
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
11,456 | 7 个实用的操作 Bash 历史记录的快捷方式 | https://opensource.com/article/19/10/bash-history-shortcuts | 2019-10-14T11:16:27 | [
"Bash",
"历史记录"
] | https://linux.cn/article-11456-1.html |
>
> 这些必不可少的 Bash 快捷键可在命令行上节省时间。
>
>
>

大多数介绍 Bash 历史记录的指南都详尽地列出了全部可用的快捷方式。这样做的问题是,你会对每个快捷方式都浅尝辄止,然后在尝试了那么多的快捷方式后就搞得目不暇接。而在开始工作时它们就全被丢在脑后,只记住了刚开始使用 Bash 时学到的 [!! 技巧](https://opensource.com/article/18/5/bash-tricks)。这些技巧大多数从未进入记忆当中。
本文概述了我每天实际使用的快捷方式。它基于我的书《[Bash 学习,艰难之旅](https://leanpub.com/learnbashthehardway)》中的某些内容(你可以阅读其中的[样章](https://leanpub.com/learnbashthehardway/read_sample)以了解更多信息)。
当人们看到我使用这些快捷方式时,他们经常问我:“你做了什么!?” 学习它们只需付出很少的精力或智力,但是要真正的学习它们,我建议每周用一天学一个,然后下次再继续学习一个。值得花时间让它们落在你的指尖下,因为从长远来看,节省的时间将很重要。
### 1、最后一个参数:`!$`
如果你仅想从本文中学习一种快捷方式,那就是这个。它会将最后一个命令的最后一个参数替换到你的命令行中。
看看这种情况:
```
$ mv /path/to/wrongfile /some/other/place
mv: cannot stat '/path/to/wrongfile': No such file or directory
```
啊哈,我在命令中写了错误的文件名 “wrongfile”,我应该用正确的文件名 “rightfile” 代替。
你可以重新键入上一个命令,并用 “rightfile” 完全替换 “wrongfile”。但是,你也可以键入:
```
$ mv /path/to/rightfile !$
mv /path/to/rightfile /some/other/place
```
这个命令也可以奏效。
在 Bash 中还有其他方法可以通过快捷方式实现相同的目的,但是重用上一个命令的最后一个参数的这种技巧是我最常使用的。
### 2、第 n 个参数:`!:2`
是不是干过像这样的事情:
```
$ tar -cvf afolder afolder.tar
tar: failed to open
```
像许多其他人一样,我也经常搞错 `tar`(和 `ln`)的参数顺序。

当你搞混了参数,你可以这样:
```
$ !:0 !:1 !:3 !:2
tar -cvf afolder.tar afolder
```
这样就不会出丑了。
上一个命令的各个参数的索引是从零开始的,并且可以用 `!:` 之后跟上该索引数字代表各个参数。
显然,你也可以使用它来重用上一个命令中的特定参数,而不是所有参数。
### 3、全部参数:`!:1-$`
假设我运行了类似这样的命令:
```
$ grep '(ping|pong)' afile
```
参数是正确的。然而,我想在文件中匹配 “ping” 或 “pong”,但我使用的是 `grep` 而不是 `egrep`。
我开始输入 `egrep`,但是我不想重新输入其他参数。因此,我可以使用 `!:1-$` 快捷方式来调取上一个命令的所有参数,从第二个(记住它们的索引从零开始,因此是 `1`)到最后一个(由 `$` 表示)。
```
$ egrep !:1-$
egrep '(ping|pong)' afile
ping
```
你不用必须用 `1-$` 选择全部参数;你也可以选择一个子集,例如 `1-2` 或 `3-9` (如果上一个命令中有那么多参数的话)。
### 4、倒数第 n 行的最后一个参数:`!-2:$`
当我输错之后马上就知道该如何更正我的命令时,上面的快捷键非常有用,但是我经常在原来的命令之后运行别的命令,这意味着上一个命令不再是我所要引用的命令。
例如,还是用之前的 `mv` 例子,如果我通过 `ls` 检查文件夹的内容来纠正我的错误:
```
$ mv /path/to/wrongfile /some/other/place
mv: cannot stat '/path/to/wrongfile': No such file or directory
$ ls /path/to/
rightfile
```
我就不能再使用 `!$` 快捷方式了。
在这些情况下,我可以在 `!` 之后插入 `-n`:(其中 `n` 是要在历史记录中回溯的命令条数),以从较旧的命令取得最后的参数:
```
$ mv /path/to/rightfile !-2:$
mv /path/to/rightfile /some/other/place
```
同样,一旦你学会了它,你可能会惊讶于你需要使用它的频率。
### 5、进入文件夹:`!$:h`
从表面上看,这个看起来不太有用,但我每天要用它几十次。
想象一下,我运行的命令如下所示:
```
$ tar -cvf system.tar /etc/system
tar: /etc/system: Cannot stat: No such file or directory
tar: Error exit delayed from previous errors.
```
我可能要做的第一件事是转到 `/etc` 文件夹,查看其中的内容并找出我做错了什么。
我可以通过以下方法来做到这一点:
```
$ cd !$:h
cd /etc
```
这是说:“获取上一个命令的最后一个参数(`/etc/system`),并删除其最后的文件名部分,仅保留 `/ etc`。”
### 6、当前行:`!#:1`
多年以来,在我最终找到并学会之前,我有时候想知道是否可以在当前行引用一个参数。我多希望我能早早学会这个快捷方式。我经常常使用它制作备份文件:
```
$ cp /path/to/some/file !#:1.bak
cp /path/to/some/file /path/to/some/file.bak
```
但当我学会之后,它很快就被下面的快捷方式替代了……
### 7、搜索并替换:`!!:gs`
这将搜索所引用的命令,并将前两个 `/` 之间的字符替换为后两个 `/` 之间的字符。
假设我想告诉别人我的 `s` 键不起作用,而是输出了 `f`:
```
$ echo my f key doef not work
my f key doef not work
```
然后我意识到这里出现的 `f` 键都是错的。要将所有 `f` 替换为 `s`,我可以输入:
```
$ !!:gs/f /s /
echo my s key does not work
my s key does not work
```
它不只对单个字符起作用。我也可以替换单词或句子:
```
$ !!:gs/does/did/
echo my s key did not work
my s key did not work
```
### 测试一下
为了向你展示如何组合这些快捷方式,你知道这些命令片段将输出什么吗?
```
$ ping !#:0:gs/i/o
$ vi /tmp/!:0.txt
$ ls !$:h
$ cd !-2:$:h
$ touch !$!-3:$ !! !$.txt
$ cat !:1-$
```
### 总结
对于日常的命令行用户,Bash 可以作为快捷方式的优雅来源。虽然有成千上万的技巧要学习,但这些是我经常使用的最喜欢的技巧。
如果你想更深入地了解 Bash 可以教给你的全部知识,请买本我的书,《[Bash 学习,艰难之旅](https://leanpub.com/learnbashthehardway)》,或查看我的在线课程《[精通 Bash shell](https://www.educative.io/courses/master-the-bash-shell)》。
---
本文最初发布在 Ian 的博客 [Zwischenzugs.com](https://zwischenzugs.com/2019/08/25/seven-god-like-bash-history-shortcuts-you-will-actually-use/) 上,并经允许重复发布。
---
via: <https://opensource.com/article/19/10/bash-history-shortcuts>
作者:[Ian Miell](https://opensource.com/users/ianmiell) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most guides to Bash history shortcuts exhaustively list every single one available. The problem with that is I would use a shortcut once, then glaze over as I tried out all the possibilities. Then I'd move onto my working day and completely forget them, retaining only the well-known [ !! trick](https://opensource.com/article/18/5/bash-tricks) I learned when I first started using Bash.
So most of them were never committed to memory.
This article outlines the shortcuts I *actually use* every day. It is based on some of the contents of my book, [ Learn Bash the hard way](https://leanpub.com/learnbashthehardway); (you can read a
[preview](https://leanpub.com/learnbashthehardway/read_sample)of it to learn more).
When people see me use these shortcuts, they often ask me, "What did you do there!?" There's minimal effort or intelligence required, but to really learn them, I recommend using one each day for a week, then moving to the next one. It's worth taking your time to get them under your fingers, as the time you save will be significant in the long run.
## 1. The "last argument" one: !$
If you only take one shortcut from this article, make it this one. It substitutes in the last argument of the last command into your line.
Consider this scenario:
```
$ mv /path/to/wrongfile /some/other/place
mv: cannot stat '/path/to/wrongfile': No such file or directory
```
Ach, I put the **wrongfile** filename in my command. I should have put **rightfile** instead.
You might decide to retype the last command and replace wrongfile with rightfile completely. Instead, you can type:
```
$ mv /path/to/rightfile !$
mv /path/to/rightfile /some/other/place
```
and the command will work.
There are other ways to achieve the same thing in Bash with shortcuts, but this trick of reusing the last argument of the last command is one I use the most.
## 2. The "*n*th argument" one: !:2
Ever done anything like this?
```
$ tar -cvf afolder afolder.tar
tar: failed to open
```
Like many others, I get the arguments to **tar** (and **ln**) wrong more often than I would like to admit.

When you mix up arguments like that, you can run:
```
$ !:0 !:1 !:3 !:2
tar -cvf afolder.tar afolder
```
and your reputation will be saved.
The last command's items are zero-indexed and can be substituted in with the number after the **!:**.
Obviously, you can also use this to reuse specific arguments from the last command rather than all of them.
## 3. The "all the arguments" one: !:1-$
Imagine I run a command like:
`$ grep '(ping|pong)' afile`
The arguments are correct; however, I want to match **ping** or **pong** in a file, but I used **grep** rather than **egrep**.
I start typing **egrep**, but I don't want to retype the other arguments. So I can use the **!:1$** shortcut to ask for all the arguments to the previous command from the second one (remember they’re zero-indexed) to the last one (represented by the **$** sign).
```
$ egrep !:1-$
egrep '(ping|pong)' afile
ping
```
You don't need to pick **1-$**; you can pick a subset like **1-2** or **3-9** (if you had that many arguments in the previous command).
## 4. The "last but *n*" one: !-2:$
The shortcuts above are great when I know immediately how to correct my last command, but often I run commands *after* the original one, which means that the last command is no longer the one I want to reference.
For example, using the **mv** example from before, if I follow up my mistake with an **ls** check of the folder's contents:
```
$ mv /path/to/wrongfile /some/other/place
mv: cannot stat '/path/to/wrongfile': No such file or directory
$ ls /path/to/
rightfile
```
I can no longer use the **!$** shortcut.
In these cases, I can insert a **- n:** (where
*is the number of commands to go back in the history) after the*
**n****!**to grab the last argument from an older command:
```
$ mv /path/to/rightfile !-2:$
mv /path/to/rightfile /some/other/place
```
Again, once you learn it, you may be surprised at how often you need it.
## 5. The "get me the folder" one: !$:h
This one looks less promising on the face of it, but I use it dozens of times daily.
Imagine I run a command like this:
```
$ tar -cvf system.tar /etc/system
tar: /etc/system: Cannot stat: No such file or directory
tar: Error exit delayed from previous errors.
```
The first thing I might want to do is go to the **/etc** folder to see what's in there and work out what I've done wrong.
I can do this at a stroke with:
```
$ cd !$:h
cd /etc
```
This one says: "Get the last argument to the last command (**/etc/system**) and take off its last filename component, leaving only the **/etc**."
## 6. The "the current line" one: !#:1
For years, I occasionally wondered if I could reference an argument on the current line before finally looking it up and learning it. I wish I'd done so a long time ago. I most commonly use it to make backup files:
```
$ cp /path/to/some/file !#:1.bak
cp /path/to/some/file /path/to/some/file.bak
```
but once under the fingers, it can be a very quick alternative to …
## 7. The "search and replace" one: !!:gs
This one searches across the referenced command and replaces what's in the first two **/** characters with what's in the second two.
Say I want to tell the world that my **s** key does not work and outputs **f** instead:
```
$ echo my f key doef not work
my f key doef not work
```
Then I realize that I was just hitting the **f** key by accident. To replace all the **f**s with **s**es, I can type:
```
$ !!:gs/f /s /
echo my s key does not work
my s key does not work
```
It doesn't work only on single characters; I can replace words or sentences, too:
```
$ !!:gs/does/did/
echo my s key did not work
my s key did not work
```
## Test them out
Just to show you how these shortcuts can be combined, can you work out what these toenail clippings will output?
```
$ ping !#:0:gs/i/o
$ vi /tmp/!:0.txt
$ ls !$:h
$ cd !-2:h
$ touch !$!-3:$ !! !$.txt
$ cat !:1-$
```
**Conclusion**
Bash can be an elegant source of shortcuts for the day-to-day command-line user. While there are thousands of tips and tricks to learn, these are my favorites that I frequently put to use.
If you want to dive even deeper into all that Bash can teach you, pick up my book, [ Learn Bash the hard way](https://leanpub.com/learnbashthehardway) or check out my online course,
[Master the Bash shell](https://www.educative.io/courses/master-the-bash-shell).
*This article was originally posted on Ian's blog, Zwischenzugs.com, and is reused with permission.*
## 12 Comments |
11,458 | 如何在 Centos 8 / RHEL 8 上安装和配置 VNC 服务器 | https://www.linuxtechi.com/install-configure-vnc-server-centos8-rhel8/ | 2019-10-14T12:02:00 | [
"VNC"
] | https://linux.cn/article-11458-1.html | 
VNC(<ruby> 虚拟网络计算 <rt> Virtual Network Computing </rt></ruby>)服务器是基于 GUI 的桌面共享平台,它可让你访问远程桌面计算机。在 Centos 8 和 RHEL 8 系统中,默认未安装 VNC 服务器,它需要手动安装。在本文中,我们将通过简单的分步指南,介绍如何在 Centos 8 / RHEL 8 上安装 VNC 服务器。
### 在 Centos 8 / RHEL 8 上安装 VNC 服务器的先决要求
要在你的系统中安装 VNC 服务器,请确保你的系统满足以下要求:
* CentOS 8 / RHEL 8
* GNOME 桌面环境
* root 用户权限
* DNF / YUM 软件包仓库
### 在 Centos 8 / RHEL 8 上安装 VNC 服务器的分步指导
#### 步骤 1)安装 GNOME 桌面环境
在 CentOS 8 / RHEL 8 中安装 VNC 服务器之前,请确保已安装了桌面环境(DE)。如果已经安装了 GNOME 桌面或安装了 GUI 支持,那么可以跳过此步骤。
在 CentOS 8 / RHEL 8 中,GNOME 是默认的桌面环境。如果你的系统中没有它,请使用以下命令进行安装:
```
[root@linuxtechi ~]# dnf groupinstall "workstation"
或者
[root@linuxtechi ~]# dnf groupinstall "Server with GUI
```
成功安装上面的包后,请运行以下命令启用图形模式:
```
[root@linuxtechi ~]# systemctl set-default graphical
```
现在重启系统,进入 GNOME 登录页面(LCTT 译注:你可以通过切换运行态来进入图形界面)。
```
[root@linuxtechi ~]# reboot
```
重启后,请取消注释 `/etc/gdm/custom.conf` 中的 `WaylandEnable=false`,以使通过 vnc 进行的远程桌面会话请求由 GNOME 桌面的 xorg 处理,来代替 Wayland 显示管理器。
注意: Wayland 是 GNOME 中的默认显示管理器 (GDM),并且未配置用于处理 X.org 等远程渲染的 API。
#### 步骤 2)安装 VNC 服务器(tigervnc-server)
接下来,我们将安装 VNC 服务器,有很多 VNC 服务器可以选择,出于安装目的,我们将安装 `TigerVNC 服务器`。它是最受欢迎的 VNC 服务器之一,并且高性能还独立于平台,它使用户可以轻松地与远程计算机进行交互。
现在,使用以下命令安装 TigerVNC 服务器:
```
[root@linuxtechi ~]# dnf install tigervnc-server tigervnc-server-module -y
```
#### 步骤 3)为本地用户设置 VNC 密码
假设我们希望用户 `pkumar` 使用 VNC 进行远程桌面会话,然后切换到该用户并使用 `vncpasswd` 命令设置其密码,
```
[root@linuxtechi ~]# su - pkumar
[root@linuxtechi ~]$ vncpasswd
Password:
Verify:
Would you like to enter a view-only password (y/n)? n
A view-only password is not used
[root@linuxtechi ~]$
[root@linuxtechi ~]$ exit
logout
[root@linuxtechi ~]#
```
#### 步骤 4)设置 VNC 服务器配置文件
下一步是配置 VNC 服务器配置文件。创建含以下内容的 `/etc/systemd/system/[email protected]`,以便为上面的本地用户 `pkumar` 启动 tigervnc-server 的服务。
```
[root@linuxtechi ~]# vim /etc/systemd/system/[email protected]
[Unit]
Description=Remote Desktop VNC Service
After=syslog.target network.target
[Service]
Type=forking
WorkingDirectory=/home/pkumar
User=pkumar
Group=pkumar
ExecStartPre=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :'
ExecStart=/usr/bin/vncserver -autokill %i
ExecStop=/usr/bin/vncserver -kill %i
[Install]
WantedBy=multi-user.target
```
保存并退出文件,
注意:替换上面文件中的用户名为你自己的。
默认情况下,VNC 服务器在 tcp 端口 5900+n 上监听,其中 n 是显示端口号,如果显示端口号为 “1”,那么 VNC 服务器将在 TCP 端口 5901 上监听其请求。
#### 步骤 5)启动 VNC 服务并允许防火墙中的端口
我将显示端口号设置为 1,因此请使用以下命令在显示端口号 “1” 上启动并启用 vnc 服务,
```
[root@linuxtechi ~]# systemctl daemon-reload
[root@linuxtechi ~]# systemctl start vncserver@:1.service
[root@linuxtechi ~]# systemctl enable vncserver@:1.service
Created symlink /etc/systemd/system/multi-user.target.wants/vncserver@:1.service → /etc/systemd/system/[email protected].
[root@linuxtechi ~]#
```
使用下面的 `netstat` 或 `ss` 命令来验证 VNC 服务器是否开始监听 5901 上的请求,
```
[root@linuxtechi ~]# netstat -tunlp | grep 5901
tcp 0 0 0.0.0.0:5901 0.0.0.0:* LISTEN 8169/Xvnc
tcp6 0 0 :::5901 :::* LISTEN 8169/Xvnc
[root@linuxtechi ~]# ss -tunlp | grep -i 5901
tcp LISTEN 0 5 0.0.0.0:5901 0.0.0.0:* users:(("Xvnc",pid=8169,fd=6))
tcp LISTEN 0 5 [::]:5901 [::]:* users:(("Xvnc",pid=8169,fd=7))
[root@linuxtechi ~]#
```
使用下面的 `systemctl` 命令验证 VNC 服务器的状态,
```
[root@linuxtechi ~]# systemctl status vncserver@:1.service
```

上面命令的输出确认在 tcp 端口 5901 上成功启动了 VNC。使用以下命令在系统防火墙中允许 VNC 服务器端口 “5901”,
```
[root@linuxtechi ~]# firewall-cmd --permanent --add-port=5901/tcp
success
[root@linuxtechi ~]# firewall-cmd --reload
success
[root@linuxtechi ~]#
```
#### 步骤 6)连接到远程桌面会话
现在,我们已经准备就绪,可以查看远程桌面连接是否正常工作。要访问远程桌面,请在 Windows / Linux 工作站中启动 VNC Viewer,然后输入 VNC 服务器的 IP 地址和端口号,然后按回车。

接下来,它将询问你的 VNC 密码。输入你先前为本地用户创建的密码,然后单击 “OK” 继续。

现在你可以看到远程桌面,

就是这样,你已经在 Centos 8 / RHEL 8 中成功安装了 VNC 服务器。
### 总结
希望这篇在 Centos 8 / RHEL 8 上安装 VNC 服务器的分步指南为你提供了轻松设置 VNC 服务器并访问远程桌面的所有信息。请在下面的评论栏中提供你的意见和建议。下篇文章再见。谢谢再见!!!
---
via: <https://www.linuxtechi.com/install-configure-vnc-server-centos8-rhel8/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A **VNC** (Virtual Network Computing) Server is a GUI based desktop sharing platform that allows you to access remote desktop machines. In **Centos 8** and **RHEL 8** systems, VNC servers are not installed by default and need to be installed manually. In this article, we’ll look at how to install VNC Server on CentOS 8 / RHEL 8 systems with a simple step-by-step installation guide.
#### Prerequisites to Install VNC Server on Centos 8 / RHEL 8
To install VNC Server in your system, make sure you have the following requirements readily available on your system:
- CentOS 8 / RHEL 8
- GNOME Desktop Environment
- Root access
- DNF / YUM Package repositories
#### Step by Step Guide to Install VNC Server on Centos 8 / RHEL 8
#### Step 1) Install GNOME Desktop environment
Before installing VNC Server in your CentOS 8 / RHEL 8, make sure you have a desktop Environment (DE) installed. In case GNOME desktop is already installed or you have installed your server with gui option then you can skip this step.
In CentOS 8 / RHEL 8, GNOME is the default desktop environment. if you don’t have it in your system, install it using the following command:
[root@linuxtechi ~]# dnf groupinstall "workstation" Or [root@linuxtechi ~]# dnf groupinstall "Server with GUI"
Once the above packages are installed successfully then run the following command to enable the graphical mode
[root@linuxtechi ~]# systemctl set-default graphical
Now reboot the system so that we get GNOME login screen.
[root@linuxtechi ~]# reboot
Once the system is rebooted successfully uncomment the line “**WaylandEnable=false**” from the file “**/etc/gdm/custom.conf**” so that remote desktop session request via vnc is handled by xorg of GNOME desktop in place of wayland display manager.
**Note:** Wayland is the default display manager (GDM) in GNOME and it not is configured to handled remote rendering API like X.org
VNC server will not work properly if SElinux is enabled on your system, as of now work around is to disable it using following commands,
[root@linuxtechi ~]# setenforce 0 [root@linuxtechi ~]# sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
#### Step 2) Install VNC Server (tigervnc-server)
Next we’ll install the VNC Server, there are lot of VNC Servers available, and for installation purposes, we’ll be installing **TigerVNC Server**. It is one of the most popular VNC Server and a high-performance and platform-independent VNC that allows users to interact with remote machines easily.
Now install TigerVNC Server using the following command:
[root@linuxtechi ~]# dnf install tigervnc-server tigervnc-server-module -y
#### Step 3) Set VNC Password for Local User
Let’s assume we want ‘pkumar’ user to use VNC for remote desktop session, then switch to the user and set its password using vncpasswd command,
[root@linuxtechi ~]# su - pkumar [pkumar@linuxtechi ~]$ vncpasswd Password: Verify: Would you like to enter a view-only password (y/n)? n A view-only password is not used [pkumar@linuxtechi ~]$ [pkumar@linuxtechi ~]$ exit logout [root@linuxtechi ~]#
#### Step 4) Setup VNC Server Configuration File
Next step is to configure VNC Server Configuration file. Create a file “**/etc/systemd/system/ [email protected]**” with the following content so that tigervnc-server’s service started for above local user “pkumar”.
[root@linuxtechi ~]# vim /etc/systemd/system/[[email protected]][Unit] Description=Remote desktop service (VNC) After=syslog.target network.target [Service] Type=forking ExecStartPre=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :' ExecStart=/sbin/runuser -l pkumar -c "/usr/bin/vncserver %i -geometry 1280x1024" PIDFile=/home/pkumar/.vnc/%H%i.pid ExecStop=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :' [Install] WantedBy=multi-user.target
Save and exit the file,
**Note: **Replace the user name in above file which suits to your setup.
By default, VNC server listen on tcp port 5900+n, where n is the display number, if the display number is “1” then VNC server will listen its request on TCP port 5901.
#### Step 5) Start VNC Service and allow port in firewall
I am using display number as 1, so use the following commands to start and enable vnc service on display number “1”,
[root@linuxtechi ~]# systemctl daemon-reload [root@linuxtechi ~]# systemctl start vncserver@:1.service [root@linuxtechi ~]# systemctl enable vncserver@:1.service Created symlink /etc/systemd/system/multi-user.target.wants/vncserver@:1.service → /etc/systemd/system/[[email protected]]. [root@linuxtechi ~]#
Use below **netstat** or **ss** command to verify whether VNC server start listening its request on 5901,
[root@linuxtechi ~]# netstat -tunlp | grep 5901 tcp 0 0 0.0.0.0:5901 0.0.0.0:* LISTEN 8169/Xvnc tcp6 0 0 :::5901 :::* LISTEN 8169/Xvnc [root@linuxtechi ~]# ss -tunlp | grep -i 5901 tcp LISTEN 0 5 0.0.0.0:5901 0.0.0.0:* users:(("Xvnc",pid=8169,fd=6)) tcp LISTEN 0 5 [::]:5901 [::]:* users:(("Xvnc",pid=8169,fd=7)) [root@linuxtechi ~]#
Use below systemctl command to verify the status of VNC server,
[root@linuxtechi ~]# systemctl status vncserver@:1.service
Above command’s output confirms that VNC is started successfully on port tcp port 5901. Use the following command allow VNC Server port “5901” in os firewall,
[root@linuxtechi ~]# firewall-cmd --permanent --add-port=5901/tcp success [root@linuxtechi ~]# firewall-cmd --reload success [root@linuxtechi ~]#
#### Step 6) Connect to Remote Desktop Session
Now we are all set to see if the remote desktop connection is working. To access the remote desktop, Start the VNC Viewer from your Windows / Linux workstation and enter your **VNC server IP Address** and **Port Number** and then hit enter
Next, it will ask for your VNC password. Enter the password that you have created earlier for your local user and click OK to continue
Now you can see the remote desktop,
That’s it, you’ve successfully installed VNC Server in Centos 8 / RHEL 8.
**Conclusion**
Hope the step-by-step guide to install VNC server on Centos 8 / RHEL 8 has provided you with all the information to easily setup VNC Server and access remote desktops. Please provide your comments and suggestion in the feedback section below. See you in the next article…Until then a big THANK YOU and BYE for now!!!
Read Also : [How to Configure Rsyslog Server in CentOS 8 / RHEL 8](https://www.linuxtechi.com/configure-rsyslog-server-centos-8-rhel-8/)
Bill SanfordAfter you install the BaseOS of RHEL 8 and add the repo files, yum update -y
After you install the workstation or server: yum install gnome* -y
Setting Graphical Login as Default – As root: systemctl set-default graphical.target and reboot.
To enable and use tigervnc, in the following steps:
yum install tigervnc-server -y
semodule -i /usr/share/selinux/packages/vncsession.pp
restorecon /usr/sbin/vncsession /usr/libexec/vncsession-start
If you already have VNC installed, you need to remove “$HOME/.vnc folder” if it exists and recreate again with vncpasswd. This is needed to have “.vnc” folder with correct SELinux context.
Alternatively you can use: restorecon -RFv $HOME/.vnc
vim /etc/tigervnc/vncserver-config-defaults and add “session=gnome”
You can also set other options here. See manual page of Xvnc.
NOTE: You can also have configuration which is specific for a given user, to do that just modify “$HOME/.vnc/config”. You can copy content of “/etc/tigervnc/vncserver-config-defaults” there and do your own modifications.
vim /etc/tigervnc/vncserver.users
Added “:2=test” If you want to add more users, just realize you need to start each instance separately.
NOTE: Spaces are a no-no
NOTE: Example is: :2= and there should be examples in the file for existing users
systemctl start vncserver@:2.service
Connect to the VNCServer
vncviewer or :2
Example: vncviewer 10.10.10.1:2
BillThat last bit about connecting should be
vncviewer or :2
Example: vncviewer 10.10.10.1:2
RomanFollowed your tutorial, but systemctl could not start the service.
Error message was ‘geometry 1280×1024 is invalid’
RobinI have the same situation.
ChrisThe x in the example service file isn’t a proper x when you copy and paste the text. Replace the × with an x and it will then give you a new error with SELinux because the first instruction on disabling SELinux doesn’t actually disable it. This tutorial is rife with FAILS.
Pradeep KumarThanks Chris, I have fixed the letter x as you mentioned in comments. I hope it helps our readers.
LuisAnyone display Black Screen?
Chanme too. did you solve it?
Chan KimI followed it, but when I type ‘netstat -tunlp | grep 5901’ there is no entry shown.
actually the vnc server doesn’t respond. What’s wrong?
ArashGUYS! I found the black screen symptom here!
Make sure the content doesn’t change while copying and pasting which happens for encoding issues or other problems.
That happened to me and the text of geometry 1280×1024 changed to 1280 ^1024. Fix it and reload the daemon and start VNC server again!
CarlI can not start the VNC server which complains geometry 1280×1024.
[root@m2-mapreng-vm167100 ~]# systemctl start vncserver@:1.service
Job for vncserver@:1.service failed because the control process exited with error code.
See “systemctl status vncserver@:1.service” and “journalctl -xe” for details.
Oct 28 09:59:46 m2-mapreng-vm167100 runuser[127322]: vncserver: geometry 1280×1024 is invalid
If I change the ‘x’ between the two number to lower case ‘x’ the VNC server started OK.
[root@m2-mapreng-vm167100 ~]# systemctl status vncserver@:1.service
● vncserver@:1.service – Remote desktop service (VNC)
Loaded: loaded (/etc/systemd/system/[email protected]; enabled; vendor preset: disabled)
Active: active (running) since Wed 2020-10-28 10:20:23 PDT; 42s ago
Main PID: 150965 (Xvnc)
Tasks: 0 (limit: 152821)
Memory: 320.0K
CGroup: /system.slice/system-vncserver.slice/vncserver@:1.service
‣ 150965 /usr/bin/Xvnc :1 -auth /root/.Xauthority -desktop m2-mapreng-vm167100:1 (root) -fp catalogue:/etc/X11/fontpath.d -geometry 1280×1024 -pn -rfbauth /root/.vnc/passwd -rfbport 5901 -rfbwait 300>
Oct 28 10:20:20 m2-mapreng-vm167100 systemd[1]: Starting Remote desktop service (VNC)…
Oct 28 10:20:23 m2-mapreng-vm167100 systemd[1]: Started Remote desktop service (VNC).
However, when connect with VNC viewer, after enter password etc, I got black screen.
Mike Landismy \ got excised… the post should have read…
I’m still experimenting so take this with a grain of salt, but I’ve found that you need to start the daemon with…
“systemctl start vncserver_\@:\.service” to match the name of its config file in /etc/systemd/system/, e.g. /etc/systemd/system/vncserver_\@:\.service
the default resolution of port 5900 (n=0) is 16x1024x768
per: ‘https://wiki.centos.org/HowTos/VNC-Server’
There will also be a /etc/systemd/system/[email protected] config file that is not specific to a user or port.
if you want to change the display geometry (e.g. to 1280×1024), you can do something like…
VNCSERVERARGS[]=”-geometry 1280×1024 -localhost”‘
Lokesh KHi,
How can I authenticate using unixpwd (PAM Authentication), We no need to manage two passwords for user.
System Password and VNC passwd have to be same and if we change the system password vnc should also update.
Please help
Regards,
Lokesh |
11,460 | Google Analytics 的一些用法介绍 | https://opensourceforu.com/2019/10/all-that-you-can-do-with-google-analytics-and-more/ | 2019-10-14T17:49:51 | [
"跟踪"
] | https://linux.cn/article-11460-1.html | 
Google Analytics (GA)这个最流行的用户活动追踪工具我们或多或少都听说过甚至使用过,但它的用途并不仅仅限于对页面访问的追踪。作为一个既实用又流行的工具,它已经受到了广泛的欢迎,因此我们将要在下文中介绍如何在各种 Angular 和 React 单页应用中使用 Google Analytics。
这篇文章源自这样一个问题:如何对单页应用中的页面访问进行跟踪?
通常来说,有很多的方法可以解决这个问题,在这里我们只讨论其中的一种方法。下面我会使用 Angular 来写出对应的实现,如果你使用的是 React,相关的用法和概念也不会有太大的差别。接下来就开始吧。
### 准备好应用程序
首先需要有一个<ruby> 追踪 ID <rt> tracking ID </rt></ruby>。在开始编写业务代码之前,要先准备好一个追踪 ID,通过这个唯一的标识,Google Analytics 才能识别出某个点击或者某个页面访问是来自于哪一个应用。
按照以下的步骤:
1. 访问 <https://analytics.google.com>;
2. 提交指定信息以完成注册,并确保可用于 Web 应用,因为我们要开发的正是一个 Web 应用;
3. 同意相关的条款,生成一个追踪 ID;
4. 保存好追踪 ID。
追踪 ID 拿到了,就可以开始编写业务代码了。
### 添加 analytics.js 脚本
Google 已经帮我们做好了接入之前需要做的所有事情,接下来就是我们的工作了。不过我们要做的也很简单,只需要把下面这段脚本添加到应用的 `index.html` 里,就可以了:
```
<script>
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','https://www.google-analytics.com/analytics.js','ga');
</script>
```
现在我们来看一下 Google Analytics 是如何在应用程序中初始化的。
### 创建追踪器
首先创建一个应用程序的追踪器。在 `app.component.ts` 中执行以下两个步骤:
1. 声明一个名为 `ga`,类型为 `any` 的全局变量(在 Typescript 中需要制定变量类型);
2. 将下面一行代码加入到 `ngInInit()` 中。
```
ga('create', <你的追踪 ID>, 'auto');
```
这样就已经成功地在应用程序中初始化了一个 Google Analytics 的追踪器了。由于追踪器的初始化是在 `OnInit()` 函数中执行的,因此每当应用程序启动,追踪器就会启动。
### 在单页应用中记录页面访问情况
我们需要实现的是记录<ruby> 访问路由 <rt> route-visits </rt></ruby>。
如何记录用户在一个应用中不同部分的访问,这是一个难点。从功能上来看,单页应用中的路由对应了传统多页面应用中各个页面之间的跳转,因此我们需要记录访问路由。要做到这一点尽管不算简单,但仍然是可以实现的。在 `app.component.ts` 的 `ngOnInit()` 函数中添加以下的代码片段:
```
import { Router, NavigationEnd } from '@angular/router';
...
constructor(public router: Router) {}
...
this.router.events.subscribe(
event => {
if (event instanceof NavigationEnd) {
ga('set', 'page', event.urlAfterRedirects);
ga('send', { hitType: 'pageview', hitCallback: () => { this.pageViewSent = true; }});
}
}
);
```
神奇的是,只需要这么几行代码,就实现了 Angular 应用中记录页面访问情况的功能。
这段代码实际上做了以下几件事情:
1. 从 Angular Router 中导入了 `Router`、`NavigationEnd`;
2. 通过构造函数中将 `Router` 添加到组件中;
3. 然后订阅 `router` 事件,也就是由 Angular Router 发出的所有事件;
4. 只要产生了一个 `NavigationEnd` 事件实例,就将路由和目标作为一个页面访问进行记录。
这样,只要使用到了页面路由,就会向 Google Analytics 发送一条页面访问记录,在 Google Analytics 的在线控制台中可以看到这些记录。
类似地,我们可以用相同的方式来记录除了页面访问之外的活动,例如某个界面的查看次数或者时长等等。只要像上面的代码那样使用 `hitCallBack()` 就可以在有需要收集的数据的时候让应用程序作出反应,这里我们做的事情仅仅是把一个变量的值设为 `true`,但实际上 `hitCallBack()` 中可以执行任何代码。
### 追踪用户交互活动
除了页面访问记录之外,Google Analytics 还经常被用于追踪用户的交互活动,例如某个按钮的点击情况。“提交按钮被用户点击了多少次?”,“产品手册会被经常查阅吗?”这些都是 Web 应用程序的产品评审会议上的常见问题。这一节我们将会介绍如何实现这些数据的统计。
#### 按钮点击
设想这样一种场景,需要统计到应用程序中某个按钮或链接被点击的次数,这是一个和注册之类的关键动作关系最密切的数据指标。下面我们来举一个例子:
假设应用程序中有一个“感兴趣”按钮,用于显示即将推出的活动,你希望通过统计这个按钮被点击的次数来推测有多少用户对此感兴趣。那么我们可以使用以下的代码来实现这个功能:
```
...
params = {
eventCategory:
'Button'
,
eventAction:
'Click'
,
eventLabel:
'Show interest'
,
eventValue:
1
};
showInterest() {
ga('send', 'event', this.params);
}
...
```
现在看下这段代码实际上做了什么。正如前面说到,当我们向 Google Analytics 发送数据的时候,Google Analytics 就会记录下来。因此我们可以向 `send()` 方法传递不同的参数,以区分不同的事件,例如两个不同按钮的点击记录。
1、首先我们定义了一个 `params` 对象,这个对象包含了以下几个字段:
1. `eventCategory` – 交互发生的对象,这里对应的是按钮(button)
2. `eventAction` – 发生的交互的类型,这里对应的是点击(click)
3. `eventLabel` – 交互动作的标识,这里对应的是这个按钮的内容,也就是“感兴趣”
4. `eventValue` – 与每个发生的事件实例相关联的值
由于这个例子中是要统计点击了“感兴趣”按钮的用户数,因此我们把 `eventValue` 的值定为 1。
2、对象构造完成之后,下一步就是将 `params` 对象作为请求负载发送到 Google Analytics,而这一步是通过事件绑定将 `showInterest()` 绑定在按钮上实现的。这也是使用 Google Analytics 追踪中最常用的发送事件方法。
至此,Google Analytics 就可以通过记录按钮的点击次数来统计感兴趣的用户数了。
#### 追踪社交活动
Google Analytics 还可以通过应用程序追踪用户在社交媒体上的互动。其中一种场景就是在应用中放置类似 Facebook 的点赞按钮,下面我们来看看如何使用 Google Analytics 来追踪这一行为。
```
...
fbLikeParams = {
socialNetwork:
'Facebook',
socialAction:
'Like',
socialTarget:
'https://facebook.com/mypage'
};
...
fbLike() {
ga('send', 'social', this.fbLikeParams);
}
```
如果你觉得这段代码似曾相识,那是因为它确实跟上面统计“感兴趣”按钮点击次数的代码非常相似。下面我们继续看其中每一步的内容:
1、构造发送的数据负载,其中包括以下字段:
1. `socialNetwork` – 交互发生的社交媒体,例如 Facebook、Twitter 等等
2. `socialAction` – 发生的交互类型,例如点赞、发表推文、分享等等
3. `socialTarget` – 交互的目标 URL,一般是社交媒体账号的主页
2、下一步是增加一个函数来发送整个交互记录。和统计按钮点击数量时相比,这里使用 `send()` 的方式有所不同。另外,我们还需要把这个函数绑定到已有的点赞按钮上。
在追踪用户交互方面,Google Analytics 还可以做更多的事情,其中最重要的一种是针对异常的追踪,这让我们可以通过 Google Analytics 来追踪应用程序中出现的错误和异常。在本文中我们就不赘述这一点了,但我们鼓励读者自行探索。
### 用户识别
#### 隐私是一项权利,而不是奢侈品
Google Analytics 除了可以记录很多用户的操作和交互活动之外,这一节还将介绍一个不太常见的功能,就是可以控制是否对用户的身份进行追踪。
#### Cookies
Google Analytics 追踪用户活动的方式是基于 Cookies 的,因此我们可以自定义 Cookies 的名称以及一些其它的内容,请看下面这段代码:
```
trackingID =
'UA-139883813-1'
;
cookieParams = {
cookieName: 'myGACookie',
cookieDomain: window.location.hostname,
cookieExpires: 604800
};
...
ngOnInit() {
ga('create', this.trackingID, this.cookieParams);
...
}
```
在上面这段代码中,我们设置了 Google Analytics Cookies 的名称、域以及过期时间,这就让我们能够将不同网站或 Web 应用的 Cookies 区分开来。因此我们需要为我们自己的应用程序的 Google Analytics 追踪器的 Cookies 设置一个自定义的标识1,而不是一个自动生成的随机标识。
#### IP 匿名
在某些场景下,我们可能不需要知道应用程序的流量来自哪里。例如对于一个按钮点击的追踪器,我们只需要关心按钮的点击量,而不需要关心点击者的地理位置。在这种场景下,Google Analytics 允许我们只追踪用户的操作行为,而不获取到用户的 IP 地址。
```
ipParams = {
anonymizeIp: true
};
...
ngOnInit() {
...
ga('set', this.ipParams);
...
}
```
在上面这段代码中,我们将 Google Analytics 追踪器的 `abibymizeIp` 参数设置为 `true`。这样用户的 IP 地址就不会被 Google Analytics 所追踪,这可以让用户知道自己的隐私正在被保护。
#### 不被跟踪
还有些时候用户可能不希望自己的行为受到追踪,而 Google Analytics 也允许这样的需求。因此也存在让用户不被追踪的选项。
```
...
optOut() {
window['ga-disable-UA-139883813-1'] = true;
}
...
```
`optOut()` 是一个自定义函数,它可以禁用页面中的 Google Analytics 追踪,我们可以使用按钮或复选框上得事件绑定来使用这一个功能,这样用户就可以选择是否会被 Google Analytics 追踪。
在本文中,我们讨论了 Google Analytics 集成到单页应用时的难点,并探索出了一种相关的解决方法。我们还了解到了如何在单页应用中追踪页面访问和用户交互,例如按钮点击、社交媒体活动等。
最后,我们还了解到 Google Analytics 为用户提供了保护隐私的功能,尤其是用户的一些隐私数据并不需要参与到统计当中的时候。而用户也可以选择完全不受到 Google Analytics 的追踪。除此以外,Google Analytics 还可以做到很多其它的事情,这就需要我们继续不断探索了。
---
via: <https://opensourceforu.com/2019/10/all-that-you-can-do-with-google-analytics-and-more/>
作者:[Ashwin Sathian](https://opensourceforu.com/author/ashwin-sathian/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,461 | 区块链 2.0:Hyperledger Fabric 介绍(十) | https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/ | 2019-10-15T08:41:42 | [
"Fabric"
] | https://linux.cn/article-11461-1.html | 
### Hyperledger Fabric
[Hyperledger 项目](https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/) 是一个伞形组织,包括许多正在开发的不同模块和系统。在这些子项目中,最受欢迎的是 “Hyperledger Fabric”。这篇博文将探讨一旦区块链系统开始大量使用到主流,将使 Fabric 在不久的将来成为几乎不可或缺的功能。最后,我们还将快速了解开发人员和爱好者们需要了解的有关 Hyperledger Fabric 技术的知识。
### 起源
按照 Hyperledger 项目的常规方式,Fabric 由其核心成员之一 IBM “捐赠”给该组织,而 IBM 以前是该组织的主要开发者。由 IBM 共享的这个技术平台在 Hyperledger 项目中进行了联合开发,来自 100 多个成员公司和机构为之做出了贡献。
目前,Fabric 正处于 LTS 版本的 v1.4,该版本已经发展很长一段时间,并且被视为企业管理业务数据的解决方案。Hyperledger 项目的核心愿景也必然会渗透到 Fabric 中。Hyperledger Fabric 系统继承了所有企业级的可扩展功能,这些功能已深深地刻入到 Hyperledger 组织旗下所有的项目当中。
### Hyperledger Fabric 的亮点
Hyperledger Fabric 提供了多种功能和标准,这些功能和标准围绕着支持快速开发和模块化体系结构的使命而构建。此外,与竞争对手(主要是瑞波和[以太坊](https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/))相比,Fabric 明确用于封闭和[许可区块链](https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/)。它们的核心目标是开发一套工具,这些工具将帮助区块链开发人员创建定制的解决方案,而不是创建独立的生态系统或产品。
Hyperledger Fabric 的一些亮点如下:
#### 许可区块链系统
这是一个 Hyperledger Fabric 与其他平台(如以太坊和瑞波)差异很大的地方。默认情况下,Fabric 是一种旨在实现私有许可的区块链的工具。此类区块链不能被所有人访问,并且其中致力于达成共识或验证交易的节点将由中央机构进行选择。这对于某些应用(例如银行和保险)可能很重要,在这些应用中,交易必须由中央机构而不是参与者来验证。
#### 机密和受控的信息流
Fabric 内置了权限系统,该权限系统将视情况限制特定组或某些个人中的信息流。与公有区块链不同,在公有区块链中,任何运行节点的人都可以对存储在区块链中的数据进行复制和选择性访问,而 Fabric 系统的管理员可以选择谁能访问共享的信息,以及访问的方式。与现有竞争产品相比,它还有以更好的安全性标准对存储的数据进行加密的子系统。
#### 即插即用架构
Hyperledger Fabric 具有即插即用类型的体系结构。可以选择实施系统的各个组件,而开发人员看不到用处的系统组件可能会被废弃。Fabric 采取高度模块化和可定制的方式进行开发,而不是一种与其竞争对手采用的“一种方法适应所有需求”的方式。对于希望快速构建精益系统的公司和公司而言,这尤其有吸引力。这与 Fabric 和其它 Hyperledger 组件的互操作性相结合,意味着开发人员和设计人员现在可以使用各种标准化工具,而不必从其他来源提取代码并随后进行集成。它还提供了一种相当可靠的方式来构建健壮的模块化系统。
#### 智能合约和链码
运行在区块链上的分布式应用程序称为[智能合约](https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/)。虽然智能合约这个术语或多或少与以太坊平台相关联,但<ruby> 链码 <rt> chaincode </rt></ruby>是 Hyperledger 阵营中为其赋予的名称。链码应用程序除了拥有 DApp 中有的所有优点之外,使 Hyperledger 与众不同的是,该应用程序的代码可以用多种高级编程语言编写。它本身支持 [Go](https://www.ostechnix.com/install-go-language-linux/) 和 JavaScript,并且在与适当的编译器模块集成后还支持许多其它编程语言。尽管这一事实在此时可能并不代表什么,但这意味着,如果可以将现有人才用于正在进行的涉及区块链的项目,从长远来看,这有可能为公司节省数十亿美元的人员培训和管理费用。开发人员可以使用自己喜欢的语言进行编码,从而在 Hyperledger Fabric 上开始构建应用程序,而无需学习或培训平台特定的语言和语法。这提供了 Hyperledger Fabric 当前竞争对手无法提供的灵活性。
### 总结
* Hyperledger Fabric 是一个后端驱动程序平台,是一个主要针对需要区块链或其它分布式账本技术的集成项目。因此,除了次要的脚本功能外,它不提供任何面向用户的服务。(认可以为它更像是一种脚本语言。)
* Hyperledger Fabric 支持针对特定用例构建侧链。如果开发人员希望将一组用户或参与者隔离到应用程序的特定部分或功能,则可以通过侧链来实现。侧链是衍生自主要父代的区块链,但在其初始块之后形成不同的链。产生新链的块将不受新链进一步变化的影响,即使将新信息添加到原始链中,新链也将保持不变。此功能将有助于扩展正在开发的平台,并引入用户特定的和案例特定的处理功能。
* 前面的功能还意味着并非所有用户都会像通常对公有链所期望的那样拥有区块链中所有数据的“精确”副本。参与节点将具有仅与之相关的数据副本。例如,假设有一个类似于印度的 PayTM 的应用程序,该应用程序具有钱包功能以及电子商务功能。但是,并非所有的钱包用户都使用 PayTM 在线购物。在这种情况下,只有活跃的购物者将在 PayTM 电子商务网站上拥有相应的交易链,而钱包用户将仅拥有存储钱包交易的链的副本。这种灵活的数据存储和检索体系结构在扩展时非常重要,因为大量的单链区块链已经显示出会增加处理交易的前置时间。这样可以保持链的精简和分类。
我们将在以后的文章中详细介绍 Hyperledger Project 下的其他模块。
---
via: <https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/>
作者:[sk](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
11,462 | 在 Linux 上以树状查看文件和进程 | https://www.networkworld.com/article/3444589/viewing-files-and-processes-as-trees-on-linux.html | 2019-10-15T09:32:22 | [
"树状"
] | https://linux.cn/article-11462-1.html |
>
> 介绍三个 Linux 命令:ps、pstree 和 tree 以类似树的格式查看文件和进程。
>
>
>

[Linux](https://www.networkworld.com/article/3215226/what-is-linux-uses-featres-products-operating-systems.html) 提供了一些方便的命令,用于以树状分支形式查看文件和进程,从而易于查看它们之间的关系。在本文中,我们将介绍 `ps`、`pstree` 和 `tree` 命令以及它们提供的一些选项,这些选项可帮助你将注意力集中在要查看的内容上。
### ps
我们用来列出进程的 `ps` 命令有一些有趣的选项,但是很多人从来没有利用过。虽然常用的 `ps -ef` 提供了正在运行的进程的完整列表,但是 `ps -ejH` 命令增加了一个不错的效果。它缩进了相关的进程以使这些进程之间的关系在视觉上更加清晰——就像这个片段:
```
$ ps -ejH
PID PGID SID TTY TIME CMD
...
1396 1396 1396 ? 00:00:00 sshd
28281 28281 28281 ? 00:00:00 sshd
28409 28281 28281 ? 00:00:00 sshd
28410 28410 28410 pts/0 00:00:00 bash
30968 30968 28410 pts/0 00:00:00 ps
```
可以看到,正在运行的 `ps` 进程是在 `bash` 中运行的,而 `bash` 是在 ssh 会话中运行的。
`-exjf` 选项字符串提供了类似的视图,但是带有一些其它细节和符号以突出显示进程的层次结构性质:
```
$ ps -exjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
...
1 1396 1396 1396 ? -1 Ss 0 0:00 /usr/sbin/sshd -D
1396 28281 28281 28281 ? -1 Ss 0 0:00 \_ sshd: shs [priv]
28281 28409 28281 28281 ? -1 S 1000 0:00 \_ sshd: shs@pts/0
28409 28410 28410 28410 pts/0 31028 Ss 1000 0:00 \_ -bash
28410 31028 31028 28410 pts/0 31028 R+ 1000 0:00 \_ ps axjf
```
命令中使用的这些选项表示:
```
-e 选择所有进程
-j 使用工作格式
-f 提供完整格式列表
-H 分层显示进程(如,树状格式)
-x 取消“必须与 tty 相关联”的限制
```
同时,该命令也有一个 `--forest` 选项提供了类似的视图。
```
$ ps -ef --forest
UID PID PPID C STIME TTY TIME CMD
...
root 1396 1 0 Oct08 ? 00:00:00 /usr/sbin/sshd -D
root 28281 1396 0 12:55 ? 00:00:00 \_ sshd: shs [priv]
shs 28409 28281 0 12:56 ? 00:00:00 \_ sshd: shs@pts/0
shs 28410 28409 0 12:56 pts/0 00:00:00 \_ -bash
shs 32351 28410 0 14:39 pts/0 00:00:00 \_ ps -ef --forest
```
注意,这些示例只是这些命令如何使用的示例。你可以选择最适合你的进程视图的任何选项组合。
### pstree
使用 `pstree` 命令可以获得类似的进程视图。尽管 `pstree` 具备了许多选项,但是该命令本身就提供了非常有用的显示。注意,许多父子进程关系显示在单行而不是后续行上。
```
$ pstree
...
├─sshd───sshd───sshd───bash───pstree
├─systemd─┬─(sd-pam)
│ ├─at-spi-bus-laun─┬─dbus-daemon
│ │ └─3*[{at-spi-bus-laun}]
│ ├─at-spi2-registr───2*[{at-spi2-registr}]
│ ├─dbus-daemon
│ ├─ibus-portal───2*[{ibus-portal}]
│ ├─pulseaudio───2*[{pulseaudio}]
│ └─xdg-permission-───2*[{xdg-permission-}]
```
通过 `-n` 选项,`pstree` 以数值(按进程 ID)顺序显示进程:
```
$ pstree -n
systemd─┬─systemd-journal
├─systemd-udevd
├─systemd-timesyn───{systemd-timesyn}
├─systemd-resolve
├─systemd-logind
├─dbus-daemon
├─atopacctd
├─irqbalance───{irqbalance}
├─accounts-daemon───2*[{accounts-daemon}]
├─acpid
├─rsyslogd───3*[{rsyslogd}]
├─freshclam
├─udisksd───4*[{udisksd}]
├─networkd-dispat
├─ModemManager───2*[{ModemManager}]
├─snapd───10*[{snapd}]
├─avahi-daemon───avahi-daemon
├─NetworkManager───2*[{NetworkManager}]
├─wpa_supplicant
├─cron
├─atd
├─polkitd───2*[{polkitd}]
├─colord───2*[{colord}]
├─unattended-upgr───{unattended-upgr}
├─sshd───sshd───sshd───bash───pstree
```
使用 `pstree` 时可以考虑的一些选项包括 `-a`(包括命令行参数)和 `-g`(包括进程组)。
以下是一些简单的示例(片段)。
命令 `pstree -a` 的输出内容:
```
└─wpa_supplicant -u -s -O /run/wpa_supplicant
```
命令 `pstree -g` 的输出内容:
```
├─sshd(1396)───sshd(28281)───sshd(28281)───bash(28410)───pstree(1115)
```
### tree
虽然 `tree` 命令听起来与 `pstree` 非常相似,但这是用于查看文件而非进程的命令。它提供了一个漂亮的树状目录和文件视图。
如果你使用 `tree` 命令查看 `/proc` 目录,你显示的开头部分将类似于这个:
```
$ tree /proc
/proc
├── 1
│ ├── attr
│ │ ├── apparmor
│ │ │ ├── current
│ │ │ ├── exec
│ │ │ └── prev
│ │ ├── current
│ │ ├── display
│ │ ├── exec
│ │ ├── fscreate
│ │ ├── keycreate
│ │ ├── prev
│ │ ├── smack
│ │ │ └── current
│ │ └── sockcreate
│ ├── autogroup
│ ├── auxv
│ ├── cgroup
│ ├── clear_refs
│ ├── cmdline
...
```
如果以 root 权限运行这条命令(`sudo tree /proc`),你将会看到更多详细信息,因为 `/proc` 目录的许多内容对于普通用户而言是无法访问的。
命令 `tree -d` 将会限制仅显示目录。
```
$ tree -d /proc
/proc
├── 1
│ ├── attr
│ │ ├── apparmor
│ │ └── smack
│ ├── fd [error opening dir]
│ ├── fdinfo [error opening dir]
│ ├── map_files [error opening dir]
│ ├── net
│ │ ├── dev_snmp6
│ │ ├── netfilter
│ │ └── stat
│ ├── ns [error opening dir]
│ └── task
│ └── 1
│ ├── attr
│ │ ├── apparmor
│ │ └── smack
...
```
使用 `-f` 选项,`tree` 命令会显示完整的路径。
```
$ tree -f /proc
/proc
├── /proc/1
│ ├── /proc/1/attr
│ │ ├── /proc/1/attr/apparmor
│ │ │ ├── /proc/1/attr/apparmor/current
│ │ │ ├── /proc/1/attr/apparmor/exec
│ │ │ └── /proc/1/attr/apparmor/prev
│ │ ├── /proc/1/attr/current
│ │ ├── /proc/1/attr/display
│ │ ├── /proc/1/attr/exec
│ │ ├── /proc/1/attr/fscreate
│ │ ├── /proc/1/attr/keycreate
│ │ ├── /proc/1/attr/prev
│ │ ├── /proc/1/attr/smack
│ │ │ └── /proc/1/attr/smack/current
│ │ └── /proc/1/attr/sockcreate
...
```
分层显示通常可以使进程和文件之间的关系更容易理解。可用选项的数量很多,而你总可以找到一些视图,帮助你查看所需的内容。
---
via: <https://www.networkworld.com/article/3444589/viewing-files-and-processes-as-trees-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,464 | Linux 内核测试的生命周期 | https://opensource.com/article/19/8/linux-kernel-testing | 2019-10-16T10:19:43 | [
"内核"
] | /article-11464-1.html |
>
> 内核持续集成(CKI)项目旨在防止错误进入 Linux 内核。
>
>
>

在 [Linux 内核的持续集成测试](https://opensource.com/article/19/6/continuous-kernel-integration-linux) 一文中,我介绍了 <ruby> <a href="https://cki-project.org/"> 内核持续集成 </a> <rt> Continuous Kernel Integration </rt></ruby>(CKI)项目及其使命:改变内核开发人员和维护人员的工作方式。本文深入探讨了该项目的某些技术方面,以及这所有的部分是如何组合在一起的。
### 从一次更改开始
内核中每一项令人兴奋的功能、改进和错误都始于开发人员提出的更改。这些更改出现在各个内核存储库的大量邮件列表中。一些存储库关注内核中的某些子系统,例如存储或网络,而其它存储库关注内核的更多方面。 当开发人员向内核提出更改或补丁集时,或者维护者在存储库本身中进行更改时,CKI 项目就会付诸行动。
CKI 项目维护的触发器用于监视这些补丁集并采取措施。诸如 [Patchwork](https://github.com/getpatchwork/patchwork) 之类的软件项目通过将多个补丁贡献整合为单个补丁系列,使此过程变得更加容易。补丁系列作为一个整体历经 CKI 系统,并可以针对该系列发布单个报告。
其他触发器可以监视存储库中的更改。当内核维护人员合并补丁集、还原补丁或创建新标签时,就会触发。测试这些关键的更改可确保开发人员始终具有坚实的基线,可以用作编写新补丁的基础。
所有这些更改都会进入 GitLab CI 管道,并历经多个阶段和多个系统。
### 准备构建
首先要准备好要编译的源代码。这需要克隆存储库、打上开发人员建议的补丁集,并生成内核配置文件。这些配置文件具有成千上万个用于打开或关闭功能的选项,并且配置文件在不同的系统体系结构之间差异非常大。 例如,一个相当标准的 x86\_64 系统在其配置文件中可能有很多可用选项,但是 s390x 系统(IBM zSeries 大型机)的选项可能要少得多。在该大型机上,某些选项可能有意义,但在消费类笔记本电脑上没有任何作用。
内核进一步转换为源代码工件。该工件包含整个存储库(已打上补丁)以及编译所需的所有内核配置文件。 上游内核会打包成压缩包,而 Red Hat 的内核会生成下一步所用的源代码 RPM 包。
### 成堆的编译
编译内核会将源代码转换为计算机可以启动和使用的代码。配置文件描述了要构建的内容,内核中的脚本描述了如何构建它,系统上的工具(例如 GCC 和 glibc)完成构建。此过程需要一段时间才能完成,但是 CKI 项目需要针对四种体系结构快速完成:aarch64(64 位 ARM)、ppc64le(POWER)、s390x(IBM zSeries)和 x86\_64。重要的是,我们必须快速编译内核,以便使工作任务不会积压,而开发人员可以及时收到反馈。
添加更多的 CPU 可以大大提高速度,但是每个系统都有其局限性。CKI 项目在 OpenShift 的部署环境中的容器内编译内核;尽管 OpenShift 可以实现高伸缩性,但在部署环境中的可用 CPU 仍然是数量有限的。CKI 团队分配了 20 个虚拟 CPU 来编译每个内核。涉及到四个体系结构,这就涨到了 80 个 CPU!
另一个速度的提高来自 [ccache](https://ccache.dev/) 工具。内核开发进展迅速,但是即使在多个发布版本之间,内核的大部分仍保持不变。ccache 工具进行编译期间会在磁盘上缓存已构建的对象(整个内核的一小部分)。稍后再进行另一个内核编译时,ccache 会查找以前看到的内核的未更改部分。ccache 会从磁盘中提取缓存的对象并重新使用它。这样可以加快编译速度并降低总体 CPU 使用率。现在,耗时 20 分钟编译的内核在不到几分钟的时间内就完成了。
### 测试时间
内核进入最后一步:在真实硬件上进行测试。每个内核都使用 Beaker 在其原生体系结构上启动,并且开始无数次的测试以发现问题。一些测试会寻找简单的问题,例如容器问题或启动时的错误消息。其他测试则深入到各种内核子系统中,以查找系统调用、内存分配和线程中的回归问题。
大型测试框架,例如 [Linux Test Project](https://linux-test-project.github.io)(LTP),包含了大量测试,这些测试在内核中寻找麻烦的回归问题。其中一些回归问题可能会回滚关键的安全修复程序,并且进行测试以确保这些改进仍保留在内核中。
测试完成后,关键的一步仍然是:报告。内核开发人员和维护人员需要一份简明的报告,准确地告诉他们哪些有效、哪些无效以及如何获取更多信息。每个 CKI 报告都包含所用源代码、编译参数和测试输出的详细信息。该信息可帮助开发人员知道从哪里开始寻找解决问题的方法。此外,它还可以帮助维护人员在漏洞进入内核存储库之前知道何时需要保留补丁集以进行其他查看。
### 总结
CKI 项目团队通过向内核开发人员和维护人员提供及时、自动的反馈,努力防止错误进入 Linux 内核。这项工作通过发现导致内核错误、安全性问题和性能问题等易于找到的问题,使他们的工作更加轻松。
---
via: <https://opensource.com/article/19/8/linux-kernel-testing>
作者:[Major Hayden](https://opensource.com/users/mhaydenhttps://opensource.com/users/mhaydenhttps://opensource.com/users/marcobravohttps://opensource.com/users/mhayden) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,467 | 在 Linux 上安装 VMware 工具 | https://itsfoss.com/install-vmware-tools-linux | 2019-10-16T12:06:00 | [
"VMware"
] | https://linux.cn/article-11467-1.html |
>
> VMware 工具通过允许你共享剪贴板和文件夹以及其他东西来提升你的虚拟机体验。了解如何在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具。
>
>
>

在先前的教程中,你学习了[在 Ubuntu 上安装 VMware 工作站](https://itsfoss.com/install-vmware-player-ubuntu-1310/)。你还可以通过安装 VMware 工具进一步提升你的虚拟机功能。
如果你已经在 VMware 上安装了一个访客机系统,你必须要注意 [VMware 工具](https://kb.vmware.com/s/article/340)的要求 —— 尽管并不完全清楚到底有什么要求。
在本文中,我们将要强调 VMware 工具的重要性、所提供的特性,以及在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具的方法。
### VMware 工具:概览及特性

出于显而易见的理由,虚拟机(你的访客机系统)并不能做到与宿主机上的表现完全一致。在其性能和操作上会有特定的限制。那就是为什么引入 VMware 工具的原因。
VMware 工具以一种高效的形式在提升了其性能的同时,也可以帮助管理访客机系统。
#### VMware 工具到底负责什么?
你大致知道它可以做什么,但让我们探讨一下细节:
* 同步访客机系统与宿主机系统间的时间以简化操作
* 提供从宿主机系统向访客机系统传递消息的能力。比如说,你可以复制文字到剪贴板,并将它轻松粘贴到你的访客机系统
* 在访客机系统上启用声音
* 提升访客机视频分辨率
* 修正错误的网络速度数据
* 减少不合适的色深
在访客机系统上安装了 VMware 工具会给它带来显著改变,但是它到底包含了什么特性才解锁或提升这些功能的呢?让我们来看看……
#### VMware 工具:核心特性细节

如果你不想知道它包含什么来启用这些功能的话,你可以跳过这部分。但是为了好奇的读者,让我们简短地讨论它一下:
**VMware 设备驱动:** 它具体取决于操作系统。大多数主流操作系统都默认包含了设备驱动,因此你不必另外安装它。这主要涉及到内存控制驱动、鼠标驱动、音频驱动、网卡驱动、VGA 驱动以及其它。
**VMware 用户进程:** 这是这里真正有意思的地方。通过它你获得了在访客机和宿主机间复制粘贴和拖拽的能力。基本上,你可以从宿主机复制粘贴文本到虚拟机,反之亦然。
你同样也可以拖拽文件。此外,在你未安装 SVGA 驱动时它会启用鼠标指针的释放/锁定。
**VMware 工具生命周期管理:** 嗯,我们会在下面看看如何安装 VMware 工具,但是这个特性帮你在虚拟机中轻松安装/升级 VMware 工具。
**共享文件夹**:除了这些。VMware 工具同样允许你在访客机与宿主机系统间共享文件夹。

当然,它的效果同样取决于访客机系统。例如在 Windows 上你通过 Unity 模式运行虚拟机上的程序并从宿主机系统上操作它。
### 如何在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具
**注意:** 对于 Linux 操作系统,你应该已经安装好了“Open VM 工具”,大多数情况下免除了额外安装 VMware 工具的需要。
大部分时候,当你安装了访客机系统时,如果操作系统支持 [Easy Install](https://docs.vmware.com/en/VMware-Workstation-Player-for-Linux/15.0/com.vmware.player.linux.using.doc/GUID-3F6B9D0E-6CFC-4627-B80B-9A68A5960F60.html) 的话你会收到软件更新或弹窗告诉你要安装 VMware 工具。
Windows 和 Ubuntu 都支持 Easy Install。因此如果你使用 Windows 作为你的宿主机或尝试在 Ubuntu 上安装 VMware 工具,你应该会看到一个和弹窗消息差不多的选项来轻松安装 VMware 工具。这是它应该看起来的样子:

这是搞定它最简便的办法。因此当你配置虚拟机时确保你有一个通畅的网络连接。
如果你没收到任何弹窗或者选项来轻松安装 VMware 工具。你需要手动安装它。以下是如何去做:
1. 运行 VMware Workstation Player。
2. 从菜单导航至 “Virtual Machine -> Install VMware tools”。如果你已经安装了它并想修复安装,你会看到 “Re-install VMware tools” 这一选项出现。
3. 一旦你点击了,你就会看到一个虚拟 CD/DVD 挂载在访客机系统上。
4. 打开该 CD/DVD,并复制粘贴那个 tar.gz 文件到任何你选择的区域并解压,这里我们选择“桌面”作为解压目的地。

5. 在解压后,运行终端并通过输入以下命令导航至里面的文件夹:
```
cd Desktop/VMwareTools-10.3.2-9925305/vmware-tools-distrib
```
你需要检查文件夹与路径名,这取决于版本与解压目的地,名字可能会改变。

用你的存储位置(如“下载”)替换“桌面”,如果你安装的也是 10.3.2 版本,其它的保持一样即可。
6. 现在仅需输入以下命令开始安装:
```
sudo ./vmware-install.pl -d
```

你会被询问密码以获得安装权限,输入密码然后应当一切都搞定了。
到此为止了,你搞定了。这系列步骤应当适用于几乎大部分基于 Ubuntu 的访客机系统。如果你想要在 Ubuntu 服务器上或其它系统安装 VMware 工具,步骤应该类似。
### 总结
在 Ubuntu Linux 上安装 VMware 工具应该挺简单。除了简单办法,我们也详述了手动安装的方法。如果你仍需帮助或者对安装有任何建议,在评论区评论让我们知道。
---
via: <https://itsfoss.com/install-vmware-tools-linux>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,468 | 变异测试是测试驱动开发(TDD)的演变 | https://opensource.com/article/19/8/mutation-testing-evolution-tdd | 2019-10-17T09:44:35 | [
"TDD",
"DevOps"
] | /article-11468-1.html |
>
> 测试驱动开发技术是根据大自然的运作规律创建的,变异测试自然成为 DevOps 演变的下一步。
>
>
>

在 “[故障是无懈可击的开发运维中的一个特点](https://opensource.com/article/19/7/failure-feature-blameless-devops)”,我讨论了故障在通过征求反馈来交付优质产品的过程中所起到的重要作用。敏捷 DevOps 团队就是用故障来指导他们并推动开发进程的。<ruby> <a href="https://en.wikipedia.org/wiki/Test-driven_development"> 测试驱动开发 </a> <rt> Test-driven development </rt></ruby>(TDD)是任何敏捷 DevOps 团队评估产品交付的[必要条件](https://www.merriam-webster.com/dictionary/conditio%20sine%20qua%20non)。以故障为中心的 TDD 方法仅在与可量化的测试配合使用时才有效。
TDD 方法仿照大自然是如何运作的以及自然界在进化博弈中是如何产生赢家和输家为模型而建立的。
### 自然选择

1859 年,<ruby> <a href="https://en.wikipedia.org/wiki/Charles_Darwin"> 查尔斯·达尔文 </a> <rt> Charles Darwin </rt></ruby>在他的《<ruby> <a href="https://en.wikipedia.org/wiki/On_the_Origin_of_Species"> 物种起源 </a> <rt> On the Origin of Species </rt></ruby>》一书中提出了进化论学说。达尔文的论点是,自然变异是由生物个体的自发突变和环境压力共同造成的。环境压力淘汰了适应性较差的生物体,而有利于其他适应性强的生物的发展。每个生物体的染色体都会发生变异,而这些自发的变异会携带给下一代(后代)。然后在自然选择下测试新出现的变异性 —— 当下存在的环境压力是由变异性的环境条件所导致的。
这张简图说明了调整适应环境条件的过程。

*图1. 不同的环境压力导致自然选择下的不同结果。图片截图来源于[理查德·道金斯的一个视频](https://www.youtube.com/watch?v=MgK5Rf7qFaU)。*
该图显示了一群生活在自己栖息地的鱼。栖息地各不相同(海底或河床底部的砾石颜色有深有浅),每条鱼长的也各不相同(鱼身图案和颜色也有深有浅)。
这张图还显示了两种情况(即环境压力的两种变化):
1. 捕食者在场
2. 捕食者不在场
在第一种情况下,在砾石颜色衬托下容易凸显出来的鱼被捕食者捕获的风险更高。当砾石颜色较深时,浅色鱼的数量会更少一些。反之亦然,当砾石颜色较浅时,深色鱼的数量会更少。
在第二种情况下,鱼完全放松下来进行交配。在没有捕食者和没有交配仪式的情况下,可以预料到相反的结果:在砾石背景下显眼的鱼会有更大的机会被选来交配并将其特性传递给后代。
### 选择标准
变异性在进行选择时,绝不是任意的、反复无常的、异想天开的或随机的。选择过程中的决定性因素通常是可以度量的。该决定性因素通常称为测试或目标。
一个简单的数学例子可以说明这一决策过程。(在该示例中,这种选择不是由自然选择决定的,而是由人为选择决定。)假设有人要求你构建一个小函数,该函数将接受一个正数,然后计算该数的平方根。你将怎么做?
敏捷 DevOps 团队的方法是快速验证失败。谦虚一点,先承认自己并不真的知道如何开发该函数。这时,你所知道的就是如何描述你想做的事情。从技术上讲,你已准备好进行单元测试。
“<ruby> 单元测试 <rt> unit test </rt></ruby>”描述了你的具体期望结果是什么。它可以简单地表述为“给定数字 16,我希望平方根函数返回数字 4”。你可能知道 16 的平方根是 4。但是,你不知道一些较大数字(例如 533)的平方根。
但至少,你已经制定了选择标准,即你的测试或你的期望值。
### 进行故障测试
[.NET Core](https://dotnet.microsoft.com/) 平台可以演示该测试。.NET 通常使用 xUnit.net 作为单元测试框架。(要跟随进行这个代码示例,请安装 .NET Core 和 xUnit.net。)
打开命令行并创建一个文件夹,在该文件夹实现平方根解决方案。例如,输入:
```
mkdir square_root
```
再输入:
```
cd square_root
```
为单元测试创建一个单独的文件夹:
```
mkdir unit_tests
```
进入 `unit_tests` 文件夹下(`cd unit_tests`),初始化 xUnit 框架:
```
dotnet new xunit
```
现在,转到 `square_root` 下, 创建 `app` 文件夹:
```
mkdir app
cd app
```
如果有必要的话,为你的代码创建一个脚手架:
```
dotnet new classlib
```
现在打开你最喜欢的编辑器开始编码!
在你的代码编辑器中,导航到 `unit_tests` 文件夹,打开 `UnitTest1.cs`。
将 `UnitTest1.cs` 中自动生成的代码替换为:
```
using System;
using Xunit;
using app;
namespace unit_tests{
public class UnitTest1{
Calculator calculator = new Calculator();
[Fact]
public void GivenPositiveNumberCalculateSquareRoot(){
var expected = 4;
var actual = calculator.CalculateSquareRoot(16);
Assert.Equal(expected, actual);
}
}
}
```
该单元测试描述了变量的**期望值**应该为 4。下一行描述了**实际值**。建议通过将输入值发送到称为`calculator` 的组件来计算**实际值**。对该组件的描述是通过接收数值来处理`CalculateSquareRoot` 信息。该组件尚未开发。但这并不重要,我们在此只是描述期望值。
最后,描述了触发消息发送时发生的情况。此时,判断**期望值**是否等于**实际值**。如果是,则测试通过,目标达成。如果**期望值**不等于**实际值**,则测试失败。
接下来,要实现称为 `calculator` 的组件,在 `app` 文件夹中创建一个新文件,并将其命名为`Calculator.cs`。要实现计算平方根的函数,请在此新文件中添加以下代码:
```
namespace app {
public class Calculator {
public double CalculateSquareRoot(double number) {
double bestGuess = number;
return bestGuess;
}
}
}
```
在测试之前,你需要通知单元测试如何找到该新组件(`Calculator`)。导航至 `unit_tests` 文件夹,打开 `unit_tests.csproj` 文件。在 `<ItemGroup>` 代码块中添加以下代码:
```
<ProjectReference Include="../app/app.csproj" />
```
保存 `unit_test.csproj` 文件。现在,你可以运行第一个测试了。
切换到命令行,进入 `unit_tests` 文件夹。运行以下命令:
```
dotnet test
```
运行单元测试,会输出以下内容:

*图2. 单元测试失败后 xUnit 的输出结果*
正如你所看到的,单元测试失败了。期望将数字 16 发送到 `calculator` 组件后会输出数字 4,但是输出(`Actual`)的是 16。
恭喜你!创建了第一个故障。单元测试为你提供了强有力的反馈机制,敦促你修复故障。
### 修复故障
要修复故障,你必须要改进 `bestGuess`。当下,`bestGuess` 仅获取函数接收的数字并返回。这不够好。
但是,如何找到一种计算平方根值的方法呢? 我有一个主意 —— 看一下大自然母亲是如何解决问题的。
### 效仿大自然的迭代
在第一次(也是唯一的)尝试中要得出正确值是非常难的(几乎不可能)。你必须允许自己进行多次尝试猜测,以增加解决问题的机会。允许多次尝试的一种方法是进行迭代。
要迭代,就要将 `bestGuess` 值存储在 `previousGuess` 变量中,转换 `bestGuess` 的值,然后比较两个值之间的差。如果差为 0,则说明问题已解决。否则,继续迭代。
这是生成任何正数的平方根的函数体:
```
double bestGuess = number;
double previousGuess;
do {
previousGuess = bestGuess;
bestGuess = (previousGuess + (number/previousGuess))/2;
} while((bestGuess - previousGuess) != 0);
return bestGuess;
```
该循环(迭代)将 `bestGuess` 值集中到设想的解决方案。现在,你精心设计的单元测试通过了!

*图 3. 单元测试通过了。*
### 迭代解决了问题
正如大自然母亲解决问题的方法,在本练习中,迭代解决了问题。增量方法与逐步改进相结合是获得满意解决方案的有效方法。该示例中的决定性因素是具有可衡量的目标和测试。一旦有了这些,就可以继续迭代直到达到目标。
### 关键点!
好的,这是一个有趣的试验,但是更有趣的发现来自于使用这种新创建的解决方案。到目前为止,`bestGuess` 从开始一直把函数接收到的数字作为输入参数。如果更改 `bestGuess` 的初始值会怎样?
为了测试这一点,你可以测试几种情况。 首先,在迭代多次尝试计算 25 的平方根时,要逐步细化观察结果:

*图 4. 通过迭代来计算 25 的平方根。*
以 25 作为 `bestGuess` 的初始值,该函数需要八次迭代才能计算出 25 的平方根。但是,如果在设计 `bestGuess` 初始值上犯下荒谬的错误,那将怎么办? 尝试第二次,那 100 万可能是 25 的平方根吗? 在这种明显错误的情况下会发生什么?你写的函数是否能够处理这种低级错误。
直接来吧。回到测试中来,这次以一百万开始:

*图 5. 在计算 25 的平方根时,运用逐步求精法,以 100 万作为 bestGuess 的初始值。*
哇! 以一个荒谬的数字开始,迭代次数仅增加了两倍(从八次迭代到 23 次)。增长幅度没有你直觉中预期的那么大。
### 故事的寓意
啊哈! 当你意识到,迭代不仅能够保证解决问题,而且与你的解决方案的初始猜测值是好是坏也没有关系。 不论你最初理解得多么不正确,迭代过程以及可衡量的测试/目标,都可以使你走上正确的道路并得到解决方案。
图 4 和 5 显示了陡峭而戏剧性的燃尽图。一个非常错误的开始,迭代很快就产生了一个绝对正确的解决方案。
简而言之,这种神奇的方法就是敏捷 DevOps 的本质。
### 回到一些更深层次的观察
敏捷 DevOps 的实践源于人们对所生活的世界的认知。我们生活的世界存在不确定性、不完整性以及充满太多的困惑。从科学/哲学的角度来看,这些特征得到了<ruby> <a href="https://en.wikipedia.org/wiki/Uncertainty_principle"> 海森堡的不确定性原理 </a> <rt> Heisenberg’s Uncertainty Principle </rt></ruby>(涵盖不确定性部分),<ruby> <a href="https://en.wikipedia.org/wiki/Tractatus_Logico-Philosophicus"> 维特根斯坦的逻辑论哲学 </a> <rt> Wittgenstein’s Tractatus Logico-Philosophicus </rt></ruby>(歧义性部分),<ruby> <a href="https://en.wikipedia.org/wiki/G%C3%B6del%27s_incompleteness_theorems"> 哥德尔的不完全性定理 </a> <rt> Gödel’s incompleteness theorems </rt></ruby>(不完全性方面)以及<ruby> <a href="https://en.wikipedia.org/wiki/Second_law_of_thermodynamics"> 热力学第二定律 </a> <rt> Second Law of Thermodynamics </rt></ruby>(无情的熵引起的混乱)的充分证明和支持。
简而言之,无论你多么努力,在尝试解决任何问题时都无法获得完整的信息。因此,放下傲慢的姿态,采取更为谦虚的方法来解决问题对我们会更有帮助。谦卑会给为你带来巨大的回报,这个回报不仅是你期望的一个解决方案,还会有它的副产品。
### 总结
大自然在不停地运作,这是一个持续不断的过程。大自然没有总体规划。一切都是对先前发生的事情的回应。 反馈循环是非常紧密的,明显的进步/倒退都是逐步实现的。大自然中随处可见,任何事物的都在以一种或多种形式逐步完善。
敏捷 DevOps 是工程模型逐渐成熟的一个非常有趣的结果。DevOps 基于这样的认识,即你所拥有的信息总是不完整的,因此你最好谨慎进行。获得可衡量的测试(例如,假设、可测量的期望结果),进行简单的尝试,大多数情况下可能失败,然后收集反馈,修复故障并继续测试。除了同意每个步骤都必须要有可衡量的假设/测试之外,没有其他方法。
在本系列的下一篇文章中,我将仔细研究变异测试是如何提供及时反馈来推动实现结果的。
---
via: <https://opensource.com/article/19/8/mutation-testing-evolution-tdd>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,469 | 命令行技巧:使用 find 和 xargs 查找和处理文件 | https://fedoramagazine.org/command-line-quick-tips-locate-and-process-files-with-find-and-xargs/ | 2019-10-17T13:00:00 | [
"find",
"xargs"
] | https://linux.cn/article-11469-1.html | 
`find` 是日常工具箱中功能强大、灵活的命令行程序之一。它如它名字所暗示的:查找符合你指定条件的文件和目录。借助 `-exec` 或 `-delete` 之类的参数,你可以让它对找到的文件进行操作。
在[命令行提示](https://fedoramagazine.org/?s=command+line+quick+tips)系列的这一期中,你将会看到 `find` 命令的介绍,并学习如何使用内置命令或使用 `xargs` 命令处理文件。
### 查找文件
`find` 至少要加上查找的路径。例如,此命令将查找(并打印)系统上的每个文件:
```
find /
```
由于一切皆文件,因此你会看到大量的输出。这可能无法帮助你找到所需的内容。你可以更改路径参数缩小范围,但这实际上并没有比使用 `ls` 命令更好。因此,你需要考虑要查找的内容。
也许你想在家目录中查找所有 JPEG 文件。 `-name` 参数允许你将结果限制为与给定模式匹配的文件。
```
find ~ -name '*jpg'
```
但是等等!如果其中一些扩展名是大写怎么办? `-iname` 类似于 `-name`,但不区分大小写:
```
find ~ -iname '*jpg'
```
很好!但是 8.3 命名方案出自 1985 年。某些图片的扩展名可能是 .jpeg。幸运的是,我们可以将模式使用“或”(`-o`)进行组合。括号需要转义,以便使 `find` 命令而不是 shell 程序尝试解释它们。
```
find ~ \( -iname 'jpeg' -o -iname 'jpg' \)
```
更进一步。如果你有一些以 `jpg` 结尾的目录怎么办?(我不懂你为什么将目录命名为 `bucketofjpg` 而不是 `pictures`?)我们可以加上 `-type` 参数来仅查找文件:
```
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f
```
或者,也许你想找到那些名字奇怪的目录,以便之后可以重命名它们:
```
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type d
```
最近你拍摄了很多照片,因此使用 `-mtime`(修改时间)将范围缩小到最近一周修改过的文件。 `-7` 表示 7 天或更短时间内修改的所有文件。
```
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f -mtime -7
```
### 使用 xargs 进行操作
`xargs` 命令从标准输入流中获取参数,并基于它们执行命令。继续使用上一节中的示例,假设你要将上周修改过的家目录中的所有 JPEG 文件复制到 U 盘,以便插到电子相册上。假设你已经将 U 盘挂载到 `/media/photo_display`。
```
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f -mtime -7 -print0 | xargs -0 cp -t /media/photo_display
```
这里的 `find` 命令与以前的版本略有不同。`-print0` 命令让输出有一些更改:它不使用换行符,而是添加了一个 `null` 字符。`xargs` 的 `-0`(零)选项可调整解析以达到预期效果。这很重要,不然对包含空格、引号或其他特殊字符的文件名执行操作可能无法按预期进行。对文件采取任何操作时,都应使用这些选项。
`cp` 命令的 `-t` 参数很重要,因为 `cp` 通常要求目的地址在最后。你可以不使用 `xargs` 而使用 `find` 的 `-exec` 执行此操作,但是 `xargs` 的方式会更快,尤其是对于大量文件,因为它会单次调用 `cp`。
### 了解更多
这篇文章仅仅是 `find` 可以做的事情的表面。 `find` 支持基于权限、所有者、访问时间等的测试。它甚至可以将搜索路径中的文件与其他文件进行比较。将测试与布尔逻辑相结合,可以为你提供惊人的灵活性,以精确地找到你要查找的文件。使用内置命令或管道传递给 `xargs`,你可以快速处理大量文件。
---
via: <https://fedoramagazine.org/command-line-quick-tips-locate-and-process-files-with-find-and-xargs/>
作者:[Ben Cotton](https://fedoramagazine.org/author/bcotton/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **find** is one of the more powerful and flexible command-line programs in the daily toolbox. It does what the name suggests: it finds files and directories that match the conditions you specify. And with arguments like **-exec** or **-delete**, you can have find take action on what it… finds.
In this installment of the [Command Line Quick Tips](https://fedoramagazine.org/?s=command+line+quick+tips) series, you’ll get an introduction to the **find** command and learn how to use it to process files with built-in commands or the **xargs** command.
## Finding files
At a minimum, **find** takes a path to find things in. For example, this command will find (and print) every file on the system:
find /
And since everything is a file, you will get a lot of output to sort through. This probably doesn’t help you locate what you’re looking for. You can change the path argument to narrow things down a bit, but it’s still not really any more helpful than using the **ls** command. So you need to think about what you’re trying to locate.
Perhaps you want to find all the JPEG files in your home directory. The **-name** argument allows you to restrict your results to files that match the given pattern.
find ~ -name '*jpg'
But wait! What if some of them have an uppercase extension? **-iname** is like **-name**, but it is case-insensitive:
find ~ -iname '*jpg'
Great! But the 8.3 name scheme is so 1985. Some of the pictures might have a .jpeg extension. Fortunately, we can combine patterns with an “or,” represented by **-o**. The parentheses are escaped so that the shell doesn’t try to interpret them instead of the **find** command.
find ~ \( -iname '*jpeg' -o -iname '*jpg' \)
We’re getting closer. But what if you have some directories that end in jpg? (Why you named a directory **bucketofjpg** instead of **pictures** is beyond me.) We can modify our command with the **-type** argument to look only for files:
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f
Or maybe you’d like to find those oddly named directories so you can rename them later:
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type d
It turns out you’ve been taking a lot of pictures lately, so narrow this down to files that have changed in the last week with **-mtime** (modification time). The **-7** means all files modified in 7 days or fewer.
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f -mtime -7
## Taking action with xargs
The **xargs** command takes arguments from the standard input stream and executes a command based on them. Sticking with the example in the previous section, let’s say you want to copy all of the JPEG files in your home directory that have been modified in the last week to a thumb drive that you’ll attach to a digital photo display. Assume you already have the thumb drive mounted as */media/photo_display*.
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f -mtime -7 -print0 | xargs -0 cp -t /media/photo_display
The **find** command is slightly modified from the previous version. The **-print0** command makes a subtle change on how the output is written: instead of using a newline, it adds a null character. The** -0** (zero) option to **xargs** adjusts the parsing to expect this. This is important because otherwise actions on file names that contain spaces, quotes, or other special characters may not work as expected. You should use these options whenever you’re taking action on files.
The **-t** argument to **cp** is important because **cp** normally expects the destination to come last. You can do this without **xargs** using **find**‘s **-exec** command, but the **xargs** method will be faster, especially with a large number of files, because it will run as a single invocation of **cp**.
## Find out more
This post only scratches the surface of what **find** can do. **find** supports testing based on permissions, ownership, access time, and much more. It can even compare the files in the search path to other files. Combining tests with Boolean logic can give you incredible flexibility to find exactly the files you’re looking for. With build in commands or piping to **xargs**, you can quickly process a large set of files.
*Portions of this article were previously published on Opensource.com.*
*Photo by*
*Warren Wong**on*.
## Seirdy
For a faster alternative, try fd 0
It’s listed as “fd-find” in Fedora’s repos.
## pamsu
I think it would be good if articles like these had their own subsection.
## Stevko
GNU find has two versions of exec. One of them ends with ; and one with +. The second one is what you may want instead of xargs.
Also, since Unix (and Linux) decided to have almost no restriction on filenames, it means that filenames can contain newlines and this will break. Use -print0 in find and -0 in xargs.
## Peder
Yes, ” time find . ( -iname ‘
jpg’ -o -iname ‘jpeg’ ) -type f -mtime -7 -exec cp -t Pics -a {} +” works just as well as the xargs version.It also handles apostrophes and newlines, is less to type but just as fast and doesn’t make you have to remember any -print0 | -0 flags.
## Peder
The forum ate my backslashes!
The -exec command should look like this, I hope : time find . \( -iname ‘
jpg’ -o -iname ‘jpeg’ \) -type f -mtime -7 -exec cp -t Pics {} \+With a backslash before each parenthesis and one before the +
## Elliott
From the POSIX standard for xargs:
“… if xargs is used to bundle the output of commands like find dir -print or ls into commands to be executed, unexpected results are likely if any filenames contain , , or quoting characters. This can be solved by using find to call a script that converts each file found into a quoted string that is then piped to xargs, but in most cases it is preferable just to have find do the argument aggregation itself by using -exec with a ‘+’ terminator instead of ‘;’.”
Also, the xargs -0 option is not in the POSIX standard so it may not be available, depending on the environment.
## Pedro
Simply amazing 🙂
## kilgoretrout
One major limiting factor with xargs is that it will refuse to process files with a single quote like “Dec. ’97” or “Jerry’s Kids”. If it encounters such a file, it will spit out an “unmatched single quote” error message and stop in its tracks. I found this out the hard way and started using exec with the find command instead of xargs.
## Ben Cotton
The -0 (zero) option will correct this. From the manual page:
I’ll update the example to include this since, as you said, it is a lesson that can be learned painfully.
## ernesto
kudos for demystifying two daunting but important commands to all shell new commers.
there are so many things you can do with ‘find’, perhaps another article show casing these features?
i do a agree with another poster, all these command line articles require a section of their own for easier access/browsing in the future 😀
## Robin
Interesting, I was looking for a way to convert all my .xls files to .ods few days ago and that will work just fine associated with LibreOffice CLI.
## chris
I much more prefer to use something of the form:
ll *.jpg| gawk ‘{system(“command_line_execution.sh “$9)}’
its simpler for me I just never tried to use xargs or find as you have to escape everthing differently
## Göran Uddeborg
Gawkor shell scripts could be used in place ofxargs, but you can’t replace all the testing features offindwithls. Try to find all JPEG files on any level below the current directory, and I think you will have problems. 🙂 When done, try to find only the new ones! 🙂## Chris
That would be ls -Rl | grep “.jpg” ….
Or you could use
ls -Rl | gawk ‘if ($9 ~ /.jpg/) {system(“bash_command.sh “$1)}’
Either way I’m just not to hip to find and the exec option. I use find all the time, and you could actually use find then pipe into gawk’s system function.
## Göran Uddeborg
ls -Rlwould not give you the full path to the file. You would have to use a longergawkscript which also records the path when the pattern fromlslists it, and combine the two when you find a match. All of whichfindwould give you for free.## Chris
As far as finding new ones, I guess I’m lost on what you mean by new ones? Do you mean past a certain date? Again I don’t have any problems with find other than the exec option. It has wierd escaping, and from what I have used of it only allows for one argument. For instance what if you wanted to mv all of those jpgs but change the name and have the name some derivative of the first name. It gets complicated and gawk system allows you to use piped in input with as many Fields as you want and put them wherever you want in the cli execution.
## Göran Uddeborg
With finding new ones, I did indeed mean files modified recently. That was an example used in the article.
As for renaming in more complicated ways, I might also use a script, possibly combined with the various
printoptions offind. But I would still call it directly via -exec and/orxargs, rather than going viasystemingawk.## chris
I think you fail to see the point of my original comment, and are trying to sell me (or someone else) on find. I use find and understand how to use it, I just feel that having a fundamental understanding of a few things and you can accomplish most tasks anyways you would like.
for instance, you can change ownership permissions either,
ie: chmod 777 exec.sh
or: chmod o+rwx,g+rwx,u+rwx exec.sh
two ways to skin a cat and for some one way is easier than the other or prefered.
## Göran Uddeborg
I was trying to show how your examples could not achieve much of what
finddoes. When it could, it made things more complicated, in my opinion.But maybe I don’t get your point. Of course, everyone should do things the way he or she prefers.
## Paul W. Frields
This thread helps to illustrate there are many ways for doing things, and they will achieve some common and some divergent goals sometimes. It would be preferable to move on since the thread value is diminishing. Thanks! — ed.
## Göran Uddeborg
The globbing stars were lost in the first example with disjunction (-o).
## Paul W. Frields
Thanks, fixed! |
11,470 | 新手教程:如何在 Linux 下解压 Zip 文件 | https://itsfoss.com/unzip-linux/ | 2019-10-17T13:05:00 | [
"unzip",
"zip"
] | https://linux.cn/article-11470-1.html |
>
> 本文将会向你展示如何在 Ubuntu 和其他 Linux 发行版本上解压文件。终端和图形界面的方法都会讨论。
>
>
>

[Zip](https://en.wikipedia.org/wiki/Zip_(file_format)) 是一种创建压缩存档文件的最普通、最流行的方法。它也是一种古老的文件归档文件格式,这种格式创建于 1989 年。由于它的广泛使用,你会经常遇见 zip 文件。
在更早的一份教程里,我介绍了[如何在 Linux 上用 zip 压缩一个文件夹](https://itsfoss.com/linux-zip-folder/)。在这篇面向初学者的快速教程中,我会介绍如何在 Linux 上解压文件。
先决条件:检查你是否安装了 `unzip`。
为了解压 zip 归档文件,你必须在你的系统上安装了 unzip 软件包。大多数现代的的 Linux 发行版本提供了解压 zip 文件的支持,但是对这些 zip 文件进行校验以避免以后出现损坏总是没有坏处的。
在基于 [Unbutu](https://ubuntu.com/) 和 [Debian](https://www.debian.org/) 的发行版上,你能够使用下面的命令来安装 `unzip`。如果你已经安装了,你会被告知已经被安装。
```
sudo apt install unzip
```
一旦你能够确认你的系统中安装了 `unzip`,你就可以通过 `unzip` 来解压 zip 归档文件。
你也能够使用命令行或者图形工具来达到目的,我会向你展示两种方法:
### 使用命令行解压文件
在 Linux 下使用 `unzip` 命令是非常简单的。在你放 zip 文件的目录,用下面的命令:
```
unzip zipped_file.zip
```
你可以给 zip 文件提供解压路径而不是解压到当前所在路径。你会在终端输出中看到提取的文件:
```
unzip metallic-container.zip -d my_zip
Archive: metallic-container.zip
inflating: my_zip/625993-PNZP34-678.jpg
inflating: my_zip/License free.txt
inflating: my_zip/License premium.txt
```
上面的命令有一个小问题。它会提取 zip 文件中所有的内容到现在的文件夹。你会在当前文件夹下留下一堆没有组织的文件,这不是一件很好的事情。
#### 解压到文件夹下
在 Linux 命令行下,对于把文件解压到一个文件夹下是一个好的做法。这种方式下,所有的提取文件都会被存储到你所指定的文件夹下。如果文件夹不存在,会创建该文件夹。
```
unzip zipped_file.zip -d unzipped_directory
```
现在 `zipped_file.zip` 中所有的内容都会被提取到 `unzipped_directory` 中。
由于我们在讨论好的做法,这里有另一个注意点,我们可以查看压缩文件中的内容而不用实际解压。
#### 查看压缩文件中的内容而不解压压缩文件
```
unzip -l zipped_file.zip
```
下面是该命令的输出:
```
unzip -l metallic-container.zip
Archive: metallic-container.zip
Length Date Time Name
--------- ---------- ----- ----
6576010 2019-03-07 10:30 625993-PNZP34-678.jpg
1462 2019-03-07 13:39 License free.txt
1116 2019-03-07 13:39 License premium.txt
--------- -------
6578588 3 files
```
在 Linux 下,还有些 `unzip` 的其它用法,但我想你现在已经对在 Linux 下使用解压文件有了足够的了解。
### 使用图形界面来解压文件
如果你使用桌面版 Linux,那你就不必总是使用终端。在图形化的界面下,我们又要如何解压文件呢? 我使用的是 [GNOME 桌面](https://gnome.org/),不过其它桌面版 Linux 发行版也大致相同。
打开文件管理器,然后跳转到 zip 文件所在的文件夹下。在文件上点击鼠标右键,你会在弹出的窗口中看到 “提取到这里”,选择它。

与 `unzip` 命令不同,这个提取选项会创建一个和压缩文件名相同的文件夹(LCTT 译注:文件夹没有 `.zip` 扩展名),并且把压缩文件中的所有内容存储到创建的文件夹下。相对于 `unzip` 命令的默认行为是将压缩文件提取到当前所在的文件下,图形界面的解压对于我来说是一件非常好的事情。
这里还有一个选项“提取到……”,你可以选择特定的文件夹来存储提取的文件。
你现在知道如何在 Linux 解压文件了。你也许还对学习[在 Linux 下使用 7zip](https://itsfoss.com/use-7zip-ubuntu-linux/) 感兴趣?
---
via: <https://itsfoss.com/unzip-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[octopus](https://github.com/singledo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Zip](https://en.wikipedia.org/wiki/Zip_(file_format)) is one of the most common and most popular ways to create compressed archive files. It is also one of the older archive file formats that were created in 1989. Since it is widely used, you’ll regularly come across a zip file.
In an earlier tutorial, I showed [how to zip a folder in Linux](https://itsfoss.com/linux-zip-folder/). In this quick tutorial for beginners, I’ll show you how to unzip files in Linux.
**Prerequisite: Verify if you have unzip installed**
In order to unzip a zip archive file, you must have the unzip package installed in your system. Most modern Linux distributions come with unzip support but there is no harm in verifying it to avoid bad surprises later.
In a terminal, use the following command:
`unzip --version`
If it gives you some details, you have unzip installed already. If you see an ‘unzip command not found’ error, you have to install.
In [Ubuntu](https://ubuntu.com/) and [Debian](https://www.debian.org/) based distributions, you can use the command below to install unzip.
`sudo apt install unzip`
Once you have made sure that your system has unzip support, it’s time to unzip a zip file in Linux.
You can use both the command line and GUI for this purpose and I’ll show you both methods.
- Unzip files in Linux terminal
- Unzip files in Ubuntu via GUI
## Unzip files in Linux command line
Using unzip command in Linux is absolutely simple. In the directory, where you have the zip file, use this command:
`unzip zipped_file.zip`
You can also provide the path to the zip file instead of going to the directory. You’ll see extracted files in the output:
```
unzip metallic-container.zip -d my_zip
Archive: metallic-container.zip
inflating: my_zip/625993-PNZP34-678.jpg
inflating: my_zip/License free.txt
inflating: my_zip/License premium.txt
```
There is a slight problem with the above command. It will extract all the contents of the zip file in the current directory. That’s not a pretty thing to do because you’ll have a handful of files leaving the current directory unorganized.
### Unzip to a specific directory
A good practice is to unzip to directory in Linux command line. This way, all the extracted files are stored in the directory you specified. If the directory doesn’t exist, it will create one.
`unzip zipped_file.zip -d unzipped_directory`
Now all the contents of the zipped_file.zip will be extracted to unzipped_directory.
Since we are discussing good practices, another tip you can use is to have a look at the content of the zip file without actually extracting it.
### See the content of the zip file without unzipping it
You can check the content of the zip file without even extracting it with the option -l.
`unzip -l zipped_file.zip`
Here’s a sample output:
```
unzip -l metallic-container.zip
Archive: metallic-container.zip
Length Date Time Name
--------- ---------- ----- ----
6576010 2019-03-07 10:30 625993-PNZP34-678.jpg
1462 2019-03-07 13:39 License free.txt
1116 2019-03-07 13:39 License premium.txt
--------- -------
6578588 3 files
```
There are many other usage of the unzip command in Linux but I guess now you have enough knowledge to unzip files in Linux.
## Unzip files in Linux using GUI
You don’t always have to go to the terminal if you are using desktop Linux. Let’s see how to unzip in Ubuntu Linux graphically. I am using [GNOME desktop](https://gnome.org/) here with Ubuntu 18.04 but the process is pretty much the same in other desktop Linux distributions.
Open the file manager and go to the folder where your zip file is stored. Right click the file and you’ll see the option “extract here”. Select this one.
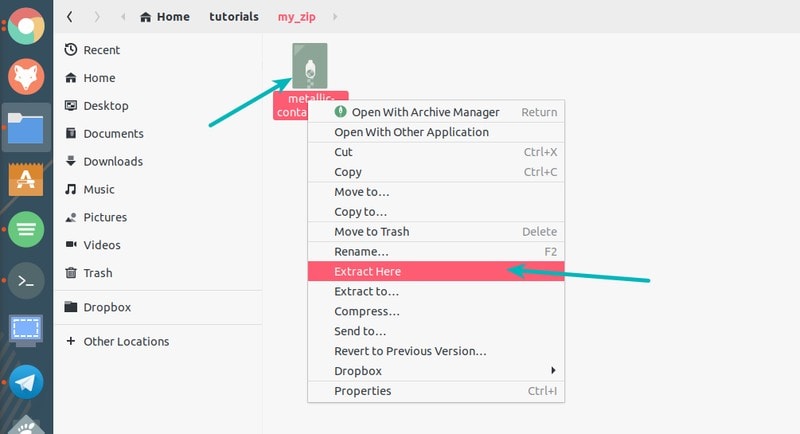
Unlike the unzip command, the extract here options create a folder of the same name as the zipped file and all the content of the zipped files are extracted to this newly created folder. I am glad that this is the default behavior instead of extracting everything in the current directory.
There is also the option of ‘extract to’ and with that you can specify the folder where you want to extract the files.
That’s it. Now you know how to unzip a file in Linux. Perhaps you might also be interested in learning about [using 7zip in Linux](https://itsfoss.com/use-7zip-ubuntu-linux/).
If you have questions or suggestions, do let me know in the comment section. |
11,474 | Adobe Photoshop 的 4 种自由开源替代品 | https://itsfoss.com/open-source-photoshop-alternatives/ | 2019-10-17T23:37:00 | [
"GIMP",
"Photoshop"
] | https://linux.cn/article-11474-1.html |
>
> 想寻找免费的 Photoshop 替代品?这里有一些最好的自由开源软件,你可以用它们来代替 Adobe Photoshop。
>
>
>
Adobe Photoshop 是一个可用于 Windows 和 macOS 的高级图像编辑和设计工具。毫无疑问,几乎每个人都知道它。其十分受欢迎。在 Linux 上,你可以在虚拟机中使用 Windows 或[通过 Wine](https://itsfoss.com/install-latest-wine/) 来使用 Photoshop,但这并不是一种理想的体验。
一般来说,我们没有太多可以替代 Adobe Photoshop 的选项。然而,在本文中,我们将提到一些在 Linux 上可用的最佳的开源 Photoshop 替代品(也支持跨平台)。
请注意 Photoshop 不仅仅是一个图片编辑器。摄影师、数码艺术家、专业编辑使用它用于各种用途。此处的替代软件可能不具备 Photoshop 的所有功能,但你可以将它们用于在 Photoshop 中完成的各种任务。
### 适用于 Linux、Windows 和 macOS 的 Adobe Photoshop 的开源替代品

最初,我想只关注 Linux 中的 Photoshop 替代品,但为什么要把这个列表局限于 Linux 呢?其他操作系统用户也可使用开源软件。
**如果你正在使用 Linux,则所有提到的软件都应该可以在你的发行版的存储库中找到。你可以使用软件中心或包管理器进行安装。**
对于其他平台,请查看官方项目网站以获取安装文件。
*该列表没有特定的排名顺序*
#### 1、GIMP:真正的 Photoshop 替代品

主要特点:
* 可定制的界面
* 数字级修饰
* 照片增强(使用变换工具)
* 支持广泛的硬件(压敏平板、音乐数字接口等)
* 几乎支持所有主要的图像文件
* 支持图层管理
可用平台:Linux、Windows 和 macOS
[GIMP](https://www.gimp.org/) 是我处理任何事情的必备工具,无论任务多么基础/高级。也许,这是你在 Linux 下最接近 Photoshop 的替代品。除此之外,它还是一个开源和免费的解决方案,适合希望在 Linux 上创作伟大作品的艺术家。
它具有任何类型的图像处理所必需的所有功能。当然,还有图层管理支持。根据你的经验水平,利用率会有所不同。因此,如果你想充分利用它,则应阅读 [文档](https://www.gimp.org/docs/) 并遵循 [官方教程](https://www.gimp.org/tutorials/)。
#### 2、Krita

主要特点:
* 支持图层管理
* 转换工具
* 丰富的笔刷/绘图工具
可用平台:Linux、Windows 和 macOS
[Krita](https://krita.org/) 是一个令人印象深刻的开源的数字绘画工具。图层管理支持和转换工具的存在使它成为 Photoshop 的基本编辑任务的替代品之一。
如果你喜欢素描/绘图,这将对你很有帮助。
#### 3、Darktable

主要特点:
* RAW 图像显影
* 支持多种图像格式
* 多个带有混合运算符的图像操作模块
可用平台:Linux、Windows 和 macOS
[Darktable](https://www.darktable.org/) 是一个由摄影师制作的开源摄影工作流应用程序。它可以让你在数据库中管理你的数码底片。从你的收藏中,显影 RAW 格式的图像并使用可用的工具对其进行增强。
从基本的图像编辑工具到支持混合运算符的多个图像模块,你将在探索中发现许多。
#### 4、Inkscape

主要特点:
* 创建对象的工具(最适合绘图/素描)
* 支持图层管理
* 用于图像处理的转换工具
* 颜色选择器(RGB、HSL、CMYK、色轮、CMS)
* 支持所有主要文件格式
可用平台:Linux、Windows 和 macOS
[Inkscape](https://inkscape.org/) 是一个非常流行的开源矢量图形编辑器,许多专业人士都使用它。它提供了灵活的设计工具,可帮助你创作漂亮的艺术作品。从技术上说,它是 Adobe Illustrator 的直接替代品,但它也提供了一些技巧,可以帮助你将其作为 Photoshop 的替代品。
与 GIMP 的官方资源类似,你可以利用 [Inkscape 的教程](https://inkscape.org/learn/) 来最大程度地利用它。
### 在你看来,真正的 Photoshop 替代品是什么?
很难提供与 Adobe Photoshop 完全相同的功能。然而,如果你遵循官方文档和资源,则可以使用上述 Photoshop 替代品做很多很棒的事情。
Adobe 提供了一系列的图形工具,并且我们有 [整个 Adobe 创意套件的开源替代方案](https://itsfoss.com/adobe-alternatives-linux/)。 你也可以去看看。
你觉得我们在此提到的 Photoshop 替代品怎么样?你是否知道任何值得提及的更好的替代方案?请在下面的评论中告诉我们。
---
via: <https://itsfoss.com/open-source-photoshop-alternatives/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[algzjh](https://github.com/algzjh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Adobe Photoshop is a premium image editing and design tool available for Windows and macOS. Undoubtedly, almost everyone knows about it. It’s that popular. Well, you can use Photoshop on Linux using Windows in a virtual machine or by [using Wine](https://itsfoss.com/install-latest-wine/) – but that is not an ideal experience.
In general, we don’t have a lot of options available as a replacement for Adobe Photoshop. However, in this article, we shall mention some of the best open-source Photoshop alternatives available for Linux (with cross-platform support as well).
Do note that Photoshop is not just a photo editor. It’s used by photographers, digital artists, professional editors for various usage. The alternative software here may not have all the features of Photoshop but you can use them for various task that you do in Photoshop.
## Open Source Alternatives to Adobe Photoshop for Linux, Windows and macOS

Initially, I thought of focusing only on Photoshop alternatives for Linux but why confine this list for Linux only? Other operating system users should also use the open source software.
*If you are using Linux, all the mentioned software should be available in the repositories of your distribution. You can install it using the software center or the package manager.*
For other platforms, please check the official project websites to get the installer files.
* The list is in no particular order of ranking*.
### 1. GIMP: The true Photoshop alternative
Key Features:
- Customizable Interface
- Digital Retouching
- Photo Enhancement (using transform tools)
- Wide range of hardware support (pressure-sensitive tablets, MIDIs, etc.)
- Almost every major image file supported
- Layer management support
**Platforms available for:** Linux, Windows and macOS
[GIMP](https://www.gimp.org/?ref=itsfoss.com) is my go-to tool for everything – no matter how basic/advanced the task is. Probably, this is the closest that you will get as a replacement for Photoshop on Linux. In addition to this, it is an open source and free solution for an artist looking to create great artwork on Linux.
It features all the necessary features for any kind of image manipulation. Of course, there’s layer management support. Depending on your experience level – the utilization will differ. So, if you are looking to make the most out of it, you should read the [documentation](https://www.gimp.org/docs/?ref=itsfoss.com) and follow the [official tutorials](https://www.gimp.org/tutorials/?ref=itsfoss.com).
### 2. Krita
Key Features:
- Layer management support
- Transformation tools
- Variety of brushes/drawing tools
**Platforms available for:** Linux, Windows and macOS
[Krita](https://krita.org/?ref=itsfoss.com) is an impressive open source tool for digital painting. The layer management support and the presence of transformation tools help makes it one of the Photoshop alternatives for basic editing tasks.
If you’re into sketching/drawing, this will help you a lot.
### 3. Darktable
Key Features:
- Develop RAW images
- Variety of Image formats supported
- Several Image operation modules with blending operators
**Platforms available for**: Linux, Windows and macOS
[Darktable](https://www.darktable.org/?ref=itsfoss.com) is an open source photography workflow application made by photographers. It lets you manage your digital negatives in a database. From your collection, develop raw images and enhance them using the tools available.
Starting from the basic image editing tools to several image modules supporting blending operators, you will find a lot of things as you explore.
### 4. Inkscape
Key Features:
- Tools for object creation (best for drawing/sketching)
- Layer management support
- Transformation tools for image manipulation
- Color selector (RGB, HSL, CMYK, color wheel, CMS)
- Support for all major file formats
**Platforms available for**: Linux, Windows and macOS
[Inkscape](https://inkscape.org/?ref=itsfoss.com) is a quite popular open-source vector graphics editor used by many professionals. It provides flexible designing tools to help you create/manipulate beautiful artworks. It is technically a direct alternative to Adobe Illustrator – but it pulls off some tricks that can help you utilize this as a Photoshop alternative as well.
Similar to GIMP’s official resources, you can utilize [Inkscape’s tutorials](https://inkscape.org/learn/?ref=itsfoss.com) to make the most out of it.
## What’s the true Photoshop alternative in your opinion?
It’s tough to offer the exact same features that Adobe Photoshop provides. However, if you follow the official documentation and resources, you can do a lot of great stuff using the above-mentioned Photoshop alternatives.
Adobe has a range of graphics tools and we have [open source alternatives to entire Adobe Creative Suite](https://itsfoss.com/adobe-alternatives-linux/). You may check that out as well.
What do you think about the Photoshop alternatives that we mentioned here? Do you know about any better alternative that deserves the mention? Let us know about it in the comments below. |
11,476 | 使用 sshuttle 构建一个穷人的虚拟专网 | https://fedoramagazine.org/use-sshuttle-to-build-a-poor-mans-vpn/ | 2019-10-18T23:50:00 | [
"VPN"
] | https://linux.cn/article-11476-1.html | 
如今,企业网络经常使用“虚拟专用网络”[来保证员工通信安全](https://en.wikipedia.org/wiki/Virtual_private_network)。但是,使用的协议有时会降低性能。如果你可以使用 SSH 连接远程主机,那么你可以设置端口转发。但这可能会很痛苦,尤其是在你需要与该网络上的许多主机一起使用的情况下。试试 `sshuttle`,它可以通过 SSH 访问来设置快速简易的虚拟专网。请继续阅读以获取有关如何使用它的更多信息。
`sshuttle` 正是针对上述情况而设计的。远程端的唯一要求是主机必须有可用的 Python。这是因为 `sshuttle` 会构造并运行一些 Python 代码来帮助传输数据。
### 安装 sshuttle
`sshuttle` 被打包在官方仓库中,因此很容易安装。打开一个终端,并[使用 sudo](https://fedoramagazine.org/howto-use-sudo/) 来运行以下命令:
```
$ sudo dnf install sshuttle
```
安装后,你可以在手册页中找到相关信息:
```
$ man sshuttle
```
### 设置虚拟专网
最简单的情况就是将所有流量转发到远程网络。这不一定是一个疯狂的想法,尤其是如果你不在自己家里这样的受信任的本地网络中。将 `-r` 选项与 SSH 用户名和远程主机名一起使用:
```
$ sshuttle -r username@remotehost 0.0.0.0/0
```
但是,你可能希望将该虚拟专网限制为特定子网,而不是所有网络流量。(有关子网的完整讨论超出了本文的范围,但是你可以在[维基百科](https://en.wikipedia.org/wiki/Subnetwork)上阅读更多内容。)假设你的办公室内部使用了预留的 A 类子网 10.0.0.0 和预留的 B 类子网 172.16.0.0。上面的命令变为:
```
$ sshuttle -r username@remotehost 10.0.0.0/8 172.16.0.0/16
```
这非常适合通过 IP 地址访问远程网络的主机。但是,如果你的办公室是一个拥有大量主机的大型网络,该怎么办?名称可能更方便,甚至是必须的。不用担心,`sshuttle` 还可以使用 `–dns` 选项转发 DNS 查询:
```
$ sshuttle --dns -r username@remotehost 10.0.0.0/8 172.16.0.0/16
```
要使 `sshuttle` 以守护进程方式运行,请加上 `-D` 选项。它会以 syslog 兼容的日志格式发送到 systemd 日志中。
根据本地和远程系统的功能,可以将 `sshuttle` 用于基于 IPv6 的虚拟专网。如果需要,你还可以设置配置文件并将其与系统启动集成。如果你想阅读更多有关 `sshuttle` 及其工作方式的信息,请[查看官方文档](https://sshuttle.readthedocs.io/en/stable/index.html)。要查看代码,请[进入 GitHub 页面](https://github.com/sshuttle/sshuttle)。
*题图由 [Kurt Cotoaga](https://unsplash.com/@kydroon?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 拍摄并发表在 [Unsplash](https://unsplash.com/s/photos/shuttle?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 上。*
---
via: <https://fedoramagazine.org/use-sshuttle-to-build-a-poor-mans-vpn/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Nowadays, business networks often use a VPN (virtual private network) for [secure communications with workers](https://en.wikipedia.org/wiki/Virtual_private_network). However, the protocols used can sometimes make performance slow. If you can reach reach a host on the remote network with SSH, you could set up port forwarding. But this can be painful, especially if you need to work with many hosts on that network. Enter **sshuttle** — which lets you set up a quick and dirty VPN with just SSH access. Read on for more information on how to use it.
The sshuttle application was designed for exactly the kind of scenario described above. The only requirement on the remote side is that the host must have Python available. This is because sshuttle constructs and runs some Python source code to help transmit data.
## Installing sshuttle
The sshuttle application is packaged in the official repositories, so it’s easy to install. Open a terminal and use the following command [with sudo](https://fedoramagazine.org/howto-use-sudo/):
$ sudo dnf install sshuttle
Once installed, you may find the manual page interesting:
$ man sshuttle
## Setting up the VPN
The simplest case is just to forward all traffic to the remote network. This isn’t necessarily a crazy idea, especially if you’re not on a trusted local network like your own home. Use the *-r* switch with the SSH username and the remote host name:
$ sshuttle [email protected]/0
However, you may want to restrict the VPN to specific subnets rather than all network traffic. (A complete discussion of subnets is outside the scope of this article, but you can read more [here on Wikipedia](https://en.wikipedia.org/wiki/Subnetwork).) Let’s say your office internally uses the reserved Class A subnet 10.0.0.0 and the reserved Class B subnet 172.16.0.0. The command above becomes:
$ sshuttle [email protected]/8 172.16.0.0/16
This works great for working with hosts on the remote network by IP address. But what if your office is a large network with lots of hosts? Names are probably much more convenient — maybe even required. Never fear, sshuttle can also forward DNS queries to the office with the *–dns* switch:
$ sshuttle --dns [email protected]/8 172.16.0.0/16
To run sshuttle like a daemon, add the *-D* switch. This also will send log information to the systemd journal via its syslog compatibility.
Depending on the capabilities of your system and the remote system, you can use sshuttle for an IPv6 based VPN. You can also set up configuration files and integrate it with your system startup if desired. If you want to read even more about sshuttle and how it works, [check out the official documentation](https://sshuttle.readthedocs.io/en/stable/index.html). For a look at the code, [head over to the GitHub page](https://github.com/sshuttle/sshuttle).
*Photo by **Kurt Cotoaga** on **Unsplash**.*
## dac.override
Could not get it to work on rawhide -> rawhide. OSerror: socket operation on non-socket or something, and also something about a deprecated python module. I was able to connect to my ISP’s shell server with it though (not sure if theyre happy about that) . With -vvv it tells you quite a bit about the network topo/connections on the server.
## Brian
Due to some latency mitigation sshuttle is also pretty slow. It unfortunately doesn’t seem to be able to balance between latency and throughput so you have to choose one or the other. If you want throughput there is a cmdline option to disable the latency control.
## Nick
Why not do port forwarding on regular SSH and use socks5 proxy?
## Paul W. Frields
@Nick, the docs on the sshuttle site describe cases in which that is less performant. Check them out.
## Vernon Van Steenkist
Didn’t find the word Socks in the sshutlle documentation. Please explain. Firefox, Thunderbird and others support an ssh created Socks5 proxy natively. Plus ssh created Socks5 procured work with any ssh server including Microsoft, Mac etc. without any additional software on the host.
## Steven Bakker
If I understand it correctly, this is more than a proxy. It can tunnel
allTCP traffic for particular hosts/ports over the VPN. This is different than a Socks5 proxy that only works from your browser, and has to be explicitly configured as such in your browser.As the manpage (https://sshuttle.readthedocs.io/en/stable/manpage.html#discussion) says:
“Unlike most VPNs, sshuttle forwards sessions, not packets. That is, it uses kernel transparent proxying (iptables REDIRECT rules on Linux) to capture outgoing TCP sessions, then creates entirely separate TCP sessions out to the original destination at the other end of the tunnel.”
## Vernon Van Steenkist
With proxychains, you only have to do one Socks 5 configuration. However, my main point is that ssh created Socks 5 proxies require no additional server side software and do not require root access and work with ssh servers on any platform. sshuttle is not an option if you do not have root access and Python on the server and want to re-direct TCP traffic.
Since sshuttle appears to require root access on both the client and server if you want to re-direct all traffic, including UDP, and additional software, why not just use openvpn instead? Openvpn can tunnel over an ssh created Socks 5 proxy and with a static key, has extremely fast connect times.
In addition, Python consumes a lot of CPU and memory resources whereas ssh proxies and openvpn can be efficiently run on routers with 32Mb of RAM and 8MB disk drives.
## Brian
SShuttle does NOT require root access on the remote (server as you put it)
## Mehdi
It is indeed a poor man’s VPN 🙂 Tried it on HomeBrew, keeps crashing.
## Brian
Because then every client needs to be socksified either directly or through a shim library which is just more work. Sshuttle is transparent to all clients.
## Stuart D Gathman
Addressing some of the previous comments:
I’m guessing the python code sent to the remote is not python3 compatible, and that is why it doesn’t work on rawhide.
socks is a fine product, but is not an alternative to sshuttle, which
transparentlyredirects all TCP sessions.The main limitation of sshuttle is that it only redirects TCP. Apps using UDP (e.g. VOIP) are out of luck. But for TCP, it is slick as a whistle.
When do I use sshuttle? When I find myself on one of those locked down WiFi setups that only let you “browse the web”. They do not let you connect on port 22, for instance. In preparation, you need to set up a server where you can login via SSH on port 443. The article should have mentioned this preparation. There is an HTTPS proxy that can distinguish between SSH and HTTPS, so you can use the same port for both.
Another possibility to escape is a web proxy allowing you to CONNECT to port 22 on a server where you have a login.
## Stuart D Gathman
Oh cool. Looks like sshuttle supports UDP since last I checked some years ago. This article got me to check the man page. Thanks!
## catafest
Use this rule:
$IPT -A INPUT -p tcp –dport 22 -m state –state NEW -s 0.0.0.0/0 -j ACCEPT
## Qoyyuum
Unfortunately, this doesn’t work on Windows 10 or on its Windows Subsystem for Linux. Something about modprobe access denied or access to its iptables via WSL. But no issue on my Fedora Workstation.
## 4e5ty
is possible using this together with iodine?
some iodine server need ip but cant use them in this same time.
meybe sshutle will be answer?
## Mariusz
Works great for me. This is something I always wanted to have instead of some home-made scripts with lots of “-L” parameters. |
11,477 | 在 Intel NUC 上安装 Linux | https://itsfoss.com/install-linux-on-intel-nuc/ | 2019-10-18T23:52:00 | [
"NUC"
] | https://linux.cn/article-11477-1.html | 
在上周,我买了一台 [InteL NUC](https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW "Intel NUC")。虽然它是如此之小,但它与成熟的桌面型电脑差别甚小。实际上,大部分的[基于 Linux 的微型 PC](https://itsfoss.com/linux-based-mini-pc/) 都是基于 Intel NUC 构建的。
我买了第 8 代 Core i3 处理器的“<ruby> 准系统 <rt> barebone </rt></ruby>” NUC。准系统意味着该设备没有 RAM、没有硬盘,显然也没有操作系统。我添加了一个 [Crucial 的 8 GB 内存条](https://www.amazon.com/Crucial-Single-PC4-19200-SODIMM-260-Pin/dp/B01BIWKP58?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01BIWKP58 "8GB RAM from Crucial")(大约 33 美元)和一个 [240 GB 的西数的固态硬盘](https://www.amazon.com/Western-Digital-240GB-Internal-WDS240G1G0B/dp/B01M9B2VB7?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01M9B2VB7 "240 GB Western Digital SSD")(大约 45 美元)。
现在,我已经有了一台不到 400 美元的电脑。因为我已经有了一个电脑屏幕和键鼠套装,所以我没有把它们计算在内。

我买这个 Intel NUC 的主要原因就是我想在实体机上测试各种各样的 Linux 发行版。我已经有一个 [树莓派 4](https://itsfoss.com/raspberry-pi-4/) 设备作为一个入门级的桌面系统,但它是一个 [ARM](https://en.wikipedia.org/wiki/ARM_architecture) 设备,因此,只有少数 Linux 发行版可用于树莓派上。(LCTT 译注:新发布的 Ubuntu 19.10 支持树莓派 4B)
*这个文章里的亚马逊链接是(原文的)受益连接。请参阅我们的[受益政策](https://itsfoss.com/affiliate-policy/)。*
### 在 NUC 上安装 Linux
现在我准备安装 Ubuntu 18.04 长期支持版,因为我现在就有这个系统的安装文件。你也可以按照这个教程安装其他的发行版。在最重要的分区之前,前边的步骤都大致相同。
#### 第一步:创建一个 USB 启动盘
你可以在 Ubuntu 官网下载它的安装文件。使用另一个电脑去[创建一个 USB 启动盘](https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/)。你可以使用像 [Rufus](https://rufus.ie/) 和 [Etcher](https://www.balena.io/etcher/) 这样的软件。在 Ubuntu上,你可以使用默认的启动盘创建工具。
#### 第二步:确认启动顺序是正确的
将你的 USB 启动盘插入到你的电脑并开机。一旦你看到 “Intel NUC” 字样出现在你的屏幕上,快速的按下 `F2` 键进入到 BIOS 设置中。

在这里,只是确认一下你的第一启动项是你的 USB 设备。如果不是,切换启动顺序。
如果你修改了一些选项,按 `F10` 键保存退出,否则直接按下 `ESC` 键退出 BIOS 设置。
#### 第三步:正确分区,安装 Linux
现在当机器重启的时候,你就可以看到熟悉的 Grub 界面,可以让你试用或者安装 Ubuntu。现在我们选择安装它。
开始的几个安装步骤非常简单,选择键盘的布局,是否连接网络还有一些其他简单的设置。

你可能会使用常规安装,默认情况下会安装一些有用的应用程序。

接下来的是要注意的部分。你有两种选择:
* “<ruby> 擦除磁盘并安装 Ubuntu <rt> Erase disk and install Ubuntu </rt></ruby>”:最简单的选项,它将在整个磁盘上安装 Ubuntu。如果你只想在 Intel NUC 上使用一个操作系统,请选择此选项,Ubuntu 将负责剩余的工作。
* “<ruby> 其他选项 <rt> Something else </rt></ruby>”:这是一个控制所有选择的高级选项。就我而言,我想在同一 SSD 上安装多个 Linux 发行版。因此,我选择了此高级选项。

**如果你选择了“<ruby> 擦除磁盘并安装 Ubuntu <rt> Erase disk and install Ubuntu </rt></ruby>”,点击“<ruby> 继续 <rt> Continue </rt></ruby>”,直接跳到第四步,**
如果你选择了高级选项,请按照下面剩下的部分进行操作。
选择固态硬盘,然后点击“<ruby> 新建分区表 <rt> New Partition Table </rt></ruby>”。

它会给你显示一个警告。直接点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

现在你就可以看到你 SSD 磁盘里的空闲空间。我的想法是为 EFI bootloader 创建一个 EFI 系统分区。一个根(`/`)分区,一个主目录(`/home`)分区。这里我并没有创建[交换分区](https://itsfoss.com/swap-size/)。Ubuntu 会根据自己的需要来创建交换分区。我也可以通过[创建新的交换文件](https://itsfoss.com/create-swap-file-linux/)来扩展交换分区。
我将在磁盘上保留近 200 GB 的可用空间,以便可以在此处安装其他 Linux 发行版。你可以将其全部用于主目录分区。保留单独的根分区和主目录分区可以在你需要重新安装系统时帮你保存里面的数据。
选择可用空间,然后单击加号以添加分区。

一般来说,100MB 足够 EFI 的使用,但是某些发行版可能需要更多空间,因此我要使用 500MB 的 EFI 分区。

接下来,我将使用 20GB 的根分区。如果你只使用一个发行版,则可以随意地将其增加到 40GB。
根目录(`/`)是系统文件存放的地方。你的程序缓存和你安装的程序将会有一些文件放在这个目录下边。我建议你可以阅读一下 [Linux 文件系统层次结构](https://linuxhandbook.com/linux-directory-structure/)来了解更多相关内容。
填入分区的大小,选择 Ext4 文件系统,选择 `/` 作为挂载点。

接下来是创建一个主目录分区,我再说一下,如果你仅仅想使用一个 Linux 发行版。那就把剩余的空间都使用完吧。为主目录分区选择一个合适的大小。
主目录是你个人的文件,比如文档、图片、音乐、下载和一些其他的文件存储的地方。

既然你创建好了 EFI 分区、根分区、主目录分区,那你就可以点击“<ruby> 现在安装 <rt> Install Now </rt></ruby>”按钮安装系统了。

它将会提示你新的改变将会被写入到磁盘,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

#### 第四步:安装 Ubuntu
事情到了这就非常明了了。现在选择你的分区或者以后选择也可以。

接下来,输入你的用户名、主机名以及密码。

看 7-8 分钟的幻灯片就可以安装完成了。

一旦安装完成,你就可以重新启动了。

当你重启的时候,你必须要移除你的 USB 设备,否则你将会再次进入安装系统的界面。
这就是在 Intel NUC 设备上安装 Linux 所需要做的一切。坦白说,你可以在其他任何系统上使用相同的过程。
### Intel NUC 和 Linux 在一起:如何使用它?
我非常喜欢 Intel NUC。它不占用太多的桌面空间,而且有足够的能力去取代传统的桌面型电脑。你可以将它的内存升级到 32GB。你也可以安装两个 SSD 硬盘。总之,它提供了一些配置和升级范围。
如果你想购买一个桌面型的电脑,我非常推荐你购买使用 [Intel NUC](https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW "Intel NUC") 迷你主机。如果你不想自己安装系统,那么你可以购买一个[基于 Linux 的已经安装好的系统迷你主机](https://itsfoss.com/linux-based-mini-pc/)。
你是否已经有了一个 Intel NUC?有一些什么相关的经验?你有什么相关的意见与我们分享吗?可以在下面评论。
---
via: <https://itsfoss.com/install-linux-on-intel-nuc/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The previous week, I got myself an [lasso link=”B07GX4X4PW” title=”Intel NUC” link_id=”15034″ ref=”intel-nuc-8-mainstream-kit-nuc8i3beh-core-i3-tall-addt-components-needed” id=”101747″]. Though it is a tiny device, it is equivalent to a full-fledged desktop CPU. Most of the [Linux-based mini PCs](https://itsfoss.com/linux-based-mini-pc/) are actually built on top of the Intel NUC devices.
I got the ‘barebone’ NUC with 8th generation Core i3 processor. Barebone means that the device has no RAM, no hard disk and obviously, no operating system. I added an [lasso link=”B01BIWKP58″ title=”8GB RAM from Crucial” link_id=”15035″ ref=”crucial-8gb-single-ddr4-2400-mt-s-pc4-19200-sr-x8-sodimm-260-pin-memory-ct8g4sfs824a” id=”101724″] (around $33) and a [lasso link=”B01M9B2VB7″ title=”240 GB Western Digital SSD” link_id=”15036″ ref=”western-digital-240gb-green-m-2-2280-internal-solid-state-drive-model-wds240g1g0b” id=”101812″] (around $45).
Altogether, I had a desktop PC ready in under $400. I already have a screen and keyboard-mouse pair so I am not counting them in the expense.

The main reason why I got Intel NUC is that I want to test and review various Linux distributions on real hardware. I have a [Raspberry Pi 4](https://itsfoss.com/raspberry-pi-4/) which works as an entry-level desktop but it’s an [ARM](https://en.wikipedia.org/wiki/ARM_architecture) device and thus there are only a handful of Linux distributions available for Raspberry Pi.
*The Amazon links in the article are affiliate links. Please read our affiliate policy.*
## Installing Linux on Intel NUC
I started with Ubuntu 18.04 LTS version because that’s what I had available at the moment. You can follow this tutorial for other distributions as well. The steps should remain the same at least till the partition step which is the most important one in the entire procedure.
### Step 1: Create a live Linux USB
Download Ubuntu 18.04 from its website. Use another computer to [create a live Ubuntu USB](https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/). You can use a tool like [Rufus](https://rufus.ie/) or [Etcher](https://www.balena.io/etcher/). On Ubuntu, you can use the default Startup Disk Creator tool.
### Step 2: Make sure the boot order is correct
Insert your USB and power on the NUC. As soon as you see the Intel NUC written on the screen, press F2 to go to BIOS settings.
In here, just make sure that boot order is set to boot from USB first. If not, change the boot order.
If you had to make any changes, press F10 to save and exit. Else, use Esc to exit the BIOS.
### Step 3: Making the correct partition to install Linux
Now when it boots again, you’ll see the familiar Grub screen that allows you to try Ubuntu live or install it. Choose to install it.
First few installation steps are simple. You choose the keyboard layout, and the network connection (if any) and other simple steps.
You may go with the normal installation that has a handful of useful applications installed by default.
The interesting screen comes next. You have two options:
**Erase disk and install Ubuntu**: Simplest option that will install Ubuntu on the entire disk. If you want to use only one operating system on the Intel NUC, choose this option and Ubuntu will take care of the rest.**Something Else**: This is the advanced option if you want to take control of things. In my case, I want to install multiple Linux distribution on the same SSD. So I am opting for this advanced option.
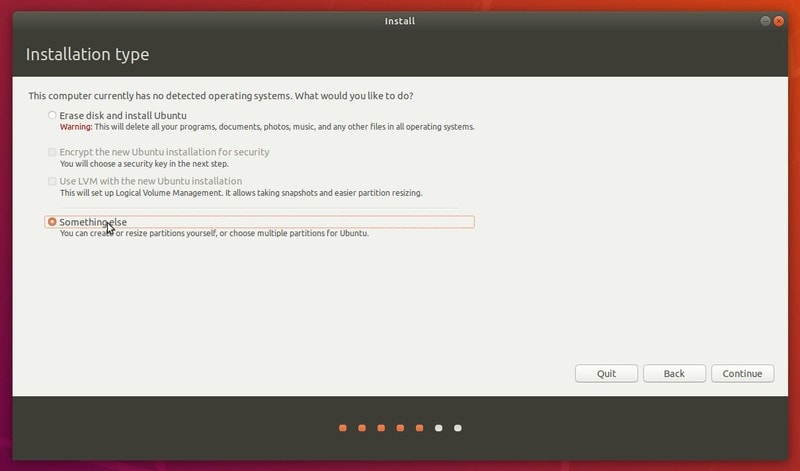
*If you opt for “Erase disk and install Ubuntu”, click continue and go to the step 4.*
If you are going with the advanced option, follow the rest of the step 3.
Select the SSD disk and click on New Partition Table.
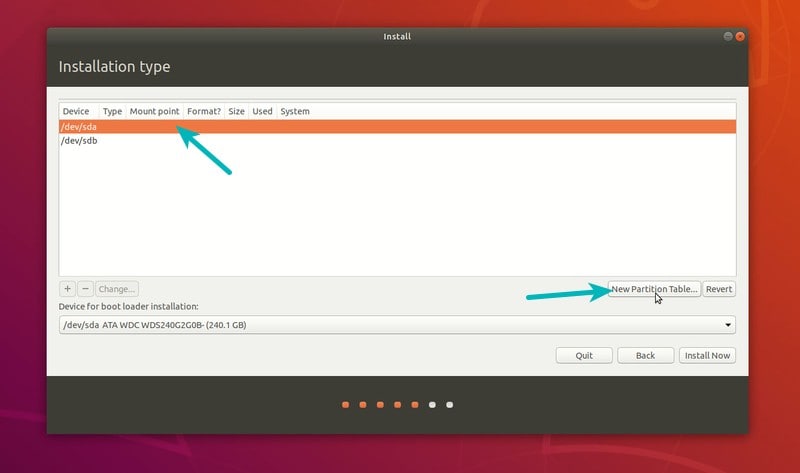
It will show you a warning. Just hit Continue.
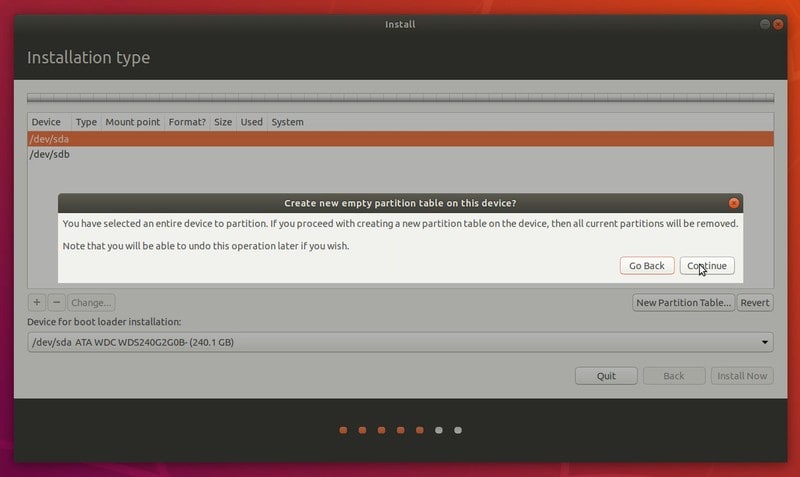
Now you’ll see a free space of the size of your SSD disk. My idea is to create an EFI System Partition for the EFI boot loader, a root partition and a home partition. I am not creating a [swap partition](https://itsfoss.com/swap-size/). Ubuntu creates a swap file on its own and if the need be, you can [easily create swap files in Linux](https://itsfoss.com/create-swap-file-linux/) to extend the swap size.
I’ll leave almost 200 GB of free space on the disk so that I could install other Linux distributions here. You can utilize all of it for your home partitions. Keeping separate root and home partitions help you when you want to save reinstall the system
Select the free space and click on the plus sign to add a partition.
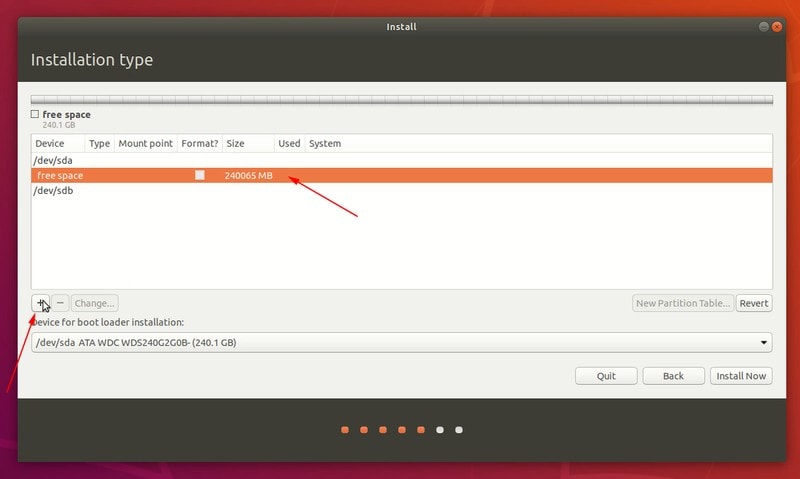
Usually 100 MB is sufficient for the EFI but some distributions may need more space so I am going with 500 MB of EFI partition.
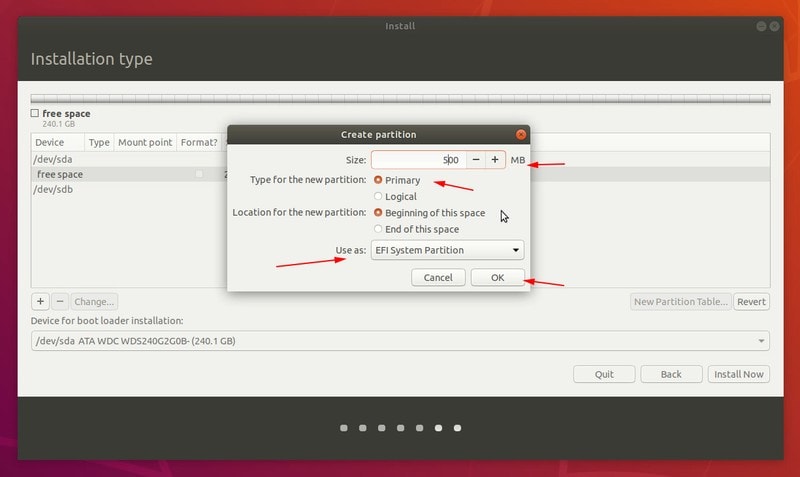
Next, I am using 20 GB of root space. If you are going to use only one distributions, you can increase it to 40 GB easily.
Root is where the system files are kept. Your program cache and installed applications keep some files under the root directory. I recommend [reading about the Linux filesystem hierarchy](https://linuxhandbook.com/linux-directory-structure/) to get more knowledge on this topic.
Provide the size, choose Ext4 file system and use / as the mount point.
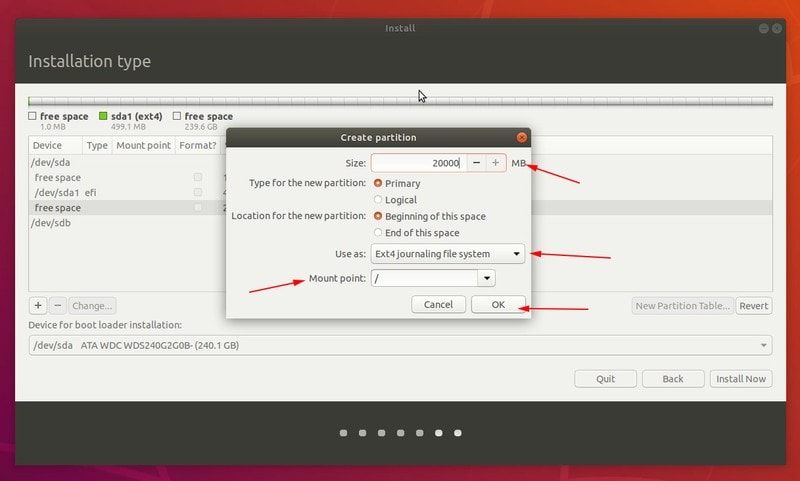
The next is to create a home partition. Again, if you want to use only one Linux distribution, go for the remaining free space. Else, choose a suitable disk space for the Home partition.
Home is where your personal documents, pictures, music, download and other files are stored.
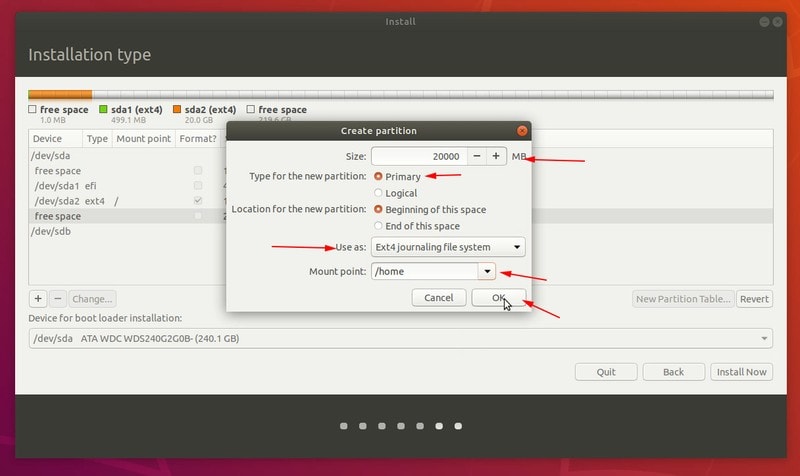
Now that you have created EFI, root and home partitions, you are ready to install Ubuntu Linux. Hit the Install Now button.
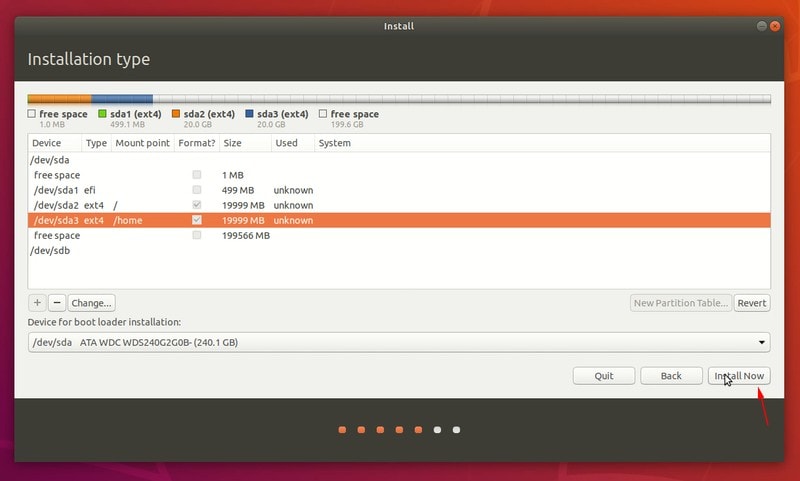
It will give you a warning about the new changes being written to the disk. Hit continue.
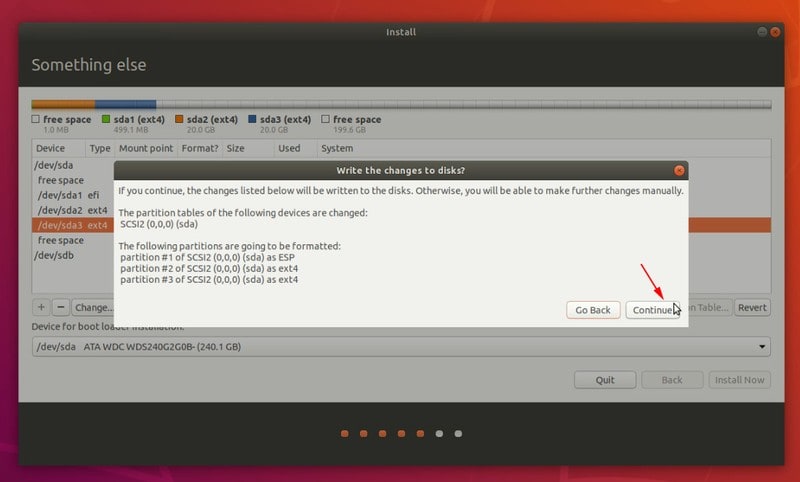
### Step 4: Installing Ubuntu Linux
Things are pretty straightforward from here onward. Choose your time zone right now or change it later.
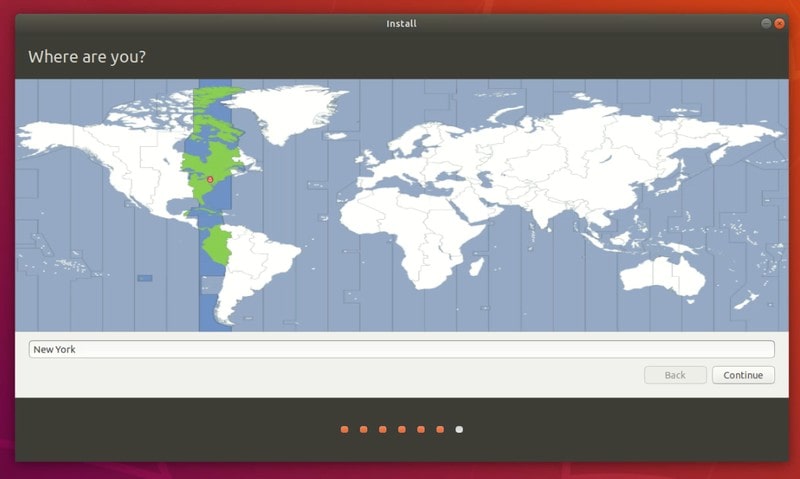
On the next screen, choose a username, hostname and the password.
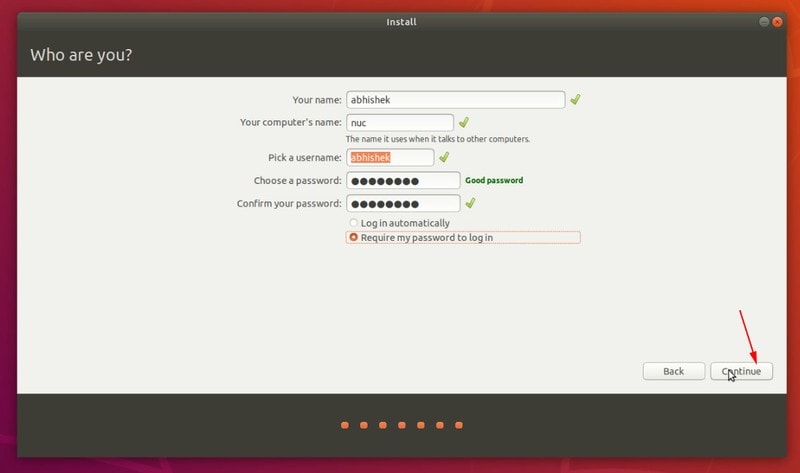
It’s a wait an watch game for next 7-8 minutes.
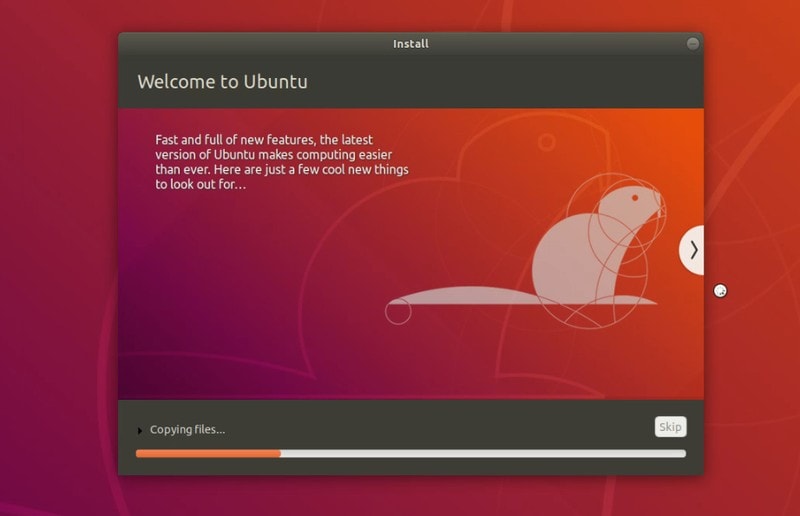
Once the installation is over, you’ll be prompted for a restart.
When you restart, you should remove the live USB otherwise you’ll boot into the installation media again.
That’s all you need to do to install Linux on an Intel NUC device. Quite frankly, you can use the same procedure on any other system.
**Intel NUC and Linux: how do you use it?**
I am loving the Intel NUC. It doesn’t take space on the desk and yet it is powerful enough to replace the regular bulky desktop CPU. You can easily upgrade it to 32GB of RAM. You can install two SSD on it. Altogether, it provides some scope of configuration and upgrade.
If you are looking to buy a desktop computer, I highly recommend [lasso link=”B07GX4X4PW” title=”Intel NUC” link_id=”15037″ ref=”intel-nuc-8-mainstream-kit-nuc8i3beh-core-i3-tall-addt-components-needed” id=”101747″] mini PC. If you are not comfortable installing the OS on your own, you can [buy one of the Linux-based mini PCs](https://itsfoss.com/linux-based-mini-pc/).
Do you own an Intel NUC? How’s your experience with it? Do you have any tips to share it with us? Do leave a comment below. |
11,478 | 什么是 Java 构造器? | https://opensource.com/article/19/6/what-java-constructor | 2019-10-18T23:55:00 | [
"Java"
] | /article-11478-1.html |
>
> 构造器是编程的强大组件。使用它们来释放 Java 的全部潜力。
>
>
>

在开源、跨平台编程领域,Java 无疑(?)是无可争议的重量级语言。尽管有许多[伟大的跨平台](https://opensource.com/resources/python)[框架](https://opensource.com/article/17/4/pyqt-versus-wxpython),但很少有像 [Java](https://opensource.com/resources/java) 那样统一和直接的。
当然,Java 也是一种非常复杂的语言,具有自己的微妙之处和惯例。Java 中与<ruby> 构造器 <rt> constructor </rt></ruby>有关的最常见问题之一是:它们是什么,它们的作用是什么?
简而言之:构造器是在 Java 中创建新<ruby> 对象 <rt> object </rt></ruby>时执行的操作。当 Java 应用程序创建一个你编写的类的实例时,它将检查构造器。如果(该类)存在构造器,则 Java 在创建实例时将运行构造器中的代码。这几句话中包含了大量的技术术语,但是当你看到它的实际应用时就会更加清楚,所以请确保你已经[安装了 Java](https://openjdk.java.net/install/index.html) 并准备好进行演示。
### 没有使用构造器的开发日常
如果你正在编写 Java 代码,那么你已经在使用构造器了,即使你可能不知道它。Java 中的所有类都有一个构造器,因为即使你没有创建构造器,Java 也会在编译代码时为你生成一个。但是,为了进行演示,请忽略 Java 提供的隐藏构造器(因为默认构造器不添加任何额外的功能),并观察没有显式构造器的情况。
假设你正在编写一个简单的 Java 掷骰子应用程序,因为你想为游戏生成一个伪随机数。
首先,你可以创建骰子类来表示一个骰子。你玩了很久[《龙与地下城》](https://opensource.com/article/19/5/free-rpg-day),所以你决定创建一个 20 面的骰子。在这个示例代码中,变量 `dice` 是整数 20,表示可能的最大掷骰数(一个 20 边骰子的掷骰数不能超过 20)。变量 `roll` 是最终的随机数的占位符,`rand` 用作随机数种子。
```
import java.util.Random;
public class DiceRoller {
private int dice = 20;
private int roll;
private Random rand = new Random();
```
接下来,在 `DiceRoller` 类中创建一个函数,以执行计算机模拟模子滚动所必须采取的步骤:从 `rand` 中获取一个整数并将其分配给 `roll`变量,考虑到 Java 从 0 开始计数但 20 面的骰子没有 0 值的情况,`roll` 再加 1 ,然后打印结果。
```
import java.util.Random;
public class DiceRoller {
private int dice = 20;
private int roll;
private Random rand = new Random();
```
最后,产生 `DiceRoller` 类的实例并调用其关键函数 `Roller`:
```
// main loop
public static void main (String[] args) {
System.out.printf("You rolled a ");
DiceRoller App = new DiceRoller();
App.Roller();
}
}
```
只要你安装了 Java 开发环境(如 [OpenJDK](https://openjdk.java.net/)),你就可以在终端上运行你的应用程序:
```
$ java dice.java
You rolled a 12
```
在本例中,没有显式构造器。这是一个非常有效和合法的 Java 应用程序,但是它有一点局限性。例如,如果你把游戏《龙与地下城》放在一边,晚上去玩一些《快艇骰子》,你将需要六面骰子。在这个简单的例子中,更改代码不会有太多的麻烦,但是在复杂的代码中这不是一个现实的选择。解决这个问题的一种方法是使用构造器。
### 构造函数的作用
这个示例项目中的 `DiceRoller` 类表示一个虚拟骰子工厂:当它被调用时,它创建一个虚拟骰子,然后进行“滚动”。然而,通过编写一个自定义构造器,你可以让掷骰子的应用程序询问你希望模拟哪种类型的骰子。
大部分代码都是一样的,除了构造器接受一个表示面数的数字参数。这个数字还不存在,但稍后将创建它。
```
import java.util.Random;
public class DiceRoller {
private int dice;
private int roll;
private Random rand = new Random();
// constructor
public DiceRoller(int sides) {
dice = sides;
}
```
模拟滚动的函数保持不变:
```
public void Roller() {
roll = rand.nextInt(dice);
roll += 1;
System.out.println (roll);
}
```
代码的主要部分提供运行应用程序时提供的任何参数。这的确会是一个复杂的应用程序,你需要仔细解析参数并检查意外结果,但对于这个例子,唯一的预防措施是将参数字符串转换成整数类型。
```
public static void main (String[] args) {
System.out.printf("You rolled a ");
DiceRoller App = new DiceRoller( Integer.parseInt(args[0]) );
App.Roller();
}
```
启动这个应用程序,并提供你希望骰子具有的面数:
```
$ java dice.java 20
You rolled a 10
$ java dice.java 6
You rolled a 2
$ java dice.java 100
You rolled a 44
```
构造器已接受你的输入,因此在创建类实例时,会将 `sides` 变量设置为用户指定的任何数字。
构造器是编程的功能强大的组件。练习用它们来解开了 Java 的全部潜力。
---
via: <https://opensource.com/article/19/6/what-java-constructor>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,480 | 如何在 Ubuntu 上安装和配置 PostgreSQL | https://itsfoss.com/install-postgresql-ubuntu/ | 2019-10-19T23:50:00 | [
"PostgreSQL"
] | https://linux.cn/article-11480-1.html |
>
> 本教程中,你将学习如何在 Ubuntu Linux 上安装和使用开源数据库 PostgreSQL。
>
>
>
[PostgreSQL](https://www.postgresql.org/) (又名 Postgres) 是一个功能强大的自由开源的关系型数据库管理系统 ([RDBMS](https://www.codecademy.com/articles/what-is-rdbms-sql)) ,其在可靠性、稳定性、性能方面获得了业内极高的声誉。它旨在处理各种规模的任务。它是跨平台的,而且是 [macOS Server](https://www.apple.com/in/macos/server/) 的默认数据库。
如果你喜欢简单易用的 SQL 数据库管理器,那么 PostgreSQL 将是一个正确的选择。PostgreSQL 对标准的 SQL 兼容的同时提供了额外的附加特性,同时还可以被用户大量扩展,用户可以添加数据类型、函数并执行更多的操作。
之前我曾论述过 [在 Ubuntu 上安装 MySQL](https://itsfoss.com/install-mysql-ubuntu/)。在本文中,我将向你展示如何安装和配置 PostgreSQL,以便你随时可以使用它来满足你的任何需求。

### 在 Ubuntu 上安装 PostgreSQL
PostgreSQL 可以从 Ubuntu 主存储库中获取。然而,和许多其它开发工具一样,它可能不是最新版本。
首先在终端中使用 [apt 命令](https://itsfoss.com/apt-command-guide/) 检查 [Ubuntu 存储库](https://itsfoss.com/ubuntu-repositories/) 中可用的 PostgreSQL 版本:
```
apt show postgresql
```
在我的 Ubuntu 18.04 中,它显示 PostgreSQL 的可用版本是 10(10+190 表示版本 10)而 PostgreSQL 版本 11 已经发布。
```
Package: postgresql
Version: 10+190
Priority: optional
Section: database
Source: postgresql-common (190)
Origin: Ubuntu
```
根据这些信息,你可以自主决定是安装 Ubuntu 提供的版本还是还是获取 PostgreSQL 的最新发行版。
我将向你介绍这两种方法:
#### 方法一:通过 Ubuntu 存储库安装 PostgreSQL
在终端中,使用以下命令安装 PostgreSQL:
```
sudo apt update
sudo apt install postgresql postgresql-contrib
```
根据提示输入你的密码,依据于你的网速情况,程序将在几秒到几分钟安装完成。说到这一点,随时检查 [Ubuntu 中的各种网络带宽](https://itsfoss.com/network-speed-monitor-linux/)。
>
> 什么是 postgresql-contrib?
>
>
> postgresql-contrib 或者说 contrib 包,包含一些不属于 PostgreSQL 核心包的实用工具和功能。在大多数情况下,最好将 contrib 包与 PostgreSQL 核心一起安装。
>
>
>
#### 方法二:在 Ubuntu 中安装最新版本的 PostgreSQL 11
要安装 PostgreSQL 11, 你需要在 `sources.list` 中添加官方 PostgreSQL 存储库和证书,然后从那里安装它。
不用担心,这并不复杂。 只需按照以下步骤。
首先添加 GPG 密钥:
```
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
```
现在,使用以下命令添加存储库。如果你使用的是 Linux Mint,则必须手动替换你的 Mint 所基于的 Ubuntu 版本号:
```
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
```
现在一切就绪。使用以下命令安装 PostgreSQL:
```
sudo apt update
sudo apt install postgresql postgresql-contrib
```
>
> PostgreSQL GUI 应用程序
>
>
> 你也可以安装用于管理 PostgreSQL 数据库的 GUI 应用程序(pgAdmin):
>
>
> `sudo apt install pgadmin4`
>
>
>
### PostgreSQL 配置
你可以通过执行以下命令来检查 PostgreSQL 是否正在运行:
```
service postgresql status
```
通过 `service` 命令,你可以启动、关闭或重启 `postgresql`。输入 `service postgresql` 并按回车将列出所有选项。现在,登录该用户。
默认情况下,PostgreSQL 会创建一个拥有所权限的特殊用户 `postgres`。要实际使用 PostgreSQL,你必须先登录该账户:
```
sudo su postgres
```
你的提示符会更改为类似于以下的内容:
```
postgres@ubuntu-VirtualBox:/home/ubuntu$
```
现在,使用 `psql` 来启动 PostgreSQL Shell:
```
psql
```
你应该会看到如下提示符:
```
postgress=#
```
你可以输入 `\q` 以退出,输入 `\?` 获取帮助。
要查看现有的所有表,输入如下命令:
```
\l
```
输出内容类似于下图所示(单击 `q` 键退出该视图):

使用 `\du` 命令,你可以查看 PostgreSQL 用户:

你可以使用以下命令更改任何用户(包括 `postgres`)的密码:
```
ALTER USER postgres WITH PASSWORD 'my_password';
```
**注意:**将 `postgres` 替换为你要更改的用户名,`my_password` 替换为所需要的密码。另外,不要忘记每条命令后面的 `;`(分号)。
建议你另外创建一个用户(不建议使用默认的 `postgres` 用户)。为此,请使用以下命令:
```
CREATE USER my_user WITH PASSWORD 'my_password';
```
运行 `\du`,你将看到该用户,但是,`my_user` 用户没有任何的属性。来让我们给它添加超级用户权限:
```
ALTER USER my_user WITH SUPERUSER;
```
你可以使用以下命令删除用户:
```
DROP USER my_user;
```
要使用其他用户登录,使用 `\q` 命令退出,然后使用以下命令登录:
```
psql -U my_user
```
你可以使用 `-d` 参数直接连接数据库:
```
psql -U my_user -d my_db
```
你可以使用其他已存在的用户调用 PostgreSQL。例如,我使用 `ubuntu`。要登录,从终端执行以下命名:
```
psql -U ubuntu -d postgres
```
**注意:**你必须指定一个数据库(默认情况下,它将尝试将你连接到与登录的用户名相同的数据库)。
如果遇到如下错误:
```
psql: FATAL: Peer authentication failed for user "my_user"
```
确保以正确的用户身份登录,并使用管理员权限编辑 `/etc/postgresql/11/main/pg_hba.conf`:
```
sudo vim /etc/postgresql/11/main/pg_hba.conf
```
**注意:**用你的版本替换 `11`(例如 `10`)。
对如下所示的一行进行替换:
```
local all postgres peer
```
替换为:
```
local all postgres md5
```
然后重启 PostgreSQL:
```
sudo service postgresql restart
```
使用 PostgreSQL 与使用其他 SQL 类型的数据库相同。由于本文旨在帮助你进行初步的设置,因此不涉及具体的命令。不过,这里有个 [非常有用的要点](https://gist.github.com/Kartones/dd3ff5ec5ea238d4c546) 可供参考! 另外, 手册(`man psql`)和 [文档](https://www.postgresql.org/docs/manuals/) 也非常有用。
### 总结
阅读本文有望指导你完成在 Ubuntu 系统上安装和准备 PostgreSQL 的过程。如果你不熟悉 SQL,你应该阅读 [基本的 SQL 命令](https://itsfoss.com/basic-sql-commands/)。
如果你有任何问题或疑惑,请随时在评论部分提出。
---
via: <https://itsfoss.com/install-postgresql-ubuntu/>
作者:[Sergiu](https://itsfoss.com/author/sergiu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lnrCoder](https://github.com/lnrCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *In this tutorial, you’ll learn how to install and use the open source database PostgreSQL on Ubuntu Linux.*
[PostgreSQL](https://www.postgresql.org/) (or Postgres) is a powerful, free and open-source relational database management system ([RDBMS](https://www.codecademy.com/articles/what-is-rdbms-sql)) that has a strong reputation for reliability, feature robustness, and performance. It is designed to handle various tasks, of any size. It is cross-platform, and the default database for [macOS Server](https://www.apple.com/in/macos/server/).
PostgreSQL might just be the right tool for you if you’re a fan of a simple to use SQL database manager. It supports SQL standards and offers additional features, while also being heavily extendable by the user as the user can add data types, functions, and do many more things.
Earlier I discussed [installing MySQL on Ubuntu](https://itsfoss.com/install-mysql-ubuntu/). In this article, I’ll show you how to install and configure PostgreSQL, so that you are ready to use it to suit whatever your needs may be.

## Installing PostgreSQL on Ubuntu
PostgreSQL is available in Ubuntu main repository. However, like many other development tools, it may not be the latest version.
First check the PostgreSQL version available in [Ubuntu repositories](https://itsfoss.com/ubuntu-repositories/) using this [apt command](https://itsfoss.com/apt-command-guide/) in the terminal:
`apt show postgresql`
In my Ubuntu 18.04, it showed that the available version of PostgreSQL is version 10 (10+190 means version 10) whereas PostgreSQL version 11 is already released.
Package: postgresql Version: 10+190 Priority: optional Section: database Source: postgresql-common (190) Origin: Ubuntu
Based on this information, you can make your mind whether you want to install the version available from Ubuntu or you want to get the latest released version of PostgreSQL.
I’ll show both methods to you.
### Method 1: Install PostgreSQL from Ubuntu repositories
In the terminal, use the following command to install PostgreSQL
```
sudo apt update
sudo apt install postgresql postgresql-contrib
```
Enter your password when asked and you should have it installed in a few seconds/minutes depending on your internet speed. Speaking of that, feel free to check various [network bandwidth in Ubuntu](https://itsfoss.com/network-speed-monitor-linux/).
What is postgresql-contrib?
The postgresql-contrib or the contrib package consists some additional utilities and functionalities that are not part of the core PostgreSQL package. In most cases, it’s good to have the contrib package installed along with the PostgreSQL core.
### Method 2: Installing the latest version 11 of PostgreSQL in Ubuntu
To install PostgreSQL 11, you need to add the official PostgreSQL repository in your sources.list, add its certificate and then install it from there.
Don’t worry, it’s not complicated. Just follow these steps.
Add the GPG key first:
`wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -`
Now add the repository with the below command. If you are using Linux Mint, you’ll have to manually replace the `lsb_release -cs` the Ubuntu version your Mint release is based on.
`sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'`
Everything is ready now. Install PostgreSQL with the following commands:
```
sudo apt update
sudo apt install postgresql postgresql-contrib
```
PostgreSQL GUI application
You may also install a GUI application (pgAdmin) for managing PostgreSQL databases:*sudo apt install pgadmin4*
## Configuring PostgreSQL
You can check if **PostgreSQL** is running by executing:
`service postgresql status`
Via the **service** command you can also **start**, **stop** or **restart** **postgresql**. Typing in **service postgresql** and pressing **Enter** should output all options. Now, onto the users.
By default, PostgreSQL creates a special user postgres that has all rights. To actually use PostgreSQL, you must first log in to that account:
`sudo su postgres`
Your prompt should change to something similar to:
`postgres@ubuntu-VirtualBox:/home/ubuntu$ `
Now, run the **PostgreSQL Shell** with the utility **psql**:
`psql`
You should be prompted with:
`postgress=# `
You can type in **\q** to **quit** and **\?** for **help**.
To see all existing tables, enter:
`\l`
The output will look similar to this (Hit the key **q** to exit this view):
With **\du** you can display the **PostgreSQL users**:
You can change the password of any user (including **postgres**) with:
`ALTER USER postgres WITH PASSWORD 'my_password';`
**Note:** *Replace postgres with the name of the user and my_password with the wanted password.* Also, don’t forget the
**;**(
**semicolumn**) after every statement.
It is recommended that you create another user (it is bad practice to use the default **postgres** user). To do so, use the command:
`CREATE USER my_user WITH PASSWORD 'my_password';`
If you run **\du**, you will see, however, that **my_user** has no attributes yet. Let’s add **Superuser** to it:
`ALTER USER my_user WITH SUPERUSER;`
You can **remove users** with:
`DROP USER my_user;`
To **log in** as another user, quit the prompt (**\q**) and then use the command:
`psql -U my_user`
You can connect directly to a database with the **-d** flag:
`psql -U my_user -d my_db`
You should call the PostgreSQL user the same as another existing user. For example, my use is **ubuntu**. To log in, from the terminal I use:
`psql -U ubuntu -d postgres`
**Note:** *You must specify a database (by default it will try connecting you to the database named the same as the user you are logged in as).*
If you have a the error:
`psql: FATAL: Peer authentication failed for user "my_user"`
Make sure you are logging as the correct user and edit **/etc/postgresql/11/main/pg_hba.conf ** with administrator rights:
`sudo vim /etc/postgresql/11/main/pg_hba.conf `
**Note:** *Replace 11 with your version (e.g. 10).*
Here, replace the line:
`local all postgres peer`
With:
`local all postgres md5`
Then restart **PostgreSQL**:
`sudo service postgresql restart`
Using **PostgreSQL** is the same as using any other **SQL** type database. I won’t go into the specific commands, since this article is about getting you started with a working setup. However, here is a [very useful gist](https://gist.github.com/Kartones/dd3ff5ec5ea238d4c546) to reference! Also, the man page (**man psql**) and the [documentation](https://www.postgresql.org/docs/manuals/) are very helpful.
**Wrapping Up**
Reading this article has hopefully guided you through the process of installing and preparing PostgreSQL on an Ubuntu system. If you are new to SQL, you should read this article to know the [basic SQL commands](https://itsfoss.com/basic-sql-commands/):
If you have any issues or questions, please feel free to ask in the comment section. |
11,481 | Linux 中的十大开源视频播放器 | https://opensourceforu.com/2019/10/top-10-open-source-video-players-for-linux/ | 2019-10-19T23:22:00 | [
"播放器",
"视频"
] | https://linux.cn/article-11481-1.html | 
>
> 选择合适的视频播放器有助于确保你获得最佳的观看体验,并为你提供[创建视频网站](https://www.ning.com/create-video-website/)的工具。你甚至可以根据个人喜好自定义正在观看的视频。
>
>
>
因此,为了帮助你挑选适合你需求的最佳播放器,我们列出了 Linux 中的十大开源播放器。
让我们来看看:
### 1、XBMC – Kodi 媒体中心
这是一个灵活的跨平台播放器,核心使用 C++ 编写,并提供 Python 脚本作为附加组件。使用 Kodi 的好处包括:
* 提供超过 69 种语言版本
* 用户可以从网络和本地存储播放音频、视频和媒体播放文件
* 可与 JeOS 一起作为应用套件用于智能电视和机顶盒等设备
* 有很多不错的附加组件,如视频和音频流插件、主题、屏幕保护程序等
* 它支持多种格式,如 MPEG-1、2、4、RealVideo、HVC、HEVC 等
### 2、VLC 媒体播放器
由于该播放器在一系列操作系统上具有令人印象深刻的功能和可用性,它出现在列表上是理所当然的。它使用 C、C++ 和 Objective C 编写,用户无需使用插件,这要归功于它对解码库的广泛支持。VLC 媒体播放器的优势包括:
* 在 Linux 上支持 DVD 播放器
* 能够播放 .iso 文件
* 能够播放高清录制的 D-VHS 磁带
* 可以直接从 U 盘或外部驱动器运行
* API 支持和浏览器支持(通过插件)
### 3、Bomi(CMPlayer)
这个灵活和强大的播放器被许多普通用户选择,它的优势有:
* 易于使用的图形用户界面(GUI)
* 令人印象深刻的播放能力
* 可以恢复播放
* 支持字幕,可以渲染多个字幕文件

### 4、Miro 音乐与视频播放器
以前被称为 Democracy Player(DTV),Miro 由<ruby> 参与文化基金会 <rt> Participatory Culture Foundation </rt></ruby>重新开发,是一个不错的跨平台音频视频播放器。令人印象深刻,因为:
* 支持一些高清音频和视频
* 提供超过 40 种语言版本
* 可以播放多种文件格式,例如,QuickTime、WMV、MPEG 文件、AVI、XVID
* 一旦可用,可以自动通知用户并下载视频
### 5、SMPlayer
这个跨平台的媒体播放器,只使用 C++ 的 Qt 库编写,它是一个强大的多功能播放器。我们喜欢它,因为:
* 有多语言选择
* 支持所有默认格式
* 支持 EDL 文件,你可以配置从互联网获取的字幕
* 可从互联网下载的各种皮肤
* 倍速播放
### 6、MPV 播放器
它用 C、Objective-C、Lua 和 Python 编写,免费、易于使用,并且有许多新功能,便于使用。主要加分是:
* 可以编译为一个库,公开客户端 API,从而增强控制
* 允许媒体编码
* 平滑动画
### 7、Deepin Movie
此播放器是开源媒体播放器的一个极好的例子,它有很多优势,包括:
* 通过键盘完成所有播放操作
* 各种格式的视频文件可以通过这个播放器轻松播放
* 流媒体功能能让用户享受许多在线视频资源
### 8、Gnome 视频
以前称为 Totem,这是 Gnome 桌面环境的播放器。
完全用 C 编写,使用 GStreamer 多媒体框架构建,高于 2.7.1 的版本使用 xine 作为后端。它是很棒的,因为:
它支持大量的格式,包括:
* SHOUTcast、SMIL、M3U、Windows 媒体播放器格式等
* 你可以在播放过程中调整灯光设置,如亮度和对比度
* 加载 SubRip 字幕
* 支持从互联网频道(如 Apple)直接播放视频
### 9、Xine 多媒体播放器
我们列表中用 C 编写的另外一个跨平台多媒体播放器。这是一个全能播放器,因为:
* 它支持物理媒体以及视频设备。3gp、MKV、 MOV、Mp4、音频格式
* 网络协议,V4L、DVB 和 PVR 等
* 它可以手动校正音频和视频流的同步
### 10、ExMPlayer
最后但同样重要的一个,ExMPlayer 是一个惊人的、强大的 MPlayer 的 GUI 前端。它的优点包括:
* 可以播放任何媒体格式
* 支持网络流和字幕
* 易于使用的音频转换器
* 高品质的音频提取,而不会影响音质
上面这些视频播放器在 Linux 上工作得很好。我们建议你尝试一下,选择一个最适合你的播放器。
---
via: <https://opensourceforu.com/2019/10/top-10-open-source-video-players-for-linux/>
作者:[Stella Aldridge](https://opensourceforu.com/author/stella-aldridge/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,483 | 变异测试:如何利用故障? | https://opensource.com/article/19/9/mutation-testing-example-tdd | 2019-10-21T07:57:00 | [
"TDD",
"变异测试"
] | https://linux.cn/article-11483-1.html | 
>
> 使用事先设计好的故障以确保你的代码达到预期的结果,并遵循 .NET xUnit.net 测试框架来进行测试。
>
>
>
[在变异测试是 TDD 的演变](/article-11468-1.html) 一文中,我谈到了迭代的力量。在可度量的测试中,迭代能够保证找到问题的解决方案。在那篇文章中,我们讨论了迭代法帮助确定实现计算给定数字平方根的代码。
我还演示了最有效的方法是找到可衡量的目标或测试,然后以最佳猜测值开始迭代。正如所预期的,第一次测试通常会失败。因此,必须根据可衡量的目标或测试对失败的代码进行完善。根据运行结果,对测试值进行验证或进一步加以完善。
在此模型中,学习获得解决方案的唯一方法是反复失败。这听起来有悖常理,但它确实有效。
按照这种分析,本文探讨了在构建包含某些依赖项的解决方案时使用 DevOps 的最佳方法。第一步是编写一个预期结果失败的用例。
### 依赖性问题是你不能依赖它们
正如<ruby> 迈克尔·尼加德 <rt> Michael Nygard </rt></ruby>在《[没有终结状态的架构](https://www.infoq.com/presentations/Architecture-Without-an-End-State/)》中机智的表示的那样,依赖问题是一个很大的话题,最好留到另一篇文章中讨论。在这里,你将会看到依赖项给项目带来的一些潜在问题,以及如何利用测试驱动开发(TDD)来避免这些陷阱。
首先,找到现实生活中的一个挑战,然后看看如何使用 TDD 解决它。
### 谁把猫放出来?

在敏捷开发环境中,通过定义期望结果开始构建解决方案会很有帮助。通常,在 <ruby> <a href="https://www.agilealliance.org/glossary/user-stories"> 用户故事 </a> <rt> user story </rt></ruby> 中描述期望结果:
>
> 我想使用我的家庭自动化系统(HAS)来控制猫何时可以出门,因为我想保证它在夜间的安全。
>
>
>
现在你已经有了一个用户故事,你需要通过提供一些功能要求(即指定验收标准)来对其进行详细说明。 从伪代码中描述的最简单的场景开始:
>
> 场景 1:在夜间关闭猫门
>
>
> * 用时钟监测到了晚上的时间
> * 时钟通知 HAS 系统
> * HAS 关闭支持物联网(IoT)的猫门
>
>
>
### 分解系统
开始构建之前,你需要将正在构建的系统(HAS)进行分解(分解为依赖项)。你必须要做的第一件事是识别任何依赖项(如果幸运的话,你的系统没有依赖项,这将会更容易,但是,这样的系统可以说不是非常有用)。
从上面的简单场景中,你可以看到所需的业务成果(自动控制猫门)取决于对夜间情况监测。这种依赖性取决于时钟。但是时钟是无法区分白天和夜晚的。需要你来提供这种逻辑。
正在构建的系统中的另一个依赖项是能够自动访问猫门并启用或关闭它。该依赖项很可能取决于具有 IoT 功能的猫门提供的 API。
### 依赖管理面临快速失败
为了满足依赖项,我们将构建确定当前时间是白天还是晚上的逻辑。本着 TDD 的精神,我们将从一个小小的失败开始。
有关如何设置此练习所需的开发环境和脚手架的详细说明,请参阅我的[上一篇文章](/article-11468-1.html)。我们将重用相同的 NET 环境和 [xUnit.net](https://xunit.net/) 框架。
接下来,创建一个名为 HAS(“家庭自动化系统”)的新项目,创建一个名为 `UnitTest1.cs` 的文件。在该文件中,编写第一个失败的单元测试。在此单元测试中,描述你的期望结果。例如,当系统运行时,如果时间是晚上 7 点,负责确定是白天还是夜晚的组件将返回值 `Nighttime`。
这是描述期望值的单元测试:
```
using System;
using Xunit;
namespace unittest
{
public class UnitTest1
{
DayOrNightUtility dayOrNightUtility = new DayOrNightUtility();
[Fact]
public void Given7pmReturnNighttime()
{
var expected = "Nighttime";
var actual = dayOrNightUtility.GetDayOrNight();
Assert.Equal(expected, actual);
}
}
}
```
至此,你可能已经熟悉了单元测试的结构。快速复习一下:在此示例中,通过给单元测试一个描述性名称`Given7pmReturnNighttime` 来描述期望结果。然后,在单元测试的主体中,创建一个名为 `expected` 的变量,并为该变量指定期望值(在该示例中,值为 `Nighttime`)。然后,为实际值指定一个 `actual`(在组件或服务处理一天中的时间之后可用)。
最后,通过断言期望值和实际值是否相等来检查是否满足期望结果:`Assert.Equal(expected, actual)`。
你还可以在上面的列表中看到名为 `dayOrNightUtility` 的组件或服务。该模块能够接收消息`GetDayOrNight`,并且返回 `string` 类型的值。
同样,本着 TDD 的精神,描述的组件或服务还尚未构建(仅为了后面说明在此进行描述)。构建这些是由所描述的期望结果来驱动的。
在 `app` 文件夹中创建一个新文件,并将其命名为 `DayOrNightUtility.cs`。将以下 C# 代码添加到该文件中并保存:
```
using System;
namespace app {
public class DayOrNightUtility {
public string GetDayOrNight() {
string dayOrNight = "Undetermined";
return dayOrNight;
}
}
}
```
现在转到命令行,将目录更改为 `unittests` 文件夹,然后运行:
```
[Xunit.net 00:00:02.33] unittest.UnitTest1.Given7pmReturnNighttime [FAIL]
Failed unittest.UnitTest1.Given7pmReturnNighttime
[...]
```
恭喜,你已经完成了第一个失败的单元测试。单元测试的期望结果是 `DayOrNightUtility` 方法返回字符串 `Nighttime`,但相反,它返回是 `Undetermined`。
### 修复失败的单元测试
修复失败的测试的一种快速而粗略的方法是将值 `Undetermined` 替换为值 `Nighttime` 并保存更改:
```
using System;
namespace app {
public class DayOrNightUtility {
public string GetDayOrNight() {
string dayOrNight = "Nighttime";
return dayOrNight;
}
}
}
```
现在运行,成功了。
```
Starting test execution, please wait...
Total tests: 1. Passed: 1. Failed: 0. Skipped: 0.
Test Run Successful.
Test execution time: 2.6470 Seconds
```
但是,对值进行硬编码基本上是在作弊,最好为 `DayOrNightUtility` 方法赋予一些智能。修改 `GetDayOrNight` 方法以包括一些时间计算逻辑:
```
public string GetDayOrNight() {
string dayOrNight = "Daylight";
DateTime time = new DateTime();
if(time.Hour < 7) {
dayOrNight = "Nighttime";
}
return dayOrNight;
}
```
该方法现在从系统获取当前时间,并与 `Hour` 比较,查看其是否小于上午 7 点。如果小于,则处理逻辑将 `dayOrNight` 字符串值从 `Daylight` 转换为 `Nighttime`。现在,单元测试通过。
### 测试驱动解决方案的开始
现在,我们已经开始了基本的单元测试,并为我们的时间依赖项提供了可行的解决方案。后面还有更多的测试案例需要执行。
在下一篇文章中,我将演示如何对白天时间进行测试以及如何在整个过程中利用故障。
---
via: <https://opensource.com/article/19/9/mutation-testing-example-tdd>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my article * Mutation testing is the evolution of TDD*, I exposed the power of iteration to guarantee a solution when a measurable test is available. In that article, an iterative approach helped to determine how to implement code that calculates the square root of a given number.
I also demonstrated that the most effective method is to find a measurable goal or test, then start iterating with best guesses. The first guess at the correct answer will most likely fail, as expected, so the failed guess needs to be refined. The refined guess must be validated against the measurable goal or test. Based on the result, the guess is either validated or must be further refined.
In this model, the only way to learn how to reach the solution is to fail repeatedly. It sounds counterintuitive, but amazingly, it works.
Following in the footsteps of that analysis, this article examines the best way to use a DevOps approach when building a solution containing some dependencies. The first step is to write a test that can be expected to fail.
## The problem with dependencies is that you can't depend on them
The problem with dependencies, as Michael Nygard wittily expresses in * Architecture without an end state*, is a huge topic better left for another article. Here, you'll look into potential pitfalls that dependencies tend to bring to a project and how to leverage test-driven development (TDD) to avoid those pitfalls.
First, pose a real-life challenge, then see how it can be solved using TDD.
## Who let the cat out?

In Agile development environments, it's helpful to start building the solution by defining the desired outcomes. Typically, the desired outcomes are described in a [ user story](https://www.agilealliance.org/glossary/user-stories):
Using my home automation system (HAS),
I want to control when the cat can go outside,
because I want to keep the cat safe overnight.
Now that you have a user story, you need to elaborate on it by providing some functional requirements (that is, by specifying the *acceptance criteria*). Start with the simplest of scenarios described in pseudo-code:
Scenario #1: Disable cat trap door during nighttime
- Given that the clock detects that it is nighttime
- When the clock notifies the HAS
- Then HAS disables the Internet of Things (IoT)-capable cat trap door
## Decompose the system
The system you are building (the HAS) needs to be *decomposed*–broken down to its dependencies–before you can start working on it. The first thing you must do is identify any dependencies (if you're lucky, your system has no dependencies, which would make it easy to build, but then it arguably wouldn't be a very useful system).
From the simple scenario above, you can see that the desired business outcome (automatically controlling a cat door) depends on detecting nighttime. This dependency hinges upon the clock. But the clock is not capable of determining whether it is daylight or nighttime. It's up to you to supply that logic.
Another dependency in the system you're building is the ability to automatically access the cat door and enable or disable it. That dependency most likely hinges upon an API provided by the IoT-capable cat door.
## Fail fast toward dependency management
To satisfy one dependency, we will build the logic that determines whether the current time is daylight or nighttime. In the spirit of TDD, we will start with a small failure.
Refer to my [previous article](https://opensource.com/article/19/8/mutation-testing-evolution-tdd) for detailed instructions on how to set the development environment and scaffolds required for this exercise. We will be reusing the same NET environment and relying on the [xUnit.net](https://xunit.net/) framework.
Next, create a new project called HAS (for "home automation system") and create a file called **UnitTest1.cs**. In this file, write the first failing unit test. In this unit test, describe your expectations. For example, when the system runs, if the time is 7pm, then the component responsible for deciding whether it's daylight or nighttime returns the value "Nighttime."
Here is the unit test that describes that expectation:
```
using System;
using Xunit;
namespace unittest
{
public class UnitTest1
{
DayOrNightUtility dayOrNightUtility = new DayOrNightUtility();
[Fact]
public void Given7pmReturnNighttime()
{
var expected = "Nighttime";
var actual = dayOrNightUtility.GetDayOrNight();
Assert.Equal(expected, actual);
}
}
}
```
By this point, you may be familiar with the shape and form of a unit test. A quick refresher: describe the expectation by giving the unit test a descriptive name, **Given7pmReturnNighttime**, in this example. Then in the body of the unit test, a variable named **expected** is created, and it is assigned the expected value (in this case, the value "Nighttime"). Following that, a variable named **actual** is assigned the actual value (available after the component or service processes the time of day).
Finally, it checks whether the expectation has been met by asserting that the expected and actual values are equal: **Assert.Equal(expected, actual)**.
You can also see in the above listing a component or service called **dayOrNightUtility**. This module is capable of receiving the message **GetDayOrNight** and is supposed to return the value of the type **string**.
Again, in the spirit of TDD, the component or service being described hasn't been built yet (it is merely being described with the intention to prescribe it later). Building it is driven by the described expectations.
Create a new file in the **app** folder and give it the name **DayOrNightUtility.cs**. Add the following C# code to that file and save it:
```
using System;
namespace app {
public class DayOrNightUtility {
public string GetDayOrNight() {
string dayOrNight = "Undetermined";
return dayOrNight;
}
}
}
```
Now go to the command line, change directory to the **unittests** folder, and run the test:
```
[Xunit.net 00:00:02.33] unittest.UnitTest1.Given7pmReturnNighttime [FAIL]
Failed unittest.UnitTest1.Given7pmReturnNighttime
[...]
```
Congratulations, you have written the first failing unit test. The unit test was expecting **DayOrNightUtility** to return string value "Nighttime" but instead, it received the string value "Undetermined."
## Fix the failing unit test
A quick and dirty way to fix the failing test is to replace the value "Undetermined" with the value "Nighttime" and save the change:
```
using System;
namespace app {
public class DayOrNightUtility {
public string GetDayOrNight() {
string dayOrNight = "Nighttime";
return dayOrNight;
}
}
}
```
Now when we run the test, it passes:
```
Starting test execution, please wait...
Total tests: 1. Passed: 1. Failed: 0. Skipped: 0.
Test Run Successful.
Test execution time: 2.6470 Seconds
```
However, hardcoding the values is basically cheating, so it's better to endow **DayOrNightUtility** with some intelligence. Modify the **GetDayOrNight** method to include some time-calculation logic:
```
public string GetDayOrNight() {
string dayOrNight = "Daylight";
DateTime time = new DateTime();
if(time.Hour < 7) {
dayOrNight = "Nighttime";
}
return dayOrNight;
}
```
The method now gets the current time from the system and compares the **Hour **value to see if it is less than 7am. If it is, the logic transforms the **dayOrNight** string value from "Daylight" to "Nighttime." The unit test now passes.
## The start of a test-driven solution
We now have the beginnings of a base case unit test and a viable solution for our time dependency. There are more than a few more cases to work through.
In the next article, I'll demonstrate how to test for daylight hours and how to leverage failure along the way.
## Comments are closed. |
11,485 | 英特尔 NUC 迷你 PC 的基本配件 | https://itsfoss.com/intel-nuc-essential-accessories/ | 2019-10-21T07:35:00 | [
"NUC"
] | https://linux.cn/article-11485-1.html | 
几周前,我买了一台 [英特尔 NUC 迷你 PC](https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW "barebone Intel NUC mini PC")。我[在上面安装了 Linux](/article-11477-1.html),我非常喜欢它。这个小巧的无风扇机器取代了台式机那庞大的 CPU。
英特尔 NUC 通常采用准系统形式,这意味着它没有任何内存、硬盘,也显然没有操作系统。许多[基于 Linux 的微型 PC](https://itsfoss.com/linux-based-mini-pc/) 定制化英特尔 NUC 并添加磁盘、RAM 和操作系统将它出售给终端用户。
不用说,它不像大多数其他台式机那样带有键盘、鼠标或屏幕。
[英特尔 NUC](https://www.intel.in/content/www/in/en/products/boards-kits/nuc.html) 是一款出色的设备,如果你要购买台式机,我强烈建议你购买它。如果你正在考虑购买英特尔 NUC,你需要买一些配件,以便开始使用它。
### 基本的英特尔 NUC 配件

\*文章中的 Amazon 链接是(原文的)受益链接。请阅读我们的[受益政策](https://itsfoss.com/affiliate-policy/)。
#### 外围设备:显示器、键盘和鼠标
这很容易想到。你需要有屏幕、键盘和鼠标才能使用计算机。你需要一台有 HDMI 连接的显示器和一个 USB 或无线键盘鼠标。如果你已经有了这些东西,那你可以继续。
如果你正在寻求建议,我建议购买 LG IPS LED 显示器。我有两台 22 英寸的型号,我对它提供的清晰视觉效果感到满意。
这些显示器有一个简单的固定支架。如果要使显示器可以上下移动并纵向旋转,请尝试使用 [HP EliteDisplay 显示器](https://www.amazon.com/HP-EliteDisplay-21-5-Inch-1FH45AA-ABA/dp/B075L4VKQF?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B075L4VKQF "HP EliteDisplay monitors")。

我在多屏设置中同时连接了三台显示器。一台显示器连接到指定的 HDMI 端口。两台显示器通过 [Club 3D 的 Thunderbolt 转 HDMI 分配器](https://www.amazon.com/Club3D-CSV-1546-USB-C-Multi-Monitor-Splitter/dp/B06Y2FX13G?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B06Y2FX13G "thunderbolt to HDMI splitter from Club 3D")连接到 Thunderbolt 端口。
你也可以选择超宽显示器。我对此没有亲身经历。
#### 内存
英特尔 NUC 有两个内存插槽,最多可支持 32GB 内存。由于我的是 i3 核心处理器,因此我选择了 [Crucial 的 8GB DDR4 内存](https://www.amazon.com/Crucial-Single-PC4-19200-SODIMM-260-Pin/dp/B01BIWKP58?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01BIWKP58 "8GB DDR4 RAM from Crucial"),价格约为 $33。

8 GB 内存在大多数情况下都没问题,但是如果你的是 i7 核心处理器,那么可以选择 [16GB 内存](https://www.amazon.com/Crucial-Single-PC4-19200-SODIMM-260-Pin/dp/B019FRBHZ0?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B019FRBHZ0 "16 GB RAM"),价格约为 $67。你可以加两条,以获得最大 32GB。选择全在于你。
#### 硬盘(重要)
英特尔 NUC 同时支持 2.5 英寸驱动器和 M.2 SSD,因此你可以同时使用两者以获得更多存储空间。
2.5 英寸插槽可同时容纳 SSD 和 HDD。我强烈建议选择 SSD,因为它比 HDD 快得多。[480GB 2.5 英寸](https://www.amazon.com/Green-480GB-Internal-SSD-WDS480G2G0A/dp/B01M3POPK3?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01M3POPK3 "480 GB 2.5")的价格是 $60。我认为这是一个合理的价格。

2.5 英寸驱动器的标准 SATA 口速度为 6 Gb/秒。根据你是否选择 NVMe SSD,M.2 插槽可能会更快。 NVMe(非易失性内存主机控制器接口规范)SSD 的速度比普通 SSD(也称为 SATA SSD)快 4 倍。但是它们可能也比 SATA M2 SSD 贵一些。
当购买 M.2 SSD 时,请检查产品图片。无论是 NVMe 还是 SATA SSD,都应在磁盘本身的图片中提到。你可以考虑使用[经济的三星 EVO NVMe M.2 SSD](https://www.amazon.com/Samsung-970-EVO-500GB-MZ-V7E500BW/dp/B07BN4NJ2J?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07BN4NJ2J "Samsung EVO is a cost effective NVMe M.2 SSD")。

M.2 插槽和 2.5 英寸插槽中的 SATA SSD 具有相同的速度。这就是为什么如果你不想选择昂贵的 NVMe SSD,建议你选择 2.5 英寸 SATA SSD,并保留 M.2 插槽供以后升级。
#### 交流电源线
当我拿到 NUC 时,为惊讶地发现,尽管它有电源适配器,但它并没有插头。
正如一些读者指出的那样,你可能有完整的电源线。这取决于你的地理区域和供应商。因此,请检查产品说明和用户评论,以验证其是否具有完整的电源线。

#### 其他配套配件
你需要使用 HDMI 线缆连接显示器。如果你要购买新显示器,通常应会有一根线缆。
如果要使用 M.2 插槽,那么可能需要螺丝刀。英特尔 NUC 是一款出色的设备,你只需用手旋转四个脚即可拧开底部面板。你必须打开设备才能放置内存和磁盘。

NUC 还有防盗孔,可与防盗绳一起使用。在业务环境中,建议使用防盗绳保护计算机安全。购买[防盗绳几美元](https://www.amazon.com/Kensington-Combination-Laptops-Devices-K64673AM/dp/B005J7Y99W?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B005J7Y99W "few dollars in the security cable")便可节省数百美元。
### 你使用什么配件?
这些就是我在使用和建议使用的英特尔 NUC 配件。你呢?如果你有一台 NUC,你会使用哪些配件并推荐给其他 NUC 用户?
---
via: <https://itsfoss.com/intel-nuc-essential-accessories/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I bought a [lasso link=”B07GX4X4PW” title=”barebone Intel NUC mini PC” link_id=”15319″ ref=”intel-nuc-8-mainstream-kit-nuc8i3beh-core-i3-tall-addt-components-needed” id=”101747″] a few weeks back. I [installed Linux on it](https://itsfoss.com/install-linux-on-intel-nuc/) and I am totally enjoying it. This tiny gadget replaces that bulky CPU of the desktop computer.
Intel NUC mostly comes in barebone format which means it doesn’t have any RAM, hard disk and obviously no operating system. Many [Linux-based mini PCs](https://itsfoss.com/linux-based-mini-pc/) customize the Intel NUC and sell them to end users by adding disk, RAM and operating systems.
Needless to say that it doesn’t come with keyboard, mouse or screen just like most other desktop computers out there.
[Intel NUC](https://www.intel.in/content/www/in/en/products/boards-kits/nuc.html) is an excellent device and if you are looking to buy a desktop computer, I highly recommend it. And if you are considering to get Intel NUC, here are a few accessories you should have in order to start using the NUC as your computer.
## Essential Intel NUC accessories

*The Amazon links in the article are affiliate links. Please read our affiliate policy.*
### The peripheral devices: monitor, keyboard and mouse
This is a no-brainer. You need to have a screen, keyboard and mouse to use a computer. You’ll need a monitor with HDMI connection and USB or wireless keyboard-mouse. If you have these things already, you are good to go.
If you are looking for recommendations, I suggest LG IPS LED monitor. I have two of them in 22 inch model and I am happy with the sharp visuals it provides.
These monitors have a simple stand that doesn’t move. If you want a monitor that can move up and down and rotate in portrait mode, try [lasso link=”B075L4VKQF” title=”HP EliteDisplay monitors” link_id=”15320″ ref=”hp-elitedisplay-e223-21-5-inch-screen-led-lit-monitor-silver-1fh45aaaba” id=”101744″].
I connect all three monitors at the same time in a multi-monitor setup. One monitor connects to the given HDMI port. Two monitors connect to thunderbolt port via a [lasso link=”B06Y2FX13G” title=”thunderbolt to HDMI splitter from Club 3D” link_id=”15321″ ref=”club3d-csv-1546-usb-c-to-hdmi-multi-monitor-splitter-2-port-mst-hub” id=”101721″].
You may also opt for the ultrawide monitors. I don’t have a personal experience with them.
### RAM
Intel NUC has two RAM slots and it can support up to 32 GB of RAM. Since I have the core i3 processor, I opted from [lasso link=”B01BIWKP58″ title=”8GB DDR4 RAM from Crucial” link_id=”15322″ id=”101724″ ref=”crucial-8gb-single-ddr4-2400-mt-s-pc4-19200-sr-x8-sodimm-260-pin-memory-ct8g4sfs824a”] that costs around $33.

8 GB RAM is fine for most cases but if you have core i7 processor, you may opt for a [lasso link=”B019FRBHZ0″ title=”16 GB RAM” link_id=”15323″ ref=”crucial-16gb-single-ddr4-2400-mt-s-pc4-19200-dr-x8-sodimm-260-pin-memory-ct16g4sfd824a” id=”101723″] one that costs almost $67. You can double it up and get the maximum 32 GB. The choice is all yours.
### Hard disk [Important]
Intel NUC supports both 2.5 drive and M.2 SSD and you can use both at the same time to get more storage.
The 2.5 inches slot can hold both SSD and HDD. I strongly recommend to opt for SSD because it’s way faster than HDD. A [lasso link=”B01M3POPK3″ title=”480 GB 2.5 SSD from WD” link_id=”15324″ ref=”wd-green-480gb-internal-pc-ssd-sata-iii-6-gb-s-2-5-7mm-wds480g2g0a” id=”101810″] costs $60. Which is a fair price in my opinion.

The 2.5″ drive is limited with the standard SATA interface speed of 6Gb/sec. The M.2 slot could be faster depending upon whether you are choosing a NVMe SSD or not. The NVMe (non volatile memory express) SSDs are up to 4 times faster than the normal SSDs (also called SATA SSD). But they may also be slightly more expensive than SATA M2 SSD.
While buying the M.2 SSD, check the product image. It should be mentioned on the image of the disk itself whether it’s a NVMe or SATA SSD. [lasso link=”B07BN4NJ2J” title=”Samsung EVO is a cost effective NVMe M.2 SSD” link_id=”15325″ ref=”samsung-mz-v7e500bw-970-evo-ssd-500gb-m-2-nvme-interface-internal-solid-state-drive-with-v-nand-technology-black-red” id=”101797″] that you may consider.

A SATA SSD in both M.2 slot and 2.5″ slot has the same speed. This is why if you don’t want to opt for the expensive NVMe SSD, I suggest you go for the 2.5″ SATA SSD and keep the M.2 slot free for future upgrades.
### Verify if it has A/C power cord
I got a surprise when I get my NUC. Though it had power adapter, it didn’t have the plug.
As several readers have pointed out, you may have the entire power cable. It depends on your geographical region and the vendor. So please check product description and user reviews to verify it has the complete power cord or not.

### Other supporting accessories
You’ll need HDMI cable to connect your monitor. If you are buying a new monitor, you should usually get a cable with it.
You may need a screw driver if you are going to use the M.2 slot. Intel NUC is an excellent device and you can unscrew the bottom panel just by rotating the four pods simply by your hands. You’ll have to open the device in order to place the RAM and disk.

[Intel](https://www.intel.com/content/www/us/en/support/articles/000032777/mini-pcs.html)
NUC also has the antitheft key lock hole that you can use with security cables. Keeping computers secure with cables is a recommended security practices in a business environment. Investing a [lasso link=”B005J7Y99W” title=”few dollars in the security cable” link_id=”15326″ ref=”kensington-combination-cable-lock-for-laptops-and-other-devices-k64673amblack” id=”101752″] could save you hundreds of dollars.
**What accessories do you use?**
That’s the Intel NUC accessories I use and I suggest. How about you? If you own a NUC, what accessories you use and recommend to other NUC users? |
11,487 | Manjaro 18.1(KDE)安装图解 | https://www.linuxtechi.com/install-manjaro-18-1-kde-edition-screenshots/ | 2019-10-22T07:00:00 | [
"Manjaro"
] | https://linux.cn/article-11487-1.html | 
在 Manjaro 18.0(Illyria)发布一年之际,该团队发布了他们的下一个重要版本,即 Manjaro 18.1,代号为 “Juhraya”。该团队还发布了一份官方声明,称 Juhraya 包含了许多改进和错误修复。
### Manjaro 18.1 中的新功能
以下列出了 Manjaro 18.1 中的一些新功能和增强功能:
* 可以在 LibreOffice 或 Free Office 之间选择
* Xfce 版的新 Matcha 主题
* 在 KDE 版本中重新设计了消息传递系统
* 使用 bhau 工具支持 Snap 和 FlatPak 软件包
### 最小系统需求
* 1 GB RAM
* 1 GHz 处理器
* 大约 30 GB 硬盘空间
* 互联网连接
* 启动介质(USB/DVD)
### 安装 Manjaro 18.1(KDE 版)的分步指南
要在系统中开始安装 Manjaro 18.1(KDE 版),请遵循以下步骤:
#### 步骤 1) 下载 Manjaro 18.1 ISO
在安装之前,你需要从位于 [这里](https://manjaro.org/download/official/kde/) 的官方下载页面下载 Manjaro 18.1 的最新副本。由于我们这里介绍的是 KDE 版本,因此我们选择 KDE 版本。但是对于所有桌面环境(包括 Xfce、KDE 和 Gnome 版本),安装过程都是相同的。
#### 步骤 2) 创建 USB 启动盘
从 Manjaro 下载页面成功下载 ISO 文件后,就可以创建 USB 磁盘了。将下载的 ISO 文件复制到 USB 磁盘中,然后创建可引导磁盘。确保将你的引导设置更改为使用 USB 引导,并重新启动系统。
#### 步骤 3) Manjaro Live 版安装环境
系统重新启动时,它将自动检测到 USB 驱动器,并开始启动进入 Manjaro Live 版安装屏幕。

接下来,使用箭头键选择 “<ruby> 启动:Manjaro x86_64 kde <rt> Boot: Manjaro x86_64 kde </rt></ruby>”,然后按回车键以启动 Manjaro 安装程序。
#### 安装 4) 选择启动安装程序
接下来,将启动 Manjaro 安装程序,如果你已连接到互联网,Manjaro 将自动检测你的位置和时区。单击 “<ruby> 启动安装程序 <rt> Launch Installer </rt></ruby>”,开始在系统中安装 Manjaro 18.1 KDE 版本。

#### 步骤 5) 选择语言
接下来,安装程序将带你选择你的首选语言。

选择你想要的语言,然后单击“<ruby> 下一步 <rt> Next </rt></ruby>”。
#### 步骤 6) 选择时区和区域
在下一个屏幕中,选择所需的时区和区域,然后单击“<ruby> 下一步 <rt> Next </rt></ruby>”继续。

#### 步骤 7) 选择键盘布局
在下一个屏幕中,选择你喜欢的键盘布局,然后单击“<ruby> 下一步 <rt> Next </rt></ruby>”继续。

#### 步骤 8) 选择分区类型
这是安装过程中非常关键的一步。 它将允许你选择分区方式:
* 擦除磁盘
* 手动分区
* 并存安装
* 替换分区
如果在 VM(虚拟机)中安装 Manjaro 18.1,则将看不到最后两个选项。
如果你不熟悉 Manjaro Linux,那么我建议你使用第一个选项(<ruby> 擦除磁盘 <rt> Erase Disk </rt></ruby>),它将为你自动创建所需的分区。如果要创建自定义分区,则选择第二个选项“<ruby> 手动分区 <rt> Manual Partitioning </rt></ruby>”,顾名思义,它将允许我们创建自己的自定义分区。
在本教程中,我将通过选择“<ruby> 手动分区 <rt> Manual Partitioning </rt></ruby>”选项来创建自定义分区:

选择第二个选项,然后单击“<ruby> 下一步 <rt> Next </rt></ruby>”继续。
如我们所见,我有 40 GB 硬盘,因此我将在其上创建以下分区,
* `/boot` – 2GB(ext4)
* `/` – 10 GB(ext4)
* `/home` – 22 GB(ext4)
* `/opt` – 4 GB(ext4)
* <ruby> 交换分区 <rt> Swap </rt></ruby> – 2 GB
当我们在上方窗口中单击“<ruby> 下一步 <rt> Next </rt></ruby>”时,将显示以下屏幕,选择“<ruby> 新建分区表 <rt> new partition table </rt></ruby>”:

点击“<ruby> 确定 <rt> OK </rt></ruby>”。
现在选择可用空间,然后单击“<ruby> 创建 <rt> create </rt></ruby>”以将第一个分区设置为大小为 2 GB 的 `/boot`,

单击“<ruby> 确定 <rt> OK </rt></ruby>”以继续操作,在下一个窗口中再次选择可用空间,然后单击“<ruby> 创建 <rt> create </rt></ruby>”以将第二个分区设置为 `/`,大小为 10 GB:

同样,将下一个分区创建为大小为 22 GB 的 `/home`:

到目前为止,我们已经创建了三个分区作为主分区,现在创建下一个分区作为扩展分区:

单击“<ruby> 确定 <rt> OK </rt></ruby>”以继续。
创建大小分别为 5 GB 和 2 GB 的 `/opt` 和交换分区作为逻辑分区。


完成所有分区的创建后,单击“<ruby> 下一步 <rt> Next </rt></ruby>”:

#### 步骤 9) 提供用户信息
在下一个屏幕中,你需要提供用户信息,包括你的姓名、用户名、密码、计算机名等:

提供所有信息后,单击“<ruby> 下一步 <rt> Next </rt></ruby>”继续安装。
在下一个屏幕中,系统将提示你选择办公套件,因此请做出适合你的选择:

单击“<ruby> 下一步 <rt> Next </rt></ruby>”以继续。
#### 步骤 10) 摘要信息
在完成实际安装之前,安装程序将向你显示你选择的所有详细信息,包括语言、时区、键盘布局和分区信息等。单击“<ruby> 安装 <rt> Install </rt></ruby>”以继续进行安装过程。

#### 步骤 11) 进行安装
现在,实际的安装过程开始,一旦完成,请重新启动系统以登录到 Manjaro 18.1 KDE 版:


#### 步骤 12) 安装成功后登录
重新启动后,我们将看到以下登录屏幕,使用我们在安装过程中创建的用户凭据登录:

点击“<ruby> 登录 <rt> Login </rt></ruby>”。

就是这样!你已经在系统中成功安装了 Manjaro 18.1 KDE 版,并探索了所有令人兴奋的功能。请在下面的评论部分中发表你的反馈和建议。
---
via: <https://www.linuxtechi.com/install-manjaro-18-1-kde-edition-screenshots/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Within a year of releasing **Manjaro 18.0** (**Illyria**), the team has come out with their next big release with **Manjaro 18.1**, codenamed “**Juhraya**“. The team also have come up with an official announcement saying that Juhraya comes packed with a lot of improvements and bug fixes.
#### New Features in Manjaro 18.1
Some of the new features and enhancements in Manjaro 18.1 are listed below:
- Option to choose between LibreOffice or Free Office
- New Matcha theme for Xfce edition
- Redesigned messaging system in KDE edition
- Support for Snap and FlatPak packages using “bhau” tool
#### Minimum System Requirements for Manjaro 18.1
- 1 GB RAM
- One GHz Processor
- Around 30 GB Hard disk space
- Internet Connection
- Bootable Media (USB/DVD)
#### Step by Step Guide to Install Manjaro 18.1 (KDE Edition)
To start installing Manjaro 18.1 (KDE Edition) in your system, please follow the steps outline below:
#### Step 1) Download Manjaro 18.1 ISO
Before installing, you need to download the latest copy of Manjaro 18.1 from its official download page located [here](https://manjaro.org/download/). Since we are seeing about the KDE version, we chose to install the KDE version. But the installation process is the same for all desktop environments including Xfce, KDE and Gnome editions.
#### Step 2) Create a USB Bootable Disk
Once you have successfully downloaded the ISO file from Manjaro downloads page, it is time to create an USB disk. Copy the downloaded ISO file in a USB disk and create a bootable disk. Make sure to change your boot settings to boot using a USB and restart your system
#### Step 3) Manjaro Live Installation Environment
When the system restarts, it will automatically detect the USB drive and starts booting into the Manjaro Live Installation Screen.
Next use the arrow keys to choose “**Boot: Manjaro x86_64 kde**” and hit enter to launch the Manjaro Installer.
#### Step 4) Choose Launch Installer
Next the Manjaro installer will be launched and If you are connected to the internet, Manjaro will automatically detect your location and time zone. Click “**Launch Installer**” start installing Manjaro 18.1 KDE edition in your system.
#### Step 5) Choose Your Language
Next the installer will take you to choose your preferred language.
Select your desired language and click “Next”
#### Step 6) Choose Your time zone and region
In the next screen, select your desired time zone and region and click “Next” to continue
#### Step 7) Choose Keyboard layout
In the next screen, select your preferred keyboard layout and click “Next” to continue.
#### Step 8) Choose Partition Type
This is a very critical step in the installation process. It will allow you to choose between:
- Erase Disk
- Manual Partitioning
- Install Alongside
- Replace a Partition
If you are installing Manjaro 18.1 in a VM (Virtual Machine), then you won’t be able to see the last 2 options.
If you are new to Manjaro Linux then I would suggest you should go with first option (**Erase Disk**), it will automatically create required partitions for you. If you want to create custom partitions then choose the second option “**Manual Partitioning**“, as its name suggests it will allow us to create our own custom partitions.
In this tutorial I will be creating custom partitions by selecting “Manual Partitioning” option,
Choose the second option and click “Next” to continue.
As we can see i have 40 GB hard disk, so I will create following partitions on it,
- /boot – 2GB (ext4 file system)
- / – 10 GB (ext4 file system)
- /home – 22 GB (ext4 file system)
- /opt – 4 GB (ext4 file system)
- Swap – 2 GB
When we click on Next in above window, we will get the following screen, choose to create a ‘**new partition table**‘,
Click on Ok,
Now choose the free space and then click on ‘**create**‘ to setup the first partition as /boot of size 2 GB,
Click on OK to proceed with further, in the next window choose again free space and then click on create to setup second partition as / of size 10 GB,
Similarly create next partition as /home of size 22 GB,
As of now we have created three partitions as primary, now create next partition as extended,
Click on OK to proceed further,
Create /opt and Swap partition of size 5 GB and 2 GB respectively as logical partitions
Once are done with all the partitions creation, click on Next
#### Step 9) Provide User Information
In the next screen, you need to provide the user information including your name, username, password, computer name etc.
Click “Next” to continue with the installation after providing all the information.
In the next screen you will be prompted to choose the office suite, so make a choice that suits to your installation,
Click on Next to proceed further,
#### Step 10) Summary Information
Before the actual installation is done, the installer will show you all the details you’ve chosen including the language, time zone, keyboard layout and partitioning information etc. Click “**Install**” to proceed with the installation process.
#### Step 11) Install Manjaro 18.1 KDE Edition
Now the actual installation process begins and once it gets completed, restart the system to login to Manjaro 18.1 KDE edition ,
#### Step:12) Login after successful installation
After the restart we will get the following login screen, use the user’s credentials that we created during the installation
Click on Login,
That’s it! You’ve successfully installed Manjaro 18.1 KDE edition in your system and explore all the exciting features. Please post your feedback and suggestions in the comments section below.
TimGood tutorial.
Only question is: do the partitions include a persistent section to save data?
What must be done to ensure changes are saved. Thanks!
MattHey I’m a little new to this all too! That /Home directory will be your files, so adjust that size as you see you may need! However if you are dual booting that will NOT be available in Windows
Pradeep KumarHi Matt,
/Home directory will not be available in your Windows OS if you have dual boot it. |
11,490 | 在 Linux 中使用 Bash 脚本删除早于 “X” 天的文件/文件夹 | https://www.2daygeek.com/bash-script-to-delete-files-folders-older-than-x-days-in-linux/ | 2019-10-22T15:07:21 | [
"日志",
"删除"
] | https://linux.cn/article-11490-1.html | 
[磁盘使用率](https://www.2daygeek.com/linux-check-disk-usage-files-and-directories-folders-size-du-command/) 监控工具能够在达到给定阈值时提醒我们。但它们无法自行解决 [磁盘使用率](https://www.2daygeek.com/linux-check-disk-space-usage-df-command/) 问题。需要手动干预才能解决该问题。
如果你想完全自动化此类操作,你会做什么。是的,可以使用 bash 脚本来完成。
该脚本可防止来自 [监控工具](https://www.2daygeek.com/category/monitoring-tools/) 的警报,因为我们会在填满磁盘空间之前删除旧的日志文件。
我们过去做了很多 shell 脚本。如果要查看,请进入下面的链接。
* [如何使用 shell 脚本自动化日常活动?](https://www.2daygeek.com/category/shell-script/)
我在本文中添加了两个 bash 脚本,它们有助于清除旧日志。
### 1)在 Linux 中删除早于 “X” 天的文件夹的 Bash 脚本
我们有一个名为 `/var/log/app/` 的文件夹,其中包含 15 天的日志,我们将删除早于 10 天的文件夹。
```
$ ls -lh /var/log/app/
drwxrw-rw- 3 root root 24K Oct 1 23:52 app_log.01
drwxrw-rw- 3 root root 24K Oct 2 23:52 app_log.02
drwxrw-rw- 3 root root 24K Oct 3 23:52 app_log.03
drwxrw-rw- 3 root root 24K Oct 4 23:52 app_log.04
drwxrw-rw- 3 root root 24K Oct 5 23:52 app_log.05
drwxrw-rw- 3 root root 24K Oct 6 23:54 app_log.06
drwxrw-rw- 3 root root 24K Oct 7 23:53 app_log.07
drwxrw-rw- 3 root root 24K Oct 8 23:51 app_log.08
drwxrw-rw- 3 root root 24K Oct 9 23:52 app_log.09
drwxrw-rw- 3 root root 24K Oct 10 23:52 app_log.10
drwxrw-rw- 3 root root 24K Oct 11 23:52 app_log.11
drwxrw-rw- 3 root root 24K Oct 12 23:52 app_log.12
drwxrw-rw- 3 root root 24K Oct 13 23:52 app_log.13
drwxrw-rw- 3 root root 24K Oct 14 23:52 app_log.14
drwxrw-rw- 3 root root 24K Oct 15 23:52 app_log.15
```
该脚本将删除早于 10 天的文件夹,并通过邮件发送文件夹列表。
你可以根据需要修改 `-mtime X` 的值。另外,请替换你的电子邮箱,而不是用我们的。
```
# /opt/script/delete-old-folders.sh
#!/bin/bash
prev_count=0
fpath=/var/log/app/app_log.*
find $fpath -type d -mtime +10 -exec ls -ltrh {} \; > /tmp/folder.out
find $fpath -type d -mtime +10 -exec rm -rf {} \;
count=$(cat /tmp/folder.out | wc -l)
if [ "$prev_count" -lt "$count" ] ; then
MESSAGE="/tmp/file1.out"
TO="[email protected]"
echo "Application log folders are deleted older than 15 days" >> $MESSAGE
echo "+----------------------------------------------------+" >> $MESSAGE
echo "" >> $MESSAGE
cat /tmp/folder.out | awk '{print $6,$7,$9}' >> $MESSAGE
echo "" >> $MESSAGE
SUBJECT="WARNING: Apache log files are deleted older than 15 days $(date)"
mail -s "$SUBJECT" "$TO" < $MESSAGE
rm $MESSAGE /tmp/folder.out
fi
```
给 `delete-old-folders.sh` 设置可执行权限。
```
# chmod +x /opt/script/delete-old-folders.sh
```
最后添加一个 [cronjob](https://www.2daygeek.com/crontab-cronjob-to-schedule-jobs-in-linux/) 自动化此任务。它于每天早上 7 点运行。
```
# crontab -e
0 7 * * * /bin/bash /opt/script/delete-old-folders.sh
```
你将看到类似下面的输出。
```
Application log folders are deleted older than 20 days
+--------------------------------------------------------+
Oct 11 /var/log/app/app_log.11
Oct 12 /var/log/app/app_log.12
Oct 13 /var/log/app/app_log.13
Oct 14 /var/log/app/app_log.14
Oct 15 /var/log/app/app_log.15
```
### 2)在 Linux 中删除早于 “X” 天的文件的 Bash 脚本
我们有一个名为 `/var/log/apache/` 的文件夹,其中包含15天的日志,我们将删除 10 天前的文件。
以下文章与该主题相关,因此你可能有兴趣阅读。
* [如何在 Linux 中查找和删除早于 “X” 天和 “X” 小时的文件?](https://www.2daygeek.com/how-to-find-and-delete-files-older-than-x-days-and-x-hours-in-linux/)
* [如何在 Linux 中查找最近修改的文件/文件夹](https://www.2daygeek.com/check-find-recently-modified-files-folders-linux/)
* [如何在 Linux 中自动删除或清理 /tmp 文件夹内容?](https://www.2daygeek.com/automatically-delete-clean-up-tmp-directory-folder-contents-in-linux/)
```
# ls -lh /var/log/apache/
-rw-rw-rw- 3 root root 24K Oct 1 23:52 2daygeek_access.01
-rw-rw-rw- 3 root root 24K Oct 2 23:52 2daygeek_access.02
-rw-rw-rw- 3 root root 24K Oct 3 23:52 2daygeek_access.03
-rw-rw-rw- 3 root root 24K Oct 4 23:52 2daygeek_access.04
-rw-rw-rw- 3 root root 24K Oct 5 23:52 2daygeek_access.05
-rw-rw-rw- 3 root root 24K Oct 6 23:54 2daygeek_access.06
-rw-rw-rw- 3 root root 24K Oct 7 23:53 2daygeek_access.07
-rw-rw-rw- 3 root root 24K Oct 8 23:51 2daygeek_access.08
-rw-rw-rw- 3 root root 24K Oct 9 23:52 2daygeek_access.09
-rw-rw-rw- 3 root root 24K Oct 10 23:52 2daygeek_access.10
-rw-rw-rw- 3 root root 24K Oct 11 23:52 2daygeek_access.11
-rw-rw-rw- 3 root root 24K Oct 12 23:52 2daygeek_access.12
-rw-rw-rw- 3 root root 24K Oct 13 23:52 2daygeek_access.13
-rw-rw-rw- 3 root root 24K Oct 14 23:52 2daygeek_access.14
-rw-rw-rw- 3 root root 24K Oct 15 23:52 2daygeek_access.15
```
该脚本将删除 10 天前的文件并通过邮件发送文件夹列表。
你可以根据需要修改 `-mtime X` 的值。另外,请替换你的电子邮箱,而不是用我们的。
```
# /opt/script/delete-old-files.sh
#!/bin/bash
prev_count=0
fpath=/var/log/apache/2daygeek_access.*
find $fpath -type f -mtime +15 -exec ls -ltrd {} \; > /tmp/file.out
find $fpath -type f -mtime +15 -exec rm -rf {} \;
count=$(cat /tmp/file.out | wc -l)
if [ "$prev_count" -lt "$count" ] ; then
MESSAGE="/tmp/file1.out"
TO="[email protected]"
echo "Apache Access log files are deleted older than 20 days" >> $MESSAGE
echo "+--------------------------------------------- +" >> $MESSAGE
echo "" >> $MESSAGE
cat /tmp/file.out | awk '{print $6,$7,$9}' >> $MESSAGE
echo "" >> $MESSAGE
SUBJECT="WARNING: Apache log folders are deleted older than 15 days $(date)"
mail -s "$SUBJECT" "$TO" < $MESSAGE
rm $MESSAGE /tmp/file.out
fi
```
给 `delete-old-files.sh` 设置可执行权限。
```
# chmod +x /opt/script/delete-old-files.sh
```
最后添加一个 [cronjob](https://www.2daygeek.com/crontab-cronjob-to-schedule-jobs-in-linux/) 自动化此任务。它于每天早上 7 点运行。
```
# crontab -e
0 7 * * * /bin/bash /opt/script/delete-old-folders.sh
```
你将看到类似下面的输出。
```
Apache Access log files are deleted older than 20 days
+--------------------------------------------------------+
Oct 11 /var/log/apache/2daygeek_access.11
Oct 12 /var/log/apache/2daygeek_access.12
Oct 13 /var/log/apache/2daygeek_access.13
Oct 14 /var/log/apache/2daygeek_access.14
Oct 15 /var/log/apache/2daygeek_access.15
```
---
via: <https://www.2daygeek.com/bash-script-to-delete-files-folders-older-than-x-days-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,491 | 如何在批处理模式下运行 top 命令 | https://www.2daygeek.com/linux-run-execute-top-command-in-batch-mode/ | 2019-10-22T23:54:52 | [
"top"
] | https://linux.cn/article-11491-1.html | 
[top 命令](https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/) 是每个人都在使用的用于 [监控 Linux 系统性能](https://www.2daygeek.com/category/system-monitoring/) 的最好的命令。你可能已经知道 `top` 命令的绝大部分操作,除了很少的几个操作,如果我没错的话,批处理模式就是其中之一。
大部分的脚本编写者和开发人员都知道这个,因为这个操作主要就是用来编写脚本。
如果你不了解这个,不用担心,我们将在这里介绍它。
### 什么是 top 命令的批处理模式
批处理模式允许你将 `top` 命令的输出发送至其他程序或者文件中。
在这个模式中,`top` 命令将不会接收输入并且持续运行,直到迭代次数达到你用 `-n` 选项指定的次数为止。
如果你想解决 Linux 服务器上的任何性能问题,你需要正确的 [理解 top 命令的输出](https://www.2daygeek.com/understanding-linux-top-command-output-usage/)。
### 1) 如何在批处理模式下运行 top 命令
默认地,`top` 命令按照 CPU 的使用率来排序输出结果,所以当你在批处理模式中运行以下命令时,它会执行同样的操作并打印前 35 行:
```
# top -bc | head -35
top - 06:41:14 up 8 days, 20:24, 1 user, load average: 0.87, 0.77, 0.81
Tasks: 139 total, 1 running, 136 sleeping, 0 stopped, 2 zombie
%Cpu(s): 0.0 us, 3.2 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880940 total, 1595932 free, 886736 used, 1398272 buff/cache
KiB Swap: 1048572 total, 514640 free, 533932 used. 2648472 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 191144 2800 1596 S 0.0 0.1 5:43.63 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
2 root 20 0 0 0 0 S 0.0 0.0 0:00.32 [kthreadd]
3 root 20 0 0 0 0 S 0.0 0.0 0:28.10 [ksoftirqd/0]
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/0:0H]
7 root rt 0 0 0 0 S 0.0 0.0 0:33.96 [migration/0]
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [rcu_bh]
9 root 20 0 0 0 0 S 0.0 0.0 63:05.12 [rcu_sched]
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [lru-add-drain]
11 root rt 0 0 0 0 S 0.0 0.0 0:08.79 [watchdog/0]
12 root rt 0 0 0 0 S 0.0 0.0 0:08.82 [watchdog/1]
13 root rt 0 0 0 0 S 0.0 0.0 0:44.27 [migration/1]
14 root 20 0 0 0 0 S 0.0 0.0 1:22.45 [ksoftirqd/1]
16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/1:0H]
18 root 20 0 0 0 0 S 0.0 0.0 0:00.01 [kdevtmpfs]
19 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [netns]
20 root 20 0 0 0 0 S 0.0 0.0 0:01.35 [khungtaskd]
21 root 0 -20 0 0 0 S 0.0 0.0 0:00.02 [writeback]
22 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kintegrityd]
23 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [bioset]
24 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kblockd]
25 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [md]
26 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [edac-poller]
33 root 20 0 0 0 0 S 0.0 0.0 1:19.07 [kswapd0]
34 root 25 5 0 0 0 S 0.0 0.0 0:00.00 [ksmd]
35 root 39 19 0 0 0 S 0.0 0.0 0:12.80 [khugepaged]
36 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [crypto]
44 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kthrotld]
46 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kmpath_rdacd]
```
### 2) 如何在批处理模式下运行 top 命令并按内存使用率排序结果
在批处理模式中运行以下命令按内存使用率对结果进行排序:
```
# top -bc -o +%MEM | head -n 20
top - 06:42:00 up 8 days, 20:25, 1 user, load average: 0.66, 0.74, 0.80
Tasks: 146 total, 1 running, 145 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880940 total, 1422044 free, 1059176 used, 1399720 buff/cache
KiB Swap: 1048572 total, 514640 free, 533932 used. 2475984 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18105 mysql 20 0 1453900 156096 8816 S 0.0 4.0 2:12.98 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
1841 root 20 0 228980 107036 5360 S 0.0 2.8 0:05.56 /usr/local/cpanel/3rdparty/perl/528/bin/perl -T -w /usr/local/cpanel/3rdparty/bin/spamd --max-children=3 --max-spare=1 --allowed-ips=127.0.0.+
4301 root 20 0 230208 104608 1816 S 0.0 2.7 0:03.77 spamd child
8139 nobody 20 0 257000 27108 3408 S 0.0 0.7 0:00.04 /usr/sbin/httpd -k start
7961 nobody 20 0 256988 26912 3160 S 0.0 0.7 0:00.05 /usr/sbin/httpd -k start
8190 nobody 20 0 256976 26812 3140 S 0.0 0.7 0:00.05 /usr/sbin/httpd -k start
8353 nobody 20 0 256976 26812 3144 S 0.0 0.7 0:00.04 /usr/sbin/httpd -k start
8629 nobody 20 0 256856 26736 3108 S 0.0 0.7 0:00.02 /usr/sbin/httpd -k start
8636 nobody 20 0 256856 26712 3100 S 0.0 0.7 0:00.03 /usr/sbin/httpd -k start
8611 nobody 20 0 256844 25764 2228 S 0.0 0.7 0:00.01 /usr/sbin/httpd -k start
8451 nobody 20 0 256844 25760 2220 S 0.0 0.7 0:00.04 /usr/sbin/httpd -k start
8610 nobody 20 0 256844 25748 2224 S 0.0 0.7 0:00.01 /usr/sbin/httpd -k start
8632 nobody 20 0 256844 25744 2216 S 0.0 0.7 0:00.03 /usr/sbin/httpd -k start
```
上面命令的详细信息:
* `-b`:批处理模式选项
* `-c`:打印运行中的进程的绝对路径
* `-o`:指定进行排序的字段
* `head`:输出文件的第一部分
* `-n`:打印前 n 行
### 3) 如何在批处理模式下运行 top 命令并按照指定的用户进程对结果进行排序
如果你想要按照指定用户进程对结果进行排序请运行以下命令:
```
# top -bc -u mysql | head -n 10
top - 06:44:58 up 8 days, 20:27, 1 user, load average: 0.99, 0.87, 0.84
Tasks: 140 total, 1 running, 137 sleeping, 0 stopped, 2 zombie
%Cpu(s): 13.3 us, 3.3 sy, 0.0 ni, 83.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880940 total, 1589832 free, 885648 used, 1405460 buff/cache
KiB Swap: 1048572 total, 514640 free, 533932 used. 2649412 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18105 mysql 20 0 1453900 156888 8816 S 0.0 4.0 2:16.42 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
```
### 4) 如何在批处理模式下运行 top 命令并按照处理时间进行排序
在批处理模式中使用以下 `top` 命令按照处理时间对结果进行排序。这展示了任务从启动以来已使用的总 CPU 时间。
但是如果你想要检查一个进程在 Linux 上运行了多长时间请看接下来的文章:
* [检查 Linux 中进程运行时间的五种方法](https://www.2daygeek.com/how-to-check-how-long-a-process-has-been-running-in-linux/)
```
# top -bc -o TIME+ | head -n 20
top - 06:45:56 up 8 days, 20:28, 1 user, load average: 0.56, 0.77, 0.81
Tasks: 148 total, 1 running, 146 sleeping, 0 stopped, 1 zombie
%Cpu(s): 0.0 us, 3.1 sy, 0.0 ni, 96.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880940 total, 1378664 free, 1094876 used, 1407400 buff/cache
KiB Swap: 1048572 total, 514640 free, 533932 used. 2440332 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 0 0 0 S 0.0 0.0 63:05.70 [rcu_sched]
272 root 20 0 0 0 0 S 0.0 0.0 16:12.13 [xfsaild/vda1]
3882 root 20 0 229832 6212 1220 S 0.0 0.2 9:00.84 /usr/sbin/httpd -k start
1 root 20 0 191144 2800 1596 S 0.0 0.1 5:43.75 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
3761 root 20 0 68784 9820 2048 S 0.0 0.3 5:09.67 tailwatchd
3529 root 20 0 404380 3472 2604 S 0.0 0.1 3:24.98 /usr/sbin/rsyslogd -n
3520 root 20 0 574208 572 164 S 0.0 0.0 3:07.74 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
444 dbus 20 0 58444 1144 612 S 0.0 0.0 2:23.90 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
18105 mysql 20 0 1453900 157152 8816 S 0.0 4.0 2:17.29 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
249 root 0 -20 0 0 0 S 0.0 0.0 1:28.83 [kworker/0:1H]
14 root 20 0 0 0 0 S 0.0 0.0 1:22.46 [ksoftirqd/1]
33 root 20 0 0 0 0 S 0.0 0.0 1:19.07 [kswapd0]
342 root 20 0 39472 2940 2752 S 0.0 0.1 1:18.17 /usr/lib/systemd/systemd-journald
```
### 5) 如何在批处理模式下运行 top 命令并将结果保存到文件中
如果出于解决问题的目的,你想要和别人分享 `top` 命令的输出,请使用以下命令重定向输出到文件中:
```
# top -bc | head -35 > top-report.txt
# cat top-report.txt
top - 06:47:11 up 8 days, 20:30, 1 user, load average: 0.67, 0.77, 0.81
Tasks: 133 total, 4 running, 129 sleeping, 0 stopped, 0 zombie
%Cpu(s): 59.4 us, 12.5 sy, 0.0 ni, 28.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880940 total, 1596268 free, 843284 used, 1441388 buff/cache
KiB Swap: 1048572 total, 514640 free, 533932 used. 2659084 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9686 daygeekc 20 0 406132 62184 43448 R 94.1 1.6 0:00.34 /opt/cpanel/ea-php56/root/usr/bin/php-cgi
9689 nobody 20 0 256588 24428 1184 S 5.9 0.6 0:00.01 /usr/sbin/httpd -k start
1 root 20 0 191144 2800 1596 S 0.0 0.1 5:43.79 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
2 root 20 0 0 0 0 S 0.0 0.0 0:00.32 [kthreadd]
3 root 20 0 0 0 0 S 0.0 0.0 0:28.11 [ksoftirqd/0]
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/0:0H]
7 root rt 0 0 0 0 S 0.0 0.0 0:33.96 [migration/0]
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [rcu_bh]
9 root 20 0 0 0 0 R 0.0 0.0 63:05.82 [rcu_sched]
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [lru-add-drain]
11 root rt 0 0 0 0 S 0.0 0.0 0:08.79 [watchdog/0]
12 root rt 0 0 0 0 S 0.0 0.0 0:08.82 [watchdog/1]
13 root rt 0 0 0 0 S 0.0 0.0 0:44.28 [migration/1]
14 root 20 0 0 0 0 S 0.0 0.0 1:22.46 [ksoftirqd/1]
16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/1:0H]
18 root 20 0 0 0 0 S 0.0 0.0 0:00.01 [kdevtmpfs]
19 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [netns]
20 root 20 0 0 0 0 S 0.0 0.0 0:01.35 [khungtaskd]
21 root 0 -20 0 0 0 S 0.0 0.0 0:00.02 [writeback]
22 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kintegrityd]
23 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [bioset]
24 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kblockd]
25 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [md]
26 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [edac-poller]
33 root 20 0 0 0 0 S 0.0 0.0 1:19.07 [kswapd0]
34 root 25 5 0 0 0 S 0.0 0.0 0:00.00 [ksmd]
35 root 39 19 0 0 0 S 0.0 0.0 0:12.80 [khugepaged]
36 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [crypto]
```
### 如何按照指定字段对结果进行排序
在 `top` 命令的最新版本中, 按下 `f` 键进入字段管理界面。
要使用新字段进行排序, 请使用 `up`/`down` 箭头选择正确的选项,然后再按下 `s` 键进行排序。最后按 `q` 键退出此窗口。
```
Fields Management for window 1:Def, whose current sort field is %CPU
Navigate with Up/Dn, Right selects for move then or Left commits,
'd' or toggles display, 's' sets sort. Use 'q' or to end!
PID = Process Id nsUTS = UTS namespace Inode
USER = Effective User Name LXC = LXC container name
PR = Priority RSan = RES Anonymous (KiB)
NI = Nice Value RSfd = RES File-based (KiB)
VIRT = Virtual Image (KiB) RSlk = RES Locked (KiB)
RES = Resident Size (KiB) RSsh = RES Shared (KiB)
SHR = Shared Memory (KiB) CGNAME = Control Group name
S = Process Status NU = Last Used NUMA node
%CPU = CPU Usage
%MEM = Memory Usage (RES)
TIME+ = CPU Time, hundredths
COMMAND = Command Name/Line
PPID = Parent Process pid
UID = Effective User Id
RUID = Real User Id
RUSER = Real User Name
SUID = Saved User Id
SUSER = Saved User Name
GID = Group Id
GROUP = Group Name
PGRP = Process Group Id
TTY = Controlling Tty
TPGID = Tty Process Grp Id
SID = Session Id
nTH = Number of Threads
P = Last Used Cpu (SMP)
TIME = CPU Time
SWAP = Swapped Size (KiB)
CODE = Code Size (KiB)
DATA = Data+Stack (KiB)
nMaj = Major Page Faults
nMin = Minor Page Faults
nDRT = Dirty Pages Count
WCHAN = Sleeping in Function
Flags = Task Flags
CGROUPS = Control Groups
SUPGIDS = Supp Groups IDs
SUPGRPS = Supp Groups Names
TGID = Thread Group Id
OOMa = OOMEM Adjustment
OOMs = OOMEM Score current
ENVIRON = Environment vars
vMj = Major Faults delta
vMn = Minor Faults delta
USED = Res+Swap Size (KiB)
nsIPC = IPC namespace Inode
nsMNT = MNT namespace Inode
nsNET = NET namespace Inode
nsPID = PID namespace Inode
nsUSER = USER namespace Inode
```
对 `top` 命令的旧版本,请按 `shift+f` 或 `shift+o` 键进入字段管理界面进行排序。
要使用新字段进行排序,请选择相应的排序字段字母, 然后按下回车键排序。
```
Current Sort Field: N for window 1:Def
Select sort field via field letter, type any other key to return
a: PID = Process Id
b: PPID = Parent Process Pid
c: RUSER = Real user name
d: UID = User Id
e: USER = User Name
f: GROUP = Group Name
g: TTY = Controlling Tty
h: PR = Priority
i: NI = Nice value
j: P = Last used cpu (SMP)
k: %CPU = CPU usage
l: TIME = CPU Time
m: TIME+ = CPU Time, hundredths
* N: %MEM = Memory usage (RES)
o: VIRT = Virtual Image (kb)
p: SWAP = Swapped size (kb)
q: RES = Resident size (kb)
r: CODE = Code size (kb)
s: DATA = Data+Stack size (kb)
t: SHR = Shared Mem size (kb)
u: nFLT = Page Fault count
v: nDRT = Dirty Pages count
w: S = Process Status
x: COMMAND = Command name/line
y: WCHAN = Sleeping in Function
z: Flags = Task Flags
Note1:
If a selected sort field can't be
shown due to screen width or your
field order, the '<' and '>' keys
will be unavailable until a field
within viewable range is chosen.
Note2:
Field sorting uses internal values,
not those in column display. Thus,
the TTY & WCHAN fields will violate
strict ASCII collating sequence.
(shame on you if WCHAN is chosen)
```
---
via: <https://www.2daygeek.com/linux-run-execute-top-command-in-batch-mode/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[way-ww](https://github.com/way-ww) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,492 | 你需要知道的 DevSecOps 流程及工具 | https://opensource.com/article/19/10/devsecops-pipeline-and-tools | 2019-10-23T00:21:03 | [
"DevSecOps"
] | https://linux.cn/article-11492-1.html |
>
> DevSecOps 对 DevOps 进行了改进,以确保安全性仍然是该过程的一个重要部分。
>
>
>

到目前为止,DevOps 在 IT 世界中已广为人知,但其并非完美无缺。试想一下,你在一个项目的现代应用程序交付中实施了所有 DevOps 工程实践。你已经到达开发流程的末尾,但是渗透测试团队(内部或外部)检测到安全漏洞并提出了报告。现在,你必须重新启动所有流程,并要求开发人员修复该漏洞。
在基于 DevOps 的软件开发生命周期(SDLC)系统中,这并不繁琐,但它确实会浪费时间并影响交付进度。如果从 SDLC 初期就已经集成了安全性,那么你可能已经跟踪到了该故障,并在开发流程中就消除了它。但是,如上述情形那样,将安全性推到开发流程的最后将导致更长的开发生命周期。
这就是引入 DevSecOps 的原因,它以自动化的方式巩固了整个软件交付周期。
在现代 DevOps 方法中,组织广泛使用容器托管应用程序,我们看到 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 和 [Istio](https://opensource.com/article/18/9/what-istio) 使用的较多。但是,这些工具都有其自身的漏洞。例如,云原生计算基金会(CNCF)最近完成了一项 [kubernetes 安全审计](https://www.cncf.io/blog/2019/08/06/open-sourcing-the-kubernetes-security-audit/),发现了几个问题。DevOps 开发流程中使用的所有工具在流程运行时都需要进行安全检查,DevSecOps 会推动管理员去监视工具的存储库以获取升级和补丁。
### 什么是 DevSecOps?
与 DevOps 一样,DevSecOps 是开发人员和 IT 运营团队在开发和部署软件应用程序时所遵循的一种思维方式或文化。它将主动和自动化的安全审计以及渗透测试集成到敏捷应用程序开发中。
要使用 [DevSecOps](https://resources.whitesourcesoftware.com/blog-whitesource/devsecops),你需要:
* 从 SDLC 开始就引入安全性概念,以最大程度地减少软件代码中的漏洞。
* 确保每个人(包括开发人员和 IT 运营团队)共同承担在其任务中遵循安全实践的责任。
* 在 DevOps 工作流程开始时集成安全控件、工具和流程。这些将在软件交付的每个阶段启用自动安全检查。
DevOps 一直致力于在开发和发布过程中包括安全性以及质量保证(QA)、数据库管理和其他所有方面。然而,DevSecOps 是该过程的一个演进,以确保安全永远不会被遗忘,成为该过程的一个重要部分。
### 了解 DevSecOps 流程
典型的 DevOps 流程有不同的阶段;典型的 SDLC 流程包括计划、编码、构建、测试、发布和部署等阶段。在 DevSecOps 中,每个阶段都会应用特定的安全检查。
* **计划**:执行安全性分析并创建测试计划,以确定在何处、如何以及何时进行测试的方案。
* **编码**:部署整理工具和 Git 控件以保护密码和 API 密钥。
* **构建**:在构建执行代码时,请结合使用静态应用程序安全测试(SAST)工具来跟踪代码中的缺陷,然后再部署到生产环境中。这些工具针对特定的编程语言。
* **测试**:在运行时使用动态应用程序安全测试(DAST)工具来测试您的应用程序。 这些工具可以检测与用户身份验证,授权,SQL 注入以及与 API 相关的端点相关的错误。
* **发布**:在发布应用程序之前,请使用安全分析工具来进行全面的渗透测试和漏洞扫描。
* **部署**:在运行时完成上述测试后,将安全的版本发送到生产中以进行最终部署。
### DevSecOps 工具
SDLC 的每个阶段都有可用的工具。有些是商业产品,但大多数是开源的。在我的下一篇文章中,我将更多地讨论在流程的不同阶段使用的工具。
随着基于现代 IT 基础设施的企业安全威胁的复杂性增加,DevSecOps 将发挥更加关键的作用。然而,DevSecOps 流程将需要随着时间的推移而改进,而不是仅仅依靠同时实施所有安全更改即可。这将消除回溯或应用交付失败的可能性。
---
via: <https://opensource.com/article/19/10/devsecops-pipeline-and-tools>
作者:[Sagar Nangare](https://opensource.com/users/sagarnangare) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lnrCoder](https://github.com/lnrCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | DevOps is well-understood in the IT world by now, but it's not flawless. Imagine you have implemented all of the DevOps engineering practices in modern application delivery for a project. You've reached the end of the development pipeline—but a penetration testing team (internal or external) has detected a security flaw and come up with a report. Now you have to re-initiate all of your processes and ask developers to fix the flaw.
This is not terribly tedious in a DevOps-based software development lifecycle (SDLC) system—but it does consume time and affects the delivery schedule. If security were integrated from the start of the SDLC, you might have tracked down the glitch and eliminated it on the go. But pushing security to the end of the development pipeline, as in the above scenario, leads to a longer development lifecycle.
This is the reason for introducing DevSecOps, which consolidates the overall software delivery cycle in an automated way.
In modern DevOps methodologies, where containers are widely used by organizations to host applications, we see greater use of [Kubernetes](https://opensource.com/resources/what-is-kubernetes) and [Istio](https://opensource.com/article/18/9/what-istio). However, these tools have their own vulnerabilities. For example, the Cloud Native Computing Foundation (CNCF) recently completed a [Kubernetes security audit](https://www.cncf.io/blog/2019/08/06/open-sourcing-the-kubernetes-security-audit/) that identified several issues. All tools used in the DevOps pipeline need to undergo security checks while running in the pipeline, and DevSecOps pushes admins to monitor the tools' repositories for upgrades and patches.
## What Is DevSecOps?
Like DevOps, DevSecOps is a mindset or a culture that developers and IT operations teams follow while developing and deploying software applications. It integrates active and automated security audits and penetration testing into agile application development.
To utilize [DevSecOps](https://resources.whitesourcesoftware.com/blog-whitesource/devsecops), you need to:
- Introduce the concept of security right from the start of the SDLC to minimize vulnerabilities in software code.
- Ensure everyone (including developers and IT operations teams) shares responsibility for following security practices in their tasks.
- Integrate security controls, tools, and processes at the start of the DevOps workflow. These will enable automated security checks at each stage of software delivery.
DevOps has always been about including security—as well as quality assurance (QA), database administration, and everyone else—in the dev and release process. However, DevSecOps is an evolution of that process to ensure security is never forgotten as an essential part of the process.
## Understanding the DevSecOps pipeline
There are different stages in a typical DevOps pipeline; a typical SDLC process includes phases like Plan, Code, Build, Test, Release, and Deploy. In DevSecOps, specific security checks are applied in each phase.
**Plan:**Execute security analysis and create a test plan to determine scenarios for where, how, and when testing will be done.**Code:**Deploy linting tools and Git controls to secure passwords and API keys.**Build:**While building code for execution, incorporate static application security testing (SAST) tools to track down flaws in code before deploying to production. These tools are specific to programming languages.**Test:**Use dynamic application security testing (DAST) tools to test your application while in runtime. These tools can detect errors associated with user authentication, authorization, SQL injection, and API-related endpoints.**Release:**Just before releasing the application, employ security analysis tools to perform thorough penetration testing and vulnerability scanning.**Deploy:**After completing the above tests in runtime, send a secure build to production for final deployment.
## DevSecOps tools
Tools are available for every phase of the SDLC. Some are commercial products, but most are open source. In my next article, I will talk more about the tools to use in different stages of the pipeline.
DevSecOps will play a more crucial role as we continue to see an increase in the complexity of enterprise security threats built on modern IT infrastructure. However, the DevSecOps pipeline will need to improve over time, rather than simply relying on implementing all security changes simultaneously. This will eliminate the possibility of backtracking or the failure of application delivery.
## 1 Comment |
11,494 | 变异测试:基于故障的试验 | https://opensource.com/article/19/9/mutation-testing-example-failure-experimentation | 2019-10-24T06:00:00 | [
"变异测试"
] | https://linux.cn/article-11494-1.html |
>
> 基于 .NET 的 xUnit.net 测试框架,开发一款自动猫门的逻辑,让门在白天开放,夜间锁定。
>
>
>

在本系列的[第一篇文章](/article-11483-1.html)中,我演示了如何使用设计的故障来确保代码中的预期结果。在第二篇文章中,我将继续开发示例项目:一款自动猫门,该门在白天开放,夜间锁定。
在此提醒一下,你可以按照[此处的说明](/article-11468-1.html)使用 .NET 的 xUnit.net 测试框架。
### 关于白天时间
回想一下,测试驱动开发(TDD)围绕着大量的单元测试。
第一篇文章中实现了满足 `Given7pmReturnNighttime` 单元测试期望的逻辑。但还没有完,现在,你需要描述当前时间大于 7 点时期望发生的结果。这是新的单元测试,称为 `Given7amReturnDaylight`:
```
[Fact]
public void Given7amReturnDaylight()
{
var expected = "Daylight";
var actual = dayOrNightUtility.GetDayOrNight();
Assert.Equal(expected, actual);
}
```
现在,新的单元测试失败了(越早失败越好!):
```
Starting test execution, please wait...
[Xunit.net 00:00:01.23] unittest.UnitTest1.Given7amReturnDaylight [FAIL]
Failed unittest.UnitTest1.Given7amReturnDaylight
[...]
```
期望接收到字符串值是 `Daylight`,但实际接收到的值是 `Nighttime`。
### 分析失败的测试用例
经过仔细检查,代码本身似乎已经出现问题。 事实证明,`GetDayOrNight` 方法的实现是不可测试的!
看看我们面临的核心挑战:
1. `GetDayOrNight` 依赖隐藏输入。
`dayOrNight` 的值取决于隐藏输入(它从内置系统时钟中获取一天的时间值)。
2. `GetDayOrNight` 包含非确定性行为。
从系统时钟中获取到的时间值是不确定的。(因为)该时间取决于你运行代码的时间点,而这一点我们认为这是不可预测的。
3. `GetDayOrNight` API 的质量差。
该 API 与具体的数据源(系统 `DateTime`)紧密耦合。
4. `GetDayOrNight` 违反了单一责任原则。
该方法实现同时使用和处理信息。优良作法是一种方法应负责执行一项职责。
5. `GetDayOrNight` 有多个更改原因。
可以想象内部时间源可能会更改的情况。同样,很容易想象处理逻辑也将改变。这些变化的不同原因必须相互隔离。
6. 当(我们)尝试了解 `GetDayOrNight` 行为时,会发现它的 API 签名不足。
最理想的做法就是通过简单的查看 API 的签名,就能了解 API 预期的行为类型。
7. `GetDayOrNight` 取决于全局共享可变状态。
要不惜一切代价避免共享的可变状态!
8. 即使在阅读源代码之后,也无法预测 `GetDayOrNight` 方法的行为。
这是一个严重的问题。通过阅读源代码,应该始终非常清晰,系统一旦开始运行,便可以预测出其行为。
### 失败背后的原则
每当你遇到工程问题时,建议使用久经考验的<ruby> 分而治之 <rt> divide and conquer </rt></ruby>策略。在这种情况下,遵循<ruby> 关注点分离 <rt> separation of concerns </rt></ruby>的原则是一种可行的方法。
>
> 关注点分离(SoC)是一种用于将计算机程序分为不同模块的设计原理,以便每个模块都可以解决一个关注点。关注点是影响计算机程序代码的一组信息。关注点可以和要优化代码的硬件的细节一样概括,也可以和要实例化的类的名称一样具体。完美体现 SoC 的程序称为模块化程序。
>
>
> ([出处](https://en.wikipedia.org/wiki/Separation_of_concerns))
>
>
>
`GetDayOrNight` 方法应仅与确定日期和时间值表示白天还是夜晚有关。它不应该与寻找该值的来源有关。该问题应留给调用客户端。
必须将这个问题留给调用客户端,以获取当前时间。这种方法符合另一个有价值的工程原理——<ruby> 控制反转 <rt> inversion of control </rt></ruby>。Martin Fowler [在这里](https://martinfowler.com/bliki/InversionOfControl.html)详细探讨了这一概念。
>
> 框架的一个重要特征是用户定义的用于定制框架的方法通常来自于框架本身,而不是从用户的应用程序代码调用来的。该框架通常在协调和排序应用程序活动中扮演主程序的角色。控制权的这种反转使框架有能力充当可扩展的框架。用户提供的方法为框架中的特定应用程序量身制定泛化算法。
>
>
> – [Ralph Johnson and Brian Foote](http://www.laputan.org/drc/drc.html)
>
>
>
### 重构测试用例
因此,代码需要重构。摆脱对内部时钟的依赖(`DateTime` 系统实用程序):
```
DateTime time = new DateTime();
```
删除上述代码(在你的文件中应该是第 7 行)。通过将输入参数 `DateTime` 时间添加到 `GetDayOrNight` 方法,进一步重构代码。
这是重构的类 `DayOrNightUtility.cs`:
```
using System;
namespace app {
public class DayOrNightUtility {
public string GetDayOrNight(DateTime time) {
string dayOrNight = "Nighttime";
if(time.Hour >= 7 && time.Hour < 19) {
dayOrNight = "Daylight";
}
return dayOrNight;
}
}
}
```
重构代码需要更改单元测试。 需要准备 `nightHour` 和 `dayHour` 的测试数据,并将这些值传到`GetDayOrNight` 方法中。 以下是重构的单元测试:
```
using System;
using Xunit;
using app;
namespace unittest
{
public class UnitTest1
{
DayOrNightUtility dayOrNightUtility = new DayOrNightUtility();
DateTime nightHour = new DateTime(2019, 08, 03, 19, 00, 00);
DateTime dayHour = new DateTime(2019, 08, 03, 07, 00, 00);
[Fact]
public void Given7pmReturnNighttime()
{
var expected = "Nighttime";
var actual = dayOrNightUtility.GetDayOrNight(nightHour);
Assert.Equal(expected, actual);
}
[Fact]
public void Given7amReturnDaylight()
{
var expected = "Daylight";
var actual = dayOrNightUtility.GetDayOrNight(dayHour);
Assert.Equal(expected, actual);
}
}
}
```
### 经验教训
在继续开发这种简单的场景之前,请先回顾复习一下本次练习中所学到的东西。
运行无法测试的代码,很容易在不经意间制造陷阱。从表面上看,这样的代码似乎可以正常工作。但是,遵循测试驱动开发(TDD)的实践(首先描述期望结果,然后才描述实现),暴露了代码中的严重问题。
这表明 TDD 是确保代码不会太凌乱的理想方法。TDD 指出了一些问题区域,例如缺乏单一责任和存在隐藏输入。此外,TDD 有助于删除不确定性代码,并用行为明确的完全可测试代码替换它。
最后,TDD 帮助交付易于阅读、逻辑易于遵循的代码。
在本系列的下一篇文章中,我将演示如何使用在本练习中创建的逻辑来实现功能代码,以及如何进行进一步的测试使其变得更好。
---
via: <https://opensource.com/article/19/9/mutation-testing-example-failure-experimentation>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the [first article](https://opensource.com/article/19/9/mutation-testing-example-part-1-how-leverage-failure) in this series, I demonstrated how to use planned failure to ensure expected outcomes in your code. In this second article, I'll continue developing my example project—an automated cat door that opens during daylight hours and locks during the night.
As a reminder, you can follow along using the .NET xUnit.net testing framework by following the [instructions here](https://opensource.com/article/19/8/mutation-testing-evolution-tdd).
## What about the daylight hours?
Recall that test-driven development (TDD) centers on a healthy amount of unit tests.
The first article implemented logic that fulfills the expectations of the **Given7pmReturnNighttime** unit test. But you're not done yet. Now you need to describe the expectations of what happens when the current time is greater than 7am. Here is the new unit test, called **Given7amReturnDaylight**:
```
[Fact]
public void Given7amReturnDaylight()
{
var expected = "Daylight";
var actual = dayOrNightUtility.GetDayOrNight();
Assert.Equal(expected, actual);
}
```
The new unit test now fails (it is very desirable to fail as early as possible!):
```
Starting test execution, please wait...
[Xunit.net 00:00:01.23] unittest.UnitTest1.Given7amReturnDaylight [FAIL]
Failed unittest.UnitTest1.Given7amReturnDaylight
[...]
```
It was expecting to receive the string value "Daylight" but instead received the string value "Nighttime."
## Analyze the failed test case
Upon closer inspection, it seems that the code has trapped itself. It turns out that the implementation of the **GetDayOrNight** method is not testable!
Take a look at the core challenge we have ourselves in:
**GetDayOrNight relies on hidden input.**
The value of**dayOrNight**is dependent upon the hidden input (it obtains the value for the time of day from the built-in system clock).**GetDayOrNight contains non-deterministic behavior.**
The value of the time of day obtained from the system clock is non-deterministic. It depends on the point in time when you run the code, which we must consider unpredictable.**Low quality of the GetDayOrNight API.**
This API is tightly coupled to the concrete data source (system**DateTime**).**GetDayOrNight violates the single responsibility principle.**
You have implemented a method that consumes and processes information at the same time. It is a good practice that a method should be responsible for performing a single duty.**GetDayOrNight has more than one reason to change.**
It is possible to imagine a scenario where the internal source of time may change. Also, it is quite easy to imagine that the processing logic will change. These disparate reasons for changing must be isolated from each other.**The API signature of GetDayOrNight is not sufficient when it comes to trying to understand its behavior.**
It is very desirable to be able to understand what type of behavior to expect from an API by simply looking at its signature.**GetDayOrNight depends on global shared mutable state.**
Shared mutable state is to be avoided at all costs!**The behavior of the GetDayOrNight method cannot be predicted even after reading the source code.**
That is a scary proposition. It should always be very clear from reading the source code what kind of behavior can be predicted once the system is operational.
## The principles behind what failed
Whenever you're faced with an engineering problem, it is advisable to use the time-tested strategy of *divide and conquer*. In this case, following the principle of *separation of concerns* is the way to go.
separation of concerns(SoC) is a design principle for separating a computer program into distinct sections, so that each section addresses a separate concern. A concern is a set of information that affects the code of a computer program. A concern can be as general as the details of the hardware the code is being optimized for, or as specific as the name of a class to instantiate. A program that embodies SoC well is called a modular program.(
[source])
The **GetDayOrNight** method should be concerned only with deciding whether the date and time value means daylight or nighttime. It should not be concerned with finding the source of that value. That concern should be left to the calling client.
You must leave it to the calling client to take care of obtaining the current time. This approach aligns with another valuable engineering principle—*inversion of control*. Martin Fowler explores this concept in [detail, here](https://martinfowler.com/bliki/InversionOfControl.html).
One important characteristic of a framework is that the methods defined by the user to tailor the framework will often be called from within the framework itself, rather than from the user's application code. The framework often plays the role of the main program in coordinating and sequencing application activity. This inversion of control gives frameworks the power to serve as extensible skeletons. The methods supplied by the user tailor the generic algorithms defined in the framework for a particular application.
## Refactoring the test case
So the code needs refactoring. Get rid of the dependency on the internal clock (the **DateTime** system utility):
` DateTime time = new DateTime();`
Delete the above line (which should be line 7 in your file). Refactor your code further by adding an input parameter **DateTime** time to the **GetDayOrNight** method.
Here's the refactored class **DayOrNightUtility.cs**:
```
using System;
namespace app {
public class DayOrNightUtility {
public string GetDayOrNight(DateTime time) {
string dayOrNight = "Nighttime";
if(time.Hour >= 7 && time.Hour < 19) {
dayOrNight = "Daylight";
}
return dayOrNight;
}
}
}
```
Refactoring the code requires the unit tests to change. You need to prepare values for the **nightHour** and the **dayHour** and pass those values into the **GetDayOrNight** method. Here are the refactored unit tests:
```
using System;
using Xunit;
using app;
namespace unittest
{
public class UnitTest1
{
DayOrNightUtility dayOrNightUtility = new DayOrNightUtility();
DateTime nightHour = new DateTime(2019, 08, 03, 19, 00, 00);
DateTime dayHour = new DateTime(2019, 08, 03, 07, 00, 00);
[Fact]
public void Given7pmReturnNighttime()
{
var expected = "Nighttime";
var actual = dayOrNightUtility.GetDayOrNight(nightHour);
Assert.Equal(expected, actual);
}
[Fact]
public void Given7amReturnDaylight()
{
var expected = "Daylight";
var actual = dayOrNightUtility.GetDayOrNight(dayHour);
Assert.Equal(expected, actual);
}
}
}
```
## Lessons learned
Before moving forward with this simple scenario, take a look back and review the lessons in this exercise.
It is easy to create a trap inadvertently by implementing code that is untestable. On the surface, such code may appear to be functioning correctly. However, following test-driven development (TDD) practice—describing the expectations first and only then prescribing the implementation—revealed serious problems in the code.
This shows that TDD is the ideal methodology for ensuring code does not get too messy. TDD points out problem areas, such as the absence of single responsibility and the presence of hidden inputs. Also, TDD assists in removing non-deterministic code and replacing it with fully testable code that behaves deterministically.
Finally, TDD helped deliver code that is easy to read and logic that's easy to follow.
In the next article in this series, I'll demonstrate how to use the logic created during this exercise to implement functioning code and how further testing can make it even better.
## Comments are closed. |
11,495 | Linux sudo 漏洞可能导致未经授权的特权访问 | https://www.networkworld.com/article/3446036/linux-sudo-flaw-can-lead-to-unauthorized-privileges.html | 2019-10-24T06:05:00 | [
"sudo"
] | https://linux.cn/article-11495-1.html |
>
> 在 Linux 中利用新发现的 sudo 漏洞可以使某些用户以 root 身份运行命令,尽管对此还有所限制。
>
>
>

[sudo](https://www.networkworld.com/article/3236499/some-tricks-for-using-sudo.html) 命令中最近发现了一个严重漏洞,如果被利用,普通用户可以 root 身份运行命令,即使在 `/etc/sudoers` 文件中明确禁止了该用户这样做。
将 `sudo` 更新到版本 1.8.28 应该可以解决该问题,因此建议 Linux 管理员尽快这样做。
如何利用此漏洞取决于 `/etc/sudoers` 中授予的特定权限。例如,一条规则允许用户以除了 root 用户之外的任何用户身份来编辑文件,这实际上将允许该用户也以 root 用户身份来编辑文件。在这种情况下,该漏洞可能会导致非常严重的问题。
用户要能够利用此漏洞,需要在 `/etc/sudoers` 中为**用户**分配特权,以使该用户可以以其他用户身份运行命令,并且该漏洞仅限于以这种方式分配的命令特权。
此问题影响 1.8.28 之前的版本。要检查你的 `sudo` 版本,请使用以下命令:
```
$ sudo -V
Sudo version 1.8.27 <===
Sudoers policy plugin version 1.8.27
Sudoers file grammar version 46
Sudoers I/O plugin version 1.8.27
```
该漏洞已在 CVE 数据库中分配了编号 [CVE-2019-14287](http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-14287)。它的风险是,任何被指定能以任意用户运行某个命令的用户,即使被明确禁止以 root 身份运行,它都能逃脱限制。
下面这些行让 `jdoe` 能够以除了 root 用户之外的其他身份使用 `vi` 编辑文件(`!root` 表示“非 root”),同时 `nemo` 有权运行以除了 root 身份以外的任何用户使用 `id` 命令:
```
# affected entries on host "dragonfly"
jdoe dragonfly = (ALL, !root) /usr/bin/vi
nemo dragonfly = (ALL, !root) /usr/bin/id
```
但是,由于存在漏洞,这些用户中要么能够绕过限制并以 root 编辑文件,或者以 root 用户身份运行 `id` 命令。
攻击者可以通过指定用户 ID 为 `-1` 或 `4294967295` 来以 root 身份运行命令。
```
sudo -u#-1 id -u
```
或者
```
sudo -u#4294967295 id -u
```
响应为 `1` 表明该命令以 root 身份运行(显示 root 的用户 ID)。
苹果信息安全团队的 Joe Vennix 找到并分析该问题。
---
via: <https://www.networkworld.com/article/3446036/linux-sudo-flaw-can-lead-to-unauthorized-privileges.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,497 | 每周开源点评:Kubernetes 网络、OpenStack Train 以及更多的行业趋势 | https://opensource.com/article/19/10/kubernetes-openstack-and-more-industry-trends | 2019-10-24T06:05:00 | [
"OpenStack",
"Kubernetes"
] | https://linux.cn/article-11497-1.html |
>
> 开源社区和行业趋势的每周总览。
>
>
>

作为我在具有开源开发模型的企业软件公司担任高级产品营销经理的角色的一部分,我为产品营销人员、经理和其他影响者定期发布有关开源社区,市场和行业趋势的定期更新。以下是该更新中我和他们最喜欢的五篇文章。
### OpenStack Train 中最令人兴奋的功能
* [文章地址](https://www.redhat.com/en/blog/look-most-exciting-features-openstack-train)
>
> 考虑到 Train 版本必须提供的所有技术优势([你可以在此处查看版本亮点](https://releases.openstack.org/train/highlights.html)),你可能会对 Red Hat 认为这些将使我们的电信和企业客户受益的顶级功能及其用例感到好奇。以下我们对该版本最兴奋的功能的概述。
>
>
>
**影响**:OpenStack 对我来说就像 Shia LaBeouf:它在几年前达到了炒作的顶峰,然后继续产出了好的作品。Train 版本看起来是又一次令人难以置信的创新下降。
### 以 Ansible 原生的方式构建 Kubernetes 操作器
* [文章地址](https://www.cncf.io/webinars/building-kubernetes-operators-in-an-ansible-native-way/)
>
> 操作器简化了 Kubernetes 上复杂应用程序的管理。它们通常是用 Go 语言编写的,并且需要懂得 Kubernetes 内部的专业知识。但是,还有另一种进入门槛较低的选择。Ansible 是操作器 SDK 中的一等公民。使用 Ansible 可以释放应用程序工程师的精力,最大限度地利用时间来自动化和协调你的应用程序,并使用一种简单的语言在新的和现有的平台上进行操作。在这里我们可以看到如何做。
>
>
>
**影响**:这就像你发现可以用搅拌器和冷冻香蕉制作出不错的冰淇淋一样:Ansible(通常被认为很容易掌握)可以使你比你想象的更容易地做一些令人印象深刻的操作器魔术。
### Kubernetes 网络:幕后花絮
* [文章地址](https://itnext.io/kubernetes-networking-behind-the-scenes-39a1ab1792bb)
>
> 尽管围绕该主题有很多很好的资源(链接在[这里](https://github.com/nleiva/kubernetes-networking-links)),但我找不到一个示例,可以将所有的点与网络工程师喜欢和讨厌的命令输出连接起来,以显示背后实际发生的情况。因此,我决定从许多不同的来源收集这些信息,以期帮助你更好地了解事物之间的联系。
>
>
>
**影响**:这是一篇对复杂主题(带有图片)阐述的很好的作品。保证可以使 Kubenetes 网络的混乱程度降低 10%。
### 保护容器供应链
* [文章地址](https://www.devprojournal.com/technology-trends/open-source/securing-the-container-supply-chain/)
>
> 随着容器、软件即服务和函数即服务的出现,人们开始着眼于在使用现有服务、函数和容器映像的过程中寻求新的价值。[Red Hat](https://www.redhat.com/en) 的容器首席产品经理 Scott McCarty 表示,关注这个重点既有优点也有缺点。“它使我们能够集中精力编写满足我们需求的新应用程序代码,同时将对基础架构的关注转移给其他人身上,”McCarty 说,“容器处于一个最佳位置,提供了足够的控制,而卸去了许多繁琐的基础架构工作。”但是,容器也会带来与安全性相关的劣势。
>
>
>
**影响**:我在一个由大约十位安全人员组成的小组中,可以肯定地说,整天要考虑软件安全性需要一定的倾向。当你长时间凝视深渊时,它也凝视着你。如果你不是如此倾向的软件开发人员,请听取 Scott 的建议并确保你的供应商考虑安全。
### 15 岁的 Fedora:为何 Matthew Miller 看到 Linux 发行版的光明前景
* [文章链接](https://www.techrepublic.com/article/fedora-at-15-why-matthew-miller-sees-a-bright-future-for-the-linux-distribution/)
>
> 在 TechRepublic 的一个大范围采访中,Fedora 项目负责人 Matthew Miller 讨论了过去的经验教训、软件容器的普遍采用和竞争性标准、Fedora 的潜在变化以及包括 systemd 在内的热门话题。
>
>
>
**影响**:我喜欢 Fedora 项目的原因是它的清晰度;该项目知道它代表什么。像 Matt 这样的人就是为什么能看到光明前景的原因。
*我希望你喜欢这张上周让我印象深刻的列表,并在下周一回来了解更多的开放源码社区、市场和行业趋势。*
---
via: <https://opensource.com/article/19/10/kubernetes-openstack-and-more-industry-trends>
作者:[Tim Hildred](https://opensource.com/users/thildred) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
[A look at the most exciting features in OpenStack Train](https://www.redhat.com/en/blog/look-most-exciting-features-openstack-train)
But given all the technology goodies (
[you can see the release highlights here]) that the Train release has to offer, you may be curious about the features that we at Red Hat believe are among the top capabilities that will benefit our telecommunications and enterprise customers and their uses cases. Here's an overview of the features we are most excited about this release.
**The impact**: OpenStack to me is like Shia LaBeouf: it reached peak hype a couple of years ago and then continued turning out good work. The Train release looks like yet another pretty incredible drop of innovation.
[Building Kubernetes Operators in an Ansible-native way](https://www.cncf.io/webinars/building-kubernetes-operators-in-an-ansible-native-way/)
Operators simplify management of complex applications on Kubernetes. They are usually written in Go and require expertise with the internals of Kubernetes. But, there’s an alternative to that with a lower barrier to entry. Ansible is a first-class citizen in the Operator SDK. Using Ansible frees up application engineers, maximizes time to automate and orchestrate your applications, and doing it across new & existing platforms with one simple language. Here we see how.
**The impact**: This is like finding out you can make pretty good ice cream with a blender and frozen bananas: Ansible (which is generally thought of as being pretty simple to pick up) lets you do some pretty impressive Operator magic way easier than you thought you could.
[Kubernetes networking: Behind the scenes](https://itnext.io/kubernetes-networking-behind-the-scenes-39a1ab1792bb)
While there are very good resources around this topic (links
[here]), I couldn’t find a single example that connects all of the dots with commands outputs that network engineers love and hate, showing what is actually happening behind the scenes. So, I decided to curate this information from a number of different sources to hopefully help you better understand how things are tied together.
**The impact**: An accessible, well-written take on a complicated topic (with pictures). Guaranteed to make Kube networking 10% less confusing.
[Securing the container supply chain](https://www.devprojournal.com/technology-trends/open-source/securing-the-container-supply-chain/)
With the emergence of containers, Software as a Service and Functions as a Service, the focus in on consuming existing services, functions and container images in the race to provide new value. Scott McCarty, Principal Product Manager, Containers at
[Red Hat], says that focus has both advantages and disadvantages. “It allows us to focus our energy on writing new application code that is specific to our needs, while shifting the concern for the underlying infrastructure to someone else,” says McCarty. “Containers are in a sweet spot providing enough control, but offloading a lot of tedious infrastructure work.” But containers can also create disadvantages related to security.
**The impact**: I sit amongst a group of ~10 security people, and can safely say that it takes a certain disposition to want to think about software security all day. When you stare into the abyss for long enough, it stares back into you. If you are a software developer who is not so disposed, please take Scott's advice and make sure your suppliers are.
[Fedora at 15: Why Matthew Miller sees a bright future for the Linux distribution](https://www.techrepublic.com/article/fedora-at-15-why-matthew-miller-sees-a-bright-future-for-the-linux-distribution/)
In a wide-ranging interview with TechRepublic, Fedora project leader Matthew Miller discussed lessons learned from the past, popular adoption and competing standards for software containers, potential changes coming to Fedora, as well as hot-button topics, including systemd.
**The impact**: What I like about the Fedora project is it's clarity; the project knows what it stands for. People like Matt are why.
*I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends.*
## Comments are closed. |
11,498 | DevOps 专业人员如何成为网络安全拥护者 | https://opensource.com/article/19/9/devops-security-champions | 2019-10-24T20:26:57 | [
"DevSecOps",
"DevOps"
] | https://linux.cn/article-11498-1.html |
>
> 打破信息孤岛,成为网络安全的拥护者,这对你、对你的职业、对你的公司都会有所帮助。
>
>
>

安全是 DevOps 中一个被误解了的部分,一些人认为它不在 DevOps 的范围内,而另一些人认为它太过重要(并且被忽视),建议改为使用 DevSecOps。无论你同意哪一方的观点,网络安全都会影响到我们每一个人,这是很明显的事实。
每年,[黑客行为的统计数据](https://hostingtribunal.com/blog/hacking-statistics/) 都会更加令人震惊。例如,每 39 秒就有一次黑客行为发生,这可能会导致你为公司写的记录、身份和专有项目被盗。你的安全团队可能需要花上几个月(也可能是永远找不到)才能发现这次黑客行为背后是谁,目的是什么,人在哪,什么时候黑进来的。
运维专家面对这些棘手问题应该如何是好?呐我说,现在是时候成为网络安全的拥护者,变为解决方案的一部分了。
### 孤岛势力范围的战争
在我和我本地的 IT 安全(ITSEC)团队一起肩并肩战斗的岁月里,我注意到了很多事情。一个很大的问题是,安全团队和 DevOps 之间关系紧张,这种情况非常普遍。这种紧张关系几乎都是来源于安全团队为了保护系统、防范漏洞所作出的努力(例如,设置访问控制或者禁用某些东西),这些努力会中断 DevOps 的工作并阻碍他们快速部署应用程序。
你也看到了,我也看到了,你在现场碰见的每一个人都有至少一个和它有关的故事。一小撮的怨恨最终烧毁了信任的桥梁,要么是花费一段时间修复,要么就是两个团体之间开始一场小型的地盘争夺战,这个结果会使 DevOps 实现起来更加艰难。
### 一种新观点
为了打破这些孤岛并结束势力战争,我在每个安全团队中都选了至少一个人来交谈,了解我们组织日常安全运营里的来龙去脉。我开始做这件事是出于好奇,但我持续做这件事是因为它总是能带给我一些有价值的、新的观点。例如,我了解到,对于每个因为失败的安全性而被停止的部署,安全团队都在疯狂地尝试修复 10 个他们看见的其他问题。他们反应的莽撞和尖锐是因为他们必须在有限的时间里修复这些问题,不然这些问题就会变成一个大问题。
考虑到发现、识别和撤销已完成操作所需的大量知识,或者指出 DevOps 团队正在做什么(没有背景信息)然后复制并测试它。所有的这些通常都要由人手配备非常不足的安全团队完成。
这就是你的安全团队的日常生活,并且你的 DevOps 团队看不到这些。ITSEC 的日常工作意味着超时加班和过度劳累,以确保公司,公司的团队,团队里工作的所有人能够安全地工作。
### 成为安全拥护者的方法
这些是你成为你的安全团队的拥护者之后可以帮到它们的。这意味着,对于你做的所有操作,你必须仔细、认真地查看所有能够让其他人登录的方式,以及他们能够从中获得什么。
帮助你的安全团队就是在帮助你自己。将工具添加到你的工作流程里,以此将你知道的要干的活和他们知道的要干的活结合到一起。从小事入手,例如阅读公共漏洞披露(CVE),并将扫描模块添加到你的 CI/CD 流程里。对于你写的所有代码,都会有一个开源扫描工具,添加小型开源工具(例如下面列出来的)在长远看来是可以让项目更好的。
**容器扫描工具:**
* [Anchore Engine](https://github.com/anchore/anchore-engine)
* [Clair](https://github.com/coreos/clair)
* [Vuls](https://vuls.io/)
* [OpenSCAP](https://www.open-scap.org/)
**代码扫描工具:**
* [OWASP SonarQube](https://github.com/OWASP/sonarqube)
* [Find Security Bugs](https://find-sec-bugs.github.io/)
* [Google Hacking Diggity Project](https://resources.bishopfox.com/resources/tools/google-hacking-diggity/)
**Kubernetes 安全工具:**
* [Project Calico](https://www.projectcalico.org/)
* [Kube-hunter](https://github.com/aquasecurity/kube-hunter)
* [NeuVector](https://github.com/neuvector/neuvector-helm)
### 保持你的 DevOps 态度
如果你的工作角色是和 DevOps 相关的,那么学习新技术和如何运用这项新技术创造新事物就是你工作的一部分。安全也是一样。我在 DevOps 安全方面保持到最新,下面是我的方法的列表。
* 每周阅读一篇你工作的方向里和安全相关的文章.
* 每周查看 [CVE](https://cve.mitre.org/) 官方网站,了解出现了什么新漏洞.
* 尝试做一次黑客马拉松。一些公司每个月都要这样做一次;如果你觉得还不够、想了解更多,可以访问 Beginner Hack 1.0 网站。
* 每年至少一次和那你的安全团队的成员一起参加安全会议,从他们的角度来看事情。
### 成为拥护者是为了变得更好
你应该成为你的安全的拥护者,下面是我们列出来的几个理由。首先是增长你的知识,帮助你的职业发展。第二是帮助其他的团队,培养新的关系,打破对你的组织有害的孤岛。在你的整个组织内建立由很多好处,包括设置沟通团队的典范,并鼓励人们一起工作。你同样能促进在整个组织中分享知识,并给每个人提供一个在安全方面更好的内部合作的新契机。
总的来说,成为一个网络安全的拥护者会让你成为你整个组织的拥护者。
---
via: <https://opensource.com/article/19/9/devops-security-champions>
作者:[Jessica Repka](https://opensource.com/users/jrepka) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Security is a misunderstood element in DevOps. Some see it as outside of DevOps' purview, while others find it important (and overlooked) enough to recommend moving to [DevSecOps](https://opensource.com/article/19/1/what-devsecops). No matter your perspective on where it belongs, it's clear that security affects everyone.
Each year, the [statistics on hacking](https://hostingtribunal.com/blog/hacking-statistics/) become more alarming. For example, there's a hacker attack every 39 seconds, which can lead to stolen records, identities, and proprietary projects you're writing for your company. It can take months (and possibly forever) for your security team to discover the who, what, where, or when behind a hack.
What are operations professionals to do about these dire problems? I say it is time for us to become part of the solution by becoming security champions.
## Silos and turf wars
Over my years of working side-by-side with my local IT security (ITSEC) teams, I've noticed a great many things. A big one is that tension is very common between DevOps and security. This tension almost always stems from the security team's efforts to protect against vulnerabilities (e.g., by setting rules or disabling things) that interrupt DevOps' work and hinder their ability to deploy apps quickly.
You've seen it, I've seen it, everyone you meet in the field has at least one story about it. A small set of grudges turns into a burned bridge that takes time to repair—or the groups begin a small turf war, and the resulting silos make achieving DevOps unlikely.
## Get a new perspective
To try to break down these silos and end the turf wars, I talk to at least one person on each security team to learn about the ins and outs of daily security operations in our organization. I started doing this out of general curiosity, but I've continued because it always gives me a valuable new perspective. For example, I've learned that for every deployment that's stopped due to failed security, the ITSEC team is feverishly trying to patch 10 other problems it sees. Their brashness and quickness to react are due to the limited time they have to fix something before it becomes a large problem.
Consider the immense amount of knowledge it takes to find, analyze, and undo what has been done. Or to figure out what the DevOps team is doing—without background information—then replicate and test it. And to do all of this with their usual greatly understaffed security team.
This is the daily life of your security team, and your DevOps team is not seeing it. ITSEC's daily work can mean overtime hours and overwork to make sure that the company, its teams, and the proprietary work its teams are producing are secure.
## Ways to be a security champion
This is where being your own security champion can help. This means—for everything you work on—you must take a good, hard look at all the ways someone could log into it and what could be taken from it.
Help your security team help you. Introduce tools into your pipelines to integrate what you know will work with what they will know will work. Start with small things, such as reading up on Common Vulnerabilities and Exposures (CVEs) and adding scanning functions to your [CI/CD](https://opensource.com/article/18/8/what-cicd) pipelines. For everything you build, there is an open source scanning tool, and adding small open source tools (such as the ones below) can go the extra mile in the long run.
**Container scanning tools:**
**Code scanning tools:**
**Kubernetes security tools:**
## Keep your DevOps hat on
Learning about new technology and how to create new things with it is part of the job if you're in a DevOps-related role. Security is no different. Here's my list of ways to keep up to date on the security front while keeping your DevOps hat on.
- Read one article each week about something related to security in whatever you're working on.
- Look at the
[CVE](https://cve.mitre.org/)website weekly to see what's new. - Try doing a hackathon. Some companies do this once a month; check out the
[Beginner Hack 1.0](https://www.hackerearth.com/challenges/hackathon/beginner-hack-10/)site if yours doesn't and you'd like to learn more. - Try to attend at least one security conference a year with a member of your security team to see things from their side.
## Be a champion for good
There are several reasons you should become your own security champion. The first and foremost is to further your knowledge and advance your career. The second reason is to help other teams, foster new relationships, and break down the silos that harm your organization. Creating friendships across your organization has multiple benefits, including setting a good example of bridging teams and encouraging people to work together. You will also foster sharing knowledge throughout the organization and provide everyone with a new lease on security and greater internal cooperation.
Overall, being a security champion will lead you to be a champion for good across your organization.
## 2 Comments |
11,499 | 用 Git 帮助写作者更好地完成工作 | https://opensource.com/article/19/4/write-git | 2019-10-24T22:30:00 | [
"Git"
] | https://linux.cn/article-11499-1.html |
>
> 如果你是一名写作者,你也能从使用 Git 中受益。在我们的系列文章中了解有关 Git 鲜为人知的用法。
>
>
>

[Git](https://git-scm.com/) 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
今天我们来看看写作者如何使用 Git 更好的地完成工作。
### 写作者的 Git
有些人写小说,也有人撰写学术论文、诗歌、剧本、技术手册或有关开源的文章。许多人都在做一些各种写作。相同的是,如果你是一名写作者,或许能从使用 Git 中受益。尽管 Git 是著名的计算机程序员所使用的高度技术性工具,但它也是现代写作者的理想之选,本文将向你演示如何改变你的书写方式以及为什么要这么做的原因。
但是,在谈论 Git 之前,重要的是先谈谈“副本”(或者叫“内容”,对于数字时代而言)到底是什么,以及为什么它与你的交付*媒介*不同。这是 21 世纪,大多数写作者选择的工具是计算机。尽管计算机看似擅长将副本的编辑和布局等过程结合在一起,但写作者还是(重新)发现将内容与样式分开是一个好主意。这意味着你应该在计算机上像在打字机上而不是在文字处理器中进行书写。以计算机术语而言,这意味着以*纯文本*形式写作。
### 以纯文本写作
这个假设曾经是毫无疑问的:你知道自己的写作所要针对的市场,你可以为书籍、网站或软件手册等不同市场编写内容。但是,近来各种市场趋于扁平化:你可能决定在纸质书中使用为网站编写的内容,并且纸质书可能会在以后发布 EPUB 版本。对于你的内容的数字版本,读者才是最终控制者:他们可以在你发布内容的网站上阅读你的文字,也可以点击 Firefox 出色的[阅读视图](https://support.mozilla.org/en-US/kb/firefox-reader-view-clutter-free-web-pages),还可能会打印到纸张上,或者可能会使用 Lynx 将网页转储到文本文件中,甚至可能因为使用屏幕阅读器而根本看不到你的内容。
你只需要逐字写下你的内容,而将交付工作留给发布者。即使你是自己发布,将字词作为写作作品的一种源代码也是一种更聪明、更有效的工作方式,因为在发布时,你可以使用相同的源(你的纯文本)生成适合你的目标输出(用于打印的 PDF、用于电子书的 EPUB、用于网站的 HTML 等)。
用纯文本编写不仅意味着你不必担心布局或文本样式,而且也不再需要专门的工具。无论是手机或平板电脑上的基本的记事本应用程序、计算机附带的文本编辑器,还是从互联网上下载的免费编辑器,任何能够产生文本内容的工具对你而言都是有效的“文字处理器”。无论你身在何处或在做什么,几乎可以在任何设备上书写,并且所生成的文本可以与你的项目完美集成,而无需进行任何修改。
而且,Git 专门用来管理纯文本。
### Atom 编辑器
当你以纯文本形式书写时,文字处理程序会显得过于庞大。使用文本编辑器更容易,因为文本编辑器不会尝试“有效地”重组输入内容。它使你可以将脑海中的单词输入到屏幕中,而不会受到干扰。更好的是,文本编辑器通常是围绕插件体系结构设计的,这样应用程序本身很基础(它用来编辑文本),但是你可以围绕它构建一个环境来满足你的各种需求。
[Atom](http://atom.io) 编辑器就是这种设计理念的一个很好的例子。这是一个具有内置 Git 集成的跨平台文本编辑器。如果你不熟悉纯文本格式,也不熟悉 Git,那么 Atom 是最简单的入门方法。
#### 安装 Git 和 Atom
首先,请确保你的系统上已安装 Git。如果运行 Linux 或 BSD,则 Git 在软件存储库或 ports 树中可用。你使用的命令将根据你的发行版而有所不同。例如在 Fedora 上:
```
$ sudo dnf install git
```
你也可以下载并安装适用于 [Mac](https://git-scm.com/download/mac) 和 [Windows](https://git-scm.com/download/win) 的 Git。
你不需要直接使用 Git,因为 Atom 会充当你的 Git 界面。下一步是安装 Atom。
如果你使用的是 Linux,请通过软件安装程序或适当的命令从软件存储库中安装 Atom,例如:
```
$ sudo dnf install atom
```
Atom 当前没有在 BSD 上构建。但是,有很好的替代方法,例如 [GNU Emacs](http://gnu.org/software/emacs)。对于 Mac 和 Windows 用户,可以在 [Atom 网站](http://atom.io)上找到安装程序。
安装完成后,启动 Atom 编辑器。
#### 快速指导
如果要使用纯文本和 Git,则需要适应你的编辑器。Atom 的用户界面可能比你习惯的更加动态。实际上,你可以将它视为 Firefox 或 Chrome,而不是文字处理程序,因为它具有可以根据需要打开或关闭的选项卡和面板,甚至还可以安装和配置附件。尝试全部掌握 Atom 如许之多的功能是不切实际的,但是你至少可以知道有什么功能。
当打开 Atom 时,它将显示一个欢迎屏幕。如果不出意外,此屏幕很好地介绍了 Atom 的选项卡式界面。你可以通过单击 Atom 窗口顶部选项卡上的“关闭”图标来关闭欢迎屏幕,并使用“文件 > 新建文件”创建一个新文件。
使用纯文本格式与使用文字处理程序有点不同,因此这里有一些技巧,以人可以理解的方式编写内容,并且 Git 和计算机可以解析,跟踪和转换。
#### 用 Markdown 书写
如今,当人们谈论纯文本时,大多是指 Markdown。Markdown 与其说是格式,不如说是样式,这意味着它旨在为文本提供可预测的结构,以便计算机可以检测自然的模式并智能地转换文本。Markdown 有很多定义,但是最好的技术定义和备忘清单在 [CommonMark 的网站](https://commonmark.org/help/)上。
```
# Chapter 1
This is a paragraph with an *italic* word and a **bold** word in it.
And it can even reference an image.

```
从示例中可以看出,Markdown 读起来感觉不像代码,但可以将其视为代码。如果你遵循 CommonMark 定义的 Markdown 规范,那么一键就可以可靠地将 Markdown 的文字转换为 .docx、.epub、.html、MediaWiki、.odt、.pdf、.rtf 和各种其他的格式,而*不会*失去格式。
你可以认为 Markdown 有点像文字处理程序的样式。如果你曾经为出版社撰写过一套样式来控制章节标题及其样式,那基本上就是一回事,除了不是从下拉菜单中选择样式以外,你需要给你的文字添加一些小记号。对于任何习惯“以文字交谈”的现代阅读者来说,这些表示法都是很自然的,但是在呈现文本时,它们会被精美的文本样式替换掉。实际上,这就是文字处理程序在后台秘密进行的操作。文字处理器显示粗体文本,但是如果你可以看到使文本变为粗体的生成代码,则它与 Markdown 很像(实际上,它是更复杂的 XML)。使用 Markdown 可以消除这种代码和样式之间的阻隔,一方面看起来更可怕一些,但另一方面,你可以在几乎所有可以生成文本的东西上书写 Markdown 而不会丢失任何格式信息。
Markdown 文件流行的文件扩展名是 .md。如果你使用的平台不知道 .md 文件是什么,则可以手动将该扩展名与 Atom 关联,或者仅使用通用的 .txt 扩展名。文件扩展名不会更改文件的性质。它只会改变你的计算机决定如何处理它的方式。Atom 和某些平台足够聪明,可以知道该文件是纯文本格式,无论你给它以什么扩展名。
#### 实时预览
Atom 具有 “Markdown 预览” 插件,该插件可以向你显示正在编写的纯文本 Markdown 及其(通常)呈现的方式。

要激活此预览窗格,请选择“包 > Markdown 预览 > 切换预览” 或按 `Ctrl + Shift + M`。
此视图为你提供了两全其美的方法。无需承担为你的文本添加样式的负担就可以写作,而你也可以看到一个通用的示例外观,至少是以典型的数字化格式显示文本的外观。当然,关键是你无法控制文本的最终呈现方式,因此不要试图调整 Markdown 来强制以某种方式显示呈现的预览。
#### 每行一句话
你的高中写作老师不会看你的 Markdown。
一开始它不那么自然,但是在数字世界中,保持每行一个句子更有意义。Markdown 会忽略单个换行符(当你按下 `Return` 或 `Enter` 键时),并且只在单个空行之后才会创建一个新段落。

每行写一个句子的好处是你的工作更容易跟踪。也就是说,假如你在段落的开头更改了一个单词,如果更改仅限于一行而不是一个长的段落中的一个单词,那么 Atom、Git 或任何应用程序很容易以有意义的方式突出显示该更改。换句话说,对一个句子的更改只会影响该句子,而不会影响整个段落。
你可能会想:“许多文字处理器也可以跟踪更改,它们可以突出显示已更改的单个单词。”但是这些修订跟踪器绑定在该字处理器的界面上,这意味着你必须先打开该字处理器才能浏览修订。在纯文本工作流程中,你可以以纯文本形式查看修订,这意味着无论手头有什么,只要该设备可以处理纯文本(大多数都可以),就可以进行编辑或批准编辑。
诚然,写作者通常不会考虑行号,但它对于计算机有用,并且通常是一个很好的参考点。默认情况下,Atom 为文本文档的行进行编号。按下 `Enter` 键或 `Return` 键后,一*行*就是一行。

如果(在 Atom 的)一行的行号中有一个点而不是一个数字,则表示它是上一行折叠的一部分,因为它超出了你的屏幕。
#### 主题
如果你是一个在意视觉形象的人,那么你可能会非常注重自己的写作环境。即使你使用普通的 Markdown 进行编写,也并不意味着你必须使用程序员的字体或在使你看起来像码农的黑窗口中进行书写。修改 Atom 外观的最简单方法是使用[主题包](https://atom.io/themes)。主题设计人员通常将深色主题与浅色主题区分开,因此你可以根据需要使用关键字“Dark”或“Light”进行搜索。
要安装主题,请选择“编辑 > 首选项”。这将在 Atom 界面中打开一个新标签页。是的,标签页可以用于处理文档*和*用于配置及控制面板。在“设置”标签页中,单击“安装”类别。
在“安装”面板中,搜索要安装的主题的名称。单击搜索字段右侧的“主题”按钮,以仅搜索主题。找到主题后,单击其“安装”按钮。

要使用已安装的主题或根据喜好自定义主题,请导航至“设置”标签页中的“主题”类别中。从下拉菜单中选择要使用的主题。更改会立即进行,因此你可以准确了解主题如何影响你的环境。
你也可以在“设置”标签的“编辑器”类别中更改工作字体。Atom 默认采用等宽字体,程序员通常首选这种字体。但是你可以使用系统上的任何字体,无论是衬线字体、无衬线字体、哥特式字体还是草书字体。无论你想整天盯着什么字体都行。
作为相关说明,默认情况下,Atom 会在其屏幕上绘制一条垂直线,以提示编写代码的人员。程序员通常不想编写太长的代码行,因此这条垂直线会提醒他们不要写太长的代码行。不过,这条竖线对写作者而言毫无意义,你可以通过禁用 “wrap-guide” 包将其删除。
要禁用 “wrap-guide” 软件包,请在“设置”标签中选择“折行”类别,然后搜索 “wrap-guide”。找到该程序包后,单击其“禁用”按钮。
#### 动态结构
创建长文档时,我发现每个文件写一个章节比在一个文件中写整本书更有意义。此外,我不会以明显的语法 `chapter-1.md` 或 `1.example.md` 来命名我的章节,而是以章节标题或关键词(例如 `example.md`)命名。为了将来为自己提供有关如何编写本书的指导,我维护了一个名为 `toc.md` (用于“目录”)的文件,其中列出了各章的(当前)顺序。
我这样做是因为,无论我多么相信第 6 章都不可能出现在第 1 章之前,但在我完成整本书之前,几乎难以避免我会交换一两个章节的顺序。我发现从一开始就保持动态变化可以帮助我避免重命名混乱,也可以帮助我避免僵化的结构。
### 在 Atom 中使用 Git
每位写作者的共同点是两件事:他们为流传而写作,而他们的写作是一段旅程。你不能一坐下来写作就完成了最终稿件。顾名思义,你有一个初稿。该草稿会经过修订,你会仔细地将每个修订保存一式两份或三份的备份,以防万一你的文件损坏了。最终,你得到了所谓的最终草稿,但很有可能你有一天还会回到这份最终草稿,要么恢复好的部分,要么修改坏的部分。
Atom 最令人兴奋的功能是其强大的 Git 集成。无需离开 Atom,你就可以与 Git 的所有主要功能进行交互,跟踪和更新项目、回滚你不喜欢的更改、集成来自协作者的更改等等。最好的学习方法就是逐步学习,因此这是在一个写作项目中从始至终在 Atom 界面中使用 Git 的方法。
第一件事:通过选择 “视图 > 切换 Git 标签页” 来显示 Git 面板。这将在 Atom 界面的右侧打开一个新标签页。现在没什么可看的,所以暂时保持打开状态就行。
#### 建立一个 Git 项目
你可以认为 Git 被绑定到一个文件夹。Git 目录之外的任何文件夹都不知道 Git,而 Git 也不知道外面。Git 目录中的文件夹和文件将被忽略,直到你授予 Git 权限来跟踪它们为止。
你可以通过在 Atom 中创建新的项目文件夹来创建 Git 项目。选择 “文件 > 添加项目文件夹”,然后在系统上创建一个新文件夹。你创建的文件夹将出现在 Atom 窗口的左侧“项目面板”中。
#### Git 添加文件
右键单击你的新项目文件夹,然后选择“新建文件”以在项目文件夹中创建一个新文件。如果你要导入文件到新项目中,请右键单击该文件夹,然后选择“在文件管理器中显示”,以在系统的文件查看器中打开该文件夹(Linux 上为 Dolphin 或 Nautilus,Mac 上为 Finder,在 Windows 上是 Explorer),然后拖放文件到你的项目文件夹。
在 Atom 中打开一个项目文件(你创建的空文件或导入的文件)后,单击 Git 标签中的 “<ruby> 创建存储库 <rt> Create Repository </rt></ruby>” 按钮。在弹出的对话框中,单击 “<ruby> 初始化 <rt> Init </rt></ruby>” 以将你的项目目录初始化为本地 Git 存储库。 Git 会将 `.git` 目录(在系统的文件管理器中不可见,但在 Atom 中可见)添加到项目文件夹中。不要被这个愚弄了:`.git` 目录是 Git 管理的,而不是由你管理的,因此一般你不要动它。但是在 Atom 中看到它可以很好地提醒你正在由 Git 管理的项目中工作。换句话说,当你看到 `.git` 目录时,就有了修订历史记录。
在你的空文件中,写一些东西。你是写作者,所以输入一些单词就行。你可以随意输入任何一组单词,但要记住上面的写作技巧。
按 `Ctrl + S` 保存文件,该文件将显示在 Git 标签的 “<ruby> 未暂存的改变 <rt> Unstaged Changes </rt></ruby>” 部分中。这意味着该文件存在于你的项目文件夹中,但尚未提交给 Git 管理。通过单击 Git 选项卡右上方的 “<ruby> 暂存全部 <rt> Stage All </rt></ruby>” 按钮,以允许 Git 跟踪这些文件。如果你使用过带有修订历史记录的文字处理器,则可以将此步骤视为允许 Git 记录更改。
#### Git 提交
你的文件现在已暂存。这意味着 Git 知道该文件存在,并且知道自上次 Git 知道该文件以来,该文件已被更改。
Git 的<ruby> 提交 <rt> commit </rt></ruby>会将你的文件发送到 Git 的内部和永久存档中。如果你习惯于文字处理程序,这就类似于给一个修订版命名。要创建一个提交,请在 Git 选项卡底部的“<ruby> 提交 <rt> Commit </rt></ruby>”消息框中输入一些描述性文本。你可能会感到含糊不清或随意写点什么,但如果你想在将来知道进行修订的原因,那么输入一些有用的信息会更有用。
第一次提交时,必须创建一个<ruby> 分支 <rt> branch </rt></ruby>。Git 分支有点像另外一个空间,它允许你从一个时间轴切换到另一个时间轴,以进行你可能想要也可能不想要永久保留的更改。如果最终喜欢该更改,则可以将一个实验分支合并到另一个实验分支,从而统一项目的不同版本。这是一个高级过程,不需要先学会,但是你仍然需要一个活动分支,因此你必须为首次提交创建一个分支。
单击 Git 选项卡最底部的“<ruby> 分支 <rt> Branch </rt></ruby>”图标,以创建新的分支。

通常将第一个分支命名为 `master`,但不是必须如此;你可以将其命名为 `firstdraft` 或任何你喜欢的名称,但是遵守当地习俗有时会使谈论 Git(和查找问题的答案)变得容易一些,因为你会知道有人提到 “master” 时,它们的真正意思是“主干”而不是“初稿”或你给分支起的什么名字。
在某些版本的 Atom 上,UI 也许不会更新以反映你已经创建的新分支。不用担心,做了提交之后,它会创建分支(并更新 UI)。按下 “<ruby> 提交 <rt> Commit </rt></ruby>” 按钮,无论它显示的是 “<ruby> 创建脱离的提交 <rt> Create detached commit </rt></ruby>” 还是 “<ruby> 提交到主干 <rt> Commit to master </rt></ruby>。
提交后,文件的状态将永久保留在 Git 的记忆之中。
#### 历史记录和 Git 差异
一个自然而然的问题是你应该多久做一次提交。这并没有正确的答案。使用 `Ctrl + S` 保存文件和提交到 Git 是两个单独的过程,因此你会一直做这两个过程。每当你觉得自己已经做了重要的事情或打算尝试一个可能会被干掉的疯狂的新想法时,你可能都会想要做次提交。
要了解提交对工作流程的影响,请从测试文档中删除一些文本,然后在顶部和底部添加一些文本。再次提交。 这样做几次,直到你在 Git 标签的底部有了一小段历史记录,然后单击其中一个提交以在 Atom 中查看它。

查看过去的提交时,你会看到三种元素:
1. 绿色文本是该提交中已被添加到文档中的内容。
2. 红色文本是该提交中已从文档中删除的内容。
3. 其他所有文字均未做更改。
#### 远程备份
使用 Git 的优点之一是,按照设计它是分布式的,这意味着你可以将工作提交到本地存储库,并将所做的更改推送到任意数量的服务器上进行备份。你还可以从这些服务器中拉取更改,以便你碰巧正在使用的任何设备始终具有最新更改。
为此,你必须在 Git 服务器上拥有一个帐户。有几种免费的托管服务,其中包括 GitHub,这个公司开发了 Atom,但奇怪的是 GitHub 不是开源的;而 GitLab 是开源的。相比私有软件,我更喜欢开源,在本示例中,我将使用 GitLab。
如果你还没有 GitLab 帐户,请注册一个帐户并开始一个新项目。项目名称不必与 Atom 中的项目文件夹匹配,但是如果匹配,则可能更有意义。你可以将项目保留为私有,在这种情况下,只有你和任何一个你给予了明确权限的人可以访问它,或者,如果你希望该项目可供任何互联网上偶然发现它的人使用,则可以将其公开。
不要将 README 文件添加到项目中。
创建项目后,它将为你提供有关如何设置存储库的说明。如果你决定在终端中或通过单独的 GUI 使用 Git,这是非常有用的信息,但是 Atom 的工作流程则有所不同。
单击 GitLab 界面右上方的 “<ruby> 克隆 <rt> Clone </rt></ruby>” 按钮。这显示了访问 Git 存储库必须使用的地址。复制 “SSH” 地址(而不是 “https” 地址)。
在 Atom 中,点击项目的 `.git` 目录,然后打开 `config` 文件。将下面这些配置行添加到该文件中,调整 `url` 值的 `seth/example.git` 部分以匹配你自己独有的地址。
```
[remote "origin"]
url = [email protected]:seth/example.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/master
```
在 Git 标签的底部,出现了一个新按钮,标记为 “<ruby> 提取 <rt> Fetch </rt></ruby>”。由于你的服务器是全新的服务器,因此没有可供你提取的数据,因此请右键单击该按钮,然后选择“<ruby> 推送 <rt> Push </rt></ruby>”。这会将你的更改推送到你的 GitLab 帐户,现在你的项目已备份到 Git 服务器上。
你可以在每次提交后将更改推送到服务器。它提供了即刻的异地备份,并且由于数据量通常很少,因此它几乎与本地保存一样快。
### 撰写而 Git
Git 是一个复杂的系统,不仅对修订跟踪和备份有用。它还支持异步协作并鼓励实验。本文介绍了一些基础知识,但还有更多关于 Git 的文章和整本的书,以及如何使用它使你的工作更高效、更具弹性和更具活力。 从使用 Git 完成小任务开始,使用的次数越多,你会发现自己提出的问题就越多,最终你将学到的技巧越多。
---
via: <https://opensource.com/article/19/4/write-git>
作者:[Seth Kenlon](https://opensource.com/users/sethhttps://opensource.com/users/noreplyhttps://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Git](https://git-scm.com/) is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at ways writers can use Git to get work done.
## Git for writers
Some people write fiction; others write academic papers, poetry, screenplays, technical manuals, or articles about open source. Many do a little of each. The common thread is that if you're a writer, you could probably benefit from using Git. While Git is famously a highly technical tool used by computer programmers, it's ideal for the modern author, and this article will demonstrate how it can change the way you write—and why you'd want it to.
Before talking about Git, though, it's important to talk about what *copy* (or *content*, for the digital age) really is, and why it's different from your delivery *medium*. It's the 21st century, and the tool of choice for most writers is a computer. While computers are deceptively good at combining processes like copy editing and layout, writers are (re)discovering that separating content from style is a good idea, after all. That means you should be writing on a computer like it's a typewriter, not a word processor. In computer lingo, that means writing in *plaintext*.
## Writing in plaintext
It used to be a safe assumption that you knew what market you were writing for. You wrote content for a book, or a website, or a software manual. These days, though, the market's flattened: you might decide to use content you write for a website in a printed book project, and the printed book might release an EPUB version later. And in the case of digital editions of your content, the person reading your content is in ultimate control: they may read your words on the website where you published them, or they might click on Firefox's excellent [Reader View](https://support.mozilla.org/en-US/kb/firefox-reader-view-clutter-free-web-pages), or they might print to physical paper, or they could dump the web page to a text file with Lynx, or they may not see your content at all because they use a screen reader.
It makes sense to write your words as words, leaving the delivery to the publishers. Even if you are also your own publisher, treating your words as a kind of source code for your writing is a smarter and more efficient way to work, because when it comes time to publish, you can use the same source (your plaintext) to generate output appropriate to your target (PDF for print, EPUB for e-books, HTML for websites, and so on).
Writing in plaintext not only means you don't have to worry about layout or how your text is styled, but you also no longer require specialized tools. Anything that can produce text becomes a valid "word processor" for you, whether it's a basic notepad app on your mobile or tablet, the text editor that came bundled with your computer, or a free editor you download from the internet. You can write on practically any device, no matter where you are or what you're doing, and the text you produce integrates perfectly with your project, no modification required.
And, conveniently, Git specializes in managing plaintext.
## The Atom editor
When you write in plaintext, a word processor is overkill. Using a text editor is easier because text editors don't try to "helpfully" restructure your input. It lets you type the words in your head onto the screen, no interference. Better still, text editors are often designed around a plugin architecture, such that the application itself is woefully basic (it edits text), but you can build an environment around it to meet your every need.
A great example of this design philosophy is the [Atom](http://atom.io) editor. It's a cross-platform text editor with built-in Git integration. If you're new to working in plaintext and new to Git, Atom is the easiest way to get started.
### Install Git and Atom
First, make sure you have Git installed on your system. If you run Linux or BSD, Git is available in your software repository or ports tree. The command you use will vary depending on your distribution; on Fedora, for instance:
`$ sudo dnf install git`
You can also download and install Git for [Mac](https://git-scm.com/download/mac) and [Windows](https://git-scm.com/download/win).
You won't need to use Git directly, because Atom serves as your Git interface. Installing Atom is the next step.
If you're on Linux, install Atom from your software repository through your software installer or the appropriate command, such as:
`$ sudo dnf install atom`
Atom does not currently build on BSD. However, there are very good alternatives available, such as [GNU Emacs](http://gnu.org/software/emacs). For Mac and Windows users, you can find installers on the [Atom website](http://atom.io).
Once your installs are done, launch the Atom editor.
### A quick tour
If you're going to live in plaintext and Git, you need to get comfortable with your editor. Atom's user interface may be more dynamic than what you are used to. You can think of it more like Firefox or Chrome than as a word processor, in fact, because it has tabs and panels that can be opened and closed as they are needed, and it even has add-ons that you can install and configure. It's not practical to try to cover all of Atom's many features, but you can at least get familiar with what's possible.
When Atom opens, it displays a welcome screen. If nothing else, this screen is a good introduction to Atom's tabbed interface. You can close the welcome screens by clicking the "close" icons on the tabs at the top of the Atom window and create a new file using **File > New File**.
Working in plaintext is a little different than working in a word processor, so here are some tips for writing content in a way that a human can connect with and that Git and computers can parse, track, and convert.
### Write in Markdown
These days, when people talk about plaintext, mostly they mean Markdown. Markdown is more of a style than a format, meaning that it intends to provide a predictable structure to your text so computers can detect natural patterns and convert the text intelligently. Markdown has many definitions, but the best technical definition and cheatsheet is on [CommonMark's website](https://commonmark.org/help/).
```
# Chapter 1
This is a paragraph with an *italic* word and a **bold** word in it.
And it can even reference an image.

```
As you can tell from the example, Markdown isn't meant to read or feel like code, but it can be treated as code. If you follow the expectations of Markdown defined by CommonMark, then you can reliably convert, with just one click of a button, your writing from Markdown to .docx, .epub, .html, MediaWiki, .odt, .pdf, .rtf, and a dozen other formats *without* loss of formatting.
You can think of Markdown a little like a word processor's styles. If you've ever written for a publisher with a set of styles that govern what chapter titles and section headings look like, this is basically the same thing, except that instead of selecting a style from a drop-down menu, you're adding little notations to your text. These notations look natural to any modern reader who's used to "txt speak," but are swapped out with fancy text stylings when the text is rendered. It is, in fact, what word processors secretly do behind the scenes. The word processor shows bold text, but if you could see the code generated to make your text bold, it would be a lot like Markdown (actually it's the far more complex XML). With Markdown, that barrier is removed, which looks scarier on the one hand, but on the other hand, you can write Markdown on literally anything that generates text without losing any formatting information.
The popular file extension for Markdown files is .md. If you're on a platform that doesn't know what a .md file is, you can associate the extension to Atom manually or else just use the universal .txt extension. The file extension doesn't change the nature of the file; it just changes how your computer decides what to do with it. Atom and some platforms are smart enough to know that a file is plaintext no matter what extension you give it.
### Live preview
Atom features the **Markdown Preview** plugin, which shows you both the plain Markdown you're writing and the way it will (commonly) render.
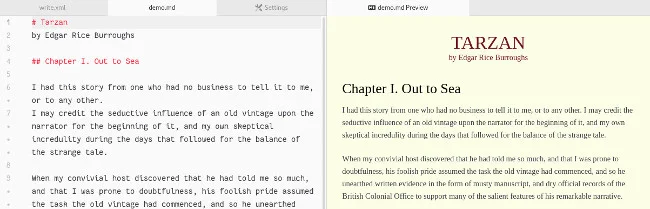
To activate this preview pane, select **Packages > Markdown Preview > Toggle Preview** or press **Ctrl+Shift+M**.
This view provides you with the best of both worlds. You get to write without the burden of styling your text, but you also get to see a common example of what your text will look like, at least in a typical digital format. Of course, the point is that you can't control how your text is ultimately rendered, so don't be tempted to adjust your Markdown to force your render preview to look a certain way.
### One sentence per line
Your high school writing teacher doesn't ever have to see your Markdown.
It won't come naturally at first, but maintaining one sentence per line makes more sense in the digital world. Markdown ignores single line breaks (when you've pressed the Return or Enter key) and only creates a new paragraph after a single blank line.

The advantage of writing one sentence per line is that your work is easier to track. That is, if you've changed one word at the start of a paragraph, then it's easy for Atom, Git, or any application to highlight that change in a meaningful way if the change is limited to one line rather than one word in a long paragraph. In other words, a change to one sentence should only affect that sentence, not the whole paragraph.
You might be thinking, "many word processors track changes, too, and they can highlight a single word that's changed." But those revision trackers are bound to the interface of that word processor, which means you can't look through revisions without being in front of that word processor. In a plaintext workflow, you can review revisions in plaintext, which means you can make or approve edits no matter what you have on hand, as long as that device can deal with plaintext (and most of them can).
Writers admittedly don't usually think in terms of line numbers, but it's a useful tool for computers, and ultimately a great reference point in general. Atom numbers the lines of your text document by default. A *line* is only a line once you have pressed the Enter or Return key.

If a line has a dot instead of a number, that means it's part of the previous line wrapped for you because it couldn't fit on your screen.
### Theme it
If you're a visual person, you might be very particular about the way your writing environment looks. Even if you are writing in plain Markdown, it doesn't mean you have to write in a programmer's font or in a dark window that makes you look like a coder. The simplest way to modify what Atom looks like is to use [theme packages](https://atom.io/themes). It's conventional for theme designers to differentiate dark themes from light themes, so you can search with the keyword Dark or Light, depending on what you want.
To install a theme, select **Edit > Preferences**. This opens a new tab in the Atom interface. Yes, tabs are used for your working documents *and* for configuration and control panels. In the **Settings** tab, click on the **Install** category.
In the **Install** panel, search for the name of the theme you want to install. Click the **Themes** button on the right of the search field to search only for themes. Once you've found your theme, click its **Install** button.
To use a theme you've installed or to customize a theme to your preference, navigate to the **Themes** category in your **Settings** tab. Pick the theme you want to use from the drop-down menu. The changes take place immediately, so you can see exactly how the theme affects your environment.
You can also change your working font in the **Editor** category of the **Settings** tab. Atom defaults to monospace fonts, which are generally preferred by programmers. But you can use any font on your system, whether it's serif or sans or gothic or cursive. Whatever you want to spend your day staring at, it's entirely up to you.
On a related note, by default Atom draws a vertical marker down its screen as a guide for people writing code. Programmers often don't want to write long lines of code, so this vertical line is a reminder to them to simplify things. The vertical line is meaningless to writers, though, and you can remove it by disabling the **wrap-guide** package.
To disable the **wrap-guide** package, select the **Packages** category in the **Settings** tab and search for **wrap-guide**. When you've found the package, click its **Disable** button.
### Dynamic structure
When creating a long document, I find that writing one chapter per file makes more sense than writing an entire book in a single file. Furthermore, I don't name my chapters in the obvious syntax **chapter-1.md** or **1.example.md**, but by chapter titles or keywords, such as **example.md**. To provide myself guidance in the future about how the book is meant to be assembled, I maintain a file called **toc.md** (for "Table of Contents") where I list the (current) order of my chapters.
I do this because, no matter how convinced I am that chapter 6 just couldn't possibly happen before chapter 1, there's rarely a time that I don't swap the order of one or two chapters or sections before I'm finished with a book. I find that keeping it dynamic from the start helps me avoid renaming confusion, and it also helps me treat the material less rigidly.
## Git in Atom
Two things every writer has in common is that they're writing for keeps and their writing is a journey. You don't sit down to write and finish with a final draft; by definition, you have a first draft. And that draft goes through revisions, each of which you carefully save in duplicate and triplicate just in case one of your files turns up corrupted. Eventually, you get to what you call a final draft, but more than likely you'll be going back to it one day, either to resurrect the good parts or to fix the bad.
The most exciting feature in Atom is its strong Git integration. Without ever leaving Atom, you can interact with all of the major features of Git, tracking and updating your project, rolling back changes you don't like, integrating changes from a collaborator, and more. The best way to learn it is to step through it, so here's how to use Git within the Atom interface from the beginning to the end of a writing project.
First thing first: Reveal the Git panel by selecting **View > Toggle Git Tab**. This causes a new tab to open on the right side of Atom's interface. There's not much to see yet, so just keep it open for now.
### Starting a Git project
You can think of Git as being bound to a folder. Any folder outside a Git directory doesn't know about Git, and Git doesn't know about it. Folders and files within a Git directory are ignored until you grant Git permission to keep track of them.
You can create a Git project by creating a new project folder in Atom. Select **File > Add Project Folder** and create a new folder on your system. The folder you create appears in the left **Project Panel** of your Atom window.
### Git add
Right-click on your new project folder and select **New File** to create a new file in your project folder. If you have files you want to import into your new project, right-click on the folder and select **Show in File Manager** to open the folder in your system's file viewer (Dolphin or Nautilus on Linux, Finder on Mac, Explorer on Windows), and then drag-and-drop your files.
With a project file (either the empty one you created or one you've imported) open in Atom, click the **Create Repository** button in the **Git** tab. In the pop-up dialog box, click **Init** to initialize your project directory as a local Git repository. Git adds a **.git** directory (invisible in your system's file manager, but visible to you in Atom) to your project folder. Don't be fooled by this: The **.git** directory is for Git to manage, not you, so you'll generally stay out of it. But seeing it in Atom is a good reminder that you're working in a project actively managed by Git; in other words, revision history is available when you see a **.git** directory.
In your empty file, write some stuff. You're a writer, so type some words. It can be any set of words you please, but remember the writing tips above.
Press **Ctrl+S** to save your file and it will appear in the **Unstaged Changes** section of the **Git** tab. That means the file exists in your project folder but has not yet been committed over to Git's purview. Allow Git to keep track of your file by clicking on the **Stage All** button in the top-right of the **Git** tab. If you've used a word processor with revision history, you can think of this step as permitting Git to record changes.
### Git commit
Your file is now staged. All that means is Git is aware that the file exists and is aware that it has been changed since the last time Git was made aware of it.
A Git commit sends your file into Git's internal and eternal archives. If you're used to word processors, this is similar to naming a revision. To create a commit, enter some descriptive text in the **Commit** message box at the bottom of the **Git** tab. You can be vague or cheeky, but it's more useful if you enter useful information for your future self so that you know why the revision was made.
The first time you make a commit, you must create a branch. Git branches are a little like alternate realities, allowing you to switch from one timeline to another to make changes that you may or may not want to keep forever. If you end up liking the changes, you can merge one experimental branch into another, thereby unifying different versions of your project. It's an advanced process that's not worth learning upfront, but you still need an active branch, so you have to create one for your first commit.
Click on the **Branch** icon at the very bottom of the **Git** tab to create a new branch.
It's customary to name your first branch **master**. You don't have to; you can name it **firstdraft** or whatever you like, but adhering to the local customs can sometimes make talking about Git (and looking up answers to questions) a little easier because you'll know that when someone mentions **master**, they really mean **master** and not **firstdraft** or whatever you called your branch.
On some versions of Atom, the UI may not update to reflect that you've created a new branch. Don't worry; the branch will be created (and the UI updated) once you make your commit. Press the **Commit** button, whether it reads **Create detached commit** or **Commit to master**.
Once you've made a commit, the state of your file is preserved forever in Git's memory.
### History and Git diff
A natural question is how often you should make a commit. There's no one right answer to that. Saving a file with **Ctrl+S** and committing to Git are two separate processes, so you will continue to do both. You'll probably want to make commits whenever you feel like you've done something significant or are about to try out a crazy new idea that you may want to back out of.
To get a feel for what impact a commit has on your workflow, remove some text from your test document and add some text to the top and bottom. Make another commit. Do this a few times until you have a small history at the bottom of your **Git** tab, then click on a commit to view it in Atom.
When viewing a past commit, you see three elements:
- Text in green was added to a document when the commit was made.
- Text in red was removed from the document when the commit was made.
- All other text was untouched.
### Remote backup
One of the advantages of using Git is that, by design, it is distributed, meaning you can commit your work to your local repository and push your changes out to any number of servers for backup. You can also pull changes in from those servers so that whatever device you happen to be working on always has the latest changes.
For this to work, you must have an account on a Git server. There are several free hosting services out there, including GitHub, the company that produces Atom but oddly is not open source, and GitLab, which is open source. Preferring open source to proprietary, I'll use GitLab in this example.
If you don't already have a GitLab account, sign up for one and start a new project. The project name doesn't have to match your project folder in Atom, but it probably makes sense if it does. You can leave your project private, in which case only you and anyone you give explicit permissions to can access it, or you can make it public if you want it to be available to anyone on the internet who stumbles upon it.
Do not add a README to the project.
Once the project is created, it provides you with instructions on how to set up the repository. This is great information if you decide to use Git in a terminal or with a separate GUI, but Atom's workflow is different.
Click the **Clone** button in the top-right of the GitLab interface. This reveals the address you must use to access the Git repository. Copy the **SSH** address (not the **https** address).
In Atom, click on your project's **.git** directory and open the **config**. Add these configuration lines to the file, adjusting the **seth/example.git** part of the **url** value to match your unique address.** **
```
[remote "origin"]
url = [email protected]:seth/example.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/master
```
At the bottom of the **Git** tab, a new button has appeared, labeled **Fetch**. Since your server is brand new and therefore has no data for you to fetch, right-click on the button and select **Push**. This pushes your changes to your Gitlab account, and now your project is backed up on a Git server.
Pushing changes to a server is something you can do after each commit. It provides immediate offsite backup and, since the amount of data is usually minimal, it's practically as fast as a local save.
## Writing and Git
Git is a complex system, useful for more than just revision tracking and backups. It enables asynchronous collaboration and encourages experimentation. This article has covered the basics, but there are many more articles—and entire books—on Git and how to use it to make your work more efficient, more resilient, and more dynamic. It all starts with using Git for small tasks. The more you use it, the more questions you'll find yourself asking, and eventually the more tricks you'll learn.
## 2 Comments |
11,502 | Pylint:让你的 Python 代码保持一致 | https://opensource.com/article/19/10/python-pylint-introduction | 2019-10-25T17:01:05 | [
"Pylint"
] | /article-11502-1.html |
>
> 当你想要争论代码复杂性时,Pylint 是你的朋友。
>
>
>
 in VIM")
Pylint 是更高层级的 Python 样式强制程序。而 [flake8](https://opensource.com/article/19/5/python-flake8) 和 [black](https://opensource.com/article/19/5/python-black) 检查的是“本地”样式:换行位置、注释的格式、发现注释掉的代码或日志格式中的错误做法之类的问题。
默认情况下,Pylint 非常激进。它将对每样东西都提供严厉的意见,从检查是否实际实现声明的接口到重构重复代码的可能性,这对新用户来说可能会很多。一种温和地将其引入项目或团队的方法是先关闭*所有*检查器,然后逐个启用检查器。如果你已经在使用 flake8、black 和 [mypy](https://opensource.com/article/19/5/python-mypy),这尤其有用:Pylint 有相当多的检查器和它们在功能上重叠。
但是,Pylint 独有之处之一是能够强制执行更高级别的问题:例如,函数的行数或者类中方法的数量。
这些数字可能因项目而异,并且可能取决于开发团队的偏好。但是,一旦团队就参数达成一致,使用自动工具*强制化*这些参数非常有用。这是 Pylint 闪耀的地方。
### 配置 Pylint
要以空配置开始,请将 `.pylintrc` 设置为
```
[MESSAGES CONTROL]
disable=all
```
这将禁用所有 Pylint 消息。由于其中许多是冗余的,这是有道理的。在 Pylint 中,`message` 是一种特定的警告。
你可以通过运行 `pylint` 来确认所有消息都已关闭:
```
$ pylint <my package>
```
通常,向 `pylint` 命令行添加参数并不是一个好主意:配置 `pylint` 的最佳位置是 `.pylintrc`。为了使它做*一些*有用的事,我们需要启用一些消息。
要启用消息,在 `.pylintrc` 中的 `[MESSAGES CONTROL]` 下添加
```
enable=<message>,
...
```
对于看起来有用的“消息”(Pylint 称之为不同类型的警告)。我最喜欢的包括 `too-many-lines`、`too-many-arguments` 和 `too-many-branches`。所有这些会限制模块或函数的复杂性,并且无需进行人工操作即可客观地进行代码复杂度测量。
*检查器*是*消息*的来源:每条消息只属于一个检查器。许多最有用的消息都在[设计检查器](https://pylint.readthedocs.io/en/latest/technical_reference/features.html#design-checker)下。默认数字通常都不错,但要调整最大值也很简单:我们可以在 `.pylintrc` 中添加一个名为 `DESIGN` 的段。
```
[DESIGN]
max-args=7
max-locals=15
```
另一个有用的消息来源是“重构”检查器。我已启用一些最喜欢的消息有 `consider-using-dict-comprehension`、`stop-iteration-return`(它会查找正确的停止迭代的方式是 `return` 而使用了 `raise StopIteration` 的迭代器)和 `chained-comparison`,它将建议使用如 `1 <= x < 5`,而不是不太明显的 `1 <= x && 5 > 5` 的语法。
最后是一个在性能方面消耗很大的检查器,但它非常有用,就是 `similarities`。它会查找不同部分代码之间的复制粘贴来强制执行“不要重复自己”(DRY 原则)。它只启用一条消息:`duplicate-code`。默认的 “最小相似行数” 设置为 4。可以使用 `.pylintrc` 将其设置为不同的值。
```
[SIMILARITIES]
min-similarity-lines=3
```
### Pylint 使代码评审变得简单
如果你厌倦了需要指出一个类太复杂,或者两个不同的函数基本相同的代码评审,请将 Pylint 添加到你的[持续集成](https://opensource.com/business/15/7/six-continuous-integration-tools)配置中,并且只需要对项目复杂性准则的争论一次就行。
---
via: <https://opensource.com/article/19/10/python-pylint-introduction>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,503 | 如何获取 Linux 中的目录大小 | https://www.2daygeek.com/find-get-size-of-directory-folder-linux-disk-usage-du-command/ | 2019-10-25T17:14:40 | [
"磁盘",
"目录"
] | https://linux.cn/article-11503-1.html | 
你应该已经注意到,在 Linux 中使用 [ls 命令](https://www.2daygeek.com/linux-unix-ls-command-display-directory-contents/) 列出的目录内容中,目录的大小仅显示 4KB。这个大小正确吗?如果不正确,那它代表什么,又该如何获取 Linux 中的目录或文件夹大小?这是一个默认的大小,是用来存储磁盘上存储目录的元数据的大小。
Linux 上有一些应用程序可以 [获取目录的实际大小](https://www.2daygeek.com/how-to-get-find-size-of-directory-folder-linux/)。其中,磁盘使用率(`du`)命令已被 Linux 管理员广泛使用。
我将向您展示如何使用各种选项获取文件夹大小。
### 什么是 du 命令?
[du 命令](https://www.2daygeek.com/linux-check-disk-usage-files-directories-size-du-command/) 表示 <ruby> 磁盘使用率 <rt> Disk Usage </rt></ruby>。这是一个标准的 Unix 程序,用于估计当前工作目录中的文件空间使用情况。
它使用递归方式总结磁盘使用情况,以获取目录及其子目录的大小。
如同我说的那样, 使用 `ls` 命令时,目录大小仅显示 4KB。参见下面的输出。
```
$ ls -lh | grep ^d
drwxr-xr-x 3 daygeek daygeek 4.0K Aug 2 13:57 Bank_Details
drwxr-xr-x 2 daygeek daygeek 4.0K Mar 15 2019 daygeek
drwxr-xr-x 6 daygeek daygeek 4.0K Feb 16 2019 drive-2daygeek
drwxr-xr-x 13 daygeek daygeek 4.0K Jan 6 2019 drive-mageshm
drwxr-xr-x 15 daygeek daygeek 4.0K Sep 29 21:32 Thanu_Photos
```
### 1) 在 Linux 上如何只获取父目录的大小
使用以下 `du` 命令格式获取给定目录的总大小。在该示例中,我们将得到 `/home/daygeek/Documents` 目录的总大小。
```
$ du -hs /home/daygeek/Documents
或
$ du -h --max-depth=0 /home/daygeek/Documents/
20G /home/daygeek/Documents
```
详细说明:
* `du` – 这是一个命令
* `-h` – 以易读的格式显示大小 (例如 1K 234M 2G)
* `-s` – 仅显示每个参数的总数
* `--max-depth=N` – 目录的打印深度
### 2) 在 Linux 上如何获取每个目录的大小
使用以下 `du` 命令格式获取每个目录(包括子目录)的总大小。
在该示例中,我们将获得每个 `/home/daygeek/Documents` 目录及其子目录的总大小。
```
$ du -h /home/daygeek/Documents/ | sort -rh | head -20
20G /home/daygeek/Documents/
9.6G /home/daygeek/Documents/drive-2daygeek
6.3G /home/daygeek/Documents/Thanu_Photos
5.3G /home/daygeek/Documents/Thanu_Photos/Camera
5.3G /home/daygeek/Documents/drive-2daygeek/Thanu-videos
3.2G /home/daygeek/Documents/drive-mageshm
2.3G /home/daygeek/Documents/drive-2daygeek/Thanu-Photos
2.2G /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month
916M /home/daygeek/Documents/drive-mageshm/Tanisha
454M /home/daygeek/Documents/drive-mageshm/2g-backup
415M /home/daygeek/Documents/Thanu_Photos/WhatsApp Video
300M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Jan-2017
288M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Oct-2017
226M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Sep-2017
219M /home/daygeek/Documents/Thanu_Photos/WhatsApp Documents
213M /home/daygeek/Documents/drive-mageshm/photos
163M /home/daygeek/Documents/Thanu_Photos/WhatsApp Video/Sent
161M /home/daygeek/Documents/Thanu_Photos/WhatsApp Images
154M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/June-2017
150M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Nov-2016
```
### 3) 在 Linux 上如何获取每个目录的摘要
使用如下 `du` 命令格式仅获取每个目录的摘要。
```
$ du -hs /home/daygeek/Documents/* | sort -rh | head -10
9.6G /home/daygeek/Documents/drive-2daygeek
6.3G /home/daygeek/Documents/Thanu_Photos
3.2G /home/daygeek/Documents/drive-mageshm
756K /home/daygeek/Documents/Bank_Details
272K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-TouchInterface1.png
172K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-NightLight.png
164K /home/daygeek/Documents/ConfigServer Security and Firewall (csf) Cheat Sheet.pdf
132K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-Todo.png
112K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-ZorinAutoTheme.png
96K /home/daygeek/Documents/distro-info.xlsx
```
### 4) 在 Linux 上如何获取每个目录的不含子目录的大小
使用如下 `du` 命令格式来展示每个目录的总大小,不包括子目录。
```
$ du -hS /home/daygeek/Documents/ | sort -rh | head -20
5.3G /home/daygeek/Documents/Thanu_Photos/Camera
5.3G /home/daygeek/Documents/drive-2daygeek/Thanu-videos
2.3G /home/daygeek/Documents/drive-2daygeek/Thanu-Photos
1.5G /home/daygeek/Documents/drive-mageshm
831M /home/daygeek/Documents/drive-mageshm/Tanisha
454M /home/daygeek/Documents/drive-mageshm/2g-backup
300M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Jan-2017
288M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Oct-2017
253M /home/daygeek/Documents/Thanu_Photos/WhatsApp Video
226M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Sep-2017
219M /home/daygeek/Documents/Thanu_Photos/WhatsApp Documents
213M /home/daygeek/Documents/drive-mageshm/photos
163M /home/daygeek/Documents/Thanu_Photos/WhatsApp Video/Sent
154M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/June-2017
150M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Nov-2016
127M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Dec-2016
100M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Oct-2016
94M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Nov-2017
92M /home/daygeek/Documents/Thanu_Photos/WhatsApp Images
90M /home/daygeek/Documents/drive-2daygeek/Thanu-photos-by-month/Dec-2017
```
### 5) 在 Linux 上如何仅获取一级子目录的大小
如果要获取 Linux 上给定目录的一级子目录(包括其子目录)的大小,请使用以下命令格式。
```
$ du -h --max-depth=1 /home/daygeek/Documents/
3.2G /home/daygeek/Documents/drive-mageshm
4.0K /home/daygeek/Documents/daygeek
756K /home/daygeek/Documents/Bank_Details
9.6G /home/daygeek/Documents/drive-2daygeek
6.3G /home/daygeek/Documents/Thanu_Photos
20G /home/daygeek/Documents/
```
### 6) 如何在 du 命令输出中获得总计
如果要在 `du` 命令输出中获得总计,请使用以下 `du` 命令格式。
```
$ du -hsc /home/daygeek/Documents/* | sort -rh | head -10
20G total
9.6G /home/daygeek/Documents/drive-2daygeek
6.3G /home/daygeek/Documents/Thanu_Photos
3.2G /home/daygeek/Documents/drive-mageshm
756K /home/daygeek/Documents/Bank_Details
272K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-TouchInterface1.png
172K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-NightLight.png
164K /home/daygeek/Documents/ConfigServer Security and Firewall (csf) Cheat Sheet.pdf
132K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-Todo.png
112K /home/daygeek/Documents/user-friendly-zorin-os-15-has-been-released-ZorinAutoTheme.png
```
---
via: <https://www.2daygeek.com/find-get-size-of-directory-folder-linux-disk-usage-du-command/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lnrCoder](https://github.com/lnrCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,504 | 用 GameHub 集中管理你 Linux 上的所有游戏 | https://itsfoss.com/gamehub/ | 2019-10-27T00:02:00 | [
"游戏",
"GameHub"
] | https://linux.cn/article-11504-1.html | 你在 Linux 上是怎么[玩游戏的呢](https://itsfoss.com/linux-gaming-guide/)? 让我猜猜,要不就是从软件中心直接安装,要不就选 Steam、GOG、Humble Bundle 等平台,对吧?但是,如果你有多个游戏启动器和客户端,又要如何管理呢?好吧,对我来说这简直令人头疼 —— 这也是我发现 [GameHub](https://tkashkin.tk/projects/gamehub/) 这个应用之后,感到非常高兴的原因。
GameHub 是为 Linux 发行版设计的一个桌面应用,它能让你“集中管理你的所有游戏”。这听起来很有趣,是不是?下面让我来具体说明一下。

### 集中管理不同平台 Linux 游戏的 GameHub
让我们看看,对玩家来说,让 GameHub 成为一个[不可或缺的 Linux 应用](https://itsfoss.com/essential-linux-applications/)的功能,都有哪些。
#### Steam、GOG & Humble Bundle 支持

它支持 Steam、[GOG](https://www.gog.com/) 和 [Humble Bundle](https://www.humblebundle.com/monthly?partner=itsfoss) 账户整合。你可以登录你的 GameHub 账号,从而在你的库管理器中管理所有游戏。
对我来说,我在 Steam 上有很多游戏,Humble Bundle 上也有一些。我不能确保它支持所有平台,但可以确信的是,主流平台游戏是没有问题的。
#### 支持原生游戏

[有很多网站专门推荐 Linux 游戏,并支持下载](https://itsfoss.com/download-linux-games/)。你可以通过下载安装包,或者添加可执行文件,从而管理原生游戏。
可惜的是,现在无法在 GameHub 内搜索 Linux 游戏。如上图所示,你需要分别下载游戏,随后再将其添加到 GameHub 中。
#### 模拟器支持
用模拟器,你可以在 [Linux 上玩复古游戏](https://itsfoss.com/play-retro-games-linux/)。正如上图所示,你可以添加模拟器(并导入模拟的镜像)。
你可以在 [RetroArch](https://www.retroarch.com/) 查看已有的模拟器,但也能根据需求添加自定义模拟器。
#### 用户界面

当然,用户体验很重要。因此,探究下用户界面都有些什么,也很有必要。
我个人觉得,这一应用很容易使用,并且黑色主题是一个加分项。
#### 手柄支持
如果你习惯在 Linux 系统上用手柄玩游戏 —— 你可以轻松在设置里添加,启用或禁用它。
#### 多个数据提供商
因为它需要获取你的游戏信息(或元数据),也意味着它需要一个数据源。你可以看到下图列出的所有数据源。

这里你什么也不用做 —— 但如果你使用的是 steam 之外的其他平台,你需要为 [IDGB 生成一个 API 密钥](https://www.igdb.com/api)。
我建议只有出现 GameHub 中的提示/通知,或有些游戏在 GameHub 上没有任何描述/图片/状态时,再这么做。
#### 兼容性选项

你有不支持在 Linux 上运行的游戏吗?
不用担心,GameHub 上提供了多种兼容工具,如 Wine/Proton,你可以利用它们来玩游戏。
我们无法确定具体哪个兼容工具适用于你 —— 所以你需要自己亲自测试。然而,对许多游戏玩家来说,这的确是个很有用的功能。
### GameHub: 如何安装它呢?

首先,你可以直接在软件中心或者应用商店内搜索。 它在 “Pop!\_Shop” 之下。所以,它在绝大多数官方源中都能找到。
如果你在这些地方都没有找到,你可以手动添加源,并从终端上安装它,你需要输入以下命令:
```
sudo add-apt-repository ppa:tkashkin/gamehub
sudo apt update
sudo apt install com.github.tkashkin.gamehub
```
如果你遇到了 “add-apt-repository command not found” 这个错误,你可以看看,[add-apt-repository not found error.](https://itsfoss.com/add-apt-repository-command-not-found/)这篇文章,它能帮你解决这一问题。
这里还提供 AppImage 和 FlatPak 版本。 在[官网](https://tkashkin.tk/projects/gamehub/) 上,你可以针对找到其他 Linux 发行版的安装手册。
同时,你还可以从它的 [GitHub 页面](https://github.com/tkashkin/GameHub/releases)下载之前版本的安装包.
[GameHub](https://tkashkin.tk/projects/gamehub/)
### 如何在 GameHub 上管理你的游戏?
在启动程序后,你可以将自己的 Steam/GOG/Humble Bundle 账号添加进来。
对于 Steam,你需要在 Linux 发行版上安装 Steam 客户端。一旦安装完成,你可以轻松将账号中的游戏导入 GameHub。

对于 GOG & Humble Bundle,登录后,就能直接在 GameHub 上管理游戏了。
如果你想添加模拟器或者本地安装文件,点击窗口右上角的 “+” 按钮进行添加。
### 如何安装游戏?
对于 Steam 游戏,它会自动启动 Steam 客户端,从而下载/安装游戏(我希望之后安装游戏,可以不用启动 Steam!)

但对于 GOG/Humble Bundle,登录后就能直接、下载安装游戏。必要的话,对于那些不支持在 Linux 上运行的游戏,你可以使用兼容工具。
无论是模拟器游戏,还是本地游戏,只需添加安装包或导入模拟器镜像就可以了。这里没什么其他步骤要做。
### 注意
GameHub 是相当灵活的一个集中游戏管理应用。 用户界面和选项设置也相当直观。
你之前是否使用过这一应用呢?如果有,请在评论里写下你的感受。
而且,如果你想尝试一些与此功能相似的工具/应用,请务必告诉我们。
---
via: <https://itsfoss.com/gamehub/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wenwensnow](https://github.com/wenwensnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | How do you [play games on Linux](https://itsfoss.com/linux-gaming-guide/)? Let me guess. Either you install games from the software center or from Steam or from GOG or Humble Bundle etc, right? But, how do you plan to manage all your games from multiple launchers and clients? Well, that sounds like a hassle to me – which is why I was delighted when I come across [GameHub](https://github.com/tkashkin/GameHub).
GameHub is a desktop application for Linux distributions that lets you manage “All your games in one place”. That sounds interesting, isn’t it? Let me share more details about it.
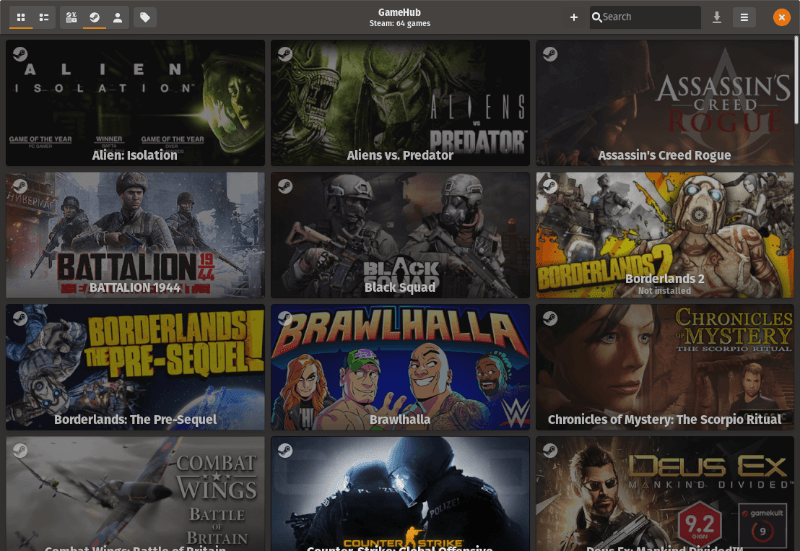
## GameHub Features to manage Linux games from different sources at one place
Let’s see all the features that make GameHub one of the [essential Linux applications](https://itsfoss.com/essential-linux-applications/), specially for gamers.
### Steam, GOG & Humble Bundle Support
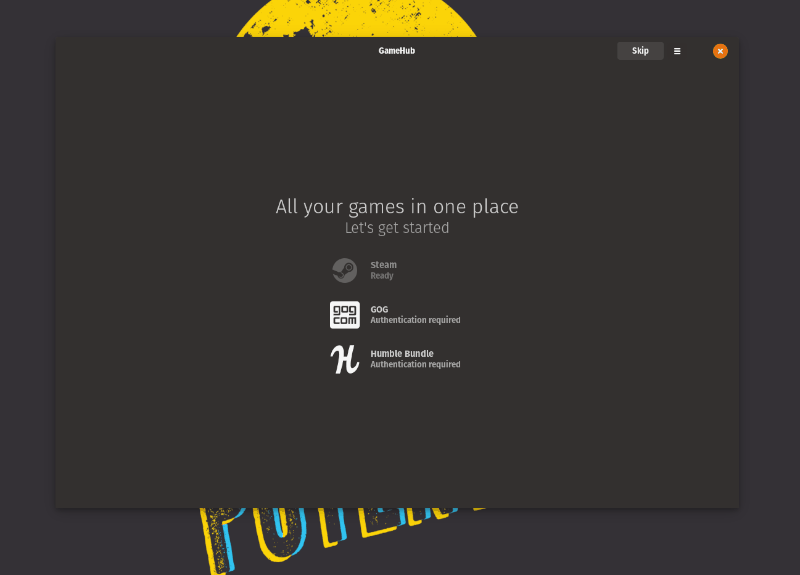
It supports Steam, [GOG](https://www.gog.com/), and [Humble Bundle](https://itsfoss.com/go/humblebundle/) account integration. You can sign in to your account to see manager your library from within GameHub.
For my usage, I have a lot of games on Steam and a couple on Humble Bundle. I can’t speak for all – but it is safe to assume that these are the major platforms one would want to have.
### Native Game Support
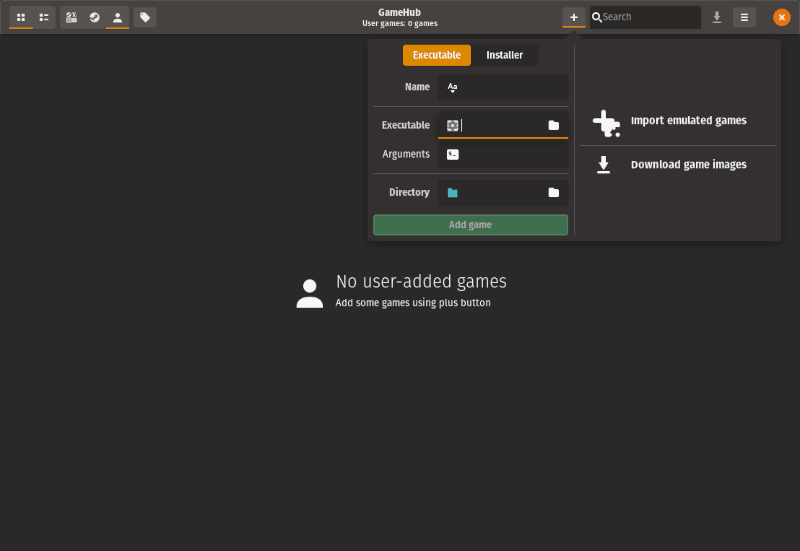
There are several [websites where you can find and download Linux games](https://itsfoss.com/download-linux-games/). You can also add native Linux games by downloading their installers or add the executable file.
Unfortunately, there’s no easy way of finding out games for Linux from within GameHub at the moment. So, you will have to download them separately and add it to the GameHub as shown in the image above.
### Emulator Support
With emulators, you can [play retro games on Linux](https://itsfoss.com/play-retro-games-linux/). As you can observe in the image above, you also get the ability to add emulators (and import emulated images).
You can see [RetroArch](https://www.retroarch.com/) listed already but you can also add custom emulators as per your requirements.
### User Interface

Of course, the user experience matters. Hence, it is important to take a look at its user interface and what it offers.
To me, I felt it very easy to use and the presence of a dark theme is a bonus.
### Controller Support
If you are comfortable using a controller with your Linux system to play games – you can easily add it, enable or disable it from the settings.
### Multiple Data Providers
Just because it fetches the information (or metadata) of your games, it needs a source for that. You can see all the sources listed in the image below.

You don’t have to do anything here – but if you are using anything else other than steam as your platform, you can generate an [API key for IDGB.](https://www.igdb.com/api)
I shall recommend you to do that only if you observe a prompt/notice within GameHub or if you have some games that do not have any description/pictures/stats on GameHub.
### Compatibility Layer
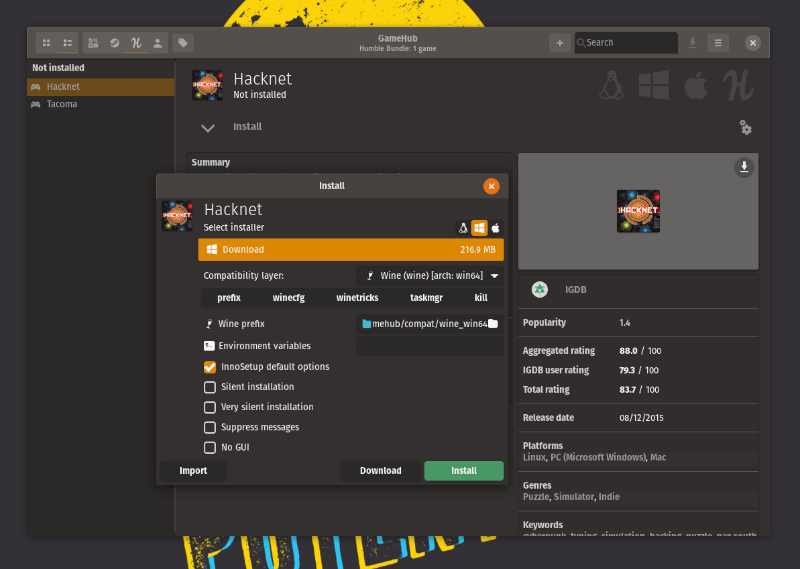
Do you have a game that does not support Linux?
You do not have to worry. GameHub offers multiple compatibility layers like Wine/Proton which you can use to get the game installed in order to make it playable.
We can’t be really sure on what works for you – so you have to test it yourself for that matter. Nevertheless, it is an important feature that could come handy for a lot of gamers.
## How Do You Manage Your Games in GameHub?
You get the option to add Steam/GOG/Humble Bundle account right after you launch it.
For Steam, you need to have the Steam client installed on your Linux distro. Once, you have it, you can easily link the games to GameHub.
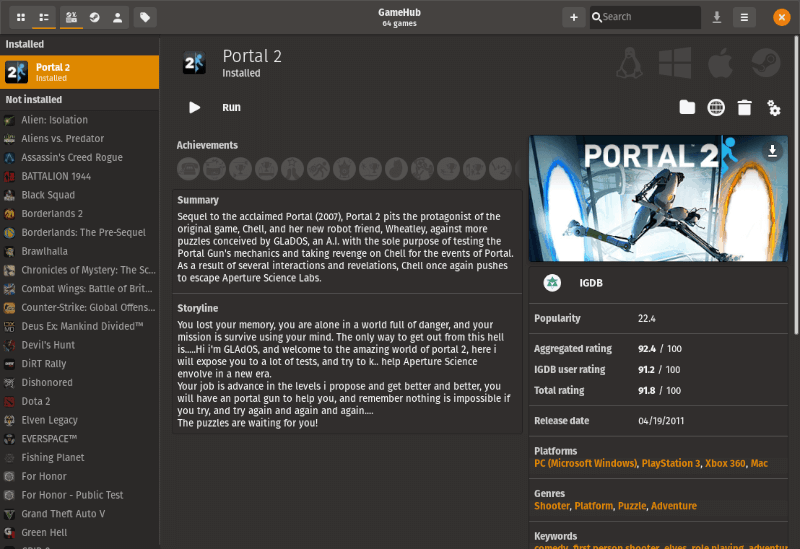
For GOG & Humble Bundle, you can directly sign in using your credentials to get your games organized in GameHub.
If you are adding an emulated image or a native installer, you can always do that by clicking on the “**+**” button that you observe in the top-right corner of the window.
## How Do You Install Games?
For Steam games, it automatically launches the Steam client to download/install (I wish if this was possible without launching Steam!)
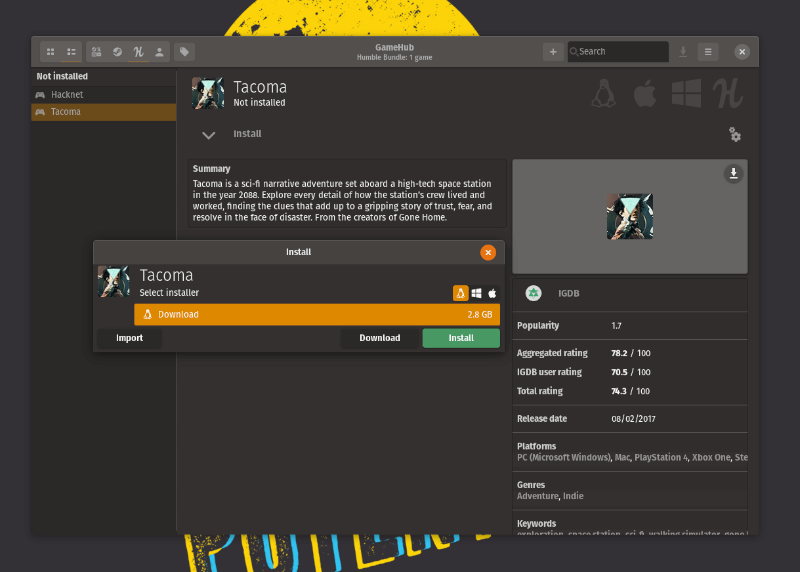
But, for GOG/Humble Bundle, you can directly start downloading to install the games after signing in. If necessary, you can utilize the compatibility layer for non-native Linux games.
In either case, if you want to install an emulated game or a native game – just add the installer or import the emulated image. There’s nothing more to it.
## GameHub: How do you install it?
To start with, you can just search for it in your software center or app center. It is available in the **Pop!_Shop**. So, it can be found in most of the official repositories.
If you don’t find it there, you can always add the repository and install it via terminal by typing these commands:
sudo add-apt-repository ppa:tkashkin/gamehub sudo apt update sudo apt install com.github.tkashkin.gamehub
In case you encounter “**add-apt-repository command not found**” error, you can take a look at our article to help fix [add-apt-repository not found error.](https://itsfoss.com/add-apt-repository-command-not-found/)
There are also AppImage and Flatpak versions available. You can find installation instructions for other Linux distros on its [official webpage](https://tkashkin.tk/projects/gamehub/).
Also, you have the option to download pre-release packages from its [GitHub page](https://github.com/tkashkin/GameHub/releases).
**Wrapping Up**
GameHub is a pretty neat application as a unified library for all your games. The user interface is intuitive and so are the options.
Have you had the chance it test it out before? If yes, let us know your experience in the comments down below.
Also, feel free to tell us about some of your favorite tools/applications similar to this which you would want us to try. |
11,505 | 如何在 CentOS8/RHEL8 中配置 Rsyslog 服务器 | https://www.linuxtechi.com/configure-rsyslog-server-centos-8-rhel-8/ | 2019-10-27T06:29:00 | [
"日志",
"Rsyslog"
] | https://linux.cn/article-11505-1.html | 
Rsyslog 是一个自由开源的日志记录程序,在 CentOS 8 和 RHEL 8 系统上默认可用。它提供了一种从客户端节点到单个中央服务器的“集中日志”的简单有效的方法。日志集中化有两个好处。首先,它简化了日志查看,因为系统管理员可以在一个中心节点查看远程服务器的所有日志,而无需登录每个客户端系统来检查日志。如果需要监视多台服务器,这将非常有用,其次,如果远程客户端崩溃,你不用担心丢失日志,因为所有日志都将保存在中心的 Rsyslog 服务器上。rsyslog 取代了仅支持 UDP 协议的 syslog。它以优异的功能扩展了基本的 syslog 协议,例如在传输日志时支持 UDP 和 TCP 协议,增强的过滤功能以及灵活的配置选项。让我们来探讨如何在 CentOS 8 / RHEL 8 系统中配置 Rsyslog 服务器。

### 预先条件
我们将搭建以下实验环境来测试集中式日志记录过程:
* Rsyslog 服务器 CentOS 8 Minimal IP 地址: 10.128.0.47
* 客户端系统 RHEL 8 Minimal IP 地址: 10.128.0.48
通过上面的设置,我们将演示如何设置 Rsyslog 服务器,然后配置客户端系统以将日志发送到 Rsyslog 服务器进行监视。
让我们开始!
### 在 CentOS 8 上配置 Rsyslog 服务器
默认情况下,Rsyslog 已安装在 CentOS 8 / RHEL 8 服务器上。要验证 Rsyslog 的状态,请通过 SSH 登录并运行以下命令:
```
$ systemctl status rsyslog
```
示例输出:

如果由于某种原因 Rsyslog 不存在,那么可以使用以下命令进行安装:
```
$ sudo yum install rsyslog
```
接下来,你需要修改 Rsyslog 配置文件中的一些设置。打开配置文件:
```
$ sudo vim /etc/rsyslog.conf
```
滚动并取消注释下面的行,以允许通过 UDP 协议接收日志:
```
module(load="imudp") # needs to be done just once
input(type="imudp" port="514")
```

同样,如果你希望启用 TCP rsyslog 接收,请取消注释下面的行:
```
module(load="imtcp") # needs to be done just once
input(type="imtcp" port="514")
```

保存并退出配置文件。
要从客户端系统接收日志,我们需要在防火墙上打开 Rsyslog 默认端口 514。为此,请运行:
```
# sudo firewall-cmd --add-port=514/tcp --zone=public --permanent
```
接下来,重新加载防火墙保存更改:
```
# sudo firewall-cmd --reload
```
示例输出:

接下来,重启 Rsyslog 服务器:
```
$ sudo systemctl restart rsyslog
```
要在启动时运行 Rsyslog,运行以下命令:
```
$ sudo systemctl enable rsyslog
```
要确认 Rsyslog 服务器正在监听 514 端口,请使用 `netstat` 命令,如下所示:
```
$ sudo netstat -pnltu
```
示例输出:

完美!我们已经成功配置了 Rsyslog 服务器来从客户端系统接收日志。
要实时查看日志消息,请运行以下命令:
```
$ tail -f /var/log/messages
```
现在开始配置客户端系统。
### 在 RHEL 8 上配置客户端系统
与 Rsyslog 服务器一样,登录并通过以下命令检查 rsyslog 守护进程是否正在运行:
```
$ sudo systemctl status rsyslog
```
示例输出:

接下来,打开 rsyslog 配置文件:
```
$ sudo vim /etc/rsyslog.conf
```
在文件末尾,添加以下行:
```
*.* @10.128.0.47:514 # Use @ for UDP protocol
*.* @@10.128.0.47:514 # Use @@ for TCP protocol
```
保存并退出配置文件。就像 Rsyslog 服务器一样,打开 514 端口,这是防火墙上的默认 Rsyslog 端口:
```
$ sudo firewall-cmd --add-port=514/tcp --zone=public --permanent
```
接下来,重新加载防火墙以保存更改:
```
$ sudo firewall-cmd --reload
```
接下来,重启 rsyslog 服务:
```
$ sudo systemctl restart rsyslog
```
要在启动时运行 Rsyslog,请运行以下命令:
```
$ sudo systemctl enable rsyslog
```
### 测试日志记录操作
已经成功安装并配置 Rsyslog 服务器和客户端后,就该验证你的配置是否按预期运行了。
在客户端系统上,运行以下命令:
```
# logger "Hello guys! This is our first log"
```
现在进入 Rsyslog 服务器并运行以下命令来实时查看日志消息:
```
# tail -f /var/log/messages
```
客户端系统上命令运行的输出显示在了 Rsyslog 服务器的日志中,这意味着 Rsyslog 服务器正在接收来自客户端系统的日志:

就是这些了!我们成功设置了 Rsyslog 服务器来接收来自客户端系统的日志信息。
---
via: <https://www.linuxtechi.com/configure-rsyslog-server-centos-8-rhel-8/>
作者:[James Kiarie](https://www.linuxtechi.com/author/james/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Rsyslog** is a free and opensource logging utility that exists by default on **CentOS** 8 and **RHEL** 8 systems. It provides an easy and effective way of **centralizing logs** from client nodes to a single central server. The centralization of logs is beneficial in two ways. First, it simplifies viewing of logs as the Systems administrator can view all the logs of remote servers from a central point without logging into every client system to check the logs. This is greatly beneficial if there are several servers that need to be monitored and secondly, in the event that a remote client suffers a crash, you need not worry about losing the logs because all the logs will be saved on the **central rsyslog server**. Rsyslog has replaced syslog which only supported **UDP** protocol. It extends the basic syslog protocol with superior features such as support for both **UDP** and **TCP** protocols in transporting logs, augmented filtering abilities, and flexible configuration options. That said, let’s explore how to configure the Rsyslog server in CentOS 8 / RHEL 8 systems.
#### Prerequisites
We are going to have the following lab setup to test the centralized logging process:
**Rsyslog server**CentOS 8 Minimal IP address: 10.128.0.47**Client system**RHEL 8 Minimal IP address: 10.128.0.48
From the setup above, we will demonstrate how you can set up the Rsyslog server and later configure the client system to ship logs to the Rsyslog server for monitoring.
Let’s get started!
#### Configuring the Rsyslog Server on CentOS 8
By default, Rsyslog comes installed on CentOS 8 / RHEL 8 servers. To verify the status of Rsyslog, log in via SSH and issue the command:
$ systemctl status rsyslog
Sample Output
If rsyslog is not present for whatever reason, you can install it using the command:
$ sudo yum install rsyslog
Next, you need to modify a few settings in the Rsyslog configuration file. Open the configuration file.
$ sudo vim /etc/rsyslog.conf
Scroll and uncomment the lines shown below to allow reception of logs via UDP protocol
module(load="imudp") # needs to be done just once input(type="imudp" port="514")
Similarly, if you prefer to enable TCP rsyslog reception uncomment the lines:
module(load="imtcp") # needs to be done just once input(type="imtcp" port="514")
Save and exit the configuration file.
To receive the logs from the client system, we need to open Rsyslog default port 514 on the firewall. To achieve this, run
# sudo firewall-cmd --add-port=514/tcp --zone=public --permanent
Next, reload the firewall to save the changes
# sudo firewall-cmd --reload
Sample Output
Next, restart Rsyslog server
$ sudo systemctl restart rsyslog
To enable Rsyslog on boot, run beneath command
$ sudo systemctl enable rsyslog
To confirm that the Rsyslog server is listening on port 514, use the netstat command as follows:
$ sudo netstat -pnltu
Sample Output
Perfect! we have successfully configured our Rsyslog server to receive logs from the client system.
To view log messages in real-time run the command:
$ tail -f /var/log/messages
Let’s now configure the client system.
#### Configuring the client system on RHEL 8
Like the Rsyslog server, log in and check if the rsyslog daemon is running by issuing the command:
$ sudo systemctl status rsyslog
Sample Output
Next, proceed to open the rsyslog configuration file
$ sudo vim /etc/rsyslog.conf
At the end of the file, append the following line
*.* @10.128.0.47:514 # Use @ for UDP protocol *.* @@10.128.0.47:514 # Use @@ for TCP protocol
Save and exit the configuration file. Just like the Rsyslog Server, open port 514 which is the default Rsyslog port on the firewall
$ sudo firewall-cmd --add-port=514/tcp --zone=public --permanent
Next, reload the firewall to save the changes
$ sudo firewall-cmd --reload
Next, restart the rsyslog service
$ sudo systemctl restart rsyslog
To enable Rsyslog on boot, run following command
$ sudo systemctl enable rsyslog
#### Testing the logging operation
Having successfully set up and configured Rsyslog Server and client system, it’s time to verify of your configuration is working as intended.
On the client system issue the command:
# logger "Hello guys! This is our first log"
Now head out to the Rsyslog server and run the command below to check the logs messages in real-time
# tail -f /var/log/messages
The output from the command run on the client system should register on the Rsyslog server’s log messages to imply that the Rsyslog server is now receiving logs from the client system.
And that’s it, guys! We have successfully setup the Rsyslog server to receive log messages from a client system.
Read Also: [How to Rotate and Compress Log Files in Linux with Logrotate](https://www.linuxtechi.com/manage-linux-log-files-using-logrotate/)
Read Also : [How to Install Redis Server on CentOS 8 / RHEL 8](https://www.linuxtechi.com/install-redis-server-on-centos-8-rhel-8/)
Roland PietteHi,
Thanks for this article. I have implement it and it works fine.
But I have a question.
Is it possible to resynchronize the logs from a clients on logs server when this is was unavailable during a certain time (reboot, maintenance, …) ?
Thanks in advance,
Roland
James KiarieHey Roland. Unfortunately no. Rsyslog does not resynchronize logs in the event of maintenance. In case of a reboot, it will log that there was an even that triggered a reboot. |
11,506 | 如何使用物联网设备来确保儿童安全? | https://opensourceforu.com/2019/10/how-to-use-iot-devices-to-keep-children-safe/ | 2019-10-27T06:42:26 | [
"IoT"
] | https://linux.cn/article-11506-1.html | 
IoT (物联网)设备正在迅速改变我们的生活。这些设备无处不在,从我们的家庭到其它行业。根据一些预测数据,到 2020 年,将会有 100 亿个 IoT 设备。到 2025 年,该数量将增长到 220 亿。目前,物联网已经在很多领域得到了应用,包括智能家居、工业生产过程、农业甚至医疗保健领域。伴随着如此广泛的应用,物联网显然已经成为近年来的热门话题之一。
多种因素促成了物联网设备在多个学科的爆炸式增长。这其中包括低成本处理器和无线连接的的可用性,以及开源平台的信息交流推动了物联网领域的创新。与传统的应用程序开发相比,物联网设备的开发成指数级增长,因为它的资源是开源的。
在解释如何使用物联网设备来保护儿童之前,必须对物联网技术有基本的了解。
### IoT 设备是什么?
IoT 设备是指那些在没有人类参与的情况下彼此之间可以通信的设备。因此,许多专家并不将智能手机和计算机视为物联网设备。此外,物联网设备必须能够收集数据并且能将收集到的数据传送到其他设备或云端进行处理。
然而,在某些领域中,我们需要探索物联网的潜力。儿童往往是脆弱的,他们很容易成为犯罪分子和其他蓄意伤害者的目标。无论在物理世界还是数字世界中,儿童都很容易面临犯罪的威胁。因为父母不能始终亲自到场保护孩子;这就是为什么需要监视工具了。
除了适用于儿童的可穿戴设备外,还有许多父母监视应用程序,例如 Xnspy,可实时监控儿童并提供信息的实时更新。这些工具可确保儿童安全。可穿戴设备确保儿童身体上的安全性,而家长监控应用可确保儿童的上网安全。
由于越来越多的孩子花费时间在智能手机上,毫无意外地,他们也就成为诈骗分子的主要目标。此外,由于恋童癖、网络自夸和其他犯罪在网络上的盛行,儿童也有可能成为网络欺凌的目标。
这些解决方案够吗?我们需要找到物联网解决方案,以确保孩子们在网上和线下的安全。在当代,我们如何确保孩子的安全?我们需要提出创新的解决方案。 物联网可以帮助保护孩子在学校和家里的安全。
### 物联网的潜力
物联网设备提供的好处很多。举例来说,父母可以远程监控自己的孩子,而又不会显得太霸道。因此,儿童在拥有安全环境的同时也会有空间和自由让自己变得独立。
而且,父母也不必在为孩子的安全而担忧。物联网设备可以提供 7x24 小时的信息更新。像 Xnspy 之类的监视应用程序在提供有关孩子的智能手机活动信息方面更进了一步。随着物联网设备变得越来越复杂,拥有更长使用寿命的电池只是一个时间问题。诸如位置跟踪器之类的物联网设备可以提供有关孩子下落的准确详细信息,所以父母不必担心。
虽然可穿戴设备已经非常好了,但在确保儿童安全方面,这些通常还远远不够。因此,要为儿童提供安全的环境,我们还需要其他方法。许多事件表明,儿童在学校比其他任何公共场所都容易受到攻击。因此,学校需要采取安全措施,以确保儿童和教师的安全。在这一点上,物联网设备可用于检测潜在威胁并采取必要的措施来防止攻击。威胁检测系统包括摄像头。系统一旦检测到威胁,便可以通知当局,如一些执法机构和医院。智能锁等设备可用于封锁学校(包括教室),来保护儿童。除此之外,还可以告知父母其孩子的安全,并立即收到有关威胁的警报。这将需要实施无线技术,例如 Wi-Fi 和传感器。因此,学校需要制定专门用于提供教室安全性的预算。
智能家居实现拍手关灯,也可以让你的家庭助手帮你关灯。同样,物联网设备也可用在屋内来保护儿童。在家里,物联网设备(例如摄像头)为父母在照顾孩子时提供 100% 的可见性。当父母不在家里时,可以使用摄像头和其他传感器检测是否发生了可疑活动。其他设备(例如连接到这些传感器的智能锁)可以锁门和窗,以确保孩子们的安全。
同样,可以引入许多物联网解决方案来确保孩子的安全。
### 有多好就有多坏
物联网设备中的传感器会创建大量数据。数据的安全性是至关重要的一个因素。收集的有关孩子的数据如果落入不法分子手中会存在危险。因此,需要采取预防措施。IoT 设备中泄露的任何数据都可用于确定行为模式。因此,必须对提供不违反用户隐私的安全物联网解决方案投入资金。
IoT 设备通常连接到 Wi-Fi,用于设备之间传输数据。未加密数据的不安全网络会带来某些风险。这样的网络很容易被窃听。黑客可以使用此类网点来入侵系统。他们还可以将恶意软件引入系统,从而使系统变得脆弱、易受攻击。此外,对设备和公共网络(例如学校的网络)的网络攻击可能导致数据泄露和私有数据盗用。 因此,在实施用于保护儿童的物联网解决方案时,保护网络和物联网设备的总体计划必须生效。
物联网设备保护儿童在学校和家里的安全的潜力尚未发现有什么创新。我们需要付出更多努力来保护连接 IoT 设备的网络安全。此外,物联网设备生成的数据可能落入不法分子手中,从而造成更多麻烦。因此,这是物联网安全至关重要的一个领域。
---
via: <https://opensourceforu.com/2019/10/how-to-use-iot-devices-to-keep-children-safe/>
作者:[Andrew Carroll](https://opensourceforu.com/author/andrew-carroll/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,509 | 随着 Debian 10.1 “Buster” 的发布,MX Linux 19 也发布了 | https://itsfoss.com/mx-linux-19/ | 2019-10-28T00:57:10 | [
"Debian"
] | https://linux.cn/article-11509-1.html | 
MX Linux 18 是我在[最佳 Linux 发行版](/article-11411-1.html)中的主要推荐的发行版之一,特别是当你在考虑 Ubuntu 以外的发行版时。
它基于 Debian 9.6 “Stretch”,具有令人难以置信的快速流畅的体验。
现在,作为该发行版的主要升级版本,MX Linux 19 带来了许多重大改进和变更。在这里,我们将看一下主要亮点。
### MX Linux 19 中的新功能
#### Debian 10 “Buster”
这个值得一提,因为 Debian 10 实际上是 MX Linux 18 所基于的 Debian 9.6 “Stretch” 的主要升级。
如果你对 Debian 10 “Buster” 的变化感到好奇,建议你阅读有关 [Debian 10 “Buster” 的新功能](/article-11071-1.html)的文章。
#### Xfce 桌面 4.14
[Xfce 4.14](https://xfce.org/about/news) 正是 Xfce 开发团队提供的最新产品。就个人而言,我不是 Xfce 桌面环境的粉丝,但是当你在 Linux 发行版(尤其是 MX Linux 19)上使用它时,它超快的性能会让你惊叹。
或许你会感兴趣,我们也有一个快速指南来帮助你[自定义 Xfce](https://itsfoss.com/customize-xfce/)。
#### 升级的软件包及最新的 Debian 内核 4.19
除了 [GIMP](https://itsfoss.com/gimp-2-10-release/)、MESA、Firefox 等的更新软件包之外,它还随附有 Debian “Buster” 可用的最新内核 4.19。
#### 升级的 MX 系列应用
如果你以前使用过 MX Linux,则可能会知道它已经预装了有用的 MX 系列应用,可以帮助你快速完成更多工作。
像 MX-installer 和 MX-packageinstaller 这样的应用程序得到了显著改进。
除了这两个以外,所有其他 MX 工具也已不同程度的进行了更新和修复错误、添加了新的翻译(或只是改善了用户体验)。
#### 其它改进
考虑到这是一次重大升级,很明显,底层的更改要多于表面(包括最新的 antiX live 系统更新)。
你可以在他们的[官方公告](https://mxlinux.org/blog/mx-19-patito-feo-released/)中查看更多详细信息。你还可以从开发人员那里观看以下视频,它介绍了 MX Linux 19 中的所有新功能:
### 获取 MX Linux 19
即使是你现在正在使用 MX Linux 18 版本,你也[无法](https://mxlinux.org/migration/)升级到 MX Linux 19。你需要像其他人一样进行全新安装。
你可以从此页面下载 MX Linux 19:
* [下载 MX Linux 19](https://mxlinux.org/download-links/)
### 结语
在 MX Linux 18 上,我在使用 WiFi 适配器时遇到了问题,通过[论坛](https://forum.mxlinux.org/viewtopic.php?t=52201)解决了该问题,但看来 MX Linux 19 仍未解决该问题。因此,如果你在安装 MX Linux 19 之后遇到了相同的问题,你可能想要查看一下我的[论坛帖子](https://forum.mxlinux.org/viewtopic.php?t=52201)。
如果你使用的是 MX Linux 18,那么这绝对是一个令人印象深刻的升级。
你尝试过了吗?你对新的 MX Linux 19 版本有何想法?让我知道你在以下评论中的想法。
---
via: <https://itsfoss.com/mx-linux-19/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | MX Linux 18 has been one of my top recommendations for the [best Linux distributions](https://itsfoss.com/best-linux-distributions/), specially when considering distros other than Ubuntu.
It is based on Debian 9.6 ‘Stretch’ – which was incredibly a fast and smooth experience.
Now, as a major upgrade to that, MX Linux 19 brings a lot of major improvements and changes. Here, we shall take a look at the key highlights.
## New features in MX Linux 19
### Debian 10 ‘Buster’
This deserves a separate mention as Debian 10 is indeed a major upgrade from Debian 9.6 ‘Stretch’ on which MX Linux 18 was based on.
In case you’re curious about what has changed with Debian 10 Buster, we suggest to check out our article on the [new features of Debian 10 Buster](https://itsfoss.com/debian-10-buster/).
### Xfce Desktop 4.14
[Xfce 4.14](https://xfce.org/about/news) happens to be the latest offering from Xfce development team. Personally, I’m not a fan of Xfce desktop environment but it screams fast performance when you get to use it on a Linux distro (especially on MX Linux 19).
Interestingly, we also have a quick guide to help you [customize Xfce](https://itsfoss.com/customize-xfce/) on your system.
### Updated Packages & Latest Debian Kernel 4.19
Along with updated packages for [GIMP](https://itsfoss.com/gimp-2-10-release/), MESA, Firefox, and so on – it also comes baked in with the latest kernel 4.19 available for Debian Buster.
### Updated MX-Apps
If you’ve used MX Linux before, you might be knowing that it comes pre-installed with useful MX-Apps that help you get more things done quickly.
The apps like MX-installer and MX-packageinstaller have significantly improved.
In addition to these two, all other MX-tools have been updated here and there to fix bugs, add new translations (or simply to improve the user experience).
### Other Improvements
Considering it a major upgrade, there’s obviously a lot of under-the-hood changes than highlighted (including the latest antiX live system updates).
You can check out more details on their [official announcement post](https://mxlinux.org/blog/mx-19-patito-feo-released/). You may also watch this video from the developers explaining all the new stuff in MX Linux 19:
## Getting MX Linux 19
Even if you are using MX Linux 18 versions right now, you [cannot upgrade](https://mxlinux.org/migration/) to MX Linux 19. You need to go for a clean install like everyone else.
You can download MX Linux 19 from this page:
**Wrapping Up**
With MX Linux 18, I had a problem using my WiFi adapter due to a driver issue which I resolved through the [forum](https://forum.mxlinux.org/viewtopic.php?t=52201), it seems that it still hasn’t been fixed with MX Linux 19. So, you might want to take a look at my [forum post](https://forum.mxlinux.org/viewtopic.php?t=52201) if you face the same issue after installing MX Linux 19.
If you’ve been using MX Linux 18, this definitely seems to be an impressive upgrade.
Have you tried it yet? What are your thoughts on the new MX Linux 19 release? Let me know what you think in the comments below. |
11,510 | 构建一个即时消息应用(二):OAuth | https://nicolasparada.netlify.com/posts/go-messenger-oauth/ | 2019-10-28T07:03:29 | [
"即时消息"
] | https://linux.cn/article-11510-1.html | 
[上一篇:模式](/article-11396-1.html)。
在这篇帖子中,我们将会通过为应用添加社交登录功能进入后端开发。
社交登录的工作方式十分简单:用户点击链接,然后重定向到 GitHub 授权页面。当用户授予我们对他的个人信息的访问权限之后,就会重定向回登录页面。下一次尝试登录时,系统将不会再次请求授权,也就是说,我们的应用已经记住了这个用户。这使得整个登录流程看起来就和你用鼠标单击一样快。
如果进一步考虑其内部实现的话,过程就会变得复杂起来。首先,我们需要注册一个新的 [GitHub OAuth 应用](https://github.com/settings/applications/new)。
这一步中,比较重要的是回调 URL。我们将它设置为 `http://localhost:3000/api/oauth/github/callback`。这是因为,在开发过程中,我们总是在本地主机上工作。一旦你要将应用交付生产,请使用正确的回调 URL 注册一个新的应用。
注册以后,你将会收到“客户端 id”和“安全密钥”。安全起见,请不要与任何人分享他们 ?
顺便让我们开始写一些代码吧。现在,创建一个 `main.go` 文件:
```
package main
import (
"database/sql"
"fmt"
"log"
"net/http"
"net/url"
"os"
"strconv"
"github.com/gorilla/securecookie"
"github.com/joho/godotenv"
"github.com/knq/jwt"
_ "github.com/lib/pq"
"github.com/matryer/way"
"golang.org/x/oauth2"
"golang.org/x/oauth2/github"
)
var origin *url.URL
var db *sql.DB
var githubOAuthConfig *oauth2.Config
var cookieSigner *securecookie.SecureCookie
var jwtSigner jwt.Signer
func main() {
godotenv.Load()
port := intEnv("PORT", 3000)
originString := env("ORIGIN", fmt.Sprintf("http://localhost:%d/", port))
databaseURL := env("DATABASE_URL", "postgresql://[email protected]:26257/messenger?sslmode=disable")
githubClientID := os.Getenv("GITHUB_CLIENT_ID")
githubClientSecret := os.Getenv("GITHUB_CLIENT_SECRET")
hashKey := env("HASH_KEY", "secret")
jwtKey := env("JWT_KEY", "secret")
var err error
if origin, err = url.Parse(originString); err != nil || !origin.IsAbs() {
log.Fatal("invalid origin")
return
}
if i, err := strconv.Atoi(origin.Port()); err == nil {
port = i
}
if githubClientID == "" || githubClientSecret == "" {
log.Fatalf("remember to set both $GITHUB_CLIENT_ID and $GITHUB_CLIENT_SECRET")
return
}
if db, err = sql.Open("postgres", databaseURL); err != nil {
log.Fatalf("could not open database connection: %v\n", err)
return
}
defer db.Close()
if err = db.Ping(); err != nil {
log.Fatalf("could not ping to db: %v\n", err)
return
}
githubRedirectURL := *origin
githubRedirectURL.Path = "/api/oauth/github/callback"
githubOAuthConfig = &oauth2.Config{
ClientID: githubClientID,
ClientSecret: githubClientSecret,
Endpoint: github.Endpoint,
RedirectURL: githubRedirectURL.String(),
Scopes: []string{"read:user"},
}
cookieSigner = securecookie.New([]byte(hashKey), nil).MaxAge(0)
jwtSigner, err = jwt.HS256.New([]byte(jwtKey))
if err != nil {
log.Fatalf("could not create JWT signer: %v\n", err)
return
}
router := way.NewRouter()
router.HandleFunc("GET", "/api/oauth/github", githubOAuthStart)
router.HandleFunc("GET", "/api/oauth/github/callback", githubOAuthCallback)
router.HandleFunc("GET", "/api/auth_user", guard(getAuthUser))
log.Printf("accepting connections on port %d\n", port)
log.Printf("starting server at %s\n", origin.String())
addr := fmt.Sprintf(":%d", port)
if err = http.ListenAndServe(addr, router); err != nil {
log.Fatalf("could not start server: %v\n", err)
}
}
func env(key, fallbackValue string) string {
v, ok := os.LookupEnv(key)
if !ok {
return fallbackValue
}
return v
}
func intEnv(key string, fallbackValue int) int {
v, ok := os.LookupEnv(key)
if !ok {
return fallbackValue
}
i, err := strconv.Atoi(v)
if err != nil {
return fallbackValue
}
return i
}
```
安装依赖项:
```
go get -u github.com/gorilla/securecookie
go get -u github.com/joho/godotenv
go get -u github.com/knq/jwt
go get -u github.com/lib/pq
ge get -u github.com/matoous/go-nanoid
go get -u github.com/matryer/way
go get -u golang.org/x/oauth2
```
我们将会使用 `.env` 文件来保存密钥和其他配置。请创建这个文件,并保证里面至少包含以下内容:
```
GITHUB_CLIENT_ID=your_github_client_id
GITHUB_CLIENT_SECRET=your_github_client_secret
```
我们还要用到的其他环境变量有:
* `PORT`:服务器运行的端口,默认值是 `3000`。
* `ORIGIN`:你的域名,默认值是 `http://localhost:3000/`。我们也可以在这里指定端口。
* `DATABASE_URL`:Cockroach 数据库的地址。默认值是 `postgresql://[email protected]:26257/messenger?sslmode=disable`。
* `HASH_KEY`:用于为 cookie 签名的密钥。没错,我们会使用已签名的 cookie 来确保安全。
* `JWT_KEY`:用于签署 JSON <ruby> 网络令牌 <rt> Web Token </rt></ruby>的密钥。
因为代码中已经设定了默认值,所以你也不用把它们写到 `.env` 文件中。
在读取配置并连接到数据库之后,我们会创建一个 OAuth 配置。我们会使用 `ORIGIN` 信息来构建回调 URL(就和我们在 GitHub 页面上注册的一样)。我们的数据范围设置为 “read:user”。这会允许我们读取公开的用户信息,这里我们只需要他的用户名和头像就够了。然后我们会初始化 cookie 和 JWT 签名器。定义一些端点并启动服务器。
在实现 HTTP 处理程序之前,让我们编写一些函数来发送 HTTP 响应。
```
func respond(w http.ResponseWriter, v interface{}, statusCode int) {
b, err := json.Marshal(v)
if err != nil {
respondError(w, fmt.Errorf("could not marshal response: %v", err))
return
}
w.Header().Set("Content-Type", "application/json; charset=utf-8")
w.WriteHeader(statusCode)
w.Write(b)
}
func respondError(w http.ResponseWriter, err error) {
log.Println(err)
http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
}
```
第一个函数用来发送 JSON,而第二个将错误记录到控制台并返回一个 `500 Internal Server Error` 错误信息。
### OAuth 开始
所以,用户点击写着 “Access with GitHub” 的链接。该链接指向 `/api/oauth/github`,这将会把用户重定向到 github。
```
func githubOAuthStart(w http.ResponseWriter, r *http.Request) {
state, err := gonanoid.Nanoid()
if err != nil {
respondError(w, fmt.Errorf("could not generte state: %v", err))
return
}
stateCookieValue, err := cookieSigner.Encode("state", state)
if err != nil {
respondError(w, fmt.Errorf("could not encode state cookie: %v", err))
return
}
http.SetCookie(w, &http.Cookie{
Name: "state",
Value: stateCookieValue,
Path: "/api/oauth/github",
HttpOnly: true,
})
http.Redirect(w, r, githubOAuthConfig.AuthCodeURL(state), http.StatusTemporaryRedirect)
}
```
OAuth2 使用一种机制来防止 CSRF 攻击,因此它需要一个“状态”(`state`)。我们使用 `Nanoid()` 来创建一个随机字符串,并用这个字符串作为状态。我们也把它保存为一个 cookie。
### OAuth 回调
一旦用户授权我们访问他的个人信息,他将会被重定向到这个端点。这个 URL 的查询字符串上将会包含状态(`state`)和授权码(`code`): `/api/oauth/github/callback?state=&code=`。
```
const jwtLifetime = time.Hour * 24 * 14
type GithubUser struct {
ID int `json:"id"`
Login string `json:"login"`
AvatarURL *string `json:"avatar_url,omitempty"`
}
type User struct {
ID string `json:"id"`
Username string `json:"username"`
AvatarURL *string `json:"avatarUrl"`
}
func githubOAuthCallback(w http.ResponseWriter, r *http.Request) {
stateCookie, err := r.Cookie("state")
if err != nil {
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
return
}
http.SetCookie(w, &http.Cookie{
Name: "state",
Value: "",
MaxAge: -1,
HttpOnly: true,
})
var state string
if err = cookieSigner.Decode("state", stateCookie.Value, &state); err != nil {
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
return
}
q := r.URL.Query()
if state != q.Get("state") {
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
return
}
ctx := r.Context()
t, err := githubOAuthConfig.Exchange(ctx, q.Get("code"))
if err != nil {
respondError(w, fmt.Errorf("could not fetch github token: %v", err))
return
}
client := githubOAuthConfig.Client(ctx, t)
resp, err := client.Get("https://api.github.com/user")
if err != nil {
respondError(w, fmt.Errorf("could not fetch github user: %v", err))
return
}
var githubUser GithubUser
if err = json.NewDecoder(resp.Body).Decode(&githubUser); err != nil {
respondError(w, fmt.Errorf("could not decode github user: %v", err))
return
}
defer resp.Body.Close()
tx, err := db.BeginTx(ctx, nil)
if err != nil {
respondError(w, fmt.Errorf("could not begin tx: %v", err))
return
}
var user User
if err = tx.QueryRowContext(ctx, `
SELECT id, username, avatar_url FROM users WHERE github_id = $1
`, githubUser.ID).Scan(&user.ID, &user.Username, &user.AvatarURL); err == sql.ErrNoRows {
if err = tx.QueryRowContext(ctx, `
INSERT INTO users (username, avatar_url, github_id) VALUES ($1, $2, $3)
RETURNING id
`, githubUser.Login, githubUser.AvatarURL, githubUser.ID).Scan(&user.ID); err != nil {
respondError(w, fmt.Errorf("could not insert user: %v", err))
return
}
user.Username = githubUser.Login
user.AvatarURL = githubUser.AvatarURL
} else if err != nil {
respondError(w, fmt.Errorf("could not query user by github ID: %v", err))
return
}
if err = tx.Commit(); err != nil {
respondError(w, fmt.Errorf("could not commit to finish github oauth: %v", err))
return
}
exp := time.Now().Add(jwtLifetime)
token, err := jwtSigner.Encode(jwt.Claims{
Subject: user.ID,
Expiration: json.Number(strconv.FormatInt(exp.Unix(), 10)),
})
if err != nil {
respondError(w, fmt.Errorf("could not create token: %v", err))
return
}
expiresAt, _ := exp.MarshalText()
data := make(url.Values)
data.Set("token", string(token))
data.Set("expires_at", string(expiresAt))
http.Redirect(w, r, "/callback?"+data.Encode(), http.StatusTemporaryRedirect)
}
```
首先,我们会尝试使用之前保存的状态对 cookie 进行解码。并将其与查询字符串中的状态进行比较。如果它们不匹配,我们会返回一个 `418 I'm teapot`(未知来源)错误。
接着,我们使用授权码生成一个令牌。这个令牌被用于创建 HTTP 客户端来向 GitHub API 发出请求。所以最终我们会向 `https://api.github.com/user` 发送一个 GET 请求。这个端点将会以 JSON 格式向我们提供当前经过身份验证的用户信息。我们将会解码这些内容,一并获取用户的 ID、登录名(用户名)和头像 URL。
然后我们将会尝试在数据库上找到具有该 GitHub ID 的用户。如果没有找到,就使用该数据创建一个新的。
之后,对于新创建的用户,我们会发出一个将用户 ID 作为主题(`Subject`)的 JSON 网络令牌,并使用该令牌重定向到前端,查询字符串中一并包含该令牌的到期日(`Expiration`)。
这一 Web 应用也会被用在其他帖子,但是重定向的链接会是 `/callback?token=&expires_at=`。在那里,我们将会利用 JavaScript 从 URL 中获取令牌和到期日,并通过 `Authorization` 标头中的令牌以 `Bearer token_here` 的形式对 `/api/auth_user` 进行 GET 请求,来获取已认证的身份用户并将其保存到 localStorage。
### Guard 中间件
为了获取当前已经过身份验证的用户,我们设计了 Guard 中间件。这是因为在接下来的文章中,我们会有很多需要进行身份认证的端点,而中间件将会允许我们共享这一功能。
```
type ContextKey struct {
Name string
}
var keyAuthUserID = ContextKey{"auth_user_id"}
func guard(handler http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
var token string
if a := r.Header.Get("Authorization"); strings.HasPrefix(a, "Bearer ") {
token = a[7:]
} else if t := r.URL.Query().Get("token"); t != "" {
token = t
} else {
http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
return
}
var claims jwt.Claims
if err := jwtSigner.Decode([]byte(token), &claims); err != nil {
http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
return
}
ctx := r.Context()
ctx = context.WithValue(ctx, keyAuthUserID, claims.Subject)
handler(w, r.WithContext(ctx))
}
}
```
首先,我们尝试从 `Authorization` 标头或者是 URL 查询字符串中的 `token` 字段中读取令牌。如果没有找到,我们需要返回 `401 Unauthorized`(未授权)错误。然后我们将会对令牌中的申明进行解码,并使用该主题作为当前已经过身份验证的用户 ID。
现在,我们可以用这一中间件来封装任何需要授权的 `http.handlerFunc`,并且在处理函数的上下文中保有已经过身份验证的用户 ID。
```
var guarded = guard(func(w http.ResponseWriter, r *http.Request) {
authUserID := r.Context().Value(keyAuthUserID).(string)
})
```
### 获取认证用户
```
func getAuthUser(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
var user User
if err := db.QueryRowContext(ctx, `
SELECT username, avatar_url FROM users WHERE id = $1
`, authUserID).Scan(&user.Username, &user.AvatarURL); err == sql.ErrNoRows {
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
return
} else if err != nil {
respondError(w, fmt.Errorf("could not query auth user: %v", err))
return
}
user.ID = authUserID
respond(w, user, http.StatusOK)
}
```
我们使用 Guard 中间件来获取当前经过身份认证的用户 ID 并查询数据库。
这一部分涵盖了后端的 OAuth 流程。在下一篇帖子中,我们将会看到如何开始与其他用户的对话。
* [源代码](https://github.com/nicolasparada/go-messenger-demo)
---
via: <https://nicolasparada.netlify.com/posts/go-messenger-oauth/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[PsiACE](https://github.com/PsiACE) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,513 | 过渡到 nftables | https://opensourceforu.com/2019/10/transition-to-nftables/ | 2019-10-29T08:58:42 | [
"nftables"
] | https://linux.cn/article-11513-1.html | 
>
> 开源世界中的每个主要发行版都在演进,逐渐将 nftables 作为了默认防火墙。换言之,古老的 iptables 现在已经消亡。本文是有关如何构建 nftables 的教程。
>
>
>
当前,有一个与 nftables 兼容的 iptables-nft 后端,但是很快,即使是它也不再提供了。另外,正如 Red Hat 开发人员所指出的那样,有时它可能会错误地转换规则。我们需要知道如何构建自己的 nftables,而不是依赖于 iptables 到 nftables 的转换器。
在 nftables 中,所有地址族都遵循一个规则。与 iptables 不同,nftables 在用户空间中运行,iptables 中的每个模块都运行在内核(空间)中。它很少需要更新内核,并带有一些新功能,例如映射、地址族和字典。
### 地址族
地址族确定要处理的数据包的类型。在 nftables 中有六个地址族,它们是:
* ip
* ipv6
* inet
* arp
* bridge
* netdev
在 nftables 中,ipv4 和 ipv6 协议可以被合并为一个称为 inet 的单一地址族。因此,我们不需要指定两个规则:一个用于 ipv4,另一个用于 ipv6。如果未指定地址族,它将默认为 ip 协议,即 ipv4。我们感兴趣的领域是 inet 地址族,因为大多数家庭用户将使用 ipv4 或 ipv6 协议。
### nftables
典型的 nftables 规则包含三个部分:表、链和规则。
表是链和规则的容器。它们由其地址族和名称来标识。链包含 inet/arp/bridge/netdev 等协议所需的规则,并具有三种类型:过滤器、NAT 和路由。nftables 规则可以从脚本加载,也可以在终端键入,然后另存为规则集。
对于家庭用户,默认链为过滤器。inet 系列包含以下钩子:
* Input
* Output
* Forward
* Pre-routing
* Post-routing
### 使用脚本还是不用?
最大的问题之一是我们是否可以使用防火墙脚本。答案是:这是你自己的选择。这里有一些建议:如果防火墙中有数百条规则,那么最好使用脚本,但是如果你是典型的家庭用户,则可以在终端中键入命令,然后(保存并在重启时)加载规则集。每种选择都有其自身的优缺点。在本文中,我们将在终端中键入它们以构建防火墙。
nftables 使用一个名为 `nft` 的程序来添加、创建、列出、删除和加载规则。确保使用以下命令将 nftables 与 conntrackd 和 netfilter-persistent 软件包一起安装,并删除 iptables:
```
apt-get install nftables conntrackd netfilter-persistent
apt-get purge iptables
```
`nft` 需要以 root 身份运行或使用 `sudo` 运行。使用以下命令分别列出、刷新、删除规则集和加载脚本。
```
nft list ruleset
nft flush ruleset
nft delete table inet filter
/usr/sbin/nft -f /etc/nftables.conf
```
### 输入策略
就像 iptables 一样,防火墙将包含三部分:输入(`input`)、转发(`forward`)和输出(`output`)。在终端中,为输入(`input`)策略键入以下命令。在开始之前,请确保已刷新规则集。我们的默认策略将会删除所有内容。我们将在防火墙中使用 inet 地址族。将以下规则以 root 身份添加或使用 `sudo` 运行:
```
nft add table inet filter
nft add chain inet filter input { type filter hook input priority 0 \; counter \; policy drop \; }
```
你会注意到有一个名为 `priority 0` 的东西。这意味着赋予该规则更高的优先级。挂钩通常赋予负整数,这意味着更高的优先级。每个挂钩都有自己的优先级,过滤器链的优先级为 0。你可以检查 nftables Wiki 页面以查看每个挂钩的优先级。
要了解你计算机中的网络接口,请运行以下命令:
```
ip link show
```
它将显示已安装的网络接口,一个是本地主机、另一个是以太网端口或无线端口。以太网端口的名称如下所示:`enpXsY`,其中 `X` 和 `Y` 是数字,无线端口也是如此。我们必须允许本地主机的流量,并且仅允许从互联网建立的传入连接。
nftables 具有一项称为裁决语句的功能,用于解析规则。裁决语句为 `accept`、`drop`、`queue`、`jump`、`goto`、`continue` 和 `return`。由于这是一个很简单的防火墙,因此我们将使用 `accept` 或 `drop` 处理数据包。
```
nft add rule inet filter input iifname lo accept
nft add rule inet filter input iifname enpXsY ct state new, established, related accept
```
接下来,我们必须添加规则以保护我们免受隐秘扫描。并非所有的隐秘扫描都是恶意的,但大多数都是。我们必须保护网络免受此类扫描。第一组规则列出了要测试的 TCP 标志。在这些标志中,第二组列出了要与第一组匹配的标志。
```
nft add rule inet filter input iifname enpXsY tcp flags \& \(syn\|fin\) == \(syn\|fin\) drop
nft add rule inet filter input iifname enpXsY tcp flags \& \(syn\|rst\) == \(syn\|rst\) drop
nft add rule inet filter input iifname enpXsY tcp flags \& \(fin\|rst\) == \(fin\|rst\) drop
nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|fin\) == fin drop
nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|psh\) == psh drop
nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|urg\) == urg drop
```
记住,我们在终端中键入这些命令。因此,我们必须在一些特殊字符之前添加一个反斜杠,以确保终端能够正确解释该斜杠。如果你使用的是脚本,则不需要这样做。
### 关于 ICMP 的警告
互联网控制消息协议(ICMP)是一种诊断工具,因此不应完全丢弃该流量。完全阻止 ICMP 的任何尝试都是不明智的,因为它还会导致停止向我们提供错误消息。仅启用最重要的控制消息,例如回声请求、回声应答、目的地不可达和超时等消息,并拒绝其余消息。回声请求和回声应答是 `ping` 的一部分。在输入策略中,我们仅允许回声应答、而在输出策略中,我们仅允许回声请求。
```
nft add rule inet filter input iifname enpXsY icmp type { echo-reply, destination-unreachable, time-exceeded } limit rate 1/second accept
nft add rule inet filter input iifname enpXsY ip protocol icmp drop
```
最后,我们记录并丢弃所有无效数据包。
```
nft add rule inet filter input iifname enpXsY ct state invalid log flags all level info prefix \”Invalid-Input: \”
nft add rule inet filter input iifname enpXsY ct state invalid drop
```
### 转发和输出策略
在转发和输出策略中,默认情况下我们将丢弃数据包,仅接受已建立连接的数据包。
```
nft add chain inet filter forward { type filter hook forward priority 0 \; counter \; policy drop \; }
nft add rule inet filter forward ct state established, related accept
nft add rule inet filter forward ct state invalid drop
nft add chain inet filter output { type filter hook output priority 0 \; counter \; policy drop \; }
```
典型的桌面用户只需要端口 80 和 443 即可访问互联网。最后,允许可接受的 ICMP 协议并在记录无效数据包时丢弃它们。
```
nft add rule inet filter output oifname enpXsY tcp dport { 80, 443 } ct state established accept
nft add rule inet filter output oifname enpXsY icmp type { echo-request, destination-unreachable, time-exceeded } limit rate 1/second accept
nft add rule inet filter output oifname enpXsY ip protocol icmp drop
nft add rule inet filter output oifname enpXsY ct state invalid log flags all level info prefix \”Invalid-Output: \”
nft add rule inet filter output oifname enpXsY ct state invalid drop
```
现在我们必须保存我们的规则集,否则重新启动时它将丢失。为此,请运行以下命令:
```
sudo nft list ruleset. > /etc/nftables.conf
```
我们须在引导时加载 nftables,以下将在 systemd 中启用 nftables 服务:
```
sudo systemctl enable nftables
```
接下来,编辑 nftables 单元文件以删除 `Execstop` 选项,以避免在每次引导时刷新规则集。该文件通常位于 `/etc/systemd/system/sysinit.target.wants/nftables.service`。现在重新启动nftables:
```
sudo systemctl restart nftables
```
### 在 rsyslog 中记录日志
当你记录丢弃的数据包时,它们直接进入 syslog,这使得读取该日志文件非常困难。最好将防火墙日志重定向到单独的文件。在 `/var/log` 目录中创建一个名为 `nftables` 的目录,并在其中创建两个名为 `input.log` 和 `output.log` 的文件,分别存储输入和输出日志。确保系统中已安装 rsyslog。现在转到 `/etc/rsyslog.d` 并创建一个名为 `nftables.conf` 的文件,其内容如下:
```
:msg,regex,”Invalid-Input: “ -/var/log/nftables/Input.log
:msg,regex,”Invalid-Output: “ -/var/log/nftables/Output.log & stop
```
现在,我们必须确保日志是可管理的。为此,使用以下代码在 `/etc/logrotate.d` 中创建另一个名为 `nftables` 的文件:
```
/var/log/nftables/* { rotate 5 daily maxsize 50M missingok notifempty delaycompress compress postrotate invoke-rc.d rsyslog rotate > /dev/null endscript }
```
重新启动 nftables。现在,你可以检查你的规则集。如果你觉得在终端中键入每个命令很麻烦,则可以使用脚本来加载 nftables 防火墙。我希望本文对保护你的系统有用。
---
via: <https://opensourceforu.com/2019/10/transition-to-nftables/>
作者:[Vijay Marcel D](https://opensourceforu.com/author/vijay-marcel/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,515 | 在 Fedora 上使用 SSH 端口转发 | https://fedoramagazine.org/using-ssh-port-forwarding-on-fedora/ | 2019-10-29T12:38:42 | [
"ssh"
] | https://linux.cn/article-11515-1.html | 
你可能已经熟悉使用 [ssh 命令](https://en.wikipedia.org/wiki/Secure_Shell)访问远程系统。`ssh` 命令背后所使用的协议允许终端的输入和输出流经[安全通道](https://fedoramagazine.org/open-source-ssh-clients/)。但是你知道也可以使用 `ssh` 来安全地发送和接收其他数据吗?一种方法是使用“<ruby> 端口转发 <rt> port forwarding </rt></ruby>”,它允许你在进行 `ssh` 会话时安全地连接网络端口。本文向你展示了它是如何工作的。
### 关于端口
标准 Linux 系统已分配了一组网络端口,范围是 0 - 65535。系统会保留 0 - 1023 的端口以供系统使用。在许多系统中,你不能选择使用这些低端口号。通常有几个端口用于运行特定的服务。你可以在系统的 `/etc/services` 文件中找到这些定义。
你可以认为网络端口是类似的物理端口或可以连接到电缆的插孔。端口可以连接到系统上的某种服务,类似物理插孔后面的接线。一个例子是 Apache Web 服务器(也称为 `httpd`)。对于 HTTP 非安全连接,Web 服务器通常要求在主机系统上使用端口 80,对于 HTTPS 安全连接通常要求使用 443。
当你连接到远程系统(例如,使用 Web 浏览器)时,你是将浏览器“连接”到你的主机上的端口。这通常是一个随机的高端口号,例如 54001。你的主机上的端口连接到远程主机上的端口(例如 443)来访问其安全的 Web 服务器。
那么,当你有这么多可用端口时,为什么还要使用端口转发呢?这是 Web 开发人员生活中的几种常见情况。
### 本地端口转发
想象一下,你正在名为 `remote.example.com` 的远程系统上进行 Web 开发。通常,你是通过 `ssh` 进入此系统的,但是它位于防火墙后面,而且该防火墙很少允许其他类型的访问,并且会阻塞大多数其他端口。要尝试你的网络应用,能够使用浏览器访问远程系统会很有帮助。但是,由于使用了讨厌的防火墙,你无法通过在浏览器中输入 URL 的常规方法来访问它。
本地转发使你可以通过 `ssh` 连接来建立可通过远程系统访问的端口。该端口在系统上显示为本地端口(因而称为“本地转发”)。
假设你的网络应用在 `remote.example.com` 的 8000 端口上运行。要将那个系统的 8000 端口本地转发到你系统上的 8000 端口,请在开始会话时将 `-L` 选项与 `ssh` 结合使用:
```
$ ssh -L 8000:localhost:8000 remote.example.com
```
等等,为什么我们使用 `localhost` 作为转发目标?这是因为从 `remote.example.com` 的角度来看,你是在要求主机使用其自己的端口 8000。(回想一下,任何主机通常可以通过网络连接 `localhost` 而连接到自身。)现在那个端口连接到你系统的 8000 端口了。`ssh` 会话准备就绪后,将其保持打开状态,然后可以在浏览器中键入 `http://localhost:8000` 来查看你的 Web 应用。现在,系统之间的流量可以通过 `ssh` 隧道安全地传输!
如果你有敏锐的眼睛,你可能已经注意到了一些东西。如果我们要 `remote.example.com` 转发到与 `localhost` 不同的主机名怎么办?如果它可以访问该网络上另一个系统上的端口,那么通常可以同样轻松地转发该端口。例如,假设你想访问也在该远程网络中的 `db.example.com` 的 MariaDB 或 MySQL 服务。该服务通常在端口 3306 上运行。因此,即使你无法 `ssh` 到实际的 `db.example.com` 主机,你也可以使用此命令将其转发:
```
$ ssh -L 3306:db.example.com:3306 remote.example.com
```
现在,你可以在 `localhost` 上运行 MariaDB 命令,而实际上是在使用 `db.example.com` 主机。
### 远程端口转发
远程转发让你可以进行相反操作。想象一下,你正在为办公室的朋友设计一个 Web 应用,并想向他们展示你的工作。不过,不幸的是,你在咖啡店里工作,并且由于网络设置,他们无法通过网络连接访问你的笔记本电脑。但是,你同时使用着办公室的 `remote.example.com` 系统,并且仍然可在这里登录。你的 Web 应用似乎在本地 5000 端口上运行良好。
远程端口转发使你可以通过 `ssh` 连接从本地系统建立端口的隧道,并使该端口在远程系统上可用。在开始 `ssh` 会话时,只需使用 `-R` 选项:
```
$ ssh -R 6000:localhost:5000 remote.example.com
```
现在,当在公司防火墙内的朋友打开浏览器时,他们可以进入 `http://remote.example.com:6000` 查看你的工作。就像在本地端口转发示例中一样,通信通过 `ssh` 会话安全地进行。
默认情况下,`sshd` 守护进程运行在设置的主机上,因此**只有**该主机可以连接它的远程转发端口。假设你的朋友希望能够让其他 `example.com` 公司主机上的人看到你的工作,而他们不在 `remote.example.com` 上。你需要让 `remote.example.com` 主机的所有者将以下选项**之一**添加到 `/etc/ssh/sshd_config` 中:
```
GatewayPorts yes # 或
GatewayPorts clientspecified
```
第一个选项意味着 `remote.example.com` 上的所有网络接口都可以使用远程转发的端口。第二个意味着建立隧道的客户端可以选择地址。默认情况下,此选项设置为 `no`。
使用此选项,你作为 `ssh` 客户端仍必须指定可以共享你这边转发端口的接口。通过在本地端口之前添加网络地址范围来进行此操作。有几种方法可以做到,包括:
```
$ ssh -R *:6000:localhost:5000 # 所有网络
$ ssh -R 0.0.0.0:6000:localhost:5000 # 所有网络
$ ssh -R 192.168.1.15:6000:localhost:5000 # 单个网络
$ ssh -R remote.example.com:6000:localhost:5000 # 单个网络
```
### 其他注意事项
请注意,本地和远程系统上的端口号不必相同。实际上,有时你甚至可能无法使用相同的端口。例如,普通用户可能不会在默认设置中转发到系统端口。
另外,可以限制主机上的转发。如果你需要在联网主机上更严格的安全性,那么这你来说可能很重要。 `sshd` 守护程进程的 `PermitOpen` 选项控制是否以及哪些端口可用于 TCP 转发。默认设置为 `any`,这让上面的所有示例都能正常工作。要禁止任何端口转发,请选择 `none`,或仅允许的特定的“主机:端口”。有关更多信息,请在手册页中搜索 `PermitOpen` 来配置 `sshd` 守护进程:
```
$ man sshd_config
```
最后,请记住,只有在 `ssh` 会话处于打开状态时才会端口转发。如果需要长时间保持转发活动,请尝试使用 `-N` 选项在后台运行会话。确保控制台已锁定,以防止在你离开控制台时其被篡夺。
---
via: <https://fedoramagazine.org/using-ssh-port-forwarding-on-fedora/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You may already be familiar with using the [ssh](https://en.wikipedia.org/wiki/Secure_Shell)[ command](https://en.wikipedia.org/wiki/Secure_Shell) to access a remote system. The protocol behind *ssh* allows terminal input and output to flow through a [secure channel](https://fedoramagazine.org/open-source-ssh-clients/). But did you know that you can also use *ssh* to send and receive other data securely as well? One way is to use *port forwarding*, which allows you to connect network ports securely while conducting your *ssh* session. This article shows you how it works.
## About ports
A standard Linux system has a set of network ports already assigned, from 0-65535. Your system reserves ports up to 1023 for system use. In many systems you can’t elect to use one of these low-numbered ports. Quite a few ports are commonly expected to run specific services. You can find these defined in your system’s */etc/services* file.
You can think of a network port like a physical port or jack to which you can connect a cable. That port may connect to some sort of service on the system, like wiring behind that physical jack. An example is the Apache web server (also known as *httpd*). The web server usually claims port 80 on the host system for HTTP non-secure connections, and 443 for HTTPS secure connections.
When you connect to a remote system, such as with a web browser, you are also “wiring” your browser to a port on your host. This is usually a random high port number, such as 54001. The port on your host connects to the port on the remote host, such as 443 to reach its secure web server.
So why use port forwarding when you have so many ports available? Here are a couple common cases in the life of a web developer.
## Local port forwarding
Imagine that you are doing web development on a remote system called *remote.example.com*. You usually reach this system via *ssh* but it’s behind a firewall that allows very little additional access, and blocks most other ports. To try out your web app, it’s helpful to be able to use your web browser to point to the remote system. But you can’t reach it via the normal method of typing the URL in your browser, thanks to that pesky firewall.
Local forwarding allows you to tunnel a port available via the remote system through your *ssh* connection. The port appears as a local port on your system (thus “local forwarding.”)
Let’s say your web app is running on port 8000 on the *remote.example.com* box. To locally forward that system’s port 8000 to your system’s port 8000, use the *-L* option with *ssh* when you start your session:
$ ssh -L 8000:localhost:8000 remote.example.com
Wait, why did we use *localhost* as the target for forwarding? It’s because from the perspective of *remote.example.com*, you’re asking the host to use its own port 8000. (Recall that any host usually can refer to itself as *localhost* to connect to itself via a network connection.) That port now connects to your system’s port 8000. Once the *ssh* session is ready, keep it open, and you can type *http://localhost:8000* in your browser to see your web app. The traffic between systems now travels securely over an *ssh* tunnel!
If you have a sharp eye, you may have noticed something. What if we used a different hostname than *localhost* for the *remote.example.com* to forward? If it can reach a port on another system on its network, it usually can forward that port just as easily. For example, say you wanted to reach a MariaDB or MySQL service on the *db.example.com* box also on the remote network. This service typically runs on port 3306. So you could forward it with this command, even if you can’t *ssh* to the actual *db.example.com* host:
$ ssh -L 3306:db.example.com:3306 remote.example.com
Now you can run MariaDB commands against your *localhost* and you’re actually using the *db.example.com* box.
## Remote port forwarding
Remote forwarding lets you do things the opposite way. Imagine you’re designing a web app for a friend at the office, and want to show them your work. Unfortunately, though, you’re working in a coffee shop, and because of the network setup, they can’t reach your laptop via a network connection. However, you both use the *remote.example.com* system at the office and you can still log in there. Your web app seems to be running well on port 5000 locally.
Remote port forwarding lets you tunnel a port from your local system through your *ssh* connection, and make it available on the remote system. Just use the *-R* option when you start your *ssh* session:
$ ssh -R 6000:localhost:5000 remote.example.com
Now when your friend inside the corporate firewall runs their browser, they can point it at *http://remote.example.com:6000* and see your work. And as in the local port forwarding example, the communications travel securely over your *ssh* session.
By default the *sshd* daemon running on a host is set so that **only** that host can connect to its remote forwarded ports. Let’s say your friend wanted to be able to let people on other *example.com* corporate hosts see your work, and they weren’t on *remote.example.com* itself. You’d need the owner of the *remote.example.com* host to add **one** of these options to */etc/ssh/sshd_config* on that box:
GatewayPorts yes # OR GatewayPorts clientspecified
The first option means remote forwarded ports are available on all the network interfaces on *remote.example.com*. The second means that the client who sets up the tunnel gets to choose the address. This option is set to **no** by default.
With this option, you as the *ssh* client must still specify the interfaces on which the forwarded port on your side can be shared. Do this by adding a network specification before the local port. There are several ways to do this, including the following:
$ ssh -R *:6000:localhost:5000 # all networks $ ssh -R 0.0.0.0:6000:localhost:5000 # all networks $ ssh -R 192.168.1.15:6000:localhost:5000 # single network $ ssh -R remote.example.com:6000:localhost:5000 # single network
## Other notes
Notice that the port numbers need not be the same on local and remote systems. In fact, at times you may not even be able to use the same port. For instance, normal users may not to forward onto a system port in a default setup.
In addition, it’s possible to restrict forwarding on a host. This might be important to you if you need tighter security on a network-connected host. The *PermitOpen* option for the *sshd* daemon controls whether, and which, ports are available for TCP forwarding. The default setting is **any**, which allows all the examples above to work. To disallow any port fowarding, choose **none**, or choose only a specific **host:port** setting to permit. For more information, search for *PermitOpen* in the manual page for *sshd* daemon configuration:
$ man sshd_config
Finally, remember port forwarding only happens as long as the controlling *ssh* session is open. If you need to keep the forwarding active for a long period, try running the session in the background using the *-N* option. Make sure your console is locked to prevent tampering while you’re away from it.
## Spike
Thank you for this nice explanation of a Port:
“You can think of a network port like a physical port or jack to which you can connect a cable. That port may connect to some sort of service on the system, like wiring behind that physical jack. “
## 445
secure connection yes
but not secure dns when starting connections
show better how making many hops
for example ssh -> A -> B -> C host
and send -Y X-windows
## Paul W. Frields
It’s hard to understand what you’re asking here, but you are correct that DNS queries aren’t secured through this connection, as they typically go out a random port to port 53 on another server. See our previous article on sshuttle, though.
## Radosław
I think this article could be extended by adding information on the -D parameter. That is hugely useful – allows creating dynamic SOCKS5-based tunnels, depending on where client connects. So all the traffic from a client side application (e.g. Firefox) is forwarded through the SSH server, and queries to destinations are proxied on-demand as necessary (including DNS traffic). |
11,516 | 2019 年最可怕的黑客事件与安全漏洞(上) | https://www.zdnet.com/article/the-scariest-hacks-and-vulnerabilities-of-2019/ | 2019-10-30T07:00:00 | [
"黑客",
"网络安全"
] | https://linux.cn/article-11516-1.html | 
是的,这是年终摘要文章之一。这是一篇很长的文章,因为就网络安全新闻来说,2019 年就是一场灾难,每周都会有一个或多个重大事件发生。
以下是按月组织的过去 10 个月安全灾难的摘要。
### 一月
[Apple FaceTime 中的严重漏洞](https://www.zdnet.com/article/apple-facetime-exploit-found-by-14-year-old-playing-fortnite/):Apple FaceTime 应用程序中的一个错误使攻击者可以在不与被呼叫者进行任何用户交互的情况下呼叫并自行应答 FaceTime 呼叫,从而为进行秘密监视打开了大门。
[在通过 Skype 面试后,朝鲜黑客渗透到智利的 ATM 网络](https://www.zdnet.com/article/north-korean-hackers-infiltrate-chiles-atm-network-after-skype-job-interview/):该文章的标题不言而喻,值得你花时间阅读该故事。
[黑客破坏并窃取了韩国国防部的数据](https://www.zdnet.com/article/hackers-breach-and-steal-data-from-south-koreas-defense-ministry/):首尔政府表示,黑客破坏了 30 台计算机并窃取了 10 台计算机中的数据。被黑客入侵的计算机存储了有关武器和弹药采购的数据。
[有人入侵了 PHP PEAR 网站](https://www.zdnet.com/article/mystery-still-surrounds-hack-of-php-pear-website/):我们仍然不知道发生了什么,但是一些黑客侵入了 PHP PEAR 存储库,并给某个版本的 PHP PEAR 软件包管理器添加了后门。
[26 种低端加密货币中发现的安全漏洞](https://www.zdnet.com/article/security-flaws-found-in-26-low-end-cryptocurrencies/):该报告显示了一些低端的不著名的加密货币的危险性,以及黑客如何随时窃取大量资金。
[俄克拉荷马州政府数据泄漏暴露了联邦调查局的调查记录](https://www.zdnet.com/article/oklahoma-gov-data-leak-exposes-millions-of-department-files-fbi-investigations/):俄克拉荷马州证券部的服务器允许任何人下载政府文件,例如内部文件,甚至是联邦调查局的调查。
[被怀疑参与了全球 DNS 劫持活动的伊朗黑客](https://www.zdnet.com/article/iranian-hackers-suspected-in-worldwide-dns-hijacking-campaign/):FireEye 和 Cisco Talos 先后披露了由伊朗黑客发起的全球劫持活动,伊朗黑客通过其伊朗服务器重定向了来自全球各地公司的流量,并记录了公司的凭据以备将来攻击。他们在域名注册商处入侵了 DNS 管理帐户,以执行 DNS 劫持攻击。这些黑客也[入侵了希腊的顶级域名注册商](https://www.zdnet.com/article/hackers-breached-greeces-top-level-domain-registrar/)。
[存在了 36 年之久的 SCP 软件安全漏洞](https://www.zdnet.com/article/scp-implementations-impacted-by-36-years-old-security-flaws/):自 1983 年以来,过去 36 年中的所有 SCP(安全复制协议)软件版本均受到了四个安全漏洞的影响,这些漏洞允许恶意的 SCP 服务器对客户(用户)的系统进行未经授权的更改,并在终端隐藏其恶意操作。
年度 LTE 安全漏洞:今年发现了两组新的 LTE 安全漏洞。一组影响 [3G、4G 和 5G](https://www.zdnet.com/article/new-security-flaw-impacts-5g-4g-and-3g-telephony-protocols/),另一组 [36 个漏洞](https://www.zdnet.com/article/researchers-find-36-new-security-flaws-in-lte-protocol/)在韩国安全研究人员进行的一项模糊项目之后被发现。
[网站可以通过浏览器扩展 API 窃取浏览器数据](https://www.zdnet.com/article/websites-can-steal-browser-data-via-extensions-apis/):研究人员发现有将近 200 个 Chrome、Firefox 和 Opera 扩展容易受到恶意站点的攻击。
[WiFi 固件错误会影响笔记本电脑、智能手机、路由器、游戏设备](https://www.zdnet.com/article/wifi-firmware-bug-affects-laptops-smartphones-routers-gaming-devices/):Marvell Avastar 芯片组中发现的重大安全漏洞。受影响的设备列表包括 PS4、Xbox One、三星 Chromebook 和微软 Surface 设备。
恶意软件被发现预装在 Android 设备上:在 2019 年发生了两次。首先,在一月份,研究人员在[预安装在阿尔卡特智能手机上的阿尔卡特应用程序](https://www.zdnet.com/article/malware-found-preinstalled-on-some-alcatel-smartphones/)中发现了恶意软件。其次,在六月,德国的网络安全机构在[四种中国智能手机型号中发现了后门](https://www.zdnet.com/article/germany-backdoor-found-in-four-smartphone-models-20000-users-infected/)。
### 二月
[重大 WinRAR 错误暴露](https://www.zdnet.com/article/winrar-versions-released-in-the-last-19-years-impacted-by-severe-security-flaw/):Check Point 研究人员发现了一个 WinRAR 错误,该错误影响了自 2000 年以来发行的所有 WinRAR 版本。超过 5 亿个 WinRAR 用户面临风险。这些漏洞最终被网络罪犯和国家黑客广泛使用。
[新的 WinPot 恶意软件可以使 ATM 吐出现金](https://www.zdnet.com/article/this-malware-turns-atm-hijacking-into-slot-machine-games/):WinPot 自 2018 年 3 月以来一直在地下论坛上出售。
[从 Tor 流量检测单个 Android 应用程序的准确性为 97%](https://www.zdnet.com/article/tor-traffic-from-individual-android-apps-detected-with-97-percent-accuracy/):新的机器学习算法可以通过 Tor 检测 Tor 用户何时使用了特定的应用程序,例如 YouTube、Instagram、Spotify 等。
[黑客抹除了电子邮件提供商 VFEmail 的美国服务器](https://www.zdnet.com/article/hackers-wipe-us-servers-of-email-provider-vfemail/):黑客没有要求赎金。VFEmail 将事件描述为“攻击并摧毁”。
[Thunderclap 漏洞](https://www.zdnet.com/article/thunderclap-flaws-impact-how-windows-mac-linux-handle-thunderbolt-peripherals/):该安全漏洞影响 Windows、Mac、Linux 处理 Thunderbolt 外围设备的方式。它们允许创建可能从操作系统内存中窃取数据的高度危险的恶意外围设备。
PDF 协议攻击:一组德国学者发现了一种在 PDF 文档中[伪造签名的方法](https://www.zdnet.com/article/researchers-break-digital-signatures-for-most-desktop-pdf-viewers/),并在今年晚些时候找到了[一种破解 PDF 加密的方法](https://www.zdnet.com/article/researchers-break-digital-signatures-for-most-desktop-pdf-viewers/)。
使用 CPU 隐藏恶意软件:学者们已经找到了在[使用推测执行](https://www.zdnet.com/article/researchers-hide-malware-in-benign-apps-with-the-help-of-speculative-execution/)和[英特尔 SGX 安全区系统](https://www.zdnet.com/article/researchers-hide-malware-in-intel-sgx-enclaves/)的计算机上隐藏恶意软件的方法。
### 三月
[黑客在大风暴发生前将龙卷风警报器离线](https://www.zdnet.com/article/hacked-tornado-sirens-taken-offline-in-two-texas-cities-ahead-of-major-storm/):是的,就是为了作恶。
[华硕供应链黑客事件](https://www.zdnet.com/article/supply-chain-attack-installs-backdoors-through-hijacked-asus-live-update-software/):黑客劫持了华硕 Live Update 实用程序,以便在用户系统上部署恶意软件。黑客攻击发生在 2018 年,但在今年 3 月被披露。据信已经影响了超过一百万台 PC。
[GitHub 帐户环推广了 300 多个带后门的应用程序](https://www.zdnet.com/article/researchers-uncover-ring-of-github-accounts-promoting-300-backdoored-apps/):该 GitHub 账户环由 89 个帐户组成,推广了 73 个仓库,其中包含 300 多个带有后门的 Windows、Mac 和 Linux 应用程序。
[Bithumb 加密货币交易所在两年内第三次被黑客入侵](https://www.zdnet.com/article/bithumb-cryptocurrency-exchange-hacked-a-third-time-in-two-years/):据信黑客已经赚了近 2000 万美元的 EOS 和瑞波加密货币。在这一点上,Bithumb 似乎放弃挣扎了。
[Chrome 零日漏洞正受到活跃攻击](https://www.zdnet.com/article/google-reveals-chrome-zero-day-under-active-attacks/):CVE-2019-5786(Chrome 的 FileReader API 中的一个错误)被广泛利用以从用户计算机中读取内容。谷歌表示,该漏洞是由一个国家攻击者[与 Windows 7 零日漏洞一起使用](https://www.zdnet.com/article/google-chrome-zero-day-was-used-together-with-a-windows-7-zero-day/)的。
[新的英特尔 CPU 错误](https://www.zdnet.com/article/researchers-discover-and-abuse-new-undocumented-feature-in-intel-chipsets/):研究人员发现了新的 Intel VISA(内部信号架构可视化)调试技术。
[法国加油站的黑客事件](https://www.zdnet.com/article/french-gas-stations-robbed-after-forgetting-to-change-gas-pump-pins/):加油站忘记更换加油站油泵的 PIN 之后,犯罪集团从巴黎附近的道达尔加油站偷走了 12 万升燃油。
[Citrix 数据泄露](https://www.zdnet.com/article/citrix-discloses-security-breach-of-internal-network/):Citrix 从 FBI 获悉了本次黑客攻击。黑客偷走了商业文件。Citrix 的许多客户都是政府机构和财富 500 强公司。
智能手机解锁问题:我们今年遇到了一些这样的案例,但第一起案例是在三月份报道的,当时用户发现三星 Galaxy S10 面部识别可能被[手机所有者的视频](https://www.zdnet.com/article/samsung-galaxy-s10-facial-recognition-fooled-by-a-video-of-the-phone-owner/)所欺骗。一个月后,用户发现他可以用[一包口香糖](https://www.zdnet.com/article/nokia-9-buggy-update-lets-anyone-bypass-fingerprint-scanner-with-a-pack-of-gum/)解锁诺基亚 9 智能手机的指纹扫描仪。然后在十月,用户发现可以在[闭着眼睛](https://www.zdnet.com/article/google-pixel-4s-face-unlock-works-even-if-you-have-your-eyes-closed/)时解锁 Pixel 4 的面部解锁技术;一对夫妇发现,如果该设备由硅保护套保护,他们可以使用任何用户的手指[解锁使用指纹保护的 Samsung S10 设备](https://www.zdnet.com/article/samsung-to-patch-s10-fingerprint-sensor-bug-next-week/)。实际上,绕过面部识别的问题非常普遍。去年,一家荷兰非营利组织进行的一项研究发现,攻击者可以在测试的 [110 部智能手机中的 42 部](https://www.zdnet.com/article/facial-recognition-doesnt-work-as-intended-on-42-of-110-tested-smartphones/)中绕过面部解锁类的功能。
### 四月
[美国联合航空公司盖上了座席摄像头](https://www.zdnet.com/article/united-airlines-covers-up-infotainment-seat-camera-following-passenger-outrage/):该航空公司坚称这些摄像头尚未投入使用;但是,客户首先仍然对该摄像头的存在感到非常不安和烦恼。
[由于未修复的 API,研究人员在数百个 GPS 手表的地图上显示 “PWNED!”](https://www.zdnet.com/article/researcher-prints-pwned-on-hundreds-of-gps-watches-maps-due-to-unfixed-api/) :超过 20 种型号的 GPS 手表允许恶意行为者跟踪设备所有者,并修改手表功能。
[成千上万辆汽车因使用硬编码的密码而暴露于小偷视野之中](https://www.zdnet.com/article/tens-of-thousands-of-cars-left-exposed-to-thieves-due-to-a-hardcoded-password/):二月中以来,MyCar 发布的 Android 和 iOS 应用程序的安全更新已删除了硬编码的密码。
[被勒索软件感染后,“天气”频道的播出空缺了 90 分钟](https://www.zdnet.com/article/the-weather-channel-goes-off-the-air-for-90-minutes-after-ransomware-infection/):10 月对[法国电视台 M6](https://www.zdnet.com/article/m6-one-of-frances-biggest-tv-channels-hit-by-ransomware/) 的类似攻击未成功。
[Facebook 承认存储了数百万个 Instagram 用户的明文密码](https://www.zdnet.com/article/facebook-admits-to-storing-plaintext-passwords-for-millions-of-instagram-users/):该事件发生的一个月前,Facebook 也承认[存储了 Facebook 帐户的明文密码](https://www.zdnet.com/article/facebook-we-stored-hundreds-of-millions-of-passwords-in-plain-text/)。
[Telegram 上泄露了伊朗网络间谍工具的源代码](https://www.zdnet.com/article/source-code-of-iranian-cyber-espionage-tools-leaked-on-telegram/):每天都有恶意软件开发人员使用这些工具,从而使更多用户受到攻击。[五月](https://www.zdnet.com/article/new-leaks-of-iranian-cyber-espionage-operations-hit-telegram-and-the-dark-web/)和[六月](https://www.zdnet.com/article/new-iranian-hacking-tool-leaked-on-telegram/)发生了第二次和第三次伊朗黑客工具泄漏。
[印度政府机构保留的数百万孕妇的详细信息暴露在线上](https://www.zdnet.com/article/indian-govt-agency-left-details-of-millions-of-pregnant-women-exposed-online/):超过 1250 万孕妇医学记录被暴露。三个多星期后,泄漏的服务器中删除了记录。
[超过 13000 个 iSCSI 存储群集暴露在网上而没有密码](https://www.zdnet.com/article/over-13k-iscsi-storage-clusters-left-exposed-online-without-a-password/):新的攻击方式在企业磁盘存储阵列和人们的 NAS 设备内部打开了后门。
[Gnosticplayers 的黑客事件](https://www.zdnet.com/article/a-hacker-has-dumped-nearly-one-billion-user-records-over-the-past-two-months/):几个月之内,一个被称为 Gnosticplayers 的黑客在网上放出了超过 10 亿条用户记录。
[黑客组织已经在 D-Link 路由器上劫持了 DNS 流量达三个月](https://www.zdnet.com/article/hacker-group-has-been-hijacking-dns-traffic-on-d-link-routers-for-three-months/):他们还针对了其他路由器型号进行了劫持,例如 ARG、DSLink、Secutech 和 TOTOLINK。这些攻击[在巴西尤其活跃](https://www.zdnet.com/article/brazil-is-at-the-forefront-of-a-new-type-of-router-attack/)。
### 五月
[黑客擦除了 Git 存储库,并要求赎金](https://www.zdnet.com/article/a-hacker-is-wiping-git-repositories-and-asking-for-a-ransom/):成千上万的存储库受到了影响,但几乎所有项目都已恢复。
[对现代 CPU 的新 MDS 攻击](https://www.zdnet.com/article/intel-cpus-impacted-by-new-zombieload-side-channel-attack/):研究人员和学者详细介绍了新的微体系结构数据采样(MDS)攻击,例如 Zombieload、Fallout 和 RIDL。
[Thrangrycat 漏洞](https://www.zdnet.com/article/thrangrycat-flaw-lets-attackers-plant-persistent-backdoors-on-cisco-gear/):Thrangrycat 漏洞使攻击者可以在 Cisco 设备上植入持久的后门。据信大多数 Cisco 设备都会受到影响。没有广泛检测到攻击。
BlueKeep 漏洞:五月中旬,微软警告了一个[新的 “可用作蠕虫的” RDP 漏洞](https://www.zdnet.com/article/microsoft-patches-windows-xp-server-2003-to-try-to-head-off-wormable-flaw/),该漏洞后来被称为 BlueKeep。后来在八月披露了两个新的类似 BlueKeep 的可用做蠕虫的漏洞([DejaBlue](https://www.zdnet.com/article/microsoft-warns-of-two-new-wormable-flaws-in-windows-remote-desktop-services/))。经过数月的迫切等待之后,九月公开发布了一种[概念验证攻击](https://www.zdnet.com/article/metasploit-team-releases-bluekeep-exploit/)。
[不安全的服务器公开了 85% 巴拿马公民的的数据](https://www.zdnet.com/article/unsecured-server-exposes-data-for-85-percent-of-all-panama-citizens/):该服务器包含患者数据,但没有公开医疗记录,仅公开了个人身份信息(PII)。
[软件更新导致荷兰警察的脚踝监控器崩溃](https://www.zdnet.com/article/software-update-crashes-police-ankle-monitors-in-the-netherlands/):有问题的更新阻止了脚踝监控器将数据发送回警察控制室。导致需要找到一些嫌疑人并送回监狱。
[以色列对空袭哈马斯的黑客首次作出回应](https://www.zdnet.com/article/in-a-first-israel-responds-to-hamas-hackers-with-an-air-strike/):以色列军方称轰炸了住着哈马斯网络部队的房屋。
[Google 替换了有问题的 Titan 安全密钥](https://www.zdnet.com/article/google-to-replace-faulty-titan-security-keys/):蓝牙配对协议中的漏洞迫使 Google 替换了在美国销售的 Titan 密钥。微软后来被迫[发布了一个特殊修复程序](https://www.zdnet.com/article/microsoft-blocks-ble-security-keys-with-known-pairing-vulnerability/)以解决该问题。
[Canva 黑客事件](https://www.zdnet.com/article/australian-tech-unicorn-canva-suffers-security-breach/):Gnosticplayers 的受害者之一。该公司被黑客窃取了 1.39 亿条用户记录。
[StackOverflow 黑客事件](https://www.zdnet.com/article/stack-overflow-says-hackers-breached-production-systems/):Stack Overflow 表示黑客破坏了生产系统,而黑客发现已经活动了[一周以上](https://www.zdnet.com/article/stack-overflow-hacker-went-undetected-for-a-week/)。
[Flipboard 黑客事件](https://www.zdnet.com/article/flipboard-says-hackers-stole-user-details/):黑客入侵的程度尚不得而知,但 Flipboard 表示,黑客已经访问其系统将近九个月的时间。
[伦敦地铁开始通过 Wi-Fi 热点跟踪乘客](https://www.zdnet.com/article/london-underground-to-begin-tracking-passengers-through-wi-fi-hotspots/):伦敦交通局(TfL)表示,计划在未来几个月内推出一种系统,以利用伦敦地铁上的公共 Wi-Fi 热点跟踪通勤者。
[安全浏览器的主要错误](https://www.zdnet.com/article/mobile-chrome-safari-and-firefox-failed-to-show-phishing-warnings-for-more-than-a-year/):移动版 Chrome、Safari 和 Firefox 一年多都未能显示网络钓鱼警告。
### 六月
[黑客攻击了 10 家电信供应商](https://www.zdnet.com/article/these-hackers-broke-into-10-telecoms-companies-to-steal-customers-phone-records/):Cybereason 的研究人员说,一个由国家支持的情报机构已经破坏了至少 10 家全球电信公司:在某种程度上,攻击者运行着“事实上的影子 IT 部门”。
[新的 Silex 恶意软件使成千上万的 IoT 设备变砖](https://www.zdnet.com/article/new-silex-malware-is-bricking-iot-devices-has-scary-plans/):攻击持续了数天,但黑客最终停止并撤回了 Silex 恶意软件代码。
[NASA 因未经授权的树莓派连接到其网络而被黑客入侵](https://www.zdnet.com/article/nasa-hacked-because-of-unauthorized-raspberry-pi-connected-to-its-network/):NASA 将该黑客攻击描述为“高级持续威胁(APT)”,该术语通常用于国家黑客组织,但未提供其他详细信息。
[流行的 Facebook 悲伤支持页面被黑客入侵](https://www.zdnet.com/article/popular-grief-support-page-hacked-ignored-by-facebook-for-weeks/):Facebok 数周都无视了该黑客攻击。
[Google Nest 的摄像头可以允许前拥有者监视新拥有者](https://www.zdnet.com/article/google-pushes-nest-cam-update-to-prevent-former-owners-spying-on-new-buyers/):Google 最终推出了更新解决这个问题。
两个 Firefox 零日漏洞:Mozilla 修复了两个 Firefox 零日漏洞[[1](https://www.zdnet.com/article/mozilla-fixes-second-firefox-zero-day-exploited-in-the-wild/)、[2](https://www.zdnet.com/article/mozilla-fixes-second-firefox-zero-day-exploited-in-the-wild/)] ,它们被用于攻击 Coinbase 员工。
[AMCA 数据泄露](https://www.zdnet.com/article/amca-data-breach-has-now-gone-over-the-20-million-mark/):去年,美国医疗保健计费供应商被黑客入侵,黑客将患者数据在线出售。该漏洞影响了多家医疗保健提供商,最终数量超过了 2000 万。
[CBP 说,黑客窃取了车牌和旅行者的照片](https://www.zdnet.com/article/cbp-says-hackers-stole-license-plate-and-travelers-photos/):CBP 说,分包商未经授权将照片存储在其内部服务器上,然后遭到黑客攻击。
[HSM 重大漏洞影响着银行、云提供商、政府](https://www.zdnet.com/article/major-hsm-vulnerabilities-impact-banks-cloud-providers-governments/):两名安全研究人员透露,可以远程利用这些漏洞来检索存储在称为 HSM(硬件安全模块)的特殊计算机组件中的敏感数据。
[SIM 交换攻击浪潮袭击了美国加密货币用户](https://www.zdnet.com/article/wave-of-sim-swapping-attacks-hit-us-cryptocurrency-users/):六月的一周,数十名美国加密货币用户认为他们是 SIM 交换攻击的受害者。
| 200 | OK | [2010s: The Decade in Review](/topic/decade-in-review/)
# The scariest hacks and vulnerabilities of 2019

Yes, this is one of those end-of-year summaries. And it's a long one, since 2019 has been a disaster in terms of cyber-security news, with one or more major stories breaking on a weekly basis.
Below is a summary for the past 10 months of security disasters, organized by month.
### January
[ Severe vulnerability in Apple FaceTime](https://www.zdnet.com/article/apple-facetime-exploit-found-by-14-year-old-playing-fortnite/) - A bug in Apple's FaceTime app let attackers call and self-answer a FaceTime call without any user interaction from the callee, opening the door for secret surveillance.
[ North Korean hackers infiltrate Chile's ATM network after Skype job interview](https://www.zdnet.com/article/north-korean-hackers-infiltrate-chiles-atm-network-after-skype-job-interview/) - the article's title is self-explanatory, and the story is worth your time to read.
[ Hackers breach and steal data from South Korea's Defense Ministry](https://www.zdnet.com/article/hackers-breach-and-steal-data-from-south-koreas-defense-ministry/) - Seoul government said hackers breached 30 computers and stole data from 10. The hacked computers stored data on weapons and munitions acquisition.
[ Someone hacked the PHP PEAR website](https://www.zdnet.com/article/mystery-still-surrounds-hack-of-php-pear-website/) - We still don't know what happened there, but some hacker breached the PHP PEAR repo and backdoored a version of the PHP PEAR package manager.
[ Security flaws found in 26 low-end cryptocurrencies](https://www.zdnet.com/article/security-flaws-found-in-26-low-end-cryptocurrencies/) - This report shows just how dangerous some low-end, no-name cryptocurrencies are, and how hackers could steal funds en-masse at any time.
[ Oklahoma gov data leak exposes FBI investigation records](https://www.zdnet.com/article/oklahoma-gov-data-leak-exposes-millions-of-department-files-fbi-investigations/) - An Oklahoma Department of Securities server allowed anyone to download government files, such as internal files, and even FBI investigations.
[ Iranian hackers suspected in worldwide DNS hijacking campaign](https://www.zdnet.com/article/iranian-hackers-suspected-in-worldwide-dns-hijacking-campaign/) -
[FireEye](https://www.fireeye.com/blog/threat-research/2019/01/global-dns-hijacking-campaign-dns-record-manipulation-at-scale.html), and later
[Cisco Talos](https://blog.talosintelligence.com/2019/04/seaturtle.html), disclosed a global campaign carried out by Iranian hackers who redirected traffic from companies all over their globe through their Iranian servers, recording company credentials for future attacks.To do this, they hacked DNS management accounts at domain name registrars, in order to execute DNS hijacking attacks. These same hackers also
[breached Greece's top-level domain registrar](https://www.zdnet.com/article/hackers-breached-greeces-top-level-domain-registrar/).
[ SCP implementations impacted by 36-years-old security flaws](https://www.zdnet.com/article/scp-implementations-impacted-by-36-years-old-security-flaws/) - All SCP (Secure Copy Protocol) implementations from the last 36 years, since 1983, were found to be vulnerable to four security bugs that allowed a malicious SCP server to make unauthorized changes to a client's (user's) system and hide malicious operations in the terminal.
**Yearly LTE security flaws** - Two sets of new LTE security flaws were discovered this year. One that impacted [3G, 4G, and 5G](https://www.zdnet.com/article/new-security-flaw-impacts-5g-4g-and-3g-telephony-protocols/), and a second set of [36 vulnerabilities](https://www.zdnet.com/article/researchers-find-36-new-security-flaws-in-lte-protocol/) found found after a fuzzing project carried out by South Korean security researchers.
[ Websites can steal browser data via extensions APIs](https://www.zdnet.com/article/websites-can-steal-browser-data-via-extensions-apis/) - Researcher finds nearly 200 Chrome, Firefox, and Opera extensions vulnerable to attacks from malicious sites.
[ WiFi firmware bug affects laptops, smartphones, routers, gaming devices](https://www.zdnet.com/article/wifi-firmware-bug-affects-laptops-smartphones-routers-gaming-devices/) - Major security flaw found in Marvell Avastar chipset. List of impacted devices includes PS4, Xbox One, Samsung Chromebooks, and Microsoft Surface devices.
**Malware found preinstalled on Android devices** - Happened twice in 2019. First, in January, when researchers found [malware inside an Alcatel app preinstalled on Alcatel smartphones](https://www.zdnet.com/article/malware-found-preinstalled-on-some-alcatel-smartphones/). Second, in June, when Germany's cyber-security agencies found [a backdoor in four Chinese smartphone models](https://www.zdnet.com/article/germany-backdoor-found-in-four-smartphone-models-20000-users-infected/).
### February
[ Leaky DB exposes China's Muslim-tracking practices](https://www.zdnet.com/article/chinese-company-leaves-muslim-tracking-facial-recognition-database-exposed-online/) - Security researcher Victor Gevers found a leaky DB from a Chinese company that exposed its Muslim-tracking facial recognition software, inadvertently revealing China's Uyghur-tracking practices.
[ Major WinRAR bugs exposed](https://www.zdnet.com/article/winrar-versions-released-in-the-last-19-years-impacted-by-severe-security-flaw/) - Check Point researchers found a WinrAR bug that impacted all the WinRAR versions releassed since 2000. Over 500 million WinRAR users were at risk.
[The bugs eventually become widely used](https://www.zdnet.com/article/100-unique-exploits-and-counting-for-latest-winrar-security-bug/)by cyber-criminals and nation-state hackers at the same time.
[ New WinPot malware can make ATMs spit out cash](https://www.zdnet.com/article/this-malware-turns-atm-hijacking-into-slot-machine-games/) - WinPot has been on sale on underground forums since March 2018.
[ Tor traffic from individual Android apps detected with 97% accuracy](https://www.zdnet.com/article/tor-traffic-from-individual-android-apps-detected-with-97-percent-accuracy/) - New machine learning algorithm can detect when Tor users are using a specific app, such as YouTube, Instagram, Spotify, others, via Tor.
[ Hackers wipe US servers of email provider VFEmail](https://www.zdnet.com/article/hackers-wipe-us-servers-of-email-provider-vfemail/) - Hackers did not ask for a ransom. VFEmail described the incident as "attack and destroy."
[ Thunderclap vulnerability](https://www.zdnet.com/article/thunderclap-flaws-impact-how-windows-mac-linux-handle-thunderbolt-peripherals/) - The security flaw impacts how Windows, Mac, Linux handle Thunderbolt peripherals. They allow the creation of highly dangerous malicious peripherals that can steal data from OS memory.
**PDF protocol attacks** - A team of German academics found [a way to fake signatures](https://www.zdnet.com/article/researchers-break-digital-signatures-for-most-desktop-pdf-viewers/) in PDF documents, and later this year, [a way to break PDF encryption](https://www.zdnet.com/article/researchers-break-digital-signatures-for-most-desktop-pdf-viewers/).
**Hiding malware using the CPU** - Academics have found ways to hide malware on a computer [using speculative execution](https://www.zdnet.com/article/researchers-hide-malware-in-benign-apps-with-the-help-of-speculative-execution/) and [Intel's SGX enclave system](https://www.zdnet.com/article/researchers-hide-malware-in-intel-sgx-enclaves/).
### March
[ Hackers take tornado sirens offline before major storm](https://www.zdnet.com/article/hacked-tornado-sirens-taken-offline-in-two-texas-cities-ahead-of-major-storm/) - Yeah. That was just evil.
[ The ASUS supply-chain hack](https://www.zdnet.com/article/supply-chain-attack-installs-backdoors-through-hijacked-asus-live-update-software/) - Hackers hijacked the ASUS Live Update utility to deploy malware on users' systems. The hack took place in 2018, but was disclosed in March.
[Over one million PCs](https://www.zdnet.com/article/researchers-publish-list-of-mac-addresses-targeted-in-asus-hack/)were believed to have been impacted.
[ Ring of GitHub accounts promoting 300+ backdoored apps](https://www.zdnet.com/article/researchers-uncover-ring-of-github-accounts-promoting-300-backdoored-apps/) - GitHub ring consisting of 89 accounts promoted 73 repos containing over 300 backdoored Windows, Mac, and Linux apps.
[ Bithumb cryptocurrency exchange hacked a third time in two years](https://www.zdnet.com/article/bithumb-cryptocurrency-exchange-hacked-a-third-time-in-two-years/) - Hackers believed to have made off with nearly $20 million in EOS and Ripple cryptocurrencies. At this point, Bithumb appears that they're not even trying anymore.
[ Chrome zero-day under active attacks](https://www.zdnet.com/article/google-reveals-chrome-zero-day-under-active-attacks/) - CVE-2019-5786, a bug in Chrome's FileReader API, was exploited in the wild to read content from a user's computer. Google said the bug was
[used together with a Windows 7 zero-day](https://www.zdnet.com/article/google-chrome-zero-day-was-used-together-with-a-windows-7-zero-day/)by a nation-state attacker.
[ New Intel CPU bug](https://www.zdnet.com/article/researchers-discover-and-abuse-new-undocumented-feature-in-intel-chipsets/) - Researchers find new Intel VISA (Visualization of Internal Signals Architecture) debugging technology.
[ Hacks at French gas stations](https://www.zdnet.com/article/french-gas-stations-robbed-after-forgetting-to-change-gas-pump-pins/)- Criminal group steals 120,000 litres of fuel from Total gas stations around Paris after gas stations forgot to change gas station pump PINs.
[ Citrix data breach](https://www.zdnet.com/article/citrix-discloses-security-breach-of-internal-network/) - Citrix learned of the hack from the FBI. Hackers stole business documents. A lot of Citrix customers' are government agencies and Fortune 500 companies.
**Smartphone unlocking issues** - We've had a few this year, but the first case was reported in March when a user found that Samsung Galaxy S10 facial recognition can be fooled by [a video of the phone owner](https://www.zdnet.com/article/samsung-galaxy-s10-facial-recognition-fooled-by-a-video-of-the-phone-owner/). A month later, a user found that he could unlock a Nokia 9 smartphone's fingerprint scanner[ with a pack of gum](https://www.zdnet.com/article/nokia-9-buggy-update-lets-anyone-bypass-fingerprint-scanner-with-a-pack-of-gum/). Then in October, users found that you could unlock a Pixel 4's facial unlock technology [while you had your eyes closed](https://www.zdnet.com/article/google-pixel-4s-face-unlock-works-even-if-you-have-your-eyes-closed/), and a couple found that they could [unlock Samsung S10 devices using fingerprint protection](https://www.zdnet.com/article/samsung-to-patch-s10-fingerprint-sensor-bug-next-week/) with any user's finger if the device was protected by a silicon case. In fact, the issue with bypassing facial recognition is quite widespread. A study by a Dutch non-profit last year found that attackers could bypass face unlock-type features [on 42 out of the 110 smartphones](https://www.zdnet.com/article/facial-recognition-doesnt-work-as-intended-on-42-of-110-tested-smartphones/) they tested.
### April
[ United Airlines covers up seat cameras](https://www.zdnet.com/article/united-airlines-covers-up-infotainment-seat-camera-following-passenger-outrage/) - The airline insists that the cameras have not been in active use; however, customers were still very disturbed and annoyed by the cameras' presence in the first place.
[ Researcher prints 'PWNED!' on hundreds of GPS watches' maps due to unfixed API](https://www.zdnet.com/article/researcher-prints-pwned-on-hundreds-of-gps-watches-maps-due-to-unfixed-api/) - Over 20 GPS watch models allowed threat actors to track device owners, tinker with watch functions.
[ Tens of thousands of cars were left exposed to thieves due to a hardcoded password](https://www.zdnet.com/article/tens-of-thousands-of-cars-left-exposed-to-thieves-due-to-a-hardcoded-password/) - Security updates that remove the hardcoded credentials have been made available for both the MyCar
[Android](https://play.google.com/store/apps/details?id=app.com.automobility.mycar.control)and
[iOS](https://itunes.apple.com/us/app/mycar-controls/id1126511815)apps since mid-February.
[ The Weather Channel goes off the air for 90 minutes after ransomware infection](https://www.zdnet.com/article/the-weather-channel-goes-off-the-air-for-90-minutes-after-ransomware-infection/) - A similar attack on
[French TV station M6](https://www.zdnet.com/article/m6-one-of-frances-biggest-tv-channels-hit-by-ransomware/), in October, was unsuccesful.
[ Facebook admits to storing plaintext passwords for millions of Instagram users](https://www.zdnet.com/article/facebook-admits-to-storing-plaintext-passwords-for-millions-of-instagram-users/) - Incident comes after a month earlier, Facebook admitted to
[storing plaintext passwords for Facebook accounts too](https://www.zdnet.com/article/facebook-we-stored-hundreds-of-millions-of-passwords-in-plain-text/).
[ Source code of Iranian cyber-espionage tools leaked on Telegram](https://www.zdnet.com/article/source-code-of-iranian-cyber-espionage-tools-leaked-on-telegram/) - Tools were made available for every-day malware developers, opening more users to attacks. A second and third leak of Iranian hacking tools occurred in
[May](https://www.zdnet.com/article/new-leaks-of-iranian-cyber-espionage-operations-hit-telegram-and-the-dark-web/)and
[June](https://www.zdnet.com/article/new-iranian-hacking-tool-leaked-on-telegram/).
[ Indian govt agency left details of millions of pregnant women exposed online](https://www.zdnet.com/article/indian-govt-agency-left-details-of-millions-of-pregnant-women-exposed-online/) - More than 12.5 million medical records for pregnant women were left exposed. Records removed from leaky server after more than three weeks.
[ Over 13K iSCSI storage clusters left exposed online without a password](https://www.zdnet.com/article/over-13k-iscsi-storage-clusters-left-exposed-online-without-a-password/) - New attack vector opens backdoor inside enterprise disk storage arrays and people's NAS devices.
[ Gnosticplayers' hacks](https://www.zdnet.com/article/a-hacker-has-dumped-nearly-one-billion-user-records-over-the-past-two-months/) - A hacker known as Gnosticplayers has dumped over one billion user records online in the span of a few months.
[ Hacker group has been hijacking DNS traffic on D-Link routers for three months](https://www.zdnet.com/article/hacker-group-has-been-hijacking-dns-traffic-on-d-link-routers-for-three-months/) - Other router models have also been targeted, such as ARG, DSLink, Secutech, and TOTOLINK. The attacks are
[especially active cross Brazil](https://www.zdnet.com/article/brazil-is-at-the-forefront-of-a-new-type-of-router-attack/).
### May
[ A hacker wiped Git repositories and asked for a ransom](https://www.zdnet.com/article/a-hacker-is-wiping-git-repositories-and-asking-for-a-ransom/) - Thousands of repos were impacted, but almost all projects were recovered.
[ New MDS attacks on modern CPUs](https://www.zdnet.com/article/intel-cpus-impacted-by-new-zombieload-side-channel-attack/) - Researchers, academics detail new Microarchitectural Data Sampling (MDS) attacks, such as Zombieload, Fallout, and RIDL.
[ Thrangrycat vulnerability](https://www.zdnet.com/article/thrangrycat-flaw-lets-attackers-plant-persistent-backdoors-on-cisco-gear/) - Thrangrycat flaw lets attackers plant persistent backdoors on Cisco gear. Most Cisco gear is believed to be impacted. No attacks detected in the wild.
**BlueKeep vulnerability** - In mid-May, Microsoft warned about a [new "wormable" RDP vulnerability](https://www.zdnet.com/article/microsoft-patches-windows-xp-server-2003-to-try-to-head-off-wormable-flaw/) that later became known as BlueKeep. Two new wormable BlueKeep-like vulnerabilities ([DejaBlue](https://www.zdnet.com/article/microsoft-warns-of-two-new-wormable-flaws-in-windows-remote-desktop-services/)) were later disclosed in August. After months of eagerly waiting attacks, a [proof-of-concept exploit](https://www.zdnet.com/article/metasploit-team-releases-bluekeep-exploit/) was publicly published in September.
[ Unsecured server exposes data for 85% of all Panama citizens](https://www.zdnet.com/article/unsecured-server-exposes-data-for-85-percent-of-all-panama-citizens/) - The server contained patient data, but no medical records were exposed -- only personally identifiable information (PII).
[ Software update crashes police ankle monitors in the Netherlands](https://www.zdnet.com/article/software-update-crashes-police-ankle-monitors-in-the-netherlands/) - Borked update prevents ankle monitors from sending data back to police control rooms. Some suspects needed to be collected and sent back to jail as a result.
[ In a first, Israel responds to Hamas hackers with an air strike](https://www.zdnet.com/article/in-a-first-israel-responds-to-hamas-hackers-with-an-air-strike/) - Israel military said it bombed building housing Hamas cyber forces.
[ Google replaces faulty Titan security keys](https://www.zdnet.com/article/google-to-replace-faulty-titan-security-keys/) - Vulnerability in Bluetooth pairing protocol forces Google to replace Titan keys sold in the US. Microsoft was later forced to
[issue a special fix](https://www.zdnet.com/article/microsoft-blocks-ble-security-keys-with-known-pairing-vulnerability/)to address the issue.
[ Canva hack](https://www.zdnet.com/article/australian-tech-unicorn-canva-suffers-security-breach/) - One of Gnosticplayers' victims. Company was hacked for 139 million user records.
[ StackOverflow hack](https://www.zdnet.com/article/stack-overflow-says-hackers-breached-production-systems/)- Stack Overflow said hackers breached production systems, and the hackers went undetected
[for more than a week](https://www.zdnet.com/article/stack-overflow-hacker-went-undetected-for-a-week/).
[ Flipboard hack](https://www.zdnet.com/article/flipboard-says-hackers-stole-user-details/) - Extent of the hack is unknown, but Flipboard said hackers had access to its systems for almost nine months.
[ London Underground to begin tracking passengers through Wi-Fi hotspots](https://www.zdnet.com/article/london-underground-to-begin-tracking-passengers-through-wi-fi-hotspots/) - Transport for London (TfL) said it was planning to roll out a system to track commuters making use of public Wi-Fi hotspots across the London Underground in coming months.
[ Major Safe Browsing bug](https://www.zdnet.com/article/mobile-chrome-safari-and-firefox-failed-to-show-phishing-warnings-for-more-than-a-year/) - Mobile Chrome, Safari, and Firefox failed to show phishing warnings for more than a year.
### June
[ Hackers breached 10 telecom providers](https://www.zdnet.com/article/these-hackers-broke-into-10-telecoms-companies-to-steal-customers-phone-records/) - Researchers at Cybereason said a nation-state-backed intelligence operation has compromised at least 10 global telco companies - to such an extent the attackers run a "de facto shadow IT department".
[ New Silex malware bricked thousands of IoT devices](https://www.zdnet.com/article/new-silex-malware-is-bricking-iot-devices-has-scary-plans/) - Attack lasted for days, but the hacker eventually stopped and retired the Silex malware code.
[ NASA hacked because of unauthorized Raspberry Pi connected to its network](https://www.zdnet.com/article/nasa-hacked-because-of-unauthorized-raspberry-pi-connected-to-its-network/) - NASA described the hackers as an "advanced persistent threat," a term generally used for nation-state hacking groups, but didn't provide other details.
[ Popular Facebook grief support page hacked](https://www.zdnet.com/article/popular-grief-support-page-hacked-ignored-by-facebook-for-weeks/) - Facebok ignored the hack for weeks.
[ Google Nest cams could have allowed former owners to spy on the new owners](https://www.zdnet.com/article/google-pushes-nest-cam-update-to-prevent-former-owners-spying-on-new-buyers/) - Google eventually pushed out an update.
**Two Firefox zero-days** - Mozilla fixed two Firefox zero-days [[1](https://www.zdnet.com/article/mozilla-fixes-second-firefox-zero-day-exploited-in-the-wild/), [2](https://www.zdnet.com/article/mozilla-fixes-second-firefox-zero-day-exploited-in-the-wild/)] that were used to attack Coinbase employees.
[ AMCA data breach](https://www.zdnet.com/article/amca-data-breach-has-now-gone-over-the-20-million-mark/) - Healthcare billing vendor got hacked last year and hackers put patient data for sale online. The breach impacted multiple healthcare providers, and eventually went over the 20 million mark.
[ CBP says hackers stole license plate and travelers' photos](https://www.zdnet.com/article/cbp-says-hackers-stole-license-plate-and-travelers-photos/) - CBP said subcontractor stored photos on its internal servers without authorization, and then got hacked.
[ Major HSM vulnerabilities impact banks, cloud providers, governments](https://www.zdnet.com/article/major-hsm-vulnerabilities-impact-banks-cloud-providers-governments/) - Two security researchers revealed vulnerabilities that can be exploited remotely to retrieve sensitive data stored inside special computer components known as HSMs (Hardware Security Modules).
[ Wave of SIM swapping attacks hit US cryptocurrency users](https://www.zdnet.com/article/wave-of-sim-swapping-attacks-hit-us-cryptocurrency-users/) - For a week in June, tens of US-based cryptocurrency users saw themselves victims of SIM swapping attacks.
### July
[ Kazakhstan government intercepted all local HTTPS traffic](https://www.zdnet.com/article/kazakhstan-government-is-now-intercepting-all-https-traffic/) - HTTPS interception efforts
[targeted Facebook, Google, Twitter](https://www.zdnet.com/article/kazakhstans-https-interception-efforts-target-facebook-google-twitter-others/), and others sites.
[Apple, Google, and Mozilla](https://www.zdnet.com/article/apple-google-and-mozilla-block-kazakhstans-https-intercepting-certificate/)eventually intervened and banned the certificate used for HTTPS MitM attacks.
[ Hacker steals data of millions of Bulgarians](https://www.zdnet.com/article/hacker-steals-data-of-millions-of-bulgarians-emails-it-to-local-media/) - A hacker stole the personal details of millions of Bulgarians and emailed download links to the stolen data to local news publications. The date, stolen from the country's National Revenue Agency,
[eventually leaked online](https://www.zdnet.com/article/bulgarias-hacked-database-is-now-available-on-hacking-forums/).
[ Hackers breach FSB contractor](https://www.zdnet.com/article/hackers-breach-fsb-contractor-expose-tor-deanonymization-project/) - Hackers have breached SyTech, a contractor for FSB, Russia's national intelligence service, from where they stole information about internal projects the company was working on behalf of the agency -- including one for deanonymizing Tor traffic.
[ iMessages could have bricked your iPhone](https://www.zdnet.com/article/google-project-zero-reveals-bad-imessages-could-have-bricked-your-iphone/) - Bug patched before being exploited in the wild.
[ Urgent/11 security flaws](https://www.zdnet.com/article/urgent11-security-flaws-impact-routers-printers-scada-and-many-iot-devices/)- Major bugs in TCP library impacted routers, printers, SCADA, medical devices, and many IoT devices.
[ Apple's AWDL protocol plagued by security flaws](https://www.zdnet.com/article/apples-awdl-protocol-plagued-by-flaws-that-enable-tracking-and-mitm-attacks/) - Apple patched a bug in May, but academics say the rest of the flaws require a redesign of some Apple services. Bugs would enable tracking and MitM attacks.
[ DHS warns about CAN bus vulnerabilities in small aircraft](https://www.zdnet.com/article/dhs-warns-about-can-bus-vulnerabilities-in-small-aircraft/) - DHS cyber-security agency CISA recommends that aircraft owners restrict access to planes "to the best of their abilities" to protect against vulnerabilities that could be used to sabotage airplanes.
[ Vulnerabilities found in GE anesthesia machines](https://www.zdnet.com/article/vulnerabilities-found-in-ge-anesthesia-machines/) - GE recommended that device owners not connect vulnerable anesthesia machines to a hospital's main networks. The company also denied the bugs could lead to patient harm, but later recanted and admitted that the issues could be dangerous to human life.
[ Los Angeles police caught up in data breach](https://www.zdnet.com/article/thousands-of-los-angeles-police-caught-up-in-data-breach-personal-records-stolen/) - Personal record of 2,500+ of LA cops stolen in the hack. The hacker emailed the department directly and included a sample of the allegedly stolen information to back up their claims.
[ Louisiana governor declares state emergency after local ransomware outbreak](https://www.zdnet.com/article/louisiana-governor-declares-state-emergency-after-local-ransomware-outbreak/) - Yep. Ransomware got so bad.
[It then hit Texas](https://www.zdnet.com/article/at-least-20-texas-local-governments-hit-in-coordinated-ransomware-attack/),
[dentist offices](https://www.zdnet.com/article/ransomware-hits-hundreds-of-dentist-offices-in-the-us/), and
[managed services providers](https://www.zdnet.com/article/ransomware-gang-hacks-msps-to-deploy-ransomware-on-customer-systems/).
[ Bluetooth exploit can track and identify iOS, Microsoft mobile device users](https://www.zdnet.com/article/bluetooth-vulnerability-can-be-exploited-to-track-and-id-iphone-smartwatch-microsoft-tablet-users/) - The vulnerability can be used to spy on users despite native OS protections that are in place and impacts Bluetooth devices on Windows 10, iOS, and macOS machines. This includes iPhones, iPads, Apple Watch models, MacBooks, and Microsoft tablets & laptops.
[ 7-Eleven Japanese customers lose $500,000 due to mobile app flaw](https://www.zdnet.com/article/7-eleven-japanese-customers-lose-500000-due-to-mobile-app-flaw/) - 7-Eleven eventually shut down the app.
### August
[ SWAPGSAttack CPU flaw](https://www.zdnet.com/article/new-windows-hack-warning-patch-intel-systems-now-to-block-swapgsattack-exploits/) - Researchers detail hardware vulnerability that bypasses mitigations against Spectre and Meltdown CPU vulnerabilities on Windows systems - and impacts all systems using Intel processors manufactured since 2012.
[ New Dragonblood vulnerabilities](https://www.zdnet.com/article/new-dragonblood-vulnerabilities-found-in-wifi-wpa3-standard/) - Earlier this year in April, two security researchers disclosed details about five vulnerabilities (
[collectively known as Dragonblood](https://www.zdnet.com/article/dragonblood-vulnerabilities-disclosed-in-wifi-wpa3-standard/)) in the WiFi Alliance's recently launched WPA3 WiFi security and authentication standard.
[ 14 iOS zero-days](https://www.zdnet.com/article/google-finds-malicious-sites-pushing-ios-exploits-for-years/) - Google finds exploits for 14 iOS vulnerabilities, grouped in five exploit chains, deployed in the wild since September 2016. Attacks aimed at Chinese Uyghur users.
[ The VPN security flaws](https://www.zdnet.com/article/hackers-mount-attacks-on-webmin-servers-pulse-secure-and-fortinet-vpns/) - Hackers mount attacks on Pulse Secure and Fortinet VPNs --
[including nation-state actors](https://www.zdnet.com/article/a-chinese-apt-is-now-going-after-pulse-secure-and-fortinet-vpn-servers/).
[ Windows CTF flaw](https://www.zdnet.com/article/vulnerability-in-microsoft-ctf-protocol-goes-back-to-windows-xp/) - Vulnerability in Microsoft CTF protocol goes back to Windows XP. Bug allows hackers to hijack any Windows app, escape sandboxes, get admin rights.
[ WS-Discovery protocol abused for DDoS attacks](https://www.zdnet.com/article/protocol-used-by-630000-devices-can-be-abused-for-devastating-ddos-attacks/) - Protocol adopted by DDoS-for-hire services, used in real-world attacks already.
[ Capitol One hack](https://www.zdnet.com/article/100-million-americans-and-6-million-canadians-caught-up-in-capital-one-breach/) - A hacker breached Capitol One, from where she stole the records of 100 million users. She also
[hacked 30 other companies](https://www.zdnet.com/article/capital-one-hacker-took-data-from-more-than-30-companies-new-court-docs-reveal/).
[ Hy-Vee card breach](https://www.zdnet.com/article/hy-vee-issues-warning-to-customers-after-discovering-point-of-sale-breach/) - Supermarket chain Hy-Vee admitted to a security breach on some of its point-of-sale (PoS) systems. The data was eventually put up for sale on hacking forums.
[ Employees connect nuclear plant to the internet so they can mine cryptocurrency](https://www.zdnet.com/article/employees-connect-nuclear-plant-to-the-internet-so-they-can-mine-cryptocurrency/) - Employees at a Ukrainian nuclear plant take unncessary security risks just to mine Bitcoin. They were eventually arrested.
[ Moscow's blockchain voting system cracked a month before election](https://www.zdnet.com/article/moscows-blockchain-voting-system-cracked-a-month-before-election/) - French researcher nets $15,000 prize for finding bugs in Moscow's Ethereum-based voting system.
[ US military purchased $32.8m worth of electronics with known security risks](https://www.zdnet.com/article/us-military-purchased-32-8m-worth-of-electronics-with-known-security-risks/) - List of vulnerable products purchased by the DoD includes Lexmark printers, GoPro cameras, and Lenovo computers.
[ AT&T employees took bribes to plant malware on the company's network](https://www.zdnet.com/article/at-t-employees-took-bribes-to-plant-malware-on-the-companys-network/) - DOJ charges Pakistani man with bribing AT&T employees more than $1 million to install malware on the company's network, unlock more than 2 million devices.
[ Windows malware strain records users on adult sites](https://www.zdnet.com/article/windows-malware-strain-records-users-on-adult-sites/) - New Varenyky trojan records videos of users navigating adult sites. Currently targeting only French users.
[ TrickBot trojan gets capability to aid SIM swapping attacks](https://www.zdnet.com/article/trickbot-todays-top-trojan-adds-feature-to-aid-sim-swapping-attacks/) - TrickBot trojan seen collecting credentials and PIN codes for Sprint, T-Mobile, and Verizon Wireless accounts.
[ Warshipping technique](https://www.zdnet.com/article/new-warshipping-technique-gives-hackers-access-to-enterprise-offices/) - Hackers could use packet delivery services to ship hacking devices right to your company's doorstep.
[ Instagram boots ad partner Hyp3r](https://www.zdnet.com/article/instagram-boots-ad-partner-hyp3r-for-mass-collection-of-user-data/) - Instagram catches ad partner collecting data on its users.
### September
[ Simjacker attack](https://www.zdnet.com/article/new-simjacker-attack-exploited-in-the-wild-to-track-users-for-at-least-two-years/) - Security researchers detailed an SMS-based attack that can allow malicious actors to track users' devices by abusing little-known apps that are running on SIM cards.
[SIM cards in 29 countries](https://www.zdnet.com/article/these-are-the-29-countries-vulnerable-to-simjacker-attacks/)were found to be impacted. A second attack named
[WIBAttack](https://www.zdnet.com/article/new-sim-card-attack-disclosed-similar-to-simjacker/)was also discovered.
[ Smart TV spying](https://www.zdnet.com/article/smart-tvs-send-user-data-to-tech-heavyweights-including-facebook-google-netflix/) - Two academic papers found that smart TVs were collecting data on users' TV-viewing habits.
[ Checkm8 iOS jailbreak](https://www.zdnet.com/article/new-checkm8-jailbreak-released-for-all-ios-devices-running-a5-to-a11-chips/) - New Checkm8 jailbreak released for all iOS devices running A5 to A11 chips, on iPhones 4S up to iPhone 8 and X. The first jailbreak exploit to work on the hardware level in the past nine years.
[ Database leaks data on most of Ecuador's citizens](https://www.zdnet.com/article/database-leaks-data-on-most-of-ecuadors-citizens-including-6-7-million-children/) - Elasticsearch server leaks personal data on Ecuador's citizens, their family trees, and children, but also some users' financial records and car registration information.
[An arrest followed](https://www.zdnet.com/article/arrest-made-in-ecuadors-massive-data-breach/).
[ Limin PDF breach](https://www.zdnet.com/article/data-of-24-3-million-lumin-pdf-users-shared-on-hacking-forum/) - The details of over 24.3 million Lumin PDF users were shared on a hacking forum in mid-September. The company acknowledged the breach a day later.
[ Heyyo dating app leak](https://www.zdnet.com/article/heyyo-dating-app-leaked-users-personal-data-photos-location-data-more/) - They leaked almost everything except private messages.
[ vBulletin zero-day and subsequent hacks](https://www.zdnet.com/article/anonymous-researcher-drops-vbulletin-zero-day-impacting-tens-of-thousands-of-sites/) - An anonymous security researcher released a zero-day in the vBulletin forum software. The vulnerability was immediately used to hack a bunch of forums.
[ Massive wave of account hijacks hits YouTube creators](https://www.zdnet.com/article/massive-wave-of-account-hijacks-hits-youtube-creators/) - YouTube creators from the auto and car community were hit with spear-phishing attacks that could bypass 2FA, allowing hackers to take over Google and YouTube accounts.
[ Lilocked (Lilu) ransomware](https://www.zdnet.com/article/thousands-of-servers-infected-with-new-lilocked-lilu-ransomware/) - Thousands of Linux servers were infected with the new Lilocked (Lilu) ransomware.
[ Over 47,000 Supermicro servers are exposing BMC ports on the internet](https://www.zdnet.com/article/over-47000-supermicro-servers-are-exposing-bmc-ports-on-the-internet/) - Researchers discovered a new remote attack vector on Supermicro servers that were found to be exposing their BMC port over the internet.
[ Ransomware incident to cost company a whopping $95 million](https://www.zdnet.com/article/ransomware-incident-to-cost-danish-company-a-whopping-95-million/) - A ransomware incident at Demant, a Danish company that makes hearing aids, has created losses of nearly $95 million, one of the most expensive incidents to date.
[ Exim vulnerability (CVE-2019-15846)](https://www.zdnet.com/article/millions-of-exim-servers-vulnerable-to-root-granting-exploit/) - Millions of Exim servers are vulnerable to a security bug that when exploited can grant attackers the ability to run malicious code with root privileges.
### October
[ Avast hack](https://www.zdnet.com/article/avast-says-hackers-breached-internal-network-through-compromised-vpn-profile/) - Czech antivirus maker discloses second attack aimed at compromising CCleaner releases, after the one suffered in 2017. Company said hacker compromised the company via a compromised VPN profile.
[ Android zero-day exploited in the wild](https://www.zdnet.com/article/google-finds-android-zero-day-impacting-pixel-samsung-huawei-xiaomi-devices/) - Google Project Zero researchers find Android zero-day exploited in the wild, impacting Pixel, Samsung, Huawei, Xiaomi devices.
[ Alexa and Google Home devices leveraged to phish and eavesdrop on users, again](https://www.zdnet.com/article/alexa-and-google-home-devices-leveraged-to-phish-and-eavesdrop-on-users-again/) - Amazon, Google fail to address security loopholes in Alexa and Home devices more than a year after first reports.
[ Czech authorities dismantle alleged Russian cyber-espionage network](https://www.zdnet.com/article/czech-authorities-dismantle-alleged-russian-cyber-espionage-network/) - Czech officials said Russian operatives used local companies to launch cyber-attacks against foreign targets. Officials said operates had support from the FSB and financial help from the local embassy.
[ Johannesburg held for ransom by hacker gang](https://www.zdnet.com/article/city-of-johannesburg-held-for-ransom-by-hacker-gang/) - A group named "Shadow Kill Hackers" is asking local officials for 4 bitcoins or they'll release city data online. Second major attack against Johannesburg after they've been hit by ransomware in July, when some locals were
[left without electricity](https://www.zdnet.com/article/ransomware-incident-leaves-some-johannesburg-residents-without-electricity/).
[ CPDoS attack](https://www.zdnet.com/article/cpdos-attack-can-poison-cdns-to-deliver-error-pages-instead-of-legitimate-sites/) - CloudFront, Cloudflare, Fastly, Akamai, and others impacted by new CPDoS web cache poisoning attack.
[ PHP7 RCE exploited in the wild](https://www.zdnet.com/article/nasty-php7-remote-code-execution-bug-exploited-in-the-wild/) - New PHP7 bug CVE-2019-11043 can allow even non-technical attackers to take over Nginx servers running the PHP-FPM module.
[ macOS systems abused in DDoS attacks](https://www.zdnet.com/article/macos-systems-abused-in-ddos-attacks/) - Up to 40,000 macOS systems expose a particular port online that can be abused for pretty big DDoS attacks.
[Editorial standards](/editorial-guidelines/) |
11,518 | 使用 ansible-bender 构建容器镜像 | https://opensource.com/article/19/10/building-container-images-ansible | 2019-10-30T09:08:37 | [
"Ansible",
"容器"
] | https://linux.cn/article-11518-1.html |
>
> 了解如何使用 Ansible 在容器中执行命令。
>
>
>

容器和 [Ansible](https://www.ansible.com/) 可以很好地融合在一起:从管理和编排到供应和构建。在本文中,我们将重点介绍构建部分。
如果你熟悉 Ansible,就会知道你可以编写一系列任务,`ansible-playbook` 命令将为你执行这些任务。你知道吗,如果你编写 Dockerfile 并运行 `podman build`,你还可以在容器环境中执行此类命令,并获得相同的结果。
这是一个例子:
```
- name: Serve our file using httpd
hosts: all
tasks:
- name: Install httpd
package:
name: httpd
state: installed
- name: Copy our file to httpd’s webroot
copy:
src: our-file.txt
dest: /var/www/html/
```
你可以在 Web 服务器本地或容器中执行这个剧本,并且只要你记得先创建 `our-file.txt`,它就可以工作。
但是这里缺少了一些东西。你需要启动(并配置)httpd 以便提供文件。这是容器构建和基础架构供应之间的区别:构建镜像时,你只需准备内容;而运行容器是另一项任务。另一方面,你可以将元数据附加到容器镜像,它会默认运行命令。
这有个工具可以帮助。试试看 `ansible-bender` 怎么样?
```
$ ansible-bender build the-playbook.yaml fedora:30 our-httpd
```
该脚本使用 `ansible-bender` 对 Fedora 30 容器镜像执行该剧本,并将生成的容器镜像命名为 `our-httpd`。
但是,当你运行该容器时,它不会启动 httpd,因为它不知道如何操作。你可以通过向该剧本添加一些元数据来解决此问题:
```
- name: Serve our file using httpd
hosts: all
vars:
ansible_bender:
base_image: fedora:30
target_image:
name: our-httpd
cmd: httpd -DFOREGROUND
tasks:
- name: Install httpd
package:
name: httpd
state: installed
- name: Listen on all network interfaces.
lineinfile:
path: /etc/httpd/conf/httpd.conf
regexp: '^Listen '
line: Listen 0.0.0.0:80
- name: Copy our file to httpd’s webroot
copy:
src: our-file.txt
dest: /var/www/html
```
现在你可以构建镜像(从这里开始,请以 root 用户身份运行所有命令。目前,Buildah 和 Podman 不会为无 root 容器创建专用网络):
```
# ansible-bender build the-playbook.yaml
PLAY [Serve our file using httpd] ****************************************************
TASK [Gathering Facts] ***************************************************************
ok: [our-httpd-20191004-131941266141-cont]
TASK [Install httpd] *****************************************************************
loaded from cache: 'f053578ed2d47581307e9ba3f64f4b4da945579a082c6f99bd797635e62befd0'
skipping: [our-httpd-20191004-131941266141-cont]
TASK [Listen on all network interfaces.] *********************************************
changed: [our-httpd-20191004-131941266141-cont]
TASK [Copy our file to httpd’s webroot] **********************************************
changed: [our-httpd-20191004-131941266141-cont]
PLAY RECAP ***************************************************************************
our-httpd-20191004-131941266141-cont : ok=3 changed=2 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
Getting image source signatures
Copying blob sha256:4650c04b851c62897e9c02c6041a0e3127f8253fafa3a09642552a8e77c044c8
Copying blob sha256:87b740bba596291af8e9d6d91e30a01d5eba9dd815b55895b8705a2acc3a825e
Copying blob sha256:82c21252bd87532e93e77498e3767ac2617aa9e578e32e4de09e87156b9189a0
Copying config sha256:44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
Writing manifest to image destination
Storing signatures
44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
Image 'our-httpd' was built successfully \o/
```
镜像构建完毕,可以运行容器了:
```
# podman run our-httpd
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.88.2.106. Set the 'ServerName' directive globally to suppress this message
```
是否提供文件了?首先,找出你容器的 IP:
```
# podman inspect -f '{{ .NetworkSettings.IPAddress }}' 7418570ba5a0
10.88.2.106
```
你现在可以检查了:
```
$ curl http://10.88.2.106/our-file.txt
Ansible is ❤
```
你文件内容是什么?
这只是使用 Ansible 构建容器镜像的介绍。如果你想了解有关 `ansible-bender` 可以做什么的更多信息,请查看它的 [GitHub](https://github.com/ansible-community/ansible-bender) 页面。构建快乐!
---
via: <https://opensource.com/article/19/10/building-container-images-ansible>
作者:[Tomas Tomecek](https://opensource.com/users/tomastomecek) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Containers and [Ansible](https://www.ansible.com/) blend together so nicely—from management and orchestration to provisioning and building. In this article, we'll focus on the building part.
If you are familiar with Ansible, you know that you can write a series of tasks, and the **ansible-playbook** command will execute them for you. Did you know that you can also execute such commands in a container environment and get the same result as if you'd written a Dockerfile and run **podman build**.
Here is an example:
```
- name: Serve our file using httpd
hosts: all
tasks:
- name: Install httpd
package:
name: httpd
state: installed
- name: Copy our file to httpd’s webroot
copy:
src: our-file.txt
dest: /var/www/html/
```
You could execute this playbook locally on your web server or in a container, and it would work—as long as you remember to create the **our-file.txt** file first.
But something is missing. You need to start (and configure) httpd in order for your file to be served. This is a difference between container builds and infrastructure provisioning: When building an image, you just prepare the content; running the container is a different task. On the other hand, you can attach metadata to the container image that tells the command to run by default.
Here's where a tool would help. How about trying **ansible-bender**?
`$ ansible-bender build the-playbook.yaml fedora:30 our-httpd`
This script uses the ansible-bender tool to execute the playbook against a Fedora 30 container image and names the resulting container image **our-httpd**.
But when you run that container, it won't start httpd because it doesn't know how to do it. You can fix this by adding some metadata to the playbook:
```
- name: Serve our file using httpd
hosts: all
vars:
ansible_bender:
base_image: fedora:30
target_image:
name: our-httpd
cmd: httpd -DFOREGROUND
tasks:
- name: Install httpd
package:
name: httpd
state: installed
- name: Listen on all network interfaces.
lineinfile:
path: /etc/httpd/conf/httpd.conf
regexp: '^Listen '
line: Listen 0.0.0.0:80
- name: Copy our file to httpd’s webroot
copy:
src: our-file.txt
dest: /var/www/html
```
Now you can build the image (from here on, please run all the commands as root—currently, Buildah and Podman won't create dedicated networks for rootless containers):
```
# ansible-bender build the-playbook.yaml
PLAY [Serve our file using httpd] ****************************************************
TASK [Gathering Facts] ***************************************************************
ok: [our-httpd-20191004-131941266141-cont]
TASK [Install httpd] *****************************************************************
loaded from cache: 'f053578ed2d47581307e9ba3f64f4b4da945579a082c6f99bd797635e62befd0'
skipping: [our-httpd-20191004-131941266141-cont]
TASK [Listen on all network interfaces.] *********************************************
changed: [our-httpd-20191004-131941266141-cont]
TASK [Copy our file to httpd’s webroot] **********************************************
changed: [our-httpd-20191004-131941266141-cont]
PLAY RECAP ***************************************************************************
our-httpd-20191004-131941266141-cont : ok=3 changed=2 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
Getting image source signatures
Copying blob sha256:4650c04b851c62897e9c02c6041a0e3127f8253fafa3a09642552a8e77c044c8
Copying blob sha256:87b740bba596291af8e9d6d91e30a01d5eba9dd815b55895b8705a2acc3a825e
Copying blob sha256:82c21252bd87532e93e77498e3767ac2617aa9e578e32e4de09e87156b9189a0
Copying config sha256:44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
Writing manifest to image destination
Storing signatures
44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
Image 'our-httpd' was built successfully \o/
```
The image is built, and it's time to run the container:
```
# podman run our-httpd
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.88.2.106. Set the 'ServerName' directive globally to suppress this message
```
Is your file being served? First, find out the IP of your container:
```
# podman inspect -f '{{ .NetworkSettings.IPAddress }}' 7418570ba5a0
10.88.2.106
```
And now you can check:
```
$ curl http://10.88.2.106/our-file.txt
Ansible is ❤
```
What were the contents of your file?
This was just an introduction to building container images with Ansible. If you want to learn more about what ansible-bender can do, please check it out on [GitHub](https://github.com/ansible-community/ansible-bender). Happy building!
## 9 Comments |
11,519 | 面向对象编程和根本状态 | https://theartofmachinery.com/2019/10/13/oop_and_essential_state.html | 2019-10-31T07:00:00 | [
"OOP"
] | https://linux.cn/article-11519-1.html | 
早在 2015 年,Brian Will 撰写了一篇有挑衅性的博客:[面向对象编程:一个灾难故事](https://medium.com/@brianwill/object-oriented-programming-a-personal-disaster-1b044c2383ab)。他随后发布了一个名为[面向对象编程很糟糕](https://www.youtube.com/watch?v=QM1iUe6IofM)的视频,该视频更加详细。
我建议你花些时间观看视频,下面是我的一段总结:
>
> OOP 的柏拉图式理想是一堆相互解耦的对象,它们彼此之间发送无状态消息。没有人真的像这样制作软件,Brian 指出这甚至没有意义:对象需要知道向哪个对象发送消息,这意味着它们需要相互引用。该视频大部分讲述的是这样一个痛点:人们试图将对象耦合以实现控制流,同时假装它们是通过设计解耦的。
>
>
>
总的来说,他的想法与我自己的 OOP 经验产生了共鸣:对象没有问题,但是我一直不满意的是*面向*对象建模程序控制流,并且试图使代码“正确地”面向对象似乎总是在创建不必要的复杂性。
有一件事我认为他无法完全解释。他直截了当地说“封装没有作用”,但在脚注后面加上“在细粒度的代码级别”,并继续承认对象有时可以奏效,并且在库和文件级别封装是可以的。但是他没有确切解释为什么有时会奏效,有时却没有奏效,以及如何和在何处划清界限。有人可能会说这使他的 “OOP 不好”的说法有缺陷,但是我认为他的观点是正确的,并且可以在根本状态和偶发状态之间划清界限。
如果你以前从未听说过“<ruby> 根本 <rt> essential </rt></ruby>”和“<ruby> 偶发 <rt> accidental </rt></ruby>”这两个术语的使用,那么你应该阅读 Fred Brooks 的经典文章《[没有银弹](http://www.cs.nott.ac.uk/%7Epszcah/G51ISS/Documents/NoSilverBullet.html)》。(顺便说一句,他写了许多很棒的有关构建软件系统的文章。)我以前曾写过[关于根本和偶发的复杂性的文章](https://theartofmachinery.com/2017/06/25/compression_complexity_and_software.html),这里有一个简短的摘要:软件是复杂的。部分原因是因为我们希望软件能够解决混乱的现实世界问题,因此我们将其称为“根本复杂性”。“偶发复杂性”是所有其它的复杂性,因为我们正尝试使用硅和金属来解决与硅和金属无关的问题。例如,对于大多数程序而言,用于内存管理或在内存与磁盘之间传输数据或解析文本格式的代码都是“偶发的复杂性”。
假设你正在构建一个支持多个频道的聊天应用。消息可以随时到达任何频道。有些频道特别有趣,当有新消息传入时,用户希望得到通知。而其他频道静音:消息被存储,但用户不会受到打扰。你需要跟踪每个频道的用户首选设置。
一种实现方法是在频道和频道设置之间使用<ruby> 映射 <rt> map </rt></ruby>(也称为哈希表、字典或关联数组)。注意,映射是 Brian Will 所说的可以用作对象的抽象数据类型(ADT)。
如果我们有一个调试器并查看内存中的映射对象,我们将看到什么?我们当然会找到频道 ID 和频道设置数据(或至少指向它们的指针)。但是我们还会找到其它数据。如果该映射是使用红黑树实现的,我们将看到带有红/黑标签和指向其他节点的指针的树节点对象。与频道相关的数据是根本状态,而树节点是偶发状态。不过,请注意以下几点:该映射有效地封装了它的偶发状态 —— 你可以用 AVL 树实现的另一个映射替换该映射,并且你的聊天程序仍然可以使用。另一方面,映射没有封装根本状态(仅使用 `get()` 和 `set()` 方法访问数据并不是封装)。事实上,映射与根本状态是尽可能不可知的,你可以使用基本相同的映射数据结构来存储与频道或通知无关的其他映射。
这就是映射 ADT 如此成功的原因:它封装了偶发状态,并与根本状态解耦。如果你思考一下,Brian 用封装描述的问题就是尝试封装根本状态。其他描述的好处是封装偶发状态的好处。
要使整个软件系统都达到这一理想状况相当困难,但扩展开来,我认为它看起来像这样:
* 没有全局的可变状态
* 封装了偶发状态(在对象或模块或以其他任何形式)
* 无状态偶发复杂性封装在单独函数中,与数据解耦
* 使用诸如依赖注入之类的技巧使输入和输出变得明确
* 组件可由易于识别的位置完全拥有和控制
其中有些违反了我很久以来的直觉。例如,如果你有一个数据库查询函数,如果数据库连接处理隐藏在该函数内部,并且唯一的参数是查询参数,那么接口会看起来会更简单。但是,当你使用这样的函数构建软件系统时,协调数据库的使用实际上变得更加复杂。组件不仅以自己的方式做事,而且还试图将自己所做的事情隐藏为“实现细节”。数据库查询需要数据库连接这一事实从来都不是实现细节。如果无法隐藏某些内容,那么显露它是更合理的。
我对将面向对象编程和函数式编程放在对立的两极非常警惕,但我认为从函数式编程进入面向对象编程的另一极端是很有趣的:OOP 试图封装事物,包括无法封装的根本复杂性,而纯函数式编程往往会使事情变得明确,包括一些偶发复杂性。在大多数时候,这没什么问题,但有时候(比如[在纯函数式语言中构建自我指称的数据结构](https://wiki.haskell.org/Tying_the_Knot))设计更多的是为了函数编程,而不是为了简便(这就是为什么 [Haskell 包含了一些“<ruby> 逃生出口 <rt> escape hatches </rt></ruby>”](https://en.wikibooks.org/wiki/Haskell/Mutable_objects#The_ST_monad))。我之前写过一篇[所谓“<ruby> 弱纯性 <rt> weak purity </rt></ruby>”的中间立场](https://theartofmachinery.com/2016/03/28/dirtying_pure_functions_can_be_useful.html)。
Brian 发现封装对更大规模有效,原因有几个。一个是,由于大小的原因,较大的组件更可能包含偶发状态。另一个是“偶发”与你要解决的问题有关。从聊天程序用户的角度来看,“偶发的复杂性”是与消息、频道和用户等无关的任何事物。但是,当你将问题分解为子问题时,更多的事情就变得“根本”。例如,在解决“构建聊天应用”问题时,可以说频道名称和频道 ID 之间的映射是偶发的复杂性,而在解决“实现 `getChannelIdByName()` 函数”子问题时,这是根本复杂性。因此,封装对于子组件的作用比对父组件的作用要小。
顺便说一句,在视频的结尾,Brian Will 想知道是否有任何语言支持*无法*访问它们所作用的范围的匿名函数。[D](https://dlang.org) 语言可以。 D 中的匿名 Lambda 通常是闭包,但是如果你想要的话,也可以声明匿名无状态函数:
```
import std.stdio;
void main()
{
int x = 41;
// Value from immediately executed lambda
auto v1 = () {
return x + 1;
}();
writeln(v1);
// Same thing
auto v2 = delegate() {
return x + 1;
}();
writeln(v2);
// Plain functions aren't closures
auto v3 = function() {
// Can't access x
// Can't access any mutable global state either if also marked pure
return 42;
}();
writeln(v3);
}
```
---
via: <https://theartofmachinery.com/2019/10/13/oop_and_essential_state.html>
作者:[Simon Arneaud](https://theartofmachinery.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Translations:[中文](https://linux.cn/article-11519-1.html)
Back in 2015, Brian Will wrote a provocative blog post: [Object-Oriented
Programming: A Disaster Story](https://medium.com/@brianwill/object-oriented-programming-a-personal-disaster-1b044c2383ab). He followed it up with a video called [Object-Oriented Programming is Bad](https://www.youtube.com/watch?v=QM1iUe6IofM), which is much more detailed. I
recommend taking the time to watch the video, but here’s my one-paragraph summary:
The Platonic ideal of OOP is a sea of decoupled objects that send stateless messages to one another. No one really makes software like that, and Brian points out that it doesn’t even make sense: objects need to know which other objects to send messages to, and that means they need to hold references to one another. Most of the video is about the pain that happens trying to couple objects for control flow, while pretending that they’re decoupled by design.
Overall his ideas resonate with my own experiences of OOP: objects can be okay, but I’ve just never been satisfied
with object-*orientation* for modelling a program’s control flow, and trying to make code “properly”
object-oriented always seems to create layers of unneccessary complexity.
There’s one thing I don’t think he explains fully. He says outright that “encapsulation does not work”, but follows it with the footnote “at fine-grained levels of code”, and goes on to acknowledge that objects can sometimes work, and that encapsulation can be okay at the level of, say, a library or file. But he doesn’t explain exactly why it sometimes works and sometimes doesn’t, and how/where to draw the line. Some people might say that makes his “OOP is bad” claim flawed, but I think his point stands, and that the line can be drawn between essential state and accidental state.
If you haven’t heard this usage of the terms “essential” and “accidental” before, you should check out Fred Brooks’
classic [No Silver Bullet](http://www.cs.nott.ac.uk/~pszcah/G51ISS/Documents/NoSilverBullet.html) essay.
(He’s written many great essays about building software systems, by the way.) I’ve aleady written [my own post about essential and accidential complexity](/2017/06/25/compression_complexity_and_software.html)
before, but here’s a quick TL;DR: Software is complex. Partly that’s because we want software to solve messy real-world
problems, and we call that “essential complexity”. “Accidental complexity” is all the other complexity that exists
because we’re trying to use silicon and metal to solve problems that have nothing to do with silicon and metal. For
example, code for memory management, or transferring data between RAM and disk, or parsing text formats, is all
“accidental complexity” for most programs.
Suppose you’re building a chat application that supports multiple channels. Messages can arrive for any channel at any time. Some channels are especially interesting and the user wants to be notified or pinged when a new message comes in. Other channels are muted: the message is stored, but the user isn’t interrupted. You need to keep track of the user’s preferred setting for each channel.
One way to do it is to use a map (a.k.a, hash table, dictionary or associative array) between the channels and channel settings. Note that a map is the kind of abstract data type (ADT) that Brian Will said can work as an object.
If we get a debugger and look inside the map object in memory, what will we see? We’ll find channel IDs and channel
settings data of course (or pointers to them, at least). But we’ll also find other data. If the map is implemented
using a red-black tree, we’ll see tree node objects with red/black labels and pointers to other nodes. The
channel-related data is the essential state, and the tree nodes are the accidental state. Notice something, though: The
map effectively encapsulates its accidental state — you could replace the map with another one implemented using AVL
trees and your chat app would still work. On the other hand, the map doesn’t encapsulate the essential state (simply
using `get()`
and `set()`
methods to access data isn’t encapsulation). In fact, the map is as
agnostic as possible about the essential state — you could use basically the same map data structure to store other
mappings unrelated to channels or notifications.
And that’s why the map ADT is so successful: it encapsulates accidental state and is decoupled from essential state. If you think about it, the problems that Brian describes with encapsulation are problems with trying to encapsulate essential state. The benefits that others describe are benefits from encapsulating accidental state.
It’s pretty hard to make entire software systems meet this ideal, but scaling up, I think it looks something like this:
- No global, mutable state
- Accidental state encapsulated (in objects or modules or whatever)
- Stateless accidental complexity enclosed in free functions, decoupled from data
- Inputs and outputs made explicit using tricks like dependency injection
- Components fully owned and controlled from easily identifiable locations
Some of this goes against instincts I had a long time ago. For example, if you have a function that makes a database query, the interface looks simpler and nicer if the database connection handling is hidden inside the function, and the only parameters are the query parameters. However, when you build a software system out of functions like this, it actually becomes more complex to coordinate the database usage. Not only are the components doing things their own ways, they’re trying to hide what they’re doing as “implementation details”. The fact that a database query requires a database connection never was an implementation detail. If something can’t be hidden, it’s saner to make it explicit.
I’m wary of feeding the OOP and functional programming false dichotomy, but I think it’s interesting that FP goes to
the opposite extreme of OOP: OOP tries to encapsulate things, including the essential complexity that can’t be
encapsulated, while pure FP tends to make things explicit, including some accidental complexity. Most of the time,
that’s the safer side to go wrong, but sometimes (such as when [building self-referential data structures in a purely functional
language](https://wiki.haskell.org/Tying_the_Knot)) you can get designs that are more for the sake of FP than for the sake of simplicity (which is why
[Haskell includes some escape hatches](https://en.wikibooks.org/wiki/Haskell/Mutable_objects#The_ST_monad)).
I’ve written before about [the middle ground of
so-called “weak purity”](/2016/03/28/dirtying_pure_functions_can_be_useful.html).
Brian found that encapsulation works at a larger scale for a couple of reasons. One is that larger components are
simply more likely to contain accidental state, just because of size. Another is that what’s “accidental” is relative
to what problem you’re solving. From the chat app user’s point of view, “accidental complexity” is anything unrelated
to messages and channels and users, etc. As you break the problems into subproblems, however, more things become
essential. For example, the mapping between channel names and channel IDs is arguably accidental complexity when
solving the “build a chat app” problem, but it’s essential complexity when solving the “implement the `getChannelIdByName()`
function” subproblem. So, encapsulation tends to be
less useful for subcomponents than supercomponents.
By the way, at the end of his video, Brian Will wonders if any language supports anonymous functions that
*can’t* access the scope they’re in. [D](https://dlang.org) does. Anonymous lambdas in D are normally
closures, but anonymous stateless functions can also be declared if that’s what you want:
```
import std.stdio;
void main()
{
int x = 41;
// Value from immediately executed lambda
auto v1 = () {
return x + 1;
}();
writeln(v1);
// Same thing
auto v2 = delegate() {
return x + 1;
}();
writeln(v2);
// Plain functions aren't closures
auto v3 = function() {
// Can't access x
// Can't access any mutable global state either if also marked pure
return 42;
}();
writeln(v3);
}
``` |
11,520 | 2019 年最可怕的黑客事件与安全漏洞(下) | https://www.zdnet.com/article/the-scariest-hacks-and-vulnerabilities-of-2019/ | 2019-10-31T07:02:00 | [
"安全"
] | https://linux.cn/article-11520-1.html | 
是的,这是年终摘要文章之一。这是一篇很长的文章,因为就网络安全新闻来说,2019 年就是一场灾难,每周都会有一个或多个重大事件发生。
以下是按月组织的过去 10 个月安全灾难的摘要。
### 七月
[哈萨克斯坦政府拦截了所有本地 HTTPS 流量](https://www.zdnet.com/article/kazakhstan-government-is-now-intercepting-all-https-traffic/):HTTPS 拦截工作[针对 Facebook,Google,Twitter 和其他站点](https://www.zdnet.com/article/kazakhstans-https-interception-efforts-target-facebook-google-twitter-others/)。[苹果、谷歌和 Mozilla](https://www.zdnet.com/article/apple-google-and-mozilla-block-kazakhstans-https-intercepting-certificate/) 最终干预并禁止了用于 HTTPS 中间人攻击的证书。
[黑客窃取了数百万保加利亚人的数据](https://www.zdnet.com/article/hacker-steals-data-of-millions-of-bulgarians-emails-it-to-local-media/):一名黑客窃取了数百万保加利亚人的个人详细信息,并将窃取的数据的下载链接通过电子邮件发送给了本地新闻出版物。该数据窃取自该国国家税务局,[最终在网上泄露](https://www.zdnet.com/article/bulgarias-hacked-database-is-now-available-on-hacking-forums/)。
[黑客侵入了 FSB 的承包商](https://www.zdnet.com/article/hackers-breach-fsb-contractor-expose-tor-deanonymization-project/):黑客侵入了俄罗斯国家情报局 FSB 的承包商 SyTech,他们从那里窃取了该公司代表该机构开展的内部项目的信息,包括将 Tor 流量匿名化的信息。
[iMessages 可能使你的 iPhone 变砖](https://www.zdnet.com/article/google-project-zero-reveals-bad-imessages-could-have-bricked-your-iphone/):该漏洞在被广泛利用之前得到了修补。
[Urgent/11 安全漏洞](https://www.zdnet.com/article/urgent11-security-flaws-impact-routers-printers-scada-and-many-iot-devices/):TCP 库中的主要错误影响了路由器、打印机、SCADA、医疗设备和许多 IoT 设备。
[苹果公司的 AWDL 协议受到安全漏洞的困扰](https://www.zdnet.com/article/apples-awdl-protocol-plagued-by-flaws-that-enable-tracking-and-mitm-attacks/):苹果公司在五月份修补了一个错误,但学者说,其余的漏洞需要重新设计某些苹果服务。错误会启用跟踪和中间人攻击。
[DHS 警告小型飞机的 CAN 总线漏洞](https://www.zdnet.com/article/dhs-warns-about-can-bus-vulnerabilities-in-small-aircraft/):DHS 网络安全机构 CISA 建议这些小型飞机的所有者“尽其所能”限制对飞机的访问,以防止这个漏洞可能被用来破坏飞机。
[GE 麻醉机中发现的漏洞](https://www.zdnet.com/article/vulnerabilities-found-in-ge-anesthesia-machines/):GE 建议设备所有者不要将脆弱的麻醉机连接到医院的主要网络。该公司否认这些漏洞可能导致患者受到伤害,但后来撤回该说法并承认这些问题可能对人类生命构成危险。
[洛杉矶警方陷入数据泄露](https://www.zdnet.com/article/thousands-of-los-angeles-police-caught-up-in-data-breach-personal-records-stolen/):黑客窃取了 2500 多名洛杉矶警察的个人记录。黑客直接通过电子邮件发送给该部门,并提供了一些据称是被盗信息的样本以支持他们的说法。
[路易斯安那州州长在当地勒索软件爆发后宣布州紧急状态](https://www.zdnet.com/article/louisiana-governor-declares-state-emergency-after-local-ransomware-outbreak/):是的。勒索软件变得非常糟糕。然后它[袭击了德克萨斯州](https://www.zdnet.com/article/at-least-20-texas-local-governments-hit-in-coordinated-ransomware-attack/)、[牙医办公室](https://www.zdnet.com/article/ransomware-hits-hundreds-of-dentist-offices-in-the-us/)和[托管服务提供商](https://www.zdnet.com/article/ransomware-gang-hacks-msps-to-deploy-ransomware-on-customer-systems/)。
[蓝牙漏洞利用可以跟踪和识别 iOS、微软移动设备用户](https://www.zdnet.com/article/bluetooth-vulnerability-can-be-exploited-to-track-and-id-iphone-smartwatch-microsoft-tablet-users/):尽管存在本机操作系统保护但该漏洞可用于监视用户,它影响 Windows 10、iOS 和 macOS 计算机上的蓝牙设备。其中包括 iPhone、iPad、Apple Watch、MacBook 和微软的平板电脑和笔记本电脑。
[“7-11” 日本的客户由于移动应用漏洞而损失了 50 万美元](https://www.zdnet.com/article/7-eleven-japanese-customers-lose-500000-due-to-mobile-app-flaw/):7-11 最终关闭了该应用。
### 八月
[SWAPGSAttack CPU 漏洞](https://www.zdnet.com/article/new-windows-hack-warning-patch-intel-systems-now-to-block-swapgsattack-exploits/):研究人员详细介绍了该硬件漏洞,它绕过了 Windows 系统上针对 Spectre 和 Meltdown CPU 漏洞的缓解措施,并影响了所有使用自 2012 年以来制造的英特尔处理器的系统。
[新的 Dragonblood 漏洞](https://www.zdnet.com/article/new-dragonblood-vulnerabilities-found-in-wifi-wpa3-standard/):今年四月初,两名安全研究人员披露了 WiFi 联盟最近发布的 WPA3 WiFi 安全和身份验证标准中五个漏洞([统称为 Dragonblood](https://www.zdnet.com/article/dragonblood-vulnerabilities-disclosed-in-wifi-wpa3-standard/))的详细信息。
[14 个 iOS 零日漏洞](https://www.zdnet.com/article/google-finds-malicious-sites-pushing-ios-exploits-for-years/):自 2016 年 9 月以来,谷歌发现了针对 14 个 iOS 漏洞的攻击,这些漏洞分为五个漏洞利用链,并已被广泛部署。
[VPN 安全漏洞](https://www.zdnet.com/article/hackers-mount-attacks-on-webmin-servers-pulse-secure-and-fortinet-vpns/):黑客对 Pulse Secure 和 Fortinet VPN 发起攻击。
[Windows CTF 漏洞](https://www.zdnet.com/article/vulnerability-in-microsoft-ctf-protocol-goes-back-to-windows-xp/):Microsoft CTF 协议中的漏洞可以追溯到 Windows XP。该错误允许黑客劫持任何 Windows 应用,逃脱沙箱并获得管理员权限。
[WS-Discovery 协议被滥用于 DDoS 攻击](https://www.zdnet.com/article/protocol-used-by-630000-devices-can-be-abused-for-devastating-ddos-attacks/):该协议被 DDoS 租用服务所利用,已在实际攻击中使用。
[Capitol One 黑客事件](https://www.zdnet.com/article/100-million-americans-and-6-million-canadians-caught-up-in-capital-one-breach/):一名黑客侵入了 Capitol One,从那里窃取了 1 亿用户的记录。她还[入侵了其他 30 家公司](https://www.zdnet.com/article/capital-one-hacker-took-data-from-more-than-30-companies-new-court-docs-reveal/)。
[Hy-Vee 卡泄露](https://www.zdnet.com/article/hy-vee-issues-warning-to-customers-after-discovering-point-of-sale-breach/):超市连锁店 Hy-Vee 承认其某些 PoS 系统存在安全漏洞。该数据最终被在黑客论坛上出售。
[员工将核电厂连接到互联网,以便他们可以开采加密货币](https://www.zdnet.com/article/employees-connect-nuclear-plant-to-the-internet-so-they-can-mine-cryptocurrency/):乌克兰核电厂的员工为了开采比特币而承担了不必要的安全风险。他们最终被捕。
[莫斯科的区块链投票系统在大选前一个月就被攻破了](https://www.zdnet.com/article/moscows-blockchain-voting-system-cracked-a-month-before-election/):法国研究人员因在基于以太坊的投票系统中发现漏洞而获得 15000 美元的奖金。
[美国军方购买了价值 3280 万美元的具有已知安全风险的电子产品](https://www.zdnet.com/article/us-military-purchased-32-8m-worth-of-electronics-with-known-security-risks/):国防部购买的易受攻击产品包括 Lexmark 打印机、GoPro相机和联想计算机。
[AT&T 员工受贿以在公司网络上植入恶意软件](https://www.zdnet.com/article/at-t-employees-took-bribes-to-plant-malware-on-the-companys-network/):美国司法部指控巴基斯坦男子贿赂 AT&T 员工超过 100 万美元,以在该公司网络上安装恶意软件,解锁超过 200 万台设备。
[Windows 恶意软件会记录用户在成人网站上的访问](https://www.zdnet.com/article/windows-malware-strain-records-users-on-adult-sites/):新的 Varenyky 木马会记录用户浏览成人网站的桌面视频。当前仅针对法国用户。
[TrickBot 木马具备协助 SIM 交换攻击的功能](https://www.zdnet.com/article/trickbot-todays-top-trojan-adds-feature-to-aid-sim-swapping-attacks/):TrickBot 木马可以收集 Sprint、T-Mobile 和 Verizon Wireless 帐户的凭据和 PIN 码。
[战争技术](https://www.zdnet.com/article/new-warshipping-technique-gives-hackers-access-to-enterprise-offices/):黑客可以使用包裹传递服务将黑客设备直接运送到你公司的门口。
[Instagram 踢掉了广告合作伙伴 Hyp3r](https://www.zdnet.com/article/instagram-boots-ad-partner-hyp3r-for-mass-collection-of-user-data/):Instagram 发现该广告合作伙伴收集其用户数据。
### 九月
[Simjacker 攻击](https://www.zdnet.com/article/new-simjacker-attack-exploited-in-the-wild-to-track-users-for-at-least-two-years/):安全研究人员详细介绍了一种基于 SMS 的攻击,该攻击可以通过滥用 SIM 卡上运行的鲜为人知的应用程序,使恶意行为者可以跟踪用户的设备。发现 [29 个国家/地区](https://www.zdnet.com/article/these-are-the-29-countries-vulnerable-to-simjacker-attacks/)的 SIM 卡受到了影响。 还发现了第二起名为 [WIBAttack](https://www.zdnet.com/article/new-sim-card-attack-disclosed-similar-to-simjacker/) 的攻击。
[智能电视间谍活动](https://www.zdnet.com/article/smart-tvs-send-user-data-to-tech-heavyweights-including-facebook-google-netflix/):两项学术论文发现,智能电视正在收集有关用户的电视观看习惯的数据。
[Checkm8 iOS 越狱](https://www.zdnet.com/article/new-checkm8-jailbreak-released-for-all-ios-devices-running-a5-to-a11-chips/):针对所有运行 A5 至 A11 芯片的 iOS 设备(在 iPhone 4S 以及 iPhone 8 和 X 上)发布的新 Checkm8 越狱。过去九年来,这是第一个在硬件级别起作用的越狱漏洞。
[数据库泄漏了厄瓜多尔大多数公民的数据](https://www.zdnet.com/article/database-leaks-data-on-most-of-ecuadors-citizens-including-6-7-million-children/):Elasticsearch 服务器泄漏了有关厄瓜多尔公民其家谱和孩子的个人数据,还泄漏了一些用户的财务记录和汽车登记信息。[该公司高管随后被捕](https://www.zdnet.com/article/arrest-made-in-ecuadors-massive-data-breach/)。
[Limin PDF 泄露事件](https://www.zdnet.com/article/data-of-24-3-million-lumin-pdf-users-shared-on-hacking-forum/):九月中旬,超过 2430 万 Lumin PDF 的用户详细信息在黑客论坛上被分享。该公司在第二天承认这次泄露。
[Heyyo 约会应用程序泄漏事件](https://www.zdnet.com/article/heyyo-dating-app-leaked-users-personal-data-photos-location-data-more/):他们泄漏了除私人消息以外的几乎所有内容。
[vBulletin 零日漏洞和随后的黑客攻击](https://www.zdnet.com/article/anonymous-researcher-drops-vbulletin-zero-day-impacting-tens-of-thousands-of-sites/):一位匿名安全研究人员发布了 vBulletin 论坛软件中的零日漏洞。该漏洞立即被黑客用于入侵一系列论坛。
[大量的帐户劫持事件袭击了 YouTube 创作者](https://www.zdnet.com/article/massive-wave-of-account-hijacks-hits-youtube-creators/):汽车社区的 YouTube 创作者遭受了鱼叉式网络钓鱼攻击,这些攻击可以绕过 2FA,从而使黑客可以接管其 Google 和 YouTube 帐户。
[Lilocked(Lilu)勒索软件](https://www.zdnet.com/article/thousands-of-servers-infected-with-new-lilocked-lilu-ransomware/):成千上万的 Linux 服务器感染了新的 Lilocked(Lilu)勒索软件。
[超过 47,000 台超微服务器正在互联网上暴露了其 BMC 端口](https://www.zdnet.com/article/over-47000-supermicro-servers-are-exposing-bmc-ports-on-the-internet/):研究人员在超微服务器上发现了一个新的远程攻击方式,发现它在互联网上暴露了其 BMC 端口。
[勒索软件事件给公司造成了高达 9500 万美元的损失](https://www.zdnet.com/article/ransomware-incident-to-cost-danish-company-a-whopping-95-million/):丹麦制造助听器 Demant 的勒索软件事件造成了近 9500 万美元的损失,这是迄今为止最昂贵的事件之一。
[Exim 漏洞(CVE-2019-15846)](https://www.zdnet.com/article/millions-of-exim-servers-vulnerable-to-root-granting-exploit/):数百万的 Exim 服务器容易受到一个安全漏洞的攻击,利用该漏洞可以使攻击者能够以 root 特权运行恶意代码。
### 十月
[Avast 黑客事件](https://www.zdnet.com/article/avast-says-hackers-breached-internal-network-through-compromised-vpn-profile/):这家捷克的杀毒软件制造商在 2017 年遭受攻击之后,披露了其受到了第二次攻击,旨在破坏 CCleaner 版本。该公司表示,黑客通过受损的 VPN 配置文件破坏了该公司。
[被广泛利用的 Android 零日漏洞](https://www.zdnet.com/article/google-finds-android-zero-day-impacting-pixel-samsung-huawei-xiaomi-devices/):Google Project Zero 研究人员发现了被广泛利用的 Android 零日漏洞,影响了 Pixel、三星、华为、小米设备。
[Alexa 和 Google Home 设备再次被利用来网络钓鱼和窃听用户](https://www.zdnet.com/article/alexa-and-google-home-devices-leveraged-to-phish-and-eavesdrop-on-users-again/):亚马逊、Google 在首次报告后一年多未能解决 Alexa 和 Home 设备中的安全漏洞。
[捷克当局拆除了据称是俄罗斯的网络间谍网络](https://www.zdnet.com/article/czech-authorities-dismantle-alleged-russian-cyber-espionage-network/):捷克官员说,俄罗斯特工利用当地公司对外国目标发起网络攻击。官员们表示,运营得到了俄罗斯国家情报局 FSB 的支持以及当地大使馆的财政帮助。
[约翰内斯堡被黑客团伙勒索赎金](https://www.zdnet.com/article/city-of-johannesburg-held-for-ransom-by-hacker-gang/):一个名为“Shadow Kill Hackers”的组织正在向当地官员索要 4 枚比特币,否则他们将在线发布该城市数据。这是在七月遭到勒索软件攻击之后对约翰内斯堡的第二次重大袭击,当时导致一些当地居民[断电](https://www.zdnet.com/article/ransomware-incident-leaves-some-johannesburg-residents-without-electricity/)。
[CPDoS 攻击事件](https://www.zdnet.com/article/cpdos-attack-can-poison-cdns-to-deliver-error-pages-instead-of-legitimate-sites/):CloudFront、Cloudflare、Fastly、Akamai 等受到新的 CPDoS Web 缓存中毒攻击的影响。
[被广泛利用的 PHP7 RCE](https://www.zdnet.com/article/nasty-php7-remote-code-execution-bug-exploited-in-the-wild/):新的 PHP7 错误 CVE-2019-11043 甚至可以使非技术攻击者接管运行 PHP-FPM 模块的 Nginx 服务器。
[遭受 DDoS 攻击的 macOS 系统](https://www.zdnet.com/article/macos-systems-abused-in-ddos-attacks/):多达 4 万个 macOS 系统在线暴露了一个特定的端口,该端口可能被滥用于相当大的 DDoS 攻击。
| 200 | OK | [2010s: The Decade in Review](/topic/decade-in-review/)
# The scariest hacks and vulnerabilities of 2019

Yes, this is one of those end-of-year summaries. And it's a long one, since 2019 has been a disaster in terms of cyber-security news, with one or more major stories breaking on a weekly basis.
Below is a summary for the past 10 months of security disasters, organized by month.
### January
[ Severe vulnerability in Apple FaceTime](https://www.zdnet.com/article/apple-facetime-exploit-found-by-14-year-old-playing-fortnite/) - A bug in Apple's FaceTime app let attackers call and self-answer a FaceTime call without any user interaction from the callee, opening the door for secret surveillance.
[ North Korean hackers infiltrate Chile's ATM network after Skype job interview](https://www.zdnet.com/article/north-korean-hackers-infiltrate-chiles-atm-network-after-skype-job-interview/) - the article's title is self-explanatory, and the story is worth your time to read.
[ Hackers breach and steal data from South Korea's Defense Ministry](https://www.zdnet.com/article/hackers-breach-and-steal-data-from-south-koreas-defense-ministry/) - Seoul government said hackers breached 30 computers and stole data from 10. The hacked computers stored data on weapons and munitions acquisition.
[ Someone hacked the PHP PEAR website](https://www.zdnet.com/article/mystery-still-surrounds-hack-of-php-pear-website/) - We still don't know what happened there, but some hacker breached the PHP PEAR repo and backdoored a version of the PHP PEAR package manager.
[ Security flaws found in 26 low-end cryptocurrencies](https://www.zdnet.com/article/security-flaws-found-in-26-low-end-cryptocurrencies/) - This report shows just how dangerous some low-end, no-name cryptocurrencies are, and how hackers could steal funds en-masse at any time.
[ Oklahoma gov data leak exposes FBI investigation records](https://www.zdnet.com/article/oklahoma-gov-data-leak-exposes-millions-of-department-files-fbi-investigations/) - An Oklahoma Department of Securities server allowed anyone to download government files, such as internal files, and even FBI investigations.
[ Iranian hackers suspected in worldwide DNS hijacking campaign](https://www.zdnet.com/article/iranian-hackers-suspected-in-worldwide-dns-hijacking-campaign/) -
[FireEye](https://www.fireeye.com/blog/threat-research/2019/01/global-dns-hijacking-campaign-dns-record-manipulation-at-scale.html), and later
[Cisco Talos](https://blog.talosintelligence.com/2019/04/seaturtle.html), disclosed a global campaign carried out by Iranian hackers who redirected traffic from companies all over their globe through their Iranian servers, recording company credentials for future attacks.To do this, they hacked DNS management accounts at domain name registrars, in order to execute DNS hijacking attacks. These same hackers also
[breached Greece's top-level domain registrar](https://www.zdnet.com/article/hackers-breached-greeces-top-level-domain-registrar/).
[ SCP implementations impacted by 36-years-old security flaws](https://www.zdnet.com/article/scp-implementations-impacted-by-36-years-old-security-flaws/) - All SCP (Secure Copy Protocol) implementations from the last 36 years, since 1983, were found to be vulnerable to four security bugs that allowed a malicious SCP server to make unauthorized changes to a client's (user's) system and hide malicious operations in the terminal.
**Yearly LTE security flaws** - Two sets of new LTE security flaws were discovered this year. One that impacted [3G, 4G, and 5G](https://www.zdnet.com/article/new-security-flaw-impacts-5g-4g-and-3g-telephony-protocols/), and a second set of [36 vulnerabilities](https://www.zdnet.com/article/researchers-find-36-new-security-flaws-in-lte-protocol/) found found after a fuzzing project carried out by South Korean security researchers.
[ Websites can steal browser data via extensions APIs](https://www.zdnet.com/article/websites-can-steal-browser-data-via-extensions-apis/) - Researcher finds nearly 200 Chrome, Firefox, and Opera extensions vulnerable to attacks from malicious sites.
[ WiFi firmware bug affects laptops, smartphones, routers, gaming devices](https://www.zdnet.com/article/wifi-firmware-bug-affects-laptops-smartphones-routers-gaming-devices/) - Major security flaw found in Marvell Avastar chipset. List of impacted devices includes PS4, Xbox One, Samsung Chromebooks, and Microsoft Surface devices.
**Malware found preinstalled on Android devices** - Happened twice in 2019. First, in January, when researchers found [malware inside an Alcatel app preinstalled on Alcatel smartphones](https://www.zdnet.com/article/malware-found-preinstalled-on-some-alcatel-smartphones/). Second, in June, when Germany's cyber-security agencies found [a backdoor in four Chinese smartphone models](https://www.zdnet.com/article/germany-backdoor-found-in-four-smartphone-models-20000-users-infected/).
### February
[ Leaky DB exposes China's Muslim-tracking practices](https://www.zdnet.com/article/chinese-company-leaves-muslim-tracking-facial-recognition-database-exposed-online/) - Security researcher Victor Gevers found a leaky DB from a Chinese company that exposed its Muslim-tracking facial recognition software, inadvertently revealing China's Uyghur-tracking practices.
[ Major WinRAR bugs exposed](https://www.zdnet.com/article/winrar-versions-released-in-the-last-19-years-impacted-by-severe-security-flaw/) - Check Point researchers found a WinrAR bug that impacted all the WinRAR versions releassed since 2000. Over 500 million WinRAR users were at risk.
[The bugs eventually become widely used](https://www.zdnet.com/article/100-unique-exploits-and-counting-for-latest-winrar-security-bug/)by cyber-criminals and nation-state hackers at the same time.
[ New WinPot malware can make ATMs spit out cash](https://www.zdnet.com/article/this-malware-turns-atm-hijacking-into-slot-machine-games/) - WinPot has been on sale on underground forums since March 2018.
[ Tor traffic from individual Android apps detected with 97% accuracy](https://www.zdnet.com/article/tor-traffic-from-individual-android-apps-detected-with-97-percent-accuracy/) - New machine learning algorithm can detect when Tor users are using a specific app, such as YouTube, Instagram, Spotify, others, via Tor.
[ Hackers wipe US servers of email provider VFEmail](https://www.zdnet.com/article/hackers-wipe-us-servers-of-email-provider-vfemail/) - Hackers did not ask for a ransom. VFEmail described the incident as "attack and destroy."
[ Thunderclap vulnerability](https://www.zdnet.com/article/thunderclap-flaws-impact-how-windows-mac-linux-handle-thunderbolt-peripherals/) - The security flaw impacts how Windows, Mac, Linux handle Thunderbolt peripherals. They allow the creation of highly dangerous malicious peripherals that can steal data from OS memory.
**PDF protocol attacks** - A team of German academics found [a way to fake signatures](https://www.zdnet.com/article/researchers-break-digital-signatures-for-most-desktop-pdf-viewers/) in PDF documents, and later this year, [a way to break PDF encryption](https://www.zdnet.com/article/researchers-break-digital-signatures-for-most-desktop-pdf-viewers/).
**Hiding malware using the CPU** - Academics have found ways to hide malware on a computer [using speculative execution](https://www.zdnet.com/article/researchers-hide-malware-in-benign-apps-with-the-help-of-speculative-execution/) and [Intel's SGX enclave system](https://www.zdnet.com/article/researchers-hide-malware-in-intel-sgx-enclaves/).
### March
[ Hackers take tornado sirens offline before major storm](https://www.zdnet.com/article/hacked-tornado-sirens-taken-offline-in-two-texas-cities-ahead-of-major-storm/) - Yeah. That was just evil.
[ The ASUS supply-chain hack](https://www.zdnet.com/article/supply-chain-attack-installs-backdoors-through-hijacked-asus-live-update-software/) - Hackers hijacked the ASUS Live Update utility to deploy malware on users' systems. The hack took place in 2018, but was disclosed in March.
[Over one million PCs](https://www.zdnet.com/article/researchers-publish-list-of-mac-addresses-targeted-in-asus-hack/)were believed to have been impacted.
[ Ring of GitHub accounts promoting 300+ backdoored apps](https://www.zdnet.com/article/researchers-uncover-ring-of-github-accounts-promoting-300-backdoored-apps/) - GitHub ring consisting of 89 accounts promoted 73 repos containing over 300 backdoored Windows, Mac, and Linux apps.
[ Bithumb cryptocurrency exchange hacked a third time in two years](https://www.zdnet.com/article/bithumb-cryptocurrency-exchange-hacked-a-third-time-in-two-years/) - Hackers believed to have made off with nearly $20 million in EOS and Ripple cryptocurrencies. At this point, Bithumb appears that they're not even trying anymore.
[ Chrome zero-day under active attacks](https://www.zdnet.com/article/google-reveals-chrome-zero-day-under-active-attacks/) - CVE-2019-5786, a bug in Chrome's FileReader API, was exploited in the wild to read content from a user's computer. Google said the bug was
[used together with a Windows 7 zero-day](https://www.zdnet.com/article/google-chrome-zero-day-was-used-together-with-a-windows-7-zero-day/)by a nation-state attacker.
[ New Intel CPU bug](https://www.zdnet.com/article/researchers-discover-and-abuse-new-undocumented-feature-in-intel-chipsets/) - Researchers find new Intel VISA (Visualization of Internal Signals Architecture) debugging technology.
[ Hacks at French gas stations](https://www.zdnet.com/article/french-gas-stations-robbed-after-forgetting-to-change-gas-pump-pins/)- Criminal group steals 120,000 litres of fuel from Total gas stations around Paris after gas stations forgot to change gas station pump PINs.
[ Citrix data breach](https://www.zdnet.com/article/citrix-discloses-security-breach-of-internal-network/) - Citrix learned of the hack from the FBI. Hackers stole business documents. A lot of Citrix customers' are government agencies and Fortune 500 companies.
**Smartphone unlocking issues** - We've had a few this year, but the first case was reported in March when a user found that Samsung Galaxy S10 facial recognition can be fooled by [a video of the phone owner](https://www.zdnet.com/article/samsung-galaxy-s10-facial-recognition-fooled-by-a-video-of-the-phone-owner/). A month later, a user found that he could unlock a Nokia 9 smartphone's fingerprint scanner[ with a pack of gum](https://www.zdnet.com/article/nokia-9-buggy-update-lets-anyone-bypass-fingerprint-scanner-with-a-pack-of-gum/). Then in October, users found that you could unlock a Pixel 4's facial unlock technology [while you had your eyes closed](https://www.zdnet.com/article/google-pixel-4s-face-unlock-works-even-if-you-have-your-eyes-closed/), and a couple found that they could [unlock Samsung S10 devices using fingerprint protection](https://www.zdnet.com/article/samsung-to-patch-s10-fingerprint-sensor-bug-next-week/) with any user's finger if the device was protected by a silicon case. In fact, the issue with bypassing facial recognition is quite widespread. A study by a Dutch non-profit last year found that attackers could bypass face unlock-type features [on 42 out of the 110 smartphones](https://www.zdnet.com/article/facial-recognition-doesnt-work-as-intended-on-42-of-110-tested-smartphones/) they tested.
### April
[ United Airlines covers up seat cameras](https://www.zdnet.com/article/united-airlines-covers-up-infotainment-seat-camera-following-passenger-outrage/) - The airline insists that the cameras have not been in active use; however, customers were still very disturbed and annoyed by the cameras' presence in the first place.
[ Researcher prints 'PWNED!' on hundreds of GPS watches' maps due to unfixed API](https://www.zdnet.com/article/researcher-prints-pwned-on-hundreds-of-gps-watches-maps-due-to-unfixed-api/) - Over 20 GPS watch models allowed threat actors to track device owners, tinker with watch functions.
[ Tens of thousands of cars were left exposed to thieves due to a hardcoded password](https://www.zdnet.com/article/tens-of-thousands-of-cars-left-exposed-to-thieves-due-to-a-hardcoded-password/) - Security updates that remove the hardcoded credentials have been made available for both the MyCar
[Android](https://play.google.com/store/apps/details?id=app.com.automobility.mycar.control)and
[iOS](https://itunes.apple.com/us/app/mycar-controls/id1126511815)apps since mid-February.
[ The Weather Channel goes off the air for 90 minutes after ransomware infection](https://www.zdnet.com/article/the-weather-channel-goes-off-the-air-for-90-minutes-after-ransomware-infection/) - A similar attack on
[French TV station M6](https://www.zdnet.com/article/m6-one-of-frances-biggest-tv-channels-hit-by-ransomware/), in October, was unsuccesful.
[ Facebook admits to storing plaintext passwords for millions of Instagram users](https://www.zdnet.com/article/facebook-admits-to-storing-plaintext-passwords-for-millions-of-instagram-users/) - Incident comes after a month earlier, Facebook admitted to
[storing plaintext passwords for Facebook accounts too](https://www.zdnet.com/article/facebook-we-stored-hundreds-of-millions-of-passwords-in-plain-text/).
[ Source code of Iranian cyber-espionage tools leaked on Telegram](https://www.zdnet.com/article/source-code-of-iranian-cyber-espionage-tools-leaked-on-telegram/) - Tools were made available for every-day malware developers, opening more users to attacks. A second and third leak of Iranian hacking tools occurred in
[May](https://www.zdnet.com/article/new-leaks-of-iranian-cyber-espionage-operations-hit-telegram-and-the-dark-web/)and
[June](https://www.zdnet.com/article/new-iranian-hacking-tool-leaked-on-telegram/).
[ Indian govt agency left details of millions of pregnant women exposed online](https://www.zdnet.com/article/indian-govt-agency-left-details-of-millions-of-pregnant-women-exposed-online/) - More than 12.5 million medical records for pregnant women were left exposed. Records removed from leaky server after more than three weeks.
[ Over 13K iSCSI storage clusters left exposed online without a password](https://www.zdnet.com/article/over-13k-iscsi-storage-clusters-left-exposed-online-without-a-password/) - New attack vector opens backdoor inside enterprise disk storage arrays and people's NAS devices.
[ Gnosticplayers' hacks](https://www.zdnet.com/article/a-hacker-has-dumped-nearly-one-billion-user-records-over-the-past-two-months/) - A hacker known as Gnosticplayers has dumped over one billion user records online in the span of a few months.
[ Hacker group has been hijacking DNS traffic on D-Link routers for three months](https://www.zdnet.com/article/hacker-group-has-been-hijacking-dns-traffic-on-d-link-routers-for-three-months/) - Other router models have also been targeted, such as ARG, DSLink, Secutech, and TOTOLINK. The attacks are
[especially active cross Brazil](https://www.zdnet.com/article/brazil-is-at-the-forefront-of-a-new-type-of-router-attack/).
### May
[ A hacker wiped Git repositories and asked for a ransom](https://www.zdnet.com/article/a-hacker-is-wiping-git-repositories-and-asking-for-a-ransom/) - Thousands of repos were impacted, but almost all projects were recovered.
[ New MDS attacks on modern CPUs](https://www.zdnet.com/article/intel-cpus-impacted-by-new-zombieload-side-channel-attack/) - Researchers, academics detail new Microarchitectural Data Sampling (MDS) attacks, such as Zombieload, Fallout, and RIDL.
[ Thrangrycat vulnerability](https://www.zdnet.com/article/thrangrycat-flaw-lets-attackers-plant-persistent-backdoors-on-cisco-gear/) - Thrangrycat flaw lets attackers plant persistent backdoors on Cisco gear. Most Cisco gear is believed to be impacted. No attacks detected in the wild.
**BlueKeep vulnerability** - In mid-May, Microsoft warned about a [new "wormable" RDP vulnerability](https://www.zdnet.com/article/microsoft-patches-windows-xp-server-2003-to-try-to-head-off-wormable-flaw/) that later became known as BlueKeep. Two new wormable BlueKeep-like vulnerabilities ([DejaBlue](https://www.zdnet.com/article/microsoft-warns-of-two-new-wormable-flaws-in-windows-remote-desktop-services/)) were later disclosed in August. After months of eagerly waiting attacks, a [proof-of-concept exploit](https://www.zdnet.com/article/metasploit-team-releases-bluekeep-exploit/) was publicly published in September.
[ Unsecured server exposes data for 85% of all Panama citizens](https://www.zdnet.com/article/unsecured-server-exposes-data-for-85-percent-of-all-panama-citizens/) - The server contained patient data, but no medical records were exposed -- only personally identifiable information (PII).
[ Software update crashes police ankle monitors in the Netherlands](https://www.zdnet.com/article/software-update-crashes-police-ankle-monitors-in-the-netherlands/) - Borked update prevents ankle monitors from sending data back to police control rooms. Some suspects needed to be collected and sent back to jail as a result.
[ In a first, Israel responds to Hamas hackers with an air strike](https://www.zdnet.com/article/in-a-first-israel-responds-to-hamas-hackers-with-an-air-strike/) - Israel military said it bombed building housing Hamas cyber forces.
[ Google replaces faulty Titan security keys](https://www.zdnet.com/article/google-to-replace-faulty-titan-security-keys/) - Vulnerability in Bluetooth pairing protocol forces Google to replace Titan keys sold in the US. Microsoft was later forced to
[issue a special fix](https://www.zdnet.com/article/microsoft-blocks-ble-security-keys-with-known-pairing-vulnerability/)to address the issue.
[ Canva hack](https://www.zdnet.com/article/australian-tech-unicorn-canva-suffers-security-breach/) - One of Gnosticplayers' victims. Company was hacked for 139 million user records.
[ StackOverflow hack](https://www.zdnet.com/article/stack-overflow-says-hackers-breached-production-systems/)- Stack Overflow said hackers breached production systems, and the hackers went undetected
[for more than a week](https://www.zdnet.com/article/stack-overflow-hacker-went-undetected-for-a-week/).
[ Flipboard hack](https://www.zdnet.com/article/flipboard-says-hackers-stole-user-details/) - Extent of the hack is unknown, but Flipboard said hackers had access to its systems for almost nine months.
[ London Underground to begin tracking passengers through Wi-Fi hotspots](https://www.zdnet.com/article/london-underground-to-begin-tracking-passengers-through-wi-fi-hotspots/) - Transport for London (TfL) said it was planning to roll out a system to track commuters making use of public Wi-Fi hotspots across the London Underground in coming months.
[ Major Safe Browsing bug](https://www.zdnet.com/article/mobile-chrome-safari-and-firefox-failed-to-show-phishing-warnings-for-more-than-a-year/) - Mobile Chrome, Safari, and Firefox failed to show phishing warnings for more than a year.
### June
[ Hackers breached 10 telecom providers](https://www.zdnet.com/article/these-hackers-broke-into-10-telecoms-companies-to-steal-customers-phone-records/) - Researchers at Cybereason said a nation-state-backed intelligence operation has compromised at least 10 global telco companies - to such an extent the attackers run a "de facto shadow IT department".
[ New Silex malware bricked thousands of IoT devices](https://www.zdnet.com/article/new-silex-malware-is-bricking-iot-devices-has-scary-plans/) - Attack lasted for days, but the hacker eventually stopped and retired the Silex malware code.
[ NASA hacked because of unauthorized Raspberry Pi connected to its network](https://www.zdnet.com/article/nasa-hacked-because-of-unauthorized-raspberry-pi-connected-to-its-network/) - NASA described the hackers as an "advanced persistent threat," a term generally used for nation-state hacking groups, but didn't provide other details.
[ Popular Facebook grief support page hacked](https://www.zdnet.com/article/popular-grief-support-page-hacked-ignored-by-facebook-for-weeks/) - Facebok ignored the hack for weeks.
[ Google Nest cams could have allowed former owners to spy on the new owners](https://www.zdnet.com/article/google-pushes-nest-cam-update-to-prevent-former-owners-spying-on-new-buyers/) - Google eventually pushed out an update.
**Two Firefox zero-days** - Mozilla fixed two Firefox zero-days [[1](https://www.zdnet.com/article/mozilla-fixes-second-firefox-zero-day-exploited-in-the-wild/), [2](https://www.zdnet.com/article/mozilla-fixes-second-firefox-zero-day-exploited-in-the-wild/)] that were used to attack Coinbase employees.
[ AMCA data breach](https://www.zdnet.com/article/amca-data-breach-has-now-gone-over-the-20-million-mark/) - Healthcare billing vendor got hacked last year and hackers put patient data for sale online. The breach impacted multiple healthcare providers, and eventually went over the 20 million mark.
[ CBP says hackers stole license plate and travelers' photos](https://www.zdnet.com/article/cbp-says-hackers-stole-license-plate-and-travelers-photos/) - CBP said subcontractor stored photos on its internal servers without authorization, and then got hacked.
[ Major HSM vulnerabilities impact banks, cloud providers, governments](https://www.zdnet.com/article/major-hsm-vulnerabilities-impact-banks-cloud-providers-governments/) - Two security researchers revealed vulnerabilities that can be exploited remotely to retrieve sensitive data stored inside special computer components known as HSMs (Hardware Security Modules).
[ Wave of SIM swapping attacks hit US cryptocurrency users](https://www.zdnet.com/article/wave-of-sim-swapping-attacks-hit-us-cryptocurrency-users/) - For a week in June, tens of US-based cryptocurrency users saw themselves victims of SIM swapping attacks.
### July
[ Kazakhstan government intercepted all local HTTPS traffic](https://www.zdnet.com/article/kazakhstan-government-is-now-intercepting-all-https-traffic/) - HTTPS interception efforts
[targeted Facebook, Google, Twitter](https://www.zdnet.com/article/kazakhstans-https-interception-efforts-target-facebook-google-twitter-others/), and others sites.
[Apple, Google, and Mozilla](https://www.zdnet.com/article/apple-google-and-mozilla-block-kazakhstans-https-intercepting-certificate/)eventually intervened and banned the certificate used for HTTPS MitM attacks.
[ Hacker steals data of millions of Bulgarians](https://www.zdnet.com/article/hacker-steals-data-of-millions-of-bulgarians-emails-it-to-local-media/) - A hacker stole the personal details of millions of Bulgarians and emailed download links to the stolen data to local news publications. The date, stolen from the country's National Revenue Agency,
[eventually leaked online](https://www.zdnet.com/article/bulgarias-hacked-database-is-now-available-on-hacking-forums/).
[ Hackers breach FSB contractor](https://www.zdnet.com/article/hackers-breach-fsb-contractor-expose-tor-deanonymization-project/) - Hackers have breached SyTech, a contractor for FSB, Russia's national intelligence service, from where they stole information about internal projects the company was working on behalf of the agency -- including one for deanonymizing Tor traffic.
[ iMessages could have bricked your iPhone](https://www.zdnet.com/article/google-project-zero-reveals-bad-imessages-could-have-bricked-your-iphone/) - Bug patched before being exploited in the wild.
[ Urgent/11 security flaws](https://www.zdnet.com/article/urgent11-security-flaws-impact-routers-printers-scada-and-many-iot-devices/)- Major bugs in TCP library impacted routers, printers, SCADA, medical devices, and many IoT devices.
[ Apple's AWDL protocol plagued by security flaws](https://www.zdnet.com/article/apples-awdl-protocol-plagued-by-flaws-that-enable-tracking-and-mitm-attacks/) - Apple patched a bug in May, but academics say the rest of the flaws require a redesign of some Apple services. Bugs would enable tracking and MitM attacks.
[ DHS warns about CAN bus vulnerabilities in small aircraft](https://www.zdnet.com/article/dhs-warns-about-can-bus-vulnerabilities-in-small-aircraft/) - DHS cyber-security agency CISA recommends that aircraft owners restrict access to planes "to the best of their abilities" to protect against vulnerabilities that could be used to sabotage airplanes.
[ Vulnerabilities found in GE anesthesia machines](https://www.zdnet.com/article/vulnerabilities-found-in-ge-anesthesia-machines/) - GE recommended that device owners not connect vulnerable anesthesia machines to a hospital's main networks. The company also denied the bugs could lead to patient harm, but later recanted and admitted that the issues could be dangerous to human life.
[ Los Angeles police caught up in data breach](https://www.zdnet.com/article/thousands-of-los-angeles-police-caught-up-in-data-breach-personal-records-stolen/) - Personal record of 2,500+ of LA cops stolen in the hack. The hacker emailed the department directly and included a sample of the allegedly stolen information to back up their claims.
[ Louisiana governor declares state emergency after local ransomware outbreak](https://www.zdnet.com/article/louisiana-governor-declares-state-emergency-after-local-ransomware-outbreak/) - Yep. Ransomware got so bad.
[It then hit Texas](https://www.zdnet.com/article/at-least-20-texas-local-governments-hit-in-coordinated-ransomware-attack/),
[dentist offices](https://www.zdnet.com/article/ransomware-hits-hundreds-of-dentist-offices-in-the-us/), and
[managed services providers](https://www.zdnet.com/article/ransomware-gang-hacks-msps-to-deploy-ransomware-on-customer-systems/).
[ Bluetooth exploit can track and identify iOS, Microsoft mobile device users](https://www.zdnet.com/article/bluetooth-vulnerability-can-be-exploited-to-track-and-id-iphone-smartwatch-microsoft-tablet-users/) - The vulnerability can be used to spy on users despite native OS protections that are in place and impacts Bluetooth devices on Windows 10, iOS, and macOS machines. This includes iPhones, iPads, Apple Watch models, MacBooks, and Microsoft tablets & laptops.
[ 7-Eleven Japanese customers lose $500,000 due to mobile app flaw](https://www.zdnet.com/article/7-eleven-japanese-customers-lose-500000-due-to-mobile-app-flaw/) - 7-Eleven eventually shut down the app.
### August
[ SWAPGSAttack CPU flaw](https://www.zdnet.com/article/new-windows-hack-warning-patch-intel-systems-now-to-block-swapgsattack-exploits/) - Researchers detail hardware vulnerability that bypasses mitigations against Spectre and Meltdown CPU vulnerabilities on Windows systems - and impacts all systems using Intel processors manufactured since 2012.
[ New Dragonblood vulnerabilities](https://www.zdnet.com/article/new-dragonblood-vulnerabilities-found-in-wifi-wpa3-standard/) - Earlier this year in April, two security researchers disclosed details about five vulnerabilities (
[collectively known as Dragonblood](https://www.zdnet.com/article/dragonblood-vulnerabilities-disclosed-in-wifi-wpa3-standard/)) in the WiFi Alliance's recently launched WPA3 WiFi security and authentication standard.
[ 14 iOS zero-days](https://www.zdnet.com/article/google-finds-malicious-sites-pushing-ios-exploits-for-years/) - Google finds exploits for 14 iOS vulnerabilities, grouped in five exploit chains, deployed in the wild since September 2016. Attacks aimed at Chinese Uyghur users.
[ The VPN security flaws](https://www.zdnet.com/article/hackers-mount-attacks-on-webmin-servers-pulse-secure-and-fortinet-vpns/) - Hackers mount attacks on Pulse Secure and Fortinet VPNs --
[including nation-state actors](https://www.zdnet.com/article/a-chinese-apt-is-now-going-after-pulse-secure-and-fortinet-vpn-servers/).
[ Windows CTF flaw](https://www.zdnet.com/article/vulnerability-in-microsoft-ctf-protocol-goes-back-to-windows-xp/) - Vulnerability in Microsoft CTF protocol goes back to Windows XP. Bug allows hackers to hijack any Windows app, escape sandboxes, get admin rights.
[ WS-Discovery protocol abused for DDoS attacks](https://www.zdnet.com/article/protocol-used-by-630000-devices-can-be-abused-for-devastating-ddos-attacks/) - Protocol adopted by DDoS-for-hire services, used in real-world attacks already.
[ Capitol One hack](https://www.zdnet.com/article/100-million-americans-and-6-million-canadians-caught-up-in-capital-one-breach/) - A hacker breached Capitol One, from where she stole the records of 100 million users. She also
[hacked 30 other companies](https://www.zdnet.com/article/capital-one-hacker-took-data-from-more-than-30-companies-new-court-docs-reveal/).
[ Hy-Vee card breach](https://www.zdnet.com/article/hy-vee-issues-warning-to-customers-after-discovering-point-of-sale-breach/) - Supermarket chain Hy-Vee admitted to a security breach on some of its point-of-sale (PoS) systems. The data was eventually put up for sale on hacking forums.
[ Employees connect nuclear plant to the internet so they can mine cryptocurrency](https://www.zdnet.com/article/employees-connect-nuclear-plant-to-the-internet-so-they-can-mine-cryptocurrency/) - Employees at a Ukrainian nuclear plant take unncessary security risks just to mine Bitcoin. They were eventually arrested.
[ Moscow's blockchain voting system cracked a month before election](https://www.zdnet.com/article/moscows-blockchain-voting-system-cracked-a-month-before-election/) - French researcher nets $15,000 prize for finding bugs in Moscow's Ethereum-based voting system.
[ US military purchased $32.8m worth of electronics with known security risks](https://www.zdnet.com/article/us-military-purchased-32-8m-worth-of-electronics-with-known-security-risks/) - List of vulnerable products purchased by the DoD includes Lexmark printers, GoPro cameras, and Lenovo computers.
[ AT&T employees took bribes to plant malware on the company's network](https://www.zdnet.com/article/at-t-employees-took-bribes-to-plant-malware-on-the-companys-network/) - DOJ charges Pakistani man with bribing AT&T employees more than $1 million to install malware on the company's network, unlock more than 2 million devices.
[ Windows malware strain records users on adult sites](https://www.zdnet.com/article/windows-malware-strain-records-users-on-adult-sites/) - New Varenyky trojan records videos of users navigating adult sites. Currently targeting only French users.
[ TrickBot trojan gets capability to aid SIM swapping attacks](https://www.zdnet.com/article/trickbot-todays-top-trojan-adds-feature-to-aid-sim-swapping-attacks/) - TrickBot trojan seen collecting credentials and PIN codes for Sprint, T-Mobile, and Verizon Wireless accounts.
[ Warshipping technique](https://www.zdnet.com/article/new-warshipping-technique-gives-hackers-access-to-enterprise-offices/) - Hackers could use packet delivery services to ship hacking devices right to your company's doorstep.
[ Instagram boots ad partner Hyp3r](https://www.zdnet.com/article/instagram-boots-ad-partner-hyp3r-for-mass-collection-of-user-data/) - Instagram catches ad partner collecting data on its users.
### September
[ Simjacker attack](https://www.zdnet.com/article/new-simjacker-attack-exploited-in-the-wild-to-track-users-for-at-least-two-years/) - Security researchers detailed an SMS-based attack that can allow malicious actors to track users' devices by abusing little-known apps that are running on SIM cards.
[SIM cards in 29 countries](https://www.zdnet.com/article/these-are-the-29-countries-vulnerable-to-simjacker-attacks/)were found to be impacted. A second attack named
[WIBAttack](https://www.zdnet.com/article/new-sim-card-attack-disclosed-similar-to-simjacker/)was also discovered.
[ Smart TV spying](https://www.zdnet.com/article/smart-tvs-send-user-data-to-tech-heavyweights-including-facebook-google-netflix/) - Two academic papers found that smart TVs were collecting data on users' TV-viewing habits.
[ Checkm8 iOS jailbreak](https://www.zdnet.com/article/new-checkm8-jailbreak-released-for-all-ios-devices-running-a5-to-a11-chips/) - New Checkm8 jailbreak released for all iOS devices running A5 to A11 chips, on iPhones 4S up to iPhone 8 and X. The first jailbreak exploit to work on the hardware level in the past nine years.
[ Database leaks data on most of Ecuador's citizens](https://www.zdnet.com/article/database-leaks-data-on-most-of-ecuadors-citizens-including-6-7-million-children/) - Elasticsearch server leaks personal data on Ecuador's citizens, their family trees, and children, but also some users' financial records and car registration information.
[An arrest followed](https://www.zdnet.com/article/arrest-made-in-ecuadors-massive-data-breach/).
[ Limin PDF breach](https://www.zdnet.com/article/data-of-24-3-million-lumin-pdf-users-shared-on-hacking-forum/) - The details of over 24.3 million Lumin PDF users were shared on a hacking forum in mid-September. The company acknowledged the breach a day later.
[ Heyyo dating app leak](https://www.zdnet.com/article/heyyo-dating-app-leaked-users-personal-data-photos-location-data-more/) - They leaked almost everything except private messages.
[ vBulletin zero-day and subsequent hacks](https://www.zdnet.com/article/anonymous-researcher-drops-vbulletin-zero-day-impacting-tens-of-thousands-of-sites/) - An anonymous security researcher released a zero-day in the vBulletin forum software. The vulnerability was immediately used to hack a bunch of forums.
[ Massive wave of account hijacks hits YouTube creators](https://www.zdnet.com/article/massive-wave-of-account-hijacks-hits-youtube-creators/) - YouTube creators from the auto and car community were hit with spear-phishing attacks that could bypass 2FA, allowing hackers to take over Google and YouTube accounts.
[ Lilocked (Lilu) ransomware](https://www.zdnet.com/article/thousands-of-servers-infected-with-new-lilocked-lilu-ransomware/) - Thousands of Linux servers were infected with the new Lilocked (Lilu) ransomware.
[ Over 47,000 Supermicro servers are exposing BMC ports on the internet](https://www.zdnet.com/article/over-47000-supermicro-servers-are-exposing-bmc-ports-on-the-internet/) - Researchers discovered a new remote attack vector on Supermicro servers that were found to be exposing their BMC port over the internet.
[ Ransomware incident to cost company a whopping $95 million](https://www.zdnet.com/article/ransomware-incident-to-cost-danish-company-a-whopping-95-million/) - A ransomware incident at Demant, a Danish company that makes hearing aids, has created losses of nearly $95 million, one of the most expensive incidents to date.
[ Exim vulnerability (CVE-2019-15846)](https://www.zdnet.com/article/millions-of-exim-servers-vulnerable-to-root-granting-exploit/) - Millions of Exim servers are vulnerable to a security bug that when exploited can grant attackers the ability to run malicious code with root privileges.
### October
[ Avast hack](https://www.zdnet.com/article/avast-says-hackers-breached-internal-network-through-compromised-vpn-profile/) - Czech antivirus maker discloses second attack aimed at compromising CCleaner releases, after the one suffered in 2017. Company said hacker compromised the company via a compromised VPN profile.
[ Android zero-day exploited in the wild](https://www.zdnet.com/article/google-finds-android-zero-day-impacting-pixel-samsung-huawei-xiaomi-devices/) - Google Project Zero researchers find Android zero-day exploited in the wild, impacting Pixel, Samsung, Huawei, Xiaomi devices.
[ Alexa and Google Home devices leveraged to phish and eavesdrop on users, again](https://www.zdnet.com/article/alexa-and-google-home-devices-leveraged-to-phish-and-eavesdrop-on-users-again/) - Amazon, Google fail to address security loopholes in Alexa and Home devices more than a year after first reports.
[ Czech authorities dismantle alleged Russian cyber-espionage network](https://www.zdnet.com/article/czech-authorities-dismantle-alleged-russian-cyber-espionage-network/) - Czech officials said Russian operatives used local companies to launch cyber-attacks against foreign targets. Officials said operates had support from the FSB and financial help from the local embassy.
[ Johannesburg held for ransom by hacker gang](https://www.zdnet.com/article/city-of-johannesburg-held-for-ransom-by-hacker-gang/) - A group named "Shadow Kill Hackers" is asking local officials for 4 bitcoins or they'll release city data online. Second major attack against Johannesburg after they've been hit by ransomware in July, when some locals were
[left without electricity](https://www.zdnet.com/article/ransomware-incident-leaves-some-johannesburg-residents-without-electricity/).
[ CPDoS attack](https://www.zdnet.com/article/cpdos-attack-can-poison-cdns-to-deliver-error-pages-instead-of-legitimate-sites/) - CloudFront, Cloudflare, Fastly, Akamai, and others impacted by new CPDoS web cache poisoning attack.
[ PHP7 RCE exploited in the wild](https://www.zdnet.com/article/nasty-php7-remote-code-execution-bug-exploited-in-the-wild/) - New PHP7 bug CVE-2019-11043 can allow even non-technical attackers to take over Nginx servers running the PHP-FPM module.
[ macOS systems abused in DDoS attacks](https://www.zdnet.com/article/macos-systems-abused-in-ddos-attacks/) - Up to 40,000 macOS systems expose a particular port online that can be abused for pretty big DDoS attacks.
[Editorial standards](/editorial-guidelines/) |
11,522 | Fedora 31 正式发布 | https://fedoramagazine.org/announcing-fedora-31/ | 2019-10-31T08:17:57 | [
"Fedora"
] | https://linux.cn/article-11522-1.html | 
这里,我们很荣幸地宣布 Fedora 31 的发布。感谢成千上万的 Fedora 社区成员和贡献者的辛勤工作,我们现在正在庆祝又一次的准时发布。这已成为一种惯例!
如果你只想立即获取它,请立即访问 <https://getfedora.org/>。要了解详细信息,请继续阅读!
### 工具箱
如果你还没有使用过 [Fedora 工具箱](https://docs.fedoraproject.org/en-US/fedora-silverblue/toolbox/),那么现在是尝试一下的好时机。这是用于启动和管理个人工作区容器的简单工具,你可以在一个单独的环境中进行开发或试验。它只需要在命令行运行 `toolbox enter` 就行。
这种容器化的工作流程对于基于 ostree 的 Fedora 变体(如 CoreOS、IoT 和 Silverblue)的用户至关重要,但在任何工作站甚至服务器系统上也非常有用。在接下来的几个月中,希望对该工具及其相关的用户体验进行更多增强,非常欢迎你提供反馈。
### Fedora 风味版
Fedora 的“版本”是针对特定的“展示柜”用途输出的。
Fedora 工作站版本专注于台式机,以及希望获得“可以工作的” Linux 操作系统体验的特定软件开发人员。此版本具有 GNOME 3.34,它带来了显著的性能增强,在功耗较低的硬件上尤其明显。
Fedora 服务器版本以易于部署的方式为系统管理员带来了最新的、最先进的开源服务器软件。
而且,我们还有处于预览状态下的 Fedora CoreOS(一个定义了现代容器世界分类的操作系统)和[Fedora IoT](https://iot.fedoraproject.org/)(用于“边缘计算”用例)。(敬请期待计划中的给该物联网版本的征集名称的活动!)
当然,我们不仅仅提供的是各种版本。还有面向各种受众和用例的 [Fedora Spins](https://spins.fedoraproject.org/) 和 [Labs](https://labs.fedoraproject.org/),包括 [Fedora 天文学](https://labs.fedoraproject.org/en/astronomy/) 版本,为业余和专业的天文学家带来了完整的开源工具链,以及支持各种桌面环境(例如 [KDE Plasma](https://spins.fedoraproject.org/en/kde/) 和 [Xfce](https://spins.fedoraproject.org/en/xfce/))。
而且,请不要忘记我们的替代架构 [ARM AArch64、Power 和 S390x](https://alt.fedoraproject.org/alt/)。特别要注意的是,我们对包括 Rock960、RockPro64 和 Rock64 在内的 Rockchip 片上系统设备的支持得到了改善,并初步支持了 “[panfrost](https://panfrost.freedesktop.org/)”,这是一种较新的开源 3D 加速图形驱动程序 Arm Mali midgard GPU。
不过,如果你使用的是只支持 32 位的 i686 旧系统,那么该找个替代方案了,[我们的基本系统告别了 32 位 Intel 架构](https://fedoramagazine.org/in-fedora-31-32-bit-i686-is-86ed/)。
### 常规改进
无论你使用哪种 Fedora 版本,你都将获得开源世界所提供的最新版本。遵循 “[First](https://docs.fedoraproject.org/en-US/project/#_first)” 准则,我们启用了 CgroupsV2(如果你使用的是 Docker,[请确保检查一下](https://fedoraproject.org/wiki/Common_F31_bugs#Docker_package_no_longer_available_and_will_not_run_by_default_.28due_to_switch_to_cgroups_v2.29))。Glibc 2.30 和 NodeJS 12 是 Fedora 31 中许多更新的软件包之一。而且,我们已经将 `python` 命令切换为 Python 3,请记住,Python 2 在[今年年底](https://pythonclock.org/)生命期就终止了。
我们很高兴你能试用新版本!转到 <https://getfedora.org/> 并立即下载吧。或者,如果你已经在运行 Fedora 操作系统,请遵循简单的[升级说明](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/)就行。
### 万一出现问题……
如果遇到问题,请查看 [Fedora 31 常见错误](https://fedoraproject.org/wiki/Common_F31_bugs)页面,如果有疑问,请访问我们的 [Ask Fedora](http://ask.fedoraproject.org) 用户支持平台。
### 谢谢大家
感谢在此发行周期中成千上万为 Fedora 项目做出贡献的人们,尤其是那些为使该发行版再次按时发行而付出更多努力的人。而且,如果你本周在波特兰参加 [USENIX LISA](https://www.usenix.org/conference/lisa19),请在博览会大厅,在 Red Hat、Fedora 和 CentOS 展位找到我。
---
via: <https://fedoramagazine.org/announcing-fedora-31/>
作者:[Matthew Miller](https://fedoramagazine.org/author/mattdm/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It’s here! We’re proud to announce the release of Fedora 31. Thanks to the hard work of thousands of Fedora community members and contributors, we’re celebrating yet another on-time release. This is getting to be a habit!
If you just want to get to the bits without delay, go to[ https://getfedora.org/](https://getfedora.org/) right now. For details, read on!
## Toolbox
If you haven’t used the [Fedora Toolbox](https://docs.fedoraproject.org/en-US/fedora-silverblue/toolbox/), this is a great time to try it out. This is a simple tool for launching and managing personal workspace containers, so you can do development or experiment in an isolated experience. It’s as simple as running “toolbox enter” from the command line.
This containerized workflow is vital for users of the ostree-based Fedora variants like CoreOS, IoT, and Silverblue, but is also extremely useful on any workstation or even server system. Look for many more enhancements to this tool and the user experience around it in the next few months — your feedback is very welcome.
## All of Fedora’s Flavors
Fedora Editions are targeted outputs geared toward specific “showcase” uses.
Fedora Workstation focuses on the desktop, and particular software developers who want a “just works” Linux operating system experience. This release features GNOME 3.34, which brings significant performance enhancements which will be especially noticeable on lower-powered hardware.
Fedora Server brings the latest in cutting-edge open source server software to systems administrators in an easy-to-deploy fashion.
And, in preview state, we have Fedora CoreOS, a category-defining operating system made for the modern container world, and[ Fedora IoT](https://iot.fedoraproject.org/) for “edge computing” use cases. (Stay tuned for a planned contest to find a shiny name for the IoT edition!)
Of course, we produce more than just the editions.[ Fedora Spins](https://spins.fedoraproject.org/) and[ Labs](https://labs.fedoraproject.org/) target a variety of audiences and use cases, including the [Fedora Astronomy](https://labs.fedoraproject.org/en/astronomy/), which brings a complete open source toolchain to both amateur and professional astronomers, and desktop environments like [KDE Plasma](https://spins.fedoraproject.org/en/kde/) and [Xfce](https://spins.fedoraproject.org/en/xfce/).
And, don’t forget our alternate architectures, [ARM AArch64, Power, and S390x](https://alt.fedoraproject.org/alt/). Of particular note, we have improved support for the Rockchip system-on-a-chip devices including the Rock960, RockPro64, and Rock64, plus initial support for “[panfrost](https://panfrost.freedesktop.org/)”, an open source 3D accelerated graphics driver for newer Arm Mali “midgard” GPUs.
If you’re using an older 32-bit only i686 system, though, it’s time to find an alternative — [we bid farewell to 32-bit Intel architecture as a base system](https://fedoramagazine.org/in-fedora-31-32-bit-i686-is-86ed/) this release.
## General improvements
No matter what variant of Fedora you use, you’re getting the latest the open source world has to offer. Following our “[First](https://docs.fedoraproject.org/en-US/project/#_first)” foundation, we’re enabling CgroupsV2 (if you’re using Docker, [make sure to check this out](https://fedoraproject.org/wiki/Common_F31_bugs#Docker_package_no_longer_available_and_will_not_run_by_default_.28due_to_switch_to_cgroups_v2.29)). Glibc 2.30 and NodeJS 12 are among the many updated packages in Fedora 31. And, we’ve switched the “python” command to by Python 3 — remember, Python 2 is end-of-life at the [end of this year](https://pythonclock.org/).
We’re excited for you to try out the new release! Go to[ https://getfedora.org/](https://getfedora.org/) and download it now. Or if you’re already running a Fedora operating system, follow the easy [upgrade instructions](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/).
## In the unlikely event of a problem….
If you run into a problem, check out the [Fedora 31 Common Bugs](https://fedoraproject.org/wiki/Common_F31_bugs) page, and if you have questions, visit our [Ask Fedora](http://ask.fedoraproject.org) user-support platform.
## Thank you everyone
Thanks to the thousands of people who contributed to the Fedora Project in this release cycle, and especially to those of you who worked extra hard to make this another on-time release. And if you’re in Portland for [USENIX LISA](https://www.usenix.org/conference/lisa19) this week, stop by the expo floor and visit me at the Red Hat, Fedora, and CentOS booth.
## Robby
Gracias al equipo de Fedora, no puedo esperar a descargarlo. Son los mejores.
## Ryan W. W.
Just downloaded the Workstation and server versions and Fedora:31 on podman, Its gonna be fun testing them once I’m on the airplane!
## Mehdi
If I already have Fedora 31 (installed the beta version), do I need to run any specific command to upgrade?
## Matthew Miller
Just a regular update will get you to the final release (plus, of course, the updates on top of that).
## Andre Gompel
No, just do the regular updates.
Either from CLI as “sudo dnf update -y”
or dnfdragora (GUI).
Also suggest that you install the two repositories (free & non-free) from :
https://rpmfusion.org/
This in order to have most applications available.
Actually if it was not for open-source purity, it would be nice to have this a an option set by default for the install.
## Richar
rpm fusion repository is not available for Fedora 31 … the video codecs and plugins not appears … I need those for video education; I need to downgrade or to come back to Ubuntu …
So sad with Fedora 31.
MIRROR] rpmfusion-free-release-31.noarch.rpm: Curl error (28): Timeout was reached for https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-31.noarch.rpm [Connection timed out after 30000 milliseconds]
## Paul W. Frields
Not having any trouble with that link here. Maybe you hit a temporary outage?
## Rob32
I love you! Keep up the good work. Very happy Fedora 31Beta User here 🙂
## victorhck
Congrats to Fedora Community!!
Spreading the word about this release, for spanish speakers:
https://victorhckinthefreeworld.com/2019/10/29/disponible-ya-para-actualizar-fedora-31/
Happy hacking!!
## zoisawen
No netinstall? Link is broken on https://alt.fedoraproject.org/
## Matthew Miller
You’re probably just hitting a mirror that isn’t synced yet. Try again.
## lemc
October 30, 8:24 (EST): I have tried several mirrors, and none has the Workstation netinstall image yet.
## Mayost
04/11/2019 21:00: I have tried several mirrors, and none has the Workstation netinstall image yet.
On this page:
https://getfedora.org/en/workstation/download/
There is still a link:
Fedora 31: 64-bit network install image
But he doesn’t work
## Paul W. Frields
The website link should be removed shortly, since it’s misleading. I think it was mentioned elsewhere you can get netinstall through Server or Everything (same image).
## Tomasz Gąsior
So, what’s the difference between “everything” and “server” netinstall ISO? 🙂
## Paul W. Frields
@Tomasz: Literally nothing.
## Mayost
I tried searching the Mirror list and I see that there is no:
Fedora Workstation-netinst-x86_64-31-1.9.iso
In the server version
The link does work
## DRRDietrich
https://dl.fedoraproject.org/pub/fedora/linux/releases/31/Everything/x86_64/iso/Fedora-Everything-netinst-x86_64-31-1.9.iso
## bkdwt
Using since the Beta. Just werks on my machine. 🙂
## Eric Mesa
If I’m upgrading, will python automatically now point to python3? Or does it need to be remapped?
## Marek Suchánek
Release notes:
https://docs.fedoraproject.org/en-US/fedora/f31/release-notes/
## Bethel
Wonderful. Already shared this article on my blog. Testing Fedora 31 as we speak. Fedora is the King of Linux.
## Eduard Lucena
Rock and roll baby!!! Fresh installed, from Everything image a i3 configured from scratch. Running so smooth!
## Avi Wollman
The Design Suite Lab page has following message:
“Although this spin failed to compose for the final release, this test compose contains fixes over the final content to allow for a successful compose and should meet most users’ needs.”
What does that mean? Thank you!
## Eduard Lucena
This just means that the iso doesn’t pass all the QA test, the iso that is provided is good enough to be used and installed.
## Luya Tshimbalanga
That information is outdated as it applied to release 29 and 30.
## Joe
I’m glad to see that Fedora is moving to Python 3, for good. This has been one of the most tedious transitions ever, and switching the python command from 2 to 3 will improve the terminal user experience for sure. (All programs should use python2/python3 in the shebang line by now, therefore switching the unversioned python command should only affect terminal users.) Python 2.7 will be EOL during Fedora 31 lifetime anyways.
## luke
Congratulations and kudos to everybody!
## Michel S.
FYI the mirrors seem to be taking a while to sync this; http://mirrors.kernel.org/fedora/releases/31 is still 403-ing and http://mirror.facebook.net/fedora/linux/releases/ does not have 31 yet.
Hope they catch up soon!
## Henry
The Fedora 31 key is missing from https://getfedora.org/static/fedora.gpg. I retrieved it from a keyserver, but the signature date is different from the one on this page: https://getfedora.org/pt_BR/security/
## ofb
Good morning all, The necessary verification key is still missing from
https://getfedora.org/static/fedora.gpg
..and while we’re on it, the verification page for alt-downloads doesn’t list the F31 key in the body text, and both ‘further information’ links on that page go to 404’d documents.
https://alt.fedoraproject.org/en/verify.html
## Paul W. Frields
This should be corrected now.
## Yuriy
The new Fedora 31 is beautiful, runs fast and stable. I have been using Fedora Workstation with GNOME from beta for a couple of days already. A real pleasure to use!
Congrats and Thanks to all the teams that made this Fedora possible!!!
## Basri Azemi
As a Linux user, my assessment is after using Ubuntu, CentOS, Kali, and Elementary OS that Fedora is by far the best. Not only in offering the newest on opensource software advancements but in user friendliness, and over all package availability. I truly love FEDORA!
## Rajib Kumar Paul
Congrats to Fedora Community!!
Spreading the word about this release
## KOUASSI GERARD
hi everybody, i’m very happy to hear fedora 31 is released ! But i can’t download it via this link http://fedora.mirror.liquidtelecom.com/fedora/linux/releases/31/Workstation/x86_64/iso/Fedora-Workstation-Live-x86_64-31-1.9.iso. it seems to be the default link since i live in cote d’ivoire (west africa).
## Paul W. Frields
This is a problem with that mirror site and not Fedora. The mirror has not updated its content yet and the Fedora Project can’t control that. You should get in touch with the managers for that mirror site to fix.
## Kouassi gerard
Merci, j’attendrai alors puisque j’ai déjà installé la version bêta sur mon Lenovo v310… j’attendrai que ce miroir se mette à jour pour le télécharger et l’installer sur mon HP G280
## MIX
My wait is end now, been trying lxqt beta
## Stan Sykes
Hi, thanks for this new release (F31) it installed perfectly on my machine (via CLI) with no apparent errors – great job as always!
I know this isn’t the place to troubleshoot but as it’s the 1st time boot after upgrade, I wonder if anyone else has noticed this : The new kernel doesn’t load even though F31 is the O.S. (I checked that the default kernel is correct:
#grubby –default-kernel
/boot/vmlinuz-5.3.7-301.fc31.x86_64
This is my hostnamectl info:
Operating System: Fedora 31 (Thirty One)
CPE OS Name: cpe:/o:fedoraproject:fedora:31
Kernel: Linux 5.0.11-300.fc30.x86_64
Architecture: x86-64
Perhaps waiting for the new kernel’s update will fix this?
## Stan Sykes
The most recent kernel update to 5.3.8-300.fc31.x86_64 has fixed this issue – all good now! 🙂
## Chandan Upendra
Thanks! I have just upgraded from fedora 30 to 31 and I notice the performance is much better now, I really like the toolbox addition here.
## tfks
Yes, I notice it with the KDE spin too. Very nice. As always!
## Mukesh Chauhan
Great news for fedora lovers!
## 3wt434
why this web are not https?
## Paul W. Frields
What do you mean? The Magazine does have a correct HTTPS certificate and offers https URLs.
## eric
Fedora LXDE v31 link is wrong;
https://spins.fedoraproject.org/lxde/download/index.html
## Ted
For myself and a number of others so far, 31 has been a dud. After using 30 flawlessly for some time, I tied to install 31 on my ASUS Vivobook laptop. Once I get to the end of the install, it simply freezes and goes to a blinking cursor without fully loading. I tried numerous methods of install including trying to just upgrade to no avail. I heard they pushed back the original release date a week due to install problems. It would seem as though those problems have yet to be rectified.
## Nery reyna
La fedora es un buen programa para usuarios y ingenieros gráficos
## Dishant Pandya
Installed in my office laptop, works smooth, but on my home desktop the GUI few minutes after starting up. Don’t know why, still trying to find some solution over the internet.
## Javier Pinilla
Gracias al equipo de Fedora y a su comunidad.
Me pase en la 17 y nunca me fui.
## Viktor
Fedora (Workstation) is a great OS. What I like the most is that it’s like one piece from the bottom to the top. Not like others where you feel you have some base system and a desktop environment on top. Thanks to everyone involved!
What about the Silverblue edition? Has it been updated? Asking because https://silverblue.fedoraproject.org/download still links to Silverblue 30.
## lemc
It’s been two days since the release of Fedora 31 has been officially announced. However, so far I still haven’t found the netinstall image file,
Fedora-Workstation-netinst-x86_64-31-1.9.iso
either by simply clicking on the “Download” button under “But wait! There’s more” at https://getfedora.org/en/workstation/download/
or by even going directly to mirrors located in the USA, as listed in
https://admin.fedoraproject.org/mirrormanager/mirrors/Fedora/31/x86_64
## Paul W. Frields
You can use the Server netinstall ISO, which is the exact same image and allows you to install any Fedora edition. The download buttons will be fixed shortly.
## iv
Fedora 31 issue with classic Zoiper version 3 not showing numbers …
## Brian D.
Just installed Fedora 31 on a system with old nvidia graphics. The install hung up on SELinux install script, just as it usually does on an SELinux upgrade, but everything worked fine on reboot. I still need to use “nomodeset” at boot, but everything works just fine.
## Brian D.
Addendum— Nov.15 I tried to update to kernel 5.3.1-300.fc31.x86_64 , intended to replace kernel 5.3.8-200.fc30.x86_64 . After downloading with dnf , the update failed with a segmentation fault. Tried again after clearing the cache, using dnfdragora — segmentation fault….repeatedly Switched from KDE to GNome and tried updating with Gnome Software app.. Upgrade appears to be successful—except that KDM manager fails to initialize . Tried — systemctl disable kdm systemctl enable gdm
GDMmanager fails to initialize. Rebooted to kernel 5.3.8-200.fx30 — system fails at kdm or gdm or lxdm or sddm. none of them work. Can’t log in with or without ‘nomodeset’ at boot screen. I may try the Fedora 30 fix for dnf —zchunk=False, when I have the time…. if I can’t find another solution.
## Brian D.
Addendum — Nov, 21–19 After failure of login managers and dnf — segmentation fault —- I finally reinstalled to Fedora 28 — Gnome only –waited until the next kernel update for Fedora 31 5.3.11-300.fc31.x86_64 —then upgraded to Fedora 31 –( F30 first) — everything works — there may be a few bugs in KDE desktop. Nvidia users might be advised to avoid Epiphany web browser — it appears to cause –keyboard/mouse lock. Found on web, possible fix for– dnf segmentation fault. After first fault—> sudo rm /var/lib/rpm.lock <— according to other Fedora 31 users this fixes the problem. Unfortunately, I had already reinstalled when I found it. Good Luck.
## Faizal Ismail
Hi Fedora,
I want dowload the iso, but the file but not found.
## PilseDude
Can docker issue in 31 be solved by installing docker from snap store?
## Leandro
Hi there – for Fedora 32 I would not announce the release is out until mirrors have all the downloaders… still today Nov 1st I cannot download the netinstall image from my local mirror here in the U.S.
## Paul W. Frields
That wouldn’t be feasible, unfortunately. Some mirrors don’t reliably report their content, and there are too many to make that a requirement. Best idea is to find another mirror in your hemisphere or geographic area.
## Leandro
I’ve used Red Hat since the 1990s and Fedora since version 1. Best Linux distribution period. I’ve used many other dists but they never feel as polished or well designed! Always excited when a new version comes out.
## woloijo
how testing on linux? virualbox only 32 bit
please help
## juergen
With Wayland the fonts look very washed-out in Thunderbird or SoftMaker Office, so I switched back to Xorg. I use a HDPI Ultrabook. Any recommendations on Wayland with the fonts problem?
## Turbovix
O Fedora é ótimo, espero que domine o mundo logo logo!
## joseinho
ThankYou for a Great Distro Fedora <3
## Fedora
Upgraded from F30 to F31. All great except for two problems:
doesn’t start due to switching cgroups default from 1 to 2. See https://bugzilla.redhat.com/show_bug.cgi?id=1757078
not starting – possibly linked to Python 2 removal (still working on why at the moment though)
The first will affect docker developers, the second only those that use SaltStack (https://www.saltstack.com/) for automated builds.
## Paul W. Frields
The first is covered in the common Fedora 31 bugs page.
## JCjr
I’d like to see how the Panfrost driver and other hardware support is on the PineBookPro. I would order one if I knew Fedora supported all of the hardware properly.
## LD Barnes
I’d like to thank all the hardworking members of the Fedora team I just upgraded and nothing is broke. You guys rock.
## Old Mozzy
The upgrade from F30 Workstation to F31 Workstation went very smoothly with no problems encountered. The only glitch I have encountered so far in running F31 is that I can no longer scroll to bookmarks in long lists that are off-screen from the Bookmarks Toolbar in Firefox 70.0. Works fine in Chromium. I know this will get rectified soon enough either by Mozilla or the Fedora teams. Hence my workaround for now is to “Show All Bookmarks” (Ctrl+Shift+O) to open the Bookmark Library and scroll from there.
Other than that, great work by all the contributors of the Fedora project yet again. I’ve been using Fedora consistently since F14 and dabbled since RedHat 4.0!
## Marten
It would be great if there was a guide on how to use F2FS for a Fedora 31 installation – not to mention the installer being able to do it for me ..
sigh## Nagaraju
I am getting an error.
python3-mypy-0.730-2.fc31.noarch conflicts with python3-mypy-0.670-1.fc30.noarch while downloading fedora31.
## Omid
I had the same issue.
I simply removed the mypy package and the problem resolved.
## Nagaraju
Yes
Even I did the same
## et4t43
How I can download whole fedora 31?
All source package, all data. I need create iso, repair source code completly offline.
## billy
an uninstall command would be nice for those using multiple boots ..pi have 5 os on my pc and the current way is too frusterating.. the only option i have right not is to do a total hard drive wipe and start from scratch. the beta version no longer works,and with as many os systems i have on the pc having a version no longer working and a current one that is will be unacceptable .. from my stand point ..
## Damien X
I love Fedora and really appreciate all the efort that goes into it. Nonetheless, this release has been extremely disappointing. It has broken compatibility with half of the devices I support and I receive constant complains about lag from the people to whom I’ve recommend it.
This lastbpart has been happening since F30. I’m really sad about no longer being able to recommend it to people.
Fedora is a great project. Hopefully this will be fixed.
## WafiyAhmad
I came bere because of guns of glory bugs. Lol
## Jürgen
Well, after upgrading F30 Workstation to F31 I’m not happy at all and obviously Gnome 3.34.1 is the culprit. Gnome extension dash-to-dock doesn’t work any longer, and the super key doesn’t give me an application overview anymore – the combination of these flaws is really annoying.
## Jürgen
And now this: “Fedora does not support VirtualBox (host nor client), because it uses kernel modules that are not included in the upstream kernel.”
So now I’m locked out of all my virtual machines all of the sudden by this upgrade. Sorry, but like this Fedora doesn’t work for me as a daily driver.
## Paul W. Frields
@Jürgen: This is not a recent change; Fedora has
neversupported VirtualBox, due to this exact same issue. It sounds like you may be using a kernel that VirtualBox has not updated to support. This is not a Fedora issue to solve. However, you can use a previous kernel that VirtualBox has modules to support, until they offer the appropriate kernel support.## itsme
Hi Jürgen,
was never a problem for me under Fedora XY (actual kernel version 5.3.11-300.fc31.x86_64).
All I do, is to download the rpm’s direct from Oracle (Virtuablbox -> https://www.virtualbox.org/wiki/Linux_Downloads and the VirtualExtensionPack) and install them from the command line.
## Stan Sykes
I am currently running Fedora 31 (kernel 5.3.8-300.fc31.x86_64) and have no problem running Virtualbox Version 6.0.14_RPMFusion r132055. Everything updated normally using DNF and the transition from Fedora 30 was seemless.
## Jürgen
Thanks for this information, Stan. The problem seems to be that I’m running Fedora 31 with kernel 5.3.11-300.fc31.x86_64.
## Jürgen
Thanks, itsme, problem solved, you made my day!
## JULIAN
Aveh el fedora ya funsiona bieh pero si nesesita unos ajustes, solo quiero desiros q sois los mejores guapos os comoia to el ojete I LOVE FEDORA > UBUTNU
## Atabuga David
congratulation for good service.
## Michael
My first ever attempt at upgrading Fedora, from 30 -> 31 was a success.
I needed to run ‘dnf module reset mysql libgit2’ before starting the upgrade, and so far everything is working as normal ( awesome ).
Thanks to everyone involved for the great work on this, and every Fedora release.
## ed
“In the unlikely event of a problem” — I like that we’re so high on our own fumes here that we think fedora is stable.
Here’s some of the game-breaking issues I’ve encountered so far:
1. Hibernate/Suspend locks system forcing restart (close lid, black screen, led flashes)
2. WiFi not working properly (e5470)
I have rpmfusion and other nonfree installed.
Granted, these seem like specific driver issues, but it seems a little early to declare victory don’t you think?
## James
Just posting to say thanks to the Fedora team.
Upgrading from 29 -> 31, I’ve seen a MASSIVE improvement in performance!
It’s like having a new laptop. I don’t know if it’s Wayland or something else, but my 5 year old Thinkpad is running at light-speed now.
🙂
## Fernando
Obrigado equipe de desenvolvedores do Fedora.
Como sempre um sistema estável e tranquilo. |
11,523 | 使用 GNOME 优化工具自定义 Linux 桌面的 10 种方法 | https://itsfoss.com/gnome-tweak-tool/ | 2019-10-31T18:27:08 | [
"Ubuntu",
"GNOME"
] | https://linux.cn/article-11523-1.html | 
你可以通过多种方法来调整 Ubuntu,以自定义其外观和行为。我发现最简单的方法是使用 [GNOME 优化工具](https://wiki.gnome.org/action/show/Apps/Tweaks?action=show&redirect=Apps%2FGnomeTweakTool)。它也被称为 GNOME Tweak 或简单地称为 Tweak(优化)。
在过去的教程中,我已经多次介绍过它。在这里,我列出了你可以使用此工具执行的所有主要优化。
我在这里使用的是 Ubuntu,但是这些步骤应该适用于使用 GNOME 桌面环境的任何 Linux 发行版。
### 在 Ubuntu 18.04 或其它版本上安装 GNOME 优化工具
GNOME 优化工具可从 [Ubuntu 中的 Universe 存储库](https://itsfoss.com/ubuntu-repositories/)中安装,因此请确保已在“软件和更新”工具中启用了该仓库:

之后,你可以从软件中心安装 GNOME 优化工具。只需打开软件中心并搜索 “GNOME Tweaks” 并从那里安装它:

或者,你也可以使用命令行通过 [apt 命令](https://itsfoss.com/apt-command-guide/)安装此软件:
```
sudo apt install gnome-tweaks
```
### 用优化工具定制 GNOME 桌面
GNOME 优化工具使你可以进行许多设置更改。其中的某些更改(例如墙纸更改、启动应用程序等)也可以在官方的“系统设置”工具中找到。我将重点介绍默认情况下“设置”中不可用的优化。
#### 1、改变主题
你可以通过各种方式[在 Ubuntu 中安装新主题](https://itsfoss.com/install-themes-ubuntu/)。但是,如果要更改为新安装的主题,则必须安装GNOME 优化工具。
你可以在“<ruby> 外观 <rt> Appearance </rt></ruby>”部分找到主题和图标设置。你可以浏览可用的主题和图标并设置你喜欢的主题和图标。更改将立即生效。

#### 2、禁用动画以提速你的桌面体验
应用程序窗口的打开、关闭、最大化等操作都有一些细微的动画。你可以禁用这些动画以稍微加快系统的速度,因为它会稍微使用一点资源。

#### 3、控制桌面图标
至少在 Ubuntu 中,你会在桌面上看到“<ruby> 家目录 <rt> Home </rt></ruby>”和“<ruby> 垃圾箱 <rt> Trash </rt></ruby>”图标。如果你不喜欢,可以选择禁用它。你还可以选择要在桌面上显示的图标。

#### 4、管理 GNOME 扩展
我想你可能知道 [GNOME 扩展](https://extensions.gnome.org/)。这些是用于桌面的小型“插件”,可扩展 GNOME 桌面的功能。有[大量的 GNOME 扩展](https://itsfoss.com/best-gnome-extensions/),可用于在顶部面板中查看 CPU 消耗、获取剪贴板历史记录等等。
我已经写了一篇[安装和使用 GNOME 扩展](https://itsfoss.com/gnome-shell-extensions/)的详细文章。在这里,我假设你已经在使用它们,如果是这样,可以从 GNOME 优化工具中对其进行管理。

#### 5、改变字体和缩放比例
你可以[在 Ubuntu 中安装新字体](https://itsfoss.com/install-fonts-ubuntu/),并使用这个优化工具在系统范围应用字体更改。如果你认为桌面上的图标和文本太小,也可以更改缩放比例。

#### 6、控制触摸板行为,例如在键入时禁用触摸板,使触摸板右键单击可以工作
GNOME 优化工具还允许你在键入时禁用触摸板。如果你在笔记本电脑上快速键入,这将很有用。手掌底部可能会触摸触摸板,并导致光标移至屏幕上不需要的位置。
在键入时自动禁用触摸板可解决此问题。

你还会注意到[当你按下触摸板的右下角以进行右键单击时,什么也没有发生](https://itsfoss.com/fix-right-click-touchpad-ubuntu/)。你的触摸板并没有问题。这是一项系统设置,可对没有实体右键按钮的任何触摸板(例如旧的 Thinkpad 笔记本电脑)禁用这种右键单击功能。两指点击可为你提供右键单击操作。
你也可以通过在“<ruby> 鼠标单击模拟 <rt> Mouse Click Simulation </rt></ruby>”下设置为“<ruby> 区域 <rt> Area </rt></ruby>”中而不是“<ruby> 手指 <rt> Fingers </rt></ruby>”来找回这项功能。

你可能必须[重新启动 Ubuntu](https://itsfoss.com/schedule-shutdown-ubuntu/) 来使这项更改生效。如果你是 Emacs 爱好者,还可以强制使用 Emacs 键盘绑定。
#### 7、改变电源设置
电源这里只有一个设置。它可以让你在盖上盖子后将笔记本电脑置于挂起模式。

#### 8、决定什么显示在顶部面板
桌面的顶部面板显示了一些重要的信息。在这里有日历、网络图标、系统设置和“<ruby> 活动 <rt> Activities </rt></ruby>”选项。
你还可以[显示电池百分比](https://itsfoss.com/display-battery-ubuntu/)、添加日期及时间,并显示星期数。你还可以启用鼠标热角,以便将鼠标移至屏幕的左上角时可以获得所有正在运行的应用程序的活动视图。

如果将鼠标焦点放在应用程序窗口上,你会注意到其菜单显示在顶部面板中。如果你不喜欢这样,可以将其关闭,然后应用程序菜单将显示应用程序本身。
#### 9、配置应用窗口
你可以决定是否在应用程序窗口中显示最大化和最小化选项(右上角的按钮)。你也可以改变它们的位置到左边或右边。

这里还有其他一些配置选项。我不使用它们,但你可以自行探索。
#### 10、配置工作区
GNOME 优化工具还允许你围绕工作区配置一些内容。

### 总结
对于任何 GNOME 用户,GNOME 优化(Tweaks)工具都是必备工具。它可以帮助你配置桌面的外观和功能。 我感到惊讶的是,该工具甚至没有出现在 Ubuntu 的主存储库中。我认为应该默认安装它,要不,你就得在 Ubuntu 中手动安装 GNOME 优化工具。
如果你在 GNOME 优化工具中发现了一些此处没有讨论的隐藏技巧,为什么不与大家分享呢?
---
via: <https://itsfoss.com/gnome-tweak-tool/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You can tweak Ubuntu in several ways to customize its looks and behavior. The easiest way I find is by using the [GNOME Tweaks](https://wiki.gnome.org/action/show/Apps/Tweaks?action=show&%3Bredirect=Apps%2FGnomeTweakTool&ref=itsfoss.com), also called Tweaks.
I have mentioned it numerous times in my tutorials in the past. I list all the significant tweaks you can perform with this tool.
I have used Ubuntu here, but the steps should apply to any Linux distribution using the GNOME desktop environment.
## Install the GNOME Tweaks on Ubuntu
The GNOME Tweaks is available in the Universe repository in Ubuntu, so [make sure that you have it enabled in your Software & Updates tool](https://itsfoss.com/ubuntu-repositories/).
After that, you can install GNOME Tweaks from the software center. Just open the Software Centre and search for GNOME Tweaks and install it from there:
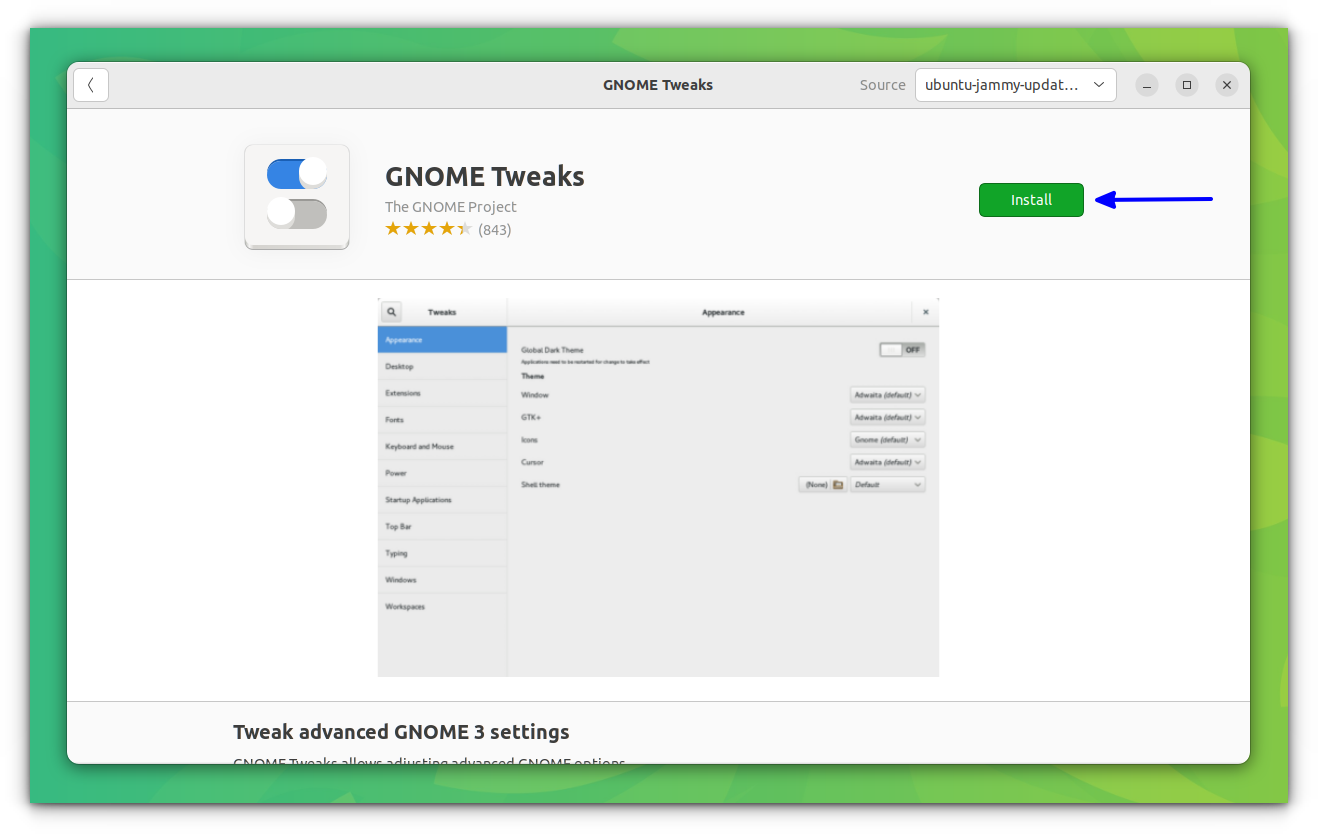
Alternatively, you may also use the command line to install software with the [apt command](https://itsfoss.com/apt-command-guide/):
```
sudo apt install gnome-tweaks
```
## Customizing GNOME desktop with the Tweaks tool
### 1. Power Settings: Suspend the Laptop when the lid is closed
It allows you to put your laptop in suspend mode when the lid is closed.
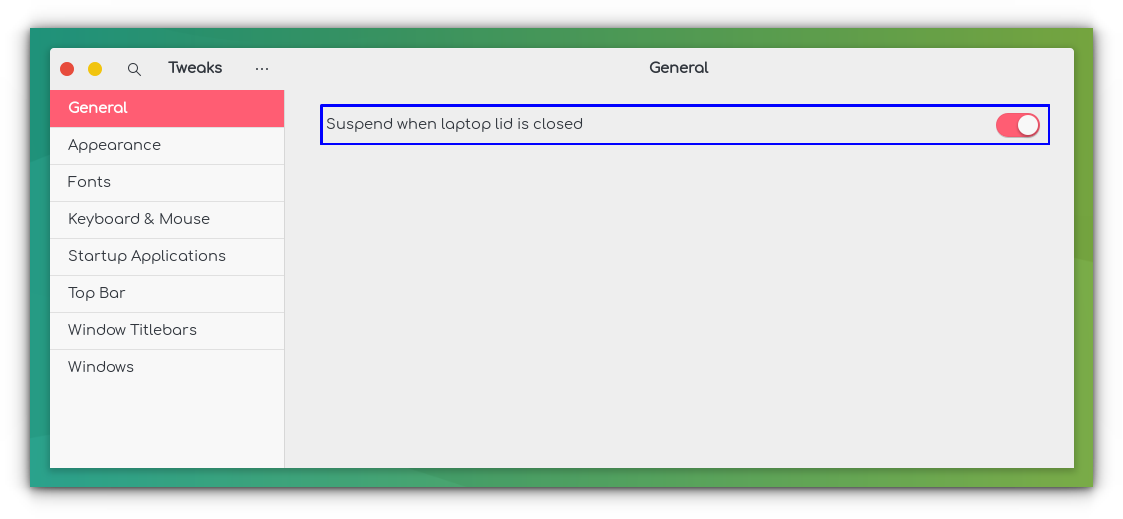
### 2. Change themes
You can [install new themes in Ubuntu](https://itsfoss.com/install-themes-ubuntu/) in various ways. But if you want to change to the newly installed theme, you’ll have to install GNOME Tweaks.
You can find the theme and icon settings in the *Appearance* section. You can browse through the available themes and icons and set the ones you like. The changes take effect immediately.
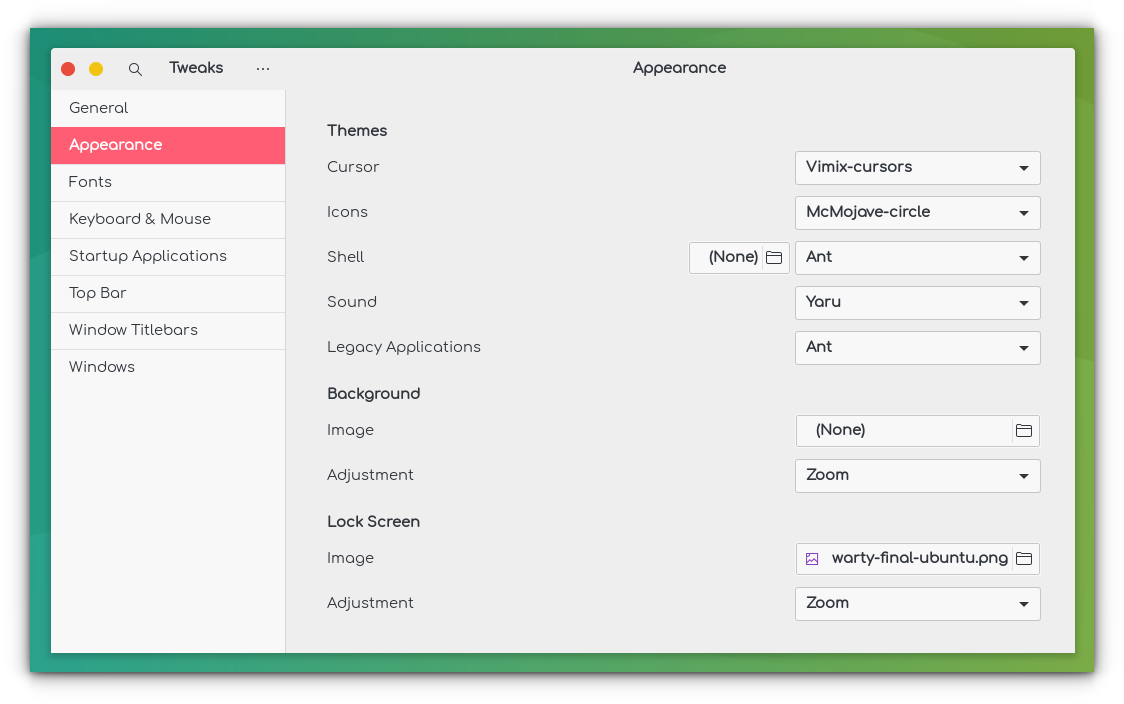
[.](https://itsfoss.com/gnome-shell-extensions/)
**extension enabled****user themes**### 3. Change fonts and scaling factor
You can [install new fonts in Ubuntu](https://itsfoss.com/install-fonts-ubuntu/) and apply the system-wide font change using the Tweaks tool. You can also change the scaling factor if you think the icons, and text are way too small on your desktop.
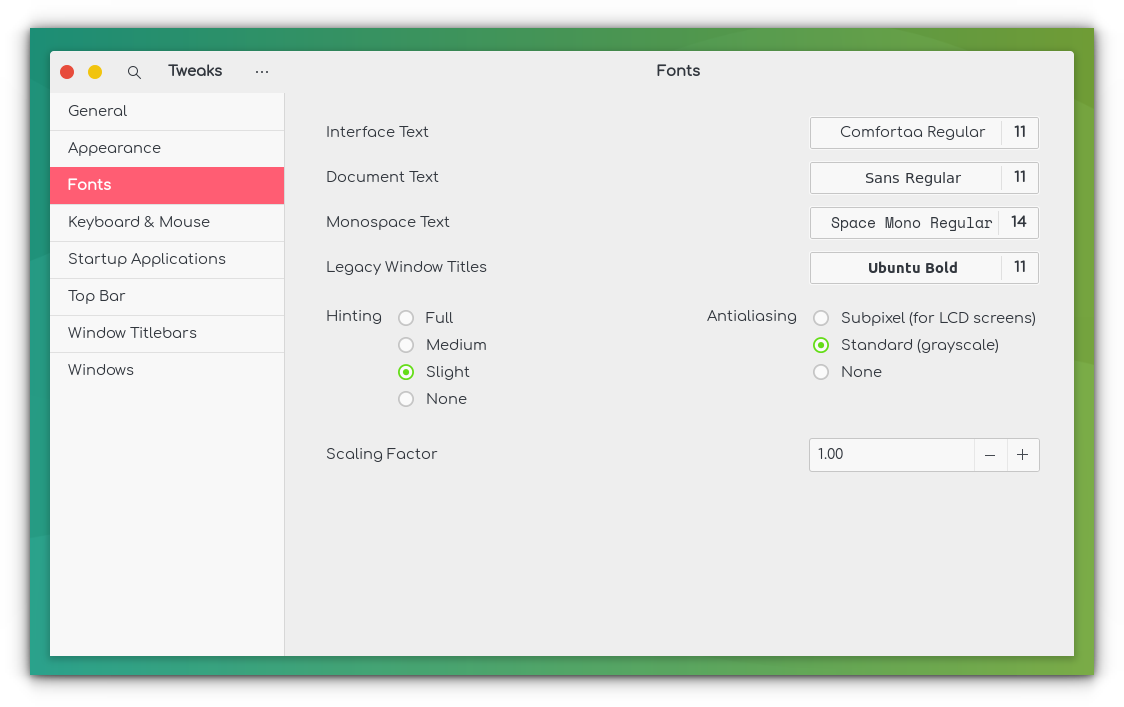
### 4. Control touchpad behaviour
The GNOME Tweaks also allow you to disable the touchpad while typing. This is useful if you type fast on a laptop. The bottom of your palm may touch the touchpad and the cursor moves away to an undesired location on the screen.
Automatically disabling the touchpad while typing fixes this problem.
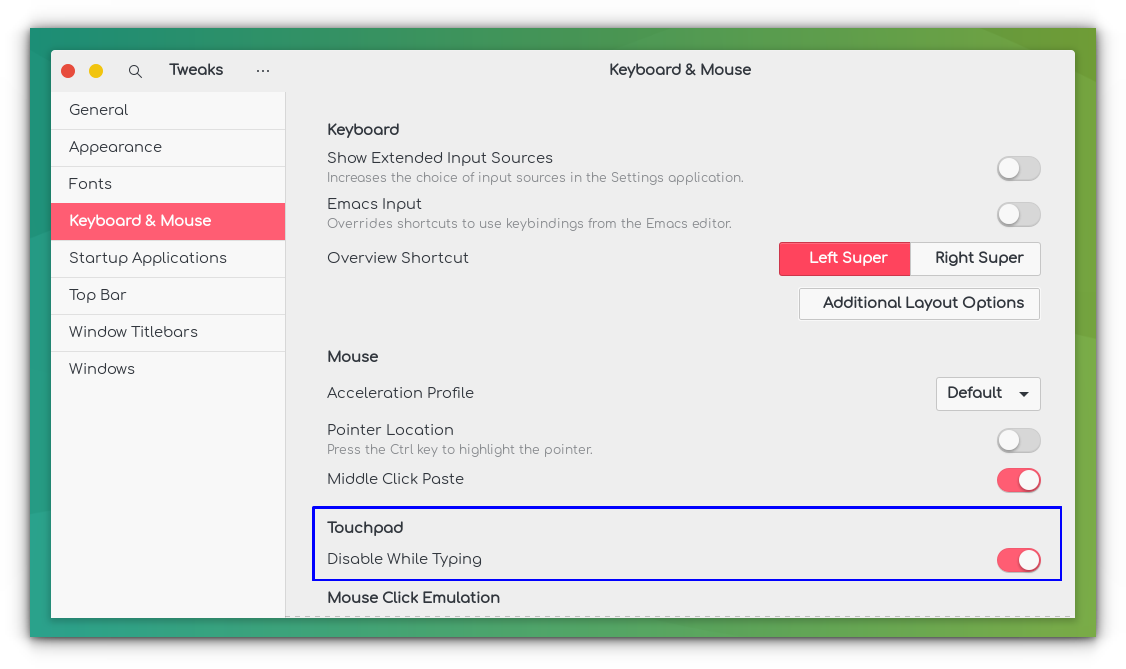
You’ll also notice that [when you press the bottom right corner of your touchpad for a right click, nothing happens](https://itsfoss.com/fix-right-click-touchpad-ubuntu/). There is nothing wrong with your touchpad. It’s a system setting, that disables the right-clicking this way for any touchpad that doesn’t have a real right-click button (like the old Thinkpad laptops). Two finger click gives you the right click.
You can also get this back by choosing Area under Mouse Click Simulation instead of Fingers.
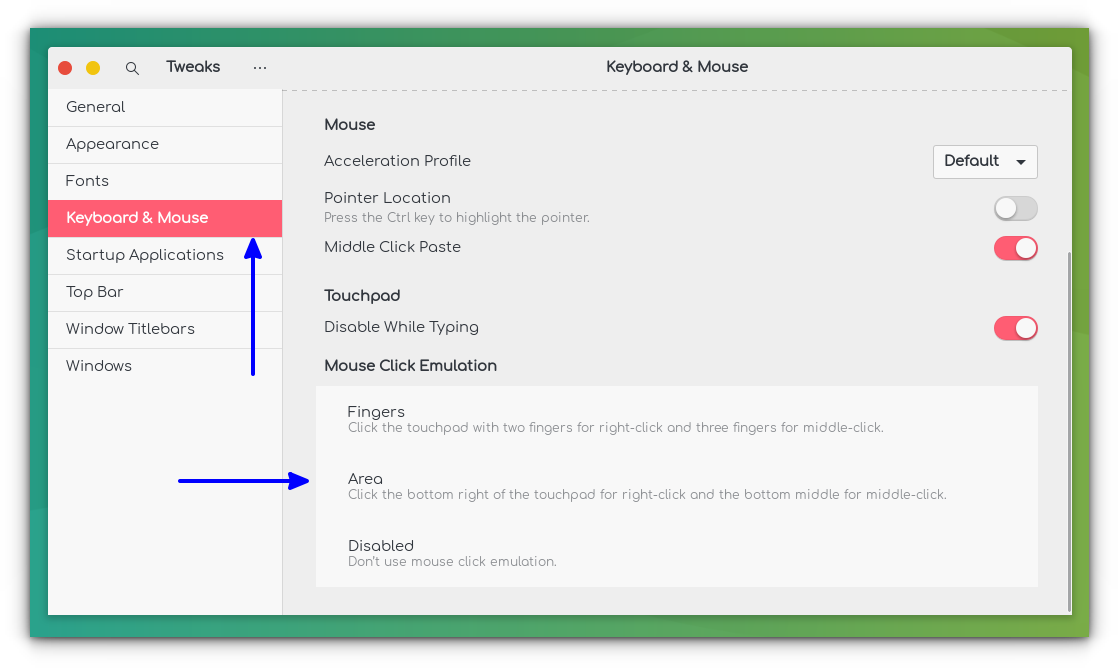
You may have to [restart Ubuntu](https://itsfoss.com/schedule-shutdown-ubuntu/) in order to take the changes into effect. If you are an Emacs lover, you can also force keybindings from Emacs.
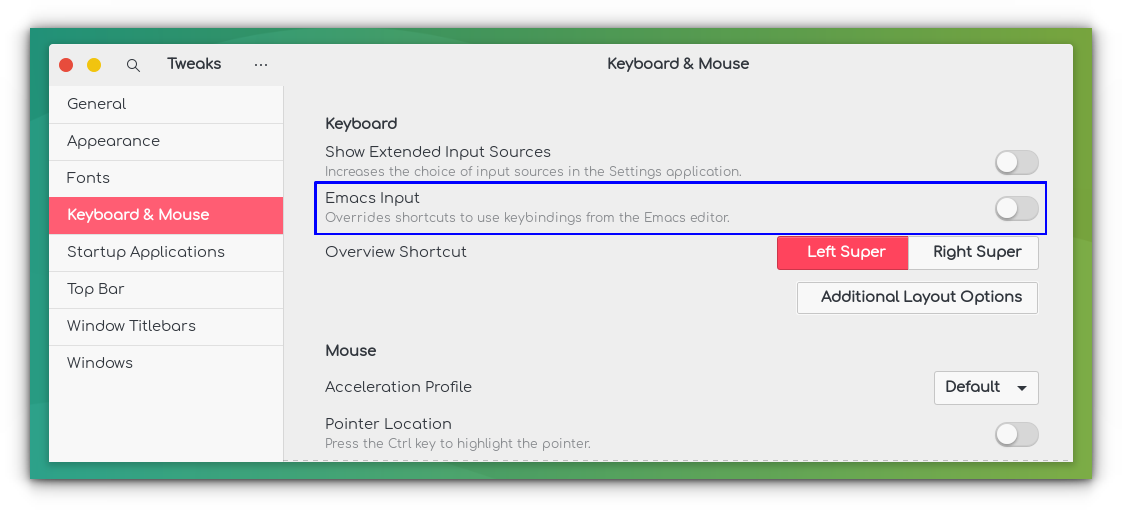
It's very easy to forget the location of your Mouse cursor sometimes. GNOME Tweaks provides an option, to highlight the current position of Mouse Cursor, in a wave manner.
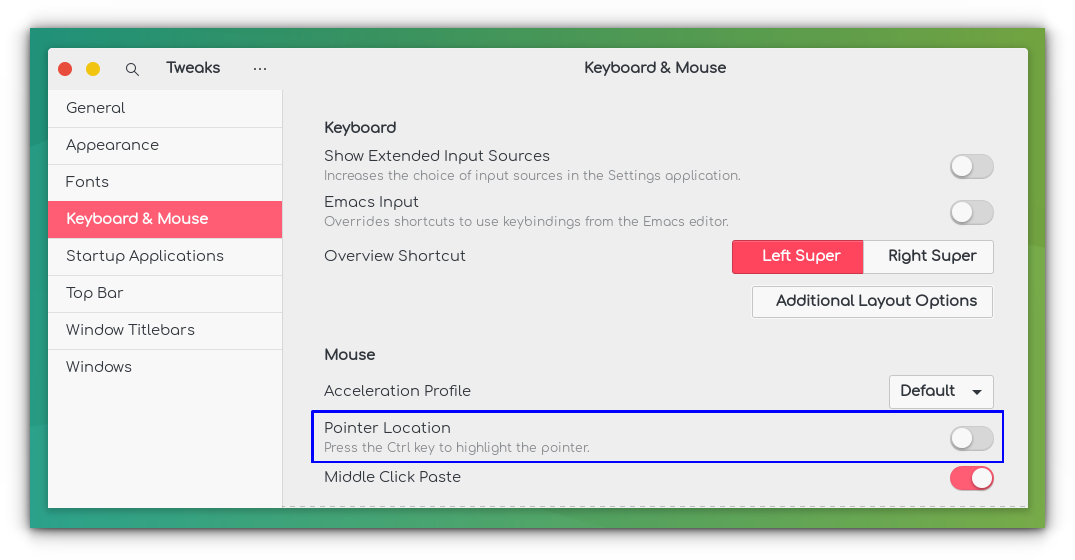
Enable this **Pointer Location** button in the *Keyboard and mouse section to get this*.
### 5. Decide what’s displayed in the top panel
The top panel on your desktop shows a few important things. You have the calendar, network icon, system settings and Activities option.
You can also [display battery percentage](https://itsfoss.com/display-battery-ubuntu/), add date along with day and time and show week numbers. You can also enable hot corners so that if you take your mouse to the top left corner of the screen, you’ll get the activities overview with all the running applications.

If you have the mouse focus on an application window, you’ll notice that its menu is displayed in the top panel. If you don’t like it, you may toggle it off and then the application menu will be available on the application itself.
### 6. Configure the application window title bar
These are minor tweaks that come in handy sometimes. By default, double-clicking on a Window will maximize it. This behaviour can be changed to some other actions using GNOME Tweaks.
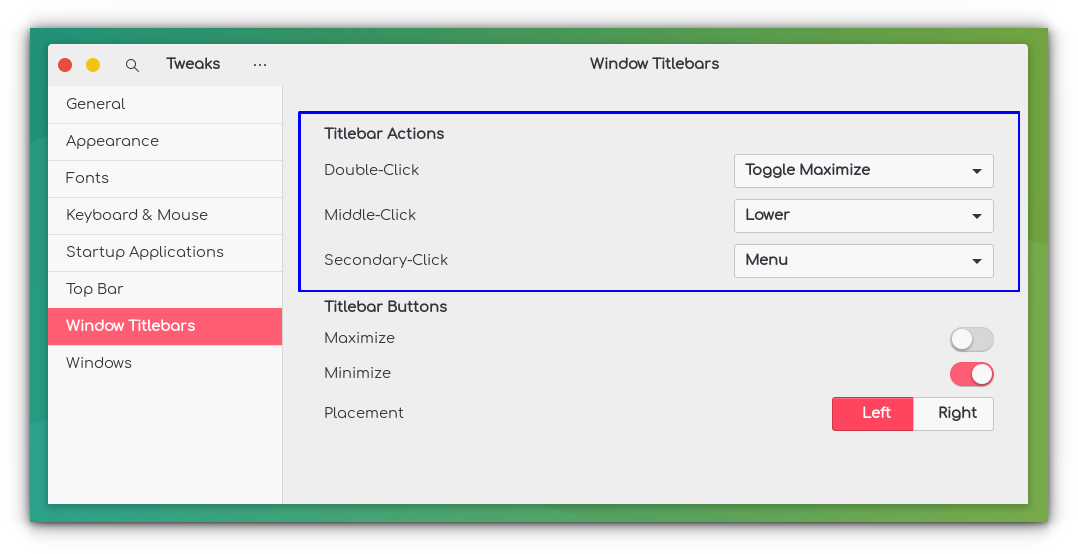
Similarly, you can change the behaviour of Middle-click or secondary click on a window title bar to your liking, from the available options.
Also, you can decide if [maximize and minimize options](https://itsfoss.com/gnome-minimize-button/) (the buttons on the top right corner) will be shown in the application window. You may also change their positioning between left and right.
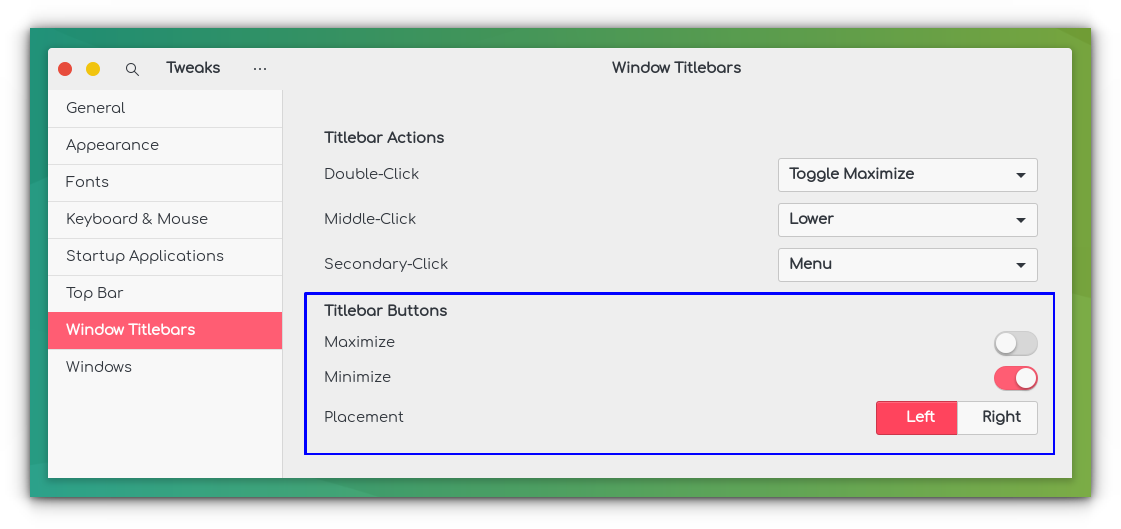
### 7. Configuring application windows
On the **Windows** tab of GNOME Tweaks, you get several tweaks related to the appearance of Windows.
- Toggling
**Attach Modal Dialogs**, will attach the dialog box to the parent windows and cannot be moved individually. - You can open new windows in the centre of the screen, by toggling the
**Centre New Windows**option.
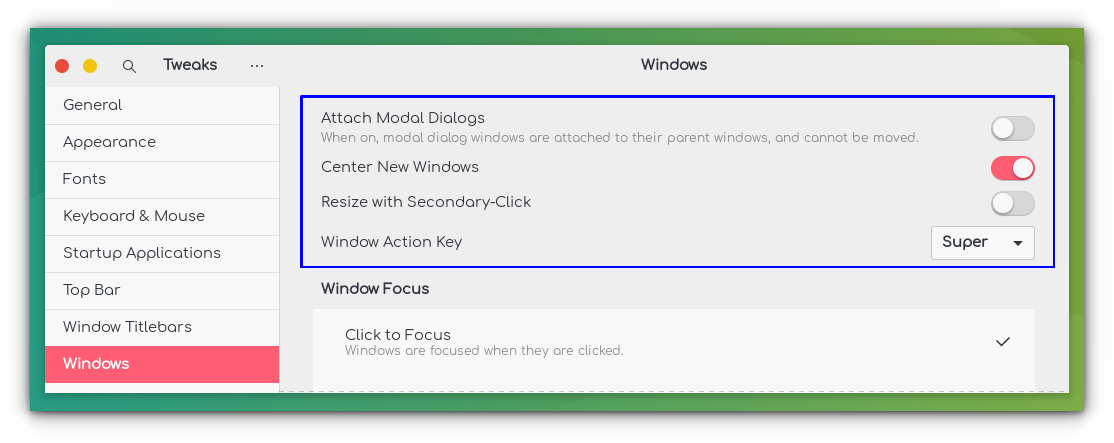
The default Window focus mode is *Click to Focus*. This means you can change the focus to another window by clicking on it. This can be changed to *hovering* or *secondary-click* to change focus.
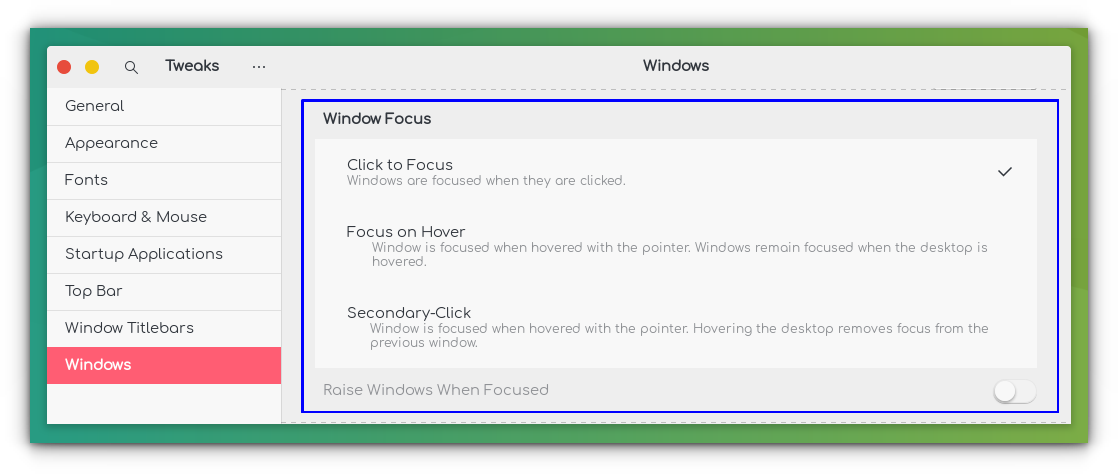
## In the end…
Now you read about the GNOME Tweaks. How about some other ways to tweak your system?
[15 Simple Tips to Customize Ubuntu GNOMESome basic and interesting GNOME customization tips for enriching your experience and getting more out of your Ubuntu desktop.](https://itsfoss.com/gnome-tricks-ubuntu/)

Maybe try some cool themes to change the looks of your system.
[18 Best GTK Themes for Ubuntu and other Linux DistributionsBrief: Let’s have a look at some beautiful GNOME themes that you can use not only in Ubuntu but other Linux distributions that use GNOME. Even though we have plenty of Linux distributions that offer a good user experience, using a custom theme can take you for a rollercoaster](https://itsfoss.com/best-gtk-themes/)

The GNOME Tweaks is a must-have utility for any GNOME user. It helps you configure the looks and functionality of the desktop. I find it surprising that this tool is not even in the Main repository of Ubuntu. In my opinion, it should be installed by default. Till then, you’ll have to install the GNOME Tweaks tool in Ubuntu manually.
If you find some hidden gem in GNOME Tweaks that hasn’t been discussed here, why not share it with the rest of us? |
11,525 | Collapse OS:为世界末日创建的操作系统 | https://itsfoss.com/collapse-os/ | 2019-11-01T06:54:09 | [
"末日"
] | https://linux.cn/article-11525-1.html | 当大多数人考虑为末日后的世界做准备时,想到的第一件事就是准备食物和其他生活必需品。最近,有一个程序员觉得,在社会崩溃之后,创建一个多功能的、且可生存的操作系统同样重要。我们今天将尽我们所能地来了解一下它。
### Collapse OS:当文明被掩埋在垃圾中

这里说的操作系统称为 [Collapse OS(崩溃操作系统)](https://collapseos.org/)。根据该官方网站的说法,Collapse OS 是 “z80 内核以及一系列程序、工具和文档的集合”。 它可以让你:
* 可在最小的和临时拼凑的机器上运行。
* 通过临时拼凑的方式(串行、键盘、显示)进行接口。
* 可编辑文本文件。
* 编译适用于各种 MCU 和 CPU 的汇编源代码文件。
* 从各种存储设备读取和写入。
* 自我复制。
其创造者 [Virgil Dupras](https://github.com/hsoft) 之所以开始这个项目,是因为[他认为](https://collapseos.org/why.html)“我们的全球供应链在我们到达 2030 年之前就会崩溃”。他是根据<ruby> 巴勃罗·塞维尼 <rt> Pablo Servigne </rt></ruby>的作品得出了这一结论的。他似乎也觉得并非所有人都会认可[他的观点](https://collapseos.org/why.html),“话虽如此,我认为不相信到 2030 年可能会发生崩溃也是可以理解的,所以请不要为我的信念而感到受到了冲击。”
该项目的总体目标是迅速让瓦解崩溃后的文明重新回到计算机时代。电子产品的生产取决于非常复杂的供应链。一旦供应链崩溃,人类将回到一个技术水平较低的时代。要恢复我们以前的技术水平,将需要数十年的时间。Dupras 希望通过创建一个生态系统来跨越几个步骤,该生态系统将与从各种来源搜寻到的更简单的芯片一起工作。
### z80 是什么?
最初的 Collapse OS 内核是为 [z80 芯片](https://en.m.wikipedia.org/wiki/Z80)编写的。作为复古计算机历史的爱好者,我对 [Zilog](https://en.wikipedia.org/wiki/Zilog) 和 z80 芯片很熟悉。在 1970 年代后期,Zilog 公司推出了 z80,以和 [Intel 的 8080](https://en.wikipedia.org/wiki/Intel_8080) CPU 竞争。z80 被用于许多早期的个人计算机中,例如 [Sinclair ZX Spectrum](https://en.wikipedia.org/wiki/ZX_Spectrum) 和 [Tandy TRS-80](https://en.wikipedia.org/wiki/TRS-80)。这些系统中的大多数使用了 [CP/M 操作系统](https://en.wikipedia.org/wiki/CP/M),这是当时最流行的操作系统。(有趣的是,Dupras 最初希望使用[一个开源版本的 CP/M](https://github.com/davidgiven/cpmish),但最终决定[从头开始](https://github.com/hsoft/collapseos/issues/52)。)
在 1981 年 [IBM PC](https://en.wikipedia.org/wiki/IBM_Personal_Computer) 发布之后,z80 和 CP/M 的普及率开始下降。Zilog 确实发布了其它几种微处理器(Z8000 和 Z80000),但并没有获得成功。该公司将重点转移到了微控制器上。今天,更新后的 z80 后代产品可以在图形计算器、嵌入式设备和消费电子产品中找到。
Dupras 在 [Reddit](https://old.reddit.com/r/collapse/comments/dejmvz/collapse_os_bootstrap_postcollapse_technology/f2w3sid/?st=k1gujoau&sh=1b344da9) 上说,他为 z80 编写了 Collapse OS,因为“它已经投入生产很长时间了,并且因为它被用于许多机器上,所以拾荒者有很大的机会拿到它。”
### 该项目的当前状态和未来发展
Collapse OS 的起步相当不错。有足够的内存和存储空间它就可以进行自我复制。它可以在 [RC2014 家用计算机](https://rc2014.co.uk/)或世嘉 Master System / MegaDrive(Genesis)上运行。它可以读取 SD 卡。它有一个简单的文本编辑器。其内核由用粘合代码连接起来的模块组成。这是为了使系统具有灵活性和适应性。
还有一个详细的[路线图](https://collapseos.org/roadmap.html)列出了该项目的方向。列出的目标包括:
* 支持其他 CPU,例如 8080 和 [6502](https://en.wikipedia.org/wiki/MOS_Technology_6502)。
* 支持临时拼凑的外围设备,例如 LCD 屏幕、电子墨水显示器和 [ACIA 设备](https://en.wikipedia.org/wiki/MOS_Technology_6551)。
* 支持更多的存储方式,例如软盘、CD、SPI RAM/ROM 和 AVR MCU。
* 使它可以在其他 z80 机器上工作,例如 [TI-83+](https://en.wikipedia.org/wiki/TI-83_series#TI-83_Plus) 和 [TI-84+](https://en.wikipedia.org/wiki/TI-84_Plus_series) 图形计算器和 TRS-80s。
如果你有兴趣帮助或只是想窥视一下这个项目,请访问其 [GitHub 页面](https://github.com/hsoft/collapseos)。
### 最后的思考
坦率地说,我认为 Collapse OS 与其说是一个有用的项目,倒不如说更像是一个有趣的爱好项目(对于那些喜欢构建操作系统的人来说)。当崩溃真的到来时,我认为 GitHub 也会宕机,那么 Collapse OS 将如何分发?我无法想像,得具有多少技能的人才能够从捡来的零件中创建出一个系统。到时候会有新一代的创客们,但大多数创客们会习惯于选择 Arduino 或树莓派来构建项目,而不是从头开始。
与 Dupras 相反,我最担心的是[电磁脉冲炸弹(EMP)](https://en.wikipedia.org/wiki/Electromagnetic_pulse) 的使用。这些东西会炸毁所有的电气系统,这意味着将没有任何构建系统的可能。如果没有发生这种事情,我想我们将能够找到过去 30 年制造的那么多的 x86 组件,以保持它们运行下去。
话虽如此,对于那些喜欢为奇奇怪怪的应用编写低级代码的人来说,Collapse OS 听起来是一个有趣且具有高度挑战性的项目。如果你是这样的人,去检出 [Collapse OS](https://collapseos.org/) 代码吧。
让我提个假设的问题:你选择的世界末日操作系统是什么?请在下面的评论中告诉我们。
如果你觉得这篇文章有趣,请花一点时间在社交媒体、Hacker News 或 [Reddit](https://reddit.com/r/linuxusersgroup) 上分享。
---
via: <https://itsfoss.com/collapse-os/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When most people think about preparing for a post-apocalyptic world, the first time that comes to mind is food and other living essentials. Recently, a programmer has decided that it would be just as important to create a versatile and survivable operating system after the collapse of society. We will be taking a look at it today, as best we can.
## Collapse OS – For when the fecal matter hits the rotating device

The operating system in question is called [Collapse OS](https://collapseos.org/). According to the website, Collapse OS is a “z80 kernel and a collection of programs, tools and documentation”. It would allow you to:
- Run on minimal and improvised machines.
- Interface through improvised means (serial, keyboard, display).
- Edit text files.
- Compile assembler source files for a wide range of MCUs and CPUs.
- Read and write from a wide range of storage devices.
- Replicate itself.
The creator, [Virgil Dupras](https://github.com/hsoft), started the project because [he sees](https://collapseos.org/why.html) “our global supply chain to collapse before we reach 2030”. He bases this conclusion on the works of Pablo Servigne. He seems to understand that not everyone shares [his views](https://collapseos.org/why.html). “That being said, I don’t consider it unreasonable to not believe that collapse is likely to happen by 2030, so please, don’t feel attacked by my beliefs.”
The overall goal of the project is to jumpstart a post-collapse civilization’s return to the computer age. The production of electronics depends on a very complex supply chain. Once that supply chain crumbles, man will go back to a less technical age. It would take decades to regain our previous technical position. Dupras hopes to jump several steps by creating an ecosystem that will work with simpler chips that can be scavenged from a wide variety of sources.
## What is the z80?
The initial CollapseOS kernel is written for the [z80 chip](https://en.m.wikipedia.org/wiki/Z80). As a retro computing history buff, I am familiar with [Zilog](https://en.wikipedia.org/wiki/Zilog) and it’s z80 chip. In the late 1970s, Zilog introduced the z80 to compete with [Intel’s 8080](https://en.wikipedia.org/wiki/Intel_8080) CPU. The z80 was used in a whole bunch of early personal computers, such as the [Sinclair ZX Spectrum](https://en.wikipedia.org/wiki/ZX_Spectrum) and the [Tandy TRS-80](https://en.wikipedia.org/wiki/TRS-80). The majority of these systems used the [CP/M operating system](https://en.wikipedia.org/wiki/CP/M), which was the top operating system of the time. (Interestingly, Dupras was originally looking to use an [open-source implementation o](https://github.com/davidgiven/cpmish)[f](https://github.com/davidgiven/cpmish)[ CP/M](https://github.com/davidgiven/cpmish), but ultimately decided to [start from scratch](https://github.com/hsoft/collapseos/issues/52).)
Both the z80 and CP/M started to decline in popularity after the [IBM PC](https://en.wikipedia.org/wiki/IBM_Personal_Computer) was released in 1981. Zilog did release several other microprocessors (Z8000 and Z80000), but these did not take off. The company switched its focus to microcontrollers. Today, an updated descendant of the z80 can be found in graphic calculators, embedded devices and consumer electronics.
Dupras said on [Reddit](https://old.reddit.com/r/collapse/comments/dejmvz/collapse_os_bootstrap_postcollapse_technology/f2w3sid/?st=k1gujoau&sh=1b344da9) that he wrote Collapse OS for the z80 because “it’s been in production for so long and because it’s been used in so many machines, scavenger have good chances of getting their hands on it.”
## Current status and future of the project
Collapse OS has a pretty decent start. It can self replicate with enough RAM and storage. It is capable of running on an [RC2014 homebrew computer](https://rc2014.co.uk/) or a Sega Master System/MegaDrive (Genesis). It can read SD cards. It has a simple text editor. The kernel is made up of modules that are connected with glue code. This is designed to make the system flexible and adaptable.
There is also a detailed [roadmap](https://collapseos.org/roadmap.html) laying out the direction of the project. Listed goals include:
- Support for other CPUs, such as 8080 and
[6502](https://en.wikipedia.org/wiki/MOS_Technology_6502) - Support for improvised peripherals, such as LCD screens, E-ink displays, and
[ACIA devices](https://en.wikipedia.org/wiki/MOS_Technology_6551). - Support for more storage options, such as floppys, CDs, SPI RAM/ROMs, and AVR MCUs
- Get it to work on other z80 machines, such as
[TI-83+](https://en.wikipedia.org/wiki/TI-83_series#TI-83_Plus)and[TI-84+](https://en.wikipedia.org/wiki/TI-84_Plus_series)graphing calculators and TRS-80s
If you are interested in helping out or just taking a peek at the project, be sure to visit their [GitHub page](https://github.com/hsoft/collapseos).
## Final Thoughts
To put it bluntly, I see Collapse OS as more of a fun hobby project (for those who like building operating systems), than something useful. When a collapse does come, how will Collapse OS get distributed, since I imagine that GitHub will be down? I can’t imagine more than a handful of skill people being able to create a system from scavenged parts. There is a whole new generation of makers out there, but most of them are used to picking up an Arduino or a Raspberry Pi and building their project than starting from scratch.
Contrary to Dupras, my biggest concern is the use of [EMPs](https://en.wikipedia.org/wiki/Electromagnetic_pulse). These things fry all electrical systems, meaning there would be nothing left to scavenge to build system. If that doesn’t happen, I imagine that we would be able to find enough x86 components made over the past 30 years to keep things going.
That being said, Collapse OS sounds like a fun and challenging project to people who like to program in low-level code for strange applications. If you are such a person, check out [Collapse OS](https://collapseos.org/).
Hypothetical question: what is your post-apocalyptic operating system of choice? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
11,527 | RPM 包是如何从源 RPM 制作的 | https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/ | 2019-11-02T09:35:46 | [
"RPM"
] | https://linux.cn/article-11527-1.html | 
在[上一篇文章中,我们研究了什么是 RPM 软件包](/article-11452-1.html)。它们是包含文件和元数据的档案文件。当安装或卸载 RPM 时,此元数据告诉 RPM 在哪里创建或删除文件。正如你将在上一篇文章中记住的,元数据还包含有关“依赖项”的信息,它可以是“运行时”或“构建时”的依赖信息。
例如,让我们来看看 `fpaste`。你可以使用 `dnf` 下载该 RPM。这将下载 Fedora 存储库中可用的 `fpaste` 最新版本。在 Fedora 30 上,当前版本为 0.3.9.2:
```
$ dnf download fpaste
...
fpaste-0.3.9.2-2.fc30.noarch.rpm
```
由于这是个构建 RPM,因此它仅包含使用 `fpaste` 所需的文件:
```
$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.noarch.rpm
/usr/bin/fpaste
/usr/share/doc/fpaste
/usr/share/doc/fpaste/README.rst
/usr/share/doc/fpaste/TODO
/usr/share/licenses/fpaste
/usr/share/licenses/fpaste/COPYING
/usr/share/man/man1/fpaste.1.gz
```
### 源 RPM
在此链条中的下一个环节是源 RPM。Fedora 中的所有软件都必须从其源代码构建。我们不包括预构建的二进制文件。因此,要制作一个 RPM 文件,RPM(工具)需要:
* 给出必须要安装的文件,
* 例如,如果要编译出这些文件,则告诉它们如何生成这些文件,
* 告知必须在何处安装这些文件,
* 该特定软件需要其他哪些依赖才能正常工作。
源 RPM 拥有所有这些信息。源 RPM 与构建 RPM 相似,但顾名思义,它们不包含已构建的二进制文件,而是包含某个软件的源文件。让我们下载 `fpaste` 的源 RPM:
```
$ dnf download fpaste --source
...
fpaste-0.3.9.2-2.fc30.src.rpm
```
注意文件的结尾是 `src.rpm`。所有的 RPM 都是从源 RPM 构建的。你也可以使用 `dnf` 轻松检查“二进制” RPM 的源 RPM:
```
$ dnf repoquery --qf "%{SOURCERPM}" fpaste
fpaste-0.3.9.2-2.fc30.src.rpm
```
另外,由于这是源 RPM,因此它不包含构建的文件。相反,它包含有关如何从中构建 RPM 的源代码和指令:
```
$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.src.rpm
fpaste-0.3.9.2.tar.gz
fpaste.spec
```
这里,第一个文件只是 `fpaste` 的源代码。第二个是 spec 文件。spec 文件是个配方,可告诉 RPM(工具)如何使用源 RPM 中包含的源代码创建 RPM(档案文件)— 它包含 RPM(工具)构建 RPM(档案文件)所需的所有信息。在 spec 文件中。当我们软件包维护人员添加软件到 Fedora 中时,我们大部分时间都花在编写和完善 spec 文件上。当软件包需要更新时,我们会回过头来调整 spec 文件。你可以在 <https://src.fedoraproject.org/browse/projects/> 的源代码存储库中查看 Fedora 中所有软件包的 spec 文件。
请注意,一个源 RPM 可能包含构建多个 RPM 的说明。`fpaste` 是一款非常简单的软件,一个源 RPM 生成一个“二进制” RPM。而 Python 则更复杂。虽然只有一个源 RPM,但它会生成多个二进制 RPM:
```
$ sudo dnf repoquery --qf "%{SOURCERPM}" python3
python3-3.7.3-1.fc30.src.rpm
python3-3.7.4-1.fc30.src.rpm
$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-devel
python3-3.7.3-1.fc30.src.rpm
python3-3.7.4-1.fc30.src.rpm
$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-libs
python3-3.7.3-1.fc30.src.rpm
python3-3.7.4-1.fc30.src.rpm
$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-idle
python3-3.7.3-1.fc30.src.rpm
python3-3.7.4-1.fc30.src.rpm
$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-tkinter
python3-3.7.3-1.fc30.src.rpm
python3-3.7.4-1.fc30.src.rpm
```
用 RPM 行话来讲,“python3” 是“主包”,因此该 spec 文件将称为 `python3.spec`。所有其他软件包均为“子软件包”。你可以下载 python3 的源 RPM,并查看其中的内容。(提示:补丁也是源代码的一部分):
```
$ dnf download --source python3
python3-3.7.4-1.fc30.src.rpm
$ rpm -qpl ./python3-3.7.4-1.fc30.src.rpm
00001-rpath.patch
00102-lib64.patch
00111-no-static-lib.patch
00155-avoid-ctypes-thunks.patch
00170-gc-assertions.patch
00178-dont-duplicate-flags-in-sysconfig.patch
00189-use-rpm-wheels.patch
00205-make-libpl-respect-lib64.patch
00251-change-user-install-location.patch
00274-fix-arch-names.patch
00316-mark-bdist_wininst-unsupported.patch
Python-3.7.4.tar.xz
check-pyc-timestamps.py
idle3.appdata.xml
idle3.desktop
python3.spec
```
### 从源 RPM 构建 RPM
现在我们有了源 RPM,并且其中有什么内容,我们可以从中重建 RPM。但是,在执行此操作之前,我们应该设置系统以构建 RPM。首先,我们安装必需的工具:
```
$ sudo dnf install fedora-packager
```
这将安装 `rpmbuild` 工具。`rpmbuild` 需要一个默认布局,以便它知道源 RPM 中每个必需组件的位置。让我们看看它们是什么:
```
# spec 文件将出现在哪里?
$ rpm -E %{_specdir}
/home/asinha/rpmbuild/SPECS
# 源代码将出现在哪里?
$ rpm -E %{_sourcedir}
/home/asinha/rpmbuild/SOURCES
# 临时构建目录是哪里?
$ rpm -E %{_builddir}
/home/asinha/rpmbuild/BUILD
# 构建根目录是哪里?
$ rpm -E %{_buildrootdir}
/home/asinha/rpmbuild/BUILDROOT
# 源 RPM 将放在哪里?
$ rpm -E %{_srcrpmdir}
/home/asinha/rpmbuild/SRPMS
# 构建的 RPM 将放在哪里?
$ rpm -E %{_rpmdir}
/home/asinha/rpmbuild/RPMS
```
我已经在系统上设置了所有这些目录:
```
$ cd
$ tree -L 1 rpmbuild/
rpmbuild/
├── BUILD
├── BUILDROOT
├── RPMS
├── SOURCES
├── SPECS
└── SRPMS
6 directories, 0 files
```
RPM 还提供了一个为你全部设置好的工具:
```
$ rpmdev-setuptree
```
然后,确保已安装 `fpaste` 的所有构建依赖项:
```
sudo dnf builddep fpaste-0.3.9.2-3.fc30.src.rpm
```
对于 `fpaste`,你只需要 Python,并且它肯定已经安装在你的系统上(`dnf` 也使用 Python)。还可以给 `builddep` 命令一个 spec 文件,而不是源 RPM。在手册页中了解更多信息:
```
$ man dnf.plugin.builddep
```
现在我们有了所需的一切,从源 RPM 构建一个 RPM 就像这样简单:
```
$ rpmbuild --rebuild fpaste-0.3.9.2-3.fc30.src.rpm
..
..
$ tree ~/rpmbuild/RPMS/noarch/
/home/asinha/rpmbuild/RPMS/noarch/
└── fpaste-0.3.9.2-3.fc30.noarch.rpm
0 directories, 1 file
```
`rpmbuild` 将安装源 RPM 并从中构建你的 RPM。现在,你可以使用 `dnf` 安装 RPM 以使用它。当然,如前所述,如果你想在 RPM 中进行任何更改,则必须修改 spec 文件,我们将在下一篇文章中介绍 spec 文件。
### 总结
总结一下这篇文章有两点:
* 我们通常安装使用的 RPM 是包含软件的构建版本的 “二进制” RPM
* 构建 RPM 来自于源 RPM,源 RPM 包括用于生成二进制 RPM 所需的源代码和规范文件。
如果你想开始构建 RPM,并帮助 Fedora 社区维护我们提供的大量软件,则可以从这里开始: <https://fedoraproject.org/wiki/Join_the_package_collection_maintainers>
如有任何疑问,请发邮件到 [Fedora 开发人员邮件列表](https://lists.fedoraproject.org/archives/list/[email protected]/),我们随时乐意为你提供帮助!
---
via: <https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/>
作者:[Ankur Sinha FranciscoD](https://fedoramagazine.org/author/ankursinha/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In a [previous post, we looked at what RPM packages are](https://fedoramagazine.org/rpm-packages-explained/). They are archives that contain files and metadata. This metadata tells RPM where to create or remove files from when an RPM is installed or uninstalled. The metadata also contains information on “dependencies”, which you will remember from the previous post, can either be “runtime” or “build time”.
As an example, we will look at *fpaste*. You can download the RPM using *dnf*. This will download the latest version of *fpaste* that is available in the Fedora repositories. On Fedora 30, this is currently 0.3.9.2:
$ dnf download fpaste ... fpaste-0.3.9.2-2.fc30.noarch.rpm
Since this is the built RPM, it contains only files needed to use *fpaste*:
$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.noarch.rpm /usr/bin/fpaste /usr/share/doc/fpaste /usr/share/doc/fpaste/README.rst /usr/share/doc/fpaste/TODO /usr/share/licenses/fpaste /usr/share/licenses/fpaste/COPYING /usr/share/man/man1/fpaste.1.gz
## Source RPMs
The next link in the chain is the source RPM. All software in Fedora must be built from its source code. We do not include pre-built binaries. So, for an RPM file to be made, RPM (the tool) needs to be:
- given the files that have to be installed,
- told how to generate these files, if they are to be compiled, for example,
- told where these files must be installed,
- what other dependencies this particular software needs to work properly.
The source RPM holds all of this information. Source RPMs are similar archives to RPM, but as the name suggests, instead of holding the built binary files, they contain the source files for a piece of software. Let’s download the source RPM for *fpaste*:
$ dnf download fpaste --source ... fpaste-0.3.9.2-2.fc30.src.rpm
Notice how the file ends with “src.rpm”. All RPMs are built from source RPMs. You can easily check what source RPM a “binary” RPM comes from using dnf too:
$ dnf repoquery --qf "%{SOURCERPM}" fpaste fpaste-0.3.9.2-2.fc30.src.rpm
Also, since this is the source RPM, it does not contain built files. Instead, it contains the sources and instructions on how to build the RPM from them:
$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.src.rpm fpaste-0.3.9.2.tar.gz fpaste.spec
Here, the first file is simply the source code for *fpaste*. The second is the “spec” file. The spec file is the recipe that tells RPM (the tool) how to create the RPM (the archive) using the sources contained in the source RPM—all the information that RPM (the tool) needs to build RPMs (the archives) are contained in spec files. When we package maintainers add software to Fedora, most of our time is spent writing and perfecting the individual spec files. When a software package needs an update, we go back and tweak the spec file. You can see the spec files for ALL packages in Fedora at our source repository at [https://src.fedoraproject.org/browse/projects/](https://src.fedoraproject.org/browse/projects/)
Note that one source RPM may contain the instructions to build multiple RPMs. *fpaste* is a very simple piece of software, where one source RPM generates one “binary” RPM. Python, on the other hand is more complex. While there is only one source RPM, it generates multiple binary RPMs:
$ sudo dnf repoquery --qf "%{SOURCERPM}" python3 python3-3.7.3-1.fc30.src.rpm python3-3.7.4-1.fc30.src.rpm $ sudo dnf repoquery --qf "%{SOURCERPM}" python3-devel python3-3.7.3-1.fc30.src.rpm python3-3.7.4-1.fc30.src.rpm $ sudo dnf repoquery --qf "%{SOURCERPM}" python3-libs python3-3.7.3-1.fc30.src.rpm python3-3.7.4-1.fc30.src.rpm $ sudo dnf repoquery --qf "%{SOURCERPM}" python3-idle python3-3.7.3-1.fc30.src.rpm python3-3.7.4-1.fc30.src.rpm $ sudo dnf repoquery --qf "%{SOURCERPM}" python3-tkinter python3-3.7.3-1.fc30.src.rpm python3-3.7.4-1.fc30.src.rpm
In RPM jargon, “python3” is the “main package”, and so the spec file will be called “python3.spec”. All the other packages are “sub-packages”. You can download the source RPM for python3 and see what’s in it too. (Hint: patches are also part of the source code):
$ dnf download --source python3 python3-3.7.4-1.fc30.src.rpm $ rpm -qpl ./python3-3.7.4-1.fc30.src.rpm 00001-rpath.patch 00102-lib64.patch 00111-no-static-lib.patch 00155-avoid-ctypes-thunks.patch 00170-gc-assertions.patch 00178-dont-duplicate-flags-in-sysconfig.patch 00189-use-rpm-wheels.patch 00205-make-libpl-respect-lib64.patch 00251-change-user-install-location.patch 00274-fix-arch-names.patch 00316-mark-bdist_wininst-unsupported.patch Python-3.7.4.tar.xz check-pyc-timestamps.py idle3.appdata.xml idle3.desktop python3.spec
## Building an RPM from a source RPM
Now that we have the source RPM, and know what’s in it, we can rebuild our RPM from it. Before we do so, though, we should set our system up to build RPMs. First, we install the required tools:
$ sudo dnf install fedora-packager
This will install the rpmbuild tool. rpmbuild requires a default layout so that it knows where each required component of the source rpm is. Let’s see what they are:
# Where should the spec file go? $ rpm -E %{_specdir} /home/asinha/rpmbuild/SPECS # Where should the sources go? $ rpm -E %{_sourcedir} /home/asinha/rpmbuild/SOURCES # Where is temporary build directory? $ rpm -E %{_builddir} /home/asinha/rpmbuild/BUILD # Where is the buildroot? $ rpm -E %{_buildrootdir} /home/asinha/rpmbuild/BUILDROOT # Where will the source rpms be? $ rpm -E %{_srcrpmdir} /home/asinha/rpmbuild/SRPMS # Where will the built rpms be? $ rpm -E %{_rpmdir} /home/asinha/rpmbuild/RPMS
I have all of this set up on my system already:
$ cd $ tree -L 1 rpmbuild/ rpmbuild/ ├── BUILD ├── BUILDROOT ├── RPMS ├── SOURCES ├── SPECS └── SRPMS 6 directories, 0 files
RPM provides a tool that sets it all up for you too:
$ rpmdev-setuptree
Then we ensure that we have all the build dependencies for *fpaste* installed:
sudo dnf builddep fpaste-0.3.9.2-3.fc30.src.rpm
For *fpaste* you only need Python and that must already be installed on your system (dnf uses Python too). The builddep command can also be given a spec file instead of an source RPM. Read more in the man page:
$ man dnf.plugin.builddep
Now that we have all that we need, building an RPM from a source RPM is as simple as:
$ rpmbuild --rebuild fpaste-0.3.9.2-3.fc30.src.rpm .. .. $ tree ~/rpmbuild/RPMS/noarch/ /home/asinha/rpmbuild/RPMS/noarch/ └── fpaste-0.3.9.2-3.fc30.noarch.rpm 0 directories, 1 file
rpmbuild will install the source RPM and build your RPM from it. You can now install the RPM to use it as you do–using dnf. Of course, as said before, if you want to change anything in the RPM, you must modify the spec file—we’ll cover spec files in next post.
## Summary
To summarise this post in two short points:
- the RPMs we generally install to use software are “binary” RPMs that contain built versions of the software
- these are built from source RPMs that include the source code and the spec file that are needed to generate the binary RPMs.
If you’d like to get started with building RPMs, and help the Fedora community maintain the massive amount of software we provide, you can start here: [https://fedoraproject.org/wiki/Join_the_package_collection_maintainers](https://fedoraproject.org/wiki/Join_the_package_collection_maintainers)
For any queries, post to the [Fedora developers mailing list](https://lists.fedoraproject.org/archives/list/[email protected]/)—we’re always happy to help!
## Silvia Sanchez
The banner image makes me so happy… that’s the Stadtbibliothek Stuttgart!
Lovely. Thanks.
Great article, by the way.
## Kees de Jong
Excellent!
## tr
brew are easy,
meybe in future somebody wrote converter brew ruby prog to rpm
## jackorp
You can make rubygem RPMs very easily with “gem2rpm” utility which basically converts gemspec to RPM spec.
## Adam Miller
There’s gem2rpm. https://github.com/fedora-ruby/gem2rpm
## jackorp
We have an even better tool 🙂 , gem2rpm, converting source gemspec into RPM spec file
## MX
man mock
## Leandro
Great article! Thanks!!
## Adam Miller
Here’s a comprehensive intro packaging guide if anyone is interested.
https://rpm-packaging-guide.github.io/
## leslie Satenstein
Hi Ankur
Thank you for this and the provious articles. I have a favour to ask.
Is there any chance that you can put the previous articles and this one together as a downloadable PDF file. Your expository is most informative. I do like
“under-the-cover” articles explaining important features of package management.
I tried with cut/paste to Libreoffice, but sections of the pasted output have very unappealing results within LibreOffice’s writer program.
## Paul W. Frields
Just print to PDF from your browser. The results look pretty good from what I can see. |
11,528 | COPR 仓库中 4 个很酷的新项目(2019.10) | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-october-2019/ | 2019-11-02T10:08:51 | [
"COPR"
] | https://linux.cn/article-11528-1.html | 
COPR 是个人软件仓库[集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
本文介绍了 COPR 中一些有趣的新项目。如果你第一次使用 COPR,请参阅 [COPR 用户文档](https://docs.pagure.org/copr.copr/user_documentation.html#)。
### Nu
[Nu](https://github.com/nushell/nushell) 也被称为 Nushell,是受 PowerShell 和现代 CLI 工具启发的 shell。通过使用基于结构化数据的方法,Nu 可轻松处理命令的输出,并通过管道传输其他命令。然后将结果显示在可以轻松排序或过滤的表中,并可以用作其他命令的输入。最后,Nu 提供了几个内置命令、多 shell 和对插件的支持。
#### 安装说明
该[仓库](https://copr.fedorainfracloud.org/coprs/atim/nushell/)目前为 Fedora 30、31 和 Rawhide 提供 Nu。要安装 Nu,请使用以下命令:
```
sudo dnf copr enable atim/nushell
sudo dnf install nushell
```
### NoteKit
[NoteKit](https://github.com/blackhole89/notekit) 是一个笔记程序。它支持 Markdown 来格式化笔记,并支持使用鼠标创建手绘笔记的功能。在 NoteKit 中,笔记以树状结构进行排序和组织。
#### 安装说明
该[仓库](https://copr.fedorainfracloud.org/coprs/lyessaadi/notekit/)目前为 Fedora 29、30、31 和 Rawhide 提供 NoteKit。要安装 NoteKit,请使用以下命令:
```
sudo dnf copr enable lyessaadi/notekit
sudo dnf install notekit
```
### Crow Translate
[Crow Translate](https://github.com/crow-translate/crow-translate) 是一个翻译程序。它可以翻译文本并且可以对输入和结果发音,它还提供命令行界面。对于翻译,Crow Translate 使用 Google、Yandex 或 Bing 的翻译 API。
#### 安装说明
该[仓库](https://copr.fedorainfracloud.org/coprs/faezebax/crow-translate/)目前为 Fedora 30、31 和 Rawhide 以及 Epel 8 提供 Crow Translate。要安装 Crow Translate,请使用以下命令:
```
sudo dnf copr enable faezebax/crow-translate
sudo dnf install crow-translate
```
### dnsmeter
[dnsmeter](https://github.com/DNS-OARC/dnsmeter) 是用于测试域名服务器及其基础设施性能的命令行工具。为此,它发送 DNS 查询并计算答复数,从而测量各种统计数据。除此之外,dnsmeter 可以使用不同的加载步骤,使用 PCAP 文件中的载荷和欺骗发送者地址。
#### 安装说明
该仓库目前为 Fedora 29、30、31、Rawhide 以及 Epel 7 提供 dnsmeter。要安装 dnsmeter,请使用以下命令:
```
sudo dnf copr enable @dnsoarc/dnsmeter
sudo dnf install dnsmeter
```
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-october-2019/>
作者:[Dominik Turecek](https://fedoramagazine.org/author/dturecek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [COPR](https://copr.fedorainfracloud.org/) is a collection of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
This article presents a few new and interesting projects in COPR. If you’re new to using COPR, see the [COPR User Documentation](https://docs.pagure.org/copr.copr/user_documentation.html#) for how to get started.
### Nu
[Nu](https://github.com/nushell/nushell), or Nushell, is a shell inspired by PowerShell and modern CLI tools. Using a structured data based approach, Nu makes it easy to work with commands that output data, piping through other commands. The results are then displayed in tables that can be sorted or filtered easily and may serve as inputs for further commands. Finally, Nu provides several builtin commands, multiple shells and support for plugins.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/atim/nushell/) currently provides Nu for Fedora 30, 31 and Rawhide. To install Nu, use these commands:
sudo dnf copr enable atim/nushell sudo dnf install nushell
### NoteKit
[NoteKit](https://github.com/blackhole89/notekit) is a program for note-taking. It supports Markdown for formatting notes, and the ability to create hand-drawn notes using mouse. In NoteKit, notes are sorted and organized in a tree structure.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/lyessaadi/notekit/) currently provides NoteKit for Fedora 29, 30, 31 and Rawhide. To install NoteKit, use these commands:
sudo dnf copr enable lyessaadi/notekit sudo dnf install notekit
### Crow Translate
[Crow Translate](https://github.com/crow-translate/crow-translate) is a program for translating. It can translate text as well as speak both the input and result, and offers a command line interface as well. For translation, Crow Translate uses Google, Yandex or Bing translate API.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/faezebax/crow-translate/) currently provides Crow Translate for Fedora 30, 31 and Rawhide, and for Epel 8. To install Crow Translate, use these commands:
sudo dnf copr enable faezebax/crow-translate sudo dnf install crow-translate
### dnsmeter
[dnsmeter](https://github.com/DNS-OARC/dnsmeter) is a command-line tool for testing performance of a nameserver and its infrastructure. For this, it sends DNS queries and counts the replies, measuring various statistics. Among other features, dnsmeter can use different load steps, use payload from PCAP files and spoof sender addresses.
#### Installation instructions
The repo currently provides dnsmeter for Fedora 29, 30, 31 and Rawhide, and EPEL 7. To install dnsmeter, use these commands:
sudo dnf copr enable @dnsoarc/dnsmeter sudo dnf install dnsmeter
## Gianni
Do you really want to enable copr.fedorainfracloud.org/atim/nushell? [y/N]: y
Errore: Il repository non ha ancora pacchetti e non può essere pertanto abilitato adesso.
## Christina
I will come back here
## Maclean
Do you really want to enable copr.fedorainfracloud.org/atim/nushell? [y/N]: y
Errore: Il repository non ha ancora pacchetti e non può essere pertanto abilitato adesso. |
11,529 | 由于 GIMP 是令人反感的字眼,有人将它复刻了 | https://itsfoss.com/gimp-fork-glimpse/ | 2019-11-02T11:14:42 | [
"GIMP"
] | https://linux.cn/article-11529-1.html | 在开源应用程序世界中,当社区成员希望以与其他人不同的方向来开发应用程序时,<ruby> 复刻 <rt> fork </rt></ruby>是很常见的。最新的具有新闻价值的一个复刻称为 [Glimpse](https://getglimpse.app/),旨在解决用户在使用 <ruby> <a href="https://www.gimp.org/"> GNU 图像处理程序 </a> <rt> GNU Image Manipulation Program </rt></ruby>(通常称为 GIMP)时遇到的某些问题。
### 为什么创建 GIMP 的复刻?

当你访问 Glimpse 应用的[主页](https://getglimpse.app/)时,它表示该项目的目标是“尝试其他设计方向并修复长期存在的错误。”这听起来并不奇怪。但是,如果你开始阅读该项目的博客文章,则是另外一种印象。
根据该项目的[第一篇博客文章](https://getglimpse.app/posts/so-it-begins/),他们创建了这个复刻是因为他们不喜欢 GIMP 这个名称。根据该帖子,“我们中的许多人不认为该软件的名称适用于所有用户,并且在拒绝该项目的 13 年后,我们决定复刻!”
如果你想知道为什么这些人认为 GIMP 令人讨厌,他们在[关于页面](https://getglimpse.app/about/)中回答该问题:
>
> “如果英语不是你的母语,那么你可能没有意识到 ‘gimp’ 一词有问题。在某些国家,这被视为针对残疾人的侮辱和针对不受欢迎儿童的操场侮辱。它也可以与成年人同意的某些‘天黑后’活动联系起来。”
>
>
>
他们还指出,他们并没有使这一举动脱离政治正确或过于敏感。“除了可能给边缘化社区带来的痛苦外,我们当中许多人都有过倡导自由软件的故事,比如在 GNU 图像处理程序没有被专业环境中的老板或同事视为可选项这件事上。”
他们似乎在回答许多质疑,“不幸的是,我们不得不复刻整个项目来更改其名称,我们认为有关此问题的讨论陷入了僵局,而这是最积极的前进方向。 ”
看起来 Glimpse 这个名称不是确定不变的。他们的 GitHub 页面上有个关于可能选择其他名称的[提案](https://github.com/glimpse-editor/Glimpse/issues/92)。也许他们应该放弃 GNU 这个词,我认为 IMP 这个词没有不好的含义。(LCTT 译注:反讽)
### 分叉之路

[GIMP](https://itsfoss.com/gimp-2-10-release/) 已经存在了 20 多年,因此任何形式的复刻都是一项艰巨的任务。当前,[他们正在计划](https://getglimpse.app/posts/six-week-checkpoint/)首先在 2019 年 9 月发布 Glimpse 0.1。这将是一个软复刻,这意味着在迁移到新身份时的更改将主要是装饰性的。(LCTT 译注:事实上到本译文发布时,该项目仍然处于蛋疼的 0.1 beta,也许 11 月,也许 12 月,才能发布 0.1 的正式版本。)
Glimpse 1.0 将是一个硬复刻,他们将积极更改代码库并将其添加到代码库中。他们想将 1.0 移植到 GTK3 并拥有自己的文档。他们估计,直到 2020 年 GIMP 3 发布之后才能做到。
除了 1.0,Glimpse 团队还计划打响自己的名声。他们计划进行“前端 UI 重写”。他们目前正在讨论[改用哪种语言](https://github.com/glimpse-editor/Glimpse/issues/70)。D 和 Rust 似乎有很多支持者。随着时间的流逝,他们也[希望](https://getglimpse.app/posts/so-it-begins/)“添加新功能以解决普通用户的抱怨”。
### 最后的思考
我过去曾经使用过一点 GIMP,但从来没有对它的名称感到困扰。老实说,我很长一段时间都不知道这意味着什么。有趣的是,当我在 Wikipedia 上搜索 GIMP 时,看到了一个 [GIMP 项目](https://en.wikipedia.org/wiki/The_Gimp_Project)的条目,这是纽约的一个现代舞蹈项目,其中包括残疾人。我想 gimp 并不是每个人视为一个贬低词汇的。
对我来说,更改名称似乎需要大量工作。似乎改写 UI 的想法会使项目看起来更有价值一些。我想知道他们是否会调整它以带来更经典的 UI,例如[使用 Ctrl + S 保存到 GIMP](https://itsfoss.com/how-to-solve-gimp-2-8-does-not-save-in-jpeg-or-png-format/) / Glimpse。让我们拭目以待。
如果你对该项目感兴趣,可以在 [Twitter](https://twitter.com/glimpse_editor) 上关注他们,查看其 [GitHub 帐户](https://github.com/glimpse-editor/Glimpse),或查看其 [Patreon 页面](https://www.patreon.com/glimpse)。
你觉得被 GIMP 名称冒犯了吗?你是否认为值得对应用程序进行复刻,以便你可以对其进行重命名?在下面的评论中让我们知道。
如果你觉得这篇文章有趣,请花一点时间在社交媒体、Hacker News 或 [Reddit](https://reddit.com/r/linuxusersgroup) 上分享。
---
via: <https://itsfoss.com/gimp-fork-glimpse/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the world of open source applications, forking is common when members of the community want to take an application in a different direction than the rest. The latest newsworthy fork is named [Glimpse](https://glimpse-editor.org/) and is intended to fix certain issues that users have with the [GNU Image Manipulation Program](https://www.gimp.org/), commonly known as GIMP.
## Why create a fork of GIMP?

When you visit the [homepage](https://glimpse-editor.org/) of the Glimpse app, it says that the goal of the project is to “experiment with other design directions and fix longstanding bugs.” That doesn’t sound too much out of the ordinary. However, if you start reading the project’s blog posts, a different image appears.
According to the project’s [first blog post](https://glimpse-editor.org/posts/so-it-begins/), they created this fork because they did not like the GIMP name. According to the post, “A number of us disagree that the name of the software is suitable for all users, and after 13 years of the project refusing to budge on this have decided to fork!”
If you are wondering why these people find the work GIMP disagreeable they answer that question on the [About page](https://glimpse-editor.org/about/):
“If English is not your first language, then you may not have realised that the word “gimp” is problematic. In some countries it is considered a slur against disabled people and a playground insult directed at unpopular children. It can also be linked to certain “after dark” activities performed by consenting adults.”
They also point out that they are not making this move out of political correctness or being oversensitive. “In addition to the pain it can cause to marginalized communities many of us have our own free software advocacy stories about the GNU Image Manipulation Program not being taken seriously as an option by bosses or colleagues in professional settings.”
As if to answer many questions, they also said, “It is unfortunate that we have to fork the whole project to change the name, but we feel that discussions about the issue are at an impasse and that this is the most positive way forward.”
It looks like the Glimpse name is not written in stone. There is [an issue](https://github.com/glimpse-editor/Glimpse/issues/92) on their GitHub page about possibly picking another name. Maybe they should just drop GNU. I don’t think the word IMP has a bad connotation.
## A diverging path
[GIMP](https://itsfoss.com/gimp-2-10-release/) has been around for over twenty years, so any kind of fork is a big task. Currently, [they are planning](https://glimpse-editor.org/posts/six-week-checkpoint/) to start by releasing Glimpse 0.1 in September 2019. This will be a soft fork, meaning that changes will be mainly cosmetic as they migrate to a new identity.
Glimpse 1.0 will be a hard fork where they will be actively changing the codebase and adding to it. They want 1.0 to be a port to GTK3 and have its own documentation. They estimate that this will not take place until GIMP 3 is released in 2020.
Beyond the 1.0, the Glimpse team has plans to forge their own identity. They plan to work on a “front-end UI rewrite”. They are currently discussing [which language](https://github.com/glimpse-editor/Glimpse/issues/70) they should use for the rewrite. There seems to be a lot of push for D and Rust. They also [hope to](https://glimpse-editor.org/posts/so-it-begins/) “add new functionality that addresses common user complaints” as time goes on.
## Final Thoughts
I have used GIMP a little bit in the past but was never too bothered by the name. To be honest, I didn’t know what it meant for quite a while. Interestingly, when I searched Wikipedia for GIMP, I came across an entry for the [GIMP Project](https://en.wikipedia.org/wiki/The_Gimp_Project), which is a modern dance project in New York that includes disabled people. I guess gimp isn’t considered a derogatory term by everyone.
To me, it seems like a lot of work to go through to change a name. It also seems like the idea of rewriting the UI was tacked to make the project look more worthwhile. I wonder if they will tweak it to bring a more classic UI like [using Ctrl+S to save in GIMP](https://itsfoss.com/how-to-solve-gimp-2-8-does-not-save-in-jpeg-or-png-format/)/Glimpse. Let’s wait and watch.
If you are interested in the project, you can follow them on [Twitter](https://twitter.com/glimpse_editor), check out their [GitHub account](https://github.com/glimpse-editor/Glimpse), or take a look at their [Patreon page](https://www.patreon.com/glimpse).
Are you offended by the GIMP name? Do you think it is worthwhile to fork an application, just so you can rename it? Let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
11,531 | 5 个 Linux 桌面上的最佳密码管理器 | https://itsfoss.com/password-managers-linux/ | 2019-11-03T10:25:57 | [
"密码管理器"
] | https://linux.cn/article-11531-1.html |
>
> 密码管理器是创建唯一密码并安全存储它们的有用工具,这样你无需记住密码。了解一下适用于 Linux 桌面的最佳密码管理器。
>
>
>

密码无处不在。网站、论坛、Web 应用等,你需要为其创建帐户和密码。麻烦在于密码,为各个帐户使用相同的密码会带来安全风险,因为[如果其中一个网站遭到入侵,黑客也会在其他网站上尝试相同的电子邮件密码组合](https://medium.com/@computerphonedude/one-of-my-old-passwords-was-hacked-on-6-different-sites-and-i-had-no-clue-heres-how-to-quickly-ced23edf3b62)。
但是,为所有新帐户设置独有的密码意味着你必须记住所有密码,这对普通人而言不太可能。这就是密码管理器可以提供帮助的地方。
密码管理应用会为你建议/创建强密码,并将其存储在加密的数据库中。你只需要记住密码管理器的主密码即可。
主流的现代浏览器(例如 Mozilla Firefox 和 Google Chrome)内置了密码管理器。这有帮助,但是你只能在浏览器上使用它。
有一些第三方专门的密码管理器,其中一些还提供 Linux 的原生桌面应用。在本文中,我们将筛选出可用于 Linux 的最佳密码管理器。
继续之前,我还建议你仔细阅读 [Linux 的免费密码生成器](https://itsfoss.com/password-generators-linux/),来为你生成强大的唯一密码。
### Linux 密码管理器
>
> 可能的非 FOSS 警报!
>
>
> 我们优先考虑开源软件(有一些专有软件,请不要讨厌我!),并提供适用于 Linux 的独立桌面应用(GUI)。专有软件已高亮显示。
>
>
>
#### 1、Bitwarden

主要亮点:
* 开源
* 免费供个人使用(可选付费升级)
* 云服务器的端到端加密
* 跨平台
* 有浏览器扩展
* 命令行工具
Bitwarden 是 Linux 上最令人印象深刻的密码管理器之一。老实说,直到现在我才知道它。我已经从 [LastPass](https://www.lastpass.com/) 切换到了它。我能够轻松地从 LastPass 导入数据,而没有任何问题和困难。
付费版本的价格仅为每年 10 美元。这似乎是值得的(我已经为个人使用进行了升级)。
它是一个开源解决方案,因此没有任何可疑之处。你甚至可以将其托管在自己的服务器上,并为你的组织创建密码解决方案。
除此之外,你还将获得所有必需的功能,例如用于登录的两步验证、导入/导出凭据、指纹短语(唯一键)、密码生成器等等。
你可以免费将帐户升级为组织帐户,以便最多与 2 个用户共享你的信息。但是,如果你想要额外的加密存储以及与 5 个用户共享密码的功能,那么付费升级的费用低至每月 1 美元。我认为绝对值得一试!
* [Bitwarden](https://bitwarden.com/)
#### 2、Buttercup

主要亮点:
* 开源
* 免费,没有付费方式。
* 跨平台
* 有浏览器扩展
这是 Linux 中的另一个开源密码管理器。Buttercup 可能不是一个非常流行的解决方案。但是,如果你在寻找一种更简单的保存凭据的方法,那么这将是一个不错的开始。
与其他软件不同,你不必对怀疑其云服务器的安全,因为它只支持离线使用并支持连接 [Dropbox](https://www.dropbox.com/)、[OwnCloud](https://owncloud.com/)、[Nextcloud](https://nextcloud.com/) 和 [WebDAV](https://en.wikipedia.org/wiki/WebDAV) 等云服务。
因此,如果需要同步数据,那么可以选择云服务。你有不同选择。
* [Buttercup](https://buttercup.pw/)
#### 3、KeePassXC

主要亮点:
* 开源
* 简单的密码管理器
* 跨平台
* 没有移动设备支持
KeePassXC 是 [KeePassX](https://www.keepassx.org/) 的社区分支,它最初是 Windows 上 [KeePass](https://keepass.info/) 的 Linux 移植版本。
除非你没意识到,KeePassX 已经多年没有维护。因此,如果你在寻找简单易用的密码管理器,那么 KeePassXC 是一个不错的选择。KeePassXC 可能不是最漂亮或最好的密码管理器,但它确实可以做到该做的事。
它也是安全和开源的。我认为这值得一试,你说呢?
* [KeePassXC](https://keepassxc.org)
#### 4、Enpass (非开源)

主要亮点:
* 专有软件
* 有许多功能,包括对“可穿戴”设备支持。
* Linux 完全免费(具有付费支持)
Enpass 是非常流行的跨平台密码管理器。即使它不是开源解决方案,但还是有很多人依赖它。因此,至少可以肯定它是可行的。
它提供了很多功能,如果你有可穿戴设备,它也可以支持它,这点很少见。
很高兴能看到 Enpass 积极管理 Linux 发行版的软件包。另外,请注意,它仅适用于 64 位系统。你可以在它的网站上找到[官方的安装说明](https://www.enpass.io/support/kb/general/how-to-install-enpass-on-linux/)。它需要使用终端,但是我按照步骤进行了测试,它非常好用。
* [Enpass](https://www.enpass.io/)
#### 5、myki (非开源)

主要亮点:
* 专有软件
* 不使用云服务器存储密码
* 专注于本地点对点同步
* 能够在移动设备上用指纹 ID 替换密码
这可能不是一个受欢迎的建议,但我发现它很有趣。它是专有软件密码管理器,它让你避免使用云服务器,而是依靠点对点同步。
因此,如果你不想使用任何云服务器来存储你的信息,那么它适合你。另外值得注意的是,用于 Android 和 iOS 的程序可让你用指纹 ID 替换密码。如果你希望便于在手机上使用,又有桌面密码管理器的基本功能,这似乎是个不错的选择。
但是,如果你选择升级到付费版,这有个付费计划供你判断,绝对不便宜。
尝试一下,让我们知道它如何!
* [myki](https://myki.com/)
### 其他一些值得说的密码管理器
即使没有为 Linux 提供独立的应用,但仍有一些密码管理器值得一提。
如果你需要使用基于浏览器的(扩展)密码管理器,建议你尝试使用 [LastPass](https://lastpass.com/)、[Dashlane](https://www.dashlane.com/) 和 [1Password](https://1password.com/)。LastPass 甚至提供了 [Linux 客户端(和命令行工具)](https://lastpass.com/misc_download2.php)。
如果你正在寻找命令行密码管理器,那你应该试试 [Pass](https://www.passwordstore.org/)。
[Password Safe](https://pwsafe.org/) 也是种选择,但它的 Linux 客户端还处于 beta 阶段。我不建议依靠 “beta” 程序来存储密码。还有 [Universal Password Manager](http://upm.sourceforge.net/),但它不再维护。你可能也听说过 [Password Gorilla](https://github.com/zdia/gorilla/wiki),但并它没有积极维护。
### 总结
目前,Bitwarden 似乎是我个人的最爱。但是,在 Linux 上有几个替代品可供选择。你可以选择提供原生应用的程序,也可选择浏览器插件,选择权在你。
如果我有错过值得尝试的密码管理器,请在下面的评论中告诉我们。与往常一样,我们会根据你的建议扩展列表。
---
via: <https://itsfoss.com/password-managers-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Passwords are everywhere. For web services, social media, web apps and what not. You need to create accounts and passwords for them. But, the trouble comes with the password; keeping the same password for various accounts poses a security risk.
Because if one of the websites is compromised, hackers can try the same email-password combination on other popular websites as well.
However, keeping unique passwords for all the new accounts means that you have to remember all of them, and it’s not possible for most people.
**This is where a secure password manager comes in.**
Web browsers like Mozilla Firefox and Google Chrome have built in password managers. This helps, but you are restricted to using it on those web browsers only.
Luckily, there are many dedicated password managers, with some of them providing native desktop applications for Linux.
In this article, I will list out some of the best password managers available for Linux.
## 1. Bitwarden
Bitwarden is one of the most impressive password managers for Linux. When I made the switch from [LastPass](https://www.lastpass.com/?ref=itsfoss.com) a few years back, I never looked back.
I could easily import the data from LastPass without any issues and had no trouble whatsoever.
The premium version costs just $10/year – which is honestly not much to support an open-source service and get some extra perks.
You can even host it on your server and create a password solution for personal use or your organization.
In addition to that, you get all the necessary features like 2FA for login, import/export options for your credentials, fingerprint phrase (a unique key), password generator, and more.
**Key Highlights:**
- Free for personal use (paid options available for upgrade)
- Cross-platform
- Command-line tools
## 2. Buttercup
Yet another open-source password manager for Linux. Buttercup may not be a very popular solution – but if you are searching for a simpler alternative to store your credentials, this would be a good start.
Unlike some others, you do not have to be skeptical about its cloud servers because it sticks to offline usage only and supports connecting cloud sources like [Dropbox](https://www.dropbox.com/?ref=itsfoss.com), [OwnCloud](https://owncloud.com/?ref=itsfoss.com), [Nextcloud](https://nextcloud.com/?ref=itsfoss.com), and [WebDAV](https://en.wikipedia.org/wiki/WebDAV?ref=itsfoss.com).
**Key Highlights:**
- Free, with no premium options.
- Cross-platform.
- Browser extensions available.
## 3. KeePassXC
[KeePassXC](https://itsfoss.com/keepassxc/) is a community fork of [KeePassX](https://www.keepassx.org/?ref=itsfoss.com) – which was originally a Linux port of [KeePass](https://keepass.info/?ref=itsfoss.com) on Windows.
But, KeePassX hasn’t been maintained for years now. So, KeePassXC acts as a viable alternative if you are looking for a dead-simple password manager. It may not be the prettiest or fanciest password manager around, but it does the job.
For Android devices, you might find some unofficial open-source apps for KeePass, but we can't recommend them without due diligence.
Nevertheless, the desktop app is secure and open source as well. You can give it a try.
**Key Highlights:**
- Simple password manager.
- Cross-platform.
- Offline only.
- Supports passkeys.
## 4. Enpass (Not Open-Source)
Enpass is a quite popular cross-platform password manager. Even though it’s not an open-source solution, plenty of people rely on it – so you can be sure that it works, at least.
It is great to see that Enpass manages the packages for Linux distros actively. Furthermore, keep in mind that it works for 64-bit systems only.
You can find the [official instructions](https://www.enpass.io/support/kb/general/how-to-install-enpass-on-linux/?ref=itsfoss.com) for installation on their website. It will require utilizing the terminal, but I followed the steps to test it out, and it worked like a charm.
**Key Highlights:**
- Intuitive user interface.
- Plenty of features.
- Cross-Platform.
## 5. Passbolt
Passbolt is a cross-platform, open-source password manager that has been the most requested by our readers to be added to this list. Primarily designed for a team of users, it is based on [OpenPGP](https://www.openpgp.org/?ref=itsfoss.com), and is extensible thanks to the use of [RESTful API](https://aws.amazon.com/what-is/restful-api/?ref=itsfoss.com).
It can either be self-hosted, or one could opt for their business plans. Pricing starts at **€19/month**.
Unfortunately, you cannot try it for free. But, it is an option for you to explore.
**Key Highlights:**
- Self-hostable.
- Tailored for enterprise use.
- Cloud servers run on 100% renewable energy.
## 6. NordPass (Not Open-Source)
NordPass, from the house of [NordVPN](https://nordvpn.com), is a password manager that claims to be “*your digital life manager*”. Even though it is a proprietary option, they offer a dedicated client for Linux in the form of a Snap package.
It has all the usual features one would expect from a password manager, with additional features such as the ability to store files with passwords and create secure notes.
If you are interested in trying it out, you can try the free version. For access to its premium features, you will have to opt for a paid plan, prices for which start from **$1.19/month**.
**Key Highlights:**
- Supports passkeys.
- Easy password importing.
- Securely store credit cards.
## Honorable Mentions
Even without offering a standalone app for Linux, there are some password managers that deserve a mention.
If you need to use browser-based (extensions) password managers, you can try [Proton Pass](https://proton.me/pass?ref=itsfoss.com), [Dashlane](https://www.dashlane.com/?ref=itsfoss.com), [RoboForm](https://www.roboform.com/?ref=itsfoss.com) and [1Password](https://1password.com/?ref=itsfoss.com).
If you are looking for a CLI password manager, you should check out [Pass](https://www.passwordstore.org/?ref=itsfoss.com).
[Password Safe](https://pwsafe.org/?ref=itsfoss.com) is also an option, then there's [Universal Password Manager](http://upm.sourceforge.net/?ref=itsfoss.com), but it’s no longer maintained. You may have also heard about [Password Gorilla](https://github.com/zdia/gorilla/wiki?ref=itsfoss.com), but it is also not actively maintained.
## Wrapping Up
Bitwarden seems to be my personal favorite for now. However, there are several options to choose from on Linux. You can either opt for something that offers a native app or just a browser extension – the choice is yours.
*💬 If we missed listing out a password manager worth trying, let us know about it in the comments below!* |
11,533 | Java 中初始化数组 | https://opensource.com/article/19/10/initializing-arrays-java | 2019-11-03T13:38:53 | [
"数组"
] | https://linux.cn/article-11533-1.html |
>
> 数组是一种有用的数据类型,用于管理在连续内存位置中建模最好的集合元素。下面是如何有效地使用它们。
>
>
>

有使用 C 或者 FORTRAN 语言编程经验的人会对数组的概念很熟悉。它们基本上是一个连续的内存块,其中每个位置都是某种数据类型:整型、浮点型或者诸如此类的数据类型。
Java 的情况与此类似,但是有一些额外的问题。
### 一个数组的示例
让我们在 Java 中创建一个长度为 10 的整型数组:
```
int[] ia = new int[10];
```
上面的代码片段会发生什么?从左到右依次是:
1. 最左边的 `int[]` 将变量的*类型*声明为 `int` 数组(由 `[]` 表示)。
2. 它的右边是变量的名称,当前为 `ia`。
3. 接下来,`=` 告诉我们,左侧定义的变量赋值为右侧的内容。
4. 在 `=` 的右侧,我们看到了 `new`,它在 Java 中表示一个对象正在*被初始化中*,这意味着已为其分配存储空间并调用了其构造函数([请参见此处以获取更多信息](https://opensource.com/article/19/8/what-object-java))。
5. 然后,我们看到 `int[10]`,它告诉我们正在初始化的这个对象是包含 10 个整型的数组。
因为 Java 是强类型的,所以变量 `ia` 的类型必须跟 `=` 右侧表达式的类型兼容。
### 初始化示例数组
让我们把这个简单的数组放在一段代码中,并尝试运行一下。将以下内容保存到一个名为 `Test1.java` 的文件中,使用 `javac` 编译,使用 `java` 运行(当然是在终端中):
```
import java.lang.*;
public class Test1 {
public static void main(String[] args) {
int[] ia = new int[10]; // 见下文注 1
System.out.println("ia is " + ia.getClass()); // 见下文注 2
for (int i = 0; i < ia.length; i++) // 见下文注 3
System.out.println("ia[" + i + "] = " + ia[i]); // 见下文注 4
}
}
```
让我们来看看最重要的部分。
1. 我们声明和初始化了长度为 10 的整型数组,即 `ia`,这显而易见。
2. 在下面的行中,我们看到表达式 `ia.getClass()`。没错,`ia` 是属于一个*类*的*对象*,这行代码将告诉我们是哪个类。
3. 在紧接的下一行中,我们看到了一个循环 `for (int i = 0; i < ia.length; i++)`,它定义了一个循环索引变量 `i`,该变量遍历了从 0 到比 `ia.length` 小 1 的序列,这个表达式告诉我们在数组 `ia` 中定义了多少个元素。
4. 接下来,循环体打印出 `ia` 的每个元素的值。
当这个程序编译和运行时,它产生以下结果:
```
me@mydesktop:~/Java$ javac Test1.java
me@mydesktop:~/Java$ java Test1
ia is class [I
ia[0] = 0
ia[1] = 0
ia[2] = 0
ia[3] = 0
ia[4] = 0
ia[5] = 0
ia[6] = 0
ia[7] = 0
ia[8] = 0
ia[9] = 0
me@mydesktop:~/Java$
```
`ia.getClass()` 的输出的字符串表示形式是 `[I`,它是“整数数组”的简写。与 C 语言类似,Java 数组以第 0 个元素开始,扩展到第 `<数组大小> - 1` 个元素。如上所见,我们可以看到数组 `ia` 的每个元素都(似乎由数组构造函数)设置为零。
所以,就这些吗?声明类型,使用适当的初始化器,就完成了吗?
好吧,并没有。在 Java 中有许多其它方法来初始化数组。
### 为什么我要初始化一个数组,有其它方式吗?
像所有好的问题一样,这个问题的答案是“视情况而定”。在这种情况下,答案取决于初始化后我们希望对数组做什么。
在某些情况下,数组自然会作为一种累加器出现。例如,假设我们正在编程实现计算小型办公室中一组电话分机接收和拨打的电话数量。一共有 8 个分机,编号为 1 到 8,加上话务员的分机,编号为 0。 因此,我们可以声明两个数组:
```
int[] callsMade;
int[] callsReceived;
```
然后,每当我们开始一个新的累计呼叫统计数据的周期时,我们就将每个数组初始化为:
```
callsMade = new int[9];
callsReceived = new int[9];
```
在每个累计通话统计数据的最后阶段,我们可以打印出统计数据。粗略地说,我们可能会看到:
```
import java.lang.*;
import java.io.*;
public class Test2 {
public static void main(String[] args) {
int[] callsMade;
int[] callsReceived;
// 初始化呼叫计数器
callsMade = new int[9];
callsReceived = new int[9];
// 处理呼叫……
// 分机拨打电话:callsMade[ext]++
// 分机接听电话:callsReceived[ext]++
// 汇总通话统计
System.out.printf("%3s%25s%25s\n", "ext", " calls made",
"calls received");
for (int ext = 0; ext < callsMade.length; ext++) {
System.out.printf("%3d%25d%25d\n", ext,
callsMade[ext], callsReceived[ext]);
}
}
}
```
这会产生这样的输出:
```
me@mydesktop:~/Java$ javac Test2.java
me@mydesktop:~/Java$ java Test2
ext calls made calls received
0 0 0
1 0 0
2 0 0
3 0 0
4 0 0
5 0 0
6 0 0
7 0 0
8 0 0
me@mydesktop:~/Java$
```
看来这一天呼叫中心不是很忙。
在上面的累加器示例中,我们看到由数组初始化程序设置的零起始值可以满足我们的需求。但是在其它情况下,这个起始值可能不是正确的选择。
例如,在某些几何计算中,我们可能需要将二维数组初始化为单位矩阵(除沿主对角线———左上角到右下角——以外所有全是零)。我们可以选择这样做:
```
double[][] m = new double[3][3];
for (int d = 0; d < 3; d++) {
m[d][d] = 1.0;
}
```
在这种情况下,我们依靠数组初始化器 `new double[3][3]` 将数组设置为零,然后使用循环将主对角线上的元素设置为 1。在这种简单情况下,我们可以使用 Java 提供的快捷方式:
```
double[][] m = {
{1.0, 0.0, 0.0},
{0.0, 1.0, 0.0},
{0.0, 0.0, 1.0}};
```
这种可视结构特别适用于这种应用程序,在这种应用程序中,它便于复查数组的实际布局。但是在这种情况下,行数和列数只在运行时确定时,我们可能会看到这样的东西:
```
int nrc;
// 一些代码确定行数和列数 = nrc
double[][] m = new double[nrc][nrc];
for (int d = 0; d < nrc; d++) {
m[d][d] = 1.0;
}
```
值得一提的是,Java 中的二维数组实际上是数组的数组,没有什么能阻止无畏的程序员让这些第二层数组中的每个数组的长度都不同。也就是说,下面这样的事情是完全合法的:
```
int [][] differentLengthRows = {
{1, 2, 3, 4, 5},
{6, 7, 8, 9},
{10, 11, 12},
{13, 14},
{15}};
```
在涉及不规则形状矩阵的各种线性代数应用中,可以应用这种类型的结构(有关更多信息,请参见[此 Wikipedia 文章](https://en.wikipedia.org/wiki/Irregular_matrix))。除此之外,既然我们了解到二维数组实际上是数组的数组,那么以下内容也就不足为奇了:
```
differentLengthRows.length
```
可以告诉我们二维数组 `differentLengthRows` 的行数,并且:
```
differentLengthRows[i].length
```
告诉我们 `differentLengthRows` 第 `i` 行的列数。
### 深入理解数组
考虑到在运行时确定数组大小的想法,我们看到数组在实例化之前仍需要我们知道该大小。但是,如果在处理完所有数据之前我们不知道大小怎么办?这是否意味着我们必须先处理一次以找出数组的大小,然后再次处理?这可能很难做到,尤其是如果我们只有一次机会使用数据时。
[Java 集合框架](https://en.wikipedia.org/wiki/Java_collections_framework)很好地解决了这个问题。提供的其中一项是 `ArrayList` 类,它类似于数组,但可以动态扩展。为了演示 `ArrayList` 的工作原理,让我们创建一个 `ArrayList` 对象并将其初始化为前 20 个[斐波那契数字](https://en.wikipedia.org/wiki/Fibonacci_number):
```
import java.lang.*;
import java.util.*;
public class Test3 {
public static void main(String[] args) {
ArrayList<Integer> fibos = new ArrayList<Integer>();
fibos.add(0);
fibos.add(1);
for (int i = 2; i < 20; i++) {
fibos.add(fibos.get(i - 1) + fibos.get(i - 2));
}
for (int i = 0; i < fibos.size(); i++) {
System.out.println("fibonacci " + i + " = " + fibos.get(i));
}
}
}
```
上面的代码中,我们看到:
* 用于存储多个 `Integer` 的 `ArrayList` 的声明和实例化。
* 使用 `add()` 附加到 `ArrayList` 实例。
* 使用 `get()` 通过索引号检索元素。
* 使用 `size()` 来确定 `ArrayList` 实例中已经有多少个元素。
这里没有展示 `put()` 方法,它的作用是将一个值放在给定的索引号上。
该程序的输出为:
```
fibonacci 0 = 0
fibonacci 1 = 1
fibonacci 2 = 1
fibonacci 3 = 2
fibonacci 4 = 3
fibonacci 5 = 5
fibonacci 6 = 8
fibonacci 7 = 13
fibonacci 8 = 21
fibonacci 9 = 34
fibonacci 10 = 55
fibonacci 11 = 89
fibonacci 12 = 144
fibonacci 13 = 233
fibonacci 14 = 377
fibonacci 15 = 610
fibonacci 16 = 987
fibonacci 17 = 1597
fibonacci 18 = 2584
fibonacci 19 = 4181
```
`ArrayList` 实例也可以通过其它方式初始化。例如,可以给 `ArrayList` 构造器提供一个数组,或者在编译过程中知道初始元素时也可以使用 `List.of()` 和 `array.aslist()` 方法。我发现自己并不经常使用这些方式,因为我对 `ArrayList` 的主要用途是当我只想读取一次数据时。
此外,对于那些喜欢在加载数据后使用数组的人,可以使用 `ArrayList` 的 `toArray()` 方法将其实例转换为数组;或者,在初始化 `ArrayList` 实例之后,返回到当前数组本身。
Java 集合框架提供了另一种类似数组的数据结构,称为 `Map`(映射)。我所说的“类似数组”是指 `Map` 定义了一个对象集合,它的值可以通过一个键来设置或检索,但与数组(或 `ArrayList`)不同,这个键不需要是整型数;它可以是 `String` 或任何其它复杂对象。
例如,我们可以创建一个 `Map`,其键为 `String`,其值为 `Integer` 类型,如下:
```
Map<String, Integer> stoi = new Map<String, Integer>();
```
然后我们可以对这个 `Map` 进行如下初始化:
```
stoi.set("one",1);
stoi.set("two",2);
stoi.set("three",3);
```
等类似操作。稍后,当我们想要知道 `"three"` 的数值时,我们可以通过下面的方式将其检索出来:
```
stoi.get("three");
```
在我的认知中,`Map` 对于将第三方数据集中出现的字符串转换为我的数据集中的一致代码值非常有用。作为[数据转换管道](https://towardsdatascience.com/data-science-for-startups-data-pipelines-786f6746a59a)的一部分,我经常会构建一个小型的独立程序,用作在处理数据之前清理数据;为此,我几乎总是会使用一个或多个 `Map`。
值得一提的是,`ArrayList` 的 `ArrayList` 和 `Map` 的 `Map` 是很可能的,有时也是合理的。例如,假设我们在看树,我们对按树种和年龄范围累计树的数目感兴趣。假设年龄范围定义是一组字符串值(“young”、“mid”、“mature” 和 “old”),物种是 “Douglas fir”、“western red cedar” 等字符串值,那么我们可以将这个 `Map` 中的 `Map` 定义为:
```
Map<String, Map<String, Integer>> counter = new Map<String, Map<String, Integer>>();
```
这里需要注意的一件事是,以上内容仅为 `Map` 的*行*创建存储。因此,我们的累加代码可能类似于:
```
// 假设我们已经知道了物种和年龄范围
if (!counter.containsKey(species)) {
counter.put(species,new Map<String, Integer>());
}
if (!counter.get(species).containsKey(ageRange)) {
counter.get(species).put(ageRange,0);
}
```
此时,我们可以这样开始累加:
```
counter.get(species).put(ageRange, counter.get(species).get(ageRange) + 1);
```
最后,值得一提的是(Java 8 中的新特性)Streams 还可以用来初始化数组、`ArrayList` 实例和 `Map` 实例。关于此特性的详细讨论可以在[此处](https://stackoverflow.com/questions/36885371/lambda-expression-to-initialize-array)和[此处](https://stackoverflow.com/questions/32868665/how-to-initialize-a-map-using-a-lambda)中找到。
---
via: <https://opensource.com/article/19/10/initializing-arrays-java>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | People who have experience programming in languages like C or FORTRAN are familiar with the concept of arrays. They’re basically a contiguous block of memory where each location is a certain type: integers, floating-point numbers, or what-have-you.
The situation in Java is similar, but with a few extra wrinkles.
## An example array
Let’s make an array of 10 integers in Java:
```
int[] ia = new int[10];
```
What’s going on in the above piece of code? From left to right:
-
The
**int[]**to the extreme left declares the*type*of the variable as an array (denoted by the**[]**) of**int**. -
To the right is the
*name*of the variable, which in this case is**ia**. -
Next, the
**=**tells us that the variable defined on the left side is set to what’s to the right side. -
To the right of the
**=**we see the word**new**, which in Java indicates that an object is being*initialized*, meaning that storage is allocated and its constructor is called ([see here for more information](https://opensource.com/article/19/8/what-object-java)). -
Next, we see
**int[10]**, which tells us that the specific object being initialized is an array of 10 integers.
Since Java is strongly-typed, the type of the variable **ia** must be compatible with the type of the expression on the right-hand side of the **=**.
## Initializing the example array
Let’s put this simple array in a piece of code and try it out. Save the following in a file called **Test1.java**, use **javac** to compile it, and use **java** to run it (in the terminal of course):
```
import java.lang.*;
public class Test1 {
public static void main(String[] args) {
int[] ia = new int[10]; // See note 1 below
System.out.println("ia is " + ia.getClass()); // See note 2 below
for (int i = 0; i < ia.length; i++) // See note 3 below
System.out.println("ia[" + i + "] = " + ia[i]); // See note 4 below
}
}
```
Let’s work through the most important bits.
- Our declaration and initialization of the array of 10 integers,
**ia**, is easy to spot. - In the line just following, we see the expression
**ia.getClass()**. That’s right,**ia**is an*object*belonging to a*class*, and this code will let us know which class that is. - In the next line following that, we see the start of the loop
**for (int i = 0; i < ia.length; i++)**, which defines a loop index variable**i**that runs through a sequence from zero to one less than**ia.length**, which is an expression that tells us how many elements are defined in the array**ia**. - Next, the body of the loop prints out the values of each element of
**ia**.
When this program is compiled and run, it produces the following results:
```
me@mydesktop:~/Java$ javac Test1.java
me@mydesktop:~/Java$ java Test1
ia is class [I
ia[0] = 0
ia[1] = 0
ia[2] = 0
ia[3] = 0
ia[4] = 0
ia[5] = 0
ia[6] = 0
ia[7] = 0
ia[8] = 0
ia[9] = 0
me@mydesktop:~/Java$
```
The string representation of the output of **ia.getClass()** is **[I**, which is shorthand for "array of integer." Similar to the C programming language, Java arrays begin with element zero and extend up to element **<array size> – 1**. We can see above that each of the elements of **ia** are set to zero (by the array constructor, it seems).
So, is that it? We declare the type, use the appropriate initializer, and we’re done?
Well, no. There are many other ways to initialize an array in Java.
## Why do I want to initialize an array, anyway?
The answer to this question, like that of all good questions, is "it depends." In this case, the answer depends on what we expect to do with the array once it is initialized.
In some cases, arrays emerge naturally as a type of accumulator. For example, suppose we are writing code for counting the number of calls received and made by a set of telephone extensions in a small office. There are eight extensions, numbered one through eight, plus the operator’s extension, numbered zero. So we might declare two arrays:
```
int[] callsMade;
int[] callsReceived;
```
Then, whenever we start a new period of accumulating call statistics, we initialize each array as:
```
callsMade = new int[9];
callsReceived = new int[9];
```
At the end of each period of accumulating call statistics, we can print out the stats. In very rough terms, we might see:
```
import java.lang.*;
import java.io.*;
public class Test2 {
public static void main(String[] args) {
int[] callsMade;
int[] callsReceived;
// initialize call counters
callsMade = new int[9];
callsReceived = new int[9];
// process calls...
// an extension makes a call: callsMade[ext]++
// an extension receives a call: callsReceived[ext]++
// summarize call statistics
System.out.printf("%3s%25s%25s\n","ext"," calls made",
"calls received");
for (int ext = 0; ext < callsMade.length; ext++)
System.out.printf("%3d%25d%25d\n",ext,
callsMade[ext],callsReceived[ext]);
}
}
```
Which would produce output something like this:
```
me@mydesktop:~/Java$ javac Test2.java
me@mydesktop:~/Java$ java Test2
ext calls made calls received
0 0 0
1 0 0
2 0 0
3 0 0
4 0 0
5 0 0
6 0 0
7 0 0
8 0 0
me@mydesktop:~/Java$
```
Not a very busy day in the call center.
In the above example of an accumulator, we see that the starting value of zero as set by the array initializer is satisfactory for our needs. But in other cases, this starting value may not be the right choice.
For example, in some kinds of geometric computations, we might need to initialize a two-dimensional array to the identity matrix (all zeros except for the ones along the main diagonal). We might choose to do this as:
```
double[][] m = new double[3][3];
for (int d = 0; d < 3; d++)
m[d][d] = 1.0;
```
In this case, we rely on the array initializer **new double[3][3]** to set the array to zeros, and then use a loop to set the diagonal elements to ones. In this simple case, we might use a shortcut that Java provides:
```
double[][] m = {
{1.0, 0.0, 0.0},
{0.0, 1.0, 0.0},
{0.0, 0.0, 1.0}};
```
This type of visual structure is particularly appropriate in this sort of application, where it can be a useful double-check to see the actual layout of the array. But in the case where the number of rows and columns is only determined at run time, we might instead see something like this:
```
int nrc;
// some code determines the number of rows & columns = nrc
double[][] m = new double[nrc][nrc];
for (int d = 0; d < nrc; d++)
m[d][d] = 1.0;
```
It’s worth mentioning that a two-dimensional array in Java is actually an array of arrays, and there’s nothing stopping the intrepid programmer from having each one of those second-level arrays be a different length. That is, something like this is completely legitimate:
```
int [][] differentLengthRows = {
{ 1, 2, 3, 4, 5},
{ 6, 7, 8, 9},
{10,11,12},
{13,14},
{15}};
```
There are various linear algebra applications that involve irregularly-shaped matrices, where this type of structure could be applied (for more information see [this Wikipedia article](https://en.wikipedia.org/wiki/Irregular_matrix) as a starting point). Beyond that, now that we understand that a two-dimensional array is actually an array of arrays, it shouldn’t be too much of a surprise that:
```
differentLengthRows.length
```
tells us the number of rows in the two-dimensional array **differentLengthRows**, and:
```
differentLengthRows[i].length
```
tells us the number of columns in row **i** of **differentLengthRows**.
## Taking the array further
Considering this idea of array size that is determined at run time, we see that arrays still require us to know that size before instantiating them. But what if we don’t know the size until we’ve processed all of the data? Does that mean we have to process it once to figure out the size of the array, and then process it again? That could be hard to do, especially if we only get one chance to consume the data.
The [Java Collections Framework](https://en.wikipedia.org/wiki/Java_collections_framework) solves this problem in a nice way. One of the things provided there is the class **ArrayList**, which is like an array but dynamically extensible. To demonstrate the workings of **ArrayList**, let’s create one and initialize it to the first 20 [Fibonacci numbers](https://en.wikipedia.org/wiki/Fibonacci_number):
```
import java.lang.*;
import java.util.*;
public class Test3 {
public static void main(String[] args) {
ArrayList<Integer> fibos = new ArrayList<Integer>();
fibos.add(0);
fibos.add(1);
for (int i = 2; i < 20; i++)
fibos.add(fibos.get(i-1) + fibos.get(i-2));
for (int i = 0; i < fibos.size(); i++)
System.out.println("fibonacci " + i +
" = " + fibos.get(i));
}
}
```
Above, we see:
- The declaration and instantiation of an
**ArrayList**that is used to store**Integer**s. - The use of
**add()**to append to the**ArrayList**instance. - The use of
**get()**to retrieve an element by index number. - The use of
**size()**to determine how many elements are already in the**ArrayList**instance.
Not shown is the **put()** method, which places a value at a given index number.
The output of this program is:
```
fibonacci 0 = 0
fibonacci 1 = 1
fibonacci 2 = 1
fibonacci 3 = 2
fibonacci 4 = 3
fibonacci 5 = 5
fibonacci 6 = 8
fibonacci 7 = 13
fibonacci 8 = 21
fibonacci 9 = 34
fibonacci 10 = 55
fibonacci 11 = 89
fibonacci 12 = 144
fibonacci 13 = 233
fibonacci 14 = 377
fibonacci 15 = 610
fibonacci 16 = 987
fibonacci 17 = 1597
fibonacci 18 = 2584
fibonacci 19 = 4181
```
**ArrayList** instances can also be initialized by other techniques. For example, an array can be supplied to the **ArrayList** constructor, or the **List.of()** and **Arrays.asList()** methods can be used when the initial elements are known at compile time. I don’t find myself using these options all that often since my primary use case for an **ArrayList** is when I only want to read the data once.
Moreover, an **ArrayList** instance can be converted to an array using its **toArray()** method, for those who prefer to work with an array once the data is loaded; or, returning to the current topic, once the **ArrayList** instance is initialized.
The Java Collections Framework provides another kind of array-like data structure called a **Map**. What I mean by "array-like" is that a **Map** defines a collection of objects whose values can be set or retrieved by a key, but unlike an array (or an **ArrayList**), this key need not be an integer; it could be a **String** or any other complex object.
For example, we can create a **Map** whose keys are **String**s and whose values are **Integer**s as follows:
```
Map<String,Integer> stoi = new Map<String,Integer>();
```
Then we can initialize this **Map** as follows:
```
stoi.set("one",1);
stoi.set("two",2);
stoi.set("three",3);
```
And so on. Later, when we want to know the numeric value of **"three"**, we can retrieve it as:
```
stoi.get("three");
```
In my world, a **Map** is useful for converting strings occurring in third-party datasets into coherent code values in my datasets. As a part of a [data transformation pipeline](https://towardsdatascience.com/data-science-for-startups-data-pipelines-786f6746a59a), I will often build a small standalone program to clean the data before processing it; for this, I will almost always use one or more **Map**s.
Worth mentioning is that it’s quite possible, and sometimes reasonable, to have **ArrayLists** of **ArrayLists** and **Map**s of **Map**s. For example, let’s assume we’re looking at trees, and we’re interested in accumulating the count of the number of trees by tree species and age range. Assuming that the age range definition is a set of string values ("young," "mid," "mature," and "old") and that the species are string values like "Douglas fir," "western red cedar," and so forth, then we might define a **Map** of **Map**s as:
```
Map<String,Map<String,Integer>> counter =
new Map<String,Map<String,Integer>>();
```
One thing to watch out for here is that the above only creates storage for the *rows* of **Map**s. So, our accumulation code might look like:
```
// assume at this point we have figured out the species
// and age range
if (!counter.containsKey(species))
counter.put(species,new Map<String,Integer>());
if (!counter.get(species).containsKey(ageRange))
counter.get(species).put(ageRange,0);
```
At which point, we can start accumulating as:
```
counter.get(species).put(ageRange,
counter.get(species).get(ageRange) + 1);
```
Finally, it’s worth mentioning that the (new in Java 8) Streams facility can also be used to initialize arrays, **ArrayList** instances, and **Map** instances. A nice discussion of this feature can be found [here](https://stackoverflow.com/questions/36885371/lambda-expression-to-initialize-array) and [here](https://stackoverflow.com/questions/32868665/how-to-initialize-a-map-using-a-lambda).
## Comments are closed. |
11,534 | 开源 CMS Ghost 3.0 发布,带来新功能 | https://itsfoss.com/ghost-3-release/ | 2019-11-03T13:57:23 | [
"Ghost"
] | https://linux.cn/article-11534-1.html | [Ghost](https://itsfoss.com/recommends/ghost/) 是一个自由开源的内容管理系统(CMS)。如果你还不了解 CMS,那我在此解释一下。CMS 是一种软件,用它可以构建主要专注于创建内容的网站,而无需了解 HTML 和其他与 Web 相关的技术。
事实上,Ghost 是目前[最好的开源 CMS](https://itsfoss.com/open-source-cms/) 之一。它主要聚焦于创建轻量级、快速加载、界面美观的博客。
Ghost 系统有一个现代直观的编辑器,该编辑器内置 SEO(搜索引擎优化)功能。你也可以用本地桌面(包括 Linux 系统)和移动应用程序。如果你喜欢终端,也可以使用其提供的 CLI(命令行界面)工具。
让我们看看 Ghost 3.0 带来了什么新功能。
### Ghost 3.0 的新功能

我通常对开源的 CMS 解决方案很感兴趣。因此,在阅读了官方公告后,我通过在 Digital Ocean 云服务器上安装新的 Ghost 实例来进一步尝试它。
与以前的版本相比,Ghost 3.0 在功能和用户界面上的改进给我留下了深刻的印象。
在此,我将列出一些值得一提的关键点。
#### 书签卡

除了编辑器的所有细微更改之外,3.0 版本现在支持通过输入 URL 添加漂亮的书签卡。
如果你使用过 WordPress(你可能已经注意到,WordPress 需要添加一个插件才能添加类似的卡片),所以该功能绝对是 Ghost 3.0 系统的一个最大改进。
#### 改进的 WordPress 迁移插件
我没有专门对此进行测试,但它更新了 WordPress 的迁移插件,可以让你轻松地将帖子(带有图片)克隆到 Ghost CMS。
基本上,使用该插件,你就能够创建一个存档(包含图片)并将其导入到 Ghost CMS。
#### 响应式图像库和图片
为了使用户体验更好,Ghost 团队还更新了图像库(现已为响应式),以便在所有设备上舒适地呈现你的图片集。
此外,帖子和页面中的图片也更改为响应式的了。
#### 添加成员和订阅选项

虽然,该功能目前还处于测试阶段,但如果你是以此平台作为维持你业务关系的重要发布平台,你可以为你的博客添加成员、订阅选项。
该功能可以确保只有订阅的成员才能访问你的博客,你也可以选择让未订阅者也可以访问。
#### Stripe:集成支付功能
默认情况下,该版本支持 Stripe 付款网关,帮助你轻松启用订阅功能(或使用任何类型的付款的付款方式),而 Ghost 不收取任何额外费用。
#### 新的应用程序集成

你现在可以在 Ghost 3.0 的博客中集成各种流行的应用程序/服务。它可以使很多事情自动化。
#### 默认主题改进
引入的默认主题(设计)已得到改进,现在也提供了夜间模式。
你也可以随时选择创建自定义主题(如果没有可用的预置主题)。
#### 其他小改进
除了所有关键亮点以外,用于创建帖子/页面的可视编辑器也得到了改进(具有某些拖放功能)。
我确定还有很多技术方面的更改,如果你对此感兴趣,可以在他们的[更改日志](https://ghost.org/faq/upgrades/)中查看。
### Ghost 影响力渐增
要在以 WordPress 为主导的世界中获得认可并不是一件容易的事。但 Ghost 逐渐形成了它的一个专门的发布者社区。
不仅如此,它的托管服务 [Ghost Pro](https://itsfoss.com/recommends/ghost-pro/) 现在拥有像 NASA、Mozilla 和 DuckDuckGo 这样的客户。
在过去的六年中,Ghost 从其 Ghost Pro 客户那里获得了 500 万美元的收入。就从它是致力于开源系统解决方案的非营利组织这一点来讲,这确实是一项成就。
这些收入有助于它们保持独立,避免风险投资家的外部资金投入。Ghost CMS 的托管客户越多,投入到免费和开源的 CMS 的研发款项就越多。
总体而言,Ghost 3.0 是迄今为止提供的最好的升级版本。这些功能给我留下了深刻的印象。
如果你拥有自己的网站,你会使用什么 CMS?你曾经使用过 Ghost 吗?你的体验如何?请在评论部分分享你的想法。
---
via: <https://itsfoss.com/ghost-3-release/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Ghost](https://itsfoss.com/recommends/ghost/) is a free and open source content management system (CMS). If you are not aware of the term, a CMS is a software that allows you to build a website that is primarily focused on creating content without knowledge of HTML and other web-related technologies.
Ghost is in fact one of the [best open source CMS](https://itsfoss.com/open-source-cms/) out there. It’s main focus is on creating lightweight, fast loading and good looking blogs.
It has a modern intuitive editor with built-in SEO features. You also have native desktop (Linux including) and mobile apps. If you like terminal, you can also use the CLI tools it provides.
Let’s see what new feature Ghost 3.0 brings.
## New Features in Ghost 3.0

I’m usually intrigued by open source CMS solutions – so after reading the official announcement post, I went ahead and gave it a try by installing a new Ghost instance via [Digital Ocean cloud server](https://itsfoss.com/recommends/digital-ocean/).
I was really impressed with the improvements they’ve made with the features and the UI compared to the previous version.
Here, I shall list out the key changes/additions worth mentioning.
### Bookmark Cards
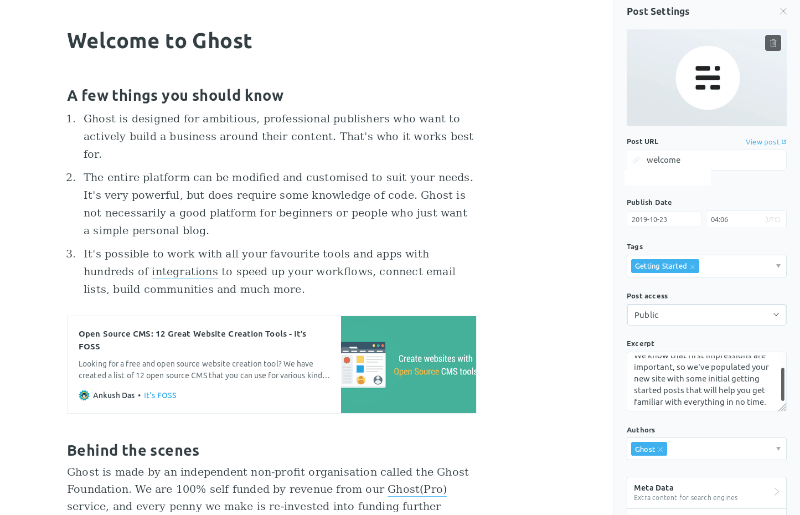
In addition to all the subtle change to the editor, it now lets you add a beautiful bookmark card by just entering the URL.
If you have used WordPress – you may have noticed that you need to have a plugin in order to add a card like that – so it is definitely a useful addition in Ghost 3.0.
### Improved WordPress Migration Plugin
I haven’t tested this in particular but they have updated their WordPress migration plugin to let you easily clone the posts (with images) to Ghost CMS.
Basically, with the plugin, you will be able to create an archive (with images) and import it to Ghost CMS.
### Responsive Image Galleries & Images
To make the user experience better, they have also updated the image galleries (which is now responsive) to present your picture collection comfortably across all devices.
In addition, the images in post/pages are now responsive as well.
### Members & Subscriptions option
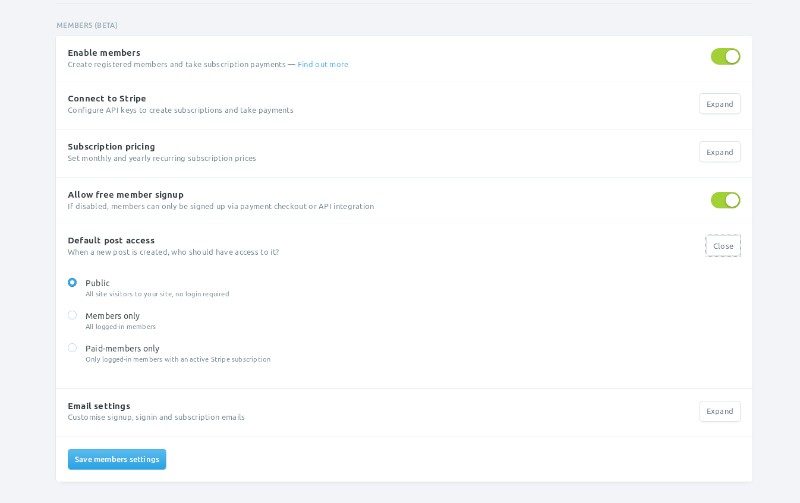
Even though the feature is still in the beta phase, it lets you add members and a subscription model for your blog if you choose to make it a premium publication to sustain your business.
With this feature, you can make sure that your blog can only be accessed by the subscribed members or choose to make it available to the public in addition to the subscription.
### Stripe: Payment Integration
It supports Stripe payment gateway by default to help you easily enable the subscription (or any type of payments) with no additional fee charged by Ghost.
### New App Integrations
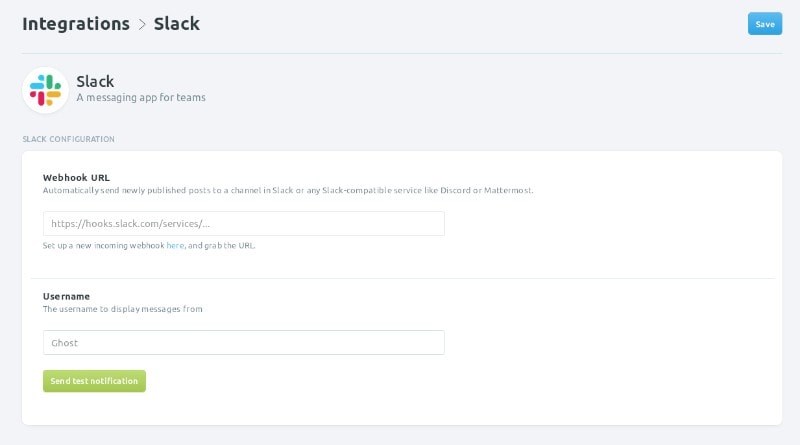
You can now integrate a variety of popular applications/services with your blog on Ghost 3.0. It could come in handy to automate a lot of things.
### Default Theme Improvement
The default theme (design) that comes baked in has improved and now offers a dark mode as well.
You can always choose to create a custom theme as well (if not pre-built themes available).
### Other Minor Improvements
In addition to all the key highlights, the visual editor to create posts/pages has improved as well (with some drag and drop capabilities).
I’m sure there’s a lot of technical changes as well – which you can check it out in their [changelog](https://ghost.org/faq/upgrades/) if you’re interested.
## Ghost is gradually getting good traction
It’s not easy to make your mark in a world dominated by WordPress. But Ghost has gradually formed a dedicated community of publishers around it.
Not only that, their managed hosting service [Ghost Pro](https://itsfoss.com/recommends/ghost-pro/) now has customers like NASA, Mozilla and DuckDuckGo.
In last six years, Ghost has made $5 million in revenue from their Ghost Pro customers . Considering that they are a non-profit organization working on open source solution, this is indeed an achievement.
This helps them remain independent by avoiding external funding from venture capitalists. The more customers for managed Ghost CMS hosting, the more funds goes into the development of the free and open source CMS.
Overall, Ghost 3.0 is by far the best upgrade they’ve offered. I’m personally impressed with the features.
If you have websites of your own, what CMS do you use? Have you ever used Ghost? How’s your experience with it? Do share your thoughts in the comment section. |
11,535 | 如何在 CentOS 8 和 RHEL 8 服务器上启用 EPEL 仓库 | https://www.linuxtechi.com/enable-epel-repo-centos8-rhel8-server/ | 2019-11-04T11:33:00 | [
"EPEL"
] | https://linux.cn/article-11535-1.html | EPEL 代表 “Extra Packages for Enterprise Linux”,它是一个自由开源的附加软件包仓库,可用于 CentOS 和 RHEL 服务器。顾名思义,EPEL 仓库提供了额外的软件包,这些软件在 [CentOS 8](https://www.linuxtechi.com/centos-8-installation-guide-screenshots/) 和 [RHEL 8](https://www.linuxtechi.com/install-configure-kvm-on-rhel-8/) 的默认软件包仓库中不可用。
在本文中,我们将演示如何在 CentOS 8 和 RHEL 8 服务器上启用和使用 EPEL 存储库。

### EPEL 仓库的先决条件
* 最小化安装的 CentOS 8 和 RHEL 8 服务器
* root 或 sudo 管理员权限
* 网络连接
### 在 RHEL 8.x 服务器上安装并启用 EPEL 仓库
登录或 SSH 到你的 RHEL 8.x 服务器,并执行以下 `dnf` 命令来安装 EPEL rpm 包,
```
[root@linuxtechi ~]# dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm -y
```
上面命令的输出将如下所示,

EPEL rpm 包成功安装后,它将自动启用并配置其 yum/dnf 仓库。运行以下 `dnf` 或 `yum` 命令,以验证是否启用了 EPEL 仓库,
```
[root@linuxtechi ~]# dnf repolist epel
或者
[root@linuxtechi ~]# dnf repolist epel -v
```

### 在 CentOS 8.x 服务器上安装并启用 EPEL 仓库
登录或 SSH 到你的 CentOS 8 服务器,并执行以下 `dnf` 或 `yum` 命令来安装 `epel-release` rpm 软件包。在 CentOS 8 服务器中,EPEL rpm 在其默认软件包仓库中。
```
[root@linuxtechi ~]# dnf install epel-release -y
或者
[root@linuxtechi ~]# yum install epel-release -y
```
执行以下命令来验证 CentOS 8 服务器上 EPEL 仓库的状态,
```
[root@linuxtechi ~]# dnf repolist epel
Last metadata expiration check: 0:00:03 ago on Sun 13 Oct 2019 04:18:05 AM BST.
repo id repo name status
*epel Extra Packages for Enterprise Linux 8 - x86_64 1,977
[root@linuxtechi ~]#
[root@linuxtechi ~]# dnf repolist epel -v
……………………
Repo-id : epel
Repo-name : Extra Packages for Enterprise Linux 8 - x86_64
Repo-status : enabled
Repo-revision: 1570844166
Repo-updated : Sat 12 Oct 2019 02:36:32 AM BST
Repo-pkgs : 1,977
Repo-size : 2.1 G
Repo-metalink: https://mirrors.fedoraproject.org/metalink?repo=epel-8&arch=x86_64&infra=stock&content=centos
Updated : Sun 13 Oct 2019 04:28:24 AM BST
Repo-baseurl : rsync://repos.del.extreme-ix.org/epel/8/Everything/x86_64/ (34 more)
Repo-expire : 172,800 second(s) (last: Sun 13 Oct 2019 04:28:24 AM BST)
Repo-filename: /etc/yum.repos.d/epel.repo
Total packages: 1,977
[root@linuxtechi ~]#
```
以上命令的输出说明我们已经成功启用了 EPEL 仓库。让我们在 EPEL 仓库上执行一些基本操作。
### 列出 EPEL 仓库种所有可用包
如果要列出 EPEL 仓库中的所有的软件包,请运行以下 `dnf` 命令,
```
[root@linuxtechi ~]# dnf repository-packages epel list
……………
Last metadata expiration check: 0:38:18 ago on Sun 13 Oct 2019 04:28:24 AM BST.
Installed Packages
epel-release.noarch 8-6.el8 @epel
Available Packages
BackupPC.x86_64 4.3.1-2.el8 epel
BackupPC-XS.x86_64 0.59-3.el8 epel
CGSI-gSOAP.x86_64 1.3.11-7.el8 epel
CGSI-gSOAP-devel.x86_64 1.3.11-7.el8 epel
Field3D.x86_64 1.7.2-16.el8 epel
Field3D-devel.x86_64 1.7.2-16.el8 epel
GraphicsMagick.x86_64 1.3.33-1.el8 epel
GraphicsMagick-c++.x86_64 1.3.33-1.el8 epel
…………………………
zabbix40-web-mysql.noarch 4.0.12-1.el8 epel
zabbix40-web-pgsql.noarch 4.0.12-1.el8 epel
zerofree.x86_64 1.1.1-3.el8 epel
zimg.x86_64 2.8-4.el8 epel
zimg-devel.x86_64 2.8-4.el8 epel
zstd.x86_64 1.4.2-1.el8 epel
zvbi.x86_64 0.2.35-9.el8 epel
zvbi-devel.x86_64 0.2.35-9.el8 epel
zvbi-fonts.noarch 0.2.35-9.el8 epel
[root@linuxtechi ~]#
```
### 从 EPEL 仓库中搜索软件包
假设我们要搜索 EPEL 仓库中的 Zabbix 包,请执行以下 `dnf` 命令,
```
[root@linuxtechi ~]# dnf repository-packages epel list | grep -i zabbix
```
上面命令的输出类似下面这样,

### 从 EPEL 仓库安装软件包
假设我们要从 EPEL 仓库安装 htop 包,运行以下 `dnf` 命令,
语法:
```
# dnf –enablerepo=”epel” install <包名>
```
```
[root@linuxtechi ~]# dnf --enablerepo="epel" install htop -y
```
注意:如果我们在上面的命令中未指定 `–enablerepo=epel`,那么它将在所有可用的软件包仓库中查找 htop 包。
本文就是这些内容了,我希望上面的步骤能帮助你在 CentOS 8 和 RHEL 8 服务器上启用并配置 EPEL 仓库,请在下面的评论栏分享你的评论和反馈。
---
via: <https://www.linuxtechi.com/enable-epel-repo-centos8-rhel8-server/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,536 | SQLite 真的很容易编译 | https://jvns.ca/blog/2019/10/28/sqlite-is-really-easy-to-compile/ | 2019-11-04T12:07:28 | [
"SQLite"
] | https://linux.cn/article-11536-1.html | 
上周,我一直在做一个 SQL 网站(<https://sql-steps.wizardzines.com/>,一个 SQL 示例列表)。我使用 sqlite 运行网站上的所有查询,并且我想在其中一个例子([这个](https://sql-steps.wizardzines.com/lag.html))中使用窗口函数。
但是我使用的是 Ubuntu 18.04 中的 sqlite 版本,它太旧了,不支持窗口函数。所以我需要升级 sqlite!
事实证明,这个过程超麻烦(如通常一样),但是非常有趣!我想起了一些有关可执行文件和共享库如何工作的信息,结论令人满意。所以我想在这里写下来。
(剧透:<https://www.sqlite.org/howtocompile.html> 中解释了如何编译 SQLite,它只需花费 5 秒左右,这比我平时从源码编译的体验容易了许多。)
### 尝试 1:从它的网站下载 SQLite 二进制文件
[SQLite 的下载页面](https://www.sqlite.org/download.html)有一个用于 Linux 的 SQLite 命令行工具的二进制文件的链接。我下载了它,它可以在笔记本电脑上运行,我以为这就完成了。
但是后来我尝试在构建服务器(Netlify) 上运行它,得到了这个极其奇怪的错误消息:“File not found”。我进行了追踪,并确定 `execve` 返回错误代码 ENOENT,这意味着 “File not found”。这有点令人发狂,因为该文件确实存在,并且有正确的权限。
我搜索了这个问题(通过搜索 “execve enoen”),找到了[这个 stackoverflow 中的答案](https://stackoverflow.com/questions/5234088/execve-file-not-found-when-stracing-the-very-same-file),它指出要运行二进制文件,你不仅需要二进制文件存在!你还需要它的**加载程序**才能存在。(加载程序的路径在二进制文件内部)
要查看加载程序的路径,可以使用 `ldd`,如下所示:
```
$ ldd sqlite3
linux-gate.so.1 (0xf7f9d000)
libdl.so.2 => /lib/i386-linux-gnu/libdl.so.2 (0xf7f70000)
libm.so.6 => /lib/i386-linux-gnu/libm.so.6 (0xf7e6e000)
libz.so.1 => /lib/i386-linux-gnu/libz.so.1 (0xf7e4f000)
libc.so.6 => /lib/i386-linux-gnu/libc.so.6 (0xf7c73000)
/lib/ld-linux.so.2
```
所以 `/lib/ld-linux.so.2` 是加载程序,而该文件在构建服务器上不存在,可能是因为 Xenial(Xenial 是 Ubuntu 16.04,本文应该使用的是 18.04 “Bionic Beaver”)安装程序不支持 32 位二进制文件(?),因此我需要尝试一些不同的东西。
### 尝试 2:安装 Debian sqlite3 软件包
好吧,我想我也许可以安装来自 [debian testing 的 sqlite 软件包](https://packages.debian.org/bullseye/amd64/sqlite3/download)。尝试从另一个我不使用的 Debian 版本安装软件包并不是一个好主意,但是出于某种原因,我还是决定尝试一下。
这次毫不意外地破坏了我计算机上的 sqlite(这也破坏了 git),但我设法通过 `sudo dpkg --purge --force-all libsqlite3-0` 恢复了,并使所有依赖于 sqlite 的软件再次工作。
### 尝试 3:提取 Debian sqlite3 软件包
我还尝试仅从 Debian sqlite 软件包中提取 sqlite3 二进制文件并运行它。毫不意外,这也行不通,但这个更容易理解:我有旧版本的 libreadline(`.so.7`),但它需要 `.so.8`。
```
$ ./usr/bin/sqlite3
./usr/bin/sqlite3: error while loading shared libraries: libreadline.so.8: cannot open shared object file: No such file or directory
```
### 尝试 4:从源代码进行编译
我花费这么多时间尝试下载 sqlite 二进制的原因是我认为从源代码编译 sqlite 既烦人又耗时。但是显然,下载随便一个 sqlite 二进制文件根本不适合我,因此我最终决定尝试自己编译它。
这有指导:[如何编译 SQLite](https://www.sqlite.org/howtocompile.html)。它是宇宙中最简单的东西。通常,编译的感觉是类似这样的:
* 运行 `./configure`
* 意识到我缺少依赖
* 再次运行 `./configure`
* 运行 `make`
* 编译失败,因为我安装了错误版本的依赖
* 去做其他事,之后找到二进制文件
编译 SQLite 的方式如下:
* [从下载页面下载整合的 tarball](https://www.sqlite.org/download.html)
* 运行 `gcc shell.c sqlite3.c -lpthread -ldl`
* 完成!!!
所有代码都在一个文件(`sqlite.c`)中,并且没有奇怪的依赖项!太奇妙了。
对我而言,我实际上并不需要线程支持或 readline 支持,因此我用编译页面上的说明来创建了一个非常简单的二进制文件,它仅使用了 libc 而没有其他共享库。
```
$ ldd sqlite3
linux-vdso.so.1 (0x00007ffe8e7e9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fbea4988000)
/lib64/ld-linux-x86-64.so.2 (0x00007fbea4d79000)
```
### 这很好,因为它使体验 sqlite 变得容易
我认为 SQLite 的构建过程如此简单很酷,因为过去我很乐于[编辑 sqlite 的源码](https://jvns.ca/blog/2014/10/02/how-does-sqlite-work-part-2-btrees/)来了解其 B 树的实现方式。
鉴于我对 SQLite 的了解,这并不令人感到意外(它在受限环境/嵌入式中确实可以很好地工作,因此可以以一种非常简单/最小的方式进行编译是有意义的)。 但这真是太好了!
---
via: <https://jvns.ca/blog/2019/10/28/sqlite-is-really-easy-to-compile/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
11,538 | 如何编写 RPM 的 spec 文件 | https://fedoramagazine.org/how-rpm-packages-are-made-the-spec-file/ | 2019-11-05T09:07:46 | [
"RPM"
] | https://linux.cn/article-11538-1.html | 
在[关于 RPM 软件包构建的上一篇文章](/article-11527-1.html)中,你了解到了源 RPM 包括软件的源代码以及 spec 文件。这篇文章深入研究了 spec 文件,该文件中包含了有关如何构建 RPM 的指令。同样,本文以 `fpaste` 为例。
### 了解源代码
在开始编写 spec 文件之前,你需要对要打包的软件有所了解。在这里,你正在研究 `fpaste`,这是一个非常简单的软件。它是用 Python 编写的,并且是一个单文件脚本。当它发布新版本时,可在 Pagure 上找到:<https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz>。
如该档案文件所示,当前版本为 0.3.9.2。下载它,以便你查看该档案文件中的内容:
```
$ wget https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz
$ tar -tvf fpaste-0.3.9.2.tar.gz
drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/
-rw-rw-r-- root/root 25 2018-07-25 02:58 fpaste-0.3.9.2/.gitignore
-rw-rw-r-- root/root 3672 2018-07-25 02:58 fpaste-0.3.9.2/CHANGELOG
-rw-rw-r-- root/root 35147 2018-07-25 02:58 fpaste-0.3.9.2/COPYING
-rw-rw-r-- root/root 444 2018-07-25 02:58 fpaste-0.3.9.2/Makefile
-rw-rw-r-- root/root 1656 2018-07-25 02:58 fpaste-0.3.9.2/README.rst
-rw-rw-r-- root/root 658 2018-07-25 02:58 fpaste-0.3.9.2/TODO
drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/
drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/
drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/
-rw-rw-r-- root/root 3867 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/fpaste.1
-rwxrwxr-x root/root 24884 2018-07-25 02:58 fpaste-0.3.9.2/fpaste
lrwxrwxrwx root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/fpaste.py -> fpaste
```
你要安装的文件是:
* `fpaste.py`:应该安装到 `/usr/bin/`。
* `docs/man/en/fpaste.1`:手册,应放到 `/usr/share/man/man1/`。
* `COPYING`:许可证文本,应放到 `/usr/share/license/fpaste/`。
* `README.rst`、`TODO`:放到 `/usr/share/doc/fpaste/` 下的其它文档。
这些文件的安装位置取决于文件系统层次结构标准(FHS)。要了解更多信息,可以在这里阅读:<http://www.pathname.com/fhs/> 或查看 Fedora 系统的手册页:
```
$ man hier
```
#### 第一部分:要构建什么?
现在我们知道了源文件中有哪些文件,以及它们要存放的位置,让我们看一下 spec 文件。你可以在此处查看这个完整的文件:<https://src.fedoraproject.org/rpms/fpaste/blob/master/f/fpaste.spec>。
这是 spec 文件的第一部分:
```
Name: fpaste
Version: 0.3.9.2
Release: 3%{?dist}
Summary: A simple tool for pasting info onto sticky notes instances
BuildArch: noarch
License: GPLv3+
URL: https://pagure.io/fpaste
Source0: https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz
Requires: python3
%description
It is often useful to be able to easily paste text to the Fedora
Pastebin at http://paste.fedoraproject.org and this simple script
will do that and return the resulting URL so that people may
examine the output. This can hopefully help folks who are for
some reason stuck without X, working remotely, or any other
reason they may be unable to paste something into the pastebin
```
`Name`、`Version` 等称为*标签*,它们定义在 RPM 中。这意味着你不能只是随意写点标签,RPM 无法理解它们!需要注意的标签是:
* `Source0`:告诉 RPM 该软件的源代码档案文件所在的位置。
* `Requires`:列出软件的运行时依赖项。RPM 可以自动检测很多依赖项,但是在某些情况下,必须手动指明它们。运行时依赖项是系统上必须具有的功能(通常是软件包),才能使该软件包起作用。这是 [dnf](https://fedoramagazine.org/managing-packages-fedora-dnf/) 在安装此软件包时检测是否需要拉取其他软件包的方式。
* `BuildRequires`:列出了此软件的构建时依赖项。这些通常必须手动确定并添加到 spec 文件中。
* `BuildArch`:此软件为该计算机体系结构所构建。如果省略此标签,则将为所有受支持的体系结构构建该软件。值 `noarch` 表示该软件与体系结构无关(例如 `fpaste`,它完全是用 Python 编写的)。
本节提供有关 `fpaste` 的常规信息:它是什么,正在将什么版本制作为 RPM,其许可证等等。如果你已安装 `fpaste`,并查看其元数据时,则可以看到该 RPM 中包含的以下信息:
```
$ sudo dnf install fpaste
$ rpm -qi fpaste
Name : fpaste
Version : 0.3.9.2
Release : 2.fc30
...
```
RPM 会自动添加一些其他标签,以代表它所知道的内容。
至此,我们掌握了要为其构建 RPM 的软件的一般信息。接下来,我们开始告诉 RPM 做什么。
#### 第二部分:准备构建
spec 文件的下一部分是准备部分,用 `%prep` 代表:
```
%prep
%autosetup
```
对于 `fpaste`,这里唯一的命令是 `%autosetup`。这只是将 tar 档案文件提取到一个新文件夹中,并为下一部分的构建阶段做好了准备。你可以在此处执行更多操作,例如应用补丁程序,出于不同目的修改文件等等。如果你查看过 Python 的源 RPM 的内容,那么你会在那里看到许多补丁。这些都将在本节中应用。
通常,spec 文件中带有 `%` 前缀的所有内容都是 RPM 以特殊方式解释的宏或标签。这些通常会带有大括号,例如 `%{example}`。
#### 第三部分:构建软件
下一部分是构建软件的位置,用 `%build` 表示。现在,由于 `fpaste` 是一个简单的纯 Python 脚本,因此无需构建。因此,这里是:
```
%build
#nothing required
```
不过,通常来说,你会在此处使用构建命令,例如:
```
configure; make
```
构建部分通常是 spec 文件中最难的部分,因为这是从源代码构建软件的地方。这要求你知道该工具使用的是哪个构建系统,该系统可能是许多构建系统之一:Autotools、CMake、Meson、Setuptools(用于 Python)等等。每个都有自己的命令和语法样式。你需要充分了解这些才能正确构建软件。
#### 第四部分:安装文件
软件构建后,需要在 `%install` 部分中安装它:
```
%install
mkdir -p %{buildroot}%{_bindir}
make install BINDIR=%{buildroot}%{_bindir} MANDIR=%{buildroot}%{_mandir}
```
在构建 RPM 时,RPM 不会修改你的系统文件。在一个可以正常运行的系统上添加、删除或修改文件的风险太大。如果发生故障怎么办?因此,RPM 会创建一个专门打造的文件系统并在其中工作。这称为 `buildroot`。 因此,在 `buildroot` 中,我们创建由宏 `%{_bindir}` 代表的 `/usr/bin` 目录,然后使用提供的 `Makefile` 将文件安装到其中。
至此,我们已经在专门打造的 `buildroot` 中安装了 `fpaste` 的构建版本。
#### 第五部分:列出所有要包括在 RPM 中的文件
spec 文件其后的一部分是文件部分:`%files`。在这里,我们告诉 RPM 从该 spec 文件创建的档案文件中包含哪些文件。`fpaste` 的文件部分非常简单:
```
%files
%{_bindir}/%{name}
%doc README.rst TODO
%{_mandir}/man1/%{name}.1.gz
%license COPYING
```
请注意,在这里,我们没有指定 `buildroot`。所有这些路径都是相对路径。`%doc` 和 `%license`命令做的稍微多一点,它们会创建所需的文件夹,并记住这些文件必须放在那里。
RPM 很聪明。例如,如果你在 `%install` 部分中安装了文件,但未列出它们,它会提醒你。
#### 第六部分:在变更日志中记录所有变更
Fedora 是一个基于社区的项目。许多贡献者维护或共同维护软件包。因此,当务之急是不要被软件包做了哪些更改所搞混。为了确保这一点,spec 文件包含的最后一部分是变更日志 `%changelog`:
```
%changelog
* Thu Jul 25 2019 Fedora Release Engineering < ...> - 0.3.9.2-3
- Rebuilt for https://fedoraproject.org/wiki/Fedora_31_Mass_Rebuild
* Thu Jan 31 2019 Fedora Release Engineering < ...> - 0.3.9.2-2
- Rebuilt for https://fedoraproject.org/wiki/Fedora_30_Mass_Rebuild
* Tue Jul 24 2018 Ankur Sinha - 0.3.9.2-1
- Update to 0.3.9.2
* Fri Jul 13 2018 Fedora Release Engineering < ...> - 0.3.9.1-4
- Rebuilt for https://fedoraproject.org/wiki/Fedora_29_Mass_Rebuild
* Wed Feb 07 2018 Fedora Release Engineering < ..> - 0.3.9.1-3
- Rebuilt for https://fedoraproject.org/wiki/Fedora_28_Mass_Rebuild
* Sun Sep 10 2017 Vasiliy N. Glazov < ...> - 0.3.9.1-2
- Cleanup spec
* Fri Sep 08 2017 Ankur Sinha - 0.3.9.1-1
- Update to latest release
- fixes rhbz 1489605
...
....
```
spec 文件的*每项*变更都必须有一个变更日志条目。如你在此处看到的,虽然我以维护者身份更新了该 spec 文件,但其他人也做过更改。清楚地记录变更内容有助于所有人知道该 spec 文件的当前状态。对于系统上安装的所有软件包,都可以使用 `rpm` 来查看其更改日志:
```
$ rpm -q --changelog fpaste
```
### 构建 RPM
现在我们准备构建 RPM 包。如果要继续执行以下命令,请确保遵循[上一篇文章](/article-11527-1.html)中的步骤设置系统以构建 RPM。
我们将 `fpaste` 的 spec 文件放置在 `~/rpmbuild/SPECS` 中,将源代码档案文件存储在 `~/rpmbuild/SOURCES/` 中,现在可以创建源 RPM 了:
```
$ cd ~/rpmbuild/SPECS
$ wget https://src.fedoraproject.org/rpms/fpaste/raw/master/f/fpaste.spec
$ cd ~/rpmbuild/SOURCES
$ wget https://pagure.io/fpaste/archive/0.3.9.2/fpaste-0.3.9.2.tar.gz
$ cd ~/rpmbuild/SOURCES
$ rpmbuild -bs fpaste.spec
Wrote: /home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
```
让我们看一下结果:
```
$ ls ~/rpmbuild/SRPMS/fpaste*
/home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
$ rpm -qpl ~/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
fpaste-0.3.9.2.tar.gz
fpaste.spec
```
我们看到源 RPM 已构建。让我们同时构建源 RPM 和二进制 RPM:
```
$ cd ~/rpmbuild/SPECS
$ rpmbuild -ba fpaste.spec
..
..
..
```
RPM 将向你显示完整的构建输出,并在我们之前看到的每个部分中详细说明它的工作。此“构建日志”非常重要。当构建未按预期进行时,我们的打包人员将花费大量时间来遍历它们,以跟踪完整的构建路径来查看出了什么问题。
就是这样!准备安装的 RPM 应该位于以下位置:
```
$ ls ~/rpmbuild/RPMS/noarch/
fpaste-0.3.9.2-3.fc30.noarch.rpm
```
### 概括
我们已经介绍了如何从 spec 文件构建 RPM 的基础知识。这绝不是一份详尽的文档。实际上,它根本不是文档。它只是试图解释幕后的运作方式。简短回顾一下:
* RPM 有两种类型:源 RPM 和 二进制 RPM。
* 二进制 RPM 包含要安装以使用该软件的文件。
* 源 RPM 包含构建二进制 RPM 所需的信息:完整的源代码,以及 spec 文件中的有关如何构建 RPM 的说明。
* spec 文件包含多个部分,每个部分都有其自己的用途。 在这里,我们已经在安装好的 Fedora 系统中本地构建了 RPM。虽然这是个基本的过程,但我们从存储库中获得的 RPM 是建立在具有严格配置和方法的专用服务器上的,以确保正确性和安全性。这个 Fedora 打包流程将在以后的文章中讨论。
你想开始构建软件包,并帮助 Fedora 社区维护我们提供的大量软件吗?你可以[从这里开始加入软件包集合维护者](https://fedoraproject.org/wiki/Join_the_package_collection_maintainers)。
如有任何疑问,请发布到 [Fedora 开发人员邮件列表](https://lists.fedoraproject.org/archives/list/[email protected]/),我们随时乐意为你提供帮助!
### 参考
这里有一些构建 RPM 的有用参考:
* <https://fedoraproject.org/wiki/How_to_create_an_RPM_package>
* <https://docs.fedoraproject.org/en-US/quick-docs/create-hello-world-rpm/>
* <https://docs.fedoraproject.org/en-US/packaging-guidelines/>
* <https://rpm.org/documentation.html>
---
via: <https://fedoramagazine.org/how-rpm-packages-are-made-the-spec-file/>
作者:[Ankur Sinha FranciscoD](https://fedoramagazine.org/author/ankursinha/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the [previous article on RPM package building](https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/), you saw that source RPMS include the source code of the software, along with a “spec” file. This post digs into the spec file, which contains instructions on how to build the RPM. Again, this article uses *fpaste* as an example.
## Understanding the source code
Before you can start writing a spec file, you need to have some idea of the software that you’re looking to package. Here, you’re looking at fpaste, a very simple piece of software. It is written in Python, and is a one file script. When a new version is released, it’s provided here on Pagure: [https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz](https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz)
The current version, as the archive shows, is 0.3.9.2. Download it so you can see what’s in the archive:
$wget https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz$tar -tvf fpaste-0.3.9.2.tar.gzdrwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/ -rw-rw-r-- root/root 25 2018-07-25 02:58 fpaste-0.3.9.2/.gitignore -rw-rw-r-- root/root 3672 2018-07-25 02:58 fpaste-0.3.9.2/CHANGELOG -rw-rw-r-- root/root 35147 2018-07-25 02:58 fpaste-0.3.9.2/COPYING -rw-rw-r-- root/root 444 2018-07-25 02:58 fpaste-0.3.9.2/Makefile -rw-rw-r-- root/root 1656 2018-07-25 02:58 fpaste-0.3.9.2/README.rst -rw-rw-r-- root/root 658 2018-07-25 02:58 fpaste-0.3.9.2/TODO drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/ drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/ drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/ -rw-rw-r-- root/root 3867 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/fpaste.1 -rwxrwxr-x root/root 24884 2018-07-25 02:58 fpaste-0.3.9.2/fpaste lrwxrwxrwx root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/fpaste.py -> fpaste
The files you want to install are:
*fpaste.py*: which should go be installed to /usr/bin/.*docs/man/en/fpaste.1*: the manual, which should go to /usr/share/man/man1/.*COPYING*: the license text, which should go to /usr/share/license/fpaste/.*README.rst, TODO*: miscellaneous documentation that goes to /usr/share/doc/fpaste.
Where these files are installed depends on the Filesystem Hierarchy Standard. To learn more about it, you can either read here: [http://www.pathname.com/fhs/](http://www.pathname.com/fhs/) or look at the man page on your Fedora system:
$ man hier
### Part 1: What are we building?
Now that we know what files we have in the source, and where they are to go, let’s look at the spec file. You can see the full file here: [https://src.fedoraproject.org/rpms/fpaste/blob/master/f/fpaste.spec](https://src.fedoraproject.org/rpms/fpaste/blob/master/f/fpaste.spec)
Here is the first part of the spec file:
Name: fpaste Version: 0.3.9.2 Release: 3%{?dist} Summary: A simple tool for pasting info onto sticky notes instances BuildArch: noarch License: GPLv3+ URL: https://pagure.io/fpaste Source0: https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz Requires: python3 %description It is often useful to be able to easily paste text to the Fedora Pastebin at http://paste.fedoraproject.org and this simple script will do that and return the resulting URL so that people may examine the output. This can hopefully help folks who are for some reason stuck without X, working remotely, or any other reason they may be unable to paste something into the pastebin
*Name*, *Version*, and so on are called *tags*, and are defined in RPM. This means you can’t just make up tags. RPM won’t understand them if you do! The tags to keep an eye out for are:
*Source0*: tells RPM where the source archive for this software is located.*Requires*: lists run-time dependencies for the software. RPM can automatically detect quite a few of these, but in some cases they must be mentioned manually. A run-time dependency is a capability (often a package) that must be on the system for this package to function. This is howdetects whether it needs to pull in other packages when you install this package.[dnf](https://fedoramagazine.org/managing-packages-fedora-dnf/)*BuildRequires*: lists the build-time dependencies for this software. These must generally be determined manually and added to the spec file.*BuildArch*: the computer architectures that this software is being built for. If this tag is left out, the software will be built for all supported architectures. The value*noarch*means the software is architecture independent (like fpaste, which is written purely in Python).
This section provides general information about fpaste: what it is, which version is being made into an RPM, its license, and so on. If you have fpaste installed, and look at its metadata, you can see this information included in the RPM:
$sudo dnf install fpaste$rpm -qi fpasteName : fpaste Version : 0.3.9.2 Release : 2.fc30 ...
RPM adds a few extra tags automatically that represent things that it knows.
At this point, we have the general information about the software that we’re building an RPM for. Next, we start telling RPM what to do.
### Part 2: Preparing for the build
The next part of the spec is the preparation section, denoted by *%prep*:
%prep %autosetup
For fpaste, the only command here is %autosetup. This simply extracts the tar archive into a new folder and keeps it ready for the next section where we build it. You can do more here, like apply patches, modify files for different purposes, and so on. If you did look at the contents of the source rpm for Python, you would have seen lots of patches there. These are all applied in this section.
Typically anything in a spec file with the **%** prefix is a macro or label that RPM interprets in a special way. Often these will appear with curly braces, such as *%{example}*.
### Part 3: Building the software
The next section is where the software is built, denoted by “%build”. Now, since fpaste is a simple, pure Python script, it doesn’t need to be built. So, here we get:
%build #nothing required
Generally, though, you’d have build commands here, like:
configure; make
The build section is often the hardest section of the spec, because this is where the software is being built from source. This requires you to know what build system the tool is using, which could be one of many: Autotools, CMake, Meson, Setuptools (for Python) and so on. Each has its own commands and style. You need to know these well enough to get the software to build correctly.
### Part 4: Installing the files
Once the software is built, it needs to be installed in the *%install* section:
%install mkdir -p %{buildroot}%{_bindir} make install BINDIR=%{buildroot}%{_bindir} MANDIR=%{buildroot}%{_mandir}
RPM doesn’t tinker with your system files when building RPMs. It’s far too risky to add, remove, or modify files to a working installation. What if something breaks? So, instead RPM creates an artificial file system and works there. This is referred to as the *buildroot*. So, here in the buildroot, we create */usr/bin*, represented by the macro *%{_bindir}*, and then install the files to it using the provided Makefile.
At this point, we have a built version of fpaste installed in our artificial buildroot.
### Part 5: Listing all files to be included in the RPM
The last section of the spec file is the files section, *%files*. This is where we tell RPM what files to include in the archive it creates from this spec file. The fpaste file section is quite simple:
%files %{_bindir}/%{name} %doc README.rst TODO %{_mandir}/man1/%{name}.1.gz %license COPYING
Notice how, here, we do not specify the buildroot. All of these paths are relative to it. The *%doc* and *%license* commands simply do a little more—they create the required folders and remember that these files must go there.
RPM is quite smart. If you’ve installed files in the *%install* section, but not listed them, it’ll tell you this, for example.
### Part 6: Document all changes in the change log
Fedora is a community based project. Lots of contributors maintain and co-maintain packages. So it is imperative that there’s no confusion about what changes have been made to a package. To ensure this, the spec file contains the last section, the Changelog, *%changelog*:
%changelog * Thu Jul 25 2019 Fedora Release Engineering < ...> - 0.3.9.2-3 - Rebuilt for https://fedoraproject.org/wiki/Fedora_31_Mass_Rebuild * Thu Jan 31 2019 Fedora Release Engineering < ...> - 0.3.9.2-2 - Rebuilt for https://fedoraproject.org/wiki/Fedora_30_Mass_Rebuild * Tue Jul 24 2018 Ankur Sinha- 0.3.9.2-1 - Update to 0.3.9.2 * Fri Jul 13 2018 Fedora Release Engineering < ...> - 0.3.9.1-4 - Rebuilt for https://fedoraproject.org/wiki/Fedora_29_Mass_Rebuild * Wed Feb 07 2018 Fedora Release Engineering < ..> - 0.3.9.1-3 - Rebuilt for https://fedoraproject.org/wiki/Fedora_28_Mass_Rebuild * Sun Sep 10 2017 Vasiliy N. Glazov < ...> - 0.3.9.1-2 - Cleanup spec * Fri Sep 08 2017 Ankur Sinha - 0.3.9.1-1 - Update to latest release - fixes rhbz 1489605 ... ....
There must be a changelog entry for *every* change to the spec file. As you see here, while I’ve updated the spec as the maintainer, others have too. Having the changes documented clearly helps everyone know what the current status of the spec is. For all packages installed on your system, you can use rpm to see their changelogs:
$ rpm -q --changelog fpaste
## Building the RPM
Now we are ready to build the RPM. If you want to follow along and run the commands below, please ensure that you followed the steps [in the previous post](https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/) to set your system up for building RPMs.
We place the fpaste spec file in *~/rpmbuild/SPECS*, the source code archive in *~/rpmbuild/SOURCES/* and can now create the source RPM:
$cd ~/rpmbuild/SPECS$wget https://src.fedoraproject.org/rpms/fpaste/raw/master/f/fpaste.spec$cd ~/rpmbuild/SOURCES$wget https://pagure.io/fpaste/archive/0.3.9.2/fpaste-0.3.9.2.tar.gz$cd ~/rpmbuild/SPECS$rpmbuild -bs fpaste.specWrote: /home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
Let’s have a look at the results:
$ls ~/rpmbuild/SRPMS/fpaste*/home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm $rpm -qpl ~/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpmfpaste-0.3.9.2.tar.gz fpaste.spec
There we are — the source rpm has been built. Let’s build both the source and binary rpm together:
$ cd ~/rpmbuild/SPECS $ rpmbuild -ba fpaste.spec .. .. ..
RPM will show you the complete build output, with details on what it is doing in each section that we saw before. This “build log” is extremely important. When builds do not go as expected, we packagers spend lots of time going through them, tracing the complete build path to see what went wrong.
That’s it really! Your ready-to-install RPMs are where they should be:
$ls ~/rpmbuild/RPMS/noarch/fpaste-0.3.9.2-3.fc30.noarch.rpm
## Recap
We’ve covered the basics of how RPMs are built from a spec file. This is by no means an exhaustive document. In fact, it isn’t documentation at all, really. It only tries to explain how things work under the hood. Here’s a short recap:
- RPMs are of two types:
*source*and*binary*. - Binary RPMs contain the files to be installed to use the software.
- Source RPMs contain the information needed to build the binary RPMs: the complete source code, and the instructions on how to build the RPM in the spec file.
- The spec file has various sections, each with its own purpose.
Here, we’ve built RPMs locally, on our Fedora installations. While this is the basic process, the RPMs we get from repositories are built on dedicated servers with strict configurations and methods to ensure correctness and security. This Fedora packaging pipeline will be discussed in a future post.
Would you like to get started with building packages, and help the Fedora community maintain the massive amount of software we provide? You can [start here by joining the package collection maintainers](https://fedoraproject.org/wiki/Join_the_package_collection_maintainers).
For any queries, post to the [Fedora developers mailing list](https://lists.fedoraproject.org/archives/list/[email protected]/)—we’re always happy to help!
## References
Here are some useful references to building RPMs:
[https://fedoraproject.org/wiki/How_to_create_an_RPM_package](https://fedoraproject.org/wiki/How_to_create_an_RPM_package)[https://docs.fedoraproject.org/en-US/quick-docs/create-hello-world-rpm/](https://docs.fedoraproject.org/en-US/quick-docs/create-hello-world-rpm/)[https://docs.fedoraproject.org/en-US/packaging-guidelines/](https://docs.fedoraproject.org/en-US/packaging-guidelines/)[https://rpm.org/documentation.html](https://rpm.org/documentation.html)
## Artem
Some nitpicks:
%{_mandir}/man1/%{name}.1.gz → %{_mandir}/man1/%{name}.1.*
https://docs.fedoraproject.org/en-US/packaging-guidelines/#_manpages
## Miroslav Suchý
I will add to references https://rpm-packaging-guide.github.io/ and you can try this wizard: https://xsuchy.github.io/rpm-spec-wizard/
## Simon
If you are looking for a full reference try this Link: http://ftp.rpm.org/max-rpm/ |
11,539 | 为什么你不必害怕 Kubernetes | https://opensource.com/article/19/10/kubernetes-complex-business-problem | 2019-11-05T11:58:13 | [
"Kubernetes"
] | /article-11539-1.html |
>
> Kubernetes 绝对是满足复杂 web 应用程序需求的最简单、最容易的方法。
>
>
>

在 90 年代末和 2000 年代初,在大型网站工作很有趣。我的经历让我想起了 American Greetings Interactive,在情人节那天,我们拥有了互联网上排名前 10 位之一的网站(以网络访问量衡量)。我们为 [AmericanGreetings.com](http://AmericanGreetings.com)、[BlueMountain.com](http://BlueMountain.com) 等公司提供了电子贺卡,并为 MSN 和 AOL 等合作伙伴提供了电子贺卡。该组织的老员工仍然深切地记得与 Hallmark 等其它电子贺卡网站进行大战的史诗般的故事。顺便说一句,我还为 Holly Hobbie、Care Bears 和 Strawberry Shortcake 运营过大型网站。
我记得那就像是昨天发生的一样,这是我们第一次遇到真正的问题。通常,我们的前门(路由器、防火墙和负载均衡器)有大约 200Mbps 的流量进入。但是,突然之间,Multi Router Traffic Grapher(MRTG)图示突然在几分钟内飙升至 2Gbps。我疯了似地东奔西跑。我了解了我们的整个技术堆栈,从路由器、交换机、防火墙和负载平衡器,到 Linux/Apache web 服务器,到我们的 Python 堆栈(FastCGI 的元版本),以及网络文件系统(NFS)服务器。我知道所有配置文件在哪里,我可以访问所有管理界面,并且我是一位经验丰富的,打过硬仗的系统管理员,具有多年解决复杂问题的经验。
但是,我无法弄清楚发生了什么……
当你在一千个 Linux 服务器上疯狂地键入命令时,五分钟的感觉就像是永恒。我知道站点可能会在任何时候崩溃,因为当它被划分成更小的集群时,压垮上千个节点的集群是那么的容易。
我迅速*跑到*老板的办公桌前,解释了情况。他几乎没有从电子邮件中抬起头来,这使我感到沮丧。他抬头看了看,笑了笑,说道:“是的,市场营销可能会开展广告活动。有时会发生这种情况。”他告诉我在应用程序中设置一个特殊标志,以减轻 Akamai 的访问量。我跑回我的办公桌,在上千台 web 服务器上设置了标志,几分钟后,站点恢复正常。灾难也就被避免了。
我可以再分享 50 个类似的故事,但你脑海中可能会有一点好奇:“这种运维方式将走向何方?”
关键是,我们遇到了业务问题。当技术问题使你无法开展业务时,它们就变成了业务问题。换句话说,如果你的网站无法访问,你就不能处理客户交易。
那么,所有这些与 Kubernetes 有什么关系?一切!世界已经改变。早在 90 年代末和 00 年代初,只有大型网站才出现大型的、<ruby> 规模级 <rt> web-scale </rt></ruby>的问题。现在,有了微服务和数字化转型,每个企业都面临着一个大型的、规模级的问题——可能是多个大型的、规模级的问题。
你的企业需要能够通过许多不同的人构建的许多不同的、通常是复杂的服务来管理复杂的规模级的网站。你的网站需要动态地处理流量,并且它们必须是安全的。这些属性需要在所有层(从基础结构到应用程序层)上由 API 驱动。
### 进入 Kubernetes
Kubernetes 并不复杂;你的业务问题才复杂。当你想在生产环境中运行应用程序时,要满足性能(伸缩性、性能抖动等)和安全性要求,就需要最低程度的复杂性。诸如高可用性(HA)、容量要求(N+1、N+2、N+100)以及保证最终一致性的数据技术等就会成为必需。这些是每家进行数字化转型的公司的生产要求,而不仅仅是 Google、Facebook 和 Twitter 这样的大型网站。
在旧时代,我还在 American Greetings 任职时,每次我们加入一个新的服务,它看起来像这样:所有这些都是由网站运营团队来处理的,没有一个是通过订单系统转移给其他团队来处理的。这是在 DevOps 出现之前的 DevOps:
1. 配置 DNS(通常是内部服务层和面向公众的外部)
2. 配置负载均衡器(通常是内部服务和面向公众的)
3. 配置对文件的共享访问(大型 NFS 服务器、群集文件系统等)
4. 配置集群软件(数据库、服务层等)
5. 配置 web 服务器群集(可以是 10 或 50 个服务器)
大多数配置是通过配置管理自动完成的,但是配置仍然很复杂,因为每个系统和服务都有不同的配置文件,而且格式完全不同。我们研究了像 [Augeas](http://augeas.net/) 这样的工具来简化它,但是我们认为使用转换器来尝试和标准化一堆不同的配置文件是一种反模式。
如今,借助 Kubernetes,启动一项新服务本质上看起来如下:
1. 配置 Kubernetes YAML/JSON。
2. 提交给 Kubernetes API(`kubectl create -f service.yaml`)。
Kubernetes 大大简化了服务的启动和管理。服务所有者(无论是系统管理员、开发人员还是架构师)都可以创建 Kubernetes 格式的 YAML/JSON 文件。使用 Kubernetes,每个系统和每个用户都说相同的语言。所有用户都可以在同一 Git 存储库中提交这些文件,从而启用 GitOps。
而且,可以弃用和删除服务。从历史上看,删除 DNS 条目、负载平衡器条目和 Web 服务器的配置等是非常可怕的,因为你几乎肯定会破坏某些东西。使用 Kubernetes,所有内容都处于命名空间下,因此可以通过单个命令删除整个服务。尽管你仍然需要确保其它应用程序不使用它(微服务和函数即服务 [FaaS] 的缺点),但你可以更加确信:删除服务不会破坏基础架构环境。
### 构建、管理和使用 Kubernetes
太多的人专注于构建和管理 Kubernetes 而不是使用它(详见 [Kubernetes 是一辆翻斗车](/article-11011-1.html))。
在单个节点上构建一个简单的 Kubernetes 环境并不比安装 LAMP 堆栈复杂得多,但是我们无休止地争论着构建与购买的问题。不是 Kubernetes 很难;它以高可用性大规模运行应用程序。建立一个复杂的、高可用性的 Kubernetes 集群很困难,因为要建立如此规模的任何集群都是很困难的。它需要规划和大量软件。建造一辆简单的翻斗车并不复杂,但是建造一辆可以运载 [10 吨垃圾并能以 200 迈的速度稳定行驶的卡车](http://crunchtools.com/kubernetes-10-ton-dump-truck-handles-pretty-well-200-mph/)则很复杂。
管理 Kubernetes 可能很复杂,因为管理大型的、规模级的集群可能很复杂。有时,管理此基础架构很有意义;而有时不是。由于 Kubernetes 是一个社区驱动的开源项目,它使行业能够以多种不同方式对其进行管理。供应商可以出售托管版本,而用户可以根据需要自行决定对其进行管理。(但是你应该质疑是否确实需要。)
使用 Kubernetes 是迄今为止运行大规模网站的最简单方法。Kubernetes 正在普及运行一组大型、复杂的 Web 服务的能力——就像当年 Linux 在 Web 1.0 中所做的那样。
由于时间和金钱是一个零和游戏,因此我建议将重点放在使用 Kubernetes 上。将你的时间和金钱花费在[掌握 Kubernetes 原语](/article-11036-1.html)或处理[活跃度和就绪性探针](https://srcco.de/posts/kubernetes-liveness-probes-are-dangerous.html)的最佳方法上(表明大型、复杂的服务很难的另一个例子)。不要专注于构建和管理 Kubernetes。(在构建和管理上)许多供应商可以为你提供帮助。
### 结论
我记得对无数的问题进行了故障排除,比如我在这篇文章的开头所描述的问题——当时 Linux 内核中的 NFS、我们自产的 CFEngine、仅在某些 Web 服务器上出现的重定向问题等)。开发人员无法帮助我解决所有这些问题。实际上,除非开发人员具备高级系统管理员的技能,否则他们甚至不可能进入系统并作为第二双眼睛提供帮助。没有带有图形或“可观察性”的控制台——可观察性在我和其他系统管理员的大脑中。如今,有了 Kubernetes、Prometheus、Grafana 等,一切都改变了。
关键是:
1. 时代不一样了。现在,所有 Web 应用程序都是大型的分布式系统。就像 AmericanGreetings.com 过去一样复杂,现在每个网站都有扩展性和 HA 的要求。
2. 运行大型的分布式系统是很困难的。绝对是。这是业务的需求,不是 Kubernetes 的问题。使用更简单的编排系统并不是解决方案。
Kubernetes 绝对是满足复杂 Web 应用程序需求的最简单,最容易的方法。这是我们生活的时代,而 Kubernetes 擅长于此。你可以讨论是否应该自己构建或管理 Kubernetes。有很多供应商可以帮助你构建和管理它,但是很难否认这是大规模运行复杂 Web 应用程序的最简单方法。
---
via: <https://opensource.com/article/19/10/kubernetes-complex-business-problem>
作者:[Scott McCarty](https://opensource.com/users/fatherlinux) 选题:[lujun9972](https://github.com/lujun9972) 译者:[laingke](https://github.com/laingke) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,541 | 将 Fedora 30 升级到 Fedora 31 | https://fedoramagazine.org/upgrading-fedora-30-to-fedora-31/ | 2019-11-05T12:20:12 | [
"Fedora"
] | https://linux.cn/article-11541-1.html | 
Fedora 31 [日前发布了](/article-11522-1.html)。你也许想要升级系统来获得 Fedora 中的最新功能。Fedora 工作站有图形化的升级方式。另外,Fedora 提供了一种命令行方式来将 Fedora 30 升级到 Fedora 31。
### 将 Fedora 30 工作站升级到 Fedora 31
在该发布不久之后,就会有通知告诉你有可用升级。你可以点击通知打开 GNOME “软件”。或者在 GNOME Shell 选择“软件”。
在 GNOME 软件中选择*更新*,你应该会看到告诉你有 Fedora 31 更新的提示。
如果你在屏幕上看不到任何内容,请尝试使用左上方的重新加载按钮。在发布后,所有系统可能需要一段时间才能看到可用的升级。
选择*下载*以获取升级包。你可以继续工作,直到下载完成。然后使用 GNOME “软件”重启系统并应用升级。升级需要时间,因此你可能需要喝杯咖啡,稍后再返回系统。
### 使用命令行
如果你是从 Fedora 以前的版本升级的,那么你可能对 `dnf upgrade` 插件很熟悉。这是推荐且支持的从 Fedora 30 升级到 Fedora 31 的方法。使用此插件能让你轻松地升级到 Fedora 31。
#### 1、更新软件并备份系统
在开始升级之前,请确保你安装了 Fedora 30 的最新软件。如果你安装了模块化软件,这点尤为重要。`dnf` 和 GNOME “软件”的最新版本对某些模块化流的升级过程进行了改进。要更新软件,请使用 GNOME “软件” 或在终端中输入以下命令:
```
sudo dnf upgrade --refresh
```
此外,在继续操作之前,请确保备份系统。有关备份的帮助,请参阅 Fedora Magazine 上的[备份系列](https://fedoramagazine.org/taking-smart-backups-duplicity/)。
#### 2、安装 DNF 插件
接下来,打开终端并输入以下命令安装插件:
```
sudo dnf install dnf-plugin-system-upgrade
```
#### 3、使用 DNF 开始更新
现在,你的系统是最新的,已经备份并且安装了 DNF 插件,你可以通过在终端中使用以下命令来开始升级:
```
sudo dnf system-upgrade download --releasever=31
```
该命令将开始在本地下载计算机的所有升级。如果由于缺乏更新包、损坏的依赖项或已淘汰的软件包而在升级时遇到问题,请在输入上面的命令时添加 `‐-allowerasing` 标志。这将使 DNF 删除可能阻止系统升级的软件包。
#### 4、重启并升级
上面的命令下载更新完成后,你的系统就可以重启了。要将系统引导至升级过程,请在终端中输入以下命令:
```
sudo dnf system-upgrade reboot
```
此后,你的系统将重启。在许多版本之前,`fedup` 工具会在内核选择/引导页面上创建一个新选项。使用 `dnf-plugin-system-upgrade` 软件包,你的系统将重新引导到当前 Fedora 30 使用的内核。这很正常。在内核选择页面之后不久,你的系统会开始升级过程。
现在也许可以喝杯咖啡休息下!升级完成后,系统将重启,你将能够登录到新升级的 Fedora 31 系统。

### 解决升级问题
有时,升级系统时可能会出现意外问题。如果遇到任何问题,请访问 [DNF 系统升级文档](https://docs.fedoraproject.org/en-US/quick-docs/dnf-system-upgrade/#Resolving_post-upgrade_issues),以获取有关故障排除的更多信息。
如果升级时遇到问题,并且系统上安装了第三方仓库,那么在升级时可能需要禁用这些仓库。对于 Fedora 不提供的仓库的支持,请联系仓库的提供者。
---
via: <https://fedoramagazine.org/upgrading-fedora-30-to-fedora-31/>
作者:[Ben Cotton](https://fedoramagazine.org/author/bcotton/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora 31 [is available now](https://fedoramagazine.org/announcing-fedora-31/). You’ll likely want to upgrade your system to get the latest features available in Fedora. Fedora Workstation has a graphical upgrade method. Alternatively, Fedora offers a command-line method for upgrading Fedora 30 to Fedora 31.
Before upgrading, visit the [wiki page of common Fedora 31 bugs](https://fedoraproject.org/wiki/Common_F31_bugs) to see if there’s an issue that might affect your upgrade. Although the Fedora community tries to ensure upgrades work well, there’s no way to guarantee this for every combination of hardware and software that users might have.
## Upgrading Fedora 30 Workstation to Fedora 31
Soon after release time, a notification appears to tell you an upgrade is available. You can click the notification to launch the **GNOME Software** app. Or you can choose Software from GNOME Shell.
Choose the *Updates* tab in GNOME Software and you should see a screen informing you that Fedora 31 is Now Available.
If you don’t see anything on this screen, try using the reload button at the top left. It may take some time after release for all systems to be able to see an upgrade available.
Choose *Download* to fetch the upgrade packages. You can continue working until you reach a stopping point, and the download is complete. Then use GNOME Software to restart your system and apply the upgrade. Upgrading takes time, so you may want to grab a coffee and come back to the system later.
## Using the command line
If you’ve upgraded from past Fedora releases, you are likely familiar with the *dnf upgrade* plugin. This method is the recommended and supported way to upgrade from Fedora 30 to Fedora 31. Using this plugin will make your upgrade to Fedora 31 simple and easy.
### 1. Update software and back up your system
Before you do start the upgrade process, make sure you have the latest software for Fedora 30. This is particularly important if you have modular software installed; the latest versions of dnf and GNOME Software include improvements to the upgrade process for some modular streams. To update your software, use *GNOME Software* or enter the following command in a terminal.
sudo dnf upgrade --refresh
Additionally, make sure you back up your system before proceeding. For help with taking a backup, see [the backup series](https://fedoramagazine.org/taking-smart-backups-duplicity/) on the Fedora Magazine.
### 2. Install the DNF plugin
Next, open a terminal and type the following command to install the plugin:
sudo dnf install dnf-plugin-system-upgrade
### 3. Start the update with DNF
Now that your system is up-to-date, backed up, and you have the DNF plugin installed, you can begin the upgrade by using the following command in a terminal:
sudo dnf system-upgrade download --releasever=31
This command will begin downloading all of the upgrades for your machine locally to prepare for the upgrade. If you have issues when upgrading because of packages without updates, broken dependencies, or retired packages, add the *‐‐allowerasing* flag when typing the above command. This will allow DNF to remove packages that may be blocking your system upgrade.
### 4. Reboot and upgrade
Once the previous command finishes downloading all of the upgrades, your system will be ready for rebooting. To boot your system into the upgrade process, type the following command in a terminal:
sudo dnf system-upgrade reboot
Your system will restart after this. Many releases ago, the *fedup* tool would create a new option on the kernel selection / boot screen. With the *dnf-plugin-system-upgrade* package, your system reboots into the current kernel installed for Fedora 30; this is normal. Shortly after the kernel selection screen, your system begins the upgrade process.
Now might be a good time for a coffee break! Once it finishes, your system will restart and you’ll be able to log in to your newly upgraded Fedora 31 system.
## Resolving upgrade problems
On occasion, there may be unexpected issues when you upgrade your system. If you experience any issues, please visit the [DNF system upgrade quick docs](https://docs.fedoraproject.org/en-US/quick-docs/dnf-system-upgrade/#Resolving_post-upgrade_issues) for more information on troubleshooting.
If you are having issues upgrading and have third-party repositories installed on your system, you may need to disable these repositories while you are upgrading. For support with repositories not provided by Fedora, please contact the providers of the repositories.
## Zlopez
I think we should also inform how to upgrade on Fedora Silverblue.
## hammerhead corvette
Absolutely !
## Otsilva
So, how do we do it? (Fedora Silverblue)
## Zlopez
There should be upgrade option in GNOME Software, but I got GPG key not trusted, when I tried it. I recommend to use this guide https://fedoramagazine.org/how-to-rebase-to-fedora-30-beta-on-silverblue, just change F30 to F31 and everything should work.
## Zlopez
I also noticed, that the refs name changed from fedora-workstation to fedora. It looks like I need to write a new article.
## Otsilva
Ok! I will wait!
## Ricky
Hit a road block. I double check eclipse-jgit is from Fedora upstream repo:
sudo dnf system-upgrade download –releasever=31
Before you continue ensure that your system is fully upgraded by running “dnf –refresh upgrade”. Do you want to continue [y/N]: y
Copr repo for bazel owned by vbatts 11 kB/s | 3.3 kB 00:00
Fedora Modular 31 – x86_64 23 kB/s | 12 kB 00:00
Fedora Modular 31 – x86_64 – Updates 32 kB/s | 9.8 kB 00:00
Fedora 31 – x86_64 – Updates 36 kB/s | 11 kB 00:00
Fedora 31 – x86_64 39 kB/s | 12 kB 00:00
Jenkins-stable 45 kB/s | 2.9 kB 00:00
Metasploit 28 kB/s | 3.0 kB 00:00
RPM Fusion for Fedora 31 – Free – Updates 9.3 kB/s | 4.2 kB 00:00
RPM Fusion for Fedora 31 – Free 7.2 kB/s | 3.2 kB 00:00
RPM Fusion for Fedora 31 – Nonfree – Updates 9.4 kB/s | 4.3 kB 00:00
RPM Fusion for Fedora 31 – Nonfree 7.1 kB/s | 3.2 kB 00:00
Error:
Problem: problem with installed package eclipse-jgit-5.4.0-4.fc30.noarch
– eclipse-jgit-5.4.0-4.fc30.noarch does not belong to a distupgrade repository
– package eclipse-jgit-5.4.0-4.module_f31+6165+9b01e00c.noarch is excluded
– package eclipse-jgit-5.5.0-1.module_f31+6519+12cd0b27.noarch is excluded
– nothing provides jgit = 5.3.0-5.fc31 needed by eclipse-jgit-5.3.0-5.fc31.noarch
(try to add ‘–skip-broken’ to skip uninstallable packages)
## Charles
Same issue here. How to resolve this problem?
## Jose
You could just add –allowerasing flag. It will remove the dependend eclipse packages and allow the upgrade to take place. Re-install eclipse after upgrade finishes.
## Zlopez
I’m usually uninstall the package and install it after upgrade. Or you could wait for few days, till this package will be ready for F31.
## jsast21
Easiest way around this is to uninstall eclipse* (dnf erase -y eclipse*) and then run the upgrade. Then you can reinstall eclipse when the upgrade is complete.
I had a similar issue with TeamViewer by the way.
Good luck.
## anony mouse
Eclipse seems broken in F31, it may be best to stay on F30.
## andrej
you can always use eclipse from https://www.eclipse.org/downloads/packages/
## Arthur
Worked a treat. Thanks.
## Yazan Al Monshed
How to do that in SB ??
## Zlopez
There should be upgrade option in GNOME Software, but I got GPG key not trusted, when I tried it. I recommend to use this guide https://fedoramagazine.org/how-to-rebase-to-fedora-30-beta-on-silverblue, just change F30 to F31 and everything should work.
## Bob
Hi,
There is kind of a shortcut here…
You are saying “If you’ve upgraded from past Fedora releases, you are likely familiar with the dnf upgrade plugin. This method is the recommended and supported way to upgrade from Fedora 30 to Fedora 31. ”
Yet the official guide says: use the gui:
This is the recommended upgrade method for the Fedora Workstation.
https://docs.fedoraproject.org/en-US/quick-docs/upgrading/
## Brandon
No key installed and system not ready for upgrade.
Fedora 31 – x86_64 1.6 MB/s | 1.6 kB 00:00
Importing GPG key 0x3C3359C4:
Userid : “Fedora (31) [email protected]”
Fingerprint: 7D22 D586 7F2A 4236 474B F7B8 50CB 390B 3C33 59C4
From : /etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-31-x86_64
[…]
Public key for abrt-addon-ccpp-2.12.2-1.fc31.x86_64.rpm is not installed. Failing package is: abrt-addon-ccpp-2.12.2-1.fc31.x86_64
GPG Keys are configured as: file:///etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-31-x86_64
Public key for abrt-addon-kerneloops-2.12.2-1.fc31.x86_64.rpm is not installed. Failing package is: abrt-addon-kerneloops-2.12.2-1.fc31.x86_64
GPG Keys are configured as: file:///etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-31-x86_64
Public key for abrt-addon-pstoreoops-2.12.2-1.fc31.x86_64.rpm is not installed. Failing package is: abrt-addon-pstoreoops-2.12.2-1.fc31.x86_64
GPG Keys are configured as: file:///etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-31-x86_64
[…]
Didn’t install any keys
The downloaded packages were saved in cache until the next successful transaction.
You can remove cached packages by executing ‘dnf clean packages’.
Error: GPG check FAILED
## lruzicka
You are experiencing the problem with modularity. For a little background, you have enabled and installed a modular stream (on purpose or accidentally) and because that stream does not have an upgrade path, it cannot be upgraded and your system stays as is. Modularity is a work-in-progress so it still is not perfect. To solve your situation. There were similar problems with
libgit2module, check if you have it. If that is the libgit problem, there should be a fix ready, make sure you have updated your system fully before upgrading. However, it can be other modules, as well:Check if any modules are installed (or enabled):
dnf module list --installedanddnf module list --enabled.For all such listed modules do
dnf module reset <modulename>This should help to get you upgraded.
## Ricky
I disabled all module and disable modular repository:
sudo dnf config-manager –set-disabled updates-modular
Run dnf update again. It replaced RPM from modular with RPM from Fedora 30 repo.
But I still hit a road block — libgit2 when upgrade:
sudo dnf system-upgrade download –releasever=31
Before you continue ensure that your system is fully upgraded by running “dnf –refresh upgrade”. Do you want to continue [y/N]: y
Copr repo for bazel owned by vbatts 11 kB/s | 3.3 kB 00:00
Fedora 31 – x86_64 – Updates 35 kB/s | 14 kB 00:00
Fedora 31 – x86_64 94 kB/s | 14 kB 00:00
Jenkins-stable 46 kB/s | 2.9 kB 00:00
Metasploit 29 kB/s | 3.0 kB 00:00
RPM Fusion for Fedora 31 – Free – Updates 6.7 kB/s | 3.0 kB 00:00
RPM Fusion for Fedora 31 – Free 7.0 kB/s | 3.2 kB 00:00
RPM Fusion for Fedora 31 – Nonfree – Updates 6.7 kB/s | 3.0 kB 00:00
RPM Fusion for Fedora 31 – Nonfree 7.1 kB/s | 3.2 kB 00:00
Unable to resolve argument libgit2
Error:
Problem: problem with installed package eclipse-jgit-5.4.0-4.fc30.noarch
– eclipse-jgit-5.4.0-4.fc30.noarch does not belong to a distupgrade repository
– nothing provides jgit = 5.3.0-5.fc31 needed by eclipse-jgit-5.3.0-5.fc31.noarch
(try to add ‘–skip-broken’ to skip uninstallable packages)
## lruzicka
Have you reset the modules first, before you disabled the modular repos? Also, I believe that libgit2 for Fedora 31 was only provided as a modular package. There has been a discussion about modular default streams and somebody suggested to create a non-modular libgit2 package, but I do not think that has happened.
So, you either remove eclipse and everything that depends on libgit2 and upgrade first, then you can install eclipse again. Or, you enable the modular repos again, you run
and this should be enough to tell your system to forget the libgit2 stream that became obsolete and move to a newer stream.
Let me know how that went, ok?
## Alastair D'Silva
You’ll probably have issues reinstalling eclipse after the upgrade, I worked around it by manually installing the Fedora 30 packages for: jgit, eclipse-jgit & glassfish-el. Download the binaries from here:
https://fedora.pkgs.org/30/fedora-updates-x86_64/jgit-5.4.0-6.fc30.noarch.rpm.html
https://fedora.pkgs.org/30/fedora-updates-x86_64/eclipse-jgit-5.4.0-4.fc30.noarch.rpm.html
https://fedora.pkgs.org/30/fedora-x86_64/glassfish-el-3.0.1-0.10.b08.fc30.noarch.rpm.html
## Al
Thanks, it worked for me perfectly!
## Dragosh
If I have fedora 31 beta, is need tot do another actions (step) or sudo dnf upgrade –refresh is enough??
## Paul W. Frields
@Dragosh. That should be enough. When you install the Beta you’re on the path toward that final release.
## BuKToP
Everything is fine, but TeamViewer is not working after the upgrade. Tried to uninstall it and then install it again. No success. It starts correctly, but then the GUI just freezes.
Any ideas?
## aa
oh,no
i completed upgrade,but i lose my root pasword
🙁
## Paul W. Frields
@aa: See if this article works for you: https://fedoramagazine.org/reset-root-password-fedora/
## VeNiX
Some packages from the old system must be removed in order the test transaction to pass.
## Charles
Hi, guys,
Running ‘dnf system-upgrade reboot’ cannot trigger the upgrade process in my case.
I can see the log ‘Starting system upgrade. This will take a while’, but after that the OS rebooted quickly. I’m able to see some failure.
But I upgraded Fedora 29 to 30 successfully.
Any ideas?
## lruzicka
Please, send the failure you see. 😀
## Charles
Hi,
I’ve resolved this issue.
1.
Run ‘journalctl’ to open the logs, then search ‘system-upgrade’ or ‘Failed to start System Upgrade using DNF’, etc. I can see error logs, like:
Package XXXXXXXX.x86_64 is already installed.
Error:
Problem: cannot install the best candidate for the job
– conflicting requests
(try to add ‘–skip-broken’ to skip uninstallable packages)
2.
My solution is rebooting to Fedora 30 and remove this annoying package.
Then run ‘dnf system-upgrade reboot’ again, but please remember that before do this run ‘dnf upgrade –refresh’ and ‘dnf system-upgrade download –releasever=31’ at first.
## Charles
But I have other issues:
1.The Nvidia video card cannot be detected, but Intel video instead.
I see these error logs:
(II) LoadModule: “nv”
(WW) Warning, couldn’t open module nv
(EE) Failed to load module “nv” (module does not exist, 0)
and:
(**) Option “fd” “51”
(II) event8 – SIGMACHIP USB Keyboard Consumer Control: device removed
(II) AIGLX: Suspending AIGLX clients for VT switch
(EE) modeset(0): failed to set mode: Permission denied
2.
The second monitor cannot detected, but it can be detected in F30. It’s strange.
Now I’m actually using Intel video card, so may be it’s due to the missing configuration?
I’ve created a configuration file at /etc/X11/xorg.conf.d/20-intel.conf, but this is not useful. The second monitor can’t be detected even after reboot.
## Charles
Hi,
The first issue had been resolved.
My solution is:
Please note that I’ve installed Nvidia packages from rpmfution.
See https://rpmfusion.org/Howto/NVIDIA for more details.
1)cp /usr/share/X11/xorg.conf.d/nvidia.conf /etc/X11/xorg.conf.d
2)Add the following lines to /etc/X11/xorg.conf.d/nvidia.conf:
Section “Module”
Load “modesetting”
EndSection
Section “Device”
Identifier “nvidia”
Driver “nvidia”
BusID “PCI:”
Option “AllowEmptyInitialConfiguration”
EndSection
3)Reboot, I can see Fedora 31 is using Nvidia graphics in the Setting/About.
Please see ‘https://wiki.archlinux.org/index.php/NVIDIA_Optimus#Use_NVIDIA_graphics_only’ for more details.
The second issue should be resolved too, since I’ve used the Nvidia graphics. I’ll reply later.
## Charles
I’m sure that enable Nvidia graphics can make the Fedora 30 to detect the second monitor by default.
## Mislav
Is upgrade from F29 -> F31 also supported? I can see upgrade to F31 option in Gnome Software on my F29 laptop but this article only mentions F30.
## Stephen
Yes it should work. There has been occasion for problems doing what you propose, but that was with way earlier versions such as F17/18/19, etc… I have done “jumpgrades” of two version changes bypassing the in between one with no adverse affects to systems.
## bb
Error: Transaction test error: file /usr/lib/python3.7/sute-packages/mypy/typeshed from install of python3-mypy-0.730-2.fc31.noarch conflicts with file from package python3-mypy-0.670-1.fc30.noarch
## andrej
dnf remove python3-mypy-0.670-1.fc30.noarch
watch for dependent packages that was removed with it
upgrade to the f31
install back those dependent packages
in my case it was thonny-3.1.1-1.fc30.noarch – see my post below for more details.
## River14
I have not yet upgraded to fedora 31 and I can’t wait for this.
But, I need to know if there is any issue about nvidia graphics card.
rpmfussion free and non-free doing the best ???
Thanks a lot
## bnjmn
None
## Charles
Unfortunately. Nvidia graphics card can’t be detected in my laptop after upgrade.
## Nanner
Running into an issue with Banshee when trying to upgrade. If I do –allowreasing, dnf will remove Banshee and install the updated gudev-sharp package for Fedora 31.
Error:
Problem: package banshee-2.6.2-34.fc31.x86_64 requires mono(gudev-sharp) = 1.0.0.0, but none of the providers can be installed
– problem with installed package banshee-2.6.2-32.fc30.x86_64
– gudev-sharp-1:0.1-25.fc30.x86_64 does not belong to a distupgrade repository
– banshee-2.6.2-32.fc30.x86_64 does not belong to a distupgrade repository
(try to add ‘–skip-broken’ to skip uninstallable packages)
However if I try to dnf install banshee from a clean install of Fedora 31 I get this:
Error:
Problem: conflicting requests
– nothing provides mono(Mono.Zeroconf) = 4.0.0.90 needed by banshee-2.6.2-34.fc31.x86_64
– nothing provides mono(gudev-sharp) = 1.0.0.0 needed by banshee-2.6.2-34.fc31.x86_64
– nothing provides mono(notify-sharp) = 0.4.0.0 needed by banshee-2.6.2-34.fc31.x86_64
(try to add ‘–skip-broken’ to skip uninstallable packages)
## lruzicka
Thanks for letting us know, I have opened a bug. Hopefully, the situation will be fixed in the future. (https://bugzilla.redhat.com/show_bug.cgi?id=1767436)
## lruzicka
Hello,
in this update (https://bodhi.fedoraproject.org/updates/FEDORA-2019-bf9384ecd1), you will find updated packages needed to install Banshee. I have tested it and it works. You can install it like this:
Create an empty temporary directory.
Install the Bodhi client
Download the packages from Bodhi using the client
.
Install the packages
.
Install Banshee
## Joachim
The upgrade 30 -> 31 worked like a charm on my old workhorse DELL Precision M6400! No issues whatsoever…
Thanks for the great work, guys!
## Stephen
For upgrading Silverblue to F31SB, the link provided in the comments above will work. There was one difference for me in that the remote ref was named simply fedora on my system. So the command I used to rebase to F31 was ‘rpm-ostree rebase fedora:fedora/31/x86_64/silverblue’. I am now going to reboot into my F31SB system.
## Stephen
This comment has been submitted using Fedora 31 Silverblue after a successful upgrade just minutes ago.
## Enio
Error: Transaction test error: file /usr/lib/python3.7/sute-packages/mypy/typeshed from install of python3-mypy-0.730-2.fc31.noarch conflicts with file from package python3-mypy-0.670-1.fc30.noarch
Even with “[…] –allowerasing”
## Murphy
I suggest “dnf remove python3-mypy”, then your upgrade should go smoothly.
## Michael
Perfect, it worked. Thanks.
## andrej
In my case the root problems seems to be within the thonny-3.1.1-1.fc30.noarch (Python IDE for beginners) from f30. It depends on python3-mypy-0.670-1.fc30.noarch.
In fedora 31 there is the same thonny-3.1.1-1.fc30.noarch but it depends on python3-mypy-0.740-2.fc31.noarch.
The thonny package was not upgraded but the new deps were requested (?) and it makes that conflict.
Removing thonny in f30, upgrading and installing thonny back in f31 solves the problem.
There is also bugzilla issue https://bugzilla.redhat.com/show_bug.cgi?id=1774344 opened for this.
## Paun Narcis-Iulian
Take care, if on ssh remotely like I was, create a user and add it to sudoers because you will lose ability to connect root on ssh after the upgrade. Had to run with keyboard and monitor to server room to login and fix my mistake. I am sure there are others running servers only with root.
## RJF
After the F30 to F31 upgrade today Gnome workspaces don’t appear which is very annoying. Yes, I’ve tried toggling the various settings and extensions.
Plus wired networking is broken, which is temporarily fixed by booting into the older (ie still F30) kernel (or using wifi).
Sound didn’t work at first out of the headphone socket but that seems OK now, not sure if it was just a reboot that fixed it.
## bnjmn
Never mind (
Kernel support EXT3 was not enabled…recompiling now!!!
## River14
I’ve just upgraded from f30 to f31.
Everything works like a charm.
Great great job guys.
Congrats !!
## Suryatej Yaramada
docker is not working after upgrading to fedora31
docker run -it –entrypoint /bin/bash amazonlinux:latest
docker: Error response from daemon: OCI runtime create failed: container_linux.go:346: starting container process caused “process_linux.go:297: applying cgroup configuration for process caused \”open /sys/fs/cgroup/docker/cpuset.cpus.effective: no such file or directory\””: unknown.
## Paul W. Frields
Out of curiosity, have you tried using podman? Same syntax:
podman run -it --entrypoint /bin/bash amazonlinux:latest## Kostya
Long time (since ~24) Fedora user.
dnf system-upgrade download is giving me network errors, on an otherwise perfect (~750 mbit) network connection.
I’ve tired several mirrors, including Yandex, U. Chemnitz and a server in Ukraine. All time out.
Anyone seen this or know of how to fix?
https://bugzilla.redhat.com/show_bug.cgi?id=1767781
## bioshark.dev
Just finished upgrading from F30 to F31 and everything ran smoothly (almost). I use Nvidia drivers from rpmfusion and the system works fine, and the latest driver is installed.
The only thing that is not working is a bunch of gnome extensions (which I believe will be fixed withing the near future):
– application menu
– dash to dock
– removable drive menu
cheers, and thank you for your work.
## Tz00
Fedora 31 leaves out cairo support (libcairo.so in /usr/…/lua/5.3/) for conky like 29 and 30 did at first. So, to use your conky scripts with rings, you need to download the old conky rpm, then dnf downgrade conky*.rpm to get cairo support (i.e. rings, clocks, etc). I tried to file a bug but the software said “not enough of a stacktrace … to file”.
So, if any other users are frustrated by this, use the aforementioned process to get your scripts running. Thanks
## bnjmn
SMB is now broken after upgrade
## Paul W. Frields
Please report bugs in Bugzilla, not here on the Magazine. We just report news and tips here. 🙂
## bnjmn
Yeah! apologies
https://bugzilla.redhat.com/show_bug.cgi?id=1768117
## Naheed Kamal
Upgrade to Fedora 31 is successful, but after selecting the fedora 31 boot from grub, no display, the PC going to sleep, so I forcefully restart and select fedora 30 to use my PC, please suggest me, what shout I do?
## Charles
Check your logs, you may find some useful information related to this issue.
eg:
1)journalctl
Just check all those lines when this issue happens.
2)/var/log/Xorg.X.log.old
X should be 0, 1 or 2, depending on your case. Use ‘ll /var/log/Xorg.* -rt’ to sort your files.
## Mark
It would be nice if when the upgrade instructions are posted for each new release they include a link to the known issues that will occur with the new release, so users can decide whether to upgrade or not.
For example one of the prior comments referred to docker not working on F31, where it was specifically decided as a release decision to let users suffer the pain of docker not working (reference https://bugzilla.redhat.com/show_bug.cgi?id=1746355 where they just decided not enough Fedora users use Docker services to care about it).
Rather than have a post saying F31 is available and here is how to upgrade, such a post really m u s t also contain a link to known issues with upgrading as part of the post. One benefit to the magazine would be a lot less comments about things breaking as users can decide what features they are willing to lose.
I believe having a post implying upgrade is easy without having a link to at a bare minimum the known issues that will occur when upgrading is reckless.
Especially when replies to comments are such as “Please report bugs in Bugzilla, not here on the Magazine” when it was the magazine that drove the upgrade.
I agree bugs should not be reported here, but nor should the magazine encourage users to blindly jump over a cliff by painting a rosy simple upgrade path. At the very least if there is not a published known bug list available to be linked to the title should include ‘how to upgrade at your own risk if you are really stupid’.
## Paul W. Frields
The announcement for the release has a prominent link to the common Fedora 31 bugs page. That page also has information on what to do if you don’t find your issue listed.
## Jery Mander
Fedora Failure – gui users and groups manager removed. Was fine in 30, no replacement installed by default. Very lame Fedora.
## Paul W. Frields
@Jery: This is incorrect. You can manage users through the Settings > Details control panel in Fedora Workstation; this allows you to add regular users as well as administrators (members of ‘wheel’). You may have another tool available if you’re using a different desktop flavor.
## sam
Going to upgrade from f30 to f31 hopefully doesn’t break things
## Jerry Mander
How does one bring up a graphical user and group control window on Fedora 31 with XFCE?
## Michal Ambroz
Hello,
upgrade of one of my machines went wrong (fc30 -> fc31)
[ OK ] Started D-Bus System message bus.
[ OK ] Started Bluetooth service.
[ OK ] Started IIO Sensor Proxy service.
[ OK ] Reached target Bluetooth.
You are in rescue mode. After logging in, type “journalctl -xb” to view system logs, “systemctl reboot” to reboot, “systemctl default” or “exit” to boot into default mode.
Give root password for maintenance
(or press Control-D to continue):
[root@machine]# exit
exit
Reloading system manager configuration
Starting default target
Failed to start default target: Operation refused, unit may not be isolated.
It turned out that for some reason the upgrade didn’t restore the default systemd target before rebooting.
This fixed the problem:
rm -f /etc/systemd/system/default.target
ln -s /lib/systemd/system/graphical.target /etc/systemd/system/default.target
On servers / machines without GUI it might be:
ln -s /lib/systemd/system/multi-user.target /etc/systemd/system/default.target
Good luck upgrading
## Marco
Hello folks,
after upgrade to Fedora 31 my laptop was unable to start into graphical.target runlevel: no errors displayed and laptop freeze after load “Gnome Display Manager”.
I’m able to start into multi-user.target runlevel and then start Gnome with startx.
Any helps on what to check?
Thanks,
Marco
## Michal Ambroz
Hello Marco,
Start with checking the error messages from the current boot and look for the errors:
journalctl -xb
Check that your local systemd configuration points to something reasonable (in my case it was pointing to /var/tmp/something and normal links were not restored with the finish of upgrade). It should be something like:
$ ls -lad /etc/systemd/system/default.target
lrwxrwxrwx. 1 root root 36 2019-11-07_18:50:49 /etc/systemd/system/default.target -> /lib/systemd/system/graphical.target
$ ls -lad /etc/systemd/system/graphical.target
lrwxrwxrwx. 1 root root 36 2019-11-06_16:35:56 /etc/systemd/system/graphical.target -> /lib/systemd/system/graphical.target
If “Gnome Display Manager” is not starting as a service, but you are able to start gnome with startx … the difference might be confined and unconfined mode. Some SElinux context might be wrong on some files, possibly from previous distro upgrades before fc30.
Try to relabel the filesystem with the default SE context by doing:
sudo touch /.autorelabel
sudo reboot
Then trying
systemctl start graphical.target
Check also the audit log for possible SE permission issues:
https://access.redhat.com/articles/2191331
tail -f /var/log/audit/audit.log
Mik
## Marco
Hello Michal,
problem solved, but because I was in a rush I did not investigate better and performed a fresh installation formatting all LV except the home to preserve my data.
Thanks,
Marco
## Jerry Mander
Several things that worked on Fedora 30 are being labeled as “broken” on Fedora 31. This seems to point to a failure in the new version of Fedora rather than all the supposed “broken” status of files that work fine in Fedor 30. Wish I could downgrade back to 30 and have my features back.
## Paul W. Frields
@Jerry: It’s inevitable that any system that allows a high degree of customization and twiddling can never achieve a “perfect” upgrade record. Unfortunately this is a pretty subjective measure. Many people upgrade with no problems. Overall Fedora keeps evolving and getting better every release though. One alternative is to try a fresh installation to see if that solves some issues for you.
## Tim Kissane
Just upgraded from Fedora 30 to 31 using the CLI. All went smoothly until I logged into the system for the first time to put the new kernel in place. Unfortunately, I get logged out less than a minute after logging in. I’ll try booting into single user mode to see if I can find a clue. This is what makes Linux fun! Since it’s not my daily driver, I can be light-hearted. 😉
## mgmg
Can not use 4 fingers Vertical Gestures (Switch Workspace action doesn’t work) after upgrade fedora 31.
## Remzi
I miss again my favorite desktop icons.
It’s ok when you don’t lik it but i like it.
I star my favorit apps verry fast when i see it on my desktop.
## Henrique Tschannerl
Hello, I’m trying to upgrade the Fedora Server 31 on the HP BL460C Gen1, but the system stop with this messages.
[OK] Reached targe Paths
[ TIME ] Timed out waiting for device
[ DEPEND ] Dependency failed for Resume from hibernation using device /dev/mapper |
11,542 | 如何在 Linux 中找出内存消耗最大的进程 | https://www.2daygeek.com/linux-find-top-memory-consuming-processes/ | 2019-11-06T11:02:00 | [
"内存"
] | https://linux.cn/article-11542-1.html | 
很多次,你可能遇见过系统消耗了过多的内存。如果是这种情况,那么最好的办法是识别出 Linux 机器上消耗过多内存的进程。我相信,你可能已经运行了下文中的命令以进行检查。如果没有,那你尝试过哪些其他的命令?我希望你可以在评论中更新这篇文章,它可能会帮助其他用户。
使用 [top 命令](https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/) 和 [ps 命令](https://www.2daygeek.com/linux-ps-command-find-running-process-monitoring/) 可以轻松的识别这种情况。我过去经常同时使用这两个命令,两个命令得到的结果是相同的。所以我建议你从中选择一个喜欢的使用就可以。
### 1) 如何使用 ps 命令在 Linux 中查找内存消耗最大的进程
`ps` 命令用于报告当前进程的快照。`ps` 命令的意思是“进程状态”。这是一个标准的 Linux 应用程序,用于查找有关在 Linux 系统上运行进程的信息。
它用于列出当前正在运行的进程及其进程 ID(PID)、进程所有者名称、进程优先级(PR)以及正在运行的命令的绝对路径等。
下面的 `ps` 命令格式为你提供有关内存消耗最大进程的更多信息。
```
# ps aux --sort -rss | head
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
mysql 1064 3.2 5.4 886076 209988 ? Ssl Oct25 62:40 /usr/sbin/mysqld
varnish 23396 0.0 2.9 286492 115616 ? SLl Oct25 0:42 /usr/sbin/varnishd -P /var/run/varnish.pid -f /etc/varnish/default.vcl -a :82 -T 127.0.0.1:6082 -S /etc/varnish/secret -s malloc,256M
named 1105 0.0 2.7 311712 108204 ? Ssl Oct25 0:16 /usr/sbin/named -u named -c /etc/named.conf
nobody 23377 0.2 2.3 153096 89432 ? S Oct25 4:35 nginx: worker process
nobody 23376 0.1 2.1 147096 83316 ? S Oct25 2:18 nginx: worker process
root 23375 0.0 1.7 131028 66764 ? Ss Oct25 0:01 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nobody 23378 0.0 1.6 130988 64592 ? S Oct25 0:00 nginx: cache manager process
root 1135 0.0 0.9 86708 37572 ? S 05:37 0:20 cwpsrv: worker process
root 1133 0.0 0.9 86708 37544 ? S 05:37 0:05 cwpsrv: worker process
```
使用以下 `ps` 命令格式可在输出中仅展示有关内存消耗过程的特定信息。
```
# ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%mem | head
PID PPID %MEM %CPU CMD
1064 1 5.4 3.2 /usr/sbin/mysqld
23396 23386 2.9 0.0 /usr/sbin/varnishd -P /var/run/varnish.pid -f /etc/varnish/default.vcl -a :82 -T 127.0.0.1:6082 -S /etc/varnish/secret -s malloc,256M
1105 1 2.7 0.0 /usr/sbin/named -u named -c /etc/named.conf
23377 23375 2.3 0.2 nginx: worker process
23376 23375 2.1 0.1 nginx: worker process
3625 977 1.9 0.0 /usr/local/bin/php-cgi /home/daygeekc/public_html/index.php
23375 1 1.7 0.0 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
23378 23375 1.6 0.0 nginx: cache manager process
1135 3034 0.9 0.0 cwpsrv: worker process
```
如果你只想查看命令名称而不是命令的绝对路径,请使用下面的 `ps` 命令格式。
```
# ps -eo pid,ppid,%mem,%cpu,comm --sort=-%mem | head
PID PPID %MEM %CPU COMMAND
1064 1 5.4 3.2 mysqld
23396 23386 2.9 0.0 cache-main
1105 1 2.7 0.0 named
23377 23375 2.3 0.2 nginx
23376 23375 2.1 0.1 nginx
23375 1 1.7 0.0 nginx
23378 23375 1.6 0.0 nginx
1135 3034 0.9 0.0 cwpsrv
1133 3034 0.9 0.0 cwpsrv
```
### 2) 如何使用 top 命令在 Linux 中查找内存消耗最大的进程
Linux 的 `top` 命令是用来监视 Linux 系统性能的最好和最知名的命令。它在交互界面上显示运行的系统进程的实时视图。但是,如果要查找内存消耗最大的进程,请 [在批处理模式下使用 top 命令](/article-11491-1.html)。
你应该正确地 [了解 top 命令输出](https://www.2daygeek.com/understanding-linux-top-command-output-usage/) 以解决系统中的性能问题。
```
# top -c -b -o +%MEM | head -n 20 | tail -15
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1064 mysql 20 0 886076 209740 8388 S 0.0 5.4 62:41.20 /usr/sbin/mysqld
23396 varnish 20 0 286492 115616 83572 S 0.0 3.0 0:42.24 /usr/sbin/varnishd -P /var/run/varnish.pid -f /etc/varnish/default.vcl -a :82 -T 127.0.0.1:6082 -S /etc/varnish/secret -s malloc,256M
1105 named 20 0 311712 108204 2424 S 0.0 2.8 0:16.41 /usr/sbin/named -u named -c /etc/named.conf
23377 nobody 20 0 153240 89432 2432 S 0.0 2.3 4:35.74 nginx: worker process
23376 nobody 20 0 147096 83316 2416 S 0.0 2.1 2:18.09 nginx: worker process
23375 root 20 0 131028 66764 1616 S 0.0 1.7 0:01.07 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
23378 nobody 20 0 130988 64592 592 S 0.0 1.7 0:00.51 nginx: cache manager process
1135 root 20 0 86708 37572 2252 S 0.0 1.0 0:20.18 cwpsrv: worker process
1133 root 20 0 86708 37544 2212 S 0.0 1.0 0:05.94 cwpsrv: worker process
3034 root 20 0 86704 36740 1452 S 0.0 0.9 0:00.09 cwpsrv: master process /usr/local/cwpsrv/bin/cwpsrv
1067 nobody 20 0 1356200 31588 2352 S 0.0 0.8 0:56.06 /usr/local/apache/bin/httpd -k start
977 nobody 20 0 1356088 31268 2372 S 0.0 0.8 0:30.44 /usr/local/apache/bin/httpd -k start
968 nobody 20 0 1356216 30544 2348 S 0.0 0.8 0:19.95 /usr/local/apache/bin/httpd -k start
```
如果你只想查看命令名称而不是命令的绝对路径,请使用下面的 `top` 命令格式。
```
# top -b -o +%MEM | head -n 20 | tail -15
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1064 mysql 20 0 886076 210340 8388 S 6.7 5.4 62:40.93 mysqld
23396 varnish 20 0 286492 115616 83572 S 0.0 3.0 0:42.24 cache-main
1105 named 20 0 311712 108204 2424 S 0.0 2.8 0:16.41 named
23377 nobody 20 0 153240 89432 2432 S 13.3 2.3 4:35.74 nginx
23376 nobody 20 0 147096 83316 2416 S 0.0 2.1 2:18.09 nginx
23375 root 20 0 131028 66764 1616 S 0.0 1.7 0:01.07 nginx
23378 nobody 20 0 130988 64592 592 S 0.0 1.7 0:00.51 nginx
1135 root 20 0 86708 37572 2252 S 0.0 1.0 0:20.18 cwpsrv
1133 root 20 0 86708 37544 2212 S 0.0 1.0 0:05.94 cwpsrv
3034 root 20 0 86704 36740 1452 S 0.0 0.9 0:00.09 cwpsrv
1067 nobody 20 0 1356200 31588 2352 S 0.0 0.8 0:56.04 httpd
977 nobody 20 0 1356088 31268 2372 S 0.0 0.8 0:30.44 httpd
968 nobody 20 0 1356216 30544 2348 S 0.0 0.8 0:19.95 httpd
```
### 3) 奖励技巧:如何使用 ps\_mem 命令在 Linux 中查找内存消耗最大的进程
[ps\_mem 程序](https://www.2daygeek.com/ps_mem-report-core-memory-usage-accurately-in-linux/) 用于显示每个程序(而不是每个进程)使用的核心内存。该程序允许你检查每个程序使用了多少内存。它根据程序计算私有和共享内存的数量,并以最合适的方式返回已使用的总内存。
它使用以下逻辑来计算内存使用量。总内存使用量 = sum(用于程序进程的专用内存使用量) + sum(用于程序进程的共享内存使用量)。
```
# ps_mem
Private + Shared = RAM used Program
128.0 KiB + 27.5 KiB = 155.5 KiB agetty
228.0 KiB + 47.0 KiB = 275.0 KiB atd
284.0 KiB + 53.0 KiB = 337.0 KiB irqbalance
380.0 KiB + 81.5 KiB = 461.5 KiB dovecot
364.0 KiB + 121.5 KiB = 485.5 KiB log
520.0 KiB + 65.5 KiB = 585.5 KiB auditd
556.0 KiB + 60.5 KiB = 616.5 KiB systemd-udevd
732.0 KiB + 48.0 KiB = 780.0 KiB crond
296.0 KiB + 524.0 KiB = 820.0 KiB avahi-daemon (2)
772.0 KiB + 51.5 KiB = 823.5 KiB systemd-logind
940.0 KiB + 162.5 KiB = 1.1 MiB dbus-daemon
1.1 MiB + 99.0 KiB = 1.2 MiB pure-ftpd
1.2 MiB + 100.5 KiB = 1.3 MiB master
1.3 MiB + 198.5 KiB = 1.5 MiB pickup
1.3 MiB + 198.5 KiB = 1.5 MiB bounce
1.3 MiB + 198.5 KiB = 1.5 MiB pipe
1.3 MiB + 207.5 KiB = 1.5 MiB qmgr
1.4 MiB + 198.5 KiB = 1.6 MiB cleanup
1.3 MiB + 299.5 KiB = 1.6 MiB trivial-rewrite
1.5 MiB + 145.0 KiB = 1.6 MiB config
1.4 MiB + 291.5 KiB = 1.6 MiB tlsmgr
1.4 MiB + 308.5 KiB = 1.7 MiB local
1.4 MiB + 323.0 KiB = 1.8 MiB anvil (2)
1.3 MiB + 559.0 KiB = 1.9 MiB systemd-journald
1.8 MiB + 240.5 KiB = 2.1 MiB proxymap
1.9 MiB + 322.5 KiB = 2.2 MiB auth
2.4 MiB + 88.5 KiB = 2.5 MiB systemd
2.8 MiB + 458.5 KiB = 3.2 MiB smtpd
2.9 MiB + 892.0 KiB = 3.8 MiB bash (2)
3.3 MiB + 555.5 KiB = 3.8 MiB NetworkManager
4.1 MiB + 233.5 KiB = 4.3 MiB varnishd
4.0 MiB + 662.0 KiB = 4.7 MiB dhclient (2)
4.3 MiB + 623.5 KiB = 4.9 MiB rsyslogd
3.6 MiB + 1.8 MiB = 5.5 MiB sshd (3)
5.6 MiB + 431.0 KiB = 6.0 MiB polkitd
13.0 MiB + 546.5 KiB = 13.6 MiB tuned
22.5 MiB + 76.0 KiB = 22.6 MiB lfd - sleeping
30.0 MiB + 6.2 MiB = 36.2 MiB php-fpm (6)
5.7 MiB + 33.5 MiB = 39.2 MiB cwpsrv (3)
20.1 MiB + 25.3 MiB = 45.4 MiB httpd (5)
104.7 MiB + 156.0 KiB = 104.9 MiB named
112.2 MiB + 479.5 KiB = 112.7 MiB cache-main
69.4 MiB + 58.6 MiB = 128.0 MiB nginx (4)
203.4 MiB + 309.5 KiB = 203.7 MiB mysqld
---------------------------------
775.8 MiB
=================================
```
---
via: <https://www.2daygeek.com/linux-find-top-memory-consuming-processes/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lnrCoder](https://github.com/lnrCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,543 | awk 入门 —— 强大的文本分析工具 | https://opensource.com/article/19/10/intro-awk | 2019-11-06T11:44:00 | [
"awk"
] | https://linux.cn/article-11543-1.html |
>
> 让我们开始使用它。
>
>
>

`awk` 是用于 Unix 和类 Unix 系统的强大文本解析工具,但是由于它有可编程函数,因此你可以用它来执行常规解析任务,因此它也被视为一种编程语言。你可能不会使用 `awk` 开发下一个 GUI 应用,并且它可能不会代替你的默认脚本语言,但是它是用于特定任务的强大程序。
这些任务或许是惊人的多样化。了解 `awk` 可以解决你的哪些问题的最好方法是学习 `awk`。你会惊讶于 `awk` 如何帮助你完成更多工作,却花费更少的精力。
`awk` 的基本语法是:
```
awk [options] 'pattern {action}' file
```
首先,创建此示例文件并将其保存为 `colours.txt`。
```
name color amount
apple red 4
banana yellow 6
strawberry red 3
grape purple 10
apple green 8
plum purple 2
kiwi brown 4
potato brown 9
pineapple yellow 5
```
数据被一个或多个空格分隔为列。以某种方式组织要分析的数据是很常见的。它不一定总是由空格分隔的列,甚至可以不是逗号或分号,但尤其是在日志文件或数据转储中,通常有一个可预测的格式。你可以使用数据格式来帮助 `awk` 提取和处理你关注的数据。
### 打印列
在 `awk` 中,`print` 函数显示你指定的内容。你可以使用许多预定义的变量,但是最常见的是文本文件中以整数命名的列。试试看:
```
$ awk '{print $2;}' colours.txt
color
red
yellow
red
purple
green
purple
brown
brown
yellow
```
在这里,`awk` 显示第二列,用 `$2` 表示。这是相对直观的,因此你可能会猜测 `print $1` 显示第一列,而 `print $3` 显示第三列,依此类推。
要显示*全部*列,请使用 `$0`。
美元符号(`$`)后的数字是*表达式*,因此 `$2` 和 `$(1+1)` 是同一意思。
### 有条件地选择列
你使用的示例文件非常结构化。它有一行充当标题,并且各列直接相互关联。通过定义*条件*,你可以限定 `awk` 在找到此数据时返回的内容。例如,要查看第二列中与 `yellow` 匹配的项并打印第一列的内容:
```
awk '$2=="yellow"{print $1}' file1.txt
banana
pineapple
```
正则表达式也可以工作。此表达式近似匹配 `$2` 中以 `p` 开头跟上任意数量(一个或多个)字符后继续跟上 `p` 的值:
```
$ awk '$2 ~ /p.+p/ {print $0}' colours.txt
grape purple 10
plum purple 2
```
数字能被 `awk` 自然解释。例如,要打印第三列包含大于 5 的整数的行:
```
awk '$3>5 {print $1, $2}' colours.txt
name color
banana yellow
grape purple
apple green
potato brown
```
### 字段分隔符
默认情况下,`awk` 使用空格作为字段分隔符。但是,并非所有文本文件都使用空格来定义字段。例如,用以下内容创建一个名为 `colours.csv` 的文件:
```
name,color,amount
apple,red,4
banana,yellow,6
strawberry,red,3
grape,purple,10
apple,green,8
plum,purple,2
kiwi,brown,4
potato,brown,9
pineapple,yellow,5
```
只要你指定将哪个字符用作命令中的字段分隔符,`awk` 就能以完全相同的方式处理数据。使用 `--field-separator`(或简称为 `-F`)选项来定义分隔符:
```
$ awk -F"," '$2=="yellow" {print $1}' file1.csv
banana
pineapple
```
### 保存输出
使用输出重定向,你可以将结果写入文件。例如:
```
$ awk -F, '$3>5 {print $1, $2} colours.csv > output.txt
```
这将创建一个包含 `awk` 查询内容的文件。
你还可以将文件拆分为按列数据分组的多个文件。例如,如果要根据每行显示的颜色将 `colours.txt` 拆分为多个文件,你可以在 `awk` 中包含重定向语句来重定向*每条查询*:
```
$ awk '{print > $2".txt"}' colours.txt
```
这将生成名为 `yellow.txt`、`red.txt` 等文件。
在下一篇文章中,你将了解有关字段,记录和一些强大的 awk 变量的更多信息。
本文改编自社区技术播客 [Hacker Public Radio](http://hackerpublicradio.org/eps.php?id=2114)。
---
via: <https://opensource.com/article/19/10/intro-awk>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Awk is a powerful text-parsing tool for Unix and Unix-like systems, but because it has programmed functions that you can use to perform common parsing tasks, it's also considered a programming language. You probably won't be developing your next GUI application with awk, and it likely won't take the place of your default scripting language, but it's a powerful utility for specific tasks.
What those tasks may be is surprisingly diverse. The best way to discover which of your problems might be best solved by awk is to learn awk; you'll be surprised at how awk can help you get more done but with a lot less effort.
Awk's basic syntax is:
`awk [options] 'pattern {action}' file`
To get started, create this sample file and save it as **colours.txt**
```
name color amount
apple red 4
banana yellow 6
strawberry red 3
grape purple 10
apple green 8
plum purple 2
kiwi brown 4
potato brown 9
pineapple yellow 5
```
This data is separated into columns by one or more spaces. It's common for data that you are analyzing to be organized in some way. It may not always be columns separated by whitespace, or even a comma or semicolon, but especially in log files or data dumps, there's generally a predictable pattern. You can use patterns of data to help awk extract and process the data that you want to focus on.
## Printing a column
In awk, the **print** function displays whatever you specify. There are many predefined variables you can use, but some of the most common are integers designating columns in a text file. Try it out:
```
$ awk '{print $2;}' colours.txt
color
red
yellow
red
purple
green
purple
brown
brown
yellow
```
In this case, awk displays the second column, denoted by **$2**. This is relatively intuitive, so you can probably guess that **print $1** displays the first column, and **print $3** displays the third, and so on.
To display *all* columns, use **$0**.
The number after the dollar sign (**$**) is an *expression*, so **$2** and **$(1+1)** mean the same thing.
## Conditionally selecting columns
The example file you're using is very structured. It has a row that serves as a header, and the columns relate directly to one another. By defining *conditional* requirements, you can qualify what you want awk to return when looking at this data. For instance, to view items in column 2 that match "yellow" and print the contents of column 1:
```
awk '$2=="yellow"{print $1}' colours.txt
banana
pineapple
```
Regular expressions work as well. This conditional looks at **$2** for approximate matches to the letter **p** followed by any number of (one or more) characters, which are in turn followed by the letter **p**:
```
$ awk '$2 ~ /p.+p/ {print $0}' colours.txt
grape purple 10
plum purple 2
```
Numbers are interpreted naturally by awk. For instance, to print any row with a third column containing an integer greater than 5:
```
awk '$3>5 {print $1, $2}' colours.txt
name color
banana yellow
grape purple
apple green
potato brown
```
## Field separator
By default, awk uses whitespace as the field separator. Not all text files use whitespace to define fields, though. For example, create a file called **colours.csv** with this content:
```
name,color,amount
apple,red,4
banana,yellow,6
strawberry,red,3
grape,purple,10
apple,green,8
plum,purple,2
kiwi,brown,4
potato,brown,9
pineapple,yellow,5
```
Awk can treat the data in exactly the same way, as long as you specify which character it should use as the field separator in your command. Use the **--field-separator** (or just **-F** for short) option to define the delimiter:
```
$ awk -F"," '$2=="yellow" {print $1}' file1.csv
banana
pineapple
```
## Saving output
Using output redirection, you can write your results to a file. For example:
`$ awk -F, '$3>5 {print $1, $2} colours.csv > output.txt`
This creates a file with the contents of your awk query.
You can also split a file into multiple files grouped by column data. For example, if you want to split colours.txt into multiple files according to what color appears in each row, you can cause awk to redirect *per query* by including the redirection in your awk statement:
`$ awk '{print > $2".txt"}' colours.txt`
This produces files named **yellow.txt**, **red.txt**, and so on.
In the next article, you'll learn more about fields, records, and some powerful awk variables.
This article is adapted from an episode of [Hacker Public Radio](http://hackerpublicradio.org/eps.php?id=2114), a community technology podcast.
## 4 Comments |
11,545 | 在 Linux 上用 strace 来理解系统调用 | https://opensource.com/article/19/10/strace | 2019-11-06T13:13:45 | [
"strace"
] | https://linux.cn/article-11545-1.html |
>
> 使用 strace 跟踪用户进程和 Linux 内核之间的交互。
>
>
>

<ruby> 系统调用 <rt> system call </rt></ruby>是程序从内核请求服务的一种编程方式,而 `strace` 是一个功能强大的工具,可让你跟踪用户进程与 Linux 内核之间的交互。
要了解操作系统的工作原理,首先需要了解系统调用的工作原理。操作系统的主要功能之一是为用户程序提供抽象机制。
操作系统可以大致分为两种模式:
* 内核模式:操作系统内核使用的一种强大的特权模式
* 用户模式:大多数用户应用程序运行的地方 用户大多使用命令行实用程序和图形用户界面(GUI)来执行日常任务。系统调用在后台静默运行,与内核交互以完成工作。
系统调用与函数调用非常相似,这意味着它们都接受并处理参数然后返回值。唯一的区别是系统调用进入内核,而函数调用不进入。从用户空间切换到内核空间是使用特殊的 [trap](https://en.wikipedia.org/wiki/Trap_(computing)) 机制完成的。
通过使用系统库(在 Linux 系统上又称为 glibc),大部分系统调用对用户隐藏了。尽管系统调用本质上是通用的,但是发出系统调用的机制在很大程度上取决于机器(架构)。
本文通过使用一些常规命令并使用 `strace` 分析每个命令进行的系统调用来探索一些实际示例。这些示例使用 Red Hat Enterprise Linux,但是这些命令运行在其他 Linux 发行版上应该也是相同的:
```
[root@sandbox ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.7 (Maipo)
[root@sandbox ~]#
[root@sandbox ~]# uname -r
3.10.0-1062.el7.x86_64
[root@sandbox ~]#
```
首先,确保在系统上安装了必需的工具。你可以使用下面的 `rpm` 命令来验证是否安装了 `strace`。如果安装了,则可以使用 `-V` 选项检查 `strace` 实用程序的版本号:
```
[root@sandbox ~]# rpm -qa | grep -i strace
strace-4.12-9.el7.x86_64
[root@sandbox ~]#
[root@sandbox ~]# strace -V
strace -- version 4.12
[root@sandbox ~]#
```
如果没有安装,运行命令安装:
```
yum install strace
```
出于本示例的目的,在 `/tmp` 中创建一个测试目录,并使用 `touch` 命令创建两个文件:
```
[root@sandbox ~]# cd /tmp/
[root@sandbox tmp]#
[root@sandbox tmp]# mkdir testdir
[root@sandbox tmp]#
[root@sandbox tmp]# touch testdir/file1
[root@sandbox tmp]# touch testdir/file2
[root@sandbox tmp]#
```
(我使用 `/tmp` 目录是因为每个人都可以访问它,但是你可以根据需要选择另一个目录。)
在 `testdir` 目录下使用 `ls` 命令验证该文件已经创建:
```
[root@sandbox tmp]# ls testdir/
file1 file2
[root@sandbox tmp]#
```
你可能每天都在使用 `ls` 命令,而没有意识到系统调用在其下面发挥的作用。抽象地来说,该命令的工作方式如下:
>
> 命令行工具 -> 从系统库(glibc)调用函数 -> 调用系统调用
>
>
>
`ls` 命令内部从 Linux 上的系统库(即 glibc)调用函数。这些库去调用完成大部分工作的系统调用。
如果你想知道从 glibc 库中调用了哪些函数,请使用 `ltrace` 命令,然后跟上常规的 `ls testdir/`命令:
```
ltrace ls testdir/
```
如果没有安装 `ltrace`,键入如下命令安装:
```
yum install ltrace
```
大量的输出会被堆到屏幕上;不必担心,只需继续就行。`ltrace` 命令输出中与该示例有关的一些重要库函数包括:
```
opendir("testdir/") = { 3 }
readdir({ 3 }) = { 101879119, "." }
readdir({ 3 }) = { 134, ".." }
readdir({ 3 }) = { 101879120, "file1" }
strlen("file1") = 5
memcpy(0x1665be0, "file1\0", 6) = 0x1665be0
readdir({ 3 }) = { 101879122, "file2" }
strlen("file2") = 5
memcpy(0x166dcb0, "file2\0", 6) = 0x166dcb0
readdir({ 3 }) = nil
closedir({ 3 })
```
通过查看上面的输出,你或许可以了解正在发生的事情。`opendir` 库函数打开一个名为 `testdir` 的目录,然后调用 `readdir` 函数,该函数读取目录的内容。最后,有一个对 `closedir` 函数的调用,该函数将关闭先前打开的目录。现在请先忽略其他 `strlen` 和 `memcpy` 功能。
你可以看到正在调用哪些库函数,但是本文将重点介绍由系统库函数调用的系统调用。
与上述类似,要了解调用了哪些系统调用,只需将 `strace` 放在 `ls testdir` 命令之前,如下所示。 再次,一堆乱码丢到了你的屏幕上,你可以按照以下步骤进行操作:
```
[root@sandbox tmp]# strace ls testdir/
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
brk(NULL) = 0x1f12000
<<< truncated strace output >>>
write(1, "file1 file2\n", 13file1 file2
) = 13
close(1) = 0
munmap(0x7fd002c8d000, 4096) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
[root@sandbox tmp]#
```
运行 `strace` 命令后屏幕上的输出就是运行 `ls` 命令的系统调用。每个系统调用都为操作系统提供了特定的用途,可以将它们大致分为以下几个部分:
* 进程管理系统调用
* 文件管理系统调用
* 目录和文件系统管理系统调用
* 其他系统调用
分析显示到屏幕上的信息的一种更简单的方法是使用 `strace` 方便的 `-o` 标志将输出记录到文件中。在 `-o` 标志后添加一个合适的文件名,然后再次运行命令:
```
[root@sandbox tmp]# strace -o trace.log ls testdir/
file1 file2
[root@sandbox tmp]#
```
这次,没有任何输出干扰屏幕显示,`ls` 命令如预期般工作,显示了文件名并将所有输出记录到文件 `trace.log` 中。仅仅是一个简单的 `ls` 命令,该文件就有近 100 行内容:
```
[root@sandbox tmp]# ls -l trace.log
-rw-r--r--. 1 root root 7809 Oct 12 13:52 trace.log
[root@sandbox tmp]#
[root@sandbox tmp]# wc -l trace.log
114 trace.log
[root@sandbox tmp]#
```
让我们看一下这个示例的 `trace.log` 文件的第一行:
```
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
```
* 该行的第一个单词 `execve` 是正在执行的系统调用的名称。
* 括号内的文本是提供给该系统调用的参数。
* 符号 `=` 后的数字(在这种情况下为 `0`)是 `execve` 系统调用的返回值。
现在的输出似乎还不太吓人,对吧。你可以应用相同的逻辑来理解其他行。
现在,将关注点集中在你调用的单个命令上,即 `ls testdir`。你知道命令 `ls` 使用的目录名称,那么为什么不在 `trace.log` 文件中使用 `grep` 查找 `testdir` 并查看得到的结果呢?让我们详细查看一下结果的每一行:
```
[root@sandbox tmp]# grep testdir trace.log
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0
openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3
[root@sandbox tmp]#
```
回顾一下上面对 `execve` 的分析,你能说一下这个系统调用的作用吗?
```
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
```
你无需记住所有系统调用或它们所做的事情,因为你可以在需要时参考文档。手册页可以解救你!在运行 `man` 命令之前,请确保已安装以下软件包:
```
[root@sandbox tmp]# rpm -qa | grep -i man-pages
man-pages-3.53-5.el7.noarch
[root@sandbox tmp]#
```
请记住,你需要在 `man` 命令和系统调用名称之间添加 `2`。如果使用 `man man` 阅读 `man` 命令的手册页,你会看到第 2 节是为系统调用保留的。同样,如果你需要有关库函数的信息,则需要在 `man` 和库函数名称之间添加一个 `3`。
以下是手册的章节编号及其包含的页面类型:
* `1`:可执行的程序或 shell 命令
* `2`:系统调用(由内核提供的函数)
* `3`:库调用(在程序的库内的函数)
* `4`:特殊文件(通常出现在 `/dev`)
使用系统调用名称运行以下 `man` 命令以查看该系统调用的文档:
```
man 2 execve
```
按照 `execve` 手册页,这将执行在参数中传递的程序(在本例中为 `ls`)。可以为 `ls` 提供其他参数,例如本例中的 `testdir`。因此,此系统调用仅以 `testdir` 作为参数运行 `ls`:
```
execve - execute program
DESCRIPTION
execve() executes the program pointed to by filename
```
下一个系统调用,名为 `stat`,它使用 `testdir` 参数:
```
stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0
```
使用 `man 2 stat` 访问该文档。`stat` 是获取文件状态的系统调用,请记住,Linux 中的一切都是文件,包括目录。
接下来,`openat` 系统调用将打开 `testdir`。密切注意返回的 `3`。这是一个文件描述符,将在以后的系统调用中使用:
```
openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3
```
到现在为止一切都挺好。现在,打开 `trace.log` 文件,并转到 `openat` 系统调用之后的行。你会看到 `getdents` 系统调用被调用,该调用完成了执行 `ls testdir` 命令所需的大部分操作。现在,从 `trace.log` 文件中用 `grep` 获取 `getdents`:
```
[root@sandbox tmp]# grep getdents trace.log
getdents(3, /* 4 entries */, 32768) = 112
getdents(3, /* 0 entries */, 32768) = 0
[root@sandbox tmp]#
```
`getdents` 的手册页将其描述为 “获取目录项”,这就是你要执行的操作。注意,`getdents` 的参数是 `3`,这是来自上面 `openat` 系统调用的文件描述符。
现在有了目录列表,你需要一种在终端中显示它的方法。因此,在日志中用 `grep` 搜索另一个用于写入终端的系统调用 `write`:
```
[root@sandbox tmp]# grep write trace.log
write(1, "file1 file2\n", 13) = 13
[root@sandbox tmp]#
```
在这些参数中,你可以看到将要显示的文件名:`file1` 和 `file2`。关于第一个参数(`1`),请记住在 Linux 中,当运行任何进程时,默认情况下会为其打开三个文件描述符。以下是默认的文件描述符:
* `0`:标准输入
* `1`:标准输出
* `2`:标准错误
因此,`write` 系统调用将在标准显示(就是这个终端,由 `1` 所标识的)上显示 `file1` 和 `file2`。
现在你知道哪个系统调用完成了 `ls testdir/` 命令的大部分工作。但是在 `trace.log` 文件中其它的 100 多个系统调用呢?操作系统必须做很多内务处理才能运行一个进程,因此,你在该日志文件中看到的很多内容都是进程初始化和清理。阅读整个 `trace.log` 文件,并尝试了解 `ls` 命令是怎么工作起来的。
既然你知道了如何分析给定命令的系统调用,那么就可以将该知识用于其他命令来了解正在执行哪些系统调用。`strace` 提供了许多有用的命令行标志,使你更容易使用,下面将对其中一些进行描述。
默认情况下,`strace` 并不包含所有系统调用信息。但是,它有一个方便的 `-v` 冗余选项,可以在每个系统调用中提供附加信息:
```
strace -v ls testdir
```
在运行 `strace` 命令时始终使用 `-f` 选项是一种好的作法。它允许 `strace` 对当前正在跟踪的进程创建的任何子进程进行跟踪:
```
strace -f ls testdir
```
假设你只需要系统调用的名称、运行的次数以及每个系统调用花费的时间百分比。你可以使用 `-c` 标志来获取这些统计信息:
```
strace -c ls testdir/
```
假设你想专注于特定的系统调用,例如专注于 `open` 系统调用,而忽略其余部分。你可以使用`-e` 标志跟上系统调用的名称:
```
[root@sandbox tmp]# strace -e open ls testdir
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libcap.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libacl.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libpcre.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libdl.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libattr.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libpthread.so.0", O_RDONLY|O_CLOEXEC) = 3
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
file1 file2
+++ exited with 0 +++
[root@sandbox tmp]#
```
如果你想关注多个系统调用怎么办?不用担心,你同样可以使用 `-e` 命令行标志,并用逗号分隔开两个系统调用的名称。例如,要查看 `write` 和 `getdents` 系统调用:
```
[root@sandbox tmp]# strace -e write,getdents ls testdir
getdents(3, /* 4 entries */, 32768) = 112
getdents(3, /* 0 entries */, 32768) = 0
write(1, "file1 file2\n", 13file1 file2
) = 13
+++ exited with 0 +++
[root@sandbox tmp]#
```
到目前为止,这些示例是明确地运行的命令进行了跟踪。但是,要跟踪已经运行并正在执行的命令又怎么办呢?例如,如果要跟踪用来长时间运行进程的守护程序,该怎么办?为此,`strace` 提供了一个特殊的 `-p` 标志,你可以向其提供进程 ID。
我们的示例不在守护程序上运行 `strace`,而是以 `cat` 命令为例,如果你将文件名作为参数,通常 `cat` 会显示文件的内容。如果没有给出参数,`cat` 命令会在终端上等待用户输入文本。输入文本后,它将重复给定的文本,直到用户按下 `Ctrl + C` 退出为止。
从一个终端运行 `cat` 命令;它会向你显示一个提示,并等待在那里(记住 `cat` 仍在运行且尚未退出):
```
[root@sandbox tmp]# cat
```
在另一个终端上,使用 `ps` 命令找到进程标识符(PID):
```
[root@sandbox ~]# ps -ef | grep cat
root 22443 20164 0 14:19 pts/0 00:00:00 cat
root 22482 20300 0 14:20 pts/1 00:00:00 grep --color=auto cat
[root@sandbox ~]#
```
现在,使用 `-p` 标志和 PID(在上面使用 `ps` 找到)对运行中的进程运行 `strace`。运行 `strace` 之后,其输出说明了所接驳的进程的内容及其 PID。现在,`strace` 正在跟踪 `cat` 命令进行的系统调用。看到的第一个系统调用是 `read`,它正在等待文件描述符 `0`(标准输入,这是运行 `cat` 命令的终端)的输入:
```
[root@sandbox ~]# strace -p 22443
strace: Process 22443 attached
read(0,
```
现在,返回到你运行 `cat` 命令的终端,并输入一些文本。我出于演示目的输入了 `x0x0`。注意 `cat` 是如何简单地重复我输入的内容的。因此,`x0x0` 出现了两次。我输入了第一个,第二个是 `cat` 命令重复的输出:
```
[root@sandbox tmp]# cat
x0x0
x0x0
```
返回到将 `strace` 接驳到 `cat` 进程的终端。现在你会看到两个额外的系统调用:较早的 `read` 系统调用,现在在终端中读取 `x0x0`,另一个为 `write`,它将 `x0x0` 写回到终端,然后是再一个新的 `read`,正在等待从终端读取。请注意,标准输入(`0`)和标准输出(`1`)都在同一终端中:
```
[root@sandbox ~]# strace -p 22443
strace: Process 22443 attached
read(0, "x0x0\n", 65536) = 5
write(1, "x0x0\n", 5) = 5
read(0,
```
想象一下,对守护进程运行 `strace` 以查看其在后台执行的所有操作时这有多大帮助。按下 `Ctrl + C` 杀死 `cat` 命令;由于该进程不再运行,因此这也会终止你的 `strace` 会话。
如果要查看所有的系统调用的时间戳,只需将 `-t` 选项与 `strace` 一起使用:
```
[root@sandbox ~]#strace -t ls testdir/
14:24:47 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
14:24:47 brk(NULL) = 0x1f07000
14:24:47 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2530bc8000
14:24:47 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
14:24:47 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
```
如果你想知道两次系统调用之间所花费的时间怎么办?`strace` 有一个方便的 `-r` 命令,该命令显示执行每个系统调用所花费的时间。非常有用,不是吗?
```
[root@sandbox ~]#strace -r ls testdir/
0.000000 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
0.000368 brk(NULL) = 0x1966000
0.000073 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fb6b1155000
0.000047 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
0.000119 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
```
### 总结
`strace` 实用程序非常有助于理解 Linux 上的系统调用。要了解它的其它命令行标志,请参考手册页和在线文档。
---
via: <https://opensource.com/article/19/10/strace>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A system call is a programmatic way a program requests a service from the kernel, and **strace** is a powerful tool that allows you to trace the thin layer between user processes and the Linux kernel.
To understand how an operating system works, you first need to understand how system calls work. One of the main functions of an operating system is to provide abstractions to user programs.
An operating system can roughly be divided into two modes:
**Kernel mode:**A privileged and powerful mode used by the operating system kernel**User mode:**Where most user applications run
Users mostly work with command-line utilities and graphical user interfaces (GUI) to do day-to-day tasks. System calls work silently in the background, interfacing with the kernel to get work done.
System calls are very similar to function calls, which means they accept and work on arguments and return values. The only difference is that system calls enter a kernel, while function calls do not. Switching from user space to kernel space is done using a special [trap](https://en.wikipedia.org/wiki/Trap_(computing)) mechanism.
Most of this is hidden away from the user by using system libraries (aka **glibc** on Linux systems). Even though system calls are generic in nature, the mechanics of issuing a system call are very much machine-dependent.
This article explores some practical examples by using some general commands and analyzing the system calls made by each command using **strace**. These examples use Red Hat Enterprise Linux, but the commands should work the same on other Linux distros:
```
[root@sandbox ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.7 (Maipo)
[root@sandbox ~]#
[root@sandbox ~]# uname -r
3.10.0-1062.el7.x86_64
[root@sandbox ~]#
```
First, ensure that the required tools are installed on your system. You can verify whether **strace** is installed using the RPM command below; if it is, you can check the **strace** utility version number using the **-V** option:
```
[root@sandbox ~]# rpm -qa | grep -i strace
strace-4.12-9.el7.x86_64
[root@sandbox ~]#
[root@sandbox ~]# strace -V
strace -- version 4.12
[root@sandbox ~]#
```
If that doesn't work, install **strace** by running:
`yum install strace`
For the purpose of this example, create a test directory within **/tmp** and create two files using the **touch** command using:
```
[root@sandbox ~]# cd /tmp/
[root@sandbox tmp]#
[root@sandbox tmp]# mkdir testdir
[root@sandbox tmp]#
[root@sandbox tmp]# touch testdir/file1
[root@sandbox tmp]# touch testdir/file2
[root@sandbox tmp]#
```
(I used the **/tmp** directory because everybody has access to it, but you can choose another directory if you prefer.)
Verify that the files were created using the **ls** command on the **testdir** directory:
```
[root@sandbox tmp]# ls testdir/
file1 file2
[root@sandbox tmp]#
```
You probably use the **ls** command every day without realizing system calls are at work underneath it. There is abstraction at play here; here's how this command works:
`Command-line utility -> Invokes functions from system libraries (glibc) -> Invokes system calls`
The **ls** command internally calls functions from system libraries (aka **glibc**) on Linux. These libraries invoke the system calls that do most of the work.
If you want to know which functions were called from the **glibc** library, use the **ltrace** command followed by the regular **ls testdir/** command:
`ltrace ls testdir/`
If **ltrace** is not installed, install it by entering:
`yum install ltrace`
A bunch of output will be dumped to the screen; don't worry about it—just follow along. Some of the important library functions from the output of the **ltrace** command that are relevant to this example include:
```
opendir("testdir/") = { 3 }
readdir({ 3 }) = { 101879119, "." }
readdir({ 3 }) = { 134, ".." }
readdir({ 3 }) = { 101879120, "file1" }
strlen("file1") = 5
memcpy(0x1665be0, "file1\0", 6) = 0x1665be0
readdir({ 3 }) = { 101879122, "file2" }
strlen("file2") = 5
memcpy(0x166dcb0, "file2\0", 6) = 0x166dcb0
readdir({ 3 }) = nil
closedir({ 3 })
```
By looking at the output above, you probably can understand what is happening. A directory called **testdir** is being opened by the **opendir** library function, followed by calls to the **readdir** function, which is reading the contents of the directory. At the end, there is a call to the **closedir** function, which closes the directory that was opened earlier. Ignore the other **strlen** and **memcpy** functions for now.
You can see which library functions are being called, but this article will focus on system calls that are invoked by the system library functions.
Similar to the above, to understand what system calls are invoked, just put **strace** before the **ls testdir** command, as shown below. Once again, a bunch of gibberish will be dumped to your screen, which you can follow along with here:
```
[root@sandbox tmp]# strace ls testdir/
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
brk(NULL) = 0x1f12000
<<< truncated strace output >>>
write(1, "file1 file2\n", 13file1 file2
) = 13
close(1) = 0
munmap(0x7fd002c8d000, 4096) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
[root@sandbox tmp]#
```
The output on the screen after running the **strace** command was simply system calls made to run the **ls** command. Each system call serves a specific purpose for the operating system, and they can be broadly categorized into the following sections:
- Process management system calls
- File management system calls
- Directory and filesystem management system calls
- Other system calls
An easier way to analyze the information dumped onto your screen is to log the output to a file using **strace**'s handy **-o** flag. Add a suitable file name after the **-o** flag and run the command again:
```
[root@sandbox tmp]# strace -o trace.log ls testdir/
file1 file2
[root@sandbox tmp]#
```
This time, no output dumped to the screen—the **ls** command worked as expected by showing the file names and logging all the output to the file **trace.log**. The file has almost 100 lines of content just for a simple **ls** command:
```
[root@sandbox tmp]# ls -l trace.log
-rw-r--r--. 1 root root 7809 Oct 12 13:52 trace.log
[root@sandbox tmp]#
[root@sandbox tmp]# wc -l trace.log
114 trace.log
[root@sandbox tmp]#
```
Take a look at the first line in the example's trace.log:
`execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0`
- The first word of the line,
**execve**, is the name of a system call being executed. - The text within the parentheses is the arguments provided to the system call.
- The number after the
**=**sign (which is**0**in this case) is a value returned by the**execve**system call.
The output doesn't seem too intimidating now, does it? And you can apply the same logic to understand other lines.
Now, narrow your focus to the single command that you invoked, i.e., **ls testdir**. You know the directory name used by the command **ls**, so why not **grep** for **testdir** within your **trace.log** file and see what you get? Look at each line of the results in detail:
```
[root@sandbox tmp]# grep testdir trace.log
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0
openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3
[root@sandbox tmp]#
```
Thinking back to the analysis of **execve** above, can you tell what this system call does?
`execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0`
You don't need to memorize all the system calls or what they do, because you can refer to documentation when you need to. Man pages to the rescue! Ensure the following package is installed before running the **man** command:
```
[root@sandbox tmp]# rpm -qa | grep -i man-pages
man-pages-3.53-5.el7.noarch
[root@sandbox tmp]#
```
Remember that you need to add a **2** between the **man** command and the system call name. If you read **man**'s man page using **man man**, you can see that section 2 is reserved for system calls. Similarly, if you need information on library functions, you need to add a **3** between **man** and the library function name.
The following are the manual's section numbers and the types of pages they contain:
```
1. Executable programs or shell commands
2. System calls (functions provided by the kernel)
3. Library calls (functions within program libraries)
4. Special files (usually found in /dev)
```
Run the following **man** command with the system call name to see the documentation for that system call:
`man 2 execve`
As per the **execve** man page, this executes a program that is passed in the arguments (in this case, that is **ls**). There are additional arguments that can be provided to **ls**, such as **testdir** in this example. Therefore, this system call just runs **ls** with **testdir** as the argument:
```
'execve - execute program'
'DESCRIPTION
execve() executes the program pointed to by filename'
```
The next system call, named **stat**, uses the **testdir** argument:
`stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0`
Use **man 2 stat** to access the documentation. **stat** is the system call that gets a file's status—remember that everything in Linux is a file, including a directory.
Next, the **openat** system call opens **testdir.** Keep an eye on the **3** that is returned. This is a file description, which will be used by later system calls:
`openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3`
So far, so good. Now, open the **trace.log** file and go to the line following the **openat** system call. You will see the **getdents** system call being invoked, which does most of what is required to execute the **ls testdir** command. Now, **grep getdents** from the **trace.log** file:
```
[root@sandbox tmp]# grep getdents trace.log
getdents(3, /* 4 entries */, 32768) = 112
getdents(3, /* 0 entries */, 32768) = 0
[root@sandbox tmp]#
```
The **getdents** man page describes it as **get directory entries**, which is what you want to do. Notice that the argument for **getdents** is **3**, which is the file descriptor from the **openat** system call above.
Now that you have the directory listing, you need a way to display it in your terminal. So, **grep** for another system call, **write**, which is used to write to the terminal, in the logs:
```
[root@sandbox tmp]# grep write trace.log
write(1, "file1 file2\n", 13) = 13
[root@sandbox tmp]#
```
In these arguments, you can see the file names that will be displayed: **file1** and **file2**. Regarding the first argument (**1**), remember in Linux that, when any process is run, three file descriptors are opened for it by default. Following are the default file descriptors:
- 0 - Standard input
- 1 - Standard out
- 2 - Standard error
So, the **write** system call is displaying **file1** and **file2** on the standard display, which is the terminal, identified by **1**.
Now you know which system calls did most of the work for the **ls testdir/** command. But what about the other 100+ system calls in the **trace.log** file? The operating system has to do a lot of housekeeping to run a process, so a lot of what you see in the log file is process initialization and cleanup. Read the entire **trace.log** file and try to understand what is happening to make the **ls** command work.
Now that you know how to analyze system calls for a given command, you can use this knowledge for other commands to understand what system calls are being executed. **strace** provides a lot of useful command-line flags to make it easier for you, and some of them are described below.
By default, **strace** does not include all system call information. However, it has a handy **-v verbose** option that can provide additional information on each system call:
`strace -v ls testdir`
It is good practice to always use the **-f** option when running the **strace** command. It allows **strace** to trace any child processes created by the process currently being traced:
`strace -f ls testdir`
Say you just want the names of system calls, the number of times they ran, and the percentage of time spent in each system call. You can use the **-c** flag to get those statistics:
`strace -c ls testdir/`
Suppose you want to concentrate on a specific system call, such as focusing on **open** system calls and ignoring the rest. You can use the **-e** flag followed by the system call name:
```
[root@sandbox tmp]# strace -e open ls testdir
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libcap.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libacl.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libpcre.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libdl.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libattr.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libpthread.so.0", O_RDONLY|O_CLOEXEC) = 3
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
file1 file2
+++ exited with 0 +++
[root@sandbox tmp]#
```
What if you want to concentrate on more than one system call? No worries, you can use the same **-e** command-line flag with a comma between the two system calls. For example, to see the **write** and **getdents** systems calls:
```
[root@sandbox tmp]# strace -e write,getdents ls testdir
getdents(3, /* 4 entries */, 32768) = 112
getdents(3, /* 0 entries */, 32768) = 0
write(1, "file1 file2\n", 13file1 file2
) = 13
+++ exited with 0 +++
[root@sandbox tmp]#
```
The examples so far have traced explicitly run commands. But what about commands that have already been run and are in execution? What, for example, if you want to trace daemons that are just long-running processes? For this, **strace** provides a special **-p** flag to which you can provide a process ID.
Instead of running a **strace** on a daemon, take the example of a **cat** command, which usually displays the contents of a file if you give a file name as an argument. If no argument is given, the **cat** command simply waits at a terminal for the user to enter text. Once text is entered, it repeats the given text until a user presses Ctrl+C to exit.
Run the **cat** command from one terminal; it will show you a prompt and simply wait there (remember **cat** is still running and has not exited):
`[root@sandbox tmp]# cat`
From another terminal, find the process identifier (PID) using the **ps** command:
```
[root@sandbox ~]# ps -ef | grep cat
root 22443 20164 0 14:19 pts/0 00:00:00 cat
root 22482 20300 0 14:20 pts/1 00:00:00 grep --color=auto cat
[root@sandbox ~]#
```
Now, run **strace **on the running process with the **-p** flag and the PID (which you found above using **ps**). After running **strace**, the output states what the process was attached to along with the PID number. Now, **strace** is tracing the system calls made by the **cat** command. The first system call you see is **read**, which is waiting for input from 0, or standard input, which is the terminal where the **cat** command ran:
```
[root@sandbox ~]# strace -p 22443
strace: Process 22443 attached
read(0,
```
Now, move back to the terminal where you left the **cat** command running and enter some text. I entered **x0x0** for demo purposes. Notice how **cat** simply repeated what I entered; hence, **x0x0** appears twice. I input the first one, and the second one was the output repeated by the **cat** command:
```
[root@sandbox tmp]# cat
x0x0
x0x0
```
Move back to the terminal where **strace** was attached to the **cat** process. You now see two additional system calls: the earlier **read** system call, which now reads **x0x0** in the terminal, and another for **write**, which wrote **x0x0** back to the terminal, and again a new **read**, which is waiting to read from the terminal. Note that Standard input (**0**) and Standard out (**1**) are both in the same terminal:
```
[root@sandbox ~]# strace -p 22443
strace: Process 22443 attached
read(0, "x0x0\n", 65536) = 5
write(1, "x0x0\n", 5) = 5
read(0,
```
Imagine how helpful this is when running **strace** against daemons to see everything it does in the background. Kill the **cat** command by pressing Ctrl+C; this also kills your **strace** session since the process is no longer running.
If you want to see a timestamp against all your system calls, simply use the **-t** option with **strace**:
```
[root@sandbox ~]#strace -t ls testdir/
14:24:47 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
14:24:47 brk(NULL) = 0x1f07000
14:24:47 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2530bc8000
14:24:47 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
14:24:47 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
```
What if you want to know the time spent between system calls? **strace** has a handy **-r** command that shows the time spent executing each system call. Pretty useful, isn't it?
```
[root@sandbox ~]#strace -r ls testdir/
0.000000 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
0.000368 brk(NULL) = 0x1966000
0.000073 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fb6b1155000
0.000047 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
0.000119 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
```
## Conclusion
The **strace** utility is very handy for understanding system calls on Linux. To learn about its other command-line flags, please refer to the man pages and online documentation.
## 2 Comments |
11,546 | 用 Jenkins 构建 CI/CD 流水线 | https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins | 2019-11-07T00:07:00 | [
"Jenkins"
] | https://linux.cn/article-11546-1.html |
>
> 通过这份 Jenkins 分步教程,构建持续集成和持续交付(CI/CD)流水线。
>
>
>

在我的文章《[使用开源工具构建 DevOps 流水线的初学者指南](/article-11307-1.html)》中,我分享了一个从头开始构建 DevOps 流水线的故事。推动该计划的核心技术是 [Jenkins](https://jenkins.io/),这是一个用于建立持续集成和持续交付(CI/CD)流水线的开源工具。
在花旗,有一个单独的团队为专用的 Jenkins 流水线提供稳定的主从节点环境,但是该环境仅用于质量保证(QA)、构建阶段和生产环境。开发环境仍然是非常手动的,我们的团队需要对其进行自动化以在加快开发工作的同时获得尽可能多的灵活性。这就是我们决定为 DevOps 建立 CI/CD 流水线的原因。Jenkins 的开源版本由于其灵活性、开放性、强大的插件功能和易用性而成为显而易见的选择。
在本文中,我将分步演示如何使用 Jenkins 构建 CI/CD 流水线。
### 什么是流水线?
在进入本教程之前,了解有关 CI/CD <ruby> 流水线 <rt> pipeline </rt></ruby>的知识会很有帮助。
首先,了解 Jenkins 本身并不是流水线这一点很有帮助。只是创建一个新的 Jenkins 作业并不能构建一条流水线。可以把 Jenkins 看做一个遥控器,在这里点击按钮即可。当你点击按钮时会发生什么取决于遥控器要控制的内容。Jenkins 为其他应用程序 API、软件库、构建工具等提供了一种插入 Jenkins 的方法,它可以执行并自动化任务。Jenkins 本身不执行任何功能,但是随着其它工具的插入而变得越来越强大。
流水线是一个单独的概念,指的是按顺序连接在一起的事件或作业组:
>
> “<ruby> 流水线 <rt> pipeline </rt></ruby>”是可以执行的一系列事件或作业。
>
>
>
理解流水线的最简单方法是可视化一系列阶段,如下所示:

在这里,你应该看到两个熟悉的概念:<ruby> 阶段 <rt> Stage </rt></ruby>和<ruby> 步骤 <rt> Step </rt></ruby>。
* 阶段:一个包含一系列步骤的块。阶段块可以命名为任何名称;它用于可视化流水线过程。
* 步骤:表明要做什么的任务。步骤定义在阶段块内。
在上面的示例图中,阶段 1 可以命名为 “构建”、“收集信息”或其它名称,其它阶段块也可以采用类似的思路。“步骤”只是简单地说放上要执行的内容,它可以是简单的打印命令(例如,`echo "Hello, World"`)、程序执行命令(例如,`java HelloWorld`)、shell 执行命令( 例如,`chmod 755 Hello`)或任何其他命令,只要通过 Jenkins 环境将其识别为可执行命令即可。
Jenkins 流水线以**编码脚本**的形式提供,通常称为 “Jenkinsfile”,尽管可以用不同的文件名。下面这是一个简单的 Jenkins 流水线文件的示例:
```
// Example of Jenkins pipeline script
pipeline {
stages {
stage("Build") {
steps {
// Just print a Hello, Pipeline to the console
echo "Hello, Pipeline!"
// Compile a Java file. This requires JDKconfiguration from Jenkins
javac HelloWorld.java
// Execute the compiled Java binary called HelloWorld. This requires JDK configuration from Jenkins
java HelloWorld
// Executes the Apache Maven commands, clean then package. This requires Apache Maven configuration from Jenkins
mvn clean package ./HelloPackage
// List the files in current directory path by executing a default shell command
sh "ls -ltr"
}
}
// And next stages if you want to define further...
} // End of stages
} // End of pipeline
```
从此示例脚本很容易看到 Jenkins 流水线的结构。请注意,默认情况下某些命令(如 `java`、`javac`和 `mvn`)不可用,需要通过 Jenkins 进行安装和配置。 因此:
>
> Jenkins 流水线是一种以定义的方式依次执行 Jenkins 作业的方法,方法是将其编码并在多个块中进行结构化,这些块可以包含多个任务的步骤。
>
>
>
好。既然你已经了解了 Jenkins 流水线是什么,我将向你展示如何创建和执行 Jenkins 流水线。在本教程的最后,你将建立一个 Jenkins 流水线,如下所示:

### 如何构建 Jenkins 流水线
为了便于遵循本教程的步骤,我创建了一个示例 [GitHub 存储库](https://github.com/bryantson/CICDPractice)和一个视频教程。
开始本教程之前,你需要:
* Java 开发工具包(JDK):如果尚未安装,请安装 JDK 并将其添加到环境路径中,以便可以通过终端执行 Java 命令(如 `java jar`)。这是利用本教程中使用的 Java Web Archive(WAR)版本的 Jenkins 所必需的(尽管你可以使用任何其他发行版)。
* 基本计算机操作能力:你应该知道如何键入一些代码、通过 shell 执行基本的 Linux 命令以及打开浏览器。
让我们开始吧。
#### 步骤一:下载 Jenkins
导航到 [Jenkins 下载页面](https://jenkins.io/download/)。向下滚动到 “Generic Java package (.war)”,然后单击下载文件;将其保存在易于找到的位置。(如果你选择其他 Jenkins 发行版,除了步骤二之外,本教程的其余步骤应该几乎相同。)使用 WAR 文件的原因是它是个一次性可执行文件,可以轻松地执行和删除。

#### 步骤二:以 Java 二进制方式执行 Jenkins
打开一个终端窗口,并使用 `cd <your path>` 进入下载 Jenkins 的目录。(在继续之前,请确保已安装 JDK 并将其添加到环境路径。)执行以下命令,该命令将 WAR 文件作为可执行二进制文件运行:
```
java -jar ./jenkins.war
```
如果一切顺利,Jenkins 应该在默认端口 8080 上启动并运行。

#### 步骤三:创建一个新的 Jenkins 作业
打开一个 Web 浏览器并导航到 `localhost:8080`。除非你有以前安装的 Jenkins,否则应直接转到 Jenkins 仪表板。点击 “Create New Jobs”。你也可以点击左侧的 “New Item”。

#### 步骤四:创建一个流水线作业
在此步骤中,你可以选择并定义要创建的 Jenkins 作业类型。选择 “Pipeline” 并为其命名(例如,“TestPipeline”)。单击 “OK” 创建流水线作业。

你将看到一个 Jenkins 作业配置页面。向下滚动以找到 “Pipeline” 部分。有两种执行 Jenkins 流水线的方法。一种方法是在 Jenkins 上直接编写流水线脚本,另一种方法是从 SCM(源代码管理)中检索 Jenkins 文件。在接下来的两个步骤中,我们将体验这两种方式。
#### 步骤五:通过直接脚本配置并执行流水线作业
要使用直接脚本执行流水线,请首先从 GitHub 复制该 [Jenkinsfile 示例](https://github.com/bryantson/CICDPractice)的内容。选择 “Pipeline script” 作为 “Destination”,然后将该 Jenkinsfile 的内容粘贴到 “Script” 中。花一些时间研究一下 Jenkins 文件的结构。注意,共有三个阶段:Build、Test 和 Deploy,它们是任意的,可以是任何一个。每个阶段中都有一些步骤;在此示例中,它们只是打印一些随机消息。
单击 “Save” 以保留更改,这将自动将你带回到 “Job Overview” 页面。

要开始构建流水线的过程,请单击 “Build Now”。如果一切正常,你将看到第一个流水线(如下面的这个)。

要查看流水线脚本构建的输出,请单击任何阶段,然后单击 “Log”。你会看到这样的消息。

#### 步骤六:通过 SCM 配置并执行流水线作业
现在,换个方式:在此步骤中,你将通过从源代码控制的 GitHub 中复制 Jenkinsfile 来部署相同的 Jenkins 作业。在同一个 [GitHub 存储库](https://github.com/bryantson/CICDPractice)中,通过单击 “Clone or download” 并复制其 URL 来找到其存储库 URL。

单击 “Configure” 以修改现有作业。滚动到 “Advanced Project Options” 设置,但这一次,从 “Destination” 下拉列表中选择 “Pipeline script from SCM” 选项。将 GitHub 存储库的 URL 粘贴到 “Repository URL” 中,然后在 “Script Path” 中键入 “Jenkinsfile”。 单击 “Save” 按钮保存。

要构建流水线,回到 “Task Overview” 页面后,单击 “Build Now” 以再次执行作业。结果与之前相同,除了多了一个称为 “Declaration: Checkout SCM” 的阶段。

要查看来自 SCM 构建的流水线的输出,请单击该阶段并查看 “Log” 以检查源代码控制克隆过程的进行情况。

### 除了打印消息,还能做更多
恭喜你!你已经建立了第一个 Jenkins 流水线!
“但是等等”,你说,“这太有限了。除了打印无用的消息外,我什么都做不了。”那没问题。到目前为止,本教程仅简要介绍了 Jenkins 流水线可以做什么,但是你可以通过将其与其他工具集成来扩展其功能。以下是给你的下一个项目的一些思路:
* 建立一个多阶段的 Java 构建流水线,从以下阶段开始:从 Nexus 或 Artifactory 之类的 JAR 存储库中拉取依赖项、编译 Java 代码、运行单元测试、打包为 JAR/WAR 文件,然后部署到云服务器。
* 实现一个高级代码测试仪表板,该仪表板将基于 Selenium 的单元测试、负载测试和自动用户界面测试,报告项目的运行状况。
* 构建多流水线或多用户流水线,以自动化执行 Ansible 剧本的任务,同时允许授权用户响应正在进行的任务。
* 设计完整的端到端 DevOps 流水线,该流水线可提取存储在 SCM 中的基础设施资源文件和配置文件(例如 GitHub),并通过各种运行时程序执行该脚本。
学习本文结尾处的任何教程,以了解这些更高级的案例。
#### 管理 Jenkins
在 Jenkins 主面板,点击 “Manage Jenkins”。

#### 全局工具配置
有许多可用工具,包括管理插件、查看系统日志等。单击 “Global Tool Configuration”。

#### 增加附加能力
在这里,你可以添加 JDK 路径、Git、Gradle 等。配置工具后,只需将该命令添加到 Jenkinsfile 中或通过 Jenkins 脚本执行即可。

### 后继
本文为你介绍了使用酷炫的开源工具 Jenkins 创建 CI/CD 流水线的方法。要了解你可以使用 Jenkins 完成的许多其他操作,请在 Opensource.com 上查看以下其他文章:
* [Jenkins X 入门](https://opensource.com/article/18/11/getting-started-jenkins-x)
* [使用 Jenkins 安装 OpenStack 云](https://opensource.com/article/18/4/install-OpenStack-cloud-Jenkins)
* [在容器中运行 Jenkins](/article-9741-1.html)
* [Jenkins 流水线入门](https://opensource.com/article/18/4/jenkins-pipelines-with-cucumber)
* [如何与 Jenkins 一起运行 JMeter](https://opensource.com/life/16/7/running-jmeter-jenkins-continuous-delivery-101)
* [将 OpenStack 集成到你的 Jenkins 工作流中](https://opensource.com/business/15/5/interview-maish-saidel-keesing-cisco)
你可能对我为你的开源之旅而写的其他一些文章感兴趣:
* [9 个用于构建容错系统的开源工具](https://opensource.com/article/19/3/tools-fault-tolerant-system)
* [了解软件设计模式](https://opensource.com/article/19/7/understanding-software-design-patterns)
* [使用开源工具构建 DevOps 流水线的初学者指南](/article-11307-1.html)
---
via: <https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my article [ A beginner's guide to building DevOps pipelines with open source tools](https://opensource.com/article/19/4/devops-pipeline), I shared a story about building a DevOps pipeline from scratch. The core technology driving that initiative was
[Jenkins](https://jenkins.io/), an open source tool to build continuous integration and continuous delivery (CI/CD) pipelines.
At Citi, there was a separate team that provided dedicated Jenkins pipelines with a stable master-slave node setup, but the environment was only used for quality assurance (QA), staging, and production environments. The development environment was still very manual, and our team needed to automate it to gain as much flexibility as possible while accelerating the development effort. This is the reason we decided to build a CI/CD pipeline for DevOps. And the open source version of Jenkins was the obvious choice due to its flexibility, openness, powerful plugin-capabilities, and ease of use.
In this article, I will share a step-by-step walkthrough on how you can build a CI/CD pipeline using Jenkins.
## What is a pipeline?
Before jumping into the tutorial, it's helpful to know something about CI/CD pipelines.
To start, it is helpful to know that Jenkins itself is not a pipeline. Just creating a new Jenkins job does not construct a pipeline. Think about Jenkins like a remote control—it's the place you click a button. What happens when you do click a button depends on what the remote is built to control. Jenkins offers a way for other application APIs, software libraries, build tools, etc. to plug into Jenkins, and it executes and automates the tasks. On its own, Jenkins does not perform any functionality but gets more and more powerful as other tools are plugged into it.
A pipeline is a separate concept that refers to the groups of events or jobs that are connected together in a sequence:
A
pipelineis a sequence of events or jobs that can be executed.
The easiest way to understand a pipeline is to visualize a sequence of stages, like this:
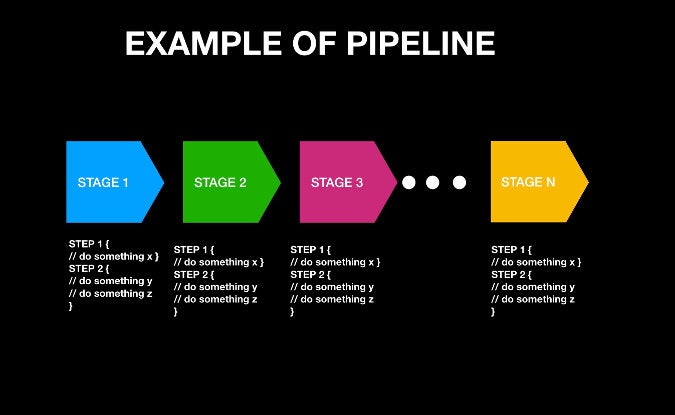
Here, you should see two familiar concepts: *Stage* and *Step*.
**Stage:**A block that contains a series of steps. A stage block can be named anything; it is used to visualize the pipeline process.**Step:**A task that says what to do. Steps are defined inside a stage block.
In the example diagram above, Stage 1 can be named "Build," "Gather Information," or whatever, and a similar idea is applied for the other stage blocks. "Step" simply says what to execute, and this can be a simple print command (e.g., **echo "Hello, World"**), a program-execution command (e.g., **java HelloWorld**), a shell-execution command (e.g., **chmod 755 Hello**), or any other command—as long as it is recognized as an executable command through the Jenkins environment.
The Jenkins pipeline is provided as a *codified script* typically called a **Jenkinsfile**, although the file name can be different. Here is an example of a simple Jenkins pipeline file.
```
// Example of Jenkins pipeline script
pipeline {
stages {
stage("Build") {
steps {
// Just print a Hello, Pipeline to the console
echo "Hello, Pipeline!"
// Compile a Java file. This requires JDKconfiguration from Jenkins
javac HelloWorld.java
// Execute the compiled Java binary called HelloWorld. This requires JDK configuration from Jenkins
java HelloWorld
// Executes the Apache Maven commands, clean then package. This requires Apache Maven configuration from Jenkins
mvn clean package ./HelloPackage
// List the files in current directory path by executing a default shell command
sh "ls -ltr"
}
}
// And next stages if you want to define further...
} // End of stages
} // End of pipeline
```
It's easy to see the structure of a Jenkins pipeline from this sample script. Note that some commands, like **java**, **javac**, and **mvn**, are not available by default, and they need to be installed and configured through Jenkins. Therefore:
A
Jenkins pipelineis the way to execute a Jenkins job sequentially in a defined way by codifying it and structuring it inside multiple blocks that can include multiple steps containing tasks.
OK. Now that you understand what a Jenkins pipeline is, I'll show you how to create and execute a Jenkins pipeline. At the end of the tutorial, you will have built a Jenkins pipeline like this:
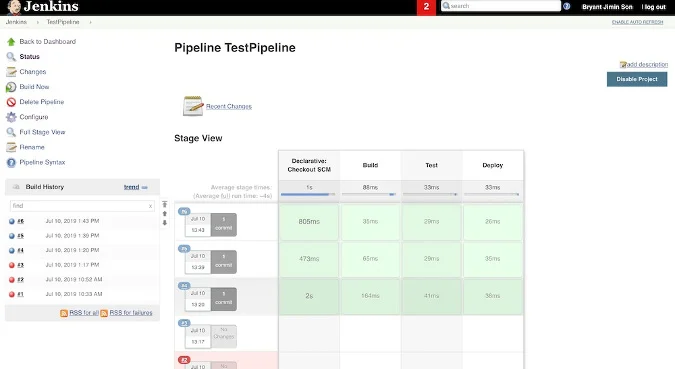
## How to build a Jenkins pipeline
To make this tutorial easier to follow, I created a sample [GitHub repository](https://github.com/bryantson/CICDPractice) and a video tutorial.
Before starting this tutorial, you'll need:
**Java Development Kit:**If you don't already have it, install a JDK and add it to the environment path so a Java command (like**java jar**) can be executed through a terminal. This is necessary to leverage the Java Web Archive (WAR) version of Jenkins that is used in this tutorial (although you can use any other distribution).**Basic computer operations:**You should know how to type some code, execute basic Linux commands through the shell, and open a browser.
Let's get started.
### Step 1: Download Jenkins
Navigate to the [Jenkins download page](https://jenkins.io/download/). Scroll down to **Generic Java package (.war)** and click on it to download the file; save it someplace where you can locate it easily. (If you choose another Jenkins distribution, the rest of tutorial steps should be pretty much the same, except for Step 2.) The reason to use the WAR file is that it is a one-time executable file that is easily executable and removable.
### Step 2: Execute Jenkins as a Java binary
Open a terminal window and enter the directory where you downloaded Jenkins with **cd <your path>**. (Before you proceed, make sure JDK is installed and added to the environment path.) Execute the following command, which will run the WAR file as an executable binary:
`java -jar ./jenkins.war`
If everything goes smoothly, Jenkins should be up and running at the default port 8080.
### Step 3: Create a new Jenkins job
Open a web browser and navigate to **localhost:8080**. Unless you have a previous Jenkins installation, it should go straight to the Jenkins dashboard. Click **Create New Jobs**. You can also click **New Item** on the left.
### Step 4: Create a pipeline job
In this step, you can select and define what type of Jenkins job you want to create. Select **Pipeline** and give it a name (e.g., TestPipeline). Click **OK** to create a pipeline job.
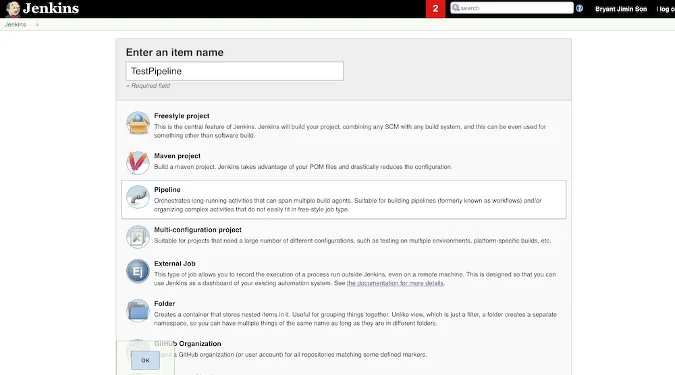
You will see a Jenkins job configuration page. Scroll down to find** Pipeline section**. There are two ways to execute a Jenkins pipeline. One way is by *directly writing a pipeline script* on Jenkins, and the other way is by retrieving the *Jenkins file from SCM* (source control management). We will go through both ways in the next two steps.
### Step 5: Configure and execute a pipeline job through a direct script
To execute the pipeline with a direct script, begin by copying the contents of the [sample Jenkinsfile](https://github.com/bryantson/CICDPractice) from GitHub. Choose **Pipeline script** as the **Destination** and paste the **Jenkinsfile** contents in **Script**. Spend a little time studying how the Jenkins file is structured. Notice that there are three Stages: Build, Test, and Deploy, which are arbitrary and can be anything. Inside each Stage, there are Steps; in this example, they just print some random messages.
Click **Save** to keep the changes, and it should automatically take you back to the Job Overview.
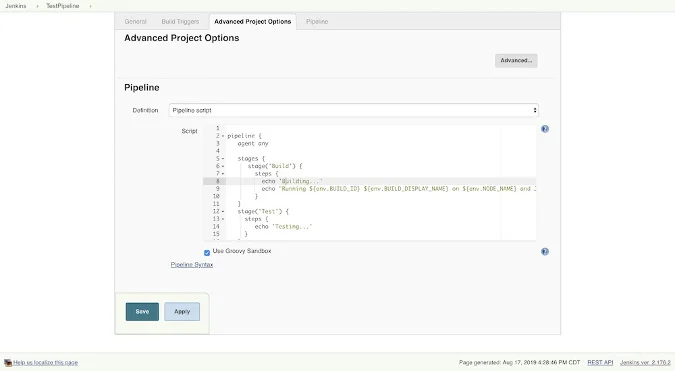
To start the process to build the pipeline, click **Build Now**. If everything works, you will see your first pipeline (like the one below).
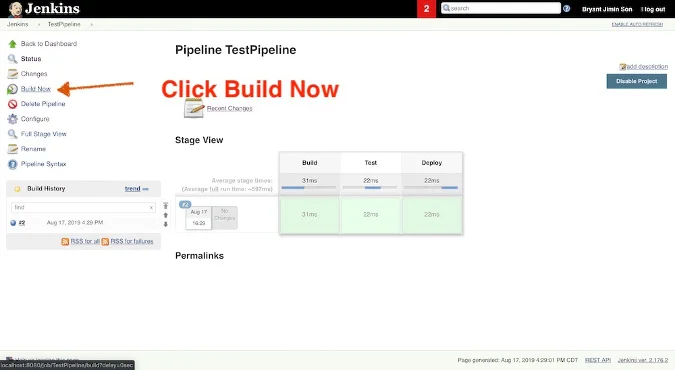
To see the output from the pipeline script build, click any of the Stages and click **Log**. You will see a message like this.
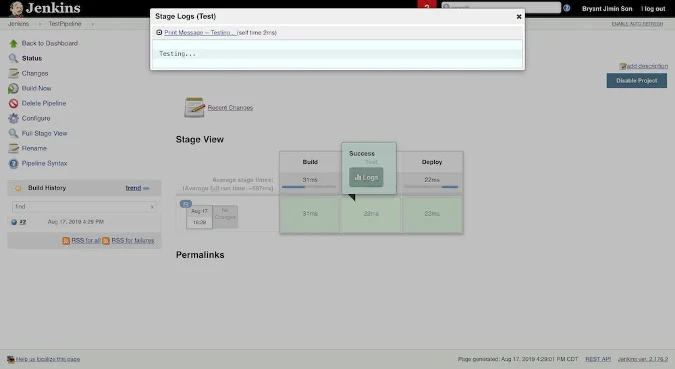
### Step 6: Configure and execute a pipeline job with SCM
Now, switch gears: In this step, you will Deploy the same Jenkins job by copying the **Jenkinsfile** from a source-controlled GitHub. In the same [GitHub repository](https://github.com/bryantson/CICDPractice), pick up the repository URL by clicking **Clone or download** and copying its URL.
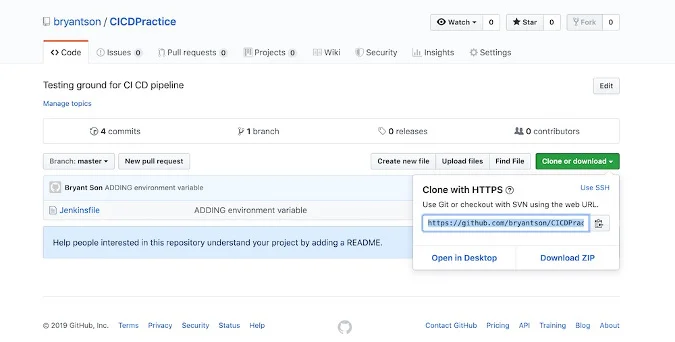
Click **Configure** to modify the existing job. Scroll to the **Advanced Project Options** setting, but this time, select the **Pipeline script from SCM** option in the **Destination** dropdown. Paste the GitHub repo's URL in the **Repository URL**, and type **Jenkinsfile** in the **Script Path**. Save by clicking the **Save** button.
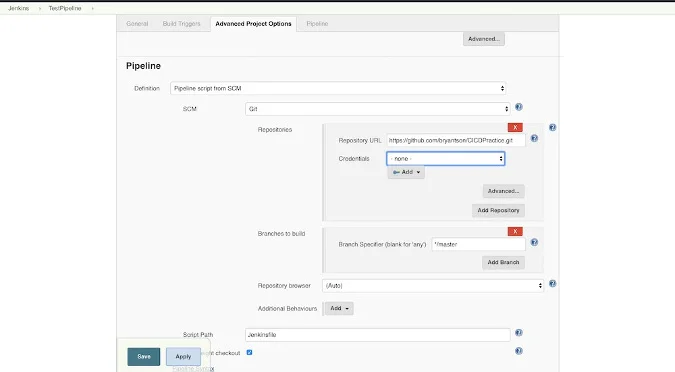
To build the pipeline, once you are back to the Task Overview page, click **Build Now** to execute the job again. The result will be the same as before, except you have one additional stage called **Declaration: Checkout SCM**.
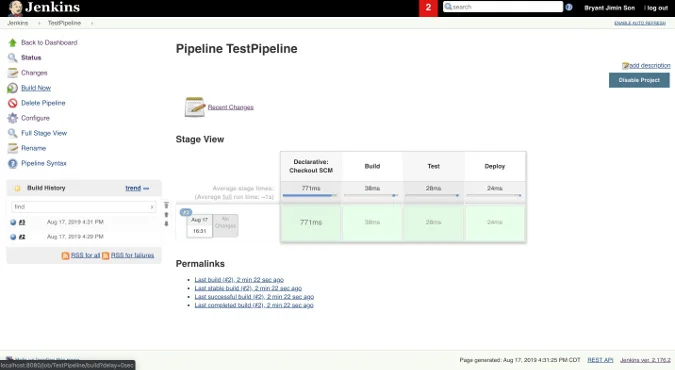
To see the pipeline's output from the SCM build, click the Stage and view the **Log** to check how the source control cloning process went.
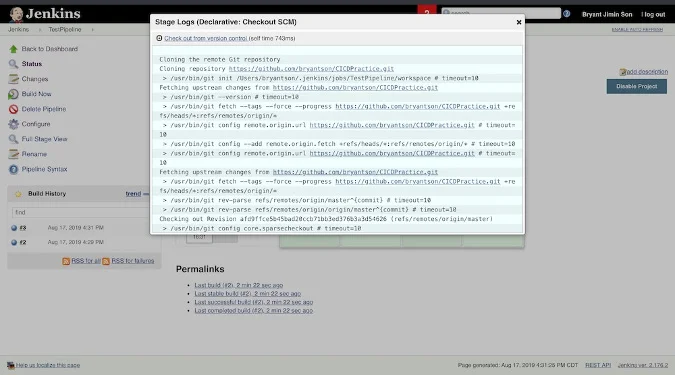
## Do more than print messages
Congratulations! You've built your first Jenkins pipeline!
"But wait," you say, "this is very limited. I cannot really do anything with it except print dummy messages." That is OK. So far, this tutorial provided just a glimpse of what a Jenkins pipeline can do, but you can extend its capabilities by integrating it with other tools. Here are a few ideas for your next project:
- Build a multi-staged Java build pipeline that takes from the phases of pulling dependencies from JAR repositories like Nexus or Artifactory, compiling Java codes, running the unit tests, packaging into a JAR/WAR file, and deploying to a cloud server.
- Implement the advanced code testing dashboard that will report back the health of the project based on the unit test, load test, and automated user interface test with Selenium.
- Construct a multi-pipeline or multi-user pipeline automating the tasks of executing Ansible playbooks while allowing for authorized users to respond to task in progress.
- Design a complete end-to-end DevOps pipeline that pulls the infrastructure resource files and configuration files stored in SCM like GitHub and executing the scripts through various runtime programs.
Follow any of the tutorials at the end of this article to get into these more advanced cases.
### Manage Jenkins
From the main Jenkins dashboard, click **Manage Jenkins**.
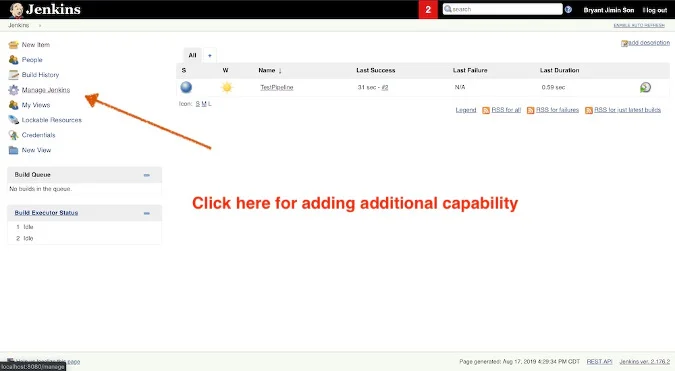
### Global tool configuration
There are many options available, including managing plugins, viewing the system log, etc. Click **Global Tool Configuration**.
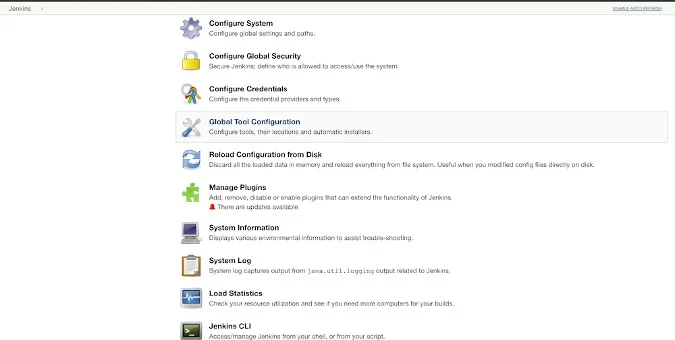
### Add additional capabilities
Here, you can add the JDK path, Git, Gradle, and so much more. After you configure a tool, it is just a matter of adding the command into your Jenkinsfile or executing it through your Jenkins script.
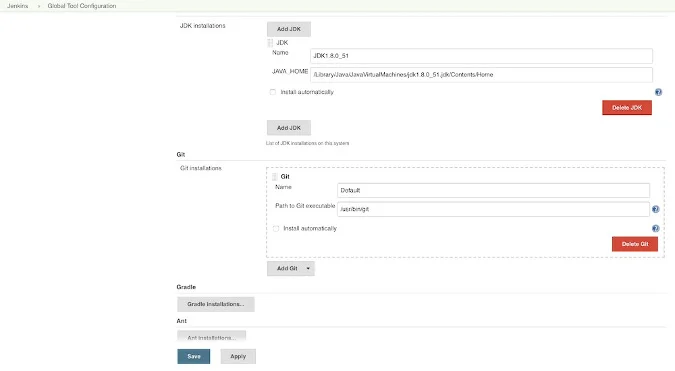
## Where to go from here?
This article put you on your way to creating a CI/CD pipeline using Jenkins, a cool open source tool. To find out about many of the other things you can do with Jenkins, check out these other articles on Opensource.com:
[Getting started with Jenkins X](https://opensource.com/article/18/11/getting-started-jenkins-x)[Install an OpenStack cloud with Jenkins](https://opensource.com/article/18/4/install-OpenStack-cloud-Jenkins)[Running Jenkins builds in containers](https://opensource.com/article/18/4/running-jenkins-builds-containers)[Getting started with Jenkins pipelines](https://opensource.com/article/18/4/jenkins-pipelines-with-cucumber)[How to run JMeter with Jenkins](https://opensource.com/life/16/7/running-jmeter-jenkins-continuous-delivery-101)[Integrating OpenStack into your Jenkins workflow](https://opensource.com/business/15/5/interview-maish-saidel-keesing-cisco)
You may be interested in some of the other articles I've written to supplement your open source journey:
## Comments are closed. |
11,547 | 用 bmon 查看网络带宽使用情况 | https://www.networkworld.com/article/3447936/viewing-network-bandwidth-usage-with-bmon.html | 2019-11-07T01:03:00 | [
"bmon"
] | https://linux.cn/article-11547-1.html |
>
> 介绍一下 bmon,这是一个监视和调试工具,可捕获网络统计信息并使它们易于理解。
>
>
>

`bmon` 是一种监视和调试工具,可在终端窗口中捕获网络统计信息,并提供了如何以易于理解的形式显示以及显示多少数据的选项。
要检查系统上是否安装了 `bmon`,请使用 `which` 命令:
```
$ which bmon
/usr/bin/bmon
```
### 获取 bmon
在 Debian 系统上,使用 `sudo apt-get install bmon` 安装该工具。
对于 Red Hat 和相关发行版,你可以使用 `yum install bmon` 或 `sudo dnf install bmon` 进行安装。或者,你可能必须使用更复杂的安装方式,例如使用以下命令,这些命令首先使用 root 帐户或 sudo 来设置所需的 `libconfuse`:
```
# wget https://github.com/martinh/libconfuse/releases/download/v3.2.2/confuse-3.2.2.zip
# unzip confuse-3.2.2.zip && cd confuse-3.2.2
# sudo PATH=/usr/local/opt/gettext/bin:$PATH ./configure
# make
# make install
# git clone https://github.com/tgraf/bmon.git &&ammp; cd bmon
# ./autogen.sh
# ./configure
# make
# sudo make install
```
前面五行会安装 `libconfuse`,而后面五行会获取并安装 `bmon` 本身。
### 使用 bmon
启动 `bmon` 的最简单方法是在命令行中键入 `bmon`。根据你正在使用的窗口的大小,你能够查看并显示各种数据。
显示区域的顶部将显示你的网络接口的统计信息:环回接口(lo)和可通过网络访问的接口(例如 eth0)。如果你的终端窗口只有区区几行高,下面这就是你可能会看到的所有内容,它将看起来像这样:
```
lo bmon 4.0
Interfaces x RX bps pps %x TX bps pps %
>lo x 4B0 x0 0 0 4B 0
qdisc none (noqueue) x 0 0 x 0 0
enp0s25 x 244B0 x1 0 0 470B 2
qdisc none (fq_codel) x 0 0 x 0 0 462B 2
q Increase screen height to see graphical statistics qq
q Press d to enable detailed statistics qq
q Press i to enable additional information qq
Wed Oct 23 14:36:27 2019 Press ? for help
```
在此示例中,网络接口是 enp0s25。请注意列出的接口下方的有用的 “Increase screen height” 提示。拉伸屏幕以增加足够的行(无需重新启动 bmon),你将看到一些图形:
```
Interfaces x RX bps pps %x TX bps pps %
>lo x 0 0 x 0 0
qdisc none (noqueue) x 0 0 x 0 0
enp0s25 x 253B 3 x 2.65KiB 6
qdisc none (fq_codel) x 0 0 x 2.62KiB 6
qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq
(RX Bytes/second)
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
1 5 10 15 20 25 30 35 40 45 50 55 60
(TX Bytes/second)
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
0.00 ............................................................
1 5 10 15 20 25 30 35 40 45 50 55 60
```
但是请注意,该图形未显示值。这是因为它正在显示环回 “>lo” 接口。按下箭头键指向公共网络接口,你将看到一些流量。
```
Interfaces x RX bps pps %x TX bps pps %
lo x 0 0 x 0 0
qdisc none (noqueue) x 0 0 x 0 0
>enp0s25 x 151B 2 x 1.61KiB 3
qdisc none (fq_codel) x 0 0 x 1.60KiB 3
qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq
B (RX Bytes/second)
635.00 ...............................|............................
529.17 .....|.........................|....|.......................
423.33 .....|................|..|..|..|..|.|.......................
317.50 .|..||.|..||.|..|..|..|..|..|..||.||||......................
211.67 .|..||.|..||.|..||||.||.|||.||||||||||......................
105.83 ||||||||||||||||||||||||||||||||||||||......................
1 5 10 15 20 25 30 35 40 45 50 55 60
KiB (TX Bytes/second)
4.59 .....................................|......................
3.83 .....................................|......................
3.06 ....................................||......................
2.30 ....................................||......................
1.53 |||..............|..|||.|...|.|||.||||......................
0.77 ||||||||||||||||||||||||||||||||||||||......................
1 5 10 15 20 25 30 35 40 45 50 55 60
q Press d to enable detailed statistics qq
q Press i to enable additional information qq
Wed Oct 23 16:42:06 2019 Press ? for help
```
通过更改接口,你可以查看显示了网络流量的图表。但是请注意,默认值是按每秒字节数显示的。要按每秒位数来显示,你可以使用 `bmon -b` 启动该工具。
如果你的窗口足够大并按下 `d` 键,则可以显示有关网络流量的详细统计信息。你看到的统计信息示例如下所示。由于其宽度太宽,该显示分为左右两部分。
左侧:
```
RX TX │ RX TX │
Bytes 11.26MiB 11.26MiB│ Packets 25.91K 25.91K │
Collisions - 0 │ Compressed 0 0 │
Errors 0 0 │ FIFO Error 0 0 │
ICMPv6 2 2 │ ICMPv6 Checksu 0 - │
Ip6 Broadcast 0 0 │ Ip6 Broadcast 0 0 │
Ip6 Delivers 8 - │ Ip6 ECT(0) Pac 0 - │
Ip6 Header Err 0 - │ Ip6 Multicast 0 152B │
Ip6 Non-ECT Pa 8 - │ Ip6 Reasm/Frag 0 0 │
Ip6 Reassembly 0 - │ Ip6 Too Big Er 0 - │
Ip6Discards 0 0 │ Ip6Octets 530B 530B │
Missed Error 0 - │ Multicast - 0 │
Window Error - 0 │ │
```
右侧:
```
│ RX TX │ RX TX
│ Abort Error - 0 │ Carrier Error - 0
│ CRC Error 0 - │ Dropped 0 0
│ Frame Error 0 - │ Heartbeat Erro -
│ ICMPv6 Errors 0 0 │ Ip6 Address Er 0 -
│ Ip6 CE Packets 0 - │ Ip6 Checksum E 0 -
│ Ip6 ECT(1) Pac 0 - │ Ip6 Forwarded - 0
│ Ip6 Multicast 0 2 │ Ip6 No Route 0 0
│ Ip6 Reasm/Frag 0 0 │ Ip6 Reasm/Frag 0 0
│ Ip6 Truncated 0 - │ Ip6 Unknown Pr 0 -
│ Ip6Pkts 8 8 │ Length Error 0
│ No Handler 0 - │ Over Error 0 -
```
如果按下 `i` 键,将显示网络接口上的其他信息。
左侧:
```
MTU 1500 | Flags broadcast,multicast,up |
Address 00:1d:09:77:9d:08 | Broadcast ff:ff:ff:ff:ff:ff |
Family unspec | Alias |
```
右侧:
```
| Operstate up | IfIndex 2 |
| Mode default | TXQlen 1000 |
| Qdisc fq_codel |
```
如果你按下 `?` 键,将会出现一个帮助菜单,其中简要介绍了如何在屏幕上移动光标、选择要显示的数据以及控制图形如何显示。
要退出 `bmon`,输入 `q`,然后输入 `y` 以响应提示来确认退出。
需要注意的一些重要事项是:
* `bmon` 会将其显示调整为终端窗口的大小
* 显示区域底部显示的某些选项仅在窗口足够大可以容纳数据时才起作用
* 除非你使用 `-R`(例如 `bmon -R 5`)来减慢显示速度,否则每秒更新一次显示
---
via: <https://www.networkworld.com/article/3447936/viewing-network-bandwidth-usage-with-bmon.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,549 | 在 Linux 中加速工作的键盘快捷键 | https://opensourceforu.com/2019/11/keyboard-shortcuts-to-speed-up-your-work-in-linux/ | 2019-11-08T07:57:00 | [
"快捷键"
] | https://linux.cn/article-11549-1.html | 
>
> 操作鼠标、键盘和菜单会占用我们很多时间,这些可以使用键盘快捷键来节省时间。这不仅节省时间,还可以使用户更高效。
>
>
>
你是否意识到每次在打字时从键盘切换到鼠标需要多达两秒钟?如果一个人每天工作八小时,每分钟从键盘切换到鼠标一次,并且一年中大约有 240 个工作日,那么所浪费的时间(根据 Brainscape 的计算)为: [每分钟浪费 2 秒] x [每天 480 分钟] x 每年 240 个工作日 = 每年浪费 64 小时 这相当于损失了八个工作日,因此学习键盘快捷键将使生产率提高 3.3%(<https://www.brainscape.com/blog/2011/08/keyboard-shortcuts-economy/>)。
键盘快捷键提供了一种更快的方式来执行任务,不然就需要使用鼠标和/或菜单分多个步骤来完成。图 1 列出了 Ubuntu 18.04 Linux 和 Web 浏览器中一些最常用的快捷方式。我省略了非常有名的快捷方式,例如复制、粘贴等,以及不经常使用的快捷方式。读者可以参考在线资源以获得完整的快捷方式列表。请注意,Windows 键在 Linux 中被重命名为 Super 键。
### 常规快捷方式
下面列出了常规快捷方式。

### 打印屏幕和屏幕录像
以下快捷方式可用于打印屏幕或录制屏幕视频。

### 在应用之间切换
此处列出的快捷键可用于在应用之间切换。

### 平铺窗口
可以使用下面提供的快捷方式以不同方式将窗口平铺。

### 浏览器快捷方式
此处列出了浏览器最常用的快捷方式。大多数快捷键对于 Chrome/Firefox 浏览器是通用的。
| **组合键** | **行为** |
| --- | --- |
| `Ctrl + T` | 打开一个新标签。 |
| `Ctrl + Shift + T` | 打开最近关闭的标签。 |
| `Ctrl + D` | 添加一个新书签。 |
| `Ctrl + W` | 关闭浏览器标签。 |
| `Alt + D` | 将光标置于浏览器的地址栏中。 |
| `F5 或 Ctrl-R` | 刷新页面。 |
| `Ctrl + Shift + Del` | 清除私人数据和历史记录。 |
| `Ctrl + N` | 打开一个新窗口。 |
| `Home` | 滚动到页面顶部。 |
| `End` | 滚动到页面底部。 |
| `Ctrl + J` | 打开下载文件夹(在 Chrome 中) |
| `F11` | 全屏视图(切换效果) |
### 终端快捷方式
这是终端快捷方式的列表。

你还可以在 Ubuntu 中配置自己的自定义快捷方式,如下所示:
* 在 Ubuntu Dash 中单击设置。
* 在“设置”窗口的左侧菜单中选择“设备”选项卡。
* 在设备菜单中选择键盘标签。
* 右面板的底部有个 “+” 按钮。点击 “+” 号打开自定义快捷方式对话框并配置新的快捷方式。
学习本文提到的三个快捷方式可以节省大量时间,并使你的工作效率更高。
### 引用
[Cohen, Andrew. How keyboard shortcuts could revive America’s economy; www.brainscape.com. [Online] Brainscape, 26 May 2017;](https://www.brainscape.com/blog/2011/08/keyboard-shortcuts-economy/)
---
via: <https://opensourceforu.com/2019/11/keyboard-shortcuts-to-speed-up-your-work-in-linux/>
作者:[S Sathyanarayanan](https://opensourceforu.com/author/s-sathyanarayanan/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,550 | 初级:如何更新 Fedora Linux 系统 | https://itsfoss.com/update-fedora/ | 2019-11-08T08:27:50 | [
"Fedora"
] | https://linux.cn/article-11550-1.html |
>
> 本快速教程介绍了更新 Fedora Linux 安装的多种方法。
>
>
>

前几天,我安装了[新发布的 Fedora 31](https://itsfoss.com/fedora-31-release/)。老实说,这是我第一次使用[非 Ubuntu 发行版](https://itsfoss.com/non-ubuntu-beginner-linux/)。
安装 Fedora 之后,我做的第一件事就是尝试安装一些软件。我打开软件中心,发现该软件中心已“损坏”。 我无法从中安装任何应用程序。
我不确定我的系统出了什么问题。在团队内部讨论时,Abhishek 建议我先更新系统。我更新了,更新后一切恢复正常。更新 [Fedora](https://getfedora.org/) 系统后,软件中心也能正常工作了。
有时我们一直尝试解决我们所面临的问题,而忽略了对系统的更新。不管问题有多大或多小,为了避免它们,你都应该保持系统更新。
在本文中,我将向你展示更新 Fedora Linux 系统的多种方法。
* 使用软件中心更新 Fedora
* 使用命令行更新 Fedora
* 从系统设置更新 Fedora
请记住,更新 Fedora 意味着安装安全补丁、更新内核和软件。如果要从 Fedora 的一个版本更新到另一个版本,这称为版本升级,你可以[在此处阅读有关 Fedora 版本升级过程的信息](https://itsfoss.com/upgrade-fedora-version/)。
### 从软件中心更新 Fedora

你很可能会收到通知,通知你有一些系统更新需要查看,你应该在单击该通知时启动软件中心。
你所要做的就是 —— 点击“更新”,并验证 root 密码开始更新。
如果你没有收到更新的通知,则只需启动软件中心并转到“更新”选项卡即可。现在,你只需要继续更新。
### 使用终端更新 Fedora
如果由于某种原因无法加载软件中心,则可以使用 `dnf` 软件包管理命令轻松地更新系统。
只需启动终端并输入以下命令即可开始更新(系统将提示你确认 root 密码):
```
sudo dnf upgrade
```
>
> \*\*dnf 更新 vs dnf 升级 \*\*
>
>
> 你会发现有两个可用的 dnf 命令:`dnf update` 和 `dnf upgrade`。这两个命令执行相同的工作,即安装 Fedora 提供的所有更新。那么,为什么要会有这两个呢,你应该使用哪一个?`dnf update` 基本上是 `dnf upgrade` 的别名。尽管 `dnf update` 可能仍然有效,但最好使用 `dnf upgrade`,因为这是真正的命令。
>
>
>
### 从系统设置中更新 Fedora

如果其它方法都不行(或者由于某种原因已经进入“系统设置”),请导航至“设置”底部的“详细信息”选项。
如上图所示,该选项中显示操作系统和硬件的详细信息以及一个“检查更新”按钮。你只需要单击它并提供 root 密码即可继续安装可用的更新。
### 总结
如上所述,更新 Fedora 系统非常容易。有三种方法供你选择,因此无需担心。
如果你按上述说明操作时发现任何问题,请随时在下面的评论部分告诉我。
---
via: <https://itsfoss.com/update-fedora/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Morisun029](https://github.com/Morisun029) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I’ll be honest with you, I don’t ave much experience with a [non-Ubuntu distribution](https://itsfoss.com/non-ubuntu-beginner-linux/). Trying Fedora was a different kind of experience for me.
The first thing I did after installing Fedora was to try and install some software. I opened the software center and found that the software center was ‘broken’. I couldn’t install any application from it.
I wasn’t sure what went wrong with my installation. Discussing within the team, Abhishek advised me to update the system first. I did that and poof! everything was back to normal. After updating the [Fedora](https://getfedora.org/?ref=itsfoss.com) system, the software center worked as it should.
Sometimes we just ignore the updates and keep troubleshooting the issue we face. No matter how big/small the issue is – to avoid them, you should keep your system up-to-date.
In this article, I’ll show you various possible methods to update your Fedora Linux system.
- Update Fedora using software center
- Update Fedora using command line
- Update Fedora from system settings
Looking for Fedora version upgrade?
Keep in mind that updating Fedora means installing the security patches, kernel updates and software updates. If you want to update from one version of Fedora to another, it is called version upgrade and you can [read about Fedora version upgrade procedure here](https://itsfoss.com/upgrade-fedora-version/).
[How to Upgrade From Fedora 37 to Fedora 38This tutorial shows you how to upgrade the Fedora version to a new major release.](https://itsfoss.com/upgrade-fedora-version/)

## Updating Fedora From The Software Center

You will most likely be notified that you have some system updates to look at, you should end up launching the software center when you click on that notification.
All you have to do is – hit ‘Update’ and verify the root password to start updating.
In case you did not get a notification for the available updates, you can simply launch the software center and head to the “Updates” tab. Now, you just need to proceed with the updates listed.
## Updating Fedora Using The Terminal
If you cannot load up the software center for some reason, you can always utilize the dnf package managing commands to easily update your system.
Simply launch the terminal and type in the following command to start updating (you should be prompted to verify the root password):
`sudo dnf upgrade`
### dnf update vs dnf upgrade
You’ll find that there are two dnf commands available: dnf update and dnf upgrade.
Both command do the same job and that is to install all the updates provided by Fedora.
Then why there is dnf update and dnf upgrade and which one should you use?
Well, dnf update is basically an alias to dnf upgrade. While dnf update may still work, the good practice is to use dnf upgrade because that is the real command.
## Updating Fedora From System Settings

If nothing else works (or if you’re already in the System settings for a reason), navigate your way to the “Details” option at the bottom of your settings.
This should show up the details of your OS and hardware along with a “Check for Updates” button as shown in the image above. You just need to click on it and provide the root/admin password to proceed to install the available updates.
## Wrapping Up
As explained above, it is quite easy to update your Fedora installation. You’ve got three available methods to choose from – so you have nothing to worry about.
If you notice any issue in following the instructions mentioned above, feel free to let me know in the comments below. |
11,552 | 怎样用 Bash 编程:语法和工具 | https://opensource.com/article/19/10/programming-bash-part-1 | 2019-11-08T09:26:00 | [
"bash",
"shell"
] | https://linux.cn/article-11552-1.html |
>
> 让我们通过本系列文章来学习基本的 Bash 编程语法和工具,以及如何使用变量和控制运算符,这是三篇中的第一篇。
>
>
>

Shell 是操作系统的命令解释器,其中 Bash 是我最喜欢的。每当用户或者系统管理员将命令输入系统的时候,Linux 的 shell 解释器就会把这些命令转换成操作系统可以理解的形式。而执行结果返回 shell 程序后,它会将结果输出到 STDOUT(标准输出),默认情况下,这些结果会[显示在你的终端](https://opensource.com/article/18/10/linux-data-streams)。所有我熟悉的 shell 同时也是一门编程语言。
Bash 是个功能强大的 shell,包含众多便捷特性,比如:tab 补全、命令回溯和再编辑、别名等。它的命令行默认编辑模式是 Emacs,但是我最喜欢的 Bash 特性之一是我可以将其更改为 Vi 模式,以使用那些储存在我肌肉记忆中的的编辑命令。
然而,如果你把 Bash 当作单纯的 shell 来用,则无法体验它的真实能力。我在设计一套包含三卷的 [Linux 自学课程](http://www.both.org/?page_id=1183)时(这个系列的文章正是基于此课程),了解到许多 Bash 的知识,这些是我在过去 20 年的 Linux 工作经验中所没有掌握的,其中的一些知识就是关于 Bash 的编程用法。不得不说,Bash 是一门强大的编程语言,是一个能够同时用于命令行和 shell 脚本的完美设计。
本系列文章将要探讨如何使用 Bash 作为命令行界面(CLI)编程语言。第一篇文章简单介绍 Bash 命令行编程、变量以及控制运算符。其他文章会讨论诸如:Bash 文件的类型;字符串、数字和一些逻辑运算符,它们能够提供代码执行流程中的逻辑控制;不同类型的 shell 扩展;通过 `for`、`while` 和 `until` 来控制循环操作。
### Shell
Bash 是 Bourne Again Shell 的缩写,因为 Bash shell 是 [基于](https://opensource.com/19/9/command-line-heroes-bash) 更早的 Bourne shell,后者是 Steven Bourne 在 1977 年开发的。另外还有很多[其他的 shell](https://en.wikipedia.org/wiki/Comparison_of_command_shells) 可以使用,但下面四个是我经常见到的:
* `csh`:C shell 适合那些习惯了 C 语言语法的开发者。
* `ksh`:Korn shell,由 David Korn 开发,在 Unix 用户中更流行。
* `tcsh`:一个 csh 的变种,增加了一些易用性。
* `zsh`:Z shell,集成了许多其他流行 shell 的特性。
所有 shell 都有内置命令,用以补充或替代核心工具集。打开 shell 的 man 说明页,找到“BUILT-INS”那一段,可以查看都有哪些内置命令。
每种 shell 都有它自己的特性和语法风格。我用过 csh、ksh 和 zsh,但我还是更喜欢 Bash。你可以多试几个,寻找更适合你的 shell,尽管这可能需要花些功夫。但幸运的是,切换不同 shell 很简单。
所有这些 shell 既是编程语言又是命令解释器。下面我们来快速浏览一下 Bash 中集成的编程结构和工具。
### 作为编程语言的 Bash
大多数场景下,系统管理员都会使用 Bash 来发送简单明了的命令。但 Bash 不仅可以输入单条命令,很多系统管理员可以编写简单的命令行程序来执行一系列任务,这些程序可以作为通用工具,能节省时间和精力。
编写 CLI 程序的目的是要提高效率(做一个“懒惰的”系统管理员)。在 CLI 程序中,你可以用特定顺序列出若干命令,逐条执行。这样你就不用盯着显示屏,等待一条命令执行完,再输入另一条,省下来的时间就可以去做其他事情了。
### 什么是“程序”?
自由在线计算机词典([FOLDOC](http://foldoc.org/program))对于程序的定义是:“由计算机执行的指令,而不是运行它们的物理硬件。”普林斯顿大学的 [WordNet](https://wordnet.princeton.edu/) 将程序定义为:“……计算机可以理解并执行的一系列指令……”[维基百科](https://en.wikipedia.org/wiki/Computer_program)上也有一条不错的关于计算机程序的条目。
总结下,程序由一条或多条指令组成,目的是完成一个具体的相关任务。对于系统管理员而言,一段程序通常由一系列的 shell 命令构成。Linux 下所有的 shell (至少我所熟知的)都有基本的编程功能,Bash 作为大多数 linux 发行版的默认 shell,也不例外。
本系列用 Bash 举例(因为它无处不在),假如你使用一个不同的 shell 也没关系,尽管结构和语法有所不同,但编程思想是相通的。有些 shell 支持某种特性而其他 shell 则不支持,但它们都提供编程功能。Shell 程序可以被存在一个文件中被反复使用,或者在需要的时候才创建它们。
### 简单 CLI 程序
最简单的命令行程序只有一或两条语句,它们可能相关,也可能无关,在按回车键之前被输入到命令行。程序中的第二条语句(如果有的话)可能取决于第一条语句的操作,但也不是必须的。
这里需要特别讲解一个标点符号。当你在命令行输入一条命令,按下回车键的时候,其实在命令的末尾有一个隐含的分号(`;`)。当一段 CLI shell 程序在命令行中被串起来作为单行指令使用时,必须使用分号来终结每个语句并将其与下一条语句分开。但 CLI shell 程序中的最后一条语句可以使用显式或隐式的分号。
### 一些基本语法
下面的例子会阐明这一语法规则。这段程序由单条命令组成,还有一个显式的终止符:
```
[student@studentvm1 ~]$ echo "Hello world." ;
Hello world.
```
看起来不像一个程序,但它确是我学习每个新编程语言时写下的第一个程序。不同语言可能语法不同,但输出结果是一样的。
让我们扩展一下这段微不足道却又无所不在的代码。你的结果可能与我的有所不同,因为我的家目录有点乱,而你可能是在 GUI 桌面中第一次登录账号。
```
[student@studentvm1 ~]$ echo "My home directory." ; ls ;
My home directory.
chapter25 TestFile1.Linux dmesg2.txt Downloads newfile.txt softlink1 testdir6
chapter26 TestFile1.mac dmesg3.txt file005 Pictures Templates testdir
TestFile1 Desktop dmesg.txt link3 Public testdir Videos
TestFile1.dos dmesg1.txt Documents Music random.txt testdir1
```
现在是不是更明显了。结果是相关的,但是两条语句彼此独立。你可能注意到我喜欢在分号前后多输入一个空格,这样会让代码的可读性更好。让我们再运行一遍这段程序,这次不要带结尾的分号:
```
[student@studentvm1 ~]$ echo "My home directory." ; ls
```
输出结果没有区别。
### 关于变量
像所有其他编程语言一样,Bash 支持变量。变量是个象征性的名字,它指向内存中的某个位置,那里存着对应的值。变量的值是可以改变的,所以它叫“变~量”。
Bash 不像 C 之类的语言,需要强制指定变量类型,比如:整型、浮点型或字符型。在 Bash 中,所有变量都是字符串。整数型的变量可以被用于整数运算,这是 Bash 唯一能够处理的数学类型。更复杂的运算则需要借助 [bc](https://www.gnu.org/software/bc/manual/html_mono/bc.html) 这样的命令,可以被用在命令行编程或者脚本中。
变量的值是被预先分配好的,这些值可以用在命令行编程或者脚本中。可以通过变量名字给其赋值,但是不能使用 `$` 符开头。比如,`VAR=10` 这样会把 `VAR` 的值设为 `10`。要打印变量的值,你可以使用语句 `echo $VAR`。变量名必须以文本(即非数字)开始。
Bash 会保存已经定义好的变量,直到它们被取消掉。
下面这个例子,在变量被赋值前,它的值是空(`null`)。然后给它赋值并打印出来,检验一下。你可以在同一行 CLI 程序里完成它:
```
[student@studentvm1 ~]$ echo $MyVar ; MyVar="Hello World" ; echo $MyVar ;
Hello World
[student@studentvm1 ~]$
```
*注意:变量赋值的语法非常严格,等号(`=`)两边不能有空格。*
那个空行表明了 `MyVar` 的初始值为空。变量的赋值和改值方法都一样,这个例子展示了原始值和新的值。
正如之前说的,Bash 支持整数运算,当你想计算一个数组中的某个元素的位置,或者做些简单的算术运算,这还是挺有帮助的。然而,这种方法并不适合科学计算,或是某些需要小数运算的场景,比如财务统计。这些场景有其它更好的工具可以应对。
下面是个简单的算术题:
```
[student@studentvm1 ~]$ Var1="7" ; Var2="9" ; echo "Result = $((Var1*Var2))"
Result = 63
```
好像没啥问题,但如果运算结果是浮点数会发生什么呢?
```
[student@studentvm1 ~]$ Var1="7" ; Var2="9" ; echo "Result = $((Var1/Var2))"
Result = 0
[student@studentvm1 ~]$ Var1="7" ; Var2="9" ; echo "Result = $((Var2/Var1))"
Result = 1
[student@studentvm1 ~]$
```
结果会被取整。请注意运算被包含在 `echo` 语句之中,其实计算在 echo 命令结束前就已经完成了,原因是 Bash 的内部优先级。想要了解详情的话,可以在 Bash 的 man 页面中搜索 “precedence”。
### 控制运算符
Shell 的控制运算符是一种语法运算符,可以轻松地创建一些有趣的命令行程序。在命令行上按顺序将几个命令串在一起,就变成了最简单的 CLI 程序:
```
command1 ; command2 ; command3 ; command4 ; . . . ; etc. ;
```
只要不出错,这些命令都能顺利执行。但假如出错了怎么办?你可以预设好应对出错的办法,这就要用到 Bash 内置的控制运算符, `&&` 和 `||`。这两种运算符提供了流程控制功能,使你能改变代码执行的顺序。分号也可以被看做是一种 Bash 运算符,预示着新一行的开始。
`&&` 运算符提供了如下简单逻辑,“如果 command1 执行成功,那么接着执行 command2。如果 command1 失败,就跳过 command2。”语法如下:
```
command1 && command2
```
现在,让我们用命令来创建一个新的目录,如果成功的话,就把它切换为当前目录。确保你的家目录(`~`)是当前目录,先尝试在 `/root` 目录下创建,你应该没有权限:
```
[student@studentvm1 ~]$ Dir=/root/testdir ; mkdir $Dir/ && cd $Dir
mkdir: cannot create directory '/root/testdir/': Permission denied
[student@studentvm1 ~]$
```
上面的报错信息是由 `mkdir` 命令抛出的,因为创建目录失败了。`&&` 运算符收到了非零的返回码,所以 `cd` 命令就被跳过,前者阻止后者继续运行,因为创建目录失败了。这种控制流程可以阻止后面的错误累积,避免引发更严重的问题。是时候讲点更复杂的逻辑了。
当一段程序的返回码大于零时,使用 `||` 运算符可以让你在后面接着执行另一段程序。简单语法如下:
```
command1 || command2
```
解读一下,“假如 command1 失败,执行 command2”。隐藏的逻辑是,如果 command1 成功,跳过 command2。下面实践一下,仍然是创建新目录:
```
[student@studentvm1 ~]$ Dir=/root/testdir ; mkdir $Dir || echo "$Dir was not created."
mkdir: cannot create directory '/root/testdir': Permission denied
/root/testdir was not created.
[student@studentvm1 ~]$
```
正如预期,因为目录无法创建,第一条命令失败了,于是第二条命令被执行。
把 `&&` 和 `||` 两种运算符结合起来才能发挥它们的最大功效。请看下面例子中的流程控制方法:
```
前置 commands ; command1 && command2 || command3 ; 跟随 commands
```
语法解释:“假如 command1 退出时返回码为零,就执行 command2,否则执行 command3。”用具体代码试试:
```
[student@studentvm1 ~]$ Dir=/root/testdir ; mkdir $Dir && cd $Dir || echo "$Dir was not created."
mkdir: cannot create directory '/root/testdir': Permission denied
/root/testdir was not created.
[student@studentvm1 ~]$
```
现在我们再试一次,用你的家目录替换 `/root` 目录,你将会有权限创建这个目录了:
```
[student@studentvm1 ~]$ Dir=~/testdir ; mkdir $Dir && cd $Dir || echo "$Dir was not created."
[student@studentvm1 testdir]$
```
像 `command1 && command2` 这样的控制语句能够运行的原因是,每条命令执行完毕时都会给 shell 发送一个返回码,用来表示它执行成功与否。默认情况下,返回码为 `0` 表示成功,其他任何正值表示失败。一些系统管理员使用的工具用值为 `1` 的返回码来表示失败,但其他很多程序使用别的数字来表示失败。
Bash 的内置变量 `$?` 可以显示上一条命令的返回码,可以在脚本或者命令行中非常方便地检查它。要查看返回码,让我们从运行一条简单的命令开始,返回码的结果总是上一条命令给出的。
```
[student@studentvm1 testdir]$ ll ; echo "RC = $?"
total 1264
drwxrwxr-x 2 student student 4096 Mar 2 08:21 chapter25
drwxrwxr-x 2 student student 4096 Mar 21 15:27 chapter26
-rwxr-xr-x 1 student student 92 Mar 20 15:53 TestFile1
drwxrwxr-x. 2 student student 663552 Feb 21 14:12 testdir
drwxr-xr-x. 2 student student 4096 Dec 22 13:15 Videos
RC = 0
[student@studentvm1 testdir]$
```
在这个例子中,返回码为零,意味着命令执行成功了。现在对 root 的家目录测试一下,你应该没有权限:
```
[student@studentvm1 testdir]$ ll /root ; echo "RC = $?"
ls: cannot open directory '/root': Permission denied
RC = 2
[student@studentvm1 testdir]$
```
本例中返回码是 `2`,表明非 root 用户没有权限进入这个目录。你可以利用这些返回码,用控制运算符来改变程序执行的顺序。
### 总结
本文将 Bash 看作一门编程语言,并从这个视角介绍了它的简单语法和基础工具。我们学习了如何将数据输出到 STDOUT,怎样使用变量和控制运算符。在本系列的下一篇文章中,将会重点介绍能够控制指令执行流程的逻辑运算符。
---
via: <https://opensource.com/article/19/10/programming-bash-part-1>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jdh8383](https://github.com/jdh8383) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,553 | 全面介绍 Linux 权限 | https://opensource.com/article/19/8/linux-permissions-101 | 2019-11-08T23:31:00 | [
"权限"
] | https://linux.cn/article-11553-1.html |
>
> 知道如何控制用户对文件的访问是一项基本的系统管理技能。
>
>
>

了解 Linux 权限以及如何控制哪些用户可以访问文件是系统管理的一项基本技能。
本文将介绍标准 Linux 文件系统权限,并进一步研究特殊权限,以及使用 `umask` 来解释默认权限作为文章的结束。
### 理解 ls 命令的输出
在讨论如何修改权限之前,我们需要知道如何查看权限。通过 `ls` 命令的长列表参数(`-l`)为我们提供了有关文件的许多信息。
```
$ ls -lAh
total 20K
-rwxr-xr--+ 1 root root 0 Mar 4 19:39 file1
-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file10
-rwxrwxr--+ 1 root root 0 Mar 4 19:39 file2
-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file8
-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file9
drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir
```
为了理解这些是什么意思,让我们将关于权限的输出分解为各个部分。单独理解每个部分会更容易。
让我们看看在上面的输出中的最后一行的每个组件:
```
drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir
```
| 第 1 节 | 第 2 节 | 第 3 节 | 第 4 节 | 第 5 节 | 第 6 节 | 第 7 节 |
| --- | --- | --- | --- | --- | --- | --- |
| `d` | `rwx` | `rwx` | `rwx` | `.` | `root` | `root` |
第 1 节(左侧)显示文件的类型。
| 符号 | 类型 |
| --- | --- |
| `d` | 目录 |
| `-` | 常规文件 |
| `l` | 软链接 |
`ls` 的 [info 页面](https://www.gnu.org/software/texinfo/manual/info-stnd/info-stnd.html)完整列出了不同的文件类型。
每个文件都有三种访问方式:
* 属主
* 组
* 所有其他人 第 2、3 和 4 节涉及用户(属主)、组和“其他用户”权限。每个部分都可以包含 `r`(读取)、`w`(写入)和 `x`(执行)权限的组合。
每个权限还分配了一个数值,这在以八进制表示形式讨论权限时很重要。
| 权限 | 八进制值 |
| --- | --- |
| `r` | 4 |
| `w` | 2 |
| `x` | 1 |
第 5 节描述了其他替代访问方法,例如 SELinux 或文件访问控制列表(FACL)。
| 访问方法 | 字符 |
| --- | --- |
| 没有其它访问方法 | `-` |
| SELinux | `.` |
| FACL | `+` |
| 各种方法的组合 | `+` |
第 6 节和第 7 节分别是属主和组的名称。
### 使用 chown 和 chmod
#### chown 命令
`chown`(更改所有权)命令用于更改文件的用户和组的所有权。
要将文件 `foo` 的用户和组的所有权更改为 `root`,我们可以使用以下命令:
```
$ chown root:root foo
$ chown root: foo
```
在用户名后跟冒号(`:`)运行该命令将同时设置用户和组所有权。
要仅将文件 `foo` 的用户所有权设置为 `root` 用户,请输入:
```
$ chown root foo
```
要仅更改文件 `foo` 的组所有权,请在组之前加冒号:
```
$ chown :root foo
```
#### chmod 命令
`chmod`(更改模式)命令控制属主、组以及既不是属主也不属于与文件关联的组的所有其他用户的文件许可权。
`chmod` 命令可以以八进制(例如 `755`、`644` 等)和符号(例如 `u+rwx`、`g-rwx`、`o=rw`)格式设置权限。
八进制表示法将 4 个“点”分配给“读取”,将 2 个“点”分配给“写入”,将 1 个点分配给“执行”。如果要给用户(属主)分配“读取”权限,则将 4 分配给第一个插槽,但是如果要添加“写入”权限,则必须添加 2。如果要添加“执行”,则要添加 1。我们对每种权限类型执行此操作:属主、组和其他。
例如,如果我们想将“读取”、“写入”和“执行”分配给文件的属主,但仅将“读取”和“执行”分配给组成员和所有其他用户,则我们应使用 `755`(八进制格式)。这是属主的所有权限位(`4+2+1`),但组和其他权限的所有权限位只有 `4` 和 `1`(`4+1`)。
>
> 细分为:4+2+1=7,4+1=5 和 4+1=5。
>
>
>
如果我们想将“读取”和“写入”分配给文件的属主,而只将“读取”分配给组的成员和所有其他用户,则可以如下使用 `chmod`:
```
$ chmod 644 foo_file
```
在下面的示例中,我们在不同的分组中使用符号表示法。注意字母 `u`、`g` 和 `o` 分别代表“用户”(属主)、“组”和“其他”。我们将 `u`、`g` 和 `o` 与 `+`、`-` 或 `=` 结合使用来添加、删除或设置权限位。
要将“执行”位添加到所有权权限集中:
```
$ chmod u+x foo_file
```
要从组成员中删除“读取”、“写入”和“执行”:
```
$ chmod g-rwx foo_file
```
要将所有其他用户的所有权设置为“读取”和“写入”:
```
$ chmod o=rw
```
### 特殊位:设置 UID、设置 GID 和粘滞位
除了标准权限外,还有一些特殊的权限位,它们具有一些别的用处。
#### 设置用户 ID(suid)
当在文件上设置 `suid` 时,将以文件的属主的身份而不是运行该文件的用户身份执行操作。一个[好的例子](https://www.theurbanpenguin.com/using-a-simple-c-program-to-explain-the-suid-permission/)是 `passwd` 命令。它需要设置 `suid` 位,以便更改密码的操作具有 root 权限。
```
$ ls -l /bin/passwd
-rwsr-xr-x. 1 root root 27832 Jun 10 2014 /bin/passwd
```
设置 `suid` 位的示例:
```
$ chmod u+s /bin/foo_file_name
```
#### 设置组 ID(sgid)
`sgid` 位与 `suid` 位类似,操作是在目录的组所有权下完成的,而不是以运行命令的用户身份。
一个使用 `sgid` 的例子是,如果多个用户正在同一个目录中工作,并且目录中创建的每个文件都需要具有相同的组权限。下面的示例创建一个名为 `collab_dir` 的目录,设置 `sgid` 位,并将组所有权更改为 `webdev`。
```
$ mkdir collab_dir
$ chmod g+s collab_dir
$ chown :webdev collab_dir
```
现在,在该目录中创建的任何文件都将具有 `webdev` 的组所有权,而不是创建该文件的用户的组。
```
$ cd collab_dir
$ touch file-sgid
$ ls -lah file-sgid
-rw-r--r--. 1 root webdev 0 Jun 12 06:04 file-sgid
```
#### “粘滞”位
粘滞位表示,只有文件所有者才能删除该文件,即使组权限允许该文件可以删除。通常,在 `/tmp` 这样的通用或协作目录上,此设置最有意义。在下面的示例中,“所有其他人”权限集的“执行”列中的 `t` 表示已应用粘滞位。
```
$ ls -ld /tmp
drwxrwxrwt. 8 root root 4096 Jun 12 06:07 /tmp/
```
请记住,这不会阻止某个人编辑该文件,它只是阻止他们删除该目录的内容(LCTT 译注:即删除目录下文件)。
我们将粘滞位设置为:
```
$ chmod o+t foo_dir
```
你可以自己尝试在目录上设置粘滞位并赋予其完整的组权限,以便多个属于同一组的用户可以在目录上进行读取、写入和执行。
接着,以每个用户的身份创建文件,然后尝试以另一个用户的身份删除它们。
如果一切配置正确,则一个用户应该不能从另一用户那里删除文件。
请注意,这些位中的每个位也可以用八进制格式设置:SUID = 4、SGID = 2 和 粘滞位 = 1。(LCTT 译注:这里是四位八进制数字)
```
$ chmod 4744
$ chmod 2644
$ chmod 1755
```
#### 大写还是小写?
如果要设置特殊位时看到大写的 `S` 或 `T` 而不是小写的字符(如我们之前所见),那是因为不存在(对应的)底层的执行位。为了说明这一点,下面的示例创建一个设置了粘滞位的文件。然后,我们可以添加和删除执行位以演示大小写更改。
```
$ touch file cap-ST-demo
$ chmod 1755 cap-ST-demo
$ ls -l cap-ST-demo
-rwxr-xr-t. 1 root root 0 Jun 12 06:16 cap-ST-demo
$ chmod o-x cap-X-demo
$ ls -l cap-X-demo
-rwxr-xr-T. 1 root root 0 Jun 12 06:16 cap-ST-demo
```
#### 有条件地设置执行位
至此,我们使用小写的 `x` 设置了执行位,而无需询问任何问题即可对其进行设置。我们还有另一种选择:使用大写的 `X` 而不是小写的,它将仅在权限组中某个位置已经有执行位时才设置执行位。这可能是一个很难解释的概念,但是下面的演示将帮助说明它。请注意,在尝试将执行位添加到组特权之后,该位没有被设置上。
```
$ touch cap-X-file
$ ls -l cap-X-file
-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
$ chmod g+X cap-X-file
$ ls -l cap-X-file
-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
```
在这个类似的例子中,我们首先使用小写的 `x` 将执行位添加到组权限,然后使用大写的 `X` 为所有其他用户添加权限。这次,大写的 `X`设置了该权限。
```
$ touch cap-X-file
$ ls -l cap-X-file
-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
$ chmod g+x cap-X-file
$ ls -l cap-X-file
-rw-r-xr--. 1 root root 0 Jun 12 06:31 cap-X-file
$ chmod o+X cap-X-file
ls -l cap-X-file
-rw-r-xr-x. 1 root root 0 Jun 12 06:31 cap-X-file
```
### 理解 umask
`umask` 会屏蔽(或“阻止”)默认权限集中的位,以定义文件或目录的权限。例如,`umask`输出中的 `2` 表示它至少在默认情况下阻止了文件的“写入”位。
使用不带任何参数的 `umask` 命令可以使我们看到当前的 `umask` 设置。共有四列:第一列为特殊的`suid`、`sgid` 或粘滞位而保留,其余三列代表属主、组和其他人的权限。
```
$ umask
0022
```
为了理解这意味着什么,我们可以用 `-S` 标志来执行 `umask`(如下所示)以解释屏蔽位的结果。例如,由于第三列中的值为 `2`,因此将“写入”位从组和其他部分中屏蔽掉了;只能为它们分配“读取”和“执行”。
```
$ umask -S
u=rwx,g=rx,o=rx
```
要查看文件和目录的默认权限集是什么,让我们将 `umask` 设置为全零。这意味着我们在创建文件时不会掩盖任何位。
```
$ umask 000
$ umask -S
u=rwx,g=rwx,o=rwx
$ touch file-umask-000
$ ls -l file-umask-000
-rw-rw-rw-. 1 root root 0 Jul 17 22:03 file-umask-000
```
现在,当我们创建文件时,我们看到所有部分的默认权限分别为“读取”(`4`)和“写入”(`2`),相当于八进制表示 `666`。
我们可以对目录执行相同的操作,并看到其默认权限为 `777`。我们需要在目录上使用“执行”位,以便可以遍历它们。
```
$ mkdir dir-umask-000
$ ls -ld dir-umask-000
drwxrwxrwx. 2 root root 4096 Jul 17 22:03 dir-umask-000/
```
### 总结
管理员还有许多其他方法可以控制对系统文件的访问。这些权限是 Linux 的基本权限,我们可以在这些基础上进行构建。如果你的工作为你引入了 FACL 或 SELinux,你会发现它们也建立在这些文件访问的首要规则之上。
---
via: <https://opensource.com/article/19/8/linux-permissions-101>
作者:[Alex Juarez](https://opensource.com/users/mralexjuarezhttps://opensource.com/users/marcobravohttps://opensource.com/users/greg-p) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Understanding Linux permissions and how to control which users have access to files is a fundamental skill for systems administration.
This article will cover standard Linux file systems permissions, dig further into special permissions, and wrap up with an explanation of default permissions using **umask**.
## Understanding the ls command output
Before we can talk about how to modify permissions, we need to know how to view them. The **ls** command with the long listing argument (**-l**) gives us a lot of information about a file.
```
$ ls -lAh
total 20K
-rwxr-xr--+ 1 root root 0 Mar 4 19:39 file1
-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file10
-rwxrwxr--+ 1 root root 0 Mar 4 19:39 file2
-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file8
-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file9
drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir
```
To understand what this means, let's break down the output regarding the permissions into individual sections. It will be easier to reference each section individually.
Take a look at each component of the final line in the output above:
`drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir`
Section 1 | Section 2 | Section 3 | Section 4 | Section 5 | Section 6 | Section 7 |
---|---|---|---|---|---|---|
d | rwx | rwx | rwx | . | root | root |
Section 1 (on the left) reveals what type of file it is.
d | Directory |
- | Regular file |
l | A soft link |
The [info page](https://www.gnu.org/software/texinfo/manual/info-stnd/info-stnd.html) for **ls** has a full listing of the different file types.
Each file has three modes of access:
- the owner
- the group
- all others
Sections 2, 3, and 4 refer to the user, group, and "other users" permissions. And each section can include a combination of **r** (read), **w** (write), and **x** (executable) permissions.
Each of the permissions is also assigned a numerical value, which is important when talking about the octal representation of permissions.
Permission | Octal Value |
---|---|
Read | 4 |
Write | 2 |
Execute | 1 |
Section 5 details any alternative access methods, such as SELinux or File Access Control List (FACL).
Method | Character |
---|---|
No other method | - |
SELinux | . |
FACLs | + |
Any combination of methods | + |
Sections 6 and 7 are the names of the owner and the group, respectively.
## Using chown and chmod
### The chown command
The **chown** (change ownership) command is used to change a file's user and group ownership.
To change both the user and group ownership of the file **foo** to **root**, we can use these commands:
```
$ chown root:root foo
$ chown root: foo
```
Running the command with the user followed by a colon (**:**) sets both the user and group ownership.
To set only the user ownership of the file **foo** to the **root** user, enter:
`$ chown root foo`
To change only the group ownership of the file **foo**, precede the group with a colon:
`$ chown :root foo`
### The chmod command
The **chmod** (change mode) command controls file permissions for the owner, group, and all other users who are neither the owner nor part of the group associated with the file.
The **chmod** command can set permissions in both octal (e.g., 755, 644, etc.) and symbolic (e.g., u+rwx, g-rwx, o=rw) formatting.
Octal notation assigns 4 "points" to **read**, 2 to **write**, and 1 to **execute**. If we want to assign the user **read **permissions, we assign 4 to the first slot, but if we want to add **write** permissions, we must add 2. If we want to add **execute**, then we add 1. We do this for each permission type: owner, group, and others.
For example, if we want to assign **read**, **write**, and **execute** to the owner of the file, but only **read** and **execute** to group members and all other users, we would use 755 in octal formatting. That's all permission bits for the owner (4+2+1), but only a 4 and 1 for the group and others (4+1).
The breakdown for that is: 4+2+1=7; 4+1=5; and 4+1=5.
If we wanted to assign **read** and **write** to the owner of the file but only **read** to members of the group and all other users, we could use **chmod** as follows:
`$ chmod 644 foo_file`
In the examples below, we use symbolic notation in different groupings. Note the letters **u**, **g**, and **o** represent **user**, **group**, and **other**. We use **u**, **g**, and **o** in conjunction with **+**, **-**, or **=** to add, remove, or set permission bits.
To add the **execute** bit to the ownership permission set:
`$ chmod u+x foo_file`
To remove **read**, **write**, and **execute** from members of the group:
`$ chmod g-rwx foo_file`
To set the ownership for all other users to **read** and **write**:
`$ chmod o=rw`
## The special bits: Set UID, set GID, and sticky bits
In addition to the standard permissions, there are a few special permission bits that have some useful benefits.
### Set user ID (suid)
When **suid** is set on a file, an operation executes as the owner of the file, not the user running the file. A [good example](https://www.theurbanpenguin.com/using-a-simple-c-program-to-explain-the-suid-permission/) of this is the **passwd** command. It needs the **suid** bit to be set so that changing a password runs with root permissions.
```
$ ls -l /bin/passwd
-rwsr-xr-x. 1 root root 27832 Jun 10 2014 /bin/passwd
```
An example of setting the **suid** bit would be:
`$ chmod u+s /bin/foo_file_name`
### Set group ID (sgid)
The **sgid** bit is similar to the **suid** bit in the sense that the operations are done under the group ownership of the directory instead of the user running the command.
An example of using **sgid** would be if multiple users are working out of the same directory, and every file created in the directory needs to have the same group permissions. The example below creates a directory called **collab_dir**, sets the **sgid** bit, and changes the group ownership to **webdev**.
```
$ mkdir collab_dir
$ chmod g+s collab_dir
$ chown :webdev collab_dir
```
Now any file created in the directory will have the group ownership of **webdev** instead of the user who created the file.
```
$ cd collab_dir
$ touch file-sgid
$ ls -lah file-sgid
-rw-r--r--. 1 root webdev 0 Jun 12 06:04 file-sgid
```
### The "sticky" bit
The sticky bit denotes that only the owner of a file can delete the file, even if group permissions would otherwise allow it. This setting usually makes the most sense on a common or collaborative directory such as **/tmp**. In the example below, the **t** in the **execute** column of the **all others** permission set indicates that the sticky bit has been applied.
```
$ ls -ld /tmp
drwxrwxrwt. 8 root root 4096 Jun 12 06:07 /tmp/
```
Keep in mind this does not prevent somebody from editing the file; it just keeps them from deleting the contents of a directory.
We set the sticky bit with:
`$ chmod o+t foo_dir`
On your own, try setting the sticky bit on a directory and give it full group permissions so that multiple users can read, write and execute on the directory because they are in the same group.
From there, create files as each user and then try to delete them as the other.
If everything is configured correctly, one user should not be able to delete users from the other user.
Note that each of these bits can also be set in octal format with SUID=4, SGID=2, and Sticky=1.
```
$ chmod 4744
$ chmod 2644
$ chmod 1755
```
### Uppercase or lowercase?
If you are setting the special bits and see an uppercase **S** or **T** instead of lowercase (as we've seen until this point), it is because the underlying execute bit is not present. To demonstrate, the following example creates a file with the sticky bit set. We can then add/remove the execute bit to demonstrate the case change.
```
$ touch file cap-ST-demo
$ chmod 1755 cap-ST-demo
$ ls -l cap-ST-demo
-rwxr-xr-t. 1 root root 0 Jun 12 06:16 cap-ST-demo
$ chmod o-x cap-X-demo
$ ls -l cap-X-demo
-rwxr-xr-T. 1 root root 0 Jun 12 06:16 cap-ST-demo
```
### Setting the execute bit conditionally
To this point, we've set the **execute** bit using a lowercase **x**, which sets it without asking any questions. We have another option: using an uppercase **X** instead of lowercase will set the **execute** bit only if it is already present somewhere in the permission group. This can be a difficult concept to explain, but the demo below will help illustrate it. Notice here that after trying to add the **execute** bit to the group privileges, it is not applied.
```
$ touch cap-X-file
$ ls -l cap-X-file
-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
$ chmod g+X cap-X-file
$ ls -l cap-X-file
-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
```
In this similar example, we add the execute bit first to the group permissions using the lowercase **x** and then use the uppercase **X** to add permissions for all other users. This time, the uppercase **X** sets the permissions.
```
$ touch cap-X-file
$ ls -l cap-X-file
-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
$ chmod g+x cap-X-file
$ ls -l cap-X-file
-rw-r-xr--. 1 root root 0 Jun 12 06:31 cap-X-file
$ chmod g+x cap-X-file
$ chmod o+X cap-X-file
ls -l cap-X-file
-rw-r-xr-x. 1 root root 0 Jun 12 06:31 cap-X-file
```
Understanding umask
The **umask** masks (or "blocks off") bits from the default permission set in order to define permissions for a file or directory. For example, a 2 in the **umask** output indicates it is blocking the **write** bit from a file, at least by default.
Using the **umask** command without any arguments allows us to see the current **umask** setting. There are four columns: the first is reserved for the special suid, sgid, or sticky bit, and the remaining three represent the owner, group, and other permissions.
```
$ umask
0022
```
To understand what this means, we can execute **umask** with a **-S** (as shown below) to get the result of masking the bits. For instance, because of the **2 **value in the third column, the **write** bit is masked off from the group and other sections; only **read **and **execute** can be assigned for those.
```
$ umask -S
u=rwx,g=rx,o=rx
```
To see what the default permission set is for files and directories, let's set our **umask** to all zeros. This means that we are not masking off any bits when we create a file.
```
$ umask 000
$ umask -S
u=rwx,g=rwx,o=rwx
$ touch file-umask-000
$ ls -l file-umask-000
-rw-rw-rw-. 1 root root 0 Jul 17 22:03 file-umask-000
```
Now when we create a file, we see the default permissions are **read** (4) and **write** (2) for all sections, which would equate to 666 in octal representation.
We can do the same for a directory and see its default permissions are 777. We need the **execute** bit on directories so we can traverse through them.
```
$ mkdir dir-umask-000
$ ls -ld dir-umask-000
drwxrwxrwx. 2 root root 4096 Jul 17 22:03 dir-umask-000/
```
## Conclusion
There are many other ways an administrator can control access to files on a system. These permissions are basic to Linux, and we can build upon these fundamental aspects. If your work takes you into FACLs or SELinux, you will see that they also build upon these first rules of file access.
## 2 Comments |
11,554 | 6 款面向 Linux 用户的开源绘图应用程序 | https://itsfoss.com/open-source-paint-apps/ | 2019-11-09T08:13:13 | [
"绘图"
] | https://linux.cn/article-11554-1.html | 小时候,当我开始使用计算机(在 Windows XP 中)时,我最喜欢的应用程序是微软的“画图”。我能在它上面涂鸦数个小时。出乎意料,孩子们仍然喜欢这个“画图”应用程序。不仅仅是孩子们,这个简单的“画图”应用程序,在很多情况下都能派上用场。
你可以找到一堆可以让你绘制/绘图或操作图片的应用程序。然而,其中一些是专有软件。既然你是一名 Linux 用户,为什么不关注一下开源绘图应用程序呢?
在这篇文章中,我们将列出一些最好的开源绘图应用程序,它们可以替代可用于 Linux 的专有绘画软件。
### 开源绘图 & 绘制应用程序

**注意:** 该列表没有特别的排名顺序。
#### 1、Pinta

主要亮点:
* Paint.NET / 微软“画图”的极好替代品
* 支持附加组件(有对 WebP 图像的支持)
* 支持图层
[Pinta](https://pinta-project.com/pintaproject/pinta/) 是一款令人赞叹的开源绘图应用程序,非常适合绘图和简单的图片编辑。换句话说,它是一款具有精美功能的简单绘图应用程序。
你可以将 [Pinta](https://itsfoss.com/pinta-1-6-ubuntu-linux-mint/) 视为 Linux 上的“画图”的一个替代品,但是带有图层支持等等。不仅仅是“画图”,它也可以替代 Windows 上的 Paint.NET。尽管 Paint.NET 更好一些,但 Pinta 似乎是个不错的选择。
几个附加组件可以用于增强功能,例如[在 Linux 上支持 WebP 图像](https://itsfoss.com/webp-ubuntu-linux/)。除了图层支持之外,你还可以轻松地调整图片大小、添加特效、进行调整(亮度、对比度等等),以及在导出图片时调整其质量。
##### 如何安装 Pinta ?
你应该能够在软件中心/应用程序中心/软件包管理器中简单地找到它。只需要输入 “Pinta”,并开始安装它。要么也可以尝试 [Flatpak](https://www.flathub.org/apps/details/com.github.PintaProject.Pinta) 软件包。
或者,你可以在终端中输入下面的命令(Ubuntu/Debian):
```
sudo apt install pinta
```
下载软件包和安装指南的更多信息,参考[官方下载页面](https://pinta-project.com/pintaproject/pinta/releases)。
#### 2、Krita

主要亮点:
* HDR 绘图
* 支持 PSD
* 支持图层
* 笔刷稳定器
* 二维动画
Krita 是 Linux 上最高级的开源绘图应用程序之一。当然,对于本文而言,它可以帮助你绘制草图和在画布上胡写乱画。除此之外,它还提供很多功能。
例如,如果你的手有点颤抖,它可以帮助你稳定笔刷的笔划。你可以使用内置的矢量工具来创建漫画画板和其它有趣的东西。如果你正在寻找具有全面的颜色管理支持、绘图助理和图层管理的软件,Krita 应该是你最好的选择。
##### 如何安装 Krita ?
类似于 pinta,你可以在软件中心/应用程序中心或软件包管理器的列表中找到它。它也可以 [Flatpak 存储库](https://www.flathub.org/apps/details/org.kde.krita)中找到。
考虑通过终端安装它?输入下面的命令:
```
sudo apt install krita
```
要么你也可以前往它们的[官方下载页面](https://krita.org/en/download/krita-desktop/)来获取 AppImage 文件并运行它。
如果你对 AppImage 文件一无所知,查看我们的指南 —— [如何使用 AppImage](https://itsfoss.com/use-appimage-linux/)。
#### 3、Tux Paint

主要亮点:
* 给儿童用的一个简单直接的绘图应用程序
我不是开玩笑,对于 3-12 岁儿童来说,Tux Paint 是最好的开源绘图应用程序之一。当然,当你只想乱画时,那无需选择,所以,在这种情况下,Tux Paint 似乎是最好的选择(即使是成年人!)。
##### 如何安装 Tuxpaint ?
Tuxpaint 可以从软件中心或软件包管理器下载。无论哪种情况,在 Ubuntu/Debian 上安装它,在终端中输入下面的命令:
```
sudo apt install tuxpaint
```
关于它的更多信息,前往[官方站点](http://www.tuxpaint.org/)。
#### 4、Drawpile

主要亮点:
* 协同绘制
* 内置聊天功能,可与其他用户互动
* 图层支持
* 记录绘制会话
Drawpile 是一个有趣的开源绘图应用程序,在该程序中,你可以与其他用户实时协作。确切地说,你们可以单个画布中同时绘制。除了这个独特的功能,它还有图层支持、记录绘制会话的能力,甚至还有与协作用户进行交互的聊天功能。
你可以主持或加入一个公共会话,或通过一个密码与你的朋友建立私有会话。默认情况下,服务器将是你的计算机,但是如果你需要远程服务器那也可以。
注意,你将需要[注册一个 Drawpile 账户](https://drawpile.net/accounts/signup/) 才能进行协作。
##### 如何安装 Drawpile ?
据我所知,你只能在 [Flatpak 存储库](https://flathub.org/apps/details/net.drawpile.drawpile)的列表中找到它。
#### 5、MyPaint

主要亮点:
* 易用的数码画家工具
* 支持图层管理
* 很多微调你的画笔和绘制的选项
对于数码画家来说,[MyPaint](https://mypaint.org/) 是一个简单而强大的工具。它具有许多选项,可以调整以制作出完美的数字画笔笔触。我不是一个数字艺术家(但我是一个涂鸦者),但是我注意到有很多调整笔刷、颜色的选项,和一个添加中间结果暂存器面板的选项。
它也支持图层管理,也许你需要它。最新的稳定版本已经有几年没有更新了,但是当前的 alpha 构建版本(我测试过)运行良好。如果你正在 Linux 上寻找一个开源绘图应用程序 —— 试试这个。
##### 如何安装 MyPaint ?
MyPaint 可在官方存储库中获得。然而,这是老旧的版本。如果你仍然想继续,你可以在软件中心搜索它,或在终端中输入下面的命令:
```
sudo apt install mypaint
```
你可以前往它的官方 [GitHub 发布页面](https://github.com/mypaint/mypaint/releases)获取最新的 alpha 构建版本,获取 [AppImage 文件](https://itsfoss.com/use-appimage-linux/)(任意版本)并使它可执行并启动应用程序。
#### 6、KolourPaint

主要亮点:
* 一个 Linux 上的“画图”的简单替代品
* 不支持图层管理
如果你不需要任何图层管理的支持,而只是想要一个开源绘图应用程序来绘制东西 —— 那就是它了。
[KolourPaint](http://kolourpaint.org/) 最初是为 KDE 桌面环境定制的,但是它在其它的桌面环境中也能完美地工作。
##### 如何安装 KolourPaint ?
你可以从软件中心安装 KolourPaint,或通过终端使用下面的命令:
```
sudo apt install kolourpaint4
```
你总可以试试 [Flathub](https://flathub.org/apps/details/org.kde.kolourpaint)。
### 总结
如果你在考虑如 GIMP/Inkscape 这样的应用程序,我们在另一篇关于[给数码艺术家的最好 Linux 工具](https://itsfoss.com/best-linux-graphic-design-software/)的文章中列出。如果你对更多的选择好奇,我建议你去查看它。
在这里,我们尝试编写一份 Linux 可用的最佳开源绘图应用程序列表。如果你认为我们错过一些东西,请在下面的评论区告诉我们!
---
via: <https://itsfoss.com/open-source-paint-apps/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

As a child, when I started using a computer (with Windows XP), my favorite application was MS Paint. I spent hours doodling on it. Years have passed by, and I still like to doodle something or the other in my spare time.
I came across a few paint applications that are open-source and available for Linux!
Allow me to take you through those.
## 1. Pinta
Pinta is an impressive open-source paint application that is perfect for drawing and basic image editing. In other words, it's a simple paint application with some fancy features.
You may consider Pinta as an alternative to MS Paint on Linux, but with layer support and more. It also acts as a nice Linux replacement for Paint.NET, which is only available for Windows.
**🔆 Key Highlights **
- Great alternative to Paint.NET / MS Paint.
- Add-ons support.
- Layer support.
**How to install? **
You should be able to easily find it in the software center of your Linux distro, just type in “**Pinta**” and get started.
If you don't find it there, then you can always opt for the [Flatpak](https://flathub.org/apps/com.github.PintaProject.Pinta), or enter the following command in the terminal (Debian/Ubuntu):
`sudo apt install pinta`
For more information on other download packages, source code, and installation instructions, refer to the official [download page](https://www.pinta-project.com/releases/) and [launchpad page](https://launchpad.net/pinta).
## 2. Dibuja
This is a simple-to-use paint program similar to the classic MS Paint experience, but for Linux. With this, you can easily create drawings, add effects, edit images, and more.
**🔆 Key Highlights:**
- Classic MS Paint-like experience.
- Variety of drawing tools.
- Small storage footprint.
**How to install?**
The [official website](https://launchpad.net/dibuja/) hosts the **tar.gz**, and .**deb** packages, you can choose between those to get started with Dibuja.
## 3. LazPaint
This is yet another app that is not just for painting, but also for image editing. It has support for editing with raster and vector layers, alongside a number of useful drawing tools.
**🔆 Key Highlights:**
- Many drawing tools.
- Keyboard shortcuts.
- Support for a variety of file formats.
**How to install?**
LazPaint is available for **Linux**, **Raspberry Pi**, **Windows**, and **macOS**. You can head over to the [official website](https://lazpaint.github.io/) to grab the package of your choice.
For accessing the source code, you may head over to its [GitHub repo](https://github.com/bgrabitmap/lazpaint).
## 4. Krita
Krita is one of the most advanced open-source paint applications for Linux. It helps you draw sketches with its clean, flexible interface. In addition to that, it also offers plenty of features.
For instance, if you have a shaky hand, it can help you stabilize the brush strokes with its in-built brush stabilizers. You also get built-in vector tools to create comic panels and other interesting things.
**🔆 Key Highlights:**
- HDR Painting
- PSD Support
- Layer Support
**How to install?**
Similar to Pinta, you should be able to find it listed in the software center of your Linux distro. If you don't find it there, then you can head over to the [Flathub store](https://flathub.org/apps/org.kde.krita) to grab it.
What if you want to install it via terminal? Well, type in the following command (Debian/Ubuntu) :
`sudo apt install krita`
You can also head over to the [official download page](https://krita.org/en/download/krita-desktop/) to get the **AppImage** file and run it.
If you have no idea about AppImage files, you can refer to our [guide](https://itsfoss.com/use-appimage-linux/).
## 5. Rnote
[Rnote](https://rnote.flxzt.net) is an open-source vector-based drawing app that allows for handwritten notes, sketching, annotating documents, and more.
Its main focus is on users with drawing tablets, and that shows in its adaptive UI that is focused on stylus input.
**🔆 Key Highlights**
- Drag/Drop Clipboard support.
- Autosave Functionality.
- Support for PDF, Bitmap, and SVG.
**How to install?**
You can grab Rnote from the [Flathub store](https://flathub.org/apps/details/com.github.flxzt.rnote), or build it from the source code by visiting its [GitHub repo](https://github.com/flxzt/rnote).
## 6. Pixelorama
This one is a bit different from the rest, [Pixelorama](https://orama-interactive.itch.io/pixelorama) is an open-source pixel art editor that has been created using the popular Godot engine.
You can use this to create game graphics, animated pixel art, tiles, and other types of pixel art.
**🔆 Key Highlights**
- Animation Timeline
- Pixel Perfect Mode
- Custom Brushes
**How to install?**
Pixelorama is available from many sources, you can either head over to the [official website](https://orama-interactive.itch.io/pixelorama), or to its [GitHub repo](https://github.com/Orama-Interactive/Pixelorama). But, the most simple way to get it would be from the [Flathub store](https://flathub.org/apps/com.orama_interactive.Pixelorama).
## 7. Tux Paint

I’m not kidding, Tux Paint is one of the best open-source paint applications for kids aged between 3–12 years. It has the combination of an easy-to-use interface coupled with fun sound effects and a cartoon mascot who acts as a helper.
**🔆 Key Highlights:**
- Simple Interface
- Multi-Platform
- Many accessibility options
**How to install?**
Tux Paint can be downloaded from the software center or from the [Flathub store](https://flathub.org/apps/org.tuxpaint.Tuxpaint). To install it using the terminal, type the following command (Debian/Ubuntu):
For other packages, you can head over to its [official site](https://tuxpaint.org/) or the Sourceforge [project page](https://sourceforge.net/projects/tuxpaint/).
## 8. Drawpile
Drawpile is an interesting open-source paint application that lets you collaborate with other users in real-time. It allows you to draw on the same canvas, and also has support for layers, brushes, recording/animation, and more.
You can host/join a public session or start a private session with your friends, which requires a code. By default, the server will be your computer. But if you want a remote server, you can opt for that as well.
[Drawpile account](https://drawpile.net/accounts/signup/?ref=itsfoss.com).
**🔆 Key Highlights:**
- Collaborative Drawing.
- Built-in chat interface.
- Record drawing sessions.
**How to install?**
You can grab it from the [Flathub store](https://flathub.org/apps/net.drawpile.drawpile?ref=itsfoss.com). For the source code, or other packages, you can refer to its [GitHub repo](https://github.com/drawpile/Drawpile).
## 9. PhotoFlare
PhotoFlare is not exactly just a paint program, it's also a powerful image editor that features plenty of painting tools.
Built on the well-known C++ language, it is a cross-platform app that offers plenty of features for a digital artist.
**🔆 Key Highlights:**
- Packed with features.
- Cross-platform.
- Keyboard shortcuts.
**How to install?**
You can head over to the [official website](https://photoflare.io/downloads/) to grab the package of your choice, it is available for **Linux,** **FreeBSD,** and **Windows**.
For installation info and the source code, you can take a look at its [GitHub repo](https://github.com/PhotoFlare/photoflare).
## 10. MyPaint
MyPaint is a simple yet powerful tool for digital artists. It features plenty of options to get the perfect brush stroke.
I’m not much of a digital artist, but I observed quite a few options to adjust the brush, the colors, and an option to add a scratchpad panel. It also supports layer management, in case you want that.
**🔆 Key Highlights:**
- Configurable brushes.
- Layer management support.
- Extensive graphic tablet support.
**How to install?**
You can head to its [GitHub repo](https://github.com/mypaint/mypaint) for getting the latest build, or to grab the AppImage file to use it as an executable app.
For Debian/Ubuntu, you can also type the following command in the terminal:
`sudo apt install mypaint`
## 11. KolourPaint
If you aren’t looking for any Layer management support and just want an open-source paint application to draw stuff in, this is it.
Even though KolourPaint has been tailored for the KDE Plasma desktop environment, it works flawlessly on other DEs too!
**🔆 Key Highlights:**
- Many tools for drawing.
- Support for transparency.
- Advanced effects.
**How to install?**
You can install KolourPaint right from the software center on your system, or from the [Flathub store](https://flathub.org/apps/org.kde.kolourpaint).
You can also take a look at its source code or alternative packages in its [KDE Invent page](https://invent.kde.org/graphics/kolourpaint).
## 12. Drawing
Even though we’ve already covered the [Drawing](https://itsfoss.com/drawing-app/) app separately, it's worth adding to this list.
You get filter support to add blur, transparency and similar effects to the drawing. Not just limited to some essential tools, you can also start drawing from scratch using the various brush tools available.
**Key Highlights:**
- Edit BMP files.
- Use pencil tool for free-hand drawing.
- Essential tools for editing.
**How to install?**
You can either get it from the [Flathub store](https://flathub.org/apps/com.github.maoschanz.drawing), or you can opt for other native packages available on the [official website](https://maoschanz.github.io/drawing/?ref=itsfoss.com).
If you want to take a look at its source code, then you can also head over to its [GitHub repo](https://github.com/maoschanz/drawing).
**Wrapping Up**
If you were wondering; **What happened to GIMP and Inkscape?**
Well, we have those listed in a separate article for the [best Linux tools for digital artists](https://itsfoss.com/best-linux-graphic-design-software/). I recommend you check that out, if you are searching for other options.
So, that's about it for this article.
*💬 If you think we missed something, feel free to let us know in the comments below!* |
11,556 | Chrome/Chromium 用户必知必会的 11 个基本快捷键 | https://itsfoss.com/google-chrome-shortcuts/ | 2019-11-09T21:42:14 | [
"Chrome"
] | https://linux.cn/article-11556-1.html |
>
> 掌握这些 Google Chrome 键盘快捷键,以获得更好、更流畅、更高效的 Web 浏览体验。还包括可下载的备忘单。
>
>
>

无可否认,Google Chrome 是[最受欢迎的网络浏览器](https://en.wikipedia.org/wiki/Usage_share_of_web_browsers)。它的开源版本 [Chromium](https://www.chromium.org/Home) 也越来越受欢迎,现在一些 Linux 发行版将其作为默认的网络浏览器。
如果你经常在台式机上使用它,则可以使用 Google Chrome 键盘快捷键来改善浏览体验。没有必要用你的鼠标移来移去、点来点去。只要掌握这些快捷方式,你可以节省一些时间并提高工作效率。
我这里使用的名称是 Google Chrome,但是这些快捷方式同样适用于 Chromium 浏览器。
### 你应该使用的 11 个酷炫的 Chrome 键盘快捷键
如果你是专业人士,可能已经知道其中一些 Chrome 快捷方式,但是有可能你仍然可以在这里找到一些隐藏的宝石。让我们来看看。
| **键盘快捷键** | **动作** |
| --- | --- |
| `Ctrl+T` | 打开一个新标签页 |
| `Ctrl+N` | 打开一个新窗口 |
| `Ctrl+Shift+N` | 打开一个新无痕式窗口 |
| `Ctrl+W` | 关闭当前标签页 |
| `Ctrl+Shift+T` | 重新打开上一个关闭的标签页 |
| `Ctrl+Shift+W` | 关闭窗口 |
| `Ctrl+Tab` 和 `Ctrl+Shift+Tab` | 切换到右侧或左侧的标签页 |
| `Ctrl+L` | 访问搜索/地址栏 |
| `Ctrl+D` | 将网址放入书签 |
| `Ctrl+H` | 访问浏览历史 |
| `Ctrl+J` | 访问下载历史 |
| `Shift+Esc` | 打开 Chrome 任务管理器 |
你可以[下载这份有用的 Chrome 键盘快捷键列表来作为快速参考](tmp.3qZNXSy2FC#download-cheatsheet)。
#### 1、用 `Ctrl+T` 打开一个新标签页
需要打开一个新标签页吗?只需同时按 `Ctrl` 和 `T` 键,你就会打开一个新标签。
#### 2、使用 `Ctrl+N` 打开一个新窗口
已经打开太多标签页?是时候打开一个新的窗口。使用 `Ctrl` 和 `N` 键打开一个新的浏览器窗口。
#### 3、使用 `Ctrl+Shift+N` 隐身
在线查询航班或酒店价格?隐身可能会有所帮助。使用 `Ctrl+Shift+N` 在 Chrome 中打开一个隐身窗口。
#### 4、使用 `Ctrl+W` 关闭标签页
使用 `Ctrl` 和 `W` 键关闭当前标签页。无需将鼠标移到顶部并寻找 `x` 按钮。
#### 5、不小心关闭了标签页?用 `Ctrl+Shift+T` 重新打开
这是我最喜欢的 Google Chrome 浏览器快捷方式。当你关闭了原本不想关的标签页时,就不用再懊悔了。使用 `Ctrl+Shift+T`,它将打开最后一个关闭的选项卡。继续按此组合键,它把关闭的选项卡再次打开。
#### 6、使用 `Ctrl+Shift+W` 关闭整个浏览器窗口
完成工作了吗?是时候关闭带有所有标签页的整个浏览器窗口了。使用 `Ctrl+Shift+W` 键,浏览器窗口将消失,就像以前不存在一样。
#### 7、使用 `Ctrl+Tab` 在标签之间切换
打开的标签页太多了吗?你可以使用 `Ctrl+Tab` 移至右侧标签页。想左移吗?使用 `Ctrl+Shift+Tab`。重复按这些键,你可以在当前浏览器窗口的所有打开的标签页之间移动。
你也可以使用 `Ctrl+0` 直到 `Ctrl+9` 转到前 10 个标签页之一。但是此 Chrome 键盘快捷键不适用于第 11 个及更多标签页。
#### 8、使用 `Ctrl+L` 转到搜索/地址栏
想要输入新的 URL 或快速搜索一些内容。你可以使用 `Ctrl+L`,它将在顶部突出显示地址栏。
#### 9、用 `Ctrl+D` 收藏当前网站
找到了有趣的东西?使用 `Ctrl+D` 组合键将其保存在书签中。
#### 10、使用 `Ctrl+H` 返回历史记录
你可以使用 `Ctrl+H` 键打开浏览器历史记录。如果你正在寻找前一段时间访问过的页面,或者删除你不想再看到的页面,可以搜索历史记录。
#### 11、使用 `Ctrl+J` 查看下载
在 Chrome 中按 `Ctrl+J` 键将带你进入下载页面。此页面将显示你执行的所有下载操作。
#### 意外惊喜:使用 `Shift+Esc` 打开 Chrome 任务管理器
很多人甚至都不知道 Chrome 浏览器中有一个任务管理器。Chrome 以消耗系统内存而臭名昭著。而且,当你打开大量标签时,找到罪魁祸首并不容易。
使用 Chrome 任务管理器,你可以查看所有打开的标签页及其系统利用率统计信息。你还可以看到各种隐藏的进程,例如 Chrome 扩展程序和其他服务。

### 下载 Chrome 快捷键备忘单
我知道掌握键盘快捷键取决于习惯,你可以通过反复使用使其习惯。为了帮助你完成此任务,我创建了此 Google Chrome 键盘快捷键备忘单。

你可以[下载以下 PDF 格式的图像](https://drive.google.com/open?id=1lZ4JgRuFbXrnEXoDQqOt7PQH6femIe3t),进行打印并将其放在办公桌上。这样,你可以一直练习快捷方式。
如果你对掌握快捷方式感兴趣,还可以查看 [Ubuntu 键盘快捷键](https://itsfoss.com/ubuntu-shortcuts/)。
顺便问一下,你最喜欢的 Chrome 快捷方式是什么?
---
via: <https://itsfoss.com/google-chrome-shortcuts/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Google Chrome is the [most popular web browser](https://en.wikipedia.org/wiki/Usage_share_of_web_browsers) and there is no denying it. Its open source version [Chromium](https://www.chromium.org/Home) also gets some attention and some Linux distributions now include it as the default web browser.
If you have installed [Google Chrome on Ubuntu](https://itsfoss.com/install-chrome-ubuntu/) or any other operating system, you can improve your browsing experience by using Google Chrome keyboard shortcuts. No need to navigate around with your cursor to get things done. Just master these shortcuts, and you’ll even save some time and be more productive.
I am using the term Google Chrome, but these shortcuts are equally applicable to many [Chromium-based browsers](https://news.itsfoss.com/chrome-like-browsers-2021/).
### 11 Cool Chrome Keyboard shortcuts you should be using
If you are a pro, you might know a few of these Chrome shortcuts already but the chances are that you may still find some hidden gems here. Let’s see.
Keyboard Shortcuts | Action |
---|---|
Ctrl+T | Open a new tab |
Ctrl+N | Open a new window |
Ctrl+Shift+N | Open incognito window |
Ctrl+W | Close current tab |
Ctrl+Shift+T | Reopen last closed tab |
Ctrl+Shift+W | Close the window |
Ctrl+Tab and Ctrl+Shift+Tab | Switch to right or left tab |
Ctrl+L | Go to search/address bar |
Ctrl+D | Bookmark the website |
Ctrl+H | Access browsing history |
Ctrl+J | Access downloads history |
Shift+Esc | Open Chrome task manager |
You can download this list of useful Chrome keyboard shortcuts for quick reference.
### 1. Open a new tab with Ctrl+T
Need to open a new tab? Just press Ctrl and T keys together and you’ll have a new tab opened.
### 2. Open a new window with Ctrl+N
Too many tabs opened already? Time to open a fresh new window. Use Ctrl and N keys to open a new browser window.
### 3. Go incognito with Ctrl+Shift+N
Checking flight or hotel prices online? Going incognito might help. Open an incognito window in Chrome with Ctrl+Shift+N.
### 4. Close a tab with Ctrl+W
Close the current tab with Ctrl and W key. No need to take the mouse to the top and look for the x button.
### 5. Accidentally closed a tab? Reopen it with Ctrl+Shift+T
This is my favorite Google Chrome shortcut. No more ‘oh crap’ when you close a tab you didn’t mean to. Use the Ctrl+Shift+T and it will open the last closed tab. Keep hitting this key combination and it will keep on bringing the closed tabs.
[Cloud Computing & Linux Servers | Alternative to AWS | LinodeSimplify your infrastructure with Linode’s cloud computing and hosting solutions and develop, deploy, and scale faster and easier.](https://www.linode.com/?r=19db9d1ce8c1c91023c7afef87a28ce8c8c067bd)

### 6. Close the entire browser window with Ctrl+Shift+W
Done with your work? Time to close the entire browser window with all the tabs. Use the keys Ctrl+Shift+W and the browser window will disappear like it never existed.
### 7. Switch between tabs with Ctrl+Tab
Too many tabs open? You can move to the right tab with Ctrl+Tab. Want to move left? Use Ctrl+Shift+Tab. Press these keys repeatedly and you can move between all the open tabs in the current browser window.
You can also use Ctrl+0 to Ctrl+9 to go to one of the first ten tabs. But this Chrome keyboard shortcut doesn’t work for the 11th tabs onward.
### 8. Go to the search/address bar with Ctrl+L
Want to type a new URL or search for something quickly? You can use Ctrl+L and it will highlight the address bar on the top.
### 9. Bookmark the current website with Ctrl+D
Found something interesting? Save it in your bookmarks with the Ctrl+D keys combination.
### 10. Go back in history with Ctrl+H
You can open up your browser history with the Ctrl+H keys. Search through the history if you are looking for a page visited some time ago or deleted something that you don’t want to be seen anymore.
### 11. See your downloads with Ctrl+J
Pressing the Ctrl+J keys in Chrome will take you to the Downloads page. This page will show you all the downloads action you performed.
### Bonus shortcut: Open Chrome task manager with Shift+Esc
Many people don’t even know that there is a task manager in the Chrome browser. Chrome is infamous for eating up your system’s RAM. And when you have plenty of tabs opened, finding the culprit is not easy.
You can see all the open tabs and their system utilization stats with Chrome task manager. You can also see hidden processes such as Chrome extensions and other services.
I am going to this table here for a quick reference.
## Download Chrome keyboard shortcuts cheatsheet
I know that mastering keyboard shortcuts depends on habit; you can make it a habit by using it repeatedly.
To help you in this task, I have created this Google Chrome keyboard shortcut cheat sheet.
You can download the below image in PDF form, print it, and put it on your desk. This way you can use practice the shortcuts frequently.

*Google Chrome Keyboard Shortcuts Cheat Sheet*
## Keyboard shortcut fan? Here are more
I guess you use more than one browser. If Firefox is the other browser, you can use similar shortcuts there as well.
[15 Useful Firefox Keyboard Shortcuts [With Cheatsheet]Love Mozilla Firefox browser? Use it more efficiently by using these keyboard shortcuts.](https://itsfoss.com/firefox-keyboard-shortcuts/)

Use Ubuntu? Feel like a pro user with these shortcuts.
[13 Keyboard Shortcuts Every Ubuntu User Should KnowKnowing keyboard shortcuts increase your productivity. Here are some useful Ubuntu shortcut keys that will help you use Ubuntu like a pro. You can use an operating system with the combination of keyboard and mouse but using the keyboard shortcuts saves your time. Note: The keyboard shortcu…](https://itsfoss.com/ubuntu-shortcuts/)

Using some other Linux distribution? The terminal shortcuts will help you a great deal.
[13 Linux Terminal Shortcuts Every Power Linux User Must Know [Free Cheatsheet]Use Linux command line like a pro by mastering these Linux terminal shortcuts and increase your productivity. It’s a must for any power Linux user.](https://linuxhandbook.com/linux-shortcuts/)

By the way, what’s your favorite Chrome shortcut? |
11,557 | 如何拥有一个 Windows 10 和 Debian 10 的双系统 | https://www.linuxtechi.com/dual-boot-windows-10-debian-10/ | 2019-11-09T23:32:00 | [
"Windows"
] | https://linux.cn/article-11557-1.html | 在无数次劝说自己后,你终于做出了一个大胆的决定,试试 Linux。不过,在完全熟悉 Linux 之前,你依旧需要使用 Windows 10 系统。幸运的是,通过一个双系统引导设置,能让你在启动时,选择自己想要进入的系统。在这个指南中,你会看到如何 如何双重引导 Windows 10 和 Debian 10。

### 前提条件
在开始之前,确保你满足下列条件:
* 一个 Debian 10 的可引导 USB 或 DVD
* 一个快速且稳定的网络(为了安装更新以及第三方软件)
另外,记得注意你系统的引导策略(UEFI 或 Legacy),需要确保两个系统使用同一种引导模式。
### 第一步:在硬盘上创建一个空余分区
第一步,你需要在你的硬盘上创建一个空余分区。之后,这将是我们安装 Debian 系统的地方。为了实现这一目的,需要使用下图所示的磁盘管理器:
同时按下 `Windows + R` 键,启动“运行程序”。接下来,输入 `diskmgmt.msc`,按回车键。

这会启动“磁盘管理”窗口,它会显示你 Windows 上所有已有磁盘。

接下来,你需要为安装的 Debian 系统创建空余空间。为此,你需要缩小其中一个磁盘(卷)上的分区,从而创建一个未分配的新分区。在这个例子里,我会从 D 盘中创建一个 30 GB 的新分区。
为了缩小一个卷,右键点击它,然后选中选项 “<ruby> 缩小 <rt> Shrink volume… </rt></ruby>”。

在弹出窗口中,定义你想缩小的空间大小。记住,这是将来要安装 Debian 10 的磁盘空间。我选择了 30000MB(大约 30 GB)。压缩完成后,点击“<ruby> 缩小 <rt> Shrink </rt></ruby>”。

在缩小操作结束后,你会看到一个如下图所示的未分配分区:

完美!现在可以准备开始安装了。
### 第二步:开始安装 Debian 10
空余分区已经创建好了,将你的可引导 USB 或安装 DVD 插入电脑,重新启动系统。记得更改 BIOS 中的引导顺序,需要在启动时按住功能键(通常,根据品牌不同,是 `F9`、`F10` 或 `F12` 中的某一个)。 这一步骤,对系统是否能进入安装媒体来说,至关重要。保存 BIOS 设置,并重启电脑。
如下图所示,界面会显示一个新的引导菜单:点击 “Graphical install”。

下一步,选择你的偏好语言,然后点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

接着,选择你的地区,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。 根据地区,系统会自动选择当地对应的时区。如果你无法找到你所对应的地区,将界面往下拉, 点击“<ruby> 其他 <rt> Other </rt></ruby>”后,选择相对应位置。

而后,选择你的键盘布局。

接下来,设置系统的主机名,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

下一步,确定域名。如果你的电脑不在域中,直接点击 “<ruby> 继续 <rt> Continue </rt></ruby>”按钮。

然后,如图所示,设置 root 密码,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

下一步骤,设置账户的用户全名,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

接着,设置与此账户相关联的用户名。

下一步,设置用户密码,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

然后,设置时区。

这时,你要为 Debian10 安装创建分区。如果你是新手用户,点击菜单中的第一个选项,“<ruby> 使用最大的连续空余空间 <rt> Use the largest continuous free space </rt></ruby>”,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

不过,如果你对创建分区有所了解的话,选择“<ruby> 手动 <rt> Manual </rt></ruby>” 选项,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

接着,选择被标记为 “<ruby> 空余空间 <rt> FREE SPACE </rt></ruby>” 的磁盘,点击 “<ruby> 继续 <rt> Continue </rt></ruby>” 。接下来,点击“<ruby> 创建新分区 <rt> Create a new partition </rt></ruby>”。

下一界面,首先确定交换空间大小。我的交换空间大小为 2GB,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

点击下一界面的 “<ruby> 主分区 <rt> Primary </rt></ruby>”,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

选择在磁盘 “<ruby> 初始位置 <rt> beginning </rt></ruby>” 创建新分区后,点击继续。

选择 “<ruby> Ext 4 日志文件系统 <rt> Ext 4 journaling file system </rt></ruby>”,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

下个界面选择“<ruby> 交换空间 <rt> swap space </rt></ruby>” ,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

选中 “<ruby> 完成此分区设置 <rt> done setting the partition </rt></ruby>”,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

返回磁盘分区界面,点击 “<ruby> 空余空间 <rt> FREE SPACE </rt></ruby>”,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

为了让自己能轻松一点,选中 “<ruby> 自动为空余空间分区 <rt> Automatically partition the free space </rt></ruby>”后,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

接着点击 “<ruby> 将所有文件存储在同一分区(新手用户推荐) <rt> All files in one partition (recommended for new users) </rt></ruby>”。

最后, 点击 “<ruby> 完成分区设置,并将改动写入磁盘 <rt> Finish partitioning and write changes to disk </rt></ruby>” ,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

确定你要将改动写入磁盘,点击 “<ruby> 是 <rt> Yes </rt></ruby>”。

而后,安装程序会开始安装所有必要的软件包。
当系统询问是否要扫描其他 CD 时,选择 “<ruby> 否 <rt> No </rt></ruby>” ,并点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

接着,选择离你最近的镜像站点地区,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

然后,选择最适合你的镜像站点,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

如果你打算使用代理服务器,在下面输入具体信息,没有的话就留空,点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

随着安装进程的继续, 你会被问到,是否想参加一个软件包用途调查。你可以选择任意一个选项,之后点击“<ruby> 继续 <rt> Continue </rt></ruby>”,我选择了“<ruby> 否 <rt> No </rt></ruby>”。

在软件选择窗口选中你想安装的软件包,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

安装程序会将选中的软件一一安装,在这期间,你可以去喝杯咖啡休息一下。
系统将会询问你,是否要将 grub 的引导装载程序安装到主引导记录表(MBR)上。点击 “<ruby> 是 <rt> Yes </rt></ruby>”,而后点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

接着,选中你想安装 grub 的硬盘,点击“<ruby> 继续 <rt> Continue </rt></ruby>”。

最后,安装完成,直接点击 “<ruby> 继续 <rt> Continue </rt></ruby>”。

你现在应该会有一个列出 Windows 和 Debian 的 grub 菜单。为了引导 Debian 系统,往下选择 Debian。之后,你就能看见登录界面。输入密码之后,按回车键。

这就完成了!这样,你就拥有了一个全新的 Debian 10 和 Windows 10 双系统。

---
via: <https://www.linuxtechi.com/dual-boot-windows-10-debian-10/>
作者:[James Kiarie](https://www.linuxtechi.com/author/james/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wenwensnow](https://github.com/wenwensnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So, you finally made the bold decision to try out **Linux** after much convincing. However, you do not want to let go of your Windows 10 operating system yet as you will still be needing it before you learn the ropes on Linux. Thankfully, you can easily have a dual boot setup that allows you to switch to either of the operating systems upon booting your system. In this guide, you will learn how to **dual boot Windows 10 alongside Debian 10**.
#### Prerequisites
Before you get started, ensure you have the following:
- A bootable USB or DVD of Debian 10
- A fast and stable internet connection ( For installation updates & third party applications)
Additionally, it worth paying attention to how your system boots (UEFI or Legacy) and ensure both the operating systems boot using the same boot mode.
#### Step 1: Create a free partition on your hard drive
To start off, you need to create a free partition on your hard drive. This is the partition where Debian will be installed during the installation process. To achieve this, you will invoke the disk management utility as shown:
Press** Windows Key + R** to launch the Run dialogue. Next, type **diskmgmt.msc** and hit **ENTER**
This launches the **disk management** window displaying all the drives existing on your Windows system.
Next, you need to create a free space for Debian installation. To do this, you need to shrink a partition from one of the volumes and create a new unallocated partition. In this case, I will create a **30 GB** partition from Volume D.
To shrink a volume, right-click on it and select the ‘**shrink**’ option
In the pop-up dialogue, define the size that you want to shrink your space. Remember, this will be the disk space on which Debian 10 will be installed. In my case, I selected **30000MB ( Approximately 30 GB)**. Once done, click on ‘**Shrink**’.
After the shrinking operation completes, you should have an unallocated partition as shown:
Perfect! We are now good to go and ready to begin the installation process.
#### Step 2: Begin the installation of Debian 10
With the free partition already created, plug in your bootable USB drive or insert the DVD installation medium in your PC and reboot your system. Be sure to make changes to the** boot order** in the **BIOS** set up by pressing the function keys (usually, **F9, F10 or F12** depending on the vendor). This is crucial so that the PC boots into your installation medium. Saves the BIOS settings and reboot.
A new grub menu will be displayed as shown below: Click on ‘**Graphical install**’
In the next step, select your** preferred language** and click ‘**Continue**’
Next, select your **location** and click ‘**Continue**’. Based on this location the time will automatically be selected for you. If you cannot find you located, scroll down and click on ‘**other**’ then select your location.
Next, select your **keyboard** layout.
In the next step, specify your system’s **hostname** and click ‘**Continue**’
Next, specify the **domain name**. If you are not in a domain environment, simply click on the ‘**continue**’ button.
In the next step, specify the** root password** as shown and click ‘**continue**’.
In the next step, specify the full name of the user for the account and click ‘**continue**’
Then set the account name by specifying the **username** associated with the account
Next, specify the username’s password as shown and click ‘**continue**’
Next, specify your **timezone**
At this point, you need to create partitions for your Debian 10 installation. If you are an inexperienced user, Click on the ‘**Use the largest continuous free space**’ and click ‘**continue**’.
However, if you are more knowledgeable about creating partitions, select the ‘**Manual**’ option and click ‘**continue**’
Thereafter, select the partition labeled ‘**FREE SPACE**’ and click ‘**continue**’ . Next click on ‘**Create a new partition**’.
In the next window, first, define the size of swap space, In my case, I specified **2GB**. Click **Continue**.
Next, click on ‘’**Primary**’ on the next screen and click ‘**continue**’
Select the partition to **start at the beginning** and click continue.
Next, click on **Ext 4 journaling file system** and click ‘**continue**’
On the next window, select **swap **and click continue
Next, click on **done setting the partition** and click continue.
Back to the **Partition disks** page, click on **FREE SPACE** and click continue
To make your life easy select **Automatically partition the free space** and click **continue**.
Next click on **All files in one partition (recommended for new users)**
Finally, click on **Finish partitioning and write changes to disk** and click **continue**.
Confirm that you want to write changes to disk and click ‘**Yes**’
Thereafter, the installer will begin installing all the requisite software packages.
When asked if you want to scan another CD, select **No** and click continue
Next, select the mirror of the Debian archive closest to you and click ‘Continue’
Next, select the **Debian mirror** that is most preferable to you and click ‘**Continue**’
If you plan on using a proxy server, enter its details as shown below, otherwise leave it blank and click ‘continue’
As the installation proceeds, you will be asked if you would like to participate in a **package usage survey**. You can select either option and click ‘continue’ . In my case, I selected ‘**No**’
Next, select the packages you need in the **software selection** window and click **continue**.
The installation will continue installing the selected packages. At this point, you can take a coffee break as the installation goes on.
You will be prompted whether to install the grub **bootloader** on** Master Boot Record (MBR)**. Click **Yes** and click **Continue**.
Next, select the hard drive on which you want to install **grub** and click **Continue**.
Finally, the installation will complete, Go ahead and click on the ‘**Continue**’ button
You should now have a grub menu with both **Windows** and **Debian** listed. To boot to Debian, scroll and click on Debian. Thereafter, you will be prompted with a login screen. Enter your details and hit ENTER.
And voila! There goes your fresh copy of Debian 10 in a dual boot setup with Windows 10.
JeffThis was perfect. I was able to breeze through a Win 10/Debian 11 partition, install, and successful boot. Thanks much! |
11,559 | 低价 Linux 智能手机 PinePhone 即将接受预订 | https://itsfoss.com/pinephone/ | 2019-11-10T22:06:43 | [
"手机"
] | https://linux.cn/article-11559-1.html | 
你还记得[在 2017 年首次披露](https://itsfoss.com/pinebook-kde-smartphone/)的 Pine64 正在开发一个基于 Linux(可以运行 KDE Plasma 及其他发行版)的智能手机的事情吗?从那以后已经有一段时间了,但是好消息是 PinePhone 将从 11 月 15 日开始接受预订。
让我来为你提供有关 PinePhone 的更多详细信息,例如其规格、价格和发布日期。
### PinePhone:基于 Linux 的廉价智能手机
PinePhone 开发者套件已经经过了一些开发人员的测试,更多此类套件将于 11 月 15 日发货。你可以查看下面的照片:



开发者套件是由 PINE A64 基板 + SOPine 模块 + 7 英寸触摸屏显示器 + 摄像头 + Wifi / BT + 外壳 + 锂离子电池盒 + LTE cat 4 USB 软件狗组成的组合套件。
这些组合套件可以使开发人员快速开始 PinePhone 开发。由于 PINE64 社区和 [KDE neon](https://neon.kde.org/) 的支持,主线 Linux 操作系统已经可以在 PINE A64 平台上构建。
#### PinePhone 规格
* Allwinner A64 四核 SoC,带有 Mali 400 MP2 GPU
* 2GB 的 LPDDR3 RAM
* 5.95 英寸 LCD 1440×720,长宽比 18:9(钢化玻璃)
* 可启动的 Micro SD
* 16GB eMMC
* 高清数字视频输出
* USB Type-C(电源、数据和视频输出)
* Quectel EG-25G 全球波段
* WiFi:802.11 b/g/n,单频,支持热点
* 蓝牙:4.0,A2DP
* GNSS:GPS,GPS-A,GLONASS
* 振动器
* RGB 状态 LED
* 自拍和主摄像头(分别为 2/5 Mpx)
* 主摄像头:单颗 OV6540、5MP,1/4 英寸,LED 闪光灯
* 自拍相机:单 GC2035、2MP,f/2.8、1/5 英寸
* 传感器:加速器、陀螺仪、距离感应器、罗盘、气压计、环境光感
* 3 个外部开关:上、下和电源
* 硬件开关:LTE/GNSS、WiFi、麦克风、扬声器、USB
* 三星 J7 外形尺寸 3000mAh 电池
* 外壳是磨砂黑色成品塑料
* 耳机插孔
#### 产品、价格和交付时间
PinePhone 的价格约为 150 美元。尝鲜版命名为“勇敢的心”,将于 2019 年 11 月 15 日开始销售。如上图所示,[Pine64 的主页](https://www.pine64.org/)包含了用于首次预订 PinePhone 的计时器。
预期“勇敢的心”尝鲜版在 2019 年 12 月或 2020 年 1 月之前发货。
大规模生产将在中国的农历新年后开始,也就是说在 2020 年第二季度早期或最早 2020 年 3 月开始。
该电话尚未在 Pine Store 中列出,因此,如果你想成为尝鲜者之一,请务必查看 [Pine64 在线商店](https://store.pine64.org/)以预订“勇敢的心”版本。
#### 你对 PinePhone 如何看?
Pine64 已经开发了一款名为 [Pinebook](https://itsfoss.com/pinebook-linux-notebook/) 的廉价笔记本电脑和一款功能相对强大的 [Pinebook Pro](https://itsfoss.com/pinebook-pro/) 笔记本电脑。因此,PinePhone 至少在 DIY 爱好者和 Linux 忠实拥护者的狭窄市场中绝对有希望获得成功。与其他价格超过 600 美元的 [Linux 智能手机 Librem5](https://itsfoss.com/librem-linux-phone/) 相比,低廉的价格绝对是一个巨大的优势。
PinePhone 的另一个优点是,你可以通过安装 Ubuntu Touch、Plasma Mobile 或 Aurora OS/Sailfish OS 来试验操作系统。
这些基于 Linux 的智能手机尚不具备取代 Android 或 iOS 的功能。如果你正在寻找功能全面的智能手机来替代你的 Android 智能手机,那么 PinePhone 当然不适合你。但对于喜欢尝试并且不害怕排除故障的人来说,它的优势更大。
如果你想购买 PinePhone,请记住这个日期并设置提醒。供应应该是限量的,到目前为止,我所了解的,Pine 设备很快就会脱销。
你要预订 PinePhone 吗?在评论部分将你的意见告知我们。
---
via: <https://itsfoss.com/pinephone/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you remember when [It’s FOSS first broke the story that Pine64 was working on a Linux-based smartphone](https://itsfoss.com/pinebook-kde-smartphone/) running KDE Plasma (among other distributions) in 2017? It’s been some time since then but the good news is that PinePhone will be available for pre-order from 15th November.
Let me provide you more details on the PinePhone like its specification, pricing and release date.
## PinePhone: Linux-based budget smartphone
The PinePhone developer kit is already being tested by some devs and more such kits will be shipped by 15th November. You can check out some of these images by clicking the photo gallery below:
[interaction id = 5dc3bd40daa2331ca527b940]
The developer kit is a combo kit of PINE A64 baseboard + SOPine module + 7″ Touch Screen Display + Camera + Wifi/BT + Playbox enclosure + Lithium-Ion battery case + LTE cat 4 USB dongle.
These combo kits allow developers to jump start PinePhone development. The PINE A64 platform already has mainline Linux OS build thanks to the PINE64 community and the support by [KDE neon](https://neon.kde.org/).
### Specifications of PinePhone

**Martjin Braam**
- Allwinner A64 Quad Core SoC with Mali 400 MP2 GPU
- 2GB of LPDDR3 RAM
- 5.95″ LCD 1440×720, 18:9 aspect ratio (hardened glass)
- Bootable Micro SD
- 16GB eMMC
- HD Digital Video Out
- USB Type C (Power, Data and Video Out)
- Quectel EG-25G with worldwide bands
- WiFi: 802.11 b/g/n, single-band, hotspot capable
- Bluetooth: 4.0, A2DP
- GNSS: GPS, GPS-A, GLONASS
- Vibrator
- RGB status LED
- Selfie and Main camera (2/5Mpx respectively)
- Main Camera: Single OV6540, 5MP, 1/4″, LED Flash
- Selfie Camera: Single GC2035, 2MP, f/2.8, 1/5″
- Sensors: accelerator, gyro, proximity, compass, barometer, ambient light
- 3 External Switches: up down and power
- HW switches: LTE/GNSS, WiFi, Microphone, Speaker, USB
- Samsung J7 form-factor 3000mAh battery
- Case is matte black finished plastic
- Headphone Jack
### Production, Price & Availability

PinePhone will cost about $150. The early adapter release has been named ‘Brave Heart’ edition and it will go on sale from November 15, 2019. As you can see in the image above, [Pine64’s homepage](https://www.pine64.org/) has included a timer for the first pre-order batch of PinePhone.
You should expect the early adopter ‘Brave Heart’ editions to be shipped and delivered by December 2019 or January 2020.
Mass production will begin only after the Chinese New Year, hinting at early Q2 of 2020 or March 2020 (at the earliest).
The phone hasn’t yet been listed on Pine Store – so make sure to check out [Pine64 online store](https://store.pine64.org/) to pre-order the ‘Brave Heart’ edition if you want to be one of the early adopters.
### What do you think of PinePhone?
Pine64 has already created a budget laptop called [Pinebook](https://itsfoss.com/pinebook-linux-notebook/) and a relatively powerful [Pinebook Pro](https://itsfoss.com/pinebook-pro/) laptop. So, there is definitely hope for PinePhone to succeed, at least in the niche of DIY enthusiasts and hardcore Linux fans. The low pricing is definitely a huge plus here compared to the other [Linux smartphone Librem5](https://itsfoss.com/librem-linux-phone/) that costs over $600.
Another good thing about PinePhone is that you can experiment with the operating system by installing Ubuntu Touch, Plasma Mobile or Aurora OS/Sailfish OS.
These Linux-based smartphones don’t have the features to replace Android or iOS, yet. If you are looking for a fully functional smartphone to replace your Android smartphone, PinePhone is certainly not for you. It’s more for people who like to experiment and are not afraid to troubleshoot.
If you are looking to buy PinePhone, mark the date and set a reminder. There will be limited supply and what I have seen so far, Pine devices go out of stock pretty soon.
*Are you going to pre-order a PinePhone? Let us know of your views in the comment section.* |
11,560 | 在 Fedora 上优化 bash 或 zsh | https://fedoramagazine.org/tuning-your-bash-or-zsh-shell-in-workstation-and-silverblue/ | 2019-11-10T23:36:26 | [
"bash",
"zsh"
] | https://linux.cn/article-11560-1.html | 
本文将向你展示如何在 Fedora 的命令行解释器(CLI)Shell 中设置一些强大的工具。如果使用bash(默认)或zsh,Fedora 可让你轻松设置这些工具。
### 前置需求
这需要一些已安装的软件包。在 Fedora 工作站上,运行以下命令:
```
sudo dnf install git wget curl ruby ruby-devel zsh util-linux-user redhat-rpm-config gcc gcc-c++ make
```
在 Silverblue 上运行:
```
sudo rpm-ostree install git wget curl ruby ruby-devel zsh util-linux-user redhat-rpm-config gcc gcc-c++ make
```
注意:在 Silverblue 上,你需要重新启动才能继续。
### 字体
你可以通过安装新字体使终端焕然一新。为什么不使用可以同时显示字符和图标的字体呢?
#### Nerd-Fonts
打开一个新终端,然后键入以下命令:
```
git clone https://github.com/ryanoasis/nerd-fonts ~/.nerd-fonts
cd .nerd-fonts
sudo ./install.sh
```
#### Awesome-Fonts
在工作站上,使用以下命令进行安装:
```
sudo dnf fontawesome-fonts
```
在 Silverblue 上键入:
```
sudo rpm-ostree install fontawesome-fonts
```
### Powerline
Powerline 是 vim 的状态行插件,并为其他几个应用程序也提供了状态行和提示符,包括 bash、zsh、tmus、i3、Awesome、IPython 和 Qtile。你也可以在官方[文档站点](https://powerline.readthedocs.io/en/latest/)上找到更多信息。
#### 安装
要在 Fedora 工作站上安装 Powerline 实用程序,请打开一个新终端并运行:
```
sudo dnf install powerline vim-powerline tmux-powerline powerline-fonts
```
在 Silverblue 上,命令更改为:
```
sudo rpm-ostree install powerline vim-powerline tmux-powerline powerline-fonts
```
注意:在 Silverblue 上,你需要重新启动才能继续。
#### 激活 Powerline
要使 Powerline 默认处于活动状态,请将下面的代码放在 `~/.bashrc` 文件的末尾:
```
if [ -f `which powerline-daemon` ]; then
powerline-daemon -q
POWERLINE_BASH_CONTINUATION=1
POWERLINE_BASH_SELECT=1
. /usr/share/powerline/bash/powerline.sh
fi
```
最后,关闭终端并打开一个新终端。它看起来像这样:

### Oh-My-Zsh
[Oh-My-Zsh](https://ohmyz.sh) 是用于管理 Zsh 配置的框架。它捆绑了有用的功能、插件和主题。要了解如何将 Zsh 设置为默认外壳程序,请参见[这篇文章](https://fedoramagazine.org/set-zsh-fedora-system/)。
#### 安装
在终端中输入:
```
sh -c "$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"
```
或者,你也可以输入以下内容:
```
sh -c "$(wget https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh -O -)"
```
最后,你将看到如下所示的终端:

恭喜,Oh-my-zsh 已安装成功。
#### 主题
安装后,你可以选择主题。我喜欢使用 powerlevel10k。优点之一是它比 powerlevel9k 主题快 100 倍。要安装它,请运行以下命令行:
```
git clone https://github.com/romkatv/powerlevel10k.git ~/.oh-my-zsh/themes/powerlevel10k
```
并在你的 `~/.zshrc` 文件设置 `ZSH_THEME`:
```
ZSH_THEME=powerlevel10k/powerlevel10k
```
关闭终端。再次打开终端时,powerlevel10k 配置向导将询问你几个问题以正确配置提示符。

完成 powerline10k 配置向导后,你的提示符将如下所示:

如果你不喜欢它。你可以随时使用 `p10k configure` 命令来运行 powerline10k 向导。
#### 启用插件
插件存储在 `.oh-my-zsh/plugins` 文件夹中。要激活插件,你需要编辑 `~/.zshrc` 文件。安装插件意味着你创建了一系列执行特定功能的别名或快捷方式。
例如,要启用 firewalld 和 git 插件,请首先编辑 `~/.zshrc`:
```
plugins=(firewalld git)
```
注意:使用空格分隔插件名称列表。
然后重新加载配置:
```
source ~/.zshrc
```
要查看创建的别名,请使用以下命令:
```
alias | grep firewall
```

#### 更多配置
我建议安装语法高亮和语法自动建议插件。
```
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
```
将它们添加到文件 `~/.zshrc` 的插件列表中。
```
plugins=( [plugins...] zsh-syntax-highlighting zsh-autosuggestions)
```
重新加载配置。
```
source ~/.zshrc
```
查看结果:

### 彩色的文件夹和图标
`colorls` 是一个 ruby gem,可使用颜色和超棒的字体图标美化终端的 `ls` 命令。你可以访问官方[网站](https://github.com/athityakumar/colorls)以获取更多信息。
因为它是个 ruby gem,所以请按照以下简单步骤操作:
```
sudo gem install colorls
```
要保持最新状态,只需执行以下操作:
```
sudo gem update colorls
```
为防止每次输入 `colorls`,你可以在 `~/.bashrc` 或 `~/.zshrc` 中创建别名。
```
alias ll='colorls -lA --sd --gs --group-directories-first'
alias ls='colorls --group-directories-first'
```
另外,你可以为 `colorls` 的选项启用制表符补完功能,只需在 shell 配置末尾输入以下行:
```
source $(dirname ($gem which colorls))/tab_complete.sh
```
重新加载并查看会发生什么:


---
via: <https://fedoramagazine.org/tuning-your-bash-or-zsh-shell-in-workstation-and-silverblue/>
作者:[George Luiz Maluf](https://fedoramagazine.org/author/georgelmaluf/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article shows you how to set up some powerful tools in your command line interpreter (CLI) shell on Fedora. If you use *bash* (the default) or *zsh*, Fedora lets you easily setup these tools.
## Requirements
Some installed packages are required. On Workstation, run the following command:
sudo dnf install git wget curl ruby ruby-devel zsh util-linux-user redhat-rpm-config gcc gcc-c++ make
On Silverblue run:
sudo rpm-ostree install git wget curl ruby ruby-devel zsh util-linux-user redhat-rpm-config gcc gcc-c++ make
**Note**: On Silverblue you need to restart before proceeding.
## Fonts
You can give your terminal a new look by installing new fonts. Why not fonts that display characters and icons together?
#### Nerd-Fonts
Open a new terminal and type the following commands:
git clone --depth=1 https://github.com/ryanoasis/nerd-fonts ~/.nerd-fonts cd .nerd-fonts sudo ./install.sh
#### Awesome-Fonts
On Workstation, install using the following command:
sudo dnf install fontawesome-fonts
On Silverblue, type:
sudo rpm-ostree install fontawesome-fonts
## Powerline
Powerline is a statusline plugin for vim, and provides statuslines and prompts for several other applications, including bash, zsh, tmus, i3, Awesome, IPython and Qtile. You can find more information about powerline on the official [documentation site](https://powerline.readthedocs.io/en/latest/).
### Installation
To install powerline utility on Fedora Workstation, open a new terminal and run:
sudo dnf install powerline vim-powerline tmux-powerline powerline-fonts
On Silverblue, the command changes to:
sudo rpm-ostree install powerline vim-powerline tmux-powerline powerline-fonts
**Note**: On Silverblue, before proceeding you need restart.
### Activating powerline
To make the powerline active by default, place the code below at the end of your *~/.bashrc* file
if [ -f `which powerline-daemon` ]; then powerline-daemon -q POWERLINE_BASH_CONTINUATION=1 POWERLINE_BASH_SELECT=1 . /usr/share/powerline/bash/powerline.sh fi
Finally, close the terminal and open a new one. It will look like this:
## Oh-My-Zsh
[Oh-My-Zsh](https://ohmyz.sh) is a framework for managing your Zsh configuration. It comes bundled with helpful functions, plugins, and themes. To learn how set Zsh as your default shell this [article](https://fedoramagazine.org/set-zsh-fedora-system/).
### Installation
Type this in the terminal:
sh -c "$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"
Alternatively, you can type this:
sh -c "$(wget https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh -O -)"
At the end, you see the terminal like this:
Congratulations, Oh-my-zsh is installed.
### Themes
Once installed, you can select your theme. I prefer to use the Powerlevel10k. One advantage is that it is 100 times faster than powerlevel9k theme. To install run this line:
git clone https://github.com/romkatv/powerlevel10k.git ~/.oh-my-zsh/themes/powerlevel10k
And set ZSH_THEME in your *~/.zshrc* file
ZSH_THEME=powerlevel10k/powerlevel10k
Close the terminal. When you open the terminal again, the Powerlevel10k configuration wizard will ask you a few questions to configure your prompt properly.
After finish Powerline10k configuration wizard, your prompt will look like this:
If you don’t like it. You can run the powerline10k wizard any time with the command *p10k configure*.
### Enable plug-ins
Plug-ins are stored in *.oh-my-zsh/plugins* folder. You can visit this site for more information. To activate a plug-in, you need edit your *~/.zshrc *file. Install plug-ins means that you are going create a series of aliases or shortcuts that execute a specific function.
For example, to enable the firewalld and git plugins, first edit ~/.zshrc:
plugins=(firewalld git)
**Note**: use a blank space to separate the plug-ins names list.
Then reload the configuration
source ~/.zshrc
To see the created aliases, use the command:
alias | grep firewall
### Additional configuration
I suggest the install syntax-highlighting and syntax-autosuggestions plug-ins.
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
Add them to your plug-ins list in your file *~/.zshrc*
plugins=( [plugins...] zsh-syntax-highlighting zsh-autosuggestions)
Reload the configuration
source ~/.zshrc
See the results:
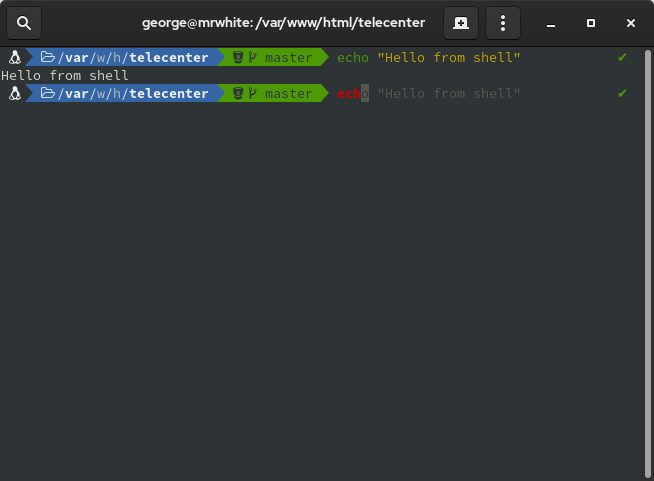
## Colored folders and icons
Colorls is a Ruby gem that beautifies the terminal’s ls command, with colors and font-awesome icons. You can visit the official [site](https://github.com/athityakumar/colorls) for more information.
Because it’s a ruby gem, just follow this simple step:
sudo gem install colorls
To keep up to date, just do:
sudo gem update colorls
To prevent type colorls everytime you can make aliases in your *~/.bashrc* or *~/.zshrc*.
alias ll='colorls -lA --sd --gs --group-directories-first' alias ls='colorls --group-directories-first'
Also, you can enable tab completion for colorls flags, just entering following line at end of your shell configuration:
source $(dirname $(gem which colorls))/tab_complete.sh
Reload it and see what it happens:
## Richzendy
Oh, thanks, i’m trying Powerline, how sysadmin it’s time to move a new and powerfull shell because i use a lot of time the CLI.
You forget “install” on the:
sudo dnf fontawesome-fonts
## Paul W. Frields
Thanks! Fixed.
## anonymous
A faster alternative to colorls is lsd (ls deluxe).
https://github.com/Peltoche/lsd
https://src.fedoraproject.org/rpms/rust-lsd
https://crates.io/crates/lsd#benchmark
## Daniel
A few suggestions for this article.
You don’t need to install git, wget or curl on SIlverblue, it ships with them.
Also, instead of util-linux-user, you can just use usermod
usermod -s /usr/bin/zsh $USER
ruby-devel will pull in ruby, so it doesn’t need to be explicitly mentioned, if you want to keep your installed packages list small on Silverblue.
## Carlos
You should take a look at Starship
https://github.com/starship/starship
## jugmac00
I ditched PowerLine for starship and it was a good decision 🙂
## ensbro
Wow, a lot to cover on this weekend \o/ Thanks
P.S. i believe awesome fonts installation snippet is missing install, e.g.:
sudo dnf install fontawesome-fonts
## Seirdy
ZSH users might appreciate
powerlevel10k0 for its faster startup speed thanks in part to its new “instant prompt”1 feature and its ultrafast reimplementation ofgit status. A brand-new transient prompt feature was described in a Reddit post[2] that allows a persistent fancy prompt at the bottom of the terminal, underneath historical commands with minimal prompts.## Lyes Saadi
You dont need to use sudo to install something with rpm-ostree ;).
## Skavoovie
Warning: The Nerd Fonts GitHub repo is more than 6 GiB in size. o_O
## Alex
Yes, they say it loud in clearly on their github page:
”
* Important Notices
master branch file paths are not considered stable. Verify your repository URI references
cloning this repository is not recommended (due to Repo size) unless you are going to be contributing to development
”
So the advice given out here to thousands of users is in two ways fatally wrong. Please do some proof reading before publishing.
## Paul W. Frields
I have yet to hear about anyone or their system dying from a large download. Whether you download the git branch or the collection of all fonts, it will be really large.
## dmaphy
Hint: Adding a
--depth=1to the git clone command reduces the 6GiB to 1.06 GiB in size, which is still a lot for slow internet connections, but significantly less than 6…I didn’t get why there doesn’t seem to be a release tarball though.
## Paul W. Frields
@dmaphy: This is a great hint, adding to the article. There is a release tarball on the releases page, and it’s 2.1 GB in size.
## Nano
this is write of this way,
source $(dirname ($gem which colorls))/tab_complete.sh
but the correct is
source $(dirname $(gem which colorls))/tab_complete.sh
## Paul W. Frields
Fixed, thanks!
## iysheng
when input sth like
$ ls *.c
data_base.c
gpsS1216F8.c
i got some confused output?how could slove this matter?
## P
In Silverblue you should keep rpm-ostree as a last resort. You can use the same commands you used for Workstation in a toolbox, so you don’t mess with the Silverblue image, don’t need to restart and make your life complicated ever time you install an OS update.
## Mark
Is there a “gitstatusd-linux-ppc64le” available?
## Mark Walker
I recently upgraded to Fedora 31, and then saw this article. After using dnf (and the git script) to install the nerd-fonts, fontawesome-fonts and powerline packages, I liked these enough to install them on my other Linux machines. The background contrast and full path current directory indication in the new Bash prompt are especially helpful for readability and awareness. Nicely done.
## Harshal Purohit
Thanks a lot! Took me some time to get it working but looks great!
Two suggestions for the above article:
After doing this step:
ZSH_THEME=powerlevel10k/powerlevel10k
I needed to log out of my session & re-login to see the changes
Add a newline between the 2 commands below:
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
## Thomas
For nerd-fonts they do not recommend cloning. There are severals alternative installation methods explained on their repo:
https://github.com/ryanoasis/nerd-fonts#font-installation
## smeg
Are any of these compatible with Guake?
## william
just a warning: Nerd-Fonts repository consumes 9.60 GB of disk.
## Daniel
Please consider modifying the pattern
to $(command -v app).
1. $() is recommended by bash hackers wiki due to nesting issues with backticks.
https://wiki.bash-hackers.org/syntax/expansion/cmdsubst
3. ‘command -v’ is recommended over ‘which’ due to possible conflicts between what is on $PATH vs. any alias or builtins with the same name.
https://unix.stackexchange.com/questions/85249/why-not-use-which-what-to-use-then
## xzj8b3 76
sudo gem install colorls
Building native extensions. This could take a while…
ERROR: Error installing colorls:
ERROR: Failed to build gem native extension.
/usr/bin/ruby -I /usr/share/rubygems -r ./siteconf20191112-13696-vliclc.rb extconf.rb
mkmf.rb can’t find header files for ruby at /usr/share/include/ruby.h |
11,562 | 确认了!微软 Edge 浏览器将发布 Linux 版 | https://itsfoss.com/microsoft-edge-linux/ | 2019-11-11T16:47:53 | [
"Edge"
] | https://linux.cn/article-11562-1.html | 
>
> 微软正在全面重制其 Edge Web 浏览器,它将基于开源 [Chromium](https://itsfoss.com/install-chromium-ubuntu/) 浏览器。微软还要将新的 Edge 浏览器带到 Linux 桌面上,但是 Linux 版本可能会有所延迟。
>
>
>
微软的 Internet Explorer 曾经一度统治了浏览器市场,但在过去的十年中,它将统治地位丢给了谷歌的 Chrome。
微软试图通过创造 Edge 浏览器来找回失去的位置,Edge 是一种使用 EdgeHTML 和 [Chakra 引擎](https://itsfoss.com/microsoft-chakra-core/)构建的全新 Web 浏览器。它与 Microsoft 的数字助手 [Cortana](https://www.microsoft.com/en-in/windows/cortana) 和 Windows 10 紧密集成。
但是,它仍然无法夺回冠军位置,截至目前,它处于[桌面浏览器使用份额的第四位](https://en.wikipedia.org/wiki/Usage_share_of_web_browsers)。
最近,微软决定通过基于[开源 Chromium 项目](https://www.chromium.org/Home)重新对 Edge 进行大修。谷歌的 Chrome 浏览器也是基于 Chromium 的。[Chromium 还可以作为独立的 Web 浏览器使用](https://itsfoss.com/install-chromium-ubuntu/),某些 Linux 发行版将其用作默认的 Web 浏览器。
### Linux 上新的微软 Edge Web 浏览器
经过最初的犹豫和不确定性之后,微软似乎最终决定把新的 Edge 浏览器引入到 Linux。
在其年度开发商大会 [Microsoft Ignite](https://www.microsoft.com/en-us/ignite) 中,[关于 Edge 浏览器的演讲](https://myignite.techcommunity.microsoft.com/sessions/79341?source=sessions)中提到了它未来将进入 Linux 中。

新的 Edge 浏览器将于 2020 年 1 月 15 日发布,但我认为 Linux 版本会推迟。
### 微软 Edge 进入 Linux 真的重要吗?
微软 Edge 进入 Linux 有什么大不了的吗?我们又不是没有很多[可用于 Linux 的 Web 浏览器](https://itsfoss.com/open-source-browsers-linux/)?
我认为这与 “微软 Linux 竞争”(如果有这样的事情)有关。微软为 Linux(特别是 Linux 桌面)做的任何事情,都会成为新闻。
我还认为 Linux 上的 Edge 对于微软和 Linux 用户都有好处。这就是为什么。
#### 对于微软有什么用?
当谷歌在 2008 年推出其 Chrome 浏览器时,没有人想到它会在短短几年内占领市场。但是,为什么作为一个搜索引擎会在一个“免费的 Web 浏览器”后面投入如此多的精力呢?
答案是谷歌是一家搜索引擎,它希望有更多的人使用其搜索引擎和其他服务,以便它可以从广告服务中获得收入。使用 Chrome,Google 是默认的搜索引擎。在 Firefox 和 Safari 等其他浏览器上,谷歌支付了数亿美元作为默认 Web 浏览器的费用。如果没有 Chrome,则谷歌必须完全依赖其他浏览器。
微软也有一个名为 Bing 的搜索引擎。Internet Explorer 和 Edge 使用 Bing 作为默认搜索引擎。如果更多用户使用 Edge,它可以增加将更多用户带到 Bing 的机会。而微软显然希望拥有更多的 Bing 用户。
#### 对 Linux 用户有什么用?
对于 Linux 桌面用户,我看到有两个好处。借助 Edge,你可以在 Linux 上使用某些微软特定的产品。 例如,微软的流式游戏服务 [xCloud](https://www.pocket-lint.com/games/news/147429-what-is-xbox-project-xcloud-cloud-gaming-service-price-release-date-devices) 可能仅能在 Edge 浏览器上使用。另一个好处是提升了 [Linux 上的 Netflix 体验](https://itsfoss.com/watch-netflix-in-ubuntu-linux/)。当然,你可以在 Linux 上使用 Chrome 或 [Firefox 观看 Netflix](https://itsfoss.com/netflix-firefox-linux/),但可能无法获得全高清或超高清流。
据我所知,[全高清和超高清 Netflix 流仅在微软 Edge 上可用](https://help.netflix.com/en/node/23742)。这意味着你可以使用 Linux 上的 Edge 以高清格式享受 Netflix。
### 你怎么看?
你对微软 Edge 进入 Linux 有什么感觉?当 Linux 版本可用时,你会使用吗?请在下面的评论部分中分享你的观点。
---
via: <https://itsfoss.com/microsoft-edge-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

After initial reluctance and uncertainties, Microsoft has finally brought the Edge browser to Linux. Initially announced in late 2019, the [stable version arrived for Linux in October 2021](https://news.itsfoss.com/microsoft-edge-stable-release/?ref=itsfoss.com).
Now that it is finally available, how do you install the Microsoft Edge browser on Linux? It’s quite simple, actually. Let me show you how to do it.
## Install Microsoft Edge browser on Linux
Microsoft provides binaries in the form of .deb (for Debian and Ubuntu based distributions) and .rpm (for Fedora, Red Hat and openSUSE based distributions).
Go to the Microsoft Edge website:
You’ll notice a ‘Download for Linux’ button. Clicking on it will bring a dropdown menu that shows options to download .deb and .rpm for Linux and other options for various Windows versions.
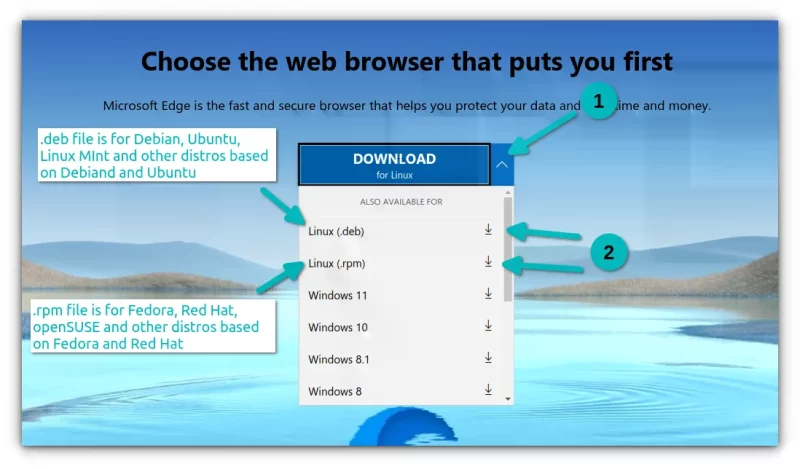
You probably already [know which Linux OS you are using](https://linuxhandbook.com/check-linux-version/?ref=itsfoss.com) and can download the appropriate file.
You’ll have to accept Microsoft’s terms and conditions before downloading the file.
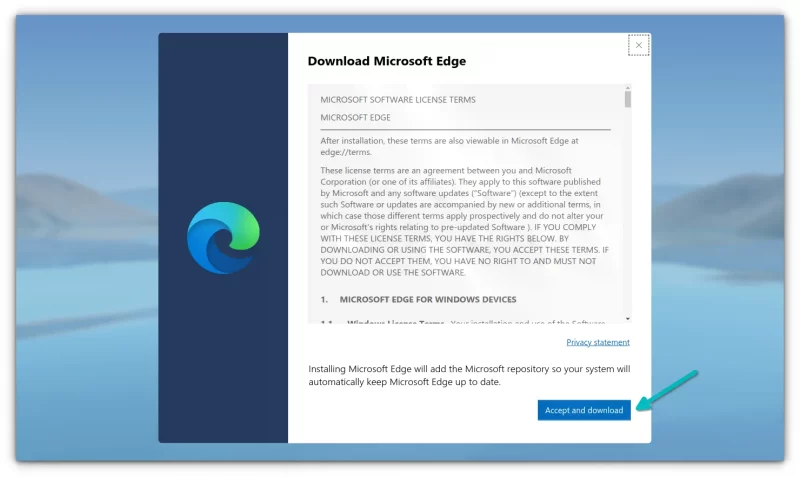
Once the download finishes, you should see the file in your Downloads folder.
Using DEB or RPM file is super easy. Just double-click on the downloaded file to install it.
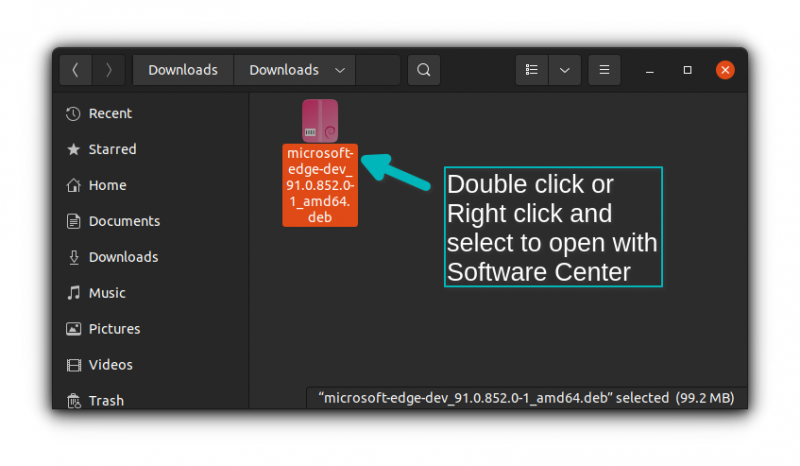
The file should be opened in the Software Center and you can install it from there. Alternatively, you can [use a tool like Gdebi](https://itsfoss.com/gdebi-default-ubuntu-software-center/) for Ubuntu/Debian based distributions.
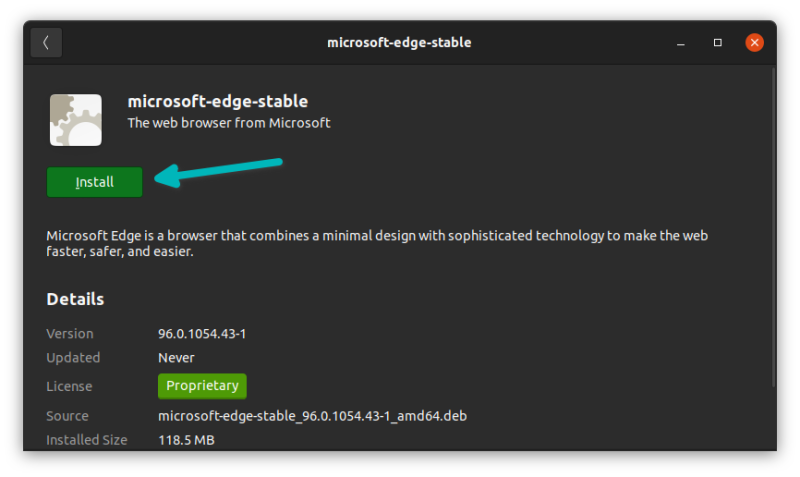
Once installed, you can launch it from the application menu:

On the first run, it asks to accept privacy policy. Uncheck the ‘Help Microsoft’ option to stop them from using ‘optional diagnostic data about you’.

You may set up the browser for your liking and start enjoying Edge on Linux.
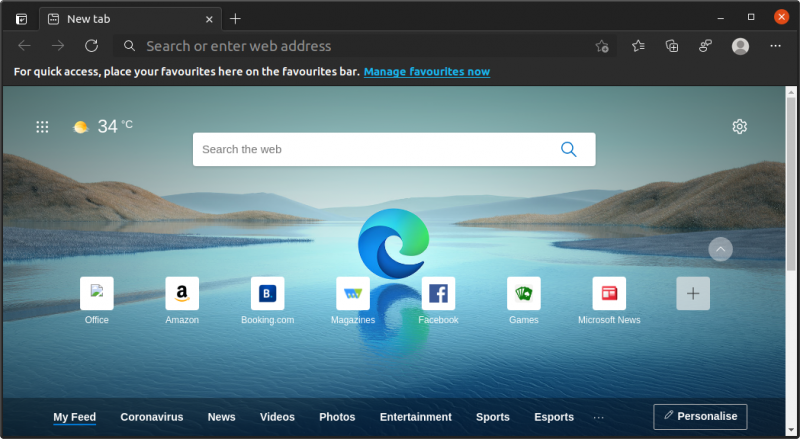
## How to update Microsoft Edge on Linux?
Microsoft adds its repository to the [sources.list](https://itsfoss.com/sources-list-ubuntu/) so that you get updates to Microsoft Edge through the system updater. Now that’s super cool, right?
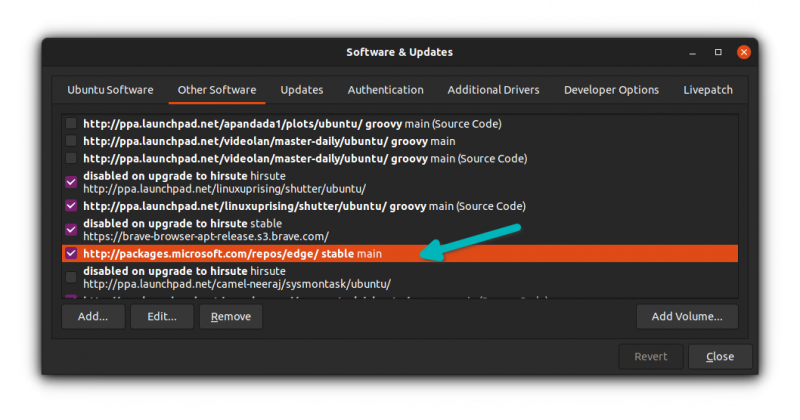
## Alternate Method: Install Microsoft Edge on Ubuntu based distros via command line
In either case, you can also add the official repository to install Microsoft Edge on Linux. Here are the commands that you have to follow through the terminal to add the repository and install Edge.
Download the GPG key for the Microsoft repository.
`curl https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > microsoft.gpg`
Add this GPG key to the trusted keys in your system.
`sudo install -o root -g root -m 644 microsoft.gpg /etc/apt/trusted.gpg.d/`
Now, add the repository to your sources.list directory.
`sudo sh -c 'echo "deb [arch=amd64] https://packages.microsoft.com/repos/edge stable main" > /etc/apt/sources.list.d/microsoft-edge-stable.list'`
It would be good to remove the downloaded GPG key because it has already been added to the system.
`sudo rm microsoft.gpg`
The above-mentioned commands add the necessary repositories. Now, you just need to install Microsoft Edge using these commands:
`sudo apt update && sudo apt install microsoft-edge-stable`
Of course, it still may not be enough to replace your primary browser like Firefox, but if the need arrives, you may use it.
## What's the advantage for Linux users?
I see a couple of benefits for desktop Linux users. With Edge, you can use some Microsoft-specific products on Linux. For example, Microsoft’s streaming gaming service [xCloud](https://www.pocket-lint.com/games/news/147429-what-is-xbox-project-xcloud-cloud-gaming-service-price-release-date-devices?ref=itsfoss.com) maybe available on the Edge browser only.
Another possible benefit is an improved [Netflix experience on Linux](https://itsfoss.com/watch-netflix-in-ubuntu-linux/). Of course, you can use Chrome or [Firefox for watching Netflix on Linux](https://itsfoss.com/netflix-firefox-linux/) but you won’t be getting the full HD or ultra HD streaming because it is only available on Microsoft Edge browser (not even Google Chrome).
I tried watching Netflix using Microsoft Edge on Linux but the streaming quality is as poor as the remake of Rebecca. I hope Microsoft brings full HD streaming on Linux through Edge in near future.
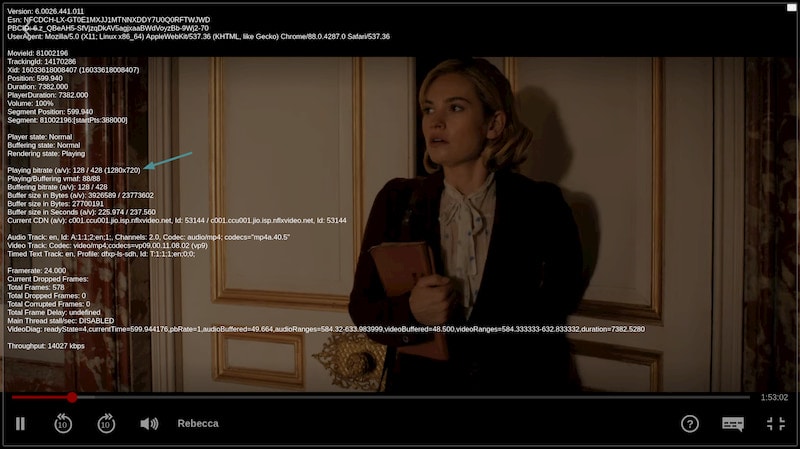
What’s your feeling about using Microsoft Edge browser on Linux? Have you tried it yet? Do share your views in the comment section below. |
11,564 | 克隆 MAC 地址来绕过强制门户 | https://fedoramagazine.org/cloning-a-mac-address-to-bypass-a-captive-portal/ | 2019-11-11T23:44:54 | [
"MAC"
] | https://linux.cn/article-11564-1.html | 
如果你曾经在家和办公室之外连接到 WiFi,那么通常会看到一个门户页面。它可能会要求你接受服务条款或其他协议才能访问。但是,当你无法通过这类门户进行连接时会发生什么?本文向你展示了如何在 Fedora 上使用 NetworkManager 在某些故障情况下让你仍然可以访问互联网。
### 强制门户如何工作
强制门户是新设备连接到网络时显示的网页。当用户首次访问互联网时,门户网站会捕获所有网页请求并将其重定向到单个门户页面。
然后,页面要求用户采取一些措施,通常是同意使用政策。用户同意后,他们可以向 RADIUS 或其他类型的身份验证系统进行身份验证。简而言之,强制门户根据设备的 MAC 地址和终端用户接受条款来注册和授权设备。(MAC 地址是附加到任何网络接口的[基于硬件的值](https://en.wikipedia.org/wiki/MAC_address),例如 WiFi 芯片或卡。)
有时设备无法加载强制门户来进行身份验证和授权以使用 WiFI 接入。这种情况的例子包括移动设备和游戏机(Switch、Playstation 等)。当连接到互联网时,它们通常不会打开强制门户页面。连接到酒店或公共 WiFi 接入点时,你可能会看到这种情况。
不过,你可以在 Fedora 上使用 NetworkManager 来解决这些问题。Fedora 可以使你临时克隆要连接的设备的 MAC 地址,并代表该设备通过强制门户进行身份验证。你需要得到连接设备的 MAC 地址。通常,它被打印在设备上的某个地方并贴上标签。它是一个六字节的十六进制值,因此看起来类似 `4A:1A:4C:B0:38:1F`。通常,你也可以通过设备的内置菜单找到它。
### 使用 NetworkManager 克隆
首先,打开 `nm-connection-editor`,或通过“设置”打开 WiFi 设置。然后,你可以使用 NetworkManager 进行克隆:
* 对于以太网:选择已连接的以太网连接。然后选择 “Ethernet” 选项卡。记录或复制当前的 MAC 地址。在 “<ruby> 克隆 MAC 地址 <rt> Cloned MAC address </rt></ruby>” 字段中输入游戏机或其他设备的 MAC 地址。
* 对于 WiFi:选择 WiFi 配置名。然后选择 “WiFi” 选项卡。记录或复制当前的 MAC 地址。在 “<ruby> 克隆 MAC 地址 <rt> Cloned MAC address </rt></ruby>” 字段中输入游戏机或其他设备的 MAC 地址。
### 启动所需的设备
当 Fedora 系统与以太网或 WiFi 配置连接,克隆的 MAC 地址将用于请求 IP 地址,并加载强制门户。输入所需的凭据和/或选择用户协议。该 MAC 地址将获得授权。
现在,断开 WiF i或以太网配置连接,然后将 Fedora 系统的 MAC 地址更改回其原始值。然后启动游戏机或其他设备。该设备现在应该可以访问互联网了,因为它的网络接口已通过你的 Fedora 系统进行了授权。
不过,这不是 NetworkManager 全部能做的。例如,请参阅[随机化系统硬件地址](/article-10028-1.html),来获得更好的隐私保护。
---
via: <https://fedoramagazine.org/cloning-a-mac-address-to-bypass-a-captive-portal/>
作者:[Esteban Wilson](https://fedoramagazine.org/author/swilson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you ever attach to a WiFi system outside your home or office, you often see a portal page. This page may ask you to accept terms of service or some other agreement to get access. But what happens when you can’t connect through this kind of portal? This article shows you how to use NetworkManager on Fedora to deal with some failure cases so you can still access the internet.
## How captive portals work
Captive portals are web pages offered when a new device is connected to a network. When the user first accesses the Internet, the portal captures all web page requests and redirects them to a single portal page.
The page then asks the user to take some action, typically agreeing to a usage policy. Once the user agrees, they may authenticate to a RADIUS or other type of authentication system. In simple terms, the captive portal registers and authorizes a device based on the device’s MAC address and end user acceptance of terms. (The MAC address is [a hardware-based value](https://en.wikipedia.org/wiki/MAC_address) attached to any network interface, like a WiFi chip or card.)
Sometimes a device doesn’t load the captive portal to authenticate and authorize the device to use the location’s WiFi access. Examples of this situation include mobile devices and gaming consoles (Switch, Playstation, etc.). They usually won’t launch a captive portal page when connecting to the Internet. You may see this situation when connecting to hotel or public WiFi access points.
You can use NetworkManager on Fedora to resolve these issues, though. Fedora will let you temporarily clone the connecting device’s MAC address and authenticate to the captive portal on the device’s behalf. You’ll need the MAC address of the device you want to connect. Typically this is printed somewhere on the device and labeled. It’s a six-byte hexadecimal value, so it might look like *4A:1A:4C:B0:38:1F*. You can also usually find it through the device’s built-in menus.
## Cloning with NetworkManager
First, open * nm-connection-editor*, or open the WiFI settings via the Settings applet. You can then use NetworkManager to clone as follows:
- For Ethernet – Select the connected Ethernet connection. Then select the
*Ethernet*tab. Note or copy the current MAC address. Enter the MAC address of the console or other device in the*Cloned MAC address*field. - For WiFi – Select the WiFi profile name. Then select the WiFi tab. Note or copy the current MAC address. Enter the MAC address of the console or other device in the
*Cloned MAC address*field.
**Bringing up the desired device**
Once the Fedora system connects with the Ethernet or WiFi profile, the cloned MAC address is used to request an IP address, and the captive portal loads. Enter the credentials needed and/or select the user agreement. The MAC address will then get authorized.
Now, disconnect the WiFi or Ethernet profile, and change the Fedora system’s MAC address back to its original value. Then boot up the console or other device. The device should now be able to access the Internet, because its network interface has been authorized via your Fedora system.
This isn’t all that NetworkManager can do, though. For instance, check out this article on [randomizing your system’s hardware address](https://fedoramagazine.org/randomize-mac-address-nm/) for better privacy.
## James
Good article, but can you please edit it to say that you absolutely must change the Fedora system’s MAC address back before you put the cloned system and the Fedora system on the same network? Ethernet (including Wi-Fi) really doesn’t like duplicate MACs on the same network.
## Paul W. Frields
Good point — the article’s been edited to add the need to note down current MAC address, and restore it after authorization.
## Michael Williamson
I think, if your traffic is 100% UDP, then it doesn’t/cannot care, provided it’s going through the same radio. This might open up some possibilites getting a headless Pi on a hotel network if combined with a UDP vpn.
## Heavy
It’s a very good article, but I have question. There’s someway to build a captive portal in a open wireless network on Fedora?
## Esteban Wilson
You can try and do something with Unbound DNS or dnsmasq . There are also several open source captive portal options available.
## Joao Rodrigues
You could roll your own solution (see CoovaChilli) but probably the easiest way is to use a firewall-centric distribution, like IPFire or OpnSense.
## puffy
And no playing with aircrack-ng on public Wifi networks.
## Mark
Also, another workaround might be to open a browser and manually enter the IP address of the gateway into the URL, i.e. http://xxx.xxx.xxx.xxx and force the device to open the captive portal page that way.
This has worked for me most times when my Linux laptop or iOs devices wouldn’t pull up the portal page automatically
## Esteban Wilson
For a Linux laptop or IOS device that could work. This article addresses the issue when a device will not load the captive portal. Devices like the Switch, PS4, and other gaming consoles do not always load the portal page and need a little help. A Fedora system can provide that help.
## Vernon Van Steenkist
If your device can’t load a portal web page it probably shouldn’t be directly connected to a portal in the first place due to security reasons. What you need is a travel router. Flash OpenWrt Linux on the travel router, set up the travel router WiFi as AP+STA (WiFi Access Point and Wi-Fi client). connect the travel router WiFi to the portal, connect a device with a web browser (phone, laptop ect.) via WiFi to the travel router and authenticate to the portal. Now you can connect any device to the travel router and it will have Internet access and be protected by the travel router’s firewall since the portal only sees the travel router MAC address, You can add OpenVPN to the travel router and give all your devices VPN access as well. The device I use is the HooToo TM03 which fits in the palm of your hand, has an Ethernet port, and contains a battery which will either charge your phone or power the router for 15 hours. Zsun makes the smallest one. It fits on your key chain. The main drawbacks are that it doesn’t have a battery (You plug it in to any USB A port for power) and it is so small I lost it somewhere in my house. |
11,565 | 为什么容器和 Kubernetes 有潜力运行一切 | https://opensource.com/article/19/6/kubernetes-potential-run-anything | 2019-11-12T01:11:50 | [
"Kubernetes"
] | https://linux.cn/article-11565-1.html |
>
> 不仅可以部署简单的应用程序,还可以用 Kubernetes 运维器应对第 2 天运营。
>
>
>

在我的第一篇文章 [为什么说 Kubernetes 是一辆翻斗车](https://opensource.com/article/19/6/kubernetes-dump-truck) 中,我谈到了 Kubernetes 如何在定义、分享和运行应用程序方面很出色,类似于翻斗车在移动垃圾方面很出色。在第二篇中,[如何跨越 Kubernetes 学习曲线](https://opensource.com/article/19/6/kubernetes-learning-curve),我解释了 Kubernetes 的学习曲线实际上与运行任何生产环境中的应用程序的学习曲线相同,这确实比学习所有传统组件要容易(如负载均衡器、路由器、防火墙、交换机、集群软件、集群文件系统等)。这是 DevOps,是开发人员和运维人员之间的合作,用于指定事物在生产环境中的运行方式,这意味着双方都需要学习。在第三篇 [Kubernetes 基础:首先学习如何使用](https://opensource.com/article/19/6/kubernetes-basics) 中,我重新设计了 Kubernetes 的学习框架,重点是驾驶翻斗车而不是制造或装备翻斗车。在第四篇文章 [帮助你驾驭 Kubernetes 的 4 个工具](https://opensource.com/article/19/6/tools-drive-kubernetes) 中,我分享了我喜爱的工具,这些工具可帮助你在 Kubernetes 中构建应用程序(驾驶翻斗车)。
在这最后一篇文章中,我会分享我为什么对在 Kubernetes 上运行应用程序的未来如此兴奋的原因。
从一开始,Kubernetes 就能够很好地运行基于 Web 的工作负载(容器化的)。Web 服务器、Java 和相关的应用程序服务器(PHP、Python等)之类的工作负载都可以正常工作。该平台处理诸如 DNS、负载平衡和 SSH(由 `kubectl exec` 取代)之类的支持服务。在我的职业生涯的大部分时间里,这些都是我在生产环境中运行的工作负载,因此,我立即意识到,除了 DevOps 之外,除了敏捷之外,使用 Kubernetes 运行生产环境工作负载的强大功能。即使是我们几乎不改变我们的文化习惯,也可以提高效率。调试和退役变得非常容易,而这对于传统 IT 来说是极为困难的。因此,从早期开始,Kubernetes 就用一种单一的配置语言(Kube YAML/Json)为我提供了对生产环境工作负载进行建模所需的所有基本原语。
但是,如果你需要运行具有复制功能的多主 MySQL,会发生什么情况?使用 Galera 的冗余数据呢?你如何进行快照和备份?那么像 SAP 这样复杂的工作呢?使用 Kubernetes,简单的应用程序(Web 服务器等)的第 0 天(部署)相当简单,但是没有解决第 2 天的运营和工作负载。这并不是说,具有复杂工作负载的第 2 天运营要比传统 IT 难解决,而是使用 Kubernetes 并没有使它们变得更容易。每个用户都要设计自己的天才想法来解决这些问题,这基本上是当今的现状。在过去的五年中,我遇到的第一类问题是复杂工作负载的第 2 天操作。(LCTT 译注:在软件生命周期中,第 0 天是指软件的设计阶段;第 1 天是指软件的开发和部署阶段;第 2 天是指生产环境中的软件运维阶段。)
值得庆幸的是,随着 Kubernetes <ruby> 运维器 <rt> Operator </rt></ruby>的出现,这种情况正在改变。随着运维器的出现,我们现在有了一个框架,可以将第 2 天的运维知识汇总到平台中。现在,我们可以应用我在 [Kubernetes 基础:首先学习如何使用](https://opensource.com/article/19/6/kubernetes-basics) 中描述的相同的定义状态、实际状态的方法,现在我们可以定义、自动化和维护各种各样的系统管理任务。
(LCTT 译注: Operator 是 Kubernetes 中的一种可以完成运维工程师的特定工作的组件,业界大多没有翻译这个名词,此处仿运维工程师例首倡翻译为“运维器”。)
我经常将运维器称为“系统管理机器人”,因为它们实质上是在第 2 天的工作中整理出一堆运维知识,该知识涉及<ruby> 主题专家 <rt> Subject Matter Expert </rt></ruby>(SME、例如数据库管理员或系统管理员)针对的工作负载类型(数据库、Web 服务器等),通常会记录在 Wiki 中的某个地方。这些知识放在 Wiki 中的问题是,为了将该知识应用于解决问题,我们需要:
1. 生成事件,通常监控系统会发现故障,然后我们创建故障单
2. SME 人员必须对此问题进行调查,即使这是我们之前见过几百万次的问题
3. SME 人员必须执行该知识(执行备份/还原、配置 Galera 或事务复制等)
通过运维器,所有这些 SME 知识都可以嵌入到单独的容器镜像中,该镜像在有实际工作负荷之前就已部署。 我们部署运维器容器,然后运维器部署和管理一个或多个工作负载实例。然后,我们使用“运维器生命周期管理器”(Katacoda 教程)之类的方法来管理运维器。
因此,随着我们进一步使用 Kubernetes,我们不仅简化了应用程序的部署,而且简化了整个生命周期的管理。运维器还为我们提供了工具,可以管理具有深层配置要求(群集、复制、修复、备份/还原)的非常复杂的有状态应用程序。而且,最好的地方是,构建容器的人员可能是做第 2 天运维的主题专家,因此现在他们可以将这些知识嵌入到操作环境中。
### 本系列的总结
Kubernetes 的未来是光明的,就像之前的虚拟化一样,工作负载的扩展是不可避免的。学习如何驾驭 Kubernetes 可能是开发人员或系统管理员可以对自己的职业发展做出的最大投资。随着工作负载的增多,职业机会也将增加。因此,这是驾驶一辆令人惊叹的 [在移动垃圾时非常优雅的翻斗车](https://opensource.com/article/19/6/kubernetes-dump-truck)……
你可能想在 Twitter 上关注我,我在 [@fatherlinux](https://twitter.com/fatherlinux) 上分享有关此主题的很多内容。
---
via: <https://opensource.com/article/19/6/kubernetes-potential-run-anything>
作者:[Scott McCarty](https://opensource.com/users/fatherlinux) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my first article, * Kubernetes is a dump truck: Here's why*, I talked about about how Kubernetes is elegant at defining, sharing, and running applications, similar to how dump trucks are elegant at moving dirt. In the second,
*, I explain that the learning curve for Kubernetes is really the same learning curve for running any applications in production, which is actually easier than learning all of the traditional pieces (load balancers, routers, firewalls, switches, clustering software, clustered files systems, etc). This is DevOps, a collaboration between Developers and Operations to specify the way things should run in production, which means there's a learning curve for both sides. In article four,*
[How to navigate the Kubernetes learning curve](https://opensource.com/article/19/6/kubernetes-learning-curve)*, I reframe learning Kubernetes with a focus on driving the dump truck instead of building or equipping it. In the fourth article,*
[Kubernetes basics: Learn how to drive first](https://opensource.com/article/19/6/kubernetes-basics)*, I share tools that I have fallen in love with to help build applications (drive the dump truck) in Kubernetes.*
[4 tools to help you drive Kubernetes](https://opensource.com/article/19/6/tools-drive-kubernetes)In this final article, I share the reasons why I am so excited about the future of running applications on Kubernetes.
From the beginning, Kubernetes has been able to run web-based workloads (containerized) really well. Workloads like web servers, Java, and associated app servers (PHP, Python, etc) just work. The supporting services like DNS, load balancing, and SSH (replaced by kubectl exec) are handled by the platform. For the majority of my career, these are the workloads I ran in production, so I immediately recognized the power of running production workloads with Kubernetes, aside from DevOps, aside from agile. There is incremental efficiency gain even if we barely change our cultural practices. Commissioning and decommissioning become extremely easy, which were terribly difficult with traditional IT. So, since the early days, Kubernetes has given me all of the basic primitives I need to model a production workload, in a single configuration language (Kube YAML/Json).
But, what happened if you needed to run Multi-master MySQL with replication? What about redundant data using Galera? How do you do snapshotting and backups? What about sophisticated workloads like SAP? Day zero (deployment) with simple applications (web servers, etc) has been fairly easy with Kubernetes, but day two operations and workloads were not tackled. That's not to say that day two operations with sophisticated workloads were harder than traditional IT to solve, but they weren't made easier with Kubernetes. Every user was left to devise their own genius ideas for solving these problems, which is basically the status quo today. Over the last 5 years, the number one type of question I get is around day two operations of complex workloads.
Thankfully, that's changing as we speak with the advent of Kubernetes Operators. With the advent of Operators, we now have a framework to codify day two operations knowledge into the platform. We can now apply the same defined state, actual state methodology that I described in [ Kubernetes basics: Learn how to drive first](https://opensource.com/article/19/6/kubernetes-basics)—we can now define, automate, and maintain a wide range of systems administration tasks.
I often refer to Operators as "Robot Sysadmins" because they essentially codify a bunch of the day two operations knowledge that a subject matter expert (SME, like database administrator or, systems administrator) for that workload type (database, web server, etc) would normally keep in their notes somewhere in a wiki. The problem with these notes being in a wiki is, for the knowledge to be applied to solve a problem, we need to:
- Generate an event, often a monitoring system finds a fault and we create a ticket
- Human SME has to investigate the problem, even if it's something we've seen a million times before
- Human SME has to execute the knowledge (perform the backup/restore, configure the Galera or transaction replication, etc)
With Operators, all of this SME knowledge can be embedded in a separate container image which is deployed before the actual workload. We deploy the Operator container, and then the Operator deploys and manages one or more instances of the workload. We then manage the Operators using something like the Operator Lifecycle Manager (Katacoda tutorial).
So, as we move forward with Kubernetes, we not only simplify the deployment of applications, but also the management over the lifecycle. Operators also give us the tools to manage very complex, stateful applications with deep configuration requirements (clustering, replication, repair, backup/restore. And, the best part is, the people who built the container are probably the subject matter experts for day two operations, so now they can embed that knowledge into the operations environment.
## The conclusion to this series
The future of Kubernetes is bright, and like virtualization before it, workload expansion is inevitable. Learning how to drive Kubernetes is probably the biggest investment that a developer or sysadmin can make in their own career growth. As the workloads expand, so will the career opportunities. So, here's to driving an amazing [dump truck that's very elegant at moving dirt](https://opensource.com/article/19/6/kubernetes-dump-truck)...
If you would like to follow me on Twitter, I share a lot of content on this topic at [@fatherlinux](https://twitter.com/fatherlinux)
## 13 Comments |
11,567 | 第 0 天/第 1 天/第 2 天:云时代的软件生命周期 | https://codilime.com/day-0-day-1-day-2-the-software-lifecycle-in-the-cloud-age/ | 2019-11-12T11:31:54 | [
"软件开发"
] | https://linux.cn/article-11567-1.html | 
在当今的专业 IT 媒体中有一个非常突出的话题,那就是在软件生命周期中的“第 0 天/第 1 天/第 2 天”。在演讲和会议讲话当中,通常着重于使软件开发过程有效且易于管理,为此,有必要明确定义所使用的概念。通常,如果直观地理解基本术语“<ruby> 第 0 天 <rp> ( </rp> <rt> Day 0 </rt> <rp> ) </rp></ruby>/<ruby> 第 1 天 <rp> ( </rp> <rt> Day 1 </rt> <rp> ) </rp></ruby>/<ruby> 第 2 天 <rp> ( </rp> <rt> Day 2 </rt> <rp> ) </rp></ruby>”,这在谈论软件生命周期时可能会引起一些歧义。因此,我决定更准确地定义它们,以展示软件开发的整个过程以及它们在实际项目中的使用方式。这篇简短的博客文章提供了“天”的定义,这些“天”被理解为软件生命周期的各个阶段。它还描述了云如何改变了有关软件开发和维护过程的传统思维方式。毕竟,正如《[RightScale 2019 云状态报告](https://www.flexera.com/about-us/press-center/rightscale-2019-state-of-the-cloud-report-from-flexera-identifies-cloud-adoption-trends.html)》所确认的那样,我们正处于“云时代”。该报告解释说,有 94% 的调查受访者正在使用云(私有云或公有云)。因此,闲话少说,让我们探讨一下“天”和云如何结合在一起。
### “天”究竟是什么?
在 IT 中,术语“第 0 天/第 1 天/第 2 天”指的是软件生命周期的不同阶段。用军事术语来说,“第 0 天”是训练的第一天,新兵进入训练阶段。在软件开发中,它代表设计阶段,在此阶段中指定项目需求并确定解决方案的体系结构。
“第 1 天”涉及开发和部署在“第 0 天”阶段设计的软件。在此阶段,我们不仅创建应用程序本身,还创建应用程序的基础设施、网络、外部服务,并实现所有部分的初始配置。
“第 2 天”是产品出厂或交付给客户的时间。在这里,大部分工作都集中在维护、监控和优化系统上。分析系统的行为并做出正确的反应至关重要,因为所产生的反馈循环将一直持续到应用程序生命周期结束为止。
在云时代之前的日子里,这些阶段是分别处理的,彼此之间没有重叠。今天,情况已不再如此。让我们看一下所有这些如何应用于现代应用程序的生命周期。
#### 第 0 天:无聊但必不可少
第 0 天经常被忽略,因为它可能很无聊,但这并不会降低其重要性。成功的软件产品是经过全面规划和设计过程的结果。必须仔细计划系统或应用程序的体系结构以及启动和运行所需的资源(CPU、存储空间、RAM)。其次,你应该定义可衡量的里程碑,以实现项目目标。每个里程碑应有一个准确的日期。这有助于衡量项目的进度,并确定你是否延迟了计划运行。所有项目时间估算都应基于概率,而不仅仅是按最佳情况预估。进行计划时,最好添加缓冲余量,因为意外事件甚至可能使精心策划的计划陷入困境。测试阶段也起着重要的作用,也应该包括在初始项目计划中。这些是基本要求,它们在“云时代”中同以往一样重要。
尽管如此,在计算资源的第 0 天计划中,云还是改变了两件事。由于云可以在项目的任何地方获得不同的资源或新资源(CPU、存储空间、RAM),因此比本地基础设施要容易得多。因此,可以避免在计划阶段犯下的一些错误。另一方面,在计划阶段对特定云供应商的承诺可能会在以后导致供应商锁定。这可能会花费你的金钱,并且需要时间来进行更改,因此选择云供应商时要明智一些。
其次,正如我们当前在向云的迁移中观察到的那样,与运维相关的工作依旧保持不变,但不再专注于基础设施。现在,正是软件在推动着自动化和价值。
#### 第 1 天:实现创意的阶段
对于开发人员和项目负责人而言,第 1 天绝对是最有趣的阶段。最初的设计得以实现,并根据项目的规范创建了基础设施。为了成为真正的云原生,必须遵守最佳实践。可以遵循诸如<ruby> <a href="https://en.wikipedia.org/wiki/Twelve-Factor_App_methodology"> 十二要素应用程序方法 </a> <rp> ( </rp> <rt> Twelve-Factor Apps methodology </rt> <rp> ) </rp></ruby>之类的准则。此外,使用云端意味着你应该遵循重要的 DevOps 惯例:持续集成/持续交付(如果你想了解有关 CI/CD 的更多信息,请参阅我们的[博客文章](https://codilime.com/what-is-ci-cd-all-you-need-to-know/))。
云为我们带来了从传统方法到软件开发的重要变化:将第一行代码拼凑在一起以进行概念验证后,应用程序即开始运行。你可以从持续集成实践开始,以测试你的应用程序的健全性,但是你很快会让企业迈入到持续交付。在开发应用程序时,我们开始引入一些运维元素,尤其是在使用多个环境的情况下。注意这些运维要素将使维护团队在维护阶段(第 2 天)的工作更加轻松。
在第 1 天期间可以使用几种工具。可以将它们按解决的问题分组。这个列表的顶部应提及“<ruby> 基础设施即代码 <rp> ( </rp> <rt> Infrastructure-as-a-code </rt> <rp> ) </rp></ruby>”(IaaC)。 IaaC 就像应用程序或代码一样管理运维环境。这种方法允许将 DevOps 最佳实践(包括版本控制、虚拟化测试和持续监视)应用于驱动基础设施的代码。这里有很多工具可供我们使用,例如 Terraform、Ansible 或 Puppet 等。第二类工具与容器的自动化部署和管理的容器编排系统有关。Kubernetes 及其实现(例如 Google Kubernetes Engine 和亚马逊的 Elastic Kubernetes Service)至关重要。最后,还有诸如 Jenkins、Zuul 和 CircleCI 之类的 CI/CD 系统,可帮助工程师自动化软件的构建、测试以及交付或部署。
### 第 2 天:日常运维环节
一旦软件准备就绪,它就会上线,客户开始使用它。第 2 天始于此,并引入了包括软件维护和客户支持在内的各个元素。该软件本身将不断发展,以适应不断变化的需求和客户需求。在第 2 天期间,主要重点是建立反馈循环。我们监控该应用程序的工作方式,收集用户反馈并将其发送给开发团队,该团队将在产品中实施该应用程序并发布新版本。军事术语“<ruby> 观察-导向-决定-行动 <rp> ( </rp> <rt> Observe-Orient-Decide-Act </rt> <rp> ) </rp></ruby>”(OODA)恰当地抓住了这一阶段发生的事情。
* 观察:从监视系统获取信息(资源使用情况和指标,应用程序性能监控)。
* 导向:执行问题的根本原因分析。
* 决定:找到解决问题的方法。
* 行动:实施解决方案。
与战斗中一样,该循环不断重复。
监控程序基于<ruby> 服务水平协议 <rp> ( </rp> <rt> Service Level Agreement </rt> <rp> ) </rp></ruby>(SLA)中定义的要求。 SLA 基于<ruby> 服务水平目标 <rp> ( </rp> <rt> Service Level Objectives </rt> <rp> ) </rp></ruby>(SLO),代表我们的<ruby> 服务水平指标 <rp> ( </rp> <rt> Service Level Indicators </rt> <rp> ) </rp></ruby>(SLI)的状态。自动化和监控是解决第 2 天职责的关键。
有几种工具可帮助完成第 2 天的工作。 <ruby> 应用程序性能监控 <rp> ( </rp> <rt> Application Performance Monitoring </rt> <rp> ) </rp></ruby>(APM)类软件可以帮助 IT 管理员监控应用程序性能,从而提供高质量的用户体验。在这里,我们可以点名 Datadog、Dynatrace、SignalFX 或 Nutanix Xi Epoch。 还有一些自动化和编排工具,例如 Ansible 或 Kubernetes,可帮助管理应用程序环境。你可能已经注意到,这些工具的应用与第 1 天的工作重叠。最后,工单系统(例如 Servicedesk 或 Zendesk)可以处理客户服务,使用户可以报告故障以及与他们正在运行的应用程序有关的问题。

### 云将改变游戏规则
在前云时代,这些阶段之间的分隔清晰可见,但是今天,随着云的日常运行,事物在不断变化。使用云和现代软件开发实践,可以更轻松地处理软件生命周期中不断变化的要求。持续集成/持续开发方法使我们能够动态响应客户反馈并实时改进应用程序,而无需等待主要版本进行改进。
基于云和原生云的软件中的 DevOps 实践有助于实现<ruby> 向左移动 <rp> ( </rp> <rt> shift left </rt> <rp> ) </rp></ruby>(LCTT 译注:环节前置的意思),这意味着传统上一直保留到最后的步骤现在可以更快地执行。除此以外,这导致第 1 天和第 2 天现在相互重叠。此外,传统软件开发的最大痛点在于从第 1 天到第 2 天的过渡:从开发人员到运维人员的过渡。现在,DevOps 展示了如何解决此问题:及早启动流程,并使流程一直运行到应用程序生命周期结束。最后但同样重要的是,工具链正在完善,这使得执行第 1 天的任务和适应第 2 天的更改成为可能。 可以根据我们的需求对所使用的工具进行建模,并且过程中涉及的每个人都可以使用同一套工具。
| 301 | Moved Permanently | null |
11,571 | 如何使用 cron 任务在 Linux 中计划和自动化任务 | https://www.linuxtechi.com/schedule-automate-tasks-linux-cron-jobs/ | 2019-11-13T22:19:00 | [
"cron"
] | https://linux.cn/article-11571-1.html | 有时,你可能需要定期或以预定的时间间隔执行任务。这些任务包括备份数据库、更新系统、执行定期重新引导等。这些任务称为 “cron 任务”。cron 任务用于“自动执行的任务”,它有助于简化重复的、有时是乏味的任务的执行。cron 是一个守护进程,可让你安排这些任务,然后按指定的时间间隔执行这些任务。在本教程中,你将学习如何使用 cron 来安排任务。

### crontab 文件
crontab 即 “cron table”,是一个简单的文本文件,其中包含指定任务执行时间间隔的规则和命令。 crontab 文件分为两类:
1)系统范围的 crontab 文件
这些通常由需要 root 特权的 Linux 服务及关键应用程序使用。系统 crontab 文件位于 `/etc/crontab` 中,并且只能由 root 用户访问和编辑。通常用于配置系统范围的守护进程。`crontab` 文件的看起来类似如下所示:

2)用户创建的 crontab 文件
Linux 用户还可以在 `crontab` 命令的帮助下创建自己的 cron 任务。创建的 cron 任务将以创建它们的用户身份运行。
所有 cron 任务都存储在 `/var/spool/cron`(对于 RHEL 和 CentOS 发行版)和 `/var/spool/cron/crontabs`(对于 Debian 和 Ubuntu 发行版)中,cron 任务使用创建该文件的用户的用户名列出。
cron 守护进程在后台静默地检查 `/etc/crontab` 文件和 `/var/spool/cron` 及 `/etc/cron.d*/` 目录。
`crontab` 命令用于编辑 cron 文件。让我们看一下 crontab 文件的结构。
### crontab 文件剖析
在继续之前,我们要首先探索 crontab 文件的格式。crontab 文件的基本语法包括 5 列,由星号表示,后跟要执行的命令。
```
* * * * * command
```
此格式也可以表示如下:
```
m h d moy dow command
```
或
```
m h d moy dow /path/to/script
```
让我们来解释一下每个条目
* `m`:代表分钟。范围是 0 到 59
* `h`:表示小时,范围是 0 到 23
* `d`:代表一个月中的某天,范围是 1 到 31
* `moy`:这是一年中的月份。范围是 1 到 12
* `dow`:这是星期几。范围是 0 到 6,其中 0 代表星期日
* `command`:这是要执行的命令,例如备份命令、重新启动和复制命令等
### 管理 cron 任务
看完 crontab 文件的结构之后,让我们看看如何创建、编辑和删除 cron 任务。
#### 创建 cron 任务
要以 root 用户身份创建或编辑 cron 任务,请运行以下命令:
```
# crontab -e
```
要为另一个用户创建或安排 cron 任务,请使用以下语法:
```
# crontab -u username -e
```
例如,要以 Pradeep 用户身份运行 cron 任务,请发出以下命令:
```
# crontab -u Pradeep -e
```
如果该 crontab 文件尚不存在,那么你将打开一个空白文本文件。如果该 crontab 文件已经存在,则 `-e` 选项会让你编辑该文件,
#### 列出 crontab 文件
要查看已创建的 cron 任务,只需传递 `-l` 选项:
```
# crontab -l
```
#### 删除 crontab 文件
要删除 cron 任务,只需运行 `crontab -e` 并删除所需的 cron 任务行,然后保存该文件。
要删除所有的 cron 任务,请运行以下命令:
```
# crontab -r
```
然后,让我们看一下安排任务的不同方式。
### 使用 crontab 安排任务示例
如图所示,所有 cron 任务文件都带有<ruby> 释伴 <rt> shebang </rt></ruby>标头。
```
#!/bin/bash
```
这表示你正在使用的 shell,在这种情况下,即 bash shell。
接下来,使用我们之前指定的 cron 任务条目指定要安排任务的时间间隔。
要每天下午 12:30 重启系统,请使用以下语法:
```
30 12 * * * /sbin/reboot
```
要安排在凌晨 4:00 重启,请使用以下语法:
```
0 4 * * * /sbin/reboot
```
注:星号 `*` 用于匹配所有记录。
要每天两次运行脚本(例如,凌晨 4:00 和下午 4:00),请使用以下语法:
```
0 4,16 * * * /path/to/script
```
要安排 cron 任务在每个星期五下午 5:00 运行,请使用以下语法:
```
0 17 * * Fri /path/to/script
```
或
```
0 17 * * * 5 /path/to/script
```
如果你希望每 30 分钟运行一次 cron 任务,请使用:
```
*/30 * * * * /path/to/script
```
要安排 cron 任务每 5 小时运行一次,请运行:
```
* */5 * * * /path/to/script
```
要在选定的日期(例如,星期三和星期五的下午 6:00)运行脚本,请执行以下操作:
```
0 18 * * wed,fri /path/to/script
```
要使用单个 cron 任务运行多个命令,请使用分号分隔任务,例如:
```
* * * * * /path/to/script1 ; /path/to/script2
```
### 使用特殊字符串节省编写 cron 任务的时间
某些 cron 任务可以使用对应于特定时间间隔的特殊字符串轻松配置。例如,
1)`@hourly` 时间戳等效于 `0 * * * *`
它将在每小时的第一分钟执行一次任务。
```
@hourly /path/to/script
```
2)`@daily` 时间戳等效于 `0 0 * * *`
它在每天的第一分钟(午夜)执行任务。它可以在执行日常工作时派上用场。
```
@daily /path/to/script
```
3)`@weekly` 时间戳等效于 `0 0 * * 0`
它在每周的第一分钟执行 cron 任务,一周第一天是从星期日开始的。
```
@weekly /path/to/script
```
3)`@monthly` 时间戳等效于 `0 0 1 * *`
它在每月第一天的第一分钟执行任务。
```
@monthly /path/to/script
```
4)`@yearly` 时间戳等效于 `0 0 1 1 *`
它在每年的第一分钟执行任务,可以用于发送新年问候。
```
@yearly /path/to/script
```
### 限制 crontab
作为 Linux 用户,你可以控制谁有权使用 `crontab` 命令。可以使用 `/etc/cron.deny` 和 `/etc/cron.allow` 文件来控制。默认情况下,只有一个 `/etc/cron.deny` 文件,并且不包含任何条目。要限制用户使用 `crontab` 实用程序,只需将用户的用户名添加到该文件中即可。当用户添加到该文件中,并且该用户尝试运行 `crontab` 命令时,他/她将遇到以下错误。

要允许用户继续使用 `crontab` 实用程序,只需从 `/etc/cron.deny` 文件中删除用户名即可。
如果存在 `/etc/cron.allow` 文件,则仅文件中列出的用户可以访问和使用 `crontab` 实用程序。
如果两个文件都不存在,则只有 root 用户具有使用 `crontab` 命令的特权。
### 备份 crontab 条目
始终建议你备份 crontab 条目。为此,请使用语法:
```
# crontab -l > /path/to/file.txt
```
例如:
```
# crontab -l > /home/james/backup.txt
```
### 检查 cron 日志
cron 日志存储在 `/var/log/cron` 文件中。要查看 cron 日志,请运行以下命令:
```
# cat /var/log/cron
```

要实时查看日志,请使用 `tail` 命令,如下所示:
```
# tail -f /var/log/cron
```

### 总结
在本指南中,你学习了如何创建 cron 任务以自动执行重复性任务,如何备份和查看 cron 日志。我们希望本文提供有关 cron 作业的有用见解。请随时分享你的反馈和意见。
---
via: <https://www.linuxtechi.com/schedule-automate-tasks-linux-cron-jobs/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sometimes, you may have tasks that need to be performed on a regular basis or at certain predefined intervals. Such tasks include backing up databases, updating the system, performing periodic reboots and so on. Such tasks in linux are referred to as** cron jobs (Crontab).** Cron jobs are used for **automation of tasks** that come in handy and help in simplifying the execution of repetitive and sometimes mundane tasks. **Cron** is a daemon that allows you to schedule these jobs which are then carried out at specified intervals. In this tutorial, you will learn how to schedule jobs using cron jobs.
#### The Crontab file
A crontab file, also known as a **cron table**, is a simple text file that contains rules or commands that specify the time interval of execution of a task. There are two categories of crontab files:
**1) System-wide crontab file**
These are usually used by Linux services & critical applications requiring root privileges. The system crontab file is located at **/etc/crontab** and can only be accessed and edited by the root user. It’s usually used for the configuration of system-wide daemons. The crontab file looks as shown:
**2) User-created crontab files**
Linux users can also create their own cron jobs with the help of the crontab command. The cron jobs created will run as the user who created them.
All cron jobs are stored in /var/spool/cron (For RHEL and CentOS distros) and /var/spool/cron/crontabs (For Debian and Ubuntu distros), the cron jobs are listed using the username of the user that created the cron job
The **cron daemon** runs silently in the background checking the **/etc/crontab** file and **/var/spool/cron** and **/etc/cron.d*/** directories
The **crontab** command is used for editing cron files. Let us take a look at the anatomy of a crontab file.
#### The anatomy of a crontab file
Before we go further, it’s important that we first explore how a crontab file looks like. The basic syntax for a crontab file comprises 5 columns represented by asterisks followed by the command to be carried out.
* * * * * command
This format can also be represented as shown below:
m h d moy dow command
OR
m h d moy dow /path/to/script
Let’s expound on each entry
**m**: This represents minutes. It’s specified from 0 to 59**h**: This denoted the hour specified from 0 to 23**d**: This represents the day of the month. Specified between 1 to 31`**moy**: This is the month of the year. It’s specified between 1 to 12**doy**: This is the day of the week. It’s specified between 0 and 6 where 0 = Sunday**Command**: This is the command to be executed e.g backup command, reboot, & copy
#### Managing cron jobs
Having looked at the architecture of a crontab file, let’s see how you can create, edit and delete cron jobs
**Creating cron jobs**
To create or edit a cron job as the root user, run the command
# crontab -e
To create a cron job or schedule a task as another user, use the syntax
# crontab -u username -e
For instance, to run a cron job as user Pradeep, issue the command:
# crontab -u Pradeep -e
If there is no preexisting crontab file, then you will get a blank text document. If a crontab file was existing, The -e option allows to edit the file,
**Listing crontab files**
To view the cron jobs that have been created, simply pass the -l option as shown
# crontab -l
**Deleting a crontab file**
To delete a cron file, simply run crontab -e and delete or the line of the cron job that you want and save the file.
To remove all cron jobs, run the command:
# crontab -r
That said, let’s have a look at different ways that you can schedule tasks
#### Crontab examples in Scheduling tasks.
All cron jobs being with a shebang header as shown
#!/bin/bash
This indicates the shell you are using, which, for this case, is bash shell.
Next, specify the interval at which you want to schedule the tasks using the cron job entries we specified earlier on.
To reboot a system daily at 12:30 pm, use the syntax:
30 12 * * * /sbin/reboot
To schedule the reboot at 4:00 am use the syntax:
0 4 * * * /sbin/reboot
**NOTE:** The asterisk * is used to match all records
To run a script twice every day, for example, 4:00 am and 4:00 pm, use the syntax.
0 4,16 * * * /path/to/script
To schedule a cron job to run every Friday at 5:00 pm use the syntax:
0 17 * * Fri /path/to/script
OR
0 17 * * * 5 /path/to/script
If you wish to run your cron job every 30 minutes then use:
*/30 * * * * /path/to/script
To schedule cron to run after every 5 hours, run
* */5 * * * /path/to/script
To run a script on selected days, for example, Wednesday and Friday at 6.00 pm execute:
0 18 * * wed,fri /path/to/script
To schedule multiple tasks to use a single cron job, separate the tasks using a semicolon for example:
* * * * * /path/to/script1 ; /path/to/script2
#### Using special strings to save time on writing cron jobs
Some of the cron jobs can easily be configured using special strings that correspond to certain time intervals. For example,
1) @hourly timestamp corresponds to 0 * * * *
It will execute a task in the first minute of every hour.
@hourly /path/to/script
2) @daily timestamp is equivalent to 0 0 * * *
It executes a task in the first minute of every day (midnight). It comes in handy when executing daily jobs.
@daily /path/to/script
3) @weekly timestamp is the equivalent to 0 0 1 * mon
It executes a cron job in the first minute of every week where a week whereby, a week starts on Monday.
@weekly /path/to/script
3) @monthly is similar to the entry 0 0 1 * *
It carries out a task in the first minute of the first day of the month.
@monthly /path/to/script
4) @yearly corresponds to 0 0 1 1 *
It executes a task in the first minute of every year and is useful in sending New year greetings 🙂
@monthly /path/to/script
#### Crontab Restrictions
As a Linux user, you can control who has the right to use the crontab command. This is possible using the **/etc/cron.deny** and **/etc/cron.allow** file. By default, only the /etc/cron.deny file exists and does not contain any entries. To restrict a user from using the crontab utility, simply add a user’s username to the file. When a user is added to this file, and the user tries to run the crontab command, he/she will encounter the error below.
To allow the user to continue using the crontab utility, simply remove the username from the /etc/cron.deny file.
If /etc/cron.allow file is present, then only the users listed in the file can access and use the crontab utility.
If neither file exists, then only the root user will have privileges to use the crontab command.
#### Backing up crontab entries
It’s always advised to backup your crontab entries. To do so, use the syntax
# crontab -l > /path/to/file.txt
For example,
# crontab -l > /home/james/backup.txt
**Checking cron logs**
Cron logs are stored in /var/log/cron file. To view the cron logs run the command:
# cat /var/log/cron
To view live logs, use the tail command as shown:
# tail -f /var/log/cron
**Conclusion**
In this guide, you learned how to create cron jobs to automate repetitive tasks, how to backup as well as how to view cron logs. We hope that this article provided useful insights with regard to cron jobs. Please don’t hesitate to share your feedback and comments.
YawarI very much appreciated to this article about Crontab and Cron Jobs
Robert Montgomery MillerI also appreciate this article about Crontab. Is it possible to export the result logs to a Windows folder? |
11,572 | 如何在 CentOS 8/RHEL 8 上安装和配置 Nagios Core | https://www.linuxtechi.com/install-nagios-core-rhel-8-centos-8/ | 2019-11-13T23:01:25 | [
"Nagios"
] | https://linux.cn/article-11572-1.html | Nagios 是一个自由开源的网络和警报引擎,它用于监控各种设备,例如网络设备和网络中的服务器。它支持 Linux 和 Windows,并提供了直观的 Web 界面,可让你轻松监控网络资源。经过专业配置后,它可以在服务器或网络设备下线或者故障时向你发出邮件警报。在本文中,我们说明了如何在 RHEL 8/CentOS 8 上安装和配置 Nagios Core。

### Nagios Core 的先决条件
在开始之前,请先检查并确保有以下各项:
* RHEL 8/CentOS 8 环境
* 能通过 SSH 访问该环境
* 快速稳定的互联网连接
满足上述要求后,我们开始吧!
### 步骤 1:安装 LAMP
为了使 Nagios 能够按预期工作,你需要安装 LAMP 或其他 Web 软件,因为它们将在浏览器上运行。为此,请执行以下命令:
```
# dnf install httpd mariadb-server php-mysqlnd php-fpm
```

你需要确保 Apache Web 服务器已启动并正在运行。为此,请使用以下命令启用并启动 Apache 服务器:
```
# systemctl start httpd
# systemctl enable httpd
```

检查 Apache 服务器运行状态:
```
# systemctl status httpd
```

接下来,我们需要启用并启动 MariaDB 服务器,运行以下命令:
```
# systemctl start mariadb
# systemctl enable mariadb
```

要检查 MariaDB 状态,请运行:
```
# systemctl status mariadb
```

另外,你可能会考虑加强或保护服务器,使其不容易受到未经授权的访问。要保护服务器,请运行以下命令:
```
# mysql_secure_installation
```
确保为你的 MySQL 实例设置一个强密码。对于后续提示,请输入 “Y” 并按回车。

### 步骤 2:安装必需的软件包
除了安装 LAMP 外,还需要一些其他软件包来安装和正确配置 Nagios。因此,如下所示安装软件包:
```
# dnf install gcc glibc glibc-common wget gd gd-devel perl postfix
```

### 步骤 3:创建 Nagios 用户帐户
接下来,我们需要为 Nagios 用户创建一个用户帐户。为此,请运行以下命令:
```
# adduser nagios
# passwd nagios
```

现在,我们需要为 Nagios 创建一个组,并将 Nagios 用户添加到该组中。
```
# groupadd nagiosxi
```
现在添加 Nagios 用户到组中:
```
# usermod -aG nagiosxi nagios
```
另外,将 Apache 用户添加到 Nagios 组:
```
# usermod -aG nagiosxi apache
```

### 步骤 4:下载并安装 Nagios Core
现在,我们可以继续安装 Nagios Core。Nagios 4.4.5 的最新稳定版本于 2019 年 8 月 19 日发布。但首先,请从它的官方网站下载 Nagios tarball 文件。
要下载 Nagios Core,请首进入 `/tmp` 目录:
```
# cd /tmp
```
接下来下载 tarball 文件:
```
# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.5.tar.gz
```

下载完 tarball 文件后,使用以下命令将其解压缩:
```
# tar -xvf nagios-4.4.5.tar.gz
```
接下来,进入未压缩的文件夹:
```
# cd nagios-4.4.5
```
按此顺序运行以下命令:
```
# ./configure --with-command-group=nagcmd
# make all
# make install
# make install-init
# make install-daemoninit
# make install-config
# make install-commandmode
# make install-exfoliation
```
要配置 Apache,请运行以下命令:
```
# make install-webconf
```
### 步骤 5:配置 Apache Web 服务器身份验证
接下来,我们将为用户 `nagiosadmin` 设置身份验证。请注意不要更改该用户名,否则,可能会要求你进一步的配置,这可能很繁琐。
要设置身份验证,请运行以下命令:
```
# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
```

系统将提示你输入 `nagiosadmin` 用户的密码。输入并按要求确认密码。在本教程结束时,你将使用该用户登录 Nagios。
为使更改生效,请重新启动 Web 服务器:
```
# systemctl restart httpd
```
### 步骤 6:下载并安装 Nagios 插件
插件可以扩展 Nagios 服务器的功能。它们将帮助你监控各种服务、网络设备和应用。要下载插件的 tarball 文件,请运行以下命令:
```
# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
```
接下来,解压 tarball 文件并进入到未压缩的插件文件夹:
```
# tar -xvf nagios-plugins-2.2.1.tar.gz
# cd nagios-plugins-2.2.1
```
要安装插件,请编译源代码,如下所示:
```
# ./configure --with-nagios-user=nagios --with-nagios-group=nagiosxi
# make
# make install
```
### 步骤 7:验证和启动 Nagios
成功安装 Nagios 插件后,验证 Nagios 配置以确保一切良好,并且配置中没有错误:
```
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
```

接下来,启动 Nagios 并验证其状态:
```
# systemctl start nagios
# systemctl status nagios
```

如果系统中有防火墙,那么使用以下命令允许 ”80“ 端口:
```
# firewall-cmd --permanent --add-port=80/tcp# firewall-cmd --reload
```
### 步骤 8:通过 Web 浏览器访问 Nagios 面板
要访问 Nagios,请打开服务器的 IP 地址,如下所示:<http://server-ip/nagios> 。
这将出现一个弹出窗口,提示输入我们在步骤 5 创建的用户名和密码。输入凭据并点击“Sign In”。

这将引导你到 Nagios 面板,如下所示:

我们终于成功地在 CentOS 8 / RHEL 8 上安装和配置了 Nagios Core。欢迎你的反馈。
---
via: <https://www.linuxtechi.com/install-nagios-core-rhel-8-centos-8/>
作者:[James Kiarie](https://www.linuxtechi.com/author/james/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Nagios** is a free and opensource network and alerting engine used to monitor various devices, such as network devices, and servers in a network. It supports both **Linux** and** Windows OS** and provides an intuitive web interface that allows you to easily monitor network resources. When professionally configured, it can alert you in the event a server or a network device goes down or malfunctions via email alerts. In this topic, we shed light on how you can install and configure Nagios core on **RHEL 8** / **CentOS 8**.
#### Prerequisites of Nagios Core
Before we begin, perform a flight check and ensure you have the following:
- An instance of RHEL 8 / CentOS 8
- SSH access to the instance
- A fast and stable internet connection
With the above requirements in check, let’s roll our sleeves!
#### Step 1: Install LAMP Stack
For Nagios to work as expected, you need to install LAMP stack or any other web hosting stack since it’s going to run on a browser. To achieve this, execute the command:
# dnf install httpd mariadb-server php-mysqlnd php-fpm
You need to ensure that Apache web server is up and running. To do so, start and enable Apache server using the commands:
# systemctl start httpd # systemctl enable httpd
To check the status of Apache server run
# systemctl status httpd
Next, we need to start and enable MariaDB server, run the following commands
# systemctl start mariadb # systemctl enable mariadb
To check MariaDB status run:
# systemctl status mariadb
Also, you might consider hardening or securing your server and making it less susceptible to unauthorized access. To secure your server, run the command:
# mysql_secure_installation
Be sure to set a strong password for your MySQL instance. For the subsequent prompts, Type **Yes** and hit **ENTER**
#### Step 2: Install Required packages
Apart from installing the LAMP server, some additional packages are needed for the installation and proper configuration of Nagios. Therefore, install the packages as shown below:
# dnf install gcc glibc glibc-common wget gd gd-devel perl postfix
#### Step 3: Create a Nagios user account
Next, we need to create a user account for the Nagios user. To achieve this , run the command:
# adduser nagios # passwd nagios
Now, we need to create a group for Nagios and add the Nagios user to this group.
# groupadd nagiosxi
Now add the Nagios user to the group
# usermod -aG nagiosxi nagios
Also, add Apache user to the Nagios group
# usermod -aG nagiosxi apache
#### Step 4: Download and install Nagios core
We can now proceed and install Nagios Core. The latest stable version in Nagios 4.4.5 which was released on August 19, 2019. But first, download the Nagios tarball file from its official site.
To download Nagios core, first head to the tmp directory
# cd /tmp
Next download the tarball file
# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.5.tar.gz
After downloading the tarball file, extract it using the command:
# tar -xvf nagios-4.4.5.tar.gz
Next, navigate to the uncompressed folder
# cd nagios-4.4.5
Run the commands below in this order
# ./configure --with-command-group=nagcmd # make all # make install # make install-init # make install-daemoninit # make install-config # make install-commandmode # make install-exfoliation
To setup Apache configuration issue the command:
# make install-webconf
#### Step 5: Configure Apache Web Server Authentication
Next, we are going to setup authentication for the user **nagiosadmin**. Please be mindful not to change the username or else, you may be required to perform further configuration which may be quite tedious.
To set up authentication run the command:
# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
You will be prompted for the password of the nagiosadmin user. Enter and confirm the password as requested. This is the user that you will use to login to Nagios towards the end of this tutorial.
For the changes to come into effect, restart your web server.
# systemctl restart httpd
#### Step 6: Download & install Nagios Plugins
Plugins will extend the functionality of the Nagios Server. They will help you monitor various services, network devices, and applications. To download the plugin tarball file run the command:
# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
Next, extract the tarball file and navigate to the uncompressed plugin folder
# tar -xvf nagios-plugins-2.2.1.tar.gz # cd nagios-plugins-2.2.1
To install the plugins compile the source code as shown
# ./configure --with-nagios-user=nagios --with-nagios-group=nagiosxi # make # make install
#### Step 7: Verify and Start Nagios
After the successful installation of Nagios plugins, verify the Nagios configuration to ensure that all is well and there is no error in the configuration:
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Next, start Nagios and verify its status
# systemctl start nagios # systemctl status nagios
In case Firewall is running on system then allow “80” using the following command
# firewall-cmd --permanent --add-port=80/tcp # firewall-cmd --reload
#### Step 8: Access Nagios dashboard via the web browser
To access Nagios, browse your server’s IP address as shown
http://server-ip/nagios
A pop-up will appear prompting for the username and the password of the user we created earlier in Step 5. Enter the credentials and hit ‘**Sign In**’
This ushers you to the Nagios dashboard as shown below
We have finally successfully installed and configured Nagios Core on CentOS 8 / RHEL 8. Your feedback is most welcome.
Also Read : [How to Add Windows and Linux host to Nagios Server for Monitoring](https://www.linuxtechi.com/add-windows-linux-host-to-nagios-server/)
Also Read : [How to Setup Multi Node Elastic Stack Cluster on RHEL 8 / CentOS 8](https://www.linuxtechi.com/setup-multinode-elastic-stack-cluster-rhel8-centos8/)
MikeThank you for posting.
It worked for me. I had one small issue near the end:
./configure –with-command-group=nagcmd #nagcmd generated make errors
./configure –with-command-group=nagiosxi #I substituted nagiosxi for nagcmd
Devang Thakkaryes its worked for me after # ./configure –with-command-group=nagiosxi
SteveThis should be on separate lines.
# firewall-cmd –permanent –add-port=80/tcp# firewall-cmd –reload
Pradeep KumarThank You Steve for pointing out the typo, i have correct it now.
Ross KhanHi – great guide – worked first time, but with one tweak. These lines seemed inconsistent…?
usermod -aG nagiosxi nagios
./configure –with-command-group=nagcmd
I think the second line should be:
./configure –with-command-group=nagiosxi
The second line worked for me and nagios now up and running…
rootagreed, good article but +1 on the slight modification
SamsonIt works, I checked it. However, I see no reason to install nagios from source codes, you can easily install the EPEL repo and get everithyng installed with a couple of commands.
Moreover, there is no need to install mariadb, nagios doesn’t use it.
Tim PerkinsFYI, in “Step 7: Verify and Start Nagios” when running “systemctl start nagios”, I got:
Failed to start nagios.service: Unit nagios.service not found.
I had to add a file:
/etc/systemd/system/nagios.service
… in order to get things working
Jhon Robinscon CortesHello, thanks for your contribution.
I have a problem, I installed everything but when I go to the http: // server-ip / nagios browser, the page does not appear. should I configure something else?
James KiarieHey Jhon Robinson, If you are accessing the Nagios server from a different machine , please check the firewall configuration and ensure that you have opened port 80 on the Nagios server.
pujathank you so much..
only one error *./configure –with-command-group=nagcmd
replace above line with ./configure –with-command-group=nagiosxi
KrishaneHow to monitor HCI nodes installed with VMWare ESXi hypervisors ( As there no OS on the host machine, how we can use nagios?/for any failing nodes of any HCI servers? |
11,574 | 开源与标准:为什么对待专利如此不同? | https://opensource.com/article/19/2/why-patents-treated-differently | 2019-11-14T13:42:00 | [
"专利"
] | https://linux.cn/article-11574-1.html |
>
> 两者之间的差异对我们如何构建软件开发过程产生了影响。
>
>
>

制定标准规范和开源软件的开发有许多共同之处:两者都是竞争者可以合作的机制;两者都可以促进互操作性;两者都可用于促进新技术的采用;两者都可用于聚合或协调成熟技术。
一项技术可以同时使用标准和开源:有时一个先于另一个;在其他情况下,它们可以并行进行。它们越来越多地使用类似的工具和流程实践(例如,细粒度版本控制;利用问题跟踪器一起推动某些开发讨论)。
相似程度可能导致过度概括,错误地暗示一切都是可互换的(混合与搭配),在这儿选择一种做法;在那儿将它与一个过程相结合。实际上,获取在一个领域中获得的经验并查看它提供的好处是否可以在其他环境中获得,可能是有价值的。但是,对于某些实践而言,背景更为重要。
虽然有相似之处,但也存在显著差异。在前面的文章《[没有规则的治理:复刻潜力如何帮助项目](https://opensource.com/article/19/1/forking-good)》中,我讨论了在利用<ruby> 复刻 <rp> ( </rp> <rt> forking </rt> <rp> ) </rp></ruby>潜力作为一种可以促进轻量级治理的力量方面,开源软件开发和标准开发治理能力的不同。另一个不同之处在于专利规则的选择。
### 如何对待专利
参与者专利权的处理通常在开源软件开发和标准开发中以不同方式排列。这种差异有一个理由。而且,这种差异会对构建开发过程产生影响。
* 开源:在为开源项目做出贡献时授予的专利许可通常由每个贡献者的贡献确定。
* 标准:参与者在标准制定方面做出的专利承诺通常由整个最终规范确定。
### 开源项目:基于贡献的专利规则
基于贡献的专利规则是什么意思?如果专利所有者提供软件,由于软件添加到项目中,项目软件侵犯了该贡献者拥有的专利,那么贡献者不应该返回来期望获得使用它所贡献的软件的专利许可费。当然,有许多不同的许可文本可以让我们忙于分析每个许可的解释,并讨论情况中的不确定性和细微差别。在另一篇文章中,我在 MIT 许可协议的背景下谈到了这个问题(《[为什么 MIT 的专利许可不讨人喜欢?](/article-9605-1.html)》)。我认为,基本上来说,开源开发中的共同期望就像我上面所描述的那样:当你为开源做出贡献时,你将为你提供的软件提供所有必需的权限,之后你将无法返回来再要求获得使用你所贡献软件的许可费。
### 标准制定:基于标准规范的专利规则
相比之下,在制定标准时,通常会有更高的期望:参与者应对专利做出承诺,这些专利对整个最终规范至关重要,而不仅仅是对其贡献。这些专利承诺并不取决于确定谁对规范提出了什么想法;对于那些参与开发规范的人来说,他们的承诺是整个标准规范。
### 包括在其中的专利
确定相关专利的分析在软件和规范之间也有所不同。软件通常包括与相应的标准规范相比不需要的实现细节;在提供软件时,将包括对这些细节使用任何专利的许可。相反,规范开发的专利承诺仅限于对规范“必要”或“必需”的专利。当然,这取决于规范的内容。对于互操作性标准,规范应仅包括实现互操作性所需的详细级别,从而允许实现细节在标准的竞争性实现之间有所不同。对必要专利的承诺不包括实施细节方面的专利,这些专利可用作竞争优势。
### 专利规则差异的基础
为什么在专利处理方面存在这种差异?鉴于标准和开源软件的开发方式存在差异,这种不同的处理方式很有意义。
更有限的与贡献范围相关的专利符合大多数协作软件开发的渐进式、开放式特性。开源项目经常持续发展,其方向可能会随着时间的推移而演化。虽然可以设置路线图和里程碑并发布快照版本,但这些不太常见,并且比标准项目中常见的范围限制和版本目标具有更少的限制性影响。
可以看出,考虑到标准规范开发结构的差异,标准开发的更高期望值(整个最终规范,不仅仅是贡献)是有意义的。标准规范通常采用具有明确范围的强版本导向演进。规范开发通常适用于特定的快照版本。标准开发活动通常具有一组目标功能(通常在诸如章程之类的文档中表示)。与许多软件开发活动的情况相比,这为可能应用到标准开发活动的技术范围提供了更清晰的公共的进展预期。这种范围的明确性有助于潜在参与者在开始参与时评估参与标准制定项目的专利影响。相比之下,开源软件开发项目更为开放,通常不会排除采用任何特定技术的可能性。
### 对开源项目和标准管理的影响
这些对待专利的不同措施需要不同的项目管理方法。
开源项目通常准备接受来自新贡献者的补丁。贡献者可能会随着时间的推移而来去。一些贡献者留下来。其他人可能会为该项目来解决一个有限的问题。通过软件贡献,可以更容易地了解谁贡献了什么软件,而不是准确理解谁以一种更抽象的方式“参与”。
另一方面,参与标准制定活动通常具有大量的正式手续。而且,在涉及专利承诺时,这种参与的正式性非常重要。当一个人参与该规范的大部分开发时,对最终规范的专利承诺是有意义的。标准制定过程是否可以从提供单一、有限贡献的人那里获得完整的最终规范承诺?重要的是要有一个过程,以便清楚地了解谁参与谁,谁不参与。需要明确参与者以支持来自实际专利所有者的专利承诺,实际专利所有者通常是由坐在桌旁(比喻,尽管这可能涉及实际的谈判桌)的个人所代表的公司。
如何获得基于规范的承诺?软件标准中典型的免许可费专利承诺最常被作为获得标准组织成员资格或负责规范开发的特定委员会成员资格的条件。为了使这一机制发挥作用,成员资格必须是一个定义明确的概念,以便有一个明确的成员资格决策点(即,用于触发专利承诺的明确行动)和承诺的受益人可以依赖的明确的记录文件。除了参与清晰度之外,为了促进持怀疑态度的专利参与者的参与,项目需要具有明确的范围和明确的开始和结束(明确指出专利承诺将适用的“最终规范”)。这种参与模式与典型的开源项目有很大不同,典型的开源项目可能有一个连续的参与,其范围包括维护几个主要的驱动程序到只提交一个补丁。
### 专利政策
虽然我所描述的差异通常是这种情况,但某些特定活动遵循不同模式可能有一些原因。例如,考虑作为标准开发活动附带的参考实现的软件。可能有一个强有力的理由期望参与者对完整的最终参考实施提供承诺,而不仅仅是限定于他们对它的贡献。当然,可能存在其他边缘情况;可能存在严格安排的开源开发;可能会有连续的、随心所欲的规范开发。
标准制定的专利政策可分为合理和非歧视(RAND)或免许可费(RF):基本上来说,实施标准的专利许可费包括需要交(RAND)或不需要交(RF)。制定与软件相关的标准(本文的重点)更多地使用免许可费政策。关于专利许可费预期问题是许可或承诺范围政策之外的另一个维度。
### 结论
标准的制定和开源软件的开发通常具有不同的参与者专利期望范围(仅限于贡献或整个最终可交付成果)。这些不同的选择基于通常如何进行开发的显著差异,而不是任意差异。
---
作者简介:Scott Peterson 是红帽公司法律团队成员。很久以前,一位工程师就一个叫做 GPL 的奇怪文件向 Scott 征询法律建议,这个致命的问题让 Scott 走上了探索包括技术标准和开源软件在内的协同开发法律问题的纠结之路。
译者简介:薛亮,集慧智佳知识产权咨询公司总监,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | Development of standards specifications and development of open source software have much in common: both are mechanisms by which competitors can collaborate; both can facilitate interoperability; both can be used to facilitate the adoption of new technologies; both can be used to crystallize or harmonize mature technologies.
A technology may use both standards and open source: sometimes one precedes the other; in other cases, they may proceed in parallel. Increasingly, they may use similar tooling and process practices (e.g., fine-grained version control; driving certain development discussions with issue trackers).
The extent of the similarities can lead to over-generalization, incorrectly implying that everything is interchangeable—mix-and-match—pick a practice here; combine it with a process there. Indeed, it can be valuable to take experience gained in one domain and see if the benefit it provides might be obtained in other contexts. However, for certain practices, the context matters more than might be apparent.
While there are similarities, there are also significant differences. In an earlier article ([Governance without rules: How the potential for forking helps projects](https://opensource.com/article/19/1/forking-good)), I discussed how governance of open source software development and standards development differ in the ability to take advantage of the potential for forking as a force that can facilitate lightweight governance. Another difference relates to the choice of patent rules.
## Treatment of patents
Treatment of participant patent rights is typically arranged differently in open source software development and in standards development. There is a rationale for the difference. And, the difference has consequences for structuring the development process.
**Open source:**Patent licenses granted when contributing to open source projects are generally scoped by each contributor's contribution.**Standards:**Patent commitments made by participants in standards development are generally scoped by the entire, final specification.
## Open source projects: contribution-based patent rules
What do I mean by a contribution-scoped patent rule? If a patent owner contributes software such that, as a result of the software's addition to the project, the project software infringes a patent owned by that contributor, then the contributor ought not to come back and expect a patent license fee for use of software that it contributed. Of course, there are plenty of different license texts that could keep us busy analyzing the interpretation of each license and talking about uncertainties and nuances in the situations. In another article, I talked about this issue in the context of the MIT License ([Why so little love for the patent grant in the MIT License?](https://opensource.com/article/18/3/patent-grant-mit-license)). I believe that, essentially, the shared expectation in open source development is as I have described above: When you contribute to open source, you are giving all the needed permissions that you have for the software that you contribute, and you will not later come back asking for a license fee for use of the software that you contributed.
## Standards development: specification-based patent rules
In contrast, in development of standards, there is generally a higher expectation: Participants are expected to make a commitment with respect to patents that are essential to the entire, final specification, not merely to their contributions. Those patent commitments do not depend on determining who contributed what idea to the specification; for those who are part of the group developing the spec, their commitment is to the whole specification.
## Patents included
The analysis to determine the relevant patents is also somewhat different between software and specifications. Software will typically include implementation details that would not be required if compared to a corresponding standards specification; permission to use any patents on those details would be included when contributing software. In contrast, the patent commitment for specification development is limited to patents that are "essential" or "necessary" to the specification. This, of course, depends on what is specified. For interoperability standards, the specification should only include the level of detail needed to accomplish interoperability, allowing implementation details to differ among competing implementations of the standard. A commitment to essential patents would not include patents on implementation details, which may be used as competitive differentiators.
## Basis for differences in patent rules
Why is there this difference in treatment of patents? This different treatment makes sense in light of differences in how standards and open source software are developed.
The more limited, contribution-based expectation concerning patents fits with the incrementally evolving, open-ended nature of most collaborative software development. Open source projects often undergo continuous development, the direction of which may evolve over time. While roadmaps and milestones may be set and snapshots taken, these are less common and have less restrictive impact than the scope limitations and version targets that are common among standards projects.
One can see how the higher expectation that is typical of standards development (the whole final spec, not only contributions) makes sense considering differences in how development of standards specifications is structured. Standards specifications typically undergo a strongly version-oriented evolution with explicit scope. Specification development typically works toward specific snapshot versions. A standards development activity will often have a target set of functionality (typically expressed in a document such as a charter). This provides a clearer shared advance expectation as to the scope of technologies that are likely to be implicated in a standards development activity than would be the case for many software development activities. This clarity of scope facilitates a potential participant's evaluation of the patent implications of participating in a standards development project at the time of beginning participation. Contrast this with a more open-ended open source software development project, which would not generally exclude the possibility of incorporating any particular technology.
## Implications on management of open source projects and standards
These different approaches to patents require different approaches in project management.
An open source project is often prepared to accept patches from new contributors. Contributors may come and go over time. Some stay. Others may stop by the project to address a single, limited issue. With software contributions, it is easier to have an understanding of who contributed what software than to have a precise understanding of who "participated" in some more abstract way.
On the other hand, there is typically greater formality associated with participation in a standards development activity. And, such formality of participation is important when it comes to the patent commitments. A patent commitment to the final spec makes sense when one participates through much of the development of that spec. Can a standards development process expect a full final specification commitment from one who provided a single, narrow contribution? It is important to have a process that leads to a clear understanding of who is participating and who is not. Clarity of participation is needed to support patent commitments from the actual patent owners, which are generally the companies who are represented by the individuals who are sitting at the table (speaking metaphorically; although this *can* involve actual tables).
How is a specification-wide commitment obtained? The royalty-free patent commitments that are typical of software standards are most commonly implemented as a condition of membership in the standards organization or membership in the particular committee that is responsible for development of the specification. In order for this mechanism to work, membership must be a well-defined concept, so that there is a clear membership decision point (i.e., a well-defined action that would be used to trigger the undertaking of patent commitments) and a clear record on which the beneficiaries of the commitments can rely. In addition to participation clarity, in order to facilitate participation by skeptical patent-owning participants, projects need to have an explicit scope and a clear beginning and end (with clarity of what is the "final specification" to which commitments will apply). This model for participation differs significantly from typical open source projects, which may have a continuum of participation extending from a few main drivers down to those who may submit only a single patch.
## Patent policies
While the difference I have described is generally the case, there may be reasons for a particular activity to follow a different pattern. For example, consider the software that is a reference implementation that accompanies a standards development activity. There may be a strong rationale for expecting participants to commit to the full, final resulting reference implementation, not only to their contributions to it. Of course, other edge cases may exist; there may be rigidly scheduled open source development; there may be continuous, free-wheeling specification development.
Patent policies for standards development can be categorized as reasonable and non-discriminatory (RAND) or royalty-free (RF): essentially, whether patent licensing fees for implementation of the standard are considered OK (RAND) or not (RF). Development of standards relating to software (the focus of this article) more often uses a royalty-free policy. This matter of whether patent license fees are expected or not is a separate dimension of the policy from the scope of the license or commitment.
## Conclusion
Development of standards and development of open source software typically have different scopes of patent expectations from participants (only to contributions or to the entire final deliverable). Rather than arbitrary differences, there is a rationale for these different choices that is based on significant differences in how development is typically undertaken.
## 1 Comment |
11,575 | 为什么区块链(可能会)来到你身边的物联网 | https://www.networkworld.com/article/3386881/why-blockchain-might-be-coming-to-an-iot-implementation-near-you.html | 2019-11-14T16:15:04 | [
"区块链",
"物联网"
] | https://linux.cn/article-11575-1.html | 
各个公司发现,物联网与最近其他许多流行的企业级计算技术有着良好的合作关系,以支持加密货币而闻名的创新的分布式信任系统的区块链也不例外。然而,在物联网应用中实施区块链可能具有挑战性,并且需要对技术有深入的了解。
区块链是一个跟踪各种交易的分布式账本。链上的每个“块”都包含要防止篡改的交易记录或其他数据,并通过加密散列链接到前一个,这意味着对块的任何篡改都将使该链接无效。节点(几乎可以是其中装有 CPU 的任何节点)通过分布式的对等网络进行通信,以共享数据并确保链中数据的有效性。
北卡罗来纳大学格林波若分校的管理学教授 Nir Kshetri 表示,区块链系统之所以有效,是因为所有的块都必须就它们所保护的数据的细节达成一致。如果有人尝试更改给定节点上先前的事务,则存储在网络上的其余数据会回推回来。“数据的旧记录仍然存在,” Kshetri 说。
这是一项强大的安全技术 —— 如果没有坏人成功控制给定区块链上的所有(LCTT 译注:应为“大部分”)节点([著名的“51% 攻击”](https://bitcoinist.com/51-percent-attack-hackers-steals-18-million-bitcoin-gold-btg-tokens/)),那么该区块链保护的数据就不会被伪造或以其他方式弄乱。因此,对于在物联网世界某些角落的公司来说,使用区块链是一种有吸引力的选择也就不足为奇了。
物联网安全初创企业 NXMLabs 的首席技术官兼联合创始人 Jay Fallah 认为,除了区块链能够在网络上安全地分发可信信息的能力这一事实之外,部分原因还在于区块链在技术堆栈中的地位。
“区块链站在一个非常有趣的交叉点。在过去的 15 年中,在存储、CPU 等方面,计算技术一直在加速发展,但是直到最近,网络技术并没有发生太大变化。”他说,“ 区块链不是网络技术、不是数据技术,而是二者兼具。”
### 区块链和物联网
区块链作为物联网世界的部分意义取决于你在和谁交谈以及他们在出售什么,但是最接近的概括可能来自企业区块链供应商 Filament 的首席执行官 Allison Clift-Jenning。
她说:“在任何地方,人们都想互相信任,并且用的是非常古老的方式,这通常是进入场景的好地方。”
直接从 Filament 自己的客户群中挑选出来的一个例子是二手车销售。Filament 与“一家主要的底特律汽车制造商”合作,创建了一个受信任的车辆历史平台,该平台基于一种设备,该设备可插入二手车的诊断端口,从那里获取信息,并将该数据写入区块链。像这样,二手车的历史记录就是不可变的,包括它的安全气囊是否曾经打开过,是否被水淹过等等。任何不道德的二手车或不诚实的前车主都无法更改数据,甚至拔掉设备也将意味着记录中存在可疑的空白期。
SAP 物联网高级副总裁兼全球负责人 Elvira Wallis 表示,当今大多数区块链物联网方案都与信任和数据验证有关。
她说:“我们遇到的大多数用例都在项目的跟踪和溯源领域,”她举例说明了高端食品的农场到餐桌跟踪系统,该系统使用安装在板条箱和卡车上的区块链节点,这样就可以为物品在运输基础设施中创建无懈可击的记录。(例如,该牛排在这样的温度下冷藏了多长时间,今天运输了多长时间,等等。)
### 将区块链与物联网一起使用是个好主意吗?
不同的供应商针对不同的用例出售不同的基于区块链的产品,这些产品使用不同的区块链技术实现,其中一些与加密货币中所使用的经典的、线性的、挖矿式交易区块链不太一样。
这意味着你目前需要从供应商那里购买特定功能。451 Research 高级分析师 Csilla Zsigri 表示,很少有客户组织拥有可以实施区块链安全系统的内部专家。
她说,区块链技术的任何智能应用的想法都是发挥其优势,为关键信息创建可信赖的平台。
Zsigri 说:“这就是我真正看到增值的地方,只是增加了一层信任和验证。”
专家们一致认为,尽管相当了解基于区块链的物联网应用程序的基本概念,但它并不适用于每个物联网用例。 将区块链应用于非交易系统(尽管有例外,包括 NXM Labs 的用于物联网设备的基于区块链配置的产品)通常不是正确的举动。
如果不需要在两个不同的参与方之间共享数据,而是简单地将数据从传感器移到后端,那么区块链通常就没有意义,因为它实际上并没有为当前大多数物联网实现中的数据分析增加任何关键的增值。
“今天,我们仍处于区块链的早期拨号时代。”Clift-Jennings 说,“它比典型的数据库要慢,它甚至无法读取,也常常没有查询引擎。从本质上讲,你并没有真正获得隐私。”
---
via: <https://www.networkworld.com/article/3386881/why-blockchain-might-be-coming-to-an-iot-implementation-near-you.html>
作者:[Jon Gold](https://www.networkworld.com/author/Jon-Gold/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,576 | 微软爱 Linux:安全杀毒软件 Defender ATP 要出 Linux 版了! | https://itsfoss.com/microsoft-defender-atp-linux/ | 2019-11-14T18:38:00 | [
"微软",
"Defender"
] | https://linux.cn/article-11576-1.html |
>
> 微软宣布将于 2020 年将其企业安全产品 Defender 高级威胁防护(ATP)引入 Linux。
>
>
>

微软的年度开发者大会 Microsoft Ignite 刚刚结束,会上发布了一些与 Linux 有关的重要公告。你可能已经知道[微软将 Edge Web 浏览器引入 Linux](/article-11562-1.html),而下一个大新闻是微软将 Defender ATP 引入 Linux!
让我们详细介绍一下它是什么,以及微软为何不厌其烦为 Linux 开发某些东西。
### 微软 Defender ATP 是什么?
如果你过去几年使用过 Windows,那么你一定遇到过 Windows Defender。它基本上可以说是微软的防病毒产品,通过检测病毒和恶意软件来提供一定程度的安全性。
微软通过引入 Windows Defender ATP(高级威胁防护)来为其企业用户改进了此功能。Defender ATP 致力于行为分析。它收集使用使用数据并将其存储在同一系统上。但是,当发现行为不一致时,它将数据发送到 Azure 服务(微软的云服务)。在这里,它将收集行为数据和异常信息。
例如,如果你收到一封包含 PDF 附件的电子邮件,你将其打开并打开了命令提示符,Defender ATP 就会注意到此异常行为。我建议[阅读本文以了解有关 Defender 和 Defender ATP 之间的区别的更多信息](https://www.concurrency.com/blog/november-2017/windows-defender-vs-windows-defender-atp)。
现在,这完全是一种企业级产品。在具有成百上千个端点(计算机)的大型企业中,Defender ATP 提供了很好的保护层。IT 管理员可以在其 Azure 实例上集中查看端点的视图,可以分析威胁并采取相应措施。
### 适用于 Linux(和 Mac)的微软 Defender ATP
通常,企业的计算机上装有 Windows,但 Mac 和 Linux 在开发人员中也特别受欢迎。在混合了 Mac 和 Linux 的 Windows 机器环境中,Defender ATP 必须将其服务扩展到这些操作系统,以便它可以为网络上的所有设备提供整体防御。
请注意,微软先是[在 2019 年 3 月将 Windows Defender ATP 更改为微软 Defender ATP](https://www.theregister.co.uk/2019/03/21/microsoft_defender_atp/),这表明该产品不仅限于 Windows 操作系统。
此后不久微软[宣布推出 Mac 版 Defender ATP](https://techcommunity.microsoft.com/t5/Microsoft-Defender-ATP/Announcing-Microsoft-Defender-ATP-for-Mac/ba-p/378010)。
现在,为了涵盖企业环境中的所有主要操作系统,[微软将于 2020 年将 Defender ATP 引入到 Linux](https://www.zdnet.com/article/microsoft-defender-atp-is-coming-to-linux-in-2020/)。
### Linux 上的微软 Defender ATP 对 Linux 用户有何影响?
由于 Defender ATP 是企业产品,因此我认为你无需为此而烦恼。组织需要保护其端点免受威胁,因此,微软也在改进其产品以使其涵盖 Linux。
对于像你我这样的普通 Linux 用户,这没有任何区别。我不会用它“保护”我的三个 Linux 系统,并为此而向微软付费。
请随时在评论部分中分享你对微软将 Defender ATP 引入 Linux 的看法。
---
via: <https://itsfoss.com/microsoft-defender-atp-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Microsoft has announced that it is bringing its enterprise security product Microsoft Defender Advanced Threat Protection (ATP) to Linux in 2020.*
Microsoft’s annual developer conference Microsoft Ignite has just been concluded and there are a few important announcements that relate to Linux. You probably already read about [Microsoft bringing its Edge web browser to Linux](https://itsfoss.com/microsoft-edge-linux/). The next big news is that Microsoft is bringing Microsoft Defender ATP to Linux.
Let’s get into some details what it is and why Microsoft is bothering itself to develop something for Linux.
## What is Microsoft Defender ATP?
If you have used Windows in past few years, you must have come across Windows Defender. It is basically an antivirus product by Microsoft that brings some level of security by detecting viruses and malware.
Microsoft improved this functionality for its enterprise users by introducing Windows Defender ATP (Advanced Threat Protection). Defender ATP works on behavioral analysis. It collects usage data and store them on the same system. However, when it notices an inconsistent behavior, it sends the data to Azure service (Microsoft’s cloud service). In here, it will have a collection of behavioral data and the anomalies.
For example, if you got a PDF attachment in the email, you open it and it opened a command prompt, Defender ATP will notice this abnormal behavior. I recommend reading this article to [learn more about the difference between Defender and Defender ATP](https://www.concurrency.com/blog/november-2017/windows-defender-vs-windows-defender-atp).
Now this is entirely an enterprise product. In a big enterprise with hundreds or thousands of end points (computers), Defender ATP provides a good layer of protection. The IT admins will have a centralized view of the end-points on their Azure instance and the threats can be analyzed and actions can be taken accordingly.
## Microsoft Defender ATP for Linux (and Mac)
Normally, enterprises have Windows on their computer but Mac and Linux are also getting popular specially among the developers. In an environment where there is a mix of Mac and Linux machines among Windows, Defender ATP has to extends its services to these operating systems so that it can provide a holistic defense to all the devices on the network.
Keeping that in mind, Microsoft first [changed Windows Defender ATP to Microsoft Defender ATP in March 201](https://www.theregister.co.uk/2019/03/21/microsoft_defender_atp/)[9](https://www.theregister.co.uk/2019/03/21/microsoft_defender_atp/), signaling that the product is not limited to just Windows operating system.
Soon after it [announced Defender ATP for Mac](https://techcommunity.microsoft.com/t5/Microsoft-Defender-ATP/Announcing-Microsoft-Defender-ATP-for-Mac/ba-p/378010).
And now to cover all the major operating systems in an enterprise environment, [Microsoft is bringing Defender ATP to Linux](https://www.zdnet.com/article/microsoft-defender-atp-is-coming-to-linux-in-2020/) in 2020.
## How Microsoft Defender ATP on Linux impacts you, a Linux user?
Since Defender ATP is an enterprise product, I don’t think you need to be bothered with this. Organizations need to secure their end-points against threats so it makes sense that Microsoft is improving its product to cover Linux as well.
For normal Linux users like you and me, it won’t make any difference. I am not going to use it ‘secure’ my three Linux systems and pay Microsoft for that.
Please feel free to share your opinion on Microsoft bringing Defender ATP to Linux in the comment section. |
11,579 | 如何使用 metaflac 管理音乐标签 | https://opensource.com/article/19/11/metaflac-fix-music-tags | 2019-11-16T09:36:00 | [
"音乐",
"metaflac"
] | /article-11579-1.html |
>
> 使用这个强大的开源工具可以在命令行中纠正音乐标签错误。
>
>
>

很久以来我就将 CD 翻录到电脑。在此期间,我用过几种不同的翻录工具,观察到每种工具在标记上似乎有不同的做法,特别是在保存哪些音乐元数据上。所谓“观察”,我是指音乐播放器似乎按照有趣的顺序对专辑进行排序,它们将一个目录中的曲目分为两张专辑,或者产生了其他令人沮丧的烦恼。
我还看到有些标签非常不明确,许多音乐播放器和标签编辑器没有显示它们。即使这样,在某些极端情况下,它们仍可以使用这些标签来分类或显示音乐,例如播放器将所有包含 XYZ 标签的音乐文件与不包含该标签的所有文件分离到不同的专辑中。
那么,如果标记应用和音乐播放器没有显示“奇怪”的标记,但是它们受到了某种影响,你该怎么办?
### Metaflac 来拯救!
我一直想要熟悉 [metaflac](https://xiph.org/flac/documentation_tools_metaflac.html),它是一款开源命令行 [FLAC 文件](https://xiph.org/flac/index.html)元数据编辑器,这是我选择的开源音乐文件格式。并不是说 [EasyTAG](https://wiki.gnome.org/Apps/EasyTAG) 这样出色的标签编辑软件有什么问题,但我想起“如果你手上有个锤子……”这句老话(LCTT 译注:指如果你手上有个锤子,那么所有的东西看起来都像钉子。意指人们惯于用熟悉的方式解决问题,而不管合不合适)。另外,从实际的角度来看,带有 [Armbian](https://www.armbian.com/) 和 [MPD](https://www.musicpd.org/) 的小型专用服务器,音乐存储在本地、运行精简的仅限音乐的无头环境就可以满足我的家庭和办公室的立体音乐的需求,因此命令行元数据管理工具将非常有用。
下面的截图显示了我的长期翻录过程中产生的典型问题:Putumayo 的哥伦比亚音乐汇编显示为两张单独的专辑,一张包含单首曲目,另一张包含其余 11 首:

我使用 `metaflac` 为目录中包含这些曲目的所有 FLAC 文件生成了所有标签的列表:
```
rm -f tags.txt
for f in *.flac; do
echo $f >> tags.txt
metaflac --export-tags-to=tags.tmp "$f"
cat tags.tmp >> tags.txt
rm tags.tmp
done
```
我将其保存为可执行的 shell 脚本(请参阅我的同事 [David Both](https://opensource.com/users/dboth) 关于 Bash shell 脚本的精彩系列专栏文章,[特别是关于循环这章](https://opensource.com/article/19/10/programming-bash-loops))。基本上,我在这做的是创建一个文件 `tags.txt`,包含文件名(`echo` 命令),后面是它的所有标签,然后是下一个文件名,依此类推。这是结果的前几行:
```
A Guapi.flac
TITLE=A Guapi
ARTIST=Grupo Bahia
ALBUMARTIST=Various Artists
ALBUM=Putumayo Presents: Colombia
DATE=2001
TRACKTOTAL=12
GENRE=Latin Salsa
MUSICBRAINZ_ALBUMARTISTID=89ad4ac3-39f7-470e-963a-56509c546377
MUSICBRAINZ_ALBUMID=6e096386-1655-4781-967d-f4e32defb0a3
MUSICBRAINZ_ARTISTID=2993268d-feb6-4759-b497-a3ef76936671
DISCID=900a920c
ARTISTSORT=Grupo Bahia
MUSICBRAINZ_DISCID=RwEPU0UpVVR9iMP_nJexZjc_JCc-
COMPILATION=1
MUSICBRAINZ_TRACKID=8a067685-8707-48ff-9040-6a4df4d5b0ff
ALBUMARTISTSORT=50 de Joselito, Los
Cumbia Del Caribe.flac
```
经过一番调查,结果发现我同时翻录了很多 Putumayo CD,并且当时我所使用的所有软件似乎给除了一个之外的所有文件加上了 `MUSICBRAINZ_*` 标签。(是 bug 么?大概吧。我在六张专辑中都看到了。)此外,关于有时不寻常的排序,我注意到,`ALBUMARTISTSORT` 标签将西班牙语标题 “Los” 移到了标题的最后面(逗号之后)。
我使用了一个简单的 `awk` 脚本来列出 `tags.txt` 中报告的所有标签:
```
awk -F= 'index($0,"=") > 0 {print $1}' tags.txt | sort -u
```
这会使用 `=` 作为字段分隔符将所有行拆分为字段,并打印包含等号的行的第一个字段。结果通过使用 `sort` 及其 `-u` 标志来传递,从而消除了输出中的所有重复项(请参阅我的同事 Seth Kenlon 的[关于 `sort` 程序的文章](https://opensource.com/article/19/10/get-sorted-sort))。对于这个 `tags.txt` 文件,输出为:
```
ALBUM
ALBUMARTIST
ALBUMARTISTSORT
ARTIST
ARTISTSORT
COMPILATION
DATE
DISCID
GENRE
MUSICBRAINZ_ALBUMARTISTID
MUSICBRAINZ_ALBUMID
MUSICBRAINZ_ARTISTID
MUSICBRAINZ_DISCID
MUSICBRAINZ_TRACKID
TITLE
TRACKTOTAL
```
研究一会后,我发现 `MUSICBRAINZ_*` 标签出现在除了一个 FLAC 文件之外的所有文件上,因此我使用 `metaflac` 命令删除了这些标签:
```
for f in *.flac; do metaflac --remove-tag MUSICBRAINZ_ALBUMARTISTID "$f"; done
for f in *.flac; do metaflac --remove-tag MUSICBRAINZ_ALBUMID "$f"; done
for f in *.flac; do metaflac --remove-tag MUSICBRAINZ_ARTISTID "$f"; done
for f in *.flac; do metaflac --remove-tag MUSICBRAINZ_DISCID "$f"; done
for f in *.flac; do metaflac --remove-tag MUSICBRAINZ_TRACKID "$f"; done
```
完成后,我可以使用音乐播放器重建 MPD 数据库。结果如下:

完成了,12 首曲目出现在了一张专辑中。
太好了,我很喜欢 `metaflac`。我希望我会更频繁地使用它,因为我会试图去纠正最后一些我弄乱的音乐收藏标签。强烈推荐!
### 关于音乐
我花了几个晚上在 CBC 音乐(CBC 是加拿大的公共广播公司)上收听 Odario Williams 的节目 After Dark。感谢 Odario,我听到了让我非常享受的 [Kevin Fox 的 Songs for Cello and Voice](https://burlingtonpac.ca/events/kevin-fox/)。在这里,他演唱了 Eurythmics 的歌曲 “[Sweet Dreams(Are Made of This)](https://www.youtube.com/watch?v=uyN66XI1zp4)”。
我购买了这张 CD,现在它在我的音乐服务器上,还有组织正确的标签!
---
via: <https://opensource.com/article/19/11/metaflac-fix-music-tags>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,580 | 在 CentOS/RHEL 系统上生成补丁合规报告的 Bash 脚本 | https://www.2daygeek.com/bash-script-to-generate-patching-compliance-report-on-centos-rhel-systems/ | 2019-11-16T10:15:08 | [
"补丁"
] | https://linux.cn/article-11580-1.html | 
如果你运行的是大型 Linux 环境,那么你可能已经将 Red Hat 与 Satellite 集成了。如果是的话,你不必担心补丁合规性报告,因为有一种方法可以从 Satellite 服务器导出它。
但是,如果你运行的是没有 Satellite 集成的小型 Red Hat 环境,或者它是 CentOS 系统,那么此脚本将帮助你创建该报告。
补丁合规性报告通常每月创建一次或三个月一次,具体取决于公司的需求。根据你的需要添加 cronjob 来自动执行此功能。
此 [bash 脚本](https://www.2daygeek.com/category/bash-script/) 通常适合于少于 50 个系统运行,但没有限制。
保持系统最新是 Linux 管理员的一项重要任务,它使你的计算机非常稳定和安全。
以下文章可以帮助你了解有关在红帽 (RHEL) 和 CentOS 系统上安装安全修补程序的更多详细信息。
* [如何在 CentOS 或 RHEL 系统上检查可用的安全更新?](/article-10938-1.html)
* [在 RHEL 和 CentOS 系统上安装安全更新的四种方法](https://www.2daygeek.com/install-security-updates-on-redhat-rhel-centos-system/)
* [在 RHEL 和 CentOS 上检查或列出已安装的安全更新的两种方法](/article-10960-1.html)
此教程中包含四个 [shell 脚本](https://www.2daygeek.com/category/shell-script/),请选择适合你的脚本。
### 方法 1:为 CentOS / RHEL 系统上的安全修补生成补丁合规性报告的 Bash 脚本
此脚本只会生成安全修补合规性报告。它会通过纯文本发送邮件。
```
# vi /opt/scripts/small-scripts/sec-errata.sh
#!/bin/sh
/tmp/sec-up.txt
SUBJECT="Patching Reports on "date""
MESSAGE="/tmp/sec-up.txt"
TO="[email protected]"
echo "+---------------+-----------------------------+" >> $MESSAGE
echo "| Server_Name | Security Errata |" >> $MESSAGE
echo "+---------------+-----------------------------+" >> $MESSAGE
for server in `more /opt/scripts/server.txt`
do
sec=`ssh $server yum updateinfo summary | grep 'Security' | grep -v 'Important|Moderate' | tail -1 | awk '{print $1}'`
echo "$server $sec" >> $MESSAGE
done
echo "+---------------------------------------------+" >> $MESSAGE
mail -s "$SUBJECT" "$TO" < $MESSAGE
```
添加完上面的脚本后运行它。
```
# sh /opt/scripts/small-scripts/sec-errata.sh
```
你会看到下面的输出。
```
# cat /tmp/sec-up.txt
+---------------+-------------------+
| Server_Name | Security Errata |
+---------------+-------------------+
server1
server2
server3 21
server4
+-----------------------------------+
```
添加下面的 cronjob 来每个月得到一份补丁合规性报告。
```
# crontab -e
@monthly /bin/bash /opt/scripts/system-uptime-script-1.sh
```
### 方法 1a:为 CentOS / RHEL 系统上的安全修补生成补丁合规性报告的 Bash 脚本
脚本会为你生成安全修补合规性报告。它会通过 CSV 文件发送邮件。
```
# vi /opt/scripts/small-scripts/sec-errata-1.sh
#!/bin/sh
echo "Server Name, Security Errata" > /tmp/sec-up.csv
for server in `more /opt/scripts/server.txt`
do
sec=`ssh $server yum updateinfo summary | grep 'Security' | grep -v 'Important|Moderate' | tail -1 | awk '{print $1}'`
echo "$server, $sec" >> /tmp/sec-up.csv
done
echo "Patching Report for `date +"%B %Y"`" | mailx -s "Patching Report on `date`" -a /tmp/sec-up.csv [email protected]
rm /tmp/sec-up.csv
```
添加完上面的脚本后运行它。
```
# sh /opt/scripts/small-scripts/sec-errata-1.sh
```
你会看到下面的输出。

### 方法 2:为 CentOS / RHEL 系统上的安全修补、bugfix、增强生成补丁合规性报告的 Bash 脚本
脚本会为你生成安全修补、bugfix、增强的补丁合规性报告。它会通过纯文本发送邮件。
```
# vi /opt/scripts/small-scripts/sec-errata-bugfix-enhancement.sh
#!/bin/sh
/tmp/sec-up.txt
SUBJECT="Patching Reports on "`date`""
MESSAGE="/tmp/sec-up.txt"
TO="[email protected]"
echo "+---------------+-------------------+--------+---------------------+" >> $MESSAGE
echo "| Server_Name | Security Errata | Bugfix | Enhancement |" >> $MESSAGE
echo "+---------------+-------------------+--------+---------------------+" >> $MESSAGE
for server in `more /opt/scripts/server.txt`
do
sec=`ssh $server yum updateinfo summary | grep 'Security' | grep -v 'Important|Moderate' | tail -1 | awk '{print $1}'`
bug=`ssh $server yum updateinfo summary | grep 'Bugfix' | tail -1 | awk '{print $1}'`
enhance=`ssh $server yum updateinfo summary | grep 'Enhancement' | tail -1 | awk '{print $1}'`
echo "$server $sec $bug $enhance" >> $MESSAGE
done
echo "+------------------------------------------------------------------+" >> $MESSAGE
mail -s "$SUBJECT" "$TO" < $MESSAGE
```
添加完上面的脚本后运行它。
```
# sh /opt/scripts/small-scripts/sec-errata-bugfix-enhancement.sh
```
你会看到下面的输出。
```
# cat /tmp/sec-up.txt
+---------------+-------------------+--------+---------------------+
| Server_Name | Security Errata | Bugfix | Enhancement |
+---------------+-------------------+--------+---------------------+
server01 16
server02 5 16
server03 21 266 20
server04 16
+------------------------------------------------------------------+
```
添加下面的 cronjob 来每三个月得到补丁合规性报告。该脚本计划在一月、四月、七月、十月的 1 号运行。
```
# crontab -e
0 0 01 */3 * /bin/bash /opt/scripts/system-uptime-script-1.sh
```
### 方法 2a:为 CentOS / RHEL 系统上的安全修补、bugfix、增强生成补丁合规性报告的 Bash 脚本
脚本会为你生成安全修补、bugfix、增强的补丁合规性报告。它会通过 CSV 文件发送邮件。
```
# vi /opt/scripts/small-scripts/sec-errata-bugfix-enhancement-1.sh
#!/bin/sh
echo "Server Name, Security Errata,Bugfix,Enhancement" > /tmp/sec-up.csv
for server in `more /opt/scripts/server.txt`
do
sec=`ssh $server yum updateinfo summary | grep 'Security' | grep -v 'Important|Moderate' | tail -1 | awk '{print $1}'`
bug=`ssh $server yum updateinfo summary | grep 'Bugfix' | tail -1 | awk '{print $1}'`
enhance=`ssh $server yum updateinfo summary | grep 'Enhancement' | tail -1 | awk '{print $1}'`
echo "$server,$sec,$bug,$enhance" >> /tmp/sec-up.csv
done
echo "Patching Report for `date +"%B %Y"`" | mailx -s "Patching Report on `date`" -a /tmp/sec-up.csv [email protected]
rm /tmp/sec-up.csv
```
添加完上面的脚本后运行它。
```
# sh /opt/scripts/small-scripts/sec-errata-bugfix-enhancement-1.sh
```
你会看到下面的输出。

---
via: <https://www.2daygeek.com/bash-script-to-generate-patching-compliance-report-on-centos-rhel-systems/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
11,582 | 用 autoplank 在多个显示器上使用 Plank 扩展坞 | https://www.linuxuprising.com/2018/08/use-plank-on-multiple-monitors-without.html | 2019-11-16T16:10:00 | [
"Plank"
] | https://linux.cn/article-11582-1.html | 
[autoplank](https://github.com/abiosoft/autoplank) 是用 Go 语言编写的小型工具,它为 Plank 扩展坞增加了多显示器支持,而无需创建[多个](https://answers.launchpad.net/plank/+question/204593)扩展坞。
当你将鼠标光标移动到显示器的底部时,`autoplank` 会使用 `xdotool` 检测到你的鼠标移动,并且自动将 Plank 扩展坞移动到该显示器。该工具仅在将 Plank 设置为在屏幕底部的情况下工作(至少目前如此)。
在 Plank 实际出现在鼠标所在的显示器上前会稍有延迟。开发人员说这是有意设计的,以确保你确实要在该显示器上访问 Plank。显示 Plank 之前的时间延迟目前尚不可配置,但将来可能会改变。
`autoplank` 可以在 elementary OS 以及其它的桌面环境或发行版上使用。
Plank 是一个简单的扩展坞,它显示了正在运行的应用程序/窗口的图标。它允许将应用程序固定到扩展坞,并带有一些内置的简单“扩展组件”:剪贴板管理器、时钟、CPU 监视器、显示桌面和垃圾桶。要访问其设置,请按住 `Ctrl` 键,同时右键单击 Plank 扩展坞上的任意位置,然后单击 “Preferences”。
Plank 默认用在 elementary OS 中,但也可以在任何桌面环境或 Linux 发行版中使用。
### 安装 autoplank
在其 GitHub 页面上,提到你需要 Go 1.8 或更高版本才能构建 `autoplank`,但我能够在 Ubuntu 16.04(elementary OS 0.4 Loki)中使用 Go 1.6 成功构建它。
开发者说:
1、安装所需的依赖项。
要构建 `autoplank`,你需要 Go(在 Debian、Ubuntu、elementary OS 等中使用 golang-go)。要获取最新的 Git 代码,你还需要 `git`,要在显示器上检测你的鼠标移动,还需要安装 `xdotool`。
使用以下命令将它们安装在 Ubuntu、Debian、elementary OS 等中:
```
sudo apt install git golang-go xdotool
```
2、从 [Git](https://github.com/abiosoft/autoplank) 获取最新的 `autoplank`,构建并将其安装在 `/usr/local/bin` 中:
```
git clone https://github.com/abiosoft/autoplank
cd autoplank
go build -o autoplank
sudo mv autoplank /usr/local/bin/
```
你现在可以从主目录中删除 `autoplank` 文件夹。
当你想卸载 `autoplank` 时,只需删除 `/usr/local/bin/autoplank` 二进制文件(`sudo rm /usr/local/bin/autoplank`)。
3、将 `autoplank` 添加到启动中。
如果你想在将 `autoplank` 添加到启动项或为其创建 systemd 服务之前尝试使用 `autoplank`,则只需在终端中键入 `/usr/local/bin/autoplank` 即可启动它。
要使 `autoplank` 在重新启动后起作用,你需要将其添加到启动项中。确切的操作步骤取决于你的桌面环境,因此我不会确切告诉你如何在每个桌面环境中执行此操作,但是请记住在启动项中将 `/usr/local/bin/autoplank` 设置为可执行文件。
在 elementary OS 中,你可以打开“系统设置”,然后在“应用程序”的“启动”选项卡上,单击窗口左下角的“+”按钮,然后在“键入自定义命令”字段中添加 “/usr/local/bin/autoplank”:

如[此处](https://github.com/abiosoft/autoplank#optional-create-a-service)的解释,使用 `autoplank` 的另一种方法是通过为其创建 systemd 服务。将 systemd 服务用于 autoplank 的优点是,无论它出于何种原因而崩溃,都可以重新启动 `autoplank`。可以使用 systemd 服务或将 `autoplank` 添加到启动应用程序中(但不要同时使用两者)。
4、完成此操作后,注销、登录,`autoplank` 应该已在运行,因此你可以将鼠标移至显示器底部以将 Plank 停靠此处。
---
via: <https://www.linuxuprising.com/2018/08/use-plank-on-multiple-monitors-without.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Use Plank On Multiple Monitors Without Creating Multiple Docks With autoplank
[autoplank](https://github.com/abiosoft/autoplank)is a small tool written in Go which adds multi-monitor support to Plank dock without having to create[multiple](https://answers.launchpad.net/plank/+question/204593)docks.When you move your mouse cursor to the bottom of a monitor, autoplank detect your mouse movement using
`xdotool`
and it automatically moves Plank to that monitor. This tool only works if Plank is set to run at the bottom of the screen, at least for now.There's a slight delay until Plank actually shows up on the monitor where the mouse is though. The developer says this is intentional, to make sure you actually want to access Plank on that monitor. The time delay before showing plank is not currently configurable, but that may change in the future.
**[Edit] autoplank stopped working and a couple of pull requests on GitHub fix that, but the autoplank developer seems inactive and did not merge those pull requests, that's why in the commands below we'll also get those these**
[1](https://github.com/abiosoft/autoplank/pull/6)[2](https://github.com/abiosoft/autoplank/pull/7)pull requests besides the autoplank code. Although it works, autoplank is a bit buggy with these pull requests.The behavior also changes when including these pull requests. With these fixes, Plank is shown on a different monitor as soon as the mouse enters that monitor, with no delay. This causes Plank to flicker slightly (I didn't find it too distracting, but you may have a different opinion) when it's moved between monitors, if Plank is set to hide, in all modes except "Autohide". With "Autohide" this is not noticeable because the dock is only shown when moving the mouse near the bottom of the screen. It is very noticeable though if hiding Plank is completely turned off, so I don't recommend using autoplank if you want to keep Plank always visible!
**It's also important to note that with these 2 extra pull requests, the Plank preferences window closes when moving the mouse to a different monitor.**
autoplank should work with elementary OS, as well as any desktop environment or Linux distribution you use Plank dock on.
Plank is a simple dock that shows icons of running applications / windows. The application allows pinning applications to the dock, and comes with a few built-in simple "docklets": a clipboard manager, clock, CPU monitor, show desktop and trash. To access its settings, hold down the
`Ctrl`
key while right clicking anywhere on the Plank dock, and then clicking on `Preferences`
.Plank is used by default in elementary OS, but it can be used on any desktop environment or Linux distribution you wish.
## Install autoplank
On its GitHub page, it's mentioned that you need Go 1.8 or newer to build autoplank but I was able to successfully build it with Go 1.6 in Ubuntu 16.04 (elementary OS 0.4 Loki).
The developer has said on
**1. Install required dependencies.**
To build autoplank you'll need Go (
`golang-go`
in Debian, Ubuntu, elementary OS, etc.). To get the latest Git code you'll also need `git`
, and for detecting the monitor on which you move the mose, you'll also need to install `xdotool`
.Install these in Ubuntu, Debian, elementary OS and so on, by using this command:
`sudo apt install git golang-go xdotool`
**2. Get the latest autoplank from**
[Git](https://github.com/abiosoft/autoplank), build it, and install it in`/usr/local/bin`
.```
git clone https://github.com/abiosoft/autoplank
cd autoplank
git fetch origin pull/6/head:fixes
git fetch origin pull/7/head:fixes
git checkout fixes
go build -o autoplank
sudo mv autoplank /usr/local/bin/
```
You can remove the autoplank folder from your home directory now.
When you want to uninstall autoplank, simply remove the
`/usr/local/bin/autoplank`
binary (`sudo rm /usr/local/bin/autoplank`
).**3. Add autoplank to startup.**
If you want to try autoplank before adding it to startup or creating a systemd service for it, you can simply type
`autoplank`
in a terminal to start it.To have autoplank work between reboots, you'll need to add it to your startup applications. The exact steps for doing this depend on your desktop environments, so I won't tell you exactly how to do that for every desktop environment, but remember to use
`/usr/local/bin/autoplank`
as the executable in Startup Applications.In elementary OS, you can open
`System Settings`
, then in `Applications`
, on the `Startup`
tab, click the `+`
button in the bottom left-hand side corner of the window, then add `/usr/local/bin/autoplank`
in the `Type in a custom command`
field:The order in which Plank and autoplank are launched shouldn't matter.
**Another way of using autoplank is by creating a systemd service for it, as explained**Using a systemd service for autoplank has the advantage of restarting autoplank if it crashes for whatever reason. Use either the systemd service or add autoplank to your startup applications (don't use both).
[here](https://github.com/abiosoft/autoplank#optional-create-a-service).**4. After you do this, logout, login and autoplank should be running so you can move the mouse at the bottom of a monitor to move Plank dock there.** |
11,583 | 红帽对 Zombieload v2 缺陷的应对 | https://www.networkworld.com/article/3453596/red-hat-responds-to-zombieload-v2.html | 2019-11-17T07:00:00 | [
"CPU"
] | https://linux.cn/article-11583-1.html | 
>
> 红帽呼吁更新 Linux 软件,以解决可能导致数据盗用的英特尔处理器缺陷。
>
>
>
前两天公开的三个“常见漏洞和披露”(CVE)跟踪的是某些英特尔处理器中的三个漏洞,如果利用这些漏洞,可能会使敏感数据面临风险。
在报告的缺陷中,新发现的英特尔处理器缺陷是今年早些时候发现的 Zombieload 攻击的变种,并且仅会影响英特尔的 Cascade Lake 芯片。
红帽强烈建议,所有的红帽系统即使不认为其配置构成直接威胁,也要对其进行更新,并且红帽正在向其客户和企业 IT 社区提供资源。
这三个 CVE 是:
* CVE-2018-12207:页面大小更改时的机器检查错误
* CVE-2019-11135:TSX异步中止
* CVE-2019-0155 和 CVE-2019-0154:i915 图形驱动程序
### CVE-2018-12207
红帽将该漏洞评为重要。此漏洞可能使本地和非特权的攻击者绕过安全控制并导致系统范围的拒绝服务。
硬件缺陷是在英特尔微处理器中发现的,并且与指令翻译后备缓冲区(ITLB)有关。它缓存从虚拟地址到物理地址的转换,旨在提高性能。但是,在缓存页面更改后,使缓存的条目无效的延迟可能导致处理器使用无效的地址转换,从而导致机器检查错误异常并使系统进入挂起状态。
攻击者可以制作这种情况来关闭系统。
### CVE-2019-11135
红帽将此漏洞评为中级。这个事务同步扩展(TSX)异步中止是一个微体系结构数据采样(MDS)缺陷。使用定制代码的本地攻击者可以利用此漏洞从处理器以及支持同时多线程(SMT)和 TSX 的处理器上的缓存内容中收集信息。
### CVE-2019-0155,CVE-2019-0154
红帽将 CVE-2019-0155 漏洞评为重要,将 CVE-2019-0154 漏洞评为中级。这两个缺陷都与 i915 图形驱动程序有关。
CVE-2019-0155 允许攻击者绕过常规的内存安全限制,从而允许对应该受到限制的特权内存进行写访问。
当图形处理单元(GPU)处于低功耗模式时,CVE-2019-0154 可能允许本地攻击者创建无效的系统状态,从而导致系统无法访问。
唯一受 CVE-2019-0154 影响的的显卡在 i915 内核模块上受到影响。`lsmod` 命令可用于指示该漏洞。 如下所示的任何输出(即以 i915 开头)都表明该系统易受攻击:
```
$ lsmod | grep ^i915
i915 2248704 10
```
### 更多资源
红帽在以下链接中向其客户和其他人提供了详细信息和进一步的说明:
* <https://access.redhat.com/security/vulnerabilities/ifu-page-mce>
* <https://access.redhat.com/solutions/tsx-asynchronousabort>
* <https://access.redhat.com/solutions/i915-graphics>
---
via: <https://www.networkworld.com/article/3453596/red-hat-responds-to-zombieload-v2.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,584 | 如何在 Linux 桌面添加用户 | https://opensource.com/article/19/11/add-user-gui-linux | 2019-11-17T07:05:00 | [
"用户"
] | https://linux.cn/article-11584-1.html |
>
> 无论是在安装过程中还是在桌面中,通过图形界面管理用户都非常容易。
>
>
>

添加用户是你在一个新系统上要做的第一件事。而且,你通常需要在计算机的整个生命周期中管理用户。
我的关于 [useradd 命令](https://opensource.com/article/19/10/linux-useradd-command)文章提供了更深入的对 Linux 的用户管理的了解。`useradd` 是一个命令行工具,但是你也可以在 Linux 上以图形方式管理用户。这就是本文的主题。
### 在 Linux 安装过程中添加用户
大多数 Linux 发行版都提供了在安装过程中创建用户的步骤。例如,Fedora 30 安装程序 Anaconda 创建标准的 `root` 用户和另一个本地用户帐户。在安装过程中进入“配置”页面时,单击“用户设置”下的“用户创建”。

在用户创建页面上,输入用户的详细信息:全名、用户名和密码。你还可以选择是否使用户成为管理员。

点击“高级”按钮打开“高级用户配置”页面。如果需要除默认设置以外的其他设置,那么可以在此处指定主目录的路径以及用户和组 ID。你也可以输入用户所属的其他组。

### 在 Linux 桌面上添加用户
#### GNOME
许多 Linux 发行版都使用 GNOME 桌面。以下截图来自 Red Hat Enterprise Linux 8.0,但是在其他发行版(如 Fedora、Ubuntu 或 Debian)中,该过程相似。
首先打开“设置”。然后打开“详细”,选择“用户”,单击“解锁”,然后输入密码(除非你已经以 root 用户登录)。这样将用“添加用户”按钮代替“解锁”按钮。

现在,你可以通过单击“添加用户”,然后选择“帐户类型”然后输入“用户名”和“密码”来添加用户。
在下面的截图中,已经输入了用户名,设置保留为默认设置。我不必输入“用户名”,因为它是在我在“全名”字段中输入时自动创建的。如果你不喜欢自动补全,你仍然可以对其进行修改。

这将为名为 Sonny 的用户创建一个标准帐户。Sonny 首次登录时需要提供密码。
接下来,将显示用户。在此页面可以选择每个用户进行自定义或者删除。例如,你可能想选择一个头像或设置默认语言。

#### KDE
KDE 是另一个流行的 Linux 桌面环境。下面是 Fedora 30 上 KDE Plasma 的截图。你可以看到,在 KDE 中添加用户与在 GNOME 中添加用户非常相似。

### 总结
除 GNOME 和 KDE 外,其他桌面环境和窗口管理器也有图形用户管理工具。无论是在安装时还是安装后,在 Linux 中以图形方式添加用户都是快速简便的。
---
via: <https://opensource.com/article/19/11/add-user-gui-linux>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Adding a user is one of the first things you do on a new computer system. And you often have to manage users throughout the computer's lifespan.
My article on the [ useradd command](https://opensource.com/article/19/10/linux-useradd-command) provides a deeper understanding of user management on Linux. Useradd is a command-line tool, but you can also manage users graphically on Linux. That's the topic of this article.
## Add a user during Linux installation
Most Linux distributions provide a step for creating a user during installation. For example, the Fedora 30 installer, Anaconda, creates the standard *root* user and one other local user account. When you reach the **Configuration** screen during installation, click **User Creation** under **User Settings**.
On the Create User screen, enter the user's details: **Full name**, **User name**, and **Password**. You can also choose whether to make the user an administrator.
The **Advanced** button opens the **Advanced User Configuration** screen. Here, you can specify the path to the home directory and the user and group IDs if you need something besides the default. You can also type a list of secondary groups that the user will be placed into.
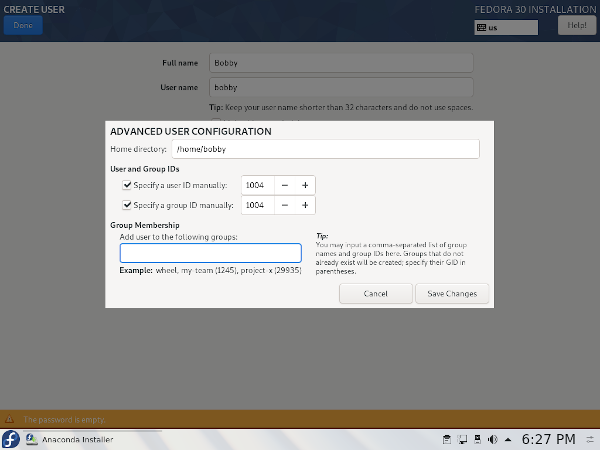
## Add a user on the Linux desktop
### GNOME
Many Linux distributions use the GNOME desktop. The following screenshots are from Red Hat Enterprise Linux 8.0, but the process is similar in other distros like Fedora, Ubuntu, or Debian.
Start by opening **Settings**. Then go to **Details**, select **Users**, click **Unlock**, and enter your password (unless you are already logged in as root). This will replace the **Unlock** button with an **Add User** button.
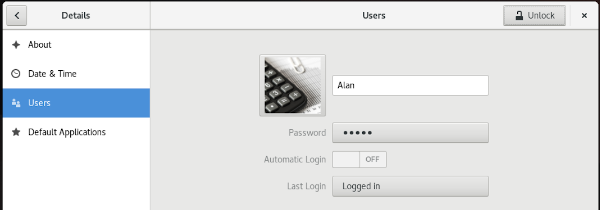
Now, you can add a user by clicking **Add User**,** **then selecting the account **Type** and the details **Name** and **Password**).
In the screenshot below, a user name has been entered, and settings are left as default. I did not have to enter the **Username**; it was created automatically as I typed in the **Full Name** field. You can still modify it though if the autocompletion is not to your liking.
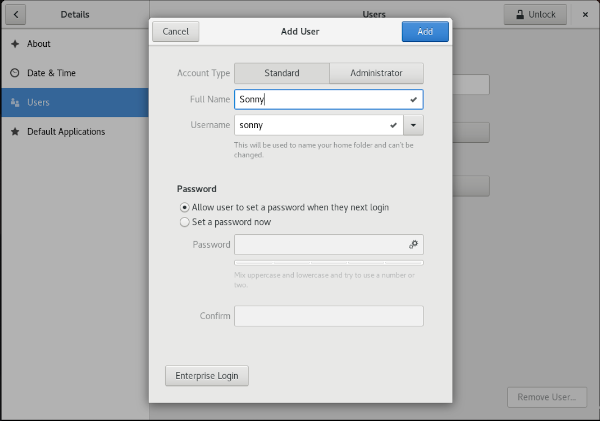
This creates a standard account for a user named Sonny. Sonny will need to provide a password the first time he or she logs in.
Next, the users will be displayed. Each user can be selected and customized or removed from this screen. For instance, you might want to choose an avatar image or set the default language.
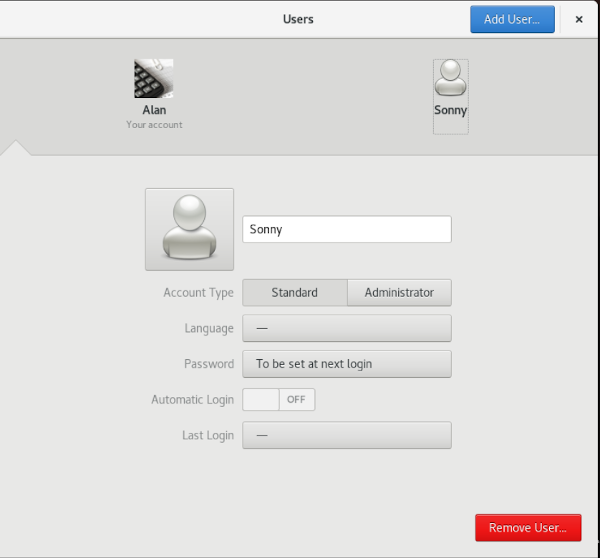
### KDE
KDE is another popular Linux desktop environment. Below is a screenshot of KDE Plasma on Fedora 30. You can see that adding a user in KDE is quite similar to doing it in GNOME.
## Conclusion
Other desktop environments and window managers in addition to GNOME and KDE include graphical user management tools. Adding a user graphically in Linux is quick and simple, whether you do it at installation or afterward.
## 7 Comments |
11,586 | 为什么我从 Mac 换到了 Linux | https://opensource.com/article/19/10/why-switch-mac-linux | 2019-11-18T07:30:00 | [
"Mac"
] | https://linux.cn/article-11586-1.html |
>
> 感谢这么多的开源开发人员,日常使用 Linux 比以往任何时候都容易得多。
>
>
>

自 2004 年开始从事 IT 工作以来,我一直是 Mac 的忠实粉丝。但是几个月前,由于种种原因,我决定将 Linux 用作日常使用的系统。这不是我第一次尝试完全采用 Linux,但是我发现它比以往更加容易。下面是促使我转换的原因。
### 我在个人电脑上的首次 Linux 体验
我记得,我抬头看着投影机,而它和我面面相觑。我们俩都不明白为什么它不显示。VGA 线完全接好了,针脚也没有弯折。我按了我所有想到的可能的按键组合,以向我的笔记本电脑发出信号,想让它克服“舞台恐惧症”。
我在大学里运行 Linux 只是作为实验。而我在 IT 部门的经理是多种口味的倡导者,随着我对桌面支持和编写脚本的信心增强,我想了解更多 Linux 的信息。对我来说,IT 比我的计算机科学学位课程有趣得多,课程的感觉是如此抽象和理论化:“二叉树有啥用?”,我如是想 —— 而我们的系统管理员团队的工作却是如此的真真切切。
这个故事的结尾是,我登录到 Windows 工作站完成了我的课堂演讲,这标志着我将 Linux 作为我的日常操作系统的第一次尝试的终结。我很欣赏 Linux 的灵活性,但是它缺乏兼容性。我偶尔会写个脚本,脚本通过 SSH 连接到一个机器中以运行另一个脚本,但是我对 Linux 的日常使用仅止于此。
### 对 Linux 兼容性的全新印象
几个月前,当我决定再试一次 Linux 时,我曾觉得我遇到更多的兼容性噩梦,但我错了。
安装过程完成后,我立即插入了 USB-C 集线器以了解兼容性到底如何。一切立即工作。连接 HDMI 的超宽显示器作为镜像显示器弹出到我的笔记本电脑屏幕上,我轻松地将其调整为第二台显示器。USB 连接的网络摄像头对我的[在家工作方式](https://opensource.com/article/19/8/rules-remote-work-sanity)至关重要,它可以毫无问题地显示视频。甚至自从我使用 Mac 以来就一直插在集线器的 Mac 充电器可以为我的非常不 Mac 的硬件充电。
我的正面体验可能与 USB-C 的一些更新有关,它在 2018 年得到一些所需的关注,因此才能与其他操作系统的体验相媲美。正如 [Phoronix 解释的那样](https://www.phoronix.com/scan.php?page=news_item&px=Linux-USB-Type-C-Port-DP-Driver):
>
> “USB Type-C 接口为非 USB 信号提供了‘替代模式’扩展,在规范中该替代模式的最大使用场景是支持 DisplayPort。除此之外,另一个替代模式是支持 Thunderbolt 3。DisplayPort 替代模式支持 4K 甚至 8Kx4K 的视频输出,包括多声道音频。
>
>
> “虽然 USB-C 替代模式和 DisplayPort 已经存在了一段时间,并且在 Windows 上很常见,但是主线 Linux 内核不支持此功能。所幸的是,多亏英特尔,这种情况正在改变。”
>
>
>
而在端口之外,快速浏览一下 [笔记本电脑 Linux](https://www.linux-laptop.net/) 的硬件选择,列出了比我 2000 年代初期所经历的更加完整的选择集。
与我第一次尝试采用 Linux 相比,这已经天差地别,这是我张开双臂欢迎的。
### 突破 Apple 的樊篱
使用 Linux 给我的日常工作流程增加了一些新的麻烦,而我喜欢这种麻烦。
我的 Mac 工作流程是无缝的:早上打开 iPad,写下关于我今天想要做什么的想法,然后开始在 Safari 中阅读一些文章;移到我的 iPhone 上可以继续阅读;然后登录我的 MacBook,这些地方我进行了多年的微调,已经弄清楚了所有这些部分之间的连接方式。键盘快捷键已内置在我的大脑中;用户体验一如既往。简直不要太舒服了。
这种舒适需要付出代价。我基本上忘记了我的环境如何运作的,也无法解答我想解答的问题。我是否自定义了一些 [PLIST 文件](https://fileinfo.com/extension/plist)以获得快捷方式,是不是记得将其签入[我的 dotfiles](https://opensource.com/article/19/3/move-your-dotfiles-version-control) 当中?当 Firefox 的功能更好时,我为何还如此依赖 Safari 和 Chrome?为什么我不使用基于 Android 的手机代替我的 i-系列产品呢?
关于这一点,我经常考虑改用基于 Android 的手机,但是我会失去在所有这些设备之间的连接性以及为这种生态系统设计的一些便利。例如,我将无法在 iPhone 上为 Apple TV 输入搜索内容,也无法与其他用 Apple 的朋友用 AirDrop 共享密码。这些功能是同类设备环境的巨大好处,并且是一项了不起的工程。也就是说,这些便利是被生态系统所困的代价。
我喜欢了解设备的工作方式。我希望能够解释使我的系统变得有趣或容易使用的环境配置,但我也想看看增加一些麻烦对我的观点有什么影响。用 [Marcel Proust](https://www.age-of-the-sage.org/quotations/proust_having_seeing_with_new_eyes.html) 的话来说,“真正的发现之旅不在于寻找新的土地,而在于用新的眼光来看待。”技术的使用是如此的方便,以至于我不再对它的工作原理感到好奇,而 Linux 使我有机会再次有了新的眼光。
### 受你的启发
以上所有内容足以成为探索 Linux 的理由,但我也受到了你的启发。尽管所有操作系统都受到开源社区的欢迎,但 Opensource.com 的作者和读者对 Linux 的喜悦是充满感染力的。它激发了我重新潜入的乐趣,我享受这段旅途的乐趣。
---
via: <https://opensource.com/article/19/10/why-switch-mac-linux>
作者:[Matthew Broberg](https://opensource.com/users/mbbroberg) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I have been a huge Mac fan and power user since I started in IT in 2004. But a few months ago—for several reasons—I made the commitment to shift to Linux as my daily driver. This isn't my first attempt at fully adopting Linux, but I'm finding it easier than ever. Here is what inspired me to switch.
## My first attempt at Linux on the desktop
I remember looking up at the projector, and it looking back at me. Neither of us understood why it wouldn't display. VGA cords were fully seated with no bent pins to be found. I tapped every key combination I could think of to signal my laptop that it's time to get over the stage fright.
I ran Linux in college as an experiment. My manager in the IT department was an advocate for the many flavors out there, and as I grew more confident in desktop support and writing scripts, I wanted to learn more about it. IT was far more interesting to me than my computer science degree program, which felt so abstract and theoretical—"who cares about binary search trees?" I thought—while our sysadmin team's work felt so tangible.
This story ends with me logging into a Windows workstation to get through my presentation for class, and marks the end of my first attempt at Linux as my day-to-day OS. I admired its flexibility, but compatibility was lacking. I would occasionally write a script that SSHed into a box to run another script, but I stopped using Linux on a day-to-day basis.
## A fresh look at Linux compatibility
When I decided to give Linux another go a few months ago, I expected more of the same compatibility nightmare, but I couldn't be more wrong.
Right after the installation process completed, I plugged in a USB-C hub to see what I'd gotten myself into. Everything worked immediately. The HDMI-connected extra-wide monitor popped up as a mirrored display to my laptop screen, and I easily adjusted it to be a second monitor. The USB-connected webcam, which is essential to my [work-from-home life](https://opensource.com/article/19/8/rules-remote-work-sanity), showed up as a video with no trouble at all. Even my Mac charger, which was already plugged into the hub since I've been using a Mac, started to charge my very-not-Mac hardware.
My positive experience was probably related to some updates to USB-C, which received some needed attention in 2018 to compete with other OS experiences. As [Phoronix explained](https://www.phoronix.com/scan.php?page=news_item&px=Linux-USB-Type-C-Port-DP-Driver):
"The USB Type-C interface offers an 'Alternate Mode' extension for non-USB signaling and the biggest user of this alternate mode in the specification is allowing DisplayPort support. Besides DP, another alternate mode is the Thunderbolt 3 support. The DisplayPort Alt Mode supports 4K and even 8Kx4K video output, including multi-channel audio.
"While USB-C alternate modes and DisplayPort have been around for a while now and is common in the Windows space, the mainline Linux kernel hasn't supported this functionality. Fortunately, thanks to Intel, that is now changing."
Thinking beyond ports, a quick scroll through the [Linux on Laptops](https://www.linux-laptop.net/) hardware options shows a much more complete set of choices than I experienced in the early 2000s.
This has been a night-and-day difference from my first attempt at Linux adoption, and it's one I welcome with open arms.
## Breaking out of Apple's walled garden
Using Linux has added new friction to my daily workflow, and I love that it has.
My Mac workflow was seamless: hop on an iPad in the morning, write down some thoughts on what my day will look like, and start to read some articles in Safari; slide over my iPhone to continue reading; then log into my MacBook where years of fine-tuning have worked out how all these pieces connect. Keyboard shortcuts are built into my brain; user experiences are as they've mostly always been. It's wildly comfortable.
That comfort comes with a cost. I largely forgot how my environment functions, and I couldn't answer questions I wanted to answer. Did I customize some [PLIST files](https://fileinfo.com/extension/plist) to get that custom shortcut, or did I remember to check it into [my dotfiles](https://opensource.com/article/19/3/move-your-dotfiles-version-control)? How did I get so dependent on Safari and Chrome when Firefox has a much better mission? Or why, specifically, won't I use an Android-based phone instead of my i-things?
On that note, I've often thought about shifting to an Android-based phone, but I would lose the connection I have across all these devices and the little conveniences designed into the ecosystem. For instance, I wouldn't be able to type in searches from my iPhone for the Apple TV or share a password with AirDrop with my other Apple-based friends. Those features are great benefits of homogeneous device environments, and it is remarkable engineering. That said, these conveniences come at a cost of feeling trapped by the ecosystem.
I love being curious about how devices work. I want to be able to explain environmental configurations that make it fun or easy to use my systems, but I also want to see what adding some friction does for my perspective. To paraphrase [Marcel Proust](https://www.age-of-the-sage.org/quotations/proust_having_seeing_with_new_eyes.html), "The real voyage of discovery consists not in seeking new lands but seeing with new eyes." My use of technology has been so convenient that I stopped being curious about how it all works. Linux gives me an opportunity to see with new eyes again.
## Inspired by you
All of the above is reason enough to explore Linux, but I have also been inspired by you. While all operating systems are welcome in the open source community, Opensource.com writers' and readers' joy for Linux is infectious. It inspired me to dive back in, and I'm enjoying the journey.
## 22 Comments |
11,587 | 7 个有助于 AI 技术的最佳开源工具 | https://opensourceforu.com/2019/11/7-best-open-source-tools-that-will-help-in-ai-technology/ | 2019-11-18T10:00:12 | [
"AI"
] | https://linux.cn/article-11587-1.html | 
>
> 人工智能是一种紧跟未来道路的卓越技术。在这个不断发展的时代,它吸引了所有跨国组织的关注。谷歌、IBM、Facebook、亚马逊、微软等业内知名公司不断投资于这种新时代技术。
>
>
>
预测业务需求需要利用人工智能,并在另一个层面上进行研发。这项先进技术正成为提供超智能解决方案的研发组织不可或缺的一部分。它可以帮助你保持准确性并以更好的结果提高生产率。
AI 开源工具和技术以频繁且准确的结果吸引了每个行业的关注。这些工具可帮助你分析绩效,同时为你带来更大的收益。
无需赘言,这里我们列出了一些最佳的开源工具,来帮助你更好地了解人工智能。
### 1、TensorFlow
TensorFlow 是用于人工智能的开源机器学习框架。它主要是为了进行机器学习和深度学习的研究和生产而开发的。TensorFlow 允许开发者创建数据流的图结构,它会在网络或系统节点中移动,图提供了数据的多维数组或张量。
TensorFlow 是一个出色的工具,它有无数的优势。
* 简化数值计算
* TensorFlow 在多种模型上提供了灵活性。
* TensorFlow 提高了业务效率
* 高度可移植
* 自动区分能力
### 2、Apache SystemML
Apache SystemML 是由 IBM 创建的非常流行的开源机器学习平台,它提供了使用大数据的良好平台。它可以在 Apache Spark 上高效运行,并自动扩展数据,同时确定代码是否可以在磁盘或 Apache Spark 集群上运行。不仅如此,它丰富的功能使其在行业产品中脱颖而出;
* 算法自定义
* 多种执行模式
* 自动优化
它还支持深度学习,让开发者更有效率地实现机器学习代码并优化。
### 3、OpenNN
OpenNN 是用于渐进式分析的开源人工智能神经网络库。它可帮助你使用 C++ 和 Python 开发健壮的模型,它还包含用于处理机器学习解决方案(如预测和分类)的算法和程序。它还涵盖了回归和关联,可提供业界的高性能和技术演化。
它有丰富的功能,如:
* 数字化协助
* 预测分析
* 快速的性能
* 虚拟个人协助
* 语音识别
* 高级分析
它可帮助你设计实现数据挖掘的先进方案,而从取得丰硕结果。
### 4、Caffe
Caffe(快速特征嵌入的卷积结构)是一个开源深度学习框架。它优先考虑速度、模块化和表达式。Caffe 最初由加州大学伯克利分校视觉和学习中心开发,它使用 C++ 编写,带有 Python 接口。能在 Linux、macOS 和 Windows 上顺利运行。
Caffe 中的一些有助于 AI 技术的关键特性。
1. 具有表现力的结构
2. 具有扩展性的代码
3. 大型社区
4. 开发活跃
5. 性能快速
它可以帮助你激发创新,同时引入刺激性增长。充分利用此工具来获得所需的结果。
### 5、Torch
Torch 是一个开源机器学习库,通过提供多种方便的功能,帮助你简化序列化、面向对象编程等复杂任务。它在机器学习项目中提供了最大的灵活性和速度。Torch 使用脚本语言 Lua 编写,底层使用 C 实现。它用于多个组织和研究实验室中。
Torch 有无数的优势,如:
* 快速高效的 GPU 支持
* 线性代数子程序
* 支持 iOS 和 Android 平台
* 数值优化子程序
* N 维数组
### 6、Accord .NET
Accord .NET 是著名的自由开源 AI 开发工具之一。它有一组库,可以用来组合使用 C# 编写的音频和图像处理库。从计算机视觉到计算机听觉、信号处理和统计应用,它可以帮助你构建用于商业用途一切需求。它附带了一套全面的示例应用来快速运行各类库。
你可以使用 Accord .NET 引人注意的功能开发一个高级应用,例如:
* 统计分析
* 数据接入
* 自适应
* 深度学习
* 二阶神经网络学习算法
* 数字协助和多语言
* 语音识别
### 7、Scikit-Learn
Scikit-Learn 是流行的辅助 AI 技术的开源工具之一。它是 Python 中用于机器学习的一个很有价值的库。它包括机器学习和统计建模(包括分类、聚类、回归和降维)等高效工具。
让我们了解下 Scikit-Learn 的更多功能:
* 交叉验证
* 聚类和分类
* 流形学习
* 机器学习
* 虚拟流程自动化
* 工作流自动化
从预处理到模型选择,Scikit-learn 可帮助你处理所有问题。它简化了从数据挖掘到数据分析的所有任务。
### 总结
这些是一些流行的开源 AI 工具,它们提供了全面的功能。在开发新时代应用之前,人们必须选择其中一个工具并做相应的工作。这些工具提供先进的人工智能解决方案,并紧跟最新趋势。
人工智能在全球范围内应用,无处不在。借助 Amazon Alexa、Siri 等应用,AI 为客户提供了很好的用户体验。它在吸引用户关注的行业中具有显著优势。在医疗保健、银行、金融、电子商务等所有行业中,人工智能在促进增长和生产力的同时节省了大量的时间和精力。
选择这些开源工具中的任何一个,获得更好的用户体验和令人难以置信的结果。它将帮助你成长,并在质量和安全性方面获得更好的结果。
---
via: <https://opensourceforu.com/2019/11/7-best-open-source-tools-that-will-help-in-ai-technology/>
作者:[Nitin Garg](https://opensourceforu.com/author/nitin-garg/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,590 | 如何修复使用 Python ORM 工具 SQLAlchemy 时的常见陷阱 | https://opensource.com/article/19/9/common-pitfalls-python | 2019-11-19T09:32:35 | [
"ORM"
] | /article-11590-1.html |
>
> 在使用 SQLAlchemy 时,那些看似很小的选择可能对这种对象关系映射工具包的性能产生重要影响。
>
>
>

<ruby> 对象关系映射 <rt> Object-relational mapping </rt></ruby>([ORM](https://en.wikipedia.org/wiki/Object-relational_mapping))使应用程序开发人员的工作更轻松,在很大程度是因为它允许你使用你可能知道的语言(例如 Python)与数据库交互,而不是使用原始 SQL 语句查询。[SQLAlchemy](https://www.sqlalchemy.org/) 是一个 Python ORM 工具包,它提供使用 Python 访问 SQL 数据库的功能。它是一个成熟的 ORM 工具,增加了模型关系、强大的查询构造范式、简单的序列化等优点。然而,它的易用性使得人们很容易忘记其背后发生了什么。使用 SQLAlchemy 时做出的看似很小的选择可能产生非常大的性能影响。
本文解释了开发人员在使用 SQLAlchemy 时遇到的一些最重要的性能问题,以及如何解决这些问题。
### 只需要计数但检索整个结果集
有时开发人员只需要一个结果计数,但是没有使用数据库计数功能,而是获取了所有结果,然后使用 Python 中的 `len` 完成计数。
```
count = len(User.query.filter_by(acct_active=True).all())
```
相反,使用 SQLAlchemy 的 `count` 方法将在服务器端执行计数,从而减少发送到客户端的数据。在前面的例子中调用 `all()` 也会导致模型对象的实例化,如果有很多数据,那么时间代价可能会非常昂贵。
除非还需要做其他的事情,否则只需使用 `count` 方法:
```
count = User.query.filter_by(acct_active=True).count()
```
### 只需要几列时检索整个模型
在许多情况下,发出查询时只需要几列数据。SQLAlchemy 可以只获取你想要的列,而不是返回整个模型实例。这不仅减少了发送的数据量,还避免了实例化整个对象。使用列数据的元组而不是模型可以快得多。
```
result = User.query.all()
for user in result:
print(user.name, user.email)
```
反之,使用 `with_entities` 方法只选择所需要的内容:
```
result = User.query.with_entities(User.name, User.email).all()
for (username, email) in result:
print(username, email)
```
### 每次循环都更新一个对象
避免使用循环来单独更新集合。虽然数据库可以非常快地执行单个更新,但应用程序和数据库服务器之间的往返时间将快速累加。通常,在合理的情况下争取更少的查询。
```
for user in users_to_update:
user.acct_active = True
db.session.add(user)
```
改用批量更新方法:
```
query = User.query.filter(user.id.in_([user.id for user in users_to_update]))
query.update({"acct_active": True}, synchronize_session=False)
```
### 触发级联删除
ORM 允许在模型关系上进行简单的配置,但是有一些微妙的行为可能会令人吃惊。大多数数据库通过外键和各种级联选项维护关系完整性。SQLAlchemy 允许你使用外键和级联选项定义模型,但是 ORM 具有自己的级联逻辑,可以取代数据库。
考虑以下模型:
```
class Artist(Base):
__tablename__ = "artist"
id = Column(Integer, primary_key=True)
songs = relationship("Song", cascade="all, delete")
class Song(Base):
__tablename__ = "song"
id = Column(Integer, primary_key=True)
artist_id = Column(Integer, ForeignKey("artist.id", ondelete="CASCADE"))
```
删除歌手将导致 ORM 在 `song` 表上发出 `delete` 查询,从而防止由于外键导致的删除操作。这种行为可能会成为复杂关系和大量记录的瓶颈。
请包含 `passive_deletes` 选项,以确保让数据库来管理关系。但是,请确保你的数据库具有此功能。例如,SQLite 默认情况下不管理外键。
```
songs = relationship("Song", cascade all, delete", passive_deletes=True)
```
### 当要使用贪婪加载时,应使用延迟加载
延迟加载是 SQLAlchemy 处理关系的默认方法。从上一个例子构建来看,加载一个歌手时不会同时加载他或她的歌曲。这通常是一个好主意,但是如果总是需要加载某些关系,单独的查询可能会造成浪费。
如果允许以延迟方式加载关系,像 [Marshmallow](https://marshmallow.readthedocs.io/en/stable/) 这样流行的序列化框架可以触发级联查询。
有几种方法可以控制此行为。最简单的方法是通过 relationship 函数本身。
```
songs = relationship("Song", lazy="joined", cascade="all, delete")
```
这将导致一个左连接被添加到任何歌手的查询中,因此,`songs` 集合将立即可用。尽管有更多数据返回给客户端,但往返次数可能会少得多。
SQLAlchemy 为无法采用这种综合方法的情况提供了更细粒度的控制,可以使用 `joinedload()` 函数在每个查询的基础上切换连接的加载。
```
from sqlalchemy.orm import joinedload
artists = Artist.query.options(joinedload(Artist.songs))
print(artists.songs) # Does not incur a roundtrip to load
```
### 使用 ORM 进行批量记录导入
导入成千上万条记录时,构建完整模型实例的开销会成为主要瓶颈。想象一下,从一个文件中加载数千首歌曲记录,其中每首歌曲都先被转换为字典。
```
for song in songs:
db.session.add(Song(`song))
```
相反,绕过 ORM,只使用核心的 SQLAlchemy 参数绑定功能。
```
batch = []
insert_stmt = Song.__table__.insert()
for song in songs:
if len(batch) > 1000:
db.session.execute(insert_stmt, batch)
batch.clear()
batch.append(song)
if batch:
db.session.execute(insert_stmt, batch)
```
请记住,此方法会自然而然地跳过你可能依赖的任何客户端 ORM 逻辑,例如基于 Python 的列默认值。尽管此方法比将对象加载为完整的模型实例要快,但是你的数据库可能具有更快的批量加载方法。例如,PostgreSQL 的 `COPY` 命令为加载大量记录提供了最佳性能。
### 过早调用提交或刷新
在很多情况下,你需要将子记录与其父记录相关联,反之亦然。一种显然的方法是刷新会话,以便为有问题的记录分配一个 ID。
```
artist = Artist(name="Bob Dylan")
song = Song(title="Mr. Tambourine Man")
db.session.add(artist)
db.session.flush()
song.artist_id = artist.id
```
对于每个请求,多次提交或刷新通常是不必要的,也是不可取的。数据库刷新涉及强制在数据库服务器上进行磁盘写入,在大多数情况下,客户端将阻塞,直到服务器确认已写入数据为止。
SQLAlchemy 可以在幕后跟踪关系和管理相关键。
```
artist = Artist(name="Bob Dylan")
song = Song(title="Mr. Tambourine Man")
artist.songs.append(song)
```
### 总结
我希望这一系列常见的陷阱可以帮助你避免这些问题,并使你的应用平稳运行。通常,在诊断性能问题时,测量是关键。大多数数据库都提供性能诊断功能,可以帮助你定位问题,例如 PostgreSQL 的 `pg_stat_statements` 模块。
---
via: <https://opensource.com/article/19/9/common-pitfalls-python>
作者:[Zach Todd](https://opensource.com/users/zchtoddhttps://opensource.com/users/lauren-pritchetthttps://opensource.com/users/liranhaimovitchhttps://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,592 | 丢失的开放剪贴画库和新的公共艺术品图书馆 FreeSVG.org 的诞生 | https://opensource.com/article/19/10/how-community-saved-artwork-creative-commons | 2019-11-19T10:21:00 | [
"CC0"
] | /article-11592-1.html |
>
> 开放剪贴画库兴衰的故事以及一个新的公共艺术品图书馆 FreeSVG.org 的诞生。
>
>
>

<ruby> 开放剪贴画库 <rt> Open Clip Art Library </rt></ruby>(OCAL)发布于 2004 年,成为了免费插图的来源,任何人都可以出于任何目的使用它们,而无需注明出处或提供任何回报。针对 1990 年代每个家庭办公室书架上的大量剪贴画 CD 以及由闭源公司和艺术品软件提供的艺术品转储,这个网站是开源世界的回应。
最初,这个剪贴画库主要由一些贡献者提供,但是在 2010 年,它重新打造成了一个全新的交互式网站,可以让任何人使用矢量插图应用程序创建和贡献剪贴画。该网站立即获得了来自全球的、各种形式的自由软件和自由文化项目的贡献。[Inkscape](https://opensource.com/article/18/1/inkscape-absolute-beginners) 中甚至包含了该库的专用导入器。
但是,在 2019 年初,托管开放剪贴画库的网站离线了,没有任何警告或解释。它已经成长为有着成千上万的人的社区,起初以为这是暂时的故障。但是,这个网站一直离线已超过六个月,而没有任何清楚的解释。
谣言开始膨胀。该网站一直在更新中(“要偿还数年的技术债务”,网站开发者 Jon Philips 在一封电子邮件中说)。一个 Twitter 帐户声称,该网站遭受了猖狂的 DDoS 攻击。另一个 Twitter 帐户声称,该网站维护者已经成为身份盗用的牺牲品。今天,在撰写本文时,该网站的一个且唯一的页面声明它处于“维护和保护模式”,其含义不清楚,只是用户无法访问其内容。
### 恢复公地
网站会随着时间的流逝而消失,但是对其社区而言,开放剪贴画库的丢失尤其令人惊讶,因为它被视为一个社区项目。很少有社区成员知道托管该库的网站已经落入单个维护者手中,因此,由于 [CC0 许可证](https://creativecommons.org/share-your-work/public-domain/cc0/),该库中的艺术品归所有人所有,但对它的访问是由单个维护者功能性拥有的。而且,由于该社区通过网站彼此保持联系,因此该维护者实际上拥有该社区。
当网站发生故障时,社区以及成员彼此之间都无法访问剪贴画。没有该网站,就没有社区。
最初,该网站离线后其上的所有东西都是被封锁的。不过,在几个月之后,用户开始意识到该网站的数据仍然在线,这意味着用户能够通过输入精确的 URL 访问单个剪贴画。换句话说,你不能通过在网站上到处点击来浏览剪贴画文件,但是如果你确切地知道该地址,你就可以在浏览器中访问它。类似的,技术型(或偷懒的)用户意识到能够通过类似 `wget` 的自动 Web 浏览器将网站“抓取”下来。
Linux 的 `wget` 命令从技术上来说是一个 Web 浏览器,虽然它不能让你像用 Firefox 一样交互式地浏览。相反,`wget` 可以连到互联网,获取文件或文件集,并下载到你的本次硬盘。然后,你可以在 Firefox、文本编辑器或最合适的应用程序中打开这些文件,查看内容。
通常,`wget` 需要知道要提取的特定文件。如果你使用的是安装了 `wget` 的 Linux 或 macOS,则可以通过下载 [example.com](http://example.com) 的索引页来尝试此过程:
```
$ wget example.org/index.html
[...]
$ tail index.html
<body><div>
<h1>Example Domain</h1>
<p>This domain is for illustrative examples in documents.
You may use this domain in examples without permission.</p>
<p><a href="http://www.iana.org/domains/example">More info</a></p>
</div></body></html>
```
为了抓取 OCAL,我使用了 `--mirror` 选项,以便可以只是将 `wget` 指向到包含剪贴画的目录,就可以下载该目录中的所有内容。此操作持续下载了连续四天(96 个小时),最终得到了超过 50,000 个社区成员贡献的 100,000 个 SVG 文件。不幸的是,任何没有适当元数据的文件的作者信息都是无法恢复的,因为此信息被锁定在该数据库中不可访问的文件中,但是 CC0 许可证意味着此问题*在技术上*无关紧要(因为 CC0 文件不需要归属)。
随意分析了一下下载的文件进行还显示,其中近 45,000 个文件是同一个文件(该网站的徽标)的副本。这是由于指向该网站徽标的重定向引起的(原因未知),仔细分析能够提取到原始的文件,又过了 96 个小时,并且恢复了直到最后一天发布在 OCAL 上的所有剪贴画:总共约有 156,000 张图像。
SVG 文件通常很小,但这仍然是大量工作,并且会带来一些非常实际的问题。首先,将需要数 GB 的在线存储空间,这样这些剪贴画才能供其先前的社区使用。其次,必须使用一种搜索剪贴画的方法,因为手动浏览 55,000 个文件是不现实的。
很明显,社区真正需要的是一个平台。
### 构建新的平台
一段时间以来,[公共领域矢量图](http://publicdomainvectors.org) 网站一直在发布公共领域的矢量图。虽然它仍然是一个受欢迎的网站,但是开源用户通常只是将其用作辅助的图片资源,因为其中大多数文件都是 EPS 和 AI 格式的,这两者均与 Adobe 相关。这两种文件格式通常都可以转换为 SVG,但是特性会有所损失。
当公共领域矢量图网站的维护者(Vedran 和 Boris)得知 OCAL 丢失时,他们决定创建一个面向开源社区的网站。诚然,他们选择了开源 [Laravel](https://github.com/viralsolani/laravel-adminpanel) 框架作为后端,该框架为网站提供了管理控制台和用户访问权限。该框架功能强大且开发完善,还使他们能够快速响应错误报告和功能请求,并根据需要升级网站。他们正在建立的网站称为 [FreeSVG.org](https://freesvg.org),已经是一个强大而繁荣的公共艺术品图书馆。
从那时起,他们就一直从 OCAL 上载所有剪贴画,并且他们甚至在努力地对这些剪贴画进行标记和分类。作为公共领域矢量图网站的创建者,他们还以 SVG 格式贡献了自己的图像。他们的目标是成为互联网上具有 CC0 许可证的 SVG 图像的主要资源。
### 贡献
[FreeSVG.org](https://freesvg.org) 的维护者意识到他们已经继承了重要的管理权。他们正在努力对网站上的所有图像加上标题和描述,以便用户可以轻松找到这些剪贴画,并在准备就绪后将其提供给社区,同时坚信同这些剪贴画一样,与这些剪贴画有关的元数据属于创建和使用它们的人。他们还意识到可能会发生无法预料的情况,因此他们会定期为其网站和内容创建备份,并打算在其网站出现故障时向公众提供最新备份。
如果要为 [FreeSVG.org](http://freesvg.org)的知识共享内容添砖加瓦,请下载 [Inkscape](http://inkscape.org) 并开始绘制。世界上有很多公共领域的艺术品,例如[历史广告](https://freesvg.org/drinking-coffee-vector-drawing)、[塔罗牌](https://freesvg.org/king-of-swords-tarot-card)和[故事书](https://freesvg.org/space-pioneers-135-scene-vector-image),只是在等待转换为 SVG,因此即使你对自己的绘画技巧没有信心你也可以做出贡献。访问 [FreeSVG 论坛](http://forum.freesvg.org/)与其他贡献者联系并支持他们。
*公地*的概念很重要。无论你是学生、老师、图书馆员、小企业主还是首席执行官,[知识共享都会使所有人受益](https://opensource.com/article/18/1/creative-commons-real-world)。如果你不直接捐款,那么你随时可以帮助推广。
这是自由文化的力量:它不仅可以扩展,而且随着更多人的参与,它会变得更好。
### 艰辛的教训
从 OCAL 的消亡到 FreeSVG.org 的兴起,开放文化社区已经吸取了一些艰辛的经验。对于以后,以下是我认为最重要的那些。
#### 维护你的元数据
如果你是内容创建者,请帮助将来的档案管理员,将元数据添加到文件中。大多数图像、音乐、字体和视频文件格式都可以嵌入 EXIF 数据,其他格式在创建它们的应用程序中具有元数据输入界面。勤于用你的姓名、网站或公共电子邮件以及许可证来标记你的作品。
#### 做个副本
不要以为别人在做备份。如果你关心公用数字内容,请自己备份,否则不要指望永远提供它。无论*任何上传到互联网上的内容是永久的*的说法是不是正确的,但这并不意味着你永远可以使用。如果 OCAL 文件不再暗地可用,那么任何人都不太可能成功地从网络上的某个位置或从全球范围内的人们的硬盘中成功地发现全部的 55,000 张图像。
#### 创建外部渠道
如果一个社区是由单个网站或实际位置来定义的,那么该社区失去访问该空间的能力就如同解散了一样。如果你是由单个组织或网站驱动的社区的成员,则你应该自己与关心的人共享联系信息,并即使在该网站不可用时也可以建立沟通渠道。
例如,[Opensource.com](http://Opensource.com) 本身维护其作者和通讯者的邮件列表和其他异地渠道,以便在有或没有网站干预或甚至没有网站的情况下相互交流。
#### 自由文化值得为此努力
互联网有时被视为懒人社交俱乐部。你可以在需要时登录并在感到疲倦时将其关闭,也可以漫步到所需的任何社交圈。
但实际上,自由文化可能是项艰难的工作。但是这种艰难从某种意义上讲并不是说要成为其中的一分子很困难,而是你必须努力维护。如果你忽略你所在的社区,那么该社区可能会在你意识到之前就枯萎并褪色。
花点时间环顾四周,确定你属于哪个社区,如果不是,那么请告诉某人你对他们带给你生活的意义表示赞赏。同样重要的是,请记住,这样你也为社区的生活做出了贡献。
几周前,知识共享组织在华沙举行了它的全球峰会,令人惊叹的国际盛会…
>
> 老王文末感想:刚刚看到这篇文章的英文标题(How I used the wget Linux command to recover lost images)时,我以为这是一篇技术文章,然而翻译校对下来之后,却是一篇披着技术外衣的对自由文化社区的教训和反思。作为一个同样建设公地社区的负责人,我不禁深深地对 “Linux 中国”社区的将来有了忧虑。如何避免 “Linux 中国”也同样陷入这种困境,这是一个问题……
>
>
> 就目前来看,我们需要定期不定期的构建离线归档,也需要以更开放的方式留下现有文章的数据,也欢迎大家来支持和帮助我们。
>
>
> 又及,再给产生这一切的 Linux 中国翻译组织 LCTT 打个招新广告吧,欢迎大家加入: <https://linux.cn/lctt/>
>
>
>
---
via: <https://opensource.com/article/19/10/how-community-saved-artwork-creative-commons>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
11,593 | PostgreSQL 入门 | https://opensource.com/article/19/11/getting-started-postgresql | 2019-11-20T09:00:01 | [
"PostgreSQL"
] | https://linux.cn/article-11593-1.html |
>
> 安装、设置、创建和开始使用 PostgreSQL 数据库。
>
>
>

每个人或许都有需要在数据库中保存的东西。即使你执着于使用纸质文件或电子文件,它们也会变得很麻烦。纸质文档可能会丢失或混乱,你需要访问的电子信息可能会隐藏在段落和页面的深处。
在我从事医学工作的时候,我使用 [PostgreSQL](https://www.postgresql.org/) 来跟踪我的住院患者名单并提交有关住院患者的信息。我将我的每日患者名单打印在口袋里,以便快速了解患者房间、诊断或其他细节的任何变化并做出快速记录。
我以为一切没问题,直到去年我妻子决定买一辆新车,我“接手”了她以前的那辆车。她保留了汽车维修和保养服务收据的文件夹,但随着时间的流逝,它变得杂乱。与其花时间筛选所有纸条以弄清楚什么时候做了什么,我认为 PostgreSQL 将是更好的跟踪此信息的方法。
### 安装 PostgreSQL
自上次使用 PostgreSQL 以来已经有一段时间了,我已经忘记了如何使用它。实际上,我甚至没有在计算机上安装它。安装它是第一步。我使用 Fedora,因此在控制台中运行:
```
dnf list postgresql*
```
请注意,你无需使用 `sudo` 即可使用 `list` 选项。该命令返回了很长的软件包列表。看了眼后,我决定只需要三个:postgresql、postgresql-server 和 postgresql-docs。
为了了解下一步需要做什么,我决定查看 [PostgreSQL 文档](http://www.postgresql.org/docs)。文档参考内容非常丰富,实际上,丰富到令人生畏。幸运的是,我发现我在升级 Fedora 时曾经做过的一些笔记,希望有效地导出数据库,在新版本上重新启动 PostgreSQL,以及导入旧数据库。
### 设置 PostgreSQL
与大多数其他软件不同,你不能只是安装好 PostgreSQL 就开始使用它。你必须预先执行两个基本步骤:首先,你需要设置 PostgreSQL,第二,你需要启动它。你必须以 `root` 用户身份执行这些操作(`sudo` 在这里不起作用)。
要设置它,请输入:
```
postgresql-setup –initdb
```
这将确定 PostgreSQL 数据库在计算机上的位置。然后(仍为 `root`)输入以下两个命令:
```
systemctl start postgresql.service
systemctl enable postgresql.service
```
第一个命令为当前会话启动 PostgreSQL(如果你关闭机器,那么 PostgreSQL 也将关闭)。第二个命令使 PostgreSQL 在随后的重启中自动启动。
### 创建用户
PostgreSQL 正在运行,但是你仍然不能使用它,因为你还没有用户。为此,你需要切换到特殊用户 `postgres`。当你仍以 `root` 身份运行时,输入:
```
su postgres
```
由于你是以 `root` 的身份执行此操作的,因此无需输入密码。root 用户可以在不知道密码的情况下以任何用户身份操作;这就是使其强大而危险的原因之一。
现在你就是 `postgres` 了,请运行下面两个命令,如下所示创建用户(创建用户 `gregp`):
```
createuser gregp
createdb gregp
```
你可能会看到错误消息,如:`Could not switch to /home/gregp`。这只是意味着用户 `postgres`不能访问该目录。尽管如此,你的用户和数据库已创建。接下来,输入 `exit` 并按回车两次,这样就回到了原来的用户下(`root`)。
### 设置数据库
要开始使用 PostgreSQL,请在命令行输入 `psql`。你应该在每行左侧看到类似 `gregp=>` 的内容,以显示你使用的是 PostgreSQL,并且只能使用它理解的命令。你自动获得一个数据库(我的名为 `gregp`),它里面完全没有内容。对 PostgreSQL 来说,数据库只是一个工作空间。在空间内,你可以创建*表*。表包含变量列表,而表中的每个变量是构成数据库的数据。
以下是我设置汽车服务数据库的方式:
```
CREATE TABLE autorepairs (
date date,
repairs varchar(80),
location varchar(80),
cost numeric(6,2)
);
```
我本可以在一行内输入,但为了更好地说明结构,并表明 PostgreSQL 不会解释制表符和换行的空白,我分成了多行。字段包含在括号中,每个变量名和数据类型与下一个变量用逗号分隔(最后一个除外),命令以分号结尾。所有命令都必须以分号结尾!
第一个变量名是 `date`,它的数据类型也是 `date`,这在 PostgreSQL 中没关系。第二个和第三个变量 `repairs` 和 `location` 都是 `varchar(80)` 类型,这意味着它们可以是最多 80 个任意字符(字母、数字等)。最后一个变量 `cost` 使用 `numeric` 类型。括号中的数字表示最多有六位数字,其中两位是小数。最初,我尝试了 `real` 类型,这将是一个浮点数。`real` 类型的问题是作为数据类型在使用时,在遇到 `WHERE` 子句,类似 `WHERE cost = 0` 或其他任何特定数字。由于 `real` 值有些不精确,因此特定数字将永远不会匹配。
### 输入数据
接下来,你可以使用 `INSERT INTO` 命令添加一些数据(在 PostgreSQL 中称为*行*):
```
INSERT INTO autorepairs VALUES ('2017-08-11', 'airbag recall', 'dealer', 0);
```
请注意,括号构成了一个值的容器,它必须以正确的顺序,用逗号分隔,并在命令末尾加上分号。`date` 和 `varchar(80)` 类型的值必须包含在单引号中,但数字值(如 `numeric`)不用。作为反馈,你应该会看到:
```
INSERT 0 1
```
与常规终端会话一样,你会有输入命令的历史记录,因此,在输入后续行时,通常可以按向上箭头键来显示最后一个命令并根据需要编辑数据,从而节省大量时间。
如果出了什么问题怎么办?使用 `UPDATE` 更改值:
```
UPDATE autorepairs SET date = '2017-11-08' WHERE repairs = 'airbag recall';
```
或者,也许你不再需要表中的行。使用 `DELETE`:
```
DELETE FROM autorepairs WHERE repairs = 'airbag recall';
```
这将删除整行。
最后一件事:即使我在 PostgreSQL 命令中一直使用大写字母(在大多数文档中也这么做),你也可以用小写字母输入,我也经常如此。
### 输出数据
如果你想展示数据,使用 `SELECT`:
```
SELECT * FROM autorepairs ORDER BY date;
```
没有 `ORDER BY` 的话,行将不管你输入的内容来显示。例如,以下就是我终端中输出的我的汽车服务数据:
```
SELECT date, repairs FROM autorepairs ORDER BY date;
date | repairs
-----------+-----------------------------------------------------------------
2008-08-08 | oil change, air filter, spark plugs
2011-09-30 | 35000 service, oil change, rotate tires/balance wheels
2012-03-07 | repl battery
2012-11-14 | 45000 maint, oil/filter
2014-04-09 | 55000 maint, oil/filter, spark plugs, air/dust filters
2014-04-21 | replace 4 tires
2014-04-21 | wheel alignment
2016-06-01 | 65000 mile service, oil change
2017-05-16 | oil change, replce oil filt housing
2017-05-26 | rotate tires
2017-06-05 | air filter, cabin filter,spark plugs
2017-06-05 | brake pads and rotors, flush brakes
2017-08-11 | airbag recall
2018-07-06 | oil/filter change, fuel filter, battery svc
2018-07-06 | transmission fl, p steering fl, rear diff fl
2019-07-22 | oil & filter change, brake fluid flush, front differential flush
2019-08-20 | replace 4 tires
2019-10-09 | replace passenger taillight bulb
2019-10-25 | replace passenger taillight assembly
(19 rows)
```
要将此发送到文件,将输出更改为:
```
\o autorepairs.txt
```
然后再次运行 `SELECT` 命令。
### 退出 PostgreSQL
最后,在终端中退出 PostgreSQL,输入:
```
quit
```
或者它的缩写版:
```
\q
```
虽然这只是 PostgreSQL 的简要介绍,但我希望它展示了将数据库用于这样的简单任务既不困难也不费时。
---
via: <https://opensource.com/article/19/11/getting-started-postgresql>
作者:[Greg Pittman](https://opensource.com/users/greg-p) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Everyone has things that would be useful to collect in a database. Even if you're obsessive about keeping paperwork or electronic files, they can become cumbersome. Paper documents can be lost or completely disorganized, and information you need to access in electronic files may be buried in depths of paragraphs and pages of information.
When I was practicing medicine, I used [PostgreSQL](https://www.postgresql.org/) to keep track of my hospital patient list and to submit information about my hospital patients. I carried a printout of my daily patient list in my pocket for quick reference and to make quick notes about any changes in the patients' room, diagnosis, or other details.
I thought that was all behind me, until last year when my wife decided to get a new car, and I "inherited" her previous one. She had kept a folder of car repair and maintenance service receipts, but over time, it lost any semblance of organization. It takes time to sift through all the slips of paper to figure out what was done when, and I thought PostgreSQL would be a better way to keep track of this information.
## Install PostgreSQL
It had been a while since I last used PostgreSQL, and I had forgotten how to get going with it. In fact, I didn't even have it on my computer. Installing it was step one. I use Fedora, so in a console, I ran:
`dnf list postgresql*`
Notice that you don't need to use sudo to use the **list** option. This command returned a long list of packages; after scanning them, I decided I only wanted three: postgresql, postgresql-server, and postgresql-docs.
To find out what I needed to do next, I decided to consult the [PostgreSQL docs](http://www.postgresql.org/docs). The docs are a very extensive reference—so extensive, in fact, that it is rather daunting. Fortunately, I found some notes I made in the past when I was upgrading Fedora and wanted to efficiently export my database, restart PostgreSQL on the new version, and import my old database.
## Set up PostgreSQL
Unlike most other software, you can't just install PostgreSQL and start using it. You must carry out two basic steps beforehand: First, you need to set up PostgreSQL, and second, you need to start it. You must do these as the **root** user (sudo will not work here).
To set it up, enter:
`postgresql-setup –initdb`
This establishes the location of the PostgreSQL databases on the computer. Then (still as **root**), enter these two commands:
```
systemctl start postgresql.service
systemctl enable postgresql.service
```
The first command starts PostgreSQL for the current session on your computer (if you turn it off, PostgreSQL shuts down). The second command causes PostgreSQL to automatically start on subsequent reboots.
## Create a user
PostgreSQL is running, but you still can't use it because you haven't been named a user yet. To do this, you need to switch to the special user **postgres**. While you are still running as **root**, type:
`su postgres`
Since you're doing this as **root**, you don't need to enter a password. The **root** user can operate as any user without knowing their password; this is part of what makes it so powerful—and dangerous.
Now that you're **postgres**, run two commands like the following example (which creates the user **gregp**) to create your user:
```
createuser gregp
createdb gregp
```
You will probably get an error message like: **Could not switch to /home/gregp**. This just means that the user **postgres **doesn't have access to that directory. Nonetheless, your user and the database have been created. Next, type **Exit** and **Enter** twice so you're back to being yourself again.
## Set up a database
To start using PostgreSQL, type **psql** on the command line. You should see something like **gregp=>** to the left of each line to show that you're using PostgreSQL and can only use commands that it understands. You automatically have a database (mine is named **gregp**)—with absolutely nothing in it. A database, in the sense of PostgreSQL, is just a space to work. Inside that space, you create *tables*. A table contains a list of variables, and underneath each variable is the data that makes up your database.
Here is how I set up my auto-service database:
```
CREATE TABLE autorepairs (
date date,
repairs varchar(80),
location varchar(80),
cost numeric(6,2)
);
```
I could have typed this continuously on a single line, but I broke it up to illustrate the parts better and to show that the white space of tabs and line feeds is not interpreted by PostgreSQL. The data points are contained within parentheses, each variable name and data type is separated from the next by a comma (except for the last), and the command ends with a semicolon. All commands must end with a semicolon!
The first variable name is **date**, and its datatype is also **date**, which is OK with PostgreSQL. The second and third variables, **repairs** and **location**, are both datatype **varchar(80)**, which means they can be any mixture of up to 80 characters (letters, numbers, whatever). The last variable, **cost**, uses the **numeric** datatype. The numbers in parentheses indicate there is a maximum of six digits and two of them are decimals. At first, I tried the **real** datatype, which would be a floating-point number. The problem with **real** as a datatype comes in more advanced commands using a **WHERE** clause, like **WHERE cost = 0** or any other specific number. Since there is some imprecision in **real** values, specific numbers will never match anything.
## Enter data
Next, you can add some data (in PostgreSQL called a **row**) with the command **INSERT INTO**:
`INSERT INTO autorepairs VALUES ('2017-08-11', 'airbag recall', 'dealer', 0);`
Notice that the parentheses form a container for the values, which must be in the correct order, separated by commas, and with a semicolon at the end of the command. The value for the **date** and **varchar(80)** datatypes must be enclosed in single quotes, but number values like **numeric** do not. As feedback, you should see:
`INSERT 0 1`
Just as in your regular terminal session, you will have a history of entered commands, so often you can save a great deal of time when entering subsequent rows by pressing the Up arrow key to show the last command and editing the data as needed.
What if you get something wrong? Use **UPDATE** to change a value:
`UPDATE autorepairs SET date = '2017-11-08' WHERE repairs = 'airbag recall';`
Or maybe you no longer want something in your table. Use **DELETE**:
`DELETE FROM autorepairs WHERE repairs = 'airbag recall';`
and the whole row will be deleted.
One last thing: Even though I used all caps in the PostgreSQL commands (which is also done in most documentation), you can type them in lowercase, which is what I generally do.
## Output data
If you want to show your data, use **SELECT**:
`SELECT * FROM autorepairs ORDER BY date;`
Without the **ORDER BY** option, the rows would appear however they were entered. For example, here's a selection of my auto-service data as it's output in my terminal:
```
SELECT date, repairs FROM autorepairs ORDER BY date;
date | repairs
-----------+-----------------------------------------------------------------
2008-08-08 | oil change, air filter, spark plugs
2011-09-30 | 35000 service, oil change, rotate tires/balance wheels
2012-03-07 | repl battery
2012-11-14 | 45000 maint, oil/filter
2014-04-09 | 55000 maint, oil/filter, spark plugs, air/dust filters
2014-04-21 | replace 4 tires
2014-04-21 | wheel alignment
2016-06-01 | 65000 mile service, oil change
2017-05-16 | oil change, replce oil filt housing
2017-05-26 | rotate tires
2017-06-05 | air filter, cabin filter,spark plugs
2017-06-05 | brake pads and rotors, flush brakes
2017-08-11 | airbag recall
2018-07-06 | oil/filter change, fuel filter, battery svc
2018-07-06 | transmission fl, p steering fl, rear diff fl
2019-07-22 | oil & filter change, brake fluid flush, front differential flush
2019-08-20 | replace 4 tires
2019-10-09 | replace passenger taillight bulb
2019-10-25 | replace passenger taillight assembly
(19 rows)
```
To send this to a file, change the output with:
`\o autorepairs.txt`
then run the **SELECT** command again.
## Exit PostgreSQL
Finally, to get out of PostgreSQL mode in the terminal, type:
`quit`
or its shorthand version:
`\q`
While this is just a brief introduction to PostgreSQL, I hope it demonstrates that it's neither difficult nor time-consuming to use the database for a simple task like this.
## 1 Comment |
11,595 | 关于 sudo 你可能不知道的 | https://opensource.com/article/19/10/know-about-sudo | 2019-11-20T09:18:37 | [
"sudo"
] | https://linux.cn/article-11595-1.html |
>
> 觉得你已经了解了 sudo 的所有知识了吗?再想想。
>
>
>

大家都知道 `sudo`,对吗?默认情况下,该工具已安装在大多数 Linux 系统上,并且可用于大多数 BSD 和商业 Unix 变体。不过,在与数百名 `sudo` 用户交谈之后,我得到的最常见的答案是 `sudo` 是一个使生活复杂化的工具。
有 root 用户和 `su` 命令,那么为什么还要使用另一个工具呢?对于许多人来说,`sudo` 只是管理命令的前缀。只有极少数人提到,当你在同一个系统上有多个管理员时,可以使用 `sudo` 日志查看谁做了什么。
那么,`sudo` 是什么? 根据 [sudo 网站](https://www.sudo.ws):
>
> “sudo 允许系统管理员通过授予某些用户以 root 用户或其他用户身份运行某些命令的能力,同时提供命令及其参数的审核记录,从而委派权限。”
>
>
>
默认情况下,`sudo` 只有简单的配置,一条规则允许一个用户或一组用户执行几乎所有操作(在本文后面的配置文件中有更多信息):
```
%wheel ALL=(ALL) ALL
```
在此示例中,参数表示以下含义:
* 第一个参数(`%wheel`)定义组的成员。
* 第二个参数(`ALL`)定义组成员可以在其上运行命令的主机。
* 第三个参数(`(ALL)`)定义了可以执行命令的用户名。
* 最后一个参数(`ALL`)定义可以运行的应用程序。
因此,在此示例中,`wheel` 组的成员可以以所有主机上的所有用户身份运行所有应用程序。但即使是这个一切允许的规则也很有用,因为它会记录谁在计算机上做了什么。
### 别名
当然,它不仅可以让你和你最好的朋友管理一个共享机器,你还可以微调权限。你可以将以上配置中的项目替换为列表:用户列表、命令列表等。多数情况下,你可能会复制并粘贴配置中的一些列表。
在这种情况下,别名可以派上用场。在多个位置维护相同的列表容易出错。你可以定义一次别名,然后可以多次使用。因此,当你对一位管理员不再信任时,将其从别名中删除就行了。使用多个列表而不是别名,很容易忘记从具有较高特权的列表之一中删除用户。
### 为特定组的用户启用功能
`sudo` 命令带有大量默认设置。不过,在某些情况下,你想覆盖其中的一些情况,这时你可以在配置中使用 `Defaults` 语句。通常,对每个用户都强制使用这些默认值,但是你可以根据主机、用户名等将设置缩小到一部分用户。这里有个我那一代的系统管理员都喜欢玩的一个示例:“羞辱”。这些只不过是一些有人输入错误密码时的有趣信息:
```
czanik@linux-mewy:~> sudo ls
[sudo] password for root:
Hold it up to the light --- not a brain in sight! # 把灯举高点,脑仁太小看不到
[sudo] password for root:
My pet ferret can type better than you! # 我的宠物貂也比你输入的好
[sudo] password for root:
sudo: 3 incorrect password attempts
czanik@linux-mewy:~>
```
由于并非所有人都喜欢系统管理员的这种幽默,因此默认情况下会禁用这些羞辱信息。以下示例说明了如何仅对经验丰富的系统管理员(即 `wheel` 组的成员)启用此设置:
```
Defaults !insults
Defaults:%wheel insults
```
我想,感谢我将这些消息带回来的人用两只手也数不过来吧。
### 摘要验证
当然,`sudo` 还有更严肃的功能。其中之一是摘要验证。你可以在配置中包括应用程序的摘要:
```
peter ALL = sha244:11925141bb22866afdf257ce7790bd6275feda80b3b241c108b79c88 /usr/bin/passwd
```
在这种情况下,`sudo` 在运行应用程序之前检查应用程序摘要,并将其与配置中存储的摘要进行比较。如果不匹配,`sudo` 拒绝运行该应用程序。尽管很难在配置中维护此信息(没有用于此目的的自动化工具),但是这些摘要可以为你提供额外的保护层。
### 会话记录
会话记录也是 `sudo` 鲜为人知的功能。在演示之后,许多人离开我的演讲后就计划在其基础设施上实施它。为什么?因为使用会话记录,你不仅可以看到命令名称,还可以看到终端中发生的所有事情。你可以看到你的管理员在做什么,要不他们用 shell 访问了机器而日志仅会显示启动了 `bash`。
当前有一个限制。记录存储在本地,因此具有足够的权限的话,用户可以删除他们的痕迹。所以请继续关注即将推出的功能。
### 插件
从 1.8 版开始,`sudo` 更改为基于插件的模块化体系结构。通过将大多数功能实现为插件,你可以编写自己的功能轻松地替换或扩展 `sudo` 的功能。已经有了 `sudo` 上的开源和商业插件。
在我的演讲中,我演示了 `sudo_pair` 插件,该插件可在 [GitHub](https://github.com/square/sudo_pair/) 上获得。这个插件是用 Rust 开发的,这意味着它不是那么容易编译,甚至更难以分发其编译结果。另一方面,该插件提供了有趣的功能,需要第二个管理员通过 `sudo` 批准(或拒绝)运行命令。不仅如此,如果有可疑活动,可以在屏幕上跟踪会话并终止会话。
在最近的 All Things Open 会议上的一次演示中,我做了一个臭名昭著的演示:
```
czanik@linux-mewy:~> sudo rm -fr /
```
看着屏幕上显示的命令。每个人都屏住呼吸,想看看我的笔记本电脑是否被毁了,然而它逃过一劫。
### 日志
正如我在开始时提到的,日志记录和警报是 `sudo` 的重要组成部分。如果你不会定期检查 `sudo` 日志,那么日志在使用 `sudo` 中并没有太多价值。该工具通过电子邮件提醒配置中指定的事件,并将所有事件记录到 syslog 中。可以打开调试日志用于调试规则或报告错误。
### 警报
电子邮件警报现在有点过时了,但是如果你使用 syslog-ng 来收集日志消息,则会自动解析 `sudo` 日志消息。你可以轻松创建自定义警报并将其发送到各种各样的目的地,包括 Slack、Telegram、Splunk 或 Elasticsearch。你可以从[我在 syslong-ng.com 上的博客](https://www.syslog-ng.com/community/b/blog/posts/alerting-on-sudo-events-using-syslog-ng)中了解有关此功能的更多信息。
### 配置
我们谈论了很多 `sudo` 功能,甚至还看到了几行配置。现在,让我们仔细看看 `sudo` 的配置方式。配置本身可以在 `/etc/sudoers` 中获得,这是一个简单的文本文件。不过,不建议直接编辑此文件。相反,请使用 `visudo`,因为此工具还会执行语法检查。如果你不喜欢 `vi`,则可以通过将 `EDITOR` 环境变量指向你的首选编辑器来更改要使用的编辑器。
在开始编辑 `sudo` 配置之前,请确保你知道 root 密码。(是的,即使在默认情况下 root 用户没有密码的 Ubuntu 上也是如此。)虽然 `visudo` 会检查语法,但创建语法正确而将你锁定在系统之外的配置也很容易。
如果在紧急情况下,而你手头有 root 密码,你也可以直接编辑配置。当涉及到 `sudoers` 文件时,有一件重要的事情要记住:从上到下读取该文件,以最后的设置为准。这个事实对你来说意味着你应该从通用设置开始,并在末尾放置例外情况,否则,通用设置会覆盖例外情况。
你可以在下面看到一个基于 CentOS 的简单 `sudoers` 文件,并添加我们之前讨论的几行:
```
Defaults !visiblepw
Defaults always_set_home
Defaults match_group_by_gid
Defaults always_query_group_plugin
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Defaults:%wheel insults
Defaults !insults
Defaults log_output
```
该文件从更改多个默认值开始。然后是通常的默认规则:`root` 用户和 `wheel` 组的成员对计算机具有完全权限。接下来,我们对 `wheel` 组启用“羞辱”,但对其他所有人禁用它们。最后一行启用会话记录。
上面的配置在语法上是正确的,但是你可以发现逻辑错误吗?是的,有一个:后一个通用设置覆盖了先前的更具体设置,让所有人均禁用了“羞辱”。一旦交换了这两行的位置,设置就会按预期进行:`wheel` 组的成员会收到有趣的消息,但其他用户则不会收到。
### 配置管理
一旦必须在多台机器上维护 `sudoers` 文件,你很可能希望集中管理配置。这里主要有两种可能的开源方法。两者都有其优点和缺点。
你可以使用也用来配置其余基础设施的配置管理应用程序之一:Red Hat Ansible、Puppet 和 Chef 都具有用于配置 `sudo` 的模块。这种方法的问题在于更新配置远非实时。同样,用户仍然可以在本地编辑 `sudoers` 文件并更改设置。
`sudo` 工具也可以将其配置存储在 LDAP 中。在这种情况下,配置更改是实时的,用户不能弄乱`sudoers` 文件。另一方面,该方法也有局限性。例如,当 LDAP 服务器不可用时,你不能使用别名或使用 `sudo`。
### 新功能
新版本的 `sudo` 即将推出。1.9 版将包含许多有趣的新功能。以下是最重要的计划功能:
* 记录服务可集中收集会话记录,与本地存储相比,它具有许多优点:
+ 在一个地方搜索更方便。
+ 即使发送记录的机器关闭,也可以进行记录。
+ 记录不能被想要删除其痕迹的人删除。
* audit 插件没有向 `sudoers` 添加新功能,而是为插件提供了 API,以方便地访问任何类型的 `sudo` 日志。这个插件允许使用插件从 `sudo` 事件创建自定义日志。
* approval 插件无需使用第三方插件即可启用会话批准。
* 以及我个人最喜欢的:插件的 Python 支持,这使你可以轻松地使用 Python 代码扩展 `sudo`,而不是使用 C 语言进行原生编码。 ### 总结
希望本文能向你证明 `sudo` 不仅仅是一个简单的命令前缀。有无数种可能性可以微调系统上的权限。你不仅可以微调权限,还可以通过检查摘要来提高安全性。会话记录使你能够检查系统上正在发生的事情。你也可以使用插件扩展 `sudo` 的功能,或者使用已有的插件或编写自己的插件。最后,从即将发布的功能列表中你可以看到,即使 `sudo` 已有数十年的历史,它也是一个不断发展的有生命力的项目。
如果你想了解有关 `sudo` 的更多信息,请参考以下资源:
* [sudo 网站](https://www.sudo.ws/)
* [sudo 博客](https://blog.sudo.ws/)
* [在 Twitter 上关注我们](https://twitter.com/sudoproject)
---
via: <https://opensource.com/article/19/10/know-about-sudo>
作者:[Peter Czanik](https://opensource.com/users/czanik) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Everybody knows **sudo**, right? This tool is installed by default on most Linux systems and is available for most BSD and commercial Unix variants. Still, after talking to hundreds of **sudo** users, the most common answer I received was that **sudo** is a tool to complicate life.
There is a root user and there is the **su** command, so why have yet another tool? For many, **sudo** was just a prefix for administrative commands. Only a handful mentioned that when you have multiple administrators for the same system, you can use **sudo** logs to see who did what.
So, what is **sudo**? According to the [ sudo website](https://www.sudo.ws):
"Sudo allows a system administrator to delegate authority by giving certain users the ability to run some commands as root or another user while providing an audit trail of the commands and their arguments."
By default, **sudo** comes with a simple configuration, a single rule allowing a user or a group of users to do practically anything (more on the configuration file later in this article):
`%wheel ALL=(ALL) ALL`
In this example, the parameters mean the following:
- The first parameter defines the members of the group.
- The second parameter defines the host(s) the group members can run commands on.
- The third parameter defines the usernames under which the command can be executed.
- The last parameter defines the applications that can be run.
So, in this example, the members of the **wheel** group can run all applications as all users on all hosts. Even this really permissive rule is useful because it results in logs of who did what on your machine.
## Aliases
Of course, once it is not just you and your best friend administering a shared box, you will start to fine-tune permissions. You can replace the items in the above configuration with lists: a list of users, a list of commands, and so on. Most likely, you will copy and paste some of these lists around in your configuration.
This situation is where aliases can come handy. Maintaining the same list in multiple places is error-prone. You define an alias once and then you can use it many times. Therefore, when you lose trust in one of your administrators, you can remove them from the alias and you are done. With multiple lists instead of aliases, it is easy to forget to remove the user from one of the lists with elevated privileges.
## Enable features for a certain group of users
The **sudo** command comes with a huge set of defaults. Still, there are situations when you want to override some of these. This is when you use the **Defaults** statement in the configuration. Usually, these defaults are enforced on every user, but you can narrow the setting down to a subset of users based on host, username, and so on. Here is an example that my generation of sysadmins loves to hear about: insults. These are just some funny messages for when someone mistypes a password:
```
czanik@linux-mewy:~> sudo ls
[sudo] password for root:
Hold it up to the light --- not a brain in sight!
[sudo] password for root:
My pet ferret can type better than you!
[sudo] password for root:
sudo: 3 incorrect password attempts
czanik@linux-mewy:~>
```
Because not everyone is a fan of sysadmin humor, these insults are disabled by default. The following example shows how to enable this setting only for your seasoned sysadmins, who are members of the **wheel** group:
```
Defaults !insults
Defaults:%wheel insults
```
I do not have enough fingers to count how many people thanked me for bringing these messages back.
## Digest verification
There are, of course, more serious features in **sudo** as well. One of them is digest verification. You can include the digest of applications in your configuration:
`peter ALL = sha244:11925141bb22866afdf257ce7790bd6275feda80b3b241c108b79c88 /usr/bin/passwd`
In this case, **sudo** checks and compares the digest of the application to the one stored in the configuration before running the application. If they do not match, **sudo** refuses to run the application. While it is difficult to maintain this information in your configuration—there are no automated tools for this purpose—these digests can provide you with an additional layer of protection.
## Session recording
Session recording is also a lesser-known feature of **sudo**. After my demo, many people leave my talk with plans to implement it on their infrastructure. Why? Because with session recording, you see not just the command name, but also everything that happened in the terminal. You can see what your admins are doing even if they have shell access and logs only show that **bash** is started.
There is one limitation, currently. Records are stored locally, so with enough permissions, users can delete their traces. Stay tuned for upcoming features.
## Plugins
Starting with version 1.8, **sudo** changed to a modular, plugin-based architecture. With most features implemented as plugins, you can easily replace or extend the functionality of **sudo** by writing your own. There are both open source and commercial plugins already available for **sudo**.
In my talk, I demonstrated the **sudo_pair** plugin, which is available [on GitHub](https://github.com/square/sudo_pair/). This plugin is developed in Rust, meaning that it is not so easy to compile, and it is even more difficult to distribute the results. On the other hand, the plugin provides interesting functionality, requiring a second admin to approve (or deny) running commands through **sudo**. Not just that, but sessions can be followed on-screen and terminated if there is suspicious activity.
In a demo I did during a recent talk at the All Things Open conference, I had the infamous:
`czanik@linux-mewy:~> sudo rm -fr /`
command displayed on the screen. Everybody was holding their breath to see whether my laptop got destroyed, but it survived.
## Logs
As I already mentioned at the beginning, logging and alerting is an important part of **sudo**. If you do not check your **sudo** logs regularly, there is not much worth in using **sudo**. This tool alerts by email on events specified in the configuration and logs all events to **syslog**. Debug logs can be turned on and used to debug rules or report bugs.
## Alerts
Email alerts are kind of old-fashioned now, but if you use **syslog-ng** for collecting your log messages, your **sudo** log messages are automatically parsed. You can easily create custom alerts and send those to a wide variety of destinations, including Slack, Telegram, Splunk, or Elasticsearch. You can learn more about this feature from [my blog on syslong-ng.com](https://www.syslog-ng.com/community/b/blog/posts/alerting-on-sudo-events-using-syslog-ng).
## Configuration
We talked a lot about **sudo** features and even saw a few lines of configuration. Now, let’s take a closer look at how **sudo** is configured. The configuration itself is available in **/etc/sudoers**, which is a simple text file. Still, it is not recommended to edit this file directly. Instead, use **visudo**, as this tool also does syntax checking. If you do not like **vi**, you can change which editor to use by pointing the **EDITOR** environment variable at your preferred option.
Before you start editing the **sudo** configuration, make sure that you know the root password. (Yes, even on Ubuntu, where root does not have a password by default.) While **visudo** checks the syntax, it is easy to create a syntactically correct configuration that locks you out of your system.
When you have a root password at hand in case of an emergency, you can start editing your configuration. When it comes to the **sudoers** file, there is one important thing to remember: This file is read from top to bottom, and the last setting wins. What this fact means for you is that you should start with generic settings and place exceptions at the end, otherwise exceptions are overridden by the generic settings.
You can find a simple **sudoers** file below, based on the one in CentOS, and add a few lines we discussed previously:
```
Defaults !visiblepw
Defaults always_set_home
Defaults match_group_by_gid
Defaults always_query_group_plugin
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Defaults:%wheel insults
Defaults !insults
Defaults log_output
```
This file starts by changing a number of defaults. Then come the usual default rules: The **root** user and members of the **wheel** group have full permissions over the machine. Next, we enable insults for the **wheel** group, but disable them for everyone else. The last line enables session recording.
The above configuration is syntactically correct, but can you spot the logical error? Yes, there is one: Insults are disabled for everyone since the last, generic setting overrides the previous, more specific setting. Once you switch the two lines, the setup works as expected: Members of the **wheel** group receive funny messages, but the rest of the users do not receive them.
## Configuration management
Once you have to maintain the **sudoers** file on multiple machines, you will most likely want to manage your configuration centrally. There are two major open source possibilities here. Both have their advantages and drawbacks.
You can use one of the configuration management applications that you also use to configure the rest of your infrastructure. Red Hat Ansible, Puppet, and Chef all have modules to configure **sudo**. The problem with this approach is that updating configurations is far from real-time. Also, users can still edit the **sudoers** file locally and change settings.
The **sudo** tool can also store its configuration in LDAP. In this case, configuration changes are real-time and users cannot mess with the **sudoers** file. On the other hand, this method also has limitations. For example, you cannot use aliases or use **sudo** when the LDAP server is unavailable.
## New features
There is a new version of **sudo** right around the corner. Version 1.9 will include many interesting new features. Here are the most important planned features:
- A recording service to collect session recordings centrally, which offers many advantages compared to local storage:
- It is more convenient to search in one place.
- Recordings are available even if the sender machine is down.
- Recordings cannot be deleted by someone who wants to delete their tracks.
- The
**audit**plugin does not add new features to**sudoers**, but instead provides an API for plugins to easily access any kind of**sudo**logs. This plugin enables creating custom logs from**sudo**events using plugins. - The
**approval**plugin enables session approvals without using third-party plugins. - And my personal favorite: Python support for plugins, which enables you to easily extend
**sudo**using Python code instead of coding natively in C.
## Conclusion
I hope this article proved to you that **sudo** is a lot more than just a simple prefix. There are tons of possibilities to fine-tune permissions on your system. You cannot just fine-tune permissions, but also improve security by checking digests. Session recordings enable you to check what is happening on your systems. You can also extend the functionality of **sudo** using plugins, either using something already available or writing your own. Finally, given the list of upcoming features you can see that even if **sudo** is decades old, it is a living project that is constantly evolving.
If you want to learn more about **sudo**, here are a few resources:
## 1 Comment |
11,597 | 如何在 CentOS 8 上安装和配置 Postfix 邮件服务器 | https://www.linuxtechi.com/install-configure-postfix-mailserver-centos-8/ | 2019-11-21T07:28:53 | [
"Postfix",
"邮件"
] | https://linux.cn/article-11597-1.html | Postfix 是一个自由开源的 MTA(邮件传输代理),用于在 Linux 系统上路由或传递电子邮件。在本指南中,你将学习如何在 CentOS 8 上安装和配置 Postfix。

实验室设置:
* 系统:CentOS 8 服务器
* IP 地址:192.168.1.13
* 主机名:server1.crazytechgeek.info(确保域名指向服务器的 IP)
### 步骤 1)更新系统
第一步是确保系统软件包是最新的。为此,请按如下所示更新系统:
```
# dnf update
```
继续之前,还请确保不存在其他 MTA(如 Sendmail),因为这将导致与 Postfix 配置冲突。例如,要删除 Sendmail,请运行以下命令:
```
# dnf remove sendmail
```
### 步骤 2)设置主机名并更新 /etc/hosts
使用下面的 `hostnamectl` 命令在系统上设置主机名:
```
# hostnamectl set-hostname server1.crazytechgeek.info
# exec bash
```
此外,你需要在 `/etc/hosts` 中添加系统的主机名和 IP:
```
# vim /etc/hosts
192.168.1.13 server1.crazytechgeek.info
```
保存并退出文件。
### 步骤 3)安装 Postfix 邮件服务器
验证系统上没有其他 MTA 在运行后,运行以下命令安装 Postfix:
```
# dnf install postfix
```

### 步骤 4)启动并启用 Postfix 服务
成功安装 Postfix 后,运行以下命令启动并启用 Postfix 服务:
```
# systemctl start postfix
# systemctl enable postfix
```
要检查 Postfix 状态,请运行以下 `systemctl` 命令:
```
# systemctl status postfix
```

太好了,我们已经验证了 Postfix 已启动并正在运行。接下来,我们将配置 Postfix 从本地发送邮件到我们的服务器。
### 步骤 5)安装 mailx 邮件客户端
在配置 Postfix 服务器之前,我们需要安装 `mailx`,要安装它,请运行以下命令:
```
# dnf install mailx
```

### 步骤 6)配置 Postfix 邮件服务器
Postfix 的配置文件位于 `/etc/postfix/main.cf` 中。我们需要对配置文件进行一些修改,因此请使用你喜欢的文本编辑器将其打开:
```
# vi /etc/postfix/main.cf
```
更改以下几行:
```
myhostname = server1.crazytechgeek.info
mydomain = crazytechgeek.info
myorigin = $mydomain
## 取消注释并将 inet_interfaces 设置为 all##
inet_interfaces = all
## 更改为 all ##
inet_protocols = all
## 注释 ##
#mydestination = $myhostname, localhost.$mydomain, localhost
## 取消注释 ##
mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain
## 取消注释并添加 IP 范围 ##
mynetworks = 192.168.1.0/24, 127.0.0.0/8
## 取消注释 ##
home_mailbox = Maildir/
```
完成后,保存并退出配置文件。重新启动 postfix 服务以使更改生效:
```
# systemctl restart postfix
```
### 步骤 7)测试 Postfix 邮件服务器
测试我们的配置是否有效,首先,创建一个测试用户。
```
# useradd postfixuser
# passwd postfixuser
```
接下来,运行以下命令,从本地用户 `pkumar` 发送邮件到另一个用户 `postfixuser`。
```
# telnet localhost smtp
或者
# telnet localhost 25
```
如果未安装 telnet 服务,那么可以使用以下命令进行安装:
```
# dnf install telnet -y
```
如前所述运行命令时,应获得如下输出:
```
[root@linuxtechi ~]# telnet localhost 25
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
220 server1.crazytechgeek.info ESMTP Postfix
```
上面的结果确认与 postfix 邮件服务器的连接正常。接下来,输入命令:
```
# ehlo localhost
```
输出看上去像这样:
```
250-server1.crazytechgeek.info
250-PIPELINING
250-SIZE 10240000
250-VRFY
250-ETRN
250-STARTTLS
250-ENHANCEDSTATUSCODES
250-8BITMIME
250-DSN
250 SMTPUTF8
```
接下来,运行橙色高亮的命令,例如 `mail from`、`rcpt to`、`data`,最后输入 `quit`:
```
mail from:<pkumar>
250 2.1.0 Ok
rcpt to:<postfixuser>
250 2.1.5 Ok
data
354 End data with <CR><LF>.<CR><LF>
Hello, Welcome to my mailserver (Postfix)
.
250 2.0.0 Ok: queued as B56BF1189BEC
quit
221 2.0.0 Bye
Connection closed by foreign host
```
完成 `telnet` 命令可从本地用户 `pkumar` 发送邮件到另一个本地用户 `postfixuser`,如下所示:

如果一切都按计划进行,那么你应该可以在新用户的家目录中查看发送的邮件:
```
# ls /home/postfixuser/Maildir/new
1573580091.Vfd02I20050b8M635437.server1.crazytechgeek.info
#
```
要阅读邮件,只需使用 cat 命令,如下所示:
```
# cat /home/postfixuser/Maildir/new/1573580091.Vfd02I20050b8M635437.server1.crazytechgeek.info
```

### Postfix 邮件服务器日志
Postfix 邮件服务器邮件日志保存在文件 `/var/log/maillog` 中,使用以下命令查看实时日志,
```
# tail -f /var/log/maillog
```

### 保护 Postfix 邮件服务器
建议始终确保客户端和 Postfix 服务器之间的通信安全,这可以使用 SSL 证书来实现,它们可以来自受信任的权威机构或自签名证书。在本教程中,我们将使用 `openssl` 命令生成用于 Postfix 的自签名证书,
我假设 `openssl` 已经安装在你的系统上,如果未安装,请使用以下 `dnf` 命令:
```
# dnf install openssl -y
```
使用下面的 `openssl` 命令生成私钥和 CSR(证书签名请求):
```
# openssl req -nodes -newkey rsa:2048 -keyout mail.key -out mail.csr
```

现在,使用以下 openssl 命令生成自签名证书:
```
# openssl x509 -req -days 365 -in mail.csr -signkey mail.key -out mail.crt
Signature ok
subject=C = IN, ST = New Delhi, L = New Delhi, O = IT, OU = IT, CN = server1.crazytechgeek.info, emailAddress = root@linuxtechi
Getting Private key
#
```
现在将私钥和证书文件复制到 `/etc/postfix` 目录下:
```
# cp mail.key mail.crt /etc/postfix
```
在 Postfix 配置文件中更新私钥和证书文件的路径:
```
# vi /etc/postfix/main.cf
………
smtpd_use_tls = yes
smtpd_tls_cert_file = /etc/postfix/mail.crt
smtpd_tls_key_file = /etc/postfix/mail.key
smtpd_tls_security_level = may
………
```
重启 Postfix 服务以使上述更改生效:
```
# systemctl restart postfix
```
让我们尝试使用 `mailx` 客户端将邮件发送到内部本地域和外部域。
从 `pkumar` 发送内部本地邮件到 `postfixuser` 中:
```
# echo "test email" | mailx -s "Test email from Postfix MailServer" -r root@linuxtechi root@linuxtechi
```
使用以下命令检查并阅读邮件:
```
# cd /home/postfixuser/Maildir/new/
# ll
total 8
-rw-------. 1 postfixuser postfixuser 476 Nov 12 17:34 1573580091.Vfd02I20050b8M635437.server1.crazytechgeek.info
-rw-------. 1 postfixuser postfixuser 612 Nov 13 02:40 1573612845.Vfd02I20050bbM466643.server1.crazytechgeek.info
# cat 1573612845.Vfd02I20050bbM466643.server1.crazytechgeek.info
```

从 `postfixuser` 发送邮件到外部域(`[email protected]`):
```
# echo "External Test email" | mailx -s "Postfix MailServer" -r root@linuxtechi root@linuxtechi
```
注意:如果你的 IP 没有被任何地方列入黑名单,那么你发送到外部域的邮件将被发送,否则它将被退回,并提示你的 IP 被 spamhaus 之类的数据库列入黑名单。
### 检查 Postfix 邮件队列
使用 `mailq` 命令列出队列中的邮件:
```
# mailq
Mail queue is empty
#
```
完成!我们的 Postfix 配置正常工作了!目前就这样了。我们希望你觉得本教程有见地,并且你可以轻松地设置本地 Postfix 服务器。
---
via: <https://www.linuxtechi.com/install-configure-postfix-mailserver-centos-8/>
作者:[James Kiarie](https://www.linuxtechi.com/author/james/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Postfix** is a free and opensource **MTA** (Mail Transfer Agent) used for routing or delivering emails on a Linux system. In this guide, you will learn how to install and configure Postfix on CentOS 8.
Lab set up:
- OS : CentOS 8 server
- IP Address : 192.168.1.13
- Hostname: server1.crazytechgeek.info (Ensure the domain name is pointed to the server’s IP)
#### Step 1) Update the system
The first step is to ensure that the system packages are up to date. To do so, update the system as follows:
# dnf update
Before proceeding further, also ensure that no other **MTAs** such as **Sendmail** are existing as this will cause conflict with Postfix configuration. To remove Sendmail, for example, run the command:
# dnf remove sendmail
#### Step 2) Set Hostname and update /etc/hosts file
Use below hostnamectl command to set the hostname on your system,
# hostnamectl set-hostname server1.crazytechgeek.info # exec bash
Additionally, you need to add the system’s hostname and IP entries in the /etc/hosts file
# vim /etc/hosts 192.168.1.13 server1.crazytechgeek.info
Save and exit the file.
**Read Also **: [How to Setup DNS Server (Bind) on CentOS 8 / RHEL8](https://www.linuxtechi.com/setup-bind-server-centos-8-rhel-8/)
#### Step 3) Install Postfix Mail Server
After verifying that no other MTA is running on the system install Postfix by executing the command:
# dnf install postfix
#### Step 4) Start and enable Postfix Service
Upon successful installation of Postfix, start and enable Postfix service by running:
# systemctl start postfix # systemctl enable postfix
To check Postfix status, run the following systemctl command
# systemctl status postfix
Great, we have verified that Postfix is up and running. Next, we are going to configure Postfix to send emails locally to our server.
#### Step 5) Install mailx email client
Before configuring the Postfix server, we need to install mailx feature, To install mailx, run the command:
# dnf install mailx
#### Step 6) Configure Postfix Mail Server
Postfix’s configuration file is located in **/etc/postfix/main.cf**. We need to make a few changes in the configuration file, so open it using your favorite text editor.
# vi /etc/postfix/main.cf
Make changes to the following lines:
myhostname = server1.crazytechgeek.info mydomain = crazytechgeek.info myorigin = $mydomain ## Uncomment and Set inet_interfaces to all ## inet_interfaces = all ## Change to all ## inet_protocols = all ## Comment ## #mydestination = $myhostname, localhost.$mydomain, localhost ##- Uncomment ## mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain ## Uncomment and add IP range ## mynetworks = 192.168.1.0/24, 127.0.0.0/8 ## Uncomment ## home_mailbox = Maildir/
Once done, save and exit the configuration file. Restart postfix service for the changes to take effect
# systemctl restart postfix
#### Step 7) Testing Postfix Mail Server
Test whether our configuration is working, first, create a test user
# useradd postfixuser # passwd postfixuser
Next, run the command below to send email from **pkumar** local user to another user ‘**postfixuser**‘
# telnet localhost smtp or # telnet localhost 25
If telnet service is not installed, you can install it using the command:
# dnf install telnet -y
When you run the command as earlier indicated, you should get the output as shown
[root@server1 ~]# telnet localhost 25 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. 220 server1.crazytechgeek.info ESMTP Postfix
Above confirm that connectivity to postfix mail server is working fine. Next, type the command:
# ehlo localhost
Output will be something like this
250-server1.crazytechgeek.info 250-PIPELINING 250-SIZE 10240000 250-VRFY 250-ETRN 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-8BITMIME 250-DSN 250 SMTPUTF8
Next, run the commands highlighted in orange, like “mail from”, “rcpt to”, data and then finally type quit,
mail from:<pkumar> 250 2.1.0 Ok rcpt to:<postfixuser> 250 2.1.5 Ok data 354 End data with <CR><LF>.<CR><LF> Hello, Welcome to my mailserver (Postfix) . 250 2.0.0 Ok: queued as B56BF1189BEC quit 221 2.0.0 Bye Connection closed by foreign host
Complete telnet command to send email from local user “**pkumar**” to another local user “**postfixuser**” would be something like below
If everything went according to plan, you should be able to view the email sent at the new user’s home directory.
# ls /home/postfixuser/Maildir/new 1573580091.Vfd02I20050b8M635437.server1.crazytechgeek.info #
To read the email, simply use the cat command as follows:
# cat /home/postfixuser/Maildir/new/1573580091.Vfd02I20050b8M635437.server1.crazytechgeek.info
#### Postfix mail server logs
Postfix mail server mail logs are stored in the file “**/var/log/maillog**“, use below command to view the live logs,
# tail -f /var/log/maillog
#### Securing Postfix Mail Server
It is always recommended secure the communication of between clients and postfix server, this can be achieved using SSL certificates, these certificates can be either from trusted authority or Self Signed Certificates. In this tutorial we will generate Self Signed certificated for postfix using **openssl** command,
I am assuming openssl is already installed on your system, in case it is not installed then use following dnf command,
# dnf install openssl -y
Generate Private key and CSR (Certificate Signing Request) using beneath openssl command,
# openssl req -nodes -newkey rsa:2048 -keyout mail.key -out mail.csr
Now Generate Self signed certificate using following openssl command,
# openssl x509 -req -days 365 -in mail.csr -signkey mail.key -out mail.crt Signature ok subject=C = IN, ST = New Delhi, L = New Delhi, O = IT, OU = IT, CN = server1.crazytechgeek.info, emailAddress =[[email protected]]Getting Private key #
Now copy private key and certificate file to /etc/postfix directory
# cp mail.key mail.crt /etc/postfix
Update Private key and Certificate file’s path in postfix configuration file,
# vi /etc/postfix/main.cf ……… smtpd_use_tls = yes smtpd_tls_cert_file = /etc/postfix/mail.crt smtpd_tls_key_file = /etc/postfix/mail.key smtpd_tls_security_level = may ………
Restart postfix service to make above changes into the effect.
# systemctl restart postfix
Let’s try to send email to internal local domain and external domain using mailx client.
**Sending local internal email from pkumar user to postfixuser**
# echo "test email" | mailx -s "Test email from Postfix MailServer" -r[[email protected]][[email protected]]
Check and read the email using the following,
# cd /home/postfixuser/Maildir/new/ # ll total 8 -rw-------. 1 postfixuser postfixuser 476 Nov 12 17:34 1573580091.Vfd02I20050b8M635437.server1.crazytechgeek.info -rw-------. 1 postfixuser postfixuser 612 Nov 13 02:40 1573612845.Vfd02I20050bbM466643.server1.crazytechgeek.info # cat 1573612845.Vfd02I20050bbM466643.server1.crazytechgeek.info
**Sending email from postfixuser to external domain ( [email protected])**
# echo "External Test email" | mailx -s "Postfix MailServer" -r[[email protected]][[email protected]]
**Note:** If Your IP is not blacklisted anywhere then your email to external domain will be delivered otherwise it will be bounced saying that IP is blacklisted in so and so spamhaus database.
#### Check Postfix mail queue
Use mailq command to list mails which are in queue.
# mailq Mail queue is empty #
And that’s it! Our Postfix configuration is working! That’s all for now. We hope you found this tutorial insightful and that you can comfortably set up your local Postfix server.
**Read Also**: [How to Install and Configure Samba on CentOS 8](https://www.linuxtechi.com/install-configure-samba-centos-8/)
**Read Also** : [How to Install Zimbra Mail Server on CentOS 8 / RHEL 8](https://www.linuxtechi.com/install-zimbra-mail-server-centos-8-rhel-8/)
BernardoHello, the local mail sending/receiving works all right for me, but when I try to send a message to my gmail account it bounces back, without saying much (like it would in the case you pointed out of blocked IPs).
If could please check out the log file and maybe point out what could be wrong from it I would greatly appreciate it!
Here is the log output:
‘https://pastebin.com/kshmHbVc’
Note: I’ve changed some usernames/domain names for privacy reasons
Pradeep KumarBy looking at the logs, it seems like issue with hostname of your mailserver. Did u update the hostname in /etc/hosts file and /etc/postfix/main.cf.
BrianThanks for your instruction.
I have received email in my Gmail, however, when I tried to reply, nothing came to my inbox. Can you give me some advice?
Pradeep KumarYou need to add MX record for your domain in DNS server to start receiving the emails from outside like Gmail, Yahoo etc
Kenny MaCould we connect to mail server with outlook after adding MX record?
Anything we need to do in server?
Pradeep KumarYes, You can configure your email id in outlook after adding MX record. MX record will route the emails from outside world to your mail server (postfix). For Sending emails locally & to outside world doesn’t need MX record.
AnindyaHi,
Thank you for this tutorial.
I am able to send email to my own domain’s email addresses but unable to send email to any other domain.
Can you please help me on this?
Thanks,
Anindya
Van TranBy default, Postfix uses port 25 for SMTP. For the sake of avoiding abuse for bad mail, most VPS service providers block this port. You can try the
`command telnet gmail-smtp-in.l.google.com 25`
, if you get a response likeTrying 74.125.68.26...
Connected to gmail-smtp-in.l.google.com.
Escape character is '^]'.
220 mx.google.com ESMTP m6si752389plx.46 - gsmtp
then you can use port 25 to send mail to external servers. Otherwise, you need to contact your service provider to ask them to open port 25. or configure Postfix to use a different port. |
11,598 | 在 Ubuntu 19.10 上入门 ZFS 文件系统 | https://itsfoss.com/zfs-ubuntu/ | 2019-11-21T08:16:06 | [
"ZFS"
] | https://linux.cn/article-11598-1.html | 
Ubuntu 19.10 的主要新特性之一就是 [ZFS](/article-10034-1.html)。现在你可以很容易的无需额外努力就可以在 Ubuntu 系统上安装 ZFS了。
一般情况下,安装 Linux 都会选择 Ext4 文件系统。但是如果是全新安装 Ubuntu 19.10,在安装的启动阶段可以看到 ZFS 选项。

让我们看看 ZFS 为何重要,以及如何在已经安装了 ZFS 的 Ubuntu 上使用它。
### ZFS 与其他文件系统有哪些区别?
ZFS 的设计初衷是:处理海量存储和避免数据损坏。ZFS 可以处理 256 千万亿的 ZB 数据。(这就是 ZFS 的 Z)且它可以处理最大 16 EB 的文件。
如果你仅有一个单磁盘的笔记本电脑,你可以体验 ZFS 的数据保护特性。写时复制(COW)特性确保正在使用的数据不会被覆盖,相反,新的数据会被写到一个新的块中,同时文件系统的元数据会被更新到新块中。ZFS 可容易的创建文件系统的快照。这个快照可追踪文件系统的更改,并共享数据块确保节省数据空间。
ZFS 为磁盘上的每个文件分配一个校验和。它会不断的校验文件的状态和校验和。如果发现文件被损坏了,它就会尝试修复文件。
我写过一个文章详细介绍 [什么是 ZFS以及它有哪些特性](/article-10034-1.html)。如果你感兴趣可以去阅读下。
注:请谨记 ZFS 的数据保护特性会导致性能下降。
### Ubuntu 下使用 ZFS [适用于中高级用户]
一旦你在你的主磁盘上全新安装了带有 ZFS 的 Ubuntu,你就可以开始体验它的特性。
请注意所有的 ZFS 设置过程都需要命令行。我不知道它有任何 GUI 工具。
#### 创建一个 ZFS 池
**这段仅针对拥有多个磁盘的系统。如果你只有一个磁盘,Ubuntu 会在安装的时候自动创建池。**
在创建池之前,你需要为池找到磁盘的 id。你可以用命令 `lsblk` 查询出这个信息。
为三个磁盘创建一个基础池,用以下命令:
```
sudo zpool create pool-test /dev/sdb /dev/sdc /dev/sdd
```
请记得替换 `pool-test` 为你选择的的命名。
这个命令将会设置“无冗余 RAID-0 池”。这意味着如果一个磁盘被破坏或有故障,你将会丢失数据。如果你执行以上命令,还是建议做一个常规备份。
你可以用下面命令将另一个磁盘增加到池中:
```
sudo zpool add pool-name /dev/sdx
```
#### 查看 ZFS 池的状态
你可以用这个命令查询新建池的状态:
```
sudo zpool status pool-test
```

#### 镜像一个 ZFS 池
为确保数据的安全性,你可以创建镜像。镜像意味着每个磁盘包含同样的数据。使用镜像设置,你可能会丢失三个磁盘中的两个,并且仍然拥有所有信息。
要创建镜像你可以用下面命令:
```
sudo zpool create pool-test mirror /dev/sdb /dev/sdc /dev/sdd
```
#### 创建 ZFS 用于备份恢复的快照
快照允许你创建一个后备,以防某个文件被删除或被覆盖。比如,我们创建一个快照,当在用户主目录下删除一些目录后,然后把它恢复。
首先,你需要找到你想要的快照数据集。你可以这样做:
```
zfs list
```

你可以看到我的家目录位于 `rpool/USERDATA/johnblood_uwcjk7`。
我们用下面命令创建一个名叫 `1910` 的快照:
```
sudo zfs snapshot rpool/USERDATA/johnblood_uwcjk7@1019
```
快照很快创建完成。现在你可以删除 `Downloads` 和 `Documents` 目录。
现在你用以下命令恢复快照:
```
sudo zfs rollback rpool/USERDATA/johnblood_uwcjk7@1019
```
回滚的时间长短取决于有多少信息改变。现在你可以查看家目录,被删除的目录(和它的内容)将会被恢复过来。
### 要不要试试 ZFS ?
这篇文章仅简单介绍的 Ubuntu下 ZFS 的用法。更多的信息请参考 [Ubuntu 的 ZFS Wiki页面](https://wiki.ubuntu.com/Kernel/Reference/ZFS)。我也推荐阅读 [ArsTechnica 的精彩文章](https://arstechnica.com/information-technology/2019/10/a-detailed-look-at-ubuntus-new-experimental-zfs-installer/)。
这个是试验性的功能。如果你还不了解 ZFS,你想用一个简单稳定的系统,请安装标准文件系统 EXT4。如果你想用闲置的机器体验,可以参照上面了解 ZFS。如果你是一个“专家”,并且知道自己在做什么,则可以随时随地随意尝试ZFS。
你之前用过 ZFS 吗?请在下面留言。
---
via: <https://itsfoss.com/zfs-ubuntu/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[guevaraya](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
know in the comments below. If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](https://reddit.com/r/linuxusersgroup).
---
via: <https://itsfoss.com/zfs-ubuntu/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the main [features of Ubuntu 19.10](https://itsfoss.com/ubuntu-19-04-release-features/) is support for [ZFS](https://itsfoss.com/what-is-zfs/). Now you can easily install Ubuntu with on ZFS without any extra effort.
Normally, you install Linux with Ext4 filesystem. But if you do a fresh install of Ubuntu 19.10, you’ll see the option to use ZFS on the root. You must not use it on a dual boot system though because it will erase the entire disk.
Let’s see why ZFS matters and how to take advantage of it on ZFS install of Ubuntu.
## How ZFS is different than other filesystems?
ZFS is designed with two major goals in mind: to handle large amounts of storage and prevent data corruption. ZFS can handle up to 256 quadrillion Zettabytes of storage. (Hence the Z in ZFS.) It can also handle files up to 16 exabytes in size.
If you are limited to a single drive laptop, you can still take advantage of the data protection features in ZFS. The copy-on-write feature ensures that data that is in use is not overwritten. Instead, the new information is written to a new block and the filesystem’s metadata is updated to point to the new block. ZFS can easily create snapshots of the filesystem. These snapshots track changes made to the filesystem and share with the filesystem the data that is the same to save space.
ZFS assigned a checksum to each file on the drive. It is constantly checking the state of the file against that checksum. If it detects that the file has become corrupt, it will attempt to automatically repair that file.
I have written a detailed article about [what is ZFS and what its features are](https://itsfoss.com/what-is-zfs/). Please read it if you are interested in knowing more on this topic.
Note
Keep in mind that the data protection features of ZFS can lead to a reduction in performance.
## Using ZFS on Ubuntu [For intermediate to advanced users]

Once you have a clean install of Ubuntu with ZFS on the main disk you can start [taking advantage](https://wiki.ubuntu.com/Kernel/Reference/ZFS) of the features that this filesystem has.
Please note that all setup of ZFS requires the command line. I am not aware of any GUI tools for it.
### Creating a ZFS pool
**The section only applies if you have a system with more than one drive. If you only have one drive, Ubuntu will automatically create the pool during installation.**
Before you create your pool, you need to find out the id of the drives for the pool. You can use the command ** lsblk** to show this information.
To create a basic pool with three drives, use the following command:
` sudo zpool create pool-test /dev/sdb /dev/sdc /dev/sdd. `
Remember to replace ** pool-test** with the pool name of your choice.
This command will set up “a zero redundancy RAID-0 pool”. This means that if one of the drives becomes damaged or corrupt, you will lose data. If you do use this setup, it is recommended that you do regular backups.
You can alos add another disk to the pool by using this command:
`sudo zpool add pool-name /dev/sdx`
### Check the status of your ZFS pool
You can check the status of your new pool using this command:
` sudo zpool status pool-test `
### Mirror a ZFS pool
To ensure that your data is safe, you can instead set up mirroring. Mirroring means that each drive contains the same data. With mirroring setup, you could lose two out of three drives and still have all of your information.
To create a mirror, you can use something like this:
`sudo zpool create pool-test mirror /dev/sdb /dev/sdc /dev/sdd`
### Create ZFS Snapshots for backup and restore
Snapshots allow you to create a fall-back position in case a file gets deleted or overwritten. For example, let’s create a snapshot, delete some folder in my home directory and restore them.
First, you need to find the dataset you want to snapshot. You can do that with the
` zfs list`
You can see that my home folder is located in **rpool/USERDATA/johnblood_uwcjk7**.
Let’s create a snapshot named **1910** using this command:
`sudo zfs snapshot rpool/USERDATA/johnblood_uwcjk7@1019`
The snapshot will be created very quickly. Now, I am going to delete the *Downloads* and *Documents* directories.
Now to restore the snapshot, all you have to do is run this command:
`sudo zfs rollback rpool/USERDATA/johnblood_uwcjk7@1019. `
The length of the rollback depends on how much the information changed. Now, you can check the home folder and the deleted folders (and their content) will be returned to their correct place.
## To ZFS or not?
This is just a quick glimpse at what you can do with ZFS on Ubuntu. For more information, check out [Ubuntu’s wiki page on ZFS.](https://wiki.ubuntu.com/Kernel/Reference/ZFS) I also recommend reading this [excellent article on ArsTechnica](https://arstechnica.com/information-technology/2019/10/a-detailed-look-at-ubuntus-new-experimental-zfs-installer/).
This is an experimental feature and if you are not aware of ZFS and you want to have a simple stable system, please go with the standard install on Ext4. If you have a spare machine that you want to experiment with, then only try something like this to learn a thing or two about ZFS. If you are an ‘expert’ and you know what you are doing, you are free to experiment ZFS wherever you like.
At this time the implementation of ZFS in Ubuntu 19.10 is experimental because of the way the disk is laid out may change in the [Ubuntu 20.04 release](https://itsfoss.com/ubuntu-20-04-release-features/). They are not guaranteeing that you will be able to upgrade if you have ZFS installed.
According to the [Ubuntu podcast](https://ubuntupodcast.org/2019/10/24/s12e29-doom/), the Ubuntu desktop team is working on a tool named [zsys](https://github.com/ubuntu/zsys). It will hook into apt and grub. As you upgrade your system, zsys will take snapshots so you can boot into a previous snapshot if the upgrade fails. It will arrive in the 20.04 release.
Have you ever used ZFS? Please let us know in the comments below. If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
11,600 | 如何使用 Protobuf 做数据交换 | https://opensource.com/article/19/10/protobuf-data-interchange | 2019-11-22T07:59:06 | [
"Protobuf",
"JSON",
"XML"
] | https://linux.cn/article-11600-1.html |
>
> 在以不同语言编写并在不同平台上运行的应用程序之间交换数据时,Protobuf 编码可提高效率。
>
>
>

<ruby> 协议缓冲区 <rt> Protocol Buffers </rt></ruby>([Protobufs](https://developers.google.com/protocol-buffers/))像 XML 和 JSON 一样,可以让用不同语言编写并在不同平台上运行的应用程序交换数据。例如,用 Go 编写的发送程序可以在 Protobuf 中对以 Go 表示的销售订单数据进行编码,然后用 Java 编写的接收方可以对它进行解码,以获取所接收订单数据的 Java 表示方式。这是在网络连接上的结构示意图:
>
> Go 销售订单 —> Pbuf 编码 —> 网络 —> Pbuf 界面 —> Java 销售订单
>
>
>
与 XML 和 JSON 相比,Protobuf 编码是二进制而不是文本,这会使调试复杂化。但是,正如本文中的代码示例所确认的那样,Protobuf 编码在大小上比 XML 或 JSON 编码要有效得多。
Protobuf 以另一种方式提供了这种有效性。在实现级别,Protobuf 和其他编码系统对结构化数据进行<ruby> 序列化 <rt> serialize </rt></ruby>和<ruby> 反序列化 <rt> deserialize </rt></ruby>。序列化将特定语言的数据结构转换为字节流,反序列化是将字节流转换回特定语言的数据结构的逆运算。序列化和反序列化可能成为数据交换的瓶颈,因为这些操作会占用大量 CPU。高效的序列化和反序列化是 Protobuf 的另一个设计目标。
最近的编码技术,例如 Protobuf 和 FlatBuffers,源自 1990 年代初期的 [DCE/RPC](https://en.wikipedia.org/wiki/DCE/RPC)(<ruby> 分布式计算环境/远程过程调用 <rt> Distributed Computing Environment/Remote Procedure Call </rt></ruby>)计划。与 DCE/RPC 一样,Protobuf 在数据交换中为 [IDL](https://en.wikipedia.org/wiki/Interface_description_language)(接口定义语言)和编码层做出了贡献。
本文将着眼于这两层,然后提供 Go 和 Java 中的代码示例以充实 Protobuf 的细节,并表明 Protobuf 是易于使用的。
### Protobuf 作为一个 IDL 和编码层
像 Protobuf 一样,DCE/RPC 被设计为与语言和平台无关。适当的库和实用程序允许任何语言和平台用于 DCE/RPC 领域。此外,DCE/RPC 体系结构非常优雅。IDL 文档是一侧的远程过程与另一侧的调用者之间的协定。Protobuf 也是以 IDL 文档为中心的。
IDL 文档是文本,在 DCE/RPC 中,使用基本 C 语法以及元数据的语法扩展(方括号)和一些新的关键字,例如 `interface`。这是一个例子:
```
[uuid (2d6ead46-05e3-11ca-7dd1-426909beabcd), version(1.0)]
interface echo {
const long int ECHO_SIZE = 512;
void echo(
[in] handle_t h,
[in, string] idl_char from_client[ ],
[out, string] idl_char from_service[ECHO_SIZE]
);
}
```
该 IDL 文档声明了一个名为 `echo` 的过程,该过程带有三个参数:类型为 `handle_t`(实现指针)和 `idl_char`(ASCII 字符数组)的 `[in]` 参数被传递给远程过程,而 `[out]` 参数(也是一个字符串)从该过程中传回。在此示例中,`echo` 过程不会显式返回值(`echo` 左侧的 `void`),但也可以返回值。返回值,以及一个或多个 `[out]` 参数,允许远程过程任意返回许多值。下一节将介绍 Protobuf IDL,它的语法不同,但同样用作数据交换中的协定。
DCE/RPC 和 Protobuf 中的 IDL 文档是创建用于交换数据的基础结构代码的实用程序的输入:
>
> IDL 文档 —> DCE/PRC 或 Protobuf 实用程序 —> 数据交换的支持代码
>
>
>
作为相对简单的文本,IDL 是同样便于人类阅读的关于数据交换细节的文档(特别是交换的数据项的数量和每个项的数据类型)。
Protobuf 可用于现代 RPC 系统,例如 [gRPC](https://grpc.io/);但是 Protobuf 本身仅提供 IDL 层和编码层,用于从发送者传递到接收者的消息。与原本的 DCE/RPC 一样,Protobuf 编码是二进制的,但效率更高。
目前,XML 和 JSON 编码仍在通过 Web 服务等技术进行的数据交换中占主导地位,这些技术利用 Web 服务器、传输协议(例如 TCP、HTTP)以及标准库和实用程序等原有的基础设施来处理 XML 和 JSON 文档。 此外,各种类型的数据库系统可以存储 XML 和 JSON 文档,甚至旧式关系型系统也可以轻松生成查询结果的 XML 编码。现在,每种通用编程语言都具有支持 XML 和 JSON 的库。那么,是什么让我们回到 Protobuf 之类的**二进制**编码系统呢?
让我们看一下负十进制值 `-128`。以 2 的补码二进制表示形式(在系统和语言中占主导地位)中,此值可以存储在单个 8 位字节中:`10000000`。此整数值在 XML 或 JSON 中的文本编码需要多个字节。例如,UTF-8 编码需要四个字节的字符串,即 `-128`,即每个字符一个字节(十六进制,值为 `0x2d`、`0x31`、`0x32` 和 `0x38`)。XML 和 JSON 还添加了标记字符,例如尖括号和大括号。有关 Protobuf 编码的详细信息下面就会介绍,但现在的关注点是一个通用点:文本编码的压缩性明显低于二进制编码。
### 在 Go 中使用 Protobuf 的示例
我的代码示例着重于 Protobuf 而不是 RPC。以下是第一个示例的概述:
* 名为 `dataitem.proto` 的 IDL 文件定义了一个 Protobuf 消息,它具有六个不同类型的字段:具有不同范围的整数值、固定大小的浮点值以及两个不同长度的字符串。
* Protobuf 编译器使用 IDL 文件生成 Go 版本(以及后面的 Java 版本)的 Protobuf 消息及支持函数。
* Go 应用程序使用随机生成的值填充原生的 Go 数据结构,然后将结果序列化为本地文件。为了进行比较, XML 和 JSON 编码也被序列化为本地文件。
* 作为测试,Go 应用程序通过反序列化 Protobuf 文件的内容来重建其原生数据结构的实例。
* 作为语言中立性测试,Java 应用程序还会对 Protobuf 文件的内容进行反序列化以获取原生数据结构的实例。
[我的网站](http://condor.depaul.edu/mkalin)上提供了该 IDL 文件以及两个 Go 和一个 Java 源文件,打包为 ZIP 文件。
最重要的 Protobuf IDL 文档如下所示。该文档存储在文件 `dataitem.proto` 中,并具有常规的`.proto` 扩展名。
#### 示例 1、Protobuf IDL 文档
```
syntax = "proto3";
package main;
message DataItem {
int64 oddA = 1;
int64 evenA = 2;
int32 oddB = 3;
int32 evenB = 4;
float small = 5;
float big = 6;
string short = 7;
string long = 8;
}
```
该 IDL 使用当前的 proto3 而不是较早的 proto2 语法。软件包名称(在本例中为 `main`)是可选的,但是惯例使用它以避免名称冲突。这个结构化的消息包含八个字段,每个字段都有一个 Protobuf 数据类型(例如,`int64`、`string`)、名称(例如,`oddA`、`short`)和一个等号 `=` 之后的数字标签(即键)。标签(在此示例中为 1 到 8)是唯一的整数标识符,用于确定字段序列化的顺序。
Protobuf 消息可以嵌套到任意级别,而一个消息可以是另外一个消息的字段类型。这是一个使用 `DataItem` 消息作为字段类型的示例:
```
message DataItems {
repeated DataItem item = 1;
}
```
单个 `DataItems` 消息由重复的(零个或多个)`DataItem` 消息组成。
为了清晰起见,Protobuf 还支持枚举类型:
```
enum PartnershipStatus {
reserved "FREE", "CONSTRAINED", "OTHER";
}
```
`reserved` 限定符确保用于实现这三个符号名的数值不能重复使用。
为了生成一个或多个声明 Protobuf 消息结构的特定于语言的版本,包含这些结构的 IDL 文件被传递到`protoc` 编译器(可在 [Protobuf GitHub 存储库](https://github.com/protocolbuffers/protobuf)中找到)。对于 Go 代码,可以以通常的方式安装支持的 Protobuf 库(这里以 `%` 作为命令行提示符):
```
% go get github.com/golang/protobuf/proto
```
将 Protobuf IDL 文件 `dataitem.proto` 编译为 Go 源代码的命令是:
```
% protoc --go_out=. dataitem.proto
```
标志 `--go_out` 指示编译器生成 Go 源代码。其他语言也有类似的标志。在这种情况下,结果是一个名为 `dataitem.pb.go` 的文件,该文件足够小,可以将其基本内容复制到 Go 应用程序中。以下是生成的代码的主要部分:
```
var _ = proto.Marshal
type DataItem struct {
OddA int64 `protobuf:"varint,1,opt,name=oddA" json:"oddA,omitempty"`
EvenA int64 `protobuf:"varint,2,opt,name=evenA" json:"evenA,omitempty"`
OddB int32 `protobuf:"varint,3,opt,name=oddB" json:"oddB,omitempty"`
EvenB int32 `protobuf:"varint,4,opt,name=evenB" json:"evenB,omitempty"`
Small float32 `protobuf:"fixed32,5,opt,name=small" json:"small,omitempty"`
Big float32 `protobuf:"fixed32,6,opt,name=big" json:"big,omitempty"`
Short string `protobuf:"bytes,7,opt,name=short" json:"short,omitempty"`
Long string `protobuf:"bytes,8,opt,name=long" json:"long,omitempty"`
}
func (m *DataItem) Reset() { *m = DataItem{} }
func (m *DataItem) String() string { return proto.CompactTextString(m) }
func (*DataItem) ProtoMessage() {}
func init() {}
```
编译器生成的代码具有 Go 结构 `DataItem`,该结构导出 Go 字段(名称现已大写开头),该字段与 Protobuf IDL 中声明的名称匹配。该结构字段具有标准的 Go 数据类型:`int32`、`int64`、`float32` 和 `string`。在每个字段行的末尾,是描述 Protobuf 类型的字符串,提供 Protobuf IDL 文档中的数字标签及有关 JSON 信息的元数据,这将在后面讨论。
此外也有函数;最重要的是 `Proto.Marshal`,用于将 `DataItem` 结构的实例序列化为 Protobuf 格式。辅助函数包括:清除 `DataItem` 结构的 `Reset`,生成 `DataItem` 的单行字符串表示的 `String`。
描述 Protobuf 编码的元数据应在更详细地分析 Go 程序之前进行仔细研究。
### Protobuf 编码
Protobuf 消息的结构为键/值对的集合,其中数字标签为键,相应的字段为值。字段名称(例如,`oddA` 和 `small`)是供人类阅读的,但是 `protoc` 编译器的确使用了字段名称来生成特定于语言的对应名称。例如,Protobuf IDL 中的 `oddA` 和 `small` 名称在 Go 结构中分别成为字段 `OddA` 和 `Small`。
键和它们的值都被编码,但是有一个重要的区别:一些数字值具有固定大小的 32 或 64 位的编码,而其他数字(包括消息标签)则是 `varint` 编码的,位数取决于整数的绝对值。例如,整数值 1 到 15 需要 8 位 `varint` 编码,而值 16 到 2047 需要 16 位。`varint` 编码在本质上与 UTF-8 编码类似(但细节不同),它偏爱较小的整数值而不是较大的整数值。(有关详细分析,请参见 Protobuf [编码指南](https://developers.google.com/protocol-buffers/docs/encoding))结果是,Protobuf 消息应该在字段中具有较小的整数值(如果可能),并且键数应尽可能少,但每个字段至少得有一个键。
下表 1 列出了 Protobuf 编码的要点:
| 编码 | 示例类型 | 长度 |
| --- | --- | --- |
| `varint` | `int32`、`uint32`、`int64` | 可变长度 |
| `fixed` | `fixed32`、`float`、`double` | 固定的 32 位或 64 位长度 |
| 字节序列 | `string`、`bytes` | 序列长度 |
*表 1. Protobuf 数据类型*
未明确固定长度的整数类型是 `varint` 编码的;因此,在 `varint` 类型中,例如 `uint32`(`u` 代表无符号),数字 32 描述了整数的范围(在这种情况下为 0 到 2<sup> 32</sup> - 1),而不是其位的大小,该位大小取决于值。相比之下,对于固定长度类型(例如 `fixed32` 或 `double`),Protobuf 编码分别需要 32 位和 64 位。Protobuf 中的字符串是字节序列;因此,字段编码的大小就是字节序列的长度。
另一个高效的方法值得一提。回想一下前面的示例,其中的 `DataItems` 消息由重复的 `DataItem` 实例组成:
```
message DataItems {
repeated DataItem item = 1;
}
```
`repeated` 表示 `DataItem` 实例是*打包的*:集合具有单个标签,在这里是 1。因此,具有重复的 `DataItem` 实例的 `DataItems` 消息比具有多个但单独的 `DataItem` 字段、每个字段都需要自己的标签的消息的效率更高。
了解了这一背景,让我们回到 Go 程序。
### dataItem 程序的细节
`dataItem` 程序创建一个 `DataItem` 实例,并使用适当类型的随机生成的值填充字段。Go 有一个 `rand` 包,带有用于生成伪随机整数和浮点值的函数,而我的 `randString` 函数可以从字符集中生成指定长度的伪随机字符串。设计目标是要有一个具有不同类型和位大小的字段值的 `DataItem` 实例。例如,`OddA` 和 `EvenA` 值分别是 64 位非负整数值的奇数和偶数;但是 `OddB` 和 `EvenB` 变体的大小为 32 位,并存放 0 到 2047 之间的小整数值。随机浮点值的大小为 32 位,字符串为 16(`Short`)和 32(`Long`)字符的长度。这是用随机值填充 `DataItem` 结构的代码段:
```
// 可变长度整数
n1 := rand.Int63() // 大整数
if (n1 & 1) == 0 { n1++ } // 确保其是奇数
...
n3 := rand.Int31() % UpperBound // 小整数
if (n3 & 1) == 0 { n3++ } // 确保其是奇数
// 固定长度浮点数
...
t1 := rand.Float32()
t2 := rand.Float32()
...
// 字符串
str1 := randString(StrShort)
str2 := randString(StrLong)
// 消息
dataItem := &DataItem {
OddA: n1,
EvenA: n2,
OddB: n3,
EvenB: n4,
Big: f1,
Small: f2,
Short: str1,
Long: str2,
}
```
创建并填充值后,`DataItem` 实例将以 XML、JSON 和 Protobuf 进行编码,每种编码均写入本地文件:
```
func encodeAndserialize(dataItem *DataItem) {
bytes, _ := xml.MarshalIndent(dataItem, "", " ") // Xml to dataitem.xml
ioutil.WriteFile(XmlFile, bytes, 0644) // 0644 is file access permissions
bytes, _ = json.MarshalIndent(dataItem, "", " ") // Json to dataitem.json
ioutil.WriteFile(JsonFile, bytes, 0644)
bytes, _ = proto.Marshal(dataItem) // Protobuf to dataitem.pbuf
ioutil.WriteFile(PbufFile, bytes, 0644)
}
```
这三个序列化函数使用术语 `marshal`,它与 `serialize` 意思大致相同。如代码所示,三个 `Marshal` 函数均返回一个字节数组,然后将其写入文件。(为简单起见,忽略可能的错误处理。)在示例运行中,文件大小为:
```
dataitem.xml: 262 bytes
dataitem.json: 212 bytes
dataitem.pbuf: 88 bytes
```
Protobuf 编码明显小于其他两个编码方案。通过消除缩进字符(在这种情况下为空白和换行符),可以稍微减小 XML 和 JSON 序列化的大小。
以下是 `dataitem.json` 文件,该文件最终是由 `json.MarshalIndent` 调用产生的,并添加了以 `##` 开头的注释:
```
{
"oddA": 4744002665212642479, ## 64-bit >= 0
"evenA": 2395006495604861128, ## ditto
"oddB": 57, ## 32-bit >= 0 but < 2048
"evenB": 468, ## ditto
"small": 0.7562016, ## 32-bit floating-point
"big": 0.85202795, ## ditto
"short": "ClH1oDaTtoX$HBN5", ## 16 random chars
"long": "xId0rD3Cri%3Wt%^QjcFLJgyXBu9^DZI" ## 32 random chars
}
```
尽管这些序列化的数据写入到本地文件中,但是也可以使用相同的方法将数据写入网络连接的输出流。
### 测试序列化和反序列化
Go 程序接下来通过将先前写入 `dataitem.pbuf` 文件的字节反序列化为 `DataItem` 实例来运行基本测试。这是代码段,其中去除了错误检查部分:
```
filebytes, err := ioutil.ReadFile(PbufFile) // get the bytes from the file
...
testItem.Reset() // clear the DataItem structure
err = proto.Unmarshal(filebytes, testItem) // deserialize into a DataItem instance
```
用于 Protbuf 反序列化的 `proto.Unmarshal` 函数与 `proto.Marshal` 函数相反。原始的 `DataItem` 和反序列化的副本将被打印出来以确认完全匹配:
```
Original:
2041519981506242154 3041486079683013705 1192 1879
0.572123 0.326855
boPb#T0O8Xd&Ps5EnSZqDg4Qztvo7IIs 9vH66AiGSQgCDxk&
Deserialized:
2041519981506242154 3041486079683013705 1192 1879
0.572123 0.326855
boPb#T0O8Xd&Ps5EnSZqDg4Qztvo7IIs 9vH66AiGSQgCDxk&
```
### 一个 Java Protobuf 客户端
用 Java 写的示例是为了确认 Protobuf 的语言中立性。原始 IDL 文件可用于生成 Java 支持代码,其中涉及嵌套类。但是,为了抑制警告信息,可以进行一些补充。这是修订版,它指定了一个 `DataMsg` 作为外部类的名称,内部类在该 Protobuf 消息后面自动命名为 `DataItem`:
```
syntax = "proto3";
package main;
option java_outer_classname = "DataMsg";
message DataItem {
...
```
进行此更改后,`protoc` 编译与以前相同,只是所期望的输出现在是 Java 而不是 Go:
```
% protoc --java_out=. dataitem.proto
```
生成的源文件(在名为 `main` 的子目录中)为 `DataMsg.java`,长度约为 1,120 行:Java 并不简洁。编译然后运行 Java 代码需要具有 Protobuf 库支持的 JAR 文件。该文件位于 [Maven 存储库](https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java)中。
放置好这些片段后,我的测试代码相对较短(并且在 ZIP 文件中以 `Main.java` 形式提供):
```
package main;
import java.io.FileInputStream;
public class Main {
public static void main(String[] args) {
String path = "dataitem.pbuf"; // from the Go program's serialization
try {
DataMsg.DataItem deserial =
DataMsg.DataItem.newBuilder().mergeFrom(new FileInputStream(path)).build();
System.out.println(deserial.getOddA()); // 64-bit odd
System.out.println(deserial.getLong()); // 32-character string
}
catch(Exception e) { System.err.println(e); }
}
}
```
当然,生产级的测试将更加彻底,但是即使是该初步测试也可以证明 Protobuf 的语言中立性:`dataitem.pbuf` 文件是 Go 程序对 Go 语言版的 `DataItem` 进行序列化的结果,并且该文件中的字节被反序列化以产生一个 Java 语言的 `DataItem` 实例。Java 测试的输出与 Go 测试的输出相同。
### 用 numPairs 程序来结束
让我们以一个示例作为结尾,来突出 Protobuf 效率,但又强调在任何编码技术中都会涉及到的成本。考虑以下 Protobuf IDL 文件:
```
syntax = "proto3";
package main;
message NumPairs {
repeated NumPair pair = 1;
}
message NumPair {
int32 odd = 1;
int32 even = 2;
}
```
`NumPair` 消息由两个 `int32` 值以及每个字段的整数标签组成。`NumPairs` 消息是嵌入的 `NumPair` 消息的序列。
Go 语言的 `numPairs` 程序(如下)创建了 200 万个 `NumPair` 实例,每个实例都附加到 `NumPairs` 消息中。该消息可以按常规方式进行序列化和反序列化。
#### 示例 2、numPairs 程序
```
package main
import (
"math/rand"
"time"
"encoding/xml"
"encoding/json"
"io/ioutil"
"github.com/golang/protobuf/proto"
)
// protoc-generated code: start
var _ = proto.Marshal
type NumPairs struct {
Pair []*NumPair `protobuf:"bytes,1,rep,name=pair" json:"pair,omitempty"`
}
func (m *NumPairs) Reset() { *m = NumPairs{} }
func (m *NumPairs) String() string { return proto.CompactTextString(m) }
func (*NumPairs) ProtoMessage() {}
func (m *NumPairs) GetPair() []*NumPair {
if m != nil { return m.Pair }
return nil
}
type NumPair struct {
Odd int32 `protobuf:"varint,1,opt,name=odd" json:"odd,omitempty"`
Even int32 `protobuf:"varint,2,opt,name=even" json:"even,omitempty"`
}
func (m *NumPair) Reset() { *m = NumPair{} }
func (m *NumPair) String() string { return proto.CompactTextString(m) }
func (*NumPair) ProtoMessage() {}
func init() {}
// protoc-generated code: finish
var numPairsStruct NumPairs
var numPairs = &numPairsStruct
func encodeAndserialize() {
// XML encoding
filename := "./pairs.xml"
bytes, _ := xml.MarshalIndent(numPairs, "", " ")
ioutil.WriteFile(filename, bytes, 0644)
// JSON encoding
filename = "./pairs.json"
bytes, _ = json.MarshalIndent(numPairs, "", " ")
ioutil.WriteFile(filename, bytes, 0644)
// ProtoBuf encoding
filename = "./pairs.pbuf"
bytes, _ = proto.Marshal(numPairs)
ioutil.WriteFile(filename, bytes, 0644)
}
const HowMany = 200 * 100 * 100 // two million
func main() {
rand.Seed(time.Now().UnixNano())
// uncomment the modulus operations to get the more efficient version
for i := 0; i < HowMany; i++ {
n1 := rand.Int31() // % 2047
if (n1 & 1) == 0 { n1++ } // ensure it's odd
n2 := rand.Int31() // % 2047
if (n2 & 1) == 1 { n2++ } // ensure it's even
next := &NumPair {
Odd: n1,
Even: n2,
}
numPairs.Pair = append(numPairs.Pair, next)
}
encodeAndserialize()
}
```
每个 `NumPair` 中随机生成的奇数和偶数值的范围在 0 到 20 亿之间变化。就原始数据(而非编码数据)而言,Go 程序中生成的整数总共为 16MB:每个 `NumPair` 为两个整数,总计为 400 万个整数,每个值的大小为四个字节。
为了进行比较,下表列出了 XML、JSON 和 Protobuf 编码的示例 `NumsPairs` 消息的 200 万个 `NumPair` 实例。原始数据也包括在内。由于 `numPairs` 程序生成随机值,因此样本运行的输出有所不同,但接近表中显示的大小。
| 编码 | 文件 | 字节大小 | Pbuf/其它 比例 |
| --- | --- | --- | --- |
| 无 | pairs.raw | 16MB | 169% |
| Protobuf | pairs.pbuf | 27MB | — |
| JSON | pairs.json | 100MB | 27% |
| XML | pairs.xml | 126MB | 21% |
*表 2. 16MB 整数的编码开销*
不出所料,Protobuf 和之后的 XML 和 JSON 差别明显。Protobuf 编码大约是 JSON 的四分之一,是 XML 的五分之一。但是原始数据清楚地表明 Protobuf 也会产生编码开销:序列化的 Protobuf 消息比原始数据大 11MB。包括 Protobuf 在内的任何编码都涉及结构化数据,这不可避免地会增加字节。
序列化的 200 万个 `NumPair` 实例中的每个实例都包含**四**个整数值:Go 结构中的 `Even` 和 `Odd` 字段分别一个,而 Protobuf 编码中的每个字段、每个标签一个。对于原始数据(而不是编码数据),每个实例将达到 16 个字节,样本 `NumPairs` 消息中有 200 万个实例。但是 Protobuf 标记(如 `NumPair` 字段中的 `int32` 值)使用 `varint` 编码,因此字节长度有所不同。特别是,小的整数值(在这种情况下,包括标签在内)需要不到四个字节进行编码。
如果对 `numPairs` 程序进行了修改,以使两个 `NumPair` 字段的值小于 2048,且其编码为一或两个字节,则 Protobuf 编码将从 27MB 下降到 16MB,这正是原始数据的大小。下表总结了样本运行中的新编码大小。
| 编码 | 文件 | 字节大小 | Pbuf/其它 比例 |
| --- | --- | --- | --- |
| None | pairs.raw | 16MB | 100% |
| Protobuf | pairs.pbuf | 16MB | — |
| JSON | pairs.json | 77MB | 21% |
| XML | pairs.xml | 103MB | 15% |
*表 3. 编码 16MB 的小于 2048 的整数*
总之,修改后的 `numPairs` 程序的字段值小于 2048,可减少原始数据中每个四字节整数值的大小。但是 Protobuf 编码仍然需要标签,这些标签会在 Protobuf 消息中添加字节。Protobuf 编码确实会增加消息大小,但是如果要编码相对较小的整数值(无论是字段还是键),则可以通过 `varint` 因子来减少此开销。
对于包含混合类型的结构化数据(且整数值相对较小)的中等大小的消息,Protobuf 明显优于 XML 和 JSON 等选项。在其他情况下,数据可能不适合 Protobuf 编码。例如,如果两个应用程序需要共享大量文本记录或大整数值,则可以采用压缩而不是编码技术。
---
via: <https://opensource.com/article/19/10/protobuf-data-interchange>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Protocol buffers ([Protobufs](https://developers.google.com/protocol-buffers/)), like XML and JSON, allow applications, which may be written in different languages and running on different platforms, to exchange data. For example, a sending application written in Go could encode a Go-specific sales order in Protobuf, which a receiver written in Java then could decode to get a Java-specific representation of the received order. Here is a sketch of the architecture over a network connection:
`Go sales order--->Pbuf-encode--->network--->Pbuf-decode--->Java sales order`
Protobuf encoding, in contrast to its XML and JSON counterparts, is binary rather than text, which can complicate debugging. However, as the code examples in this article confirm, the Protobuf encoding is significantly more efficient in size than either XML or JSON encoding.
Protobuf is efficient in another way. At the implementation level, Protobuf and other encoding systems serialize and deserialize structured data. Serialization transforms a language-specific data structure into a bytestream, and deserialization is the inverse operation that transforms a bytestream back into a language-specific data structure. Serialization and deserialization may become the bottleneck in data interchange because these operations are CPU-intensive. Efficient serialization and deserialization is another Protobuf design goal.
Recent encoding technologies, such as Protobuf and FlatBuffers, derive from the [DCE/RPC](https://en.wikipedia.org/wiki/DCE/RPC) (Distributed Computing Environment/Remote Procedure Call) initiative of the early 1990s. Like DCE/RPC, Protobuf contributes to both the [IDL](https://en.wikipedia.org/wiki/Interface_description_language) (interface definition language) and the encoding layer in data interchange.
This article will look at these two layers then provide code examples in Go and Java to flesh out Protobuf details and show that Protobuf is easy to use.
## Protobuf as an IDL and encoding layer
DCE/RPC, like Protobuf, is designed to be language- and platform-neutral. The appropriate libraries and utilities allow any language and platform to play in the DCE/RPC arena. Furthermore, the DCE/RPC architecture is elegant. An IDL document is the contract between the remote procedure on the one side and callers on the other side. Protobuf, too, centers on an IDL document.
An IDL document is text and, in DCE/RPC, uses basic C syntax along with syntactic extensions for metadata (square brackets) and a few new keywords such as **interface**. Here is an example:
```
[uuid (2d6ead46-05e3-11ca-7dd1-426909beabcd), version(1.0)]
interface echo {
const long int ECHO_SIZE = 512;
void echo(
[in] handle_t h,
[in, string] idl_char from_client[ ],
[out, string] idl_char from_service[ECHO_SIZE]
);
}
```
This IDL document declares a procedure named **echo**, which takes three arguments: the **[in]** arguments of type **handle_t** (implementation pointer) and **idl_char** (array of ASCII characters) are passed to the remote procedure, whereas the **[out]** argument (also a string) is passed back from the procedure. In this example, the **echo** procedure does not explicitly return a value (the **void** to the left of **echo**) but could do so. A return value, together with one or more **[out]** arguments, allows the remote procedure to return arbitrarily many values. The next section introduces a Protobuf IDL, which differs in syntax but likewise serves as a contract in data interchange.
The IDL document, in both DCE/RPC and Protobuf, is the input to utilities that create the infrastructure code for exchanging data:
`IDL document--->DCE/PRC or Protobuf utilities--->support code for data interchange`
As relatively straightforward text, the IDL is likewise human-readable documentation about the specifics of the data interchange—in particular, the number of data items exchanged and the data type of each item.
Protobuf can used in a modern RPC system such as [gRPC](https://grpc.io/); but Protobuf on its own provides only the IDL layer and the encoding layer for messages passed from a sender to a receiver. Protobuf encoding, like the DCE/RPC original, is binary but more efficient.
At present, XML and JSON encodings still dominate in data interchange through technologies such as web services, which make use of in-place infrastructure such as web servers, transport protocols (e.g., TCP, HTTP), and standard libraries and utilities for processing XML and JSON documents. Moreover, database systems of various flavors can store XML and JSON documents, and even legacy relational systems readily generate XML encodings of query results. Every general-purpose programming language now has libraries that support XML and JSON. What, then, recommends a return to a *binary* encoding system such as Protobuf?
Consider the negative decimal value **-128**. In the 2's complement binary representation, which dominates across systems and languages, this value can be stored in a single 8-bit byte: 10000000. The text encoding of this integer value in XML or JSON requires multiple bytes. For example, UTF-8 encoding requires four bytes for the string, literally **-128**, which is one byte per character (in hex, the values are 0x2d, 0x31, 0x32, and 0x38). XML and JSON also add markup characters, such as angle brackets and braces, to the mix. Details about Protobuf encoding are forthcoming, but the point of interest now is a general one: Text encodings tend to be significantly less compact than binary ones.
## A code example in Go using Protobuf
My code examples focus on Protobuf rather than RPC. Here is an overview of the first example:
- The IDL file named
*dataitem.proto*defines a Protobuf**message**with six fields of different types: integer values with different ranges, floating-point values of a fixed size, and strings of two different lengths. - The Protobuf compiler uses the IDL file to generate a Go-specific version (and, later, a Java-specific version) of the Protobuf
**message**together with supporting functions. - A Go app populates the native Go data structure with randomly generated values and then serializes the result to a local file. For comparison, XML and JSON encodings also are serialized to local files.
- As a test, the Go application reconstructs an instance of its native data structure by deserializing the contents of the Protobuf file.
- As a language-neutrality test, the Java application also deserializes the contents of the Protobuf file to get an instance of a native data structure.
This IDL file and two Go and one Java source files are available as a ZIP file on [my website](http://condor.depaul.edu/mkalin).
The all-important Protobuf IDL document is shown below. The document is stored in the file *dataitem.proto*, with the customary *.proto* extension.
### Example 1. Protobuf IDL document
```
syntax = "proto3";
package main;
message DataItem {
int64 oddA = 1;
int64 evenA = 2;
int32 oddB = 3;
int32 evenB = 4;
float small = 5;
float big = 6;
string short = 7;
string long = 8;
}
```
The IDL uses the current proto3 rather than the earlier proto2 syntax. The package name (in this case, **main**) is optional but customary; it is used to avoid name conflicts. The structured **message** contains eight fields, each of which has a Protobuf data type (e.g., **int64**, **string**), a name (e.g., **oddA**, **short**), and a numeric tag (aka key) after the equals sign **=**. The tags, which are 1 through 8 in this example, are unique integer identifiers that determine the order in which the fields are serialized.
Protobuf messages can be nested to arbitrary levels, and one message can be the field type in the other. Here's an example that uses the **DataItem** message as a field type:
```
message DataItems {
repeated DataItem item = 1;
}
```
A single **DataItems** message consists of repeated (none or more) **DataItem** messages.
Protobuf also supports enumerated types for clarity:
```
enum PartnershipStatus {
reserved "FREE", "CONSTRAINED", "OTHER";
}
```
The **reserved** qualifier ensures that the numeric values used to implement the three symbolic names cannot be reused.
To generate a language-specific version of one or more declared Protobuf **message** structures, the IDL file containing these is passed to the *protoc* compiler (available in the [Protobuf GitHub repository](https://github.com/protocolbuffers/protobuf)). For the Go code, the supporting Protobuf library can be installed in the usual way (with **%** as the command-line prompt):
`% go get github.com/golang/protobuf/proto`
The command to compile the Protobuf IDL file *dataitem.proto* into Go source code is:
`% protoc --go_out=. dataitem.proto`
The flag **--go_out** directs the compiler to generate Go source code; there are similar flags for other languages. The result, in this case, is a file named *dataitem.pb.go*, which is small enough that the essentials can be copied into a Go application. Here are the essentials from the generated code:
```
var _ = proto.Marshal
type DataItem struct {
OddA int64 `protobuf:"varint,1,opt,name=oddA" json:"oddA,omitempty"`
EvenA int64 `protobuf:"varint,2,opt,name=evenA" json:"evenA,omitempty"`
OddB int32 `protobuf:"varint,3,opt,name=oddB" json:"oddB,omitempty"`
EvenB int32 `protobuf:"varint,4,opt,name=evenB" json:"evenB,omitempty"`
Small float32 `protobuf:"fixed32,5,opt,name=small" json:"small,omitempty"`
Big float32 `protobuf:"fixed32,6,opt,name=big" json:"big,omitempty"`
Short string `protobuf:"bytes,7,opt,name=short" json:"short,omitempty"`
Long string `protobuf:"bytes,8,opt,name=long" json:"long,omitempty"`
}
func (m *DataItem) Reset() { *m = DataItem{} }
func (m *DataItem) String() string { return proto.CompactTextString(m) }
func (*DataItem) ProtoMessage() {}
func init() {}
```
The compiler-generated code has a Go structure **DataItem**, which exports the Go fields—the names are now capitalized—that match the names declared in the Protobuf IDL. The structure fields have standard Go data types: **int32**, **int64**, **float32**, and **string**. At the end of each field line, as a string, is metadata that describes the Protobuf types, gives the numeric tags from the Protobuf IDL document, and provides information about JSON, which is discussed later.
There are also functions; the most important is **proto.Marshal** for serializing an instance of the **DataItem** structure into Protobuf format. The helper functions include **Reset**, which clears a **DataItem** structure, and **String**, which produces a one-line string representation of a **DataItem**.
The metadata that describes Protobuf encoding deserves a closer look before analyzing the Go program in more detail.
## Protobuf encoding
A Protobuf message is structured as a collection of key/value pairs, with the numeric tag as the key and the corresponding field as the value. The field names, such as **oddA** and **small**, are for human readability, but the *protoc* compiler does use the field names in generating language-specific counterparts. For example, the **oddA** and **small** names in the Protobuf IDL become the fields **OddA** and **Small**, respectively, in the Go structure.
The keys and their values both get encoded, but with an important difference: some numeric values have a fixed-size encoding of 32 or 64 bits, whereas others (including the **message** tags) are *varint* encoded—the number of bits depends on the integer's absolute value. For example, the integer values 1 through 15 require 8 bits to encode in *varint*, whereas the values 16 through 2047 require 16 bits. The *varint* encoding, similar in spirit (but not in detail) to UTF-8 encoding, favors small integer values over large ones. (For a detailed analysis, see the Protobuf [encoding guide](https://developers.google.com/protocol-buffers/docs/encoding).) The upshot is that a Protobuf **message** should have small integer values in fields, if possible, and as few keys as possible, but one key per field is unavoidable.
Table 1 below gives the gist of Protobuf encoding:
**Table 1. Protobuf data types**
Encoding | Sample types | Length |
---|---|---|
varint |
int32, uint32, int64 |
Variable length |
fixed |
fixed32, float, double |
Fixed 32-bit or 64-bit length |
byte sequence |
string, bytes |
Sequence length |
Integer types that are not explicitly **fixed** are *varint* encoded; hence, in a *varint* type such as **uint32** (**u** for unsigned), the number 32 describes the integer's range (in this case, 0 to 232 - 1) rather than its bit size, which differs depending on the value. For fixed types such as **fixed32** or **double**, by contrast, the Protobuf encoding requires 32 and 64 bits, respectively. Strings in Protobuf are byte sequences; hence, the size of the field encoding is the length of the byte sequence.
Another efficiency deserves mention. Recall the earlier example in which a **DataItems** message consists of repeated **DataItem** instances:
```
message DataItems {
repeated DataItem item = 1;
}
```
The **repeated** means that the **DataItem** instances are *packed*: the collection has a single tag, in this case, 1. A **DataItems** message with repeated **DataItem** instances is thus more efficient than a message with multiple but separate **DataItem** fields, each of which would require a tag of its own.
With this background in mind, let's return to the Go program.
## The dataItem program in detail
The *dataItem* program creates a **DataItem** instance and populates the fields with randomly generated values of the appropriate types. Go has a **rand** package with functions for generating pseudo-random integer and floating-point values, and my **randString** function generates pseudo-random strings of specified lengths from a character set. The design goal is to have a **DataItem** instance with field values of different types and bit sizes. For example, the **OddA** and **EvenA** values are 64-bit non-negative integer values of odd and even parity, respectively; but the **OddB** and **EvenB** variants are 32 bits in size and hold small integer values between 0 and 2047. The random floating-point values are 32 bits in size, and the strings are 16 (**Short**) and 32 (**Long**) characters in length. Here is the code segment that populates the **DataItem** structure with random values:
```
// variable-length integers
n1 := rand.Int63() // bigger integer
if (n1 & 1) == 0 { n1++ } // ensure it's odd
...
n3 := rand.Int31() % UpperBound // smaller integer
if (n3 & 1) == 0 { n3++ } // ensure it's odd
// fixed-length floats
...
t1 := rand.Float32()
t2 := rand.Float32()
...
// strings
str1 := randString(StrShort)
str2 := randString(StrLong)
// the message
dataItem := &DataItem {
OddA: n1,
EvenA: n2,
OddB: n3,
EvenB: n4,
Big: f1,
Small: f2,
Short: str1,
Long: str2,
}
```
Once created and populated with values, the **DataItem** instance is encoded in XML, JSON, and Protobuf, with each encoding written to a local file:
```
func encodeAndserialize(dataItem *DataItem) {
bytes, _ := xml.MarshalIndent(dataItem, "", " ") // Xml to dataitem.xml
ioutil.WriteFile(XmlFile, bytes, 0644) // 0644 is file access permissions
bytes, _ = json.MarshalIndent(dataItem, "", " ") // Json to dataitem.json
ioutil.WriteFile(JsonFile, bytes, 0644)
bytes, _ = proto.Marshal(dataItem) // Protobuf to dataitem.pbuf
ioutil.WriteFile(PbufFile, bytes, 0644)
}
```
The three serializing functions use the term *marshal*, which is roughly synonymous with *serialize*. As the code indicates, each of the three **Marshal** functions returns an array of bytes, which then are written to a file. (Possible errors are ignored for simplicity.) On a sample run, the file sizes were:
```
dataitem.xml: 262 bytes
dataitem.json: 212 bytes
dataitem.pbuf: 88 bytes
```
The Protobuf encoding is significantly smaller than the other two. The XML and JSON serializations could be reduced slightly in size by eliminating indentation characters, in this case, blanks and newlines.
Below is the *dataitem.json* file resulting eventually from the **json.MarshalIndent** call, with added comments starting with **##**:
```
{
"oddA": 4744002665212642479, ## 64-bit >= 0
"evenA": 2395006495604861128, ## ditto
"oddB": 57, ## 32-bit >= 0 but < 2048
"evenB": 468, ## ditto
"small": 0.7562016, ## 32-bit floating-point
"big": 0.85202795, ## ditto
"short": "ClH1oDaTtoX$HBN5", ## 16 random chars
"long": "xId0rD3Cri%3Wt%^QjcFLJgyXBu9^DZI" ## 32 random chars
}
```
Although the serialized data goes into local files, the same approach would be used to write the data to the output stream of a network connection.
## Testing serialization/deserialization
The Go program next runs an elementary test by deserializing the bytes, which were written earlier to the *dataitem.pbuf* file, into a **DataItem** instance. Here is the code segment, with the error-checking parts removed:
```
filebytes, err := ioutil.ReadFile(PbufFile) // get the bytes from the file
...
testItem.Reset() // clear the DataItem structure
err = proto.Unmarshal(filebytes, testItem) // deserialize into a DataItem instance
```
The **proto.Unmarshal** function for deserializing Protbuf is the inverse of the **proto.Marshal** function. The original **DataItem** and the deserialized clone are printed to confirm an exact match:
```
Original:
2041519981506242154 3041486079683013705 1192 1879
0.572123 0.326855
boPb#T0O8Xd&Ps5EnSZqDg4Qztvo7IIs 9vH66AiGSQgCDxk&
Deserialized:
2041519981506242154 3041486079683013705 1192 1879
0.572123 0.326855
boPb#T0O8Xd&Ps5EnSZqDg4Qztvo7IIs 9vH66AiGSQgCDxk&
```
## A Protobuf client in Java
The example in Java is to confirm Protobuf's language neutrality. The original IDL file could be used to generate the Java support code, which involves nested classes. To suppress warnings, however, a slight addition can be made. Here is the revision, which specifies a **DataMsg** as the name for the outer class, with the inner class automatically named **DataItem** after the Protobuf message:
```
syntax = "proto3";
package main;
option java_outer_classname = "DataMsg";
message DataItem {
...
```
With this change in place, the *protoc* compilation is the same as before, except the desired output is now Java rather than Go:
`% protoc --java_out=. dataitem.proto`
The resulting source file (in a subdirectory named *main*) is *DataMsg.java* and about 1,120 lines in length: Java is not terse. Compiling and then running the Java code requires a JAR file with the library support for Protobuf. This file is available in the [Maven repository](https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java).
With the pieces in place, my test code is relatively short (and available in the ZIP file as *Main.java*):
```
package main;
import java.io.FileInputStream;
public class Main {
public static void main(String[] args) {
String path = "dataitem.pbuf"; // from the Go program's serialization
try {
DataMsg.DataItem deserial =
DataMsg.DataItem.newBuilder().mergeFrom(new FileInputStream(path)).build();
System.out.println(deserial.getOddA()); // 64-bit odd
System.out.println(deserial.getLong()); // 32-character string
}
catch(Exception e) { System.err.println(e); }
}
}
```
Production-grade testing would be far more thorough, of course, but even this preliminary test confirms the language-neutrality of Protobuf: the *dataitem.pbuf* file results from the Go program's serialization of a Go **DataItem**, and the bytes in this file are deserialized to produce a **DataItem** instance in Java. The output from the Java test is the same as that from the Go test.
## Wrapping up with the numPairs program
Let's end with an example that highlights Protobuf efficiency but also underscores the cost involved in any encoding technology. Consider this Protobuf IDL file:
```
syntax = "proto3";
package main;
message NumPairs {
repeated NumPair pair = 1;
}
message NumPair {
int32 odd = 1;
int32 even = 2;
}
```
A **NumPair** message consists of two **int32** values together with an integer tag for each field. A **NumPairs** message is a sequence of embedded **NumPair** messages.
The *numPairs* program in Go (below) creates 2 million **NumPair** instances, with each appended to the **NumPairs** message. This message can be serialized and deserialized in the usual way.
### Example 2. The numPairs program
```
package main
import (
"math/rand"
"time"
"encoding/xml"
"encoding/json"
"io/ioutil"
"github.com/golang/protobuf/proto"
)
// protoc-generated code: start
var _ = proto.Marshal
type NumPairs struct {
Pair []*NumPair `protobuf:"bytes,1,rep,name=pair" json:"pair,omitempty"`
}
func (m *NumPairs) Reset() { *m = NumPairs{} }
func (m *NumPairs) String() string { return proto.CompactTextString(m) }
func (*NumPairs) ProtoMessage() {}
func (m *NumPairs) GetPair() []*NumPair {
if m != nil { return m.Pair }
return nil
}
type NumPair struct {
Odd int32 `protobuf:"varint,1,opt,name=odd" json:"odd,omitempty"`
Even int32 `protobuf:"varint,2,opt,name=even" json:"even,omitempty"`
}
func (m *NumPair) Reset() { *m = NumPair{} }
func (m *NumPair) String() string { return proto.CompactTextString(m) }
func (*NumPair) ProtoMessage() {}
func init() {}
// protoc-generated code: finish
var numPairsStruct NumPairs
var numPairs = &numPairsStruct
func encodeAndserialize() {
// XML encoding
filename := "./pairs.xml"
bytes, _ := xml.MarshalIndent(numPairs, "", " ")
ioutil.WriteFile(filename, bytes, 0644)
// JSON encoding
filename = "./pairs.json"
bytes, _ = json.MarshalIndent(numPairs, "", " ")
ioutil.WriteFile(filename, bytes, 0644)
// ProtoBuf encoding
filename = "./pairs.pbuf"
bytes, _ = proto.Marshal(numPairs)
ioutil.WriteFile(filename, bytes, 0644)
}
const HowMany = 200 * 100 * 100 // two million
func main() {
rand.Seed(time.Now().UnixNano())
// uncomment the modulus operations to get the more efficient version
for i := 0; i < HowMany; i++ {
n1 := rand.Int31() // % 2047
if (n1 & 1) == 0 { n1++ } // ensure it's odd
n2 := rand.Int31() // % 2047
if (n2 & 1) == 1 { n2++ } // ensure it's even
next := &NumPair {
Odd: n1,
Even: n2,
}
numPairs.Pair = append(numPairs.Pair, next)
}
encodeAndserialize()
}
```
The randomly generated odd and even values in each **NumPair** range from zero to 2 billion and change. In terms of raw rather than encoded data, the integers generated in the Go program add up to 16MB: two integers per **NumPair** for a total of 4 million integers in all, and each value is four bytes in size.
For comparison, the table below has entries for the XML, JSON, and Protobuf encodings of the 2 million **NumPair** instances in the sample **NumsPairs** message. The raw data is included, as well. Because the *numPairs* program generates random values, output differs across sample runs but is close to the sizes shown in the table.
**Table 2. Encoding overhead for 16MB of integers**
Encoding | File | Byte size | Pbuf/other ratio |
---|---|---|---|
None |
pairs.raw |
16MB |
169% |
Protobuf |
pairs.pbuf |
27MB |
— |
JSON |
pairs.json |
100MB |
27% |
XML |
pairs.xml |
126MB |
21% |
As expected, Protobuf shines next to XML and JSON. The Protobuf encoding is about a quarter of the JSON one and about a fifth of the XML one. But the raw data make clear that Protobuf incurs the overhead of encoding: the serialized Protobuf message is 11MB larger than the raw data. Any encoding, including Protobuf, involves structuring the data, which unavoidably adds bytes.
Each of the serialized 2 million **NumPair** instances involves *four* integer values: one apiece for the **Even** and **Odd** fields in the Go structure, and one tag per each field in the Protobuf encoding. As raw rather than encoded data, this would come to 16 bytes per instance, and there are 2 million instances in the sample **NumPairs** message. But the Protobuf tags, like the **int32** values in the **NumPair** fields, use *varint* encoding and, therefore, vary in byte length; in particular, small integer values (which include the tags, in this case) require fewer than four bytes to encode.
If the *numPairs* program is revised so that the two **NumPair** fields hold values less than 2048, which have encodings of either one or two bytes, then the Protobuf encoding drops from 27MB to 16MB—the very size of the raw data. The table below summarizes the new encoding sizes from a sample run.
**Table 3. Encoding with 16MB of integers < 2048**
Encoding | File | Byte size | Pbuf/other ratio |
---|---|---|---|
None |
pairs.raw |
16MB |
100% |
Protobuf |
pairs.pbuf |
16MB |
— |
JSON |
pairs.json |
77MB |
21% |
XML |
pairs.xml |
103MB |
15% |
In summary, the modified *numPairs* program, with field values less than 2048, reduces the four-byte size for each integer value in the raw data. But the Protobuf encoding still requires tags, which add bytes to the Protobuf message. Protobuf encoding does have a cost in message size, but this cost can be reduced by the *varint* factor if relatively small integer values, whether in fields or keys, are being encoded.
For moderately sized messages consisting of structured data with mixed types—and relatively small integer values—Protobuf has a clear advantage over options such as XML and JSON. In other cases, the data may not be suited for Protobuf encoding. For example, if two applications need to share a huge set of text records or large integer values, then compression rather than encoding technology may be the way to go.
## Comments are closed. |
11,601 | 使用 apt-get 清理 | https://www.networkworld.com/article/3453032/cleaning-up-with-apt-get.html | 2019-11-22T08:20:49 | [
"apt-get"
] | https://linux.cn/article-11601-1.html |
>
> 大多数使用基于 Debian 的系统的人通常会使用 apt-get 来安装软件包和升级,但是我们多久才清理一次?让我们看下该工具本身的一些清理选项。
>
>
>

在基于 Debian 的系统上运行 `apt-get` 命令是很常规的。软件包的更新相当频繁,诸如 `apt-get update` 和 `apt-get upgrade` 之类的命令使此过程非常容易。另一方面,你多久使用一次 `apt-get clean`、`apt-get autoclean` 或 `apt-get autoremove`?
这些命令会在 `apt-get` 的安装操作后清理并删除仍在系统上但不再需要的文件,这通常是因为需要它们的程序已经卸载。
### apt-get clean
`apt-get clean` 命令清除遗留在 `/var/cache` 中的已取回的包文件的本地仓库。它清除的目录是 `/var/cache/apt/archives/` 和 `/var/cache/apt/archives/partial/`。它留在 `/var/cache/apt/archives` 中的唯一文件是 `lock` 文件和 `partial` 子目录。
在运行清理操作之前,目录中可能包含许多文件:
```
/var/cache/apt/archives/db5.3-util_5.3.28+dfsg1-0.6ubuntu1_amd64.deb
/var/cache/apt/archives/db-util_1%3a5.3.21~exp1ubuntu2_all.deb
/var/cache/apt/archives/lock
/var/cache/apt/archives/postfix_3.4.5-1ubuntu1_amd64.deb
/var/cache/apt/archives/sasl2-bin_2.1.27+dfsg-1build3_amd64.deb
```
之后,只会存在这些:
```
$ sudo ls -lR /var/cache/apt/archives
/var/cache/apt/archives:
total 4
-rw-r----- 1 root root 0 Jan 5 2018 lock
drwx------ 2 _apt root 4096 Nov 12 07:24 partial
/var/cache/apt/archives/partial:
total 0 <== 空
```
`apt-get clean` 命令通常用于根据需要清除磁盘空间,一般作为定期计划维护的一部分。
### apt-get autoclean
`apt-get autoclean` 类似于 `apt-get clean`,它会清除已检索包文件的本地仓库,但它只会删除不会再下载且几乎无用的文件。它有助于防止缓存过大。
### apt-get autoremove
`apt-get autoremove` 将删除自动安装的软件包,因为某些其他软件包需要它们,但是在删除了其他软件包之后,而不再需要它们。有时会在升级时建议运行此命令。
```
The following packages were automatically installed and are no longer required:
g++-8 gir1.2-mutter-4 libapache2-mod-php7.2 libcrystalhd3
libdouble-conversion1 libgnome-desktop-3-17 libigdgmm5 libisl19 libllvm8
liblouisutdml8 libmutter-4-0 libmysqlclient20 libpoppler85 libstdc++-8-dev
libtagc0 libvpx5 libx265-165 php7.2 php7.2-cli php7.2-common php7.2-json
php7.2-opcache php7.2-readline
Use 'sudo apt autoremove' to remove them. <==
```
要删除的软件包通常称为“未使用的依赖项”。实际上,一个好的做法是在卸载软件包后使用 `autoremove`,以确保不会留下不需要的文件。
---
via: <https://www.networkworld.com/article/3453032/cleaning-up-with-apt-get.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,603 | Zorin OS 15 Lite 发布:好看的轻量级 Linux | https://itsfoss.com/zorin-os-lite/ | 2019-11-23T09:37:06 | [
"Zorin"
] | https://linux.cn/article-11603-1.html |
>
> Zorin OS 15 Lite 版刚刚发布。我们将向你展示此新版本的桌面体验,并向你重点展示其主要功能。
>
>
>
[Zorin OS](https://zorinos.com/) 是一款日益流行的 Linux 发行版。它基于 Ubuntu,因此,毫不奇怪,它也正是[适合初学者的最佳 Linux 发行版](https://itsfoss.com/best-linux-beginners/)之一。 类似 Windows 的界面是许多从 Windows 到 Linux 的迁移者偏爱它的主要原因之一。
Zorin OS 有两个主要变体:
* Zorin Core:它使用 GNOME 桌面,用于较新的机器。
* Zorin Lite:它使用轻量级的 [Xfce 桌面](https://www.xfce.org/),可以用作[老旧的笔记本电脑和计算机的 Linux](https://itsfoss.com/lightweight-linux-beginners/)。
### Zorin OS 15 Lite:新特性
Zorin OS 15 Core 发布之后过了很久,Zorin OS 15 Lite 版终于出现了。你现在就可以使用免费的 Lite 版或付费的 Lite Ultimate 版。
我尝试了 Zorin OS 15 Lite Ultimate 版。在本文中,我将介绍此版本的详细信息以及在为你的计算机下载 Zorin OS 15 Lite 之前应了解的知识。
Zorin OS 15 Lite 与全面的 Zorin OS 15 版本基本差不多。你可以在我们的原来的报道中查看 [Zorin OS 15 的功能](/article-11058-1.html)。
此发行版重点关注资源,因此过去十年中任何类型的旧硬件配置都可以轻松地在其上运行。

在此版本中,它们依靠基于 Xfce 4.14 的轻量级桌面环境在低规格计算机上提供了最佳体验。除了 Xfce 桌面环境外,与使用 GNOME 的完整版本相比,它还做了一些底层更改。
#### Zorin OS 15 Lite 是针对 Windows 7 用户的

Zorin OS 15 Lite 主要针对 Windows 7 用户,因为对 Windows 7 的官方支持结束于今年 1 月。因此,如果你对 Windows 7 感到满意,可以尝试一下,切换到此版本应该是一种流畅的体验。
Zorin OS 15 Lite 允许你在 “Zorin 外观”设置中将布局切换为 macOS 风格/ Windows 风格的外观。
#### 32 位和 64 位支持
很高兴看到 Zorin OS 考虑到对 32 位/ 64 位 ISO 的支持,因为 Lite 版本是针对具有低规格硬件的用户的。
#### 默认启用 Flatpak 支持

你可以使用软件中心利用 Flathub 来立即安装 Flatpak 软件包。如果你不确定该怎么做,请务必查看有关[使用 Flatpak](https://itsfoss.com/flatpak-guide/)的指南。
除此之外,你已经拥有 Snap 软件包支持。因此,通过软件中心安装任何内容应该更容易。
#### 用户界面的印象

老实说,默认的 Xfce 界面看起来很陈旧。有一些方法可以 [定制 Xfce](https://itsfoss.com/customize-xfce/),但是 Zorin 也可以开箱即用。定制外观给人以良好印象。它看起来非常整洁,可以按预期工作。
#### 性能

即使我没有在超级老旧的系统上尝试过,但我也在老式硬盘上安装了它,它难以启动 Ubuntu 或类似发行版。
根据我的体验,我可以肯定该性能非常出色。感觉就好像我将其安装在 SSD 上。这显然是一件好事。如果你碰巧在超级老旧的系统上尝试使用它,可以在本文底部的评论部分中告诉我您的经验。
### Ultimate Lite 版和免费的 Lite 版有何区别?

没错,你可以免费下载 Zorin OS 15。
但是,有一个单独的“终极版”(Ultimate),其基本目的是用来支持该项目及其开发者。除此之外,它还捆绑了许多预安装的软件,作为计算机的“最终”软件包。
因此,如果你购买 Ultimate 版,则可以访问 Lite 版和完整版。
如果你不想为此付费,仍然可以根据需要选择免费版本(Core、Lite、Education)。你可以在它们的[下载页面](https://zorinos.com/download/)上了解更多信息。
### 如何下载 Zorin OS 15 Lite?
你可以转到其[官方下载网页](https://zorinos.com/download/),然后向下滚动找到 Zorin OS 15 Lite 版。
你可以找到 32 位/ 64 位的 ISO,可以下载所需的 ISO。
* [Zorin OS 15 Lite](https://zorinos.com/download/)
安装 Zorin OS 与安装 Ubuntu 类似。
### 总结
虽然 Zorin OS 15 作为向 Windows / macOS 老手提供的 Linux 发行版已经是一个不错的产品,但新的 Lite 版本肯定会吸引更多的眼球。
您是否尝试过 Lite 版?在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/zorin-os-lite/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Zorin OS 15 Lite edition has just been released. We’ll show take you to a desktop tour of this new release and highlight its main features for you. *
[Zorin OS](https://zorinos.com/) is an increasingly popular Linux distribution. It is based on Ubuntu and thus , unsurprisingly, it also happens to be one of the [best Linux distributions for beginners](https://itsfoss.com/best-linux-beginners/). It’s Windows-like interface is one of the major reasons why it is preferred by many Windows-to-Linux migrants.
Zorin OS comes in two main variants:
- Zorin Core: It uses GNOME desktop and is intended for newer systems
- Zorin Lite: It uses lightweight
[Xfce desktop](https://www.xfce.org/)and is intended to be the[Linux for old laptops and computers](https://itsfoss.com/lightweight-linux-beginners/)
## Zorin OS 15 Lite: What’s New?
Zorin OS 15 Lite edition has finally landed after a long time of Zorin OS 15 Core release. You can get your hands on the free lite editions or the paid ultimate lite edition now.
I tried the Zorin OS 15 Lite Ultimate edition. In this article, I shall cover the details for this release and what you should know before choosing to download Zorin OS 15 Lite for your computer.
Zorin OS 15 Lite is almost similar to the full-fledged Zorin OS 15 release. You can check out [Zorin OS 15 features](https://itsfoss.com/zorin-os-15-release/) in our original coverage for that.
This release entirely focuses to be light on resources so that any type of old hardware configuration from the past decade can easily run on it.
With this release, they rely on the lightweight XFCE 4.14-based desktop environment to give the best possible experience on a low-spec computer.
In addition to the XFCE desktop environment, there are some under-the-hood changes when compared to its full-fledged version that uses GNOME.
### Zorin OS 15 Lite Targets Windows 7 Users
Primarily, Zorin OS 15 Lite targets the Windows 7 users because the official support for Windows 7 ends this January.
So, if you are someone who’s comfortable with Windows 7, you can give this a try, it should be a smooth experience switching to this.
Zorin OS 15 Lite gives you the option to switch the layout to a macOS style / Windows-style appearance from the “**Zorin Appearance**” settings. This is an Ultimate Edition feature though.
### 32-bit and 64-bit Support
It was good to see Zorin OS considering the support for 32-bit/64-bit ISOs just because the lite edition is being targeted for users with low-spec hardware.
### Flatpak Support Enabled By Default

You can utilize Flathub to install Flatpak packages out of the box using the Software Center. Make sure to check out our guide on [using Flatpak](https://itsfoss.com/flatpak-guide/) if you’re not sure what to do.
In addition to this, you already have the Snap package support. So, it should be easier to install anything through the Software Center.
### User Interface Impression
To be honest, the default Xfce interface looks old. There are ways to [customize Xfce](https://itsfoss.com/customize-xfce/) but Zorin does it out of the box. The customized look gives a good impression. It looks pretty damn neat and works as expected.
### Performance
Even though I haven’t tried this on a super old system, I did install it on a vintage hard disk drive which struggles to boot up Ubuntu or similar distributions.
As per my experience, I would definitely rate the performance to be super snappy.
It feels like I have it installed on my SSD. So, that’s obviously a good thing. If you happen to try it on a super old system, you can let me know your experience in the comments section at the bottom of this article.
## What’s The Difference Between The ‘Ultimate Lite’ edition & Free ‘Lite’ edition?
Make no mistake, you can download Zorin OS 15 for free.
However, there’s a separate ‘Ultimate’ edition which is basically meant to support the developers and the project. In addition to that, it also bundles a lot of pre-installed software as an “ultimate” package for your computer.
So, if you purchase the Ultimate edition, you get access to both the lite and full version.
In case you do not want to pay for it, you can still opt for the free editions (Core, Lite, Education) depending on your requirements. You can learn more about it on their [download page](https://zorinos.com/download/).
## How To Download Zorin OS 15 Lite?
You can just head on to its [official download webpage](https://zorinos.com/download/) and scroll down to find the Zorin OS 15 lite edition.
You will find 32-bit/64-bit ISOs available, download the one you require.
Installing Zorin OS is similar to installing Ubuntu.
**Wrapping Up**
While Zorin OS 15 is already a great offering as a Linux distribution to Windows/macOS veterans, the new Lite edition surely turns more eyes to it.
Have you tried the ‘Lite’ edition yet? Let me know your thoughts in the comments below. |
11,604 | 使用 Flutter 开发简单的 Web 应用 | https://opensourceforu.com/2019/11/developing-a-simple-web-application-using/ | 2019-11-23T10:01:00 | [
"Flutter"
] | https://linux.cn/article-11604-1.html | 
>
> 本文指导读者如何使用 Flutter 运行和部署第一个 Web 应用。
>
>
>
Flutter 在 Android 和 iOS 开发方面走了很长一段路之后,已经迈入了一个新的阶段,即 Web 开发。Google 发布了 Flutter 1.5,同时支持 Web 应用开发。
### 为 Web 开发配置 Flutter
为了使用 Web 包,输入命令 `flutter upgrade` 更新到 Flutter 1.5.4。
* 打开终端
* 输入 `flutter upgrade`
* 输入 `flutter –version` 检查版本

也可以将 Android Studio 3.0 或更高版本用于 Flutter Web 开发,但在本教程中,我们使用 Visual Studio Code。
### 使用 Flutter Web 创建新项目
打开 Visual Studio Code,然后按 `Shift+Ctrl+P` 开始一个新项目。输入 `flutter` 并选择 “New Web Project”。

现在,为项目命名。我将其命名为 `open_source_for_you`。

在 VSC 中打开终端窗口,然后输入以下命令:
```
flutter packages pub global activate webdev
flutter packages upgrade
```
现在,使用以下命令在 localhost 上运行网站,IP 地址是 127.0.0.1。
```
flutter packages pub global run webdev serve
```
打开任何浏览器,然后输入 `http://127.0.0.1:8080/`。

在项目目录中有个 Web 文件夹,其中包含了 `index.html`。`dart` 文件被编译成 JavaScript 文件,并使用以下代码包含在 HTML 文件中:
```
<script defer src="main.dart.js" type="application/javascript"></script>
```
### 编码和修改演示页面
让我们创建一个简单的应用,它会在网页上打印 “Welcome to OSFY”。
现在打开 Dart 文件,它位于 `lib` 文件夹 `main.dart`(默认名)中(参见图 5)。

现在,我们可以在 `MaterialApp` 的属性中删除调试标记,如下所示:
```
debugShowCheckedModeBanner: false
```
现在,向 Dart 中添加更多内容与用 Dart 编写 Flutter 很类似。为此,我们可以声明一个名为 `MyClass` 的类,它继承了 `StatelessWidget`。
我们使用 `Center` 部件将元素定位到中心。我们还可以添加 `Padding` 部件来添加填充。使用以下代码获得图 5 所示的输出。使用刷新按钮查看更改。
```
class MyClass extends StatelessWidget {
@override
Widget build(BuildContext context) {
return Scaffold(
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
Padding(
padding: EdgeInsets.all(20.0),
child: Text(
'Welcome to OSFY',
style: TextStyle(fontSize: 24.0, fontWeight: FontWeight.bold),
),
),
],
),
),
);
}
}
```

让我们从互联网中添加一张图片,我已经从一个杂志网站选择了一张 “Open Source for You” 徽标。我们使用 `Image.network`。
```
Image.network(
'https://opensourceforu.com/wp-content/uploads/2014/03/OSFY-Logo.jpg',
height: 100,
width: 150
),
```
最终输出如图 7 所示。

---
via: <https://opensourceforu.com/2019/11/developing-a-simple-web-application-using/>
作者:[Jis Joe Mathew](https://opensourceforu.com/author/jis-joe/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,605 | 容器如何工作:OverlayFS | https://jvns.ca/blog/2019/11/18/how-containers-work--overlayfs/ | 2019-11-23T10:25:32 | [
"容器"
] | https://linux.cn/article-11605-1.html | 今天早上,我为未来潜在容器[杂志](https://wizardzines.com)画了一幅 OverlayFS 的漫画,我对这个主题感到兴奋,想写一篇关于它的博客来提供更多详细信息。

### 容器镜像很大
容器镜像可能会很大(尽管有些很小,例如 [alpine linux 才 2.5MB](https://hub.docker.com/_/alpine?tab=tags))。Ubuntu 16.04 约为 27 MB,[Anaconda Python 发行版为 800MB 至 1.5GB](https://hub.docker.com/r/continuumio/anaconda3/tags)。
你以镜像启动的每个容器都是原始空白状态,仿佛它只是为使用容器而复制的一份镜像拷贝一样。但是对于大的容器镜像,像 800MB 的 Anaconda 镜像,复制一份拷贝既浪费磁盘空间也很慢。因此 Docker 不会复制,而是采用**叠加**。
### 叠加如何工作
OverlayFS,也被称为 **联合文件系统**或 **联合挂载**,它可让你使用 2 个目录挂载文件系统:“下层”目录和“上层”目录。
基本上:
* 文件系统的**下层**目录是只读的
* 文件系统的**上层**目录可以读写
当进程“读取”文件时,OverlayFS 文件系统驱动将在上层目录中查找并从该目录中读取文件(如果存在)。否则,它将在下层目录中查找。
当进程“写入”文件时,OverlayFS 会将其写入上层目录。
### 让我们使用 mount 制造一个叠加层!
这有点抽象,所以让我们制作一个 OverlayFS 并尝试一下!这将只包含一些文件:我将创建上、下层目录,以及用来挂载合并的文件系统的 `merged` 目录:
```
$ mkdir upper lower merged work
$ echo "I'm from lower!" > lower/in_lower.txt
$ echo "I'm from upper!" > upper/in_upper.txt
$ # `in_both` is in both directories
$ echo "I'm from lower!" > lower/in_both.txt
$ echo "I'm from upper!" > upper/in_both.txt
```
合并上层目录和下层目录非常容易:我们可以通过 `mount` 来完成!
```
$ sudo mount -t overlay overlay
-o lowerdir=/home/bork/test/lower,upperdir=/home/bork/test/upper,workdir=/home/bork/test/work
/home/bork/test/merged
```
在执行此操作时,我不断收到一条非常烦人的错误消息,内容为:`mount: /home/bork/test/merged: special device overlay does not exist.`。这条消息是错误的,实际上只是意味着我指定的一个目录缺失(我写成了 `~/test/merged`,但它没有被展开)。
让我们尝试从 OverlayFS 中读取其中一个文件!文件 `in_both.txt` 同时存在于 `lower/` 和 `upper/` 中,因此应从 `upper/` 目录中读取该文件。
```
$ cat merged/in_both.txt
"I'm from upper!
```
可以成功!
目录的内容就是我们所期望的:
```
find lower/ upper/ merged/
lower/
lower/in_lower.txt
lower/in_both.txt
upper/
upper/in_upper.txt
upper/in_both.txt
merged/
merged/in_lower.txt
merged/in_both.txt
merged/in_upper.txt
```
### 创建新文件时会发生什么?
```
$ echo 'new file' > merged/new_file
$ ls -l */new_file
-rw-r--r-- 1 bork bork 9 Nov 18 14:24 merged/new_file
-rw-r--r-- 1 bork bork 9 Nov 18 14:24 upper/new_file
```
这是有作用的,新文件会在 `upper` 目录创建。
### 删除文件时会发生什么?
读写似乎很简单。但是删除会发生什么?开始试试!
```
$ rm merged/in_both.txt
```
发生了什么?让我们用 `ls` 看下:
```
ls -l upper/in_both.txt lower/lower1.txt merged/lower1.txt
ls: cannot access 'merged/in_both.txt': No such file or directory
-rw-r--r-- 1 bork bork 6 Nov 18 14:09 lower/in_both.txt
c--------- 1 root root 0, 0 Nov 18 14:19 upper/in_both.txt
```
所以:
* `in_both.txt` 仍在 `lower` 目录中,并且保持不变
* 它不在 `merged` 目录中。到目前为止,这就是我们所期望的。
* 但是在 `upper` 中发生的事情有点奇怪:有一个名为 `upper/in_both.txt` 的文件,但是它是字符设备?我想这就是 overlayfs 驱动表示删除的文件的方式。
如果我们尝试复制这个奇怪的字符设备文件,会发生什么?
```
$ sudo cp upper/in_both.txt upper/in_lower.txt
cp: cannot open 'upper/in_both.txt' for reading: No such device or address
```
好吧,这似乎很合理,复制这个奇怪的删除信号文件并没有任何意义。
### 你可以挂载多个“下层”目录
Docker 镜像通常由 25 个“层”组成。OverlayFS 支持具有多个下层目录,因此你可以运行:
```
mount -t overlay overlay
-o lowerdir:/dir1:/dir2:/dir3:...:/dir25,upperdir=...
```
因此,我假设这是有多个 Docker 层的容器的工作方式,它只是将每个层解压缩到一个单独的目录中,然后要求 OverlayFS 将它们全部合并在一起,并使用一个空的上层目录,容器将对其进行更改。
### Docker 也可以使用 btrfs 快照
现在,我使用的是 ext4,而 Docker 使用 OverlayFS 快照来运行容器。但是我曾经用过 btrfs,接着 Docker 将改为使用 btrfs 的写时复制快照。(这是 Docker 何时使用哪种[存储驱动](https://docs.docker.com/storage/storagedriver/select-storage-driver/)的列表)
以这种方式使用 btrfs 快照会产生一些有趣的结果:去年某个时候,我在笔记本上运行了数百个临时的 Docker 容器,这导致我用尽了 btrfs 元数据空间(像[这个人](https://www.reddit.com/r/archlinux/comments/5jrmfe/btrfs_metadata_and_docker/)一样)。这真的很令人困惑,因为我以前从未听说过 btrfs 元数据,而且弄清楚如何清理文件系统以便再次运行 Docker 容器非常棘手。([这个 docker github 上的提案](https://github.com/moby/moby/issues/27653)描述了 Docker 和 btrfs 的类似问题)
### 以简单的方式尝试容器功能很有趣!
我认为容器通常看起来像是在做“复杂的”事情,我认为将它们分解成这样很有趣。你可以运行一条 `mount` 咒语,而实际上并没有做任何与容器相关的其他事情,看看叠加层是如何工作的!
---
via: [https://jvns.ca/blog/2019/11/18/how-containers-work–overlayfs/](https://jvns.ca/blog/2019/11/18/how-containers-work--overlayfs/)
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
11,607 | 更好的任务窃取可以使 Linux 更快吗? | https://www.linux.com/blog/can-better-task-stealing-make-linux-faster | 2019-11-23T23:58:15 | [
"内核",
"CPU"
] | https://linux.cn/article-11607-1.html | 
>
> Oracle Linux 内核开发人员 Steve Sistare 参与了这场有关内核调度程序改进的讨论。
>
>
>
### 通过可扩展的任务窃取进行负载平衡
Linux 任务调度程序通过将唤醒的任务推送到空闲的 CPU,以及在 CPU 空闲时从繁忙的 CPU 中拉取任务来平衡整个系统的负载。在大型系统上的推送侧和拉取侧,有效的伸缩都是挑战。对于拉取,调度程序搜索连续的更大范围中的所有 CPU,直到找到过载的 CPU,然后从最繁忙的组中拉取任务。这代价非常昂贵,在大型系统上要花费 10 到 100 微秒,因此搜索时间受到平均空闲时间的限制,并且某些范围不会被搜索。并非总能达到平衡,而且闲置的 CPU 依旧闲置。
我实现了一种备用机制,该机制在 `idle_balance()` 中的现有搜索中自身受限并且没有找到之后被调用。我维护了一个过载的 CPU 的位图,当可运行的 CFS 任务计数超过 1 时,CPU 会设置该位。这个位图是稀疏的,每个高速缓存线的有效位数量有限。当许多线程同时设置、清除和访问元素时,这可以减少缓存争用。每个末级缓存都有一个位图。当 CPU 空闲时,它将搜索该位图以查找第一个具有可迁移任务的过载 CPU,然后将其窃取。这种简单的窃取会比单独的 `idle_balance()` 产生更高的 CPU 利用率,因为该搜索的成本很便宜,花费 1 到 2 微秒,因此每次 CPU 即将空闲时都可以调用它。窃取不会减轻全局最繁忙的队列的负担,但是它比根本不执行任何操作要好得多。
### 结果
偷窃仅在调度程序代码中占用少量 CPU 开销即可提高利用率。在以下实验中,以不同数量的组(每个组 40 个任务)运行 hackbench,并对每次运行结果显示 `/proc/schedstat` 中的增量(按 CPU 平均),并增加了这些非标准的统计信息:
* `%find`:在旧函数和新函数中花费的时间百分比,这些函数用于搜索空闲的 CPU 和任务以窃取并设置过载的 CPU 位图。
* `steal`:任务从另一个 CPU 窃取的次数。经过的时间增加了 8% 到 36%,最多增加了 0.4% 的发现时间。

如下图的绿色曲线所示,新内核的 CPU 繁忙利用率接近 100%,作为比较的基线内核是橙色曲线: 
根据负载的不同,窃取可将 Oracle 数据库 OLTP 性能提高多达 9%,并且我们已经看到 MySQL、Pgsql、gcc、Java 和网络方面有了一些不错的改进。通常,窃取对上下文切换率高的工作负载最有帮助。
### 代码
截至撰写本文时,这项工作尚未完成,但最新的修补程序系列位于 <https://lkml.org/lkml/2018/12/6/1253>。如果你的内核是使用 `CONFIG_SCHED_DEBUG=y` 构建的,则可以使用以下命令验证其是否包含窃取优化:
```
# grep -q STEAL /sys/kernel/debug/sched_features && echo Yes
Yes
```
如果要尝试使用,请注意,对于具有 2 个以上 NUMA 节点的系统,禁用了窃取功能,因为 hackbench 在此类系统上发生了回归,正如我在 <https://lkml.org/lkml/2018/12/6/1250> 中解释的那样。但是,我怀疑这种影响是特定于 hackbench 的,并且窃取将有助于多节点系统上的其他工作负载。要尝试使用它,请用内核参数 `sched_steal_node_limit=8`(或更大)重新启动。
### 进一步工作
在将基本盗用算法推向上游之后,我正在考虑以下增强功能:
* 如果在末级缓存中进行窃取找不到候选者,在 LLC 和 NUMA 节点之间进行窃取。
* 维护稀疏位图以标识 RT 调度类中的偷窃候选者。当前 `pull_rt_task()` 搜索所有运行队列。
* 从 `idle_balance()` 中删除核心和套接字级别,因为窃取会处理这些级别。当支持跨 LLC 窃取时,完全删除 `idle_balance()`。
* 维护位图以标识空闲核心和空闲 CPU,以实现推平衡。
这篇文章最初发布于 [Oracle Developers Blog](https://blogs.oracle.com/linux/can-better-task-stealing-make-linux-faster)。
---
via: <https://www.linux.com/blog/can-better-task-stealing-make-linux-faster>
作者:[Oracle](https://www.linux.com/author/oracle/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,608 | 你需要知道什么才能成为系统管理员? | https://opensource.com/article/19/7/be-a-sysadmin | 2019-11-24T10:39:18 | [
"系统管理员"
] | https://linux.cn/article-11608-1.html |
>
> 通过获得这些起码的能力,开始你的系统管理员职业。
>
>
>

昔日的系统管理员整天都在调教用户和摆弄服务器,一天的时间都奔波在几百米长的电缆之间。随着云计算、容器和虚拟机的复杂性的增加,而今依然如此。
以外行人来看,很难准确确定系统管理员的确切职能,因为他们在许多地方都扮演着一个不起眼的角色。没人能在培训中知道自己工作中所需要的一切知识,但是每个人其实都需要一个坚实的基础。如果你想走上系统管理的道路,那么这是你个人自学或在正式培训中应重点关注的内容。
### Bash
当你学习 Bash Shell 时,你学习的不仅是 Bash Shell,你学习的也是 Linux、BSD、MacOS 甚至Windows(在适当条件下)的通用界面。你将了解语法的重要性,因此可以快速适应思科路由器的命令行或微软 PowerShell 等系统,最终你甚至可以学习更强大的语言,如 Python 或 Go。而且,你还会开始进行程序性思考,以便可以分析复杂的问题并将其分解为单个组件,这很关键,因为这就是系统(例如互联网、组织的内部网、Web 服务器、备份解决方案)是如何设计的。
不止于此,还有更多。
由于最近 DevOps 和[容器](https://opensource.com/article/19/6/kubernetes-dump-truck)的发展趋势,了解 Bash shell 变得尤为重要。你的系统管理员职业可能会将你带入一个视基础设施为代码的世界,这通常意味着你必须了解脚本编写的基础知识、[基于 YAML](https://www.redhat.com/sysadmin/yaml-tips)配置的结构,以及如何与[容器](https://opensource.com/resources/what-are-linux-containers)(运行在[沙盒文件](https://opensource.com/article/18/11/behind-scenes-linux-containers)内部的微型 Linux 系统)[交互](https://opensource.com/article/19/6/how-ssh-running-container)。你会知道 Bash 是高效管理激动人心的开源技术的门户,因此请进入 [Bash](https://opensource.com/article/18/7/admin-guide-bash) 世界吧。
#### 资源
有很多方法可以在 Bash shell 中进行练习。
尝试一下[便携式 Linux 发行版](https://opensource.com/article/19/6/linux-distros-to-try)。你无需安装 Linux 即可使用 Linux,因此,请拿一块闲置的 U 盘,花个晚上或周末的空闲时光,来适应基于文本的界面。
这里有[几篇很棒的](https://www.redhat.com/sysadmin/managing-files-linux-terminal) [Bash 文章](https://opensource.com/tags/bash)。
要注意的是 Bash 练习的关键在于要练习,你必须有要做的练习才行。而且,在你知道如何使用 Bash 之前,你可能不知道该练习什么。如果是这样,请去 Over The Wire 玩一下 [Bandit](http://overthewire.org/wargames/bandit) 游戏。这是一款针对绝对初学者的游戏,具有 34 个级别的交互式基本技巧,可让你熟悉 Linux shell。
### Web 服务器设置
一旦你习惯了 Bash,你应该尝试设置一个 Web 服务器。并不是所有的系统管理员都会四处设置 Web 服务器甚至维护 Web 服务器,但是你在安装和启动 HTTP 守护程序、配置 Apache 或 Nginx,设置[正确权限](https://opensource.com/article/19/6/understanding-linux-permissions)和[配置防火墙](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd)时所掌握的技能是你每天都需要使用的技能。经过一些努力,你可能会开始注意到自己的某些工作模式。在尝试管理可用于生产环境的软件和硬件之前,你可能认为某些概念是理所当然的,而你在成为新手的管理员角色时,将不再受到它们的影响。起初这可能会令人沮丧,因为每个人都喜欢在自己做好所做的事情,但这实际上是一件好事。让自己接触新技能,那就是你学习的方式。
此外,你在第一步中付出的努力越多,最终当你在默认的 index.html 上看到胜利的“it works!”就越甜蜜!
#### 资源
David Both 撰写了有关 [Apache Web 服务器](https://opensource.com/article/18/2/how-configure-apache-web-server)配置的出色文章。值得一提的是,请逐步阅读他的后续文章,其中介绍了如何在一台计算机上[托管多个站点](https://opensource.com/article/18/3/configuring-multiple-web-sites-apache)。
### DHCP
动态主机配置协议(DHCP)是为网络上的设备分配 IP 地址的系统。在家里,ISP(互联网服务提供商)支持的调制解调器或路由器可能内置了 DHCP 服务器,因此可能不在你的权限范围内。如果你曾经登录家用路由器来调整 IP 地址范围或为某些网络设备设置了静态地址,那么你至少对该概念有所了解。你可能会将其理解为对网络上的设备分配了一种 IP 地址形式的电话号码,并且你可能会意识到计算机之间通过广播发送到特定 IP 地址的消息彼此进行通信。消息标头由路径上的路由器读取,每个消息标头都将消息定向到路径上的第二个逻辑路由器,以达到其最终目标。
即使你了解了这些概念,要从对 DHCP 的基本了解再进一步是架设 DHCP 服务器。安装和配置自己的 DHCP 服务器可能会导致家庭网络中的 DHCP 冲突(如果可以的话,请尽量避免这样做,因为它肯定会干掉你的网络,直到解决为止),要控制地址的分配、创建子网,并监控连接和租赁时间。
更重要的是,设置 DHCP 并尝试不同的配置有助于你了解网络之间的关系。你会了解网络如何在数据传输中表示“分区”,以及必须采取哪些步骤才能将信息从一个网络传递到另一个。这对于系统管理员来说至关重要,因为网络肯定是工作中最重要的方面之一。
#### 资源
在运行自己的 DHCP 服务器之前,请确保家庭路由器(如果有)中的 DHCP 服务器处于非活动状态。一旦启动并运行了 DHCP 服务器,请阅读 Archit Modi 的[网络命令指南](https://opensource.com/article/18/7/sysadmin-guide-networking-commands),以获取有关如何探索网络的提示。
### 网络电缆
这听起来很普通,但是熟悉网络电缆的工作方式不仅使你的周末变得非常有趣,而且还使你对数据是如何通过缆线的得到了全新的了解。最好的学习方法是去当地的业余爱好商店并购买五类线剥线钳和压线钳以及一些五类线水晶头。然后回家,拿一根备用的以太网电缆,切断水晶头,花一些时间重新制作网线接头,将电缆重新投入使用。
解决了这个难题后,请再做一次,这次创建一条有效的[交叉电缆](https://en.wikipedia.org/wiki/Ethernet_crossover_cable)。
你现在应该还在沉迷于有关电缆管理。如果你有些强迫症,喜欢沿着地板线或桌子的边缘整齐地排列电缆,或者将电缆绑在一起以保持它们的整齐有序,那么就可以使自己免受永久混乱的电缆困扰。你一开始可能不会理解这样做的必要性,但是当你第一次走进服务器机房时,你会马上知道原因。
### Ansible
[Ansible](https://opensource.com/sitewide-search?search_api_views_fulltext=ansible) 是配置管理软件,它在系统管理员和 DevOps 之间架起了一座桥梁。系统管理员使用 Ansible 来配置全新安装的操作系统并在计算机上维护特定的状态。DevOps 使用 Ansible 减少了在工具上花费的时间和精力,从而在开发上可以花费更多的时间和精力。作为系统管理员培训的一部分,你应该学习 Ansible,并着眼于 DevOps 实践,因为 DevOps 现在开创的大多数功能将最终成为将来系统管理中工作流的一部分。
Ansible 的好处是你可以立即开始使用它。它是跨平台的,并且可以向上和向下缩放。对于单用户计算机, Ansible 可能是小题大做,但是话又说回来,Ansible 可能会改变你启动虚拟机的方式,或者可以帮助你同步家庭或[家庭实验室](https://opensource.com/article/19/6/create-centos-homelab-hour)中所有计算机的状态。
#### 资源
阅读 Jay LaCroix 的[如何使用 Ansible 管理工作站配置](https://opensource.com/article/18/3/manage-workstation-ansible)中的典型介绍,以轻松地在日常之中开始使用 Ansible。
### 破坏
由于用户的错误、软件的错误、管理员(就是你!)的错误以及许多其他因素,计算机上会出现问题。无法预测将要失败的原因,因此你的个人系统管理员培训制度的一部分应该是破坏你设置的系统,直到它们失败为止。你自己的实验室基础设施越是脆弱,发现弱点的可能性就越大。而且,你越是经常修复这些弱点,你对解决问题的能力就越有信心。
除了严格设置所有常见的软件和硬件之外,作为系统管理员的主要工作是查找解决方案。有时候,你可能会遇到职位描述之外的问题,甚至可能无法解决,但这完全取决于你的解决方法。
现在,你越多地折腾并努力加以解决,则以系统管理员的身份进行的准备就越充分。
你是系统管理员吗?你是否希望自己为更好的任务做好准备?在下面的评论中写下它们!
---
via: <https://opensource.com/article/19/7/be-a-sysadmin>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The system administrator of yesteryear jockeyed users and wrangled servers all day, in between mornings and evenings spent running hundreds of meters of hundreds of cables. This is still true today, with the added complexity of cloud computing, containers, and virtual machines.
Looking in from the outside, it can be difficult to pinpoint what exactly a sysadmin does, because they play at least a small role in so many places. Nobody goes into a career already knowing everything they need for a job, but everyone needs a strong foundation. If you're looking to start down the path of system administration, here's what you should be concentrating on in your personal or formal training.
## Bash
When you learn the Bash shell, you don't just learn the Bash shell. You learn a common interface to Linux systems, BSD, MacOS, and even Windows (under the right conditions). You learn the importance of syntax, so you can quickly adapt to systems like Cisco routers' command line or Microsoft's PowerShell, and eventually, you can even learn more powerful languages like Python or Go. And you also begin to think procedurally so you can analyze complex problems and break them down into individual components, which is key because *that's* how systems, like the internet, or an organization's intranet, or a web server, or a backup solution, are designed.
But wait. There's more.
Knowing the Bash shell has become particularly important because of the recent trend toward DevOps and [containers](https://opensource.com/article/19/6/kubernetes-dump-truck). Your career as a sysadmin may lead you into a world where infrastructure is treated like code, which usually means you'll have to know the basics of scripting, the structure of [YAML-based](https://www.redhat.com/sysadmin/yaml-tips) configuration, and how to [interact](https://opensource.com/article/19/6/how-ssh-running-container) with [containers](https://opensource.com/resources/what-are-linux-containers) (tiny Linux systems running inside a [sandboxed file](https://opensource.com/article/18/11/behind-scenes-linux-containers)). Knowing Bash is the gateway to efficient management of the most exciting open source technology, so go get [Bourne Again](https://opensource.com/article/18/7/admin-guide-bash).
### Resources
There are many ways to get practice in the Bash shell.
Try a [portable Linux distribution](https://opensource.com/article/19/6/linux-distros-to-try). You don't have to install Linux to use Linux, so grab a spare thumb drive and spend your evenings or weekends getting comfortable with a text-based interface.
There are several excellent [Bash articles](https://opensource.com/tags/bash) available here on opensource.com as well as [on Enable SysAdmin](https://www.redhat.com/sysadmin/managing-files-linux-terminal).
The problem with telling someone to practice with Bash is that to practice, you must have something to do. And until you know how to use Bash, you probably won't be able to think of anything to do. If that's your situation, go to Over The Wire and play [Bandit](http://overthewire.org/wargames/bandit). It's a game aimed at absolute beginners, with 34 levels of interactive basic hacking to get you comfortable with the Linux shell.
## Web server setup
Once you're comfortable with Bash, you should try setting up a web server. Not all sysadmins go around setting up web servers or even maintain web servers, but the skills you acquire while installing and starting the HTTP daemon, configuring Apache or Nginx, setting up the [correct permissions](https://opensource.com/article/19/6/understanding-linux-permissions), and [configuring a firewall](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd), are the same skills you need on a daily basis. After a little bit of effort, you may start to notice certain patterns in your labor. There are concepts you probably took for granted before trying to administer production-ready software and hardware, and you're no longer shielded from them in your fledgling role as an administrator. It might be frustrating at first because everyone likes to be good at everything they do, but that's actually a good thing. Let yourself be bad at new skills. That's how you learn.
And besides, the more you struggle through your first steps, the sweeter it is when you finally see that triumphant "it works!" default index.html.
### Resources
David Both wrote an excellent article on [Apache web server](https://opensource.com/article/18/2/how-configure-apache-web-server) configuration. For extra credit, step through his follow-up article on how to [host multiple sites](https://opensource.com/article/18/3/configuring-multiple-web-sites-apache) on one machine.
## DHCP
The Dynamic Host Configuration Protocol (DHCP) is the system that assigns IP addresses to devices on a network. At home, the modem or router your ISP (internet service provider) supports probably has an embedded DHCP server in it, so it's likely out of your purview. If you've ever logged into your home router to adjust the IP address range or set up a static address for some of your network devices, then you're at least somewhat familiar with the concept. You may understand that devices on a network are assigned the equivalent of phone numbers in the form of IP addresses, and you may realize that computers communicate with one another by broadcasting messages addressed to a specific IP address. Message headers are read by routers along the path, each of which works to direct the message to the next most logical router along the path toward its ultimate goal.
Even if you understand these concepts, the inevitable escalation of basic familiarity with DHCP is to set up a DHCP server. Installing and configuring your own DHCP server provides you the opportunity to introduce DHCP collisions on your home network (try to avoid that, if you can, as it will definitely kill your network until it's resolved), control the distribution of addresses, create subnets, and monitor connections and lease times.
More importantly, setting up DHCP and experimenting with different configurations helps you understand inter-networking. You understand how networks represent "partitions" in data transference and what steps you have to take to pass information from one to the other. That's vital for a sysadmin to know because the network is easily one of the most important aspects of the job.
### Resources
Before running your own DHCP server, ensure that the DHCP server in your home router (if you have one) is inactive. Once you have it up and running, read Archit Modi's [guide to network commands](https://opensource.com/article/18/7/sysadmin-guide-networking-commands) for tips on how to explore your network.
## Network cables
It might sound mundane, but getting familiar with how network cables work not only makes for a really fun weekend but also gives you a whole new understanding of how data gets across the wires. The best way to learn is to go to your local hobby shop and purchase a Cat 5 cutter and crimper and a few Cat 5 terminators. Then head home, grab a spare Ethernet cable, and cut the terminators off. Spend whatever amount of time it takes to get that cable back in commission.
Once you have solved that puzzle, do it again, this time creating a working [crossover cable](https://en.wikipedia.org/wiki/Ethernet_crossover_cable).
You should also start obsessing *now* about cable management. If you're not naturally inclined to run cables neatly along the floor molding or the edges of a desk or to bind cables together to keep them orderly, then make it a goal to permanently condition yourself with a phobia of messy cables. You won't understand why this is necessary at first, but the first time you walk into a server room, you will immediately know.
## Ansible
[Ansible](https://opensource.com/sitewide-search?search_api_views_fulltext=ansible) is configuration management software, and it's a bit of a bridge between sysadmin and DevOps. Sysadmins use Ansible to configure fresh installs of an operating system and to maintain specific states on machines. DevOps uses Ansible to reduce time and effort spent on tooling so that more time and effort gets spent on developing. You should learn Ansible as part of your sysadmin training, with an eye toward the practices of DevOps, because most of what DevOps is pioneering now will end up as part of your workflow in the system administration of the future.
The good thing about Ansible is that you can start using it now. It's cross-platform, and it scales both up and down. Ansible may be overkill for a single-user computer, but then again, Ansible could change the way you spin up virtual machines, or it could help you synchronize the states of all the computers in your home or [home lab](https://opensource.com/article/19/6/create-centos-homelab-hour).
### Resources
Read "[How to manage your workstation configuration with Ansible](https://opensource.com/article/18/3/manage-workstation-ansible)" by Jay LaCroix for the quintessential introduction to get started with Ansible on a casual basis.
## Break stuff
Problems arise on computers because of user error, buggy software, administrator (that's you!) error, and any number of other factors. There's no way to predict what's going to fail or why, so part of your personal sysadmin training regime should be to poke at the systems you set up until they fail. The worse you are to your own lab infrastructure, the more likely you are to find weak points. And the more often you repair those weak spots, the more confident you become in your problem-solving skills.
Aside from the rigors of setting up all the usual software and hardware, your primary job as a sysadmin is to find solutions. There will be times when you encounter a problem outside your job description, and it may not even be possible for you to fix it, but it'll be up to you to find a workaround.
The more you break stuff now and work to fix it, the better prepared you will be to work as a sysadmin.
Are you a working sysadmin? Are there tasks you wish you'd prepared better for? Add them in the comments below!
## 13 Comments |
11,610 | Linux 平台上的写作者必备工具 | https://www.linux.com/learn/2018/11/must-have-tools-writers-linux-platform | 2019-11-25T00:02:00 | [
"写作"
] | https://linux.cn/article-11610-1.html | 
我从事作家已有 20 多年了。我撰写了数千篇有关各种技术主题的文章和指南,并撰写了 40 多本小说。因此,书面文字不仅对我很重要,还很熟悉,成为了我的第二种自然交流的方式。在过去的二十年中(而且还在继续),我几乎都是在 Linux 平台上完成的所有工作。我必须承认,在早期,这并不总是那么容易。格式并不总是与编辑器所需要的相吻合,在某些情况下,开源平台根本没有完成工作所需的必要工具。
那时已经过去,现在已经不同了。
Linux 演进和基于 Web 的工具的相得益彰使得它可以让任何写作者都能在 Linux 上完成工作(并且做得很好)。但是你需要什么工具?你可能会惊讶地发现,在某些情况下,使用 100% 开源的工具无法有效完成这项工作。不过即使如此,工作总是可以完成的。让我们来看看我作为技术作家和小说作者一直使用的工具。我将通过小说和非小说类的写作过程来概述这一点(因为过程不同,需要特定的工具)。
对认真的 Linux 硬核用户预先做个预警。很久以前,我就放弃了使用 LaTeX 和 DocBook 之类的工具进行写作。为什么?因为对我而言,重点必须放在内容上,而不是过程上。当你面临最后期限时,必须以效率为先。
### 非小说类
我们将从非虚构写作入手,因为这是两者中较简单的过程。为了编写技术指南,我与不同的编辑人员合作,并且在某些情况下,必须将内容复制/粘贴到 CMS 中。但是就像我的小说一样,整个过程总是从 Google 云端硬盘开始。在这一点上,许多开源纯粹主义者会转身走开。不用担心,你始终可以选择将所有文件保存在本地,也可以使用更开放友好的云服务(例如 [Zoho](https://www.zoho.com/) 或 [nextCloud](https://nextcloud.com/))。
为什么要从云端开始?多年来,我发现我需要能够随时随地访问那些内容。最简单的解决方案是迁移到云上。我对丢失工作成果这件事也很偏执。为此,我使用了 [Insync](https://www.insynchq.com) 之类的工具来使我的 Google 云端硬盘与桌面保持同步。有了桌面同步功能,我知道我的工作成果总是有备份,以防万一 Google 云端硬盘出了问题。
对于那些我必须与之一起将内容输入到内容管理系统(CMS)的客户,该过程到此结束。我可以直接从 Google 文档复制/粘贴到 CMS 中,并完成此操作。当然,对于技术内容,总是涉及到屏幕截图。为此,我使用 [Gimp](https://www.gimp.org/),它使得截取屏幕截图变得简单:

*图 1:使用 Gimp 截屏。*
1. 打开 Gimp。
2. 单击“文件>创建>屏幕快照”。
3. 选择单个窗口、整个屏幕或要抓取的区域(图 1)。
4. 单击“抓取”。
我的大多数客户倾向于使用 Google 文档,因为我可以共享文件夹,以便他们可以可靠地访问该内容。我有一些无法使用 Google 文档的客户,因此我必须将文件下载为可以使用的格式。为此,我要做的是下载 .odt 格式,以 [LibreOffice](https://www.libreoffice.org/) 打开文档(图 2),根据需要设置格式,保存为客户所需的格式,然后发送文档。

*图 2:在 LibreOffice 中打开我下载的 Google 文档。*
非小说类作品这样就行了。
### 小说类
这里会稍微变得有点复杂。开始的步骤是相同的,因为我总是在 Google 文档中写小说的每个初稿。完成后,我将文件下载到 Linux 桌面,在 LibreOffice 中打开文件,根据需要设置格式,然后另存为编辑器支持的文件类型(不幸的是,这意味着是 .docx)。
该过程的下一步变得有些琐碎。我的编辑更喜欢使用注释来跟踪更改(因为这使我们俩阅读文档和做出更改一样容易)。因此,一个 60k 的 word 文档可以包含成百上千的注释,这会使 LibreOffice 慢的像爬一样。从前,你可以增加用于文档的内存,但是从 LibreOffice 6 开始,这不再可行。这意味着任何较大的、像小说一样长的、带有大量注释的文档都将无法使用。因此,我不得不采取一些极端的措施,使用 [WPS Office](https://www.wps.com/en-US/)(图 3)。尽管这不是开源解决方案,但 WPS Office 在文档中包含大量注释的情况下做得很好,因此无需处理 LibreOffice 所带来的麻烦(当处理带有数百个注释的大型文件时)。

*图 3:WPS 可以轻松处理大量注释。*
一旦我和我的编辑完成了对书的编辑(所有评论都已删除),我就可以在 LibreOffice 中打开文件进行最终格式化。格式化完成后,我将文件保存为 .html 格式,然后以 [Calibre](https://calibre-ebook.com/) 打开文件以将文件导出为 .mobi 和 .epub 格式。
对于希望在 Amazon、Barnes&Noble、Smashwords 或其他平台上出版的任何人,Calibre 都是必备工具。Caliber 比其他类似解决方案更好地方是,它使你可以直接编辑 .epub 文件(图 4)。对于 Smashword 来说,这是绝对必要的(因为导出过程将添加 Smashwords 转换工具上不接受的元素)。

*图 4:直接在 Calibre 中编辑 epub 文件。*
写作过程结束后(或有时在等待编辑完成一校时),我将开始为书制作封面。该任务完全在 Gimp 中处理(图 5)。

*图 5:在 Gimp 中创建 POTUS 的封面。*
这样就完成了在 Linux 平台上创建小说的过程。由于文档的篇幅以及某些编辑人员的工作方式,与创建非小说类的过程相比,它可能会变得有些复杂,但这远没有挑战性。实际上,在 Linux 上创建小说与其他平台一样简单(并且更可靠)。
### 希望这可以帮助你
我希望这可以帮助有抱负的作家有信心在 Linux 平台上进行写作。还有许多其他工具可供使用,但是多年来我在这里列出的工具很好地服务了我。而且,尽管我确实使用了几个专有的工具,但只要它们在 Linux 上都能正常运行,我觉得是可以的。
---
via: <https://www.linux.com/learn/2018/11/must-have-tools-writers-linux-platform>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
11,611 | awk 中的字段、记录和变量 | https://opensource.com/article/19/11/fields-records-variables-awk | 2019-11-25T09:03:54 | [
"awk"
] | https://linux.cn/article-11611-1.html |
>
> 这个系列的第二篇,我们会学习字段,记录和一些非常有用的 Awk 变量。
>
>
>

Awk 有好几个变种:最早的 `awk`,是 1977 年 AT&T 贝尔实验室所创。它还有一些重构版本,例如 `mawk`、`nawk`。在大多数 Linux 发行版中能见到的,是 GNU awk,也叫 `gawk`。在大多数 Linux 发行版中,`awk` 和 `gawk` 都是指向 GNU awk 的软链接。输入 `awk`,调用的是同一个命令。[GNU awk 用户手册](https://www.gnu.org/software/gawk/manual/html_node/History.html#History)中,能看到 `awk` 和 `gawk` 的全部历史。
这一系列的[第一篇文章](/article-11543-1.html) 介绍了 `awk` 命令的基本格式:
```
$ awk [选项] '模式 {动作}' 输入文件
```
`awk` 是一个命令,后面要接选项 (比如用 `-F` 来定义字段分隔符)。想让 `awk` 执行的部分需要写在两个单引号之间,至少在终端中需要这么做。在 `awk` 命令中,为了进一步强调你想要执行的部分,可以用 `-e` 选项来突出显示(但这不是必须的):
```
$ awk -F, -e '{print $2;}' colours.txt
yellow
blue
green
[...]
```
### 记录和字段
`awk` 将输入数据视为一系列*记录*,通常是按行分割的。换句话说,`awk` 将文本中的每一行视作一个记录。每一记录包含多个*字段*。一个字段由*字段分隔符*分隔开来,字段是记录的一部分。
默认情况下,`awk` 将各种空白符,如空格、制表符、换行符等视为分隔符。值得注意的是,在 `awk` 中,多个*空格*将被视为一个分隔符。所以下面这行文本有两个字段:
```
raspberry red
```
这行也是:
```
tuxedo black
```
其他分隔符,在程序中不是这么处理的。假设字段分隔符是逗号,如下所示的记录,就有三个字段。其中一个字段可能会是 0 个字节(假设这一字段中不包含隐藏字符)
```
a,,b
```
### awk 程序
`awk` 命令的*程序部分*是由一系列规则组成的。通常来说,程序中每个规则占一行(尽管这不是必须的)。每个规则由一个模式,或一个或多个动作组成:
```
模式 { 动作 }
```
在一个规则中,你可以通过定义模式,来确定动作是否会在记录中执行。模式可以是简单的比较条件、正则表达式,甚至两者结合等等。
这个例子中,程序*只会*显示包含单词 “raspberry” 的记录:
```
$ awk '/raspberry/ { print $0 }' colours.txt
raspberry red 99
```
如果没有文本符合模式,该动作将会应用到所有记录上。
并且,在一条规则只包含模式时,相当于对整个记录执行 `{ print }`,全部打印出来。
Awk 程序本质上是*数据驱动*的,命令执行结果取决于数据。所以,与其他编程语言中的程序相比,它还是有些区别的。
### NF 变量
每个字段都有指定变量,但针对字段和记录,也存在一些特殊变量。`NF` 变量,能存储 `awk` 在当前记录中找到的字段数量。其内容可在屏幕上显示,也可用于测试。下面例子中的数据,来自上篇文章[文本](/article-11543-1.html):
```
$ awk '{ print $0 " (" NF ")" }' colours.txt
name color amount (3)
apple red 4 (3)
banana yellow 6 (3)
[...]
```
`awk` 的 `print` 函数会接受一系列参数(可以是变量或者字符串),并将它们拼接起来。这就是为什么在这个例子里,每行结尾处,`awk` 会以一个被括号括起来的整数表示字段数量。
### NR 变量
另外,除了统计每个记录中的字段数,`awk` 也统计输入记录数。记录数被存储在变量 `NR` 中,它的使用方法和其他变量没有任何区别。例如,为了在每一行开头显示行号:
```
$ awk '{ print NR ": " $0 }' colours.txt
1: name color amount
2: apple red 4
3: banana yellow 6
4: raspberry red 3
5: grape purple 10
[...]
```
注意,写这个命令时可以不在 `print` 后的多个参数间添加空格,尽管这样会降低可读性:
```
$ awk '{print NR": "$0}' colours.txt
```
### printf() 函数
为了让输出结果时格式更灵活,你可以使用 `awk` 的 `printf()` 函数。 它与 C、Lua、Bash 和其他语言中的 `printf` 相类似。它也接受以逗号分隔的*格式*参数。参数列表需要写在括号里。
```
$ printf 格式, 项目1, 项目2, ...
```
格式这一参数(也叫*格式符*)定义了其他参数如何显示。这一功能是用*格式修饰符*实现的。`%s` 输出字符,`%d` 输出十进制数字。下面的 `printf` 语句,会在括号内显示字段数量:
```
$ awk 'printf "%s (%d)\n",$0,NF}' colours.txt
name color amount (3)
raspberry red 4 (3)
banana yellow 6 (3)
[...]
```
在这个例子里,`%s (%d)` 确定了每一行的输出格式,`$0,NF` 定义了插入 `%s` 和 `%d` 位置的数据。注意,和 `print` 函数不同,在没有明确指令时,输出不会转到下一行。出现转义字符 `\n` 时才会换行。
### Awk 脚本编程
这篇文章中出现的所有 `awk` 代码,都在 Bash 终端中执行过。面对更复杂的程序,将命令放在文件(*脚本*)中会更容易。`-f FILE` 选项(不要和 `-F` 弄混了,那个选项用于字段分隔符),可用于指明包含可执行程序的文件。
举个例子,下面是一个简单的 awk 脚本。创建一个名为 `example1.awk` 的文件,包含以下内容:
```
/^a/ {print "A: " $0}
/^b/ {print "B: " $0}
```
如果一个文件包含 `awk` 程序,那么在给文件命名时,最好写上 `.awk` 的扩展名。 这样命名不是强制的,但这么做,会给文件管理器、编辑器(和你)一个关于文件内容的很有用的提示。
执行这一脚本:
```
$ awk -f example1.awk colours.txt
A: raspberry red 4
B: banana yellow 6
A: apple green 8
```
一个包含 `awk` 命令的文件,在最开头一行加上释伴 `#!`,就能变成可执行脚本。创建一个名为 `example2.awk` 的文件,包含以下内容:
```
#!/usr/bin/awk -f
#
# 除了第一行,在其他行前显示行号
#
NR > 1 {
printf "%d: %s\n",NR,$0
}
```
可以说,脚本中只有一行,大多数情况下没什么用。但在某些情况下,执行一个脚本,比记住,然后打一条命令要容易的多。一个脚本文件,也提供了一个记录命令具体作用的好机会。以 `#` 号开头的行是注释,`awk` 会忽略它们。
给文件可执行权限:
```
$ chmod u+x example2.awk
```
执行脚本:
```
$ ./example2.awk colours.txt
2: apple red 4
2: banana yellow 6
4: raspberry red 3
5: grape purple 10
[...]
```
将 `awk` 命令放在脚本文件中,有一个好处就是,修改和格式化输出会更容易。在终端中,如果能用一行执行多条 `awk` 命令,那么输入多行,才能达到同样效果,就显得有些多余了。
### 试一试
你现在已经足够了解,`awk` 是如何执行指令的了。现在你应该能编写复杂的 `awk` 程序了。试着编写一个 awk 脚本,它需要: 至少包括一个条件模式,以及多个规则。如果你想使用除 `print` 和 `printf` 以外的函数,可以参考在线 [gawk 手册](https://www.gnu.org/software/gawk/manual/)。
下面这个例子是个很好的切入点:
```
#!/usr/bin/awk -f
#
# 显示所有记录 除了出现以下情况
# 如果第一个记录 包含 “raspberry”
# 将 “red” 替换成 “pi”
$1 == "raspberry" {
gsub(/red/,"pi")
}
{ print }
```
试着执行这个脚本,看看输出是什么。接下来就看你自己的了。
这一系列的下一篇文章,将会介绍更多,能在更复杂(更有用!) 脚本中使用的函数。
这篇文章改编自 [Hacker Public Radio](http://hackerpublicradio.org/eps.php?id=2129) 系列,一个技术社区博客。
---
via: <https://opensource.com/article/19/11/fields-records-variables-awk>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wenwensnow](https://github.com/wenwensnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Awk comes in several varieties: There is the original **awk**, written in 1977 at AT&T Bell Laboratories, and several reimplementations, such as **mawk**, **nawk**, and the one that ships with most Linux distributions, GNU awk, or **gawk**. On most Linux distributions, awk and gawk are synonyms referring to GNU awk, and typing either invokes the same awk command. See the [GNU awk user's guide](https://www.gnu.org/software/gawk/manual/html_node/History.html#History) for the full history of awk and gawk.
The [first article](https://opensource.com/article/19/10/intro-awk) in this series showed that awk is invoked on the command line with this syntax:
`$ awk [options] 'pattern {action}' inputfile`
Awk is the command, and it can take options (such as **-F** to define the field separator). The action you want awk to perform is contained in single quotes, at least when it's issued in a terminal. To further emphasize which part of the awk command is the action you want it to take, you can precede your program with the **-e** option (but it's not required):
```
$ awk -F, -e '{print $2;}' colours.txt
yellow
blue
green
[...]
```
## Records and fields
Awk views its input data as a series of *records*, which are usually newline-delimited lines. In other words, awk generally sees each line in a text file as a new record. Each record contains a series of *fields*. A field is a component of a record delimited by a *field separator*.
By default, awk sees whitespace, such as spaces, tabs, and newlines, as indicators of a new field. Specifically, awk treats multiple *space* separators as one, so this line contains two fields:
`raspberry red`
As does this one:
`tuxedo black`
Other separators are not treated this way. Assuming that the field separator is a comma, the following example record contains three fields, with one probably being zero characters long (assuming a non-printable character isn't hiding in that field):
`a,,b`
## The awk program
The *program* part of an awk command consists of a series of rules. Normally, each rule begins on a new line in the program (although this is not mandatory). Each rule consists of a pattern and one or more actions:
`pattern { action }`
In a rule, you can define a pattern as a condition to control whether the action will run on a record. Patterns can be simple comparisons, regular expressions, combinations of the two, and more.
For instance, this will print a record *only* if it contains the word "raspberry":
```
$ awk '/raspberry/ { print $0 }' colours.txt
raspberry red 99
```
If there is no qualifying pattern, the action is applied to every record.
Also, a rule can consist of only a pattern, in which case the entire record is written as if the action was **{ print }**.
Awk programs are essentially *data-driven* in that actions depend on the data, so they are quite a bit different from programs in many other programming languages.
## The NF variable
Each field has a variable as a designation, but there are special variables for fields and records, too. The variable **NF** stores the number of fields awk finds in the current record. This can be printed or used in tests. Here is an example using the [text file](https://opensource.com/article/19/10/intro-awk) from the previous article:
```
$ awk '{ print $0 " (" NF ")" }' colours.txt
name color amount (3)
apple red 4 (3)
banana yellow 6 (3)
[...]
```
Awk's **print** function takes a series of arguments (which may be variables or strings) and concatenates them together. This is why, at the end of each line in this example, awk prints the number of fields as an integer enclosed by parentheses.
## The NR variable
In addition to counting the fields in each record, awk also counts input records. The record number is held in the variable **NR**, and it can be used in the same way as any other variable. For example, to print the record number before each line:
```
$ awk '{ print NR ": " $0 }' colours.txt
1: name color amount
2: apple red 4
3: banana yellow 6
4: raspberry red 3
5: grape purple 10
[...]
```
Note that it's acceptable to write this command with no spaces other than the one after **print**, although it's more difficult for a human to parse:
`$ awk '{print NR": "$0}' colours.txt`
## The printf() function
For greater flexibility in how the output is formatted, you can use the awk **printf()** function. This is similar to **printf** in C, Lua, Bash, and other languages. It takes a *format* argument followed by a comma-separated list of items. The argument list may be enclosed in parentheses.
`$ printf format, item1, item2, ...`
The format argument (or *format string*) defines how each of the other arguments will be output. It uses *format specifiers* to do this, including **%s** to output a string and **%d** to output a decimal number. The following **printf** statement outputs the record followed by the number of fields in parentheses:
```
$ awk 'printf "%s (%d)\n",$0,NF}' colours.txt
name color amount (3)
raspberry red 4 (3)
banana yellow 6 (3)
[...]
```
In this example, **%s (%d)** provides the structure for each line, while **$0,NF** defines the data to be inserted into the **%s** and **%d** positions. Note that, unlike with the **print** function, no newline is generated without explicit instructions. The escape sequence **\n** does this.
## Awk scripting
All of the awk code in this article has been written and executed in an interactive Bash prompt. For more complex programs, it's often easier to place your commands into a file or *script*. The option **-f FILE** (not to be confused with **-F**, which denotes the field separator) may be used to invoke a file containing a program.
For example, here is a simple awk script. Create a file called **example1.awk** with this content:
```
/^a/ {print "A: " $0}
/^b/ {print "B: " $0}
```
It's conventional to give such files the extension **.awk** to make it clear that they hold an awk program. This naming is not mandatory, but it gives file managers and editors (and you) a useful clue about what the file is.
Run the script:
```
$ awk -f example1.awk colours.txt
A: raspberry red 4
B: banana yellow 6
A: apple green 8
```
A file containing awk instructions can be made into a script by adding a **#!** line at the top and making it executable. Create a file called **example2.awk** with these contents:
```
#!/usr/bin/awk -f
#
# Print all but line 1 with the line number on the front
#
NR > 1 {
printf "%d: %s\n",NR,$0
}
```
Arguably, there's no advantage to having just one line in a script, but sometimes it's easier to execute a script than to remember and type even a single line. A script file also provides a good opportunity to document what a command does. Lines starting with the **#** symbol are comments, which awk ignores.
Grant the file executable permission:
`$ chmod u+x example2.awk`
Run the script:
```
$ ./example2.awk colours.txt
2: apple red 4
2: banana yellow 6
4: raspberry red 3
5: grape purple 10
[...]
```
An advantage of placing your awk instructions in a script file is that it's easier to format and edit. While you can write awk on a single line in your terminal, it can get overwhelming when it spans several lines.
## Try it
You now know enough about how awk processes your instructions to be able to write a complex awk program. Try writing an awk script with more than one rule and at least one conditional pattern. If you want to try more functions than just **print **and **printf**, refer to [the gawk manual](https://www.gnu.org/software/gawk/manual/) online.
Here's an idea to get you started:
```
#!/usr/bin/awk -f
#
# Print each record EXCEPT
# IF the first record contains "raspberry",
# THEN replace "red" with "pi"
$1 == "raspberry" {
gsub(/red/,"pi")
}
{ print }
```
Try this script to see what it does, and then try to write your own.
The next article in this series will introduce more functions for even more complex (and useful!) scripts.
*This article is adapted from an episode of Hacker Public Radio, a community technology podcast.*
## 1 Comment |
11,613 | 如何在 Linux 上使用 pkgsrc | https://opensource.com/article/19/11/pkgsrc-netbsd-linux | 2019-11-26T06:46:07 | [
"pkgsrc"
] | /article-11613-1.html |
>
> NetBSD 的软件包管理器通用、灵活又容易。下面是如何使用它。
>
>
>

NetBSD 以能在几乎所有平台上运行而闻名,但你知道它*第二*有名的 [pkgsrc](http://pkgsrc.org) 包管理器吗?像 NetBSD 一样,pkgsrc 基本上可以在任何系统上运行,或者至少在任意 Unix 和类 Unix 的系统上上运行。你可以在 BSD、Linux、Illumos、Solaris 和 Mac 上安装 pkgsrc。它总共支持 20 多种操作系统。
### 为什么使用 pkgsrc?
除了 MacOS 之外,所有 Unix 操作系统均自带包管理器。你不一定*需要* pkgsrc,但这可能是你想尝试的三个重要原因:
* **打包**。如果你对打包感到好奇,但尚未尝试自己创建一个软件包,那么 pkgsrc 是一个相对简单的系统,尤其是如果你已经熟悉 Makefile 和类似 [GNU Autotools](https://opensource.com/article/19/7/introduction-gnu-autotools) 之类的构建系统时。
* **通用**。如果你使用多个操作系统或发行版,那么可能会遇到每个系统的包管理器。你可以在不同的系统上使用 pkgsrc,以便你为一个系统打包了程序,就为所有系统打包了。
* **灵活**。在许多打包系统中,如何选择二进制包或源码包并不总是很明显。使用 pkgsrc,区别很明显,两种安装方法都一样容易,并且都可以为你解决依赖关系。
### 如何安装 pkgsrc
无论你使用的是 BSD、Linux、Illumos、Solaris 还是 MacOS,安装过程都基本相同:
1. 使用 CVS 检出 pkgsrc 树
2. 引导 pkgsrc 系统
3. 安装软件包
#### 使用 CVS 检出 pkgsrc 树
在 Git 和 Subversion 之前,就有了 [CVS](http://www.netbsd.org/developers/cvs-repos/cvs_intro.html#intro)。要检出代码你无需了解 CVS 太多,如果你习惯 Git,那么可以将<ruby> 检出 <rt> checkout </rt></ruby>称为<ruby> 克隆 <rt> clone </rt></ruby>。当你用 CVS 检出 pkgsrc 时,你就下载了详细说明如何构建每个软件包的“<ruby> 配方 <rt> recipes </rt></ruby>”。它有很多文件,但是它们都很小,因为你实际上并没有拉取每个包的源码,而只有按需构建时需要的构建基础架构和 Makefile。使用 CVS,你可以轻松地在新版本发布时更新 pkgsrc 检出。
pkgsrc 文档建议将其源码树放在 `/usr` 目录下,因此你必须使用 `sudo`(或成为 root)运行此命令:
```
$ cd /usr
$ sudo cvs -q -z2 -d [email protected]:/cvsroot checkout -r pkgsrc-2019Q3 -P pkgsrc
```
在我撰写本文时,最新版本是 2019Q3。请检查 [pkgsrc.org](http://pkgsrc.org/) 主页的新闻部分或 [NetBSD文档](http://www.netbsd.org/docs/pkgsrc/getting.html),以确定最新版本。
#### 引导 pkgsrc
pkgsrc 树复制到你的计算机后,你会看到一个充满构建脚本的 `/usr/pkgsrc` 目录。在使用之前,你必须引导 pkgsrc,以便你可以轻松地访问构建和安装软件所需的相关命令。
引导 pkgsrc 的方式取决于你所使用操作系统。
对于 NetBSD,你只需使用捆绑的引导器:
```
# cd pkgsrc/bootstrap
# ./bootstrap
```
在其他系统上,还有更好的方法,包括一些自定义功能,它是由 Joyent 提供的。要了解运行的确切命令,请访问 [pkgsrc.joyent.com](http://pkgsrc.joyent.com/)。比如,在 Linux(Fedora、Debian、Slackware 等)上:
```
$ curl -O https://pkgsrc.joyent.com/packages/Linux/el7/bootstrap/bootstrap-trunk-x86_64-20170127.tar.gz
$ BOOTSTRAP_SHA="eb0d6911489579ca893f67f8a528ecd02137d43a"
```
尽管路径暗示文件适用于 RHEL 7,但二进制文件往往与所有(最前沿的 Linux 发行版)兼容。如果你发现二进制文件与你的发行版不兼容,你可以选择从源码构建。
验证 SHA1 校验和:
```
$ echo "${BOOTSTRAP_SHA}" bootstrap-trunk*gz > check-shasum
sha1sum -c check-shasum
```
你还可以验证 PGP 签名:
```
$ curl -O https://pkgsrc.joyent.com/packages/Linux/el7/bootstrap/bootstrap-trunk-x86_64-20170127.tar.gz.asc
$ curl -sS https://pkgsrc.joyent.com/pgp/56AAACAF.asc | gpg --import
$ gpg --verify ${BOOTSTRAP_TAR}{.asc,}
```
当你确认你已有正确的引导套件,将其安装到 `/usr/pkg`:
```
sudo tar -zxpf ${BOOTSTRAP_TAR} -C /
```
它为你提供了通常的 pkgsrc 命令。将这些位置添加到[你的 PATH 环境变量中](https://opensource.com/article/17/6/set-path-linux):
```
$ echo "PATH=/usr/pkg/sbin:/usr/pkg/bin:$PATH" >> ~/.bashrc
$ echo "MANPATH=/usr/pkg/man:$MANPATH" >> ~/.bashrc
```
如果你宁愿使用 pkgsrc 而不依赖于 Joyent 的构建,那么只需运行 pkgsrc 源码树的引导脚本即可。在运行特定于系统的脚本之前,请先阅读 `bootstrap` 目录中相关 `README` 文件。

### 如何使用 pkgsrc 安装软件
使用 pkgsrc 安装预编译的二进制文件(就像使用 DNF 或 Apt 一样)是很容易的。二进制安装的命令是 `pgkin`,它有自己的专门网站 [pkgin.net](http://pkgin.net)。对于任何用过 Linux 的人来说,这个过程应该感觉相当熟悉。
要搜索 `tmux` 包:
```
$ pkgin search tmux
```
要安装 tmux 包:
```
$ sudo pkgin install tmux
```
`pkgin` 命令的目的是模仿典型的 Linux 包管理器的行为,因此有选项可以列出可用的包、查找包提供的特定可执行文件,等等。
### 如何使用 pkgsrc 从源码构建
然而,pkgsrc 真正强大的地方是方便地从源码构建包。你在第一步中检出了所有 20000 多个构建脚本,你可以直接进入 pkgsrc 源码树来访问这些脚本。
例如,要从源码构建 `tcsh`,首先找到构建脚本:
```
$ find /usr/pkgsrc -type d -name "tcsh"
/usr/pkgsrc/shells/tcsh
```
接下来,进入源码目录:
```
$ cd /usr/pgksrc/shells/tcsh
```
构建脚本目录包含许多文件来帮助在你的系统上构建应用,但值得注意的是,这里面有包含了软件说明的 `DESCR` 文件,以及触发构建的 `Makefile`。
```
$ ls
CVS DESCR Makefile
PLIST distinfo patches
$ cat DESCR
TCSH is an extended C-shell with many useful features like
filename completion, history editing, etc.
$
```
准备就绪后,构建并安装:
```
$ sudo bmake install
```
pkgsrc 系统使用 `bmake` 命令(在第一步检出 pkgsrc 后提供),因此请务必使用 `bmake`(而不是出于习惯使用 `make`)。
如果要为多个系统构建,那么你可以创建一个包,而不是立即安装:
```
$ cd /usr/pgksrc/shells/tcsh
$ sudo bmake package
[...]
=> Creating binary package in /usr/pkgsrc/packages/All/tcsh-X.Y.Z.tgz
```
pkgsrc 创建的包是标准的 tarball,但它可以方便地通过 `pkg_add` 安装:
```
$ sudo pkg_add /usr/pkgsrc/packages/All/tcsh-X.Y.Z.tgz
tcsh-X.Y.Z: adding /usr/pkg/bin/tcsh to /etc/shells
$ tcsh
localhost%
```
pkgsrc 的 pkgtools 集合提供 `pkg_add`、`pkg_info`、`pkg_admin`、`pkg_create` 和 `pkg_delete` 命令,来帮助管理你在系统上构建和维护软件包。
### pkgsrc,易于管理
pkgsrc 系统提供了直接,容易上手的软件包管理方法。如果你正在寻找一个不妨碍你并且可以定制的包管理器,请在任何运行 Unix 或类 Unix 的系统上试试 pkgsrc。
---
via: <https://opensource.com/article/19/11/pkgsrc-netbsd-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.