
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
11,771 | 我的树莓派项目回顾 | https://opensource.com/article/20/1/raspberry-pi-best | 2020-01-11T09:18:12 | [
"树莓派"
] | https://linux.cn/article-11771-1.html |
>
> 看看我在好玩、能学习、有用处的树莓派上做了些什么。
>
>
>

无论是从历史上,还是从理论上讲,当时钟走到一个十年份第一年的 1 月 1 日的午夜 0 点时,就开始了一个十年或一个世纪或一个千年纪元。例如,20 世纪始于 1901 年 1 月 1 日,而不是 1900 年 1 月 1 日。原因很简单:现代日历中没有 0 年,因此这些时间段始于 1 年(使用公历)。但这不是我们在口语上和文化上指代时间段的方式。例如,当我们提到 80 年代的音乐或电影时,我们所说的是 1980 年至 1989 年。
我可以说,最近过去的 21 世纪 10 年代是云计算、社交媒体、移动技术和物联网(IoT)的十年,这其中就包括[树莓派](https://www.raspberrypi.org/)。最近,《时代》杂志将树莓派称为[过去十年中 10 个最佳小玩意](https://time.com/5745302/best-gadgets-of-the-2010s-decade/?utm_source=reddit.com)之一。我非常同意这点。
树莓派最初的于 2012 年推出,我过了几年才使用上了它。不过从那以后,我在家中做了许多有趣的教育项目,还在 Opensource.com 中记录了一些。
### 圣诞灯三部曲
三年来,我写了三篇探讨如何使用树莓派和开源项目 LightShowPi 控制圣诞灯的文章。第一篇文章《[用树莓派创建你自己的音乐灯光秀](https://opensource.com/life/15/2/music-light-show-with-raspberry-pi)》,非常基础地介绍了电子开发介绍和灯光秀的结合。第二篇文章,《[使用树莓派 SSH 进入你的圣诞树](https://opensource.com/life/15/12/ssh-your-christmas-tree-raspberry-pi)》,稍微深入地介绍了通过远程管理和电子按钮控制灯光的方法。三部曲的最后一章《[用树莓派设置假期心情](https://opensource.com/article/18/12/lightshowpi-raspberry-pi)》,回顾了上一年 LightShowPi 项目中引入的更改。
### DIY 项目
多年来,我已经将树莓派变成了几种有用的设备。有一次,我将树莓派变成了 [Pi MusicBox 音乐播放设备](https://opensource.com/life/15/3/pi-musicbox-guide),它可以让你在 Web 界面中导入你喜欢的音乐流并在房间中播放。
将树莓派做成[移动视频录制设备](https://opensource.com/life/15/9/turning-raspberry-pi-portable-streaming-camera)是另一个 DIY 项目。它需要一些额外的硬件,例如触摸屏、树莓派摄像头和电池组,但是它工作的很好。这个设备的最大缺点之一是当时树莓派的可用内存很小。我认为如果我将它重新配置在具有 4GB 内存的树莓派 4 上,那么这款便携式摄像机的功能可能会更好。这可能是一个会在 2020 年重新打造的项目。
我做的另一个小项目[客厅的数字时钟](https://opensource.com/article/17/7/raspberry-pi-clock)使用了 Adafruit PiTFT 小屏幕。尽管这个项目很简单,但它可能是我使用时间最长的项目。那个时钟在我的电视机上呆了一年多,一天 24 小时不间断运行,直到屏幕烧坏为止。
### 圆周率日系列
最后但并非最不重要的一点是,在 2019 年的圆周率日(3 月 14 日)之前,我在 [14 内发布了 14 篇文章](https://opensource.com/article/19/3/happy-pi-day)。这是迄今为止我完成过的最具挑战性的写作项目,但是它使我能够涵盖许多不同的主题,并希望使读者对树莓派的丰富功能有更多的了解。
### 走向未来
我不认识树莓派基金会中的任何人,因此我不了解它的任何路线图和未来计划。我可以(但我不会)推测品牌及其设备的未来,它们让世界各地这么多不同社会地位的人扩展他们对计算机科学、电子和开源开发的知识。我希望基金会的管理层能够忠于其愿景和使命,并继续为世界各地的人们提供价格合理的技术。
21 世纪 10 年代过去了,那是多么甜蜜的十年。对我来说,它闻起来就像树莓派馅饼。
---
via: <https://opensource.com/article/20/1/raspberry-pi-best>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Historically and theoretically speaking, a decade, a century, or a millennium starts when the clock turns midnight on January 1 of the year one of its decimal order. For example, the 20th century started on January 1, 1901, not on January 1, 1900. The reason for this is simple: there is no year 0 in our modern calendar, so these periods of time start on year 1 (using the Gregorian calendar). But that's not how we refer to time periods colloquially and culturally; for example, when we mention '80s music or movies, we're talking about the period from 1980 to 1989.
The recently passed 2010s, I could argue, was the decade of the cloud, social media, mobile technology, and the Internet of Things (IoT), which includes the [Raspberry Pi](https://www.raspberrypi.org/). Recently, *Time* magazine called the Raspberry Pi one of the [10 best gadgets of the past decade](https://time.com/5745302/best-gadgets-of-the-2010s-decade/?utm_source=reddit.com). And I very much agree.
The original Raspberry Pi launched in 2012, and it took me a couple of years to jump on the bandwagon and ride on the Pi-train. But since then, I have built many fun educational projects at home and even documented a few of them for Opensource.com.
## The Christmas light trilogy
I wrote three articles over three years that explored controlling Christmas lights with the Raspberry Pi and the open source project LightShowPi. The first article, [ Create your own musical light show with Raspberry Pi](https://opensource.com/life/15/2/music-light-show-with-raspberry-pi), was a mix between a very basic introduction to electronics development and building a Christmas light show. The second article,
[, went a little deeper into controlling the lights with things such as remote management and electronic buttons. The last chapter of the trilogy,](https://opensource.com/life/15/12/ssh-your-christmas-tree-raspberry-pi)
*SSH into your Christmas tree with Raspberry Pi*[, reviewed changes introduced in the LightShowPi project in the prior year.](https://opensource.com/article/18/12/lightshowpi-raspberry-pi)
*Set the holiday mood with your Raspberry Pi*## DIY projects
Over the years, I've turned my Raspberry Pi into several useful devices. One time, I turned the Pi into a [music-playing device with the Pi MusicBox](https://opensource.com/life/15/3/pi-musicbox-guide), which allows you to plug your favorite music streaming services into a common web interface and play your favorite tunes around the house.
Making the Raspberry Pi into a [mobile video recording device](https://opensource.com/life/15/9/turning-raspberry-pi-portable-streaming-camera) was another DIY project I put together. It required a few extra pieces of hardware, like a touchscreen, a Pi Camera, and a battery pack, but it worked. One of the biggest drawbacks of this setup was the small amount of memory available on the Pi at the time. I think the capabilities of this little portable camera could be a lot better if I re-did it on a Raspberry Pi 4 with 4GB of RAM. This may be a project to revisit in 2020.
Another small project I built, a [digital clock for my living room](https://opensource.com/article/17/7/raspberry-pi-clock), used the small Adafruit PiTFT screen. As simple as this project was, it probably was the one that I used the longest. That clock stood by my TV set for over a year, running 24 hours a day… until the day the screen burned out.
## The Pi Day series
Last but not least, in 2019, I contributed [14 articles in 14 days](https://opensource.com/article/19/3/happy-pi-day) leading up to Pi Day (March 14). This was by far the most challenging writing project I've ever done, but it allowed me to cover many different topics and hopefully expose readers to even more ideas about the versatility of the Raspberry Pi.
## To infinity and beyond
I don't know anyone in the Raspberry Pi Foundation, so I don't have any special access to its roadmaps and future plans. I could (but I won't) speculate on what the future holds for the brand and its devices that have allowed so many people of different social statuses around the world to expand their knowledge about computer science, electronics, and open source development. All I hope is for the foundation's management to stay true to its vision and mission and continue making affordable technology for people everywhere.
The 2010s are over, and what a sweet decade it was. To me, it smelled like pie, raspberry pie.
## 2 Comments |
11,773 | 如何借助 Django 来编写一个 Python Web API | https://opensource.com/article/19/11/python-web-api-django | 2020-01-11T14:25:00 | [
"Python",
"Django"
] | https://linux.cn/article-11773-1.html |
>
> Django 是 Python API 开发中最流行的框架之一,在这个教程中,我们来学习如何使用它。
>
>
>

[Django](https://www.djangoproject.com/) 所有 Web 框架中最全面的,也是最受欢迎的一个。自 2005 年以来,其流行度大幅上升。
Django 是由 Django 软件基金会维护,并且获得了社区的大力支持,在全球拥有超过 11,600 名成员。在 Stack Overflow 上,约有 191,000 个带 Django 标签的问题。Spotify、YouTube 和 Instagram 等都使用 Django 来构建应用程序和数据管理。
本文演示了一个简单的 API,通过它可以使用 HTTP 协议的 GET 方法来从服务器获取数据。
### 构建一个项目
首先,为你的 Django 应用程序创建一个目录结构,你可以在系统的任何位置创建:
```
$ mkdir myproject
$ cd myproject
```
然后,在项目目录中创建一个虚拟环境来隔离本地包依赖关系:
```
$ python3 -m venv env
$ source env/bin/activate
```
在 Windows 上,使用命令 `env\Scripts\activate` 来激活虚拟环境。
### 安装 Django 和 Django REST framework
然后,安装 Django 和 Django REST 模块:
```
$ pip3 install django
$ pip3 install djangorestframework
```
### 实例化一个新的 Django 项目
现在你的应用程序已经有了一个工作环境,你必须实例化一个新的 Django 项目。与 [Flask](https://opensource.com/article/19/11/python-web-api-flask) 这样微框架不同的是,Django 有专门的命令来创建(注意第一条命令后的 `.` 字符)。
```
$ django-admin startproject tutorial .
$ cd tutorial
$ django-admin startapp quickstart
```
Django 使用数据库来管理后端,所以你应该在开始开发之前同步数据库,数据库可以通过 `manage.py` 脚本管理,它是在你运行 `django-admin` 命令时创建的。因为你现在在 `tutorial` 目录,所以使用 `../` 符号来运行脚本,它位于上一层目录:
```
$ python3 ../manage.py makemigrations
No changes detected
$ python3 ../manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying sessions.0001_initial... OK
```
### 在 Django 中创建用户
创建一个名为 `admin`,示例密码为 `password123` 的初始用户:
```
$ python3 ../manage.py createsuperuser \
--email [email protected] \
--username admin
```
在提示时创建密码。
### 在 Django 中实现序列化和视图
为了使 Django 能够将信息传递给 HTTP GET 请求,必须将信息对象转化为有效的响应数据。Django 为此实现了“序列化类” `serializers`。
在你的项目中,创建一个名为 `quickstart/serializers.py` 的新模块,使用它来定义一些序列化器,模块将用于数据展示:
```
from django.contrib.auth.models import User, Group
from rest_framework import serializers
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ['url', 'username', 'email', 'groups']
class GroupSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Group
fields = ['url', 'name']
```
Django 中的[视图](https://docs.djangoproject.com/en/2.2/topics/http/views/)是一个接受 Web 请求并返回 Web 响应的函数。响应可以是 HTML、HTTP 重定向、HTTP 错误、JSON 或 XML 文档、图像或 TAR 文件,或者可以是从 Internet 获得的任何其他内容。要创建视图,打开 `quickstart/views.py` 并输入以下代码。该文件已经存在,并且其中包含一些示例文本,保留这些文本并将以下代码添加到文件中:
```
from django.contrib.auth.models import User, Group
from rest_framework import viewsets
from tutorial.quickstart.serializers import UserSerializer, GroupSerializer
class UserViewSet(viewsets.ModelViewSet):
"""
API 允许查看或编辑用户
"""
queryset = User.objects.all().order_by('-date_joined')
serializer_class = UserSerializer
class GroupViewSet(viewsets.ModelViewSet):
"""
API 允许查看或编辑组
"""
queryset = Group.objects.all()
serializer_class = GroupSerializer
```
### 使用 Django 生成 URL
现在,你可以生成 URL 以便人们可以访问你刚起步的 API。在文本编辑器中打开 `urls.py` 并将默认示例代码替换为以下代码:
```
from django.urls import include, path
from rest_framework import routers
from tutorial.quickstart import views
router = routers.DefaultRouter()
router.register(r'users', views.UserViewSet)
router.register(r'groups', views.GroupViewSet)
# 使用自动路由 URL
# 还有登录 URL
urlpatterns = [
path('', include(router.urls)),
path('api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]
```
### 调整你的 Django 项目设置
这个示例项目的设置模块存储在 `tutorial/settings.py` 中,因此在文本编辑器中将其打开,然后在 `INSTALLED_APPS` 列表的末尾添加 `rest_framework`:
```
INSTALLED_APPS = [
...
'rest_framework',
]
```
### 测试 Django API
现在,你可以测试构建的 API。首先,从命令行启动内置服务器:
```
$ python3 manage.py runserver
```
你可以通过使用 `curl` 导航至 URL `http://localhost:8000/users` 来访问 API:
```
$ curl --get http://localhost:8000/users/?format=json
[{"url":"http://localhost:8000/users/1/?format=json","username":"admin","email":"[email protected]","groups":[]}]
```
使用 Firefox 或你选择的[开源浏览器](https://opensource.com/article/19/7/open-source-browsers):

有关使用 Django 和 Python 的 RESTful API 的更多深入知识,参考出色的 [Django 文档](https://docs.djangoproject.com/en/2.2)。
### 为什么要使用 Djago?
Django 的主要优点:
1. Django 社区的规模正在不断扩大,因此即使你做一个复杂项目,也会有大量的指导资源。
2. 默认包含模板、路由、表单、身份验证和管理工具等功能,你不必寻找外部工具,也不必担心第三方工具会引入兼容性问题。
3. 用户、循环和条件的简单结构使你可以专注于编写代码。
4. 这是一个成熟且经过优化的框架,它非常快速且可靠。
Django 的主要缺点:
1. Django 很复杂!从开发人员视角的角度来看,它可能比简单的框架更难学。
2. Django 有一个很大的生态系统。一旦你熟悉它,这会很棒,但是当你深入学习时,它可能会令人感到无所适从。
对你的应用程序或 API 来说,Django 是绝佳选择。下载并熟悉它,开始开发一个迷人的项目!
---
via: <https://opensource.com/article/19/11/python-web-api-django>
作者:[Rachel Waston](https://opensource.com/users/rachelwaston) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Django](https://www.djangoproject.com/) is the comprehensive web framework by which all other frameworks are measured. One of the most popular names in Python API development, Django has surged in popularity since its start in 2005.
Django is maintained by the Django Software Foundation and has experienced great community support, with over 11,600 members worldwide. On Stack Overflow, Django has around 191,000 tagged questions. Websites like Spotify, YouTube, and Instagram rely on Django for application and data management.
This article demonstrates a simple API to fetch data from a server using the GET method of the HTTP protocol.
## Set up a project
First, create a structure for your Django application; you can do this at any location on your system:
```
$ mkdir myproject
$ cd myproject
```
Then, create a virtual environment to isolate package dependencies locally within the project directory:
```
$ python3 -m venv env
$ source env/bin/activate
```
On Windows, use the command **env\Scripts\activate** to activate your Python virtual environment.
## Install Django and the Django REST framework
Next, install the Python modules for Django and Django REST:
```
$ pip3 install django
$ pip3 install djangorestframework
```
## Instantiate a new Django project
Now that you have a work environment for your app, you must instantiate a new Django project. Unlike a minimal framework like [Flask](https://opensource.com/article/19/11/python-web-api-flask), Django includes dedicated commands for this process (note the trailing **.** character in the first command):
```
$ django-admin startproject tutorial .
$ cd tutorial
$ django-admin startapp quickstart
```
Django uses a database as its backend, so you should sync your database before beginning development. The database can be managed with the **manage.py** script that was created when you ran the **django-admin** command. Because you're currently in the **tutorial** directory, use the **../** notation to run the script, located one directory up:
```
$ python3 ../manage.py makemigrations
No changes detected
$ python4 ../manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying sessions.0001_initial... OK
```
## Create users in Django
Create an initial user named **admin** with the example password of **password123**:
```
$ python3 ../manage.py createsuperuser \
--email [email protected] \
--username admin
```
Create a password when you're prompted.
## Implement serializers and views in Django
For Django to be able to pass information over to an HTTP GET request, the information object must be translated into valid response data. Django implements **serializers** for this.
In your project, define some serializers by creating a new module named **quickstart/serializers.py**, which you'll use for data representations:
```
from django.contrib.auth.models import User, Group
from rest_framework import serializers
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ['url', 'username', 'email', 'groups']
class GroupSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Group
fields = ['url', 'name']
```
A [view](https://docs.djangoproject.com/en/2.2/topics/http/views/) in Django is a function that takes a web request and returns a web response. The response can be HTML, or an HTTP redirect, or an HTTP error, a JSON or XML document, an image or TAR file, or anything else you can get over the internet. To create a view, open **quickstart/views.py** and enter the following code. This file already exists and has some boilerplate text in it, so keep that and append this text to the file:
```
from django.contrib.auth.models import User, Group
from rest_framework import viewsets
from tutorial.quickstart.serializers import UserSerializer, GroupSerializer
class UserViewSet(viewsets.ModelViewSet):
"""
API endpoint allows users to be viewed or edited.
"""
queryset = User.objects.all().order_by('-date_joined')
serializer_class = UserSerializer
class GroupViewSet(viewsets.ModelViewSet):
"""
API endpoint allows groups to be viewed or edited.
"""
queryset = Group.objects.all()
serializer_class = GroupSerializer
```
## Generate URLs with Django
Now you can generate URLs so people can access your fledgling API. Open **urls.py** in a text editor and replace the default sample code with this code:
```
from django.urls import include, path
from rest_framework import routers
from tutorial.quickstart import views
router = routers.DefaultRouter()
router.register(r'users', views.UserViewSet)
router.register(r'groups', views.GroupViewSet)
# Use automatic URL routing
# Can also include login URLs for the browsable API
urlpatterns = [
path('', include(router.urls)),
path('api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]
```
## Adjust your Django project settings
The settings module for this example project is stored in **tutorial/settings.py**, so open that in a text editor and add **rest_framework** to the end of the **INSTALLED_APPS** list:
```
INSTALLED_APPS = [
...
'rest_framework',
]
```
## Test your Django API
You're now ready to test the API you've built. First, start up the built-in server from the command line:
`$ python3 manage.py runserver`
You can access your API by navigating to the URL ** http://localhost:8000/users** using
**curl**:
```
$ curl --get http://localhost:8000/users/?format=json
[{"url":"http://localhost:8000/users/1/?format=json","username":"admin","email":"[email protected]","groups":[]}]
```
Or use Firefox or the [open source web browser](https://opensource.com/article/19/7/open-source-browsers) of your choice:
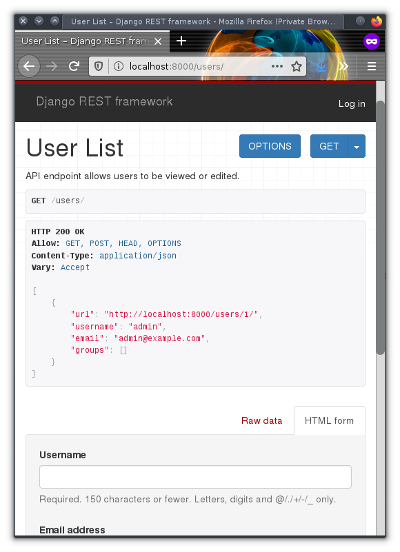
For more in-depth knowledge about RESTful APIs using Django and Python, see the excellent [Django documentation](https://docs.djangoproject.com/en/2.2).
## Why should I use Django?
The major benefits of Django:
- The size of the Django community is ever-growing, so you have lots of resources for guidance, even on a complicated project.
- Features like templating, routing, forms, authentication, and management tools are included by default. You don't have to hunt for external tools or worry about third-party tools introducing compatibility issues.
- Simple constructs for users, loops, and conditions allow you to focus on writing code.
- It's a mature and optimized framework that is extremely fast and reliable.
The major drawbacks of Django are:
- Django is complex! From a developer's point of view, Django can be trickier to learn than a simpler framework.
- There's a big ecosystem around Django. This is great once you're comfortable with Django, but it can be overwhelming when you're still learning.
Django is a great option for your application or API. Download it, get familiar with it, and start developing an amazing project!
## 1 Comment |
11,774 | Sweet Home 3D 开放源码室内设计 | https://opensource.com/article/19/10/interior-design-sweet-home-3d | 2020-01-12T09:28:12 | [
"室内设计"
] | /article-11774-1.html |
>
> 在你去真实世界购物前,在虚拟世界中尝试家具布局、配色方案等等。
>
>
>

这里有关于如何装饰房间的三大流派:
1. 购买一堆家具,并把它们塞进房间。
2. 仔细测量每件家具,计算房间的理论容量,然后把它们全部塞进房间,忽略你在床上放置一个书架的事实。
3. 使用一台计算机进行预先可视化。
之前,我还实践了鲜为人知的第四个方式:不要家具。然而,自从我成为一个远程工作者,我发现家庭办公需要一些便利的设施,像一张桌子和一张椅子,一个用于存放参考书和技术手册的书架等等。因此,我一直在制定一个使用实际的家具来迁移我的生活和工作空间的计划,在该*计划*上强调由实木制作,而不是牛奶箱子(或胶水和锯末板之类的东西)。我最不想做的一件事:从旧货市场淘到得宝贝带回家时,发现其进不了门,或者比另一件家具大很多。
是时候做专业人士该做的事了,是时候做视觉预览了。
### 开放源码室内设计
[Sweet Home 3D](http://www.sweethome3d.com/) 是一个开源的(GPLv2)室内设计应用程序,可以帮助你绘制你的住宅平面图,然后定义、重新调整大小以及安排家具。你可以使用精确的尺寸来完成这些,精确到一厘米以下,而不使用任何数学运算,仅使用简单的拖拽操作就行。当你完成后,你可以以 3D 方式查看结果。在 Sweet Home 3D 中规划你家的室内设计,就和在 Word 程序中创建基本的表格一样简单。
### 安装
Sweet Home 3D 是一个 [Java](https://opensource.com/resources/java) 应用程序,因此它是平台通用的。它运行在任何可以运行 Java 的操作系统上,包括 Linux、Windows、MacOS 和 BSD 。不用理会你的操作系统,你可以从网站[下载](http://www.sweethome3d.com/download.jsp)该应用程序。
* 在 Linux 上,[untar](https://opensource.com/article/17/7/how-unzip-targz-file) 存档文件。在 `SweetHome3D` 文件上右键单击,并选择**属性**。在**权限**选项卡中,授予文件可执行权限。
* 在 MacOS 和 Windows 上,展开存档文件并启动应用程序。当系统提示时,你必需授予它权限来在你的系统上运行。

在 Linux 上,你也可以像一个 Snap 软件包一样安装 Sweet Home 3D ,前提是你已经安装并启用 **snapd**。
### 成功的测量
首先:打开你的卷尺。为充分利用 Sweet Home 3D,你必须知道你所计划的生活空间的实际尺寸。你可能需要测量精度到毫米或 1/16 英寸;你可以自己把握对偏差幅度的容忍度。但是你必需获得基本的尺寸,包括测量墙壁和门窗。
用你最好的判断力来判断常识。例如,当测量门时,包括门框;虽然从技术上讲它不是*门*本身的一部分,但它可能是你不想用家具遮挡的一部分墙壁空间。

### 创建一间房间
当你第一次启动 Sweet Home 3D 时,它会以其默认查看模式来打开一个空白的画布,蓝图视图在顶部面板中,3D 渲染在底部面板中。在我的 [Slackware](http://www.slackware.com/) 桌面计算机上,它可以很好地工作,不过我的桌面计算机也是我的视频编辑和游戏计算机,所以它有一个极好的 3D 渲染显卡。在我的笔记本计算机上,这种视图模式是非常慢的。为了最好的性能(尤其是在一台计没有 3D 渲染的专用计算机上),转到窗口顶部的 **3D 视图** 菜单,并选择 **虚拟访问** 。这个视图模式基于虚拟访客的位置从地面视图渲染你的工作。这意味着你可以控制渲染的内容和时机。
不管你计算机是否强力,切换到这个视图的有意义的,因为地表以上的 3D 渲染不比蓝图平面图向你提供更多有用的详细信息。在你更改视图模式后,你可以开始设计。
第一步是定义你家的墙壁。使用**创建墙壁**工具完成,可以在顶部工具栏的**手形**图标右侧找到。绘制墙壁很简单:单击你想要墙壁开始的位置,单击以锚定位置,不断单击锚定,直到你的房间完成。

在你闭合墙壁后,按 `Esc` 来退出工具。
#### 定义一间房间
Sweet Home 3D 在你如何创建墙壁的问题上是灵活的。你可以先绘制你房子的外部边界,然后再细分内部,或者你可以绘制每个房间作为结成一体的“容器”,最终形成你房子所占的空间量。这种灵活性是能做到的,因为在现实生活中和在 Sweet Home 3D 中,墙壁并不总是用来定义一间房间。为定义一间房间,使用在顶部工具栏的**创建墙壁**按钮右侧的**创建房间**按钮。
如果房间的地板空间是通过四面墙所定义,你需要做的全部的定义是像一间房间一样在四面墙壁内双击来圈占地方。Sweet Home 3D 将定义该空间为一间房间,并根据你的喜好,以英尺或米为单位向你提供房间的面积。
对于不规则的房间,你必需使用每次单击来手动定义房间的每个墙角。根据房间形状的复杂性,你可能不得不进行试验来发现你是否需要从你的原点来顺时针或逆时针工作,以避免奇怪的莫比斯条形地板。不过,一般来说,定义一间房间的地板空间是简单的。

在你给定房间一层地板后,你可以更改到**箭头**工具,并在房间上双击来给予它一个名称。你也可以设置地板、墙壁、天花板和踢脚线的颜色及纹理。

默认情况下,这些都不会在蓝图视图中渲染。为启用在你蓝图面板中的房间渲染,转到**文件**菜单并选择**首选项**。在**首选项**面板中,设置**平面图中房间渲染**为**地板颜色或纹理**。
### 门和窗
在你完成基本的地板平面图后,你可以长期地切换到**箭头**工具。
你可以在 Sweet Home 3D 的左栏中的**门和窗**类别下找到门和窗。你有很多选择,所以选择最接近你家的东西。

为放置一扇门或窗到你的平面图中,在你的蓝图平面图中的合适的墙壁上拖拽门或窗。要调整它的位置和大小,请双击门或窗。
### 添加家具
随着基本平面图完成,这部分工作感觉像是结束了!从这点继续,你可以摆弄家具布置以及其它装饰。
你可以在左栏中找到家具,按预期的方式来组织每个房间。你可以拖拽任何项目到你的蓝图平面图中,当你的鼠标悬停在项目的区域上时,使用可视化工具控制方向和大小。在任何项目上双击双击来调整它的颜色和成品表面。
### 查看和导出
为了看看你未来的家将会看起来是什么样子,在你的蓝图视图中拖拽“人”图标到一个房间中。

你可以在现实和空间感受之间找到自己的平衡,你的想象力是你唯一的限制。你可以从 Sweet Home 3D [下载页面](http://www.sweethome3d.com/download.jsp)获取附加的有用的资源来添加到你的家中。你甚至可以使用**库编辑器**应用程序创建你自己的家具和纹理,它可以从该项目的网站下载。
Sweet Home 3D 可以导出你的蓝图平面图为 SVG 格式,以便在 [Inkscape](http://inkscape.org) 中使用,并且它可以导出你的 3D 模型为 OBJ 格式,以便在 [Blender](http://blender.org) 中使用。为导出你的蓝图,转到**平面图**菜单,并选择**导出为 SVG 格式**。为导出一个 3D 模型,转到 **3D 视图** 菜单并选择**导出为 OBJ 格式**。
你也可以拍摄你家的"快照,以便于不打开 Sweet Home 3D 而回顾你的想法。为创建一个快照,转到 **3D 视图**菜单并选择**创建照片**。快照是按照蓝图视图中的人的图标的角度展现的,因此按照需要调整,然后在**创建照片**窗口中单击**创建**按钮。如果你对快照满意,单击**保存**。
### 甜蜜的家
在 Sweet Home 3D 中有更多的特色。你可以添加一片天空和一片草坪,为你的照片定位光线,设置天花板高度,给你房子添加另一楼层等等。不管你是打算租一套公寓,还是买一套房子,或是(尚)不存在的房子,Sweet Home 3D 是一款简单迷人的应用程序,当你匆忙购买家具时,它可以帮助你快乐地做出更好的购买选择。因此,你终于可以停止在厨房的柜台上吃早餐以及蹲在地上工作了。
---
via: <https://opensource.com/article/19/10/interior-design-sweet-home-3d>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,776 | 这些简单的技巧使 VLC 更加出色 | https://itsfoss.com/simple-vlc-tips/ | 2020-01-13T09:06:00 | [
"VLC"
] | https://linux.cn/article-11776-1.html | 
如果 [VLC](https://www.videolan.org/) 不是最好的播放器,那它也是[最好的开源视频播放器](https://itsfoss.com/video-players-linux/)之一。大多数人不知道的是,它不仅仅是视频播放器。
你可以进行许多复杂的任务,如直播视频、捕捉设备等。只需打开菜单,你就可以看到它有多少选项。
我们有一个详细的教程,讨论一些[专业的 VLC 技巧](https://itsfoss.com/vlc-pro-tricks-linux/),但这些对于普通用户太复杂。
这就是为什么我要写另一篇文章的原因,来向你展示一些可以在 VLC 中使用的简单技巧。
### 使用这些简单技巧让 VLC 做更多事
让我们看看除了播放视频文件之外,你还可以使用 VLC 做什么。
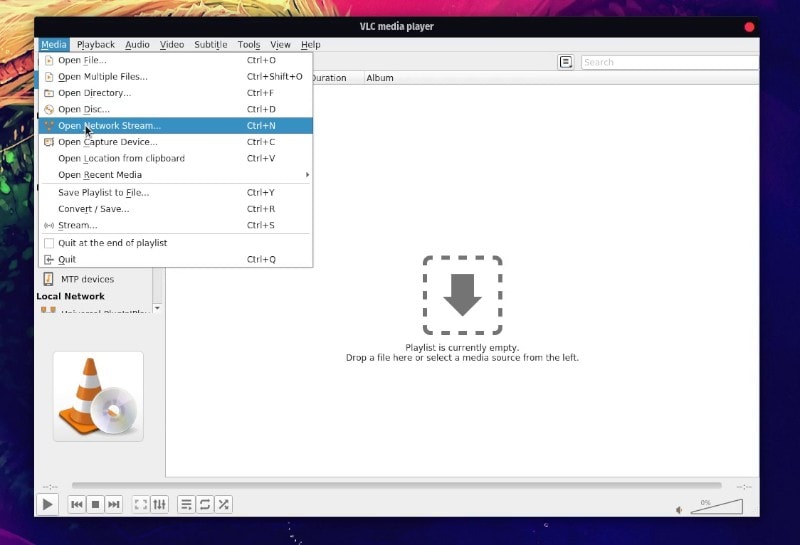
#### 1、使用 VLC 观看 YouTube 视频

如果你不想在 [YouTube](https://www.youtube.com/) 上观看令人讨厌的广告,或者只想体验没有打扰地观看 YouTube 视频,你可以使用 VLC。
是的,在 VLC 上流式传输 YouTube 视频是非常容易的。
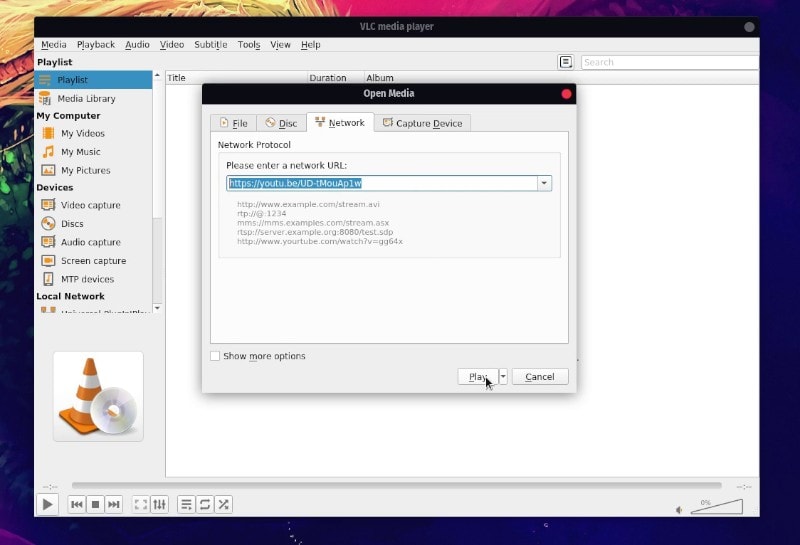
只需启动 VLC 播放器,前往媒体设置,然后单击 ”Open Network Stream“ 或使用快捷方式 `CTRL + N`。

接下来,你只需要粘贴要观看的视频的 URL。有一些选项可以调整,但通常你无需担心这些。如果你好奇,你可以点击 ”Advanced options“ 来探索。
你还可以通过这种方式向 YouTube 视频添加字幕。然而,[一个更简单的带字幕观看 Youtube 视频的办法是使用 Penguin 字幕播放器](https://itsfoss.com/penguin-subtitle-player/)。
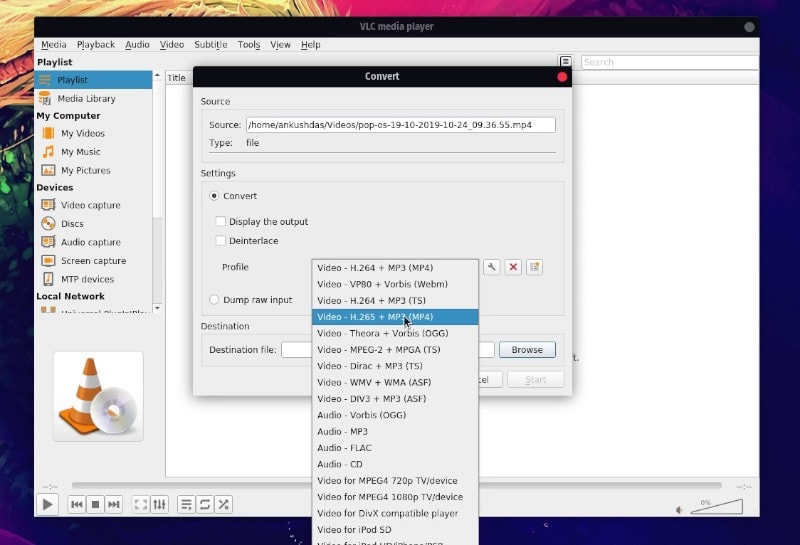
#### 2、将视频转换为不同格式

你可以[在 Linux 命令行使用 ffmpeg 转换视频](https://itsfoss.com/ffmpeg/)。你还可以使用图形工具,如 [HandBrake 转换视频格式](https://itsfoss.com/handbrake/)。
但是,如果你不想用一个单独的应用来转码视频,你可以使用 VLC 播放器来完成该工作。
为此,只需点击 VLC 上的媒体选项,然后单击 “Convert/Save”,或者在 VLC 播放器处于活动状态时按下快捷键 `CTRL + R`。接下来,你需要从计算机/硬盘或者 URL 导入你想保存/转换的的视频。
不管是什么来源,只需选择文件后点击 “Convert/Save” 按钮。你现在会看到另外一个窗口可以更改 “Profile” 设置。点击并选择你想转换的格式(并保存)。
你还可以在转换之前通过在屏幕底部设置目标文件夹来更改转换文件的存储路径。
#### 3、从源录制音频/视频

你是否想在 VLC 播放器中录制正在播放的音频/视频?
如果是的话,有一个简单的解决方案。只需通过 “View”,然后点击 “Advanced Controls”。
完成后,你会看到一个新按钮(包括 VLC 播放器中的红色录制按钮)。
#### 4、自动下载字幕

是的,你可以[使用 VLC 自动下载字幕](https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/)。你甚至不必在单独的网站上查找字幕。你只需点击 “View”->“VLSub”。
默认情况下,它是禁用的,因此当你单击该选项时,它会被激活,并允许你搜索/下载想要的字幕。
[VLC 还能让你使用简单的键盘快捷键同步字幕](https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/)
#### 5、截图

你可以在观看视频时使用 VLC 获取一些视频的截图/图像。你只需在视频播放/暂停时右击播放器,你会看到一组选项,点击 “Video”->“Take Snapshot”。
如果安装了旧版本,你可能在右键时看到截图选项。
#### 额外技巧:给视频添加音频/视频效果
在菜单中,进入 “Tools” 选项。单击 “Effects and Filters”,或者在 VLC 播放器窗口中按 `CTRL + E` 打开选项。
好了,你可以观察你给视频添加的音频和视频效果了。你也许无法实时看到效果,因此你需要调整并保存来看发生了什么。

我建议在修改视频之前保存一份原始视频备份。
#### 你最喜欢的 VLC 技巧是什么?
我分享了一些我最喜欢的 VLC 技巧。你知道什么你经常使用的很酷的 VLC 技巧吗?为什么不和我们分享呢?我可以把它添加到列表中。
---
via: <https://itsfoss.com/simple-vlc-tips/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [VLC](https://www.videolan.org/) is one of the [best open source video players](https://itsfoss.com/video-players-linux/), if not the best. What most people don’t know about it is that it is a lot more than just a video player.
You can do a lot of complex tasks like broadcasting live videos, capturing devices etc. Just open its menu and you’ll see how many options it has.
It’s FOSS has a detailed tutorial discussing some of the [pro VLC tricks](https://itsfoss.com/vlc-pro-tricks-linux/) but those are way too complicated for normal users.
This is why I am writing another article to show you some of the simple tips that you can use with VLC.
## Do more with VLC with these simple tips
Let’s see what can you do with VLC other than just playing a video file.
### 1. Watch YouTube videos with VLC
If you do not want to watch the annoying advertisements on [YouTube](https://www.youtube.com/) or simply want a distraction-free experience for watching a YouTube video, you can use VLC.
Yes, it is very easy to stream a YouTube video on VLC.
Simply launch the VLC player, head to the Media settings and click on “**Open Network Stream**” or **CTRL + N** as a shortcut to that.
Next, you just have to paste the URL of the video that you want to watch. There are some options to tweak – usually, you should not bother using them. But, if you are curious you can click on the “**Advanced options**” to explore.
You can also add subtitles to the YouTube videos this way. However, an easier way to [watch YouTube or any online video with subtitles is using Penguin subtitle player](https://itsfoss.com/penguin-subtitle-player/).
### 2. Convert videos to different formats
You can [use ffmpeg to convert videos in Linux command line](https://itsfoss.com/ffmpeg/). You can also use a graphical tool like [HandBrake to convert video formats](https://itsfoss.com/handbrake/).
But if you do not want a separate app to transcode videos, you can use VLC media player to get the job done.
To do that, just head on to the Media option on VLC and then click on “**Convert/Save**” or press CTRL + R as a shortcut to get there while you have VLC media player active.
Next, you will need to either import the video from your computer/disk or paste the URL of the video that you want to save/convert.
Whatever your input source is – just hit the “**Convert/Save**” button after selecting the file.
Now, you will find another window that gives you the option to change the “**Profile**” from the settings. Click on it and choose a format that you’d like the video to be converted to (and saved).
You can also change the storage path for the converted file by setting the destination folder at the bottom of the screen before converting it.
### 3. Record Audio/Video From Source
Do you want to record the audio/video you’re playing on VLC Media Player?
If yes, there’s an easy solution to that. Simply navigate your way through **View->click on “Advanced Controls”**.
Once you do that, you should observe new buttons (including a red record button in your VLC player).
### 4. Download subtitles automatically
Yes, you can [automatically download subtitles with VLC](https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/). You do not even have to look for it on a separate website. You just have to navigate your way to **View->VLSub**.
By default, it is deactivated, so when you click on the option it gets activated and lets you search/download the subtitles you wanted.
[VLC also lets you synchronize the subtitles](https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/) with simple keyboard shortcuts.
### 5. Take A Snapshot
With VLC, you can get some screenshots/images of the video while watching it.
You just need to right-click on the player while the video is playing/paused, you will notice a bunch of options now, navigate through **Video->Take Snapshot**.
If you have an old version installed, you might observe the snapshot option right after performing a right-click.
### Bonus Tip: Add Audio/Video Effects to a video
From the menu, go to the “**Tools**” option. Now, click on “**Effects and Filters**” or simply press **CTRL + E **from the VLC player window to open up the option.
Here, you can observe audio effects and video effects that you can add to your video. You may not be able to see all the changes in real-time, so you will have to tweak it and save it in order to see what happens.
I’ll suggest keeping a backup of the original video before you modify the video.
### What’s your favorite VLC tip?
I shared some of my favourite VLC tips. Do you know some cool tip that you use regularly with VLC? Why not share it with us? I may add it to the list here. |
11,778 | Go 并发编程中的经验教训 | https://opensource.com/article/19/12/go-common-pitfalls | 2020-01-13T15:12:00 | [
"Go",
"并发"
] | https://linux.cn/article-11778-1.html |
>
> 通过学习如何定位并发处理的陷阱来避免未来处理这些问题时的困境。
>
>
>

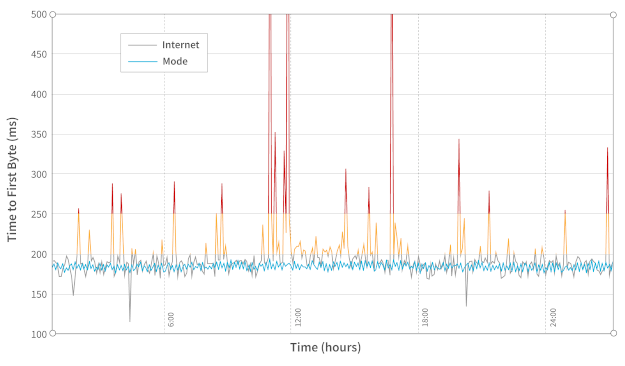
在复杂的分布式系统进行任务处理时,你通常会需要进行并发的操作。在 [Mode.net](http://mode.net) 公司,我们每天都要和实时、快速和灵活的软件打交道。而没有一个高度并发的系统,就不可能构建一个毫秒级的动态地路由数据包的全球专用网络。这个动态路由是基于网络状态的,尽管这个过程需要考虑众多因素,但我们的重点是链路指标。在我们的环境中,链路指标可以是任何跟网络链接的状态和当前属性(如链接延迟)有关的任何内容。
### 并发探测链接监控
我们的动态路由算法 [H.A.L.O.](https://people.ece.cornell.edu/atang/pub/15/HALO_ToN.pdf)(<ruby> 逐跳自适应链路状态最佳路由 <rt> Hop-by-Hop Adaptive Link-State Optimal Routing </rt></ruby>)部分依赖于链路指标来计算路由表。这些指标由位于每个 PoP(<ruby> 存活节点 <rt> Point of Presence </rt></ruby>)上的独立组件收集。PoP 是表示我们的网络中单个路由实体的机器,通过链路连接并分布在我们的网络拓扑中的各个位置。某个组件使用网络数据包探测周围的机器,周围的机器回复数据包给前者。从接收到的探测包中可以获得链路延迟。由于每个 PoP 都有不止一个临近节点,所以这种探测任务实质上是并发的:我们需要实时测量每个临近连接点的延迟。我们不能串行地处理;为了计算这个指标,必须尽快处理每个探测。

### 序列号和重置:一个重新排列场景
我们的探测组件互相发送和接收数据包,并依靠序列号进行数据包处理。这旨在避免处理重复的包或顺序被打乱的包。我们的第一个实现依靠特殊的序列号 0 来重置序列号。这个数字仅在组件初始化时使用。主要的问题是我们考虑了递增的序列号总是从 0 开始。在该组件重启后,包的顺序可能会重新排列,某个包的序列号可能会轻易地被替换成重置之前使用过的值。这意味着,后继的包都会被忽略掉,直到排到重置之前用到的序列值。
### UDP 握手和有限状态机
这里的问题是该组件重启前后的序列号是否一致。有几种方法可以解决这个问题,经过讨论,我们选择了实现一个带有清晰状态定义的三步握手协议。这个握手过程在初始化时通过链接建立会话。这样可以确保节点通过同一个会话进行通信且使用了适当的序列号。
为了正确实现这个过程,我们必须定义一个有清晰状态和过渡的有限状态机。这样我们就可以正确管理握手过程中的所有极端情况。

会话 ID 由握手的初始化程序生成。一个完整的交换顺序如下:
1. 发送者发送一个 `SYN(ID)` 数据包。
2. 接收者存储接收到的 `ID` 并发送一个 `SYN-ACK(ID)`。
3. 发送者接收到 `SYN-ACK(ID)` 并发送一个 `ACK(ID)`。它还发送一个从序列号 0 开始的数据包。
4. 接收者检查最后接收到的 `ID`,如果 ID 匹配,则接受 `ACK(ID)`。它还开始接受序列号为 0 的数据包。
### 处理状态超时
基本上,每种状态下你都需要处理最多三种类型的事件:链接事件、数据包事件和超时事件。这些事件会并发地出现,因此你必须正确处理并发。
* 链接事件包括网络连接或网络断开的变化,相应的初始化一个链接会话或断开一个已建立的会话。
* 数据包事件是控制数据包(`SYN`/`SYN-ACK`/`ACK`)或只是探测响应。
* 超时事件在当前会话状态的预定超时时间到期后触发。
这里面临的最主要的问题是如何处理并发的超时到期和其他事件。这里很容易陷入死锁和资源竞争的陷阱。
### 第一种方法
本项目使用的语言是 [Golang](https://golang.org/)。它确实提供了原生的同步机制,如自带的通道和锁,并且能够使用轻量级线程来进行并发处理。

*gopher 们聚众狂欢*
首先,你可以设计两个分别表示我们的会话和超时处理程序的结构体。
```
type Session struct {
State SessionState
Id SessionId
RemoteIp string
}
type TimeoutHandler struct {
callback func(Session)
session Session
duration int
timer *timer.Timer
}
```
`Session` 标识连接会话,内有表示会话 ID、临近的连接点的 IP 和当前会话状态的字段。
`TimeoutHandler` 包含回调函数、对应的会话、持续时间和指向调度计时器的指针。
每一个临近连接点的会话都包含一个保存调度 `TimeoutHandler` 的全局映射。
```
SessionTimeout map[Session]*TimeoutHandler
```
下面方法注册和取消超时:
```
// schedules the timeout callback function.
func (timeout* TimeoutHandler) Register() {
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time.Second, func() {
timeout.callback(timeout.session)
})
}
func (timeout* TimeoutHandler) Cancel() {
if timeout.timer == nil {
return
}
timeout.timer.Stop()
}
```
你可以使用类似下面的方法来创建和存储超时:
```
func CreateTimeoutHandler(callback func(Session), session Session, duration int) *TimeoutHandler {
if sessionTimeout[session] == nil {
sessionTimeout[session] := new(TimeoutHandler)
}
timeout = sessionTimeout[session]
timeout.session = session
timeout.callback = callback
timeout.duration = duration
return timeout
}
```
超时处理程序创建后,会在经过了设置的 `duration` 时间(秒)后执行回调函数。然而,有些事件会使你重新调度一个超时处理程序(与 `SYN` 状态时的处理一样,每 3 秒一次)。
为此,你可以让回调函数重新调度一次超时:
```
func synCallback(session Session) {
sendSynPacket(session)
// reschedules the same callback.
newTimeout := NewTimeoutHandler(synCallback, session, SYN_TIMEOUT_DURATION)
newTimeout.Register()
sessionTimeout[state] = newTimeout
}
```
这次回调在新的超时处理程序中重新调度自己,并更新全局映射 `sessionTimeout`。
### 数据竞争和引用
你的解决方案已经有了。可以通过检查计时器到期后超时回调是否执行来进行一个简单的测试。为此,注册一个超时,休眠 `duration` 秒,然后检查是否执行了回调的处理。执行这个测试后,最好取消预定的超时时间(因为它会重新调度),这样才不会在下次测试时产生副作用。
令人惊讶的是,这个简单的测试发现了这个解决方案中的一个问题。使用 `cancel` 方法来取消超时并没有正确处理。以下顺序的事件会导致数据资源竞争:
1. 你有一个已调度的超时处理程序。
2. 线程 1:
1. 你接收到一个控制数据包,现在你要取消已注册的超时并切换到下一个会话状态(如发送 `SYN` 后接收到一个 `SYN-ACK`)
2. 你调用了 `timeout.Cancel()`,这个函数调用了 `timer.Stop()`。(请注意,Golang 计时器的停止不会终止一个已过期的计时器。)
3. 线程 2:
1. 在取消调用之前,计时器已过期,回调即将执行。
2. 执行回调,它调度一次新的超时并更新全局映射。
4. 线程 1:
1. 切换到新的会话状态并注册新的超时,更新全局映射。
两个线程并发地更新超时映射。最终结果是你无法取消注册的超时,然后你也会丢失对线程 2 重新调度的超时的引用。这导致处理程序在一段时间内持续执行和重新调度,出现非预期行为。
### 锁也解决不了问题
使用锁也不能完全解决问题。如果你在处理所有事件和执行回调之前加锁,它仍然不能阻止一个过期的回调运行:
```
func (timeout* TimeoutHandler) Register() {
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time._Second_, func() {
stateLock.Lock()
defer stateLock.Unlock()
timeout.callback(timeout.session)
})
}
```
现在的区别就是全局映射的更新是同步的,但是这还是不能阻止在你调用 `timeout.Cancel()` 后回调的执行 —— 这种情况出现在调度计时器过期了但是还没有拿到锁的时候。你还是会丢失一个已注册的超时的引用。
### 使用取消通道
你可以使用取消通道,而不必依赖不能阻止到期的计时器执行的 golang 函数 `timer.Stop()`。
这是一个略有不同的方法。现在你可以不用再通过回调进行递归地重新调度;而是注册一个死循环,这个循环接收到取消信号或超时事件时终止。
新的 `Register()` 产生一个新的 go 线程,这个线程在超时后执行你的回调,并在前一个超时执行后调度新的超时。返回给调用方一个取消通道,用来控制循环的终止。
```
func (timeout *TimeoutHandler) Register() chan struct{} {
cancelChan := make(chan struct{})
go func () {
select {
case _ = <- cancelChan:
return
case _ = <- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
func () {
stateLock.Lock()
defer stateLock.Unlock()
timeout.callback(timeout.session)
} ()
}
} ()
return cancelChan
}
func (timeout* TimeoutHandler) Cancel() {
if timeout.cancelChan == nil {
return
}
timeout.cancelChan <- struct{}{}
}
```
这个方法给你注册的所有超时提供了取消通道。一个取消调用向通道发送一个空结构体并触发取消操作。然而,这并不能解决前面的问题;可能在你通过通道取消之前以及超时线程拿到锁之前,超时时间就已经到了。
这里的解决方案是,在拿到锁**之后**,检查一下超时范围内的取消通道。
```
case _ = <- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
func () {
stateLock.Lock()
defer stateLock.Unlock()
select {
case _ = <- handler.cancelChan:
return
default:
timeout.callback(timeout.session)
}
} ()
}
```
最终,这可以确保在拿到锁之后执行回调,不会触发取消操作。
### 小心死锁
这个解决方案看起来有效;但是还是有个隐患:[死锁](https://en.wikipedia.org/wiki/Deadlock)。
请阅读上面的代码,试着自己找到它。考虑下描述的所有函数的并发调用。
这里的问题在取消通道本身。我们创建的是无缓冲通道,即发送的是阻塞调用。当你在一个超时处理程序中调用取消函数时,只有在该处理程序被取消后才能继续处理。问题出现在,当你有多个调用请求到同一个取消通道时,这时一个取消请求只被处理一次。当多个事件同时取消同一个超时处理程序时,如连接断开或控制包事件,很容易出现这种情况。这会导致死锁,可能会使应用程序停机。

*有人在听吗?*
(已获得 Trevor Forrey 授权。)
这里的解决方案是创建通道时指定缓存大小至少为 1,这样向通道发送数据就不会阻塞,也显式地使发送变成非阻塞的,避免了并发调用。这样可以确保取消操作只发送一次,并且不会阻塞后续的取消调用。
```
func (timeout* TimeoutHandler) Cancel() {
if timeout.cancelChan == nil {
return
}
select {
case timeout.cancelChan <- struct{}{}:
default:
// can’t send on the channel, someone has already requested the cancellation.
}
}
```
### 总结
在实践中你学到了并发操作时出现的常见错误。由于其不确定性,即使进行大量的测试,也不容易发现这些问题。下面是我们在最初的实现中遇到的三个主要问题:
#### 在非同步的情况下更新共享数据
这似乎是个很明显的问题,但如果并发更新发生在不同的位置,就很难发现。结果就是数据竞争,由于一个更新会覆盖另一个,因此对同一数据的多次更新中会有某些更新丢失。在我们的案例中,我们是在同时更新同一个共享映射里的调度超时引用。(有趣的是,如果 Go 检测到在同一个映射对象上的并发读写,会抛出致命错误 — 你可以尝试下运行 Go 的[数据竞争检测器](https://golang.org/doc/articles/race_detector.html))。这最终会导致丢失超时引用,且无法取消给定的超时。当有必要时,永远不要忘记使用锁。

*不要忘记同步 gopher 们的工作*
#### 缺少条件检查
在不能仅依赖锁的独占性的情况下,就需要进行条件检查。我们遇到的场景稍微有点不一样,但是核心思想跟[条件变量](https://en.wikipedia.org/wiki/Monitor_%28synchronization%29#Condition_variables)是一样的。假设有个一个生产者和多个消费者使用一个共享队列的经典场景,生产者可以将一个元素添加到队列并唤醒所有消费者。这个唤醒调用意味着队列中的数据是可访问的,并且由于队列是共享的,消费者必须通过锁来进行同步访问。每个消费者都可能拿到锁;然而,你仍然需要检查队列中是否有元素。因为在你拿到锁的瞬间并不知道队列的状态,所以还是需要进行条件检查。
在我们的例子中,超时处理程序收到了计时器到期时发出的“唤醒”调用,但是它仍需要检查是否已向其发送了取消信号,然后才能继续执行回调。

*如果你要唤醒多个 gopher,可能就需要进行条件检查*
#### 死锁
当一个线程被卡住,无限期地等待一个唤醒信号,但是这个信号永远不会到达时,就会发生这种情况。死锁可以通过让你的整个程序停机来彻底杀死你的应用。
在我们的案例中,这种情况的发生是由于多次发送请求到一个非缓冲且阻塞的通道。这意味着向通道发送数据只有在从这个通道接收完数据后才能返回。我们的超时线程循环迅速从取消通道接收信号;然而,在接收到第一个信号后,它将跳出循环,并且再也不会从这个通道读取数据。其他的调用会一直被卡住。为避免这种情况,你需要仔细检查代码,谨慎处理阻塞调用,并确保不会发生线程饥饿。我们例子中的解决方法是使取消调用成为非阻塞调用 — 我们不需要阻塞调用。
---
via: <https://opensource.com/article/19/12/go-common-pitfalls>
作者:[Eduardo Ferreira](https://opensource.com/users/edufgf) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you are working with complex distributed systems, you will likely come across the need for concurrent processing. At [Mode.net](http://mode.net), we deal daily with real-time, fast and resilient software. Building a global private network that dynamically routes packets at the millisecond scale wouldn’t be possible without a highly concurrent system. This dynamic routing is based on the state of the network and, while there are many parameters to consider here, our focus is on link [metrics](https://en.wikipedia.org/wiki/Metrics_%28networking%29). In our context, link metrics can be anything related to the status or current properties of a network link (e.g.: link latency).
## Concurrent probing for link metrics
[H.A.L.O.](https://people.ece.cornell.edu/atang/pub/15/HALO_ToN.pdf) (Hop-by-Hop Adaptive Link-State Optimal Routing), our dynamic routing algorithm relies partially on link metrics to compute its routing table. Those metrics are collected by an independent component that sits on each [PoP](https://en.wikipedia.org/wiki/Point_of_presence) (Point of Presence). PoPs are machines that represent a single routing entity in our networks, connected by links and spread around multiple locations shaping our network. This component probes neighboring machines using network packets, and those neighbors will bounce back the initial probe. Link latency values can be derived from the received probes. Because each PoP has more than one neighbor, the nature of such a task is intrinsically concurrent: we need to measure latency for each neighboring link in real-time. We can’t afford sequential processing; each probe must be processed as soon as possible in order to compute this metric.
## Sequence numbers and resets: A reordering situation
Our probing component exchanges packets and relies on sequence numbers for packet processing. This aims to avoid processing of packet duplication or out-of-order packets. Our first implementation relied on a special sequence number 0 to reset sequence numbers. Such a number was only used during initialization of a component. The main problem was that we were considering an increasing sequence number value that always started at 0. After the component restarts, packet reordering could happen, and a packet could easily replace the sequence number with the value that was being used before the reset. This meant that the following packets would be ignored until it reaches the sequence number that was in use just before the reset.
## UDP handshake and finite state machine
The problem here was proper agreement of a sequence number after a component restarts. There are a few ways to handle this and, after discussing our options, we chose to implement a 3-way handshake protocol with a clear definition of states. This handshake establishes sessions over links during initialization. This guarantees that nodes are communicating over the same session and using the appropriate sequence number for it.
To properly implement this, we have to define a finite state machine with clear states and transitions. This allows us to properly manage all corner cases for the handshake formation.
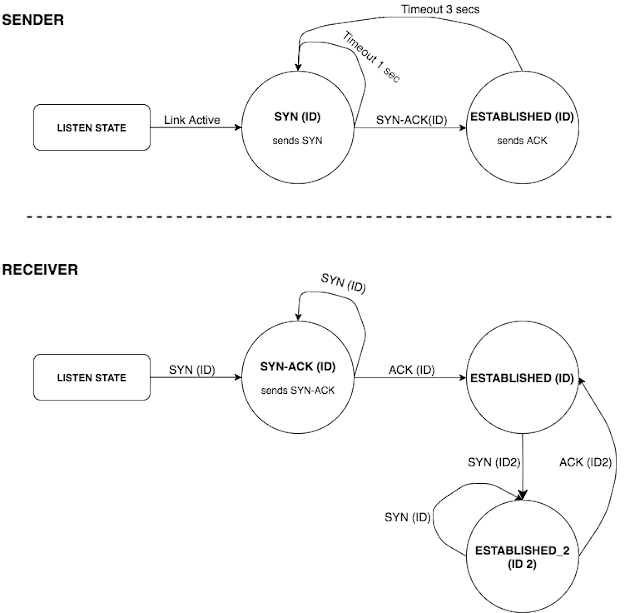
Session IDs are generated by the handshake initiator. A full exchange sequence is as follows:
- The sender sends out a
**SYN (ID)** - The receiver stores the received
**ID**and sends a**SYN-ACK (ID)**. - The sender receives the
**SYN-ACK (ID)**and sends out an**ACK (ID)**. - The receiver checks the last received
**ID****ACK (ID)**
## Handling state timeouts
Basically, at each state, you need to handle, at most, three types of events: link events, packet events, and timeout events. And those events show up concurrently, so here you have to handle concurrency properly.
- Link events are either link up or link down updates. This can either initiate a link session or break an existing session.
- Packet events are control packets
**(SYN/SYN-ACK/ACK)**or just probe responses. - Timeout events are the ones triggered after a scheduled timeout expires for the current session state.
The main challenge here is how to handle concurrent timeout expiration and other events. And this is where one can easily fall into the traps of deadlocks and race conditions.
## A first approach
The language used for this project is [Golang](https://golang.org/). It does provide native synchronization mechanisms such as native channels and locks and is able to spin lightweight threads for concurrent processing.

Gophers hacking together
by Ashley McNamara, CC BY-NC-SA 4.0
You can start first by designing a structure that represents our **Session **and **Timeout Handlers**.
```
type Session struct {
State SessionState
Id SessionId
RemoteIp string
}
type TimeoutHandler struct {
callback func(Session)
session Session
duration int
timer *timer.Timer
}
```
**Session** identifies the connection session, with the session ID, neighboring link IP, and the current session state.
**TimeoutHandler** holds the callback function, the session for which it should run, the duration, and a pointer to the scheduled timer.
There is a global map that will store, per neighboring link session, the scheduled timeout handler.
`SessionTimeout map[Session]*TimeoutHandler`
Registering and canceling a timeout is achieved by the following methods:
```
// schedules the timeout callback function.
func (timeout* TimeoutHandler) Register() {
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time.Second, func() {
timeout.callback(timeout.session)
})
}
func (timeout* TimeoutHandler) Cancel() {
if timeout.timer == nil {
return
}
timeout.timer.Stop()
}
```
For the timeouts creation and storage, you can use a method like the following:
```
func CreateTimeoutHandler(callback func(Session), session Session, duration int) *TimeoutHandler {
if sessionTimeout[session] == nil {
sessionTimeout[session] := new(TimeoutHandler)
}
timeout = sessionTimeout[session]
timeout.session = session
timeout.callback = callback
timeout.duration = duration
return timeout
}
```
Once the timeout handler is created and registered, it runs the callback after *duration* seconds have elapsed. However, some events will require you to reschedule a timeout handler (as it happens at **SYN** state — every 3 seconds).
For that, you can have the callback rescheduling a new timeout:
```
func synCallback(session Session) {
sendSynPacket(session)
// reschedules the same callback.
newTimeout := NewTimeoutHandler(synCallback, session, SYN_TIMEOUT_DURATION)
newTimeout.Register()
sessionTimeout[state] = newTimeout
}
```
This callback reschedules itself in a new timeout handler and updates the global **sessionTimeout** map.
**Data race and references**
Your solution is ready. One simple test is to check that a timeout callback is executed after the timer has expired. To do this, register a timeout, sleep for its duration, and then check whether the callback actions were done. After the test is executed, it is a good idea to cancel the scheduled timeout (as it reschedules), so it won’t have side effects between tests.
Surprisingly, this simple test found a bug in the solution. Canceling timeouts using the cancel method was just not doing its job. The following order of events would cause a data race condition:
- You have one scheduled timeout handler.
- Thread 1:
a) You receive a control packet, and you now want to cancel the registered timeout and move on to the next session state. (e.g. received a**SYN-ACK****SYN**).
b) You call**timeout.Cancel()**, which calls a**timer.Stop()**. (Note that a Golang timer stop doesn’t prevent an already expired timer from running.) - Thread 2:
a) Right before that cancel call, the timer has expired, and the callback was about to execute.
b) The callback is executed, it schedules a new timeout and updates the global map. - Thread 1:
a) Transitions to a new session state and registers a new timeout, updating the global map.
Both threads were updating the timeout map concurrently. The end result is that you failed to cancel the registered timeout, and then you also lost the reference to the rescheduled timeout done by thread 2. This results in a handler that keeps executing and rescheduling for a while, doing unwanted behavior.
## When locking is not enough
Using locks also doesn’t fix the issue completely. If you add locks before processing any event and before executing a callback, it still doesn’t prevent an expired callback to run:
```
func (timeout* TimeoutHandler) Register() {
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time._Second_, func() {
stateLock.Lock()
defer stateLock.Unlock()
timeout.callback(timeout.session)
})
}
```
The difference now is that the updates in the global map are synchronized, but this doesn’t prevent the callback from running after you call the **timeout.Cancel() **— This is the case if the scheduled timer expired but didn’t grab the lock yet. You should again lose reference to one of the registered timeouts.
## Using cancellation channels
Instead of relying on golang’s **timer.Stop()**, which doesn’t prevent an expired timer to execute, you can use cancellation channels.
It is a slightly different approach. Now you won’t do a recursive re-scheduling through callbacks; instead, you register an infinite loop that waits for cancellation signals or timeout events.
The new **Register() **spawns a new go thread that runs your callback after a timeout and schedules a new timeout after the previous one has been executed. A cancellation channel is returned to the caller to control when the loop should stop.
```
func (timeout *TimeoutHandler) Register() chan struct{} {
cancelChan := make(chan struct{})
go func () {
select {
case _ = <- cancelChan:
return
case _ = <- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
func () {
stateLock.Lock()
defer stateLock.Unlock()
timeout.callback(timeout.session)
} ()
}
} ()
return cancelChan
}
func (timeout* TimeoutHandler) Cancel() {
if timeout.cancelChan == nil {
return
}
timeout.cancelChan <- struct{}{}
}
```
This approach gives you a cancellation channel for each timeout you register. A cancel call sends an empty struct to the channel and triggers the cancellation. However, this doesn’t resolve the previous issue; the timeout can expire right before you call cancel over the channel, and before the lock is grabbed by the timeout thread.
The solution here is to check the cancellation channel inside the timeout scope __after__ you grab the lock.
```
case _ = <- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
func () {
stateLock.Lock()
defer stateLock.Unlock()
select {
case _ = <- handler.cancelChan:
return
default:
timeout.callback(timeout.session)
}
} ()
}
```
Finally, this guarantees that the callback is only executed after you grab the lock and no cancellation was triggered.
## Beware of deadlocks
This solution seems to work; however, there is one hidden pitfall here: [deadlocks](https://en.wikipedia.org/wiki/Deadlock).
Please read the code above again and try to find it yourself. Think of concurrent calls to any of the methods described.
The last problem here is with the cancellation channel itself. We made it an unbuffered channel, which means that sending is a blocking call. Once you call cancel in a timeout handler, you only proceed once that handler is canceled. The problem here is when you have multiple calls to the same cancelation channel, where a cancel request is only consumed once. And this can easily happen if concurrent events were to cancel the same timeout handler, like a link down or control packet event. This results in a deadlock situation, possibly bringing the application to a halt.
Is anyone listening?
By Trevor Forrey. Used with permission.
The solution here is to at least make the channel buffered by one, so sends are not always blocking, and also explicitly make the send non-blocking in case of concurrent calls. This guarantees the cancellation is sent once and won’t block the subsequent cancel calls.
```
func (timeout* TimeoutHandler) Cancel() {
if timeout.cancelChan == nil {
return
}
select {
case timeout.cancelChan <- struct{}{}:
default:
// can’t send on the channel, someone has already requested the cancellation.
}
}
```
## Conclusion
You learned in practice how common mistakes can show up while working with concurrent code. Due to their non-deterministic nature, those issues can go easily undetected, even with extensive testing. Here are the three main problems we encountered in the initial implementation.
### Updating shared data without synchronization
This seems like an obvious one, but it’s actually hard to spot if your concurrent updates happen in different locations. The result is data race, where multiple updates to the same data can cause update loss, due to one update overriding another. In our case, we were updating the scheduled timeout reference on the same shared map. (Interestingly, if Go detects a concurrent read/write on the same Map object, it throws a fatal error —you can try to run Go’s[ data race detector](https://golang.org/doc/articles/race_detector.html)). This eventually results in losing a timeout reference and making it impossible to cancel that given timeout. Always remember to use locks when they are needed.
don’t forget to synchronize gophers’ work
### Missing condition checks
Condition checks are needed in situations where you can’t rely only on the lock exclusivity. Our situation is a bit different, but the core idea is the same as [condition variables](https://en.wikipedia.org/wiki/Monitor_%28synchronization%29#Condition_variables). Imagine a classic situation where you have one producer and multiple consumers working with a shared queue. A producer can add one item to the queue and wake up all consumers. The wake-up call means that some data is available at the queue, and because the queue is shared, access must be synchronized through a lock. Every consumer has a chance to grab the lock; however, you still need to check if there are items in the queue. A condition check is needed because you don’t know the queue status by the time you grab the lock.
In our example, the timeout handler got a ‘wake up’ call from a timer expiration, but it still needed to check if a cancel signal was sent to it before it could proceed with the callback execution.
Condition checks might be needed if you wake up multiple gophers
### Deadlocks
This happens when one thread is stuck, waiting indefinitely for a signal to wake up, but this signal will never arrive. Those can completely kill your application by halting your entire program execution.
In our case, this happened due to multiple send calls to a non-buffered and blocking channel. This meant that the send call would only return after a receive is done on the same channel. Our timeout thread loop was promptly receiving signals on the cancellation channel; however, after the first signal is received, it would break off the loop and never read from that channel again. The remaining callers are stuck forever. To avoid this situation, you need to carefully think through your code, handle blocking calls with care, and guarantee that thread starvation doesn’t happen. The fix in our example was to make the cancellation calls non-blocking—we didn’t need a blocking call for our needs.
## Comments are closed. |
11,779 | PaperWM:GNOME 下的平铺窗口管理 | https://jvns.ca/blog/2020/01/05/paperwm/ | 2020-01-13T21:29:00 | [
"窗口管理器"
] | https://linux.cn/article-11779-1.html | 
当我开始在个人计算机上使用 Linux 时,首先令我兴奋的就是轻巧的窗口管理器,这主要是因为当时我的笔记本电脑只有有 32MB 的内存,其它的都运行不了了。
接着我开始接触 [xmonad](https://xmonad.org/) 之类的平铺窗口管理器!我可以用键盘管理窗口了!它们是如此之快!我可以通过编写 Haskell 程序来配置 xmonad!我可以用各种有趣的方式自定义所有内容(例如使用 [dmenu](https://wiki.archlinux.org/index.php/Dmenu) 作为启动器)!这些年来,我用过 3、4 个不同的平铺窗口管理器,它们都很有趣。
大约 6 年前,我觉得配置平铺窗口管理器对我来说不再是一件有趣的事情,因此转而使用 Ubuntu 桌面环境 Gnome。(现在,我的笔记本电脑中的内存增加了 500 倍,这要快得多 :) )
我使用 Gnome 已有很长时间了,但是我仍然有点想念平铺窗口管理器。六个月前,一个朋友告诉我有关 [PaperWM](https://github.com/paperwm/PaperWM) 的消息,它使你可以在 Gnome 中平铺窗口!我立即安装了它,并从那时起我一直在使用它。
### PaperWM:Gnome 下的平铺窗口管理
[PaperWM](https://github.com/paperwm/PaperWM) 的基本思想是:你想继续使用 Gnome(因为在 Gnome 中各种任务都能完成),但是你也希望使用平铺窗口管理器。
它是一个 Gnome 扩展程序(而不是一个独立的窗口管理器),并且使用 Javascript。
### “Paper” 表示你的所有窗户都在一行中
PaperWM 的主要想法是将所有窗口排成一行,这实际上与传统的平铺窗口管理器大不相同,在传统的平铺窗口管理器中,你可以按任意方式平铺窗口。这是我写这篇博客时在几个窗口之间切换/调整大小的 gif 图像(有一个浏览器和两个终端窗口):

PaperWM 的 Github README 链接了此视频:<http://10gui.com/video/>,它描述为一个类似的”线性窗口管理器“。
我以前从未听说过这种组织窗口的方式,但是我喜欢它的简单性。如果要查找特定的窗口,只需向左/向右移动,直到找到它。
### 我在 PaperWM 中所做的一切
还有很多其他功能,但这是我使用的功能:
* 在窗口之间左右移动(`Super + ,`、`Super + .`)
* 按顺序向左/向右移动窗口(`Super+Shift+,`、`Super+Shift+.`)
* 全屏显示窗口(`Super + f`)
* 缩小窗口(`Super + r`)
### 我喜欢不需要配置的工具
我在笔记本上使用 PaperWM 已经 6 个月了,我真的很喜欢它!即使它是可配置(通过编写 Javascript 配置文件),我也非常欣赏它,它自带我想要的功能,我无需研究如何去配置。
[fish shell](https://jvns.ca/blog/2017/04/23/the-fish-shell-is-awesome/) 是另一个类似的令人愉悦的工具,我基本上没有配置 fish(除了设置环境变量等),我真的很喜欢它的默认功能。
---
via: <https://jvns.ca/blog/2020/01/05/paperwm/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
11,780 | 在你的 Python 游戏中模拟引力 | https://opensource.com/article/19/11/simulate-gravity-python | 2020-01-13T22:39:00 | [
"Pygame",
"引力"
] | https://linux.cn/article-11780-1.html |
>
> 学习如何使用 Python 的 Pygame 模块编程电脑游戏,并开始操作引力。
>
>
>

真实的世界充满了运动和生活。物理学使得真实的生活如此忙碌和动态。物理学是物质在空间中运动的方式。既然一个电脑游戏世界没有物质,它也就没有物理学规律,使用游戏程序员不得不*模拟*物理学。
从大多数电脑游戏来说,这里基本上仅有两个方面的物理学是重要的:引力和碰撞。
当你[添加一个敌人](/article-10883-1.html)到你的游戏中时,你实现了一些碰撞检测,但是这篇文章要添加更多的东西,因为引力需要碰撞检测。想想为什么引力可能涉及碰撞。如果你不能想到任何原因,不要担心 —— 它会随着你开发示例代码工作而且显然。
在真实世界中的引力是有质量的物体来相互吸引的倾向性。物体(质量)越大,它施加越大的引力作用。在电脑游戏物理学中,你不必创建质量足够大的物体来证明引力的正确;你可以在电脑游戏世界本身中仅编程一个物体落向假设的最大的对象的倾向。
### 添加一个引力函数
记住你的玩家已经有了一个决定动作的属性。使用这个属性来将玩家精灵拉向屏幕底部。
在 Pygame 中,较高的数字更接近屏幕的底部边缘。
在真实的世界中,引力影响一切。然而,在平台游戏中,引力是有选择性的 —— 如果你添加引力到你的整个游戏世界,你的所有平台都将掉到地上。反之,你可以仅添加引力到你的玩家和敌人精灵中。
首先,在你的 `Player` 类中添加一个 `gravity` 函数:
```
def gravity(self):
self.movey += 3.2 # 玩家掉落的多快
```
这是一个简单的函数。首先,不管你的玩家是否想运动,你设置你的玩家垂直运动。也就是说,你已经编程你的玩家总是在下降。这基本上就是引力。
为使引力函数生效,你必须在你的主循环中调用它。这样,当每一个处理循环时,Python 都应用下落运动到你的玩家。
在这代码中,添加第一行到你的循环中:
```
player.gravity() # 检查引力
player.update()
```
启动你的游戏来看看会发生什么。要注意,因为它发生的很快:你是玩家从天空上下落,马上掉出了你的游戏屏幕。
你的引力模拟是工作的,但是,也许太好了。
作为一次试验,尝试更改你玩家下落的速度。
### 给引力添加一个地板
你的游戏没有办法发现你的角色掉落出世界的问题。在一些游戏中,如果一个玩家掉落出世界,该精灵被删除,并在某个新的位置重生。在另一些游戏中,玩家会丢失分数或一条生命。当一个玩家掉落出世界时,不管你想发生什么,你必须能够侦测出玩家何时消失在屏幕外。
在 Python 中,要检查一个条件,你可以使用一个 `if` 语句。
你必需查看你玩家**是否**正在掉落,以及你的玩家掉落的程度。如果你的玩家掉落到屏幕的底部,那么你可以做*一些事情*。简化一下,设置玩家精灵的位置为底部边缘上方 20 像素。
使你的 `gravity` 函数看起来像这样:
```
def gravity(self):
self.movey += 3.2 # 玩家掉落的多快
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty
```
然后,启动你的游戏。你的精灵仍然下落,但是它停在屏幕的底部。不过,你也许不能*看到*你在地面层之上的精灵。一个简单的解决方法是,在精灵碰撞游戏世界的底部后,通过添加另一个 `-ty` 到它的新 Y 位置,从而使你的精灵弹跳到更高处:
```
def gravity(self):
self.movey += 3.2 # 玩家掉落的多快
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty-ty
```
现在你的玩家在屏幕底部弹跳,恰好在你地面精灵上面。
你的玩家真正需要的是反抗引力的方法。引力问题是,你不能反抗它,除非你有一些东西来推开引力作用。因此,在接下来的文章中,你将添加地面和平台碰撞以及跳跃能力。在这期间,尝试应用引力到敌人精灵。
到目前为止,这里是全部的代码:
```
#!/usr/bin/env python3
# draw a world
# add a player and player control
# add player movement
# add enemy and basic collision
# add platform
# add gravity
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
import pygame
import sys
import os
'''
Objects
'''
class Platform(pygame.sprite.Sprite):
# x location, y location, img width, img height, img file
def __init__(self,xloc,yloc,imgw,imgh,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img)).convert()
self.image.convert_alpha()
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
'''
Spawn a player
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.score = 1
self.images = []
for i in range(1,9):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def gravity(self):
self.movey += 3.2 # how fast player falls
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty-ty
def control(self,x,y):
'''
control player movement
'''
self.movex += x
self.movey += y
def update(self):
'''
Update sprite position
'''
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[self.frame//ani]
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in enemy_hit_list:
self.health -= 1
print(self.health)
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.health -= 1
print(self.health)
class Enemy(pygame.sprite.Sprite):
'''
Spawn an enemy
'''
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
#self.image.convert_alpha()
#self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
'''
enemy movement
'''
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
enemy_list = pygame.sprite.Group() # create enemy group
enemy_list.add(enemy) # add enemy to group
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
def loot(lvl,lloc):
print(lvl)
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
def platform(lvl,tx,ty):
plat_list = pygame.sprite.Group()
ploc = []
i=0
if lvl == 1:
ploc.append((0,worldy-ty-128,3))
ploc.append((300,worldy-ty-256,3))
ploc.append((500,worldy-ty-128,4))
while i < len(ploc):
j=0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
plat_list.add(plat)
j=j+1
print('run' + str(i) + str(ploc[i]))
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
'''
Setup
'''
worldx = 960
worldy = 720
fps = 40 # frame rate
ani = 4 # animation cycles
clock = pygame.time.Clock()
pygame.init()
main = True
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
ALPHA = (0,255,0)
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = world.get_rect()
player = Player() # spawn player
player.rect.x = 0
player.rect.y = 0
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10 # how fast to move
eloc = []
eloc = [200,20]
gloc = []
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
tx = 64 #tile size
ty = 64 #tile size
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,gloc,tx,ty )
plat_list = Level.platform( 1,tx,ty )
'''
Main loop
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print("LEFT")
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print("RIGHT")
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
world.blit(backdrop, backdropbox)
player.gravity() # check gravity
player.update()
player_list.draw(world)
enemy_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
---
这是仍在进行中的关于使用 [Pygame](https://www.pygame.org) 模块来在 [Python 3](https://www.python.org/) 在创建电脑游戏的第七部分。先前的文章是:
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
* [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
* [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
* [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
* [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
* [在 Pygame 游戏中放置平台](/article-10902-1.html)
---
via: <https://opensource.com/article/19/11/simulate-gravity-python>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The real world is full of movement and life. The thing that makes the real world so busy and dynamic is physics. Physics is the way matter moves through space. Since a video game world has no matter, it also has no physics, so game programmers have to *simulate* physics.
In terms of most video games, there are basically only two aspects of physics that are important: gravity and collision.
You implemented some collision detection when you [added an enemy](https://opensource.com/article/18/5/pygame-enemy) to your game, but this article adds more because gravity requires collision detection. Think about why gravity might involve collisions. If you can't think of any reasons, don't worry—it'll become apparent as you work through the sample code.
Gravity in the real world is the tendency for objects with mass to be drawn toward one another. The larger the object, the more gravitational influence it exerts. In video game physics, you don't have to create objects with mass great enough to justify a gravitational pull; you can just program a tendency for objects to fall toward the presumed largest object in the video game world: the world itself.
## Adding a gravity function
Remember that your player already has a property to determine motion. Use this property to pull the player sprite toward the bottom of the screen.
In Pygame, higher numbers are closer to the bottom edge of the screen.
In the real world, gravity affects everything. In platformers, however, gravity is selective—if you add gravity to your entire game world, all of your platforms would fall to the ground. Instead, you add gravity just to your player and enemy sprites.
First, add a **gravity** function in your **Player** class:
```
def gravity(self):
self.movey += 3.2 # how fast player falls
```
This is a simple function. First, you set your player in vertical motion, whether your player wants to be in motion or not. In other words, you have programmed your player to always be falling. That's basically gravity.
For the gravity function to have an effect, you must call it in your main loop. This way, Python applies the falling motion to your player once every clock tick.
In this code, add the first line to your loop:
```
player.gravity() # check gravity
player.update()
```
Launch your game to see what happens. Look sharp, because it happens fast: your player falls out of the sky, right off your game screen.
Your gravity simulation is working, but maybe too well.
As an experiment, try changing the rate at which your player falls.
## Adding a floor to gravity
The problem with your character falling off the world is that there's no way for your game to detect it. In some games, if a player falls off the world, the sprite is deleted and respawned somewhere new. In other games, the player loses points or a life. Whatever you want to happen when a player falls off the world, you have to be able to detect when the player disappears offscreen.
In Python, to check for a condition, you can use an **if** statement.
You must check to see **if** your player is falling and how far your player has fallen. If your player falls so far that it reaches the bottom of the screen, then you can do *something*. To keep things simple, set the position of the player sprite to 20 pixels above the bottom edge.
Make your **gravity** function look like this:
```
def gravity(self):
self.movey += 3.2 # how fast player falls
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty
```
Then launch your game. Your sprite still falls, but it stops at the bottom of the screen. You may not be able to *see* your sprite behind the ground layer, though. An easy fix is to make your player sprite bounce higher by adding another **-ty** to its new Y position after it hits the bottom of the game world:
```
def gravity(self):
self.movey += 3.2 # how fast player falls
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty-ty
```
Now your player bounces at the bottom of the screen, just behind your ground sprites.
What your player really needs is a way to fight gravity. The problem with gravity is, you can't fight it unless you have something to push off of. So, in the next article, you'll add ground and platform collision and the ability to jump. In the meantime, try applying gravity to the enemy sprite.
Here's all the code so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
'''
Objects
'''
# x location, y location, img width, img height, img file
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def gravity(self):
self.movey += 3.2
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty-ty
def control(self, x, y):
"""
control player movement
"""
self.movex += x
self.movey += y
def update(self):
"""
Update sprite position
"""
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = self.images[self.frame // ani]
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in hit_list:
self.health -= 1
print(self.health)
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
enemy movement
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance * 2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level:
def ground(lvl, gloc, tx, ty):
ground_list = pygame.sprite.Group()
i = 0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i], worldy - ty, tx, ty, 'tile-ground.png')
ground_list.add(ground)
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return ground_list
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl))
return enemy_list
# x location, y location, img width, img height, img file
def platform(lvl, tx, ty):
plat_list = pygame.sprite.Group()
ploc = []
i = 0
if lvl == 1:
ploc.append((200, worldy - ty - 128, 3))
ploc.append((300, worldy - ty - 256, 3))
ploc.append((500, worldy - ty - 128, 4))
while i < len(ploc):
j = 0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0] + (j * tx)), ploc[i][1], tx, ty, 'tile.png')
plat_list.add(plat)
j = j + 1
print('run' + str(i) + str(ploc[i]))
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return plat_list
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 30 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
eloc = []
eloc = [300, 0]
enemy_list = Level.bad(1, eloc)
gloc = []
tx = 64
ty = 64
i = 0
while i <= (worldx / tx) + tx:
gloc.append(i * tx)
i = i + 1
ground_list = Level.ground(1, gloc, tx, ty)
plat_list = Level.platform(1, tx, ty)
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
world.blit(backdrop, backdropbox)
player.gravity()
player.update()
player_list.draw(world)
enemy_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
This is part 6 in an ongoing series about creating video games in [Python 3](https://www.python.org/) using the [Pygame](https://www.pygame.org) module. Previous articles are:
[Learn how to program in Python by building a simple dice game](https://opensource.com/article/17/10/python-101)[Build a game framework with Python using the Pygame module](https://opensource.com/article/17/12/game-framework-python)[How to add a player to your Python game](https://opensource.com/article/17/12/game-python-add-a-player)[Using Pygame to move your game character around](https://opensource.com/article/17/12/game-python-moving-player)[What's a hero without a villain? How to add one to your Python game](https://opensource.com/article/18/5/pygame-enemy)[Put platforms in a Python game with Pygame](https://opensource.com/article/18/7/put-platforms-python-game)
## 6 Comments |
11,781 | 使用 Bash 脚本发送包含几天内到期的用户账号列表的电子邮件 | https://www.2daygeek.com/bash-script-to-check-user-account-password-expiry-linux/ | 2020-01-13T23:21:09 | [
"密码"
] | https://linux.cn/article-11781-1.html | 
密码强制策略对所有操作系统和应用程序都是通用的。如果要[在 Linux 上实现密码强制策略](/article-11709-1.html),请参阅以下文章。
默认情况下,大多数公司都会强制执行密码强制策略,但根据公司的要求,密码的时间周期会有所不同。通常每个人都使用 90 天的密码周期。用户只会在他们使用的一些服务器上[更改密码](https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/),而不会在他们不经常使用的服务器上更改密码。
特别地,大多数团队忘记更改服务帐户密码,这可能导致日常工作的中断,即使他们配置有[基于 SSH 密钥的身份验证](https://www.2daygeek.com/configure-setup-passwordless-ssh-key-based-authentication-linux/)。如果用户帐户密码过期,基于SSH密钥的身份验证和 [cronjob](https://www.2daygeek.com/linux-crontab-cron-job-to-schedule-jobs-task/) 将不起作用。
为了避免这种情况,我们创建了一个 [shell 脚本](https://www.2daygeek.com/category/shell-script/)来向你发送 10 天内到期的用户帐户列表。
本教程中包含两个 [bash 脚本](https://www.2daygeek.com/category/bash-script/)可以帮助你收集系统中用户到期天数的信息。
### 1) 检查 10 天后到期的用户帐户列表
此脚本将帮助你在终端上检查 10 天内到期的用户帐户列表。
```
# vi /opt/script/user-password-expiry.sh
```
```
#!/bin/sh
/tmp/user-expiry-1.txt
/tmp/user-expiry.txt
echo "-------------------------------------------------"
echo "UserName The number of days the password expires"
echo "-------------------------------------------------"
for usern in u1 u2 u3 u4
do
today=$(date +%s)
userexpdate=$(chage -l $usern | grep 'Password expires' |cut -d: -f2)
passexp=$(date -d "$userexpdate" "+%s")
exp=`expr \( $passexp - $today \)`
expday=`expr \( $exp / 86400 \)`
echo "$usern $expday" >> /tmp/user-expiry.txt
done
cat /tmp/user-expiry.txt | awk '$2 <= 10' > /tmp/user-expiry-1.txt
cat /tmp/user-expiry-1.txt | column -t
```
将文件 `user-password-expiry.sh` 设置为可执行的 Linux 文件权限。
```
# chmod +x /opt/script/user-password-expiry.sh
```
你将得到如下输出,但用户与天数可能不同。
```
# sh /opt/script/user-password-expiry.sh
-------------------------------------------------
UserName The number of days the password expires
-------------------------------------------------
u1 -25
u2 9
u3 3
u4 5
```
### 2) 发送包含 10 天内到期的用户帐户列表的电子邮件
此脚本将发送一封包含 10 天内到期的用户帐户列表的邮件。
```
# vi /opt/script/user-password-expiry-mail.sh
```
```
#!/bin/sh
SUBJECT="Information About User Password Expiration on "`date`""
MESSAGE="/tmp/user-expiry.txt"
MESSAGE1="/tmp/user-expiry-1.txt"
TO="[email protected]"
echo "-------------------------------------------------" >> $MESSAGE1
echo "UserName The number of days the password expires" >> $MESSAGE1
echo "-------------------------------------------------" >> $MESSAGE1
for usern in u1 u2 u3 u4
do
today=$(date +%s)
userexpdate=$(chage -l $usern | grep 'Password expires' |cut -d: -f2)
passexp=$(date -d "$userexpdate" "+%s")
exp=`expr \( $passexp - $today \)`
expday=`expr \( $exp / 86400 \)`
echo "$usern $expday" >> $MESSAGE
done
cat $MESSAGE | awk '$2 <= 10' >> $MESSAGE1
mail -s "$SUBJECT" "$TO" < $MESSAGE1
rm $MESSAGE
rm $MESSAGE1
```
将文件 `user-password-expiry-mail.sh` 设置为可执行的 Linux 文件权限。
```
# chmod +x /opt/script/user-password-expiry-mail.sh
```
最后,添加一个 [cronjob](https://www.2daygeek.com/linux-crontab-cron-job-to-schedule-jobs-task/) 去自动执行脚本。每天早上 8 点运行一次。
```
# crontab -e
0 8 * * * /bin/bash /opt/script/user-password-expiry-mail.sh
```
你将收到一封与第一个脚本输出类似的电子邮件。
---
via: <https://www.2daygeek.com/bash-script-to-check-user-account-password-expiry-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qianmingtian](https://github.com/qianmingtian) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,784 | 使用 Linux seq 命令生成数字序列 | https://www.networkworld.com/article/3511954/generating-numeric-sequences-with-the-linux-seq-command.html | 2020-01-15T11:28:31 | [
"seq"
] | https://linux.cn/article-11784-1.html |
>
> Linux 的 seq 命令可以以闪电般的速度生成数字列表,而且它也易于使用而且灵活。
>
>
>

在 Linux 中生成数字列表的最简单方法之一是使用 `seq`(<ruby> 系列 <rt> sequence </rt></ruby>)命令。其最简单的形式是,`seq` 接收一个数字参数,并输出从 1 到该数字的列表。例如:
```
$ seq 5
1
2
3
4
5
```
除非另有指定,否则 `seq` 始终以 1 开头。你可以在最终数字前面插上不同数字开始一个序列。
```
$ seq 3 5
3
4
5
```
### 指定增量
你还可以指定增量步幅。假设你要列出 3 的倍数。指定起点(在此示例中为第一个 3 ),增量(第二个 3)和终点(18)。
```
$ seq 3 3 18
3
6
9
12
15
18
```
你可以选择使用负增量(即减量)将数字从大变小。
```
$ seq 18 -3 3
18
15
12
9
6
3
```
`seq` 命令也非常快。你或许可以在 10 秒内生成一百万个数字的列表。
```
$ time seq 1000000
1
2
3
…
…
999998
999999
1000000
real 0m9.290s <== 9+ seconds
user 0m0.020s
sys 0m0.899s
```
### 使用分隔符
另一个非常有用的选项是使用分隔符。你可以插入逗号、冒号或其他一些字符,而不是在每行上列出单个数字。`-s` 选项后跟要使用的字符。
```
$ seq -s: 3 3 18
3:6:9:12:15:18
```
实际上,如果只是希望将数字列在一行上,那么可以使用空格代替默认的换行符。
```
$ seq -s' ' 3 3 18
3 6 9 12 15 18
```
### 开始数学运算
从生成数字序列到进行数学运算似乎是一个巨大的飞跃,但是有了正确的分隔符,`seq` 可以轻松地传递给 `bc` 进行计算。例如:
```
$ seq -s* 5 | bc
120
```
该命令中发生了什么?让我们来看看。首先,`seq` 生成一个数字列表,并使用 `*` 作为分隔符。
```
$ seq -s* 5
1*2*3*4*5
```
然后,它将字符串传递给计算器(`bc`),计算器立即将数字相乘。你可以在不到一秒的时间内进行相当庞大的计算。
```
$ time seq -s* 117 | bc
39699371608087208954019596294986306477904063601683223011297484643104\
22041758630649341780708631240196854767624444057168110272995649603642\
560353748940315749184568295424000000000000000000000000000
real 0m0.003s
user 0m0.004s
sys 0m0.000s
```
### 局限性
你只能选择一个分隔符,因此计算将非常有限。而单独使用 `bc` 可进行更复杂的数学运算。此外,`seq` 仅适用于数字。要生成单个字母的序列,请改用如下命令:
```
$ echo {a..g}
a b c d e f g
```
---
via: <https://www.networkworld.com/article/3511954/generating-numeric-sequences-with-the-linux-seq-command.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,786 | piwheels 是如何为树莓派用户节省时间的 | https://opensource.com/article/20/1/piwheels | 2020-01-15T13:05:43 | [
"树莓派",
"Python"
] | /article-11786-1.html |
>
> 通过为树莓派提供预编译的 Python 包,piwheels 项目为用户节省了大量的时间和精力。
>
>
>

piwheels 自动为 Python 包索引 [PiPi](https://pypi.org/) 上的所有项目构建 Python wheels(预编译的 Python包),并使用了树莓派硬件以确保其兼容性。这意味着,当树莓派用户想要使用 `pip` 安装一个 Python 库时,他们会得到一个现成编译好的版本,并保证可以在树莓派上良好的工作。这使得树莓派用户更容易入门并开始他们的项目。

当我在 2018 年 10 月写 [piwheels:为树莓派提供快速 Python 包安装](https://opensource.com/article/18/10/piwheels-python-raspberrypi)时,那时 piwheels 项目已经有一年了,并且已经证明了其为树莓派用户节省大量时间和精力。但当这个项目进入第二年时,它为树莓派提供了预编译的 Python 包做了更多工作。

### 它是怎么工作的
树莓派的主要操作系统 [Raspbian](https://www.raspberrypi.org/downloads/raspbian/) 预配置使用了 piwheels,所以用户不需要做任何特殊的事情就可以使用 piwheels。
配置文件(在 `/etc/pip.conf`)告诉 `pip` 使用 [piwheels.org](http://piwheels.org) 作*附加索引*,因此 `pip` 会首先查找 PyPI,然后查找 piwheels。piwheels 的网站被托管在一个树莓派 3 上,该项目构建的所有 wheels 都托管在该树莓派上。它每月提供 100 多万个软件包——这对于一台 35 美元的电脑来说还真不赖!
除了提供网站服务的主树莓派以外,piwheels 项目还使用其他七个树莓派来构建软件包。其中一些运行 Raspbian Jessie,为 Python 3.4 构建 wheels;另外一些运行 Raspbian Stretch 为 Python 3.5 构建;还有一些运行 Raspbian Buster 为 Python 3.7 构建。该项目通常不支持其他 Python 版本。还有一个“合适的服务器”——一台运行 Postgres 数据库的虚拟机。由于树莓派 3 只有 1GB 的内存,所以(非常大的)数据库不能在其上很好地运行,所以我们把它移到了虚拟机上。带 4GB 内存的树莓派 4 可能是合用的,所以我们将来可能会用到它。
这些树莓派都在“派云”中的 IPv6 网络上——这是一项由总部位于剑桥的托管公司 [Mythic Beasts](https://www.mythic-beasts.com/order/rpi) 提供的卓越服务。

### 下载和统计趋势
每次下载 piwheels 文件时,它都会记录在数据库中。这提供了对什么包最受欢迎以及人们使用什么 Python 版本和操作系统的统计。我们没有太多来自用户代理的信息,但是因为树莓派 1/Zero 的架构显示为 “armv6”,树莓派 2/¾ 显示为 “armv7”,所以我们可以将它们区分开来。
截至 2019 年 12 月中旬,从 piwheels 下载的软件包超过 1400 万个,仅 2019 年就有近 900 万个。
自项目开始以来最受欢迎的 10 个软件包是:
1. [pycparser](https://www.piwheels.org/project/pycparser)(821,060 个下载)
2. [PyYAML](https://www.piwheels.org/project/PyYAML)(366,979 个下载)
3. [numpy](https://www.piwheels.org/project/numpy)(354,531 个下载)
4. [cffi](https://www.piwheels.org/project/cffi)(336,982 个下载)
5. [MarkupSafe](https://www.piwheels.org/project/MarkupSafe)(318,878 个下载)
6. [future](https://www.piwheels.org/project/future)(282,349 个下载)
7. [aiohttp](https://www.piwheels.org/project/aiohttp)(277,046 个下载)
8. [cryptography](https://www.piwheels.org/project/cryptography)(276,167 个下载)
9. [home-assistant-frontend](https://www.piwheels.org/project/home-assistant-frontend)(266,667 个下载)
10. [multidict](https://www.piwheels.org/project/multidict)(256,185 个下载)
请注意,许多纯 Python 包,如 [urllib3](https://piwheels.org/project/urllib3/),都是作为 PyPI 上的 wheels 提供的;因为这些是跨平台兼容的,所以通常不会从 piwheels 下载,因为 PyPI 优先。
随着时间的推移,我们也看到了使用哪些 Python 版本的趋势。这里显示了 Raspbian Buster 发布时从 3.5 版快速升级到了 Python 3.7:

你可以在我们的这篇 [统计博文](https://blog.piwheels.org/piwheels-stats-for-2019/) 看到更多的统计趋势。
### 节省的时间
每个包构建都被记录在数据库中,并且每个下载也被存储。交叉引用下载数和构建时间显示了节省了多少时间。一个例子是 numpy —— 最新版本大约需要 11 分钟来构建。
迄今为止,piwheels 项目已经为用户节省了总计超过 165 年的构建时间。按照目前的使用率,piwheels 项目每天可以节省 200 多天。
除了节省构建时间,拥有预编译的 wheels 也意味着人们不必安装各种开发工具来构建包。一些包需要其他 apt 包来访问共享库。弄清楚你需要哪一个可能会很痛苦,所以我们也让这一步变得容易了。首先,我们找到了这个过程,[在博客上记录了这个过程](https://blog.piwheels.org/how-to-work-out-the-missing-dependencies-for-a-python-package/)。然后,我们将这个逻辑添加到构建过程中,这样当构建一个 wheels 时,它的依赖关系会被自动计算并添加到包的项目页面中:

### piwheels 的下一步是什么?
今年,我们推出了项目页面(例如,[numpy](https://www.piwheels.org/project/numpy/)),这是一种非常有用的方式,可以让人们以人类可读的方式查找项目信息。它们还使人们更容易报告问题,例如 piwheels 中缺少一个项目,或者他们下载的包有问题。
2020 年初,我们计划对 piwheels 项目进行一些升级,以启用新的 JSON 应用编程接口,这样你就可以自动检查哪些版本可用,查找项目的依赖关系,等等。
下一次 Debian/Raspbian 升级要到 2021 年年中才会发生,所以在那之前我们不会开始为任何新的 Python 版本构建 wheels。
你可以在这个项目的[博客](https://blog.piwheels.org/)上读到更多关于 piwheels 的信息,我将在 2020 年初在那里发表一篇 2019 年的综述。你也可以在推特上关注 [@piwheels](https://twitter.com/piwheels),在那里你可以看到每日和每月的统计数据以及任何达到的里程碑。
当然,piwheels 是一个开源项目,你可以在 [GitHub](https://github.com/piwheels/) 上看到整个项目源代码。
---
via: <https://opensource.com/article/20/1/piwheels>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,787 | 外媒:华为的 Linux 发行版 openEuler 可以使用了! | https://itsfoss.com/openeuler/ | 2020-01-16T10:57:36 | [
"EulerOS",
"openEuler",
"华为"
] | https://linux.cn/article-11787-1.html |
>
> 华为提供了一个基于 CentOS 的企业级 Linux 发行版 EulerOS。最近,华为发布了一个名为 [openEuler](https://openeuler.org/en/) 的 EulerOS 社区版。
>
>
>
openEuler 的源代码也一同发布了。你在微软旗下的 GitHub 上找不到它——源代码可以在 [Gitee](https://gitee.com/openeuler) 找到,这是一个中文的 [GitHub 的替代品](https://itsfoss.com/github-alternatives/)。
它有两个独立的存储库,一个用于存储[源代码](https://gitee.com/openeuler);另一个作为[软件包的源代码](https://gitee.com/src-openeuler),存储有助于构建该操作系统的软件包。

openEuler 基础架构团队分享了他们使源代码可用的经验:
>
> 我们现在很兴奋。很难想象我们会管理成千上万的仓库。为了确保它们能被成功地编译,我们要感谢所有参与贡献的人。
>
>
>
### openEuler 是基于 CentOS 的 Linux 发行版
与 EulerOS 一样,openEuler OS 也是基于 [CentOS](https://www.centos.org/),但华为技术有限公司为企业应用进一步开发了该操作系统。
它是为 ARM64 架构的服务器量身定做的,同时华为声称已经做了一些改变来提高其性能。你可以在[华为开发博客](https://developer.huaweicloud.com/en-us/euleros/euleros-introduction.html)上了解更多。

目前,根据 openEuler 的官方声明,有 50 多名贡献者为 openEuler 贡献了近 600 个提交。
贡献者们使源代码对社区可用成为可能。
值得注意的是,存储库还包括两个与之相关的新项目(或子项目),[iSulad](https://gitee.com/openeuler/iSulad) 和 A-Tune。
A-Tune 是一个基于 AI 的操作系统调优软件,iSulad 是一个轻量级的容器运行时守护进程,如在 [Gitee](https://gitee.com/openeuler) 中提到的那样,它是为物联网和云基础设施设计的。
另外,官方的[公告](https://openeuler.org/en/news/20200101.html)提到,这些系统是在华为云上通过脚本自动构建的。这确实十分有趣。
### 下载 openEuler

到目前为止,你找不到它的英文文档,所以你必须等待或选择通过(贡献)[文档](https://gitee.com/openeuler/docs)来帮助他们。
你可以直接从它的[官方网站](https://openeuler.org/en/download.html)下载 ISO 来测试它:
* [下载 openEuler](https://openeuler.org/en/download.html)
### 你认为华为的 openEuler 怎么样?
据 cnTechPost 报道,华为曾宣布 EulerOS 将以新名字 openEuler 成为开源软件。
目前还不清楚 openEuler 是否会取代 EulerOS ,或者两者会像 CentOS(社区版)和 Red Hat(商业版)一样同时存在。
我还没有测试过它,所以我不能说 openEuler 是否适合英文用户。
你愿意试一试吗?如果你已经尝试过了,欢迎在下面的评论中告诉我你的体验。
---
via: <https://itsfoss.com/openeuler/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qianmingtian]((https://github.com/qianmingtian)) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Huawei offers a CentOS based enterprise Linux distribution called EulerOS. Recently, Huawei has released a community edition of EulerOS called [openEuler](https://openeuler.org/en/).
The source code of openEuler is released as well. You won’t find it on Microsoft owned GitHub – the source code is available at [Gitee](https://gitee.com/openeuler), a Chinese [alternative of GitHub](https://itsfoss.com/github-alternatives/).
There are two separate repositories, one for the [source code](https://gitee.com/openeuler) and the other as a [package source](https://gitee.com/src-openeuler) to store software packages that help to build the OS.

The openEuler infrastructure team shared their experience to make the source code available:
We are very excited at this moment. It was hard to imagine that we will manage thousands of repositories. And to ensure that they can be compiled successfully, we would like to thank all those who participated in contributing
## openEuler is a Linux distribution based on CentOS
Like EulerOS, openEuler OS is also based on [CentOS](https://www.centos.org/) but is further developed by Huawei Technologies for enterprise applications.
It is tailored for ARM64 architecture servers and Huawei claims to have made changes to boost its performance. You can read more about it at [Huawei’s dev blog](https://developer.huaweicloud.com/en-us/euleros/euleros-introduction.html).
At the moment, as per the official openEuler announcement, there are more than 50 contributors with nearly 600 commits for openEuler.
The contributors made it possible to make the source code available to the community.
It is also worth noting that the repositories also include two new projects (or sub-projects) associated with it, [iSulad](https://gitee.com/openeuler/iSulad)** and A-Tune**.
A-Tune is an AI-based OS tuning software and iSulad is a lightweight container runtime daemon that is designed for IoT and Cloud infrastructure, as mentioned on [Gitee](https://gitee.com/openeuler).
Also, the official [announcement post](https://openeuler.org/en/news/20200101.html) mentioned that these systems are built on the Huawei Cloud through script automation. So, that is definitely something interesting.
## Downloading openEuler

As of now, you won’t find the documentation for it in English – so you will have to wait for it or choose to help them with the [documentation](https://gitee.com/openeuler/docs).
You can download the ISO directly from its [official website](https://openeuler.org/en/download.html) to test it out:
## What do you think of Huawei openEuler?
As per cnTechPost, Huawei had announced that EulerOS would become open source under the new name openEuler.
At this point, it’s not clear if openEuler is replacing EulerOS or both will exist together like CentOS (community edition) and Red Hat (commercial edition).
I haven’t tested it yet so I cannot say if openEuler is suitable for English speaking users or not.
My teammate Abhishek tried to use openEuler but the ISO provided on their website is not suitable for making a bootable USB. This is the error it shows:
An incomplete website, broken ISO. It seems Huawei was in too much of a hurry and didn’t prepare things very well.
[interaction id=”5e1740b087e704664d6077a8″]
Are you willing to give this a try? In case you managed to try it out, feel free to let me know your experience with it in the comments below. |
11,788 | 如何使用 Pyramid 和 Cornice 编写 Python Web API | https://opensource.com/article/20/1/python-web-api-pyramid-cornice | 2020-01-16T12:04:50 | [
"Pyramid",
"Python"
] | /article-11788-1.html |
>
> 使用 Pyramid 和 Cornice 构建和描述可扩展的 RESTful Web 服务。
>
>
>

[Python](https://opensource.com/resources/python) 是一种高级的、面向对象的编程语言,它以其简单的语法而闻名。它一直是构建 RESTful API 的顶级编程语言之一。
[Pyramid](https://opensource.com/article/18/5/pyramid-framework) 是一个 Python Web 框架,旨在随着应用的扩展而扩展:这可以让简单的应用很简单,也可以增长为大型、复杂的应用。此外,Pyramid 为 PyPI (Python 软件包索引)提供了强大的支持。[Cornice](https://cornice.readthedocs.io/en/latest/) 为使用 Pyramid 构建和描述 RESTful Web 服务提供了助力。
本文将使用 Web 服务的例子来获取名人名言,来展示如何使用这些工具。
### 建立 Pyramid 应用
首先为你的应用创建一个虚拟环境,并创建一个文件来保存代码:
```
$ mkdir tutorial
$ cd tutorial
$ touch main.py
$ python3 -m venv env
$ source env/bin/activate
(env) $ pip3 install cornice twisted
```
### 导入 Cornice 和 Pyramid 模块
使用以下命令导入这些模块:
```
from pyramid.config import Configurator
from cornice import Service
```
### 定义服务
将引用服务定义为 `Service` 对象:
```
QUOTES = Service(name='quotes',
path='/',
description='Get quotes')
```
### 编写引用逻辑
到目前为止,这仅支持获取名言。用 `QUOTES.get` 装饰函数。这是将逻辑绑定到 REST 服务的方法:
```
@QUOTES.get()
def get_quote(request):
return {
'William Shakespeare': {
'quote': ['Love all, trust a few, do wrong to none',
'Some are born great, some achieve greatness, and some have greatness thrust upon them.']
},
'Linus': {
'quote': ['Talk is cheap. Show me the code.']
}
}
```
请注意,与其他框架不同,装饰器*不会*更改 `get_quote` 函数。如果导入此模块,你仍然可以定期调用该函数并检查结果。
在为 Pyramid RESTful 服务编写单元测试时,这很有用。
### 定义应用对象
最后,使用 `scan` 查找所有修饰的函数并将其添加到配置中:
```
with Configurator() as config:
config.include("cornice")
config.scan()
application = config.make_wsgi_app()
```
默认扫描当前模块。如果要扫描软件包中的所有模块,你也可以提供软件包的名称。
### 运行服务
我使用 Twisted 的 WSGI 服务器运行该应用,但是如果需要,你可以使用任何其他 [WSGI](https://en.wikipedia.org/wiki/Web_Server_Gateway_Interface) 服务器,例如 Gunicorn 或 uWSGI。
```
(env)$ python -m twisted web --wsgi=main.application
```
默认情况下,Twisted 的 WSGI 服务器运行在端口 8080 上。你可以使用 [HTTPie](https://opensource.com/article/19/8/getting-started-httpie) 测试该服务:
```
(env) $ pip install httpie
...
(env) $ http GET <http://localhost:8080/>
HTTP/1.1 200 OK
Content-Length: 220
Content-Type: application/json
Date: Mon, 02 Dec 2019 16:49:27 GMT
Server: TwistedWeb/19.10.0
X-Content-Type-Options: nosniff
{
"Linus": {
"quote": [
"Talk is cheap. Show me the code."
]
},
"William Shakespeare": {
"quote": [
"Love all,trust a few,do wrong to none",
"Some are born great, some achieve greatness, and some greatness thrust upon them."
]
}
}
```
### 为什么要使用 Pyramid?
Pyramid 并不是最受欢迎的框架,但它已在 [PyPI](https://pypi.org/) 等一些引人注目的项目中使用。我喜欢 Pyramid,因为它是认真对待单元测试的框架之一:因为装饰器不会修改函数并且没有线程局部变量,所以可以直接从单元测试中调用函数。例如,需要访问数据库的函数将从通过 `request.config` 传递的 `request.config` 对象中获取它。这允许单元测试人员将模拟(或真实)数据库对象放入请求中,而不用仔细设置全局变量、线程局部变量或其他特定于框架的东西。
如果你正在寻找一个经过测试的库来构建你接下来的 API,请尝试使用 Pyramid。你不会失望的。
---
via: <https://opensource.com/article/20/1/python-web-api-pyramid-cornice>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,790 | 为你的 Python 平台类游戏添加跳跃功能 | https://opensource.com/article/19/12/jumping-python-platformer-game | 2020-01-16T21:49:55 | [
"Pygame"
] | /article-11790-1.html |
>
> 在本期使用 Python Pygame 模块编写视频游戏中,学会如何使用跳跃来对抗重力。
>
>
>

在本系列的 [前一篇文章](/article-11780-1.html) 中,你已经模拟了重力。但现在,你需要赋予你的角色跳跃的能力来对抗重力。
跳跃是对重力作用的暂时延缓。在这一小段时间里,你是向*上*跳,而不是被重力拉着向下落。但你一旦到达了跳跃的最高点,重力就会重新发挥作用,将你拉回地面。
在代码中,这种变化被表示为变量。首先,你需要为玩家精灵建立一个变量,使得 Python 能够跟踪该精灵是否正在跳跃中。一旦玩家精灵开始跳跃,他就会再次受到重力的作用,并被拉回最近的物体。
### 设置跳跃状态变量
你需要为你的 `Player` 类添加两个新变量:
* 一个是为了跟踪你的角色是否正在跳跃中,可通过你的玩家精灵是否站在坚实的地面来确定
* 一个是为了将玩家带回地面
将如下两个变量添加到你的 `Player` 类中。在下方的代码中,注释前的部分用于提示上下文,因此只需要添加最后两行:
```
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
# 此处是重力相关变量
self.collide_delta = 0
self.jump_delta = 6
```
第一个变量 `collide_delta` 被设为 0 是因为在正常状态下,玩家精灵没有处在跳跃中的状态。另一个变量 `jump_delta` 被设为 6,是为了防止精灵在第一次进入游戏世界时就发生反弹(实际上就是跳跃)。当你完成了本篇文章的示例,尝试把该变量设为 0 看看会发生什么。
### 跳跃中的碰撞
如果你是跳到一个蹦床上,那你的跳跃一定非常优美。但是如果你是跳向一面墙会发生什么呢?(千万不要去尝试!)不管你的起跳多么令人印象深刻,当你撞到比你更大更硬的物体时,你都会立马停下。(LCTT 译注:原理参考动量守恒定律)
为了在你的视频游戏中模拟这一点,你需要在你的玩家精灵与地面等东西发生碰撞时,将 `self.collide_delta` 变量设为 0。如果你的 `self.collide_delta` 不是 0 而是其它的什么值,那么你的玩家就会发生跳跃,并且当你的玩家与墙或者地面发生碰撞时无法跳跃。
在你的 `Player` 类的 `update` 方法中,将地面碰撞相关代码块修改为如下所示:
```
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.y = worldy-ty-ty
self.collide_delta = 0 # 停止跳跃
if self.rect.y > g.rect.y:
self.health -=1
print(self.health)
```
这段代码块检查了地面精灵和玩家精灵之间发生的碰撞。当发生碰撞时,它会将玩家 Y 方向的坐标值设置为游戏窗口的高度减去一个瓷砖的高度再减去另一个瓷砖的高度。以此保证了玩家精灵是站在地面*上*,而不是嵌在地面里。同时它也将 `self.collide_delta` 设为 0,使得程序能够知道玩家未处在跳跃中。除此之外,它将 `self.movey` 设为 0,使得程序能够知道玩家当前未受到重力的牵引作用(这是游戏物理引擎的奇怪之处,一旦玩家落地,也就没有必要继续将玩家拉向地面)。
此处 `if` 语句用来检测玩家是否已经落到地面之*下*,如果是,那就扣除一点生命值作为惩罚。此处假定了你希望当你的玩家落到地图之外时失去生命值。这个设定不是必需的,它只是平台类游戏的一种惯例。更有可能的是,你希望这个事件能够触发另一些事件,或者说是一种能够让你的现实世界玩家沉迷于让精灵掉到屏幕之外的东西。一种简单的恢复方式是在玩家精灵掉落到地图之外时,将 `self.rect.y` 重新设置为 0,这样它就会在地图上方重新生成,并落到坚实的地面上。
### 撞向地面
模拟的重力使你玩家的 Y 坐标不断增大(LCTT 译注:此处原文中为 0,但在 Pygame 中越靠下方 Y 坐标应越大)。要实现跳跃,完成如下代码使你的玩家精灵离开地面,飞向空中。
在你的 `Player` 类的 `update` 方法中,添加如下代码来暂时延缓重力的作用:
```
if self.collide_delta < 6 and self.jump_delta < 6:
self.jump_delta = 6*2
self.movey -= 33 # 跳跃的高度
self.collide_delta += 6
self.jump_delta += 6
```
根据此代码所示,跳跃使玩家精灵向空中移动了 33 个像素。此处是*负* 33 是因为在 Pygame 中,越小的数代表距离屏幕顶端越近。
不过此事件视条件而定,只有当 `self.collide_delta` 小于 6(缺省值定义在你 `Player` 类的 `init` 方法中)并且 `self.jump_delta` 也于 6 的时候才会发生。此条件能够保证直到玩家碰到一个平台,才能触发另一次跳跃。换言之,它能够阻止空中二段跳。
在某些特殊条件下,你可能不想阻止空中二段跳,或者说你允许玩家进行空中二段跳。举个栗子,如果玩家获得了某个战利品,那么在他被敌人攻击到之前,都能够拥有空中二段跳的能力。
当你完成本篇文章中的示例,尝试将 `self.collide_delta` 和 `self.jump_delta` 设置为 0,从而获得百分之百的几率触发空中二段跳。
### 在平台上着陆
目前你已经定义了在玩家精灵摔落地面时的抵抗重力条件,但此时你的游戏代码仍保持平台与地面置于不同的列表中(就像本文中做的很多其他选择一样,这个设定并不是必需的,你可以尝试将地面作为另一种平台)。为了允许玩家精灵站在平台之上,你必须像检测地面碰撞一样,检测玩家精灵与平台精灵之间的碰撞。将如下代码放于你的 `update` 方法中:
```
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.collide_delta = 0 # 跳跃结束
self.movey = 0
```
但此处还有一点需要考虑:平台悬在空中,也就意味着玩家可以通过从上面或者从下面接触平台来与之互动。
确定平台如何与玩家互动取决于你,阻止玩家从下方到达平台也并不稀奇。将如下代码加到上方的代码块中,使得平台表现得像天花板或者说是藤架。只有在玩家精灵跳得比平台上沿更高时才能跳到平台上,但会阻止玩家从平台下方跳上来:
```
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
```
此处 `if` 语句代码块的第一个子句阻止玩家精灵从平台正下方跳到平台上。如果它检测到玩家精灵的坐标比平台更大(在 Pygame 中,坐标更大意味着在屏幕的更下方),那么将玩家精灵新的 Y 坐标设置为当前平台的 Y 坐标加上一个瓷砖的高度。实际效果就是保证玩家精灵距离平台一个瓷砖的高度,防止其从下方穿过平台。
`else` 子句做了相反的事情。当程序运行到此处时,如果玩家精灵的 Y 坐标*不*比平台的更大,意味着玩家精灵是从空中落下(不论是由于玩家刚刚从此处生成,或者是玩家执行了跳跃)。在这种情况下,玩家精灵的 Y 坐标被设为平台的 Y 坐标减去一个瓷砖的高度(切记,在 Pygame 中更小的 Y 坐标代表在屏幕上的更高处)。这样就能保证玩家在平台*上*,除非他从平台上跳下来或者走下来。
你也可以尝试其他的方式来处理玩家与平台之间的互动。举个栗子,也许玩家精灵被设定为处在平台的“前面”,他能够无障碍地跳跃穿过平台并站在上面。或者你可以设计一种平台会减缓而又不完全阻止玩家的跳跃过程。甚至你可以通过将不同平台分到不同列表中来混合搭配使用。
### 触发一次跳跃
目前为此,你的代码已经模拟了所有必需的跳跃条件,但仍缺少一个跳跃触发器。你的玩家精灵的 `self.jump_delta` 初始值被设置为 6,只有当它比 6 小的时候才会触发更新跳跃的代码。
为跳跃变量设置一个新的设置方法,在你的 `Player` 类中创建一个 `jump` 方法,并将 `self.jump_delta` 设为小于 6 的值。通过使玩家精灵向空中移动 33 个像素,来暂时减缓重力的作用。
```
def jump(self,platform_list):
self.jump_delta = 0
```
不管你相信与否,这就是 `jump` 方法的全部。剩余的部分在 `update` 方法中,你已经在前面实现了相关代码。
要使你游戏中的跳跃功能生效,还有最后一件事情要做。如果你想不起来是什么,运行游戏并观察跳跃是如何生效的。
问题就在于你的主循环中没有调用 `jump` 方法。先前你已经为该方法创建了一个按键占位符,现在,跳跃键所做的就是将 `jump` 打印到终端。
### 调用 jump 方法
在你的主循环中,将*上*方向键的效果从打印一条调试语句,改为调用 `jump` 方法。
注意此处,与 `update` 方法类似,`jump` 方法也需要检测碰撞,因此你需要告诉它使用哪个 `plat_list`。
```
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump(plat_list)
```
如果你倾向于使用空格键作为跳跃键,使用 `pygame.K_SPACE` 替代 `pygame.K_UP` 作为按键。另一种选择,你可以同时使用两种方式(使用单独的 `if` 语句),给玩家多一种选择。
现在来尝试你的游戏吧!在下一篇文章中,你将让你的游戏卷动起来。

以下是目前为止的所有代码:
```
#!/usr/bin/env python3
# draw a world
# add a player and player control
# add player movement
# add enemy and basic collision
# add platform
# add gravity
# add jumping
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
import pygame
import sys
import os
'''
Objects
'''
class Platform(pygame.sprite.Sprite):
# x 坐标,y 坐标,图像宽度,图像高度,图像文件
def __init__(self,xloc,yloc,imgw,imgh,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img)).convert()
self.image.convert_alpha()
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
'''
生成一个玩家
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.collide_delta = 0
self.jump_delta = 6
self.score = 1
self.images = []
for i in range(1,9):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def jump(self,platform_list):
self.jump_delta = 0
def gravity(self):
self.movey += 3.2 # how fast player falls
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty
def control(self,x,y):
'''
控制玩家移动
'''
self.movex += x
self.movey += y
def update(self):
'''
更新精灵位置
'''
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# 向左移动
if self.movex < 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[self.frame//ani]
# 向右移动
if self.movex > 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
# 碰撞
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in enemy_hit_list:
self.health -= 1
#print(self.health)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.collide_delta = 0 # stop jumping
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.y = worldy-ty-ty
self.collide_delta = 0 # stop jumping
if self.rect.y > g.rect.y:
self.health -=1
print(self.health)
if self.collide_delta < 6 and self.jump_delta < 6:
self.jump_delta = 6*2
self.movey -= 33 # how high to jump
self.collide_delta += 6
self.jump_delta += 6
class Enemy(pygame.sprite.Sprite):
'''
生成一个敌人
'''
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.movey = 0
#self.image.convert_alpha()
#self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
'''
敌人移动
'''
distance = 80
speed = 8
self.movey += 3.2
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
if not self.rect.y >= worldy-ty-ty:
self.rect.y += self.movey
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.rect.y = worldy-ty-ty
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # 生成敌人
enemy_list = pygame.sprite.Group() # 创建敌人组
enemy_list.add(enemy) # 将敌人添加到敌人组
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
def loot(lvl,lloc):
print(lvl)
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
def platform(lvl,tx,ty):
plat_list = pygame.sprite.Group()
ploc = []
i=0
if lvl == 1:
ploc.append((0,worldy-ty-128,3))
ploc.append((300,worldy-ty-256,3))
ploc.append((500,worldy-ty-128,4))
while i < len(ploc):
j=0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
plat_list.add(plat)
j=j+1
print('run' + str(i) + str(ploc[i]))
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
'''
Setup
'''
worldx = 960
worldy = 720
fps = 40 # 帧率
ani = 4 # 动画循环
clock = pygame.time.Clock()
pygame.init()
main = True
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
ALPHA = (0,255,0)
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = world.get_rect()
player = Player() # 生成玩家
player.rect.x = 0
player.rect.y = 0
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10 # how fast to move
jump = -24
eloc = []
eloc = [200,20]
gloc = []
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
tx = 64 # 瓷砖尺寸
ty = 64 # 瓷砖尺寸
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,gloc,tx,ty )
plat_list = Level.platform( 1,tx,ty )
'''
主循环
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print("LEFT")
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print("RIGHT")
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump(plat_list)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
# world.fill(BLACK)
world.blit(backdrop, backdropbox)
player.gravity() # 检查重力
player.update()
player_list.draw(world) # 刷新玩家位置
enemy_list.draw(world) # 刷新敌人
ground_list.draw(world) # 刷新地面
plat_list.draw(world) # 刷新平台
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
本期是使用 [Pygame](https://www.pygame.org/) 模块在 [Python 3](https://www.python.org/) 中创建视频游戏连载系列的第 7 期。往期文章为:
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
* [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
* [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
* [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
* [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
* [在 Pygame 游戏中放置平台](/article-10902-1.html)
* [在你的 Python 游戏中模拟引力](/article-11780-1.html)
---
via: <https://opensource.com/article/19/12/jumping-python-platformer-game>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,791 | 为什么你的发行版仍然在使用“过时的”Linux 内核? | https://itsfoss.com/why-distros-use-old-kernel/ | 2020-01-16T22:59:00 | [
"内核"
] | https://linux.cn/article-11791-1.html | 
[检查一下你的系统所使用的 Linux 内核版本](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/),你十有八九会发现,按照 Linux 内核官网提供的信息,该内核版本已经达到使用寿命终期(EOL)了。
一个软件一旦达到了使用寿命终期,那么就意味着它再也不会得到 bug 修复和维护了。
这自然会引发一连串问题:为什么我的 Linux 发行版会使用一个已经达到使用寿命终期的内核呢?这样做有没有安全风险?我的系统还安全吗?
下面将逐一解答这些问题。
>
> **总结**
>
>
> 上游内核维护与你的发行版的内核维护是两个不同的概念。
>
>
> 例如,根据 Linux 内核官网,Linux 内核 4.15 版本可能已经达到使用寿命终期了,但是在 2023 年 4 月之前,Ubuntu 18.04 长期维护版本将会继续使用这个版本,并通过向后移植安全补丁和修复 bug 来提供维护。
>
>
>
### 检查 Linux 内核版本,以及是否达到使用寿命终期
首先,查看你的系统所使用的 Linux 内核版本:
```
uname -r
```
我使用的是 Ubuntu 18.04,输出的 Linux 内核版本如下:
```
abhishek@itsfoss:~$ uname -r
5.0.0-37-generic
```
接下来,可以到 [Linux 内核官网](https://www.kernel.org/)上看看哪些 Linux 内核版本仍然在维护状态。在网站主页上就可以看到相关信息。
你看到的内核版本状态应该类似于下图:

如果你的内核版本没有列在内核官网主页上,就说明该版本已经达到了使用寿命终期。
可以看到,5.0 内核版本并不在列,这说明该内核版本已经不再得到维护。事实上,该版本在 [2019 年 6 月就已经达到使用寿命终期了](http://lkml.iu.edu/hypermail/linux/kernel/1906.0/02354.html)。
不幸的是,Linux 内核的生命周期没有任何规律可循。不是说常规的内核稳定发布版可以得到 X 月的维护、长期维护版本(LTS)可以得到 Y 年的维护。没有这回事。
根据实际需求,可能会存在内核的多个 LTS 版本,其使用寿命终期各不相同。在[这个页面](https://www.kernel.org/category/releases.html)上可以查到这些 LTS 版本的相关信息,包括计划的使用寿命终期。
那么问题来了:既然 Linux 内核官网上明确表示 5.0 版本的内核已经达到了使用寿命终期,Ubuntu 为什么还在提供这个内核版本呢?
### 你的发行版使用的 Linux 内核已经达到了使用寿命终期,但是没关系!

你是否想过,为什么 Ubuntu/Debian/Fedora 等发行版被称为 Linux “发行版”?这是因为,它们“发行” Linux 内核。
这些发行版会对 Linux 内核进行不同的修改,并添加各种 GUI 元素(包括桌面环境、显示服务器等)以及软件,然后再呈现给用户。
按照通常的工作流,Linux 发行版会选择一个内核,提供给其用户,然后在接下来的几个月、几年中,甚至是达到内核的使用寿命终期之后,仍然会继续使用该内核。
这样能够保障安全吗?其实是可以的,因为 **发行版会通过向后移植全部的重要修补来维护内核**。
换句话说,你的 Linux 发行版会确保 Linux 内核没有漏洞和 bug,并且已经通过向后移植获得了重要的新特性。在“过时的旧版本 Linux 内核”上,其实有着数以千计的改动。
如果 Linux 内核网站上说某个内核版本已经达到了使用寿命终期,那么就意味着 Linux 内核的核心维护团队不会再对该内核版本进行升级和打补丁了。
但与此同时,Debian/Ubuntu 或者其他发行版的开发者们会继续工作,通过从(由内核核心团队维护的)更新的内核版本中迁移相关的修改,维持这个老版本的生命力。
重点在于,即使你的发行版看上去是在使用一个已经过时的 Linux 内核,其实该内核也得到了良好的维护,并非是真的过时了。
### 你是否应该使用最新的稳定内核版本?

新的 Linux 内核稳定版本每隔 2 到 3 个月发布一次,有不少用户跃跃欲试。
实话说,除非有十分充分的理由,否则不应该使用最新版本的稳定内核。你使用的发行版并不会提供这个选项,你也不能指望通过在键盘上敲出 `sudo apt give-me-the-latest-stable-kernel` 解决问题。
此外,手动[安装主流 Linux 内核版本](https://wiki.ubuntu.com/Kernel/MainlineBuilds)本身就是一个挑战。即使安装成功,之后每次发布 bug 修复的时候,负责更新内核的就会是你了。此外,当新内核达到使用寿命终期之后,你就有责任将它升级到更新的内核版本了。和常规的 [Ubuntu 更新](https://itsfoss.com/update-ubuntu/)不同,内核升级无法通过 `apt upgrade` 完成。
同样需要记住的是,切换到主流内核之后,可能就无法使用你的发行版提供的一些驱动程序和补丁了。
正如 [Greg Kroah-Hartman](https://en.wikipedia.org/wiki/Greg_Kroah-Hartman)所言,“**你能使用的最好的内核,就是别人在维护的内核。**”除了你的 Linux 发行版之外,又有谁更胜任这份工作呢!
希望你对这个主题已经有了更好的理解。下回发现你的系统正在使用的内核版本已经达到使用寿命终期的时候,希望你不会感到惊慌失措。
欢迎在下面的评论区中留下你的疑问或建议。
---
via: <https://itsfoss.com/why-distros-use-old-kernel/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chen-ni](https://github.com/chen-ni) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Check your Linux kernel version](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/). Chances are that you’ll find that the kernel version your system is using has already reached end of life (EOL) as listed on Linux Kernel website.
End of life means the software won’t get bug fixes and support anymore.v
That poses some valid questions. Why is my Linux distribution using a kernel that has reached the end of life? Is this not a security risk? Is my system safe?
Let me explain all these questions in this article.
## Checking Linux kernel version and finding its end of life status
Let’s first check the Linux kernel version on your system:
`uname -r`
I am using Ubuntu 18.04 here and it shows the Linux kernel version like this:
```
abhishek@itsfoss:~$ uname -r
5.0.0-37-generic
```
Now, you may go to the official Linux kernel website and see what Linux kernels are still being supported. It’s displayed on the homepage itself.
You should see a status like this:
If you don’t see a kernel version listed on the homepage of the kernel website, it means that the specific version has reached the end of life.
As you can see, kernel 5.0 is not listed here. It indicates that this kernel version is not being supported anymore. Actually, it [reached end of life in June 2019](http://lkml.iu.edu/hypermail/linux/kernel/1906.0/02354.html).
The life cycle of a Linux kernel doesn’t follow a set pattern, unfortunately. It’s NOT like a regular kernel stable release will be supported for X months and a long term support(LTS) kernel will be supported for Y years.
Based on the demand and requirements, there could be several LTS kernel versions with different EOL. You can find them along with their projected EOL on [this page](https://www.kernel.org/category/releases.html).
Now comes the big question. Why is Ubuntu providing kernel 5.0 if the Linux kernel website shows that it has reached its end of life?
## Your distribution uses an EOL Linux kernel but that’s Okay!

Have you ever wondered why Ubuntu/Debian/Fedora etc are called Linux distributions? It’s because they ‘distribute’ the Linux kernel.
They have their own modification of the Linux kernel, they add the GUI elements ([desktop environment](https://itsfoss.com/what-is-desktop-environment/), [display server](https://itsfoss.com/display-server/) etc) and software and they make it available to their users.
In the typical workflow, a Linux distribution will choose a kernel to provide to its users. And then it will hold on to this kernel for months or years even after the kernel has reached end of life.
How is it safe then? It’s because the **distribution maintains the kernel by backporting all the important fixes to its kernel**.
In other words, your Linux distribution makes sure that your Linux kernel is patched well and has all the bug fixes and important new features backported to it. There will be thousands of changes on top of the ‘old outdated Linux kernel’.
When the Linux kernel website says that a certain kernel version has reached EOL, it means that the core Linux kernel maintainers are not going to update/patch that kernel version anymore.
But at the same time, the developers at Debian/Ubuntu or other distributions work to keep the same old version alive by bringing the relevant changes from the newer kernel versions (being maintained by the core kernel team) to your distribution’s old kernel.
Bottom line is that even if it seems like your distribution is using an outdated Linux kernel, it is actually being well maintained and not really outdated.
## Should you use the latest stable kernel version?

A new stable Linux kernel version is released every 2-3 months. And this makes many users wonder how they can get their hands on that new shiny thing.
To be frank, you should not do that unless you have a pretty good reason for it. Your distribution doesn’t provide it to you. You cannot just use ‘* sudo apt give-me-the-latest-stable-kernel' *in most distributions.
Now, manually [installing the mainline Linux kernel version](https://wiki.ubuntu.com/Kernel/MainlineBuilds) could be a challenge in itself. Even if you manage to install it, it is now up to you to make sure that this kernel is updated every time there is a bug fix. And when this new kernel reaches end of life, it becomes your responsibility to upgrade to the newer kernel version. It won’t be handled with `apt upgrade`
like regular [Ubuntu updates](https://itsfoss.com/update-ubuntu/).
You should also keep in mind that your distribution also has drivers and patches which you may not be able to use if you switch to the mainline kernel.
As [Greg Kroah-Hartman](https://en.wikipedia.org/wiki/Greg_Kroah-Hartman) puts it, “*the best kernel you can use is one that someone else supports*“. And who can be better at this job than your Linux distribution?
I hope you have a better understanding on this topic and you won’t panic the next time you find out that the kernel version your system is using has reached the end of life.
I welcome your questions and suggestions. Please feel free to use the comment section. |
11,793 | 使用 Syncthing 在多个设备间同步文件 | https://opensource.com/article/20/1/sync-files-syncthing | 2020-01-18T12:34:28 | [
"Syncthing",
"同步"
] | https://linux.cn/article-11793-1.html |
>
> 2020 年,在我们的 20 个使用开源提升生产力的系列文章中,首先了解如何使用 Syncthing 同步文件。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 Synthing 同步文件
设置新机器很麻烦。我们都有在机器之间复制的“标准设置”。多年来,我使用了很多方法来使它们在计算机之间同步。在过去(这会告诉你我年纪有多大了),曾经是软盘、然后是 Zip 磁盘、U 盘、SCP、Rsync、Dropbox、ownCloud,你想到的都试过。但这些似乎对我都不够好。
然后我偶然发现了 [Syncthing](https://syncthing.net/)。

Syncthing 是一个轻量级的点对点文件同步系统。你不需要为服务付费,也不需要第三方服务器,而且速度很快。以我的经验,比文件同步中的许多“大牌”要快得多。
Syncthing 可在 Linux、MacOS、Windows 和多种 BSD 中使用。还有一个 Android 应用(但尚无官方 iOS 版本)。以上所有终端都有方便的图形化前端(尽管我不会在这里介绍)。在 Linux 上,大多数发行版都有可用的软件包,因此安装非常简单。

首次启动 Syncthing 时,它将启动 Web 浏览器以配置守护程序。第一台计算机上没有太多要做,但是这是一个很好的机会来介绍一下用户界面 (UI)。最重要的是在右上方的 “Actions” 菜单下的 “System ID”。

设置第一台计算机后,请在第二台计算机上重复安装。在 UI 中,右下方将显示一个按钮,名为 “Add Remote Device”。单击该按钮,你将会看到一个要求输入 “Device ID and a Name” 的框。从第一台计算机上复制并粘贴 “Device ID”,然后单击 “Save”。
你应该会在第一台上看到一个请求添加第二台的弹出窗口。接受后,新机器将显示在第一台机器的右下角。与第二台计算机共享默认目录。单击 “Default Folder”,然后单击 “Edit” 按钮。弹出窗口的顶部有四个链接。单击 “Sharing”,然后选择第二台计算机。单击 “Save”,然后查看第二台计算机。你会看到一个接受共享目录的提示。接受后,它将开始在两台计算机之间同步文件。

测试从一台计算机上复制文件到默认目录(“/你的家目录/Share”)。它应该很快会在另一台上出现。
你可以根据需要添加任意数量的目录,这非常方便。如你在第一张图中所看到的,我有一个用于保存配置的 `myconfigs` 文件夹。当我买了一台新机器时,我只需安装 Syncthing,如果我在一台机器上调整了配置,我不必更新所有,它会自动更新。
---
via: <https://opensource.com/article/20/1/sync-files-syncthing>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Syncing files with Synthing
Setting up a new machine is a pain. We all have our "standard setups" that we copy from machine to machine. And over the years, I've used a lot of ways to keep them in sync between machines. In the old days (and this will tell you how old I am), it was with floppy disks, then Zip disks, USB sticks, SCP, Rsync, Dropbox, ownCloud—you name it. And they never seemed to work right for me.
Then I stumbled upon [Syncthing](https://syncthing.net/).
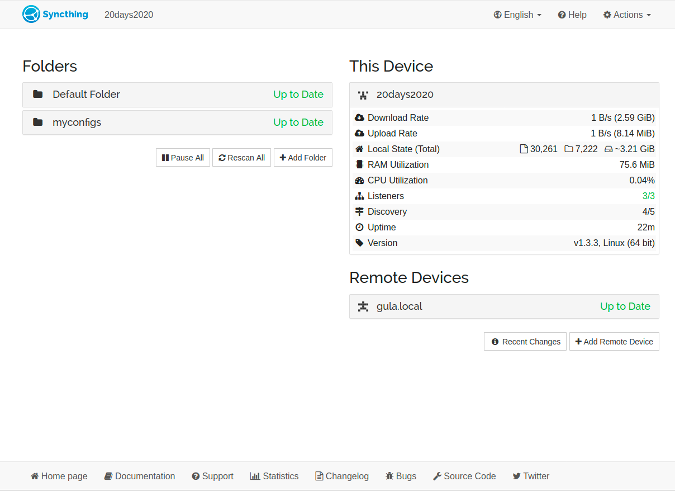
Syncthing is a lightweight, peer-to-peer file-synchronization system. You don't need to pay for a service, you don't need a third-party server, and it's fast. Much faster, in my experience, than many of the "big names" in file synchronization.
Syncthing is available for Linux, MacOS, Windows, and several flavors of BSD. There is also an Android app (but nothing official for iOS yet). There are even handy graphical frontends for all of the above (although I'm not going to cover those here). On Linux, there are packages available for most distributions, so installation is very straightforward.
When you start Syncthing the first time, it launches a web browser to configure the daemon. There's not much to do on the first machine, but it is a good chance to poke around the user interface (UI) a little bit. The most important thing to see is System ID under the **Actions** menu in the top-right.
Once the first machine is set up, repeat the installation on the second machine. In the UI, there will be a button on the lower-right labeled **Add Remote Device**. Click the button, and you will be presented with a box to enter a **Device ID and a Name**. Copy and paste the **Device ID** from the first machine and click **Save**.
You should see a pop-up on the first node asking to add the second. Once you accept it, the new machine will show up on the lower-right of the first one. Share the default directory with the second machine. Click on **Default Folder** and then click the **Edit** button. There are four links at the top of the pop-up. Click on **Sharing** and then select the second machine. Click **Save** and look at the second machine. You should get a prompt to accept the shared directory. Once you accept that, it will start synchronizing files between the two machines.
Test it out by copying a file to the default directory (**/your/home/Share**) on one of the machines. It should show up on the other one very quickly.
You can add as many directories as you want or need to the sharing, which is pretty handy. As you can see in the first image, I have one for **myconfigs**—that's where I keep my configuration files. When I get a new machine, I just install Syncthing, and if I tune a configuration on one, I don't have to update all of them—it happens automatically.
## 1 Comment |
11,795 | 使用 Git 来管理 Git 服务器 | https://opensource.com/article/19/4/server-administration-git | 2020-01-18T13:20:57 | [
"Git"
] | https://linux.cn/article-11795-1.html |
>
> 借助 Gitolite,你可以使用 Git 来管理 Git 服务器。在我们的系列文章中了解这些鲜为人知的 Git 用途。
>
>
>

正如我在系列文章中演示的那样,[Git](https://git-scm.com/) 除了跟踪源代码外,还可以做很多事情。信不信由你,Git 甚至可以管理你的 Git 服务器,因此你可以或多或少地使用 Git 本身来运行 Git 服务器。
当然,这涉及除日常使用 Git 之外的许多组件,其中最重要的是 [Gitolite](http://gitolite.com),该后端应用程序可以管理你使用 Git 的每个细微的配置。Gitolite 的优点在于,由于它使用 Git 作为其前端接口,因此很容易将 Git 服务器管理集成到其他基于 Git 的工作流中。Gitolite 可以精确控制谁可以访问你服务器上的特定存储库以及他们具有哪些权限。你可以使用常规的 Linux 系统工具自行管理此类事务,但是如果有好几个用户和不止一两个仓库,则需要大量的工作。
Gitolite 的开发人员做了艰苦的工作,使你可以轻松地为许多用户提供对你的 Git 服务器的访问权,而又不让他们访问你的整个环境 —— 而这一切,你可以使用 Git 来完成全部工作。
Gitolite 并**不是**图形化的管理员和用户面板。优秀的 [Gitea](http://gitea.io) 项目可提供这种体验,但是本文重点介绍 Gitolite 的简单优雅和令人舒适的熟悉感。
### 安装 Gitolite
假设你的 Git 服务器运行在 Linux 上,则可以使用包管理器安装 Gitolite(在 CentOS 和 RHEL 上为 `yum`,在 Debian 和 Ubuntu 上为 `apt`,在 OpenSUSE 上为 `zypper` 等)。例如,在 RHEL 上:
```
$ sudo yum install gitolite3
```
许多发行版的存储库提供的仍是旧版本的 Gitolite,但最新版本为版本 3。
你必须具有对服务器的无密码 SSH 访问权限。如果愿意,你可以使用密码登录服务器,但是 Gitolite 依赖于 SSH 密钥,因此必须配置使用密钥登录的选项。如果你不知道如何配置服务器以进行无密码 SSH 访问,请首先学习如何进行操作(Steve Ovens 的 Ansible 文章的[设置 SSH 密钥身份验证](Setting%20up%20SSH%20key%20authentication)部分对此进行了很好的说明)。这是加强服务器管理的安全以及运行 Gitolite 的重要组成部分。
### 配置 Git 用户
如果没有 Gitolite,则如果某人请求访问你在服务器上托管的 Git 存储库时,则必须向该人提供用户帐户。Git 提供了一个特殊的外壳,即 `git-shell`,这是一个仅执行 Git 任务的特别的特定 shell。这可以让你有个只能通过非常受限的 Shell 环境来过滤访问你的服务器的用户。
这个解决方案是一个办法,但通常意味着用户可以访问服务器上的所有存储库,除非你具有用于组权限的良好模式,并在创建新存储库时严格遵循这些权限。这种方式还需要在系统级别进行大量手动配置,这通常是只有特定级别的系统管理员才能做的工作,而不一定是通常负责 Git 存储库的人员。
Gitolite 通过为需要访问任何存储库的每个人指定一个用户名来完全回避此问题。默认情况下,该用户名是 `git`,并且由于 Gitolite 的文档中假定使用的是它,因此在学习该工具时保留它是一个很好的默认设置。对于曾经使用过 GitLab 或 GitHub 或任何其他 Git 托管服务的人来说,这也是一个众所周知的约定。
Gitolite 将此用户称为**托管用户**。在服务器上创建一个帐户以充当托管用户(我习惯使用 `git`,因为这是惯例):
```
$ sudo adduser --create-home git
```
为了控制该 `git` 用户帐户,该帐户必须具有属于你的有效 SSH 公钥。你应该已经进行了设置,因此复制你的公钥(**而不是你的私钥**)添加到 `git` 用户的家目录中:
```
$ sudo cp ~/.ssh/id_ed25519.pub /home/git/
$ sudo chown git:git /home/git/id_ed25519.pub
```
如果你的公钥不以扩展名 `.pub` 结尾,则 Gitolite 不会使用它,因此请相应地重命名该文件。切换为该用户帐户以运行 Gitolite 的安装程序:
```
$ sudo su - git
$ gitolite setup --pubkey id_ed25519.pub
```
安装脚本运行后,`git` 的家用户目录将有一个 `repository` 目录,该目录(目前)包含存储库 `git-admin.git` 和 `testing.git`。这就是该服务器所需的全部设置,现在请登出 `git` 用户。
### 使用 Gitolite
管理 Gitolite 就是编辑 Git 存储库中的文本文件,尤其是 `gitolite-admin.git` 中的。你不会通过 SSH 进入服务器来进行 Git 管理,并且 Gitolite 也建议你不要这样尝试。在 Gitolite 服务器上存储你和你的用户的存储库是个**裸**存储库,因此最好不要使用它们。
```
$ git clone [email protected]:gitolite-admin.git gitolite-admin.git
$ cd gitolite-admin.git
$ ls -1
conf
keydir
```
该存储库中的 `conf` 目录包含一个名为 `gitolite.conf` 的文件。在文本编辑器中打开它,或使用 `cat` 查看其内容:
```
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
```
你可能对该配置文件的功能有所了解:`gitolite-admin` 代表此存储库,并且 `id_ed25519` 密钥的所有者具有读取、写入和管理 Git 的权限。换句话说,不是将用户映射到普通的本地 Unix 用户(因为所有用户都使用 `git` 用户托管用户身份),而是将用户映射到 `keydir` 目录中列出的 SSH 密钥。
`testing.git` 存储库使用特殊组符号为访问服务器的每个人提供了全部权限。
#### 添加用户
如果要向 Git 服务器添加一个名为 `alice` 的用户,Alice 必须向你发送她的 SSH 公钥。Gitolite 使用文件名的 `.pub` 扩展名左边的任何内容作为该 Git 用户的标识符。不要使用默认的密钥名称值,而是给密钥指定一个指示密钥所有者的名称。如果用户有多个密钥(例如,一个用于笔记本电脑,一个用于台式机),则可以使用子目录来避免文件名冲突。例如,Alice 在笔记本电脑上使用的密钥可能是默认的 `id_rsa.pub`,因此将其重命名为`alice.pub` 或类似名称(或让用户根据其计算机上的本地用户帐户来命名密钥),然后将其放入 `gitolite-admin.git/keydir/work/laptop/` 目录中。如果她从她的桌面计算机发送了另一个密钥,命名为 `alice.pub`(与上一个相同),然后将其添加到 `keydir/home/desktop/` 中。另一个密钥可能放到 `keydir/home/desktop/` 中,依此类推。Gitolite 递归地在 `keydir` 中搜索与存储库“用户”相匹配的 `.pub` 文件,并将所有匹配项视为相同的身份。
当你将密钥添加到 `keydir` 目录时,必须将它们提交回服务器。这是一件很容易忘记的事情,这里有一个使用自动化的 Git 应用程序(例如 [Sparkleshare](https://opensource.com/article/19/4/file-sharing-git))的真正的理由,因此任何更改都将立即提交给你的 Gitolite 管理员。第一次忘记提交和推送,在浪费了三个小时的你和你的用户的故障排除时间之后,你会发现 Gitolite 是使用 Sparkleshare 的完美理由。
```
$ git add keydir
$ git commit -m 'added alice-laptop-0.pub'
$ git push origin HEAD
```
默认情况下,Alice 可以访问 `testing.git` 目录,因此她可以使用该目录测试连接性和功能。
#### 设置权限
与用户一样,目录权限和组也是从你可能习惯的的常规 Unix 工具中抽象出来的(或可从在线信息查找)。在 `gitolite-admin.git/conf` 目录中的 `gitolite.conf` 文件中授予对项目的权限。权限分为四个级别:
* `R` 允许只读。在存储库上具有 `R` 权限的用户可以克隆它,仅此而已。
* `RW` 允许用户执行分支的快进推送、创建新分支和创建新标签。对于大多数用户来说,这个基本上就像是一个“普通”的 Git 存储库。
* `RW+` 允许可能具有破坏性的 Git 动作。用户可以执行常规的快进推送、回滚推送、变基以及删除分支和标签。你可能想要或不希望将其授予项目中的所有贡献者。
* `-` 明确拒绝访问存储库。这与未在存储库的配置中列出的用户相同。
通过调整 `gitolite.conf` 来创建一个新的存储库或修改现有存储库的权限。例如,授予 Alice 权限来管理一个名为 `widgets.git` 的新存储库:
```
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
repo widgets
RW+ = alice
```
现在,Alice(也仅有 Alice 一个人)可以克隆该存储库:
```
[alice]$ git clone [email protected]:widgets.git
Cloning into 'widgets'...
warning: You appear to have cloned an empty repository.
```
在第一次推送时,Alice 必须使用 `-u` 选项将其分支发送到空存储库(如同她在任何 Git 主机上做的一样)。
为了简化用户管理,你可以定义存储库组:
```
@qtrepo = widgets
@qtrepo = games
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
repo @qtrepo
RW+ = alice
```
正如你可以创建组存储库一样,你也可以对用户进行分组。默认情况下存在一个用户组:`@all`。如你所料,它包括所有用户,无一例外。你也可以创建自己的组:
```
@qtrepo = widgets
@qtrepo = games
@developers = alice bob
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
repo @qtrepo
RW+ = @developers
```
与添加或修改密钥文件一样,对 `gitolite.conf` 文件的任何更改都必须提交并推送以生效。
### 创建存储库
默认情况下,Gitolite 假设存储库的创建是从上至下进行。例如,有权访问 Git 服务器的项目经理创建了一个项目存储库,并通过 Gitolite 管理仓库添加了开发人员。
实际上,你可能更愿意向用户授予创建存储库的权限。Gitolite 称这些为“<ruby> 野生仓库(通配仓库) <rt> wild repos </rt></ruby>”(我不确定这是关于仓库的形成方式的描述,还是指配置文件所需的通配符)。这是一个例子:
```
@managers = alice bob
repo foo/CREATOR/[a-z]..*
C = @managers
RW+ = CREATOR
RW = WRITERS
R = READERS
```
第一行定义了一组用户:该组称为 `@managers`,其中包含用户 `alice` 和 `bob`。下一行设置了通配符允许创建尚不存在的存储库,放在名为 `foo` 的目录下的创建该存储库的用户名的子目录中。例如:
```
[alice]$ git clone [email protected]:foo/alice/cool-app.git
Cloning into cool-app'...
Initialized empty Git repository in /home/git/repositories/foo/alice/cool-app.git
warning: You appear to have cloned an empty repository.
```
野生仓库的创建者可以使用一些机制来定义谁可以读取和写入其存储库,但是他们是有范围限定的。在大多数情况下,Gitolite 假定由一组特定的用户来管理项目权限。一种解决方案是使用 Git 挂钩来授予所有用户对 `gitolite-admin` 的访问权限,以要求管理者批准将更改合并到 master 分支中。
### 了解更多
Gitolite 具有比此介绍性文章所涵盖的更多功能,因此请尝试一下。其[文档](http://gitolite.com/gitolite/quick_install.html)非常出色,一旦你通读了它,就可以自定义 Gitolite 服务器,以向用户提供你喜欢的任何级别的控制。Gitolite 是一种维护成本低、简单的系统,你可以安装、设置它,然后基本上就可以将其忘却。
---
via: <https://opensource.com/article/19/4/server-administration-git>
作者:[Seth Kenlon](https://opensource.com/users/seth/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As I've tried to demonstrate in this series leading up to Git's 14th anniversary on April 7, [Git](https://git-scm.com/) can do a wide range of things beyond tracking source code. Believe it or not, Git can even manage your Git server, so you can, more or less, run a Git server with Git itself.
Of course, this involves a lot of components beyond everyday Git, not the least of which is [Gitolite](http://gitolite.com), the backend application managing the fiddly bits that you configure using Git. The great thing about Gitolite is that, because it uses Git as its frontend interface, it's easy to integrate Git server administration within the rest of your Git-based workflow. Gitolite provides precise control over who can access specific repositories on your server and what permissions they have. You can manage that sort of thing yourself with the usual Linux system tools, but it takes a lot of work if you have more than just one or two repos across a half-dozen users.
Gitolite's developers have done the hard work to make it easy for you to provide many users with access to your Git server without giving them access to your entire environment—and you can do it all with Git.
What Gitolite is *not* is a GUI admin and user panel. That sort of experience is available with the excellent [Gitea](http://gitea.io) project, but this article focuses on the simple elegance and comforting familiarity of Gitolite.
## Install Gitolite
Assuming your Git server runs Linux, you can install Gitolite with your package manager (**yum** on CentOS and RHEL, **apt** on Debian and Ubuntu, **zypper** on OpenSUSE, and so on). For example, on RHEL:
`$ sudo yum install gitolite3`
Many repositories still have older versions of Gitolite for legacy support, but the current version is version 3.
You must have passwordless SSH access to your server. You can use a password to log in if you prefer, but Gitolite relies on SSH keys, so you must configure the option to log in with keys. If you don't know how to configure a server for passwordless SSH access, go learn how to do that first (the Setting up SSH key authentication section of [Steve Ovens's Ansible article](https://opensource.com/article/17/7/automate-sysadmin-ansible) explains it well). It's an essential part of secure server administration—as well as of running Gitolite.
## Configure a Git user
Without Gitolite, if a person requests access to a Git repository you host on a server, you have to provide that person with a user account. Git provides a special shell, the **git-shell**, which is an ultra-specific shell that performs only Git tasks. This lets you have users who can access your server only through the filter of a very limited shell environment.
That solution works, but it usually means a user gains access to all repositories on your server unless you have a very good schema for group permissions and maintain those permissions strictly whenever a new repository is created. It also requires a lot of manual configuration at the system level, an area usually reserved for a specific tier of sysadmins and not necessarily the person usually in charge of Git repositories.
Gitolite sidesteps this issue entirely by designating one username for every person who needs access to any repository. By default, the username is **git**, and because Gitolite's documentation assumes that's what is used, it's a good default to keep when you're learning the tool. It's also a well-known convention for anyone who's ever used GitLab or GitHub or any other Git hosting service.
Gitolite calls this user the *hosting user*. Create an account on your server to act as the hosting user (I'll stick with **git** because that's the convention):
` $ sudo adduser --create-home git`
For you to control the **git** user account, it must have a valid public SSH key that belongs to you. You should already have this set up, so **cp** your public key (*not your private key*) to the **git** user's home directory:
```
$ sudo cp ~/.ssh/id_ed25519.pub /home/git/
$ sudo chown git:git /home/git/id_ed25519.pub
```
If your public key doesn't end with the extension **.pub**, Gitolite will not use it, so rename the file accordingly. Change to that user account to run Gitolite's setup:
```
$ sudo su - git
$ gitolite setup --pubkey id_ed25519.pub
```
After the setup script runs, the **git** home's user directory will have a **repositories** directory, which (for now) contains the files **git-admin.git** and **testing.git**. That's all the setup the server requires, so log out.
## Use Gitolite
Managing Gitolite is a matter of editing text files in a Git repository, specifically **gitolite-admin.git**. You won't SSH into your server for Git administration, and Gitolite encourages you not to try. The repositories you and your users store on the Gitolite server are *bare* repositories, so it's best to stay out of them.
```
$ git clone [email protected]:gitolite-admin.git gitolite-admin.git
$ cd gitolite-admin.git
$ ls -1
conf
keydir
```
The **conf** directory in this repository contains a file called **gitolite.conf**. Open it in a text editor or use **cat** to view its contents:
```
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
```
You may have an idea of what this configuration file does: **gitolite-admin** represents this repository, and the owner of the **id_ed25519** key has read, write, and Git administrative privileges. In other words, rather than mapping users to normal local Unix users (because all your users log in using the **git** hosting user identity), Gitolite maps users to SSH keys listed in the **keydir** directory.
The **testing.git** repository gives full permissions to everyone with access to the server using special group notation.
### Add users
If you want to add a user called **alice** to your Git server, the person Alice must send you her public SSH key. Gitolite uses whatever is to the left of the **.pub** extension as the identifier for your Git users. Rather than using the default key name values, give keys a name indicative of the key owner. If a user has more than one key (e.g., one for her laptop, one for her desktop), you can use subdirectories to avoid file name collisions. For instance, the key Alice uses from her laptop might come to you as the default **id_rsa.pub**, so rename it **alice.pub** or similar (or let the users name the key according to their local user accounts on their computers), and place it into the **gitolite-admin.git/keydir/work/laptop/** directory. If she sends you another key from her desktop, name it **alice.pub** (the same as the previous one) and add it to **keydir/work/desktop/**. Another key might go into **keydir/home/desktop/**, and so on. Gitolite recursively searches **keydir** for a **.pub** file matching a repository "user" and treats any match as the same identity.
When you add keys to the **keydir** directory, you must commit them back to your server. This is such an easy thing to forget that there's a real argument here for using an automated Git application like [ Sparkleshare](https://opensource.com/article/19/4/file-sharing-git) so any change is committed back to your Gitolite admin immediately. The first time you forget to commit and push—and waste three hours of your time and your user's time troubleshooting—you'll see that Gitolite is the perfect justification for using Sparkleshare.
```
$ git add keydir
$ git commit -m 'added alice-laptop-0.pub'
$ git push origin HEAD
```
Alice, by default, gains access to the **testing.git** directory so she can test connectivity and functionality with that.
### Set permissions
As with users, directory permissions and groups are abstracted away from the normal Unix tools you might be used to (or find information about online). Permissions to projects are granted in the **gitolite.conf** file in **gitolite-admin.git/conf** directory. There are four levels of permissions:
**R**allows read-only. A user with**R**permissions on a repository may clone it, and that's all.**RW**allows a user to perform a fast-forward push of a branch, create new branches, and create new tags. More or less, this one feels like a "normal" Git repository to most users.**RW+**allows Git actions that are potentially destructive. A user can perform normal fast-forward pushes, as well as rewind pushes, do rebases, and delete branches and tags. This may or may not be something you want to grant to all contributors on a project.**-**explicitly denies access to a repository. This is essentially the same as a user not being listed in the repository's configuration.
Create a new repository or modify an existing repository's permissions by adjusting **gitolite.conf**. For instance, to give Alice permissions to administrate a new repository called **widgets.git**:
```
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
repo widgets
RW+ = alice
```
Now Alice—and Alice alone—can clone the repo:
```
[alice]$ git clone [email protected]:widgets.git
Cloning into 'widgets'...
warning: You appear to have cloned an empty repository.
```
On her initial push, Alice must use the **-u** option to send her branch to the empty repository (as she would have to do with any Git host).
To make user management easier, you can define groups of repositories:
```
@qtrepo = widgets
@qtrepo = games
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
repo @qtrepo
RW+ = alice
```
Just as you can create group repositories, you can group users. One user group exists by default: **@all**. As you might expect, it includes all users, without exception. You can create your own:
```
@qtrepo = widgets
@qtrepo = games
@developers = alice bob
repo gitolite-admin
RW+ = id_ed22519
repo testing
RW+ = @all
repo @qtrepo
RW+ = @developers
```
As with adding or modifying key files, any change to the **gitolite.conf** file must be committed and pushed to take effect.
## Create a repository
By default, Gitolite assumes repository creation happens from the top down. For instance, a project manager with access to the Git server creates a project repository and, through the Gitolite administration repo, adds developers.
In practice, you might prefer to grant users permission to create repositories. Gitolite calls these "wild repos" (I'm not sure whether that's commentary on how the repos come into being or a reference to the wildcard characters required by the configuration file to let it happen). Here's an example:
```
@managers = alice bob
repo foo/CREATOR/[a-z]..*
C = @managers
RW+ = CREATOR
RW = WRITERS
R = READERS
```
The first line defines a group of users: the group is called **@managers** and contains users **alice** and **bob**. The next line sets up a wildcard allowing repositories that do not yet exist to be created in a directory called **foo** followed by a subdirectory named for the user creating the repo. For example:
```
[alice]$ git clone [email protected]:foo/alice/cool-app.git
Cloning into cool-app'...
Initialized empty Git repository in /home/git/repositories/foo/alice/cool-app.git
warning: You appear to have cloned an empty repository.
```
There are some mechanisms for the creator of a wild repo to define who can read and write to their repository, but they're limited in scope. For the most part, Gitolite assumes that a specific set of users governs project permission. One solution is to grant all users access to **gitolite-admin** using a Git hook to require manager approval to merge changes into the master branch.
## Learn more
Gitolite has many more features than what this introductory article covers, so try it out. The [documentation](http://gitolite.com/gitolite/quick_install.html) is excellent, and once you read through it, you can customize your Gitolite server to provide your users whatever level of control you are comfortable with. Gitolite is a low-maintenance, simple system that you can install, set up, and then more or less forget about.
## 2 Comments |
11,796 | 使用 Stow 管理多台机器配置 | https://opensource.com/article/20/1/configuration-management-stow | 2020-01-18T14:14:05 | [
"Stow"
] | https://linux.cn/article-11796-1.html |
>
> 2020 年,在我们的 20 个使用开源提升生产力的系列文章中,让我们了解如何使用 Stow 跨机器管理配置。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 Stow 管理符号链接
昨天,我解释了如何使用 [Syncthing](https://syncthing.net/) 在多台计算机上保持文件同步。但是,这只是我用来保持配置一致性的工具之一。还有另一个表面上看起来更简单的工具:[Stow](https://www.gnu.org/software/stow/)。

Stow 管理符号链接。默认情况下,它会链接目录到上一级目录。还有设置源和目标目录的选项,但我通常不使用它们。
正如我在 Syncthing 的[文章](/article-11793-1.html) 中提到的,我使用 Syncthing 来保持 `myconfigs` 目录在我所有的计算机上一致。`myconfigs` 目录下面有多个子目录。每个子目录包含我经常使用的应用之一的配置文件。

在每台计算机上,我进入 `myconfigs` 目录,并运行 `stow -S <目录名称>` 以将目录中的文件符号链接到我的家目录。例如,在 `vim` 目录下,我有 `.vimrc` 和 `.vim` 目录。在每台机器上,我运行 `stow -S vim` 来创建符号链接 `~/.vimrc` 和 `~/.vim`。当我在一台计算机上更改 Vim 配置时,它会应用到我的所有机器上。
然而,有时候,我需要一些特定于机器的配置,这就是为什么我有如 `msmtp-personal` 和 `msmtp-elastic`(我的雇主)这样的目录。由于我的 `msmtp` SMTP 客户端需要知道要中继电子邮件服务器,并且每个服务器都有不同的设置和凭据,我会使用 `-D` 标志来取消链接,接着链接另外一个。

有时我要给配置添加文件。为此,有一个 `-R` 选项来“重新链接”。例如,我喜欢在图形化 Vim 中使用一种与控制台不同的特定字体。除了标准 `.vimrc` 文件,`.gvimrc` 文件能让我设置特定于图形化版本的选项。当我第一次设置它时,我移动 `~/.gvimrc` 到 `~/myconfigs/vim` 中,然后运行 `stow -R vim`,它取消链接并重新链接该目录中的所有内容。
Stow 让我使用一个简单的命令行在多种配置之间切换,并且,结合 Syncthing,我可以确保无论我身在何处或在哪里进行更改,我都有我喜欢的工具的设置。
---
via: <https://opensource.com/article/20/1/configuration-management-stow>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Manage symlinks with Stow
Yesterday, I explained how I keep my files in sync across multiple machines with [Syncthing](https://syncthing.net/). But that's only one of the tools I use to keep my configurations consistent. The other is a seemingly simple tool called [Stow](https://www.gnu.org/software/stow/).
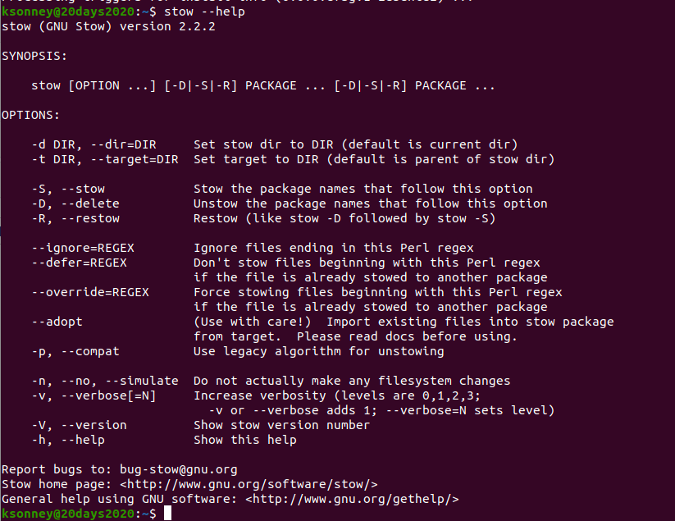
Stow manages symlinks. By default, it makes symlinks from the directory it is in to the directory below it. There are also options to set a source and target directory, but I don't usually use them.
As I mentioned in the Syncthing [article](https://opensource.com/article/20/1/20-productivity-tools-syncthing), I use Syncthing to keep a directory called **myconfigs** consistent across all of my machines. The **myconfigs** directory has several subdirectories underneath it. Each subdirectory contains the configuration files for one of the applications I use regularly.

On each machine, I change to the **myconfigs** directory and run **stow -S <directory name>** to symlink the files inside the directory to my home directory. For example, under the **vim** directory, I have my **.vimrc** and **.vim** directories. On each machine, I run **stow -S vim** to create the symlinks **~/.vimrc** and **~/.vim**. When I make a change to my Vim configuration on one machine, it applies to ALL of my machines.
Sometimes, though, I need something machine-specific, which is why I have directories like **msmtp-personal** and **msmtp-elastic** (my employer). Since my **msmtp** SMTP client needs to know what email server to relay through, and each one has different setups and credentials, I can use Stow to swap between the two by "unstowing" one with the **-D** flag and then putting the other in place.

Sometimes I find myself adding files to a configuration. For that, there is the "restow" option with **-R**. For example, I like to use a specific font when I use Vim as a graphical application and not a console. The **.gvimrc** file lets me set options that apply only to the graphical version, in addition to the standard **.vimrc** file. When I first set this up, I moved **~/.gvimrc** to **~/myconfigs/vim** and then ran **stow -R vim**, which unlinks and relinks everything in that directory.
Stow lets me switch between several configurations with a simple command line and, in combination with Syncthing, I can be sure that I have the setup I like for the tools I use ready to go, no matter where I am or where I make changes.
## Comments are closed. |
11,797 | 6 个方便的 Git 脚本 | https://opensource.com/article/20/1/bash-scripts-git | 2020-01-18T23:17:58 | [
"Git"
] | https://linux.cn/article-11797-1.html |
>
> 当使用 Git 存储库时,这六个 Bash 脚本将使你的生活更轻松。
>
>
>

我编写了许多 Bash 脚本,这些脚本使我在使用 Git 存储库时工作更加轻松。我的许多同事说没有必要:我所做的一切都可以用 Git 命令完成。虽然这可能是正确的,但我发现脚本远比尝试找出适当的 Git 命令来执行我想要的操作更加方便。
### 1、gitlog
`gitlog` 打印针对 master 分支的当前补丁的简短列表。它从最旧到最新打印它们,并显示作者和描述,其中 `H` 代表 `HEAD`,`^` 代表 `HEAD^`,`2` 代表 `HEAD~2`,依此类推。例如:
```
$ gitlog
-----------------------[ recovery25 ]-----------------------
(snip)
11 340d27a33895 Bob Peterson gfs2: drain the ail2 list after io errors
10 9b3c4e6efb10 Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
9 d2e8c22be39b Bob Peterson gfs2: Do proper error checking for go_sync family of glops
8 9563e31f8bfd Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
7 ebac7a38036c Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
6 f703a3c27874 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
5 a3e86d2ef30e Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
4 da3c604755b0 Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
3 4525c2f5b46f Bob Peterson Rafael Aquini's slab instrumentation
2 a06a5b7dea02 Bob Peterson GFS2: Add go_get_holdtime to gl_ops
^ 8ba93c796d5c Bob Peterson gfs2: introduce new function remaining_hold_time and use it in dq
H e8b5ff851bb9 Bob Peterson gfs2: Allow rgrps to have a minimum hold time
```
如果我想查看其他分支上有哪些补丁,可以指定一个替代分支:
```
$ gitlog recovery24
```
### 2、gitlog.id
`gitlog.id` 只是打印出补丁的 SHA1 ID:
```
$ gitlog.id
-----------------------[ recovery25 ]-----------------------
56908eeb6940 2ca4a6b628a1 fc64ad5d99fe 02031a00a251 f6f38da7dd18 d8546e8f0023 fc3cc1f98f6b 12c3e0cb3523 76cce178b134 6fc1dce3ab9c 1b681ab074ca 26fed8de719b 802ff51a5670 49f67a512d8c f04f20193bbb 5f6afe809d23 2030521dc70e dada79b3be94 9b19a1e08161 78a035041d3e f03da011cae2 0d2b2e068fcd 2449976aa133 57dfb5e12ccd 53abedfdcf72 6fbdda3474b3 49544a547188 187032f7a63c 6f75dae23d93 95fc2a261b00 ebfb14ded191 f653ee9e414a 0e2911cb8111 73968b76e2e3 8a3e4cb5e92c a5f2da803b5b 7c9ef68388ed 71ca19d0cba8 340d27a33895 9b3c4e6efb10 d2e8c22be39b 9563e31f8bfd ebac7a38036c f703a3c27874 a3e86d2ef30e da3c604755b0 4525c2f5b46f a06a5b7dea02 8ba93c796d5c e8b5ff851bb9
```
同样,它假定是当前分支,但是如果需要,我可以指定其他分支。
### 3、gitlog.id2
`gitlog.id2` 与 `gitlog.id` 相同,但顶部没有显示分支的行。这对于从一个分支挑选所有补丁到当前分支很方便:
```
$ # 创建一个新分支
$ git branch --track origin/master
$ # 检出刚刚创建的新分支
$ git checkout recovery26
$ # 从旧的分支挑选所有补丁到新分支
$ for i in `gitlog.id2 recovery25` ; do git cherry-pick $i ;done
```
### 4、gitlog.grep
`gitlog.grep` 会在该补丁集合中寻找一个字符串。例如,如果我发现一个错误并想修复引用了函数 `inode_go_sync` 的补丁,我可以简单地执行以下操作:
```
$ gitlog.grep inode_go_sync
-----------------------[ recovery25 - 50 patches ]-----------------------
(snip)
11 340d27a33895 Bob Peterson gfs2: drain the ail2 list after io errors
10 9b3c4e6efb10 Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
9 d2e8c22be39b Bob Peterson gfs2: Do proper error checking for go_sync family of glops
152:-static void inode_go_sync(struct gfs2_glock *gl)
153:+static int inode_go_sync(struct gfs2_glock *gl)
163:@@ -296,6 +302,7 @@ static void inode_go_sync(struct gfs2_glock *gl)
8 9563e31f8bfd Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
7 ebac7a38036c Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
6 f703a3c27874 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
5 a3e86d2ef30e Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
4 da3c604755b0 Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
3 4525c2f5b46f Bob Peterson Rafael Aquini's slab instrumentation
2 a06a5b7dea02 Bob Peterson GFS2: Add go_get_holdtime to gl_ops
^ 8ba93c796d5c Bob Peterson gfs2: introduce new function remaining_hold_time and use it in dq
H e8b5ff851bb9 Bob Peterson gfs2: Allow rgrps to have a minimum hold time
```
因此,现在我知道补丁 `HEAD~9` 是需要修复的补丁。我使用 `git rebase -i HEAD~10` 编辑补丁 9,`git commit -a --amend`,然后 `git rebase --continue` 以进行必要的调整。
### 5、gitbranchcmp3
`gitbranchcmp3` 使我可以将当前分支与另一个分支进行比较,因此我可以将较旧版本的补丁与我的较新版本进行比较,并快速查看已更改和未更改的内容。它生成一个比较脚本(使用了 KDE 工具 [Kompare](https://kde.org/applications/development/org.kde.kompare),该工具也可在 GNOME3 上使用)以比较不太相同的补丁。如果除行号外没有其他差异,则打印 `[SAME]`。如果仅存在注释差异,则打印 `[same]`(小写)。例如:
```
$ gitbranchcmp3 recovery24
Branch recovery24 has 47 patches
Branch recovery25 has 50 patches
(snip)
38 87eb6901607a 340d27a33895 [same] gfs2: drain the ail2 list after io errors
39 90fefb577a26 9b3c4e6efb10 [same] gfs2: clean up iopen glock mess in gfs2_create_inode
40 ba3ae06b8b0e d2e8c22be39b [same] gfs2: Do proper error checking for go_sync family of glops
41 2ab662294329 9563e31f8bfd [SAME] gfs2: use page_offset in gfs2_page_mkwrite
42 0adc6d817b7a ebac7a38036c [SAME] gfs2: don't use buffer_heads in gfs2_allocate_page_backing
43 55ef1f8d0be8 f703a3c27874 [SAME] gfs2: Improve mmap write vs. punch_hole consistency
44 de57c2f72570 a3e86d2ef30e [SAME] gfs2: Multi-block allocations in gfs2_page_mkwrite
45 7c5305fbd68a da3c604755b0 [SAME] gfs2: Fix end-of-file handling in gfs2_page_mkwrite
46 162524005151 4525c2f5b46f [SAME] Rafael Aquini's slab instrumentation
47 a06a5b7dea02 [ ] GFS2: Add go_get_holdtime to gl_ops
48 8ba93c796d5c [ ] gfs2: introduce new function remaining_hold_time and use it in dq
49 e8b5ff851bb9 [ ] gfs2: Allow rgrps to have a minimum hold time
Missing from recovery25:
The missing:
Compare script generated at: /tmp/compare_mismatches.sh
```
### 6、gitlog.find
最后,我有一个 `gitlog.find` 脚本,可以帮助我识别补丁程序的上游版本在哪里以及每个补丁的当前状态。它通过匹配补丁说明来实现。它还会生成一个比较脚本(再次使用了 Kompare),以将当前补丁与上游对应补丁进行比较:
```
$ gitlog.find
-----------------------[ recovery25 - 50 patches ]-----------------------
(snip)
11 340d27a33895 Bob Peterson gfs2: drain the ail2 list after io errors
lo 5bcb9be74b2a Bob Peterson gfs2: drain the ail2 list after io errors
10 9b3c4e6efb10 Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
fn 2c47c1be51fb Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
9 d2e8c22be39b Bob Peterson gfs2: Do proper error checking for go_sync family of glops
lo feb7ea639472 Bob Peterson gfs2: Do proper error checking for go_sync family of glops
8 9563e31f8bfd Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
ms f3915f83e84c Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
7 ebac7a38036c Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
ms 35af80aef99b Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
6 f703a3c27874 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
fn 39c3a948ecf6 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
5 a3e86d2ef30e Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
fn f53056c43063 Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
4 da3c604755b0 Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
fn 184b4e60853d Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
3 4525c2f5b46f Bob Peterson Rafael Aquini's slab instrumentation
Not found upstream
2 a06a5b7dea02 Bob Peterson GFS2: Add go_get_holdtime to gl_ops
Not found upstream
^ 8ba93c796d5c Bob Peterson gfs2: introduce new function remaining_hold_time and use it in dq
Not found upstream
H e8b5ff851bb9 Bob Peterson gfs2: Allow rgrps to have a minimum hold time
Not found upstream
Compare script generated: /tmp/compare_upstream.sh
```
补丁显示为两行,第一行是你当前的修补程序,然后是相应的上游补丁,以及 2 个字符的缩写,以指示其上游状态:
* `lo` 表示补丁仅在本地(`local`)上游 Git 存储库中(即尚未推送到上游)。
* `ms` 表示补丁位于 Linus Torvald 的主(`master`)分支中。
* `fn` 意味着补丁被推送到我的 “for-next” 开发分支,用于下一个上游合并窗口。 我的一些脚本根据我通常使用 Git 的方式做出假设。例如,当搜索上游补丁时,它使用我众所周知的 Git 树的位置。因此,你需要调整或改进它们以适合你的条件。`gitlog.find` 脚本旨在仅定位 [GFS2](https://en.wikipedia.org/wiki/GFS2) 和 [DLM](https://en.wikipedia.org/wiki/Distributed_lock_manager) 补丁,因此,除非你是 GFS2 开发人员,否则你需要针对你感兴趣的组件对其进行自定义。
### 源代码
以下是这些脚本的源代码。
#### 1、gitlog
```
#!/bin/bash
branch=$1
if test "x$branch" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
patches=0
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
LIST=`git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '`
for i in $LIST; do patches=$(echo $patches + 1 | bc);done
if [[ $branch =~ .*for-next.* ]]
then
start=HEAD
# start=origin/for-next
else
start=origin/master
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
/usr/bin/echo "-----------------------[" $branch "]-----------------------"
patches=$(echo $patches - 1 | bc);
for i in $LIST; do
if [ $patches -eq 1 ]; then
cnt=" ^"
elif [ $patches -eq 0 ]; then
cnt=" H"
else
if [ $patches -lt 10 ]; then
cnt=" $patches"
else
cnt="$patches"
fi
fi
/usr/bin/git show --abbrev-commit -s --pretty=format:"$cnt %h %<|(32)%an %s %n" $i
patches=$(echo $patches - 1 | bc)
done
#git log --reverse --abbrev-commit --pretty=format:"%h %<|(32)%an %s" $tracking..$branch
#git log --reverse --abbrev-commit --pretty=format:"%h %<|(32)%an %s" ^origin/master ^linux-gfs2/for-next $branch
```
#### 2、gitlog.id
```
#!/bin/bash
branch=$1
if test "x$branch" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
/usr/bin/echo "-----------------------[" $branch "]-----------------------"
git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '
```
#### 3、gitlog.id2
```
#!/bin/bash
branch=$1
if test "x$branch" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '
```
#### 4、gitlog.grep
```
#!/bin/bash
param1=$1
param2=$2
if test "x$param2" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
string=$param1
else
branch=$param1
string=$param2
fi
patches=0
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
LIST=`git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '`
for i in $LIST; do patches=$(echo $patches + 1 | bc);done
/usr/bin/echo "-----------------------[" $branch "-" $patches "patches ]-----------------------"
patches=$(echo $patches - 1 | bc);
for i in $LIST; do
if [ $patches -eq 1 ]; then
cnt=" ^"
elif [ $patches -eq 0 ]; then
cnt=" H"
else
if [ $patches -lt 10 ]; then
cnt=" $patches"
else
cnt="$patches"
fi
fi
/usr/bin/git show --abbrev-commit -s --pretty=format:"$cnt %h %<|(32)%an %s" $i
/usr/bin/git show --pretty=email --patch-with-stat $i | grep -n "$string"
patches=$(echo $patches - 1 | bc)
done
```
#### 5、gitbranchcmp3
```
#!/bin/bash
#
# gitbranchcmp3 <old branch> [<new_branch>]
#
oldbranch=$1
newbranch=$2
script=/tmp/compare_mismatches.sh
/usr/bin/rm -f $script
echo "#!/bin/bash" > $script
/usr/bin/chmod 755 $script
echo "# Generated by gitbranchcmp3.sh" >> $script
echo "# Run this script to compare the mismatched patches" >> $script
echo " " >> $script
echo "function compare_them()" >> $script
echo "{" >> $script
echo " git show --pretty=email --patch-with-stat \$1 > /tmp/gronk1" >> $script
echo " git show --pretty=email --patch-with-stat \$2 > /tmp/gronk2" >> $script
echo " kompare /tmp/gronk1 /tmp/gronk2" >> $script
echo "}" >> $script
echo " " >> $script
if test "x$newbranch" = x; then
newbranch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
declare -a oldsha1s=(`git log --reverse --abbrev-commit --pretty=oneline $tracking..$oldbranch | cut -d ' ' -f1 |paste -s -d ' '`)
declare -a newsha1s=(`git log --reverse --abbrev-commit --pretty=oneline $tracking..$newbranch | cut -d ' ' -f1 |paste -s -d ' '`)
#echo "old: " $oldsha1s
oldcount=${#oldsha1s[@]}
echo "Branch $oldbranch has $oldcount patches"
oldcount=$(echo $oldcount - 1 | bc)
#for o in `seq 0 ${#oldsha1s[@]}`; do
# echo -n ${oldsha1s[$o]} " "
# desc=`git show $i | head -5 | tail -1|cut -b5-`
#done
#echo "new: " $newsha1s
newcount=${#newsha1s[@]}
echo "Branch $newbranch has $newcount patches"
newcount=$(echo $newcount - 1 | bc)
#for o in `seq 0 ${#newsha1s[@]}`; do
# echo -n ${newsha1s[$o]} " "
# desc=`git show $i | head -5 | tail -1|cut -b5-`
#done
echo
for new in `seq 0 $newcount`; do
newsha=${newsha1s[$new]}
newdesc=`git show $newsha | head -5 | tail -1|cut -b5-`
oldsha=" "
same="[ ]"
for old in `seq 0 $oldcount`; do
if test "${oldsha1s[$old]}" = "match"; then
continue;
fi
olddesc=`git show ${oldsha1s[$old]} | head -5 | tail -1|cut -b5-`
if test "$olddesc" = "$newdesc" ; then
oldsha=${oldsha1s[$old]}
#echo $oldsha
git show $oldsha |tail -n +2 |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk1
git show $newsha |tail -n +2 |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk2
diff /tmp/gronk1 /tmp/gronk2 &> /dev/null
if [ $? -eq 0 ] ;then
# No differences
same="[SAME]"
oldsha1s[$old]="match"
break
fi
git show $oldsha |sed -n '/diff/,$p' |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk1
git show $newsha |sed -n '/diff/,$p' |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk2
diff /tmp/gronk1 /tmp/gronk2 &> /dev/null
if [ $? -eq 0 ] ;then
# Differences in comments only
same="[same]"
oldsha1s[$old]="match"
break
fi
oldsha1s[$old]="match"
echo "compare_them $oldsha $newsha" >> $script
fi
done
echo "$new $oldsha $newsha $same $newdesc"
done
echo
echo "Missing from $newbranch:"
the_missing=""
# Now run through the olds we haven't matched up
for old in `seq 0 $oldcount`; do
if test ${oldsha1s[$old]} != "match"; then
olddesc=`git show ${oldsha1s[$old]} | head -5 | tail -1|cut -b5-`
echo "${oldsha1s[$old]} $olddesc"
the_missing=`echo "$the_missing ${oldsha1s[$old]}"`
fi
done
echo "The missing: " $the_missing
echo "Compare script generated at: $script"
#git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '
```
#### 6、gitlog.find
```
#!/bin/bash
#
# Find the upstream equivalent patch
#
# gitlog.find
#
cwd=$PWD
param1=$1
ubranch=$2
patches=0
script=/tmp/compare_upstream.sh
echo "#!/bin/bash" > $script
/usr/bin/chmod 755 $script
echo "# Generated by gitbranchcmp3.sh" >> $script
echo "# Run this script to compare the mismatched patches" >> $script
echo " " >> $script
echo "function compare_them()" >> $script
echo "{" >> $script
echo " cwd=$PWD" >> $script
echo " git show --pretty=email --patch-with-stat \$2 > /tmp/gronk2" >> $script
echo " cd ~/linux.git/fs/gfs2" >> $script
echo " git show --pretty=email --patch-with-stat \$1 > /tmp/gronk1" >> $script
echo " cd $cwd" >> $script
echo " kompare /tmp/gronk1 /tmp/gronk2" >> $script
echo "}" >> $script
echo " " >> $script
#echo "Gathering upstream patch info. Please wait."
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
cd ~/linux.git
if test "X${ubranch}" = "X"; then
ubranch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
utracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
#
# gather a list of gfs2 patches from master just in case we can't find it
#
#git log --abbrev-commit --pretty=format:" %h %<|(32)%an %s" master |grep -i -e "gfs2" -e "dlm" > /tmp/gronk
git log --reverse --abbrev-commit --pretty=format:"ms %h %<|(32)%an %s" master fs/gfs2/ > /tmp/gronk.gfs2
# ms = in Linus's master
git log --reverse --abbrev-commit --pretty=format:"ms %h %<|(32)%an %s" master fs/dlm/ > /tmp/gronk.dlm
cd $cwd
LIST=`git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '`
for i in $LIST; do patches=$(echo $patches + 1 | bc);done
/usr/bin/echo "-----------------------[" $branch "-" $patches "patches ]-----------------------"
patches=$(echo $patches - 1 | bc);
for i in $LIST; do
if [ $patches -eq 1 ]; then
cnt=" ^"
elif [ $patches -eq 0 ]; then
cnt=" H"
else
if [ $patches -lt 10 ]; then
cnt=" $patches"
else
cnt="$patches"
fi
fi
/usr/bin/git show --abbrev-commit -s --pretty=format:"$cnt %h %<|(32)%an %s" $i
desc=`/usr/bin/git show --abbrev-commit -s --pretty=format:"%s" $i`
cd ~/linux.git
cmp=1
up_eq=`git log --reverse --abbrev-commit --pretty=format:"lo %h %<|(32)%an %s" $utracking..$ubranch | grep "$desc"`
# lo = in local for-next
if test "X$up_eq" = "X"; then
up_eq=`git log --reverse --abbrev-commit --pretty=format:"fn %h %<|(32)%an %s" master..$utracking | grep "$desc"`
# fn = in for-next for next merge window
if test "X$up_eq" = "X"; then
up_eq=`grep "$desc" /tmp/gronk.gfs2`
if test "X$up_eq" = "X"; then
up_eq=`grep "$desc" /tmp/gronk.dlm`
if test "X$up_eq" = "X"; then
up_eq=" Not found upstream"
cmp=0
fi
fi
fi
fi
echo "$up_eq"
if [ $cmp -eq 1 ] ; then
UP_SHA1=`echo $up_eq|cut -d' ' -f2`
echo "compare_them $UP_SHA1 $i" >> $script
fi
cd $cwd
patches=$(echo $patches - 1 | bc)
done
echo "Compare script generated: $script"
```
---
via: <https://opensource.com/article/20/1/bash-scripts-git>
作者:[Bob Peterson](https://opensource.com/users/bobpeterson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I wrote a bunch of Bash scripts that make my life easier when I'm working with Git repositories. Many of my colleagues say there's no need; that everything I need to do can be done with Git commands. While that may be true, I find the scripts infinitely more convenient than trying to figure out the appropriate Git command to do what I want.
## 1. gitlog
**gitlog** prints an abbreviated list of current patches against the master version. It prints them from oldest to newest and shows the author and description, with **H** for **HEAD**, **^** for **HEAD^**, **2** for **HEAD~2,** and so forth. For example:
```
$ gitlog
-----------------------[ recovery25 ]-----------------------
(snip)
11 340d27a33895 Bob Peterson gfs2: drain the ail2 list after io errors
10 9b3c4e6efb10 Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
9 d2e8c22be39b Bob Peterson gfs2: Do proper error checking for go_sync family of glops
8 9563e31f8bfd Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
7 ebac7a38036c Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
6 f703a3c27874 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
5 a3e86d2ef30e Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
4 da3c604755b0 Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
3 4525c2f5b46f Bob Peterson Rafael Aquini's slab instrumentation
2 a06a5b7dea02 Bob Peterson GFS2: Add go_get_holdtime to gl_ops
^ 8ba93c796d5c Bob Peterson gfs2: introduce new function remaining_hold_time and use it in dq
H e8b5ff851bb9 Bob Peterson gfs2: Allow rgrps to have a minimum hold time
```
If I want to see what patches are on a different branch, I can specify an alternate branch:
`$ gitlog recovery24`
## 2. gitlog.id
**gitlog.id** just prints the patch SHA1 IDs:
```
$ gitlog.id
-----------------------[ recovery25 ]-----------------------
56908eeb6940 2ca4a6b628a1 fc64ad5d99fe 02031a00a251 f6f38da7dd18 d8546e8f0023 fc3cc1f98f6b 12c3e0cb3523 76cce178b134 6fc1dce3ab9c 1b681ab074ca 26fed8de719b 802ff51a5670 49f67a512d8c f04f20193bbb 5f6afe809d23 2030521dc70e dada79b3be94 9b19a1e08161 78a035041d3e f03da011cae2 0d2b2e068fcd 2449976aa133 57dfb5e12ccd 53abedfdcf72 6fbdda3474b3 49544a547188 187032f7a63c 6f75dae23d93 95fc2a261b00 ebfb14ded191 f653ee9e414a 0e2911cb8111 73968b76e2e3 8a3e4cb5e92c a5f2da803b5b 7c9ef68388ed 71ca19d0cba8 340d27a33895 9b3c4e6efb10 d2e8c22be39b 9563e31f8bfd ebac7a38036c f703a3c27874 a3e86d2ef30e da3c604755b0 4525c2f5b46f a06a5b7dea02 8ba93c796d5c e8b5ff851bb9
```
Again, it assumes the current branch, but I can specify a different branch if I want.
## 3. gitlog.id2
**gitlog.id2** is the same as **gitlog.id** but without the branch line at the top. This is handy for cherry-picking all patches from one branch to the current branch:
```
$ # create a new branch
$ git branch --track origin/master
$ # check out the new branch I just created
$ git checkout recovery26
$ # cherry-pick all patches from the old branch to the new one
$ for i in `gitlog.id2 recovery25` ; do git cherry-pick $i ;done
```
## 4. gitlog.grep
**gitlog.grep** greps for a string within that collection of patches. For example, if I find a bug and want to fix the patch that has a reference to function **inode_go_sync**, I simply do:
```
$ gitlog.grep inode_go_sync
-----------------------[ recovery25 - 50 patches ]-----------------------
(snip)
11 340d27a33895 Bob Peterson gfs2: drain the ail2 list after io errors
10 9b3c4e6efb10 Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
9 d2e8c22be39b Bob Peterson gfs2: Do proper error checking for go_sync family of glops
152:-static void inode_go_sync(struct gfs2_glock *gl)
153:+static int inode_go_sync(struct gfs2_glock *gl)
163:@@ -296,6 +302,7 @@ static void inode_go_sync(struct gfs2_glock *gl)
8 9563e31f8bfd Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
7 ebac7a38036c Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
6 f703a3c27874 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
5 a3e86d2ef30e Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
4 da3c604755b0 Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
3 4525c2f5b46f Bob Peterson Rafael Aquini's slab instrumentation
2 a06a5b7dea02 Bob Peterson GFS2: Add go_get_holdtime to gl_ops
^ 8ba93c796d5c Bob Peterson gfs2: introduce new function remaining_hold_time and use it in dq
H e8b5ff851bb9 Bob Peterson gfs2: Allow rgrps to have a minimum hold time
```
So, now I know that patch **HEAD~9** is the one that needs fixing. I use **git rebase -i HEAD~10** to edit patch 9, **git commit -a --amend**, then **git rebase --continue** to make the necessary adjustments.
## 5. gitbranchcmp3
**gitbranchcmp3** lets me compare my current branch to another branch, so I can compare older versions of patches to my newer versions and quickly see what's changed and what hasn't. It generates a compare script (that uses the KDE tool [Kompare](https://kde.org/applications/development/org.kde.kompare), which works on GNOME3, as well) to compare the patches that aren't quite the same. If there are no differences other than line numbers, it prints **[SAME]**. If there are only comment differences, it prints **[same]** (in lower case). For example:
```
$ gitbranchcmp3 recovery24
Branch recovery24 has 47 patches
Branch recovery25 has 50 patches
(snip)
38 87eb6901607a 340d27a33895 [same] gfs2: drain the ail2 list after io errors
39 90fefb577a26 9b3c4e6efb10 [same] gfs2: clean up iopen glock mess in gfs2_create_inode
40 ba3ae06b8b0e d2e8c22be39b [same] gfs2: Do proper error checking for go_sync family of glops
41 2ab662294329 9563e31f8bfd [SAME] gfs2: use page_offset in gfs2_page_mkwrite
42 0adc6d817b7a ebac7a38036c [SAME] gfs2: don't use buffer_heads in gfs2_allocate_page_backing
43 55ef1f8d0be8 f703a3c27874 [SAME] gfs2: Improve mmap write vs. punch_hole consistency
44 de57c2f72570 a3e86d2ef30e [SAME] gfs2: Multi-block allocations in gfs2_page_mkwrite
45 7c5305fbd68a da3c604755b0 [SAME] gfs2: Fix end-of-file handling in gfs2_page_mkwrite
46 162524005151 4525c2f5b46f [SAME] Rafael Aquini's slab instrumentation
47 a06a5b7dea02 [ ] GFS2: Add go_get_holdtime to gl_ops
48 8ba93c796d5c [ ] gfs2: introduce new function remaining_hold_time and use it in dq
49 e8b5ff851bb9 [ ] gfs2: Allow rgrps to have a minimum hold time
Missing from recovery25:
The missing:
Compare script generated at: /tmp/compare_mismatches.sh
```
## 6. gitlog.find
Finally, I have **gitlog.find**, a script to help me identify where the upstream versions of my patches are and each patch's current status. It does this by matching the patch description. It also generates a compare script (again, using Kompare) to compare the current patch to the upstream counterpart:
```
$ gitlog.find
-----------------------[ recovery25 - 50 patches ]-----------------------
(snip)
11 340d27a33895 Bob Peterson gfs2: drain the ail2 list after io errors
lo 5bcb9be74b2a Bob Peterson gfs2: drain the ail2 list after io errors
10 9b3c4e6efb10 Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
fn 2c47c1be51fb Bob Peterson gfs2: clean up iopen glock mess in gfs2_create_inode
9 d2e8c22be39b Bob Peterson gfs2: Do proper error checking for go_sync family of glops
lo feb7ea639472 Bob Peterson gfs2: Do proper error checking for go_sync family of glops
8 9563e31f8bfd Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
ms f3915f83e84c Christoph Hellwig gfs2: use page_offset in gfs2_page_mkwrite
7 ebac7a38036c Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
ms 35af80aef99b Christoph Hellwig gfs2: don't use buffer_heads in gfs2_allocate_page_backing
6 f703a3c27874 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
fn 39c3a948ecf6 Andreas Gruenbacher gfs2: Improve mmap write vs. punch_hole consistency
5 a3e86d2ef30e Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
fn f53056c43063 Andreas Gruenbacher gfs2: Multi-block allocations in gfs2_page_mkwrite
4 da3c604755b0 Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
fn 184b4e60853d Andreas Gruenbacher gfs2: Fix end-of-file handling in gfs2_page_mkwrite
3 4525c2f5b46f Bob Peterson Rafael Aquini's slab instrumentation
Not found upstream
2 a06a5b7dea02 Bob Peterson GFS2: Add go_get_holdtime to gl_ops
Not found upstream
^ 8ba93c796d5c Bob Peterson gfs2: introduce new function remaining_hold_time and use it in dq
Not found upstream
H e8b5ff851bb9 Bob Peterson gfs2: Allow rgrps to have a minimum hold time
Not found upstream
Compare script generated: /tmp/compare_upstream.sh
```
The patches are shown on two lines, the first of which is your current patch, followed by the corresponding upstream patch, and a 2-character abbreviation to indicate its upstream status:
**lo**means the patch is in the local upstream Git repo only (i.e., not pushed upstream yet).**ms**means the patch is in Linus Torvald's master branch.**fn**means the patch is pushed to my "for-next" development branch, intended for the next upstream merge window.
Some of my scripts make assumptions based on how I normally work with Git. For example, when searching for upstream patches, it uses my well-known Git tree's location. So, you will need to adjust or improve them to suit your conditions. The **gitlog.find** script is designed to locate [GFS2](https://en.wikipedia.org/wiki/GFS2) and [DLM](https://en.wikipedia.org/wiki/Distributed_lock_manager) patches only, so unless you're a GFS2 developer, you will want to customize it to the components that interest you.
## Source code
Here is the source for these scripts.
### 1. gitlog
```
#!/bin/bash
branch=$1
if test "x$branch" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
patches=0
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
LIST=`git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '`
for i in $LIST; do patches=$(echo $patches + 1 | bc);done
if [[ $branch =~ .*for-next.* ]]
then
start=HEAD
# start=origin/for-next
else
start=origin/master
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
/usr/bin/echo "-----------------------[" $branch "]-----------------------"
patches=$(echo $patches - 1 | bc);
for i in $LIST; do
if [ $patches -eq 1 ]; then
cnt=" ^"
elif [ $patches -eq 0 ]; then
cnt=" H"
else
if [ $patches -lt 10 ]; then
cnt=" $patches"
else
cnt="$patches"
fi
fi
/usr/bin/git show --abbrev-commit -s --pretty=format:"$cnt %h %<|(32)%an %s %n" $i
patches=$(echo $patches - 1 | bc)
done
#git log --reverse --abbrev-commit --pretty=format:"%h %<|(32)%an %s" $tracking..$branch
#git log --reverse --abbrev-commit --pretty=format:"%h %<|(32)%an %s" ^origin/master ^linux-gfs2/for-next $branch
```
### 2. gitlog.id
```
#!/bin/bash
branch=$1
if test "x$branch" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
/usr/bin/echo "-----------------------[" $branch "]-----------------------"
git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '
```
### 3. gitlog.id2
```
#!/bin/bash
branch=$1
if test "x$branch" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '
```
### 4. gitlog.grep
```
#!/bin/bash
param1=$1
param2=$2
if test "x$param2" = x; then
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
string=$param1
else
branch=$param1
string=$param2
fi
patches=0
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
LIST=`git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '`
for i in $LIST; do patches=$(echo $patches + 1 | bc);done
/usr/bin/echo "-----------------------[" $branch "-" $patches "patches ]-----------------------"
patches=$(echo $patches - 1 | bc);
for i in $LIST; do
if [ $patches -eq 1 ]; then
cnt=" ^"
elif [ $patches -eq 0 ]; then
cnt=" H"
else
if [ $patches -lt 10 ]; then
cnt=" $patches"
else
cnt="$patches"
fi
fi
/usr/bin/git show --abbrev-commit -s --pretty=format:"$cnt %h %<|(32)%an %s" $i
/usr/bin/git show --pretty=email --patch-with-stat $i | grep -n "$string"
patches=$(echo $patches - 1 | bc)
done
```
### 5. gitbranchcmp3
```
#!/bin/bash
#
# gitbranchcmp3 <old branch> [<new_branch>]
#
oldbranch=$1
newbranch=$2
script=/tmp/compare_mismatches.sh
/usr/bin/rm -f $script
echo "#!/bin/bash" > $script
/usr/bin/chmod 755 $script
echo "# Generated by gitbranchcmp3.sh" >> $script
echo "# Run this script to compare the mismatched patches" >> $script
echo " " >> $script
echo "function compare_them()" >> $script
echo "{" >> $script
echo " git show --pretty=email --patch-with-stat \$1 > /tmp/gronk1" >> $script
echo " git show --pretty=email --patch-with-stat \$2 > /tmp/gronk2" >> $script
echo " kompare /tmp/gronk1 /tmp/gronk2" >> $script
echo "}" >> $script
echo " " >> $script
if test "x$newbranch" = x; then
newbranch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
declare -a oldsha1s=(`git log --reverse --abbrev-commit --pretty=oneline $tracking..$oldbranch | cut -d ' ' -f1 |paste -s -d ' '`)
declare -a newsha1s=(`git log --reverse --abbrev-commit --pretty=oneline $tracking..$newbranch | cut -d ' ' -f1 |paste -s -d ' '`)
#echo "old: " $oldsha1s
oldcount=${#oldsha1s[@]}
echo "Branch $oldbranch has $oldcount patches"
oldcount=$(echo $oldcount - 1 | bc)
#for o in `seq 0 ${#oldsha1s[@]}`; do
# echo -n ${oldsha1s[$o]} " "
# desc=`git show $i | head -5 | tail -1|cut -b5-`
#done
#echo "new: " $newsha1s
newcount=${#newsha1s[@]}
echo "Branch $newbranch has $newcount patches"
newcount=$(echo $newcount - 1 | bc)
#for o in `seq 0 ${#newsha1s[@]}`; do
# echo -n ${newsha1s[$o]} " "
# desc=`git show $i | head -5 | tail -1|cut -b5-`
#done
echo
for new in `seq 0 $newcount`; do
newsha=${newsha1s[$new]}
newdesc=`git show $newsha | head -5 | tail -1|cut -b5-`
oldsha=" "
same="[ ]"
for old in `seq 0 $oldcount`; do
if test "${oldsha1s[$old]}" = "match"; then
continue;
fi
olddesc=`git show ${oldsha1s[$old]} | head -5 | tail -1|cut -b5-`
if test "$olddesc" = "$newdesc" ; then
oldsha=${oldsha1s[$old]}
#echo $oldsha
git show $oldsha |tail -n +2 |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk1
git show $newsha |tail -n +2 |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk2
diff /tmp/gronk1 /tmp/gronk2 &> /dev/null
if [ $? -eq 0 ] ;then
# No differences
same="[SAME]"
oldsha1s[$old]="match"
break
fi
git show $oldsha |sed -n '/diff/,$p' |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk1
git show $newsha |sed -n '/diff/,$p' |grep -v "index.*\.\." |grep -v "@@" > /tmp/gronk2
diff /tmp/gronk1 /tmp/gronk2 &> /dev/null
if [ $? -eq 0 ] ;then
# Differences in comments only
same="[same]"
oldsha1s[$old]="match"
break
fi
oldsha1s[$old]="match"
echo "compare_them $oldsha $newsha" >> $script
fi
done
echo "$new $oldsha $newsha $same $newdesc"
done
echo
echo "Missing from $newbranch:"
the_missing=""
# Now run through the olds we haven't matched up
for old in `seq 0 $oldcount`; do
if test ${oldsha1s[$old]} != "match"; then
olddesc=`git show ${oldsha1s[$old]} | head -5 | tail -1|cut -b5-`
echo "${oldsha1s[$old]} $olddesc"
the_missing=`echo "$the_missing ${oldsha1s[$old]}"`
fi
done
echo "The missing: " $the_missing
echo "Compare script generated at: $script"
#git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '
```
### 6. gitlog.find
```
#!/bin/bash
#
# Find the upstream equivalent patch
#
# gitlog.find
#
cwd=$PWD
param1=$1
ubranch=$2
patches=0
script=/tmp/compare_upstream.sh
echo "#!/bin/bash" > $script
/usr/bin/chmod 755 $script
echo "# Generated by gitbranchcmp3.sh" >> $script
echo "# Run this script to compare the mismatched patches" >> $script
echo " " >> $script
echo "function compare_them()" >> $script
echo "{" >> $script
echo " cwd=$PWD" >> $script
echo " git show --pretty=email --patch-with-stat \$2 > /tmp/gronk2" >> $script
echo " cd ~/linux.git/fs/gfs2" >> $script
echo " git show --pretty=email --patch-with-stat \$1 > /tmp/gronk1" >> $script
echo " cd $cwd" >> $script
echo " kompare /tmp/gronk1 /tmp/gronk2" >> $script
echo "}" >> $script
echo " " >> $script
#echo "Gathering upstream patch info. Please wait."
branch=`git branch -a | grep "*" | cut -d ' ' -f2`
tracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
cd ~/linux.git
if test "X${ubranch}" = "X"; then
ubranch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
utracking=`git rev-parse --abbrev-ref --symbolic-full-name @{u}`
#
# gather a list of gfs2 patches from master just in case we can't find it
#
#git log --abbrev-commit --pretty=format:" %h %<|(32)%an %s" master |grep -i -e "gfs2" -e "dlm" > /tmp/gronk
git log --reverse --abbrev-commit --pretty=format:"ms %h %<|(32)%an %s" master fs/gfs2/ > /tmp/gronk.gfs2
# ms = in Linus's master
git log --reverse --abbrev-commit --pretty=format:"ms %h %<|(32)%an %s" master fs/dlm/ > /tmp/gronk.dlm
cd $cwd
LIST=`git log --reverse --abbrev-commit --pretty=oneline $tracking..$branch | cut -d ' ' -f1 |paste -s -d ' '`
for i in $LIST; do patches=$(echo $patches + 1 | bc);done
/usr/bin/echo "-----------------------[" $branch "-" $patches "patches ]-----------------------"
patches=$(echo $patches - 1 | bc);
for i in $LIST; do
if [ $patches -eq 1 ]; then
cnt=" ^"
elif [ $patches -eq 0 ]; then
cnt=" H"
else
if [ $patches -lt 10 ]; then
cnt=" $patches"
else
cnt="$patches"
fi
fi
/usr/bin/git show --abbrev-commit -s --pretty=format:"$cnt %h %<|(32)%an %s" $i
desc=`/usr/bin/git show --abbrev-commit -s --pretty=format:"%s" $i`
cd ~/linux.git
cmp=1
up_eq=`git log --reverse --abbrev-commit --pretty=format:"lo %h %<|(32)%an %s" $utracking..$ubranch | grep "$desc"`
# lo = in local for-next
if test "X$up_eq" = "X"; then
up_eq=`git log --reverse --abbrev-commit --pretty=format:"fn %h %<|(32)%an %s" master..$utracking | grep "$desc"`
# fn = in for-next for next merge window
if test "X$up_eq" = "X"; then
up_eq=`grep "$desc" /tmp/gronk.gfs2`
if test "X$up_eq" = "X"; then
up_eq=`grep "$desc" /tmp/gronk.dlm`
if test "X$up_eq" = "X"; then
up_eq=" Not found upstream"
cmp=0
fi
fi
fi
fi
echo "$up_eq"
if [ $cmp -eq 1 ] ; then
UP_SHA1=`echo $up_eq|cut -d' ' -f2`
echo "compare_them $UP_SHA1 $i" >> $script
fi
cd $cwd
patches=$(echo $patches - 1 | bc)
done
echo "Compare script generated: $script"
```
## 2 Comments |
11,799 | 在 GIMP 中如何在文本周围添加边框 | https://itsfoss.com/gimp-text-outline/ | 2020-01-19T23:00:00 | [
"GIMP"
] | https://linux.cn/article-11799-1.html | 
这个简单的教程介绍了在 [GIMP](https://www.gimp.org/) 中显示文本的轮廓的步骤。文本轮廓可以帮助你在其它颜色下高亮显示该文本。

让我们看看如何在你的文本周围添加一个边框。
### 在 GIMP 中添加文本轮廓
整个过程可以用这些简单的步骤描述:
* 创建文本,并复制它的轮廓路径
* 添加一层新的透明层,并添加轮廓路径到透明层中
* 更改轮廓的大小,给它添加一种不同的颜色
这就是全部的东西。不用担心,我将使用适当地截图详细的展示每个步骤。按照这个教程,你应该能够为文本添加轮廓,即使你在此之前从未使用过 GIMP 。
仅需要确保你已经 [在 Linux 上安装 GIMP](https://itsfoss.com/gimp-2-10-release/),或者也可以使用的其它任何操作系统。
这篇教程在 GIMP 2.10 版本下演示。
#### 步骤 1: 创建你的主要文本,并复制它的轮廓
打开 GIMP ,并通过转到 “菜单 -> 文件 -> 新建” 来创建一个新的文件。你应该可以使用 `Ctrl+N` 键盘快捷键。

你可以在这里选择画布的大小。你也可以选择要白色背景或一种透明背景。它在 “高级选项 -> 颜色” 配置文件下。
我选择默认的白色背景。它在以后能够更改。
现在从左边栏的工具箱中选择文本工具。

写你想要的文本。你可以根据你的选择以更改文本的字体、大小和对齐方式。我保持这篇文章的文本的默认左对齐。
我故意为文本选择一种浅色,以便难于阅读。在这篇教程中我将添加一个深色轮廓到这个浅色的文本。

当你写完文本后,右键文本框并选择 “文本的路径” 。

#### 步骤 2: 添加一个带有文本轮廓的透明层
现在,转到顶部菜单,转到“层”,并添加一个新层。

确保添加新层为透明的。你可以给它一个合适的名称,像“文本大纲”。单击确定来添加这个透明层。

再次转到菜单,这次转到 “选择” ,并单击 “来自路径” 。你将看到你的文本应该被高亮显示。

总的来说,你只创建了一个透明层,它有像你的原文一样相同的文本(但是透明)。现在你需要做的是在这个层上增加文本的大小。
#### 步骤 3: 通过增加它的大小和更改它的颜色来添加文本轮廓
为此,再次在菜单中转到 “选择” ,这次选择 “增加”。这将允许增大透明层上的文本的大小。

以 5 或 10 像素增加,或者你喜欢的任意像素。

你选择需要做是使用一种你选择的颜色来填充这个扩大的选择区。因为我的原文是浅色,在这里我将为轮廓使用背景色。
如果尚未选择的话,先选择你的主图像层。这些层在右侧栏中可视。然后转到工具箱并选择油漆桶工具。为你的轮廓选择想要的颜色。
选择使用该工具来填充黑色到你的选择区。记住。你填充文本外部的轮廓,而不是文本本身。

在这里你完成了很多。使用 `Ctrl+Shift+A` 来取消你当前的选择区。

如此,你现在已经在 GIMP 中成功地添加轮廓到你的文本。它是在白色背景中,如果你想要一个透明背景,只需要在右侧栏的图层菜单中删除背景层。

如果你对结果感到满意,保存文件未 PNG 文件(来保留透明背景),或你喜欢的任何文件格式。
### 你使它工作了吗?
就这样。这就是你在 GIMP 中为添加一个文本轮廓而需要做的全部工作。
我希望你发现这个 GIMP 教程有帮助。你可能想查看另一个 [关于在 GIMP 中添加一个水印的简单教程](https://itsfoss.com/add-watermark-gimp-linux/)。
如果你有问题或建议,请在下面自由留言。
---
via: <https://itsfoss.com/gimp-text-outline/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

This simple tutorial explains the steps to outline text in [GIMP](https://www.gimp.org/?ref=itsfoss.com). The text outline helps you highlight text against the background of other colors.

Let’s see how you can add a border around your text.
## Adding text outline in GIMP
The entire procedure can be described in these easy steps:
- Create your text and copy its outlined path
- Add a new transparent layer and add the outlined path to this layer
- Change the size of the outline, add a different color to it
That’s all. Don’t worry, I am going to show each steps in detail with proper screenshots. By following this tutorial, you should be able to add outline to text even if you never used GIMP before.
Just make sure that you have [GIMP installed on Linux](https://itsfoss.com/gimp-2-10-release/) or whatever operating system you are using.
This tutorial has been performed with GIMP 2.10 version.
### Step 1: Create your primary text and copy its outline
Open GIMP and create a new file by going to the top menu->File->New. You can also use Ctrl+N keyboard shortcut.
You can select the size of your canvas here. You may also choose if you want white background or a transparent background. It is under the Advanced Options->Color profile.
I have chosen the default white background. It can be changed later.
Now select the Text tool from the toolbox in the left sidebar.
Write the text you want. You can change the font, size and alignment of the text as per your choice. I have kept the default left alignment of the text for this article.
I have deliberately chose a light color for the text so that it is difficult to read. I’ll add a darker outline to this light text in this tutorial.
When you are done writing your text, right click the text box and select **Path from Text**.
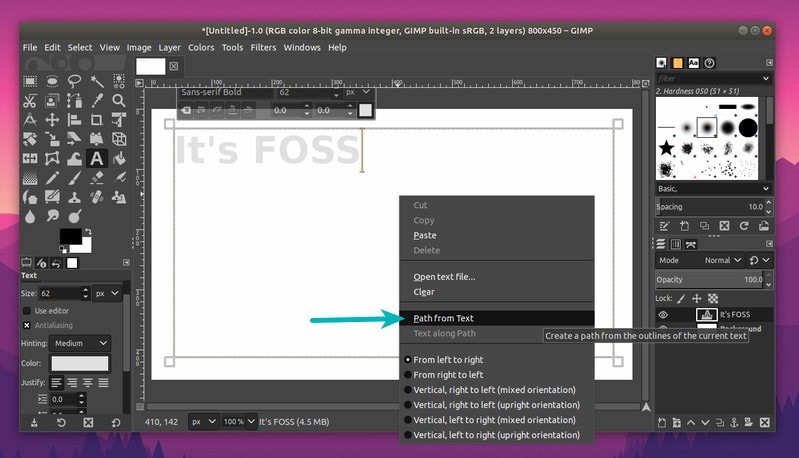
### Step 2: Add a transparent layer with the text outline
Now, go to the top menu, go to Layer and add a new layer.
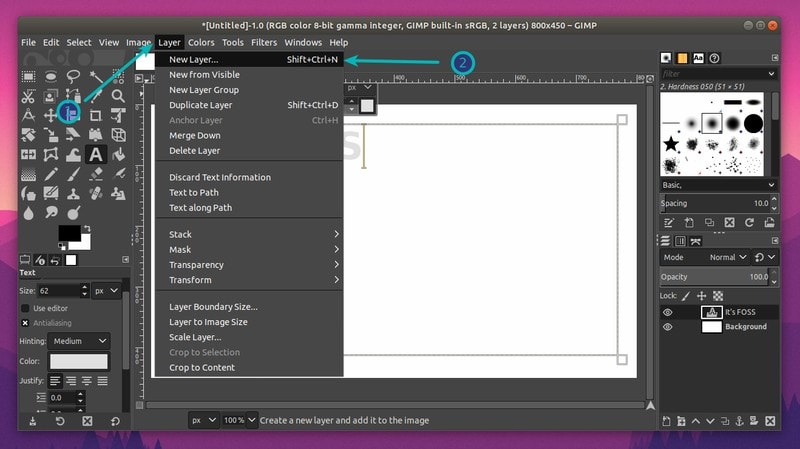
Make sure to add the new layer as transparent. You can give it a suitable name like ‘outline for text’. Click OK to add this transparent layer.
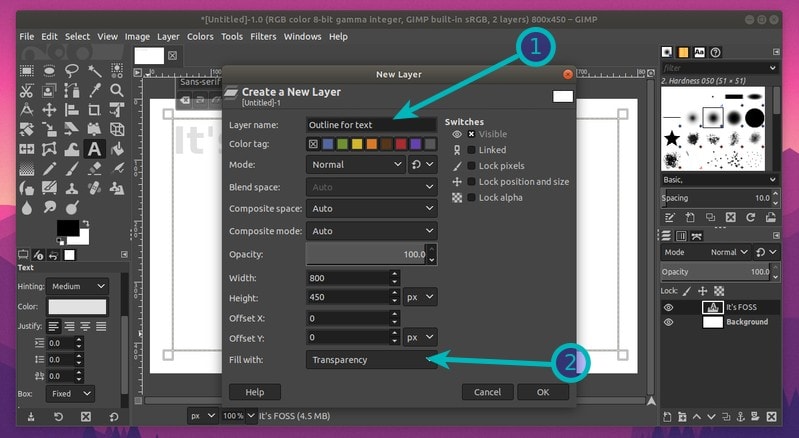
Go to the menu again and this time go to **Select** and click **From path**. You’ll see that your text has been highlighted.
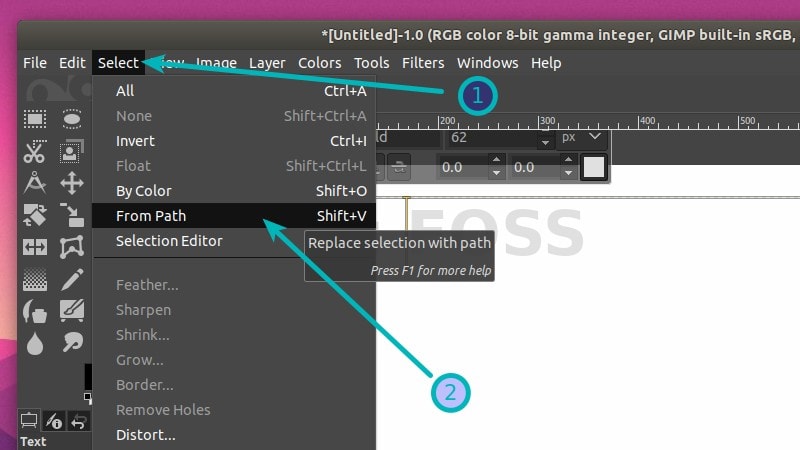
Basically, you just created a transparent layer that has the same text (but transparent) as your original text. What you need to do now is to increase the size of the text on this layer.
### Step 3: Adding the text outline by increasing its size and changing its color
To do that, go to Select in menu once again and this time choose Grow. This will allow you to grow the size of the text on the transparent layer.
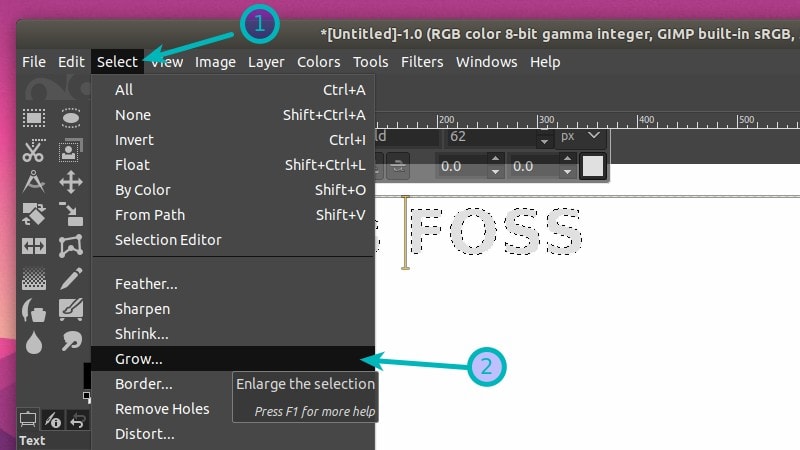
Grow it by 5 or 10 pixel or whatever you prefer.
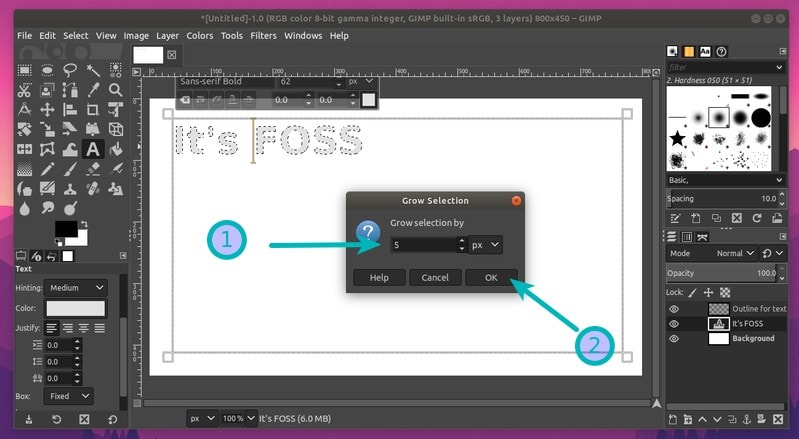
What you need to do now is to fill this enlarged selection with a choice of your color. Since my original text is of light color, I am going to use back color for the outline here.
**Select your main image layer** if it’s not already selected. The layers are visible at the right sidebar. Then go to the toolbox and select the bucket fill tool. Select the desired color you want for the outline.
Now use the tool to fill black color to your selection. Mind that you fill the outer outline of the text, not the text itself.
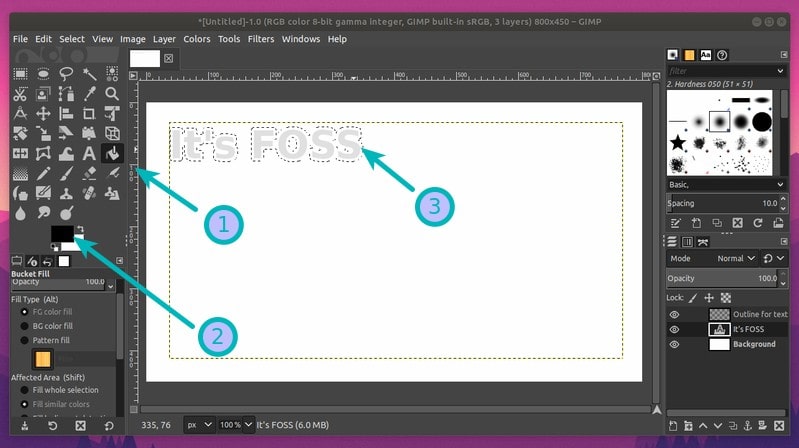
You are pretty much done here. Use Ctrl+Shift+A to de-select your current selection.
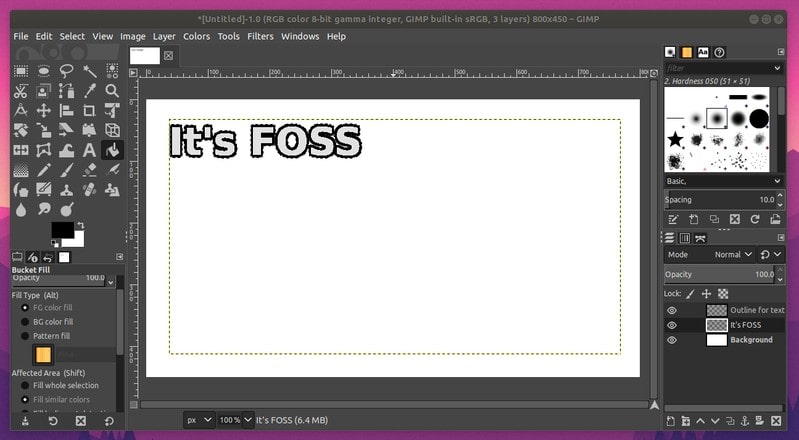
So now you have successfully added outline to your text in GIMP. It is on white background and if you want a transparent background, just delete the background layer from the layer menu in the right sidebar.
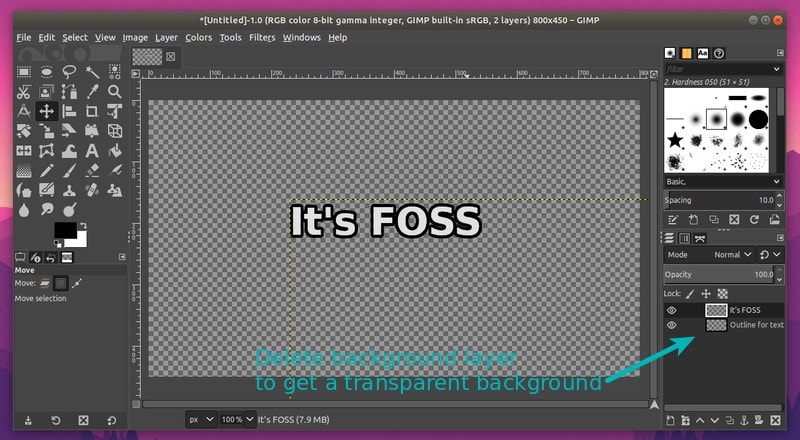
If you are happy with the result, save the file as PNG file (to keep transparent background) or whichever file format you prefer.
## Did you make it work?
That’s it. That’s all you need to do to add a text outline in GIMP.
I hope you find this GIMP tutorial helpful. You may want to check out another [simple tutorial about adding a watermark in GIMP](https://itsfoss.com/add-watermark-gimp-linux/) or [adding brushes in GIMP](https://itsfoss.com/add-brushes-gimp/).
If you have questions or suggestions, please feel free to leave a comment below. |
11,800 | setV:一个管理 Python 虚拟环境的 Bash 函数 | https://opensource.com/article/20/1/setv-bash-function | 2020-01-19T23:43:19 | [
"Python"
] | https://linux.cn/article-11800-1.html |
>
> 了解一下 setV,它是一个轻量级的 Python 虚拟环境管理器,是 virtualenvwrapper 的替代产品。
>
>
>

这一年多来,我的 [bash\_scripts](https://github.com/psachin/bash_scripts) 项目中悄悄隐藏这 [setV](https://gitlab.com/psachin/setV),但现在是时候该公开了。setV 是一个 Bash 函数,我可以用它代替 [virtualenvwrapper](https://virtualenvwrapper.readthedocs.org/)。它提供了使你能够执行以下操作的基本功能:
* 默认使用 Python 3
* 创建一个新的虚拟环境
* 使用带有 `-p`(或 `--python`)的自定义 Python 路径来创建新的虚拟环境
* 删除现有的虚拟环境
* 列出所有现有的虚拟环境
* 使用制表符补全(以防你忘记虚拟环境名称)
### 安装
要安装 setV,请下载该脚本:
```
curl https://gitlab.com/psachin/setV/raw/master/install.sh
```
审核一下脚本,然后运行它:
```
sh ./install.sh
```
当安装 setV 时,安装脚本会要求你引入(`source`)一下 `~/.bashrc` 或 `~/.bash_profile` 的配置,根据你的喜好选择一个。
### 用法
基本的命令格式是 `setv`。
#### 创建虚拟环境
```
setv --new rango # setv -n rango
# 或使用定制的 Python 路径
setv --new --python /opt/python/python3 rango # setv -n -p /opt/python/python3 rango
```
#### 激活已有的虚拟环境
```
setv VIRTUAL_ENVIRONMENT_NAME
```
```
# 示例
setv rango
```
#### 列出所有的虚拟环境
```
setv --list
# 或
setv [TAB] [TAB]
```
#### 删除虚拟环境
```
setv --delete rango
```
#### 切换到另外一个虚拟环境
```
# 假设你现在在 'rango',切换到 'tango'
setv tango
```
#### 制表符补完
如果你不完全记得虚拟环境的名称,则 Bash 式的制表符补全也可以适用于虚拟环境名称。
### 参与其中
setV 在 GNU [GPLv3](https://gitlab.com/psachin/setV/blob/master/LICENSE)下开源,欢迎贡献。要了解更多信息,请访问它的 GitLab 存储库中的 setV 的 [README](https://gitlab.com/psachin/setV/blob/master/ReadMe.org) 的贡献部分。
### setV 脚本
```
#!/usr/bin/env bash
# setV - A Lightweight Python virtual environment manager.
# Author: Sachin (psachin) <[email protected]>
# Author's URL: https://psachin.gitlab.io/about
#
# License: GNU GPL v3, See LICENSE file
#
# Configure(Optional):
# Set `SETV_VIRTUAL_DIR_PATH` value to your virtual environments
# directory-path. By default it is set to '~/virtualenvs/'
#
# Usage:
# Manual install: Added below line to your .bashrc or any local rc script():
# ---
# source /path/to/virtual.sh
# ---
#
# Now you can 'activate' the virtual environment by typing
# $ setv <YOUR VIRTUAL ENVIRONMENT NAME>
#
# For example:
# $ setv rango
#
# or type:
# setv [TAB] [TAB] (to list all virtual envs)
#
# To list all your virtual environments:
# $ setv --list
#
# To create new virtual environment:
# $ setv --new new_virtualenv_name
#
# To delete existing virtual environment:
# $ setv --delete existing_virtualenv_name
#
# To deactivate, type:
# $ deactivate
# Path to virtual environment directory
SETV_VIRTUAL_DIR_PATH="$HOME/virtualenvs/"
# Default python version to use. This decides whether to use `virtualenv` or `python3 -m venv`
SETV_PYTHON_VERSION=3 # Defaults to Python3
SETV_PY_PATH=$(which python${SETV_PYTHON_VERSION})
function _setvcomplete_()
{
# Bash-autocompletion.
# This ensures Tab-auto-completions work for virtual environment names.
local cmd="${1##*/}" # to handle command(s).
# Not necessary as such. 'setv' is the only command
local word=${COMP_WORDS[COMP_CWORD]} # Words thats being completed
local xpat='${word}' # Filter pattern. Include
# only words in variable '$names'
local names=$(ls -l "${SETV_VIRTUAL_DIR_PATH}" | egrep '^d' | awk -F " " '{print $NF}') # Virtual environment names
COMPREPLY=($(compgen -W "$names" -X "$xpat" -- "$word")) # compgen generates the results
}
function _setv_help_() {
# Echo help/usage message
echo "Usage: setv [OPTIONS] [NAME]"
echo Positional argument:
echo -e "NAME Activate virtual env."
echo Optional arguments:
echo -e "-l, --list List all Virtual Envs."
echo -e "-n, --new NAME Create a new Python Virtual Env."
echo -e "-d, --delete NAME Delete existing Python Virtual Env."
echo -e "-p, --python PATH Python binary path."
}
function _setv_custom_python_path()
{
if [ -f "${1}" ];
then
if [ "`expr $1 : '.*python\([2,3]\)'`" = "3" ];
then
SETV_PYTHON_VERSION=3
else
SETV_PYTHON_VERSION=2
fi
SETV_PY_PATH=${1}
_setv_create $2
else
echo "Error: Path ${1} does not exist!"
fi
}
function _setv_create()
{
# Creates new virtual environment if ran with -n|--new flag
if [ -z ${1} ];
then
echo "You need to pass virtual environment name"
_setv_help_
else
echo "Creating new virtual environment with the name: $1"
if [ ${SETV_PYTHON_VERSION} -eq 3 ];
then
${SETV_PY_PATH} -m venv ${SETV_VIRTUAL_DIR_PATH}${1}
else
virtualenv -p ${SETV_PY_PATH} ${SETV_VIRTUAL_DIR_PATH}${1}
fi
echo "You can now activate the Python virtual environment by typing: setv ${1}"
fi
}
function _setv_delete()
{
# Deletes virtual environment if ran with -d|--delete flag
# TODO: Refactor
if [ -z ${1} ];
then
echo "You need to pass virtual environment name"
_setv_help_
else
if [ -d ${SETV_VIRTUAL_DIR_PATH}${1} ];
then
read -p "Really delete this virtual environment(Y/N)? " yes_no
case $yes_no in
Y|y) rm -rvf ${SETV_VIRTUAL_DIR_PATH}${1};;
N|n) echo "Leaving the virtual environment as it is.";;
*) echo "You need to enter either Y/y or N/n"
esac
else
echo "Error: No virtual environment found by the name: ${1}"
fi
fi
}
function _setv_list()
{
# Lists all virtual environments if ran with -l|--list flag
echo -e "List of virtual environments you have under ${SETV_VIRTUAL_DIR_PATH}:\n"
for virt in $(ls -l "${SETV_VIRTUAL_DIR_PATH}" | egrep '^d' | awk -F " " '{print $NF}')
do
echo ${virt}
done
}
function setv() {
# Main function
if [ $# -eq 0 ];
then
_setv_help_
elif [ $# -le 3 ];
then
case "${1}" in
-n|--new) _setv_create ${2};;
-d|--delete) _setv_delete ${2};;
-l|--list) _setv_list;;
*) if [ -d ${SETV_VIRTUAL_DIR_PATH}${1} ];
then
# Activate the virtual environment
source ${SETV_VIRTUAL_DIR_PATH}${1}/bin/activate
else
# Else throw an error message
echo "Sorry, you don't have any virtual environment with the name: ${1}"
_setv_help_
fi
;;
esac
elif [ $# -le 5 ];
then
case "${2}" in
-p|--python) _setv_custom_python_path ${3} ${4};;
*) _setv_help_;;
esac
fi
}
# Calls bash-complete. The compgen command accepts most of the same
# options that complete does but it generates results rather than just
# storing the rules for future use.
complete -F _setvcomplete_ setv
```
---
via: <https://opensource.com/article/20/1/setv-bash-function>
作者:[Sachin Patil](https://opensource.com/users/psachin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For more than a year, [setV](https://gitlab.com/psachin/setV) has been hidden away within my [bash_scripts](https://github.com/psachin/bash_scripts) project, but it's time for it to become public. setV is a Bash function I use as an alternative to [virtualenvwrapper](https://virtualenvwrapper.readthedocs.org/). It provides basic features that enable you to do things such as:
- Use Python 3 by default
- Create a new virtual environment
- Create a new virtual environment using a custom Python path with
**-p**(or**--python**) - Delete an existing virtual environment
- List all existing virtual environment
- Use Tab completion (in case you don't remember the virtual environment name)
## Installation
To install setV, download the script:
`curl https://gitlab.com/psachin/setV/raw/master/install.sh`
Review the script, and then run it:
`sh ./install.sh`
When you install setV, the installation script asks you to source **~/.bashrc** or **~/.bash_profile**. Be sure to do that.
## Usage
The basic command is **setv**.
### Create a virtual environment:
```
setv --new rango # setv -n rango
# Or using a custom Python binary path
setv --new --python /opt/python/python3 rango # setv -n -p /opt/python/python3 rango
```
### Activate an existing environment:
```
setv VIRTUAL_ENVIRONMENT_NAME
# For example
setv rango
```
### List all virtual environments:
```
setv --list
# or
setv [TAB] [TAB]
```
### Delete a virtual environment:
`setv --delete rango`
### Switch to another virtual environment:
```
# Assuming you are in 'rango', switch to 'tango' using
setv tango
```
### Tab Completion
If you don't fully remember the virtual environment's name, Bash-like Tab completion works for virtual environment names.
## Get involved
setV is open source under the GNU [GPLv3](https://gitlab.com/psachin/setV/blob/master/LICENSE), and contributions are welcome. To learn more, visit the Contribute section of setV's [README](https://gitlab.com/psachin/setV/blob/master/ReadMe.org) in its GitLab repository.
## The setV script
```
#!/usr/bin/env bash
# setV - A Lightweight Python virtual environment manager.
# Author: Sachin (psachin) <[email protected]>
# Author's URL: https://psachin.gitlab.io/about
#
# License: GNU GPL v3, See LICENSE file
#
# Configure(Optional):
# Set `SETV_VIRTUAL_DIR_PATH` value to your virtual environments
# directory-path. By default it is set to '~/virtualenvs/'
#
# Usage:
# Manual install: Added below line to your .bashrc or any local rc script():
# ---
# source /path/to/virtual.sh
# ---
#
# Now you can 'activate' the virtual environment by typing
# $ setv <YOUR VIRTUAL ENVIRONMENT NAME>
#
# For example:
# $ setv rango
#
# or type:
# setv [TAB] [TAB] (to list all virtual envs)
#
# To list all your virtual environments:
# $ setv --list
#
# To create new virtual environment:
# $ setv --new new_virtualenv_name
#
# To delete existing virtual environment:
# $ setv --delete existing_virtualenv_name
#
# To deactivate, type:
# $ deactivate
# Path to virtual environment directory
SETV_VIRTUAL_DIR_PATH="$HOME/virtualenvs/"
# Default python version to use. This decides whether to use `virtualenv` or `python3 -m venv`
SETV_PYTHON_VERSION=3 # Defaults to Python3
SETV_PY_PATH=$(which python${SETV_PYTHON_VERSION})
function _setvcomplete_()
{
# Bash-autocompletion.
# This ensures Tab-auto-completions work for virtual environment names.
local cmd="${1##*/}" # to handle command(s).
# Not necessary as such. 'setv' is the only command
local word=${COMP_WORDS[COMP_CWORD]} # Words thats being completed
local xpat='${word}' # Filter pattern. Include
# only words in variable '$names'
local names=$(ls -l "${SETV_VIRTUAL_DIR_PATH}" | egrep '^d' | awk -F " " '{print $NF}') # Virtual environment names
COMPREPLY=($(compgen -W "$names" -X "$xpat" -- "$word")) # compgen generates the results
}
function _setv_help_() {
# Echo help/usage message
echo "Usage: setv [OPTIONS] [NAME]"
echo Positional argument:
echo -e "NAME Activate virtual env."
echo Optional arguments:
echo -e "-l, --list List all Virtual Envs."
echo -e "-n, --new NAME Create a new Python Virtual Env."
echo -e "-d, --delete NAME Delete existing Python Virtual Env."
echo -e "-p, --python PATH Python binary path."
}
function _setv_custom_python_path()
{
if [ -f "${1}" ];
then
if [ "`expr $1 : '.*python\([2,3]\)'`" = "3" ];
then
SETV_PYTHON_VERSION=3
else
SETV_PYTHON_VERSION=2
fi
SETV_PY_PATH=${1}
_setv_create $2
else
echo "Error: Path ${1} does not exist!"
fi
}
function _setv_create()
{
# Creates new virtual environment if ran with -n|--new flag
if [ -z ${1} ];
then
echo "You need to pass virtual environment name"
_setv_help_
else
echo "Creating new virtual environment with the name: $1"
if [ ${SETV_PYTHON_VERSION} -eq 3 ];
then
${SETV_PY_PATH} -m venv ${SETV_VIRTUAL_DIR_PATH}${1}
else
virtualenv -p ${SETV_PY_PATH} ${SETV_VIRTUAL_DIR_PATH}${1}
fi
echo "You can now activate the Python virtual environment by typing: setv ${1}"
fi
}
function _setv_delete()
{
# Deletes virtual environment if ran with -d|--delete flag
# TODO: Refactor
if [ -z ${1} ];
then
echo "You need to pass virtual environment name"
_setv_help_
else
if [ -d ${SETV_VIRTUAL_DIR_PATH}${1} ];
then
read -p "Really delete this virtual environment(Y/N)? " yes_no
case $yes_no in
Y|y) rm -rvf ${SETV_VIRTUAL_DIR_PATH}${1};;
N|n) echo "Leaving the virtual environment as it is.";;
*) echo "You need to enter either Y/y or N/n"
esac
else
echo "Error: No virtual environment found by the name: ${1}"
fi
fi
}
function _setv_list()
{
# Lists all virtual environments if ran with -l|--list flag
echo -e "List of virtual environments you have under ${SETV_VIRTUAL_DIR_PATH}:\n"
for virt in $(ls -l "${SETV_VIRTUAL_DIR_PATH}" | egrep '^d' | awk -F " " '{print $NF}')
do
echo ${virt}
done
}
function setv() {
# Main function
if [ $# -eq 0 ];
then
_setv_help_
elif [ $# -le 3 ];
then
case "${1}" in
-n|--new) _setv_create ${2};;
-d|--delete) _setv_delete ${2};;
-l|--list) _setv_list;;
*) if [ -d ${SETV_VIRTUAL_DIR_PATH}${1} ];
then
# Activate the virtual environment
source ${SETV_VIRTUAL_DIR_PATH}${1}/bin/activate
else
# Else throw an error message
echo "Sorry, you don't have any virtual environment with the name: ${1}"
_setv_help_
fi
;;
esac
elif [ $# -le 5 ];
then
case "${2}" in
-p|--python) _setv_custom_python_path ${3} ${4};;
*) _setv_help_;;
esac
fi
}
# Calls bash-complete. The compgen command accepts most of the same
# options that complete does but it generates results rather than just
# storing the rules for future use.
complete -F _setvcomplete_ setv
```
## 3 Comments |
11,803 | 假期志愿服务的 4 种方式 | https://opensource.com/article/19/12/ways-volunteer | 2020-01-20T22:37:54 | [
"志愿者"
] | https://linux.cn/article-11803-1.html |
>
> 想要洒播些节日的快乐吗?为开源组织做贡献,帮助有需要的社区。
>
>
>

当领导者们配置人员和资源以做出积极改变时,就会产生社会影响。但是,许多社会努力都缺乏能够为这些改变者提供服务的技术资源。然而,有些组织通过将想要做出改变的开发人员与迫切需要更好技术的社区和非营利组织联系起来,来促进技术进步。这些组织通常为特定的受众提供服务,并招募特定种类的技术人员,它们有一个共同点:开源。
作为开发人员,我们出于各种原因试图加入开源社区。有些是为了专业发展,有些是为了能够与广阔的网络上令人印象深刻的技术人员合作,还有其他人则是因为他们清楚自己的贡献对于项目的成功的必要性。为什么不将你作为开发人员的才华投入到需要它的地方,而同时又为开源组织做贡献呢?以下组织是实现此目标的一些主要事例。
### Code for America
“Code for America” 是在数字时代,政府如何依靠人民为人民服务的一个例子。通过其 Brigade Network,该组织在美国各个城市中组织了一个由志愿程序员、数据科学家、相关公民和设计师组成的全国联盟。这些本地分支机构定期举行聚会,向社区开放。这样既可以向小组推出新项目,又可以协调正在进行的工作。为了使志愿者与项目相匹配,该网站经常列出项目所需的特定技能,例如数据分析、内容创建和JavaScript。同时,Brigade 网站也会关注当地问题,分享自然灾害等共同经验,这些都可以促进成员之间的合作。例如,新奥尔良、休斯敦和坦帕湾团队合作开发了一个飓风响应网站,当灾难发生时,该网站可以快速响应不同的城市灾难情况。
想要加入该组织,请访问 [该网站](https://brigade.codeforamerica.org/) 获取 70 多个 Brigade 的清单,以及个人加入组织的指南。
### Code for Change
“Code for Change” 显示了即使在高中时期,也可以为社会做贡献。印第安纳波利斯的一群高中开发爱好者成立了自己的俱乐部,他们通过创建针对社区问题的开源软件解决方案来回馈当地组织。“Code for Change” 鼓励当地组织提出项目构想,学生团体加入并开发完全自由和开源的解决方案。该小组已经开发了诸如“蓝宝石”之类的项目,该项目优化了当地难民组织的志愿者管理系统,并建立了民权委员会的投诉表格,方便公民就他们所关心的问题在网上发表意见。
有关如何在你自己的社区中创建 “Code for Change”,[访问他们的网站](http://codeforchange.herokuapp.com/)。
### Python for Good/Ruby for Good
“Python for Good” 和 “Ruby for Good” 是在俄勒冈州波特兰市和弗吉尼亚州费尔法克斯市举办的双年展活动,该活动将人们聚集在一起,为各自的社区开发和制定解决方案。
在周末,人们聚在一起聆听当地非营利组织的建议,并通过构建开源解决方案来解决他们的问题。 2017 年,“Ruby For Good” 参与者创建了 “Justice for Juniors”,该计划指导当前和以前被监禁的年轻人,并将他们重新融入社区。参与者还创建了 “Diaperbase”,这是一种库存管理系统,为美国各地的<ruby> 尿布库 <rt> diaper bank </rt></ruby>所使用。这些活动的主要目标之一是将看似不同的行业和思维方式的组织和个人聚集在一起,以谋求共同利益。公司可以赞助活动,非营利组织可以提交项目构想,各种技能的人都可以注册参加活动并做出贡献。通过两岸(美国大西洋和太平洋东西海岸)的努力,“Ruby for Good” 和 “Python for Good” 一直恪守“使世界变得更好”的座右铭。
“[Ruby for Good](https://rubyforgood.org/)” 在夏天举行,举办地点在弗吉尼亚州费尔法克斯的乔治•梅森大学。
### Social Coder
英国的 Ed Guiness 创建了 “Social Coder”,将志愿者和慈善机构召集在一起,为六大洲的非营利组织创建和使用开源项目。“Social Coder” 积极招募来自世界各地的熟练 IT 志愿者,并将其与通过 Social Coder 注册的慈善机构和非营利组织进行匹配。项目范围从简单的网站更新到整个移动应用程序的开发。
例如,PHASE Worldwide 是一个在尼泊尔支持工作的小型非政府组织,因为 “Social Coder”,它获得了利用开源技术的关键支持和专业知识。
有许多慈善机构已经与英国的 “Social Coder”进行了合作,也欢迎其它国家的组织加入。通过他们的网站,个人可以注册为社会软件项目工作,找到寻求帮助的组织和慈善机构。
对 “Social Coder” 的志愿服务感兴趣的个人可以 [在此](https://socialcoder.org/Home/Programmer)注册.
---
via: <https://opensource.com/article/19/12/ways-volunteer>
作者:[John Jones](https://opensource.com/users/johnjones4) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Social impact happens when leaders deploy individuals and resources to make positive change, but many social efforts are lacking technology resources that are up to the task of serving these change-makers. However, there are organizations helping to accelerate tech for good by connecting developers who want to make a change with communities and nonprofits who desperately need better technology. These organizations often serve specific audiences and recruit specific kinds of technologists, but they all share a common thread: open source.
As developers, we all seek to participate in the open source community for a variety of reasons. Some participate for professional development, some participate so that they may collaborate with a vast, impressive network of technologists, and others participate because they know their contributions are necessary for the success of a project. Why not also volunteer your talents as a developer to an effort that needs them, and contribute to open source all at the same time? The organizations below are prime examples of how you can do that.
## Code for America
Code for America is an example of how government can still be by the people and for the people in the digital age. Through its Brigade Network, the organization has cultivated a national alliance of volunteer programmers, data scientists, concerned citizens, and designers organized in cities all over the United States. These local affiliates host regular meet-ups which are open to the community to both pitch new projects to the group and collaborate on ongoing efforts. To match volunteers with projects, the brigades’ websites often list the specific skills needed for a project such as data analysis, content creation, and JavaScript. While the brigades focus on local issues, shared experiences like natural disasters can foster collaboration. For example, a multi-brigade effort from the New Orleans, Houston, and Tampa Bay teams developed a hurricane response website that can be quickly adapted to different cities when disaster strikes.
To get involved, visit Code for America’s [website](https://brigade.codeforamerica.org/) for a list of its over 70 brigades, and a path for individuals to start their own if there is not one already in their community.
## Code for Change
Code for Change shows that social impact can start even in high school. A group of high school coders in Indianapolis started their own club to give back to local organizations by creating open source software solutions to issues in their community. Code for Change encourages local organizations to reach out with a project idea, and the student group steps in to develop a completely free and open source solution. The group has developed projects such as "Sapphire," which optimized volunteer management systems for a local refugee organization, and a Civil Rights Commission complaint form that makes it easier for citizens to voice their concerns online.
For more information on how to create a Code for Change chapter in your own community, [visit their website](http://codeforchange.herokuapp.com/).
## Python for Good/Ruby for Good
Python for Good and Ruby for Good are twin annual events in Portland, Oregon and Fairfax, Virginia, that bring people together to develop and program solutions for those respective communities. Over a weekend, individuals get together to hear pitches from local nonprofits and tackle their issues by building open source solutions. In 2017, Ruby For Good participants created "Justice for Juniors," which mentors and tutors current and formerly incarcerated youths to integrate them back into the community. Participants have also created "Diaperbase," an inventory management system that has been used by diaper banks all over the United States. One of the main objectives of these events is to bring organizations and people from seemingly different industries and mindsets to come together for a common good. Companies can sponsor the events, nonprofits can submit project ideas, and people of all skill levels can register to attend the event and contribute. Through their bicoastal efforts, Ruby for Good and Python for Good are living up to their motto of "making the world gooder."
[Ruby for Good](https://rubyforgood.org/) is held in the summer and hosted on George Mason’s campus in Fairfax, Virginia.
## Social Coder
UK-based Ed Guiness created Social Coder to bring together volunteers and charities to create and use open source projects for nonprofits across six continents. Social Coder actively recruits a network of skilled IT volunteers from all over the world and matches them to charities and nonprofits registered through Social Coder. Projects can range from simple website updates to entire mobile app development.
For example, PHASE Worldwide, a small non-governmental association supporting efforts in Nepal, got access to key support and expertise leveraging open source technology because of Social Coder.
While a bulk of the charities already partnered with Social Coder are based in the UK, organizations in other countries are welcome. Through their website, individuals can register to work on social software projects and connect with organizations and charities seeking their help.
Individuals interested in volunteering with Social Coder can sign up [here](https://socialcoder.org/Home/Programmer).
## Comments are closed. |
11,804 | 使用 OfflineIMAP 同步邮件 | https://opensource.com/article/20/1/sync-email-offlineimap | 2020-01-20T23:53:00 | [
"邮件",
"IMAP"
] | https://linux.cn/article-11804-1.html |
>
> 将邮件镜像保存到本地是整理消息的第一步。在我们的 20 个使用开源提升生产力的系列的第三篇文章中了解该如何做。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 OfflineIMAP 在本地同步你的邮件
我与邮件之间存在爱恨交织的关系。我喜欢它让我与世界各地的人交流的方式。但是,像你们中的许多人一样,我收到过很多邮件,许多是来自邮件列表的,但也有很多垃圾邮件、广告等。这些积累了很多。

我尝试过的大多数工具(除了大型邮件服务商外)都可以很好地处理大量邮件,它们都有一个共同点:它们都依赖于以 [Maildir](https://en.wikipedia.org/wiki/Maildir) 格式存储的本地邮件副本。这其中最有用的是 [OfflineIMAP](http://www.offlineimap.org/)。OfflineIMAP 是将 IMAP 邮箱镜像到本地 Maildir 文件夹树的 Python 脚本。我用它来创建邮件的本地副本并使其保持同步。大多数 Linux 发行版都包含它,并且可以通过 Python 的 pip 包管理器获得。
示例的最小配置文件是一个很好的模板。首先将其复制到 `~/.offlineimaprc`。我的看起来像这样:
```
[general]
accounts = LocalSync
ui=Quiet
autorefresh=30
[Account LocalSync]
localrepository = LocalMail
remoterepository = MirrorIMAP
[Repository MirrorIMAP]
type = IMAP
remotehost = my.mail.server
remoteuser = myusername
remotepass = mypassword
auth_mechanisms = LOGIN
createfolder = true
ssl = yes
sslcacertfile = OS-DEFAULT
[Repository LocalMail]
type = Maildir
localfolders = ~/Maildir
sep = .
createfolder = true
```
我的配置要做的是定义两个仓库:远程 IMAP 服务器和本地 Maildir 文件夹。还有一个**帐户**,告诉 OfflineIMAP 运行时要同步什么。你可以定义链接到不同仓库的多个帐户。除了本地复制外,这还允许你从一台 IMAP 服务器复制到另一台作为备份。
如果你有很多邮件,那么首次运行 OfflineIMAP 将花费一些时间。但是完成后,下次会花*少得多*的时间。你也可以将 OfflineIMAP 作为 cron 任务(我的偏好)或作为守护程序在仓库之间不断进行同步。其文档涵盖了所有这些内容以及 Gmail 等高级配置选项。
现在,我的邮件已在本地复制,并有多种工具用来加快搜索、归档和管理邮件的速度。这些我明天再说。
---
via: <https://opensource.com/article/20/1/sync-email-offlineimap>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Sync your email locally with OfflineIMAP
I have a love/hate relationship with email. I love the way it allows me to communicate with people all over the world. But, like many of you, I get a lot of mail, much of it from lists as well as spammers, advertisers, and the like. And it builds up.
Almost all the tools I've tried (outside of the big mail providers) that work really well with large amounts of mail have one thing in common: they all rely on a local copy of your mail stored in [Maildir](https://en.wikipedia.org/wiki/Maildir) format. And the most useful tool for that is [OfflineIMAP](http://www.offlineimap.org/). OfflineIMAP is a Python script that mirrors IMAP mailboxes to a local Maildir folder tree. I use it to create a local copy of my mail and keep it in sync. Most Linux distributions include it, and it is available via Python's pip package manager.
The sample minimal configuration file is a good template to start with; begin by copying it to **~/.offlineimaprc**. Mine looks something like this:
```
[general]
accounts = LocalSync
ui=Quiet
autorefresh=30
[Account LocalSync]
localrepository = LocalMail
remoterepository = MirrorIMAP
[Repository MirrorIMAP]
type = IMAP
remotehost = my.mail.server
remoteuser = myusername
remotepass = mypassword
auth_mechanisms = LOGIN
createfolder = true
ssl = yes
sslcacertfile = OS-DEFAULT
[Repository LocalMail]
type = Maildir
localfolders = ~/Maildir
sep = .
createfolder = true
```
What my configuration does is define two repositories: the remote IMAP server and the local Maildir folder. There is also the **Account** that tells OfflineIMAP what to sync when it runs. You can define multiple accounts linked to different repositories. This allows you to copy from one IMAP server to another as a backup, in addition to making a copy locally.
The first run of OfflineIMAP will take a while if you have a lot of mail. But once it is done, future runs take a *lot* less time. You can also run OfflineIMAP as a cron job (my preference) or as a daemon constantly syncing between repositories. The documentation covers all of this, as well as advanced configuration options for things like Gmail.
Now that my mail is copied locally, there is a whole range of tools I can work with to speed up searching, filing, and managing mail. And I'll talk about that tomorrow.
## Comments are closed. |
11,806 | 一个非技术人员对 GNOME 项目使用 GitLab 的感受 | https://opensource.com/article/19/10/how-gnome-uses-git | 2020-01-21T09:27:47 | [
"GitLab",
"GNOME"
] | /article-11806-1.html |
>
> 将 GNOME 项目集中在 GitLab 上的决定为整个社区(不只是开发人员)带来了好处。
>
>
>

“您的 GitLab 是什么?”这是我在 [GNOME 基金会](https://www.gnome.org/foundation/)工作的第一天被问到的第一个问题之一,该基金会是支持 GNOME 项目(包括[桌面环境](https://gnome.org/)、[GTK](https://www.gtk.org/) 和 [GStreamer](https://gstreamer.freedesktop.org/))的非盈利组织。此人问的是我在 [GNOME 的 GitLab 实例](https://gitlab.gnome.org/)上的用户名。我在 GNOME 期间,经常有人要求我提供我的 GitLab。
我们使用 GitLab 进行几乎所有操作。通常情况下,我会收到一些<ruby> 提案 <rt> issue </rt></ruby>和参考错误报告,有时还需要修改文件。我不是以开发人员或系统管理员的身份进行此操作的。我参与了“参与度、包容性和多样性(I&D)”团队。我为 GNOME 朋友们撰写新闻通讯,并采访该项目的贡献者。我为 GNOME 活动提供赞助。我不写代码,但我每天都使用 GitLab。
在过去的二十年中,GNOME 项目的管理采用了各种方式。该项目的不同部分使用不同的系统来跟踪代码更改、协作以及作为项目和社交空间共享信息。但是,该项目决定,它需要更加地一体化,这从构思到完成大约花费了一年的时间。
GNOME 希望切换到单个工具供整个社区使用的原因很多。外部项目与 GNOME 息息相关,并为它们提供更简单的与资源交互的方式对于项目至关重要,无论是支持社区还是发展生态系统。我们还希望更好地跟踪 GNOME 的指标,即贡献者的数量、贡献的类型和数量以及项目不同部分的开发进度。
当需要选择一种协作工具时,我们考虑了我们需要的东西。最重要的要求之一是它必须由 GNOME 社区托管。由第三方托管并不是一种选择,因此像 GitHub 和 Atlassian 这样的服务就不在考虑之中。而且,当然了,它必须是自由软件。很快,唯一真正的竞争者出现了,它就是 GitLab。我们希望确保进行贡献很容易。GitLab 具有诸如单点登录的功能,该功能允许人们使用 GitHub、Google、GitLab.com 和 GNOME 帐户登录。
我们认为 GitLab 是一条出路,我们开始从许多工具迁移到单个工具。GNOME 董事会成员 [Carlos Soriano](https://twitter.com/csoriano1618?lang=en) 领导这项改变。在 GitLab 和 GNOME 社区的大力支持下,我们于 2018 年 5 月完成了该过程。
人们非常希望迁移到 GitLab 有助于社区的发展,并使贡献更加容易。由于 GNOME 以前使用了许多不同的工具,包括 Bugzilla 和 CGit,因此很难定量地评估这次切换对贡献量的影响。但是,我们可以更清楚地跟踪一些统计数据,例如在 2018 年 6 月至 2018 年 11 月之间关闭了近 10,000 个提案,合并了 7,085 个合并请求。人们感到社区在发展壮大,越来越受欢迎,而且贡献实际上也更加容易。
人们因不同的原因而开始使用自由软件,重要的是,可以通过为需要软件的人提供更好的资源和更多的支持来公平竞争。Git 作为一种工具已被广泛使用,并且越来越多的人使用这些技能来参与到自由软件当中。自托管的 GitLab 提供了将 Git 的熟悉度与 GitLab 提供的功能丰富、用户友好的环境相结合的绝佳机会。
切换到 GitLab 已经一年多了,变化确实很明显。持续集成(CI)为开发带来了巨大的好处,并且已经完全集成到 GNOME 的几乎每个部分当中。不进行代码开发的团队也转而使用 GitLab 生态系统进行工作。无论是使用问题跟踪来管理分配的任务,还是使用版本控制来共享和管理资产,就连“参与度、包容性和多样性(I&D)”这样的团队都已经使用了 GitLab。
一个社区,即使是一个正在开发的自由软件,也很难适应新技术或新工具。在类似 GNOME 的情况下,这尤其困难,该项目[最近已经 22 岁了](https://opensource.com/article/19/8/poll-favorite-gnome-version)。像 GNOME 这样经过了 20 多年建设的项目,太多的人和组织使用了太多的部件,但迁移工作之所以能实现,这要归功于 GNOME 社区的辛勤工作和 GitLab 的慷慨帮助。
在为使用 Git 进行版本控制的项目工作时,我发现很方便。这是一个令人感觉舒适和熟悉的系统,是一个在工作场所和爱好项目之间保持一致的工具。作为 GNOME 社区的新成员,能够参与并使用 GitLab 真是太好了。作为社区建设者,看到这样结果是令人鼓舞的:越来越多的相关项目加入并进入生态系统;新的贡献者和社区成员对该项目做出了首次贡献;以及增强了衡量我们正在做的工作以了解其成功和成功的能力。
如此多的做着完全不同的事情(例如他们正在从事的不同工作以及所使用的不同技能)的团队同意汇集在一个工具上(尤其是被认为是跨开源的标准工具),这一点很棒。作为 GNOME 的贡献者,我真的非常感谢我们使用了 GitLab。
---
via: <https://opensource.com/article/19/10/how-gnome-uses-git>
作者:[Molly de Blanc](https://opensource.com/users/mollydb) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,807 | 使用 Notmuch 组织你的邮件 | https://opensource.com/article/20/1/organize-email-notmuch | 2020-01-22T11:24:29 | [
"邮件"
] | https://linux.cn/article-11807-1.html |
>
> Notmuch 可以索引、标记和排序电子邮件。在我们的 20 个使用开源提升生产力的系列的第四篇文章中了解该如何使用它。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 用 Notmuch 为你的邮件建立索引
昨天,我谈到了如何使用 OfflineIMAP [将我的邮件同步](/article-11804-1.html)到本地计算机。今天,我将讨论如何在阅读之前预处理所有邮件。

[Maildir](https://en.wikipedia.org/wiki/Maildir) 可能是最有用的邮件存储格式之一。有很多工具可以帮助你管理邮件。我经常使用一个名为 [Notmuch](https://notmuchmail.org/) 的小程序,它能索引、标记和搜索邮件。Notmuch 配合其他几个程序一起使用可以使处理大量邮件更加容易。
大多数 Linux 发行版都包含 Notmuch,你也可以在 MacOS 上获得它。Windows 用户可以通过 Linux 的 Windows 子系统([WSL](https://docs.microsoft.com/en-us/windows/wsl/install-win10))访问它,但可能需要进行一些其他调整。

Notmuch 首次运行时,它将询问你一些问题,并在家目录中创建 `.notmuch-config` 文件。接下来,运行 `notmuch new` 来索引并标记所有邮件。你可以使用 `notmuch search tag:new` 进行验证,它会找到所有带有 `new` 标签的消息。这可能会有很多邮件,因为 Notmuch 使用 `new` 标签来指示新邮件,因此你需要对其进行清理。
运行 `notmuch search tag:unread` 来查找未读消息,这会减少很多邮件。要从你已阅读的消息中删除 `new` 标签,请运行 `notmuch tag -new not tag:unread`,它将搜索所有没有 `unread` 标签的消息,并从其中删除 `new` 标签。现在,当你运行 `notmuch search tag:new` 时,它将仅显示未读邮件。
但是,批量标记消息可能更有用,因为在每次运行时手动更新标记可能非常繁琐。`--batch` 命令行选项告诉 Notmuch 读取多行命令并执行它们。还有一个 `--input=filename` 选项,该选项从文件中读取命令并应用它们。我有一个名为 `tagmail.notmuch` 的文件,用于给“新”邮件添加标签;它看起来像这样:
```
# Manage sent, spam, and trash folders
-unread -new folder:Trash
-unread -new folder:Spam
-unread -new folder:Sent
# Note mail sent specifically to me (excluding bug mail)
+to-me to:kevin at sonney.com and tag:new and not tag:to-me
# And note all mail sent from me
+sent from:kevin at sonney.com and tag:new and not tag:sent
# Remove the new tag from messages
-new tag:new
```
我可以在运行 `notmuch new` 后运行 `notmuch tag --input=tagmail.notmuch` 批量处理我的邮件,之后我也可以搜索这些标签。
Notmuch 还支持 `pre-new` 和 `post-new` 钩子。这些脚本存放在 `Maildir/.notmuch/hooks` 中,它们定义了在使用 `notmuch new` 索引新邮件之前(`pre-new`)和之后(`post-new`)要做的操作。在昨天的文章中,我谈到了使用 [OfflineIMAP](http://www.offlineimap.org/) 同步来自 IMAP 服务器的邮件。从 `pre-new` 钩子运行它非常容易:
```
#!/bin/bash
# Remove the new tag from messages that are still tagged as new
notmuch tag -new tag:new
# Sync mail messages
offlineimap -a LocalSync -u quiet
```
你还可以使用可以操作 Notmuch 数据库的 Python 应用 [afew](https://afew.readthedocs.io/en/latest/index.html),来为你标记*邮件列表*和*垃圾邮件*。你可以用类似的方法在 `post-new` 钩子中使用 `afew`:
```
#!/bin/bash
# tag with my custom tags
notmuch tag --input=~/tagmail.notmuch
# Run afew to tag new mail
afew -t -n
```
我建议你在使用 `afew` 标记邮件时,不要使用 `[ListMailsFilter]`,因为某些邮件处理程序会在邮件中添加模糊或者彻头彻尾是垃圾的列表标头(我说的就是你 Google)。

此时,任何支持 Notmuch 或 Maildir 的邮件阅读器都可以读取我的邮件。有时,我会使用 [alot](https://github.com/pazz/alot)(一个 Notmuch 特定的客户端)在控制台中阅读邮件,但是它不像其他邮件阅读器那么美观。
在接下来的几天,我将向你展示其他一些邮件客户端,它们可能会与你在使用的工具集成在一起。同时,请查看可与 Maildir 邮箱一起使用的其他工具。你可能会发现我没发现的好东西。
---
via: <https://opensource.com/article/20/1/organize-email-notmuch>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Index your email with Notmuch
Yesterday, I talked about how I use OfflineIMAP to [sync my mail](https://opensource.com/article/20/1/sync-email-offlineimap) to my local machine. Today, I'll talk about how I preprocess all that mail before I read it.

[Maildir](https://en.wikipedia.org/wiki/Maildir) is probably one of the most useful mail storage formats out there. And there are a LOT of tools to help with managing your mail. The one I keep coming back to is a little program called [Notmuch](https://notmuchmail.org/) that indexes, tags, and searches mail messages. And there are several programs that work with Notmuch to make it even easier to handle a large amount of mail.
Most Linux distributions include Notmuch, and you can also get it for MacOS. Windows users can access it through Windows Subsystem for Linux ([WSL](https://docs.microsoft.com/en-us/windows/wsl/install-win10)), but it may require some additional tweaks.
On Notmuch's very first run, it will ask you some questions and create a **.notmuch-config** file in your home directory. Next, index and tag all your mail by running **notmuch new**. You can verify it with **notmuch search tag:new**; this will find all messages with the "new" tag. That's probably a lot of mail since Notmuch uses the "new" tag to indicate messages that are new to it, so you'll want to clean that up.
Run **notmuch search tag:unread** to find any unread messages; that should result in quite a lot less mail. To remove the "new" tag from messages you've already seen, run **notmuch tag -new not tag:unread**, which will search for all messages without the "unread" tag and remove the "new" tag from them. Now when you run **notmuch search tag:new**, it should show only the unread mail messages.
Tagging messages in bulk is probably more useful, though, since manually updating tags at every run can be really tedious. The **--batch** command-line option tells Notmuch to read multiple lines of commands and execute them. There is also the **--input=filename** option, which reads commands from a file and applies them. I have a file called **tagmail.notmuch** that I use to add tags to mail that is "new"; it looks something like this:
```
# Manage sent, spam, and trash folders
-unread -new folder:Trash
-unread -new folder:Spam
-unread -new folder:Sent
# Note mail sent specifically to me (excluding bug mail)
+to-me to:kevin at sonney.com and tag:new and not tag:to-me
# And note all mail sent from me
+sent from:kevin at sonney.com and tag:new and not tag:sent
# Remove the new tag from messages
-new tag:new
```
I can then run **notmuch tag --input=tagmail.notmuch** to bulk-process my mail messages after running **notmuch new**, and then I can search on those tags as well.
Notmuch also supports running pre- and post-new hooks. These scripts, stored in **Maildir/.notmuch/hooks**, define actions to run before (pre-new) and after (post-new) to index new mail with **notmuch new**. In yesterday's article, I talked about using [OfflineIMAP](http://www.offlineimap.org/) to sync mail from my IMAP server. It's very easy to run it from the "pre-new" hook:
```
#!/bin/bash
# Remove the new tag from messages that are still tagged as new
notmuch tag -new tag:new
# Sync mail messages
offlineimap -a LocalSync -u quiet
```
You can also use the Python application [afew](https://afew.readthedocs.io/en/latest/index.html), which interfaces with the Notmuch database, to tag things like *Mailing List* and *Spam* for you. You can run afew from the post-new hook in a similar way:
```
#!/bin/bash
# tag with my custom tags
notmuch tag --input=~/tagmail.notmuch
# Run afew to tag new mail
afew -t -n
```
I recommend that when using afew to tag messages, you do NOT use the **[ListMailsFilter]** since some mail handlers add obscure or downright junk List-ID headers to mail messages (I'm looking at you, Google).
At this point, any mail reader that supports Notmuch or Maildir can work with my email. I'll sometimes use [alot](https://github.com/pazz/alot), a Notmuch-specific client, to read mail at the console, but it's not as fancy as some other mail readers.
In the coming days, I'll show you some other mail clients that will likely integrate with tools you already use. In the meantime, check out some of the other tools that work with Maildir mailboxes—you might find a hidden gem I've not tried yet.
## Comments are closed. |
11,809 | 如何在 Sway 中设置多个显示器 | https://fedoramagazine.org/how-to-setup-multiple-monitors-in-sway/ | 2020-01-22T15:09:50 | [
"Sway"
] | https://linux.cn/article-11809-1.html | 
Sway 是一种平铺式 Wayland 合成器,具有与 [i3 X11 窗口管理器](https://fedoramagazine.org/getting-started-i3-window-manager/)相同的功能、外观和工作流程。由于 Sway 使用 Wayland 而不是 X11,因此就不能一如既往地使用设置 X11 的工具。这包括 `xrandr` 之类的工具,这些工具在 X11 窗口管理器或桌面中用于设置显示器。这就是为什么必须通过编辑 Sway 配置文件来设置显示器的原因,这就是本文的目的。
### 获取你的显示器 ID
首先,你必须获得 Sway 用来指代显示器的名称。你可以通过运行以下命令进行操作:
```
$ swaymsg -t get_outputs
```
你将获得所有显示器的相关信息,每个显示器都用空行分隔。
你必须查看每个部分的第一行,以及 `Output` 之后的内容。例如,当你看到 `Output DVI-D-1 'Philips Consumer Electronics Company'` 之类的行时,则该输出 ID 为 `DVI-D-1`。注意这些 ID 及其所属的物理监视器。
### 编辑配置文件
如果你之前没有编辑过 Sway 配置文件,则必须通过运行以下命令将其复制到主目录中:
```
cp -r /etc/sway/config ~/.config/sway/config
```
现在,默认配置文件位于 `~/.config/sway` 中,名为 `config`。你可以使用任何文本编辑器进行编辑。
现在你需要做一点数学。想象有一个网格,其原点在左上角。X 和 Y 坐标的单位是像素。Y 轴反转。这意味着,例如,如果你从原点开始,向右移动 100 像素,向下移动 80 像素,则坐标将为 `(100, 80)`。
你必须计算最终显示在此网格上的位置。显示器的位置由左上方的像素指定。例如,如果我们要使用名称为“HDMI1”且分辨率为 1920×1080 的显示器,并在其右侧使用名称为 “eDP1” 且分辨率为 1600×900 的笔记本电脑显示器,则必须在配置文件中键入 :
```
output HDMI1 pos 0 0
output eDP1 pos 1920 0
```
你还可以使用 `res` 选项手动指定分辨率:
```
output HDMI1 pos 0 0 res 1920x1080
output eDP1 pos 1920 0 res 1600x900
```
### 将工作空间绑定到显示器上
与多个监视器一起使用 Sway 在工作区管理中可能会有些棘手。幸运的是,你可以将工作区绑定到特定的显示器上,因此你可以轻松地切换到该显示器并更有效地使用它。只需通过配置文件中的 `workspace` 命令即可完成。例如,如果要绑定工作区 1 和 2 到显示器 “DVI-D-1”,绑定工作区 8 和 9 到显示器 “HDMI-A-1”,则可以使用以下方法:
```
workspace 1 output DVI-D-1
workspace 2 output DVI-D-1
```
```
workspace 8 output HDMI-A-1
workspace 9 output HDMI-A-1
```
就是这样。这就在 Sway 中多显示器设置的基础知识。可以在 <https://github.com/swaywm/sway/wiki#Wiki#Multihead> 中找到更详细的指南。
---
via: <https://fedoramagazine.org/how-to-setup-multiple-monitors-in-sway/>
作者:[arte219](https://fedoramagazine.org/author/arte219/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sway is a tiling Wayland compositor which has mostly the same features, look and workflow as the [i3 X11 window manager](https://fedoramagazine.org/getting-started-i3-window-manager/). Because Sway uses Wayland instead of X11, the tools to setup X11 don’t always work in sway. This includes tools like *xrandr*, which are used in X11 window managers or desktops to setup monitors. This is why monitors have to be setup by editing the sway config file, and that’s what this article is about.
**Getting your monitor ID’s**
First, you have to get the names sway uses to refer to your monitors. You can do this by running:
$ swaymsg -t get_outputs
You will get information about all of your monitors, every monitor separated by an empty line.
You have to look for the first line of every section, and for what’s after “Output”. For example, when you see a line like “*Output DVI-D-1 ‘Philips Consumer Electronics Company’*”, the output ID is “DVI-D-1”. Note these ID’s and which physical monitors they belong to.
**Editing the config file**
If you haven’t edited the Sway config file before, you have to copy it to your home directory by running this command:
cp -r /etc/sway/config ~/.config/sway/config
Now the default config file is located in *~/.config/sway *and called “config”. You can edit it using any text editor.
Now you have to do a little bit of math. Imagine a grid with the origin in the top left corner. The units of the X and Y coordinates are pixels. The Y axis is inverted. This means that if you, for example, start at the origin and you move 100 pixels to the right and 80 pixels down, your coordinates will be (100, 80).
You have to calculate where your displays are going to end up on this grid. The locations of the displays are specified with the top left pixel. For example, if we want to have a monitor with name HDMI1 and a resolution of 1920×1080, and to the right of it a laptop monitor with name eDP1 and a resolution of 1600×900, you have to type this in your config file:
output HDMI1 pos 0 0 output eDP1 pos 1920 0
You can also specify the resolutions manually by using the *res* option:
output HDMI1 pos 0 0 res 1920x1080 output eDP1 pos 1920 0 res 1600x900
**Binding workspaces to monitors**
Using sway with multiple monitors can be a little bit tricky with workspace management. Luckily, you can bind workspaces to a specific monitor, so you can easily switch to that monitor and use your displays more efficiently. This can simply be done by the workspace command in your config file. For example, if you want to bind workspace 1 and 2 to monitor DVI-D-1 and workspace 8 and 9 to monitor HDMI-A-1, you can do that by using:
workspace 1 output DVI-D-1 workspace 2 output DVI-D-1
workspace 8 output HDMI-A-1 workspace 9 output HDMI-A-1
That’s it! These are the basics of multi monitor setup in sway. A more detailed guide can be found at [https://github.com/swaywm/sway/wiki#Multihead](https://github.com/swaywm/sway/wiki#Multihead).
## Onyeibo
Refreshing and resourceful. Thank you
## onyx
So are you saying through this, mixed with the Nvidia proprietary drivers on an Optimus laptop, I can render a second workspace on another monitor? As far as I know we cant do this right now with Optimus but this would be awesome as a workaround.
## Sebastiaan
Sway doesn’t work with proprietary drivers, at all. There’s a work around for it with a argument you can pass to Sway, but it’s not very user friendly.
## Diego Abad
This this the argument you need to pass if want use nvidia:
“–my-next-gpu-wont-be-nvidia and DO NOT report issues.” 🙂
## sygnal
No, and you should consider using more user & open source friendly hardware in the future. AMD work fantastic on Linux and Sway out of the box! Hell, even Intel is getting in the game!
## arte219
Sway won’t work with the nvidia proprietary drivers, but you can use the i3 window manager. it has the same workflow, it only misses a few things the sway devs added in (such as native i3-gaps and wallpaper support) but these functionalities can be added by installing a few packages.
## raphgro
Thanks.
## Klaus
And what about multiple touch screens? Is there any support for having multiple touch screens now? In X it was so easy, but with wayland I did not know anyone who was able to get it work. |
11,810 | OpenSSL 入门:密码学基础知识 | https://opensource.com/article/19/6/cryptography-basics-openssl-part-1 | 2020-01-23T14:23:44 | [
"OpenSSL",
"HTTPS"
] | https://linux.cn/article-11810-1.html |
>
> 想要入门密码学的基础知识,尤其是有关 OpenSSL 的入门知识吗?继续阅读。
>
>
>

本文是使用 [OpenSSL](https://www.openssl.org/) 的密码学基础知识的两篇文章中的第一篇,OpenSSL 是在 Linux 和其他系统上流行的生产级库和工具包。(要安装 OpenSSL 的最新版本,请参阅[这里](https://www.howtoforge.com/tutorial/how-to-install-openssl-from-source-on-linux/)。)OpenSSL 实用程序可在命令行使用,程序也可以调用 OpenSSL 库中的函数。本文的示例程序使用的是 C 语言,即 OpenSSL 库的源语言。
本系列的两篇文章涵盖了加密哈希、数字签名、加密和解密以及数字证书。你可以从[我的网站](http://condor.depaul.edu/mkalin)的 ZIP 文件中找到这些代码和命令行示例。
让我们首先回顾一下 OpenSSL 名称中的 SSL。
### OpenSSL 简史
<ruby> <a href="https://en.wikipedia.org/wiki/Transport_Layer_Security"> 安全套接字层 </a> <rt> Secure Socket Layer </rt></ruby>(SSL)是 Netscape 在 1995 年发布的一种加密协议。该协议层可以位于 HTTP 之上,从而为 HTTPS 提供了 S:<ruby> 安全 <rt> secure </rt></ruby>。SSL 协议提供了各种安全服务,其中包括两项在 HTTPS 中至关重要的服务:
* <ruby> 对等身份验证 <rt> Peer authentication </rt></ruby>(也称为相互质询):连接的每一边都对另一边的身份进行身份验证。如果 Alice 和 Bob 要通过 SSL 交换消息,则每个人首先验证彼此的身份。
* <ruby> 机密性 <rt> Confidentiality </rt></ruby>:发送者在通过通道发送消息之前先对其进行加密。然后,接收者解密每个接收到的消息。此过程可保护网络对话。即使窃听者 Eve 截获了从 Alice 到 Bob 的加密消息(即*中间人*攻击),Eve 会发现他无法在计算上解密此消息。
反过来,这两个关键 SSL 服务与其他不太受关注的服务相关联。例如,SSL 支持消息完整性,从而确保接收到的消息与发送的消息相同。此功能是通过哈希函数实现的,哈希函数也随 OpenSSL 工具箱一起提供。
SSL 有多个版本(例如 SSLv2 和 SSLv3),并且在 1999 年出现了一个基于 SSLv3 的类似协议<ruby> 传输层安全性 <rt> Transport Layer Security </rt></ruby>(TLS)。TLSv1 和 SSLv3 相似,但不足以相互配合工作。不过,通常将 SSL/TLS 称为同一协议。例如,即使正在使用的是 TLS(而非 SSL),OpenSSL 函数也经常在名称中包含 SSL。此外,调用 OpenSSL 命令行实用程序以 `openssl` 开始。
除了 man 页面之外,OpenSSL 的文档是零零散散的,鉴于 OpenSSL 工具包很大,这些页面很难以查找使用。命令行和代码示例可以将主要主题集中起来。让我们从一个熟悉的示例开始(使用 HTTPS 访问网站),然后使用该示例来选出我们感兴趣的加密部分进行讲述。
### 一个 HTTPS 客户端
此处显示的 `client` 程序通过 HTTPS 连接到 Google:
```
/* compilation: gcc -o client client.c -lssl -lcrypto */
#include <stdio.h>
#include <stdlib.h>
#include <openssl/bio.h> /* BasicInput/Output streams */
#include <openssl/err.h> /* errors */
#include <openssl/ssl.h> /* core library */
#define BuffSize 1024
void report_and_exit(const char* msg) {
perror(msg);
ERR_print_errors_fp(stderr);
exit(-1);
}
void init_ssl() {
SSL_load_error_strings();
SSL_library_init();
}
void cleanup(SSL_CTX* ctx, BIO* bio) {
SSL_CTX_free(ctx);
BIO_free_all(bio);
}
void secure_connect(const char* hostname) {
char name[BuffSize];
char request[BuffSize];
char response[BuffSize];
const SSL_METHOD* method = TLSv1_2_client_method();
if (NULL == method) report_and_exit("TLSv1_2_client_method...");
SSL_CTX* ctx = SSL_CTX_new(method);
if (NULL == ctx) report_and_exit("SSL_CTX_new...");
BIO* bio = BIO_new_ssl_connect(ctx);
if (NULL == bio) report_and_exit("BIO_new_ssl_connect...");
SSL* ssl = NULL;
/* 链路 bio 通道,SSL 会话和服务器端点 */
sprintf(name, "%s:%s", hostname, "https");
BIO_get_ssl(bio, &ssl); /* 会话 */
SSL_set_mode(ssl, SSL_MODE_AUTO_RETRY); /* 鲁棒性 */
BIO_set_conn_hostname(bio, name); /* 准备连接 */
/* 尝试连接 */
if (BIO_do_connect(bio) <= 0) {
cleanup(ctx, bio);
report_and_exit("BIO_do_connect...");
}
/* 验证信任库,检查证书 */
if (!SSL_CTX_load_verify_locations(ctx,
"/etc/ssl/certs/ca-certificates.crt", /* 信任库 */
"/etc/ssl/certs/")) /* 其它信任库 */
report_and_exit("SSL_CTX_load_verify_locations...");
long verify_flag = SSL_get_verify_result(ssl);
if (verify_flag != X509_V_OK)
fprintf(stderr,
"##### Certificate verification error (%i) but continuing...\n",
(int) verify_flag);
/* 获取主页作为示例数据 */
sprintf(request,
"GET / HTTP/1.1\x0D\x0AHost: %s\x0D\x0A\x43onnection: Close\x0D\x0A\x0D\x0A",
hostname);
BIO_puts(bio, request);
/* 从服务器读取 HTTP 响应并打印到输出 */
while (1) {
memset(response, '\0', sizeof(response));
int n = BIO_read(bio, response, BuffSize);
if (n <= 0) break; /* 0 代表流结束,< 0 代表有错误 */
puts(response);
}
cleanup(ctx, bio);
}
int main() {
init_ssl();
const char* hostname = "www.google.com:443";
fprintf(stderr, "Trying an HTTPS connection to %s...\n", hostname);
secure_connect(hostname);
return 0;
}
```
可以从命令行编译和执行该程序(请注意 `-lssl` 和 `-lcrypto` 中的小写字母 `L`):
```
gcc -o client client.c -lssl -lcrypto
```
该程序尝试打开与网站 [www.google.com](http://www.google.com) 的安全连接。在与 Google Web 服务器的 TLS 握手过程中,`client` 程序会收到一个或多个数字证书,该程序会尝试对其进行验证(但在我的系统上失败了)。尽管如此,`client` 程序仍继续通过安全通道获取 Google 主页。该程序取决于前面提到的安全工件,尽管在上述代码中只着重突出了数字证书。但其它工件仍在幕后发挥作用,稍后将对它们进行详细说明。
通常,打开 HTTP(非安全)通道的 C 或 C++ 的客户端程序将使用诸如*文件描述符*或*网络套接字*之类的结构,它们是两个进程(例如,这个 `client` 程序和 Google Web 服务器)之间连接的端点。另一方面,文件描述符是一个非负整数值,用于在程序中标识该程序打开的任何文件类的结构。这样的程序还将使用一种结构来指定有关 Web 服务器地址的详细信息。
这些相对较低级别的结构不会出现在客户端程序中,因为 OpenSSL 库会将套接字基础设施和地址规范等封装在更高层面的安全结构中。其结果是一个简单的 API。下面首先看一下 `client` 程序示例中的安全性详细信息。
* 该程序首先加载相关的 OpenSSL 库,我的函数 `init_ssl` 中对 OpenSSL 进行了两次调用:
```
SSL_load_error_strings();
SSL_library_init();
```
* 下一个初始化步骤尝试获取安全*上下文*,这是建立和维护通往 Web 服务器的安全通道所需的信息框架。如对 OpenSSL 库函数的调用所示,在示例中使用了 TLS 1.2:
```
const SSL_METHOD* method = TLSv1_2_client_method(); /* TLS 1.2 */
```
如果调用成功,则将 `method` 指针被传递给库函数,该函数创建类型为 `SSL_CTX` 的上下文:
```
SSL_CTX* ctx = SSL_CTX_new(method);
```
`client` 程序会检查每个关键的库调用的错误,如果其中一个调用失败,则程序终止。
* 现在还有另外两个 OpenSSL 工件也在发挥作用:SSL 类型的安全会话,从头到尾管理安全连接;以及类型为 BIO(<ruby> 基本输入/输出 <rt> Basic Input/Output </rt></ruby>)的安全流,用于与 Web 服务器进行通信。BIO 流是通过以下调用生成的:
```
BIO* bio = BIO_new_ssl_connect(ctx);
```
请注意,这个最重要的上下文是其参数。`BIO` 类型是 C 语言中 `FILE` 类型的 OpenSSL 封装器。此封装器可保护 `client` 程序与 Google 的网络服务器之间的输入和输出流的安全。
* 有了 `SSL_CTX` 和 `BIO`,然后程序在 SSL 会话中将它们组合在一起。三个库调用可以完成工作:
```
BIO_get_ssl(bio, &ssl); /* 会话 */
SSL_set_mode(ssl, SSL_MODE_AUTO_RETRY); /* 鲁棒性 */
BIO_set_conn_hostname(bio, name); /* 准备连接 */
```
安全连接本身是通过以下调用建立的:
```
BIO_do_connect(bio);
```
如果最后一个调用不成功,则 `client` 程序终止;否则,该连接已准备就绪,可以支持 `client` 程序与 Google Web 服务器之间的机密对话。
在与 Web 服务器握手期间,`client` 程序会接收一个或多个数字证书,以认证服务器的身份。但是,`client` 程序不会发送自己的证书,这意味着这个身份验证是单向的。(Web 服务器通常配置为**不**需要客户端证书)尽管对 Web 服务器证书的验证失败,但 `client` 程序仍通过了连接到 Web 服务器的安全通道继续获取 Google 主页。
为什么验证 Google 证书的尝试会失败?典型的 OpenSSL 安装目录为 `/etc/ssl/certs`,其中包含 `ca-certificates.crt` 文件。该目录和文件包含着 OpenSSL 自带的数字证书,以此构成<ruby> 信任库 <rt> truststore </rt></ruby>。可以根据需要更新信任库,尤其是可以包括新信任的证书,并删除不再受信任的证书。
`client` 程序从 Google Web 服务器收到了三个证书,但是我的计算机上的 OpenSSL 信任库并不包含完全匹配的证书。如目前所写,`client` 程序不会通过例如验证 Google 证书上的数字签名(一个用来证明该证书的签名)来解决此问题。如果该签名是受信任的,则包含该签名的证书也应受信任。尽管如此,`client` 程序仍继续获取页面,然后打印出 Google 的主页。下一节将更详细地介绍这些。
### 客户端程序中隐藏的安全性
让我们从客户端示例中可见的安全工件(数字证书)开始,然后考虑其他安全工件如何与之相关。数字证书的主要格式标准是 X509,生产级的证书由诸如 [Verisign](https://www.verisign.com) 的<ruby> 证书颁发机构 <rt> Certificate Authority </rt></ruby>(CA)颁发。
数字证书中包含各种信息(例如,激活日期和失效日期以及所有者的域名),也包括发行者的身份和*数字签名*(这是加密过的*加密哈希*值)。证书还具有未加密的哈希值,用作其标识*指纹*。
哈希值来自将任意数量的二进制位映射到固定长度的摘要。这些位代表什么(会计报告、小说或数字电影)无关紧要。例如,<ruby> 消息摘要版本 5 <rt> Message Digest version 5 </rt></ruby>(MD5)哈希算法将任意长度的输入位映射到 128 位哈希值,而 SHA1(<ruby> 安全哈希算法版本 1 <rt> Secure Hash Algorithm version 1 </rt></ruby>)算法将输入位映射到 160 位哈希值。不同的输入位会导致不同的(实际上在统计学上是唯一的)哈希值。下一篇文章将会进行更详细的介绍,并着重介绍什么使哈希函数具有加密功能。
数字证书的类型有所不同(例如根证书、中间证书和最终实体证书),并形成了反映这些证书类型的层次结构。顾名思义,*根*证书位于层次结构的顶部,其下的证书继承了根证书所具有的信任。OpenSSL 库和大多数现代编程语言都具有 X509 数据类型以及处理此类证书的函数。来自 Google 的证书具有 X509 格式,`client` 程序会检查该证书是否为 `X509_V_OK`。
X509 证书基于<ruby> 公共密钥基础结构 <rt> public-key infrastructure </rt></ruby>(PKI),其中包括的算法(RSA 是占主导地位的算法)用于生成*密钥对*:公共密钥及其配对的私有密钥。公钥是一种身份:[Amazon](https://www.amazon.com) 的公钥对其进行标识,而我的公钥对我进行标识。私钥应由其所有者负责保密。
成对出现的密钥具有标准用途。可以使用公钥对消息进行加密,然后可以使用同一个密钥对中的私钥对消息进行解密。私钥也可以用于对文档或其他电子工件(例如程序或电子邮件)进行签名,然后可以使用该对密钥中的公钥来验证签名。以下两个示例补充了一些细节。
在第一个示例中,Alice 将她的公钥分发给全世界,包括 Bob。然后,Bob 用 Alice 的公钥加密邮件,然后将加密的邮件发送给 Alice。用 Alice 的公钥加密的邮件将可以用她的私钥解密(假设是她自己的私钥),如下所示:
```
+------------------+ encrypted msg +-------------------+
Bob's msg--->|Alice's public key|--------------->|Alice's private key|---> Bob's msg
+------------------+ +-------------------+
```
理论上可以在没有 Alice 的私钥的情况下解密消息,但在实际情况中,如果使用像 RSA 这样的加密密钥对系统,则在计算上做不到。
现在,第二个示例,请对文档签名以证明其真实性。签名算法使用密钥对中的私钥来处理要签名的文档的加密哈希:
```
+-------------------+
Hash of document--->|Alice's private key|--->Alice's digital signature of the document
+-------------------+
```
假设 Alice 以数字方式签署了发送给 Bob 的合同。然后,Bob 可以使用 Alice 密钥对中的公钥来验证签名:
```
+------------------+
Alice's digital signature of the document--->|Alice's public key|--->verified or not
+------------------+
```
假若没有 Alice 的私钥,就无法轻松伪造 Alice 的签名:因此,Alice 有必要保密她的私钥。
在 `client` 程序中,除了数字证书以外,这些安全性都没有明确展示。下一篇文章使用使用 OpenSSL 实用程序和库函数的示例填充更多详细的信息。
### 命令行的 OpenSSL
同时,让我们看一下 OpenSSL 命令行实用程序:特别是在 TLS 握手期间检查来自 Web 服务器的证书的实用程序。调用 OpenSSL 实用程序可以使用 `openssl` 命令,然后添加参数和标志的组合以指定所需的操作。
看看以下命令:
```
openssl list-cipher-algorithms
```
该输出是组成<ruby> 加密算法套件 <rt> cipher suite </rt> <rt> </rt></ruby>的相关算法的列表。下面是列表的开头,加了澄清首字母缩写词的注释:
```
AES-128-CBC ## Advanced Encryption Standard, Cipher Block Chaining
AES-128-CBC-HMAC-SHA1 ## Hash-based Message Authentication Code with SHA1 hashes
AES-128-CBC-HMAC-SHA256 ## ditto, but SHA256 rather than SHA1
...
```
下一条命令使用参数 `s_client` 将打开到 [www.google.com](http://www.google.com) 的安全连接,并在屏幕上显示有关此连接的所有信息:
```
openssl s_client -connect www.google.com:443 -showcerts
```
端口号 443 是 Web 服务器用于接收 HTTPS(而不是 HTTP 连接)的标准端口号。(对于 HTTP,标准端口为 80)Web 地址 [www.google.com:443](http://www.google.com:443) 也出现在 `client` 程序的代码中。如果尝试连接成功,则将显示来自 Google 的三个数字证书以及有关安全会话、正在使用的加密算法套件以及相关项目的信息。例如,这是开头的部分输出,它声明*证书链*即将到来。证书的编码为 base64:
```
Certificate chain
0 s:/C=US/ST=California/L=Mountain View/O=Google LLC/CN=www.google.com
i:/C=US/O=Google Trust Services/CN=Google Internet Authority G3
-----BEGIN CERTIFICATE-----
MIIEijCCA3KgAwIBAgIQdCea9tmy/T6rK/dDD1isujANBgkqhkiG9w0BAQsFADBU
MQswCQYDVQQGEwJVUzEeMBwGA1UEChMVR29vZ2xlIFRydXN0IFNlcnZpY2VzMSUw
...
```
诸如 Google 之类的主要网站通常会发送多个证书进行身份验证。
输出以有关 TLS 会话的摘要信息结尾,包括加密算法套件的详细信息:
```
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES128-GCM-SHA256
Session-ID: A2BBF0E4991E6BBBC318774EEE37CFCB23095CC7640FFC752448D07C7F438573
...
```
`client` 程序中使用了协议 TLS 1.2,`Session-ID` 唯一地标识了 `openssl` 实用程序和 Google Web 服务器之间的连接。`Cipher` 条目可以按以下方式进行解析:
* `ECDHE`(<ruby> 椭圆曲线 Diffie-Hellman(临时) <rt> Elliptic Curve Diffie Hellman Ephemeral </rt></ruby>)是一种用于管理 TLS 握手的高效的有效算法。尤其是,ECDHE 通过确保连接双方(例如,`client` 程序和 Google Web 服务器)使用相同的加密/解密密钥(称为*会话密钥*)来解决“密钥分发问题”。后续文章会深入探讨该细节。
* `RSA`(Rivest Shamir Adleman)是主要的公共密钥密码系统,并以 1970 年代末首次描述了该系统的三位学者的名字命名。这个正在使用的密钥对是使用 RSA 算法生成的。
* `AES128`(<ruby> 高级加密标准 <rt> Advanced Encryption Standard </rt></ruby>)是一种<ruby> 块式加密算法 <rt> block cipher </rt></ruby>,用于加密和解密<ruby> 位块 <rt> blocks of bits </rt></ruby>。(另一种算法是<ruby> 流式加密算法 <rt> stream cipher </rt></ruby>,它一次加密和解密一个位。)这个加密算法是对称加密算法,因为使用同一个密钥进行加密和解密,这首先引起了密钥分发问题。AES 支持 128(此处使用)、192 和 256 位的密钥大小:密钥越大,安全性越好。
通常,像 AES 这样的对称加密系统的密钥大小要小于像 RSA 这样的非对称(基于密钥对)系统的密钥大小。例如,1024 位 RSA 密钥相对较小,而 256 位密钥则当前是 AES 最大的密钥。
* `GCM`(<ruby> 伽罗瓦计数器模式 <rt> Galois Counter Mode </rt></ruby>)处理在安全对话期间重复应用的加密算法(在这种情况下为 AES128)。AES128 块的大小仅为 128 位,安全对话很可能包含从一侧到另一侧的多个 AES128 块。GCM 非常有效,通常与 AES128 搭配使用。
* `SHA256`(<ruby> 256 位安全哈希算法 <rt> Secure Hash Algorithm 256 bits </rt></ruby>)是我们正在使用的加密哈希算法。生成的哈希值的大小为 256 位,尽管使用 SHA 甚至可以更大。
加密算法套件正在不断发展中。例如,不久前,Google 使用 RC4 流加密算法(RSA 的 Ron Rivest 后来开发的 Ron’s Cipher 版本 4)。 RC4 现在有已知的漏洞,这大概部分导致了 Google 转换为 AES128。
### 总结
我们通过安全的 C Web 客户端和各种命令行示例对 OpenSSL 做了首次了解,使一些需要进一步阐明的主题脱颖而出。[下一篇文章会详细介绍](https://opensource.com/article/19/6/cryptography-basics-openssl-part-2),从加密散列开始,到对数字证书如何应对密钥分发挑战为结束的更全面讨论。
---
via: <https://opensource.com/article/19/6/cryptography-basics-openssl-part-1>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu/users/akritiko/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article is the first of two on cryptography basics using [OpenSSL](https://www.openssl.org/), a production-grade library and toolkit popular on Linux and other systems. (To install the most recent version of OpenSSL, see [here](https://www.howtoforge.com/tutorial/how-to-install-openssl-from-source-on-linux/).) OpenSSL utilities are available at the command line, and programs can call functions from the OpenSSL libraries. The sample program for this article is in C, the source language for the OpenSSL libraries.
The two articles in this series cover—collectively—cryptographic hashes, digital signatures, encryption and decryption, and digital certificates. You can find the code and command-line examples in a ZIP file from [my website](http://condor.depaul.edu/mkalin).
Let’s start with a review of the SSL in the OpenSSL name.
## A quick history
[Secure Socket Layer (SSL)](https://en.wikipedia.org/wiki/Transport_Layer_Security) is a cryptographic protocol that [Netscape](https://en.wikipedia.org/wiki/Netscape) released in 1995. This protocol layer can sit atop HTTP, thereby providing the *S* for *secure* in HTTPS. The SSL protocol provides various security services, including two that are central in HTTPS:
- Peer authentication (aka mutual challenge): Each side of a connection authenticates the identity of the other side. If Alice and Bob are to exchange messages over SSL, then each first authenticates the identity of the other.
- Confidentiality: A sender encrypts messages before sending these over a channel. The receiver then decrypts each received message. This process safeguards network conversations. Even if eavesdropper Eve intercepts an encrypted message from Alice to Bob (a
*man-in-the-middle*attack), Eve finds it computationally infeasible to decrypt this message.
These two key SSL services, in turn, are tied to others that get less attention. For example, SSL supports message integrity, which assures that a received message is the same as the one sent. This feature is implemented with hash functions, which likewise come with the OpenSSL toolkit.
SSL is versioned (e.g., SSLv2 and SSLv3), and in 1999 Transport Layer Security (TLS) emerged as a similar protocol based upon SSLv3. TLSv1 and SSLv3 are alike, but not enough so to work together. Nonetheless, it is common to refer to SSL/TLS as if they are one and the same protocol. For example, OpenSSL functions often have SSL in the name even when TLS rather than SSL is in play. Furthermore, calling OpenSSL command-line utilities begins with the term **openssl**.
The documentation for OpenSSL is spotty beyond the **man** pages, which become unwieldy given how big the OpenSSL toolkit is. Command-line and code examples are one way to bring the main topics into focus together. Let’s start with a familiar example—accessing a web site with HTTPS—and use this example to pick apart the cryptographic pieces of interest.
## An HTTPS client
The **client** program shown here connects over HTTPS to Google:
```
/* compilation: gcc -o client client.c -lssl -lcrypto */
#include <stdio.h>
#include <stdlib.h>
#include <openssl/bio.h> /* BasicInput/Output streams */
#include <openssl/err.h> /* errors */
#include <openssl/ssl.h> /* core library */
#define BuffSize 1024
void report_and_exit(const char* msg) {
perror(msg);
ERR_print_errors_fp(stderr);
exit(-1);
}
void init_ssl() {
SSL_load_error_strings();
SSL_library_init();
}
void cleanup(SSL_CTX* ctx, BIO* bio) {
SSL_CTX_free(ctx);
BIO_free_all(bio);
}
void secure_connect(const char* hostname) {
char name[BuffSize];
char request[BuffSize];
char response[BuffSize];
const SSL_METHOD* method = TLSv1_2_client_method();
if (NULL == method) report_and_exit("TLSv1_2_client_method...");
SSL_CTX* ctx = SSL_CTX_new(method);
if (NULL == ctx) report_and_exit("SSL_CTX_new...");
BIO* bio = BIO_new_ssl_connect(ctx);
if (NULL == bio) report_and_exit("BIO_new_ssl_connect...");
SSL* ssl = NULL;
/* link bio channel, SSL session, and server endpoint */
sprintf(name, "%s:%s", hostname, "https");
BIO_get_ssl(bio, &ssl); /* session */
SSL_set_mode(ssl, SSL_MODE_AUTO_RETRY); /* robustness */
BIO_set_conn_hostname(bio, name); /* prepare to connect */
/* try to connect */
if (BIO_do_connect(bio) <= 0) {
cleanup(ctx, bio);
report_and_exit("BIO_do_connect...");
}
/* verify truststore, check cert */
if (!SSL_CTX_load_verify_locations(ctx,
"/etc/ssl/certs/ca-certificates.crt", /* truststore */
"/etc/ssl/certs/")) /* more truststore */
report_and_exit("SSL_CTX_load_verify_locations...");
long verify_flag = SSL_get_verify_result(ssl);
if (verify_flag != X509_V_OK)
fprintf(stderr,
"##### Certificate verification error (%i) but continuing...\n",
(int) verify_flag);
/* now fetch the homepage as sample data */
sprintf(request,
"GET / HTTP/1.1\x0D\x0AHost: %s\x0D\x0A\x43onnection: Close\x0D\x0A\x0D\x0A",
hostname);
BIO_puts(bio, request);
/* read HTTP response from server and print to stdout */
while (1) {
memset(response, '\0', sizeof(response));
int n = BIO_read(bio, response, BuffSize);
if (n <= 0) break; /* 0 is end-of-stream, < 0 is an error */
puts(response);
}
cleanup(ctx, bio);
}
int main() {
init_ssl();
const char* hostname = "www.google.com:443";
fprintf(stderr, "Trying an HTTPS connection to %s...\n", hostname);
secure_connect(hostname);
return 0;
}
```
This program can be compiled and executed from the command line (note the lowercase L in **-lssl** and **-lcrypto**):
**gcc**** -o ****client client****.c -****lssl**** -****lcrypto**
This program tries to open a secure connection to the web site [www.google.com](http://www.google.com). As part of the TLS handshake with the Google web server, the **client** program receives one or more digital certificates, which the program tries (but, on my system, fails) to verify. Nonetheless, the **client** program goes on to fetch the Google homepage through the secure channel. This program depends on the security artifacts mentioned earlier, although only a digital certificate stands out in the code. The other artifacts remain behind the scenes and are clarified later in detail.
Generally, a client program in C or C++ that opened an HTTP (non-secure) channel would use constructs such as a *file descriptor* for a *network socket*, which is an endpoint in a connection between two processes (e.g., the client program and the Google web server). A file descriptor, in turn, is a non-negative integer value that identifies, within a program, any file-like construct that the program opens. Such a program also would use a structure to specify details about the web server’s address.
None of these relatively low-level constructs occurs in the client program, as the OpenSSL library wraps the socket infrastructure and address specification in high-level security constructs. The result is a straightforward API. Here’s a first look at the security details in the example **client** program.
-
The program begins by loading the relevant OpenSSL libraries, with my function
**init_ssl**making two calls into OpenSSL:**SSL_library_init(); SSL_load_error_strings();** -
The next initialization step tries to get a security
*context*, a framework of information required to establish and maintain a secure channel to the web server.**TLS 1.2**is used in the example, as shown in this call to an OpenSSL library function:**const SSL_METHOD* method = TLSv1_2_client_method(); /* TLS 1.2 */**If the call succeeds, then the
**method**pointer is passed to the library function that creates the context of type**SSL_CTX**:**SSL_CTX*****ctx****= SSL_CTX_new(method);**The
**client**program checks for errors on each of these critical library calls, and then the program terminates if either call fails. -
Two other OpenSSL artifacts now come into play: a security session of type
**SSL**, which manages the secure connection from start to finish; and a secured stream of type**BIO**(Basic Input/Output), which is used to communicate with the web server. The**BIO**stream is generated with this call:**BIO* bio = BIO_new_ssl_connect(****ctx****);**Note that the all-important context is the argument. The
**BIO**type is the OpenSSL wrapper for the**FILE**type in C. This wrapper secures the input and output streams between the**client**program and Google's web server. -
With the
**SSL_CTX**and**BIO**in hand, the program then links these together in an**SSL**session. Three library calls do the work:**BIO_get_ssl(bio, &ssl); /* get a TLS session */****SSL_set_mode(ssl, SSL_MODE_AUTO_RETRY); /* for robustness */****BIO_set_conn_hostname(bio, name); /* prepare to connect to Google */**The secure connection itself is established through this call:
**BIO_do_connect(bio);**If this last call does not succeed, the
**client**program terminates; otherwise, the connection is ready to support a confidential conversation between the**client**program and the Google web server.
During the handshake with the web server, the **client** program receives one or more digital certificates that authenticate the server’s identity. However, the **client** program does not send a certificate of its own, which means that the authentication is one-way. (Web servers typically are configured *not* to expect a client certificate.) Despite the failed verification of the web server’s certificate, the **client** program continues by fetching the Google homepage through the secure channel to the web server.
Why does the attempt to verify a Google certificate fail? A typical OpenSSL installation has the directory **/etc/ssl/certs**, which includes the **ca-certificates.crt** file. The directory and the file together contain digital certificates that OpenSSL trusts out of the box and accordingly constitute a *truststore*. The truststore can be updated as needed, in particular, to include newly trusted certificates and to remove ones no longer trusted.
The client program receives three certificates from the Google web server, but the OpenSSL truststore on my machine does not contain exact matches. As presently written, the **client** program does not pursue the matter by, for example, verifying the digital signature on a Google certificate (a signature that vouches for the certificate). If that signature were trusted, then the certificate containing it should be trusted as well. Nonetheless, the client program goes on to fetch and then to print Google’s homepage. The next section gets into more detail.
## The hidden security pieces in the client program
Let’s start with the visible security artifact in the client example—the digital certificate—and consider how other security artifacts relate to it. The dominant layout standard for a digital certificate is X509, and a production-grade certificate is issued by a certificate authority (CA) such as [Verisign](https://www.verisign.com).
A digital certificate contains various pieces of information (e.g., activation and expiration dates, and a domain name for the owner), including the issuer’s identity and *digital signature*, which is an encrypted *cryptographic hash* value. A certificate also has an unencrypted hash value that serves as its identifying *fingerprint*.
A hash value results from mapping an arbitrary number of bits to a fixed-length digest. What the bits represent (an accounting report, a novel, or maybe a digital movie) is irrelevant. For example, the Message Digest version 5 (MD5) hash algorithm maps input bits of whatever length to a 128-bit hash value, whereas the SHA1 (Secure Hash Algorithm version 1) algorithm maps input bits to a 160-bit value. Different input bits result in different—indeed, statistically unique—hash values. The next article goes into further detail and focuses on what makes a hash function *cryptographic*.
Digital certificates differ in type (e.g., *root*, *intermediate*, and *end-entity* certificates) and form a hierarchy that reflects these types. As the name suggests, a *root* certificate sits atop the hierarchy, and the certificates under it inherit whatever trust the root certificate has. The OpenSSL libraries and most modern programming languages have an X509 type together with functions that deal with such certificates. The certificate from Google has an X509 format, and the **client** program checks whether this certificate is **X509_V_OK**.
X509 certificates are based upon public-key infrastructure (PKI), which includes algorithms—RSA is the dominant one—for generating *key pairs*: a public key and its paired private key. A public key is an identity: [Amazon’s](https://www.amazon.com) public key identifies it, and my public key identifies me. A private key is meant to be kept secret by its owner.
The keys in a pair have standard uses. A public key can be used to encrypt a message, and the private key from the same pair can then be used to decrypt the message. A private key also can be used to sign a document or other electronic artifact (e.g., a program or an email), and the public key from the pair can then be used to verify the signature. The following two examples fill in some details.
In the first example, Alice distributes her public key to the world, including Bob. Bob then encrypts a message with Alice’s public key, sending the encrypted message to Alice. The message encrypted with Alice’s public key is decrypted with her private key, which (by assumption) she alone has, like so:
```
+------------------+ encrypted msg +-------------------+
Bob's msg--->|Alice's public key|--------------->|Alice's private key|---> Bob's msg
+------------------+ +-------------------+
```
Decrypting the message without Alice’s private key is possible in principle, but infeasible in practice given a sound cryptographic key-pair system such as RSA.
Now, for the second example, consider signing a document to certify its authenticity. The signature algorithm uses a private key from a pair to process a cryptographic hash of the document to be signed:
```
+-------------------+
Hash of document--->|Alice's private key|--->Alice's digital signature of the document
+-------------------+
```
Assume that Alice digitally signs a contract sent to Bob. Bob then can use Alice’s public key from the key pair to verify the signature:
```
+------------------+
Alice's digital signature of the document--->|Alice's public key|--->verified or not
+------------------+
```
It is infeasible to forge Alice’s signature without Alice’s private key: hence, it is in Alice’s interest to keep her private key secret.
None of these security pieces, except for digital certificates, is explicit in the **client** program. The next article fills in the details with examples that use the OpenSSL utilities and library functions.
## OpenSSL from the command line
In the meantime, let’s take a look at OpenSSL command-line utilities: in particular, a utility to inspect the certificates from a web server during the TLS handshake. Invoking the OpenSSL utilities begins with the **openssl** command and then adds a combination of arguments and flags to specify the desired operation.
Consider this command:
**openssl list-cipher-algorithms**
The output is a list of associated algorithms that make up a *cipher suite*. Here’s the start of the list, with comments to clarify the acronyms:
```
AES-128-CBC ## Advanced Encryption Standard, Cipher Block Chaining
AES-128-CBC-HMAC-SHA1 ## Hash-based Message Authentication Code with SHA1 hashes
AES-128-CBC-HMAC-SHA256 ## ditto, but SHA256 rather than SHA1
...
```
The next command, using the argument **s_client**, opens a secure connection to ** www.google.com** and prints screens full of information about this connection:
**openssl s_client -connect www.google.com:443 -**
**showcerts**
The port number 443 is the standard one used by web servers for receiving HTTPS rather than HTTP connections. (For HTTP, the standard port is 80.) The network address ** www.google.com:443** also occurs in the
**client**program's code. If the attempted connection succeeds, the three digital certificates from Google are displayed together with information about the secure session, the cipher suite in play, and related items. For example, here is a slice of output from near the start, which announces that a
*certificate chain*is forthcoming. The encoding for the certificates is base64:
```
Certificate chain
0 s:/C=US/ST=California/L=Mountain View/O=Google LLC/CN=www.google.com
i:/C=US/O=Google Trust Services/CN=Google Internet Authority G3
-----BEGIN CERTIFICATE-----
MIIEijCCA3KgAwIBAgIQdCea9tmy/T6rK/dDD1isujANBgkqhkiG9w0BAQsFADBU
MQswCQYDVQQGEwJVUzEeMBwGA1UEChMVR29vZ2xlIFRydXN0IFNlcnZpY2VzMSUw
...
```
A major web site such as Google usually sends multiple certificates for authentication.
The output ends with summary information about the TLS session, including specifics on the cipher suite:
```
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES128-GCM-SHA256
Session-ID: A2BBF0E4991E6BBBC318774EEE37CFCB23095CC7640FFC752448D07C7F438573
...
```
The protocol **TLS 1.2** is used in the **client** program, and the **Session-ID** uniquely identifies the connection between the **openssl** utility and the Google web server. The **Cipher** entry can be parsed as follows:
-
**ECDHE**(Elliptic Curve Diffie Hellman Ephemeral) is an effective and efficient algorithm for managing the TLS handshake. In particular, ECDHE solves the*key-distribution problem*by ensuring that both parties in a connection (e.g., the client program and the Google web server) use the same encryption/decryption key, which is known as the*session key*. The follow-up article digs into the details. -
**RSA**(Rivest Shamir Adleman) is the dominant public-key cryptosystem and named after the three academics who first described the system in the late 1970s. The key-pairs in play are generated with the RSA algorithm. -
**AES128**(Advanced Encryption Standard) is a*block cipher*that encrypts and decrypts blocks of bits. (The alternative is a*stream cipher*, which encrypts and decrypts bits one at a time.) The cipher is*symmetric*in that the same key is used to encrypt and to decrypt, which raises the key-distribution problem in the first place. AES supports key sizes of 128 (used here), 192, and 256 bits: the larger the key, the better the protection.Key sizes for symmetric cryptosystems such as AES are, in general, smaller than those for asymmetric (key-pair based) systems such as RSA. For example, a 1024-bit RSA key is relatively small, whereas a 256-bit key is currently the largest for AES.
-
**GCM**(Galois Counter Mode) handles the repeated application of a cipher (in this case, AES128) during a secured conversation. AES128 blocks are only 128-bits in size, and a secure conversation is likely to consist of multiple AES128 blocks from one side to the other. GCM is efficient and commonly paired with AES128. -
**SHA256**(Secure Hash Algorithm 256 bits) is the cryptographic hash algorithm in play. The hash values produced are 256 bits in size, although even larger values are possible with SHA.
Cipher suites are in continual development. Not so long ago, for example, Google used the RC4 stream cipher (Ron’s Cipher version 4 after Ron Rivest from RSA). RC4 now has known vulnerabilities, which presumably accounts, at least in part, for Google’s switch to AES128.
## Wrapping up
This first look at OpenSSL, through a secure C web client and various command-line examples, has brought to the fore a handful of topics in need of more clarification. [The next article gets into the details](https://opensource.com/article/19/6/cryptography-basics-openssl-part-2), starting with cryptographic hashes and ending with a fuller discussion of how digital certificates address the key distribution challenge.
## 2 Comments |
11,812 | 使用 khal 和 vdirsyncer 组织和同步你的日历 | https://opensource.com/article/20/1/open-source-calendar | 2020-01-23T15:02:44 | [
"日历"
] | https://linux.cn/article-11812-1.html |
>
> 保存和共享日历可能会有点麻烦。在我们的 20 个使用开源提升生产力的系列的第五篇文章中了解如何让它更简单。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 khal 和 vdirsyncer 跟踪你的日程
处理日历很*麻烦*,要找到好的工具总是很困难的。但是自从我去年将日历列为[我的“失败"之一](https://opensource.com/article/19/1/productivity-tool-wish-list)以来,我已经取得了一些进步。
目前使用日历最困难的是一直需要以某种方式在线共享。两种最受欢迎的在线日历是 Google Calendar 和 Microsoft Outlook/Exchange。两者都在公司环境中大量使用,这意味着我的日历必须支持其中之一或者两个。

[Khal](https://khal.readthedocs.io/en/v0.9.2/index.html) 是基于控制台的日历,可以读取和写入 VCalendar 文件。它配置相当容易,但是不支持与其他应用同步。
幸运的是,khal 能与 [vdirsyncer](https://github.com/pimutils/vdirsyncer) 一起使用,它是一个漂亮的命令行程序,可以将在线日历(和联系人,我将在另一篇文章中讨论)同步到本地磁盘。是的,它还可以上传新事件。

Vdirsyncer 是个 Python 3 程序,可以通过软件包管理器或 `pip` 安装。它可以同步 CalDAV、VCalendar/iCalendar、Google Calendar 和目录中的本地文件。由于我使用 Google Calendar,尽管这不是最简单的设置,我也将以它为例。
在 vdirsyncer 中设置 Google Calendar 是[有文档参考的](https://vdirsyncer.pimutils.org/en/stable/config.html#google),所以这里我不再赘述。重要的是确保设置你的同步对,将 Google Calendar 设置为冲突解决的“赢家”。也就是说,如果同一事件有两个更新,那么需要知道哪个更新优先。类似这样做:
```
[general]
status_path = "~/.calendars/status"
[pair personal_sync]
a = "personal"
b = "personallocal"
collections = ["from a", "from b"]
conflict_resolution = "a wins"
metadata = ["color"]
[storage personal]
type = "google_calendar"
token_file = "~/.vdirsyncer/google_calendar_token"
client_id = "google_client_id"
client_secret = "google_client_secret"
[storage personallocal]
type = "filesystem"
path = "~/.calendars/Personal"
fileext = ".ics"
```
在第一次 vdirsyncer 同步之后,你将在存储路径中看到一系列目录。每个文件夹都将包含多个文件,日历中的每个事件都是一个文件。下一步是导入 khal。首先运行 `khal configure` 进行初始设置。

现在,运行 `khal interactive` 将显示本文开头的界面。输入 `n` 将打开“新事件”对话框。这里要注意的一件事:日历的名称与 vdirsyncer 创建的目录匹配,但是你可以更改 khal 配置文件来指定更清晰的名称。根据条目所在的日历,向条目添加颜色还可以帮助你确定日历内容:
```
[calendars]
[[personal]]
path = ~/.calendars/Personal/[email protected]/
color = light magenta
[[holidays]]
path = ~/.calendars/Personal/cln2stbjc4hmgrrcd5i62ua0ctp6utbg5pr2sor1dhimsp31e8n6errfctm6abj3dtmg@virtual/
color = light blue
[[birthdays]]
path = ~/.calendars/Personal/c5i68sj5edpm4rrfdchm6rreehgm6t3j81jn4rrle0n7cbj3c5m6arj4c5p2sprfdtjmop9ecdnmq@virtual/
color = brown
```
现在,当你运行 `khal interactive` 时,每个日历将被着色以区别于其他日历,并且当你添加新条目时,它将有更具描述性的名称。

设置有些麻烦,但是完成后,khal 和 vdirsyncer 可以一起为你提供一种简便的方法来管理日历事件并使它们与你的在线服务保持同步。
---
via: <https://opensource.com/article/20/1/open-source-calendar>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Keep track of your schedule with khal and vdirsyncer
Calendars are a *pain* to deal with, and finding good tooling is always hard. But I've made some progress since last year when I listed calendaring as [one of my "fails."](https://opensource.com/article/19/1/productivity-tool-wish-list)
The most difficult thing about calendars today is that now they almost always need to be shared online in some way. The two most popular online calendars are Google Calendar and Microsoft Outlook/Exchange. Both are used heavily in corporate environments, which means my calendar has to support one or both options.
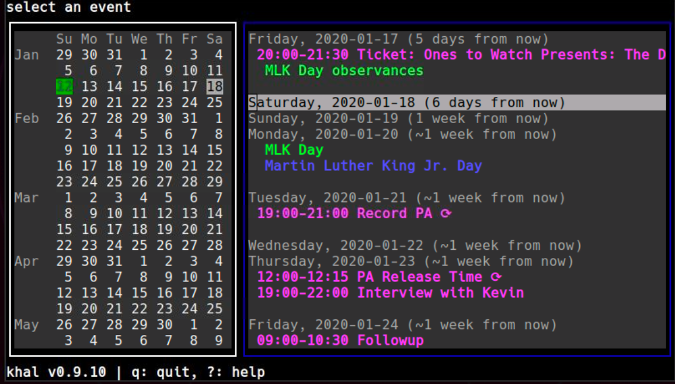
[Khal](https://khal.readthedocs.io/en/v0.9.2/index.html) is a console-based calendar that reads and writes VCalendar files. It's fairly easy to configure, but it does not support syncing with other applications.
Fortunately, khal works with [vdirsyncer](https://github.com/pimutils/vdirsyncer), a nifty command-line program that can synchronize online calendars (and contacts, which I'll talk about in a separate article) to your local drive. And yes, this includes uploading new events, too.

Vdirsyncer is a Python 3 program, and it can be installed via your package manager or pip. It can synchronize CalDAV, VCalendar/iCalendar, Google Calendar, and local files in a directory. Since I use Google Calendar, I'll use that as an example, although it is not the easiest thing to set up.
Setting vdirsyncer up for Google is [well-documented](https://vdirsyncer.pimutils.org/en/stable/config.html#google), so I won't go into the nuts and bolts here. The important thing is to make sure your sync pairs are set up in a way that sets Google Calendar as the "winner" for conflict resolution. That is, if there are two updates to the same event, it needs to know which one takes precedence. Do so with something like this:
```
[general]
status_path = "~/.calendars/status"
[pair personal_sync]
a = "personal"
b = "personallocal"
collections = ["from a", "from b"]
conflict_resolution = "a wins"
metadata = ["color"]
[storage personal]
type = "google_calendar"
token_file = "~/.vdirsyncer/google_calendar_token"
client_id = "google_client_id"
client_secret = "google_client_secret"
[storage personallocal]
type = "filesystem"
path = "~/.calendars/Personal"
fileext = ".ics"
```
After the first sync of vdirsyncer, you will end up with a series of directories in the storage path. Each will contain several files, one for each entry in the calendar. The next step is to get them into khal. Start by running **khal configure** to do the initial setup.
Now, running **khal interactive** will bring up the display shown at the beginning of this article. Typing **n** will bring up the New Event dialog. One small thing to note here: the calendars are named to match the directories that vdirsyncer creates, but you can change the khal config file to give them clearer names. Adding colors to entries based on which calendar they're on will also help you identify which is which on the list:
```
[calendars]
[[personal]]
path = ~/.calendars/Personal/[email protected]/
color = light magenta
[[holidays]]
path = ~/.calendars/Personal/cln2stbjc4hmgrrcd5i62ua0ctp6utbg5pr2sor1dhimsp31e8n6errfctm6abj3dtmg@virtual/
color = light blue
[[birthdays]]
path = ~/.calendars/Personal/c5i68sj5edpm4rrfdchm6rreehgm6t3j81jn4rrle0n7cbj3c5m6arj4c5p2sprfdtjmop9ecdnmq@virtual/
color = brown
```
Now when you run **khal interactive**, each calendar will be colored to distinguish it from the others, and when you add a new entry, it will have a more descriptive name.
The setup is a little tricky, but once it's done, khal with vdirsyncer gives you an easy way to manage calendar events and keep them in sync with your online services.
## Comments are closed. |
11,813 | 在 Linux 系统中禁用与解禁用户的账号 | https://www.networkworld.com/article/3513982/locking-and-unlocking-accounts-on-linux-systems.html | 2020-01-23T21:43:04 | [
"密码",
"账户"
] | https://linux.cn/article-11813-1.html |
>
> 总有这样的时候:有时你需要禁用某位 Linux 用户的账号,有时你还需要反过来解禁用户的账号。 本文将介绍一些管理用户访问的命令,并介绍它们背后的原理。
>
>
>

假如你正管理着一台 [Linux](https://www.networkworld.com/article/3215226/what-is-linux-uses-featres-products-operating-systems.html) 系统,那么很有可能将遇到需要禁用一个账号的情况。可能是某人已经换了职位,他们是否还需要该账号仍是个问题;或许有理由相信再次使用该账号并没有大碍。不管上述哪种情况,知晓如何禁用账号并解禁账号都是你需要知道的知识。
需要你记住的一件重要的事是尽管有多种方法来禁用账号,但它们并不都达到相同的效果。假如用户使用公钥/私钥来使用该账号而不是使用密码来访问,那么你使用的某些命令来阻止用户获取该账号或许将不会生效。
### 使用 passwd 来禁用一个账号
最为简单的用来禁用一个账号的方法是使用 `passwd -l` 命令。例如:
```
$ sudo passwd -l tadpole
```
上面这个命令的效果是在加密后的密码文件 `/etc/shadow` 中,用户对应的那一行的最前面加上一个 `!` 符号。这样就足够阻止用户使用密码来访问账号了。
在没有使用上述命令前,加密后的密码行如下所示(请注意第一个字符):
```
$6$IC6icrWlNhndMFj6$Jj14Regv3b2EdK.8iLjSeO893fFig75f32rpWpbKPNz7g/eqeaPCnXl3iQ7RFIN0BGC0E91sghFdX2eWTe2ET0:18184:0:99999:7:::
```
而禁用该账号后,这一行将变为:
```
!$6$IC6icrWlNhndMFj6$Jj14Regv3b2EdK.8iLjSeO893fFig75f32rpWpbKPNz7g/eqeaPCnXl3iQ7RFIN0BGC0E91sghFdX2eWTe2ET0:18184:0:99999:7:::
```
在 tadpole 下一次尝试登录时,他可能会使用他原有的密码来尝试多次登录,但就是无法再登录成功了。另一方面,你则可以使用下面的命令来查看他这个账号的状态(`-S` = status):
```
$ sudo passwd -S tadpole
tadpole L 10/15/2019 0 99999 7 -1
```
第二项的 `L` 告诉你这个账号已经被禁用了。在该账号被禁用前,这一项应该是 `P`。如果显示的是 `NP` 则意味着该账号还没有设置密码。
命令 `usermod -L` 也具有相同的效果(添加 `!` 来禁用账号的使用)。
使用这种方法来禁用某个账号的一个好处是当需要解禁某个账号时非常容易。只需要使用一个文本编辑器或者使用 `passwd -u` 命令来执行相反的操作,即将添加的 `!` 移除即可。
```
$ sudo passwd -u tadpole
passwd: password expiry information changed.
```
但使用这种方式的问题是如果用户使用公钥/私钥对的方式来访问他/她的账号,这种方式将不能阻止他们使用该账号。
### 使用 chage 命令来禁用账号
另一种禁用用户账号的方法是使用 `chage` 命令,它可以帮助管理用户账号的过期日期。
```
$ sudu chage -E0 tadpole
$ sudo passwd -S tadpole
tadpole P 10/15/2019 0 99999 7 -1
```
`chage` 命令将会稍微修改 `/etc/shadow` 文件。在这个使用 `:` 来分隔的文件(下面将进行展示)中,某行的第 8 项将被设置为 `0`(先前为空),这就意味着这个账号已经过期了。`chage` 命令会追踪密码更改期间的天数,通过选项也可以提供账号过期信息。第 8 项如果是 0 则意味着这个账号在 1970 年 1 月 1 日后的一天过期,当使用上面显示的那个命令时可以用来禁用账号。
```
$ sudo grep tadpole /etc/shadow | fold
tadpole:$6$IC6icrWlNhndMFj6$Jj14Regv3b2EdK.8iLjSeO893fFig75f32rpWpbKPNz7g/eqeaPC
nXl3iQ7RFIN0BGC0E91sghFdX2eWTe2ET0:18184:0:99999:7::0:
^
|
+--- days until expiration
```
为了执行相反的操作,你可以简单地使用下面的命令将放置在 `/etc/shadow` 文件中的 `0` 移除掉:
```
% sudo chage -E-1 tadpole
```
一旦一个账号使用这种方式被禁用,即便是无密码的 [SSH](https://www.networkworld.com/article/3441777/how-the-linux-screen-tool-can-save-your-tasks-and-your-sanity-if-ssh-is-interrupted.html) 登录也不能再访问该账号了。
---
via: <https://www.networkworld.com/article/3513982/locking-and-unlocking-accounts-on-linux-systems.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,814 | 你最喜欢的终端模拟器是什么? | https://opensource.com/article/19/12/favorite-terminal-emulator | 2020-01-24T00:09:02 | [
"终端"
] | /article-11814-1.html |
>
> 我们让社区讲述他们在终端仿真器方面的经验。以下是我们收到的一些回复。
>
>
>

终端仿真器的偏好可以说明一个人的工作流程。无鼠标操作能力是否必须具备?你想要标签页还是窗口?对于终端仿真器你还有什么选择的原因?是否有酷的因素?欢迎参加调查或给我们留下评论,告诉我们你最喜欢的终端模拟器。你尝试过多少种终端仿真器呢?
我们让社区讲述他们在终端仿真器方面的经验。以下是我们收到的一些回复。
“我最喜欢的终端仿真器是用 Powerline 定制的 Tilix。我喜欢它支持在一个窗口中打开多个终端。” —Dan Arel
“[urxvt](https://opensource.com/article/19/10/why-use-rxvt-terminal)。它可以通过文件简单配置,轻巧,并且在大多数程序包管理器存储库中都很容易找到。” —Brian Tomlinson
“即使我不再使用 GNOME,gnome-terminal 仍然是我的首选。:)” —Justin W. Flory
“现在 FC31 上的 Terminator。我刚刚开始使用它,我喜欢它的分屏功能,对我来说感觉很轻巧。我正在研究它的插件。” —Marc Maxwell
“不久前,我切换到了 Tilix,它完成了我需要终端执行的所有工作。:) 多个窗格、通知,很精简,用来运行我的 tmux 会话很棒。” —Kevin Fenzi
“alacritty。它针对速度进行了优化,是用 Rust 实现的,并且具有很多常规功能,但是老实说,我只关心一个功能:可配置的字形间距,使我可以进一步压缩字体。” —Alexander Sosedkin “我是个老古板:KDE Konsole。如果是远程会话,请使用 tmux。” —Marcin Juszkiewicz
“在 macOS 上用 iTerm2。是的,它是开源的。:-) 在 Linux 上是 Terminator。” —Patrick Mullins
“我现在已经使用 alacritty 一两年了,但是最近我在全屏模式下使用 cool-retro-term,因为我必须运行一个输出内容有很多的脚本,而它看起来很酷,让我感觉很酷。这对我很重要。” —Nick Childers
“我喜欢 Tilix,部分是因为它擅长免打扰(我通常全屏运行它,里面是 tmux),而且还提供自定义热链接支持:在我的终端中,像 ‘rhbz#1234’ 之类的文本是将我带到 Bugzilla 的热链接。类似的还有 LaunchPad 提案,OpenStack 的 Gerrit 更改 ID 等。” —Lars Kellogg-Stedman
“Eterm,在使用 Vintage 配置文件的 cool-retro-term 中,演示效果也最好。” —Ivan Horvath
“Tilix +1。这是 GNOME 用户最好的选择,我是这么觉得的!” —Eric Rich
“urxvt。快速、小型、可配置、可通过 Perl 插件扩展,这使其可以无鼠标操作。” —Roman Dobosz
“Konsole 是最好的,也是 KDE 项目中我唯一使用的应用程序。所有搜索结果都高亮显示是一个杀手级功能,据我所知没有任何其它 Linux 终端有这个功能(如果能证明我错了,那我也很高兴)。最适合搜索编译错误和输出日志。” —Jan Horak
“我过去经常使用 Terminator。现在我在 Tilix 中克隆了它的主题(深色主题),而感受一样好。它可以在选项卡之间轻松移动。就是这样。” —Alberto Fanjul Alonso
“我开始使用的是 Terminator,自从差不多过去这三年,我已经完全切换到 Tilix。” —Mike Harris
“我使用下拉式终端 X。这是 GNOME 3 的一个非常简单的扩展,使我始终可以通过一个按键(对于我来说是`F12`)拉出一个终端。它还支持制表符,这正是我所需要的。 ” —Germán Pulido
“xfce4-terminal:支持 Wayland、缩放、无边框、无标题栏、无滚动条 —— 这就是我在 tmux 之外全部想要的终端仿真器的功能。我希望我的终端仿真器可以尽可能多地使用屏幕空间,我通常在 tmux 窗格中并排放着编辑器(Vim)和 repl。” —Martin Kourim
“别问,问就是 Fish ! ;-)” —Eric Schabell
---
via: <https://opensource.com/article/19/12/favorite-terminal-emulator>
作者:[Opensource.com](https://opensource.com/users/admin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,816 | 敏捷软件开发的最佳资源 | https://opensource.com/article/19/12/agile-resources | 2020-01-25T12:13:19 | [
"敏捷"
] | https://linux.cn/article-11816-1.html |
>
> 请阅读我们的热门文章,这些文章着重讨论了敏捷的过去、现在和未来。
>
>
>

对于 Opensource.com 上的敏捷主题来说,2019 年是非常棒的一年。随着 2020 年的到来,我们回顾了我们读者所读的与敏捷相关的热门文章。
### 小规模 Scrum 指南
Opensource.com 关于[小规模 Scrum](https://opensource.com/downloads/small-scale-scrum) 的指南(我曾参与合著)由六部分组成,为小型团队提供了关于如何将敏捷引入到他们的工作中的建议。在官方的 [Scrum 指南](https://scrumguides.org/scrum-guide.html)的概述中,传统的 Scrum 框架推荐至少三个人来实现,以充分发挥其潜力。但是,它并没有为一两个人的团队如何成功遵循 Scrum 提供指导。我们的六部分系列旨在规范化小规模的 Scrum,并检验我们在现实世界中使用它的经验。该系列受到了读者的热烈欢迎,以至于这六篇文章占据了前 10 名文章的 60%。因此,如果你还没有阅读的话,一定要从我们的[小规模 Scrum 介绍页面](https://opensource.com/downloads/small-scale-scrum)下载。
### 全面的敏捷项目管理指南
遵循传统项目管理方法的团队最初对敏捷持怀疑态度,现在已经热衷于敏捷的工作方式。目前,敏捷已被接受,并且一种更加灵活的混合风格已经找到了归宿。Matt Shealy 撰写的[有关敏捷项目管理的综合指南](https://opensource.com/article/19/8/guide-agile-project-management)涵盖了敏捷项目管理的 12 条指导原则,对于希望为其项目带来敏捷性的传统项目经理而言,它是完美的选择。
### 成为出色的敏捷开发人员的 4 个步骤
DevOps 文化已经出现在许多现代软件团队中,这些团队采用了敏捷软件开发原则,利用了最先进的工具和自动化技术。但是,这种机械的敏捷方法并不能保证开发人员在日常工作中遵循敏捷实践。Daniel Oh 在[成为出色的敏捷开发人员的 4 个步骤](https://opensource.com/article/19/2/steps-agile-developer)中给出了一些很棒的技巧,通过关注设计思维,使用可预测的方法,以质量为中心并不断学习和探索来提高你的敏捷性。用你的敏捷工具补充这些方法将形成非常灵活和强大的敏捷开发人员。
### Scrum 和 kanban:哪种敏捷框架更好?
对于以敏捷方式运行的团队来说,Scrum 和 kanban 是两种最流行的方法。在 “[Scrum 与 kanban:哪种敏捷框架更好?](https://opensource.com/article/19/8/scrum-vs-kanban)” 中,Taz Brown 探索了两者的历史和目的。在阅读本文时,我想起一句名言:“如果你的工具箱里只有锤子,那么所有问题看起来都像钉子。”知道何时使用 kanban 以及何时使用 Scrum 非常重要,本文有助于说明两者都有一席之地,这取决于你的团队、挑战和目标。
### 开发人员对敏捷发表意见的 4 种方式
当采用敏捷的话题出现时,开发人员常常会担心自己会被强加上一种工作风格。在“[开发人员对敏捷发表意见的 4 种方式](https://opensource.com/article/19/10/ways-developers-what-agile)”中,[Clément Verna](https://twitter.com/clemsverna) 着眼于开发人员通过帮助确定敏捷在其团队中的表现形式来颠覆这种说法的方法。检查敏捷的起源和基础是一个很好的起点,但是真正的价值在于拥有可帮助指导你的过程的指标。知道你将面临什么样的挑战会给你的前进提供坚实的基础。根据经验进行决策不仅可以增强团队的能力,还可以使他们对整个过程有一种主人翁意识。Verna 的文章还探讨了将人置于过程之上并作为一个团队来实现目标的重要性。
### 敏捷的现在和未来
今年,Opensource.com 的作者围绕敏捷的过去、现在以及未来可能会是什么样子进行了大量的讨论。感谢他们所有人,请一定于 2020 年在这里分享[你自己的敏捷故事](https://opensource.com/how-submit-article)。
---
via: <https://opensource.com/article/19/12/agile-resources>
作者:[Leigh Griffin](https://opensource.com/users/lgriffin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[algzjh](https://github.com/algzjh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It has been a great year for agile topics on Opensource.com. As we approach the end of 2019, reviewed our top agile-related articles, as read by you, our readers!
## Small Scale Scrum guide
Opensource.com's six-part guide to [Small Scale Scrum](https://opensource.com/downloads/small-scale-scrum) (which I helped co-author) advises smaller teams on how to bring agile into their work. The traditional scrum framework outlined in the official [Scrum Guide](https://scrumguides.org/scrum-guide.html) recommends a minimum of three people for the framework to realize its full potential. However, it provides no guidance for how teams of one or two people can follow scrum successfully. Our six-part series aims to formalize Small Scale Scrum and examines our experience with it in the real world. The series was received very warmly by our readers—so much such that the six individual articles comprise 60% of our Top 10 list. So, if you haven't already, make sure to download them from our [ Introduction to Small Scale Scrum page](https://opensource.com/downloads/small-scale-scrum).
## A comprehensive guide to agile project management
Teams following traditional project management approaches, initially skeptical about agile, have warmed up to the agile way of working. Now agile has reached acceptance, and a more flexible, hybrid style has found a home. [ A comprehensive guide to agile project management](https://opensource.com/article/19/8/guide-agile-project-management) by Matt Shealy covers 12 guiding principles of agile project management and is perfect for traditional project managers looking to bring some agility to their projects.
## 4 steps to becoming an awesome agile developer
A DevOps culture has emerged in many modern software teams that embrace agile software development principles that leverage cutting-edge tooling and automation. But this mechanically agile approach does not guarantee that developers are following agile practices in their day-to-day work. In [ 4 steps to becoming an awesome agile developer](https://opensource.com/article/19/2/steps-agile-developer), Daniel Oh gives great tips for increasing your agility by focusing on design thinking, using predictable approaches, putting quality at the center, and continuously learning and exploring. Complementing these methods with your agile tooling will create very flexible and strong agile developers.
## Scrum vs. kanban: Which agile framework is better?
Scrum and kanban are two of the most popular approaches for teams running in an agile manner, and in [ Scrum vs. kanban: Which agile framework is better?](https://opensource.com/article/19/8/scrum-vs-kanban) Taz Brown explores the history and purpose of both. While reading this article, a great saying came to my mind: "If the only tool in your toolbox is a hammer, every problem looks like a nail." Knowing when to use kanban and when to use scrum is important, and this article helps show that both have a place, depending on your team, your challenge, and your goals.
## 4 ways developers can have a say in what agile looks like
Developers often have a fear of having a workstyle imposed upon them when the topic of adopting agile comes up. In [ 4 ways developers can have a say in what agile looks like](https://opensource.com/article/19/10/ways-developers-what-agile),
[Clément Verna](https://twitter.com/clemsverna)looks at ways that developers can flip that narrative by helping to determine what agile looks like on their team. Examining the origins and the basics of agile is a great starting point, but the real value is in having metrics to help guide your journey. Knowing what challenges you can expect to have will give you a firm ground to move forward. And making decisions empirically not only empowers teams but gives them a sense of ownership of the journey. Verna's article also examines the importance of putting people over processes and working as a team to achieve your goals.
## Agile now and later
This year, Opensource.com authors created a lot of discussion around agile's past, present, and what it may look like in the future. Thank you to all of them, and be sure to [share your own agile story](https://opensource.com/how-submit-article) here in 2020.
## 1 Comment |
11,817 | 你有什么喜欢的 Linux 终端技巧? | https://opensource.com/article/20/1/linux-terminal-trick | 2020-01-25T13:59:17 | [
"终端"
] | https://linux.cn/article-11817-1.html |
>
> 告诉我们你最喜欢的终端技巧,无论是提高生产率的快捷方式还是有趣的彩蛋。
>
>
>

新年伊始始终是评估提高效率的新方法的好时机。许多人尝试使用新的生产力工具,或者想找出如何优化其最常用的流程。终端是一个需要评估的领域,尤其是在开源世界中,有无数种方法可以通过快捷键和命令使终端上的生活更加高效(又有趣!)。
我们向作者们询问了他们最喜欢的终端技巧。他们分享了一些节省时间的技巧,甚至还有一个有趣的终端彩蛋。你会采用这些键盘快捷键或命令行技巧吗?你有喜欢分享的最爱吗?请发表评论来告诉我们。
“我找不出哪个是我最喜欢的;每天我都会使用这三个:
* `Ctrl + L` 来清除屏幕(而不是键入 `clear`)。
* `sudo !!` 以 `sudo` 特权运行先前的命令。
* `grep -Ev '^#|^$' <file>` 将显示文件内容,不带注释或空行。” —Mars Toktonaliev
“对我来说,如果我正在使用终端文本编辑器,并且希望将其丢开,以便可以快速执行其他操作,则可以使用 `Ctrl + Z` 将其放到后台,接着执行我需要做的一切,然后用 `fg` 将其带回前台。有时我也会对 `top` 或 `htop` 做同样的事情。我可以将其丢到后台,并在我想检查当前性能时随时将其带回前台。我不会将通常很快能完成的任务在前后台之间切换,它确实可以增强终端上的多任务处理能力。” —Jay LaCroix
“我经常在某一天在终端中做很多相同的事情,有两件事是每天都不变的:
* `Ctrl + R` 反向搜索我的 Bash 历史记录以查找我已经运行并且希望再次执行的命令。
* 插入号(`^`)替换是最好的,因为我经常做诸如 `sudo dnf search <package name>` 之类的事情,然后,如果我以这种方式找到合适的软件包,则执行 `^search^install` 来重新运行该命令,以 `install` 替换 `search`。
这些东西肯定是很基本的,但是对我来说却节省了时间。” —Steve Morris
“我的炫酷终端技巧不是我在终端上执行的操作,而是我使用的终端。有时候我只是想要使用 Apple II 或旧式琥珀色终端的感觉,那我就启动了 Cool-Retro-Term。它的截屏可以在这个[网站](https://github.com/Swordfish90/cool-retro-term)上找到。” —Jim Hall
“可能是用 `ssh -X` 来在其他计算机上运行图形程序。(在某些终端仿真器上,例如 gnome-terminal)用 `C-S c` 和 `C-S v` 复制/粘贴。我不确定这是否有价值(因为它有趣的是以 ssh 启动的图形化)。最近,我需要登录另一台计算机,但是我的孩子们可以在笔记本电脑的大屏幕上看到它。这个[链接](https://elinux.org/Screen_Casting_on_a_Raspberry_Pi)向我展示了一些我从未见过的内容:通过局域网从我的笔记本电脑上镜像来自另一台计算机屏幕上的活动会话(`x11vnc -desktop`),并能够同时从两台计算机上进行控制。” —Kyle R. Conway
“你可以安装 `sl`(`$ sudo apt install sl` 或 `$ sudo dnf install sl`),并且当在 Bash 中输入命令 `sl` 时,一个基于文本的蒸汽机车就会在显示屏上移动。” —Don Watkins
---
via: <https://opensource.com/article/20/1/linux-terminal-trick>
作者:[Opensource.com](https://opensource.com/users/admin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The beginning of a new year is always a great time to evaluate new ways to become more efficient. Many people try out new productivity tools or figure out how to optimize their most mundane processes. One area to assess is the terminal. Especially in the world of open source, there are tons of ways to make life at the terminal more efficient (and fun!) with shortcuts and commands.
We asked our writers about their favorite terminal trick. They shared their time-saving tips and even a fun terminal Easter egg. Will you adopt one of these keyboard shortcuts or command line hacks? Do you have a favorite you'd like to share? Tell us about it by taking our poll or leaving a comment.
"I couldn't choose a favorite; I use all three of these daily:
-
**Ctrl + L**to clear screen (instead of typing "clear"). -
**sudo !!**to run previous command with sudo privileges. -
**grep -Ev '^#|^$' <file>**will display file content without comments or empty lines."
—Mars Toktonaliev
"For me, if I'm in a terminal text editor and I want to make it go away so I can quickly do something else, I background it with
**Ctrl + Z**, do whatever I need to do, and then bring it back with**fg**. I will also sometimes do the same thing with**top**or**htop.**I can background it, and bring it back anytime I want to check current performance. I don't see backgrounding and foregrounding done in the wild very often, and it can really enhance multitasking on the terminal."—Jay LaCroix
"Because I tend to do much of the same things at the terminal on a given day, two things are constants in my day:
-
**Ctrl + R**to reverse search my Bash history for a command that I have already run and wish to do so again -
Caret substitution is the best as I often do things like
**sudo dnf****search <package name>**then if I find a suitable package that way I then do**^search^install**to rerun the command replacing the search with install.
Sure these things are basic but so time-saving for me."
—Steve Morris
"My cool terminal trick isn't something I do in the terminal, but *which terminal* I use. Sometimes I just want the feeling of using an Apple II, or an old amber-on-black terminal. That's when I fire up Cool Retro Term. Screenshots are on the [website](https://github.com/Swordfish90/cool-retro-term)."
—Jim Hall
"Probably
**ssh -X**to run graphical programs on other machines. Copy/pasting (on some terminal emulators, like gnome-terminal) C-S c and C-S v. I'm not sure if this counts (as it goes graphical in the interesting part, but starts with**ssh**). Most recently I had a need to log in to another machine but have my kids be able to follow along on the bigger screen from my laptop. This[link](https://elinux.org/Screen_Casting_on_a_Raspberry_Pi)showed me something I'd never before seen: mirroring the active session from another computer screen on my laptop over the local network (x11vnc -desktop) and being able to control it from both machines at the same time."—Kyle R. Conway
"You can install
**Install 'sl' $ sudo apt install sl**or**$ sudo dnf install sl**, and when the command**sl**is entered at the Bash prompt a text-based steam locomotive moves across the display."—Don Watkins
## 23 Comments |
11,819 | 使你的 Python 游戏玩家能够向前和向后跑 | https://opensource.com/article/19/12/python-platformer-game-run | 2020-01-25T22:07:00 | [
"Pygame"
] | https://linux.cn/article-11819-1.html |
>
> 使用 Pygame 模块来使你的 Python 平台开启侧滚效果,来让你的玩家自由奔跑。
>
>
>

这是仍在进行中的关于使用 Pygame 模块来在 Python 3 中在创建电脑游戏的第九部分。先前的文章是:
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
* [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
* [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
* [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
* [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
* [在 Pygame 游戏中放置平台](/article-10902-1.html)
* [在你的 Python 游戏中模拟引力](/article-11780-1.html)
* [为你的 Python 平台类游戏添加跳跃功能](/article-11790-1.html)
在这一系列关于使用 [Pygame](https://www.pygame.org/news) 模块来在 [Python 3](https://www.python.org/) 中创建电脑游戏的先前文章中,你已经设计了你的关卡设计布局,但是你的关卡的一些部分可能已近超出你的屏幕的可视区域。在平台类游戏中,这个问题的普遍解决方案是,像术语“<ruby> 侧滚 <rt> side-scroller </rt></ruby>”表明的一样,滚动。
滚动的关键是当玩家精灵接近屏的幕边缘时,使在玩家精灵周围的平台移动。这样给予一种错觉,屏幕是一个在游戏世界中穿梭追拍的摄像机。
这个滚动技巧需要两个在屏幕边缘的绝对区域,在绝对区域内的点处,在世界滚动期间,你的化身静止不动。
### 在侧滚动条中放置卷轴
如果你希望你的玩家能够后退,你需要一个触发点来向前和向后。这两个点仅仅是两个变量。设置它们各个距各个屏幕边缘大约 100 或 200 像素。在你的设置部分中创建变量。在下面的代码中,前两行用于上下文说明,所以仅需要添加这行后的代码:
```
player_list.add(player)
steps = 10
forwardX = 600
backwardX = 230
```
在主循环中,查看你的玩家精灵是否在 `forwardx` 或 `backwardx` 滚动点处。如果是这样,向左或向右移动使用的平台,取决于世界是向前或向后移动。在下面的代码中,代码的最后三行仅供你参考:
```
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
## scrolling code above
world.blit(backdrop, backdropbox)
player.gravity() # check gravity
player.update()
```
启动你的游戏,并尝试它。

滚动像预期的一样工作,但是你可能注意到一个发生的小问题,当你滚动你的玩家和非玩家精灵周围的世界时:敌人精灵不随同世界滚动。除非你要你的敌人精灵要无休止地追逐你的玩家,你需要修改敌人代码,以便当你的玩家快速撤退时,敌人被留在后面。
### 敌人卷轴
在你的主循环中,你必须对卷轴平台为你的敌人的位置的应用相同的规则。因为你的游戏世界将(很可能)有不止一个敌人在其中,该规则应该被应用于你的敌人列表,而不是一个单独的敌人精灵。这是分组类似元素到列表中的优点之一。
前两行用于上下文注释,所以只需添加这两行后面的代码到你的主循环中:
```
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
```
来滚向另一个方向:
```
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
```
再次启动游戏,看看发生什么。
这里是到目前为止你已经为这个 Python 平台所写所有的代码:
```
#!/usr/bin/env python3
# draw a world
# add a player and player control
# add player movement
# add enemy and basic collision
# add platform
# add gravity
# add jumping
# add scrolling
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
import pygame
import sys
import os
'''
Objects
'''
class Platform(pygame.sprite.Sprite):
# x location, y location, img width, img height, img file
def __init__(self,xloc,yloc,imgw,imgh,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img)).convert()
self.image.convert_alpha()
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
'''
Spawn a player
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.collide_delta = 0
self.jump_delta = 6
self.score = 1
self.images = []
for i in range(1,9):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def jump(self,platform_list):
self.jump_delta = 0
def gravity(self):
self.movey += 3.2 # how fast player falls
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty
def control(self,x,y):
'''
control player movement
'''
self.movex += x
self.movey += y
def update(self):
'''
Update sprite position
'''
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[self.frame//ani]
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in enemy_hit_list:
self.health -= 1
#print(self.health)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.collide_delta = 0 # stop jumping
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.y = worldy-ty-ty
self.collide_delta = 0 # stop jumping
if self.rect.y > g.rect.y:
self.health -=1
print(self.health)
if self.collide_delta < 6 and self.jump_delta < 6:
self.jump_delta = 6*2
self.movey -= 33 # how high to jump
self.collide_delta += 6
self.jump_delta += 6
class Enemy(pygame.sprite.Sprite):
'''
Spawn an enemy
'''
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.movey = 0
#self.image.convert_alpha()
#self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
'''
enemy movement
'''
distance = 80
speed = 8
self.movey += 3.2
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
if not self.rect.y >= worldy-ty-ty:
self.rect.y += self.movey
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.rect.y = worldy-ty-ty
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
enemy_list = pygame.sprite.Group() # create enemy group
enemy_list.add(enemy) # add enemy to group
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
def loot(lvl,lloc):
print(lvl)
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
def platform(lvl,tx,ty):
plat_list = pygame.sprite.Group()
ploc = []
i=0
if lvl == 1:
ploc.append((0,worldy-ty-128,3))
ploc.append((300,worldy-ty-256,3))
ploc.append((500,worldy-ty-128,4))
while i < len(ploc):
j=0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
plat_list.add(plat)
j=j+1
print('run' + str(i) + str(ploc[i]))
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
'''
Setup
'''
worldx = 960
worldy = 720
fps = 40 # frame rate
ani = 4 # animation cycles
clock = pygame.time.Clock()
pygame.init()
main = True
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
ALPHA = (0,255,0)
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = world.get_rect()
player = Player() # spawn player
player.rect.x = 0
player.rect.y = 0
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
forwardx = 600
backwardx = 230
eloc = []
eloc = [200,20]
gloc = []
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
tx = 64 #tile size
ty = 64 #tile size
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,gloc,tx,ty )
plat_list = Level.platform( 1,tx,ty )
'''
Main loop
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print("LEFT")
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print("RIGHT")
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump(plat_list)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
world.blit(backdrop, backdropbox)
player.gravity() # check gravity
player.update()
player_list.draw(world) #refresh player position
enemy_list.draw(world) # refresh enemies
ground_list.draw(world) # refresh enemies
plat_list.draw(world) # refresh platforms
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
---
via: <https://opensource.com/article/19/12/python-platformer-game-run>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part 9 in an ongoing series about creating video games in Python 3 using the Pygame module. Previous articles are:
[Learn how to program in Python by building a simple dice game](https://opensource.com/article/17/10/python-101)[Build a game framework with Python using the Pygame module](https://opensource.com/article/17/12/game-framework-python)[How to add a player to your Python game](https://opensource.com/article/17/12/game-python-add-a-player)[Using Pygame to move your game character around](https://opensource.com/article/17/12/game-python-moving-player)[What's a hero without a villain? How to add one to your Python game](https://opensource.com/article/18/5/pygame-enemy)[Add platforms to your game](https://opensource.com/article/18/7/put-platforms-python-game)[Simulate gravity in your Python game](https://opensource.com/article/19/11/simulate-gravity-python)[Add jumping to your Python platformer game](https://opensource.com/article/19/12/jumping-python-platformer-game)
In previous entries of this series about creating video games in [Python 3](https://www.python.org/) using the [Pygame](https://www.pygame.org/news) module, you designed your level-design layout, but some portion of your level probably extended past your viewable screen. The ubiquitous solution to that problem in platformer games is, as the term "side-scroller" suggests, scrolling.
The key to scrolling is to make the platforms around the player sprite move when the player sprite gets close to the edge of the screen. This provides the illusion that the screen is a "camera" panning across the game world.
This scrolling trick requires two dead zones at either edge of the screen, at which point your avatar stands still while the world scrolls by.
## Putting the scroll in side-scroller
You need one trigger point to go forward and another if you want your player to be able to go backward. These two points are simply two variables. Set them each about 100 or 200 pixels from each screen edge. Create the variables in your **variables** section:
```
forwardx = 600
backwardx = 230
```
In the main loop, check to see whether your hero sprite is at the **forwardx** or **backwardx** scroll point. If so, move all platforms either left or right, depending on whether the world is moving forward or backward. In the following code, the final three lines of code are only for your reference (be careful not to place this code in the **for** loop checking for keyboard events):
```
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
# scrolling code above
world.blit(backdrop, backdropbox)
player.gravity() # check gravity
player.update()
```
Launch your game and try it out.

Scrolling works as expected, but you may notice a small problem that happens when you scroll the world around your player and non-player sprites: the enemy sprite doesn't scroll along with the world. Unless you want
your enemy sprite to pursue your player endlessly, you need to modify the enemy code so that when your player makes an expeditious retreat, the enemy is left behind.
## Enemy scroll
In your main loop, you must apply the same rules for scrolling platforms to your enemy's position. Because your game world will (presumably) have more than one enemy in it, the rules are applied to your enemy list rather than an individual enemy sprite. That's one of the advantages of grouping similar elements into lists.
The first two lines are for context, so just add the final two to your main loop:
```
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list: # enemy scroll
e.rect.x -= scroll # enemy scroll
```
To scroll in the other direction (again, only add the final two lines to your existing code):
```
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list: # enemy scroll
e.rect.x += scroll # enemy scroll
```
Launch the game again and see what happens.
Here's all the code you've written for this Python platformer so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
forwardx = 600
backwardx = 230
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
'''
Objects
'''
# x location, y location, img width, img height, img file
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.is_jumping = True
self.is_falling = True
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def gravity(self):
if self.is_jumping:
self.movey += 3.2
def control(self, x, y):
"""
control player movement
"""
self.movex += x
def jump(self):
if self.is_jumping is False:
self.is_falling = False
self.is_jumping = True
def update(self):
"""
Update sprite position
"""
# moving left
if self.movex < 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = self.images[self.frame // ani]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in enemy_hit_list:
self.health -= 1
# print(self.health)
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.bottom = g.rect.top
self.is_jumping = False # stop jumping
# fall off the world
if self.rect.y > worldy:
self.health -=1
print(self.health)
self.rect.x = tx
self.rect.y = ty
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.is_jumping = False # stop jumping
self.movey = 0
if self.rect.bottom <= p.rect.bottom:
self.rect.bottom = p.rect.top
else:
self.movey += 3.2
if self.is_jumping and self.is_falling is False:
self.is_falling = True
self.movey -= 33 # how high to jump
self.rect.x += self.movex
self.rect.y += self.movey
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
enemy movement
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance * 2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level:
def ground(lvl, gloc, tx, ty):
ground_list = pygame.sprite.Group()
i = 0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i], worldy - ty, tx, ty, 'tile-ground.png')
ground_list.add(ground)
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return ground_list
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl))
return enemy_list
# x location, y location, img width, img height, img file
def platform(lvl, tx, ty):
plat_list = pygame.sprite.Group()
ploc = []
i = 0
if lvl == 1:
ploc.append((200, worldy - ty - 128, 3))
ploc.append((300, worldy - ty - 256, 3))
ploc.append((550, worldy - ty - 128, 4))
while i < len(ploc):
j = 0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0] + (j * tx)), ploc[i][1], tx, ty, 'tile.png')
plat_list.add(plat)
j = j + 1
print('run' + str(i) + str(ploc[i]))
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return plat_list
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 30 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
eloc = []
eloc = [300, 0]
enemy_list = Level.bad(1, eloc)
gloc = []
tx = 64
ty = 64
i = 0
while i <= (worldx / tx) + tx:
gloc.append(i * tx)
i = i + 1
ground_list = Level.ground(1, gloc, tx, ty)
plat_list = Level.platform(1, tx, ty)
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump()
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list: # enemy scroll
e.rect.x -= scroll # enemy scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list: # enemy scroll
e.rect.x += scroll # enemy scroll
world.blit(backdrop, backdropbox)
player.update()
player.gravity()
player_list.draw(world)
enemy_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
## Comments are closed. |
11,822 | 如果 SSH 被中断,Linux screen 工具如何拯救你的任务以及理智 | https://www.networkworld.com/article/3441777/how-the-linux-screen-tool-can-save-your-tasks-and-your-sanity-if-ssh-is-interrupted.html | 2020-01-26T21:28:36 | [
"screen"
] | https://linux.cn/article-11822-1.html |
>
> 当你需要确保长时间运行的任务不会在 SSH 会话中断时被杀死时,Linux screen 命令可以成为救生员。以下是使用方法。
>
>
>

如果因 SSH 会话断开而不得不重启一个耗时的进程,那么你可能会很高兴了解一个有趣的工具,可以用来避免此问题:`screen` 工具。
`screen` 是一个终端多路复用器,它使你可以在单个 SSH 会话中运行多个终端会话,并随时从它们之中脱离或重新接驳。做到这一点的过程非常简单,仅涉及少数命令。
要启动 `screen` 会话,只需在 SSH 会话中键入 `screen`。 然后,你可以开始启动需要长时间运行的进程,并在适当的时候键入 `Ctrl + A Ctrl + D` 从会话中脱离,然后键入 `screen -r` 重新接驳。
如果你要运行多个 `screen` 会话,更好的选择是为每个会话指定一个有意义的名称,以帮助你记住正在处理的任务。使用这种方法,你可以在启动每个会话时使用如下命令命名:
```
$ screen -S slow-build
```
一旦运行了多个会话,要重新接驳到一个会话,需要从列表中选择它。在以下命令中,我们列出了当前正在运行的会话,然后再重新接驳其中一个。请注意,一开始这两个会话都被标记为已脱离。
```
$ screen -ls
There are screens on:
6617.check-backups (09/26/2019 04:35:30 PM) (Detached)
1946.slow-build (09/26/2019 02:51:50 PM) (Detached)
2 Sockets in /run/screen/S-shs
```
然后,重新接驳到该会话要求你提供分配给会话的名称。例如:
```
$ screen -r slow-build
```
在脱离的会话中,保持运行状态的进程会继续进行处理,而你可以执行其他工作。如果你使用这些 `screen` 会话之一来查询 `screen` 会话情况,可以看到当前重新接驳的会话再次显示为 `Attached`。
```
$ screen -ls
There are screens on:
6617.check-backups (09/26/2019 04:35:30 PM) (Attached)
1946.slow-build (09/26/2019 02:51:50 PM) (Detached)
2 Sockets in /run/screen/S-shs.
```
你可以使用 `-version` 选项查询正在运行的 `screen` 版本。
```
$ screen -version
Screen version 4.06.02 (GNU) 23-Oct-17
```
### 安装 screen
如果 `which screen` 未在屏幕上提供信息,则可能你的系统上未安装该工具。
```
$ which screen
/usr/bin/screen
```
如果你需要安装它,则以下命令之一可能适合你的系统:
```
sudo apt install screen
sudo yum install screen
```
当你需要运行耗时的进程时,如果你的 SSH 会话由于某种原因断开连接,则可能会中断这个耗时的进程,那么 `screen` 工具就会派上用场。而且,如你所见,它非常易于使用和管理。
以下是上面使用的命令的摘要:
```
screen -S <process description> 开始会话
Ctrl+A Ctrl+D 从会话中脱离
screen -ls 列出会话
screen -r <process description> 重新接驳会话
```
尽管还有更多关于 `screen` 的知识,包括可以在 `screen` 会话之间进行操作的其他方式,但这已经足够帮助你开始使用这个便捷的工具了。
---
via: <https://www.networkworld.com/article/3441777/how-the-linux-screen-tool-can-save-your-tasks-and-your-sanity-if-ssh-is-interrupted.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,823 | 为什么每个人都在谈论 WebAssembly | https://opensource.com/article/20/1/webassembly | 2020-01-27T12:54:39 | [
"WebAssembly"
] | /article-11823-1.html |
>
> 了解有关在 Web 浏览器中运行任何代码的最新方法的更多信息。
>
>
>

如果你还没有听说过 [WebAssembly](https://opensource.com/article/19/8/webassembly-speed-code-reuse),那么你很快就会知道。这是业界最保密的秘密之一,但它无处不在。所有主流的浏览器都支持它,并且它也将在服务器端使用。它很快,它能用于游戏编程。这是主要的国际网络标准组织万维网联盟(W3C)的一个开放标准。
你可能会说:“哇,这听起来像是我应该学习编程的东西!”你可能是对的,但也是错的。你不需要用 WebAssembly 编程。让我们花一些时间来学习这种通常被缩写为“Wasm”的技术。
### 它从哪里来?
大约十年前,人们越来越认识到,广泛使用的 JavaScript 不够快速,无法满足许多目的。JavaScript 无疑是成功和方便的。它可以在任何浏览器中运行,并启用了今天我们认为理所当然的动态网页类型。但这是一种高级语言,在设计时并没有考虑到计算密集型工作负载。
然而,尽管负责主流 web 浏览器的工程师们对性能问题的看法大体一致,但他们对如何解决这个问题却意见不一。出现了两个阵营,谷歌开始了它的<ruby> 原生客户端 <rt> Native Client </rt></ruby>项目,后来又推出了<ruby> 可移植原生客户端 <rt> Portable Native Client </rt></ruby>变体,着重于允许用 C/C++ 编写的游戏和其它软件在 Chrome 的一个安全隔间中运行。与此同时,Mozilla 赢得了微软对 asm.js 的支持。该方法更新了浏览器,因此它可以非常快速地运行 JavaScript 指令的低级子集(有另一个项目可以将 C/C++ 代码转换为这些指令)。
由于这两个阵营都没有得到广泛采用,各方在 2015 年同意围绕一种称为 WebAssembly 的新标准,以 asm.js 所采用的基本方法为基础,联合起来。[如 CNET 的 Stephen Shankland 当时所写](https://www.cnet.com/news/the-secret-alliance-that-could-give-the-web-a-massive-speed-boost/),“在当今的 Web 上,浏览器的 JavaScript 将这些指令转换为机器代码。但是,通过 WebAssembly,程序员可以在此过程的早期阶段完成很多工作,从而生成介于两种状态之间的程序。这使浏览器摆脱了创建机器代码的繁琐工作,但也实现了 Web 的承诺 —— 该软件将在具有浏览器的任何设备上运行,而无需考虑基础硬件的细节。”
在 2017 年,Mozilla 宣布了它的最小可行的产品(MVP),并使其脱离预览版阶段。到该年年底,所有主流的浏览器都采用了它。[2019 年 12 月](https://www.w3.org/blog/news/archives/8123),WebAssembly 工作组发布了三个 W3C 推荐的 WebAssembly 规范。
WebAssembly 定义了一种可执行程序的可移植二进制代码格式、相应的文本汇编语言以及用于促进此类程序与其宿主环境之间的交互接口。WebAssembly 代码在低级虚拟机中运行,这个可运行于许多微处理器之上的虚拟机可模仿这些处理器的功能。通过即时(JIT)编译或解释,WebAssembly 引擎可以以近乎原生平台编译代码的速度执行。
### 为什么现在感兴趣?
当然,最近对 WebAssembly 感兴趣的部分原因是最初希望在浏览器中运行更多计算密集型代码。尤其是笔记本电脑用户,越来越多的时间都花在浏览器上(或者,对于 Chromebook 用户来说,基本上是所有时间)。这种趋势已经迫切需要消除在浏览器中运行各种应用程序的障碍。这些障碍之一通常是性能的某些方面,这正是 WebAssembly 及其前身最初旨在解决的问题。
但是,WebAssembly 并不仅仅适用于浏览器。在 2019 年,[Mozilla 宣布了一个名为 WASI](https://hacks.mozilla.org/2019/03/standardizing-wasi-a-webassembly-system-interface/)(<ruby> WebAssembly 系统接口 <rt> WebAssembly System Interface </rt></ruby>)的项目,以标准化 WebAssembly 代码如何与浏览器上下文之外的操作系统进行交互。通过将浏览器对 WebAssembly 和 WASI 的支持结合在一起,编译后的二进制文件将能够以接近原生的速度,跨不同的设备和操作系统在浏览器内外运行。
WebAssembly 的低开销立即使它可以在浏览器之外使用,但这无疑是赌注;显然,还有其它不会引入性能瓶颈的运行应用程序的方法。为什么要专门使用 WebAssembly?
一个重要的原因是它的可移植性。如今,像 C++ 和 Rust 这样的广泛使用的编译语言可能是与 WebAssembly 关联最紧密的语言。但是,[各种各样的其他语言](https://github.com/appcypher/awesome-wasm-langs)可以编译为 WebAssembly 或拥有它们的 WebAssembly 虚拟机。此外,尽管 WebAssembly 为其执行环境[假定了某些先决条件](https://webassembly.org/docs/portability/),但它被设计为在各种操作系统和指令集体系结构上有效执行。因此,WebAssembly 代码可以使用多种语言编写,并可以在多种操作系统和处理器类型上运行。
另一个 WebAssembly 优势源于这样一个事实:代码在虚拟机中运行。因此,每个 WebAssembly 模块都在沙盒环境中执行,并使用故障隔离技术将其与宿主机运行时环境分开。这意味着,对于其它部分而言,应用程序独立于其宿主机环境的其余部分执行,如果不调用适当的 API,就无法摆脱沙箱。
### WebAssembly 现状
这一切在实践中意味着什么?
如今在运作中的 WebAssembly 的一个例子是 [Enarx](https://enarx.io)。
Enarx 是一个提供硬件独立性的项目,可使用<ruby> 受信任的执行环境 <rt> Trusted Execution Environments </rt></ruby>(TEE)保护应用程序的安全。Enarx 使你可以安全地将编译为 WebAssembly 的应用程序始终交付到云服务商,并远程执行它。正如 Red Hat 安全工程师 [Nathaniel McCallum 指出的那样](https://enterprisersproject.com/article/2019/9/application-security-4-facts-confidential-computing-consortium):“我们这样做的方式是,我们将你的应用程序作为输入,并使用远程硬件执行认证过程。我们使用加密技术验证了远程硬件实际上是它声称的硬件。最终的结果不仅是我们对硬件的信任度提高了;它也是一个会话密钥,我们可以使用它将加密的代码和数据传递到我们刚刚要求加密验证的环境中。”
另一个例子是 OPA,<ruby> 开放策略代理 <rt> Open Policy Agent </rt></ruby>,它[发布](https://blog.openpolicyagent.org/tagged/webassembly)于 2019 年 11 月,你可以[编译](https://github.com/open-policy-agent/opa/tree/master/wasm)他们的策略定义语言 Rego 为 WebAssembly。Rego 允许你编写逻辑来搜索和组合来自不同来源的 JSON/YAML 数据,以询问诸如“是否允许使用此 API?”之类的问题。
OPA 已被用于支持策略的软件,包括但不限于 Kubernetes。使用 OPA 之类的工具来简化策略[被认为是在各种不同环境中正确保护 Kubernetes 部署的重要步骤](https://enterprisersproject.com/article/2019/11/kubernetes-reality-check-3-takeaways-kubecon)。WebAssembly 的可移植性和内置的安全功能非常适合这些工具。
我们的最后一个例子是 [Unity](https://opensource.com/article/20/1/www.unity.com)。还记得我们在文章开头提到过 WebAssembly 可用于游戏吗?好吧,跨平台游戏引擎 Unity 是 WebAssembly 的较早采用者,它提供了在浏览器中运行的 Wasm 的首个演示品,并且自 2018 年 8 月以来,[已将 WebAssembly](https://blogs.unity3d.com/2018/08/15/webassembly-is-here/)用作 Unity WebGL 构建目标的输出目标。
这些只是 WebAssembly 已经开始产生影响的几种方式。你可以在 <https://webassembly.org/> 上查找更多信息并了解 Wasm 的所有最新信息。
---
via: <https://opensource.com/article/20/1/webassembly>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,825 | C 还是 Rust:选择哪个用于硬件抽象编程 | https://opensource.com/article/20/1/c-vs-rust-abstractions | 2020-01-28T12:35:00 | [
"Rust",
"寄存器"
] | https://linux.cn/article-11825-1.html |
>
> 在 Rust 中使用类型级编程可以使硬件抽象更加安全。
>
>
>

Rust 是一种日益流行的编程语言,被视为硬件接口的最佳选择。通常会将其与 C 的抽象级别相比较。本文介绍了 Rust 如何通过多种方式处理按位运算,并提供了既安全又易于使用的解决方案。
| 语言 | 诞生于 | 官方描述 | 总览 |
| --- | --- | --- | --- |
| C | 1972 年 | C 是一种通用编程语言,具有表达式简约、现代的控制流和数据结构,以及丰富的运算符集等特点。(来源:[CS 基础知识](https://cs-fundamentals.com/c-programming/history-of-c-programming-language.php)) | C 是(一种)命令式语言,旨在以相对简单的方式进行编译,从而提供对内存的低级访问。(来源:[W3schools.in](https://www.w3schools.in/c-tutorial/history-of-c/)) |
| Rust | 2010 年 | 一种赋予所有人构建可靠、高效的软件的能力的语言(来源:[Rust 网站](https://www.rust-lang.org/)) | Rust 是一种专注于安全性(尤其是安全并发性)的多范式系统编程语言。(来源:[维基百科](https://en.wikipedia.org/wiki/Rust_(programming_language))) |
### 在 C 语言中对寄存器值进行按位运算
在系统编程领域,你可能经常需要编写硬件驱动程序或直接与内存映射设备进行交互,而这些交互几乎总是通过硬件提供的内存映射寄存器来完成的。通常,你通过对某些固定宽度的数字类型进行按位运算来与这些寄存器进行交互。
例如,假设一个 8 位寄存器具有三个字段:
```
+----------+------+-----------+---------+
| (unused) | Kind | Interrupt | Enabled |
+----------+------+-----------+---------+
5-7 2-4 1 0
```
字段名称下方的数字规定了该字段在寄存器中使用的位。要启用该寄存器,你将写入值 `1`(以二进制表示为 `0000_0001`)来设置 `Enabled` 字段的位。但是,通常情况下,你也不想干扰寄存器中的现有配置。假设你要在设备上启用中断功能,但也要确保设备保持启用状态。为此,必须将 `Interrupt` 字段的值与 `Enabled` 字段的值结合起来。你可以通过按位操作来做到这一点:
```
1 | (1 << 1)
```
通过将 1 和 2(`1` 左移一位得到)进行“或”(`|`)运算得到二进制值 `0000_0011` 。你可以将其写入寄存器,使其保持启用状态,但也启用中断功能。
你的头脑中要记住很多事情,特别是当你要在一个完整的系统上和可能有数百个之多的寄存器打交道时。在实践上,你可以使用助记符来执行此操作,助记符可跟踪字段在寄存器中的位置以及字段的宽度(即它的上边界是什么)
下面是这些助记符之一的示例。它们是 C 语言的宏,用右侧的代码替换它们的出现的地方。这是上面列出的寄存器的简写。`&` 的左侧是该字段的起始位置,而右侧则限制该字段所占的位:
```
#define REG_ENABLED_FIELD(x) (x << 0) & 1
#define REG_INTERRUPT_FIELD(x) (x << 1) & 2
#define REG_KIND_FIELD(x) (x << 2) & (7 << 2)
```
然后,你可以使用这些来抽象化寄存器值的操作,如下所示:
```
void set_reg_val(reg* u8, val u8);
fn enable_reg_with_interrupt(reg* u8) {
set_reg_val(reg, REG_ENABLED_FIELD(1) | REG_INTERRUPT_FIELD(1));
}
```
这就是现在的做法。实际上,这就是大多数驱动程序在 Linux 内核中的使用方式。
有没有更好的办法?如果能够基于对现代编程语言研究得出新的类型系统,就可能能够获得安全性和可表达性的好处。也就是说,如何使用更丰富、更具表现力的类型系统来使此过程更安全、更持久?
### 在 Rust 语言中对寄存器值进行按位运算
继续用上面的寄存器作为例子:
```
+----------+------+-----------+---------+
| (unused) | Kind | Interrupt | Enabled |
+----------+------+-----------+---------+
5-7 2-4 1 0
```
你想如何用 Rust 类型来表示它呢?
你将以类似的方式开始,为每个字段的*偏移*定义常量(即,距最低有效位有多远)及其掩码。*掩码*是一个值,其二进制表示形式可用于更新或读取寄存器内部的字段:
```
const ENABLED_MASK: u8 = 1;
const ENABLED_OFFSET: u8 = 0;
const INTERRUPT_MASK: u8 = 2;
const INTERRUPT_OFFSET: u8 = 1;
const KIND_MASK: u8 = 7 << 2;
const KIND_OFFSET: u8 = 2;
```
接下来,你将声明一个 `Field` 类型并进行操作,将给定值转换为与其位置相关的值,以供在寄存器内使用:
```
struct Field {
value: u8,
}
impl Field {
fn new(mask: u8, offset: u8, val: u8) -> Self {
Field {
value: (val << offset) & mask,
}
}
}
```
最后,你将使用一个 `Register` 类型,该类型会封装一个与你的寄存器宽度匹配的数字类型。 `Register` 具有 `update` 函数,可使用给定字段来更新寄存器:
```
struct Register(u8);
impl Register {
fn update(&mut self, val: Field) {
self.0 = self.0 | field.value;
}
}
fn enable_register(&mut reg) {
reg.update(Field::new(ENABLED_MASK, ENABLED_OFFSET, 1));
}
```
使用 Rust,你可以使用数据结构来表示字段,将它们与特定的寄存器联系起来,并在与硬件交互时提供简洁明了的工效。这个例子使用了 Rust 提供的最基本的功能。无论如何,添加的结构都会减轻上述 C 示例中的某些晦涩的地方。现在,字段是个带有名字的事物,而不是从模糊的按位运算符派生而来的数字,并且寄存器是具有状态的类型 —— 这在硬件上多了一层抽象。
### 一个易用的 Rust 实现
用 Rust 重写的第一个版本很好,但是并不理想。你必须记住要带上掩码和偏移量,并且要手工进行临时计算,这容易出错。人类不擅长精确且重复的任务 —— 我们往往会感到疲劳或失去专注力,这会导致错误。一次一个寄存器地手动记录掩码和偏移量几乎可以肯定会以糟糕的结局而告终。这是最好留给机器的任务。
其次,从结构上进行思考:如果有一种方法可以让字段的类型携带掩码和偏移信息呢?如果可以在编译时就发现硬件寄存器的访问和交互的实现代码中存在错误,而不是在运行时才发现,该怎么办?也许你可以依靠一种在编译时解决问题的常用策略,例如类型。
你可以使用 [typenum](https://docs.rs/crate/typenum) 来修改前面的示例,该库在类型级别提供数字和算术。在这里,你将使用掩码和偏移量对 `Field` 类型进行参数化,使其可用于任何 `Field` 实例,而无需将其包括在调用处:
```
#[macro_use]
extern crate typenum;
use core::marker::PhantomData;
use typenum::*;
// Now we'll add Mask and Offset to Field's type
struct Field<Mask: Unsigned, Offset: Unsigned> {
value: u8,
_mask: PhantomData<Mask>,
_offset: PhantomData<Offset>,
}
// We can use type aliases to give meaningful names to
// our fields (and not have to remember their offsets and masks).
type RegEnabled = Field<U1, U0>;
type RegInterrupt = Field<U2, U1>;
type RegKind = Field<op!(U7 << U2), U2>;
```
现在,当重新访问 `Field` 的构造函数时,你可以忽略掩码和偏移量参数,因为类型中包含该信息:
```
impl<Mask: Unsigned, Offset: Unsigned> Field<Mask, Offset> {
fn new(val: u8) -> Self {
Field {
value: (val << Offset::U8) & Mask::U8,
_mask: PhantomData,
_offset: PhantomData,
}
}
}
// And to enable our register...
fn enable_register(&mut reg) {
reg.update(RegEnabled::new(1));
}
```
看起来不错,但是……如果你在给定的值是否*适合*该字段方面犯了错误,会发生什么?考虑一个简单的输入错误,你在其中放置了 `10` 而不是 `1`:
```
fn enable_register(&mut reg) {
reg.update(RegEnabled::new(10));
}
```
在上面的代码中,预期结果是什么?好吧,代码会将启用位设置为 0,因为 `10&1 = 0`。那真不幸;最好在尝试写入之前知道你要写入字段的值是否适合该字段。事实上,我认为截掉错误字段值的高位是一种 1*未定义的行为*(哈)。
### 出于安全考虑使用 Rust
如何以一般方式检查字段的值是否适合其规定的位置?需要更多类型级别的数字!
你可以在 `Field` 中添加 `Width` 参数,并使用它来验证给定的值是否适合该字段:
```
struct Field<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> {
value: u8,
_mask: PhantomData<Mask>,
_offset: PhantomData<Offset>,
_width: PhantomData<Width>,
}
type RegEnabled = Field<U1,U1, U0>;
type RegInterrupt = Field<U1, U2, U1>;
type RegKind = Field<U3, op!(U7 << U2), U2>;
impl<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> Field<Width, Mask, Offset> {
fn new(val: u8) -> Option<Self> {
if val <= (1 << Width::U8) - 1 {
Some(Field {
value: (val << Offset::U8) & Mask::U8,
_mask: PhantomData,
_offset: PhantomData,
_width: PhantomData,
})
} else {
None
}
}
}
```
现在,只有给定值适合时,你才能构造一个 `Field` !否则,你将得到 `None` 信号,该信号指示发生了错误,而不是截掉该值的高位并静默写入意外的值。
但是请注意,这将在运行时环境中引发错误。但是,我们事先知道我们想写入的值,还记得吗?鉴于此,我们可以教编译器完全拒绝具有无效字段值的程序 —— 我们不必等到运行它!
这次,你将向 `new` 的新实现 `new_checked` 中添加一个特征绑定(`where` 子句),该函数要求输入值小于或等于给定字段用 `Width` 所能容纳的最大可能值:
```
struct Field<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> {
value: u8,
_mask: PhantomData<Mask>,
_offset: PhantomData<Offset>,
_width: PhantomData<Width>,
}
type RegEnabled = Field<U1, U1, U0>;
type RegInterrupt = Field<U1, U2, U1>;
type RegKind = Field<U3, op!(U7 << U2), U2>;
impl<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> Field<Width, Mask, Offset> {
const fn new_checked<V: Unsigned>() -> Self
where
V: IsLessOrEqual<op!((U1 << Width) - U1), Output = True>,
{
Field {
value: (V::U8 << Offset::U8) & Mask::U8,
_mask: PhantomData,
_offset: PhantomData,
_width: PhantomData,
}
}
}
```
只有拥有此属性的数字才实现此特征,因此,如果使用不适合的数字,它将无法编译。让我们看一看!
```
fn enable_register(&mut reg) {
reg.update(RegEnabled::new_checked::<U10>());
}
12 | reg.update(RegEnabled::new_checked::<U10>());
| ^^^^^^^^^^^^^^^^ expected struct `typenum::B0`, found struct `typenum::B1`
|
= note: expected type `typenum::B0`
found type `typenum::B1`
```
`new_checked` 将无法生成一个程序,因为该字段的值有错误的高位。你的输入错误不会在运行时环境中才爆炸,因为你永远无法获得一个可以运行的工件。
就使内存映射的硬件进行交互的安全性而言,你已经接近 Rust 的极致。但是,你在 C 的第一个示例中所写的内容比最终得到的一锅粥的类型参数更简洁。当你谈论潜在可能有数百甚至数千个寄存器时,这样做是否容易处理?
### 让 Rust 恰到好处:既安全又方便使用
早些时候,我认为手工计算掩码有问题,但我又做了同样有问题的事情 —— 尽管是在类型级别。虽然使用这种方法很不错,但要达到编写任何代码的地步,则需要大量样板和手动转录(我在这里谈论的是类型的同义词)。
我们的团队想要像 [TockOS mmio 寄存器](https://docs.rs/tock-registers/0.3.0/tock_registers/)之类的东西,而以最少的手动转录生成类型安全的实现。我们得出的结果是一个宏,该宏生成必要的样板以获得类似 Tock 的 API 以及基于类型的边界检查。要使用它,请写下一些有关寄存器的信息,其字段、宽度和偏移量以及可选的[枚举](https://en.wikipedia.org/wiki/Enumerated_type)类的值(你应该为字段可能具有的值赋予“含义”):
```
register! {
// The register's name
Status,
// The type which represents the whole register.
u8,
// The register's mode, ReadOnly, ReadWrite, or WriteOnly.
RW,
// And the fields in this register.
Fields [
On WIDTH(U1) OFFSET(U0),
Dead WIDTH(U1) OFFSET(U1),
Color WIDTH(U3) OFFSET(U2) [
Red = U1,
Blue = U2,
Green = U3,
Yellow = U4
]
]
}
```
由此,你可以生成寄存器和字段类型,如上例所示,其中索引:`Width`、`Mask` 和 `Offset` 是从一个字段定义的 `WIDTH` 和 `OFFSET` 部分的输入值派生的。另外,请注意,所有这些数字都是 “类型数字”;它们将直接进入你的 `Field` 定义!
生成的代码通过为寄存器及字段指定名称来为寄存器及其相关字段提供名称空间。这很绕口,看起来是这样的:
```
mod Status {
struct Register(u8);
mod On {
struct Field; // There is of course more to this definition
}
mod Dead {
struct Field;
}
mod Color {
struct Field;
pub const Red: Field = Field::<U1>new();
// &c.
}
}
```
生成的 API 包含名义上期望的读取和写入的原语,以获取原始寄存器的值,但它也有办法获取单个字段的值、执行集合操作以及确定是否设置了任何(或全部)位集合的方法。你可以阅读[完整生成的 API](https://github.com/auxoncorp/bounded-registers#the-register-api)上的文档。
### 粗略检查
将这些定义用于实际设备会是什么样?代码中是否会充斥着类型参数,从而掩盖了视图中的实际逻辑?
不会!通过使用类型同义词和类型推断,你实际上根本不必考虑程序的类型层面部分。你可以直接与硬件交互,并自动获得与边界相关的保证。
这是一个 [UART](https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter) 寄存器块的示例。我会跳过寄存器本身的声明,因为包括在这里就太多了。而是从寄存器“块”开始,然后帮助编译器知道如何从指向该块开头的指针中查找寄存器。我们通过实现 `Deref` 和 `DerefMut` 来做到这一点:
```
#[repr(C)]
pub struct UartBlock {
rx: UartRX::Register,
_padding1: [u32; 15],
tx: UartTX::Register,
_padding2: [u32; 15],
control1: UartControl1::Register,
}
pub struct Regs {
addr: usize,
}
impl Deref for Regs {
type Target = UartBlock;
fn deref(&self) -> &UartBlock {
unsafe { &*(self.addr as *const UartBlock) }
}
}
impl DerefMut for Regs {
fn deref_mut(&mut self) -> &mut UartBlock {
unsafe { &mut *(self.addr as *mut UartBlock) }
}
}
```
一旦到位,使用这些寄存器就像 `read()` 和 `modify()` 一样简单:
```
fn main() {
// A pretend register block.
let mut x = [0_u32; 33];
let mut regs = Regs {
// Some shenanigans to get at `x` as though it were a
// pointer. Normally you'd be given some address like
// `0xDEADBEEF` over which you'd instantiate a `Regs`.
addr: &mut x as *mut [u32; 33] as usize,
};
assert_eq!(regs.rx.read(), 0);
regs.control1
.modify(UartControl1::Enable::Set + UartControl1::RecvReadyInterrupt::Set);
// The first bit and the 10th bit should be set.
assert_eq!(regs.control1.read(), 0b_10_0000_0001);
}
```
当我们使用运行时值时,我们使用如前所述的**选项**。这里我使用的是 `unwrap`,但是在一个输入未知的真实程序中,你可能想检查一下从新调用中返回的**某些东西**: <sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> <sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>
```
fn main() {
// A pretend register block.
let mut x = [0_u32; 33];
let mut regs = Regs {
// Some shenanigans to get at `x` as though it were a
// pointer. Normally you'd be given some address like
// `0xDEADBEEF` over which you'd instantiate a `Regs`.
addr: &mut x as *mut [u32; 33] as usize,
};
let input = regs.rx.get_field(UartRX::Data::Field::Read).unwrap();
regs.tx.modify(UartTX::Data::Field::new(input).unwrap());
}
```
### 解码失败条件
根据你的个人痛苦忍耐程度,你可能已经注意到这些错误几乎是无法理解的。看一下我所说的不那么微妙的提醒:
```
error[E0271]: type mismatch resolving `<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UTerm, typenum::B1>, typenum::B0>, typenum::B1>, typenum::B0>, typenum::B0> as typenum::IsLessOrEqual<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UTerm, typenum::B1>, typenum::B0>, typenum::B1>, typenum::B0>>>::Output == typenum::B1`
--> src/main.rs:12:5
|
12 | less_than_ten::<U20>();
| ^^^^^^^^^^^^^^^^^^^^ expected struct `typenum::B0`, found struct `typenum::B1`
|
= note: expected type `typenum::B0`
found type `typenum::B1`
```
`expected struct typenum::B0, found struct typenum::B1` 部分是有意义的,但是 `typenum::UInt<typenum::UInt, typenum::UInt...` 到底是什么呢?好吧,`typenum` 将数字表示为二进制 [cons](https://en.wikipedia.org/wiki/Cons) 单元!像这样的错误使操作变得很困难,尤其是当你将多个这些类型级别的数字限制在狭窄的范围内时,你很难知道它在说哪个数字。当然,除非你一眼就能将巴洛克式二进制表示形式转换为十进制表示形式。
在第 U100 次试图从这个混乱中破译出某些含义之后,我们的一个队友简直《<ruby> 疯了,地狱了,不要再忍受了 <rt> Mad As Hell And Wasn’t Going To Take It Anymore </rt></ruby>》,并做了一个小工具 `tnfilt`,从这种命名空间的二进制 cons 单元的痛苦中解脱出来。`tnfilt` 将 cons 单元格式的表示法替换为可让人看懂的十进制数字。我们认为其他人也会遇到类似的困难,所以我们分享了 [tnfilt](https://github.com/auxoncorp/tnfilt)。你可以像这样使用它:
```
$ cargo build 2>&1 | tnfilt
```
它将上面的输出转换为如下所示:
```
error[E0271]: type mismatch resolving `<U20 as typenum::IsLessOrEqual<U10>>::Output == typenum::B1`
```
现在*这*才有意义!
### 结论
当在软件与硬件进行交互时,普遍使用内存映射寄存器,并且有无数种方法来描述这些交互,每种方法在易用性和安全性上都有不同的权衡。我们发现使用类型级编程来取得内存映射寄存器交互的编译时检查可以为我们提供制作更安全软件的必要信息。该代码可在 [bounded-registers](https://crates.io/crates/bounded-registers) crate(Rust 包)中找到。
我们的团队从安全性较高的一面开始,然后尝试找出如何将易用性滑块移近易用端。从这些雄心壮志中,“边界寄存器”就诞生了,我们在 Auxon 公司的冒险中遇到内存映射设备的任何时候都可以使用它。
---
此内容最初发布在 [Auxon Engineering 博客](https://blog.auxon.io/2019/10/25/type-level-registers/)上,并经许可进行编辑和重新发布。
---
1. 从技术上讲,从定义上看,从寄存器字段读取的值只能在规定的范围内,但是我们当中没有一个人生活在一个纯净的世界中,而且你永远都不知道外部系统发挥作用时会发生什么。你是在这里接受硬件之神的命令,因此与其强迫你进入“可能的恐慌”状态,还不如给你提供处理“这将永远不会发生”的机会。 [↩](#fnref1)
2. `get_field` 看起来有点奇怪。我正在专门查看 `Field::Read` 部分。`Field` 是一种类型,你需要该类型的实例才能传递给 `get_field`。更干净的 API 可能类似于:`regs.rx.get_field::<UartRx::Data::Field>();` 但是请记住,`Field` 是一种具有固定的宽度、偏移量等索引的类型的同义词。要像这样对 `get_field` 进行参数化,你需要使用更高级的类型。 [↩](#fnref2)
---
via: <https://opensource.com/article/20/1/c-vs-rust-abstractions>
作者:[Dan Pittman](https://opensource.com/users/dan-pittman) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Rust is an increasingly popular programming language positioned to be the best choice for hardware interfaces. It's often compared to C for its level of abstraction. This article explains how Rust can handle bitwise operations in a number of ways and offers a solution that provides both safety and ease of use.
Language | Origin | Official description | Overview |
---|---|---|---|
C | 1972 | C is a general-purpose programming language which features economy of expression, modern control flow and data structures, and a rich set of operators. (Source:
|
[W3schools.in](https://www.w3schools.in/c-tutorial/history-of-c/))[Rust website](https://www.rust-lang.org/))[Wikipedia](https://en.wikipedia.org/wiki/Rust_(programming_language)))## Bitwise operation over register values in C
In the world of systems programming, where you may find yourself writing hardware drivers or interacting directly with memory-mapped devices, interaction is almost always done through memory-mapped registers provided by the hardware. You typically interact with these things through bitwise operations on some fixed-width numeric type.
For instance, imagine an 8-bit register with three fields:
```
+----------+------+-----------+---------+
| (unused) | Kind | Interrupt | Enabled |
+----------+------+-----------+---------+
5-7 2-4 1 0
```
The number below the field name prescribes the bits used by that field in the register. To enable this register, you would write the value **1**, represented in binary as **0000_0001**, to set the enabled field's bit. Often, though, you also have an existing configuration in the register that you don't want to disturb. Say you want to enable interrupts on the device but also want to be sure the device remains enabled. To do that, you must combine the Interrupt field's value with the Enabled field's value. You would do that with bitwise operations:
`1 | (1 << 1)`
This gives you the binary value **0000_0011** by **or**-ing 1 with 2, which you get by shifting 1 left by 1. You can write this to your register, leaving it enabled but also enabling interrupts.
This is a lot to keep in your head, especially when you're dealing with potentially hundreds of registers for a complete system. In practice, you do this with mnemonics which track a field's position in a register and how wide the field is—i.e., *what's its upper bound?*
Here's an example of one of these mnemonics. They are C macros that replace their occurrences with the code on the right-hand side. This is the shorthand for the register laid out above. The left-hand side of the **&** puts you in position for that field, and the right-hand side limits you to only that field's bits:
```
#define REG_ENABLED_FIELD(x) (x << 0) & 1
#define REG_INTERRUPT_FIELD(x) (x << 1) & 2
#define REG_KIND_FIELD(x) (x << 2) & (7 << 2)
```
You'd then use these to abstract over the derivation of a register's value with something like:
```
void set_reg_val(reg* u8, val u8);
fn enable_reg_with_interrupt(reg* u8) {
set_reg_val(reg, REG_ENABLED_FIELD(1) | REG_INTERRUPT_FIELD(1));
}
```
This is the state of the art. In fact, this is how the bulk of drivers appear in the Linux kernel.
Is there a better way? Consider the boon to safety and expressibility if the type system was borne out of research on modern programming languages. That is, what could you do with a richer, more expressive type system to make this process safer and more tenable?
## Bitwise operation over register values in Rust
Continuing with the register above as an example:
```
+----------+------+-----------+---------+
| (unused) | Kind | Interrupt | Enabled |
+----------+------+-----------+---------+
5-7 2-4 1 0
```
How might you want to express such a thing in Rust types?
You'll start in a similar way, by defining constants for each field's *offset*—that is, how far it is from the least significant bit—and its mask. A *mask* is a value whose binary representation can be used to update or read the field from inside the register:
```
const ENABLED_MASK: u8 = 1;
const ENABLED_OFFSET: u8 = 0;
const INTERRUPT_MASK: u8 = 2;
const INTERRUPT_OFFSET: u8 = 1;
const KIND_MASK: u8 = 7 << 2;
const KIND_OFFSET: u8 = 2;
```
Next, you'll declare a field type and do your operations to convert a given value into its position-relevant value for use inside the register:
```
struct Field {
value: u8,
}
impl Field {
fn new(mask: u8, offset: u8, val: u8) -> Self {
Field {
value: (val << offset) & mask,
}
}
}
```
Finally, you'll use a **Register** type, which wraps around a numeric type that matches the width of your register. **Register** has an **update** function that updates the register with the given field:
```
struct Register(u8);
impl Register {
fn update(&mut self, val: Field) {
self.0 = self.0 | field.value;
}
}
fn enable_register(&mut reg) {
reg.update(Field::new(ENABLED_MASK, ENABLED_OFFSET, 1));
}
```
With Rust, you can use data structures to represent fields, attach them to specific registers, and provide concise and sensible ergonomics while interacting with the hardware. This example uses the most basic facilities provided by Rust; regardless, the added structure alleviates some of the density from the C example above. Now a field is a named thing, not a number derived from shadowy bitwise operators, and registers are types with state—one extra layer of abstraction over the hardware.
## A Rust implementation for ease of use
The first rewrite in Rust is nice, but it's not ideal. You have to remember to bring the mask and offset, and you're calculating them ad hoc, by hand, which is error-prone. Humans aren't great at precise and repetitive tasks—we tend to get tired or lose focus, and this leads to mistakes. Transcribing the masks and offsets by hand, one register at a time, will almost certainly end badly. This is the kind of task best left to a machine.
Second, thinking more structurally: What if there were a way to have the field's type carry the mask and offset information? What if you could catch mistakes in your implementation for how you access and interact with hardware registers at compile time instead of discovering them at runtime? Perhaps you can lean on one of the strategies commonly used to suss out issues at compile time, like types.
You can modify the earlier example by using [ typenum](https://docs.rs/crate/typenum), a library that provides numbers and arithmetic at the type level. Here, you'll parameterize the
**Field**type with its mask and offset, making it available for any instance of
**Field**without having to include it at the call site:
```
#[macro_use]
extern crate typenum;
use core::marker::PhantomData;
use typenum::*;
// Now we'll add Mask and Offset to Field's type
struct Field<Mask: Unsigned, Offset: Unsigned> {
value: u8,
_mask: PhantomData<Mask>,
_offset: PhantomData<Offset>,
}
// We can use type aliases to give meaningful names to
// our fields (and not have to remember their offsets and masks).
type RegEnabled = Field<U1, U0>;
type RegInterrupt = Field<U2, U1>;
type RegKind = Field<op!(U7 << U2), U2>;
```
Now, when revisiting **Field**'s constructor, you can elide the mask and offset parameters because the type contains that information:
```
impl<Mask: Unsigned, Offset: Unsigned> Field<Mask, Offset> {
fn new(val: u8) -> Self {
Field {
value: (val << Offset::U8) & Mask::U8,
_mask: PhantomData,
_offset: PhantomData,
}
}
}
// And to enable our register...
fn enable_register(&mut reg) {
reg.update(RegEnabled::new(1));
}
```
It looks pretty good, but… what happens when you make a mistake regarding whether a given value will *fit* into a field? Consider a simple typo where you put **10** instead of **1**:
```
fn enable_register(&mut reg) {
reg.update(RegEnabled::new(10));
}
```
In the code above, what is the expected outcome? Well, the code will set that enabled bit to 0 because **10 & 1 = 0**. That's unfortunate; it would be nice to know whether a value you're trying to write into a field will fit into the field before attempting a write. As a matter of fact, I'd consider lopping off the high bits of an errant field value *undefined behavior* (gasps).
## Using Rust with safety in mind
How can you check that a field's value fits in its prescribed position in a general way? More type-level numbers!
You can add a **Width** parameter to **Field** and use it to verify that a given value can fit into the field:
```
struct Field<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> {
value: u8,
_mask: PhantomData<Mask>,
_offset: PhantomData<Offset>,
_width: PhantomData<Width>,
}
type RegEnabled = Field<U1,U1, U0>;
type RegInterrupt = Field<U1, U2, U1>;
type RegKind = Field<U3, op!(U7 << U2), U2>;
impl<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> Field<Width, Mask, Offset> {
fn new(val: u8) -> Option<Self> {
if val <= (1 << Width::U8) - 1 {
Some(Field {
value: (val << Offset::U8) & Mask::U8,
_mask: PhantomData,
_offset: PhantomData,
_width: PhantomData,
})
} else {
None
}
}
}
```
Now you can construct a **Field** only if the given value fits! Otherwise, you have **None**, which signals that an error has occurred, rather than lopping off the high bits of the value and silently writing an unexpected value.
Note, though, this will raise an error at runtime. However, we knew the value we wanted to write beforehand, remember? Given that, we can teach the compiler to reject entirely a program which has an invalid field value—we don’t have to wait until we run it!
This time, you'll add a *trait bound* (the **where** clause) to a new realization of new, called **new_checked**, that asks the incoming value to be less than or equal to the maximum possible value a field with the given **Width** can hold:
```
struct Field<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> {
value: u8,
_mask: PhantomData<Mask>,
_offset: PhantomData<Offset>,
_width: PhantomData<Width>,
}
type RegEnabled = Field<U1, U1, U0>;
type RegInterrupt = Field<U1, U2, U1>;
type RegKind = Field<U3, op!(U7 << U2), U2>;
impl<Width: Unsigned, Mask: Unsigned, Offset: Unsigned> Field<Width, Mask, Offset> {
const fn new_checked<V: Unsigned>() -> Self
where
V: IsLessOrEqual<op!((U1 << Width) - U1), Output = True>,
{
Field {
value: (V::U8 << Offset::U8) & Mask::U8,
_mask: PhantomData,
_offset: PhantomData,
_width: PhantomData,
}
}
}
```
Only numbers for which this property holds has an implementation of this trait, so if you use a number that does not fit, it will fail to compile. Take a look!
```
fn enable_register(&mut reg) {
reg.update(RegEnabled::new_checked::<U10>());
}
12 | reg.update(RegEnabled::new_checked::<U10>());
| ^^^^^^^^^^^^^^^^ expected struct `typenum::B0`, found struct `typenum::B1`
|
= note: expected type `typenum::B0`
found type `typenum::B1`
```
**new_checked** will fail to produce a program that has an errant too-high value for a field. Your typo won't blow up at runtime because you could never have gotten an artifact to run.
You're nearing Peak Rust in terms of how safe you can make memory-mapped hardware interactions. However, what you wrote back in the first example in C was far more succinct than the type parameter salad you ended up with. Is doing such a thing even tractable when you're talking about potentially hundreds or even thousands of registers?
## Just right with Rust: both safe and accessible
Earlier, I called out calculating masks by hand as being problematic, but I just did that same problematic thing—albeit at the type level. While using such an approach is nice, getting to the point when you can write any code requires quite a bit of boilerplate and manual transcription (I'm talking about the type synonyms here).
Our team wanted something like the [TockOS mmio registers](https://docs.rs/tock-registers/0.3.0/tock_registers/), but one that would generate typesafe implementations with the least amount of manual transcription possible. The result we came up with is a macro that generates the necessary boilerplate to get a Tock-like API plus type-based bounds checking. To use it, write down some information about a register, its fields, their width and offsets, and optional [enum](https://en.wikipedia.org/wiki/Enumerated_type)-like values (should you want to give "meaning" to the possible values a field can have):
```
register! {
// The register's name
Status,
// The type which represents the whole register.
u8,
// The register's mode, ReadOnly, ReadWrite, or WriteOnly.
RW,
// And the fields in this register.
Fields [
On WIDTH(U1) OFFSET(U0),
Dead WIDTH(U1) OFFSET(U1),
Color WIDTH(U3) OFFSET(U2) [
Red = U1,
Blue = U2,
Green = U3,
Yellow = U4
]
]
}
```
From this, you can generate register and field types like the previous example where the indices—the **Width**, **Mask**, and **Offset**—are derived from the values input in the **WIDTH** and **OFFSET** sections of a field's definition. Also, notice that all of these numbers are **typenums**; they're going to go directly into your **Field** definitions!
The generated code provides namespaces for registers and their associated fields through the name given for the register and the fields. That's a mouthful; here's what it looks like:
```
mod Status {
struct Register(u8);
mod On {
struct Field; // There is of course more to this definition
}
mod Dead {
struct Field;
}
mod Color {
struct Field;
pub const Red: Field = Field::<U1>new();
// &c.
}
}
```
The generated API contains the nominally expected read and write primitives to get at the raw register value, but it also has ways to get a single field's value, do collective actions, and find out if any (or all) of a collection of bits is set. You can read the documentation on the [complete generated API](https://github.com/auxoncorp/bounded-registers#the-register-api).
## Kicking the tires
What does it look like to use these definitions for a real device? Will the code be littered with type parameters, obscuring any real logic from view?
No! By using type synonyms and type inference, you effectively never have to think about the type-level part of the program at all. You get to interact with the hardware in a straightforward way and get those bounds-related assurances automatically.
Here's an example of a [UART](https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter) register block. I'll skip the declaration of the registers themselves, as that would be too much to include here. Instead, it starts with a register "block" then helps the compiler know how to look up the registers from a pointer to the head of the block. We do that by implementing **Deref** and **DerefMut**:
```
#[repr(C)]
pub struct UartBlock {
rx: UartRX::Register,
_padding1: [u32; 15],
tx: UartTX::Register,
_padding2: [u32; 15],
control1: UartControl1::Register,
}
pub struct Regs {
addr: usize,
}
impl Deref for Regs {
type Target = UartBlock;
fn deref(&self) -> &UartBlock {
unsafe { &*(self.addr as *const UartBlock) }
}
}
impl DerefMut for Regs {
fn deref_mut(&mut self) -> &mut UartBlock {
unsafe { &mut *(self.addr as *mut UartBlock) }
}
}
```
Once this is in place, using these registers is as simple as **read()** and **modify()**:
```
fn main() {
// A pretend register block.
let mut x = [0_u32; 33];
let mut regs = Regs {
// Some shenanigans to get at `x` as though it were a
// pointer. Normally you'd be given some address like
// `0xDEADBEEF` over which you'd instantiate a `Regs`.
addr: &mut x as *mut [u32; 33] as usize,
};
assert_eq!(regs.rx.read(), 0);
regs.control1
.modify(UartControl1::Enable::Set + UartControl1::RecvReadyInterrupt::Set);
// The first bit and the 10th bit should be set.
assert_eq!(regs.control1.read(), 0b_10_0000_0001);
}
```
When we're working with runtime values we use **Option** like we saw earlier. Here I'm using **unwrap**, but in a real program with unknown inputs, you'd probably want to check that you got a **Some** back from that new call:1, 2
```
fn main() {
// A pretend register block.
let mut x = [0_u32; 33];
let mut regs = Regs {
// Some shenanigans to get at `x` as though it were a
// pointer. Normally you'd be given some address like
// `0xDEADBEEF` over which you'd instantiate a `Regs`.
addr: &mut x as *mut [u32; 33] as usize,
};
let input = regs.rx.get_field(UartRX::Data::Field::Read).unwrap();
regs.tx.modify(UartTX::Data::Field::new(input).unwrap());
}
```
## Decoding failure conditions
Depending on your personal pain threshold, you may have noticed that the errors are nearly unintelligible. Take a look at a not-so-subtle reminder of what I'm talking about:
```
error[E0271]: type mismatch resolving `<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UTerm, typenum::B1>, typenum::B0>, typenum::B1>, typenum::B0>, typenum::B0> as typenum::IsLessOrEqual<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UInt<typenum::UTerm, typenum::B1>, typenum::B0>, typenum::B1>, typenum::B0>>>::Output == typenum::B1`
--> src/main.rs:12:5
|
12 | less_than_ten::<U20>();
| ^^^^^^^^^^^^^^^^^^^^ expected struct `typenum::B0`, found struct `typenum::B1`
|
= note: expected type `typenum::B0`
found type `typenum::B1`
```
The **expected typenum::B0 found typenum::B1** part kind of makes sense, but what on earth is the **typenum::UInt<typenum::UInt, typenum::UInt…** nonsense? Well, **typenum** represents numbers as binary [cons](https://en.wikipedia.org/wiki/Cons) cells! Errors like this make it hard, especially when you have several of these type-level numbers confined to tight quarters, to know which number it's talking about. Unless, of course, it's second nature for you to translate baroque binary representations to decimal ones.
After the **U100**th time attempting to decipher any meaning from this mess, a teammate got Mad As Hell And Wasn't Going To Take It Anymore and made a little utility, **tnfilt**, to parse the meaning out from the misery that is namespaced binary cons cells. **tnfilt** takes the cons cell-style notation and replaces it with sensible decimal numbers. We imagine that others will face similar difficulties, so we shared [ tnfilt](https://github.com/auxoncorp/tnfilt). You can use it like this:
`$ cargo build 2>&1 | tnfilt`
It transforms the output above into something like this:
`error[E0271]: type mismatch resolving `<U20 as typenum::IsLessOrEqual<U10>>::Output == typenum::B1``
Now *that* makes sense!
## In conclusion
Memory-mapped registers are used ubiquitously when interacting with hardware from software, and there are myriad ways to portray those interactions, each of which has a different place on the spectra of ease-of-use and safety. We found that the use of type-level programming to get compile-time checking on memory-mapped register interactions gave us the necessary information to make safer software. That code is available in the ** bounded-registers crate **(Rust package).
Our team started out right at the edge of the more-safe side of that safety spectrum and then tried to figure out how to move the ease-of-use slider closer to the easy end. From those ambitions, **bounded-registers** was born, and we use it anytime we encounter memory-mapped devices in our adventures at Auxon.
-
[Technically, a read from a register field, by definition, will only give a value within the prescribed bounds, but none of us lives in a pure world, and you never know what's going to happen when external systems come into play. You're at the behest of the Hardware Gods here, so instead of forcing you into a "might panic" situation, it gives you the]**Option**to handle a "This Should Never Happen" case. -
looks a little weird. I'm looking at the[get_field]**Field::Read**part, specifically.**Field**is a type, and you need an instance of that type to pass to**get_field**. A cleaner API might be something like:`regs.rx.get_field::<UartRx::Data::Field>();`
But remember that
**Field**is a type synonym that has fixed indices for width, offset, etc. To be able to parameterize**get_field**like this, you'd need higher-kinded types.
*This originally appeared on the Auxon Engineering blog and is edited and republished with permission.*
## 2 Comments |
11,827 | Wine 5.0 发布了! | https://itsfoss.com/wine-5-release/ | 2020-01-28T14:15:23 | [
"Wine"
] | https://linux.cn/article-11827-1.html |
>
> Wine 的一个新的主要版本发布了。使用 Wine 5.0,在 Linux 上运行 Windows 应用程序和游戏的体验得到进一步改进。
>
>
>
通过一些努力,你可以使用 Wine [在 Linux 上运行 Windows 应用程序](https://itsfoss.com/use-windows-applications-linux/)。当你必须使用一个仅在 Windows 上可用的软件时,Wine 是一个可以尝试的工具。它支持许多这样的软件。
Wine 的一个新的主要发布版本已经降临,即 Wine 5.0,几乎距它的 4.0 发布一年之后。
Wine 5.0 发布版本引进了几个主要特性和很多显著的更改/改进。在这篇文章中,我将重点介绍新的特性是什么,并且也将提到安装说明。
### 在 Wine 5.0 中有什么新的特性?

如他们的[官方声明](https://www.winehq.org/news/2020012101)所述,这是 5.0 发布版本中的关键更改:
* PE 格式的内置模块。
* 支持多显示器。
* 重新实现了 XAudio2。
* 支持 Vulkan 1.1。
* 支持微软安装程序(MSI)补丁文件。
* 性能提升。
因此,随着 Vulkan 1.1 和对多显示器的支持 —— Wine 5.0 发布版本是一件大事。
除了上面强调的这些关键内容以外,在新的版本中包含成千上万的更改/改进中,你还可以期待对控制器的支持更好。
值得注意的是,此版本特别纪念了 **Józef Kucia**(vkd3d 项目的首席开发人员)。
他们也已经在[发布说明](https://www.winehq.org/announce/5.0)中提到这一点:
>
> 这个发布版本特别纪念了 Józef Kucia,他于 2019 年 8 月去世,年仅 30 岁。Józef 是 Wine 的 Direct3D 实现的一个主要贡献者,并且是 vkd3d 项目的首席开发人员。我们都非常怀念他的技能和友善。
>
>
>
### 如何在 Ubuntu 和 Linux Mint 上安装 Wine 5.0
>
> 注意:
>
>
> 如果你在以前安装过 Wine,你应该将其完全移除,以(如你希望的)避免一些冲突。此外,WineHQ 存储库的密钥最近已被更改,针对你的 Linux 发行版的更多的操作指南,你可以参考它的[下载页面](https://wiki.winehq.org/Download)。
>
>
>
Wine 5.0 的源码可在它的[官方网站](https://www.winehq.org/news/2020012101)上获得。为了使其工作,你可以阅读更多关于[构建 Wine](https://wiki.winehq.org/Building_Wine) 的信息。基于 Arch 的用户应该很快就会得到它。
在这里,我将向你展示在 Ubuntu 和其它基于 Ubuntu 的发行版上安装 Wine 5.0 的步骤。请耐心,并按照步骤一步一步安装和使用 Wine。这里涉及几个步骤。
请记住,Wine 安装了太多软件包。你会看到大量的软件包列表,下载大小约为 1.3 GB。
### 在 Ubuntu 上安装 Wine 5.0(不适用于 Linux Mint)
首先,使用这个命令来移除现存的 Wine:
```
sudo apt remove winehq-stable wine-stable wine1.6 wine-mono wine-geco winetricks
```
然后确保添加 32 位体系结构支持:
```
sudo dpkg --add-architecture i386
```
下载并添加官方 Wine 存储库密钥:
```
wget -qO - https://dl.winehq.org/wine-builds/winehq.key | sudo apt-key add -
```
现在,接下来的步骤需要添加存储库,为此, 你需要首先[知道你的 Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/)。
对于 **Ubuntu 18.04 和 19.04**,用这个 PPA 添加 FAudio 依赖, **Ubuntu 19.10** 不需要它:
```
sudo add-apt-repository ppa:cybermax-dexter/sdl2-backport
```
现在使用此命令添加存储库:
```
sudo apt-add-repository "deb https://dl.winehq.org/wine-builds/ubuntu $(lsb_release -cs) main"
```
现在你已经添加了正确的存储库,可以使用以下命令安装 Wine 5.0:
```
sudo apt update && sudo apt install --install-recommends winehq-stable
```
请注意,尽管[在软件包列表中将 Wine 5 列为稳定版](https://dl.winehq.org/wine-builds/ubuntu/dists/bionic/main/binary-amd64/),但你仍可能会看到 winehq-stable 的 wine 4.0.3。也许它不会传播到所有地理位置。从今天早上开始,我可以看到 Wine 5.0。
### 在 Linux Mint 19.1、19.2 和 19.3 中安装 Wine 5.0
正如一些读者通知我的那样,[apt-add 存储库命令](https://itsfoss.com/add-apt-repository-command-not-found/)不适用于 Linux Mint 19.x 系列。
这是添加自定义存储库的另一种方法。你必须执行与 Ubuntu 相同的步骤。如删除现存的 Wine 包:
```
sudo apt remove winehq-stable wine-stable wine1.6 wine-mono wine-geco winetricks
```
添加 32 位支持:
```
sudo dpkg --add-architecture i386
```
然后添加 GPG 密钥:
```
wget -qO - https://dl.winehq.org/wine-builds/winehq.key | sudo apt-key add -
```
添加 FAudio 依赖:
```
sudo add-apt-repository ppa:cybermax-dexter/sdl2-backport
```
现在为 Wine 存储库创建一个新条目:
```
sudo sh -c "echo 'deb https://dl.winehq.org/wine-builds/ubuntu/ bionic main' >> /etc/apt/sources.list.d/winehq.list"
```
更新软件包列表并安装Wine:
```
sudo apt update && sudo apt install --install-recommends winehq-stable
```
### 总结
你尝试过最新的 Wine 5.0 发布版本吗?如果是的话,在运行中你看到什么改进?
在下面的评论区域,让我知道你对新的发布版本的看法。
---
via: <https://itsfoss.com/wine-5-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,828 | 在你的 Python 平台类游戏中放一些奖励 | https://opensource.com/article/20/1/loot-python-platformer-game | 2020-01-29T13:12:48 | [
"Pygame"
] | https://linux.cn/article-11828-1.html |
>
> 这部分是关于在使用 Python 的 Pygame 模块开发的视频游戏总给你的玩家提供收集的宝物和经验值的内容。
>
>
>

这是正在进行的关于使用 [Python 3](https://www.python.org/) 的 [Pygame](https://www.pygame.org/news) 模块创建视频游戏的系列文章的第十部分。以前的文章有:
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
* [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
* [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
* [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
* [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
* [在 Pygame 游戏中放置平台](/article-10902-1.html)
* [在你的 Python 游戏中模拟引力](/article-11780-1.html)
* [为你的 Python 平台类游戏添加跳跃功能](/article-11790-1.html)
* [使你的 Python 游戏玩家能够向前和向后跑](/article-11819-1.html)
如果你已经阅读了本系列的前几篇文章,那么你已经了解了编写游戏的所有基础知识。现在你可以在这些基础上,创造一个全功能的游戏。当你第一次学习时,遵循本系列代码示例,这样的“用例”是有帮助的,但是,用例也会约束你。现在是时候运用你学到的知识,以新的方式应用它们了。
如果说,说起来容易做起来难,这篇文章展示了一个如何将你已经了解的内容用于新目的的例子中。具体来说,就是它涵盖了如何使用你以前的课程中已经了解到的来实现奖励系统。
在大多数电子游戏中,你有机会在游戏世界中获得“奖励”或收集到宝物和其他物品。奖励通常会增加你的分数或者你的生命值,或者为你的下一次任务提供信息。
游戏中包含的奖励类似于编程平台。像平台一样,奖励没有用户控制,随着游戏世界的滚动进行,并且必须检查与玩家的碰撞。
### 创建奖励函数
奖励和平台非常相似,你甚至不需要一个奖励的类。你可以重用 `Platform` 类,并将结果称为“奖励”。
由于奖励类型和位置可能因关卡不同而不同,如果你还没有,请在你的 `Level` 中创建一个名为 `loot` 的新函数。因为奖励物品不是平台,你也必须创建一个新的 `loot_list` 组,然后添加奖励物品。与平台、地面和敌人一样,该组用于检查玩家碰撞:
```
def loot(lvl,lloc):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(300,ty*7,tx,ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
```
你可以随意添加任意数量的奖励对象;记住把每一个都加到你的奖励清单上。`Platform` 类的参数是奖励图标的 X 位置、Y 位置、宽度和高度(通常让你的奖励精灵保持和所有其他方块一样的大小最为简单),以及你想要用作的奖励的图片。奖励的放置可以和贴图平台一样复杂,所以使用创建关卡时需要的关卡设计文档。
在脚本的设置部分调用新的奖励函数。在下面的代码中,前三行是上下文,所以只需添加第四行:
```
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,gloc,tx,ty )
plat_list = Level.platform( 1,tx,ty )
loot_list = Level.loot(1,tx,ty)
```
正如你现在所知道的,除非你把它包含在你的主循环中,否则奖励不会被显示到屏幕上。将下面代码示例的最后一行添加到循环中:
```
enemy_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
loot_list.draw(world)
```
启动你的游戏看看会发生什么。

你的奖励将会显示出来,但是当你的玩家碰到它们时,它们不会做任何事情,当你的玩家经过它们时,它们也不会滚动。接下来解决这些问题。
### 滚动奖励
像平台一样,当玩家在游戏世界中移动时,奖励必须滚动。逻辑与平台滚动相同。要向前滚动奖励物品,添加最后两行:
```
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list:
l.rect.x -= scroll
```
要向后滚动,请添加最后两行:
```
for e in enemy_list:
e.rect.x += scroll
for l in loot_list:
l.rect.x += scroll
```
再次启动你的游戏,看看你的奖励物品现在表现得像在游戏世界里一样了,而不是仅仅画在上面。
### 检测碰撞
就像平台和敌人一样,你可以检查奖励物品和玩家之间的碰撞。逻辑与其他碰撞相同,除了撞击不会(必然)影响重力或生命值。取而代之的是,命中会导致奖励物品会消失并增加玩家的分数。
当你的玩家触摸到一个奖励对象时,你可以从 `loot_list` 中移除该对象。这意味着当你的主循环在 `loot_list` 中重绘所有奖励物品时,它不会重绘那个特定的对象,所以看起来玩家已经获得了奖励物品。
在 `Player` 类的 `update` 函数中的平台碰撞检测之上添加以下代码(最后一行仅用于上下文):
```
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
```
当碰撞发生时,你不仅要把奖励从它的组中移除,还要给你的玩家一个分数提升。你还没有创建分数变量,所以请将它添加到你的玩家属性中,该属性是在 `Player` 类的 `__init__` 函数中创建的。在下面的代码中,前两行是上下文,所以只需添加分数变量:
```
self.frame = 0
self.health = 10
self.score = 0
```
当在主循环中调用 `update` 函数时,需要包括 `loot_list`:
```
player.gravity()
player.update()
```
如你所见,你已经掌握了所有的基本知识。你现在要做的就是用新的方式使用你所知道的。
在下一篇文章中还有一些提示,但是与此同时,用你学到的知识来制作一些简单的单关卡游戏。限制你试图创造的东西的范围是很重要的,这样你就不会埋没自己。这也使得最终的成品看起来和感觉上更容易完成。
以下是迄今为止你为这个 Python 平台编写的所有代码:
```
#!/usr/bin/env python3
# draw a world
# add a player and player control
# add player movement
# add enemy and basic collision
# add platform
# add gravity
# add jumping
# add scrolling
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
import pygame
import sys
import os
'''
Objects
'''
class Platform(pygame.sprite.Sprite):
# x location, y location, img width, img height, img file
def __init__(self,xloc,yloc,imgw,imgh,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img)).convert()
self.image.convert_alpha()
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
'''
Spawn a player
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.collide_delta = 0
self.jump_delta = 6
self.score = 1
self.images = []
for i in range(1,9):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def jump(self,platform_list):
self.jump_delta = 0
def gravity(self):
self.movey += 3.2 # how fast player falls
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty
def control(self,x,y):
'''
control player movement
'''
self.movex += x
self.movey += y
def update(self):
'''
Update sprite position
'''
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[self.frame//ani]
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in enemy_hit_list:
self.health -= 1
#print(self.health)
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.collide_delta = 0 # stop jumping
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.y = worldy-ty-ty
self.collide_delta = 0 # stop jumping
if self.rect.y > g.rect.y:
self.health -=1
print(self.health)
if self.collide_delta < 6 and self.jump_delta < 6:
self.jump_delta = 6*2
self.movey -= 33 # how high to jump
self.collide_delta += 6
self.jump_delta += 6
class Enemy(pygame.sprite.Sprite):
'''
Spawn an enemy
'''
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.movey = 0
#self.image.convert_alpha()
#self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
'''
enemy movement
'''
distance = 80
speed = 8
self.movey += 3.2
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
if not self.rect.y >= worldy-ty-ty:
self.rect.y += self.movey
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.rect.y = worldy-ty-ty
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
enemy_list = pygame.sprite.Group() # create enemy group
enemy_list.add(enemy) # add enemy to group
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
def loot(lvl,tx,ty):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(200,ty*7,tx,ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
def platform(lvl,tx,ty):
plat_list = pygame.sprite.Group()
ploc = []
i=0
if lvl == 1:
ploc.append((20,worldy-ty-128,3))
ploc.append((300,worldy-ty-256,3))
ploc.append((500,worldy-ty-128,4))
while i < len(ploc):
j=0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
plat_list.add(plat)
j=j+1
print('run' + str(i) + str(ploc[i]))
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
'''
Setup
'''
worldx = 960
worldy = 720
fps = 40 # frame rate
ani = 4 # animation cycles
clock = pygame.time.Clock()
pygame.init()
main = True
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
ALPHA = (0,255,0)
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = world.get_rect()
player = Player() # spawn player
player.rect.x = 0
player.rect.y = 0
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
forwardx = 600
backwardx = 230
eloc = []
eloc = [200,20]
gloc = []
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
tx = 64 #tile size
ty = 64 #tile size
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,gloc,tx,ty )
plat_list = Level.platform( 1,tx,ty )
loot_list = Level.loot(1,tx,ty)
'''
Main loop
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print("LEFT")
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print("RIGHT")
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump(plat_list)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list:
l.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
for l in loot_list:
l.rect.x += scroll
world.blit(backdrop, backdropbox)
player.gravity() # check gravity
player.update()
player_list.draw(world) #refresh player position
enemy_list.draw(world) # refresh enemies
ground_list.draw(world) # refresh enemies
plat_list.draw(world) # refresh platforms
loot_list.draw(world) # refresh loot
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
---
via: <https://opensource.com/article/20/1/loot-python-platformer-game>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part of an ongoing series about creating video games in [Python 3](https://www.python.org/) using the [Pygame](https://www.pygame.org/news) module. Previous articles are:
[Learn how to program in Python by building a simple dice game](https://opensource.com/article/17/10/python-101)[Build a game framework with Python using the Pygame module](https://opensource.com/article/17/12/game-framework-python)[How to add a player to your Python game](https://opensource.com/article/17/12/game-python-add-a-player)[Using Pygame to move your game character around](https://opensource.com/article/17/12/game-python-moving-player)[What's a hero without a villain? How to add one to your Python game](https://opensource.com/article/18/5/pygame-enemy)[Put platforms in your Python platformer](https://opensource.com/article/18/7/put-platforms-python-game)[Simulate gravity in your Python game](https://opensource.com/article/19/11/simulate-gravity-python)[Add jumping to your Python platformer game](https://opensource.com/article/19/12/jumping-python-platformer-game)[Enable your Python game player to run forward and backward](https://opensource.com/article/19/12/python-platformer-game-run)
If you've followed along with the previous articles in this series, then you know all the basics of programming video game mechanics. You can build upon these basics to create a fully functional video game all your own. Following a "recipe" like the code samples in this series is helpful when you're first learning, but eventually, the recipe becomes a constraint. It's time to use the principles you've learned and apply them in new ways.
If that sounds easier said than done, this article demonstrates an example of how to leverage what you already know for new purposes. Specifically, it covers how to implement a looting system
using what you have already learned about platforms from previous lessons.
In most video games, you have the opportunity to "loot," or collect treasures and other items within the game world. Loot usually increases your score or your health or provides information leading to your next quest.
Including loot in your game is similar to programming platforms. Like platforms, loot has no user controls, scrolls with the game world, and must check for collisions with the player sprite.
Before you begin, you must have a loot graphic, such as a coin or a treasure chest. If you've already downloaded my recommended tile set, the [simplified-platformer-pack from Kenney.nl](https://kenney.nl/assets/simplified-platformer-pack), then you can use a diamond or key from that.
## Creating the loot function
Loot is so similar to platforms that you don't even need a Loot class. You can just reuse the **Platform** class and call the results loot.
Since loot type and placement probably differ from level to level, create a new function called **loot** in your **Level** class, if you don't already have one. Since loot items are not platforms, you must also create a new **loot_list** group and then add loot objects to it. As with platforms, ground, and enemies, this group is used when checking for collisions:
```
def loot(lvl):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(tx*9, ty*5, tx, ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
```
In this code, I express the location of the loot as multiples of the tile size: **tx **on the X axis and **ty **for the Y axis. I do this because i mapped my level on graph paper, so it's easy to just count the squares on my map and then multiply it by the tile size, rather than calculating the pixel count. This is especially true for very long levels. You can hard code the pixel count, if you prefer.
You can add as many loot objects as you like; just remember to add each one to your loot list. The arguments for the **Platform** class are the X position, the Y position, the width and height of the loot sprite (it's usually easiest to keep your loot sprite the same size as all other tiles), and the image you want to use as loot. Placement of loot can be just as complex as mapping platforms, so use the level design document you created when creating the level.
Call your new loot function in the **Setup** section of your script. In the following code, the first three lines are for context, so just add the fourth:
`loot_list = Level.loot(1)`
As you know by now, the loot won't get drawn to the screen unless you include it in your main loop. Add this line to your loop:
` loot_list.draw(world)`
Launch your game to see what happens.

Your loot objects are spawned, but they don't do anything when your player runs into them, nor do they scroll when your player runs past them. Fix these issues next.
## Scrolling loot
Like platforms, loot has to scroll when the player moves through the game world. The logic is identical to platform scrolling. To scroll the loot forward, add the last two lines:
```
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list: # loot scroll
l.rect.x -= scroll # loot scroll
```
To scroll it backward, add the last two lines:
```
for e in enemy_list:
e.rect.x += scroll
for l in loot_list: # loot scroll
l.rect.x += scroll # loot scroll
```
Launch your game again to see that your loot objects now act like they're *in* the game world instead of just painted on top of it.
## Detecting collisions
As with platforms and enemies, you can check for collisions between loot and your player. The logic is the same as other collisions, except that a hit doesn't (necessarily) affect gravity or health. Instead, a hit causes the loot to disappear and increment the player's score.
When your player touches a loot object, you can remove that object from the **loot_list**. This means that when your main loop redraws all loot items in **loot_list**, it won't redraw that particular object, so it will look like the player has grabbed the loot.
Add the following code above the platform collision detection in the **update** function of your **Player** class (the last line is just for context):
```
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
```
Not only do you remove the loot object from its group when a collision happens, but you also award your player a bump in score. You haven't created a score variable yet, so add that to your player's properties, created in the **__init__** function of the **Player** class. In the following code, the first two lines are for context, so just add the score variable:
```
self.frame = 0
self.health = 10
self.score = 0
```
## Applying what you know
As you can see, you've got all the basics. All you have to do now is use what you know in new ways. For instance, if you haven't already placed your enemies in a sensible place, take some time to do that now using the same method you've used to place platforms and loot.
There are a few more tips in the next article, but in the meantime, use what you've learned to make a few simple, single-level games. Limiting the scope of what you are trying to create is important so that you don't overwhelm yourself. It also makes it easier to end up with a finished product that looks and feels finished.
Here's all the code you've written for this Python platformer so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
forwardx = 600
backwardx = 120
BLUE = (25, 25, 200)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
'''
Objects
'''
# x location, y location, img width, img height, img file
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.score = 0
self.is_jumping = True
self.is_falling = True
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def gravity(self):
if self.is_jumping:
self.movey += 3.2
def control(self, x, y):
"""
control player movement
"""
self.movex += x
def jump(self):
if self.is_jumping is False:
self.is_falling = False
self.is_jumping = True
def update(self):
"""
Update sprite position
"""
# moving left
if self.movex < 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = self.images[self.frame // ani]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
for enemy in enemy_hit_list:
self.health -= 1
# print(self.health)
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.bottom = g.rect.top
self.is_jumping = False # stop jumping
# fall off the world
if self.rect.y > worldy:
self.health -=1
print(self.health)
self.rect.x = tx
self.rect.y = ty
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.is_jumping = False # stop jumping
self.movey = 0
if self.rect.bottom <= p.rect.bottom:
self.rect.bottom = p.rect.top
else:
self.movey += 3.2
if self.is_jumping and self.is_falling is False:
self.is_falling = True
self.movey -= 33 # how high to jump
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
self.rect.x += self.movex
self.rect.y += self.movey
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
enemy movement
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance * 2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level:
def ground(lvl, gloc, tx, ty):
ground_list = pygame.sprite.Group()
i = 0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i], worldy - ty, tx, ty, 'tile-ground.png')
ground_list.add(ground)
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return ground_list
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl))
return enemy_list
# x location, y location, img width, img height, img file
def platform(lvl, tx, ty):
plat_list = pygame.sprite.Group()
ploc = []
i = 0
if lvl == 1:
ploc.append((200, worldy - ty - 128, 3))
ploc.append((300, worldy - ty - 256, 3))
ploc.append((550, worldy - ty - 128, 4))
while i < len(ploc):
j = 0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0] + (j * tx)), ploc[i][1], tx, ty, 'tile.png')
plat_list.add(plat)
j = j + 1
print('run' + str(i) + str(ploc[i]))
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return plat_list
def loot(lvl):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(tx*5, ty*5, tx, ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 30 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
eloc = []
eloc = [300, 0]
enemy_list = Level.bad(1, eloc)
gloc = []
tx = 64
ty = 64
i = 0
while i <= (worldx / tx) + tx:
gloc.append(i * tx)
i = i + 1
ground_list = Level.ground(1, gloc, tx, ty)
plat_list = Level.platform(1, tx, ty)
enemy_list = Level.bad( 1, eloc )
loot_list = Level.loot(1)
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump()
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list:
l.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
for l in loot_list:
l.rect.x += scroll
world.blit(backdrop, backdropbox)
player.update()
player.gravity()
player_list.draw(world)
enemy_list.draw(world)
loot_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
pygame.display.flip()
clock.tick(fps)
```
## 6 Comments |
11,830 | 使用公钥/私钥对设定免密的 Linux 登录方式 | https://www.networkworld.com/article/3514607/setting-up-passwordless-linux-logins-using-publicprivate-keys.html | 2020-01-29T14:10:00 | [
"密码",
"SSH"
] | https://linux.cn/article-11830-1.html |
>
> 使用一组公钥/私钥对让你不需要密码登录到远程 Linux 系统或使用 ssh 运行命令,这会非常方便,但是设置过程有点复杂。下面是帮助你的方法和脚本。
>
>
>

在 [Linux](https://www.networkworld.com/article/3215226/what-is-linux-uses-featres-products-operating-systems.html) 系统上设置一个允许你无需密码即可远程登录或运行命令的帐户并不难,但是要使它正常工作,你还需要掌握一些繁琐的细节。在本文,我们将完成整个过程,然后给出一个可以帮助处理琐碎细节的脚本。
设置好之后,如果希望在脚本中运行 `ssh` 命令,尤其是希望配置自动运行的命令,那么免密访问特别有用。
需要注意的是,你不需要在两个系统上使用相同的用户帐户。实际上,你可以把公用密钥用于系统上的多个帐户或多个系统上的不同帐户。
设置方法如下。
### 在哪个系统上启动?
首先,你需要从要发出命令的系统上着手。那就是你用来创建 `ssh` 密钥的系统。你还需要可以访问远程系统上的帐户并在其上运行这些命令。
为了使角色清晰明了,我们将场景中的第一个系统称为 “boss”,因为它将发出要在另一个系统上运行的命令。
因此,命令提示符如下:
```
boss$
```
如果你还没有在 boss 系统上为你的帐户设置公钥/私钥对,请使用如下所示的命令创建一个密钥对。注意,你可以在各种加密算法之间进行选择。(一般使用 RSA 或 DSA。)注意,要在不输入密码的情况下访问系统,你需要在下面的对话框中的两个提示符出不输入密码。
如果你已经有一个与此帐户关联的公钥/私钥对,请跳过此步骤。
```
boss$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/myself/.ssh/id_rsa):
Enter passphrase (empty for no passphrase): <== 按下回车键即可
Enter same passphrase again: <== 按下回车键即可
Your identification has been saved in /home/myself/.ssh/id_rsa.
Your public key has been saved in /home/myself/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:1zz6pZcMjA1av8iyojqo6NVYgTl1+cc+N43kIwGKOUI myself@boss
The key's randomart image is:
+---[RSA 3072]----+
| . .. |
| E+ .. . |
| .+ .o + o |
| ..+.. .o* . |
| ... So+*B o |
| + ...==B . |
| . o . ....++. |
|o o . . o..o+ |
|=..o.. ..o o. |
+----[SHA256]-----+
```
上面显示的命令将创建公钥和私钥。其中公钥用于加密,私钥用于解密。因此,这些密钥之间的关系是关键的,私有密钥**绝不**应该被共享。相反,它应该保存在 boss 系统的 `.ssh` 文件夹中。
注意,在创建时,你的公钥和私钥将会保存在 `.ssh` 文件夹中。
下一步是将**公钥**复制到你希望从 boss 系统免密访问的系统。你可以使用 `scp` 命令来完成此操作,但此时你仍然需要输入密码。在本例中,该系统称为 “target”。
```
boss$ scp .ssh/id_rsa.pub myacct@target:/home/myaccount
myacct@target's password:
```
你需要安装公钥在 target 系统(将运行命令的系统)上。如果你没有 `.ssh` 目录(例如,你从未在该系统上使用过 `ssh`),运行这样的命令将为你设置一个目录:
```
target$ ssh localhost date
target$ ls -la .ssh
total 12
drwx------ 2 myacct myacct 4096 Jan 19 11:48 .
drwxr-xr-x 6 myacct myacct 4096 Jan 19 11:49 ..
-rw-r--r-- 1 myacct myacct 222 Jan 19 11:48 known_hosts
```
仍然在目标系统上,你需要将从“boss”系统传输的公钥添加到 `.ssh/authorized_keys` 文件中。如果该文件已经存在,使用下面的命令将把它添加到文件的末尾;如果文件不存在,则创建该文件并添加密钥。
```
target$ cat id_rsa.pub >> .ssh/authorized_keys
```
下一步,你需要确保你的 `authorized_keys` 文件权限为 600。如果还不是,执行命令 `chmod 600 .ssh/authorized_keys`。
```
target$ ls -l authorized_keys
-rw------- 1 myself myself 569 Jan 19 12:10 authorized_keys
```
还要检查目标系统上 `.ssh` 目录的权限是否设置为 700。如果需要,执行 `chmod 700 .ssh` 命令修改权限。
```
target$ ls -ld .ssh
drwx------ 2 myacct myacct 4096 Jan 14 15:54 .ssh
```
此时,你应该能够从 boss 系统远程免密运行命令到目标系统。除非目标系统上的目标用户帐户拥有与你试图连接的用户和主机相同的旧公钥,否则这应该可以工作。如果是这样,你应该删除早期的(并冲突的)条目。
### 使用脚本
使用脚本可以使某些工作变得更加容易。但是,在下面的示例脚本中,你会遇到的一个烦人的问题是,在配置免密访问权限之前,你必须多次输入目标用户的密码。一种选择是将脚本分为两部分——需要在 boss 系统上运行的命令和需要在 target 系统上运行的命令。
这是“一步到位”版本的脚本:
```
#!/bin/bash
# NOTE: This script requires that you have the password for the remote acct
# in order to set up password-free access using your public key
LOC=`hostname` # the local system from which you want to run commands from
# wo a password
# get target system and account
echo -n "target system> "
read REM
echo -n "target user> "
read user
# create a key pair if no public key exists
if [ ! -f ~/.ssh/id_rsa.pub ]; then
ssh-keygen -t rsa
fi
# ensure a .ssh directory exists in the remote account
echo checking for .ssh directory on remote system
ssh $user@$REM "if [ ! -d /home/$user/.ssh ]; then mkdir /home/$user/.ssh; fi"
# share the public key (using local hostname)
echo copying the public key
scp ~/.ssh/id_rsa.pub $user@$REM:/home/$user/$user-$LOC.pub
# put the public key into the proper location
echo adding key to authorized_keys
ssh $user@$REM "cat /home/$user/$user-$LOC.pub >> /home/$user/.ssh/authorized_ke
ys"
# set permissions on authorized_keys and .ssh (might be OK already)
echo setting permissions
ssh $user@$REM "chmod 600 ~/.ssh/authorized_keys"
ssh $user@$REM "chmod 700 ~/.ssh"
# try it out -- should NOT ask for a password
echo testing -- if no password is requested, you are all set
ssh $user@$REM /bin/hostname
```
脚本已经配置为在你每次必须输入密码时告诉你它正在做什么。交互看起来是这样的:
```
$ ./rem_login_setup
target system> fruitfly
target user> lola
checking for .ssh directory on remote system
lola@fruitfly's password:
copying the public key
lola@fruitfly's password:
id_rsa.pub 100% 567 219.1KB/s 00:00
adding key to authorized_keys
lola@fruitfly's password:
setting permissions
lola@fruitfly's password:
testing -- if no password is requested, you are all set
fruitfly
```
在上面的场景之后,你就可以像这样登录到 lola 的帐户:
```
$ ssh lola@fruitfly
[lola@fruitfly ~]$
```
一旦设置了免密登录,你就可以不需要键入密码从 boss 系统登录到 target 系统,并且运行任意的 `ssh` 命令。以这种免密的方式运行并不意味着你的帐户不安全。然而,根据 target 系统的性质,保护你在 boss 系统上的密码可能变得更加重要。
---
via: <https://www.networkworld.com/article/3514607/setting-up-passwordless-linux-logins-using-publicprivate-keys.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,831 | 我的 Linux 故事:在 90 年代学习 Linux | https://opensource.com/article/19/11/learning-linux-90s | 2020-01-29T21:38:00 | [
"Linux"
] | https://linux.cn/article-11831-1.html |
>
> 这是一个关于我如何在 WiFi 时代之前学习 Linux 的故事,那时的发行版还以 CD 的形式出现。
>
>
>

大部分人可能不记得 1996 年时计算产业或日常生活世界的样子。但我很清楚地记得那一年。我那时候是堪萨斯中部一所高中的二年级学生,那是我的自由与开源软件(FOSS)旅程的开端。
我从这里开始进步。我在 1996 年之前就开始对计算机感兴趣。我在我家的第一台 Apple ][e 上启蒙成长,然后多年之后是 IBM Personal System/2。(是的,在这过程中有一些代际的跨越。)IBM PS/2 有一个非常激动人心的特性:一个 1200 波特的 Hayes 调制解调器。
我不记得是怎样了,但在那不久之前,我得到了一个本地 [BBS](https://en.wikipedia.org/wiki/Bulletin_board_system) 的电话号码。一旦我拨号进去,我可以得到本地的一些其他 BBS 的列表,我的网络探险就此开始了。
在 1995 年,[足够幸运](https://en.wikipedia.org/wiki/Global_Internet_usage#Internet_users)的人拥有了家庭互联网连接,每月可以使用不到 30 分钟。那时的互联网不像我们现代的服务那样,通过卫星、光纤、有线电视同轴电缆或任何版本的铜线提供。大多数家庭通过一个调制解调器拨号,它连接到他们的电话线上。(这时离移动电话无处不在的时代还早得很,大多数人只有一部家庭电话。)尽管这还要取决你所在的位置,但我不认为那时有很多独立的互联网服务提供商(ISP),所以大多数人从仅有的几家大公司获得服务,包括 America Online,CompuServe 以及 Prodigy。
你能获取到的服务速率非常低,甚至在拨号上网革命性地达到了顶峰的 56K,你也只能期望得到最高 3.5Kbps 的速率。如果你想要尝试 Linux,下载一个 200MB 到 800MB 的 ISO 镜像或(更加切合实际的)一套软盘镜像要贡献出时间、决心,以及减少电话的使用。
我走了一条简单一点的路:在 1996 年,我从一家主要的 Linux 发行商订购了一套 “tri-Linux” CD 集。这些光盘提供了三个发行版,我的这套包含了 Debian 1.1(Debian 的第一个稳定版本)、Red Hat Linux 3.0.3 以及 Slackware 3.1(代号 Slackware ‘96)。据我回忆,这些光盘是从一家叫做 [Linux Systems Labs](https://web.archive.org/web/19961221003003/http://lsl.com/) 的在线商店购买的。这家在线商店如今已经不存在了,但在 90 年代和 00 年代早期,这样的发行商很常见。这些是多光盘 Linux 套件。这是 1998 年的一套光盘,你可以了解到他们都包含了什么:


在 1996 年夏天一个命中注定般的日子,那时我住在堪萨斯一个新的并且相对较为乡村的城市,我做出了安装并使用 Linux 的第一次尝试。在 1996 年的整个夏天,我尝试了那套三张 Linux CD 套件里的全部三个发行版。他们都在我母亲的老 Pentium 75MHz 电脑上完美运行。
我最终选择了 [Slackware](http://slackware.com) 3.1 作为我的首选发行版,相比其它发行版可能更多的是因为它的终端的外观,这是决定选择一个发行版前需要考虑的重要因素。
我将系统设置完毕并运行了起来。我连接到一家 “不太知名的” ISP(一家这个区域的本地服务商),通过我家的第二条电话线拨号(为了满足我的所有互联网使用而订购)。那就像在天堂一样。我有一台完美运行的双系统(Microsoft Windows 95 和 Slackware 3.1)电脑。我依然拨号进入我所知道和喜爱的 BBS,游玩在线 BBS 游戏,比如 Trade Wars、Usurper 以及 Legend of the Red Dragon。
我能够记得在 EFNet(IRC)上 #Linux 频道上渡过的日子,帮助其他用户,回答他们的 Linux 问题以及和版主们互动。
在我第一次在家尝试使用 Linux 系统的 20 多年后,已经是我进入作为 Red Hat 顾问的第五年,我仍然在使用 Linux(现在是 Fedora)作为我的日常系统,并且依然在 IRC 上帮助想要使用 Linux 的人们。
---
via: <https://opensource.com/article/19/11/learning-linux-90s>
作者:[Mike Harris](https://opensource.com/users/mharris) 选题:[lujun9972](https://github.com/lujun9972) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most people probably don't remember where they, the computing industry, or the everyday world were in 1996. But I remember that year very clearly. I was a sophomore in high school in the middle of Kansas, and it was the start of my journey into free and open source software (FOSS).
I'm getting ahead of myself here. I was interested in computers even before 1996. I was born and raised on my family's first Apple ][e, followed many years later by the IBM Personal System/2. (Yes, there were definitely some generational skips along the way.) The IBM PS/2 had a very exciting feature: a 1200 baud Hayes modem.
I don't remember how, but early on, I got the phone number of a local [BBS](https://en.wikipedia.org/wiki/Bulletin_board_system). Once I dialed into it, I could get a list of other BBSes in the local area, and my adventure into networked computing began.
In 1995, the people [lucky enough](https://en.wikipedia.org/wiki/Global_Internet_usage#Internet_users) to have a home internet connection spent less than 30 minutes a month using it. That internet was nothing like our modern services that operate over satellite, fiber, CATV coax, or any version of copper lines. Most homes dialed in with a modem, which tied up their phone line. (This was also long before cellphones were pervasive, and most people had just one home phone line.) I don't think there were many independent internet service providers (ISPs) back then, although that may have depended upon where you were located, so most people got service from a handful of big names, including America Online, CompuServe, and Prodigy.
And the service you did get was very slow; even at dial-up's peak evolution at 56K, you could only expect to get a maximum of about 3.5 Kbps. If you wanted to try Linux, downloading a 200MB to 800MB ISO image or (more realistically) a disk image set was a dedication to time, determination, and lack of phone usage.
I went with the easier route: In 1996, I ordered a "tri-Linux" CD set from a major Linux distributor. These tri-Linux disks provided three distributions; mine included Debian 1.1 (the first stable release of Debian), Red Hat Linux 3.0.3, and Slackware 3.1 (nicknamed Slackware '96). As I recall, the discs were purchased from an online store called [Linux Systems Labs](https://web.archive.org/web/19961221003003/http://lsl.com/). The online store doesn't exist now, but in the 90s and early 00s, such distributors were common. And so were multi-disc sets of Linux. This one's from 1998 but gives you an idea of what they involved:


On a fateful day in the summer of 1996, while living in a new and relatively rural city in Kansas, I made my first attempt at installing and working with Linux. Throughout the summer of '96, I tried all three distributions on that tri-Linux CD set. They all ran beautifully on my mom's older Pentium 75MHz computer.
I ended up choosing [Slackware](http://slackware.com) 3.1 as my preferred distribution, probably more because of the terminal's appearance than the other, more important reasons one should consider before deciding on a distribution.
I was up and running. I was connecting to an "off-brand" ISP (a local provider in the area), dialing in on my family's second phone line (ordered to accommodate all my internet use). I was in heaven. I had a dual-boot (Microsoft Windows 95 and Slackware 3.1) computer that worked wonderfully. I was still dialing into the BBSes that I knew and loved and playing online BBS games like Trade Wars, Usurper, and Legend of the Red Dragon.
I can remember spending days upon days of time in #Linux on EFNet (IRC), helping other users answer their Linux questions and interacting with the moderation crew.
More than 20 years after taking my first swing at using the Linux OS at home, I am now entering my fifth year as a consultant for Red Hat, still using Linux (now Fedora) as my daily driver, and still on IRC helping people looking to use Linux.
## 17 Comments |
11,832 | 免费电子书《Linux 进程间通信指南》介绍 | https://opensource.com/article/20/1/inter-process-communication-linux | 2020-01-30T11:56:51 | [
"IPC"
] | https://linux.cn/article-11832-1.html |
>
> 这本免费的电子书使经验丰富的程序员更深入了解 Linux 中进程间通信(IPC)的核心概念和机制。
>
>
>

让一个软件过程与另一个软件过程进行对话是一个微妙的平衡行为。但是,它对于应用程序而言可能是至关重要的功能,因此这是任何从事复杂项目的程序员都必须解决的问题。你的应用程序是否需要启动由其它软件处理的工作;监视外设或网络上正在执行的操作;或者检测来自其它来源的信号,当你的软件需要依赖其自身代码之外的东西来知道下一步做什么或什么时候做时,你就需要考虑<ruby> 进程间通信 <rt> inter-process communication </rt></ruby>(IPC)。
这在 Unix 操作系统上已经由来已久了,这可能是因为人们早期预期软件会来自各种来源。按照相同的传统,Linux 提供了一些同样的 IPC 接口和一些新接口。Linux 内核具有多种 IPC 方法,[util-linux 包](https://mirrors.edge.kernel.org/pub/linux/utils/util-linux/)包含了 `ipcmk`、`ipcrm`、`ipcs` 和 `lsipc` 命令,用于监视和管理 IPC 消息。
### 显示进程间通信信息
在尝试 IPC 之前,你应该知道系统上已经有哪些 IPC 设施。`lsipc` 命令提供了该信息。
```
RESOURCE DESCRIPTION LIMIT USED USE%
MSGMNI Number of message queues 32000 0 0.00%
MSGMAX Max size of message (byt.. 8192 - -
MSGMNB Default max size of queue 16384 - -
SHMMNI Shared memory segments 4096 79 1.93%
SHMALL Shared memory pages 184[...] 25452 0.00%
SHMMAX Max size of shared memory 18446744073692774399
SHMMIN Min size of shared memory 1 - -
SEMMNI Number of semaphore ident 32000 0 0.00%
SEMMNS Total number of semaphore 1024000.. 0 0.00%
SEMMSL Max semaphores per semap 32000 - -
SEMOPM Max number of operations p 500 - -
SEMVMX Semaphore max value 32767 - -
```
你可能注意到,这个示例清单包含三种不同类型的 IPC 机制,每种机制在 Linux 内核中都是可用的:消息(MSG)、共享内存(SHM)和信号量(SEM)。你可以用 `ipcs` 命令查看每个子系统的当前活动:
```
$ ipcs
------ Message Queues Creators/Owners ---
msqid perms cuid cgid [...]
------ Shared Memory Segment Creators/Owners
shmid perms cuid cgid [...]
557056 700 seth users [...]
3571713 700 seth users [...]
2654210 600 seth users [...]
2457603 700 seth users [...]
------ Semaphore Arrays Creators/Owners ---
semid perms cuid cgid [...]
```
这表明当前没有消息或信号量阵列,但是使用了一些共享内存段。
你可以在系统上执行一个简单的示例,这样就可以看到正在工作的系统之一。它涉及到一些 C 代码,所以你必须在系统上有构建工具。必须安装这些软件包才能从源代码构建软件,这些软件包的名称取决于发行版,因此请参考文档以获取详细信息。例如,在基于 Debian 的发行版上,你可以在 wiki 的[构建教程](https://wiki.debian.org/BuildingTutorial)部分了解构建需求,而在基于 Fedora 的发行版上,你可以参考该文档的[从源代码安装软件](https://docs.pagure.org/docs-fedora/installing-software-from-source.html)部分。
### 创建一个消息队列
你的系统已经有一个默认的消息队列,但是你可以使用 `ipcmk` 命令创建你自己的消息队列:
```
$ ipcmk --queue
Message queue id: 32764
```
编写一个简单的 IPC 消息发送器,为了简单,在队列 ID 中硬编码:
```
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdio.h>
#include <string.h>
struct msgbuffer {
char text[24];
} message;
int main() {
int msqid = 32764;
strcpy(message.text,"opensource.com");
msgsnd(msqid, &message, sizeof(message), 0);
printf("Message: %s\n",message.text);
printf("Queue: %d\n",msqid);
return 0;
}
```
编译该应用程序并运行:
```
$ gcc msgsend.c -o msg.bin
$ ./msg.bin
Message: opensource.com
Queue: 32769
```
你刚刚向你的消息队列发送了一条消息。你可以使用 `ipcs` 命令验证这一点,可以使用 `——queue` 选项将输出限制到该消息队列:
```
$ ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x7b341ab9 0 seth 666 0 0
0x72bd8410 32764 seth 644 24 1
```
你也可以检索这些消息:
```
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdio.h>
struct msgbuffer {
char text[24];
} message;
int main() {
int msqid = 32764;
msgrcv(msqid, &message, sizeof(message),0,0);
printf("\nQueue: %d\n",msqid);
printf("Got this message: %s\n", message.text);
msgctl(msqid,IPC_RMID,NULL);
return 0;
```
编译并运行:
```
$ gcc get.c -o get.bin
$ ./get.bin
Queue: 32764
Got this message: opensource.com
```
### 下载这本电子书
这只是 Marty Kalin 的《[Linux 进程间通信指南](https://opensource.com/downloads/guide-inter-process-communication-linux)》中课程的一个例子,可从 Opensource.com 下载的这本最新免费(且 CC 授权)的电子书。在短短的几节课中,你将从消息队列、共享内存和信号量、套接字、信号等中了解 IPC 的 POSIX 方法。认真阅读 Marty 的书,你将成为一个博识的程序员。而这不仅适用于经验丰富的编码人员,如果你编写的只是 shell 脚本,那么你将拥有有关管道(命名和未命名)和共享文件的大量实践知识,以及使用共享文件或外部消息队列时需要了解的重要概念。
如果你对制作具有动态和具有系统感知的优秀软件感兴趣,那么你需要了解 IPC。让[这本书](https://opensource.com/downloads/guide-inter-process-communication-linux)做你的向导。
---
via: <https://opensource.com/article/20/1/inter-process-communication-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Getting one software process to talk to another software process is a delicate balancing act. It can be a vital function for an application, though, so it's a problem any programmer embarking on a complex project has to solve. Whether your application needs to kick off a job being handled by someone else's software; to monitor an action being performed by a peripheral or over a network; or to detect a signal from some other source, when your software relies on something outside of its own code to know what to do next or when to do it, you need to think about inter-process communication (IPC).
The Unix operating system accounted for this long ago, possibly because of an early expectation that software would originate from diverse sources. In the same tradition, Linux provides many of the same interfaces for IPC and some new ones. The Linux kernel features several IPC methods, and the [util-linux package](https://mirrors.edge.kernel.org/pub/linux/utils/util-linux/) contains the **ipcmk**, **ipcrm**, **ipcs**, and **lsipc** commands for monitoring and managing IPC messages.
## Show IPC information
Before experimenting with IPC, you should know what IPC facilities are already on your system. The **lsipc** command provides that information.
```
RESOURCE DESCRIPTION LIMIT USED USE%
MSGMNI Number of message queues 32000 0 0.00%
MSGMAX Max size of message (byt.. 8192 - -
MSGMNB Default max size of queue 16384 - -
SHMMNI Shared memory segments 4096 79 1.93%
SHMALL Shared memory pages 184[...] 25452 0.00%
SHMMAX Max size of shared memory 18446744073692774399
SHMMIN Min size of shared memory 1 - -
SEMMNI Number of semaphore ident 32000 0 0.00%
SEMMNS Total number of semaphore 1024000.. 0 0.00%
SEMMSL Max semaphores per semap 32000 - -
SEMOPM Max number of operations p 500 - -
SEMVMX Semaphore max value 32767 - -
```
You may notice that this sample listing includes three different types of IPC mechanisms, each available in the Linux kernel: messages (MSG), shared memory (SHM), and semaphores (SEM). You can view current activity in each of those subsystems with the **ipcs** command:
```
$ ipcs
------ Message Queues Creators/Owners ---
msqid perms cuid cgid [...]
------ Shared Memory Segment Creators/Owners
shmid perms cuid cgid [...]
557056 700 seth users [...]
3571713 700 seth users [...]
2654210 600 seth users [...]
2457603 700 seth users [...]
------ Semaphore Arrays Creators/Owners ---
semid perms cuid cgid [...]
```
This shows that there currently are no messages or semaphore arrays, but a number of shared memory segments are in use.
There's a simple example you can perform on your system so you can see one of these systems at work. It involves some C code, so you must have build tools on your system. The names of the packages you must install to be able to build from source code vary depending on your distro, so refer to your documentation for specifics. For example, on Debian-based distributions, you can learn about build requirements on the [BuildingTutorial](https://wiki.debian.org/BuildingTutorial) section of the wiki, and on Fedora-based distributions, refer to the [Installing software from source](https://docs.pagure.org/docs-fedora/installing-software-from-source.html) section of the docs.
## Create a message queue
Your system has a default message queue already, but you can create your own using the **ipcmk** command:
```
$ ipcmk --queue
Message queue id: 32764
```
Write a simple IPC message sender, hard-coding in the queue ID for simplicity:
```
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdio.h>
#include <string.h>
struct msgbuffer {
char text[24];
} message;
int main() {
int msqid = 32764;
strcpy(message.text,"opensource.com");
msgsnd(msqid, &message, sizeof(message), 0);
printf("Message: %s\n",message.text);
printf("Queue: %d\n",msqid);
return 0;
}
```
Compile the application and run it:
```
$ gcc msgsend.c -o msg.bin
$ ./msg.bin
Message: opensource.com
Queue: 32769
```
You just sent a message to your message queue. You can verify that with the **ipcs** command, using the **--queue** option to limit output to the message queue:
```
$ ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x7b341ab9 0 seth 666 0 0
0x72bd8410 32764 seth 644 24 1
```
You can also retrieve those messages with:
```
#include <sys/ipc.h>
#include <sys/msg.h>
#include <stdio.h>
struct msgbuffer {
char text[24];
} message;
int main() {
int msqid = 32764;
msgrcv(msqid, &message, sizeof(message),0,0);
printf("\nQueue: %d\n",msqid);
printf("Got this message: %s\n", message.text);
msgctl(msqid,IPC_RMID,NULL);
return 0;
```
Compile and run with:
```
$ gcc get.c -o get.bin
$ ./get.bin
Queue: 32764
Got this message: opensource.com
```
## Download [the eBook](https://opensource.com/downloads/guide-inter-process-communication-linux)
This is just one example of the lessons available in Marty Kalin's [A guide to inter-process communication in Linux](https://opensource.com/downloads/guide-inter-process-communication-linux), the latest free (and Creative Commons) downloadable eBook from Opensource.com. In just a few short lessons, you will learn about POSIX methods of IPC from message queues, shared memory and semaphores, sockets, signals, and much more. Sit down with Marty's book, and you'll emerge a better-informed programmer. But it isn't just for seasoned coders—if all you ever write are shell scripts, there's plenty of practical knowledge about pipes (named and unnamed) and shared files, as well as important concepts you need to know when you use a shared file or an external message queue.
If you're interested in making great software that's written to be dynamic and system-aware, you need to know about IPC. Let [this book](https://opensource.com/downloads/guide-inter-process-communication-linux) be your guide.
## Comments are closed. |
11,834 | 用于联系人管理的三个开源工具 | https://opensource.com/article/20/1/sync-contacts-locally | 2020-01-30T19:48:39 | [
"联系人"
] | /article-11834-1.html |
>
> 通过将联系人同步到本地从而更快访问它。在我们的 20 个使用开源提升生产力的系列的第六篇文章中了解该如何做。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 用于联系人管理的开源工具
在本系列之前的文章中,我解释了如何在本地同步你的[邮件](/article-11804-1.html)和[日历](/article-11812-1.html)。希望这些加速了你访问邮件和日历。现在,我将讨论联系人同步,你可以给他们发送邮件和日历邀请。

我目前收集了很多邮件地址。管理这些数据可能有点麻烦。有基于 Web 的服务,但它们不如本地副本快。
几天前,我谈到了用于管理日历的 [vdirsyncer](https://github.com/pimutils/vdirsyncer)。vdirsyncer 还使用 CardDAV 协议处理联系人。vdirsyncer 除了可以使用**文件系统**存储日历外,还支持通过 **google\_contacts** 和 **carddav** 进行联系人同步,但 `fileext` 设置会被更改,因此你无法在日历文件中存储联系人。
我在配置文件添加了一块配置,并从 Google 镜像了我的联系人。设置它需要额外的步骤。从 Google 镜像完成后,配置非常简单:
```
[pair address_sync]
a = "googlecard"
b = "localcard"
collections = ["from a", "from b"]
conflict_resolution = "a wins"
[storage googlecard]
type = "google_contacts"
token_file = "~/.vdirsyncer/google_token"
client_id = "my_client_id"
client_secret = "my_client_secret"
[storage localcard]
type = "filesystem"
path = "~/.calendars/Addresses/"
fileext = ".vcf"
```
现在,当我运行 `vdirsyncer discover` 时,它会找到我的 Google 联系人,并且 `vdirsyncer sync` 将它们复制到我的本地计算机。但同样,这只进行到一半。现在我想查看和使用联系人。需要 [khard](https://github.com/scheibler/khard) 和 [abook](http://abook.sourceforge.net/)。

为什么选择两个应用?因为每个都有它自己的使用场景,在这里,越多越好。khard 用于管理地址,类似于 [khal](https://khal.readthedocs.io/en/v0.9.2/index.html) 用于管理日历条目。如果你的发行版附带了旧版本,你可能需要通过 `pip` 安装最新版本。安装 khard 后,你需要创建 `~/.config/khard/khard.conf`,因为 khard 没有与 khal 那样漂亮的配置向导。我的看起来像这样:
```
[addressbooks]
[[addresses]]
path = ~/.calendars/Addresses/default/
[general]
debug = no
default_action = list
editor = vim, -i, NONE
merge_editor = vimdiff
[contact table]
display = first_name
group_by_addressbook = no
reverse = no
show_nicknames = yes
show_uids = no
sort = last_name
localize_dates = yes
[vcard]
preferred_version = 3.0
search_in_source_files = yes
skip_unparsable = no
```
这会定义源通讯簿(并给它一个友好的名称)、显示内容和联系人编辑程序。运行 `khard list` 将列出所有条目,`khard list <[email protected]>` 可以搜索特定条目。如果要添加或编辑条目,`add` 和 `edit` 命令将使用相同的基本模板打开配置的编辑器,唯一的区别是 `add` 命令的模板将为空。

abook 需要你导入和导出 VCF 文件,但它为查找提供了一些不错的功能。要将文件转换为 abook 格式,请先安装 abook 并创建 `~/.abook` 默认目录。然后让 abook 解析所有文件,并将它们放入 `~/.abook/addresses` 文件中:
```
apt install abook
ls ~/.calendars/Addresses/default/* | xargs cat | abook --convert --informat vcard --outformat abook > ~/.abook/addresses
```
现在运行 `abook`,你将有一个非常漂亮的 UI 来浏览、搜索和编辑条目。将它们导出到单个文件有点痛苦,所以我用 khard 进行大部分编辑,并有一个 cron 任务将它们导入到 abook 中。
abook 还可在命令行中搜索,并有大量有关将其与邮件客户端集成的文档。例如,你可以在 `.config/alot/config` 文件中添加一些信息,从而在 [Nmuch](https://opensource.com/article/20/1/organize-email-notmuch) 的邮件客户端 [alot](https://github.com/pazz/alot) 中使用 abook 查询联系人:
```
[accounts]
[[Personal]]
realname = Kevin Sonney
address = [email protected]
alias_regexp = kevin\[email protected]
gpg_key = 7BB612C9
sendmail_command = msmtp --account=Personal -t
# ~ expansion works
sent_box = maildir://~/Maildir/Sent
draft_box = maildir://~/Maildir/Drafts
[[[abook]]]
type = abook
```
这样你就可以在邮件和日历中快速查找联系人了!
---
via: <https://opensource.com/article/20/1/sync-contacts-locally>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,835 | 开始使用开源待办事项清单管理器 | https://opensource.com/article/20/1/open-source-to-do-list | 2020-01-31T11:11:22 | [
"Todo"
] | https://linux.cn/article-11835-1.html |
>
> 待办事项清单是跟踪任务列表的强大方法。在我们的 20 个使用开源提升生产力的系列的第七篇文章中了解如何使用它。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 todo 跟踪任务
任务管理和待办事项清单是我非常喜欢0的东西。我是一位生产效率的狂热粉丝(以至于我为此做了一个[播客](https://productivityalchemy.com/)),我尝试了各种不同的应用。我甚至为此[做了演讲](https://www.slideshare.net/AllThingsOpen/getting-to-done-on-the-command-line)并[写了些文章](https://opensource.com/article/18/2/getting-to-done-agile-linux-command-line)。因此,当我谈到提高工作效率时,肯定会出现任务管理和待办事项清单工具。

说实话,由于简单、跨平台且易于同步,用 [todo.txt](http://todotxt.org/) 肯定不会错。它是我不断反复提到的两个待办事项清单以及任务管理应用之一(另一个是 [Org 模式](https://orgmode.org/))。让我反复使用它的原因是它简单、可移植、易于理解,并且有许多很好的附加组件,并且当一台机器有附加组件,而另一台没有,也不会破坏它。由于它是一个 Bash shell 脚本,我还没发现一个无法支持它的系统。
#### 设置 todo.txt
首先,你需要安装基本 shell 脚本并将默认配置文件复制到 `~/.todo` 目录:
```
git clone https://github.com/todotxt/todo.txt-cli.git
cd todo.txt-cli
make
sudo make install
mkdir ~/.todo
cp todo.cfg ~/.todo/config
```
接下来,设置配置文件。一般,我想取消对颜色设置的注释,但必须马上设置的是 `TODO_DIR` 变量:
```
export TODO_DIR="$HOME/.todo"
```
#### 添加待办事件
要添加第一个待办事件,只需输入 `todo.sh add <NewTodo>` 就能添加。这还将在 `$HOME/.todo/` 中创建三个文件:`todo.txt`、`done.txt` 和 `reports.txt`。
添加几个项目后,运行 `todo.sh ls` 查看你的待办事项。

#### 管理任务
你可以通过给项目设置优先级来稍微改善它。要向项目添加优先级,运行 `todo.sh pri # A`。数字是列表中任务的数量,而字母 `A` 是优先级。你可以将优先级设置为从 A 到 Z,因为这是它的排序方式。
要完成任务,运行 `todo.sh do #` 来标记项目已完成并将它移动到 `done.txt`。运行 `todo.sh report` 会向 `report.txt` 写入已完成和未完成项的数量。
所有这三个文件的格式都有详细的说明,因此你可以使用你的文本编辑器修改。`todo.txt` 的基本格式是:
```
(Priority) YYYY-MM-DD Task
```
该日期表示任务的到期日期(如果已设置)。手动编辑文件时,只需在任务前面加一个 `x` 来标记为已完成。运行 `todo.sh archive` 会将这些项目移动到 `done.txt`,你可以编辑该文本文件,并在有时间时将已完成的项目归档。
#### 设置重复任务
我有很多重复的任务,我需要以每天/周/月来计划。

这就是 `todo.txt` 的灵活性所在。通过在 `~/.todo.actions.d/` 中使用[附加组件](https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory),你可以添加命令并扩展基本 `todo.sh` 的功能。附加组件基本上是实现特定命令的脚本。对于重复执行的任务,插件 [ice\_recur](https://github.com/rlpowell/todo-text-stuff) 应该符合要求。按照其页面上的说明操作,你可以设置任务以非常灵活的方式重复执行。

在该[附加组件目录](https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory)中有很多附加组件,包括同步到某些云服务,也有链接到桌面或移动端应用的组件,这样你可以随时看到待办列表。
我只是简单介绍了这个代办事项清单功能,请花点时间深入了解这个工具的强大!它确实可以帮助我每天完成任务。
---
via: <https://opensource.com/article/20/1/open-source-to-do-list>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Track your tasks with todo.txt
Tasks and to-do lists are very near and dear to my heart. I'm a big fan of productivity (so much so that I do a [podcast](https://productivityalchemy.com/) about it) and try all sorts of different applications. I've even [given presentations](https://www.slideshare.net/AllThingsOpen/getting-to-done-on-the-command-line) and [written articles](https://opensource.com/article/18/2/getting-to-done-agile-linux-command-line) about them. So it only makes sense that, when I talk about being productive, task and to-do list tools are certain to come up.
In all honesty, for being simple, cross-platform, and easily synchronized, you cannot go wrong with [todo.txt](http://todotxt.org/). It is one of the two to-do list and task management apps that I keep coming back to over and over again (the other is [Org mode](https://orgmode.org/)). And what keeps me coming back is that it is simple, portable, understandable, and has many great add-ons that don't break it if one machine has them and the others don't. And since it is a Bash shell script, I have never found a system that cannot support it.
### Set up todo.txt
First things first, you need to install the base shell script and copy the default configuration file to the **~/.todo** directory:
```
git clone https://github.com/todotxt/todo.txt-cli.git
cd todo.txt-cli
make
sudo make install
mkdir ~/.todo
cp todo.cfg ~/.todo/config
```
Next, set up the configuration file. I like to uncomment the color settings at this point, but the only thing that must be set up right away is the **TODO_DIR** variable:
`export TODO_DIR="$HOME/.todo"`
### Add to-do's
To add your first to-do item, simply type **todo.sh add <NewTodo>**, and it will be added. This will also create three files in **$HOME/.todo/**: todo.txt, done.txt, and reports.txt.
After adding a few items, run **todo.sh ls** to see your to-do list.
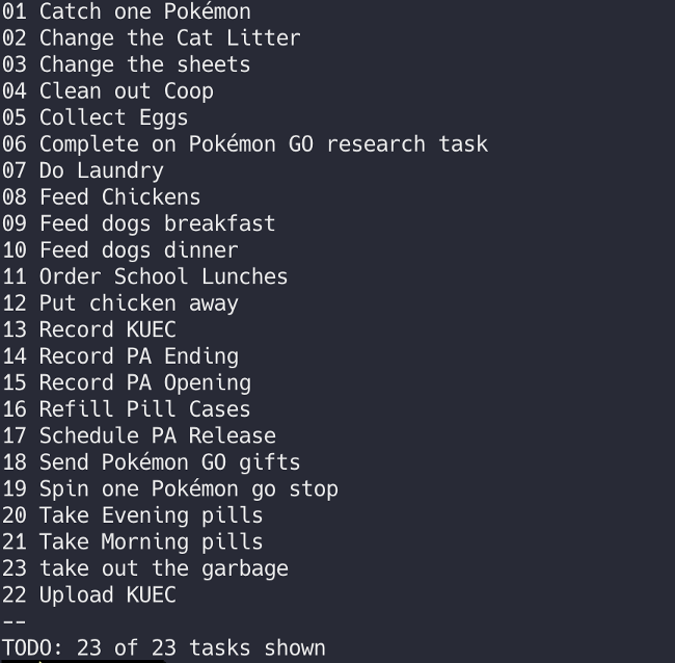
### Manage your tasks
You can improve it a little by prioritizing the items. To add a priority to an item, run **todo.sh pri # A**. The number is the number of the task on the list, and the letter "A" is the priority. You can set the priority as anything from A to Z since that's how it will get sorted.
To complete a task, run **todo.sh do #** to mark the item done and move the item to done.txt. Running **todo.sh report** will write a count of done and not done items to reports.txt.
The file format used for all three files is well documented, so you can make changes with your text editor of choice. The basic format of todo.txt is:
`(Priority) YYYY-MM-DD Task`
The date indicates the due date of a task, if one is set. When editing the file manually, just put an "x" in front of the task to mark it as done. Running **todo.sh archive** will move these items to done.txt, and you can work in that text file and archive the done items when you have time.
### Set up recurring tasks
I have a lot of recurring tasks that I need to schedule every day/week/month.
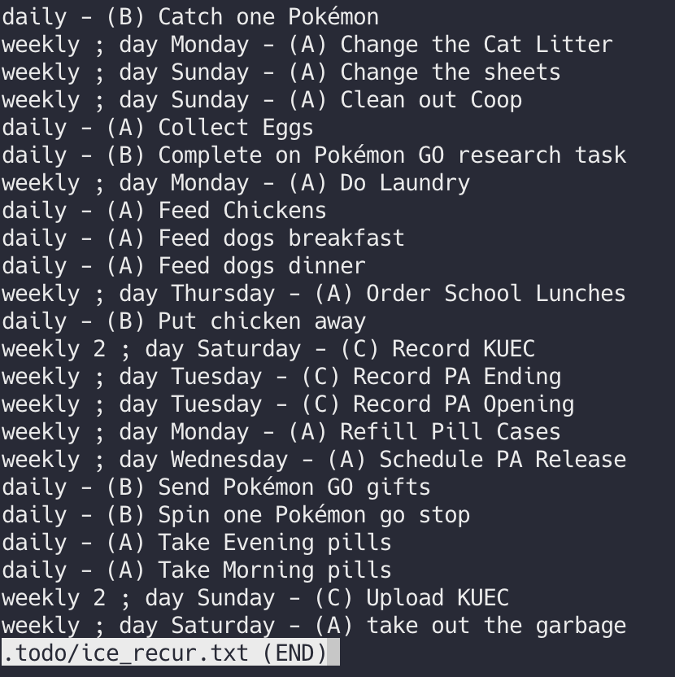
This is where todo.txt's flexibility comes in. By using [add-ons](https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory) in **~/.todo.actions.d/**, you can add commands and extend the functionality of the base todo.sh. The add-ons are basically scripts that implement specific commands. For recurring tasks, the plugin [ice_recur](https://github.com/rlpowell/todo-text-stuff) should fit the bill. By following the instructions on the page, you can set up tasks to recur in a very flexible manner.
There are a lot of add-ons in the directory, including syncing to some cloud services. There are also links to desktop and mobile apps, so you can keep your to-do list with you on the go.
I've only scratched the surface of todo's functionality, so take some time to dig in and see how powerful this tool is! It really helps me keep on task every day.
## 2 Comments |
11,837 | Ubuntu 中的 root 用户:你应该知道的重要事情 | https://itsfoss.com/root-user-ubuntu/ | 2020-01-31T13:05:49 | [
"root",
"sudo"
] | https://linux.cn/article-11837-1.html | 
当你刚开始使用 Linux 时,你将发现与 Windows 的很多不同。其中一个“不同的东西”是 root 用户的概念。
在这个初学者系列中,我将解释几个关于 Ubuntu 的 root 用户的重要的东西。
**请记住,尽管我正在从 Ubuntu 用户的角度编写这篇文章,它应该对大多数的 Linux 发行版也是有效的。**
你将在这篇文章中学到下面的内容:
* 为什么在 Ubuntu 中禁用 root 用户
* 像 root 用户一样使用命
* 切换为 root 用户
* 解锁 root 用户
### 什么是 root 用户?为什么它在 Ubuntu 中被锁定?
在 Linux 中,有一个称为 [root](http://www.linfo.org/root.html) 的超级用户。这是超级管理员账号,它可以做任何事以及使用系统的一切东西。它可以在你的 Linux 系统上访问任何文件和运行任何命令。
能力越大,责任越大。root 用户给予你完全控制系统的能力,因此,它应该被谨慎地使用。root 用户可以访问系统文件,运行更改系统配置的命令。因此,一个错误的命令可能会破坏系统。
这就是为什么 [Ubuntu](https://ubuntu.com/) 和其它基于 Ubuntu 的发行版默认锁定 root 用户,以从意外的灾难中挽救你的原因。
对于你的日常任务,像移动你家目录中的文件,从互联网下载文件,创建文档等等,你不需要拥有 root 权限。
**打个比方来更好地理解它。假设你想要切一个水果,你可以使用一把厨房用刀。假设你想要砍一颗树,你就得使用一把锯子。现在,你可以使用锯子来切水果,但是那不明智,不是吗?**\_
这意味着,你不能是 Ubuntu 中 root 用户或者不能使用 root 权限来使用系统吗?不,你仍然可以在 `sudo` 的帮助下来拥有 root 权限来访问(在下一节中解释)。
>
> **要点:** 使用于常规任务,root 用户权限太过强大。这就是为什么不建议一直使用 root 用户。你仍然可以使用 root 用户来运行特殊的命令。
>
>
>
### 如何在 Ubuntu 中像 root 用户一样运行命令?

对于一些系统的特殊任务来说,你将需要 root 权限。例如。如果你想[通过命令行更新 Ubuntu](https://itsfoss.com/update-ubuntu/),你不能作为一个常规用户运行该命令。它将给出权限被拒绝的错误。
```
apt update
Reading package lists... Done
E: Could not open lock file /var/lib/apt/lists/lock - open (13: Permission denied)
E: Unable to lock directory /var/lib/apt/lists/
W: Problem unlinking the file /var/cache/apt/pkgcache.bin - RemoveCaches (13: Permission denied)
W: Problem unlinking the file /var/cache/apt/srcpkgcache.bin - RemoveCaches (13: Permission denied)
```
那么,你如何像 root 用户一样运行命令?简单的答案是,在命令前添加 `sudo`,来像 root 用户一样运行。
```
sudo apt update
```
Ubuntu 和很多其它的 Linux 发行版使用一个被称为 `sudo` 的特殊程序机制。`sudo` 是一个以 root 用户(或其它用户)来控制运行命令访问的程序。
实际上,`sudo` 是一个非常多用途的工具。它可以配置为允许一个用户像 root 用户一样来运行所有的命令,或者仅仅一些命令。你也可以配置为无需密码即可使用 sudo 运行命令。这个主题内容比较丰富,也许我将在另一篇文章中详细讨论它。
就目前而言,你应该知道[当你安装 Ubuntu 时](https://itsfoss.com/install-ubuntu/),你必须创建一个用户账号。这个用户账号在你系统上以管理员身份来工作,并且按照 Ubuntu 中的默认 sudo 策略,它可以在你的系统上使用 root 用户权限来运行任何命令。
`sudo` 的问题是,运行 **sudo 不需要 root 用户密码,而是需要用户自己的密码**。
并且这就是为什么当你使用 `sudo` 运行一个命令,会要求输入正在运行 `sudo` 命令的用户的密码的原因:
```
[email protected]:~$ sudo apt update
[sudo] password for abhishek:
```
正如你在上面示例中所见 `abhishek` 在尝试使用 `sudo` 来运行 `apt update` 命令,系统要求输入 `abhishek` 的密码。
**如果你对 Linux 完全不熟悉,当你在终端中开始输入密码时,你可能会惊讶,在屏幕上什么都没有发生。这是十分正常的,因为作为默认的安全功能,在屏幕上什么都不会显示。甚至星号(`*`)都没有。输入你的密码并按回车键。**
>
> **要点:**为在 Ubuntu 中像 root 用户一样运行命令,在命令前添加 `sudo`。 当被要求输入密码时,输入你的账户的密码。当你在屏幕上输入密码时,什么都看不到。请继续输入密码,并按回车键。
>
>
>
### 如何在 Ubuntu 中成为 root 用户?
你可以使用 `sudo` 来像 root 用户一样运行命令。但是,在某些情况下,你必须以 root 用户身份来运行一些命令,而你总是忘了在命令前添加 `sudo`,那么你可以临时切换为 root 用户。
`sudo` 命令允许你来模拟一个 root 用户登录的 shell ,使用这个命令:
```
sudo -i
```
```
[email protected]:~$ sudo -i
[sudo] password for abhishek:
[email protected]:~# whoami
root
```
你将注意到,当你切换为 root 用户时,shell 命令提示符从 `$`(美元符号)更改为 `#`(英镑符号)。我开个(拙劣的)玩笑,英镑比美元强大。
**虽然我已经向你显示如何成为 root 用户,但是我必须警告你,你应该避免作为 root 用户使用系统。毕竟它有阻拦你使用 root 用户的原因。**
另外一种临时切换为 root 用户的方法是使用 `su` 命令:
```
sudo su
```
如果你尝试使用不带有的 `sudo` 的 `su` 命令,你将遇到 “su authentication failure” 错误。
你可以使用 `exit` 命令来恢复为正常用户。
```
exit
```
### 如何在 Ubuntu 中启用 root 用户?
现在你知道,root 用户在基于 Ubuntu 发行版中是默认锁定的。
Linux 给予你在系统上想做什么就做什么的自由。解锁 root 用户就是这些自由之一。
如果出于某些原因,你决定启用 root 用户,你可以通过为其设置一个密码来做到:
```
sudo passwd root
```
再强调一次,不建议使用 root 用户,并且我也不鼓励你在桌面上这样做。如果你忘记了密码,你将不能再次[在 Ubuntu 中更改 root 用户密码](https://itsfoss.com/how-to-hack-ubuntu-password/)。(LCTT 译注:可以通过单用户模式修改。)
你可以通过移除密码来再次锁定 root 用户:
```
sudo passwd -dl root
```
### 最后…
我希望你现在对 root 概念理解得更好一点。如果你仍然有些关于它的困惑和问题,请在评论中让我知道。我将尝试回答你的问题,并且也可能更新这篇文章。
---
via: <https://itsfoss.com/root-user-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

How do you become a root user in Ubuntu?
Either you run commands with root privilege like this:
`sudo any_command`
Or you [switch user in Ubuntu](https://itsfoss.com/switch-users-ubuntu/) to root user like this:
`sudo su`
In both cases, you’ll have to enter your own user account’s password. But there’s more to root account in Ubuntu that you should know.
When you have just started using Linux, you’ll find many things that are different from Windows. One of those ‘different things’ is the concept of the root user.
In this beginner series, I’ll explain a few important things about the root user in Ubuntu.
**Please keep in mind that while I am writing this from Ubuntu user’s perspective, it should be valid for most Linux distributions.**
You’ll learn the following in this article:
- Why root user is disabled in Ubuntu
- Using commands as root
- Switch to root user
- Unlock the root user
## What is root user? Why is it locked in Ubuntu?

In Linux, there is always a super user called [root](http://www.linfo.org/root.html?ref=itsfoss.com). This is the super admin account that can do anything and everything with the system. It can access any file and run any command on your Linux system.
With great power comes great responsibility. Root user gives you complete power over the system and hence it should be used with great caution. Root user can access system files and run commands to make changes to the system configuration. And hence, an incorrect command may destroy the system.
This is why [Ubuntu](https://ubuntu.com/?ref=itsfoss.com) and other Ubuntu-based distributions lock the root user by default to save you from accidental disasters.
You don’t need to have root privilege for your daily tasks like moving file in your home directory, downloading files from internet, creating documents etc.
*Take this analogy for understanding it better. If you have to cut a fruit, you use a kitchen knife. If you have to cut down a tree, you have to use a saw. Now, you may use the saw to cut fruits but that’s not wise, is it?*
Does this mean that you cannot be root in Ubuntu or use the system with root privileges? No, you can still have root access with the help of ‘sudo’ (explained in the next section).
**Root user is too powerful to be used for regular tasks. This is why it is not recommended to use root all the time. You can still run specific commands with root.**
**Bottom line:**## How to run commands as root user in Ubuntu?

[xkcd](https://xkcd.com/149/?ref=itsfoss.com)
You’ll need root privileges for some system specific tasks. For example, if you want to [update Ubuntu via command line](https://itsfoss.com/update-ubuntu/), you cannot run the command as a regular user. It will give you permission denied error or show [‘are you root’ error](https://itsfoss.com/fixed-are-you-root-error/).
```
apt update
Reading package lists... Done
E: Could not open lock file /var/lib/apt/lists/lock - open (13: Permission denied)
E: Unable to lock directory /var/lib/apt/lists/
W: Problem unlinking the file /var/cache/apt/pkgcache.bin - RemoveCaches (13: Permission denied)
W: Problem unlinking the file /var/cache/apt/srcpkgcache.bin - RemoveCaches (13: Permission denied)
```
So, how do you run commands as root? The simple answer is to add sudo before the commands that require to be run as root.
`sudo apt update`
Ubuntu and many other Linux distributions use a special mechanism called sudo. Sudo is a program that controls access to running commands as root (or other users).
Sudo is actually quite a versatile tool. It can be configured to allow a user to run all commands as root. You may configure it run only a selected few commands as root. You can also configure to [run sudo without password](https://linuxhandbook.com/sudo-without-password/?ref=itsfoss.com). It’s an extensive topic and maybe I’ll discuss it in details in another article.
For the moment, you should know that [when you install Ubuntu](https://itsfoss.com/install-ubuntu/), you are forced to create a user account. This user account works as the admin on your system and as per the default sudo policy in Ubuntu, it can run any command on your system with root privileges.
The thing with sudo is that running **sudo doesn’t require root password but the user’s own password**.
And this is why when you run a command with sudo, it asks for the password of the user who is running the sudo command:
```
abhishek@nuc:~$ sudo apt update
[sudo] password for abhishek:
```
As you can see in the example above, user *abhishek* was trying to run the ‘apt update’ command with *sudo* and the system asked the password for *abhishek*.
*If you are absolutely new to Linux, you might be surprised that when you start typing your password in the terminal, nothing happens on the screen. This is perfectly normal because as the default security feature, nothing is displayed on the screen. Not even the asterisks (*). You type your password and press enter.*
**To run commands as root in Ubuntu, add sudo before the command. When asked for password, enter your account’s password. When you type the password on the screen, nothing is visible. Just keep on typing the password and press enter.**
**Bottom line:**## How to become root user in Ubuntu?
You can use sudo to run the commands as root. However, in situations, where you have to run several commands as root and you keep forgetting to add sudo before the commands, you may switch to root user temporarily.
The sudo command allows you to simulate a root login shell with this command:
`sudo -i`
```
abhishek@nuc:~$ sudo -i
[sudo] password for abhishek:
root@nuc:~# whoami
root
root@nuc:~#
```
*Though I have shown you how to become the root user, I must warn you that you should avoid using the system as root. It’s discouraged for a reason after all.*
You can [use su command to switch users in Ubuntu](https://itsfoss.com/switch-users-ubuntu/). You can use it with sudo to temporarly switch to root user:
`sudo su`
If you try to use the su command without sudo, you’ll encounter ‘su authentication failure’ error.
You can go back to being the normal user by using the exit command.
`exit`
## How to enable root user in Ubuntu?
By now, you know that the root user is locked by default in Ubuntu-based distributions.
Linux gives you the freedom to do whatever you want with your system. Unlocking the root user is one of those freedoms.
If, for some reason, you decide to enable the root user, you can do so by setting up a password for it:
`sudo passwd root`
Again, this is not recommended and I won’t encourage you to do that on your desktop. If you forget it, you won’t be able to [change the root password in Ubuntu](https://itsfoss.com/how-to-hack-ubuntu-password/) again.
You can lock the root user again by removing the password:
`sudo passwd -dl root`
[How to Reset Forgotten Ubuntu Password in 2 MinutesIf you forgot your user password on Ubuntu, don’t worry. You can reset an Ubuntu password very easily. This guide explains an easy method for changing the root password on Ubuntu. The method should also be applicable to other Linux distributions.](https://itsfoss.com/how-to-hack-ubuntu-password/)

## In the end…
I hope you have a slightly better understanding of the root concept now. If you still have some confusion and questions about it, please let me know in the comments. I’ll try to answer your questions and might update the article as well. |
11,838 | 如何在 Ubuntu Linux 中设置或更改时区 | https://itsfoss.com/change-timezone-ubuntu/ | 2020-02-01T12:53:26 | [
"时区"
] | https://linux.cn/article-11838-1.html | [你安装 Ubuntu 时](https://itsfoss.com/install-ubuntu/),它会要求你设置时区。如果你选择一个错误的时区,或者你移动到世界的一些其它地方,你可以很容易地在以后更改它。
### 如何在 Ubuntu 和其它 Linux 发行版中更改时区
这里有两种方法来更改 Ubuntu 中的时区。你可以使用图形化设置或在终端中使用 `timedatectl` 命令。你也可以直接更改 `/etc/timezone` 文件,但是我不建议这样做。
在这篇初学者教程中,我将向你展示图形化和终端两种方法:
* [通过 GUI 更改 Ubuntu 中的时区](tmp.bHvVztzy6d#change-timezone-gui) (适合桌面用户)
* [通过命令行更改 Ubuntu 中的时区](tmp.bHvVztzy6d#change-timezone-command-line) (桌面和服务器都工作)

#### 方法 1: 通过终端更改 Ubuntu 时区
[Ubuntu](https://ubuntu.com/) 或一些使用 systemd 的其它发行版可以在 Linux 终端中使用 `timedatectl` 命令来设置时区。
你可以使用没有任何参数的 `timedatectl` 命令来检查当前是日期和时区设置:
```
[email protected]:~$ timedatectl
Local time: Sat 2020-01-18 17:39:52 IST
Universal time: Sat 2020-01-18 12:09:52 UTC
RTC time: Sat 2020-01-18 12:09:52
Time zone: Asia/Kolkata (IST, +0530)
System clock synchronized: yes
systemd-timesyncd.service active: yes
RTC in local TZ: no
```
正如你在上面的输出中所看,我的系统使用 Asia/Kolkata 。它也告诉我现在比世界时早 5 小时 30 分钟。
为在 Linux 中设置时区,你需要知道准确的时区。你必需使用时区的正确的格式 (时区格式是洲/城市)。
为获取时区列表,使用 `timedatectl` 命令的 `list-timezones` 参数:
```
timedatectl list-timezones
```
它将向你显示大量可用的时区列表。

你可以使用向上箭头和向下箭头或 `PgUp` 和 `PgDown` 键来在页面之间移动。
你也可以 `grep` 输出,并搜索你的时区。例如,假如你正在寻找欧洲的时区,你可以使用:
```
timedatectl list-timezones | grep -i europe
```
比方说,你想设置时区为巴黎。在这里,使用的时区值的 Europe/Paris :
```
timedatectl set-timezone Europe/Paris
```
它虽然不显示任何成功信息,但是时区会立即更改。你不需要重新启动或注销。
记住,虽然你不需要成为 root 用户并对命令使用 `sudo`,但是你的账户仍然需要拥有管理器权限来更改时区。
你可以使用 [date 命令](https://linuxhandbook.com/date-command/) 来验证更改的时间好时区:
```
[email protected]:~$ date
Sat Jan 18 13:56:26 CET 2020
```
#### 方法 2: 通过 GUI 更改 Ubuntu 时区
按下 `super` 键 (Windows 键) ,并搜索设置:

在左侧边栏中,向下滚动一点,查看详细信息:

在详细信息中,你将在左侧边栏中找到“日期和时间”。在这里,你应该关闭自动时区选项(如果它已经被启用),然后在时区上单击:

当你单击时区时,它将打开一个交互式地图,你可以在你选择的地理位置上单击,关闭窗口。

在选择新的时区后,除了关闭这个地图后,你不必做任何事情。不需要注销或 [关闭 Ubuntu](https://itsfoss.com/schedule-shutdown-ubuntu/)。
我希望这篇快速教程能帮助你在 Ubuntu 和其它 Linux 发行版中更改时区。如果你有问题或建议,请告诉我。
---
via: <https://itsfoss.com/change-timezone-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[When you install Ubuntu](https://itsfoss.com/install-ubuntu/), it asks you to set a timezone. If you chose a wrong timezone or if you have moved to some other part of the world, you can easily change it later.
So, how can you change the timezone on Ubuntu?
## Here's How to change Timezone on Ubuntu and other Linux distributions
There are two ways to change the timezone on Ubuntu. You can use the graphical settings or use the `timedatectl`
command in the terminal.
You may also change the /etc/timezone file directly, but I won’t advise that, unless you want to experiment (and know what you are doing).
I’ll show you both graphical and terminal methods in this tutorial:
**Change timezone on Ubuntu via GUI (suitable for desktop users)****Change timezone on Ubuntu via command line (works for both desktop and servers)**
## Change Ubuntu timezone via GUI
Press the super key (Windows key) and in the Activities Overview, search for Settings:
Scroll down a little and look for “*Date and Time*” in the left sidebar. Here, you should turn off the Automatic Time Zone option (if it is enabled) and then click on the Time Zone:
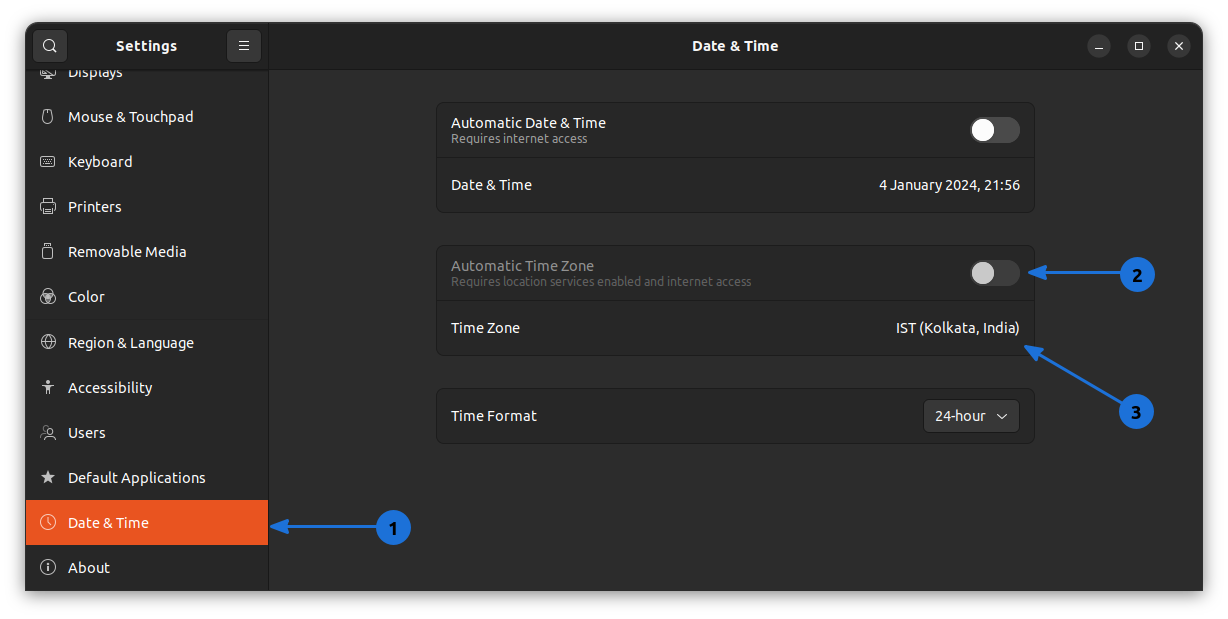
When you click the Time Zone, it will open an interactive map, and you can click on the geographical location of your choice or type the city name. Once you have selected the correct timezone, close the window.
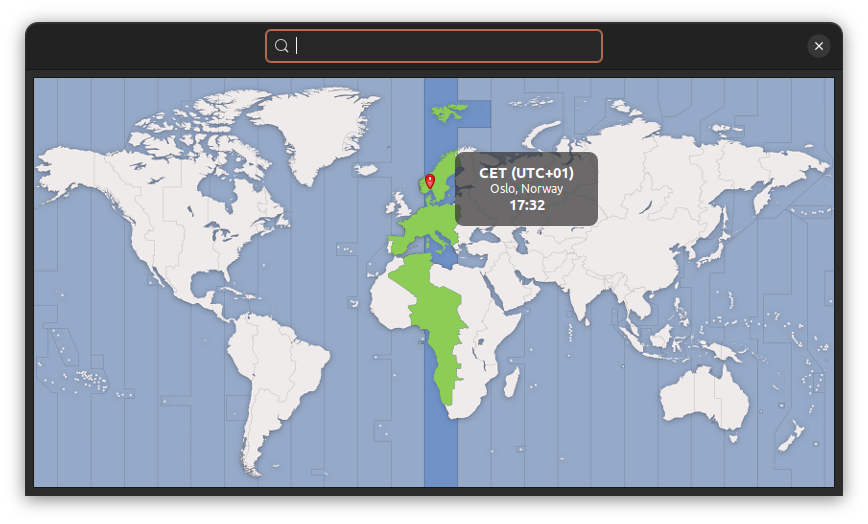
You don’t have to do anything apart from closing this map after selecting the new timezone. No need to logout or [shutdown Ubuntu](https://itsfoss.com/schedule-shutdown-ubuntu/).
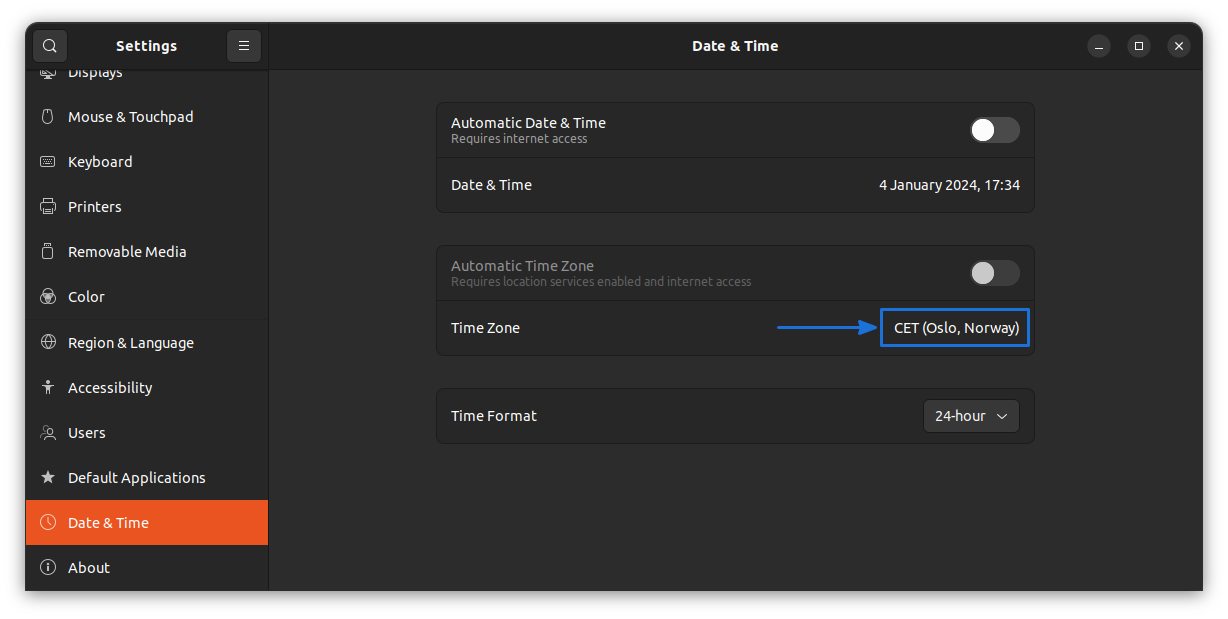
## Change Ubuntu timezone via terminal
[Ubuntu](https://ubuntu.com/?ref=itsfoss.com) or [any other distributions using systemd](https://itsfoss.com/check-if-systemd/) can use the timedatectl command to set timezone in Linux terminal.
You can check the current date and timezone setting using timedatectl command:
`timedatectl`
As you can see, in the output above, my system uses Asia/Kolkata. It also tells me that it is 5:30 hours ahead of GMT.
To set a timezone on Linux, you need to know the exact timezone. You must use the correct format of the timezone (which is Continent/City).
To get the timezone list, use the *list-timezones* option of *timedatectl* command:
`timedatectl list-timezones`
It will show you a list of the available time zones.
You can use the up and down arrow or *PgUp *and *PgDown* keys to move between the pages.
You may also use the grep command to search for your timezone. For example, if you are looking for time zones in Europe, you may use:
`timedatectl list-timezones | grep -i europe`
Let’s say you want to set the timezone to Paris. The timezone value to be used here is Europe/Paris:
`timedatectl set-timezone Europe/Paris`
It won’t show any success message, but the timezone is changed instantly. You don’t need to restart or log out.
You can verify the changed time and timezone by using the [date command](https://linuxhandbook.com/date-command/?ref=itsfoss.com):
## Wrapping Up
I hope this quick tutorial helped you to change timezone on Ubuntu and other Linux distributions.
Oh, wait! Do you want to [add multiple time zones on Ubuntu](https://itsfoss.com/add-multiple-time-zones-ubuntu/)? You might want to check our article on that:
[How to Add Multiple Time Zones in UbuntuThis quick tutorial shows the steps for adding additional clocks for multiple time zones in Ubuntu and other distributions using GNOME desktop environment. If you have family members or colleagues in another country or if you live in a country with multiple time zones, keeping a track of the time](https://itsfoss.com/add-multiple-time-zones-ubuntu/)

You can also explore similar [Ubuntu tips](https://itsfoss.com/tag/ubuntu/) on our site:
[Ubuntu Tips, Tweaks and Tutorials CollectionLove Ubuntu? We do, too. And we cover it extensively. Here, you’ll find lots of tips, tweaks and tutorials on Ubuntu, the most popular distro out there.](https://itsfoss.com/tag/ubuntu/)

*💬 Do you have any suggestions on what other types of Ubuntu tips would you like us to cover?* |
11,839 | 添加计分到你的 Python 游戏 | https://opensource.com/article/20/1/add-scorekeeping-your-python-game | 2020-02-01T15:48:00 | [
"Pygame"
] | https://linux.cn/article-11839-1.html |
>
> 在本系列的第十一篇有关使用 Python Pygame 模块进行编程的文章中,显示玩家获得战利品或受到伤害时的得分。
>
>
>

这是仍在进行中的关于使用 [Pygame](https://www.pygame.org/news) 模块来在 [Python 3](https://www.python.org/) 在创建电脑游戏的第十一部分。先前的文章是:
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程](/article-9071-1.html)
* [使用 Python 和 Pygame 模块构建一个游戏框架](/article-10850-1.html)
* [如何在你的 Python 游戏中添加一个玩家](/article-10858-1.html)
* [用 Pygame 使你的游戏角色移动起来](/article-10874-1.html)
* [如何向你的 Python 游戏中添加一个敌人](/article-10883-1.html)
* [在 Pygame 游戏中放置平台](/article-10902-1.html)
* [在你的 Python 游戏中模拟引力](/article-11780-1.html)
* [为你的 Python 平台类游戏添加跳跃功能](/article-11790-1.html)
* [使你的 Python 游戏玩家能够向前和向后跑](/article-11819-1.html)
* [在你的 Python 平台类游戏中放一些奖励](/article-11828-1.html)
如果你已经跟随这一系列很久,那么已经学习了使用 Python 创建一个视频游戏所需的所有基本语法和模式。然而,它仍然缺少一个至关重要的组成部分。这一组成部分不仅仅对用 Python 编程游戏重要;不管你探究哪个计算机分支,你都必需精通:作为一个程序员,通过阅读一种语言的或库的文档来学习新的技巧。
幸运的是,你正在阅读本文的事实表明你熟悉文档。为了使你的平台类游戏更加美观,在这篇文章中,你将在游戏屏幕上添加得分和生命值显示。不过,教你如何找到一个库的功能以及如何使用这些新的功能的这节课程并没有多神秘。
### 在 Pygame 中显示得分
现在,既然你有了可以被玩家收集的奖励,那就有充分的理由来记录分数,以便你的玩家看到他们收集了多少奖励。你也可以跟踪玩家的生命值,以便当他们被敌人击中时会有相应结果。
你已经有了跟踪分数和生命值的变量,但是这一切都发生在后台。这篇文章教你在游戏期间在游戏屏幕上以你选择的一种字体来显示这些统计数字。
### 阅读文档
大多数 Python 模块都有文档,即使那些没有文档的模块,也能通过 Python 的帮助功能来进行最小的文档化。[Pygame 的主页面](http://pygame.org/news) 链接了它的文档。不过,Pygame 是一个带有很多文档的大模块,并且它的文档不像在 Opensource.com 上的文章一样,以同样易理解的(和友好的、易解释的、有用的)叙述风格来撰写的。它们是技术文档,并且列出在模块中可用的每个类和函数,各自要求的输入类型等等。如果你不适应参考代码组件描述,这可能会令人不知所措。
在烦恼于库的文档前,第一件要做的事,就是来想想你正在尝试达到的目标。在这种情况下,你想在屏幕上显示玩家的得分和生命值。
在你确定你需要的结果后,想想它需要什么的组件。你可以从变量和函数的方面考虑这一点,或者,如果你还没有自然地想到这一点,你可以进行一般性思考。你可能意识到需要一些文本来显示一个分数,你希望 Pygame 在屏幕上绘制这些文本。如果你仔细思考,你可能会意识到它与在屏幕上渲染一个玩家、奖励或一个平台并多么大的不同。
从技术上讲,你*可以*使用数字图形,并让 Pygame 显示这些数字图形。它不是达到你目标的最容易的方法,但是如果它是你唯一知道的方法,那么它是一个有效的方法。不过,如果你参考 Pygame 的文档,你看到列出的模块之一是 `font`,这是 Pygame 使得在屏幕上来使打印文本像输入文字一样容易的方法。
### 解密技术文档
`font` 文档页面以 `pygame.font.init()` 开始,它列出了用于初始化字体模块的函数。它由 `pygame.init()` 自动地调用,你已经在代码中调用了它。再强调一次,从技术上讲,你已经到达一个*足够好*的点。虽然你尚不知道*如何做*,你知道你*能够*使用 `pygame.font` 函数来在屏幕上打印文本。
然而,如果你阅读更多一些,你会找到这里还有一种更好的方法来打印字体。`pygame.freetype` 模块在文档中的描述方式如下:
>
> `pygame.freetype` 模块是 `pygame.fontpygame` 模块的一个替代品,用于加载和渲染字体。它有原函数的所有功能,外加很多新的功能。
>
>
>
在 `pygame.freetype` 文档页面的下方,有一些示例代码:
```
import pygame
import pygame.freetype
```
你的代码应该已经导入了 Pygame,不过,请修改你的 `import` 语句以包含 Freetype 模块:
```
import pygame
import sys
import os
import pygame.freetype
```
### 在 Pygame 中使用字体
从 `font` 模块的描述中可以看出,显然 Pygame 使用一种字体(不管它的你提供的或内置到 Pygame 的默认字体)在屏幕上渲染字体。滚动浏览 `pygame.freetype` 文档来找到 `pygame.freetype.Font` 函数:
```
pygame.freetype.Font
从支持的字体文件中创建一个新的字体实例。
Font(file, size=0, font_index=0, resolution=0, ucs4=False) -> Font
pygame.freetype.Font.name
符合规则的字体名称。
pygame.freetype.Font.path
字体文件路径。
pygame.freetype.Font.size
在渲染中使用的默认点大小
```
这描述了如何在 Pygame 中构建一个字体“对象”。把屏幕上的一个简单对象视为一些代码属性的组合对你来说可能不太自然,但是这与你构建英雄和敌人精灵的方式非常类似。你需要一个字体文件,而不是一个图像文件。在你有一个字体文件后,你可以在你的代码中使用 `pygame.freetype.Font` 函数来创建一个字体对象,然后使用该对象来在屏幕上渲染文本。
因为并不是世界上的每个人的电脑上都有完全一样的字体,因此将你选择的字体与你的游戏捆绑在一起是很重要的。要捆绑字体,首先在你的游戏文件夹中创建一个新的目录,放在你为图像而创建的文件目录旁边。称其为 `fonts` 。
即使你的计算机操作系统随附了几种字体,但是将这些字体给予其他人是非法的。这看起来很奇怪,但法律就是这样运作的。如果想与你的游戏一起随附一种字体,你必需找到一种开源或知识共享的字体,以允许你随游戏一起提供该字体。
专门提供自由和合法字体的网站包括:
* [Font Library](https://fontlibrary.org/)
* [Font Squirrel](https://www.fontsquirrel.com/)
* [League of Moveable Type](https://www.theleagueofmoveabletype.com/)
当你找到你喜欢的字体后,下载下来。解压缩 ZIP 或 [TAR](https://opensource.com/article/17/7/how-unzip-targz-file) 文件,并移动 `.ttf` 或 `.otf` 文件到你的项目目录下的 `fonts` 文件夹中。
你没有安装字体到你的计算机上。你只是放置字体到你游戏的 `fonts` 文件夹中,以便 Pygame 可以使用它。如果你想,你*可以*在你的计算机上安装该字体,但是没有必要。重要的是将字体放在你的游戏目录中,这样 Pygame 可以“描绘”字体到屏幕上。
如果字体文件的名称复杂且带有空格或特殊字符,只需要重新命名它即可。文件名称是完全任意的,并且对你来说,文件名称越简单,越容易将其键入你的代码中。
现在告诉 Pygame 你的字体。从文档中你知道,当你至少提供了字体文件路径给 `pygame.freetype.Font` 时(文档明确指出所有其余属性都是可选的),你将在返回中获得一个字体对象:
```
Font(file, size=0, font_index=0, resolution=0, ucs4=False) -> Font
```
创建一个称为 `myfont` 的新变量来充当你在游戏中字体,并放置 `Font` 函数的结果到这个变量中。这个示例中使用 `amazdoom.ttf` 字体,但是你可以使用任何你想使用的字体。在你的设置部分放置这些代码:
```
font_path = os.path.join(os.path.dirname(os.path.realpath(__file__)),"fonts","amazdoom.ttf")
font_size = tx
myfont = pygame.freetype.Font(font_path, font_size)
```
### 在 Pygame 中显示文本
现在你已经创建一个字体对象,你需要一个函数来绘制你想绘制到屏幕上的文本。这和你在你的游戏中绘制背景和平台是相同的原理。
首先,创建一个函数,并使用 `myfont` 对象来创建一些文本,设置颜色为某些 RGB 值。这必须是一个全局函数;它不属于任何具体的类:
```
def stats(score,health):
myfont.render_to(world, (4, 4), "Score:"+str(score), WHITE, None, size=64)
myfont.render_to(world, (4, 72), "Health:"+str(health), WHITE, None, size=64)
```
当然,你此刻已经知道,如果它不在主循环中,你的游戏将不会发生任何事,所以在文件的底部添加一个对你的 `stats` 函数的调用:
```
for e in enemy_list:
e.move()
stats(player.score,player.health) # draw text
pygame.display.flip()
```
尝试你的游戏。
当玩家收集奖励品时,得分会上升。当玩家被敌人击中时,生命值下降。成功!

不过,这里有一个问题。当一个玩家被敌人击中时,健康度会*一路*下降,这是不公平的。你刚刚发现一个非致命的错误。非致命的错误是这些在应用程序中小问题,(通常)不会阻止应用程序启动或甚至导致停止工作,但是它们要么没有意义,要么会惹恼用户。这里是如何解决这个问题的方法。
### 修复生命值计数
当前生命值系统的问题是,敌人接触玩家时,Pygame 时钟的每一次滴答,健康度都会减少。这意味着一个缓慢移动的敌人可能在一次遭遇中将一个玩家降低健康度至 -200 ,这不公平。当然,你可以给你的玩家一个 10000 的起始健康度得分,而不用担心它;这可以工作,并且可能没有人会注意。但是这里有一个更好的方法。
当前,你的代码侦查出一个玩家和一个敌人发生碰撞的时候。生命值问题的修复是检测*两个*独立的事件:什么时候玩家和敌人碰撞,并且,在它们碰撞后,什么时候它们*停止*碰撞。
首先,在你的玩家类中,创建一个变量来代表玩家和敌人碰撞在一起:
```
self.frame = 0
self.health = 10
self.damage = 0
```
在你的 `Player` 类的 `update` 函数中,*移除*这块代码块:
```
for enemy in enemy_hit_list:
self.health -= 1
#print(self.health)
```
并且在它的位置,只要玩家当前没有被击中,检查碰撞:
```
if self.damage == 0:
for enemy in enemy_hit_list:
if not self.rect.contains(enemy):
self.damage = self.rect.colliderect(enemy)
```
你可能会在你删除的语句块和你刚刚添加的语句块之间看到相似之处。它们都在做相同的工作,但是新的代码更复杂。最重要的是,只有当玩家*当前*没有被击中时,新的代码才运行。这意味着,当一个玩家和敌人碰撞时,这些代码运行一次,而不是像以前那样一直发生碰撞。
新的代码使用两个新的 Pygame 函数。`self.rect.contains` 函数检查一个敌人当前是否在玩家的边界框内,并且当它是 `true` 时, `self.rect.colliderect` 设置你的新的 `self.damage` 变量为 1,而不管它多少次是 `true` 。
现在,即使被一个敌人击中 3 秒,对 Pygame 来说仍然看作一次击中。
我通过通读 Pygame 的文档而发现了这些函数。你没有必要一次阅读完全部的文档,并且你也没有必要阅读每个函数的每个单词。不过,花费时间在你正在使用的新的库或模块的文档上是很重要的;否则,你极有可能在重新发明轮子。不要花费一个下午的时间来尝试修改拼接一个解决方案到一些东西,而这些东西已经被你正在使用的框架的所解决。阅读文档,知悉函数,并从别人的工作中获益!
最后,添加另一个代码语句块来侦查出什么时候玩家和敌人不再接触。然后直到那时,才从玩家减少一个生命值。
```
if self.damage == 1:
idx = self.rect.collidelist(enemy_hit_list)
if idx == -1:
self.damage = 0 # set damage back to 0
self.health -= 1 # subtract 1 hp
```
注意,*只有*当玩家被击中时,这个新的代码才会被触发。这意味着,在你的玩家在你的游戏世界正在探索或收集奖励时,这个代码不会运行。它仅当 `self.damage` 变量被激活时运行。
当代码运行时,它使用 `self.rect.collidelist` 来查看玩家是否*仍然*接触在你敌人列表中的敌人(当其未侦查到碰撞时,`collidelist` 返回 -1)。在它没有接触敌人时,是该处理 `self.damage` 的时机:通过设置 `self.damage` 变量回到 0 来使其无效,并减少一点生命值。
现在尝试你的游戏。
### 得分反应
现在,你有一个来让你的玩家知道它们分数和生命值的方法,当你的玩家达到某些里程碑时,你可以确保某些事件发生。例如,也许这里有一个特殊的恢复一些生命值的奖励项目。也许一个到达 0 生命值的玩家不得不从一个关卡的起始位置重新开始。
你可以在你的代码中检查这些事件,并且相应地操纵你的游戏世界。你已经知道该怎么做,所以请浏览文档来寻找新的技巧,并且独立地尝试这些技巧。
这里是到目前为止所有的代码:
```
#!/usr/bin/env python3
# draw a world
# add a player and player control
# add player movement
# add enemy and basic collision
# add platform
# add gravity
# add jumping
# add scrolling
# add loot
# add score
# GNU All-Permissive License
# Copying and distribution of this file, with or without modification,
# are permitted in any medium without royalty provided the copyright
# notice and this notice are preserved. This file is offered as-is,
# without any warranty.
import pygame
import sys
import os
import pygame.freetype
'''
Objects
'''
class Platform(pygame.sprite.Sprite):
# x location, y location, img width, img height, img file
def __init__(self,xloc,yloc,imgw,imgh,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img)).convert()
self.image.convert_alpha()
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
'''
Spawn a player
'''
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.damage = 0
self.collide_delta = 0
self.jump_delta = 6
self.score = 1
self.images = []
for i in range(1,9):
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def jump(self,platform_list):
self.jump_delta = 0
def gravity(self):
self.movey += 3.2 # how fast player falls
if self.rect.y > worldy and self.movey >= 0:
self.movey = 0
self.rect.y = worldy-ty
def control(self,x,y):
'''
control player movement
'''
self.movex += x
self.movey += y
def update(self):
'''
Update sprite position
'''
self.rect.x = self.rect.x + self.movex
self.rect.y = self.rect.y + self.movey
# moving left
if self.movex < 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[self.frame//ani]
# moving right
if self.movex > 0:
self.frame += 1
if self.frame > ani*3:
self.frame = 0
self.image = self.images[(self.frame//ani)+4]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
if self.damage == 0:
for enemy in enemy_hit_list:
if not self.rect.contains(enemy):
self.damage = self.rect.colliderect(enemy)
if self.damage == 1:
idx = self.rect.collidelist(enemy_hit_list)
if idx == -1:
self.damage = 0 # set damage back to 0
self.health -= 1 # subtract 1 hp
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.collide_delta = 0 # stop jumping
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.y = worldy-ty-ty
self.collide_delta = 0 # stop jumping
if self.rect.y > g.rect.y:
self.health -=1
print(self.health)
if self.collide_delta < 6 and self.jump_delta < 6:
self.jump_delta = 6*2
self.movey -= 33 # how high to jump
self.collide_delta += 6
self.jump_delta += 6
class Enemy(pygame.sprite.Sprite):
'''
Spawn an enemy
'''
def __init__(self,x,y,img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images',img))
self.movey = 0
#self.image.convert_alpha()
#self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
'''
enemy movement
'''
distance = 80
speed = 8
self.movey += 3.2
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance*2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
if not self.rect.y >= worldy-ty-ty:
self.rect.y += self.movey
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.movey = 0
if self.rect.y > p.rect.y:
self.rect.y = p.rect.y+ty
else:
self.rect.y = p.rect.y-ty
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.rect.y = worldy-ty-ty
class Level():
def bad(lvl,eloc):
if lvl == 1:
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
enemy_list = pygame.sprite.Group() # create enemy group
enemy_list.add(enemy) # add enemy to group
if lvl == 2:
print("Level " + str(lvl) )
return enemy_list
def loot(lvl,tx,ty):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(200,ty*7,tx,ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
def ground(lvl,gloc,tx,ty):
ground_list = pygame.sprite.Group()
i=0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
ground_list.add(ground)
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return ground_list
def platform(lvl,tx,ty):
plat_list = pygame.sprite.Group()
ploc = []
i=0
if lvl == 1:
ploc.append((20,worldy-ty-128,3))
ploc.append((300,worldy-ty-256,3))
ploc.append((500,worldy-ty-128,4))
while i < len(ploc):
j=0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
plat_list.add(plat)
j=j+1
print('run' + str(i) + str(ploc[i]))
i=i+1
if lvl == 2:
print("Level " + str(lvl) )
return plat_list
def stats(score,health):
myfont.render_to(world, (4, 4), "Score:"+str(score), SNOWGRAY, None, size=64)
myfont.render_to(world, (4, 72), "Health:"+str(health), SNOWGRAY, None, size=64)
'''
Setup
'''
worldx = 960
worldy = 720
fps = 40 # frame rate
ani = 4 # animation cycles
clock = pygame.time.Clock()
pygame.init()
main = True
BLUE = (25,25,200)
BLACK = (23,23,23 )
WHITE = (254,254,254)
SNOWGRAY = (137,164,166)
ALPHA = (0,255,0)
world = pygame.display.set_mode([worldx,worldy])
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
backdropbox = world.get_rect()
player = Player() # spawn player
player.rect.x = 0
player.rect.y = 0
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
forwardx = 600
backwardx = 230
eloc = []
eloc = [200,20]
gloc = []
tx = 64 #tile size
ty = 64 #tile size
font_path = os.path.join(os.path.dirname(os.path.realpath(__file__)),"fonts","amazdoom.ttf")
font_size = tx
myfont = pygame.freetype.Font(font_path, font_size)
i=0
while i <= (worldx/tx)+tx:
gloc.append(i*tx)
i=i+1
enemy_list = Level.bad( 1, eloc )
ground_list = Level.ground( 1,gloc,tx,ty )
plat_list = Level.platform( 1,tx,ty )
loot_list = Level.loot(1,tx,ty)
'''
Main loop
'''
while main == True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit(); sys.exit()
main = False
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT or event.key == ord('a'):
print("LEFT")
player.control(-steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
print("RIGHT")
player.control(steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
print('jump')
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps,0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps,0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump(plat_list)
if event.key == ord('q'):
pygame.quit()
sys.exit()
main = False
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list:
l.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
for l in loot_list:
l.rect.x += scroll
world.blit(backdrop, backdropbox)
player.gravity() # check gravity
player.update()
player_list.draw(world) #refresh player position
enemy_list.draw(world) # refresh enemies
ground_list.draw(world) # refresh enemies
plat_list.draw(world) # refresh platforms
loot_list.draw(world) # refresh loot
for e in enemy_list:
e.move()
stats(player.score,player.health) # draw text
pygame.display.flip()
clock.tick(fps)
```
---
via: <https://opensource.com/article/20/1/add-scorekeeping-your-python-game>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part 11 in an ongoing series about creating video games in [Python 3](https://www.python.org/) using the [Pygame](https://www.pygame.org/news) module. Previous articles are:
[Learn how to program in Python by building a simple dice game](https://opensource.com/article/17/10/python-101)[Build a game framework with Python using the Pygame module](https://opensource.com/article/17/12/game-framework-python)[How to add a player to your Python game](https://opensource.com/article/17/12/game-python-add-a-player)[Using Pygame to move your game character around](https://opensource.com/article/17/12/game-python-moving-player)[What's a hero without a villain? How to add one to your Python game](https://opensource.com/article/18/5/pygame-enemy)[Add platforms to your game](https://opensource.com/article/18/7/put-platforms-python-game)[Simulate gravity in your Python game](https://opensource.com/article/19/11/simulate-gravity-python)[Add jumping to your Python platformer game](https://opensource.com/article/19/12/jumping-python-platformer-game)[Enable your Python game player to run forward and backward](https://opensource.com/article/19/12/python-platformer-game-run)[Using Python to set up loot in Pygame](https://opensource.com/article/19/12/loot-python-platformer-game)
If you've followed along with this series, you've learned all the essential syntax and patterns you need to create a video game with Python. However, it still lacks one vital component. This component isn't important just for programming games in Python; it's something you must master no matter what branch of computing you explore: Learning new tricks as a programmer by reading a language's or library's documentation.
Luckily, the fact that you're reading this article is a sign that you're comfortable with documentation. For the practical purpose of making your platform game more polished, in this article, you will add a score and health display to your game screen. But the not-so-secret agenda of this lesson is to teach you how to find out what a library offers and how you can use new features.
## Displaying the score in Pygame
Now that you have loot that your player can collect, there's every reason to keep score so that your player sees just how much loot they've collected. You can also track the player's health so that when they hit one of the enemies, it has a consequence.
You already have variables that track score and health, but it all happens in the background. This article teaches you to display these statistics in a font of your choice on the game screen during gameplay.
## Read the docs
Most Python modules have documentation, and even those that do not can be minimally documented by Python's Help function. [Pygame's main page](http://pygame.org/news) links to its documentation. However, Pygame is a big module with a lot of documentation, and its docs aren't exactly written in the same approachable (and friendly and elucidating and helpful) narrative style as articles on Opensource.com. They're technical documents, and they list each class and function available in the module, what kind of inputs each expects, and so on. If you're not comfortable referring to descriptions of code components, this can be overwhelming.
The first thing to do, before bothering with a library's documentation, is to think about what you are trying to achieve. In this case, you want to display the player's score and health on the screen.
Once you've determined your desired outcome, think about what components are required for it. You can think of this in terms of variables and functions or, if that doesn't come naturally to you yet, you can think generically. You probably recognize that displaying a score requires some text, which you want Pygame to draw on the screen. If you think it through, you might realize that it's not very different from rendering a player or loot or a platform on screen.
Technically, you *could* use graphics of numbers and have Pygame display those. It's not the easiest way to achieve your goal, but if it's the only way you know, then it's a valid way. However, if you refer to Pygame's docs, you see that one of the modules listed is **font**, which is Pygame's method for making printing text on the screen as easy as typing.
## Deciphering technical documentation
The **font** documentation page starts with **pygame.font.init()**, which it lists as the function that is used to initialize the font module. It's called automatically by **pygame.init()**, which you already call in your code. Once again, you've reached a point that that's technically *good enough*. While you don't know *how* yet, you know that you *can* use the **pygame.font** functions to print text on the screen.
If you read further, however, you find that there's yet an even better way to print fonts. The **pygame.freetype** module is described in the docs this way:
The pygame.freetype module is a replacement for pygame.fontpygame module for loading and rendering fonts. It has all of the functionality of the original, plus many new features.
Further down the **pygame.freetype** documentation page, there's some sample code:
```
import pygame
import pygame.freetype
```
Your code already imports Pygame, but modify your **import** statements to include the Freetype module:
```
import pygame
import sys
import os
import pygame.freetype
```
## Using a font in Pygame
From the description of the font modules, it's clear that Pygame uses a font, whether it's one you provide or a default font built into Pygame, to render text on the screen. Scroll through the **pygame.freetype** documentation to find the **pygame.freetype.Font** function:
```
pygame.freetype.Font
Create a new Font instance from a supported font file.
Font(file, size=0, font_index=0, resolution=0, ucs4=False) -> Font
pygame.freetype.Font.name
Proper font name.
pygame.freetype.Font.path
Font file path
pygame.freetype.Font.size
The default point size used in rendering
```
This describes how to construct a font "object" in Pygame. It may not feel natural to you to think of a simple object onscreen as the combination of several code attributes, but it's very similar to how you built your hero and enemy sprites. Instead of an image file, you need a font file. Once you have a font file, you can create a font object in your code with the **pygame.freetype.Font** function and then use that object to render text on the screen.
## Asset management
Because not everyone in the world has the exact same fonts on their computers, it's important to bundle your chosen font with your game. To bundle a font, first create a new directory in your game folder, right along with the directory you created for your images. Call it **fonts**.
Even though several fonts come with your computer, it's not legal to give those fonts away. It seems strange, but that's how the law works. If you want to ship a font with your game, you must find an open source or Creative Commons font that permits you to give the font away along with your game.
Sites that specialize in free and legal fonts include:
When you find a font that you like, download it. Extract the ZIP or [TAR](https://opensource.com/article/17/7/how-unzip-targz-file) file and move the **.ttf** or **.otf** file into the **fonts** folder in your game project directory.
You aren't installing the font on your computer. You're just placing it in your game's **fonts** folder so that Pygame can use it. You *can* install the font on your computer if you want, but it's not necessary. The important thing is to have it in your game directory, so Pygame can "trace" it onto the screen.
If the font file has a complicated name with spaces or special characters, just rename it. The filename is completely arbitrary, and the simpler it is, the easier it is for you to type into your code.
## Using a font in Pygame
Now tell Pygame about your font. From the documentation, you know that you'll get a font object in return when you provide at least the path to a font file to **pygame.freetype.Font** (the docs state explicitly that all remaining attributes are optional):
`Font(file, size=0, font_index=0, resolution=0, ucs4=False) -> Font`
Create a new variable called **myfont** to serve as your font in the game, and place the results of the **Font** function into that variable. This example uses the **amazdoom.ttf** font, but you can use whatever font you want. Place this code in your Setup section:
```
font_path = os.path.join(os.path.dirname(os.path.realpath(__file__)),"fonts","amazdoom.ttf")
font_size = tx
pygame.freetype.init()
myfont = pygame.freetype.Font(font_path, font_size)
```
## Displaying text in Pygame
Now that you've created a font object, you need a function to draw the text you want onto the screen. This is the same principle you used to draw the background and platforms in your game.
First, create a function, and use the **myfont** object to create some text, setting the color to some RGB value. This must be a global function; it does not belong to any specific class. Place it in the **objects **section of your code, but keep it as a stand-alone function:
```
def stats(score,health):
myfont.render_to(world, (4, 4), "Score:"+str(score), BLACK, None, size=64)
myfont.render_to(world, (4, 72), "Health:"+str(health), BLACK, None, size=64)
```
Of course, you know by now that nothing happens in your game if it's not in the Main loop, so add a call to your **stats** function near the bottom of the file:
` stats(player.score,player.health) # draw text`
Try your game. If you've been following the sample code in this article exactly, you'll get an error when you try to launch the game now.
## Interpreting errors
Errors are important to programmers. When something fails in your code, one of the best ways to understand why is by reading the error output. Unfortunately, Python doesn't communicate the same way a human does. While it does have relatively friendly errors, you still have to interpret what you're seeing.
In this case, launching the game produces this output:
```
Traceback (most recent call last):
File "/home/tux/PycharmProjects/game_001/main.py", line 41, in <module>
font_size = tx
NameError: name 'tx' is not defined
```
Python is aserting that the variable **tx** is not defined. You know this isn't true, because you've used **tx** in several places by now and it's worked as expected.
But Python also cites a line number. This is the line that caused Python to stop executing the code. It is *not* necessarily the line containing the error.
Armed with this knowledge, you can look at your code in an attempt to understand what has failed.
Line 41 attempts to set the font size to the value of **tx**. However, reading through the file in reverse, up from line 41, you might notice that **tx **(and **ty**) are not listed. In fact, **tx **and **ty **were placed haphazardly in your setup section because, at the time, it seemed easy and logical to place them along with other important tile information.
Moving the **tx** and **ty** lines from your setup section to some line above line 41 fixes the error.
When you entcounter errors in Python, take note of the hints it provides, and then read your source code carefully. It can take time to find an error, even for experienced programmers, but the better you understand Python the easier it becomes.
## Running the game
When the player collects loot, the score goes up. When the player gets hit by an enemy, health goes down. Success!

There is one problem, though. When a player gets hit by an enemy, health goes *way* down, and that's not fair. You have just discovered a non-fatal bug. Non-fatal bugs are those little problems in applications that don't keep the application from starting up or even from working (mostly), but they either don't make sense, or they annoy the user. Here's how to fix this one.
## Fixing the health counter
The problem with the current health point system is that health is subtracted for every tick of the Pygame clock that the enemy is touching the player. That means that a slow-moving enemy can take a player down to –200 health in just one encounter, and that's not fair. You could, of course, just give your player a starting health score of 10,000 and not worry about it; that would work, and possibly no one would mind. But there is a better way.
Currently, your code detects when a player and an enemy collide. The fix for the health-point problem is to detect *two* separate events: when the player and enemy collide and, once they have collided, when they *stop* colliding.
First, in your Player class, create a variable to represent when a player and enemy have collided:
```
self.frame = 0
self.health = 10
self.damage = 0
```
In the update function of your Player class, *remove* this block of code:
```
for enemy in enemy_hit_list:
self.health -= 1
#print(self.health)
```
And in its place, check for collision as long as the player is not currently being hit:
```
if self.damage == 0:
for enemy in enemy_hit_list:
if not self.rect.contains(enemy):
self.damage = self.rect.colliderect(enemy)
```
You might see similarities between the block you deleted and the one you just added. They're both doing the same job, but the new code is more complex. Most importantly, the new code runs only if the player is not *currently* being hit. That means that this code runs once when a player and enemy collide and not constantly for as long as the collision happens, the way it used to.
The new code uses two new Pygame functions. The **self.rect.contains** function checks to see if an enemy is currently within the player's bounding box, and **self.rect.colliderect** sets your new **self.damage** variable to one when it is true, no matter how many times it is true.
Now even three seconds of getting hit by an enemy still looks like one hit to Pygame.
I discovered these functions by reading through Pygame's documentation. You don't have to read all the docs at once, and you don't have to read every word of each function. However, it's important to spend time with the documentation of a new library or module that you're using; otherwise, you run a high risk of reinventing the wheel. Don't spend an afternoon trying to hack together a solution to something that's already been solved by the framework you're using. Read the docs, find the functions, and benefit from the work of others!
Finally, add another block of code to detect when the player and the enemy are no longer touching. Then and only then, subtract one point of health from the player.
```
if self.damage == 1:
idx = self.rect.collidelist(enemy_hit_list)
if idx == -1:
self.damage = 0 # set damage back to 0
self.health -= 1 # subtract 1 hp
```
Notice that this new code gets triggered *only* when the player has been hit. That means this code doesn't run while your player is running around your game world exploring or collecting loot. It only runs when the **self.damage** variable gets activated.
When the code runs, it uses **self.rect.collidelist** to see whether or not the player is *still* touching an enemy in your enemy list (**collidelist** returns negative one when it detects no collision). Once it is not touching an enemy, it's time to pay the **self.damage** debt: deactivate the **self.damage** variable by setting it back to zero and subtract one point of health.
Try your game now.

Now that you have a way for your player to know their score and health, you can make certain events occur when your player reaches certain milestones. For instance, maybe there's a special loot item that restores some health points. And maybe a player who reaches zero health points has to start back at the beginning of a level.
You can check for these events in your code and manipulate your game world accordingly.
## Level up
You already know how to do so much. Now it's time to level up your skills. Go skim the documentation for new tricks and try them out on your own. Programming is a skill you develop, so don't stop with this project. Invent another game, or a useful application, or just use Python to experiment around with crazy ideas. The more you use it, the more comfortable you get with it, and eventually it'll be second nature.
Keep it going, and keep it open!
Here's all the code so far:
```
#!/usr/bin/env python3
# by Seth Kenlon
# GPLv3
# This program is free software: you can redistribute it and/or
# modify it under the terms of the GNU General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
# General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import pygame
import pygame.freetype
import sys
import os
'''
Variables
'''
worldx = 960
worldy = 720
fps = 40
ani = 4
world = pygame.display.set_mode([worldx, worldy])
forwardx = 600
backwardx = 120
BLUE = (80, 80, 155)
BLACK = (23, 23, 23)
WHITE = (254, 254, 254)
ALPHA = (0, 255, 0)
tx = 64
ty = 64
font_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), "fonts", "amazdoom.ttf")
font_size = tx
pygame.freetype.init()
myfont = pygame.freetype.Font(font_path, font_size)
'''
Objects
'''
def stats(score,health):
myfont.render_to(world, (4, 4), "Score:"+str(score), BLUE, None, size=64)
myfont.render_to(world, (4, 72), "Health:"+str(health), BLUE, None, size=64)
# x location, y location, img width, img height, img file
class Platform(pygame.sprite.Sprite):
def __init__(self, xloc, yloc, imgw, imgh, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img)).convert()
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.y = yloc
self.rect.x = xloc
class Player(pygame.sprite.Sprite):
"""
Spawn a player
"""
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.movex = 0
self.movey = 0
self.frame = 0
self.health = 10
self.damage = 0
self.score = 0
self.is_jumping = True
self.is_falling = True
self.images = []
for i in range(1, 5):
img = pygame.image.load(os.path.join('images', 'hero' + str(i) + '.png')).convert()
img.convert_alpha()
img.set_colorkey(ALPHA)
self.images.append(img)
self.image = self.images[0]
self.rect = self.image.get_rect()
def gravity(self):
if self.is_jumping:
self.movey += 3.2
def control(self, x, y):
"""
control player movement
"""
self.movex += x
def jump(self):
if self.is_jumping is False:
self.is_falling = False
self.is_jumping = True
def update(self):
"""
Update sprite position
"""
# moving left
if self.movex < 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = pygame.transform.flip(self.images[self.frame // ani], True, False)
# moving right
if self.movex > 0:
self.is_jumping = True
self.frame += 1
if self.frame > 3 * ani:
self.frame = 0
self.image = self.images[self.frame // ani]
# collisions
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
if self.damage == 0:
for enemy in enemy_hit_list:
if not self.rect.contains(enemy):
self.damage = self.rect.colliderect(enemy)
if self.damage == 1:
idx = self.rect.collidelist(enemy_hit_list)
if idx == -1:
self.damage = 0 # set damage back to 0
self.health -= 1 # subtract 1 hp
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
for g in ground_hit_list:
self.movey = 0
self.rect.bottom = g.rect.top
self.is_jumping = False # stop jumping
# fall off the world
if self.rect.y > worldy:
self.health -=1
print(self.health)
self.rect.x = tx
self.rect.y = ty
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
for p in plat_hit_list:
self.is_jumping = False # stop jumping
self.movey = 0
if self.rect.bottom <= p.rect.bottom:
self.rect.bottom = p.rect.top
else:
self.movey += 3.2
if self.is_jumping and self.is_falling is False:
self.is_falling = True
self.movey -= 33 # how high to jump
loot_hit_list = pygame.sprite.spritecollide(self, loot_list, False)
for loot in loot_hit_list:
loot_list.remove(loot)
self.score += 1
print(self.score)
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
self.rect.x += self.movex
self.rect.y += self.movey
class Enemy(pygame.sprite.Sprite):
"""
Spawn an enemy
"""
def __init__(self, x, y, img):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.image.load(os.path.join('images', img))
self.image.convert_alpha()
self.image.set_colorkey(ALPHA)
self.rect = self.image.get_rect()
self.rect.x = x
self.rect.y = y
self.counter = 0
def move(self):
"""
enemy movement
"""
distance = 80
speed = 8
if self.counter >= 0 and self.counter <= distance:
self.rect.x += speed
elif self.counter >= distance and self.counter <= distance * 2:
self.rect.x -= speed
else:
self.counter = 0
self.counter += 1
class Level:
def ground(lvl, gloc, tx, ty):
ground_list = pygame.sprite.Group()
i = 0
if lvl == 1:
while i < len(gloc):
ground = Platform(gloc[i], worldy - ty, tx, ty, 'tile-ground.png')
ground_list.add(ground)
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return ground_list
def bad(lvl, eloc):
if lvl == 1:
enemy = Enemy(eloc[0], eloc[1], 'enemy.png')
enemy_list = pygame.sprite.Group()
enemy_list.add(enemy)
if lvl == 2:
print("Level " + str(lvl))
return enemy_list
# x location, y location, img width, img height, img file
def platform(lvl, tx, ty):
plat_list = pygame.sprite.Group()
ploc = []
i = 0
if lvl == 1:
ploc.append((200, worldy - ty - 128, 3))
ploc.append((300, worldy - ty - 256, 3))
ploc.append((550, worldy - ty - 128, 4))
while i < len(ploc):
j = 0
while j <= ploc[i][2]:
plat = Platform((ploc[i][0] + (j * tx)), ploc[i][1], tx, ty, 'tile.png')
plat_list.add(plat)
j = j + 1
print('run' + str(i) + str(ploc[i]))
i = i + 1
if lvl == 2:
print("Level " + str(lvl))
return plat_list
def loot(lvl):
if lvl == 1:
loot_list = pygame.sprite.Group()
loot = Platform(tx*5, ty*5, tx, ty, 'loot_1.png')
loot_list.add(loot)
if lvl == 2:
print(lvl)
return loot_list
'''
Setup
'''
backdrop = pygame.image.load(os.path.join('images', 'stage.png'))
clock = pygame.time.Clock()
pygame.init()
backdropbox = world.get_rect()
main = True
player = Player() # spawn player
player.rect.x = 0 # go to x
player.rect.y = 30 # go to y
player_list = pygame.sprite.Group()
player_list.add(player)
steps = 10
eloc = []
eloc = [300, worldy-ty-80]
enemy_list = Level.bad(1, eloc)
gloc = []
i = 0
while i <= (worldx / tx) + tx:
gloc.append(i * tx)
i = i + 1
ground_list = Level.ground(1, gloc, tx, ty)
plat_list = Level.platform(1, tx, ty)
enemy_list = Level.bad( 1, eloc )
loot_list = Level.loot(1)
'''
Main Loop
'''
while main:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.type == pygame.KEYDOWN:
if event.key == ord('q'):
pygame.quit()
try:
sys.exit()
finally:
main = False
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(-steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(steps, 0)
if event.key == pygame.K_UP or event.key == ord('w'):
player.jump()
if event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == ord('a'):
player.control(steps, 0)
if event.key == pygame.K_RIGHT or event.key == ord('d'):
player.control(-steps, 0)
# scroll the world forward
if player.rect.x >= forwardx:
scroll = player.rect.x - forwardx
player.rect.x = forwardx
for p in plat_list:
p.rect.x -= scroll
for e in enemy_list:
e.rect.x -= scroll
for l in loot_list:
l.rect.x -= scroll
# scroll the world backward
if player.rect.x <= backwardx:
scroll = backwardx - player.rect.x
player.rect.x = backwardx
for p in plat_list:
p.rect.x += scroll
for e in enemy_list:
e.rect.x += scroll
for l in loot_list:
l.rect.x += scroll
world.blit(backdrop, backdropbox)
player.update()
player.gravity()
player_list.draw(world)
enemy_list.draw(world)
loot_list.draw(world)
ground_list.draw(world)
plat_list.draw(world)
for e in enemy_list:
e.move()
stats(player.score, player.health)
pygame.display.flip()
clock.tick(fps)
```
## 5 Comments |
11,841 | 我珍藏的 Bash 秘籍 | https://opensource.com/article/20/1/bash-scripts-aliases | 2020-02-02T12:01:38 | [
"Bash"
] | https://linux.cn/article-11841-1.html |
>
> 通过别名和其他捷径来提高你经常忘记的那些事情的效率。
>
>
>

要是你整天使用计算机,如果能找到需要重复执行的命令并记下它们以便以后轻松使用那就太棒了。它们全都呆在那里,藏在 `~/.bashrc` 中(或 [zsh 用户](https://opensource.com/article/19/9/getting-started-zsh)的 `~/.zshrc` 中),等待着改善你的生活!
在本文中,我分享了我最喜欢的这些助手命令,对于我经常遗忘的事情,它们很有用,也希望这可以帮助到你,以及为你解决一些经常头疼的问题。
### 完事吱一声
当我执行一个需要长时间运行的命令时,我经常采用多任务的方式,然后就必须回头去检查该操作是否已完成。然而通过有用的 `say` 命令,现在就不用再这样了(这是在 MacOS 上;请根据你的本地环境更改为等效的方式):
```
function looooooooong {
START=$(date +%s.%N)
$*
EXIT_CODE=$?
END=$(date +%s.%N)
DIFF=$(echo "$END - $START" | bc)
RES=$(python -c "diff = $DIFF; min = int(diff / 60); print('%s min' % min)")
result="$1 completed in $RES, exit code $EXIT_CODE."
echo -e "\n⏰ $result"
( say -r 250 $result 2>&1 > /dev/null & )
}
```
这个命令会记录命令的开始和结束时间,计算所需的分钟数,并“说”出调用的命令、花费的时间和退出码。当简单的控制台铃声无法使用时,我发现这个超级有用。
### 安装小助手
我在小时候就开始使用 Ubuntu,而我需要学习的第一件事就是如何安装软件包。我曾经首先添加的别名之一是它的助手(根据当天的流行梗命名的):
```
alias canhas="sudo apt-get install -y"
```
### GPG 签名
有时候,我必须在没有 GPG 扩展程序或应用程序的情况下给电子邮件签署 [GPG](https://gnupg.org/) 签名,我会跳到命令行并使用以下令人讨厌的别名:
```
alias gibson="gpg --encrypt --sign --armor"
alias ungibson="gpg --decrypt"
```
### Docker
Docker 的子命令很多,但是 Docker compose 的更多。我曾经使用这些别名来将 `--rm` 标志丢到脑后,但是现在不再使用这些有用的别名了:
```
alias dc="docker-compose"
alias dcr="docker-compose run --rm"
alias dcb="docker-compose run --rm --build"
```
### Google Cloud 的 gcurl 助手
对于我来说,Google Cloud 是一个相对较新的东西,而它有[极多的文档](https://cloud.google.com/service-infrastructure/docs/service-control/getting-started)。`gcurl` 是一个别名,可确保在用带有身份验证标头的本地 `curl` 命令连接 Google Cloud API 时,可以获得所有正确的标头。
### Git 和 ~/.gitignore
我工作中用 Git 很多,因此我有一个专门的部分来介绍 Git 助手。
我最有用的助手之一是我用来克隆 GitHub 存储库的。你不必运行:
```
git clone [email protected]:org/repo /Users/glasnt/git/org/repo
```
我设置了一个克隆函数:
```
clone(){
echo Cloning $1 to ~/git/$1
cd ~/git
git clone [email protected]:$1 $1
cd $1
}
```
即使每次进入 `~/.bashrc` 文件看到这个时,我总是会忘记和傻笑,我也有一个“刷新上游”命令:
```
alias yoink="git checkout master && git fetch upstream master && git merge upstream/master"
```
给 Git 一族的另一个助手是全局忽略文件。在你的 `git config --global --list` 中,你应该看到一个 `core.excludesfile`。如果没有,请[创建一个](https://help.github.com/en/github/using-git/ignoring-files#create-a-global-gitignore),然后将你总是放到各个 `.gitignore` 文件中的内容填满它。作为 MacOS 上的 Python 开发人员,对我来说,这些内容是:
```
.DS_Store # macOS clutter
venv/ # I never want to commit my virtualenv
*.egg-info/* # ... nor any locally compiled packages
__pycache__ # ... or source
*.swp # ... nor any files open in vim
```
你可以在 [Gitignore.io](https://www.gitignore.io/) 或 GitHub 上的 [Gitignore 存储库](https://github.com/github/gitignore)上找到其他建议。
### 轮到你了
你最喜欢的助手命令是什么?请在评论中分享。
---
via: <https://opensource.com/article/20/1/bash-scripts-aliases>
作者:[Katie McLaughlin](https://opensource.com/users/glasnt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you work with computers all day, it's fantastic to find repeatable commands and tag them for easy use later on. They all sit there, tucked away in **~/.bashrc **(or ~/.zshrc for [Zsh users](https://opensource.com/article/19/9/getting-started-zsh)), waiting to help improve your day!
In this article, I share some of my favorite of these helper commands for things I forget a lot, in hopes that they will save you, too, some heartache over time.
## Say when it's over
When I'm using longer-running commands, I often multitask and then have to go back and check if the action has completed. But not anymore, with this helpful invocation of **say** (this is on MacOS; change for your local equivalent):
```
function looooooooong {
START=$(date +%s.%N)
$*
EXIT_CODE=$?
END=$(date +%s.%N)
DIFF=$(echo "$END - $START" | bc)
RES=$(python -c "diff = $DIFF; min = int(diff / 60); print('%s min' % min)")
result="$1 completed in $RES, exit code $EXIT_CODE."
echo -e "\n⏰ $result"
( say -r 250 $result 2>&1 > /dev/null & )
}
```
This command marks the start and end time of a command, calculates the minutes it takes, and speaks the command invoked, the time taken, and the exit code. I find this super helpful when a simple console bell just won't do.
## Install helpers
I started using Ubuntu back in the Lucid days, and one of the first things I needed to learn was how to install packages. And one of the first aliases I ever added was a helper for this (named based on the memes of the day):
`alias canhas="sudo apt-get install -y"`
## GNU Privacy Guard (GPG) signing
On the off chance I have to sign a [GPG](https://gnupg.org/) email without having an extension or application to do it for me, I drop down into the command line and use these terribly dorky aliases:
```
alias gibson="gpg --encrypt --sign --armor"
alias ungibson="gpg --decrypt"
```
## Docker
There are many Docker commands, but there are even more **docker compose** commands. I used to forget the **--rm** flags, but not anymore with these useful aliases:
```
alias dc="docker-compose"
alias dcr="docker-compose run --rm"
alias dcb="docker-compose run --rm --build"
```
## gcurl helper for Google Cloud
This one is relatively new to me, but it's [heavily documented](https://cloud.google.com/service-infrastructure/docs/service-control/getting-started). gcurl is an alias to ensure you get all the correct flags when using local curl commands with authentication headers when working with Google Cloud APIs.
## Git and ~/.gitignore
I work a lot in Git, so I have a special section dedicated to Git helpers.
One of my most useful helpers is one I use to clone GitHub repos. Instead of having to run:
`git clone [email protected]:org/repo /Users/glasnt/git/org/repo`
I set up a clone function:
```
clone(){
echo Cloning $1 to ~/git/$1
cd ~/git
git clone [email protected]:$1 $1
cd $1
}
```
Even though I always forget and giggle any time I'm diving into my **~/.bashrc** file, I also have my "refresh upstream" command:
`alias yoink="git checkout master && git fetch upstream master && git merge upstream/master"`
Another helper for Git-ville is a global ignore file. In your **git config --global --list** you should see a **core.excludesfile**. If not, [create one](https://help.github.com/en/github/using-git/ignoring-files#create-a-global-gitignore), and fill it full of things that you always put into your individual **.gitignore** files. As a Python developer on MacOS, for me this is:
```
.DS_Store # macOS clutter
venv/ # I never want to commit my virtualenv
*.egg-info/* # ... nor any locally compiled packages
__pycache__ # ... or source
*.swp # ... nor any files open in vim
```
You can find other suggestions over on [Gitignore.io](https://www.gitignore.io/) or on the [Gitignore repo](https://github.com/github/gitignore) on GitHub.
## Your turn
What are your favorite helper commands? Please share them in the comments.
## 9 Comments |
11,845 | 分布式跟踪系统的四大功能模块如何协同工作 | https://opensource.com/article/18/5/distributed-tracing | 2020-02-03T00:44:37 | [
"跟踪"
] | https://linux.cn/article-11845-1.html |
>
> 了解分布式跟踪中的主要体系结构决策,以及各部分如何组合在一起。
>
>
>

早在十年前,认真研究过分布式跟踪基本上只有学者和一小部分大型互联网公司中的人。对于任何采用微服务的组织来说,它如今成为一种筹码。其理由是确立的:微服务通常会发生让人意想不到的错误,而分布式跟踪则是描述和诊断那些错误的最好方法。
也就是说,一旦你准备将分布式跟踪集成到你自己的应用程序中,你将很快意识到对于不同的人来说“<ruby> 分布式跟踪 <rt> Distributed Tracing </rt></ruby>”一词意味着不同的事物。此外,跟踪生态系统里挤满了具有相似内容的重叠项目。本文介绍了分布式跟踪系统中四个(可能)独立的功能模块,并描述了它们间将如何协同工作。
### 分布式跟踪:一种思维模型
大多数用于跟踪的思维模型来源于 [Google 的 Dapper 论文](https://research.google.com/pubs/pub36356.html)。[OpenTracing](http://opentracing.io/) 使用相似的术语,因此,我们从该项目借用了以下术语:

* <ruby> 跟踪 <rt> Trace </rt></ruby>:事物在分布式系统运行的过程描述。
* <ruby> 跨度 <rt> Span </rt></ruby>:一种命名的定时操作,表示工作流的一部分。跨度可接受键值对标签以及附加到特定跨度实例的细粒度的、带有时间戳的结构化日志。
* <ruby> 跨度上下文 <rt> Span context </rt></ruby>:携带分布式事务的跟踪信息,包括当它通过网络或消息总线将服务传递给服务时。跨度上下文包含跟踪标识符、跨度标识符以及跟踪系统所需传播到下游服务的任何其他数据。
如果你想要深入研究这种思维模式的细节,请仔细参照 [OpenTracing 技术规范](https://research.google.com/pubs/pub36356.html)。
### 四大功能模块
从应用层分布式跟踪系统的观点来看,现代软件系统架构如下图所示:

现代软件系统的组件可分为三类:
* **应用程序和业务逻辑**:你的代码。
* **广泛共享库**:他人的代码
* **广泛共享服务**:他人的基础架构
这三类组件有着不同的需求,驱动着监控应用程序的分布式跟踪系统的设计。最终的设计得到了四个重要的部分:
* <ruby> 跟踪检测 API <rt> A tracing instrumentation API </rt></ruby>:修饰应用程序代码
* <ruby> 线路协议 <rt> Wire protocol </rt></ruby>:在 RPC 请求中与应用程序数据一同发送的规定
* <ruby> 数据协议 <rt> Data protocol </rt></ruby>:将异步信息(带外)发送到你的分析系统的规定
* <ruby> 分析系统 <rt> Analysis system </rt></ruby>:用于处理跟踪数据的数据库和交互式用户界面
为了更深入的解释这个概念,我们将深入研究驱动该设计的细节。如果你只需要我的一些建议,请跳转至下方的四大解决方案。
### 需求,细节和解释
应用程序代码、共享库以及共享式服务在操作上有显著的差别,这种差别严重影响了对其进行检测的请求操作。
#### 检测应用程序代码和业务逻辑
在任何特定的微服务中,由微服务开发者编写的大部分代码是应用程序或者商业逻辑。这部分代码规定了特定区域的操作。通常,它包含任何特殊、独一无二的逻辑判断,这些逻辑判断首先证明了创建新型微服务的合理性。基本上按照定义,**该代码通常不会在多个服务中共享或者以其他方式出现。**
也即是说你仍需了解它,这也意味着需要以某种方式对它进行检测。一些监控和跟踪分析系统使用<ruby> 黑盒代理 <rt> black-box agents </rt></ruby>自动检测代码,另一些系统更想使用显式的白盒检测工具。对于后者,抽象跟踪 API 提供了许多对于微服务的应用程序代码来说更为实用的优势:
* 抽象 API 允许你在不重新编写检测代码的条件下换新的监视工具。你可能想要变更云服务提供商、供应商和监测技术,而一大堆不可移植的检测代码将会为该过程增加有意义的开销和麻烦。
* 事实证明,除了生产监控之外,该工具还有其他有趣的用途。现有的项目使用相同的跟踪工具来驱动测试工具、分布式调试器、“混沌工程”故障注入器和其他元应用程序。
* 但更重要的是,若将应用程序组件提取到共享库中要怎么办呢?由上述内容可得到结论:
#### 检测共享库
在大多数应用程序中出现的实用程序代码(处理网络请求、数据库调用、磁盘写操作、线程、并发管理等)通常情况下是通用的,而非特别应用于某个特定应用程序。这些代码会被打包成库和框架,而后就可以被装载到许多的微服务上并且被部署到多种不同的环境中。
其真正的不同是:对于共享代码,其他人则成为了使用者。大多数用户有不同的依赖关系和操作风格。如果尝试去使用该共享代码,你将会注意到几个常见的问题:
* 你需要一个 API 来编写检测。然而,你的库并不知道你正在使用哪个分析系统。会有多种选择,并且运行在相同应用下的所有库无法做出不兼容的选择。
* 由于这些包封装了所有网络处理代码,因此从请求报头注入和提取跨度上下文的任务往往指向 RPC 库。然而,共享库必须了解到每个应用程序正在使用哪种跟踪协议。
* 最后,你不想强制用户使用相互冲突的依赖项。大多数用户有不同的依赖关系和操作风格。即使他们使用 gRPC,绑定的 gRPC 版本是否相同?因此任何你的库附带用于跟踪的监控 API 必定是免于依赖的。
**因此,一个(a)没有依赖关系、(b)与线路协议无关、(c)使用流行的供应商和分析系统的抽象 API 应该是对检测共享库代码的要求。**
#### 检测共享式服务
最后,有时整个服务(或微服务集合体)的通用性足以使许多独立的应用程序使用它们。这种共享式服务通常由第三方托管和管理,例如缓存服务器、消息队列以及数据库。
从应用程序开发者的角度来看,理解共享式服务本质上是黑盒子是极其重要的。它不可能将你的应用程序监控注入到共享式服务。恰恰相反,托管服务通常会运行它自己的监控方案。
### 四个方面的解决方案
因此,抽象的跟踪应用程序接口将会帮助库发出数据并且注入/抽取跨度上下文。标准的线路协议将会帮助黑盒服务相互连接,而标准的数据格式将会帮助分离的分析系统合并其中的数据。让我们来看一下部分有希望解决这些问题的方案。
#### 跟踪 API:OpenTracing 项目
如你所见,我们需要一个跟踪 API 来检测应用程序代码。为了将这种工具扩展到大多数进行跨度上下文注入和提取的共享库中,则必须以某种关键方式对 API 进行抽象。
[OpenTracing](http://opentracing.io/) 项目主要针对解决库开发者的问题,OpenTracing 是一个与供应商无关的跟踪 API,它没有依赖关系,并且迅速得到了许多监控系统的支持。这意味着,如果库附带了内置的本地 OpenTracing 工具,当监控系统在应用程序启动连接时,跟踪将会自动启动。
就个人而言,作为一个已经编写、发布和操作开源软件十多年的人,在 OpenTracing 项目上工作并最终解决这个观察性的难题令我十分满意。
除了 API 之外,OpenTracing 项目还维护了一个不断增长的工具列表,其中一些可以在[这里](https://github.com/opentracing-contrib/)找到。如果你想参与进来,无论是通过提供一个检测插件,对你自己的 OSS 库进行本地测试,或者仅仅只想问个问题,都可以通过 [Gitter](https://gitter.im/opentracing/public) 向我们打招呼。
#### 线路协议: HTTP 报头 trace-context
为了监控系统能进行互操作,以及减轻从一个监控系统切换为另外一个时带来的迁移问题,需要标准的线路协议来传播跨度上下文。
[w3c 分布式跟踪上下文社区小组](https://www.w3.org/community/trace-context/)在努力制定此标准。目前的重点是制定一系列标准的 HTTP 报头。该规范的最新草案可以在[此处](https://w3c.github.io/distributed-tracing/report-trace-context.html)找到。如果你对此小组有任何的疑问,[邮件列表](http://lists.w3.org/Archives/Public/public-trace-context/)和[Gitter 聊天室](https://gitter.im/TraceContext/Lobby)是很好的解惑地点。
(LCTT 译注:本文原文发表于 2018 年 5 月,可能现在社区已有不同进展)
#### 数据协议 (还未出现!!)
对于黑盒服务,在无法安装跟踪程序或无法与程序进行交互的情况下,需要使用数据协议从系统中导出数据。
目前这种数据格式和协议的开发工作尚处在初级阶段,并且大多在 w3c 分布式跟踪上下文工作组的上下文中进行工作。需要特别关注的是在标准数据模式中定义更高级别的概念,例如 RPC 调用、数据库语句等。这将允许跟踪系统对可用数据类型做出假设。OpenTracing 项目也通过定义一套[标准标签集](https://github.com/opentracing/specification/blob/master/semantic_conventions.md)来解决这一事务。该计划是为了使这两项努力结果相互配合。
注意当前有一个中间地带。对于由应用程序开发者操作但不想编译或以其他方式执行代码修改的“网络设备”,动态链接可以帮助避免这种情况。主要的例子就是服务网格和代理,就像 Envoy 或者 NGINX。针对这种情况,可将兼容 OpenTracing 的跟踪器编译为共享对象,然后在运行时动态链接到可执行文件中。目前 [C++ OpenTracing API](https://github.com/opentracing/opentracing-cpp) 提供了该选项。而 JAVA 的 OpenTracing [跟踪器解析](https://github.com/opentracing-contrib/java-tracerresolver)也在开发中。
这些解决方案适用于支持动态链接,并由应用程序开发者部署的的服务。但从长远来看,标准的数据协议可以更广泛地解决该问题。
#### 分析系统:从跟踪数据中提取有见解的服务
最后不得不提的是,现在有足够多的跟踪监视解决方案。可以在[此处](http://opentracing.io/documentation/pages/supported-tracers)找到已知与 OpenTracing 兼容的监控系统列表,但除此之外仍有更多的选择。我更鼓励你研究你的解决方案,同时希望你在比较解决方案时发现本文提供的框架能派上用场。除了根据监控系统的操作特性对其进行评级外(更不用提你是否喜欢 UI 和其功能),确保你考虑到了上述三个重要方面、它们对你的相对重要性以及你感兴趣的跟踪系统如何为它们提供解决方案。
### 结论
最后,每个部分的重要性在很大程度上取决于你是谁以及正在建立什么样的系统。举个例子,开源库的作者对 OpenTracing API 非常感兴趣,而服务开发者对 trace-context 规范更感兴趣。当有人说一部分比另一部分重要时,他们的意思通常是“一部分对我来说比另一部分重要”。
然而,事实是:分布式跟踪已经成为监控现代系统所必不可少的事物。在为这些系统进行构建模块时,“尽可能解耦”的老方法仍然适用。在构建像分布式监控系统一样的跨系统的系统时,干净地解耦组件是维持灵活性和前向兼容性地最佳方式。
感谢你的阅读!现在当你准备好在你自己的应用程序中实现跟踪服务时,你已有一份指南来了解他们正在谈论哪部分部分以及它们之间如何相互协作。
---
via: <https://opensource.com/article/18/5/distributed-tracing>
作者:[Ted Young](https://opensource.com/users/tedsuo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ten years ago, essentially the only people thinking hard about distributed tracing were academics and a handful of large internet companies. Today, it’s turned into table stakes for any organization adopting microservices. The rationale is well-established: microservices fail in surprising and often spectacular ways, and distributed tracing is the best way to describe and diagnose those failures.
That said, if you set out to integrate distributed tracing into your own application, you’ll quickly realize that the term “Distributed Tracing” means different things to different people. Furthermore, the tracing ecosystem is crowded with partially-overlapping projects with similar charters. This article describes the four (potentially) independent components in distributed tracing, and how they fit together.
## Distributed tracing: A mental model
Most mental models for tracing descend from [Google’s Dapper paper](https://research.google.com/pubs/pub36356.html). [OpenTracing](http://opentracing.io/) uses similar nouns and verbs, so we will borrow the terms from that project:
**Trace:**The description of a transaction as it moves through a distributed system.**Span:**A named, timed operation representing a piece of the workflow. Spans accept key:value tags as well as fine-grained, timestamped, structured logs attached to the particular span instance.**Span context:**Trace information that accompanies the distributed transaction, including when it passes from service to service over the network or through a message bus. The span context contains the trace identifier, span identifier, and any other data that the tracing system needs to propagate to the downstream service.
If you would like to dig into a detailed description of this mental model, please check out the [OpenTracing specification](https://github.com/opentracing/specification/blob/master/specification.md).
## The four big pieces
From the perspective of an application-layer distributed tracing system, a modern software system looks like the following diagram:
The components in a modern software system can be broken down into three categories:
**Application and business logic:**Your code.**Widely shared libraries:**Other people's code.**Widely shared services:**Other people’s infrastructure.
These three components have different requirements and drive the design of the Distributed Tracing systems which is tasked with monitoring the application. The resulting design yields four important pieces:
**A tracing instrumentation API:**What decorates application code.**Wire protocol:**What gets sent alongside application data in RPC requests.**Data protocol:**What gets sent asynchronously (out-of-band) to your analysis system.**Analysis system:**A database and interactive UI for working with the trace data.
To explain this further, we’ll dig into the details which drive this design. If you just want my suggestions, please skip to the four big solutions at the bottom.
## Requirements, details, and explanations
Application code, shared libraries, and shared services have notable operational differences, which heavily influence the requirements for instrumenting them.
### Instrumenting application code and business logic
In any particular microservice, the bulk of the code written by the microservice developer is the application or business logic. This is the code that defines domain-specific operations; typically, it contains whatever special, unique logic justified the creation of a new microservice in the first place. Almost by definition, **this code is usually not shared or otherwise present in more than one service.**
That said, you still need to understand it, and that means it needs to be instrumented somehow. Some monitoring and tracing analysis systems auto-instrument code using black-box agents, and others expect explicit "white-box" instrumentation. For the latter, abstract tracing APIs offer many practical advantages for microservice-specific application code:
- An abstract API allows you to swap in new monitoring tools without re-writing instrumentation code. You may want to change cloud providers, vendors, and monitoring technologies, and a huge pile of non-portable instrumentation code would add meaningful overhead and friction to that procedure.
- It turns out there are other interesting uses for instrumentation, beyond production monitoring. There are existing projects that use this same tracing instrumentation to power testing tools, distributed debuggers, “chaos engineering” fault injectors, and other meta-applications.
- But most importantly, what if you wanted to extract an application component into a shared library? That leads us to:
### Instrumenting shared libraries
The utility code present in most applications—code that handles network requests, database calls, disk writes, threading, queueing, concurrency management, and so on—is often generic and not specific to any particular application. This code is packaged up into libraries and frameworks which are then installed in many microservices, and deployed into many different environments.
This is the real difference: with shared code, someone else is the user. Most users have different dependencies and operational styles. If you attempt to instrument this shared code, you will note a couple of common issues:
- You need an API to write instrumentation. However, your library does not know what analysis system is being used. There are many choices, and all the libraries running in the same application cannot make incompatible choices.
- The task of injecting and extracting span contexts from request headers often falls on RPC libraries, since those packages encapsulate all network-handling code. However, a shared library cannot not know which tracing protocol is being used by each application.
- Finally, you don’t want to force conflicting dependencies on your user. Most users have different dependencies and operational styles. Even if they use gRPC, will it be the same version of gRPC you are binding to? So any monitoring API your library brings in for tracing must be free of dependencies.
**So, an abstract API which (a) has no dependencies, (b) is wire protocol agnostic, and (c) works with popular vendors and analysis systems should be a requirement for instrumenting shared library code.**
### Instrumenting shared services
Finally, sometimes entire services—or sets of microservices—are general-purpose enough that they are used by many independent applications. These shared services are often hosted and managed by third parties. Examples might be cache servers, message queues, and databases.
It’s important to understand that **shared services are essentially "black boxes" from the perspective of application developers.** It is not possible to inject your application’s monitoring solution into a shared service. Instead, the hosted service often runs its own monitoring solution.
**The four big solutions**
So, an abstracted tracing API would help libraries emit data and inject/extract Span Context. A standard wire protocol would help black-box services interconnect, and a standard data format would help separate analysis systems consolidate their data. Let's have a look at some promising options for solving these problems.
### Tracing API: The OpenTracing project
### As shown above, in order to instrument application code, a tracing API is required. And in order to extend that instrumentation to shared libraries, where most of the Span Context injection and extraction occurs, the API must be abstracted in certain critical ways.
The [OpenTracing](http://opentracing.io/) project aims to solve this problem for library developers. OpenTracing is a vendor-neutral tracing API which comes with no dependencies, and is quickly gaining support from a large number of monitoring systems. This means that, increasingly, if libraries ship with native OpenTracing instrumentation baked in, tracing will automatically be enabled when a monitoring system connects at application startup.
Personally, as someone who has been writing, shipping, and operating open source software for over a decade, it is profoundly satisfying to work on the OpenTracing project and finally scratch this observability itch.
In addition to the API, the OpenTracing project maintains a growing list of contributed instrumentation, some of which can be found [here](https://github.com/opentracing-contrib/). If you would like to get involved, either by contributing an instrumentation plugin, natively instrumenting your own OSS libraries, or just want to ask a question, please find us on [Gitter](https://gitter.im/opentracing/public) and say hi.
### Wire Protocol: The trace-context HTTP headers
In order for monitoring systems to interoperate, and to mitigate migration issues when changing from one monitoring system to another, a standard wire protocol is needed for propagating Span Context.
The [w3c Distributed Trace Context Community Group](https://www.w3.org/community/trace-context/) is hard at work defining this standard. Currently, the focus is on defining a set of standard HTTP headers. The latest draft of the specification can be found [here](https://w3c.github.io/distributed-tracing/report-trace-context.html). If you have questions for this group, the [mailing list](http://lists.w3.org/Archives/Public/public-trace-context/) and [Gitter chatroom](https://gitter.im/TraceContext/Lobby) are great places to go for answers.
### Data protocol (Doesn't exist yet!!)
For black-box services, where it is not possible to install a tracer or otherwise interact with the program, a data protocol is needed to export data from the system.
Work on this data format and protocol is currently at an early stage, and mostly happening within the context of the w3c Distributed Trace Context Working Group. There is particular interest is in defining higher-level concepts, such as RPC calls, database statements, etc, in a standard data schema. This would allow tracing systems to make assumptions about what kind of data would be available. The OpenTracing project is also working on this issue, by starting to define a [standard set of tags](https://github.com/opentracing/specification/blob/master/semantic_conventions.md). The plan is for these two efforts to dovetail with each other.
Note that there is a middle ground available at the moment. For “network appliances” that the application developer operates, but does not want to compile or otherwise perform code modifications to, dynamic linking can help. The primary examples of this are service meshes and proxies, such as Envoy or NGINX. For this situation, an OpenTracing-compliant tracer can be compiled as a shared object, and then dynamically linked into the executable at runtime. This option is currently provided by the [C++ OpenTracing API](https://github.com/opentracing/opentracing-cpp). For Java, an OpenTracing [Tracer Resolver](https://github.com/opentracing-contrib/java-tracerresolver) is also under development.
These solutions work well for services that support dynamic linking, and are deployed by the application developer. But in the long run, a standard data protocol may solve this problem more broadly.
### Analysis system: A service for extracting insights from trace data
Last but not least, there is now a cornucopia of tracing and monitoring solutions. A list of monitoring systems known to be compatible with OpenTracing can be found [here](http://opentracing.io/documentation/pages/supported-tracers), but there are many more options out there. I would encourage you to research your options, and I hope you find the framework provided in this article to be useful when comparing options. In addition to rating monitoring systems based on their operational characteristics (not to mention whether you like the UI and features), make sure you think about the three big pieces above, their relative importance to you, and how the tracing system you are interested in provides a solution to them.
## Conclusion
In the end, how important each piece is depends heavily on who you are and what kind of system you are building. For example, open source library authors are very interested in the OpenTracing API, while service developers tend to be more interested in the Trace-Context specification. When someone says one piece is more important than the other, they usually mean “one piece is more important to *me* than the other."
However, the reality is this: Distributed Tracing has become a necessity for monitoring modern systems. In designing the building blocks for these systems, the age-old approach—"decouple where you can"—still holds true. Cleanly decoupled components are the best way to maintain flexibility and forwards-compatibility when building a system as cross-cutting as a distributed monitoring system.
Thanks for reading! Hopefully, now when you're ready to implement tracing in your own application, you have a guide to understanding which pieces they are talking about, and how they fit together.
*Want to learn more? Sign up to attend KubeCon EU in May or KubeCon North America in December.*
## Comments are closed. |
11,846 | 使用这个 Python 程序记录你的活动 | https://opensource.com/article/20/1/python-journal | 2020-02-03T10:57:00 | [
"日记"
] | /article-11846-1.html |
>
> jrnl 可以创建可搜索、带时间戳、可导出、加密的(如果需要)的日常活动日志。在我们的 20 个使用开源提升生产力的系列的第八篇文章中了解更多。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 jrnl 记录日志
在我的公司,许多人会在下班之前在 Slack 上发送一个“一天结束”的状态。在有着许多项目和全球化的团队里,这是一个分享你已完成、未完成以及你需要哪些帮助的一个很好的方式。但有时候我太忙了,以至于我忘了做了什么。这时候就需要记录日志了。

打开一个文本编辑器并在你做一些事的时候添加一行很容易。但是在需要找出你在什么时候做的笔记,或者要快速提取相关的行时会有挑战。幸运的是,[jrnl](https://jrnl.sh/) 可以提供帮助。
jrnl 能让你在命令行中快速输入条目、搜索过去的条目并导出为 HTML 和 Markdown 等富文本格式。你可以有多个日志,这意味着你可以将工作条目与私有条目分开。它将条目存储为纯文本,因此即使 jrnl 停止工作,数据也不会丢失。
由于 jrnl 是一个 Python 程序,最简单的安装方法是使用 `pip3 install jrnl`。这将确保你获得最新和最好的版本。第一次运行它会询问一些问题,接下来就能正常使用。

现在,每当你需要做笔记或记录日志时,只需输入 `jrnl <some text>`,它将带有时间戳的记录保存到默认文件中。你可以使用 `jrnl -on YYYY-MM-DD` 搜索特定日期条目,`jrnl -from YYYY-MM-DD` 搜索在那日期之后的条目,以及用 `jrnl -to YYYY-MM-DD` 搜索到那日期的条目。搜索词可以与 `-and` 参数结合使用,允许像 `jrnl -from 2019-01-01 -and -to 2019-12-31` 这类搜索。
你还可以使用 `--edit` 标志编辑日志中的条目。开始之前,通过编辑文件 `~/.config/jrnl/jrnl.yaml` 来设置默认编辑器。你还可以指定日志使用什么文件、用于标签的特殊字符以及一些其他选项。现在,重要的是设置编辑器。我使用 Vim,jrnl 的文档中有一些使用其他编辑器如 VSCode 和 Sublime Text 的[有用提示](https://jrnl.sh/recipes/#external-editors)。

jrnl 还可以加密日志文件。通过设置全局 `encrypt` 变量,你将告诉 jrnl 加密你定义的所有日志。还可在配置文件中的针对文件设置 `encrypt: true` 来加密文件。
```
journals:
default: ~/journals/journal.txt
work: ~/journals/work.txt
private:
journal: ~/journals/private.txt
encrypt: true
```
如果日志尚未加密,系统将提示你输入在对它进行任何操作的密码。日志文件将加密保存在磁盘上,以免受窥探。[jrnl 文档](https://jrnl.sh/encryption/) 中包含其工作原理、使用哪些加密方式等的更多信息。

日志记录帮助我记住什么时候做了什么事,并在我需要的时候能够找到它。
---
via: <https://opensource.com/article/20/1/python-journal>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,849 | 查看 Linux 系统中进程和用户的内存使用情况 | https://www.networkworld.com/article/3516319/showing-memory-usage-in-linux-by-process-and-user.html | 2020-02-03T20:55:20 | [
"内存"
] | https://linux.cn/article-11849-1.html |
>
> 有一些命令可以用来检查 Linux 系统中的内存使用情况,下面是一些更好的命令。
>
>
>

有许多工具可以查看 Linux 系统中的内存使用情况。一些命令被广泛使用,比如 `free`、`ps`。而另一些命令允许通过多种方式展示系统的性能统计信息,比如 `top`。在这篇文章中,我们将介绍一些命令以帮助你确定当前占用着最多内存资源的用户或者进程。
下面是一些按照进程查看内存使用情况的命令:
### 按照进程查看内存使用情况
#### 使用 top
`top` 是最好的查看内存使用情况的命令之一。为了查看哪个进程使用着最多的内存,一个简单的办法就是启动 `top`,然后按下 `shift+m`,这样便可以查看按照内存占用百分比从高到底排列的进程。当你按下了 `shift+m` ,你的 `top` 应该会得到类似于下面这样的输出结果:
```
$top
top - 09:39:34 up 5 days, 3 min, 3 users, load average: 4.77, 4.43, 3.72
Tasks: 251 total, 3 running, 247 sleeping, 1 stopped, 0 zombie
%Cpu(s): 50.6 us, 35.9 sy, 0.0 ni, 13.4 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 5944.4 total, 128.9 free, 2509.3 used, 3306.2 buff/cache
MiB Swap: 2048.0 total, 2045.7 free, 2.2 used. 3053.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
400 nemo 20 0 3309580 550188 168372 S 0.3 9.0 1:33.27 Web Content
32469 nemo 20 0 3492840 447372 163296 S 7.3 7.3 3:55.60 firefox
32542 nemo 20 0 2845732 433388 140984 S 6.0 7.1 4:11.16 Web Content
342 nemo 20 0 2848520 352288 118972 S 10.3 5.8 4:04.89 Web Content
2389 nemo 20 0 1774412 236700 90044 S 39.7 3.9 9:32.64 vlc
29527 nemo 20 0 2735792 225980 84744 S 9.6 3.7 3:02.35 gnome-shell
30497 nemo 30 10 1088476 159636 88884 S 0.0 2.6 0:11.99 update-manager
30058 nemo 20 0 1089464 140952 33128 S 0.0 2.3 0:04.58 gnome-software
32533 nemo 20 0 2389088 104712 79544 S 0.0 1.7 0:01.43 WebExtensions
2256 nemo 20 0 1217884 103424 31304 T 0.0 1.7 0:00.28 vlc
1713 nemo 20 0 2374396 79588 61452 S 0.0 1.3 0:00.49 Web Content
29306 nemo 20 0 389668 74376 54340 S 2.3 1.2 0:57.25 Xorg
32739 nemo 20 0 289528 58900 34480 S 1.0 1.0 1:04.08 RDD Process
29732 nemo 20 0 789196 57724 42428 S 0.0 0.9 0:00.38 evolution-alarm
2373 root 20 0 150408 57000 9924 S 0.3 0.9 10:15.35 nessusd
```
注意 `%MEM` 排序。列表的大小取决于你的窗口大小,但是占据着最多的内存的进程将会显示在列表的顶端。
#### 使用 ps
`ps` 命令中的一列用来展示每个进程的内存使用情况。为了展示和查看哪个进程使用着最多的内存,你可以将 `ps` 命令的结果传递给 `sort` 命令。下面是一个有用的示例:
```
$ ps aux | sort -rnk 4 | head -5
nemo 400 3.4 9.2 3309580 563336 ? Sl 08:59 1:36 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 9086 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 32469 8.2 7.7 3492840 469516 ? Sl 08:54 4:15 /usr/lib/firefox/firefox -new-window
nemo 32542 8.9 7.6 2875428 462720 ? Sl 08:55 4:36 /usr/lib/firefox/firefox -contentproc -childID 2 -isForBrowser -prefsLen 1 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 342 9.9 5.9 2854664 363528 ? Sl 08:59 4:44 /usr/lib/firefox/firefox -contentproc -childID 5 -isForBrowser -prefsLen 8763 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 2389 39.5 3.8 1774412 236116 pts/1 Sl+ 09:15 12:21 vlc videos/edge_computing.mp4
```
在上面的例子中(文中已截断),`sort` 命令使用了 `-r` 选项(反转)、`-n` 选项(数字值)、`-k` 选项(关键字),使 `sort` 命令对 `ps` 命令的结果按照第四列(内存使用情况)中的数字逆序进行排列并输出。如果我们首先显示 `ps` 命令的标题,那么将会便于查看。
```
$ ps aux | head -1; ps aux | sort -rnk 4 | head -5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
nemo 400 3.4 9.2 3309580 563336 ? Sl 08:59 1:36 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 9086 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 32469 8.2 7.7 3492840 469516 ? Sl 08:54 4:15 /usr/lib/firefox/firefox -new-window
nemo 32542 8.9 7.6 2875428 462720 ? Sl 08:55 4:36 /usr/lib/firefox/firefox -contentproc -childID 2 -isForBrowser -prefsLen 1 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 342 9.9 5.9 2854664 363528 ? Sl 08:59 4:44 /usr/lib/firefox/firefox -contentproc -childID 5 -isForBrowser -prefsLen 8763 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 2389 39.5 3.8 1774412 236116 pts/1 Sl+ 09:15 12:21 vlc videos/edge_computing.mp4
```
如果你喜欢这个命令,你可以用下面的命令为他指定一个别名,如果你想一直使用它,不要忘记把该命令添加到你的 `~/.bashrc` 文件中。
```
$ alias mem-by-proc="ps aux | head -1; ps aux | sort -rnk 4"
```
下面是一些根据用户查看内存使用情况的命令:
### 按用户查看内存使用情况
#### 使用 top
按照用户检查内存使用情况会更复杂一些,因为你需要找到一种方法把用户所拥有的所有进程统计为单一的内存使用量。
如果你只想查看单个用户进程使用情况,`top` 命令可以采用与上文中同样的方法进行使用。只需要添加 `-U` 选项并在其后面指定你要查看的用户名,然后按下 `shift+m` 便可以按照内存使用有多到少进行查看。
```
$ top -U nemo
top - 10:16:33 up 5 days, 40 min, 3 users, load average: 1.91, 1.82, 2.15
Tasks: 253 total, 2 running, 250 sleeping, 1 stopped, 0 zombie
%Cpu(s): 28.5 us, 36.8 sy, 0.0 ni, 34.4 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 5944.4 total, 224.1 free, 2752.9 used, 2967.4 buff/cache
MiB Swap: 2048.0 total, 2042.7 free, 5.2 used. 2812.0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
400 nemo 20 0 3315724 623748 165440 S 1.0 10.2 1:48.78 Web Content
32469 nemo 20 0 3629380 607492 161688 S 2.3 10.0 6:06.89 firefox
32542 nemo 20 0 2886700 404980 136648 S 5.6 6.7 6:50.01 Web Content
342 nemo 20 0 2922248 375784 116096 S 19.5 6.2 8:16.07 Web Content
2389 nemo 20 0 1762960 234644 87452 S 0.0 3.9 13:57.53 vlc
29527 nemo 20 0 2736924 227260 86092 S 0.0 3.7 4:09.11 gnome-shell
30497 nemo 30 10 1088476 156372 85620 S 0.0 2.6 0:11.99 update-manager
30058 nemo 20 0 1089464 138160 30336 S 0.0 2.3 0:04.62 gnome-software
32533 nemo 20 0 2389088 102532 76808 S 0.0 1.7 0:01.79 WebExtensions
```
#### 使用 ps
你依旧可以使用 `ps` 命令通过内存使用情况来排列某个用户的进程。在这个例子中,我们将使用 `grep` 命令来筛选得到某个用户的所有进程。
```
$ ps aux | head -1; ps aux | grep ^nemo| sort -rnk 4 | more
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
nemo 32469 7.1 11.5 3724364 701388 ? Sl 08:54 7:21 /usr/lib/firefox/firefox -new-window
nemo 400 2.0 8.9 3308556 543232 ? Sl 08:59 2:01 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 9086 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni/usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 32542 7.9 7.1 2903084 436196 ? Sl 08:55 8:07 /usr/lib/firefox/firefox -contentproc -childID 2 -isForBrowser -prefsLen 1 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 342 10.8 7.0 2941056 426484 ? Rl 08:59 10:45 /usr/lib/firefox/firefox -contentproc -childID 5 -isForBrowser -prefsLen 8763 -prefMapSize 210653 -parentBuildID 20200107212822 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 32469 true tab
nemo 2389 16.9 3.8 1762960 234644 pts/1 Sl+ 09:15 13:57 vlc videos/edge_computing.mp4
nemo 29527 3.9 3.7 2736924 227448 ? Ssl 08:50 4:11 /usr/bin/gnome-shell
```
### 使用 ps 和其他命令的搭配
如果你想比较某个用户与其他用户内存使用情况将会比较复杂。在这种情况中,创建并排序一个按照用户总的内存使用量是一个不错的方法,但是它需要做一些更多的工作,并涉及到许多命令。在下面的脚本中,我们使用 `ps aux | grep -v COMMAND | awk '{print $1}' | sort -u` 命令得到了用户列表。其中包含了系统用户比如 `syslog`。我们对每个任务使用 `awk` 命令以收集每个用户总的内存使用情况。在最后一步中,我们展示每个用户总的内存使用量(按照从大到小的顺序)。
```
#!/bin/bash
stats=””
echo "% user"
echo "============"
# collect the data
for user in `ps aux | grep -v COMMAND | awk '{print $1}' | sort -u`
do
stats="$stats\n`ps aux | egrep ^$user | awk 'BEGIN{total=0}; \
{total += $4};END{print total,$1}'`"
done
# sort data numerically (largest first)
echo -e $stats | grep -v ^$ | sort -rn | head
```
这个脚本的输出可能如下:
```
$ ./show_user_mem_usage
% user
============
69.6 nemo
5.8 root
0.5 www-data
0.3 shs
0.2 whoopsie
0.2 systemd+
0.2 colord
0.2 clamav
0 syslog
0 rtkit
```
在 Linux 有许多方法可以报告内存使用情况。可以通过一些用心设计的工具和命令,来查看并获得某个进程或者用户占用着最多的内存。
---
via: <https://www.networkworld.com/article/3516319/showing-memory-usage-in-linux-by-process-and-user.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,853 | 四大亮点带你看 Linux 内核 5.6 | https://itsfoss.com/linux-kernel-5-6/ | 2020-02-05T11:31:58 | [
"内核"
] | https://linux.cn/article-11853-1.html | 当我们还在体验 Linux 5.5 稳定发行版带来更好的硬件支持时,Linux 5.6 已经来了。
说实话,Linux 5.6 比 5.5 更令人兴奋。即使即将发布的 Ubuntu 20.04 LTS 发行版将自带 Linux 5.5,你也需要切实了解一下 Linux 5.6 内核为我们提供了什么。
我将在本文中重点介绍 Linux 5.6 发布版中值得期待的关键更改和功能:
### Linux 5.6 功能亮点

当 Linux 5.6 有新消息时,我会努力更新这份功能列表。但现在让我们先看一下当前已知的内容:
#### 1、支持 WireGuard
WireGuard 将被添加到 Linux 5.6,出于各种原因的考虑它可能将取代 [OpenVPN](https://openvpn.net/)。
你可以在官网上进一步了解 [WireGuard](https://www.wireguard.com/) 的优点。当然,如果你使用过它,那你可能已经知道它比 OpenVPN 更好的原因。
同样,[Ubuntu 20.04 LTS 将支持 WireGuard](https://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-20.04-Adds-WireGuard)。
#### 2、支持 USB4
Linux 5.6 也将支持 **USB4**。
如果你不了解 USB 4.0 (USB4),你可以阅读这份[文档](https://www.usb.org/sites/default/files/2019-09/USB-IF_USB4%20spec%20announcement_FINAL.pdf)。
根据文档,“USB4 将使 USB 的最大带宽增大一倍并支持<ruby> 多并发数据和显示协议 <rt> multiple simultaneous data and display protocols </rt></ruby>。”
另外,虽然我们都知道 USB4 基于 Thunderbolt 接口协议,但它将向后兼容 USB 2.0、USB 3.0 以及 Thunderbolt 3,这将是一个好消息。
#### 3、使用 LZO/LZ4 压缩 F2FS 数据
Linux 5.6 也将支持使用 LZO/LZ4 算法压缩 F2FS 数据。
换句话说,这只是 Linux 文件系统的一种新压缩技术,你可以选择待定的文件扩展技术。
#### 4、解决 32 位系统的 2038 年问题
Unix 和 Linux 将时间值以 32 位有符号整数格式存储,其最大值为 2147483647。时间值如果超过这个数值则将由于整数溢出而存储为负数。
这意味着对于 32 位系统,时间值不能超过 1970 年 1 月 1 日后的 2147483647 秒。也就是说,在 UTC 时间 2038 年 1 月 19 日 03:14:07 时,由于整数溢出,时间将显示为 1901 年 12 月 13 日而不是 2038 年 1 月 19 日。
Linux kernel 5.6 解决了这个问题,因此 32 位系统也可以运行到 2038 年以后。
#### 5、改进硬件支持
很显然,在下一个发布版中,硬件支持也将继续提升。而支持新式无线外设的计划也同样是优先的。
新内核中将增加对 MX Master 3 鼠标以及罗技其他无线产品的支持。
除了罗技的产品外,你还可以期待获得许多不同硬件的支持(包括对 AMD GPU、NVIDIA GPU 和 Intel Tiger Lake 芯片组的支持)。
#### 6、其他更新
此外,Linux 5.6 中除了上述主要的新增功能或支持外,下一个内核版本也将进行其他一些改进:
* 改进 AMD Zen 的温度/功率报告
* 修复华硕飞行堡垒系列笔记本中 AMD CPU 过热
* 开源支持 NVIDIA RTX 2000 图灵系列显卡
* 内建 FSCRYPT 加密
[Phoronix](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.6-Spectacular) 跟踪了 Linux 5.6 带来的许多技术性更改。因此,如果你好奇 Linux 5.6 所涉及的全部更改,则可以亲自了解一下。
现在你已经了解了 Linux 5.6 发布版带来的新功能,对此有什么看法呢?在下方评论中留下你的看法。
---
via: <https://itsfoss.com/linux-kernel-5-6/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LazyWolfLin](https://github.com/LazyWolfLin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While we’ve already witnessed the stable release of Linux 5.5 with better hardware support, Linux 5.6 is an even more exciting release.
Linus Torvalds has [announced the release of Kernel 5.6](https://lore.kernel.org/lkml/CAHk-=wi9ZT7Stg-uSpX0UWQzam6OP9Jzz6Xu1CkYu1cicpD5OA@mail.gmail.com/). He also noted that kernel development is not impacted with the Coronavirus lockdown:
I haven’t really seen any real sign of kernel development being impacted by all the coronavirus activity – I suspect a lot of us work from home even normally
Torvalds also expect a normal Kernel 5.7 release in coming months but certainly not at the cost of health of the contributors:
I’m currently going by the assumption that we’ll have a fairly normal 5.7 release, and there doesn’t seem to be any signs saying otherwise, but hey, people may have better-than-usual reasons for missing the merge window. Let me know if you know of some subsystem that ends up being affected.
So we’ll play it by ear and see what happens. It’s not like the merge window is more important than your health, or the health of people around you.
It’s nice of Linus Torvalds to highlight that in these difficult times with all the stuff going around with Coronavuirus.
Let me highlight the key changes and features of Linux kernel 5.6 release:
## Linux 5.6 features highlight

Here’s all the major new changes:
### 1. WireGuard Support
[WireGuard](https://itsfoss.com/wireguard/) has been added to Linux 5.6 – potentially replacing [OpenVPN](https://openvpn.net/) for a variety of reasons.
You can learn more about [WireGuard](https://www.wireguard.com/) on their official site to know the benefits. Of course, if you’ve used it, you might be aware of the reasons why it’s potentially better than OpenVPN.
Also, [Ubuntu 20.04 LTS will be adding support for WireGuard](https://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-20.04-Adds-WireGuard).
### 2. USB4 Support
Linux 5.6 also includes the support of** USB4**.
In case you didn’t know about USB 4.0 (USB4), you can read the [announcement post](https://www.usb.org/sites/default/files/2019-09/USB-IF_USB4%20spec%20announcement_FINAL.pdf).
As per the announcement – “*USB4 doubles the maximum aggregate bandwidth of USB and enables multiple simultaneous data and display protocols.*“
Also, while we know that USB4 is based on the Thunderbolt protocol specification, it will be backward compatible with USB 2.0, USB 3.0, and Thunderbolt 3 – which is great news.
### 3. F2FS Data Compression Using LZO/LZ4
Linux 5.6 also comes with the support for F2FS data compression using LZO/LZ4 algorithms.
In other words, it is just a new compression technique for the Linux file-system where you will be able to select particular file extensions.
### 4. Fixing the Year 2038 problem for 32-bit systems
Unix and Linux store the time value in a 32-bit signed integer format which has the maximum value of 2147483647. Beyond this number, due to integer overflow, the values will be stored as a negative number.
This means that for a 32-bit system, the time value cannot go beyond 2147483647 seconds after Jan. 1, 1970. In simpler terms, after 03:14:07 UTC on Jan. 19, 2038, due to integer overflow, the time will read as Dec. 13, 1901 instead of Jan. 19, 2038.
Linux kernel 5.6 has a fix for this problem so that 32-bit systems can run beyond the year 2038.
### 5. Improved Hardware Support
Like every new kernel release, the hardware support improves in kernel 5.6 as well. The plan to support newer wireless peripherals is a priority here.
The new kernel adds the support for MX Master 3 mouse and other wireless Logitech products.
In addition to Logitech products, you can expect a lot of different hardware support as well (including the support for AMD GPUs, NVIDIA GPUs, and Intel Tiger Lake chipset support).
### 6. Other Changes
Also, in addition to all these major additions/support in Linux 5.6, there are several other changes that have been added to this kernel release:
- Improvements in AMD Zen temperature/power reporting
- A fix for AMD CPUs overheating in ASUS TUF laptops
- Open-source NVIDIA RTX 2000 “Turing” graphics support
- FSCRYPT inline encryption.
[Phoronix](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.6-Spectacular) tracked a lot of technical changes arriving with Linux 5.6. So, if you’re curious about every bit of the changes involved in Linux kernel 5.6, you can check for yourself.
Now that you’ve known the Linux kernel 5.6 release – what do you think about it? Let me know your thoughts in the comments below. |
11,856 | 一个通过 IRC 管理所有聊天的开源聊天工具 | https://opensource.com/article/20/1/open-source-chat-tool | 2020-02-05T12:37:05 | [
"IRC",
"聊天"
] | https://linux.cn/article-11856-1.html |
>
> BitlBee 将多个聊天应用集合到一个界面中。在我们的 20 个使用开源提升生产力的系列的第九篇文章中了解如何设置和使用 BitlBee。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 将所有聊天都放到 BitlBee 中
即时消息和聊天已经成为网络世界的主要内容。如果你像我一样,你可能打开五六个不同的应用与你的朋友、同事和其他人交谈。关注所有聊天真的很痛苦。谢天谢地,你可以使用一个应用(好吧,是两个)将这些聊天整个到一个地方。

[BitlBee](https://www.bitlbee.org/) 是作为服务运行的应用,它可以将标准的 IRC 客户端与大量的消息服务进行桥接。而且,由于它本质上是 IRC 服务器,因此你可以选择很多客户端。
BitlBee 几乎包含在所有 Linux 发行版中。在 Ubuntu 上安装(我选择的 Linux 桌面),类似这样:
```
sudo apt install bitlbee-libpurple
```
在其他发行版上,包名可能略有不同,但搜索 “bitlbee” 应该就能看到。
你会注意到我用的 libpurple 版的 BitlBee。这个版本能让我使用 [libpurple](https://developer.pidgin.im/wiki/WhatIsLibpurple) 即时消息库中提供的所有协议,该库最初是为 [Pidgin](http://pidgin.im/) 开发的。
安装完成后,服务应会自动启动。现在,使用一个 IRC 客户端(图片中为 [XChat](http://xchat.org/)),我可以连接到端口 6667(标准 IRC 端口)上的服务。

你将自动连接到控制频道 &bitlbee。此频道对于你是独一无二的,在多用户系统上每个人都有一个自己的。在这里你可以配置该服务。
在控制频道中输入 `help`,你可以随时获得完整的文档。浏览它,然后使用 `register` 命令在服务器上注册帐户。
```
register <mypassword>
```
现在,你在服务器上所做的任何配置更改(IM 帐户、设置等)都将在输入 `save` 时保存。每当你连接时,使用 `identify <mypassword>` 连接到你的帐户并加载这些设置。

命令 `help purple` 将显示 libpurple 提供的所有可用协议。例如,我安装了 [telegram-purple](https://github.com/majn/telegram-purple) 包,它增加了连接到 Telegram 的能力。我可以使用 `account add` 命令将我的电话号码作为帐户添加。
```
account add telegram +15555555
```
BitlBee 将显示它已添加帐户。你可以使用 `account list` 列出你的帐户。因为我只有一个帐户,我可以通过 `account 0 on` 登录,它会进行 Telegram 登录,列出我所有的朋友和聊天,接下来就能正常聊天了。
但是,对于 Slack 这个最常见的聊天系统之一呢?你可以安装 [slack-libpurple](https://github.com/dylex/slack-libpurple) 插件,并且对 Slack 执行同样的操作。如果你不愿意编译和安装这些,这可能不适合你。
按照插件页面上的说明操作,安装后重新启动 BitlBee 服务。现在,当你运行 `help purple` 时,应该会列出 Slack。像其他协议一样添加一个 Slack 帐户。
```
account add slack [email protected]
account 1 set password my_legcay_API_token
account 1 on
```
你知道么,你已经连接到 Slack 中,你可以通过 `chat add` 命令添加你感兴趣的 Slack 频道。比如:
```
chat add 1 happyparty
```
将 Slack 频道 happyparty 添加为本地频道 #happyparty。现在可以使用标准 IRC `/join` 命令访问该频道。这很酷。
BitlBee 和 IRC 客户端帮助我的(大部分)聊天和即时消息保存在一个地方,并减少了我的分心,因为我不再需要查找并切换到任何一个刚刚找我的应用上。
---
via: <https://opensource.com/article/20/1/open-source-chat-tool>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Bring all your chats into one interface with BitlBee
Instant messaging and chat have become a staple of the online world. And if you are like me, you probably have about five or six different apps running to talk to your friends, co-workers, and others. It really is a pain to keep up with it all. Thankfully, you can use one app (OK, two apps) to consolidate a lot of those chats into a single point.
[BitlBee](https://www.bitlbee.org/) is an application that you run as a service that can bridge a standard IRC client with a whole bunch of messaging services. And since it is essentially an IRC server, you have a wealth of clients to choose from.
BitlBee is included with almost all Linux distributions. Installing on Ubuntu (my Linux desktop of choice) goes something like this:
`sudo apt install bitlbee-libpurple`
On other distributions, the name of the package may be slightly different, but a search for *bitlbee* should reveal your options.
You'll notice I use the libpurple version of BitlBee. This version allows me to use all the protocols available in the [libpurple](https://developer.pidgin.im/wiki/WhatIsLibpurple) instant messaging library, which was originally developed for [Pidgin](http://pidgin.im/).
Once the package is installed, the service should start automatically. Now, using an IRC client ([XChat](http://xchat.org/) in these pictures), I can connect to the service on port 6667 (the standard IRC port).
You will be automatically connected to the control channel **&bitlbee**. This channel is unique to you—every person gets their own on multi-user systems. This is where you can configure the services.
The full documentation is available at any time by typing **help** in the control channel. Explore here, then register an account on the server with the **register** command.
`register <mypassword>`
Now, any configuration changes you make on the server—IM accounts, settings, etc.—will be saved when you type **save**. Whenever you connect, use **identify <mypassword>** to connect to your account and load all those settings.
The command **help purple** will show you all the available protocols that libpurple provides. For example, I've installed the [ telegram-purple](https://github.com/majn/telegram-purple) package, which adds the ability to connect to Telegram. I can add an account by using my phone number with the
**account add**command.
`account add telegram +15555555`
BitlBee will show that it has added the account. You can list your accounts with **account list**. Since I only have one account, I can log into it with **account 0 on**, and it will go through the Telegram login process, list all my friends and chats, and I am good to go.
But what about Slack, one of the most common chat systems out there? Well, you can install the [ slack-libpurple](https://github.com/dylex/slack-libpurple) plugin, and do the same for Slack. If you aren't comfortable compiling and installing things, this may not be for you.
Follow the instructions on the plugin page, and after you have installed it, restart the BitlBee service. Now when you run **help purple**, Slack should be listed. Adding a Slack account happens the same as with all the other protocols.
```
account add slack [email protected]
account 1 set password my_legcay_API_token
account 1 on
```
And what do you know? You're connected to Slack, and you can add the Slack channels you're interested in with the **chat add** command. For example:
`chat add 1 happyparty`
adds the Slack channel happyparty as the local channel #happyparty. You can use the standard IRC **/join** command to access the channel now. Pretty cool.
BitlBee and an IRC client help me keep (most of) my chats and instant messages in a single place and reduces my distractions because I no longer have to find and switch to whichever app just pinged me.
## Comments are closed. |
11,857 | Java 中的数据流和函数式编程 | https://opensource.com/article/20/1/javastream | 2020-02-06T00:25:00 | [
"Java",
"函数式编程"
] | https://linux.cn/article-11857-1.html |
>
> 学习如何使用 Java 8 中的流 API 和函数式编程结构。
>
>
>

当 Java SE 8(又名核心 Java 8)在 2014 年被推出时,它引入了一些更改,从根本上影响了用它进行的编程。这些更改中有两个紧密相连的部分:流 API 和函数式编程构造。本文使用代码示例,从基础到高级特性,介绍每个部分并说明它们之间的相互作用。
### 基础特性
流 API 是在数据序列中迭代元素的简洁而高级的方法。包 `java.util.stream` 和 `java.util.function` 包含了用于流 API 和相关函数式编程构造的新库。当然,代码示例胜过千言万语。
下面的代码段用大约 2,000 个随机整数值填充了一个 `List`:
```
Random rand = new Random2();
List<Integer> list = new ArrayList<Integer>(); // 空 list
for (int i = 0; i < 2048; i++) list.add(rand.nextInt()); // 填充它
```
另外用一个 `for` 循环可用于遍历填充列表,以将偶数值收集到另一个列表中。
流 API 提供了一种更简洁的方法来执行此操作:
```
List <Integer> evens = list
.stream() // 流化 list
.filter(n -> (n & 0x1) == 0) // 过滤出奇数值
.collect(Collectors.toList()); // 收集偶数值
```
这个例子有三个来自流 API 的函数:
* `stream` 函数可以将**集合**转换为流,而流是一个每次可访问一个值的传送带。流化是惰性的(因此也是高效的),因为值是根据需要产生的,而不是一次性产生的。
* `filter` 函数确定哪些流的值(如果有的话)通过了处理管道中的下一个阶段,即 `collect` 阶段。`filter` 函数是 <ruby> 高阶的 <rt> higher-order </rt></ruby>,因为它的参数是一个函数 —— 在这个例子中是一个 lambda 表达式,它是一个未命名的函数,并且是 Java 新的函数式编程结构的核心。
lambda 语法与传统的 Java 完全不同:
```
n -> (n & 0x1) == 0
```
箭头(一个减号后面紧跟着一个大于号)将左边的参数列表与右边的函数体分隔开。参数 `n` 虽未明确类型,但也可以明确。在任何情况下,编译器都会发现 `n` 是个 `Integer`。如果有多个参数,这些参数将被括在括号中,并用逗号分隔。
在本例中,函数体检查一个整数的最低位(最右)是否为零,这用来表示偶数。过滤器应返回一个布尔值。尽管可以,但该函数的主体中没有显式的 `return`。如果主体没有显式的 `return`,则主体的最后一个表达式即是返回值。在这个例子中,主体按照 lambda 编程的思想编写,由一个简单的布尔表达式 `(n & 0x1) == 0` 组成。
* `collect` 函数将偶数值收集到引用为 `evens` 的列表中。如下例所示,`collect` 函数是线程安全的,因此,即使在多个线程之间共享了过滤操作,该函数也可以正常工作。
### 方便的功能和轻松实现多线程
在生产环境中,数据流的源可能是文件或网络连接。为了学习流 API, Java 提供了诸如 `IntStream` 这样的类型,它可以用各种类型的元素生成流。这里有一个 `IntStream` 的例子:
```
IntStream // 整型流
.range(1, 2048) // 生成此范围内的整型流
.parallel() // 为多个线程分区数据
.filter(i -> ((i & 0x1) > 0)) // 奇偶校验 - 只允许奇数通过
.forEach(System.out::println); // 打印每个值
```
`IntStream` 类型包括一个 `range` 函数,该函数在指定的范围内生成一个整数值流,在本例中,以 1 为增量,从 1 递增到 2048。`parallel` 函数自动划分该工作到多个线程中,在各个线程中进行过滤和打印。(线程数通常与主机系统上的 CPU 数量匹配。)函数 `forEach` 参数是一个*方法引用*,在本例中是对封装在 `System.out` 中的 `println` 方法的引用,方法输出类型为 `PrintStream`。方法和构造器引用的语法将在稍后讨论。
由于具有多线程,因此整数值整体上以任意顺序打印,但在给定线程中是按顺序打印的。例如,如果线程 T1 打印 409 和 411,那么 T1 将按照顺序 409-411 打印,但是其它某个线程可能会预先打印 2045。`parallel` 调用后面的线程是并发执行的,因此它们的输出顺序是不确定的。
### map/reduce 模式
*map/reduce* 模式在处理大型数据集方面变得很流行。一个 map/reduce 宏操作由两个微操作构成。首先,将数据分散(<ruby> 映射 <rt> mapped </rt></ruby>)到各个工作程序中,然后将单独的结果收集在一起 —— 也可能收集统计起来成为一个值,即<ruby> 归约 <rt> reduction </rt></ruby>。归约可以采用不同的形式,如以下示例所示。
下面 `Number` 类的实例用 `EVEN` 或 `ODD` 表示有奇偶校验的整数值:
```
public class Number {
enum Parity { EVEN, ODD }
private int value;
public Number(int n) { setValue(n); }
public void setValue(int value) { this.value = value; }
public int getValue() { return this.value; }
public Parity getParity() {
return ((value & 0x1) == 0) ? Parity.EVEN : Parity.ODD;
}
public void dump() {
System.out.format("Value: %2d (parity: %s)\n", getValue(),
(getParity() == Parity.ODD ? "odd" : "even"));
}
}
```
下面的代码演示了用 `Number` 流进行 map/reduce 的情形,从而表明流 API 不仅可以处理 `int` 和 `float` 等基本类型,还可以处理程序员自定义的类类型。
在下面的代码段中,使用了 `parallelStream` 而不是 `stream` 函数对随机整数值列表进行流化处理。与前面介绍的 `parallel` 函数一样,`parallelStream` 变体也可以自动执行多线程。
```
final int howMany = 200;
Random r = new Random();
Number[] nums = new Number[howMany];
for (int i = 0; i < howMany; i++) nums[i] = new Number(r.nextInt(100));
List<Number> listOfNums = Arrays.asList(nums); // 将数组转化为 list
Integer sum4All = listOfNums
.parallelStream() // 自动执行多线程
.mapToInt(Number::getValue) // 使用方法引用,而不是 lambda
.sum(); // 将流值计算出和值
System.out.println("The sum of the randomly generated values is: " + sum4All);
```
高阶的 `mapToInt` 函数可以接受一个 lambda 作为参数,但在本例中,它接受一个方法引用,即 `Number::getValue`。`getValue` 方法不需要参数,它返回给定的 `Number` 实例的 `int` 值。语法并不复杂:类名 `Number` 后跟一个双冒号和方法名。回想一下先前的例子 `System.out::println`,它在 `System` 类中的 `static` 属性 `out` 后面有一个双冒号。
方法引用 `Number::getValue` 可以用下面的 lambda 表达式替换。参数 `n` 是流中的 `Number` 实例中的之一:
```
mapToInt(n -> n.getValue())
```
通常,lambda 表达式和方法引用是可互换的:如果像 `mapToInt` 这样的高阶函数可以采用一种形式作为参数,那么这个函数也可以采用另一种形式。这两个函数式编程结构具有相同的目的 —— 对作为参数传入的数据执行一些自定义操作。在两者之间进行选择通常是为了方便。例如,lambda 可以在没有封装类的情况下编写,而方法则不能。我的习惯是使用 lambda,除非已经有了适当的封装方法。
当前示例末尾的 `sum` 函数通过结合来自 `parallelStream` 线程的部分和,以线程安全的方式进行归约。但是,程序员有责任确保在 `parallelStream` 调用引发的多线程过程中,程序员自己的函数调用(在本例中为 `getValue`)是线程安全的。
最后一点值得强调。lambda 语法鼓励编写<ruby> 纯函数 <rt> pure function </rt></ruby>,即函数的返回值仅取决于传入的参数(如果有);纯函数没有副作用,例如更新一个类中的 `static` 字段。因此,纯函数是线程安全的,并且如果传递给高阶函数的函数参数(例如 `filter` 和 `map` )是纯函数,则流 API 效果最佳。
对于更细粒度的控制,有另一个流 API 函数,名为 `reduce`,可用于对 `Number` 流中的值求和:
```
Integer sum4AllHarder = listOfNums
.parallelStream() // 多线程
.map(Number::getValue) // 每个 Number 的值
.reduce(0, (sofar, next) -> sofar + next); // 求和
```
此版本的 `reduce` 函数带有两个参数,第二个参数是一个函数:
* 第一个参数(在这种情况下为零)是*特征*值,该值用作求和操作的初始值,并且在求和过程中流结束时用作默认值。
* 第二个参数是*累加器*,在本例中,这个 lambda 表达式有两个参数:第一个参数(`sofar`)是正在运行的和,第二个参数(`next`)是来自流的下一个值。运行的和以及下一个值相加,然后更新累加器。请记住,由于开始时调用了 `parallelStream`,因此 `map` 和 `reduce` 函数现在都在多线程上下文中执行。
在到目前为止的示例中,流值被收集,然后被规约,但是,通常情况下,流 API 中的 `Collectors` 可以累积值,而不需要将它们规约到单个值。正如下一个代码段所示,收集活动可以生成任意丰富的数据结构。该示例使用与前面示例相同的 `listOfNums`:
```
Map<Number.Parity, List<Number>> numMap = listOfNums
.parallelStream()
.collect(Collectors.groupingBy(Number::getParity));
List<Number> evens = numMap.get(Number.Parity.EVEN);
List<Number> odds = numMap.get(Number.Parity.ODD);
```
第一行中的 `numMap` 指的是一个 `Map`,它的键是一个 `Number` 奇偶校验位(`ODD` 或 `EVEN`),其值是一个具有指定奇偶校验位值的 `Number` 实例的 `List`。同样,通过 `parallelStream` 调用进行多线程处理,然后 `collect` 调用(以线程安全的方式)将部分结果组装到 `numMap` 引用的 `Map` 中。然后,在 `numMap` 上调用 `get` 方法两次,一次获取 `evens`,第二次获取 `odds`。
实用函数 `dumpList` 再次使用来自流 API 的高阶 `forEach` 函数:
```
private void dumpList(String msg, List<Number> list) {
System.out.println("\n" + msg);
list.stream().forEach(n -> n.dump()); // 或者使用 forEach(Number::dump)
}
```
这是示例运行中程序输出的一部分:
```
The sum of the randomly generated values is: 3322
The sum again, using a different method: 3322
Evens:
Value: 72 (parity: even)
Value: 54 (parity: even)
...
Value: 92 (parity: even)
Odds:
Value: 35 (parity: odd)
Value: 37 (parity: odd)
...
Value: 41 (parity: odd)
```
### 用于代码简化的函数式结构
函数式结构(如方法引用和 lambda 表达式)非常适合在流 API 中使用。这些构造代表了 Java 中对高阶函数的主要简化。即使在糟糕的过去,Java 也通过 `Method` 和 `Constructor` 类型在技术上支持高阶函数,这些类型的实例可以作为参数传递给其它函数。由于其复杂性,这些类型在生产级 Java 中很少使用。例如,调用 `Method` 需要对象引用(如果方法是非**静态**的)或至少一个类标识符(如果方法是**静态**的)。然后,被调用的 `Method` 的参数作为**对象**实例传递给它,如果没有发生多态(那会出现另一种复杂性!),则可能需要显式向下转换。相比之下,lambda 和方法引用很容易作为参数传递给其它函数。
但是,新的函数式结构在流 API 之外具有其它用途。考虑一个 Java GUI 程序,该程序带有一个供用户按下的按钮,例如,按下以获取当前时间。按钮按下的事件处理程序可能编写如下:
```
JButton updateCurrentTime = new JButton("Update current time");
updateCurrentTime.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
currentTime.setText(new Date().toString());
}
});
```
这个简短的代码段很难解释。关注第二行,其中方法 `addActionListener` 的参数开始如下:
```
new ActionListener() {
```
这似乎是错误的,因为 `ActionListener` 是一个**抽象**接口,而**抽象**类型不能通过调用 `new` 实例化。但是,事实证明,还有其它一些实例被实例化了:一个实现此接口的未命名内部类。如果上面的代码封装在名为 `OldJava` 的类中,则该未命名的内部类将被编译为 `OldJava$1.class`。`actionPerformed` 方法在这个未命名的内部类中被重写。
现在考虑使用新的函数式结构进行这个令人耳目一新的更改:
```
updateCurrentTime.addActionListener(e -> currentTime.setText(new Date().toString()));
```
lambda 表达式中的参数 `e` 是一个 `ActionEvent` 实例,而 lambda 的主体是对按钮上的 `setText` 的简单调用。
### 函数式接口和函数组合
到目前为止,使用的 lambda 已经写好了。但是,为了方便起见,我们可以像引用封装方法一样引用 lambda 表达式。以下一系列简短示例说明了这一点。
考虑以下接口定义:
```
@FunctionalInterface // 可选,通常省略
interface BinaryIntOp {
abstract int compute(int arg1, int arg2); // abstract 声明可以被删除
}
```
注释 `@FunctionalInterface` 适用于声明*唯一*抽象方法的任何接口;在本例中,这个抽象接口是 `compute`。一些标准接口,(例如具有唯一声明方法 `run` 的 `Runnable` 接口)同样符合这个要求。在此示例中,`compute` 是已声明的方法。该接口可用作引用声明中的目标类型:
```
BinaryIntOp div = (arg1, arg2) -> arg1 / arg2;
div.compute(12, 3); // 4
```
包 `java.util.function` 提供各种函数式接口。以下是一些示例。
下面的代码段介绍了参数化的 `Predicate` 函数式接口。在此示例中,带有参数 `String` 的 `Predicate<String>` 类型可以引用具有 `String` 参数的 lambda 表达式或诸如 `isEmpty` 之类的 `String` 方法。通常情况下,Predicate 是一个返回布尔值的函数。
```
Predicate<String> pred = String::isEmpty; // String 方法的 predicate 声明
String[] strings = {"one", "two", "", "three", "four"};
Arrays.asList(strings)
.stream()
.filter(pred) // 过滤掉非空字符串
.forEach(System.out::println); // 只打印空字符串
```
在字符串长度为零的情况下,`isEmpty` Predicate 判定结果为 `true`。 因此,只有空字符串才能进入管道的 `forEach` 阶段。
下一段代码将演示如何将简单的 lambda 或方法引用组合成更丰富的 lambda 或方法引用。考虑这一系列对 `IntUnaryOperator` 类型的引用的赋值,它接受一个整型参数并返回一个整型值:
```
IntUnaryOperator doubled = n -> n * 2;
IntUnaryOperator tripled = n -> n * 3;
IntUnaryOperator squared = n -> n * n;
```
`IntUnaryOperator` 是一个 `FunctionalInterface`,其唯一声明的方法为 `applyAsInt`。现在可以单独使用或以各种组合形式使用这三个引用 `doubled`、`tripled` 和 `squared`:
```
int arg = 5;
doubled.applyAsInt(arg); // 10
tripled.applyAsInt(arg); // 15
squared.applyAsInt(arg); // 25
```
以下是一些函数组合的样例:
```
int arg = 5;
doubled.compose(squared).applyAsInt(arg); // 5 求 2 次方后乘 2:50
tripled.compose(doubled).applyAsInt(arg); // 5 乘 2 后再乘 3:30
doubled.andThen(squared).applyAsInt(arg); // 5 乘 2 后求 2 次方:100
squared.andThen(tripled).applyAsInt(arg); // 5 求 2 次方后乘 3:75
```
函数组合可以直接使用 lambda 表达式实现,但是引用使代码更简洁。
### 构造器引用
构造器引用是另一种函数式编程构造,而这些引用在比 lambda 和方法引用更微妙的上下文中非常有用。再一次重申,代码示例似乎是最好的解释方式。
考虑这个 [POJO](https://en.wikipedia.org/wiki/Plain_old_Java_object) 类:
```
public class BedRocker { // 基岩的居民
private String name;
public BedRocker(String name) { this.name = name; }
public String getName() { return this.name; }
public void dump() { System.out.println(getName()); }
}
```
该类只有一个构造函数,它需要一个 `String` 参数。给定一个名字数组,目标是生成一个 `BedRocker` 元素数组,每个名字代表一个元素。下面是使用了函数式结构的代码段:
```
String[] names = {"Fred", "Wilma", "Peebles", "Dino", "Baby Puss"};
Stream<BedRocker> bedrockers = Arrays.asList(names).stream().map(BedRocker::new);
BedRocker[] arrayBR = bedrockers.toArray(BedRocker[]::new);
Arrays.asList(arrayBR).stream().forEach(BedRocker::dump);
```
在较高的层次上,这个代码段将名字转换为 `BedRocker` 数组元素。具体来说,代码如下所示。`Stream` 接口(在包 `java.util.stream` 中)可以被参数化,而在本例中,生成了一个名为 `bedrockers` 的 `BedRocker` 流。
`Arrays.asList` 实用程序再次用于流化一个数组 `names`,然后将流的每一项传递给 `map` 函数,该函数的参数现在是构造器引用 `BedRocker::new`。这个构造器引用通过在每次调用时生成和初始化一个 `BedRocker` 实例来充当一个对象工厂。在第二行执行之后,名为 `bedrockers` 的流由五项 `BedRocker` 组成。
这个例子可以通过关注高阶 `map` 函数来进一步阐明。在通常情况下,一个映射将一个类型的值(例如,一个 `int`)转换为另一个*相同*类型的值(例如,一个整数的后继):
```
map(n -> n + 1) // 将 n 映射到其后继
```
然而,在 `BedRocker` 这个例子中,转换更加戏剧化,因为一个类型的值(代表一个名字的 `String`)被映射到一个*不同*类型的值,在这个例子中,就是一个 `BedRocker` 实例,这个字符串就是它的名字。转换是通过一个构造器调用来完成的,它是由构造器引用来实现的:
```
map(BedRocker::new) // 将 String 映射到 BedRocker
```
传递给构造器的值是 `names` 数组中的其中一项。
此代码示例的第二行还演示了一个你目前已经非常熟悉的转换:先将数组先转换成 `List`,然后再转换成 `Stream`:
```
Stream<BedRocker> bedrockers = Arrays.asList(names).stream().map(BedRocker::new);
```
第三行则是另一种方式 —— 流 `bedrockers` 通过使用*数组*构造器引用 `BedRocker[]::new` 调用 `toArray` 方法:
```
BedRocker[ ] arrayBR = bedrockers.toArray(BedRocker[]::new);
```
该构造器引用不会创建单个 `BedRocker` 实例,而是创建这些实例的整个数组:该构造器引用现在为 `BedRocker[]:new`,而不是 `BedRocker::new`。为了进行确认,将 `arrayBR` 转换为 `List`,再次对其进行流式处理,以便可以使用 `forEach` 来打印 `BedRocker` 的名字。
```
Fred
Wilma
Peebles
Dino
Baby Puss
```
该示例对数据结构的微妙转换仅用几行代码即可完成,从而突出了可以将 lambda,方法引用或构造器引用作为参数的各种高阶函数的功能。
### <ruby> 柯里化 <rt> Currying </rt></ruby>
*柯里化*函数是指减少函数执行任何工作所需的显式参数的数量(通常减少到一个)。(该术语是为了纪念逻辑学家 Haskell Curry。)一般来说,函数的参数越少,调用起来就越容易,也更健壮。(回想一下一些需要半打左右参数的噩梦般的函数!)因此,应将柯里化视为简化函数调用的一种尝试。`java.util.function` 包中的接口类型适合于柯里化,如以下示例所示。
引用的 `IntBinaryOperator` 接口类型是为函数接受两个整型参数,并返回一个整型值:
```
IntBinaryOperator mult2 = (n1, n2) -> n1 * n2;
mult2.applyAsInt(10, 20); // 200
mult2.applyAsInt(10, 30); // 300
```
引用 `mult2` 强调了需要两个显式参数,在本例中是 10 和 20。
前面介绍的 `IntUnaryOperator` 比 `IntBinaryOperator` 简单,因为前者只需要一个参数,而后者则需要两个参数。两者均返回整数值。因此,目标是将名为 `mult2` 的两个参数 `IntBinraryOperator` 柯里化成一个单一的 `IntUnaryOperator` 版本 `curriedMult2`。
考虑 `IntFunction<R>` 类型。此类型的函数采用整型参数,并返回类型为 `R` 的结果,该结果可以是另一个函数 —— 更准确地说,是 `IntBinaryOperator`。让一个 lambda 返回另一个 lambda 很简单:
```
arg1 -> (arg2 -> arg1 * arg2) // 括号可以省略
```
完整的 lambda 以 `arg1` 开头,而该 lambda 的主体以及返回的值是另一个以 `arg2` 开头的 lambda。返回的 lambda 仅接受一个参数(`arg2`),但返回了两个数字的乘积(`arg1` 和 `arg2`)。下面的概述,再加上代码,应该可以更好地进行说明。
以下是如何柯里化 `mult2` 的概述:
* 类型为 `IntFunction<IntUnaryOperator>` 的 lambda 被写入并调用,其整型值为 10。返回的 `IntUnaryOperator` 缓存了值 10,因此变成了已柯里化版本的 `mult2`,在本例中为 `curriedMult2`。
* 然后使用单个显式参数(例如,20)调用 `curriedMult2` 函数,该参数与缓存的参数(在本例中为 10)相乘以生成返回的乘积。。
这是代码的详细信息:
```
// 创建一个接受一个参数 n1 并返回一个单参数 n2 -> n1 * n2 的函数,该函数返回一个(n1 * n2 乘积的)整型数。
IntFunction<IntUnaryOperator> curriedMult2Maker = n1 -> (n2 -> n1 * n2);
```
调用 `curriedMult2Maker` 生成所需的 `IntUnaryOperator` 函数:
```
// 使用 curriedMult2Maker 获取已柯里化版本的 mult2。
// 参数 10 是上面的 lambda 的 n1。
IntUnaryOperator curriedMult2 = curriedMult2Maker2.apply(10);
```
值 `10` 现在缓存在 `curriedMult2` 函数中,以便 `curriedMult2` 调用中的显式整型参数乘以 10:
```
curriedMult2.applyAsInt(20); // 200 = 10 * 20
curriedMult2.applyAsInt(80); // 800 = 10 * 80
```
缓存的值可以随意更改:
```
curriedMult2 = curriedMult2Maker.apply(50); // 缓存 50
curriedMult2.applyAsInt(101); // 5050 = 101 * 50
```
当然,可以通过这种方式创建多个已柯里化版本的 `mult2`,每个版本都有一个 `IntUnaryOperator`。
柯里化充分利用了 lambda 的强大功能:可以很容易地编写 lambda 表达式来返回需要的任何类型的值,包括另一个 lambda。
### 总结
Java 仍然是基于类的面向对象的编程语言。但是,借助流 API 及其支持的函数式构造,Java 向函数式语言(例如 Lisp)迈出了决定性的(同时也是受欢迎的)一步。结果是 Java 更适合处理现代编程中常见的海量数据流。在函数式方向上的这一步还使以在前面的代码示例中突出显示的管道的方式编写清晰简洁的 Java 代码更加容易:
```
dataStream
.parallelStream() // 多线程以提高效率
.filter(...) // 阶段 1
.map(...) // 阶段 2
.filter(...) // 阶段 3
...
.collect(...); // 或者,也可以进行归约:阶段 N
```
自动多线程,以 `parallel` 和 `parallelStream` 调用为例,建立在 Java 的 fork/join 框架上,该框架支持 <ruby> 任务窃取 <rt> task stealing </rt></ruby> 以提高效率。假设 `parallelStream` 调用后面的线程池由八个线程组成,并且 `dataStream` 被八种方式分区。某个线程(例如,T1)可能比另一个线程(例如,T7)工作更快,这意味着应该将 T7 的某些任务移到 T1 的工作队列中。这会在运行时自动发生。
在这个简单的多线程世界中,程序员的主要职责是编写线程安全函数,这些函数作为参数传递给在流 API 中占主导地位的高阶函数。尤其是 lambda 鼓励编写纯函数(因此是线程安全的)函数。
---
via: <https://opensource.com/article/20/1/javastream>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When Java SE 8 (aka core Java 8) was introduced in 2014, it introduced changes that fundamentally impact programming in it. The changes have two closely linked parts: the stream API and the functional programming constructs. This article uses code examples, from the basics through advanced features, to introduce each part and illustrate the interplay between them.
## The basics
The stream API is a concise and high-level way to iterate over the elements in a data sequence. The packages **java.util.stream** and **java.util.function** house the new libraries for the stream API and related functional programming constructs. Of course, a code example is worth a thousand words.
The code segment below populates a **List** with about 2,000 random integer values:
```
Random rand = new Random();
List<Integer> list = new ArrayList<Integer>(); // empty list
for (int i = 0; i < 2048; i++) list.add(rand.nextInt()); // populate it
```
Another **for** loop could be used to iterate over the populated list to collect the even values into another list. The stream API is a cleaner way to do the same:
```
List <Integer> evens = list
.stream() // streamify the list
.filter(n -> (n & 0x1) == 0) // filter out odd values
.collect(Collectors.toList()); // collect even values
```
The example has three functions from the stream API:
-
The
**stream**function can turn a**Collection**into a stream, which is a conveyor belt of values accessible one at a time. The streamification is lazy (and therefore efficient) in that the values are produced as needed rather than all at once. -
The
**filter**function determines which streamed values, if any, get through to the next stage in the processing pipeline, the**collect**stage. The**filter**function is*higher-order*in that its argument is a function—in this example, a lambda, which is an unnamed function and at the center of Java's new functional programming constructs.The lambda syntax departs radically from traditional Java:
`n -> (n & 0x1) == 0`
The arrow (a minus sign followed immediately by a greater-than sign) separates the argument list on the left from the function's body on the right. The argument
**n**is not explicitly typed, although it could be; in any case, the compiler figures out that**n**is an**Integer**. If there were multiple arguments, these would be enclosed in parentheses and separated by commas.The body, in this example, checks whether an integer's lowest-order (rightmost) bit is a zero, which indicates an even value. A filter should return a boolean value. There is no explicit
**return**in the function's body, although there could be. If the body has no explicit**return**, then the body's last expression is the returned value. In this example, written in the spirit of lambda programming, the body consists of the single, simple boolean expression**(n & 0x1) == 0**. -
The
**collect**function gathers the even values into a list whose reference is**evens**. As an example below illustrates, the**collect**function is thread-safe and, therefore, would work correctly even if the filtering operation was shared among multiple threads.
## Convenience functions and easy multi-threading
In a production environment, a data stream might have a file or a network connection as its source. For learning the stream API, Java provides types such as **IntStream**, which can generate streams with elements of various types. Here is an **IntStream** example:
```
IntStream // integer stream
.range(1, 2048) // generate a stream of ints in this range
.parallel() // partition the data for multiple threads
.filter(i -> ((i & 0x1) > 0)) // odd parity? pass through only odds
.forEach(System.out::println); // print each
```
The **IntStream** type includes a **range** function that generates a stream of integer values within a specified range, in this case, from 1 through 2,048, with increments of 1. The **parallel** function automatically partitions the work to be done among multiple threads, each of which does the filtering and printing. (The number of threads typically matches the number of CPUs on the host system.) The argument to the **forEach** function is a *method reference*, in this case, a reference to the **println** method encapsulated in **System.out**, which is of type **PrintStream**. The syntax for method and constructor references will be discussed shortly.
Because of the multi-threading, the integer values are printed in an arbitrary order overall but in sequence within a given thread. For example, if thread T1 prints 409 and 411, then T1 does so in the order 409–411, but some other thread might print 2,045 beforehand. The threads behind the **parallel** call execute concurrently, and the order of their output is therefore indeterminate.
## The map/reduce pattern
The *map/reduce* pattern has become popular in processing large datasets. A map/reduce macro operation is built from two micro-operations. The data first are scattered (*mapped*) among various workers, and the separate results then are gathered together—perhaps as a single value, which would be the *reduction*. Reduction can take different forms, as the following examples illustrate.
Instances of the **Number** class below represent integer values with either **EVEN** or **ODD** parity:
```
public class Number {
enum Parity { EVEN, ODD }
private int value;
public Number(int n) { setValue(n); }
public void setValue(int value) { this.value = value; }
public int getValue() { return this.value; }
public Parity getParity() {
return ((value & 0x1) == 0) ? Parity.EVEN : Parity.ODD;
}
public void dump() {
System.out.format("Value: %2d (parity: %s)\n", getValue(),
(getParity() == Parity.ODD ? "odd" : "even"));
}
}
```
The following code illustrates map/reduce with a **Number** stream, thereby showing that the stream API can handle not only primitive types such as **int** and **float** but programmer-defined class types as well.
In the code segment below, a list of random integer values is streamified using the **parallelStream** rather than the **stream** function. The **parallelStream** variant, like the **parallel** function introduced earlier, does automatic multithreading.
```
final int howMany = 200;
Random r = new Random();
Number[ ] nums = new Number[howMany];
for (int i = 0; i < howMany; i++) nums[i] = new Number(r.nextInt(100));
List<Number> listOfNums = Arrays.asList(nums); // listify the array
Integer sum4All = listOfNums
.parallelStream() // automatic multi-threading
.mapToInt(Number::getValue) // method reference rather than lambda
.sum(); // reduce streamed values to a single value
System.out.println("The sum of the randomly generated values is: " + sum4All);
```
The higher-order **mapToInt** function could take a lambda as an argument, but in this case, it takes a method reference instead, which is **Number::getValue**. The **getValue** method expects no arguments and returns its **int** value for a given **Number** instance. The syntax is uncomplicated: the class name **Number** followed by a double colon and the method's name. Recall the earlier **System.out::println** example, which has the double colon after the **static** field **out** in the **System** class.
The method reference **Number::getValue** could be replaced by the lambda below. The argument **n** is one of the **Number** instances in the stream:
`mapToInt(n -> n.getValue())`
In general, lambdas and method references are interchangeable: if a higher-order function such as **mapToInt** can take one form as an argument, then this function could take the other as well. The two functional programming constructs have the same purpose—to perform some customized operation on data passed in as arguments. Choosing between the two is often a matter of convenience. For example, a lambda can be written without an encapsulating class, whereas a method cannot. My habit is to use a lambda unless the appropriate encapsulated method is already at hand.
The **sum** function at the end of the current example does the reduction in a thread-safe manner by combining the partial sums from the **parallelStream** threads. However, the programmer is responsible for ensuring that, in the course of the multi-threading induced by the **parallelStream** call, the programmer's own function calls (in this case, to **getValue**) are thread-safe.
The last point deserves emphasis. Lambda syntax encourages the writing of *pure functions*, which are functions whose return values depend only on the arguments, if any, passed in; a pure function has no side effects such as updating a **static** field in a class. Pure functions are thereby thread-safe, and the stream API works best if the functional arguments passed to higher-order functions, such as **filter** and **map**, are pure functions.
For finer-grained control, there is another stream API function, named **reduce**, that could be used for summing the values in the **Number** stream:
```
Integer sum4AllHarder = listOfNums
.parallelStream() // multi-threading
.map(Number::getValue) // value per Number
.reduce(0, (sofar, next) -> sofar + next); // reduction to a sum
```
This version of the **reduce** function takes two arguments, the second of which is a function:
- The first argument (in this case, zero) is the
*identity*value, which serves as the initial value for the reduction operation and as the default value should the stream run dry during the reduction. - The second argument is the
*accumulator*, in this case, a lambda with two arguments: the first argument (**sofar**) is the running sum, and the second argument (**next**) is the next value from the stream. The running sum and next value then are added to update the accumulator. Keep in mind that both the**map**and the**reduce**functions now execute in a multi-threaded context because of the**parallelStream**call at the start.
In the examples so far, stream values are collected and then reduced, but, in general, the **Collectors** in the stream API can accumulate values without reducing them to a single value. The collection activity can produce arbitrarily rich data structures, as the next code segment illustrates. The example uses the same **listOfNums** as the preceding examples:
```
Map<Number.Parity, List<Number>> numMap = listOfNums
.parallelStream()
.collect(Collectors.groupingBy(Number::getParity));
List<Number> evens = numMap.get(Number.Parity.EVEN);
List<Number> odds = numMap.get(Number.Parity.ODD);
```
The **numMap** in the first line refers to a **Map** whose key is a **Number** parity (**ODD** or **EVEN**) and whose value is a **List** of **Number** instances with values having the designated parity. Once again, the processing is multi-threaded through the **parallelStream** call, and the **collect** call then assembles (in a thread-safe manner) the partial results into the single **Map** to which **numMap** refers. The **get** method then is called twice on the **numMap**, once to get the **evens** and a second time to get the **odds**.
The utility function **dumpList** again uses the higher-order **forEach** function from the stream API:
```
private void dumpList(String msg, List<Number> list) {
System.out.println("\n" + msg);
list.stream().forEach(n -> n.dump()); // or: forEach(Number::dump)
}
```
Here is a slice of the program's output from a sample run:
```
The sum of the randomly generated values is: 3322
The sum again, using a different method: 3322
Evens:
Value: 72 (parity: even)
Value: 54 (parity: even)
...
Value: 92 (parity: even)
Odds:
Value: 35 (parity: odd)
Value: 37 (parity: odd)
...
Value: 41 (parity: odd)
```
## Functional constructs for code simplification
Functional constructs, such as method references and lambdas, fit nicely into the stream API. These constructs represent a major simplification of higher-order functions in Java. Even in the bad old days, Java technically supported higher-order functions through the **Method** and **Constructor** types, instances of which could be passed as arguments to other functions. These types were used—but rarely in production-grade Java precisely because of their complexity. Invoking a **Method**, for example, requires either an object reference (if the method is non-**static**) or at least a class identifier (if the method is **static**). The arguments for the invoked **Method** then are passed to it as **Object** instances, which may require explicit downcasting if polymorphism (another complexity!) is not in play. By contrast, lambdas and method references are easy to pass as arguments to other functions.
The new functional constructs have uses beyond the stream API, however. Consider a Java GUI program with a button for the user to push, for example, to get the current time. The event handler for the button push might be written as follows:
```
JButton updateCurrentTime = new JButton("Update current time");
updateCurrentTime.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
currentTime.setText(new Date().toString());
}
});
```
This short code segment is a challenge to explain. Consider the second line in which the argument to the method **addActionListener** begins as follows:
`new ActionListener() {`
This seems wrong in that **ActionListener** is an **abstract** interface, and **abstract** types cannot be instantiated with a call to **new**. However, it turns out that something else entirely is being instantiated: an unnamed inner class that implements this interface. If the code above were encapsulated in a class named **OldJava**, then this unnamed inner class would be compiled as **OldJava$1.class**. The **actionPerformed** method is overridden in the unnamed inner class.
Now consider this refreshing change with the new functional constructs:
`updateCurrentTime.addActionListener(e -> currentTime.setText(new Date().toString()));`
The argument **e** in the lambda is an **ActionEvent** instance, and the lambda's body is a simple call to **setText** on the button.
## Functional interfaces and composition
The lambdas used so far have been written in place. For convenience, however, there can be references to lambdas just as there are to encapsulated methods. The following series of short examples illustrate this.
Consider this interface definition:
```
@FunctionalInterface // optional, usually omitted
interface BinaryIntOp {
abstract int compute(int arg1, int arg2); // abstract could be dropped
}
```
The annotation **@FunctionalInterface** applies to any interface that declares a *single* abstract method; in this case, **compute**. Several standard interfaces (e.g., the **Runnable** interface with its single declared method, **run**) fit the bill. In this example, **compute** is the declared method. The interface can be used as the target type in a reference declaration:
```
BinaryIntOp div = (arg1, arg2) -> arg1 / arg2;
div.compute(12, 3); // 4
```
The package **java.util.function** provides various functional interfaces. Some examples follow.
The code segment below introduces the parameterized **Predicate** functional interface. In this example, the type **Predicate<String>** with parameter **String** can refer to either a lambda with a **String** argument or a **String** method such as **isEmpty**. In general, a *predicate* is a function that returns a boolean value.
```
Predicate<String> pred = String::isEmpty; // predicate for a String method
String[ ] strings = {"one", "two", "", "three", "four"};
Arrays.asList(strings)
.stream()
.filter(pred) // filter out non-empty strings
.forEach(System.out::println); // only the empty string is printed
```
The **isEmpty** predicate evaluates to **true** just in case a string's length is zero; hence, only the empty string makes it through to the **forEach** stage in the pipeline.
The next code segments illustrate how simple lambdas or method references can be composed into richer ones. Consider this series of assignments to references of the **IntUnaryOperator** type, which takes an integer argument and returns an integer value:
```
IntUnaryOperator doubled = n -> n * 2;
IntUnaryOperator tripled = n -> n * 3;
IntUnaryOperator squared = n -> n * n;
```
**IntUnaryOperator** is a **FunctionalInterface** whose single declared method is **applyAsInt**. The three references **doubled**, **tripled**, and **squared** now can be used standalone or in various compositions:
```
int arg = 5;
doubled.applyAsInt(arg); // 10
tripled.applyAsInt(arg); // 15
squared.applyAsInt(arg); // 25
```
Here are some sample compositions:
```
int arg = 5;
doubled.compose(squared).applyAsInt(arg); // doubled-the-squared: 50
tripled.compose(doubled).applyAsInt(arg); // tripled-the-doubled: 30
doubled.andThen(squared).applyAsInt(arg); // doubled-andThen-squared: 100
squared.andThen(tripled).applyAsInt(arg); // squared-andThen-tripled: 75
```
Compositions could be done with in-place lambdas, but the references make the code cleaner.
## Constructor references
Constructor references are yet another of the functional programming constructs, but these references are useful in more subtle contexts than lambdas and method references. Once again, a code example seems the best way to clarify.
Consider this [POJO](https://en.wikipedia.org/wiki/Plain_old_Java_object) class:
```
public class BedRocker { // resident of Bedrock
private String name;
public BedRocker(String name) { this.name = name; }
public String getName() { return this.name; }
public void dump() { System.out.println(getName()); }
}
```
The class has a single constructor, which requires a **String** argument. Given an array of names, the goal is to generate an array of **BedRocker** elements, one per name. Here is the code segment that uses functional constructs to do so:
```
String[ ] names = {"Fred", "Wilma", "Peebles", "Dino", "Baby Puss"};
Stream<BedRocker> bedrockers = Arrays.asList(names).stream().map(BedRocker::new);
BedRocker[ ] arrayBR = bedrockers.toArray(BedRocker[]::new);
Arrays.asList(arrayBR).stream().forEach(BedRocker::dump);
```
At a high level, this code segment transforms names into **BedRocker** array elements. In detail, the code works as follows. The **Stream** interface (in the package **java.util.stream**) can be parameterized, in this case, to generate a stream of **BedRocker** items named **bedrockers**.
The **Arrays.asList** utility again is used to streamify an array, **names**, with each stream item then passed to the **map** function whose argument now is the constructor reference **BedRocker::new**. This constructor reference acts as an object factory by generating and initializing, on each call, a **BedRocker** instance. After the second line executes, the stream named **bedrockers** consists of five **BedRocker** items.
The example can be clarified further by focusing on the higher-order **map** function. In a typical case, a mapping transforms a value of one type (e.g., an **int**) into a different value of the *same* type (e.g., an integer's successor):
`map(n -> n + 1) // map n to its successor`
In the **BedRocker** example, however, the transformation is more dramatic because a value of one type (a **String** representing a name) is mapped to a value of a *different* type, in this case, a **BedRocker** instance with the string as its name. The transformation is done through a constructor call, which is enabled by the constructor reference:
`map(BedRocker::new) // map a String to a BedRocker`
The value passed to the constructor is one of the names in the **names** array.
The second line of this code example also illustrates the by-now-familiar transformation of an array first into a **List** and then into a **Stream**:
`Stream<BedRocker> bedrockers = Arrays.asList(names).stream().map(BedRocker::new);`
The third line goes the other way—the stream **bedrockers** is transformed into an array by invoking the **toArray** method with the *array* constructor reference **BedRocker[]::new**:
`BedRocker[ ] arrayBR = bedrockers.toArray(BedRocker[]::new);`
This constructor reference does not create a single **BedRocker** instance, but rather an entire array of these: the constructor reference is now **BedRocker[]::new** rather than **BedRocker::new**. For confirmation, the **arrayBR** is transformed into a **List**, which again is streamified so that **forEach** can be used to print the **BedRocker** names:
```
Fred
Wilma
Peebles
Dino
Baby Puss
```
The example's subtle transformations of data structures are done with but few lines of code, underscoring the power of various higher-order functions that can take a lambda, a method reference, or a constructor reference as an argument
## Currying
To *curry* a function is to reduce (typically by one) the number of explicit arguments required for whatever work the function does. (The term honors the logician Haskell Curry.) In general, functions are easier to call and are more robust if they have fewer arguments. (Recall some nightmarish function that expects a half-dozen or so arguments!) Accordingly, currying should be seen as an effort to simplify a function call. The interface types in the **java.util.function** package are suited for currying, as the next example shows.
References of the **IntBinaryOperator** interface type are for functions that take two integer arguments and return an integer value:
```
IntBinaryOperator mult2 = (n1, n2) -> n1 * n2;
mult2.applyAsInt(10, 20); // 200
mult2.applyAsInt(10, 30); // 300
```
The reference name **mult2** underscores that two explicit arguments are required, in this example, 10 and 20.
The previously introduced **IntUnaryOperator** is simpler than an **IntBinaryOperator** because the former requires just one argument, whereas the latter requires two arguments. Both return an integer value. The goal, therefore, is to curry the two-argument **IntBinraryOperator** named **mult2** into a one-argument **IntUnaryOperator** version **curriedMult2**.
Consider the type **IntFunction<R>**. A function of this type takes an integer argument and returns a result of type **R**, which could be another function—indeed, an **IntBinaryOperator**. Having a lambda return another lambda is straightforward:
`arg1 -> (arg2 -> arg1 * arg2) // parentheses could be omitted`
The full lambda starts with **arg1,** and this lambda's body—and returned value—is another lambda, which starts with **arg2**. The returned lambda takes just one argument (**arg2**) but returns the product of two numbers (**arg1** and **arg2**). The following overview, followed by the code, should clarify.
Here is an overview of how **mult2** can be curried:
- A lambda of type
**IntFunction<IntUnaryOperator>**is written and called with an integer value such as 10. The returned**IntUnaryOperator**caches the value 10 and thereby becomes the curried version of**mult2**, in this example,**curriedMult2**. - The
**curriedMult2**function then is called with a single explicit argument (e.g., 20), which is multiplied with the cached argument (in this case, 10) to produce the product returned.
Here are the details in code:
```
// Create a function that takes one argument n1 and returns a one-argument
// function n2 -> n1 * n2 that returns an int (the product n1 * n2).
IntFunction<IntUnaryOperator> curriedMult2Maker = n1 -> (n2 -> n1 * n2);
```
Calling the **curriedMult2Maker** generates the desired **IntUnaryOperator** function:
```
// Use the curriedMult2Maker to get a curried version of mult2.
// The argument 10 is n1 from the lambda above.
IntUnaryOperator curriedMult2 = curriedMult2Maker2.apply(10);
```
The value 10 is now cached in the **curriedMult2** function so that the explicit integer argument in a **curriedMult2** call will be multiplied by 10:
```
curriedMult2.applyAsInt(20); // 200 = 10 * 20
curriedMult2.applyAsInt(80); // 800 = 10 * 80
```
The cached value can be changed at will:
```
curriedMult2 = curriedMult2Maker.apply(50); // cache 50
curriedMult2.applyAsInt(101); // 5050 = 101 * 50
```
Of course, multiple curried versions of **mult2**, each an **IntUnaryOperator**, can be created in this way.
Currying takes advantage of a powerful feature about lambdas: a lambda is easily written to return whatever type of value is needed, including another lambda.
## Wrapping up
Java remains a class-based object-oriented programming language. But with the stream API and its supporting functional constructs, Java takes a decisive (and welcomed) step toward functional languages such as Lisp. The result is a Java better suited to process the massive data streams so common in modern programming. This step in the functional direction also makes it easier to write clear, concise Java in the pipeline style highlighted in previous code examples:
```
dataStream
.parallelStream() // multi-threaded for efficiency
.filter(...) // stage 1
.map(...) // stage 2
.filter(...) // stage 3
...
.collect(...); // or, perhaps, reduce: stage N
```
The automatic multi-threading, illustrated with the **parallel** and **parallelStream** calls, is built upon Java's fork/join framework, which supports *task stealing* for efficiency. Suppose that the thread pool behind a **parallelStream** call consists of eight threads and that the **dataStream** is partitioned eight ways. Some thread (e.g., T1) might work faster than another (e.g., T7), which means that some of T7's tasks ought to be moved into T1's work queue. This happens automatically at runtime.
The programmer's chief responsibility in this easy multi-threading world is to write thread-safe functions passed as arguments to the higher-order functions that dominate in the stream API. Lambdas, in particular, encourage the writing of pure—and, therefore, thread-safe—functions.
## 3 Comments |
11,858 | 使用这个 Twitter 客户端在 Linux 终端中发推特 | https://opensource.com/article/20/1/tweet-terminal-rainbow-stream | 2020-02-06T11:38:21 | [
"twitter"
] | https://linux.cn/article-11858-1.html |
>
> 在我们的 20 个使用开源提升生产力的系列的第十篇文章中,使用 Rainbow Stream 跟上你的 Twitter 流而无需离开终端。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 通过 Rainbow Stream 跟上Twitter
我喜欢社交网络和微博。它快速、简单,还有我可以与世界分享我的想法。当然,缺点是几乎所有非 Windows 的桌面客户端都对是网站的封装。[Twitter](https://twitter.com/home) 有很多客户端,但我真正想要的是轻量、易于使用,最重要的是吸引人的客户端。

[Rainbow Stream](https://rainbowstream.readthedocs.io/en/latest/) 是好看的 Twitter 客户端之一。它简单易用,并且可以通过 `pip3 install rainbowstream` 快速安装。第一次运行时,它将打开浏览器窗口,并让你通过 Twitter 授权。完成后,你将回到命令行,你的 Twitter 时间线将开始滚动。

要了解的最重要的命令是 `p` 暂停推流、`r` 继续推流、`h` 得到帮助,以及 `t` 发布新的推文。例如,`h tweets` 将提供发送和回复推文的所有选项。另一个有用的帮助页面是 `h messages`,它提供了处理直接消息的命令,这是我妻子和我经常使用的东西。还有很多其他命令,我会回头获得很多帮助。
随着时间线的滚动,你可以看到它有完整的 UTF-8 支持,并以正确的字体显示推文被转推以及喜欢的次数,图标和 emoji 也能正确显示。

关于 Rainbow Stream 的*最好*功能之一就是你不必放弃照片和图像。默认情况下,此功能是关闭的,但是你可以使用 `config` 命令尝试它。
```
config IMAGE_ON_TERM = true
```
此命令将任何图像渲染为 ASCII 艺术。如果你有大量照片流,它可能会有点多,但是我喜欢。它有非常复古的 1990 年代 BBS 感觉,我也确实喜欢 1990 年代的 BBS 场景。
你还可以使用 Rainbow Stream 管理列表、屏蔽某人、拉黑某人、关注、取消关注以及 Twitter API 的所有其他功能。它还支持主题,因此你可以用喜欢的颜色方案自定义流。
当我正在工作并且不想在浏览器上打开另一个选项卡时,Rainbow Stream 让我可以留在终端中。
---
via: <https://opensource.com/article/20/1/tweet-terminal-rainbow-stream>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Keep up with Twitter with Rainbow Stream
I love social networking and microblogging. It's quick, it's easy, and I can share my thoughts with the world really quickly. The drawback is, of course, that almost all the desktop options for non-Windows users are wrappers around the website. [Twitter](https://twitter.com/home) has a lot of clients, but what I really want is something lightweight, easy to use, and most importantly, attractive.
[Rainbow Stream](https://rainbowstream.readthedocs.io/en/latest/) is one of the prettier Twitter clients. It is easy to use and installs quickly with a simple **pip3 install rainbowstream**. On the first run, it will open a browser window and have you authorize with Twitter. Once that is done, you land at a prompt, and your Twitter timeline will start scrolling by.
The most important commands to know are **p** to pause the stream, **r** to resume the stream, **h** to get help, and **t** to post a new tweet. For example, **h tweets** will give you all the options for sending and replying to tweets. Another useful help screen is **h messages**, which gives the commands for working with direct messages, which is something my wife and I use a lot. There are a lot of other commands, and I refer back to help a lot.
As your timeline scrolls by, you can see that it has full UTF-8 support and, with the right font, will show indicators for how many times something was retweeted and liked, as well as icons and emojis.
One of the *best* things about Rainbow Stream is that you don't have to give up on photos and images. This feature is off by default, but you can try it out with the **config** command.
`config IMAGE_ON_TERM = true`
This command renders any images as ASCII art. If you have a photo-heavy stream, this may be a bit much, but I like it. It has a very retro-1990s BBS feel, and I did love the BBS scene in the 1990s.
You can also use Rainbow Stream to manage lists, mute people, block people, follow, unfollow, and everything else that is available with the Twitter API. There is also theme support, so you can customize the stream to your favorite color scheme.
When I'm working and don't want to have yet-another-tab open on my browser, Rainbow Stream lets me keep up in a terminal off to the side.
## Comments are closed. |
11,861 | MidnightBSD:或许是你通往 FreeBSD 的大门 | https://www.linux.com/learn/intro-to-linux/2018/5/midnightbsd-could-be-your-gateway-freebsd | 2020-02-06T15:41:10 | [
"FreeBSD",
"MidnightBSD"
] | https://linux.cn/article-11861-1.html | 
[FreeBSD](https://www.freebsd.org/) 是一个开源操作系统,衍生自著名的 <ruby> <a href="https://en.wikipedia.org/wiki/Berkeley_Software_Distribution"> 伯克利软件套件 </a> <rt> Berkeley Software Distribution </rt></ruby>(BSD)。FreeBSD 的第一个版本发布于 1993 年,并且仍然在继续发展。2007 年左右,Lucas Holt 想要利用 OpenStep(现在是 Cocoa)的 Objective-C 框架、widget 工具包和应用程序开发工具的 [GnuStep](https://en.wikipedia.org/wiki/GNUstep) 实现,来创建一个 FreeBSD 的分支。为此,他开始开发 MidnightBSD 桌面发行版。
MidnightBSD(以 Lucas 的猫 Midnight 命名)仍然在积极地(尽管缓慢)开发。从 2017 年 8 月开始,可以获得最新的稳定发布版本(0.8.6)(LCTT 译注:截止至本译文发布时,当前是 2019/10/31 发布的 1.2 版)。尽管 BSD 发行版不是你所说的用户友好型发行版,但上手安装是熟悉如何处理 文本(ncurses)安装过程以及通过命令行完成安装的好方法。
这样,你最终会得到一个非常可靠的 FreeBSD 分支的桌面发行版。这需要花费一点精力,但是如果你是一名正在寻找扩展你的技能的 Linux 用户……这是一个很好的起点。
我将带你走过安装 MidnightBSD 的流程,如何添加一个图形桌面环境,然后如何安装应用程序。
### 安装
正如我所提到的,这是一个文本(ncurses)安装过程,因此在这里找不到可以用鼠标点击的地方。相反,你将使用你键盘的 `Tab` 键和箭头键。在你下载[最新的发布版本](http://www.midnightbsd.org/download/)后,将它刻录到一个 CD/DVD 或 USB 驱动器,并启动你的机器(或者在 [VirtualBox](https://www.virtualbox.org/) 中创建一个虚拟机)。安装程序将打开并给你三个选项(图 1)。使用你的键盘的箭头键选择 “Install”,并敲击回车键。

*图 1: 启动 MidnightBSD 安装程序。*
在这里要经历相当多的屏幕。其中很多屏幕是一目了然的:
1. 设置非默认键盘映射(是/否)
2. 设置主机名称
3. 添加可选系统组件(文档、游戏、32 位兼容性、系统源码代码)
4. 对硬盘分区
5. 管理员密码
6. 配置网络接口
7. 选择地区(时区)
8. 启用服务(例如 ssh)
9. 添加用户(图 2)

*图 2: 向系统添加一个用户。*
在你向系统添加用户后,你将被进入到一个窗口中(图 3),在这里,你可以处理任何你可能忘记配置或你想重新配置的东西。如果你不需要作出任何更改,选择 “Exit”,然后你的配置就会被应用。

*图 3: 应用你的配置。*
在接下来的窗口中,当出现提示时,选择 “No”,接下来系统将重启。在 MidnightBSD 重启后,你已经为下一阶段的安装做好了准备。
### 后安装阶段
当你最新安装的 MidnightBSD 启动时,你将发现你自己处于命令提示符当中。此刻,还没有图形界面。要安装应用程序,MidnightBSD 依赖于 `mport` 工具。比如说你想安装 Xfce 桌面环境。为此,登录到 MidnightBSD 中,并发出下面的命令:
```
sudo mport index
sudo mport install xorg
```
你现在已经安装好 Xorg 窗口服务器了,它允许你安装桌面环境。使用命令来安装 Xfce :
```
sudo mport install xfce
```
现在 Xfce 已经安装好。不过,我们必须让它同命令 `startx` 一起启用。为此,让我们先安装 nano 编辑器。发出命令:
```
sudo mport install nano
```
随着 nano 安装好,发出命令:
```
nano ~/.xinitrc
```
这个文件仅包含一行内容:
```
exec startxfce4
```
保存并关闭这个文件。如果你现在发出命令 `startx`, Xfce 桌面环境将会启动。你应该会感到有点熟悉了吧(图 4)。

*图 4: Xfce 桌面界面已准备好服务。*
因为你不会总是想必须发出命令 `startx`,你希望启用登录守护进程。然而,它却没有安装。要安装这个子系统,发出命令:
```
sudo mport install mlogind
```
当完成安装后,通过在 `/etc/rc.conf` 文件中添加一个项目来在启动时启用 mlogind。在 `rc.conf` 文件的底部,添加以下内容:
```
mlogind_enable=”YES”
```
保存并关闭该文件。现在,当你启动(或重启)机器时,你应该会看到图形登录屏幕。在写这篇文章的时候,在登录后我最后得到一个空白屏幕和讨厌的 X 光标。不幸的是,目前似乎并没有这个问题的解决方法。所以,要访问你的桌面环境,你必须使用 `startx` 命令。
### 安装应用
默认情况下,你找不到很多能可用的应用程序。如果你尝试使用 `mport` 安装应用程序,你很快就会感到沮丧,因为只能找到很少的应用程序。为解决这个问题,我们需要使用 `svnlite` 命令来查看检出的可用 mport 软件列表。回到终端窗口,并发出命令:
```
svnlite co http://svn.midnightbsd.org/svn/mports/trunk mports
```
在你完成这些后,你应该看到一个命名为 `~/mports` 的新目录。使用命令 `cd ~/.mports` 更改到这个目录。发出 `ls` 命令,然后你应该看到许多的类别(图 5)。

*图 5: mport 现在可用的应用程序类别。*
你想安装 Firefox 吗?如果你查看 `www` 目录,你将看到一个 `linux-firefox` 列表。发出命令:
```
sudo mport install linux-firefox
```
现在你应该会在 Xfce 桌面菜单中看到一个 Firefox 项。翻找所有的类别,并使用 `mport` 命令来安装你需要的所有软件。
### 一个悲哀的警告
一个悲哀的小警告是,`mport` (通过 `svnlite`)仅能找到的一个办公套件的版本是 OpenOffice 3 。那是非常过时的。尽管在 `~/mports/editors` 目录中能找到 Abiword ,但是它看起来不能安装。甚至在安装 OpenOffice 3 后,它会输出一个执行格式错误。换句话说,你不能使用 MidnightBSD 在办公生产效率方面做很多的事情。但是,嘿嘿,如果你周围正好有一个旧的 Palm Pilot,你可以安装 pilot-link。换句话说,可用的软件不足以构成一个极其有用的桌面发行版……至少对普通用户不是。但是,如果你想在 MidnightBSD 上开发,你将找到很多可用的工具可以安装(查看 `~/mports/devel` 目录)。你甚至可以使用命令安装 Drupal :
```
sudo mport install drupal7
```
当然,在此之后,你将需要创建一个数据库(MySQL 已经安装)、安装 Apache(`sudo mport install apache24`),并配置必要的 Apache 配置。
显然地,已安装的和可以安装的是一个应用程序、系统和服务的大杂烩。但是随着足够多的工作,你最终可以得到一个能够服务于特殊目的的发行版。
### 享受 \*BSD 优良
这就是如何使 MidnightBSD 启动,并使其运行某种有用的桌面发行版的方法。它不像很多其它的 Linux 发行版一样快速简便,但是如果你想要一个促使你思考的发行版,这可能正是你正在寻找的。尽管大多数竞争对手都准备了很多可以安装的应用软件,但 MidnightBSD 无疑是一个 Linux 爱好者或管理员应该尝试的有趣挑战。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/5/midnightbsd-could-be-your-gateway-freebsd>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,863 | COPR 仓库中 4 个很酷的新项目(2020.01) | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january-2020/ | 2020-02-06T21:17:00 | [
"COPR"
] | https://linux.cn/article-11863-1.html | 
COPR 是个人软件仓库[集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
本文介绍了 COPR 中一些有趣的新项目。如果你第一次使用 COPR,请参阅 [COPR 用户文档](https://docs.pagure.org/copr.copr/user_documentation.html#)。
### Contrast
[Contrast](https://gitlab.gnome.org/World/design/contrast) 是一款小应用,用于检查两种颜色之间的对比度并确定其是否满足 [WCAG](https://www.w3.org/WAI/standards-guidelines/wcag/) 中指定的要求。可以使用十六进制 RGB 代码或使用颜色选择器选择颜色。除了显示对比度之外,Contrast 还以选定的颜色为背景上显示短文本来显示比较。

#### 安装说明
[仓库](https://copr.fedorainfracloud.org/coprs/atim/contrast/)当前为 Fedora 31 和 Rawhide 提供了 Contrast。要安装 Contrast,请使用以下命令:
```
sudo dnf copr enable atim/contrast
sudo dnf install contrast
```
### Pamixer
[Pamixer](https://github.com/cdemoulins/pamixer) 是一个使用 PulseAudio 调整和监控声音设备音量的命令行工具。你可以显示设备的当前音量并直接增加/减小它,或静音/取消静音。Pamixer 可以列出所有源和接收器。
#### 安装说明
[仓库](https://copr.fedorainfracloud.org/coprs/atim/contrast/)当前为 Fedora 31 和 Rawhide 提供了 Pamixer。要安装 Pamixer,请使用以下命令:
```
sudo dnf copr enable opuk/pamixer
sudo dnf install pamixer
```
### PhotoFlare
[PhotoFlare](https://photoflare.io/) 是一款图像编辑器。它有简单且布局合理的用户界面,其中的大多数功能都可在工具栏中使用。尽管它不支持使用图层,但 PhotoFlare 提供了诸如各种颜色调整、图像变换、滤镜、画笔和自动裁剪等功能。此外,PhotoFlare 可以批量编辑图片,来对所有图片应用相同的滤镜和转换,并将结果保存在指定目录中。

#### 安装说明
[仓库](https://copr.fedorainfracloud.org/coprs/atim/contrast/)当前为 Fedora 31 提供了 PhotoFlare。要安装 PhotoFlare,请使用以下命令:
```
sudo dnf copr enable adriend/photoflare
sudo dnf install photoflare
```
### Tdiff
[Tdiff](https://github.com/F-i-f/tdiff) 是用于比较两个文件树的命令行工具。除了显示某些文件或目录仅存在于一棵树中之外,tdiff 还显示文件大小、类型和内容,所有者用户和组 ID、权限、修改时间等方面的差异。
#### 安装说明
[仓库](https://copr.fedorainfracloud.org/coprs/atim/contrast/)当前为 Fedora 29-31、Rawhide、EPEL 6-8 和其他发行版提供了 tdiff。要安装 tdiff,请使用以下命令:
```
sudo dnf copr enable fif/tdiff
sudo dnf install tdiff
```
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january-2020/>
作者:[Dominik Turecek](https://fedoramagazine.org/author/dturecek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
This article presents a few new and interesting projects in COPR. If you’re new to using COPR, see the [COPR User Documentation](https://docs.pagure.org/copr.copr/user_documentation.html#) for how to get started.
### Contrast
[Contrast](https://gitlab.gnome.org/World/design/contrast) is a small app used for checking contrast between two colors and to determine if it meets the requirements specified in [WCAG](https://www.w3.org/WAI/standards-guidelines/wcag/). The colors can be selected either using their RGB hex codes or with a color picker tool. In addition to showing the contrast ratio, Contrast displays a short text on a background in selected colors to demonstrate comparison.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/atim/contrast/) currently provides contrast for Fedora 31 and Rawhide. To install Contrast, use these commands:
sudo dnf copr enable atim/contrast sudo dnf install contrast
### Pamixer
[Pamixer](https://github.com/cdemoulins/pamixer) is a command-line tool for adjusting and monitoring volume levels of sound devices using PulseAudio. You can display the current volume of a device and either set it directly or increase/decrease it, or (un)mute it. Pamixer can list all sources and sinks.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/opuk/pamixer/) currently provides Pamixer for Fedora 31 and Rawhide. To install Pamixer, use these commands:
sudo dnf copr enable opuk/pamixer sudo dnf install pamixer
### PhotoFlare
[PhotoFlare](https://photoflare.io/) is an image editor. It has a simple and well-arranged user interface, where most of the features are available in the toolbars. PhotoFlare provides features such as various color adjustments, image transformations, filters, brushes and automatic cropping, although it doesn’t support working with layers. Also, PhotoFlare can edit pictures in batches, applying the same filters and transformations on all pictures and storing the results in a specified directory.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/adriend/photoflare/) currently provides PhotoFlare for Fedora 31. To install Photoflare, use these commands:
sudo dnf copr enable adriend/photoflare sudo dnf install photoflare
### Tdiff
[Tdiff](https://github.com/F-i-f/tdiff) is a command-line tool for comparing two file trees. In addition to showing that some files or directories exist in one tree only, tdiff shows differences in file sizes, types and contents, owner user and group ids, permissions, modification time and more.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/fif/tdiff/) currently provides tdiff for Fedora 29-31 and Rawhide, EPEL 6-8 and other distributions. To install tdiff, use these commands:
sudo dnf copr enable fif/tdiff sudo dnf install tdiff
## Thomas Klein
Nice picks! Thank you Dominik.
## Yann
Thanks for your articles. Always interesting.
A suggestion for the next one :
https://copr.fedorainfracloud.org/coprs/ycollet/linuxmao/
A repository dedicated to music and computer.
I am the owner of this repo.
## Silvia
Installing Photo Flare. Let’s see how it goes. Thanks! |
11,864 | Linux 命令行简介 | https://www.networkworld.com/article/3518440/intro-to-the-linux-command-line.html | 2020-02-06T23:08:00 | [
"Linux"
] | https://linux.cn/article-11864-1.html |
>
> 下面是一些针对刚开始使用 Linux 命令行的人的热身练习。警告:它可能会上瘾。
>
>
>

如果你是 Linux 新手,或者从来没有花时间研究过命令行,你可能不会理解为什么这么多 Linux 爱好者坐在舒适的桌面前兴奋地输入命令来使用大量工具和应用。在这篇文章中,我们将快速浏览一下命令行的奇妙之处,看看能否让你着迷。
首先,要使用命令行,你必须打开一个命令工具(也称为“命令提示符”)。如何做到这一点将取决于你运行的 Linux 版本。例如,在 RedHat 上,你可能会在屏幕顶部看到一个 “Activities” 选项卡,它将打开一个选项列表和一个用于输入命令的小窗口(类似 “cmd” 为你打开的窗口)。在 Ubuntu 和其他一些版本中,你可能会在屏幕左侧看到一个小的终端图标。在许多系统上,你可以同时按 `Ctrl+Alt+t` 键打开命令窗口。
如果你使用 PuTTY 之类的工具登录 Linux 系统,你会发现自己已经处于命令行界面。
一旦你得到你的命令行窗口,你会发现自己坐在一个提示符面前。它可能只是一个 `$` 或者像 `user@system:~$` 这样的东西,但它意味着系统已经准备好为你运行命令了。
一旦你走到这一步,就应该开始输入命令了。下面是一些要首先尝试的命令,以及这里是一些特别有用的命令的 [PDF](https://www.networkworld.com/article/3391029/must-know-linux-commands.html) 和适合打印和做成卡片的双面命令手册。
| 命令 | 用途 |
| --- | --- |
| `pwd` | 显示我在文件系统中的位置(在最初进入系统时运行将显示主目录) |
| `ls` | 列出我的文件 |
| `ls -a` | 列出我更多的文件(包括隐藏文件) |
| `ls -al` | 列出我的文件,并且包含很多详细信息(包括日期、文件大小和权限) |
| `who` | 告诉我谁登录了(如果只有你,不要失望) |
| `date` | 日期提醒我今天是星期几(也显示时间) |
| `ps` | 列出我正在运行的进程(可能只是你的 shell 和 `ps` 命令) |
一旦你从命令行角度习惯了 Linux 主目录之后,就可以开始探索了。也许你会准备好使用以下命令在文件系统中闲逛:
| 命令 | 用途 |
| --- | --- |
| `cd /tmp` | 移动到其他文件夹(本例中,打开 `/tmp` 文件夹) |
| `ls` | 列出当前位置的文件 |
| `cd` | 回到主目录(不带参数的 `cd` 总是能将你带回到主目录) |
| `cat .bashrc` | 显示文件的内容(本例中显示 `.bashrc` 文件的内容) |
| `history` | 显示最近执行的命令 |
| `echo hello` | 跟自己说 “hello” |
| `cal` | 显示当前月份的日历 |
要了解为什么高级 Linux 用户如此喜欢命令行,你将需要尝试其他一些功能,例如重定向和管道。“重定向”是当你获取命令的输出并将其放到文件中而不是在屏幕上显示时。“管道”是指你将一个命令的输出发送给另一条将以某种方式对其进行操作的命令。这是可以尝试的命令:
| 命令 | 用途 |
| --- | --- |
| `echo "echo hello" > tryme` | 创建一个新的文件并将 “echo hello” 写入该文件 |
| `chmod 700 tryme` | 使新建的文件可执行 |
| `tryme` | 运行新文件(它应当运行文件中包含的命令并且显示 “hello” ) |
| `ps aux` | 显示所有运行中的程序 |
| `ps aux | grep $USER` | 显示所有运行中的程序,但是限制输出的内容包含你的用户名 |
| `echo $USER` | 使用环境变量显示你的用户名 |
| `whoami` | 使用命令显示你的用户名 |
| `who | wc -l` | 计数所有当前登录的用户数目 |
### 总结
一旦你习惯了基本命令,就可以探索其他命令并尝试编写脚本。 你可能会发现 Linux 比你想象的要强大并且好用得多.
---
via: <https://www.networkworld.com/article/3518440/intro-to-the-linux-command-line.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qianmingtian](https://github.com/qianmingtian) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,866 | Ubuntu 19.04 已经到期!现有用户必须升级到 Ubuntu 19.10 | https://itsfoss.com/ubuntu-19-04-end-of-life/ | 2020-02-07T23:40:28 | [
"Ubuntu"
] | https://linux.cn/article-11866-1.html |
>
> Ubuntu 19.04 已在 2020 年 1 月 23 日到期,这意味着运行 Ubuntu 19.04 的系统将不再会接收到安全和维护更新,因此将使其容易受到攻击。
>
>
>

[Ubuntu 19.04](https://itsfoss.com/ubuntu-19-04-release/) 发布于 2019 年 4 月 18 日。由于它不是长期支持(LTS)版本,因此只有 9 个月的支持。完成它的发行周期后,Ubuntu 19.04 于 2020 年 1 月 23 日到期。
Ubuntu 19.04 带来了一些视觉和性能方面的改进,为时尚和美观的 Ubuntu 外观铺平了道路。与其他常规 Ubuntu 版本一样,它的生命周期为 9 个月。它如今结束了。
### Ubuntu 19.04 终止了吗?这是什么意思?
EOL(End of life)是指在某个日期之后操作系统版本将无法获得更新。你可能已经知道 Ubuntu(或其他操作系统)提供了安全性和维护升级,以使你的系统免受网络攻击。当发行版到期后,操作系统将停止接收这些重要更新。
如果你的操作系统版本到期后继续使用该系统,那么系统将容易受到网络和恶意软件的攻击。不仅如此。在 Ubuntu 中,你使用 APT 从软件中心下载的应用也不会更新。实际上,你将不再能够[使用 apt-get 命令安装新软件](https://itsfoss.com/apt-get-linux-guide/)(如果不是立即,那就是逐渐地)。
### 所有 Ubuntu 19.04 用户必须升级到 Ubuntu 19.10
从 2020 年 1 月 23 日开始,Ubuntu 19.04 将停止接收更新。你必须升级到 2020 年 7 月之前受支持的 Ubuntu 19.10。这也适用于其他[官方 Ubuntu 衍生版](https://itsfoss.com/which-ubuntu-install/),例如 Lubuntu、Xubuntu、Kubuntu 等。
你可以在“设置 -> 细节” 或使用如下命令来[检查你的 Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/):
```
lsb_release -a
```
#### 如何升级到 Ubuntu 19.10?
值得庆幸的是,Ubuntu 提供了简单的方法来将现有系统升级到新版本。实际上,Ubuntu 还会提示你有新的 Ubuntu 版本可用,你应该升级到该版本。

如果你的互联网连接良好,那么可以使用[和更新 Ubuntu 一样的 Software Updater 工具](https://itsfoss.com/update-ubuntu/)。在上图中,你只需单击 “Upgrade” 按钮并按照说明进行操作。我已经编写了有关使用此方法[升级到 Ubuntu 18.04](https://itsfoss.com/upgrade-ubuntu-version/)的文章。
如果你没有良好的互联网连接,那么有一种临时方案。在外部磁盘上备份家目录或重要数据。
然后,制作一个 Ubuntu 19.10 的 Live USB。下载 Ubuntu 19.10 ISO,并使用 Ubuntu 系统上已安装的启动磁盘创建器从该 ISO 创建 Live USB。
从该 Live USB 引导,然后继续“安装” Ubuntu 19.10。在安装过程中,你应该看到一个删除 Ubuntu 19.04 并将其替换为 Ubuntu 19.10 的选项。选择此选项,然后像重新[安装 Ubuntu](https://itsfoss.com/install-ubuntu/)一样进行下去。
#### 你是否仍在使用 Ubuntu 19.04、18.10、17.10 或其他不受支持的版本?
你应该注意,目前仅 Ubuntu 16.04、18.04 和 19.10(或更高版本)版本还受支持。如果你运行的不是这些 Ubuntu 版本,那么你必须升级到较新版本。
---
via: <https://itsfoss.com/ubuntu-19-04-end-of-life/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: Ubuntu 19.04 has reached the end of life on 23rd January 2020. This means that systems running Ubuntu 19.04 won’t receive security and maintenance updates anymore and thus leaving them vulnerable.**

[Ubuntu 19.04](https://itsfoss.com/ubuntu-19-04-release/) was released on 18th April, 2019. Since it was not a long term support (LTS) release, it was supported only for nine months.
Completing its release cycle, Ubuntu 19.04 reached end of life on 23rd January, 2020.
Ubuntu 19.04 brought a few visual and performance improvements and paved the way for a sleek and aesthetically pleasant Ubuntu look.
Like any other regular Ubuntu release, it had a life span of nine months. And that has ended now.
## End of life for Ubuntu 19.04? What does it mean?
End of life is means a certain date after which an operating system release won’t get updates.
You might already know that Ubuntu (or any other operating system for that matter) provides security and maintenance upgrades in order to keep your systems safe from cyber attacks.
Once a release reaches the end of life, the operating system stops receiving these important updates.
If you continue using a system after the end of life of your operating system release, your system will be vulnerable to cyber attacks and malware.
That’s not it. In Ubuntu, the applications that you downloaded using APT from Software Center won’t be updated as well. In fact, you won’t be able to [install new software using apt-get command](https://itsfoss.com/apt-get-linux-guide/) anymore (gradually, if not immediately).
## All Ubuntu 19.04 users must upgrade to Ubuntu 19.10
Starting 23rd January 2020, Ubuntu 19.04 will stop receiving updates. You must upgrade to Ubuntu 19.10 which will be supported till July 2020. This is also applicable to other [official Ubuntu flavors](https://itsfoss.com/which-ubuntu-install/) such as Lubuntu, Xubuntu, Kubuntu etc.
You can [check the Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/) either from the settings->Details or by using the command:
`lsb_release -a`
### How to upgrade to Ubuntu 19.10?
Thankfully, Ubuntu provides easy ways to upgrade the existing system to a newer version.
In fact, Ubuntu also prompts you that a new Ubuntu version is available and that you should upgrade to it.
If you have a good internet connection, you can use the same [Software Updater tool that you use to update Ubuntu](https://itsfoss.com/update-ubuntu/). In the above image, you just need to click the Upgrade button and follow the instructions. I have written a detailed guide about [upgrading to Ubuntu 18.04](https://itsfoss.com/upgrade-ubuntu-version/) using this method.
If you don’t have a good internet connection, there is a workaround for you. Make a backup of your home directory or your important data on an external disk.
Then, make a live USB of Ubuntu 19.10. Download Ubuntu 19.10 ISO and use the Startup Disk Creator tool already installed on your Ubuntu system to create a live USB out of this ISO.
Boot from this live USB and go on ‘installing’ Ubuntu 19.10. In the installation procedure, you should see an option to remove Ubuntu 19.04 and replace it with Ubuntu 19.10. Choose this option and proceed as if you are [installing Ubuntu](https://itsfoss.com/install-ubuntu/) afresh.
### Are you still using Ubuntu 19.04, 18.10, 17.10 or some other unsupported version?
You should note that at present only Ubuntu 16.04, 18.04 and 19.10 (or higher) versions are supported. If you are running an Ubuntu version other than these, you must upgrade to a newer version. |
11,867 | 你最喜欢哪个 Linux 发行版? | https://opensource.com/article/20/1/favorite-linux-distribution | 2020-02-08T00:45:00 | [
"Linux"
] | https://linux.cn/article-11867-1.html | 
你最喜欢哪个 Linux 发行版?虽然有所变化,但现在仍有数百种 [Linux 发行版](https://distrowatch.com/)保持活跃且运作良好。发行版、包管理器和桌面的组合为 Linux 用户创建了无数客制化系统环境。
我们询问了社区的作者们,哪个是他们的最爱以及原因。尽管回答中存在一些共性(由于各种原因,Fedora 和 Ubuntu 是最受欢迎的选择),但我们也听到一些惊奇的回答。以下是他们的一些回答:
>
> “我使用 Fedora 发行版!我喜欢这样的社区,成员们共同创建一个令人惊叹的操作系统,展现了开源软件世界最伟大的造物。”——Matthew Miller
>
>
>
>
> “我在家中使用 Arch。作为一名游戏玩家,我希望可以轻松使用最新版本的 Wine 和 GFX 驱动,同时最大限度地掌控我的系统。所以我选择一个滚动升级并且每个包都保持领先的发行版。”——Aimi Hobson
>
>
>
>
> “NixOS,在业余爱好者市场中没有比这更合适的。”——Alexander Sosedkin
>
>
>
>
> “我用过每个 Fedora 版本作为我的工作系统。这意味着我从第一个版本开始使用。从前,我问自己是否会忘记我使用的是哪一个版本。而这一天已经到来了,是从什么时候开始忘记了的呢?”——Hugh Brock
>
>
>
>
> “通常,在我的家里和办公室里都有运行 Ubuntu、CentOS 和 Fedora 的机器。我依赖这些发行版来完成各种工作。Fedora 速度很快,而且可以获取最新版本的应用和库。Ubuntu 有大型社区支持,可以轻松使用。CentOS 则当我们需要稳如磐石的服务器平台时。”——Steve Morris
>
>
>
>
> “我最喜欢?对于社区以及如何为发行版构建软件包(从源码构建而非二进制文件),我选择 Fedora。对于可用包的范围和包的定义和开发,我选择 Debian。对于文档,我选择 Arch。对于新手的提问,我以前会推荐 Ubuntu,而现在会推荐 Fedora。”——Al Stone
>
>
>
---
自从 2014 以来,我们一直向社区提出这一问题。除了 2015 年 PCLinuxOS 出乎意料的领先,Ubuntu 往往每年都获得粉丝们的青睐。其他受欢迎的竞争者还包括 Fedora、Debian、Mint 和 Arch。在新的十年里,哪个发行版更吸引你?如果我们的投票列表中没有你最喜欢的选择,请在评论中告诉我们。
下面是过去七年来你最喜欢的 Linux 发行版投票的总览。你可以在我们去年的年刊《[Opensource.com 上的十年最佳](https://opensource.com/downloads/2019-yearbook-special-edition)》中看到它。[点击这里](https://opensource.com/downloads/2019-yearbook-special-edition)下载完整版电子书!

---
via: <https://opensource.com/article/20/1/favorite-linux-distribution>
作者:[Opensource.com](https://opensource.com/users/admin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LazyWolfLin](https://github.com/LazyWolfLin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | What's your favorite Linux distribution? Take our 7th annual poll. Some have come and gone, but there are hundreds of [Linux distributions](https://distrowatch.com/) alive and well today. The combination of distribution, package manager, and desktop creates an endless amount of customized environments for Linux users.
We asked the community of writers what their favorite is and why. While there were some commonalities (Fedora and Ubuntu were popular choices for a variety of reasons), we heard a few surprises as well. Here are a few of their responses:
"I use the Fedora distro! I love the community of people who work together to make an awesome operating system that showcases the greatest innovations in the free and open source software world." — Matthew Miller
"I use Arch at home. As a gamer, I want easy access to the latest Wine versions and GFX drivers, as well as large amounts of control over my OS. Give me a rolling-release distro with every package at bleeding-edge." —Aimi Hobson
"NixOS, with nothing coming close in the hobbyist niche." —Alexander Sosedkin
"I have used every Fedora version as my primary work OS. Meaning, I started with the first one. Early on, I asked myself if there would ever come a time when I couldn't remember which number I was on. That time has arrived. What year is it, anyway?" —Hugh Brock
"I usually have Ubuntu, CentOS, and Fedora boxes running around the house and the office. We depend on all of these distributions for various things. Fedora for speed and getting the latest versions of applications and libraries. Ubuntu for those that need easy of use with a large community of support. CentOS when we need a rock-solid server platform that just runs." —Steve Morris
"My favorite? For the community, and how packages are built for the distribution (from source, not binaries), I choose Fedora. For pure breadth of packages available and elegance in how packages are defined and developed, I choose Debian. For documentation, I choose Arch. For newbies that ask, I used to recommend Ubuntu but now recommend Fedora." —Al Stone
We've been asking the community this question since 2014. With the exception of PCLinuxOS taking the lead in 2015, Ubuntu tends to be the fan-favorite from year to year. Other popular contenders have been Fedora, Debian, Mint, and Arch. Which distribution stands out to you in the new decade? If we didn't include your favorite in the list of choices, tell us about it in the comments.
Here's a look at your favorite Linux distributions throughout the last seven years. You can find this in our latest yearbook, [Best of a decade on Opensource.com](https://opensource.com/downloads/2019-yearbook-special-edition). To download the whole eBook, [click here](https://opensource.com/downloads/2019-yearbook-special-edition)!
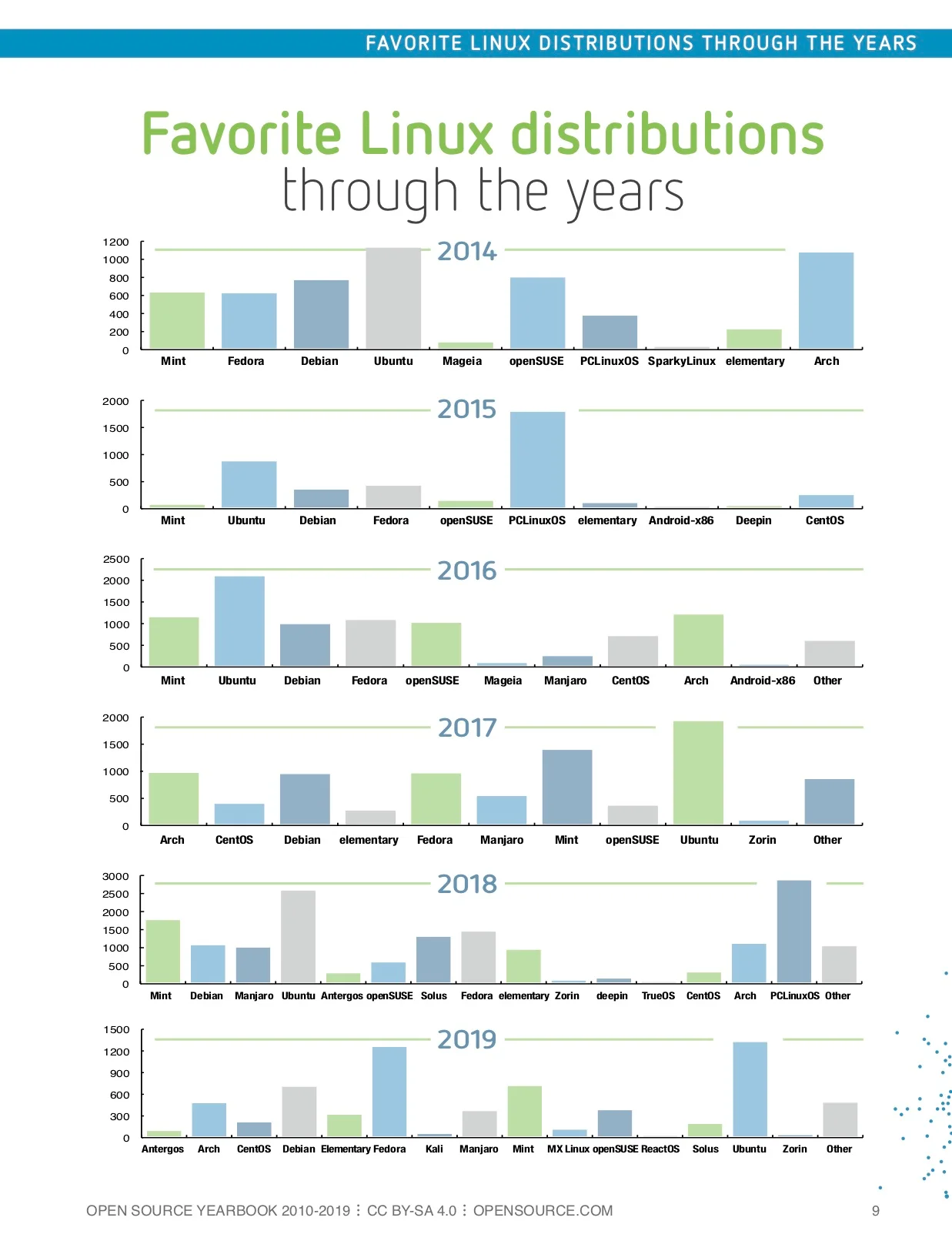
opensource.com
## 48 Comments |
11,869 | 在 Linux 终端中阅读 Reddit | https://opensource.com/article/20/1/open-source-reddit-client | 2020-02-09T10:41:25 | [
"Reddit"
] | https://linux.cn/article-11869-1.html |
>
> 在我们的 20 个使用开源提升生产力的系列的第十一篇文章中使用 Reddit 客户端 Tuir 在工作中短暂休息一下。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 Tuir 阅读 Reddit
短暂休息对于保持生产力很重要。我休息时喜欢去的地方之一是 [Reddit](https://www.reddit.com/),如果你愿意,这可能是一个很好的资源。我在那里发现了各种有关 DevOps、生产力、Emacs、鸡和 ChromeOS 项目的文章。这些讨论可能很有价值。我还关注了一些只有动物图片的子板,因为我喜欢动物(而不只是鸡)照片,有时经过长时间的工作后,我真正需要的是小猫照片。

当我阅读 Reddit(不仅仅是看动物宝宝的图片)时,我使用 [Tuir](https://gitlab.com/ajak/tuir)(Reddit 终端 UI)。Tuir 是功能齐全的 Reddit 客户端,可以在运行 Python 的任何系统上运行。安装是通过 `pip` 完成的,非常简单。
首次运行时,Tuir 会进入 Reddit 默认文章列表。屏幕的顶部和底部有列出不同命令的栏。顶部栏显示你在 Reddit 上的位置,第二行显示根据 Reddit “Hot/New/Controversial” 等类别筛选的命令。按下筛选器前面的数字触发筛选。

你可以使用箭头键或 `j`、`k`、`h` 和 `l` 键浏览列表,这与 Vi/Vim 使用的键相同。底部栏有用于应用导航的命令。如果要跳转到另一个子板,只需按 `/` 键打开提示,然后输入你要进入的子板名称。

某些东西除非你登录,否则无法访问。如果你尝试执行需要登录的操作,那么 Tuir 就会提示你,例如发布新文章 (`c`)或赞成/反对 (`a` 和 `z`)。要登录,请按 `u` 键。这将打开浏览器以通过 OAuth2 登录,Tuir 将保存令牌。之后,你的用户名应出现在屏幕的右上方。
Tuir 还可以打开浏览器来查看图像、加载链接等。稍作调整,它甚至可以在终端中显示图像(尽管我没有让它可以正常工作)。
总的来说,我对 Tuir 在我需要休息时能快速跟上 Reddit 感到很满意。
Tuir 是现已淘汰的 [RTV](https://github.com/michael-lazar/rtv) 的两个分叉之一。另一个是 [TTRV](https://github.com/tildeclub/ttrv),它还无法通过 `pip` 安装,但功能相同。我期待看到它们随着时间的推移脱颖而出。
---
via: <https://opensource.com/article/20/1/open-source-reddit-client>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Read Reddit with Tuir
Taking short breaks is essential in staying productive. One of the places I like to go when taking a break is [Reddit](https://www.reddit.com/), which can be a great resource if you want it to be. I find all kinds of articles there about DevOps, productivity, Emacs, chickens, and some ChromeOS projects I play with. These discussions can be valuable. I also follow a couple of subreddits that are just pictures of animals because I like pictures of animals (and not just chickens), and sometimes after a long work session, what I really need are kitten pictures.
When I'm reading Reddit (and not just looking at pictures of baby animals), I use [Tuir](https://gitlab.com/ajak/tuir), which stands for Terminal UI for Reddit. Tuir is a feature-complete Reddit client and can be run on any system that runs Python. Installation is done through the pip Python installer and is exceptionally painless.
On its first run, Tuir will take you to the default article list on Reddit. The top and bottom of the screen have bars that list different commands. The top bar shows your location on Reddit, and the second line shows the commands filtered by the Reddit "Hot/New/Controversial/etc." categories. Filtering is invoked by pressing the number next to the filter you want to use.
You can navigate through the list with the arrow keys, or with the **j**, **k**, **h**, and **l** keys, the same ones you use for Vi/Vim. The bottom bar has commands for navigating the app. If you want to jump to another subreddit, simply hit the **/** key to open a prompt and type the name of the subreddit you want to interact with.
Some things aren't accessible unless you are logged in. Tuir will prompt you if you try to do something that requires logging in, like posting a new article (**c**) or up/down voting (**a** and **z**, respectively). To log in, press the **u** key. This will launch a browser to log in via OAuth2, and Tuir will save the token. Afterward, your username should appear in the top-right of the screen.
Tuir can also launch your browser to view images, load links, and so on. With a little tuning, it can even show images on the terminal (although I didn't manage to get that to work properly).
Overall, I'm pretty happy with Tuir for quickly catching up on Reddit when I need a break.
Tuir is one of two forks of the now-defunct [RTV](https://github.com/michael-lazar/rtv). The other is [TTRV](https://github.com/tildeclub/ttrv), which isn't available via pip (yet) but has the same features. I'm looking forward to seeing how they differentiate themselves over time.
## Comments are closed. |
11,870 | 检查 Linux 中内存使用情况的 8 条命令 | https://www.2daygeek.com/linux-commands-check-memory-usage/ | 2020-02-09T12:11:22 | [
"内存"
] | https://linux.cn/article-11870-1.html | 
Linux 并不像 Windows,你经常不会有图形界面可供使用,特别是在服务器环境中。
作为一名 Linux 管理员,知道如何获取当前可用的和已经使用的资源情况,比如内存、CPU、磁盘等,是相当重要的。如果某一应用在你的系统上占用了太多的资源,导致你的系统无法达到最优状态,那么你需要找到并修正它。
如果你想找到消耗内存前十名的进程,你需要去阅读这篇文章:[如何在 Linux 中找出内存消耗最大的进程](/article-11542-1.html)。
在 Linux 中,命令能做任何事,所以使用相关命令吧。在这篇教程中,我们将会给你展示 8 个有用的命令来即查看在 Linux 系统中内存的使用情况,包括 RAM 和交换分区。
创建交换分区在 Linux 系统中是非常重要的,如果你想了解如何创建,可以去阅读这篇文章:[在 Linux 系统上创建交换分区](/article-9579-1.html)。
下面的命令可以帮助你以不同的方式查看 Linux 内存使用情况。
* `free` 命令
* `/proc/meminfo` 文件
* `vmstat` 命令
* `ps_mem` 命令
* `smem` 命令
* `top` 命令
* `htop` 命令
* `glances` 命令
### 1)如何使用 free 命令查看 Linux 内存使用情况
[free 命令](/article-8314-1.html) 是被 Linux 管理员广泛使用的主要命令。但是它提供的信息比 `/proc/meminfo` 文件少。
`free` 命令会分别展示物理内存和交换分区内存中已使用的和未使用的数量,以及内核使用的缓冲区和缓存。
这些信息都是从 `/proc/meminfo` 文件中获取的。
```
# free -m
total used free shared buff/cache available
Mem: 15867 9199 1702 3315 4965 3039
Swap: 17454 666 16788
```
* `total`:总的内存量
* `used`:被当前运行中的进程使用的内存量(`used` = `total` – `free` – `buff/cache`)
* `free`: 未被使用的内存量(`free` = `total` – `used` – `buff/cache`)
* `shared`: 在两个或多个进程之间共享的内存量
* `buffers`: 内存中保留用于内核记录进程队列请求的内存量
* `cache`: 在 RAM 中存储最近使用过的文件的页缓冲大小
* `buff/cache`: 缓冲区和缓存总的使用内存量
* `available`: 可用于启动新应用的可用内存量(不含交换分区)
### 2) 如何使用 /proc/meminfo 文件查看 Linux 内存使用情况
`/proc/meminfo` 文件是一个包含了多种内存使用的实时信息的虚拟文件。它展示内存状态单位使用的是 kB,其中大部分属性都难以理解。然而它也包含了内存使用情况的有用信息。
```
# cat /proc/meminfo
MemTotal: 16248572 kB
MemFree: 1764576 kB
MemAvailable: 3136604 kB
Buffers: 234132 kB
Cached: 4731288 kB
SwapCached: 28516 kB
Active: 9004412 kB
Inactive: 3552416 kB
Active(anon): 8094128 kB
Inactive(anon): 2896064 kB
Active(file): 910284 kB
Inactive(file): 656352 kB
Unevictable: 80 kB
Mlocked: 80 kB
SwapTotal: 17873388 kB
SwapFree: 17191328 kB
Dirty: 252 kB
Writeback: 0 kB
AnonPages: 7566736 kB
Mapped: 3692368 kB
Shmem: 3398784 kB
Slab: 278976 kB
SReclaimable: 125480 kB
SUnreclaim: 153496 kB
KernelStack: 23936 kB
PageTables: 73880 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 25997672 kB
Committed_AS: 24816804 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
Percpu: 3392 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
DirectMap4k: 1059088 kB
DirectMap2M: 14493696 kB
DirectMap1G: 2097152 kB
```
### 3) 如何使用 vmstat 命令查看 Linux 内存使用情况
[vmstat 命令](/article-8157-1.html) 是另一个报告虚拟内存统计信息的有用工具。
`vmstat` 报告的信息包括:进程、内存、页面映射、块 I/O、陷阱、磁盘和 CPU 特性信息。`vmstat` 不需要特殊的权限,并且它可以帮助诊断系统瓶颈。
```
# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 682060 1769324 234188 4853500 0 3 25 91 31 16 34 13 52 0 0
```
如果你想详细了解每一项的含义,阅读下面的描述。
* `procs`:进程
+ `r`: 可以运行的进程数目(正在运行或等待运行)
+ `b`: 处于不可中断睡眠中的进程数目
* `memory`:内存
+ `swpd`: 使用的虚拟内存数量
+ `free`: 空闲的内存数量
+ `buff`: 用作缓冲区内存的数量
+ `cache`: 用作缓存内存的数量
+ `inact`: 不活动的内存数量(使用 `-a` 选项)
+ `active`: 活动的内存数量(使用 `-a` 选项)
* `Swap`:交换分区
+ `si`: 每秒从磁盘交换的内存数量
+ `so`: 每秒交换到磁盘的内存数量
* `IO`:输入输出
+ `bi`: 从一个块设备中收到的块(块/秒)
+ `bo`: 发送到一个块设备的块(块/秒)
* `System`:系统
+ `in`: 每秒的中断次数,包括时钟。
+ `cs`: 每秒的上下文切换次数。
* `CPU`:下面这些是在总的 CPU 时间占的百分比
+ `us`: 花费在非内核代码上的时间占比(包括用户时间,调度时间)
+ `sy`: 花费在内核代码上的时间占比 (系统时间)
+ `id`: 花费在闲置的时间占比。在 Linux 2.5.41 之前,包括 I/O 等待时间
+ `wa`: 花费在 I/O 等待上的时间占比。在 Linux 2.5.41 之前,包括在空闲时间中
+ `st`: 被虚拟机偷走的时间占比。在 Linux 2.6.11 之前,这部分称为 unknown
运行下面的命令查看详细的信息。
```
# vmstat -s
16248580 K total memory
2210256 K used memory
2311820 K active memory
2153352 K inactive memory
11368812 K free memory
107584 K buffer memory
2561928 K swap cache
17873388 K total swap
0 K used swap
17873388 K free swap
44309 non-nice user cpu ticks
164 nice user cpu ticks
14332 system cpu ticks
382418 idle cpu ticks
1248 IO-wait cpu ticks
1407 IRQ cpu ticks
2147 softirq cpu ticks
0 stolen cpu ticks
1022437 pages paged in
260296 pages paged out
0 pages swapped in
0 pages swapped out
1424838 interrupts
4979524 CPU context switches
1577163147 boot time
3318 forks
```
### 4) 如何使用 ps\_mem 命令查看 Linux 内存使用情况
[ps\_mem](/article-8639-1.html) 是一个用来查看当前内存使用情况的简单的 Python 脚本。该工具可以确定每个程序使用了多少内存(不是每个进程)。
该工具采用如下的方法计算每个程序使用内存:总的使用 = 程序进程私有的内存 + 程序进程共享的内存。
计算共享内存是存在不足之处的,该工具可以为运行中的内核自动选择最准确的方法。
```
# ps_mem
Private + Shared = RAM used Program
180.0 KiB + 30.0 KiB = 210.0 KiB xf86-video-intel-backlight-helper (2)
192.0 KiB + 66.0 KiB = 258.0 KiB cat (2)
312.0 KiB + 38.5 KiB = 350.5 KiB lvmetad
380.0 KiB + 25.5 KiB = 405.5 KiB crond
392.0 KiB + 32.5 KiB = 424.5 KiB rtkit-daemon
852.0 KiB + 117.0 KiB = 969.0 KiB gnome-session-ctl (2)
928.0 KiB + 56.5 KiB = 984.5 KiB gvfs-mtp-volume-monitor
1.0 MiB + 42.5 KiB = 1.0 MiB dconf-service
1.0 MiB + 106.5 KiB = 1.1 MiB gvfs-goa-volume-monitor
1.0 MiB + 180.5 KiB = 1.2 MiB gvfsd
.
.
5.3 MiB + 3.0 MiB = 8.3 MiB evolution-addressbook-factory
8.5 MiB + 1.2 MiB = 9.7 MiB gnome-session-binary (4)
7.5 MiB + 3.1 MiB = 10.5 MiB polkitd
7.4 MiB + 3.3 MiB = 10.7 MiB pulseaudio (2)
7.0 MiB + 7.0 MiB = 14.0 MiB msm_notifier
12.7 MiB + 2.3 MiB = 15.0 MiB evolution-source-registry
13.3 MiB + 2.5 MiB = 15.8 MiB gnome-terminal-server
15.8 MiB + 1.0 MiB = 16.8 MiB tracker-miner-fs
18.7 MiB + 1.8 MiB = 20.5 MiB python3.7
16.6 MiB + 4.0 MiB = 20.5 MiB evolution-calendar-factory
22.3 MiB + 753.0 KiB = 23.0 MiB gsd-keyboard (2)
22.4 MiB + 832.0 KiB = 23.2 MiB gsd-wacom (2)
20.8 MiB + 2.5 MiB = 23.3 MiB blueman-tray
22.0 MiB + 1.8 MiB = 23.8 MiB blueman-applet
23.1 MiB + 934.0 KiB = 24.0 MiB gsd-xsettings (2)
23.7 MiB + 1.2 MiB = 24.9 MiB gsd-media-keys (2)
23.4 MiB + 1.6 MiB = 25.0 MiB gsd-color (2)
23.9 MiB + 1.2 MiB = 25.1 MiB gsd-power (2)
16.5 MiB + 8.9 MiB = 25.4 MiB evolution-alarm-notify
27.2 MiB + 2.0 MiB = 29.2 MiB systemd-journald
28.7 MiB + 2.8 MiB = 31.5 MiB c
29.6 MiB + 2.2 MiB = 31.8 MiB chrome-gnome-sh (2)
43.9 MiB + 6.8 MiB = 50.7 MiB WebExtensions
46.7 MiB + 6.7 MiB = 53.5 MiB goa-daemon
86.5 MiB + 55.2 MiB = 141.7 MiB Xorg (2)
191.4 MiB + 24.1 MiB = 215.4 MiB notepadqq-bin
306.7 MiB + 29.0 MiB = 335.7 MiB gnome-shell (2)
601.6 MiB + 77.7 MiB = 679.2 MiB firefox
1.0 GiB + 109.7 MiB = 1.1 GiB chrome (15)
2.3 GiB + 123.1 MiB = 2.5 GiB Web Content (8)
----------------------------------
5.6 GiB
==================================
```
### 5)如何使用 smem 命令查看 Linux 内存使用情况
[smem](/article-7681-1.html) 是一个可以为 Linux 系统提供多种内存使用情况报告的工具。不同于现有的工具,`smem` 可以报告<ruby> 比例集大小 <rt> Proportional Set Size </rt></ruby>(PSS)、<ruby> 唯一集大小 <rt> Unique Set Size </rt></ruby>(USS)和<ruby> 驻留集大小 <rt> Resident Set Size </rt></ruby>(RSS)。
* 比例集大小(PSS):库和应用在虚拟内存系统中的使用量。
* 唯一集大小(USS):其报告的是非共享内存。
* 驻留集大小(RSS):物理内存(通常多进程共享)使用情况,其通常高于内存使用量。
```
# smem -tk
PID User Command Swap USS PSS RSS
3383 daygeek cat 0 92.0K 123.0K 1.7M
3384 daygeek cat 0 100.0K 129.0K 1.7M
1177 daygeek /usr/lib/gnome-session-ctl 0 436.0K 476.0K 4.6M
1171 daygeek /usr/bin/dbus-daemon --conf 0 524.0K 629.0K 3.8M
1238 daygeek /usr/lib/xdg-permission-sto 0 592.0K 681.0K 5.9M
1350 daygeek /usr/lib/gsd-screensaver-pr 0 652.0K 701.0K 5.8M
1135 daygeek /usr/lib/gdm-x-session --ru 0 648.0K 723.0K 6.0M
.
.
1391 daygeek /usr/lib/evolution-data-ser 0 16.5M 25.2M 63.3M
1416 daygeek caffeine-ng 0 28.7M 31.4M 66.2M
4855 daygeek /opt/google/chrome/chrome - 0 38.3M 46.3M 120.6M
2174 daygeek /usr/lib/firefox/firefox -c 0 44.0M 50.7M 120.3M
1254 daygeek /usr/lib/goa-daemon 0 46.7M 53.3M 80.4M
3416 daygeek /opt/google/chrome/chrome - 0 44.7M 54.2M 103.3M
4782 daygeek /opt/google/chrome/chrome - 0 57.2M 65.8M 142.3M
1137 daygeek /usr/lib/Xorg vt2 -displayf 0 77.2M 129.6M 192.3M
3376 daygeek /opt/google/chrome/chrome 0 117.8M 131.0M 210.9M
4448 daygeek /usr/lib/firefox/firefox -c 0 124.4M 133.8M 224.1M
3558 daygeek /opt/google/chrome/chrome - 0 157.3M 165.7M 242.2M
2310 daygeek /usr/lib/firefox/firefox -c 0 159.6M 169.4M 259.6M
4331 daygeek /usr/lib/firefox/firefox -c 0 176.8M 186.2M 276.8M
4034 daygeek /opt/google/chrome/chrome - 0 179.3M 187.9M 264.6M
3911 daygeek /opt/google/chrome/chrome - 0 183.1M 191.8M 269.4M
3861 daygeek /opt/google/chrome/chrome - 0 199.8M 208.2M 285.2M
2746 daygeek /usr/bin/../lib/notepadqq/n 0 193.5M 217.5M 261.5M
1194 daygeek /usr/bin/gnome-shell 0 203.7M 219.0M 285.1M
2945 daygeek /usr/lib/firefox/firefox -c 0 294.5M 308.0M 410.2M
2786 daygeek /usr/lib/firefox/firefox -c 0 341.2M 354.3M 459.1M
4193 daygeek /usr/lib/firefox/firefox -c 0 417.4M 427.6M 519.3M
2651 daygeek /usr/lib/firefox/firefox -c 0 417.0M 430.1M 535.6M
2114 daygeek /usr/lib/firefox/firefox -c 0 430.6M 473.9M 610.9M
2039 daygeek /usr/lib/firefox/firefox -- 0 601.3M 677.5M 840.6M
-------------------------------------------------------------------------------
90 1 0 4.8G 5.2G 8.0G
```
### 6) 如何使用 top 命令查看 Linux 内存使用情况
[top 命令](https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/) 是一个 Linux 系统的管理员最常使用的用于查看进程的资源使用情况的命令。
该命令会展示了系统总的内存量、当前内存使用量、空闲内存量和缓冲区使用的内存总量。此外,该命令还会展示总的交换空间内存量、当前交换空间的内存使用量、空闲的交换空间内存量和缓存使用的内存总量。
```
# top -b | head -10
top - 11:04:39 up 40 min, 1 user, load average: 1.59, 1.42, 1.28
Tasks: 288 total, 2 running, 286 sleeping, 0 stopped, 0 zombie
%Cpu(s): 13.3 us, 1.5 sy, 0.0 ni, 84.4 id, 0.0 wa, 0.3 hi, 0.5 si, 0.0 st
KiB Mem : 16248572 total, 7755928 free, 4657736 used, 3834908 buff/cache
KiB Swap: 17873388 total, 17873388 free, 0 used. 9179772 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2114 daygeek 20 3182736 616624 328228 R 83.3 3.8 7:09.72 Web Content
2039 daygeek 20 4437952 849616 261364 S 13.3 5.2 7:58.54 firefox
1194 daygeek 20 4046856 291288 165460 S 4.2 1.8 1:57.68 gnome-shell
4034 daygeek 20 808556 273244 88676 S 4.2 1.7 1:44.72 chrome
2945 daygeek 20 3309832 416572 150112 S 3.3 2.6 4:04.60 Web Content
1137 daygeek 20 564316 197292 183380 S 2.5 1.2 2:55.76 Xorg
2651 daygeek 20 3098420 547260 275700 S 1.7 3.4 2:15.96 Web Content
2786 daygeek 20 2957112 463912 240744 S 1.7 2.9 3:22.29 Web Content
1 root 20 182756 10208 7760 S 0.8 0.1 0:04.51 systemd
442 root -51 S 0.8 0:05.02 irq/141-iw+
1426 daygeek 20 373660 48948 29820 S 0.8 0.3 0:03.55 python3
2174 daygeek 20 2466680 122196 78604 S 0.8 0.8 0:17.75 WebExtensi+
```
### 7) 如何使用 htop 命令查看 Linux 内存使用情况
[htop 命令](https://www.2daygeek.com/linux-htop-command-linux-system-performance-resource-monitoring-tool/) 是一个可交互的 Linux/Unix 系统进程查看器。它是一个文本模式应用,且使用它需要 Hisham 开发的 ncurses 库。
该名令的设计目的使用来代替 `top` 命令。该命令与 `top` 命令很相似,但是其允许你可以垂直地或者水平地的滚动以便可以查看系统中所有的进程情况。
`htop` 命令拥有不同的颜色,这个额外的优点当你在追踪系统性能情况时十分有用。
此外,你可以自由地执行与进程相关的任务,比如杀死进程或者改变进程的优先级而不需要其进程号(PID)。

### 8)如何使用 glances 命令查看 Linux 内存使用情况
[Glances](https://www.2daygeek.com/linux-glances-advanced-real-time-linux-system-performance-monitoring-tool/) 是一个 Python 编写的跨平台的系统监视工具。
你可以在一个地方查看所有信息,比如:CPU 使用情况、内存使用情况、正在运行的进程、网络接口、磁盘 I/O、RAID、传感器、文件系统信息、Docker、系统信息、运行时间等等。

---
via: <https://www.2daygeek.com/linux-commands-check-memory-usage/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,875 | 顶级 CI / CD 资源,助您成功 | https://opensource.com/article/19/12/cicd-resources | 2020-02-10T16:05:00 | [
"CI/CD"
] | /article-11875-1.html |
>
> 随着企业期望实现无缝、灵活和可扩展的部署,持续集成和持续部署成为 2019 年的关键主题。
>
>
>

对于 CI/CD 和 DevOps 来说,2019 年是非常棒的一年。Opensource.com 的作者分享了他们专注于无缝、灵活和可扩展部署时是如何朝着敏捷和 scrum 方向发展的。以下是我们 2019 年发布的 CI/CD 文章中的一些重要文章。
### 学习和提高你的 CI/CD 技能
我们最喜欢的一些文章集中在 CI/CD 的实操经验上,并涵盖了许多方面。通常以 [Jenkins](https://jenkins.io/) 管道开始,Bryant Son 的文章《[用 Jenkins 构建 CI/CD 管道](/article-11546-1.html)》将为你提供足够的经验,以开始构建你的第一个管道。Daniel Oh 在《[用 DevOps 管道进行自动验收测试](https://opensource.com/article/19/4/devops-pipeline-acceptance-testing)》一文中,提供了有关验收测试的重要信息,包括可用于自行测试的各种 CI/CD 应用程序。我写的《[安全扫描 DevOps 管道](https://opensource.com/article/19/7/security-scanning-your-devops-pipeline)》非常简短,其中简要介绍了如何使用 Jenkins 平台在管道中设置安全性。
### 交付工作流程
正如 Jithin Emmanuel 在《[Screwdriver:一个用于持续交付的可扩展构建平台](https://opensource.com/article/19/3/screwdriver-cicd)》中分享的,在学习如何使用和提高你的 CI/CD 技能方面,工作流程很重要,特别是当涉及到管道时。Emily Burns 在《[为什么 Spinnaker 对 CI/CD 很重要](https://opensource.com/article/19/8/why-spinnaker-matters-cicd)》中解释了灵活地使用 CI/CD 工作流程准确构建所需内容的原因。Willy-Peter Schaub 还盛赞了为所有产品创建统一管道的想法,以便《[在一个 CI/CD 管道中一致地构建每个产品](https://opensource.com/article/19/7/cicd-pipeline-rule-them-all)》。这些文章将让你很好地了解在团队成员加入工作流程后会发生什么情况。
### CI/CD 如何影响企业
2019 年也是认识到 CI/CD 的业务影响以及它是如何影响日常运营的一年。Agnieszka Gancarczyk 分享了 Red Hat 《[小型 Scrum vs. 大型 Scrum](https://opensource.com/article/19/3/small-scale-scrum-vs-large-scale-scrum)》的调查结果, 包括受访者对 Scrum、敏捷运动及对团队的影响的不同看法。Will Kelly 的《[持续部署如何影响整个组织](https://opensource.com/article/19/7/organizational-impact-continuous-deployment)》,也提及了开放式沟通的重要性。Daniel Oh 也在《[DevOps 团队必备的 3 种指标仪表板](/article-11183-1.html)》中强调了指标和可观测性的重要性。最后是 Ann Marie Fred 的精彩文章《[不在生产环境中测试?要在生产环境中测试!](https://opensource.com/article/19/5/dont-test-production)》详细说明了在验收测试前在生产环境中测试的重要性。
感谢许多贡献者在 2019 年与 Opensource 的读者分享他们的见解,我期望在 2020 年里从他们那里了解更多有关 CI/CD 发展的信息。
---
via: <https://opensource.com/article/19/12/cicd-resources>
作者:[Jessica Cherry](https://opensource.com/users/jrepka) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,876 | 使用此开源工具在一起收取你的 RSS 订阅源和播客 | https://opensource.com/article/20/1/open-source-rss-feed-reader | 2020-02-10T16:26:15 | [
"RSS"
] | https://linux.cn/article-11876-1.html |
>
> 在我们的 20 个使用开源提升生产力的系列的第十二篇文章中使用 Newsboat 收取你的新闻 RSS 源和播客。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 Newsboat 访问你的 RSS 源和播客
RSS 新闻源是了解各个网站最新消息的非常方便的方法。除了 Opensource.com,我还会关注 [SysAdvent](https://sysadvent.blogspot.com/) sysadmin 年度工具,还有一些我最喜欢的作者以及一些网络漫画。RSS 阅读器可以让我“批处理”阅读内容,因此,我每天不会在不同的网站上花费很多时间。

[Newsboat](https://newsboat.org) 是一个基于终端的 RSS 订阅源阅读器,外观感觉很像电子邮件程序 [Mutt](http://mutt.org/)。它使阅读新闻变得容易,并有许多不错的功能。
安装 Newsboat 非常容易,因为它包含在大多数发行版(以及 MacOS 上的 Homebrew)中。安装后,只需在 `~/.newsboat/urls` 中添加订阅源。如果你是从其他阅读器迁移而来,并有导出的 OPML 文件,那么可以使用以下方式导入:
```
newsboat -i </path/to/my/feeds.opml>
```
添加订阅源后,Newsboat 的界面非常熟悉,特别是如果你使用过 Mutt。你可以使用箭头键上下滚动,使用 `r` 检查某个源中是否有新项目,使用 `R` 检查所有源中是否有新项目,按回车打开订阅源,并选择要阅读的文章。

但是,你不仅限于本地 URL 列表。Newsboat 还是 [Tiny Tiny RSS](https://tt-rss.org/)、ownCloud 和 Nextcloud News 等新闻阅读服务以及一些 Google Reader 后续产品的客户端。[Newsboat 的文档](https://newsboat.org/releases/2.18/docs/newsboat.html)中涵盖了有关此的详细信息以及其他许多配置选项。

#### 播客
Newsboat 还通过 Podboat 提供了[播客支持](https://newsboat.org/releases/2.18/docs/newsboat.html#_podcast_support),Podboat 是一个附带的应用,它可帮助下载和排队播客节目。在 Newsboat 中查看播客源时,按下 `e` 将节目添加到你的下载队列中。所有信息将保存在 `~/.newsboat` 目录中的队列文件中。Podboat 读取此队列并将节目下载到本地磁盘。你可以在 Podboat 的用户界面(外观和行为类似于 Newsboat)执行此操作,也可以使用 `podboat -a` 让 Podboat 下载所有内容。作为播客人和播客听众,我认为这*真的*很方便。

总体而言,Newsboat 有一些非常好的功能,并且是一些基于 Web 或桌面应用的不错的轻量级替代方案。
---
via: <https://opensource.com/article/20/1/open-source-rss-feed-reader>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Access your RSS feeds and podcasts with Newsboat
RSS news feeds are an exceptionally handy way to keep up to date on various websites. In addition to Opensource.com, I follow the annual [SysAdvent](https://sysadvent.blogspot.com/) sysadmin tools feed, some of my favorite authors, and several webcomics. RSS readers allow me to "batch up" my reading, so I'm not spending every day on a bunch of different websites.
[Newsboat](https://newsboat.org) is a terminal-based RSS feed reader that looks and feels a lot like the email program [Mutt](http://mutt.org/). It makes news reading easy and has a lot of nice features.
Installing Newsboat is pretty easy since it is included with most distributions (and Homebrew on MacOS). Once it is installed, adding the first feed is as easy as adding the URL to the **~/.newsboat/urls** file. If you are migrating from another feed reader and have an OPML file export of your feeds, you can import that file with:
`newsboat -i </path/to/my/feeds.opml>`
After you've added your feeds, the Newsboat interface is *very* familiar, especially if you've used Mutt. You can scroll up and down with the arrow keys, check for new items in a feed with **r**, check for new items in all feeds with **R**, press **Enter** to open a feed and select an article to read.
You are not limited to just the local URL list, though. Newsboat is also a client for news reading services like [Tiny Tiny RSS](https://tt-rss.org/), ownCloud and Nextcloud News, and a few Google Reader successors. Details on that and a whole host of other configuration options are covered in [Newsboat's documentation](https://newsboat.org/releases/2.18/docs/newsboat.html).
### Podcasts
Newsboat also provides [podcast support](https://newsboat.org/releases/2.18/docs/newsboat.html#_podcast_support) through Podboat, an included application that facilitates downloading and queuing podcast episodes. While viewing a podcast feed in Newsboat, press **e** to add the episode to your download queue. All the information will be stored in a queue file in the **~/.newsboat** directory. Podboat reads this queue and downloads the episode(s) to your local drive. You can do this from the Podboat user interface (which looks and acts like Newsboat), or you can tell Podboat to download them all with **podboat -a**. As a podcaster and podcast listener, I think this is *really* handy.
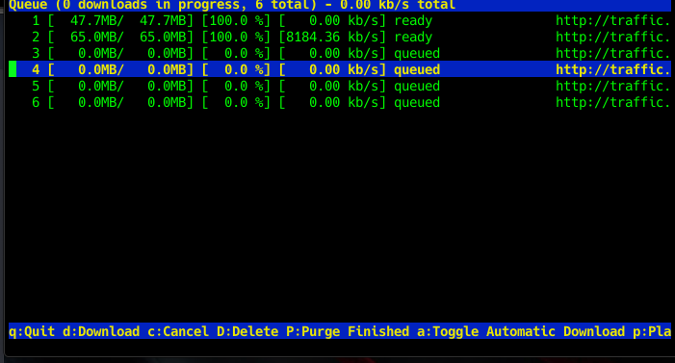
Overall, Newsboat has some really great features and is a nice, lightweight alternative to web-based or desktop apps.
## 1 Comment |
11,877 | 用于安全计算的 HTTPS 是什么? | https://opensource.com/article/20/1/confidential-computing | 2020-02-11T12:36:05 | [
"安全"
] | https://linux.cn/article-11877-1.html |
>
> 在默认的情况下,网站的安全性还不足够。
>
>
>

在过去的几年里,寻找一个只以 “http://…” 开头的网站变得越来越难,这是因为业界终于意识到,网络安全“是件事”,同时也是因为客户端和服务端之间建立和使用 https 连接变得更加容易了。类似的转变可能正以不同的方式发生在云计算、边缘计算、物联网、区块链,人工智能、机器学习等领域。长久以来,我们都知道我们应该对存储的静态数据和在网络中传输的数据进行加密,但是在使用和处理数据的时候对它进行加密是困难且昂贵的。可信计算(使用例如<ruby> 受信任的执行环境 <rt> Trusted Execution Environments </rt></ruby> TEEs 这样的硬件功能来提供数据和算法这种类型的保护)可以保护主机系统中的或者易受攻击的环境中的数据。
关于 [TEEs](https://aliceevebob.com/2019/02/26/oh-how-i-love-my-tee-or-do-i/),当然,还有我和 Nathaniel McCallum 共同创立的 [Enarx 项目](https://enarx.io/),我已经写了几次文章(参见《[给每个人的 Enarx(一个任务)](https://aliceevebob.com/2019/08/20/enarx-for-everyone-a-quest/)》 和 《[Enarx 迈向多平台](https://aliceevebob.com/2019/10/29/enarx-goes-multi-platform/)》)。Enarx 使用 TEEs 来提供独立于平台和语言的部署平台,以此来让你能够安全地将敏感应用或者敏感组件(例如微服务)部署在你不信任的主机上。当然,Enarx 是完全开源的(顺便提一下,我们使用的是 Apache 2.0 许可证)。能够在你不信任的主机上运行工作负载,这是可信计算的承诺,它扩展了使用静态敏感数据和传输中数据的常规做法:
* **存储**:你要加密你的静态数据,因为你不完全信任你的基础存储架构。
* **网络**:你要加密你正在传输中的数据,因为你不完全信任你的基础网络架构。
* **计算**:你要加密你正在使用中的数据,因为你不完全信任你的基础计算架构。
关于信任,我有非常多的话想说,而且,上述说法里的单词“**完全**”是很重要的(在重新读我写的这篇文章的时候,我新加了这个单词)。不论哪种情况,你必须在一定程度上信任你的基础设施,无论是传递你的数据包还是存储你的数据块,例如,对于计算基础架构,你必须要去信任 CPU 和与之关联的固件,这是因为如果你不信任他们,你就无法真正地进行计算(现在有一些诸如<ruby> 同态加密 <rt> homomorphic encryption </rt></ruby>一类的技术,这些技术正在开始提供一些可能性,但是它们依然有限,这些技术还不够成熟)。
考虑到发现的一些 CPU 安全性问题,是否应该完全信任 CPU 有时自然会产生疑问,以及它们是否在针对其所在的主机的物理攻击中具有完全的安全性。
这两个问题的回答都是“不”,但是在考虑到大规模可用性和普遍推广的成本,这已经是我们当前拥有的最好的技术了。为了解决第二个问题,没有人去假装这项技术(或者任何的其他技术)是完全安全的:我们需要做的是思考我们的[威胁模型](https://aliceevebob.com/2018/02/20/there-are-no-absolutes-in-security/)并确定这个情况下的 TEEs 是否为我们的特殊需求提供了足够的安全防护。关于第一个问题,Enarx 采用的模型是在部署时就对你是否信任一个特定的 CPU 组做出决定。举个例子,如果供应商 Q 的 R 代芯片被发现有漏洞,可以很简单地说“我拒绝将我的工作内容部署到 Q 的 R 代芯片上去,但是仍然可以部署到 Q 的 S 型号、T 型号和 U 型号的芯片以及任何 P、M 和 N 供应商的任何芯片上去。”
我认为这里发生了三处改变,这些改变引起了人们现在对<ruby> 机密计算 <rt> confidential computing </rt></ruby>的兴趣和采用。
1. **硬件可用**:只是在过去的 6 到 12 个月里,支持 TEEs 的硬件才开始变得广泛可用,这会儿市场上的主要例子是 Intel 的 SGX 和 AMD 的 SEV。我们期望在未来可以看到支持 TEE 的硬件的其他例子。
2. **行业就绪**:就像上云越来越多地被接受作为应用程序部署的模型,监管机构和立法机构也在提高各类组织保护其管理的数据的要求。组织开始呼吁在不受信任的主机运行敏感程序(或者是处理敏感数据的应用程序)的方法,更确切地说,是在无法完全信任且带有敏感数据的主机上运行的方法。这不足为奇:如果芯片制造商看不到这项技术的市场,他们就不会投太多的钱在这项技术上。Linux 基金会的[机密计算联盟(CCC)](https://confidentialcomputing.io/)的成立就是业界对如何寻找使用加密计算的通用模型并且鼓励开源项目使用这些技术感兴趣的案例。(红帽发起的 Enarx 是一个 CCC 项目。)
3. **开放源码**:就像区块链一样,机密计算是使用开源绝对明智的技术之一。如果你要运行敏感程序,你需要去信任正在为你运行的程序。不仅仅是 CPU 和固件,同样还有在 TEE 内执行你的工作负载的框架。可以很好地说,“我不信任主机机器和它上面的软件栈,所以我打算使用 TEE,”但是如果你不够了解 TEE 软件环境,那你就是将一种软件不透明换成另外一种。TEEs 的开源支持将允许你或者社区(实际上是你与社区)以一种专有软件不可能实现的方式来检查和审计你所运行的程序。这就是为什么 CCC 位于 Linux 基金会旗下(这个基金会致力于开放式开发模型)并鼓励 TEE 相关的软件项目加入且成为开源项目(如果它们还没有成为开源)。
我认为,在过去的 15 到 20 年里,硬件可用、行业就绪和开放源码已成为推动技术改变的驱动力。区块链、人工智能、云计算、<ruby> 大规模计算 <rt> webscale computing </rt></ruby>、大数据和互联网商务都是这三个点同时发挥作用的例子,并且在业界带来了巨大的改变。
在一般情况下,安全是我们这数十年来听到的一种承诺,并且其仍然未被实现。老实说,我不确定它未来会不会实现。但是随着新技术的到来,特定用例的安全变得越来越实用和无处不在,并且在业内受到越来越多的期待。这样看起来,机密计算似乎已准备好成为成为下一个重大变化 —— 而你,我亲爱的读者,可以一起来加入到这场革命(毕竟它是开源的)。
这篇文章最初是发布在 Alice, Eve, and Bob 上的,这是得到了作者许可的重发。
---
via: <https://opensource.com/article/20/1/confidential-computing>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Over the past few years, it's become difficult to find a website that is just "http://…" This is because the industry has finally realised that security on the web is "a thing," and also because it has become easy for both servers and clients to set up and use HTTPS connections. A similar shift may be on its way in computing across cloud, edge, Internet of Things, blockchain, artificial intelligence, machine learning, and beyond. We've known for a long time that we should encrypt data at rest (in storage) and in transit (on the network), but encrypting it in use (while processing) has been difficult and expensive. Confidential computing—providing this type of protection for data and algorithms in use using hardware capabilities such as trusted execution environments (TEEs)—protects data on hosted systems or vulnerable environments.
I've written several times about [TEEs](https://aliceevebob.com/2019/02/26/oh-how-i-love-my-tee-or-do-i/) and, of course, the [Enarx project](https://enarx.io/) of which I'm a co-founder with Nathaniel McCallum (see [ Enarx for everyone (a quest)](https://aliceevebob.com/2019/08/20/enarx-for-everyone-a-quest/) and
[for examples). Enarx uses TEEs and provides a platform- and language-independent deployment platform to allow you safely to deploy sensitive applications or components (such as microservices) onto hosts that you don't trust. Enarx is, of course, completely open source (we're using the Apache 2.0 licence, for those with an interest). Being able to run workloads on hosts that you don't trust is the promise of confidential computing, which extends normal practice for sensitive data at rest and in transit to data in use:](https://aliceevebob.com/2019/10/29/enarx-goes-multi-platform/)
*Enarx goes multi-platform***Storage:**You encrypt your data at rest because you don't fully trust the underlying storage infrastructure.**Networking:**You encrypt your data in transit because you don't fully trust the underlying network infrastructure.**Compute:**You encrypt your data in use because you don't fully trust the underlying compute infrastructure.
I've got a lot to say about trust, and the word "fully" in the statements above is important (I added it on re-reading what I'd written). In each case, you have to trust the underlying infrastructure to some degree, whether it's to deliver your packets or store your blocks, for instance. In the case of the compute infrastructure, you're going to have to trust the CPU and associated firmware, just because you can't really do computing without trusting them (there are techniques such as homomorphic encryption, which are beginning to offer some opportunities here, but they're limited and the technology still immature).
Questions sometimes come up about whether you should fully trust CPUs, given some of the security problems that have been found with them, and also about whether they are fully secure against physical attacks on the host on which they reside.
The answer to both questions is "no," but this is the best technology we currently have available at scale and at a price point to make it generally deployable. To address the second question, nobody is pretending that this (or any other technology) is fully secure: what we need to do is consider our [threat model](https://aliceevebob.com/2018/02/20/there-are-no-absolutes-in-security/) and decide whether TEEs (in this case) provide sufficient security for our specific requirements. In terms of the first question, the model that Enarx adopts is to allow decisions to be made at deployment time as to whether you trust a particular set of CPUs. So, for example, if vendor Q's generation R chips are found to contain a vulnerability, it will be easy to say "refuse to deploy my workloads to R-type CPUs from Q, but continue to deploy to S-type, T-type, and U-type chips from Q and any CPUs from vendors P, M, and N."
I think there are three changes in the landscape that are leading to the interest and adoption of confidential computing right now:
**Hardware availability:**It is only over the past six to 12 months that hardware supporting TEEs has started to become widely available, with the key examples in the market at the moment being Intel's SGX and AMD's SEV. We can expect to see other examples of TEE-enabled hardware coming out in the fairly near future.**Industry readiness:**Just as cloud use is increasingly becoming accepted as a model for application deployment, regulators and legislators are increasing the requirements on organisations to protect the data they manage. Organisations are beginning to clamour for ways to run sensitive applications (or applications that handle sensitive data) on untrusted hosts—or, to be more accurate, on hosts that they cannot fully trust with that sensitive data. This should be no surprise: the chip vendors would not have invested so much money into this technology if they saw no likely market for it. Formation of the Linux Foundation's[Confidential Computing Consortium](https://confidentialcomputing.io/)(CCC) is another example of how the industry is interested in finding common models for the use of confidential computing and encouraging open source projects to employ these technologies.1**Open source:**Like blockchain, confidential computing is one of those technologies where it's an absolute no-brainer to use open source. If you are going to run sensitive applications, you need to trust what's doing the running for you. That's not just the CPU and firmware but also the framework that supports the execution of your workload within the TEE. It's all very well saying, "I don't trust the host machine and its software stack, so I'm going to use a TEE," but if you don't have visibility into the TEE software environment, then you're just swapping one type of software opacity for another. Open source support for TEEs allows you or the community—in fact, you*and*the community—to check and audit what you're running in a way that is impossible for proprietary software. This is why the CCC sits within the Linux Foundation (which is committed to the open development model) and is encouraging TEE-related software projects to join and go open source (if they weren't already).
I'd argue that this triad of hardware availability, industry readiness, and open source has become the driver for technology change over the past 15 to 20 years. Blockchain, AI, cloud computing, webscale computing, big data, and internet commerce are all examples of these three meeting at the same time and leading to extraordinary changes in our industry.
Security by default is a promise that we've been hearing for decades now, and it hasn't arrived yet. Honestly, I'm not sure it ever will. But as new technologies become available, security ubiquity for particular use cases becomes more practical and more expected within the industry. It seems that confidential computing is ready to be the next big change—and you, dear reader, can join the revolution (it's open source, after all).
*This article was originally published on Alice, Eve, and Bob and is reprinted with the author's permission.*
## 3 Comments |
11,879 | 使用这个开源工具获取本地天气预报 | https://opensource.com/article/20/1/open-source-weather-forecast | 2020-02-11T14:08:00 | [
"气候"
] | /article-11879-1.html |
>
> 在我们的 20 个使用开源提升生产力的系列的第十三篇文章中使用 wego 来了解出门前你是否要需要外套、雨伞或者防晒霜。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 wego 了解天气
过去十年我对我的职业最满意的地方之一是大多数时候是远程工作。尽管现实情况是我很多时候是在家里办公,但我可以在世界上任何地方工作。缺点是,离家时我会根据天气做出一些决定。在我居住的地方,“晴朗”可以表示从“酷热”、“低于零度”到“一小时内会小雨”。能够了解实际情况和快速预测非常有用。

[Wego](https://github.com/schachmat/wego) 是用 Go 编写的程序,可以获取并显示你的当地天气。如果你愿意,它甚至可以用闪亮的 ASCII 艺术效果进行渲染。
要安装 `wego`,你需要确保在系统上安装了[Go](https://golang.org/doc/install)。之后,你可以使用 `go get` 命令获取最新版本。你可能还想将 `~/go/bin` 目录添加到路径中:
```
go get -u github.com/schachmat/wego
export PATH=~/go/bin:$PATH
wego
```
首次运行时,`wego` 会报告缺失 API 密钥。现在你需要决定一个后端。默认后端是 [Forecast.io](https://forecast.io),它是 [Dark Sky](https://darksky.net)的一部分。`wego` 还支持 [OpenWeatherMap](https://openweathermap.org/) 和 [WorldWeatherOnline](https://www.worldweatheronline.com/)。我更喜欢 OpenWeatherMap,因此我将在此向你展示如何设置。
你需要在 OpenWeatherMap 中[注册 API 密钥](https://openweathermap.org/api)。注册是免费的,尽管免费的 API 密钥限制了一天可以查询的数量,但这对于普通用户来说应该没问题。得到 API 密钥后,将它放到 `~/.wegorc` 文件中。现在可以填写你的位置、语言以及使用公制、英制(英国/美国)还是国际单位制(SI)。OpenWeatherMap 可通过名称、邮政编码、坐标和 ID 确定位置,这是我喜欢它的原因之一。
```
# wego configuration for OEM
aat-coords=false
aat-monochrome=false
backend=openweathermap
days=3
forecast-lang=en
frontend=ascii-art-table
jsn-no-indent=false
location=Pittsboro
owm-api-key=XXXXXXXXXXXXXXXXXXXXX
owm-debug=false
owm-lang=en
units=imperial
```
现在,在命令行运行 `wego` 将显示接下来三天的当地天气。
`wego` 还可以输出 JSON 以便程序使用,还可显示 emoji。你可以使用 `-f` 参数或在 `.wegorc` 文件中指定前端。

如果你想在每次打开 shell 或登录主机时查看天气,只需将 wego 添加到 `~/.bashrc`(我这里是 `~/.zshrc`)即可。
[wttr.in](https://github.com/chubin/wttr.in) 项目是 wego 上的基于 Web 的封装。它提供了一些其他显示选项,并且可以在同名网站上看到。关于 wttr.in 的一件很酷的事情是,你可以使用 `curl` 获取一行天气信息。我有一个名为 `get_wttr` 的 shell 函数,用于获取当前简化的预报信息。
```
get_wttr() {
curl -s "wttr.in/Pittsboro?format=3"
}
```

现在,在我离开家之前,我就可以通过命令行快速简单地获取我是否需要外套、雨伞或者防晒霜了。
---
via: <https://opensource.com/article/20/1/open-source-weather-forecast>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,881 | 如何进行 Linux 启动时间优化 | https://opensourceforu.com/2019/10/how-to-go-about-linux-boot-time-optimisation/ | 2020-02-11T23:36:00 | [
"启动",
"引导"
] | https://linux.cn/article-11881-1.html | 
>
> 快速启动嵌入式设备或电信设备,对于时间要求紧迫的应用程序是至关重要的,并且在改善用户体验方面也起着非常重要的作用。这个文章给予一些关于如何增强任意设备的启动时间的重要技巧。
>
>
>
快速启动或快速重启在各种情况下起着至关重要的作用。为了保持所有服务的高可用性和更好的性能,嵌入式设备的快速启动至关重要。设想有一台运行着没有启用快速启动的 Linux 操作系统的电信设备,所有依赖于这个特殊嵌入式设备的系统、服务和用户可能会受到影响。这些设备维持其服务的高可用性是非常重要的,为此,快速启动和重启起着至关重要的作用。
一台电信设备的一次小故障或关机,即使只是几秒钟,都可能会对无数互联网上的用户造成破坏。因此,对于很多对时间要求严格的设备和电信设备来说,在它们的设备中加入快速启动的功能以帮助它们快速恢复工作是非常重要的。让我们从图 1 中理解 Linux 启动过程。

### 监视工具和启动过程
在对机器做出更改之前,用户应注意许多因素。其中包括计算机的当前启动速度,以及占用资源并增加启动时间的服务、进程或应用程序。
#### 启动图
为监视启动速度和在启动期间启动的各种服务,用户可以使用下面的命令来安装:
```
sudo apt-get install pybootchartgui
```
你每次启动时,启动图会在日志中保存一个 png 文件,使用户能够查看该 png 文件来理解系统的启动过程和服务。为此,使用下面的命令:
```
cd /var/log/bootchart
```
用户可能需要一个应用程序来查看 png 文件。Feh 是一个面向控制台用户的 X11 图像查看器。不像大多数其它的图像查看器,它没有一个精致的图形用户界面,但它只用来显示图片。Feh 可以用于查看 png 文件。你可以使用下面的命令来安装它:
```
sudo apt-get install feh
```
你可以使用 `feh xxxx.png` 来查看 png 文件。

图 2 显示了一个正在查看的引导图 png 文件。
#### systemd-analyze
但是,对于 Ubuntu 15.10 以后的版本不再需要引导图。为获取关于启动速度的简短信息,使用下面的命令:
```
systemd-analyze
```

图表 3 显示命令 `systemd-analyze` 的输出。
命令 `systemd-analyze blame` 用于根据初始化所用的时间打印所有正在运行的单元的列表。这个信息是非常有用的,可用于优化启动时间。`systemd-analyze blame` 不会显示服务类型为简单(`Type=simple`)的服务,因为 systemd 认为这些服务应是立即启动的;因此,无法测量初始化的延迟。

图 4 显示 `systemd-analyze blame` 的输出。
下面的命令打印时间关键的服务单元的树形链条:
```
command systemd-analyze critical-chain
```
图 5 显示命令 `systemd-analyze critical-chain` 的输出。

### 减少启动时间的步骤
下面显示的是一些可以减少启动时间的各种步骤。
#### BUM(启动管理器)
BUM 是一个运行级配置编辑器,允许在系统启动或重启时配置初始化服务。它显示了可以在启动时启动的每个服务的列表。用户可以打开和关闭各个服务。BUM 有一个非常清晰的图形用户界面,并且非常容易使用。
在 Ubuntu 14.04 中,BUM 可以使用下面的命令安装:
```
sudo apt-get install bum
```
为在 15.10 以后的版本中安装它,从链接 <http://apt.ubuntu.com/p/bum> 下载软件包。
以基本的服务开始,禁用扫描仪和打印机相关的服务。如果你没有使用蓝牙和其它不想要的设备和服务,你也可以禁用它们中一些。我强烈建议你在禁用相关的服务前学习服务的基础知识,因为这可能会影响计算机或操作系统。图 6 显示 BUM 的图形用户界面。

#### 编辑 rc 文件
要编辑 rc 文件,你需要转到 rc 目录。这可以使用下面的命令来做到:
```
cd /etc/init.d
```
然而,访问 `init.d` 需要 root 用户权限,该目录基本上包含的是开始/停止脚本,这些脚本用于在系统运行时或启动期间控制(开始、停止、重新加载、启动启动)守护进程。
在 `init.d` 目录中的 `rc` 文件被称为<ruby> 运行控制 <rt> run control </rt></ruby>脚本。在启动期间,`init` 执行 `rc` 脚本并发挥它的作用。为改善启动速度,我们可以更改 `rc` 文件。使用任意的文件编辑器打开 `rc` 文件(当你在 `init.d` 目录中时)。
例如,通过输入 `vim rc` ,你可以更改 `CONCURRENCY=none` 为 `CONCURRENCY=shell`。后者允许某些启动脚本同时执行,而不是依序执行。
在最新版本的内核中,该值应该被更改为 `CONCURRENCY=makefile`。
图 7 和图 8 显示编辑 `rc` 文件前后的启动时间比较。可以注意到启动速度有所提高。在编辑 `rc` 文件前的启动时间是 50.98 秒,然而在对 `rc` 文件进行更改后的启动时间是 23.85 秒。
但是,上面提及的更改方法在 Ubuntu 15.10 以后的操作系统上不工作,因为使用最新内核的操作系统使用 systemd 文件,而不再是 `init.d` 文件。


#### E4rat
E4rat 代表 e4 <ruby> 减少访问时间 <rt> reduced access time </rt></ruby>(仅在 ext4 文件系统的情况下)。它是由 Andreas Rid 和 Gundolf Kiefer 开发的一个项目。E4rat 是一个通过碎片整理来帮助快速启动的应用程序。它还会加速应用程序的启动。E4rat 使用物理文件的重新分配来消除寻道时间和旋转延迟,因而达到较高的磁盘传输速度。
E4rat 可以 .deb 软件包形式获得,你可以从它的官方网站 <http://e4rat.sourceforge.net/> 下载。
Ubuntu 默认安装的 ureadahead 软件包与 e4rat 冲突。因此必须使用下面的命令安装这几个软件包:
```
sudo dpkg purge ureadahead ubuntu-minimal
```
现在使用下面的命令来安装 e4rat 的依赖关系:
```
sudo apt-get install libblkid1 e2fslibs
```
打开下载的 .deb 文件,并安装它。现在需要恰当地收集启动数据来使 e4rat 工作。
遵循下面所给的步骤来使 e4rat 正确地运行并提高启动速度。
* 在启动期间访问 Grub 菜单。这可以在系统启动时通过按住 `shift` 按键来完成。
* 选择通常用于启动的选项(内核版本),并按 `e`。
* 查找以 `linux /boot/vmlinuz` 开头的行,并在该行的末尾添加下面的代码(在句子的最后一个字母后按空格键):`init=/sbin/e4rat-collect or try - quiet splash vt.handsoff =7 init=/sbin/e4rat-collect`。
* 现在,按 `Ctrl+x` 来继续启动。这可以让 e4rat 在启动后收集数据。在这台机器上工作,并在接下来的两分钟时间内打开并关闭应用程序。
* 通过转到 e4rat 文件夹,并使用下面的命令来访问日志文件:`cd /var/log/e4rat`。
* 如果你没有找到任何日志文件,重复上面的过程。一旦日志文件就绪,再次访问 Grub 菜单,并对你的选项按 `e`。
* 在你之前已经编辑过的同一行的末尾输入 `single`。这可以让你访问命令行。如果出现其它菜单,选择恢复正常启动(Resume normal boot)。如果你不知为何不能进入命令提示符,按 `Ctrl+Alt+F1` 组合键。
* 在你看到登录提示后,输入你的登录信息。
* 现在输入下面的命令:`sudo e4rat-realloc /var/lib/e4rat/startup.log`。此过程需要一段时间,具体取决于机器的磁盘速度。
* 现在使用下面的命令来重启你的机器:`sudo shutdown -r now`。
* 现在,我们需要配置 Grub 来在每次启动时运行 e4rat。
* 使用任意的编辑器访问 grub 文件。例如,`gksu gedit /etc/default/grub`。
* 查找以 `GRUB CMDLINE LINUX DEFAULT=` 开头的一行,并在引号之间和任何选项之前添加下面的行:`init=/sbin/e4rat-preload 18`。
* 它应该看起来像这样:`GRUB CMDLINE LINUX DEFAULT = init=/sbin/e4rat- preload quiet splash`。
* 保存并关闭 Grub 菜单,并使用 `sudo update-grub` 更新 Grub 。
* 重启系统,你将发现启动速度有明显变化。
图 9 和图 10 显示在安装 e4rat 前后的启动时间之间的差异。可注意到启动速度的提高。在使用 e4rat 前启动所用时间是 22.32 秒,然而在使用 e4rat 后启动所用时间是 9.065 秒。


### 一些易做的调整
使用很小的调整也可以达到良好的启动速度,下面列出其中两个。
#### SSD
使用固态设备而不是普通的硬盘或者其它的存储设备将肯定会改善启动速度。SSD 也有助于加快文件传输和运行应用程序方面的速度。
#### 禁用图形用户界面
图形用户界面、桌面图形和窗口动画占用大量的资源。禁用图形用户界面是获得良好的启动速度的另一个好方法。
---
via: <https://opensourceforu.com/2019/10/how-to-go-about-linux-boot-time-optimisation/>
作者:[B Thangaraju](https://opensourceforu.com/author/b-thangaraju/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,882 | 3 个方便的命令行网速度测试工具 | https://opensource.com/article/20/1/internet-speed-tests | 2020-02-12T11:59:00 | [
"网速"
] | https://linux.cn/article-11882-1.html |
>
> 用这三个开源工具检查你的互联网和局域网速度。
>
>
>

能够验证网络连接速度使您可以控制计算机。 使您可以在命令行中检查互联网和网络速度的三个开源工具是 Speedtest、Fast 和 iPerf。
### Speedtest
[Speedtest](https://github.com/sivel/speedtest-cli) 是一个旧宠。它用 Python 实现,并打包在 Apt 中,也可用 `pip` 安装。你可以将它作为命令行工具或在 Python 脚本中使用。
使用以下命令安装:
```
sudo apt install speedtest-cli
```
或者
```
sudo pip3 install speedtest-cli
```
然后使用命令 `speedtest` 运行它:
```
$ speedtest
Retrieving speedtest.net configuration...
Testing from CenturyLink (65.128.194.58)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by CenturyLink (Cambridge, UK) [20.49 km]: 31.566 ms
Testing download speed................................................................................
Download: 68.62 Mbit/s
Testing upload speed......................................................................................................
Upload: 10.93 Mbit/s
```
它给你提供了互联网上传和下载的网速。它快速而且可脚本调用,因此你可以定期运行它,并将输出保存到文件或数据库中,以记录一段时间内的网络速度。
### Fast
[Fast](https://github.com/sindresorhus/fast-cli) 是 Netflix 提供的服务。它的网址是 [Fast.com](https://fast.com/),同时它有一个可通过 `npm` 安装的命令行工具:
```
npm install --global fast-cli
```
网站和命令行程序都提供了相同的基本界面:它是一个尽可能简单的速度测试:
```
$ fast
82 Mbps ↓
```
该命令返回你的网络下载速度。要获取上传速度,请使用 `-u` 标志:
```
$ fast -u
⠧ 80 Mbps ↓ / 8.2 Mbps ↑
```
### iPerf
[iPerf](https://iperf.fr/) 测试的是局域网速度(而不是像前两个工具一样测试互联网速度)的好方法。Debian、Raspbian 和 Ubuntu 用户可以使用 apt 安装它:
```
sudo apt install iperf
```
它还可用于 Mac 和 Windows。
安装完成后,你需要在同一网络上的两台计算机上使用它(两台都必须安装 iPerf)。指定其中一台作为服务器。
获取服务端计算机的 IP 地址:
```
ip addr show | grep inet.*brd
```
你的本地 IP 地址(假设为 IPv4 本地网络)以 `192.168` 或 `10` 开头。记下 IP 地址,以便可以在另一台计算机(指定为客户端的计算机)上使用它。
在服务端启动 `iperf`:
```
iperf -s
```
它会等待来自客户端的传入连接。将另一台计算机作为为客户端并运行此命令,将示例中的 IP 替换为服务端计算机的 IP:
```
iperf -c 192.168.1.2
```

只需几秒钟即可完成测试,然后返回传输大小和计算出的带宽。我使用家用服务器作为服务端,在 PC 和笔记本电脑上进行了一些测试。我最近在房屋周围安装了六类线以太网,因此我的有线连接速度达到 1Gbps,但 WiFi 连接速度却低得多。

你可能注意到它记录到 16Gbps。那是我使用服务器进行自我测试,因此它只是在测试写入磁盘的速度。该服务器具有仅 16 Gbps 的硬盘驱动器,但是我的台式机有 46Gbps,另外我的(较新的)笔记本超过了 60Gbps,因为它们都有固态硬盘。

### 总结
通过这些工具来了解你的网络速度是一项非常简单的任务。如果你更喜欢脚本或者在命令行中运行,上面的任何一个都能满足你。如果你要了解点对点的指标,iPerf 能满足你。
你还使用其他哪些工具来衡量家庭网络?在评论中分享你的评论。
本文最初发表在 Ben Nuttall 的 [Tooling blog](https://tooling.bennuttall.com/command-line-speedtest-tools/) 上,并获准在此使用。
---
via: <https://opensource.com/article/20/1/internet-speed-tests>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Being able to validate your network connection speed puts you in control of your computer. Three open source tools that enable you to check your internet and network speeds at the command line are Speedtest, Fast, and iPerf.
## Speedtest
[Speedtest](https://github.com/sivel/speedtest-cli) is an old favorite. It's implemented in Python, packaged in Apt, and also available with pip. You can use it as a command-line tool or within a Python script.
Install it with:
`sudo apt install speedtest-cli`
or
`sudo pip3 install speedtest-cli`
Then run it with the command **speedtest**:
```
$ speedtest
Retrieving speedtest.net configuration...
Testing from CenturyLink (65.128.194.58)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by CenturyLink (Cambridge, UK) [20.49 km]: 31.566 ms
Testing download speed................................................................................
Download: 68.62 Mbit/s
Testing upload speed......................................................................................................
Upload: 10.93 Mbit/s
```
This gives you your download and upload Internet speeds. It's fast and scriptable, so you can run it regularly and save the output to a file or database for a record of your network speed over time.
## Fast
[Fast](https://github.com/sindresorhus/fast-cli) is a service provided by Netflix. Its web interface is located at [Fast.com](https://fast.com/), and it has a command-line interface available through npm:
`npm install --global fast-cli`
Both the website and command-line utility provide the same basic interface: it's a simple-as-possible speed test:
```
$ fast
82 Mbps ↓
```
The command returns your Internet download speed. To get your upload speed, use the **-u** flag:
```
$ fast -u
⠧ 80 Mbps ↓ / 8.2 Mbps ↑
```
## iPerf
[iPerf](https://iperf.fr/) is a great way to test your LAN speed (rather than your Internet speed, as the two previous tools do). Debian, Raspbian, and Ubuntu users can install it with **apt**:
`sudo apt install iperf`
It's also available for Mac and Windows.
Once it's installed, you need two machines on the same network to use it (both must have iPerf installed). Designate one as the server.
Obtain the IP address of the server machine:
`ip addr show | grep inet.*brd`
Your local IP address (assuming an IPv4 local network) starts with either **192.168** or **10**. Take note of the IP address so you can use it on the other machine (the one designated as the client).
Start **iperf** on the server:
`iperf -s`
This waits for incoming connections from clients. Designate another machine as a client and run this command, substituting the IP address of your server machine for the sample one here:
`iperf -c 192.168.1.2`

It only takes a few seconds to do a test, and it returns the transfer size and calculated bandwidth. I ran a few tests from my PC and my laptop, using my home server as the server machine. I recently put in Cat6 Ethernet around my house, so I get up to 1Gbps speeds from my wired connections but much lower speeds on WiFi connections.
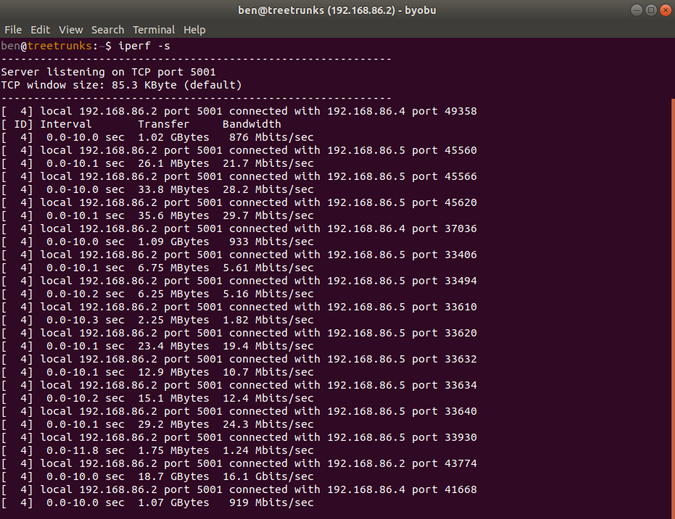
You may notice where it recorded 16Gbps. That was me using the server to test itself, so it's just testing how fast it can write to its own disk. The server has hard disk drives, which are only 16Gbps, but my desktop PC gets 46Gbps, and my (newer) laptop gets over 60Gbps, as they have solid-state drives.
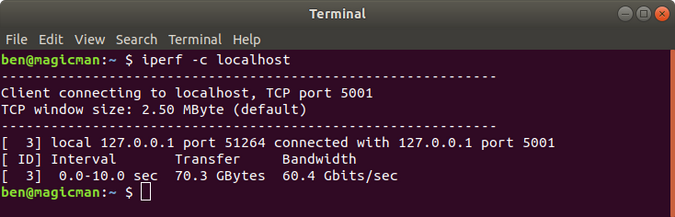
## Wrapping up
Knowing the speed of your network is a rather straightforward task with these tools. If you prefer to script or run these from the command line for the fun of it, any of the above projects will get you there. If you're after specific point-to-point metrics, iPerf is your go-to.
What other tools do you use to measure the network at home? Share in the comments.
*This article was originally published on Ben Nuttall's Tooling blog and is used here with permission.*
## 7 Comments |
11,884 | 7 个可用于自建电商站点的开源解决方案 | https://itsfoss.com/open-source-ecommerce/ | 2020-02-12T13:14:22 | [
"电子商务"
] | https://linux.cn/article-11884-1.html | 在[之前的文章](https://itsfoss.com/open-source-cms/)中,我介绍过一些开源<ruby> 内容管理系统 <rt> Content Management System </rt></ruby>(CMS),顾名思义,这些 CMS 平台更适用于以内容为主的站点。
那如果想要建立自己的线上购物站点呢?我们正好还有一些优秀的开源电商解决方案,可以自行部署在自己的 Linux 服务器上。
这些电商解决方案是专为搭建线上购物站点设计的,因此都集成了库存管理、商品列表、购物车、下单、愿望清单以及支付这些必需的基础功能。
但请注意,这篇文章并不会进行深入介绍。因此,我建议最好广泛试用其中的多个产品,以便进一步的了解和比较。
### 优秀的开源电商解决方案

开源电商解决方案种类繁多,一些缺乏维护的都会被我们忽略掉,以免搭建出来的站点因维护不及时而受到影响。
另外,以下的列表排名不分先后。
#### 1、nopCommerce

nopCommerce 是基于 [ASP.NET Core](https://en.wikipedia.org/wiki/ASP.NET_Core) 的自由开源的电商解决方案。如果你要找的是基于 PHP 的解决方案,可以跳过这一节了。
nopCommerce 的管理面板界面具有简洁易用的特点,如果你还使用过 OpenCart,就可能会感到似曾相识(我不是在抱怨)。在默认情况下,它就已经自带了很多基本的功能,同时还为移动端用户提供了响应式的设计。
你可以在其[官方商店](https://www.nopcommerce.com/marketplace)中获取到一些兼容的界面主题和应用扩展,还可以选择付费的支持服务。
在开始使用前,你可以从 nopCommerce 的[官方网站](https://www.nopcommerce.com/download-nopcommerce)下载源代码包,然后进行自定义配置和部署;也可以直接下载完整的软件包快速安装到 web 服务器上。详细信息可以查阅 nopCommerce 的 [GitHub 页面](https://github.com/nopSolutions/nopCommerce)或官方网站。
* [nopCommerce](https://www.nopcommerce.com/)
#### 2、OpenCart

OpenCart 是一个基于 PHP 的非常流行的电商解决方案,就我个人而言,我曾为一个项目用过它,并且体验非常好,如果不是最好的话。
或许你会觉得它维护得不是很频繁,但实际上使用 OpenCart 的开发者并不在少数。你可以获得许多受支持的扩展并将它们的功能加入到 OpenCart 中。
OpenCart 不一定是适合所有人的“现代”电商解决方案,但如果你需要的只是一个基于 PHP 的开源解决方案,OpenCart 是个值得一试的选择。在大多数具有一键式应用程序安装支持的网络托管平台中,应该可以安装 OpenCart。想要了解更多,可以查阅 OpenCart 的官方网站或 [GitHub 页面](https://github.com/opencart/opencart)。
* [OpenCart](https://www.opencart.com/)
#### 3、PrestaShop

PrestaShop 也是一个可以尝试的开源电商解决方案。
PrestaShop 是一个积极维护下的开源解决方案,它的官方商店中也有额外提供主题和扩展。与 OpenCart 不同,在托管服务平台上,你可能找不到一键安装的 PrestaShop。但不需要担心,从官方网站下载下来之后,它的部署过程也并不复杂。如果你需要帮助,也可以参考 PrestaShop 的[安装指南](http://doc.prestashop.com/display/PS17/Installing+PrestaShop)。
PrestaShop 的特点就是配置丰富和易于使用,我发现很多其它用户也在用它,你也不妨试用一下。
你也可以在 PrestaShop 的 [GitHub 页面](https://github.com/PrestaShop/PrestaShop)查阅到更多相关内容。
* [PrestaShop](https://www.prestashop.com/en)
#### 4、WooCommerce

如果你想用 [WordPress](https://wordpress.org/) 来搭建电商站点,不妨使用 WooCommerce。
从技术上来说,这种方式其实是搭建一个 WordPress 应用,然后把 WooCommerce 作为一个插件或扩展以实现电商站点所需要的功能。很多 web 开发者都知道如何使用 WordPress,因此 WooCommerce 的学习成本不会很高。
WordPress 作为目前最好的开源站点项目之一,对大部分人来说都不会有太高的门槛。它具有易用、稳定的特点,同时还支持大量的扩展插件。
WooCommerce 的灵活性也是一大亮点,在它的线上商店提供了许多设计和扩展可供选择。你也可以到它的 [GitHub 页面](https://github.com/woocommerce/woocommerce)查看相关介绍。
* [WooCommerce](https://woocommerce.com/)
#### 5、Zen Cart

这或许是一个稍显古老的电商解决方案,但同时也是最好的开源解决方案之一。如果你喜欢老式风格的模板(主要基于 HTML),而且只需要一些基础性的扩展,那你也可以尝试使用 Zen Cart。
就我个人而言,我不建议把 Zen Cart 用在一个新项目当中。但考虑到它仍然是一个活跃更新中的解决方案,如果你喜欢的话,也不妨用它来进行试验。
你也可以在 [SourceForge](https://sourceforge.net/projects/zencart/) 找到 Zen Cart 这个项目。
* [Zen Cart](https://www.zen-cart.com/)
#### 6、Magento

Magento 是 Abode 旗下的开源电商解决方案,从某种角度来说,可能比 WordPress 表现得更为优秀。
Magento 完全是作为电商应用程序而生的,因此你会发现它的很多基础功能都非常好用,甚至还提供了高级的定制。
但如果你使用的是 Magento 的开源版,可能会接触不到托管版的一些高级功能,两个版本的差异,可以在[官方文档](https://magento.com/compare-open-source-and-magento-commerce)中查看到。如果你使用托管版,还可以选择相关的托管支持服务。
想要了解更多,可以查看 Magento 的 [GitHub 页面](https://github.com/magento)。
* [Magento](https://magento.com/)
#### 7、Drupal

Drupal 是一个适用于创建电商站点的开源 CMS 解决方案。
我没有使用过 Drupal,因此我不太确定它用起来是否足够灵活。但从它的官方网站上来看,它提供的扩展模块和主题列表,足以让你轻松完成一个电商站点需要做的任何事情。
跟 WordPress 类似,Drupal 在服务器上的部署并不复杂,不妨看看它的使用效果。在它的[下载页面](https://www.drupal.org/project/drupal)可以查看这个项目以及下载最新的版本。
* [Drupal](https://www.drupal.org/industries/ecommerce)
#### 8、Odoo eCommerce

如果你还不知道,Odoo 提供了一套开源商务应用程序。他们还提供了[开源会计软件](https://itsfoss.com/open-source-accounting-software/)和 CRM 解决方案,我们将会在单独的列表中进行介绍。
对于电子商务门户,你可以根据需要使用其在线拖放生成器自定义网站。你也可以推广该网站。除了简单的主题安装和自定义选项之外,你还可以利用 HTML/CSS 在一定程度上手动自定义外观。
你也可以查看其 [GitHub](https://github.com/odoo/odoo) 页面以进一步了解它。
* [Odoo eCommerce](https://www.odoo.com/page/open-source-ecommerce)
### 总结
我敢肯定还有更多的开源电子商务平台,但是,我现在还没有遇到比我上面列出的更好的东西。
如果你还有其它值得一提的产品,可以在评论区发表。也欢迎在评论区分享你对开源电商解决方案的经验和想法。
---
via: <https://itsfoss.com/open-source-ecommerce/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In an earlier article, I listed some of the [best open-source CMS](https://itsfoss.com/open-source-cms/) options available out there. These CMS software, as the name suggests, are more suitable for content focused websites.
But what if you want to build your own online shopping website? Thankfully, we have some good open source eCommerce solutions that you can deploy on your own Linux server.
These eCommerce software are tailored for the sole purpose of giving you a shopping website. So they have essential features like inventory management, product listings, cart, checkout, wishlisting and option to integrate a payment solution.
*Please note that this is not an in-depth review article. So, I insist that you should try the platforms mentioned in this list to know more about them.*
## Best Open Source eCommerce Platforms

There are many open source eCommerce software available. I have filtered the ones which are actively maintained so that your shopping website doesn’t suffer because of obsolete or unmaintained software stack.
*It is also worth noting that the list here is in no particular order of ranking. *
### 1. nopCommerce
nopCommerce is a free and open-source eCommerce platform based on [ASP.NET Core](https://en.wikipedia.org/wiki/ASP.NET_Core). If you were looking for a PHP-based solution – you can skip to the next option on the list.
The user interface of its admin panel is clean and easy to use. If you’ve used OpenCart – you might feel the similarity (but I’m not complaining). By default, it has got all the essential features while offering a responsive design for mobile users as well.
You get access to an [official marketplace](https://www.nopcommerce.com/marketplace) where you can get supported themes and extensions. You can opt for premium support or manage it yourself for free.
To get started, you can download the package with its source code from its [official download page](https://www.nopcommerce.com/download-nopcommerce) if you want to customize it and deploy it. In either case, you can also download the complete package to get it installed on a web server quickly. You can check out their [GitHub page](https://github.com/nopSolutions/nopCommerce) and the official website to learn more.
### 2. OpenCart
OpenCart is a quite popular PHP-based eCommerce platform. Personally, I’ve worked on it for a project and the experience was good enough – if not excellent.
You may find it that it isn’t super actively maintained – but it’s still there and being utilized by a lot of web developers. You get support for a lot of extensions while having most of the essential features baked right into it.
For some, it may not be the best “modern” eCommerce platform but if you want a good open-source PHP-based alternative, it is worth a try. In most of the web hosting platforms with one-click app installation support, OpenCart should be available to setup. To learn more about it, you can head to its official website and check out the [GitHub page](https://github.com/opencart/opencart).
### 3. PrestaShop
PrestaShop is yet another open-source eCommerce platform that you can utilize.
An actively maintained open-source solution with an official marketplace for [themes](https://addons.prestashop.com/en/3-templates-prestashop) and [extensions](https://addons.prestashop.com/en/). Unlike OpenCart, you may not find it available as a one-click app on hosting services – but you can download it from its official website and it is quite easy to set it up. You can also refer to their [installation guide](http://doc.prestashop.com/display/PS17/Installing+PrestaShop) if you need help.
It features a lot of options while being easy to use at the same time. I find a lot of users trying out PrestaShop – you should take a look as well!
You can also take a look at their [GitHub page](https://github.com/PrestaShop/PrestaShop) to learn more.
### 4. WooCommerce
If you want to utilize [WordPress](https://wordpress.org/) for your eCommerce website, WooCommerce will help you out.
Technically, you’re using WordPress as the platform and WooCommerce as a plugin/extension to enable the features needed for an eCommerce website. Potentially, a lot of people (web devs) know how to use WordPress – so it will be easier to learn/create using WooCommerce, I think.
You shouldn’t have a problem using WordPress, being one of the [best open source website builder](https://itsfoss.com/open-source-cms/) out there. It’s easy to use, reliable and supports a ton of extensions and integrations for your online store.
The best part about using WooCommerce is its flexibility. You get tons of choices for the design and extensions of your online store. It’s worth checking out! You can also head to its [GitHub page](https://github.com/woocommerce/woocommerce).
### 5. Zen Cart
This may not be a modern eCommerce platform but one of the best open-source solutions. If you’re a fan of old school templates (HTML-based primarily) and do not need a whole lot of extensions but just the basics, you can try it out.
Personally, I wouldn’t recommend this for a new project – but just because it is still an active platform, feel free to experiment on it if you like it.
You can find the project on [SourceForge](https://sourceforge.net/projects/zencart/) as well.
### 6. Magento
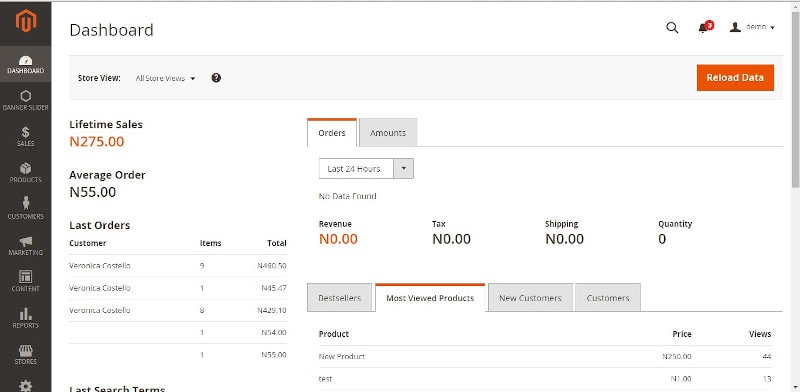
An Adobe-owned open-source eCommerce platform that is potentially better than WordPress (depending on your preferences obviously).
Magento is completely tailored for e-commerce applications – so you will find a lot of essential features easy to use while offering advanced customizations as well.
However, when utilizing the open-source edition, you might miss some of the features available in their hosted offering. You can refer to their [comparison guide](https://magento.com/compare-open-source-and-magento-commerce) for details. Of course, you can self-host it but if you want a managed hosting support, that’s available as well.
You can also take a look at their [GitHub page ](https://github.com/magento)to learn more.
### 7. Drupal
Drupal is another open-source CMS platform that is suitable for creating an eCommerce website.
I’ve never used it – so I’m not really sure of its flexibility but looking at its list of modules (Extensions) and themes available on its official site, it looks like you can do almost everything you need for an eCommerce platform easily.
You should be able to install it easily on any web server just like you install WordPress – so give it a try and see how it goes. You can even download the latest releases and check out the project on their [download page](https://www.drupal.org/project/drupal).
### 8. Odoo eCommerce
In case you didn’t know, Odoo offers a suite of open source business apps. They also offer [open source accounting software](https://itsfoss.com/open-source-accounting-software/) and CRM solutions that we’ve covered in a separate list.
For the eCommerce portal, you can utilize its online drag and drop builder to customize your site as per your requirements. You also have options to promote the website. In addition to the easy theme installation and customization options, you get to utilize HTML/CSS to manually customize the look and feel to some extent.
You may also check out its [GitHub page](https://github.com/odoo/odoo) to explore more about it.
### 9. Bagisto
Bagisto is an interesting open-source eCommerce framework built on top of [Laravel](https://laravel.com/).
It offers a clean user experience and offers a lot of options baked right in without needing any extensions. Of course, to extend the functionality of your site, you can explore its [extension marketplace](https://bagisto.com/en/extensions/).
They do offer a demo experience through their [official website](https://bagisto.com/en) if you’re looking to see what it offers. I really liked the user experience of the admin panel and the front-end as well. In my case, I couldn’t find any options to easily change the design (or applying a new theme). So, I’d advise you to look around thoroughly in their demo instance to see if it fits your requirements.
You may head to their [GitHub page](https://github.com/bagisto/bagisto) and refer to the [official documentation](https://devdocs.bagisto.com/) before getting started.
**Wrapping Up**
And since you are working on your e-Commerce site, it will be a good idea to have an [open source community forum software](https://itsfoss.com/open-source-forum-software/) to support the customers.
I’m sure there are a few more open-source eCommerce platforms out there – however, I haven’t come across anything that’s better than what I’ve listed above (yet).
If you think that I missed one of your favorites that deserves a mention, let me know in the comments. Also, feel free to share your experience and thoughts about the open-source eCommcerce platforms available in the comments section below. |
11,886 | 用 Python 脚本发现 OpenStack Overcloud 中的问题 | https://opensource.com/article/20/1/logtool-root-cause-identification | 2020-02-12T21:15:14 | [
"OpenStack"
] | https://linux.cn/article-11886-1.html |
>
> LogTool 是一组 Python 脚本,可帮助你找出 Overcloud 节点中问题的根本原因。
>
>
>

OpenStack 在其 Overcloud 节点和 Undercloud 主机上存储和管理了一堆日志文件。因此,使用 OSP 日志文件来排查遇到的问题并不是一件容易的事,尤其在你甚至都不知道是什么原因导致问题时。
如果你正处于这种情况,那么 [LogTool](https://github.com/zahlabut/LogTool) 可以使你的生活变得更加轻松!它会为你节省本需要人工排查问题所需的时间和精力。LogTool 基于模糊字符串匹配算法,可提供过去发生的所有唯一错误和警告信息。你可以根据日志中的时间戳导出特定时间段(例如 10 分钟前、一个小时前、一天前等)的这些信息。
LogTool 是一组 Python 脚本,其主要模块 `PyTool.py` 在 Undercloud 主机上执行。某些操作模式使用直接在 Overcloud 节点上执行的其他脚本,例如从 Overcloud 日志中导出错误和警告信息。
LogTool 支持 Python 2 和 Python 3,你可以根据需要更改工作目录:[LogTool\_Python2](https://github.com/zahlabut/LogTool/tree/master/LogTool_Python2) or [LogTool\_Python3](https://github.com/zahlabut/LogTool/tree/master/LogTool_Python3)。
### 操作方式
#### 1、从 Overcloud 日志中导出错误和警告信息
此模式用于从过去发生的 Overcloud 节点中提取 **错误** 和 **警告** 信息。作为用户,系统将提示你提供“开始时间”和“调试级别”,以用于提取错误或警告消息。例如,如果在过去 10 分钟内出了问题,你则可以只提取该时间段内的错误和警告消息。
此操作模式将为每个 Overcloud 节点生成一个包含结果文件的目录。结果文件是经过压缩的简单文本文件(`*.gz`),以减少从 Overcloud 节点下载所需的时间。将压缩文件转换为常规文本文件,可以使用 `zcat` 或类似工具。此外,Vi 的某些版本和 Emacs 的任何最新版本均支持读取压缩数据。结果文件分为几部分,并在底部包含目录。
LogTool 可以即时检测两种日志文件:标准和非标准。在标准文件中,每条日志行都有一个已知的和已定义的结构:时间戳、调试级别、信息等等。在非标准文件中,日志的结构未知。例如,它可能是第三方的日志。在目录中,你可以找到每个部分的“名称 –> 行号”例如:
* **原始数据 - 从标准 OSP 日志中提取的错误/警告消息:** 这部分包含所有提取的错误/警告消息,没有任何修改或更改。这些消息是 LogTool 用于模糊匹配分析的原始数据。
* **统计信息 - 每个标准 OSP 日志的错误/警告信息数量:** 在此部分,你将找到每个标准日志文件的错误和警告数量。这些信息可以帮助你了解用于排查问题根本原因的潜在组件。
* **统计信息 - 每个标准 OSP 日志文件的唯一消息:** 这部分提供指定时间戳内的唯一的错误和警告消息。有关每个唯一错误或警告的更多详细信息,请在“原始数据”部分中查找相同的消息。
* **统计信息 - 每个非标准日志文件在任意时间的唯一消息:** 此部分包含非标准日志文件中的唯一消息。遗憾的是,LogTool 无法像标准日志文件那样的处理方式处理这些日志文件。因此,在你提取“特定时间”的日志信息时会被忽略,你会看到过去创建的所有唯一的错误/警告消息。因此,首先,向下滚动到结果文件底部的目录并查看其部分-使用目录中的行索引跳到相关部分,其中第 3、4 和 5 行的信息最重要。
#### 2、从 Overcloud 节点下载所有日志
所有 Overcloud 节点的日志将被压缩并下载到 Undercloud 主机上的本地目录。
#### 3、所有 Overcloud 日志中搜索字符串
该模式“grep”(搜索)由用户在所有 Overcloud 日志上提供的字符串。例如,你可能希望查看特定请求的所有日志消息,例如,“Create VM”的失败的请求 ID。
#### 4、检查 Overcloud 上当前的 CPU、RAM 和磁盘使用情况
该模式显示每个 Overcloud 节点上的当前 CPU、RAM 和磁盘信息。
#### 5、执行用户脚本
该模式使用户可以在 Overcloud 节点上运行自己的脚本。例如,假设 Overcloud 部署失败,你就需要在每个控制器节点上执行相同的过程来修复该问题。你可以实现“替代方法”脚本,并使用此模式在控制器上运行它。
#### 6、仅按给定的时间戳下载相关日志
此模式仅下载 Overcloud 上 “给定的时间戳”的“上次修改时间”的日志。例如,如果 10 分钟前出现错误,则与旧日志文件就没有关系,因此无需下载。此外,你不能(或不应)在某些错误报告工具中附加大文件,因此此模式可能有助于编写错误报告。
#### 7、从 Undercloud 日志中导出错误和警告信息
这与上面的模式 1 相同。
#### 8、在 Overcloud 上检查不正常的 docker
此模式用于在节点上搜索不正常的 Docker。
#### 9、下载 OSP 日志并在本地运行 LogTool
此模式允许你从 Jenkins 或 Log Storage 下载 OSP 日志(例如,`cougar11.scl.lab.tlv.redhat.com`),并在本地分析。
#### 10、在 Undercloud 上分析部署日志
此模式可以帮助你了解 Overcloud 或 Undercloud 部署过程中出了什么问题。例如,在`overcloud_deploy.sh` 脚本中,使用 `--log` 选项时会生成部署日志;此类日志的问题是“不友好”,你很难理解是什么出了问题,尤其是当详细程度设置为 `vv` 或更高时,使得日志中的数据难以读取。此模式提供有关所有失败任务的详细信息。
#### 11、分析 Gerrit(Zuul)失败的日志
此模式用于分析 Gerrit(Zuul)日志文件。它会自动从远程 Gerrit 门下载所有文件(HTTP 下载)并在本地进行分析。
### 安装
GitHub 上有 LogTool,使用以下命令将其克隆到你的 Undercloud 主机:
```
git clone https://github.com/zahlabut/LogTool.git
```
该工具还使用了一些外部 Python 模块:
#### Paramiko
默认情况下,SSH 模块通常会安装在 Undercloud 上。使用以下命令来验证是否已安装:
```
ls -a /usr/lib/python2.7/site-packages | grep paramiko
```
如果需要安装模块,请在 Undercloud 上执行以下命令:
```
sudo easy_install pip
sudo pip install paramiko==2.1.1
```
#### BeautifulSoup
此 HTML 解析器模块仅在使用 HTTP 下载日志文件的模式下使用。它用于解析 Artifacts HTML 页面以获取其中的所有链接。安装 BeautifulSoup,请输入以下命令:
```
pip install beautifulsoup4
```
你还可以通过执行以下命令使用 [requirements.txt](https://github.com/zahlabut/LogTool/blob/master/LogTool_Python3/requirements.txt) 文件安装所有必需的模块:
```
pip install -r requirements.txt
```
### 配置
所有必需的参数都直接在 `PyTool.py` 脚本中设置。默认值为:
```
overcloud_logs_dir = '/var/log/containers'
overcloud_ssh_user = 'heat-admin'
overcloud_ssh_key = '/home/stack/.ssh/id_rsa'
undercloud_logs_dir ='/var/log/containers'
source_rc_file_path='/home/stack/'
```
### 用法
此工具是交互式的,因此要启动它,只需输入:
```
cd LogTool
python PyTool.py
```
### 排除 LogTool 故障
在运行时会创建两个日志文件:`Error.log` 和 `Runtime.log`。请在你要打开的问题的描述中添加两者的内容。
### 局限性
LogTool 进行硬编码以处理最大 500 MB 的文件。
### LogTool\_Python3 脚本
在 [github.com/zahlabut/LogTool](https://github.com/zahlabut/LogTool) 获取。
---
via: <https://opensource.com/article/20/1/logtool-root-cause-identification>
作者:[Arkady Shtempler](https://opensource.com/users/ashtempl) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | OpenStack stores and manages a bunch of log files on its Overcloud nodes and Undercloud host. Therefore, it's not easy to use OSP log files to investigate a problem you're having, especially when you don't even know what could have caused the problem.
If that's your situation, [LogTool](https://github.com/zahlabut/LogTool) makes your life much easier! It saves you the time and work it would otherwise take to investigate the root cause manually. Based on a fuzzy string matching algorithm, LogTool provides all the unique error and warning messages that have occurred in the past. You can export these messages for a particular time period, such as 10 minutes ago, an hour ago, a day ago, and so on, based on timestamp in the log.
LogTool is a set of Python scripts, and its main module, **PyTool.py**, is executed on the Undercloud host. Some operation modes use additional scripts that are executed directly on Overcloud nodes, such as exporting errors and warnings from Overcloud logs.
LogTool supports Python 2 and 3, and you can change the working directory according to your needs: [LogTool_Python2](https://github.com/zahlabut/LogTool/tree/master/LogTool_Python2) or [LogTool_Python3](https://github.com/zahlabut/LogTool/tree/master/LogTool_Python3).
## Operation modes
### 1. Export errors and warnings from Overcloud logs
This mode is used to extract all unique **ERROR** and **WARNING** messages from Overcloud nodes that took place in the past. As the user, you're prompted to provide the "since time" and debug level to be used for extraction of errors or warnings. For example, if something went wrong in the last 10 minutes, you're be able to extract error and warning messages for just that time period.
This operation mode generates a directory containing a result file for each Overcloud node. A result file is a simple text file that is compressed (***.gz**) to reduce the time needed to download it from the Overcloud node. To convert a compressed file to a regular text file, you can use [zcat](https://opensource.com/article/19/2/getting-started-cat-command) or a similar tool. Also, some versions of Vi and any recent version of Emacs both support reading compressed data. The result file is divided into sections and contains a table of contents at the bottom.
There are two kinds of log files LogTool detects on the fly: *Standard* and *Not Standard*. In *Standard*, each log line has a known and defined structure: timestamp, debug level, msg, and so on. In *Not Standard*, the log's structure is unknown; it could be a third party's logs, for example. In the table of contents, you find a "Section name --> Line number" per section, for example:
**Raw Data - extracted Errors/Warnings from standard OSP logs since:**This section contains all extracted Error/Warning messages as-is without any modifications or changes. These messages are the raw data LogTool uses for fuzzy matching analysis.**Statistics - Number of Errors/Warnings per standard OSP log since:**In this section, you find the amount of Errors and Warnings per Standard log file. This may help you understand potential components used to search for the root cause of your issue.**Statistics - Unique messages, per STANDARD OSP log file since:**This section addresses unique Error and Warning messages since a timestamp you provide. For more details about each unique Error or Warning, search for the same message in the Raw Data section.**Statistics - Unique messages per NON STANDARD log file, since any time:**This section contains the unique messages in nonstandard log files. Unfortunately, LogTool cannot handle these log files in the same manner as Standard Log files; therefore, the "since time" you provide on extraction will be ignored, and you'll see all of the unique Errors/Warnings messages ever created. So first, scroll down to the table of contents at the bottom of the result file and review its sections—use the line indexes in the table of contents to jump to the relevant sections, where numbers 3, 4, and 5 are most important.
### 2. Download all logs from Overcloud nodes
Logs from all Overcloud nodes are compressed and downloaded to a local directory on your Undercloud host.
### 3. Grep for a string in all Overcloud logs
This mode "greps" (searches) a string provided by the user on all Overcloud logs. For example, you might want to see all logged messages for a specific request ID, such as the request ID for a "Create VM" that has failed.
### 4. Check current CPU,RAM and Disk on Overcloud
This mode displays the current CPU, RAM, and disk info on each Overcloud node.
### 5. Execute user's script
This enables users to run their own scripts on Overcloud nodes. For instance, say an Overcloud deployment failed, so you need to execute the same procedure on each Controller node to fix that. You can implement a "work around" script and to run it on Controllers using this mode.
### 6. Download relevant logs only, by given timestamp
This mode downloads only the Overcloud logs with *"Last Modified" > "given by user timestamp."* For example, if you got an error 10 minutes ago, old log files won't be relevant, so downloading them is unnecessary. In addition, you can't (or shouldn't) attach large files in some bug reporting tools, so this mode might help with making bug reports.
### 7. Export errors and warnings from Undercloud logs
This is the same as mode #1 above, but for Undercloud logs.
### 8. Check Unhealthy dockers on the Overcloud
This mode is used to search for unhealthy Dockers on nodes.
### 9. Download OSP logs and run LogTool locally
This mode allows you to download OSP logs from Jenkins or Log Storage (for example, **cougar11.scl.lab.tlv.redhat.com**) and to analyze the downloaded logs locally.
### 10. Analyze deployment log on the Undercloud
This mode may help you understand what went wrong during Overcloud or Undercloud deployment. Deployment logs are generated when the **--log** option is used, for example, inside the **overcloud_deploy.sh** script; the problem is that such logs are not "friendly," and it's hard to understand what went wrong, especially when verbosity is set to **vv** or more, as this makes the log unreadable with a bunch of data inside it. This mode provides some details about all failed tasks.
### 11. Analyze Gerrit(Zuul) failed gate logs
This mode is used to analyze Gerrit(Zuul) log files. It automatically downloads all files from a remote Gerrit gate (HTTP download) and analyzes all files locally.
## Installation
LogTool is available on GitHub. Clone it to your Undercloud host with:
`git clone https://github.com/zahlabut/LogTool.git`
Some external Python modules are also used by the tool:
### Paramiko
This SSH module is usually installed on Undercloud by default. Use the following command to verify whether it's installed:
`ls -a /usr/lib/python2.7/site-packages | grep paramiko `
If you need to install the module, on your Undercloud, execute the following commands:
```
sudo easy_install pip
sudo pip install paramiko==2.1.1
```
### BeautifulSoup
This HTML parser module is used only in modes where log files are downloaded using HTTP. It's used to parse the Artifacts HTML page to get all of the links in it. To install BeautifulSoup, enter this command:
`pip install beautifulsoup4`
You can also use the [requirements.txt](https://github.com/zahlabut/LogTool/blob/master/LogTool_Python3/requirements.txt) file to install all the required modules by executing:
`pip install -r requirements.txt`
## Configuration
All required parameters are set directly inside the** PyTool.py** script. The defaults are:
```
overcloud_logs_dir = '/var/log/containers'
overcloud_ssh_user = 'heat-admin'
overcloud_ssh_key = '/home/stack/.ssh/id_rsa'
undercloud_logs_dir ='/var/log/containers'
source_rc_file_path='/home/stack/'
```
## Usage
This tool is interactive, so to start it, just enter:
```
cd LogTool
python PyTool.py
```
## Troubleshooting LogTool
Two log files are created on runtime: Error.log and Runtime.log*.* Please add the contents of both in the description of the issue you'd like to open.
## Limitations
LogTool is hardcoded to handle files up to 500 MB.
## LogTool_Python3 script
Get it at [github.com/zahlabut/LogTool](https://github.com/zahlabut/LogTool)
## 2 Comments |
11,888 | NVIDIA 的云游戏服务 GeForce NOW 无耻地忽略了Linux | https://itsfoss.com/geforce-now-linux/ | 2020-02-13T22:27:37 | [
"NVIDIA",
"游戏"
] | https://linux.cn/article-11888-1.html | NVIDIA 的 [GeForce NOW](https://www.nvidia.com/en-us/geforce-now/) 云游戏服务对于那些可能没有硬件但想使用 GeForce NOW 在最新的最好的游戏上获得尽可能好的游戏体验玩家来说是充满前景的(在线推流游戏,并可以在任何设备上玩)。
该服务仅限于一些用户(以等待列表的形式)使用。然而,他们最近宣布 [GeForce NOW 面向所有人开放](https://blogs.nvidia.com/blog/2020/02/04/geforce-now-pc-gaming/)。但实际上并不是。
有趣的是,它**并不是面向全球所有区域**。而且,更糟的是 **GeForce NOW 不支持 Linux**。

### GeForce NOW 并不是向“所有人开放”
制作一个基于订阅的云服务来玩游戏的目的是消除平台依赖性。
就像你通常使用浏览器访问网站一样,你应该能够在每个平台上玩游戏。是这个概念吧?

好吧,这绝对不是火箭科学,但是 NVIDIA 仍然不支持 Linux(和 iOS)?
### 是因为没有人使用 Linux 吗?
我非常不同意这一点,即使这是某些不支持 Linux 的原因。如果真是这样,我不会使用 Linux 作为主要桌面操作系统来为 “It’s FOSS” 写文章。
不仅如此,如果 Linux 不值一提,你认为为何一个 Twitter 用户会提到缺少 Linux 支持?

是的,也许用户群不够大,但是在考虑将其作为基于云的服务时,**不支持 Linux** 显得没有意义。
从技术上讲,如果 Linux 上没有游戏,那么 **Valve** 就不会在 Linux 上改进 [Steam Play](https://itsfoss.com/steam-play/) 来帮助更多用户在 Linux 上玩纯 Windows 的游戏。
我不想说任何不正确的说法,但台式机 Linux 游戏的发展比以往任何时候都要快(即使统计上要比 Mac 和 Windows 要低)。
### 云游戏不应该像这样

如上所述,找到使用 Steam Play 的 Linux 玩家不难。只是你会发现 Linux 上游戏玩家的整体“市场份额”低于其他平台。
即使这是事实,云游戏也不应该依赖于特定平台。而且,考虑到 GeForce NOW 本质上是一种基于浏览器的可以玩游戏的流媒体服务,所以对于像 NVIDIA 这样的大公司来说,支持 Linux 并不困难。
来吧,Nvidia,*你想要我们相信在技术上支持 Linux 有困难?或者,你只是想说不值得支持 Linux 平台?*
### 结语
不管我为 GeForce NOW 服务发布而感到多么兴奋,当看到它根本不支持 Linux,我感到非常失望。
如果像 GeForce NOW 这样的云游戏服务在不久的将来开始支持 Linux,**你可能没有理由使用 Windows 了**(*咳嗽*)。
你怎么看待这件事?在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/geforce-now-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | NVIDIA’s [GeForce NOW](https://www.nvidia.com/en-us/geforce-now/) cloud gaming service is something promising for gamers who probably don’t have the hardware but want to experience the latest and greatest games with the best possible experience using GeForce NOW (stream the game online and play it on any device you want).
The service was limited to a few users (in the form of the waitlist) to access. However, recently, they announced that [GeForce NOW is open to all](https://blogs.nvidia.com/blog/2020/02/04/geforce-now-pc-gaming/). But, it really isn’t.
Interestingly, it’s **not available for all the regions** across the globe. And, worse- **GeForce NOW does not support Linux**.

## GeForce NOW is Not ‘Open For All’
The whole point of making a subscription-based cloud service to play games is to eliminate platform dependence.
Just like you would normally visit a website using a web browser – you should be able to stream a game on every platform. That’s the concept, right?

Well, that’s definitely not rocket science – but NVIDIA still missed supporting Linux (and iOS)?
## Is it because no one uses Linux?
I would strongly disagree with this – even if it’s the reason for some to not support Linux. If that was the case, I wouldn’t be writing for It’s FOSS while using Linux as my primary desktop OS.
Not just that – why do you think a Twitter user mentioned the lack of support for Linux if it wasn’t a thing?

Yes, maybe the userbase isn’t large enough but while considering this as a cloud-based service – it doesn’t make sense to **not support Linux**.
Technically, if no one games on Linux, **Valve** wouldn’t have noticed Linux as a platform to improve [Steam Play](https://itsfoss.com/steam-play/) to help more users play Windows-only games on Linux.
I don’t want to claim anything that’s not true – but the desktop Linux scene is evolving faster than ever for gaming (even if the stats are low when compared to Windows and Mac).
## Cloud gaming isn’t supposed to work like this

As I mentioned above, it isn’t tough to find Linux gamers using Steam Play. It’s just that you’ll find the overall “market share” of gamers on Linux to be less than its counterparts.
Even though that’s a fact – cloud gaming isn’t supposed to depend on a specific platform. And, considering that the GeForce NOW is essentially a browser-based streaming service to play games, it shouldn’t be tough for a big shot like NVIDIA to support Linux.
Come on, team green – *you want us to believe that supporting Linux is technically tough*? Or, you just want to say that i*t’s not worth supporting the Linux platform*?
**Wrapping Up**
No matter how excited I was for the GeForce NOW service to launch – it was very disappointing to see that it does not support Linux at all.
If cloud gaming services like GeForce NOW start supporting Linux in the near future –** you probably won’t need a reason to use Windows **(*coughs*).
What do you think about it? Let me know your thoughts in the comments below. |
11,889 | 通过 Git 来管理多媒体文件 | https://opensource.com/article/19/4/manage-multimedia-files-git | 2020-02-13T23:54:48 | [
"Git"
] | https://linux.cn/article-11889-1.html |
>
> 在我们有关 Git 鲜为人知的用法系列的最后一篇文章中,了解如何使用 Git 跟踪项目中的大型多媒体文件。
>
>
>

Git 是专用于源代码版本控制的工具。因此,Git 很少被用于非纯文本的项目以及行业。然而,异步工作流的优点是十分诱人的,尤其是在一些日益增长的行业中,这种类型的行业把重要的计算和重要的艺术创作结合起来,这包括网页设计、视觉效果、视频游戏、出版、货币设计(是的,这是一个真实的行业)、教育……等等。还有许多行业属于这个类型。
在这个 Git 系列文章中,我们分享了六种鲜为人知的 Git 使用方法。在最后一篇文章中,我们将介绍将 Git 的优点带到管理多媒体文件的软件。
### Git 管理多媒体文件的问题
众所周知,Git 用于处理非文本文件不是很好,但是这并不妨碍我们进行尝试。下面是一个使用 Git 来复制照片文件的例子:
```
$ du -hs
108K .
$ cp ~/photos/dandelion.tif .
$ git add dandelion.tif
$ git commit -m 'added a photo'
[master (root-commit) fa6caa7] two photos
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 dandelion.tif
$ du -hs
1.8M .
```
目前为止没有什么异常。增加一个 1.8MB 的照片到一个目录下,使得目录变成了 1.8 MB 的大小。所以下一步,我们尝试删除文件。
```
$ git rm dandelion.tif
$ git commit -m 'deleted a photo'
$ du -hs
828K .
```
在这里我们可以看到有些问题:删除一个已经被提交的文件,还是会使得存储库的大小扩大到原来的 8 倍(从 108K 到 828K)。我们可以测试多次来得到一个更好的平均值,但是这个简单的演示与我的经验一致。提交非文本文件,在一开始花费空间比较少,但是一个工程活跃地时间越长,人们可能对静态内容修改的会更多,更多的零碎文件会被加和到一起。当一个 Git 存储库变的越来越大,主要的成本往往是速度。拉取和推送的时间,从最初抿一口咖啡的时间到你觉得你可能断网了。
静态内容导致 Git 存储库的体积不断扩大的原因是什么呢?那些通过文本的构成的文件,允许 Git 只拉取那些修改的部分。光栅图以及音乐文件对 Git 文件而言与文本不同,你可以查看一下 .png 和 .wav 文件中的二进制数据。所以,Git 只不过是获取了全部的数据,并且创建了一个新的副本,哪怕是一张图仅仅修改了一个像素。
### Git-portal
在实践中,许多多媒体项目不需要或者不想追踪媒体的历史记录。相对于文本或者代码的部分,项目的媒体部分一般有一个不同的生命周期。媒体资源一般按一个方向产生:一张图片从铅笔草稿开始,以数字绘画的形式抵达它的目的地。然后,尽管文本能够回滚到早起的版本,但是艺术制品只会一直向前发展。工程中的媒体很少被绑定到一个特定的版本。例外情况通常是反映数据集的图形,通常是可以用基于文本的格式(如 SVG)完成的表、图形或图表。
所以,在许多同时包含文本(无论是叙事散文还是代码)和媒体的工程中,Git 是一个用于文件管理的,可接受的解决方案,只要有一个在版本控制循环之外的游乐场来给艺术家游玩就行。

一个启用这个特性的简单方法是 [Git-portal](http://gitlab.com/slackermedia/git-portal.git),这是一个通过带有 Git 钩子的 Bash 脚本,它可将静态文件从文件夹中移出 Git 的范围,并通过符号链接来取代它们。Git 提交链接文件(有时候称作别名或快捷方式),这种符号链接文件比较小,所以所有的提交都是文本文件和那些代表媒体文件的链接。因为替身文件是符号链接,所以工程还会像预期的运行,因为本地机器会处理他们,转换成“真实的”副本。当用符号链接替换出文件时,Git-portal 维护了项目的结构,因此,如果你认为 Git-portal 不适合你的项目,或者你需要构建项目的一个没有符号链接的版本(比如用于分发),则可以轻松地逆转该过程。
Git-portal 也允许通过 `rsync` 来远程同步静态资源,所以用户可以设置一个远程存储位置,来做为一个中心的授权源。
Git-portal 对于多媒体的工程是一个理想的解决方案。类似的多媒体工程包括视频游戏、桌面游戏、需要进行大型 3D 模型渲染和纹理的虚拟现实工程、[带图](https://www.apress.com/gp/book/9781484241691)以及 .odt 输出的书籍、协作型的[博客站点](http://mixedsignals.ml)、音乐项目,等等。艺术家在应用程序中以图层(在图形世界中)和曲目(在音乐世界中)的形式执行版本控制并不少见——因此,Git 不会向多媒体项目文件本身添加任何内容。Git 的功能可用于艺术项目的其他部分(例如散文和叙述、项目管理、字幕文件、致谢、营销副本、文档等),而结构化远程备份的功能则由艺术家使用。
#### 安装 Git-portal
Git-portal 的 RPM 安装包位于 <https://klaatu.fedorapeople.org/git-portal>,可用于下载和安装。
此外,用户可以从 Git-portal 的 Gitlab 主页手动安装。这仅仅是一个 Bash 脚本以及一些 Git 钩子(也是 Bash 脚本),但是需要一个快速的构建过程来让它知道安装的位置。
```
$ git clone https://gitlab.com/slackermedia/git-portal.git git-portal.clone
$ cd git-portal.clone
$ ./configure
$ make
$ sudo make install
```
#### 使用 Git-portal
Git-portal 与 Git 一起使用。这意味着,如同 Git 的所有大型文件扩展一样,都需要记住一些额外的步骤。但是,你仅仅需要在处理你的媒体资源的时候使用 Git-portal,所以很容易记住,除非你把大文件都当做文本文件来进行处理(对于 Git 用户很少见)。使用 Git-portal 必须做的一个安装步骤是:
```
$ mkdir bigproject.git
$ cd !$
$ git init
$ git-portal init
```
Git-portal 的 `init` 函数在 Git 存储库中创建了一个 `_portal` 文件夹并且添加到 `.gitignore` 文件中。
在平日里使用 Git-portal 和 Git 协同十分平滑。一个较好的例子是基于 MIDI 的音乐项目:音乐工作站产生的项目文件是基于文本的,但是 MIDI 文件是二进制数据:
```
$ ls -1
_portal
song.1.qtr
song.qtr
song-Track_1-1.mid
song-Track_1-3.mid
song-Track_2-1.mid
$ git add song*qtr
$ git-portal song-Track*mid
$ git add song-Track*mid
```
如果你查看一下 `_portal` 文件夹,你会发现那里有最初的 MIDI 文件。这些文件在原本的位置被替换成了指向 `_portal` 的链接文件,使得音乐工作站像预期一样运行。
```
$ ls -lG
[...] _portal/
[...] song.1.qtr
[...] song.qtr
[...] song-Track_1-1.mid -> _portal/song-Track_1-1.mid*
[...] song-Track_1-3.mid -> _portal/song-Track_1-3.mid*
[...] song-Track_2-1.mid -> _portal/song-Track_2-1.mid*
```
与 Git 相同,你也可以添加一个目录下的文件。
```
$ cp -r ~/synth-presets/yoshimi .
$ git-portal add yoshimi
Directories cannot go through the portal. Sending files instead.
$ ls -lG _portal/yoshimi
[...] yoshimi.stat -> ../_portal/yoshimi/yoshimi.stat*
```
删除功能也像预期一样工作,但是当从 `_portal` 中删除一些东西时,你应该使用 `git-portal rm` 而不是 `git rm`。使用 Git-portal 可以确保文件从 `_portal` 中删除:
```
$ ls
_portal/ song.qtr song-Track_1-3.mid@ yoshimi/
song.1.qtr song-Track_1-1.mid@ song-Track_2-1.mid@
$ git-portal rm song-Track_1-3.mid
rm 'song-Track_1-3.mid'
$ ls _portal/
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
```
如果你忘记使用 Git-portal,那么你需要手动删除 `_portal` 下的文件:
```
$ git-portal rm song-Track_1-1.mid
rm 'song-Track_1-1.mid'
$ ls _portal/
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
$ trash _portal/song-Track_1-1.mid
```
Git-portal 其它的唯一功能,是列出当前所有的链接并且找到里面可能已经损坏的符号链接。有时这种情况会因为项目文件夹中的文件被移动而发生:
```
$ mkdir foo
$ mv yoshimi foo
$ git-portal status
bigproject.git/song-Track_2-1.mid: symbolic link to _portal/song-Track_2-1.mid
bigproject.git/foo/yoshimi/yoshimi.stat: broken symbolic link to ../_portal/yoshimi/yoshimi.stat
```
如果你使用 Git-portal 用于私人项目并且维护自己的备份,以上就是技术方面所有你需要知道关于 Git-portal 的事情了。如果你想要添加一个协作者或者你希望 Git-portal 来像 Git 的方式来管理备份,你可以创建一个远程位置。
#### 增加 Git-portal 远程位置
为 Git-portal 增加一个远程位置是通过 Git 已有的远程功能来实现的。Git-portal 实现了 Git 钩子(隐藏在存储库 `.git` 文件夹中的脚本),来寻找你的远程位置上是否存在以 `_portal` 开头的文件夹。如果它找到一个,它会尝试使用 `rsync` 来与远程位置同步文件。Git-portal 在用户进行 Git 推送以及 Git 合并的时候(或者在进行 Git 拉取的时候,实际上是进行一次获取和自动合并),都会执行此操作。
如果你仅克隆了 Git 存储库,那么你可能永远不会自己添加一个远程位置。这是一个标准的 Git 过程:
```
$ git remote add origin [email protected]:seth/bigproject.git
$ git remote -v
origin [email protected]:seth/bigproject.git (fetch)
origin [email protected]:seth/bigproject.git (push)
```
对你的主要 Git 存储库来说,`origin` 这个名字是一个流行的惯例,将其用于 Git 数据是有意义的。然而,你的 Git-portal 数据是分开存储的,所以你必须创建第二个远程位置来让 Git-portal 了解向哪里推送和从哪里拉取。取决于你的 Git 主机,你可能需要一个单独的服务器,因为空间有限的 Git 主机不太可能接受 GB 级的媒体资产。或者,可能你的服务器仅允许你访问你的 Git 存储库而不允许访问外部的存储文件夹:
```
$ git remote add _portal [email protected]:/home/seth/git/bigproject_portal
$ git remote -v
origin [email protected]:seth/bigproject.git (fetch)
origin [email protected]:seth/bigproject.git (push)
_portal [email protected]:/home/seth/git/bigproject_portal (fetch)
_portal [email protected]:/home/seth/git/bigproject_portal (push)
```
你可能不想为所有用户提供服务器上的个人帐户,也不必这样做。为了提供对托管资源库大文件资产的服务器的访问权限,你可以运行一个 Git 前端,比如 [Gitolite](https://opensource.com/article/19/4/file-sharing-git) 或者你可以使用 `rrsync` (受限的 rsync)。
现在你可以推送你的 Git 数据到你的远程 Git 存储库,并将你的 Git-portal 数据到你的远程的门户:
```
$ git push origin HEAD
master destination detected
Syncing _portal content...
sending incremental file list
sent 9,305 bytes received 18 bytes 1,695.09 bytes/sec
total size is 60,358,015 speedup is 6,474.10
Syncing _portal content to example.com:/home/seth/git/bigproject_portal
```
如果你已经安装了 Git-portal,并且配置了 `_portal` 的远程位置,你的 `_portal` 文件夹将会被同步,并且从服务器获取新的内容,以及在每一次推送的时候发送新的内容。尽管你不需要进行 Git 提交或者推送来和服务器同步(用户可以使用直接使用 `rsync`),但是我发现对于艺术性内容的改变,提交是有用的。这将会把艺术家及其数字资产集成到工作流的其余部分中,并提供有关项目进度和速度的有用元数据。
### 其他选择
如果 Git-portal 对你而言太过简单,还有一些用于 Git 管理大型文件的其他选择。[Git 大文件存储](https://git-lfs.github.com/)(LFS)是一个名为 git-media 的停工项目的分支,这个分支由 GitHub 维护和支持。它需要特殊的命令(例如 `git lfs track` 来保护大型文件不被 Git 追踪)并且需要用户维护一个 `.gitattributes` 文件来更新哪些存储库中的文件被 LFS 追踪。对于大文件而言,它**仅**支持 HTTP 和 HTTPS 远程主机。所以你必须配置 LFS 服务器,才能使得用户可以通过 HTTP 而不是 SSH 或 `rsync` 来进行鉴权。
另一个相对 LFS 更灵活的选择是 [git-annex](https://git-annex.branchable.com/)。你可以在我的文章 [管理 Git 中大二进制 blob](https://opensource.com/life/16/8/how-manage-binary-blobs-git-part-7) 中了解更多(忽略其中 git-media 这个已经废弃项目的章节,因为其灵活性没有被它的继任者 Git LFS 延续下来)。Git-annex 是一个灵活且优雅的解决方案。它拥有一个细腻的系统来用于添加、删除、移动存储库中的大型文件。因为它灵活且强大,有很多新的命令和规则需要进行学习,所以建议看一下它的[文档](https://git-annex.branchable.com/walkthrough/)。
然而,如果你的需求很简单,你可能更加喜欢整合已有技术来进行简单且明显任务的解决方案,则 Git-portal 可能是对于工作而言比较合适的工具。
---
via: <https://opensource.com/article/19/4/manage-multimedia-files-git>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[svtter](https://github.com/svtter) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Git is very specifically designed for source code version control, so it's rarely embraced by projects and industries that don't primarily work in plaintext. However, the advantages of an asynchronous workflow are appealing, especially in the ever-growing number of industries that combine serious computing with seriously artistic ventures, including web design, visual effects, video games, publishing, currency design (yes, that's a real industry), education… the list goes on and on.
In this series leading up to Git's 14th anniversary, we've shared six little-known ways to use Git. In this final article, we'll look at software that brings the advantages of Git to managing multimedia files.
## The problem with managing multimedia files with Git
It seems to be common knowledge that Git doesn't work well with non-text files, but it never hurts to challenge assumptions. Here's an example of copying a photo file using Git:
```
$ du -hs
108K .
$ cp ~/photos/dandelion.tif .
$ git add dandelion.tif
$ git commit -m 'added a photo'
[master (root-commit) fa6caa7] two photos
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 dandelion.tif
$ du -hs
1.8M .
```
Nothing unusual so far; adding a 1.8MB photo to a directory results in a directory 1.8MB in size. So, let's try removing the file:
```
$ git rm dandelion.tif
$ git commit -m 'deleted a photo'
$ du -hs
828K .
```
You can see the problem here: Removing a large file after it's been committed increases a repository's size roughly eight times its original, barren state (from 108K to 828K). You can perform tests to get a better average, but this simple demonstration is consistent with my experience. The cost of committing files that aren't text-based is minimal at first, but the longer a project stays active, the more changes people make to static content, and the more those fractions start to add up. When a Git repository becomes very large, the major cost is usually speed. The time to perform pulls and pushes goes from being how long it takes to take a sip of coffee to how long it takes to wonder if your computer got kicked off the network.
The reason static content causes Git to grow in size is that formats based on text allow Git to pull out just the parts that have changed. Raster images and music files make as much sense to Git as they would to you if you looked at the binary data contained in a .png or .wav file. So Git just takes all the data and makes a new copy of it, even if only one pixel changes from one photo to the next.
## Git-portal
In practice, many multimedia projects don't need or want to track the media's history. The media part of a project tends to have a different lifecycle than the text or code part of a project. Media assets generally progress in one direction: a picture starts as a pencil sketch, proceeds toward its destination as a digital painting, and, even if the text is rolled back to an earlier version, the art continues its forward progress. It's rare for media to be bound to a specific version of a project. The exceptions are usually graphics that reflect datasets—usually tables or graphs or charts—that can be done in text-based formats such as SVG.
So, on many projects that involve both media and text (whether it's narrative prose or code), Git is an acceptable solution to file management, as long as there's a playground outside the version control cycle for artists to play in.

A simple way to enable that is [Git-portal](http://gitlab.com/slackermedia/git-portal.git), a Bash script armed with Git hooks that moves your asset files to a directory outside Git's purview and replaces them with symlinks. Git commits the symlinks (sometimes called aliases or shortcuts), which are trivially small, so all you commit are your text files and whatever symlinks represent your media assets. Because the replacement files are symlinks, your project continues to function as expected because your local machine follows the symlinks to their "real" counterparts. Git-portal maintains a project's directory structure when it swaps out a file with a symlink, so it's easy to reverse the process, should you decide that Git-portal isn't right for your project or you need to build a version of your project without symlinks (for distribution, for instance).
Git-portal also allows remote synchronization of assets over rsync, so you can set up a remote storage location as a centralized source of authority.
Git-portal is ideal for multimedia projects, including video game and tabletop game design, virtual reality projects with big 3D model renders and textures, [books](https://www.apress.com/gp/book/9781484241691) with graphics and .odt exports, collaborative [blog websites](http://mixedsignals.ml), music projects, and much more. It's not uncommon for an artist to perform versioning in their application—in the form of layers (in the graphics world) and tracks (in the music world)—so Git adds nothing to multimedia project files themselves. The power of Git is leveraged for other parts of artistic projects (prose and narrative, project management, subtitle files, credits, marketing copy, documentation, and so on), and the power of structured remote backups is leveraged by the artists.
### Install Git-portal
There are RPM packages for Git-portal located at [https://klaatu.fedorapeople.org/git-portal](https://klaatu.fedorapeople.org/git-portal), which you can download and install.
Alternately, you can install Git-portal manually from its home on GitLab. It's just a Bash script and some Git hooks (which are also Bash scripts), but it requires a quick build process so that it knows where to install itself:
```
$ git clone https://gitlab.com/slackermedia/git-portal.git git-portal.clone
$ cd git-portal.clone
$ ./configure
$ make
$ sudo make install
```
### Use Git-portal
Git-portal is used alongside Git. This means, as with all large-file extensions to Git, there are some added steps to remember. But you only need Git-portal when dealing with your media assets, so it's pretty easy to remember unless you've acclimated yourself to treating large files the same as text files (which is rare for Git users). There's one setup step you must do to use Git-portal in a project:
```
$ mkdir bigproject.git
$ cd !$
$ git init
$ git portal init
```
Git-portal's **init** function creates a **_portal** directory in your Git repository and adds it to your .gitignore file.
Using Git-portal in a daily routine integrates smoothly with Git. A good example is a MIDI-based music project: the project files produced by the music workstation are text-based, but the MIDI files are binary data:
```
$ ls -1
_portal
song.1.qtr
song.qtr
song-Track_1-1.mid
song-Track_1-3.mid
song-Track_2-1.mid
$ git add song*qtr
$ git portal song-Track*mid
$ git add song-Track*mid
```
If you look into the **_portal** directory, you'll find the original MIDI files. The files in their place are symlinks to **_portal**, which keeps the music workstation working as expected:
```
$ ls -lG
[...] _portal/
[...] song.1.qtr
[...] song.qtr
[...] song-Track_1-1.mid -> _portal/song-Track_1-1.mid*
[...] song-Track_1-3.mid -> _portal/song-Track_1-3.mid*
[...] song-Track_2-1.mid -> _portal/song-Track_2-1.mid*
```
As with Git, you can also add a directory of files:
```
$ cp -r ~/synth-presets/yoshimi .
$ git portal add yoshimi
Directories cannot go through the portal. Sending files instead.
$ ls -lG _portal/yoshimi
[...] yoshimi.stat -> ../_portal/yoshimi/yoshimi.stat*
```
Removal works as expected, but when removing something in **_portal**, you should use **git-portal rm** instead of **git rm**. Using Git-portal ensures that the file is removed from **_portal**:
```
$ ls
_portal/ song.qtr song-Track_1-3.mid@ yoshimi/
song.1.qtr song-Track_1-1.mid@ song-Track_2-1.mid@
$ git portal rm song-Track_1-3.mid
rm 'song-Track_1-3.mid'
$ ls _portal/
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
```
If you forget to use Git-portal, then you have to remove the portal file manually:
```
$ git portal rm song-Track_1-1.mid
rm 'song-Track_1-1.mid'
$ ls _portal/
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
$ trash _portal/song-Track_1-1.mid
```
Git-portal's only other function is to list all current symlinks and find any that may have become broken, which can sometimes happen if files move around in a project directory:
```
$ mkdir foo
$ mv yoshimi foo
$ git portal status
bigproject.git/song-Track_2-1.mid: symbolic link to _portal/song-Track_2-1.mid
bigproject.git/foo/yoshimi/yoshimi.stat: broken symbolic link to ../_portal/yoshimi/yoshimi.stat
```
If you're using Git-portal for a personal project and maintaining your own backups, this is technically all you need to know about Git-portal. If you want to add in collaborators or you want Git-portal to manage backups the way (more or less) Git does, you can a remote.
### Add Git-portal remotes
Adding a remote location for Git-portal is done through Git's existing remote function. Git-portal implements Git hooks, scripts hidden in your repository's .git directory, to look at your remotes for any that begin with **_portal**. If it finds one, it attempts to **rsync** to the remote location and synchronize files. Git-portal performs this action anytime you do a Git push or a Git merge (or pull, which is really just a fetch and an automatic merge).
If you've only cloned Git repositories, then you may never have added a remote yourself. It's a standard Git procedure:
```
$ git remote add origin [email protected]:seth/bigproject.git
$ git remote -v
origin [email protected]:seth/bigproject.git (fetch)
origin [email protected]:seth/bigproject.git (push)
```
The name **origin** is a popular convention for your main Git repository, so it makes sense to use it for your Git data. Your Git-portal data, however, is stored separately, so you must create a second remote to tell Git-portal where to push to and pull from. Depending on your Git host, you may need a separate server because gigabytes of media assets are unlikely to be accepted by a Git host with limited space. Or maybe you're on a server that permits you to access only your Git repository and not external storage directories:
```
$ git remote add _portal [email protected]:/home/seth/git/bigproject_portal
$ git remote -v
origin [email protected]:seth/bigproject.git (fetch)
origin [email protected]:seth/bigproject.git (push)
_portal [email protected]:/home/seth/git/bigproject_portal (fetch)
_portal [email protected]:/home/seth/git/bigproject_portal (push)
```
You may not want to give all of your users individual accounts on your server, and you don't have to. To provide access to the server hosting a repository's large file assets, you can run a Git frontend like ** Gitolite**, or you can use
**rrsync**(i.e., restricted rsync).
Now you can push your Git data to your remote Git repository and your Git-portal data to your remote portal:
```
$ git push origin HEAD
master destination detected
Syncing _portal content...
sending incremental file list
sent 9,305 bytes received 18 bytes 1,695.09 bytes/sec
total size is 60,358,015 speedup is 6,474.10
Syncing _portal content to example.com:/home/seth/git/bigproject_portal
```
If you have Git-portal installed and a **_portal** remote configured, your **_portal** directory will be synchronized, getting new content from the server and sending fresh content with every push. While you don't have to do a Git commit and push to sync with the server (a user could just use rsync directly), I find it useful to require commits for artistic changes. It integrates artists and their digital assets into the rest of the workflow, and it provides useful metadata about project progress and velocity.
## Other options
If Git-portal is too simple for you, there are other options for managing large files with Git. [Git Large File Storage](https://git-lfs.github.com/) (LFS) is a fork of a defunct project called git-media and is maintained and supported by GitHub. It requires special commands (like **git lfs track** to protect large files from being tracked by Git) and requires the user to manage a .gitattributes file to update which files in the repository are tracked by LFS. It supports *only* HTTP and HTTPS remotes for large files, so your LFS server must be configured so users can authenticate over HTTP rather than SSH or rsync.
A more flexible option than LFS is [git-annex](https://git-annex.branchable.com/), which you can learn more about in my article about [managing binary blobs in Git](https://opensource.com/life/16/8/how-manage-binary-blobs-git-part-7) (ignore the parts about the deprecated git-media, as its former flexibility doesn't apply to its successor, Git LFS). Git-annex is a flexible and elegant solution with a detailed system for adding, removing, and moving large files within a repository. Because it's flexible and powerful, there are lots of new commands and rules to learn, so take a look at its [documentation](https://git-annex.branchable.com/walkthrough/).
If, however, your needs are simple and you like a solution that utilizes existing technology to do simple and obvious tasks, Git-portal might be the tool for the job.
## Comments are closed. |
11,892 | 使用此开源窗口环境一次运行多个控制台 | https://opensource.com/article/20/1/multiple-consoles-twin | 2020-02-14T19:37:00 | [
"DESQview"
] | https://linux.cn/article-11892-1.html |
>
> 在我们的 20 个使用开源提升生产力的系列的第十四篇文章中用 twin 模拟了老式的 DESQview 体验。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 通过 twin 克服“一个屏幕,一个应用程序”的限制
还有人记得 [DESQview](https://en.wikipedia.org/wiki/DESQview) 吗?我们在 Windows、Linux 和 MacOS 中理所当然地可以在屏幕上同时运行多个程序,而 DESQview 赋予了 DOS 同样的功能。在我运营拨号 BBS 服务的初期,DESQview 是必需的,它使我能够让 BBS 在后台运行,同时在前台进行其他操作。例如,当有人拨打电话时,我可能正在开发新功能或设置新的外部程序而不会影响他们的体验。后来,在我早期做支持工作的时候,我可以同时运行我的工作电子邮件([MHS 上的 DaVinci 电子邮件](https://en.wikipedia.org/wiki/Message_Handling_System))、支持单据系统和其他 DOS 程序。这是令人吃惊的!

从那时起,运行多个控制台应用程序的功能已经发展了很多。但是 [tmux](https://github.com/tmux/tmux/wiki) 和 [Screen](https://www.gnu.org/software/screen/) 等应用仍然遵循“一个屏幕,一个应用”的显示方式。好吧,是的,tmux 具有屏幕拆分和窗格,但是不像 DESQview 那样具有将窗口“浮动”在其他窗口上的功能,就我个人而言,我怀念那个功能。
让我们来看看 [twin](https://github.com/cosmos72/twin)(文本模式窗口环境)。我认为,这个相对年轻的项目是 DESQview 的精神继任者。它支持控制台和图形环境,并具有与会话脱离和重新接驳的功能。设置起来并不是那么容易,但是它可以在大多数现代操作系统上运行。
Twin 是从源代码安装的(现在是这样)。但是首先,你需要安装所需的开发库。库名称将因操作系统而异。 以下示例显示了在我的 Ubuntu 19.10 系统中的情况。一旦安装了依赖库,请从 Git 中检出 twin 源代码,并运行 `./configure` 和 `make`,它们应自动检测所有内容并构建 twin:
```
sudo apt install libx11-dev libxpm-dev libncurses-dev zlib1g-dev libgpm-dev
git clone [email protected]:cosmos72/twin.git
cd twin
./configure
make
sudo make install
```
注意:如果要在 MacOS 或 BSD 上进行编译,则需要在运行 `make` 之前在文件 `include/Tw/autoconf.h` 和 `include/twautoconf.h` 中注释掉 `#define socklen_t int`。这个问题应该在 [twin #57](https://github.com/cosmos72/twin/issues/57) 解决了。

第一次调用 twin 是一个挑战。你需要通过 `--hw` 参数告诉它正在使用哪种显示。例如,要启动文本模式的 twin,请输入 `twin --hw=tty,TERM=linux`。这里指定的 `TERM` 变量替代了你当前 Shell 中终端变量。要启动图形版本,运行 `twin --hw=X@$DISPLAY`。在 Linux 上,twin 一般都“可以正常工作”,而在 MacOS 上,Twin 基本是只能在终端上使用。
*真正*的乐趣是可以通过 `twattach` 和 `twdisplay` 命令接驳到正在运行的会话的功能。它们使你可以接驳到其他正在运行的 twin 会话。例如,在 Mac 上,我可以运行以下命令以接驳到演示机器上运行的 twin 会话:
```
twdisplay [email protected]:0 --hw=tty,TERM=linux
```

通过多做一些工作,你还可以将其用作登录外壳,以代替控制台上的 [getty](https://en.wikipedia.org/wiki/Getty_(Unix))。这需要 gdm 鼠标守护程序、twdm 应用程序(包括)和一些额外的配置。在使用 systemd 的系统上,首先安装并启用 gdm(如果尚未安装),然后使用 `systemctl` 为控制台(我使用 tty6)创建一个覆盖。这些命令必须以 root 用户身份运行;在 Ubuntu 上,它们看起来像这样:
```
apt install gdm
systemctl enable gdm
systemctl start gdm
systemctl edit getty@tty6
```
`systemctl edit getty@tty6` 命令将打开一个名为 `override.conf` 的空文件。它可以定义 systemd 服务设置以覆盖 tty6 的默认设置。将内容更新为:
```
[service]
ExecStart=
ExecStart=-/usr/local/sbin/twdm --hw=tty@/dev/tty6,TERM=linux
StandardInput=tty
StandardOutput=tty
```
现在,重新加载 systemd 并重新启动 tty6 以获得 twin 登录提示界面:
```
systemctl daemon-reload
systemctl restart getty@tty6
```

这将为登录的用户启动一个 twin 会话。我不建议在多用户系统中使用此会话,但是对于个人桌面来说,这是很酷的。并且,通过使用 `twattach` 和 `twdisplay`,你可以从本地 GUI 或远程桌面访问该会话。
我认为 twin 真是太酷了。它还有一些细节不够完善,但是基本功能都已经有了,并且有一些非常好的文档。另外,它也使我可以在现代操作系统上稍解对 DESQview 式的体验的渴望。我希望随着时间的推移它会有所改进,希望你和我一样喜欢它。
---
via: <https://opensource.com/article/20/1/multiple-consoles-twin>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Overcome "one screen, one app" limits with twin
Who remembers [DESQview](https://en.wikipedia.org/wiki/DESQview)? It allowed for things in DOS we take for granted now in Windows, Linux, and MacOS—namely the ability to run and have multiple programs running onscreen at once. In my early days running a dial-up BBS, DESQview was a necessity—it enabled me to have the BBS running in the background while doing other things in the foreground. For example, I could be working on new features or setting up new external programs while someone was dialed in without impacting their experience. Later, in my early days in support, I could have my work email ([DaVinci email on MHS](https://en.wikipedia.org/wiki/Message_Handling_System)), the support ticket system, and other DOS programs running all at once. It was amazing!
Running multiple console applications has come a long way since then. But applications like [tmux](https://github.com/tmux/tmux/wiki) and [Screen](https://www.gnu.org/software/screen/) still follow the "one screen, one app" kind of display. OK, yes, tmux has screen splitting and panes, but not like DESQview, with the ability to "float" windows over others, and I, for one, miss that.
Enter [twin](https://github.com/cosmos72/twin), the text-mode window environment. This relatively young project is, in my opinion, a spiritual successor to DESQview. It supports console and graphical environments, as well as the ability to detach from and reattach to sessions. It's not as easy to set up as some things, but it will run on most modern operating systems.
Twin is installed from source (for now). But first, you need to install the required development libraries. The library names will vary by operating system. The following example shows it for my Ubuntu 19.10 installation. Once the libraries are installed, check out the twin source from Git and run **./configure** and **make**, which should auto-detect everything and build twin:
```
sudo apt install libx11-dev libxpm-dev libncurses-dev zlib1g-dev libgpm-dev
git clone [email protected]:cosmos72/twin.git
cd twin
./configure
make
sudo make install
```
Note: If you are compiling this on MacOS or BSD, you will need to comment out **#define socklen_t int** in the files **include/Tw/autoconf.h** and **include/twautoconf.h** before running **make**. This should be addressed by [twin issue number 57](https://github.com/cosmos72/twin/issues/57).
Invoking twin for the first time can be a bit of a challenge. You need to tell it what kind of display it is using with the **--hw** parameter. For example, to launch a text-mode version of twin, you would enter **twin --hw=tty,TERM=linux**. The **TERM** variable specifies an override to the current terminal variable in your shell. To launch a graphical version, run **twin --hw=X@$DISPLAY**. On Linux, twin mostly "just works," and on MacOS, it mostly only works in terminals.
The *real* fun comes with the ability to attach to running sessions with the **twattach** and **twdisplay** commands. They allow you to attach to a running twin session somewhere else. For example, on my Mac, I can run the following command to connect to the twin session running on my demo box:
`twdisplay [email protected]:0 --hw=tty,TERM=linux`
With some extra work, you can also use it as a login shell in place of [getty](https://en.wikipedia.org/wiki/Getty_(Unix)) on consoles. This requires the gdm mouse daemon, the twdm application (included), and a little extra configuration. On systems that use systemd, start by installing and enabling gdm (if it isn't already installed). Then use systemctl to create an override for a console (I used tty6). The commands must be run as the root user; on Ubuntu, they look something like this:
```
apt install gdm
systemctl enable gdm
systemctl start gdm
systemctl edit getty@tty6
```
The **systemctl edit getty@tty6** command will open an empty file named **override.conf**. This defines systemd service settings to override the default for console 6. Update the contents to:
```
[service]
ExecStart=
ExecStart=-/usr/local/sbin/twdm --hw=tty@/dev/tty6,TERM=linux
StandardInput=tty
StandardOutput=tty
```
Now, reload systemd and restart tty6 to get a twin login prompt:
```
systemctl daemon-reload
systemctl restart getty@tty6
```
This will launch a twin session for the user who logs in. I do not recommend this for a multi-user system, but it is pretty cool for a personal desktop. And, by using **twattach** and **twdisplay**, you can access that session from the local GUI or remote desktops.
I think twin is pretty darn cool. It has some rough edges, but the basic functionality is there, and it has some pretty good documentation. Also, it scratches the itch I have for a DESQview-like experience on modern operating systems. I look forward to improvements over time, and I hope you like it as much as I do.
## 5 Comments |
11,893 | 从监狱到 Python | https://opensource.com/article/20/1/prison-to-python | 2020-02-15T11:49:29 | [
"Python",
"监狱"
] | https://linux.cn/article-11893-1.html |
>
> 入狱后,开源编程是如何提供机会的。
>
>
>

不到一年前,我还在圣昆廷州立监狱服刑,我是无期徒刑。
我高三的时候,我抢劫了一个人并向他开了枪。现在,我经过一段时间才意识到并承认自己做错了,这是在经历了陪审团审判并看到我的行为带来的恶果后,我知道需要改变自己,我也确实做到了。尽管我对我的行为表示懊悔,但我毕竟开枪打了一个人,并差点杀了他。做这样的事是有后果的,这是理所当然的。所以在我 18 岁的时候,我被判了终身监禁。
监狱是一个非常可怕的地方;我是不推荐你去的。但是我必须去,所以我去了。我不告诉你具体的细节,但你可以放心,这是一个没有太多动机去改变的地方,许多人在这里养成的坏习惯比他们过去在别处养成的更多。
我是幸运儿之一。当我在服刑的时候,发生了一些不同寻常的事情。我开始想象自己出狱后的的未来,虽然在这之前,我还是已经在那里度过了我整个成年生活。
现在你想想:我是黑人,只受过高中教育。我没有工作经历,如果我离开监狱,在被释放前,我还是一个被定罪的重罪犯。当每个雇主看到我的简历,都不会有“我需要雇用这个人”想法,我认为是正常的。
我不知道我的选择是什么,但我已经下定决心了。我需要做些活下去的事情,并且这和我入狱前的生活一点也不像。
### Python 之路
最终,我被关在了圣昆廷州立监狱,我不知道我为何幸运地被关在那里。圣昆廷提供了几个自助和教育编程项目。这些[改造机会](https://www.dailycal.org/2019/02/27/san-quentin-rehabilitation-programs-offer-inmates-education-a-voice/)帮助囚犯使他们拥有在获释后避免再次犯罪的技能。
作为其中一个编程项目的一部分,2017 年我通过圣昆廷媒体项目认识了[杰西卡·麦凯拉](https://twitter.com/jessicamckellar?lang=en)。杰西卡是编程语言 [Python](https://www.python.org/) 的爱好者,她开始向我推荐 Python 有多棒,以及它是刚起步的人学习的完美语言。这就是故事变得比小说更精彩的地方。
>
> 感谢 [@northbaypython](https://twitter.com/northbaypython?ref_src=twsrc%5Etfw) 让 [@ShaStepter](https://twitter.com/ShaStepter?ref_src=twsrc%5Etfw) 和我重复 [@pycon](https://twitter.com/pycon?ref_src=twsrc%5Etfw) 的主题演讲,让他们被录制下来。我很荣幸与大家分享:
>
>
> 从监狱到 Pythone: <https://t.co/rcumoAgZHm>
>
>
> 大规模裁员:如果我们不雇佣被判重罪的人,谁会呢? <https://t.co/fENDUFdxfX>
>
>
> [pic.Twitter.com/kpjo8d3ul6](https://t.co/Kpjo8d3ul6)
>
>
> —杰西卡·麦凯拉(@jessicamckellar)[2019 年 11 月 5 日](https://twitter.com/jessicamckellar/status/1191601209917837312?ref_src=twsrc%5Etfw)
>
>
>
杰西卡向我介绍了一些 Python 视频教程,这些教程是她为一家名叫 [O’Reilly Media](http://shop.oreilly.com/product/110000448.do) 的公司做的,课程是在线的,如果我能接触到它们,那该有多好呀。不幸的是,在监狱里上网是不可能的。但是,我遇到了一个叫 Tim O’Reilly 的人,他最近刚来到圣昆廷。在他访问之后,Tim 从他的公司 O’Reilly Media 公司向监狱的编程班捐赠了大量内容。最终,我拿到了一款平板电脑,上面有杰西卡的 Python 教程,并学会了如何使用这些 Python 教程进行编码。
真是难以置信。背景和生活与我完全不同的陌生人把这些联系在一起,让我学会了编码。
### 对 Python 社区的热爱
在这之后,我开始经常和杰西卡见面,她开始告诉我关于开源社区的情况。我了解到,从根本上说,开源社区就是关于伙伴关系和协作的社区。之所以如此有效,是因为没有人被排除在外。
对我来说,一个努力寻找自己定位的人,我所看到的是一种非常基本的爱——通过合作和接受的爱,通过接触的爱,通过包容的爱。我渴望成为其中的一部分。所以我继续学习 Python,不幸的是,我无法获得更多的教程,但是我能够从开源社区收集的大量书面知识中获益。我读一切提到 Python 的东西,从平装本到晦涩难懂的杂志文章,我使用平板电脑来解决我读到的 Python 问题。
我对 Python 和编程的热情不是我的许多同龄人所共有的。除了监狱编程课上的极少数人之外,我认识的其他人都没有提到过编程;一般囚犯都不知道。我认为这是因为有过监禁经历的人无法接触编程,尤其是如果你是有色人种。
### 监狱外的 Python 生活
然而,在 2018 年 8 月 17 日,我得到了生命中的惊喜。时任州长的杰里·布朗将我 27 年的刑期减刑,在服刑将近 19 年后,我被释放出狱了。
但现实情况是,这也是为什么我认为编程和开源社区如此有价值。我是一名 37 岁的黑人罪犯,没有工作经历,刚刚在监狱服刑 18 年。我有犯罪史,并且现存偏见导致没有多少职业适合我。但是编程是少数例外之一。
现在,监禁后重返社会的人们迫切需要包容,但当谈及工作场所的多样性以及对多样性的需求时,你真的听不到这个群体被提及或包容。
>
> 还有什么:
>
>
> 1、背景调查:询问他们在你的公司是如何使用的。
>
>
> 2、初级角色:删除虚假的、不必要的先决条件,这些条件将排除有记录的合格人员。
>
>
> 3、积极拓展:与当地再就业项目合作,创建招聘渠道。
>
>
> [pic.twitter.com/WnzdEUTuxr](https://t.co/WnzdEUTuxr)
>
>
> —杰西卡·麦凯拉(@jessicamckellar)[2019 年 5 月 12 日](https://twitter.com/jessicamckellar/status/1127640222504636416?ref_src=twsrc%5Etfw)
>
>
>
因此,我想谦卑地挑战开源社区的所有程序员和成员,让他们围绕包容和多样性展开思考。今天,我自豪地站在你们面前,代表一个大多数人都没有想到的群体——以前被监禁的人。但是我们存在,我们渴望证明我们的价值,最重要的是,我们期待被接受。当我们重返社会时,许多挑战等待着我们,我请求你们允许我们有机会展示我们的价值。欢迎我们,接受我们,最重要的是,包容我们。
---
via: <https://opensource.com/article/20/1/prison-to-python>
作者:[Shadeed Sha Wallace-Stepter](https://opensource.com/users/shastepter) 选题:[lujun9972](https://github.com/lujun9972) 译者:[heguangzhi](https://github.com/heguangzhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Less than a year ago, I was in San Quentin State Prison serving a life sentence.
In my junior year in high school, I shot a man while robbing him. Now, it took a while for me to see or even admit that what I did was wrong, but after going through a jury trial and seeing the devastating consequences of my actions, I knew that I needed to make a change, and I did. And although it was a great thing that I had changed, I had still shot a man and nearly killed him. And there are consequences to doing something like that, and rightfully so. So at the age of 18, I was sentenced to life in prison.
Now prison is a terrible place; I do not recommend it. But I had to go and so I went. I’ll spare you the details, but you can rest assured it’s a place where there isn’t much incentive to change, and many people pick up more bad habits than they went in with.
I’m one of the lucky ones. While I was in prison, something different happened. I started to imagine a future for myself beyond the prison bars where, up until that point, I had spent all of my adult life.
Now YOU think about this: I’m black, with nothing more than a high school education. I had no work history, and if I ever were to leave prison, I would be a convicted felon upon my release. And I think I’m being fair when I say that the first thought for an employer who sees this profile is not "I need to hire this person."
My options weren’t clear, but my mind was made up. I needed to do something to survive that wouldn’t look anything like my life before prison.
## A path to Python
Eventually, I wound up in San Quentin State Prison, and I had no idea how lucky I was to be there. San Quentin offered several self-help and education programs. These [rehabilitation opportunities](https://www.dailycal.org/2019/02/27/san-quentin-rehabilitation-programs-offer-inmates-education-a-voice/) ensured prisoners had skills that helped them avoid being repeat offenders upon release.
As part of one of these programs, I met [Jessica McKellar](https://twitter.com/jessicamckellar?lang=en) in 2017 through her work with the San Quentin Media Program. Jessica is an enthusiast of the programming language [Python](https://www.python.org/), and she started to sell me on how great Python is and how it’s the perfect language to learn for someone just starting out. And this is where the story becomes stranger than fiction.
Thanks
[@northbaypython]for letting[@ShaStepter]and me reprise our[@pycon]keynotes to get them recorded. I'm honored to share:
From Prison to Python:[https://t.co/rcumoAgZHm]
Mass Decarceration: If We Don't Hire People With Felony Convictions, Who Will?[https://t.co/fENDUFdxfX][pic.twitter.com/Kpjo8d3ul6]— Jessica McKellar (@jessicamckellar)
[November 5, 2019]
Jessica told me about these Python video tutorials that she did for a company called [O’Reilly Media](http://shop.oreilly.com/product/110000448.do), that they were online, and how great it would be if I could get access to them. Unfortunately, internet access in prison isn’t a thing. But, I had met this guy named Tim O’Reilly, who had recently come to San Quentin. It turns out that, after his visit, Tim had donated a ton of content from his company, O’Reilly Media, to the prison’s programming class. I wound up getting my hands on a tablet that had Jessica’s Python tutorials on it and learned how to code using those Python tutorials.
It was incredible. Total strangers with a very different background and life from my own had connected the dots in a way that led to me learning to code.
## The love of the Python community
After this point, I started meeting with Jessica pretty frequently, and she began to tell me about the open source community. What I learned is that, on a fundamental level, open source is about fellowship and collaboration. It works so well because no one is excluded.
And for me, someone who struggled to see where they fit, what I saw was a very basic form of love—love by way of collaboration and acceptance, love by way of access, love by way of inclusion. And my spirit yearned to be a part of it. So I continued my education with Python, and, unfortunately, I wasn’t able to get more tutorials, but I was able to draw from the vast wealth of written knowledge that has been compiled by the open source community. I read anything that even mentioned Python, from paperback books to obscure magazine articles, and I used the tablet that I had to solve the Python problems that I read about.
My passion for Python and programming wasn’t something that many of my peers shared. Aside from the very small group of people who were in the prison’s programming class, no one else that I knew had ever mentioned programming; it’s just not on the average prisoner’s radar. I believe that this is due to the perception that programming isn’t accessible to people who have experienced incarceration, especially if you are a person of color.
## Life with Python outside of prison
Then, on August 17, 2018, I got the surprise of my life. Then-Governor Jerry Brown commuted my 27-years-to-life sentence, and I was released from prison after serving almost 19 years.
But here’s the reality of my situation and why I believe that programming and the open source community are so valuable. I am a 37-year-old, black, convicted felon, with no work history, who just served 18 years in prison. There aren’t many professions that exist that would prevent me from being at the mercy of the stigmas and biases that inevitably accompany my criminal past. But one of the few exceptions is programming.
The people who are now returning back to society after incarceration are in desperate need of inclusion, but when the conversation turns to diversity in the workplace and how much it’s needed, you really don’t hear this group being mentioned or included.
What else:
1. Background checks: ask how they are used at your company.
2. Entry-level roles: remove fake, unnecessary prerequisites that will exclude qualified people with records.
3. Active outreach: partner with local re-entry programs to create hiring pipelines.[pic.twitter.com/WnzdEUTuxr]— Jessica McKellar (@jessicamckellar)
[May 12, 2019]
So with that, I want to humbly challenge all of the programmers and members of the open source community to expand your thinking around inclusion and diversity. I proudly stand before you today as the representative of a demographic that most people don’t think about—formerly incarcerated people. But we exist, and we are eager to prove our value, and, above all else, we are looking to be accepted. Many challenges await us upon our reentry back into society, and I ask that you allow us to have the opportunity to demonstrate our worth. Welcome us, accept us, and, more than anything else, include us.
## 15 Comments |
11,895 | 开始使用 GnuCash | https://opensource.com/article/20/2/gnucash | 2020-02-15T12:42:45 | [
"GnuCash"
] | https://linux.cn/article-11895-1.html |
>
> 使用 GnuCash 管理你的个人或小型企业会计。
>
>
>

在过去的四年里,我一直在用 [GnuCash](https://www.gnucash.org/) 来管理我的个人财务,我对此非常满意。这个开源(GPL v3)项目自 1998 年首次发布以来一直成长和改进,2019 年 12 月发布的最新版本 3.8 增加了许多改进和 bug 修复。
GnuCash 可在 Windows、MacOS 和 Linux 中使用。它实现了一个复式记账系统,并可以导入各种流行的开放和专有文件格式,包括 QIF、QFX、OFX、CSV 等。这使得从其他财务应用转换(包括 Quicken)而来很容易,它是为取代这些而出现的。
借助 GnuCash,你可以跟踪个人财务状况以及小型企业会计和开票。它没有集成的工资系统。根据文档,你可以在 GnuCash 中跟踪工资支出,但你必须在该软件外计算税金和扣减。
### 安装
要在 Linux 上安装 GnuCash:
* 在 Red Hat、CentOS 或 Fedora 中: `$ sudo dnf install gnucash`
* 在 Debian、Ubuntu 或 Pop\_OS 中: `$ sudo apt install gnucash`
你也可以从 [Flathub](https://flathub.org/apps/details/org.gnucash.GnuCash) 安装它,我在运行 Elementary OS 的笔记本上使用它。(本文中的所有截图都来自此次安装)。
### 设置
安装并启动程序后,你将看到一个欢迎屏幕,该页面提供了创建新账户集、导入 QIF 文件或打开新用户教程的选项。

#### 个人账户
如果你选择第一个选项(正如我所做的那样),GnuCash 会打开一个页面帮你起步。它收集初始数据并设置账户首选项,例如账户类型和名称、商业数据(例如,税号)和首选货币。

GnuCash 支持个人银行账户、商业账户、汽车贷款、CD 和货币市场账户、儿童保育账户等。
例如,首先创建一个简单的支票簿。你可以输入账户的初始余额或以多种格式导入现有账户数据。

#### 开票
GnuCash 还支持小型企业功能,包括客户、供应商和开票。要创建发票,请在 “Business -> Invoice” 中输入数据。

然后,你可以将发票打印在纸上,也可以将其导出到 PDF 并通过电子邮件发送给你的客户。

### 获取帮助
如果你有任何疑问,它有一个优秀的帮助,你可在菜单栏的右侧获取指导。

该项目的网站包含许多有用的信息的链接,例如 GnuCash [功能](https://www.gnucash.org/features.phtml)的概述。GnuCash 还提供了[详细的文档](https://www.gnucash.org/docs/v3/C/gnucash-help.pdf),可供下载和离线阅读,它还有一个 [wiki](https://wiki.gnucash.org/wiki/GnuCash),为用户和开发人员提供了有用的信息。
你可以在项目的 [GitHub](https://github.com/Gnucash) 仓库中找到其他文件和文档。GnuCash 项目由志愿者驱动。如果你想参与,请查看项目的 wiki 上的 [Getting involved](https://wiki.gnucash.org/wiki/GnuCash#Getting_involved_in_the_GnuCash_project) 部分。
---
via: <https://opensource.com/article/20/2/gnucash>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For the past four years, I've been managing my personal finances with [GnuCash](https://www.gnucash.org/), and I'm quite satisfied with it. The open source (GPL v3) project has been growing and improving since its initial release in 1998, and the latest version, 3.8, released in December 2019, adds many improvements and bug fixes.
GnuCash is available for Windows, MacOS, and Linux. The application implements a double-entry bookkeeping system and can import a variety of popular open and proprietary file formats, including QIF, QFX, OFX, CSV, and more. This makes it easy to convert from other personal finance applications, including Quicken, which it was created to replicate.
With GnuCash, you can track personal finances as well as small business accounting and invoicing. It doesn't have an integrated payroll system; according to the documentation, you can track payroll expenses in GnuCash, but you have to calculate taxes and deductions outside the software.
## Installation
To install GnuCash on Linux:
- On Red Hat, CentOS, or Fedora:
**$ sudo dnf install gnucash** - On Debian, Ubuntu, or Pop_OS:
**$ sudo apt install gnucash**
You can also install it from [Flathub](https://flathub.org/apps/details/org.gnucash.GnuCash), which is what I used on my laptop running Elementary OS. (All the screenshots in this article are from that installation.)
## Setup
After you install and launch the program, you will see a welcome screen that gives you the option to create a new set of accounts, import QIF files, or open a new user tutorial.
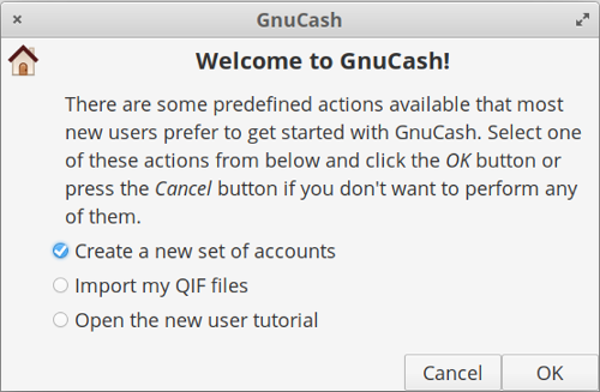
### Personal accounts
If you choose the first option (as I did), GnuCash opens a screen to help you get up and running. It collects initial data and sets up your account preferences, such as your account types and names, business data (e.g., tax ID number), and preferred currency.
GnuCash supports personal bank accounts, business accounts, car loans, CD and money market accounts, childcare accounts, and more.
As an example, start by creating a simple checkbook. You can either enter your account's beginning balance or import existing account data in multiple formats.
### Invoicing
GnuCash also supports small business functions, including customers, vendors, and invoicing. To create an invoice, enter the data in the **Business ->Invoice** section.
Then you can either print the invoice on paper or export it to a PDF and email it to your customer.
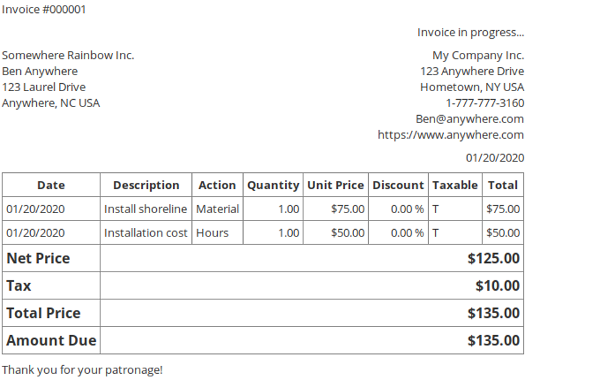
## Get help
If you have questions, there's an excellent Help section that's guide accessible from the far-right side of the menu bar.
The project's website includes links to lots of helpful information, such as a great overview of GnuCash [features](https://www.gnucash.org/features.phtml). GnuCash also has [detailed documentation](https://www.gnucash.org/docs/v3/C/gnucash-help.pdf) available to download and read offline and a [wiki](https://wiki.gnucash.org/wiki/GnuCash) with helpful information for users and developers.
You can find other files and documentation in the project's [GitHub](https://github.com/Gnucash) repository. The GnuCash project is volunteer-driven. If you would like to contribute, please check out [Getting involved](https://wiki.gnucash.org/wiki/GnuCash#Getting_involved_in_the_GnuCash_project) on the project's wiki.
## 2 Comments |
11,896 | Joplin:真正的 Evernote 开源替代品 | https://itsfoss.com/joplin/ | 2020-02-15T21:01:00 | [
"笔记",
"Joplin"
] | https://linux.cn/article-11896-1.html |
>
> Joplin 是一个开源笔记记录和待办应用。你可以将笔记组织到笔记本中并标记它们。Joplin 还提供网络剪贴板来保存来自互联网的文章。
>
>
>
### Joplin:开源笔记管理器

如果你喜欢 [Evernote](https://evernote.com/),那么你不会不太适应这个开源软件 [Joplin](https://joplinapp.org/)。
Joplin 是一个优秀的开源笔记应用,拥有丰富的功能。你可以记笔记、记录待办事项并且通过和 Dropbox 和 NextCloud 等云服务链接来跨设备同步笔记。同步过程通过端到端加密保护。
Joplin 还有一个 Web 剪贴板,能让你将网页另存为笔记。这个网络剪贴板可用于 Firefox 和 Chrome/Chromium 浏览器。
Joplin 可以导入 enex 格式的 Evernote 文件,这让从 Evernote 切换变得容易。
因为数据自行保存,所以你可以用 Joplin 格式或者原始格式导出所有文件。
### Joplin 的功能

以下是 Joplin 的所有功能列表:
* 将笔记保存到笔记本和子笔记本中,以便更好地组织
* 创建待办事项清单
* 可以标记和搜索笔记
* 离线优先,因此即使没有互联网连接,所有数据始终在设备上可用
* Markdown 笔记支持图片、数学符号和复选框
* 支持附件
* 可在桌面、移动设备和终端(CLI)使用
* 可在 Firefox 和 Chrome 使用[网页剪切板](https://joplinapp.org/clipper/)
* 端到端加密
* 保留笔记历史
* 根据名称、时间等对笔记进行排序
* 可与 [Nextcloud](https://nextcloud.com/)、Dropbox、WebDAV 和 OneDrive 等各种[云服务](https://itsfoss.com/cloud-services-linux/)同步
* 从 Evernote 导入文件
* 导出 JEX 文件(Joplin 导出格式)和原始文件
* 支持笔记、待办事项、标签和笔记本
* 任意跳转功能
* 支持移动设备和桌面应用通知
* 地理位置支持
* 支持多种语言
* 外部编辑器支持:在 Joplin 中一键用你最喜欢的编辑器打开笔记
### 在 Linux 和其它平台上安装 Joplin

[Joplin](https://github.com/laurent22/joplin) 是一个跨平台应用,可用于 Linux、macOS 和 Windows。在移动设备上,你可以[获取 APK 文件](https://itsfoss.com/download-apk-ubuntu/)将其安装在 Android 和基于 Android 的 ROM 上。你也可以[从谷歌 Play 商店下载](https://play.google.com/store/apps/details?id=net.cozic.joplin&hl=en_US)。
在 Linux 中,你可以获取 Joplin 的 [AppImage](https://itsfoss.com/use-appimage-linux/) 文件,并作为可执行文件运行。你需要为下载的文件授予执行权限。
* [下载 Joplin](https://github.com/laurent22/joplin/releases)
### 体验 Joplin
Joplin 中的笔记使用 Markdown,但你不需要了解它。编辑器的顶部面板能让你以图形方式选择项目符号、标题、图像、链接等。
虽然 Joplin 提供了许多有趣的功能,但你需要自己去尝试。例如,默认情况下未启用 Web 剪切板,我需要发现如何打开它。
你需要从桌面应用启用剪切板。在顶部菜单中,进入 “Tools->Options”。你可以在此处找到 Web 剪切板选项:

它的 Web 剪切板不如 Evernote 的 Web 剪切板聪明,后者可以以图形方式剪辑网页文章的一部分。但是,也足够了。
这是一个在活跃开发中的开源软件,我希望它随着时间的推移得到更多的改进。
### 总结
如果你正在寻找一个不错的拥有 Web 剪切板的笔记应用,你可以试试 Joplin。如果你喜欢它,并将继续使用,尝试通过捐赠或改进代码和文档来帮助 Joplin 开发。我以 FOSS 的名义[捐赠](https://itsfoss.com/donations-foss/)了 25 欧。
如果你曾经使用过 Joplin,或者仍在使用它,你对此的体验如何?如果你用的是其他笔记应用,你会切换到 Joplin 么?欢迎分享你的观点。
---
via: <https://itsfoss.com/joplin/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you like [Evernote](https://evernote.com/?ref=itsfoss.com), you won’t be too uncomfortable with the open-source software, [Joplin](https://joplinapp.org/?ref=itsfoss.com).
Joplin is an [excellent open-source note-taking application](https://itsfoss.com/note-taking-apps-linux/) with plenty of features. You can take notes, make to-do list and sync your notes across devices by linking it with Joplin Cloud or other cloud services like Dropbox and Nextcloud. The synchronization is protected with end-to-end encryption.
Joplin also has a web clipper that allows you to save webpages as notes. The web clipper is available for Firefox and Chrome/Chromium browsers.
Joplin makes the switch from Evernote easier by allowing importing Evernote files in ENEX format.
Since you own the data, you can export all your files either in Joplin format or in the raw format.
## Features of Joplin
Here’s a list of all the features Joplin provides:
- Save notes into notebooks and sub-notebooks for better organization
- Create to-do list
- Notes can be tagged and searched, sorted (based on name, time etc.)
- Offline first, so the entire data is always available on the device even without an internet connection
- Markdown notes with pictures, math notation and checkboxes support
- File attachment support
- Application available for desktop, mobile, and terminal (CLI)
[Web Clipper](https://joplinapp.org/clipper/?ref=itsfoss.com)for Firefox and Chrome- End-To-End Encryption
- Keeps note history
- Notes sorting based on name, time etc.
- External editor support – open notes in your favorite external editor with one click in Joplin
- Supports multiple languages
- Geo-location support
- Support for notifications in mobile and desktop applications
- Goto Anything feature
- Export JEX files (Joplin Export format) and raw files.
- Import files from Evernote
- Synchronization with various
[cloud services](https://itsfoss.com/cloud-services-linux/)like[Nextcloud](https://nextcloud.com/?ref=itsfoss.com), Dropbox, WebDAV and OneDrive or Joplin's own Cloud (paid service)
[Start free with $5 welcome credit](https://www.pikapods.com/)😎
## Installing Joplin on Linux and other platforms
[Joplin](https://github.com/laurent22/joplin?ref=itsfoss.com) is a cross-platform application available for Linux, macOS, and Windows. On the mobile, you can [get the APK file](https://itsfoss.com/download-apk-ubuntu/) to install it on Android and Android-based ROMs. You can also [get it from the Google Play Store](https://play.google.com/store/apps/details?id=net.cozic.joplin&hl=en_US&ref=itsfoss.com).
For Linux users, the preferred method is using the official installation script.
```
wget -O - https://raw.githubusercontent.com/laurent22/joplin/dev/Joplin_install_and_update.sh | bash
```
This will download the AppImage and place it in the appropriate places. Furthermore, you don't need to take care of the desktop integration, as the script will do all by itself.
You can also download the AppImage file for Joplin and [run the AppImage application as an executable](https://itsfoss.com/use-appimage-linux/). You’ll have to give execute permission to the downloaded file.
An Unofficial version of Joplin is available on Flathub and Snap Store. To install, first, you need to set up [Flatpak](https://itsfoss.com/flatpak-guide/) or [Snap](https://itsfoss.com/install-snap-linux/) support and then use the respective command below:
```
flatpak install flathub net.cozic.joplin_desktop
```
```
sudo snap install joplin-desktop
```
## Using Joplin Web Clipper
As said earlier, Joplin provides a Web Clipper for Firefox and Chromium browsers. You can install the same for your browser of choice.
First, open Joplin and select Tools ⇾ Option
In the window, go to the Web Clipper tab and then click on the “Enable Web Clipper Service” button.
Now, click on the browser of your choice, to go to the respective extensions download page.
Install the Add-on.
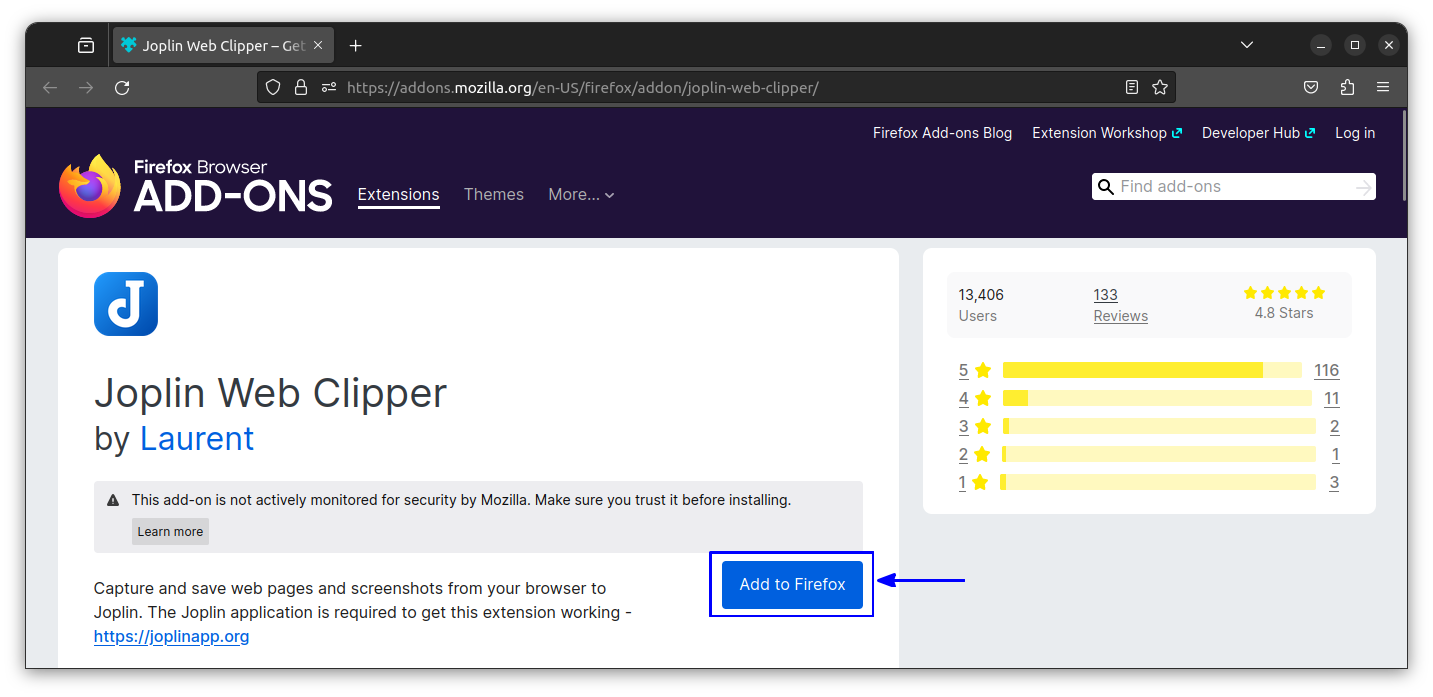
Once installed, click on the Add-on.
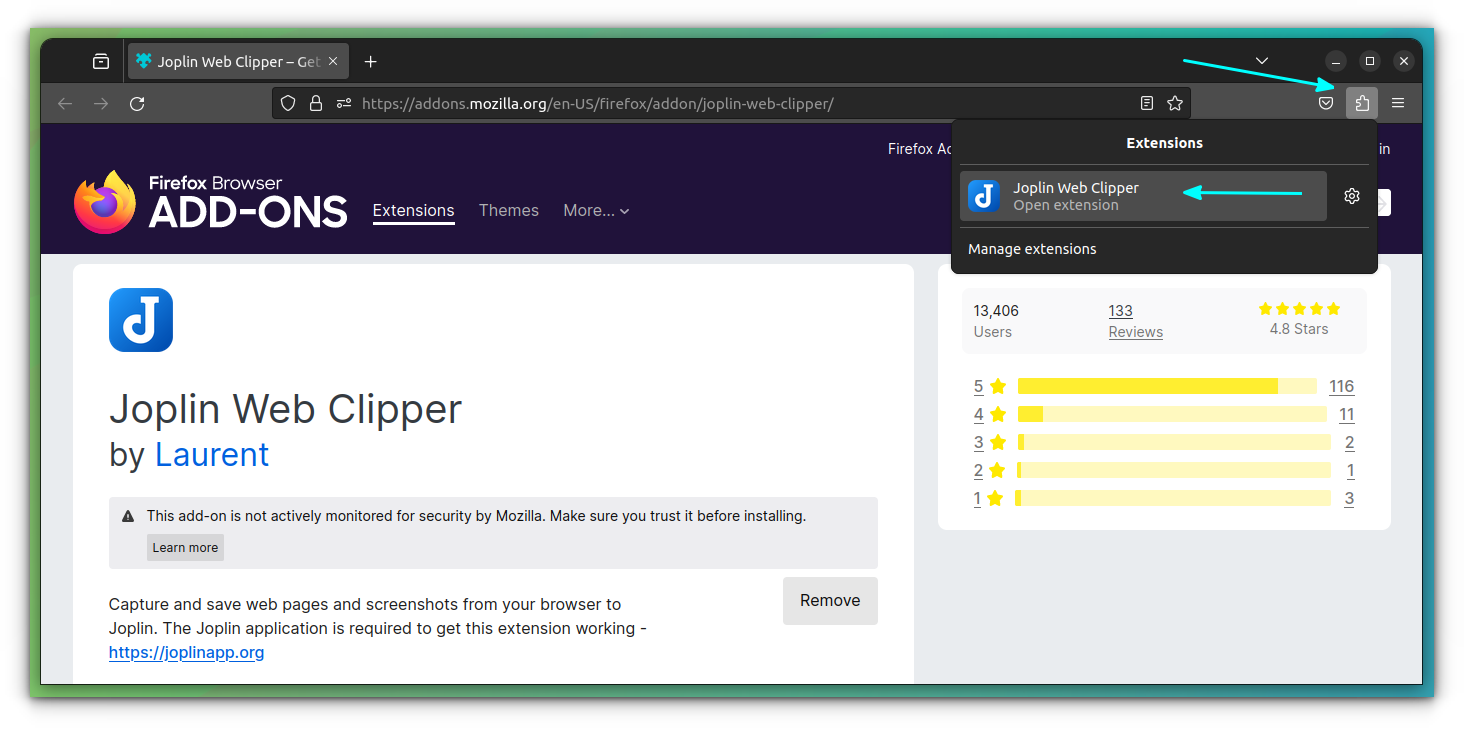
This will ask for an authorization in Joplin. Allow, by clicking the “Grant authorization” button.
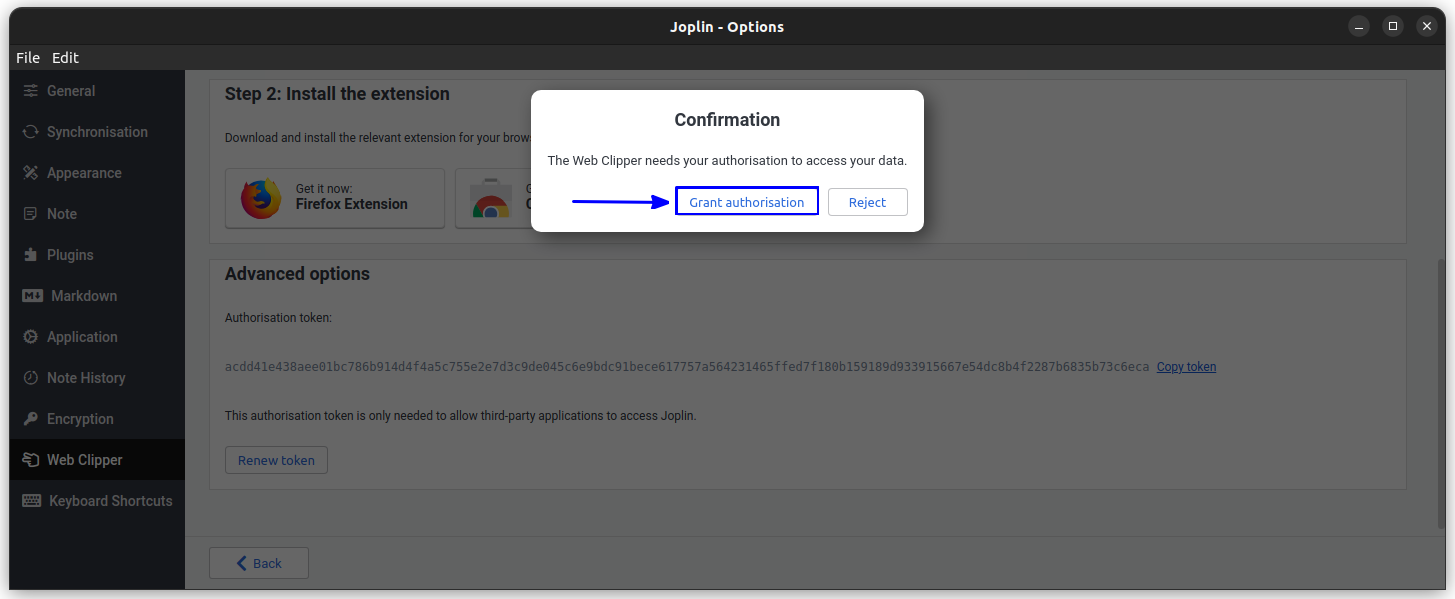
That's it. You can now go and save important resources in Joplin.
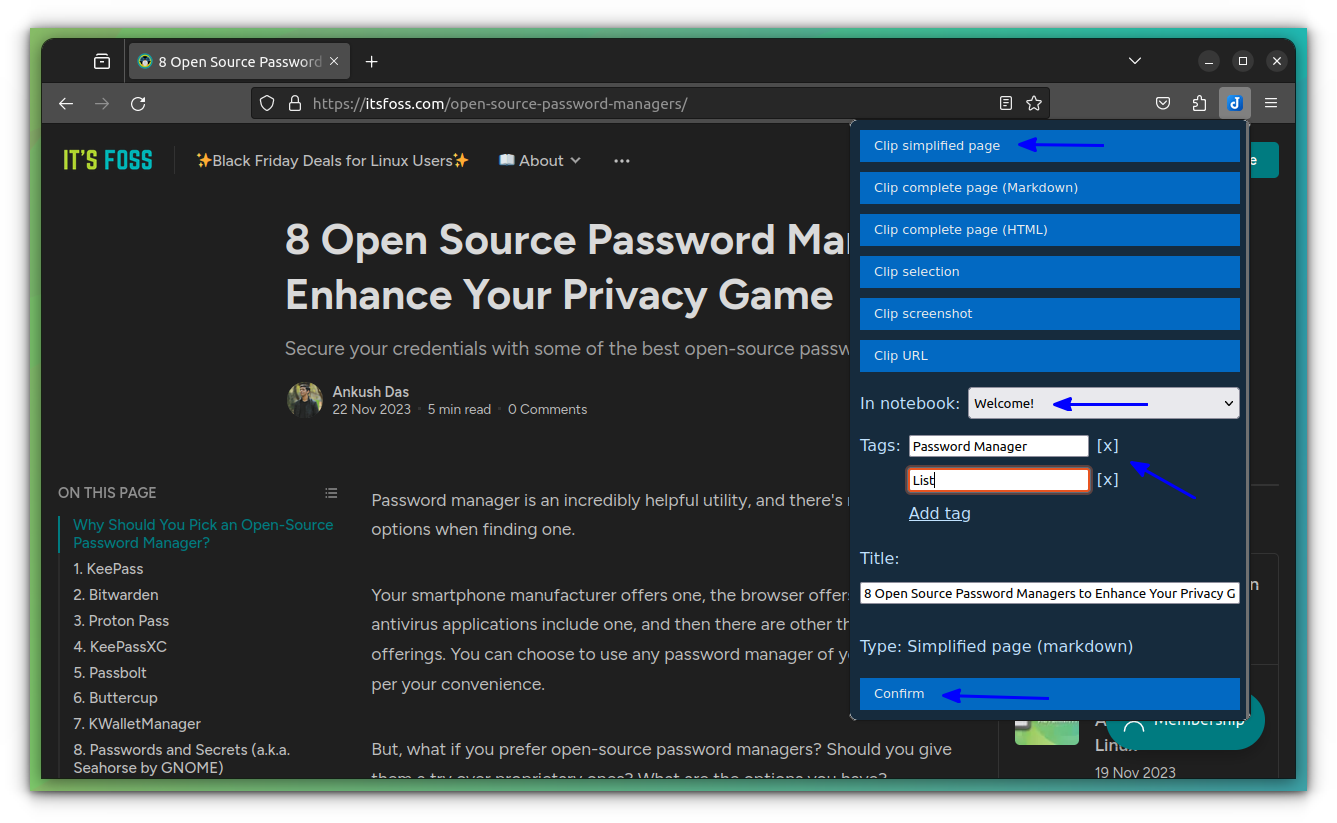
You can see that, it offers several kinds of clippings, like Complete page as markdown/html, simplified page, screenshot etc.
## Experiencing Joplin
Joplin is one of the smooth note-taking applications for Linux, that offers a cross-platform experience. Over the time, Joplin has improved a lot.
By default, it offers some neat features like notebook stacking and a very rich markdown experience (for those who are good with Markdown syntax).
The default markdown editor does not offer much GUI buttons to add blocks. For example, tables. But this won't be a problem when you switch to the rich editor, where, you can even play with the tables! But, the rich editor comes with its limitations, compared to the original Markdown editor.
The mobile version of Joplin is not a super cool visual experience. It looks simple, but I felt it a bit old looking.
The end-to-end encryption is a very good feature and this alone makes the app a special one. Almost all other apps put some kind of restriction on the user, while offering end-to-end encryption. Say [Standard Notes](https://itsfoss.com/standard-notes/), for example. It is a great app with E2EE, except, it only allows the rich text editing and markdown capabilities to the paid users.
Here comes the specialty of Joplin, which offers all the features, along with a choice to select your favorite cloud service provider, along with E2EE. If you want Joplin Cloud, then you need to [pay some subscription fees](https://joplinapp.org/plans/?ref=itsfoss.com).
A small issue for some people is the inability to Sync with Google Drive. But that's not a problem at all, given the other solutions.
## Conclusion
If you are looking for a good note-taking application with a web-clipper feature, do give Joplin a try. And if you like it and would continue using, try to help Joplin development by making a donation or improving its code and documentation. I made a sweet little [donation](https://itsfoss.com/donations-foss/) of 25 Euro on behalf of It’s FOSS.
If you start using Joplin, take a look at these cools tricks to make the most out of it.
[Mastering Joplin Notes: Tips and TweaksJoplin is an awesome open source note taking application. Here’s how you can make the best of it.](https://itsfoss.com/joplin-tips/)

Not satisfied with Joplin and still looking for some Evernote alternatives? Do check our list!
[Here are the Evernote Alternative Note Taking Apps for LinuxEvernote is a great note taking app that can be used across Windows, macOS and all major smartphone OS.There is one problem with it though. It is not properly supported on Linux desktop yet. There is a beta version and thanks to that you can install Evernote on Ubuntu](https://itsfoss.com/5-evernote-alternatives-linux/)

Not particularly Evernote and Notion, but a simpler note taking app? There is no dearth for it on Linux.
[Top 16 Best Note Taking Apps For Linux [2023]Plenty of amazing note-taking apps for Linux. Here’s what we recommend you to check out.](https://itsfoss.com/note-taking-apps-linux/)

If you have used Joplin in the past or still using it, how’s your experience with it? If you use some other note-taking application, would you switch to Joplin? Feel free to share your views. |
11,897 | 使用 GSConnect 将 Android 手机连接到 Fedora 系统 | https://fedoramagazine.org/connect-fedora-to-your-android-phone-with-gsconnect/ | 2020-02-15T22:27:13 | [
"手机"
] | https://linux.cn/article-11897-1.html | 
苹果和微软公司都不同程度的提供了桌面产品与移动设备集成。Fedora 提供了类似甚至更高集成度的工具——GSConnect。它可以让你将安卓手机和你的 Fedora 桌面配对并使用。请继续阅读,以了解更多关于它的情况以及它是如何工作的信息。
### GSConnect 是什么?
GSConnect 是针对 GNOME 桌面定制的 KDE Connect 程序。KDE Connect 可以使你的设备能够互相通信。但是,在 Fedora 默认的 GNOME 桌面上安装它需要安装大量的 KDE 依赖。
GSConnect 是一个 KDE Connect 的完整实现,其以 GNOME shell 的拓展形式出现。安装后,GSConnect 允许你执行以下操作及更多:
* 在计算机上接收电话通知并回复信息
* 用手机操纵你的桌面
* 在不同设备之间分享文件与链接
* 在计算机上查看手机电量
* 让手机响铃以便你能找到它
### 设置 GSConnect 扩展
设置 GSConnect 需要安装两个组件:计算机上的 GSConnect 扩展和 Android 设备上的 KDE Connect 应用。
首先,从 GNOME Shell 扩展网站上安装 [GSConnect](https://extensions.gnome.org/extension/1319/gsconnect/) 扩展。(Fedora Magazine 有一篇关于[如何安装 GNOME Shell 扩展](https://fedoramagazine.org/install-gnome-shell-extension/)的文章,可以帮助你完成这一步。)
KDE Connect 应用程序可以在 Google 的 [Play 商店](https://play.google.com/store/apps/details?id=org.kde.kdeconnect_tp)上找到。它也可以在 FOSS Android 应用程序库 [F-Droid](https://f-droid.org/en/packages/org.kde.kdeconnect_tp/) 上找到。
一旦安装了这两个组件,就可以配对两个设备。安装扩展后它在你的系统菜单中显示为“<ruby> 移动设备 <rt> Mobile Devices </rt></ruby>”。单击它会出现一个下拉菜单,你可以从中访问“<ruby> 移动设置 <rt> Mobile Settings </rt></ruby>”。

你可以在这里用 GSConnect 查看并管理已配对的设备。进入此界面后,需要在 Android 设备上启动应用程序。
你可以在任意一台设备上进行配对初始化,在这里我们从 Android 设备连接到计算机。点击应用程序上的“刷新”,只要两个设备都在同一个无线网络环境中,你的 Android 设备便可以搜索到你的计算机。现在可以向桌面发送配对请求,并在桌面上接受配对请求以完成配对。

### 使用 GSConnect
配对后,你将需要在 Android 设备授予权限,才能使用 GSConnect 上提供的许多功能。单击设备列表中的已配对设备,便可以查看所有可用功能,并根据你的偏好和需要启用或禁用它们。

请记住,你还需要在这个 Android 应用程序中授予相应的权限才能使用这些功能。启用权限后,你现在可以访问桌面上的移动联系人,获得消息通知并回复消息,甚至同步桌面和 Android 设备的剪贴板。
### 将你的浏览器与“文件”应用集成
GSConnect 允许你直接从计算机上的文件资源管理器的关联菜单向 Android 设备发送文件。
在 Fedora 的默认 GNOME 桌面上,你需要安装 `nautilus-python` 依赖包,以便在关联菜单中显示配对的设备。安装此命令非常简单,只需要在你的首选终端运行以下命令:
```
$ sudo dnf install nautilus-python
```
完成后,将在“<ruby> 文件 <rt> Files </rt></ruby>”应用的关联菜单中显示“<ruby> 发送到移动设备 <rt> Send to Mobile Device </rt></ruby>”选项。

同样,为你的浏览器安装相应的 WebExtension,无论是 [Firefox](https://addons.mozilla.org/en-US/firefox/addon/gsconnect/) 还是 [Chrome](https://chrome.google.com/webstore/detail/gsconnect/jfnifeihccihocjbfcfhicmmgpjicaec) 浏览器,都可以将链接发送到你的 Android 设备。你可以选择直接发送链接以在浏览器中直接打开,或将其作为短信息发送。
### 运行命令
GSConnect 允许你定义命令,然后可以从远程设备在计算机上运行这些命令。这使得你可以远程截屏,或者从你的 Android 设备锁定和解锁你的桌面。

要使用此功能,可以使用标准的 shell 命令和 GSConnect 提供的 CLI。该项目的 GitHub 存储库(CLI Scripting)中提供了有关此操作的文档。
[KDE UserBase Wiki](https://userbase.kde.org/KDE_Connect/Tutorials/Useful_commands) 有一个命令示例列表。这些例子包括控制桌面的亮度和音量、锁定鼠标和键盘,甚至更改桌面主题。其中一些命令是针对 KDE Plasma 设计的,需要进行修改才能在 GNOME 桌面上运行。
### 探索并享受乐趣
GSConnect 使我们能够享受到极大的便利和舒适。深入研究首选项,查看你可以做的所有事情,灵活的使用这些命令功能发挥创意,并在下面的评论中自由分享你解锁的新方式。
---
via: <https://fedoramagazine.org/connect-fedora-to-your-android-phone-with-gsconnect/>
作者:[Lokesh Krishna](https://fedoramagazine.org/author/lowkeyskywalker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chai-yuan](https://github.com/chai-yuan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Both Apple and Microsoft offer varying levels of integration of their desktop offerings with your mobile devices. Fedora offers a similar if not greater degree of integration with **GSConnect**. It lets you pair your Android phone with your Fedora desktop and opens up a lot of possibilities. Keep reading to discover more about what it is and how it works.
### What is GSConnect?
GSConnect is an implementation of the KDE Connect project tailored for the GNOME desktop. KDE Connect makes it possible for your devices to communicate with each other. However, installing it on Fedora’s default GNOME desktop requires pulling in a large number of KDE dependencies.
GSConnect is a complete implementation of KDE Connect, but in the form of a GNOME shell extension. Once installed, GSConnect lets you do the following and a lot more:
- Receive phone notifications on your desktop and reply to messages
- Use your phone as a remote control for your desktop
- Share files and links between devices
- Check your phone’s battery level from the desktop
- Ring your phone to help find it
### Setting up the GSConnect extension
Setting up GSConnect requires installing two components: the GSConnect extension on your desktop and the KDE Connect app on your Android device.
First, install the GSConnect extension from the GNOME Shell extensions website: [GSConnect](https://extensions.gnome.org/extension/1319/gsconnect/). (Fedora Magazine has a handy article on [How to install a GNOME Shell extension](https://fedoramagazine.org/install-gnome-shell-extension/) to help you with this step.)
The KDE Connect app is available on Google’s [Play Store](https://play.google.com/store/apps/details?id=org.kde.kdeconnect_tp). It’s also available on the FOSS Android apps repository, [F-Droid](https://f-droid.org/en/packages/org.kde.kdeconnect_tp/).
Once you have installed both these components, you can pair your two devices. Installing the extension makes it show up in your system menu as *Mobile Devices*. Clicking on it displays a drop down menu, from which you can access *Mobile Settings*.
Here’s where you can view your paired devices and manage the features offered by GSConnect. Once you are on this screen, launch the app on your Android device.
You can initiate pairing from either device, but here you’ll be connecting to your desktop from the Android device. Simply hit refresh on the app, and as long as both devices are on the same wireless network, your desktop shows up in your Android device. You can now send a pair request to the desktop. Accept the pair request on your desktop to complete the pairing.
### Using GSConnect
Once paired, you’ll need to grant permissions on your Android device to make use of the many features available on GSConnect. Click on the paired device in the list of devices to see all available functions and enable or disable them according to your preferences.
Remember that you’ll also need to grant corresponding permissions in the Android app to be able to use these functions. Depending upon the features you’ve enabled and the permissions you’ve granted, you can now access your mobile contacts on your desktop, get notified of messages and reply to them, and even sync the desktop and Android device clipboards.
### Integration with Files and your web browsers
GSConnect allows you to directly send files to your Android device from your desktop file explorer’s context menu.
On Fedora’s default GNOME desktop, you will need to install the *nautilus-python* package in order to make your paired devices show up in the context menu. Installing this is as straightforward as running the following command from your preferred terminal:
$ sudo dnf install nautilus-python
Once done, the *Send to Mobile Device* entry appears in the context menu of the Files app.
Similarly, install the corresponding WebExtension for your browser, be it [Firefox](https://addons.mozilla.org/en-US/firefox/addon/gsconnect/) or [Chrome](https://chrome.google.com/webstore/detail/gsconnect/jfnifeihccihocjbfcfhicmmgpjicaec), to send links to your Android device. You have the option to send the link to launch directly in your browser or to deliver it as SMS.
### Running Commands
GSConnect lets you define commands which you can then run on your desktop, from your remote device. This allows you to do things such as take a screenshot of your desktop, or lock and unlock your desktop from your Android device, remotely.
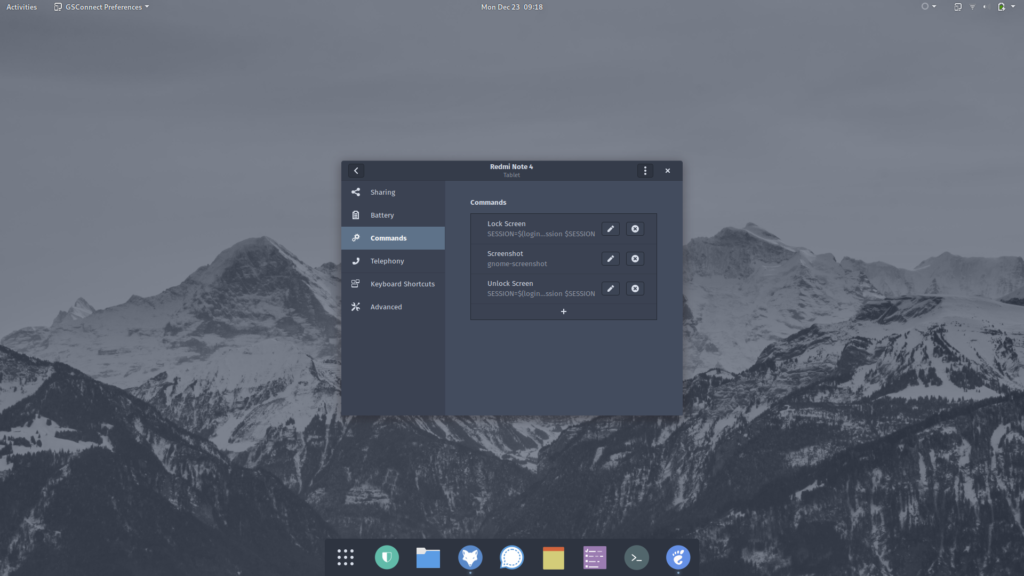
To make use of this feature, you can use standard shell commands and the CLI exposed by GSConnect. Documentation on this is provided in the project’s GitHub repository: *CLI Scripting*.
The [KDE UserBase Wiki ](https://userbase.kde.org/KDE_Connect/Tutorials/Useful_commands)has a list of example commands. These examples cover controlling the brightness and volume on your desktop, locking the mouse and keyboard, and even changing the desktop theme. Some of the commands are specific for KDE Plasma, and modifications are necessary to make it run on the GNOME desktop.
### Explore and have fun
GSConnect makes it possible to enjoy a great degree of convenience and comfort. Dive into the preferences to see all that you can do and get creative with the commands function. Feel free to share all the possibilities this utility unlocked in your workflow in the comments below.
*Photo by Pathum Danthanarayana on Unsplash.*
## Hans
Got a bug where the MPRIS media player controls don’t work with Celluloid/gnome-mpv.
Connecting to the phone after starting celluloid works, starting celluloid with the phone already connected doesn’t. Other media players such as Spotify control fine.
## svsv sarma
As it is, I can access the Android device for sharing files, photos and images etc from the device storage. Certainly GSConnect can’t make or receive calls from desk top. I strongly feel that any thing more is injurious to the Android device.
## Lokesh Krishna
Not sure about what you mean by injurious but GSConnect goes beyond just mounting your filesystem. You also get the view notifications and control media and also use it to remotely control your desktop, from using the phone as a remote keyboard or mouse and also using the commands.
## Morvan
A native Plasma user needs exactly what, to use GSConnect?
## ondrej
You can freely use the original KDE Connect! No need to use GS Connect
## Sinan
It should be natively available on plasma. Else just dnf install kde-connect, and kde-connect client on your phone.
It appears in the system settings and you also have a plasmoid to go with it.
The best thing since sliced bread.
## Markus S.
kdeconnect-kde
## Guilherme
What about KDEConnect? 😀
You should try this: https://github.com/guinuxbr/KDEConnect-commands
## johanh
@Morvan You don’t, you use KDE Connect.
## Pedro Fleck
GSConnect is an implementation of KDE Connect on Gnome Shell, in Plasma you could just use KDE Connect (I think it even comes preinstalled these days).
## Ivan
KDE Connect, of course! That is what GSConnect is based on.
## Morvan
I thought it, but it need stay clear, for me too. Thanks.
## Euan
The KDE Connect app only pairs with the Gnome desktop when the phone is unlocked. I am running the KDE Connect app on an Android 10 device (Huawei Mate P20 Pro)
Is there a special setting to enable it to run in the background. I have tried all the
setting on the phone, and have disabled auto-management of the app, and allowed it to run in the background.
## Karlis K.
I think this is a Huawei specific problem related to background app and power optimization settings – I experience this same problem on my Mate 10 Lite
## psychoslave
Seemed interesting, but after 10 minutes trying to monkey click every option possible, and even typing the IP of the laptop directly on the phone, my devices still don’t see each other. :-/
## Karlis K.
Did you rule out Firewall blocking? You can temporarily stop the firewall to check that it’s not blocking.
## Maxi
Neat article but maybe cut the screenshots to what is really relevant? I cannot even click on them to see them bigger but have to manually load their URL and the tiny embed is nearly unreadable even on my 4K HiDPI monitor.
Btw: My first comment was discarded yesterday.
## Wojciech
Nice, remember to open the ports for KDE connect. Also works with MATE.
## Andrew
Works fine though on Silverblue you need to reboot before attempting to pair.
I’d like to see persistent desktop notifications. Right now notifications flash on the screen for less than five seconds so if you’re away from your desk you’ll miss them.
## Karlis K.
I use the “Grown-up notifications” extension by yupi from but that’s because I like to keep all my notifs until I’ve ackowleged them myself.
## FeRD (Frank Dana)
@Andrew Unacknowledged notifications will usually stick around in the notification shade/drawer. (At least until they’re dismissed on the Android device — the dismissal should also be mirrored, so it’ll clear the desktop notification as well.) So you should be able to click on the GNOME Shell top-bar clock to see the ones you missed (though they don’t offer the same interaction options as the popup versions do).
If anything, the problem I tend to have is notifications being TOO persistent — my phone is a source of pretty active app-spam. If I go a bunch of hours without picking it up, and it’s connected to my desktop the whole time, I can end up with a backlog of mirrored notifications that stretches all the way to the bottom of the screen.
## Chris Cowley
Important step that has been left out is that you need to add a firewall service by running
.
Also, if you want to have available to all users, do not install it though the extensions website. It is packaged up, so you can simply install it with
.
## FeRD (Frank Dana)
@Chris
webextension-gsconnect is actually the browser extension, it probably pulls in GSConnect itself as a dependency but it’s usually a better idea to install browser extensions from their official app “store”s.
To install GSConnect itself system-wide, you’d want to use
(Not
superrecommended because it can interfere with users trying to install the extension locally in their home directory, say to get the latest version. But, it is an option for those who want a central install.)## Christian
Hmmm… Given that connectivity would be via WiFi and the default on Fedora 31 is to not allow any incoming services and port 1716 is required for connectivity a brief reference to allowing services would be useful. I can’t find any obvious, menu based approach in Gnome to manage firewall!
## Frank Dana
The optional
tool (which is installable from the standard repos using
) is a GUI for managing firewalld. IMHO it’s
more usable and friendly than the weird, verbose, annoyingmuchsyntax.
The .desktop file just lists it as “Firewall”, and for some reason it ends up in the Other group (if you use a categorized application launcher).
## sver
Off topic: Which theme, icons, fonts and other extensions are used on the screenshots? Looks awesome!
## Lokesh Krishna
Thanks!
The GTK theme is Nordic and the icon theme is Zafiro. The font in the terminal is Hack.
## Matthew Bunt
This is a really cool project. Thanks for sharing. The articles posted here just keep getting better and better. That being said…
The images in most articles are less than helpful due to small size and low resolution. A solution would be to show full size high resolution images when they are clicked on. Many websites do this so it is a pretty familiar design and I think it would be a fairly easy way to make a big improvement to Fedora Magazine.
## Brian
If I had a smart phone, could I then access the internet through the phone from my desktop, without another ISP?
## FeRD (Frank Dana)
@Brian
Most likely, but GSConnect won’t help with that. It’s strictly for local communication between devices.
There ARE various ways to get a Linux PC online using a mobile device (either by tethering over a USB cable, having the phone act as a WiFi hotspot, or using a Bluetooth connection between the two devices), but they don’t require GSConnect. It’s all handled by the OS networking and/or hardware interface layers — e.g., bluez handles Bluetooth network sharing.
Some methods also require subscription or authorization from your phone carrier. (Like, WiFi hotspot mode is usually an added-cost feature in most US cellular plans, and may have separate monthly data limits even on an unlimited-data phone plan.)
## Brian
Thankyou. I might just look into this.
## หวยออนไลน์ บาทละเท่าไหร่
Thanks a bunch for sharing this with all people you really recognize what
you are talking about! Bookmarked. Kindly additionally visit my website =).
We may have a hyperlink trade contract between us |
11,899 | 如何防范误植攻击 | https://opensource.com/article/20/1/stop-typosquatting-attacks | 2020-02-16T21:32:55 | [
"误植",
"钓鱼"
] | https://linux.cn/article-11899-1.html |
>
> <ruby> 误植 <rt> Typosquatting </rt></ruby>是一种引诱用户将敏感数据泄露给不法分子的方式,针对这种攻击方式,我们很有必要了解如何保护我们的组织、我们的开源项目以及我们自己。
>
>
>

除了常规手段以外,网络罪犯还会利用社会工程的方式,试图让安全意识较弱的人泄露私人信息或是有价值的证书。很多[网络钓鱼骗局](https://www.cloudberrylab.com/resources/guides/types-of-phishing/)的实质都是攻击者伪装成信誉良好的公司或组织,然后借此大规模传播病毒或恶意软件。
<ruby> <a href="https://en.wikipedia.org/wiki/Typosquatting"> 误植 </a> <rt> Typosquatting </rt></ruby>就是其中一个常用的手法。它是一种社会工程学的攻击方式,通过使用一些合法网站的错误拼写的 URL 以引诱用户访问恶意网站,这样的做法既使真正的原网站遭受声誉上的损害,又诱使用户向这些恶意网站提交个人敏感信息。因此,网站的管理人员和用户双方都应该意识到这个问题带来的风险,并采取措施加以保护。
一些由广大开发者在公共代码库中维护的开源软件通常都被认为具有安全上的优势,但当面临社会工程学攻击或恶意软件植入时,开源软件也需要注意以免受到伤害。
下面就来关注一下误植攻击的发展趋势,以及这种攻击方式在未来可能对开源软件造成的影响。
### 什么是误植?
误植是一种非常特殊的网络犯罪形式,其背后通常是一个更大的网络钓鱼骗局。不法分子首先会购买和注册域名,而他们注册的域名通常是一个常用网站的错误拼写形式,例如在正确拼写的基础上添加一个额外的元音字母,又或者是将字母“i”替换成字母“l”。对于同一个正常域名,不法分子通常会注册数十个拼写错误的变体域名。
用户一旦访问这样的域名,不法分子的目的就已经成功了一半。为此,他们会通过电子邮件的方式,诱导用户访问这样的伪造域名。伪造域名指向的页面中,通常都带有一个简单的登录界面,还会附上熟悉的被模仿网站的徽标,尽可能让用户认为自己访问的是真实的网站。
如果用户没有识破这一个骗局,在页面中提交了诸如银行卡号、用户名、密码等敏感信息,这些数据就会被不法分子所完全掌控。进一步来看,如果这个用户在其它网站也使用了相同的用户名和密码,那就有同样受到波及的风险。受害者最终可能会面临身份被盗、信用记录被破坏等危险。
### 最近的一些案例
从网站的所有方来看,遭到误植攻击可能会带来一场公关危机。尽管网站域名的所有者没有参与到犯罪当中,但这会被认为是一次管理上的失职,因为域名所有者有主动防御误植攻击的责任,以避免这一类欺诈事件的发生。
在几年之前就发生过[一起案件](https://www.menlosecurity.com/blog/-a-new-approach-to-end-typosquatting),很多健康保险客户收到了一封指向 we11point.com 的钓鱼电子邮件,其中 URL 里正确的字母“l”被换成了数字“1”,从而导致一批用户成为了这一次攻击的受害者。
最初,与特定国家/地区相关的顶级域名是不允许随意注册的。但后来国际域名规则中放开这一限制之后,又兴起了一波新的误植攻击。例如最常见的一种手法就是注册一个与 .com 域名类似的 .om 域名,一旦在输入 URL 时不慎遗漏了字母 c 就会给不法分子带来可乘之机。
### 网站如何防范误植攻击
对于一个公司来说,最好的策略就是永远比误植攻击采取早一步的行动。
也就是说,在注册域名的时候,不仅要注册自己商标名称的域名,最好还要同时注册可能由于拼写错误产生的其它域名。当然,没有太大必要把可能导致错误的所有顶级域名都注册掉,但至少要把可能导致错误的一些一级域名抢注下来。
如果你有让用户跳转到一个第三方网站的需求,务必要让用户从你的官方网站上进行跳转,而不应该通过类似群发邮件的方式向用户告知 URL。因此,必须明确一个策略:在与用户通信交流时,不将用户引导到官方网站以外的地方去。在这样的情况下,如果有不法分子试图以你公司的名义发布虚假消息,用户将会从带有异样的页面或 URL 上有所察觉。
你可以使用类似 [DNS Twist](https://github.com/elceef/dnstwist) 的开源工具来扫描公司正在使用的域名,它可以确定是否有相似的域名已被注册,从而暴露潜在的误植攻击。DNS Twist 可以在 Linux 系统上通过一系列的 shell 命令来运行。
还有一些网络提供商(ISP)会将防护误植攻击作为他们网络产品的一部分。这就相当于一层额外的保护,如果用户不慎输入了带有拼写错误的 URL,就会被提示该页面已经被阻止并重定向到正确的域名。
如果你是系统管理员,还可以考虑运行一个自建的 [DNS 服务器](https://opensource.com/article/17/4/build-your-own-name-server),以便通过黑名单的机制禁止对某些域名的访问。
你还可以密切监控网站的访问流量,如果来自某个特定地区的用户被集体重定向到了虚假的站点,那么访问量将会发生骤降。这也是一个有效监控误植攻击的角度。
防范误植攻击与防范其它网络攻击一样需要保持警惕。所有用户都希望网站的所有者能够扫除那些与正主类似的假冒站点,如果这项工作没有做好,用户的信任对你的信任程度就会每况愈下。
### 误植对开源软件的影响
因为开源项目的源代码是公开的,所以其中大部分项目都会进行安全和渗透测试。但错误是不可能完全避免的,如果你参与了开源项目,还是有需要注意的地方。
当你收到一个不明来源的<ruby> 合并请求 <rt> Merge Request </rt></ruby>或补丁时,必须在合并之前仔细检查,尤其是相关代码涉及到网络层面的时候。不要屈服于只测试构建的诱惑; 一定要进行严格的检查和测试,以确保没有恶意代码混入正常的代码当中。
同时,还要严格按照正确的方法使用域名,避免不法分子创建仿冒的下载站点并提供带有恶意代码的软件。可以通过如下所示的方法使用数字签名来确保你的软件没有被篡改:
```
gpg --armor --detach-sig \
--output advent-gnome.sig \
example-0.0.1.tar.xz
```
同时给出你提供的文件的校验和:
```
sha256sum example-0.0.1.tar.xz > example-0.0.1.txt
```
无论你的用户会不会去用上这些安全措施,你也应该提供这些必要的信息。因为只要有那么一个人留意到签名有异样,就能为你敲响警钟。
### 总结
人类犯错在所难免。世界上数百万人输入同一个网址时,总会有人出现拼写的错误。不法分子也正是抓住了这个漏洞才得以实施误植攻击。
用抢注域名的方式去完全根治误植攻击也是不太现实的,我们更应该关注这种攻击的传播方式以减轻它对我们的影响。最好的保护就是和用户之间建立信任,并积极检测误植攻击的潜在风险。作为开源社区,我们更应该团结起来一起应对误植攻击。
---
via: <https://opensource.com/article/20/1/stop-typosquatting-attacks>
作者:[Sam Bocetta](https://opensource.com/users/sambocetta) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Cybercriminals are turning to social engineering to try to trick unsuspecting people into divulging private information or valuable credentials. It is behind many [phishing scams](https://www.cloudberrylab.com/resources/guides/types-of-phishing/) where the attacker poses as a reputable company or organization and uses it as a front to distribute a virus or other piece of malware.
One such risk is [typosquatting](https://en.wikipedia.org/wiki/Typosquatting), a form of social engineering attack that tries to lure users into visiting malicious sites with URLs that are common misspellings of legitimate sites. These sites can cause significant damage to the reputation of organizations that are victimized by these attackers and harm users who are tricked into entering sensitive details into fake sites. Both system administrators and users need to be aware of the risks and take steps to protect themselves.
Open source software, which is developed and tested by large groups in public repositories, is often lauded for its security benefits. However, when it comes to social engineering schemes and malware implantation, even open source tools can fall victim.
This article looks at the rising trend of typosquatting and what these attacks could mean for open source software in the future.
## What is typosquatting?
Typosquatting is a very specific form of cybercrime that is often tied to a larger phishing attack. It begins with the cybercriminal buying and registering a domain name that is the misspelling of a popular site. For example, the cybercriminal might add an extra vowel or replace an "i" with a lowercase "l" character. Sometimes a cybercriminal obtains dozens of domain names, each with a different spelling variation.
A typosquatting attack does not become dangerous until real users start visiting the site. To make that happen, the criminal runs a phishing scam, typically over email, to urge people to click a link and visit the typosquatting website. Normally these rogue pages have simple login screens bearing familiar logos that try to imitate the real company's design.
If the user does not realize they are visiting a fake website and enters sensitive details, such as their password, username, or credit card number, into the page, the cybercriminal gets full access to that data. If a user is utilizing the same password across several sites, their other online accounts are likely to be exploited as well. This is a cybercriminal's payout: identity theft, ruined credit reports, stolen records, and sometimes worse.
## Some recent attacks
From a company perspective, having a typosquatting attack connected to your domain name can be a public relations disaster, even though you played no direct role in it, because it's seen as irresponsible internet stewardship. As a domain owner, you have a responsibility to be proactive in defending against typosquatting to limit the pain caused by this type of fraud.
A few years ago, many [health insurance customers fell victim](https://www.menlosecurity.com/blog/-a-new-approach-to-end-typosquatting) to a typosquatting attack when they received a phishing email that pointed to we11point.com, with the number 1 replacing the character "l" in the URL.
When the international domain name rules were changed to allow anyone to register a URL with an extension previously tied to specific countries, it created a brand new wave of typosquatting attacks. One of the most prevalent ones seen today is when a cybercriminal registers a .om domain that matches a popular .com domain to take advantage of accidental omissions of the letter "c" when entering a web address.
## How to protect your website from typosquatting
For companies, the best strategy is to try to stay ahead of typosquatting attacks.
That means spending the money to trademark your domain and purchase all related URLs that could be easy misspellings. You don't need to buy all top-level domain variants of your site name, but at least focus on common misspellings to your primary site name.
If you need to send your users to third-party sites, do so from your official website, not in a mass email. It's important to firmly establish a policy that official communication always and only sends users to your site. That way, should a cybercriminal attempt to spoof communication from you, your users will know something's amiss when they end up on an unfamiliar page or URL structure.
Use an open source tool like [DNS Twist](https://github.com/elceef/dnstwist) to automatically scan your company's domain and determine whether there could already be a typosquatting attack in progress. DNS Twist runs on Linux operating systems and can be used through a series of shell commands.
Some ISPs offer typosquatting protection as part of their product offering. This functions as an extra layer of web filtering—if a user in your organization accidentally misspells a common URL, they are alerted that the page is blocked and redirected to the proper domain.
If you are a system administrator, consider running your own [DNS server](https://opensource.com/article/17/4/build-your-own-name-server) along with a blacklist of incorrect and forbidden domains.
Another effective way to spot a typosquatting attack in progress is to monitor your site traffic closely and set an alert for a sudden decrease in visitors from a particular region. It could be that a large number of your regular users have been redirected to a fake site.
As with almost any form of cyberattack, the key to stopping typosquatting is constant vigilance. Your users are counting on you to identify and shut down any fake sites that are operating under your name, and if you don't, you could lose your audience's trust.
## Typosquatting threats to open source software
Most major open source projects go through security and penetration testing, largely because the code is public. However, mistakes happen under even the best of conditions. Here are some things to watch for if you're involved in an open source project.
When you get a merge request or patch from an unknown source, review it carefully before merging, especially if there's a networking stack involved. Don't fall prey to the temptation of only testing your build; look at the code to ensure that nothing nefarious has been embedded into an otherwise functional enhancement.
Also, use the same rigor in protecting your project's identity as a business does for its domain. Don't let a cybercriminal create alternate download sites and offer a version of your project with additional harmful code. Use digital signatures, like the following, to create an assurance of authenticity for your software:
```
gpg --armor --detach-sig \
--output advent-gnome.sig \
example-0.0.1.tar.xz
```
You should also provide a checksum for the file you deliver:
`sha256sum example-0.0.1.tar.xz > example-0.0.1.txt`
Provide these safeguards even if you don't believe your users will take advantage of them, because all it takes is one perceptive user to notice a missing signature on an alternative download to alert you that someone, somewhere is spoofing your project.
## Final thoughts
Humans are prone to making mistakes. When you have millions of people around the world typing in a common web address, it's no surprise that a certain percentage enter a typo in the URL. Cybercriminals are trying to capitalize on that trend with typosquatting.
It's hard to stop cybercriminals from registering domains that are available for purchase, so mitigate against typosquatting attacks by focusing on the ways they spread. The best protection is to build trust with your users and to be diligent in detecting typosquatting attempts. Together, as a community, we can all help ensure that typosquatting attempts are ineffective.
## 1 Comment |
11,900 | 使用 tmux 创建你的梦想主控台 | https://opensource.com/article/20/1/tmux-console | 2020-02-16T22:08:44 | [
"tmux"
] | /article-11900-1.html |
>
> 使用 tmux 可以做很多事情,尤其是在将 tmuxinator 添加到其中时。在我们的二十篇系列文章的第十五期中查看它们,以在 2020 年实现开源生产力的提高。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 使用 tmux 和 tmuxinator 全部放到主控台上
到目前为止,在本系列文章中,我已经撰写了有关单个应用程序和工具的文章。从今天开始,我将把它们放在一起进行全面设置以简化操作。让我们从命令行开始。为什么使用命令行?简而言之,在命令行上工作可以使我能够从运行 SSH 的任何位置访问许多这些工具和功能。我可以 SSH 进入我的一台个人计算机,并在工作计算机上运行与我的个人计算机上所使用的相同设置。我要使用的主要工具是 [tmux](https://github.com/tmux/tmux)。
大多数人都只使用了 tmux 非常基础的功能,比如说在远程服务器上打开 tmux,然后启动进程,也许还会打开第二个会话以查看日志文件或调试信息,然后断开连接并在稍后返回。但是其实你可以使用 tmux 做很多工作。

首先,如果你有一个已有的 tmux 配置文件,请对其进行备份。tmux 的配置文件是 `~/.tmux.conf`。将其移动到另一个目录,例如 `~/tmp`。现在,用 Git 克隆 [Oh My Tmux](https://github.com/gpakosz/.tmux) 项目。从该克隆目录中将 `.tmux.conf` 符号链接到你的家目录,并复制该克隆目录中的 `.tmux.conf.local` 文件到家目录中以进行调整:
```
cd ~
mkdir ~/tmp
mv ~/.tmux.conf ~/tmp/
git clone https://github.com/gpakosz/.tmux.git
ln -s ~/.tmux/.tmux.conf ./
cp ~/.tmux/.tmux.conf.local ./
```
`.tmux.conf.local` 文件包含了本地设置和覆盖的设置。例如,我稍微更改了默认颜色,然后启用了 [Powerline](https://github.com/powerline/powerline) 分隔线。下面的代码段仅显示了我更改过的内容:
```
tmux_conf_theme_24b_colour=true
tmux_conf_theme_focused_pane_bg='default'
tmux_conf_theme_pane_border_style=fat
tmux_conf_theme_left_separator_main='\uE0B0'
tmux_conf_theme_left_separator_sub='\uE0B1'
tmux_conf_theme_right_separator_main='\uE0B2'
tmux_conf_theme_right_separator_sub='\uE0B3'
#tmux_conf_battery_bar_symbol_full='◼'
#tmux_conf_battery_bar_symbol_empty='◻'
tmux_conf_battery_bar_symbol_full='♥'
tmux_conf_battery_bar_symbol_empty='·'
tmux_conf_copy_to_os_clipboard=true
set -g mouse on
```
请注意,你不需要安装 Powerline,你只需要支持 Powerline 符号的字体即可。我在与控制台相关的所有内容中几乎都使用 [Hack Nerd Font](https://www.nerdfonts.com/),因为它易于阅读并且具有许多有用的额外符号。你还会注意到,我打开了操作系统剪贴板支持和鼠标支持。
现在,当 tmux 启动时,底部的状态栏会以吸引人的颜色提供更多信息。`Ctrl` + `b` 仍然是输入命令的 “引导” 键,但其他一些进行了更改。现在水平拆分(顶部/底部)窗格为 `Ctrl` + `b` + `-`,垂直拆分为 `Ctrl` + `b` + `_`。启用鼠标模式后,你可以单击以在窗格之间切换,并拖动分隔线以调整其大小。打开新窗口仍然是 `Ctrl` + `b` + `n`,你现在可以单击底部栏上的窗口名称在它们之间进行切换。同样,`Ctrl` + `b` + `e` 将打开 `.tmux.conf.local` 文件以进行编辑。退出编辑器时,tmux 将重新加载配置,而不会重新加载其他任何内容。这很有用。
到目前为止,我仅对功能和视觉显示进行了一些简单的更改,并增加了鼠标支持。现在,我将它设置为以一种有意义的方式启动我想要的应用程序,而不必每次都重新定位和调整它们的大小。为此,我将使用 [tmuxinator](https://github.com/tmuxinator/tmuxinator)。tmuxinator 是 tmux 的启动器,它允许你指定和管理布局以及使用 YAML 文件自动启动应用程序。要使用它,请启动 tmux 并创建要在其中运行程序的窗格。然后,使用 `Ctrl` + `b` + `n` 打开一个新窗口,并执行 `tmux list-windows`。你将获得有关布局的详细信息。

请注意上面代码中的第一行,我在其中设置了四个窗格,每个窗格中都有一个应用程序。保存运行时的输出以供以后使用。现在,运行 `tmuxinator new 20days` 以创建名为 “20days” 的布局。这将显示一个带有默认布局文件的文本编辑器。它包含很多有用的内容,我建议你阅读所有选项。首先输入上方的布局信息以及所需的应用程序:
```
# /Users/ksonney/.config/tmuxinator/20days.yml
name: 20days
root: ~/
windows:
- mail:
layout: d9da,208x60,0,0[208x26,0,0{104x26,0,0,0,103x26,105,0,5},208x33,0,27{104x33,0,27,1,103x33,105,27,4}]] @0
panes:
- alot
- abook
- ikhal
- todo.sh ls +20days
```
注意空格缩进!与 Python 代码一样,空格和缩进关系到文件的解释方式。保存该文件,然后运行 `tmuxinator 20days`。你应该会得到四个窗格,分别是 [alot](https://opensource.com/article/20/1/organize-email-notmuch) 邮件程序、[abook](https://opensource.com/article/20/1/sync-contacts-locally)、ikhal(交互式 [khal](https://opensource.com/article/20/1/open-source-calendar) 的快捷方式)以及 [todo.txt](https://opensource.com/article/20/1/open-source-to-do-list) 中带有 “+20days” 标签的任何内容。

你还会注意到,底部栏上的窗口标记为 “Mail”。你可以单击该名称(以及其他命名的窗口)以跳到该视图。漂亮吧?我在同一个文件中还设置了名为 “Social” 的第二个窗口,包括 [Tuir](https://opensource.com/article/20/1/open-source-reddit-client)、[Newsboat](https://opensource.com/article/20/1/open-source-rss-feed-reader)、连接到 [BitlBee](https://opensource.com/article/20/1/open-source-chat-tool) 的 IRC 客户端和 [Rainbow Stream](https://opensource.com/article/20/1/tweet-terminal-rainbow-stream)。
tmux 是我跟踪所有事情的生产力动力之源,有了 tmuxinator,我不必在不断调整大小、放置和启动我的应用程序上费心。
---
via: <https://opensource.com/article/20/1/tmux-console>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,902 | 用 Linux 让旧 MacBook 焕发新生 | https://opensource.com/article/20/2/macbook-linux-elementary | 2020-02-18T11:37:00 | [
"Macbook"
] | https://linux.cn/article-11902-1.html |
>
> Elementary OS 的最新版本 Hera 是一个令人印象深刻的平台,它可以让过时的 MacBook 得以重生。
>
>
>

当我安装苹果的 [MacOS Mojave](https://en.wikipedia.org/wiki/MacOS_Mojave) 时,它使我以前可靠的 MacBook Air 慢得像爬一样。我的计算机发售于 2015 年,具有 4 GB 内存、i5 处理器和 Broadcom 4360 无线卡,但是对于我的日常使用来说,Mojava 有点过分了,它不能和 [GnuCash](https://www.gnucash.org/) 一起工作,这激起了我重返 Linux 的欲望。我很高兴能重返,但是我深感遗憾的是,我的这台出色的 MacBook 被闲置了。
我在 MacBook Air 上尝试了几种 Linux 发行版,但总会有缺陷。有时是无线网卡;还有一次,它缺少对触摸板的支持。看了一些不错的评论后,我决定尝试 [Elementary OS](https://elementary.io/) 5.0(Juno)。我用 USB [制作了启动盘](https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive),并将其插入 MacBook Air 。我来到了一个<ruby> 现场 <rt> live </rt></ruby>桌面,并且操作系统识别出了我的 Broadcom 无线芯片组 —— 我认为这可能行得通!
我喜欢在 Elementary OS 中看到的内容。它的 [Pantheon](https://opensource.com/article/19/12/pantheon-linux-desktop) 桌面真的很棒,并且其外观和使用起来的感觉对 Apple 用户来说很熟悉 —— 它的显示屏底部有一个扩展坞,并带有一些指向常用应用程序的图标。我对我之前期待的预览感到满意,所以我决定安装它,然后我的无线设备消失了。真的很令人失望。我真的很喜欢 Elementary OS ,但是没有无线网络是不行的。
时间快进到 2019 年 12 月,当我在 [Linux4Everyone](https://www.linux4everyone.com/20-macbook-pro-elementary-os) 播客上听到有关 Elementary 最新版本 v.5.1(Hera) 使 MacBook 复活的评论时,我决定用 Hera 再试一次。我下载了 ISO ,创建了可启动驱动器,将其插入电脑,这次操作系统识别了我的无线网卡。我可以在上面工作了。

我非常高兴我轻巧又功能强大的 MacBook Air 通过 Linux 焕然一新。我一直在更详细地研究 Elementary OS,我可以告诉你我印象深刻的东西。
### Elementary OS 的功能
根据 [Elementary 的博客](https://blog.elementary.io/introducing-elementary-os-5-1-hera/),“新设计的登录和锁定屏幕问候语看起来更清晰、效果更好,并且修复了以前问候语中报告的许多问题,包括输入焦点问题,HiDPI 问题和更好的本地化。Hera 的新设计是为了响应来自 Juno 的用户反馈,并启用了一些不错的新功能。”
“不错的新功能”是在轻描淡写 —— Elementary OS 拥有我见过的最佳设计的 Linux 用户界面之一。默认情况下,系统上的“系统设置”图标位于扩展坞上。更改设置很容易,很快我就按照自己的喜好配置了系统。我需要的文字大小比默认值大,辅助功能是易于使用的,允许我设置大文字和高对比度。我还可以使用较大的图标和其他选项来调整扩展坞。

按下 Mac 的 Command 键将弹出一个键盘快捷键列表,这对新用户非常有帮助。

Elementary OS 附带的 [Epiphany](https://en.wikipedia.org/wiki/GNOME_Web) Web 浏览器,我发现它非常易于使用。它与 Chrome、Chromium 或 Firefox 略有不同,但它已经绰绰有余。
对于注重安全的用户(我们应该都是),Elementary OS 的安全和隐私设置提供了多个选项,包括防火墙、历史记录、锁定,临时和垃圾文件的自动删除以及用于位置服务开/关的开关。

### 有关 Elementray OS 的更多信息
Elementary OS 最初于 2011 年发布,其最新版本 Hera 于 2019 年 12 月 3 日发布。 Elementary 的联合创始人兼 CXO 的 [Cassidy James Blaede](https://github.com/cassidyjames) 是操作系统的 UX 架构师。 Cassidy 喜欢使用开放技术来设计和构建有用、可用和令人愉悦的数字产品。
Elementary OS 具有出色的用户[文档](https://elementary.io/docs/learning-the-basics#learning-the-basics),其代码(在 GPL 3.0 下许可)可在 [GitHub](https://github.com/elementary) 上获得。Elementary OS 鼓励参与该项目,因此请务必伸出援手并[加入社区](https://elementary.io/get-involved)。
---
via: <https://opensource.com/article/20/2/macbook-linux-elementary>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qianmingtian](https://github.com/qianmingtian) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I installed Apple's [MacOS Mojave](https://en.wikipedia.org/wiki/MacOS_Mojave), it slowed my formerly reliable MacBook Air to a crawl. My computer, released in 2015, has 4GB RAM, an i5 processor, and a Broadcom 4360 wireless card, but Mojave proved too much for my daily driver—it made working with [GnuCash](https://www.gnucash.org/) impossible, and it whetted my appetite to return to Linux. I am glad I did, but I felt bad that I had this perfectly good MacBook lying around unused.
I tried several Linux distributions on my MacBook Air, but there was always a gotcha. Sometimes it was the wireless card; another time, it was a lack of support for the touchpad. After reading some good reviews, I decided to try [Elementary OS](https://elementary.io/) 5.0 (Juno). I [made a boot drive](https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive) with my USB creator and inserted it into the MacBook Air. I got to a live desktop, and the operating system recognized my Broadcom wireless chipset—I thought this just might work!
I liked what I saw in Elementary OS; its [Pantheon](https://opensource.com/article/19/12/pantheon-linux-desktop) desktop is really great, and its look and feel are familiar to Apple users—it has a dock at the bottom of the display and icons that lead to useful applications. I liked the preview of what I could expect, so I decided to install it—and then my wireless disappeared. That was disappointing. I really liked Elementary OS, but no wireless is a non-starter.
Fast-forward to December 2019, when I heard a review on the [Linux4Everyone](https://www.linux4everyone.com/20-macbook-pro-elementary-os) podcast about Elementary's latest release, v.5.1 (Hera) bringing a MacBook back to life. So, I decided to try again with Hera. I downloaded the ISO, created the bootable drive, plugged it in, and this time the operating system recognized my wireless card. I was in business!

I was overjoyed that my very light, yet powerful MacBook Air was getting a new life with Linux. I have been exploring Elementary OS in greater detail, and I can tell you that I am impressed.
## Elementary OS's features
According to [Elementary's blog](https://blog.elementary.io/introducing-elementary-os-5-1-hera/), "The newly redesigned login and lock screen greeter looks sharper, works better, and fixes many reported issues with the previous greeter including focus issues, HiDPI issues, and better localization. The new design in Hera was in response to user feedback from Juno, and enables some nice new features."
"Nice new features" in an understatement—Elementary OS easily has one of the best-designed Linux user interfaces I have ever seen. A System Settings icon is on the dock by default; it is easy to change the settings, and soon I had the system configured to my liking. I need larger text sizes than the defaults, and the Universal Access controls are easy to use and allow me to set large text and high contrast. I can also adjust the dock with larger icons and other options.
Pressing the Mac's Command key brings up a list of keyboard shortcuts, which is very helpful to new users.

Elementary OS ships with the [Epiphany](https://en.wikipedia.org/wiki/GNOME_Web) web browser, which I find quite easy to use. It's a bit different than Chrome, Chromium, or Firefox, but it is more than adequate.
For security-conscious users (as we should all be), Elementary OS's Security and Privacy settings provide multiple options, including a firewall, history, locking, automatic deletion of temporary and trash files, and an on/off switch for location services.
## More on Elementary OS
Elementary OS was originally released in 2011, and its latest version, Hera, was released on December 3, 2019. [Cassidy James Blaede](https://github.com/cassidyjames), Elementary's co-founder and CXO, is the operating system's UX architect. Cassidy loves to design and build useful, usable, and delightful digital products using open technologies.
Elementary OS has excellent user [documentation](https://elementary.io/docs/learning-the-basics#learning-the-basics), and its code (licensed under GPL 3.0) is available on [GitHub](https://github.com/elementary). Elementary OS encourages involvement in the project, so be sure to reach out and [join the community](https://elementary.io/get-involved).
## 9 Comments |
11,903 | 如何在 Ubuntu 中更改默认终端 | https://itsfoss.com/change-default-terminal-ubuntu/ | 2020-02-18T11:49:39 | [
"终端"
] | https://linux.cn/article-11903-1.html | <ruby> 终端 <rt> Terminal </rt></ruby>是 Linux 系统的关键部分。它能让你通过 shell 访问 Linux 系统。Linux 上有多个终端应用(技术上称为终端仿真器)。
大多数[桌面环境](https://itsfoss.com/best-linux-desktop-environments/)都有自己的终端实现。它们的外观可能有所不同,并且可能有不同的快捷键。例如,[Guake 终端](http://guake-project.org/)对高级用户非常有用,它提供了一些可能无法在发行版默认终端中使用的功能。
你可以在系统上安装其他终端,并将其设为默认,并能通过[快捷键 Ctrl+Alt+T](https://itsfoss.com/ubuntu-shortcuts/) 打开。
现在问题来了,如何在 Ubuntu 中更改默认终端。它没有遵循[更改 Ubuntu 中的默认应用](https://itsfoss.com/change-default-applications-ubuntu/)的标准方式,要怎么做?
### 更改 Ubuntu 中的默认终端

在基于 Debian 的发行版中,有一个方便的命令行程序,称为 [update-alternatives](https://manpages.ubuntu.com/manpages/trusty/man8/update-alternatives.8.html),可用于处理默认应用。
你可以使用它来更改默认的命令行文本编辑器、终端等。为此,请运行以下命令:
```
sudo update-alternatives --config x-terminal-emulator
```
它将显示系统上存在的所有可作为默认值的终端仿真器。当前的默认终端标有星号。
```
abhishek@nuc:~$ sudo update-alternatives --config x-terminal-emulator
There are 2 choices for the alternative x-terminal-emulator (providing /usr/bin/x-terminal-emulator).
Selection Path Priority Status
------------------------------------------------------------
0 /usr/bin/gnome-terminal.wrapper 40 auto mode
1 /usr/bin/gnome-terminal.wrapper 40 manual mode
* 2 /usr/bin/st 15 manual mode
Press <enter> to keep the current choice[*], or type selection number:
```
你要做的就是输入选择编号。对我而言,我想使用 GNOME 终端,而不是来自 [Regolith 桌面](https://itsfoss.com/regolith-linux-desktop/)的终端。
```
Press <enter> to keep the current choice[*], or type selection number: 1
update-alternatives: using /usr/bin/gnome-terminal.wrapper to provide /usr/bin/x-terminal-emulator (x-terminal-emulator) in manual mode
```
>
> **自动模式 vs 手动模式**
>
>
> 你可能已经在 `update-alternatives` 命令的输出中注意到了自动模式和手动模式。
>
>
> 如果选择自动模式,那么在安装或删除软件包时,系统可能会自动决定默认应用。该决定受优先级数字的影响(如上一节中的命令输出所示)。
>
>
> 假设你的系统上安装了 5 个终端仿真器,并删除了默认的仿真器。现在,你的系统将检查哪些仿真器处于自动模式。如果有多个,它将选择优先级最高的一个作为默认仿真器。
>
>
>
我希望你觉得这个小技巧有用。随时欢迎提出问题和建议。
---
via: <https://itsfoss.com/change-default-terminal-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The terminal (or more accurately, terminal emulator) is a crucial part of any Linux system. It allows you to access your Linux systems through a shell. There are [several terminal applications on Linux](https://itsfoss.com/linux-terminal-emulators/).
Most of the [desktop environments](https://itsfoss.com/best-linux-desktop-environments/) have their own implementation of the terminal. It may look different and may have different keyboard shortcuts.
For example, [Guake Terminal](http://guake-project.org/) is extremely useful for power users and provides several features you might not get in your distribution’s terminal by default.
You can install other terminals on your system and use it as default that opens up with the usual [keyboard shortcut of Ctrl+Alt+T](https://itsfoss.com/ubuntu-shortcuts/).
Now the question comes, how do you change the default terminal in Ubuntu. It doesn’t follow the standard way of [changing default applications in Ubuntu](https://itsfoss.com/change-default-applications-ubuntu/) then how to do it?
## Change the default terminal in Ubuntu

On Debian-based distributions, there is a handy command line utility called [update-alternatives](http://manpages.ubuntu.com/manpages/trusty/man8/update-alternatives.8.html) that allows you to handle the default applications.
You can use it to change the default command line text editor, terminal and more. To do that, run the following command:
`sudo update-alternatives --config x-terminal-emulator`
It will show all the terminal emulators present on your system that can be used as default. The current default terminal is marked with the asterisk.
```
abhishek@nuc:~$ sudo update-alternatives --config x-terminal-emulator
There are 2 choices for the alternative x-terminal-emulator (providing /usr/bin/x-terminal-emulator).
Selection Path Priority Status
------------------------------------------------------------
0 /usr/bin/gnome-terminal.wrapper 40 auto mode
1 /usr/bin/gnome-terminal.wrapper 40 manual mode
* 2 /usr/bin/st 15 manual mode
Press <enter> to keep the current choice[*], or type selection number:
```
All you have to do is to enter the selection number. In my case, I want to use the GNOME terminal instead of the one from [Regolith desktop](https://itsfoss.com/regolith-linux-desktop/).
```
Press <enter> to keep the current choice[*], or type selection number: 1
update-alternatives: using /usr/bin/gnome-terminal.wrapper to provide /usr/bin/x-terminal-emulator (x-terminal-emulator) in manual mode
```
#### Auto mode vs manual mode
You might have noticed the auto mode and manual mode in the output of update-alternatives command.
If you choose auto mode, your system may automatically decide on the default application as the packages are installed or removed. The decision is influenced by the priority number (as seen in the output of the command in the previous section).
Suppose you have 5 terminal emulators installed on your system and you delete the default one. Now, your system will check which of the emulators are in auto mode. If there are more than one, it will choose the one with the highest priority as the default emulator.
I hope you find this quick little tip useful. Your questions and suggestions are always welcome. |
11,904 | 3 种使用 PostgreSQL 命令的方式 | https://opensource.com/article/20/2/postgresql-commands | 2020-02-18T12:40:32 | [
"PostgreSQL"
] | /article-11904-1.html |
>
> 无论你需要的东西简单(如一个购物清单)亦或复杂(如色卡生成器) ,PostgreSQL 命令都能使它变得容易起来。
>
>
>

在 [PostgreSQL 入门](/article-11593-1.html)一文中, 我解释了如何安装、设置和开始使用这个开源数据库软件。不过,使用 [PostgreSQL](https://www.postgresql.org/) 中的命令可以做更多事情。
例如,我使用 Postgres 来跟踪我的杂货店购物清单。我的大多数杂货店购物是在家里进行的,而且每周进行一次大批量的采购。我去几个不同的地方购买清单上的东西,因为每家商店都提供特定的选品或质量,亦或更好的价格。最初,我制作了一个 HTML 表单页面来管理我的购物清单,但这样无法保存我的输入内容。因此,在想到要购买的物品时我必须马上列出全部清单,然后到采购时我常常会忘记一些我需要或想要的东西。
相反,使用 PostgreSQL,当我想到需要的物品时,我可以随时输入,并在购物前打印出来。你也可以这样做。
### 创建一个简单的购物清单
首先,输入 `psql` 命令进入数据库,然后用下面的命令创建一个表:
```
Create table groc (item varchar(20), comment varchar(10));
```
输入如下命令在清单中加入商品:
```
insert into groc values ('milk', 'K');
insert into groc values ('bananas', 'KW');
```
括号中有两个信息(逗号隔开):前面是你需要买的东西,后面字母代表你要购买的地点以及哪些东西是你每周通常都要买的(`W`)。
因为 `psql` 有历史记录,你可以按向上键在括号内编辑信息,而无需输入商品的整行信息。
在输入一小部分商品后,输入下面命令来检查前面的输入内容。
```
Select * from groc order by comment;
item | comment
----------------+---------
ground coffee | H
butter | K
chips | K
steak | K
milk | K
bananas | KW
raisin bran | KW
raclette | L
goat cheese | L
onion | P
oranges | P
potatoes | P
spinach | PW
broccoli | PW
asparagus | PW
cucumber | PW
sugarsnap peas | PW
salmon | S
(18 rows)
```
此命令按 `comment` 列对结果进行排序,以便按购买地点对商品进行分组,从而使你的购物更加方便。
使用 `W` 来指明你每周要买的东西,当你要清除表单为下周的列表做准备时,你可以将每周的商品保留在购物清单上。输入:
```
delete from groc where comment not like '%W';
```
注意,在 PostgreSQL 中 `%` 表示通配符(而非星号)。所以,要保存输入内容,需要输入:
```
delete from groc where item like 'goat%';
```
不能使用 `item = 'goat%'`,这样没用。
在购物时,用以下命令输出清单并打印或发送到你的手机:
```
\o groclist.txt
select * from groc order by comment;
\o
```
最后一个命令 `\o` 后面没有任何内容,将重置输出到命令行。否则,所有的输出会继续输出到你创建的杂货店购物文件 `groclist.txt` 中。
### 分析复杂的表
这个逐项列表对于数据量小的表来说没有问题,但是对于数据量大的表呢?几年前,我帮 [FreieFarbe.de](http://freiefarbe.de) 的团队从 HLC 调色板中创建一个自由色的色样册。事实上,任何能想象到的打印色都可按色调、亮度、浓度(饱和度)来规定。最终结果是 [HLC Color Atlas](https://www.freiefarbe.de/en/thema-farbe/hlc-colour-atlas/),下面是我们如何实现的。
该团队向我发送了具有颜色规范的文件,因此我可以编写可与 Scribus 配合使用的 Python 脚本,以轻松生成色样册。一个例子像这样开始:
```
HLC, C, M, Y, K
H010_L15_C010, 0.5, 49.1, 0.1, 84.5
H010_L15_C020, 0.0, 79.7, 15.1, 78.9
H010_L25_C010, 6.1, 38.3, 0.0, 72.5
H010_L25_C020, 0.0, 61.8, 10.6, 67.9
H010_L25_C030, 0.0, 79.5, 18.5, 62.7
H010_L25_C040, 0.4, 94.2, 17.3, 56.5
H010_L25_C050, 0.0, 100.0, 15.1, 50.6
H010_L35_C010, 6.1, 32.1, 0.0, 61.8
H010_L35_C020, 0.0, 51.7, 8.4, 57.5
H010_L35_C030, 0.0, 68.5, 17.1, 52.5
H010_L35_C040, 0.0, 81.2, 22.0, 46.2
H010_L35_C050, 0.0, 91.9, 20.4, 39.3
H010_L35_C060, 0.1, 100.0, 17.3, 31.5
H010_L45_C010, 4.3, 27.4, 0.1, 51.3
```
这与原始数据相比,稍有修改,原始数据用制表符分隔。我将其转换成 CSV 格式(用逗号分割值),我更喜欢其与 Python 一起使用(CSV 文也很有用,因为它可轻松导入到电子表格程序中)。
在每一行中,第一项是颜色名称,其后是其 C、M、Y 和 K 颜色值。 该文件包含 1,793 种颜色,我想要一种分析信息的方法,以了解这些值的范围。这就是 PostgreSQL 发挥作用的地方。我不想手动输入所有数据 —— 我认为输入过程中我不可能不出错,而且令人头痛。幸运的是,PostgreSQL 为此提供了一个命令。
首先用以下命令创建数据库:
```
Create table hlc_cmyk (color varchar(40), c decimal, m decimal, y decimal, k decimal);
```
然后通过以下命令引入数据:
```
\copy hlc_cmyk from '/home/gregp/HLC_Atlas_CMYK_SampleData.csv' with (header, format CSV);
```
开头有反斜杠,是因为使用纯 `copy` 命令的权限仅限于 root 用户和 Postgres 的超级用户。在括号中,`header` 表示第一行包含标题,应忽略,`CSV` 表示文件格式为 CSV。请注意,在此方法中,颜色名称不需要用括号括起来。
如果操作成功,会看到 `COPY NNNN`,其中 N 表示插入到表中的行数。
最后,可以用下列命令查询:
```
select * from hlc_cmyk;
color | c | m | y | k
---------------+-------+-------+-------+------
H010_L15_C010 | 0.5 | 49.1 | 0.1 | 84.5
H010_L15_C020 | 0.0 | 79.7 | 15.1 | 78.9
H010_L25_C010 | 6.1 | 38.3 | 0.0 | 72.5
H010_L25_C020 | 0.0 | 61.8 | 10.6 | 67.9
H010_L25_C030 | 0.0 | 79.5 | 18.5 | 62.7
H010_L25_C040 | 0.4 | 94.2 | 17.3 | 56.5
H010_L25_C050 | 0.0 | 100.0 | 15.1 | 50.6
H010_L35_C010 | 6.1 | 32.1 | 0.0 | 61.8
H010_L35_C020 | 0.0 | 51.7 | 8.4 | 57.5
H010_L35_C030 | 0.0 | 68.5 | 17.1 | 52.5
```
所有的 1,793 行数据都是这样的。回想起来,我不能说此查询对于 HLC 和 Scribus 任务是绝对必要的,但是它减轻了我对该项目的一些担忧。
为了生成 HLC 色谱,我使用 Scribus 为色板页面中的 13,000 多种颜色自动创建了颜色图表。
我可以使用 `copy` 命令输出数据:
```
\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV);
```
我还可以使用 `where` 子句根据某些值来限制输出。
例如,以下命令将仅发送以 `H10` 开头的色调值。
```
\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV) where color like 'H10%';
```
### 备份或传输数据库或表
我在此要提到的最后一个命令是 `pg_dump`,它用于备份 PostgreSQL 数据库,并在 `psql` 控制台之外运行。 例如:
```
pg_dump gregp -t hlc_cmyk > hlc.out
pg_dump gregp > dball.out
```
第一行是导出 `hlc_cmyk` 表及其结构。第二行将转储 `gregp` 数据库中的所有表。这对于备份或传输数据库或表非常有用。
要将数据库或表传输到另一台电脑(查看 [PostgreSQL 入门](/article-11593-1.html)那篇文章获取详细信息),首先在要转入的电脑上创建一个数据库,然后执行相反的操作。
```
psql -d gregp -f dball.out
```
一步创建所有表并输入数据。
### 总结
在本文中,我们了解了如何使用 `WHERE` 参数限制操作,以及如何使用 PostgreSQL 通配符 `%`。我们还了解了如何将大批量数据加载到表中,然后将部分或全部表数据输出到文件,甚至是将整个数据库及其所有单个表输出。
---
via: <https://opensource.com/article/20/2/postgresql-commands>
作者:[Greg Pittman](https://opensource.com/users/greg-p) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,905 | 用开源搜索引擎定制你的互联网 | https://opensource.com/article/20/2/open-source-search-engine | 2020-02-19T10:35:57 | [
"搜索引擎",
"YaCy"
] | /article-11905-1.html |
>
> 上手开源的对等 Web 索引器 YaCy。
>
>
>

很久以前,互联网很小,小到几个人就可以索引它们,这些人收集了所有网站的名称和链接,并按主题将它们分别列在页面或印刷书籍中。随着万维网网络的发展,形成了“网站环”形式,具有类似的内容、主题或敏感性的站点捆绑在一起,形成了通往每个成员的循环路径。环中任何站点的访问者都可以单击按钮以转到环中的下一个或上一个站点,以发现与其兴趣相关的新站点。
又过了一段时间,互联网似乎变得臃肿不堪了。每个人都在网络上,有很多冗余信息和垃圾邮件,多到让你无法找到任何东西。Yahoo 和 AOL、CompuServe 以及类似的服务各自采用了不同的方法来解决这个问题,但是直到谷歌出现后,现代的搜索模型才得以普及。按谷歌的做法,互联网应该通过搜索引擎进行索引、排序和排名。
### 为什么选择开源替代品?
像谷歌和 DuckDuckGo 这样的搜索引擎显然是卓有成效的。你可能是通过搜索引擎访问的本站。尽管对于因主机没有选择遵循优化搜索引擎的最佳实践从而导致会内容陷入困境这件事仍存在争论,但用于管理丰富的文化、知识和轻率的信息(即互联网)的现代解决方案是冷冰冰的索引。
但是也许出于隐私方面的考虑,或者你希望为使互联网更加独立而做出贡献,你或许不愿意使用谷歌或 DuckDuckGo。如果你对此感兴趣,那么可以考虑参加 [YaCy](https://yacy.net/),这是一个对等互联网索引器和搜索引擎。
### 安装 YaCy
要安装并尝试 YaCy,请首先确保已安装 Java。如果你使用的是 Linux,则可以按照我的《[如何在 Linux 上安装 Java](/article-11614-1.html)》中的说明进行操作。如果你使用 Windows 或 MacOS,请从 [AdoptOpenJDK.net](https://adoptopenjdk.net/releases.html) 获取安装程序。
安装 Java 后,请根据你的平台[下载安装程序](https://yacy.net/download_installation/)。
如果你使用的是 Linux,请解压缩 tarball 并将其移至 `/opt` 目录:
```
$ sudo tar --extract --file yacy_*z --directory /opt
```
根据下载的安装程序的说明启动 YaCy。
在 Linux 上,启动在后台运行的 YaCy:
```
$ /opt/startYACY.sh &
```
在 Web 浏览器中,导航到 `localhost:8090` 并进行搜索。

### 将 YaCy 添加到你的地址栏
如果你使用的是 Firefox Web 浏览器,则只需单击几下,即可在 Awesome Bar(Mozilla 给 URL 栏起的名称)中将 YaCy 设置为默认搜索引擎。
首先,如果尚未显示,在 Firefox 工具栏中使专用搜索栏显示出来(你不必使搜索栏保持一直可见;只需要激活它足够长的时间即可添加自定义搜索引擎)。Firefox 右上角的“汉堡”菜单中的“自定义”菜单中提供了搜索栏。在 Firefox 工具栏上的搜索栏可见后,导航至 `localhost:8090`,然后单击刚添加的 Firefox 搜索栏中的放大镜图标。单击选项将 YaCy 添加到你的 Firefox 的搜索引擎中。

完成此操作后,你可以在 Firefox 首选项中将其标记为默认值,或者仅在 Firefox 搜索栏中执行的搜索中选择性地使用它。如果将其设置为默认搜索引擎,则可能不需要专用搜索栏,因为 Awesome Bar 也使用默认引擎,因此可以将其从工具栏中删除。
### 对等搜索引擎如何工作
YaCy 是一个开源的分布式搜索引擎。它是用 [Java](https://opensource.com/resources/java) 编写的,因此可以在任何平台上运行,并且可以执行 Web 爬网、索引和搜索。这是一个对等(P2P)网络,因此每个运行 YaCy 的用户都将努力地不断跟踪互联网的变化情况。当然,没有单个用户能拥有整个互联网的完整索引,因为这将需要一个数据中心来容纳,但是该索引分布在所有 YaCy 用户中且是冗余的。它与 BitTorrent 非常相似(因为它使用分布式哈希表 DHT 来引用索引条目),只不过你所共享的数据是单词和 URL 关联的矩阵。通过混合哈希表返回的结果,没人能说出谁搜索了哪些单词,因此所有搜索在功能上都是匿名的。这是用于无偏见、无广告、未跟踪和匿名搜索的有效系统,你只需要使用它就加入了它。
### 搜索引擎和算法
索引互联网的行为是指将网页分成单个单词,然后将页面的 URL 与每个单词相关联。在搜索引擎中搜索一个或多个单词将获取与该查询关联的所有 URL。YaCy 客户端在运行时也是如此。
客户端要做的另一件事是为你的浏览器提供搜索界面。你可以将 Web 浏览器指向 `localhost:8090` 来搜索 YaCy,而不是在要搜索时导航到谷歌。你甚至可以将其添加到浏览器的搜索栏中(取决于浏览器的可扩展性),因此可以从 URL 栏中进行搜索。
### YaCy 的防火墙设置
首次开始使用 YaCy 时,它可能运行在“初级”模式下。这意味着你的客户端爬网的站点仅对你可用,因为其他 YaCy 客户端无法访问你的索引条目。要加入对等环境,必须在路由器的防火墙(或者你正在运行的软件防火墙)中打开端口 8090,这称为“高级”模式。
如果你使用的是 Linux,则可以在《[使用防火墙让你的 Linux 更加强大](https://opensource.com/article/19/7/make-linux-stronger-firewalls)》中找到有关计算机防火墙的更多信息。在其他平台上,请参考操作系统的文档。
互联网服务提供商(ISP)提供的路由器上几乎总是启用了防火墙,并且有太多种类的防火墙无法准确说明。大多数路由器都提供了在防火墙上“打洞”的选项,因为许多流行的联网游戏都需要双向流量。
如果你知道如何登录路由器(通常为 192.168.0.1 或 10.1.0.1,但可能因制造商的设置而异),则登录并查找配置面板来控制“防火墙”或“端口转发”或“应用”。
找到路由器防火墙的首选项后,将端口 8090 添加到白名单。例如:

如果路由器正在进行端口转发,则必须使用相同的端口将传入的流量转发到计算机的 IP 地址。例如:

如果由于某种原因无法调整防火墙设置,那也没事。YaCy 将继续以初级模式运行并作为对等搜索网络的客户端运行。
### 你的互联网
使用 YaCy 搜索引擎可以做的不仅仅是被动搜索。你可以强制抓取不太显眼的网站,可以请求对网站进行网络抓取,可以选择使用 YaCy 进行本地搜索等等。你可以更好地控制*你的*互联网的所呈现的一切。高级用户越多,索引的网站就越多。索引的网站越多,所有用户的体验就越好。加入吧!
---
via: <https://opensource.com/article/20/2/open-source-search-engine>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,906 | 一条命令在 Ubuntu 中安装所有基本的媒体编解码器 | https://itsfoss.com/install-media-codecs-ubuntu/ | 2020-02-19T11:14:00 | [
"媒体编解码器"
] | https://linux.cn/article-11906-1.html | 如果你刚刚安装了 Ubuntu 或其他 [Ubuntu 特色版本](https://itsfoss.com/which-ubuntu-install/) 如 Kubuntu、Lubuntu 等,你会注意到系统无法播放某些音频或视频文件。
对于视频文件,你可以[在 Ubuntu 上安装 VLC](https://itsfoss.com/install-latest-vlc/)。[VLC](https://www.videolan.org/index.html) 是 [Linux 上的最佳视频播放器](https://itsfoss.com/video-players-linux/)之一,它几乎可以播放任何视频文件格式。但你仍然会遇到无法播放音频和 flash 的麻烦。
好消息是 [Ubuntu](https://ubuntu.com/) 提供了一个软件包来安装所有基本的媒体编解码器:ubuntu-restricted-extras。

### 什么是 Ubuntu Restricted Extras?
ubuntu-restricted-extras 是一个包含各种基本软件,如 Flash 插件、[unrar](https://itsfoss.com/use-rar-ubuntu-linux/)、[gstreamer](https://gstreamer.freedesktop.org/)、mp4、[Ubuntu 中的 Chromium 浏览器](https://itsfoss.com/install-chromium-ubuntu/)的编解码器等的软件包。
由于这些软件不是开源软件,并且其中一些涉及软件专利,因此 Ubuntu 默认情况下不会安装它们。你必须使用 multiverse 仓库,它是 Ubuntu 专门为用户提供非开源软件而创建的仓库。
请阅读本文以[了解有关各种 Ubuntu 仓库的更多信息](https://itsfoss.com/ubuntu-repositories/)。
### 如何安装 Ubuntu Restricted Extras?
令我惊讶的是,我发现软件中心未列出 Ubuntu Restricted Extras。不管怎样,你都可以使用命令行安装该软件包,这非常简单。
在菜单中搜索或使用[终端键盘快捷键 Ctrl+Alt+T](https://itsfoss.com/ubuntu-shortcuts/) 打开终端。
由于 ubuntu-restrcited-extras 软件包在 multiverse 仓库中,因此你应验证系统上已启用 multiverse 仓库:
```
sudo add-apt-repository multiverse
```
然后你可以使用以下命令安装:
```
sudo apt install ubuntu-restricted-extras
```
输入回车后,你会被要求输入密码,**当你输入密码时,屏幕不会有显示**。这是正常的。输入你的密码并回车。
它将显示大量要安装的包。按回车确认选择。
你会看到 [EULA](https://en.wikipedia.org/wiki/End-user_license_agreement)(最终用户许可协议),如下所示:

浏览此页面可能会很麻烦,但是请放心。只需按 Tab 键,它将高亮选项。当高亮在正确的选项上,按下回车确认你的选择。

安装完成后,由于新安装的媒体编解码器,你应该可以播放 MP3 和其他媒体格式了。
#### 在 Kubuntu、Lubuntu、Xubuntu 上安装受限制的额外软件包
请记住,Kubuntu、Lubuntu 和 Xubuntu 都有此软件包,并有各自不同的名称。它们本应使用相同的名字,但不幸的是并不是。
在 Kubuntu 上,使用以下命令:
```
sudo apt install kubuntu-restricted-extras
```
在 Lubuntu 上,使用:
```
sudo apt install lubuntu-restricted-extras
```
在 Xubuntu 上,你应该使用:
```
sudo apt install xubuntu-restricted-extras
```
我一直建议将 ubuntu-restricted-extras 作为[安装 Ubuntu 后要做的基本事情](https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/)之一。只需一个命令即可在 Ubuntu 中安装多个编解码器。
希望你喜欢 Ubuntu 初学者系列中这一技巧。以后,我将分享更多此类技巧。
---
via: <https://itsfoss.com/install-media-codecs-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you have just installed Ubuntu or some other [Ubuntu flavors](https://itsfoss.com/which-ubuntu-install/) like Kubuntu, Lubuntu etc, you’ll notice that your system doesn’t play some audio or video file.
For video files, you can [install VLC on Ubuntu](https://itsfoss.com/install-latest-vlc/). [VLC](https://www.videolan.org/index.html) one of the [best video players for Linux](https://itsfoss.com/video-players-linux/) and can play almost any video file format. But you’ll still have troubles with audio media files and flash player.
The good thing is that [Ubuntu](https://ubuntu.com/) provides a single package to install all the essential media codecs: ubuntu-restricted-extras.

## What is Ubuntu Restricted Extras?
The ubuntu-restricted-extras is a software package that consists various essential software like flash plugin, [unrar](https://itsfoss.com/use-rar-ubuntu-linux/), [gstreamer](https://gstreamer.freedesktop.org/), mp4, codecs for [Chromium browser in Ubuntu](https://itsfoss.com/install-chromium-ubuntu/) etc.
Since these software are not open source and some of them involve software patents, Ubuntu doesn’t install them by default. You’ll have to use multiverse repository, the software repository specifically created by Ubuntu to provide non-open source software to its users.
Please read this article to [learn more about various Ubuntu repositories](https://itsfoss.com/ubuntu-repositories/).
[What are Ubuntu Repositories? How to enable or disable them?This detailed article tells you about various repositories like universe, multiverse in Ubuntu and how to enable or disable them. So, you are trying to follow a tutorial from the web and installing a software using apt-get command and it throws you an error: E: Unable to locate package xyz](https://itsfoss.com/ubuntu-repositories/)

## How to install Ubuntu Restricted Extras?
I find it surprising that the software center doesn’t list Ubuntu Restricted Extras. In any case, you can install the package using command line and it’s very simple.
[Open a terminal in Ubuntu](https://itsfoss.com/open-terminal-ubuntu/) by searching for it in the menu or using the [terminal keyboard shortcut Ctrl+Alt+T](https://itsfoss.com/ubuntu-shortcuts/).
Since ubuntu-restrcited-extras package is available in the multiverse repository, you should verify that the multiverse repository is enabled on your system:
`sudo add-apt-repository multiverse`
You may want to update the package cache if you are not running Ubuntu (Ubuntu does it automatically):
`sudo apt update`
And then you can install it in Ubuntu default edition using this command:
`sudo apt install ubuntu-restricted-extras`
When you enter the command, you’ll be asked to enter your password. When **you type the password, nothing is displayed on the screen**. That’s normal. Type your password and press enter.
It will show a huge list of packages to be installed. Press enter to confirm your selection when it asks.
You’ll also encounter an [EULA](https://en.wikipedia.org/wiki/End-user_license_agreement) (End User License Agreement) screen like this:
It could be overwhelming to navigate this screen but don’t worry. Just press tab and it will highlight the options. When the correct options are highlighted, press enter to confirm your selection.
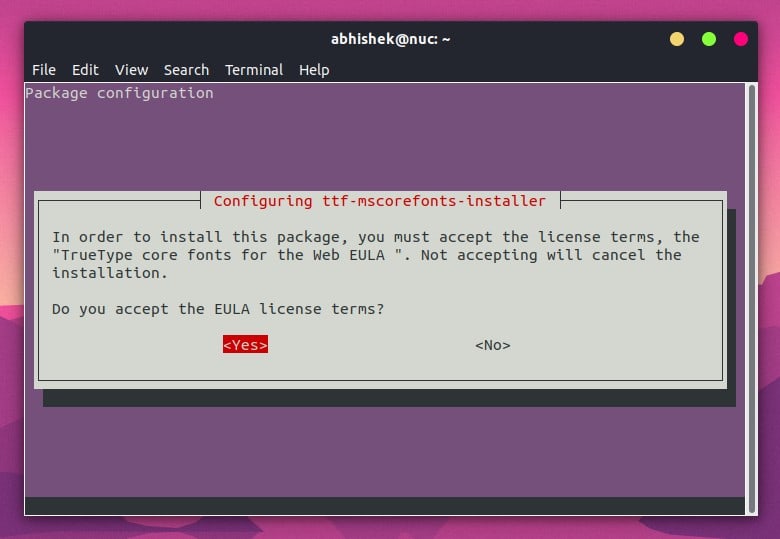
Once the process finishes, you should be able to play MP3 and other media formats thanks to newly installed media codecs.
## Installing restricted extra package on Kubuntu, Lubuntu, Xubuntu
Do keep in mind that Kubuntu, Lubuntu and Xubuntu has this package available with their own respective names. They should have just used the same name but they don’t unfortunately.
On Kubuntu, use this command:
`sudo apt install kubuntu-restricted-extras`
On Lubuntu, use:
`sudo apt install lubuntu-restricted-extras`
On Xubuntu, you should use:
`sudo apt install xubuntu-restricted-extras`
I always recommend getting ubuntu-restricted-extras as one of the [essential things to do after installing Ubuntu](https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/). It’s good to have a single command to install multiple codecs in Ubuntu.
I hope you like this quick tip in the Ubuntu beginner series. I’ll share more such tips in the future. |
11,908 | 使用 Vim 发送邮件和检查日历 | https://opensource.com/article/20/1/vim-email-calendar | 2020-02-19T18:59:27 | [
"邮件",
"日历"
] | https://linux.cn/article-11908-1.html |
>
> 在 2020 年用开源实现更高生产力的二十种方式的第十六篇文章中,直接通过文本编辑器管理你的电子邮件和日历。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 用 Vim 做(几乎)所有事情,第一部分
我经常使用两个文本编辑器 —— [Vim](https://www.vim.org/) 和 [Emacs](https://www.gnu.org/software/emacs/)。为什么两者都用呢?它们有不同的使用场景,在本系列的后续几篇文章中,我将讨论其中的一些用例。

好吧,为什么要在 Vim 中执行所有操作?因为如果有一个应用程序是我可以访问的每台计算机上都有的,那就是 Vim。如果你像我一样,可能已经在 Vim 中打发了很多时光。那么,为什么不将其用于**所有事情**呢?
但是,在此之前,你需要做一些事情。首先是确保你的 Vim 具有 Ruby 支持。你可以使用 `vim --version | grep ruby`。如果结果不是 `+ruby`,则需要解决这个问题。这可能有点麻烦,你应该查看发行版的文档以获取正确的软件包。在 MacOS 上,用的是官方的 MacVim(不是 Brew 发行的),在大多数 Linux 发行版中,用的是 vim-nox 或 vim-gtk,而不是 vim-gtk3。
我使用 [Pathogen](https://github.com/tpope/vim-pathogen) 自动加载插件和捆绑软件。如果你使用 [Vundle](https://github.com/VundleVim/Vundle.vim) 或其他 Vim 软件包管理器,则需要调整以下命令才能使用它。
#### 在 Vim 中管理你的邮件
使 Vim 在你的生产力计划中发挥更大作用的一个很好的起点是使用它通过 [Notmuch](https://opensource.com/article/20/1/organize-email-notmuch) 发送和接收电子邮件,和使用 [abook](https://opensource.com/article/20/1/sync-contacts-locally) 访问你的联系人列表。你需要为此安装一些东西。下面的所有示例代码都运行在 Ubuntu 上,因此如果你使用其他发行版,则需要对此进行调整。通过以下步骤进行设置:
```
sudo apt install notmuch-vim ruby-mail
curl -o ~/.vim/plugin/abook --create-dirs https://raw.githubusercontent.com/dcbaker/vim-abook/master/plugin/abook.vim
```
到目前为止,一切都很顺利。现在启动 Vim 并执行 `:NotMuch`。由于是用较旧版本的邮件库 `notmuch-vim` 编写的,可能会出现一些警告,但总的来说,Vim 现在将成为功能齐全的 Notmuch 邮件客户端。

如果要搜索特定标签,请输入 `\t`,输入标签名称,然后按回车。这将拉出一个带有该标签的所有消息的列表。`\s` 组合键会弹出 `Search:` 提示符,可以对 Notmuch 数据库进行全面搜索。使用箭头键浏览消息列表,按回车键显示所选项目,然后输入 `\q` 退出当前视图。
要撰写邮件,请使用 `\c` 按键。你将看到一条空白消息。这是 `abook.vim` 插件发挥作用的位置。按下 `Esc` 并输入 `:AbookQuery <SomeName>`,其中 `<SomeName>` 是你要查找的名称或电子邮件地址的一部分。你将在 abook 数据库中找到与你的搜索匹配的条目列表。通过键入你想要的地址的编号,将其添加到电子邮件的地址行中。完成电子邮件的键入和编辑,按 `Esc` 退出编辑模式,然后输入 `,s` 发送。
如果要在 `:NotMuch` 启动时更改默认文件夹视图,则可以将变量 `g:notmuch_folders` 添加到你的 `.vimrc` 文件中:
```
let g:notmuch_folders = [
\ [ 'new', 'tag:inbox and tag:unread' ],
\ [ 'inbox', 'tag:inbox' ],
\ [ 'unread', 'tag:unread' ],
\ [ 'News', 'tag:@sanenews' ],
\ [ 'Later', 'tag:@sanelater' ],
\ [ 'Patreon', 'tag:@patreon' ],
\ [ 'LivestockConservancy', 'tag:livestock-conservancy' ],
\ ]
```
Notmuch 插件的文档中涵盖了更多设置,包括设置标签键和使用其它的邮件程序。
#### 在 Vim 中查询日历

遗憾的是,似乎没有使用 vCalendar 或 iCalendar 格式的 Vim 日历程序。有个 [Calendar.vim](https://github.com/itchyny/calendar.vim),做得很好。设置 Vim 通过以下方式访问你的日历:
```
cd ~/.vim/bundle
git clone [email protected]:itchyny/calendar.vim.git
```
现在,你可以通过输入 `:Calendar` 在 Vim 中查看日历。你可以使用 `<` 和 `>` 键在年、月、周、日和时钟视图之间切换。如果要从一个特定的视图开始,请使用 `-view=` 标志告诉它你希望看到哪个视图。你也可以在任何视图中定位日期。例如,如果我想查看 2020 年 7 月 4 日这一周的情况,请输入 `:Calendar -view week 7 4 2020`。它的帮助信息非常好,可以使用 `?` 键参看。

Calendar.vim 还支持 Google Calendar(我需要),但是在 2019 年 12 月,Google 禁用了它的访问权限。作者已在 [GitHub 上的这个提案](https://github.com/itchyny/calendar.vim/issues/156)中发布了一种变通方法。
这样你就在 Vim 中有了这些:你的邮件、地址簿和日历。但是这些还没有完成; 下一篇你将在 Vim 上做更多的事情!
Vim 为作家提供了很多好处,无论他们是否具有技术意识。
需要保持时间表正确吗?了解如何使用这些免费的开源软件来做到这一点。
---
via: <https://opensource.com/article/20/1/vim-email-calendar>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Doing (almost) all the things with Vim, part 1
I use two text editors regularly—[Vim](https://www.vim.org/) and [Emacs](https://www.gnu.org/software/emacs/). Why both? They have different use cases, and I'll talk about some of them in the next few articles in this series.
OK, so why do everything in Vim? Because if there is one application that is on every machine I have access to, it's Vim. And if you are like me, you probably already spend a lot of time in Vim. So why not use it for *all the things*?
Before that, though, you need to do some things. The first is to make sure you have Ruby support in Vim. You can check that with **vim --version | grep ruby**. If the result is not **+ruby**, that needs to be fixed. This can be tricky, and you should check your distribution's documentation for the right package to install. On MacOS, this is the official MacVim (not from Brew), and on most Linux distributions, this is either vim-nox or vim-gtk—NOT vim-gtk3.
I use [Pathogen](https://github.com/tpope/vim-pathogen) to autoload my plugins and bundles. If you use [Vundle](https://github.com/VundleVim/Vundle.vim) or another Vim package manager, you'll need to adjust the commands below to work with it.
### Do your email in Vim
A good starting place for making Vim a bigger part of your productivity plan is using it to send and receive email with [Notmuch](https://opensource.com/article/20/1/organize-email-notmuch) using [abook](https://opensource.com/article/20/1/sync-contacts-locally) to access your contact list. You need to install some things for this. All the sample code below is on Ubuntu, so you'll need to adjust for that if you are using a different distribution. Do the setup with:
```
sudo apt install notmuch-vim ruby-mail
curl -o ~/.vim/plugin/abook --create-dirs https://raw.githubusercontent.com/dcbaker/vim-abook/master/plugin/abook.vim
```
So far, so good. Now start Vim and execute **:NotMuch**. There may be some warnings due to the older version of the mail library **notmuch-vim** was written for, but in general, Vim will now be a full-featured Notmuch mail client.
If you want to perform a search for a specific tag, type **\t**, enter the name of the tag, and press Enter. This will pull up a list of all messages with that tag. The **\s** key combination brings up a **Search:** prompt that will do a full search of the Notmuch database. Navigate the message list with the arrow keys, press Enter to display the selected item, and enter **\q** to exit the current view.
To compose mail, use the **\c** keystroke. You will see a blank message. This is where the **abook.vim** plugin comes in. Hit **Esc** and enter **:AbookQuery <SomeName>**, where <SomeName> is a part of the name or email address you want to look for. You will get a list of entries in the abook database that match your search. Select the address you want by typing its number to add it to the email's address line. Finish typing and editing the email, press **Esc** to exit edit mode, and enter **,s** to send.
If you want to change the default folder view when **:NotMuch** starts up, you can add the variable **g:notmuch_folders** to your **.vimrc** file:
```
let g:notmuch_folders = [
\ [ 'new', 'tag:inbox and tag:unread' ],
\ [ 'inbox', 'tag:inbox' ],
\ [ 'unread', 'tag:unread' ],
\ [ 'News', 'tag:@sanenews' ],
\ [ 'Later', 'tag:@sanelater' ],
\ [ 'Patreon', 'tag:@patreon' ],
\ [ 'LivestockConservancy', 'tag:livestock-conservancy' ],
\ ]
```
There are many more settings covered in the Notmuch plugin's documentation, including setting up keys for tags and using alternate mail programs.
### Consult your calendar in Vim
Sadly, there do not appear to be any calendar programs for Vim that use the vCalendar or iCalendar formats. There is [Calendar.vim](https://github.com/itchyny/calendar.vim), which is very well done. Set up Vim to access your calendar with:
```
cd ~/.vim/bundle
git clone [email protected]:itchyny/calendar.vim.git
```
Now, you can see your calendar in Vim by entering **:Calendar**. You can switch between year, month, week, day, and clock views with the **<** and **>** keys. If you want to start with a particular view, use the **-view=** flag to tell it which one you wish to see. You can also add a date to any of the views. For example, if I want to see what is going on the week of July 4, 2020, I would enter **:Calendar -view week 7 4 2020**. The help is pretty good and can be accessed with the **?** key.
Calendar.vim also supports Google Calendar (which I need), but in December 2019 Google disabled the access for it. The author has posted a workaround in [the issue on
GitHub](https://github.com/itchyny/calendar.vim/issues/156).
So there you have it, your mail, addresses, and calendars in Vim. But you aren't done yet; you'll do even more with Vim tomorrow!
## 4 Comments |
11,909 | 在你的 Fedora 终端上播放音乐 | https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/ | 2020-02-20T10:20:11 | [
"音乐"
] | https://linux.cn/article-11909-1.html | 
MPD(Music Playing Daemon),顾名思义,是一个音乐(Music)播放(Playing)守护进程(Daemon)。它可以播放音乐,并且作为一个守护进程,任何软件都可以与之交互并播放声音,包括一些 CLI 客户端。
其中一个被称为 `ncmpcpp`,它是对之前 `ncmpc` 工具的改进。名字的变化与编写它们的语言没有太大关系:都是 C++,而之所以被称为 `ncmpcpp`,因为它是 “NCurses Music Playing Client Plus Plus”。 缘故
### 安装 MPD 和 ncmpcpp
`ncmpmpcc` 的客户端可以从官方 Fedora 库中通过 `dnf` 命令直接安装。
```
$ sudo dnf install ncmpcpp
```
另一方面,MPD 必须从 RPMFusion free 库安装,你可以通过运行:
```
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
```
然后你可以运行下面的命令安装它:
```
$ sudo dnf install mpd
```
### 配置并启用 MPD
设置 MPD 最简单的方法是以普通用户的身份运行它。默认情况是以专用 `mpd` 用户的身份运行它,但这会导致各种权限问题。
在运行它之前,我们需要创建一个本地配置文件,允许我们作为普通用户运行。
首先在 `~/.config` 里创建一个名叫 `mpd` 的目录:
```
$ mkdir ~/.config/mpd
```
将配置文件拷贝到此目录下:
```
$ cp /etc/mpd.conf ~/.config/mpd
```
然后用 `vim`、`nano` 或 `gedit` 之类的软件编辑它:
```
$ nano ~/.config/mpd/mpd.conf
```
我建议你通读所有内容,检查是否有任何需要做的事情,但对于大多数设置你都可以删除,只需保留以下内容:
```
db_file "~/.config/mpd/mpd.db"
log_file "syslog"
```
现在你可以运行它了:
```
$ mpd
```
没有报错,这将在后台启动 MPD 守护进程。
### 使用 ncmpcpp
只需运行:
```
$ ncmpcpp
```
你将在终端中看到一个由 ncurses 所支持的图形用户界面。
按下 `4` 键,然后就可以看到本地的音乐目录,用方向键进行选择并按下回车进行播放。
多播放几个歌曲就会创建一个*播放列表*,让你可以使用 `>` 键(不是右箭头, 是右尖括号)移动到下一首,并使用 `<` 返回上一首。`+` 和 `–` 键可以调节音量。`Q` 键可以让你退出 `ncmpcpp` 但不停止播放音乐。你可以按下 `P` 来控制暂停和播放。
你可以按下 `1` 键来查看当前播放列表(这是默认的视图)。从这个视图中,你可以按 `i` 查看有关当前歌曲的信息(标签)。按 `6` 可更改当前歌曲的标签。
按 `\` 按钮将在视图顶部添加(或删除)信息面板。在左上角,你可以看到如下的内容:
```
[------]
```
按下 `r`、`z`、`y`、`R`、`x` 将会分别切换到 `repeat`、`random`、`single`、`consume` 和 `crossfade` 等播放模式,并将这个小指示器中的 `–` 字符替换为选定模式。
按下 `F1` 键将会显示一些帮助文档,包含一系列的键绑定列表,因此无需在此处列出完整列表。所以继续吧!做一个极客,在你的终端上播放音乐!
---
via: <https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/>
作者:[Carmine Zaccagnino](https://fedoramagazine.org/author/carzacc/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chai-yuan](https://github.com/chai-yuan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | MPD, as the name implies, is a Music Playing Daemon. It can play music but, being a daemon, any piece of software can interface with it and play sounds, including some CLI clients.
One of them is called *ncmpcpp*, which is an improvement over the pre-existing *ncmpc* tool. The name change doesn’t have much to do with the language they’re written in: they’re both C++, but *ncmpcpp* is called that because it’s the *NCurses Music Playing Client* *Plus Plus*.
## Installing MPD and ncmpcpp
The *ncmpmpcc* client can be installed from the official Fedora repositories with DNF directly with
$ sudo dnf install ncmpcpp
On the other hand, MPD has to be installed from the RPMFusion *free* repositories, which you can enable, [as per the official installation instructions](https://rpmfusion.org/Configuration), by running
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
and then you can install MPD by running
$ sudo dnf install mpd
## Configuring and Starting MPD
The most painless way to set up MPD is to run it as a regular user. The default is to run it as the dedicated *mpd* user, but that causes all sorts of issues with permissions.
Before we can run it, we need to create a local config file that will allow it to run as a regular user.
To do that, create a subdirectory called *mpd* in *~/.config*:
$ mkdir ~/.config/mpd
copy the default config file into this directory:
$ cp /etc/mpd.conf ~/.config/mpd
and then edit it with a text editor like *vim*, *nano* or *gedit*:
$ nano ~/.config/mpd/mpd.conf
I recommend you read through all of it to check if there’s anything you need to do, but for most setups you can delete everything and just leave the following:
db_file "~/.config/mpd/mpd.db" log_file "syslog"
At this point you should be able to just run
$ mpd
with no errors, which will start the MPD daemon in the background.
## Using ncmpcpp
Simply run
$ ncmpcpp
and you’ll see a ncurses-powered graphical user interface in your terminal.
Press *4* and you should see your local music library, be able to change the selection using the arrow keys and press *Enter* to play a song.
Doing this multiple times will create a *playlist*, which allows you to move to the next track using the *>* button (not the right arrow, the *>* closing angle bracket character) and go back to the previous track with *<*. The + and – buttons increase and decrease volume. The *Q* button quits ncmpcpp but it doesn’t stop the music. You can play and pause with *P*.
You can see the current playlist by pressing the *1* button (this is the default view). From this view you can press *i* to look at the information (tags) about the current song. You can change the tags of the currently playing (or paused) song by pressing *6*.
Pressing the \ button will add (or remove) an informative panel at the top of the view. In the top left, you should see something that looks like this:
[------]
Pressing the *r*, *z*, *y*, *R*, *x* buttons will respectively toggle the *repeat*, *random*, *single*, *consume* and *crossfade* playback modes and will replace one of the *–* characters in that little indicator to the initial of the selected mode.
Pressing the *F1* button will display some help text, which contains a list of keybindings, so there’s no need to write a complete list here. So now go on, be geeky, and play all your music from your terminal!
## Paul
Thanks, I’ll give it a try, still prefer MOC for music on console 🙂
## Foo
Cmus is the best player.
## Andy Mender
I second this :).
## Jonny
Cmus was my go to player before I switched full time to mpd / ncmpcpp. Never looked back because life has just been easier….
## dac.override
Long time user of mpc and ncmpc here. I recently rediscovered Emacs mpc major mode. This thing takes a bit of getting used to but I currently prefer it because you get a good oversight of your music collection. I often search for tunes based on genre, and I never really got used to doing that with ncmpc. With emacs all the available genres are in plain sight and easy to peruse.
## homme
:coffee:
## webpage
I am in fact pleased to read this webpage posts which includes
plenty of useful information, thanks for providing such statistics.
## erte
How playing i tmux?
with resize for setup and small icon ot in window no see anything? |
11,912 | 使用 Vim 管理任务列表和访问 Reddit 和 Twitter | https://opensource.com/article/20/1/vim-task-list-reddit-twitter | 2020-02-21T11:28:01 | [
"TODO"
] | https://linux.cn/article-11912-1.html |
>
> 在 2020 年用开源实现更高生产力的二十种方式的第十七篇文章中,了解在编辑器中处理待办列表以及获取社交信息。
>
>
>

去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
### 用 Vim 做(几乎)所有事情,第 2 部分
在[昨天的文章](/article-11908-1.html)中,你开始用 Vim 检查邮件和日历。今天,你可以做的更多。首先,你会在 Vim 编辑器中跟踪任务,然后获取社交信息。
#### 使用 todo.txt-vim 在 Vim 中跟踪待办任务

使用 Vim 编辑一个文本待办事件是一件自然的事,而 [todo.txt-vim](https://github.com/freitass/todo.txt-vim) 包使其更加简单。首先安装 todo.txt-vim 包:
```
git clone https://github.com/freitass/todo.txt-vim ~/.vim/bundle/todo.txt-vim
vim ~/path/to/your/todo.txt
```
todo.txt-vim 自动识别以 `todo.txt` 和 `done.txt` 结尾的文件作为 [todo.txt](http://todotxt.org) 文件。它添加特定于 todo.txt 格式的键绑定。你可以使用 `\x` 标记“已完成”的内容,使用 `\d` 将其设置为当前日期,然后使用 `\a`、`\b` 和 `\c` 更改优先级。你可以提升(`\k`)或降低(`\j`)优先级,并根据项目(`\s+`)、上下文(`\s@`)或日期(`\sd`)排序(`\s`)。完成后,你可以和平常一样关闭和保存文件。
todo.txt-vim 包是我几天前写的 [todo.sh 程序](https://opensource.com/article/20/1/open-source-to-do-list)的一个很好的补充,使用 [todo edit](https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory#edit-open-in-text-editor) 加载项,它可以增强的你待办事项列表跟踪。
#### 使用 vim-reddit 读取 Reddit

Vim 还有一个不错的用于 [Reddit](https://reddit.com) 的加载项,叫 [vim-reddit](https://github.com/DougBeney/vim-reddit)。它不如 [Tuir](https://opensource.com/article/20/1/open-source-reddit-client) 好,但是用于快速查看最新的文章,它还是不错的。首先安装捆绑包:
```
git clone https://github.com/DougBeney/vim-reddit.git ~/.vim/bundle/vim-reddit
vim
```
现在输入 `:Reddit` 将加载 Reddit 首页。你可以使用 `:Reddit name` 加载特定子板。打开文章列表后,使用箭头键导航或使用鼠标滚动。按 `o` 将在 Vim 中打开文章(除非它多媒体文章,它会打开浏览器),然后按 `c` 打开评论。如果要直接转到页面,请按 `O` 而不是 `o`。只需按 `u` 就能返回。当你 Reddit 看完后,输入 `:bd` 就行。vim-reddit 唯一的缺点是无法登录或发布新文章和评论。话又说回来,有时这是一件好事。
#### 使用 twitvim 在 Vim 中发推

最后,我们有 [twitvim](https://github.com/twitvim/twitvim),这是一个于阅读和发布 Twitter 的 Vim 软件包。它需要更多设置。首先从 GitHub 安装 twitvim:
```
git clone https://github.com/twitvim/twitvim.git ~/.vim/bundle/twitvim
```
现在你需要编辑 `.vimrc` 文件并设置一些选项。它帮助插件知道使用哪些库与 Twitter 交互。运行 `vim --version` 并查看哪些语言的前面有 `+` 就代表你的 Vim 支持它。

因为我的是 `+perl -python +python3`,所以我知道我可以启用 Perl 和 Python 3 但不是 Python 2 (python)。
```
" TwitVim Settings
let twitvim_enable_perl = 1
" let twitvim_enable_python = 1
let twitvim_enable_python3 = 1
```
现在,你可以通过运行 `:SetLoginTwitter` 启动浏览器窗口,它会打开一个浏览器窗口要求你授权 VimTwit 访问你的帐户。在 Vim 中输入提供的 PIN 后就可以了。
Twitvim 的命令不像其他包中一样简单。要加载好友和关注者的时间线,请输入 `:FriendsTwitter`。要列出提及你的和回复,请使用 `:MentionsTwitter`。发布新推文是 `:PosttoTwitter <Your message>`。你可以滚动列表并输入 `\r` 回复特定推文,你可以用 `\d` 直接给某人发消息。
就是这些了。你现在可以在 Vim 中做(几乎)所有事了!
---
via: <https://opensource.com/article/20/1/vim-task-list-reddit-twitter>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
## Doing (almost) all the things with Vim, part 2
In [yesterday's article](https://opensource.com/article/20/1/send-email-and-check-your-calendar-vim), you started reading mail and checking your calendars with Vim. Today, you're going to do even more. First, you'll take care of your task tracking, and then you'll get social, directly in the Vim text editor.
### Track your to-do's in Vim with todo.txt-vim
Editing a text-based to-do file with Vim is a natural fit, and the [todo.txt-vim](https://github.com/freitass/todo.txt-vim) package makes it even easier. Start by installing the todo.txt-vim package:
```
git clone https://github.com/freitass/todo.txt-vim ~/.vim/bundle/todo.txt-vim
vim ~/path/to/your/todo.txt
```
Todo.txt-vim automatically recognizes files ending in todo.txt and done.txt as [todo.txt](http://todotxt.org) files. It adds key bindings specific to the todo.txt format. You can mark things "done" with **\x**, set them to the current date with **\d**, and change the priority with **\a**, **\b**, and **\c**. You can bump the priorities up (**\k**) or down (**\j**) and sort (**\s**) based on project (**\s+**), context (**\s@**), or date (**\sd**). And when you are finished, you can close and save the file like normal.
The todo.txt-vim package is a great addition to the [todo.sh program](https://opensource.com/article/20/1/open-source-to-do-list) I wrote about a few days ago, and with the [todo edit](https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory#edit-open-in-text-editor) add-on, it can really supercharge your to-do list tracking.
### Read Reddit in Vim with vim-reddit
Vim also has a nice add-on for [Reddit](https://reddit.com) called [vim-reddit](https://github.com/DougBeney/vim-reddit). It isn't as nice as [Tuir](https://opensource.com/article/20/1/open-source-reddit-client), but for a quick review of the latest posts, it works really well. Start by installing the bundle:
```
git clone https://github.com/DougBeney/vim-reddit.git ~/.vim/bundle/vim-reddit
vim
```
Now type **:Reddit** and the Reddit frontpage will load. You can load a specific subreddit with **:Reddit name**. Once the article list is onscreen, navigate with the arrow keys or scroll with the mouse. Pressing **o** will open the article in Vim (unless it is a media post, in which case it opens a browser), and pressing **c** brings up the comments. If you want to go right to the page, press **O** instead of **o**. Going back a screen is as easy as **u**. And when you are done with Reddit, type **:bd**. The only drawback is vim-reddit cannot log in or post new stories or comments. Then again, sometimes that is a good thing.
### Tweet from Vim with twitvim
And last, we have [twitvim](https://github.com/twitvim/twitvim), a Vim package for reading and posting to Twitter. This one takes a bit more to set up. Start by installing twitvim from GitHub:
`git clone https://github.com/twitvim/twitvim.git ~/.vim/bundle/twitvim`
Now you need to edit the **.vimrc** file and set some options. These help the plugin know which libraries it can use to talk to Twitter. Run **vim --version** and see what languages have a **+** next to them—those languages are supported by your copy of Vim.
Since mine says **+perl -python +python3**, I know I can enable Perl and Python 3, but not Python 2 (python).
```
" TwitVim Settings
let twitvim_enable_perl = 1
" let twitvim_enable_python = 1
let twitvim_enable_python3 = 1
```
Now you can start up Vim and log into Twitter by running **:SetLoginTwitter**, which launches a browser window asking you to authorize VimTwit as an application with access to your account. Once you enter
the supplied PIN into Vim, you're good to go.
Twitvim's commands are not as simple as in the other packages. To load up the timeline of your friends and followers, type in **:FriendsTwitter**. To list your mentions and replies, use **:MentionsTwitter**. Posting a new tweet is **:PosttoTwitter <Your message>**. You can scroll through the list and reply to a specific tweet by typing **\r**, and you can start a direct message with someone using **\d**.
And there you have it; you're doing (almost) all the things in Vim!
## 1 Comment |
11,913 | 在 Linux 上压缩文件:zip 命令的各种变体及用法 | https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-the-many-variations-and-how-to-use-them.html | 2020-02-21T12:08:48 | [
"zip",
"压缩"
] | https://linux.cn/article-11913-1.html |
>
> 除了压缩和解压缩文件外,你还可以使用 zip 命令执行许多有趣的操作。这是一些其他的 zip 选项以及它们如何提供帮助。
>
>
>

为了节省一些磁盘空间并将文件打包在一起进行归档,我们中的一些人已经在 Unix 和 Linux 系统上压缩文件数十年了。即使这样,并不是所有人都尝试过一些有趣的压缩工具的变体。因此,在本文中,我们将介绍标准的压缩和解压缩以及其他一些有趣的压缩选项。
### 基本的 zip 命令
首先,让我们看一下基本的 `zip` 命令。它使用了与 `gzip` 基本上相同的压缩算法,但是有一些重要的区别。一方面,`gzip` 命令仅用于压缩单个文件,而 `zip` 既可以压缩文件,也可以将多个文件结合在一起成为归档文件。另外,`gzip` 命令是“就地”压缩。换句话说,它会只留下一个压缩文件,而原始文件则没有了。 这是工作中的 `gzip` 示例:
```
$ gzip onefile
$ ls -l
-rw-rw-r-- 1 shs shs 10514 Jan 15 13:13 onefile.gz
```
而下面是 `zip`。请注意,此命令要求为压缩存档提供名称,其中 `gzip`(执行压缩操作后)仅使用原始文件名并添加 `.gz` 扩展名。
```
$ zip twofiles.zip file*
adding: file1 (deflated 82%)
adding: file2 (deflated 82%)
$ ls -l
-rw-rw-r-- 1 shs shs 58021 Jan 15 13:25 file1
-rw-rw-r-- 1 shs shs 58933 Jan 15 13:34 file2
-rw-rw-r-- 1 shs shs 21289 Jan 15 13:35 twofiles.zip
```
请注意,原始文件仍位于原处。
所节省的磁盘空间量(即获得的压缩程度)将取决于每个文件的内容。以下示例中的变化很大。
```
$ zip mybin.zip ~/bin/*
adding: bin/1 (deflated 26%)
adding: bin/append (deflated 64%)
adding: bin/BoD_meeting (deflated 18%)
adding: bin/cpuhog1 (deflated 14%)
adding: bin/cpuhog2 (stored 0%)
adding: bin/ff (deflated 32%)
adding: bin/file.0 (deflated 1%)
adding: bin/loop (deflated 14%)
adding: bin/notes (deflated 23%)
adding: bin/patterns (stored 0%)
adding: bin/runme (stored 0%)
adding: bin/tryme (deflated 13%)
adding: bin/tt (deflated 6%)
```
### unzip 命令
`unzip` 命令将从一个 zip 文件中恢复内容,并且,如你所料,原来的 zip 文件还保留在那里,而类似的 `gunzip` 命令将仅保留未压缩的文件。
```
$ unzip twofiles.zip
Archive: twofiles.zip
inflating: file1
inflating: file2
$ ls -l
-rw-rw-r-- 1 shs shs 58021 Jan 15 13:25 file1
-rw-rw-r-- 1 shs shs 58933 Jan 15 13:34 file2
-rw-rw-r-- 1 shs shs 21289 Jan 15 13:35 twofiles.zip
```
### zipcloak 命令
`zipcloak` 命令对一个 zip 文件进行加密,提示你输入两次密码(以确保你不会“胖手指”),然后将该文件原位存储。你可以想到,文件大小与原始文件会有所不同。
```
$ zipcloak twofiles.zip
Enter password:
Verify password:
encrypting: file1
encrypting: file2
$ ls -l
total 204
-rw-rw-r-- 1 shs shs 58021 Jan 15 13:25 file1
-rw-rw-r-- 1 shs shs 58933 Jan 15 13:34 file2
-rw-rw-r-- 1 shs shs 21313 Jan 15 13:46 twofiles.zip <== slightly larger than
unencrypted version
```
请记住,压缩包之外的原始文件仍处于未加密状态。
### zipdetails 命令
`zipdetails` 命令将向你显示详细信息:有关压缩文件的详细信息,可能比你想象的要多得多。即使我们正在查看一个加密的文件,`zipdetails` 也会显示文件名以及文件修改日期、用户和组信息、文件长度数据等。请记住,这都是“元数据”。我们看不到文件的内容。
```
$ zipdetails twofiles.zip
0000 LOCAL HEADER #1 04034B50
0004 Extract Zip Spec 14 '2.0'
0005 Extract OS 00 'MS-DOS'
0006 General Purpose Flag 0001
[Bit 0] 1 'Encryption'
[Bits 1-2] 1 'Maximum Compression'
0008 Compression Method 0008 'Deflated'
000A Last Mod Time 4E2F6B24 'Tue Jan 15 13:25:08 2019'
000E CRC F1B115BD
0012 Compressed Length 00002904
0016 Uncompressed Length 0000E2A5
001A Filename Length 0005
001C Extra Length 001C
001E Filename 'file1'
0023 Extra ID #0001 5455 'UT: Extended Timestamp'
0025 Length 0009
0027 Flags '03 mod access'
0028 Mod Time 5C3E2584 'Tue Jan 15 13:25:08 2019'
002C Access Time 5C3E27BB 'Tue Jan 15 13:34:35 2019'
0030 Extra ID #0002 7875 'ux: Unix Extra Type 3'
0032 Length 000B
0034 Version 01
0035 UID Size 04
0036 UID 000003E8
003A GID Size 04
003B GID 000003E8
003F PAYLOAD
2943 LOCAL HEADER #2 04034B50
2947 Extract Zip Spec 14 '2.0'
2948 Extract OS 00 'MS-DOS'
2949 General Purpose Flag 0001
[Bit 0] 1 'Encryption'
[Bits 1-2] 1 'Maximum Compression'
294B Compression Method 0008 'Deflated'
294D Last Mod Time 4E2F6C56 'Tue Jan 15 13:34:44 2019'
2951 CRC EC214569
2955 Compressed Length 00002913
2959 Uncompressed Length 0000E635
295D Filename Length 0005
295F Extra Length 001C
2961 Filename 'file2'
2966 Extra ID #0001 5455 'UT: Extended Timestamp'
2968 Length 0009
296A Flags '03 mod access'
296B Mod Time 5C3E27C4 'Tue Jan 15 13:34:44 2019'
296F Access Time 5C3E27BD 'Tue Jan 15 13:34:37 2019'
2973 Extra ID #0002 7875 'ux: Unix Extra Type 3'
2975 Length 000B
2977 Version 01
2978 UID Size 04
2979 UID 000003E8
297D GID Size 04
297E GID 000003E8
2982 PAYLOAD
5295 CENTRAL HEADER #1 02014B50
5299 Created Zip Spec 1E '3.0'
529A Created OS 03 'Unix'
529B Extract Zip Spec 14 '2.0'
529C Extract OS 00 'MS-DOS'
529D General Purpose Flag 0001
[Bit 0] 1 'Encryption'
[Bits 1-2] 1 'Maximum Compression'
529F Compression Method 0008 'Deflated'
52A1 Last Mod Time 4E2F6B24 'Tue Jan 15 13:25:08 2019'
52A5 CRC F1B115BD
52A9 Compressed Length 00002904
52AD Uncompressed Length 0000E2A5
52B1 Filename Length 0005
52B3 Extra Length 0018
52B5 Comment Length 0000
52B7 Disk Start 0000
52B9 Int File Attributes 0001
[Bit 0] 1 Text Data
52BB Ext File Attributes 81B40000
52BF Local Header Offset 00000000
52C3 Filename 'file1'
52C8 Extra ID #0001 5455 'UT: Extended Timestamp'
52CA Length 0005
52CC Flags '03 mod access'
52CD Mod Time 5C3E2584 'Tue Jan 15 13:25:08 2019'
52D1 Extra ID #0002 7875 'ux: Unix Extra Type 3'
52D3 Length 000B
52D5 Version 01
52D6 UID Size 04
52D7 UID 000003E8
52DB GID Size 04
52DC GID 000003E8
52E0 CENTRAL HEADER #2 02014B50
52E4 Created Zip Spec 1E '3.0'
52E5 Created OS 03 'Unix'
52E6 Extract Zip Spec 14 '2.0'
52E7 Extract OS 00 'MS-DOS'
52E8 General Purpose Flag 0001
[Bit 0] 1 'Encryption'
[Bits 1-2] 1 'Maximum Compression'
52EA Compression Method 0008 'Deflated'
52EC Last Mod Time 4E2F6C56 'Tue Jan 15 13:34:44 2019'
52F0 CRC EC214569
52F4 Compressed Length 00002913
52F8 Uncompressed Length 0000E635
52FC Filename Length 0005
52FE Extra Length 0018
5300 Comment Length 0000
5302 Disk Start 0000
5304 Int File Attributes 0001
[Bit 0] 1 Text Data
5306 Ext File Attributes 81B40000
530A Local Header Offset 00002943
530E Filename 'file2'
5313 Extra ID #0001 5455 'UT: Extended Timestamp'
5315 Length 0005
5317 Flags '03 mod access'
5318 Mod Time 5C3E27C4 'Tue Jan 15 13:34:44 2019'
531C Extra ID #0002 7875 'ux: Unix Extra Type 3'
531E Length 000B
5320 Version 01
5321 UID Size 04
5322 UID 000003E8
5326 GID Size 04
5327 GID 000003E8
532B END CENTRAL HEADER 06054B50
532F Number of this disk 0000
5331 Central Dir Disk no 0000
5333 Entries in this disk 0002
5335 Total Entries 0002
5337 Size of Central Dir 00000096
533B Offset to Central Dir 00005295
533F Comment Length 0000
Done
```
### zipgrep命令
`zipgrep` 命令将使用 `grep` 类的功能来找到压缩文件中的特定内容。如果文件已加密,则需要为要检查的每个文件输入为加密所提供的密码。如果只想检查归档文件中单个文件的内容,请将其名称添加到 `zipgrep` 命令的末尾,如下所示。
```
$ zipgrep hazard twofiles.zip file1
[twofiles.zip] file1 password:
Certain pesticides should be banned since they are hazardous to the environment.
```
### zipinfo 命令
`zipinfo` 命令提供有关压缩文件内容的信息,无论是否加密。这包括文件名、大小、日期和权限。
```
$ zipinfo twofiles.zip
Archive: twofiles.zip
Zip file size: 21313 bytes, number of entries: 2
-rw-rw-r-- 3.0 unx 58021 Tx defN 19-Jan-15 13:25 file1
-rw-rw-r-- 3.0 unx 58933 Tx defN 19-Jan-15 13:34 file2
2 files, 116954 bytes uncompressed, 20991 bytes compressed: 82.1%
```
### zipnote 命令
`zipnote` 命令可用于从 zip 归档中提取注释或添加注释。要显示注释,只需在命令前面加上归档名称即可。如果之前未添加任何注释,你将看到类似以下内容:
```
$ zipnote twofiles.zip
@ file1
@ (comment above this line)
@ file2
@ (comment above this line)
@ (zip file comment below this line)
```
如果要添加注释,请先将 `zipnote` 命令的输出写入到文件:
```
$ zipnote twofiles.zip > comments
```
接下来,编辑你刚刚创建的文件,将注释插入到 `(comment above this line)` 行上方。然后使用像这样的 `zipnote` 命令添加注释:
```
$ zipnote -w twofiles.zip < comments
```
### zipsplit 命令
当归档文件太大时,可以使用 `zipsplit` 命令将一个 zip 归档文件分解为多个 zip 归档文件,这样你就可以将其中某一个文件放到小型 U 盘中。最简单的方法似乎是为每个部分的压缩文件指定最大大小,此大小必须足够大以容纳最大的所包含的文件。
```
$ zipsplit -n 12000 twofiles.zip
2 zip files will be made (100% efficiency)
creating: twofile1.zip
creating: twofile2.zip
$ ls twofile*.zip
-rw-rw-r-- 1 shs shs 10697 Jan 15 14:52 twofile1.zip
-rw-rw-r-- 1 shs shs 10702 Jan 15 14:52 twofile2.zip
-rw-rw-r-- 1 shs shs 21377 Jan 15 14:27 twofiles.zip
```
请注意,提取的文件是如何依次命名为 `twofile1` 和 `twofile2` 的。
### 总结
`zip` 命令及其一些压缩工具变体,对如何生成和使用压缩文件归档提供了很多控制。
---
via: <https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-the-many-variations-and-how-to-use-them.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,915 | 认识 FuryBSD:一个新的桌面 BSD 发行版 | https://itsfoss.com/furybsd/ | 2020-02-21T13:29:33 | [
"BSD"
] | https://linux.cn/article-11915-1.html | 在过去的几个月中,出现了一些新的桌面 BSD。之前有 [HyperbolaBSD,它之前是 Hyperbola GNU/Linux](https://itsfoss.com/hyperbola-linux-bsd/)。[BSD](https://itsfoss.com/bsd/) 世界中的另一个新入者是 [FuryBSD](https://www.furybsd.org/)。
### FuryBSD:一个新的 BSD 发行版

从本质上讲,FuryBSD 是一个非常简单的小东西。根据[它的网站](https://www.furybsd.org/manifesto/):“FuryBSD 一个是基于 FreeBSD 的轻量级桌面发行版。” 它基本上是预配置了桌面环境,并预安装了多个应用的 FreeBSD。目地是快速地在你的计算机上运行基于 FreeBSD 的系统。
你可能会认为这听起来很像其他几个已有的 BSD,例如 [NomadBSD](https://itsfoss.com/nomadbsd/) 和 [GhostBSD](https://ghostbsd.org/)。这些 BSD 与 FuryBSD 之间的主要区别在于 FuryBSD 与现有的 FreeBSD 更加接近。例如,FuryBSD 使用 FreeBSD 安装程序,而其他发行版则用了自己的安装程序和工具。
正如[它的网站](https://www.furybsd.org/furybsd-video-overview-at-knoxbug/)所说:“尽管 FuryBSD 可能类似于 PC-BSD 和 TrueOS 等图形化 BSD 项目,但 FuryBSD 是由不同的团队创建的,并且采用了不同与 FreeBSD 着重于紧密集成的方法。这样可以降低开销,并保持与上游的兼容性。”开发负责人还告诉我:“FuryBSD 的一个主要重点是使其成为一种小型现场版介质,并带有一些测试硬件驱动程序的辅助工具。”
当前,你可以进入 [FuryBSD 主页](https://www.furybsd.org/)并下载 XFCE 或 KDE 的 LiveCD。GNOME 版本正在开发中。
### FuryBSD 的背后是谁
FuryBSD 的主要开发者是 [Joe Maloney](https://github.com/pkgdemon)。Joe 多年来一直是 FreeBSD 的用户。他为 PC-BSD 等其他 BSD 项目做过贡献。他还与 GhostBSD 的创建者 Eric Turgeon 一起重写了 GhostBSD LiveCD。在此过程中,他对 BSD 有了更好的了解,并开始形成自己如何做一个发行版的想法。
Joe 与其他参与 BSD 世界多年的开发者一起加入了开发,例如 Jaron Parsons、Josh Smith 和 Damian Szidiropulosz。
### FuryBSD 的未来
目前,FuryBSD 仅仅是预配置的 FreeBSD。但是,开发者有一份[要改进的清单](https://www.furybsd.org/manifesto/)。包括:
* 可靠的加载框架、第三方专有图形驱动、无线网络
* 进一步整理 LiveCD 体验,以使其更加友好
* 开箱即用的打印支持
* 包含更多默认应用,以提供完整的桌面体验
* 集成的 [ZFS](https://itsfoss.com/what-is-zfs/) 复制工具,用于备份和还原
* Live 镜像持久化选项
* 默认自定义 pkg 仓库
* 用于应用更新的持续集成
* 桌面 FreeBSD 的质量保证
* 自定义、色彩方案和主题
* 目录服务集成
* 安全加固
开发者非常清楚地表明,他们所做的任何更改都需要大量的思考和研究。他们不会改进某个功能,只会在它破坏一些东西时删除或者修改它。

### 你可以如何帮助 FuryBSD?
目前,该项目还很年轻。由于所有项目都需要帮助才能生存,所以我问 Joe 他们正在寻求什么样的帮助。他说:“我们可以帮助[在论坛上回答问题](https://forums.furybsd.org/)、回答 [GitHub](https://github.com/furybsd) 上的问题,完善文档。”他还说如果人们想增加对其他桌面环境的支持,欢迎发起拉取请求。
### 最后的想法
尽管我还没有尝试过,但是我对 FuryBSD 感觉不错。听起来项目在掌握中。十多年来,Joe Maloney 一直在思考如何达到最佳的 BSD 桌面体验。与大多数 Linux 发行版基本上都是经过重新设计的 Ubuntu 不同,FuryBSD 背后的开发者知道他们在做什么,并且他们在更看重质量而不是花哨的功能。
你对这个在不断增长的桌面 BSD 市场的新入者怎么看?你尝试过 FuryBSD 或者会尝试一下吗?请在下面的评论中告诉我们。
如果你觉得这篇文章有趣,请在 Hacker News 或 [Reddit](https://reddit.com/r/linuxusersgroup) 等社交媒体上分享它。
---
via: <https://itsfoss.com/furybsd/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Important update
FuryBSD project has been discontinued.
In the last couple of months, a few new desktop BSD have been announced. There is [HyperbolaBSD which was Hyperbola GNU/Linux](https://itsfoss.com/hyperbola-linux-bsd/) previously. Another new entry in the [BSD](https://itsfoss.com/bsd/) world is [FuryBSD](https://www.furybsd.org/).
## FuryBSD: A new BSD distribution

At its heart, FuryBSD is a very simple beast. According to [the site](https://www.furybsd.org/manifesto/), “FuryBSD is a back to basics lightweight desktop distribution based on stock FreeBSD.” It is basically FreeBSD with a desktop environment pre-configured and several apps preinstalled. The goal is to quickly get a FreeBSD-based system running on your computer.
You might be thinking that this sounds a lot like a couple of other BSDs that are available, such as [NomadBSD](https://itsfoss.com/nomadbsd/) and [GhostBSD](https://ghostbsd.org/). The major difference between those BSDs and FuryBSD is that FuryBSD is much closer to stock FreeBSD. For example, FuryBSD uses the FreeBSD installer, while others have created their own installers and utilities.
As it states on the [site](https://www.furybsd.org/furybsd-video-overview-at-knoxbug/), “Although FuryBSD may resemble past graphical BSD projects like PC-BSD and TrueOS, FuryBSD is created by a different team and takes a different approach focusing on tight integration with FreeBSD. This keeps overhead low and maintains compatibility with upstream.” The lead dev also told me that “One key focus for FuryBSD is for it to be a small live media with a few assistive tools to test drivers for hardware.”
Currently, you can go to the [FuryBSD homepage](https://www.furybsd.org/) and download either an XFCE or KDE LiveCD. A GNOME version is in the works.
## Who’s is Behind FuryBSD?
The lead dev behind FuryBSD is [Joe Maloney](https://github.com/pkgdemon). Joe has been a FreeBSD user for many years. He contributed to other BSD projects, such as PC-BSD. He also worked with Eric Turgeon, the creator of GhostBSD, to rewrite the GhostBSD LiveCD. Along the way, he picked up a better understanding of BSD and started to form an idea of how he would make a distribution on his own.
Joe is joined by several other devs who have also spent many years in the BSD world, such as Jaron Parsons, Josh Smith, and Damian Szidiropulosz.
## The Future for FuryBSD
At the moment, FuryBSD is nothing more than a pre-configured FreeBSD setup. However, the devs have a [list of improvements](https://www.furybsd.org/manifesto/) that they want to make going forward. These include:
- A sane framework for loading, 3rd party proprietary drivers graphics, wireless
- Cleanup up the LiveCD experience a bit more to continue to make it more friendly
- Printing support out of box
- A few more default applications included to provide a complete desktop experience
- Integrated
[ZFS](https://itsfoss.com/what-is-zfs/)replication tools for backup and restore - Live image persistence options
- A custom pkg repo with sane defaults
- Continuous integration for applications updates
- Quality assurance for FreeBSD on the desktop
- Tailored artwork, color scheming, and theming
- Directory services integration
- Security hardening
The devs make it quite clear that any changes they make will have a lot of thought and research behind them. They don’t want to compliment a feature, only to have to remove it or change it when it breaks something.

## How You Can Help FuryBSD?
At this moment the project is still very young. Since all projects need help to survive, I asked Joe what kind of help they were looking for. He said, “We could use help [answering questions on the forums](https://forums.furybsd.org/), [GitHub](https://github.com/furybsd) tickets, help with documentation are all needed.” He also said that if people wanted to add support for other desktop environments, pull requests are welcome.
## Final Thoughts
Although I have not tried it yet, I have a good feeling about FuryBSD. It sounds like the project is in capable hands. Joe Maloney has been thinking about how to make the best BSD desktop experience for over a decade. Unlike majority of Linux distros that are basically a rethemed Ubuntu, the devs behind FuryBSD know what they are doing and they are choosing quality over the fancy bells and whistles.
What are your thoughts on this new entry into the every growing desktop BSD market? Have you tried out FuryBSD or will you give it a try? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
11,916 | 什么是 WireGuard?为什么 Linux 用户为它疯狂? | https://itsfoss.com/wireguard/ | 2020-02-21T21:59:42 | [
"WireGuard"
] | https://linux.cn/article-11916-1.html | 从普通的 Linux 用户到 Linux 创建者 [Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/),每个人都对 WireGuard 很感兴趣。什么是 WireGuard,它为何如此特别?
### 什么是 WireGuard?

[WireGuard](https://www.wireguard.com/) 是一个易于配置、快速且安全的开源 [VPN](https://en.wikipedia.org/wiki/Virtual_private_network),它利用了最新的加密技术。目的是提供一种更快、更简单、更精简的通用 VPN,它可以轻松地在树莓派这类低端设备到高端服务器上部署。
[IPsec](https://en.wikipedia.org/wiki/IPsec) 和 OpenVPN 等大多数其他解决方案是几十年前开发的。安全研究人员和内核开发人员 Jason Donenfeld 意识到它们速度慢且难以正确配置和管理。
这让他创建了一个新的开源 VPN 协议和解决方案,它更加快速、安全、易于部署和管理。
WireGuard 最初是为 Linux 开发的,但现在可用于 Windows、macOS、BSD、iOS 和 Android。它仍在活跃开发中。
### 为什么 WireGuard 如此受欢迎?

除了可以跨平台之外,WireGuard 的最大优点之一就是易于部署。配置和部署 WireGuard 就像配置和使用 SSH 一样容易。
看看 [WireGuard 设置指南](https://www.linode.com/docs/networking/vpn/set-up-wireguard-vpn-on-ubuntu/)。安装 WireGuard、生成公钥和私钥(像 SSH 一样),设置防火墙规则并启动服务。现在将它和 [OpenVPN 设置指南](https://www.digitalocean.com/community/tutorials/how-to-set-up-an-openvpn-server-on-ubuntu-16-04)进行比较——有太多要做的了。
WireGuard 的另一个好处是它有一个仅 4000 行代码的精简代码库。将它与 [OpenVPN](https://openvpn.net/)(另一个流行的开源 VPN)的 100,000 行代码相比。显然,调试 WireGuard 更加容易。
不要因其简单而小看它。WireGuard 支持所有最新的加密技术,例如 [Noise 协议框架](https://noiseprotocol.org/)、[Curve25519](https://cr.yp.to/ecdh.html)、[ChaCha20](https://cr.yp.to/chacha.html)、[Poly1305](https://cr.yp.to/mac.html)、[BLAKE2](https://blake2.net/)、[SipHash24](https://131002.net/siphash/)、[HKDF](https://eprint.iacr.org/2010/264) 和安全受信任结构。
由于 WireGuard 运行在[内核空间](http://www.linfo.org/kernel_space.html),因此可以高速提供安全的网络。
这些是 WireGuard 越来越受欢迎的一些原因。Linux 创造者 Linus Torvalds 非常喜欢 WireGuard,以至于将其合并到 [Linux Kernel 5.6](https://itsfoss.com/linux-kernel-5-6/) 中:
>
> 我能否再次声明对它的爱,并希望它能很快合并?也许代码不是完美的,但我不在乎,与 OpenVPN 和 IPSec 的恐怖相比,这是一件艺术品。
>
>
> Linus Torvalds
>
>
>
### 如果 WireGuard 已经可用,那么将其包含在 Linux 内核中有什么大惊小怪的?
这可能会让新的 Linux 用户感到困惑。你知道可以在 Linux 上安装和配置 WireGuard VPN 服务器,但同时也会看到 Linux Kernel 5.6 将包含 WireGuard 的消息。让我向您解释。
目前,你可以将 WireGuard 作为[内核模块](https://wiki.archlinux.org/index.php/Kernel_module)安装在 Linux 中。而诸如 VLC、GIMP 等常规应用安装在 Linux 内核之上(在 [用户空间](http://www.linfo.org/user_space.html)中),而不是内部。
当将 WireGuard 安装为内核模块时,基本上需要你自行修改 Linux 内核并向其添加代码。从 5.6 内核开始,你无需手动添加内核模块。默认情况下它将包含在内核中。
在 5.6 内核中包含 WireGuard 很有可能[扩展 WireGuard 的采用,从而改变当前的 VPN 场景](https://www.zdnet.com/article/vpns-will-change-forever-with-the-arrival-of-wireguard-into-linux/)。
### 总结
WireGuard 之所以受欢迎是有充分理由的。诸如 [Mullvad VPN](https://mullvad.net/en/) 之类的一些流行的[关注隐私的 VPN](https://itsfoss.com/best-vpn-linux/) 已经在使用 WireGuard,并且在不久的将来,采用率可能还会增长。
希望你对 WireGuard 有所了解。与往常一样,欢迎提供反馈。
---
via: <https://itsfoss.com/wireguard/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | From normal Linux users to Linux creator [Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/), everyone is in awe of WireGuard. What is WireGuard and what makes it so special?
## What is WireGuard?

[WireGuard](https://www.wireguard.com/) is an easy to configure, fast, and secure open source [VPN](https://en.wikipedia.org/wiki/Virtual_private_network) that utilizes state-of-the-art cryptography. It’s aim is to provide a faster, simpler and leaner general purpose VPN that can be easily deployed on low-end devices like Raspberry Pi to high-end servers.
Most of the other solutions like [IPsec](https://en.wikipedia.org/wiki/IPsec) and OpenVPN were developed decades ago. Security researcher and kernel developer Jason Donenfeld realized that they were slow and difficult to configure and manage properly.
This made him create a new open source VPN protocol and solution which is faster, secure easier to deploy and manage.
WireGuard was originally developed for Linux but it is now available for Windows, macOS, BSD, iOS and Android. It is still under heavy development.
## Why is WireGuard so popular?

Apart from being a cross-platform, one of the biggest plus point for WireGuard is the ease of deployment. Configuring and deploying WireGuard is as easy as configuring and using SSH.
Look at [WireGuard set up guide](https://www.linode.com/docs/networking/vpn/set-up-wireguard-vpn-on-ubuntu/). You install WireGuard, generate public and private keys (like SSH), set up firewall rules and start the service. Now compare it to the [OpenVPN set up guide](https://www.digitalocean.com/community/tutorials/how-to-set-up-an-openvpn-server-on-ubuntu-16-04). There are way too many things to do here.
Another good thing about WireGuard is that it has a lean codebase with just 4000 lines of code. Compare it to 100,000 lines of code of [OpenVPN](https://openvpn.net/) (another popular open source VPN). It is clearly easier to debug WireGuard.
Don’t go by its simplicity. WireGuard supports all the state-of-the-art cryptography like like the [Noise protocol framework](http://www.noiseprotocol.org/), [Curve25519](http://cr.yp.to/ecdh.html), [ChaCha20](http://cr.yp.to/chacha.html), [Poly1305](http://cr.yp.to/mac.html), [BLAKE2](https://blake2.net/), [SipHash24](https://131002.net/siphash/), [HKDF](https://eprint.iacr.org/2010/264), and secure trusted constructions.
Since WireGuard runs in the [kernel space](http://www.linfo.org/kernel_space.html), it provides secure networking at a high speed.
These are some of the reasons why WireGuard has become increasingly popular. Linux creator Linus Torvalds loves WireGuard so much that he is merging it in the [Linux Kernel 5.6](https://itsfoss.com/linux-kernel-5-6/):
Can I just once again state my love for it and hope it gets merged soon? Maybe the code isn’t perfect, but I’ve skimmed it, and compared to the horrors that are OpenVPN and IPSec, it’s a work of art.
Linus Torvalds
## If WireGuard is already available, then what’s the fuss about including it in Linux kernel?
This could be confusing to new Linux users. You know that you can install and configure a WireGuard VPN server on Linux but then you also read the news that Linux Kernel 5.6 is going to include WireGuard. Let me explain it to you.
At present, you can install WireGuard on Linux as a [kernel module](https://wiki.archlinux.org/index.php/Kernel_module). Regular applications like VLC, GIMP etc are installed on top of the Linux kernel (in [user space](http://www.linfo.org/user_space.html)), not inside it.
When you install WireGuard as a kernel module, you are basically modifying the Linux kernel on your own and add some code to it. Starting kernel 5.6, you won’t need manually add the kernel module. It will be included in the kernel by default.
The inclusion of WireGuard in Kernel 5.6 will most likely [extend the adoption of WireGuard and thus change the current VPN scene](https://www.zdnet.com/article/vpns-will-change-forever-with-the-arrival-of-wireguard-into-linux/).
**Conclusion**
WireGuard is gaining popularity for the good reasons. Some of the popular [privacy focused VPNs](https://itsfoss.com/best-vpn-linux/) like [Mullvad VPN](https://mullvad.net/) are already using WireGuard and the adoption is likely to grow in the near future.
I hope you have a slightly better understanding of WireGuard. Your feedback is welcome, as always. |
11,917 | Dino:一个有着现代外观的开源 XMPP 客户端 | https://itsfoss.com/dino-xmpp-client/ | 2020-02-22T10:28:51 | [
"XMPP"
] | https://linux.cn/article-11917-1.html |
>
> Dino 是一个相对较新的开源 XMPP 客户端,它试图提供良好的用户体验,鼓励注重隐私的用户使用 XMPP 发送消息。
>
>
>

### Dino:一个开源 XMPP 客户端

[XMPP](https://xmpp.org/about/)(<ruby> 可扩展通讯和表示协议 <rt> eXtensible Messaging Presence Protocol </rt></ruby>) 是一个去中心化的网络模型,可促进即时消息传递和协作。去中心化意味着没有中央服务器可以访问你的数据。通信直接点对点。
我们中的一些人可能会称它为“老派”技术,可能是因为 XMPP 客户端通常用户体验非常糟糕,或者仅仅是因为它需要时间来适应(或设置它)。
这时候 [Dino](https://dino.im/) 作为现代 XMPP 客户端出现了,在不损害你的隐私的情况下提供干净清爽的用户体验。
### 用户体验

Dino 试图改善 XMPP 客户端的用户体验,但值得注意的是,它的外观和感受将在一定程度上取决于你的 Linux 发行版。你的图标主题或 Gnome 主题会让你的个人体验更好或更糟。
从技术上讲,它的用户界面非常简单,易于使用。所以,我建议你看下 Ubuntu 中的[最佳图标主题](https://itsfoss.com/best-icon-themes-ubuntu-16-04/)和 [GNOME 主题](https://itsfoss.com/best-gtk-themes/)来调整 Dino 的外观。
### Dino 的特性

你可以将 Dino 用作 Slack、[Signal](https://itsfoss.com/signal-messaging-app/) 或 [Wire](https://itsfoss.com/wire-messaging-linux/) 的替代产品,来用于你的业务或个人用途。
它提供了消息应用所需的所有基本特性,让我们看下你可以从中得到的:
* 去中心化通信
* 如果无法设置自己的服务器,它支持公共 XMPP 的服务器
* 和其他流行消息应用相似的 UI,因此易于使用
* 图像和文件共享
* 支持多个帐户
* 高级消息搜索
* 支持 [OpenPGP](https://www.openpgp.org/) 和 [OMEMO](https://en.wikipedia.org/wiki/OMEMO) 加密
* 轻量级原生桌面应用
### 在 Linux 上安装 Dino
你可能会发现它列在你的软件中心中,也可能未找到。Dino 为基于 Debian(deb)和 Fedora(rpm)的发行版提供了可用的二进制文件。
Dino 在 Ubuntu 的 universe 仓库中,你可以使用以下命令安装它:
```
sudo apt install dino-im
```
类似地,你可以在 [GitHub 分发包页面](https://github.com/dino/dino/wiki/Distribution-Packages)上找到其他 Linux 发行版的包。
如果你想要获取最新的,你可以在 [OpenSUSE 的软件页面](https://software.opensuse.org/download.html?project=network:messaging:xmpp:dino&package=dino)找到 Dino 的 **.deb** 和 .**rpm** (每日构建版)安装在 Linux 中。
在任何一种情况下,前往它的 [Github 页面](https://github.com/dino/dino)或点击下面的链接访问官方网站。
* [下载 Dino](https://dino.im/)
### 总结
在我编写这篇文章时快速测试过它,它工作良好,没有出过问题。我将尝试探索更多,并希望能涵盖更多有关 XMPP 的文章来鼓励用户使用 XMPP 的客户端和服务器用于通信。
你觉得 Dino 怎么样?你会推荐另一个可能好于 Dino 的开源 XMPP 客户端吗?在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/dino-xmpp-client/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Dino is a relatively new open-source XMPP client that tries to offer a good user experience while encouraging privacy-focused users to utilize XMPP for messaging.*
## Dino: An Open Source XMPP Client
[XMPP](https://xmpp.org/about/) (Extensible Messaging Presence Protocol) is a decentralized model of network to facilitate instant messaging and collaboration. Decentralize means there is no central server that has access to your data. The communication is directly between the end-points.
Some of us might call it an “old school” tech probably because the XMPP clients usually have a very bad user experience or simply just because it takes time to get used to (or set it up).
That’s when [Dino](https://dino.im/) comes to the rescue as a modern XMPP client to provide a clean and snappy user experience without compromising your privacy.
## The User Experience
Dino does try to improve the user experience as an XMPP client but it is worth noting that the look and feel of it will depend on your Linux distribution to some extent. Your icon theme or the gnome theme might make it look better or worse for your personal experience.
Technically, the user interface is quite simple and easy to use. So, I suggest you take a look at some of the [best icon themes](https://itsfoss.com/best-icon-themes-ubuntu-16-04/) and [GNOME themes](https://itsfoss.com/best-gtk-themes/) for Ubuntu to tweak the look of Dino.
## Features of Dino
You can expect to use Dino as an alternative to Slack, [Signal](https://itsfoss.com/signal-messaging-app/) or [Wire](https://itsfoss.com/wire-messaging-linux/) for your business or personal usage.
It offers all of the essential features you would need in a messaging application, let us take a look at a list of things that you can expect from it:
- Decentralized Communication
- Public XMPP Servers supported if you cannot setup your own server
- Similar to UI to other popular messengers – so it’s easy to use
- Image & File sharing
- Multiple accounts supported
- Advanced message search
[OpenPGP](https://www.openpgp.org/)&[OMEMO](https://en.wikipedia.org/wiki/OMEMO)encryption supported- Lightweight native desktop application
## Installing Dino on Linux
You may or may not find it listed in your software center. Dino does provide ready to use binaries for Debian (deb) and Fedora (rpm) based distributions.
**For Ubuntu:**
Dino is available in the universe repository on Ubuntu and you can install it using this command:
`sudo apt install dino-im`
Similarly, you can find packages for other Linux distributions on their [GitHub distribution packages page](https://github.com/dino/dino/wiki/Distribution-Packages).
If you want the latest and greatest, you can also find both **.deb** and .**rpm** files for Dino to install on your Linux distribution (nightly builds) from [OpenSUSE’s software webpage](https://software.opensuse.org/download.html?project=network:messaging:xmpp:dino&package=dino).
In either case, head to their [GitHub page](https://github.com/dino/dino) or click on the link below to visit the official site.
**Wrapping Up**
It works quite well without any issues (at the time of writing this and quick testing it). I’ll try exploring more about it and hopefully cover more XMPP-centric articles to encourage users to use XMPP clients and servers for communication.
What do you think about Dino? Would you recommend another open-source XMPP client that’s potentially better than Dino? Let me know your thoughts in the comments below. |
11,919 | 使用开源搜索引擎 YaCy 的技巧 | https://opensource.com/article/20/2/yacy-search-engine-hacks | 2020-02-23T11:58:36 | [
"YaCY"
] | https://linux.cn/article-11919-1.html |
>
> 无需适应其他人的眼光,而是使用 YaCY 搜索引擎定义你想要的互联网。
>
>
>

在我以前介绍 [YaCy 入门](/article-11905-1.html)的文章中讲述过 [YaCy](https://yacy.net/) 这个<ruby> 对等 <rt> peer-to-peer </rt></ruby>式的搜索引擎是如何安装和使用的。YaCy 最令人兴奋的一点就是它事实上是一个本地客户端,全球范围内的每一个 YaCy 用户都是构成整个这个分布式搜索引擎架构的一个节点,这意味着每个用户都可以掌控自己的互联网搜索体验。
Google 曾经提供过 google.com/linux 这样的主题简便方式以便快速筛选出和 Linux 相关的搜索内容,这个小功能受到了很多人的青睐,但 Google 最终还是在 2011 年的时候把它[下线](https://www.linuxquestions.org/questions/linux-news-59/is-there-no-more-linux-google-884306/)了。
而 YaCy 则让自定义搜索引擎变得可能。
### 自定义 YaCy
YaCy 安装好之后,只需要访问 `localhost:8090` 就可以使用了。要自定义搜索引擎,只需要点击右上角的“<ruby> 管理 <rt> Administration </rt></ruby>”按钮(它可能隐藏在小屏幕的菜单图标中)。
你可以在管理面板中配置 YaCy 对系统资源的使用策略,以及如何跟其它的 YaCy 客户端进行交互。

例如,点击侧栏中的“<ruby> 第一步 <rt> First steps </rt></ruby>”按钮可以配置备用端口,以及设置 YaCy 对内存和硬盘的使用量;而“<ruby> 监控 <rt> Monitoring </rt></ruby>”面板则可以监控 YaCy 的运行状况。大多数功能都只需要在面板上点击几下就可以完成了,例如以下几个常用的功能。
### 内网搜索应用
目前市面上也有不少公司推出了[内网搜索应用](https://en.wikipedia.org/wiki/Vivisimo),而 YaCy 可以免费为你提供一个。对于能够通过 HTTP、FTP、Samba 等协议访问的文件,YaCy 都可以进行索引,因此无论是作为私人的文件搜索还是企业内部的本地共享文件搜索,YaCy 都可以实现。它可以让内部网络中的用户使用你个人的 YaCy 实例来查找共享文件,于此同时保持对内部网络以外的用户不可见。
### 网络配置
YaCy 在默认情况下就支持隐私和隔离。点击“<ruby> 用例与账号 <rt> Use Case & Account </rt></ruby>”页面顶部的“<ruby> 网络配置 <rt> Network Configuration </rt></ruby>”链接,即可进入网络配置面板设置对等网络。

### 爬取站点
YaCy 的分布式运作方式决定了它对页面的爬取是由用户驱动的。并没有一个大型公司对整个互联网上的所有可访问页面都进行搜索,对于 YaCy 来说也是这样,一个站点只有在被用户指定爬取的前提下,才会被 YaCy 爬取并进入索引。
YaCy 客户端提供了两种爬取页面的方式:你可以手动爬取,并让 YaCy 根据建议去爬取。

#### 手动爬取
手动爬取是指由用户输入指定的网站 URL 并启动 YaCy 的爬虫任务。只需要点击“<ruby> 高级爬虫 <rt> Advanced Crawler </rt></ruby>”并输入计划爬取的若干 URL,然后选择页面底部的“<ruby> 进行远程索引 <rt> Do Remote indexing </rt></ruby>”选项,这个选项会让客户端向互联网广播它要索引的 URL,可选地接受这些请求的客户端可以帮助你爬取这些 URL。
点击页面底部的“<ruby> 开始新爬虫任务 <rt> Start New Crawl Job </rt></ruby>”按钮就可以开始进行爬取了,我就是这样对一些常用和有用站点进行爬取和索引的。
爬虫任务启动之后,YaCy 会将这些 URL 对应的页面在本地生成和存储索引。在高级模式下,也就是本地计算机允许 8090 端口流量进出时,全网的 YaCy 用户都可以使用到这一份索引。
#### 加入爬虫网络
尽管一些非常敬业的 YaCy 高级用户已经强迫症般地在互联网上爬取了很多页面,但对于全网浩如烟海的页面而言也只是沧海一粟。单个用户所拥有的资源远不及很多大公司的网络爬虫,但大量 YaCy 用户如果联合起来成为一个社区,能产生的力量就大得多了。只要开启了 YaCy 的爬虫请求广播功能,就可以让其它客户端参与进来爬取更多页面。
只需要在“<ruby> 高级爬虫 <rt> Advanced Crawler </rt></ruby>”面板中点击页面顶部的“<ruby> 远程爬取 <rt> Remote Crawling </rt></ruby>”,勾选“<ruby> 加载 <rt> Load </rt></ruby>”旁边的复选框,就可以让你的客户端接受其它人发来的爬虫任务请求了。

### YaCy 监控相关
YaCy 除了作为一个非常强大的搜索引擎,还提供了很丰富的主题和用户体验。你可以在“<ruby> 监控 <rt> Monitor </rt></ruby>”面板中监控 YaCy 客户端的网络运行状况,甚至还可以了解到有多少人从 YaCy 社区中获取到了自己所需要的东西。

### 搜索引擎发挥了作用
你使用 YaCy 的时间越长,就越会思考搜索引擎如何改变自己的视野,因为你对互联网的体验很大一部分来自于你在搜索引擎中一次次简单查询的结果。实际上,当你和不同行业的人交流时,可能会注意到每个人对“互联网”的理解都有所不同。有些人会认为,互联网的搜索引擎中充斥着各种广告和推广,同时也仅仅能从搜索结果中获取到有限的信息。例如,假设有人不断搜索关于关键词 X 的内容,那么大部分商业搜索引擎都会在搜索结果中提高关键词 X 的权重,但与此同时,另一个关键词 Y 的权重则会相对降低,从而让关键词 Y 被淹没在搜索结果当中,即使这样对完成特定任务更好。
就像在现实生活中一样,走出虚拟的世界视野会让你看到一个更广阔的世界。尝试使用 YaCy,看看你发现了什么。
---
via: <https://opensource.com/article/20/2/yacy-search-engine-hacks>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my article about [getting started with YaCy](https://opensource.com/article/20/2/open-source-search-engine), I explained how to install and start using the [YaCy](https://yacy.net/) peer-to-peer search engine. One of the most exciting things about YaCy, however, is the fact that it's a local client. Each user owns and operates a node in a globally distributed search engine infrastructure, which means each user is in full control of how they navigate and experience the World Wide Web.
For instance, Google used to provide the URL google.com/linux as a shortcut to filter searches for Linux-related topics. It was a small feature that many people found useful, but [topical shortcuts were dropped](https://www.linuxquestions.org/questions/linux-news-59/is-there-no-more-linux-google-884306/) in 2011.
YaCy makes it possible to customize your search experience.
## Customize YaCy
Once you've installed YaCy, navigate to your search page at **localhost:8090**. To customize your search engine, click the **Administration** button in the top-right corner (it may be concealed in a menu icon on small screens).
The admin panel allows you to configure how YaCy uses your system resources and how it interacts with other YaCy clients.
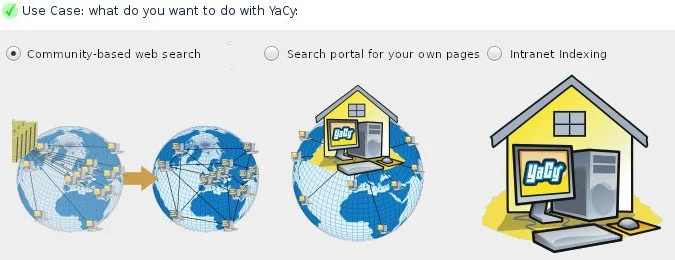
For instance, to configure an alternative port and set RAM and disk usage, use the **First steps** menu in the sidebar. To monitor YaCy activity, use the **Monitoring** panel. Most features are discoverable by clicking through the panels, but here are some of my favorites.
## Search appliance
Several companies have offered [intranet search appliances](https://en.wikipedia.org/wiki/Vivisimo), but with YaCy, you can implement it for free. Whether you want to search through your own data or to implement a search system for local file shares at your business, you can choose to run YaCy as an internal indexer for files accessible over HTTP, FTP, and SMB (Samba). People in your local network can use your personalized instance of YaCy to find shared files, and none of the data is shared with users outside your network.
## Network configuration
YaCy favors isolation and privacy by default. You can adjust how you connect to the peer-to-peer network in the **Network Configuration** panel, which is revealed by clicking the link located at the top of the **Use Case & Account** configuration screen.
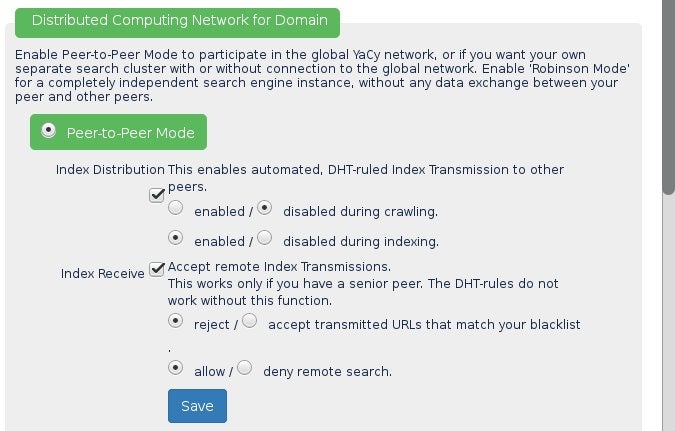
## Crawl a site
Peer-to-peer indexing is user-driven. There's no mega-corporation initiating searches on every accessible page on the internet, so a site isn't indexed until someone deliberately crawls it with YaCy.
The YaCy client provides two options to help you help crawl the web: you can perform a manual crawl, and you can make YaCy available for suggested crawls.

### Start a manual crawling job
A manual crawl is when you enter the URL of a site you want to index and start a YaCy crawl job. To do this, click the **Advanced Crawler** link in the **Production** sidebar. Enter one or more URLs, then scroll to the bottom of the page and enable the **Do remote indexing** option. This enables your client to broadcast the URLs it is indexing, so clients that have opted to accept requests can help you perform the crawl.
To start the crawl, click the **Start New Crawl Job** button at the bottom of the page. I use this method to index sites I use frequently or find useful.
Once the crawl job starts, YaCy indexes the URLs you enter and stores the index on your local machine. As long as you are running in senior mode (meaning your firewall permits incoming and outgoing traffic on port 8090), your index is available to YaCy users all over the globe.
### Join in on a crawl
While some very dedicated YaCy senior users may crawl the internet compulsively, there are a *lot* of sites out there in the world. It might seem impossible to match the resources of popular spiders and bots, but because YaCy has so many users, they can band together as a community to index more of the internet than any one user could do alone. If you activate YaCy to broadcast requests for site crawls, participating clients can work together to crawl sites you might not otherwise think to crawl manually.
To configure your client to accept jobs from others, click the **Advanced Crawler** link in the left sidebar menu. In the **Advanced Crawler** panel, click the **Remote Crawling** link under the **Network Harvesting** heading at the top of the page. Enable remote crawls by placing a tick in the checkbox next to the **Load** setting.
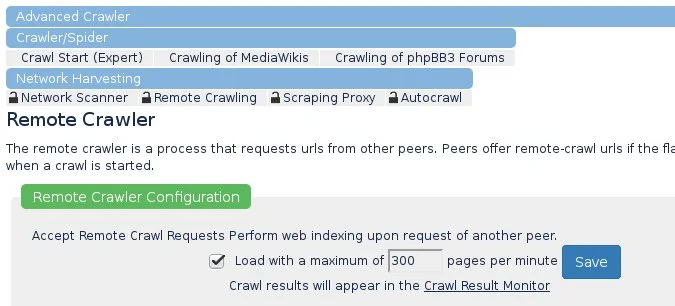
## YaCy monitoring and more
YaCy is a surprisingly robust search engine, providing you with the opportunity to theme and refine your experience in nearly any way you could want. You can monitor the activity of your YaCy client in the **Monitoring** panel, so you can get an idea of how many people are benefiting from the work of the YaCy community and also see what kind of activity it's generating for your computer and network.
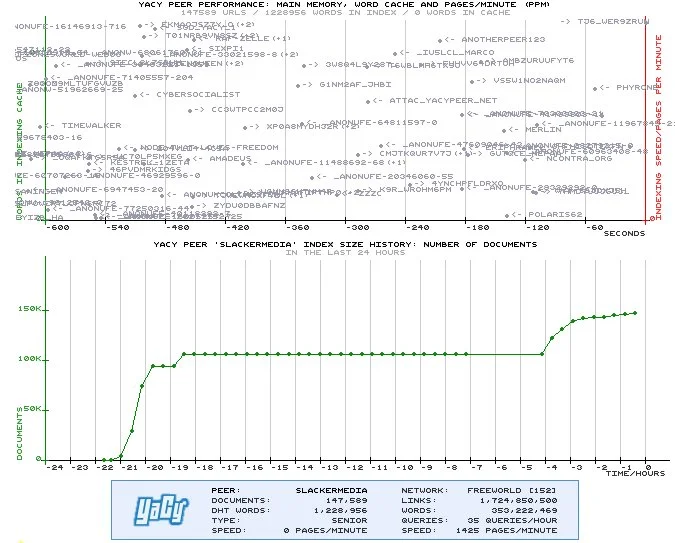
## Search engines make a difference
The more time you spend with the Administration screen, the more fun it becomes to ponder how the search engine you use can change your perspective. Your experience of the internet is shaped by the results you get back for even the simplest of queries. You might notice, in fact, how different one person's "internet" is from another person's when you talk to computer users from a different industry. For some people, the web is littered with ads and promoted searches and suffers from the tunnel vision of learned responses to queries. For instance, if someone consistently searches for answers about X, most commercial search engines will give weight to query responses that concern X. That's a useful feature on the one hand, but it occludes answers that require Y, even though that might be the better solution for a specific task.
As in real life, stepping outside a manufactured view of the world can be healthy and enlightening. Try YaCy, and see what you discover.
## Comments are closed. |
11,920 | 使用 Bash 工具截屏 Linux 系统配置 | https://opensource.com/article/20/1/screenfetch-neofetch | 2020-02-23T12:45:37 | [
"ScreenFetch",
"Neofetch"
] | https://linux.cn/article-11920-1.html |
>
> 使用 ScreenFetch 和 Neofetch 与其他人轻松分享你的 Linux 环境。
>
>
>

你可能有很多原因想要与他人分享你的 Linux 配置。你可能正在寻求帮助来对系统上的问题进行故障排除,或者你对所创建的环境感到非常自豪,因此想向其他开源爱好者展示。
你可以在 Bash 提示符下使用 `cat /proc/cpuinfo` 或 `lscpu` 命令获取某些信息。但是,如果你想共享更多详细信息,例如你的操作系统、内核、运行时间、shell 环境,屏幕分辨率等,那么可以选择两个很棒的工具:screenFetch 和 Neofetch。
### screenFetch
[screenFetch](https://github.com/KittyKatt/screenFetch) 是 Bash 命令行程序,它可以产生非常漂亮的系统配置和运行时间的截图。这是方便的与它人共享系统配置的方法。
在许多 Linux 发行版上安装 screenFetch 很简单。
在 Fedora 上,输入:
```
$ sudo dnf install screenfetch
```
在 Ubuntu 上,输入:
```
$ sudo apt install screenfetch
```
对于其他操作系统,包括 FreeBSD、MacOS 等,请查阅 screenFetch 的 wiki [安装页面](https://github.com/KittyKatt/screenFetch/wiki/Installation)。安装 screenFetch 后,它可以生成详细而彩色的截图,如下所示:

ScreenFetch 还提供各种命令行选项来调整你的结果。例如,`screenfetch -v` 返回详细输出,逐行显示每个选项以及上面的显示。
`screenfetch -n` 在显示系统信息时消除了操作系统图标。

其他选项包括 `screenfetch -N`,它去除所有输出的颜色。`screenfetch -t`,它根据终端的大小截断输出。`screenFetch -E`,它可抑制错误输出。
请检查手册页来了解其他选项。screenFetch 在 GPLv3 许可证下的开源,你可以在它的 [GitHub 仓库](http://github.com/KittyKatt/screenFetch)中了解有关该项目的更多信息。
### Neofetch
[Neofetch](https://github.com/dylanaraps/neofetch) 是创建系统信息截图的另一个工具。它是用 Bash 3.2 编写的,在 [MIT 许可证](https://github.com/dylanaraps/neofetch/blob/master/LICENSE.md)下开源。
根据项目网站所述,“Neofetch 支持近 150 种不同的操作系统。从 Linux 到 Windows,一直到 Minix、AIX 和 Haiku 等更晦涩的操作系统。”

该项目维护了一个 wiki,其中包含用于各种发行版和操作系统的出色的[安装文档](https://github.com/dylanaraps/neofetch/wiki/Installation)。
如果你使用的是 Fedora、RHEL 或 CentOS,那么可以在 Bash 提示符下使用以下命令安装 Neofetch:
```
$ sudo dnf install neofetch
```
在 Ubuntu 17.10 及更高版本上,你可以使用:
```
$ sudo apt install neofetch
```
首次运行时,Neofetch 将 `~/.config/neofetch/config.conf` 文件写入主目录(`.config/config.conf`),它让你可以[自定义和控制](https://github.com/dylanaraps/neofetch/wiki/Customizing-Info) Neofetch 输出的各个方面。例如,你可以配置 Neofetch 使用图像、ASCII 文件、你选择的壁纸,或者完全不使用。config.conf 文件还让与它人分享配置变得容易。
如果 Neofetch 不支持你的操作系统或不提供所需选项,请在项目的 [GitHub 仓库](https://github.com/dylanaraps/neofetch/issues)中打开一个问题。
### 总结
无论为什么要共享系统配置,screenFetch 或 Neofetch 都应该能做到。你是否知道在 Linux 上提供此功能的另一个开源工具?请在评论中分享你的最爱。
---
via: <https://opensource.com/article/20/1/screenfetch-neofetch>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are many reasons you might want to share your Linux configuration with other people. You might be looking for help troubleshooting a problem on your system, or maybe you're so proud of the environment you've created that you want to showcase it to fellow open source enthusiasts.
You could get some of that information with a **cat /proc/cpuinfo** or **lscpu** command at the Bash prompt. But if you want to share more details, such as your operating system, kernel, uptime, shell environment, screen resolution, etc., you have two great tools to choose: screenFetch and Neofetch.
## ScreenFetch
[ScreenFetch](https://github.com/KittyKatt/screenFetch) is a Bash command-line utility that can produce a very nice screenshot of your system configuration and uptime. It is an easy way to share your system's configuration with others in a colorful way.
It's simple to install screenFetch for many Linux distributions.
On Fedora, enter:
`$ sudo dnf install screenfetch`
On Ubuntu, enter:
`$ sudo apt install screenfetch`
For other operating systems, including FreeBSD, MacOS, and more, consult the screenFetch wiki's [installation page](https://github.com/KittyKatt/screenFetch/wiki/Installation). Once screenFetch is installed, it can produce a detailed and colorful screenshot like this:
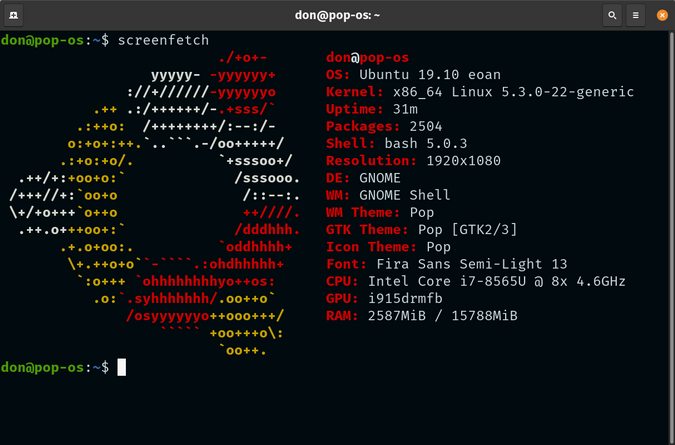
ScreenFetch also provides various command-line options to fine-tune your results. For example, **screenfetch -v** returns verbose output that presents each option line-by-line along with the display shown above.
And **screenfetch -n** eliminates the operating system icon when it displays your system information.
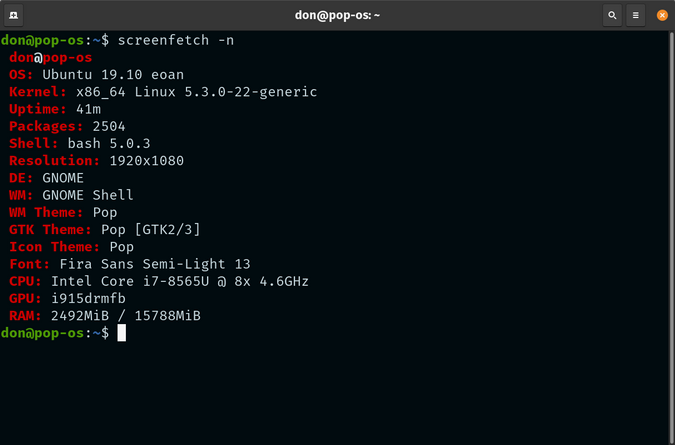
Other options include **screenfetch -N**, which strips all color from the output; **screenfetch -t**, which truncates the output depending on the size of the terminal; and **screenFetch -E**, which suppresses errors.
Be sure to check the man page on your system for other options. ScreenFetch is open source under the GPLv3, and you can learn more about the project in its [GitHub repository](http://github.com/KittyKatt/screenFetch).
## Neofetch
[Neofetch](https://github.com/dylanaraps/neofetch) is another tool to create a screenshot with your system information. It is written in Bash 3.2 and is open source under the [MIT License](https://github.com/dylanaraps/neofetch/blob/master/LICENSE.md).
According to the project's website, "Neofetch supports almost 150 different operating systems. From Linux to Windows, all the way to more obscure operating systems like Minix, AIX, and Haiku."
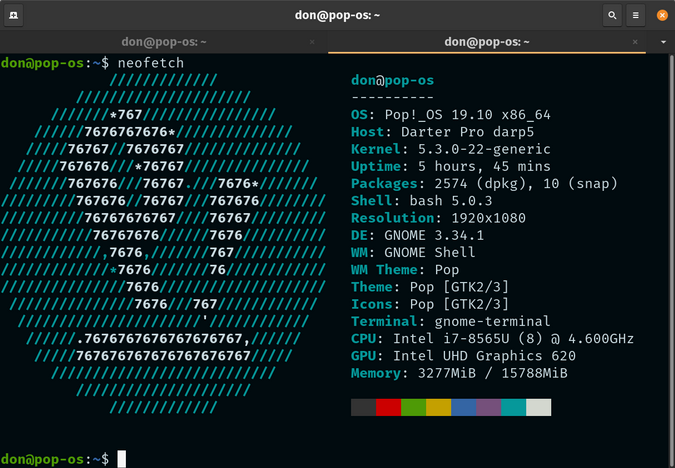
The project maintains a wiki with excellent [installation documentation](https://github.com/dylanaraps/neofetch/wiki/Installation) for a variety of distributions and operating systems.
If you are on Fedora, RHEL, or CentOS, you can install Neofetch at the Bash prompt with:
`$ sudo dnf install neofetch`
On Ubuntu 17.10 and greater, you can use:
`$ sudo apt install neofetch`
On its first run, Neofetch writes a **~/.config/neofetch/config.co nf** file to your home directory (
**.config/config.conf**), which enables you to
[customize and control](https://github.com/dylanaraps/neofetch/wiki/Customizing-Info)every aspect of Neofetch's output. For example, you can configure Neofetch to use the image, ASCII file, or wallpaper of your choice—or nothing at all. The config.conf file also makes it easy to share your customization with others.
If Neofetch doesn't support your operating system or provide all the options you are looking for, be sure to open up an issue in the project's [GitHub repo](https://github.com/dylanaraps/neofetch/issues).
## Conclusion
No matter why you want to share your system configuration, screenFetch or Neofetch should enable you to do so. Do you know of another open source tool that provides this functionality on Linux? Please share your favorite in the comments.
## 3 Comments |
11,922 | 微软为 Linux 发布了 Defender 防病毒软件公开预览版 | https://www.zdnet.com/article/microsoft-linux-defender-antivirus-now-in-public-preview-ios-and-android-are-next/ | 2020-02-23T14:04:00 | [
"微软"
] | https://linux.cn/article-11922-1.html | 
### Microsoft Defender ATP 将保护所有现代工作场所环境
微软宣布了针对 Linux 的 Microsoft Defender <ruby> 高级威胁防护 <rp> ( </rp> <rt> Advanced Threat Protection </rt> <rp> ) </rp></ruby>(ATP)防病毒软件的公开预览版,[正如 ZDNet 报道的那样](https://www.zdnet.com/article/microsoft-defender-atp-is-coming-to-linux-in-2020/),它将在 2020 年的某个时候发布。
在微软去年增加了对 macOS 的支持并将其名称从 Windows Defender ATP 更改为 Microsoft Defender ATP 之后,新的 Defender Linux 端点保护软件在桌面上进一步完善了 Microsoft Defender ATP。
接下来,微软希望增加对移动设备的支持,将 Microsoft Defender 引入 iOS 和 Android,并将在本周的 RSA Conference上 发布预览版。
微软威胁防护产品的副总裁 Moti Gindi 表示:“我们的目标是将保护带到所有现代工作场所环境,无论是微软环境还是非微软环境。我们正在保护 Mac 上的端点设备,而今天,我们要将端点保护延伸到 Linux 以及 iOS 和 Android 上。”
### MTP 全面可用
[微软还宣布了 Microsoft Threat Protection(MTP)全面可用](https://docs.microsoft.com/en-us/microsoft-365/security/mtp/microsoft-threat-protection),该服务捆绑包包括了 Microsoft Defender ATP、Office ATP、Azure ATP 及其云应用程序安全套件。
“我们正在努力在与微软平台直接或间接相关的端点设备、身份、数据和应用程序上保持整体性。”Gindi 说,“当然,许多组织使用 Windows 以及 Office 和 Active Directory 作为协作系统的基础这一事实也意味着我们需要保护这些系统。”
MTP 要依赖于微软对大量信息的访问,这些信息来自不同端点设备、电子邮件帐户、Azure Active Directory 身份和 Office 365 等应用程序。MTP 服务有望通过在单个仪表板上提供安全专家的信息来帮助安全运营中心团队了解这些领域的威胁。
“你必须是该领域的专家,但你还需要成为跨领域的专家——跨端点设备、电子邮件、云、身份和应用程序来将数据统合起来,为检测提供数据基础,甚至是更重要的是补救和预防。”Gindi 解释说。
MTP 还向微软的 Azure Sentinel 提供数据,Azure Sentinel 是基于云的安全信息和事件管理器(SIEM),它是[去年 9 月公开发布的](https://www.zdnet.com/article/azure-sentinel-microsofts-cloud-based-siem-hits-general-availability/)。
Sentinel 从操作系统、应用程序、防病毒、数据库和服务器日志等来源收集信息,以为安全团队构建威胁情报。MTP 与 Sentinel 共享这些警报和威胁情报,使安全团队可以查看和管理微软和第三方安全产品中的威胁。
客户可以在 Microsoft 365 E5、Microsoft 365 E5 Security、Office 365 E5、Enterprise Mobility + Security E5 和 Windows E5 上使用 MTP。
微软还通过云计算竞争对手 AWS 来吸引客户。在 2020 年 6 月之前,微软将提供从 AWS CloudTrail data 到 Sentinel 的免费数据导入。AWS CloudTrail data 包括 AWS 服务中所有事件历史记录的日志,90 天后会收取数据保留费,Sentinel 服务旨在帮助安全团队识别和响应 AWS 环境中的威胁。
| 200 | OK | # Microsoft: Linux Defender antivirus now in public preview, iOS and Android are next

Microsoft has announced the public preview of Microsoft Defender Advanced Threat Protection (ATP) antivirus for Linux, as ZDNet [reported it would at some point in 2020](https://www.zdnet.com/article/microsoft-defender-atp-is-coming-to-linux-in-2020/).
The new Defender Linux endpoint protection rounds out Microsoft Defender ATP on the desktop after Microsoft added [support for macOS last year](https://www.zdnet.com/article/microsoft-brings-windows-10-security-to-apple-macs-with-defender-atp/) and changed its name from Windows Defender ATP.
### More Microsoft
Next, Microsoft is looking to add support for mobile, [bringing Microsoft Defender to iOS and Android](https://www.microsoft.com/security/blog/2020/02/20/microsoft-threat-protection-intelligence-automation/), which it's previewing this week at the RSA Conference.
"We're aiming to protect the modern workplace environment across everything that it is, being Microsoft or non-Microsoft. We're protecting endpoints across Mac and today we're extending this endpoint protection to Linux and to iOS and Android," Moti Gindi, corporate vice president of Microsoft Threat Protection told ZDNet.
**SEE: ****A winning strategy for cybersecurity**** (ZDNet special report) | ****Download the report as a PDF**** (TechRepublic)**
Microsoft has also announced [general availability of Microsoft Threat Protection (MTP)](https://docs.microsoft.com/en-us/microsoft-365/security/mtp/microsoft-threat-protection), a bundle of services that includes Microsoft Defender ATP, Office ATP, Azure ATP, and its cloud app security suite.
"We're trying to be holistic across endpoint, identity, data, and applications that relate directly or indirectly to Microsoft platforms," said Gindi.
"Of course, the fact that many organizations are using Windows and Office and Active Directory as the backbone of the cooperating systems also means we need to protect these systems."
MTP relies on Microsoft's access to vast amounts of information from different devices, email accounts, identities through Azure Active Directory, and applications such as Office 365.
The MTP service promises to help security operations-center teams understand threats across these domains by providing security experts' information in a single dashboard.
"You must be an expert in the domain, but you also need to be an expert across the domain – to stick data across endpoints, email, cloud, identity, and applications, and then connect it into to make one basis for detection, and even more importantly remediation and prevention," explained Gindi.
MTP also feeds data to Microsoft's Azure Sentinel, its cloud-based security information and event manager (SIEM) that [launched publicly last September](https://www.zdnet.com/article/azure-sentinel-microsofts-cloud-based-siem-hits-general-availability/).
**SEE: ****On data protection, the UK says it will go it alone. It probably won't.**
Sentinel gathers information from sources such as the OS, applications, antivirus, database, and server logs to build threat intelligence for security teams. MTP shares alerts and threat intelligence with Sentinel allowing security teams to view and manage threats across Microsoft and third-party security products.
MTP is available to customers on Microsoft 365 E5, Microsoft 365 E5 Security, Office 365 E5, Enterprise Mobility + Security E5, and Windows E5.
Microsoft is also making a grab for customers using cloud rival Amazon Web Services. Until the end of June 2020 Microsoft is offering a [free import of data from AWS CloudTrail data into Sentinel](https://www.microsoft.com/security/blog/2020/02/20/free-import-of-aws-cloudtrail-logs-through-june-2020-and-other-exciting-azure-sentinel-updates/).
AWS CloudTrail data includes logs of all event history in AWS services. There are data-retention charges after 90 days, but the Sentinel service is aimed at helping security teams identify and respond to threats in an AWS environment.
[Editorial standards](/editorial-guidelines/) |
11,923 | 如何安装 Vim 插件 | https://opensource.com/article/20/2/how-install-vim-plugins | 2020-02-23T21:57:30 | [
"Vim",
"插件"
] | https://linux.cn/article-11923-1.html |
>
> 无论你是手动安装还是通过包管理器安装,插件都可以帮助你在工作流中打造一个完美的 Vim 。
>
>
>

虽然 [Vim](https://www.vim.org/) 是快速且高效的,但在默认情况下,它仅仅只是一个文本编辑器。至少,这就是没有插件的情况 Vim 应当具备的样子,插件构建在 Vim 之上,并添加额外的功能,使 Vim 不仅仅是一个输入文本的窗口。有了合适的插件组合,你可以控制你的生活,形成你自己独特的 Vim 体验。你可以[自定义你的主题](https://opensource.com/article/19/12/colors-themes-vim),你可以添加语法高亮,代码 linting,版本跟踪器等等。
### 怎么安装 Vim 插件
Vim 可以通过插件进行扩展,但很长一段时间以来,并没有官方的安装方式去安装这些插件。从 Vim 8 开始,有一个关于插件如何安装和加载的结构。你可能会在网上或项目自述文件中遇到旧的说明,但只要你运行 Vim 8 或更高版本,你应该根据 Vim 的[官方插件安装方法](https://github.com/vim/vim/blob/03c3bd9fd094c1aede2e8fe3ad8fd25b9f033053/runtime/doc/repeat.txt#L515)安装或使用 Vim 包管理器。你可以使用包管理器,无论你运行的是什么版本(包括比 8.x 更老的版本),这使得安装过程比你自己维护更新更容易。
手动和自动安装方法都值得了解,所以请继续阅读以了解这两种方法。
### 手动安装插件(Vim 8 及以上版本)
所谓的 “Vim 包”是一个包含一个或多个插件的目录。默认情况下,你的 Vim 设置包含在 `~/.vim` 中,这是 Vim 在启动时寻找插件的地方。(下面的示例使用了通用名称 `vendor` 来表示插件是从其它地方获得的。)
当你启动 Vim 时,它首先处理你的 `.vimrc`文件,然后扫描 `~/.vim` 中的所有目录,查找包含在 `pack/*/start` 中的插件。
默认情况下,你的 `~/.vim` 目录(如果你有的话)中没有这样的文件结构,所以设置为:
```
$ mkdir -p ~/.vim/pack/vendor/start
```
现在,你可以将 Vim 插件放在 `~/.vim/pack/vendor/start` 中,它们会在你启动 Vim 时自动加载。
例如,尝试安装一下 [NERDTree](https://github.com/preservim/nerdtree),这是一个基于文本的 Vim 文件管理器。首先,使用 Git 克隆 NERDTree 存储库的快照:
```
$ git clone --depth 1 \
https://github.com/preservim/nerdtree.git \
~/.vim/pack/vendor/start/nerdtree
```
启动 Vim 或者 gvim,然后键入如下命令:
```
:NERDTree
```
Vim 窗口左侧将打开一个文件树。

如果你不想让一个插件每次启动 Vim 时都自动加载,你可以在 `~/.vim/pack/vendor` 中创建 `opt` 文件夹:
```
$ mkdir ~/.vim/pack/vendor/opt
```
任何安装到 `opt` 的插件都可被 Vim 使用,但是只有当你使用 `packadd` 命令将它们添加到一个会话中时,它们才会被加载到内存中。例如,一个虚构的叫 foo 的插件:
```
:packadd foo
```
Vim 官方建议每个插件项目在 `~/.Vim/pack` 中创建自己的目录。例如,如果你要安装 NERDTree 插件和假想的 foo 插件,你需要创建这样的目录结构:
```
$ mkdir -p ~/.vim/pack/NERDTree/start/
$ git clone --depth 1 \
https://github.com/preservim/nerdtree.git \
~/.vim/pack/NERDTree/start/NERDTree
$ mkdir -p ~/.vim/pack/foo/start/
$ git clone --depth 1 \
https://notabug.org/foo/foo.git \
~/.vim/pack/foo/start/foo
```
这样做是否方便取决于你。
### 使用 Vim 包管理器(任何 Vim 版本)
自从 Vim 8 以后,包管理器变得不那么有用了,但是一些用户仍然喜欢它们,因为它们能够自动更新一些插件。有几个包管理器可供选择,并且它们各不相同,但是 [vim-plug](https://github.com/junegunn/vim-plug) 有一些很棒的特性和最好的文档,这使我们很容易开始并在以后深入研究。
#### 使用 vim-plug 安装插件
安装 vim-plug,以便它在启动时自动加载:
```
$ curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
```
创建一个 `~/.vimrc` 文件(如果你还没有这个文件),然后输入以下文本:
```
call plug#begin()
Plug 'preservim/NERDTree'
call plug#end()
```
每次要安装插件时,都必须在 `plug#begin()` 和 `plug#end()` 之间输入插件的名称和位置(上面以 NERDTree 文件管理器为例)。如果你所需的插件未托管在 GitHub 上,你可以提供完整的 URL,而不仅仅是 GitHub 的用户名和项目 ID。你甚至可以在 `~/.vim` 目录之外“安装”本地插件。
最后,启动 Vim 并提示 vim-plug 安装 `~/.vimrc` 中列出的插件:
```
:PlugInstall
```
等待插件下载。
#### 通过 vim-plug 更新插件
与手动安装过程相比,编辑 `~/.vimrc` 并使用命令来进行安装可能看起来并没有多省事,但是 vim-plug 的真正优势在更新。更新所有安装的插件,使用这个 Vim 命令:
```
:PlugUpdate
```
如果你不想更新所有的插件,你可以通过添加插件的名字来更新任何插件:
```
:PlugUpdate NERDTree
```
#### 恢复插件
vim-plug 的另一个优点是它的导出和恢复功能。Vim 用户都知道,正是插件的缘故,通常每个用户使用 Vim 的工作方式都是独一无二的。一旦你安装和配置了正确的插件组合,你最不想要的局面就是再也找不到它们。
Vim-plug 有这个命令来生成一个脚本来恢复所有当前的插件:
```
:PlugSnapshot ~/vim-plug.list
```
vim-plug 还有许多其他的功能,所以请参考它的[项目页面](https://github.com/junegunn/vim-plug)以获得完整的文档。
### 打造一个完美的 Vim
当你整天都在做一个项目时,你希望每一个小细节都能为你提供最好的服务。了解 Vim 和它的许多插件,直到你为你所做的事情构建出一个完美的应用程序。
有喜欢的 Vim 插件吗?请在评论中告诉我们吧!
---
via: <https://opensource.com/article/20/2/how-install-vim-plugins>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qianmingtian](https://github.com/qianmingtian) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While [Vim](https://www.vim.org/) is fast and efficient, by default, it is but a mere text editor. At least, that's what it would be without plugins, which build upon Vim and add extra features to make it so much more than just a window for typing text. With the right mix of plugins, you can take control of your life and forge your own unique Vim experience. You can [customize your theme](https://opensource.com/article/19/12/colors-themes-vim), and you can add syntax highlighting, code linting, version trackers, and much much more.
## How to install Vim plugins
Vim is extensible through plugins, but for a long time, there was no official method for installing them. As of the Vim 8.x series, however, there's a structure around how plugins are intended to be installed and loaded. You may encounter old instructions online or in project README files, but as long as you're running Vim 8 or greater, you should install according to Vim's [official plugin install method](https://github.com/vim/vim/blob/03c3bd9fd094c1aede2e8fe3ad8fd25b9f033053/runtime/doc/repeat.txt#L515) or with a Vim package manager. You can use a package manager regardless of what version you run (including releases older than 8.x), which makes the install process easier than maintaining updates yourself.
Both the manual and automated methods are worth knowing, so keep reading to learn about both.
## Install plugins manually (Vim 8 and above)
A Vim package is a directory containing one or more plugins. By default, your Vim settings are contained in **~/.vim**, so that's where Vim looks for plugins when you launch it. (The examples below use the generic name **vendor** to indicate that the plugins are obtained from an entity that is not you.)
When you start Vim, it first processes your **.vimrc** file, and then it scans all directories in **~/.vim** for plugins contained in **pack/*/start**.
By default, your **~/.vim** directory (if you even have one) has no such file structure, so set that up with:
`$ mkdir -p ~/.vim/pack/vendor/start`
Now you can place Vim plugins in **~/.vim/pack/vendor/start**, and they'll automatically load when you launch Vim.
For example, try installing [NERDTree](https://github.com/preservim/nerdtree), a text-based file manager for Vim. First, use Git to clone a snapshot of the NERDTree repository:
```
$ git clone --depth 1 \
https://github.com/preservim/nerdtree.git \
~/.vim/pack/vendor/start/nerdtree
```
Launch Vim or gvim, and type this command:
`:NERDTree`
A file tree will open along the left side of your Vim window.
If you don't want a plugin to load automatically every time you launch Vim, you can create an **opt** directory within your **~/.vim/pack/vendor** directory:
`$ mkdir ~/.vim/pack/vendor/opt`
Any plugins installed into **opt** are available to Vim, but they're not loaded into memory until you add them to a session with the **packadd** command.
For example, to load an imaginary plugin called **foo**:
`:packadd foo`
Officially, Vim recommends that each plugin project gets its own directory within **~/.vim/pack**. For example, if you were to install the NERDTree plugin and the imaginary foo plugin, you would create this structure:
```
$ mkdir -p ~/.vim/pack/NERDTree/start/
$ git clone --depth 1 \
https://github.com/preservim/nerdtree.git \
~/.vim/pack/NERDTree/start/NERDTree
$ mkdir -p ~/.vim/pack/foo/start/
$ git clone --depth 1 \
https://notabug.org/foo/foo.git \
~/.vim/pack/foo/start/foo
```
Whether that's convenient is up to you.
## Using a Vim package manager (any Vim version)
Since Vim series 8, package managers have become less useful, but some users still prefer them because of their ability to auto-update several plugins. There are several package managers to choose from, and they're each different, but [vim-plug](https://github.com/junegunn/vim-plug) has some great features and the best documentation of them all, which makes it easy to start with and to explore in depth later.
### Installing plugins with vim-plug
Install vim-plug so that it auto-loads at launch with:
```
$ curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
```
Create a **~/.vimrc** file (if you don't have one already), and enter this text:
```
call plug#begin()
Plug 'preservim/NERDTree'
call plug#end()
```
Each time you want to install a plugin, you must enter the name and location of the plugin between the **plug#begin()** and **plug#end** lines. (The NERDTree file manager is used above as an example.) If the plugin you want isn't hosted on GitHub, then you can provide the full URL instead of just the GitHub username and project ID. You can even "install" local plugins outside of your **~/.vim** directory.
Finally, start Vim and prompt vim-plug to install the plugins listed in **~/.vimrc**:
`:PlugInstall`
Wait for the plugins to be downloaded.
### Update plugins with vim-plug
Editing **~/.vimrc** and issuing a command to do the installation probably doesn't seem like much of a savings over the manual install process, but the real benefit to vim-plug is in updates. To update all installed plugins, issue this Vim command:
`:PlugUpdate`
If you don't want to update all plugins, you can update any subset by adding the plugin's name:
`:PlugUpdate NERDTree`
### Restore plugins
Another vim-plug benefit is its export and recovery function. As any Vim user knows, the way Vim works is often unique to each user—in part because of plugins. Once you get the right blend of plugins installed and configured, the last thing you want is to lose track of them.
Vim-plug has this command to generate a script for restoring all current plugins:
`:PlugSnapshot ~/vim-plug.list`
There are many other functions for vim-plug, so refer to its [project page](https://github.com/junegunn/vim-plug) for the full documentation.
## Create the perfect Vim
When you spend all day in a program, you want every little detail to serve you the best it possibly can. Get to know Vim and its many plugins until you build the perfect application for what you do.
Got a favorite Vim plugin? Tell us all about it in the comments!
## 5 Comments |
11,924 | 程序员为什么喜欢在晚上编码 | https://opensource.com/article/20/2/why-developers-code-night | 2020-02-24T10:43:48 | [
"夜间"
] | /article-11924-1.html |
>
> 对许多开源程序员来说,夜间的工作计划是创造力和生产力来源的关键。
>
>
>

如果你问大多数开发人员更喜欢在什么时候工作,大部人会说他们最高效的时间在晚上。这对于那些在工作之余为开源项目做贡献的人来说更是如此(尽管如此,希望在他们的健康范围内[避免透支](https://opensource.com/article/19/11/burnout-open-source-communities))。
有些人喜欢从晚上开始,一直工作到凌晨,而另一些人则很早就起床(例如,凌晨 4 点),以便在开始日常工作之前完成大部分编程工作。
这种工作习惯可能会使许多开发人员看起来像个怪人,不合时宜。但是,为什么有这么多的程序员喜欢在非正常时间工作,原因有很多:
### 制造者日程
根据 <ruby> <a href="http://www.paulgraham.com/makersschedule.html"> 保罗·格雷厄姆 </a> <rt> Paul Graham </rt></ruby> 的观点,“生产东西”的人倾向于遵守 制造者日程 —— 他们更愿意以半天或更长时间为单位使用时间。事实上,大多数[开发人员也有相同的偏好](https://www.chamberofcommerce.com/business-advice/software-development-trends-overtaking-the-market)。(LCTT 译注:保罗·格雷厄姆有[一篇文章](http://www.paulgraham.com/makersschedule.html)述及制造者日程和管理者日程。)
一方面,开发人员从事大型抽象系统工作,需要思维空间来处理整个模型。将他们的日程分割成 15 分钟或 30 分钟的时间段来处理电子邮件、会议、电话以及来自同事的打断,工作效果只会适得其反。
另一方面,通常不可能以小时为单位进行有效编程。因为这么短的时间几乎不够让你把思绪放在手头的任务上并开始工作。
上下文切换也会对编程产生不利影响。在晚上工作,开发人员可以避免尽可能多的干扰。在没有不断的干扰的情况下,他们可以花几个小时专注于手头任务,并尽可能提高工作效率。
### 平和安静的环境
由于晚上或凌晨不太会有来自各种活动的噪音(例如,办公室闲谈、街道上的交通),这使许多程序员感到放松,促使他们更具创造力和生产力,特别是在处理诸如编码之类的精神刺激任务时。
独处与平静,加上他们知道自己将有几个小时不被中断的工作时间,通常会使他们摆脱白天工作计划相关的时间压力,从而产出高质量的工作。
更不用说了,当解决了一个棘手的问题后,没有什么比尽情享受自己最喜欢的午夜小吃更美好的事情了!
### 沟通
与在公司内工作的程序员相比,从事开源项目的开发人员可以拥有不同的沟通节奏。大多数开源项目的沟通都是通过邮件或 GitHub 上的评论等渠道异步完成的。很多时候,其他程序员在不同的国家和时区,因此实时交流通常需要开发人员变成一个夜猫子。
### 昏昏欲睡的大脑
这听起来可能违反直觉,但是随着时间的推移,大脑会变得非常疲倦,因此只能专注于一项任务。晚上工作从根本上消除了多任务处理,而这是保持专注和高效的主要障碍。当大脑处于昏昏欲睡的状态时,你是无法保持专注的!
此外,许多开发人员在入睡时思考要解决的问题通常会取得重大进展。潜意识开始工作,答案通常在他们半睡半醒的凌晨时分就出现了。
这不足为奇,因为[睡眠可增强大脑功能](https://amerisleep.com/blog/sleep-impacts-brain-health/),可帮助我们理解新信息并进行更有创造性的思考。当解决方案在凌晨出现时,这些开发人员便会起来开始工作,不错过任何机会。
### 灵活和创造性思考
许多程序员体会到晚上创造力会提升。前额叶皮层,即大脑中与集中能力有关的部分,在一天结束时会感到疲倦。这似乎为某些人提供了更灵活和更具创造性的思考。
匹兹堡大学医学院精神病学助理教授 [Brant Hasler](https://www.vice.com/en_us/article/mb58a8/late-night-creativity-spike) 表示:“由于自上而下的控制和‘认知抑制’的减少,大脑可能会解放出来进行更发散的思考,从而使人们更容易地将不同概念之间的联系建立起来。” 结合轻松环境所带来的积极情绪,开发人员可以更轻松地产生创新想法。
此外,在没有干扰的情况下集中精力几个小时,“沉浸在你做的事情中”。这可以帮助你更好地专注于项目并参与其中,而不必担心周围发生的事情。
### 明亮的电脑屏幕
因为整天看着明亮的屏幕, 许多程序员的睡眠周期被延迟。电脑屏幕发出的蓝光[扰乱我们的昼夜节律](https://www.sleepfoundation.org/articles/how-blue-light-affects-kids-sleep),延迟了释放诱发睡眠的褪黑激素和提高人的机敏性,并将人体生物钟重置到更晚的时间。从而导致,开发人员往往睡得越来越晚。
### 来自过去的影响
过去,大多数开发人员是出于必要在晚上工作,因为在白天当公司其他人都在使用服务器时,共享服务器的计算能力支撑不了编程工作,所以开发人员需要等到深夜才能执行白天无法进行的任务,例如测试项目、运行大量的“编码-编译-运行-调试”周期以及部署新代码。现在尽管服务器功能变强大了,大多数可以满足需求,但夜间工作的趋势仍是这种文化的一部分。
### 结语
尽管开发人员喜欢在晚上工作的原因很多,但请记住,做为夜猫子并不意味着你应该克扣睡眠时间。睡眠不足会导致压力和焦虑,并最终导致倦怠。
获得足够质量的睡眠是维持良好身体健康和大脑功能的关键。例如,它可以帮助你整合新信息、巩固记忆、创造性思考、清除身体积聚的毒素、调节食欲并防止过早衰老。
无论你是哪种日程,请确保让你的大脑得到充分的休息,这样你就可以在一整天及每天的工作中发挥最大的作用!
---
via: <https://opensource.com/article/20/2/why-developers-code-night>
作者:[Matt Shealy](https://opensource.com/users/mshealy) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,926 | 通过 Org 模式管理 Chromium 和 Firefox 会话 | https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions-with-org-mode.html | 2020-02-24T11:30:57 | [
"浏览器",
"Org模式"
] | https://linux.cn/article-11926-1.html | 
我是[会话管理器](https://chrome.google.com/webstore/detail/session-manager/mghenlmbmjcpehccoangkdpagbcbkdpc?hl=en-US)的铁粉,它是 Chrome 和 Chromium 的小插件,可以保存所有打开的选项卡,为会话命名,并在需要时恢复会话。
它非常有用,特别是如果你像我一样,白天的时候需要在多个“思维活动”之间切换——研究、开发或者阅读新闻。或者你只是单纯地希望记住几天前的工作流(和选项卡)。
在我决定放弃 chromium 上除了 [uBlock Origin](https://chrome.google.com/webstore/detail/ublock-origin/cjpalhdlnbpafiamejdnhcphjbkeiagm?hl=en) 之外的所有扩展后,就必须寻找一些替代品了。我的主要目标是使之与浏览器无关,同时会话链接必须保存在文本文件中,这样我就可以享受所有纯文本的好处了。还有什么比 [org 模式](https://orgmode.org/)更好呢 ;)
很久以前我就发现了这个小诀窍:[通过命令行获取当前在谷歌 Chrome 中打开的标签](https://superuser.com/a/1310873) 再加上些 elisp 代码:
```
(require 'cl-lib)
(defun save-chromium-session ()
"Reads chromium current session and generate org-mode heading with items."
(interactive)
(save-excursion
(let* ((cmd "strings ~/'.config/chromium/Default/Current Session' | 'grep' -E '^https?://' | sort | uniq")
(ret (shell-command-to-string cmd)))
(insert
(concat
"* "
(format-time-string "[%Y-%m-%d %H:%M:%S]")
"\n"
(mapconcat 'identity
(cl-reduce (lambda (lst x)
(if (and x (not (string= "" x)))
(cons (concat " - " x) lst)
lst))
(split-string ret "\n")
:initial-value (list))
"\n"))))))
(defun restore-chromium-session ()
"Restore session, by openning each link in list with (browse-url).
Make sure to put cursor on date heading that contains list of urls."
(interactive)
(save-excursion
(beginning-of-line)
(when (looking-at "^\\*")
(forward-line 1)
(while (looking-at "^[ ]+-[ ]+\\(http.?+\\)$")
(let* ((ln (thing-at-point 'line t))
(ln (replace-regexp-in-string "^[ ]+-[ ]+" "" ln))
(ln (replace-regexp-in-string "\n" "" ln)))
(browse-url ln))
(forward-line 1)))))
```
那么,它的工作原理是什么呢?
运行上述代码,打开一个新 org 模式文件并调用 `M-x save-chromium-session`。它会创建类似这样的东西:
```
* [2019-12-04 12:14:02]
- https://www.reddit.com/r/emacs/comments/...
- https://www.reddit.com/r/Clojure
- https://news.ycombinator.com
```
也就是任何在 chromium 实例中运行着的 URL。要还原的话,则将光标置于所需日期上然后运行 `M-x restore-chromium-session`。所有标签都应该恢复了。
以下是我的使用案例,其中的数据是随机生成的:
```
#+TITLE: Browser sessions
* [2019-12-01 23:15:00]...
* [2019-12-02 18:10:20]...
* [2019-12-03 19:00:12]
- https://www.reddit.com/r/emacs/comments/...
- https://www.reddit.com/r/Clojure
- https://news.ycombinator.com
* [2019-12-04 12:14:02]
- https://www.reddit.com/r/emacs/comments/...
- https://www.reddit.com/r/Clojure
- https://news.ycombinator.com
```
请注意,用于读取 Chromium 会话的方法并不完美:`strings` 将从二进制数据库中读取任何类似 URL 字符串的内容,有时这将产生不完整的 URL。不过,你可以很方便地地编辑它们,从而保持会话文件简洁。
为了真正打开标签,elisp 代码中使用到了 [browse-url](https://www.gnu.org/software/emacs/manual/html_node/emacs/Browse_002dURL.html),它可以通过 `browse-url-browser-function` 变量进一步定制成运行 Chromium、Firefox 或任何其他浏览器。请务必阅读该变量的相关文档。
别忘了把会话文件放在 git、mercurial 或 svn 中,这样你就再也不会丢失会话历史记录了 :)
### 那么 Firefox 呢?
如果你正在使用 Firefox(最近的版本),并且想要获取会话 URL,下面是操作方法。
首先,下载并编译 [lz4json](https://github.com/andikleen/lz4json),这是一个可以解压缩 Mozilla lz4json 格式的小工具,Firefox 以这种格式来存储会话数据。会话数据(在撰写本文时)存储在 `$HOME/.mozilla/firefox/<unique-name>/sessionstore-backup /recovery.jsonlz4` 中。
如果 Firefox 没有运行,则没有 `recovery.jsonlz4`,这种情况下用 `previous.jsonlz4` 代替。
要提取网址,尝试在终端运行:
```
$ lz4jsoncat recovery.jsonlz4 | grep -oP '"(http.+?)"' | sed 's/"//g' | sort | uniq
```
然后更新 `save-chromium-session` 为:
```
(defun save-chromium-session ()
"Reads chromium current session and converts it to org-mode chunk."
(interactive)
(save-excursion
(let* ((path "~/.mozilla/firefox/<unique-name>/sessionstore-backups/recovery.jsonlz4")
(cmd (concat "lz4jsoncat " path " | grep -oP '\"(http.+?)\"' | sed 's/\"//g' | sort | uniq"))
(ret (shell-command-to-string cmd)))
...
;; rest of the code is unchanged
```
更新本函数的文档字符串、函数名以及进一步的重构都留作练习。
---
via: <https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions-with-org-mode.html>
作者:[Sanel Z](https://acidwords.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I was big fan of
[Session Manager](https://chrome.google.com/webstore/detail/session-manager/mghenlmbmjcpehccoangkdpagbcbkdpc?hl=en-US),
small addon for Chrome and Chromium that will save all open tabs,
assign the name to session and, when is needed, restore it.
Very useful, especially if you are like me, switching between multiple "mind sessions" during the day - research, development or maybe news reading. Or simply, you'd like to remember workflow (and tabs) you had few days ago.
After I decided to ditch all extensions from Chromium except
[uBlock Origin](https://chrome.google.com/webstore/detail/ublock-origin/cjpalhdlnbpafiamejdnhcphjbkeiagm?hl=en),
it was time to look for alternative. My main goal was it to
be browser agnostic and session links had to be stored in text file,
so I can enjoy all the goodies of plain text file. What would be
better for that than good old [org-mode](https://orgmode.org/) ;)
Long time ago I found this trick:
[Get the currently open tabs in Google Chrome via the command line](https://superuser.com/a/1310873)
and with some elisp sugar and coffee, here is the code:
```
(require 'cl-lib)
(defun save-chromium-session ()
"Reads chromium current session and generate org-mode heading with items."
(interactive)
(save-excursion
(let* ((cmd "strings ~/'.config/chromium/Default/Current Session' | 'grep' -E '^https?://' | sort | uniq")
(ret (shell-command-to-string cmd)))
(insert
(concat
"* "
(format-time-string "[%Y-%m-%d %H:%M:%S]")
"\n"
(mapconcat 'identity
(cl-reduce (lambda (lst x)
(if (and x (not (string= "" x)))
(cons (concat " - " x) lst)
lst))
(split-string ret "\n")
:initial-value (list))
"\n"))))))
(defun restore-chromium-session ()
"Restore session, by openning each link in list with (browse-url).
Make sure to put cursor on date heading that contains list of urls."
(interactive)
(save-excursion
(beginning-of-line)
(when (looking-at "^\\*")
(forward-line 1)
(while (looking-at "^[ ]+-[ ]+\\(http.?+\\)$")
(let* ((ln (thing-at-point 'line t))
(ln (replace-regexp-in-string "^[ ]+-[ ]+" "" ln))
(ln (replace-regexp-in-string "\n" "" ln)))
(browse-url ln))
(forward-line 1)))))
```
So, how does it work?
Evaluate above code, open new org-mode file and call `M-x save-chromium-session`
.
It will create something like this:
```
* [2019-12-04 12:14:02]
- https://www.reddit.com/r/emacs/comments/...
- https://www.reddit.com/r/Clojure
- https://news.ycombinator.com
```
or whatever urls are running in Chromium instance. To restore it back,
put cursor on desired date and run `M-x restore-chromium-session`
. All tabs
should be back.
Here is how I use it, with randomly generated data for the purpose of this text:
```
#+TITLE: Browser sessions
* [2019-12-01 23:15:00]...
* [2019-12-02 18:10:20]...
* [2019-12-03 19:00:12]
- https://www.reddit.com/r/emacs/comments/...
- https://www.reddit.com/r/Clojure
- https://news.ycombinator.com
* [2019-12-04 12:14:02]
- https://www.reddit.com/r/emacs/comments/...
- https://www.reddit.com/r/Clojure
- https://news.ycombinator.com
```
Note that hack for reading Chromium session isn't perfect: `strings`
will read whatever looks like string and url from binary database and
sometimes that will yield small artifacts in urls. But, you can
easily edit those and keep session file lean and clean.
To actually open tabs, elisp code will use
[browse-url](https://www.gnu.org/software/emacs/manual/html_node/emacs/Browse_002dURL.html)
and it can be further customized to run Chromium, Firefox or any other
browser with `browse-url-browser-function`
variable. Make sure to read
documentation for this variable.
Don't forget to put session file in git, mercurial or svn and enjoy the fact that you will never loose your session history again :)
## What about Firefox?
If you are using Firefox (recent versions) and would like to pull session urls, here is how to do it.
First, download and compile
[lz4json](https://github.com/andikleen/lz4json), small tool that
will decompress Mozilla lz4json format, where Firefox stores session
data. Session data (at the time of writing this post) is stored in
`$HOME/.mozilla/firefox/<unique-name>/sessionstore-backups/recovery.jsonlz4`
.
If Firefox is not running, `recovery.jsonlz4`
will not be present, but
use `previous.jsonlz4`
instead.
To extract urls, try this in terminal:
```
$ lz4jsoncat recovery.jsonlz4 | grep -oP '"(http.+?)"' | sed 's/"//g' | sort | uniq
```
and update `save-chromium-session`
with:
```
(defun save-chromium-session ()
"Reads chromium current session and converts it to org-mode chunk."
(interactive)
(save-excursion
(let* ((path "~/.mozilla/firefox/<unique-name>/sessionstore-backups/recovery.jsonlz4")
(cmd (concat "lz4jsoncat " path " | grep -oP '\"(http.+?)\"' | sed 's/\"//g' | sort | uniq"))
(ret (shell-command-to-string cmd)))
...
;; rest of the code is unchanged
```
Updating documentation strings, function name and any further refactoring is left for exercise. |
11,927 | 12 种自然语言处理的开源工具 | https://opensource.com/article/19/3/natural-language-processing-tools | 2020-02-25T10:32:51 | [
"NLP"
] | https://linux.cn/article-11927-1.html |
>
> 让我们看看可以用在你自己的 NLP 应用中的十几个工具吧。
>
>
>

在过去的几年里,自然语言处理(NLP)推动了聊天机器人、语音助手、文本预测等这些渗透到我们的日常生活中的语音或文本应用程技术的发展。目前有着各种各样开源的 NLP 工具,所以我决定调查一下当前开源的 NLP 工具来帮助你制定开发下一个基于语音或文本的应用程序的计划。
尽管我并不熟悉所有工具,但我将从我所熟悉的编程语言出发来介绍这些工具(对于我不熟悉的语言,我无法找到大量的工具)。也就是说,出于各种原因,我排除了三种我熟悉的语言之外的工具。
R 语言可能是没有被包含在内的最重要的语言,因为我发现的大多数库都有一年多没有更新了。这并不一定意味着它们没有得到很好的维护,但我认为它们应该得到更多的更新,以便和同一领域的其他工具竞争。我还选择了最有可能用在生产场景中的语言和工具(而不是在学术界和研究中使用),而我主要是使用 R 作为研究和发现工具。
我也惊讶地发现 Scala 的很多库都没有更新了。我上次使用 Scala 已经过去了两年了,当时它非常流行。但是大多数库从那个时候就再没有更新过,或者只有少数一些有更新。
最后,我排除了 C++。 这主要是因为我上次使用 C++ 编写程序已经有很多年了,而我所工作的组织还没有将 C++ 用于 NLP 或任何数据科学方面的工作。
### Python 工具
#### 自然语言工具包(NLTK)
毋庸置疑,[自然语言工具包(NLTK)](http://www.nltk.org/)是我调研过的所有工具中功能最完善的一个。它几乎实现了自然语言处理中多数功能组件,比如分类、令牌化、词干化、标注、分词和语义推理。每一个都有多种不同的实现方式,所以你可以选择具体的算法和方式。同时,它也支持不同的语言。然而,它以字符串的形式表示所有的数据,对于一些简单的数据结构来说可能很方便,但是如果要使用一些高级的功能来说就可能有点困难。它的使用文档有点复杂,但也有很多其他人编写的使用文档,比如[这本很棒的书](http://www.nltk.org/book_1ed/)。和其他的工具比起来,这个工具库的运行速度有点慢。但总的来说,这个工具包非常不错,可以用于需要具体算法组合的实验、探索和实际应用当中。
#### SpaCy
[SpaCy](https://spacy.io/) 可能是 NLTK 的主要竞争者。在大多数情况下都比 NLTK 的速度更快,但是 SpaCy 的每个自然语言处理的功能组件只有一个实现。SpaCy 把所有的东西都表示为一个对象而不是字符串,从而简化了应用构建接口。这也方便它与多种框架和数据科学工具的集成,使得你更容易理解你的文本数据。然而,SpaCy 不像 NLTK 那样支持多种语言。它确实接口简单,具有简化的选项集和完备的文档,以及用于语言处理和分析各种组件的多种神经网络模型。总的来说,对于需要在生产中表现出色且不需要特定算法的新应用程序,这是一个很不错的工具。
#### TextBlob
[TextBlob](https://textblob.readthedocs.io/en/dev/) 是 NLTK 的一个扩展库。你可以通过 TextBlob 用一种更简单的方式来使用 NLTK 的功能,TextBlob 也包括了 Pattern 库中的功能。如果你刚刚开始学习,这将会是一个不错的工具,可以用于对性能要求不太高的生产环境的应用。总体来说,TextBlob 适用于任何场景,但是对小型项目尤佳。
#### Textacy
这个工具是我用过的名字最好听的。先重读“ex”再带出“cy”,多读“[Textacy](https://readthedocs.org/projects/textacy/)”几次试试。它不仅仅是名字读起来好,同时它本身也是一个很不错的工具。它使用 SpaCy 作为它自然语言处理核心功能,但它在处理过程的前后做了很多工作。如果你想要使用 SpaCy,那么最好使用 Textacy,从而不用去编写额外的附加代码就可以处理不同种类的数据。
#### PyTorch-NLP
[PyTorch-NLP](https://pytorchnlp.readthedocs.io/en/latest/) 才出现短短的一年,但它已经有一个庞大的社区了。它适用于快速原型开发。当出现了最新的研究,或大公司或者研究人员推出了完成新奇的处理任务的其他工具时,比如图像转换,它就会被更新。总体来说,PyTorch 的目标用户是研究人员,但它也能用于原型开发,或使用最先进算法的初始生产载荷中。基于此基础上的创建的库也是值得研究的。
### Node.js 工具
#### Retext
[Retext](https://www.npmjs.com/package/retext) 是 [Unified 集合](https://unified.js.org/)的一部分。Unified 是一个接口,能够集成不同的工具和插件以便它们能够高效的工作。Retext 是 Unified 工具中使用的三种语法之一,另外的两个分别是用于 Markdown 的 Remark 和用于 HTML 的 Rehype。这是一个非常有趣的想法,我很高兴看到这个社区的发展。Retext 没有涉及很多的底层技术,更多的是使用插件去完成你在 NLP 任务中想要做的事情。拼写检查、字形修复、情绪检测和增强可读性都可以用简单的插件来完成。总体来说,如果你不想了解底层处理技术又想完成你的任务的话,这个工具和社区是一个不错的选择。
#### Compromise
[Compromise](https://www.npmjs.com/package/compromise) 显然不是最复杂的工具,如果你正在找拥有最先进的算法和最完备的系统的话,它可能不适合你。然而,如果你想要一个性能好、功能广泛、还能在客户端运行的工具的话,Compromise 值得一试。总体来说,它的名字(“折中”)是准确的,因为作者更关注更具体功能的小软件包,而在功能性和准确性上有所折中,这些小软件包得益于用户对使用环境的理解。
#### Natural
[Natural](https://www.npmjs.com/package/natural) 包含了常规自然语言处理库所具有的大多数功能。它主要是处理英文文本,但也包括一些其它语言,它的社区也欢迎支持其它的语言。它能够进行令牌化、词干化、分类、语音处理、词频-逆文档频率计算(TF-IDF)、WordNet、字符相似度计算和一些变换。它和 NLTK 有的一比,因为它想要把所有东西都包含在一个包里头,但它更易于使用,而且不一定专注于研究。总的来说,这是一个非常完整的库,目前仍在活跃开发中,但可能需要对底层实现有更多的了解才能完全发挥效力。
#### Nlp.js
[Nlp.js](https://www.npmjs.com/package/node-nlp) 建立在其他几个 NLP 库之上,包括 Franc 和 Brain.js。它为许多 NLP 组件提供了一个很好的接口,比如分类、情感分析、词干化、命名实体识别和自然语言生成。它也支持一些其它语言,在你处理英语之外的语言时能提供一些帮助。总之,它是一个不错的通用工具,并且提供了调用其他工具的简化接口。在你需要更强大或更灵活的工具之前,这个工具可能会在你的应用程序中用上很长一段时间。
### Java 工具
#### OpenNLP
[OpenNLP](https://opennlp.apache.org/) 是由 Apache 基金会管理的,所以它可以很方便地集成到其他 Apache 项目中,比如 Apache Flink、Apache NiFi 和 Apache Spark。这是一个通用的 NLP 工具,包含了所有 NLP 组件中的通用功能,可以通过命令行或者以包的形式导入到应用中来使用它。它也支持很多种语言。OpenNLP 是一个很高效的工具,包含了很多特性,如果你用 Java 开发生产环境产品的话,它是个很好的选择。
#### Stanford CoreNLP
[Stanford CoreNLP](https://stanfordnlp.github.io/CoreNLP/) 是一个工具集,提供了统计 NLP、深度学习 NLP 和基于规则的 NLP 功能。这个工具也有许多其他编程语言的版本,所以可以脱离 Java 来使用。它是由高水平的研究机构创建的一个高效的工具,但在生产环境中可能不是最好的。此工具采用双许可证,具有可以用于商业目的的特定许可证。总之,在研究和实验中它是一个很棒的工具,但在生产系统中可能会带来一些额外的成本。比起 Java 版本来说,读者可能对它的 Python 版本更感兴趣。同样,在 Coursera 上最好的机器学习课程之一是斯坦福教授提供的,[点此](https://opensource.com/article/19/2/learn-data-science-ai)访问其他不错的资源。
#### CogCompNLP
[CogCompNLP](https://github.com/CogComp/cogcomp-nlp) 由伊利诺斯大学开发的一个工具,它也有一个相似功能的 Python 版本。它可以用于处理文本,包括本地处理和远程处理,能够极大地缓解你本地设备的压力。它提供了很多处理功能,比如令牌化、词性标注、断句、命名实体标注、词型还原、依存分析和语义角色标注。它是一个很好的研究工具,你可以自己探索它的不同功能。我不确定它是否适合生产环境,但如果你使用 Java 的话,它值得一试。
---
你最喜欢的开源 NLP 工具和库是什么?请在评论区分享文中没有提到的工具。
---
via: <https://opensource.com/article/19/3/natural-language-processing-tools>
作者:[Dan Barker](https://opensource.com/users/barkerd427) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zxp](https://github.com/zhangxiangping) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Natural language processing (NLP), the technology that powers all the chatbots, voice assistants, predictive text, and other speech/text applications that permeate our lives, has evolved significantly in the last few years. There are a wide variety of open source NLP tools out there, so I decided to survey the landscape to help you plan your next voice- or text-based application.
For this review, I focused on tools that use languages I'm familiar with, even though I'm not familiar with all the tools. (I didn't find a great selection of tools in the languages I'm not familiar with anyway.) That said, I excluded tools in three languages I am familiar with, for various reasons.
The most obvious language I didn't include might be R, but most of the libraries I found hadn't been updated in over a year. That doesn't always mean they aren't being maintained well, but I think they should be getting updates more often to compete with other tools in the same space. I also chose languages and tools that are most likely to be used in production scenarios (rather than academia and research), and I have mostly used R as a research and discovery tool.
I was also surprised to see that the Scala libraries are fairly stagnant. It has been a couple of years since I last used Scala, when it was pretty popular. Most of the libraries haven't been updated since that time—or they've only had a few updates.
Finally, I excluded C++. This is mostly because it's been many years since I last wrote in C++, and the organizations I've worked in have not used C++ for NLP or any data science work.
## Python tools
### Natural Language Toolkit (NLTK)
It would be easy to argue that [Natural Language Toolkit (NLTK)](http://www.nltk.org/) is the most full-featured tool of the ones I surveyed. It implements pretty much any component of NLP you would need, like classification, tokenization, stemming, tagging, parsing, and semantic reasoning. And there's often more than one implementation for each, so you can choose the exact algorithm or methodology you'd like to use. It also supports many languages. However, it represents all data in the form of strings, which is fine for simple constructs but makes it hard to use some advanced functionality. The documentation is also quite dense, but there is a lot of it, as well as [a great book](http://www.nltk.org/book_1ed/). The library is also a bit slow compared to other tools. Overall, this is a great toolkit for experimentation, exploration, and applications that need a particular combination of algorithms.
### SpaCy
[SpaCy](https://spacy.io/) is probably the main competitor to NLTK. It is faster in most cases, but it only has a single implementation for each NLP component. Also, it represents everything as an object rather than a string, which simplifies the interface for building applications. This also helps it integrate with many other frameworks and data science tools, so you can do more once you have a better understanding of your text data. However, SpaCy doesn't support as many languages as NLTK. It does have a simple interface with a simplified set of choices and great documentation, as well as multiple neural models for various components of language processing and analysis. Overall, this is a great tool for new applications that need to be performant in production and don't require a specific algorithm.
### TextBlob
[TextBlob](https://textblob.readthedocs.io/en/dev/) is kind of an extension of NLTK. You can access many of NLTK's functions in a simplified manner through TextBlob, and TextBlob also includes functionality from the Pattern library. If you're just starting out, this might be a good tool to use while learning, and it can be used in production for applications that don't need to be overly performant. Overall, TextBlob is used all over the place and is great for smaller projects.
### Textacy
This tool may have the best name of any library I've ever used. Say "[Textacy](https://readthedocs.org/projects/textacy/)" a few times while emphasizing the "ex" and drawing out the "cy." Not only is it great to say, but it's also a great tool. It uses SpaCy for its core NLP functionality, but it handles a lot of the work before and after the processing. If you were planning to use SpaCy, you might as well use Textacy so you can easily bring in many types of data without having to write extra helper code.
### PyTorch-NLP
[PyTorch-NLP](https://pytorchnlp.readthedocs.io/en/latest/) has been out for just a little over a year, but it has already gained a tremendous community. It is a great tool for rapid prototyping. It's also updated often with the latest research, and top companies and researchers have released many other tools to do all sorts of amazing processing, like image transformations. Overall, PyTorch is targeted at researchers, but it can also be used for prototypes and initial production workloads with the most advanced algorithms available. The libraries being created on top of it might also be worth looking into.
## Node tools
### Retext
[Retext](https://www.npmjs.com/package/retext) is part of the [unified collective](https://unified.js.org/). Unified is an interface that allows multiple tools and plugins to integrate and work together effectively. Retext is one of three syntaxes used by the unified tool; the others are Remark for markdown and Rehype for HTML. This is a very interesting idea, and I'm excited to see this community grow. Retext doesn't expose a lot of its underlying techniques, but instead uses plugins to achieve the results you might be aiming for with NLP. It's easy to do things like checking spelling, fixing typography, detecting sentiment, or making sure text is readable with simple plugins. Overall, this is an excellent tool and community if you just need to get something done without having to understand everything in the underlying process.
### Compromise
[Compromise](https://www.npmjs.com/package/compromise) certainly isn't the most sophisticated tool. If you're looking for the most advanced algorithms or the most complete system, this probably isn't the right tool for you. However, if you want a performant tool that has a wide breadth of features and can function on the client side, you should take a look at Compromise. Overall, its name is accurate in that the creators compromised on functionality and accuracy by focusing on a small package with much more specific functionality that benefits from the user understanding more of the context surrounding the usage.
### Natural
[Natural](https://www.npmjs.com/package/natural) includes most functions you might expect in a general NLP library. It is mostly focused on English, but some other languages have been contributed, and the community is open to additional contributions. It supports tokenizing, stemming, classification, phonetics, term frequency–inverse document frequency, WordNet, string similarity, and some inflections. It might be most comparable to NLTK, in that it tries to include everything in one package, but it is easier to use and isn't necessarily focused around research. Overall, this is a pretty full library, but it is still in active development and may require additional knowledge of underlying implementations to be fully effective.
### Nlp.js
[Nlp.js](https://www.npmjs.com/package/node-nlp) is built on top of several other NLP libraries, including Franc and Brain.js. It provides a nice interface into many components of NLP, like classification, sentiment analysis, stemming, named entity recognition, and natural language generation. It also supports quite a few languages, which is helpful if you plan to work in something other than English. Overall, this is a great general tool with a simplified interface into several other great tools. This will likely take you a long way in your applications before you need something more powerful or more flexible.
## Java tools
### OpenNLP
[OpenNLP](https://opennlp.apache.org/) is hosted by the Apache Foundation, so it's easy to integrate it into other Apache projects, like Apache Flink, Apache NiFi, and Apache Spark. It is a general NLP tool that covers all the common processing components of NLP, and it can be used from the command line or within an application as a library. It also has wide support for multiple languages. Overall, OpenNLP is a powerful tool with a lot of features and ready for production workloads if you're using Java.
### StanfordNLP
[Stanford CoreNLP](https://stanfordnlp.github.io/CoreNLP/) is a set of tools that provides statistical NLP, deep learning NLP, and rule-based NLP functionality. Many other programming language bindings have been created so this tool can be used outside of Java. It is a very powerful tool created by an elite research institution, but it may not be the best thing for production workloads. This tool is dual-licensed with a special license for commercial purposes. Overall, this is a great tool for research and experimentation, but it may incur additional costs in a production system. The Python implementation might also interest many readers more than the Java version. Also, one of the best Machine Learning courses is taught by a Stanford professor on Coursera. [Check it out](https://opensource.com/article/19/2/learn-data-science-ai) along with other great resources.
### CogCompNLP
[CogCompNLP](https://github.com/CogComp/cogcomp-nlp), developed by the University of Illinois, also has a Python library with similar functionality. It can be used to process text, either locally or on remote systems, which can remove a tremendous burden from your local device. It provides processing functions such as tokenization, part-of-speech tagging, chunking, named-entity tagging, lemmatization, dependency and constituency parsing, and semantic role labeling. Overall, this is a great tool for research, and it has a lot of components that you can explore. I'm not sure it's great for production workloads, but it's worth trying if you plan to use Java.
What are your favorite open source tools and libraries for NLP? Please share in the comments—especially if there's one I didn't include.
## 3 Comments |
11,929 | 如何在 Ubuntu 上安装最新版本的 Git | https://itsfoss.com/install-git-ubuntu/ | 2020-02-25T11:49:04 | [
"Git"
] | https://linux.cn/article-11929-1.html | 在 Ubuntu 上安装 Git 非常容易。它存在于 [Ubuntu 的主仓库](https://itsfoss.com/ubuntu-repositories/)中,你可以像这样[使用 apt 命令](https://itsfoss.com/apt-command-guide/)安装它:
```
sudo apt install git
```
很简单?是不是?
只有一点点小问题(这可能根本不是问题),就是它安装的 [Git](https://git-scm.com/) 版本。
在 LTS 系统上,软件稳定性至关重要,这就是为什么 Ubuntu 18.04 和其他发行版经常提供较旧但稳定的软件版本的原因,它们都经过发行版的良好测试。
这就是为什么当你检查 Git 版本时,会看到安装的版本会比 [Git 网站上当前最新 Git 版本](https://git-scm.com/downloads)旧:
```
$ git --version
git version 2.17.1
```
在编写本教程时,网站上提供的版本为 2.25。那么,如何在 Ubuntu 上安装最新的 Git?
### 在基于 Ubuntu 的 Linux 发行版上安装最新的 Git

一种方法是[从源代码安装](https://itsfoss.com/install-software-from-source-code/)。这种很酷又老派的方法不适合所有人。值得庆幸的是,Ubuntu Git 维护团队提供了 [PPA](https://launchpad.net/%7Egit-core/+archive/ubuntu/ppa),莫可以使用它轻松地安装最新的稳定 Git 版本。
```
sudo add-apt-repository ppa:git-core/ppa
sudo apt update
sudo apt install git
```
即使你以前使用 `apt` 安装了 Git,它也将更新为最新的稳定版本。
```
$ git --version
git version 2.25.0
```
[使用PPA](https://itsfoss.com/ppa-guide/) 的好处在于,如果发布了新的 Git 稳定版本,那么就可以通过系统更新获得它。[仅更新 Ubuntu](https://itsfoss.com/update-ubuntu/) 来获取最新的 Git 稳定版本。
### 配置 Git (推荐给开发者)
如果你出于开发目的安装了 Git,你会很快开始克隆仓库,进行更改并提交更改。
如果你尝试提交代码,那么你可能会看到 “Please tell me who you are” 这样的错误:
```
$ git commit -m "update readme"
*** Please tell me who you are.
Run
git config --global user.email "[email protected]"
git config --global user.name "Your Name"
to set your account's default identity.
Omit --global to set the identity only in this repository.
fatal: unable to auto-detect email address (got 'abhishek@itsfoss.(none)')
```
这是因为你还没配置必要的个人信息。
正如错误已经暗示的那样,你可以像这样设置全局 Git 配置:
```
git config --global user.name "Your Name"
git config --global user.email "[email protected]"
```
你可以使用以下命令检查 Git 配置:
```
git config --list
```
它应该显示如下输出:
```
[email protected]
user.name=Your Name
```
配置保存在 `~/.gitconfig` 中。你可以手动修改配置。
### 结尾
我希望这个小教程可以帮助你在 Ubuntu 上安装 Git。使用 PPA,你可以轻松获得最新的 Git 版本。
如果你有任何疑问或建议,请随时在评论部分提问。也欢迎直接写“谢谢” :)
---
via: <https://itsfoss.com/install-git-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Installing Git on Ubuntu is very easy. It is available in the [main repository of Ubuntu](https://itsfoss.com/ubuntu-repositories/) and you can install it [using the apt command](https://itsfoss.com/apt-command-guide/) like this:
`sudo apt install git`
Easy? Isn’t it?
There is only a slight little problem (which might not be a problem at all) and that is the version of [Git](https://git-scm.com/?ref=itsfoss.com) it installs.
On an LTS system, software stability is of utmost importance this is why Ubuntu 18.04 and other distributions often provide older but stable versions of software that are well-tested with the distribution release.
This is why when you check the Git version, you’ll see that it installs a version which is older than the [current Git version available on Git project’s website](https://git-scm.com/downloads?ref=itsfoss.com):
```
abhishek@itsfoss:~$ git --version
git version 2.17.1
```
At the time of writing this tutorial, the version available on its website is 2.25. So how do you install the latest Git on Ubuntu then?
## Install latest Git on Ubuntu-based Linux distributions
One way would be to [install from source code](https://itsfoss.com/install-software-from-source-code/). That cool, old school method is not everyone’s cup of tea. Thankfully, there is a [PPA available from Ubuntu Git Maintainers team](https://launchpad.net/~git-core/+archive/ubuntu/ppa?ref=itsfoss.com) that you can use to easily install the latest stable Git version.
```
sudo add-apt-repository ppa:git-core/ppa
sudo apt update
sudo apt install git
```
Even if you had installed Git using apt previously, it will get updated to the latest stable version.
```
abhishek@itsfoss:~$ git --version
git version 2.25.0
```
The beauty of [using PPA](https://itsfoss.com/ppa-guide/) is that if there is a new stable version of Git released, you’ll get it with the system updates. [Just update Ubuntu](https://itsfoss.com/update-ubuntu/) to get the latest Git stable version.
[Linux creator Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/)?
## Configure Git [Recommended for developers]
If you have installed Git for development purposes, you’ll soon start cloning repos, make your changes and commit your change.
If you try to commit your code, you may see a ‘Please tell me who you are’ error like this:
```
abhishek@itsfoss:~/compress-pdf$ git commit -m "update readme"
*** Please tell me who you are.
Run
git config --global user.email "
```[[email protected]](/cdn-cgi/l/email-protection)"
git config --global user.name "Your Name"
to set your account's default identity.
Omit --global to set the identity only in this repository.
fatal: unable to auto-detect email address (got 'abhishek@itsfoss.(none)')
This is because you haven’t configured Git with your personal information which is mandatory.
As the error already hints, you can set up global Git configuration like this:
```
git config --global user.name "Your Name"
git config --global user.email "
```[[email protected]](/cdn-cgi/l/email-protection)"
You can check the Git configuration with this command:
`git config --list`
It should show an output like this:
[[email protected]](/cdn-cgi/l/email-protection)
user.name=abhishek
This configuration is stored in ~/.gitconfig file. You may also change it manually to change the configuration.
## Start learning Git
If you are new to Git, here's a quick primer into [basic Git commands](https://itsfoss.com/basic-git-commands-cheat-sheet/).
[Basic Git Commands You Must Know [Download Cheat Sheet]This quick guide shows you all the basic Git commands and their usage. You can also download these commands for quick reference.](https://itsfoss.com/basic-git-commands-cheat-sheet/)

I hope this quick little tutorial helped you to install Git on Ubuntu. With the PPA, you easily get the latest Git version.
If you have any questions or suggestions, please feel free to ask in the comment section. A quick ‘thank you’ is also welcomed :) |
11,930 | 利用 Tmux 和 kubectl 解决 Kubernetes 故障 | https://opensource.com/article/20/2/kubernetes-tmux-kubectl | 2020-02-25T12:55:18 | [
"kubectl",
"tmux"
] | https://linux.cn/article-11930-1.html |
>
> 一个使用 tmux 的 kubectl 插件可以使 Kubernetes 疑难问题变得更简单。
>
>
>

[Kubernetes](https://opensource.com/resources/what-is-kubernetes) 是一个活跃的开源容器管理平台,它提供了可扩展性、高可用性、健壮性和富有弹性的应用程序管理。它的众多特性之一是支持通过其主要的二进制客户端 [kubectl](https://kubernetes.io/docs/reference/kubectl/overview/) 运行定制脚本或可执行程序,kubectl 很强大的,允许用户在 Kubernetes 集群上用它直接做很多事情。
### 使用别名进行 Kubernetes 的故障排查
使用 Kubernetes 进行容器编排的人都知道由于设计上原因带来了其功能的复杂性。举例说,迫切需要以更快的速度并且几乎不需要手动干预的方式来简化 Kubernetes 中的故障排除(除过特殊情况)。
在故障排查功能方面,有很多场景需要考虑。在一种场景下,你知道你需要运行什么,但是这个命令的语法(即使作为一个单独的命令运行)过于复杂,或需要一、两次交互才能起作用。
例如,如果你需要经常进入一个系统命名空间中运行的容器,你可能发现自己在重复地键入:
```
kubectl --namespace=kube-system exec -i -t <your-pod-name>
```
为了简化故障排查,你可以用这些指令的命令行别名。比如,你可以增加下面命令到你的隐藏配置文件(`.bashrc` 或 `.zshrc`):
```
alias ksysex='kubectl --namespace=kube-system exec -i -t'
```
这是来自于 [Kubernetes 常见别名](https://github.com/ahmetb/kubectl-aliases/blob/master/.kubectl_aliases)存储库的一个例子,它展示了一种简化 `kubectl` 中的功能的方法。像这种场景下的简单情形,使用别名很有用。
### 切换到 kubectl 插件
更复杂的故障排查场景是需要一个一个的执行很多命令,调查环境,最后得出结论。仅仅用别名方法是不能解决这种情况的;你需要知道你所部署的 Kubernetes 之间逻辑和相关性,你真正需要的是自动化,以在更短的时间内输出你想要的。
考虑到你的集群有 10 ~ 20 或 50 ~ 100 个命名空间来提供不同的微服务。一般在进行故障排查时,什么对你有帮助?
* 你需要能够快速分辨出抛出错误的是哪个 命名空间的哪个 Pod 的东西。
* 你需要一些可监视一个命名空间的所有 Pod 日志的东西。
* 你可能也需要监视特定命名空间的出现错误的某个 Pod 的日志。
涵盖这些要点的解决方案对于定位生产环境的问题有很大的帮助,以及在开发和测试环节中也很有用。
你可以用 [kubectl 插件](https://kubernetes.io/docs/tasks/extend-kubectl/kubectl-plugins/)创建比简单的别名更强大的功能。插件类似于其它用任何语言编写的独立脚本,但被设计为可以扩充 Kubernetes 管理员的主要命令。
创建一个插件,你必须用 `kubectl-<your-plugin-name>` 的正确的语法来拷贝这个脚本到 `$PATH` 中的导出目录之一,并需要为其赋予可执行权限(`chmod +x`)。
创建插件之后将其移动到路径中,你可以立即运行它。例如,我的路径下有一个 `kubectl-krawl` 和 `kubectl-kmux`:
```
$ kubectl plugin list
The following compatible plugins are available:
/usr/local/bin/kubectl-krawl
/usr/local/bin/kubectl-kmux
$ kubectl kmux
```
现在让我们见识下带有 tmux 的 Kubernetes 的有多强大。
### 驾驭强大的 tmux
[Tmux](https://opensource.com/article/19/6/tmux-terminal-joy) 是一个非常强大的工具,许多管理员和运维团队都依赖它来解决与易操作性相关的问题:通过将窗口分成多个窗格以便在多台计算机上运行并行的调试来监视日志。它的主要的优点是可在命令行或自动化脚本中使用。
我创建[一个 kubectl 插件](https://github.com/abhiTamrakar/kube-plugins),使用 tmux 使故障排查更加简单。我将通过注释来解析插件背后的逻辑(插件的完整代码留待给你实现):
```
# NAMESPACE 是要监控的名字空间
# POD 是 Pod 名称
# Containers 是容器名称
# 初始化一个计数器 n 以计算循环计数的数量,
# 之后 tmux 使用它来拆分窗格。
n=0;
# 在 Pod 和容器列表上开始循环
while IFS=' ' read -r POD CONTAINERS
do
# tmux 为每个 Pod 创建一个新窗口
tmux neww $COMMAND -n $POD 2>/dev/null
# 对运行中的 Pod 中 的所有容器启动循环
for CONTAINER in ${CONTAINERS//,/ }
do
if [ x$POD = x -o x$CONTAINER = x ]; then
# 如果任何值为 null,则退出。
warn "Looks like there is a problem getting pods data."
break
fi
# 设置要执行的命令
COMMAND=”kubectl logs -f $POD -c $CONTAINER -n $NAMESPACE”
# 检查 tmux 会话
if tmux has-session -t <会话名> 2>/dev/null;
then
<设置会话退出>
else
<创建会话>
fi
# 在当前窗口为每个容器切分窗格
tmux selectp -t $n \; \
splitw $COMMAND \; \
select-layout tiled \;
# 终止容器循环
done
# 用 Pod 名称重命名窗口以识别
tmux renamew $POD 2>/dev/null
# 增加计数器
((n+=1))
# 终止 Pod 循环
done<<(<从 kubernetes 集群获取 Pod 和容器的列表>)
# 最后选择窗口并附加会话
tmux selectw -t <会话名>:1 \; \
attach-session -t <会话名>\;
```
运行插件脚本后,将产生类似于下图的输出。每个 Pod 有一个自己的窗口,每个容器(如果有多个)被分割到其窗口中 Pod 窗格中,并在日志到达时输出。Tmux 之美如下可见;通过正确的配置,你甚至会看到哪个窗口正处于激活运行状态(可看到标签是白色的)。

### 总结
别名是在 Kubernetes 环境下常见的也有用的简易故障排查方法。当环境变得复杂,用高级脚本生成的kubectl 插件是一个更强大的方法。至于用哪个编程语言来编写 kubectl 插件是没有限制。唯一的要求是该名字在路径中是可执行的,并且不能与已知的 kubectl 命令重复。
要阅读完整的插件源码,或试试我创建的插件,请查看我的 [kube-plugins-github](https://github.com/abhiTamrakar/kube-plugins) 存储库。欢迎提交提案和补丁。
---
via: <https://opensource.com/article/20/2/kubernetes-tmux-kubectl>
作者:[Abhishek Tamrakar](https://opensource.com/users/tamrakar) 选题:[lujun9972](https://github.com/lujun9972) 译者:[guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Kubernetes](https://opensource.com/resources/what-is-kubernetes) is a thriving open source container orchestration platform that offers scalability, high availability, robustness, and resiliency for applications. One of its many features is support for running custom scripts or binaries through its primary client binary, [kubectl](https://kubernetes.io/docs/reference/kubectl/overview/). Kubectl is very powerful and allows users to do anything with it that they could do directly on a Kubernetes cluster.
## Troubleshooting Kubernetes with aliases
Anyone who uses Kubernetes for container orchestration is aware of its features—as well as the complexity it brings because of its design. For example, there is an urgent need to simplify troubleshooting in Kubernetes with something that is quicker and has little need for manual intervention (except in critical situations).
There are many scenarios to consider when it comes to troubleshooting functionality. In one scenario, you know what you need to run, but the command's syntax—even when it can run as a single command—is excessively complex, or it may need one or two inputs to work.
For example, if you frequently need to jump into a running container in the System namespace, you may find yourself repeatedly writing:
`kubectl --namespace=kube-system exec -i -t <your-pod-name>`
To simplify troubleshooting, you could use command-line aliases of these commands. For example, you could add the following to your dotfiles (.bashrc or .zshrc):
`alias ksysex='kubectl --namespace=kube-system exec -i -t'`
This is one of many examples from a [repository of common Kubernetes aliases](https://github.com/ahmetb/kubectl-aliases/blob/master/.kubectl_aliases) that shows one way to simplify functions in kubectl. For something simple like this scenario, an alias is sufficient.
## Switching to a kubectl plugin
A more complex troubleshooting scenario involves the need to run many commands, one after the other, to investigate an environment and come to a conclusion. Aliases alone are not sufficient for this use
case; you need repeatable logic and correlations between the many parts of your Kubernetes deployment. What you really need is automation to deliver the desired output in less time.
Consider 10 to 20—or even 50 to 100—namespaces holding different microservices on your cluster. What would be helpful for you to start troubleshooting this scenario?
- You would need something that can quickly tell which pod in which namespace is throwing errors.
- You would need something that can watch logs of all the pods in a namespace.
- You might also need to watch logs of certain pods in a specific namespace that have shown errors.
Any solution that covers these points would be very useful in investigating production issues as well as during development and testing cycles.
To create something more powerful than a simple alias, you can use [kubectl plugins](https://kubernetes.io/docs/tasks/extend-kubectl/kubectl-plugins/). Plugins are like standalone scripts written in any scripting language but are designed to extend the functionality of your main command when serving as a Kubernetes admin.
To create a plugin, you must use the proper syntax of **kubectl-<your-plugin-name>** to copy the script to one of the exported pathways in your **$PATH** and give it executable permissions (**chmod +x**).
After creating a plugin and moving it into your path, you can run it immediately. For example, I have kubectl-krawl and kubectl-kmux in my path:
```
$ kubectl plugin list
The following compatible plugins are available:
/usr/local/bin/kubectl-krawl
/usr/local/bin/kubectl-kmux
$ kubectl kmux
```
Now let's explore what this looks like when you power Kubernetes with tmux.
## Harnessing the power of tmux
[Tmux](https://opensource.com/article/19/6/tmux-terminal-joy) is a very powerful tool that many sysadmins and ops teams rely on to troubleshoot issues related to ease of operability—from splitting windows into panes for running parallel debugging on multiple machines to monitoring logs. One of its major advantages is that it can be used on the command line or in automation scripts.
I created [a kubectl plugin](https://github.com/abhiTamrakar/kube-plugins) that uses tmux to make troubleshooting much simpler. I will use annotations to walk through the logic behind the plugin (and leave it for you to go through the plugin's full code):
```
#NAMESPACE is namespace to monitor.
#POD is pod name
#Containers is container names
# initialize a counter n to count the number of loop counts, later be used by tmux to split panes.
n=0;
# start a loop on a list of pod and containers
while IFS=' ' read -r POD CONTAINERS
do
# tmux create the new window for each pod
tmux neww $COMMAND -n $POD 2>/dev/null
# start a loop for all containers inside a running pod
for CONTAINER in ${CONTAINERS//,/ }
do
if [ x$POD = x -o x$CONTAINER = x ]; then
# if any of the values is null, exit.
warn "Looks like there is a problem getting pods data."
break
fi
# set the command to execute
COMMAND=”kubectl logs -f $POD -c $CONTAINER -n $NAMESPACE”
# check tmux session
if tmux has-session -t <session name> 2>/dev/null;
then
<set session exists>
else
<create session>
fi
# split planes in the current window for each containers
tmux selectp -t $n \; \
splitw $COMMAND \; \
select-layout tiled \;
# end loop for containers
done
# rename the window to identify by pod name
tmux renamew $POD 2>/dev/null
# increment the counter
((n+=1))
# end loop for pods
done< <(<fetch list of pod and containers from kubernetes cluster>)
# finally select the window and attach session
tmux selectw -t <session name>:1 \; \
attach-session -t <session name>\;
```
After the plugin script runs, it will produce output similar to the image below. Each pod has its own window, and each container (if there is more than one) is split by the panes in its pod window, streaming logs as they arrive. The beauty of tmux can be seen below; with the proper configuration, you can even see which window has activity going on (see the white tabs).
## Conclusion
Aliases are always helpful for simple troubleshooting in Kubernetes environments. When the environment gets more complex, a kubectl plugin is a powerful option for using more advanced scripting. There are no limits on which programming language you can use to write kubectl plugins. The only requirements are that the naming convention in the path is executable, and it doesn't have the same name as an existing kubectl command.
To read the complete code or try the plugins I created, check my [kube-plugins-github](https://github.com/abhiTamrakar/kube-plugins) repository. Issues and pull requests are welcome.
## 5 Comments |
11,931 | 使用 dig 命令挖掘域名解析信息 | https://www.networkworld.com/article/3527430/digging-up-ip-addresses-with-the-dig-command.html | 2020-02-26T09:41:19 | [
"dig"
] | https://linux.cn/article-11931-1.html |
>
> 命令行工具 `dig` 是用于解析域名和故障排查的一个利器。
>
>
>

从主要功能上来说,`dig` 和 `nslookup` 之间差异不大,但 `dig` 更像一个加强版的 `nslookup`,可以查询到一些由域名服务器管理的信息,这在排查某些问题的时候非常有用。总的来说,`dig` 是一个既简单易用又功能强大的命令行工具。(LCTT 译注:`dig` 和 `nslookup` 行为的主要区别来自于 `dig` 使用是是操作系统本身的解析库,而 `nslookup` 使用的是该程序自带的解析库,这有时候会带来一些行为差异。此外,从表现形式上看,`dig` 返回是结果是以 BIND 配置信息的格式返回的,也带有更多的技术细节。)
`dig` 最基本的功能就是查询域名信息,因此它的名称实际上是“<ruby> 域名信息查询工具 <rt> Domain Information Groper </rt></ruby>”的缩写。`dig` 向用户返回的内容可以非常详尽,也可以非常简洁,展现内容的多少完全由用户在查询时使用的选项来决定。
### 我只需要查询 IP 地址
如果只需要查询某个域名指向的 IP 地址,可以使用 `+short` 选项:
```
$ dig facebook.com +short
31.13.66.35
```
在查询的时候发现有的域名会指向多个 IP 地址?这其实是网站提高其可用性的一种措施。
```
$ dig networkworld.com +short
151.101.2.165
151.101.66.165
151.101.130.165
151.101.194.165
```
也正是由于这些网站通过负载均衡实现高可用,在下一次查询的时候,或许会发现这几个 IP 地址的排序有所不同。(LCTT 译注:浏览器等应用默认会使用返回的第一个 IP 地址,因此这样实现了一种简单的负载均衡。)
```
$ dig networkworld.com +short
151.101.130.165
151.101.194.165
151.101.2.165
151.101.66.165
```
### 标准返回
`dig` 的标准返回内容则包括这个工具本身的一些信息,以及请求域名服务器时返回的响应内容:
```
$ dig networkworld.com
; <<>> DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu <<>*gt; networkworld.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 39932
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 65494
;; QUESTION SECTION:
;networkworld.com. IN A
;; ANSWER SECTION:
networkworld.com. 300 IN A 151.101.194.165
networkworld.com. 300 IN A 151.101.130.165
networkworld.com. 300 IN A 151.101.66.165
networkworld.com. 300 IN A 151.101.2.165
;; Query time: 108 msec
;; SERVER: 127.0.0.53#53(127.0.0.53)
;; WHEN: Thu Feb 13 13:49:53 EST 2020
;; MSG SIZE rcvd: 109
```
由于域名服务器有缓存机制,返回的内容可能是之前缓存好的信息。在这种情况下,`dig` 最后显示的<ruby> 查询时间 <rt> Query time </rt></ruby>会是 0 毫秒(0 msec):
```
;; Query time: 0 msec <==
;; SERVER: 127.0.0.53#53(127.0.0.53)
;; WHEN: Thu Feb 13 15:30:09 EST 2020
;; MSG SIZE rcvd: 109
```
### 向谁查询?
在默认情况下,`dig` 会根据 `/etc/resolv.conf` 这个文件的内容决定向哪个域名服务器获取查询结果。你也可以使用 `@` 来指定 `dig` 请求的域名服务器。
在下面的例子中,就指定了 `dig` 向 Google 的域名服务器 8.8.8.8 查询域名信息。
```
$ dig @8.8.8.8 networkworld.com
; <<>> DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu <<>> @8.8.8.8 networkworld.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 21163
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;networkworld.com. IN A
;; ANSWER SECTION:
networkworld.com. 299 IN A 151.101.130.165
networkworld.com. 299 IN A 151.101.66.165
networkworld.com. 299 IN A 151.101.194.165
networkworld.com. 299 IN A 151.101.2.165
;; Query time: 48 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Thu Feb 13 14:26:14 EST 2020
;; MSG SIZE rcvd: 109
```
想要知道正在使用的 `dig` 工具的版本,可以使用 `-v` 选项。你会看到类似这样:
```
$ dig -v
DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu
```
或者这样的返回信息:
```
$ dig -v
DiG 9.11.4-P2-RedHat-9.11.4-22.P2.el8
```
如果你觉得 `dig` 返回的内容过于详细,可以使用 `+noall`(不显示所有内容)和 `+answer`(仅显示域名服务器的响应内容)选项,域名服务器的详细信息就会被忽略,只保留域名解析结果。
```
$ dig networkworld.com +noall +answer
; <<>> DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu <<>> networkworld.com +noall +answer
;; global options: +cmd
networkworld.com. 300 IN A 151.101.194.165
networkworld.com. 300 IN A 151.101.130.165
networkworld.com. 300 IN A 151.101.66.165
networkworld.com. 300 IN A 151.101.2.165
```
### 批量查询域名
如果你要查询多个域名,可以把这些域名写入到一个文件内(`domains`),然后使用下面的 `dig` 命令遍历整个文件并给出所有查询结果。
```
$ dig +noall +answer -f domains
networkworld.com. 300 IN A 151.101.66.165
networkworld.com. 300 IN A 151.101.2.165
networkworld.com. 300 IN A 151.101.130.165
networkworld.com. 300 IN A 151.101.194.165
world.std.com. 77972 IN A 192.74.137.5
uushenandoah.org. 1982 IN A 162.241.24.209
amazon.com. 18 IN A 176.32.103.205
amazon.com. 18 IN A 176.32.98.166
amazon.com. 18 IN A 205.251.242.103
```
你也可以在上面的命令中使用 `+short` 选项,但如果其中有些域名指向多个 IP 地址,就无法看出哪些 IP 地址对应哪个域名了。在这种情况下,更好地做法应该是让 `awk` 对返回内容进行处理,只留下第一列和最后一列:
```
$ dig +noall +answer -f domains | awk '{print $1,$NF}'
networkworld.com. 151.101.66.165
networkworld.com. 151.101.130.165
networkworld.com. 151.101.194.165
networkworld.com. 151.101.2.165
world.std.com. 192.74.137.5
amazon.com. 176.32.98.166
amazon.com. 205.251.242.103
amazon.com. 176.32.103.205
```
---
via: <https://www.networkworld.com/article/3527430/digging-up-ip-addresses-with-the-dig-command.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,932 | 使用 Emacs 发送电子邮件和检查日历 | https://opensource.com/article/20/1/emacs-mail-calendar | 2020-02-26T10:37:00 | [
"Emacs"
] | /article-11932-1.html |
>
> 在 2020 年用开源实现更高生产力的二十种方式的第十八篇文章中,使用 Emacs 文本编辑器管理电子邮件和查看日程安排。
>
>
>

去年,我给你们带来了 2019 年的 19 天新生产力工具系列。今年,我将采取一种不同的方式:建立一个新的环境,让你使用已用或未用的工具来在新的一年里变得更有效率。
### 使用 Emacs 做(几乎)所有的事情,第 1 部分
两天前,我曾经说过我经常使用 [Vim](https://www.vim.org/) 和 [Emacs](https://www.gnu.org/software/emacs/),在本系列的 [16](/article-11908-1.html) 和 [17](/article-11912-1.html) 天,我讲解了如何在 Vim 中做几乎所有的事情。现在,Emacs 的时间到了!

在深入之前,我需要说明两件事。首先,我这里使用默认的 Emacs 配置,而不是我之前[写过](https://opensource.com/article/19/12/spacemacs)的 [Spacemacs](https://www.spacemacs.org/)。为什么呢?因为这样一来我使用的就是默认快捷键,从而使你可以参考文档,而不必将“原生的 Emacs” 转换为 Spacemacs。第二,在本系列文章中我没有对 Org 模式进行任何设置。Org 模式本身几乎可以自成一个完整的系列,它非常强大,但是设置可能非常复杂。
#### 配置 Emacs
配置 Emacs 比配置 Vim 稍微复杂一些,但以我之见,从长远来看,这样做是值得的。首先我们创建一个配置文件,并在 Emacs 中打开它:
```
mkdir ~/.emacs.d
emacs ~/.emacs.d/init.el
```
接下来,向内置的包管理器添加一些额外的包源。在 `init.el` 中添加以下内容:
```
(package-initialize)
(add-to-list 'package-archives '("melpa" . "<http://melpa.org/packages/>"))
(add-to-list 'package-archives '("org" . "<http://orgmode.org/elpa/>") t)
(add-to-list 'package-archives '("gnu" . "<https://elpa.gnu.org/packages/>"))
(package-refresh-contents)
```
使用 `Ctrl+x Ctrl+s` 保存文件,然后按下 `Ctrl+x Ctrl+c` 退出,再重启 Emacs。Emacs 会在启动时下载所有的插件包列表,之后你就可以使用内置的包管理器安装插件了。输入 `Meta+x` 会弹出命令提示符(大多数键盘上 `Meta` 键就是的 `Alt` 键,而在 MacOS 上则是 `Option`)。在命令提示符下输入 `package-list-packages` 就会显示可以安装的包列表。遍历该列表并使用 `i` 键选择以下包:
```
bbdb
bbdb-vcard
calfw
calfw-ical
notmuch
```
选好软件包后按 `x` 安装它们。根据你的网络连接情况,这可能需要一段时间。你也许会看到一些编译错误,但是可以忽略它们。安装完成后,使用组合键 `Ctrl+x Ctrl+f` 打开 `~/.emacs.d/init.el`,并在 `(package-refresh-packages)` 之后、 `(custom-set-variables` 之前添加以下行到文件中。 `(custom-set-variables` 行由 Emacs 内部维护,你永远不应该修改它之后的任何内容。以 `;;` 开头的行则是注释。
```
;; Set up bbdb
(require 'bbdb)
(bbdb-initialize 'message)
(bbdb-insinuate-message)
(add-hook 'message-setup-hook 'bbdb-insinuate-mail)
;; set up calendar
(require 'calfw)
(require 'calfw-ical)
;; Set this to the URL of your calendar. Google users will use
;; the Secret Address in iCalendar Format from the calendar settings
(cfw:open-ical-calendar "<https://path/to/my/ics/file.ics>")
;; Set up notmuch
(require 'notmuch)
;; set up mail sending using sendmail
(setq send-mail-function (quote sendmail-send-it))
(setq user-mail-address "[[email protected]][9]"
user-full-name "My Name")
```
现在,你已经准备好使用自己的配置启动 Emacs 了!保存 `init.el` 文件(`Ctrl+x Ctrl+s`),退出 Emacs(`Ctrl+x Ctrl+c`),然后重启之。这次重启要多花些时间。
#### 使用 Notmuch 在 Emacs 中读写电子邮件
一旦你看到了 Emacs 启动屏幕,你就可以使用 [Notmuch](https://notmuchmail.org/) 来阅读电子邮件了。键入 `Meta+x notmuch`,你将看到 notmuch 的 Emacs 界面。

所有加粗的项目都是指向电子邮件视图的链接。你可以通过点击鼠标或者使用 `tab` 键在它们之间跳转并按回车来访问它们。你可以使用搜索栏来搜索 Notmuch 的数据库,语法与 Notmuch 命令行上的[语法](/article-11807-1.html) 相同。如果你愿意,还可以使用 `[save]` 按钮保存搜索以便未来使用,这些搜索会被添加到屏幕顶部的列表中。如果你进入一个链接就会看到一个相关电子邮件的列表。你可以使用箭头键在列表中导航,并在要读取的消息上按回车。按 `r` 可以回复一条消息,`f` 转发该消息,`q` 退出当前屏幕。
你可以通过键入 `Meta+x compose-mail` 来编写新消息。撰写、回复和转发都将打开编写邮件的界面。写完邮件后,按 `Ctrl+c Ctrl+c` 发送。如果你决定不发送它,按 `Ctrl+c Ctrl+k` 关闭消息撰写缓冲区(窗口)。
#### 使用 BBDB 在 Emacs 中自动补完电子邮件地址

那么通讯录怎么办?这就是 [BBDB](https://www.jwz.org/bbdb/) 发挥作用的地方。但首先我们需要从 [abook](/article-11834-1.html) 导入所有地址,方法是打开命令行并运行以下导出命令:
```
abook --convert --outformat vcard --outfile ~/all-my-addresses.vcf --infile ~/.abook/addresses
```
Emacs 启动后,运行 `Meta+x bbdb-vcard-import-file`。它将提示你输入要导入的文件名,即 `~/all-my-address.vcf`。导入完成后,在编写消息时,可以开始输入名称并使用 `Tab` 搜索和自动完成 “to” 字段的内容。BBDB 还会打开一个联系人缓冲区,以便你确保它是正确的。
既然在 [vdirsyncer](/article-11812-1.html) 中已经为每个地址都生成了对应的 .vcf 文件了,为什么我们还要这样做呢?如果你像我一样,有许多地址,一次处理一个地址是很麻烦的。这样做,你就可以把所有的东西都放在 abook 里,做成一个大文件。
#### 使用 calfw 在 Emacs 中浏览日历

最后,你可以使用 Emacs 查看日历。在上面的配置中,你安装了 [calfw](https://github.com/kiwanami/emacs-calfw) 包,并添加了一些行来告诉它在哪里可以找到要加载的日历。Calfw 是 “<ruby> Emacs 日历框架 <rt> Calendar Framework for Emacs </rt></ruby>”的简称,它支持多种日历格式。我使用的是谷歌日历,这也是我放在配置中的链接。日历将在启动时自动加载,你可以通过 `Ctrl+x+b` 命令切换到 cfw-calendar 缓冲区来查看日历。
Calfw 提供日、周、双周和月视图。你可以在日历顶部选择视图,并使用箭头键导航日历。不幸的是,calfw 只能查看日历,所以你仍然需要使用 [khal](https://khal.readthedocs.io/en/v0.9.2/index.html) 之类的工具或通过 web 界面来添加、删除和修改事件。
这就是 Emacs 中的邮件、日历和邮件地址。明天我会展示更多。
---
via: <https://opensource.com/article/20/1/emacs-mail-calendar>
作者:[Kevin Sonney](https://opensource.com/users/ksonney) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.