda.gov/regulatory-information/search-fda-guidance-documents/policy-diagnostics-testing-laboratories-certified-perform-high-complexity-testing-under-clia-prior). Opentrons is shared under an [Apache 2.0 license](https://github.com/Opentrons/opentrons/blob/edge/LICENSE). I first learned of it from biologist Kristin Ellis, who is affiliated with the project.
### Chai Open qPCR
Chai's [Open qPCR](https://www.chaibio.com/openqpcr) device uses [polymerase chain reaction](https://en.wikipedia.org/wiki/Polymerase_chain_reaction) (PCR) to rapidly test swabs from surfaces (e.g., door handles and elevator buttons) to see if the novel coronavirus is present. This open source hardware shared under an [Apache 2.0 license](https://github.com/chaibio/chaipcr) uses a [BeagleBone](https://beagleboard.org/bone) low-power Linux computer. Data from the Chai Open qPCR can enable public health, civic, and business leaders to make more informed decisions about cleaning, mitigation, facility closures, contract tracing, and testing.
### OpenPCR
[OpenPCR](https://openpcr.org/) is a PCR testing device kit from Josh Perfetto and Jessie Ho, the creators behind the Chai Open qPCR. This is more of a DIY open source device than their previous project, but it has the same use case: using environmental testing to identify the coronavirus in the field. As the project page states, "traditional real-time PCR machines capable of detecting these pathogens typically cost upwards of $30,000 US dollars and are not suitable for field usage." Because OpenPCR is a kit users build and is shared under a [GPLv3.0 license](https://github.com/jperfetto/OpenPCR/blob/master/license.txt), the device aims to democratize access to molecular diagnostics.

And, like any good open source project, there is a derivative! [WildOpenPCR](https://github.com/GenericLab/WildOpenPCR) by [GaudiLabs](http://www.gaudi.ch/GaudiLabs/?page_id=328) in Switzerland is also shared under a [GPLv3.0 license](https://github.com/GenericLab/WildOpenPCR/blob/master/license.txt).
### PocketPCR
Gaudi Labs' [PocketPCR](http://gaudi.ch/PocketPCR/) thermocycler is used to activate biological reactions by raising and lowering the temperature of a liquid in small test tubes. It can be powered with a simple USB power adapter, either tethered to a device or on its own, with preset parameters that don't require a computer or smartphone.

Like the other PCR options described in this article, this device may facilitate environmental testing for coronavirus, although its project page does not explicitly state so. PocketPCR is shared under a [GPLv3.0 license](https://github.com/GaudiLabs/PocketPCR/blob/master/LICENSE).
### Open Lung Low Resource Ventilator
The [Open Lung Low Resource Ventilator](https://gitlab.com/TrevorSmale/low-resource-ambu-bag-ventilor) is a quick-deployment ventilator that utilizes a [bag valve mask](https://en.wikipedia.org/wiki/Bag_valve_mask) (BVM), also known as an Ambu-bag, as a core component. Ambu-bags are mass-produced, certified, small, mechanically simple, and adaptable to both invasive tubing and masks. The OPEN LUNG ventilator will use micro-electronics to sense and control air pressure and flow, with the goal to enable semi-autonomous operation.
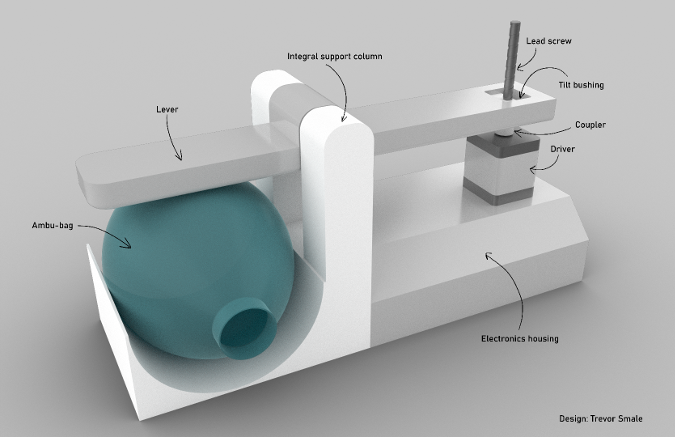
This early-stage project boasts a large team with hundreds of contributors, led by: Colin Keogh, David Pollard, Connall Laverty, and Gui Calavanti. It is shared under a [GPLv3.0 license](https://gitlab.com/TrevorSmale/low-resource-ambu-bag-ventilor/-/blob/master/LICENSE).
### Pandemic Ventilator
The [Pandemic Ventilator](https://www.instructables.com/id/The-Pandemic-Ventilator/) is a DIY ventilator prototype. Like the RepRap project, it uses commonly available hardware components in its design. The project was uploaded by user Panvent to Instructables more than 10 years ago, and there are six major steps to producing it. The project is shared under a [CC BY-NC-SA license](https://www.instructables.com/id/The-Pandemic-Ventilator/). This video shows the system in action:
### Folding at Home
[Folding at Home](https://foldingathome.org/) is a distributed computing project for simulating protein dynamics, including the process of protein folding and the movements of proteins implicated in a variety of diseases. It is a call-to-action for citizen scientists, researchers, and volunteers to use their computers at home to help run simulations, similar to the decommissioned [SETI@Home project](https://setiathome.ssl.berkeley.edu/). If you're a technologist with capable computer hardware, Folding at Home is for you.
Folding at Home uses Markov state models (shown above) to model the possible shapes and folding pathways a protein can take in order to look for new therapeutic opportunities. You can find out more about the project in Washington University biophysicist Greg Bowman's post on [how it works and how you can help](https://foldingathome.org/2020/03/15/coronavirus-what-were-doing-and-how-you-can-help-in-simple-terms/).
The project involves a consortium of academic laboratories, contributors, and corporate sponsors from many countries, including Hong Kong, Croatia, Sweden, and the United States. Folding at Home is shared under a [mix of GPL and proprietary licenses](https://en.wikipedia.org/wiki/Folding@home) on [GitHub](https://github.com/FoldingAtHome) and is multi-platform for Windows, macOS, and GNU/Linux (e.g., Debian, Ubuntu, Mint, RHEL, CentOS, Fedora).
## Many other interesting projects
These projects are just a fraction of the activity happening in the open hardware space to solve or treat COVID-19. In researching this article, I discovered other projects worth exploring, such as:
[Open source ventilators, oxygen concentrators, etc.](https://coronavirustechhandbook.com/hardware)by Coronavirus Tech Handbook[Helpful engineering](https://app.jogl.io/project/121#about)by ProjectOpenAir[Open source ventilator hackathon](https://hackaday.com/2020/03/12/ultimate-medical-hackathon-how-fast-can-we-design-and-deploy-an-open-source-ventilator/)on Hackaday[Specifications for simple open source mechanical ventilator](https://docs.google.com/document/d/1FNPwrQjB1qW1330s5-S_-VB0vDHajMWKieJRjINCNeE/edit?fbclid=IwAR3ugu1SGMsacwKi6ycAKJFOMduInSO4WVM8rgmC4CgMJY6cKaGBNR14mpM)by Johns Hopkins emergency medicine resident Julian Botta[Coronavirus-related phishing, malware, and randomware on the rise](https://www.youtube.com/watch?v=dmQ1twpPpXA)by Shannon Morse[Converting a low-cost CPAP blower into a rudimentary ventilator](https://github.com/jcl5m1/ventilator)by jcl5m1[Forum A.I.R.E. discussion on open respirators and fans](https://foro.coronavirusmakers.org/)(Spanish/español)[Special Issue on Open-Source COVID19 Medical Hardware](https://www.journals.elsevier.com/hardwarex/call-for-papers/special-issue-on-open-source-covid19-medical-hardware)by Elsevier HardwareX
These projects are based all over the world, and this type of global cooperation is exactly what we need, as the virus ignores borders. The novel coronavirus pandemic affects countries at different times and in different ways, so we need a distributed approach.
As my colleague Steven Abadie and I write in the [OSHdata 2020 Report](https://oshdata.com/2020-report), the open source hardware movement is a global movement. Participating individuals and organizations with certified projects are located in over 35 countries around the world and in every hemisphere.
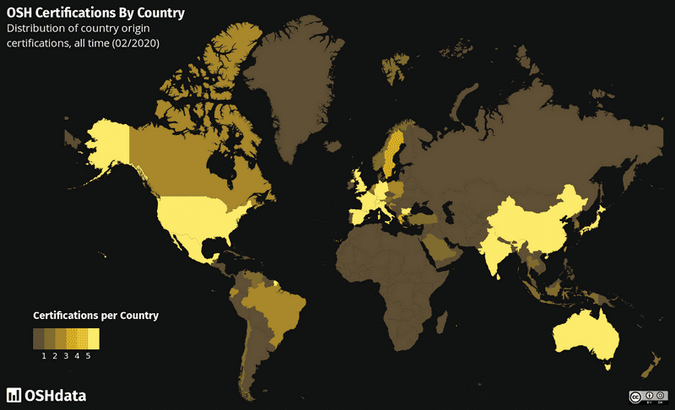
If you are interested in joining this conversation with open source hardware developers around the world, join the [Open Hardware Summit Discord](https://discord.gg/duAtG5h) server with a dedicated channel for conversations about COVID-19. You can find roboticists, designers, artists, firmware and mechanical engineers, students, researchers, and others who are fighting this war together. We hope to see you there.
## 6 Comments |
12,048 | 4 个 Linux 命令行下的 Markdown 工具 | https://opensource.com/article/20/3/markdown-apps-linux-command-line | 2020-03-29T11:21:24 | [
"Markdown",
"Pandoc"
] | https://linux.cn/article-12048-1.html |
>
> 命令行 Markdown 工具快速、强大、灵活。以下是 4 个值得试一下的工具。
>
>
>

(在 Linux 上)在处理 [Markdown](https://opensource.com/article/19/9/introduction-markdown) 格式的文件时,命令行工具会占据主导地位。它们轻巧、快速、强大、灵活,它们大多数都遵循 Unix 哲学只做好一件事。
看一下这四个程序,它们可以帮助你在命令行中更有效地处理 Markdown 文件。
### mdless
如果你使用过一段时间的 Linux 命令行,那么你可能对名为 [less](https://opensource.com/article/18/4/using-less-view-text-files-command-line) 的文本查看器很熟悉。当然,你可以使用 `less` 查看 Markdown 文件,但结果有点枯燥。如何在终端中查看 Markdown 文件效果更好一点?来使用 [mdless](https://github.com/ttscoff/mdless)。

你可以使用键盘上的箭头键四处移动,并且 `mdless` 提供了很好的搜索功能。
`mdless` 不仅会显示文本,而且还会渲染标题、粗体和斜体等格式。它还可以显示表格并语法高亮代码块。你还可以创建一个或多个主题文件来[定制](https://github.com/ttscoff/mdless#customization) `mdless` 的外观。
### Markdown lint 工具
你在快速输入时会犯错误。如果你在使用 Markdown(或其他任何标记语言)时丢失了一些格式,那么在将文件转换为另一种格式时可能会有问题。
程序员通常使用名为 linter 的工具来检查语法是否正确。你可以使用 [Markdown lint 工具](https://github.com/markdownlint/markdownlint)对 Markdown 执行相同的操作。
在你对 Markdown 文件运行该工具时,它会根据[规则集](https://github.com/markdownlint/markdownlint/blob/master/docs/RULES.md)检查格式。这些规则控制着文档的结构,包括标题级别的顺序、不正确的缩进和间距、代码块问题、文件中存在 HTML 等等。

规则可能有点严格。但是,在将文件转换为其他格式之前对文件运行 Markdown lint 工具可以防止由于格式错误或不一致引起的麻烦。
### mdmerge
合并任何类型的文件可能会很痛苦。例如,我在整理一本电子书。它是一篇文章集,最初发布在我的[每周邮件](https://buttondown.email/weeklymusings)中。这些文章都放在单独的文件中,作为受虐狂,我以凌乱、手动的方式将它们组合在一起。
我希望在开始这个项目之前就知道 [mdmerge](https://github.com/JeNeSuisPasDave/MarkdownTools)。这样我可以节省很多时间和精力。
`mdmerge`,你可能已经从名称中猜到了它的作用,它将两个或多个 Markdown 文件合并为一个文件。你无需在命令行中输入文件名。相反,你可以将它们添加到名为 `book.txt` 的文件中,并将其用作 `mdmerge` 的输入文件。
这并不是 `mdmerge` 能做的一切。你可以添加对另一个文档的引用(使用 Markdown 格式引用或一段源代码),然后将其放入主文档中。这样一来,你就可以创建针对特定受众定制的[主文档](https://help.libreoffice.org/6.2/en-US/text/swriter/guide/globaldoc.html)。
`mdmerge` 不会是你经常使用的程序。但当你需要时,你会很高兴硬盘上有它。
### bashblog
严格说 [bashblog](https://github.com/cfenollosa/bashblog) 并不是 Markdown 工具。它获取 Markdown 文件,并使用它们来构建简单的博客或网站。你可以将 bashblog 视为[静态站点生成器](https://en.wikipedia.org/wiki/Web_template_system#Static_site_generators),但是它没有很多脆弱的依赖关系。一切几乎都在一个不到 50KB 的 shell 脚本中。
要使用 bashblog,只需在计算机上安装 Markdown 处理器即可。在此,你可以编辑 Shell 脚本添加有关博客的信息,例如标题、名字、社交媒体链接等。然后运行该脚本。之后会在默认文本编辑器中新建一篇文章。开始输入。
保存文章后,你可以发布它或将其另存为草稿。如果你选择发布文章,那么 bashblog 会将你的博客、文章和所有内容生成为一组 HTML 文件,你可以将它们上传到 Web 服务器。
它开箱即用,你的博客或许会平淡无奇,但可以使用。你可以根据自己喜好编辑站点的 CSS 文件来改变外观。

### Pandoc 如何?
当然,Panddoc 是一个非常强大的工具,可以将 Markdown 文件转换为其他标记语言。但是,在命令行上使用 Markdown 要比 Pandoc 多。
如果你需要 Pandoc,请查看我们发布的文章:
* [在命令行使用 Pandoc 进行文件转换](/article-10228-1.html)
* [使用 Pandoc 将你的书转换成网页和电子书](/article-10287-1.html)
* [用 Pandoc 生成一篇调研论文](/article-10179-1.html)
* [使用 pandoc 将 Markdown 转换为格式化文档](/article-11160-1.html)
---
via: <https://opensource.com/article/20/3/markdown-apps-linux-command-line>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When it comes to working with files formatted with [Markdown](https://opensource.com/article/19/9/introduction-markdown), command-line tools rule the roost. They're light, fast, powerful, and flexible, and most of them follow the Unix philosophy of doing one thing well.
Take a look at four utilities that can help you work more efficiently with Markdown files at the command line.
## mdless
If you've hung around the Linux command line for a while, you're probably familiar with a text-file viewer called [less](https://opensource.com/article/18/4/using-less-view-text-files-command-line). Sure, you can use less to view Markdown files—but the result is a tad dull. How can you view Markdown files with a bit of pizzazz in a terminal window? By using [mdless](https://github.com/ttscoff/mdless).
You can move around using the arrow keys on your keyboard, and mdless packs quite a good search function.
Not only does mdless display text, but it also renders formatting like headings, bold, and italics. It can also display tables and do syntax highlighting of code blocks. You can also [customize](https://github.com/ttscoff/mdless#customization) the look and feel of mdless by creating one or more theme files.
## Markdown lint tool
When you're typing quickly, you make mistakes. If you miss a bit of formatting when using Markdown (or any other markup language), it can cause problems when you convert your file to another format.
Coders often use tools called *linters* to check for correct syntax. You can do the same for Markdown using the [Markdown lint tool](https://github.com/markdownlint/markdownlint).
When you run this tool over a file that's formatted with Markdown, it checks the formatting against a [set of rules](https://github.com/markdownlint/markdownlint/blob/master/docs/RULES.md). Those rules govern the structure of a document, including the order of header levels, incorrect indentation and spacing, problems with code blocks, the existence of HTML in a file, and more.
The rules can be a bit strict. But running the Markdown lint tool over a file before converting it to another format can prevent the grief that comes from bad or inconsistent formatting.
## mdmerge
Combining files of any kind can be a pain. Take, for example, an eBook I'm pulling together. It's a collection of essays that were first published in my [weekly email letter](https://buttondown.email/weeklymusings). Those essays were in individual files, and being the masochist that I am, I combined them in a messy, manual way.
I wish I'd known about [mdmerge](https://github.com/JeNeSuisPasDave/MarkdownTools) before I started that project. It would have saved me a lot of time and energy.
mdmerge, as you've probably guessed from its name, combines two or more Markdown files into a single file. You don't need to type the names of the files at the command line. Instead, you can add them to a file called **book.txt** and use that as an input file for mdmerge.
That's not all mdmerge can do. You can add a reference to another document—either one formatted with Markdown or a piece of source code—and pull it into your main document. That enables you to create [master documents](https://help.libreoffice.org/6.2/en-US/text/swriter/guide/globaldoc.html) that you can tailor to specific audiences.
mdmerge isn't one of those utilities you'll use all the time. When you need it, you'll be glad it's on your hard drive.
## bashblog
[bashblog](https://github.com/cfenollosa/bashblog) isn't strictly a tool for working with Markdown. It takes files that are formatted using Markdown and uses them to build a simple blog or website. Think of bashblog as a [static site generator](https://en.wikipedia.org/wiki/Web_template_system#Static_site_generators), but one that doesn't have a bunch of fragile dependencies. Just about everything you need is in a shell script weighing just under 50KB.
To use bashblog, all you need is a Markdown processor installed on your computer. From there, you edit the shell script to add information about your blog—for example, its title, your name, your social media links, and the like. Then run the script. A new post opens in your default text editor. Start typing.
After you save a post, you can publish it or save it as a draft. If you choose to publish the post, bashblog generates your blog, posts and all, as a set of HTML files that you can upload to a web server.
Out of the box, your blog is bland but serviceable. You can edit the site's CSS file to give it a look and feel all your own.
## What about Pandoc?
Sure, Pandoc is a very powerful tool for converting files formatted with Markdown to other markup languages. But there's more to working with Markdown at the command line than Pandoc.
If you need a Pandoc fix, check out these articles that we've published on Opensource.com:
## 5 Comments |
12,049 | 使用 K3s 在树莓派上运行 Kubernetes 集群 | https://opensource.com/article/20/3/kubernetes-raspberry-pi-k3s | 2020-03-29T12:18:00 | [
"Kubernetes",
"k3s",
"树莓派"
] | https://linux.cn/article-12049-1.html |
>
> 跟随接下来的介绍,自己搭建一个三节点的 Kubernetes 集群。
>
>
>

我对在树莓派上搭建 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 集群已经感兴趣很长时间了,只要照着网上的教程,我可以在由三个树莓派组成的集群中搭建一套 Kubernetes 并正常运行。但在这种情况下,主节点上的内存和 CPU 资源捉襟见肘,执行 Kubernetes 任务的时候往往性能不佳,想要升级 Kubernetes 就更不可能了。
这个时候,我非常激动地发现了 [K3s](https://k3s.io/) 这个项目。K3s 被誉为在可用于资源受限环境下的轻量级 Kubernetes,它还针对 ARM 处理器做出了优化,这让 Kubernetes 集群可以在树莓派上运行得更好。在下文中,我们将会使用 K3s 来创建一个 Kubernetes 集群。
### 准备
要按照本文介绍的方式创建 Kubernetes 集群,首先需要准备:
* 至少一个树莓派(包括 SD 卡和电源)
* 网线
* 将所有树莓派连接到一起的交换机或路由器
我们会通过在线安装的方式安装 K3s,因此还需要可以连接到互联网。
### 集群概览
在这个集群里,我们会使用三个树莓派。其中一个树莓派作为主节点,我们将它命名为 `kmaster`,并为其分配一个静态 IP `192.168.0.50`(注:假设使用的私有网段是 192.168.0.0/24),而另外两个树莓派作为工作节点,分别命名为 `knode1` 和 `knode2`,也分别分配 `192.168.0.51` 和 `192.168.0.52` 两个 IP 地址。
当然,如果你实际的网络布局和上面不同,只要将文中所提及到的 IP 替换成你实际可用的 IP 就可以了。
为了不需要通过 IP 来引用某一个节点,我们将每个节点的主机名记录到 PC 的 `/etc/hosts` 文件当中:
```
echo -e "192.168.0.50\tkmaster" | sudo tee -a /etc/hosts
echo -e "192.168.0.51\tknode1" | sudo tee -a /etc/hosts
echo -e "192.168.0.52\tknode2" | sudo tee -a /etc/hosts
```
### 部署主节点
我们首先部署主节点。最开始的步骤当然是使用镜像安装最新的 Raspbian,这个步骤可以参考我的[另一篇文章](https://carpie.net/articles/headless-pi-with-static-ip-wired-edition),在这里就不展开介绍了。在安装完成之后,启动 SSH 服务,将主机名设置为 `kmaster`,然后分配静态 IP `192.168.0.50`。
在主节点上安装 Raspbian 完成后,启动树莓派并通过 `ssh` 连接上去:
```
ssh pi@kmaster
```
在主节点上执行以下命令安装 K3s:
```
curl -sfL https://get.k3s.io | sh -
```
等到命令跑完以后,一个单节点集群就已经运行起来了。让我们检查一下,还在这个树莓派上执行:
```
sudo kubectl get nodes
```
就会看到这样的输出:
```
NAME STATUS ROLES AGE VERSION
kmaster Ready master 2m13s v1.14.3-k3s.1
```
### 获取<ruby> 连接令牌 <rt> join token </rt></ruby>
之后我们需要部署工作节点。在工作节点上安装 K3s 的时候,会需要用到连接令牌,它放置在主节点的文件系统上。首先把连接令牌保存出来以便后续使用:
```
sudo cat /var/lib/rancher/k3s/server/node-token
```
### 部署工作节点
通过 SD 卡在每个作为工作节点的树莓派上安装 Raspbian。在这里,我们把其中一个树莓派的主机名设置为 `knode1`,为其分配 IP 地址 `192.168.0.51`,另一个树莓派的主机名设置为 `knode2`,分配 IP 地址 `192.168.0.52`。接下来就可以安装 K3s 了。
启动主机名为 `knode1` 的树莓派,通过 `ssh` 连接上去:
```
ssh pi@knode1
```
在这个树莓派上,安装 K3s 的过程和之前差不多,但需要另外加上一些参数,表示它是一个工作节点,需要连接到一个已有的集群上:
```
curl -sfL http://get.k3s.io | K3S_URL=https://192.168.0.50:6443 \
K3S_TOKEN=刚才保存下来的连接令牌 sh -
```
`K3S_TOKEN` 的值需要替换成刚才保存下来的实际的连接令牌。完成之后,在主机名为 `knode2` 的树莓派上重复这个安装过程。
### 通过 PC 访问集群
现在如果我们想要查看或者更改集群,都必须 `ssh` 到集群的主节点才能使用 `kubectl`,这是比较麻烦的。因此我们会将 `kubectl` 放到 PC 上使用。首先,在主节点上获取一些必要的配置信息,`ssh` 到 `kmaster` 上执行:
```
sudo cat /etc/rancher/k3s/k3s.yaml
```
复制上面命令的输出,然后在你的 PC 上创建一个目录用来放置配置文件:
```
mkdir ~/.kube
```
将复制好的内容写入到 `~/.kube/config` 文件中,然后编辑该文件,将
```
server: https://localhost:6443
```
改为
```
server: https://kmaster:6443
```
出于安全考虑,只对自己保留这个配置文件的读写权限:
```
chmod 600 ~/.kube/config
```
如果 PC 上还没有安装 `kubectl` 的话,就可以开始安装了。Kubernetes 官方网站上有各种平台安装 `kubectl` 的[方法说明](https://kubernetes.io/docs/tasks/tools/install-kubectl/),我使用的是 Ubuntu 的衍生版 Linux Mint,所以我的安装方法是这样的:
```
sudo apt update && sudo apt install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee -a /etc/apt/sources.list.d/kubernetes.list
sudo apt update && sudo apt install kubectl
```
上面几个命令的作用是添加了一个包含 Kubernetes 的 Debian 软件库,获取 GPG 密钥以确保安全,然后更新软件包列表并安装 `kubectl`。如果 `kubectl` 有更新,我们将会通过<ruby> 标准软件更新机制 <rt> standard software update mechanism </rt></ruby>收到通知。
现在在 PC 上就可以查看 Kubernetes 集群了:
```
kubectl get nodes
```
输出大概会是这样:
```
NAME STATUS ROLES AGE VERSION
kmaster Ready master 12m v1.14.3-k3s.1
knode1 Ready worker 103s v1.14.3-k3s.1
knode1 Ready worker 103s v1.14.3-k3s.1
```
至此,我们已经搭建了一个三节点的 Kubernetes 集群。
### K3s 的彩蛋
如果执行 `kubectl get pods --all-namespaces`,就会看到其它服务的一些 Pod,比如 [Traefik](https://traefik.io/)。Traefik 在这里起到是反向代理和负载均衡器的作用,它可以让流量从单个入口进入集群后引导到集群中的各个服务。Kubernetes 支持这种机制,但 Kubernetes 本身不提供这个功能,因此 Traefik 是一个不错的选择,K3s 安装后立即可用的优点也得益于此。
在后续的文章中,我们会继续探讨 Traefik 在 Kubernetes ingress 中的应用,以及在集群中部署其它组件。敬请关注。
---
via: <https://opensource.com/article/20/3/kubernetes-raspberry-pi-k3s>
作者:[Lee Carpenter](https://opensource.com/users/carpie) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For a long time, I've been interested in building a [Kubernetes](https://opensource.com/resources/what-is-kubernetes) cluster out of a stack of inexpensive Raspberry Pis. Following along with various tutorials on the web, I was able to get Kubernetes installed and working in a three Pi cluster. However, the RAM and CPU requirements on the master [node](https://www.kubernetesbyexample.com/en/concept/nodes) overwhelmed my Pi. This caused poor performance when doing various Kubernetes tasks. It also made an in-place upgrade of Kubernetes impossible.
As a result, I was very excited to see the [k3s project](https://k3s.io/). K3s is billed as a lightweight Kubernetes for use in resource-constrained environments. It is also optimized for ARM processors. This makes running a Raspberry Pi-based Kubernetes cluster much more feasible. In fact, we are going to create one in this article.
## Materials needed
To create the Kubernetes cluster described in this article, we are going to need:
- At least one Raspberry Pi (with SD card and power adapter)
- Ethernet cables
- A switch or router to connect all our Pis together
We will be installing k3s from the internet, so they will need to be able to access the internet through the router.
## An overview of our cluster
For this cluster, we are going to use three Raspberry Pis. The first we'll name **kmaster** and assign a static IP of 192.168.0.50 (since our local network is 192.168.0.0/24). The first worker node (the second Pi), we'll name **knode1** and assign an IP of 192.168.0.51. The final worker node we'll name **knode2** and assign an IP of 192.168.0.52.
Obviously, if you have a different network layout, you may use any network/IPs you have available. Just substitute your own values anywhere IPs are used in this article.
So that we don't have to keep referring to each node by IP, let's add their host names to our **/etc/hosts** file on our PC.
```
echo -e "192.168.0.50\tkmaster" | sudo tee -a /etc/hosts
echo -e "192.168.0.51\tknode1" | sudo tee -a /etc/hosts
echo -e "192.168.0.52\tknode2" | sudo tee -a /etc/hosts
```
## Installing the master node
Now we're ready to install the master node. The first step is to install the latest Raspbian image. I am not going to explain that here, but I have a [detailed article](https://carpie.net/articles/headless-pi-with-static-ip-wired-edition) on how to do this if you need it. So please go install Raspbian, enable the SSH server, set the hostname to **kmaster**, and assign a static IP of 192.168.0.50.
Now that Raspbian is installed on the master node, let's boot our master Pi and **ssh** into it:
`ssh pi@kmaster`
Now we're ready to install **k3s**. On the master Pi, run:
`curl -sfL https://get.k3s.io | sh -`
When the command finishes, we already have a single node cluster set up and running! Let's check it out. Still on the Pi, run:
`sudo kubectl get nodes`
You should see something similar to:
```
NAME STATUS ROLES AGE VERSION
kmaster Ready master 2m13s v1.14.3-k3s.1
```
## Extracting the join token
We want to add a couple of worker nodes. When installing **k3s** on those nodes we will need a join token. The join token exists on the master node's filesystem. Let's copy that and save it somewhere we can get to it later:
`sudo cat /var/lib/rancher/k3s/server/node-token`
## Installing the worker nodes
Grab some SD cards for the two worker nodes and install Raspbian on each. For one, set the hostname to **knode1** and assign an IP of 192.168.0.51. For the other, set the hostname to **knode2** and assign an IP of 192.168.0.52. Now, let's install **k3s**.
Boot your first worker node and **ssh** into it:
`ssh pi@knode1`
On the Pi, we'll install **k3s** as before, but we will give the installer extra parameters to let it know that we are installing a worker node and that we'd like to join the existing cluster:
```
curl -sfL http://get.k3s.io | K3S_URL=https://192.168.0.50:6443 \
K3S_TOKEN=join_token_we_copied_earlier sh -
```
Replace **join_token_we_copied_earlier** with the token from the "Extracting the join token" section. Repeat these steps for **knode2**.
## Access the cluster from our PC
It'd be annoying to have to **ssh** to the master node to run **kubectl** anytime we wanted to inspect or modify our cluster. So, we want to put **kubectl** on our PC. But first, let's get the configuration information we need from our master node. **Ssh** into **kmaster** and run:
`sudo cat /etc/rancher/k3s/k3s.yaml`
Copy this configuration information and return to your PC. Make a directory for the config:
`mkdir ~/.kube`
Save the copied configuration as **~/.kube/config**. Now edit the file and change the line:
`server: https://localhost:6443`
to be:
`server: https://kmaster:6443`
For security purpose, limit the file's read/write permissions to just yourself:
`chmod 600 ~/.kube/config`
Now let's install **kubectl** on our PC (if you don't already have it). The Kubernetes site has [instructions](https://kubernetes.io/docs/tasks/tools/install-kubectl/) for doing this for various platforms. Since I'm running Linux Mint, an Ubuntu derivative, I'll show the Ubuntu instructions here:
```
sudo apt update && sudo apt install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" | \
sudo tee -a /etc/apt/sources.list.d/kubernetes.list
sudo apt update && sudo apt install kubectl
```
If you're not familiar, the above commands add a Debian repository for Kubernetes, grab its GPG key for security, and then update the list of packages and install **kubectl**. Now, we'll get notifications of any updates for **kubectl** through the standard software update mechanism.
Now we can check out our cluster from our PC! Run:
`kubectl get nodes`
You should see something like:
```
NAME STATUS ROLES AGE VERSION
kmaster Ready master 12m v1.14.3-k3s.1
knode1 Ready worker 103s v1.14.3-k3s.1
knode1 Ready worker 103s v1.14.3-k3s.1
```
Congratulations! You have a working 3-node Kubernetes cluster!
## The k3s bonus
If you run **kubectl get pods --all-namespaces**, you will see some extra pods for [Traefik](https://traefik.io/). Traefik is a reverse proxy and load balancer that we can use to direct traffic into our cluster from a single entry point. Kubernetes allows for this but doesn't provide such a service directly. Having Traefik installed by default is a nice touch by Rancher Labs. This makes a default **k3s** install fully complete and immediately usable!
We're going to explore using Traefik through Kubernetes **ingress** rules and deploy all kinds of goodies to our cluster in future articles. Stay tuned!
## 10 Comments |
12,051 | ffsend:在命令行中通过 FireFox Send 分享文件 | https://www.2daygeek.com/ffsend-securely-share-files-folders-from-linux-command-line-using-firefox-send-client/ | 2020-03-29T20:25:33 | [
"ffsend",
"Firefox"
] | https://linux.cn/article-12051-1.html | 
Linux 用户偏爱使用 `scp` 或 `rsync` 来进行文件或目录的复制拷贝。不过在 Linux 上正出现了许多新的可选方式,因为 Linux 是开源的,所以任何人都可以为 Linux 开发一个安全软件。
在过去我们已经写了多篇有关安全分享这个话题的文章,它们分别是 [OnionShare](/article-9177-1.html)、[Magic Wormhole](https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/)、[Transfer.sh](https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/) 和 [Dcp – Dat Copy](/article-10516-1.html)。
今天我们甚至还将继续讨论这个话题,我们将介绍名为 `ffsend` 的工具。
### ffsend 是什么?
[ffsend](https://github.com/timvisee/ffsend) 是 Firefox Send 服务的一个命令行客户端,允许用户通过命令行来传递和接收文件或目录。
它允许我们通过一个安全、私密、加密的链接,使用一个简单的命令来轻易安全地分享文件和目录。
通过 Firefox 的 Send 服务共享的文件最大大小为 2GB(LCTT 译注:现在官网上写的是最大 1GB,登录后最大 2.5GB)。其他人可以通过这个工具或者网页浏览器来下载这些分享的文件。
所有的文件都是在客户端加密的,并且秘钥将不会被共享到远程主机。另外,你还可以为上传的文件额外设置一个密码。
上传的文件在下载(默认被下载 1 次,最多可被下载 10 次)后或者 24 小时后,就会自动删除。这将确保你的文件不会一直保留在网络上。
该工具当前处于 alpha 阶段,使用时请自担风险。而且,当前只有有限的安装方式可用。
### ffsend 的特点:
* 全功能且使用友好的命令行工具
* 可以安全地上传和下载文件与目录
* 总是在客户端加密
* 可用额外的密码进行保护、密码生成和可配置下载次数限制
* 内置的文件或目录的打包和解压
* 可以轻松地管理你的历史分享记录
* 能够使用你自己的 Send 主机
* 审查或者删除共享文件
* 精准的错误报告
* 低内存消耗,用于加密或上传下载
* 无需交互,可以集成在脚本中
### 如何在 LInux 中安装 ffsend 呢?
当前除了 Debian 和 Arch Linux 系统,其他发行版还没有相应的安装包(LCTT 译注:这个信息已过时,最新内容请看[这里](https://github.com/timvisee/ffsend#install))。然而,我们可以轻易地根据我们自己的操作系统和架构下载到相应的预编译二进制文件。
运行下面的命令来为你的操作系统下载 `ffsend` 最新可用的版本(LCTT 译注:当前最新版本为 v0.2.58):
```
$ wget https://github.com/timvisee/ffsend/releases/download/v0.1.2/ffsend-v0.1.2-linux-x64.tar.gz
```
然后使用下面的命令来解压 tar 包:
```
$ tar -xvf ffsend-v0.1.2-linux-x64.tar.gz
```
接着运行下面的命令来查看你的 `PATH` 环境变量:
```
$ echo $PATH
/home/daygeek/.cargo/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/lib/jvm/default/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl
```
正如我先前告知的那样,下面我们要做的就是将这个可执行文件放置到 `PATH` 环境变量中的某个目录中:
```
$ sudo mv ffsend /usr/local/sbin
```
直接运行 `ffsend` 可以获取其基本使用信息:
```
$ ffsend
ffsend 0.1.2
Usage: ffsend [FLAGS] ...
Easily and securely share files from the command line.
A fully featured Firefox Send client.
Missing subcommand. Here are the most used:
ffsend upload ...
ffsend download ...
To show all subcommands, features and other help:
ffsend help [SUBCOMMAND]
```
对于使用基于 Arch Linux 系统的用户可以简单地借助 [AUR 助手](https://www.2daygeek.com/category/aur-helper/)来安装它,因为这个包已经在 AUR 软件仓库中了。
```
$ yay -S ffsend
```
对于使用 Debian/Ubuntu 系统的用户,使用 [DPKG 命令](https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/)来安装 `ffsend`。
```
$ wget https://github.com/timvisee/ffsend/releases/download/v0.1.2/ffsend_0.1.2_amd64.deb
$ sudo dpkg -i ffsend_0.1.2_amd64.deb
```
### 如何使用 ffsend
这并不复杂,我们可以简单地通过下面的语法来发送文件。
**语法:**
```
$ ffsend upload [/Path/to/the/file/name]
```
在下面的例子中,我们将上传一个名为 `passwd-up1.sh` 的文件,一旦你上传了该文件,你将得到一个唯一的 URL。
```
$ ffsend upload passwd-up1.sh --copy
Upload complete
Share link: https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ
```

在任何远端的系统上,只需要使用上面那个唯一的 URL 就可以下载上传的文件了。
**语法:**
```
$ ffsend download [Generated URL]
```
命令的输出如下:
```
$ ffsend download https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ
Download complete
```

使用下面的语法来对目录进行上传:
```
$ ffsend upload [/Path/to/the/Directory] --copy
```
在下面的例子中,我们将上传一个名为 `2g` 的目录:
```
$ ffsend upload /home/daygeek/2g --copy
You've selected a directory, only a single file may be uploaded.
Archive the directory into a single file? [Y/n]: y
Archiving...
Upload complete
Share link: https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg
```
在任意的远端系统中,只需要利用上面生成的唯一 URL 就可以获取到刚才上传的目录了。
```
$ ffsend download https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg
You're downloading an archive, extract it into the selected directory? [Y/n]: y
Extracting...
Download complete
```
上面已经通过安全、私密和加密过的链接来发送了文件。然而,如果你想在你的掌控范围内再添加额外的安全措施,你可以为文件添加密码。
```
$ ffsend upload file-copy-rsync.sh --copy --password
Password:
Upload complete
Share link: https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA
```
当你在远端系统中尝试下载该文件时,它将要求你输入密码:
```
$ ffsend download https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA
This file is protected with a password.
Password:
Download complete
```
另外,你还可以在上传过程中提供下载次数限制来限制文件被下载的次数。
```
$ ffsend upload file-copy-scp.sh --copy --downloads 10
Upload complete
Share link: https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
```
然后你可以在任意的远程系统中使用上面的唯一 URL 来下载该文件:
```
ffsend download https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
Download complete
```
假如你想看这个链接的更多细节,你可以使用下面的命令来查看它的信息,它将为你展示文件名称、文件大小、被下载次数以及过期时间。
**语法:**
```
$ ffsend info [Generated URL]
$ ffsend info https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
ID: 23cb923c4e
Name: file-copy-scp.sh
Size: 115 B
MIME: application/x-sh
Downloads: 3 of 10
Expiry: 23h58m (86280s)
```
此外,你还可以使用下面的命令来查看你的传输历史:
```
$ ffsend history
# LINK EXPIRY
1 https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw 23h57m
2 https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA 23h55m
3 https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg 23h52m
4 https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ 23h46m
5 https://send.firefox.com/download/74ff30e43e/#NYfDOUp_Ai-RKg5g0fCZXw 23h44m
6 https://send.firefox.com/download/69afaab1f9/#5z51_94jtxcUCJNNvf6RcA 23h43m
```
假如你不想再分享某个链接,你可以使用下面的语法来删除它:
**语法:**
```
$ ffsend delete [Generated URL]
$ ffsend delete https://send.firefox.com/download/69afaab1f9/#5z51_94jtxcUCJNNvf6RcA
File deleted
```
### 如何在浏览器中使用 Send
另外,你还可以通过使用 firefox 浏览器打开 <https://send.firefox.com/> 来完成相应的分享。
只需要拖拽该文件就可以上传它:

一旦该文件被下载,它将展示 100% 的下载状态。

想查看其他的可能选项,请浏览它对应的 man 信息或者帮助页。
---
via: <https://www.2daygeek.com/ffsend-securely-share-files-folders-from-linux-command-line-using-firefox-send-client/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,052 | 如何为你的开源项目编写实用的文档 | https://opensource.com/article/20/3/documentation | 2020-03-29T21:54:45 | [
"文档"
] | https://linux.cn/article-12052-1.html |
>
> 一份优质的文档可以让很多用户对你的项目路人转粉。
>
>
>

好的代码很多时候并不代表一切。或许你能用最精巧的代码解决了世界上最迫切需要解决的问题,但如果你作为一个开源开发者,没能用准确的语言将你的作品公之于世,你的代码也只能成为沧海遗珠。因此,技术写作和文档编写是很重要的技能。
一般来说,项目中的文档是最受人关注的部分,很多用户会通过文档来决定自己是否应该对某个项目开始学习或研究。所以,我们不能忽视技术写作和文档编写的工作,尤其要重点关注其中的“<ruby> 入门 <rt> Getting Started </rt></ruby>”部分,这会对你项目的发展起到关键性的作用。
对于很多人来说,写作是一件令人厌烦甚至恐惧的事情。我们这些工程师出身的人,更多学习的是“写代码”而不是学习“为代码写文档”。不少人会把英语作为自己的第二语言或者第三语言,他们可能会对英语写作感到不自信甚至害怕(我的母语是汉语,英语是作为我的第二语言学习的,所以我也能感受到这种痛苦)。
但如果你希望自己的项目能在全球范围内产生一定的影响力,英语就是你必须使用的语言,这是一个无法避免的现实。但不必害怕,我在写这篇文章的时候就考虑到了这些可能带来的挑战,并给出了我的一些建议。
### 五条有用的写作建议
这五条建议你马上就可以用起来,尽管看起来似乎有些浅显,但在技术写作时却经常被忽视。
1. **使用主动语态**:感受一下[主动语态](https://www.grammar-monster.com/glossary/active_voice.htm)下的“你可以这样更改配置(You can change these configurations by…)”和被动语态下的“配置可以这样更改(These configurations can be changed by…)”有什么不同之处。
2. **使用简洁明了的句子**:可以借助 [Hemingway App](http://www.hemingwayapp.com/) 或者 [Grammarly](https://www.grammarly.com/) 这样的工具,尽管它们并不开源。
3. **保持条理性**:你可以在文档中通过写标题、划重点、引链接等方式,把各类信息划分为不同的部分,避免将所有内容都杂糅在一大段冗长的文字当中。
4. **提高可读性**:除了单纯的文字之外,运用图表也是从多种角度表达的手段之一。
5. **注意拼写和语法**:必须记得检查文档中是否有拼写错误或者语法错误。
只要在文档的写作和编辑过程中应用到这些技巧,你就能够和读者建立起沟通和信任。
* **高效沟通**:对于工程师们来说,阅读长篇大论的冗长文字,还不如去看小说。在阅读技术文档时,他们总是希望能够从中快速准确地获取到有用的信息。因此,技术文档的最佳风格应该是精简而有效的,不过这并不代表文档中不能出现类似幽默、emoji 甚至段子这些东西,这些元素可以当你的文档更有个性、更使人印象深刻。当然,具体的实现方式就因人而异了
* **建立信任**:你需要取得文档读者们的信任,这在一个项目的前期尤为重要。读者对你的信任除了来源于你代码的质量,还跟你文档编写的质量有关。所以你不仅要打磨代码,还要润色好相关的文档,这也是上面第 5 点建议拼写和语法检查的原因。
### 从编写“入门”文档开始
现在,最需要花费功夫的应该就是“入门”部分了,这是一篇技术文档最重要的部分,[二八定律](https://en.wikipedia.org/wiki/Pareto_principle)在这里得到了充分体现:访问一个项目的大部分流量都会落在项目文档上,而访问项目文档的大部分流量则会落在文档的“入门”部分中。因此,如果文档的“入门”部分写得足够好,项目就会吸引到很多用户,反之,用户会对你的项目敬而远之。
那么如何写好“入门”部分呢?我建议按照以下三步走:
1. **任务化**:入门指南应该以任务为导向。这里的任务指的是对于开发者来说可以完成的离散的小项目,而不应该包含太多涉及到体系结构、核心概念等的抽象信息,因此在“入门”部分只需要提供一个简单明了的概述就可以了。也不要在“入门”部分大谈这个项目如何优秀地解决了问题,这个话题可以放在文档中别的部分进行说明。总而言之,“入门”部分最好是给出一些主要的操作步骤,这样显得开门见山。
2. **30 分钟内能够完成**:这一点的核心是耗时尽可能短,不宜超过 30 分钟,这个时间上限是考虑到用户可能对你的项目并不了解。这一点很重要,大部分愿意浏览文档的人都是有技术基础的,但对你的项目也仅仅是一知半解。首先让这些读者尝试进行一些相关操作,在收到一定效果后,他们才会愿意花更多时间深入研究整个项目。因此,你可以从耗时这个角度来评估你的文档“入门”部分有没有需要改进之处。
3. **有意义的任务**:这里“有意义”的含义取决于你的开源项目。最重要的是认真思考并将“入门”部分严格定义为一项任务,然后交给你的读者去完成。这个项目的价值应该在这项有意义的任务中有所体现,不然读者可能会感觉这是一个浪费时间的行为。
提示:假如你的项目是一个分布式数据库,那么达到“整个集群在某些节点故障的情况下可以不中断地保持可用”的目标就可以认为是“有意义”的;假如你的项目是一个数据分析工具或者是商业智能工具,“有意义”的目标也可以是“加载数据后能快速生成多种可视化效果的仪表板”。总之,无论你的项目需要达到什么“有意义”的目标,都应该能在笔记本电脑上本地快速实现。
[Linkerd 入门](https://linkerd.io/2/getting-started/)就是一个很好的例子。Linkerd 是一个开源的 Kubernetes <ruby> 服务网格 <rt> Service Mesh </rt></ruby>,当时我对 Kubernetes 了解并不多,也不熟悉服务网格。但我在自己的笔记本电脑上很轻松地就完成了其中的任务,同时也加深了对服务网格的理解。
上面提到的三步过程是一个很有用的框架,对一篇文档“入门”部分的设计和量化评估很有帮助。今后你如果想将你的[开源项目产品化](https://opensource.com/article/19/11/products-open-source-projects),这个框架还可能对<ruby> 实现价值的时间 <rt> time-to-value </rt></ruby>产生影响。
### 其它核心部分
认真写好“入门”部分之后,你的文档中还需要有这五个部分:架构设计、生产环境使用指导、使用案例、参考资料以及未来展望,这五个部分在一份完整的文档中是必不可少的。
* **架构设计**:这一部分需要深入探讨整个项目架构设计的依据,“入门”部分中那些一笔带过的关键细节就应该在这里体现。在产品化过程中,这个部分将会是[产品推广计划](https://opensource.com/article/20/2/product-marketing-open-source-project)的核心,因此通常会包含一些可视化呈现的内容,期望的效果是让更多用户长期参与到项目中来。
* **生产环境使用指导**:对于同一个项目,在生产环境中部署比在笔记本电脑上部署要复杂得多。因此,指导用户认真使用就尤为重要。同时,有些用户可能对项目很感兴趣,但对生产环境下的使用有所顾虑,而指导和展示的过程则正好能够吸引到这类潜在的用户。
* **使用案例**:<ruby> 社会认同 <rt> social proof </rt></ruby>的力量是有目共睹的,所以很有必要列出正在生产环境使用这个项目的其他用户,并把这些信息摆放在显眼的位置。这个部分的浏览量甚至仅次于“入门”部分。
* **参考资料**:这个部分是对项目的一些详细说明,让用户得以进行详细的研究以及查阅相关信息。一些开源作者会在这个部分事无巨细地列出项目中的每一个细节和<ruby> 边缘情况 <rt> edge case </rt></ruby>,这种做法可以理解,但不推荐在项目初期就在这个部分花费过多的时间。你可以采取更折中的方式,在质量和效率之间取得平衡,例如提供一些相关社区的链接、Stack Overflow 上的标签或单独的 FAQ 页面。
* **未来展望**:你需要制定一个简略的时间表,规划这个项目的未来发展方向,这会让用户长期保持兴趣。尽管项目在当下可能并不完美,但要让用户知道你仍然有完善这个项目的计划。这个部分也能让整个社区构建一个强大的生态,因此还要向用户提供表达他们对未来展望的看法的交流区。
以上这几个部分或许还没有在你的文档中出现,甚至可能会在后期才能出现,尤其是“使用案例”部分。尽管如此,还是应该在文档中逐渐加入这些部分。如果用户对“入门”部分已经感觉良好,那以上这几个部分将会提起用户更大的兴趣。
最后,请在“入门”部分、README 文件或其它显眼的位置注明整个项目所使用的许可证。这个细节会让你的项目更容易通过最终用户的审核。
### 花 20% 的时间写作
一般情况下,我建议把整个项目 10% 到 20% 的时间用在文档写作上。也就是说,如果你是全职进行某一个项目的,文档写作需要在其中占半天到一天。
再细致一点,应该将写作纳入到常规的工作流程中,这样它就不再是一件孤立的琐事,而是日常的事务。文档写作应该随着工作进度同步进行,切忌将所有写作任务都堆积起来最后完成,这样才可以帮助你的项目达到最终目标:吸引用户、获得信任。
---
*特别鸣谢云原生计算基金会的布道师 [Luc Perkins](https://twitter.com/lucperkins) 给出的宝贵意见。*
*本文首发于 [COSS Media](https://coss.media/open-source-documentation-technical-writing-101/) 并经许可发布。*
---
via: <https://opensource.com/article/20/3/documentation>
作者:[Kevin Xu](https://opensource.com/users/kevin-xu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Unfortunately, good code won't speak for itself. Even the most elegantly designed and well-written codebase that solves the most pressing problem in the world won't just get adopted on its own. You, the open source creator, need to speak for your code and breathe life into your creation. That's where technical writing and documentation come in.
A project's documentation gets the most amount of traffic, by far. It's the place where people decide whether to continue learning about your project or move on. Thus, spending time and energy on documentation and technical writing, focusing on the most important section, "Getting Started," will do wonders for your project's traction.
Writing may feel uncomfortable, even daunting, to many of you. As engineers, we are trained more to write code than to write *about* code. Many people also speak English as a second or even third language and may feel insecure or intimidated about writing in English. (I learned English as a second language, and my mother tongue is Mandarin Chinese, so I feel your pain.)
But we can't get around the reality that, if you want your project to have a broad, global reach, English is the language you must use. Don't fear. I wrote this post with those challenges in mind. You don't need to be the next Shakespeare to find the advice here useful.
## Five actionable writing tips
Here are five actionable writing tips you can apply today. They may seem painfully simple and obvious, yet they are ignored over and over again in technical writing.
**Use****active voice****:**Active voice: "You can change these configurations by…" vs. passive voice: "These configurations can be changed by…"**Use simple, short sentences:**While not open source,[Hemingway App](http://www.hemingwayapp.com/)and[Grammarly](https://www.grammarly.com/)are both helpful tools.**Format for easy reading:**Use headings, bullet points, and links to break up information into chunks instead of long explanatory paragraphs.**Keep it visual:**Use tables and diagrams, not sentences, to represent information with multiple dimensions.**Mind your spelling and grammar:**Always, always, always spell check for typos and grammar check for polish.
By applying these tips consistently in your writing and editing workflow, you achieve two big goals: efficient communication and building trust.
**Efficient communication:**Engineers don't want to read long-winded, meandering paragraphs in documentation (they have novels for that). They want to get technical information or instructions (when it's a guide) as efficiently as possible. Thus, your writing needs to be lean and useful. (That being said, it's fine to apply some humor, emojis, and "fluff" here and there to give your project some personality and make it more memorable. How exactly you do that will depend on*your*personality.)**Building trust:**The most valuable currency you must accrue, especially in the early days of building your project, is trust. Trust comes not only from your code quality but also from the quality of writing that talks about your code. Thus, please apply the same polish to your writing that you would to your code. This is the main reason for point 5 above (on spelling and grammar checks).
## Start with Getting Started documentation
With these fundamental techniques baked into your writing, the section you should spend the most time on in your documentation is the Getting Started section. This is, by far, the most important section and a classic example of the "[80/20 rule](https://en.wikipedia.org/wiki/Pareto_principle)" in action. Most of the web traffic to your project lands on your documentation, and most of *that* lands on Getting Started. If it is well-constructed, you will get a new user right away. If not, the visitor will bounce and likely never come back.
How do you construct a good Getting Started section? I propose this three-step process:
**Make it a task:**An effective Getting Started guide should be task-oriented—a discrete mini-project that a developer can accomplish. It should*not*contain too much information about the architectural design, core concept, and other higher-level information. A single, visual architectural overview is fine, but don't devote multiple paragraphs to how and why your project is the best-designed solution. That information belongs somewhere else (more on that below). Instead, the Getting Started section should mostly be a list of steps and commands to… well, get your project started!**Can be finished in less than 30 minutes:**The core takeaway here is that the time to completion should be as low as possible; 30 minutes is the upper bound. This time limit also assumes the user has relatively little context about your project. This is important to keep in mind. Most people who bother to go through your Getting Started guide are members of a technical audience with a vague understanding of your project but not much more than that. They are there to try something out before they decide to spend more time digging deeper. "Time to completion" is a metric you should measure to continuously improve your Getting Started guide.**Do something meaningful:**What "meaningful" means depends on the open source project. It is important to think hard about what that is, tightly define it into a task, and allow a developer who completes your Getting Started guide to achieve that meaningful task. This meaningful task must speak directly to your project's value; otherwise, it will leave developers feeling like they just wasted their time.
For inspiration: If you are a distributed database project, perhaps "meaningful" means the whole cluster remains available with no downtime after you kill some nodes. If you are a data analytics or business intelligence tool, perhaps "meaningful" means quickly generating a dashboard with different visualizations after loading some data. Whatever "meaningful" means to your project, it should be achievable quickly and locally on a laptop.
A good example is [Linkerd's Getting Started](https://linkerd.io/2/getting-started/). Linkerd is an open source service mesh for Kubernetes. I'm a novice in Kubernetes and even less familiar with service mesh. Yet, I completed Linkerd's Getting Started guide on my laptop without much hassle, and the experience gave me a taste of what operating a service mesh is all about.
The three-step process above could be a helpful framework for designing a highly efficient Getting Started section in a measurable way. It is also related to the time-to-value metric when it comes to [productizing your open source project](https://opensource.com/article/19/11/products-open-source-projects).
## Other core components
Besides carefully calibrating and optimizing your Getting Started, there are five other top-level components that are necessary to build full-fledged documentation: architectural design, in-production usage guide, use cases, references, and roadmap.
**Architectural design:**This is a deep-dive into your project's architecture and the rationales behind your design decisions, full of the details that you strategically glossed over in your Getting Started guide. This section is a big part of your overall[product marketing plan](https://opensource.com/article/20/2/product-marketing-open-source-project). This section, usually filled with visuals and drawings, is meant to turn a casual hobbyist into an expert enthusiast who is interested in investing time in your project for the long term.**In-production usage guide:**There is a world of difference between trying something out on a laptop and deploying it in production. Guiding a user who wants to use your project more seriously is an important next step. Demonstrating in-production operational knowledge is also how you attract your initial business customers who may like the promise of the technology but don't know or don't feel confident about using it in a production environment.**Use cases:**The value of social proof is obvious, so listing your in-production adopters is important. The key here is to make sure this information is easy to find. It will likely be the second most popular link after Getting Started.**References:**This section explains the project in detail and allows the user to examine and understand it under a microscope. It also functions as a dictionary where people look up information when needed. Some open source creators spend an inordinate amount of time spelling out every nuance and edge case of their project here. The motivation is understandable but unnecessary at the outset when your time is limited. It's more effective to reach a balance between detail and ways to get help: links to your community forum, Stack Overflow tag, or a separate FAQ page would do.**Roadmap:**Laying out your future vision and plan with a rough timeline will keep users interested and incentivized for the long-term. Your project may not be perfect now, but you have a plan to perfect it. The Roadmap section is also a great place to get your community involved to build a strong ecosystem, so make sure you have a link that tells people how to voice their thoughts and opinions regarding the roadmap. (I'll write about community-building specifics in the future.)
You may not have all these components fully fleshed out yet, and some parts may materialize later than others, especially the use cases. However, be intentional about building these out over time. Addressing these five elements is the critical next step to your users' journey into your project, assuming they had a good experience with Getting Started.
One last note: include a clear one-sentence statement on what license you are using (probably in Getting Started, README, or somewhere else highly visible). This small touch will make vetting your project for adoption from the end user's side much more efficient.
## Spend 20% of your time writing
Generally, I recommend spending 10–20% of your time writing. Putting it in context: If you are working on your project full time, it's about half a day to one full day per week.
The more nuanced point here is you should work writing into your normal workflow, so it becomes a routine, not an isolated chore. Making incremental progress over time, rather than doing all the writing in one giant sitting, is what will help your project reach that ultimate goal: traction and trust.
*Special thanks to Luc Perkins, developer advocate at the Cloud Native Computing Foundation, for his invaluable input.*
*This article originally appeared on* [COSS Media](https://coss.media/open-source-documentation-technical-writing-101/)*and is republished with permission.*
## 4 Comments |
12,053 | 必知必会的 Vim 编辑器基础命令 | https://www.2daygeek.com/basic-vim-commands-cheat-sheet-quick-start-guide/ | 2020-03-30T12:07:01 | [
"Vim",
"Vi"
] | https://linux.cn/article-12053-1.html | 
如果你是一名系统管理员或者开发者,当你在终端工作时有时会需要编辑一个文件。在 Linux 系统中有几种文件编辑器,你可以根据需求选择合适的文件编辑器。在这里,我想推荐 Vim 编辑器。
### 为什么推荐 Vim 编辑器
相对于创建新文件,你更多是修改已经存在的文件。在这种情况下,Vim 快捷键可以有效地满足你的需求。
下列文章可以帮助你了解对文件和目录的操作。
* [Linux 基础:对文件和目录进行操作的 Linux 和 Unix 命令](https://www.2daygeek.com/linux-basic-commands-file-directory-manipulation/)
* [在 Linux 中查看不同文件格式的 10 种方法](https://www.2daygeek.com/unix-linux-command-to-view-file/)
### 什么是 Vim
Vim 是被 Linux 管理员和开发者广泛使用的最流行和功能强大的编辑器之一。它可以通过高度的自定义配置来提高文本编辑效率。它是在众多 Unix 默认安装的 Vi 编辑器的升级版。
Vim 通常被称为“程序员的编辑器”,但并不限于此,它也可用于编辑任何类型的文件。它具有许多功能,例如:多次撤销、多窗口和缓冲区、语法高亮、命令行编辑、文件名补全、可视选择等等。你可以使用 `:help` 命令来获取在线帮助。
### 理解 Vim 的模式
Vim 有两种模式,详细介绍如下:
**命令模式:** 当启动 Vim 编辑器后,默认处在命令模式下。你可以在文件中移动并且修改内容,剪切、复制和粘贴文件的一部分,同时发出命令执行更多操作(按 `ESC` 键进入命令模式)
**插入模式:** 插入模式用于在给定的文档位置插入文本(按 `i` 键进入插入模式)
### 我如何知道我正使用哪种 Vim 模式呢?
如果你正在使用插入模式,你会在编辑器的底部看到 `INSERT`。如果编辑器底部没有显示任何内容,或者在编辑器底部显示了文件名,则处于 “命令模式”。
### 命令模式下的光标移动
Vim 快捷键允许你使用不同的方式来移动光标:
* `G` – 跳转到文件最后一行
* `gg` – 跳转到文件首行
* `$` – 跳转到行末尾
* `0`(数字 0) – 跳转到行开头
* `w` – 跳转到下一个单词的开始(单词的分隔符可以是空格或其他符号)
* `W` – 跳转到下一个单词的开始(单词的分隔符只能是空格)
* `b` – 跳转到下一个单词的末尾(单词的分隔符可以是空格或其他符号)
* `B` – 跳转到下一个单词的末尾(单词的分隔符只能是空格)
* `PgDn` 键 – 向下移动一页
* `PgUp` 键 – 向上移动一页
* `Ctrl+d` – 向下移动半页
* `Ctrl+u` – 向上移动半页
### 插入模式:插入文字
下面的 Vim 快捷键允许你根据需要在光标的不同位置插入内容。
* `i` – 在光标之前插入
* `a` – 在光标之后插入
* `I` – 在光标所在行的开头插入。当光标位于行中间时,这个键很有用
* `A` – 在光标所在行的末尾插入。
* `o` – 在光标所在行的下面插入新行
* `O` – 在光标所在行的上面插入新行
* `ea` – 在单词的末尾插入
### 拷贝、粘贴和删除一行
* `yy` – 复制一行
* `p` / `P` – 将内容粘贴到光标之后 / 之前
* `dd` – 删除一行
* `dw` – 删除一个单词
### 在 Vim 中搜索和替换匹配的模式
* `/模式` – 向后搜索给定的模式
* `?模式` – 向前搜索给定的模式
* `n` – 向后重复搜索之前给定的模式
* `N` – 向前重复搜索之前给定的模式
* `:%s/旧模式/新模式/g` – 将文件中所有的旧模式替换为新模式
* `:s/旧模式/新模式/g` – 将当前行中所有的旧模式替换为新模式
* `:%s/旧模式/新模式/gc` – 逐个询问是否文件中的旧模式替换为新模式
### 如何在 Vim 编辑器中跳转到特定行
你可以根据需求以两种方式达到该目的,如果你不知道行号,建议采用第一种方法。
通过打开文件并运行下面的命令来显示行号
```
:set number
```
当你设置好显示行号后,按 `:n` 跳转到相应的行号。例如,如果你想跳转到第 15 行,请输入:
```
:15
```
如果你已经知道行号,请使用以下方法在打开文件时直接跳转到相应行。例如,如果在打开文件时直接跳转到 20 行,请输入下面的命令:
```
$ vim +20 [文件名]
```
### 撤销操作/恢复上一次操作/重复上一次操作
* `u` – 撤销更改
* `Ctrl+r` – 恢复更改
* `.` – 重复上一条命令
### 保存和退出 Vim
* `:w` – 保存更改但不退出 vim
* `:wq` – 写并退出
* `:q!` – 强制退出
---
via: <https://www.2daygeek.com/basic-vim-commands-cheat-sheet-quick-start-guide/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,056 | 构建一个即时消息应用(三):对话 | https://nicolasparada.netlify.com/posts/go-messenger-conversations/ | 2020-03-30T19:40:01 | [
"即时消息"
] | https://linux.cn/article-12056-1.html | 
本文是该系列的第三篇。
* [第一篇:模式](/article-11396-1.html)
* [第二篇:OAuth](/article-11510-1.html)
在我们的即时消息应用中,消息表现为两个参与者对话的堆叠。如果你想要开始一场对话,就应该向应用提供你想要交谈的用户,而当对话创建后(如果该对话此前并不存在),就可以向该对话发送消息。
就前端而言,我们可能想要显示一份近期对话列表。并在此处显示对话的最后一条消息以及另一个参与者的姓名和头像。
在这篇帖子中,我们将会编写一些<ruby> 端点 <rt> endpoint </rt></ruby>来完成像“创建对话”、“获取对话列表”以及“找到单个对话”这样的任务。
首先,要在主函数 `main()` 中添加下面的路由。
```
router.HandleFunc("POST", "/api/conversations", requireJSON(guard(createConversation)))
router.HandleFunc("GET", "/api/conversations", guard(getConversations))
router.HandleFunc("GET", "/api/conversations/:conversationID", guard(getConversation))
```
这三个端点都需要进行身份验证,所以我们将会使用 `guard()` 中间件。我们也会构建一个新的中间件,用于检查请求内容是否为 JSON 格式。
### JSON 请求检查中间件
```
func requireJSON(handler http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
if ct := r.Header.Get("Content-Type"); !strings.HasPrefix(ct, "application/json") {
http.Error(w, "Content type of application/json required", http.StatusUnsupportedMediaType)
return
}
handler(w, r)
}
}
```
如果<ruby> 请求 <rt> request </rt></ruby>不是 JSON 格式,那么它会返回 `415 Unsupported Media Type`(不支持的媒体类型)错误。
### 创建对话
```
type Conversation struct {
ID string `json:"id"`
OtherParticipant *User `json:"otherParticipant"`
LastMessage *Message `json:"lastMessage"`
HasUnreadMessages bool `json:"hasUnreadMessages"`
}
```
就像上面的代码那样,对话中保持对另一个参与者和最后一条消息的引用,还有一个 `bool` 类型的字段,用来告知是否有未读消息。
```
type Message struct {
ID string `json:"id"`
Content string `json:"content"`
UserID string `json:"-"`
ConversationID string `json:"conversationID,omitempty"`
CreatedAt time.Time `json:"createdAt"`
Mine bool `json:"mine"`
ReceiverID string `json:"-"`
}
```
我们会在下一篇文章介绍与消息相关的内容,但由于我们这里也需要用到它,所以先定义了 `Message` 结构体。其中大多数字段与数据库表一致。我们需要使用 `Mine` 来断定消息是否属于当前已验证用户所有。一旦加入实时功能,`ReceiverID` 可以帮助我们过滤消息。
接下来让我们编写 HTTP 处理程序。尽管它有些长,但也没什么好怕的。
```
func createConversation(w http.ResponseWriter, r *http.Request) {
var input struct {
Username string `json:"username"`
}
defer r.Body.Close()
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
input.Username = strings.TrimSpace(input.Username)
if input.Username == "" {
respond(w, Errors{map[string]string{
"username": "Username required",
}}, http.StatusUnprocessableEntity)
return
}
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
tx, err := db.BeginTx(ctx, nil)
if err != nil {
respondError(w, fmt.Errorf("could not begin tx: %v", err))
return
}
defer tx.Rollback()
var otherParticipant User
if err := tx.QueryRowContext(ctx, `
SELECT id, avatar_url FROM users WHERE username = $1
`, input.Username).Scan(
&otherParticipant.ID,
&otherParticipant.AvatarURL,
); err == sql.ErrNoRows {
http.Error(w, "User not found", http.StatusNotFound)
return
} else if err != nil {
respondError(w, fmt.Errorf("could not query other participant: %v", err))
return
}
otherParticipant.Username = input.Username
if otherParticipant.ID == authUserID {
http.Error(w, "Try start a conversation with someone else", http.StatusForbidden)
return
}
var conversationID string
if err := tx.QueryRowContext(ctx, `
SELECT conversation_id FROM participants WHERE user_id = $1
INTERSECT
SELECT conversation_id FROM participants WHERE user_id = $2
`, authUserID, otherParticipant.ID).Scan(&conversationID); err != nil && err != sql.ErrNoRows {
respondError(w, fmt.Errorf("could not query common conversation id: %v", err))
return
} else if err == nil {
http.Redirect(w, r, "/api/conversations/"+conversationID, http.StatusFound)
return
}
var conversation Conversation
if err = tx.QueryRowContext(ctx, `
INSERT INTO conversations DEFAULT VALUES
RETURNING id
`).Scan(&conversation.ID); err != nil {
respondError(w, fmt.Errorf("could not insert conversation: %v", err))
return
}
if _, err = tx.ExecContext(ctx, `
INSERT INTO participants (user_id, conversation_id) VALUES
($1, $2),
($3, $2)
`, authUserID, conversation.ID, otherParticipant.ID); err != nil {
respondError(w, fmt.Errorf("could not insert participants: %v", err))
return
}
if err = tx.Commit(); err != nil {
respondError(w, fmt.Errorf("could not commit tx to create conversation: %v", err))
return
}
conversation.OtherParticipant = &otherParticipant
respond(w, conversation, http.StatusCreated)
}
```
在此端点,你会向 `/api/conversations` 发送 POST 请求,请求的 JSON 主体中包含要对话的用户的用户名。
因此,首先需要将请求主体解析成包含用户名的结构。然后,校验用户名不能为空。
```
type Errors struct {
Errors map[string]string `json:"errors"`
}
```
这是错误消息的结构体 `Errors`,它仅仅是一个映射。如果输入空用户名,你就会得到一段带有 `422 Unprocessable Entity`(无法处理的实体)错误消息的 JSON 。
```
{
"errors": {
"username": "Username required"
}
}
```
然后,我们开始执行 SQL 事务。收到的仅仅是用户名,但事实上,我们需要知道实际的用户 ID 。因此,事务的第一项内容是查询另一个参与者的 ID 和头像。如果找不到该用户,我们将会返回 `404 Not Found`(未找到) 错误。另外,如果找到的用户恰好和“当前已验证用户”相同,我们应该返回 `403 Forbidden`(拒绝处理)错误。这是由于对话只应当在两个不同的用户之间发起,而不能是同一个。
然后,我们试图找到这两个用户所共有的对话,所以需要使用 `INTERSECT` 语句。如果存在,只需要通过 `/api/conversations/{conversationID}` 重定向到该对话并将其返回。
如果未找到共有的对话,我们需要创建一个新的对话并添加指定的两个参与者。最后,我们 `COMMIT` 该事务并使用新创建的对话进行响应。
### 获取对话列表
端点 `/api/conversations` 将获取当前已验证用户的所有对话。
```
func getConversations(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
rows, err := db.QueryContext(ctx, `
SELECT
conversations.id,
auth_user.messages_read_at < messages.created_at AS has_unread_messages,
messages.id,
messages.content,
messages.created_at,
messages.user_id = $1 AS mine,
other_users.id,
other_users.username,
other_users.avatar_url
FROM conversations
INNER JOIN messages ON conversations.last_message_id = messages.id
INNER JOIN participants other_participants
ON other_participants.conversation_id = conversations.id
AND other_participants.user_id != $1
INNER JOIN users other_users ON other_participants.user_id = other_users.id
INNER JOIN participants auth_user
ON auth_user.conversation_id = conversations.id
AND auth_user.user_id = $1
ORDER BY messages.created_at DESC
`, authUserID)
if err != nil {
respondError(w, fmt.Errorf("could not query conversations: %v", err))
return
}
defer rows.Close()
conversations := make([]Conversation, 0)
for rows.Next() {
var conversation Conversation
var lastMessage Message
var otherParticipant User
if err = rows.Scan(
&conversation.ID,
&conversation.HasUnreadMessages,
&lastMessage.ID,
&lastMessage.Content,
&lastMessage.CreatedAt,
&lastMessage.Mine,
&otherParticipant.ID,
&otherParticipant.Username,
&otherParticipant.AvatarURL,
); err != nil {
respondError(w, fmt.Errorf("could not scan conversation: %v", err))
return
}
conversation.LastMessage = &lastMessage
conversation.OtherParticipant = &otherParticipant
conversations = append(conversations, conversation)
}
if err = rows.Err(); err != nil {
respondError(w, fmt.Errorf("could not iterate over conversations: %v", err))
return
}
respond(w, conversations, http.StatusOK)
}
```
该处理程序仅对数据库进行查询。它通过一些联接来查询对话表……首先,从消息表中获取最后一条消息。然后依据“ID 与当前已验证用户不同”的条件,从参与者表找到对话的另一个参与者。然后联接到用户表以获取该用户的用户名和头像。最后,再次联接参与者表,并以相反的条件从该表中找出参与对话的另一个用户,其实就是当前已验证用户。我们会对比消息中的 `messages_read_at` 和 `created_at` 两个字段,以确定对话中是否存在未读消息。然后,我们通过 `user_id` 字段来判定该消息是否属于“我”(指当前已验证用户)。
注意,此查询过程假定对话中只有两个用户参与,它也仅仅适用于这种情况。另外,该设计也不很适用于需要显示未读消息数量的情况。如果需要显示未读消息的数量,我认为可以在 `participants` 表上添加一个`unread_messages_count` `INT` 字段,并在每次创建新消息的时候递增它,如果用户已读则重置该字段。
接下来需要遍历每一条记录,通过扫描每一个存在的对话来建立一个<ruby> 对话切片 <rt> slice of conversations </rt></ruby>并在最后进行响应。
### 找到单个对话
端点 `/api/conversations/{conversationID}` 会根据 ID 对单个对话进行响应。
```
func getConversation(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
conversationID := way.Param(ctx, "conversationID")
var conversation Conversation
var otherParticipant User
if err := db.QueryRowContext(ctx, `
SELECT
IFNULL(auth_user.messages_read_at < messages.created_at, false) AS has_unread_messages,
other_users.id,
other_users.username,
other_users.avatar_url
FROM conversations
LEFT JOIN messages ON conversations.last_message_id = messages.id
INNER JOIN participants other_participants
ON other_participants.conversation_id = conversations.id
AND other_participants.user_id != $1
INNER JOIN users other_users ON other_participants.user_id = other_users.id
INNER JOIN participants auth_user
ON auth_user.conversation_id = conversations.id
AND auth_user.user_id = $1
WHERE conversations.id = $2
`, authUserID, conversationID).Scan(
&conversation.HasUnreadMessages,
&otherParticipant.ID,
&otherParticipant.Username,
&otherParticipant.AvatarURL,
); err == sql.ErrNoRows {
http.Error(w, "Conversation not found", http.StatusNotFound)
return
} else if err != nil {
respondError(w, fmt.Errorf("could not query conversation: %v", err))
return
}
conversation.ID = conversationID
conversation.OtherParticipant = &otherParticipant
respond(w, conversation, http.StatusOK)
}
```
这里的查询与之前有点类似。尽管我们并不关心最后一条消息的显示问题,并因此忽略了与之相关的一些字段,但是我们需要根据这条消息来判断对话中是否存在未读消息。此时,我们使用 `LEFT JOIN` 来代替 `INNER JOIN`,因为 `last_message_id` 字段是 `NULLABLE`(可以为空)的;而其他情况下,我们无法得到任何记录。基于同样的理由,我们在 `has_unread_messages` 的比较中使用了 `IFNULL` 语句。最后,我们按 ID 进行过滤。
如果查询没有返回任何记录,我们的响应会返回 `404 Not Found` 错误,否则响应将会返回 `200 OK` 以及找到的对话。
---
本篇帖子以创建了一些对话端点结束。
在下一篇帖子中,我们将会看到如何创建并列出消息。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-conversations/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[PsiACE](https://github.com/PsiACE) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,057 | 开源软件在应对新冠病毒中的贡献 | https://opensource.com/article/20/3/open-source-software-covid19 | 2020-03-30T21:06:49 | [
"新冠病毒"
] | https://linux.cn/article-12057-1.html |
>
> 在新冠疫情爆发之际,涌现了数以千计的开源项目,今天我们来了解其中四个。
>
>
>

在当前紧张的疫情环境下,保持专注和积极性是一个很大的挑战。而研究开源社区如何应对这一次疫情爆发,对于我来说却成为了一种宣泄。
从今年一月底开始,整个开源社区已经贡献了数以千计关于冠状病毒或新冠病毒的[开源软件仓库](https://github.com/search?q=coronavirus+OR+covid19),其中涉及的内容包括但不限于数据集、模型、可视化、Web 应用、移动应用,且大多数都使用了 JavaScript 和 Python 编写。
之前我们分享过一些关于[开源硬件创客们在帮助](/article-12047-1.html)遏制冠状病毒传播方面做的贡献,现在将继续分享四个由开源社区作出的应对冠状病毒和新冠病毒的项目,这体现了开发者们和整个开源社区在当下对整个世界的影响力。
### 1. PennSignals:CHIME

<ruby> 新冠病毒流行病医院影响模型 <rt> COVID-19 Hospital Impact Model for Epidemics </rt></ruby>([CHIME](http://penn-chime.phl.io/))是由宾夕法尼亚大学 Penn Medicine 机构的数据科学家们建立的开源在线应用,它可以让医院更好地了解本次新型冠状病毒对医院需求的影响。
医院的管理人员可以通过 CHIME 来大致预测未来几天和几周内将会有多少患者需要住院治疗,并推算 ICU 和呼吸机的需求量。只需要输入当前住院患者数以及一些相关的变量,就可以看到未来几天内需求的变化情况。
CHIME 主要使用 Python 开发,并通过 [Pandas](https://tidelift.com/subscription/pkg/pypi-pandas) 这个开源库实现了大部分的数据转换和数值计算,最终得出相关的估计值。Pandas 的背后有一个强大的团队进行支持,它是在数据分析方面被广泛使用的 Python 库之一。和很多其它的开源项目一样,Pandas 团队的收入大部分来源于[用户的资金支持](https://pandas.pydata.org/about/sponsors.html)。
### 2. Locale.ai:实时新冠病毒可视化

实时显示世界各地病例数量分布的地图可以让我们直观了解新冠病毒的规模和扩散程度。Locale.ai 就开发了这样一个开源、可交互的[新冠病毒已知病例可视化分布图](https://github.com/localeai/covid19-live-visualization),这个图会根据最新的可靠数据实时进行更新。
这个项目有趣的地方在于,它的数据是是通过 GitHub 用户 ExpDev07 创建的[开源 API](https://github.com/CSSEGISandData/COVID-19) 进行检索的,这个 API 的数据来源是[约翰·霍普金斯大学的开源数据集](https://tidelift.com/subscription/pkg/npm-vue),而约翰·霍普金斯大学这份聚合了多个来源的数据集则是 GitHub 上新冠病毒相关的最受欢迎的项目。这就是开源项领域中分支带来的一大好处。
Locale.ai 的这个图表通过 [Vue.js](https://tidelift.com/subscription/pkg/npm-vue) 开发。Vue.js 是一个在 Web 应用开发方面非常流行的框架,它是由[尤雨溪](https://blog.tidelift.com/vuejs-evan-you-javascript-framework)创造并维护的。值得一提的是,尤雨溪是少数以全职参与开源项目维护的人之一。
### 3. BlankerL:DXY-COVID-19-Crawler

[DXY-COVID-19-Crawler](https://github.com/BlankerL/DXY-COVID-19-Crawler) 建立于今年 1 月份,是开源社区对新冠病毒最早发起响应的项目之一。当时该病毒主要在中国范围内传播,中国医学界通过[丁香园](https://dxy.cn)网站来进行病例的报告和跟踪。为了使这些疫情信息具有更高的可读性和易用性,GitHub 用户 BlankerL 开发了一个爬虫,系统地从丁香园网站获取数据,并通过 API 和数据仓库的方式对外公开。这些数据也被学术研究人员用于研究病毒传播趋势和制作相关的可视化图表。到目前为止,DXY-COVID-19-Crawler 这个项目已经获得了超过 1300 个星标和近 300 次的复刻。
BlankerL 使用 Python 和 [Beautiful Soup](https://blog.tidelift.com/beautiful-soup-is-now-part-of-the-tidelift-subscription) 库开发了这个爬虫。Beautiful Soup 是 Python 开发者用于从页面 HTML DOM 中提取信息的库,它由 Leonard Richardson 维护,这位作者另外还全职担任软件架构师。
### 4. 东京新冠病毒工作组网站

世界各地很多城市都在网络上持续更新当地的新冠病毒信息。东京都政府则为此创建了一个[综合性的网站](https://stopcovid19.metro.tokyo.lg.jp/en/),让东京当地居民、在东京设有办事处的公司以及到东京的游客了解最新情况,并采取相应的预防措施。
这个网站的不同之处在于它是由东京都政府[开源](https://github.com/tokyo-metropolitan-gov/covid19)的。这个项目受到了来自 180 多名用户的贡献,日本的[长野市、千叶市、福冈市](https://github.com/tokyo-metropolitan-gov/covid19/issues/1802)还对这个网站进行了改造。这个项目是城市公共建设更好地服务大众的有力示范。
这个开源网站也使用了很多开源技术。通过 [Tidelift](https://tidelift.com/),我留意到项目中存在了 1365 个依赖项,而这都是由 38 个由开发者明确使用的直接依赖项所依赖的。也就是说,超过一千多个开源项目(包括 [Nuxt.js](https://tidelift.com/subscription/pkg/npm-nuxt)、[Prettier](https://blog.tidelift.com/prettier-is-now-part-of-the-tidelift-subscriptions)、[Babel](https://tidelift.com/subscription/pkg/npm-babel)、[Ajv](https://blog.tidelift.com/ajv-is-now-part-of-the-tidelift-subscription) 等等)都为东京向市民共享信息提供了帮助。

### 其它项目
除此以外,还有很多[应对新冠病毒的重要项目](https://github.com/soroushchehresa/awesome-coronavirus)正在公开进行当中。在这次研究中,开源社区应对流行病以及利用开源技术开展工作的方式让我深受启发。接下来的一段时间都是应对疫情的关键时期,我们也可以继续在开源社区中寻找到更大的动力。
如果你也参与到了新冠病毒相关的开源项目当中,欢迎在评论区分享。
---
via: <https://opensource.com/article/20/3/open-source-software-covid19>
作者:[Jeff Stern](https://opensource.com/users/jeffstern) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Work is hard right now. COVID-19 makes it a challenge to stay focused and motivated. But it was cathartic for me to do some research into how the open source community is responding to the global pandemic.
Since the end of January, the community has contributed to [thousands of open source repositories](https://github.com/search?q=coronavirus+OR+covid19) that mention coronavirus or COVID-19. These repositories consist of datasets, models, visualizations, web and mobile applications, and more, and the majority are written in JavaScript and Python.
Previously, we shared information about several [open hardware makers helping](https://opensource.com/article/20/3/open-hardware-covid19) to stop the spread and suffering caused by the coronavirus. Here, we're sharing four (of many) examples of how the open source software community is responding to coronavirus and COVID-19, with the goal of celebrating the creators and the overall impact the open source community is making on the world right now.
## 1. CHIME by PennSignals
COVID-19 Hospital Impact Model for Epidemics ([CHIME](http://penn-chime.phl.io/)) is an open source application built by data scientists at Penn Medicine at the University of Pennsylvania. The online tool allows hospitals to better understand the impact the virus will have on hospital demand.
Hospital leaders can use CHIME to "get more informed estimates of how many patients will need hospitalization, ICU beds, and mechanical ventilation over the coming days and weeks." A user can input how many patients are currently hospitalized and see, based on other variables, how demand might increase over the coming days.
CHIME is primarily built with Python and uses the [pandas](https://tidelift.com/subscription/pkg/pypi-pandas) open source dependency for much of the underlying data-transformation number-crunching to generate the estimates. Pandas has a relatively robust team and is one of the most commonly used Python libraries for data analysis and, like all open source projects, is highly dependent on [users' support](https://pandas.pydata.org/about/sponsors.html) for income.
## 2. Real-time COVID-19 visualization by Locale.ai
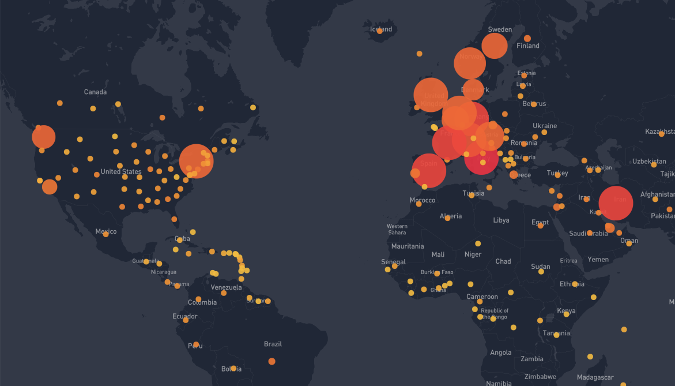
Maps that track the number of cases help us visualize the relative scale and spread of COVID-19. [Locale.ai created an open source, interactive visualization](https://github.com/localeai/covid19-live-visualization) of all known cases of COVID-19. The map provides live updates with new data as it becomes available.
I find this project especially interesting because the data is retrieved via [an open source API](https://github.com/localeai/covid19-live-visualization) created by GitHub user ExpDev07 that queries [an open source dataset](https://github.com/CSSEGISandData/COVID-19) from John Hopkins University. The John Hopkins dataset (an aggregate of more than a dozen other sources) is currently the most popular COVID19-related project on GitHub. This is the branching nature of open source at its finest!
Locale.ai built the visualization website using [Vue.js](https://tidelift.com/subscription/pkg/npm-vue), a popular framework that allows web developers to create modern web apps. Vue.js was created and continues to be maintained by [Evan You](https://blog.tidelift.com/vuejs-evan-you-javascript-framework), one of the few people who have made a full-time career as an open source maintainer.
## 3. DXY-COVID-19-Crawler by BlankerL
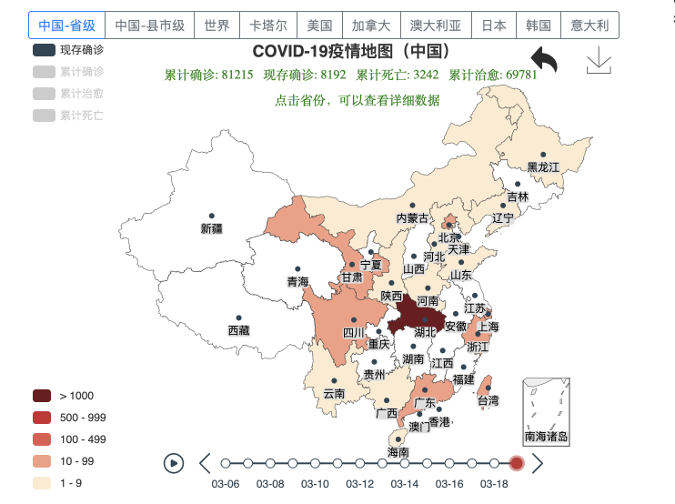
[DXY-COVID-19-Crawler](https://github.com/BlankerL/DXY-COVID-19-Crawler) was created in January and is one of the earliest responses from the open source community to COVID-19. When the virus was spreading primarily in China, the Chinese medical community was using a site called [DXY.cn](https://dxy.cn) to report and track cases. To make the information more readily available and usable by others, GitHub user BlankerL wrote a web crawler to systematically collect data from the DXY.cn site and make it available via an API and data warehouse. That data has been used by academic researchers and others to examine trends and visualize the spread of the virus. So far, DXY-COVID-19-Crawler has been starred more than 1,300 times and forked nearly 300 times.
BlankerL wrote the web crawler using Python and a package called [Beautiful Soup](https://blog.tidelift.com/beautiful-soup-is-now-part-of-the-tidelift-subscription). Beautiful Soup is an application that allows Python developers to easily scrape information from websites. Beautiful Soup is maintained by Leonard Richardson, who also works full-time as a software architect.
## 4. City of Tokyo's COVID-19 task force website
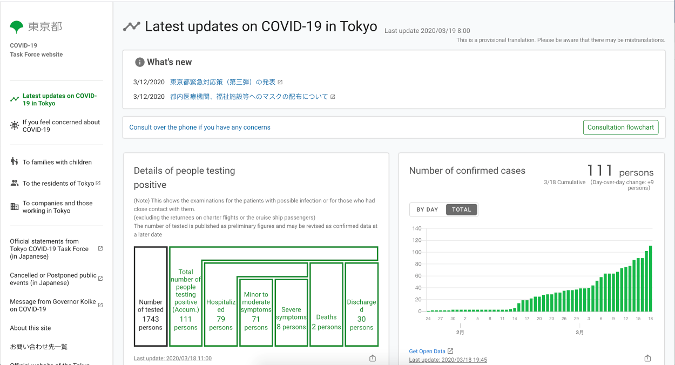
Many cities around the world have updated their websites with information for their residents about COVID-19. The Tokyo Metropolitan Government created a [comprehensive website](https://stopcovid19.metro.tokyo.lg.jp/en/) that "aims to allow Tokyo residents, companies with offices in Tokyo, and visitors to Tokyo to grasp the current situation and take measures and precautions accordingly."
Unlike many other cities, Tokyo decided to [open source its site](https://github.com/tokyo-metropolitan-gov/covid19). The project boasts contributions by more than 180 different users, and [at least three other cities](https://github.com/tokyo-metropolitan-gov/covid19/issues/1802) in Japan (Nagano, Chiba, and Fukuoka City) remixed the site. The project is an example of how cities can better serve their citizens by building openly.
There's an incredible amount of open source technology powering Tokyo's open source website. Using the [Tidelift](https://tidelift.com/) application, I identified 1,365 dependencies used in the project. All of this complexity happens because 38 direct dependencies (i.e., dependencies the developers explicitly decided to use) have dependencies of their own. That said, maintainers of more than a thousand different open source dependencies (including [Nuxt.js](https://tidelift.com/subscription/pkg/npm-nuxt), [Prettier](https://blog.tidelift.com/prettier-is-now-part-of-the-tidelift-subscriptions), [Babel](https://tidelift.com/subscription/pkg/npm-babel), [Ajv](https://blog.tidelift.com/ajv-is-now-part-of-the-tidelift-subscription), and more) are in a small way responsible for helping Tokyo share information with their citizens.
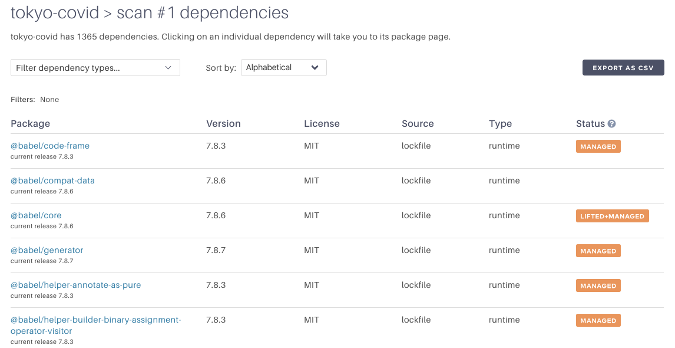
## Other projects
There are [many other important projects](https://github.com/soroushchehresa/awesome-coronavirus) being built in the open in response to COVID-19. I am inspired by how the open source community is responding to this pandemic and leveraging other open source technologies to work quickly. The weeks ahead will be difficult, but I know we can continue to find motivation in the open source community.
If you are working on an open source project related to COVID-19, please share it in the comments so we can help spread the word.
## 3 Comments |
12,059 | 体验 DebianDog:Puppy 式的 Debian Linux | https://itsfoss.com/debiandog/ | 2020-03-31T10:47:00 | [] | https://linux.cn/article-12059-1.html | 不久前,我偶然发现了一个有趣的 Linux 项目。这个项目旨在为 Debian 和基于 Debian 的系统创建一个小型的现场版 CD,类似于 [Puppy Linux 项目](http://puppylinux.com/) 。让我们看看 DebianDog 。
### DebianDog 是什么?
正如字面所述,[DebianDog](https://debiandog.github.io/doglinux/) “是一个被塑造成一个外观和动作都像 Puppy Linux 的小型 Debian 现场版 CD。没有改动 Debian 结构和方式,Debian 的文档对 DebianDog 来说是完全有效的。你可以使用 `apt-get` 或 synaptic 来访问所有的 Debian 存储库。”

对于那些不熟悉 [Puppy Linux](http://puppylinux.com/) 的人来说,该项目是 “多个 Linux 发行版的一个集合,建立在相同的共享准则之上”。这些准则能够实现快速、小型(300 MB 或更少)、易于使用。这里有为支持 Ubuntu, Slackware 和 Raspbian 软件包构建的 Puppy Linux 变种。
DebianDog 和 Puppy Linux 之间最大的不同是,Puppy Linux 有其自己的软件包管理器 [Puppy 软件包管理器](http://wikka.puppylinux.com/PPM?redirect=no) 。如上所述,DebianDog 使用 Debian 软件包管理器及其软件包。甚至 DebianDog 网站也试图澄清这一点:“它不是 Puppy Linux,并且也与基于 Debian 的 Puppy 无关。”
### 为什么一些人使用 DebianDog ?
安装 DebianDog(或其任何衍生产品)的主要原因是让一台较旧电脑重焕新生。在 DebianDog 上的每个版本都有一个 32 位版本。它们还有更轻量级的桌面环境/窗口管理器,例如 [Openbox](http://openbox.org/wiki/Main_Page) 或 [Trinity Desktop](https://www.trinitydesktop.org/) 环境。它们中大多数也都有一个 systemd 的可替代版本。它们也安装更轻的应用程序,例如 [PCManFM](https://wiki.lxde.org/en/PCManFM) 。
### DebianDog 有哪些可用的变体版本?
尽管 DebianDog 在本系列中是第一个,但是该项目被称为 ‘Dog Linux’ ,提供各种基于Debian 和 Ubuntu的流行发行版的 ‘Dog 变体’。
#### DebianDog Jessie
DebianDog 的第一个(也是最初的)版本是 DebianDog Jessie。它有两个 [32 位版本](https://debiandog.github.io/doglinux/zz01debiandogjessie.html) ,一个使用 [Joe’s Window Manager (JWM)](https://en.wikipedia.org/wiki/JWM) 作为默认桌面环境,另一个使用 XFCE 作为默认桌面环境。systemd 和 sysvinit 都是可用的。它还有一个 [64 位版本](https://debiandog.github.io/doglinux/zz02debiandog64.html)。DebianDog Jessie 基于 Debian 8.0(Jessie)。Debian 8.0 的支持将于 2020 年 6 月 30 日结束,因此安装需谨慎。
#### StretchDog
[StretchDog](https://debiandog.github.io/doglinux/zz02stretchdog.html) 基于 Debian 9.0(Stretch)。它有 32 位和 64 位两种版本可用。Openbox 是默认的窗口管理器,但是我们可以切换到 JWM 。Debian 9.0 的支持将于 2022 年 6 月 30 日结束。
#### BusterDog
[BusterDog](https://debiandog.github.io/doglinux/zz03busterdog.html) 是很有趣的。它基于 [Debian 10](https://itsfoss.com/debian-10-buster/)(Buster)。它不使用 systemd,反而像 [AntiX](https://antixlinux.com/) 一样使用 [elogind](https://github.com/elogind/elogind) 。Debian 10.0 的支持将于 2024 年 6 月结束。
#### MintPup
[MintPup](https://debiandog.github.io/doglinux/zz04mintpup.html) 基于 [Linux Mint](https://linuxmint.com/) 17.1。现场版 CD 仅有 32 位版本。你也可以使用 “apt-get 或 synaptic 访问 Ubuntu/Mint 的存储库”。考虑到 Mint 17 已经到了生命的尽头,这一版本必须避免使用。
#### XenialDog
XenialDog 有 [32 位](https://debiandog.github.io/doglinux/zz05xenialdog.html)和 [64 位](https://debiandog.github.io/doglinux/zz05zxenialdog.html) 两种变种,基于 Ubuntu 16.04 LTS 。两个变种都使用 Openbox 作为默认版本,JWM 可选。Ubuntu 16.04 LTS 的支持将于 2021 年 4 月结束, 因此安装需谨慎。
#### TrinityDog
[TrintyDog](https://debiandog.github.io/doglinux/zz06-trinitydog.html) 有两种变体。一个基于 Debian 8 ,另一个基于 Debian 9 。两种变体都有 32 位版本,并且都使用 [Trinity Desktop Environment](https://www.trinitydesktop.org/) ,以此得名。

#### BionicDog
你应该能够从名称猜到。[BionicDog](https://debiandog.github.io/doglinux/zz06-zbionicdog.html) 基于 [Ubuntu 18.04 LTS](https://itsfoss.com/ubuntu-18-04-released/)。主要版本有 32 位和 64 位两个版本,Openbox 是默认的窗口管理器。这里也有一个使用 [Cinnamon desktop](https://en.wikipedia.org/wiki/Cinnamon_(desktop_environment)) 的版本,并且只有 64 位版本。

### 结束语
我喜欢任何 [想让较旧电脑系统有用的 Linux 项目](https://itsfoss.com/lightweight-linux-beginners/)。但是,通过 DebianDog 项目提供的大多数操作系统不再受支持,或者接近它们的生命尽头。从长远来看,这就不那么有用了。
**我不建议在你的主计算机上使用它。**在现场版 USB 中或一台闲置的系统上尝试它。此外,如果你想使用较新的基础系统,[你可以创建](https://github.com/DebianDog/MakeLive)你自己的现场版 CD 。
似乎冥冥中自有天意,我总是在探索鲜为人知的 Linux 发行版的路上艰难地前行,像 [FatDog64](https://itsfoss.com/fatdog64-linux-review/)、[4M Linux](https://itsfoss.com/4mlinux-review/) 以及 [Vipper Linux](https://itsfoss.com/viperr-linux-review/) 。虽然我不建议使用它们,但是知晓这些项目的存在的意义总是好的。
你对 DebianDog 有什么看法?你最最喜欢的 Puppy 式的操作系统是什么?请在下面的评论区中告诉我们。
如果你觉得这篇文章很有趣,请花点时间在社交媒体、黑客新闻或 Reddit 上分享。
---
via: <https://itsfoss.com/debiandog/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently I stumbled upon an intriguing Linux project. This project aims to create small live CDs for Debian and Debian-based systems, similar to the [Puppy Linux project](http://puppylinux.com/). Let’s take a look at DebianDog.
## What is DebianDog?
As it says on the tin, [DebianDog](https://debiandog.github.io/doglinux/) “is a small Debian Live CD shaped to look like Puppy and act like Puppy. Debian structure and Debian behaviour are untouched and Debian documentation is 100% valid for DebianDog. You have access to all Debian repositories using apt-get or synaptic.”
For those of you who are not familiar with [Puppy Linux](http://puppylinux.com/), the project is “a collection of multiple Linux distributions, built on the same shared principles”. Those principles are to be fast, small (300 MB or less), and easy to use. There are versions of Puppy Linux built to support Ubuntu, Slackware, and Raspbian packages.
The major difference between DebianDog and Puppy Linux is that Puppy Linux has its own package manager [the [Puppy Package Manager](http://wikka.puppylinux.com/PPM?redirect=no)]. As stated above, DebianDog using the Debian package manager and packages. Even the DebianDog website tries to make that clear: “It is not Puppy Linux and it has nothing to do with Puppy based on Debian.”
## Why should anyone use DebianDog?
The main reason to install DebianDog (or any of its derivatives) would be to restore an older system to operability. Every entry on DebianDog has a 32-bit option. They also have lighter desktop environments/window managers, such as [Openbox](http://openbox.org/wiki/Main_Page) or the [Trinity Desktop](https://www.trinitydesktop.org/) environment. Most of those also have an alternative to systemd. They also come with lighter applications installed, such as [PCManFM](https://wiki.lxde.org/en/PCManFM).
## What versions of DebianDog are available?
Though DebianDog was the first in the series, the project is called ‘Dog Linux’ and provides various ‘Dog variants’ on popular distributions based on Debian and Ubuntu.
### DebianDog Jessie
The first (and original) version of DebianDog is DebianDog Jessie. There are two [32-bit versions](https://debiandog.github.io/doglinux/zz01debiandogjessie.html) of it. One uses [Joe’s Window Manager (JWM)](https://en.wikipedia.org/wiki/JWM) as default and the other uses XFCE. Both systemd and sysvinit are available. There is also a [64-bit version](https://debiandog.github.io/doglinux/zz02debiandog64.html). DebianDog Jessie is based on Debian 8.0 (codename Jessie). Support for Debian 8.0 ends on June 30th, 2020, so install with caution.
### StretchDog
[Stret](https://debiandog.github.io/doglinux/zz02stretchdog.html)[c](https://debiandog.github.io/doglinux/zz02stretchdog.html)[hDog](https://debiandog.github.io/doglinux/zz02stretchdog.html) is based on Debian 9.0 (codename Stretch). It is available in 32 and 64-bit. Openbox is the default window manager, but we can also switch to JWM. Support for Debian 9.0 ends on June 30th, 2022.
### BusterDog
[BusterDog](https://debiandog.github.io/doglinux/zz03busterdog.html) is interesting. It is based on [Debian 10](https://itsfoss.com/debian-10-buster/) (codename Buster). It does not use systemd, instead, it uses [elogind](https://github.com/elogind/elogind) just like [AntiX](https://antixlinux.com/). Support for Debian 10.0 ends on June 2024.
### MintPup
[MintPup](https://debiandog.github.io/doglinux/zz04mintpup.html) is based on [Linux Mint](https://linuxmint.com/) 17.1. This LiveCD is 32-bit only. You can also access all of the “Ubuntu/Mint repositories using apt-get or synaptic”. Considering that Mint 17 has reached end of life, this version must be avoided.
### XenialDog
There are both [32-bit](https://debiandog.github.io/doglinux/zz05xenialdog.html) and [64-bit versions](https://debiandog.github.io/doglinux/zz05zxenialdog.html) of this spin based on the Ubuntu 16.04 LTS. Both versions come with Openbox as default with JWM as an option. Support for Ubuntu 16.04 LTS ends in April of 2021, so install with caution.
### TrinityDog
There are two versions of the [TrintyDog](https://debiandog.github.io/doglinux/zz06-trinitydog.html) spin. One is based on Debian 8 and the other is based on Debian 9. Both are 32-bit and both use the [Trinity Desktop Environment](https://www.trinitydesktop.org/), thus the name.
### BionicDog
As you should be able to guess by the name. [BionicDog](https://debiandog.github.io/doglinux/zz06-zbionicdog.html) is based on [Ubuntu 18.04 LTS](https://itsfoss.com/ubuntu-18-04-released/). The main version of this spin has both 32 and 64-bit with Openbox as the default window manager. There is also a version that uses the [Cinnamon desktop](https://en.wikipedia.org/wiki/Cinnamon_(desktop_environment)) and is only 64-bit.
## Final Thoughts
I like any [Linux project that wants to make older systems usable](https://itsfoss.com/lightweight-linux-beginners/). However, most of the operating systems available through DebianDog are no longer supported or nearing the end of their life span. This makes it less than useful for the long run.
**I wouldn’t really advise to use it on your main computer.** Try it in live USB or on a spare system. Also, [you can create](https://github.com/DebianDog/MakeLive) your own LiveCD spin if you want to take advantage of a newer base system.
Somehow I keep on stumbling across obscure Linux distributions like [FatDog64](https://itsfoss.com/fatdog64-linux-review/), [4M Linux](https://itsfoss.com/4mlinux-review/) and [Viperr Linux](https://itsfoss.com/viperr-linux-review/). Even though I may not always recommend them to use, it’s still good to know about the existence of such projects.
What are your thoughts on the DebianDog? What is your favorite Puppy-syle OS? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
12,060 | 塑造 Linux 历史的 10 个时刻 | https://opensource.com/article/19/4/top-moments-linux-history | 2020-04-01T09:33:13 | [
"Linux",
"历史"
] | https://linux.cn/article-12060-1.html |
>
> 自 1991 年诞生以来,Linux 已经走了漫长的一段路,而这些事件标志着它的发展。
>
>
>

在 2018 年 8 月,Opensource.com 发布了一项包含七个选项的民意测验,询问读者:[Linux 历史上最重要的时刻是什么?](https://opensource.com/article/18/8/linux-history)我觉得我需要扩大这个清单,并提出我认为的 10 个在塑造 Linux 历史上发挥了重要作用的时刻。
### 1、Linus 发布 Linux
Linus Torvalds 最初是在 1991 年将 Linux 当成一个业余爱好发布到世上的。结果这个业余爱好成了他的职业!
### 2、出现 Linux 发行版
1993 年,出现了几个 Linux 发行版,需要特别指出的有 [Debian](https://www.debian.org/doc/manuals/project-history/ch-intro.en.html)、[Red Hat](https://brand.redhat.com/foundations/history) 和 [Slackware](https://opensource.com/article/18/7/stackware-turns-25)。这个时刻之所以重要是因为它们证明了 Linux 在市场认可度和开发水平方面的成就,使其能够在 1990 年代动荡的操作系统战争、浏览器战争和协议战争中生存下来。相反,那时许多成熟的、商业的和专有的产品并没有活过千禧年之交!
### 3、IBM 斥巨资投注 Linux
2000 年,IBM 宣布将在 Linux 上投资 10 亿美元。Richard Richtmyer 在他的 CNN Money [有关投资的文章](https://money.cnn.com/2000/12/12/technology/ibm_linux) 中写道:“这一声明强调了蓝色巨人对 Linux 的承诺,标志着将这个替代操作系统推向主流商业市场的重大进展。”
### 4、好莱坞接纳 Linux
在 2002 年,整个好莱坞电影业似乎都采用了 Linux。[迪尼斯](https://www.nytimes.com/2002/06/18/business/technology-disney-shifting-to-linux-for-film-animation.html)、[梦工厂](https://www.linux.com/news/stallion-and-penguin-dreamworks-uses-linux-create-new-animated-film) 和 [工业光魔](https://www.linuxjournal.com/article/6011) 都在那一年开始用 Linux 制作电影。
### 5、Linux 得到政府认可
2003 年,美国政府对 Linux 的接受是它的又一个重要时刻。红帽 Linux 被[授予](https://www.cnet.com/news/government-tips-hat-to-red-hat)美国防部通用操作环境(COE)认证。这很重要,因为政府(特别是情报和军事机构)对计算机系统有非常严格的要求,以防止攻击和支持国家安全。这为其他机构使用 Linux 打开了大门。在那年晚些时候,[美国国家气象局宣布](https://www.computerworld.com/article/2574142/national-weather-service-migrates-to-linux-based-ibm-workstations.html),它将用运行 Linux 的新计算机代替过时的系统。
### 6、我管理的系统
这个“时刻”确实是我个人经历的集合。随着在 2000 年代我的职业发展,我发现自己管理的几种类型的系统和设备都运行着 Linux。我在 VMware ESX、F5 Big-IP、Check Point UTM Edge、Cisco ASA 和 PIX 这些地方发现了 Linux。这使我意识到 Linux 确实可行并且可以继续存在下去。
### 7、Ubuntu
2004 年,Mark Shuttleworth 创立了 Canonical,该公司基于 Debian 发行版提供了易于使用的 Linux 桌面:[Ubuntu Linux](https://www.ubuntu.com/about)。我认为 Ubuntu Linux 帮助扩展了桌面 Linux 安装基数。从休闲的家庭用户到专业软件开发人员,它使 Linux 出现在更多人面前。
### 8、Google 的 Linux
Google 发行了两种基于 Linux 内核的操作系统:2008 年中期的 Android 移动操作系统和 2011 年在 Chromebook 上运行的 Chrome OS。在那之后,已经售出了数百万部 Android 手机和 Chromebook。
### 9、云计算即 Linux
在过去这十年左右的时间里,云计算已经从互联网计算的宏伟愿景变成了我们如何个人和专业地使用计算机的全新方式。云计算领域中的主要参与者都是构建于 Linux 之上的,包括 [Amazon Web Services(AWS)](https://aws.amazon.com/amazon-linux-2)、[Google Cloud Services(GCS)](https://cloud.google.com) 和 [Linode](https://www.linode.com/docs/getting-started)。即使在一些我们不能确信的地方(例如 Microsoft Azure),也很好地支持运行 Linux 工作负载。
### 10、我的汽车运行着 Linux
你的也一样!许多汽车制造商几年前开始引入 Linux。这导致了名为 [汽车级 Linux(AGL)](https://www.automotivelinux.org) 的协作开源项目的形成。丰田和斯巴鲁等主要汽车制造商已经联合开发基于 Linux 的汽车娱乐、导航和引擎管理系统。
### 分享你的最爱
这是我从贯穿我的职业生涯的 Linux 文章和事件的档案库中提取出来的主观清单,因此可能还有其他更值得注意的时刻。请分享你的评论吧。
---
via: <https://opensource.com/article/19/4/top-moments-linux-history>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In August 2018, Opensource.com posted a poll with seven options asking readers: * What was the most important moment in the history of Linux?* I thought I would expand on the list and present 10 moments that I think have played an important part in shaping the history of Linux.
## 1. Linus releases Linux
Linus Torvalds initially released Linux to the world in 1991 as a hobby. It didn't remain a hobby for long!
## 2. Linux distributions
In 1993, several Linux distributions were founded, notably [Debian](https://www.debian.org/doc/manuals/project-history/ch-intro.en.html), [Red Hat](https://brand.redhat.com/foundations/history), and [Slackware](https://opensource.com/article/18/7/stackware-turns-25). These were important because they demonstrated Linux's gains in market acceptance and development that enabled it to survive the tumultuous OS wars, browser wars, and protocol wars of the 1990s. In contrast, many established, commercial, and proprietary products did not make it past the turn of the millennium!
## 3. IBM's big investment in Linux
In 2000, IBM announced it would invest US$1 billion dollars in Linux. In his CNN Money [article about the investment](https://money.cnn.com/2000/12/12/technology/ibm_linux), Richard Richtmyer wrote: "The announcement underscores Big Blue's commitment to Linux and marks significant progress in moving the alternative operating system into the mainstream commercial market."
## 4. Hollywood adopts Linux
In 2002, it seemed the entire Hollywood movie industry adopted Linux. [Disney](https://www.nytimes.com/2002/06/18/business/technology-disney-shifting-to-linux-for-film-animation.html), [Dreamworks](https://www.linux.com/news/stallion-and-penguin-dreamworks-uses-linux-create-new-animated-film), and [Industrial Light & Magic](https://www.linuxjournal.com/article/6011) all began making movies with Linux that year.
## 5. Linux for national security
In 2003, another big moment came with the US government's acceptance of Linux. Red Hat Linux was [awarded](https://www.cnet.com/news/government-tips-hat-to-red-hat) the Department of Defense Common Operating Environment (COE) certification. This is significant because the government—intelligence and military agencies in particular—have very strict requirements for computing systems to prevent attacks and support national security. This opened the door for other agencies to use Linux. Later that year, the [National Weather Service announced](https://www.computerworld.com/article/2574142/national-weather-service-migrates-to-linux-based-ibm-workstations.html) it would replace outdated systems with new computers running Linux.
## 6. The systems I managed
This "moment" is really a collection of my personal experiences. As my career progressed in the 2000s, I discovered several types of systems and devices that I managed were all running Linux. Some of the places I found Linux were VMware ESX, F5 Big-IP, Check Point UTM Edge, Cisco ASA, and PIX. This made me realize that Linux was truly viable and here to stay.
## 7. Ubuntu
In 2004, Canonical was founded by Mark Shuttleworth to provide an easy-to-use Linux desktop—[Ubuntu Linux](https://www.ubuntu.com/about)—based on the Debian distribution. I think Ubuntu Linux helped to expand the desktop Linux install base. It put Linux in front of many more people, from casual home users to professional software developers.
## 8. Google Linux
Google released two operating systems based on the Linux kernel: the Android mobile operating system in mid-2008 and Chrome OS, running on a Chromebook, in 2011. Since then, millions of Android mobile phones and Chromebooks have been sold.
## 9. The cloud is Linux
In the past 10 years or so, cloud computing has gone from a grandiose vision of computing on the internet to a reinvention of how we use computers personally and professionally. The big players in the cloud space are built on Linux, including [Amazon Web Services](https://aws.amazon.com/amazon-linux-2), [Google Cloud Services](https://cloud.google.com), and [Linode](https://www.linode.com/docs/getting-started). Even in cases where we aren't certain, such as Microsoft Azure, running Linux workloads is well supported.
## 10. My car runs Linux
And so will yours! Many automakers began introducing Linux a few years ago. This led to the formation of the collaborative open source project called [Automotive Grade Linux](https://www.automotivelinux.org). Major car makers, such as Toyota and Subaru, have joined together to develop Linux-based automotive entertainment, navigation, and engine-management systems.
### Share your favorite
This is my subjective list pulled from archives of Linux articles and events throughout my career, so there may be other more notable moments that I am overlooking. Share in the comments. Also, the [Linux history poll](https://opensource.com/article/18/8/linux-history) is still open for voting if you're interested.
## 11 Comments |
12,062 | 如何在 Linux 上检查所有用户密码到期日期 | https://www.2daygeek.com/linux-check-user-password-expiration-date/ | 2020-04-01T10:50:05 | [
"密码"
] | https://linux.cn/article-12062-1.html | 
如果你在 [Linux 上启用了密码策略](/article-10698-1.html)。密码必须在到期前进行更改,并且登录到系统时会收到通知。
如果你很少使用自己的帐户,那么可能由于密码过期而被锁定。在许多情况下,这可能会在[无需密码登录](https://www.2daygeek.com/configure-setup-passwordless-ssh-key-based-authentication-linux/)的服务帐户中发生,因为没人会注意到它。
这将导致停止服务器上配置的 [cronjob/crontab](https://www.2daygeek.com/linux-crontab-cron-job-to-schedule-jobs-task/)。
如果如此,该如何缓解这种情况。
你可以写一个 shell 脚本来获得有关它的通知,我们前一段时间为此写了一篇文章。
* [使用 Bash 脚本发送包含几天内到期的用户账号列表的电子邮件](/article-11781-1.html)
它将给出天数,但是本文旨在在终端中给你实际日期。
这可以使用 `chage` 命令来实现。
### 什么是 chage 命令?
`chage` 代表<ruby> 更改时效 <rt> change age </rt></ruby>。它更改用户密码到期信息。
`chage` 命令可以修改两次密码更改之间的天数,以及最后一次更改密码的日期。
系统使用此信息来确定用户何时应更改密码。
它还允许用户执行其他功能,例如设置帐户到期日期、在到期后将密码设置为无效、显示帐户时效信息、设置密码更改之前的最小和最大天数以及设置到期警告天数。
### 1)如何在 Linux 上检查特定用户的密码到期日期
如果要检查 Linux 上特定用户的密码到期日期,请使用以下命令。
```
# chage -l daygeek
Last password change : Feb 13, 2020
Password expires : May 13, 2020
Password inactive : never
Account expires : never
Minimum number of days between password change : 7
Maximum number of days between password change : 90
Number of days of warning before password expires : 7
```
### 2)如何在 Linux 上检查所有用户的密码到期日期
你可以直接对单个用户使用 chage 命令,不过可能你对多个用户使用时可能无效。
为此,你需要编写一个小的 shell 脚本。下面的 shell 脚本可以列出添加到系统中的所有用户,包括系统用户。
```
# for user in $(cat /etc/passwd |cut -d: -f1); do echo $user; chage -l $user | grep "Password expires"; done | paste -d " " - - | sed 's/Password expires//g'
```
你将得到类似以下的输出,但是用户名可能不同。
```
root : never
bin : never
daemon : never
adm : never
lp : never
sync : never
shutdown : never
u1 : Nov 12, 2018
u2 : Jun 17, 2019
u3 : Jun 17, 2019
u4 : Jun 17, 2019
u5 : Jun 17, 2019
```
### 3)如何检查 Linux 上除系统用户外的所有用户的密码有效期
下面的 shell 脚本将显示有到期日期的用户列表。
```
# for user in $(cat /etc/passwd |cut -d: -f1); do echo $user; chage -l $user | grep "Password expires"; done | paste -d " " - - | sed 's/Password expires//g' | grep -v "never"
```
你将得到类似以下的输出,但是用户名可能不同。
```
u1 : Nov 12, 2018
u2 : Jun 17, 2019
u3 : Jun 17, 2019
u4 : Jun 17, 2019
u5 : Jun 17, 2019
```
---
via: <https://www.2daygeek.com/linux-check-user-password-expiration-date/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,063 | 用 KDE “等离子大屏幕”把你的普通电视变成智能电视 | https://itsfoss.com/kde-plasma-bigscreen/ | 2020-04-01T19:54:07 | [
"KDE",
"智能电视"
] | https://linux.cn/article-12063-1.html |
>
> KDE 即将推出的“等离子大屏幕”项目可让你使用开源技术将普通电视变成智能电视。
>
>
>
如今,智能电视已成为新的常态。这些智能电视主要基于 Android,可让你播放 YouTube、Netflix、Spotify 和其他流媒体服务。你甚至可以使用语音命令来控制你的智能电视。
这些所谓的“智能电视”的一个主要问题是它们可能正在[监视你](https://www.zdnet.com/article/fbi-warns-about-snoopy-smart-tvs-spying-on-you/)。你的数据在你或许知道或许不知道的情况下被收集。
这就是 KDE 的“[等离子大屏幕项目](https://plasma-bigscreen.org/)”旨在解决的问题。(LCTT 译注: <ruby> 等离子 <rt> Plasma </rt></ruby>恰是 KDE 桌面环境的名称,和<ruby> 大屏幕 <rt> Bigscreen </rt></ruby>很搭,因此这个惯常不翻译的名称这里翻译出来。)
### “等离子大屏幕”:通过开源技术使电视更智能

你可能了解 [KDE](https://kde.org/) 项目。它开始是一个 Linux 桌面环境项目,而在发展了 20 多年后,KDE 项目变得越来越大,这就是为什么他们创建了 Plasma 桌面环境的原因,以明确表明 KDE 不再仅仅是“<ruby> K 桌面环境 <rt> K Desktop Environment </rt></ruby>(KDE)”了。
Plasma 项目本身具有多种用途,当然,你可以在台式机 Linux 计算机上使用它,而 [Plasma 也具有移动版本](https://itsfoss.com/kde-announces-plasma-mobile/),你可以在基于 Linux 的智能手机上运行它,例如 [Librem5](https://itsfoss.com/librem-linux-phone/) 和 [PinePhone](https://itsfoss.com/pinephone/)。
“<ruby> 等离子大屏幕 <rt> Plasma Bigscreen </rt></ruby>”是 KDE 的一个新项目,旨在提供类似于智能电视所提供的界面和功能。
你需要的是一台[树莓派之类的单板计算机](https://itsfoss.com/raspberry-pi-alternatives/)和一台带 HDMI 端口的电视,然后在你的树莓派设备上安装“等离子大屏幕”,将其连接到电视就行。
### “等离子大屏幕”的功能:不仅仅是媒体服务器

乍一看,它看起来很像是一个媒体服务器,但“等离子大屏幕”却和 Kodi 及其它 [Linux 媒体服务器](https://itsfoss.com/best-linux-media-server/) 不同,它不止于此。
#### 使用常规遥控器进行控制
你不需要新的专用遥控器。多亏了 [CEC](http://libcec.pulse-eight.com/),你可以使用常规的电视遥控器。
#### 带有开源 Mycroft AI 的语音控制
“等离子大屏幕”利用了开源 Mycroft AI 项目。借助“等离子大屏幕”内置的 Mycroft AI,你可以使用语音命令播放内容、检查天气并控制智能电视的其他方面。你可以通过教它新技能来进一步训练它。
#### 传统的桌面应用程序
“等离子大屏幕”不仅提供丰富的媒体应用程序,还提供经过重新设计,适合它的体验的传统桌面应用程序。
#### 自由开源软件
最重要的是它是一个开源项目,它使用其他开源技术为你提供对数据和智能电视的完全控制。
由于它是开源的,我相信一旦发布,就会有一些供应商将其作为即插即用设备提供。
### 如何获取“等离子大屏幕”?
“等离子大屏幕”仍处于测试阶段,没有确定稳定版发布的时间表。
但是,测试版已经可以在树莓派 4 等设备上正常运行。下面是一个从事此项目的开发人员的视频。
如果你有树莓派 4,则可以从其官方下载页面上下载“[等离子大屏幕](https://plasma-bigscreen.org/#download-jumpto)”的测试版,然后按照[此处](https://plasma-bigscreen.org/manual/)的步骤进行安装。
就个人而言,我对此感到非常兴奋。我要花一些时间在[树莓派 4](https://itsfoss.com/raspberry-pi-4/)上尝试一下。你呢?你认为该项目具有潜力吗?你想试试看吗?
---
via: <https://itsfoss.com/kde-plasma-bigscreen/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: KDE’s upcoming Plasma Bigscreen project lets you use open source technologies to turn your regular TV into a smart one. *
Smart TVs are the new normal these days. Mostly based on Android, these smart TVs let you play YouTube, Netflix, Spotify and other streaming services. You can even use voice commands to control your smart TV.
One major problem with these so-called [smart TVs are that they probably are spying on you](https://www.zdnet.com/article/fbi-warns-about-snoopy-smart-tvs-spying-on-you/). Your data is being collected with or without your knowledge.
This is the problem KDE’s [Plasma Bigscreen project](https://plasma-bigscreen.org/) is aiming to solve.
## Plasma Bigscreen: Make your TV smart with open source technologies
You probably already know about the [KDE](https://kde.org/) project. It started as a Linux desktop environment project more than 20 years ago. The KDE project grew bigger and this is why they created Plasma desktop environment to make it clear that KDE is no more just “K Desktop Environment”.
The Plasma project itself is quite versatile. You can of course use it on your desktop Linux computer. [Plasma also has a mobile version](https://itsfoss.com/kde-announces-plasma-mobile/) that you can run on Linux-based smartphones like [Librem5](https://itsfoss.com/librem-linux-phone/) and [PinePhone](https://itsfoss.com/pinephone/).
The Plasma Bigscreen is a new project from KDE that aims to provide interface and features similar to what Smart TVs provide.
All you need is a [single board computer like Raspberry Pi](https://itsfoss.com/raspberry-pi-alternatives/) and a TV with HDMI port. Install Plasma Bigscreen on your device and connect it to your TV.
## Plasma Bigscreen features: More than just a media server
Though it may look like one at the first glance, but Plasma Bigscreen is not like Kodi and other [media servers for Linux](https://itsfoss.com/best-linux-media-server/). It’s more than that.
### Control with your regular remote
You don’t need a new specialized remote control. Thanks to [CEC](http://libcec.pulse-eight.com/), you can use your regular TV remote control.
### Voice control with open source Mycroft AI
Plasma Bigscreen takes advantage of the open source Mycroft AI project. With Mycroft built in to Bigscreen, you can use voice command to play content, check weather and control other aspects of your smart TV. You can further train this AI by teaching it new skills.
### Traditional desktop applications
Plasma Bigscreen delivers not only media-rich applications, but also traditional desktop applications redesigned to fit the Bigscreen experience.
### Free and open source software
The most important feature is that it is an open source project and it uses other open source technologies to give you the complete control over your data and your smart TV.
Since it is open source, I believe once it is released, there will be a few vendors providing it as a plug and play device.
## How to get Plasma Bigscreen?
Plasma Bigscreen is still in beta phase and there is no definite timeline for the stable release.
However, the beta version is also working good on devices like Raspberry Pi 4. Here’s a video by one of the developers working on this project.
If you have a Raspberry Pi 4, you can [download Plasma Bigscreen](https://plasma-bigscreen.org/#download-jumpto) beta version from its official download page and follow the steps [here](https://plasma-bigscreen.org/manual/) to install it.
Personally, I am really excited about it. I am going to take out some time and try it on my [Raspberry Pi 4](https://itsfoss.com/raspberry-pi-4/). What about you? Do you think the project has potential? Will you give it a try? |
12,064 | 使用 Python 在 GitHub 上运行你的博客 | https://opensource.com/article/19/5/run-your-blog-github-pages-python | 2020-04-02T10:10:48 | [
"GitHub",
"Pelican"
] | https://linux.cn/article-12064-1.html |
>
> 使用 Pelican 创建博客,这是一个基于 Python 的平台,与 GitHub 配合的不错。
>
>
>

[GitHub](https://github.com/) 是一个非常流行的用于源代码控制的 Web 服务,它使用 [Git](https://git-scm.com) 同步本地文件和 GitHub 服务器上保留的副本,这样你就可以轻松地共享和备份你的工作。
除了为代码仓库提供用户界面之外,GitHub 还运允许用户直接从仓库[发布网页](https://help.github.com/en/categories/github-pages-basics)。GitHub 推荐的网站生成软件包是 [Jekll](https://jekyllrb.com),是使用 Ruby 编写的。因为我是 [Python](https://python.org) 的忠实粉丝,所以我更喜欢 [Pelican](https://blog.getpelican.com),这是一个基于 Python 的博客平台,可与 GitHub 很好地协同工作。
Pelican 和 Jekll 都可以将 [Markdown](https://guides.github.com/features/mastering-markdown) 或 [reStructuredText](http://docutils.sourceforge.net/docs/user/rst/quickref.html) 中编写的内容转换为 HTML 以生成静态网站,并且两个生成器都支持定制的主题。
在本文中,我将介绍如何安装 Pelican、设置 GitHub 仓库、运行快速入门帮助、编写一些 Markdown 文件以及发布第一篇博客。我假设你有一个 [GitHub 账户](https://github.com/join?source=header-home),熟悉[基础的 Git 命令](https://git-scm.com/docs),并且想使用 Pelican 发布博客。
### 安装 Pelican 并创建仓库
首先,你必须在本地计算机上安装 Pelican 和 `ghp-import`。使用 Python 软件包安装工具 [pip](https://pip.pypa.io/en/stable/)(你有,对吧?),这非常容易:
```
$ pip install pelican ghp-import Markdown
```
然后,打开浏览器并在 GitHub 上为你新鲜出炉的博客创建一个新仓库,命名如下(在此处以及整个教程中,用 GitHub 用户名替换 `username`):
```
https://GitHub.com/username/username.github.io
```
让它保持为空,稍后我们用引人注目的博客内容来填充它。
使用命令行(确保正确),将这个空 Git 仓库克隆到本地计算机:
```
$ git clone <https://GitHub.com/username/username.github.io> blog
$ cd blog
```
### 奇怪的把戏…
在 GitHub 上发布 Web 内容有一个不太引入注意的技巧,对于托管在名为 `username.github.io` 的仓库的用户页面,其内容由 `master` 分支提供服务。
我强烈建议所有的 Pelican 配置文件和原始的 Markdown 文件都不要保留在 `master` 中,`master` 中只保留 Web 内容。因此,我将 Pelican 配置和原始内容保留在一个我喜欢称为 `content` 的单独分支中。(你可以随意创建一个分支,但以下内容沿用 `content`。)我喜欢这种结构,因为我可以放弃掉 `master` 中的所有文件,然后用 `content` 分支重新填充它。
```
$ git checkout -b content
Switched to a new branch 'content'
```
### 配置 Pelican
现在该进行内容配置了。Pelican 提供了一个很棒的初始化工具 `pelican-quickstart`,它会询问你有关博客的一系列问题。
```
$ pelican-quickstart
Welcome to pelican-quickstart v3.7.1.
This script will help you create a new Pelican-based website.
Please answer the following questions so this script can generate the files
needed by Pelican.
> Where do you want to create your new web site? [.]
> What will be the title of this web site? Super blog
> Who will be the author of this web site? username
> What will be the default language of this web site? [en]
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n)
> How many articles per page do you want? [10]
> What is your time zone? [Europe/Paris] US/Central
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) y
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) y
> Do you want to upload your website using FTP? (y/N) n
> Do you want to upload your website using SSH? (y/N) n
> Do you want to upload your website using Dropbox? (y/N) n
> Do you want to upload your website using S3? (y/N) n
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
> Do you want to upload your website using GitHub Pages? (y/N) y
> Is this your personal page (username.github.io)? (y/N) y
Done. Your new project is available at /Users/username/blog
```
你可以对每个问题都采用默认值,但除了以下这些问题:
* 网站标题,应该唯一且特殊
* 网站作者,可以是个人用户名或你的全名
* 时区,可能你不在巴黎
* 上传到 GitHub 页面,我们选择 `y`
回答完所有问题后,Pelican 会在当前目录中留下以下内容:
```
$ ls
Makefile content/ develop_server.sh*
fabfile.py output/ pelicanconf.py
publishconf.py
```
你可以查看 [Pelican 文档](https://docs.getpelican.com)来了解如何使用这些文件,但**现在**我们要做的是完成手头的工作。说实话,我也没有阅读文档。
### 继续
将所有 Pelican 生成的文件添加到本地 Git 仓库的 `content` 分支,提交更改,然后将本地更改推送到 Github 上托管的远程仓库:
```
$ git add .
$ git commit -m 'initial pelican commit to content'
$ git push origin content
```
这件事情并不是特别令人兴奋,但是如果我们需要撤销这些文件之一的修改时,这将非常方便。
### 终于
终于,现在你得到一个博客了!你所有的博客文章、照片、图像、PDF 等都将位于 `content` 目录中,它最初是空的。要开始创建第一篇博客和关于页面,输入:
```
$ cd content
$ mkdir pages images
$ cp /Users/username/SecretStash/HotPhotoOfMe.jpg images
$ touch first-post.md
$ touch pages/about.md
```
接下来,在你喜欢的文本编辑器中打开 `first-post.md`,并添加以下内容:
```
title: First Post on My Sweet New Blog
date: <today's date>
author: Your Name Here
# I am On My Way To Internet Fame and Fortune!
This is my first post on my new blog. While not super informative it
should convey my sense of excitement and eagerness to engage with you,
the reader!
```
前三行是 Pelican 用于组织内容的元数据。有很多不同的元数据可供你选择。再说一次,文档是你了解更多选项的最佳选择。
现在,打开空白文件 `pages/about.md` 并添加以下文本:
```
title: About
date: <today's date>
![So Schmexy][my_sweet_photo]
Hi, I am <username> and I wrote this epic collection of Interweb
wisdom. In days of yore, much of this would have been deemed sorcery
and I would probably have been burned at the stake.
?
```
现在,`content` 目录中将包含三个新的 Web 内容,在 `content` 分支中还有很多内容。
### 发布
不要急,马上要见到成果了!
剩下要做的就是:
* 运行 Pelican 以在 `output` 中生成静态 HTML 文件:
```
$ pelican content -o output -s publishconf.py
```
* 使用 `ghp-import` 将 `output` 目录的内容添加到 `master` 分支中:
```
$ ghp-import -m "Generate Pelican site" --no-jekyll -b master output
```
* 将本地 `master` 分支推送到远程仓库:
```
$ git push origin master
```
* 提交新内容并将其推送到 `content` 分支
```
$ git add content
$ git commit -m 'added a first post, a photo and an about page'
$ git push origin content
```
### OMG,我成功了
现在最激动的时候到了,当你想要看到你发布给大家的博客内容时,打开浏览器输入:
```
https://username.github.io
```
恭喜你可以在 GitHub 上发布自己的博客了!当你想添加更多页面或文章时,都可以按照上面的步骤来。希望你可以愉快地发布博客。
---
via: <https://opensource.com/article/19/5/run-your-blog-github-pages-python>
作者:[Erik O'Shaughnessy](https://opensource.com/users/jnyjny/users/jasperzanjani/users/jasperzanjani/users/jasperzanjani/users/jnyjny/users/jasperzanjani) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [GitHub](https://github.com/) is a hugely popular web service for source code control that uses [Git](https://git-scm.com) to synchronize local files with copies kept on GitHub's servers so you can easily share and back up your work.
In addition to providing a user interface for code repositories, GitHub also enables users to [publish web pages](https://help.github.com/en/categories/github-pages-basics) directly from a repository. The website generation package GitHub recommends is [Jekyll](https://jekyllrb.com), written in Ruby. Since I'm a bigger fan of [Python](https://python.org), I prefer [Pelican](https://blog.getpelican.com), a Python-based blogging platform that works well with GitHub.
Pelican and Jekyll both transform content written in [Markdown](https://guides.github.com/features/mastering-markdown) or [reStructuredText](http://docutils.sourceforge.net/docs/user/rst/quickref.html) into HTML to generate static websites, and both generators support themes that allow unlimited customization.
In this article, I'll describe how to install Pelican, set up your GitHub repository, run a quickstart helper, write some Markdown files, and publish your first page. I'll assume that you have a [GitHub account](https://github.com/join?source=header-home), are comfortable with [basic Git commands](https://git-scm.com/docs), and want to publish a blog using Pelican.
## Install Pelican and create the repo
First things first, Pelican (and **ghp-import**) must be installed on your local machine. This is super easy with [pip](https://pip.pypa.io/en/stable/), the Python package installation tool (you have pip right?):
`$ pip install pelican ghp-import Markdown`
Next, open a browser and create a new repository on GitHub for your sweet new blog. Name it as follows (substituting your GitHub username for <username> here and throughout this tutorial):
`https://GitHub.com/username/username.github.io`
Leave it empty; we will fill it with compelling blog content in a moment.
Using a command line (you command line right?), clone your empty Git repository to your local machine:
```
$ git clone https://GitHub.com/username/username.github.io blog
$ cd blog
```
## That one weird trick…
Here's a not-super-obvious trick about publishing web content on GitHub. For user pages (pages hosted in repos named *username.github.io*), the content is served from the **master** branch.
I strongly prefer not to keep all the Pelican configuration files and raw Markdown files in **master**, rather just the web content. So I keep the Pelican configuration and the raw content in a separate branch I like to call **content**. (You can call it whatever you want, but the following instructions will call it **content**.) I like this structure since I can throw away all the files in **master** and re-populate it with the **content** branch.
```
$ git checkout -b content
Switched to a new branch 'content'
```
## Configure Pelican
Now it's time for content configuration. Pelican provides a great initialization tool called **pelican-quickstart** that will ask you a series of questions about your blog.
```
$ pelican-quickstart
Welcome to pelican-quickstart v3.7.1.
This script will help you create a new Pelican-based website.
Please answer the following questions so this script can generate the files
needed by Pelican.
> Where do you want to create your new web site? [.]
> What will be the title of this web site? Super blog
> Who will be the author of this web site? username
> What will be the default language of this web site? [en]
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n)
> How many articles per page do you want? [10]
> What is your time zone? [Europe/Paris] US/Central
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) y
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) y
> Do you want to upload your website using FTP? (y/N) n
> Do you want to upload your website using SSH? (y/N) n
> Do you want to upload your website using Dropbox? (y/N) n
> Do you want to upload your website using S3? (y/N) n
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
> Do you want to upload your website using GitHub Pages? (y/N) y
> Is this your personal page (username.github.io)? (y/N) y
Done. Your new project is available at /Users/username/blog
```
You can take the defaults on every question except:
- Website title, which should be unique and special
- Website author, which can be a personal username or your full name
- Time zone, which may not be in Paris
- Upload to GitHub Pages, which is a "y" in our case
After answering all the questions, Pelican leaves the following in the current directory:
```
$ ls
Makefile content/ develop_server.sh*
fabfile.py output/ pelicanconf.py
publishconf.py
```
You can check out the [Pelican docs](https://docs.getpelican.com) to find out how to use those files, but we're all about getting things done *right now*. No, I haven't read the docs yet either.
## Forge on
Add all the Pelican-generated files to the **content** branch of the local Git repo, commit the changes, and push the local changes to the remote repo hosted on GitHub by entering:
```
$ git add .
$ git commit -m 'initial pelican commit to content'
$ git push origin content
```
This isn't super exciting, but it will be handy if we need to revert edits to one of these files.
## Finally getting somewhere
OK, now you can get bloggy! All of your blog posts, photos, images, PDFs, etc., will live in the **content** directory, which is initially empty. To begin creating a first post and an About page with a photo, enter:
```
$ cd content
$ mkdir pages images
$ cp /Users/username/SecretStash/HotPhotoOfMe.jpg images
$ touch first-post.md
$ touch pages/about.md
```
Next, open the empty file **first-post.md** in your favorite text editor and add the following:
```
title: First Post on My Sweet New Blog
date: <today's date>
author: Your Name Here
# I am On My Way To Internet Fame and Fortune!
This is my first post on my new blog. While not super informative it
should convey my sense of excitement and eagerness to engage with you,
the reader!
```
The first three lines contain metadata that Pelican uses to organize things. There are lots of different metadata you can put there; again, the docs are your best bet for learning more about the options.
Now, open the empty file **pages/about.md** and add this text:
```
title: About
date: <today's date>
![So Schmexy][my_sweet_photo]
Hi, I am <username> and I wrote this epic collection of Interweb
wisdom. In days of yore, much of this would have been deemed sorcery
and I would probably have been burned at the stake.
?
[my_sweet_photo]: {static}/images/HotPhotoOfMe.jpg
```
You now have three new pieces of web content in your content directory. Of the content branch. That's a lot of content.
## Publish
Don't worry; the payoff is coming!
All that's left to do is:
- Run Pelican to generate the static HTML files in
**output**:
`$ pelican content -o output -s publishconf.py`
- Use
**ghp-import**to add the contents of the**output**directory to the**master**branch:
`$ ghp-import -m "Generate Pelican site" --no-jekyll -b master output`
- Push the local master branch to the remote repo:
`$ git push origin master`
- Commit and push the new content to the
**content**branch:
`$ git add content $ git commit -m 'added a first post, a photo and an about page' $ git push origin content`
## OMG, I did it!
Now the exciting part is here when you get to view what you've published for everyone to see! Open your browser and enter:
`https://username.github.io`
Congratulations on your new blog, self-published on GitHub! You can follow this pattern whenever you want to add more pages or articles. Happy blogging.
## 6 Comments |
12,067 | 不喜欢 diff 么?试试 Meld 吧 | https://opensource.com/article/20/3/meld | 2020-04-03T12:24:53 | [
"Meld",
"diff",
"比较"
] | https://linux.cn/article-12067-1.html |
>
> Meld 是一个可视化 diff 工具,它可让你轻松比较和合并文件、目录、Git 仓库等的更改。
>
>
>

Meld 是我处理代码和数据文件的基本工具之一。它是一个图形化的 diff 工具,因此,如果你曾经使用过 `diff` 命令并难以理解输出,那么 [Meld](https://meldmerge.org/) 可以为你提供帮助。
这是该项目网站的精彩描述:
>
> “Meld 是面向开发人员的可视化 diff 和合并工具。Meld 可以帮助你比较文件、目录和版本控制的项目。它提供文件和目录的双向和三向比较,并支持许多流行的版本控制系统。”
>
>
> “Meld 可以帮助你检查代码更改并了解补丁。它甚至可以帮助你弄清你一直在避免的合并中发生了什么。”
>
>
>
你可以使用以下命令在 Debian/Ubuntu 系统(包括 Raspbian)上安装 Meld:
```
$ sudo apt install meld
```
在 Fedora 或类似产品上:
```
$ sudo dnf install meld
```
Meld 是跨平台的,它有一个使用 [Chocolately](https://opensource.com/article/20/3/chocolatey) 包管理器的 [Windows 安装包](https://chocolatey.org/packages/meld)。尽管它在 macOS 上不受官方支持,但有[可用于 Mac 的版本](https://yousseb.github.io/meld/),你可以使用 Homebrew 安装:
```
$ brew cask install meld
```
有关[其他系统](https://meldmerge.org/),请参见 Meld 的主页。
### Meld 对比 diff 命令
如果你有两个相似的文件(也许一个是另一个的修改版本),并想要查看它们之间的更改,那么可以在终端中运行 `diff` 命令查看它们的区别:

此例显示了 `conway1.py` 和 `conway2.py` 之间的区别。表明我:
* 删除了[释伴](https://en.wikipedia.org/wiki/Shebang_(Unix))和第二行
* 从类声明中删除了 `(object)`
* 为类添加了 docstring
* 在方法中交换了 `alive` 和 `neighbours == 2` 的顺序
这是使用 `meld` 命令的相同例子。你可以在命令行中运行以下命令进行相同的比较:
```
$ meld conway1.py conway2.py
```

Meld 更清晰!
你可以轻松查看并单击箭头(左右都行)合并文件之间的更改。你甚至可以实时编辑文件(在输入时,Meld 可以用作具有实时比较功能的简单文本编辑器)—只是要记得在关闭窗口之前保存。
你甚至可以比较和编辑三个不同的文件:

### Meld 的 Git 感知
希望你正在使用 [Git](https://opensource.com/resources/what-is-git) 之类的版本控制系统。如果是这样,那么你的比较就不是在两个不同文件之间进行,而是要查找当前文件与 Git 历史文件之间的差异。Meld 理解这一点,因此,如果你运行 `meld conway.py`(`conway.py` 在 Git 中),它将显示自上次 Git 提交以来所做的更改:

你可以看到当前版本(右侧)和仓库版本(左侧)之间的更改。你可以看到,自上次提交以来,我删除了一个方法,并添加了一个参数和一个循环。
如果你运行 `meld .`,你将看到当前目录(如果位于仓库的根目录,就是整个仓库)中的所有更改:

你会看到一个文件被修改了,另一个文件未加入版本控制(这意味着它对 Git 是新的,因此在比较之前,我需要 `git add` 添加该文件),以及许多其他未修改的文件。顶部的图标提供了各种显示选项。
你还可以比较两个目录,这有时很方便:

### 结论
即使是普通用户也会觉得 diff 的比较难以理解。我发现 Meld 提供的可视化在找出文件之间的更改方面有很大的不同。最重要的是,Meld 有一些有用的版本控制认知,可以帮助你在不考虑太多内容的情况下对 Git 提交进行比较。快来试试 Meld,并轻松解决问题。
---
*本文最初发表在 Ben Nuttall 的 [Tooling blog](https://tooling.bennuttall.com/meld/) 上,并经允许重新使用。*
---
via: <https://opensource.com/article/20/3/meld>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Meld is one of my essential tools for working with code and data files. It's a graphical diff tool, so if you've ever used the **diff** command and struggled to make sense of the output, [Meld](https://meldmerge.org/) is here to help.
Here is a brilliant description from the project's website:
"Meld is a visual diff and merge tool targeted at developers. Meld helps you compare files, directories, and version controlled projects. It provides two- and three-way comparison of both files and directories, and has support for many popular version control systems.
"Meld helps you review code changes and understand patches. It might even help you to figure out what is going on in that merge you keep avoiding."
You can install Meld on Debian/Ubuntu systems (including Raspbian) with:
`$ sudo apt install meld`
On Fedora or similar, it's:
`$ sudo dnf install meld`
Meld is cross-platform—there's a [Windows install](https://chocolatey.org/packages/meld) using the [Chocolately](https://opensource.com/article/20/3/chocolatey) package manager. While it's not officially supported on macOS, there are [builds available for Mac](https://yousseb.github.io/meld/), and you can install it on Homebrew with:
`$ brew cask install meld`
See Meld's homepage for [additional options](https://meldmerge.org/).
## Meld vs. the diff command
If you have two similar files (perhaps one is a modified version of the other) and want to see the changes between them, you could run the **diff** command to see their differences in the terminal:
This example shows the differences between **conway1.py** and **conway2.py**. It's showing that I:
- Removed the
[shebang](https://en.wikipedia.org/wiki/Shebang_(Unix))and second line - Removed
**(object)**from the class declaration - Added a docstring to the class
- Swapped the order of
**alive**and**neighbours == 2**in a method
Here's the same example using the **meld** command. You can run the same comparison from the command line with:
`$ meld conway1.py conway2.py`
Much clearer!
You can easily see changes and merge changes between files by clicking the arrows (they work both ways). You can even edit the files live (Meld doubles up as a simple text editor with live comparisons as you type)—just be sure to save before you close the window.
You can even compare and edit three different files:
## Meld's Git-awareness
Hopefully, you're using a version control system like [Git](https://opensource.com/resources/what-is-git). If so, your comparison isn't between two different files but to find differences between the current working file and the one Git knows. Meld understands this, so if you run **meld conway.py**, where **conway.py** is known by Git, it'll show you any changes made since the last Git commit:
You can see changes made in the current version (on the right) and the repository version (on the left). You can see I deleted a method and added a parameter and a loop since the last commit.
If you run **meld .**, you'll see all the changes in the current directory (or the whole repository, if you're in its root):
You can see a single file is modified, another file is unversioned (meaning it's new to Git, so I need to **git add** the file before comparing it), and lots of other unmodified files. Various display options are provided by icons along the top.
You can also compare two directories, which is sometimes handy:
## Conclusion
Even regular users can find comparisons with diff difficult to decipher. I find the visualizations Meld provides make a big difference in troubleshooting what's changed between files. On top of that, Meld comes with some helpful awareness of version control and helps you compare across Git commits without thinking much about it. Give Meld a go, and make troubleshooting a little easier on the eyes.
*This was originally published on Ben Nuttall's Tooling blog and is reused with permission.*
## 6 Comments |
12,068 | Linux 桌面史话 | https://opensource.com/article/19/8/how-linux-desktop-grown | 2020-04-03T14:25:14 | [
"Linux",
"桌面",
"GNOME",
"KDE"
] | https://linux.cn/article-12068-1.html |
>
> 自 20 世纪 90 年代初以来,Linux 桌面已从一个简单的窗口管理器发展为一个完整的桌面。让我们一起来回顾一下 Linux 桌面的历史。
>
>
>

我第一次安装 Linux 是在 1993 年。那时,安装这种操作系统没有太多的选择。早期,许多人只是从别人那里复制一个运行中的镜像。然后有人有了一个很好的想法,创建一个 Linux 的“发行版”,让你可以自定义要安装的软件。这就是 Softlanding Linux 系统(SLS),也是我首次接触 Linux。
当时我的 386 PC 虽然内存不多,但已经足够了。SLS 1.03 需要 2MB 的内存才能运行,如果要编译程序,则需要 4MB 的内存。如果要运行 X 窗口系统,则需要多达 8MB 的内存!而我的电脑正好有足够的内存来运行 X 窗口系统。
因为我是在命令行中成长的,所以图形化的用户界面对我来说并不重要,但它确实很方便,我可以在不同的窗口中运行应用程序,并在任务间轻松切换。
从我第一次尝试 Linux 开始,我就迷上了它。从那以后,我一直在台式机上使用 Linux。和许多人一样,我也曾有一段时间以双引导配置运行 Linux,这样我就可以跳回到 MS-DOS 和 Windows 来运行某些程序。直到 1998 年,我终于冒了个险,全面投身于 Linux 之中。
在过去的 26 年中,我看着 Linux 桌面逐渐成熟。在这段时间里,我还尝试了各种有趣的桌面环境,下面我来分享一下 Linux 桌面的历史。
### X 和窗口管理器
Linux 上的第一个“桌面”还不是桌面。相反,它们是运行在 X 窗口系统上的“<ruby> 窗口管理器 <rt> window manager </rt></ruby>”(WM)。X 提供了图形用户界面的基本构件,比如在屏幕上创建窗口,并提供键盘和鼠标输入。就其本身而言,X 的用处并不大。为了使 X 图形环境变得有用,你需要一种方法来管理会话中的所有窗口。这就出现了<ruby> 窗口管理器 <rt> window manager </rt></ruby>。运行 xterm 或 xclock 之类的 X 程序就会在一个窗口中打开该程序。窗口管理器可以跟踪窗口并进行基本的内部管理,例如让你可以来回移动窗口并将其最小化。其余的事情取决于你自己。你可以通过将程序名列在 `~/.xinitrc` 文件中以在 X 开始时启动这些程序,但是通常,你会从 xterm 中运行新程序。
在 1993 年,最常见的窗口管理器是 TWM,它的历史可以追溯到 1988 年。TWM 相当简单,仅仅提供了基本的窗口管理功能。

*SLS 1.05 上的 TWM,显示了 xterm、xclock 和 Emacs 编辑器*
另一个早期的窗口管理器是 OpenLook 虚拟窗口管理器(OLVWM)。OpenLook 是 Sun 微系统公司在 20世纪 80 年代开发的图形用户界面,后来被移植到其它 Unix 平台。作为一个*虚拟*窗口管理器,OLVWM 支持多个工作区。

*SLS 1.05 上的 OLVWM,显示了 xterm 和虚拟工作区选择器*
当 Linux 开始流行起来的时候,没多久就有人创建出性能更流畅、界面更好的新窗口管理器。这些新的窗口管理器中首先出现的是虚拟窗口管理器 FVWM。FVWM 比 TWM 或 OLVWM 更具现代感。但是,我们仍然没有桌面。

*SLS 1.05 上的 FVWM,显示了 xterm 和文件管理器*
以现代的眼光来看,TWM 和 FVWM 可能看起来很朴素。但重要的是要想想当时其它图形环境是什么样子。 Windows 当时的版本看起来也相当简单。Windows 版本 1 到版本 3 使用了一个称为“程序管理器”的普通启动器。

*Windows 3.11,显示程序管理器和记事本编辑器*
1995 年 8 月,微软发布了 Windows 95,改变了现代 PC 桌面的格局。当然,我当时对此印象很深刻。我曾觉得 Windows 3.x 笨拙而丑陋,但 Windows 95 却流畅而漂亮。更重要的是,我们现在将 Windows 95 视为“**桌面**”。新的“桌面”隐喻是一个巨大的进步。你可以在桌面上放置图标——事实上,Windows 95 提供了两个默认的桌面图标,分别是“我的电脑”(用于打开文件管理器)和“回收站”(用于放置以后要删除的文件)。
但是,更重要的是,Windows 95 桌面的意味着*整合*。程序管理器不见了,取而代之的是屏幕底部的任务栏,可让你使用更简单的“开始”菜单启动新程序。任务栏是多功能的,还通过一系列的按钮显示了你正在运行的程序,而托盘显示了时间、扬声器音量和其它简单的控件。你可以在这个新桌面上右键单击任何对象, Windows 95 会为你提供一个上下文相关的菜单,其中又你可以执行的操作。

*Windows 95,显示了记事本编辑器*
与以前版本的 Windows 甚至其它 Linux 窗口管理器相比,Windows 95 的界面更加流畅并且易于使用。值得一提的是,Linux 开发人员创建了一个模仿 Windows 95 界面的 FVWM 的新版本。名为 FVWM95 的新窗口管理器仍然不是桌面,但它看起来非常漂亮。新的任务栏让你可以使用“开始”菜单启动新的 X 程序。任务栏还可以使用类似于 Windows 95 的按钮显示了正在运行的程序。

*在 Red Hat Linux 5.2 上的 FVWM95,显示了 xterm 和一个带有 xterm 图标、文件管理器和其他程序的快速访问程序启动器*
虽然 FVWM95 和其他窗口管理器都在改进,但核心问题仍然存在:Linux 并没有真正的桌面。它具有一堆窗口管理器,仅此而已。使用图形用户界面的 Linux 应用程序(基本上意味着它们是 X 应用程序)看起来形态各异且工作方式也不同。除了 X 窗口系统提供的简单的纯文本复制/粘贴功能外,你不能从一个应用程序复制和粘贴到另一个应用程序里。Linux 真正需要的是在其图形用户界面中进行彻底的重新打造,以创建它的第一个桌面。
### Linux 桌面之初啼
在 1996 年,Matthias Ettrich 有感于 X 之下 Linux 应用程序体验不一致的困扰。他想使找个更易于使用的图形环境,而且更重要的是,他想让所有东西都“集成”在一起,就像真正的桌面一样。
Matthias 开始了<ruby> K 桌面环境 <rt> K Desktop Environment </rt></ruby>(KDE)的工作。那个 K 代表着 “Kool”(LCTT 译注:即 Cool)。但是 KDE 这个名字也意味着可以类似<ruby> 通用桌面环境 <rt> Common Desktop Environment </rt></ruby>(CDE)的做法,而 CDE 是“大 Unix”世界的标准。尽管到了 1996 年,CDE 看起来已经有点过时了。CDE 基于 Motif 部件集,这也是 FVWM 所模仿的设计。KDE 1.0 于 1998 年 7 月完成,与 FVWM95 等普通窗口管理器相比,它有了明显改进。

*K 桌面环境(KDE)版本 1.0。图片来源:Paul Brown / KDE*
KDE 是 Linux 向前迈出的一大步。最终,Linux 有了一个真正的桌面,集成了应用程序和更多现代的桌面图标。KDE 的设计与 Windows 95 并无不同。屏幕底部有一个任务栏,它提供了相当于 Windows 95 的“开始”菜单以及一些应用程序的快捷键。KDE 还支持虚拟桌面,这些桌面被巧妙地标记为 “One”、“ Two”、“Three” 和 “Four”。正在运行的应用程序通过位于屏幕顶部单独的任务栏的按钮表示。
但并不是每个人都对 KDE 感到满意。为了将 GUI 从系统中抽象出来,KDE 使用了 Trolltech 的 Qt 工具套件库。不幸的是,Qt 并不是以自由软件的许可证进行分发的。Trolltech 允许 Qt 在自由软件应用程序中免费使用,但在商业或专有应用程序中要收取使用费。而且这种二分法与自由软件不符。这给 Linux 发行版带来了问题:它们应该包括 KDE 吗?还是默认使用 FVWM 这样老式但属于自由软件的图形用户界面?
面对这种情况,Miguel de Icaza 和 Federico Mena 于 1997 年开始开发新的 Linux 桌面上。这个新项目被称为 GNOME,即<ruby> GNU 网络对象模型环境 <rt> GNU Network Object Model Environment </rt></ruby>的缩写。GNOME 旨在成为一个完全自由的软件,并使用了一个不同的工具套件库 —— 来自 GIMP 图像编辑器的 GTK。GTK 从字面上的意思 <ruby> GIMP 工具套件 <rt> GIMP Tool Kit </rt></ruby>。当 GNOME 1.0 终于在 1999 年发布时,Linux 又多了一个现代化的桌面环境。

*GNOME 1.0 版。图片来源:GNOME 文档项目*
有两个 Linux 桌面环境固然很棒,但“KDE 与 GNOME”之争仍持续了一段时间。到了 1999 年,Trolltech 以新的公共许可证 <ruby> Q 公共许可证 <rt> Q Public License </rt></ruby>(QPL)重新发布了 Qt 库。但是,新许可证有其自身的包袱—-QPL 仅适用于 Qt 在开源软件项目中的使用,而不适用于商业项目。因此,<ruby> 自由软件基金会 <rt> Free Software Foundation </rt></ruby>(FSF)认为 QPL 与 <ruby> GNU 通用公共许可证 <rt> GNU General Public License </rt></ruby>(GNU GPL)[不兼容](https://www.linuxtoday.com/developer/2000090500121OPLFKE)。这个许可证问题一直持续到 2000 年 Trolltech 在 GNU GPL v2 下重新发布 Qt 库。
### 随着时间的发展
Linux 桌面继续走向成熟。KDE 和 GNOME 进行了一场友好的竞争,促使双方都在增加了新的功能,还互相交流了思想和观念。到了 2004 年,GNOME 和 KDE 都取得了长足的进步,但只是给用户界面带来了渐进式的变化。
KDE 2 和 3 继续依赖屏幕底部的任务栏概念,但并入了用于运行应用程序的按钮。KDE 最明显的变化之一是添加了 Konqueror 浏览器,该浏览器首次出现在 KDE 2 中。
 showing the Konqueror browser")
*KDE 2.2.2(2001),显示了 Konqueror 浏览器。图片来源:Paul Brown / KDE*

*Fedora Core 2 上的 KDE 3.2.2(2004),显示了 Konqueror 文件管理器(使用 Fedora Core 2 主题)*
GNOME 2 也使用了任务栏概念,但将任务栏一分为二:屏幕顶部的任务栏用于启动应用程序并响应桌面提示,屏幕底部的任务栏用于显示正在运行的应用程序。我把这两个任务栏称之为“你可以做的事情”(顶部)和“你正在做的事情”(底部)。除了精简的用户界面外,GNOME 还添加了由 Eazel 开发的更新过的文件管理器,名为 Nautilus。

*Fedora Core 2 上的 GNOME 2.6.0(2004),显示了 Nautilus 文件管理器(使用 Fedora Core 2 主题)*
随着时间的流逝,KDE 和 GNOME 走了不同的道路。两者都提供了功能丰富、健壮且现代化的桌面环境,但是却具有不同的用户界面目标。2011 年,GNOME 和 KDE 在桌面界面上出现了很大的偏差。KDE 4.6(2011 年 1 月)和 KDE 4.7(2011 年 7 月)提供了更传统的桌面感受,同时继续根植于许多用户熟悉的任务栏概念。当然,KDE 的底层发生很多变化,但是它仍然保留了熟悉的外观。

*KDE 4.6,显示 Gwenview 图像查看器。图片来源:KDE*
2011 年,GNOME 以一个新的桌面概念彻底改变了走向。GNOME 3 旨在创建一个更简单、更精简的桌面体验,使用户能够专注于自己的工作。任务栏消失了,取而代之的是屏幕顶部的黑色状态栏,其中包括音量和网络控件,显示了时间和电池状态,并允许用户通过重新设计过的菜单启动新程序。
菜单的变化最具最戏剧性。单击“活动”菜单或将鼠标移到“活动”的“热角”,所有打开的应用程序会显示为单独的窗口。用户还可以从“概述”中单击“应用程序”选项卡以启动新程序。“概述”还提供了一个内部集成的搜索功能。

*GNOME 3.0,显示 GNOME 图片应用程序。图片来源:GNOME*

*GNOME 3.0,显示活动概述。图片来源:GNOME*
### 你的桌面之选
拥有两个 Linux 桌面意味着用户有很大的选择余地。有些人喜欢 KDE,而另一些人喜欢 GNOME。没关系,选择最适合你的桌面就行。
可以肯定的是,KDE 和 GNOME 都有拥护者和批评者。例如,GNOME 因为放弃任务栏而改成“活动概述”而受到了不少批评。也许最著名的批评者是 Linus Torvalds,他在 2011 年[大声斥责并抛弃了](https://www.theregister.co.uk/2011/08/05/linus_slams_gnome_three/)新的 GNOME,将其视为“邪恶的烂摊子”,然后在两年后又[回到了](https://www.phoronix.com/scan.php?page=news_item&px=MTMxNjc) GNOME。
其他人也对 GNOME 3 提出了类似的批评,以至于一些开发人员复刻 GNOME 2 的源代码创建了 MATE 桌面。MATE(是<ruby> MATE 高级传统环境 <rt> MATE Advanced Traditional Environment </rt></ruby>的递归缩写)延续了 GNOME 2 的传统任务栏界面。
无论如何,毫无疑问当今两个最受欢迎的 Linux 桌面是 KDE 和 GNOME。它们的当前版本非常成熟,功能也很丰富。KDE 5.16(2019)和 GNOME 3.32(2019)都试图简化和精简 Linux 桌面体验,但是方式有所不同。GNOME 3.32 继续致力于极简外观,删除所有分散用户注意力的用户界面元素,以便用户可以专注于其应用程序和工作。KDE 5.16 采用了更为熟悉的任务栏方法,但也增加了其他视觉上的改进和亮点,尤其是改进的小部件处理和图标。

*KDE 5.16 Plasma。图片来源:KDE*

*GNOME 3.32。图片来源:GNOME*
同时,你也不会完全失去它们之间的兼容性。每个主要的 Linux 发行版都提供了兼容性库,因此你可以在运行 GNOME 的同时来运行 KDE 应用程序。当你真正想使用的应用程序是为其他桌面环境编写的,这一点非常有用。你可以在 GNOME 上运行 KDE 应用程序,反之亦然。
我认为这种态势不会很快改变,这是一件好事。KDE 和 GNOME 之间的良性竞争使这两个阵营的开发人员可以避免故步自封。无论你使用 KDE 还是 GNOME,你都将拥有一个集成度很高的现代化桌面。而最重要的是,这意味着 Linux 拥有自由软件最好的特点:选择。
---
via: <https://opensource.com/article/19/8/how-linux-desktop-grown>
作者:[Jim Hall](https://opensource.com/users/jim-hallhttps://opensource.com/users/jason-bakerhttps://opensource.com/users/jlacroixhttps://opensource.com/users/doni08521059https://opensource.com/users/etc-eterahttps://opensource.com/users/marcobravohttps://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I first installed Linux in 1993. At that time, you really didn't have many options for installing the operating system. In those early days, many people simply copied a running image from someone else. Then someone had the neat idea to create a "distribution" of Linux that let you customize what software you wanted to install. That was the Softlanding Linux System (SLS) and my first introduction to Linux.
My '386 PC didn't have much memory, but it was enough. SLS 1.03 required 2MB of memory to run, or 4MB if you wanted to compile programs. If you wanted to run the X Window System, you needed a whopping 8MB of memory. And my PC had just enough memory to run X.
As I'd grown up with the command line, a graphical user interface wasn't essential to me. But it sure was convenient. I could run applications in different windows and easily switch between tasks.
From my first experiment with Linux, I was hooked. I've stuck with Linux on my desktop ever since. Like many people, I ran Linux in a dual-boot configuration for a while so I could jump back to MS-DOS and Windows to run certain programs. Until 1998, when I finally took the plunge and went all-in with Linux.
Over the last 26 years, I have watched the Linux desktop mature. I've also tried an interesting combination of desktop environments over that time, which I'll share by taking a journey through the history of the Linux desktop.
## X and window managers
The first "desktops" on Linux weren't yet desktops. Instead, they were *window managers* running on the X Window System. X provided the basic building blocks for a graphical user interface, such as creating windows on the screen and providing keyboard and mouse input. By itself, X didn't do much. To make the X graphical environment useful, you needed a way to manage all the windows in your session. That's where the *window manager* came in. Running an X program like xterm or xclock opens that program in a window. The window manager keeps track of windows and does basic housekeeping, such as letting you move windows around and minimize them. The rest is up to you. You could launch programs when X started by listing them in the **~/.xinitrc** file, but usually, you'd run new programs from an xterm.
The most common window manager in 1993 was TWM, which dates back to 1988. TWM was quite simple and provided only basic window management.
TWM on SLS 1.05 showing xterm, xclock, and the emacs editor
Yet another early window manager was the OpenLook Virtual Window Manager (OLVWM). OpenLook was a graphical user interface developed by Sun Microsystems in the 1980s and later ported to other Unix platforms. As a *virtual* window manager, OLVWM supported multiple workspaces.
OLVWM on SLS 1.05 showing xterm and the virtual workspaces selector
When Linux began to grow in popularity, it didn't take long for others to create new window managers with smoother performance and improved interfaces. The first of these new window managers was FVWM, a virtual window manager. FVWM sported a more modern look than TWM or OLVWM. But we didn't yet have a desktop.
FVWM on SLS 1.05 showing xterm and a file manager
To modern eyes, TWM and FVWM may look pretty plain. But it's important to remember what other graphical environments looked like at the time. The then-current version of Windows looked rather simple. Windows versions 1 through 3 used a plain launcher called the Program Manager.
Windows 3.11 showing the Program Manager and the Notepad editor
In August 1995, Microsoft released Windows 95 and changed the modern PC desktop landscape. Certainly, I was impressed. I thought Windows 3.x was ungainly and ugly, but Windows 95 was smooth and pretty. More importantly, Windows 95 was what we now consider a *desktop*. The new desktop metaphor was a huge step forward. You could put icons on the desktop—and in fact, Windows 95 presented two default desktop icons, for My Computer (to open a file manager) and the Recycle Bin (where you put files to be deleted later).
But more importantly, the Windows 95 desktop meant *integration*. The Program Manager was gone, replaced by a Taskbar at the bottom of the screen that let you launch new programs using a simpler Start menu. The Taskbar was multifunctional and also showed your running programs via a series of buttons and a dock showing the time, speaker volume, and other simple controls. You could right-click on any object on the new desktop, and Windows 95 would present you with a context-sensitive menu with actions you could perform.
Windows 95 showing the Notepad editor
The Windows 95 interface was slick and much easier to use than previous versions of Windows—and even other Linux window managers. Not to be outdone, Linux developers created a new version of FVWM that mimicked the Windows 95 interface. Called FVWM95, the new window manager still wasn't a desktop, but it looked very nice. The new taskbar let you start new X programs using the Start menu. The taskbar also showed your running programs using buttons similar to Windows 95's.
FVWM95 on Red Hat Linux 5.2 showing xterm and a quick-access program launcher with icons for xterm, the file manager, and other programs
While FVWM95 and other window managers were improving, the core problem remained: Linux didn't really have a desktop. It had a collection of window managers, and that was about it. Linux applications that used a graphical user interface (GUI, pretty much meaning they were X applications) all looked different and worked differently. You couldn't copy and paste from one application to another, except the simple text-only copy/paste provided by the X Window System. What Linux really needed was a complete redo in its GUI to create the first desktop.
## The first Linux desktop
In 1996, Matthias Ettrich was troubled by the inconsistency of Linux applications under X. He wanted to make the graphical environment easy to use. And more importantly, he wanted to make everything *integrated*—like an actual desktop.
Matthias started work on the K Desktop Environment. That's K for "Kool." But the name KDE was also meant to be a play on the Common Desktop Environment (CDE) that was the standard in the "Big Unix" world. Although by 1996, CDE was looking pretty dated. CDE was based on the Motif widget set, which is the same design that FVWM mimicked. Finalized in July 1998, KDE 1.0 was a definite improvement over plain window managers like FVWM95.
K Desktop Environment (KDE) version 1.0
KDE was a big step forward for Linux. Finally, Linux had a true desktop with application integration and more modern desktop icons. KDE's design was not dissimilar from Windows 95. You had a kind-of taskbar along the bottom of the screen that provided the equivalent of Windows 95's Start menu as well as several application shortcuts. KDE also supported virtual desktops, which were cleverly labeled One, Two, Three, and Four. Running applications were represented via buttons in a separate taskbar at the top of the screen.
But not everyone was happy with KDE. To abstract the GUI from the system, KDE used Trolltech's Qt toolkit library. Unfortunately, Qt was not distributed under a free software license. Trolltech allowed Qt to be used at no charge in free software applications but charged a fee to use it in commercial or proprietary applications. And that dichotomy is not aligned with free software. This caused problems for Linux distributions: Should they include KDE? Or default to an older but free software graphical user interface like FVWM?
In response, Miguel de Icaza and Federico Mena started work in 1997 on a new Linux desktop. The new project was dubbed GNOME, for GNU Network Object Model Environment. GNOME aimed to be completely free software and used a different toolkit, called GTK, from the GIMP image editor. GTK literally stood for GIMP Tool Kit. When GNOME 1.0 was finally released in 1999, Linux had another modern desktop environment.
GNOME version 1.0
While it was great to have two desktop environments for Linux, the "KDE versus GNOME" rivalry continued for some time. By 1999, Trolltech re-released the Qt library under a new public license, the Q Public License (QPL). But the new license carried its own baggage—the QPL only applied to Qt's use in open source software projects, not commercial projects. Thus the Free Software Foundation deemed the QPL [not compatible](https://www.linuxtoday.com/developer/2000090500121OPLFKE) with the GNU General Public License (GNU GPL). This licensing issue would remain until Trolltech re-re-released the Qt library under the GNU GPL version 2 in 2000.
## Development over time
The Linux desktop continued to mature. KDE and GNOME settled into a friendly competition that pushed both to add new features and to exchange ideas and concepts. By 2004, both GNOME and KDE had made significant strides, yet brought only incremental changes to the user interface.
KDE 2 and 3 continued to rely on a taskbar concept at the bottom of the screen but incorporated the buttons for running applications. One of KDE's most visible changes was the addition of the Konqueror browser, which first appeared in KDE 2.
KDE 2.2.2 (2001) showing the Konqueror browser
KDE 3.2.2 (2004) on Fedora Core 2 showing the Konqueror file manager (using a Fedora Core 2 theme)
GNOME 2 also used a taskbar concept but split the bar into two: a taskbar at the top of the screen to launch applications and respond to desktop alerts, and a taskbar at the bottom of the page to show running applications. On my own, I referred to the two taskbars as "things you can do" (top) and "things are you doing" (bottom). In addition to the streamlined user interface, GNOME also added an updated file manager called Nautilus, developed by Eazel.
GNOME 2.6.0 (2004) on Fedora Core 2 showing the Nautilus file manager (using a Fedora Core 2 theme)
Over time, KDE and GNOME have taken different paths. Both provide a feature-rich, robust, and modern desktop environment—but with different user interface goals. In 2011, there was a major deviation between how GNOME and KDE approached the desktop interface. KDE 4.6 (January 2011) and KDE 4.7 (July 2011) provided a more traditional desktop metaphor while continuing to rely on the taskbar concept familiar to many users. Of course, KDE saw lots of changes under the hood, but the familiar look and feel remained.
KDE 4.6 showing the Gwenview image viewer
In 2011, GNOME completely changed gears with a new desktop concept. GNOME 3 aimed to create a simpler, more streamlined desktop experience, allowing users to focus on what they were working on. The taskbar disappeared, replaced by a black status bar at the top of the screen that included volume and network controls, displayed the time and battery status, and allowed users to launch new programs via a redesigned menu.
The menu was the most dramatic change. Clicking the Activities menu or moving the mouse into the Activities "hot corner" showed all open applications as separate windows. Users could also click an Applications tab from the Overview to start a new program. The Overview also provided an integrated search function.
GNOME 3.0 showing the GNOME Pictures application
GNOME 3.0 showing the Activities Overview
## Your choice of desktop
Having two desktops for Linux means users have great choice. Some prefer KDE and others like GNOME. That's fine. Pick the desktop that best suits you.
To be sure, both KDE and GNOME have fans and detractors. For example, GNOME received a fair bit of criticism for dropping the taskbar in favor of the Activities Overview. Perhaps the most well-known critic was Linus Torvalds, who [loudly denounced and abandoned](https://www.theregister.co.uk/2011/08/05/linus_slams_gnome_three/) the new GNOME as an "unholy mess" in 2011—before [moving back](https://www.phoronix.com/scan.php?page=news_item&px=MTMxNjc) to GNOME two years later.
Others have made similar criticisms of GNOME 3, to the point that some developers forked the GNOME 2 source code to create the MATE desktop. MATE (which stands for MATE Advanced Traditional Environment) continues the traditional taskbar interface from GNOME 2.
Regardless, there's no doubt that the two most popular Linux desktops today are KDE and GNOME. Their current versions are both very mature and packed with features. Both KDE 5.16 (2019) and GNOME 3.32 (2019) try to simplify and streamline the Linux desktop experience—but in different ways. GNOME 3.32 continues to aim for a minimal appearance, removing all distracting user interface elements so users can focus on their applications and work. KDE 5.16 takes a more familiar approach with the taskbar but has added other visual improvements and flair, especially around improved widget handling and icons.
KDE 5.16 Plasma
GNOME 3.32
At the same time, you don't completely lose out on compatibility. Every major Linux distribution provides compatibility libraries, so you can run applications from, say, KDE while running GNOME. This is immensely useful when an application you really want to use is written for the other desktop environment—not a problem; you can run KDE applications on GNOME and vice versa.
I don't see this changing anytime soon. And I think that's a good thing. Healthy competition between KDE and GNOME has allowed developers in both camps to push the envelope. Whether you use KDE or GNOME, you have a modern desktop with great integration. And above all, this means Linux has the best feature in free software: choice.
## 10 Comments |
12,069 | Fish:一个友好的交互式 Shell | https://fedoramagazine.org/fish-a-friendly-interactive-shell/ | 2020-04-03T21:43:59 | [
"Fish",
"shell",
"Bash"
] | https://linux.cn/article-12069-1.html | 
你是否正在寻找 bash 的替代品?你是否在寻找更人性化的东西?不用再看了,因为你刚发现了 fish!
Fish(友好的交互式 shell)是一个智能且用户友好的命令行 shell,可在 Linux、MacOS 和其他操作系统上运行。可以将其用于终端的日常工作和脚本编写。用 fish 编写的脚本比相同的 bash 版本具有更少的神秘性。
### Fish 的用户友好功能
* **建议**:Fish 会提示你之前写过的命令。当经常输入相同命令时,这样可以提高生产率。
* **健全的脚本能力**:Fish 避免使用那些隐秘字符。这提供了更清晰和更友好的语法。
* **基于手册页的补全**:Fish 会根据命令的手册页自动补全参数。
* **语法高亮**:Fish 会高亮显示命令语法以使其在视觉上友好。
### 安装
#### Fedora 工作站
使用 `dnf` 命令安装 fish:
```
$ sudo dnf install fish
```
安装 `util-linux-user` 包,然后使用适当的参数运行 `chsh`(更改 shell 程序)命令,将 fish 设置为默认 shell 程序:
```
$ sudo dnf install util-linux-user
$ chsh -s /usr/bin/fish
```
你需要注销然后重新登录,更改才能生效。
#### Fedora Silverblue
由于它不是 GUI 应用,因此你需要使用 `rpm-ostree` 将其加到层内。使用以下命令在 Fedora Silverblue 上安装 fish:
```
$ rpm-ostree install fish
```
在 Fedora Silverblue 上,你需要重启 PC 才能切换到新的 ostree 镜像。
如果你想在 Fedora Silverblue 用 fish 作为主要 shell,最简单的方法是更新 `/etc/passwd` 文件。找到你的用户,并将 `/bin/bash` 更改为 `/usr/bin/fish`。
你需要 [root 权限](https://fedoramagazine.org/howto-use-sudo/)来编辑 `/etc/passwd` 文件。另外,你需要注销并重新登录才能使更改生效。
### 配置
fish 的用户配置文件在 `~/.config/fish/config.fish`。要更改所有用户的配置,请编辑 `/etc/fish/config.fish`。
用户配置文件必须手动创建。安装脚本不会创建 `~/.config/fish/config.fish`。
以下是两个个配置示例以及它们的 bash 等效项,以帮助你入门:
#### 创建别名
* `~/.bashrc`:`alias ll='ls -lh'`
* `~/.config/fish/config.fish`: `alias ll='ls -lh'`
#### 设置环境变量
* `~/.bashrc`:`export PATH=$PATH:~/bin`
* `~/.config/fish/config.fish`:`set -gx PATH $PATH ~/bin`
### 使用 fish 工作
将 fish 配置为默认 shell 程序后,命令提示符将类似于下图所示。如果尚未将 fish 配置为默认 shell,只需运行 `fish` 命令以在当前终端会话中启动。

在你开始输入命令时,你会注意到语法高亮显示:

很酷,不是吗??
你还将在输入时看到建议的命令。例如,再次开始输入上一个命令:

注意输入时出现的灰色文本。灰色文本显示建议之前编写的命令。要自动补全,只需按 `CTRL+F`。
通过输入连接号(`–`)然后使用 `TAB` 键,它会根据前面命令的手册页获取参数建议:

如果你按一次 `TAB`,它将显示前几个建议(或所有建议,如果只有少量参数可用)。如果再次按 `TAB`,它将显示所有建议。如果连续三次按 `TAB`,它将切换到交互模式,你可以使用箭头键选择一个参数。
除此之外,fish 的工作与大多数其他 shell 相似。其他差异已经写在文档中。因此,找到你可能感兴趣的其他功能应该不难。
### 让 fish 变得更强大
使用 [powerline](https://github.com/oh-my-fish/theme-bobthefish) 使 fish 变得更强大。Powerline 可以为 fish 的界面添加命令执行时间、彩色化 git 状态、当前 git 分支等。
在安装 powerline 之前,你必须先安装 [Oh My Fish](https://github.com/oh-my-fish/oh-my-fish)。Oh My Fish 扩展了 fish 的核心基础架构,以支持安装其他插件。安装 Oh My Fish 的最简单方法是使用 `curl` 命令:
```
> curl -L https://get.oh-my.fish | fish
```
如果你不想直接将安装命令管道传给 `fish`,请参见 Oh My Fish 的 [README](https://github.com/oh-my-fish/oh-my-fish/blob/master/README.md#installation) 的安装部分,以了解其他安装方法。
Fish 的 powerline 插件是 [bobthefish](https://github.com/oh-my-fish/theme-bobthefish)。Bobthefish 需要 `powerline-fonts` 包。
在 Fedora 工作站上:
```
> sudo dnf install powerline-fonts
```
在 Fedora Silverblue 上:
```
> rpm-ostree install powerline-fonts
```
在 Fedora Silverblue 上,你必须重启以完成字体的安装。
安装 `powerline-fonts` 之后,安装 `bobthefish`:
```
> omf install bobthefish
```
现在你可以通过 powerline 体验 fish 的全部奇妙之处:

### 更多资源
查看这些网页,了解更多 fish 内容:
* [官网](https://fishshell.com/)
* [文档](https://fishshell.com/docs/current/index.html)
* [教程](https://fishshell.com/docs/current/tutorial.html)
* [常见问题](https://fishshell.com/docs/current/faq.html)
* [在线体验](https://rootnroll.com/d/fish-shell/)
* [邮件列表](https://sourceforge.net/projects/fish/lists/fish-users)
* [GitHub](https://github.com/fish-shell/fish-shell/)
---
via: <https://fedoramagazine.org/fish-a-friendly-interactive-shell/>
作者:[Michal Konečný](https://fedoramagazine.org/author/zlopez/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Are you looking for an alternative to bash? Are you looking for something more user-friendly? Then look no further because you just found the golden fish!
Fish (friendly interactive shell) is a smart and user-friendly command line shell that works on Linux, MacOS, and other operating systems. Use it for everyday work in your terminal and for scripting. Scripts written in fish are less cryptic than their equivalent bash versions.
## Fish’s user-friendly features
**Suggestions**
Fish will suggest commands that you have written before. This boosts productivity when typing same commands often.**Sane scripting**
Fish avoids using cryptic characters. This provides a clearer and friendlier syntax.**Completion based on man pages**
Fish will autocomplete parameters based on the the command’s man page.**Syntax highlighting**
Fish will highlight command syntax to make it visually friendly.
## Installation
### Fedora Workstation
Use the *dnf* command to install fish:
$ sudo dnf install fish
Make fish your default shell by installing the *util-linux-user* package and then running the *chsh* (change shell) command with the appropriate parameters:
$ sudo dnf install util-linux-user $ chsh -s /usr/bin/fish
You will need to log out and back in for this change to take effect.
### Fedora Silverblue
Because this is not GUI application, you will need to layer it using *rpm-ostree*. Use the following command to install fish on Fedora Silverblue:
$ rpm-ostree install fish
On Fedora Silverblue you will need to reboot your PC to switch to the new ostree image.
If you want to make fish your main shell on Fedora Silverblue, the easiest way is to update the */etc/passwd* file. Find your user and change */bin/bash* to */usr/bin/fish*.
You will need [root privileges](https://fedoramagazine.org/howto-use-sudo/) to edit the */etc/passwd* file. Also you will need to log out and back in for this change to take effect.
## Configuration
The per-user configuration file for fish is *~/.config/fish/config.fish*. To make configuration changes for all users, edit */etc/fish/config.fish* instead.
The per-user configuration file must be created manually. The installation scripts will not create *~/.config/fish/config.fish*.
Here are a couple configuration examples shown alongside their bash equivalents to get you started:
### Creating aliases
*~/.bashrc*:alias ll='ls -lh'*~/.config/fish/config.fish*:alias ll='ls -lh'
### Setting environment variables
*~/.bashrc*:export PATH=$PATH:~/bin*~/.config/fish/config.fish*:set -gx PATH $PATH ~/bin
## Working with fish
When fish is configured as your default shell, the command prompt will look similar to what is shown in the below image. If you haven’t configured fish to be your default shell, just run the *fish* command to start it in your current terminal session.

As you start typing commands, you will notice the syntax highlighting:

Cool, isn’t it? 🙂
You will also see commands being suggested as you type. For example, start typing the previous command a second time:

Notice the gray text that appears as you type. The gray text is fish suggesting the command you wrote before. To autocomplete it, just press **CTRL+F**.
Get argument suggestions based on the preceding command’s man page by typing a dash (**–**) and then the **TAB** key:

If you press **TAB** once, it will show you the first few suggestions (or every suggestion, if there are only a few arguments available). If you press **TAB** a second time, it will show you all suggestions. If you press **TAB** three times consecutively, it will switch to interactive mode and you can select an argument using the arrow keys.
Otherwise, fish works similar to most other shells. The remaining differences are well documented. So it shouldn’t be difficult to find other features that you may be interested in.
## Make fish even more powerful
Make the fish even more powerful with [powerline](https://github.com/oh-my-fish/theme-bobthefish). Powerline adds command execution time, colored git status, current git branch and much more to fish’s interface.
Before installing powerline for fish, you must install [Oh My Fish](https://github.com/oh-my-fish/oh-my-fish). Oh My Fish extends fish’s core infrastructure to enable the installation of additional plugins. The easiest way to install Oh My Fish is to use the *curl* command:
> curl -L https://get.oh-my.fish | fish
If you don’t want to pipe the installation commands directly to *curl*, see the installation section of Oh My Fish’s [README](https://github.com/oh-my-fish/oh-my-fish/blob/master/README.md#installation) for alternative installation methods.
Fish’s powerline plugin is [bobthefish](https://github.com/oh-my-fish/theme-bobthefish). Bobthefish requires the *powerline-fonts* package.
**On Fedora Workstation**:
> sudo dnf install powerline-fonts
**On Fedora Silverblue**:
> rpm-ostree install powerline-fonts
On Fedora Silverblue you will have to reboot to complete the installation of the fonts.
After you have installed the *powerline-fonts* package, install *bobthefish*:
> omf install bobthefish
Now you can experience the full awesomeness of fish with powerline:

## Additional resources
Check out these web pages to learn even more about fish:
## Martin Sehnoutka
Fish is really awesome :), but is it safe to modify /etc/passwd with a shell that is incompatible with bash? The last time I tried something broke so I decided to only configure my terminal emulator to start fish instead of the default shell.
## Sebastiaan Franken
The shell doesn’t edit. The program (chsh) does, the only thing the shell does is invoke that program, nothing more.
If something broke in the past is probably bad luck, or a bad program. Chsh is old as nails though, so you can safely assume it’ll do it’s job without killing your install.
## Eduard Lucena
I have 2 questions:
1.- How do I install it without enabling modules?
2.- What is ofm?
## xr
omf is OhMyFish’s plugin manager.
## Michal Konečný
Look at the official site, there is guide for installation from source or directly from git.
omf is OhMyFish, which I described earlier in the article.
## ee3w
instaling trought runing bash are extremely dangerous!
curl -L https://web | bash
## Michal Konečný
You can use other installation options, just look at the OhMyFish repo.
## AsciiWolf
Do not edit /etc/passwd manually, it is always a bad idea that can break your system! You can use lchsh on Silverblue.
## Michal Konečný
Thanks for info. I didn’t knew lchsh exists till now.
## someSay
Fish is great, I use it for years 🙂 Some additions to that article:
dnf installs fish from modularity by default, which is bad because it only contains version 3.0. The fedora-updates repo already contains the latest and greatest fish 3.1 which comes with a lots of improvements. No need to build from source. Better do:
dnf module disable fish
dnf distro-sync fish
One can create aliases, e.g. for ll=’ls -lh’ but this is not necessary in this case. Fish has an ll wrapper function shipped by default for this common scenario. One of the things that makes fish great 🙂
While the ability of parsing man pages for completions is cool, the cd completion isn’t derived from the man page. It’s an explicitly written completion script among many others. Have a look at different completion scripts written for fish. They are much more readable than for bash.
For starters, I highly recommend going through the tutorial linked in the article. It explains further niceties.
## Rafael
Hi,
first everything looks very nice with colorful syntax, but sadly, now I have to put expressions like URLs or with blank separated words into “-Quotes.
I am used not to do this since over 10 years.
Is it possible to use fish but without using “-Quotes, like in bash?
Thanks |
12,070 | 什么是 GraphQL? | https://opensource.com/article/19/6/what-is-graphql | 2020-04-04T11:30:27 | [
"GraphQL",
"API"
] | https://linux.cn/article-12070-1.html |
>
> GraphQL 是一种查询语言、一个执行引擎,也是一种规范,它让开发人员重新思考如何构建客户端和 API 应用。
>
>
>

GraphQL 是当今软件技术中最大的流行语之一。但它*究竟*是什么?是像 [SQL](https://opensource.com/article/18/2/getting-started-sql) 一样的查询语言吗?是像 [JVM](https://www.cubrid.org/blog/understanding-jvm-internals/) 这样的执行引擎?还是像 [XML](https://www.w3.org/TR/xml/) 这样的规范?
如果你回答上面这些都是,那么你是对的 是一种查询语言的语法、是一种编程语言无关的执行引擎,也是一种不断发展的规范。
让我们深入了解一下 GraphQL 如何成为所有这些东西的,并了解一下人们为什么对它感到兴奋。
### 查询语言
GraphQL 作为查询语言似乎是合理的 —— 毕竟 “QL” 似乎重要到出现在名称中。但是我们查询什么呢?看一个示例查询请求和相应的响应可能会有所帮助。
以下的用户查询:
```
{
user(id: 4) {
name
email
phoneNumber
}
}
```
可能会返回下面的 JSON 结果:
```
{
"user": {
"name": "Zach Lendon"
“email”: “[email protected]”
“phoneNumber”: “867-5309”
}
}
```
想象一下,客户端应用查询用户详细信息、获取结果,并使用它填充配置屏幕。作为查询语言,GraphQL 的核心优势之一是客户端应用可以*只请求它需要*的数据,并期望以一致的方式返回这些数据。
那么 GraphQL 响应返回的*什么*呢?这就是执行引擎发挥的作用,通常是以 GraphQL 服务器的形式出现。
### 执行引擎

GraphQL 执行引擎负责处理 GraphQL 查询并返回 JSON 响应。所有 GraphQL 服务器由两个核心组件组成,分别定义了执行引擎的结构和行为:模式和解析器。
GraphQL 模式是一种自定义类型语言,它公开哪些查询既允许(有效),又由 GraphQL 服务器实现处理。上面用户示例查询的模式可能如下所示:
```
type User {
name: String
email: String
phoneNumber: String
}
type Query {
user: User
}
```
此模式定义了一个返回用户的用户查询。客户端可以通过用户查询请求用户上的任何字段,并且 GraphQL 服务器将仅返回请求的字段。通过使用强类型模式,GraphQL 服务器可以根据定义的模式验证传入的查询,以确保是有效的。
确定查询有效后,就会由 GraphQL 服务器的解析器处理。解析器函数支持每个 GraphQL 类型的每个字段。我们的这个用户查询的示例解析器可能如下所示:
```
Query: {
user(obj, args, context, info) {
return context.db.loadUserById(args.id).then(
userData => new User(userData)
)
}
}
```
虽然上面的例子是用 JavaScript 编写的,但 GraphQL 服务器可以用任意语言编写。这是因为 GraphQL 也是*也是*一种规范!
### 规范
GraphQL 规范定义了 GraphQL 实现必须遵循的功能和特性。作为一个在开放网络基金会的最终规范协议([OWFa 1.0](http://www.openwebfoundation.org/legal/the-owf-1-0-agreements/owfa-1-0---patent-only))下提供的开放规范,技术社区可以审查 GraphQL 实现必须符合规范的要求,并帮助制定 GraphQL 的未来。
虽然该规范对 GraphQL 的语法,什么是有效查询以及模式的工作方式进行了非常具体的说明,但它没有提供有关如何存储数据或 GraphQL 服务器应使用哪种编程语言实现的指导。这在软件领域是非常强大的,也是相对独特的。它允许以各种编程语言创建 GraphQL 服务器,并且由于它们符合规范,因此客户端会确切知道它们的工作方式。GraphQL 服务器已经有多种语言实现,人们不仅可以期望像 JavaScript、Java和 C# 这样的语言,还可以使用 Go、Elixir 和 Haskell 等。服务器实现所使用的语言不会成为采用过程的障碍。它不仅存在多种语言实现,而且它们都是开源的。如果没有你选择的语言的实现,那么可以自己实现。
### 总结
GraphQL 是开源 API 领域中一个令人兴奋的、相对较新的参与者。它将查询语言、执行引擎与开源规范结合在一起,它定义了 GraphQL 实现的外观和功能。
GraphQL 已经开始改变企业对构建客户端和 API 应用的看法。通过将 GraphQL 作为技术栈的一部分,前端开发人员可以自由地查询所需的数据,而后端开发人员可以将客户端应用需求与后端系统架构分离。通常,公司在使用 GraphQL 的过程中,首先会在其现有的后端服务之上构建一个 GraphQL API “层”。这使得客户端应用开始获得他们所追求的性能和运营效率,同时使后端团队有机会确定他们可能需要在 GraphQL 层后面的“幕后”进行哪些更改。通常,这些更改都是为了优化,这些优化有助于确保使用 GraphQL 的应用可以尽可能高效地运行。由于 GraphQL 提供了抽象性,因此系统团队可以进行更改的同时继续在其 GraphQL API 级别上遵守 GraphQL 的“合约”。
由于 GraphQL 相对较新,因此开发人员仍在寻找新颖而激动人心的方法来利用它构建更好的软件解决方案。GraphQL 将如何改变你构建应用的方式,它是否对得起众望所归?只有一种方法可以找到答案 —— 用 GraphQL 构建一些东西!
---
via: <https://opensource.com/article/19/6/what-is-graphql>
作者:[Zach Lendon](https://opensource.com/users/zachlendon) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | GraphQL is one of the biggest buzzwords in software tech today. But *what is it* *actually*? Is it a query language like [SQL](https://opensource.com/article/18/2/getting-started-sql)? An execution engine like the [JVM](https://www.cubrid.org/blog/understanding-jvm-internals/)? A specification like [XML](https://www.w3.org/TR/xml/)?
If you answered all of the above, you are correct! [GraphQL](http://graphql.org/) is a query language syntax, a programming language-agnostic execution engine, and a continuously evolving specification.
Let's dive into how GraphQL can be all of these things and get a glimpse of why people are excited about it.
## Query language
GraphQL as a query language seems reasonable—"QL" seemed important enough to be in the name, after all. But what are we querying? It probably helps to look at a sample query request and the corresponding response.
The following user query:
```
{
user(id: 4) {
name
email
phoneNumber
}
}
```
might return the following JSON response:
```
{
"user": {
"name": "Zach Lendon"
“email”: “[email protected]”
“phoneNumber”: “867-5309”
}
}
```
Imagine a client application querying for user details, taking the result, and using it to populate a profile screen. As a query language, one of GraphQL's core benefits is that a client application can request *only the data it needs* and expect it to be returned in a consistent manner.
*What* is returning the GraphQL response, though? This is where the execution engine, typically in the form of a GraphQL server, comes into play.
## Execution engine
The GraphQL execution engine is what is responsible for processing a GraphQL query and returning a JSON response. All GraphQL servers are made up of two core components that define the structure and behavior of the execution engine: a schema and resolvers, respectively.
A GraphQL schema is a custom typed language that exposes which queries are both permitted (valid) and handled by a GraphQL server implementation. The schema for our user example query above might look like:
```
type User {
name: String
email: String
phoneNumber: String
}
type Query {
user: User
}
```
This schema defines a user query that returns a user. Clients can request any of the fields on a user via the user query, and the GraphQL server will return only those fields in its response. By using the strongly typed schema, a GraphQL server can validate incoming queries to ensure they are valid based on the defined schema.
Once a query is determined to be valid, it is processed by a GraphQL server by resolvers. A resolver function backs each field of each GraphQL type. An example resolver for our user query might look like:
```
Query: {
user(obj, args, context, info) {
return context.db.loadUserById(args.id).then(
userData => new User(userData)
)
}
}
```
While the above example is in JavaScript, GraphQL servers can be written in any number of languages. This is due to the fact that GraphQL is *also* a specification!
## Specification
The GraphQL specification defines the capabilities and characteristics that GraphQL implementations must follow. As an open specification available under the Open Web Foundation Final Specification Agreement ([OWFa 1.0](http://www.openwebfoundation.org/legal/the-owf-1-0-agreements/owfa-1-0---patent-only)), the technology community has the opportunity to both review what a GraphQL implementation must do to be spec-compliant and help craft the future of the language.
While the specification is very specific about GraphQL's syntax, what is a valid query, and how a schema works, it provides no direction on how to store data or what implementation programming languages GraphQL servers should use. This is incredibly powerful and relatively unique in the software space—it allows GraphQL servers to be created in any number of programming languages, and clients will know exactly how they function since they are spec-compliant. And GraphQL server implementations have been created across many programming languages, not just ones folks might expect like JavaScript, Java, and C#, but languages like Go, Elixir, and Haskell. The language a server is implemented in will not be a barrier to adoption—not only are there implementations in many languages, but they are all open source. If there isn't an implementation in your language of choice, you are free to create your own.
## Conclusion
GraphQL is an exciting, relatively new entrant into the open source API space. It couples a query language and execution engine with an open source specification that defines how GraphQL implementations should look and function.
GraphQL has already started to change how companies think about building both client and API applications. With GraphQL as part of a technology stack, front-end developers are freed to query for the data they want, and back-end developers can decouple client application needs from their back-end system architectures. Often companies journey into GraphQL by first building a GraphQL API "layer" that sits on top of their existing back-end services. This allows the client applications to begin to gain the performance and operational efficiencies they seek, while allowing the back-end teams an opportunity to determine what, if any, changes they might want to make "under the hood," behind their GraphQL layer. Often, those changes will be geared towards optimizations that will help ensure that applications using GraphQL can operate as performantly as possible. Because of the abstraction GraphQL provides, systems teams can make those changes while continuing to honor the GraphQL "contract" at their GraphQL API level.
Because GraphQL is relatively new, developers are still finding new and exciting ways to leverage it to build better software solutions. How will GraphQL change how you build applications, and does it live up to the hype? There's only one way to find out—go out there and build something with GraphQL!
## 1 Comment |
12,072 | 3 个控制预算的开源工具 | https://opensource.com/article/20/3/open-source-budget | 2020-04-05T09:27:55 | [
"税务",
"预算"
] | /article-12072-1.html |
>
> 在这篇开源预算工具汇总中找到适合你的解决方案。另外学习有关开源的备税务软件。
>
>
>

鉴于目前世界上许多国家/地区的经济形势都在变化,你可能会想改造或改善财务状况和你对它的了解。或者,也许你的新年决心之一是开始预算?你并不孤单。
坚持该决心的最佳方法是定期跟踪你的支出和收入。问题是,许多流行的个人理财应用都是专有的。你是否正在寻找 Quicken、Mint 或 You Need a Budget 的开源替代方案?无论你是开源软件新手,还是预算新手,这些工具之一都将满足你的需求和舒适度。
### LibreOffice Calc
我向希望做预算的任何开源新手推荐使用 LibreOffice Calc。如果你使用过 Google Sheets 或 Microsoft Excel 等专有电子表格,那么 LibreOffice Calc 模板将非常熟悉。在此[预算教程](https://opensource.com/article/20/3/libreoffice-open-source-budget)中,作者 Jess Weichler 已经为你提供了方便、可下载的模板。该模板已经有费用类别,例如水电费、杂货、外出就餐等,但是你可以自由地根据自己的生活方式对其进行自定义。在第二篇文章中,她向你展示了如何[创建自己的模板](https://opensource.com/article/20/3/libreoffice-templates)。
### HomeBank
对于所有的开源用户来说,HomeBank 都是另一个不错的选择。HomeBank 是免费的,但它拥有许多它同类专有软件的分析和交易功能。实际上,你可以将 Quicken 文件导入到 HomeBank 中,这使得转换到它变得轻而易举。最后,你可以使用一种工具来帮助你明智地做出有关资金的决定,而无需花费更多的钱。在 Jessica Cherry 的[教程](https://opensource.com/article/20/2/open-source-homebank)中学习如何入门。
### GnuCash
就像这里提到的其他预算工具一样,GnuCash 可以在 Windows、macOS 和 Linux 上使用。它提供了大量文档,但 Don Watkins 会在[此教程](https://opensource.com/article/20/2/gnucash)中指导你在 Linux 上设置 GnuCash。GnuCash 不仅是控制个人财务的绝佳选择,而且还有开发票等功能来帮助你管理小型企业。
### 赠品:OpenTaxSolver
对许多美国人来说,可怕的税收季可能是一个压力很大的时期。许多人购买 TurboTax 或请会计师或税务服务来缴税。与普遍的看法相反,开源的备税务软件是存在的!作者 Jessica Cherry 在[本文](https://opensource.com/article/20/2/open-source-taxes)中做了研究,并向读者介绍 OpenTaxSolver。要正确使用 OpenTaxSolver,你需要特别注意细节,但是你不必担心进行复杂的数学运算。
你会尝试使用哪个开源预算应用?你是否有我在此列表中未提及的最喜欢的工具?请在评论区分享你的观点。
---
via: <https://opensource.com/article/20/3/open-source-budget>
作者:[Lauren Pritchett](https://opensource.com/users/lauren-pritchett) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,074 | 如何在基于 Ubuntu 的发行版上安装微软 TrueType 字体 | https://itsfoss.com/install-microsoft-fonts-ubuntu/ | 2020-04-05T10:06:00 | [
"微软",
"字体"
] | https://linux.cn/article-12074-1.html | 如果你在 Linux 上用 LibreOffice 打开一些微软文档,你会发现字体看起来有一点不同。你也将注意到有些常用字体找不到,如 [Times New Roman](https://en.wikipedia.org/wiki/Times_New_Roman)、Arial 等等。
不用担心。我将向你展示如何在 Ubuntu 上和其它基于 Ubuntu 的 Linux 发行版上安装这些字体。但是在此之前,让我告诉你为什么这些字体没有被默认安装。
### 为什么微软字体不被默认安装在 Linux 中?

Times New Roman、Arial 等字体都是微软的,并且这些字体不是开源的。很多 Linux 发行版默认不提供专有软件,以避免授权问题。
这就是为什么在默认情况下 Ubuntu 和其它 Linux 发行版使用开源字体 “Liberation” 字体来替代微软字体的原因。[Red Hat](https://en.wikipedia.org/wiki/Red_Hat) 创建 [Liberation 字体](https://en.wikipedia.org/wiki/Liberation_fonts) 来代替 Arial、Arial Narrow、 Times New Roman 和 Courier New,因为这些字体的宽度一样。当你打开一个使用 Times New Roman 字体书写的文档时,会使用对应的 Liberation 字体来保持文档不被破坏。
不过,Liberation 字体与微软的字体并不是完全相同的,在一些情况下,你可能需要使用 Arial 或 Times New Roman。一个非常常见的情况是,在学校、大学和其他公共或私人机构中,微软的字体是唯一的选择。他们要求你使用这些字体之一来提交文档。
好在,你可以在 Ubuntu 和其它发行版上很容易地安装微软字体。以这种方式,你将增强 LibreOffice 的兼容性,并可以自由选择开源办公软件。
### 在基于 Ubuntu 的 Linux 发行版上安装微软字体
你可以自行下载字体,并[在 Ubuntu 中安装新的字体](https://itsfoss.com/install-fonts-ubuntu/)。但是由于微软字体非常受欢迎(并且是免费提供的),所以 Ubuntu 提供了一种简单的方法来安装它们。
要知道尽管微软已经免费发布了其核心字体,在其它操作系统中使用该字体依然是受到限制的。在 Ubuntu 中安装微软字体前,你必须阅读并接受 EULA (最终用户许可协议) 。
这些字体 [可在 multiverse 存储库中获得,首先要确保启用它](https://itsfoss.com/ubuntu-repositories/):
```
sudo add-apt-repository multiverse
```
在此之后,你可以更新你的 Ubuntu 存储库缓存,并像这样安装微软字体:
```
sudo apt update && sudo apt install ttf-mscorefonts-installer
```
当微软的最终用户协议出现时,按 `tab` 键来选择 “OK” ,并按回车键。

单击 “Yes” 来接受微软的协议:

当安装完成后,你应该使用下面的命令来更新字体缓存:
```
sudo fc-cache -f -v
```

如果你现在打开 LibreOffice ,你将看到微软 [TrueType 字体](https://en.wikipedia.org/wiki/TrueType) 。

如果意外地拒绝了许可协议,你可以使用这个命令来重新安装安装程序:
```
sudo apt install –reinstall ttf-mscorefonts-installer
```
微软的 TrueType 字体也可以通过 [Ubuntu Restricted Extras package](https://itsfoss.com/install-media-codecs-ubuntu/) 获得,其包含用来播放 MP3 等文件的其它专有的多媒体编解码器。
>
> 不要轻视专有字体。
>
>
> 你可能认为字体有什么大不了的呢?毕竟,它只是一款字体,而不是软件的一个关键部分,对吧?但是你知道,这些年来 [Netflix 为其使用的专有字体支付了数百万美元](https://thehustle.co/nextflix-sans-custom-font/)吗?最后,他们创建了自己的自定义字体,这为他们节省了一大笔钱。
>
>
>
希望这个快速教程有用。更多的生产力教程即将上线,请在下面留下你的评论,了解更多信息请订阅我们的社交媒体!
---
via: <https://itsfoss.com/install-microsoft-fonts-ubuntu/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/itsfoss/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you open some Microsoft documents in LibreOffice on Linux, you’ll notice that the fonts look a bit different. You’ll also notice that you cannot find common fonts like [Times New Roman](https://en.wikipedia.org/wiki/Times_New_Roman?ref=itsfoss.com), [Arial](https://en.wikipedia.org/wiki/Arial) etc.
Don’t worry. I’ll show you how to install these fonts in Ubuntu and other Ubuntu-based Linux distributions.
But before that, let me tell you why these fonts are not available by default.
## Why are Microsoft fonts not installed by default in Linux?
Times New Roman, Arial, and other such fonts are owned by Microsoft, and they are not open source. Many Linux distributions don’t provide proprietary software by default to avoid licensing issues. This is why Ubuntu and other Linux distributions use open-source fonts “Liberation fonts” to substitute Microsoft fonts by default.
The [Liberation Fonts](https://en.wikipedia.org/wiki/Liberation_fonts?ref=itsfoss.com) were created by [Red Hat](https://en.wikipedia.org/wiki/Red_Hat?ref=itsfoss.com) to substitute Arial, Arial Narrow, Times New Roman and Courier New as their width is the same. When you open a document written in Times New Roman, the equivalent Liberation Font will be used to keep the document uninterrupted.
However, Liberation fonts are not identical to Microsoft’s fonts and in some cases, you may need to use Arial or Times New Roman. A very common scenario is that Microsoft’s fonts are the only option in schools, universities and other public and private organizations. They require you to submit the documents in one of those fonts.
Good thing is that you can install the Microsoft fonts on Ubuntu and other distributions easily. This way, you will be able to increase the compatibility with LibreOffice and have the freedom to choose [open-source office software](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/).
## Installing Microsoft fonts on Ubuntu-based Linux distributions
You can [install new fonts in Ubuntu](https://itsfoss.com/install-fonts-ubuntu/) by downloading them on your own. But since Microsoft fonts are very popular (and are provided free of cost), Ubuntu provides an easy way of installing them.
Be aware that despite Microsoft having released its core fonts free of charge, the usage of the fonts is restricted in other operating systems. You’ll have to read and accept [EULA (End User License Agreement)](https://en.wikipedia.org/wiki/End-user_license_agreement) before installing Microsoft fonts in Ubuntu.
These fonts are [available in the multiverse repositories](https://itsfoss.com/ubuntu-repositories/). Usually, they are enabled by default, but you should make sure it is enabled:
`sudo add-apt-repository multiverse`
After that, you can update your Ubuntu repository cache and install the Microsoft fonts like this:
`sudo apt update && sudo apt install ttf-mscorefonts-installer`
**Press the tab to select OK and press Enter when Microsoft’s End user agreement appears.**
Click Yes to accept Microsoft’s agreement:
**Yes**and then press Enter
When the installation is done, you should update the font cache using the command below:
`sudo fc-cache -f -v`
If you open LibreOffice now, you’ll see the Microsoft [TrueType fonts](https://en.wikipedia.org/wiki/TrueType?ref=itsfoss.com).
**In case you accidentally reject the license agreement, you can reinstall the installer with this command:**
`sudo apt install --reinstall ttf-mscorefonts-installer`
Microsoft TrueType fonts are also available via the [Ubuntu Restricted Extras package](https://itsfoss.com/install-media-codecs-ubuntu/) that contains other proprietary media codecs to play files like MP3 etc.
## Don’t underestimate proprietary fonts
You may think, what the big deal with fonts is? After all, it’s just a font, not a crucial piece of software, right?
But did you know that for years, [Netflix paid millions of dollars for the proprietary font](https://thehustle.co/nextflix-sans-custom-font/?ref=itsfoss.com) it used? In the end, they created their own custom fonts and that saved them a considerable amount of money.
By the way, you can easily install new fonts in Ubuntu. This tutorial will help you with that.
[How to Install New Fonts in Ubuntu and Other Linux DistributionsUbuntu does come with a bunch of fonts installed by default in it. But at times you might not be satisfied with the available fonts. If that’s the case, you can easily install additional fonts in Ubuntu, or any other Linux system such as Linux Mint. In this tutorial,](https://itsfoss.com/install-fonts-ubuntu/)

Now you know about the fonts, what about [installing some Windows-only apps in Linux](https://itsfoss.com/use-windows-applications-linux/)?
Or do you want to try some [open-source alternatives to MS Office](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/)?
More productivity tutorials are down the line; leave your comments below and subscribe to our social media for more! |
12,075 | 为什么使用 GraphQL? | https://opensource.com/article/19/6/why-use-graphql | 2020-04-05T10:58:35 | [
"GraphQL"
] | /article-12075-1.html |
>
> 以下是 GraphQL 在标准 REST API 技术上获得发展的原因。
>
>
>

正如我[以前](/article-12070-1.html)所写,[GraphQL](https://graphql.org/) 是一种下一代 API 技术,它正在改变客户端应用程序与后端系统的通信方式以及后端系统的设计方式。
由于一开始就从创建它的组织 Facebook 获得了支持,并得到了其他技术巨头(如 Github、Twitter 和 AirBnB)的支持,因此 GraphQL 作为应用程序系统的关键技术的地位似乎是稳固的 —— 无论现在还是将来。
### GraphQL 的崛起
移动应用程序性能和组织敏捷性重要性的提高为 GraphQL 登上现代企业体系结构的顶端提供了助推器。
鉴于 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) 是一种非常流行的体系结构风格,早已提供了数据交互机制,与 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) 相比,GraphQL 这项新技术具有哪些优势呢?GraphQL 中的 “QL” 代表着查询语言,而这是一个很好的起点。
借助 GraphQL,组织内的不同客户端应用程序可以轻松地仅查询所需数据,这一点超越了其它 REST 方法,并带来了实际应用程序性能的提高。使用传统的 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) API 端点,客户端应用程序将详询服务器资源,并接受包含了与请求匹配的所有数据的响应。如果来自 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) API 端点的成功响应返回 35 个字段,那么客户端应用程序就会收到 35 个字段。
### 获取的问题
传统上,[REST](https://en.wikipedia.org/wiki/Representational_state_transfer) API 没有为客户端应用程序提供简便的方法来仅检索或只更新它们关心的数据。这通常被描述为“<ruby> 过度获取 <rt> over-fetching </rt></ruby>”的问题。随着移动应用程序在人们的日常生活中的普遍使用,过度获取问题会给现实世界带来不良后果。移动应用程序发出的每个请求、每一个字节的接受和发送,对终端用户的性能影响越来越大。数据连接速度较慢的用户尤其会受到不太好的 API 设计方案的影响。使用移动应用程序而性能体验不佳的客户更有可能不购买产品或不使用服务。低效的 API 设计只会浪费企业的钱。
并非只有“过度获取”是问题,“欠缺获取”同样也是问题。默认情况下,端点只返回客户端实际需要的部分数据,这需要客户端进行额外的调用以满足其数据需求,这就产生了额外的 HTTP 请求。由于过度和欠缺的获取问题及其对客户端应用程序性能的影响,促进有效获取的 API 技术才有机会在市场上引起轰动 —— GraphQL 大胆地介入并填补了这一空白。
### REST 的应对
[REST](https://en.wikipedia.org/wiki/Representational_state_transfer) API 设计师不甘心不战而退,他们试图通过以下几种方式来应对移动应用程序性能问题:
* “包含”和“排除”查询参数,允许客户端应用程序通过可能较长的查询格式来指定所需的字段。
* “复合”服务,将多个端点组合在一起,以使客户端应用程序在其发出的请求数量和接收到的数据方面更高效。 尽管这些模式是 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) API 社区为解决移动客户端所面临的挑战而做出的英勇尝试,但它们在以下几个关键方面仍存在不足:
* 包含和排除查询键/值对很快就会变得混乱,特别是对于需要用嵌套“点表示法”语法(或类似方法)以对目标数据进行包含和排除的深层对象图而言,更是如此。此外,在此模型中调试查询字符串的问题通常需要手动分解 URL。
* 包含和排除查询的服务器的实现往往是自定义的,因为基于服务器的应用程序没有标准的方式来处理包含和排除查询的使用,就像没有定义包含和排除查询的标准方式一样。
* 复合服务的兴起形成了更加紧密耦合的后端和前端系统,这就需要加强协调以交付项目,并且将曾经的敏捷项目转回瀑布式开发。这种协调和耦合还有一个痛苦的副作用,那就是减宦了组织的敏捷性。此外,顾名思义,组合服务不是 RESTful。
### GraphQL 的起源
对于 Facebook 来说,从其 2011-2012 年基于 HTML5 版本的旗舰移动应用程序中感受到的痛点和体验,才造就了 GraphQL。Facebook 工程师意识到提高性能至关重要,因此意识到他们需要一种新的 API 设计来确保最佳性能。可能考虑到上述 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) 的局限性,并且需要支持许多 API 客户端的不同需求,因此人们可以理解是什么导致其共同创建者 Lee Byron 和 Dan Schaeffer(那时尚是 Facebook 员工)创建了后来被称之为 GraphQL 的技术的早期种子。
通过 GraphQL 查询语言,客户端(通常是单个 GraphQL 端点)应用程序通常可以显著减少所需的网络调用数量,并确保仅检索所需的数据。在许多方面,这可以追溯到早期的 Web 编程模型,在该模型中,客户端应用程序代码会直接查询后端系统 —— 比如说,有些人可能还记得 10 到 15 年前在 JSP 上用 JSTL 编写 SQL 查询的情形吧!
现在最大的区别是使用 GraphQL,我们有了一个跨多种客户端和服务器语言和库实现的规范。借助 GraphQL 这样一种 API 技术,我们通过引入 GraphQL 应用程序中间层来解耦后端和前端应用程序系统,该层提供了一种机制,以与组织的业务领域相一致的方式来访问组织数据。
除了解决软件工程团队遇到的技术挑战之外,GraphQL 还促进了组织敏捷性的提高,特别是在企业中。启用 GraphQL 的组织敏捷性通常归因于以下因素:
* GraphQL API 设计人员和开发人员无需在客户端需要一个或多个新字段时创建新的端点,而是能够将这些字段包含在现有的图实现中,从而以较少的开发工作量和跨应用程序系统的较少更改的方式展示出新功能。
* 通过鼓励 API 设计团队将更多的精力放在定义对象图上,而不是在专注于客户端应用程序交付上,前端和后端软件团队为客户交付解决方案的速度日益解耦。 ### 采纳之前的注意事项
尽管 GraphQL 具有引人注目的优势,但 GraphQL 并非没有实施挑战。一些例子包括:
* 为 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) API 建立的缓存机制更加成熟。
* 使用 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) 来构建 API 的模式更加完善。
* 尽管工程师可能更喜欢 GraphQL 等新技术,但与 GraphQL 相比,市场上的人才库更多是从事于构建基于 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) 的解决方案。
### 结论
通过同时提高性能和组织敏捷性,GraphQL 在过去几年中被企业采纳的数量激增。但是,与 API 设计的 RESTful 生态系统相比,它确实还需要更成熟一些。
GraphQL 的一大优点是,它并不是作为替代 API 解决方案的批发替代品而设计的。相反,GraphQL 可以用来补充或增强现有的 API。因此,鼓励企业探索在 GraphQL 对其最有意义的地方逐步采用 GraphQL —— 在他们发现它对应用程序性能和组织敏捷性具有最大的积极影响的地方。
---
via: <https://opensource.com/article/19/6/why-use-graphql>
作者:[Zach Lendon](https://opensource.com/users/zachlendon/users/goncasousa/users/patrickhousley) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,076 | 如何在 Ubuntu Linux 上安装 Oracle Java 14 | https://itsfoss.com/java-14-ubuntu/ | 2020-04-05T20:54:24 | [
"Java"
] | https://linux.cn/article-12076-1.html | 
最近,Oracle 宣布 Java 14(或 Oracle JDK 14)公开可用。如果你想进行最新的实验或者开发的话,那么你可以试试在 Linux 系统上安装 Java 14。
Oracle JDK 14(或简称 Java 14)[发布版](https://www.oracle.com/corporate/pressrelease/oracle-announces-java14-031720.html)包含几个新功能,如果你想预览它们的话。我已添加了链接:
* [instanceof 的模式匹配](https://openjdk.java.net/jeps/305)
* [Records](https://openjdk.java.net/jeps/359)
* [Text Blocks](https://openjdk.java.net/jeps/368)
除预览功能外,它还包含一些改进和补充。在新闻中,他们还提到了其他改进:
>
> 此外,最新的 Java 版本增加了 Java 语言对 switch 表达式的支持,新增了用于持续监控 JDK Flight Recorder 数据的新 API,将低延迟 zgc 扩展到了 macOS 和 Windows,并添加在 incubator 模块中,独立的 Java 应用打包,以及为了安全、有效地访问 Java 堆外部内存的新的外部内存访问 API。
>
>
>
当然,如果你想深入了解细节,那么你应查看[官方公告](https://www.oracle.com/corporate/pressrelease/oracle-announces-java14-031720.html)。
在本教程中,我将向你展示在 Ubuntu 系统上安装 Java 14 的简便方法。请继续阅读。
**注意:**如果你选择使用 Oracle Java 11 或更高版本,那么应该了解新的 [Oracle 技术网络许可协议](https://www.oracle.com/technetwork/java/javase/overview/oracle-jdk-faqs.html),以了解它如何影响个人用户、开发人员和商业组织。通常,它们可以免费用于开发和测试,但不能用于生产环境。
### 如何在 Ubuntu Linux 上安装 Java 14?
作为参考,我已成功在默认安装 **OpenJDK 11** 的 **Pop!\_OS 19.10** 上成功安装了它。
这里,我们将使用 [Linux Uprising](https://www.linuxuprising.com/2020/03/how-to-install-oracle-java-14-jdk14-on.html) 的 Java 14 安装程序(最初基于 WebUpd8 Java 软件包)。
只需在终端中输入以下命令即可进行安装:
```
sudo add-apt-repository ppa:linuxuprising/java
sudo apt update
sudo apt install oracle-java14-installer
```
这应该就完成了,如果你想将它设为默认,那么你可以输入以下命令:
```
sudo apt install oracle-java14-set-default
```
值得注意的是,这仅适用于基于 Ubuntu 的发行版。如果要在 Debian 和其他 Linux 发行版上安装它,那么也可以按照 [Linux Uprising 中的详细指南](https://www.linuxuprising.com/2020/03/how-to-install-oracle-java-14-jdk14-on.html)安装 Java 14。
### 总结
当然,这些会带来最新的特性,如果你不想破环原有环境,你或许会希望继续使用 Java 11。如果你想在了解风险的情况下进行试验,请继续尝试!
欢迎在下面的评论中让我知道你对 Java 14 的想法。
---
via: <https://itsfoss.com/java-14-ubuntu/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,077 | 提升你的 Vim 技能的 5 个方法 | https://opensource.com/article/20/3/vim-skills | 2020-04-05T23:24:59 | [
"Vim"
] | https://linux.cn/article-12077-1.html |
>
> 通过一些有趣的小技巧使你的文本编辑器更上一层楼。
>
>
>

Vim 是最受欢迎的文本编辑器之一,因此绝对值得你花时间去学习如何使用它。就算你只是学习使用这个无处不在的 [Vi(m)](https://www.vim.org/) 命令行文本编辑器打开文件、输入和编辑一些文本、保存编辑的文件并退出程序,你都会受益匪浅。
你会发现,使用 Vim 非常方便的的场景几乎总是涉及到运行远程 Shell 操作的任务。如果你时不时地使用 ssh,比如
```
$ ssh [email protected]
```
并在虚拟专用服务器(VPS)或本地虚拟化容器中工作,那么就可以从这些强大的 Vim 技能中受益匪浅。
### 将 Vim 设置为默认的文本编辑器
几乎所有的现代 Linux(或 BSD)发行版中,都可以在终端仿真器的 shell 命令提示符下使用 Vim。一旦在你的用户 shell 程序中将 Vim 定义为默认编辑器后,那么就可以使用熟悉的 Vim 键绑定来在内置的实用程序(例如 `man`)中导航。我将说明如何使用 Bash 和 Z shell(zsh)来实现此目的,zsh 现在是 macOS 用户的默认 shell(自 Catalina 起)。
#### 在 Bash 中将 Vim 设置为默认
Bash 通过点文件的组合来管理设置。最常见的的做法将你的编辑器添加到主目录中的 `.bashrc` 文件中,但也可以将其添加到 `.bash_profile` 中。(请阅读 [GNU Bash 文档](https://www.gnu.org/software/bash/manual/html_node/Bash-Startup-Files.html)了解两者的不同之处)。
通过在 `~/.bashrc` 中添加以下内容,将 Vim 设置为默认编辑器:
```
# set default editor to Vim
export EDITOR=vim
```
以 `#` 开头的行是可选的注释,这是一个好方法,可以提醒自己该命令的作用。
#### 在 zsh 中将 Vim 设置为默认
zsh 是一种越来越流行的终端仿真器,尤其是在苹果公司的基于 FreeBSD 的 Darwin 系统最近从 Bash 转向 zsh 以来。
zsh 点文件与 Bash 的文件相当,因此你可以在 `~/.zshrc` 或 `~/.zprofile` 之间进行选择。有关何时使用哪一个的详细信息,请参见 [zsh文档](http://zsh.sourceforge.net/Intro/intro_3.html)。
将其设置为默认:
```
# set default editor to Vim
export EDITOR=vim
```
### 优化 Vim 配置
Vim 像是终端仿真器 shell 一样,也使用点文件来设置个人偏好。如果你发现了这种模式,则可能已经猜到它是 `~/.vimrc`。
你可能要更改的第一个设置是将对传统的 Vi 兼容模式切换为“关闭”。由于 Vim 是 Vi 的超集,因此 Vi 中的所有功能在 Vim 中都是可用的,并且在 Vim 中得到了很大的改进,你可以获得许多高级功能。最新版本(8.2)允许你在分割的窗口中以子进程 shell 的方式打开一个终端。
顺便说一句,明确关闭对传统的 Vi 的兼容性看起来没有什么作用([事实上,可能并没有什么作用](http://vimdoc.sourceforge.net/htmldoc/starting.html#compatible-default))。当 Vim 遇到 `.vimrc` 文件时,它会暗暗地自动将兼容模式切换到关闭。但有时将其明确关闭仍然很重要。缩写 `nocp` 是 `nocompatible` 的同义词,作用是一样的。[条条大道通罗马](https://en.wikipedia.org/wiki/There%27s_more_than_one_way_to_do_it),切换首选项有很多方式。
在 `.vimrc` 语法中, 以 `"` 开头的行是注释(就像 `.bashrc` 文件中的 `#` 一样),这些注释可以帮助你记住诸如为何选择了一个隐晦的设置名称之类的内容。
要关闭 Vi 兼容性,请将以下内容添加到 `~/.vimrc` 文件中:
```
" ensure that legacy compatibility mode is off
" documentation: <http://vimdoc.sourceforge.net/htmldoc/options.html\#'compatible>'
set nocp
```
### 理解模式
Vim 的 “模式”概念是非常重要的,尤其是“普通模式”和“插入模式”之间的区别。对模式的混淆是大多数新用户的困扰。模式并不是 Vim 所独有的,甚至也不是 Vi 所引入的。命令模式是如此的古老,以至于它比 70 年代发明的[复制和粘贴](https://www.npr.org/2020/02/22/808404858/remembering-the-pioneer-behind-your-computers-cut-copy-and-paste-functions)功能还要早。
#### 重要的模式
Vim 依赖于不同的模式来定义键盘的敲击行为。需要了解的重要模式有:
* 普通模式:默认模式,主要用于导航和打开文件。
* 插入模式(包括替换):这种模式下 Vim 允许将文本输入到打开的文件中。
* 可视模式:Vim 的行为类似于基于鼠标的输入方式,如复制、编辑、替换等。
* 命令模式(包括行模式、Ex 命令模式和末行模式):是在 Vim 中做更多事情的强大方法。
每种模式都有很多值得探索的地方。使用 [Vimtutor](http://www2.geog.ucl.ac.uk/%7Eplewis/teaching/unix/vimtutor)(`vimtutor`)可以交互式地学习移动光标、模式和在末行模式下运行 Ex 命令。一些不可缺少的生产力操作符包括:
| 操作符 | 说明 |
| --- | --- |
| `:E` | 打开资源管理器,用于定位文件和目录。 |
| `.` | 重复上次的编辑操作。 |
| `;` | 向前重复上一次的动作或移动 |
| `,` | 向后重复上一次的动作或移动。 |
| `/` | 向前搜索文档。 |
| `?` | 向后搜索文档。 |
| `*` | 查找光标所在处的单词的下一个出现的地方。 |
| `#` | 查找光标所在处的单词的上一次出现的地方。 |
| `~` | 切换大小写。 |
| `%` | 在 `()`、`[]` 和 `{}` 的开闭符号之间切换;对编码非常有用。 |
| `z=` | 提出拼写建议。 |
### 像钢琴一样弹奏 Vim
尽管把 Vim 的操作符“语言”记在记忆中是很重要的,但要想掌握它,难点在于学会像音乐家一样思考,把操作符和动作组合成“和弦”,这样你就可以像弹钢琴一样弹奏 Vim。这就是 Vim 的文本操作能力可以与另一个著名的命令行编辑器 Emacs 相媲美的地方。(虽然其中一个编辑器会让磨损掉你的 `Esc` 键,而另一个编辑器会让你的 `Ctrl` 键磨损掉。)
在描述键“和弦”时,Vim 中的传统做法是用大写字母 C 后面加上一个连字符(`C-`)来指代 `Ctrl` 键。这并不是通用的,但我将从这里开始遵循这一惯例,并在有可能引起混淆的时候加以说明。
如果你在 Vim 中键入长行,你会想把它设置成可以换行。想要根据你的工作方式对 Vim 进行个性化设置,请考虑一下这个设置:默认情况下,你希望 Vim 启动时如何处理文本换行?开还是关?我喜欢将其关闭,并将其留在运行命令文件之外。当我想让文本自动换行时,我只需在命令行模式下用 `:set wrap` 设置即可。
让 Vim 设置为默认情况下自动换行并没有错,这只是一个偏好问题 —— 它可能随着时间的推移而改变。同样你也可以控制粘贴、代码语言缩进语法和 `Tab` 键的设置(制表符还是空格?多少个空格?可也在[这里](https://opensource.com/article/18/9/vi-editor-productivity-powerhouse)深入研究这些选项)。所有这些默认行为的选项都是完全可配置和可更改的,并且在你使用命令行模式操作时可以实时更改。
你会在社区论坛、Vim 维基和文章(比如这篇文章)中找到很多关于设置 Vim 默认设置的建议。你应该很熟悉为你的个人计算环境设置首选项,Vim 也不例外。我强烈建议你从对设置进行很小的更改开始,慢慢地进行其它更改,以便你可以轻松地恢复设置。这样一来,你就可以好多年避免使用插件或完全不用插件。
### Vim 8.2 中的分割、标签和终端
有两种方法可以将你正在处理的文件分割成不同的视图:它们可以并排显示,也可以使用应用程序标签页在全屏(窗口)中切换。这些对应用程序窗口的更改是从命令模式启动的,这需要使用冒号(`:`)来调起提示符。
每个分割的窗口可以容纳一个文件进行编辑,你可以通过标签页在更多的文件之间随意切换。分割的屏幕空间有限,所以当你想分割更多的屏幕时,标签页是很方便的。想要如何设置,纯属个人喜好的问题。要水平分割一个窗口,使用 `:sp`,垂直分割时使用 `:vs`。
从 [Vim 8.2](https://www.vim.org/vim-8.2-released.php) 开始,你可以用 `:vert term` 打开一个垂直分割的终端 shell 子进程,以在你的代码旁边的命令行上进行操作。你需要键入 `exit` 来关闭你的终端进程,就像你结束一个 shell 会话一样,但你关闭这个分割的窗口和标签页的方式和关闭任何普通的 Vim 窗口一样,要用 `:q` 来关闭。
要初始化一个标签页,请使用一个特殊的编辑命令:`:tabedit`,它会自动切换到新打开的标签页。如果你给该命令一个文件名作为参数,会打开该文件并进行编辑。如果你忽略了给它一个文件名作为参数,可以在命令行模式下的使用编辑命令 `:e filename.txt`,就像在任何一个普通的 Vim 窗口中一样。可以使用下一个(`:tabn`)和上一个(`:tabp`)命令在标签页间导航。
要使用分割,你需要知道如何使用组合键 `C-w` 和你想要移动的方向的移动键,例如左(`h`)、下(`j`)、左(`k`)、右(`l`)。如果你想学习更多的组合键,请阅读 Vim 手册中的 `:help split` 和 `:help tabpage`。
### 获取帮助
虽然可以在 Vimtutor 中打开参考 Vim 手册,但用 `:help` 打开 Vim 帮助,可以让你自己把时间花在编辑器上,不用完全依赖像这样的文章,就能获得更多的成果。经验是掌握 Vim 的关键。经验有助于提高你的整体计算直觉,因为 Vim 中的很多东西都是从 Unix 宇宙中汲取的。
祝你在探索 Vim 之美的过程中玩得开心,有什么问题可以在评论中分享。
---
via: <https://opensource.com/article/20/3/vim-skills>
作者:[Detlef Johnson](https://opensource.com/users/deckart) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Vim is one of the most popular text editors out there, so it is definitely worth taking time to learn how to use it. If the only things you learn how to do with the ubiquitous [Vi(m)](https://www.vim.org/) command-line text editor are to open a file, enter and edit some text, save the edited files, and exit the program, you will be much better off for it.
Circumstances where you will find it extremely convenient to know Vim nearly always involve tasks running remote shell operations. If you regularly use secure shell:
`$ ssh [email protected]`
and work with virtual private servers (VPS) or local virtualization containers, for that matter, you could benefit greatly from strong Vim skills.
## Set Vim as your default text editor
Vim is readily available in nearly all modern Linux (or BSD) distributions at the terminal emulator shell-command prompt. Once you've defined Vim as your default editor in your user shell, then you can navigate built-in utilities like **$ man** using familiar Vim key bindings. I'll explain how to do that with both Bash and Z shell (zsh), which is now the default shell for macOS users (since Catalina).
### Set Vim as default in Bash
Bash manages settings through a combination of dotfiles. It's most common to add your preferred editor to your **.bashrc** file in your home directory, but it can be added to **.bash_profile** as well. (Read the [GNU Bash documentation](https://www.gnu.org/software/bash/manual/html_node/Bash-Startup-Files.html) to understand the difference).
Set Vim as your default editor by adding the following to **~/.bashrc**:
```
# set default editor to Vim
export EDITOR=vim
```
A line starting with a **#** is an optional comment, which is a good way to remind yourself what a command does.
### Set Vim as default in Zsh
Zsh is an increasingly popular terminal emulator, especially since Apple's FreeBSD-based Darwin system recently switched from Bash to zsh.
The zsh dotfile parallels Bash's, so you can choose between **~/.zshrc** or **~/.zprofile**. See [the zsh documentation](http://zsh.sourceforge.net/Intro/intro_3.html) for details on when to use which one.
Set it as default with:
```
# set default editor to Vim
export EDITOR=vim
```
## Optimize your Vim configuration
Vim, much like a terminal emulator shell, uses dotfiles to set personal preferences. If you spotted the pattern, you might have guessed it's **~/.vimrc**.
The first setting you may want to change is switching legacy Vi compatibility mode to Off. Since Vim is a superset of Vi, everything in Vi is available and vastly improved in Vim, and you get many advanced features. The latest version (8.2) allows you to open a terminal as a subprocess shell running in a split window.
As an aside, setting legacy compatibility off might not seem like it's doing anything ([and in fact, it might not be](http://vimdoc.sourceforge.net/htmldoc/starting.html#compatible-default)). Vim automatically switches the mode to Off by implication when it encounters a **.vimrc** file. It can still be important at times to explicitly turn it off. The shorthand "nocp" is synonymous with "nocompatible," which also works. There are many "[TIMTOWTDI](https://en.wikipedia.org/wiki/There%27s_more_than_one_way_to_do_it)" conveniences for switching preferences as you work.
Lines that begin with **"** are comments in **.vimrc** syntax (just like **#** in **.bashrc** files). They can help you remember things like why you chose a cryptic setting name.
To turn off Vi compatibility, add the following to your **~/.vimrc** file:
```
" ensure that legacy compatibility mode is off
" documentation: http://vimdoc.sourceforge.net/htmldoc/options.html#'compatible'
set nocp
```
## Understand modes
The notion of Vim's "modes" is very important to learn about, especially the difference between the very distinct **Normal** and **Insert** modes. Confusion about modes is what trips up most new users. Modes aren't unique to Vim, nor were they introduced by Vi. Command mode is so old that it predates the invention of [copy and paste](https://www.npr.org/2020/02/22/808404858/remembering-the-pioneer-behind-your-computers-cut-copy-and-paste-functions) functionality in the 1970s.
### Important modes
Vim depends on different modes to define keyboard-stroke behavior. The important modes to know are:
**Normal mode**: Default mode used primarily for navigation and opening files**Insert mode**(includes Replace): Where Vim allows for text input to an open file**Visual mode**: Where Vim acts similar to mouse-based input, such as copying, editing, replacing, and more**Command mode**(including Line, Ex command, and Last-line mode): A powerful way to do more in Vim
Each mode has a great deal to explore. Use [Vimtutor](http://www2.geog.ucl.ac.uk/~plewis/teaching/unix/vimtutor) (**$ vimtutor**) to interactively learn about movement, modes, and running Ex commands in "Last Line" mode. Some indispensable productivity operators include:
:E |
Opens explorer for locating files and directories |
. |
Repeats the last edit action |
; |
Repeats the last motion or movement forward |
, |
Repeats the last motion or movement backward |
/ |
Searches document forward |
? |
Searches document backward |
* |
Finds next occurrence of the word under the cursor |
# |
Finds the previous occurrence of the word under the cursor |
~ |
Toggles case |
% |
Toggles between opening and closing (), [], and {}; highly useful for coding |
z= |
Makes spelling suggestions |
## Play Vim like a piano
While it's important to commit Vim's operator "language" to memory, the challenge to gaining mastery is to learn to think like a musician and combine operators and movements into "key chords in harmony" so that you can play Vim like a piano. That's where the power of text manipulation with Vim rivals that of the other notable command-line editor, Emacs. (While one of these editors will wear down your **Esc** key, using the other will wear down your **Ctrl** key.)
When describing key chords, it's conventional in Vim to designate the **Ctrl** key using the capital letter C, followed by a hyphen (**C-**). It's not universal, but I will follow that convention from here onward and clarify when there is any potential for confusion.
If you type long lines in Vim, you'll want to set it to wrap your text. To start personalizing Vim for the way you work, think about that setting: How would you like Vim to handle text wrapping by default when it starts? On or off? I like it turned off and leave it out of the runtime commands file. When I want text to wrap, I simply set it in command-line mode with **:set wrap**.
There's nothing wrong with having Vim set to wrap text by default. It's simply a matter of preference—which can change over time. The same goes for handling paste, code language indent syntax, and the **Tab** key (tabs or spaces? and how many spaces then? Dive into these options [here](https://opensource.com/article/18/9/vi-editor-productivity-powerhouse)). All these options for default behavior are entirely configurable and changeable in real time as you work with command-line mode operations.
You will find many suggestions for setting Vim defaults in community forums, on Vim wikis, and in articles (like this one). Setting preferences for your personal computing environment should be fairly familiar to you, and Vim is no different. I highly recommend that you start by making very small changes to your settings, and make additional changes slowly so that you can easily revert settings. This way, you might avoid the use of plugins for years—or entirely.
## Splits, tabs, and terminals in Vim 8.2
There are two ways to split your working files into different views: they can appear side-by-side, or you can switch between them with full (window) screens using application tabs. These changes to your application window are initiated from command-line mode, which requires a colon (**:**) to call up the prompt.
Each window split can host a file for editing, and you can arrange tabs to switch between additional files as much as you like. There is limited screen space for splits, so tabs are handy when you want to split more screens. How you decide to work is purely a matter of preference. To split a window horizontally, use **:sp**, and use **:vs** for vertical splits.
As of [Vim 8.2](https://www.vim.org/vim-8.2-released.php), you can open a terminal shell sub-process in a vertical split with **:vert term** to run operations on the command line right alongside your code. You need to type **exit** to close your terminal process, just like you would end a shell session, but you close splits and tabs the same way you would close any ordinary Vim window, with **:q**.
To initialize a tab, use a special edit command: **:tabedit**, which automatically switches you to the new open tab. If you give the command a file name as an argument, that file will open for editing. If you neglect to give it a file name as an argument, the command-line mode edit **:e filename.txt** works just like it would in any ordinary Vim window. Navigate tabs with the next (**:tabn**) and previous (**:tabp**) commands.
To use splits, you need to know how to navigate among them using the key-chord combination **C-w** plus a movement key in the direction you want to move, such as left (**h**), down (**j**), up (**k**), or right (**l**). When you want to learn more key chords specific to splits and tabs, read the **:help split** and **:help tabpage** for the Vim manual entries.
## Get help
While the Vim manual is referenced in Vimtutor, opening Vim help with **:help** will let you spend time with the editor on your own and get more productive without wholly relying on articles like this one. Experience is key to Vim mastery. The experience contributes to your overall computing intuition since so much of what has gone into Vim is drawn from the Unix universe.
Have fun exploring the beauty of Vim, and share any questions you have in the comments.
## 3 Comments |
12,079 | Linux 防火墙 ufw 简介 | https://www.networkworld.com/article/3533551/linux-firewall-basics-with-ufw.html | 2020-04-06T21:42:36 | [
"ufw",
"防火墙"
] | https://linux.cn/article-12079-1.html |
>
> 我们来研究下 Linux 上的 ufw(简单防火墙),为你更改防火墙提供一些见解和命令。
>
>
>

`ufw`(<ruby> 简单防火墙 <rt> Uncomplicated FireWall </rt></ruby>)真正地简化了 [iptables](https://www.networkworld.com/article/2716098/working-with-iptables.html),它从出现的这几年,已经成为 Ubuntu 和 Debian 等系统上的默认防火墙。而且 `ufw` 出乎意料的简单,这对新管理员来说是一个福音,否则他们可能需要投入大量时间来学习防火墙管理。
`ufw` 也有 GUI 客户端(例如 `gufw`),但是 `ufw` 命令通常在命令行上执行的。本文介绍了一些使用 `ufw` 的命令,并研究了它的工作方式。
首先,快速查看 `ufw` 配置的方法是查看其配置文件 —— `/etc/default/ufw`。使用下面的命令可以查看其配置,使用 `grep` 来抑制了空行和注释(以 # 开头的行)的显示。
```
$ grep -v '^#\|^$' /etc/default/ufw
IPV6=yes
DEFAULT_INPUT_POLICY="DROP"
DEFAULT_OUTPUT_POLICY="ACCEPT"
DEFAULT_FORWARD_POLICY="DROP"
DEFAULT_APPLICATION_POLICY="SKIP"
MANAGE_BUILTINS=no
IPT_SYSCTL=/etc/ufw/sysctl.conf
IPT_MODULES="nf_conntrack_ftp nf_nat_ftp nf_conntrack_netbios_ns"
```
正如你所看到的,默认策略是丢弃输入但允许输出。允许你接受特定的连接的其它规则是需要单独配置的。
`ufw` 命令的基本语法如下所示,但是这个概要并不意味着你只需要输入 `ufw` 就行,而是一个告诉你需要哪些参数的快速提示。
```
ufw [--dry-run] [options] [rule syntax]
```
`--dry-run` 选项意味着 `ufw` 不会运行你指定的命令,但会显示给你如果执行后的结果。但是它会显示假如更改后的整个规则集,因此你要做有好多行输出的准备。
要检查 `ufw` 的状态,请运行以下命令。注意,即使是这个命令也需要使用 `sudo` 或 root 账户。
```
$ sudo ufw status
Status: active
To Action From
-- ------ ----
22 ALLOW 192.168.0.0/24
9090 ALLOW Anywhere
9090 (v6) ALLOW Anywhere (v6)
```
否则,你会看到以下内容:
```
$ ufw status
ERROR: You need to be root to run this script
```
加上 `verbose` 选项会提供一些其它细节:
```
$ sudo ufw status verbose
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
To Action From
-- ------ ----
22 ALLOW IN 192.168.0.0/24
9090 ALLOW IN Anywhere
9090 (v6) ALLOW IN Anywhere (v6)
```
你可以使用以下命令轻松地通过端口号允许和拒绝连接:
```
$ sudo ufw allow 80 <== 允许 http 访问
$ sudo ufw deny 25 <== 拒绝 smtp 访问
```
你可以查看 `/etc/services` 文件来找到端口号和服务名称之间的联系。
```
$ grep 80/ /etc/services
http 80/tcp www # WorldWideWeb HTTP
socks 1080/tcp # socks proxy server
socks 1080/udp
http-alt 8080/tcp webcache # WWW caching service
http-alt 8080/udp
amanda 10080/tcp # amanda backup services
amanda 10080/udp
canna 5680/tcp # cannaserver
```
或者,你可以命令中直接使用服务的名称。
```
$ sudo ufw allow http
Rule added
Rule added (v6)
$ sudo ufw allow https
Rule added
Rule added (v6)
```
进行更改后,你应该再次检查状态来查看是否生效:
```
$ sudo ufw status
Status: active
To Action From
-- ------ ----
22 ALLOW 192.168.0.0/24
9090 ALLOW Anywhere
80/tcp ALLOW Anywhere <==
443/tcp ALLOW Anywhere <==
9090 (v6) ALLOW Anywhere (v6)
80/tcp (v6) ALLOW Anywhere (v6) <==
443/tcp (v6) ALLOW Anywhere (v6) <==
```
`ufw` 遵循的规则存储在 `/etc/ufw` 目录中。注意,你需要 root 用户访问权限才能查看这些文件,每个文件都包含大量规则。
```
$ ls -ltr /etc/ufw
total 48
-rw-r--r-- 1 root root 1391 Aug 15 2017 sysctl.conf
-rw-r----- 1 root root 1004 Aug 17 2017 after.rules
-rw-r----- 1 root root 915 Aug 17 2017 after6.rules
-rw-r----- 1 root root 1130 Jan 5 2018 before.init
-rw-r----- 1 root root 1126 Jan 5 2018 after.init
-rw-r----- 1 root root 2537 Mar 25 2019 before.rules
-rw-r----- 1 root root 6700 Mar 25 2019 before6.rules
drwxr-xr-x 3 root root 4096 Nov 12 08:21 applications.d
-rw-r--r-- 1 root root 313 Mar 18 17:30 ufw.conf
-rw-r----- 1 root root 1711 Mar 19 10:42 user.rules
-rw-r----- 1 root root 1530 Mar 19 10:42 user6.rules
```
本文前面所作的更改,为 `http` 访问添加了端口 `80` 和为 `https` 访问添加了端口 `443`,在 `user.rules` 和 `user6.rules` 文件中看起来像这样:
```
# grep " 80 " user*.rules
user6.rules:### tuple ### allow tcp 80 ::/0 any ::/0 in
user6.rules:-A ufw6-user-input -p tcp --dport 80 -j ACCEPT
user.rules:### tuple ### allow tcp 80 0.0.0.0/0 any 0.0.0.0/0 in
user.rules:-A ufw-user-input -p tcp --dport 80 -j ACCEPT
You have new mail in /var/mail/root
# grep 443 user*.rules
user6.rules:### tuple ### allow tcp 443 ::/0 any ::/0 in
user6.rules:-A ufw6-user-input -p tcp --dport 443 -j ACCEPT
user.rules:### tuple ### allow tcp 443 0.0.0.0/0 any 0.0.0.0/0 in
user.rules:-A ufw-user-input -p tcp --dport 443 -j ACCEPT
```
使用 `ufw`,你还可以使用以下命令轻松地阻止来自一个 IP 地址的连接:
```
$ sudo ufw deny from 208.176.0.50
Rule added
```
`status` 命令将显示更改:
```
$ sudo ufw status verbose
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
To Action From
-- ------ ----
22 ALLOW IN 192.168.0.0/24
9090 ALLOW IN Anywhere
80/tcp ALLOW IN Anywhere
443/tcp ALLOW IN Anywhere
Anywhere DENY IN 208.176.0.50 <== new
9090 (v6) ALLOW IN Anywhere (v6)
80/tcp (v6) ALLOW IN Anywhere (v6)
443/tcp (v6) ALLOW IN Anywhere (v6)
```
总而言之,`ufw` 不仅容易配置,而且且容易理解。
---
via: <https://www.networkworld.com/article/3533551/linux-firewall-basics-with-ufw.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,081 | 使用 Traefik 引导 Kubernetes 流量 | https://opensource.com/article/20/3/kubernetes-traefik | 2020-04-07T10:35:24 | [
"Kubernetes",
"k3s"
] | https://linux.cn/article-12081-1.html |
>
> 将流量引入 Kubernetes 树莓派集群的分步指南。
>
>
>

在本文中,我们将部署几个简单的网站,并学习如何使用 Traefik 将来自外部世界的流量引入到我们的集群中。之后,我们还将学习如何删除 Kubernetes 资源。让我们开始吧!
### 准备
要继续阅读本文,你只需要我们在上一篇文章中构建的 [k3s 树莓派集群](/article-12049-1.html)。由于你的集群将从网络上拉取镜像,因此该集群需要能够访问互联网。
出于解释目的,本文将显示一些配置文件和示例 HTML 文件。所有示例文件都可以在[此处](https://gitlab.com/carpie/ingressing_with_k3s/-/archive/master/ingressing_with_k3s-master.zip)下载。
### 部署一个简单的网站
之前,我们使用 `kubectl` 进行了直接部署。但是,这不是典型的部署方法。一般情况都会使用 YAML 配置文件,这也是我们要在本文中使用的配置文件。我们将从顶部开始,并以自顶向下的方式创建该配置文件。
### 部署配置
首先是部署配置。配置如下所示,并在下面进行说明。我通常以 [Kubernetes 文档](https://kubernetes.io/docs/)中的示例为起点,然后根据需要对其进行修改。例如,下面的配置是复制了[部署文档](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#creating-a-deployment)中的示例后修改的。
创建一个文件 `mysite.yaml`,其内容如下:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysite-nginx
labels:
app: mysite-nginx
spec:
replicas: 1
selector:
matchLabels:
app: mysite-nginx
template:
metadata:
labels:
app: mysite-nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
```
其中大部分是样板。重要的部分,我们会将该部署命名为 `mysite-nginx`,并为其加上同名的 `app` 标签。我们指定了一个<ruby> 副本 <rt> replica </rt></ruby>,这意味着将只创建一个 Pod。我们还指定了一个容器,我们将其命名为 `nginx`。我们将<ruby> 镜像 <rt> image </rt></ruby>指定为 `nginx`。这意味着在部署时,k3s 将从 DockerHub 下载 `nginx` 镜像并从中创建一个 Pod。最后,我们指定了<ruby> 容器端口 <rt> containerPort </rt></ruby>为 `80`,这只意味着在容器内部 Pod 会监听 `80` 端口。
我在上面强调了“在容器内部”,因为这是一个重要的区别。由于我们是按容器配置的,因此只能在容器内部访问它,并且进一步将其限制为内部网络。这对于允许多个容器在同一容器端口上监听所是必要的。换句话说,通过这种配置,其他一些 Pod 也可以在其容器端口 80 上侦听,并且不会与此容器冲突。为了提供对该 Pod 的正式访问权限,我们需要一个<ruby> 服务 <rt> service </rt></ruby>配置。
### 服务配置
在 Kubernetes 中,<ruby> 服务 <rt> service </rt></ruby>是一种抽象。它提供了一种访问 Pod 或 Pod 集合的方法。当连接到服务时,服务会路由到单个 Pod,或者如果定义了多个 Pod 副本,会通过负载均衡路由到多个 Pod。
可以在同一配置文件中指定该服务,这就是我们将在此处要做的。用 `---` 分隔配置区域,将以下内容添加到 `mysite.yaml` 中:
```
---
apiVersion: v1
kind: Service
metadata:
name: mysite-nginx-service
spec:
selector:
app: mysite-nginx
ports:
- protocol: TCP
port: 80
```
在此配置中,我们将服务命名为 `mysite-nginx-service`。我们提供了一个<ruby> 选择器 <rt> selector </rt></ruby>:`app: mysite-nginx`。这是服务选择其路由到的应用程序容器的方式。请记住,我们为容器提供了 `app` 标签:`mysite-nginx` 。这就是服务用来查找我们的容器的方式。最后,我们指定服务协议为 `TCP`,在端口 `80` 上监听。
### 入口配置
<ruby> 入口 <rt> Ingress </rt></ruby>配置指定了如何将流量从集群外部传递到集群内部的服务。请记住,k3s 预先配置了 Traefik 作为入口控制器。因此,我们将编写特定于 Traefik 的入口配置。将以下内容添加到 `mysite.yaml` 中(不要忘了用 `---` 分隔):
```
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: mysite-nginx-ingress
annotations:
kubernetes.io/ingress.class: "traefik"
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: mysite-nginx-service
servicePort: 80
```
在此配置中,我们将入口记录命名为 `mysite-nginx-ingress`。我们告诉 Kubernetes,我们希望 `traefik` 成为我们的入口控制器,再加上 `kubernetes.io/ingress.class` 的注解。
在<ruby> 规则 <rt> rules </rt></ruby>部分中,我们基本上是说,当 `http` 流量进入时,并且 `path` 匹配 `/`(或其下的任何内容),将其路由到由 `serviceName mysite-nginx-service` 指定的<ruby> 后端 <rt> backend </rt></ruby>服务中,并将其路由到 `servicePort 80`。这会将传入的 HTTP 流量连接到我们之前定义的服务。
### 需要部署的东西
就配置而言,就是这样了。如果我们现在部署,我们将获得默认的 nginx 页面,但这不是我们想要的。让我们创建一些简单但可自定义的部署方式。创建具有以下内容的文件 `index.html`:
```
<html>
<head><title>K3S!</title>
<style>
html {
font-size: 62.5%;
}
body {
font-family: sans-serif;
background-color: midnightblue;
color: white;
display: flex;
flex-direction: column;
justify-content: center;
height: 100vh;
}
div {
text-align: center;
font-size: 8rem;
text-shadow: 3px 3px 4px dimgrey;
}
</style>
</head>
<body>
<div>Hello from K3S!</div>
</body>
</html>
```
我们尚未介绍 Kubernetes 中的存储机制,因此在这里我们偷懒一下,仅将该文件存储在 Kubernetes 配置映射中。这不是我们推荐的部署网站的方式,但对于我们的目的来说是可行的。运行以下命令:
```
kubectl create configmap mysite-html --from-file index.html
```
该命令从本地文件 `index.html` 创建名为 `mysite-html` 的<ruby> 配置映射 <rt> configmap </rt></ruby>资源。这实际上是在 Kubernetes 资源中存储一个文件(或一组文件),我们可以在配置中调出该文件。它通常用于存储配置文件(因此而得名),我们在这里稍加滥用。在以后的文章中,我们将讨论 Kubernetes 中适当的存储解决方案。
创建配置映射后,让我们将其挂载在我们的 `nginx` 容器中。我们分两个步骤进行。首先,我们需要指定一个<ruby> 卷 <rt> volume </rt></ruby>来调出配置映射。然后我们需要将该卷挂载到 `nginx` 容器中。通过在 `mysite.yaml` 中的 `container` 后面的 `spec` 标签下添加以下内容来完成第一步:
```
volumes:
- name: html-volume
configMap:
name: mysite-html
```
这告诉 Kubernetes 我们要定义一个名为 `html-volume` 的卷,并且该卷应包含名为 `html-volume`(我们在上一步中创建的)的配置映射的内容。
接下来,在 `nginx` 容器规范中的<ruby> 端口 <rt> ports </rt></ruby>下方,添加以下内容:
```
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html
```
这告诉 Kubernetes,对于 `nginx` 容器,我们想在容器中的 `/usr/share/nginx/html` 路径上挂载名为 `html-volume` 的卷。 为什么要使用 `/usr/share/nginx/html`?那个位置就是 `nginx` 镜像提供 HTML 服务的地方。通过在该路径上挂载卷,我们用该卷内容替换了默认内容。
作为参考,配置文件的 `deployment` 部分现在应如下所示:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysite-nginx
labels:
app: mysite-nginx
spec:
replicas: 1
selector:
matchLabels:
app: mysite-nginx
template:
metadata:
labels:
app: mysite-nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html
volumes:
- name: html-volume
configMap:
name: mysite-html
```
### 部署它!
现在我们准备部署! 我们可以这样做:
```
kubectl apply -f mysite.yaml
```
你应该看到类似于以下内容:
```
deployment.apps/mysite-nginx created
service/mysite-nginx-service created
ingress.networking.k8s.io/mysite-nginx-ingress created
```
这意味着 Kubernetes 为我们指定的三个配置分别创建了资源。使用以下方法检查 Pod 的状态:
```
kubectl get pods
```
如果看到状态为 `ContainerCreating`,请给它一些时间并再次运行 `kubectl get pods`。通常,第一次会花一些时间,因为 k3s 必须下载 `nginx` 镜像来创建 Pod。一段时间后,你应该看到 `Running` 的状态。
### 尝试一下!
Pod 运行之后,就该尝试了。打开浏览器,然后在地址栏中输入 `kmaster`。

恭喜你!你已经在 k3s 集群上部署了一个网站!
### 另一个
因此,现在我们有了一个运行单个网站的整个 k3s 集群。但是我们可以有更多的网站!如果我们要在同一集群中提供另一个网站怎么办?让我们看看如何做到这一点。
同样,我们需要部署一些东西。碰巧我的狗有一条她想让全世界都知道的信息,她想了好久了。因此,我专门为她制作了一些 HTML(可从示例 zip 文件中获得)。同样,我们将使用配置映射的技巧来托管这些 HTML。这次我们将把整个目录(`html` 目录)放到配置映射中,但是调用是相同的。
```
kubectl create configmap mydog-html --from-file html
```
现在,我们需要为此站点创建一个配置文件。它几乎与用于 `mysite.yaml` 的完全相同,因此首先将 `mysite.yaml` 复制为 `mydog.yaml`。现在将 `mydog.yaml` 修改为:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydog-nginx
labels:
app: mydog-nginx
spec:
replicas: 1
selector:
matchLabels:
app: mydog-nginx
template:
metadata:
labels:
app: mydog-nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html
volumes:
- name: html-volume
configMap:
name: mydog-html
---
apiVersion: v1
kind: Service
metadata:
name: mydog-nginx-service
spec:
selector:
app: mydog-nginx
ports:
- protocol: TCP
port: 80
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: mydog-nginx-ingress
annotations:
kubernetes.io/ingress.class: "traefik"
traefik.frontend.rule.type: PathPrefixStrip
spec:
rules:
- http:
paths:
- path: /mydog
backend:
serviceName: mydog-nginx-service
servicePort: 80
```
我们只需进行搜索并将 `mysite` 替换为 `mydog`即可完成大多数修改。其他两个修改在入口部分中。我们将 `path` 更改为 `/mydog`,并添加了一个注解 `traefik.frontend.rule.type: PathPrefixStrip`。
`/mydog` 路径的规范指示 Traefik 将以 `/mydog` 路径开头的所有传入请求路由到 `mydog-nginx-service`。任何其他路径将继续路由到 `mysite-nginx-service`。
新的注解 `PathPrefixStrip` 告诉 Traefik 在将请求发送到 `mydog-nginx-service` 之前先去除前缀 `/mydog`。我们这样做是因为 `mydog-nginx` 应用程序不需要前缀。这意味着我们可以简单地通过更改入口记录中的前缀来更改挂载的服务的位置。
现在我们可以像以前一样进行部署:
```
kubectl apply -f mydog.yaml
```
现在,我的狗的消息应该可以在 <http://kmaster/mydog/> 上找到。

呼!消息发出去了!也许今晚我们都可以睡一觉。
因此,现在,我们有了一个 k3s 集群,该集群托管了两个网站,Traefik 根据路径名决定将请求传递给哪个服务!但是,不仅限于基于路径的路由,我们也可以使用基于主机名的路由,我们将在以后的文章中进行探讨。
另外,我们刚刚托管的网站是标准的未加密 HTML 网站,而如今的所有内容都使用 SSL/TLS 加密。在我们的下一篇文章中,我们将为 k3s 集群添加支持以托管 SSL/TLS HTTPS 站点!
### 清理
在开始之前,由于本文主要涉及的是示例站点,因此我想向你展示如何删除内容,以防万一你不希望将这些示例丢在集群中。
对于大多数配置,只需使用与部署时使用的相同配置文件运行 `delete` 命令即可撤消配置。因此,让我们同时清理 `mysite` 和 `mydog`。
```
kubectl delete -f mysite.yaml
kubectl delete -f mydog.yaml
```
由于我们是手动创建配置映射的,因此我们也需要手动删除它们。
```
kubectl delete configmap mysite-html
kubectl delete configmap mydog-html
```
现在,如果我们执行 `kubectl get pods`,我们应该看到我们的 nginx Pod 不存在了。
```
$ kubectl get pods
No resources found in default namespace.
```
一切都清理了。
请在下面的评论中告诉我你对这个项目有什么想法。
---
via: <https://opensource.com/article/20/3/kubernetes-traefik>
作者:[Lee Carpenter](https://opensource.com/users/carpie) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this article, we will deploy a couple of simple websites and learn how to ingress traffic from the outside world into our cluster using Traefik. After that, we will learn how to remove Kubernetes resources as well. Let’s get started!
## Materials needed
To follow along with the article, you only need [the k3s Raspberry Pi cluster](https://opensource.com/article/20/3/kubernetes-raspberry-pi) we built in a previous article. Since your cluster will be pulling images from the web, the cluster will need to be able to access the internet.
Some configuration files and sample HTML files will be shown in this article for explanation purposes. All sample files can be downloaded [here](https://gitlab.com/carpie/ingressing_with_k3s/-/archive/master/ingressing_with_k3s-master.zip).
## Deploying a simple website
Previously, we did a direct deploy with **kubectl**. This is not the typical way to deploy things, however. Generally, YAML configuration files are used, and that is what we will use in this article. We will start at the top and create our configuration files in a top-down approach.
## Deployment configuration
First up is the deployment configuration. The configuration is shown below, and the explanation follows. I typically use the samples from the [Kubernetes documentation](https://kubernetes.io/docs/) as a starting point and then modify them to suit my needs. For example, the configuration below was modified after copying the sample from the [deployment docs](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#creating-a-deployment).
Create a file, **mysite.yaml**, with the following contents:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysite-nginx
labels:
app: mysite-nginx
spec:
replicas: 1
selector:
matchLabels:
app: mysite-nginx
template:
metadata:
labels:
app: mysite-nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
```
Most of this is boilerplate. The important parts, we have named our deployment **mysite-nginx** with an **app** label of **mysite-nginx **as well. We have specified that we want one **replica** which means there will only be one pod created. We also specified **one container**, which we named **nginx**. We specified the **image** to be **nginx**. This means, on deployment, k3s will download the **nginx** image from DockerHub and create a pod from it. Finally, we specified a **containerPort** of **80**, which just means that inside the container the pod will listen on port **80**.
I emphasized "inside the container" above because it is an important distinction. As we have the container configured, it is only accessible inside the container, and it is further restricted to an internal network. This is necessary to allow multiple containers to listen on the same container ports. In other words, with this configuration, some other pod could listen on its container port 80 as well and not conflict with this one. To provide formal access to this pod, we need a **service** configuration.
## Service configuration
In Kubernetes, a **service** is an abstraction. It provides a means to access a pod or set of pods. One connects to the service and the service routes to a single pod or load balances to multiple pods if multiple pod replicas are defined.
The service can be specified in the same configuration file, and that is what we will do here. Separate configuration areas with ** ---**. Add the following to
**mysite.yaml**:
```
---
apiVersion: v1
kind: Service
metadata:
name: mysite-nginx-service
spec:
selector:
app: mysite-nginx
ports:
- protocol: TCP
port: 80
```
In this configuration, we have named our service **mysite-nginx-service**. We provided a `selector`
of **app: mysite-nginx**. This is how the service chooses the application containers it routes to. Remember, we provided an **app **label for our container as **mysite-nginx**. This is what the service will use to find our container. Finally, we specified that the service protocol is **TCP** and the service listens on port **80**.
## Ingress configuration
The ingress configuration specifies how to get traffic from outside our cluster to services inside our cluster. Remember, k3s comes pre-configured with Traefik as an ingress controller. Therefore, we will write our ingress configuration specific to Traefik. Add the following to **mysite.yaml **( and don’t forget to separate with ** ---**):
```
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: mysite-nginx-ingress
annotations:
kubernetes.io/ingress.class: "traefik"
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: mysite-nginx-service
servicePort: 80
```
In this configuration, we have named the ingress record **mysite-nginx-ingress**. And we told Kubernetes that we expect **traefik** to be our ingress controller with the **kubernetes.io/ingress.class** annotation.
In the **rules** section, we are basically saying, when **http** traffic comes in, and the **path** matches ** /** (or anything below that), route it to the
**backend**service specified by the
**serviceName mysite-nginx-service**, and route it to
**servicePort 80**. This connects incoming HTTP traffic to the service we defined earlier.
## Something to deploy
That is really it as far as configuration goes. If we deployed now, we would get the default **nginx** page, but that is not what we want. Let’s create something simple but custom to deploy. Create the file **index.html** with the following contents:
```
<html>
<head><title>K3S!</title>
<style>
html {
font-size: 62.5%;
}
body {
font-family: sans-serif;
background-color: midnightblue;
color: white;
display: flex;
flex-direction: column;
justify-content: center;
height: 100vh;
}
div {
text-align: center;
font-size: 8rem;
text-shadow: 3px 3px 4px dimgrey;
}
</style>
</head>
<body>
<div>Hello from K3S!</div>
</body>
</html>
```
We have not yet covered storage mechanisms in Kubernetes, so we are going to cheat a bit and just store this file in a Kubernetes config map. This is not the recommended way to deploy a website, but it will work for our purposes. Run the following:
`kubectl create configmap mysite-html --from-file index.html`
This command creates a `configmap`
resource named **mysite-html** from the local file **index.html**. This essentially stores a file (or set of files) inside a Kubernetes resource that we can call out in configuration. It is typically used to store configuration files (hence the name), so we are abusing it a bit here. In a later article, we will discuss proper storage solutions in Kubernetes.
With the config map created, let’s mount it inside our **nginx** container. We do this in two steps. First, we need to specify a **volume**, calling out the config map. Then we need to mount the volume into the **nginx** container. Complete the first step by adding the following under the **spec** label, just after **containers** in **mysite.yaml**:
```
volumes:
- name: html-volume
configMap:
name: mysite-html
```
This tells Kubernetes that we want to define a **volume**, with the name **html-volume** and that volume should contain the contents of the **configMap** named **html-volume** (which we created in the previous step).
Next, in the **nginx** container specification, just under **ports**, add the following:
```
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html
```
This tells Kubernetes, for the **nginx** container, we want to mount a **volume** named **html-volume** at the path (in the container) **/usr/share/nginx/html**. Why **/usr/share/nginx/html**? That is where the **nginx** image serves HTML from. By mounting our volume at that path, we have replaced the default contents with our volume contents.
For reference, the **deployment** section of the configuration file should now look like this:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysite-nginx
labels:
app: mysite-nginx
spec:
replicas: 1
selector:
matchLabels:
app: mysite-nginx
template:
metadata:
labels:
app: mysite-nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html
volumes:
- name: html-volume
configMap:
name: mysite-html
```
## Deploy it!
Now we are ready to deploy! We can do that with:
`kubectl apply -f mysite.yaml`
You should see something similar to the following:
```
deployment.apps/mysite-nginx created
service/mysite-nginx-service created
ingress.networking.k8s.io/mysite-nginx-ingress created
```
This means that Kubernetes created resources for each of the three configurations we specified. Check on the status of the pods with:
`kubectl get pods`
If you see a status of **ContainerCreating**, give it some time and run **kubectl get pods** again. Typically, the first time, it will take a while because k3s has to download the **nginx** image to create the pod. After a while, you should get a status of **Running**.
## Try it!
Once the pod is running, it is time to try it. Open up a browser and type **kmaster** into the address bar.

Congratulations! You’ve deployed a website on your k3s cluster!
## Another one
So now we have a whole k3s cluster running a single website. But we can do more! What if we have another website we want to serve on the same cluster? Let’s see how to do that.
Again, we need something to deploy. It just so happens that my dog has a message she has wanted the world to know for some time. So, I crafted some HTML just for her (available from the samples zip file). Again, we will use the config map trick to host our HTML. This time we are going to poke a whole directory (the **html** directory) into a config map, but the invocation is the same.
`kubectl create configmap mydog-html --from-file html`
Now we need to create a configuration file for this site. It is almost exactly the same as the one for **mysite.yaml**, so start by copying **mysite.yaml** to **mydog.yaml**. Now edit **mydog.yaml** to be:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydog-nginx
labels:
app: mydog-nginx
spec:
replicas: 1
selector:
matchLabels:
app: mydog-nginx
template:
metadata:
labels:
app: mydog-nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html
volumes:
- name: html-volume
configMap:
name: mydog-html
---
apiVersion: v1
kind: Service
metadata:
name: mydog-nginx-service
spec:
selector:
app: mydog-nginx
ports:
- protocol: TCP
port: 80
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: mydog-nginx-ingress
annotations:
kubernetes.io/ingress.class: "traefik"
traefik.frontend.rule.type: PathPrefixStrip
spec:
rules:
- http:
paths:
- path: /mydog
backend:
serviceName: mydog-nginx-service
servicePort: 80
```
We can do most of the edits by simply doing a search and replace of **mysite** to **mydog**. The two other edits are in the ingress section. We changed **path** to** /mydog **and we added an annotation, **traefik.frontend.rule.type: PathPrefixStrip**.
The specification of the path **/mydog** instructs Traefik to route any incoming request that requests a path starting with **/mydog** to the **mydog-nginx-service**. Any other path will continue to be routed to **mysite-nginx-service.**
The new annotation, **PathPrefixStrip**, tells Traefik to strip off the prefix **/mydog** before sending the request to **mydog-nginx-service**. We did this because the **mydog-nginx** application doesn’t expect a prefix. This means we could change where the service was mounted simply by changing the prefix in the ingress record.
Now we can deploy like we did before:
`kubectl apply -f mydog.yaml`
And now, my dog’s message should be available at [http://kmaster/mydog/](http://kmaster/mydog/).

Phew! The message is out! Maybe we can all get some sleep tonight.
So now, we have a k3s cluster hosting two websites with Traefik making decisions, based on path names, as to which service to pass the request to! We are not limited to path-based routing, however. We could use hostname based routing as well, which we will explore in a future article.
Also, the websites we just hosted are standard unencrypted HTML sites. Everything these days is encrypted with SSL/TLS. In our next article, we will add support to our k3s cluster to host SSL/TLS HTTPS sites as well!
## Cleaning up
Before you go, since this article mostly dealt with sample sites, I would like to show you how to delete things in case you don’t want the samples hanging around on your cluster.
For most configurations, you can undo the configuration simply by running the **delete** command with the same configuration file you deployed with. So let’s clean up both **mysite** and **mydog**.
```
kubectl delete -f mysite.yaml
kubectl delete -f mydog.yaml
```
Since we manually created the config maps, we’ll need to delete those manually as well.
```
kubectl delete configmap mysite-html
kubectl delete configmap mydog-html
```
Now if we do a **kubectl get pods**, we should see that our nginx pods are no longer around.
```
$ kubectl get pods
No resources found in default namespace.
```
Everything is cleaned up.
Tell me what thoughts you have on this project in the comments below.
## 3 Comments |
12,082 | 使用 Fluxbox 桌面作为你的窗口管理器 | https://opensource.com/article/19/12/fluxbox-linux-desktop | 2020-04-07T11:33:56 | [
"Fluxbox",
"桌面"
] | https://linux.cn/article-12082-1.html |
>
> 本文是 24 天 Linux 桌面特别系列的一部分。Fluxbox 对系统资源的占用非常轻量,但它拥有重要的 Linux 桌面功能,让你的用户体验轻松、高效、快捷。
>
>
>

桌面的概念可谓是仁者见仁智者见智。很多人把桌面看作一个家的基地,或者一个舒适的客厅,甚至是一个字面意义上的桌面,在其中放置着他们经常使用的记事本、最好的笔和铅笔,还有他们最喜欢的咖啡杯。KDE、 GNOME、Pantheon 等等在 Linux 上提供了这种舒适的生活方式。
但是对一些用户来说,桌面只是一个空荡荡的显示器空间,这是还没有任何可以自由浮动的应用程序窗口直接投射到他们的视网膜上的副作用。对于这些用户来说,桌面是一个空的空间,他们可以在上面运行应用程序 —— 无论是大型办公软件和图形套件,还是一个简单的终端窗口,或是来管理服务的托盘小程序。这种操作 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 计算机的模式由来已久,该家族树的一支是 \*box 窗口管理器:Blackbox、Fluxbox 和 Openbox。
[Fluxbox](http://fluxbox.org) 是一个 X11 系统的窗口管理器,它基于一个较老的名为 Blackbox 的项目。当我发现 Linux 时,Blackbox 的开发已进入衰退期,因此我就喜欢上了 Fluxbox ,此后我至少在一个以上的常用的系统上使用过它。它是用 C++ 编写的,并在 MIT 开源许可证下授权。
### 安装 Fluxbox
你很可能会在你的 Linux 发行版的软件库中找到 Fluxbox,但是你也可以在 [Fluxbox.org](http://fluxbox.org/download/) 上找到它。如果你正在运行另外一个桌面,在同一个系统上安装 Fluxbox 是安全的,因为 Fluxbox 不会预设任何配置或附带的应用程序。
在安装 Fluxbox 后,注销你当前的桌面会话,以便你可以登录一个新的桌面会话。默认情况下,你的桌面会话管理器 (KDM、GDM、LightDM 或 XDM,取决于你的安装设置) 将继续让登录到之前的桌面,所以你在登录前必需要覆盖上一个桌面。
使用 GDM 覆盖一个桌面:

或者使用 KDM:

### 配置 Fluxbox 桌面
当你第一次登录到桌面时,屏幕基本是空的,因为 Fluxbox 提供的所有东西是面板(用于任务栏、系统托盘等等)和用于应用程序窗口的窗口装饰品。

如果你的发行版提供一个简单的 Fluxbox 桌面,你可以使用 `feh` 命令(你可能需要从你的发行版的软件库中安装它)来为你的桌面设置背景。这个命令有几个用于设置背景的选项,包括使用你选择的墙纸来填充屏幕的 `--bg-fill` 选项,来按比例缩放的 `--bg-scale` 等等选项。
```
$ feh --bg-fill ~/photo/oamaru/leaf-spiral.jpg
```

默认情况下,Fluxbox 自动生成一个菜单,在桌面上任意位置右键单击可用该菜单,这给予你访问应用程序的能力。根据你的发行版的不同,这个菜单可能非常小,也可能列出 `/usr/share/applications` 目录中的所有启动程序。
Fluxbox 配置是在文本文件中设置的,这些文本文件包含在 `$HOME/.fluxbox` 目录中。你可以:
* 在 `keys` 中设置键盘快捷键
* 在 `startup` 中启动的服务和应用程序
* 在 `init` 设置桌面首选项(例如工作区数量、面板位置等等)
* 在 `menu` 中设置菜单项
该文本配置文件非常易于推断,但是你也可以(并且是应该)阅读 Fluxbox 的[文档](http://fluxbox.org/features/)。
例如,这是我的典型菜单(或者说至少有它的基本结构):
```
# 为使用你自己的菜单,复制这些文本到 ~/.fluxbox/menu,然后编辑
# ~/.fluxbox/init ,并更改 session.menuFile 文件路径到 ~/.fluxbox/menu
[begin] (fluxkbox)
[submenu] (apps) {}
[submenu] (txt) {}
[exec] (Emacs 23 (text\)) { x-terminal-emulator -T "Emacs (text)" -e /usr/bin/emacs -nw} <>
[exec] (Emacs (X11\)) {/usr/bin/emacs} <>
[exec] (LibreOffice) {/usr/bin/libreoffice}
[end]
[submenu] (code) {}
[exec] (qtCreator) {/usr/bin/qtcreator}
[exec] (eclipse) {/usr/bin/eclipse}
[end]
[submenu] (graphics) {}
[exec] (ksnapshot) {/usr/bin/ksnapshot}
[exec] (gimp) {/usr/bin/gimp}
[exec] (blender) {/usr/bin/blender}
[end]
[submenu] (files) {}
[exec] (dolphin) {/usr/bin/dolphin}
[exec] (konqueror) { /usr/bin/kfmclient openURL $HOME }
[end]
[submenu] (network) {}
[exec] (firefox) {/usr/bin/firefox}
[exec] (konqueror) {/usr/bin/konqueror}
[end]
[end]
## 更改窗口管理器或工作环境
[submenu] (environments) {}
[restart] (flux) {/usr/bin/startfluxbox}
[restart] (ratpoison) {/usr/bin/ratpoison}
[exec] (openIndiana) {/home/kenlon/qemu/startSolaris.sh}
[end]
[config] (config)
[submenu] (styles) {}
[stylesdir] (/usr/share/fluxbox/styles)
[stylesdir] (~/.fluxbox/styles)
[end]
[workspaces] (workspaces)
[reconfig] (reconfigure)
[restart] (restart)
[exit] (exeunt)
[end]
```
该菜单也提供一些首选项设置,例如,选择一个主题,从 Fluxbox 会话中重启或注销的能力。
我使用键盘快捷键来启动大多数的应用程序,这些快捷键写入到 `keys` 配置文件中。这里有一些示例(`Mod4` 按键是 `Super` 键,我使用其来指定全局快捷键):
```
# 打开应用程序
Mod4 t :Exec konsole
Mod4 k :Exec konqueror
Mod4 z :Exec fbrun
Mod4 e :Exec emacs
Mod4 f :Exec firefox
Mod4 x :Exec urxvt
Mod4 d :Exec dolphin
Mod4 q :Exec xscreensaver-command -activate
Mod4 3 :Exec ksnapshot
```
在这些快捷方式和一个打开的终端之间,在我工作日的大部分时间内很少使用鼠标,因此从一个控制器切换到另一个控制器不会浪费时间。并且因为 Fluxbox 很好地避开了控制器之间切换的方法,因此在其中操作没有一丝干扰。
### 为什么你应该使用 Fluxbox
Fluxbox 对系统资源的占用非常轻量,但是它拥有重要的功能,可以使你的用户体验轻松、快速、高效。它很容易定制,并且允许你定义你自己的工作流。你不必使用 Fluxbox 的面板,因为还有其它优秀的面板。你甚至可以鼠标中键点击并拖动两个独立的应用程序窗口到彼此之中,以便它们成为一个窗口,每个窗口都有自己的选项卡。
可能性是无穷的,所以今天就在你的 Linux 上尝试一下 Fluxbox 的简单稳定吧!
---
via: <https://opensource.com/article/19/12/fluxbox-linux-desktop>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The concept of a desktop may differ from one computer user to another. Many people see the desktop as a home base, or a comfy living room, or even a literal desktop where they place frequently used notepads, their best pens and pencils, and their favorite coffee mug. KDE, GNOME, Pantheon (and so on) provide that kind of comfort on Linux.
But for some users, the desktop is just empty monitor space, a side effect of not yet having any free-floating application windows projected directly onto their retina. For these users, the desktop is a void over which they can run applications—whether big office and graphic suites, or a simple terminal window, or docked applets—to manage services. This model of operating a [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) computer has a long history, and one branch of that family tree is the *box window managers: Blackbox, Fluxbox, and Openbox.
[Fluxbox](http://fluxbox.org) is a window manager for X11 systems that's based on an older project called Blackbox. Blackbox development was waning when I discovered Linux, so I fell into Fluxbox, and I've used it ever since on at least one of my active systems. It is written in C++ and is licensed under the MIT open source license.
## Installing Fluxbox
You are likely to find Fluxbox included in the software repository of your Linux distribution, but you can also find it on [Fluxbox.org](http://fluxbox.org/download/). If you're already running a different desktop, it's safe to install Fluxbox on the same system because Fluxbox doesn't predetermine any configuration or accompanying applications.
After installing Fluxbox, log out of your current desktop session so you can log into your new one. By default, your session manager (KDM, GDM, LightDM, or XDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
To override the desktop with GDM:
Or with SDDM:
## Configuring the Fluxbox desktop
When you first log in, the screen is mostly empty because all Fluxbox provides are panels (for a taskbar, system tray, and so on) and window decoration for application windows.
If your distribution delivers a plain Fluxbox desktop, you can set a background for your desktop using the **feh** command (you may need to install it from your distribution's repository). This command has a few options for setting the background, including **--bg-fill** to fill the screen with your wallpaper of choice, **--bg-scale** to scale it to fit, and so on.
`$ feh --bg-fill ~/photo/oamaru/leaf-spiral.jpg`
By default, Fluxbox auto-generates a menu, available with a right-click anywhere on the desktop, that gives you access to applications. Depending on your distribution, this menu may be very minimal, or it may list all the launchers in your **/usr/share/applications** directory.
Fluxbox configuration is set in text files, and those text files are contained in the **$HOME/.fluxbox** directory. You can:
- Set keyboard shortcuts in
**keys** - Set startup services and applications in
**startup** - Set desktop preferences (such as the number of workspaces, locations of panels, and so on) in
**init** - Set menu items in
**menu**
The text configuration files are easy to reverse-engineer, but you also can (and should) read the Fluxbox [documentation](http://fluxbox.org/features/).
For example, this is my typical menu (or at least the basic structure of it):
```
# to use your own menu, copy this to ~/.fluxbox/menu, then edit
# ~/.fluxbox/init and change the session.menuFile path to ~/.fluxbox/menu
[begin] (fluxkbox)
[submenu] (apps) {}
[submenu] (txt) {}
[exec] (Emacs 23 (text\)) { x-terminal-emulator -T "Emacs (text)" -e /usr/bin/emacs -nw} <>
[exec] (Emacs (X11\)) {/usr/bin/emacs} <>
[exec] (LibreOffice) {/usr/bin/libreoffice}
[end]
[submenu] (code) {}
[exec] (qtCreator) {/usr/bin/qtcreator}
[exec] (eclipse) {/usr/bin/eclipse}
[end]
[submenu] (graphics) {}
[exec] (ksnapshot) {/usr/bin/ksnapshot}
[exec] (gimp) {/usr/bin/gimp}
[exec] (blender) {/usr/bin/blender}
[end]
[submenu] (files) {}
[exec] (dolphin) {/usr/bin/dolphin}
[exec] (konqueror) { /usr/bin/kfmclient openURL $HOME }
[end]
[submenu] (network) {}
[exec] (firefox) {/usr/bin/firefox}
[exec] (konqueror) {/usr/bin/konqueror}
[end]
[end]
## change window manager or work env
[submenu] (environments) {}
[restart] (flux) {/usr/bin/startfluxbox}
[restart] (ratpoison) {/usr/bin/ratpoison}
[exec] (openIndiana) {/home/kenlon/qemu/startSolaris.sh}
[end]
[config] (config)
[submenu] (styles) {}
[stylesdir] (/usr/share/fluxbox/styles)
[stylesdir] (~/.fluxbox/styles)
[end]
[workspaces] (workspaces)
[reconfig] (reconfigure)
[restart] (restart)
[exit] (exeunt)
[end]
```
The menu also provides a few preference settings, such as the ability to pick a theme and restart or log out from your Fluxbox session.
I launch most applications using keyboard shortcuts, which are entered into the **keys** configuration file. Here are some examples (the **Mod4** key is the Super key, which I use to designate global shortcuts):
```
# open apps
Mod4 t :Exec konsole
Mod4 k :Exec konqueror
Mod4 z :Exec fbrun
Mod4 e :Exec emacs
Mod4 f :Exec firefox
Mod4 x :Exec urxvt
Mod4 d :Exec dolphin
Mod4 q :Exec xscreensaver-command -activate
Mod4 3 :Exec ksnapshot
```
Between these shortcuts and an open terminal, I have little use for a mouse during most of my workday, so there's no wasted time switching from one controller to another. And because Fluxbox stays well out of the way, there's little distraction.
## Why you should use Fluxbox
Fluxbox is very light on system resources, yet it has vital features to make your user experience easy, blazingly efficient, and unduly fast. It's simple to customize, and it allows you to define your own workflow. You don't have to use Fluxbox's panels, because there are other excellent panels out there. You can even middle-click and drag two separate application windows into one another so that they become one window, each in its own tab.
The possibilities are endless, so try the steady simplicity that is Fluxbox on your Linux box today!
## Comments are closed. |
12,085 | 如何将 Ubuntu 18.04 LTS/19.10 升级到 Ubuntu 20.04 beta | https://itsfoss.com/upgrade-ubuntu-beta/ | 2020-04-08T12:51:36 | [
"Ubuntu"
] | https://linux.cn/article-12085-1.html | 
[Ubuntu 20.04 LTS 版本](https://itsfoss.com/ubuntu-20-04-release-features/)还有不到一个月就发布了,Ubuntu 在这一个版本中对视觉效果作出了大变动,同时在性能方面也有所提高。
如果你还在使用 Ubuntu 18.04 LTS 版本,你会发现 Ubuntu 20.04 配合深色 Yaru 主题非常惊艳,看过 [Ubuntu 20.04 的展示视频](https://www.youtube.com/watch?v=9u5B0njRgOw)你就知道了。
感觉确实不错。如果你想在 4 月 23 日最终稳定版正式发布前率先使用 Ubuntu 20.04,也可以在官方网站上下载 beta 版本。尽管是测试版本,但它的稳定性并不差,同时你也可以在使用这个版本的过程中帮助 Ubuntu 团队进行测试。
你可以下载<ruby> 每日构建 <rt> daily build </rt></ruby>版并进行重新安装,如果你正在使用的是 Ubuntu 18.04 或 Ubuntu 19.10,也可以在现有系统的基础上直接升级到 Ubuntu 20.04 beta 版本。
从现有系统中升级是很方便的,因为你不会丢失系统设置和其他文件。与重新安装不同的是,你不需要从头开始重新安装所有的软件。当你切换到新版本时,你的主目录、应用程序(大部分)、文件都会保持原样。
>
> 如果你需要确认正在使用的 Ubuntu 版本,可以参考[这篇文章](/article-9872-1.html)。
>
>
>
在本文中,我将会介绍如何升级到 Ubuntu 20.04 beta 版本。
### 如何将 Ubuntu 18.04/19.10 升级到 Ubuntu 20.04 beta
在你阅读后面的内容之前,我首先说明一些关于升级到 Ubuntu beta 版本的常见问题。
* 版本升级的过程并不复杂,但在整个过程中需要有良好的网络连接,以便下载高达好几 GB 的数据。
* 版本升级的过程中,第三方存储库(比如你自行添加的 [PPA](https://itsfoss.com/ppa-guide/))会被禁用,有些 PPA 可能也和新版本不兼容,在版本升级完毕后,你可以手动启用这些 PPA。
* 强烈建议将重要数据备份到外部的 USB 硬盘上。你只需要将各个目录下的重要文件直接复制到外部 USB 硬盘上保存即可。
* 升级到新版本之后,就无法再回滚到之前的旧版本了,如果需要旧版本的系统,只能重新安装。
* 如果你选择升级到 Ubuntu 20.04 beta 版本,那么在 Ubuntu 20.04 最终稳定版发布之后,你也不需要重新安装。只需要保持定期更新 Ubuntu 系统,届时你就可以直接用上最终稳定版了。
* Ubuntu 16.04/17/18/19.04 都无法直接升级到 Ubuntu 20.04。
了解完上面的内容之后,下面开始从 Ubuntu 18.04/19.10 升级到 Ubuntu 20.04。
#### 步骤 1:检查设置是否正确
进入“<ruby> 软件和升级 <rt> Software & Updates </rt></ruby>”应用:

在“<ruby> 升级 <rt> Updates </rt></ruby>”选项卡中,设置“有任何新版本 Ubuntu 都提醒我”或“有 LTS 版本 Ubuntu 就提醒我”:

设置完成后,系统会刷新软件库缓存。
#### 步骤 2:安装系统更新
在上面的步骤完成之后,打开终端(在 Ubuntu 中可以使用 `Ctrl+Alt+T` [快捷键](https://itsfoss.com/ubuntu-shortcuts/)),然后使用以下命令[更新 Ubuntu 系统](https://itsfoss.com/update-ubuntu/):
```
sudo apt update && sudo apt full-upgrade
```
`apt full-upgrade` 或 `apt dist-upgrade` 的功能和 `apt upgrade` 大致相同,但对于系统版本的升级,`apt full-upgrade` 会在需要的情况下将当前已安装的软件移除掉。
更新安装完成后,系统可能会需要重新启动。在重新启动之后,就可以进入步骤 3 了。
#### 步骤 3:使用更新管理器查找开发版本
在步骤 2 中已经安装了所有必要的更新,现在通过下面的命令打开更新管理器,其中 `-d` 参数表示需要查找开发版本:
```
update-manager -d
```
整个过程可能需要好几分钟,随后会提示有新版本的 Ubuntu 可用:

在 Ubuntu 18.04 上的提示是这样的:

然后点击对话框中的“<ruby> 升级 <rt> upgrade </rt></ruby>”按钮。
#### 步骤 4:开始升级到 Ubuntu 20.04 beta
接下来只要等待下载更新就可以了,遇到对话框直接点击 “OK” 即可。

点击“<ruby> 升级 <rt> upgrade </rt></ruby>”按钮,然后按照提示进行操作。

在升级过程中,可能会有提示信息告知所有第三方源都已经禁用。有时候还会提示有哪些软件包需要升级或删除,以及是否需要保留一些已经过时了的软件包。一般情况下,我会选择直接删除。
整个升级过程通常会需要几个小时,但主要还是取决于实际的网速。升级完成后,系统会提示需要重新启动。

下面的视频展示了所有相关步骤。
由此可见,这个升级流程并不复杂。欢迎体验 Ubuntu 20.04 带来的新特性。
如果你有疑问或建议,欢迎在评论区留言。
---
via: <https://itsfoss.com/upgrade-ubuntu-beta/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

** This is a regularly updated guide to show the steps for upgrading your current Ubuntu system to the next version which is currently under development.** In other words, you learn how to upgrade to beta version of Ubuntu’s next release.
At present, Ubuntu 24.04 LTS is under development. There are plenty of [new features in Ubuntu 24.04 Noble Numbat release](https://news.itsfoss.com/ubuntu-24-04-features/) and it is natural to get excited about it.
The stable release will be coming in a couple of weeks, and the beta (testing) version should be here when you are reading this.
Can’t wait that long? If you are using Ubuntu 22.04 LTS or 23.10, you can upgrade to Ubuntu 24.04 beta release right now.
All you have to do is to update your Ubuntu system and then run the following command:
`update-manager -d`
It should provide you the option to upgrade to the beta version.
Don’t worry. I’ll show you the steps in details along with necessary explanation.
## How to upgrade to Ubuntu 24.04 beta from Ubuntu 23.10 or 22.04
Upgrading from your existing system is convenient because you don’t lose your system settings and other files. Unlike a fresh install, you don’t have to reinstall all the software from scratch here. Your Home directory, applications (most of them), files remain as it is when you switch to the new version.
That being said, you need to keep a few things in mind before performing an upgrade.
### Know this before you upgrade Ubuntu version
Before you see the steps, let me answer some of the common questions regarding upgrading to Ubuntu beta version:
- The upgrade from one version to another is an easy process but you need to have a good internet connection that could download a couple of GBs of data at a good speed.
- Upgrading to a newer version disables the third-party repositories (
[PPA](https://itsfoss.com/ppa-guide/)you added on your own). Some of these PPAs might not be available for the new version yet. You can manually enable the PPAs after upgrading. - Having a backup of your important data on an external disk is always recommended. Just copy all your important files from Documents, Pictures, Music, Downloads and other places and put it on an external USB or hard disk.
- If you want to be extra careful, keep a Ubuntu live USB with you (or have access to an additional computer to create one). If something doesn’t go according to plan, you can reinstall Ubuntu and copy the backed up data.
- Once you have upgraded to a newer version, you cannot go back to the older version you were using. Reinstalling the older version is the only option.
- If you upgrade to the Ubuntu 24.04 beta version, you don’t need to install it again when the final stable version is released. Just update your Ubuntu system regularly and you’ll already be using the same 24.04 when it is released.
- You cannot upgrade to Ubuntu 24.04 directly from Ubuntu 20.04, 23.04 or any version other than 23.10 and 22.04 LTS.
Alright! You know enough now. Let’s see the steps to upgrade to Ubuntu 24.04 beta from Ubuntu 23.10.
### Step 0. Check your current Ubuntu version
You can upgrade to Ubuntu 24.04 from 23.10 or 22.04 LTS only. Please [check the Ubuntu version you are running](https://itsfoss.com/how-to-know-ubuntu-unity-version/) to ensure that you meet this condition.
In a terminal, run this command:
`lsb_release -a`
Its output will show the Ubuntu version number.
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 23.10
Release: 23.10
Codename: mantic
```
### Step 1: Make sure the settings are right
Go to Software & Updates application:

In the Updates tab, check that Notify me of a new Ubuntu version is set to “For any new version”:
This may reload the Software repository cache.
### Step 2: Update your system for any pending software updates
Once you have the correct settings in place, open a terminal ([use Ctrl+Alt+T shortcut in Ubuntu](https://itsfoss.com/ubuntu-shortcuts/)) and use the following [command to update your Ubuntu system](https://itsfoss.com/update-ubuntu/):
`sudo apt update && sudo apt full-upgrade`
The apt full-upgrade or dist-upgrade function the same as ‘apt upgrade’ but it will remove currently installed packages if this is needed to upgrade the system as a whole (i.e. a version upgrade).
Your system may ask to restart after installing updates. That’s fine. Restart and resume upgrading to beta release from step 3.
### Step 3: Run update manager with development release upgrade option
Now that you have all the necessary updates installed, you can open the update manager but with -d option. The -d option tells it to look for development releases.
`update-manager -d`
It may take a couple of minutes before informing you that a new version of Ubuntu is available.
Hit the upgrade button when you see the above message.
### Step 4: Start upgrading to Ubuntu 24.04 beta
The rest of the upgrade procedure is basically waiting for update downloads and clicking okay wherever requested.
Hit the upgrade button and follow the on-screen instructions.
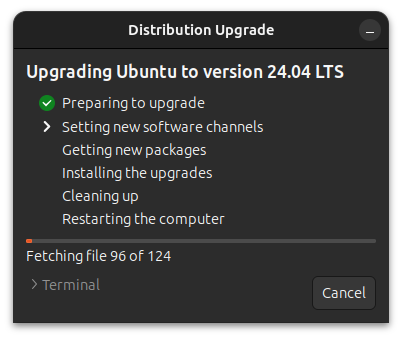
You might be notified that all the third party sources have been disabled. At some point, it will also inform you of the packages that will be upgraded, removed etc. It will also ask if you want to keep obsolete packages or not. I prefer to remove them.
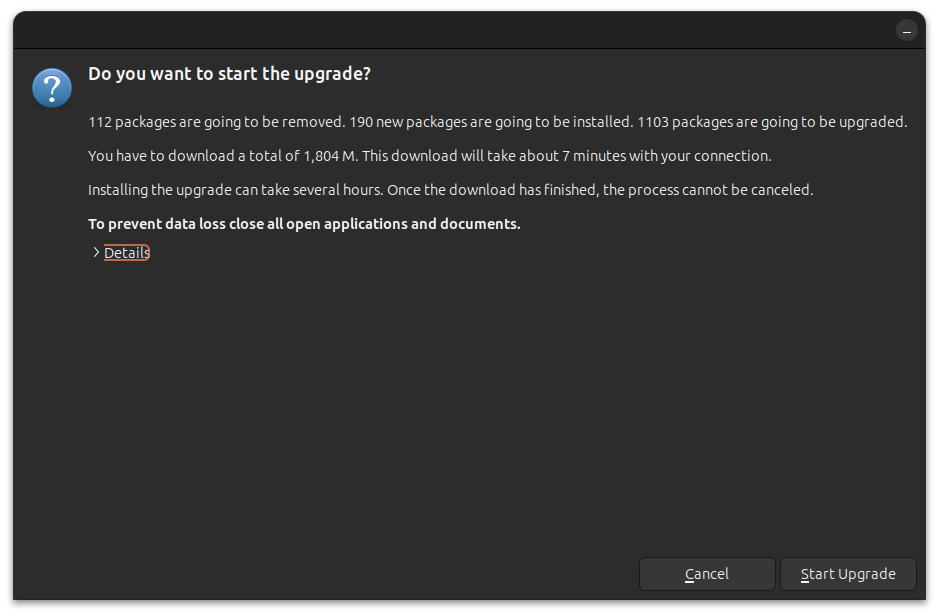
Depending on your internet speed, the upgrade may take a couple of hours. Once the upgrade process is complete, you’ll be asked to restart your system.
See, it wasn’t that difficult. Enjoy all the new features in Ubuntu 24.04.
*Questions or suggestions? Feel free to leave a comment below.* |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.