
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
12,427 | GIMP 教程:如何使用 GIMP 裁剪图像 | https://itsfoss.com/crop-images-gimp/ | 2020-07-17T23:25:42 | [
"GIMP"
] | https://linux.cn/article-12427-1.html | 你可能想在 [GIMP](https://www.gimp.org/) 中裁剪图像的原因有很多。例如,你可能希望删除无用的边框或信息来改善图像,或者你可能希望最终图像的焦点是在一个特定细节上。
在本教程中,我将演示如何在 GIMP 中快速裁剪图像而又不影响精度。让我们一起来看看吧。
### 如何在 GIMP 中裁剪图像

#### 方法 1
裁剪只是一种将图像修整成比原始图像更小区域的操作。裁剪图像的过程很简单。
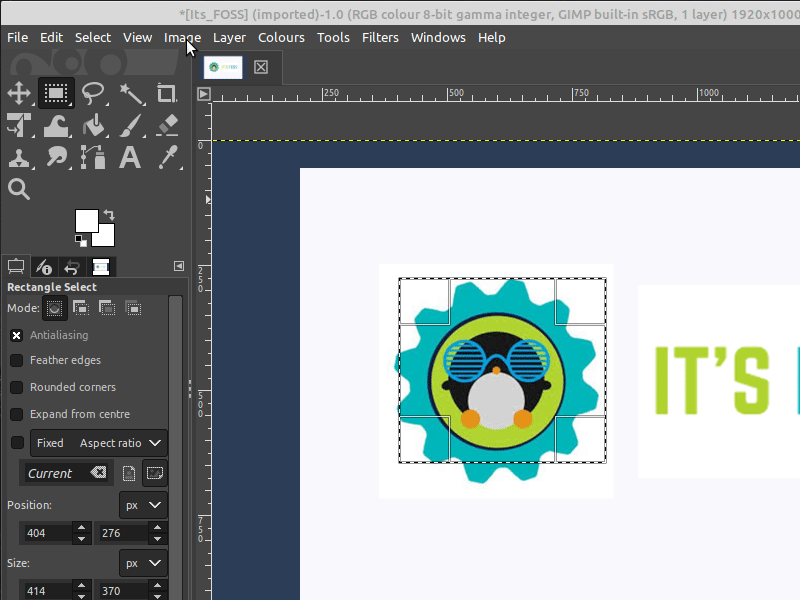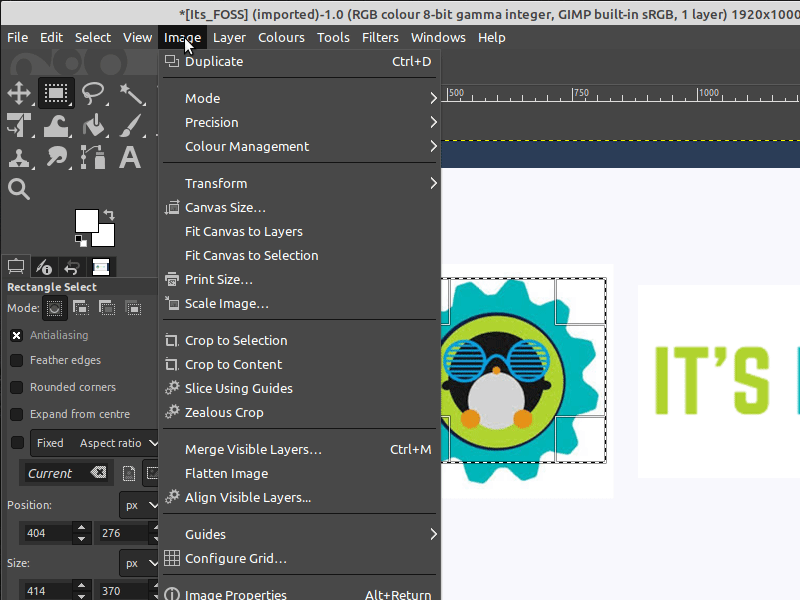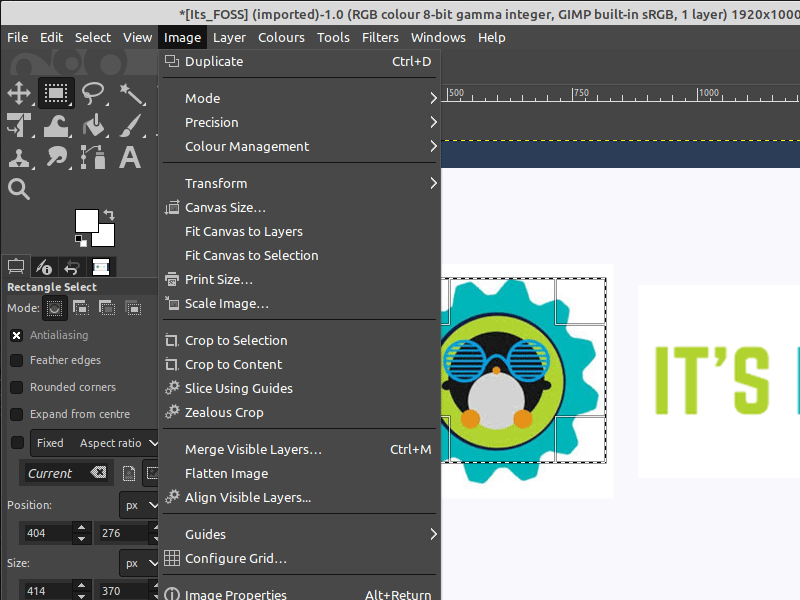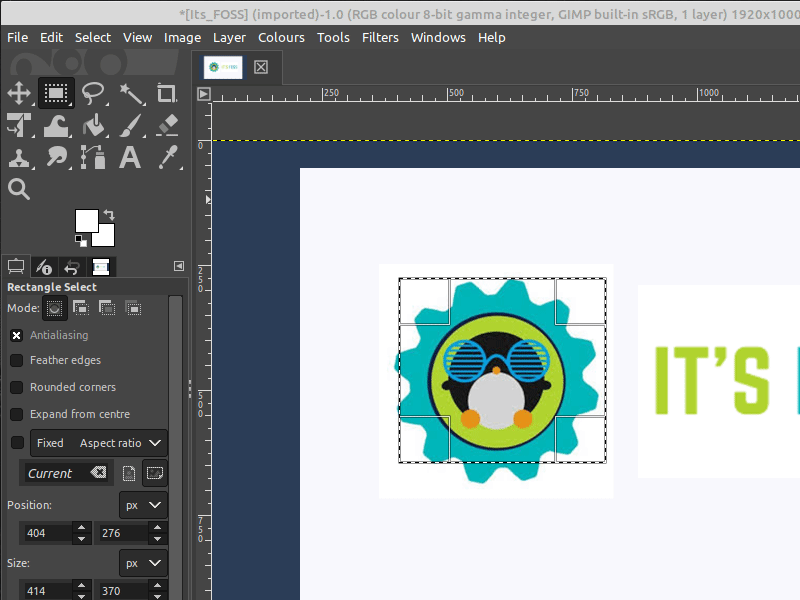
你可以通过“工具”面板访问“裁剪工具”,如下所示:

你还可以通过菜单访问裁剪工具:“<ruby> 工具 → 变形工具 → 裁剪 <rt> Tools → Transform Tools → Crop </rt></ruby>”。
激活该工具后,你会注意到画布上的鼠标光标会发生变化,以表示正在使用“裁剪工具”。
现在,你可以在图像画布上的任意位置单击鼠标左键,并将鼠标拖到某个位置以创建裁剪边界。此时你不必担心精度,因为你可以在实际裁剪之前修改最终选区。

此时,将鼠标光标悬停在所选内容的四个角上会更改鼠标光标并高亮显示该区域。现在,你可以微调裁剪的选区。你可以单击并拖动任何边或角来移动部分选区。
选定完区域后,你只需按键盘上的回车键即可进行裁剪。
如果你想重新开始或者不裁剪,你可以按键盘上的 `Esc` 键。
#### 方法 2
裁剪图像的另一种方法是使用“矩形选择工具”进行选择:“<ruby> 工具 → 选择工具 → 选择矩形 <rt> Tools → Selection Tools → Rectangle Select </rt></ruby>”。

然后,你可以使用与“裁剪工具”相同的方式高亮选区,并调整选区。选择好后,可以通过以下方式裁剪图像来适应选区:“<ruby> 图像 → 裁剪为选区 <rt> Image → Crop to Selection </rt></ruby>”。

### 总结
对于 GIMP 用户而言,精确裁剪图像可以视为一项基本功能。你可以选择哪种方法更适合你的需求并探索其潜力。
如果你对过程有任何疑问,请在下面的评论中告诉我。如果你“渴望”更多 [GIMP 教程](https://itsfoss.com/tag/gimp-tips/),请确保在你喜欢的社交媒体平台上订阅!
---
via: <https://itsfoss.com/crop-images-gimp/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There are many reasons you may want to crop an image in [GIMP](https://www.gimp.org/?ref=itsfoss.com). You may want to remove useless borders or information to improve your image, or you may want the focus of the final image to be a specific detail for example.
In this tutorial, I will demonstrate how to cut out an image in GIMP quickly and without compromising the precision. Let’s see.
## Method 1: Use the crop tool in GIMP
Cropping is just an operation to trim the image down to a smaller region than the original one. The procedure to crop an image is straightforward.
You can get to the Crop Tool through the Tools palette like this:
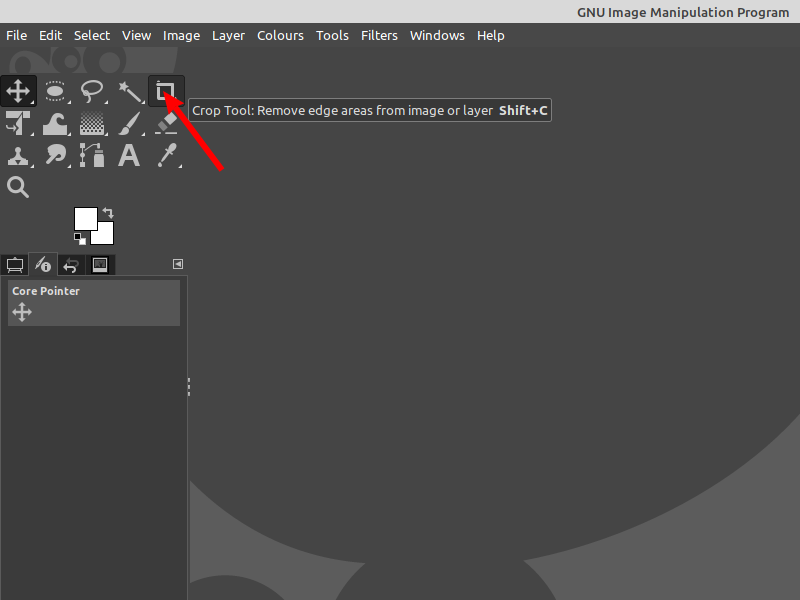
Use Crop Tool for cropping images in GIMP
You can also access the crop tool through the menus:
**Tools → Transform Tools → Crop**
Once the tool is activated, you’ll notice that your mouse cursor on the canvas will change to indicate the Crop Tool is being used.
Now you can Left-Click anywhere on your image canvas, and drag the mouse to a location to create the cropping boundaries. You don’t have to worry about the precision at this point, as you will be able to modify the final selection before actually cropping.
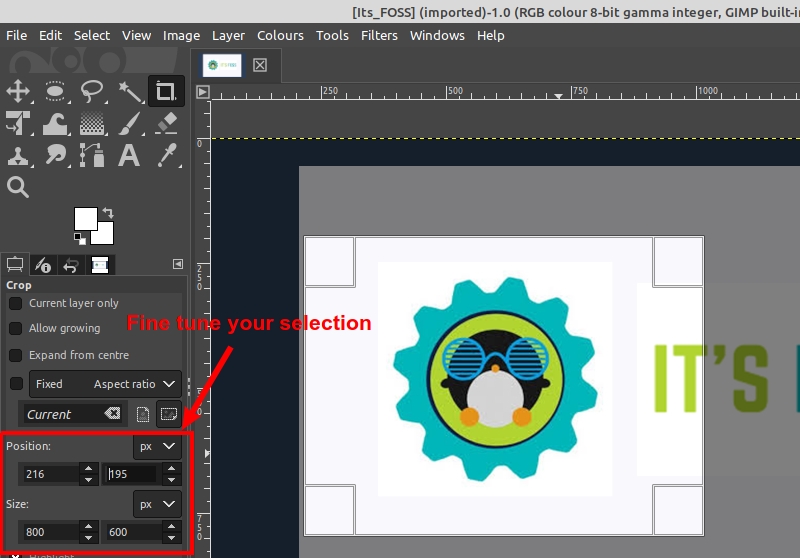
At this point hovering your mouse cursor over any of the four corners of the selection will change the mouse cursor, and highlight that region. This allows you to now fine-tune the selection for cropping. You can click and drag any side or corner to move that portion of the selection.
Once the region is good enough to be cropped, you can just press the “**Enter**” key on your keyboard to crop.
If at any time you’d like to start over or decide not to crop at all, you can press the “**Esc**” key on your keyboard.
## Method 2: Use rectangle select tool to crop images
Another way to crop an image is to make a selection first, using the **Rectangle Select Tool**.
**Tools → Selection Tools → Rectangle Select**
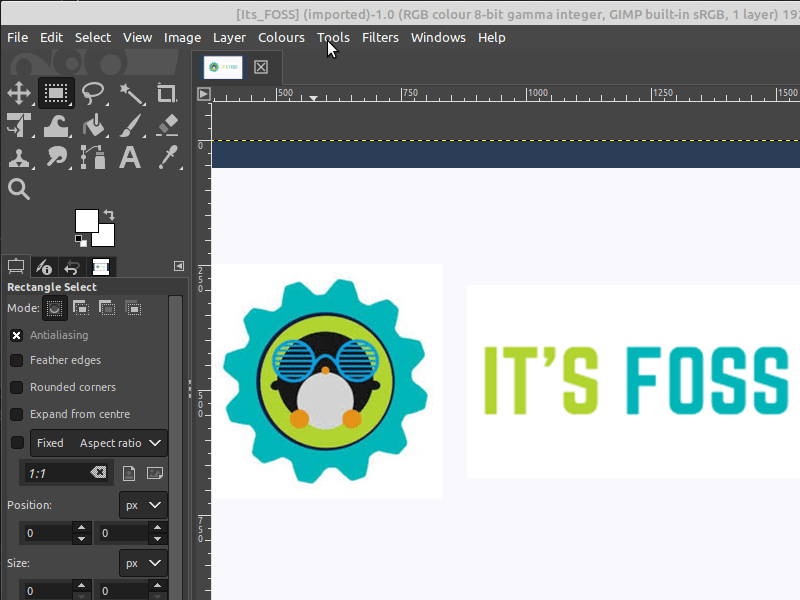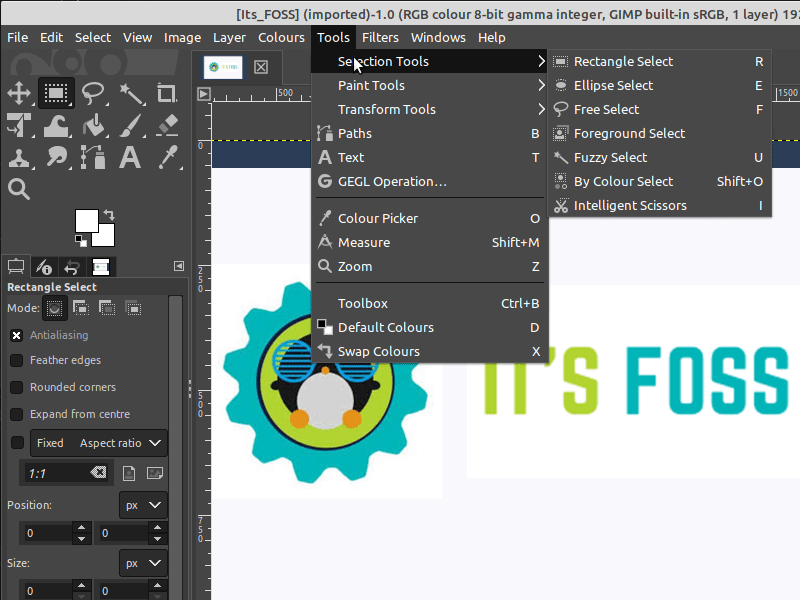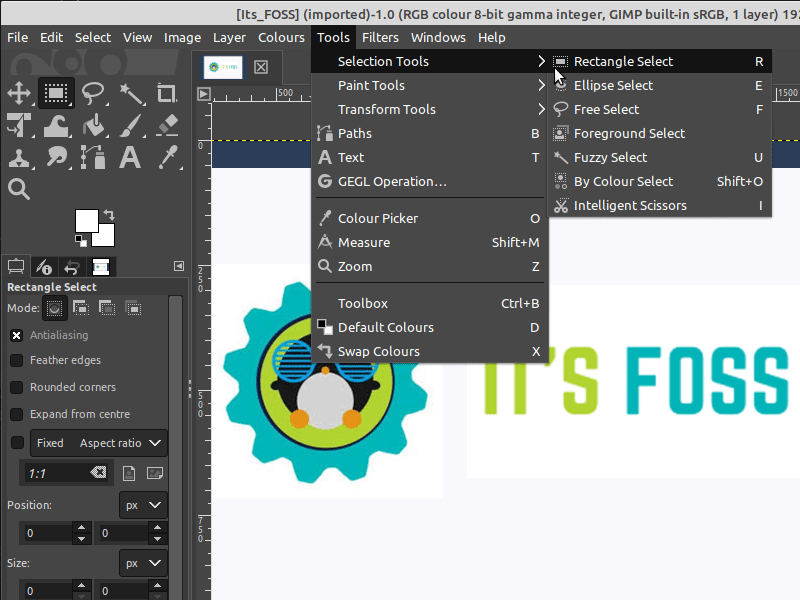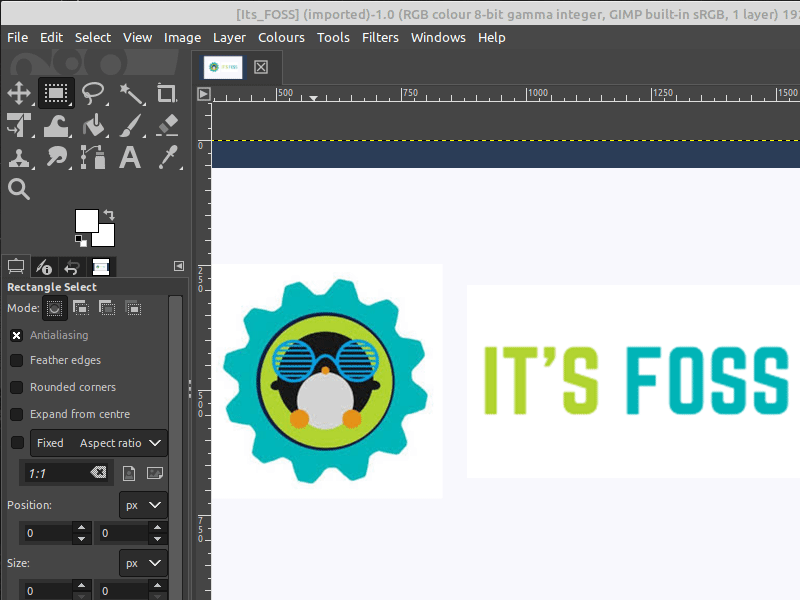
You can then highlight a selection the same way as the **Crop Tool**, and adjust the selection as well. Once you have a selection you like, you can crop the image to fit that selection through
**Image → Crop to Selection**
## Conclusion
Cropping precisely an image can be considered a fundamental asset for a GIMP user. You may choose which method fits better to your needs and explore its potential.
If you have any questions about the procedure, please let me know in the comments below. If you are “craving” more [GIMP tutorials](https://itsfoss.com/tag/gimp/), make sure to subscribe on your favorite social media platforms! |
12,429 | 深入了解定制 Bash | https://fedoramagazine.org/customizing-bash/ | 2020-07-19T11:04:00 | [
"Bash",
"点文件"
] | https://linux.cn/article-12429-1.html | 
操作系统的最外层 —— 也就是跟你直接打交道的 —— 叫做 [shell](https://en.wikipedia.org/wiki/Shell_(computing))(“外壳”)。Fedora 预装了好几种不同的 shell。shell 可以是图形界面,或者字符界面。在文档中,你常常能见到两个母缩写词 GUI (<ruby> 图形用户界面 <rt> Graphical User Interface </rt></ruby>)跟 CLI(<ruby> 命令行界面 <rt> Command-Line Interface </rt></ruby>),它们用来区分图形和基于字符的 shell/界面。[GNOME](https://en.wikipedia.org/wiki/GNOME) 和 [Bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) 分别是 Fedora 默认的图形和命令行界面,不过你也可以使用其它 [GUI](https://fedoramagazine.org/fedoras-gaggle-of-desktops/) 或者 [CLI](https://en.wikipedia.org/wiki/Comparison_of_command_shells) shell。
接下来在这篇文章中,我们会讨论一些比较推荐的 Bash 字符界面的点文件配置。
### Bash 概览
Bash 参考手册中写道:
>
> 根本上来说,shell 只是一个能执行命令的宏处理器。宏处理器这个词意味着通过扩展文本跟符号,从而构成更复杂的表达式。
>
>
> **Bash 参考手册** **第五版,Bash 5.0** **2019 年 5 月**
>
>
>
除了能使用其它程序之外,Bash shell 还含有一些内置命令和关键字。Bash 内置功能很强大,甚至能够作为一门 [高级语言](https://en.wikipedia.org/wiki/High-level_programming_language) 独当一面。Bash 的几个关键字和操作符类似于 [C 语言](https://en.wikipedia.org/wiki/C_(programming_language))。
Bash 能够以交互式或非交互式模式启动。Bash 的交互模式是一个很多人都熟悉的典型的终端/命令行界面。[GNOME 终端](https://en.wikipedia.org/wiki/GNOME_Terminal) 默认以交互模式打开 Bash。Bash 在非交互模式下运行的例子是,当命令和数据从文件或 shell 脚本通过 [管道](https://en.wikipedia.org/wiki/Pipeline_(Unix)) 传送到 Bash 时。其它 Bash 可以运行的模式包括:<ruby> 登录 <rt> login </rt></ruby>、<ruby> 非登录 <rt> non-login </rt></ruby>、<ruby> 远程 <rt> remote </rt></ruby>、POSIX、Unix sh、<ruby> 受限 <rt> restricted </rt></ruby>,以及使用与用户不同的 UID/GID 模式。各种模式是可以相互组合的。比如,交互式 + 受限 + POSIX 或者非交互式 + 非登录 + 远程。不同的启动模式,决定着 Bash 所读取的启动文件。理解这些操作模式,有助于帮助我们修改启动文件。
根据 Bash 参考手册,它会:
>
> 1. 从文件中...、从作为 `-c` 调用选项传入参数的字符...,或者从用户的终端中读取输入。
> 2. 将输入分解成单词和操作符,遵循 [它的] 引用规则。...这些标记使用元字符隔开。这一步执行别名展开。
> 3. 将标记解析成简单与复合命令。
> 4. 执行各种 shell 展开...,将展开之后的标记分解成文件名...以及命令和参数的列表。
> 5. 执行必要的重定向...并从参数列表中去除重定向操作符及其操作数。
> 6. 执行命令。
> 7. 必要时等待命令完成,并收集退出状态。
>
>
> **Bash 参考文档** **第五版,Bash 版本 5.0** **2019 年 5 月**
>
>
>
当用户开启终端模拟器进入命令行环境时,便启动了一次交互式 shell 会话。GNOME 终端默认以非登录模式为用户打开 Shell。你可以在 “<ruby> 编辑 → 首选项 → 配置文件 → 命令 <rt> Edit → Preferences → Profilles → Command </rt></ruby>” 中配置 GNOME 终端以何种模式(登录与非登录式)启动。也可以在 Bash 启动时通过向其传递 `-login` 标志来要求进入登录模式。要注意一点,Bash 的登录模式与非交互模式并不互斥。可以让 Bash 同时以登录模式和非交互模式运行。
### 启动 Bash
除非传入 `-noprofile` 选项,否则登录模式的 Bash shell 会默认读取并执行某些初始化文件中命令。如果 `/etc/profile` 存在,它会是第一个被执行的文件,紧接着是按 `~/.bash_profile`、`~/.bash_login` 或 `~/.profile`顺序找到的第一个文件。当用户退出登录模式的 shell 时,或者有脚本在非交互式登录模式的 shell 中调用了内置 `exit`命令,Bash 会读取并执行 `~/.bash_logout` 中的命令,如果 `/etc/bash_logout` 存在的话,会紧接着执行它。通常来说,`/etc/profile` 会<ruby> 援引 <rt> source </rt></ruby> `/etc/bashrc` 文件,读取并执行其中的命令,然后查找并读取执行 `/etc/profile.d` 目录中以 `.sh` 结尾的文件。同样的,`~/.bash_profile` 通常也会<ruby> 援引 <rt> source </rt></ruby> `~/.bashrc` 文件。`/etc/bashrc` 和 `~/.bashrc` 都会进行检查,避免重复<ruby> 援引 <rt> source </rt></ruby>。
(LCTT 译注:在 Bash 中,脚本会通过 `source` 或 `.` 命令来将另外一个脚本引入其中,这个行为称之为 “source”、“sourcing”,但是该行为一直没有公认且常用的翻译方法。经过多番斟酌,我认为可以译做“援引”,理由如下:1、“援引”具有“引用、引入”的意思,符合该行为;2、“援”这个词的发音和“source” 常见的汉语意思“源”同音,便于记忆。以上是我们的愚见,供大家参考讨论。—— 老王,2020/7/19)
一个交互式的 shell,如果不是登录 shell,那么当它第一次被调用的时候,会执行 `~/.bashrc` 文件。这是用户在 Fedora 上打开终端时通常会进入的 shell 类型。当 Bash 以非交互模式启动 —— 就像运行脚本时那样 —— 它会寻找 `BASH_ENV`环境变量。如果找到了,就会展开它的值作为文件名,接着读取并执行该文件。效果跟执行以下命令相同:
```
if [ -n "$BASH_ENV" ]; then . "$BASH_ENV"; fi
```
值得注意的是,不会使用 `PATH` 环境变量的值来搜索该文件名(LCTT 译注:意即不会检索搜索路径)。
### 重要的用户点文件
Bash 最广为人知的用户点文件是 `~/.bashrc`。通过编辑该文件,可以设置大多数个性化选项。由于我们常常需要设置一些选项,会改动上面提及甚至没有提及的文件,所以大部分自定义选项会成为一个麻烦事。Bash 环境具有很高的可定制性,正是为了适应不同用户的不同需求。

当登录 shell 正常退出时,如果 `~/.bash_logout` 和 `/etc/bash_logout` 存在,它们会被调用。下一幅图展示了 Bash 作为交互式 shell 启动时的过程。例如,当用户从桌面环境打开终端模拟器时,会按照以下顺序进行。

我们已经知道,在不同的启动模式下,Bash 会执行不同的命令,所以很明显,只有几种最需要关注的典型启动模式。分别是非交互、交互式登录 shell,和非交互式、交互式非登录 shell。如果想定义某些全局环境,那么需要将一个具有唯一名称、以 `.sh` 为后缀的文件(例如 `custom.sh`)放置在 `/etc/profile.d` 目录。
对于非交互式非登录启动方式,需要特别注意。在这种模式下,Bash 会检查 `BASH_ENV` 变量。如果定义了该变量,Bash 会援引它所指向的文件。另外,处理 `BASH_ENV` 时并不会使用 `PATH` 变量所存储的值(LCTT 译注:意即不会检索搜索路径),所以它必须包含执行文件的绝对路径。比如说,如果有人希望非交互式执行脚本时,shell 能读取 `~/.bashrc` 文件中的设置,那么他可以把类似下面这样的内容放在一个名为 `/etc/profile.d/custom.sh` 的文件中...
```
# custom.sh
.
.
.
# 如果使用 Fedora Workstation
BASH_ENV="/home/username/.bashrc"
.
.
.
# 如果使用 Fedora Silverblue Workstation
BASH_ENV="/var/home/username/.bashrc"
export BASH_ENV
```
上面这份脚本会让每个 shell 脚本在运行之前先执行该用户的 `~/.bashrc`。
用户一般都会自定义他们的系统环境,以便契合他们自己的工作习惯与偏好。举例来说,用户可以通过别名来实现这种程度的自定义。拥有相同起始参数、需要频繁使用的命令是制作别名的最佳选择。以下展示了一些来自 `~/.bashrc` 文件中定义的别名。
```
# .bashrc
# 执行全局文件
if [ -f /etc/bashrc ];
then . /etc/bashrc
fi
.
.
.
# 用户别名和函数
alias ls='ls -hF --color=auto'
alias la='ls -ahF --color=auto'
# 让 dir 命令用起来像在 Windows 那样
alias dir='ls --color=auto --format=long'
# 用颜色高亮 grep 结果
alias grep='grep --color=auto'
```
在系统中,别名是一种自定义各种命令的方法。它能减少击键次数,而且让命令用起来更方便。针对用户级别的别名通常存放在该用户的 `~/.bashrc` 文件中。
如果你发现自己经常要去历史中查找曾经执行过的某条命令,那可能需要改改历史设置了。你依然可以在 `~/.bashrc` 文件中设置针对用户级别的历史选项。比如说,如习惯同时使用多个终端,那你可能要启用 `histappend` 选项。某些 Bash 相关的 shell 选项本质上是布尔值(接收 `on` 或 `off`),通常可以用内置命令 `shopt` 启用或禁用。接收更复杂的值的 Bash 选项(如 `HISTTIMEFORMAT`),常常通过赋值给环境变量来达到配置目的。以下演示如何以 shell 选项和环境变量定制 Bash。
```
# 配置 Bash 历史
# 用制表符扩展目录环境变量,并设置 histappend
shopt -s direxpand histappend
# ignoreboth 等同于 ignorespace 和 ignoredup
HISTCONTROL='ignoreboth'
# 控制 `history` 输出中的时间格式
HISTTIMEFORMAT="[%F %T] "
# 无限历史记录
# NB:在新版 Bash 中,任何 < 0 的写法都有效,但是在 CentOS/RHEL 中,只有这样才行得通
HISTSIZE=
HISTFILESIZE=
# 或者对于使用新版 Bash 的人
HISTSIZE=-1
HISTFILESIZE=-1
```
上面例子中的 `direxpand` 选项,可以让 Bash 在文件名补全时,用单词展开结果替换目录名。它会改变 readline 编辑缓冲区的内容,所以你所输入的东西已经被补全得到的结果替换了。
`HISTCONTROL` 变量用于启用或禁用命令历史的某些过滤选项。重复行、以空白打头的行,都能通过该选项将它们从命令历史中过滤掉。引用自 Dusty Mabe,这是我从他那儿得到的技巧:
>
> `ignoredup` 可以让历史不记录重复条目(如果你反复执行同一条命令)。`ignorespace` 会忽略前面有空白的条目,当你在设置一个包含敏感信息的环境变量或者执行一条不想被记录进磁盘的命令时,这就很有用。`ignoreboth`相当于这两条选项的结合体。
>
>
> **Dusty Mabe – Redhat首席软件工程师,2020.6.19**
>
>
>
对于命令行重度用户,Bash 有一个 `CDPATH` 环境变量。如果 `CDPATH` 包含一系列供 `cd` 命令搜索的目录,且提供一个相对路径作为第一个参数,那么它会按顺序检查所有列出的目录,寻找匹配的子目录并切换到第一个匹配结果目录。
```
# .bash_profile
# 设置 CDPATH
CDPATH="/var/home/username/favdir1:/var/home/username/favdir2:/var/home/username/favdir3"
# 也可以写成这样
CDPATH="/:~:/var:~/favdir1:~/favdir2:~/favdir3"
export CDPATH
```
`CDPATH` 通常像 `PATH` 一样的方式进行更新 —— 通过在赋值右侧引用自身来保留原来的值。
```
# .bash_profile
# 设置 CDPATH
CDPATH="/var/home/username/favdir1:/var/home/username/favdir2:/var/home/username/favdir3"
# 或者写成这样
CDPATH="/:~:/var:~/favdir1:~/favdir2:~/favdir3"
CDPATH="$CDPATH:~/favdir4:~/favdir5"
export CDPATH
```
`PATH` 是另一个极其重要的变量。它是系统上的命令的搜索路径。注意,有些应用要求将它们自己的目录加入 `PATH` 变量,这样才能正常使用。跟 `CDPATH` 一样,通过在赋值右侧引用原值来追加新值到 `PATH` 变量。如果你希望将新值前置,只需要把原来的值(`$PATH`)放到列表末尾即可。还有注意的是在 Fedora,这一列值通过冒号分隔(`:`)。
```
# .bash_profile
# 添加 PATH 值到 PAHT 环境变量
PATH="$PATH:~/bin:~:/usr/bin:/bin:~/jdk-13.0.2:~/apache-maven-3.6.3"
export PATH
```
命令提示符是另一个流行的自定义选项。它有七个可定制的参数:
>
> * `PROMPT_COMMAND`:如果设置了,会在每一个主提示符(`$PS1`)出现之前执行该值。
> * `PROMPT_DIRTRIM`:如果设置成大于零的数,则该值用作展开 `\w` 和 `\W` 提示符字符串转义符时保留的尾随目录组件数量。删除的字符将替换为省略号。
> * `PS0`:这个参数的值像 `PS1` 一样展开,在交互式 shell 读取命令之后、执行命令之前展示。
> * `PS1`:主提示符字符串。默认值是 `\s-\v\$` 。
> * `PS2`:次提示符字符串。默认是 `>` 。在显示之前,`PS2` 像 `PS1` 那样展开。
> * `PS3`:这个参数的值用作 `select` 命令的提示符。如果这个变量没有设置,`select` 命令会用 `#?` 作为提示符。
> * `PS4`:这个参数的值像 `PS1` 那样展开,如果设置了 `-x` 选项,这个展开值会在命令行被回显之前作为提示符显示。展开后的值的第一个字符在必要时会复制数次,指示间接层数。默认值是 `+` 。
>
>
> **Bash 参考文档** **第五版,Bash 版本 5.0** **2019 年 5 月**
>
>
>
Bash 的这一个方面就可以用整篇文章来讨论。你可以找到许许多多信息和例子。在本文末尾链接的存储库中提供了一些点文件范例,包括提示符重新配置。你可以随意使用该存储库中的例子进行学习和体验。
### 总结
既然你已经掌握了一些 Bash 的工作原理,那就可以轻松修改你的 Bash 点文件,满足你自己的需求和习惯。美化你的提示符,制作一些别名,这样你的电脑才真的属于你。查看 `/etc/profile`、`/etc/bashrc` 和 `/etc/profile.d/` 这些文件的内容,获得一些启发。
你也可以在这里写一些关于终端模拟器的评论。有很多办法可以将你最喜欢的终端,完全配置成你想要的样子。你或许早就想到了,但是通常可以通过……嗯……用户家目录的点文件实现这个目的。终端模拟器也可以作为登录会话启动,有些人总喜欢用登录环境。你使用终端和电脑的姿势,取决于你如何修改(或不修改)你的点文件。
如果你很好奇自己的命令行处于什么会话状态,使用下面这个脚本来判断一下。
```
#!/bin/bash
case "$-" in
(*i*) echo This shell is interactive ;;
(*) echo This shell is not interactive ;;
esac
```
把这几行放到一个文件里,加上可执行权限,然后运行,就能看到你当前处于何种类型的 shell。`$-` 在 Bash 中是一个变量,如果是交互式 shell,它会包含字母 `i`。此外,你可以直接输出 `$-` 变量然后检查它的输出中是否含有 `i` 标记。
```
$ echo $-
```
### 参考信息
可以参考以下资料以获取更多信息和示例。Bash 手册也是一个很好的信息来源。请注意,确保你的本地手册页记录了你当前运行的 Bash 版本的特性,因为在网上找到的信息有时可能太老(过时了)或太新(你的系统还没有安装)。
* <https://opensource.com/tags/command-line>
* <https://opensource.com/downloads/bash-cheat-sheet>(在该网站中,你必须要输入一个有效的电子邮箱地址,或者注册,才能下载。)
* <https://opensource.com/article/19/12/bash-script-template>
对本文有各种形式(点文件示例、提示,以及脚本文件)贡献的社区成员:
* Micah Abbott – 首席质量工程师
* John Lebon – 首席软件工程师
* Dusty Mabe – 首席软件工程师
* Colin Walters – 高级首席软件工程师
示例点文件和脚本可以在这个存储库中找到:
* <https://github.com/TheOneandOnlyJakfrost/bash-article-repo>
请仔细检查上面所提供的存储库中的信息。有些可能已经过时了。里面还包含很多开发中的自定义脚本和<ruby> 宠物容器 <rt> pet container </rt></ruby>配置例子,那些不是点文件。我推荐从 John Lebon 的点文件开始学习,从头到尾都含有完善的解说,它们是我见过的最详细的,并且包含了非常好的描述。祝你学得开心!
---
via: <https://fedoramagazine.org/customizing-bash/>
作者:[Stephen Snow](https://fedoramagazine.org/author/jakfrost/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[nophDog](https://github.com/nophDog) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The outermost layer of your operating system – the part you interact with – is called the [shell](https://en.wikipedia.org/wiki/Shell_(computing)). Fedora comes with several preinstalled shells. Shells can be either graphical or text-based. In documentation, you will often see the acronyms GUI (Graphical User Interface) and CLI (Command-Line Interface) used to distinguish between graphical and text-based shells/interfaces. Other [GUI](https://fedoramagazine.org/fedoras-gaggle-of-desktops/) and [CLI](https://en.wikipedia.org/wiki/Comparison_of_command_shells) shells can be used, but [GNOME](https://en.wikipedia.org/wiki/GNOME) is Fedora’s default GUI and [Bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) is its default CLI.
The remainder of this article will cover recommended dotfile practices for the Bash CLI.
## Bash overview
From the Bash reference manual:
At its base, a shell is simply a macro processor that executes commands. The term macro processor means functionality where text and symbols are expanded to create larger expressions.
Reference Documentation for Bash
Edition 5.0, for Bash Version 5.0.
May 2019
In addition to helping the user start and interact with other programs, the Bash shell also includes several built-in commands and keywords. Bash’s built-in functionality is extensive enough that it is considered a [high-level programming language](https://en.wikipedia.org/wiki/High-level_programming_language) in its own right. Several of Bash’s keywords and operators resemble those of [the C programming language](https://en.wikipedia.org/wiki/C_(programming_language)).
Bash can be invoked in either interactive or non-interactive mode. Bash’s interactive mode is the typical terminal/command-line interface that most people are familiar with. [GNOME Terminal](https://en.wikipedia.org/wiki/GNOME_Terminal), by default, launches Bash in interactive mode. An example of when Bash runs in non-interactive mode is when commands and data are [piped](https://en.wikipedia.org/wiki/Pipeline_(Unix)) to it from a file or shell script. Other modes of operation that Bash can operate in include: login, non-login, remote, POSIX, unix sh, restricted, and with a different UID/GID than the user. Various combinations of these modes are possible. For example interactive+restricted+POSIX or non-interactive+non-login+remote. Which startup files Bash will process depends on the combination of modes that are requested when it is invoked. Understanding these modes of operation is necessary when modifying the startup files.
According to the Bash reference manual, Bash …
1. Reads its input from a file …, from a string supplied as an argument to the -c invocation option …, or from the user’s terminal.
2. Breaks the input into words and operators, obeying [its] quoting rules. … These tokens are separated by metacharacters. Alias expansion is performed by this step.
3. Parses the tokens into simple and compound commands.
4. Performs the various shell expansions …, breaking the expanded tokens into lists of filenames … and commands and arguments.
5. Performs any necessary redirections … and removes the redirection operators and their operands from the argument list.
6. Executes the command.
7. Optionally waits for the command to complete and collects its exit status.
Reference Documentation for Bash
Edition 5.0, for Bash Version 5.0.
May 2019
When a user starts a terminal emulator to access the command line, an interactive shell session is started. GNOME Terminal, by default, launches the user’s shell in non-login mode. Whether GNOME Terminal launches the shell in login or non-login mode can be configured under *Edit* → *Preferences* → *Profiles* → *Command*. Login mode can also be requested by passing the *–login* flag to Bash on startup. Also note that Bash’s *login* and *non-interactive* modes are not exclusive. It is possible to run Bash in both *login* and *non-interactive* mode at the same time.
## Invoking Bash
Unless it is passed the *—**noprofile* flag, a Bash login shell will read and execute the commands found in certain initialization files. The first of those files is */etc/profile* if it exists, followed by one of *~/.bash_profile*, *~/.bash_login*, or *~/.profile*; searched in that order. When the user exits the login shell, or if the script calls the *exit* built-in in the case of a non-interactive login shell, Bash will read and execute the commands found in *~/.bash_logout* followed by */etc/bash_logout* if it exists. The file */etc/profile* will normally source */etc/bashrc*, reading and executing commands found there, then search through */etc/profile.d* for any files with an *sh* extension to read and execute. As well, the file *~/.bash_profile* will normally source the file *~/.bashrc*. Both */etc/bashrc* and *~/.bashrc* have checks to prevent double sourcing.
An interactive shell that is not a login shell, will source the *~/.bashrc* file when it is first invoked. This is the usual type of shell a user will enter when opening a terminal on Fedora. When Bash is started in non-interactive mode – as it is when running a shell script – it will look for the *BASH_ENV* variable in the environment. If it is found, will expand the value, and use the expanded value as the name of a file to read and execute. Bash behaves just as if the following command were executed:
if [ -n "$BASH_ENV" ]; then . "$BASH_ENV"; fi
It is important to note that the value of the *PATH* variable is not used to search for the filename.
## Important user-specific dotfiles
Bash’s best-known user dotfile is *~/.bashrc*. Most user customization is done by editing this file. Most user customization, may be a stretch since there are reasons to modify all of the mentioned files; as well as other files that have not been mentioned. Bash’s environment is designed to be highly customizable in order to suit the needs of many different users with many different tastes.
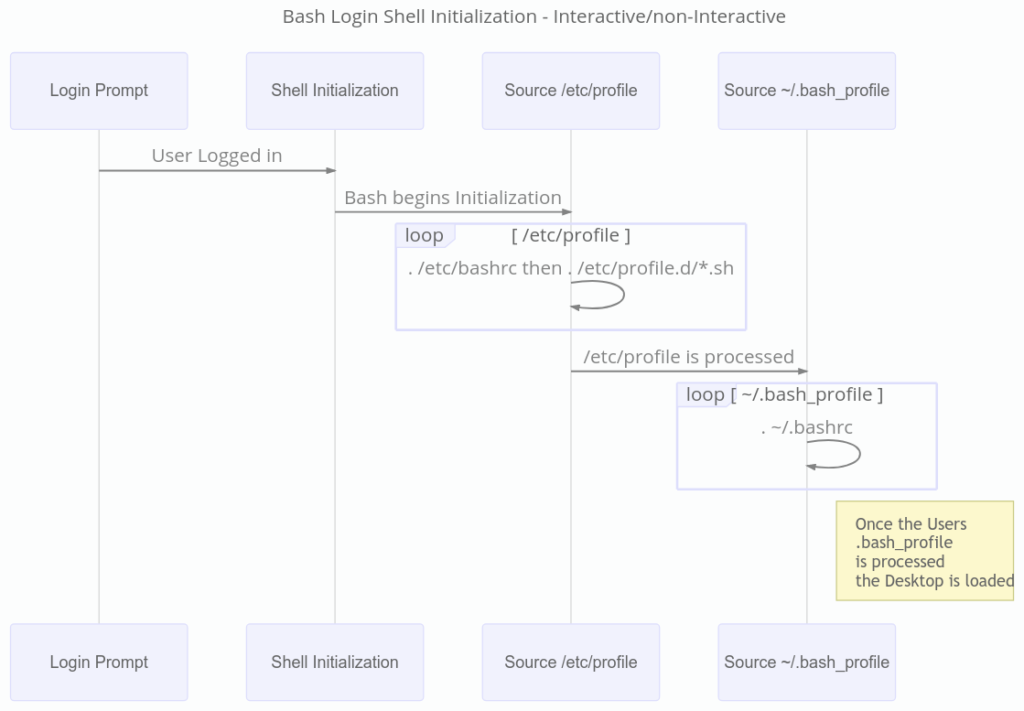
When a Bash login shell exits cleanly, *~/.bash_logout* and then */etc/bash_logout* will be called if they exist. The next diagram is a sequence diagram showing the process Bash follows when being invoked as an interactive shell. The below sequence is followed, for example, when the user opens a terminal emulator from their desktop environment.
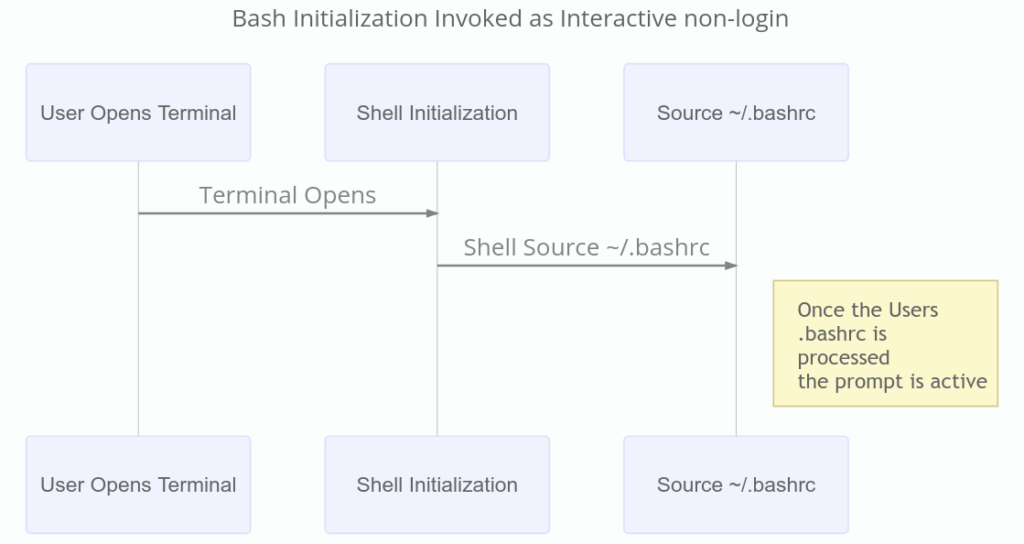
Armed with the knowledge of how Bash behaves under different invocation methods, it becomes apparent that there are only a few typical invocation methods to be most concerned with. These are the non-interactive and interactive login shell, and the non-interactive and interactive non-login shell. If global environment customizations are needed, then the desired settings should be placed in a uniquely-named file with a *.sh* extension (*custom.sh*, for example) and that file should be placed in the */etc/profile.d* directory.
The non-interactive, non-login invocation method needs special attention. This invocation method causes Bash to check the *BASH_ENV* variable. If this variable is defined, the file it references will be sourced. Note that the values stored in the *PATH* environment variable are not utilized when processing *BASH_ENV*. So it must contain the full path to the file to be sourced. For example, if someone wanted the settings from their *~/.bashrc* file to be available to shell scripts they run non-interactively, they could place something like the following in a file named */etc/profile.d/custom.sh* …
# custom.sh . . . #If Fedora Workstation BASH_ENV="/home/username/.bashrc" . . . #If Fedora Silverblue Workstation BASH_ENV="/var/home/username/.bashrc" export BASH_ENV
The above profile drop-in script will cause the user’s *~/.bashrc* file to be sourced just before every shell script is executed.
Users typically customizie their system environment so that it will better fit their work habits and preferences. An example of the sort of customization that a user can make is an alias. Commands frequently run with the same set of starting parameters are good candidates for aliases. Some example aliases are provided in the *~/.bashrc* file shown below.
# .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi . . . # User specific aliases and functions alias ls='ls -hF --color=auto' alias la='ls -ahF --color=auto' # make the dir command work kinda like in windows (long format) alias dir='ls --color=auto --format=long' # make grep highlight results using color alias grep='grep --color=auto'
Aliases are a way to customize various commands on your system. They can make commands more convenient to use and reduce your keystrokes. Per-user aliases are often configured in the user’s *~/.bashrc* file.
If you find you are looking back through your command line history a lot, you may want to configure your history settings. Per-user history options can also be configured in *~/.bashrc*. For example, if you have a habit of using multiple terminals at once, you might want to enable the *histappend* option. Bash-specific shell options that are [boolean](https://en.wikipedia.org/wiki/Boolean_data_type) in nature (take either *on* or *off* as a value) are typically enabled or disabled using the *shopt* built-in command. Bash settings that take a more complex value (for example, *HISTTIMEFORMAT*) tend to be configured by assigning the value to an environment variable. Customizing Bash with both shell options and environment variable is demonstrated below.
# Configure Bash History # Expand dir env vars on tab and set histappend shopt -s direxpand histappend # - ignoreboth = ignorespace and ignoredup HISTCONTROL='ignoreboth' # Controls the format of the time in output of `history` HISTTIMEFORMAT="[%F %T] " # Infinite history # NB: on newer bash, anything < 0 is the supported way, but on CentOS/RHEL # at least, only this works HISTSIZE= HISTFILESIZE= # or for those of us on newer Bash HISTSIZE=-1 HISTFILESIZE=-1
The *direxpand* option shown in the example above will cause Bash to replace directory names with the results of word expansion when performing filename completion. This will change the contents of the readline editing buffer, so what you typed is masked by what the completion expands it to.
The *HISTCONTROL* variable is used to enable or disable some filtering options for the command history. Duplicate lines, lines with leading blank spaces, or both can be filtered from the command history by configuring this setting. To quote Dusty Mabe, the engineer I got the tip from:
Dusty Mabe – Redhat Principle Software Engineer, June 19, 2020
ignoredupmakes history not log duplicate entries (if you are running a command over and over).ignorespaceignores entries with a space in the front, which is useful if you are setting an environment variable with a secret or running a command with a secret that you don’t want logged to disk.ignorebothdoes both.
For users who do a lot of work on the command line, Bash has the *CDPATH* environment variable. If *CDPATH* is configured with a list of directories to search, the *cd* command, when provided a relative path as its first argument, will check all the listed directories in order for a matching subdirectory and change to the first one found.
# .bash_profile # set CDPATH CDPATH="/var/home/username/favdir1:/var/home/username/favdir2:/var/home/username/favdir3" # or could look like this CDPATH="/:~:/var:~/favdir1:~/favdir2:~/favdir3"
*CDPATH* should be updated the same way *PATH* is typically updated – by referencing itself on the right hand side of the assignment to preserve the previous values.
# .bash_profile # set CDPATH CDPATH="/var/home/username/favdir1:/var/home/username/favdir2:/var/home/username/favdir3" # or could look like this CDPATH="/:~:/var:~/favdir1:~/favdir2:~/favdir3" CDPATH="$CDPATH:~/favdir4:~/favdir5"
*PATH* is another very important variable. It is the search path for commands on the system. Be aware that some applications require that their own directories be included in the *PATH* variable to function properly. As with *CDPATH*, appending new values to *PATH* can be done by referencing the old values on the right hand side of the assignment. If you want to prepend the new values instead, simply place the old values (*$PATH*) at the end of the list. Note that on Fedora, the list values are separated with the colon character (**:**).
# .bash_profile # Add PATH values to the PATH Environment Variable PATH="$PATH:~/bin:~:/usr/bin:/bin:~/jdk-13.0.2:~/apache-maven-3.6.3" export PATH
The command prompt is another popular candidate for customization. The command prompt has seven customizable parameters:
PROMPT_COMMANDIf set, the value is executed as a command prior to issuing each primary prompt ($PS1).
PROMPT_DIRTRIMIf set to a number greater than zero, the value is used as the number of trailing directory components to retain when expanding the \w and \W prompt string escapes. Characters removed are replaced with an ellipsis.
PS0The value of this parameter is expanded likePS1and displayed by interactive shells after reading a command and before the command is executed.
PS1The primary prompt string. The default value is ‘\s-\v\$‘. …
PS2The secondary prompt string. The default is ‘‘.>PS2is expanded in the same way asPS1before being displayed.
PS3The value of this parameter is used as the prompt for theselectcommand. If this variable is not set, theselectcommand prompts with ‘#?‘Reference Documentation for Bash
PS4The value of this parameter is expanded likePS1and the expanded value is the prompt printed before the command line is echoed when the-xoption is set. The first character of the expanded value is replicated multiple times, as necessary, to indicate multiple levels of indirection. The default is ‘‘.+
Edition 5.0, for Bash Version 5.0.
May 2019
An entire article could be devoted to this one aspect of Bash. There are copious quantities of information and examples available. Some example dotfiles, including prompt reconfiguration, are provided in a repository linked at the end of this article. Feel free to use and experiment with the examples provided in the repository.
## Conclusion
Now that you are armed with a little knowledge about how Bash works, feel free to modify your Bash dotfiles to suit your own needs and preferences. Pretty up your prompt. Go nuts making aliases. Or otherwise make your computer truly yours. Examine the content of */etc/profile*, */etc/bashrc*, and */etc/profile.d/* for inspiration.
Some comments about terminal emulators are fitting here. There are ways to setup your favorite terminal to behave exactly as you want. You may have already realized this, but often this modification is done with a … wait for it … dotfile in the users home directory. The terminal emulator can also be started as a login session, and some people always use login sessions. How you use your terminal, and your computer, will have a bearing on how you modify (or not) your dotfiles.
If you’re curious about what type session you are in at the command line the following script can help you determine that.
#!/bin/bash case "$-" in (*i*) echo This shell is interactive ;; (*) echo This shell is not interactive ;; esac
Place the above in a file, mark it executable, and run it to see what type of shell you are in. *$-* is a variable in Bash that contains the letter **i** when the shell is interactive. Alternatively, you could just echo the $- variable and inspect the output for the presence of the **i** flag:
$ echo $-
## Reference information
The below references can be consulted for more information and examples. The Bash man page is also a great source of information. Note that your local man page is guaranteed to document the features of the version of Bash you are running whereas information found online can sometimes be either too old (outdated) or too new (not yet available on your system).
[https://opensource.com/tags/command-line](https://opensource.com/tags/command-line)
[https://opensource.com/downloads/bash-cheat-sheet](https://opensource.com/downloads/bash-cheat-sheet)
You will have to enter a valid email address at the above site, or sign up, to download from it.
[https://opensource.com/article/19/12/bash-script-template](https://opensource.com/article/19/12/bash-script-template)
Community members who provided contributions to this article in the form of example dotfiles, tips, and other script files:
- Micah Abbott – Principal Quality Engineer
- John Lebon – Principal Software Engineer
- Dusty Mabe – Principal Software Engineer
- Colin Walters – Senior Principal Software Engineer
A repository of example dotfiles and scripts can be found here:
[https://github.com/TheOneandOnlyJakfrost/bash-article-repo](https://github.com/TheOneandOnlyJakfrost/bash-article-repo)
Please carefully review the information provided in the above repository. Some of it may be outdated. There are many examples of not only dotfiles for Bash, but also custom scripts and pet container setups for development. I recommend starting with John Lebon’s dotfiles. They are some of the most detailed I have seen and contain very good descriptions throughout. Enjoy!
## Esc
Respect, wow
## Duke
Engineering precision. Nice job!
## Vernon Van Steenkist
A couple of my favorites.
set -o vi
This command puts your shell in vi keybindings mode (normally it is in Emacs keybindings mode). Especially useful if you use a keyboard that doesn’t have arrow keys like an IPhone or IPad. Good quick tutorial and references at
https://catonmat.net/bash-vi-editing-mode-cheat-sheet
Automatically add sub-directories to your PATH
export PATH=$PATH$(find $HOME/.scripts -not ( -name CVS -prune ) -type d -printf “:%p”)
This command adds all the sub-directories in $HOME/.scripts which contain my personal scripts to my PATH while excluding the CVS version control directories.
Also, if you quickly don’t want to run the alias version of a command, just put a backslash in front of it. For example
\ls
will output a directory listing without all the color etc directives that you put in you alias version of ls.
## geirha
Never export CDPATH! You’ll get some unpleasant surprises when a script using cd accidentally hits a path from CDPATH
## Stephen Snow
Hello @geirha,
Thank you for the information. Could you possibly elaborate on the “unpleasant surprises” for everyone’s edification?
Stephen
## geirha
Sorry, I meant to link to the pitfalls page. Here:
https://mywiki.wooledge.org/BashPitfalls#pf48
In short, if cd gets a hit in CDPATH, it will output the absolute path of the directory it ends up in (to alert the user it “ended up” elsewhere), which causes breakage if a script is using cd as part of a command substitution
## Stephen Snow
Hello,
Thanks for the link. I corrected the article to reflect your advice. I could see this being a problem under certain situations.
## geirha
You should also move it to .bashrc. .bash_profile is only meant to be read during login, so it’s mainly useful for setting environment variables like PATH, not for setting variables that configure your interactive session like HISTSIZE, PS1 and CDPATH.
## Jan
Hi Stephen,
geirha possibly refers to the following:
https://mywiki.wooledge.org/BashPitfalls#export_CDPATH.3D.:.2BAH4-.2FmyProject
## Stephen Snow
Thank you @Jan,
I think exporting CDPATH is fine since the potential error would really be a problem of the script writer as opposed to a problem with CDPATH being exported. The script writer should never assume anything about the environment of the system beforehand. When I write scripts for a specific function on my system, I know the environment and write with that in mind, but not so for generic scripts I am sharing with others. Therefore I then have to account for the potential pitfalls within the script or with specific instructions on how to use it.
## Steve
Additionally, always have “.” as the first component of your CDPATH variable, else you shall see surprising behaviour (eg; you have, ~/images and CDPATH=~/Projects/. Now, if you are in ~ and do ‘cd images’ you will end up in ~/Projects/images, if it exists)
## Robin Meade
I like how the author followed the best practice of putting PATH customizations in
, which is where Fedora always put them prior to this commit: https://src.fedoraproject.org/rpms/bash/c/739b272e5f5d10cf27a847a44d09eb7f4b6ec89b?branch=master
## Gregory Bartholomew
Putting PATH in the login profile makes more sense to me as well. Especially when you understand that environment variables are always inherited by sub-processes. It is inefficient and you shouldn’t need to recreate or redefine a bunch of variables every time you spawn a shell. Doing that is also quite error-prone as can be seen from commit https://src.fedoraproject.org/rpms/bash/c/e3b3cd9cec4a3bd12a792536c0ea131f5ba5bd72?branch=master.
I also don’t like that /etc/bashrc gets sourced from /etc/profile or that everything under /etc/profile.d gets sourced by both /etc/profile and /etc/bashrc. Everything sourcing everything else, multiple times, seems like a bit of an inefficient mess. And I’ve seen plenty of cases where scripts under /etc/profile.d ended up creating massively long environment variables as well because of this problem (it’s not just a problem for the PATH environment variable). And what if I place a script under /etc/profile.d that does something like a file system mount? Would I potentially end up with infinite mounts on top of each other? Would I have to wait on the mount to complete every time a bash shell gets spawned?
What if, for efficiency’s sake, I want to spawn a bash login shell with the just the minimal login environment defined, but I don’t want to run all the start-up scripts that every installed program has dropped under the /etc directory? From the documentation, it would seem like bash –norc ought to do that, but the way everything is sourced (multiple times) from everything else, it appears that that option to the bash command is completely meaningless at this time.
I think a much cleaner design would be to simply source ~/.bash_profile once on bash login shells (falling back to /etc/profile if that doesn’t exist). And to always source ~/.bashrc (falling back to /etc/bashrc if that doesn’t exist). ~/.bash_profile should be for stuff that should only be run once and ~/.bashrc should be stuff that should be run every time.
Just my two cents.
## Stephen Snow
Hello Gregory,
Multiple sourcing is a poor practice, and there is a check in /etc/bashrc to prevent dual sourcing it but not in ~/.bashrc. I chose to present the tips as the GNU Bash manual indicates. For example, the documentation purposely shows alias’s and functions in /etc/bashrc and ~/.bashrc and this is noted in comments in the profile files /etc/profile and ~/.bash_profile as well.
From /etc/profile …
Stephen
## Gregory Bartholomew
Yeah, those comments seem inaccurate at the least. If they were true, how would ~/.bash_profile and ~/.bashrc get called? I know they aren’t called from the global scripts.
That check for double sourcing appears unreliable/bogus too. What if I run “bash –login” followed by “bash –login”? Since the only double sourcing check in done in /etc/bashrc, and since everything under /etc/profile.d is sourced from /etc/profile, all the scripts under /etc/profile.d will still get double sourced.
I suspect there should really be a /etc/bashrc.d in addition to /etc/profile.d so that there would be a cleaner divide between the two types of scripts rather than all the stuff under /etc/profile.d getting run many many many times over every time a bash script is run somewhere.
Again, just my two cents. There may well be some details of which I am unaware that make a cleaner divide between run-once and run-always scripts impractical.
## Stephen Snow
The article was more about Bash than Fedora per se. I didn’t mean to give the impression that you should follow everything I typed there verbatim. In fact I would expect those interested to review the material, read the links to get more informed, then customize their system to their own needs. What I was trying to get across specifically was the order of startup, what files are or could be accessed then, and how might you do some customization to suit your workflow and use case needs.
## George N. White III
In these days of projects with participants spread across multiple organizations and using different linux distros it is worth mentioning a common source of confusion when fedora users interact with debian/Ubuntu or macOS users. It is helpful to realize that users of other distros may have dash (default system shell on debian) or zsh (default user shell on recent macOS).
## Stephen Snow
Hello, and thank you for noting there are different default shells in use by other Linux Distro’s as well as Mac’s. I had originally opened this article stating that there is a large variety of choice of shell to use even in Fedora, but the focus would be on Bash, and it’s use within the context of a Fedora system. The broader topic of different shells, and their relative benefits/drawbacks would be a rather large (amount of) content (for a magazine article) if you wanted to attempt to do the topic justice. It would likely need to be a multi-part series. Generally, as a preference, I use zsh on my Fedora system. For this article and some time leading up to it, I have been using Bash.
## John
Please correct me if I’m wrong but in Wayland the ‘profile’ scripts are no longer sourced.
## Stephen Snow
Hello John,
You are likely referring to the discussion around this https://ask.fedoraproject.org/t/ld-library-path-is-not-set-by-bash-profile-anymore-after-upgrade-to-fedora-31/4247/13. In particular, this is relevant in how the startup scripts are processed, and in fact if they are processed as expected in the first place. The article is written from the POV of the Bash manual, so there are certain expectations on the startup behavior and the subsequent behavior of the shell. Specifically, that the distro is following the suggested sequence of login and startup for processing the environment scripts. This is not so clear cut now with Fedora as of F31, since for instance the Gnome Session is now managed by systemd(https://blogs.gnome.org/benzea/2019/10/01/gnome-3-34-is-now-managed-using-systemd/). So the ~/.bash_profile file is sourced (for now, but this may change) and for the interactive terminal sessions ~/.bashrc is still sourced.
## Gregory Bartholomew
For anyone who might be interested, I’ve found that an easy way to block a lot of the double sourcing is to add the following line to /etc/profile.d/sh.local:
The above will block /etc/bashrc from ever being run, however, so if you use it, you will need to duplicate anything in /etc/bashrc that you want in your ~/.bashrc. For me, this amounted to the following:
You want to keep ~/.bashrc very minimal because everything in it is run every time bash is executed (without the –norc parameter).
I’ve also tweaked my ~/.bash_profile and added a /etc/profile.d/ps1.sh to set the bash prompt for login shells. The end result of editing these four files is that now when I run just
bash(or when a bash script is run), there is no chance that any of the content under /etc/profile.d will be re-evaluated. This is easily verified because spawning a non-login bash shell reveils the default bash prompt (because /etc/profile.d/ps1.sh was not sourced). Below are the four files I’ve changed in their entirety. This is just an experiment at this time, so there may be problems with this setup that I have not noticed yet./etc/profile.d/sh.local
/etc/profile.d/ps1.sh
~/.bash_profile
~/.bashrc
I’ve also set gnome-terminal to always run bash as a login shell. This makes sense because the shell that gnome-terminal starts is never the child process of another bash shell — it cannot inherit an already initialized bash environment, so it needs to be run as login shell each time.
## Robin Meade
Cool! Thanks for writing that up.
I don’t find the need to set gnome-terminal to always run bash as a login shell. On my system, gnome-session is run by a bash login shell. My process table shows:
I do need to log out and back in for changes to my .bash_profile to take effect; that’s the only downside I see to not setting gnome-terminal to always run bash as a login shell.
## Gregory Bartholomew
Yeah, it looks like you have a somewhat non-standard setup there where gnome-session is a child process of a bash login shell.
I think your best option to get around having to logout and back in in that case would be to create something like ~/.gnome-terminal that ends with “exec bash”. Then set as a custom command for gnome-terminal something like:
/bin/bash -c “source $HOME/.gnome-terminal”
instead of your login shell. I haven’t tested such a setup, but it should give your a third option for where you can place configuration settings that would not require you to log out and back in (and also would not get run every time bash is run).
Just an idea,
gb
## Gregory Bartholomew
Just realized that you should probably check for the existence of the file first, so maybe something more like:
And if you want to eliminate the requirement that ~/.gnome-terminal end in “exec bash”, maybe something like:
## Robin Meade
OK, thanks Gregory. I was running Gnome using X. But with Wayland, bash is still executed as a login shell when gnome-session starts. See https://gitlab.gnome.org/GNOME/gnome-session/-/blob/master/gnome-session/gnome-session.in Anyway, I’m OK with needing to log out and back into my Gnome session to pick-up any changes to environment variables that I set in my ~/.bash_profile.
## Gregory Bartholomew
Interesting. I too now see that gnome-session is listed as being spawned from a bash login shell. However, experiments suggest that gnome-terminal is not a child of that bash login shell. I still have to set gnome-terminal to run bash as a login shell to get the content under /etc/profile.d processed (e.g. PS1) with my setup.
What I can make of the output of pstree seems to suggest that gnome-terminal is being spawned directly from systemd somehow (or perhaps from DBus as the article Steven linked earlier suggests).
## smeagol
export HISTTIMEFORMAT=”%m/%d/%y %H:%M:%S ”
^^ this is what I use. Do you like it? Can it be improved upon? |
12,430 | 将英式英语翻译成美式英语的开源工具 | https://opensource.com/article/20/6/british-american-cli-translator | 2020-07-19T11:56:51 | [
"翻译"
] | https://linux.cn/article-12430-1.html |
>
> 使用这些命令行翻译器将英式英语转换为美式英语(或反之)。
>
>
>

去年圣诞节,我和我的妻子去了家乡佛罗里达的皮尔斯堡,并且经常光顾海滩上的一家当地人场所。在那儿,我们遇到了一对来自英国中部地区的夫妇。音乐很响,喝酒也很闹,所以很难听清楚。另外,即使他们“似乎”在说英语,但有时理解他们在说什么仍然是一个挑战。我以为我在澳大利亚的时光会给我足够的语言能力,但是,可惜,很多东西都超出了我的想象。不止是一般的 “soccer 是 football” 或 “trunk是 boot” 之类的困惑。
幸运的是,有开源方案可以将“英式”翻译成“美式”。我们可能使用相同的语言,但是我们共同的言语却比多塞特郡沙夫茨伯里的之字形山要曲折得多!
如果你碰巧在酒吧有 Linux 笔记本,那么你可以使用方便的开源命令行程序,它就叫 [美英英语翻译器](https://github.com/hyperreality/American-British-English-Translator)(MIT 许可证)。
我在我的改造运行 Linux 的 MacBook 上安装这个翻译器:
```
$ npm install -g american-british-english-translator
```
这需要我首先[安装 Node.js](https://nodejs.org/en/download/)。
### 声明!
除了翻译单词和短语,美英英语翻译器还能分析(嗯,剖析)文档。我用一个叫《独立宣言》的流行文件试了一下。它分析并返回了许多结果。其中一个比较有趣的是:
```
fall:
issue: Different meanings(意思不同)
details:
American English: autumn(秋天)
British English:
"""
to become pregnant. (Either as in 'I fell pregnant' or as in 'She fell for a baby.');(怀孕 —— 无论是“我怀孕了”还是“她怀孕了”)
```
并非如《宣言》作者所指控的“在公海俘虏”(taken captive on the high seas):
>
> ”他在公海上俘虏我们的同胞,强迫他们拿起武器来反对自己的国家,成为残杀自己亲人和朋友的刽子手,或是死于自己的亲人和朋友的手下。“(He has constrained our fellow Citizens taken Captive on the high Seas to bear Arms against their Country, to become the executioners of their friends and Brethren, or to fall themselves by their Hands.)
>
>
>
### 还有一个
对于简单的单词替换,你可以尝试 [Common\_Language](https://github.com/willettk/common_language),这是一个开源(MIT 许可)Python 脚本。
当然,要与同伴一起喝几杯,你也许需要实际交流,并能理解他们。这就是需要用到 MARY 了。
[MaryTTS](https://github.com/marytts/marytts) 是一个使用 Java(GNU 许可)编写的开源多语言文本到语音合成平台。方便的[基于浏览器的界面](http://mary.dfki.de:59125/)使你可以轻松地将美国酒吧谈话内容转换为男声或女声的正确英语(或其他语言)。
现在我可以和我的英国朋友们见面了(可以安全地再来一次),喝几杯!像当地人一样讲英语!大家干杯!
---
via: <https://opensource.com/article/20/6/british-american-cli-translator>
作者:[Jeff Macharyas](https://opensource.com/users/jeffmacharyas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last Christmas, my wife and I traveled to my hometown of Ft. Pierce, Florida, and frequented a local establishment on the beach. There, we met a couple from The Midlands in the UK. The music was loud and so was the beer, so it was a bit hard to hear. Plus, even though it "seemed" they were speaking English, it was sometimes a challenge to understand what they were saying. I thought my time in Australia would have given me enough linguistic power, but, alas, a lot went over my head. There was more than the usual "soccer is football" or "trunk is a boot" sort of confusion.
Fortunately, there are open source solutions to translate "British" into "American." We may speak the same language, but our shared speech takes more twists and turns than Zig Zag Hill in Shaftesbury, Dorset!
If you happen to be at the bar with your Linux laptop, you can use a handy open source command-line program, cleverly called the [American British English Translator](https://github.com/hyperreality/American-British-English-Translator) (MIT license).
I installed the Translator on my repurposed MacBook running Linux with:
`$ npm install -g american-british-english-translator`
Which required me to [install Node.js](https://nodejs.org/en/download/) first.
## I do declare!
In addition to translating words and phrases, the American British English Translator will analyze, ummm, analyse, documents. I gave this a go with a popular document called *The Declaration of Independence*. (tl;dr). It analyzed the document and returned many results. One of the more interesting was:
```
fall:
issue: Different meanings
details:
American English: autumn
British English:
"""
to become pregnant. (Either as in 'I fell pregnant' or as in 'She fell for a baby.');
```
Not exactly "taken captive on the high seas" as the *Declaration's *authors accused:
"He has constrained our fellow Citizens taken Captive on the high Seas to bear Arms against their Country, to become the executioners of their friends and Brethren, or to fall themselves by their Hands."
## Along comes MARY
For simple word replacements, you can try [Common_Language](https://github.com/willettk/common_language), an open source (MIT license) Python script.
Of course, if you're sharing a pint with your mates, you may need to actually speak to them in a voice and language they will understand. This would be a good time to bring MARY along with you.
[MaryTTS](https://github.com/marytts/marytts) is an open source, multilingual text-to-speech synthesis platform written in Java (GNU license). The handy [browser-based interface](http://mary.dfki.de:59125/) makes it easy to translate your American bar talk into right good English (or other languages) in either a male or female voice.
So, now I am ready to meet my British friends (when it is safe to do so again), grab a few pints, and—Bob's your uncle—speak English like a native! Cheerio, y'all!
## 4 Comments |
12,432 | 让你的 Linux 终端变得酷炫复古 | https://itsfoss.com/cool-retro-term/ | 2020-07-19T21:41:00 | [
"终端",
"怀旧"
] | https://linux.cn/article-12432-1.html |
>
> 怀旧?那就安装复古终端应用程序 [cool-retro-term](https://github.com/Swordfish90/cool-retro-term) 吧 —— 顾名思义,它既酷又复古。
>
>
>

你还记得那个到处都是 CRT 显示器,终端屏幕经常闪烁的年代吗?你不需要那么老,就能见证它的存在。如果你看上世纪九十年代初的电影,你会看到大量的 CRT 显示器和绿色/黑白的命令提示符。那种极客的光环,让它感觉很酷。
如果你厌倦了你的仿真终端的外观,你需要一些酷炫的“新”东西,[cool-retro-term](https://github.com/Swordfish90/cool-retro-term) 会给你一个复古的终端机外观,让你重温过去。你还可以改变它的颜色、动画种类,并为它添加一些效果。
### Linux 中用 Snap 包安装
在 Linux 中安装 `cool-retro-term` 的方法有很多种。一种与发行版无关的方法是使用 Snap 软件包。如果你的 Linux 发行版支持 Snap,你可以使用这个命令来安装 `cool-retro-term`:
```
sudo snap install cool-retro-term --classic
```
Ubuntu 用户也可以在软件中心找到它。
如果你不想使用 Snap 包,也不用担心。还有其他的方法来安装它。

### 在基于 Ubuntu 的 Linux 发行版中安装
有一些 PPA 可以轻松地将 `cool-retro-term` 安装到基于 Ubuntu 的发行版上,如 Linux Mint、Elementary OS、Linux Lite 等。
对于 Ubuntu 18.04、18.10、19.04、Linux Mint 19 及更高版本,请使用此 PPA:
```
sudo add-apt-repository ppa:vantuz/cool-retro-term
sudo apt update
sudo apt install cool-retro-term
```
对于 Ubuntu 16.04 和 Linux Mint 18 系列,请用此 PPA:
```
sudo add-apt-repository ppa:noobslab/apps
sudo apt update
sudo apt-get install cool-retro-term
```
### 在基于 Arch 的 Linux 发行版中安装
在基于 Arch 的 Linux 发行版(如 Antergos 和 Manjaro)中安装 `cool-retro-term`,使用以下命令:
```
sudo pacman -S cool-retro-term
```

### 从源码中安装
如果要[从源代码中安装](https://itsfoss.com/install-software-from-source-code/)这个应用程序,你需要先[安装 Git 和一些依赖关系](https://itsfoss.com/install-git-ubuntu/)。在基于 Ubuntu 的发行版中,一些已知的依赖关系是:
```
sudo apt-get install git build-essential qmlscene qt5-qmake qt5-default qtdeclarative5-dev qtdeclarative5-controls-plugin qtdeclarative5-qtquick2-plugin libqt5qml-graphicaleffects qtdeclarative5-dialogs-plugin qtdeclarative5-localstorage-plugin qtdeclarative5-window-plugin
```
其他发行版的已知依赖关系可以在 [cool-retro-term 的 GitHub 存储库](https://github.com/Swordfish90/cool-retro-term)上找到。
现在使用下面的命令来编译程序:
```
git clone https://github.com/Swordfish90/cool-retro-term.git
cd cool-retro-term
qmake && make
```
程序编译完成后,你可以用这个命令来运行它:
```
./cool-retro-term
```

如果你喜欢把这个应用放在程序菜单中,以便快速访问,而不用每次都用命令手动运行它,你可以使用下面的命令:
```
sudo cp cool-retro-term.desktop /usr/share/applications
```
你可以在这里学习更多的终端技巧。享受 Linux 中的复古终端 :)
---
via: <https://itsfoss.com/cool-retro-term/>
作者: [Abhishek Prakash](https://itsfoss.com/author/abhishek/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-11810-1.html) 荣誉推出
| 200 | OK | 

Nostalgic about the past? Get a slice of the past by installing the retro terminal app [cool-retro-term](https://github.com/Swordfish90/cool-retro-term?ref=its-foss), which, as the name suggests, is both cool and retro at the same time.
Do you remember the time when there were CRT monitors everywhere and the terminal screen used to flicker? You don’t need to be old to have witnessed it. If you watch movies set in the early ’90s, you’ll see plenty of CRT monitors with green/B&W command prompts. It has a geeky aura which makes it cooler.
If you are tired of terminal appearance and you need something cool and ‘new’, cool-retro-term will give you a vintage terminal appearance to relive the past. You can also change its color, and animation kind, and add some effect to it.
## Install Cool Retro Term in Linux [Recommended]
Since it is a quite popular tool, it is available on the official repositories of almost all Linux distributions. In Ubuntu, you can install it by running the following command a terminal:
`sudo apt install cool-retro-term`
Similarly, if you are running Arch Linux, use:
`sudo pacman -S cool-retro-term`
Or, in Fedora:
`sudo dnf install cool-retro-term`
To remove the package installed from repositories, you can use the respective removal command:
```
sudo apt remove cool-retro-term
sudo pacman -Rs cool-retro-term
sudo dnf remove cool-retro-term
```
Respectively for Ubuntu, Arch Linux, and Fedora.
## Install Cool Retro Term in Older Ubuntu-based Linux distributions
There are PPAs available for easily installing cool-retro-term for Ubuntu 18.04 and Linux Mint 19.
```
sudo add-apt-repository ppa:vantuz/cool-retro-term
sudo apt update
sudo apt install cool-retro-term
```
To remove, run:
```
sudo apt remove cool-retro-term
sudo add-apt-repository --remove ppa:vantuz/cool-retro-term
sudo apt update
```
## Install cool-retro-term from the source code [Not Recommended]
For [installing this application from the source code](https://itsfoss.com/install-software-from-source-code/), you need to [install Git and a number of dependencies](https://itsfoss.com/install-git-ubuntu/) first. Some of the known dependencies in Ubuntu-based distributions are:
```
sudo apt install \
git \
build-essential \
qmlscene \
qt5-qmake \
qt5-default \
qtdeclarative5-dev \
qml-module-qtquick-controls2 \
qml-module-qtgraphicaleffects \
qml-module-qtquick-dialogs \
qml-module-qtquick-localstorage \
qml-module-qtquick-window2 \
qml-module-qt-labs-settings \
qml-module-qt-labs-folderlistmodel \
qtquickcontrols2-5-dev
```
Extra packages needed for at least Ubuntu 20.04
```
sudo apt install \
qtquickcontrols2-5-dev \
qml-module-qt-labs-platform \
qml-module-qtquick-controls \
qml-module-qtquick-layouts \
qml-module-qtquick-localstorage
```
Now, run the following command to install it:
```
git clone --recursive https://github.com/Swordfish90/cool-retro-term.git
cd cool-retro-term
qmake && make
```
Once the program is compiled, you can run it with this command:
`./cool-retro-term`
If you like to have this app in the program menu for quick access so that you won’t have to run it manually each time with the commands, you can use the command below:
`sudo cp cool-retro-term.desktop /usr/share/applications`
To remove the Cool Retro Term, if you did not copy the desktop file to */usr/share/applications*, just remove the `cool-retro-term`
folder from the location, where you performed the commands. Else, delete the desktop file from */usr/share/applications* also.
Now run:
`sudo apt autoremove`
Or remove all the unnecessary dependency packages.
## Install Cool Retro Term in Linux as Snap
If [your Linux distribution has Snap support enabled](https://itsfoss.com/install-snap-linux/), you can use this command to install cool-retro-term:
`sudo snap install cool-retro-term --classic`
Ubuntu users can find it in the Software Center as well.
To remove it, use:
`sudo snap remove cool-retro-term`
## Tweaking Cool Retro Term
Cool-retro-term offers several ways to tweak the appearance. You can access the settings by right-clicking on the interface if there is no menu panel by default.
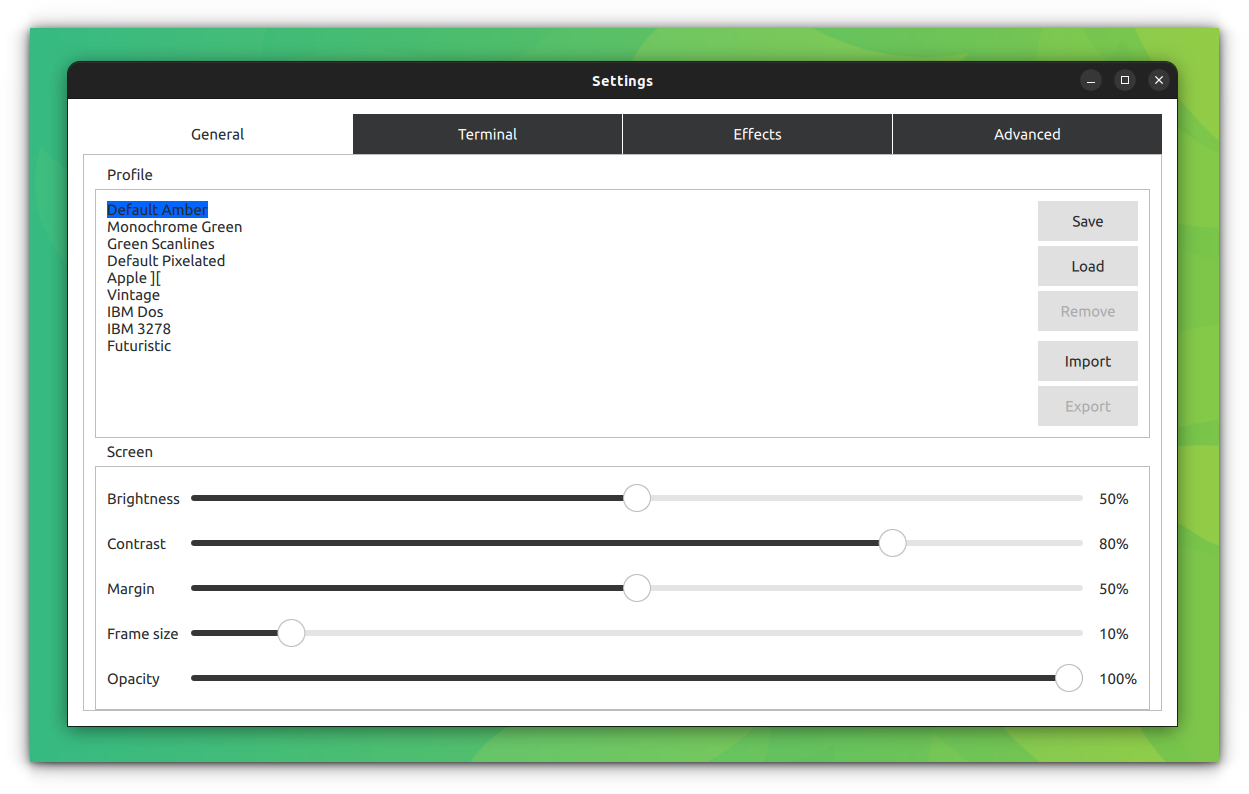
From here, you can go to the **Settings **option for further granular tweaks.
In my opinion, it’s one of the [best terminal emulators for Linux](https://itsfoss.com/linux-terminal-emulators/). It gets all the points for bringing back memories. Enjoy the vintage terminal in Linux :)
## Want more retro stuff in Linux?
If you like retro stuff like this, there are plenty more such thing to take you back into the 80s and 90s.
For example, playing [retro games with DOSBox](https://itsfoss.com/ubuntu-dosbox/).
[Install DOSBox in Ubuntu to Play Retro GamesThe DOSbox emulator lets you use the disk operating systems of the 80s. You can also use it to play retro games on Linux.](https://itsfoss.com/ubuntu-dosbox/)

Got a spare system? Turn it into a retro gaming console with specially crafted Linux distros.
[Linux Distros That Turn Your PC into Retro Gaming ConsoleSteam Deck is making news for all the right reasons. It is a fantastic piece of tech, powered by a variant of Arch Linux (SteamOS 3.0) developed by Valve. While you can install any other operating system in it, it is best to have it as it is for](https://itsfoss.com/retro-gaming-console-linux-distros/)

Or just read about others re-exploring the software from the bygone era.
[Trying Common Desktop Environment on a Modern Linux DistroBill shares his re-experience with Common Desktop Environment (CDE), the de-facto standard windowing environment on UNIX systems in the 90s.](https://itsfoss.com/common-desktop-environment/)
 |
12,433 | 在 Fedora 32 上运行 Docker | https://fedoramagazine.org/docker-and-fedora-32/ | 2020-07-20T09:16:00 | [
"Docker",
"Fedora"
] | https://linux.cn/article-12433-1.html | 
随着 Fedora 32 的发布,[Docker](https://docs.docker.com/) 的普通用户面临着一个小挑战。在编写本文时,Fedora 32 不支持 Docker。虽然还有其他选择,例如 [Podman](https://podman.io/getting-started/) 和 [Buildah](https://buildah.io/),但是对于许多现有用户而言,现在切换可能不是最佳时机。因此,本文可以帮助你在 Fedora 32 上设置 Docker 环境。
### 步骤 0:消除冲突
此步骤适用于从 Fedora 30 或 31 升级的任何用户。如果全新安装的 Fedora 32,那么可以跳到步骤 1。
删除 docker 及其所有相关组件:
```
sudo dnf remove docker-*
sudo dnf config-manager --disable docker-*
```
### 步骤 1:系统准备
在 Fedora 的最后两个版本中,操作系统已迁移到两项新技术: CGroups 和用于防火墙的 NFTables。尽管这些新技术的详细信息不在本教程的讨论范围之内,但是令人遗憾的是,Docker 还不支持这些新技术。因此,你必须进行一些更改才能在 Fedora 上使用 Docker。
#### 启用旧的 CGroups
Fedora 仍然支持 CGroups 的先前实现,可以使用以下命令启用它:
```
sudo grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=0"
```
#### 在防火墙中将 Docker 列入白名单
为了让 Docker 具有网络访问权限,需要两个命令:
```
sudo firewall-cmd --permanent --zone=trusted --add-interface=docker0
sudo firewall-cmd --permanent --zone=FedoraWorkstation --add-masquerade
```
第一个命令将 Docker 接口添加到受信任的环境,它允许 Docker 建立远程连接。第二个命令将允许 Docker 建立本地连接。当有多个 Docker 容器作为开发环境时,这特别有用。
### 步骤 2:安装 Moby
[Moby](https://mobyproject.org/) 是 Docker 的开源白牌版本。它基于相同的代码,但不带商标。它包含在 Fedora 的主仓库中,因此很容易安装:
```
sudo dnf install moby-engine docker-compose
```
这将安装 `moby-engine`、`docker-compose`、`containerd` 和其他一些相关的库。安装完成后,你必须启用系统级守护程序才能运行 Docker:
```
sudo systemctl enable docker
```
### 步骤 3:重新启动并测试
为了确保正确处理所有系统和设置,你现在必须重启计算机:
```
sudo systemctl reboot
```
之后,你可以使用 Docker hello-world 包来验证安装:
```
sudo docker run hello-world
```
除非遇到问题,不然你就会看到来自 Docker 的问候!
#### 以管理员身份运行
可选地,你现在还可以将用户添加到 Docker 的组帐户中,以便无需输入 `sudo` 即可启动 Docker 镜像:
```
sudo groupadd docker
sudo usermod -aG docker $USER
```
注销并登录以使更改生效。如果以管理员权限运行容器的想法让你有所顾虑,那么你应该研究 Podman。
### 总结
从现在起,Docker 将按照你的习惯工作,包括 `docker-compose` 和所有与 `docker` 相关的工具。不要忘记查看官方文档,这在很多情况下可以为你提供帮助。
Fedora 32 上 Docker 的当前状态并不理想。缺少官方软件包可能会困扰一些人,有一个[上游问题](https://github.com/docker/for-linux/issues/955)对此进行了讨论。对 [CGroups](https://github.com/moby/moby/issues/40360) 和 [NFTables](https://github.com/moby/moby/issues/26824) 缺少支持更多是技术问题,但是你可以查看它们在其公共问题上的进展。
这些指导应可以让你就像什么都没有发生一样继续工作。如果这不能满足你的需求,请不要忘记到 Moby 或 Docker Github 页面去寻求解决你的技术问题,或者看看 Podman,长期来看,它可能会更加强大。
---
via: <https://fedoramagazine.org/docker-and-fedora-32/>
作者:[Kevin "Eonfge" Degeling](https://fedoramagazine.org/author/eonfge/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | With the release of Fedora 32, regular users of [Docker](https://docs.docker.com/) have been confronted by a small challenge. At the time of writing, Docker is not supported on Fedora 32. There are alternatives, like [Podman](https://podman.io/getting-started/) and [Buildah](https://buildah.io/), but for many existing users, switching now might not be the best time. As such, this article can help you set up your Docker environment on Fedora 32.
*NOTE*: A more recent article covering[ Docker and Fedora 34/35](https://fedoramagazine.org/docker-and-fedora-35/) is now available.
## Step 0: Removing conflicts
This step is for any user upgrading from Fedora 30 or 31. If this is a fresh installation of Fedora 32, you can move on to step 1.
To remove docker and all its related components:
sudo dnf remove docker-* sudo dnf config-manager --disable docker-*
## Step 1: System preparation
With the last two versions of Fedora, the operating system has moved to two new technologies: CGroups and NFTables for the Firewall. While the details of these new technologies is behind the scope of this tutorial, it’s a sad fact that docker doesn’t support them yet. As such, you’ll have to make some changes to facilitate Docker on Fedora.
### Enable old CGroups
The previous implementation of CGroups is still supported and it can be enabled using the following command.
sudo grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=0"
### Whitelist docker in firewall
To allow Docker to have network access, two commands are needed.
sudo firewall-cmd --permanent --zone=trusted --add-interface=docker0 sudo firewall-cmd --permanent --zone=FedoraWorkstation --add-masquerade
The first command will add the Docker-interface to the trusted environment which allows Docker to make remote connections. The second command will allow docker to make local connections. This is particularly useful when multiple Docker containers are in as a development environment.
## Step 2: installing Moby
[Moby](https://mobyproject.org/) is the open-source, white label version of Docker. It’s based on the same code but it does not carry the trademark. It’s included in the main Fedora repository, which makes it easy to install.
sudo dnf install moby-engine docker-compose
This installs *moby-engine*, *docker-compose*, *containerd* and some other related libraries. Once installed, you’ll have to enable the system-wide daemon to run docker.
sudo systemctl enable docker
## Step 3: Restart and test
To ensure that all systems and settings are properly processed, you’ll now have to reboot your machine.
sudo systemctl reboot
After that, you can validate your installation using the Docker hello-world package.
sudo docker run hello-world
You are then greeted by the Hello from Docker! unless something went wrong.
### Running as admin
Optionally, you can now also add your user to the group account of Docker, so that you can start docker images without typing *sudo*.
sudo groupadd docker sudo usermod -aG docker $USER
Logout and login for the change to take effect. If the thought of running containers with administrator privileges concerns you, then you should look into Podman.
## In summary
From this point on, Docker will work how you’re used to, including docker-compose and all docker-related tools. Don’t forget to check out the official documentation which can help you in many cases where something isn’t quite right.
The current state of Docker on Fedora 32 is not ideal. The lack of an official package might bother some, and there is an [issue upstream](https://github.com/docker/for-linux/issues/955) where this is discussed. The missing support for both [CGroups](https://github.com/moby/moby/issues/40360) and [NFTables](https://github.com/moby/moby/issues/26824) is more technical, but you can check their progress in their public issues.
These instruction should allow you to continue working like nothing has happened. If this has not satisfied your needs, don’t forget to address your technical issues at the Moby or Docker Github pages, or take a look at Podman which might prove more robust in the long-term future.
## Vincent Rubiolo
Hi there and thanks for the article, a useful sumup of the various threads lying around which will benefit a lot of people moving to Fedora32!
Just a note that w.r.t cgroups, it’s the move to cgroupsv2 which is a problem for Docker and which requires to move back to cgroupsv1.
The Redhat Enable Sysadmin site did a great article about this when Fedora 31 was released: https://www.redhat.com/sysadmin/fedora-31-control-group-v2, I can only recommend it.
## Ricky Zhang
I confirmed this is the exact problem starting form Fedora 31.
## Christian Groove
Podman is a wonderful replacement for the unsafe docker. I used it to run my accounting software, in a container that is executed as a non-root service under a technical user and a customized selinux config.
## Guus
It would be interesting to know why you find docker unsafe. Do you have a link to a document that explains this?
P.S. I am currently not a user of docker, neither of podman. But I do want to understand the technologies behind both and I would like to know why pod is safe and docker is not.
## Stephen Snow
One of the reasons Podman was created was to facilitate the use of rootless containers. or containers without root privileges on the host. Docker requires the Docker Daemon which runs as root. That is the fundamental difference.
## Mark
I prefer docker to podman from an admin and disk space point of view. With the docker daemon you have a single point to view all running containers that may impact your system plus all the images are stored in one place. Plus while ‘docker stats’ is not that accurate you do get an idea of what impact each container is having.
With podman and users building and running containers as they see fit, plus each user having their own images and container overlays in their home directory structure, on a multi-user system it is a waste of disk space an no easy overview of what containers are running.
From a system admin viewpoint Podman should be used only on single user developer workstations, not on a multi-user server.
## Stephen Snow
I would think that the added security of Podman would have been a plus from the Sys Admin POV. Podman is part of a trio of software for managing containers and images > buildah, podman, and skopeo.
## shy
There are certain things everyone show know about Docker:
https://github.com/docker/for-linux/issues/477
## Mehdi
But, podman also gives a root shell when you run a container (using run -ti) with it. How is that rootless? Would you please explain?
## Stephen Snow
Hello @Medhi,
When a user starts podman using the run command and the -ti options, they are running a container in their own namespace, which should be specified in /etc/subuid . The -ti just tells the podman run command it is a tty(-t) and interactive(-i). While you can be “root” within the container since you are the owner of the namespace used when the container is run, the container is rootless on your system.
## Olivier
To me all the unsafe is here :
and dockerd run as root. You can access host through volume and do what you want, such as change root password on the host…
## kayke
you can use this command is a little bit safer then usermod
sudo setfacl –modify user:$USER:rw /var/run/docker.sock
## shy
Podman development is progressing. There is podman-compose to replace docker-compose https://github.com/containers/podman-compose/
XWIKI runs on podman using podman-compose https://forum.xwiki.org/t/xwiki-docker-images-run-on-podman/6869
Pi-hole runs on podman using podman-compose https://discourse.pi-hole.net/t/pi-hole-runs-on-podman/34719
## Alejandro
Awesome, this is exactly what I mentioned in previous comment! Will have a look 😀
## Daniel
Thank you! I was missing an article to point this out.
## Yogesh Sharma
Following can also help
sudo dnf install podman-docker
Description : This package installs a script named docker that emulates the Docker CLI by executes podman commands, it also creates links between all Docker CLI man pages and podman.
## Alejandro
Nice article, I struggled to find an article a few months back when I moved to Fedora 32 regarding the state of Docker. Or one that actually worked for me, anyway. I decided to start investing time in Podman*, which I love, although for some reason -probably me- not all the same commands I had for docker worked.
Slightly off-topic, I wish Podman had a gender neutral name.
## Einer
Hmmmm ….. is “Alejandro” a “gender neutral name”? …….. Maybe you should change it ……..
(Podman == Pod Manager … looks pretty “gender neutral” to me ..)
## Alberto Patino
podmanwoman or podwomanman or podwo(man)^2 maybe
## John
What’s wrong with the name Podman?
## Alan
PodMan is a gender neutral name. The man stands for manager not male.
## W T Costa
There is also a question of the docker network and the firewallD. I managed to make it work by adding the docker0 network to the default group.
But I’m a user of another distribution (‘de’ …) and I’m still getting started with Fedora.
Aguém indicates a good tutorial, even simple, FirewallD?
## Sebastiaan Franken
I’ve found the firewalld man page to be a good starting point. Also, the firewalld website (firewalld [dot] org) has quite a bit of info!
## Stephane
Heads up, this worked but completely broke my libvirtd virtual machine.. Something about python-nftables failing.
I had to revert all the steps to boot the VM again… I will probably have to use podman instead of docker.
## Esteban
Check to make sure the bridges don’t overlap. It’s happened to me.
## drakkai
I’m using the docker repo for F31 on F32 without problems.
[docker-ce-stable]
name=Docker CE Stable – $basearch
baseurl=https://download.docker.com/linux/fedora/31/$basearch/stable
enabled=1
gpgcheck=1
gpgkey=https://download.docker.com/linux/fedora/gpg
## Elad
How is this working ? 🙂
## Bruno
Same for me. The fedora 31 Docker repo works fine in Fedora 32.
Fortunately I also don’t use firewalld but ufw, so I didn’t have to change anything in the Firewall also 😉
Great article,
## Tomasz Gąsior
For me, reverting firewalld backend from nftables to iptables worked better than changing firewalld settings.
## Mark
Yes, as far as I am aware docker-ce runs without any issues. While I don’t use it on Fedora I run it on CentOS8 which is also cgroups2 without any issues.
## Sergey
https://www.redhat.com/en/blog/world-domination-cgroups-rhel-8-welcome-cgroups-v2
RHEL 8 ships with cgroups v1 as the default.
## Heiko Loewe
Hi,
awesome article.
But what about Nvidia integration. I found nothing on github how to install the nvidia-docker-plugin with moby.
Heiko
## vic
This is sad. I loved using older Fedora, due to RedHat heritage.
Due to Docker issues, I’m starting to look at PopOS.
## Trung LE
I am not a big fan of moby and love to switch to podman if possible. I wish one day commercial support for podman would get on par with docker.
Btw, if people start running into issue with libvirt after installing moby-engine, check this https://bugzilla.redhat.com/show_bug.cgi?id=1829090
## Anonymous
Thanks for the guide, this publication rocks! Zsh users here will need to quote “docker-*” in the first two commands to avoid expansion.
sudo dnf ‘remove docker-
‘‘sudo dnf config-manager ‘–disable docker-
## Tim Hughes
This breaks vagrant-libvirt integration with the following error:
To fix I deleted everything under
and then reinstall firewalld
sudo dnf reinstall -y firewalld
restarted firewalld and libvirt
sudo systemctl restart libvirtd
## Hubbs
This has completely broken libvirtd VM networking. The VMs can not access the Internet. The docker rules prevent libvirtd for putting the proper firewall rules in places. If VMs need to access the Internet, I need to restart firewalld and libvirtd. In turn, my docker containers will fail. Podman is useless because the work flow at my employer, where no one else is using a linux box, requires the ability to manipulate docker containers that podman doesn’t support now or doesn’t easily support. |
12,435 | OWL 项目:物联网正尝试在灾难中让一切保持联络 | https://www.networkworld.com/article/3564980/project-owl-iot-trying-to-hold-connectivity-together-in-disasters.html | 2020-07-21T13:56:28 | [
"IoT"
] | https://linux.cn/article-12435-1.html |
>
> 当自然灾害破坏了传统的通信连接时,配置在<ruby> 多跳网络 <rt> mesh network </rt></ruby>的物联网设备可以迅速部署以提供基本的连接。
>
>
>

OWL 项目负责人在最近的开源峰会上说,一个以多跳网络、物联网和 LoRa 连接为中心的开源项目可以帮助急救和受灾人员在自然灾害之后保持联系。
OWL 项目的应用场景是当在自然灾害之后频繁发生的通信中断时。无论是蜂窝网络还是有线网络,大范围的中断会频繁阻碍急救服务、供应和在暴风雨或其他重大灾难后必须解决关键问题的信息流。
该项目通过一大群“<ruby> 鸭子 <rt> duck </rt></ruby>”(便宜、易于部署且不需要现有基础设施支持的小型无线模块)实现这个目的。一些“鸭子”是太阳能的,其它一些则用的是耐用电池。每只“鸭子”配备一个 LoRa 无线电,用于在网络上和其它“鸭子”进行通信,同时还配备有 Wi-Fi,而且可能配备蓝牙和 GPS 来实现其他功能。
这个想法是这样的,当网络瘫痪时,用户可以使用他们的智能手机或者笔记本电脑与“鸭子”建立一个 Wi-Fi 连接,这个“鸭子”可以将小块的信息传递到网络的其他部分。信息向网络后端传递,直到到达“<ruby> 鸭子爸爸 <rt> papaduck </rt></ruby>”,“鸭子爸爸”装备了可以与云上的 OWL 数据管理系统连接的卫星系统(OWL 代表 ”<ruby> 组织 <rt> organization </rt></ruby>、<ruby> 位置 <rt> whereabouts </rt></ruby>和<ruby> 物流 <rt> logistics </rt></ruby>”)。信息可以通过云在智能手机或者网页上进行可视化,甚至可以通过 API 插入到现有的系统中。
秘密在于“<ruby> 鸭群 <rt> ClusterDuck </rt></ruby>” 协议,这是一个开源固件,即使在一些模块不能正常工作的网络中,它仍然能保持信息流通。它就是设计用来工作在大量便宜且容易获取的计算硬件上,类似树莓派的硬件,这样可以更容易且更快捷的建立一个“鸭群”网络。
创始人 Bryan Knouse 表示,这个项目的创建,是因为在 2017 年和 2018 年的毁灭性飓风中,要与受影响社区进行有效的通信而采取救援措施,面临着巨大的困难。
“我们的一些创始成员经历了这些灾难,然后我们会问‘我们该做些什么?’”,他说道。
在马亚圭斯,该项目有一批来自波多黎各大学的学生和教授,大多数的系统测试都在那里进行。Knouse 说,校园中目前有 17 个太阳能“鸭子”,分布在屋顶和树上,并且计划增加数量。
他说,“这种关系实际上创建了一个开源社区,这些学生和教授正在帮助我们开发这个项目。”
---
via: <https://www.networkworld.com/article/3564980/project-owl-iot-trying-to-hold-connectivity-together-in-disasters.html>
作者:[Jon Gold](https://www.networkworld.com/author/Jon-Gold/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,438 | 我的 Linux 故事:从用户到贡献者 | https://opensource.com/article/20/7/linux-user-contributor | 2020-07-22T11:41:00 | [
"Linux",
"故事"
] | /article-12438-1.html |
>
> 开源社区欢迎来自不同背景和技能的贡献者。
>
>
>

我是一名 IT 专业人士,拥有超过 15 年经验,担任过不同职位 —— 包括系统管理员、高级 Linux 管理员、DevOps 工程师、自动化顾问和高级<ruby> 敏捷专家 <rt> scrum master </rt></ruby>。我开始是在 Ubuntu 上学习 Linux,但是后来作为系统管理员转到 CentOS,然后我又转到 Fedora 作为个人使用。但是我对技术的喜爱要远比我使用第一个 Linux 发行版要早的多,而且是来自于一部电影。
我最喜欢的电影是《<ruby> 黑客 <rt> Hackers </rt></ruby>》。最精彩的一幕发生在电影的开头。电影一开始,一群特工冲进一所房子抓捕臭名昭著的黑客 Zero Cool。我们马上发现 Zero Cool 其实是 11 岁的 Dade Murphy,他在一天之内成功瘫痪了 1507 台计算机系统。他被指控犯罪,他的家人被处以重罚。而且,在他 18 岁之前,他都被禁止使用电脑或按键式电话。
<ruby> 劳伦斯·梅森 <rt> Laurence Mason </rt></ruby>扮演的 Paul Cook,又名 Nikon 勋爵,是我最喜欢角色。其中一个主要原因是,我从没有看过一个黑客电影里面的人物长的像我,所以我被他的形象深深吸引了。他很神秘。这让我耳目一新,并且感到自豪,我对 IT 充满了热情,我也是一个和他很像的极客。

### 成为一个 Linux 贡献者
15 年前,我开始使用 Linux。当我成为一个 Linux 管理员的时候,Linux 就成了我的激情所在。我一直尝试找到某种方式能够为开源作出贡献,当时我还不知道该从哪开始。因为这个社区实在是太大了,我不知道自己能否真正成为一个有影响力的人,但当我发现一些人认可我的兴趣,还对我进行指导,我开始彻底打开心扉,问各种问题,并且从社区中学习。自从那以后,Fedora 社区一直是我做贡献的最主要社区。
我现在对于向开源做贡献还是有点稚嫩。当我意识到我可以用代码以外的方式来贡献时,我对开源的想法发生了改变。我更喜欢通过文档做一些贡献,因为我本质上不是一个软件开发人员,而且社区里面最迫切的需求正是文档。请记住:用户的技能和开发人员的技能同样重要。
### 我的硬件是什么?
硬件也很重要,而且现在几乎所有东西都可以运行 Linux。现在,我家里的配置包括:
* 联想 Thinksever TS140,64 GB 内存,4 x 1 TB SSD 和一个存储数据的 1 TB 机械硬盘
* 使用 RAID 5 配置的 164 TB Synology NAS
* 输入输出使用罗技 MX Master 和 MX Master 2S
* 一个定制的并且符合人体工学的 Kinesis Advantage 2 键盘
* 两个 38 寸 LG 超宽曲面显示器和一个 34 寸 LG 超宽显示器
* 一台配备 i7 六核十二线程 CPU 和 16.1 英寸 IPS 显示器的 System76 笔记本
我很喜欢 Fedora 处理外置设备的方式,比如说我的鼠标和键盘。一切都完美融合。即插即用工作正常,性能从来不受影响。

### 软件是什么?
使用开源软件对我的工作非常重要。我依赖于:
* Fedora 30 作为我日常使用的 Linux 发行版
* Wekan 作为我的项目的开源<ruby> 看板 <rt> kanban </rt></ruby>
* [Atom](https://fedoramagazine.org/install-atom-fedora/) 作为我的文本编辑器
* Terminator 作为我日常使用的终端,因为它的网格布局以及丰富的键盘快捷键
* Neofetch 用来显示每次登录到终端时的系统信息
最后同样重要的是,我把 Powerline、Powerlevel9k 和 Vim-Powerline 搞到我的终端上来跟别人装酷。

### Linux 让我们走到一起
美国是个大熔炉,我也是这么看待 Linux 和像 Fedora 项目这样的特定社区的。在每个 Linux 社区中,对于不同的贡献都有很大的空间。也有很多方式可以参与进来,而且对于新的想法,也总是有发挥的空间。通过分享我过去 15 年在开源方面的经验,我希望帮助更多在科技领域的少数族裔体会到来自开源社区对多样性和包容性的认同感。
*编者注:这篇文章改编自[“Taz Brown:你怎么搞 Fedora?”](https://fedoramagazine.org/taz-brown-how-do-you-fedora/),并得到许可重新发布*
---
via: <https://opensource.com/article/20/7/linux-user-contributor>
作者:[Taz Brown](https://opensource.com/users/heronthecli) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,439 | 我的功能丰富却又保持简约的 Linux 终端 | https://opensource.com/article/20/7/minimal-linux-terminal | 2020-07-22T12:32:17 | [
"终端"
] | https://linux.cn/article-12439-1.html |
>
> 这些应用和主题可以你真正拥有你的终端。
>
>
>

每个人都喜欢以特定的方式设置他们的工作区:它可以帮助你提高效率,并使生活更容易以一种感觉有机的方式组织事物,并拥有一个对你来说感觉良好的环境。这也绝对适用于终端。这可能就是为什么有这么多可用终端的原因。
在使用新的计算机时,我做的第一件事就是设置我的终端,让它成为我自己的终端。
我最喜欢的终端应用是 [Terminator](https://terminator-gtk3.readthedocs.io/en/latest/),因为它的设计简约,并且内置了窗口选项。但从这里开始变得更加复杂。我将自己喜欢的终端风格描述为“功能丰富却又保持简约”。这种平衡是我经常在微调的。
我使用 zsh 作为默认 shell,并使用 Ohmyzsh 来提供额外的功能。可以下载它的安装脚本来安装 Ohmyzsh:
```
$ curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh --output install-zsh.sh
```
查看一遍脚本了解它做什么,并确保你有信心在计算机上运行该脚本。完成后,运行脚本:
```
$ sh ./install-zsh.sh
```
我最喜欢的主题/提示符是 [Powerlevel 10k](https://github.com/romkatv/powerlevel10k),它是一个非常详细的环境视图。它包含了从命令的颜色高亮到运行时间的时间戳等所有内容。所有细节都集成到一个优雅的、具有上下文感知的提示符中。
要安装 Powerlevel10k,请先在 `.oh-my-zsh/` 自定义主题目录中下载源码。
```
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git
${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/themes/powerlevel10k
```
但是,为了让 Powerlevel10k 看起来如其存储库中所示,我们需要添加一些默认不包括的字体。它们是:
* [MesloLGS NF Regular.ttf](https://github.com/romkatv/powerlevel10k-media/raw/master/MesloLGS%20NF%20Regular.ttf)
* [MesloLGS NF Bold.ttf](https://github.com/romkatv/powerlevel10k-media/raw/master/MesloLGS%20NF%20Bold.ttf)
* [MesloLGS NF Italic.ttf](https://github.com/romkatv/powerlevel10k-media/raw/master/MesloLGS%20NF%20Italic.ttf)
* [MesloLGS NF Bold Italic.ttf](https://github.com/romkatv/powerlevel10k-media/raw/master/MesloLGS%20NF%20Bold%20Italic.ttf)
这将产生一个美观且具有上下文感知的终端(如 [screenfetch](https://github.com/KittyKatt/screenFetch) 所示):

我已经习惯了这个特殊的设置,但是,把工作环境变成自己的环境固然重要,但这也并不是一个固执地尝试新事物的理由。新终端的出现,是为了满足新一代用户的需求和要求。这意味着,即使一开始不熟悉,但最近开发的一种终端可能比你的老旧备用机更适合当今的环境和职责。
我最近一直在考虑其他选择。我开始关注 [Starship](https://starship.rs/) 的开发情况,它将自己描述为简约的、快速的、可无限定制的提示符,适用于任何 shell。它仍然有很多在视觉上可以身临其境的细节,而不会像 Powerlevel10k 那样使人分心。
你最喜欢的终端是什么?为什么?请在评论栏分享!
---
via: <https://opensource.com/article/20/7/minimal-linux-terminal>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Everyone likes to set up their workspaces in a specific way; it helps your productivity and makes life easier to have things organized in a way that feels organic and to have an environment that feels good to you. That definitely applies to terminals too; that's probably why there are so many terminal options available.
When starting on a new computer, the very first thing I do is set up my terminal to make it my own.
My preferred terminal app is [terminator](https://terminator-gtk3.readthedocs.io/en/latest/) because of its minimalist design and built-in windowing options. But it gets more complex from there. I would describe my preferred terminal style as "feature-rich yet, keeping it minimal." That balance is one I'm often fine-tuning.
I use zsh as my default shell, and Ohmyzsh to give is additional features. One can install Ohmyzsh by downloading its install script:
```
$ curl -fsSL \
https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh \
--output install-zsh.sh
```
Read the script over to see what it does, and to ensure you feel confident in running it on your computer. Once you're ready, run the script:
`$ sh ./install-zsh.sh`
My favorite theme/prompt is [Powerlevel 10k](https://github.com/romkatv/powerlevel10k), which is an incredibly detailed view of my environment. It includes everything from color highlighting of commands to timestamps for when they were run. All the details integrate into an elegant, context-aware prompt. [context-aware is used as a benefit twice, here and below, can author provide more here on what that means and why it is a good thing in a terminal?}
Installing Powerlevel10k begins with downloading the source code in the `.oh-my-zsh/`
custom theme directory.
```
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git
${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/themes/powerlevel10k
```
However, to make Powerlevel10k look as it is shown in the repository, we need to add some fonts that are not included by default; these are listed below:
This results in a beautiful and context-aware terminal (as shown by [screenfetch](https://github.com/KittyKatt/screenFetch))
I've become accustomed to this particular setup, but, as important as it is to make your work environment your own, that's also not a reason to be stubborn about trying new things. New terminals emerge in order to answer the needs and demands of new generations of users. That means that, even if it's unfamiliar at first, one of the more recently developed terminals could be better suited to today's environments and responsibilities than your old standby.
I have been considering other options recently. I started watching the development of [Starship](https://starship.rs/), which describes itself as a minimal, blazing-fast, and infinitely customizable prompt for any shell. It still has a lot of visually immersive details without as much of what some might find distracting from Powerlevel10k.
What's your favorite terminal, and why? Share in the comments!
## 14 Comments |
12,441 | 《A Byte of Vim》书评 | https://itsfoss.com/book-review-a-byte-of-vim/ | 2020-07-22T18:05:16 | [
"Vim"
] | https://linux.cn/article-12441-1.html | [Vim](https://www.vim.org/) 是一个简单而又强大的文本编辑工具。大多数新用户都会被它吓倒,因为它不像常规的图形化文本编辑器那样“工作”。Vim “不寻常”的键盘快捷键让人不知道[如何保存并退出 Vim](https://itsfoss.com/how-to-exit-vim/)。但一旦你掌握了 Vim,就没有什么能比得上它了。
网上有大量的 [Vim 资源](https://linuxhandbook.com/basic-vim-commands/)。我们也在介绍了一些 Vim 技巧。除了线上资源,也有很多书致力于介绍这个编辑器。今天,我们要介绍的是一本旨在使大多数用户轻松理解 Vim 的书。我们将讨论的书是 [Swaroop C H](https://swaroopch.com/) 撰写的《[A Byte of Vim](https://vim.swaroopch.com/)》。
本书作者 [Swaroop C H](https://swaroopch.com/) 已经在计算机领域工作了十余年,他曾在 Yahoo 和 Adobe 工作过。大学毕业后,他卖过 Linux CD,也曾多次创业,也是一个创建了一个名为 ion 的 iPod 充电器的团队的联合创始人。他目前是 [Helpshift](https://www.helpshift.com/) AI 团队的工程经理。
### 《A Byte of Vim》

像所有好书一样,《A Byte of Vim》一开始就谈到了什么是 Vim:“一个用于写各类文本的计算机程序。”他接着说:“Vim 之所以与众不同,是因为它是为数不多的既简单又强大的软件之一。”
在深入讲解如何使用 Vim 之前,Swaroop 先告诉读者如何在 Windows、Mac、Linux 和 BSD 上安装 Vim。安装完成后,他进而指导读者完成如何启动 Vim,以及如何创建第一个文件。
接着,Swaroop 讨论了 Vim 的不同模式,以及如何通过 Vim 的键盘快捷键来浏览文档。接着是使用 Vim 编辑文档的基础知识,包括如何在 Vim 中剪切/复制/粘帖以及撤销/重做。
在介绍了编辑基础知识后,Swaroop 介绍了如何使用 Vim 来编辑单个文档的多个部分。你也可以使用多个标签和窗口来同时编辑多个文档。
本书还涵盖了通过编写脚本和安装插件来扩展 Vim 的功能。在 Vim 中使用脚本有两种方法,一种是使用 Vim 的内置脚本语言,另一种是使用 Python 或 Perl 等编程语言来访问 Vim 的内核。可以编写或下载五种类型的 Vim 插件:vimrc、全局插件、文件类型插件、语法高亮插件和编译器插件。
在一个单独的章节中,Swaroop C H 介绍了使 Vim 更适合编程的特点。这些功能包括语法高亮、智能缩进、对 Shell 命令的支持、全局补全以及可用作 IDE 使用的功能。
#### 获取《A Byte of Vim》一书并为之贡献
《A Byte of Vim》按照 [共创协议 4.0](https://creativecommons.org/licenses/by/4.0/)授权。读者可以在[作者的主页](https://vim.swaroopch.com/)上免费阅读其在线版本。你也可以免费下载其 [PDF](https://www.gitbook.com/download/pdf/book/swaroopch/byte-of-vim)、[Epub](https://www.gitbook.com/download/epub/book/swaroopch/byte-of-vim) 或者 [Mobi](https://www.gitbook.com/download/mobi/book/swaroopch/byte-of-vim) 版本。
* [免费获取《A Byte of Vim》](https://vim.swaroopch.com/)
如果你更喜欢阅读[纸质版本](https://swaroopch.com/buybook/),你也可以选择该方式。
请注意,**《A Byte of Vim》的初始版本写于 2008**,并转换为 PDf。不幸的是,Swaroop CH丢失了原始源文件。他正在努力将该书转换为 [Markdown](https://itsfoss.com/best-markdown-editors-linux/)。如果你想提供帮助,请访问[该书的 GitHub 页面](https://github.com/swaroopch/byte-of-vim#status-incomplete)。
#### 结语
当我初次对着 Vim 生气时,我不知道该怎么办。我希望那时候我就知道《A Byte of Vim》这本书。对于任何学习 Linux 的人来说,这本书都是不错的资源,特别是当你开始学习命令行的时候。
你读过 Swaroop C H 的《[A Byte of Vim](https://vim.swaroopch.com/)》吗?如果读过,你是如何找到它的?如果不是,那么你最喜欢关于开源主题的是哪本书?请在下方评论区告诉我们。
---
via: <https://itsfoss.com/book-review-a-byte-of-vim/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,445 | 为什么人们对 Arch Linux 如此着迷?它有什么特别之处? | https://itsfoss.com/why-arch-linux/ | 2020-07-23T22:44:19 | [] | https://linux.cn/article-12445-1.html | 顺便说一句(利益相关),**我用 Arch!**
你或许已经在 Linux 论坛、朋友相互讨论或表情包里看到过这个术语。
你可能想知道为什么 Arch Linux 如此受欢迎,为什么人们这么喜欢它?因为有更容易使用,甚至更好的[基于 Arch 的发行版](https://itsfoss.com/arch-based-linux-distros/)。
在本文中,我将列出 Linux 用户喜欢使用 [Arch Linux](https://www.archlinux.org/) 的一些原因。
### 人们喜欢使用 Arch Linux 的六个原因

这些只是我的看法,当然,为什么你应该使用 Arch Linux 并没有固定的原因。这是我在十多年里与 Linux 用户和社区打交道的经验中观察到的。
让我们一起看看为什么 Arch Linux 如此受欢迎。
#### 1、DIY 的方式可以让你掌控操作系统的各个方面
我一直认为 Arch Linux 是一个可以让你自己动手打造的操作系统。从安装到管理,Arch Linux 放手让你处理一切。
你可以自己决定使用哪种桌面环境、安装哪些组件和服务。这种精细化的控制能够赋予你一个精简的操作系统,可以让你自由选择所需的组件来构建属于你自己的系统。
如果你是一个 DIY 爱好者,你会喜欢 Arch Linux 的。
#### 2、通过 Arch Linux,可以更好地理解 Linux 的工作原理

如果你曾经尝试过安装 Arch Linux,你就会知道它的复杂性。
但这种复杂性同时也意味着你将被迫学习一些在其他发行版中可能永远不会费心学习的东西。
比如说在安装 Arch Linux 过程中配置网络本身就是一个很好的学习课程。
如果开始你有感到有困惑不懂的时候,Arch Linux 的[维基](https://wiki.archlinux.org/)可以帮助你。它是互联网上最广泛和最棒的由社区管理的文档。仅仅只是浏览 Arch Linux 的维基,就可以学到很多东西。
#### 3、滚动发行模式可以为你提供最新的内核和软件

Arch Linux 是一个滚动发行版,这意味着新的内核和应用程序版本一经发布,就会立即向你推送。
当大多数其他 [Linux 发行版还在提供旧的 Linux 内核版本](https://itsfoss.com/why-distros-use-old-kernel/)时,Arch 会迅速向你提供最新的内核。
而软件也是如此。如果 Arch 资源库中的软件发布了新版本,Arch 用户通常会比其他用户先获得新版本。
在滚动发行模式下,一切都是新鲜和前沿的。你不必把操作系统从一个版本升级到另一个版本,只要使用 [pacman 命令](https://itsfoss.com/pacman-command/),你会始终保持最新的版本。
#### 4、Arch 用户资源库,即 AUR

Arch Linux 的资源库中有大量的软件。AUR 扩展了 Arch Linux 的软件产品。在 Arch Linux 中,你可以通过 [AUR](https://itsfoss.com/aur-arch-linux/) 得到相当多的软件。
AUR 是采用社区驱动的方式来提供更新的应用程序。你可以在 [AUR 辅助工具](https://itsfoss.com/best-aur-helpers/)的帮助下搜索和安装应用程序。
#### 5、成就感

正如 James Clear 在他的书《<ruby> 原子习惯 <rt> Atomic Habits </rt></ruby>》中提到的那样,**人类的大脑喜欢挑战,但前提是在一个最理想的困难区域**。
还记得你第一次安装成功 Linux 时的感觉吗?即便你安装的是 Linux Mint。这给了你一种成就感:你成功安装了 Linux!
如果你已经使用 Ubuntu、Fedora 或其他发行版一段时间了,现在开始感到舒适(或厌倦),你可以尝试安装一下 Arch Linux。
对于一个有一定经验的 Linux 用户来说,[成功安装 Arch Linux](https://itsfoss.com/install-arch-linux/)本身就会给你一种成就感。
这是一个挑战,但却是可以实现的。如果你建议一个新的 Linux 用户尝试 Arch Linux 或者更复杂的 Linux 发行版比如 [Linux From Scratch(LFS)](http://www.linuxfromscratch.org/),这个挑战就太难实现了。
这种成功完成挑战的感觉也是人们使用 Arch Linux 的原因之一。
#### 6、没有企业的参与!Arch 是由社区创建、支持和拥有的
Ubuntu 由 Canonical 支持,Fedora 来自 Red Hat(现在是 IBM 的一部分),openSUSE 来自 SUSE。所有这些主流发行版都是企业支持的。
这本身并不是坏事或过错,但是有一些人不喜欢企业参与开源项目。
正如 Debian 一样,Arch Linux 是为数不多的仅由社区参与的 Linux 发行项目之一。
你可能会指出,许多其他发行版如 Linux Mint 等不是由企业赞助的。好吧,这可能是真的,但 Linux Mint 本身就是基于 Ubuntu 的,并且使用 Ubuntu 的资源库。而 Arch Linux 不是另一个发行版的衍生物。
从这个意义上说,[Debian](https://www.debian.org/) 和 Arch Linux 是更纯粹的社区驱动项目。这对很多人来说可能无关紧要,但确实有一些人在意这些事情。
#### 对你来说,为什么 Arch Linux 如此受欢迎?
现在你可能不同意我提出的所有观点,那没关系。我想知道你是怎么看待 Arch Linux 在 Linux 用户中如此受欢迎,并具有崇拜的地位的?
当你写评论时,让我分享一下“我用 Arch”的表情包 ?

---
via: <https://itsfoss.com/why-arch-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Mikedkmilk](https://github.com/Mikedkmilk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

BTW, I use Arch!
You may have come across this term in Linux forums, discussions or memes.
You might wonder why Arch Linux is so popular. Why do people like it so much when there are easier-to-use, if not better, [Arch-based distributions](https://itsfoss.com/arch-based-linux-distros/) available.
In this article, I’ll list some reasons why Linux users like to use [Arch Linux](https://www.archlinux.org/).
## 6 reasons why people love to use Arch Linux

Now, this is my perception. There is no set rule, of course, why you should be using Arch Linux. It’s what I have observed in my over a decade of experience with Linux users and communities.
Let’s see why Arch Linux is so popular.
### 1. The DIY approach gives you control over every aspect of your operating system
I have always found Arch Linux as a DIY (Do It Yourself) operating system. From installing to managing, Arch Linux lets you handle everything.
You decide which desktop environment to use, and which components and services to install. This granular control gives you a minimal operating system to build upon with elements of your choice.
If you are a DIY enthusiast, you’ll love Arch Linux.
### 2. With Arch Linux, you get a better understanding of how Linux works

If you have ever tried to install Arch Linux, you know the complexity that comes with it.
But that complexity also means that you’ll be forced to learn things that you probably never bothered to in other distributions.
For example, configuring the network itself while installing Arch Linux is a good learning lesson.
If you start to get overwhelmed, [Arch Wiki](https://wiki.archlinux.org/) is there for you. It is the most extensive and awesome community-managed documentation on the internet. Just browsing through Arch Wiki will teach you plenty of things.
### 3. Latest kernel and software with rolling release model
Arch Linux is a [rolling release distribution](https://itsfoss.com/rolling-release/). That means new kernel and application versions are rolled out to you as soon as they are released.
While most other [Linux distributions serve you old Linux kernel versions](https://itsfoss.com/why-distros-use-old-kernel/), Arch is quick to provide you the latest kernel.
The same goes for software. If a new version of software in the Arch repositories is released, Arch users get the new versions before other users most of the time.
Everything is fresh and cutting-edge in the rolling release model. You don’t have to upgrade the operating system from one version to another. Just use the [pacman command](https://itsfoss.com/pacman-command/) and you always have the latest version.
This makes Arch one of [best rolling release Linux distributions](https://itsfoss.com/best-rolling-release-distros/).
### 4. Arch User Repository aka AUR
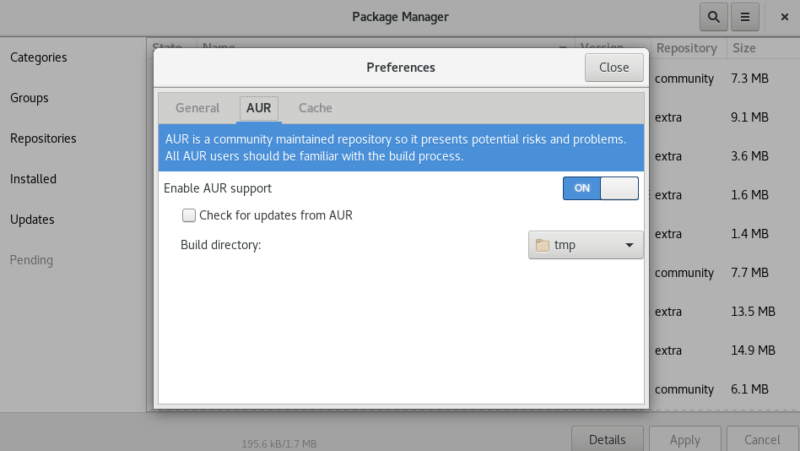
Arch Linux has plenty of software in its repository. The AUR extends the software offering of Arch Linux. You get a huge number of software with [AUR in Arch Linux](https://itsfoss.com/aur-arch-linux/).
AUR is a community-driven approach to providing newer applications. You can search and install applications with the help of an [AUR helper](https://itsfoss.com/best-aur-helpers/) tool.
### 5. Sense of accomplishment

As James Clear mentions in his book Atomic Habits, **human brain loves a challenge, but only if it is within an optimal zone of difficulty**.
Remember the feeling when you first installed any Linux distribution, even if it was [installing Linux Mint](https://itsfoss.com/install-linux-mint/)? That gave you a sense of achievement. You successfully installed Linux!
If you have been using Ubuntu or Fedora or other distribution for some time and you start to get comfortable (or bored), try installing Arch Linux.
For a moderately experienced Linux user, [successfully installing Arch Linux](https://itsfoss.com/install-arch-linux/) itself gives a sense of accomplishment.
It is a challenge but an achievable one. If you suggest a new Linux user try Arch Linux or an even more complicated one like [Linux From Scratch](http://www.linuxfromscratch.org/), the challenge would be too difficult to achieve.
This sense of successfully completing a challenge is also one of the reasons why people use Arch Linux.
Want to experience it? Try [installing Arch Linux in VirtualBox](https://itsfoss.com/install-arch-linux-virtualbox/). This is a safe and easy way of using an operating system without disrupting the current one.
### 6. No corporate involvement! Arch is created, supported and owned by community
Ubuntu is backed by Canonical, Fedora is from Red Hat (part of IBM now) and openSUSE is from SUSE. All these major distributions are corporate-backed.
This is not bad or a crime in itself. But a few people do not like corporate involvement in open source projects.
Like Debian, Arch Linux is one of the rare few community-only Linux distribution projects.
You may point out that many other distributions like Linux Mint etc are also not sponsored by corporate. Well, that might be true but Linux Mint itself is based on Ubuntu and uses Ubuntu’s repositories. Arch Linux is not derivative of another distribution.
In that sense, [Debian](https://www.debian.org/) and Arch Linux are more pure community-driven projects. It may not matter to many people but a few people do care about such things.
### According to you, why Arch Linux is so popular?
Now, you may not agree with all the points I made and that’s okay. I would like your views on why Arch Linux is so popular and has cult status among Linux users?
While you write the comments, let me share a BTW, I use Arch meme :)
 |
12,446 | Ubuntu 19.10 产品寿命结束,尽快升级到 Ubuntu 20.04! | https://itsfoss.com/ubuntu-19-10-end-of-life/ | 2020-07-23T23:41:23 | [
"Ubuntu"
] | https://linux.cn/article-12446-1.html |
>
> Ubuntu 19.10 Eoan Ermine 产品寿命结束。这意味着它不会获得任何安全或维护更新。继续使用 Ubuntu 19.10 将很危险,因为你的系统将来可能会因为缺少安全更新而变得脆弱。你应该升级到 Ubuntu 20.04。
>
>
>
[2019 年 10 月发布的 Ubuntu 19.10](https://itsfoss.com/ubuntu-19-10-released/) 带来了一些为 [Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/) 做准备的新功能。
作为非 LTS 版本,它有 9 个月的寿命。截至 2020 年 7 月 17 日,它的生命周期结束,并不会再收到任何更新。
### Ubuntu 19.10 生命周期结束

我之前已经[详细解释了 Ubuntu 的发布周期和产品寿命结束](https://itsfoss.com/end-of-life-ubuntu/)。如果此后继续使用 Ubuntu 19.10,我会重申这对你和你的系统意味着什么。
[软件通常有预定义的生命周期](https://en.wikipedia.org/wiki/Systems_development_life_cycle),一旦软件版本到达生命周期结束,它将停止获取更新和支持。生命周期结束后,Ubuntu 19.10 不再会从 Ubuntu 获得系统更新、安全更新或应用更新。
如果你继续使用它,你的系统可能会成为潜在的网络攻击的受害者,因为黑客往往会利用脆弱的系统。
之后,你可能无法使用 `apt` 命令安装新软件,因为 Ubuntu 将归档 19.10 的仓库。
### 如果你使用的是 Ubuntu 19.10,该怎么办?
首先,[检查你使用的 Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/)。这可以在终端中输入此命令完成:
```
lsb_release -a
```
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 19.10
Release: 19.10
Codename: Eoan
```
如果你看到 Ubuntu 19.10,你应该做以下两项工作之一:
* 如果你有良好、稳定的互联网连接,从 Ubuntu 19.10 升级到 20.04。你的个人文件和大多数软件保持不变。
* 如果你有着缓慢或不稳定的互联网连接,你应该[全新安装的 Ubuntu 20.04](https://itsfoss.com/install-ubuntu/)。你的文件和磁盘上的所有内容将被擦除,因此你应该在外部磁盘上备份重要数据。
#### 如何从 19.10 升级到 20.04 (如果你有良好的互联网连接)
我之前已经详细讨论了 Ubuntu 版本升级。我会在这里快速说下步骤。
首先,请确保在“软件和更新”中已设置接收新版本通知。
进入“软件和更新”:

进入“更新”选项卡,将“通知我新的 Ubuntu 版本”设置为“对于任何新版本”:

现在,安装所有挂起的更新。
现在,再次运行更新管理器工具。你应该可以选择升级到 Ubuntu 20.04。点击升级按钮并按照说明操作。
它会安装大约 1.2GB 的软件包。这就是为什么你需要一个良好和稳定的互联网连接。

这样的升级会保持你的家目录。不过,仍建议在外部磁盘进行备份。
### 你仍在使用 Ubuntu 19.10 吗?
如果你仍在使用 Ubuntu 19.10,那么必须为升级或全新安装做好准备。你不能忽视它。
如果你不喜欢这样的频繁版本升级,你应该使用支持五年的 LTS 版本。当前的 LTS 版本是 Ubuntu 20.04,你无论如何都应该升级到它。
你是否正在使用 Ubuntu 19.10?你是否已升级到 Ubuntu 20.04?如果你面临任何问题,或者如果你有任何问题,请让我知道。
---
via: <https://itsfoss.com/ubuntu-19-10-end-of-life/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Ubuntu 19.10 Eoan Ermine**has reached end of life. That it means it won’t get any security or maintenance updates. Continue using Ubuntu 19.10 would be risky as your system may be vulnerable in future for the lack of security updates. You should upgrade to Ubuntu 20.04.*
[Ubuntu 19.10 was released in October 2019](https://itsfoss.com/ubuntu-19-10-released/) bringing some new features that prepared a base for [Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/).
As a non-LTS release, it had a lifespan of nine months. It has completed its life cycle and as of 17th July 2020, it won’t be getting any updates.
## End of life for Ubuntu 19.10

I have [explained Ubuntu release cycle and end of life](https://itsfoss.com/end-of-life-ubuntu/) in detail earlier. I’ll reiterate what it means to you and your system if continue using Ubuntu 19.10 beyond this point.
[Software usually hav](https://en.wikipedia.org/wiki/Systems_development_life_cycle)[e](https://en.wikipedia.org/wiki/Systems_development_life_cycle)[ a predefined life cycle](https://en.wikipedia.org/wiki/Systems_development_life_cycle) and once a software version reaches end of life, it stops getting updates and support.
Beyond the end of life, Ubuntu 19.10 won’t get system updates, security updates or application updates from Ubuntu anymore.
If you continue using it, your system may fell victim to potential cyberattacks as hackers tend to exploit vulnerable system.
Later, you might not be able to install new software using apt command as Ubuntu will archive the repository for 19.10.
## What to do if you are using Ubuntu 19.10?
First, [check which version of Ubuntu you are using](https://itsfoss.com/how-to-know-ubuntu-unity-version/). This can be done quickly by entering this command in the terminal:
`lsb_release -a`
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 19.10
Release: 19.10
Codename: Eoan
```
If you see Ubuntu 19.10, you should do either of these two things:
- If you have a good speed, consistent internet connection, upgrade to Ubuntu 20.04 from within 19.10. Your personal files and most software remain untouched.
- If you have a slow or inconsistent internet connection, you should do a
[fresh installation of Ubuntu 20.04](https://itsfoss.com/install-ubuntu/). Your files and everything else on the disk will be erased so you should make backup of your important data on an external disk.
### How to upgrade to Ubuntu 20.04 from 19.10 (if you have good internet connection)
I have discussed the Ubuntu version upgrade in details previously. I’ll quickly mention the steps here as well.
First, make sure that your system is set to be notified of new version in Software & Updates.
Go to Software & Updates:
Go to Updates tab and set “Notify me of a new Ubuntu version” to “For any new version”:
Now, install any pending updates.
Now, run Update Manager tool again. You should be given the option to upgrade to Ubuntu 20.04. Hit the upgrade button and follow the instructions.
It installs packages of around 1.2 GB. This is why you need a good and consistent internet connection.
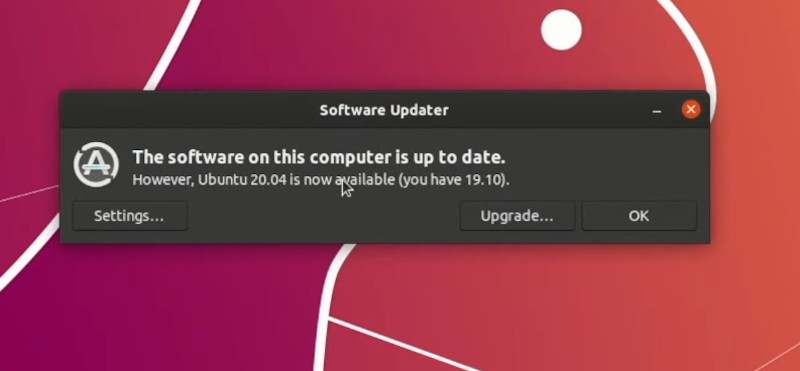
Upgrading this way keeps your home directory as it is. Having a backup on external disk is still suggested, though.
## Are you still using Ubuntu 19.10?
If you are still using Ubuntu 19.10, you must prepare for the upgrade or fresh installation. You must not ignore it.
If you don’t like frequent version upgrades like this, you should stick with LTS versions that are supported for five years. The current LTS version is Ubuntu 20.04 which you’ll be upgrading to anyway.
Were/are you using Ubuntu 19.10? Have you already upgraded to Ubuntu 20.04? Let me know if you face any issue or if you have any questions. |
12,448 | 如何用树莓派制作 WiFi 相框 | https://opensource.com/article/19/2/wifi-picture-frame-raspberry-pi | 2020-07-24T21:28:55 | [
"数码相框"
] | https://linux.cn/article-12448-1.html |
>
> DIY 一个数码相框,图片流来自云端。
>
>
>

数码相框真的很好,因为它可以让你查看你自己的相片而不必打印出来。更棒的是,当你想要展示一张新的相片的时候,增加和删除数字图片要比打开传统的相框然后替换里面的相框更简单。不过,这还是需要一点手动的操作,比如从数字相框取出 SD 卡、U 盘或者其他的存储介质,然后把存储介质接入电脑,接着再复制图片进入存储介质。
一个更简单的选项是数字相框通过 WiFi 获得图片,例如从云端服务器获得。下面就是如何制作这样的一个数字相框。
### 需要使用的材料
* 老式 [TFT](https://en.wikipedia.org/wiki/Thin-film-transistor_liquid-crystal_display) 的 LCD 显示屏
* HDMI 到 DVI 的转接线(因为 TFT 屏幕支持 DVI)
* 树莓派 3
* Micro SD 卡
* 树莓派的电源
* 键盘
* 鼠标(可选)
使用线缆连接树莓派到显示器,并连接电源。
### 安装 Raspbian
按照以下[指示](https://www.raspberrypi.org/documentation/installation/installing-images/README.md)下载并将 Raspbian 烧录到 Micro SD 卡中。将 Micro SD 卡插入树莓派,启动它,并配置你的 WiFi。在安装完 Raspbian 后,我的第一个操作通常是运行 `sudo raspi-config`。在那里,我在网络选项中更改主机名(例如,改为 `picframe`),并在接口选项中启用 SSH 以远程连接到树莓派。使用(例如)`ssh pi@picframe` 连接到树莓派。
### 建立并安装云客户端
我使用 [Nextcloud](https://nextcloud.com/) 来同步我的图片,但是你可以使用 NFS、[Dropbox](http://dropbox.com/),或者其他的适合你的需求的方式上传图片到相框。
如果你使用 Nextcloud,请按照[以下说明](https://github.com/nextcloud/client_theming#building-on-debian)在 Raspbian 上安装客户端。这可以很方便的放图片到你的相框,并且你可能很熟悉安装在台式机的这个客户端应用。当连接客户端到 Nextcloud 服务器上的时候,请确保只选择存储你要在相框上显示的图片的文件夹。
### 设置幻灯片放映
我发现设置幻灯片放映最简单的方式是使用一个专门为这个目的建立的[轻量级的幻灯片项目](https://github.com/NautiluX/slide/releases/tag/v0.9.0)。还有一些备用方案,像是配置屏保,这个应用似乎是最最简单设置幻灯片放映的方式了。
在你的树莓派上下载最新的二进制程序,解包并移动到一个可执行的文件夹里:
```
wget https://github.com/NautiluX/slide/releases/download/v0.9.0/slide_pi_stretch_0.9.0.tar.gz
tar xf slide_pi_stretch_0.9.0.tar.gz
mv slide_0.9.0/slide /usr/local/bin/
```
安装依赖关系:
```
sudo apt install libexif12 qt5-default
```
通过执行下面的命令播放幻灯片(不要忘记修改图片的路径)。如果你通过 SSH 访问你树莓派,设置 `DISPLAY` 变量来在连接到树莓派显示屏上开始播放幻灯片。
```
DISPLAY=:0.0 slide -p /home/pi/nextcloud/picframe
```
### 自动播放幻灯片
为了在 Raspbian Stretch 上自动播放幻灯片,建立如下的文件夹并且添加一个 `autostart` 文件到里面:
```
mkdir -p /home/pi/.config/lxsession/LXDE/
vi /home/pi/.config/lxsession/LXDE/autostart
```
在文件中输入如下的命令来自动开启幻灯片。`slide` 命令可以调整到你需要的地方:
```
@xset s noblank
@xset s off
@xset -dpms
@slide -p -t 60 -o 200 -p /home/pi/nextcloud/picframe
```
禁止屏幕空白,树莓派通常会在 10 分钟后这样做,通过编辑下面的文件修改:
```
vi /etc/lightdm/lightdm.conf
```
添加这两行到文件末尾:
```
[SeatDefaults]
xserver-command=X -s 0 -dpms
```
### 配置上电时间
你可以安排你的相框什么时候打开和关闭通过使用两个简单的定时任务。例如,你想在上午 7 点自动打开,在晚上 11 点自动关闭。运行 `crontab -e` 并且输入下面的两行:
```
0 23 * * * /opt/vc/bin/tvservice -o
0 7 * * * /opt/vc/bin/tvservice -p && sudo systemctl restart display-manager
```
注意这不会打开或关闭树莓派的电源;这只会关闭 HDMI,它会关闭屏幕。第一行命令将在晚上 11 点关闭 HDMI。第二行将在早上 7 点打开显示屏并重启显示器管理器。
### 附言
通过这些简单的步骤,你创建了你自己 WiFi 相框。如果你想要让它更好看,为显示屏做一个木质相框吧。
---
via: <https://opensource.com/article/19/2/wifi-picture-frame-raspberry-pi>
作者:[Manuel Dewald](https://opensource.com/users/ntlx) 选题:[lujun9972](https://github.com/lujun9972) 译者:[this-is-name-right](https://github.com/this-is-name-right) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Digital picture frames are really nice because they let you enjoy your photos without having to print them out. Plus, adding and removing digital files is a lot easier than opening a traditional frame and swapping the picture inside when you want to display a new photo. Even so, it's still a bit of overhead to remove your SD card, USB stick, or other storage from a digital picture frame, plug it into your computer, and copy new pictures onto it.
An easier option is a digital picture frame that gets its pictures over WiFi, for example from a cloud service. Here's how to make one.
## Gather your materials
- Old
[TFT](https://en.wikipedia.org/wiki/Thin-film-transistor_liquid-crystal_display)LCD screen - HDMI-to-DVI cable (as the TFT screen supports DVI)
- Raspberry Pi 3
- Micro SD card
- Raspberry Pi power supply
- Keyboard
- Mouse (optional)
Connect the Raspberry Pi to the display using the cable and attach the power supply.
## Install Raspbian
Download and flash Raspbian to the Micro SD card by following these [directions](https://www.raspberrypi.org/documentation/installation/installing-images/README.md). Plug the Micro SD card into the Raspberry Pi, boot it up, and configure your WiFi. My first action after a new Raspbian installation is usually running **sudo raspi-config**. There I change the hostname (e.g., to **picframe**) in Network Options and enable SSH to work remotely on the Raspberry Pi in Interfacing Options. Connect to the Raspberry Pi using (for example) **ssh pi@picframe**.
## Build and install the cloud client
I use [Nextcloud](https://nextcloud.com/) to synchronize my pictures, but you could use NFS, [Dropbox](http://dropbox.com/), or whatever else fits your needs to upload pictures to the frame.
If you use Nextcloud, get a client for Raspbian by following these [instructions](https://github.com/nextcloud/client_theming#building-on-debian). This is handy for placing new pictures on your picture frame and will give you the client application you may be familiar with on a desktop PC. When connecting the client application to your Nextcloud server, make sure to select only the folder where you'll store the images you want to be displayed on the picture frame.
## Set up the slideshow
The easiest way I've found to set up the slideshow is with a [lightweight slideshow project](https://github.com/NautiluX/slide/releases/tag/v0.9.0) built for exactly this purpose. There are some alternatives, like configuring a screensaver, but this application appears to be the simplest to set up.
On your Raspberry Pi, download the binaries from the latest release, unpack them, and move them to an executable folder:
```
wget https://github.com/NautiluX/slide/releases/download/v0.9.0/slide_pi_stretch_0.9.0.tar.gz
tar xf slide_pi_stretch_0.9.0.tar.gz
mv slide_0.9.0/slide /usr/local/bin/
```
Install the dependencies:
`sudo apt install libexif12 qt5-default`
Run the slideshow by executing the command below (don't forget to modify the path to your images). If you access your Raspberry Pi via SSH, set the **DISPLAY** variable to start the slideshow on the display attached to the Raspberry Pi.
`DISPLAY=:0.0 slide -p /home/pi/nextcloud/picframe`
## Autostart the slideshow
To autostart the slideshow on Raspbian Stretch, create the following folder and add an **autostart** file to it:
```
mkdir -p /home/pi/.config/lxsession/LXDE/
vi /home/pi/.config/lxsession/LXDE/autostart
```
Insert the following commands to autostart your slideshow. The **slide** command can be adjusted to your needs:
```
@xset s noblank
@xset s off
@xset -dpms
@slide -p -t 60 -o 200 -p /home/pi/nextcloud/picframe
```
Disable screen blanking, which the Raspberry Pi normally does after 10 minutes, by editing the following file:
`vi /etc/lightdm/lightdm.conf`
and adding these two lines to the end:
```
[SeatDefaults]
xserver-command=X -s 0 -dpms
```
## Configure a power-on schedule
You can schedule your picture frame to turn on and off at specific times by using two simple cronjobs. For example, say you want it to turn on automatically at 7 am and turn off at 11 pm. Run **crontab -e** and insert the following two lines.
```
0 23 * * * /opt/vc/bin/tvservice -o
0 7 * * * /opt/vc/bin/tvservice -p && sudo systemctl restart display-manager
```
Note that this won't turn the Raspberry Pi power's on and off; it will just turn off HDMI, which will turn the screen off. The first line will power off HDMI at 11 pm. The second line will bring the display back up and restart the display manager at 7 am.
## Add a final touch
By following these simple steps, you can create your own WiFi picture frame. If you want to give it a nicer look, build a wooden frame for the display.
## 9 Comments |
12,449 | DevSecOps 和敏捷软件开发有什么不同? | https://opensource.com/article/20/7/devsecops-vs-agile | 2020-07-24T22:53:52 | [
"DevSecOps",
"敏捷"
] | https://linux.cn/article-12449-1.html |
>
> 你更专注于安全性还是软件交付,还是可以两者兼得?
>
>
>

技术社区中存在一种趋势,经常互换地使用 DevSecOps 和敏捷软件开发这两个术语。尽管它们有一些相似性,例如都旨在更早地检测风险,但在改变团队的[工作方式层面有很大不同](https://tech.gsa.gov/guides/understanding_differences_agile_devsecops/)。
DevSecOps 建立在敏捷开发建立的一些原则上。但是,DevSecOps 特别专注于[集成安全功能](https://www.redhat.com/en/topics/devops/what-is-devsecops),而敏捷开发则专注于交付软件。
知道如何保护你们的网站或应用程序免受勒索程序和其他威胁的侵害,实际上取决于你使用的软件和系统开发。这可能会影响你选择使用 DevSecOps、敏捷软件开发还是两者兼而有之。
### DevSecOps 和敏捷软件开发的不同之处
两者的主要区别可以归结为一个简单的概念:安全性。这取决于你的软件开发实践,你们公司的安全措施 —— 以及何时、何地以及由谁实施,都可能会有很大不同。
每个企业都[需要 IT 安全](https://www.redhat.com/en/topics/security)来保护其重要数据。如果企业真正重视 IT 安全,一般都会采取虚拟专用网(VPN)、数字证书、防火墙保护、多因子身份验证、安全的云存储,包括向员工介绍基本的网络安全措施。
当你信任 DevSecOps 时,你就会把公司的安全问题,本质上使其等同于持续集成和交付。 DevSecOps 方法论在开发之初就强调安全性,并使其成为整体软件质量不可或缺的组成部分。
基于 DevSecOps 安全性的三大原则:
* 平衡用户访问难易程度及数据安全性
* 使用 VPN 和 SSL [加密数据](https://surfshark.com/blog/does-vpn-protect-you-from-hackers)可防止数据在传输过程中受到入侵者的攻击
* 使用可以扫描新代码的安全漏洞并能通知开发人员该漏洞的工具来预测防范未来的风险
尽管 DevOps 一直打算包含安全性,但并非每个实践 DevOps 的组织都牢记这一点。DevSecOps 在 DevOps 的演进形式中,可以提供更加清晰的信息。尽管它们的名称相似,但这两个[不应混淆] [6](https://www.infoq.com/articles/evolve-devops-devsecops/)。在 DevSecOps 模型中,安全性是团队的主要驱动力。
同时,敏捷开发更专注于迭代开发周期,这意味着反馈意见会不断融入到持续的软件开发中。[敏捷的关键原则](https://enterprisersproject.com/article/2019/9/agile-project-management-explained)是拥抱不断变化的环境,为客户和使用者提供竞争优势,让开发人员和利益相关者紧密合作,并在整个过程中始终保持关注技术卓越,以提升效率。换句话说,除非敏捷团队在其定义中包括安全性,否则安全性在敏捷软件开发中算是事后思考。
### 国防机构面临的挑战
如果要说专门致力于最大程度地提高安全性的组织,美国国防部(DoD)就是其中之一。在 2018 年,美国国防部发布了针对软件开发中的“假敏捷”或“以敏捷为名”的[指南](https://www.governmentciomedia.com/defense-innovation-board-issues-guide-detecting-agile-bs)。该指南旨在警告美国国防部高管注意不良编程的问题,并说明如何发现它以避免风险。
使用这些方法不仅可以使美国国防部受益。医疗保健和金融部门也[保存着](https://www.redhat.com/en/solutions/financial-services)必须保证安全的大量敏感数据。
美国国防部通过其现代化战略(包括采用 DevSecOps)来改变防范形式至关重要。尤其在这个连美国国防部容易受到黑客攻击和数据泄露的时代,这一点在 2020 年 2 月的[大规模数据泄露](https://www.military.com/daily-news/2020/02/25/dod-agency-suffers-data-breach-potentially-compromising-ssns.html)中已经得到了证明。
将网络安全最佳实践转化为现实生活中的开发仍然还存在固有的风险。事情不可能 100% 完美地进行。最好的状况是稍微有点不舒服,最坏的情况下,它们可能会带来全新的风险。
开发人员,尤其是那些为军用软件编写代码的开发人员,可能对[所有应该采用 DevSecOps 的情境](https://fcw.com/articles/2020/01/23/dod-devsecops-guidance-williams.aspx)没有透彻的了解。学习曲线会很陡峭,但是为了获得更大的安全性,必须承受这些必不可少的痛苦。
### 自动化时代的新模式
为了解决对先前安全措施日益增长的担忧,美国国防部承包商已开始评估 DevSecOps 模型。关键是将该方法论部署到持续的服务交付环境中。
应对这个问题,出现了三个方向。第一种涉及到自动化,自动化已在大多数隐私和安全工具中[广泛使用](https://privacyaustralia.net/privacy-tools/),包括 VPN 和增强隐私的移动操作系统。大型云基础架构中的自动化无需依赖于人为的检查和平衡,可以自动处理持续的维护和进行安全评估。
第二种专注于对于过渡到 DevSecOps 很重要的安全检查点。而传统上,系统设计初期对于数据在各个组件之间移动时依旧可以访问是不做期望的。
第三种也是最后一种涉及将企业方式用于军用软件开发。国防部的许多承包商和雇员来自商业领域,而不是军事领域。他们的背景为他们提供了为大型企业[提供网络安全](https://www.securitymagazine.com/articles/88301-cybersecurity-is-standard-business-practice-for-large-companies)的知识和经验,他们可以将其带入政府部门职位中。
### 值得克服的挑战
转向基于 DevSecOps 的方法论也提出了一些挑战。在过去的十年中,许多组织已经完全重新设计了其开发生命周期,以适应敏捷开发实践,在不久之后进行再次转换看起来令人生畏。
企业应该安下心来,因为即使美国国防部也遇到了这种过渡带来的麻烦,他们在应对推出新流程使得商业技术和工具广泛可用的挑战上并不孤独。
展望一下未来,其实切换到 DevSecOps 不会比切换到敏捷软件开发更痛苦。而且通过将[创建安全性的价值](https://www.redhat.com/en/topics/security)添加到开发工作流程中,以及利用现有敏捷开发的优势,企业可以获得很多收益。
---
via: <https://opensource.com/article/20/7/devsecops-vs-agile>
作者:[Sam Bocetta](https://opensource.com/users/sambocetta) 选题:[lujun9972](https://github.com/lujun9972) 译者:[windgeek](https://github.com/windgeek) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There is a tendency in the tech community to use the terms DevSecOps and agile development interchangeably. While there are some similarities, such as that both aim to detect risks earlier, there are also distinctions that [drastically alter how each would work](https://tech.gsa.gov/guides/understanding_differences_agile_devsecops/) in your organization.
DevSecOps built on some of the principles that agile development established. However, DevSecOps is [especially focused on integrating security features](https://www.redhat.com/en/topics/devops/what-is-devsecops), while agile is focused on delivering software.
Knowing how to protect your website or application from ransomware and other threats really comes down to the software and systems development you use. Your needs may impact whether you choose to utilize DevSecOps, agile development, or both.
## Differences between DevSecOps and agile
The main distinction between these two systems comes down to one simple concept: security. Depending on your software development practices, your company's security measures—and when, where, and who implements them—may differ significantly.
Every business [needs IT security](https://www.redhat.com/en/topics/security) to protect their vital data. Virtual private networks (VPNs), digital certificates, firewall protection, multi-factor authentication, secure cloud storage, and teaching employees about basic cybersecurity measures are all actions a business should take if it truly values IT security.
When you trust DevSecOps, you're taking your company's security and essentially making it tantamount to continuous integration and delivery. DevSecOps methodologies emphasize security at the very beginning of development and make it an integral component of overall software quality.
This is due to three major principles in DevSecOps security:
- Balancing user access with data security
[Encrypting data](https://surfshark.com/blog/does-vpn-protect-you-from-hackers)with VPN and SSL to protect it from intruders while it is in transit- Anticipating future risks with tools that scan new code for security flaws and notifying developers about the flaws
While DevOps has always intended to include security, not every organization practicing DevOps has kept it in mind. That is where DevSecOps as an evolution of DevOps can offer clarity. Despite the similarity of their names, the two [should not be confused](https://www.infoq.com/articles/evolve-devops-devsecops/). In a DevSecOps model, security is the primary driving force for the organization.
Meanwhile, agile development is more focused on iterative development cycles, which means feedback is constantly integrated into continuous software development. [Agile's key principles](https://enterprisersproject.com/article/2019/9/agile-project-management-explained) are to embrace changing environments to provide customers and clients with competitive advantages, to collaborate closely with developers and stakeholders, and to maintain a consistent focus of technical excellence throughout the process to help boost efficiency. In other words, unless an agile team includes security in its definition of excellence, security *is* an afterthought in agile.
## Challenges for defense agencies
If there's any organization dedicated to the utmost in security, it's the U.S. Department of Defense. In 2018, the DoD published a [guide to "fake agile"](https://www.governmentciomedia.com/defense-innovation-board-issues-guide-detecting-agile-bs) or "agile in name only" in software development. The guide was designed to warn DoD executives about bad programming and explain how to spot it to avoid risks.
It's not only DoD that has something to gain by using these methodologies. The healthcare and financial sectors also [maintain massive quantities](https://www.redhat.com/en/solutions/financial-services) of sensitive data that must remain secure.
DoD's changing of the guard with its modernization strategy, which includes the adoption of DevSecOps, is essential. This is particularly pertinent in an age when even the DoD is susceptible to hacker attacks and data breaches, as evidenced by its [massive data breach](https://www.military.com/daily-news/2020/02/25/dod-agency-suffers-data-breach-potentially-compromising-ssns.html) in February 2020.
There are also risks inherent in transferring cybersecurity best practices into real-life development. Things won't go perfectly 100% of the time. At best, things will be uncomfortable, and at worst, they could create a whole new set of risks.
Developers, especially those working on code for military software, may not have a thorough [understanding of all contexts](https://fcw.com/articles/2020/01/23/dod-devsecops-guidance-williams.aspx) where DevSecOps should be employed. There will be a steep learning curve, but for the greater good of security, these are necessary growing pains.
## New models in the age of automation
To address growing concerns about previous security measures, DoD contractors have begun to assess the DevSecOps model. The key is deploying the methodology into continuous service delivery contexts.
There are three ways this can happen. The first involves automation, which is [already being used](https://privacyaustralia.net/privacy-tools/) in most privacy and security tools, including VPNs and privacy-enhanced mobile operating systems. Instead of relying on human-based checks and balances, automation in large-scale cloud infrastructures can handle ongoing maintenance and security assessments.
The second element involves the transition to DevSecOps as the primary security checkpoint. Traditionally, systems were designed with zero expectation that data would be accessible as it moves between various components.
The third and final element involves bringing corporate approaches to military software development. Many DoD contractors and employees come from the commercial sector rather than the military. Their background gives them knowledge and experience in [providing cybersecurity](https://www.securitymagazine.com/articles/88301-cybersecurity-is-standard-business-practice-for-large-companies) to large-scale businesses, which they can bring into government positions.
## Challenges worth overcoming
Switching to a DevSecOps-based methodology presents some challenges. In the last decade, many organizations have completely redesigned their development lifecycles to comply with agile development practices, and making another switch so soon may seem daunting.
Businesses should gain peace of mind knowing that even the DoD has had trouble with this transition, and they're not alone in the challenges of rolling out new processes to make commercial techniques and tools more widely accessible.
Looking into the future, the switch to DevSecOps will be no more painful than the switch to agile development was. Firms have a lot to gain by acknowledging the [value of building security](https://www.redhat.com/en/topics/security) into development workflows, as well as building upon the advantages of existing agile networks.
## 1 Comment |
12,450 | 使用 tmux 和 Git 自定义我的 Linux 终端 | https://opensource.com/article/20/7/tmux-git | 2020-07-25T10:28:58 | [
"终端",
"提示符"
] | https://linux.cn/article-12450-1.html |
>
> 设置你的控制台,以便你能知道身处哪个目录和该做什么
>
>
>

我使用 GNOME 终端,主要是因为它是我的发行版的默认设置。但是我终端内远非“默认值”。在我开始解释如何自定义它之前,它现在是这个样子:

### 从底部开始
我使用终端多路复用技术 [tmux](https://opensource.com/article/20/1/tmux-console) 管理我的终端体验。
在上图的底部,你可以看到我的绿色 tmux 栏。底部的 `[3]` 表示它是第三个终端:每个终端都运行自己的 tmux 会话。(我创建了一个新会话来放大字体,这样可在截图中更容易看到;这是它与其他终端之间的唯一区别。)
提示符看起来也很有趣,对吧?在提示符中塞入了太多信息后,我喜欢插上一个换行符,这样一来,如果我想即兴进行 shell 编程或编写一个传递了五次的管道,也不会超出屏幕界限。这样做的代价是简单的命令序列(新建、复制、移动)会更快地滚动出我的屏幕。
行末是 <ruby> <a href="https://simple.wikipedia.org/wiki/Aleph_null"> 阿列夫零 </a> <rt> Aleph null </rt></ruby> 字符,它是最小的[无穷基数](https://gizmodo.com/a-brief-introduction-to-infinity-5809689)。我希望内容行的结束很明显,并且当我意识到“阿列夫”和下标 0 都是 Unicode 字符时,我无法抗拒使用“阿列夫零”作为提示符的一部分的诱惑。(数学极客们,团结起来!)
在此之前是我的用户名。由于我在不同用户名的多台计算机上使用相同的[点文件](https://opensource.com/article/19/3/move-your-dotfiles-version-control)(保存在 Git 中),因此这个还算有用。
在我的用户名之前,是我所在目录的最后一部分。完整路径通常太长且无用,而当前目录对于像我这样的经常忘记在做什么人来说是很有用的。在此之前是机器的名称。我所有的机器都以我喜欢的电视节目命名。我的旧笔记本是 `mcgyver`。
提示符中的第一位是我最喜欢的:一个让我知道目录的 Git 状态的字母。如果目录为“不在 Git 中”,那么是 `G`。如果目录为“没有问题”(OK),且无需任何操作,那么是 `K`。如果有 Git 未知的文件需要添加或忽略,那么是 `!`。如果需要提交,那么是 `C`。如果没有上游,那么是 `U`。如果存在上游,但我没有推送,那么是 `P`。该方案不是基于当前状态,而是描述了我要做的*下一个动作*。(要回顾 Git 术语,请阅读[本文](https://opensource.com/article/19/2/git-terminology)。)
终端功能是通过一个有趣的 Python 程序完成的。它运行 `python -m howsit`(在我把 [howsit](https://pypi.org/project/howsit/) 安装在虚拟环境中之后)。
你可以在上图中看到渲染效果,但是为了完整起见,这是我的 `PS1`:
```
[$(~/.virtualenvs/howsit/bin/python -m howsit)]\h:\W \u ℵ₀
$
```
---
via: <https://opensource.com/article/20/7/tmux-git>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I use GNOME Terminal, mostly because it is my distribution's default. But what happens inside my terminal is far from "default." Before I get into how I customize it, here is what it looks like:
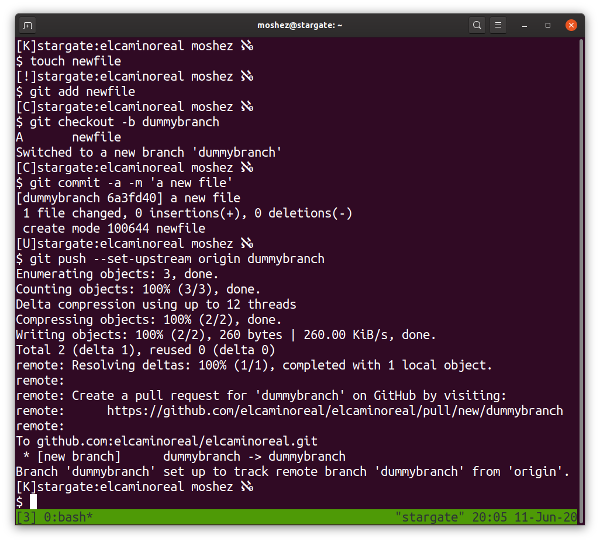
(Moshe Zadka, CC BY-SA 4.0)
## Start at the bottom
I use [tmux](https://opensource.com/article/20/1/tmux-console), a terminal multiplexer technology, to manage my terminal experience.
At the bottom of the image above, you can see my green tmux bar. The `[3]`
at the bottom indicates this terminal is the third one: each terminal runs its own tmux session. (I created a new one to make the font larger, so it's easier to see in this screenshot; this is the only difference between this terminal and my real ones.)
The prompt also looks funny, right? With so much information jammed into the prompt, I like to stick in a newline so that if I want to do impromptu shell programming or write a five-step pipeline, I can do it without having things spill over. The trade-off is that simple sequences of commands—touch this, copy that, move this—scroll off my screen faster.
The last thing on the line with the content is [Aleph null](https://simple.wikipedia.org/wiki/Aleph_null#:~:text=Aleph%20null%20(also%20Aleph%20naught,series%20of%20infinite%20cardinal%20numbers.), the smallest [infinite cardinality](https://gizmodo.com/a-brief-introduction-to-infinity-5809689). I like it when it is obvious where a content line ends, and when I realized that both Aleph and subscript 0 are Unicode characters, I could not resist the temptation to make Aleph null part of my prompt. (Math nerds, unite!)
Before that is my username; this is moderately useful since I use the same [dotfiles](https://opensource.com/article/19/3/move-your-dotfiles-version-control) (stored in Git) on multiple machines with different usernames.
Before my username is the last component of the directory I am in. The full path is often too long and useless, but the current directory is invaluable for someone, like me, who constantly forgets what he's working on. Before that is the name of the machine. All my machines are named after TV shows that I like. My older laptop is `mcgyver`
.
The first bit in the prompt is the bit I like the most: one letter that lets me know the Git status of the directory. It is `G`
if the directory is "(not in) Git," `K`
if the directory is "OK" and nothing needs to be done, `!`
if there are files unknown to Git that must be added or ignored, `C`
if I need to commit, `U`
if there is no upstream, and `P`
if an upstream exists, but I have not pushed. This scheme is not based on the current status but describes the *next action* I need to do. (To review Git terminology, give [this article](https://opensource.com/article/19/2/git-terminology) a read.)
This terminal functionality is accomplished with an interesting Python utility. It runs `python -m howsit`
(after I installed [howsit](https://pypi.org/project/howsit/) in a dedicated virtual environment).
You can see the rendering in the image above, but for completeness, here is my PS1:
```
[$(~/.virtualenvs/howsit/bin/python -m howsit)]\h:\W \u ℵ₀
$
```
## Comments are closed. |
12,452 | 使用 Mailmerge 发送定制邮件 | https://opensource.com/article/19/8/sending-custom-emails-python | 2020-07-25T23:37:37 | [
"邮件",
"群发"
] | /article-12452-1.html |
>
> Mailmerge 是一个可以定制群发邮件的命令行程序,它可以处理简单和复杂的邮件。
>
>
>

电子邮件还是生活的一部分,尽管有种种不足,它仍然是大多数人发送信息的最佳方式,尤其是在按队列将邮件发送给收件人的自动化方式中。
作为 [Fedora 社区行动和影响协调员](https://docs.fedoraproject.org/en-US/council/fcaic/),我的工作之一就是给人们发送资助旅行相关的好消息,我经常通过电子邮件做这些事。这里,我将给你展示如何使用 [Mailmerge](https://github.com/awdeorio/mailmerge) 向一群人发送定制邮件的,Mailmerge 是一个可以处理简单和复杂的邮件的命令行程序。
### 安装 Mailmerge
在 Fedora 中,Mailmerge 已经打包可用,你可以通过在命令行中运行 `sudo dnf install python3-mailmerge` 来安装它。你还可以使用 `pip` 命令从 PyPi 中安装,具体可以参阅该项目的 [README](https://github.com/awdeorio/mailmerge#install)。
### 配置 Mailmerge
三个配置文件控制着 Mailmerge 的工作模式。运行 `mailmerge --sample`,将生成配置文件模板。这些文件包括:
* `mailmerge_server.conf:` 这里保存着 SMTP 服务端邮件发送相关详细配置,但你的密码 *不* 在这里保存。
* `mailmerge_database.csv:` 这里保存每封邮件的定制数据,包括收件人的电子邮件地址。
* `mailmerge_template.txt:` 这里保存电子邮件的文本,文本中包含占位符,这些占位符会使用 `mailmerge_database.csv` 中的数据替换。
#### Server.conf
配置模板文件 `mailmerge_server.conf` 包含几个大家应该很熟悉的例子。如果你曾经往手机上添加过电子邮件或者设置过桌面电子邮件客户端,那你就应该看到过这些数据。需要提醒的是要记得把你的用户名更新到这个文件中,尤其是在你使用模板所提供的配置时。
#### Database.csv
`mailmerge_database.csv` 这个配置文件稍微有点复杂。最起码要将邮件接收者的电子邮件地址保存在这里,其它在电子邮件中任何需要替换的定制信息也要保存在这里。推荐在创建本文件的占位符列表时,同步编辑 `mailmerge_template.txt` 文件。我发现一个有效的做法是,使用电子表格软件录入这些数据,完成后导出为 CSV 文件。使用下面的示例文件:
```
email,name,number
[email protected],"Myself",17
[email protected],"Bob",42
```
可以你向这两个人发送电子邮件,使用他们的名字并告诉他们一个数字。这个示例文件虽然不是特别有趣,但应用了一个重要的原则,那就是:始终让自己处于邮件接收列表的首位。这样你可以在向列表全员发送邮件之前,先给自己发送一个测试邮件,以验证邮件的效果是否如你预期。
任何包含半角逗号的值,都 **必须** 以半角双引号(`"`)封闭。如果恰好在半角双引号封闭的区域需要有一个半角双引号,那就在同一行中连续使用两个半角双引号。引号的规则比较有趣,去 [Python 3 中关于 CSV 的内容中](https://docs.python.org/3/library/csv.html) 一探究竟吧。
#### Template.txt
我的工作之一,就是为我们 Fedora 贡献者会议 [Flock](https://flocktofedora.org/) 发送与旅行基金有关的信息。通过简单的邮件告诉有关的人,他被选中为旅行基金支持的幸运者,以及相应基金支持的详细信息。与接收者相关的具体信息之一就是我们可以为他的旅行提供多少资助。下面是一份我的节略后的模板文件(为了简洁,已经移除大量的文本):
```
$ cat mailmerge_template.txt
TO: {{Email}}
SUBJECT: Flock 2019 Funding Offer
FROM: Brian Exelbierd <[email protected]>
Hi {{Name}},
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
Travel Budget: {{Travel_Budget}}
<<snip>>
```
模板的起头定义了邮件的接收者、发送者和主题。在空行之后,是邮件的内容。该邮件需要从 `database.csv` 文件中获取接收者的 `Email` 、`Name` 和 `Travel_Budget` 。注意,上述这些占位符是由双大括弧( `{{`、`}}` )封闭的。相应的 `mailmerge_database.csv` 如下:
```
$ cat mailmerge_database.csv
Name,Email,Travel_Budget
Brian,[email protected],1000
PersonA,[email protected],1500
PèrsonB,[email protected],500
```
注意,我把自己的信息放在了首条,这是为了测试方便。除了我,还有另外两个人的信息在文档中。列表中的第二个人 PèrsonB,他的名字中有一个包含变音符号的字母,Mailmerge 会对这类字母自动编码。
以上包含了模板的全部知识点:写上你自己的电子邮件信息,并编写好以双大括弧封闭的占位符。接下来创建用来提供前述占位符具体值的数据文件。现在测试一下电子邮件的效果。
### 测试并发送简单邮件
#### 试运行
测试从邮件的试运行开始,试运行就是讲邮件内容显示出来,所有的占位符都会被具体值取代。默认情况下,如果你运行不带参数的命令 `mailmerge`,它将对收件列表中的第一个人进行试运行:
```
$ mailmerge
>>> encoding ascii
>>> message 0
TO: [email protected]
SUBJECT: Flock 2019 Funding Offer
FROM: Brian Exelbierd <[email protected]>
MIME-Version: 1.0
Content-Type: text/plain; charset="us-ascii"
Content-Transfer-Encoding: 7bit
Date: Sat, 20 Jul 2019 18:17:15 -0000
Hi Brian,
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
Travel Budget: 1000
<<snip>>
>>> sent message 0 DRY RUN
>>> No attachments were sent with the emails.
>>> Limit was 1 messages. To remove the limit, use the --no-limit option.
>>> This was a dry run. To send messages, use the --no-dry-run option.
```
从试运行生成的邮件中(列表中的 `message 0` ,和计算机中很多计数场景一样,计数从 0 开始),可以看到我的名字及旅行预算是正确的。如果你想检视所有的邮件,运行 `mailmerge --no-limit`,告诉 Mailmerge 不要仅仅处理第一个收件人的信息。下面是第三个收件人邮件的试运行结果,用来测试特殊字符的编码:
```
>>> message 2
TO: [email protected]
SUBJECT: Flock 2019 Funding Offer
FROM: Brian Exelbierd <[email protected]>
MIME-Version: 1.0
Content-Type: text/plain; charset="iso-8859-1"
Content-Transfer-Encoding: quoted-printable
Date: Sat, 20 Jul 2019 18:22:48 -0000
Hi P=E8rsonB,
```
没有问题,`P=E8rsonB` 是 `PèrsonB` 的编码形式。
#### 发送测试信息
现在,运行 `mailmerge --no-dry-run`,Mailmerge 将向收件人列表中的第一个人发送电子邮件:
```
$ mailmerge --no-dry-run
>>> encoding ascii
>>> message 0
TO: [email protected]
SUBJECT: Flock 2019 Funding Offer
FROM: Brian Exelbierd <[email protected]>
MIME-Version: 1.0
Content-Type: text/plain; charset="us-ascii"
Content-Transfer-Encoding: 7bit
Date: Sat, 20 Jul 2019 18:25:45 -0000
Hi Brian,
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
Travel Budget: 1000
<<snip>>
>>> Read SMTP server configuration from mailmerge_server.conf
>>> host = smtp.gmail.com
>>> port = 587
>>> username = [email protected]
>>> security = STARTTLS
>>> password for [email protected] on smtp.gmail.com:
>>> sent message 0
>>> No attachments were sent with the emails.
>>> Limit was 1 messages. To remove the limit, use the --no-limit option.
```
在倒数第 4 行,它将要求你输入你的密码。如果你使用的是双因素认证或者域控制登录,那就需要创建应用密码来绕过这些控制。如果你使用的是 Gmail 或者类似的系统,可以直接在界面上完成密码验证。如果不行的话,联系你的邮件系统管理员。上述这些操作不会影响邮件系统的安全性,但是仍然有必要采用复杂的安全性好的密码。
我在我的邮件收件箱中,看到了这封格式美观的测试邮件。如果测试邮件看起来没有问题,那就可以运行 `mailmerge --no-dry-run --no-limit` 发送所有的邮件了。
### 发送复杂邮件
只有充分了解了 [Jinja2 模板](http://jinja.pocoo.org/docs/latest/templates/) ,你才可能充分领略 Mailmerge 真正的威力。在邮件模板中使用条件语句及附带附件,是很有用的。下面就是一个复杂邮件的模板及对应的数据文件:
```
$ cat mailmerge_template.txt
TO: {{Email}}
SUBJECT: Flock 2019 Funding Offer
FROM: Brian Exelbierd <[email protected]>
ATTACHMENT: attachments/{{File}}
Hi {{Name}},
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
Travel Budget: {{Travel_Budget}}
{% if Hotel == "Yes" -%}
Lodging: Lodging in the hotel Wednesday-Sunday (4 nights)
{%- endif %}
<<snip>>
$ cat mailmerge_database.csv
Name,Email,Travel_Budget,Hotel,File
Brian,[email protected],1000,Yes,visa_bex.pdf
PersonA,[email protected],1500,No,visa_person_a.pdf
PèrsonB,[email protected],500,Yes,visa_person_b.pdf
```
在这个邮件中有两项新内容。首先是附件,我需要向参加国际旅行的人发送签证邀请信,帮助他们来 Flock,文件头的 `ATTACHMENT` 部分说明了要包含什么文件;为了保持我的文档目录清晰,我将所有需要作为附件的文档保存于附件子目录下。其次是包含了关于宾馆的条件信息,因为有些人的旅行资金包含了住宿费用,我需要对涉及住宿的人员诉及相关信息,而这是通过 `if` 判断实现的:
```
{% if Hotel == "Yes" -%}
Lodging: Lodging in the hotel Wednesday-Sunday (4 nights)
{%- endif %}
```
这和大多数编程语言中的 `if` 判断是一样的。Jinja2 实力非凡,可以实现多级判断。通过包含数据元素控制邮件内容,能大大简化相关的日常工作。空格的正确使用对邮件的易读性很重要。`if` 和 `endif` 语句中的短线( `-` )是 Jinja2 控制 [空白字符](http://jinja.pocoo.org/docs/2.10/templates/#whitespace-control) 的一部分。这里面选项很多,所以还是要通过试验找到最适合自己的方式。
在上面的例子中,我在数据文件扩充了 `Hotel` 和 `File` 两个字段,这些字段的值控制着宾馆信息和附件文件名。另外,在上例中,我和 PèrsonB 有住宿资助,但 PersonA 没有。
对于简单邮件和复杂邮件而言,试运行及正式发送邮件的操作都是相同的。快去试试吧!
你还可以尝试在邮件头中使用条件判断( `if` … `endif` ),比如你可以使发送给在数据库中的某人的邮件包含附件,或者改变对部分人改变发送人的信息。
### Mailmerge 的优点
Mailmerge 是用来批量发送定制邮件的简洁而高效的工具。每个人只接受到他需要的信息,其它额外的操作和细节都是透明的。
我还发现,即使是在发送简单的集团邮件时,相对于使用 CC 或者 BCC 向一组受众发送一封邮件,采用 Mailmerge 也是非常高效的。很多人使用了邮件过滤,那些不是直接发给他们的邮件,他们一律不会立刻处理。使用 Mailmerge 保证了每名接收者收到的就是自己的邮件。所有的信息会对接收者进行正确过滤,再也不会有人无意间回复到整个邮件组。
---
via: <https://opensource.com/article/19/8/sending-custom-emails-python>
作者:[Brian "bex" Exelbierd](https://opensource.com/users/bexelbie) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,453 | 5 个流行的用于远程工作和在线会议的开源视频会议工具 | https://itsfoss.com/open-source-video-conferencing-tools/ | 2020-07-26T10:52:46 | [
"视频会议"
] | https://linux.cn/article-12453-1.html | 你会发现网上有一些视频会议工具。一些是为专业用户量身定制的,另一些是为了日常闲聊的。
然而面对着成百上千的选择,当选择视频会议应用或服务时,安全和隐私是往往是一个重要的点。在众多选择中,哪些是最好最安全的?
所有这些(或大多数)都宣称要提供最好的安全和隐私。但是,你要知道这可不能只看表面。
幸运的是在这里,我们专注于开源和隐私友好的解决方案,所以,让我们看看你可以使用的开源视频会议工具列表。
### 顶级开源视频会议解决方案

如果你是商企用户,大多数视频会议解决方案可以被安装在你自己的服务器上。
对于不是系统管理员的普通人来说,其中一些解决方案还提供了现成的、免费的、基于 Web 的视频会议服务。我将在列表中每个项目的描述中提及此信息。
**备注:** 列表中的排名不分先后。
#### 1、Jitsi Meet

Jitsi Meet 是一个令人印象深刻的开源视频会议服务。你可以在我们关于 [Jitsi Meet](https://itsfoss.com/jitsi-meet/) 的单独报道中轻松找到更多信息。
为了给你一个好的开始,Jitsi Meet 提供免费[官方公共实例](https://meet.jit.si/)来测试它,只要你需要,就可以免费使用它。
如果你需要将其托管在你的服务器上,同时根据你的需求定制一些选项,你可以从它的[官网](https://jitsi.org/jitsi-meet/)下载到你的服务器。
尽管他们在 Linux 上提供了一个基于 Electron 的应用,其实你不必下载一个应用到你的桌面上来设置它。你只需要一个浏览器就足够了。在移动端,安卓和 iOS 都有应用。
* [Jitsi Meet](https://jitsi.org/jitsi-meet/)
#### 2、Jami

Jami 是一个基于点对点的开源视频会议解决方案。很高兴看到分布式的服务,这意味着不依靠服务器,而只是点对点的连接。
当然了,分布式的服务有优点也有缺点。但是它是自由而开源的,那才是最重要的。
Jami 之前被称为 Ring messenger,但它改了名字,现在是一个 GNU 项目。
Jami 有 Linux、Windows、macOS、Android 和 iOS 的版本,所以它是一个完全跨平台的安全传送信息和视频会议的解决方案。你可以看看他们的 [GitLab 页面](https://git.jami.net/savoirfairelinux/ring-project)浏览更多信息。
* [Jami](https://jami.net/)
#### 3、Nextcloud Talk

[Nextcloud](https://itsfoss.com/nextcloud/) 毫无疑问是开源远程办公工具的瑞士军刀。我们就在使用 Nextcloud。所以如果你已经配置了服务器,[Nextcloud Talk](https://nextcloud.com/talk/) 显然是一个优秀的视频会议和聊天工具。
当然了,如果你还没有自己的 Nextcloud 服务器,你需要一些技术知识来进行设置它,然后才能开始使用 Nextcloud Talk。
* [Nextcloud Talk](https://nextcloud.com/talk/)
#### 4、[Riot.im](http://Riot.im)

[Riot.im](http://Riot.im)(不久会更名)已经是 Slack [最好的开源替代品](https://itsfoss.com/open-source-slack-alternative/)之一。
它能让你可以创建社区、发送信息,并在一个小组/社区中开始视频会议。你可以通过任何可用的公共 [Matrix 服务器](https://matrix.org/)来免费使用它。
如果你想要自己专用的去中心化的 Matrix 网络,你也可以在 [Modular.im](https://modular.im/) 上选择付费托管计划。
* [Riot.im](https://about.riot.im/)
#### 5、BigBlueButton

BigBlueButton 是一个有趣的开源视频会议方案,专门为线上学习打造。
如果你是老师或者经营着一个学校,你也许会想试试。虽然你可以免费试用,但免费演示使用会有一定的限制。所以,最好将其托管到自己的服务器上,并且,如果你有其他的产品/服务的话,你也可以把它整合进其中。
它提供了一套很好的功能,能让你很轻松的教学生。你可以浏览它的 [GitHub 页面](https://github.com/bigbluebutton/bigbluebutton)以了解更多信息。
* [BigBlueButton](https://itsfoss.com/open-source-video-conferencing-tools/bigbluebutton.org/)
#### 补充:Wire

Wire 是一个十分流行的开源的安全消息平台,为商企用户量身打造。它也提供视频电话或者网络会议选项。
如果你想要一个为你的企业或团队提供的商业开源方案,你可以试试 Wire,并在试用 30 天后决定是否升级它。
就个人而言,我喜欢它的用户体验,但它是要付费的。所以我建议你决定之前,先试试看并浏览它的 [GitHub 页面](https://github.com/wireapp)。
* [Wire](https://wire.com/en/)
### 总结
现在你知道一些流行开源网络视频会议方案了,你更喜欢使用哪一个?
我是否错过了任何你的最爱?请在下面的评论中告诉我你的想法!
---
via: <https://itsfoss.com/open-source-video-conferencing-tools/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[this-is-name-right](https://github.com/this-is-name-right) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You will find several video conferencing tools available online. Some are tailored for professional use and some for daily casual conversations.
However, with hundreds of options to choose from, [security and privacy is often a concern when picking a video conferencing app or service](https://neat.no/resources/8-security-best-practices-for-private-video-conferencing/). Among the list of options, what’s usually the best and the most secure service?
Well, all (or most of them) claim to provide the best possible security and privacy. But you know that this cannot be taken at face value.
Fortunately, at It’s FOSS, we focus on open-source solutions and privacy-friendly options. So, let’s take a look at a list of open-source video conferencing tools that you can utilize.
## Top Open Source Video Conferencing Solutions

Most of the video conferencing software can be installed on your own servers if you are a small business or enterprise.
For normal, non-sysadmins, some of these solutions also provide ready-to-use, free, web-based video conferencing service. I’ll mention this information in the description of each item on the list.
**Note:** The list is in no particular order of ranking.
### 1. Jitsi Meet
Jitsi Meet is an impressive open-source video conferencing service. You can easily find out more about it in our separate coverage on [Jitsi Meet](https://itsfoss.com/jitsi-meet/).
To give you a head start, it offers you free [official public instance](https://meet.jit.si/?ref=itsfoss.com) to test it and use it for free as long as you need it. That makes it one of the best video conferencing apps that can be counted as an alternative to Google Meet.
If you need to [host Jitsi Meet on your server](https://linuxhandbook.com/self-host-jitsi-meet/?ref=itsfoss.com) while customizing some options for your requirements, you can download it from its [official website](https://jitsi.org/jitsi-meet/?ref=itsfoss.com) for your server.
Even though they offer an electron-based app on Linux, you don’t need to download an app on your desktop to set it up. All you need is a browser and you’re good to host a group video call. For mobile, you will find apps for both Android and iOS.
### 2. Jami
Jami is a peer-to-peer based open-source video conferencing solution. It’s good to see a distributed service that does not rely on servers but peer-to-peer connections.
Of course, a distributed service has its pros and cons. But, it’s free and open-source, that’s what matters.
Jami was previously known as [Ring messenger](https://itsfoss.com/ring-messenger/) but it changed its name and is now a GNU project.
Jami is available for Linux, Windows, macOS, Android, and iOS, So, it’s a pure cross-platform solution for secure messaging and video conferencing. You can take a look at their [GitLab page](https://git.jami.net/savoirfairelinux/ring-project?ref=itsfoss.com) to explore more about it.
### 3. Nextcloud Talk
[Nextcloud](https://itsfoss.com/nextcloud/) is undoubtedly the open-source Swiss army of remote working tools. We at It’s FOSS utilize Nextcloud. So, if you already have your server set up, [Nextcloud Talk](https://nextcloud.com/talk/?ref=itsfoss.com) can prove to be an excellent video conferencing and communication tool. From screen sharing to messages, it comes with all the features you expect in a video conferencing software.
Of course, if you don’t have your own Nextcloud instance, you will require some technical expertise to set it up and start using Nextcloud Talk.
### 4. Element
Previously known as Riot.im was [rebranded to Element](https://itsfoss.com/riot-to-element/). While Element is already one of the [best open source alternatives to slack](https://itsfoss.com/open-source-slack-alternative/), it gives you the ability to create communities, send text messages, and start video conferences in a group/community. You can use it for free by using any of the public [Matrix servers](https://matrix.org/?ref=itsfoss.com) available.
If you want your own dedicated decentralized Matrix network, you can also opt for paid hosting plans on [Element Matrix Service](https://ems.element.io/?ref=itsfoss.com).
### 5. BigBlueButton
BigBlueButton is an interesting open-source video conferencing option tailored for online learning.
If you are a teacher or running a school, you might want to try this out. Even though you can try it for free, there will be limitations for the free demo usage. So, it’s best to host it on your own server and you can also integrate it with your other products/services, if any.
It offers a good set of features that let you easily teach the students. You can explore its [GitHub page](https://github.com/bigbluebutton/bigbluebutton?ref=itsfoss.com) to know more about it.
### Additional mention: Wire
Wire is a quite popular open-source secure messaging platform tailored for business and enterprise users. It also offers video calls or web conferencing options. And, all of that is completely end-to-end encrypted.
If you wanted a premium open-source option dedicated for your business or your team, you can try Wire and decide to upgrade it after the 30-day trial expires.
Personally, I love the user experience, but it comes at a cost. So, I’d recommend you to give it a try and explore its [GitHub page](https://github.com/wireapp?ref=itsfoss.com) before you decide
## Wrapping Up
Now that you know some popular open-source web conferencing options, which one do you prefer to use?
Did I miss any of your favorites? Let me know your thoughts in the comments below! |
12,455 | Fedora 33 开始测试切换到 Btrfs | https://itsfoss.com/btrfs-default-fedora/ | 2020-07-26T19:03:08 | [
"Fedora",
"Btrfs"
] | https://linux.cn/article-12455-1.html | 尽管距离 Fedora 的下一个稳定版本([Fedora 33](https://fedoraproject.org/wiki/Releases/33/ChangeSet))还有几个月的距离,但仍有一些值得关注的变化。
在所有其他 [Fedora 33 接受的系统范围的更改](https://fedoraproject.org/wiki/Releases/33/ChangeSet)中,最有趣的提议是将 Btrfs 作为桌面的默认文件系统,这个提议现在已经被批准了。
这是 Fedora 对该提案的评价:
>
> 对于安装 Fedora 的笔记本电脑和工作站,我们希望以透明的方式向用户提供文件系统功能。我们希望添加新功能,同时减少处理磁盘空间不足之类的情况所需的专业知识。Btrfs 它的设计理念非常适合这个角色,让我们将其设为默认设置。
>
>
>
值得注意的是,在测试的最终投票结果出来之前,这不是系统范围内的更改。
但是,现在测试已经成功完成,投票结果也是赞成的 —— Fedora 33 版本已经接受了这个改动。
那么,为什么 Fedora 提出这一更改?这会有什么用么?这是糟糕的举动吗?对 Fedora 的发行有何影响?让我们在这里谈论下。

### 它会影响哪些 Fedora 版本?
根据提议,如果测试成功,那么 Fedora 33 的所有桌面版本、spins 和 labs 都受此影响。
因此,你可以期望[工作站版本](https://getfedora.org/en/workstation/)将 Btrfs 作为 Fedora 33 上的默认文件系统。
### 实施此更改的潜在好处
为了改进 Fedora 在笔记本和工作站的使用,Btrfs 文件系统提供了一些好处。
现在 Fedora 33 将成为默认文件系统 —— 让我来指出使用 Btrfs 作为默认文件系统的好处:
* 延长存储硬件的使用寿命
* 提供一个简单的方案来解决用户耗尽根目录或主目录上的可用空间的情况
* 不易造成数据损坏,易于恢复
* 提供更好的调整文件系统大小的功能
* 通过强制 I/O 限制来确保桌面在高内存压力下的响应能力
* 使复杂的存储设置易于管理
如果你感到好奇,你可能想更深入地了解 [Btrfs](https://en.wikipedia.org/wiki/Btrfs) 及其总体优点。
不要忘记,Btrfs 已经是受支持的选项,它只是不是默认的文件系统而已。
但是,总的来说,感觉在Fedora 33上引入Btrfs作为默认文件系统是一个有用的变化。
### Red Hat Enterprise Linux 会不会实现它?
很明显,Fedora 被认为是 [Red Hat Enterprise Linux](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux) 的前沿版本。
因此,如果 Fedora 拒绝更改,那么 Red Hat 将不会实施。另一方面,如果你希望 RHEL 使用 Btrfs,那么 Fedora 应该首先同意更改。
为了让你更加清楚,Fedora 对其进行了详细介绍:
>
> Red Hat 在许多方面都很好地支持 Fedora。但是 Fedora 已经与上游紧密合作,并依赖上游。这将是其中之一。这是该提案的重要考虑因素。社区有责任确保它得到支持。如果 Fedora 拒绝,那么 Red Hat 将永远不会支持 Btrfs。Fedora 必然需要成为第一个,并提出令人信服的理由,说明它比替代方案能解决更多的问题。它的负责人相信它确实如此,毫无疑问。
>
>
>
另外,值得注意的是,如果你不想在 Fedora 中使用 btrfs,你应该看看 [OpenSUSE](https://www.opensuse.org) 和 [SUSE Linux Enterprise](https://www.suse.com)。
### 总结
即使这个更改看起来不会影响任何升级或兼容性,你也可以在 [Fedora 项目的 Wiki 页面](https://fedoraproject.org/wiki/Changes/BtrfsByDefault)中找到有关 Btrfs 的更改的更多信息。
你对针对 Fedora 33 发行版的这一更改有何看法?你是否要将 btrfs 文件系统作为默认文件系统?
请在下面的评论中让我知道你的想法!
---
via: <https://itsfoss.com/btrfs-default-fedora/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While we’re months away from Fedora’s next stable release ([Fedora 33](https://fedoraproject.org/wiki/Releases/33/ChangeSet)), there are a few changes worth keeping tabs on.
Among all the other [accepted system-wide changes for Fedora 33](https://fedoraproject.org/wiki/Releases/33/ChangeSet), the proposal of having Btrfs as the default file system for desktop variants was the most interesting one, which has now been approved.
Here’s what Fedora mentioned for the proposal:
For laptop and workstation installs of Fedora, we want to provide file system features to users in a transparent fashion. We want to add new features, while reducing the amount of expertise needed to deal with situations like running out of disk space. Btrfs is well adapted to this role by design philosophy, let’s make it the default.
It’s worth noting that this wasn’t an accepted system-wide change until the final vote result of the test.
But, now that the test has successfully completed and the votes are in favour — the [change has been accepted](https://pagure.io/fesco/issue/2429) for Fedora 33 release.
So, why did Fedora propose this change? Is it going to be useful in any way? Is it a bad move? How is it going to affect Fedora distributions? Let’s talk a few things about it here.

## What Fedora Editions will it Affect?
As per the proposal, all the **desktop editions** of Fedora 33, **spins**, and **labs** will be subject to this change.
So, you should expect the [workstation editions](https://getfedora.org/en/workstation/) to get Btrfs as the default file system on Fedora 33.
## Potential Benefits of Implementing This Change
To improve Fedora for laptops and workstation use-cases, Btrfs file system offers some benefits.
Now that Btrf is going to be the default file system — let me point out the advantages of having Btrfs as the default file system:
- Improves the lifespan of storage hardware
- Providing an easy solution to resolve when a user runs out of free space on the root or home directory.
- Less-prone to data corruption and easy to recover
- Gives better file system re-size ability
- Ensure desktop responsiveness under heavy memory pressure by enforcing I/O limit
- Makes complex storage setups easy to manage
If you’re curious, you might want to dive in deeper to know about [Btrfs](https://en.wikipedia.org/wiki/Btrfs) and its benefits in general.
Not to forget, Btrf was already a supported option — it just wasn’t the default file system.
But, overall, it feels like introducing Btrfs as the default file system on Fedora 33 is a useful change.
## Will Red Hat Enterprise Linux Implement This?
It’s quite obvious that Fedora is considered as the cutting-edge version of [Red Hat Enterprise Linux](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux).
So, if Fedora rejects the change, Red Hat won’t implement it. On the other hand, if you’d want RHEL to use Btrfs, Fedora should be the first to approve the change.
To give you more clarity on this, Fedora has mentioned it in detail:
Red Hat supports Fedora well, in many ways. But Fedora already works closely with, and depends on, upstreams. And this will be one of them. That’s an important consideration for this proposal. The community has a stake in ensuring it is supported. Red Hat will never support Btrfs if Fedora rejects it. Fedora necessarily needs to be first, and make the persuasive case that it solves more problems than alternatives. Feature owners believe it does, hands down.
Now, that Fedora has accepted the change, we’ll have to wait for Red Hat to make its move, if needed.
Also, it’s worth noting that if you’re someone who’s not interested in btrfs on Fedora, you should be looking at [OpenSUSE](https://www.opensuse.org) and [SUSE Linux Enterprise](https://www.suse.com) instead.
## Wrapping Up
Even though it looks like the change should not affect any upgrades or compatibility, you can find more information on the changes with Btrfs by default in [Fedora Project’s wiki page](https://fedoraproject.org/wiki/Changes/BtrfsByDefault).
What do you think about this change targeted for Fedora 33 release? Do you like the idea of btrfs file system as the default on Fedora 33?
Feel free to let me know your thoughts in the comments below! |
12,456 | 50 个绝佳的必备 Ubuntu 应用 | https://itsfoss.com/best-ubuntu-apps/ | 2020-07-26T23:45:28 | [
"Ubuntu",
"应用"
] | https://linux.cn/article-12456-1.html |
>
> 这是一份详尽清单,给所有用户的优秀的 Ubuntu 应用。这些应用将帮助你获得更好的 Linux 桌面使用体验。
>
>
>
过去,我已经多次写过关于 [安装 Ubuntu 之后该做什么](/article-12183-1.html)。每次我都建议在 Ubuntu 上安装某些关键的应用程序。
那么问题来了,什么是关键的 Ubuntu 应用程序?没有绝对的答案。这取决于你的需要和你在 Ubuntu 上要做的工作。
然而还是有很多读者请我推荐一些优秀的 Ubuntu 应用。这就是为什么我创建了这个全面的Ubuntu应用程序列表,你可以经常使用。
为了方便阅读和理解,清单划分为不同应用种类。
### 提供更好使用体验的优秀 Ubuntu 应用

当然,你不必使用以下全部应用。只须浏览这份 Ubuntu 关键应用清单,阅读描述并安装你需要或想要的应用。将这篇文章保存在你的浏览器收藏夹以备将来参考或者通过搜索引擎搜索即可。
这份 Ubuntu 优秀应用清单是准备给普通 Ubuntu 用户的,因此这些应用不全是开源的。我也标记了某些可能不适合新手的稍微复杂的应用。清单适用于 Ubuntu 16.04、18.04 和其他版本。
除非特别声明,所有列出的软件都可以在 Ubuntu 软件中心获得。
如果你没有在软件中心找到应用或者缺失安装说明,请告知我,我会补充安装步骤。
话不多说!让我们看看有哪些优秀 Ubuntu 应用。
#### 浏览器
Ubuntu 以 Firefox 为默认浏览器。自从 Quantum 版本发布以来,Firefox 已有显著提升。就个人而言,我经常使用多个浏览器来应对不同的工作。
##### Google Chrome

由于某种原因,Google Chrome 是最为广泛使用的浏览器。使用 Google 账号,你可以在不同设备无缝同步。大量拓展和应用进一步增强 Chrome 的能力。你可以 [点击此处在 Ubuntu 上安装 Chrome](https://www.google.com/chrome/)。
##### Brave

Google Chrome 可能是最广泛使用的浏览器,但也是隐私窥探者。一个 [替代浏览器](https://itsfoss.com/open-source-browsers-linux/) 是 [Brave](https://brave.com/),它可以默认拦截广告和追踪脚本。它为你提供了更快、更安全的浏览体验。
#### 音乐应用

Ubuntu 将 Rhythmbox 作为默认音乐播放器,这是个相当不坏的选择。不过,你当然可以安装更好的音乐播放器。
##### Sayonara
[Sayonara](https://itsfoss.com/sayonara-music-player/) 是一个小型、轻量并具备漂亮的深色用户界面的音乐播放器。它拥有所有你期望的标准音乐播放器应有的关键功能。它与 Ubuntu 桌面环境整合良好并且不会大量消耗你的内存。
##### Audacity
[Audacity](https://www.audacityteam.org/) 与其说是音频播放器,不如说是音频编辑器。你可以使用这款自由且开源的工具录制和编辑音频。它支持 Linux、Windows 和 macOS。你可以从软件中心安装它。
##### MusicBrainz Picard
[Picard](https://itsfoss.com/musicbrainz-picard/) 不是一个音乐播放器,而是个音乐标签软件。如果你有大量本地音乐文件,Picard 可以帮助你自动更新音乐文件的正确的曲目、专辑、艺人资料和专辑封面。
#### 流媒体音乐应用

在这个时代的互联网,听音乐的方式显然发生了改变。现在的人更依赖于流媒体音乐播放器而不是收藏上百首本地音乐文件。让我们看看你可以用于收听流媒体音乐的一些应用吧。
##### Spotify
[Spotify](https://www.spotify.com//) 是流媒体音乐之王。好消息是它具有官方 Linux 版本。[Ubuntu 上的 Spotify 应用](/article-9415-1.html) 与媒体键和声音菜单以及桌面通知中心整合良好。请注意,Spotify 服务可能在你的国家有,也可能没有。
##### Nuvola 音乐播放器
[Nuvola](https://tiliado.eu/nuvolaplayer/) 不是像 Spotify 那样的流媒体音乐服务。它是一款在单一应用内支持多个流媒体音乐服务的桌面音乐播放器。你可以使用 Spotify、Deezer、Google Play Music、Amazon Cloud Player 和更多类似服务。
#### 视频播放器

Ubuntu 有默认的 GNOME 视频播放器(从前名为 Totem),表现尚可,但不支持多种视频编码。当然有很多播放器比 GNOME 视频播放器更优秀。
##### VLC
自由开源的 [VLC](https://www.videolan.org/index.html) 摘得视频播放器桂冠。它几乎支持全部的视频编码。它还允许你将音量增至最高的 200%。它也支持从最后一个已知位置继续播放。有很多 [VLC 使用技巧](/article-11776-1.html) 供你参考以尽兴使用。
##### MPV
[MPV](https://mpv.io/) 是款值得更多关注的视频播放器。别致轻量的界面和丰富的功能,MPV 拥有你对一个好的视频播放器的一切期望。你甚至可以在命令行使用它。如果你对 VLC 不够满意,你完全可以尝试 MPV。
#### 云端存储服务
本地备份很好,但云端存储给你更多维度的自由。使用云存储,你再也不必总是随身携带 U 盘或担心硬盘故障。
##### Dropbox

[Dropbox](https://www.dropbox.com/) 是最流行的云存储提供商之一。你会获得 2GB 免费存储空间,并通过推介给他人得到更多存储空间。Dropbox 提供了一个原生的 Linux 客户端,你可以从官网下载获得。它会在你的系统创建一个本地文件夹,以和云端服务器同步。
##### pCloud

[pCloud](https://itsfoss.com/recommends/pcloud/) 是另一个优秀的 Linux 云存储提供商。它也拥有原生的 Linux 客户端,你可以从官网下载。你可以获得高达 20GB 的免费存储空间,如果你需要更多,价格也比 Dropbox 实惠。pCloud 总部位于瑞士,这个国家以严格的数据隐私法而闻名。
#### 图片编辑器
我相信你一定会在某个时间点上需要一个照片编辑器。这里有些优秀的 Ubuntu 图片编辑应用。
##### GIMP

[GIMP](https://www.gimp.org/) 是一个自由开源的图片编辑器,它支持 Linux、Windows 和 macOS。它是 Adobe Photoshop 在 Linux 上最优秀的替代软件。你可以使用它执行任何图片编辑。网上有许多资源帮助你使用 GIMP。
##### Inkscape

[Inkscape](https://inkscape.org/en/) 也是一个自由开源的图片编辑器,专用于矢量图形编辑。你可以在 Inkscape 上设计矢量图形和徽标。你可以把它比做 Adobe Illustrator。与 GIMP 一样,网上也有诸多 Inkscape 教程。
#### 绘图应用

绘图应用和图片编辑器不完全等同,尽管它们有时功能重叠。以下是你能在 Ubuntu 使用的一些绘图应用。
##### Krita
[Krita](https://krita.org/en/) 是一款自由开源的数字绘图应用。你可以用它创建数字绘画、漫画和动画。这是款专业软件,甚至被美术学校作为主要软件使用。
##### Pinta
[Pinta](https://pinta-project.com/pintaproject/pinta/) 虽然不像 Krita 功能强大,但也可圈可点。你可以把它视为 Linux 端的微软画图软件。你可以绘制、画图、添加文字和执行绘图应用可行的其他诸如此类的小任务。
#### 摄影应用
摄影爱好者还是专家?你将随手获得大量 [摄影工具](https://itsfoss.com/image-applications-ubuntu-linux/),以下是一些推荐应用。
##### digiKam

使用开源软件 [digKam](https://www.digikam.org/),你可以专业地处理你的高品质摄影作品。digKam 提供用于查看、管理、编辑、增强、组织、标记和分享照片所需的所有工具。
##### Darktable

[darktable](https://www.darktable.org/) 是一款开源的摄影工作流应用程序,特别是专注于 raw 图像的开发。这会是你取代 Adobe Lightroom 的最佳替代品。它同样支持 Windows 和 macOS。
#### 视频编辑器

[Linux 上的视频编辑器](/article-10185-1.html) 并不匮乏,毋庸赘述。看看 Ubuntu 中一些功能丰富但相对简单的视频编辑器。
##### Kdenlive
[Kdenlive](https://kdenlive.org/en/) 是 Linux 端最好的全能型视频编辑器。它与 iMovie 或 Movie Maker 相比功能毫不逊色。
##### Shotcut
[Shotcut](https://shotcut.org/) 是视频编辑的另一个好选择。它是一款开源软件,拥有标准视频编辑器的所有功能。
#### 图片和视频格式转换器
如果你需要为你的图片和视频 [转换文件格式](https://itsfoss.com/format-factory-alternative-linux/),这些是我的推荐。
##### Xnconvert

[Xnconvert](https://www.xnview.com/en/xnconvert/) 是一款优秀的批量图像转换工具。你可以批量调整图片尺寸、转换文件类型并重命名。
##### Handbrake

[HandBrake](https://handbrake.fr/) 是一款易用的开源工具,用于将多种格式的视频转换为一些现代流行的格式。
#### 截图和录屏工具

以下是截图和录屏的优秀 Ubuntu 应用。
##### Shutter
[Shutter](http://shutter-project.org/) 是我截图的常用工具。你也可以对这些截图进行一些快速编辑,比如添加箭头、文字或调整图片尺寸。你在我们网站看到的截图都是用 Shutter 编辑的。绝对是 Ubuntu 上最好的应用程序之一。
##### Kazam
[Kazam](https://launchpad.net/kazam) 是我最喜欢的 [Linux 上的录屏工具](https://itsfoss.com/best-linux-screen-recorders/)。这个是小巧的工具,可以让你录制全屏、某个应用程序窗口或选定区域。你也可以使用快捷键暂停或恢复录屏。[我们的 YouTube 频道](https://www.youtube.com/c/itsfoss?sub_confirmation=1) 上的教程都是用 Kazam 录制的。
#### 办公套件
我无法想象你在使用计算机时没有文档编辑器。又何必把自己局限在一个文档编辑器上呢?去寻找一个完整的办公套件吧。
##### LibreOffice

Ubuntu 预装了 [LibreOffice](https://www.libreoffice.org/download/download/),它无疑是 [最佳的开源办公软件](/article-9379-1.html)。它是个组件完整的办公软件,包括文档编辑器、电子表格工具、演示软件、数学工具和作图工具。你甚至可以用它编辑部分 PDF 文件。
##### WPS Office

[WPS Office](http://wps-community.org/) 因酷似微软 Office 而广受欢迎。它的界面与微软 Office 几乎一样并且号称与微软 Office 更加兼容。如果你正在寻找类似微软 Office 的办公软件,WPS Office 是个好选择。
#### 下载工具

如果你经常从网上下载视频或其他大型文件,这些工具会帮助你。
##### youtube-dl
这是本清单少有的基于命令行的 Ubuntu 应用之一。如果你想从 YouTube、DailyMotion 或其他视频网站下载视频,youtube-dl 是个绝好的选择。它提供了大量 [视频下载高级选项](/article-9244-1.html)。
##### uGet
[uGet](http://ugetdm.com/) 是一款功能丰富的 [Linux 下载管理器](https://itsfoss.com/4-best-download-managers-for-linux/)。它允许你暂停和恢复下载、定时下载、监控剪贴板上的可下载内容。如果你的网络速度很慢、不稳定,或者每天的流量有限,这是一个完美的应对工具。
#### 代码编辑器

如果你喜欢编程,默认的 Gedit 文本编辑器可能无法满足你的编程需求。下面就为你介绍一些比较好用的代码编辑器。
##### Atom
[Atom](https://atom.io/) 是一款由 GitHub 推出的 [自由开源的代码编辑器](/article-7468-1.html)。早在它推出第一个稳定版之前,它就因其用户界面、功能和海量插件而成为程序员的至宠。
##### Visual Studio Code
[VS Code](https://itsfoss.com/install-visual-studio-code-ubuntu/) 是一款微软出品的开源代码编辑器。别忌惮微软之名,VS Code 是款很棒的 Web 开发编辑器,它还支持许多其他编程语言。
#### PDF 和电子书相关应用

在这个数字时代,你不能只依靠真正的纸质书籍,特别是当有大量的免费电子书唾手可得。这里有一些 Ubuntu 应用以供管理 PDF 和电子书。
##### Calibre
如果你是个书虫,并收集电子书,你应该使用 [Calibre](https://calibre-ebook.com/)。它是一个电子书管理器,拥有 [创建电子书](/article-7977-1.html)、转换电子书格式和管理电子书库的所有必要组件。
##### Okular
Okular 主要是一个 PDF 查看器,有编辑 PDF 文件的选项。你可以用 Okular 在 Linux 上做一些基本的 [PDF 编辑](https://itsfoss.com/pdf-editors-linux/),如添加弹出式备注、内联式备注、手绘、荧光笔、印章等。
#### 通讯应用

我相信你在 Linux 上使用至少一款 [通讯应用](https://itsfoss.com/best-messaging-apps-linux/)。以下是我的推荐。
##### Skype
[Skype](https://www.skype.com/en/) 是最流行的视频通讯应用。它也被许多公司和企业用于面试和会议。这使得 Skype 成为 Ubuntu 必备的应用程序之一。
##### Rambox
[Rambox](https://rambox.pro/) 本身不是一个通讯应用,但它允许你从单一窗口中使用 Skype、Viber、Facebook Messanger、WhatsApp、Slack 和其他一些通讯应用。
#### 笔记和待办事项应用
需要一个待办事项应用或简单的应用来做笔记吗?看看这些吧。
##### Simplenote

[Simplenote](http://simplenote.com/) 是 WordPress 创建者 [Automattic](https://automattic.com/) 推出的一款自由开源的笔记应用。它适用于 Windows、Linux、macOS、iOS 和 Android。你的笔记会同步到云服务器上,你可以在任何设备上访问它们。你可以从官网下载 DEB 文件。
##### Remember The Milk

[Remember The Milk](https://itsfoss.com/remember-the-milk-linux/) 是一款流行的待办事项应用。它适用于 Windows、Linux、macOS、iOS 和 Android。你可以在拥有的所有设备上访问你的待办事项。你也可以从浏览器访问它。它还有一个官方的 Linux 原生版本,你可以从官网下载。
#### 密码保护和加密

如果有其他人经常使用你的电脑,也许你会考虑通过密码保护文件和文件夹来增加额外的安全。
##### EncryptPad
[EncryptPad](/article-9377-1.html) 是一个开源文本编辑器,它允许你用密码锁定你的文件。你可以选择加密的类型。这个工具也有一个命令行版本。
##### Gnome Encfs Manager
Gnome Encfs Manager 允许你 [在 Linux 中用密码锁定文件夹](https://itsfoss.com/password-protect-folder-linux/)。你可以将任何你想要的文件保存在一个加密文件夹中,然后用密码锁定它。
#### 游戏

[Linux 上的游戏](/article-7316-1.html) 体验比几年前改进很多。你可以在 Linux 上畅玩大量游戏,而不用回到 Windows 了。
##### Steam
[Steam](https://store.steampowered.com/) 是一个数字发行平台,允许你购买游戏(如果需要的话)。Steam 拥有超过 1500 款 [Linux 游戏](https://itsfoss.com/free-linux-games/)。你可以从软件中心下载 Steam 客户端。
##### PlayOnLinux
[PlayOnLinux](https://www.playonlinux.com/en/) 允许你在 Linux 上通过 WINE 兼容层运行 Windows 游戏。不要对它抱有太高的期望,因为并不是每个游戏都能在 PlayOnLinux 下完美运行。
#### 软件包管理工具 [中高级用户]

Ubuntu 软件中心满足普通 Ubuntu 用户的软件需求,但你可以使用以下应用程序对其进行更多的深入操作。
##### Gdebi
Gedbi 是一款小巧的软件包管理器,你可以用它来安装 DEB 文件。它比软件中心更快,而且还能处理依赖问题。
##### Synaptic
十年前,Synaptic 是大多数 Linux 发行版的默认 GUI 软件包管理器。在一些 Linux 发行版中,它仍然是默认的软件包管理器。这个强大的软件包管理器在 [查找已安装的应用程序并删除它们](https://itsfoss.com/how-to-add-remove-programs-in-ubuntu/) 方面特别有用。
#### 备份和恢复工具

任何操作系统都应该有备份和恢复工具。让我们来看看 Ubuntu 上有哪些软件是你必须拥有的。
##### Timeshift
Timeshift 是一个帮助你 [对系统进行快照](/article-11619-1.html) 的工具。这可以让你在系统配置混乱的情况下,在发生不幸的事时将系统恢复到以前的状态。不过要注意的是,它并不是你个人数据备份的最佳工具。对此,你可以使用U buntu 默认的 Deja Dup(也叫做“备份”)。
##### TestDisk [中级用户]
这是本清单里另一个命令行工具。[TestDisk](https://www.cgsecurity.org/wiki/TestDisk) 可以让你 [恢复 Linux 上的数据](/article-7974-1.html)。如果你不小心删除了文件,使用 TestDisk 还有机会找回来。
#### 系统调整和管理工具

##### GNOME/Unity Tweak Tool
这些调整工具是每个 Ubuntu 用户必备的。它们允许你访问一些高级系统设置。最重要的是,你可以使用这些调整工具 [改变 Ubuntu 的主题](https://itsfoss.com/install-themes-ubuntu/)。
##### UFW Firewall
[UFW](https://wiki.ubuntu.com/UncomplicatedFirewall) 意指“不复杂的防火墙”,这一点是贴切的。UFW 为家庭、工作和公共网络预先定义了防火墙设置。
##### Stacer
如果你想释放 Ubuntu 的存储空间,可以试试 Stacer。这个图形化工具可以让你通过删除不必要的文件和完全卸载软件来 [优化你的 Ubuntu 系统](https://itsfoss.com/optimize-ubuntu-stacer/)。可以从 [官网](https://github.com/oguzhaninan/Stacer) 下载 Stacer。
#### 其他工具

最后,我会列一些其他我很喜欢但无法归类的 Ubuntu 应用。
##### Neofetch
又多了一个命令行工具!Neofetch 可以显示你的系统信息,如 [Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/)、桌面环境、主题、图标、内存和其他信息,并附有 [发行版的 ASCII 徽标](https://itsfoss.com/display-linux-logo-in-ascii/)。使用以下命令安装 Neofetch。
```
sudo apt install neofetch
```
##### Etcher
Ubuntu 已经带有一个即用 USB 创建工具,但 Etcher 能更好地完成这项任务。它同样支持 Windows 和 macOS。你可以 [点击这里](https://etcher.io/) 下载 Etcher。
##### gscan2pdf
我使用这个小工具的唯一目的是 [将图片转换为 PDF](https://itsfoss.com/convert-multiple-images-pdf-ubuntu-1304/)。你也可以用它将多张图片合并成一个 PDF 文件。
##### 音频记录器
另一个小巧而又必不可少的 Ubuntu 应用,用于 [在 Ubuntu 上录制音频](https://itsfoss.com/record-streaming-audio/)。你可以用它来录制来自系统麦克风、音乐播放器或任何其他来源的声音。
### 你对 Ubuntu 关键应用的建议?
我想在这里结束我的优秀 Ubuntu 应用清单。我知道你可能不需要或使用所有的应用,但我确信你会喜欢这里列出的大部分应用。
你是否找到几款以前从未知道的应用呢?如果要你推荐最爱的 Ubuntu 应用,你会选择哪个呢?
最后,如果你觉得这篇文章有用,请把它分享到社交媒体或其他你常访问的社区或论坛。这样,你也帮助了我们的成长 ?
---
via: <https://itsfoss.com/best-ubuntu-apps/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LikChung](https://github.com/LikChung) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I have written about [things to do after installing Ubuntu](https://itsfoss.com/things-to-do-after-installing-ubuntu-24-04/) several times in the past. Each time, I suggest installing the essential applications on Ubuntu.
But the question arises, **what are the essential Ubuntu applications? **There is no set answer here. It depends on your need and the kind of work you do on your Ubuntu desktop.
Still, I have been asked to recommend some good Ubuntu apps by many readers. This is the reason I have created this comprehensive list of Ubuntu applications you can use regularly.
The list has been divided into respective categories for ease of reading.
I suggest you to keep the page bookmarked for future reference you will find it up-to-date with newer options 😉
**. I have also marked the slightly complicated applications that might not be suitable for a beginner.**
**not all the applications here are open source**Enough talk! Let’s see what are the best apps for Ubuntu.
[affiliate policy](https://itsfoss.com/affiliate-policy/).
## Web Browser Apps

Ubuntu comes with Firefox as the default web browser. Personally, I always use more than one web browser to distinguish between different type of work.
### 1. Google Chrome (Not FOSS)
Google Chrome is the most used web browser on the internet for a reason. With your Google account, it allows you seamless syncing across devices. Plenty of extensions and apps further enhance its capabilities. You can easily [install Google Chrome on Ubuntu](https://itsfoss.com/install-chrome-ubuntu/).
Of course, if you do not like Google as a company, and want to take control of your privacy. You can try the [privacy-focused web browsers](https://itsfoss.com/privacy-web-browsers/).
[How to Install Google Chrome on Ubuntu [GUI & Terminal]A step-by-step screenshot guide for beginners that shows how to install Google Chrome on Ubuntu. Learn both the GUI and command line methods.](https://itsfoss.com/install-chrome-ubuntu/)

### 2. Brave
Google Chrome might be the most used web browser, but it may not be the most privacy-friendly option. An [alternative browser](https://itsfoss.com/open-source-browsers-linux/) is [Brave](https://brave.com/?ref=itsfoss.com) that blocks ads and tracking scripts by default. This provides you with a faster and secure web browsing experience.
You can refer to the [installation guide on Brave](https://itsfoss.com/brave-web-browser/) for help. If you do not like Brave, you can compare it with Firefox as well:
[Comparing Brave vs. Firefox: Which one Should You Use?The evergreen open-source browser Firefox compared to Brave. What would you pick?](https://itsfoss.com/brave-vs-firefox/)

## Music applications

Ubuntu has Rhythmbox as the default music player, which is not at all a bad choice for the default music player. However, you can definitely install a better music player.
### 1. Sayonara
[Sayonara](https://sayonara-player.com/) is a small, lightweight music player with a nice dark user interface. It comes with all the essential features you would expect in a standard music player. It integrates well with the Ubuntu desktop environment and doesn’t eat up your RAM.
### 2. Audacity
[Audacity](https://www.audacityteam.org/?ref=itsfoss.com) is more of an audio editor than an audio player. You can record and edit audio with this free and open-source tool. It is available for Linux, Windows, and macOS.
### 3. MusicBrainz Picard
[Picard](https://picard.musicbrainz.org/) is not a music player, it is a music tagger. If you have tons of local music files, Picard allows you to automatically update the music files with correct tracks, album, artist info and album cover art.
## Streaming Music Applications
In this age of the internet, music listening habits have surely changed. People these days rely more on streaming music players rather than storing hundreds of local music files. Let’s see some apps you can use for streaming music.
### 1. Spotify
[Spotify](https://www.spotify.com//?ref=itsfoss.com) is a big deal in streaming music. And the good thing is that it has a native Linux app. The [Spotify app on Ubuntu](https://itsfoss.com/install-spotify-ubuntu-1404/) integrates well with the media key and sound menu, along with the desktop notification.
### 2. MusicPod
[MusicPod](https://github.com/ubuntu-flutter-community/musicpod) is a minimal music player, which you can also use to tune into your favorite radio and podcast network streams. It is based on Flutter and provides a good user experience as well.
You can learn more about it here:
[MusicPod: A Beautiful Flutter-based Music, Radio, and Podcast Player for UbuntuA pretty, minimal, and useful music player to tune in to your favorite songs, radio channel, and podcast networks.](https://news.itsfoss.com/musicpod/)

## Video Players

Ubuntu has the default GNOME video player (formerly known as Totem) which is okay, but it may not support all media codecs. There are certainly other video players better than the GNOME video player.
#### 1. VLC
The free and open-source software [VLC](https://www.videolan.org/index.html?ref=itsfoss.com) is the king of video players. It supports almost all possible media codecs, with plenty of features like video conversion, audio controls, and more. There are several [VLC tricks](https://itsfoss.com/simple-vlc-tips/) you can use to get the most out of it.
#### 2. MPV
[MPV](https://mpv.io/?ref=itsfoss.com) is another solid video player. A sleek, minimalist GUI and plenty of features, MPV has everything you would expect from a good video player. You can even use it on the command line. If you are not happy with VLC, you should surely give MPV a try.
## Cloud Storage Service

Local backups are fine, but cloud storage gives an additional degree of freedom and reliability. You don’t have to carry a USB key with you all the time or worry about a hard disk crash with cloud services.
### 1. Dropbox
[Dropbox](https://www.dropbox.com/?ref=itsfoss.com) is one of the most popular Cloud service providers. You get 2 GB of free storage with the [basic account](https://www.dropbox.com/basic). You get a native Linux client, and you can download it from its website.
### 2. pCloud
[pCloud](https://partner.pcloud.com/r/1935) is a privacy-friendly Cloud storage service fit for Linux users. It has a native Linux client which works well. You get up to 20 GB of free storage and if you need more, you can opt for the premium subscription. pCloud is based in Switzerland, a country renowned for strict data privacy laws.
## Image Editors

I am certain that you would need a photo editor at some point. Here are some of the best Ubuntu apps for editing images.
### 1. GIMP
[GIMP](https://www.gimp.org/?ref=itsfoss.com) is a free and open-source image editor available for Linux, Windows, and macOS. It features several tools for image editing, even for professionals.
Not just limited to image editing, you can get plenty of things done with GIMP. It is easy to use and overwhelming with functionalities at the same time.
### 2. Inkscape
[Inkscape](https://inkscape.org/en/?ref=itsfoss.com) is also a free and open-source image editor specifically focusing on vector graphics. You can design vector arts and logos on it. You can compare some of its features to Adobe Illustrator.
If you are a digital artist looking to explore more tools on Linux, I suggest you read this:
[8 Best Linux Tools For Digital Artists in 2023Linux has no dearth of graphic design software. In this list, we’ll see the best Linux graphic design software.](https://itsfoss.com/best-linux-graphic-design-software/)

## Paint applications

Painting applications are not the same as image editors, though their functionalities overlap at times. Here are some paint apps you can use on Ubuntu.
### 1. Krita
[Krita](https://krita.org/en/?ref=itsfoss.com) is a free and open-source digital painting application. You can create digital art, comics, and animation with it. It’s a professional grade software and is even used as the primary software in art schools.
### 2. Pinta
[Pinta](https://www.pinta-project.com) might not be as feature rich as Krita, but that’s deliberate. You can think of Pinta as Microsoft Paint for Linux but better. You can draw, paint, add text and do other such small tasks you do in a paint application.
Furthermore, you can also explore other [paint applications for Linux](https://itsfoss.com/open-source-paint-apps/) as per your needs.
[12 Open Source Paint Applications for Linux UsersWant to doodle something? Taking your baby step to become a digital artist? Explore these paint applications.](https://itsfoss.com/open-source-paint-apps/)

## Photography applications

Amateur photographer or a professional? You have plenty of [photography tools](https://itsfoss.com/image-applications-ubuntu-linux/) at your disposal. Here are some recommended applications.
### 1. digiKam
With open source software [digiKam](https://www.digikam.org/?ref=itsfoss.com), you can handle your high-end camera images professionally. digiKam provides all the tools required for viewing, managing, editing, enhancing, organizing, tagging and sharing photographs.
### 2. Darktable
[darktable](https://www.darktable.org/?ref=itsfoss.com) is an open source photography workflow application with a special focus on raw image development. This is the best alternative you can get to Adobe Lightroom. It is also available for Windows and macOS.
## Video editors

There is no dearth of [video editors for Linux](https://itsfoss.com/best-video-editing-software-linux/), so I give you some must-have suggestions. The options I mention are feature-rich and yet simple to use.
### 1. Kdenlive
[Kdenlive](https://kdenlive.org/en/?ref=itsfoss.com) is the best all-purpose video editor for Linux. It offers enough features that you can compare it to any other full-fledged video editor like Adobe Premier Pro.
### 2. Shotcut
[Shotcut](https://shotcut.org/?ref=itsfoss.com) is another good choice for a video editor. It is an open-source software with all the features you can expect in a standard video editor.
### 3. Gyroflow
[Gyroflow](https://gyroflow.xyz) is a video stabilization tool that helps you enhance the shaky footage.
It is a free and open-source tool useful for a wide range of videography, including drone footage. You may not find it as a full-fledged video editor, but it offers several essential features.
You can explore more about the app in our coverage on it:
[Gyroflow: An Open-Source App to Stabilize Video FootageA free and open-source app to smoothen your videos with stabilization? Sounds impressive! Let’s check it out!](https://news.itsfoss.com/gyroflow/)

**Suggested Read 📖**
[9 Best Free Video Editing Software for Linux in 2023Looking for a free video editor for Linux? Here are the best options for various kind of video editing needs on Linux.](https://itsfoss.com/best-video-editing-software-linux/)

## Image and video converter

If you need to [convert the file format](https://itsfoss.com/format-factory-alternative-linux/) of your images and videos, here are some of my recommendations.
### 1. Xnconvert (Not FOSS)
[Xnconvert](https://www.xnview.com/en/xnconvert/?ref=itsfoss.com) is an excellent batch image conversion tool. You can bulk resize images, convert the file type and rename them.
### 2. Handbrake
[HandBrake](https://handbrake.fr/?ref=itsfoss.com) is an easy-to-use open-source tool for converting videos from several formats to a few modern, popular formats.
## Screenshot and screen recording tools

Here are the best Ubuntu [apps for taking screenshots](https://itsfoss.com/take-screenshot-linux/) and recording your screen.
### 1. Shutter
[Shutter](http://shutter-project.org/?ref=itsfoss.com) is my go-to tool for taking screenshots. You can also do some quick editing to those screenshots such as adding arrows, text or resizing the images. Many screenshots that you see on our portal were edited with Shutter.
Sure, you can explore more options like it here:
[Best Tools For Taking and Editing Screenshots in LinuxHere are several ways you can take screenshots and edit the screenshots by adding text, arrows etc. Instructions and mentioned screenshot tools are valid for Ubuntu and other major Linux distributions.](https://itsfoss.com/take-screenshot-linux/)

### 2. Kazam
[Kazam](https://launchpad.net/kazam?ref=itsfoss.com) is my favorite [screen recorder for Linux](https://itsfoss.com/best-linux-screen-recorders/). It’s a tiny tool that allows you to record the entire window, an application window or a selected area. You can also use shortcuts to pause or resume recording. Some tutorials on [It’s FOSS YouTube channel](https://www.youtube.com/c/itsfoss?sub_confirmation=1&ref=itsfoss.com) have been recorded with this tool.
Again, if you would rather not stop with Kazam as an option, feel free to try others:
[10 Best Screen Recorders for Linux in 2023Take a look at the best screen recorders available for Linux. Learn its key features, pros, and cons.](https://itsfoss.com/best-linux-screen-recorders/)

## Office suites

It is highly likely that you already have LibreOffice pre-installed, unless you are using a minimal image of Ubuntu.
Even though it is the default, I would suggest sticking to LibreOffice for the most part. Let me tell you more about it with an alternative.
### 1. LibreOffice
[LibreOffice](https://www.libreoffice.org/download/download/?ref=itsfoss.com) is undoubtedly the [best open source office software](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/). It is a complete package comprising a document editor, spreadsheet tool, presentation software, math, and a graphics tool. You can even [edit some PDF files with LibreOffice](https://itsfoss.com/edit-pdf-files-ubuntu-linux/).
### 2. WPS Office (Not FOSS)
[WPS Office](https://www.wps.com) is a popular option as a Microsoft Office clone. It has an interface identical to Microsoft Office, and it claims to be more compatible with MS Office. If you are looking for something similar to the Microsoft Office, WPS Office is a good choice.
If you want an open-source alternative to WPS Office, you can try ONLYOFFICE as well by learning more about it in this article:
[Surprisingly, Many Linux Users Don’t Know About This Office SuiteDo you know about ONLYOFFICE? We tell you more about it here.](https://itsfoss.com/onlyoffice-feature/)

## Downloading tools
If you often download videos or other big files from the internet, these tools will help you.
### 1. youtube-dl
This is one of the rare Ubuntu application on the list that is command line based. If you want to download videos from YouTube, DailyMotion or other video websites, youtube-dl is an excellent choice. It provides plenty of [advanced option for video downloading](https://itsfoss.com/download-youtube-linux/).
Explore more about it here:
[Download YouTube Videos in Linux Command Line Using youtube-dlBrief: Easily download YouTube videos in Linux using youtube-dl command line tool. With this tool, you can also choose video format and video quality such as 1080p or 4K. There are various ways to download YouTube videos. But when it comes to Linux, nothing beats youtube-dl. In this tutorial, I](https://itsfoss.com/download-youtube-linux/)

### 2. uGet
[uGet](http://ugetdm.com/?ref=itsfoss.com) is a feature-rich [download manager for Linux](https://itsfoss.com/4-best-download-managers-for-linux/). It allows you to pause and resume your downloads, schedule your downloads, monitor the clipboard for downloadable content. A perfect tool if you have a slow, inconsistent internet or daily data limit.
## Code Editors

If you are into programming, the default GNOME text editor might not be sufficient for your coding needs. Here are some of the better [code editors](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) for you.
### 1. Kate
[Kate](https://kate-editor.org) is an impressive open-source code editor with numerous features. The user interface is straightforward and easy to use.
It can be a suitable alternative to Microsoft's Visual Studio Code if you would rather not use it.
### 2. Visual Studio Code
[VS Code](https://itsfoss.com/install-visual-studio-code-ubuntu/) is an open source code editor from Microsoft. Don’t worry about Microsoft, VS Code is a remarkable editor for coding.
It supports a number of programming languages, and extensions to expand functionalities.
### 3. Lite XL
Lite XL is a simple and lightweight code editor written in C and Lua.
If you are looking for a code editor with a minimal memory footprint, and yet packed with essential features with extension support, [Lite XL](https://lite-xl.com/en/downloads?ref=news.itsfoss.com) is a great option.
You can explore more such code editors here:
[8 Best Open Source Code Editors for LinuxLooking for the best text editors in Linux for coding? Here’s a list of the best code open source code editors for Linux.](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/#3-kate)

## PDF and eBooks related applications

In this digital age, you cannot only rely on the real paper books, especially when there are plenty of free eBooks available. Here are some Ubuntu apps for managing PDFs and eBooks.
### 1. Calibre
If you are a bibliophile and collect eBooks, you should use [Calibre](https://calibre-ebook.com/?ref=itsfoss.com). It is an eBook manager with all the necessary software for [creating eBooks](https://itsfoss.com/create-ebook-calibre-linux/), converting eBook formats and managing an eBook library.
#### 2. Okular
Okular is mostly a PDF viewer with options for editing PDF files. You can do some basic [PDF editing on Linux](https://itsfoss.com/pdf-editors-linux/) with Okular such as adding pop-ups notes, inline notes, freehand line drawing, highlighter, stamps etc.
## Messaging applications

I believe you use at least one [messaging app on Linux](https://itsfoss.com/best-messaging-apps-linux/). While I leave my recommendations below, you will always end up using what your friends/peers use. Some of my favorites include:
#### 1. Element
[Element](https://element.io) is a secure open-source decentralized matrix client with end-to-end encryption. You can use it for personal or professional communication.
#### 2. Rambox
[Rambox](https://rambox.pro/?ref=itsfoss.com) is not a messaging application on its own. But it allows you to use Skype, Viber, Facebook Messenger, WhatsApp, Slack, and a number of other messaging applications from a single application window.
## Notes and To-do List applications

Need a to-do list app or simple an app for taking notes? Take a look at these:
#### 1. Simplenote
[Simplenote](http://simplenote.com/?ref=itsfoss.com) is a free and open source note-taking application from WordPress creators [Automattic](https://automattic.com/?ref=itsfoss.com). It is available for Windows, Linux, macOS, iOS, and Android. Your notes are synced to a cloud server, and you can access them on any device.
#### 2. Remember The Milk
[Remember The Milk](https://itsfoss.com/remember-the-milk-linux/) is a popular to-do list application. It is available for Windows, Linux, macOS, iOS, and Android. Your to-do list is accessible on all the devices you own. You can also access it from a web browser. It also has an official native application for Linux that you can download from its website.
Explore more [to-do list apps for Linux](https://itsfoss.com/to-do-list-apps-linux/) here:
**Suggested Read 📖**
[7 Best To Do List Apps for Linux Desktop [2023]A good to-do list app helps you organize your work and be more productive by focusing on meaningful work. Here are the best to-do list apps for Linux desktop.](https://itsfoss.com/to-do-list-apps-linux/)

## Password protection and encryption

If there are other people regularly using your computer, perhaps you would like to add an extra layer of security by password protecting files and folders.
#### 1. EncryptPad
[EncryptPad](https://evpo.net/encryptpad/) is an open source text editor that allows you to lock your files with a password. You can choose the type of encryption. There is also a command line version of this tool.
#### 2. Gnome Encfs Manager
Gnome Encfs Manager allows you to [lock folders with a password on Linux](https://itsfoss.com/password-protect-folder-linux/). You can keep whatever files you want in a secret folder and then lock it with a password.
## Gaming

[Gaming on Linux](https://itsfoss.com/linux-gaming-guide/) is a lot better than what it used to be a few years ago. You can enjoy plenty of games on Linux without going back to Windows.
#### 1. Steam
[Steam](https://store.steampowered.com/?ref=itsfoss.com) is a digital distribution platform that allows you to purchase (if required) games. The store has thousands of [games for Linux](https://itsfoss.com/free-linux-games/). You can download the Steam client from the Software Center.
#### 2. PlayOnLinux
[PlayOnLinux](https://www.playonlinux.com/en/?ref=itsfoss.com) allows you to run Windows games on Linux over the WINE compatibility layer. Don’t expect too much out of it because not every game will run flawlessly with PlayOnLinux.
### 3. Lutris
[Lutris](https://lutris.net) is an open-source gaming platform that lets you access games from Steam, Epic Games, GOG, and more.
It makes running games on Linux an easy affair. You can refer to our [Epic Games Store guide](https://itsfoss.com/epic-games-linux/) to learn how it works.
[The Ultimate Guide to Epic Games Store on LinuxWant to use Epic Games Store (EGS) on Linux? Here’s you can do that.](https://itsfoss.com/epic-games-linux/)

## Package Managers [Intermediate to advanced users]

Ubuntu Software Center is more than enough for an average Ubuntu user’s software needs, but you can have more control on it using these applications.
#### 1. Gdebi
Gdebi is a tiny package manager that you can use for installing DEB files. It is faster than the Software Center and it also handles dependency issues.
Not to forget, [Gdebi](https://itsfoss.com/install-deb-files-ubuntu/) is one of the best ways to install Deb files on Ubuntu or Ubuntu-based distributions. Some distributions may have it pre-installed to give the user convenience.
#### 2. Synaptic
Synaptic was the default GUI package manager for most Linux distributions a decade ago. It still is in some Linux distributions. This powerful package manager is particularly helpful in [finding installed applications and removing them](https://itsfoss.com/how-to-add-remove-programs-in-ubuntu/).
You can explore more about the package manager via our [Synaptic usage guide](https://itsfoss.com/synaptic-package-manager/):
[Using the Lightweight Apt Package Manager Synaptic in Ubuntu and Other Debian-based Linux DistributionsThis week’s open source software highlight is Synaptic. Learn what this good old package manager can do that the modern software managers cannot. What is Synaptic package manager? Synaptic is a lightweight GUI front end to apt package management system used in Debian, Ubuntu, Linux Mint a…](https://itsfoss.com/synaptic-package-manager/)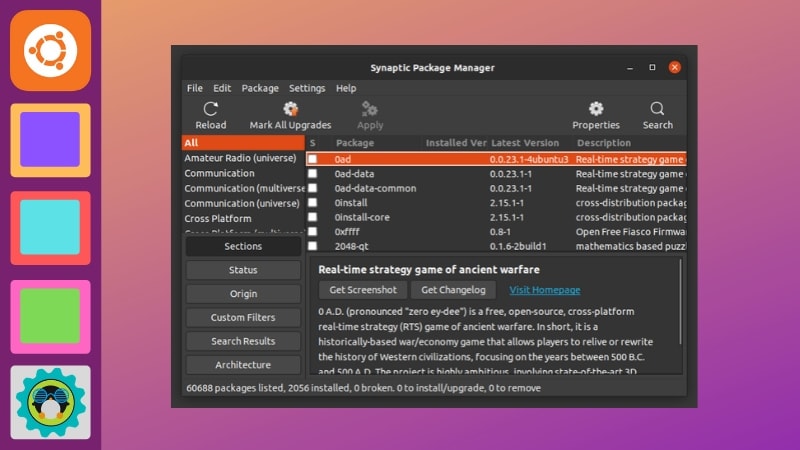

## Backup and Recovery tools

Backup and recovery tools are must-have software for any system. Let's take a look at some recommendations:
#### 1. Timeshift
Timeshift is a tool that allows you to [take a snapshot of your system](https://itsfoss.com/backup-restore-linux-timeshift/). This allows you to restore your system to a previous state in case of an unfortunate incident when your system configuration is messed up. Note that it’s not the best tool for your personal data backup, though. For that, you can use Ubuntu’s default Deja Dup (also known as Backups) tool.
#### 2. TestDisk [Intermediate Users]
This is another command line tool on this list of the best Ubuntu applications. [TestDisk](https://www.cgsecurity.org/wiki/TestDisk?ref=itsfoss.com) allows you to [recover data on Linux](https://itsfoss.com/recover-deleted-files-linux/). If you accidentally deleted files, there are still chances that you can get it back using TestDisk.
## System Tweaking and Management Tools

#### 1. GNOME/Unity Tweak Tool
These Tweak tools are a must for every Ubuntu user. They allow you to access some advanced system settings. Best of all, you can [change themes on Ubuntu](https://itsfoss.com/install-themes-ubuntu/) using these tweak tools.
#### 2. UFW Firewall
[UFW](https://wiki.ubuntu.com/UncomplicatedFirewall?ref=itsfoss.com) stands for Uncomplicated Firewall and rightly so. UFW has predefined firewall settings for Home, Work and Public networks.
#### 3. Stacer
If you want to free up space and monitor system resources on Ubuntu, try [Stacer](https://github.com/oguzhaninan/Stacer?ref=itsfoss.com). This graphical tool allows you to [optimize your Ubuntu system](https://itsfoss.com/optimize-ubuntu-stacer/) by removing unnecessary files and completely uninstalling software.
**Suggested Read 📖**
[7 System Monitoring Tools for Linux That are Better Than TopTop command is good but there are better alternatives. Take a look at these system monitoring tools that are similar to top, but better than it.](https://itsfoss.com/linux-system-monitoring-tools/)

## Other Utilities
In the end, I’ll list some of my other favorite Ubuntu apps that I could not put into a certain category.
#### 1. Neofetch
One more command line tool! Neofetch displays your system information such as [Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/), desktop environment, theme, icons, RAM etc. info along with [ASCII logo of the distribution](https://itsfoss.com/display-linux-logo-in-ascii/). Use this command for installing Neofetch.
`sudo apt install neofetch`
#### 2. Etcher
Ubuntu has a live USB creator tool installed already, but [Etcher](https://etcher.balena.io) is a better application for this task. It is also available for Windows and macOS.
#### 3. gscan2pdf
I use this tiny tool for the sole purpose of [converting images into PDF](https://itsfoss.com/convert-multiple-images-pdf-ubuntu-1304/). You can use it for combining multiple images into one PDF file as well.
#### 4. Audio Recorder
Another tiny yet essential Ubuntu application is for [recording audio on Ubuntu](https://itsfoss.com/record-streaming-audio/). You can use it to record sound from the system microphone, from a music player or from any other source.
**Suggested Read 📖**
[Best Linux Software: 39 Essential Linux Apps [2023]What are the must-have applications for Linux? The answer is subjective. Here, we’ve listed some of the best options.](https://itsfoss.com/essential-linux-applications/)

## Your suggestions for essential Ubuntu applications?
I would like to conclude my list of the best Ubuntu apps here. I know that you might not need or use all of them, but I am certain that you would like most of the software listed here.
*Did you find some useful applications that you didn’t know about before? If you had to suggest your favorite Ubuntu application, which one would it be?* |
12,458 | CI/CD 中的自动化测试的概要知识 | https://opensource.com/article/20/7/automation-testing-cicd | 2020-07-27T21:01:32 | [
"测试",
"CI/CD"
] | /article-12458-1.html |
>
> 持续集成和持续交付是由测试驱动的。以下是如何做到的。
>
>
>

>
> “如果一切似乎都在控制之中,那只是你走的不够快而已。” —Mario Andretti
>
>
>
测试自动化是指在软件开发过程中尽可能早、尽可能快地持续关注检测缺陷、错误和 bug。这是通过使用那些追求质量为最高价值的工具完成的,它们旨在*确保*质量,而不仅仅是追求质量。
持续集成/持续交付(CI/CD)解决方案(也称为 DevOps 管道)最引人注目的功能之一是可以更频繁地进行测试,而又不会给开发人员或操作人员增加更多的手动工作。让我们谈谈为什么这很重要。
### 为什么要在 CI/CD 中实现自动化测试?
敏捷团队要更快的迭代,以更高的速度交付软件和客户满意度,而这些压力可能会危及质量。全球竞争制造了对缺陷的*低容忍度*,同时也增加了敏捷团队的压力,要求软件交付的*迭代更快*。减轻这种压力的行业解决方案是什么?是 [DevOps](https://opensource.com/resources/devops)。
DevOps 是一个大概念,有很多定义,但是对 DevOps 成功至关重要的一项技术是 CI/CD。通过软件开发流程设计一个连续的改进循环,可以为测试带来新的机会。
### 这对测试人员意味着什么?
对于测试人员,这通常意味着他们必须:
* 更早且更频繁地进行测试(使用自动化)
* 持续测试“真实世界”的工作流(自动和手动)
更具体地说,任何形式的测试,无论是由编写代码的开发人员运行还是由质量保证工程师团队设计,其作用都是利用 CI/CD 基础架构在快速推进的同时提高质量。
### 测试人员还需要做什么?
具体点说,测试人员负责:
* 测试新的和现有的软件应用
* 根据系统要求评估软件来验证和确认功能
* 利用自动化测试工具来开发和维护可重复使用的自动化测试
* 与 scrum 团队的所有成员合作,了解正在开发的功能以及实施的技术设计,以设计和开发准确、高质量的自动化测试
* 分析记录在案的用户需求,并针对中等到高度复杂的软件或 IT 系统制定或协助设计测试计划
* 开发自动化测试,并与功能团队一起审查和评估测试方案
* 与技术团队合作,确定在开发环境中自动化测试的正确方法
* 与团队合作,通过自动化测试来了解和解决软件问题,并回应有关修改或增强的建议
* 参与需求梳理、估算和其他敏捷 scrum 仪式
* 协助制定标准和流程,以支持测试活动和材料(例如脚本、配置、程序、工具、计划和结果)
测试是一项艰巨的工作,但这是有效构建软件的重要组成部分。
### 哪些持续测试很重要?
你可以使用多种测试。不同的类型并不是学科之间的牢固界限。相反,它们是表示如何测试的不同方式。比较测试类型不太重要,更重要的是对每一种测试类型都要有覆盖率。
* **功能测试:** 确保软件具有其要求的功能
* **单元测试:** 独立测试软件的较小单元/组件以检查其功能
* **负载测试:** 测试软件在重负载或使用期间的性能
* **压力测试:** 确定软件承受压力(最大负载)时的断点
* **集成测试:** 测试组合或集成的一组组件的输出
* **回归测试:** 当修改任意组件(无论多么小),测试整个应用的功能
### 总结
任何包含持续测试的软件开发过程都将朝着建立关键反馈环路的方向发展,以实现快速和构建有效的软件。最重要的是,该实践将质量内置到 CI/CD 管道中,并意味着了解在软件开发生命周期中提高速度同时减少风险和浪费之间的联系。
---
via: <https://opensource.com/article/20/7/automation-testing-cicd>
作者:[Taz Brown](https://opensource.com/users/heronthecli) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,459 | 开启天文之路的 4 个 Python 工具 | https://opensource.com/article/19/10/python-astronomy-open-data | 2020-07-27T22:32:31 | [
"天文",
"Python"
] | https://linux.cn/article-12459-1.html |
>
> 使用 NumPy、SciPy、Scikit-Image 和 Astropy 探索宇宙
>
>
>

### 天文学与 Python
对科学界而言,尤其是对天文学界来说,Python 是一种伟大的语言工具。各种软件包,如 [NumPy](http://numpy.scipy.org/)、[SciPy](http://www.scipy.org/)、[Scikit-Image](http://scikit-image.org/) 和 [Astropy](http://www.astropy.org/),(仅举几例) ,都充分证明了 Python 对天文学的适用性,而且有很多用例。(NumPy、Astropy 和 SciPy 是 NumFOCUS 提供资金支持的项目;Scikit-Image 是个隶属项目)。我在十几年前脱离天文研究领域,成为了软件开发者之后,对这些工具包的演进一直很感兴趣。我的很多前天文界同事在他们的研究中,使用着前面提到的大部分甚至是全部工具包。以我为例,我也曾为位于智利的超大口径望远镜(VLT)上的仪器编写过专业天文软件工具包。
最近令我吃惊的是,Python 工具包竟然演进到如此好用,任何人都可以轻松编写 <ruby> <a href="https://en.wikipedia.org/wiki/Data_reduction"> 数据还原 </a> <rt> data reduction </rt></ruby> 脚本,产生出高质量的数据产品。天文数据易于获取,而且大部分是可以公开使用的,你要做的只是去寻找相关数据。
比如,负责 VLT 运行的 ESO,直接在他们的网站上提供数据下载服务,只要访问 [www.eso.org/UserPortal](http://www.eso.org/UserPortal) 并在首页创建用户就可以享有数据下载服务。如果你需要 SPHERE 数据,可以下载附近任何一个包含<ruby> 系外行星 <rt> exoplanet </rt></ruby>或者<ruby> 原恒星盘 <rt> proto-stellar discs </rt></ruby>的恒星的全部数据集。对任何 Python 高手而言,通过还原数据发现深藏于噪声中的行星或者原恒星盘,实在是件令人兴奋的事。
我鼓励你下载 ESO 或其它天文影像数据,开启你的探索历程。这里提供几条建议:
1. 首先要有一个高质量的数据集。看一些有关包含系外行星或者原恒星盘的较近恒星的论文,然后在 <http://archive.eso.org/wdb/wdb/eso/sphere/query> 之类的网站检索数据。需要注意的是,前述网站上的数据有的标注为红色,有的标注为绿色,标注为红色的数据是尚未公开的,在相应的“发布日期”处会注明数据将来公开的时间。
2. 了解一些用于获取你所用数据的仪器的信息。尽量对数据的获取有一个基本的理解,对标准的数据还原之后应该是什么样子做到心中有数。所有的望远镜和仪器都有这方面的文档供公开获取。
3. 必须考虑天文数据的标准问题,并予以校正:
1. 数据以 FITS 格式文件保存。需要使用 `pyfits` 或者 `astropy` (包含 `pyfits` )将其读入到 `NumPy` 数组。有些情况下,数据是三维的,需要沿 z 轴使用 `numpy.median` 将数据转换为二维数组。有些 SPHERE 数据在同一幅影像中包含了同一片天空的两份拷贝(各自使用了不同的滤波器),这时候需要使用 **索引** 和 **切片** 将它们分离出来。
2. <ruby> 全黑图 <rt> master dark </rt></ruby>和<ruby> 坏点图 <rt> bad pixel map </rt></ruby>。所有仪器都有快门全关(完全无光)状态拍摄的特殊图片,使用 **NumPy 掩膜数组** 从中分离出坏点图。坏点图非常重要,你在合成最终的清晰图像过程中,需要持续跟踪坏点。有些情况下,这还有助于你从原始科学数据中扣除暗背景的操作。
3. 一般情况下,天文仪器还要拍<ruby> 标准响应图 <rt> master flat frame </rt></ruby>。这是对均匀的单色标准光源拍摄的一张或者一组图片。你需要将所有的原始数据除以标准响应之后再做后续处理(同样,使用 Numpy 掩膜数组实现的话,这仅仅是一个简单的除法运算)。
4. 对行星影像,为了使行星在明亮恒星背景下变得可见,需要仰仗<ruby> 日冕仪 <rt> coronagraph </rt></ruby>和<ruby> 角差分成像 <rt> angular differential imaging </rt></ruby>技术。这一步需要识别影像的光学中心,这是比较棘手的环节之一,过程中要使用 `skimage.feature.blob_dog` 从原始影像中寻找一些人工辅助影像作为帮助。
4. 要有耐心。理解数据格式并弄清如何操作需要一些时间,绘出像素数据曲线图或者统计图有助于你的理解。贵在坚持,必有收获!你会从中学到很多关于图像数据及其处理的知识。
综合应用 NumPy、SciPy、Astropy、scikit-image 及其它工具,结合耐心和恒心,通过分析大量可用的天文数据分析实现重大的发现是非常有可能的。说不定,你会成为某个之前被忽略的系外行星的第一发现者呢。祝你好运!
---
NumFOCUS 是个非盈利组织,维护着一套科学计算与数据科学方面的杰出开源工具集。如果想了解我们的任务及代码,可以访问 [numfocus.org](https://numfocus.org)。如果你有兴趣以个人身份加入 NumFOCUS 社区,可以关注你所在地区的 [PyData 活动](https://pydata.org/)。
本文基于 Pivigo CTO [Ole Moeller-Nilsson](https://twitter.com/olly_mn) 的一次 [谈话](https://www.slideshare.net/OleMoellerNilsson/pydata-lonon-finding-planets-with-python),最初发布于 NumFOCUS 的博客,蒙允再次发布。如果你有意支持 NumFOCUS,可以 [捐赠](https://numfocus.org/donate),也可以参与遍布全球的 [PyData 活动](https://pydata.org/) 中你身边的那些。
---
via: <https://opensource.com/article/19/10/python-astronomy-open-data>
作者:[Gina Helfrich, Ph.D.](https://opensource.com/users/ginahelfrich) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | NumFOCUS is a nonprofit charity that supports amazing open source toolkits for scientific computing and data science. As part of the effort to connect Opensource.com readers with the NumFOCUS community, we are republishing some of the most popular articles from [our blog](https://numfocus.org/blog). To learn more about our mission and programs, please visit [numfocus.org](https://numfocus.org). If you're interested in participating in the NumFOCUS community in person, check out a local [PyData event](https://pydata.org/) happening near you.
## Astronomy with Python
Python is a great language for science, and specifically for astronomy. The various packages such as [NumPy](http://numpy.scipy.org/), [SciPy](http://www.scipy.org/), [Scikit-Image](http://scikit-image.org/) and [Astropy](http://www.astropy.org/) (to name but a few) are all a great testament to the suitability of Python for astronomy, and there are plenty of use cases. [NumPy, Astropy, and SciPy are NumFOCUS fiscally sponsored projects; Scikit-Image is an affiliated project.] Since leaving the field of astronomical research behind more than 10 years ago to start a second career as software developer, I have always been interested in the evolution of these packages. Many of my former colleagues in astronomy used most if not all of these packages for their research work. I have since worked on implementing professional astronomy software packages for instruments for the Very Large Telescope (VLT) in Chile, for example.
It struck me recently that the Python packages have evolved to such an extent that it is now fairly easy for anyone to build [data reduction](https://en.wikipedia.org/wiki/Data_reduction) scripts that can provide high-quality data products. Astronomical data is ubiquitous, and what is more, it is almost all publicly available—you just need to look for it.
For example, ESO, which runs the VLT, offers the data for download on their site. Head over to [www.eso.org/UserPortal](http://www.eso.org/UserPortal) and create a user name for their portal. If you look for data from the instrument SPHERE you can download a full dataset for any of the nearby stars that have exoplanet or proto-stellar discs. It is a fantastic and exciting project for any Pythonista to reduce that data and make the planets or discs that are deeply hidden in the noise visible.
I encourage you to download the ESO or any other astronomy imaging dataset and go on that adventure. Here are a few tips:
- Start off with a good dataset. Have a look at papers about nearby stars with discs or exoplanets and then search, for example:
[http://archive.eso.org/wdb/wdb/eso/sphere/query](http://archive.eso.org/wdb/wdb/eso/sphere/query). Notice that some data on this site is marked as red and some as green. The red data is not publicly available yet — it will say under “release date” when it will be available. - Read something about the instrument you are using the data from. Try and get a basic understanding of how the data is obtained and what the standard data reduction should look like. All telescopes and instruments have publicly available documents about this.
- You will need to consider the standard problems with astronomical data and correct for them:
- Data comes in FITS files. You will need
**pyfits**or**astropy**(which contains pyfits) to read them into**NumPy**arrays. In some cases the data comes in a cube and you should to use**numpy.median**along the z-axis to turn them into 2-D arrays. For some SPHERE data you get two copies of the same piece of sky on the same image (each has a different filter) which you will need to extract using**indexing and slicing.** - The master dark and bad pixel map. All instruments will have specific images taken as “dark frames” that contain images with the shutter closed (no light at all). Use these to extract a mask of bad pixels using
**NumPy masked arrays**for this. This mask of bad pixels will be very important — you need to keep track of it as you process the data to get a clean combined image in the end. In some cases it also helps to subtract this master dark from all scientific raw images. - Instruments will typically also have a master flat frame. This is an image or series of images taken with a flat uniform light source. You will need to divide all scientific raw images by this (again, using numpy masked array makes this an easy division operation).
- For planet imaging, the fundamental technique to make planets visible against a bright star rely on using a coronagraph and a technique known as angular differential imaging. To that end, you need to identify the optical centre on the images. This is one of the most tricky steps and requires finding some artificial helper images embedded in the images using
**skimage.feature.blob_dog**.
- Data comes in FITS files. You will need
- Be patient. It can take a while to understand the data format and how to handle it. Making some plots and histograms of the pixel data can help you to understand it. It is well worth it to be persistent! You will learn a lot about imaging data and processing.
Using the tools offered by NumPy, SciPy, Astropy, scikit-image and more in combination, with some patience and persistence, it is possible to analyse the vast amount of available astronomical data to produce some stunning results. And who knows, maybe you will be the first one to find a planet that was previously overlooked! Good luck!
*This article was originally published on the NumFOCUS blog and is republished with permission. It is based on a talk by Ole Moeller-Nilsson, CTO at Pivigo. If you want to support NumFOCUS, you can donate here or find your local PyData event happening around the world.*
## Comments are closed. |
12,461 | 每周开源点评:开源建设者入门,以及更多的行业趋势 | https://opensource.com/article/20/7/open-source-industry-trends | 2020-07-28T17:55:00 | [
"开源"
] | https://linux.cn/article-12461-1.html |
>
> 每周关注开源社区和行业趋势。
>
>
>

我在一家采用开源软件开发模型的企业软件公司任高级产品营销经理,我的一部分职责是为产品营销人员、经理和其他相关人定期发布有关开源社区、市场和业界发展趋势的更新。以下是该更新中我和他们最喜欢的五篇文章。
### 《开放源码建设者:入门》
* [文章链接](https://idk.dev/open-source-builders-getting-started/)
>
> "最后,我发现自己想要自己修改代码,"Liz 说。她的第一个贡献是为 Django 框架做了一个授权扩展。她补充说:"我记得当时我很担心维护者可能不希望一个完全陌生的人做的改动,所以当它被接受时,我感到很兴奋,也很欣慰……得到认可,甚至感谢你的贡献,这种感觉总是很好。"
>
>
>
**分析:** 这一系列对开源维护者的采访(引自 [Liz Rice](https://twitter.com/lizrice))交汇了跳入开源领域的动机和经验。这也是对天才独狼开发者神话的一个点赞,你可以自己走很远的路,但如果你知道如何与其他人很好地合作,你会走得更远,建立更好的东西。如果你知道如何说服和激励他们,你会走得更远。
### 《Fluent Bit v1.5:轻量级和高性能日志处理器》
* [文章链接](https://www.cncf.io/blog/2020/07/14/fluent-bit-v1-5-lightweight-and-high-performance-log-processor/)
>
> 本次主要版本的最大亮点之一是不同公司与 Fluent Bit 核心维护者的联合工作,为 Google、Amazon、LogDNA、New Relic 和 Sumo Logic 等公司内部提供的可观察性云服务带来了改进和新的连接器。
>
>
>
**分析:**“从不同来源收集数据/日志,统一并将其发送到多个目的地”是一项繁琐的任务,但这是超大规模企业及其客户共同的任务。证据 A:一个开源工作完全如其预期的典型例子。祝贺 Fluent Bit 团队的这次发布!
### 《Kubernetes 如何让 Nubank 工程师每周部署 700 次》
* [文章链接](https://www.cncf.io/blog/2020/07/10/how-kubernetes-empowered-nubank-engineers-to-deploy-200-times-a-week/)
>
> 因此,生产环境的部署时间从 90 分钟变成了 15 分钟。而 Nobre 说,这是“最主要的好处,因为它有助于开发人员的体验”。如今,Nubank 的工程师每周部署 700 次。“对于一家银行来说,你会说这太疯狂了,”Capaverde 笑着说。“但这并不疯狂,因为有了 Kubernetes 和金丝雀部署,回滚变化更容易,因为部署速度也更快。人们的出货频率更高,更有信心。”
>
>
>
**分析:** 我觉得这是个赢家,也是个输家。当然,他们降低了做出改变的成本,以一种让人们更有信心去尝试的方式。但他们的开发人员不能再在等待部署完成的同时跑 10 公里,现在只能在一次 TED 演讲中凑合。
希望你喜欢这个列表,下周再见。
---
via: <https://opensource.com/article/20/7/open-source-industry-trends>
作者:[Tim Hildred](https://opensource.com/users/thildred) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As part of my role as a principal communication strategist at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are three of my and their favorite articles from that update.
[Open source builders: Getting started](https://aws.amazon.com/blogs/opensource/open-source-builders-getting-started/)
“Eventually I found myself wanting to make code changes myself,” Liz says. One of her first contributions was an authorization extension for the Django framework. “I remember being worried that the maintainers might not want a change from a complete stranger, so it was exciting and something of a relief that it was accepted,” she adds. “It’s always a great feeling to get approval and even thanks for your contribution.”
**The impact**: This series of interviews with open source maintainers (quote from [Liz Rice](https://twitter.com/lizrice)) is an intersection of motivations and experiences jumping into open source. It's also a nod to the myth of the genius lone wolf developer; you can get a long ways by yourself, but you'll get further and build better things if you know how to work well with other people. Farther still if you figure out how to persuade and inspire them.
[Fluent Bit v1.5: Lightweight and high-performance log processor](https://www.cncf.io/blog/2020/07/14/fluent-bit-v1-5-lightweight-and-high-performance-log-processor/)
One of the biggest highlights of this major release is the joint work of different companies contributing with Fluent Bit core maintainers to bring improved and new connectors for observability cloud services provided by Google, Amazon, LogDNA, New Relic and Sumo Logic within others.
**The impact**: To "collect data/logs from different sources, unify and send them to multiple destinations" is as tedious of a task as you can come across, yet it's one shared both by the hyperscalers and their customers. Exhibit A: a prime example of open source working exactly as intended. Congrats to the Fluent Bit team on this release!
[How Kubernetes empowered Nubank engineers to deploy 700 times a week](https://www.cncf.io/blog/2020/07/10/how-kubernetes-empowered-nubank-engineers-to-deploy-200-times-a-week/)
As a result, deployment has gone from 90 minutes to 15 minutes for production environments. And that, says Nobre, was “the main benefit because it helps the developer experience.” Today, Nubank engineers are deploying 700 times a week. “For a bank you would say that’s insane,” Capaverde says with a laugh. “But it’s not insane because with Kubernetes and canary deployments, it’s easier to roll back a change because it’s also faster to deploy. People are shipping more often and with more confidence.”
**The impact:** This feels like a win and a loss to me. Sure they lowered the cost of making a change in a way that gave people more confidence to try things out. But their developers can no longer run 10k while waiting for their deployment to finish and can now only fit in a single TED talk.
*I hope you enjoyed this list and come back next week for more open source community, market, and industry trends.*
## 2 Comments |
12,462 | Foliate:适用于 Linux 的现代电子书阅读器应用 | https://itsfoss.com/foliate-ebook-viewer/ | 2020-07-28T23:04:00 | [
"电子书",
"Foliate"
] | https://linux.cn/article-12462-1.html |
>
> Foliate 是一款简洁、优雅的开源电子书阅读器,可在 Linux 桌面上提供类似 Kindle 的阅读体验。
>
>
>

虽然我们已经有了一个 [Linux 最佳电子书阅读器](/article-10383-1.html)的列表,但最近我遇到了另一个 Linux 电子书阅读器。它叫 [Foliate](https://johnfactotum.github.io/foliate/)。

Foliate 是一个现代的 GTK 电子书查看器,它有许多基本功能。如果你拥有亚马逊 Kindle 或其他电子书阅读器,那么你可能会想念那种在桌面上阅读的体验。

Foliate 解决了那些抱怨。Foliate 会显示书的估计剩余阅读时间和页数。你可以添加书签、高亮文本和添加注释。你可以导出数据,也可以轻松同步它们。

你也可以使用维基词典和维基百科查询单词。你可以在页面视图和滚动视图之间切换。它还有几个主题,以满足你的阅读偏好。

最棒的是,它正在积极维护和开发。
### Foliate 的功能

让我们来看看 Foliate 提供的所有功能:
* 支持 .epub、.mobi、.azw、未打包的 EPUB 文件、文本文件、漫画存档(cbr、.cbz、.cbt、.cb7),小说书(.fb2、.fb2.zip)和 .azw3 文件。它不支持 PDF 文件。
* 它让你可以在双页浏览模式下阅读电子书,并提供滚动查看模式。
* 能够自定义字体、行距、边距和亮度。
* 图书馆视图,显示最近的书籍和阅读进度。
* 默认主题包括浅色、棕褐色、深色、Solarized 深色/浅色、Gruvbox 浅色/深色、灰色、Nord 和反转模式。
* 你还可以添加自定义主题调整电子书浏览器的外观。
* 带有章节标记的阅读进度滑块。
* 书签和注释支持。
* 能够在书中查找文本。
* 能够放大和缩小。
* 启用/禁用侧边栏进行导航。
* 使用 [维基词典](https://en.wiktionary.org/wiki/Wiktionary:Main_Page) 和 [维基百科](https://en.wikipedia.org/wiki/Main_Page) 快速查找字典
* 使用谷歌翻译翻译文字
* 触摸板手势,使用两指滑动即可翻页
* 使用 [eSpeak NG](https://github.com/espeak-ng/espeak-ng) 和 [Festival](http://www.cstr.ed.ac.uk/projects/festival/) 支持文字转语音
### 在 Linux 上安装 Foliate
对于基于 Ubuntu 和 Debian 的 Linux 发行版,你可以从它的 [GitHub 发布页面](https://github.com/johnfactotum/foliate/releases)获取 .deb 文件。只需双击即可[从 deb 文件安装应用](https://itsfoss.com/install-deb-files-ubuntu/)。
对于 Fedora、Arch、SUSE 等其他 Linux 发行版。Foliate 可提供 [Flatpak](https://flathub.org/apps/details/com.github.johnfactotum.Foliate) 和 [Snap](https://snapcraft.io/foliate) 包。如果你不知道如何使用它们,那么你可以按照我们[使用 flatpak](https://itsfoss.com/flatpak-guide/) 和[使用 snap 包](https://itsfoss.com/use-snap-packages-ubuntu-16-04/)指南来开始使用。
如果需要,你可以浏览它的 [GitHub 页面](https://github.com/johnfactotum/foliate)以从源代码开始构建。
* [下载 Foliate 应用](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tmp.6FO70BtAuy)
### 总结
我使用 GitHub 上提供的最新 .deb 文件在 Pop!\_OS 19.10 上进行了尝试,并且效果很好。我不喜欢在桌面上阅读很久,但我喜欢它的功能。
你是否尝试过 Foliate?请随时分享你的经验。
---
via: <https://itsfoss.com/foliate-ebook-viewer/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Foliate is simple and elegant open source eBook viewer that provides a Kindle-like reading experience on Linux desktop.*
## Foliate provides modern reading experience on Linux desktop
While we already have a list of [best eBook readers for Linux](https://itsfoss.com/best-ebook-readers-linux/), I recently came across another eBook viewer for Linux. It is called [Foliate](https://johnfactotum.github.io/foliate/).
Foliate is a modern GTK eBook viewer that offers quite a lot of essential features. If you own an Amazon Kindle or some other eBook reader, you probably miss that kind of reading experience on the desktop.
Foliate addresses those complaints. Foliate shows an estimate of remaining reading time and pages in the book. You can add bookmarks, highlight text and add notes. You can export this data or sync them easily.
You can also look up for words using Wiktionary and Wikipedia. You can switch between two page view and scroll view. It also has several themes to suit you reading preference.

And the best thing is that it is being actively maintained and developed.
## Features of Foliate
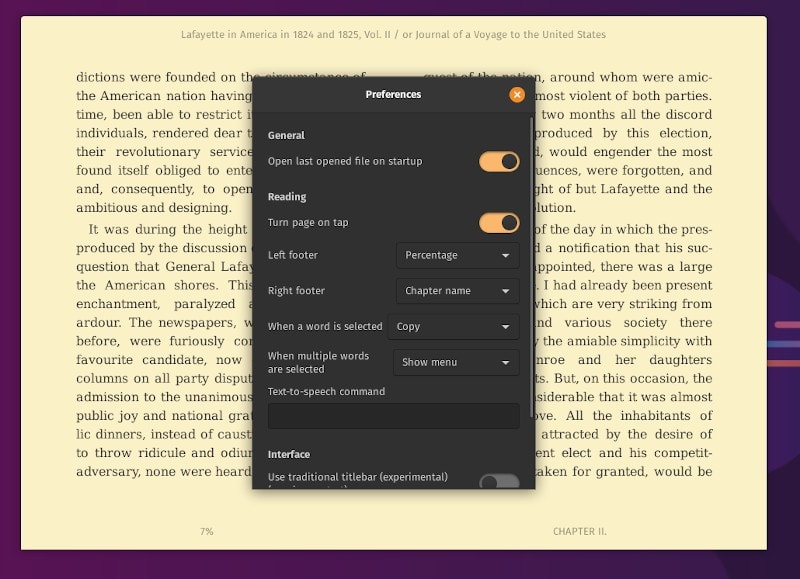
Let’s take a look at all the features Foliate offers:
- Supports .epub, .mobi, .azw, unpacked EPUB files, text files, comic book archive (cbr, .cbz, .cbt, .cb7) , fiction book (.fb2, .fb2.zip) and .azw3 files. It DOES NOT support PDF files.
- It lets you read the eBook on a two-page view mode and offers a scroll view mode as well.
- Ability to customize font, line-spacing, margins, and brightness
- A library view to show recent books and reading progress
- Default themes include Light, sepia, dark, Solarized dark/light, Gruvbox light/dark, Grey, Nord, and invert mode.
- You can also add custom themes to tweak the appearance of the eBook viewer
- Reading progress slider with chapter marks
- Bookmarks and annotations support
- Ability to find a text in the book
- Ability to zoom in and zoom out
- Enable/Disable sidebar for navigation
- Quick dictionary lookup using
[Wiktionary](https://en.wiktionary.org/wiki/Wiktionary:Main_Page)and[Wikipedia](https://en.wikipedia.org/wiki/Main_Page) - Translation of text using Google Translate
- Touchpad gestures—use a two-finger swipe to turn the page
- Text-to-Speech support with
[eSpeak NG](https://github.com/espeak-ng/espeak-ng)and[Festival](http://www.cstr.ed.ac.uk/projects/festival/)
**Recommended Read:**
## Installing Foliate on Linux
For Ubuntu and Debian based Linux distributions, you can get the .deb file from its [GitHub releases section](https://github.com/johnfactotum/foliate/releases) to download the .deb file. [Installing applications from deb file](https://itsfoss.com/install-deb-files-ubuntu/) is as easy as double-clicking on it.
For other Linux distributions like Fedora, Arch, SUSE etc, Foliate is available as [Flatpak](https://flathub.org/apps/details/com.github.johnfactotum.Foliate) and [Snap](https://snapcraft.io/foliate) package. In if you don’t know how to use them, you may follow our guide on [using flatpak](https://itsfoss.com/flatpak-guide/) and using [snap packages](https://itsfoss.com/use-snap-packages-ubuntu-16-04/) in Linux to get started with it.
You can explore its [GitHub page](https://github.com/johnfactotum/foliate) to build from source if you need it.
There is no mobile app for Foliate but if you really want to use it on your Android phone, there is a [tweaking workaround](https://github.com/johnfactotum/foliate/issues/690) available.
**Wrapping Up**
I tried it on **Pop!_OS 19.10** using the latest **.deb** file available on GitHub and it worked well. I liked its features though I don’t read a lot on my desktop.
Have you tried Foliate yet? Feel free to share your experience with it. |
12,463 | 通过 VSCode RTOS 插件使用 Python 为物联网系统编写程序 | https://opensource.com/article/20/7/python-rt-thread | 2020-07-29T00:11:45 | [
"RTOS",
"VSCode"
] | https://linux.cn/article-12463-1.html |
>
> RTOS 之类的实时嵌入式操作系统使嵌入式系统的编程更简单
>
>
>

物联网(IoT)无处不在,它意味着几乎所有的产品,从冰箱到口袋手表,都可以连网。为了实现这个目标,每个产品都需要拥有一个嵌入式计算机来运行网络栈,有些产品几乎是小的不可思议。这就是嵌入式软件出现的场景:现代科技打造的非常小的计算机,硬编码到硬件芯片,不需要任何板外处理器、内存或者存储盘。
就传统视角而言,这种场景意味着没有操作系统可用,但是因为种种 [原因](https://opensource.com/article/20/6/open-source-rtos),开发者发现,类似于 RTOS 之类的实时嵌入式操作系统能让嵌入式系统的编程变得非常简单。
虽然 RT-Thread 嵌入式操作系统致力于鼓励程序员新手进入物联网领域,但并非所有的人都具备使用 C 语言硬编码微芯片的能力。幸运的是,MicroPython 通过让开发者创建运行于嵌入式系统的 Python 代码的方式,逐渐填补了这个鸿沟。为了让整个过程更简单,RT-Thread 有一个可以用于 VSCode 和 [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code) 的插件,为开发者提供了物联网方面的开发环境。其部分特性包括:
* 方便的连接方式,可以很容易的通过串口、网络或者 USB 连接到开发板(如果你使用过 Arduino,肯定会很熟悉这个流程)。
* 支持上传文件或目录到开发板。
* 支持基于 MicroPython 的代码,而且具有智能的代码补完、语法检查功能。
* 支持 MicroPython REPL 交互式环境。
* 丰富的示例代码和演示程序。
* 完整的工程同步功能。
* 快速运行内存中的程序代码。
* 运行函数的代码片段。
* 支持主流的 MicroPython 开发板。
* 支持 Linux 和 Windows 操作系统,并经过充分测试。
### 准备
在开始之前,如果你使用的是 Windows 操作系统,那么必须保证 VSCode 的默认终端是 [PowerShell](https://opensource.com/article/18/2/powershell-people)。运行 VSCodium,从 “Terminal” 菜单项启动一个终端. 在显示在 VSCodium 窗口底部的终端界面,从下拉菜单顶端选择 “PowerShell”。 不论你是在 [Windows](https://opensource.com/article/19/8/how-install-python-windows) 还是 Linux 系统下工作,必须保证安装了 Python 3(在 Linux 上,它可能已经安装了,否则可以通过软件库安装它)。
还要安装的是微软提供的通用 VSCode Python 插件。安装方法是点击 “File” 菜单,找到 “Preferences” 子菜单,从中打开 “Extensions” 面板。在扩展中,搜索 “Python”,找到来自微软的 Python 插件。

当然,在上述操作之前,你要先正确安装 [VSCodium](http://vscodium.com) 或 [VSCode](https://github.com/microsoft/vscode)。
### 安装插件
安装 MicroPython 开发插件的方法与安装 Python 插件一样,点击 “File” 菜单,找到 “Preferences” 子菜单,选择 “Extensions”。
在扩展中,搜索 “MicroPython”,安装 RT-Thread 插件。

### 使用插件
你的开发板必须能访问串口,这需要组策略的允许。你可能需要将自己的账户加入该组,通常在默认情况下你的账户可能并不在该组。首先,确认你的账户不在 “dialout” 组:
```
$ groups
tux users
```
本例中,用户“tux”只是“tux”组和“users”组的成员,所以需要将用户“tux”添加到“dialout”组:
```
$ sudo usermod --append --groups dialout tux
```
退出登录或重启以载入你新的组权限。
### 创建 MicroPython 工程
MicroPython 开发的第一步是创建 MicroPython 工程用来编写和运行代码。使用 MicroPython 插件创建工程的方法是,点击左下方的 “Create MicroPython project” 按钮。

之后会有一些提示,让你选择创建空白工程还是包含例程的工程。
### 连接到开发板
点击 VSCodium 左下方的 “Connection” 按钮,进行 VSCodium 与开发板的连接,在弹出的列表中,选择要连接的物理设备。
### 查看例程
MicroPython 插件提供了许多例程和例库,供学习和调用。获取例程的过程是,激活 MicroPython 之后,VSCodium 左侧按钮条会出现“新建”快捷图标,点击该图标就可以了。点击“文档”快捷图标,会显示例程文件列表;点击“文件夹”快捷图标,会显示例库列表。

### 直接在开发板上运行 MicroPython 文件
在 VSCodium 中可以通过在开发板上运行单个程序文件,很方便快捷的进行程序调试。快捷键 `Alt+Q` 会触发一个特定的插件,该插件会将当前的 Python 文件上传到开发板内存中。你还可以在当前 Python 文档界面点击右键,然后选择 “Run the MicroPython file directly on the device” 实现同样的功能。

如果你需要以不上传代码的方式检查一组代码,可以使用“代码片段”功能。要运行 MicroPython REPL 环境中的代码片段,在编辑器中选中要运行的片段,右键菜单中点击 “Execute the selected MicroPython code on the device” (也可以使用 `Alt+Q` 快捷键)。
### 加载文件和目录到开发板
如果需要加载文件或目录到开发板,有现成的方法可用:选中工程中要加载到开发板的文件或目录,在选中的对象上右键,点击右键菜单中的 “Download the file/folder to the device”。
注意,如果开发板中已有与要加载的文件或目录同名者,加载操作将导致开发板原有的内容被覆盖。
在 REPL 环境中运行 `os.listdir()` 命令,可以检查文件和目录是否成功加载。当然,也可以通过相应的命令删除 REPL 中的文件或目录。
删除文件的命令如下:
```
os.remove('file_to_delete')
```
删除目录的命令如下:
```
os.rmdir('folder_to_delete')
```
### 工程的同步
点击左下角“同步”按钮可以启动工程同步,该操作将把本地工程中所有的文件和目录同步到开发板的文件系统。建议在完成程序调试之后进行该操作,调试过程中不需要频繁进行同步操作。
工程的同步操作完成后,开发板上的文件列表可以在 “Device Files List” 列看到。
### 放手尝试
RT-Thread 以开源的方式发布 MicroPython 插件,意在为新老开发者提供帮助,它的很多特性,如代码自动补全等,与开源插件之间互有影响和促进。你如果想为嵌入式系统或物联网系统编写软件,这就是最简单的方式,没有之一。
---
via: <https://opensource.com/article/20/7/python-rt-thread>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The pervasiveness of the Internet of Things (IoT) means nearly every product, from refrigerators to pocket watches, can connect to a network. For that to happen, all these products must have an embedded computer running a networking stack, and some of these products are almost impossibly small. That's where embedded software comes in: modern technology provides a tiny computer, hard-coded into a hardware chip, without any need for offboard CPU, RAM, or hard drive.
Traditionally, that meant there was no operating system (OS), but [for many reasons](https://opensource.com/article/20/6/open-source-rtos), developers find a real-time embedded OS like [RT-Thread](https://www.rt-thread.io/) makes programming embedded systems much easier.
The RT-Thread embedded operating system aims to encourage new programmers to get into IoT, but not everyone can hard-code a microchip in C. Luckily, MicroPython is filling that niche by enabling developers to create software in Python that runs on embedded systems. To make it even easier, RT-Thread has a plugin for VSCode and [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code) that provides a development environment developers can use to get started with IoT. Some of its features include:
- A convenient connection mode, so you can easily connect to your development board over a serial port, over the network, or over USB (if you've used an Arduino, you'll be familiar with the workflow)
- Support for uploading files or folders to your development board
- Support for MicroPython-based code, with intelligent code completion and linting (syntax checking)
- Support for the MicroPython REPL interactive environment
- Many code examples and demo programs
- Full project synchronization
- Fast-running code files stored in memory
- Code snippets to run functions
- Support for several major MicroPython development boards
- Support for and tested on Linux and Windows
## Requirements
Before getting started, if you're using Windows, you must ensure that your default VSCode terminal is set to [PowerShell](https://opensource.com/article/18/2/powershell-people). Launch VSCodium and start a terminal from the **Terminal** menu. In the terminal that appears at the bottom of your VSCodium window, select **PowerShell** from the drop-down menu in the top bar.
Whether you're [on Windows](https://opensource.com/article/19/8/how-install-python-windows) or Linux, you must have Python 3 installed. (On Linux, it's probably already installed or available in your software repository.)
You should also install the general Python plugin for VSCode from Microsoft. To install it, click the **File** menu and find the **Preferences** submenu. Open the **Extensions** panel from the **Preferences** menu. In **Extensions**, search for Python, and install the Microsoft plugin.

(Seth Kenlon, CC BY-SA 4.0)
Finally, you must have [VSCodium](http://vscodium.com) or [VSCode](https://github.com/microsoft/vscode) installed.
## Install the plugin
Installing the MicroPython development plugin follows the same process as installing the Python plugin. Click the **File** menu, find the **Preferences** submenu, and select **Extensions**.
In **Extensions**, search for **MicroPython**, and install the RT-Thread plugin.
(Seth Kenlon, CC BY-SA 4.0)
## Use the plugin
Your board must have access to a serial port, which it gets through your group permissions. You probably need to add yourself to this group, because it's not usually set by default. First, verify that you're not already a member of `dialout`
:
```
$ groups
tux users
```
In this example, the user `tux`
is only a member of `tux`
and `users`
, so it needs to be added to `dialout`
:
`$ sudo usermod --append --groups dialout tux`
Log out or reboot to load your new group permissions.
## Create a MicroPython project
The first step in MicroPython development is to create a MicroPython project to write and run your code. To create a MicroPython project using the plugin, click the **Create MicroPython project** button in the bottom bar (on the left).
(Seth Kenlon, CC BY-SA 4.0)
This leads you through a few prompts, letting you choose either an empty project structure or a project containing example code.
## Connect your dev board
You can connect from VSCodium to your physical development board by clicking the **Connection** button in the lower-left corner of VSCodium. Select the device you want to connect to in the pop-up list of devices.
## Review sample code
The MicroPython plugin offers a lot of sample code and library files you can use and learn from. These are available from new icons, visible when the MicroPython plugin is active, in VSCodium's left button bar. The **Document** icon lists example code files, and the **Folder** icon lists example libraries.
(Seth Kenlon, CC BY-SA 4.0)
## Run MicroPython files directly on your development board
You can debug a single file quickly and easily by running code on your board within VSCodium. The shortcut **Alt**+**Q** triggers a special plugin function to upload your current Python file to the memory of your connected development board. Alternatively, you can right-click on your current Python file and select **Run the MicroPython file directly on the device**.
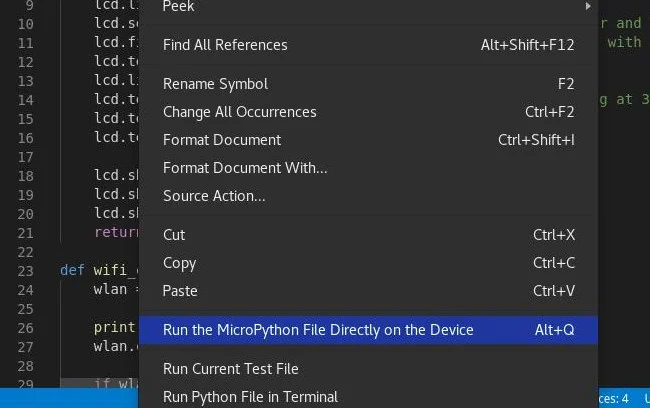
(Seth Kenlon, CC BY-SA 4.0)
If you want to debug a small amount of code without loading files to your board, you can use the code-snippet function. To run selected code in the MicroPython REPL environment, select the snippet you want to run in the editor, and select **Execute the selected MicroPython code on the device** option from the right-click menu (or just press **Alt**+**Q** on your keyboard).
## Load files and folders to your dev board
If you want to load individual files or folders to your development board, there's a handy function for that. First, select the file or folder you want to upload in the project. Next, right-click on one of your selections and choose **Download the file/folder to the device**.
Note that if there are files or folders with the same name on the development board, the download overwrites the existing ones.
By entering the command `os.listdir()`
in REPL, you can check whether the corresponding file or folder has been downloaded successfully. Similarly, you can also use the corresponding command to delete the file or folder in REPL.
To remove a file:
`os.remove('file_to_delete')`
To remove a folder:
`os.rmdir('folder_to_delete')`
## Project synchronization
Click the **Synchronization** button in the lower-left corner to start the project synchronization function. This feature synchronizes all directory files in the local project to the development board's filesystem. This feature is recommended to be used after the code is debugged, without the need to synchronize the project frequently during debugging.
After the project synchronization completes, the list of files in the device can be seen in the **Device Files List** column.
## Try it yourself
RT-Thread released the MicroPython plugin as an open source extension in hopes that it will be useful for new and experienced coders alike. It has many features and leverages others (like code completion and linting) from open source plugins. If you're interested in coding for embedded and IoT devices, there's no easier way to get started.
## Comments are closed. |
12,466 | 我的 Linux 故事:用开源打破语言壁垒 | https://opensource.com/article/20/7/linux-bengali | 2020-07-29T23:07:43 | [
"开源"
] | https://linux.cn/article-12466-1.html |
>
> 开源项目可以通过消除语言和其他障碍来帮着改变世界。
>
>
>

相较于我的许多同行和同事,我的开源之旅开始得着实很晚。
2000 年,我实现了我从高中开始的梦想 —— 买一台属于我自己的个人计算机,当时我正在攻读医学研究生学位。在那之前,我对计算机的唯一接触是偶尔在图书馆或网吧上网,当时这些地方电脑使用的收费都相当高昂。所以我省下了一部分研究生津贴,设法买了一台 Pentium III 550 Mhz、128MB 内存的电脑,并且像当时大多数印度电脑的标准配置一样,装着盗版的 Windows 98 系统。
我的宿舍房间上不了网。我不得不去附近的网吧,在那里下载软件,然后随身带着几十张软盘。
当我终于拥有了自己的计算机,我非常高兴,但有一点也让我感到困扰,那就是我无法用我的母语孟加拉语写东西。我碰到了 CDAC 提供的资源,CDAC 是一个政府机构,它提供的印度语言工具是基于 ISCII 的,ISCII 是一个较早的国家标准,而印度语的 Unicode 标准就是基于这个标准。很难学习它的键盘布局。
### 我的第一次贡献
不久后,我遇到了一款名叫 [Yudit](http://www.yudit.org/) 的软件,它使用标准的 QWERTY 键盘布局来提供印地语的拼音输入。正是在通过 Yudit,我第一次遇到了诸如开源和自由软件、GNU 和 Linux 之类的术语。Yudit 也允许我把 UI 组件翻译成孟加拉语,当我将翻译提交给开发人员时,他很高兴地将它们合并到了下一个版本中,并在软件的 README 文件中称赞了我的功劳。
第一次看到一款应用程序的用户元素以我的母语呈现,我感到十分兴奋。此外,尽管对写代码的知识几乎为零,我依然能够为软件开发做出贡献。我继续为 Yudit 创建了一个从 ISCII 到 Unicode 的转换器,这个转换器还可以用于各种印度语言之间的直译。我还买了本 Linux 杂志,随刊附赠了一张 Knoppix 的免费 live CD,正是通过它我体验到了 Linux 桌面。
我面临的另一个问题是缺乏与 Unicode 兼容的 OpenType Bangla 字体。我使用的字体是共享软件,我需要为它支付许可费用。我在想,“为什么不尝试亲自开发呢?”在此过程中,我通过 [bengalinux.org](http://bengalinux.org)(后来更名为 Ankur 小组)接触到了分散在世界各地的孟加拉语使用者,他们正试图在 Linux 操作系统中使用孟加拉语。
我加入了他们的邮件列表,我们在内部与当局之间讨论了孟加拉语的 Unicode 和 OpenType 规范中的各种缺陷,然后在适当的时候进行了纠正。我的贡献是将传统的孟加拉字体转换为兼容 Unicode 的 OpenType 字体,翻译 UI 等。这个小组还发行了世界上第一张带有孟加拉语 UI 的 Live Linux CD。
2003 年,我搬家到了一个无法访问互联网的地方。我只有在周日去加尔各答时才能联系到小组。当时,Linux 的孟加拉语本地化已经成为了主流。我们的一些志愿者加入了 Red Hat 从事翻译和字体开发工作。我也忙于我的医疗工作,几乎没时间去进行开源开发。
如今,我觉得使用 Linux 做日常工作比其他任何操作系统都要舒服。我也为能与一个能让人们用自己的语言交流的项目联系在一起而感到自豪。它也为长期以来由于不会说英语而被认为处于“<ruby> 数字鸿沟 <rt> digital divide </rt></ruby>”另一端的人们带来了计算能力。孟加拉语实际上是世界上使用最广泛的语言之一,这个项目消除了全球人口中很大一部分人接触数字科技的主要语言壁垒。
### 加入开源
加入到开源运动中来很容易。主动做一些对自己有用的事情,然后思索一下所做的事情如何能对他人也有帮助。关键在于使它免费可用,它可以给世界带来难以估量的价值。
---
via: <https://opensource.com/article/20/7/linux-bengali>
作者:[Dr Anirban Mitra](https://opensource.com/users/mitradranirban) 选题:[lujun9972](https://github.com/lujun9972) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | My open source journey started rather late in comparison to many of my peers and colleagues.
I was pursuing a post-graduate degree in medicine in 2000 when I managed to fulfill a dream I’d had since high school—to buy my own PC. Before that, my only exposure to computers was through occasional access in libraries or cyber cafés, which charged exorbitant prices for access at that time. So I saved up portions of my grad student stipend and managed to buy a Pentium III 550 Mhz with 128MB RAM, and as came standard in most computers in India at that time, a pirated version of Windows 98.
There was no Internet access in my hostel room. I had to go to the nearby cyber café, download software there, and then carry around dozens of floppy discs.
As happy as I was finally owning my own computer, it bothered me that I could not write in my mother tongue, Bangla. I came across resources provided by CDAC, a government agency that provided Indian language tools based on ISCII, an older national standard upon which the Unicode standard of Indic language was based. It was difficult to learn the keyboard layouts.
## My first contribution
Soon, I came across a software called [Yudit](http://www.yudit.org/), which offered phonetic typing of Indic language using the standard QWERTY keyboard. It was with Yudit that I first came across terms like open source and free software, GNU, and Linux. Yudit allowed me to translate UI elements into Bengali too, and when I submitted the translations to the developer, he gladly incorporated them into the next version and credited me in the README of the software.
This was exciting for me, as I was seeing, for the very first time, an application user element in my mother tongue. Moreover, I had been able to contribute to the development of a software despite having almost zero knowledge of coding. I went on to create an ISCII-to-Unicode converter for Yudit, which can also be used for transliteration between various Indian languages. I also bought a Linux magazine that came with a free live CD of Knoppix, and that’s how I got a feel for the Linux desktop.
Another issue I faced was the lack of availability of Unicode-compliant OpenType Bangla font. The font I used was shareware, and I was supposed to pay a license fee for it. I thought, “Why not try my hand at developing it myself?” In the process, I came in contact with Bangla speakers scattered worldwide who were trying to enable Bangla in the Linux operating system, via `bengalinux.org`
(later renamed Ankur group).
I joined their mailing list, and we discussed among ourselves and the authorities the various flaws in the Unicode and OpenType specifications of Bangla, which were then corrected in due course. I contributed by converting legacy Bangla fonts into OpenType Unicode-compliant fonts, translating UI, and so on. That group also came out with the world’s first Live Linux CD with a Bangla user interface.
In 2003, I had moved to a place where I did not have access to the Internet; I could only connect to the group on Sundays when I came to Kolkata. By that time, Bangla localization of Linux had become a mainstream thing. Some of our volunteers joined Red Hat to work on translation and font development. I also became busy in my medical practice and had little time left for open source development.
Now, I feel more comfortable using Linux to do my daily work than any other operating system. I also feel proud to be associated with a project which allows people to communicate in their own language. It also brought computing power to a population who were for a long time considered to be on the other side of the “digital divide” because they did not speak English. Bangla is actually one of the most widely spoken languages in the world, and this project removed a major barrier to access for a large chunk of the global population.
## Joining open source
Joining in on the open source movement is easy. Take the initiative to do something that is useful to yourself, and then think about how it could be useful to others. The key is to keep it freely available, and it can add untold value to the world.
## Comments are closed. |
12,469 | 2020 年关于 Rust 你所需要知道的 | https://opensource.com/article/20/1/rust-resources | 2020-07-31T00:11:42 | [
"Rust"
] | https://linux.cn/article-12469-1.html |
>
> 尽管许多程序员长期以来一直将 Rust 用于业余爱好项目,但正如许多有关 Rust 的热门文章所解释的那样,该语言在 2019 年吸引了主要技术公司的支持。
>
>
>

一段时间以来, [Rust](http://rust-lang.org/) 在诸如 Hacker News 之类的网站上引起了程序员大量的关注。尽管许多人一直喜欢在业余爱好项目中[使用该语言](https://insights.stackoverflow.com/survey/2019#technology-_-most-loved-dreaded-and-wanted-languages),但直到 2019 年它才开始在业界流行,直到那会儿情况才真正开始有所转变。
在过去的一年中,包括[微软](https://youtu.be/o01QmYVluSw)、 [Facebook](https://youtu.be/kylqq8pEgRs) 和 [Intel](https://youtu.be/l9hM0h6IQDo) 在内的许多大公司都出来支持 Rust,许多[较小的公司](https://oxide.computer/blog/introducing-the-oxide-computer-company/)也注意到了这一点。2016 年,作为欧洲最大的 Rust 大会 [RustFest](https://rustfest.eu) 的第一任主持人,除了 Mozilla,我没见到任何一个人在工作中使用 Rust。三年后,似乎我在 RustFest 2019 所交流的每个人都在不同的公司的日常工作中使用 Rust,无论是作为游戏开发人员、银行的后端工程师、开发者工具的创造者或是其他的一些岗位。
在 2019 年, [Opensource.com](http://Opensource.com) 也通过报道 Rust 日益增长的受欢迎程度而发挥了作用。万一你错过了它们,这里是过去一年里 [Opensource.com](http://Opensource.com) 上关于 Rust 的热门文章。
### 《使用 rust-vmm 构建未来的虚拟化堆栈》
Amazon 的 [Firecracker](https://firecracker-microvm.github.io/) 是支持 AWS Lambda 和 Fargate 的虚拟化技术,它是完全使用 Rust 编写的。这项技术的作者之一 Andreea Florescu 在 《[使用 rust-vmm 构建未来的虚拟化堆栈](https://opensource.com/article/19/3/rust-virtual-machine)》中对 Firecracker 及其相关技术进行了深入探讨。
Firecracker 最初是 Google [CrosVM](https://chromium.googlesource.com/chromiumos/platform/crosvm/) 的一个分支,但是很快由于两个项目的不同需求而分化。尽管如此,在这个项目与其他用 Rust 所编写的虚拟机管理器(VMM)之间仍有许多得到了很好共享的通用片段。考虑到这一点,[rust-vmm](https://github.com/rust-vmm) 项目起初是以一种让 Amazon 和 Google、Intel 和 Red Hat 以及其余开源社区去相互共享通用 Rust “crates” (即程序包)的方式开始的。其中包括 KVM 接口(Linux 虚拟化 API)、Virtio 设备支持以及内核加载程序。
看到软件行业的一些巨头围绕用 Rust 编写的通用技术栈协同工作,实在是很神奇。鉴于这种和其他[使用 Rust 编写的技术堆栈](https://bytecodealliance.org/)之间的伙伴关系,到了 2020 年,看到更多这样的情况我不会感到惊讶。
### 《为何选择 Rust 作为你的下一门编程语言》
采用一门新语言,尤其是在有着建立已久技术栈的大公司,并非易事。我很高兴写了《[为何选择 Rust 作为你的下一门编程语言](https://opensource.com/article/19/10/choose-rust-programming-language)》,书中讲述了微软是如何在许多其他有趣的编程语言没有被考虑的情况下考虑采用 Rust 的。
选择编程语言涉及许多不同的标准——从技术上到组织上,甚至是情感上。其中一些标准比其他的更容易衡量。比方说,了解技术变更的成本(例如适应构建系统和构建新工具链)要比理解组织或情感问题(例如高效或快乐的开发人员将如何使用这种新语言)容易得多。此外,易于衡量的标准通常与成本相关,而难以衡量的标准通常以收益为导向。这通常会导致成本在决策过程中变得越来越重要,即使这不一定就是说成本要比收益更重要——只是成本更容易衡量。这使得公司不太可能采用新的语言。
然而,Rust 最大的好处之一是很容易衡量其编写安全且高性能系统软件的能力。鉴于微软 70% 的安全漏洞是由于内存安全问题导致的,而 Rust 正是旨在防止这些问题的,而且这些问题每年都使公司付出了几十亿美元的代价,所以很容易衡量并理解采用这门语言的好处。
是否会在微软全面采用 Rust 尚待观察,但是仅凭着相对于现有技术具有明显且可衡量的好处这一事实,Rust 的未来一片光明。
### 2020 年的 Rust
尽管要达到 C++ 等语言的流行度还有很长的路要走。Rust 实际上已经开始在业界引起关注。我希望更多公司在 2020 年开始采用 Rust。Rust 社区现在必须着眼于欢迎开发人员和公司加入社区,同时确保将推动该语言发展到现在的一切都保留下来。
Rust 不仅仅是一个编译器和一组库,而是一群想要使系统编程变得容易、安全而且有趣的人。即将到来的这一年,对于 Rust 从业余爱好语言到软件行业所使用的主要语言之一的转型至关重要。
---
via: <https://opensource.com/article/20/1/rust-resources>
作者:[Ryan Levick](https://opensource.com/users/ryanlevick) 选题:[lujun9972](https://github.com/lujun9972) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Rust](http://rust-lang.org/) has drawn plenty of attention from programmers on sites like Hacker News for a while. While many have long [loved using the language](https://insights.stackoverflow.com/survey/2019#technology-_-most-loved-dreaded-and-wanted-languages) for hobby projects, it didn't start catching on in industry until 2019, when this really started to change.
Over the last year, many large companies, including [Microsoft](https://youtu.be/o01QmYVluSw), [Facebook](https://youtu.be/kylqq8pEgRs), and [Intel](https://youtu.be/l9hM0h6IQDo), came out in support of Rust, and many [smaller ones](https://oxide.computer/blog/introducing-the-oxide-computer-company/) took notice. As the first emcee at [RustFest](https://rustfest.eu), the largest Rust conference in Europe, in 2016, I didn't meet a single person professionally using Rust who didn't work at Mozilla. Three years later, it seemed like every other person I talked to at RustFest 2019 was using Rust in their day job for another company, whether as a game developer, a backend engineer at a bank, a creator of developer tools, or something else.
In 2019, Opensource.com also played a role by reporting on the growing interest in Rust. In case you missed them, here are the top articles about Rust on Opensource.com over the last year.
## Building the virtualization stack of the future with rust-vmm
Amazon's [Firecracker](https://firecracker-microvm.github.io/) is the virtualization technology that powers AWS Lambda and Fargate, and it is written completely in Rust. One of the technology's authors, Andreea Florescu, offers insight into Firecracker and its related technologies in [Building the virtualization stack of the future with rust-vmm](https://opensource.com/article/19/3/rust-virtual-machine).
Firecracker started life as a fork of Google's [CrosVM](https://chromium.googlesource.com/chromiumos/platform/crosvm/) but quickly diverged due to the differing needs of the two projects. Despite this, there are many common pieces that are best shared across the project and in any other virtual machine manager (VMM) written in Rust. With that in mind, the [rust-vmm](https://github.com/rust-vmm) project started as a way for Amazon and Google, as well as Intel and Red Hat, to share common Rust "crates" (i.e., packages) with each other and the rest of the open source community. These include interfaces to KVM (Linux virtualization APIs), Virtio device support, and a kernel loader.
It's truly amazing to see some of the titans of the software industry working together around a common technology stack written in Rust. Given this and other partnerships around [technology stacks written in Rust](https://bytecodealliance.org/), I wouldn't be surprised to see more of this in 2020.
## Why to choose Rust as your next programming language
Adopting a new language, especially at a large company with a long-established technology stack, is no easy task. I had the pleasure of writing [Why to choose Rust as your next programming language](https://opensource.com/article/19/10/choose-rust-programming-language) about how Microsoft is looking into adopting Rust when so many other interesting programming languages have not been considered.
Choosing a programming language involves many different criteria—from technical to organizational to even emotional. Some of these criteria are easier to measure than others. For instance, it's easier to understand the costs of technical changes, like adapting build systems and building new tooling, than it is to understand organizational or emotional issues like how productive or happy developers will be using this new language. What's more, the easy-to-measure criteria are often cost-related, while the hard-to-measure criteria are often benefits-oriented. This often leads to costs getting more weight in the decision-making process, even though it's not necessarily true that the costs outweigh the benefits—it's just that they're easier to measure. This makes it unlikely for a company to adopt a new language.
However, one of Rust's largest benefits is how easy it is to measure its ability to write secure yet performant systems software. Given that 70% of severe vulnerabilities at Microsoft are due to memory-safety issues that Rust is designed to prevent, and that these issues cost the company billions of dollars per year, it's easy to measure and understand the benefits of adopting the language.
Whether full-scale adoption of Rust at Microsoft will happen remains to be seen, but Rust's future is bright if only for the fact that is has a clear and measurable benefit over existing technologies.
## Rust in 2020
Rust is really starting to gain traction in industry. Although it still has a long way to go to reach the popularity of languages like C++. I expect more companies to start adopting Rust in 2020. The Rust community must now set its sights on welcoming people and companies into the community while ensuring that the things that have driven the language to this point remain in place.
Rust is more than just a compiler and a set of libraries. It's a group of people who care about making systems programming easy, safe, and fun. The coming year will be critical in Rust's journey from a hobbyist language to one of the main languages used in the software industry.
## Comments are closed. |
12,471 | 适于初学者的基于终端的文本编辑器 GNU Nano 5.0 版发布 | https://itsfoss.com/nano-5-release/ | 2020-07-31T21:23:00 | [
"nano"
] | https://linux.cn/article-12471-1.html |
>
> 开源文本编辑器 GNU nano 已经达到了 5.0 版本的里程碑。看看这个新版本带来了哪些功能。
>
>
>
Linux 上有很多[基于终端的文本编辑器](https://itsfoss.com/nano-editor-guide/)。像 Emacs 和 Vim 这样的编辑器需要经历陡峭的学习曲线和掌握一堆不寻常的键盘快捷键,但公认 GNU nano 更容易使用。
也许这就是为什么 Nano 是 Ubuntu 和许多其他发行版中默认的基于终端的文本编辑器的原因,而即将发布的 [Fedora 33 版本](https://itsfoss.com/fedora-33/)也将把 Nano 设置为终端的默认文本编辑器。
### GNU nano 5.0 的新功能

在 GNU nano 5.0 的[变更日志](https://www.nano-editor.org/news.php)中提到的一些主要亮点是:
* `-indicator` 选项将在屏幕右侧显示一种滚动条,以指示视口在缓冲区中的位置和覆盖范围。
* 可以用 `Alt+Insert` 键标记行,你可以用 `Alt+Page` 和 `Alt+PageDown` 键跳转到这些标记的行。
* 执行命令提示符现在可以直接从主菜单中访问。
* 在支持至少 256 种颜色的终端上,有新的颜色可用。
* 新的 `-bookstyle` 模式,任何以空格开头的行都会被认为是一个段落的开始。
* 用 `^L` 刷新屏幕现在在每个菜单中都可以使用。它还会将行与光标居中。
* 可绑定函数 `curpos` 已经改名为 `location`,长选项 `-tempfile` 已经改名为 `-saveonexit`,短选项 `-S` 现在是 `-softwrap` 的同义词。
* 备份文件将保留其组的所有权(如果可能的话)。
* 数据会在显示 “……行写入” 之前同步到磁盘。
* 增加了 Markdown、Haskell 和 Ada 语法的支持。
### 获取 GNU nano 5.0
目前 Ubuntu 20.04 中的 nano 版本是 4.8,而在这个 LTS 版本中,你不太可能在短时间内获得新版本。如果 Ubuntu 有新版本的话,你应该会通过系统更新得到它。
Arch 用户应该会比其他人更早得到它,就像往常一样。其他发行版也应该迟早会提供新版本。
如果你是少数喜欢[从源代码安装软件](https://itsfoss.com/install-software-from-source-code/)的人,你可以从它的[下载页面](https://www.nano-editor.org/download.php)中获得。
如果你是新手,我强烈推荐这篇 [Nano 编辑器初学者指南](https://itsfoss.com/nano-editor-guide/)。
你喜欢这个新版本吗?你期待使用 Nano 5 吗?
---
via: <https://itsfoss.com/nano-5-release/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,473 | 每周开源点评:定义云原生、拓展生态系统,以及更多的行业趋势 | https://opensource.com/article/20/7/cloud-native-expanding-and-more-industry-trends | 2020-08-01T00:01:11 | [
"云原生"
] | /article-12473-1.html |
>
> 每周关注开源社区和行业趋势。
>
>
>

我在一家采用开源软件开发模型的企业软件公司任高级产品营销经理,我的一部分职责是为产品营销人员、经理和其他相关人定期发布有关开源社区、市场和业界发展趋势的更新。以下是该更新中我和他们最喜欢的几篇文章。
### 《随着云原生计算的兴起,它和代码一样在改变文化》
* [文章链接](https://siliconangle.com/2020/07/18/cloud-native-computing-rises-transforming-culture-much-code/)
>
> 现在是围绕一套云原生计算的共同原则进行行业整合的时候了,因为许多企业已经意识到,他们最初进入云计算的回报有限。国际数据公司去年的一项调查发现,[80% 的受访者曾将工作负载从公有云环境遣返到企业内部](https://www.networkworld.com/article/3400872/uptick-in-cloud-repatriation-fuels-rise-of-hybrid-cloud.html),平均而言,他们预计在未来两年内将一半的公有云应用转移到私有场所。
>
>
>
**分析**:在云端的第一次运行主要是大量的“提升和转移”尝试,以提取工作负载并将其投放到云端。第二次运行将涉及更多的工作,以确定转移什么以及如何转移,但随着开发人员对理所当然的事情越来越满意,最终应该会带来更多价值。
### 《为什么云原生基础设施的自动化是所有参与者的胜利》
* [文章链接](https://thenewstack.io/why-automating-for-cloud-native-infrastructures-is-a-win-for-all-involved/)
>
> 开发的圣杯是创建和维护安全的应用程序,产生强大的投资回报率和满意的客户。但如果这种开发不是高效、高速和可扩展的,那么这个圣杯很快就会变得遥不可及。如果你发现自己对当前的基础设施有更高的期望,那么可能是时候考虑云原生了。它不仅可以检查所有这些机器,而且为云原生基础设施进行自动化可以提高效率和结果。
>
>
>
**分析**:我还要补充一点,如果没有大量的自动化,真正采用云原生方法是不可能的;涉及的移动部件数量太多,不可能用人的头脑来处理。
### 《Linkerd 案例研究:满足安全要求、减少延迟和从 Istio 迁移》
* [文章链接](https://www.cncf.io/blog/2020/07/21/linkerd-case-studies-meeting-security-requirements-reducing-latency-and-migrating-from-istio/)
>
> 最后,Subspace 分享了其使用 Linkerd 提供“光速”多人游戏的经验。虽然在超低延迟环境中使用服务网状物起初似乎有悖常理,但 Subspace 发现 Linkerd 的战略使用实际上降低了总延迟 —— 服务网状物是如此轻巧,以至于它增加的最小延迟被它通过可观察性降低的延迟所掩盖。简而言之,Linkerd 的这一独特用例使 Subspace 在运营结果上获得了巨大的净收益。[阅读完整的用户故事](https://buoyant.io/case-studies/subspace/)。
>
>
>
**分析**:我听说过这样一个观点:你并不能真正降低一个系统的复杂性,你只是把它抽象化,改变它的接触对象。似乎对延迟也有类似的观察:如果你仔细选择你接受延迟的地方,你可以因此减少系统中其他地方的延迟。
### 一位高层管理人员解释了 IBM 的“重要支点”,以赢得开发者、初创企业和合作伙伴的青睐,这是其从微软等竞争对手手中赢得混合云市场计划的一部分
* [文章链接](https://www.businessinsider.com/ibm-developers-tech-ecosystem-red-hat-hybrid-cloud-bob-lord-2020-7?r=AU&IR=T)
>
> 蓝色巨人正在转向一个新的战略,专注于建立一个由开发者、合作伙伴和初创公司组成的生态系统。“我们的服务组织无法接触到所有客户。获取这些客户的唯一方法是激活一个生态系统。”
>
>
>
**分析**:越来越多的公司开始接受这样的理念:有些客户的问题,他们没有帮助就无法解决。也许这可以减少从每个单独客户身上赚到的钱,因为它扩大了更广泛地参与更多问题空间的机会。
希望你喜欢这个列表,下周再见。
---
via: <https://opensource.com/article/20/7/cloud-native-expanding-and-more-industry-trends>
作者:[Tim Hildred](https://opensource.com/users/thildred) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,474 | 国王的秘密:如何保护你的主密码 | https://opensource.com/article/20/6/python-passwords | 2020-08-01T10:59:14 | [
"密码",
"加密"
] | https://linux.cn/article-12474-1.html |
>
> 这种使用 Python 和 Shamir 秘密共享的独特算法可以保护你的主密码,可以有效避免黑客窃取和自己不经意忘记引发的风险和不便。
>
>
>

很多人使用密码管理器来保密存储自己在用的各种密码。密码管理器的关键环节之一是主密码,主密码保护着所有其它密码。这种情况下,主密码本身就是风险所在。任何知道你的主密码的人,都可以视你的密码保护若无物,畅行无阻。自然而然,为了保证主密码的安全性,你会选用很难想到的密码,把它牢记在脑子里,并做[所有其他](https://monitor.firefox.com/security-tips)你应该做的事情。
但是万一主密码泄露了或者忘记了,后果是什么?也许你去了个心仪的岛上旅行上个把月,没有现代技术覆盖,在开心戏水之后享用美味菠萝的时刻,突然记不清自己的密码是什么了。是“山巅一寺一壶酒”?还是“一去二三里,烟村四五家”?反正当时选密码的时候感觉浑身都是机灵,现在则后悔当初何必作茧自缚。

*([XKCD](https://imgs.xkcd.com/comics/password_strength.png), [CC BY-NC 2.5](https://creativecommons.org/licenses/by-nc/2.5/))*
当然,你不会把自己的主密码告诉其它任何人,因为这是密码管理的首要原则。有没有其它变通的办法,免除这种难以承受的密码之重?
试试 <ruby> <a href="https://en.wikipedia.org/wiki/Secret_sharing#Shamir's_scheme"> Shamir 秘密共享算法 </a> <rt> Shamir's Secret Sharing </rt></ruby>,这是一种可以将保密内容进行分块保存,且只能将片段拼合才能恢复保密内容的算法。
先分别通过一个古代的和一个现代的故事,看看 Shamir 秘密共享算法究竟是怎么回事吧。
这些故事的隐含前提是你对密码学有起码的了解,必要的话,你可以先温习一下 [密码学与公钥基础设施引论](https://opensource.com/article/18/5/cryptography-pki).
### 一个古代关于加解密的故事
古代某国,国王有个大秘密,很大很大的秘密:
```
def int_from_bytes(s):
acc = 0
for b in s:
acc = acc * 256
acc += b
return acc
secret = int_from_bytes("terrible secret".encode("utf-8"))
```
大到连他自己的孩子都不能轻易信任。他有五个子女,但他知道前路危机重重。他的孩子需要在他百年之后用这个秘密来保卫国家,而国王又不能忍受自己的孩子在他们还记得自己的时候就知道这些秘密,尤其是这种状态可能要持续几十年。
所以,国王动用大力魔术,将这个秘密分为了五个部分。他知道,可能有一两个孩子不会遵从他的遗嘱,但绝对不会同时有三个或三个以上会这样:
```
from mod import Mod
from os import urandom
```
国王精通 [有限域](https://en.wikipedia.org/wiki/Finite_field) 和 *随机* 魔法,当然,对他来说,使用巨蟒分割这个秘密也是小菜一碟。
第一步是选择一个大质数——第 13 个 [梅森质数](https://en.wikipedia.org/wiki/Mersenne_prime)(`2**521 - 1`),他让人把这个数铸造在巨鼎上,摆放在大殿上:
```
P = 2**521 - 1
```
但这不是要保密的秘密:这只是 *公开数据*。
国王知道,如果 `P` 是一个质数,用 `P` 对数字取模,就形成了一个数学 [场](https://en.wikipedia.org/wiki/Field_(mathematics)):在场中可以自由进行加、减、乘、除运算。当然,做除法运算时,除数不能为 0。
国王日理万机,方便起见,他在做模运算时使用了 PyPI 中的 [mod](https://pypi.org/project/mod/) 模块,这个模块实现了各种模数运算算法。
他确认过,自己的秘密比 `P` 要短:
```
secret < P
```
```
TRUE
```
将秘密转换为 `P` 的模,`mod P`:
```
secret = mod.Mod(secret, P)
```
为了使任意三个孩子掌握的片段就可以重建这个秘密,他还得生成另外两个部分,并混杂到一起:
```
polynomial = [secret]
for i in range(2):
polynomial.append(Mod(int_from_bytes(urandom(16)), P))
len(polynomial)
```
```
3
```
下一步就是在随机选择的点上计算某 [多项式](https://en.wikipedia.org/wiki/Polynomial) 的值,即计算 `polynomial[0] + polynomial[1]*x + polynomial[2]*x**2 ...`。
虽然有第三方模块可以计算多项式的值,但那并不是针对有限域内的运算的,所以,国王还得亲自操刀,写出计算多项式的代码:
```
def evaluate(coefficients, x):
acc = 0
power = 1
for c in coefficients:
acc += c * power
power *= x
return acc
```
再下一步,国王选择五个不同的点,计算多项式的值,并分别交给五个孩子,让他们各自保存一份:
```
shards = {}
for i in range(5):
x = Mod(int_from_bytes(urandom(16)), P)
y = evaluate(polynomial, x)
shards[i] = (x, y)
```
正如国王所虑,不是每个孩子都正直守信。其中有两个孩子,在他尸骨未寒的时候,就想从自己掌握的秘密片段中窥出些什么,但穷极所能,终无所获。另外三个孩子听说了这个事,合力将这两人永远驱逐:
```
del shards[2]
del shards[3]
```
二十年弹指一挥间,奉先王遗命,三个孩子将合力恢复出先王的大秘密。他们将各自的秘密片段拼合在一起:
```
retrieved = list(shards.values())
```
然后是 40 天没日没夜的苦干。这是个大工程,他们虽然都懂些 Python,但都不如前国王精通。
最终,揭示秘密的时刻到了。
用于反算秘密的代码基于 [拉格朗日差值](https://www.math.usm.edu/lambers/mat772/fall10/lecture5.pdf),它利用多项式在 `n` 个非 0 位置的值,来计算其在 `0` 处的值。前面的 `n` 指的是多项式的阶数。这个过程的原理是,可以为一个多项式找到一个显示方程,使其满足:其在 `t[0]` 处的值是 `1`,在 `i` 不为 `0` 的时候,其在 `t[i]` 处的值是 `0`。因多项式值的计算属于线性运算,需要计算 *这些* 多项式各自的值,并使用多项式的值进行插值:
```
from functools import reduce
from operator import mul
def retrieve_original(secrets):
x_s = [s[0] for s in secrets]
acc = Mod(0, P)
for i in range(len(secrets)):
others = list(x_s)
cur = others.pop(i)
factor = Mod(1, P)
for el in others:
factor *= el * (el - cur).inverse()
acc += factor * secrets[i][1]
return acc
```
这代码是在太复杂了,40 天能算出结果已经够快了。雪上加霜的是,他们只能利用五个秘密片段中的三个来完成这个运算,这让他们万分紧张:
```
retrieved_secret = retrieve_original(retrieved)
```
后事如何?
```
retrieved_secret == secret
```
```
TRUE
```
数学这个魔术的优美之处就在于它每一次都是那么靠谱,无一例外。国王的孩子们,曾经的孩童,而今已是壮年,足以理解先王的初衷,并以先王的锦囊妙计保卫了国家,并继之以繁荣昌盛!
### 关于 Shamir 秘密共享算法的现代故事
现代,很多人都对类似的大秘密苦不堪言:密码管理器的主密码!几乎没有谁能有足够信任的人去完全托付自己最深的秘密,好消息是,找到至少有三个不会串通起来搞鬼的五人组不是个太困难的事。
同样是在现代,比较幸运的是,我们不必再像国王那样自己动手分割要守护的秘密。拜现代 *开源* 技术所赐,这都可以使用现成的软件完成。
假设你有五个不敢完全信任,但还可以有点信任的人:张三、李四、王五、赵六和钱大麻子。
安装并运行 `ssss` 分割密钥:
```
$ echo 'long legs travel fast' | ssss-split -t 3 -n 5
Generating shares using a (3,5) scheme with dynamic security level.
Enter the secret, at most 128 ASCII characters: Using a 168 bit security level.
1-797842b76d80771f04972feb31c66f3927e7183609
2-947925f2fbc23dc9bca950ef613da7a4e42dc1c296
3-14647bdfc4e6596e0dbb0aa6ab839b195c9d15906d
4-97c77a805cd3d3a30bff7841f3158ea841cd41a611
5-17da24ad63f7b704baed220839abb215f97d95f4f8
```
这确实是个非常牛的主密码:`long legs travel fast`,绝不能把它完整的托付给任何人!那就把五个片段分别交给还比较可靠的伙伴,张三、李四、王五、赵六和钱大麻子。
* 把 `1` 给张三。
* 把 `2` 给李四。
* 把 `3` 给王五。
* 把 `4` 给赵六。
* 把 `5` 给钱大麻子。
然后,你开启你的惬意之旅,整整一个月,流连于海边温暖的沙滩,整整一个月,没碰过任何电子设备。没用多久,把自己的主密码忘到了九霄云外。
李四和王五也在和你一起旅行,你托付给他们保管的密钥片段保存的好好的,在他们各自的密码管理器中,但不幸的是,他们和你一样,也忘了自己的 *主密码*。
没关系。
联系张三,他保管的密钥片段是 `1-797842b76d80771f04972feb31c66f3927e7183609`;赵六,一直替你的班,很高兴你能尽快重返岗位,把自己掌握的片段给了你,`4-97c77a805cd3d3a30bff7841f3158ea841cd41a611`;钱大麻子,收到你给的跑腿费才将自己保管的片段翻出来发给你,`5-17da24ad63f7b704baed220839abb215f97d95f4f8`。
有了这三个密钥片段,运行:
```
$ ssss-combine -t 3
Enter 3 shares separated by newlines:
Share [1/3]: 1-797842b76d80771f04972feb31c66f3927e7183609
Share [2/3]: 4-97c77a805cd3d3a30bff7841f3158ea841cd41a611
Share [3/3]: 5-17da24ad63f7b704baed220839abb215f97d95f4f8
Resulting secret: long legs travel fast
```
就这么简单,有了 *开源* 技术加持,你也可以活的像国王一样滋润!
### 自己的安全不是自己一个人的事
密码管理是当今网络生活必备技能,当然要选择复杂的密码,来保证安全性,但这不是全部。来用 Shamir 秘密共享算法,和他人共同安全的存储你的密码吧。
---
via: <https://opensource.com/article/20/6/python-passwords>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many of us use password managers to securely store our many unique passwords. A critical part of a password manager is the master password. This password protects all others, and in that way, it is a risk. Anyone who has it can pretend to be you… anywhere! Naturally, you keep your master password hard to guess, commit it to memory, and do all the other things you are [supposed to do](https://monitor.firefox.com/security-tips).
But what if something happens and you forget it? Maybe you took a vacation to a lovely, far-away island with no technology for a month. After frolicking in the water daily and eating pineapples, you cannot quite remember your password. Maybe it was "long legs travel fast"? Or was it something like "sharp spoons eat quick"? It was definitely clever when you thought of it.
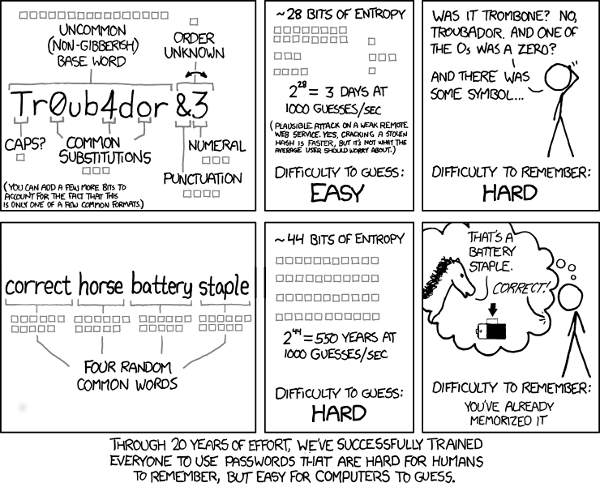
(XKCD, [CC BY-NC 2.5](https://creativecommons.org/licenses/by-nc/2.5/))
Of course, you never told a single soul your password. Why, this is literally the first rule of password management. What could you have done differently?
Enter [Shamir's Secret Sharing](https://en.wikipedia.org/wiki/Secret_sharing#Shamir's_scheme)**,** an algorithm that allows users to divide a secret into parts that can be used only in combination with the other pieces.
Let's take a look at Shamir's Secret Sharing in action through a story of ancient times and modern times.
This story does assume some knowledge of cryptography. You can brush up on it with this [introduction to cryptography and public key infrastructure](https://opensource.com/article/18/5/cryptography-pki).
## A story of secrets in ancient times
In an ancient kingdom, it came to pass that the king had a secret. A terrible secret:
```
def int_from_bytes(s):
acc = 0
for b in s:
acc = acc * 256
acc += b
return acc
secret = int_from_bytes("terrible secret".encode("utf-8"))
```
So terrible, the king could entrust it to none of his offspring. He had five of them but knew that there would be dangers on the road ahead. The king knew his children would need the secret to protect the kingdom after his death, but he could not bear the thought of the secret being known for two decades, while they were still mourning him.
So he used powerful magic to split the secret into five shards. He knew that it was possible that one child or even two would not respect his wishes, but he did not believe three of them would:
```
from mod import Mod
from os import urandom
```
The king was well-versed in the magical arts of [finite fields](https://en.wikipedia.org/wiki/Finite_field) and *randomness*. As a wise king, he used Python to split the secret.
The first thing he did was choose a large prime—the 13th [Mersenne Prime](https://en.wikipedia.org/wiki/Mersenne_prime) (`2**521 - 1`
)—and ordered it be written in letters 10 feet high, wrought of gold, above the palace:
`P = 2**521 - 1`
This was not part of the secret: it was *public data*.
The king knew that if `P`
is a prime, numbers modulo `P`
form a mathematical [field](https://en.wikipedia.org/wiki/Field_(mathematics)): they can be added, multiplied, subtracted, and divided as long as the divisor is not zero.
As a busy king, he used the PyPI [package mod](https://pypi.org/project/mod/), which implements modulus arithmetic.
He made sure his terrible secret was less than `P`
:
`secret < P`
`TRUE`
And he converted it to its modulus `mod P`
:
`secret = mod.Mod(secret, P)`
In order to allow three offspring to reconstruct the secret, the king had to generate two more parts to mix together:
```
polynomial = [secret]
for i in range(2):
polynomial.append(Mod(int_from_bytes(urandom(16)), P))
len(polynomial)
```
`3`
The king next needed to evaluate this [polynomial](https://en.wikipedia.org/wiki/Polynomial) at random points. Evaluating a polynomial is calculating `polynomial[0] + polynomial[1]*x + polynomial[2]*x**2 ...`
While there are third-party modules to evaluate polynomials, they do not work with finite fields. The king needed to write the evaluation code himself:
```
def evaluate(coefficients, x):
acc = 0
power = 1
for c in coefficients:
acc += c * power
power *= x
return acc
```
Next, the king evaluated the polynomial at five different points, to give one piece to each offspring:
```
shards = {}
for i in range(5):
x = Mod(int_from_bytes(urandom(16)), P)
y = evaluate(polynomial, x)
shards[i] = (x, y)
```
Sadly, as the king feared, not all his offspring were honest and true. Two of them, shortly after his death, tried to figure out the terrible secret from the parts they had. Try as they could, they did not succeed. However, when the others learned this, they exiled them from the kingdom forever:
```
del shards[2]
del shards[3]
```
Twenty years later, as the king had decreed, the oldest sibling and the two youngest came together to figure out their father's terrible secret. They put together their shards:
`retrieved = list(shards.values())`
For 40 days and 40 nights, they struggled with finding the king's secret. No easy task was it before them. Like the king, they knew Python, but none were as wise as he.
Finally, the answer came to them.
The retrieval code is based on a concept called [lagrange interpolation](https://www.math.usm.edu/lambers/mat772/fall10/lecture5.pdf). It evaluates a polynomial at `0`
based on its values in `n`
other places, where `n`
is the degree of the polynomial. The way it works is that you can explicitly find a formula for a polynomial that is `1`
at `t[0]`
and `0`
at `t[i]`
for `i`
different from `0`
. Since evaluating a polynomial is a linear function, you evaluate each of *these* polynomials and interpolate the results of the evaluations with the values the polynomial has:
```
from functools import reduce
from operator import mul
def retrieve_original(secrets):
x_s = [s[0] for s in secrets]
acc = Mod(0, P)
for i in range(len(secrets)):
others = list(x_s)
cur = others.pop(i)
factor = Mod(1, P)
for el in others:
factor *= el * (el - cur).inverse()
acc += factor * secrets[i][1]
return acc
```
It is no surprise this took them 40 days and 40 nights—this code is pretty complicated! But they ran it on the surviving shards, waiting with bated breath:
`retrieved_secret = retrieve_original(retrieved)`
Did the children get the correct secret?
`retrieved_secret == secret`
`TRUE`
The beauty of math's magic is that it works reliably every time! The children, now older and able to understand their father's choices, used the terrible secret to defend the kingdom. The kingdom prospered and grew.
## A modern story of Shamir's Secret Sharing
In modern times, many of us are also burdened with a terrible secret: the master password to our password manager. While few people have one person they can trust completely with their deepest, darkest secrets, many can find a group of five where it is unlikely three will break their trust together.
Luckily, in these modern times, we do not need to split our secrets ourselves, as the king did. Through the modern technology of *open source*, we can use software that exists.
Let's say you have five people you trust—not absolutely, but quite a bit: Your best friend, your spouse, your mom, a close colleague, and your lawyer.
You can install and run the program `ssss`
to split the key:
```
$ echo 'long legs travel fast' | ssss-split -t 3 -n 5
Generating shares using a (3,5) scheme with dynamic security level.
Enter the secret, at most 128 ASCII characters: Using a 168 bit security level.
1-797842b76d80771f04972feb31c66f3927e7183609
2-947925f2fbc23dc9bca950ef613da7a4e42dc1c296
3-14647bdfc4e6596e0dbb0aa6ab839b195c9d15906d
4-97c77a805cd3d3a30bff7841f3158ea841cd41a611
5-17da24ad63f7b704baed220839abb215f97d95f4f8
```
Ah, a strong, powerful, master password: `long legs travel fast`
. Never can it be entrusted to a single soul, but you can send the five shards to your five guardians.
- You send
`1`
to your best friend, F. - You send
`2`
to your spouse, S. - You send
`3`
to your mom, M. - You send
`4`
to your colleague, C. - You send
`5`
to your lawyer, L.
Now, say you go on a family vacation. For a month, you frolic on the warm sands of the beach. While you frolic, you touch not one electronic device. Soon enough, your powerful master password is forgotten.
Your loving spouse and your dear mother were with you on vacation. They kept their shards safe in their password manager—and they have forgotten *their passwords*.
This is fine.
You contact your best friend, F, who gives you `1-797842b76d80771f04972feb31c66f3927e7183609`
. Your colleague, who covered all your shifts, is glad to have you back and gives you `4-97c77a805cd3d3a30bff7841f3158ea841cd41a611`
. Your lawyer charges you $150 per hour, goes into their password manager, and digs up `5-17da24ad63f7b704baed220839abb215f97d95f4f8`
.
With those three pieces, you run:
```
$ ssss-combine -t 3
Enter 3 shares separated by newlines:
Share [1/3]: 1-797842b76d80771f04972feb31c66f3927e7183609
Share [2/3]: 4-97c77a805cd3d3a30bff7841f3158ea841cd41a611
Share [3/3]: 5-17da24ad63f7b704baed220839abb215f97d95f4f8
Resulting secret: long legs travel fast
```
And so, with the technology of *open source*, you too can live like a king!
## Share safely for your safety
Password management is an essential skill for today's online life. Create a complex password, of course, but don't stop there. Use the handy Shamir's Secret Sharing algorithm to safely share it with others.
## 11 Comments |
12,476 | 如何使用 Squid 配置 SSH 代理服务器 | https://fedoramagazine.org/configure-ssh-proxy-server/ | 2020-08-01T16:28:00 | [
"Squid",
"SSH"
] | https://linux.cn/article-12476-1.html | 
有时你无法从本地连接到 SSH 服务器。还有时,你可能想为 SSH 连接添加额外的安全层。在这些情况下,通过代理服务器连接到 SSH 服务器是一种解决方式。
[Squid](http://www.squid-cache.org/) 是提供缓存和代理服务的全功能代理服务器应用。它通常用于在浏览过程中重用和缓存以前请求的网页来帮助缩短响应时间并减少网络带宽。
但是在本篇中,你将配置 Squid 作为 SSH 代理服务器,因为它是强大的受信任代理服务器,易于配置。
### 安装和配置
使用 [sudo](https://fedoramagazine.org/howto-use-sudo/) 安装 squid 软件包:
```
$ sudo dnf install squid -y
```
squid 配置文件非常庞大,但是我们只需要配置其中一些。Squid 使用访问控制列表来管理连接。
编辑 `/etc/squid/squid.conf` 文件,确保你有下面解释的两行。
首先,指定你的本地 IP 网络。默认配置文件已经列出了最常用的,但是如果没有,你需要添加你的配置。例如,如果你的本地 IP 网络范围是 192.168.1.X,那么这行会是这样:
```
acl localnet src 192.168.1.0/24
```
接下来,添加以下行,将 SSH 端口添加为安全端口:
```
acl Safe_ports port 22
```
保存该文件。现在启用并重启 squid 代理服务:
```
$ sudo systemctl enable squid
$ sudo systemctl restart squid
```
squid 代理默认监听 3128 端口。配置 firewalld 允许此服务:
```
$ sudo firewall-cmd --add-service=squid --perm
$ sudo firewall-cmd --reload
```
### 测试 ssh 代理连接
要通过 ssh 代理服务器连接到服务器,我们将使用 `netcat`。
如果尚未安装 `nmap-ncat`,请安装它:
```
$ sudo dnf install nmap-ncat -y
```
这是标准 ssh 连接示例:
```
$ ssh [email protected]
```
这是使用 squid 代理服务器作为网关连接到该服务器的方式。
此示例假定 squid 代理服务器的 IP 地址为 192.168.1.63。你还可以使用 squid 代理服务器的主机名或 FQDN:
```
$ ssh [email protected] -o "ProxyCommand nc --proxy 192.168.1.63:3128 %h %p"
```
以下是这些选项的含义:
* `ProxyCommand` – 告诉 ssh 使用代理命令。
* `nc` – 用于建立与代理服务器连接的命令。这是 netcat 命令。
* `%h` – 代理服务器的主机名或 IP 地址的占位符。
* `%p` – 代理服务器端口号的占位符。
有很多方法可以配置 SSH 代理服务器,但这是入门的简单方法。
---
via: <https://fedoramagazine.org/configure-ssh-proxy-server/>
作者:[Curt Warfield](https://fedoramagazine.org/author/rcurtiswarfield/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sometimes you can’t connect to an SSH server from your current location. Other times, you may want to add an extra layer of security to your SSH connection. In these cases connecting to another SSH server via a proxy server is one way to get through.
[Squid](http://www.squid-cache.org/) is a full-featured proxy server application that provides caching and proxy services. It’s normally used to help improve response times and reduce network bandwidth by reusing and caching previously requested web pages during browsing.
However for this setup you’ll configure Squid to be used as an SSH proxy server since it’s a robust trusted proxy server that is easy to configure.
## Installation and configuration
Install the squid package using [sudo](https://fedoramagazine.org/howto-use-sudo/):
$ sudo dnf install squid -y
The squid configuration file is quite extensive but there are only a few things we need to configure. Squid uses access control lists to manage connections.
Edit the */etc/squid/squid.conf* file to make sure you have the two lines explained below.
First, specify your local IP network. The default configuration file already has a list of the most common ones but you will need to add yours if it’s not there. For example, if your local IP network range is 192.168.1.X, this is how the line would look:
acl localnet src 192.168.1.0/24
Next, add the SSH port as a safe port by adding the following line:
acl Safe_ports port 22
Save that file. Now enable and restart the squid proxy service:
$ sudo systemctl enable squid $ sudo systemctl restart squid
4.) By default squid proxy listens on port 3128. Configure firewalld to allow for this:
$ sudo firewall-cmd --add-service=squid --perm $ sudo firewall-cmd --reload
## Testing the ssh proxy connection
To connect to a server via ssh through a proxy server we’ll be using netcat.
Install *nmap-ncat* if it’s not already installed:
$ sudo dnf install nmap-ncat -y
Here is an example of a standard ssh connection:
$ ssh [email protected]
Here is how you would connect to that same server using the squid proxy server as a gateway.
This example assumes the squid proxy server’s IP address is 192.168.1.63. You can also use the host-name or the FQDN of the squid proxy server:
$ ssh [email protected] -o "ProxyCommand nc --proxy 192.168.1.63:3128 %h %p"
Here are the meanings of the options:
*ProxyCommand*– Tells ssh a proxy command is going to be used.
*nc*– The command used to establish the connection to the proxy server. This is the netcat command.
*%**h*– The placeholder for the proxy server’s host-name or IP address.
*%**p*– The placeholder for the proxy server’s port number.
There are many ways to configure an SSH proxy server but this is a simple way to get started.
## Nachfuellbar
Why wouldn’t you just use ProxyJump and use another sshd as Proxy
Would probably be more secure than a unsecured squid
## Joao Rodrigues
Or… If you already have sshd running on your proxy server (192.168.1.63) you could ditch squid and use ssh’s ProxyJump option like this:
ssh -J [email protected] [email protected]
You could even save it on your ~/.ssh/config:
Host: 192.168.1.63
User: proxyserveruser
Host: example.com
User: user
ProxyJump: 192.168.1.63
And next time you want to connect you just type “ssh example.com”.
You can even set up multiple jumps:
$ ssh -J [email protected],[email protected] [email protected]
This will establish a connection to serverA.example.com, that in turn will connect to serverB.example.com and finally connect to example.com
## Brian Ward
This is precisely what I was thinking when I read this. The concept of using squid with netcat introduces two new surface areas for attack. Just use the built in features of modern sshd.
“However for this setup you’ll configure Squid to be used as an SSH proxy server since it’s a robust trusted proxy server that is easy to configure.”
This is a terrible reason to do something.
## Stuart Gathman
When the target system can run cjdns, no need for proxy servers:
$ ssh [email protected]
https://fedoramagazine.org/decentralize-common-fedora-apps-cjdns/
## Mohammed El-Afifi
I think %h and %p in the command string to ProxyCommand denote the host and port of the remote ssh server respectively, not those of the proxy.
## Curt Warfield
You are correct the %h:%p arguments specify to forward standard in and out to the remote host (%h) and the remote host’s port (%p).
## yukyu
better way are tox communicator proxy/ssh |
12,477 | 实用脚本:检查高 CPU / 内存消耗进程 | https://www.2daygeek.com/bash-script-to-check-how-long-the-high-cpu-memory-consumption-processes-runs-on-linux/ | 2020-08-01T20:54:52 | [
"进程"
] | https://linux.cn/article-12477-1.html | 
过去,我们写了三篇不同的文章来使用 Linux 命令来识别这些进程。
你可以通过下面相关的 URL 立即访问:
* [如何在 Linux 中找出 CPU 占用高的进程](/article-11678-1.html)
* [如何在 Linux 中找出内存消耗最大的进程](/article-11542-1.html)
* [在 Linux 中如何查找一个命令或进程的执行时间](/article-10261-1.html)
本教程中包含两个脚本,它们可以帮助你确定 Linux 上高 CPU/内存消耗进程的运行时间。
该脚本将显示进程 ID、进程的所有者、进程的名称以及进程的运行时间。这将帮助你确定哪些(必须事先完成)作业正在超时运行。这可以使用 `ps` 命令来实现。
### 什么是 ps 命令
`ps` 是<ruby> 进程状态 <rt> processes status </rt></ruby>,它显示有关系统上活动/正在运行的进程的信息。
它提供了当前进程的快照以及详细信息,例如用户名、用户 ID、CPU 使用率、内存使用率、进程开始日期和时间等。
#### 1)检查高 CPU 消耗进程在 Linux 上运行了多长时间的 Bash 脚本
该脚本将帮助你确定高 CPU 消耗进程在 Linux 上运行了多长时间。
```
# vi /opt/scripts/long-running-cpu-proc.sh
#!/bin/bash
ps -eo pid,user,ppid,%mem,%cpu,cmd --sort=-%cpu | head | tail -n +2 | awk '{print $1}' > /tmp/long-running-processes.txt
echo "--------------------------------------------------"
echo "UName PID CMD Process_Running_Time"
echo "--------------------------------------------------"
for userid in `cat /tmp/long-running-processes.txt`
do
username=$(ps -u -p $userid | tail -1 | awk '{print $1}')
pruntime=$(ps -p $userid -o etime | tail -1)
ocmd=$(ps -p $userid | tail -1 | awk '{print $4}')
echo "$username $userid $ocmd $pruntime"
done | column -t
echo "--------------------------------------------------"
```
给 `long-running-cpu-proc.sh` 设置可执行的 [Linux 文件权限](https://www.2daygeek.com/understanding-linux-file-permissions/)。
```
# chmod +x /opt/scripts/long-running-cpu-proc.sh
```
运行此脚本时,你将获得类似以下的输出:
```
# sh /opt/scripts/long-running-cpu-proc.sh
----------------------------------------------------
UName PID CMD Process_Running_Time
----------------------------------------------------
daygeek 5214 Web 01:18:48
daygeek 5748 Web 01:08:20
daygeek 8043 inkscape 22:11
daygeek 5269 Web 01:18:31
daygeek 1712 Web 10:44:50
daygeek 5335 RDD 01:17:54
daygeek 1639 firefox 10:44:51
daygeek 7793 nautilus 24:14
daygeek 6301 Web 57:40
----------------------------------------------------
```
#### 2)检查高内存消耗进程在 Linux 上运行了多长时间的 Bash 脚本
该脚本将帮助你确定最大的内存消耗进程在 Linux 上运行了多长时间。
```
# sh /opt/scripts/long-running-memory-proc.sh
#!/bin/bash
ps -eo pid,user,ppid,%mem,%cpu,cmd --sort=-%mem | head | tail -n +2 | awk '{print $1}' > /tmp/long-running-processes-1.txt
echo "--------------------------------------------------"
echo "UName PID CMD Process_Running_Time"
echo "--------------------------------------------------"
for userid in `cat /tmp/long-running-processes-1.txt`
do
username=$(ps -u -p $userid | tail -1 | awk '{print $1}')
pruntime=$(ps -p $userid -o etime | tail -1)
ocmd=$(ps -p $userid | tail -1 | awk '{print $4}')
echo "$username $userid $ocmd $pruntime"
done | column -t
echo "--------------------------------------------------"
```
给 `long-running-memory-proc.sh` 设置可执行的 Linux 文件权限。
```
# chmod +x /opt/scripts/long-running-memory-proc.sh
```
运行此脚本时,你将获得类似以下的输出:
```
# sh /opt/scripts/long-running-memory-proc.sh
----------------------------------------------------
UName PID CMD Process_Running_Time
----------------------------------------------------
daygeek 1639 firefox 10:44:56
daygeek 2997 Web 10:39:54
daygeek 5269 Web 01:18:37
daygeek 1712 Web 10:44:55
daygeek 8043 inkscape 22:17
daygeek 5214 Web 01:18:54
daygeek 1898 Web 10:44:48
daygeek 1129 Xorg 10:45:07
daygeek 6301 Web 57:45
----------------------------------------------------
```
---
via: <https://www.2daygeek.com/bash-script-to-check-how-long-the-high-cpu-memory-consumption-processes-runs-on-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,479 | 屡屡失败犯错的我为什么没有被开除 | https://opensource.com/article/20/3/failure-driven-development | 2020-08-02T21:20:00 | [
"失败"
] | https://linux.cn/article-12479-1.html |
>
> 我是词典里 “失败” 一词旁边的插图,这就是为什么我擅长我的工作的原因。
>
>
>

我的职称是高级软件工程师,但我最亲近的同事并不这么称呼我。由于我摧毁一切,他们管我叫“樱桃炸弹”(正巧我姓“樱桃”)。我定期会遇到的失败已经可以影响到我们的季度性收益和停机时间。简单的来说,我就是你所听说过的生产灾难:“别动,啥都别做,无论何时何地。”
我的职业生涯始于支持服务台,在那里我写了一些循环,破坏了高端客户的服务器。我曾在没有警告的情况下将生产应用程序关闭了长达八个小时,并且在试图使得情况好转的过程中摧毁了无数个集群,有几次只是因为我打错了字。
我是我们在 [Kubernetes](https://www.redhat.com/en/topics/containers/what-is-kubernetes) 中设有灾难恢复(DR)集群的原因。我是个混乱的工程师,我们有一个应用程序,它的故障恢复计划还从未测试过,而我在没有警告的情况下,就教人们如何快速行动和排除故障。我作为可能失败的最好例子而存在,这实际上是有史以来最酷的事情。
### 我和消失的 K8s 集群
我的正式职责之一涉及到我们的应用架构。对于任何形式的架构改动,我都要进行代码的编写与测试,看看有什么可能性。近来,据说这成了我老板史诗级的痛苦,这只是轻描淡写。
我们在 Kubernetes 上运行我们的大多数基础架构,Kubernetes 以其弹性著称。尽管有这样的声誉,我还是使得两个集群,好吧,消失了。你可能会好奇我是怎么做到的,很容易,`terraform destroy`。我们通过 [Terraform](https://github.com/hashicorp/terraform) 以代码的方式管理我们的基础架构,并且不需要任何软件知识就知道 `destroy` 可做坏事。在你惊慌失措之前,好吧,是开发集群,所以我还活着。
鉴于此,你们肯定会问我为什么还没丢掉饭碗,以及为什么我要写下这些事情。这很好回答:我仍然有工作,是因为我更新的基础架构代码比起起初的代码工作得更好更快了。我写下这些是因为每个人都会经常性地遭遇失败,这是非常非常正常的。如果你没有时不时遭遇失败,我认为你并没有足够努力地学习。
### 破坏东西并培训人们
你可能还会认为永远不会有人让我去培训任何人。那是最糟糕的主意,因为(就像我的团队开玩笑说的)你永远都不应该做我所做的事情。但是我的老板却让我定期去训练新人。我甚至为整个团队提供使用我们的基础设施或代码的培训,教人们如何建立自己的基础设施。
原因是这样的:失败是你迈向成功的第一步。失败的教训绝不只是“备份是个绝佳的主意”。不,从失败中,你学会了更快地恢复、更快地排除故障并且在你工作中取得惊人的进步。当你在工作中变得惊人的时候,你就可以培训其他人,教给他们什么事情不要做,并且帮助他们去理解一切是如何工作的。由于你的经验,他们会比你开始时更进一步 —— 而且他们也很可能以新的、惊人的、史诗般的方式失败,每个人都可以从中学到东西。
### 你的成功取决于你的失败
没有人生来就具有软件工程和云基础架构方面的天赋,就像没有人天生就会走路。我们都是从滚动和翻爬开始的。从那时起,我们学会爬行,然后能够站立一会儿。当我们开始走路后,我们会跌倒并且擦伤膝盖,撞到手肘,还有,比如像我哥哥,走着走着撞上桌子的尖角,然后在眉毛中间缝了针。
凡事都需要时间去学习。一路上阅读手边能获得的一切来帮助你,但这永远只是个开始。完美是无法实现的幻想,你必须通过失败来取得成功。
每走一步,我的失败都教会我如何把事情做得更好。
最终,你的成功和你累积的失败一样多,这标志着你成功的程度。
---
via: <https://opensource.com/article/20/3/failure-driven-development>
作者:[Jessica Cherry](https://opensource.com/users/jrepka) 选题:[lujun9972](https://github.com/lujun9972) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | My job title is senior software engineer, but that's not what my closest co-workers call me. They call me "Cherrybomb" because of all the things I blow up. My regularly scheduled failures have been tracked down to our quarterly earnings and outage times. Literally, I am the production disaster you read about that says, "what not to do ever, in any case, at any time."
I started my career at a helpdesk where I wrote loops that wrecked servers in high-end companies. I have taken production applications down for up to eight hours without warning, and I have destroyed endless numbers of clusters in an attempt to make things better—and a couple just because I mistyped something.
I am the reason we have disaster recovery (DR) clusters in [Kubernetes](https://www.redhat.com/en/topics/containers/what-is-kubernetes). I am the chaos engineer that, without warning, teaches people how to act and troubleshoot quickly when we have an application that has never been tested for an outage recovery plan. I exist as the best example of failure possible, and it's actually the coolest thing ever.
## Jess and the disappearing K8s clusters
One of my official responsibilities involves our application architecture. For any sort of architectural change, I get to make and test the code and see what is possible. Recently, this has been an epic pain in my bosses' side, to put it gently.
We run most of our infrastructure on Kubernetes, which is known for its resiliency. Despite that reputation, I managed to make two clusters just, well, disappear. You may be wondering how I could do that; it's pretty easy: **terraform destroy**. We manage our infrastructure as code through [Terraform](https://github.com/hashicorp/terraform), and it won't take any knowledge of the software to know that **destroy** can do something bad. Before you panic, it was the dev clusters, so life went on.
In light of this, it's reasonable to ask why I am still employed—and why am I writing about this. Those are easy to answer: I'm still employed because my infrastructure code updates work better and faster than the code we started with. And am I writing about this because everyone fails regularly; it is so very, very normal. If you're not failing regularly, I don't think you're trying hard enough to learn.
## Break things and train people
You'd also think no one would let me train anyone ever; that it's the worst idea ever because (as my team jokes) you should never, ever do the things I do. However, my boss has me train anyone walking in the door pretty regularly. I even provide training for entire teams using our infrastructure or code to teach people how to build their own infrastructure.
Here's why: Failure is your first step to success. Failure's lesson isn't just "backups are a fantastic idea." No, from failure, you learn to recover faster, troubleshoot quicker, and get amazingly better at your job. When you get amazing at your job, you can train others about what not to do and help them understand how everything works. Because of your experience, they will be a step ahead of you were when you started—and they, too, will most likely fail in new, amazing, epic ways that everyone can learn from.
## You are only as good as your failures
Nobody is born with talent in software engineering and cloud infrastructure, just like no one is born walking. We all start by rolling and bumping into things. From there, we learn to crawl and then stand for a moment or two. When we start walking, we fall and scratch our knees, bump our elbows, and—at least in my brother's case—walk right into a table's sharp corner and get stitches in the center of your eyebrow.
Things take time to learn. Read everything you can get your hands on to help you along your way—but that is always the beginning. Perfection is some fantasy that's impossible to achieve; you must fail to reach success.
Every step of the way, my failures teach me how to do things better.
Ultimately, you are only as good as the sum of your failures, because that's what shows you how successful you are.
## Comments are closed. |
12,480 | Video Trimmer:Linux 桌面中的傻瓜级的视频修剪应用 | https://itsfoss.com/video-trimmer/ | 2020-08-02T21:47:38 | [
"视频"
] | https://linux.cn/article-12480-1.html |
>
> 一个非常简单的工具,无需重新编码即可快速修剪视频。我们来看看它提供了什么。
>
>
>
你可能已经知道 Linux 的一些[最佳免费视频编辑器](https://itsfoss.com/open-source-video-editors/),但并不是每个人都需要它们提供的所有功能。
有时,你只想快速执行一项操作,例如修剪视频。你是选择探索功能完善的视频编辑器但只是执行简单的修剪操作,还是希望使用便捷工具来修剪视频?
当然,这取决于你的个人喜好以及处理视频的方式。但是,对于大多数用户而言,首选是使用非常容易使用的修剪工具。
因此,我想重点介绍一个傻瓜级的开源工具,即 “[Video Trimmer](https://gitlab.gnome.org/YaLTeR/video-trimmer)”,它可以快速修剪视频。

### Video Trimmer:一个用于快速修剪视频的傻瓜应用
Video Trimmer 是一个开源应用,它可帮助你修剪视频片段而无需重新编码。因此,基本上,你可以能够修剪视频而不会失去原始质量。
你要做的就是使用 Video Trimmer 打开视频文件,然后使用鼠标选择要修剪的时间区域。
你可以手动设置要修剪的时间范围,也可以仅使用鼠标拖动区域进行修剪。当然,如果视频文件很长,而且你不知道从哪里看,手动设置时间戳可能需要一段时间。
为了让你有个印象,请看下面的截图,看看在使用 Video Trimmer 时可用的选项:

### 在 Linux 上安装 Video Trimmer
Video Trimmer 仅作为 [Flathub](https://flathub.org/apps/details/org.gnome.gitlab.YaLTeR.VideoTrimmer) 上的 Flatpak 软件包提供。因此,你应该能够在 Flatpak 支持的任何 Linux 发行版上安装它,而不会出现任何问题。
以防你不了解 Flatpak,你可能想要参考我们的[使用和安装 Flatpak](https://itsfoss.com/flatpak-guide/) 指南。
* [下载 Video Trimmer(Flathub)](https://flathub.org/apps/details/org.gnome.gitlab.YaLTeR.VideoTrimmer)
### 总结
Video Trimmer 底层使用 [ffmpeg](https://ffmpeg.org/)。它所做的可以在终端中轻松[使用 ffmpeg 命令](https://itsfoss.com/ffmpeg/)完成。但是,并非所有人都希望使用终端来剪辑视频的一部分。Video Trimmer 之类的工具可以帮助像我这样的人。
由于某些原因,如果你想寻找一种替代方法,也可以尝试使用 [VidCutter](https://itsfoss.com/vidcutter-video-editor-linux/)。当然,你始终可以依靠 [Linux 中的顶级视频编辑器](/article-10185-1.html)(例如 [OpenShot](https://itsfoss.com/openshot-video-editor-release/)) 来修剪视频以及执行一些高级操作的能力。
你认为在 Linux 中使用 Video Trimmer 如何?你是否有其他喜欢的视频修剪工具?在下面的评论中让我知道你的想法!
---
via: <https://itsfoss.com/video-trimmer/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You probably already know some of the [best free video editors](https://itsfoss.com/open-source-video-editors/) for Linux, but not everyone needs all the features offered.
Sometimes you want to perform a single operation quickly, for instance — trimming a video.
Would you rather explore a full-fledged video editor to perform a simple trim operation, or prefer a quick tool to help you trim the video?
Of course, it would depend on your preferences and what you want to do with the video. But, for most users, a tool that makes it super easy to trim a video will be the solution.
Hence, I’d like to highlight a simple open-source tool to quickly trim videos – [Video Trimmer](https://gitlab.gnome.org/YaLTeR/video-trimmer?ref=itsfoss.com).
# Installing Video Trimmer on Linux
Video Trimmer is only available as a Flatpak package on [Flathub](https://flathub.org/apps/details/org.gnome.gitlab.YaLTeR.VideoTrimmer?ref=itsfoss.com). So, you should be able to install it on any Linux distribution with Flatpak support.
`flatpak install flathub org.gnome.gitlab.YaLTeR.VideoTrimmer`
If you didn’t know about Flatpak, you might want to refer to our guide on [installing and using Flatpak](https://itsfoss.com/flatpak-guide/).
If you’re using Arch or Manjaro, you can find it listed on [AUR](https://itsfoss.com/aur-arch-linux/) (Arch User Repository).
# Video Trimmer: Overview
Video Trimmer is an open-source application that helps trim video clips without re-encoding them.
So, you’ll be able to trim videos without losing the original quality.
All you have to do is – open the video file using Video Trimmer and then select the region to trim using the mouse.
You can manually set the time range to trim, or drag the region to trim using the mouse. Of course, manually setting the timestamp could take a while if it’s a long video file and you don’t know where to look.
To give you an idea, take a look at the screenshot below to see the options available when using Video Trimmer:
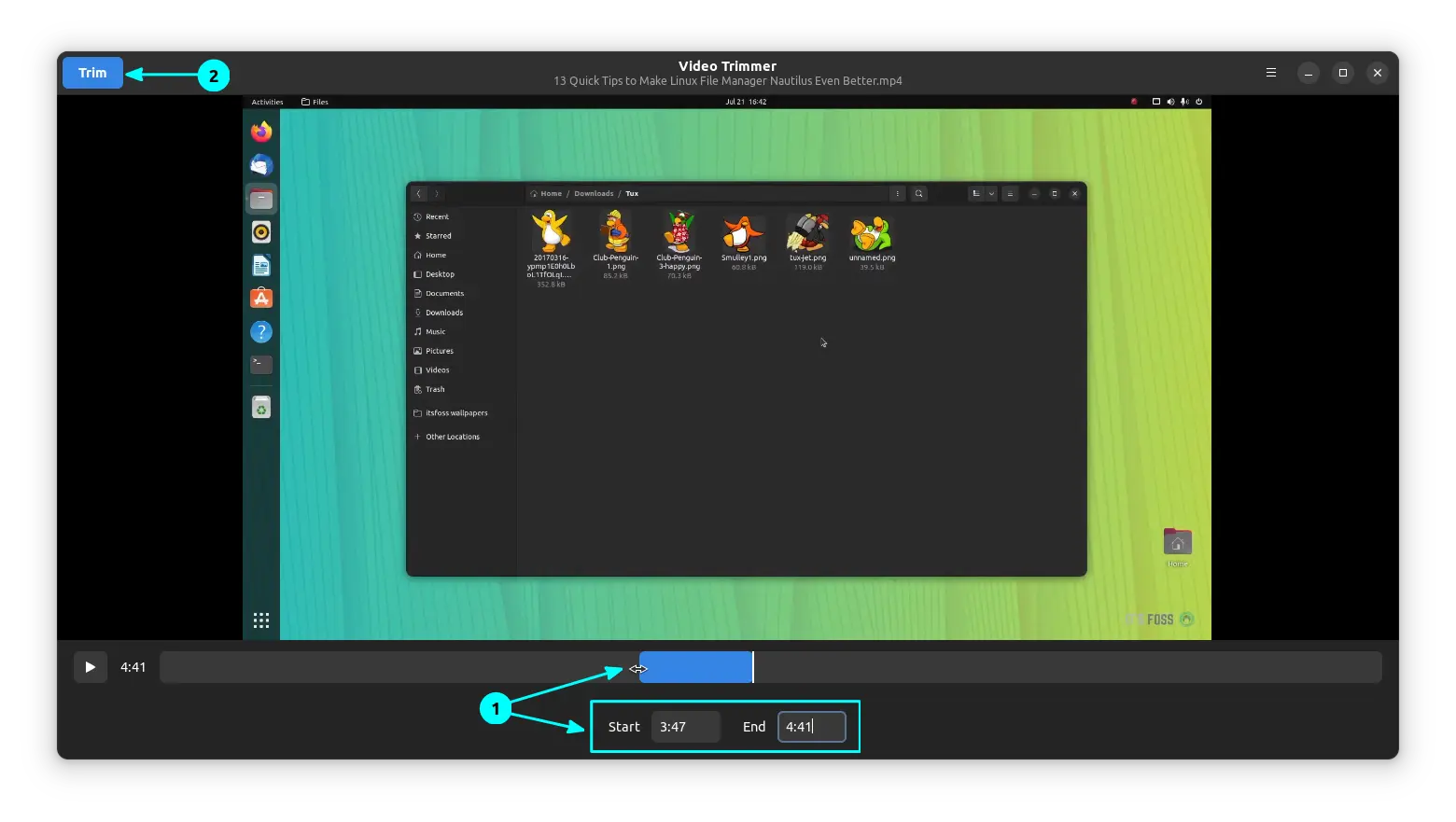
**Suggested Read 📖**
If you don't want a dedicated app to trim a video, you can use VLC in some emergency cases:
[How to Trim a Video in VLC Player [If You Really Want to]VLC is a versatile media player. It even allows trimming videos with some effort. Here’s how to do it.](https://itsfoss.com/vlc-trim-video/)

## Wrapping Up
Video Trimmer uses [FFmpeg](https://ffmpeg.org/?ref=itsfoss.com) underneath it. What it does can be done easily [using FFmpeg commands](https://itsfoss.com/ffmpeg/) in the terminal. But then, not everyone wants to use the terminal for cutting part of a video. Tools like Video Trimmer help such people (like me).
For some reason, if you want to look for an alternative, you may also try [VidCutter](https://itsfoss.com/vidcutter-video-editor-linux/). Of course, you can always rely on [top video editors available for Linux](https://itsfoss.com/best-video-editing-software-linux/) (like [OpenShot](https://itsfoss.com/openshot-video-editor-release/)) to trim videos, along with the ability to perform some advanced operations.
**Suggested Read 📖**
[9 Best Free Video Editing Software for Linux in 2023Looking for a free video editor for Linux? Here are the best options for various kind of video editing needs on Linux.](https://itsfoss.com/best-video-editing-software-linux/)

*What do you think about using “ Video Trimmer” on Linux? Do you already have another favorite video-trimming tool? Let me know your thoughts in the comments below!* |
12,483 | 使用 DNS over TLS | https://fedoramagazine.org/use-dns-over-tls/ | 2020-08-03T20:01:00 | [
"DNS",
"TLS"
] | https://linux.cn/article-12483-1.html | 
现代计算机用来在互联网种查找资源的 [域名系统(DNS)](https://en.wikipedia.org/wiki/Domain_Name_System) 是在 [35 年前](https://tools.ietf.org/html/rfc1035)设计的,没有考虑用户隐私。它会面临安全风险和攻击,例如 [DNS 劫持](https://en.wikipedia.org/wiki/DNS_hijacking)。它还能让 [ISP](https://en.wikipedia.org/wiki/Internet_service_provider) 拦截查询。
幸运的是,现在有 [DNS over TLS](https://en.wikipedia.org/wiki/DNS_over_TLS) 和 [DNSSEC](https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions) 两种技术。DNS over TLS 和 DNSSEC 允许创建从计算机到它配置的 DNS 服务器之间的安全且加密的端到端隧道。在 Fedora 上,部署这些技术的步骤很容易,并且所有必要的工具也很容易获得。
本指南将演示如何使用 `systemd-resolved` 在 Fedora 上配置 DNS over TLS。有关 `systemd-resolved` 服务的更多信息,请参见[文档](https://www.freedesktop.org/wiki/Software/systemd/resolved/)。
### 步骤 1:设置 systemd-resolved
类似于下面所示修改 `/etc/systemd/resolved.conf`。确保启用 DNS over TLS 并配置要使用的 DNS 服务器的 IP 地址。
```
$ cat /etc/systemd/resolved.conf
[Resolve]
DNS=1.1.1.1 9.9.9.9
DNSOverTLS=yes
DNSSEC=yes
FallbackDNS=8.8.8.8 1.0.0.1 8.8.4.4
#Domains=~.
#LLMNR=yes
#MulticastDNS=yes
#Cache=yes
#DNSStubListener=yes
#ReadEtcHosts=yes
```
关于选项的简要说明:
* `DNS`:以空格分隔的 IPv4 和 IPv6 地址列表,用作系统 DNS 服务器。
* `FallbackDNS`:以空格分隔的 IPv4 和 IPv6 地址列表,用作后备 DNS 服务器。
* `Domains`:在解析单标签主机名时,这些域名用于搜索后缀。 `~.` 代表对于所有域名,优先使用 `DNS=` 定义的系统 DNS 服务器。
* `DNSOverTLS`:如果启用,那么将加密与服务器的所有连接。请注意,此模式要求 DNS 服务器支持 DNS-over-TLS,并具有其 IP 的有效证书。
>
> 注意:上面示例中列出的 DNS 服务器是我个人的选择。你要确定要使用的 DNS 服务器。要注意你要向谁请求 IP。
>
>
>
### 步骤 2:告诉 NetworkManager 将信息推给 systemd-resolved
在 `/etc/NetworkManager/conf.d` 中创建一个名为 `10-dns-systemd-resolved.conf` 的文件。
```
$ cat /etc/NetworkManager/conf.d/10-dns-systemd-resolved.conf
[main]
dns=systemd-resolved
```
上面的设置(`dns=systemd-resolved`)让 `NetworkManager` 将从 DHCP 获得的 DNS 信息推送到 `systemd-resolved` 服务。这将覆盖*步骤 1* 中配置的 DNS 设置。这在受信任的网络中没问题,但是也可以设置为 `dns=none` 从而使用 `/etc/systemd/resolved.conf` 中配置的 DNS 服务器。
### 步骤 3: 启动和重启服务
若要使上述步骤中的配置生效,请启动并启用 `systemd-resolved` 服务。然后重启 `NetworkManager` 服务。
注意:在 `NetworkManager` 重启时,连接会中断几秒钟。
```
$ sudo systemctl start systemd-resolved
$ sudo systemctl enable systemd-resolved
$ sudo systemctl restart NetworkManager
```
>
> 注意:目前,systemd-resolved 服务默认处于禁用状态,是可选使用的。[有计划][33]在 Fedora 33 中默认启用systemd-resolved。
>
>
>
### 步骤 4:检查是否一切正常
现在,你应该在使用 DNS over TLS。检查 DNS 解析状态来确认这一点:
```
$ resolvectl status
MulticastDNS setting: yes
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Current DNS Server: 1.1.1.1
DNS Servers: 1.1.1.1
9.9.9.9
Fallback DNS Servers: 8.8.8.8
1.0.0.1
8.8.4.4
```
`/etc/resolv.conf` 应该指向 `127.0.0.53`。
```
$ cat /etc/resolv.conf
# Generated by NetworkManager
search lan
nameserver 127.0.0.53
```
若要查看 `systemd-resolved` 发送和接收安全查询的地址和端口,请运行:
```
$ sudo ss -lntp | grep '\(State\|:53 \)'
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=10410,fd=18))
```
若要进行安全查询,请运行:
```
$ resolvectl query fedoraproject.org
fedoraproject.org: 8.43.85.67 -- link: wlp58s0
8.43.85.73 -- link: wlp58s0
[..]
-- Information acquired via protocol DNS in 36.3ms.
-- Data is authenticated: yes
```
### 额外步骤 5:使用 Wireshark 验证配置
首先,安装并运行 [Wireshark](https://www.wireshark.org/):
```
$ sudo dnf install wireshark
$ sudo wireshark
```
它会询问你在哪个设备上捕获数据包。在我这里,因为我使用无线接口,我用的是 `wlp58s0`。在 Wireshark 中设置筛选器,`tcp.port == 853`(853 是 DNS over TLS 协议端口)。在捕获 DNS 查询之前,你需要刷新本地 DNS 缓存:
```
$ sudo resolvectl flush-caches
```
现在运行:
```
$ nslookup fedoramagazine.org
```
你应该会看到你的计算机和配置的 DNS 服务器之间的 TLS 加密交换:

---
via: <https://fedoramagazine.org/use-dns-over-tls/>
作者:[Thomas Bianchi](https://fedoramagazine.org/author/thobianchi/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Domain Name System (DNS)](https://en.wikipedia.org/wiki/Domain_Name_System) that modern computers use to find resources on the internet was designed [35 years ago](https://tools.ietf.org/html/rfc1035) without consideration for user privacy. It is exposed to security risks and attacks like [DNS Hijacking](https://en.wikipedia.org/wiki/DNS_hijacking). It also allows [ISPs](https://en.wikipedia.org/wiki/Internet_service_provider) to intercept the queries.
Luckily, [DNS over TLS](https://en.wikipedia.org/wiki/DNS_over_TLS) and [DNSSEC](https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions) are available. DNS over TLS and DNSSEC allow safe and encrypted end-to-end tunnels to be created from a computer to its configured DNS servers. On Fedora, the steps to implement these technologies are easy and all the necessary tools are readily available.
This guide will demonstrate how to configure DNS over TLS on Fedora using systemd-resolved. Refer to the [documentation](https://www.freedesktop.org/wiki/Software/systemd/resolved/) for further information about the systemd-resolved service.
## Step 1 : Set-up systemd-resolved
Modify */etc/systemd/resolved.conf* so that it is similar to what is shown below. Be sure to enable DNS over TLS and to configure the IP addresses of the DNS servers you want to use.
$ cat /etc/systemd/resolved.conf[Resolve] DNS=1.1.1.1 9.9.9.9 DNSOverTLS=yes DNSSEC=yes FallbackDNS=8.8.8.8 1.0.0.1 8.8.4.4 #Domains=~. #LLMNR=yes #MulticastDNS=yes #Cache=yes #DNSStubListener=yes #ReadEtcHosts=yes
A quick note about the options:
**DNS**: A space-separated list of IPv4 and IPv6 addresses to use as system DNS servers**FallbackDNS**: A space-separated list of IPv4 and IPv6 addresses to use as the fallback DNS servers.**Domains**: These domains are used as search suffixes when resolving single-label host names,*~.*stand for use the system DNS server defined with DNS= preferably for all domains.**DNSOverTLS:**If true all connections to the server will be encrypted. Note that this mode requires a DNS server that supports DNS-over-TLS and has a valid certificate for it’s IP.
NOTE: The DNS servers listed in the above example are my personal choices. You should decide which DNS servers you want to use; being mindful of whom you are asking IPs for internet navigation.
## Step 2 : Tell NetworkManager to push info to systemd-resolved
Create a file in */etc/NetworkManager/conf.d* named *10-dns-systemd-resolved.conf*.
$ cat /etc/NetworkManager/conf.d/10-dns-systemd-resolved.conf[main] dns=systemd-resolved systemd-resolved=false
The setting shown above (*dns=systemd-resolved*) will cause NetworkManager to push DNS information acquired from DHCP to the systemd-resolved service. This will override the DNS settings configured in *Step 1*. This is fine on a trusted network, but feel free to set *dns=none* instead to use the DNS servers configured in */etc/systemd/resolved.conf*.
## Step 3 : start & restart services
To make the settings configured in the previous steps take effect, start and enable *systemd-resolved*. Then restart *NetworkManager*.
**CAUTION**: This will lead to a loss of connection for a few seconds while NetworkManager is restarting.
$ sudo systemctl start systemd-resolved $ sudo systemctl enable systemd-resolved $ sudo systemctl restart NetworkManager
NOTE: Currently, the systemd-resolved service is disabled by default and its use is opt-in.[There are plans]to enable systemd-resolved by default in Fedora 33.
## Step 4 : Check if everything is fine
Now you should be using DNS over TLS. Confirm this by checking DNS resolution status with:
$ resolvectl statusMulticastDNS setting: yes DNSOverTLS setting: yes DNSSEC setting: yes DNSSEC supported: yes Current DNS Server: 1.1.1.1 DNS Servers: 1.1.1.1 9.9.9.9 Fallback DNS Servers: 8.8.8.8 1.0.0.1 8.8.4.4
/etc/resolv.conf should point to 127.0.0.53
$ cat /etc/resolv.conf# Generated by NetworkManager search lan nameserver 127.0.0.53
To see the address and port that systemd-resolved is sending and receiving secure queries on, run:
$ sudo ss -lntp | grep '\(State\|:53 \)'State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=10410,fd=18))
To make a secure query, run:
$ resolvectl query fedoraproject.orgfedoraproject.org: 8.43.85.67 -- link: wlp58s0 8.43.85.73 -- link: wlp58s0 [..] -- Information acquired via protocol DNS in 36.3ms. -- Data is authenticated: yes
## BONUS Step 5 : Use Wireshark to verify the configuration
First, install and run [Wireshark](https://www.wireshark.org/):
$ sudo dnf install wireshark $ sudo wireshark
It will ask you which link device it have to begin capturing packets on. In my case, because I use a wireless interface, I will go ahead with *wlp58s0*. Set up a filter in Wireshark like *tcp.port == 853* (853 is the DNS over TLS protocol port). You need to flush the local DNS caches before you can capture a DNS query:
$ sudo resolvectl flush-caches
Now run:
$ nslookup fedoramagazine.org
You should see a TLS-encryped exchange between your computer and your configured DNS server:
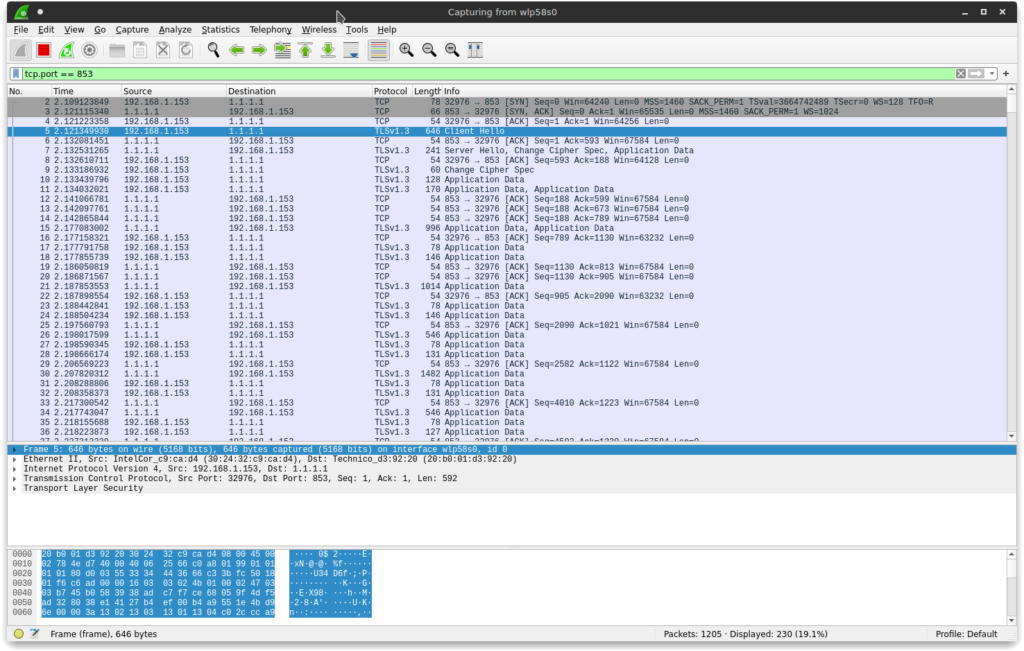
— *Poster in Cover Image Approved for Release by NSA on 04-17-2018, FOIA Case # 83661* —
## David Yip
Even Network Solutions doesn’t support DNSSEC DS upload….
## Geoffrey Gordon Ashbrook
Thank you very much. From listening to Steve Gibson’s Security Now on Twit (not twitch) and GRC I have been aware of the importance of DNS. It is wonderful that the topic is be written about.
However, following your instructions above disabled by network completely and I had use the backups I made of everything (just in case) to roll back and get my computer un-bricked.
Please check your article’s instructions and perhaps advise people on what to do if they need to roll back the changes (e.g. back up any changed files before hand).
I very, very much look forward to a version of this article that works. Thank you very much.
## Vernon Van Steenkist
Does this bypass the DNS servers obtained from DHCP? If so, it seems this would cause problems accessing servers at workplaces, etc that run their own local DNS services behind firewalls.
## Gregory Bartholomew
Hi Vernon:
It is possible to set up separate DNS servers for separate networks (domains). I do exactly that on my home system. I disable NetworkManager and use systemd-netword instead though. That topic would need an article of its own, but below are my systemd-networkd config files as an example to get you started.
## Vernon Van Steenkist
Thanks for your response. Looks pretty complicated for someone who takes their laptop to different companies. I think we need to take a look at the issue we are trying to solve which I assume is DNS poisoning. Note that DNS poisoning is not always malicious. Many large companies have local DNS servers purposely DNS poison to keep their users away from questionable sites. The above configurations prevents this behavior and worse, breaks the ability to connect to machines behind a firewall.
If you are worried about DNS poisoning on a public WiFi network for web browsing, Firefox allows you to easily enable DNS over HTTPS (Preferences->Network Settings->DNS of HTTPS) assuming you trust Cloudflare. This can easily be disabled through the same settings when you are behind a company firewall.
I am not sure what benefit DNS over TLS provides inside your home network. Many home WiFi routers ship with dnsmask which acts as both a DNS and DHCP server. dnsmask automatically updates its DNS with the computer name whenever a new host gets connected (search Dynamic DNS for more details). The above configurations breaks this convenience.
If your goal in anonymity, then you can use openvpn to connect to many vpn providers. https://freevpn.me is a good, free, anonymous choice that doesn’t restrict any kind of traffic. Be sure to modify their .ovpn files to include using their DNS servers instead of yours. You can verify that you are not leaking DNS information by going to https://www.dnsleaktest.com/
Please don’t hesitate to provide corrections or comments.
## Gregory Bartholomew
Are you sure about that? I think it is the DHCP that triggers the Dynamic DNS update, not the DNS query. It doesn’t seem like DNS over TLS should interfere with Dynamic DNS.
## Gregory Bartholomew
Nevermind, I see what you are saying. At first I thought you were referring to the public dynamic dns service that some routers support. If you are talking about running your own local dns server, then yes, you would have to configure an exception for your “.local” domain (or whatever you name it) so that dns searches in that domain would would still be routed to your local dnsmask server rather than to your DNS over TLS server.
## Gregory Bartholomew
I think that is the key question — “who do you trust”. What DNS over TLS does is to provide the user a way to decide for themselves who they want to trust rather than having to rely on whoever is running the network that they are currently plugged into.
Unfortunately, I think some ISPs block users from making this choice and require all queries to be routed through their servers. As you say, it isn’t always malicious, but I suspect that may be why this setup is failing for several users.
## Vernon Van Steenkist
Personally, the only DNS servers I trust is my own. If I remember correctly, Fedora allows you to install a fully functioning, fully configured DNS server by simply issuing the commands
dnf install bind
systemctl start named
as root.
Then all you have to do is tell your DHCP server to specify the Fedora DNS.
These are my rules.
At home, I use my local Fedora DNS server. If I desire anonymity, I use my VPN provider DNS. I never do any banking transactions, or anything that requires a username/password through my VPN provider since they could DNS poison or man in the middle.
Remotely, I don’t care about DNS poisoning unless I want to do banking or something that requires username/password access. Then, I openvpn into my home VPN server. Note that my .ovpn file ensures that I am using my home DNS server.
Comments welcome.
## Graham King
This did not work for me on Fedora 32.
If I follow step 2,
gets
but I can’t connect (NetworkManager icon stays on question mark).
If at step 2 I do
then /etc/resolv.conf has it’s previous value (from DHCP) and everything works, but I’m probably not using TLS.
What am I missing?
## Brian
I got exactly the same response NetworkManager failed to restart– error . I had to back track and restore my old settings to get NetworkManager to restart. I guess I’ll wait for Fedora 33.
## Johannes
Wont work, thanks anyway though!
## John Harris
It’d be preferable not to suggest using Cloudflare and Google DNS.. They have no respect for your privacy.
## Resynth
Agreed. I would prefer using other alternatives, such as the ones listed here: https://www.privacytools.io/providers/dns/
## hilltothesouth
Cloudflare is listed as one of those alternatives. You guys sure they don’t respect our privacy?
## Andre
Works, thanks!
Is it possible to do a “round robin” with the dns-servers i choose?
## Mark
It does prevent access to existing local dns servers if used.
As noted by Graham King above it overwrites resolv.conf with “nameserver 127.0.0.53” which may be valid if the service systemd-resolved hooks in there somewhere; but not just internal but also external dns lookups failed after making the changes in the article.
I suppose theoretically if all internal dns servers were upgraded to ipsec they could just be prepended to the dns= list and internal/local-network lookups would work ?… although as with the examples used in this article even external lookups do not work possibly not.
So I can just hope the quoted section in the article that included “There are plans to enable systemd-resolved by default in Fedora 33” is enthusiasm rather than fact. While Fedora are used to having to google for solutions after upgrades that would be a bit difficult to do if systemd-resolvd started and nobody had any working dns lookup facility to get them to google.
## Matti
Two questions;
1. Does this work with a VPN (in my case, Mullvad using the WireGuard protocol) active?
2. Is there an GUI alternative to Wireshark that doesn’t need qt/kde dependencies?
## Gregory Bartholomew
It should work with anything that doesn’t need to see your DNS queries. I suspect that would include the typical VPN, but I don’t know that much about them. I would say the only way to really know is to try it and see.
Interesting … It looks like there used to be a gtk version of wireshark, but it is no longer available:
In the good old days, you used to be able to get away with installing an older package (or newer one from rawhide) once in a while, but since modularity, I’m not sure that that works any more. I guess you could try to install it, but if it wants to pull in more than a handful of packages, I’d abort the install.
## Stan Sykes
I have exactly the same issue as G.King above.
After step 2 ( “Tell NetworkManager to push info to systemd-resolved”) I lose the internet connection (can’t resolve host names).
If I remove the file 10-dns-systemd-resolved.conf all works as before.
We’re missing something …
Linux Z380-10F.localdomain 5.7.7-200.fc32.x86_64
## Eric L.
It must be clear that the solution described overwrites the DNS server(s) normally configured through DHCP. The approach might break a lot of things, depending on the setup of the IT provider (home or office).
I would personally be more interested in still using the default DNS server(s) but checking if they support those security features, and accordingly enforce them.
## Alan Olsen
This doesn’t work with VPN tunnels. (At least mine.) Also needs more info on IPv6 usage.
## james
Sounds like a really good idea, but it doesn’t work on my workstation f32.
## Ole Aamot
This guide does not work on Fedora Core 32.
Please remove it.
## Ole Aamot
This guide left me and is likely to leave its followers with a broken DNS resolver.
Please remove this “guide” from Fedora Magazine.
## Michael W
This is just way too short of a discussion over the value of this, and the issues that this suggestion could cause.
## Gregory Bartholomew
It is indeed a HUGE topic. I tried to google for something that tries to explain and illustrate some of the concepts in a simple way. I like the following article because it has some nice diagrams and even includes a small section on encrypted DNS:
https://schub.wtf/blog/2019/04/08/very-precarious-narrative.html
## cedzik
i found a soulution: in /etc/systemd/resolved.conf uncoment #Domains=~. then restart systemd-resolved
## Rojen
Although I apply the settings, it is based on the DNS address of the device ‘wlp2s0’, what should I do to prevent this from happening?
(let’s not forget that the global dns name server appears in the settings I made but not in wlp2s0)
## Gregory Bartholomew
Hi Rojen:
According to the article, you should be able to accomplish that by setting “dns=none” in /etc/NetworkManager/conf.d/10-dns-systemd-resolved.conf.
You might also want to verify that /etc/resolv.conf is a symlink pointing to the right systemd-resolved file:
Unfortunately, my setup is a little different (I use systemd-networkd instead of NetworkManager), so I am not easily able to confirm that this works.
## Rojen
Hi, firstly thanks for respond.
But also i try it whatever you said but not worked.
My problems that:
1) My ISP Service use Cloudflare DNS server.
2) I want use NIX DNS server.
I do makes whole configuration as complete. not have a error.
My outputs,
Global Output:
Global
LLMNR setting: yes
MulticastDNS setting: yes
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Current DNS Server: 104.244.78.231
DNS Servers: 104.244.78.231
Fallback DNS Servers: 198.251.90.91
wlp2s0 Device Output:
Link 3 (wlp2s0)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
DefaultRoute setting: yes
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Current DNS Server: 1.1.1.1
DNS Servers: 192.168.1.1
1.1.1.1
DNS Domain: ~.
The device ‘wlp2s0’ uses the wrong DNS server as it appears here. I need to fix this.
DNS Leak Test:
Your IP:
X.X.X.X [Turkey ASTURKNET]
You use 1 DNS server:
172.69.117.143 [Turkey AS13335 CLOUDFLARENET]
Conclusion:
DNS may be leaking.
ALSO
When I hardly put ‘104.244.78.231’ dns server in the /etc/resolv.conf file
I get correct output but as you know DoT not have.
Your IP:
X.X.X.X [Turkey ASTURKNET]
You use 1 DNS server:
104.244.78.231 [Luxembourg AS53667 PONYNET]
Conclusion:
DNS may be leaking.
What should I do?
My configurations:
[Resolve]
DNS=104.244.78.231
DNSOverTLS=yes
DNSSEC=yes
FallbackDNS=198.251.90.91
#Domains=~.
#LLMNR=yes
#MulticastDNS=yes
#Cache=yes
#DNSStubListener=yes
ReadEtcHosts=yes
[main]
dns=none
My status:
● systemd-resolved.service - Network Name Resolution
Loaded: loaded (/usr/lib/systemd/system/systemd-resolved.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2020-07-13 00:58:19 +03; 28min ago
Docs: man:systemd-resolved.service(8)
https://www.freedesktop.org/wiki/Software/systemd/resolved
https://www.freedesktop.org/wiki/Software/systemd/writing-network-configuration-managers
https://www.freedesktop.org/wiki/Software/systemd/writing-resolver-clients
Main PID: 8906 (systemd-resolve)
Status: "Processing requests..."
Tasks: 1 (limit: 4539)
Memory: 9.4M
CPU: 784ms
CGroup: /system.slice/systemd-resolved.service
└─8906 /usr/lib/systemd/systemd-resolved
Jul 13 00:58:19 linux systemd[1]: Starting Network Name Resolution...
Jul 13 00:58:19 linux systemd-resolved[8906]: Positive Trust Anchors:
Jul 13 00:58:19 linux systemd-resolved[8906]: . IN DS 20326 8 2 e06d44b80b8f1d39a95c0b0d7c65d08458e880409bbc683457104237c7f8ec8d
Jul 13 00:58:19 linux systemd-resolved[8906]: Negative trust anchors: 10.in-addr.arpa 16.172.in-addr.arpa 17.172.in-addr.arpa 18.17>
Jul 13 00:58:19 linux systemd-resolved[8906]: Using system hostname 'linux'.
Jul 13 00:58:19 linux systemd[1]: Started Network Name Resolution.
● NetworkManager.service - Network Manager
Loaded: loaded (/usr/lib/systemd/system/NetworkManager.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-07-13 00:58:22 +03; 30min ago
Docs: man:NetworkManager(8)
Main PID: 8912 (NetworkManager)
Tasks: 3 (limit: 4539)
Memory: 5.4M
CPU: 705ms
CGroup: /system.slice/NetworkManager.service
└─8912 /usr/sbin/NetworkManager --no-daemon
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0180] dhcp4 (wlp2s0): state changed unknown -> bound
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0460] device (wlp2s0): state change: ip-config -> ip-check (reason 'none', sys-iface-state: 'managed')
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0486] device (wlp2s0): state change: ip-check -> secondaries (reason 'none', sys-iface-state: 'managed')
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0490] device (wlp2s0): state change: secondaries -> activated (reason 'none', sys-iface-state: 'managed')
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0498] manager: NetworkManager state is now CONNECTED_LOCAL
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0519] manager: NetworkManager state is now CONNECTED_SITE
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0521] policy: set 'Amedî' (wlp2s0) as default for IPv4 routing and DNS
Jul 13 00:58:26 linux NetworkManager[8912]: <info> [1594591106.0532] device (wlp2s0): Activation: successful, device activated.
Jul 13 00:58:27 linux NetworkManager[8912]: <info> [1594591107.1187] manager: NetworkManager state is now CONNECTED_GLOBAL
Jul 13 00:58:28 linux NetworkManager[8912]: <info> [1594591108.8328] manager: startup complete
Global
LLMNR setting: yes
MulticastDNS setting: yes
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Current DNS Server: 104.244.78.231
DNS Servers: 104.244.78.231
Fallback DNS Servers: 198.251.90.91
DNSSEC NTA: 10.in-addr.arpa
16.172.in-addr.arpa
168.192.in-addr.arpa
17.172.in-addr.arpa
18.172.in-addr.arpa
19.172.in-addr.arpa
20.172.in-addr.arpa
21.172.in-addr.arpa
22.172.in-addr.arpa
23.172.in-addr.arpa
24.172.in-addr.arpa
25.172.in-addr.arpa
26.172.in-addr.arpa
27.172.in-addr.arpa
28.172.in-addr.arpa
29.172.in-addr.arpa
30.172.in-addr.arpa
31.172.in-addr.arpa
corp
d.f.ip6.arpa
home
internal
intranet
lan
local
private
test
Link 5 (virbr0-nic)
Current Scopes: none
DefaultRoute setting: no
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Link 4 (virbr0)
Current Scopes: none
DefaultRoute setting: no
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Link 3 (wlp2s0)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
DefaultRoute setting: yes
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Current DNS Server: 1.1.1.1
DNS Servers: 192.168.1.1
1.1.1.1
DNS Domain: ~.
Link 2 (enp10s0)
Current Scopes: none
DefaultRoute setting: no
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
thanks.. I wait your response
## Gregory Bartholomew
Hi Rojen:
From man nm-settings-ifcfg-rh:
I would suggest that you try adding the line:
to /etc/sysconfig/network-scripts/ifcfg-wlp2s0
My environment is just too different for me to be able to say for sure what will work. It is possible that your ISP is blocking DNS over TLS and that this simply will not work for you.
Good luck!
## Rojen
Hi, yep.
I understond the my ISP Service blocking different DNS server. Not only that, it is does hijacking and changing the DNS. This was already known in our geography, DNS does hijacking. We need to use VPN. However, this is not always fast, I just wanted to use a different DNS in my normal work…
anyway:
It’s have DNS1=”bla.bla” line at /etc/sysconfig/network-scripts/ifcfg-wlp2s0 file.
When I added a diffrent DNS “except 1.1.1.1, 8.8.8.8, 9.9.9.9” to this, ISP blocking my input DNS and so internet not working. (I have a question at en of line)
Hijacking example:
18-DEVICE=wlp2s0
19-ONBOOT=yes
20-PEERDNS="no"
21:DNS1=9.9.9.9
runuser -l work -c 'dnsleaktest.sh'
Your IP:
X.X.X.X [Turkey ASTURKNET]
You use 1 DNS server: #?! wtf
213.74.50.82 [Turkey AS34984 TELLCOM-AS]
Conclusion:
DNS may be leaking.
Link 3 (wlp2s0)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
DefaultRoute setting: yes
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: yes
DNSSEC setting: yes
DNSSEC supported: yes
Current DNS Server: 9.9.9.9
DNS Servers: 9.9.9.9
DNS Domain: ~.
I have a last question to you. So what I do to set the Fallback DNS in to /etc/sysconfig/network-scripts/ifcfg-wlp2s0 file? Apparently FALLBACK DNS is not seems in the resolvectl status. (I look the documents but not find anything so i want.
as: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/networking_guide/sec-configuring_ip_networking_with_ifcg_files document. maybe you know the this.)
## Gregory Bartholomew
Hi Rogen:
The Fallback DNS servers should show up in the output of resovectl status:
Fallback DNS Servers: 1.1.1.1
8.8.8.8
1.0.0.1
8.8.4.4
2606:4700:4700::1111
2001:4860:4860::8888
2606:4700:4700::1001
2001:4860:4860::8844
Personally, I like to disable them completely:
[Resolve]
FallbackDNS=
# systemctl restart systemd-resolved.service
# resolvectl status | grep -A 7 "^Fallback DNS Servers:"
#
## rtghrt
why not show example in ipv6?
## tmp2k
this is not good because it does not work
## tmp2k
ok uncommented domains ~. works 😉
## Gregory Bartholomew
Interesting. That setting should only be necessary when you want to setup per-domain DNS routing. The idea is that you can configure different domains to use different DNS servers (e.g. ~example.com -> 8.8.8.8, ~demo.net -> 1.1.1.1, etc.). You would then set ~. -> 1.0.0.1 or something like that as a “catch all” for any domain that didn’t have a more-specific specification. ~.
shouldn’tbe necessary if you don’t have the more-specific sub-domains defined. It sounds like there is an interoperability problem between systemd-reloved and NetworkManager. Maybe it depends on the versions used or maybe the author had something non-standard in his NetworkManager configuration (e.g. “PEERDNS=no” in /etc/sysconfig/network) and forgot about it.I could edit the article, but I’m weary of doing that without the author’s permission and without knowing for sure what is going on.
## anonymous
I haven’t verified this, so it might have been another issue, but I think I had to set Domains=~. when DNS is set to automatic in the Gnome Control Center.
## fds
You may also just use your own internal dns server, this is cheap and much easy to use because you won’t depend of anybody.
Furthermore you can add your own localdomain to map your internal network
## taufik.bonaedy
The instruction above doesn’t work at all on Fedora 32. I’ve tried with DHCP or static IP, non of them work. Please check again your instruction.
## Gregory Bartholomew
Taufik:
Some people have reported that it works, so I don’t thing the guide is too far off. I think this is something that ISPs are known to block (I think it runs on a different port than standard DNS), so if it isn’t working for you, it isn’t necessarily a problem with the guide or the OS. It could be a “problem” with your internet connection.
## Vernon Van Steenkist
If you want to know if your ISP is blocking DNS over TLS, issue the following commands.
sudo dnf install nmap
nmap -p 853 1.1.1.1
If your ISP is allowing DNS over TLS, you should see the following output
Starting Nmap 7.80 ( https://nmap.org ) at 2020-07-14 17:34 PDT
Nmap scan report for one.one.one.one (1.1.1.1)
Host is up (0.036s latency).
PORT STATE SERVICE
853/tcp open domain-s
The key output line is
853/tcp open domain-s
You can repeat the above nmap command for each IP address in the tutorial.
If your ISP is blocking DNS over TLS, the simplest solution is to enable Firefox DNS over HTTPS which can be set at Preferences->Network Settings->DNS over HTTPS. In fact, if you are going to follow the tutorial which uses Cloudflare’s and Google’s DNS servers, Firefox’s DNS over HTTPS it the simplest solution for web browsing, gives you at least as much security as DNS over TLS and affords you more privacy than DNS over TLS..
## pgbross
I followed the steps in the article on my Fedora 32 workstation shortly after it was posted and it worked flawlessly.
Yesterday (Jul 23rd) for unrelated reasons I installed a fresh copy of Fedora 32 from scratch (deleting partitions etc). Now when following the steps I see the same behaviour that others have reported, namely that name resolution is not working when DNSOverTLS=yes.
So I wonder if previously on my system that had upgraded through earlier versions of Fedora over the last couple of years had some other setting or configuration that is required but is not present in a clean F32 setup.
I can’t find any obvious faults in the system logs or audits so am also stumped for now.
## Gregory Bartholomew
If you figure it out, please do let us know what needs to be changed in the article. Thanks.
## pgbross
Ok, so I think I know what was going wrong for me, even if I am not 100% sure of the exact reason/sequence that makes it behave in an undesirable way (ie.it breaks).
I used Wireshark to look at the network traffic after following the instructions in the article and discovered it was correctly using the DNSOverTLS protocol but it was not using the specified DNS servers. It was actually still trying to use the DHCP acquired local router address. Then I remembered in my previous setup I was using a static address (so my earlier theory about something from earlier versions of Fedora were not right, though led me in the right direction). So with that information and a recollection of another article here in Fedora Magazine from about a year ago on Dnsmasq that talked about per-connection DNS overrides I wondered if there was some cached information or something keeping the DHCP server DNS server address.
So I went into Gnome Settings -> Networks and changed my connection to (temporarily) use a specified DNS server (1.1.1.1) and for good measure disabled IP6. Restarted NetworkManager and I could then resolve IP addresses (as that server understands DNS over TLS). The best part though is I have now reset my connection to use the automatic DHCP DNS, reanabled IP6, restarted NetworkManager, and it is correctly using the servers from the resolved.conf.
How many of those steps were actually needed – not sure. Is there another service that could have been restarted or a cached file/config that could have been edited/deleted maybe, but I don’t know enough about the interactions between the different components to answer that.
I am however happy it is now working and works across reboots. Perhaps someone with more knowledge can use this information to work out the optimal solution/steps and if course just because this fixed my system doesn’t mean it is the same root cause for everyone who has observed similar problems, but at least just poking the connection settings in Gnome Settings is relatively safe.
Hope this helps some others.
## pgbross
Doh!
So when a connection is getting a dynamic IP address via DHCP it will almost certainly receive the address of the DNS server to use, and likely it is you local router. So if you switch on DNSOverTLS and the local router doesn’t support it, then addresses resolution will fail.
To use the new settings specified in the resolved.conf as per the original article there are two options:
1) Enter the desired DNS server addresses in the Settings->Network tool (or editing the interface config in /etc/NetworkManager/network-scripts if one exists). E.g. 1.1.1.1,9.9.9.9
2) Enter the local systemd-resolved address 127.0.0.53 in the Settings->Network UI at which point the connection will ultimately use the local systemd resolver and pick its DNS and fallback from the settings in /etc/systemd/resolved.conf.
Once the change is made restart the NetworkManager and DNS resolution should work.
## Gregory Bartholomew
Thanks for troubleshooting this for us pgbross.
So are you saying that it is the “dns=none” option documented in Step 2 that does not work?
P.S. The “dns=none” option is documented in “man NetworkManager.conf” and appears correct according to the documentation. I do note, however, that there is some strange wording about behaviors being dependent on what /etc/resolv.conf happens to be symlinked to. Considering the complexity of the documentation for the “dns” option, I’m not too surprised that people are having trouble with NetworkManager.
## smeagol
Hi,
Thanks for the post.
Can the same be done when only using ifupdown? I don’t use Network Manager for several reasons, and ifupdown is much simpler.
## dxdt
This post needs an update. You also need to add
as NetworkManager pushes DNS servers from DHCP servers by default. This post is the top result on Google, so..
https://unix.stackexchange.com/questions/602314/how-to-properly-enable-dnsovertls-on-systemd
## Gregory Bartholomew
Done.
The resulting config file looks a little counter-intuitive, but it does appear to be what is suggested in the documentation (man NetworkManager.conf). I’m not able to verify this change personally as I do not use NetworkManager (I use systemd-networkd). Someone please let me know if the change in incorrect.
Thanks.
## Marcelo
Not working for me. Can’t use Internet using those settings.
Any advice? |
12,484 | Jitsi Meet:自由开源的视频会议解决方案,无需设置即可免费使用 | https://itsfoss.com/jitsi-meet/ | 2020-08-04T20:00:00 | [
"视频会议"
] | https://linux.cn/article-12484-1.html |
> Jitsi Meet 是一个开源视频会议服务,你可以免费使用它来组织在线课程、会议和聚会。你也可以在自己的服务器上托管 Jitsi。
在 COVID-19 大流行期间,远程工作趋势显著增长。无论你是否喜欢,视频会议对于个人和企业都是一个很好的解决方案。
在过去的几个月中,非常流行的视频会议服务之一就是 Zoom。但是,[关于 Zoom 视频通话](https://www.tomsguide.com/news/zoom-security-privacy-woes)存在很多安全和隐私问题。
因此,选择一个安全且易于使用的视频会议应用来完成工作是很重要的。我敢肯定有很多选择,但是在这里,让我们看一下开源选项 [Jitsi Meet](https://meet.jit.si/)。
### Jitsi Meet:免费使用的开源视频会议服务

Jitsi Meet 是开源语音、视频会议和即时消息服务 [Jitsi](https://jitsi.org/) 集合的一部分。
通过 Jitsi Meet,你可以即刻主持群组视频通话(即视频会议),你甚至都不需要建立帐户。
对于桌面端,它是基于浏览器的,但它以 AppImage 的形式为 Linux 提供了一个基于 Electron 的桌面应用。它也可以用在 Windows 和 macOS 上。
对于智能手机,它提供了 iOS 和 Android 应用,你可以分别从 App Store 和 Play Store 进行安装。除了这些,你还可以在开源 Android 应用商店 [F-Droid](https://f-droid.org/en/packages/org.jitsi.meet/) 中找到它。
如果你想更进一步,你可以在你的服务器上部署 Jitsi Meet。对于那些不想使用第三方服务器的企业来说,这是理想的选择,即使该服务器来自软件开发商。
### Jitsi Meet 的功能

Jitsi Meet 简单但功能丰富。这是你将获得的功能:
* 不需要用户注册
* 使用 Etherpad 共同编辑文档
* 能够自己部署
* 支持集成 Slack 和 Rocket.chat
* 如果需要,提供密码保护
* 端到端加密(beta 版)
* 背景模糊(beta 版)
* 录音选项
* 直播流支持
* YouTube 视频分享
* 查看用户的网络状态
* 集成 Google 和 Microsoft 日历
* 聊天功能
* 屏幕共享
* 支持国际连接拨入
* 你可以稍后继续视频通话,而无需会议代码
* 低带宽模式选项
* Jitsi 可选的桌面版本

出于显而易见的原因,你在移动应用上只能找到较少的功能。
请注意,[端到端加密仍处于 beta 阶段](https://jitsi.org/blog/e2ee/)。但是,即使没有它,Jitsi Meet 也应该是一个隐私友好且安全的视频会议解决方案。
在移动设备上,我只希望它有屏幕共享功能。除此之外,其他所有功能都很好。
### 如何使用 Jitsi Meet?

要使它在 Linux 上运行,你不需要做任何其他事情。你只需要前往它的[官方 Jitsi Meet 实例](https://meet.jit.si/),然后输入会议名称即可创建或加入。
如果您使用的是基于 Electron的应用程序,则完全一样。 使用桌面应用程序时的外观如下:

如你在上面的截图中所见,你还可以找到你最近使用的会议室的列表,这样就不必再次输入或创建会议室。

如果你要创建它,那么最好使用唯一的名称,并且如果你不需要其他任何人意外加入,那么还应为其添加密码保护。

如果你要参加其他人的会议,只需询问会议名称或会议链接即可使用台式机或智能手机轻松加入。
除了少一些功能,它与桌面端的工作方式相同。我已经使用了一段时间,并且还鼓励和培训了我父亲的单位(我们的附近学校)使用 Jitsi Meet 主持在线课程。
即使有最多 75 名参与者的限制,它的表现也很好,而且工作良好。
[Jitsi Meet](https://meet.jit.si)
### 总结
如果你希望托管自己的 Jitsi 实例,建议你遵循它的[官方自托管指南](https://jitsi.github.io/handbook/docs/devops-guide/devops-guide-quickstart)来启动并运行它。你还可以在[它的 GitHub 页面中找到实例列表](https://github.com/jitsi/jitsi-meet/wiki/Jitsi-Meet-Instances)。
Jitsi Meet 是个了不起的开源视频会议应用。它是 Zoom 和其他此类视频通话服务的一种隐私保护替代方案。
我还建议查看 [NextCloud,它是 MS Office 365 的开源替代方案](https://itsfoss.com/nextcloud/)。
你如何看待 Jitsi Meet?你尝试过了吗?你最喜欢的视频会议工具是什么?
---
via: <https://itsfoss.com/jitsi-meet/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: Jitsi Meet is an open-source video conferencing service that you can use for free to organize online classes, conferences and meet ups. You can also host Jitsi on your own server**.
The remote work trend grew significantly amidst the COVID-19 pandemic. No matter whether you like it or not, video conferencing is proving to be a great solution for both individuals and businesses.
One of the video conferencing services that got insanely popular in last few months is Zoom. You can [install Zoom on Ubuntu](https://itsfoss.com/zoom-ubuntu/) and other Linux. However, there are plenty of security and privacy concerns [about Zoom video calls](https://www.tomsguide.com/news/zoom-security-privacy-woes).
So, it’s important to choose a secure and easy-to-use video conferencing app that gets the work done. I’m sure there are numerous alternatives, but here — let’s take a look at an open-source option [Jitsi Meet](https://meet.jit.si/).
## Jitsi Meet: Free to Use, Open-Source Video Conferencing Service
Jitsi Meet is a part of [Jitsi](https://jitsi.org/), which is a collection of open-source voice, video conferencing, and instant messaging services.
The Jitsi Meet allows you to host group video calls, i.e. video conferencing in seconds. You don’t even need an account with them.
For desktop, it is mostly browser-based but it does offer an [electron-based desktop app](https://github.com/jitsi/jitsi-meet-electron) in the form of [AppImage](https://itsfoss.com/use-appimage-linux/) file for Linux. It’s also available for Windows and macOS.
And, for smartphones, it does offer both iOS and Android apps that you can install from the App Store and the Play Store respectively. In addition to these, you can also find it on the open source Android app store [F-Droid](https://f-droid.org/en/packages/org.jitsi.meet/).
If you want to go the extra mile, you can deploy Jitsi Meet on your server. This is ideal for businesses who don’t want to use a third-party server even if it is from the developers of the software.
## Features of Jitsi Meet
Jitsi Meet is simple and yet feature-rich. Here’s the set of features that you’ll get:
- Does not need user registration
- Edit documents together using Etherpad
- Gives you the ability to self-host
- Supports Slack and Rocket.chat integration
- Offers password protection if needed
- End-to-End encryption (beta)
- Background blur (beta)
- Recording option
- Live stream support
- YouTube video sharing
- View the network status of users
- Google and Microsoft Calendar Integration
- Chat feature
- Screen sharing
- Supports International dial-in connection to join
- The session exists for you to continue the video call later without needing the meeting code.
- Low-bandwidth mode option
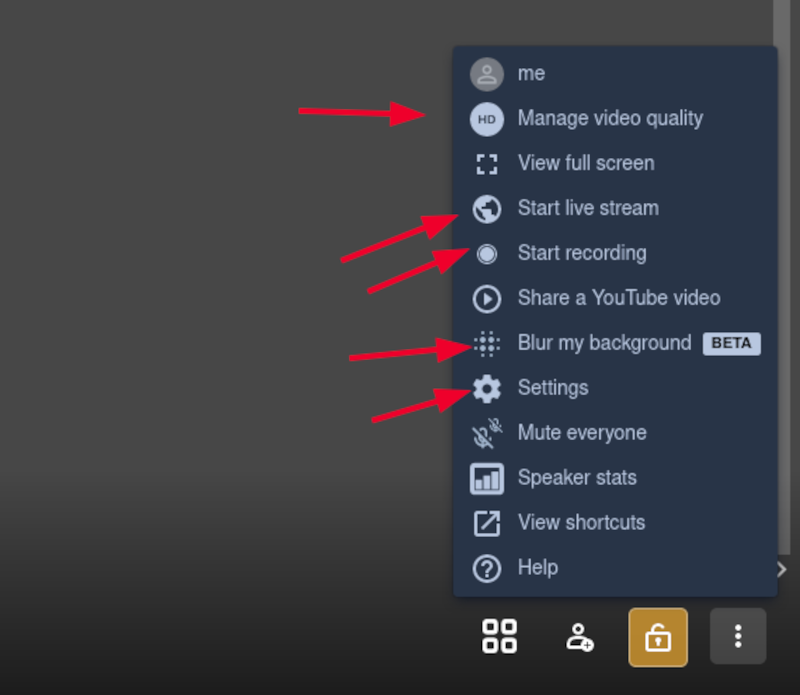
For obvious reasons, you will find fewer options on the mobile app.
Do note that [end-to-end encryption is still in beta](https://jitsi.org/blog/e2ee/). But, even without it, Jitsi Meet should be a privacy-friendly and secure video conferencing solution.
On mobile, I just wish if it had the screen sharing option — except that, everything else works just fine.
## How To Use Jitsi Meet?
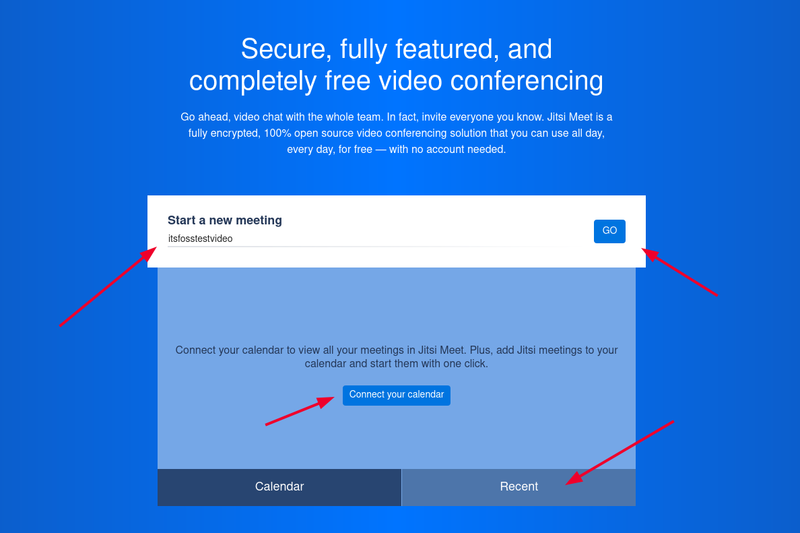
There’s nothing extra that you need to do in order to make it work on Linux. You just need to head over to their [official Jitsi Meet instance](https://meet.jit.si/) and then type in the name of the meeting to create or join.
If you’re using the electron-based app, it’s all the same. Here’s how it looks when using the desktop app:
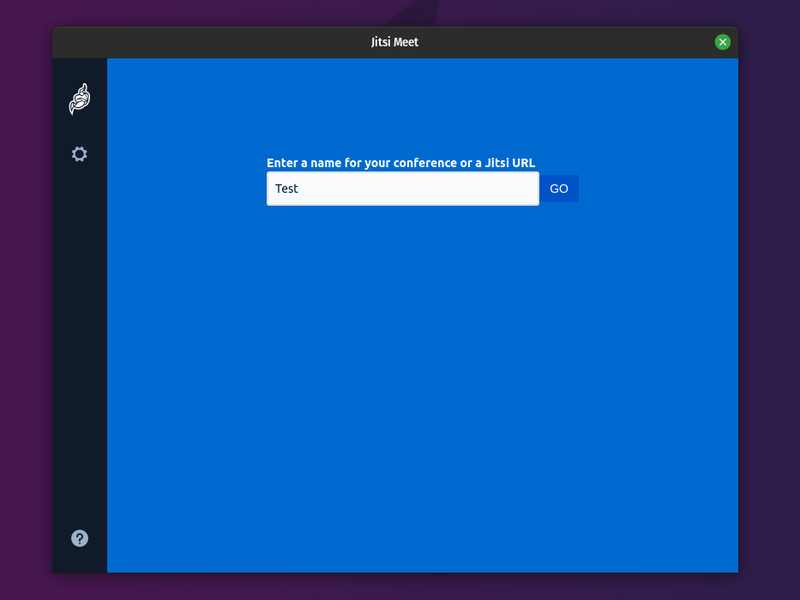
As you can see in the screenshot above, you can also find a list of your recent meeting rooms so that you don’t have to type or create the meeting room again.

If you’re creating it, it’s best to go with a unique name and also add a password protection to it if you do not need anyone else to join in accidentally.
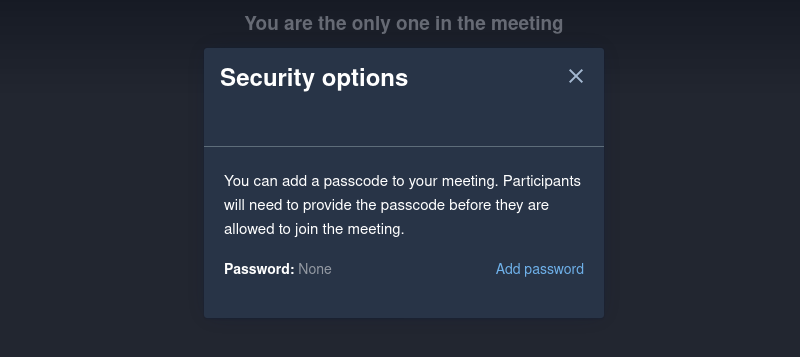
If you’re joining someone else’s meeting, simply ask for the meeting name or the link of the meeting to be able to easily join using your desktop or smartphone.
It works the same way on desktop minus some options. I’ve been using it for a while and I’ve also encouraged and trained my dad’s employer (our neighborhood school) to use Jitsi Meet to host online classes.
Even though it has a limit of up to 75 participants, it holds up pretty well and works perfectly fine.
**Wrapping Up**
If you’re looking to host your own Jitsi instance, I suggest you to follow their [official self-hosting guide](https://jitsi.github.io/handbook/docs/devops-guide/devops-guide-quickstart) to get it up and running. We also have [Jitsi deployment guide with Docker](https://linuxhandbook.com/self-host-jitsi-meet/). You can also find a [list of instances on their GitHub page](https://github.com/jitsi/jitsi-meet/wiki/Jitsi-Meet-Instances).
Jitsi Meet is an amazing open-source video conferencing application. It’s a privacy-friendly alternative to Zoom and other video calling services of that kind.
I also suggest looking at [NextCloud, an open source alternative to MS Office 365](https://itsfoss.com/nextcloud/).
What do you think about Jitsi Meet? Have you tried it yet? What’s your favorite video conferencing tool? |
12,485 | 气球驱动的互联网服务在肯尼亚上线 | https://www.networkworld.com/article/3566295/balloon-powered-internet-service-goes-live-in-kenya.html | 2020-08-03T21:30:26 | [
"Loon"
] | https://linux.cn/article-12485-1.html |
>
> Alphabet 的衍生产品 [Loon](https://loon.com/) 使用气球创建了一个由蜂窝塔构成的漂浮网络。
>
>
>

ISP [Telkom Kenya](https://www.telkom.co.ke/) 正在启动第一个使用气球的商业化 4G LTE 服务,气球的作用是在漂浮在平流层中作为蜂窝塔网络。
据 Alphabet 的衍生产品及底层技术提供商 [Loon](https://loon.com/) 的首席执行官 Alastair Westgarth 所说,这项服务起初将会覆盖肯尼亚接近 19000 平方英里的范围。 Westgarth 在 [Medium](https://medium.com/loon-for-all/loon-is-live-in-kenya-259d81c75a7a) 上的一篇文章中说,将会有大约 35 个或更多的气球组成编队,它们持续不断地移动,漂浮在地表上方大约 12 英里的平流层中。“我们将 Loon 称为漂浮的蜂窝塔网络。” Westgarth 说道。
Telkom Kenya 的首席执行官 Mugo Kibati 在一篇[新闻稿](https://telkom.co.ke/telkom-and-loon-announce-progressive-deployment-loon-technology-customers-july)中提到,传统互联网对肯尼亚的服务不足,这是采用这种输送装置的原因。“…… 具有互联网功能的气球能够为生活在偏远地区的许多肯尼亚人提供联系,这些地区服务不足或是完全没有服务,仍然处于不利地位。” Kibati 说道。远程医疗和在线教育是两个预期的用例。
在测试中, Loon 实现了 19 毫秒延迟的 18.9 Mbps 下行速度,以及 4.74 Mbps 的上行速度。 Westgarth 说,该服务能够用于“语音通话、视频通话、 YouTube、 WhatsApp、电子邮件、发短信、网页浏览”和其他应用程序。
从更大的角度看,从平流层提供互联网服务对于[物联网(IoT )](https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html)来说是一个诱人的主张。在高空,网络覆盖范围可能会更广泛,并且覆盖范围可以随着需求的变化而变化(例如,采矿区的移动)。此外,要建立或处理的地面基础设施更少。 比方说,开发人员可以避免铺设电缆所需的私有地产的纠纷。
可以想象,服务中断也更加可控。提供商可以发射另一台设备,而不必通过复杂的远程地面基础设施来跟踪故障。备用气球可随时备用。
### 基于无人机的互联网交付
另一家正在探索大气层互联网的组织是软银,它称其 260 英尺宽的 HAWK30 无人机是“平流层中的漂浮基站”。(参见相关故事:[软银计划到 2023 年实现无人机交付的物联网和互联网](https://www.networkworld.com/article/3405170/softbank-plans-drone-delivered-iot-and-internet-by-2023.html))
日本大型电信公司对平流层传输的互联网感兴趣的原因之一是,该群岛易于发生自然灾害,例如地震。与传统的基站相比,地球上空的浮动基站更容易移动,从而可以更快、更灵活地应对自然灾害。
实际上,Loon 的气球已经成功地用于在灾难后提供互联网服务:例如,在 2017 年波多黎各的飓风 Maria 之后,Loon 提供了连接。
Westgarth 说,自最初开发以来,Loon 的气球已经取得了长足的发展。现如今,发射是通过自动设备执行的,该设备可以每半小时一次将与地面站点相连的气球推到 60000 英尺高空,而不像以前那样人工进行。
机器学习算法会处理导航,以尝试向用户提供持续的服务。但是,这并非总是可能的,因为风(尽管在地面上没有那么大)和受限的空域都会影响覆盖范围,尽管 Westgarth 称之为“精心编排组织的气球舞蹈”。
此外,这些设备是太阳能供电的,这意味着它们只能够在白天工作并提供互联网(或重新定位自身,或向其他气球传输互联网)。出于上述原因和其他的一些原因, Westgarth 和 Kibati 指出,气球必须扩大现有的基础设施和计划,但这并不是一个完整的解决方案。
Westgarth 说:“为了连接现在和将来需要它的所有人员和事物,我们需要开阔我们的思维;我们需要在连通性生态系统中增加新的一层。”
---
via: <https://www.networkworld.com/article/3566295/balloon-powered-internet-service-goes-live-in-kenya.html>
作者:[Patrick Nelson](https://www.networkworld.com/author/Patrick-Nelson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,487 | 24 个值得尝试的 Linux 桌面环境 | https://opensource.com/article/20/5/linux-desktops | 2020-08-04T22:26:00 | [] | https://linux.cn/article-12487-1.html |
>
> 我全要!
>
>
>

Linux 桌面的最大优点之一是它提供给用户选择的权利。如果你不喜欢你屏幕左下角的应用程序菜单,你可以移除它。如果你不喜欢你的文件管理器组织文件的方式,你可以使用另外一个文件管理器。不过,不可否认的是,这对那些不习惯自己选择如何使用计算机的用户来说可能会感到困惑。如果你正在考虑安装 Linux,你要做的选择之一就是你想使用哪一个桌面,最好的方法就是尝试几个不同的桌面,直到你找到感觉适合你的桌面。
### 默认桌面

作为在 Fedora、Ubuntu、Debian 和一些其它操作系统上的默认桌面,GNOME 桌面可能是最流行的 Linux 桌面。它有一个易于使用和现代化的界面,并带有为手机环境设计的小点缀,因此即使在触摸屏上也感觉很自然。
不过,一些 Linux 发行版选择了不同的桌面环境,如 KDE Plasma、Pantheon、Cinnamon 和 Mate。
* [GNOME](/article-11675-1.html): 现代化和易于使用,默认桌面
* [Mate](/article-11703-1.html): 传统的 GNOME
* [KDE](/article-11728-1.html): 功能强大、可配置的 Plasma 桌面
* [Cinnamon](/article-8606-1.html): 经典的 GNOME
* [Pantheon](/article-11660-1.html): [ElementaryOS](https://elementary.io/) 的默认桌面
* [Budgie](/article-10547-1.html): 一个柔和的桌面
* [Trinity](https://opensource.com/article/19/12/linux-trinity-desktop-environment-tde): 传统的 KDE
### 传统的 Unix

Unix 是现代操作系统的鼻祖,也是 Linux 的直接灵感来源,拥有令人吃惊的丰富的桌面历史。大多数人都不熟悉 Unix 桌面设计,因为 Unix 计算机被认为是学术界、科学界和电影界常见的专业机器,而不是家用计算机。如果你是一名 Unix、IRIX 或 NeXT 的用户,那么你可能会对类似于 [CDE](https://sourceforge.net/projects/cdesktopenv/) 或 NeXTStep 的桌面有着美好的回忆。你很幸运,因为这一传统延续至今:
* [Windowmaker](/article-11650-1.html): NeXT 界面的复兴
* [Enlightenment](https://opensource.com/article/19/12/linux-enlightenment-desktop): 一个现代化的改进型 Windowmaker 风格的桌面
* [Fluxbox](/article-12082-1.html): 跳出 Blackbox 思维定式
* [Openbox](/article-11698-1.html): 改善 Blackbox 的可用性
* [TWM](/article-11734-1.html): 与 X11 绑定至死的示例桌面
* [Fvwm](/article-11712-1.html): 改进的 TWM
### 轻量级桌面

你可能想知道为什么 Linux 有那么多的桌面可供选择。你可以把它归结为个人喜好和对效率低下的低容忍度,但优化用户界面也有技术上的好处。例如,老电脑难以跟上用户界面的更新,可以使用轻量级桌面[赋予它新的生命](https://opensource.com/article/20/2/macbook-linux-elementary) 。另外,你可能只是想把 CPU 处理能力分配到除桌面以外的其它东西上,所以保持你的主用户界面极简是有意义的。不管你的动机是什么,这里有一些你可以尝试的桌面:
* [XFCE](/article-10413-1.html): 熟悉的桌面,极少的性能损失
* [LXQT 和 LXDE](https://opensource.com/article/19/12/lxqt-lxde-linux-desktop): 熟悉的桌面,较少的性能损失
* [PekWM](/article-11670-1.html): 一个 Blackbox 式的窗口管理器
* [Joe's Window Manager](https://opensource.com/article/19/12/joes-window-manager-linux-desktop): 另一个 Blackbox 式的窗口管理器
* [Ratpoison](https://opensource.com/article/19/12/ratpoison-linux-desktop): 不使用鼠标
* [Herbstluftwm](/article-11734-1.html): 针对 [Vim 用户](https://opensource.com/resources/what-vim) 的Ratpoison
* [Lumina](/article-11706-1.html): 一个为 PC-BSD 开发的桌面
### 实验性桌面

当创建一个桌面并将其集成到一个系统中相对容易的时候,会发生的事情之一就是你会得到一些有趣的概念验证项目和试验性项目。有一些会比其它的更精致,有一些则不是很容易安装。这些很可能注定不会成为你的永久桌面,但是它们可以是很有趣的体验:
* [Unix Desktop Environment](https://opensource.com/article/19/12/linux-unix-desktop-environment-ude): 该桌面的重塑版
* [Rox](/article-12123-1.html): 在它那个时代是先进和现代的桌面
* [MLVWM](/article-11720-1.html): 要是 Apple IIe 运行 Unix 怎么样?
* [Equinox](https://opensource.com/article/19/12/ede-linux-desktop): 只是个最基础的东西
### 选择你的桌面
如果太多的选择让你不知所措,那么记住:桌面意味着 *可选*。你没有义务来尝试发行版附带的多个桌面。
许多 Linux 的高级用户都会满足于他们的发行版所提供的某个桌面。最重要的是得到一个可以与你的计算机一起工作的 Linux 系统系统,并花费时间来学习它是如何工作的。归根结底,所有的桌面都只是为了做同一件事:帮助你组织和管理你的重要数据。让你了解你的桌面是如何工作的,这才是最重要的。但是如果你已经了解了你的默认桌面的各个方面,那你现在有了可以在周末尝试的大量选择。祝你玩得开心!
---
via: <https://opensource.com/article/20/5/linux-desktops>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the great strengths of the Linux desktop is the choice it affords its users. If you don't like your application menu in the lower left of your screen, you can move it. If you don't like the way your file manager organizes your documents, you can use a different one. Admittedly, however, that can be confusing for new users who aren't used to having a say in how they use their computers. If you're looking at installing Linux, one of the choices you're going to have to make is which desktop you want to use, and the best way to do that is to try a few different ones until you find the one that feels right for you.
## The defaults
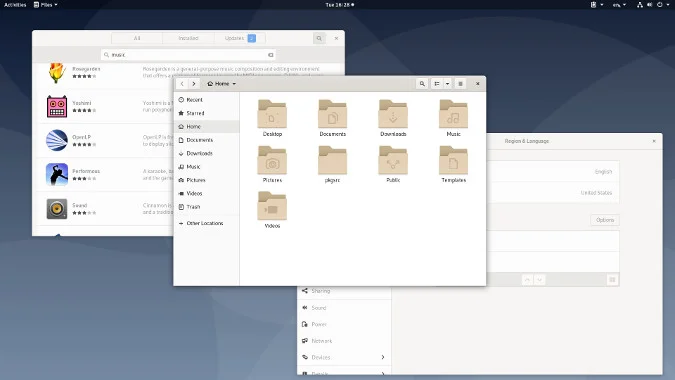
opensource.com
As the default on Fedora, Ubuntu, Debian, and several others, the GNOME desktop is probably the most popular desktop for Linux. It's an intuitive and modern interface, with little nods to mobile design so it feels natural even on a touch screen.
Some distributions of Linux opt for something different, though, including KDE Plasma, Pantheon, Cinnamon, and Mate.
[GNOME](https://opensource.com/article/19/12/gnome-linux-desktop): the modern and intuitive default[Mate](https://opensource.com/article/19/12/mate-linux-desktop): legacy GNOME[KDE](https://opensource.com/article/19/12/linux-kde-plasma): the powerful and configurable Plasma desktop[Cinnamon](https://opensource.com/article/19/12/cinnamon-linux-desktop): classic GNOME[Pantheon](https://opensource.com/article/19/12/pantheon-linux-desktop): the divine default of[ElementaryOS](https://elementary.io/)[Budgie](https://opensource.com/article/19/12/budgie-linux-desktop): a subdued desktop[Trinity](https://opensource.com/article/19/12/linux-trinity-desktop-environment-tde): legacy KDE
## Traditional Unix
Unix, the progenitor of modern operating systems and the direct inspiration for Linux, has a surprisingly rich history of desktops. Most people aren't familiar with Unix desktop design because Unix computers were considered specialist machines common to academic, scientific, and film settings rather than the household. If you were a Unix, IRIX, or NeXT user, then you might have fond memories of desktops like [CDE](https://sourceforge.net/projects/cdesktopenv/) or NeXTStep. You're in luck because the tradition lives on:
[Windowmaker](https://opensource.com/article/19/12/linux-window-maker-desktop): the NeXT interface reborn[Enlightenment](https://opensource.com/article/19/12/linux-enlightenment-desktop): a modernized and improved Windowmaker-style desktop[Fluxbox](https://opensource.com/article/19/12/fluxbox-linux-desktop): thinking outside the box[Openbox](https://opensource.com/article/19/12/openbox-linux-desktop): improving the usability of the box[TWM](https://opensource.com/article/19/12/twm-linux-desktop): the timeless sample desktop bundled with X11[Fvwm](https://opensource.com/article/19/12/fvwm-linux-desktop): TWM improved
## Lightweight desktops
You might wonder why Linux has so many desktops to choose from. While you can chalk a lot of it up to personal preference and a low tolerance for inefficiency, there are technical benefits to optimizing an interface. For instance, old computers struggling to keep up with an update to its UI [can be given new life](https://opensource.com/article/20/2/macbook-linux-elementary) with a lightweight desktop. Alternately, you may simply want to allocate CPU cycles to everything *but* your desktop, so keeping your primary UI minimal just makes sense. Whatever your reason, there are several you can try:
[XFCE](https://opensource.com/article/19/12/xfce-linux-desktop): delivers a familiar desktop for a fraction of the cost[LXQT and LXDE](https://opensource.com/article/19/12/lxqt-lxde-linux-desktop): familiar desktops for a smaller fraction of the cost[PekWM](https://opensource.com/article/19/12/pekwm-linux-desktop): a box-style window manager[Joe's Window Manager](https://opensource.com/article/19/12/joes-window-manager-linux-desktop): another box-style window manager[Ratpoison](https://opensource.com/article/19/12/ratpoison-linux-desktop): don't touch that mouse[Herbstluftwm](https://opensource.com/article/19/12/herbstluftwm-linux-desktop): Ratpoison for[Vim users](https://opensource.com/resources/what-vim)[Lumina](https://opensource.com/article/19/12/linux-lumina-desktop): a desktop developed for PC-BSD
## Experimental desktops
One of the things that happens when it's relatively easy to create and integrate a desktop into a system is that you get interesting proof-of-concepts and experimental projects. Some are more polished than others, and some aren't terribly easy to install. These probably aren't destined to be your permanent desktop, but they can be fun to experience:
[Unix Desktop Environment](https://opensource.com/article/19/12/linux-unix-desktop-environment-ude): a reinvention of the desktop[Rox](https://opensource.com/article/19/12/linux-rox-desktop): a progressive and modern desktop in its day[MLVWM](https://opensource.com/article/19/12/linux-mlvwm-desktop): what if the Apple IIe had run Unix?[Equinox](https://opensource.com/article/19/12/ede-linux-desktop): just the basics
## Choose your desktop
If you're overwhelmed by choice, then keep in mind that desktops are meant to be *optional*. There's no obligation to try more than the one that ships with your distribution.
Many a power user of Linux settles for whatever desktop their distribution puts in front of them. The important thing is to get a Linux install that works with your computer, and spend time with it to learn how it works. Ultimately, all desktops are only meant to do the same thing: help you organize and manage your important data. As long as you know how your desktop works, that's all that matters. But if you've learned everything you need to know about your default desktop, you now have plenty of options to try out on the weekend. Have fun!
## 51 Comments |
12,489 | 我最喜欢的 D 语言功能 | https://opensource.com/article/20/7/d-programming | 2020-08-05T21:55:41 | [
"D语言"
] | https://linux.cn/article-12489-1.html |
>
> UFCS 能让你能够编写自然的可重用代码而不会牺牲便利性。
>
>
>

早在 2017 年,我就写过为什么 [D 语言是开发的绝佳选择](https://opensource.com/article/17/5/d-open-source-software-development)的文章。但是 D 语言中有一个出色的功能我没有充分的展开介绍:<ruby> <a href="http://ddili.org/ders/d.en/ufcs.html"> 通用函数调用语法 </a> <rt> Universal Function Call Syntax </rt></ruby>(UFCS)。UFCS 是 D 语言中的一种[语法糖](https://en.wikipedia.org/wiki/Syntactic_sugar),它可以在类型(字符串、数字、布尔值等)上链接任何常规函数,就像该类型的成员函数一样。
如果你尚未安装 D 语言,请[安装 D 语言编译器](https://tour.dlang.org/tour/en/welcome/install-d-locally),以便你可以自己[运行 D 代码](https://tour.dlang.org/tour/en/welcome/run-d-program-locally)。
看一下以下示例代码:
```
// file: ufcs_demo.d
module ufcs_demo;
import std.stdio : writeln;
int[] evenNumbers(int[] numbers)
{
import std.array : array;
import std.algorithm : filter;
return numbers.filter!(n => n % 2 == 0).array;
}
void main()
{
writeln(evenNumbers([1, 2, 3, 4]));
}
```
使用你喜欢的 D 语言编译器进行编译,查看这个简单示例应用做了什么:
```
$ dmd ufcs_demo.d
$ ./ufcs_demo
[2, 4]
```
但是,使用作为 D 语言的内置功能的 UFCS ,你还可以自然方式编写代码:
```
...
writeln([1, 2, 3, 4].evenNumbers());
...
```
或完全删除现在多余的括号,使 `evenNumbers` 看起来像是一个属性:
```
...
writeln([1, 2, 3, 4].evenNumbers); // prints 2, 4
...
```
因此,完整的代码现在变为:
```
// file: ufcs_demo.d
module ufcs_demo;
import std.stdio : writeln;
int[] evenNumbers(int[] numbers)
{
import std.array : array;
import std.algorithm : filter;
return numbers.filter!(n => n % 2 == 0).array;
}
void main()
{
writeln([1, 2, 3, 4].evenNumbers);
}
```
使用你最喜欢的 D 语言编译器进行编译,然后尝试一下。 如预期的那样,它产生相同的输出:
```
$ dmd ufcs_demo.d
$ ./ufcs_demo
[2, 4]
```
在编译过程中,编译器*自动地*将数组作为函数的第一个参数。这是一个常规模式,使得使用 D 语言成为一种乐趣,因此,它与你自然而然考虑代码的感觉非常相似。结果就是函数式编程。
你可能会猜出这打印的是什么:
```
//file: cool.d
import std.stdio : writeln;
import std.uni : asLowerCase, asCapitalized;
void main()
{
string mySentence = "D IS COOL";
writeln(mySentence.asLowerCase.asCapitalized);
}
```
确认一下:
```
$ dmd cool.d
$ ./cool
D is cool
```
结合[其他 D 语言的功能](https://dlang.org/comparison.html),UFCS 使你能够编写可重用的代码,并在不牺牲便利性的情况下自然地进行编写。
### 是时候尝试 D 语言了
就像我之前写的那样,D 语言是一种很棒的开发语言。从 [D 语言的下载页面](https://dlang.org/download.html)可以很容易地进行安装,因此请下载编译器,查看示例,并亲自体验 D 语言。
---
via: <https://opensource.com/article/20/7/d-programming>
作者:[Lawrence Aberba](https://opensource.com/users/aberba) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Back in 2017, I wrote about why the [D programming language is a great choice for development](https://opensource.com/article/17/5/d-open-source-software-development). But there is one outstanding feature in D I didn't expand enough on: the [Universal Function Call Syntax](http://ddili.org/ders/d.en/ufcs.html) (UFCS). UFCS is a [syntactic sugar](https://en.wikipedia.org/wiki/Syntactic_sugar) in D that enables chaining any regular function on a type (string, number, boolean, etc.) like its member function of that type.
If you don't already have D installed, [install a D compiler](https://tour.dlang.org/tour/en/welcome/install-d-locally) so you can [run the D code](https://tour.dlang.org/tour/en/welcome/run-d-program-locally) in this article yourself.
Consider this example code:
```
// file: ufcs_demo.d
module ufcs_demo;
import std.stdio : writeln;
int[] evenNumbers(int[] numbers)
{
import std.array : array;
import std.algorithm : filter;
return numbers.filter!(n => n % 2 == 0).array;
}
void main()
{
writeln(evenNumbers([1, 2, 3, 4]));
}
```
Compile this with your favorite D compiler to see what this simple example application does:
```
$ dmd ufcs_demo.d
$ ./ufcs_demo
[2, 4]
```
But with UFCS as a built-in feature of D, you can also write your code in a natural way:
```
...
writeln([1, 2, 3, 4].evenNumbers());
...
```
or completely remove the now-redundant parenthesis to make it feel like `evenNumbers`
is a property:
```
...
writeln([1, 2, 3, 4].evenNumbers); // prints 2, 4
...
```
So the complete code now becomes:
```
// file: ufcs_demo.d
module ufcs_demo;
import std.stdio : writeln;
int[] evenNumbers(int[] numbers)
{
import std.array : array;
import std.algorithm : filter;
return numbers.filter!(n => n % 2 == 0).array;
}
void main()
{
writeln([1, 2, 3, 4].evenNumbers);
}
```
Compile it with your favorite D compiler and try it out. As expected, it produces the same output:
```
$ dmd ufcs_demo.d
$ ./ufcs_demo
[2, 4]
```
During compilation, the compiler *automatically* places the array as the first argument to the function. This is a regular pattern that makes using D such a joy, so it very much feels the same as you naturally think about your code. The result is functional-style programming.
You can probably guess what this prints:
```
//file: cool.d
import std.stdio : writeln;
import std.uni : asLowerCase, asCapitalized;
void main()
{
string mySentence = "D IS COOL";
writeln(mySentence.asLowerCase.asCapitalized);
}
```
But just to confirm:
```
$ dmd cool.d
$ ./cool
D is cool
```
Combined with [other D features](https://dlang.org/comparison.html), UFCS gives you the power to compose reusable code that has a natural flow to it without sacrificing convenience.
## Time to try D
As I've written before, D is a great language for development. It's easy to install from [the D download page](https://dlang.org/download.html), so download the compiler, take a look at the examples, and experience D for yourself.
## 29 Comments |
12,490 | Linux 系统管理员的 10 份速查表 | https://opensource.com/article/20/7/sysadmin-cheat-sheets | 2020-08-05T22:22:30 | [
"速查表"
] | /article-12490-1.html |
>
> 这些快速参考指南让系统管理员的生活和日常工作变得更轻松,而且它们都是免费提供的。
>
>
>

作为一名系统管理员,你做所的不是一件工作,而是**全部**工作,而且往往每一件工作都是随时随地出现,毫无预兆。除非你每天都只做一项任务,否则当需要的时候,你可能并不总是都能将所有的命令和选项都记在脑海里。这就是为什么我喜欢速查表的原因。
速查表可以帮助你避免愚蠢的错误,它们可以让你不必翻阅数页的文档,并让你高效地完成任务。我为每位系统管理员挑选了我最喜欢的 10 个速查表,无论他的经验水平如何。
### 网络
我们的《[Linux 网络](https://opensource.com/downloads/cheat-sheet-networking)》速查表是速查表界的的瑞士军刀,它包含了最常见的网络命令的简单提醒,包括 `nslookup`、`tcpdump`、`nmcli`、`netstat`、`traceroute` 等。最重要的是,它用了 `ip` 命令,所以你终于可以不用再默认使用 `ifconfig` 命令了!
### 防火墙
系统管理员有两种:了解 `iptables` 的和使用前一类人编写的 `iptables` 配置文件的。如果你是第一类人,你可以继续使用你的 `iptables` 配置,有没有 [firewalld](https://firewalld.org/) 都无所谓。
如果你是第二类人,你终于可以放下你的 iptables 焦虑,拥抱 firewalld 的轻松。阅读《[用 firewall-cmd 保护你的 Linux 网络](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd)》,然后下载我们的《[firewalld 速查表](https://opensource.com/downloads/firewall-cheat-sheet)》来记住你所学到的东西,保护你的网络端口从未如此简单。
### SSH
许多系统管理员都用的是 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) shell,所以可以在别人的计算机上运行的远程 shell 是 Linux 上最重要的工具之一也就不足为奇了。任何学习服务器管理的人通常很早就学会了使用 SSH,但我们中的许多人只学习了基础知识。
当然,SSH 可以在远程机器上打开一个交互式的 shell,但它的功能远不止这些。比如说,你需要在远程机器上进行图形化登录。远程主机的用户要么不在键盘旁边,要么无法理解你启用 VNC 的指令。只要你有 SSH 权限,就可以为他们打开端口。
```
$ ssh -L 5901:localhost:5901 <remote_host>
```
通过我们的《[SSH 速查表](https://opensource.com/downloads/advanced-ssh-cheat-sheet)》了解更多。
### Linux 用户和权限
传统的大型机和 UNIX 超级计算机风格的用户账户现在基本上已经被 Samba、LDAP 和 OpenShift等系统所取代。然而,这并没有改变对管理员和服务账户仔细管理的需求。为此,你仍然需要熟悉`useradd`、`usermod`、`chown`、`chmod`、`passwd`、`gpasswd`、`umask` 等命令。
把我的《[用户和权限速查表](https://opensource.com/downloads/linux-permissions-cheat-sheet)》放在手边,你就可以随时对与用户管理有关的任务进行合理的概览,并有实例命令演示你需要做的任何事情的正确语法。
### 基本的 Linux 命令
并不是所有的系统管理员都会把所有的时间花在终端上。无论你是否喜欢在桌面上工作,还是刚开始使用 Linux,有时为常用的终端命令提供一个任务导向的参考是很好的。
对于一个为灵活性和即兴性而设计的界面来说,找到所有你可能需要的东西是很困难的,但我的《[常用命令速查表](https://opensource.com/downloads/linux-common-commands-cheat-sheet)》是相当全面的。这张速查表以任何技术型桌面用户的典型生活为蓝本,涵盖了用命令在计算机内导航、寻找文件的绝对路径、复制和重命名文件、建立目录、启动系统服务等内容。
### Git
在计算机的历史上,版本控制曾经是只有开发者才需要的东西。但那是过去,而 Git 是现在。对于任何希望跟踪从 Bash 脚本到配置文件、文档和代码的变化的人来说,版本控制是一个重要的工具。Git 适用于每个人,包括程序员、网站可靠性工程师(SRE),甚至系统管理员。
获取我们的《[Git 速查表](https://opensource.com/downloads/cheat-sheet-git)》来学习要领、基本工作流程和最重要的 Git 标志。
### Curl
Curl 不一定是系统管理员专用的工具,从技术上讲,它“只是”一个用于终端的非交互式 Web 浏览器。你可能几天都不用它一次。然而,你很有可能会发现 Curl 对你每天要做的事情很有用,不管是快速参考网站上的一些信息,还是排除网络主机的故障,或者是验证你运行或依赖的一个重要 API。
Curl 是一个向服务器传输数据的命令,它支持的协议包括 HTTP、FTP、IMAP、LDAP、POP3、SCP、SFTP、SMB、SMTP 等。它是一个重要的网络工具,所以下载我们的《[Curl 速查表](https://opensource.com/downloads/curl-command-cheat-sheet)》,开始探索 Curl 吧。
### SELinux
Linux 的安全策略在默认情况下是很好的,root 权限和用户权限之间有很强的分离,但 SELinux 使用标签系统对其进行了改进。在配置了 SELinux 的主机上,每个进程和每个文件对象(或目录、网络端口、设备等)都有一个标签。SELinux 提供了一套规则来控制进程标签对对象(如文件)标签的访问。
有时候你需要调整 SELinux 策略,或者调试一些安装时没有正确设置的东西,或者深入了解当前的策略。我们的《[SELinux 速查表](https://opensource.com/downloads/cheat-sheet-selinux)》可以提供帮助。
### Kubectl
无论你是已经迁移到了开放的混合云、封闭的私有云,还是你还在研究这样的迁移需要准备什么,你都需要了解 Kubernetes。虽然云确实还需要人去摆弄物理服务器,但作为一个系统管理员,你的未来肯定会涉及到容器,而没有什么比 Kubernetes 更能做到这一点。
虽然 [OpenShift](https://opensource.com/tags/openshift) 为 Kubernetes 提供了流畅的“仪表盘”体验,但有时需要一种直接的方法,这正是 `kubectl` 提供的。下一次当你不得不到处推送容器时,请确保你手头有我们的《[kubectl 速查表](https://opensource.com/downloads/kubectl-cheat-sheet)》。
### awk
近几年来,Linux 经历了很多创新,有虚拟机、容器、新的安全模型、新的初始化系统、云等等。然而有些东西似乎永远不会改变。尤其是,系统管理员需要从日志文件和其它无尽的数据流中解析和隔离信息。仍然没有比 Aho、Weinberger 和 Kernighan 的经典 `awk` 命令更适合这项工作的工具。
当然,自从 1977 年它被编写出来后,`awk` 已经走过了很长的路,新的选项和功能使它更容易使用。但如果你不是每天都在使用 `awk`,那么多的选项和语法可能会让你有点不知所措。下载我们的《[awk 速查表](https://opensource.com/downloads/cheat-sheet-awk-features)》,了解 GNU awk 的工作原理。
### 赠品:Bash 脚本编程
速查表是有用的,但如果你想找更全面的东西,你可以下载我们的《[Bash 脚本编程手册](https://opensource.com/downloads/bash-scripting-ebook)》。这本指南教你如何将你从速查表中了解到的所有命令和经验结合到脚本中,帮助你建立一个随时能用的自动化解决方案库来解决你的日常问题。本书内容丰富,详细讲解了 Bash 的工作原理、脚本与交互式命令的区别、如何捕捉错误等。
### 赋能系统管理员
你是一名系统管理员吗?
你正在成为一名系统管理员的路上吗?
你是否对系统管理员一天都在做什么感到好奇?
如果是的话,请查看《[赋能系统管理员](http://redhat.com/sysadmin)》,这里有来自业界最勤奋的系统管理员的新文章,讲述他们的工作,以及 Linux 和开源如何让这一切成为可能。
---
via: <https://opensource.com/article/20/7/sysadmin-cheat-sheets>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,492 | BigBlueButton:开源在线教学软件 | https://itsfoss.com/bigbluebutton/ | 2020-08-06T10:35:05 | [
"视频会议"
] | https://linux.cn/article-12492-1.html |
>
> BigBlueButton 是一个为在线教学量身定制的开源视频会议工具。让我们来看看它提供了什么。
>
>
>
在 2020 年,在家远程工作是一种新常态。当然,你不可能远程完成所有事情,但是在线教学是可以的。
尽管许多老师和学校组织不熟悉那些所有的出色工具,但某些[最好的开源视频会议工具](/article-12453-1.html)在一定程度上满足了要求。
在我提到的视频通话软件中,[BigBlueButton](https://bigbluebutton.org/) 引起了我的注意。在这里,我将为你简单介绍。
### BigBlueButton:用于在线教学的开源 Web 会议系统

BigBlueButton 是一个开源的网络会议方案,它旨在简化在线学习。
它是完全免费的,但是需要你在自己的服务器上安装才能将其用作成熟的在线学习解决方案。
BigBlueButton 提供了非常好的一组功能。你可以轻松地尝试[演示实例](http://demo.bigbluebutton.org/),并在学校的服务器上进行安装。
开始之前,请先了解以下功能:
### BigBlueButton 的功能
BigBlueButton 为教师和学校的量身定制了一系列在线课堂的有用功能,你可以获得:
* 现场白板
* 给公共和私人发消息
* 支持网络摄像头
* 支持会话记录
* 支持表情符号
* 能够将用户分组以进行团队协作
* 支持投票
* 屏幕共享
* 支持多用户白板
* 能够自行托管
* 提供用于轻松集成到 Web 应用中的 API
除了提供的功能外,你还能看到易于使用的 UI,即 [Greenlight](https://bigbluebutton.org/2018/07/09/greenlight-2-0/) (BigBlueButton 的前端界面),当你在服务器上配置时可以安装它。
你可以尝试演示实例来临时免费地教你的学生。但是,考虑到使用[演示实例](http://demo.bigbluebutton.org/)来尝试 BigBlueButton 的局限性(限制为 60 分钟),建议你将它托管在服务器上,以探索其提供的所有功能。
为了更清楚地了解这些功能是如何工作的,你可能需要看下它的[官方教程](https://www.youtube.com/embed/Q2tG2SS4gXA)。
### 在你的服务器上安装 BigBlueButton
他们提供了[详细文档](https://docs.bigbluebutton.org/),它对每个开发人员都会有用。安装它最简单、最快捷的方法是使用 [bbb-install 脚本](https://github.com/bigbluebutton/bbb-install),但是如果不成功,你也可以探索其他选项。
对于刚接触的人,你需要一台至少运行 Ubuntu 16.04 LTS 的服务器。在为 BigBlueButton 部署服务器之前,你应该查看[最低要求](https://docs.bigbluebutton.org/2.2/install.html#minimum-server-requirements)。
你可以在它的 [GitHub 页面](https://github.com/bigbluebutton)中进一步了解该项目。
* [试用 BigBlueButton](https://bigbluebutton.org/)
如果你正在为在线教学寻求解决方案,那么 BigBlueButton 是一个不错的选择。
它可能不提供原生的智能手机应用,但你肯定可以用手机上的网络浏览器来访问它。当然,最好找一台笔记本电脑/计算机来访问在线教学平台,但它也可以在移动设备上使用。
你认为 BigBlueButton 的在线教学如何?有没有更好的开源项目可以替代?在下面的评论中让我知道!
---
via: <https://itsfoss.com/bigbluebutton/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: BigBlueButton is an open-source tool for video conferencing tailored for online teaching. Let’s take a look at what it offers.*
In the year 2020, remote working from home is kind of the new normal. Of course, you cannot do everything remotely — but online teaching is something that’s possible.
Even though a lot of teachers and school organizations aren’t familiar with all the amazing tools available out there, some of the [best open-source video conferencing tools](https://itsfoss.com/open-source-video-conferencing-tools/) are filling in the requirements to some extent.
Among the ones I mentioned for video calls, [BigBlueButton](https://bigbluebutton.org/) caught my attention. Here, I’ll give you an overview of what it offers.
## BigBlueButton: An Open Source Web Conferencing System for Online Teaching

BigBlueButton is an open-source web conferencing solution that aims to make online learning easy.
It is completely free to use but it requires you to set it up on your own server to use it as a full-fledged online learning solution.
BigBlueButton offers a really good set of features. You can easily try the [demo instance](http://demo.bigbluebutton.org/) and set it up on your server for your school.
Before you get started, take a look at the features:
## Features of BigBlueButton
BigBlueButton provides a bunch of useful features tailored for teachers and schools for online classes, here’s what you get:
- Live whiteboard
- Public and private messaging options
- Webcam support
- Session recording support
- Emojis support
- Ability to group users for team collaboration
- Polling options available
- Screen sharing
- Multi-user support for whiteboard
- Ability to self-host it
- Provides an API for easy integration on web applications
In addition to the features offered, you will find an easy-to-use UI i.e. [Greenlight](https://bigbluebutton.org/2018/07/09/greenlight-2-0/) (the front-end interface for BigBlueButton) to set up when you configure it on your server.
You can try using the demo instance for casual usage to teach your students for free. However, considering the limitations (60 minutes limit) of using the [demo instance](http://demo.bigbluebutton.org/) to try BigBlueButton, I’d suggest you to host it on your server to explore all the functionality that it offers.
To get more clarity on how the features work, you might want to take a look at one of their official tutorials:
## Installing BigBlueButton On Your Server
They offer a [detailed documentation](https://docs.bigbluebutton.org/) which should come in handy for every developer. The easiest and quickest way of setting it up is by using the [bbb-install script](https://github.com/bigbluebutton/bbb-install) but you can also explore other options if that does not work out for you.
For starters, you need a server running Ubuntu 16.04 LTS at least. You should take a look at the [minimum requirements](https://docs.bigbluebutton.org/2.2/install.html#minimum-server-requirements) before deploying a server for BigBlueButton.
You can explore more about the project in their [GitHub page](https://github.com/bigbluebutton).
If you’re someone who’s looking to set up a solution for online teaching, BigBlueButton is a great choice to explore.
It may not offer native smartphone apps — but you can surely access it using the web browser on your mobile. Of course, it’s better to find a laptop/computer to access an online teaching platform — but it works with mobile too.
What do you think about BigBlueButton for online teaching? Is there a better open-source project as an alternative to this? Let me know in the comments below! |
12,493 | Python 下使用 Altair 数据制图 | https://opensource.com/article/20/6/altair-python | 2020-08-06T11:07:13 | [
"绘图"
] | https://linux.cn/article-12493-1.html |
>
> Altair 作为一个 Python 数据制图库,提供了优雅的接口及自有的绘图语言。
>
>
>

Python 中的 [绘图库](/article-12327-1.html) 提供了呈现数据的多种方式,可以满足你不同的偏好,如灵活性、布局、易用性,或者特殊的风格。
和其它方式相比,我发现,Altair 提供的是一种不同的解决方案,且总体而言使用起来更为简单。得益于声明式的绘图语言 [Vega](https://vega.github.io/vega/),Altair 拥有一套优雅的接口,可以直接定义要绘的图应该是什么样子,而不是通过写一大堆循环和条件判断去一步步构建。
### 绘图流程
我通过绘制同一个多柱状图比较了多个 Python 绘图库的差异。正式开始之前,你需要将你的 Python 环境调整到能运行下面代码的状态。具体就是:
* 安装最新版的 Python( [Linux](https://opensource.com/article/20/4/install-python-linux)、[Mac](https://opensource.com/article/19/5/python-3-default-mac) 和 [Windows](https://opensource.com/article/19/8/how-install-python-windows) 系统下的安装方法)
* 确认该版本 Python 可以运行本教程所使用的库
演示用数据可从网络下载,并且可以用 pandas 直接导入:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
准备开始吧。为了做个比较,先看下面这个用 [Matplotlib](https://opensource.com/article/20/5/matplotlib-python) 做的图:

使用 Matplotlib 需要 16 行代码,图柱的位置需要自己计算。
使用 Altair 绘制相似的图,代码如下:
```
import altair as alt
chart = alt.Chart(df).mark_bar().encode(
x='party',
y='seats',
column='year',
color='party',
)
chart.save('altair-elections.html')
```
真是简洁多了!与 [Seaborn](https://anvil.works/blog/plotting-in-seaborn) 类似,Altair 所用数据的组织形式是每个变量一列(即 [数据列](https://anvil.works/blog/tidy-data) )。这种方式下可以将每个变量映射到图的一个属性上 —— Altair 称之为“通道”。在上例中,我们期望每个 “党派” 在 `x` 轴上显示为一组图柱, 其 “席位” 显示在 `y` 轴,且将图柱按照 “年份” 分开为 “列”。我们还想根据 “党派” 给图柱使用不同的 “颜色”。用语言表述需求的话就是上面这个样子,而这也正是代码所要表述的!
现在把图画出来:

### 调整样式
这和我们期待的效果有点接近了。与 Matplotlib 方案相比,主要区别在于 Altair 方案中,每个 `year` 组显示的时候,内部之间都有个小空白 —— 这不是问题,这只是 Altair 多柱状图显示的一个特性。
所以说呢,还需要对显示样式再做一些改进。
#### 非整形数据
两个不是整数的年份名称(`Feb 1974` 和 `Oct 1974`)显示为 `NaN` 了。这可以通过将年份数值 `year` 转换为字符串来解决:
```
df['year'] = df['year'].astype(str)
```
#### 指定数据排序方法
还需要让 Altair 知道如何对数据进行排序。Altair 允许通过传给它一个 `Column` 对象,来设定 `Column` 通道的更多细节。现在让 Altair 按照数据在数据集中出现的顺序排列:
```
chart = alt.Chart(df).mark_bar().encode(
# ...
column=alt.Column('year', sort=list(df['year']), title=None),
# ...
)
```
#### 移除坐标轴标签
我们通过设置 `title=None` 移除了图顶的 "year" 标签。下面再一处每列数据的 "party" 标签:
```
chart = alt.Chart(df).mark_bar().encode(
x=alt.X('party', title=None),
# ...
)
```
#### 指定颜色图
最后,我们还想自己指定图柱的颜色。Altair 允许建立 `domain` 中数值与 `range` 中颜色的映射来实现所需功能,太贴心了:
```
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
chart = alt.Chart(df).mark_bar().encode(
# ...
color=alt.Color('party', scale=alt.Scale(domain=list(cmap.keys()), range=list(cmap.values())))
)
```
#### 样式调整后的最终代码
应用上述样式调整之后,代码看起来不那么悦目了,但我们仍然是用声明的方式实现的,这正是 Altair 如此有弹性的原因所在。实现过程中,仍然是使用的异于显示数据的独立变量来分离图中不同属性的,而不是像在 Matplotlib 中那样直接对显示数据做复杂的操作。唯一的不同是,我们的变量名字封装在类似 `alt.X()` 的对象中,从而实现对显示效果的控制:
```
import altair as alt
from votes import long as df
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
df['year'] = df['year'].astype(str)
# We're still assigning, e.g. 'party' to x, but now we've wrapped it
# in alt.X in order to specify its styling
chart = alt.Chart(df).mark_bar().encode(
x=alt.X('party', title=None),
y='seats',
column=alt.Column('year', sort=list(df['year']), title=None),
color=alt.Color('party', scale=alt.Scale(domain=list(cmap.keys()), range=list(cmap.values())))
)
chart.save('altair-elections.html')
```
现在与 Matplotlib 方案扯平了,代码数量达到了 16 行!
下图是使用我们的样式调整方案之后的 Altair 效果图:

### 结论
尽管在代码数量上,使用 Altair 绘图没有表现出优势,但它的声明式绘图语言使得对图层的操控更为精密,这是我比较欣赏的。Altair 还提供了清晰而独立的方式来调校显示样式,这使得 相关代码与绘图的代码块分离开来。Altair 确实是使用 Python 绘图时又一个很棒的工具库。
本文首次发布于 [这里](https://anvil.works/blog/plotting-in-altair),蒙允编辑后再次发布。
---
via: <https://opensource.com/article/20/6/altair-python>
作者:[Shaun Taylor-Morgan](https://opensource.com/users/shaun-taylor-morgan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [plotting libraries](https://opensource.com/article/20/4/plot-data-python) available in Python offer multiple ways to present data according to your preferences, whether you prize flexibility, design, ease-of-use, or a particular style.
Plotting in Altair delivers a different solution than others which I find to be simpler as the amount of plotting done scales. It has an elegant interface, thanks to [Vega](https://vega.github.io/vega/), the declarative plotting language that allows you to define what your plots should look like, rather than writing loops and conditionals to construct them.
## Fluent in plotting
I compare each Python plotting library by plotting the same multi-bar plot. Before we go further, note that you may need to tune your Python environment to get this code to run, including the following.
- Installing a recent version of Python (instructions for
[Linux](https://opensource.com/article/20/4/install-python-linux),[Mac](https://opensource.com/article/19/5/python-3-default-mac), and[Windows](https://opensource.com/article/19/8/how-install-python-windows)) - Verify that version of Python works with the libraries used in the tutorial
The data is available online and can be imported using pandas:
```
import pandas as pd
df = pd.read_csv('https://anvil.works/blog/img/plotting-in-python/uk-election-results.csv')
```
Now we're ready to go. As a point of comparison, this is the plot we made in [Matplotlib](https://opensource.com/article/20/5/matplotlib-python):
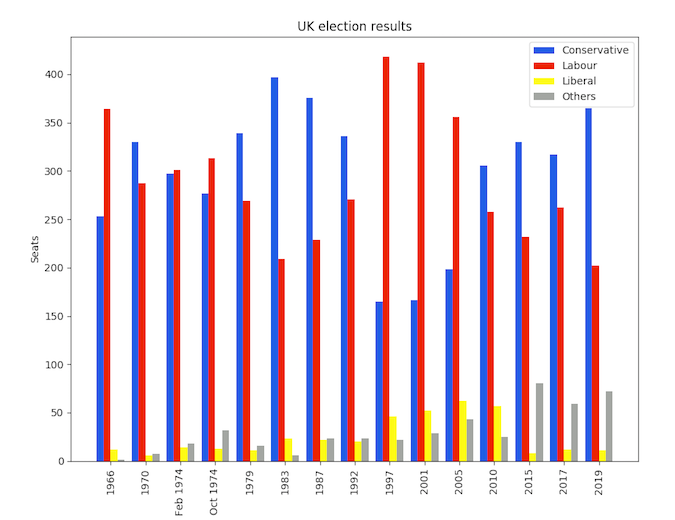
Matplotlib plot of UK election results (© 2020 [Anvil](https://anvil.works/blog/plotting-in-altair))
The Matplotlib plot took 16 lines of code to create, including manually calculating the positions of each bar.
Here's how to make a similar plot in Altair:
```
import altair as alt
chart = alt.Chart(df).mark_bar().encode(
x='party',
y='seats',
column='year',
color='party',
)
chart.save('altair-elections.html')
```
Much more concise! Just like [Seaborn](https://anvil.works/blog/plotting-in-seaborn), Altair works with data that has one column per variable ([Long Form](https://anvil.works/blog/tidy-data)). This allows you to map each variable onto an aspect of the plot—Altair calls these aspects "channels." In our case, we want one bar per `party`
on the `x`
-axis, we want the `seats`
each party won on the `y`
-axis, and we want to group the bars into `column`
s by `year`
. We also want to `color`
the bars by `party`
. That's how you would describe it in words, and it's exactly what the code says!
Here's what the plot looks like:
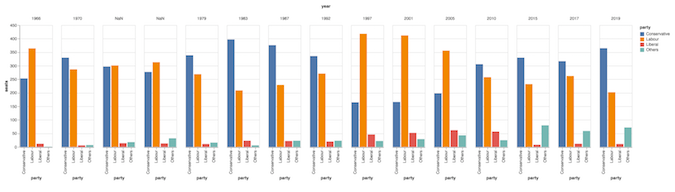
Altair plot with default styling (© 2020 Anvil)
## Tweaking the style
That's not too far from what we want. The main difference from the Matplotlib plot is that each Altair `year`
group is displayed with a little white space in between—this is just a feature of Altair's multi-bar plots, and it's not a problem.
However, there are a few other little style improvements that we do want to make.
### Non-integer values
The two non-integer year names (`Feb 1974`
and `Oct 1974`
) are displayed as `NaN`
. We can fix these by casting our `year`
values to strings:
` df['year'] = df['year'].astype(str)`
### Specifying sort order
We then also need to tell Altair how to sort the data. Altair allows us to specify more details about the `column`
channel by passing it a `Column`
object. So we tell it to sort in the order that the data appears in the DataFrame:
```
chart = alt.Chart(df).mark_bar().encode(
# ...
column=alt.Column('year', sort=list(df['year']), title=None),
# ...
)
```
### Removing axis titles
We have removed the "year" label from the top of the plot by setting `title=None`
. Let's also remove the "party" labels from each column:
```
chart = alt.Chart(df).mark_bar().encode(
x=alt.X('party', title=None),
# ...
)
```
### Specifying a colormap
Finally, we want to specify our own colors to use for the bars. Altair lets us specify a mapping between values in a `domain`
and colors in a `range`
, which is exactly what we need:
```
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
chart = alt.Chart(df).mark_bar().encode(
# ...
color=alt.Color('party', scale=alt.Scale(domain=list(cmap.keys()), range=list(cmap.values())))
)
```
### Final code with style tweaks
After applying these styling tweaks, our code is a little less pleasing to the eye, but it still uses the declarative approach that makes Altair so scalable. We're still assigning independent variables from our data to separate aspects of our plot, rather than performing complex data manipulations as we often need to do in Matplotlib. The only difference is that our variable names are now wrapped in objects such as `alt.X()`
that let us tweak how they appear:
```
import altair as alt
from votes import long as df
cmap = {
'Conservative': '#0343df',
'Labour': '#e50000',
'Liberal': '#ffff14',
'Others': '#929591',
}
df['year'] = df['year'].astype(str)
# We're still assigning, e.g. 'party' to x, but now we've wrapped it
# in alt.X in order to specify its styling
chart = alt.Chart(df).mark_bar().encode(
x=alt.X('party', title=None),
y='seats',
column=alt.Column('year', sort=list(df['year']), title=None),
color=alt.Color('party', scale=alt.Scale(domain=list(cmap.keys()), range=list(cmap.values())))
)
chart.save('altair-elections.html')
```
In fairness to Matplotlib, we've now reached the same number of lines of code (16) as we used there!
Here's the Altair plot with our styling tweaks applied:
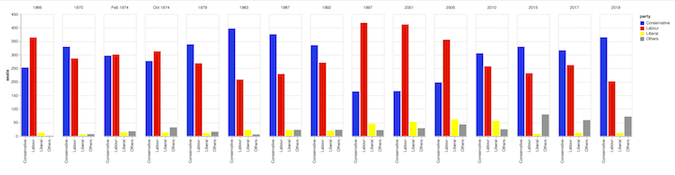
The Altair plot with our custom styling (© 2020 Anvil)
## Conclusion** **
While the amount of code it takes to plot using Altair is similar to other libraries, its declarative plotting language adds a layer of sophistication I have grown to appreciate. Altair also offers a cleanly separate way to tune and tweak the style, which keeps that syntax out of the code blocks meant for plotting. Altair is another great library when considering a plotting solution for Python. You can run this code [interactively on Anvil](https://anvil.works/blog/plotting-in-pygal) (with an account) or locally using [this open source runtime](https://github.com/anvil-works/anvil-runtime).
---
*This article is based on Plotting in Altair on Anvil's blog and is reused with permission.*
## Comments are closed. |
12,494 | [重制版]《代码英雄》第一季(1):操作系统战争(上) | https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-1 | 2020-08-06T16:05:00 | [
"代码英雄"
] | https://linux.cn/article-12494-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(1):操作系统战争(上)](https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-1) 的[音频](https://dts.podtrac,com/redirect.mp3/audio.simplecast.com/f7670e99.mp3)脚本。
**Saron Yitbarek**: 有些故事如史诗般,惊险万分,在我脑海中似乎出现了星球大战电影开头的滑动文本。你知道的,就像 ——
**配音**: “第一集,操作系统大战”
**Saron Yitbarek**: 是的,就像那样子。
**00:00:30 - 配音**: 这是一个局势加剧紧张的时期。<ruby> 比尔·盖茨 <rt> Bill Gates </rt></ruby>与<ruby> 史蒂夫·乔布斯 <rt> Steve Jobs </rt></ruby>的帝国发起了一场无可避免的专有软件之战。盖茨与 IBM 结成了强大的联盟,而乔布斯则拒绝开放它的硬件和操作系统授权。他们争夺统治地位的战争,简直席卷了操作系统的“银河系”。与此同时,在这些“帝王们”所不知道的偏远之地,信奉开源的“反叛者们”开始聚集。
**00:01:00 - Saron Yitbarek**: 好吧。这也许有点戏剧性,但当我们谈论上世纪八九十年代和 2000 年左右的操作系统之争时,这也不算言过其实。确实曾经发生过一场史诗级的统治之战。史蒂夫·乔布斯和比尔·盖茨确实掌握着许多人的命运。掌控了操作系统,你就掌握了绝大多数人使用计算机的方式、互相通讯的方式、获取信息的方式。我可以一直罗列下去,不过你知道我的意思。掌握了操作系统,你就是帝王。
**00:01:30 - Saron Yitbarek**: 我是 Saron Yitbarek,你现在收听的是代码英雄,一款红帽公司原创的博客节目。你问什么是<ruby> 代码英雄 <rt> Command Line Hero </rt></ruby>?嗯,如果你愿意用创造代替使用,如果你相信开发者拥有构建美好未来的能力,如果你希望拥有一个大家都有权利用科技塑造生活的世界,那么你,我的朋友,就是一位代码英雄。在本系列节目中,我们将为你带来那些“白码起家”(LCTT 译注:原文是 “from the command line up”,应该是演绎自 “from the ground up” —— 白手起家)改变技术的程序员故事。
**00:02:00 - Saron Yitbarek**: 那么我是谁,凭什么指引你踏上这段艰苦的旅程?Saron Yitbarek 是哪根葱?嗯,事实上我觉得我跟你差不多。我是一名为初学者服务的开发人员,我做的任何事都依赖于开源软件,我的世界就是如此。通过在博客中讲故事,我可以跳出无聊的日常工作,鸟瞰全景,希望这对你也一样有用。
**00:02:30 - Saron Yitbarek**: 我迫不及待地想知道,开源技术从何而来?我的意思是,我对<ruby> 林纳斯·托瓦兹 <rt> Linus Torvalds </rt></ruby>和 Linux^® 的荣耀有一些了解,我相信你也一样。但是说真的,开源并不是一开始就有的对吗?如果我想发表对这些最新、最棒的技术 —— 比如 DevOps 和容器的感激,我感觉我亏欠那些早期的开发者许多,我有必要了解这些东西来自何处。所以,让我们暂时先不用担心内存泄露和缓冲溢出。我们的旅程将从操作系统之战开始,这是一场波澜壮阔的桌面控制之战。
**00:03:00 - Saron Yitbarek**: 这场战争亘古未有,因为:首先,在计算机时代,大公司拥有指数级的规模优势;其次,从未有过这么一场控制争夺战是如此变化多端。比尔·盖茨和史蒂夫·乔布斯? 目前为止他们也不知道事情会如何发展,但是到这个故事进行到一半的时候,他们所争夺的所有东西都将发生改变、进化,最终上升到云端。
**00:03:30 - Saron Yitbarek**: 好的,让我们回到 1983 年的秋季,还有六年我才出生。那时候的总统还是<ruby> 罗纳德·里根 <rt> Ronald Reagan </rt></ruby>,美国和苏联扬言要把地球拖入核战争之中。在檀香山(火奴鲁鲁)的市政中心正在举办一年一度的苹果公司销售会议。一群苹果公司的员工正在等待史蒂夫·乔布斯上台。他 28 岁,热情洋溢,看起来非常自信。乔布斯很严肃地对着麦克风说,他邀请了三个行业专家,来就他的软件进行了一次小组讨论。
**00:04:00 - Saron Yitbarek**: 然而随后发生的事情你肯定想不到。超级俗气的 80 年代音乐响彻整个房间,一堆多彩灯管照亮了舞台,然后一个播音员的声音响起 ——
**配音**: 女士们,先生们,现在是麦金塔软件的约会游戏时间。
**00:04:30 - Saron Yitbarek**: 当乔布斯意识到这三个 CEO 都要向他轮流示好的时候,脸上露出一个大大的笑容。他简直就是 80 年代科技界的钻石王老五。两个软件大佬讲完话后就轮到第三个人讲话了,事情就这样结束了?才不是呢。新面孔比尔·盖茨带着一个大大的,遮住了半张脸的方框眼镜。他宣称在 1984 年,微软的一半收入将来自于麦金塔软件。他的这番话引来了观众热情的掌声。
**00:05:00 - Saron Yitbarek**: 但是他们不知道的是,在一个月后,比尔·盖茨将会宣布发布 Windows 1.0 的计划。你永远也猜不到乔布斯正在跟苹果未来最大的敌人打情骂俏,但微软和苹果即将举行科技史上最糟糕的婚礼。他们会彼此背叛、相互毁灭,但又深深地、痛苦地捆绑在一起。
**00:05:30 - James Allworth**: 我猜从哲学角度上来讲,苹果是更理想化、注重用户体验高于一切,一体化的组织,而微软则更务实,更模块化 ——
**Saron Yitbarek**: 这位是 James Allworth。他是一位高产的科技作家,曾在苹果零售的企业团队工作。注意他对苹果的定义,一个一体化的组织,那种只对自己负责,不想依赖别人的公司,这是关键。
**00:06:00 - James Allworth**: 苹果是一家一体化的公司,它希望专注于令人愉悦的用户体验,这意味着它希望控制整个技术栈以及交付的一切内容:从硬件到操作系统,甚至运行在操作系统上的应用程序。新的,重要的创新需要横跨软硬件才能很好地进入市场。当你能够根据自己意愿来改变软件和硬件时,你就有了极大的优势。例如 ——
**00:06:30 - Saron Yitbarek**: 很多人喜欢这种一体化的模式,并因此成为了苹果的铁杆粉丝,不过还有是很多人则选择了微软。让我们回到檀香山的销售会议上,在同一场活动中,乔布斯向观众展示了他即将发布的超级碗广告,你可能已经亲眼见过这则广告了。想想<ruby> 乔治·奥威尔 <rt> George Orwell </rt> <rt> </rt></ruby>的 《一九八四》。在这个冰冷、灰暗的世界里,无意识的机器人正在独裁者投射的凝视下徘徊。
**00:07:00 - Saron Yitbarek**: 这些机器人就像是 IBM 的用户们。然后,代表苹果公司的,漂亮而健美的<ruby> 安娅·梅杰 <rt> Anya Major </rt></ruby>穿着鲜艳的衣服跑过大厅。她向着大佬们的屏幕猛地投出大锤,将它砸成了碎片。老大哥的咒语解除了,一个低沉的声音响起,苹果公司要开始介绍麦金塔了。
**配音**: 这就是为什么我们的 1984 年,跟小说《一九八四》描写的不一样。
**00:07:30 - Saron Yitbarek**: 是的,现在回顾那则广告,认为苹果是一个致力于解放大众的自由斗士的想法有点过分,但这件事触动了我的神经。Ken Segal 曾在为苹果制作这则广告的广告公司工作过,他为史蒂夫·乔布斯工作了十多年。
**00:08:00 - Ken Segal**: 1984 这则广告的负担的风险很大。事实上,它的风险实在太大,乃至苹果公司在看到它的时候都不想播出它。你可能听说了史蒂夫喜欢它,但苹果公司董事会的人并不喜欢它。事实上他们很愤怒,为什么这么多钱被花在这样一件事情上,以至于他们想解雇广告代理商。史蒂夫则为我们公司辩护。
**Saron Yitbarek**: 乔布斯一如既往地,慧眼识英雄。
**Ken Segal**: 这则广告在公司内、在业界内都引起了共鸣,成为了苹果产品的代表。无论人们那天是否有在购买电脑,它都带来了一种持之以恒的影响,并让大家在心里定义了这家公司的立场:我们是叛军,我们是拿着大锤的人。
**00:08:30 - Saron Yitbarek**: 因此,在争夺数十亿潜在消费者心智的过程中,苹果公司和微软公司的帝王们正在学着把自己塑造成救世主、非凡的英雄,选择自己就是选择一种生活方式。但比尔·盖茨明白一些苹果难以理解的事情,那就是在一个相互连接的世界里,没有人 —— 即便他是帝王,能独自完成任务。
**00:09:00 - Saron Yitbarek**: 1985 年 6 月 25 日。盖茨给当时的苹果 CEO John Scully 发了一份备忘录。那是一个迷失的年代。乔布斯刚刚被逐出公司,直到 1996 年才回到苹果。也许正是因为乔布斯离开了,盖茨才敢写这份东西。在备忘录中,他鼓励苹果授权制造商分发他们的操作系统。我想读一下备忘录的最后部分,让你们知道这份备忘录是多么的有洞察力。
**00:09:30 - Saron Yitbarek**: 盖茨写道:“如果没有其他个人电脑制造商的支持,苹果现在不可能让他们的创新技术成为标准。苹果必须开放麦金塔的架构,以获得个人建造商的支持来快速发展和建立标准。”换句话说,你们不要再自己玩自己的了。你们必须有与他人合作的意愿。你们必须与开发者合作。
**00:10:00 - Saron Yitbarek**: 多年后你依然可以看到这条思想的哲学性,当微软首席执行官<ruby> 史蒂夫·鲍尔默 <rt> Steve Ballmer </rt></ruby>上台做主题演讲时,他开始大喊:“开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者。”你懂我的意思了吧。微软喜欢开发人员。虽然目前(LCTT 译注:本播客发布于 2018 年初)他们不打算与这些开发人员共享源代码,但是他们确实想建立起整个为合作伙伴服务的生态系统。
**00:10:30 - Saron Yitbarek**: 而当比尔·盖茨建议苹果公司也这么做时,如你可能已经猜到的,这个想法被苹果公司抛到了九霄云外。他们的关系产生了间隙,五个月后,微软发布了 Windows 1.0。战争开始了。
>
> 开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者、开发者。
>
>
>
**00:11:00 - Saron Yitbarek**: 你正在收听的是来自红帽公司的原创播客《代码英雄》。本集是第一集,我们将回到过去,重温操作系统战争的史诗,我们将会发现,科技巨头之间的战争,是如何为我们今天所生活的开源世界开辟前路的。
**00:11:30 - Saron Yitbarek**: 好的,让我们先来个背景故事吧,它很经典。如果你已经听过了,那么请原谅我。当时是 1979 年,史蒂夫·乔布斯开车去<ruby> 帕洛阿尔托 <rt> Palo Alto </rt></ruby>的<ruby> 施乐公园研究中心 <rt> Xerox Park research center </rt></ruby>。那里的工程师一直在为他们所谓的图形用户界面,开发一系列的元素。也许你听说过,它们有菜单、滚动条、按钮、文件夹和层叠的窗口。这是对计算机界面的一个前所未有的美丽新设想。作家兼记者 Steve Levy 谈到了它的潜力。
**00:12:00 - Steven Levy**: 这个新界面有很多令人感到激动的地方,它比以前的交互界面更友好,以前用的交互界面被称为命令行 —— 这不是在现实生活中使用的交互方式。鼠标和电脑上的图像,让你可以像指向现实生活中的东西一样,指向电脑上的东西。这让事情变得简单多了,你不需要记住那些代码。
**00:12:30 - Saron Yitbarek**: 不过,施乐的高管们并没有意识到他们正坐在金矿上。一如既往地,工程师比主管们更清楚它的价值。因此那些工程师,在被要求向乔布斯展示这些东西是如何工作时,有点紧张。然而这毕竟是高管的命令。用乔布斯的话来说,他认为“这个天才产品本来能够让施乐公司垄断整个行业,可是它最终会被公司的经营者毁掉,因为他们对产品的好坏没有概念。”
**00:13:00 - Saron Yitbarek**: 这话有些苛刻,但是,乔布斯带着一卡车施乐高管忽视的想法离开了会议。这几乎包含了所有,他革新桌面计算体验需要的东西。1983 年,苹果发布了 Lisa 电脑,1984 年又发布了 Mac 电脑。这些设备的创意都是抄袭自施乐公司的。
**00:13:50 - Saron Yitbarek**: 让我感兴趣的是,乔布斯对控诉他偷了图形用户界面的反应。他对此很冷静,他引用毕加索的话:“好的艺术家抄袭,伟大的艺术家偷窃。”他告诉一位记者,“我们总是无耻地窃取伟大的创意。”伟大的艺术家偷窃,好吧,我的意思是,我们说的并不是严格意义上的“偷窃”。没人拿到了专有的源代码并公然将其集成到他们自己的操作系统中去。这事情更温和些,更像是创意的借用。但乔布斯自己即将学到,这东西很难以控制。传奇的软件奇才、真正的代码英雄 Andy Hertzfeld 就是麦金塔开发团队的最初成员。
**00:14:00 - Andy Hertzfeld**: 是的,微软是麦金塔电脑软件的第一个合作伙伴。当时,我们并没有把他们当成是竞争对手。他们是苹果之外,我们第一家交付麦金塔电脑原型的公司。我通常每周都会和微软的技术主管聊一次,他们是第一个试用我们所编写软件的外部团队。
**00:14:30 - Andy Hertzfeld**: 他们给了我们非常重要的反馈,总的来说,我认为我们的关系非常好。但我也注意到,在我与技术主管的交谈中,他开始问一些系统实现方面的问题,而他本无需知道这些,我觉得他们想要复制麦金塔电脑。我很早以前就向史蒂夫·乔布斯反馈过这件事,但在 1983 年秋天,这件事发展到了高潮。
**00:15:00 - Andy Hertzfeld**: 我们发现,他们在 1983 年 11 月的 COMDEX 上发布了 Windows,但却没有提前告诉我们。对此史蒂夫·乔布斯勃然大怒,他认为那是一种背叛。
**00:15:30 - Saron Yitbarek**: 很明显,微软从苹果那里学到了,苹果从施乐那里学来的所有想法。随着新版 Windows 的发布,乔布斯变得很易怒。他发表的伟大艺术家善于偷窃的毕加索名言被别人学去了 —— 盖茨也正是这么做的。据报道,当乔布斯怒斥盖茨偷了他们的东西时,盖茨回应道:“史蒂夫,我觉得这更像是我们都有一个叫施乐的富有邻居,我闯进他家偷电视机,却发现你已经偷过了”。苹果最终以窃取 GUI 的外观和风格为名起诉了微软。这个案子持续了好几年,但是在 1993 年,第 9 巡回上诉法院的一名法官最终站在了微软一边。
**00:16:00 - Saron Yitbarek**: Vaughn Walker 法官宣布外观和风格不受版权保护,这是非常重要的事情。这一决定让苹果再无法垄断桌面计算的界面。很快,苹果短暂的领先优势消失了。以下是 Steven Levy 的观点。
**00:16:30 - Steven Levy**: 他们之所以失去领先地位,不是因为微软方面窃取了知识产权,而是因为他们无法巩固自己在上世纪 80 年代就拥有的,更优越的操作系统的优势。坦率地说,他们的电脑索价过高。微软从 20 世纪 80 年代中期开始开发 Windows 系统,但直到 1990 年才开发出来 Windows 3。我想,这算是第一个开启黄金时代的版本,真正可供大众使用。
**00:17:00 - Steven Levy**: 从此以后,微软能够将数以亿计的用户迁移到图形界面,而这是苹果无法做到的。虽然苹果公司有一个非常好的操作系统,但是那已经是 1984 年的产品了。
**00:17:30 - Saron Yitbarek**: 现在微软主导着操作系统的战场。他们占据了 90% 的市场份额,并且针对各种各样的个人电脑进行了标准化。操作系统的未来看起来会由微软掌控。在此后发生了什么?1997 年,波士顿 Macworld 博览会上,你看到了一个几近破产的苹果,一个比之前谦逊得多的史蒂夫·乔布斯走上舞台,开始谈论伙伴关系的重要性 —— 特别是他们与微软的。史蒂夫·乔布斯呼吁双方缓和关系,停止火拼,微软将坐享巨大的市场份额。从表面看,我们可能会认为世界和平了。
**00:18:00 - Saron Yitbarek**: 但当利益如此巨大时,事情就没那么简单了。就在苹果和微软在数十年的争斗中伤痕累累、最终败退到死角之际,一名 21 岁的芬兰计算机科学专业学生出现了。十分偶然的,他彻底改变了一切。
我是 Saron Yitbarek,这里是代码英雄。
**00:18:30 - Saron Yitbarek**: 正当某些科技巨头正忙着就专有软件相互攻击时,自由软件和开源软件的新领军者如雨后春笋般涌现。其中一位优胜者就是<ruby> 理查德·斯托曼 <rt> Richard Stallman </rt></ruby>,你也许对他的工作很熟悉,他想要拥有自由软件的自由社会。这就像言论自由一样的<ruby> 自由 <rt> free </rt></ruby>,而不是像免费啤酒一样的<ruby> 免费 <rt> free </rt></ruby>。早在 80 年代,斯托尔曼就发现,除了昂贵的专有操作系统(如 UNIX)外,没有其他可行的替代品,因此他决定自己做一个。斯托尔曼的<ruby> 自由软件基金会 <rt> Free Software Foundation </rt></ruby>开发了 GNU,当然,它的意思是 “GNU's not UNIX”。它将是一个像 UNIX 一样的操作系统,但不包含 UNIX 代码,而且所有用户可以自由共享它。
**00:19:00 - Saron Yitbarek**: 为了让你体会到上世纪 80 年代自由软件概念的重要性,从不同角度来说拥有 UNIX 代码的两家公司,<ruby> AT&T 贝尔实验室 <rt> AT&T Bell Laboratories </rt></ruby>以及<ruby> UNIX 系统实验室 <rt> UNIX System Laboratories </rt></ruby>威胁将会起诉任何看过 UNIX 源代码后又创建自己操作系统的人。这些人是次级专利所属。
**00:19:30 - Saron Yitbarek**: 用这两家公司的话来说,所有这些程序员都在“精神上受到了污染”,因为他们都见过 UNIX 代码。在 UNIX 系统实验室和<ruby> 伯克利软件设计公司 <rt> Berkeley Software Design </rt></ruby>之间的一个著名的法庭案例中,有人认为即使它本身没有使用 UNIX 代码,拥有类似功能的系统也侵犯版权。Paul Jones 当时是一名开发人员。他现在是数字图书馆 ibiblio。org 的主管。
**00:20:00 - Paul Jones**: 他们的观点是,任何看过代码的人,都受到了精神污染。因此,几乎所有在安装有与 UNIX 相关操作系统的电脑上工作过的人,以及任何在计算机科学部门工作的人都受到精神上的污染。在 USENIX 的一年里,我们都得到了一个写着红色字母的白色小别针,上面写着“精神受到了污染”。我们很喜欢带着这些别针到处走,以表达我们曾经跟着贝尔实验室混,所以我们的精神受到了污染。
**00:20:30 - Saron Yitbarek**: 整个世界都被精神污染了。想要保持纯粹、保持事物的美好,和完整地拥有一个软件的旧思想正变得越来越不现实。正是在这被污染的现实中,历史上最伟大的代码英雄之一诞生了,他是一个芬兰男孩,名叫<ruby> 林纳斯·托瓦兹 <rt> Linus Torvalds </rt></ruby>。如果这是《星球大战》,那么林纳斯·托瓦兹就是我们的<ruby> 卢克·天行者 <rt> Luke Skywalker </rt></ruby>。他是赫尔辛基大学的一名温文尔雅的研究生。
**00:21:00 - Saron Yitbarek**: 有才华,但缺乏大志,典型的被逼上梁山的英雄。和其他年轻的英雄一样,他也感到沮丧。他想把 386 处理器整合到他的新电脑中。他对自己兼容 IBM 的电脑上运行 MS-DOS 操作系统并不感冒,也负担不起 UNIX 软件 5000 美元的价格,但只有 UNIX 才能让他自由地编程。解决方案是,托瓦兹在 1991 年春天基于 MINIX 开发了一个名为 Linux 的操作系统内核,他自己的操作系统内核。
**00:21:30 - Steven Vaughan-Nichols**: 林纳斯·托瓦兹真的只是想找点乐子而已。
**Saron Yitbarek**: Steven Vaughan-Nichols 是 [ZDNet.com](http://ZDNet.com) 的特约编辑,而且他从科技行业出现以来就一直在写科技行业相关的内容。
**Steven Vaughan-Nichols**: 当时有几个类似的操作系统。他最关注的是一个名叫 MINIX ,旨在让学生学习如何构建操作系统的项目。林纳斯看到了这些并且觉得这个它很有趣,所以他打算建立自己的操作系统。
**00:22:00 - Steven Vaughan-Nichols**: 所以,Liunux 实际上始于赫尔辛基的一个 DIY 项目。一切就这样开始了,基本上就是一个大孩子在玩耍,学习如何做些什么。但不同之处在于,他足够聪明、足够执着,也足够友好,能让其他人都参与进来,然后他开始把这个项目进行到底。
**00:22:30 - Steven Vaughan-Nichols**: 27 年后,这个项目变得比他想象的要大得多。
**00:23:00 - Saron Yitbarek**: 到 1991 年秋季,托瓦兹发布了 10000 行代码,世界各地的人们开始评头论足,然后进行优化、添加和修改代码。对于今天的开发人员来说似乎很正常,但请记住,在那个时候,微软、苹果和 IBM 已经在系统开发上做得很完善,虽然同时这些软件也是专有的。因此像这样的开放协作操作系统,是对这些公司一种精神上的侮辱,但随后这种开放性被奉上神坛。托瓦兹将 Linux 置于 <ruby> GNU 通用公共许可证 <rt> GPL </rt></ruby>之下。曾经保障斯托尔曼的 GNU 系统自由的许可证,现在也将保障 Linux 的自由。Vaughan-Nichols 解释道,GPL 许可基本上能永远保证软件的自由和开放性,它的重要性被怎么强调都不过分。
**00:23:30 - Steven Vaughan-Nichols**: 事实上,根据 Linux 所遵循的许可协议,即 GPL 第 2 版,如果你想贩卖 Linux 或者向全世界展示它,你必须与他人共享代码。所以如果你对其做了一些改进,仅仅给别人使用打包的代码是不够的,你必须和他们分享这些变化的所有细节代码。然后这些改进足够好时,也许就会被 Linux 所吸收。
**00:24:00 - Saron Yitbarek**: 事实证明,这种公开的方式极具吸引力。<ruby> 埃里克·雷蒙德Eric Raymond</ruby> 是这场运动的早期传道者之一,他在他那篇著名的文章中写道:“微软和苹果这样的公司一直在试图建造软件大教堂,而 Linux 及类似的软件则提供了一个由不同议程和方法组成的巨大集市,集市比大教堂有趣多了。”
**Stormy Peters**: 我认为在那个时候,真正吸引人们的是 —— 他们终于可以掌控这个属于他们的世界了。
**Saron Yitbarek**: Stormy Peters 是一位行业分析师,也是自由和开源软件的倡导者。
**00:24:30 - Stormy Peters**: 当开源软件第一次出现的时候,所有的操作系统都是专有的。如果不使用专有软件,你甚至不能添加打印机,不能添加耳机,不能自己开发一个小型硬件设备,然后让它在你的笔记本电脑上运行。你甚至不能放入 DVD 并复制它,因为你不能改变软件,即使你拥有这张 DVD,你也无法改变它的内容。
**00:25:00 - Stormy Peters**: 你无法掌控你购买的硬件 / 软件系统。你不能从中创造出任何新的、更大的、更好的东西。这就是为什么开源操作系统在一开始就如此重要。我们需要一个开源协作环境,在那里我们可以构建更大更好的东西。
**00:25:30 - Saron Yitbarek**: 请注意,Linux 并不是一个纯粹的平等乌托邦。林纳斯·托瓦兹并没有负责批准所有对内核的修改,但他主导了内核的变更。他安排了十几个人来管理内核的不同部分。这些人也会信任自己下面的人,以此类推,形成信任金字塔。变化可能来自任何地方,但它们都经过了判断和策划。
**00:26:00 - Saron Yitbarek**: 然而,考虑到到林纳斯的 DIY 项目一开始是多么的简陋和随意,这项成就令人十分惊讶。他完全不知道自己就是这一切中的卢克·天行者。当时他已经编程了半辈子,但当时只有 21 岁。不过当魔盒第一次被打开时,人们开始给他反馈。几十个,然后几百个,成千上万的贡献者。有了这样的众包基础,Linux 很快就开始成长,而且成长得很快,甚至最终引起了微软的注意。他们的首席执行官<ruby> 史蒂夫·鲍尔默 <rt> Steve Ballmer </rt></ruby>将 Linux 称为是“一种癌症,从知识产权的角度来看,它传染了任何它接触的东西”。Steven Levy 将会描述 Ballmer 的立场。
**00:26:30 - Steven Levy**: 一旦微软真正巩固了它的垄断地位 —— 而且它也确实被联邦法院判定为垄断,他们将会对任何可能对其构成威胁的事情做出强烈反应。它们很自然的将自由软件看成是一种癌症,因为微软要通过软件来赚钱。他们试图提出一个知识产权理论,来解释为什么开源对消费者不利。
**00:27:00 - Saron Yitbarek**: Linux 在不断传播,微软也开始担心起来。到了 2006 年,Linux 成为仅次于 Windows 的第二大常用操作系统,约有 5000 名开发者在世界各地开发它。5000 名开发者!还记得比尔·盖茨给苹果公司的备忘录吗?在那份备忘录中,他向苹果公司的员工们论述了与他人合作的重要性。事实证明,开源将把伙伴关系的概念提升到一个全新的水平,这是比尔·盖茨从未预见到的。
**00:27:30 - Saron Yitbarek**: 我们一直在谈论操作系统之间的大战,但是到目前为止,无名英雄和开发者们还没有完全介入战场。在下集中,情况就不同了。第二集讲的还是操作系统大战,关于 Linux 崛起的第二部分。资本们醒悟过来,认识到了开发人员的重要性。
**00:28:00 - Saron Yitbarek**: 这些开源反叛者变得越来越强大,战场从桌面转移到了服务器领域。这里有商业间谍活动、新的英雄人物,还有科技史上最不可思议的改变。这一切都在操作系统大战的后半集内达到了高潮。
**00:28:30 - Saron Yitbarek**: 要想免费自动获得新一集的代码英雄,请点击订阅苹果播客、Spotify、Google Play,或其他应用获取该播客。在这一季剩下的时间里,我们将参观最新的战场,相互争斗的版图,这里是下一代的代码英雄留下印记的地方。更多信息,请访问 <https://www.redhat.com/en/command-line-heroes> 。我是 Saron Yitbarek,在下次节目之前,请坚持编程。
>
> **什么是 LCTT SIG 和 LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。也欢迎更多贡献者加入 LCRH SIG :</article-12436-1.html>
>
>
>
>
> **关于重制版**
>
>
> 本系列第一季的前三篇我们已经发布过,这次根据新的 SIG 规范重新修订发布。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-1>
作者:[redhat](https://www.redhat.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[acyanbird](https://github.com/acyanbird)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The OS wars. It is a period of mounting tensions. The empires of Bill Gates and Steve Jobs careen toward an inevitable battle over proprietary software—only one empire can emerge as the purveyor of a standard operating system for millions of users. Gates has formed a powerful alliance with IBM while Jobs tries to maintain the purity of his brand. Their struggle for dominance threatens to engulf the galaxy. Meanwhile, in distant lands, and unbeknownst to the Emperors, open source rebels have begun to gather...
Veterans from computer history, including [ Andy Hertzfeld](https://twitter.com/andyhertzfeld), from the original Macintosh team, and acclaimed tech journalist
[, recount the moments of genius, and tragic flaws, that shaped our technology for decades to come.](https://twitter.com/StevenLevy)
__Steven Levy__*Saron Yitbarek*
Some stories are so epic, with such high stakes , that in my head, it's like that crawling text at the start of a Star Wars movie. You know, like-
*Voice Actor*
Episode One, The OS Wars.
*Saron Yitbarek*
Yeah, like that.
**00:30** - *Voice Actor*
It is a period of mounting tensions. The empires of Bill Gates and Steve Jobs careen toward an inevitable battle over proprietary software. Gates has formed a powerful alliance with IBM, while Jobs refuses to license his hardware or operating system. Their battle for dominance threatens to engulf the galaxy in an OS war. Meanwhile, in distant lands, and unbeknownst to the emperors, open source rebels have begun to gather.
**01:00** - *Saron Yitbarek*
Okay. Maybe that's a bit dramatic, but when we're talking about the OS wars of the 1980s, '90s, and 2000s, it's hard to overstate things. There really was an epic battle for dominance. Steve Jobs and Bill Gates really did hold the fate of billions in their hands. Control the operating system, and you control how the vast majority of people use computers, how we communicate with each other, how we source information. I could go on, but you know all this. Control the OS, and you would be an emperor.
**01:30** - *Saron Yitbarek*
I'm Saron Yitbarek [00:01:24], and you're listening to Command Line Heroes, an original podcast from Red Hat. What is a Command Line Hero, you ask? Well, if you would rather make something than just use it, if you believe developers have the power to build a better future, if you want a world where we all get a say in how our technologies shape our lives, then you, my friend, are a command line hero. In this series, we bring you stories from the developers among us who are transforming tech from the command line up.
**02:00** - *Saron Yitbarek*
And who am I to be guiding you on this trek? Who is Saron Yitbarek? Well, actually I'm guessing I'm a lot like you. I'm a developer for starters, and everything I do depends on open source software. It's my world. The stories we tell on this podcast are a way for me to get above the daily grind of my work, and see that big picture. I hope it does the same thing for you, too.
**02:30** - *Saron Yitbarek*
What I wanted to know right off the bat was, where did open source technology even come from? I mean, I know a fair bit about Linus Torvalds and the glories of Linux® , as I'm sure you do , too, but really, there was life before open source, right? And if I want to truly appreciate the latest and greatest of things like DevOps and containers, and on and on, well, I feel like I owe it to all those earlier developers to know where this stuff came from. So, let's take a short break from worrying about memory leaks and buffer overflows.
**03:00** - *Saron Yitbarek*
Our journey begins with the OS wars, the epic battle for control of the desktop. It was like nothing the world had ever seen, and I'll tell you why. First, in the age of computing, you've got exponentially scaling advantages for the big fish ; and second, there's never been such a battle for control on ground that's constantly shifting. Bill Gates and Steve Jobs? They don't know it yet, but by the time this story is halfway done, everything they're fighting for is going to change, evolve, and even ascend into the cloud.
**03:30** - *Saron Yitbarek*
Okay, it's the fall of 1983. I was negative six years old. Ronald Reagan was president, and the U . S . and the Soviet Union are threatening to drag the planet into nuclear war. Over at the Civic Center in Honolulu, it's the annual Apple sales conference. An exclusive bunch of Apple employees are waiting for Steve Jobs to get onstage. He's this super bright-eyed 28-year-old, and he's looking pretty confident. In a very serious voice, Jobs speaks into the mic and says that he's invited three industry experts to have a panel discussion on software.
**04:00** - *Saron Yitbarek*
But the next thing that happens is not what you'd expect. Super cheesy '80s music fills the room. A bunch of multi-colored tube lights light up the stage, and then an announcer voice says-
*Voice Actor*
And now, ladies and gentlemen, the Macintosh software dating game.
**04:30** - *Saron Yitbarek*
Jobs has this big grin on his face as he reveals that the three CEOs on stage have to take turns wooing him. It's essentially an '80s version of The Bachelor, but for tech love. Two of the software bigwigs say their bit, and then it's over to contestant number three. Is that? Yup. A fresh - faced Bill Gates with large square glasses that cover half his face. He proclaims that during 1984, half of Microsoft's revenue is going to come from Macintosh software.
**05:00** - *Saron Yitbarek*
The audience loves it, and gives him a big round of applause. What they don't know is that one month after this event, Bill Gates will announce his plans to release Windows 1.0. You'd never guess Jobs is flirting with someone who'd end up as Apple's biggest rival. But Microsoft and Apple are about to live through the worst marriage in tech history. They're going to betray each other, they're going to try and destroy each other, and they're going to be deeply, painfully bound to each other.
**05:30** - *James Allworth*
I guess philosophically, one was more idealistic and focused on the user experience above all else, and was an integrated organization, whereas Microsoft much more pragmatic, a modular focus-
*Saron Yitbarek*
That's James Allworth. He's a prolific tech writer who worked inside the corporate team of Apple Retail. Notice that definition of Apple he gives. An integrated organization. That sense of a company beholden only to itself. A company that doesn't want to rely on others. That's key.
**06:00** - *James Allworth*
Apple was the integrated player, and it wanted to focus on a delightful user experience, and that meant that it wanted to control the entire stack and everything that was delivered, from the hardware to the operating system, to even some of the applications that ran on top of the operating system. That always served it well in periods where new innovations, important innovations, were coming to market where you needed to be across both hardware and software, and where being able to change the hardware based on what you wanted to do and what t was new in software was an advantage. For example-
**06:30** - *Saron Yitbarek*
A lot of people loved that integration, and became die hard Apple fans. Plenty of others stuck with Microsoft. Back to that sales conference in Honolulu. At that very same event, Jobs gave his audience a sneak peek at the Superbowl ad he was about to release. You might have seen it for yourself. Think George Orwell's 1984. In this cold and gray world, mindless automatons are shuffling along under a dictator's projected gaze.
**07:00** - *Saron Yitbarek*
They represent IBM users. Then, beautiful, athletic Anya Major, representing Apple, comes running through the hall in full color. She hurls her sledgehammer at Big Brother's screen, smashing it to bits. Big Brother's spell is broken, and a booming voice tells us that Apple is about to introduce the Macintosh.
*Voice Actor*
And you'll see why 1984 will not be like 1984.
**07:30** - *Saron Yitbarek*
And yeah, looking back at that commercial, the idea that Apple was a freedom fighter working to set the masses free is a bit much. But the thing hit a nerve. Ken Segal worked at the advertising firm that made the commercial for Apple. He was Steve Jobs' advertising guy for more than a decade in the early days.
**08:00** - *Ken Segal*
Well, the 1984 commercial came with a lot of risk. In fact, it was so risky that Apple didn't want to run it when they saw it. You've probably heard stories that Steve liked it, but the Apple board did not like it. In fact, they were so outraged that so much money had been spent on such a thing that they wanted to fire the ad agency. Steve was the one sticking up for the agency.
*Saron Yitbarek*
Jobs, as usual, knew a good mythology when he saw one.
*Ken Segal*
That commercial struck such a chord within the company, within the industry, that it became this thing for Apple. Whether or not people were buying computers that day, it had a sort of an aura that stayed around for years and years and years, and helped define the character of the company. We're the rebels. We're the guys with the sledgehammer.
**08:30** - *Saron Yitbarek*
So in their battle for the hearts and minds of literally billions of potential consumers, the emperors of Apple and Microsoft were learning to frame themselves as redeemers. As singular heroes. As lifestyle choices. But Bill Gates knew something that Apple had trouble understanding. This idea that in a wired world, nobody, not even an emperor, can really go it alone.
**09:00** - *Saron Yitbarek*
June 25th, 1985. Gates sends a memo to Apple's then CEO John Scully. This was during the wilderness years. Jobs had just been excommunicated, and wouldn't return to Apple until 1996. Maybe it was because Jobs was out that Gates felt confident enough to write what he wrote. In the memo, he encourages Apple to license their OS to clone makers. I want to read a bit from the end of the memo, just to give you a sense of how perceptive it was.
**09:30** - *Saron Yitbarek*
Gates writes, "It is now impossible for Apple to create a standard out of their innovative technology without support from other personal computer manufacturers. Apple must open the Macintosh architecture to have the independent support required to gain momentum and establish a standard." In other words, no more operating in a silo, you guys. You've got to be willing to partner with others. You have to work with developers.
**10:00** - *Saron Yitbarek*
You see this philosophy years later, when Microsoft CEO Steve Ballmer gets up on stage to give a keynote and he starts shouting, "Developers, developers, developers, developers, developers, developers. Developers, developers, developers, developers, developers, developers, developers, developers." You get the idea. Microsoft likes developers. Now, they're not about to share source code with them, but they do want to build this whole ecosystem of partners. And when Bill Gates suggests that Apple do the same, as you might have guessed, the idea is tossed out the window.
**10:30** - *Saron Yitbarek*
Apple had drawn a line in the sand, and five months after they trashed Gates' memo, Microsoft released Windows 1.0. The war was on.
Developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers, developers.
**11:00** - *Saron Yitbarek*
You're listening to Command Line Heroes, an original podcast from Red Hat. In this inaugural episode, we go back in time to relive the epic story of the OS wars, and we're going to find out, how did a war between tech giants clear the way for the open source world we all live in today?
**11:30** - *Saron Yitbarek*
Okay, a little backstory. Forgive me if you've heard this one, but it's a classic. It's 1979, and Steve Jobs drives up to the Xerox Park research center in Palo Alto. The engineers there have been developing this whole fleet of elements for what they call a graphical user interface. Maybe you've heard of it. They've got menus, they've got scroll bars, they've got buttons and folders and overlapping windows. It was a beautiful new vision of what a computer interface could look like. And nobody had any of this stuff. Author and journalist Steven Levy talks about its potential.
**12:00** - *Steven Levy*
There was a lot of excitement about this new interface that was going to be much friendlier than what we had before, which used what was called the command line, where there was really no interaction between you and the computer in the way you'd interact with something in real life. The mouse and the graphics on the computer gave you a way to do that, to point to something just like you'd point to something in real life. It made it a lot easier. You didn't have to memorize all these codes.
**12:30** - *Saron Yitbarek*
Except, the Xerox executives did not get that they were sitting on top of a platinum mine. The engineers were more aware than the execs. Typical. So those engineers were, yeah, a little stressed out that they were instructed to show Jobs how everything worked. But the executives were calling the shots. Jobs felt, quote, "The product genius that brought them to that monopolistic position gets rotted out by people running these companies that have no conception of a good product versus a bad product."
**13:00** - *Saron Yitbarek*
That's sort of harsh, but hey, Jobs walked out of that meeting with a truckload of ideas that Xerox executives had missed. Pretty much everything he needed to revolutionize the desktop computing experience. Apple releases the Lisa in 1983, and then the Mac in 1984. These devices are made by the ideas swiped from Xerox.
**13:50** - *Saron Yitbarek*
What's interesting to me is Jobs' reaction to the claim that he stole the GUI. He's pretty philosophical about it. He quotes Picasso, saying, "Good artists copy, great artists steal." He tells one reporter, "We have always been shameless about stealing great ideas." Great artists steal. Okay. I mean, we're not talking about stealing in a hard sense. Nobody's obtaining proprietary source code and blatantly incorporating it into their operating system. This is softer, more like idea borrowing. And that's much more difficult to control, as Jobs himself was about to learn. Legendary software wizard, and true command line hero, Andy Hertzfeld, was an original member of the Macintosh development team.
**14:00** - *Andy Hertzfeld*
Yeah, Microsoft was our first software partner with the Macintosh. At the time, we didn't really consider them a competitor. They were the very first company outside of Apple that we gave Macintosh prototypes to. I talked with the technical lead at Microsoft usually once a week. They were the first outside party trying out the software that we wrote.
**14:30** - *Andy Hertzfeld*
They gave us very important feedback, and in general I would say the relationship was pretty good. But I also noticed in my conversations with the technical lead, he started asking questions that he didn't really need to know about how the system was implemented, and I got the idea that they were trying to copy the Macintosh. I t old Steve Jobs about it pretty early on, but it really came to a head in the fall of 1983.
**15:00** - *Andy Hertzfeld*
We discovered that they actually, without telling us ahead of time, they announced Windows at the COMDEX in November 1983 and Steve Jobs hit the roof. He really considered that a betrayal.
**15:30** - *Saron Yitbarek*
As newer versions of Windows were released, it became pretty clear that Microsoft had lifted from Apple all the ideas that Apple had lifted from Xerox. Jobs was apoplectic. His Picasso line about how great artists steal. Yeah. That goes out the window. Though maybe Gates was using it now. Reportedly, when Jobs screamed at Gates that he'd stolen from them, Gates responded, "Well Steve, I think it's more like we both had this rich neighbor named Xerox, and I broke into his house to steal the TV set, and found out that you'd already stolen it." Apple ends up suing Microsoft for stealing the look and feel of their GUI. The case goes on for years, but in 1993, a judge from the 9th Circuit Court of Appeals finally sides with Microsoft.
**16:00** - *Saron Yitbarek*
Judge Vaughn Walker declares that look and feel are not covered by copyright. This is super important. That decision prevented Apple from creating a monopoly with the interface that would dominate desktop computing. Soon enough, Apple's brief lead had vanished. Here's Steven Levy's take.
**16:30** - *Steven Levy*
They lost the lead not because of intellectual property theft on Microsoft's part, but because they were unable to consolidate their advantage in having a better operating system during the 1980s. They overcharged for their computers, quite frankly. So Microsoft had been developing Windows, starting with the mid-1980s, but it wasn't until Windows 3 in 1990, I believe, where they really came across with a version that was ready for prime time. Ready for masses of people to use.
**17:00** - *Steven Levy*
At that point is where Microsoft was able to migrate huge numbers of people, hundreds of millions, over to the graphical interface in a way that Apple had not been able to do. Even though they had a really good operating system, they used it since 1984.
**17:30** - *Saron Yitbarek*
Microsoft now dominated the OS battlefield. They held 90% of the market, and standardized their OS across a whole variety of PCs. The future of the OS looked like it'd be controlled by Microsoft. And then? Well, at the 1997 Macworld Expo in Boston, you have an almost bankrupt Apple. A more humble Steve Jobs gets on stage, and starts talking about the importance of partnerships, and one in particular, he says, has become very, very meaningful. Their new partnership with Microsoft. Steve Jobs is calling for a détente, a ceasefire. Microsoft could have their enormous market share. If we didn't know better, we might think we were entering a period of peace in the kingdom.
**18:30** - *Saron Yitbarek*
But when stakes are this high, it's never that simple. Just as Apple and Microsoft were finally retreating to their corners, pretty bruised from decades of fighting, along came a 21-year-old Finnish computer science student who, almost by accident, changed absolutely everything.
I'm Saron Yitbarek, and this is Command Line Heroes.
**18:30** - *Saron Yitbarek*
While certain tech giants were busy bashing each other over proprietary software, there were new champions of free and open source software popping up like mushrooms. One of these champions was Richard Stallman. You're probably familiar with his work. He wanted free software and a free society. That's free as in free speech, not free as in free beer. Back in the '80s, Stallman saw that there was no viable alternative to pricey, proprietary OSs, like UNIX . So, he decided to make his own. Stallman's Free Software Foundation developed GNU, which stood for GNU's not UNIX , of course. It'd be an OS like UNIX, but free of all UNIX code, and free for users to share.
**19:00** - *Saron Yitbarek*
Just to give you a sense of how important that idea of free software was in the 1980s, the companies that owned the UNIX code at different points, AT&T Bell Laboratories and then UNIX System Laboratories, they threatened lawsuits on anyone making their own OS after looking at UNIX source code. These guys were next - level proprietary.
**19:30** - *Saron Yitbarek*
All those programmers were, in the words of the two companies, "mentally contaminated," because they'd seen UNIX code. In a famous court case between UNIX System Laboratories and Berkeley Software Design, it was argued that any functionally similar system, even though it didn't use the UNIX code itself, was a bre a ch of copyright. Paul Jones was a developer at that time. He's now the director of the digital library ibiblio.org.
**20:00** - *Paul Jones*
Anyone who has seen any of the code is mentally contaminated was their argument. That would have made almost anyone who had worked on a computer operating system that involved UNIX , in any computer science department, was mentally contaminated. So in one year at USENIX, we all got little white bar pin s with red letters that say mentally contaminated, and we all wear those around to our own great pleasure, to show that we were sticking it to Bell because we were mentally contaminated.
**20:30** - *Saron Yitbarek*
The whole world was getting mentally contaminated. Staying pure, keeping things nice and proprietary, that old philosophy was getting less and less realistic. It was into this contaminated reality that one of history's biggest command line heroes was born, a boy in Finland named Linus Torvalds. If this is Star Wars, then Linus Torvalds is our Luke Skywalker. He was a mild-mannered grad student at the University of Helsinki.
**21:00** - *Saron Yitbarek*
Talented, but lacking in grand visions. The classic reluctant hero. And, like any young hero, he was also frustrated. He wanted to incorporate the 386 processor into his new PC's functions. He wasn't impressed by the MS-DOS running on his IBM clone, and he couldn't afford the $5,000 price tag on the UNIX software that would have given him some programming freedom. The solution, which Torvalds crafted on MINIX in the spring of 1991, was an OS kernel called Linux. The kernel of an OS of his very own.
**21:30** - *Steven Vaughan-Nichols*
Linus Torvalds really just wanted to have something to play with.
*Saron Yitbarek*
Steven Vaughan-Nichols is a contributing editor at ZDNet.com, and he's been writing about the business of technology since there was a business of technology.
*Steven Vaughan-Nichols*
There were a couple of operating systems like it at the time. The main one that he was concerned about was called MINIX. That was an operating system that was meant for students to learn how to build operating systems. Linus looked at that, and thought that it was interesting, but he wanted to build his own.
**22:00** - *Steven Vaughan-Nichols*
So it really started as a do-it-yourself project at Helsinki. That's how it all started, is just basically a big kid playing around and learning how to do things. But what was different in his case is that he was both bright enough and persistent enough, and also friendly enough to get all these other people working on it, and then he started seeing the project through.
**22:30** - *Steven Vaughan-Nichols*
27 years later, it is much, much bigger than he ever dreamed it would be.
**23:00** - *Saron Yitbarek*
By the fall of 1991, Torvalds releases 10,000 lines of code, and people around the world start offering comments, then tweaks, additions, edits. That might seem totally normal to you as a developer today, but remember, at that time, open collaboration like that was a moral affront to the whole proprietary system that Microsoft, Apple, and IBM had done so well by. Then that openness gets enshrined. Torvalds places Linux under the GNU general public license. The license that had kept Stallman's GNU system free was now going to keep Linux free , too. The importance of that move to incorporate GPL, basically preserving the freedom and openness of the software forever, cannot be overstated. Vaughan-Nichols explains.
**23:30** - *Steven Vaughan-Nichols*
In fact, by the license that it's under, which is called GPL version 2, you have to share the code if you're going to try to sell it or present it to the world, so that if you make an improvement, it's not enough just to give someone the improvement. You actually have to share with them the nuts and bolts of all those changes. Then they are adapted into Linux if they're good enough.
**24:00** - *Saron Yitbarek*
That public approach proved massively attractive. Eric Raymond, one of the early evangelists of the movement wrote in his famous essay that, "Corporations like Microsoft and Apple have been trying to build software cathedrals, while Linux and its kind were offering a great babbling bazaar of different agendas and approaches. The bazaar was a lot more fun than the cathedral."
*Stormy Peters*
I think at the time, what attracted people is that they were going to be in control of their own world.
*Saron Yitbarek*
Stormy Peters is an industry analyst, and an advocate for free and open source software.
**24:30** - *Stormy Peters*
When open source software first came out, the OS was all proprietary. You couldn't even add a printer without going through proprietary software. You couldn't add a headset. You couldn't develop a small hardware device of your own, and make it work with your laptop. You couldn't even put in a DVD and copy it, because you couldn't change the software. Even if you owned the DVD, you couldn't copy it.
**25:00** - *Stormy Peters*
You had no control over this hardware/software system that you'd bought. You couldn't create anything new and bigger and better out of it. That's why an open source operating system was so important at the beginning. We needed an open source collaborative environment where we could build bigger and better things.
**25:30** - *Saron Yitbarek*
Mind you, Linux isn't a purely egalitarian utopia. Linus Torvalds doesn't approve everything that goes into the kernel, but he does preside over its changes. He's installed a dozen or so people below him to manage different parts of the kernel. They, in turn, trust people under themselves, and so on, in a pyramid of trust. Changes might come from anywhere, but they're all judged and curated.
**26:00** - *Saron Yitbarek*
It is amazing, though, to think how humble, and kind of random, Linus' DIY project was to begin with. He didn't have a clue he was the Luke Skywalker figure in all this. He was just 21, and had been programming half his life. But this was the first time the silo opened up, and people started giving him feedback. Dozens, then hundreds, and thousands of contributors. With crowdsourcing like that, it doesn't take long before Linux starts growing. Really growing. It even finally gets noticed by Microsoft. Their CEO, Steve Ballmer, called Linux, and I quote, "A cancer that attaches itself in an intellectual property sense to everything it touches." Steven Levy describes where Ballmer was coming from.
**26:30** - *Steven Levy*
Once Microsoft really solidified its monopoly, and indeed it was judged in federal court as a monopoly, anything that could be a threat to that, they reacted very strongly to. So of course, the idea that free software would be emerging, when they were charging for software, they saw as a cancer. They tried to come up with an intellectual property theory about why this was going to be bad for consumers.
**27:00** - *Saron Yitbarek*
Linux was spreading, and Microsoft was worried. By 2006, Linux would become the second most widely used operating system after Windows, with about 5,000 developers working on it worldwide. Five thousand. Remember that memo that Bill Gates sent to Apple, the one where he's lecturing them about the importance of partnering with other people? Turns out, open source would take that idea of partnerships to a whole new level, in a way Bill Gates would have never foreseen.
**27:30** - *Saron Yitbarek*
We've been talking about these huge battles for the OS, but so far, the unsung heroes, the developers, haven't fully made it onto the battlefield. That changes next time, on Command Line Heroes. In episode two, part two of the OS wars, it's the rise of Linux. Businesses wake up, and realize the importance of developers.
**28:00** - *Saron Yitbarek*
These open source rebels grow stronger, and the battlefield shifts from the desktop to the server room. There's corporate espionage, new heroes, and the unlikeliest change of heart in tech history. It all comes to a head in the concluding half of the OS wars.
**28:30** - *Saron Yitbarek*
To get new episodes of Command Line Heroes delivered automatically for free, make sure you hit subscribe on Apple podcasts, Spotify, Google Play, or however you get your podcasts. Over the rest of the season, we're visiting the latest battlefields, the up-for-grab territories where the next generation of Command Line Heroes are making their mark. For more info, check us out at redhat.com/commandlineheroes. I'm Saron Yitbarek. Until next time, keep on coding.
### Keep going
### (Linux and) the enduring magic of UNIX
Ross Turk—Red Hatter, gadget lover, open source advocate—shares the reason why he fell in love with UNIX in his youth and how Linux® has kept that love going for 25 years.
### How to install SQL Server 2017 on Red Hat Enterprise Linux with Ansible
Learn how to get started with Microsoft SQL Server 2017 on Red Hat® Enterprise Linux 7. |
12,496 | 使用 PowerDNS 轻松配置 DNS 名称服务器 | https://opensource.com/article/20/5/powerdns | 2020-08-07T20:30:00 | [
"DNS"
] | https://linux.cn/article-12496-1.html |
>
> 使用 PDNS 为你的项目提供稳定可靠的域名系统(DNS)服务器。
>
>
>

几个月前,我们接到了一个要求,为一个新项目提供一个稳定可靠的域名系统([DNS](https://en.wikipedia.org/wiki/Domain_Name_System))服务器。该项目使用容器进行自动部署,每个新环境都会生成唯一的随机 URL。在对可能的方案进行了大量研究之后,我们决定尝试一下 [PowerDNS](https://www.powerdns.com/opensource.html)(PDNS)。
一开始,我们发现 PowerDNS 在所有主流 Linux 发行版中都得到了支持,它采用 GPL 许可,且仓库保持更新。我们还在官方网站上发现了整洁、组织良好的[文档](https://doc.powerdns.com/),以及大量来自真正喜欢和使用该产品的人在网络上的使用方法。看了一些并学习了一些基本命令之后,安装了 PDNS,启动并运行,我们的旅程开始了。
### 数据库驱动
PowerDNS 将记录保存在 SQL 数据库中。这对我们来说是新变化,不必使用文本文件来保存记录是一个不错的更改。我们选择 MariaDB 作为首选的强大工具,由于有大量的正确地设置来安装名称服务器的信息,我们可以完美地设置和加固我们的数据库。
### 简单配置
其次使我们感兴趣的是 PDNS 的所有功能都在配置文件中。`pdns.conf` 有许多选项,你可以通过添加或删除 `#` 号来启用或禁用这些选项。这真是太神奇了,因为它使我们有机会将这项新的服务集成到我们现有的基础架构中,并且只有我们想要的功能,不多也不少。一个简单的例子:
谁可以访问你的网络服务器?
```
webserver-allow-from=172.10.0.1,172.10.1.2
```
我可以转发基于域的请求吗?当然!
```
forward-zones=mylocal.io=127.0.0.1:5300
forward-zones+=example.com=172.10.0.5:53
forward-zones+=lucky.tech=172.10.1.5:53
```
### 包含 API
我们可以使用配置文件进行激活 API 服务,解决了我们开发团队的第一个需求,让我们见识到了 PDNS 的强大。这个功能让我们通过发送请求,简单、干净地创建、修改或删除 DNS 服务器中的记录。
这个 API 有一些基本的安全性参数,因此,只需几步,你就可以基于 IP 地址和预共享密钥验证的组合来控制谁有权与名称服务器进行交互。这是配置文件的样子:
```
api=yes
api-key=lkjdsfpoiernf
webserver-allow-from=172.10.7.13,172.10.7.5
```
### 日志
在日志方面,PDNS 做得非常出色。你可以使用日志文件和一个简单的内置 Web 服务器来监控服务器并查看计算机的运行状况。你可以使用浏览器查看服务器不同类型的统计信息,例如 CPU 使用率和收到的 DNS 查询。这非常有价值。例如,我们能够检测到一些“不太健康”的 PC,它们正在向我们的服务器发送与恶意流量相关的站点的 DNS 请求。深入查看日志后,我们可以看到流量来自何处,并对这些 PC 进行清理操作。
### 其他功能
这只是你使用 PowerDNS 可以做的所有事情的一点点。它还有更多的功能。它是一个拥有很多功能和特性的完整名称服务器,因此值得一试。
目前,我们尚未部署 [DNSSEC](https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions),但似乎只需点击一下即可将其快速投入生产环境。另外,在将递归服务与名称服务器分离时,PowerDNS 有个不错的方法。我了解到它还支持 [DNS RPZ](https://dnsrpz.info/)(响应策略区域),并且还提供了非常不错且设计良好的前端,可让你使用 Web 浏览器来管理服务器,如下图。

信不信由你,你只需花费几个小时了解 PDNS,就可以大大提高你对 DNS 和 IT 操作的了解。
---
via: <https://opensource.com/article/20/5/powerdns>
作者:[Jonathan Garrido](https://opensource.com/users/jgarrido) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A few months ago, we got a requirement to provide a stable and reliable Domain Name System ([DNS](https://en.wikipedia.org/wiki/Domain_Name_System)) server for a new project. The project dealt with auto-deployment using containers and where each new environment would generate a unique, random URL. After a lot of research on possible solutions, we decided to give [PowerDNS](https://www.powerdns.com/opensource.html) (PDNS) a try.
At the outset, we discovered that PowerDNS is supported in all major Linux distros, is available under the GPL license, and keeps its repositories up to date. We also found neat and well-organized [documentation](https://doc.powerdns.com/) on the official site and tons of how-to's around the web from people who really like and use the product. After reading a few pages and learning some basic commands, PDNS was installed, up, and running, and our journey began.
## Database-driven
PowerDNS keeps its records in a SQL database. This was new for us, and not having to use flat files to keep records was a good change. We picked MariaDB as our power tool of choice, and since there is tons of advance information about the proper settings for installing the nameserver, we could set up and harden our database flawlessly.
## Easy configuration
The second thing that engaged us was all the features PDNS has in its config file. This file, pdns.conf, has a lot of options that you can enable or disable just by adding or removing the # sign. This was truly amazing because it gave us the chance to integrate this new service into our current infrastructure with only the values that we want, no more, no less, just the features that we need. A quick example:
Who can access your webserver?
`webserver-allow-from=172.10.0.1,172.10.1.2`
Can I forward requests based in a domain? Sure!
```
forward-zones=mylocal.io=127.0.0.1:5300
forward-zones+=example.com=172.10.0.5:53
forward-zones+=lucky.tech=172.10.1.5:53
```
## API included
We could activate using this config file, and this is when we started to meet PDNS's "power" by solving the first request from our development team, the API service. This feature gave us the ability to send requests to simply and cleanly create, modify, or remove records in our DNS server.
This API has some basic security parameters, so in just a few steps, you can control who has the right to interact with the nameserver based on a combination of an IP address and a pre-share key as a way of authentication. Here's what the configuration for this looks like:
```
api=yes
api-key=lkjdsfpoiernf
webserver-allow-from=172.10.7.13,172.10.7.5
```
## Logging
PDNS does an extraordinary job when it comes to logging. You can monitor your server and see how the machine is doing by using the log files and a simple built-in web server. Using a browser, you can see different types of statistics from the machine, like CPU usage and the DNS queries received. This is very valuable—for example, we were able to detect a few "not-so-healthy" PCs that were sending DNS requests to our server looking for sites that are related to malicious traffic. After digging into the logs, we could see where traffic was coming from and do a clean operation on those PCs.
## Other features
This is only a glimpse of all the things you can do with PowerDNS; there is much more to it. It is a complete nameserver with a lot of features and functionalities that make it worth giving it a try.
At this moment, we are not implementing [DNSSEC](https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions), but it appears that it can be put into production quickly with just one click. Also, PowerDNS has a nice approach when it comes to separating the recursor service from the nameserver. I read that it also supports [DNS RPZ](https://dnsrpz.info/) (Response Policy Zones), and there are also some very nice and well-designed frontends available that let you manage your server using a simple web browser, like the one in the image below.
(PowerDNS documentation, MIT License)
Believe it or not, you can boost your knowledge about DNS and IT ops a lot just by expending a few hours "playing" with PDNS.
## 1 Comment |
12,497 | 开发者的福音:你需要知道的事 | https://opensource.com/article/19/2/developer-happiness | 2020-08-07T21:41:26 | [
"开发"
] | https://linux.cn/article-12497-1.html |
>
> 开发者需要快速编程的工具和自由,而不会因为合规性和安全性所困扰。
>
>
>

一个人需要合适的工具来完成工作。比如说没有比修车修到一半,却发现你没有完成工作的专业工具更沮丧的事情了。同样的道理也适用在开发者身上:你需要工具来发挥你的才能,而不会因为合规性和安全性的需求打断你的工作流程,这样你才可以更快速地编码。
根据 ActiveState 的研究《[2018 年开发者调查:开源运行时的痛苦](https://www.activestate.com/company/press/press-releases/activestate-developer-survey-examines-open-source-challenges/)》显示,超过一半的开发人员(具体为 51%),每天只需要花费 1-4 小时的时间进行编程。换句话说,大多数开发人员花费不到一半的时间编程。根据调查,一半的开发人员认为安全是他们最大的担忧之一,但是由于公司政策方面的原因,67% 的开发人员选择在编程时不添加新的语言。
结果是开发人员不得不投入更多的精力在非编码的活动上,例如在构建软件和语言之后检查软件的安全性和合规性标准。而且由于公司政策的原因,他们无法选择适合的开发工具或语言。他们的满意度会下降,同时风险提高。
因此,开发人员无法将时间投入在高价值的工作上。这会带来额外的商业风险,因为他们的软件上市时间变慢了,并且公司因为没有授权开发人员在不受公司政策影响的前提下决定“最佳的”技术的能力,从而增加了技术债务。
### 纳入安全性和合规性的工作流程
我们如何解决这个问题呢?一种方式是通过四个简单的步骤将安全性和合规性的工作流程集成到软件开发中:
#### 1、集中你的力量
获得所有相关人员的支持,这是一个经常被遗忘但却至关重要的第一步。确保考虑到了广泛的利益相关者,包括:
* 开发运维(DevOps)
* 开发人员
* 信息安全
* 合法/合规
* IT 安全
利益相关者想要了解相关的商业利益,因此要为消除软件构建后的安全和合规性检查点提供坚实的理由。你可以在构建你的商业案例中考虑以下任何一个(或者全部)因素:节省时间、机会成本和开发人员生产力。在开发流程中,你也可以通过集成安全性和合规性来避免语言的改造。
#### 2、寻找可信赖的资源
接下来,选择可使用的可信资源,以及他们的许可证和安全要求。考虑到如下相关信息:
* 基于环境或应用程序类型的使用限制以及每种语言的版本控制
* 允许哪些开源组件,例如,特定的程序包
* 哪种环境类型可以使用哪种许可证(例如,研究与生产)
* 安全级别的定义、可接受的脆弱性风险等级、什么样的风险级别会触发一个措施,这个措施是什么并且谁来负责它的执行
#### 3、从一开始就纳入安全性和合规性
纳入安全性和合规性的工作流程的结果是,它最终将安全性和合规性融入到代码的第一行。它消除了公司政策的拖累,因为你是按照规范进行编码,而不是必须事后解决问题。但要做到这一点,请考虑在构建代码时采用自动扫描代码的机制,以及使用无代理监控你的运行时代码。你可以节省时间,还可以通过编程实施策略来确保整个组织的合规性。
#### 4、监控、报告和更新
出现新的漏洞,新的补丁和版本也会出现。所以,将代码部署到生产中以及运行代码时,需要考虑安全性和合规性。你需要知道哪些(如果有的话)代码存在风险以及该代码在何处运行。所以,部署和运行代码的过程应该包括监视、报告和更新生产中的代码。
通过一开始就在你的软件开发过程中集成安全性和合规性,你还可以在部署后跟踪代码的运行位置,并在新的威胁出现时获得警报。你也能追踪当你的应用程序何时受到攻击,并通过自动执行软件策略做出响应。
如果你的软件开发过程中已经引入了安全性和合规性的工作流程,你将会提高你的生产率。你将能够通过增加编码时间、提高安全性和稳定性、以及在维护和发现安全性和合规性的威胁方面节省的成本和时间来衡量价值。
### 集成所带来的幸福
如果你不开发和更新软件,你的组织将无法前进。开发人员是公司成功的关键,这意味着他们需要快速编写代码的工具和自由。尽管合规性和安全性至关重要,但你不能让这个需求阻碍你的发展。开发人员显然很担心安全性,因此最好的办法就是“左移”,从一开始就集成安全性和合规性的工作流程。你将可以做更多的事情,在第一次就可以完成,而花费更少的时间进行代码更新。
---
via: <https://opensource.com/article/19/2/developer-happiness>
作者:[Bart Copeland](https://opensource.com/users/bartcopeland) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A person needs the right tools for the job. There's nothing as frustrating as getting halfway through a car repair, for instance, only to discover you don't have the specialized tool you need to complete the job. The same concept applies to developers: you need the tools to do what you are best at, without disrupting your workflow with compliance and security needs, so you can produce code faster.
Over half—51%, to be specific—of developers spend only one to four hours each day programming, according to ActiveState's recent [Developer Survey 2018: Open Source Runtime Pains](https://www.activestate.com/company/press/press-releases/activestate-developer-survey-examines-open-source-challenges/). In other words, the majority of developers spend less than half of their time coding. According to the survey, 50% of developers say security is one of their biggest concerns, but 67% of developers choose not to add a new language when coding because of the difficulties related to corporate policies.
The result is developers have to devote time to non-coding activities like retrofitting software for security and compliance criteria checked after software and languages have been built. And they won't choose the best tool or language for the job because of corporate policies. Their satisfaction goes down and risk goes up.
So, developers aren't able to devote time to high-value work. This creates additional business risk because their time-to-market is slowed, and the organization increases tech debt by not empowering developers to decide on "the best" tech, unencumbered by corporate policy drag.
## Baking in security and compliance workflows
How can we solve this issue? One way is to integrate security and compliance workflows into the software development process in four easy steps:
### 1. Gather your forces
Get support from everyone involved. This is an often-forgotten but critical first step. Make sure to consider a wide range of stakeholders, including:
- DevOps
- Developers
- InfoSec
- Legal/compliance
- IT security
Stakeholders want to understand the business benefits, so make a solid case for eliminating the security and compliance checkpoints after software builds. You can consider any (or all) of the following in building your business case: time savings, opportunity cost, and developer productivity. By integrating security and compliance workflows into the development process, you also avoid retrofitting of languages.
### 2. Find trustworthy sources
Next, choose the trusted sources that can be used, along with their license and security requirements. Consider including information such as:
- Restrictions on usage based on environment or application type and version controls per language
- Which open source components are allowable, e.g., specific packages
- Which licenses can be used in which types of environments (e.g., research vs. production)
- The definition of security levels, acceptable vulnerability risk levels, what risk levels trigger an action, what that action would be, and who would be responsible for its implementation
### 3. Incorporate security and compliance from day one
The upshot of incorporating security and compliance workflows is that it ultimately bakes security and compliance into the first line of code. It eliminates the drag of corporate policy because you're coding to spec versus having to fix things after the fact. But to do this, consider mechanisms for automatically scanning code as it's being built, along with using agentless monitoring of your runtime code. You're freeing up your time, and you'll also be able to programmatically enforce policies to ensure compliance across your entire organization.
### 4. Monitor, report, and update
New vulnerabilities arise, and new patches and versions become available. Consequently, security and compliance need to be considered when deploying code into production and also when running code. You need to know what, if any, code is at risk and where that code is running. So, the process for deploying and running code should include monitoring, reporting, and updating code in production.
By integrating security and compliance into your software development process from the start, you can also benefit by tracking where your code is running once deployed and be alerted of new threats as they arise. You will be able to track when your applications were vulnerable and respond with automatic enforcement of your software policies.
If your software development process has security and compliance workflows baked in, you will improve your productivity. And you'll be able to measure value through increased time spent coding; gains in security and stability; and cost- and time-savings in maintenance and discovery of security and compliance threats.
## Happiness through integration
If you don't develop and update software, your organization can't go forward. Developers are a linchpin in the success of your company, which means they need the tools and the freedom to code quickly. You can't let compliance and security needs—though they are critical—bog you down. Developers clearly worry about security, so the happy medium is to "shift left" and integrate security and compliance workflows from the start. You'll get more done, get it right the first time, and spend far less time retrofitting code.
## Comments are closed. |
12,499 | 使用 ZeroMQ 消息库在 C 和 Python 间共享数据 | https://opensource.com/article/20/3/zeromq-c-python | 2020-08-08T20:21:31 | [
"ZeroMQ"
] | https://linux.cn/article-12499-1.html |
>
> ZeroMQ 是一个快速灵活的消息库,用于数据收集和不同编程语言间的数据共享。
>
>
>

作为软件工程师,我有多次在要求完成指定任务时感到浑身一冷的经历。其中有一次,我必须在一些新的硬件基础设施和云基础设施之间写一个接口,这些硬件需要 C 语言,而云基础设施主要是用 Python。
实现的方式之一是 [用 C 写扩展模块](https://docs.python.org/3/extending/extending.html),Python 支持 C 扩展的调用。快速浏览文档后发现,这需要编写大量的 C 代码。这样做的话,在有些情况下效果还不错,但不是我喜欢的方式。另一种方式就是将两个任务放在不同的进程中,并使用 [ZeroMQ 消息库](https://zeromq.org/) 在两者之间交换消息。
在发现 ZeroMQ 之前,遇到这种类型的情况时,我选择了编写扩展的方式。这种方式不算太差,但非常费时费力。如今,为了避免那些问题,我将一个系统细分为独立的进程,通过 [通信套接字](https://en.wikipedia.org/wiki/Network_socket) 发送消息来交换信息。这样,不同的编程语言可以共存,每个进程也变简单了,同时也容易调试。
ZeroMQ 提供了一个更简单的过程:
1. 编写一小段 C 代码,从硬件读取数据,然后把发现的东西作为消息发送出去。
2. 使用 Python 编写接口,实现新旧基础设施之间的对接。
[Pieter Hintjens](https://en.wikipedia.org/wiki/Pieter_Hintjens) 是 ZeroMQ 项目发起者之一,他是个拥有 [有趣视角和作品](http://hintjens.com/) 的非凡人物。
### 准备
本教程中,需要:
* 一个 C 编译器(例如 [GCC](https://gcc.gnu.org/) 或 [Clang](https://clang.llvm.org/))
* [libzmq 库](https://github.com/zeromq/libzmq#installation-of-binary-packages-)
* [Python 3](https://www.python.org/downloads/)
* [ZeroMQ 的 Python 封装](https://zeromq.org/languages/python/)
Fedora 系统上的安装方法:
```
$ dnf install clang zeromq zeromq-devel python3 python3-zmq
```
Debian 和 Ubuntu 系统上的安装方法:
```
$ apt-get install clang libzmq5 libzmq3-dev python3 python3-zmq
```
如果有问题,参考对应项目的安装指南(上面附有链接)。
### 编写硬件接口库
因为这里针对的是个设想的场景,本教程虚构了包含两个函数的操作库:
* `fancyhw_init()` 用来初始化(设想的)硬件
* `fancyhw_read_val()` 用于返回从硬件读取的数据
将库的完整代码保存到文件 `libfancyhw.h` 中:
```
#ifndef LIBFANCYHW_H
#define LIBFANCYHW_H
#include <stdlib.h>
#include <stdint.h>
// This is the fictitious hardware interfacing library
void fancyhw_init(unsigned int init_param)
{
srand(init_param);
}
int16_t fancyhw_read_val(void)
{
return (int16_t)rand();
}
#endif
```
这个库可以模拟你要在不同语言实现的组件间交换的数据,中间有个随机数发生器。
### 设计 C 接口
下面从包含管理数据传输的库开始,逐步实现 C 接口。
#### 需要的库
开始先加载必要的库(每个库的作用见代码注释):
```
// For printf()
#include <stdio.h>
// For EXIT_*
#include <stdlib.h>
// For memcpy()
#include <string.h>
// For sleep()
#include <unistd.h>
#include <zmq.h>
#include "libfancyhw.h"
```
#### 必要的参数
定义 `main` 函数和后续过程中必要的参数:
```
int main(void)
{
const unsigned int INIT_PARAM = 12345;
const unsigned int REPETITIONS = 10;
const unsigned int PACKET_SIZE = 16;
const char *TOPIC = "fancyhw_data";
...
```
#### 初始化
所有的库都需要初始化。虚构的那个只需要一个参数:
```
fancyhw_init(INIT_PARAM);
```
ZeroMQ 库需要实打实的初始化。首先,定义对象 `context`,它是用来管理全部的套接字的:
```
void *context = zmq_ctx_new();
if (!context)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
```
之后定义用来发送数据的套接字。ZeroMQ 支持若干种套接字,各有其用。使用 `publish` 套接字(也叫 `PUB` 套接字),可以复制消息并分发到多个接收端。这使得你可以让多个接收端接收同一个消息。没有接收者的消息将被丢弃(即不会入消息队列)。用法如下:
```
void *data_socket = zmq_socket(context, ZMQ_PUB);
```
套接字需要绑定到一个具体的地址,这样客户端就知道要连接哪里了。本例中,使用了 [TCP 传输层](https://en.wikipedia.org/wiki/Transmission_Control_Protocol)(当然也有 [其它选项](http://zguide.zeromq.org/page:all#Plugging-Sockets-into-the-Topology),但 TCP 是不错的默认选择):
```
const int rb = zmq_bind(data_socket, "tcp://*:5555");
if (rb != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
```
下一步, 计算一些后续要用到的值。 注意下面代码中的 `TOPIC`,因为 `PUB` 套接字发送的消息需要绑定一个主题。主题用于供接收者过滤消息:
```
const size_t topic_size = strlen(TOPIC);
const size_t envelope_size = topic_size + 1 + PACKET_SIZE * sizeof(int16_t);
printf("Topic: %s; topic size: %zu; Envelope size: %zu\n", TOPIC, topic_size, envelope_size);
```
#### 发送消息
启动一个发送消息的循环,循环 `REPETITIONS` 次:
```
for (unsigned int i = 0; i < REPETITIONS; i++)
{
...
```
发送消息前,先填充一个长度为 `PACKET_SIZE` 的缓冲区。本库提供的是 16 个位的有符号整数。因为 C 语言中 `int` 类型占用空间大小与平台相关,不是确定的值,所以要使用指定宽度的 `int` 变量:
```
int16_t buffer[PACKET_SIZE];
for (unsigned int j = 0; j < PACKET_SIZE; j++)
{
buffer[j] = fancyhw_read_val();
}
printf("Read %u data values\n", PACKET_SIZE);
```
消息的准备和发送的第一步是创建 ZeroMQ 消息,为消息分配必要的内存空间。空白的消息是用于封装要发送的数据的:
```
zmq_msg_t envelope;
const int rmi = zmq_msg_init_size(&envelope, envelope_size);
if (rmi != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_init_size(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
```
现在内存空间已分配,数据保存在 ZeroMQ 消息 “信封”中。函数 `zmq_msg_data()` 返回一个指向封装数据缓存区顶端的指针。第一部分是主题,之后是一个空格,最后是二进制数。主题和二进制数据之间的分隔符采用空格字符。需要遍历缓存区的话,使用类型转换和 [指针算法](https://en.wikipedia.org/wiki/Pointer_%28computer_programming%29%23C_and_C++)。(感谢 C 语言,让事情变得直截了当。)做法如下:
```
memcpy(zmq_msg_data(&envelope), TOPIC, topic_size);
memcpy((void*)((char*)zmq_msg_data(&envelope) + topic_size), " ", 1);
memcpy((void*)((char*)zmq_msg_data(&envelope) + 1 + topic_size), buffer, PACKET_SIZE * sizeof(int16_t))
```
通过 `data_socket` 发送消息:
```
const size_t rs = zmq_msg_send(&envelope, data_socket, 0);
if (rs != envelope_size)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_send(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
```
使用数据之前要先解除封装:
```
zmq_msg_close(&envelope);
printf("Message sent; i: %u, topic: %s\n", i, TOPIC);
```
#### 清理
C 语言不提供 [垃圾收集](https://en.wikipedia.org/wiki/Garbage_collection_(computer_science)) 功能,用完之后记得要自己扫尾。发送消息之后结束程序之前,需要运行扫尾代码,释放分配的内存:
```
const int rc = zmq_close(data_socket);
if (rc != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_close(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
const int rd = zmq_ctx_destroy(context);
if (rd != 0)
{
printf("Error occurred during zmq_ctx_destroy(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
```
#### 完整 C 代码
保存下面完整的接口代码到本地名为 `hw_interface.c` 的文件:
```
// For printf()
#include <stdio.h>
// For EXIT_*
#include <stdlib.h>
// For memcpy()
#include <string.h>
// For sleep()
#include <unistd.h>
#include <zmq.h>
#include "libfancyhw.h"
int main(void)
{
const unsigned int INIT_PARAM = 12345;
const unsigned int REPETITIONS = 10;
const unsigned int PACKET_SIZE = 16;
const char *TOPIC = "fancyhw_data";
fancyhw_init(INIT_PARAM);
void *context = zmq_ctx_new();
if (!context)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
void *data_socket = zmq_socket(context, ZMQ_PUB);
const int rb = zmq_bind(data_socket, "tcp://*:5555");
if (rb != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
const size_t topic_size = strlen(TOPIC);
const size_t envelope_size = topic_size + 1 + PACKET_SIZE * sizeof(int16_t);
printf("Topic: %s; topic size: %zu; Envelope size: %zu\n", TOPIC, topic_size, envelope_size);
for (unsigned int i = 0; i < REPETITIONS; i++)
{
int16_t buffer[PACKET_SIZE];
for (unsigned int j = 0; j < PACKET_SIZE; j++)
{
buffer[j] = fancyhw_read_val();
}
printf("Read %u data values\n", PACKET_SIZE);
zmq_msg_t envelope;
const int rmi = zmq_msg_init_size(&envelope, envelope_size);
if (rmi != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_init_size(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
memcpy(zmq_msg_data(&envelope), TOPIC, topic_size);
memcpy((void*)((char*)zmq_msg_data(&envelope) + topic_size), " ", 1);
memcpy((void*)((char*)zmq_msg_data(&envelope) + 1 + topic_size), buffer, PACKET_SIZE * sizeof(int16_t));
const size_t rs = zmq_msg_send(&envelope, data_socket, 0);
if (rs != envelope_size)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_send(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
zmq_msg_close(&envelope);
printf("Message sent; i: %u, topic: %s\n", i, TOPIC);
sleep(1);
}
const int rc = zmq_close(data_socket);
if (rc != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_close(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
const int rd = zmq_ctx_destroy(context);
if (rd != 0)
{
printf("Error occurred during zmq_ctx_destroy(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
```
用如下命令编译:
```
$ clang -std=c99 -I. hw_interface.c -lzmq -o hw_interface
```
如果没有编译错误,你就可以运行这个接口了。贴心的是,ZeroMQ `PUB` 套接字可以在没有任何应用发送或接受数据的状态下运行,这简化了使用复杂度,因为这样不限制进程启动的次序。
运行该接口:
```
$ ./hw_interface
Topic: fancyhw_data; topic size: 12; Envelope size: 45
Read 16 data values
Message sent; i: 0, topic: fancyhw_data
Read 16 data values
Message sent; i: 1, topic: fancyhw_data
Read 16 data values
...
...
```
输出显示数据已经通过 ZeroMQ 完成发送,现在要做的是让一个程序去读数据。
### 编写 Python 数据处理器
现在已经准备好从 C 程序向 Python 应用传送数据了。
#### 库
需要两个库帮助实现数据传输。首先是 ZeroMQ 的 Python 封装:
```
$ python3 -m pip install zmq
```
另一个就是 [struct 库](https://docs.python.org/3/library/struct.html),用于解码二进制数据。这个库是 Python 标准库的一部分,所以不需要使用 `pip` 命令安装。
Python 程序的第一部分是导入这些库:
```
import zmq
import struct
```
#### 重要参数
使用 ZeroMQ 时,只能向常量 `TOPIC` 定义相同的接收端发送消息:
```
topic = "fancyhw_data".encode('ascii')
print("Reading messages with topic: {}".format(topic))
```
#### 初始化
下一步,初始化上下文和套接字。使用 `subscribe` 套接字(也称为 `SUB` 套接字),它是 `PUB` 套接字的天生伴侣。这个套接字发送时也需要匹配主题。
```
with zmq.Context() as context:
socket = context.socket(zmq.SUB)
socket.connect("tcp://127.0.0.1:5555")
socket.setsockopt(zmq.SUBSCRIBE, topic)
i = 0
...
```
#### 接收消息
启动一个无限循环,等待接收发送到 `SUB` 套接字的新消息。这个循环会在你按下 `Ctrl+C` 组合键或者内部发生错误时终止:
```
try:
while True:
... # we will fill this in next
except KeyboardInterrupt:
socket.close()
except Exception as error:
print("ERROR: {}".format(error))
socket.close()
```
这个循环等待 `recv()` 方法获取的新消息,然后将接收到的内容从第一个空格字符处分割开,从而得到主题:
```
binary_topic, data_buffer = socket.recv().split(b' ', 1)
```
#### 解码消息
Python 此时尚不知道主题是个字符串,使用标准 ASCII 编解码器进行解码:
```
topic = binary_topic.decode(encoding = 'ascii')
print("Message {:d}:".format(i))
print("\ttopic: '{}'".format(topic))
```
下一步就是使用 `struct` 库读取二进制数据,它可以将二进制数据段转换为明确的数值。首先,计算数据包中数值的组数。本例中使用的 16 个位的有符号整数对应的是 `struct` [格式字符](https://docs.python.org/3/library/struct.html#format-characters) 中的 `h`:
```
packet_size = len(data_buffer) // struct.calcsize("h")
print("\tpacket size: {:d}".format(packet_size))
```
知道数据包中有多少组数据后,就可以通过构建一个包含数据组数和数据类型的字符串,来定义格式了(比如“`16h`”):
```
struct_format = "{:d}h".format(packet_size)
```
将二进制数据串转换为可直接打印的一系列数字:
```
data = struct.unpack(struct_format, data_buffer)
print("\tdata: {}".format(data))
```
#### 完整 Python 代码
下面是 Python 实现的完整的接收端:
```
#! /usr/bin/env python3
import zmq
import struct
topic = "fancyhw_data".encode('ascii')
print("Reading messages with topic: {}".format(topic))
with zmq.Context() as context:
socket = context.socket(zmq.SUB)
socket.connect("tcp://127.0.0.1:5555")
socket.setsockopt(zmq.SUBSCRIBE, topic)
i = 0
try:
while True:
binary_topic, data_buffer = socket.recv().split(b' ', 1)
topic = binary_topic.decode(encoding = 'ascii')
print("Message {:d}:".format(i))
print("\ttopic: '{}'".format(topic))
packet_size = len(data_buffer) // struct.calcsize("h")
print("\tpacket size: {:d}".format(packet_size))
struct_format = "{:d}h".format(packet_size)
data = struct.unpack(struct_format, data_buffer)
print("\tdata: {}".format(data))
i += 1
except KeyboardInterrupt:
socket.close()
except Exception as error:
print("ERROR: {}".format(error))
socket.close()
```
将上面的内容保存到名为 `online_analysis.py` 的文件。Python 代码不需要编译,你可以直接运行它。
运行输出如下:
```
$ ./online_analysis.py
Reading messages with topic: b'fancyhw_data'
Message 0:
topic: 'fancyhw_data'
packet size: 16
data: (20946, -23616, 9865, 31416, -15911, -10845, -5332, 25662, 10955, -32501, -18717, -24490, -16511, -28861, 24205, 26568)
Message 1:
topic: 'fancyhw_data'
packet size: 16
data: (12505, 31355, 14083, -19654, -9141, 14532, -25591, 31203, 10428, -25564, -732, -7979, 9529, -27982, 29610, 30475)
...
...
```
### 小结
本教程介绍了一种新方式,实现从基于 C 的硬件接口收集数据,并分发到基于 Python 的基础设施的功能。借此可以获取数据供后续分析,或者转送到任意数量的接收端去。它采用了一个消息库实现数据在发送者和处理者之间的传送,来取代同样功能规模庞大的软件。
本教程还引出了我称之为“软件粒度”的概念,换言之,就是将软件细分为更小的部分。这种做法的优点之一就是,使得同时采用不同的编程语言实现最简接口作为不同部分之间沟通的组件成为可能。
实践中,这种设计使得软件工程师能以更独立、合作更高效的方式做事。不同的团队可以专注于数据分析的不同方面,可以选择自己中意的实现工具。这种做法的另一个优点是实现了零代价的并行,因为所有的进程都可以并行运行。[ZeroMQ 消息库](https://zeromq.org/) 是个令人赞叹的软件,使用它可以让工作大大简化。
---
via: <https://opensource.com/article/20/3/zeromq-c-python>
作者:[Cristiano L. Fontana](https://opensource.com/users/cristianofontana) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've had moments as a software engineer when I'm asked to do a task that sends shivers down my spine. One such moment was when I had to write an interface between some new hardware infrastructure that requires C and a cloud infrastructure, which is primarily Python.
One strategy could be to [write an extension in C](https://docs.python.org/3/extending/extending.html), which Python supports by design. A quick glance at the documentation shows this would mean writing a good amount of C. That can be good in some cases, but it's not what I prefer to do. Another strategy is to put the two tasks in separate processes and exchange messages between the two with the [ZeroMQ messaging library](https://zeromq.org/).
When I experienced this type of scenario before discovering ZeroMQ, I went through the extension-writing path. It was not that bad, but it is very time-consuming and convoluted. Nowadays, to avoid that, I subdivide a system into independent processes that exchange information through messages sent over [communication sockets](https://en.wikipedia.org/wiki/Network_socket). With this approach, several programming languages can coexist, and each process is simpler and thus easier to debug.
ZeroMQ provides an even easier process:
- Write a small shim in C that reads data from the hardware and sends whatever it finds as a message.
- Write a Python interface between the new and existing infrastructure.
One of ZeroMQ's project's founders is [Pieter Hintjens](https://en.wikipedia.org/wiki/Pieter_Hintjens), a remarkable person with [interesting views and writings](http://hintjens.com/).
## Prerequisites
For this tutorial, you will need:
- A C compiler (e.g.,
[GCC](https://gcc.gnu.org/)or[Clang](https://clang.llvm.org/)) - The
**libzmq**library [Python 3](https://www.python.org/downloads/)[ZeroMQ bindings](https://zeromq.org/languages/python/)for python
Install them on Fedora with:
`$ dnf install clang zeromq zeromq-devel python3 python3-zmq`
For Debian or Ubuntu:
`$ apt-get install clang libzmq5 libzmq3-dev python3 python3-zmq`
If you run into any issues, refer to each project's installation instructions (which are linked above).
## Writing the hardware-interfacing library
Since this is a hypothetical scenario, this tutorial will write a fictitious library with two functions:
**fancyhw_init()**to initiate the (hypothetical) hardware**fancyhw_read_val()**to return a value read from the hardware
Save the library's full source code to a file named **libfancyhw.h**:
```
#ifndef LIBFANCYHW_H
#define LIBFANCYHW_H
#include <stdlib.h>
#include <stdint.h>
// This is the fictitious hardware interfacing library
void fancyhw_init(unsigned int init_param)
{
srand(init_param);
}
int16_t fancyhw_read_val(void)
{
return (int16_t)rand();
}
#endif
```
This library can simulate the data you want to pass between languages, thanks to the random number generator.
## Designing a C interface
The following will go step-by-step through writing the C interface—from including the libraries to managing the data transfer.
### Libraries
Begin by loading the necessary libraries (the purpose of each library is in a comment in the code):
```
// For printf()
#include <stdio.h>
// For EXIT_*
#include <stdlib.h>
// For memcpy()
#include <string.h>
// For sleep()
#include <unistd.h>
#include <zmq.h>
#include "libfancyhw.h"
```
### Significant parameters
Define the **main** function and the significant parameters needed for the rest of the program:
```
int main(void)
{
const unsigned int INIT_PARAM = 12345;
const unsigned int REPETITIONS = 10;
const unsigned int PACKET_SIZE = 16;
const char *TOPIC = "fancyhw_data";
...
```
### Initialization
Both libraries need some initialization. The fictitious one needs just one parameter:
`fancyhw_init(INIT_PARAM);`
The ZeroMQ library needs some real initialization. First, define a **context**—an object that manages all the sockets:
```
void *context = zmq_ctx_new();
if (!context)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
```
Then define the socket used to deliver data. ZeroMQ supports several types of sockets, each with its application. Use a **publish** socket (also known as **PUB** socket), which can deliver copies of a message to multiple receivers. This approach enables you to attach several receivers that will all get the same messages. If there are no receivers, the messages will be discarded (i.e., they will not be queued). Do this with:
`void *data_socket = zmq_socket(context, ZMQ_PUB);`
The socket must be bound to an address so that the clients know where to connect. In this case, use the [TCP transport layer](https://en.wikipedia.org/wiki/Transmission_Control_Protocol) (there are [other options](http://zguide.zeromq.org/page:all#Plugging-Sockets-into-the-Topology), but TCP is a good default choice):
```
const int rb = zmq_bind(data_socket, "tcp://*:5555");
if (rb != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
```
Next, calculate some useful values that you will need later. Note **TOPIC** in the code below; **PUB** sockets need a topic to be associated with the messages they send. Topics can be used by the receivers to filter messages:
```
const size_t topic_size = strlen(TOPIC);
const size_t envelope_size = topic_size + 1 + PACKET_SIZE * sizeof(int16_t);
printf("Topic: %s; topic size: %zu; Envelope size: %zu\n", TOPIC, topic_size, envelope_size);
```
### Sending messages
Start a loop that sends **REPETITIONS** messages:
```
for (unsigned int i = 0; i < REPETITIONS; i++)
{
...
```
Before sending a message, fill a buffer of **PACKET_SIZE** values. The library provides signed integers of 16 bits. Since the dimension of an **int** in C is not defined, use an **int** with a specific width:
```
int16_t buffer[PACKET_SIZE];
for (unsigned int j = 0; j < PACKET_SIZE; j++)
{
buffer[j] = fancyhw_read_val();
}
printf("Read %u data values\n", PACKET_SIZE);
```
The first step in message preparation and delivery is creating a ZeroMQ message and allocating the memory necessary for your message. This empty message is an envelope to store the data you will ship:
```
zmq_msg_t envelope;
const int rmi = zmq_msg_init_size(&envelope, envelope_size);
if (rmi != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_init_size(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
```
Now that the memory is allocated, store the data in the ZeroMQ message "envelope." The **zmq_msg_data()** function returns a pointer to the beginning of the buffer in the envelope. The first part is the topic, followed by a space, then the binary data. Add whitespace as a separator between the topic and the data. To move along the buffer, you have to play with casts and [pointer arithmetic](https://en.wikipedia.org/wiki/Pointer_%28computer_programming%29%23C_and_C++). (Thank you, C, for making things straightforward.) Do this with:
```
memcpy(zmq_msg_data(&envelope), TOPIC, topic_size);
memcpy((void*)((char*)zmq_msg_data(&envelope) + topic_size), " ", 1);
memcpy((void*)((char*)zmq_msg_data(&envelope) + 1 + topic_size), buffer, PACKET_SIZE * sizeof(int16_t));
```
Send the message through the **data_socket**:
```
const size_t rs = zmq_msg_send(&envelope, data_socket, 0);
if (rs != envelope_size)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_send(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
```
Make sure to dispose of the envelope after you use it:
```
zmq_msg_close(&envelope);
printf("Message sent; i: %u, topic: %s\n", i, TOPIC);
```
### Clean it up
Because C does not provide [garbage collection](https://en.wikipedia.org/wiki/Garbage_collection_(computer_science)), you have to tidy up. After you are done sending your messages, close the program with the clean-up needed to release the used memory:
```
const int rc = zmq_close(data_socket);
if (rc != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_close(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
const int rd = zmq_ctx_destroy(context);
if (rd != 0)
{
printf("Error occurred during zmq_ctx_destroy(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
```
### The entire C program
Save the full interface library below to a local file called **hw_interface.c**:
```
// For printf()
#include <stdio.h>
// For EXIT_*
#include <stdlib.h>
// For memcpy()
#include <string.h>
// For sleep()
#include <unistd.h>
#include <zmq.h>
#include "libfancyhw.h"
int main(void)
{
const unsigned int INIT_PARAM = 12345;
const unsigned int REPETITIONS = 10;
const unsigned int PACKET_SIZE = 16;
const char *TOPIC = "fancyhw_data";
fancyhw_init(INIT_PARAM);
void *context = zmq_ctx_new();
if (!context)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
void *data_socket = zmq_socket(context, ZMQ_PUB);
const int rb = zmq_bind(data_socket, "tcp://*:5555");
if (rb != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_ctx_new(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
const size_t topic_size = strlen(TOPIC);
const size_t envelope_size = topic_size + 1 + PACKET_SIZE * sizeof(int16_t);
printf("Topic: %s; topic size: %zu; Envelope size: %zu\n", TOPIC, topic_size, envelope_size);
for (unsigned int i = 0; i < REPETITIONS; i++)
{
int16_t buffer[PACKET_SIZE];
for (unsigned int j = 0; j < PACKET_SIZE; j++)
{
buffer[j] = fancyhw_read_val();
}
printf("Read %u data values\n", PACKET_SIZE);
zmq_msg_t envelope;
const int rmi = zmq_msg_init_size(&envelope, envelope_size);
if (rmi != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_init_size(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
memcpy(zmq_msg_data(&envelope), TOPIC, topic_size);
memcpy((void*)((char*)zmq_msg_data(&envelope) + topic_size), " ", 1);
memcpy((void*)((char*)zmq_msg_data(&envelope) + 1 + topic_size), buffer, PACKET_SIZE * sizeof(int16_t));
const size_t rs = zmq_msg_send(&envelope, data_socket, 0);
if (rs != envelope_size)
{
printf("ERROR: ZeroMQ error occurred during zmq_msg_send(): %s\n", zmq_strerror(errno));
zmq_msg_close(&envelope);
break;
}
zmq_msg_close(&envelope);
printf("Message sent; i: %u, topic: %s\n", i, TOPIC);
sleep(1);
}
const int rc = zmq_close(data_socket);
if (rc != 0)
{
printf("ERROR: ZeroMQ error occurred during zmq_close(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
const int rd = zmq_ctx_destroy(context);
if (rd != 0)
{
printf("Error occurred during zmq_ctx_destroy(): %s\n", zmq_strerror(errno));
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
```
Compile using the command:
`$ clang -std=c99 -I. hw_interface.c -lzmq -o hw_interface`
If there are no compilation errors, you can run the interface. What's great is that ZeroMQ **PUB** sockets can run without any applications sending or retrieving data. That reduces complexity because there is no obligation in terms of which process needs to start first.
Run the interface:
```
$ ./hw_interface
Topic: fancyhw_data; topic size: 12; Envelope size: 45
Read 16 data values
Message sent; i: 0, topic: fancyhw_data
Read 16 data values
Message sent; i: 1, topic: fancyhw_data
Read 16 data values
...
...
```
The output shows the data being sent through ZeroMQ. Now you need an application to read the data.
## Write a Python data processor
You are now ready to pass the data from C to a Python application.
### Libraries
You need two libraries to help transfer data. First, you need ZeroMQ bindings in Python:
`$ python3 -m pip install zmq`
The other is the [ struct library](https://docs.python.org/3/library/struct.html), which decodes binary data. It's commonly available with the Python standard library, so there's no need to
**pip install**it.
The first part of the Python program imports both of these libraries:
```
import zmq
import struct
```
### Significant parameters
To use ZeroMQ, you must subscribe to the same topic used in the constant **TOPIC** above:
```
topic = "fancyhw_data".encode('ascii')
print("Reading messages with topic: {}".format(topic))
```
### Initialization
Next, initialize the context and the socket. Use a **subscribe** socket (also known as a **SUB** socket), which is the natural partner of the **PUB **socket. The socket also needs to subscribe to the right topic:
```
with zmq.Context() as context:
socket = context.socket(zmq.SUB)
socket.connect("tcp://127.0.0.1:5555")
socket.setsockopt(zmq.SUBSCRIBE, topic)
i = 0
...
```
### Receiving messages
Start an infinite loop that waits for new messages to be delivered to the SUB socket. The loop will be closed if you press **Ctrl+C** or if an error occurs:
```
try:
while True:
... # we will fill this in next
except KeyboardInterrupt:
socket.close()
except Exception as error:
print("ERROR: {}".format(error))
socket.close()
```
The loop waits for new messages to arrive with the **recv()** method. Then it splits whatever is received at the first space to separate the topic from the content:
`binary_topic, data_buffer = socket.recv().split(b' ', 1)`
### Decoding messages
Python does yet not know that the topic is a string, so decode it using the standard ASCII encoding:
```
topic = binary_topic.decode(encoding = 'ascii')
print("Message {:d}:".format(i))
print("\ttopic: '{}'".format(topic))
```
The next step is to read the binary data using the **struct** library, which can convert shapeless binary blobs to significant values. First, calculate the number of values stored in the packet. This example uses 16-bit signed integers that correspond to an "h" in the **struct** [format](https://docs.python.org/3/library/struct.html#format-characters):
```
packet_size = len(data_buffer) // struct.calcsize("h")
print("\tpacket size: {:d}".format(packet_size))
```
By knowing how many values are in the packet, you can define the format by preparing a string with the number of values and their types (e.g., "**16h**"):
`struct_format = "{:d}h".format(packet_size)`
Convert that binary blob to a series of numbers that you can immediately print:
```
data = struct.unpack(struct_format, data_buffer)
print("\tdata: {}".format(data))
```
### The full Python program
Here is the complete data receiver in Python:
```
#! /usr/bin/env python3
import zmq
import struct
topic = "fancyhw_data".encode('ascii')
print("Reading messages with topic: {}".format(topic))
with zmq.Context() as context:
socket = context.socket(zmq.SUB)
socket.connect("tcp://127.0.0.1:5555")
socket.setsockopt(zmq.SUBSCRIBE, topic)
i = 0
try:
while True:
binary_topic, data_buffer = socket.recv().split(b' ', 1)
topic = binary_topic.decode(encoding = 'ascii')
print("Message {:d}:".format(i))
print("\ttopic: '{}'".format(topic))
packet_size = len(data_buffer) // struct.calcsize("h")
print("\tpacket size: {:d}".format(packet_size))
struct_format = "{:d}h".format(packet_size)
data = struct.unpack(struct_format, data_buffer)
print("\tdata: {}".format(data))
i += 1
except KeyboardInterrupt:
socket.close()
except Exception as error:
print("ERROR: {}".format(error))
socket.close()
```
Save it to a file called **online_analysis.py**. Python does not need to be compiled, so you can run the program immediately.
Here is the output:
```
$ ./online_analysis.py
Reading messages with topic: b'fancyhw_data'
Message 0:
topic: 'fancyhw_data'
packet size: 16
data: (20946, -23616, 9865, 31416, -15911, -10845, -5332, 25662, 10955, -32501, -18717, -24490, -16511, -28861, 24205, 26568)
Message 1:
topic: 'fancyhw_data'
packet size: 16
data: (12505, 31355, 14083, -19654, -9141, 14532, -25591, 31203, 10428, -25564, -732, -7979, 9529, -27982, 29610, 30475)
...
...
```
## Conclusion
This tutorial describes an alternative way of gathering data from C-based hardware interfaces and providing it to Python-based infrastructures. You can take this data and analyze it or pass it off in any number of directions. It employs a messaging library to deliver data between a "gatherer" and an "analyzer" instead of having a monolithic piece of software that does everything.
This tutorial also increases what I call "software granularity." In other words, it subdivides the software into smaller units. One of the benefits of this strategy is the possibility of using different programming languages at the same time with minimal interfaces acting as shims between them.
In practice, this design allows software engineers to work both more collaboratively and independently. Different teams may work on different steps of the analysis, choosing the tool they prefer. Another benefit is the parallelism that comes for free since all the processes can run in parallel. The [ZeroMQ messaging library](https://zeromq.org/) is a remarkable piece of software that makes all of this much easier.
## 8 Comments |
12,501 | 开源绘画应用 Pinta 在 5 年后迎来新版本 | https://itsfoss.com/pinta-new-release/ | 2020-08-09T22:23:33 | [
"Pinta",
"绘画"
] | https://linux.cn/article-12501-1.html |
>
> 开源绘画应用 Pinta 时隔 5 年多迎来新版本。新版本修复了众多 BUG,并增加了新功能。
>
>
>
[Pinta](https://www.pinta-project.com/) 是一款[开源绘画应用,适用于 Linux](https://itsfoss.com/open-source-paint-apps/)、Windows 和 macOS。你可以用它来进行自由手绘/素描。你也可以用它在现有的图片上添加箭头、方框、文字等。

日前,Pinta 1.7 版本在时隔近 5 年后发布。让我们来看看新版本中都有哪些功能。
### Pinta 1.7 的新功能
以下是最新版本的 Pinta 带来的新功能:
* 可以在图片之间切换的标签视图
* 增加了一个平滑擦除工具
* 拖放 URL 以在 Pinta 中下载并打开图像进行编辑
* 铅笔工具可以在不同的混合模式之间切换
* 按住 Ctrl 键可以缩放“选定移动”工具
* 矩形选择工具现在在选区的每个角落显示不同的箭头光标
* 提高了与选区互动时的性能,特别是对大图像而言
还有许多 bug 修复,这应该会改善整个 Pinta 的体验。你可以在[官方发布说明](https://www.pinta-project.com/releases/1-7)中了解更多变化。
### 在 Ubuntu 和其他 Linux 发行版上安装 Pinta 1.7
对于 Ubuntu 和基于 Ubuntu 的 Linux 发行版,有一个[官方 PPA 可用](https://launchpad.net/~pinta-maintainers/+archive/ubuntu/pinta-stable)。如果你使用的是 Ubuntu 18.04 或 20.04,可以使用这个 PPA。
打开一个终端,使用下面的命令来添加新的仓库。你会被要求输入你的密码。你可能已经知道,当你在终端中输入密码时,不会有任何显示。只要输入密码,然后按回车键就可以了。
```
sudo add-apt-repository ppa:pinta-maintainers/pinta-stable
```
在 Ubuntu 18.04 和更高版本上已不再需要,但其他一些发行版可能需要更新缓存:
```
sudo apt update
```
现在用这个命令安装最新版本的 Pinta:
```
sudo apt install pinta
```
好的是,如果你之前安装了 Pinta 1.6,它就会更新到新版本。
#### 移除 Pinta
要删除通过 PPA 安装的 Pinta,请使用此命令:
```
sudo apt remove pinta
```
你还应该[删除此 PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/):
```
sudo add-apt-repository -r ppa:pinta-maintainers/pinta-stable
```
#### 在其他发行版上安装 Pinta
在我上次检查时,Pinta 1.7 还没有在 Fedora 或 AUR 上出现。你可以等待一段时间,或者下载源码自己试试。
* [下载 Pinta 1.7](https://www.pinta-project.com/releases/)
Pinta 团队也更新了用户指南,提供了详细的文档。如果你是新手或者想深入使用 Pinta,可以参考[本用户指南](https://www.pinta-project.com/user-guide/)进行参考。
### 结束语
我很高兴能看到 Pinta 的新版本。它是我编辑图像的常用工具,可以为教程添加箭头、方框和文字。最近我使用 [Shutter](https://itsfoss.com/install-shutter-ubuntu/) 来达到这个目的,但有了这个新版本,我也许会再次改用 Pinta。
你呢?你使用 Pinta 吗,或者你过去用过它吗?你期待使用新版本吗?
---
via: <https://itsfoss.com/pinta-new-release/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Open source painting and drawing application has a new release after more than 5 years. The new release fixes numerous bugs and adds new features.*
[Pinta](https://www.pinta-project.com/) is an [open source drawing application for Linux](https://itsfoss.com/open-source-paint-apps/), Windows and macOS. You can use it for freehand drawing/sketching. You may also use it to add arrows, boxes, text etc on an existing image.
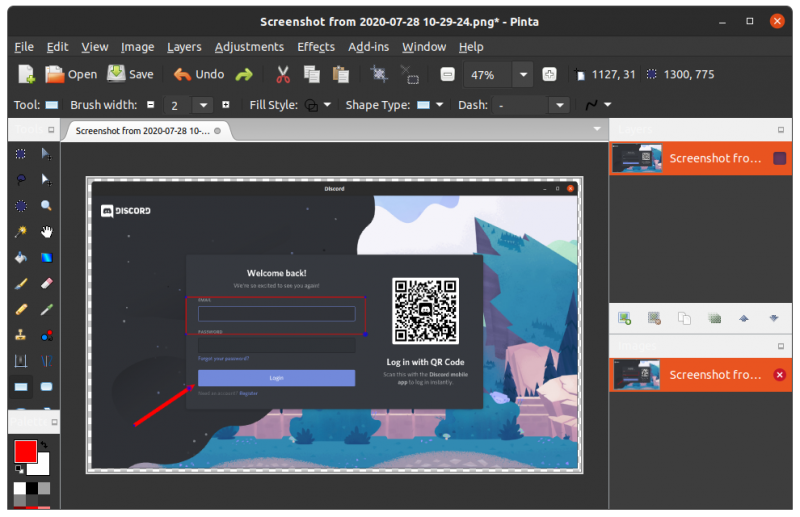
Pinta version 1.7 was released a few days ago after a gap of almost five years. Let’s see what do we have in the new version.
## New features in Pinta 1.7
Here are the new features the latest version of Pinta brings:
- Tab view to switch between images
- Addition of a Smooth Erase tool
- Drag and drop URL to download and open the image in Pinta for editing
- The Pencil tool can switch between different blend modes
- ‘Move Selected’ tool can be scaled by holding Ctrl
- The Rectangle Select tool now shows different arrow cursors at each corner of the selection
- Performance improvements when interacting with selections, particularly for large images
There are numerous bug fixes as well and this should improve the overall Pinta experience. You can learn about more changes in the [official release note](https://www.pinta-project.com/releases/1-7).
## Installing Pinta 1.7 on Ubuntu and other Linux distributions
For Ubuntu and Ubuntu-based Linux distributions, there is an [official PPA available](https://launchpad.net/~pinta-maintainers/+archive/ubuntu/pinta-stable). If you are using Ubuntu 18.04 or 20.04, you can use this PPA.
Open a terminal and use the following command to add the new repository. You’ll be asked to enter your password. You probably already know that when you type password in terminal, nothing is displayed. Just type the password and press enter.
`sudo add-apt-repository ppa:pinta-maintainers/pinta-stable`
Not required on Ubuntu 18.04 and higher version anymore but some other distributions may need to update the cache:
`sudo apt update`
Now install the latest version of Pinta using this command.
`sudo apt install pinta`
Good thing here is that if you had Pinta 1.6 installed previously, it gets updated to the new version.
### Removing Pinta
To remove Pinta installed via PPA, use this command:
`sudo apt remove pinta`
You should also [delete the PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/):
`sudo add-apt-repository -r ppa:pinta-maintainers/pinta-stable`
### Installing Pinta on other distributions
When I last checked Pinta 1.7 wasn’t available for Fedora or AUR yet. You may wait for some time or download the source code and try it on your own.
Pinta team has also refreshed its user guide with detailed documentation. If you are new to Pinta or if you want to use it extensively, you may refer to [this user guide](https://www.pinta-project.com/user-guide/) for reference.
**Conclusion**
I am happy to see a new release of Pinta. It was my go-to tool for editing images to add arrows, boxes and text for tutorials on It’s FOSS. I use [Shutter](https://itsfoss.com/install-shutter-ubuntu/) for this purpose these days but with this new release, I might perhaps switch to Pinta again.
What about you? Do you use Pinta or have you used it in the past? Are you looking forward to use the new version? |
12,502 | 个头小本事大:13 种 20 美元以下的树莓派 Zero 替代品 | https://itsfoss.com/raspberry-pi-zero-alternatives/ | 2020-08-10T14:38:55 | [
"树莓派"
] | https://linux.cn/article-12502-1.html | 最近两年,[树莓派 Zero](https://www.raspberrypi.org/products/raspberry-pi-zero/) 和 [树莓派 Zero W](https://itsfoss.com/raspberry-pi-zero-w/) 作为新成员出现在树莓派产品线中。这些超小型的单板计算机大受欢迎,而且会在相当长的一段时间内成为创客和 DIY 社区的 [树莓派项目](https://itsfoss.com/raspberry-pi-projects/) 的一部分。
为了实现更小尺寸和有效地控制价位,它们不得不在许多特性上做出让步,如放弃专用网口、采用更慢的处理器等(与其它们同族的全功能版相比)。
早先的一篇文章中,我们罗列了 [树莓派的最佳替代品](/article-10823-1.html)。这里,我将给出树莓派 Zero 和树莓派 Zero W 的一些替代品。
### 树莓派 Zero 替代品:应用于物联网和嵌入式项目的超小单板计算机

受益于开源设计和开源软件栈,我们有为不同项目提供的具有各种功能集的优秀替代品。所有这些板子运行的都是嵌入式 Linux 的各种变体。
尽管树莓派 Zero 和树莓派 Zero W 的发布价格分别是 5 美元和 10 美元,但即使是在美国境内,也很难按这个价格买到。在美国之外,更是要花 12 和 20 美元才有可能买到。
知道了这些,让我们看看一些 20 美元以下的树莓派 Zero 替代品。
#### 1、香蕉派 BPI M2 Zero

香蕉派 M2 Zero 售价 **18 美元**,与树莓派 Zero W 拥有相同的布局。它看起来像是树莓派 Zero W 的复制品,但也仅仅是外形像而已。它使用的是更快的全志 H2+ SOC 芯片,而且可以外接网络模块。它还可以运行多种基于 Linux 的操作系统。
**主要参数**
* 全志 H2+ 四核 Cortex-A7 处理器,Mali400MP2 GPU,H265/HEVC 1080P
* 512M DDR3 内存(与 GPU 共享)
* 40 针接口,与树莓派 3 兼容
* 板载 WiFi(AP6212)、蓝牙,外部天线连接口
* CSI 摄像头输入接口
* 电源及复位按钮
* Mini HDMI 视频输出
详情可参阅 [Banana Pi Wiki](http://wiki.banana-pi.org/Banana_Pi_BPI-M2_ZERO#Hardware_interfaces)。
#### 2、香蕉派 BPI-M2 Magic(BPi-M2M)

这个型号有 2 个变体,无板载 eMMC 闪存的标价 **20 美元**。这是相对其尺寸而言拥有更大处理能力的小型单板计算机。我觉得毫无疑问它很适合作为物联网和自动家居中的触控面板和显示面板。其板载电源管理系统也很有吸引力。
**主要参数**
* 全志 A33/R16 四核 ARM Cortex-A7 处理器,MALI 400 MP2 GPU
* 板载 802.11 b/g/n 2.4GHz WiFi(AP6212),蓝牙 4.0,支持 BLE
* 512MB DDR3(与 GPU 共享)
* MIPI 串行显示接口(DSI),4 数据通道
* CSI 摄像头输入接口,最大分辨率 1080p 时可达 30 帧/秒
* 板载话筒和电池管理
* 无 HDMI 输出
详情可参阅 [Banana Pi Wiki](http://wiki.banana-pi.org/Banana_Pi_BPI-M2M)。
#### 3、香蕉派 BPI-P2 Maker

它是带有板载网络模块及支持网口供电(POE)的最小的单板计算机之一,此板售价 **13 美元**(带有 POE 模块的版本售价 **19 美元**)。和香蕉派 M2 Zero 一样,使用的是全志 H2+ SOC 芯片,是块非常有趣的板子。它具有板载 8 GB eMMC 存储空间及摄像头接口,同时具有 POE 功能,可用于 DIY 监控摄像,也可以作为基本的机器学习处理器使用。
**主要参数**
* 处理器:全志 H2+,四核,Cortex-A7 架构
* 512MB DDR 3 同步动态随机存取内存
* 板载 WiFi(AP6212)和蓝牙
* 板载 8G eMMC 闪存
* 100M 网络
* Mini HDMI
* CSI 摄像头接口
* 具有 POE 模块,支持 IEEE 802.3af PoE 标准
详情可参阅 [Banana Pi Wiki](http://wiki.banana-pi.org/Banana_Pi_BPI-P2_Zero)。
#### 4、桔子派 Zero LTS

当前支持板载网络及 POE 的最小且最便宜的单板计算机,售价仅为 **11.49 美元**(256 MB 内存版本售价 **9.49 美元**)。其采用非常常见的全志 H2+ 处理器,并通过 GPIO 和 13 针功能头提供可靠的扩展方式。
**主要参数**
* 全志 H2+ 四核 Cortex-A7 架构处理器,视频支持 H.265/HEVC 1080P
* Mali400MP2 GPU @600MHz
* 256MB/512MB DDR3 SDRAM(与 GPU 共用)(256 MB 版为标准版)
* 10/100M 自适应网络,RJ45 网口,POE 功能默认关闭
* WiFi 使用 XR819 方案,支持 IEEE 802.11 b/g/n
* 26 针 GPIO 连接头
* 13 针连接头,包含 2 路 USB、红外线接口和声音端口(MIC、AV)
详情可参阅 [官方网站](http://www.orangepi.org/orangepizerolts/)。
#### 5、桔子派 i96

尺寸仅有 6×3 平方厘米,个头最小的型号之一,售价 **8.8 美元**。该板使用 [RDA8810PL 处理器](https://www.openhacks.com/uploadsproductos/2016030304473558.pdf),可作为相当先进的功能手机,(据厂商称)适合摄像应用,最高可以 30 帧/秒的速率采集 1080p 分辨率的图像。在同等价位产品中,输入输出功能出色。
**主要参数**
* RDA8810PL ARM Cortex-A5 32 位单核处理器
* Vivante 出品 GC860 GPU
* 集成 256MB LPDDR2 SDRAM
* RDA5991 方案的 WiFi 和蓝牙
* CSI 摄像头输入接口
* 40 针 GPIO 头
详情可参阅 [官方网站](http://www.orangepi.org/OrangePii96/)。
#### 6、桔子派 PC

该板售价 **15 美元**,包含了很多功能。是在同等价位板子中少有的集成了 1 GB 内存的型号之一。采用全志 H3 SoC 芯片,可解码 4K HEVC/H.265 视频。具有 HDMI 输出口并支持 HDCP 和 CEC。该单板计算机可以通过安装软件成为一个很好用的媒体盒子。它竟然还配备了板载红外接收器和话筒。
**主要参数**
* 全志 H3 四核 Cortex-A7 架构处理器,主频 1.6 GHz
* 1GB DDR3 内存(与 GPU 共享)
* 支持 4K 输出的 HDMI
* CSI 摄像头接口,板载话筒
* SD 卡槽
* IR 接收器
* 3.5mm 音频接口
* 网络接口
* 板上无 WiFi 和蓝牙
桔子派 PC 还有一种减配版,使用的是同样的处理器,只是内存容量要小。
详情可参阅 [官方网站](http://www.orangepi.org/orangepipc/)。
#### 7、桔子派 One 和桔子派 Lite
这两种板子与桔子派 PC 一样,使用的是全志 H3 处理器,但配备的是 512MB 内存。
**主要参数**
* 全志 H3 四核处理器
* HDMI 输出,支持 4K 高清
* SD 卡槽
* 512 MB DDR3 内存
* CSI 摄像头接口


桔子派 Lite 售价 **12 美元**,不支持板载有线网络,但提供了 WiFi 联网功能。其具有板载话筒和红外接收器。详情可参阅 [官方网站](http://www.orangepi.org/orangepilite/)。
桔子派 One 售价 **11 美元**,具有板载有线网络,但不支持 WiFi。详情可参阅 [官方网站](http://www.orangepi.org/orangepione/)。
在桔子派相关内容的最后,我想简单提一下他们提供的几种适合自定义应用的板子。
* 桔子派 R1 – 具有双有线网口的小板子,可用于构建网络设备。
* Orange Pi 2G IOT 和 Orange Pi 3G IOT - 这些板子分别提供了 2G 和 3G 蜂窝网络连接能力,适合作为物联网设备。
这些板子都不超过 **20 美元**,详情可参阅 [官方网站](http://www.orangepi.org)。
#### 8、NanoPi Neo LTS

起步价 **9.99 美元**,该板非常袖珍(4x4 平方厘米),与桔子派 Zero 规格相似。不同的是,它使用的是更为强悍的全志 H3 SoC 芯片和高达 512MB 的内存。虽然无任何板载 WiFi 和蓝牙芯片,但可以通过 USB 接口外接相关器件获得相应功能。该板非常适合作为无显示器的 Linux 服务器、DNS 过滤器(如 Pi-Hole),同时也很适合作为物联网应用的边缘设备使用。通过 GPIO 可以扩展出你需要的很多功能。
**主要参数**
* 全志 H3 四核处理器,Cortex A7 内核,主频 1.2 GHz
* 512 MB 内存
* Micro SD 卡槽(最高支持 128 GB)
* 10/100 Mbps 网口
* 冗余 GPIO 针可实现其它所需功能
可从 [官方网站](https://www.friendlyarm.com/index.php?route=product/product&path=69&product_id=132&sort=p.price&order=ASC) 了解详情及购买。

NanoPi NEO 的极简版称为 NanoPi NEO Core LTS,该极简版为满足工业应用需求增加了 eMMC 存储,且通过扩展 GPIO 提供了板载 USB 接口和板载网络接口。详情参阅 [这里](https://www.friendlyarm.com/index.php?route=product/product&path=69&product_id=212&sort=p.price&order=ASC)。

Nano NEO Air 的 WiFi/蓝牙版称为 NanoPi NEO Air,提供了 eMMC 存储和摄像头输入接口,提供了板载 USB 接口和板载网络接口。详情参阅 [这里](https://www.friendlyarm.com/index.php?route=product/product&path=69&product_id=151&sort=p.price&order=ASC).
#### 9、Zero Pi

这是所有这里提到的板子中,我最感兴趣的板子之一,售价 **9.99 美元**,具有板载千兆网口,使用全志 H3 处理器,小而强悍,适合应用于网络相关场景。它可以运行 OpenWRT,和其配备的千兆网络相得益彰。在作为 DNS 服务器运行的同时,还可以运行 Pi-Hole 的多个实例。
**主要参数**
* 全志 H3 四核处理器,Cortex A7 架构,主频最高 1.2GHz
* 512MB 内存
* USB 2.0 接口
* 可运行 OpenWRT
可从 [官方网站](https://www.friendlyarm.com/index.php?route=product/product&path=69&product_id=266&sort=p.price&order=ASC) 了解详情及下单购买。
#### 10、NanoPi NEO 2

NanoPi NEO 2 售价 **19.99 美元**,是 NanoPi NEO 的 2 倍。其外形尺寸与 NanoPi Neo 相同,但使用的是全志 H5 处理器,并配备了千兆网功能。这使得该板子个头小而性能强。
**主要参数**
* 全志 H5 处理器,四核 64 位,高性能 Cortex A53 架构
* Hexacore Mali450 GPU
* 512MB 内存
* 1Gbps 板载网络
* 24 针 GPIO
* 包含音频及红外之类功能的外接口
可从 [官方网站](https://www.friendlyarm.com/index.php?route=product/product&product_id=180) 了解详情及下单购买。
上面的链接是关于 NanoPi 系列板子的。除此之外,还有一些其它有趣的板子,如配备双千兆网口的,以及针对摄像头应用的。
#### 11、La Frite

出品商是 [Le Potato](https://libre.computer/products/boards/aml-s905x-cc/),售价 **20 美元**,主要面向媒体消费及流媒体。它通过 HDMI 2.0 接口以 HDR 方式实现 1080p 视频播放,支持最新的安卓 9 /电视、上游的 Linux、u-boot、Kodi 等。
**主要参数**
* Amlogic S805X 处理器,四核,Cortex-A53 架构,主频 1.2GHz
* 最大 1GB DDR4 SDRAM
* Amlogic 视频引擎 10,支持 H.264、H.265 和 VP9 解码,最高能以 60 帧/秒的速率实现 1080p 高清
* 百兆网
* 红外接器
* 40 针 GPIO
详情可参阅 [官方网站](https://libre.computer/products/boards/aml-s805x-ac/)。
#### 12、Onion Omega2+

如果你需要的是应用于物联网场景的单板计算机,那么 [Onion Omega](https://itsfoss.com/onion-omega-2/) 2+ 是替代树莓派 Zero 的很好选择。它是针对物联网的开发平台,运行的是基于 [OpenWRT](https://openwrt.org/) 的嵌入式 Linux 开发环境。
**主要参数**
* MT7688 SoC 芯片
* 2.4 GHz WiFi,支持 IEEE 802.11 b/g/n
* 128 MB DDR2 内存
* 32 MB 板载闪存
* MicroSD 卡槽
* USB 2.0
* 12 个 GPIO 引针
你可以 **13 美元** 的单价从 [官方网站](https://onion.io/) 购买其极简版,并可以选配各种附件。
#### 13、VoCore2

VoCore2 肯定是类似产品中最小的一款,极简版尺寸只有 1 英寸见方,售价 **17.99 美元**。小巧的尺寸使得其能方便的嵌入到不同的应用场合,而且允许根据需要扩充不同的特性。该板使用过的是联发科针对中低端路由器的处理器 MT7628 处理器。生产商声明将持续供应至 2025 年,这是个不错的消息。
**主要参数**
* 联发科 MT7628 处理器,主频 580 MHz,MIPS 24K
* 128MB DDR2 内存, 内存刷新率 166 MHz
* 1 或 5 网口,100 Mbps 网络
* 无线网,支持 802.11n,双收双发,网速最高 300Mbps
* 板载 16M NOR 存储器,支持最大 2TB SDXC 卡
* 一个板载 U.FL 槽(天线接口)
你可以从 [此处](https://vocore.io/v2.html) 了解更多细节。
### 结束语
无可否认,不同规格和特性的各种单板计算机可以满足千变万化的使用需求。另外,绝大部分此类产品都基于开源设计,运行着开源软件。这绝对是硬核玩家不可多得的乐园。
由于新冠病毒的肆虐,要上手这些板子可能要稍费周折,期待情况能尽快好转!
如果各位知道树莓派 Zero 和树莓派 Zero W 的其它有趣的替代型号,请留言。我们根据情况检查充实。
---
via: <https://itsfoss.com/raspberry-pi-zero-alternatives/>
作者:[Chinmay](https://itsfoss.com/author/chinmay/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The [Raspberry Pi Zero](https://www.raspberrypi.org/products/raspberry-pi-zero/?ref=itsfoss.com) and the [Raspberry Pi Zero W](https://itsfoss.com/raspberry-pi-zero-w/) were added to the line-up of Raspberry Pi’s a while back. These ultra-small form-factor SBC’s have been a big hit and continue to be a part of [Raspberry Pi projects](https://itsfoss.com/raspberry-pi-projects/) from the maker and DIY communities.
Due to the smaller form factor and the prices these boards are targeting, they have had to cut down on many features like a dedicated Ethernet port, slower processor (compared to their full-fledged cousins).
However, you can still build [some really cool projects](https://itsfoss.com/raspberry-pi-zero-projects/) with tiny Raspberry Pi Zero W like devices.
In an earlier article, we listed the [best alternatives to Raspberry Pi](https://itsfoss.com/raspberry-pi-alternatives/). In this one, I’ll list some alternatives to Raspberry Pi Zero and Zero W. These should be the perfect tiny single board computers for IoT and embedded systems.
**Suggested Read 📖**
[27 Super Cool Raspberry Pi Zero W Projects for DIY EnthusiastsThe small form factor of the Raspberry Pi Zero W enables a new range of projects. In fact, a lot of people use the Pi Zero in the final version of the project after prototyping on a different full-sized Pi board. And, that’s because it consumes much less power](https://itsfoss.com/raspberry-pi-zero-projects/)

## Why Do We Need Raspberry Pi Zero Alternatives?

Even though the **Raspberry Pi Zero was released at $5** and the **Zero W at $10**, it’s often **very challenging to find them at those prices** even in the US. Outside the US, they usually cost around $12 – $20.
Whether Raspberry Pi releases a successor to it when you read it (or discontinues the Zero), you will always find the replacements handy.
Sure, Raspberry Pi boards are considered as the de-facto standard. But, you might find the alternatives offering something better for your use-case.
While most of the board run a type of embedded Linux distro, you should be able to try other operating systems tailored for
Let's get started!
## 1. Banana Pi BPI M2 Zero

The Banana Pi M2 Zero, at **$18,** has the same layout as a Raspberry Pi Zero W. It looks like a clone of the Pi Zero W, but apart from the form factor, it is anything but a clone.
It has a faster **Allwinner H2+ SOC** at its heart, and Ethernet can be added externally. It can also run a variety of Linux based operating systems.
**Key Specifications**
- Allwinner H2+ Quad-core Cortex-A7 H265/HEVC 1080P with Mali400MP2 for the GPU.
- 512 MB DDR3 (Shared with GPU).
- 40 Pins Header, compatible with Raspberry Pi 3.
- Wi-Fi (AP6212) & Bluetooth onboard. Extra antenna connector.
- A CSI input connector Camera.
- Power and Reset Button.
- Mini HDMI Output.
You can get more information from the [Banana Pi Wiki](http://wiki.banana-pi.org/Banana_Pi_BPI-M2_ZERO?ref=itsfoss.com#Hardware_interfaces).
## 2. Banana Pi BPI-M2 Magic (BPi-M2M)

There are two variants of this board, the one **without the eMMC flash onboard** costs **$20**. It is another tiny SBC with quite a lot of processing power for its size.
Off the top of my head, this board is a good fit for a touch control panel and dashboard for IoT and home automation. The on-board battery management system is quite attractive.
**Key Specifications**
- Allwinner A33/R16 Quad Core ARM Cortex-A7, MALI 400 MP2 GPU.
- Wi-Fi 802.11 b/g/n 2.4GHz (AP6212) & BT v4.0 with BLE.
- 512 MB DDR3 (shared with GPU).
- MIPI Display Serial Interface (DSI) interface(4 data lanes).
- A CSI input connector Camera, video capture up-to 1080p at 30fps.
- Onboard microphone and battery management.
- No HDMI output.
You can get more information from the [Banana Pi Wiki](http://wiki.banana-pi.org/Banana_Pi_BPI-M2M?ref=itsfoss.com).
## 3. Banana Pi BPI-P2 Maker

This board, at **$13** (**$19** with POE module) is one of the smallest SBC’s with on board Ethernet and support for PoE (Power over Ethernet). With the same **Allwinner H2+ SOC **as the M2 zero, this is quite an interesting board.
It has an onboard eMMC storage of 8Gb and a camera interface, **with PoE you can convert this into a DIY security camera** and also use the powerful processor for basic ML.
**Key Specifications**
- Allwinner H2+, Quad-core Cortex-A7.
- 512 MB DDR 3 SDRAM.
- Wi-Fi (AP6212) & Bluetooth onboard.
- 8 GB eMMC flash onboard.
- Mini HDMI.
- CSI Camera Interface.
- IEEE 802.3af PoE standard PoE module support.
You can get more information from the [Banana Pi Wiki](http://wiki.banana-pi.org/Banana_Pi_BPI-P2_Zero?ref=itsfoss.com).
## 4. Orange Pi Zero LTS

At **$32.99** (**$9.49** for the 256 MB version) this is the smallest board with onboard Ethernet and POE functionality. It has the ever common **Allwinner H2+ at its heart** and a solid expansion options via the GPIO and the 13 pin functional header.
**Key Specifications**
- Allwinner H2+ Quad-core Cortex-A7 H.265/HEVC 1080P.
- Mali400MP2 GPU @600MHz.
- 256 MB/512 MB DDR3 SDRAM (Shared with GPU) (256 MB version is Standard version).
- 10/100M Ethernet RJ45, POE is default off.
- Wi-Fi with XR819, IEEE 802.11 b/g/n.
- 26 Pin GPIO Header.
- 13 Pins Header, with 2x USB, IR pin, AUDIO(MIC, AV).
You can get more information from their [official page](http://www.orangepi.org/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-Zero-LTS.html).
## 5. Orange Pi i96

At **$8.8** this board is the smallest one yet at 6 cm x 3 cm. It uses the [RDA8810PL SOC](https://www.openhacks.com/uploadsproductos/2016030304473558.pdf?ref=itsfoss.com) meant for a fairly advanced feature phone.
The board is **suited for camera applications** (according to the manufacturer) **can capture up to 1080p at 30fps**. It has a fairly good IO for the price.
**Key Specifications**
- RDA8810PL ARM Cortex-A5 32bit single core processor.
- Vivante’s GC860 GPU.
- Integrated 256 MB LPDDR2 SDRAM.
- Wi-Fi + BT using the RDA5991.
- CSI Camera Input.
- 40 pin GPIO header.
You can get more information from their [official page](http://www.orangepi.org/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-I96.html).
## 6. Orange Pi PC

This board packs in lots of goodies for **$15**. It’s one of the very few boards which offer 1 GB of RAM at such a price point. It uses the **Allwinner H3 SOC** and **can decode 4K HEVC/H.265 video**.
Furthermore, it has an **HDMI port with support for HDCP and CEC** as well. This SBC can make a good media box with the right software. It even has **an onboard IR Receiver** and a Microphone.
**Key Specifications**
- Allwinner H3 Quad-core Cortex-A7, 1.6GHz.
- 1 GB DDR3 (shared with GPU).
- HDMI with support for 4K video.
- CSI Camera interface and onboard microphone.
- SD Card slot.
There is also a cut down version of the Orange Pi PC powered by the same SOC but with less RAM.
You can get additional information from their [official page](http://www.orangepi.org/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-PC.html).
## 7. Orange Pi One & Orange Pi Lite
These two boards are also** powered by the Allwinner H3 SoC** used in the Orange Pi PC. But these come with 512 MB of RAM instead of the 1 GB offered by the Orange Pi PC.
**Key Specifications**
- Allwinner H3 Quad Core.
- HDMI with 4K support.
- SD Card slot.
- 512 MB of DDR3 RAM.
- CSI Camera Interface.

The **Orange Pi Lite** comes in at **$12**, it does not feature an on-board Ethernet and offers Wi-Fi instead. It also has an onboard microphone and IR receiver. You can get more info from their [official page](http://www.orangepi.org/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-Lite.html).
The **Orange Pi One** comes in at **$11** and features on-board Ethernet for wired networking and **does not offer any Wi-Fi support**. You can get further information from their [official page](http://www.orangepi.org/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-One.html).
## 8. Orange Pi Zero3

Powered by an **Allwinner H618 processor**, the Orange Pi Zero3 is a powerful offering for video processing use cases that **can also act as a TV box** with the right software.
The on-board ARM Mali-G31 MP2 GPU opens the door for support such as **4K display output**, **OpenGL ES 1.0/2.0/3.2**, **Vulkan 1.1**, **OpenCL 2.0 and more**.
**Key Specifications**
- Allwinner H618 Quad-Core Cortex-A53
- 1 GB/1.5 GB/2 GB/4 GB LPDDR4 RAM
- Gigabit Ethernet Port
- Type-C Power Supply
- Wi-Fi 5 + Bluetooth 5.0
You can grab Orange Pi Zero3 for as low as **$22.99** on Amazon for the 1 GB variant. You can also visit the [official website](http://www.orangepi.org/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-Zero-3.html) for more details.
Before we finish up with the Orange Pi boards, I do want to quickly mention a couple more boards that they offer for custom applications.
**Orange Pi R1**– This is a tiny board with dual Ethernet ports, you can use it to build a network device.**Orange Pi 2G IOT & Orange Pi 3G IOT –**These boards feature 2G & 3G cellular connectivity for IoT Applications.
These boards also cost less than **$20**, and you can check them out on their [official website](http://www.orangepi.org/?ref=itsfoss.com).
## 9. NanoPi Neo LTS

Starting at **$9**.**99**, this board is very simple and tiny(4 cm x 4 cm), a similar form factor as the Orange Pi Zero. Unlike the Orange Pi Zero, it is **powered by the more powerful Allwinner H3 SoC** and up to 512 MB of RAM.
It **does not feature any onboard Wi-Fi/BT chipset**, but you can add one via the USB port. This is** a really good board to run headless Linux servers** and DNS filters like Pi-Hole.
It’ll make a r**eally good edge device for any IoT Applications**. Using the GPIO you can expand the functionality to match your needs.
**Key Specifications**
- Allwinner H3 Quad Core Cortex A7 up to 1.2GHz.
- Up to 512 MB of RAM.
- Micro SD slot (up to 128 GB).
- 10/100 Ethernet.
- Additional interfaces via the abundant GPIO.
You can get further information and also purchase them from their [official page](https://www.friendlyelec.com/index.php?route=product/product&product_id=132).

There is **a bare-bones version of the NanoPi NEO** called the **NanoPi NEO Core-LTS**, which **adds eMMC for industrial applications** and let's go of the onboard USB and Ethernet ports. All features are available via the GPIO expansion.
You can check it out on the [official page](https://www.friendlyelec.com/index.php?route=product/product&product_id=212).

There is also **a Wi-Fi/BT version of the NanoPi NEO** called the **NanoPi NEO Air** which also adds eMMC and camera input while letting go of the onboard USB and Ethernet ports.
You can check it out on the [official page](https://www.friendlyelec.com/index.php?route=product/product&product_id=151).
## 10. Zero Pi

This is one of my favorite boards from this round up, it costs **$9.99** and has **a fast 1Gbps Ethernet onboard**. With the **Allwinner H3 at its heart**, this can be a very powerful and tiny machine on your network.
It **supports **[ OpenWRT](https://openwrt.org), which is great considering the 1Gbps Ethernet. You can easily run multiple instances of Pi-Hole along with a DNS Server.
**Key Specifications**
- Allwinner H3 Quad Core Cortex A7 at up to 1.2GHz.
- 512 MB of RAM.
- USB 2.0 Port.
- Support for OpenWRT.
You can get more information and also purchase them from their [official page](https://www.friendlyelec.com/index.php?route=product/product&product_id=266).
## 11. NanoPi NEO 2

At **$19.99**, the **NanoPi NEO 2 costs twice the NEO**. It retains the same form factor and brings in the **Allwinner H5 SoC** and **1Gbps Ethernet**. This makes the board **a tiny power house**.
**Key Specifications**
- Allwinner H5, Quad-core 64-bit high-performance Cortex A53.
- Hexa Core Mali450 GPU.
- 512 MB RAM.
- 1Gbps onboard Ethernet.
- 24 pin GPIO.
- Functional headers for Audio and other interfaces like IR.
You can get more information and also purchase them from their [official page](https://wiki.friendlyelec.com/wiki/index.php/NanoPi_NEO2).
That’s about all the boards in the NanoPi series, they also have a few more interesting boards with dual 1Gbps ports and a couple focused around camera applications.
## 12. La Frite (AML-S805X-AC)

From the makers of [Le Potato](https://libre.computer/products/aml-s905x-cc/), this board at **$20** is **mainly geared towards applications involving media consumption or media streaming**. It **supports 1080p video playback** with HDR metadata via the HDMI 2.0 port. It supports the latest Android 9/TV, upstream Linux, u-boot, Kodi, and more.
**Key Specifications**
- Amlogic S805X SoC, Quad Core Cortex-A53 @ 1.2GHz.
- Up to 1 GB DDR4 SDRAM.
- Amlogic Video Engine 10, support for H.264,H.265, and VP9 decoding up to 1080p 60fps.
- 100 Mbps Ethernet.
- IR Receiver.
- 40 pin GPIO.
You can get more information from their [official page](https://libre.computer/products/aml-s805x-ac/).
## 13. Onion Omega2+

If you’re looking for an IoT application, the **Onion Omega 2+ can be a good alternative to the Raspberry Pi Zero**. It is **an IoT-centric development platform** and runs on [LEDE](https://lede.readthedocs.io/en/latest/) (Linux Embedded Development Environment) Linux OS – a distribution based on [OpenWRT](https://openwrt.org/?ref=itsfoss.com).
**Key Specifications**
- MT7688 SoC
- 2.4 GHz IEEE 802.11 b/g/n Wi-Fi
- 128 MB DDR2 RAM
- 32 MB on-board flash storage
- MicroSD slot
- USB 2.0
- 12 GPIO pins
You can pick one up as a bare-bones module or various kits from their [website](https://onion.io/omega2s/).
## 14. VoCore2

The VoCore2 is definitely the smallest of the bunch, **the bare-bones module is only 1″ x 1″ in size** and costs **$17.99**. The **tiny size makes it easy to embed in different application**s and **allows selective expansion of features based on the need**.
It is **powered by a** **MediaTek MT7628** chip, which was specially designed for low to mid-range routers. The manufacturer claims that they’ll keep up the production until 2025, which is really good.
**Key Specifications**
- MediaTek MT7628, 580 MHz, MIPS 24K.
- 128 MB RAM, DDR2 166MHz.
- Ethernet – 1-5 ports, up to 100Mbps.
- Wireless – 802.11n, 2T2R, speeds up to 300Mbps.
- Storage – 16 MB NOR on board, supports SDXC up to 2 TB.
- 1x on-board U.FL slot (Antenna Connector).
You can get further details about the board on the [product page](https://vocore.io/v2.html?ref=itsfoss.com) and pick one up from their [official website](https://vocore.io/?ref=itsfoss.com).
**Suggested Read 📖**
[Top 21 Raspberry Pi OS for Various Purposes [2024]Power up your Raspberry Pi with a versatile operating system that serves your purpose.](https://itsfoss.com/raspberry-pi-os/)

**W**r**apping up**
It’s undeniable that there are all kinds of SBC’s available in various form factors and feature sets for a wide variety of use cases.
Moreover, most of these are open-source designs, running on open-source software. An absolute wonderland for a hardcore tinkerer.
*💬 If you guys know of any other interesting alternatives for the Raspberry Pi Zero and Zero W, put them in the comments below!* |
12,504 | 借助 HTTP 通过 SSH 绕过 Linux 防火墙 | https://opensource.com/article/20/7/linux-shellhub | 2020-08-10T23:18:39 | [
"ssh",
"http"
] | https://linux.cn/article-12504-1.html |
>
> 需要远程工作的看一下。使用这个有用的开源解决方案,从任何地方快速地连接和访问你的所有设备。
>
>
>

随着对连接和远程工作的需求的增长,访问远程计算资源变得越来越重要。但是,提供对设备和硬件的外部访问的要求使此任务变得复杂而有风险。旨在减少此类麻烦的 [ShellHub](https://github.com/shellhub-io/shellhub) 是一个云服务器,允许从任何外部网络常规访问这些设备。
ShellHub 是一个 Apache 2.0 许可的开源解决方案,它可满足所有这些需求,并允许用户通过一个帐户连接和管理多个设备。它的开发是为了方便开发者和程序员的工作,使得任何硬件架构的 Linux 设备的远程访问成为可能。
仔细观察,ShellHub 方案使用 HTTP 传输层来封装 SSH 协议。这种传输层的选择可以在大多数网络上无缝使用,因为大多数公司的防火墙规则和策略通常都可以使用并接受它。
下面这些示例使用 2020 年 6 月 10 日发布的 ShellHub 版本 0.3.2。
### 使用 ShellHub
要访问该平台,只需进入 [shellhub.io](https://www.shellhub.io/) 并注册一个自己的帐户。你的注册数据将帮助开发团队了解用户资料并提供有关如何改进平台的更多信息。

*图 1:[shellhub.io](https://opensource.com/article/20/7/www.shellhub.io) 中的注册表格*
ShellHub 有直观、简洁的界面,这让所有的信息和功能都能以最快的方式呈现。注册后,你会看到一块仪表板,这时可以注册你的第一台设备。
### 添加设备
要启用通过 ShellHub 连接设备,你需要生成一个标识符,它用于在设备连接到服务器时对你的设备进行身份验证。
此标识必须配置在代理(ShellHub 客户端)内部,该代理必须与镜像一起保存在设备中,或者必须添加为 Docker 容器。
ShellHub 默认使用 Docker 运行代理,这非常方便,因为它在现有系统上提供了一种无痛的添加方式,支持 Docker 是唯一的要求。要添加设备,你需要粘贴命令行,它显示在 ShellHub Cloud 的对话框中(请参见图 2)。

*图 2:将设备添加到 ShellHub Cloud*
设备默认使用它的 MAC 地址作为其主机名。在内部,该设备由其密钥标识,这是在设备注册期间生成的,用于与服务器进行身份验证。
### 访问设备
要访问你的设备,只需进入仪表板中的“查看所有设备”,或单击左侧菜单上的“设备”。这将列出你所有已注册的设备。
设备状态可在页面上轻松看到。在线设备旁边会显示一个绿色图标,可以单击终端图标进行连接。你接着输入密码,最后单击”连接“按钮,请参见(图 3)。

*图 3:使用网络上的终端访问设备*
另一种访问设备的方法是从类似 [PuTTY](https://www.putty.org/)、[Termius](https://termius.com/) 之类的 SSH 客户端,甚至 Linux 终端访问。我们可以使用称为 SSHID 的 ShellHub 标识作为连接的目的地址(例如 `ssh username@SSHID`)。图 4 说明了如何使用在终端中使用 Linux SSH 客户端连接到我们的计算机。

*图 4:使用 Linux 终端连接到设备*
无论你何时登录 ShellHub Cloud 平台,你都可以访问仪表板上的所有已注册设备,这样你可以随时随地访问它们。ShellHub 通过一个开源平台,以透明的方式为您与远程机器保持通信安全的过程增加了简单性。
在 [GitHub](https://github.com/shellhub-io/shellhub) 上加入 ShellHub 社区,或随时通过 [Gitter](https://gitter.im/shellhub-io/community?at=5e39ad8b3aca1e4c5f633e8f) 或通过电子邮件 [[email protected]](mailto:[email protected]) 向开发团队发送你的建议或反馈。我们很乐意收到社区成员的贡献!
---
via: <https://opensource.com/article/20/7/linux-shellhub>
作者:[Domarys](https://opensource.com/users/domarys) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | With the growth of connectivity and remote jobs, accessing remote computing resources becomes more important every day. But the requirements for providing external access to devices and hardware make this task complex and risky. Aiming to reduce this friction, [ShellHub](https://github.com/shellhub-io/shellhub) is a cloud server that allows universal access to those devices, from any external network.
ShellHub is an open source solution, licensed under Apache 2.0, that covers all those needs and allows users to connect and manage multiple devices through a single account. It was developed to facilitate developers' and programmers' tasks, making remote access to Linux devices possible for any hardware architecture.
Looking more closely, the ShellHub solution uses the HTTP transport layer to encapsulate the SSH protocol. This transport layer choice allows for seamless use on most networks as it is commonly available and accepted by most companies' firewall rules and policies.
These examples use ShellHub version 0.3.2, released on Jun 10, 2020.
## Using ShellHub
To access the platform, just go to [shellhub.io](https://www.shellhub.io/) and register yourself to create an account. Your registration data will help the development team to understand the user profile and provide more insight into how to improve the platform.
Figure 1: Registration form available in [shellhub.io](https://opensource.com/www.shellhub.io)
ShellHub's design has an intuitive and clean interface that makes all information and functionality available in the fastest way. After you've registered, you will be on the dashboard, ready to register your first device.
## Adding a device
To enable the connection of devices via ShellHub, you'll need to generate an identifier that will be used to authenticate your device when it connects to the server.
This identification must be configured inside the agent (ShellHub client) that will be saved in the device along with the image or it must be added as a Docker container.
By default, ShellHub uses Docker to run the agent, which is very convenient, as it provides frictionless addition of devices on the existing system, with Docker support being the only requirement. To add a device, you need to paste the command line, which is presented inside the ShellHub Cloud dialog (see Figure 2).
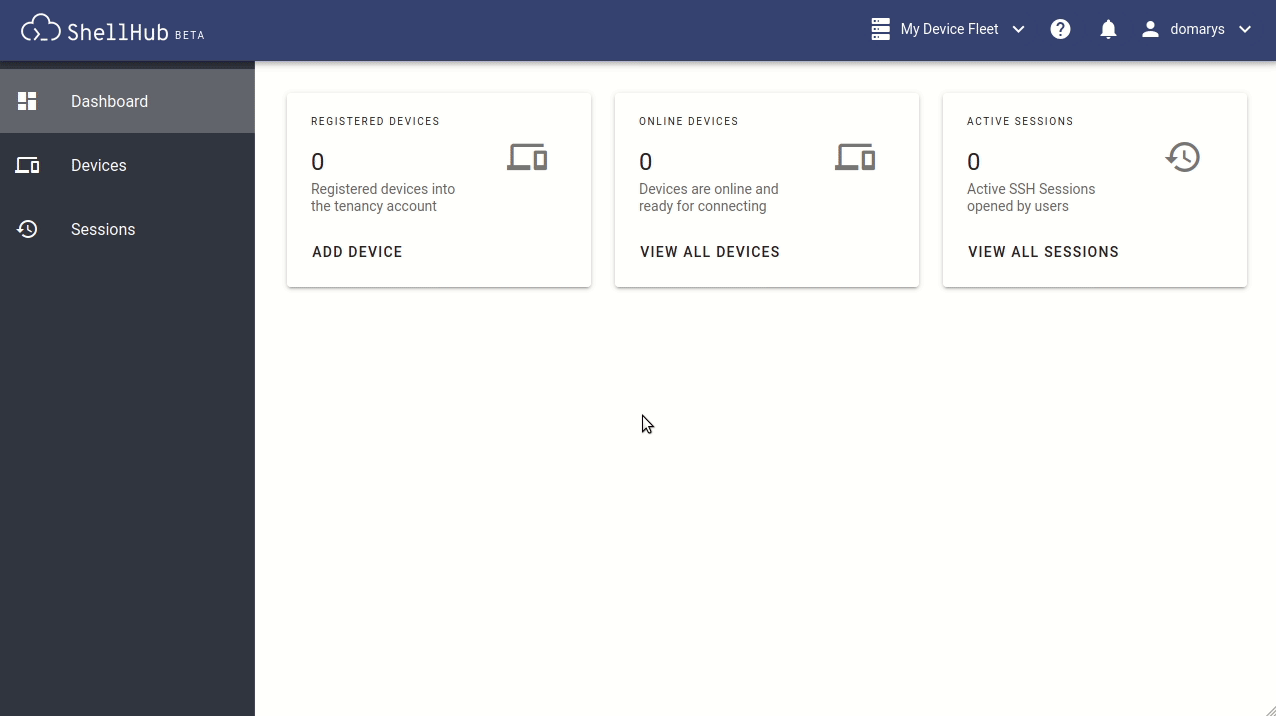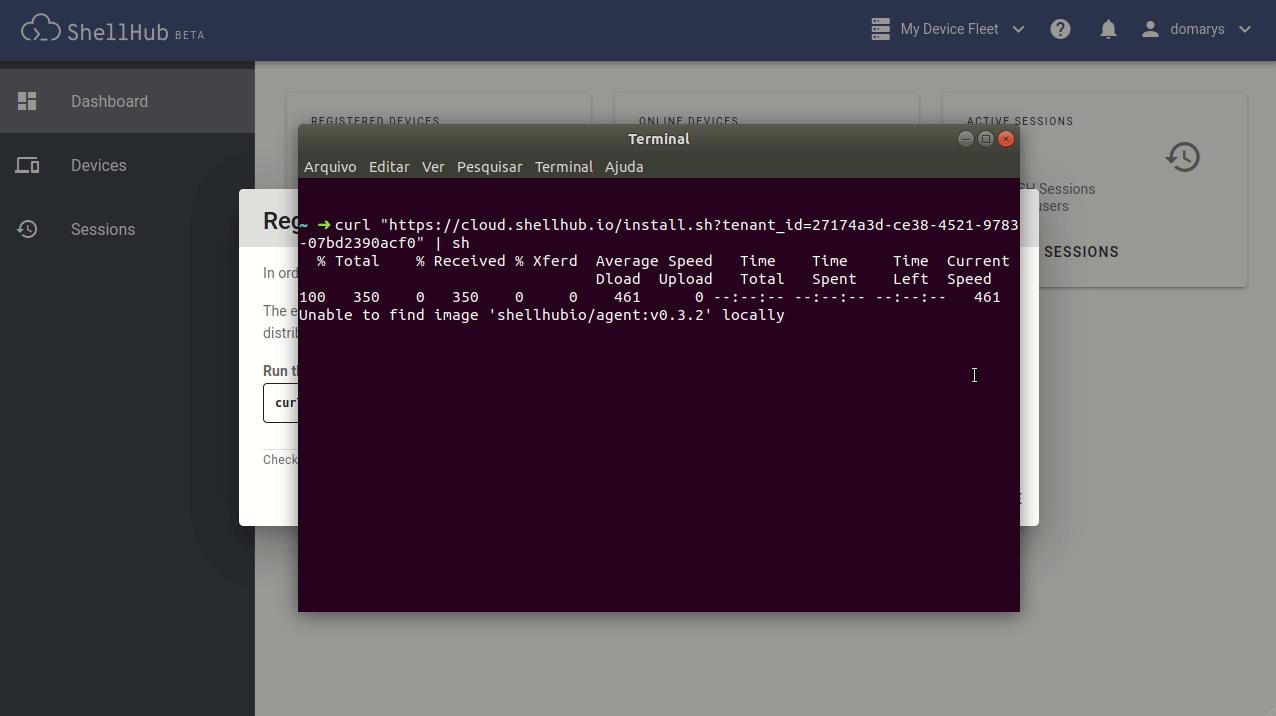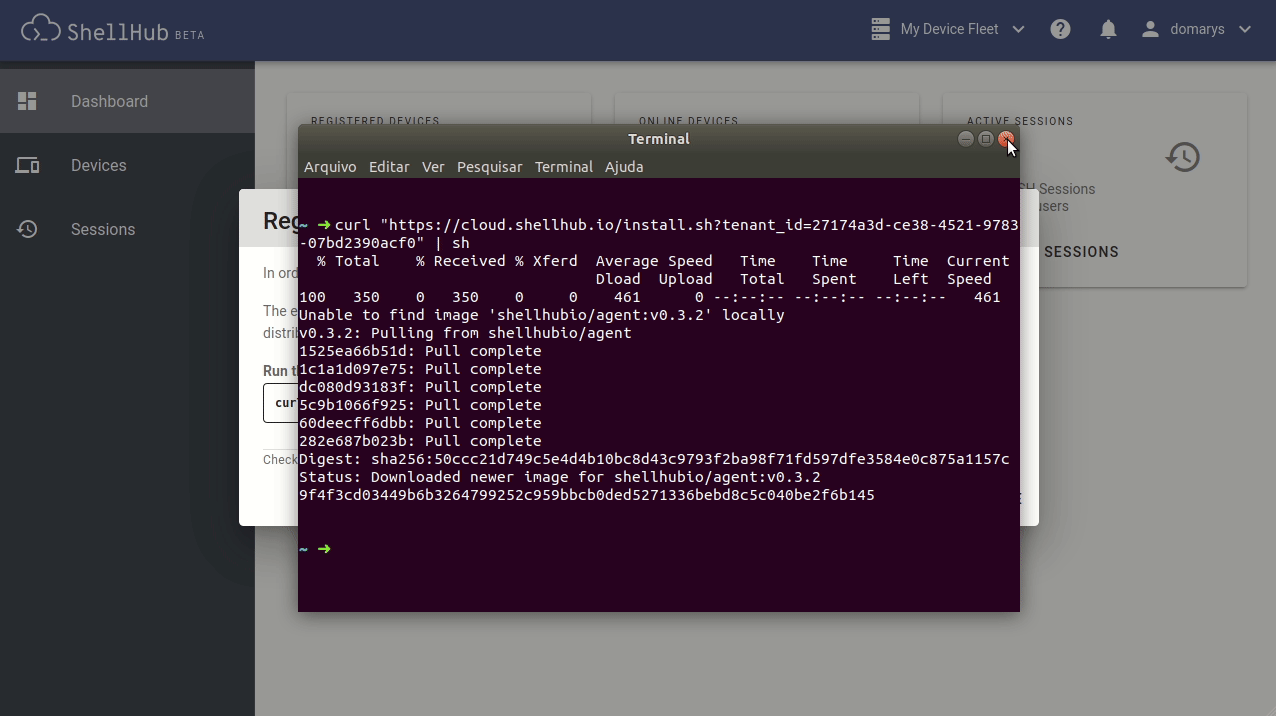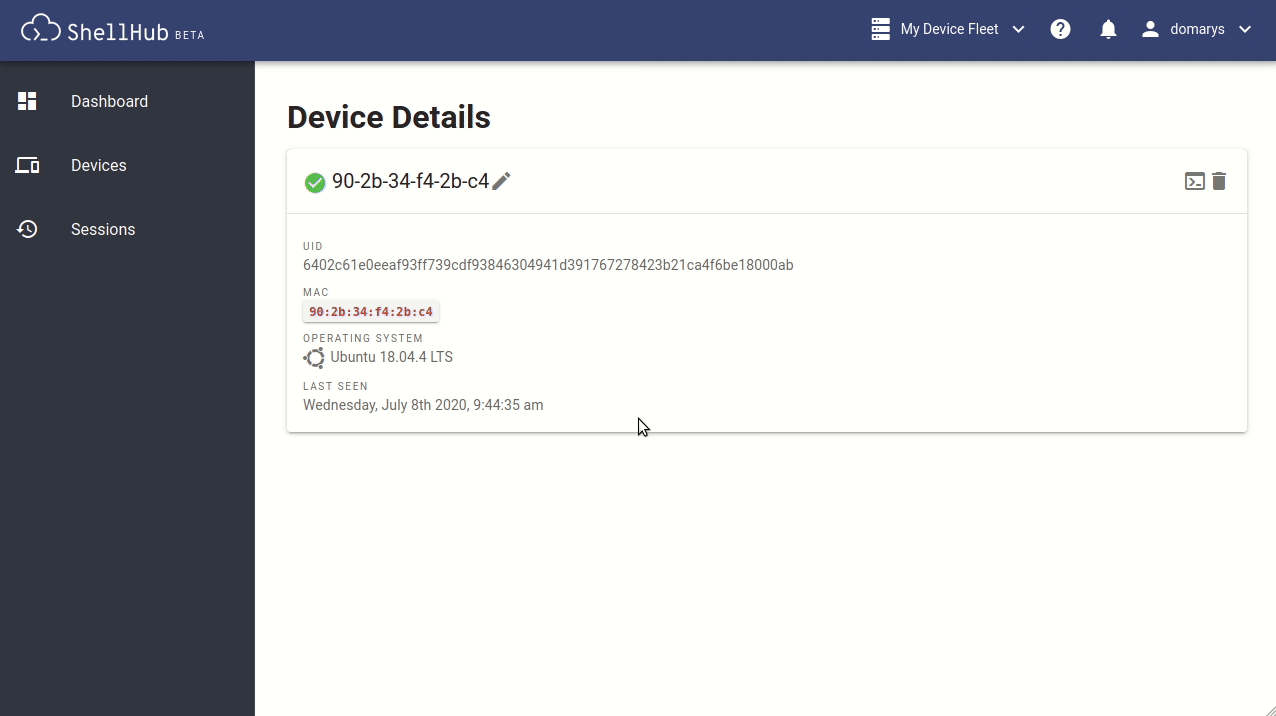
By default, the device uses its MAC address as its hostname. Internally, the device is identified by its key, which is generated during the device registration to authenticate it with the server.
## Accessing devices
To access your devices, just go to View All Devices in the dashboard, or click on Devices** **on the left side menu; these will list all your registered devices.
The device state can be easily seen on the page. The online ones show a green icon next to them and can be connected by clicking on the terminal icon. You then enter the credentials and, finally, click the Connect button, see (Figure 3).
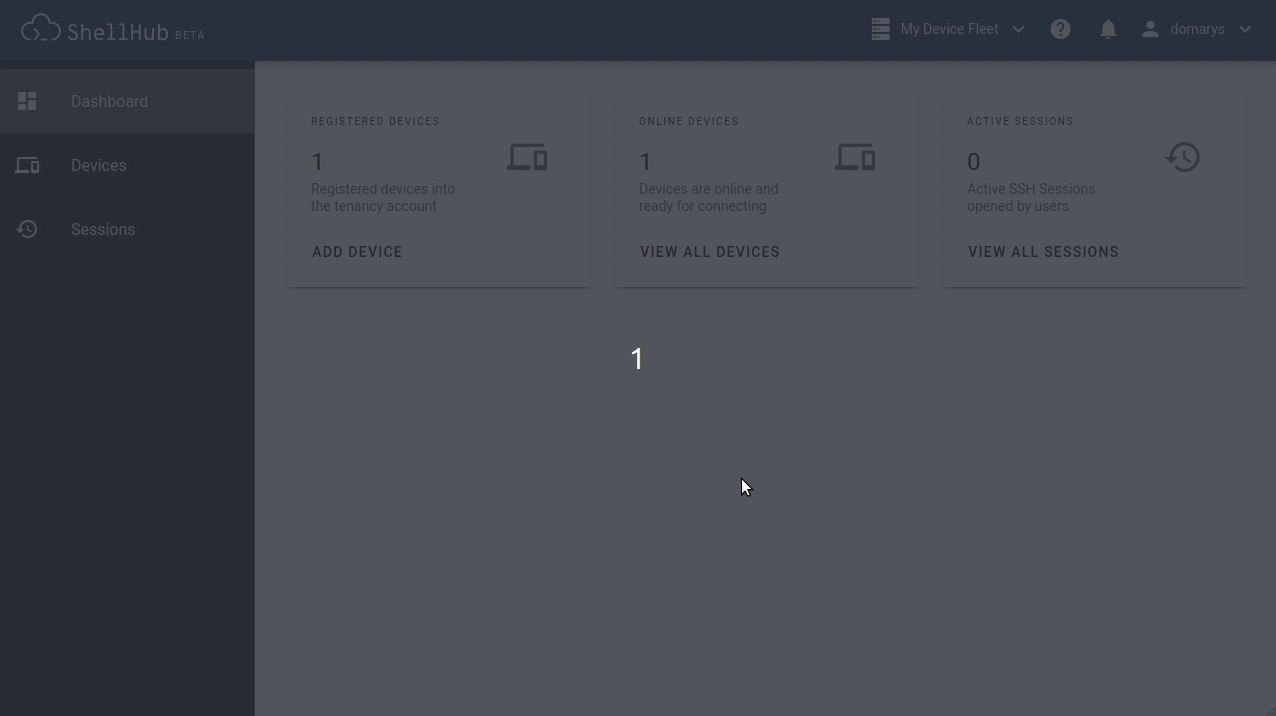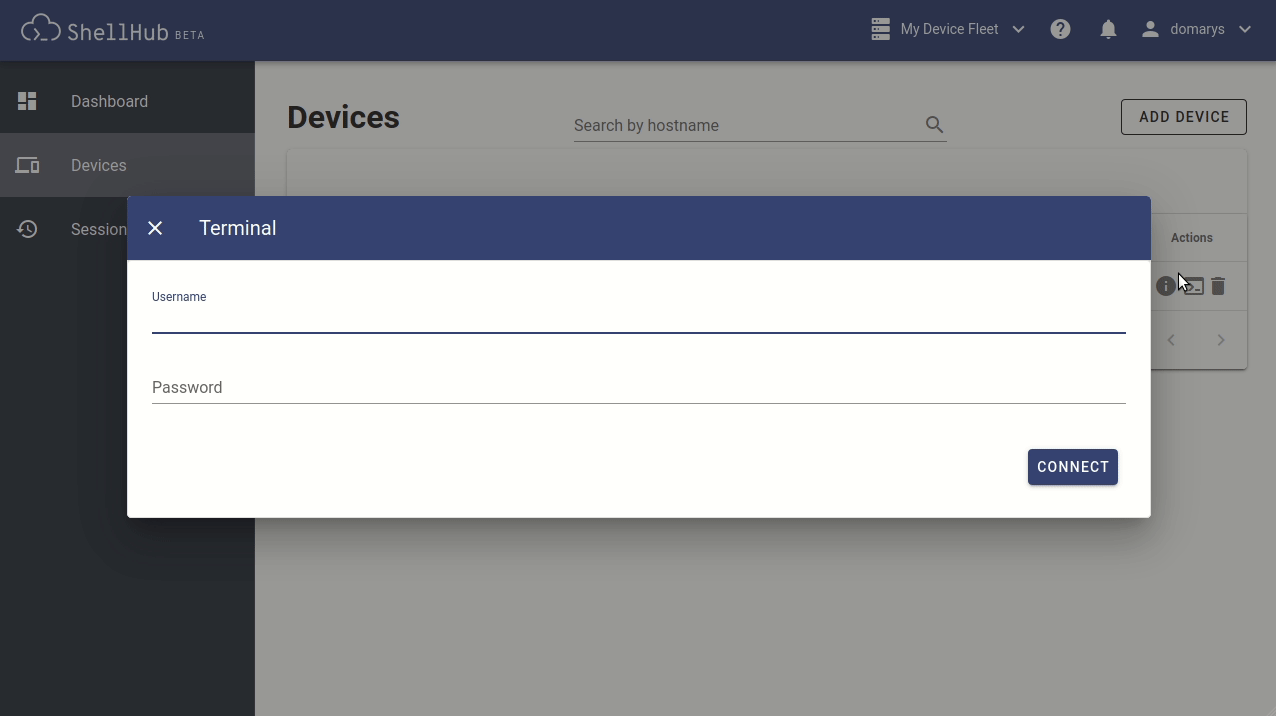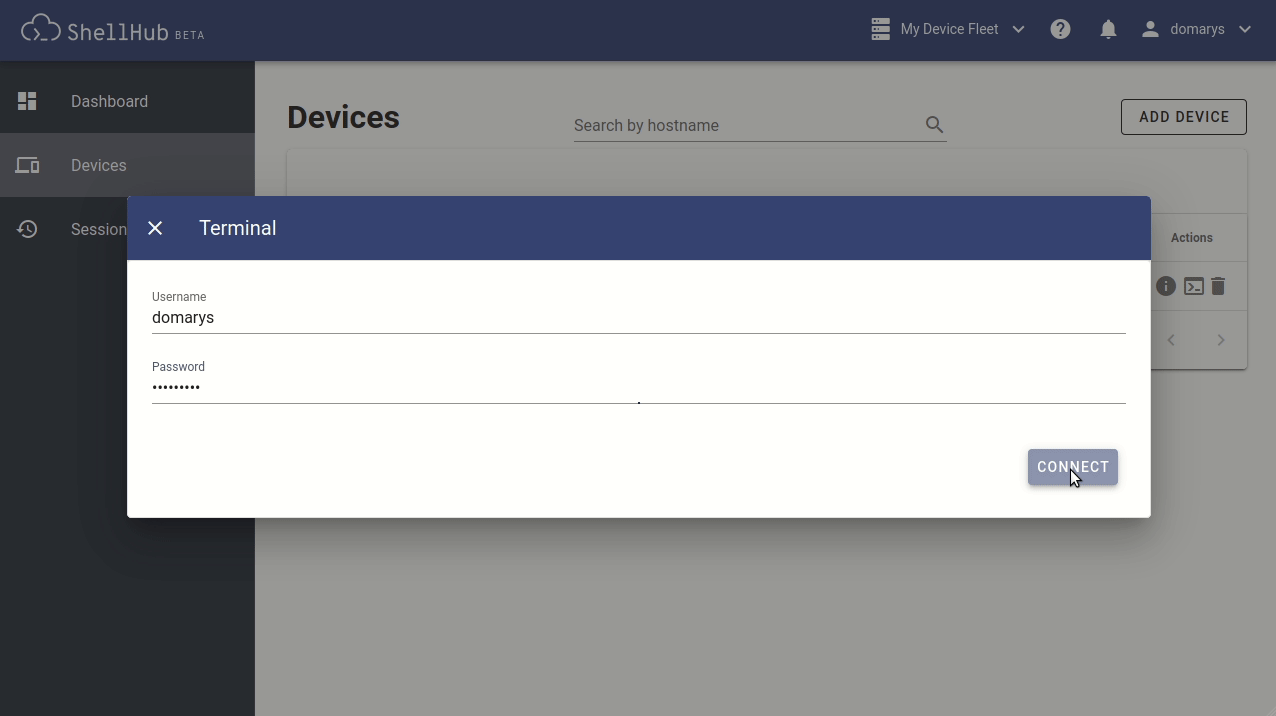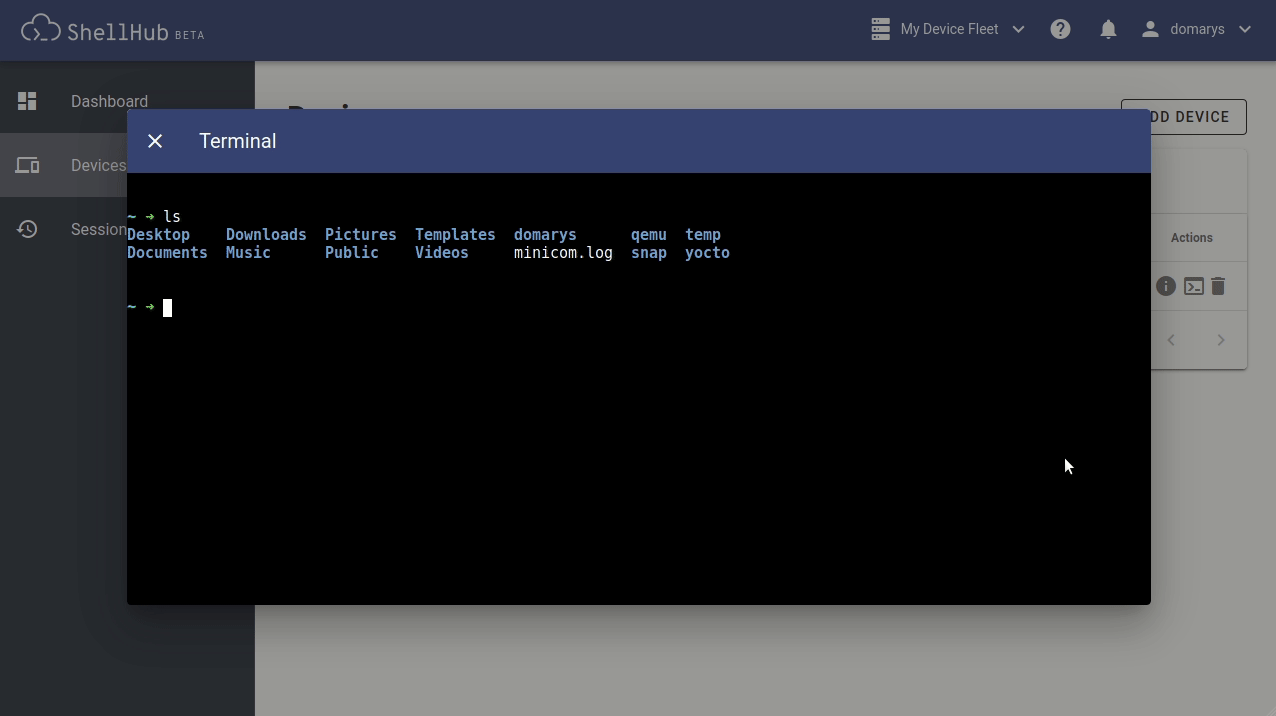
Another way to access your devices is from any SSH client like [PuTTY](https://www.putty.org/), [Termius](https://termius.com/), or even the Linux terminal. We can use the ShellHub Identification, called SSHID, as the destination address to connect (e.g., ssh username@SSHID). Figure 4 illustrates how we can connect to our machine using the Linux SSH client on the terminal.
Whenever you log in to the ShellHub Cloud platform, you'll have access to all your registered devices on the dashboard so you can access them from everywhere, anytime. ShellHub adds simplicity to the process of keeping communications secure with your remote machines through an open source platform and in a transparent way.
Join ShellHub Community on [GitHub](https://github.com/shellhub-io/shellhub) or feel free to send your suggestions or feedback to the developers' team through [Gitter](https://gitter.im/shellhub-io/community?at=5e39ad8b3aca1e4c5f633e8f) or by emailing [[email protected]](mailto:[email protected]). We love to receive contributions from community members!
## 7 Comments |
12,505 | 现在贡献开源的 3 个理由 | https://opensource.com/article/20/6/why-contribute-open-source | 2020-08-11T10:14:00 | [
"开源"
] | https://linux.cn/article-12505-1.html |
>
> 现在比以往任何时候都更是为开源做出贡献的理想时机。下面是为什么。
>
>
>

开源软件已经[遍及世界](https://techcrunch.com/2019/01/12/how-open-source-software-took-over-the-world/)。从 Linux 和 MySQL 的早期开始,开源就以前所未有的方式推动创新,仅 GitHub 上就有 [180,000 个公共仓库](https://github.com/search?q=stars%3A%3E100&s=stars&type=Repositories)。
对于尚未进入开源世界的那些人,下面是如今天开始的三个原因。
### 建立你作为开发人员的信心
如果你还很年轻,在职业生涯初期,甚至只是在学习一种新的编程语言,那么开源是入门的最佳方法。
通过参与一个开源项目,你会立即收到有关你的开发和编程技能的反馈。你可能会获得有关如何选择函数名称、条件逻辑的使用方式或如何使用不了解的 goroutine 来加快程序执行速度的建议。这是你在学习新东西时获得的宝贵反馈。
此外,随着你创建更多的拉取请求并应用从先前提交的内容中学到的知识,你将开始学习如何编写良好的代码并[提交优秀的拉取请求进行代码审查](https://mattermost.com/blog/submitting-great-prs/)。最后,许多开源项目提供指导计划,以帮助指导你完成前几个贡献。这是一个非常友好、安全的环境,可树立你作为开发人员的信心。
有关例子故事,请阅读 [Allan Guwatudde 作为一名自学开发者在开源方面的经验](https://mattermost.com/blog/building-confidence-and-gaining-experience-with-good-open-source-projects/)这篇文章。
### 丰富你的简历
即使你是一位经验丰富的开发人员,你也可能希望丰富自己的简历,以帮助职业发展和未来的寻找工作。也许你有兴趣探索新的前沿框架或新的编程模块,而你却没有机会在工作中用到。
你可以通过报名一个课程或在日常工作中找到一个方式引入这些概念来获得经验。但是,当这些选项不可用(或不希望使用)时,开源将提供绝佳的机会!除了建立技能和提高信心之外,所有开源贡献都是公开的,它们可以证明你已掌握的技能和已完成的项目。实际上,你的开源方面的个人资料本身可以为你提供强大的作品集,从而使你与其他应聘者脱颖而出。
此外,许多开源项目,例如 [Mattermost](https://docs.mattermost.com/overview/faq.html#can-contributors-add-themselves-to-the-mattermost-company-page-on-linkedin),允许你在 LinkedIn 上添加自己为贡献者,以直接提升自己的专业形象。
[阅读 Siyuan Liu 的旅程](https://mattermost.com/blog/open-source-contributor-journey-with-mattermost/)这篇文章,了解如何从第一次开源贡献到两次成为 Mattermost 项目 MVP。
### 建立你的专业网络
建立强大的专业网络可以帮助你实现职业目标,了解有关你自己或相邻领域的更多信息,并有助于寻找工作。为开源做贡献是建立该网络的绝佳方法。你加入了一个由成百上千的贡献者组成的温馨社区,在开源空间中与志趣相投的开发人员进行互动,并一路建立联系。你甚至可能会被介绍给行业中的关键人物,例如知名的开源工具的维护者。这样的关系可以变成改变职业生涯的关系。
最后,为开源项目做贡献甚至可以让你找到工作!例如,[Mattermost](https://mattermost.com/careers/) 已经从它的开源社区聘请了一些贡献者,全职在工程团队中工作。
### 从今天开始为开源做贡献
开源让你能够树立开发者的信心,建立简历和建立专业网络。而且,无论你的贡献大小,它都会对开源项目的未来产生直接影响。因此,许多项目都会向贡献者发放礼物以表示感谢(例如,[为所有首次贡献者送上一个定制的杯子](https://forum.mattermost.org/t/limited-edition-mattermost-mugs/143))。
准备开始进入开源了吗?查看[这些开源项目](https://firstcontributions.github.io/)来进行首次开源贡献,或了解[如何为 Mattermost 做贡献](http://mattermost.com/contribute)。
---
via: <https://opensource.com/article/20/6/why-contribute-open-source>
作者:[Jason Blais](https://opensource.com/users/jasonblais) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Open source software has [taken over the world](https://techcrunch.com/2019/01/12/how-open-source-software-took-over-the-world/). From the early days of Linux and MySQL, open source is driving innovation like never before, with more than [180,000 public repositories on GitHub](https://github.com/search?q=stars%3A%3E100&s=stars&type=Repositories) alone.
For those of you who have not yet ventured into the open source world, here are the three reasons to start today.
## Build your confidence as a developer
If you're young, early in your career, or are even just learning a new programming language, open source is the best way to get started.
By contributing to an open source project, you receive immediate feedback on your development and programming skills. You may get suggestions about the choice of a function name, the way you used conditional logic, or how using a goroutine you didn't know about speeds up the execution of your program. This is all invaluable feedback to receive when you're learning something new.
Moreover, as you create more pull requests and apply what you learned from previous submissions, you begin to learn how to write good code and [submit great pull requests for code review](https://mattermost.com/blog/submitting-great-prs/). Finally, many open source projects offer mentorship programs to help guide you through your first few contributions. It is a very welcoming, safe environment to build your confidence as a developer.
For an example story, read about [Allan Guwatudde's experience in open source](https://mattermost.com/blog/building-confidence-and-gaining-experience-with-good-open-source-projects/) as a self-taught developer.
## Build your resume or CV
Even if you're a seasoned developer, you may want to build your resume to help with career development and future job searches. Perhaps you're interested in exploring a new cutting-edge framework or a new programming module, and you don't have opportunities to do either at work.
You may be able to get experience by registering for a course or finding a way to introduce these concepts at your day job. But when those options are not available (or desirable), open source provides the perfect opportunity! In addition to building your skills and increasing your confidence, all of your open source contributions are public and demonstrate the skills you have mastered and the projects you've tackled. In fact, your open source profile by itself could provide you with a strong portfolio that sets you apart from other job candidates.
Moreover, many open source projects—[such as Mattermost](https://docs.mattermost.com/overview/faq.html#can-contributors-add-themselves-to-the-mattermost-company-page-on-linkedin)—allow you to add yourself as a Contributor on LinkedIn to directly promote your professional profile.
[Read about Siyuan Liu's journey](https://mattermost.com/blog/open-source-contributor-journey-with-mattermost/) from the first open source contribution to becoming a two-time MVP of the Mattermost project.
## Build your professional network
Building a strong professional network can help you achieve your career goals, learn more about your own or adjacent fields, and help with a job search. Contributing to open source is an excellent way to build that network. You join a welcoming community of hundreds or thousands of contributors, interact with likeminded developers in the open source space, and build connections along the way. You might even get introduced to key people in the industry, like the maintainer of a high-profile open source tool. Such relationships can turn into career-changing connections.
Finally, contributing to an open source project may even land you a job! For example, [Mattermost](https://mattermost.com/careers/) has hired several contributors from its open source community to work full-time on the engineering team.
## Start contributing to open source today
Open source empowers you to build your confidence as a developer, build your resume, and build your professional network. Moreover, your contribution—no matter how big or small—makes a direct impact on the future of the open source project. That's why many projects send gifts as a thank you to contributors (e.g., a [customized mug to all first-time contributors](https://forum.mattermost.org/t/limited-edition-mattermost-mugs/143)).
Ready to get started with open source? Check out [these open source projects](https://firstcontributions.github.io/) for first-time open source contributions or find out [how to contribute to Mattermost](http://mattermost.com/contribute) to get started.
## 2 Comments |
12,506 | 使用 GNU bc 在 Linux Shell 中进行数学运算 | https://opensource.com/article/20/7/bc-math | 2020-08-11T10:51:45 | [
"bc",
"数学"
] | /article-12506-1.html |
>
> 在 shell 中使用 bc 更好地做算数,它是一种用于高级计算的数学语言。
>
>
>

大多数 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 系统带有 [GNU bc](https://www.gnu.org/software/bc/),这是一种任意精度的数字处理语言。它的语法类似于 C,但是它也支持交互式执行语句和处理来自标准输入(`stdin`)的数据。因此,它通常是以下问题的答案:“我如何在 Linux shell 中进行数学运算?”这种回应方式在网上很常见:
```
$ echo "1+1" | bc
2
```
尽管这是完全正确的,但很少有用户认为,与更直观的方式相比,它很优雅,例如:
```
$ 1+1 # 这不能工作
2
```
交互模式要容易一些:
```
$ bc
1+1
2
quit
$
```
但是交互模式并不总是适合简单计算想要的直观工作流,比如直接输入你想要的计算。因此我推荐 Bluebat 的[纯 Bash 计算器](https://raw.githubusercontent.com/bluebat/.bash/master/bashbc.sh)。
`bc` 实际上提供了一种用于高级计算的数学语言。
### 含高级函数的 mathlib
`bc` 本身提供了基本的数学函数。你可以在交互式模式下测试它们:
```
$ bc
3^2
9
(3^2)*(9)/3
27
```
使用 `--mathlib` 选项获取高级函数,包括正弦、余弦、正切等。在交互式模式下,你可以测试其中一些。下面是 90 度的余弦:
```
c(90)
-.44807361612917015236
```
9 的正弦:
```
s(9)
.41211848524175656975
```
### 创建你自己的 bc 函数
你还可以在 `bc` 中创建自己的函数。函数定义以 `define` 关键字开始,并用大括号括起来。下面是一个输入到交互式会话中的简单函数,它返回给它的任意数字:
```
$ bc
define echo(n) {
return (n);
}
```
在同一个交互式会话中,测试一下:
```
echo(2)
2
echo(-2)
-2
```
### bc 中的 if 语句
`bc` 语言还有各种控制语句,其中最简单的是 `if`/`else`。语法乍一看可能很熟悉,但在如何处理大括号方面有些不同。请注意,`if` 语句的 `else` 子句包含在大括号中,而 `then` 子句不是,但两者都用分号终止。下面是一个返回数字 `n` 的绝对值的函数:
```
define abso(n) {
if ( n > 0 ) return (n);
{ return (-n); }
}
```
在同一个交互式会话中,测试一下:
```
abso(-5)
5
abso(5)
5
```
### 将数据导入 bc
使用交互式会话对于快速计算和实验是可以容忍的,但在退出时会丢失数据,并且在出错时很难编辑。幸运的是,`bc` 可以从外部文件加载变量和函数。
下面是一个包含两个变量(`sol` 和 `foo`)的文件,以及一个用于查找绝对值的自定义 `abso` 函数:
```
sol=299792458
foo=42
define abso(n) {
if ( n > 0 ) return (n);
{ return (-n); }
}
```
将它保存到名为 `bcvars.bc` 的文件中,以便导入 `bc` 交互式会话:
```
$ bc bcvars.bc
foo
42
sol
299792458
abso(-23)
23
```
### 使用 bc 助力你的数学
`bc` 语言相对简单,前提是你知道足够的数学知识来构造任何你想完成的方程。虽然 `bc` 默认提供了有用的基本函数,并允许你创建自己的函数,但你可以通过站在巨人的肩膀上来减少工作量。加载了用于数学基础知识和特定任务(例如,计算复利)的新函数的文件可从 [GNU bc 页](http://phodd.net/gnu-bc/)获得,同时也可获得 `bc` [完整文档](https://www.gnu.org/software/bc/manual/html_mono/bc.html)。
如果你有兴趣在 shell 里更好地处理数学,试试 `bc` 。它不会使你成为数学天才,但它可能会让过程更简单。
---
via: <https://opensource.com/article/20/7/bc-math>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,508 | [重制版]《代码英雄》第一季(2):操作系统战争(下)Linux 崛起 | https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux | 2020-08-11T18:18:00 | [
"代码英雄"
] | https://linux.cn/article-12508-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(2):操作系统战争(下)](https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux) 的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/2199861a.mp3)脚本。
**Saron Yitbarek**: 这玩意开着的吗?让我们播放一段跟星球大战电影一样的开场字幕吧,第二集开始了!
**00:00:30 - 配音**: OS 战争第二部分:Linux 的崛起。微软帝国控制着 90% 的用桌面用户,操作系统的完全标准化似乎是板上钉钉的事了。所以公司们把它们的注意力从桌面端的个人用户,转移到了专业人士上,它们为了服务器的所有权打得不可开交。但是一个有点让人意想不到的英雄出现在开源“反叛组织”中。戴着眼镜,固执的<ruby> 林纳斯·托瓦兹 <rt> Linus Torvalds </rt></ruby>免费发布了他的 Linux® 程序。微软摔了个趔趄,并且开始重新调整战略。
**00:01:00 - Saron Yitbarek**: 哦,我们极客们就是喜欢那样。上一次我们讲到哪了?苹果和微软互相攻伐,试图在争夺桌面用户的战争中占据主导地位。在第一集的结尾,我们看到微软获得了大部分的市场份额。很快,互联网的兴起以及随之而来的开发者大军,让整个市场都经历了一场地震。互联网将战场从在家庭和办公室中的个人电脑用户转移到拥有数百台服务器的大型商业客户中。
**00:01:30 - Saron Yitbarek**: 这意味着巨量资源的迁移。突然间,所有相关企业不仅被迫为服务器空间和网站建设付费,还必须集成软件来进行资源跟踪和数据库监控等工作。至少那时候大家都是这么做的,你需要很多开发人员来帮助你。
在操作系统之战的第二部分,我们将看到固有优势的巨大转变,以及像林纳斯·托瓦兹和<ruby> 理查德·斯托尔曼 <rt> Richard Stallman </rt></ruby>这样的开源反叛者,是如何成功地在微软和整个软件行业的核心引发恐惧的。
**00:02:00 - Saron Yitbarek**: 我是 Saron Yitbarek,你现在收听的是代码英雄,一款红帽公司原创的播客节目。每一集,我们都会给你带来“从码开始”,用技术改变科技的人,他们的故事。
**00:02:30 - Saron Yitbarek**: 好。想象一下你是 1991 年时的微软。你自我感觉良好,对吧?你满怀信心,确立了全球主导地位的感觉真不错。你已经掌握了与其他企业合作的艺术,但是仍然将大部分开发人员、程序员和系统管理员排除在联盟之外,而他们才是真正的武装力量。这时出现了一个叫林纳斯·托瓦兹的芬兰极客。他和一帮信奉开源的程序员开始发布 Linux,这个操作系统内核是由他们一起编写出来的。
**00:03:00 - Saron Yitbarek**: 坦白地说,如果你是微软公司,你并不会太在意 Linux,甚至不太关心开源运动,但是最终,Linux 的规模变得如此之大,以至于微软不可能不注意到。Linux 第一个版本出现在 1991 年,当时大概有 1 万行代码。十年后,则是 300 万行代码。如果你想了解知道现在的 Linux 怎么样了 —— 它有 2000 万行代码。
**00:03:30 - Saron Yitbarek**: 让我们在 90 年代初停留一会儿,那时 Linux 还没有成为我们现在所知道的庞然大物。这只是一个正在蔓延的,拥有病毒一般感染力的奇怪操作系统,不过全世界的极客和黑客都爱上了它。那时候我还太年轻,但有点希望我曾经历过那个年代。在那个时候,发现 Linux 就如同进入了一个秘密社会,程序员与朋友们分享刻录的 Linux CD 集,就像其他人分享地下音乐混音带一样。
**00:03:40**: 开发者 Tristram Oaten 讲讲你 16 岁时第一次接触 Linux 的故事吧。
**00:04:00 - Tristram Oaten**: 我和我的家人去了红海的 Hurghada 潜水度假,那是一个美丽的地方,强烈推荐。也许我妈妈跟我说过不要这么做,但第一天,我还是喝了自来水。所以我整个星期都病得很厉害,没法离开旅馆房间。当时我只带了一台新安装了 Slackware Linux 的笔记本电脑,我只是听说过这玩意,现在却要尝试使用它。我手上没有其他的应用程序,我能接触的所有东西只有刻录在 8 张 CD 上的代码。这种情况下,我整个星期能做的事情,就是了解这个外星造物一般的系统。我阅读手册,摆弄着终端。我记得当时我甚至不知道一个点(表示当前目录)和两个点(表示前一个目录)之间的区别。
**00:04:30 - Tristram Oaten**: 我一点头绪都没有。犯过很多错误。但慢慢的,在这种被迫造成的孤独中,我突破了障碍,开始明白并理解命令行到底是怎么回事。假期结束时,我没有看过金字塔、尼罗河等任何埃及遗址,但我解锁了现代世界的一个奇迹。我接触了 Linux,接下来的事大家都知道了。
**Saron Yitbarek**: 你会从很多人那里听到关于这个故事的不同版本,访问 Linux 命令行是一种革命性的体验。
**00:05:00 - David Cantrell**: 它提供了源代码。我当时的感觉是,“太神奇了。”
**Saron Yitbarek**: 我们正在参加一个名为 Flock to Fedora 的 2017 年 Linux 开发者大会。
**David Cantrell**: ……非常有吸引力。我觉得随着我掌控这个系统越深,它就越吸引我。我想,从 1995 年我第一次编译 Linux 内核那时起,我就迷上了它。
**Saron Yitbarek**: 这是开发者 David Cantrell 与 Joe Brockmire。
**00:05:30 - Joe Brockmeier**: 我在 Cheap Software 转的时候发现了一套四张 CD 的 Slackware Linux。它看起来会非常令人兴奋而且很有趣,所以我把它带回家,安装在我的第二台电脑上,开始摆弄它,有两件事情让我感到很兴奋:一个是我运行的不是 Windows,另一个是 Linux 的开源特性。
**00:06:00 - Saron Yitbarek**: 某种程度上来说,使用命令行的人总是存在的。在开源真正开始流行起来的二十年前,人们(至少在开发人员是这样)总是希望能够做到完全控制机器。让我们回到操作系统大战之前的那个时代,在苹果和微软为他们的 GUI 而战之前,那时也有代码英雄。<ruby> 保罗·琼斯 <rt> Paul Jones </rt></ruby>教授(在线图书馆 [ibiblio.org](http://ibiblio.org) 的负责人)就是一名那个古老年代的开发人员。
**00:06:30 - Paul Jones**: 从本质上讲,互联网在那个时候客户端-服务器架构还是比较少的,而更多的是点对点架构的。确实,我们会说,某种 VAX 到 VAX 的连接(LCTT 译注:DEC 的一种操作系统),某种科学工作站到科学工作站的连接。这并不意味着没有客户端-服务端的架构及应用程序,但这的确意味着,最初的设计是思考如何实现点对点,它与 IBM 一直在做的东西相对立。IBM 给你的只有哑终端,这种终端只能让你管理用户界面,却无法让你像真正的终端一样为所欲为。
**00:07:00 - Saron Yitbarek**: 当图形用户界面在普通用户中普及的同时,在工程师和开发人员中总是存在着一股相反的力量。早在 Linux 出现之前的二十世纪七八十年代,这股力量就存在于 Emacs 和 GNU 中。斯托曼的自由软件基金会中的某些人想要使用完全命令行,但直到上世纪 90 年代的 Linux 出现,才提供了前所未有的东西。
**00:07:30 - Saron Yitbarek**: Linux 和其他开源软件的早期爱好者是都是先驱。我正站在他们的肩膀上,我们都是。
你现在收听的是代码英雄,一款由红帽公司原创的播客。这是操作系统大战的第二部分:Linux 崛起。
**Steven Vaughan-Nichols**: 1998 年的时候,情况发生了变化。
**00:08:00 - Saron Yitbarek**: Steven Vaughan-Nichols 是 [zdnet.com](http://zdnet.com) 的特约编辑,他已经写了几十年从商业方面论述技术的文章了。他将向我们讲述 Linux 是如何慢慢变得越来越流行,直到自愿贡献者的数量远远超过了工作于 Windows 上的微软开发人员的数量。不过,Linux 桌面版本从未真正追上 Windows,这也许就是微软最开始时忽略了 Linux 及其开发者的原因。Linux 真正大放光彩的地方是服务器机房,当企业开始线上业务时,每个企业都需要一个满足其独特需求的解决方案。
**00:08:30 - Saron Yitbarek**: WindowsNT 于 1993 年问世,当时它已经在与其他的服务器操作系统展开竞争了,但是许多开发人员都在想,“既然我可以通过 Apache 构建出基于 Linux 的廉价系统,那我为什么要购买 AIX 设备或大型 Windows 设备呢?”鉴于这个优点,Linux 代码已经开始渗透到几乎所有的在线机器中。
**00:09:00 - Steven Vaughan-Nichols**: 让微软开始意识到并感到惊讶的是,Linux 实际上已经有了一些商业应用,不是在桌面环境,而是在商业服务器上。因此,他们发起了一场运动,我们称之为 FUD - <ruby> 恐惧、不确定和怀疑 <rt> fear, uncertainty and double </rt></ruby>。他们说,“哦,Linux 这玩意,真的没有那么好。它不太可靠,你根本不能相信它”。
**00:09:30 - Saron Yitbarek**: 这种软宣传式的攻击持续了一段时间。微软也不是唯一一个对 Linux 感到紧张的公司,整个行业其实都在对抗这个奇怪新人的挑战。例如,任何与 UNIX 有利害关系的人都可能将 Linux 视为篡夺者。有一个案例很著名,那就是 SCO 组织(它发行过一种 UNIX 版本)在过去 10 多年里发起一系列的诉讼,试图阻止 Linux 的传播,而 SCO 最终失败而且破产了。与此同时,微软一直在寻找机会,他们必须要采取动作,只是不清楚具体该怎么做。
**00:10:00 - Steven Vaughan-Nichols**: 第二年,真正让微软担心的事情发生了。在 2000 年的时候,IBM 宣布,他们将于 2001 年投资 10 亿美元在 Linux 上。现在,IBM 已经不再涉足个人电脑业务。那时他们还没有走出那一步,但他们正朝着这个方向前进,他们将 Linux 视为服务器和大型计算机的未来,在这一点上 —— 剧透警告,IBM 是正确的。
**00:10:30 - Steven Vaughan-Nichols**: Linux 将主宰服务器世界。
**Saron Yitbarek**: 这已经不再仅仅是一群黑客所钟爱的,对命令行绝地武士式的控制了。金钱的投入对 Linux 助力极大。<ruby> Linux 国际 <rt> Linux International </rt></ruby>的执行董事 John “Mad Dog” Hall 有一个可以解释为什么事情会变成这样的故事分享,我们通过电话与他取得了联系。
**00:11:00 - John Hall**: 我有一个名叫 Dirk Holden 的朋友,他是德国德意志银行的系统管理员,他也参与了个人电脑上早期 X Windows 系统图形项目的工作。有一天我去银行拜访他,我说:“Dirk,你银行里有 3000 台服务器,用的都是 Linux。为什么不用 Microsoft NT 呢?”
**00:11:30 - John Hall**: 他看着我说:“是的,我有 3000 台服务器,如果使用微软的 Windows NT 系统,我需要 2999 名系统管理员。”他继续说道:“而使用 Linux,我只需要四个。”这真是完美的答案。
**00:12:00 - Saron Yitbarek**: 程序员们着迷的这些东西恰好对大公司也极具吸引力。但由于 FUD 的作用,一些企业对此持谨慎态度。他们听到开源,就想:“开源。这看起来不太可靠,很混乱,充满了 BUG”。但正如那位银行经理所指出的,金钱有一种有趣的魔力,可以说服人们不再踌躇。甚至那些只需要网站的小公司也加入了 Linux 阵营。与一些昂贵的专有选择相比,使用一个廉价的 Linux 系统在成本上是无法比拟的。如果你是一家雇佣专业人员来构建网站的商店,那么你肯定想让他们使用 Linux。
**00:12:30 - Saron Yitbarek**: 让我们快进几年。Linux 充当着几乎所有网站的服务器,Linux 已经征服了服务器世界,然后智能手机也随之诞生。当然,苹果和他们的 iPhone 占据了相当大的市场份额,而且微软也希望能进入这个市场。但令人惊讶的是,Linux 已经等在那里并做好准备,迫不及待要大展拳脚。
这是作家兼记者 James Allworth。
**00:13:00 - James Allworth**: 肯定还有容纳第二个竞争者的空间,那本可以是微软,但是实际上却是 Android,而 Andrid 是基于 Linux 的。众所周知,Android 被谷歌所收购,现在运行在世界上大部分的智能手机上,谷歌在 Linux 的基础上创建了 Android。Linux 使他们能够以零成本,基于一个非常复杂的操作系统构建一个新的东西。他们盘算着推广这个系统,并最终成功地实现了这一目标。至少从操作系统的角度来看是这样,他们将微软挡在了下一代手机竞争之外。
**00:13:30 - Saron Yitbarek**: 这可是个大地震,很大程度上,微软有被埋没的风险。John Gossman 是微软 Azure 团队的首席架构师。他还记得当时公司的迷茫。
**00:14:00 - John Gossman**: 像许多公司一样,微软也非常担心知识产权污染。他们认为,如果允许开发人员使用开源代码,即使只是将一些代码复制粘贴到某些产品中,也会让某种病毒式的许可证生效从而引发未知的风险……他们也很困惑,我认为,这跟公司文化有关,很多公司,包括微软,都对开源开发的意义和商业模式之间的分歧感到困惑。有一种观点认为,开源意味着你所有的软件都是免费的,人们永远不会付钱。
**00:14:30 - Saron Yitbarek**: 任何习惯于投资于旧的、专有软件模式的人都会觉得这里发生的一切对他们构成了威胁。当你威胁到像微软这样的大公司时,是的,他们一定会做出反应。他们推动所有这些 FUD —— 恐惧、不确定性和怀疑是有道理的。当时,商业运作的方式基本上就是相互竞争。不过,如果是其他公司的话,他们可能还会一直怀恨在心,抱残守缺,但到了 2013 年的微软,一切都变了。
**00:15:00 - Saron Yitbarek**: 微软的云计算服务 Azure 上线了,令人震惊的是,它从第一天开始就提供了 Linux 虚拟机。 <ruby> 史蒂夫·鲍尔默 <rt> Steve Ballmer </rt></ruby>,这位把 Linux 称为癌症的首席执行官,已经离开了,代替他的是一位新的有远见的首席执行官<ruby> 萨提亚·纳德拉 <rt> Satya Nadella </rt></ruby>。
**John Gossman**: 萨提亚有不同的看法,他属于另一个世代。比保罗、比尔和史蒂夫更年轻的世代,他对开源有不同的看法。
**Saron Yitbarek**: 这是John Gossman,他还是来自微软 Azure 团队。
**00:15:30 - John Gossman**: 大约四年前,出于实际需要,我们在 Azure 中添加了 Linux 支持。如果访问任何一家企业客户,你都会发现他们并不是现在才决定是使用 Windows 还是使用 Linux、使用 .net 还是使用 Java。他们在很久以前就做出了决定 —— 大约 15 年前,虽然对此有一些争论。
**00:16:00 - John Gossman**: 现在,我见过的每一家公司都混合了 Linux 和 Java、Windows 和 .net、SQL Server、Oracle 和 MySQL —— 基于专有源代码的产品和开放源代码的产品。
如果你打算运维一个云服务,允许这些公司在云上运行他们的业务,那么你根本不能告诉他们,“你可以使用这个软件,不能使用那个软件。”
**00:16:30 - Saron Yitbarek**: 这正是萨提亚·纳德拉采纳的哲学思想。2014 年秋季,他站在舞台上,希望传递一个重要信息。“微软爱 Linux”。他接着说,“20% 的 Azure 业务已经是 Linux 了,微软将始终对 Linux 发行版提供一流的支持。”没有哪怕一丝对开源的宿怨。
为了说明这一点,在他们的背后有一个巨大的标志,上面写着:“Microsoft ❤️ Linux”。哇噢。对我们中的一些人来说,这种转变有点令人震惊,但实际上,无需如此震惊。下面是 Steven Levy,一名科技记者兼作家。
**00:17:00 - Steven Levy**: 当你在踢足球的时候,如果草坪变滑了,那么你也许会换一种不同的鞋子。微软当初就是这么做的。
**00:17:30 - Steven Levy**: 他们不能否认现实,而且他们也是聪明人。所以他们必须意识到,这就是这个世界的运行方式。即使他们有一点尴尬,但是不管他们早些时候说了什么现在都要抛开。不然让他们之前那些“开源多么可怕”的言论影响到现在的决策,才真的是不明智之举。
**00:18:00 - Saron Yitbarek**: 微软低下了它高傲的头。你可能还记得苹果公司,经过多年的孤立无援,最终转向与微软构建合作伙伴关系。现在轮到微软进行 180 度转变了。经过多年的与开源方式的战斗后,他们正在重塑自己。要么改变,要么死亡。下一个发言的是 Steven Vaughan-Nichols。
**00:18:30 - Steven Vaughan-Nichols**: 即使是像微软这样规模的公司,也无法与数千个开发着包括 Linux 在内的其它开源大项目的开发者竞争。很长时间以来他们都不愿意合作,前微软首席执行官史蒂夫·鲍尔默对 Linux 用接近信仰的方式深恶痛绝。由于它使用的 GPL 许可证,他视 Linux 为一种癌症。不过一旦鲍尔默被扫地出门,新的微软领导层表示,“这就好像试图命令潮流不要过来,但潮水依然会不断涌进来。我们应该与 Linux 合作,而不是与之对抗。”
**00:19:30 - Steven Vaughan-Nichols**: 2017 年的微软既不是史蒂夫·鲍尔默的微软,也不是比尔·盖茨的微软。这是一家完全不同的公司,有着完全不同的理念,而且,一旦使用了开源,你就无法退回到之前的阶段。开源已经吞噬了整个技术世界。从未听说过 Linux 的人可能对它并不了解,但是每次他们访问 Facebook,他们都在运行 Linux。每次执行谷歌搜索时,你都在运行 Linux。
**00:20:00 - Steven Vaughan-Nichols**: 每次你用 Android 手机,你都在运行 Linux。它确实无处不在,微软无法阻止它,而且我认为,以为微软想用某种方式接管它的想法太天真了。
**00:20:30 - Saron Yitbarek**: 开源支持者可能一直担心微软会像混入羊群中的狼一样,但事实是,开源软件的本质保护了它,让它无法被完全控制。没有一家公司能够拥有 Linux 并以某种特定的方式控制它。Greg Kroah-Hartman 是 Linux 基金会的一名成员。
**Greg Kroah-Hartman**: 每个公司和个人都因为自己的利益对 Linux 做出贡献。他们之所以这样做是因为他们想要解决他们所面临的问题,可能是硬件无法工作,或者是他们想要添加一个新功能来做其他事情,又或者想引导 Linux 的开发轨道,这样他们的新产品就能使用它。这很棒,因为他们会把代码贡献回去,此后每个人都会从中受益,这样每个人都可以用到这份代码。正是因为这种自私,所有的公司,所有的人都能从中受益。
**00:21:00 - Saron Yitbarek**: 微软已经意识到,在即将到来的云战争中,与 Linux 作战就像与空气作战一样。Linux 和开源不是敌人,它们是空气。如今,微软以白金会员的身份加入了 Linux 基金会。他们成为 GitHub 开源项目的头号贡献者。
**00:21:30 - Saron Yitbarek**: 2017 年 9 月,他们甚至加入了<ruby> 开源促进联盟 <rt> Open Source Initiative </rt></ruby>(OSI)。现在,微软在开源许可证下发布了很多代码。微软的 John Gossman 描述了他们开源 .net 时所发生的事情。起初,他们并不认为自己能得到什么回报。
**00:22:00 - John Gossman**: 我们本没有指望来自社区的贡献,然而,三年后,超过 50% 的对 .net 框架库的贡献来自于微软之外,这些是大量的代码。三星为 .net 提供了 ARM 支持。Intel 和 ARM 以及其他一些芯片厂商已经为 .net 框架贡献了特定于他们处理器的代码,以及数量惊人的修复 bug、性能改进等等 —— 既有单个贡献者也有社区。
**Saron Yitbarek**: 直到几年前,今天的这个微软,这个开放的微软,还是不可想象的。
**00:22:30 - Saron Yitbarek**: 我是 Saron Yitbarek,这里是代码英雄。好吧,我们已经看到了为了赢得数百万桌面用户的爱而战的激烈场面。我们已经看到开源软件在专有软件巨头的背后悄然崛起,并攫取了巨大的市场份额。
**00:23:00 - Saron Yitbarek**: 我们已经看到了一批批的代码英雄将编程领域变成了我你今天看到的这个样子。如今,大企业正在吸收开源软件,通过这一切,每个人都从他人那里受益。
**00:23:30 - Saron Yitbarek**: 在技术的西部荒野,一贯如此。苹果受到施乐的启发,微软受到苹果的启发,Linux 受到 UNIX 的启发。进化、借鉴、不断成长。如果比喻成大卫和歌利亚(LCTT 译注:西方经典的以弱胜强战争中的两个主角)的话,开源软件不再是大卫,但是,你知道吗?它也不是歌利亚。开源已经超越了这些角色,它成为了其他人战斗的战场。随着开源变得不可避免,新的战争,那些在云计算中进行的战争,那些在开源战场上进行的战争正在加剧。
这是 Steven Levy,他是一名作者。
**00:24:00 - Steven Levy**: 基本上,到目前为止,包括微软在内,有四到五家公司,正以各种方式努力把自己打造成为全方位的平台,比如人工智能领域。你能看到智能助手之间的战争,你猜怎么着?苹果有一个智能助手,叫 Siri。微软有一个,叫 Cortana。谷歌有谷歌助手,三星也有一个智能助手,亚马逊也有一个,叫 Alexa。我们看到这些战斗遍布各地。也许,你可以说,最热门的人工智能平台将控制我们生活中所有的东西,而这五家公司就是在为此而争斗。
**00:24:30 - Saron Yitbarek**: 如果你正在寻找另一个反叛者,它们就像 Linux 奇袭微软那样,偷偷躲在 Facebook、谷歌或亚马逊身后,你也许要等很久,因为正如作家 James Allworth 所指出的,成为一个真正的反叛者只会变得越来越难。
**00:25:00 - James Allworth**: 规模一直以来都是一种优势,但规模优势本质上……怎么说呢,我认为以前它们在本质上是线性的,现在它们在本质上是指数型的了,所以,一旦你开始以某种方法走在前面,另一个新玩家要想赶上来就变得越来越难了。我认为在互联网时代这大体来说来说是正确的,无论是因为规模,还是数据赋予组织的竞争力的重要性和优势。
**00:25:30 - James Allworth**: 一旦你走在前面,你就会吸引更多的客户,这就给了你更多的数据,让你能做得更好,这之后,客户还有什么理由选择排名第二的公司呢,难道是因为因为他们落后了这么远么?我认为在云的时代这个逻辑也不会有什么不同。
**00:26:00 - Saron Yitbarek**: 这个故事始于史蒂夫·乔布斯和比尔·盖茨这样的非凡的英雄,但科技的进步已经呈现出一种众包、自有生命的感觉。我认为据说我们的开源英雄林纳斯·托瓦兹在第一次发明 Linux 内核时甚至没有一个真正的计划。他无疑是一位才华横溢的年轻开发者,但他也像潮汐前的一滴水一样。变革是不可避免的。据估计,对于一家专有软件公司来说,用他们老式的、专有的方式创建一个 Linux 发行版将花费他们超过 100 亿美元。这说明了开源的力量。
**00:26:30 - Saron Yitbarek**: 最后,这并不是一个专有模型所能与之竞争的东西。成功的公司必须保持开放。这是最大、最终极的教训。还有一点要记住:当我们团结在一起的时候,我们在已有基础上成长和建设的能力是无限的。不管这些公司有多大,我们都不必坐等他们给我们更好的东西。想想那些为了纯粹的创造乐趣而学习编码的新开发者,那些自己动手丰衣足食的人。
未来的优秀程序员无管来自何方,只要能够访问代码,他们就能构建下一个大项目。
**00:27:00 - Saron Yitbarek**: 以上就是我们关于操作系统战争的故事。这场战争塑造了我们的数字生活的形态,争夺主导地位的斗争从桌面转移到了服务器机房,最终进入了云计算领域。过去的敌人难以置信地变成了盟友,众包的未来让一切都变得开放。
**00:27:30 - Saron Yitbarek**: 听着,我知道,在这段历史之旅中,还有很多英雄我们没有提到。所以给我们写信吧,分享你的故事。[Redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 。我恭候佳音。
在本季剩下的时间里,我们将学习今天的英雄们在创造什么,以及他们要经历什么样的战斗才能将他们的创造物带入我们的生活。让我们从壮丽的编程一线,回来看看更多的传奇故事吧。我们每两周放一集新的博客。几周后,我们将为你带来第三集:敏捷革命。
**00:28:00 - Saron Yitbarek**: 代码英雄是一款红帽公司原创的播客。要想免费自动获得新一集的代码英雄,请订阅我们的节目。只要在苹果播客、Spotify、Google Play,或其他应用中搜索“Command Line Heroes”。然后点击“订阅”。这样你就会第一个知道什么时候有新剧集了。
我是 Saron Yitbarek。感谢收听,在下期节目之前,请坚持编程。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。欢迎加入 LCRH SIG :</article-12436-1.html>
>
>
>
>
> **关于重制版**
>
>
> 本系列第一季的前三篇我们已经发布过,这次根据新的 SIG 规范重新修订发布。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux>
作者:[redhat](https://www.redhat.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[acyanbird](https://github.com/acyanbird)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The empire of Microsoft controls 90% of users. Complete standardization of operating systems seems assured. But an unlikely hero arises from amongst the band of open source rebels. [ Linus Torvalds](https://twitter.com/linus__torvalds)—meek, bespectacled—releases his Linux® program free of charge. While Microsoft reels and regroups, the battleground shifts from personal computers to the Internet.
Acclaimed tech journalist [ Steven Vaughan-Nichols](https://twitter.com/sjvn) is joined by a team of veterans who relive the tech revolution that reimagined our future.
Editor's note: A previous version of this episode featured a short clip with Jon “maddog” Hall. It has been removed at his request.
*Saron Yitbarek*
Is this thing on? Cue the epic Star Wars crawl, and, action.
**00:30** - *Voice Actor*
Episode Two: Rise of Linux® . The empire of Microsoft controls 90 % of desktop users . Complete standardization of operating systems seems assured. However, the advent of the internet swerves the focus of the war from the desktop toward enterprise, where all businesses scramble to claim a server of their own. Meanwhile, an unlikely hero arises from amongst the band of open source rebels . Linus Torvalds, head strong, bespectacled, releases his Linux system free of charge. Microsoft reels — and regroups.
**01:00** - *Saron Yitbarek*
Oh, the nerd in me just loves that. So, where were we? Last time, Apple and Microsoft were trading blows, trying to dominate in a war over desktop users. By the end of episode one, we saw Microsoft claiming most of the prize. Soon, the entire landscape went through a seismic upheaval. That's all because of the rise of the internet and the army of developers that rose with it. The internet moves the battlefield from PC users in their home offices to giant business clients with hundreds of servers.
**01:30** - *Saron Yitbarek*
This is a huge resource shift. Not only does every company out there wanting to remain relevant suddenly have to pay for server space and get a website built — they also have to integrate software to track resources, monitor databases, et cetera, et cetera. You're going to need a lot of developers to help you with that. At least, back then you did.
In part two of the OS wars, we'll see how that enormous shift in priorities, and the work of a few open source rebels like Linus Torvalds and Richard Stallman, managed to strike fear in the heart of Microsoft, and an entire software industry.
**02:00** - *Saron Yitbarek*
I'm Saron Yitbarek and you're listening to Command Line Heroes, an original podcast from Red Hat. In each episode, we're bringing you stories about the people who transform technology from the command line up.
**02:30** - *Saron Yitbarek*
Okay. Imagine for a second that you're Microsoft in 1991. You're feeling pretty good, right? Pretty confident. Assured global domination feels nice. You've mastered the art of partnering with other businesses, but you're still pretty much cutting out the developers, programmers, and sys admins that are the real foot soldiers out there. There is this Finnish geek named Linus Torvalds. He and his team of open source programmers are starting to put out versions of Linux, this OS kernel that they're duct taping together.
**03:00** - *Saron Yitbarek*
If you're Microsoft, frankly, you're not too concerned about Linux or even about open source in general, but eventually, the sheer size of Linux gets so big that it becomes impossible for Microsoft not to notice. The first version comes out in 1991 and it's got maybe 10,000 lines of code. A decade later, there will be three million lines of code. In case you're wondering, today it's at 20 million.
**03:30** - *Saron Yitbarek*
For a moment, let's stay in the early 90s. Linux hasn't yet become the behemoth we know now. It's just this strangely viral OS that's creeping across the planet, and the geeks and hackers of the world are falling in love with it. I was too young in those early days, but I sort of wish I'd been there. At that time, discovering Linux was like gaining access to a secret society. Programmers would share the Linux CD set with friends the same way other people would share mixtapes of underground music.
Developer Tristram Oaten [00:03:40] tells the story of how he first encountered Linux when he was 16 years old.
**04:00** - *Tristram Oaten*
We went on a scuba diving holiday, my family and I, to Hurghada, which is on the Red Sea. Beautiful place, highly recommend it. The first day, I drank the tap water. Probably, my mom told me not to. I was really sick the whole week — didn't leave the hotel room. All I had with me was a laptop with a fresh install of Slackware Linux, this thing that I'd heard about and was giving it a try. There were no extra apps, just what came on the eight CDs. By necessity, all I had to do this whole week was to get to grips with this alien system. I read man pages, played around with the terminal. I remember not knowing the difference between a single dot, meaning the current directory, and two dots, meaning the previous directory.
**04:30** - *Tristram Oaten*
I had no clue. I must have made so many mistakes, but slowly, over the course of this forcible solitude, I broke through this barrier and started to understand and figure out what this command line thing was all about. By the end of the holiday, I hadn't seen the pyramids, the Nile, or any Egyptian sites, but I had unlocked one of the wonders of the modern world. I'd unlocked Linux, and the rest is history.
*Saron Yitbarek*
You can hear some variation on that story from a lot of people. Getting access to that Linux command line was a transformative experience.
**05:00** - *David Cantrell*
This thing gave me the source code. I was like, "That's amazing."
*Saron Yitbarek*
We're at a 2017 Linux developers conference called Flock to Fedora.
*David Cantrell*
... very appealing. I felt like I had more control over the system and it just drew me in more and more. From there, I guess, after my first Linux kernel compile in 1995, I was hooked, so, yeah.
*Saron Yitbarek*
Developers David Cantrell and Joe Brockmire.
**05:30** - *Joe Brockmeier*
I was going through the cheap software and found a four - CD set of Slackware Linux. It sounded really exciting and interesting so I took it home, installed it on a second computer, started playing with it, and really got excited about two things. One was, I was excited not to be running Windows, and I was excited by the open source nature of Linux.
**06:00** - *Saron Yitbarek*
That access to the command line was, in some ways, always there. Decades before open source really took off, there was always a desire to have complete control, at least among developers. Go way back to a time before the OS wars, before Apple and Microsoft were fighting over their GUIs. There were command line heroes then, too. Professor Paul Jones is the director of the online library ibiblio.org. He worked as a developer during those early days.
**06:30** - *Paul Jones*
The internet, by its nature, at that time, was less client server, totally, and more peer to peer. We're talking about, really, some sort of VAX to VAX, some sort of scientific workstation, the scientific workstation. That doesn't mean that client and server relationships and applications weren't there, but it does mean that the original design was to think of how to do peer - to - peer things, the opposite of what IBM had been doing, in which they had dumb terminals that had only enough intelligence to manage the user interface, but not enough intelligence to actually let you do anything in the terminal that would expose anything to it.
**07:00** - *Saron Yitbarek*
As popular as GUI was becoming among casual users, there was always a pull in the opposite direction for the engineers and developers. Before Linux in the 1970s and 80s, that resistance was there, with EMAX and GNU . W ith Stallman's free software foundation, certain folks were always begging for access to the command line, but it was Linux in the 1990s that delivered like no other.
**07:30** - *Saron Yitbarek*
The early lovers of Linux and other open source software were pioneers. I'm standing on their shoulders. We all are.
You're listening to Command Line Heroes, an original podcast from Red Hat. This is part two of the OS wars: Rise of Linux.
*Steven Vaughan-Nichols*
By 1998, things have changed.
**08:00** - *Saron Yitbarek*
Steven Vaughan-Nichols is a contributing editor at zdnet.com, and he's been writing for decades about the business side of technology. He describes how Linux slowly became more and more popular until the number of volunteer contributors was way larger than the number of Microsoft developers working on Windows. Linux never really went after Microsoft's desktop customers, though, and maybe that's why Microsoft ignored them at first. Where Linux did shine was in the server room. When businesses went online, each one required a unique programming solution for their needs.
**08:30** - *Saron Yitbarek*
Windows NT comes out in 1993 and it's competing with other server operating systems, but lots of developers are thinking, "Why am I going to buy an AIX box or a large windows box when I could set up a cheap Linux-based system with Apache?" Point is, Linux code started seeping into just about everything online.
**09:00** - *Steven Vaughan-Nichols*
Microsoft realizes that Linux, quite to their surprise, is actually beginning to get some of the business, not so much on the desktop, but on business servers. As a result of that, they start a campaign, what we like to call FUD — fear, uncertainty and doubt — saying, "Oh this Linux stuff, it's really not that good. It's not very reliable. You can't trust it with anything."
**09:30** - *Saron Yitbarek*
That soft propaganda style attack goes on for a while. Microsoft wasn't the only one getting nervous about Linux, either. It was really a whole industry versus that weird new guy. For example, anyone with a stake in UNIX was likely to see Linux as a usurper. Famously, the SCO Group, which had produced a version of UNIX, waged lawsuits for over a decade to try and stop the spread of Linux. SCO ultimately failed and went bankrupt. Meanwhile, Microsoft kept searching for their opening. They were a company that needed to make a move. It just wasn't clear what that move was going to be.
**10:00** - *Steven Vaughan-Nichols*
What will make Microsoft really concerned about it is the next year, in 2000, IBM will announce that they will invest a billion dollars in Linux in 2001. Now, IBM is not really in the PC business anymore. They're not out yet, but they're going in that direction, but what they are doing is they see Linux as being the future of servers and mainframe computers, which, spoiler alert, IBM was correct.
**10:30** - *Steven Vaughan-Nichols*
Linux is going to dominate the server world.
*Saron Yitbarek*
This was no longer just about a bunch of hackers loving their Jedi-like control of the command line. This was about the money side working in Linux's favor in a major way. John "Mad Dog" Hall, the executive director of Linux International, has a story that explains why that was. We reached him by phone.
**11:00** - *John Hall*
A friend of mine named Dirk Holden [00:10:56] was a German systems administrator at Deutsche Bank in Germany, and he also worked in the graphics projects for the early days of the X Windows system for PCs. I visited him one day at the bank, and I said, "Dirk, you have 3,000 servers here at the bank and you use Linux.
**11:30** - *John Hall*
Why don't you use Microsoft NT?" He looked at me and he said, "Yes, I have 3,000 servers , and if I used Microsoft Windows NT, I would need 2,999 systems administrators." He says, "With Linux, I only need four." That was the perfect answer.
**12:00** - *Saron Yitbarek*
The thing programmers are getting obsessed with also happens to be deeply attractive to big business. Some businesses were wary. The FUD was having an effect. They heard open source and thought, "Open. That doesn't sound solid. It's going to be chaotic, full of bugs," but as that bank manager pointed out, money has a funny way of convincing people to get over their hangups. Even little businesses, all of which needed websites, were coming on board. The cost of working with a cheap Linux system over some expensive proprietary option, there was really no comparison. If you were a shop hiring a pro to build your website, you wanted them to use Linux.
**12:30** - *Saron Yitbarek*
Fast forward a few years. Linux runs everybody's website. Linux has conquered the server world, and then, along comes the smartphone. Apple and their iPhones take a sizeable share of the market, of course, and Microsoft hoped to get in on that, except, surprise, Linux was there, too, ready and raring to go.
Author and journalist James Allworth.
**13:00** - *James Allworth*
There was certainly room for a second player, and that could well have been Microsoft, but for the fact of Android, which was fundamentally based on Linux, and because Android, famously acquired by Google, and now running a majority of the world's smartphones, Google built it on top of that. They were able to start with a very sophisticated operating system and a cost basis of zero. They managed to pull it off, and it ended up locking Microsoft out of the next generation of devices, by and large, at least from an operating system perspective.
**13:30** - *Saron Yitbarek*
The ground was breaking up, big time, and Microsoft was in danger of falling into the cracks. John Gossman is the chief architect on the Azure team at Microsoft. He remembers the confusion that gripped the company at that time.
**14:00** - *John Gossman*
Like a lot of companies, Microsoft was very concerned about IP pollution. They thought that if you let developers use open source they would likely just copy and paste bits of code into some product and then some sort of a viral license might take effect that ... They were also very confused, I think, it was just culturally, a lot of companies, Microsoft included, were confused on the difference between what open source development meant and what the business model was. There was this idea that open source meant that all your software was free and people were never going to pay anything.
**14:30** - *Saron Yitbarek*
Anybody invested in the old, proprietary model of software is going to feel threatened by what's happening here. When you threaten an enormous company like Microsoft, yeah, you can bet they're going to react. It makes sense they were pushing all that FUD — fear, uncertainty and doubt. At the time, an “ us versus them ” attitude was pretty much how business worked. If they'd been any other company, though, they might have kept that old grudge, that old thinking, but then, in 2013, everything changes.
**15:00** - *Saron Yitbarek*
Microsoft's cloud computing service, Azure, goes online and, shockingly, it offers Linux virtual machines from day one. Steve Ballmer, the CEO who called Linux a cancer, he's out, and a new forward - thinking CEO, Satya Nadella, has been brought in.
*John Gossman*
Satya has a different attitude. He's another generation. He's a generation younger than Paul and Bill and Steve were, and had a different perspective on open source.
*Saron Yitbarek*
John Gossman, again, from Microsoft's Azure team.
**15:30** - *John Gossman*
We added Linux support into Azure about four years ago, and that was for very pragmatic reasons. If you go to any enterprise customer, you will find that they are not trying to decide whether to use Windows or to use Linux or to use .net or to use Java TM . They made all those decisions a long time ago — about 15 years or so ago, there was some of this argument.
**16:00** - *John Gossman*
Now, every company that I have ever seen has a mix of Linux and Java and Windows and .net and SQL Server and Oracle and MySQL — proprietary source code - based products and open source code products.
f you're going to operate a cloud and you're going to allow and enable those companies to run their businesses on the cloud, you simply cannot tell them, "You can use this software but you can't use this software."
**16:30** - *Saron Yitbarek*
That's exactly the philosophy that Satya Nadella adopted. In the fall of 2014, he gets up on stage and he wants to get across one big, fat point. Microsoft loves Linux. He goes on to say that 20 % of Azure is already Linux and that Microsoft will always have first - class support for Linux distros. There's not even a whiff of that old antagonism toward open source.
To drive the point home, there's literally a giant sign behind them that reads, "Microsoft hearts Linux." Aww. For some of us, that turnaround was a bit of a shock, but really, it shouldn't have been. Here's Steven Levy, a tech journalist and author.
**17:00** - *Steven Levy*
When you're playing a football game and the turf becomes really slick, maybe you switch to a different kind of footwear in order to play on that turf. That's what they were doing.
**17:30** - *Steven Levy*
They can't deny reality and there are smart people there so they had to realize that this is the way the world is and put aside what they said earlier, even though they might be a little embarrassed at their earlier statements, but it would be crazy to let their statements about how horrible open source was earlier, affect their smart decisions now.
**18:00** - *Saron Yitbarek*
Microsoft swallowed its pride in a big way. You might remember that Apple, after years of splendid isolation, finally shifted toward a partnership with Microsoft. Now it was Microsoft's turn to do a 180. After years of battling the open source approach, they were reinventing themselves. It was change or perish. Steven Vaughan-Nichols.
**18:30** - *Steven Vaughan-Nichols*
Even a company the size of Microsoft simply can't compete with the thousands of open source developers working on all these other major projects , including Linux. They were very loath e to do so for a long time. The former Microsoft CEO, Steve Ballmer, hated Linux with a passion. Because of its GPL license, it was a cancer, but once Ballmer was finally shown the door, the new Microsoft leadership said, "This is like trying to order the tide to stop coming in. The tide is going to keep coming in. We should work with Linux, not against it."
**19:30** - *Steven Vaughan-Nichols*
Microsoft 2017 is not Steve Ballmer's Microsoft, nor is it Bill Gates' Microsoft. It's an entirely different company with a very different approach and, again, once you start using open source, it's not like you can really pull back. Open source has devoured the entire technology world. People who have never heard of Linux as such, don't know it, but every time they're on Facebook, they're running Linux. Every time you do a Google search, you're running Linux.
**20:00** - *Steven Vaughan-Nichols*
Every time you do anything with your Android phone, you're running Linux again. It literally is everywhere, and Microsoft can't stop that, and thinking that Microsoft can somehow take it all over, I think is naïve.
**20:30** - *Saron Yitbarek*
Open source supporters might have been worrying about Microsoft coming in like a wolf in the flock, but the truth is, the very nature of open source software protects it from total domination. No single company can own Linux and control it in any specific way. Greg Kroah-Hartman is a fellow at the Linux Foundation.
*Greg Kroah-Hartman*
Every company and every individual contributes to Linux in a selfish manner. They're doing so because they want to solve a problem that they have, be it hardware isn't working , or they want to add a new feature to do something else , or want to take it in a direction that they'll build that they can use for their product. That's great, because then everybody benefits from that because they're releasing the code back, so that everybody can use it. It's because of that selfishness that all companies and all people have, everybody benefits.
**21:00** - *Saron Yitbarek*
Microsoft has realized that in the coming cloud wars, fighting Linux would be like going to war with, well, a cloud. Linux and open source aren't the enemy, they're the atmosphere. Today, Microsoft has joined the Linux Foundation as a platinum member. They became the number one contributor to open source on GitHub.
**21:30** - *Saron Yitbarek*
In September, 2017, they even joined the Open Source Initiative. These days, Microsoft releases a lot of its code under open licenses. Microsoft's John Gossman describes what happened when they open sourced .net. At first, they didn't really think they'd get much back.
**22:00** - *John Gossman*
We didn't count on contributions from the community, and yet, three years in, over 50 per cent of the contributions to the .net framework libraries, now, are coming from outside of Microsoft. This includes big pieces of code. Samsung has contributed ARM support to .net. Intel and ARM and a couple other chip people have contributed code generation specific for their processors to the .net framework, as well as a surprising number of fixes, performance improvements , and stuff — from just individual contributors to the community.
*Saron Yitbarek*
Up until a few years ago, the Microsoft we have today, this open Microsoft, would have been unthinkable.
**22:30** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes. Okay, we've seen titanic battles for the love of millions of desktop users. We've seen open source software creep up behind the proprietary titans, and nab huge market share.
**23:00** - *Saron Yitbarek*
We've seen fleets of command line heroes transform the programming landscape into the one handed down to people like me and you. Today, big business is absorbing open source software, and through it all, everybody is still borrowing from everybody.
**22:30** - *Saron Yitbarek*
In the tech wild west, it's always been that way. Apple gets inspired by Xerox, Microsoft gets inspired by Apple, Linux gets inspired by UNIX. Evolve, borrow, constantly grow. In David and Goliath terms, open source software is no longer a David, but, you know what? It's not even Goliath, either. Open source has transcended. It's become the battlefield that others fight on. As the open source approach becomes inevitable, new wars, wars that are fought in the cloud, wars that are fought on the open source battlefield, are ramping up.
Here's author Steven Levy.
**24:00** - *Steven Levy*
Basically, right now, we have four or five companies, if you count Microsoft, that in various ways are fighting to be the platform for all we do, for artificial intelligence, say. You see wars between intelligent assistants, and guess what? Apple has an intelligent assistant, Siri. Microsoft has one, Cortana. Google has the Google Assistant. Samsung has an intelligent assistant. Amazon has one, Alexa. We see these battles shifting to different areas, there. Maybe, you could say, the hottest one is would be, whose AI platform is going to control all the stuff in our lives there, and those five companies are all competing for that.
**24:30** - *Saron Yitbarek*
If you're looking for another rebel that's going to sneak up behind Facebook or Google or Amazon and blindside them the way Linux blindsided Microsoft, you might be looking a long time, because as author James Allworth points out, being a true rebel is only getting harder and harder.
**25:00** - *James Allworth*
Scale's always been an advantage but the nature of scale advantages are almost ... Whereas, I think previously they were more linear in nature, now it's more exponential in nature, and so, once you start to get out in front with something like this , it becomes harder and harder for a new player to come in and catch up. I think this is true of the internet era in general, whether it's scale like that or the importance and advantages that data bestow on an organization in terms of its ability to compete.
**25:30** - *James Allworth*
Once you get out in front, you attract more customers, and then that gives you more data and that enables you to do an even better job, and then, why on earth would you want to go with the number two player, because they're so far behind? I think it's going to be no different in cloud.
**26:00** - *Saron Yitbarek*
This story began with singular heroes like Steve Jobs and Bill Gates, but the progress of technology has taken on a crowdsourced, organic feel. I think it's telling that our open source hero, Linus Torvalds, didn't even have a real plan when he first invented the Linux kernel. He was a brilliant, young developer for sure, but he was also like a single drop of water at the very front of a tidal wave. The revolution was inevitable. It's been estimated that for a proprietary company to create a Linux distribution in their old - fashioned, proprietary way, it would cost them well over $10 billion. That points to the power of open source.
**26:30** - *Saron Yitbarek*
In the end, it's not something that a proprietary model is going to compete with. Successful companies have to remain open. That's the big, ultimate lesson in all this. Something else to keep in mind: W hen we're wired together, our capacity to grow and build on what we've already accomplished becomes limitless. As big as these companies get, we don't have to sit around waiting for them to give us something better. Think about the new developer who learns to code for the sheer joy of creating, the mom who decides that if nobody's going to build what she needs, then she'll build it herself.
Wherever tomorrow's great programmers come from, they're always going to have the capacity to build the next big thing, so long as there's access to the command line.
**27:00** - *Saron Yitbarek*
That's it for our two - part tale on the OS wars that shaped our digital lives. The struggle for dominance moved from the desktop to the server room, and ultimately into the cloud. Old enemies became unlikely allies, and a crowdsourced future left everything open.
**27:30** - *Saron Yitbarek*
Listen, I know, there are a hundred other heroes we didn't have space for in this history trip, so drop us a line. Share your story. Redhat.com/commandlineheroes. I'm listening.
We're spending the rest of the season learning what today's heroes are creating, and what battles they're going through to bring their creations to life. Come back for more tales — from the epic front lines of programming. We drop a new episode every two weeks. In a couple weeks' time, we bring you episode three: the Agile Revolution.
**28:00** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. To get new episodes delivered automatically for free, make sure to subscribe to the show. Just search for “ Command Line Heroes ” in Apple p odcast s , Spotify, Google Play, and pretty much everywhere else you can find podcasts. Then, hit “ subscribe ” so you will be the first to know when new episodes are available.
I'm Saron Yitbarek. Thanks for listening. Keep on coding.
### Keep going
### From police officer to open source devotee: One man's story
How Red Hat’s Thomas Cameron became an accidental technologist, and fell in love with Linux along the way
### Red Hat + Microsoft: To boldly go where no partnership has gone before
A partnership that would have once been deemed unimaginable?and what it means for developers, sysadmins, and DevOps engineers |
12,509 | 在 Linux 上挖掘 DNS 应答中的秘密 | https://www.networkworld.com/article/3568488/digging-for-dns-answers-on-linux.html | 2020-08-11T23:52:16 | [
"dig",
"DNS"
] | https://linux.cn/article-12509-1.html |
>
> dig 是一个强大而灵活的工具,用于查询域名系统(DNS)服务器。在这篇文章中,我们将深入了解它的工作原理以及它能告诉你什么。
>
>
>

`dig` 是一款强大而灵活的查询 DNS 名称服务器的工具。它执行 DNS 查询,并显示参与该过程的名称服务器返回的应答以及与搜索相关的细节。系统管理员和 [DNS](https://www.networkworld.com/article/3268449/what-is-dns-and-how-does-it-work.html) 管理员经常使用 `dig` 来帮助排除 DNS 问题。在这篇文章中,我们将深入了解它的工作原理,看看它能告诉我们什么。
开始之前,对 DNS(域名系统)的工作方式有一个基本的印象是很有帮助的。它是全球互联网的关键部分,因为它提供了一种查找世界各地的服务器的方式,从而可以与之连接。你可以把它看作是互联网的地址簿,任何正确连接到互联网的系统,都应该能够使用它来查询任何正确注册的服务器的 IP 地址。
### dig 入门
Linux 系统上一般都默认安装了 `dig` 工具。下面是一个带有一点注释的 `dig` 命令的例子:
```
$ dig www.networkworld.com
; <<>> DiG 9.16.1-Ubuntu <<>> www.networkworld.com <== 你使用的 dig 版本
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 6034
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 65494
;; QUESTION SECTION: <== 你的查询细节
;www.networkworld.com. IN A
;; ANSWER SECTION: <== 结果
www.networkworld.com. 3568 IN CNAME idg.map.fastly.net.
idg.map.fastly.net. 30 IN A 151.101.250.165
;; Query time: 36 msec <== 查询用时
;; SERVER: 127.0.0.53#53(127.0.0.53) <== 本地缓存解析器
;; WHEN: Fri Jul 24 19:11:42 EDT 2020 <== 查询的时间
;; MSG SIZE rcvd: 97 <== 返回的字节数
```
如果你得到了一个这样的应答,是好消息吗?简短的回答是“是”。你得到了及时的回复。状态字段(`status: NOERROR`)显示没有问题。你正在连接到一个能够提供所要求的信息的名称服务器,并得到一个回复,告诉你一些关于你所查询的系统的重要细节。简而言之,你已经验证了你的系统和域名系统相处得很好。
其他可能的状态指标包括:
* `SERVFAIL`:被查询的名称存在,但没有数据或现有数据无效。
* `NXDOMAIN`:所查询的名称不存在。
* `REFUSED`:该区域的数据不存在于所请求的权威服务器中,并且在这种情况下,基础设施没有设置为提供响应服务。
下面是一个例子,如果你要查找一个不存在的域名,你会看到什么?
```
$ dig cannotbe.org
; <<>> DiG 9.16.1-Ubuntu <<>> cannotbe.org
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 35348
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
```
一般来说,`dig` 比 `ping` 会提供更多的细节,如果域名不存在,`ping` 会回复 “名称或服务未知”。当你查询一个合法的系统时,你可以看到域名系统对该系统知道些什么,这些记录是如何配置的,以及检索这些数据需要多长时间。
(LCTT 译注:`dig` 也比 `nslookup` 提供的数据更多。此外,`dig` 采用的是操作系统的解析库,而 `nslookup` 采用的是自己提供的解析库,这有时候会带来不同的行为。最后,有趣的一点是,`dig` 的返回的格式是符合 BIND 区域文件格式的。)
事实上,有时 `dig` 可以在 `ping` 完全不能响应的时候进行响应,当你试图确定一个连接问题时,这种信息是非常有用的。
### DNS 记录类型和标志
在上面的第一个查询中,我们可以看到一个问题,那就是同时存在 `CNAME` 和 `A` 记录。`CNAME`(<ruby> 规范名称 <rt> canonical name </rt></ruby>)就像一个别名,把一个域名指向另一个域名。你查询的大多数系统不会有 `CNAME` 记录,而只有 `A` 记录。如果你运行 `dig localhost` 命令,你会看到一个 `A` 记录,它就指向 `127.0.0.1` —— 这是每个系统都使用的“回环”地址。`A` 记录用于将一个名字映射到一个 IP 地址。
DNS 记录类型包括:
* `A` 或 `AAAA`:IPv4 或 IPv6 地址
* `CNAME`:别名
* `MX`:邮件交换器
* `NS`:名称服务器
* `PTR`:一个反向条目,让你根据 IP 地址找到系统名称
* `SOA`:表示授权记录开始
* `TXT` 一些相关文本
我们还可以在上述输出的第五行看到一系列的“标志”。这些定义在 [RFC 1035](https://tools.ietf.org/html/rfc1035) 中 —— 它定义了 DNS 报文头中包含的标志,甚至显示了报文头的格式。
```
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ID |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
|QR| Opcode |AA|TC|RD|RA| Z | RCODE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QDCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ANCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| NSCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ARCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
```
在上面的初始查询中,第五行显示的标志是:
* `qr` = 查询
* `rd` = 进行递归查询
* `ra` = 递归数据可用
RFC 中描述的其他标志包括:
* `aa` = 权威答复
* `cd` = 检查是否禁用
* `ad` = 真实数据
* `opcode` = 一个 4 位字段
* `tc` = 截断
* `z`(未使用)
### 添加 +trace 选项
如果你添加 `+trace` 选项,你将从 `dig` 得到更多的输出。它会添加更多信息,显示你的 DNS 查询如何通过名称服务器的层次结构找到你要找的答案。
下面显示的所有 `NS` 记录都反映了名称服务器 —— 这只是你将看到的数据的第一部分,因为查询通过名称服务器的层次结构来追踪你要找的东西:
```
$ dig +trace networkworld.com
; <<>> DiG 9.16.1-Ubuntu <<>> +trace networkworld.com
;; global options: +cmd
. 84895 IN NS k.root-servers.net.
. 84895 IN NS e.root-servers.net.
. 84895 IN NS m.root-servers.net.
. 84895 IN NS h.root-servers.net.
. 84895 IN NS c.root-servers.net.
. 84895 IN NS f.root-servers.net.
. 84895 IN NS a.root-servers.net.
. 84895 IN NS g.root-servers.net.
. 84895 IN NS l.root-servers.net.
. 84895 IN NS d.root-servers.net.
. 84895 IN NS b.root-servers.net.
. 84895 IN NS i.root-servers.net.
. 84895 IN NS j.root-servers.net.
;; Received 262 bytes from 127.0.0.53#53(127.0.0.53) in 28 ms
...
```
最终,你会得到与你的要求直接挂钩的信息:
```
networkworld.com. 300 IN A 151.101.2.165
networkworld.com. 300 IN A 151.101.66.165
networkworld.com. 300 IN A 151.101.130.165
networkworld.com. 300 IN A 151.101.194.165
networkworld.com. 14400 IN NS ns-d.pnap.net.
networkworld.com. 14400 IN NS ns-a.pnap.net.
networkworld.com. 14400 IN NS ns0.pcworld.com.
networkworld.com. 14400 IN NS ns1.pcworld.com.
networkworld.com. 14400 IN NS ns-b.pnap.net.
networkworld.com. 14400 IN NS ns-c.pnap.net.
;; Received 269 bytes from 70.42.185.30#53(ns0.pcworld.com) in 116 ms
```
### 挑选响应者
你可以使用 `@` 符号来指定一个特定的名称服务器来处理你的查询。在这里,我们要求 Google 的主名称服务器响应我们的查询:
```
$ dig @8.8.8.8 networkworld.com
; <<>> DiG 9.16.1-Ubuntu <<>> @8.8.8.8 networkworld.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43640
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;networkworld.com. IN A
;; ANSWER SECTION:
networkworld.com. 299 IN A 151.101.66.165
networkworld.com. 299 IN A 151.101.194.165
networkworld.com. 299 IN A 151.101.130.165
networkworld.com. 299 IN A 151.101.2.165
;; Query time: 48 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Sat Jul 25 11:21:19 EDT 2020
;; MSG SIZE rcvd: 109
```
下面所示的命令对 `8.8.8.8` IP 地址进行反向查找,以显示它属于 Google 的 DNS 服务器。
```
$ nslookup 8.8.8.8
8.8.8.8.in-addr.arpa name = dns.google.
```
### 总结
`dig` 命令是掌握 DNS 工作原理和在出现连接问题时排除故障的重要工具。
---
via: <https://www.networkworld.com/article/3568488/digging-for-dns-answers-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,511 | 如何使用 OpenSSL:哈希值、数字签名等 | https://opensource.com/article/19/6/cryptography-basics-openssl-part-2 | 2020-08-13T15:03:00 | [
"OpenSSL"
] | https://linux.cn/article-12511-1.html |
>
> 通过 OpenSSL 深入了解密码学的细节:哈希值、数字签名、数字证书等。
>
>
>

[本系列的第一篇文章](/article-11810-1.html)通过 OpenSSL 库和命令行实用程序介绍了哈希、加密/解密、数字签名和数字证书。这第二篇文章将对细节进行深入探讨。让我们从计算中无处不在的哈希开始,并考虑是什么使哈希函数*具备密码学意义*。
### 密码学哈希
OpenSSL 源代码的[下载页面](https://www.openssl.org/source/)包含了一个带有最新版本的表格。每个版本都有两个<ruby> 哈希值 <rt> hash </rt></ruby>:160 位 SHA1 和 256 位 SHA256。这些值可以用来验证下载的文件是否与存储库中的原始文件相匹配:下载者在本地重新计算下载文件的哈希值,然后将结果与原始文件进行比较。现代系统有计算这种哈希值的实用程序。例如,Linux 有 `md5sum` 和 `sha256sum`。OpenSSL 本身也提供了类似的命令行实用程序。
哈希值被用于计算的许多领域。例如,比特币区块链使用 SHA256 哈希值作为区块标识符。挖比特币就是生成一个低于指定阈值的 SHA256 哈希值,也就是至少有 N 个前导零的哈希值。(N 的值可以上升或下降,这取决于特定时间的挖矿生产力)。作为一个兴趣点,如今的矿机是为并行生成 SHA256 哈希值而设计的硬件集群。在 2018 年的一个高峰期,全球的比特币矿工每秒产生约 7500 万个<ruby> 太哈希值 <rt> terahash </rt></ruby> —— 这真是一个不可思议的数字。
网络协议也使用哈希值(在这里通常叫做“<ruby> 校验和 <rt> checksum </rt></ruby>”)来支持消息的完整性;也就是说,保证收到的消息与发送的消息是一样的。消息发送者计算消息的校验和,并将结果与消息一起发送。当消息到达时,接收方重新计算校验和。如果发送的校验和与重新计算的校验和不一致,那么消息在传输过程中可能出现了一些问题,或者发送的校验和出现了问题,或者两者都出现了问题。在这种情况下,应该重新发送消息和它的校验和,或者至少应该触发一个错误情况。(如 UDP 这样的低级网络协议不会理会校验和。)
哈希的其他例子大家都很熟悉。比如一个网站,要求用户用密码进行验证,用户在浏览器中输入密码,然后,他们通过 HTTPS 连接到服务器,密码从浏览器加密发送到服务器。一旦密码到达服务器,就会被解密,然后进行数据库表的查询。
在这个查询表中应该存储什么?存储密码本身是有风险的。风险要小得多的方式是存储一个由密码生成的哈希值,也许在计算哈希值之前“加一些<ruby> 盐 <rt> salt </rt></ruby>(额外的位)改善口味”。你的密码可能会被发送到 Web 服务器上,但网站可以向你保证,密码不会存储在那里。
哈希值还出现在安全的各个领域。例如,<ruby> 基于哈希值的消息认证码 <rt> hash-based message authentication code </rt></ruby>([HMAC](https://en.wikipedia.org/wiki/HMAC))使用一个哈希值和一个秘密的<ruby> 加密密钥 <rt> cryptographic key </rt></ruby>来认证通过网络发送的消息。HMAC 码轻量级且易于在程序中使用,在 Web 服务中很受欢迎。一个 X509 数字证书包括一个称为<ruby> 指纹 <rt> fingerprint </rt></ruby>的哈希值,它可以方便证书验证。一个存放于内存中的<ruby> 可信存储 <rt> truststore </rt></ruby>可以实现为一个以这种指纹为键的查找表 —— 作为一个支持恒定查找时间的<ruby> 哈希映射 <rt> hash map </rt></ruby>。来自传入的证书的指纹可以与可信存储中的密钥进行比较,以确定是否匹配。
<ruby> 密码学哈希函数 <rt> cryptographic hash function </rt></ruby>应该具有什么特殊属性?它应该是<ruby> 单向 <rt> one-way </rt></ruby>的,这意味着很难被逆转。一个加密哈希函数应该是比较容易计算的,但是计算它的反函数(将哈希值映射回输入位串的函数)在计算上应该是困难的。下面是一个描述,用 `chf` 作为加密哈希函数,我的密码 `foobar` 作为样本输入。
```
+---+
foobar—>|chf|—>hash value ## 简单直接
+--–+
```
相比之下,逆向操作是不可行的:
```
+-----------+
hash value—>|chf inverse|—>foobar ## 棘手困难
+-----------+
```
例如,回忆一下 SHA256 哈希函数。对于一个任意长度为 N > 0 的输入位串,这个函数会生成一个 256 位的固定长度的哈希值;因此,这个哈希值甚至不会反映出输入位串的长度 N,更不用说字符串中每个位的值了。顺便说一下,SHA256 不容易受到<ruby> <a href="https://en.wikipedia.org/wiki/Length_extension_attack"> 长度扩展攻击 </a> <rt> length extension attack </rt></ruby>。唯一有效的逆向工程方法是通过蛮力搜索将计算出的 SHA256 哈希值逆向返回到输入位串,这意味着需要尝试所有可能的输入位串,直到找到与目标哈希值匹配的位串。这样的搜索在 SHA256 这样一个完善的加密哈希函数上是不可行的。
现在,最后一个回顾的知识点是<ruby> 有序 <rt> in order </rt></ruby>。加密哈希值是统计学上的唯一,而不是无条件的唯一,这意味着两个不同的输入位串产生相同的哈希值是不太可能的,但也不是不可能的 —— 这称之为<ruby> 碰撞 <rt> collision </rt></ruby>。[生日问题](https://en.wikipedia.org/wiki/Birthday_problem)提供了一个很好的反直觉的碰撞例子。对各种哈希算法的<ruby> 抗碰撞性 <rt> collision resistance </rt></ruby>有着广泛的研究。例如,MD5(128 位哈希值)在大约 2<sup> 21</sup> 次哈希之后,抗碰撞能力就会崩溃。对于 SHA1(160 位哈希值),大约在 2<sup> 61</sup> 次哈希后开始崩溃。
对于 SHA256 的抗碰撞能力的剖析,目前还没有一个很好的估计。这个事实并不奇怪。SHA256 有 2<sup> 256</sup> 个不同的哈希值范围,这个数字的十进制表示法有 78 位之多!那么,SHA256 哈希会不会发生碰撞呢?当然可能,但可能性极小。
在下面的命令行示例中,有两个输入文件被用作位串源:`hashIn1.txt` 和 `hashIn2.txt`。第一个文件包含 `abc`,第二个文件包含 `1a2b3c`。
为了便于阅读,这些文件包含的是文本,但也可以使用二进制文件代替。
在命令行(百分号 `%` 是提示符)使用 Linux `sha256sum` 实用程序对这两个文件进行处理产生以下哈希值(十六进制):
```
% sha256sum hashIn1.txt
9e83e05bbf9b5db17ac0deec3b7ce6cba983f6dc50531c7a919f28d5fb3696c3 hashIn1.txt
% sha256sum hashIn2.txt
3eaac518777682bf4e8840dd012c0b104c2e16009083877675f00e995906ed13 hashIn2.txt
```
OpenSSL 哈希对应的结果与预期相同:
```
% openssl dgst -sha256 hashIn1.txt
SHA256(hashIn1.txt)= 9e83e05bbf9b5db17ac0deec3b7ce6cba983f6dc50531c7a919f28d5fb3696c3
% openssl dgst -sha256 hashIn2.txt
SHA256(hashIn2.txt)= 3eaac518777682bf4e8840dd012c0b104c2e16009083877675f00e995906ed13
```
这种对密码学哈希函数的研究,为我们仔细研究数字签名及其与密钥对的关系奠定了基础。
### 数字签名
顾名思义,<ruby> 数字签字 <rt> digital signature </rt></ruby>可以附在文件或其他一些电子<ruby> 工件 <rt> artifact </rt></ruby>(如程序)上,以证明其真实性。因此,这种签名类似于纸质文件上的手写签名。验证数字签名就是要确认两件事:第一,被担保的工件在签名被附上后没有改变,因为它部分是基于文件的加密学哈希值。第二,签名属于一个人(例如 Alice),只有她才能获得一对密钥中的私钥。顺便说一下,对代码(源码或编译后的代码)进行数字签名已经成为程序员的普遍做法。
让我们来了解一下数字签名是如何创建的。如前所述,没有公钥和私钥对就没有数字签名。当使用 OpenSSL 创建这些密钥时,有两个独立的命令:一个是创建私钥,另一个是从私钥中提取匹配的公钥。这些密钥对用 base64 编码,在这个过程中可以指定它们的大小。
<ruby> 私钥 <rt> private key </rt></ruby>由数值组成,其中两个数值(一个<ruby> 模数 <rt> modulus </rt></ruby>和一个<ruby> 指数 <rt> exponent </rt></ruby>)组成了公钥。虽然私钥文件包含了<ruby> 公钥 <rt> public key </rt></ruby>,但提取出来的公钥并**不会**透露相应私钥的值。
因此,生成的带有私钥的文件包含了完整的密钥对。将公钥提取到自己的文件中是很实用的,因为这两把钥匙有不同的用途,而这种提取方式也将私钥可能被意外公开的危险降到最低。
接下来,这对密钥的私钥被用来生成目标工件(如电子邮件)的哈希值,从而创建签名。在另一端,接收者的系统使用这对密钥的公钥来验证附在工件上的签名。
现在举个例子。首先,用 OpenSSL 生成一个 2048 位的 RSA 密钥对:
```
openssl genpkey -out privkey.pem -algorithm rsa 2048
```
在这个例子中,我们可以舍去 `-algorithm rsa` 标志,因为 `genpkey` 默认为 RSA 类型。文件的名称(`privkey.pem`)是任意的,但是<ruby> 隐私增强邮件 <rt> Privacy Enhanced Mail </rt></ruby>(PEM)扩展名 `.pem` 是默认 PEM 格式的惯用扩展名。(如果需要的话,OpenSSL 有命令可以在各种格式之间进行转换。)如果需要更大的密钥大小(例如 4096),那么最后一个参数 `2048` 可以改成 `4096`。这些大小总是二的幂。
下面是产生的 `privkey.pem` 文件的一个片断,它是 base64 编码的:
```
-----BEGIN PRIVATE KEY-----
MIICdgIBADANBgkqhkiG9w0BAQEFAASCAmAwggJcAgEAAoGBANnlAh4jSKgcNj/Z
JF4J4WdhkljP2R+TXVGuKVRtPkGAiLWE4BDbgsyKVLfs2EdjKL1U+/qtfhYsqhkK
...
-----END PRIVATE KEY-----
```
接下来的命令就会从私钥中提取出这对密钥的公钥:
```
openssl rsa -in privkey.pem -outform PEM -pubout -out pubkey.pem
```
由此产生的 `pubkey.pem` 文件很小,可以在这里完整地显示出来:
```
-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDZ5QIeI0ioHDY/2SReCeFnYZJY
z9kfk11RrilUbT5BgIi1hOAQ24LMilS37NhHYyi9VPv6rX4WLKoZCmkeYaWk/TR5
4nbH1E/AkniwRoXpeh5VncwWMuMsL5qPWGY8fuuTE27GhwqBiKQGBOmU+MYlZonO
O0xnAKpAvysMy7G7qQIDAQAB
-----END PUBLIC KEY-----
```
现在,有了密钥对,数字签名就很容易了 —— 在本例中,源文件 `client.c` 是要签名的工件:
```
openssl dgst -sha256 -sign privkey.pem -out sign.sha256 client.c
```
`client.c` 源文件的摘要是 SHA256,私钥在前面创建的 `privkey.pem` 文件中。由此产生的二进制签名文件是 `sign.sha256`,这是一个任意的名字。要得到这个文件的可读版本(比如 base64),后续命令是:
```
openssl enc -base64 -in sign.sha256 -out sign.sha256.base64
```
文件 `sign.sha256.base64` 现在包含如下内容:
```
h+e+3UPx++KKSlWKIk34fQ1g91XKHOGFRmjc0ZHPEyyjP6/lJ05SfjpAJxAPm075
VNfFwysvqRGmL0jkp/TTdwnDTwt756Ej4X3OwAVeYM7i5DCcjVsQf5+h7JycHKlM
o/Jd3kUIWUkZ8+Lk0ZwzNzhKJu6LM5KWtL+MhJ2DpVc=
```
或者,可执行文件 `client` 也可以被签名,由此产生的 base64 编码签名将如预期的不同:
```
VMVImPgVLKHxVBapJ8DgLNJUKb98GbXgehRPD8o0ImADhLqlEKVy0HKRm/51m9IX
xRAN7DoL4Q3uuVmWWi749Vampong/uT5qjgVNTnRt9jON112fzchgEoMb8CHNsCT
XIMdyaPtnJZdLALw6rwMM55MoLamSc6M/MV1OrJnk/g=
```
这一过程的最后一步是用公钥验证数字签名。作为验证的一个重要步骤,应重新计算用于签署工件(在本例中,是可执行的 `client` 程序)的哈希值,因为验证过程应表明工件在签署后是否发生了变化。
有两个 OpenSSL 命令用于这个目的。第一条命令是对 base64 签名进行解码。
```
openssl enc -base64 -d -in sign.sha256.base64 -out sign.sha256
```
第二条是核实签名:
```
openssl dgst -sha256 -verify pubkey.pem -signature sign.sha256 client
```
第二条命令的输出,应该是这样的:
```
Verified OK
```
为了了解验证失败时的情况,一个简短但有用的练习是将最后一个 OpenSSL 命令中的可执行的 `client` 文件替换为源文件 `client.c`,然后尝试验证。另一个练习是改变 `client` 程序,无论多么轻微,然后再试一次。
### 数字证书
<ruby> 数字证书 <rt> digital certificate </rt></ruby>汇集了到目前为止所分析的各个部分:哈希值、密钥对、数字签名和加密/解密。生产级证书的第一步是创建一个<ruby> 证书签名请求 <rt> certificate signing request </rt></ruby>(CSR),然后将其发送给<ruby> 证书颁发机构 <rt> certificate authority </rt></ruby>(CA)。在 OpenSSL 的例子中,要做到这一点,请运行:
```
openssl req -out myserver.csr -new -newkey rsa:4096 -nodes -keyout myserverkey.pem
```
这个例子生成了一个 CSR 文档,并将该文档存储在文件 `myserver.csr`(base64 文本)中。这里的目的是:CSR 文档要求 CA 保证与指定域名相关联的身份,域名也就是 CA 所说的<ruby> 通用名 <rt> common name </rt></ruby>(CN)。
尽管可以使用现有的密钥对,但这个命令也会生成一个新的密钥对。请注意,在诸如 `myserver.csr` 和 `myserverkey.pem` 等名称中使用 `server` 暗示了数字证书的典型用途:作为与 www.google.com 等域名相关的 Web 服务器的身份担保。
然而,无论数字证书如何使用,同样使用这个命令都会创建一个 CSR。它还会启动一个问题/回答的交互式会话,提示有关域名的相关信息,以便与请求者的数字证书相连接。这个交互式会话可以通过在命令中提供基本的信息,用反斜杠来续行一步完成。`-subj` 标志提供了所需的信息。
```
% openssl req -new \
-newkey rsa:2048 -nodes -keyout privkeyDC.pem \
-out myserver.csr \
-subj "/C=US/ST=Illinois/L=Chicago/O=Faulty Consulting/OU=IT/CN=myserver.com"
```
产生的 CSR 文件在发送给 CA 之前可以进行检查和验证。这个过程可以创建具有所需格式(如 X509)、签名、有效期等的数字证书。
```
openssl req -text -in myserver.csr -noout -verify
```
这是输出的一个片断:
```
verify OK
Certificate Request:
Data:
Version: 0 (0x0)
Subject: C=US, ST=Illinois, L=Chicago, O=Faulty Consulting, OU=IT, CN=myserver.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:ba:36:fb:57:17:65:bc:40:30:96:1b:6e:de:73:
…
Exponent: 65537 (0x10001)
Attributes:
a0:00
Signature Algorithm: sha256WithRSAEncryption
…
```
### 自签证书
在开发 HTTPS 网站的过程中,手头有一个不用经过 CA 流程的数字证书是很方便的。在 HTTPS 握手的认证阶段,<ruby> 自签证书 <rt> self-signed certificate </rt></ruby>就能满足要求,尽管任何现代浏览器都会警告说这样的证书毫无价值。继续这个例子,自签证书的 OpenSSL 命令(有效期为一年,使用 RSA 公钥)如下:
```
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:4096 -keyout myserver.pem -out myserver.crt
```
下面的 OpenSSL 命令呈现了生成的证书的可读版本:
```
openssl x509 -in myserver.crt -text -noout
```
这是自签证书的部分输出:
```
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 13951598013130016090 (0xc19e087965a9055a)
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=US, ST=Illinois, L=Chicago, O=Faulty Consulting, OU=IT, CN=myserver.com
Validity
Not Before: Apr 11 17:22:18 2019 GMT
Not After : Apr 10 17:22:18 2020 GMT
Subject: C=US, ST=Illinois, L=Chicago, O=Faulty Consulting, OU=IT, CN=myserver.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
Modulus:
00:ba:36:fb:57:17:65:bc:40:30:96:1b:6e:de:73:
...
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Key Identifier:
3A:32:EF:3D:EB:DF:65:E5:A8:96:D7:D7:16:2C:1B:29:AF:46:C4:91
X509v3 Authority Key Identifier:
keyid:3A:32:EF:3D:EB:DF:65:E5:A8:96:D7:D7:16:2C:1B:29:AF:46:C4:91
X509v3 Basic Constraints:
CA:TRUE
Signature Algorithm: sha256WithRSAEncryption
3a:eb:8d:09:53:3b:5c:2e:48:ed:14:ce:f9:20:01:4e:90:c9:
...
```
如前所述,RSA 私钥包含的值是用来生成公钥的。但是,给定的公钥**不会**泄露匹配的私钥。关于底层数学理论的介绍,见 <https://simple.wikipedia.org/wiki/RSA_algorithm>。
数字证书与用于生成该证书的密钥对之间存在着重要的对应关系,即使证书只是自签的:
* 数字证书包含构成公钥的指数和模数值。这些值是最初生成的 PEM 文件中密钥对的一部分,在本例中,是文件 `myserver.pem`。
* <ruby> 指数 <rt> exponent </rt></ruby>几乎总是 65,537(如本例中),所以可以忽略。
* 密钥对的<ruby> 模数 <rt> modulus </rt></ruby>应该与数字证书的模数相匹配。
模数是一个很大的值,为了便于阅读,可以进行哈希处理。下面是两个 OpenSSL 命令,它们检查相同的模数,从而确认数字证书是基于 PEM 文件中的密钥对。
```
% openssl x509 -noout -modulus -in myserver.crt | openssl sha1 ## 证书中的模数
(stdin)= 364d21d5e53a59d482395b1885aa2c3a5d2e3769
% openssl rsa -noout -modulus -in myserver.pem | openssl sha1 ## 密钥中的模数
(stdin)= 364d21d5e53a59d482395b1885aa2c3a5d2e3769
```
所产生的哈希值匹配,从而确认数字证书是基于指定的密钥对。
### 回到密钥分发问题上
让我们回到第一部分末尾提出的一个问题:`client` 程序和 Google Web 服务器之间的 TLS 握手。握手协议有很多种,即使是用在 `client` 例子中的 Diffie-Hellman 版本也有不同的方式。尽管如此,`client` 例子遵循了一个共同的模式。
首先,在 TLS 握手过程中,`client` 程序和 Web 服务器就<ruby> 加密套件 <rt> cipher suite </rt></ruby>达成一致,其中包括要使用的算法。在本例中,该套件是 `ECDHE-RSA-AES128-GCM-SHA256`。
现在值得关注的两个要素是 RSA 密钥对算法和 AES128 块密码,用于在握手成功的情况下对消息进行加密和解密。关于加密/解密,这个过程有两种流派:<ruby> 对称 <rt> symmetric </rt></ruby>和<ruby> 非对称 <rt> asymmetric </rt></ruby>。在对称流派中,加密和解密使用的是*相同的*密钥,这首先就引出了<ruby> 密钥分发问题 <rt> key distribution problem </rt></ruby>。如何将密钥安全地分发给双方?在非对称流派中,一个密钥用于加密(在这种情况下,是 RSA 公钥),但另一个密钥用于解密(在这种情况下,是来自同一对密钥的 RSA 私钥)。
`client` 程序拥有来认证证书的 Google Web 服务器的公钥,而 Web 服务器拥有来自同一对密钥的私钥。因此,`client` 程序可以向 Web 服务器发送加密信息,而 Web 服务器可以单独对该通信进行解密。
在 TLS 的情况下,对称方式有两个显著的优势:
* 在 `client` 程序与 Google Web 服务器之间的互动中,认证是单向的。Google Web 服务器向 `client` 程序发送三张证书,但 `client` 程序并没有向 Web 服务器发送证书,因此,Web 服务器没有来自客户端的公钥,无法加密发给客户端的消息。
* 使用 AES128 的对称加密/解密比使用 RSA 密钥的非对称加密/解密快了**近千倍**。
TLS 握手将两种加密/解密方式巧妙地结合在一起。在握手过程中,`client` 程序会生成随机位,即所谓的<ruby> 预主密 <rt> pre-master secret </rt></ruby>(PMS)。然后,`client` 程序用服务器的公钥对 PMS 进行加密,并将加密后的 PMS 发送给服务器,服务器再用 RSA 密钥对的私钥对 PMS 信息进行解密:
```
+-------------------+ encrypted PMS +--------------------+
client PMS--->|server’s public key|--------------->|server’s private key|--->server PMS
+-------------------+ +--------------------+
```
在这个过程结束时,`client` 程序和 Google Web 服务器现在拥有相同的 PMS 位。每一方都使用这些位生成一个<ruby> 主密码 <rt> master secret </rt></ruby>,并立即生成一个称为<ruby> 会话密钥 <rt> session key </rt></ruby>的对称加密/解密密钥。现在有两个不同但等价的会话密钥,连接的每一方都有一个。在 `client` 的例子中,会话密钥是 AES128 类的。一旦在 `client` 程序和 Google Web 服务器两边生成了会话密钥,每一边的会话密钥就会对双方的对话进行保密。如果任何一方(例如,`client` 程序)或另一方(在这种情况下,Google Web 服务器)要求重新开始握手,握手协议(如 Diffie-Hellman)允许整个 PMS 过程重复进行。
### 总结
在命令行上说明的 OpenSSL 操作也可以通过底层库的 API 完成。这两篇文章重点使用了这个实用程序,以保持例子的简短,并专注于加密主题。如果你对安全问题感兴趣,OpenSSL 是一个很好的开始地方,并值得深入研究。
---
via: <https://opensource.com/article/19/6/cryptography-basics-openssl-part-2>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [first article in this series](https://opensource.com/article/19/6/cryptography-basics-openssl-part-1) introduced hashes, encryption/decryption, digital signatures, and digital certificates through the OpenSSL libraries and command-line utilities. This second article drills down into the details. Let’s begin with hashes, which are ubiquitous in computing, and consider what makes a hash function *cryptographic*.
## Cryptographic hashes
The download page for the OpenSSL source code ([https://www.openssl.org/source/](https://www.openssl.org/source/)) contains a table with recent versions. Each version comes with two hash values: 160-bit SHA1 and 256-bit SHA256. These values can be used to verify that the downloaded file matches the original in the repository: The downloader recomputes the hash values locally on the downloaded file and then compares the results against the originals. Modern systems have utilities for computing such hashes. Linux, for instance, has **md5sum** and **sha256sum**. OpenSSL itself provides similar command-line utilities.
Hashes are used in many areas of computing. For example, the Bitcoin blockchain uses SHA256 hash values as block identifiers. To mine a Bitcoin is to generate a SHA256 hash value that falls below a specified threshold, which means a hash value with at least N leading zeroes. (The value of N can go up or down depending on how productive the mining is at a particular time.) As a point of interest, today’s miners are hardware clusters designed for generating SHA256 hashes in parallel. During a peak time in 2018, Bitcoin miners worldwide generated about 75 million terahashes per second—yet another incomprehensible number.
Network protocols use hash values as well—often under the name **checksum**—to support message integrity; that is, to assure that a received message is the same as the one sent. The message sender computes the message’s checksum and sends the results along with the message. The receiver recomputes the checksum when the message arrives. If the sent and the recomputed checksum do not match, then something happened to the message in transit, or to the sent checksum, or to both. In this case, the message and its checksum should be sent again, or at least an error condition should be raised. (Low-level network protocols such as UDP do not bother with checksums.)
Other examples of hashes are familiar. Consider a website that requires users to authenticate with a password, which the user enters in their browser. Their password is then sent, encrypted, from the browser to the server via an HTTPS connection to the server. Once the password arrives at the server, it's decrypted for a database table lookup.
What should be stored in this lookup table? Storing the passwords themselves is risky. It’s far less risky is to store a hash generated from a password, perhaps with some *salt* (extra bits) added to taste before the hash value is computed. Your password may be sent to the web server, but the site can assure you that the password is not stored there.
Hash values also occur in various areas of security. For example, hash-based message authentication code ([HMAC](https://en.wikipedia.org/wiki/HMAC)) uses a hash value and a secret cryptographic key to authenticate a message sent over a network. HMAC codes, which are lightweight and easy to use in programs, are popular in web services. An X509 digital certificate includes a hash value known as the *fingerprint*, which can facilitate certificate verification. An in-memory truststore could be implemented as a lookup table keyed on such fingerprints—as a *hash map*, which supports constant-time lookups. The fingerprint from an incoming certificate can be compared against the truststore keys for a match.
What special property should a *cryptographic hash function* have? It should be *one-way*, which means very difficult to invert. A cryptographic hash function should be relatively straightforward to compute, but computing its inverse—the function that maps the hash value back to the input bitstring—should be computationally intractable. Here is a depiction, with **chf** as a cryptographic hash function and my password **foobar** as the sample input:
```
+---+
foobar—>|chf|—>hash value ## straightforward
+--–+
```
By contrast, the inverse operation is infeasible:
```
+-----------+
hash value—>|chf inverse|—>foobar ## intractable
+-----------+
```
Recall, for example, the SHA256 hash function. For an input bitstring of any length N > 0, this function generates a fixed-length hash value of 256 bits; hence, this hash value does not reveal even the input bitstring’s length N, let alone the value of each bit in the string. By the way, SHA256 is not susceptible to a [ length extension attack](https://en.wikipedia.org/wiki/Length_extension_attack). The only effective way to reverse engineer a computed SHA256 hash value back to the input bitstring is through a brute-force search, which means trying every possible input bitstring until a match with the target hash value is found. Such a search is infeasible on a sound cryptographic hash function such as SHA256.
Now, a final review point is in order. Cryptographic hash values are statistically rather than unconditionally unique, which means that it is unlikely but not impossible for two different input bitstrings to yield the same hash value—a *collision*. The [ birthday problem](https://en.wikipedia.org/wiki/Birthday_problem) offers a nicely counter-intuitive example of collisions. There is extensive research on various hash algorithms’
*collision resistance*. For example, MD5 (128-bit hash values) has a breakdown in collision resistance after roughly 2
21hashes. For SHA1 (160-bit hash values), the breakdown starts at about 2
61hashes.
A good estimate of the breakdown in collision resistance for SHA256 is not yet in hand. This fact is not surprising. SHA256 has a range of 2256 distinct hash values, a number whose decimal representation has a whopping 78 digits! So, can collisions occur with SHA256 hashing? Of course, but they are extremely unlikely.
In the command-line examples that follow, two input files are used as bitstring sources: **hashIn1.txt** and **hashIn2.txt**. The first file contains **abc** and the second contains **1a2b3c**.
These files contain text for readability, but binary files could be used instead.
Using the Linux **sha256sum** utility on these two files at the command line—with the percent sign (**%**) as the prompt—produces the following hash values (in hex):
```
% sha256sum hashIn1.txt
9e83e05bbf9b5db17ac0deec3b7ce6cba983f6dc50531c7a919f28d5fb3696c3 hashIn1.txt
% sha256sum hashIn2.txt
3eaac518777682bf4e8840dd012c0b104c2e16009083877675f00e995906ed13 hashIn2.txt
```
The OpenSSL hashing counterparts yield the same results, as expected:
```
% openssl dgst -sha256 hashIn1.txt
SHA256(hashIn1.txt)= 9e83e05bbf9b5db17ac0deec3b7ce6cba983f6dc50531c7a919f28d5fb3696c3
% openssl dgst -sha256 hashIn2.txt
SHA256(hashIn2.txt)= 3eaac518777682bf4e8840dd012c0b104c2e16009083877675f00e995906ed13
```
This examination of cryptographic hash functions sets up a closer look at digital signatures and their relationship to key pairs.
## Digital signatures
As the name suggests, a digital signature can be attached to a document or some other electronic artifact (e.g., a program) to vouch for its authenticity. Such a signature is thus analogous to a hand-written signature on a paper document. To verify the digital signature is to confirm two things. First, that the vouched-for artifact has not changed since the signature was attached because it is based, in part, on a cryptographic *hash* of the document. Second, that the signature belongs to the person (e.g., Alice) who alone has access to the private key in a pair. By the way, digitally signing code (source or compiled) has become a common practice among programmers.
Let’s walk through how a digital signature is created. As mentioned before, there is no digital signature without a public and private key pair. When using OpenSSL to create these keys, there are two separate commands: one to create a private key, and another to extract the matching public key from the private one. These key pairs are encoded in base64, and their sizes can be specified during this process.
The private key consists of numeric values, two of which (a *modulus* and an *exponent*) make up the public key. Although the private key file contains the public key, the extracted public key does *not* reveal the value of the corresponding private key.
The resulting file with the private key thus contains the full key pair. Extracting the public key into its own file is practical because the two keys have distinct uses, but this extraction also minimizes the danger that the private key might be publicized by accident.
Next, the pair’s private key is used to process a hash value for the target artifact (e.g., an email), thereby creating the signature. On the other end, the receiver’s system uses the pair’s public key to verify the signature attached to the artifact.
Now for an example. To begin, generate a 2048-bit RSA key pair with OpenSSL:
**openssl genpkey -out privkey.pem -algorithm rsa 2048**
We can drop the **-algorithm rsa** flag in this example because **genpkey** defaults to the type RSA. The file’s name (**privkey.pem**) is arbitrary, but the Privacy Enhanced Mail (PEM) extension **pem** is customary for the default PEM format. (OpenSSL has commands to convert among formats if needed.) If a larger key size (e.g., 4096) is in order, then the last argument of **2048** could be changed to **4096**. These sizes are always powers of two.
Here’s a slice of the resulting **privkey.pem** file, which is in base64:
```
-----BEGIN PRIVATE KEY-----
MIICdgIBADANBgkqhkiG9w0BAQEFAASCAmAwggJcAgEAAoGBANnlAh4jSKgcNj/Z
JF4J4WdhkljP2R+TXVGuKVRtPkGAiLWE4BDbgsyKVLfs2EdjKL1U+/qtfhYsqhkK
…
-----END PRIVATE KEY-----
```
The next command then extracts the pair’s public key from the private one:
**openssl rsa -in privkey.pem -outform PEM -pubout -out pubkey.pem**
The resulting **pubkey.pem** file is small enough to show here in full:
```
-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDZ5QIeI0ioHDY/2SReCeFnYZJY
z9kfk11RrilUbT5BgIi1hOAQ24LMilS37NhHYyi9VPv6rX4WLKoZCmkeYaWk/TR5
4nbH1E/AkniwRoXpeh5VncwWMuMsL5qPWGY8fuuTE27GhwqBiKQGBOmU+MYlZonO
O0xnAKpAvysMy7G7qQIDAQAB
-----END PUBLIC KEY-----
```
Now, with the key pair at hand, the digital signing is easy—in this case with the source file **client.c** as the artifact to be signed:
**openssl dgst -sha256 -sign privkey.pem -out sign.sha256 client.c**
The digest for the **client.c** source file is SHA256, and the private key resides in the **privkey.pem** file created earlier. The resulting binary signature file is **sign.sha256**, an arbitrary name. To get a readable (if base64) version of this file, the follow-up command is:
**openssl enc -base64 -in sign.sha256 -out sign.sha256.base64**
The file **sign.sha256.base64** now contains:
```
h+e+3UPx++KKSlWKIk34fQ1g91XKHOGFRmjc0ZHPEyyjP6/lJ05SfjpAJxAPm075
VNfFwysvqRGmL0jkp/TTdwnDTwt756Ej4X3OwAVeYM7i5DCcjVsQf5+h7JycHKlM
o/Jd3kUIWUkZ8+Lk0ZwzNzhKJu6LM5KWtL+MhJ2DpVc=
```
Or, the executable file **client** could be signed instead, and the resulting base64-encoded signature would differ as expected:
```
VMVImPgVLKHxVBapJ8DgLNJUKb98GbXgehRPD8o0ImADhLqlEKVy0HKRm/51m9IX
xRAN7DoL4Q3uuVmWWi749Vampong/uT5qjgVNTnRt9jON112fzchgEoMb8CHNsCT
XIMdyaPtnJZdLALw6rwMM55MoLamSc6M/MV1OrJnk/g=
```
The final step in this process is to verify the digital signature with the public key. The hash used to sign the artifact (in this case, the executable **client** program) should be recomputed as an essential step in the verification since the verification process should indicate whether the artifact has changed since being signed.
There are two OpenSSL commands used for this purpose. The first decodes the base64 signature:
**openssl enc -base64 -d -in sign.sha256.base64 -out sign.sha256**
The second verifies the signature:
**openssl dgst -sha256 -verify pubkey.pem -signature sign.sha256 client**
The output from this second command is, as it should be:
`Verified OK`
To understand what happens when verification fails, a short but useful exercise is to replace the executable **client** file in the last OpenSSL command with the source file **client.c** and then try to verify. Another exercise is to change the **client** program, however slightly, and try again.
## Digital certificates
A digital certificate brings together the pieces analyzed so far: hash values, key pairs, digital signatures, and encryption/decryption. The first step toward a production-grade certificate is to create a certificate signing request (CSR), which is then sent to a certificate authority (CA). To do this for the example with OpenSSL, run:
**openssl req -out myserver.csr -new -newkey rsa:4096 -nodes -keyout myserverkey.pem**
This example generates a CSR document and stores the document in the file **myserver.csr** (base64 text). The purpose here is this: the CSR document requests that the CA vouch for the identity associated with the specified domain name—the common name (CN) in CA-speak.
A new key pair also is generated by this command, although an existing pair could be used. Note that the use of **server** in names such as **myserver.csr** and **myserverkey.pem** hints at the typical use of digital certificates: as vouchers for the identity of a web server associated with a domain such as [www.google.com](http://www.google.com).
The same command, however, creates a CSR regardless of how the digital certificate might be used. It also starts an interactive question/answer session that prompts for relevant information about the domain name to link with the requester’s digital certificate. This interactive session can be short-circuited by providing the essentials as part of the command, with backslashes as continuations across line breaks. The **-subj** flag introduces the required information:
```
% openssl req -new
-newkey rsa:2048 -nodes -keyout privkeyDC.pem
-out myserver.csr
-subj "/C=US/ST=Illinois/L=Chicago/O=Faulty Consulting/OU=IT/CN=myserver.com"
```
The resulting CSR document can be inspected and verified before being sent to a CA. This process creates the digital certificate with the desired format (e.g., X509), signature, validity dates, and so on:
**openssl req -text -in myserver.csr -noout -verify**
Here’s a slice of the output:
```
verify OK
Certificate Request:
Data:
Version: 0 (0x0)
Subject: C=US, ST=Illinois, L=Chicago, O=Faulty Consulting, OU=IT, CN=myserver.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:ba:36:fb:57:17:65:bc:40:30:96:1b:6e:de:73:
…
Exponent: 65537 (0x10001)
Attributes:
a0:00
Signature Algorithm: sha256WithRSAEncryption
…
```
## A self-signed certificate
During the development of an HTTPS web site, it is convenient to have a digital certificate on hand without going through the CA process. A self-signed certificate fills the bill during the HTTPS handshake’s authentication phase, although any modern browser warns that such a certificate is worthless. Continuing the example, the OpenSSL command for a self-signed certificate—valid for a year and with an RSA public key—is:
**openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:4096 -keyout myserver.pem -out myserver.crt**
The OpenSSL command below presents a readable version of the generated certificate:
**openssl x509 -in myserver.crt -text -noout**
Here’s part of the output for the self-signed certificate:
```
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 13951598013130016090 (0xc19e087965a9055a)
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=US, ST=Illinois, L=Chicago, O=Faulty Consulting, OU=IT, CN=myserver.com
Validity
Not Before: Apr 11 17:22:18 2019 GMT
Not After : Apr 10 17:22:18 2020 GMT
Subject: C=US, ST=Illinois, L=Chicago, O=Faulty Consulting, OU=IT, CN=myserver.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
Modulus:
00:ba:36:fb:57:17:65:bc:40:30:96:1b:6e:de:73:
…
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Key Identifier:
3A:32:EF:3D:EB:DF:65:E5:A8:96:D7:D7:16:2C:1B:29:AF:46:C4:91
X509v3 Authority Key Identifier:
keyid:3A:32:EF:3D:EB:DF:65:E5:A8:96:D7:D7:16:2C:1B:29:AF:46:C4:91
X509v3 Basic Constraints:
CA:TRUE
Signature Algorithm: sha256WithRSAEncryption
3a:eb:8d:09:53:3b:5c:2e:48:ed:14:ce:f9:20:01:4e:90:c9:
...
```
As mentioned earlier, an RSA private key contains values from which the public key is generated. However, a given public key does *not* give away the matching private key. For an introduction to the underlying mathematics, see [https://simple.wikipedia.org/wiki/RSA_algorithm](https://simple.wikipedia.org/wiki/RSA_algorithm).
There is an important correspondence between a digital certificate and the key pair used to generate the certificate, even if the certificate is only self-signed:
- The digital certificate contains the
*exponent*and*modulus*values that make up the public key. These values are part of the key pair in the originally-generated PEM file, in this case, the file**myserver.pem**. - The exponent is almost always 65,537 (as in this case) and so can be ignored.
- The modulus from the key pair should match the modulus from the digital certificate.
The modulus is a large value and, for readability, can be hashed. Here are two OpenSSL commands that check for the same modulus, thereby confirming that the digital certificate is based upon the key pair in the PEM file:
```
% openssl x509 -noout -modulus -in myserver.crt | openssl sha1 ## modulus from CRT
(stdin)= 364d21d5e53a59d482395b1885aa2c3a5d2e3769
% openssl rsa -noout -modulus -in myserver.pem | openssl sha1 ## modulus from PEM
(stdin)= 364d21d5e53a59d482395b1885aa2c3a5d2e3769
```
The resulting hash values match, thereby confirming that the digital certificate is based upon the specified key pair.
## Back to the key distribution problem
Let’s return to an issue raised at the end of Part 1: the TLS handshake between the **client** program and the Google web server. There are various handshake protocols, and even the Diffie-Hellman version at work in the **client** example offers wiggle room. Nonetheless, the **client** example follows a common pattern.
To start, during the TLS handshake, the **client** program and the web server agree on a cipher suite, which consists of the algorithms to use. In this case, the suite is **ECDHE-RSA-AES128-GCM-SHA256**.
The two elements of interest now are the RSA key-pair algorithm and the AES128 block cipher used for encrypting and decrypting messages if the handshake succeeds. Regarding encryption/decryption, this process comes in two flavors: symmetric and asymmetric. In the symmetric flavor, the *same* key is used to encrypt and decrypt, which raises the *key distribution problem* in the first place: How is the key to be distributed securely to both parties? In the asymmetric flavor, one key is used to encrypt (in this case, the RSA public key) but a different key is used to decrypt (in this case, the RSA private key from the same pair).
The **client** program has the Google web server’s public key from an authenticating certificate, and the web server has the private key from the same pair. Accordingly, the **client** program can send an encrypted message to the web server, which alone can readily decrypt this message.
In the TLS situation, the symmetric approach has two significant advantages:
- In the interaction between the
**client**program and the Google web server, the authentication is one-way. The Google web server sends three certificates to the**client**program, but the**client**program does not send a certificate to the web server; hence, the web server has no public key from the client and can’t encrypt messages to the client. - Symmetric encryption/decryption with AES128 is nearly a
*thousand times faster*than the asymmetric alternative using RSA keys.
The TLS handshake combines the two flavors of encryption/decryption in a clever way. During the handshake, the **client** program generates random bits known as the pre-master secret (PMS). Then the **client** program encrypts the PMS with the server’s public key and sends the encrypted PMS to the server, which in turn decrypts the PMS message with its private key from the RSA pair:
```
+-------------------+ encrypted PMS +--------------------+
client PMS--->|server’s public key|--------------->|server’s private key|--->server PMS
+-------------------+ +--------------------+
```
At the end of this process, the **client** program and the Google web server now have the same PMS bits. Each side uses these bits to generate a *master secret* and, in short order, a symmetric encryption/decryption key known as the *session key*. There are now two distinct but identical session keys, one on each side of the connection. In the **client** example, the session key is of the AES128 variety. Once generated on both the **client** program’s and Google web server’s sides, the session key on each side keeps the conversation between the two sides confidential. A handshake protocol such as Diffie-Hellman allows the entire PMS process to be repeated if either side (e.g., the **client** program) or the other (in this case, the Google web server) calls for a restart of the handshake.
## Wrapping up
The OpenSSL operations illustrated at the command line are available, too, through the API for the underlying libraries. These two articles have emphasized the utilities to keep the examples short and to focus on the cryptographic topics. If you have an interest in security issues, OpenSSL is a fine place to start—and to stay.
## Comments are closed. |
12,512 | 使用这个 Python 工具分析你的 Web 服务器日志文件 | https://opensource.com/article/20/7/python-lars | 2020-08-13T16:01:59 | [
"日志"
] | https://linux.cn/article-12512-1.html |
>
> 这个 Python 模块可以以多种格式收集网站使用日志并输出良好结构化数据以进行分析。
>
>
>

是否想知道有多少访问者访问过你的网站?或哪个页面、文章或下载最受欢迎?如果你是自托管的博客或网站,那么无论你使用的是 Apache、Nginx 还是 Microsoft IIS(是的,没错),[lars](https://lars.readthedocs.io/en/latest/)都可以为你提供帮助。
Lars 是 [Python](https://opensource.com/resources/python) 写的 Web 服务器日志工具包。这意味着你可以使用 Python 通过简单的代码来回溯(或实时)解析日志,并对数据做任何你想做的事:将它存储在数据库中、另存为 CSV 文件,或者立即使用 Python 进行更多分析。
Lars 是 [Dave Jones](https://twitter.com/waveform80/) 写的另一个隐藏的宝石。我最初是在本地 Python 用户组中看到 Dave 演示 lars。几年后,我们开始在 [piwheels](https://opensource.com/article/18/10/piwheels-python-raspberrypi) 项目中使用它来读取 Apache 日志并将行插入到我们的 Postgres 数据库中。当树莓派用户从 [piwheels.org](http://piwheels.org)下载 Python 包时,我们会记录文件名、时间戳、系统架构(Arm 版本)、发行版名称/版本,Python 版本等。由于它是一个关系数据库,因此我们可以将这些结果加入其他表中以获得有关文件的更多上下文信息。
你可以使用以下方法安装lars:
```
$ pip install lars
```
在某些系统上,正确的方式是 `sudo` `pip3 install lars`。
首先,找到一个 Web 访问日志并制作一个副本。你需要将日志文件下载到计算机上进行操作。我在示例中使用的是 Apache 日志,但是经过一些小(且直观)的更改,你可以使用 Nginx 或 IIS。在典型的 Web 服务器上,你会在 `/var/log/apache2/` 中找到 Apache 日志,通常是 `access.log`、`ssl_access.log`(对于 HTTPS)或 gzip 压缩后的轮转日志文件,如 `access-20200101.gz` 或者 `ssl_access-20200101.gz` 。
首先,日志是什么样的?
```
81.174.152.222 - - [30/Jun/2020:23:38:03 +0000] "GET / HTTP/1.1" 200 6763 "-" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:77.0) Gecko/20100101 Firefox/77.0"
```
这是一个显示了请求源 IP 地址、时间戳、请求文件路径(在本例中是主页 `/`)、HTTP 状态代码,用户代理(Ubuntu 上的 Firefox)等的请求。
你的日志文件将充满这样的条目,不仅是每个打开的页面,还包括返回的每个文件和资源:每个 CSS 样式表、JavaScript 文件和图像,每个 404 请求、每个重定向、每个爬虫。要从日志中获取有意义的数据,你需要对条目进行解析、过滤和排序。这就是 Lars 的用处。本示例将打开一个日志文件并打印每一行的内容:
```
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
print(row)
```
它会为每条日志显示如下结果:
```
Row(remote_host=IPv4Address('81.174.152.222'), ident=None, remote_user=None, time=DateTime(2020, 6, 30, 23, 38, 3), request=Request(method='GET', url=Url(scheme='', netloc='', path_str='/', params='', query_str='', fragment=''), protocol='HTTP/1.1'), status=200, size=6763)
```
它解析了日志条目,并将数据放入结构化格式中。该条目已成为具有与条目数据相关属性的<ruby> <a href="https://docs.python.org/3/library/collections.html#collections.namedtuple"> 命名元组 </a> <rt> namedtuple </rt></ruby>,因此,例如,你可以使用 `row.status` 访问状态代码,并使用 `row.request.url.path_str` 访问路径:
```
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
print(f'hit {row.request.url.path_str} with status code {row.status}')
```
如果你只想显示 404 请求,可以执行以下操作:
```
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
if row.status == 404:
print(row.request.url.path_str)
```
你可能要对这些数据去重,并打印独立的 404 页面数量:
```
s = set()
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
if row.status == 404:
s.add(row.request.url.path_str)
print(len(s))
```
我和 Dave 一直在努力扩展 piwheel 的日志记录器,使其包含网页点击量、软件包搜索等内容,归功于 lars,这些并不难。它不会告诉我们有关用户的任何答案。我们仍然需要进行数据分析,但它去掉了复杂不便的文件格式,并以我们可以利用的方式将它放入我们的数据库。
查阅 lars 的文档,以了解如何读取 Apache、Nginx 和 IIS 日志,并了解你还可以使用它做什么。再次感谢 Dave 提供的出色工具!
最初发布在 Ben Nuttall 的 Tooling Blog 中,并获许重新发布。
---
via: <https://opensource.com/article/20/7/python-lars>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ever wanted to know how many visitors you've had to your website? Or which pages, articles, or downloads are the most popular? If you're self-hosting your blog or website, whether you use Apache, Nginx, or even Microsoft IIS (yes, really), [lars](https://lars.readthedocs.io/en/latest/) is here to help.
Lars is a web server-log toolkit for [Python](https://opensource.com/resources/python). That means you can use Python to parse log files retrospectively (or in real time) using simple code, and do whatever you want with the data—store it in a database, save it as a CSV file, or analyze it right away using more Python.
Lars is another hidden gem written by [Dave Jones](https://twitter.com/waveform80/). I first saw Dave present lars at a local Python user group. Then a few years later, we started using it in the [piwheels](https://opensource.com/article/18/10/piwheels-python-raspberrypi) project to read in the Apache logs and insert rows into our Postgres database. In real time, as Raspberry Pi users download Python packages from [piwheels.org](http://piwheels.org), we log the filename, timestamp, system architecture (Arm version), distro name/version, Python version, and so on. Since it's a relational database, we can join these results on other tables to get more contextual information about the file.
You can install lars with:
`$ pip install lars`
On some systems, the right route will be [ `sudo`
] `pip3 install lars`
.
To get started, find a single web access log and make a copy of it. You'll want to download the log file onto your computer to play around with it. I'm using Apache logs in my examples, but with some small (and obvious) alterations, you can use Nginx or IIS. On a typical web server, you'll find Apache logs in `/var/log/apache2/`
then usually `access.log`
, `ssl_access.log`
(for HTTPS), or gzipped rotated logfiles like `access-20200101.gz`
or `ssl_access-20200101.gz`
.
First of all, what does a log entry look like?
`81.174.152.222 - - [30/Jun/2020:23:38:03 +0000] "GET / HTTP/1.1" 200 6763 "-" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:77.0) Gecko/20100101 Firefox/77.0"`
This is a request showing the IP address of the origin of the request, the timestamp, the requested file path (in this case `/`
, the homepage, the HTTP status code, the user agent (Firefox on Ubuntu), and so on.
Your log files will be full of entries like this, not just every single page hit, but every file and resource served—every CSS stylesheet, JavaScript file and image, every 404, every redirect, every bot crawl. To get any sensible data out of your logs, you need to parse, filter, and sort the entries. That's what lars is for. This example will open a single log file and print the contents of every row:
```
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
print(row)
```
Which will show results like this for every log entry:
`Row(remote_host=IPv4Address('81.174.152.222'), ident=None, remote_user=None, time=DateTime(2020, 6, 30, 23, 38, 3), request=Request(method='GET', url=Url(scheme='', netloc='', path_str='/', params='', query_str='', fragment=''), protocol='HTTP/1.1'), status=200, size=6763)`
It's parsed the log entry and put the data into a structured format. The entry has become a [namedtuple](https://docs.python.org/3/library/collections.html#collections.namedtuple) with attributes relating to the entry data, so for example, you can access the status code with `row.status`
and the path with `row.request.url.path_str`
:
```
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
print(f'hit {row.request.url.path_str} with status code {row.status}')
```
If you wanted to show only the 404s, you could do:
```
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
if row.status == 404:
print(row.request.url.path_str)
```
You might want to de-duplicate these and print the number of unique pages with 404s:
```
s = set()
with open('ssl_access.log') as f:
with ApacheSource(f) as source:
for row in source:
if row.status == 404:
s.add(row.request.url.path_str)
print(len(s))
```
Dave and I have been working on expanding piwheels' logger to include web-page hits, package searches, and more, and it's been a piece of cake, thanks to lars. It's not going to tell us any answers about our users—we still have to do the data analysis, but it's taken an awkward file format and put it into our database in a way we can make use of it.
Check out [lars' documentation](https://lars.readthedocs.io/en/latest/api.html) to see how to read Apache, Nginx, and IIS logs, and learn what else you can do with it. Thanks, yet again, to Dave for another great tool!
*This originally appeared on Ben Nuttall's Tooling Blog and is republished with permission.*
## Comments are closed. |
12,514 | [重制版]《代码英雄》第一季(3):敏捷革命 | https://www.redhat.com/en/command-line-heroes/season-1/agile-revolution | 2020-08-13T21:33:00 | [
"敏捷",
"代码英雄"
] | https://linux.cn/article-12514-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(3):敏捷革命](https://www.redhat.com/en/command-line-heroes/season-1/agile-revolution) 的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/acf5928d.mp3)脚本。
现在是 21 世纪之交,开源软件正在改变着科技的格局,现在已经需要一种新的工作模式了。开发者们在寻找一种革命性的方法,让开源开发蓬勃发展。一群开发者在犹他州的一个滑雪场召开了会议,形成的是一份改变一切的宣言。
《<ruby> 敏捷软件开发宣言 <rt> Manifesto for Agile Software Development </rt></ruby>》的作者之一<ruby> 戴夫·托马斯 <rt> Dave Thomas </rt></ruby>将我们带回了那个现在著名的静修之地,敏捷革命就是在那里第一次组织起来的。不过,并不是每个人都那么快就签下了这种新方法,在这一集里,我们听听原因。
**Saron Yitbarek**: 有些故事的走向和结局会重新定义一个行业。在这些故事中也传唱着,我们来自哪里,我们是谁,我们正在做什么。[上一集](/article-12508-1.html)中,我们追溯了 Linux<sup> ®</sup> 开源技术的崛起。但这一集我要讲的,是紧接着发生的故事。操作系统之战结束后,开发者们成为了战争争夺的对象和核心。
**00:00:30**: 在那个新的战场,开发者们将要重塑自己的工作。本集播客,我们将深入了解以开发人员为核心,产生的一种全新的软件开发方法论。这种新颖的工作流程产生了哪些远超我们屏幕上显示的代码所能控制的、意想不到的事情。
我是 Saron Yitbarek,欢迎收听红帽的原创播客《代码英雄 第三集 敏捷革命》。今天的故事始于 2001 年 2 月,发生在美国犹他州的滑雪小屋里。
**00:01:00 - Dave Thomas**: 我们面前有个小屋,眼前是松树梁和壁炉,还有进入屋子的小门。我们前一天晚上到达这里时,然后基本上只是围坐在一起,讨论谈我们准备探讨的内容。紧接着第二天,我们都起床,并来到了预定的会议室。先把桌子移到边上去,然后将椅子摆放成一圈,确切地说是一个椭圆,这样一来我们就可以面对面交流,一定程度上也让人感觉到可以敞开心扉,畅所欲言 。
**00:01:30 - Saron Yitbarek**: 刚才提到的这群人都是开源开发人员,所以保持开放是他们的特点。Dave Thomas 和其他的 16 个人,在那个冬天集聚在雪鸟滑雪场。但是他们的目的并不是滑雪,而是探讨在 90 年代开发者的世界所面临的问题。在这里我用“探讨”,但实际上用“辩论”更准确。他们最初是在<ruby> 面向对象编程、语言及系统 <rt> Object-Oriented Programming, Languages and Systems </rt></ruby>(OOPSLA)的会议上认识的,这个会议主要议题是面向对象程序设计、编程、语言和系统。
**00:02:00**: 实际上正是那次会议,让他们意识到当前的软件开发方式很混乱,只是对于该怎么办没有达成一致。
所以此次在雪鸟山上的开会,试图寻找解决这个问题的方法。那么究竟是这个问题具体该怎么描述?于是我询问 Dave,开发人员之前的使用方式到底出现了什么问题。
**Dave Thomas**: 所以,我不知道……你有没有装饰过房间?
**Saron Yitbarek**: 我有。
**00:02:30 - Dave Thomas**: ……好。如果我先告诉你,“我想让你坐下来,然后给你一张白纸。接着我希望你能描绘下来这个房间完成后大概的样子。”可以想象吗?
**Saron Yitbarek**: 嗯嗯(肯定的语气)。
**Dave Thomas**: 你能做到吗?
**Saron Yitbarek**: 实际上,我的办公室就是这么布置出来的。首先,我画了一个简单的草图,然后加上一些修饰,最后把所有架子摆放在我觉得合适的位置。不过这种方式没有真正起到作用,我的计划也没有实现。
**Dave Thomas**: 但是,即使你尝试了这种方式,你都做了什么?先把架子放起来,然后说,“哦……这样放不行,因为会挡道。”所以,你又紧接着把架子移到其它地方,或者你会说,“你知道吗,我真的不能把地毯放在那里,因为我的椅子脚会陷进去。”状况频发。
**00:03:00 -Dave Thomas**: 遇到未知的情况,你总需要一种“迭代”的方式去应对。人类的大脑无法准确地对现实世界的发展进行预判,从而提前预知哪里需要改变。所以,软件开发也是一样的,人们不知道他们的需求会怎么改变。对吗?
**Saron Yitbarek**: 嗯嗯(肯定的语气)。
**00:03:30 - Dave Thomas**: 我经历过太多这样的情况,当我从客户那里拿到了详细的要求,然后我已经很好地完成了每一条细则,但却总是吵得不欢而散。“这不是我们想要的。” 但我想说的是,“这就是你要求的啊。”他们说,“是的,但这不是我的意思。”你懂这种情况吗?
**Saron Yitbarek**: 嗯嗯(肯定的语气)。
**Dave Thomas**: 所以说,理想情况是,你可以详细说明流程的每一步,然后通过非常机械的步骤就可以完成一切。
**Saron Yitbarek**: 是啊。
**00:04:00 - Dave Thomas**: 但是在软件行业可行不通。这种方式不适用于有任何模棱两可的情况,也不适用于需要判断的情况。就像任何艺术尝试一样,这种方式就是行不通。总是缺失了关键的一步:反馈。
**Saron Yitbarek**: 也许你已经听说过上世纪 90 年代的软件危机。当时的软件开发一团糟。相比于开发软件的费用,公司在修复软件上的钱花的多得多。与此同时,你我这样的开发人员进退不得。有时候,我们每隔好几年时间才能推出新的软件。
**00:04:30**: 我们疲于应付这些缓慢、陈旧、瀑布式开发的工作流程。从 A 到 B 到 C,完全都是提前确定好的。因此,那时的时间消耗主要在寻找新的流程,寻找更好的软件开发方式上。事实上,每个月似乎都有新的开发者,对如何改善软件开发的过程提出宏伟的设想。
**00:05:00**: 其中就有极限编程、有 Kanban、还有统一软件开发过程等,不胜枚举。在这些方法论的激烈竞争中,也催生出了新的观点和改进方法。那就是 Dave Thomas 和他在雪鸟滑雪场的朋友们迫不及待开始探讨的领域。
值得让这群人齐声欢呼喝彩的就是《敏捷软件开发宣言》。当时的开发速度正在以前所未有的速度保持增长 —— 而开源使开发人员变得更强大。另一方面,开发人员也需要一种新的敏捷的开发模式。
**00:05:30**: 顺便提一下,那些在雪鸟滑雪场会面的人,在经过一番你来我往的争论后,才确定用这个词。<ruby> 敏捷 <rt> Agile </rt></ruby>,这个词非常切题。这种方式就好像国家地理描述大型猫科动物的方式,一个与瀑布式开发预设路径正好相反的词。随着新的信息层出不穷,这个词让那些愿意改变航向的人看到了一线曙光。请注意这可不是一个名词,而是一个形容词。
**00:06:00**: 敏捷将会是一种习惯,而不是一种具体的说辞。那么,那些采用敏捷的开发者提供了什么呢?他们的总体解决方案是什么?现在很多人都认为敏捷是一个复杂的集合,包括不同的角色和是系统。会有一个<ruby> 项目经理 <rt> scrum master </rt></ruby>,一个<ruby> 项目 <rt> scrum </rt></ruby>团队,一个产品负责人。同时他们都要进行一到两周的冲刺工作。
**00:06:30**: 与此同时,工作都堆积在“冰盒”和“沙盒”中。好吧,听起来感觉流程很多。但一开始的时候是没有这些流程的。撰写该敏捷宣言的人,目标是简单和清晰。实际上,简单是它制胜的法宝。从那时起,它就具有定义几乎每个开发人员命运之路的能力。
**Dave Thomas**: 我们已经提到了,我们更喜欢某种方式,而不是另一种方式。事实上,在午餐这段时间,我们就写下了几乎所有的观点,现在都是敏捷宣言的一部分。
**00:07:00 - Saron Yitbarek**: 这是可以管理开发的四个奇思妙想。如果你尚且还不熟悉那些敏捷的诫命,他们会这样解释:
>
> 个体和互动胜过流程和工具;可工作的软件胜过文档;客户协作胜过合同谈判;响应变化胜过遵循计划。
>
>
>
**00:07:30**: 我记得第一次看到这个宣言时的情形。我刚开始学习编程,老实说,当时我并没有觉得这个想法有多棒。一直到我了解到那些支持敏捷开发的工具和平台。对我来说,这只是一些模糊的概念。但是,对于长期以来一直被这些问题纠缠的开发人员来说,这是一个很好的行动方案。
该宣言是一盏灯,可以激发更多奇思妙想。这四点宣言和一些支持材料都发布在 [Agilemanifesto.org](http://Agilemanifesto.org) 网站上,并且呼吁其他开发者签名以表示支持。
**00:08:00 - Dave Thomas**: 很快获得了 1000 个签名,接着 10,000 个,然后签名数一直在增长,我想我们都惊呆了。这基本上变成了一场革新运动。
**Saron Yitbarek**: 他们从来没有计划过把这份敏捷宣言带出滑雪小屋。这只是一群热衷于软件开发的人,并且对帮助他人更好地发展充满热情。但很明显,“敏捷” 本身像长了腿一样。红帽公司首席开发倡导者 Burr Sutter 谈到了“敏捷”对于还困在“瀑布”中的开发人员来说是一种解脱。
**00:08:30 - Burr Sutter**: 因此,敏捷的概念从根本上引起了人们的共鸣,基本上是在说:“看,我们专注于人员而不是流程。我们专注于交互和协作而不是工具和文档。我们认为工作软件高于一切,我们宁愿人们通过小批量的工作,实现高度互动、快速迭代。”
**00:09:00 - Saron Yitbarek**: 而对于一些人来说,这个开发者的革新走得太远。敏捷甚至被视为是给那些不负责任的黑客心态的合理说辞。早期反对敏捷最重要的声音之一是 Steve Rakitin。他是一名软件工程师,拥有超过 40 年的行业经验。
**00:09:30**: 当他大学毕业时,Rakitin 就开始建造第一个核电站数字控制系统。几十年来,他一直致力于研发电力软件和医疗设备软件。这些都是对安全很注重的软件。没错。你可以预料到,他可不会对这种手忙脚乱的开发方式感兴趣。
因此,在方法论战争的尾声,敏捷横空出世,Rakitin 对此翻了个白眼。
**Steve Rakitin**: 就像是,“好吧,我们换种方式说,如同一群人围坐着喝着啤酒,就想出了开发软件的其他办法。”顺便提一下,敏捷宣言中许多已经得到进一步发展,并应用于早期的开发方法里了。
**00:10:00 - Saron Yitbarek**: 他这么想其实也没有什么错。实际上你可以在 “雪鸟峰会” 前几十年就追溯到敏捷哲学的踪迹。例如,像<ruby> 看板 <rt> Kanban </rt></ruby>这样的精益工作方法可以追溯到 20 世纪 40 年代,当时丰田受到超市货架存货技术的启发……
他们的精益制造理念最终被用于软件开发。不过 Rakitin 有另外一个担忧。
**00:10:30 - Steve Rakitin**: 这篇宣言发表时我非常怀疑它,因为它基本上是为了让软件工程师花更多的时间编写代码,花更少的时间搞清楚需要做什么,同时记录文档的时间少了很多。
**Saron Yitbarek**: 对于 Rakitin 来说,这不仅仅是提出新的工作流程创意。这也关乎到他职业生涯的清白声誉。
**00:11:00 - Steve Rakitin**: 长期以来,相比于电气工程和所有其他工程学科,软件工程并未被视为正规的工程学科。在我看来,部分原因是因为普遍缺乏软件工程师认可的公认实践。
**00:11:30**: 当我们经历了 90 年代的十年,逐渐开始明晰其中的一些流程。似乎其中一些已经在事实上被实施,而且也很合理。
然后敏捷宣言的出现了。如果软件工程将成为正规的工程学科,那么你就需要流程化的东西。其他所有工程学科都有流程,为什么软件工程就没有?
**00:12:00 - Saron Yitbarek**: 我是 Saron Yitbarek,你正在收听的是红帽的原创播客代码英雄。那么,如果我们把在核电站工作的人士的观点放在一边,转而关注更广阔的企业界,我们发现敏捷已经逐渐广受认可。但这件事不是自然而然,没有丝毫阻力就发生的。
**Darrell Rigby**: 我想我们在采用敏捷开发中,受到的最大阻力来自中高级管理层。
**00:12:30 - Saron Yitbarek**: 这位是 Bain&Company 的合伙人 Darrell Rigby。他们一直尝试在软件开发公司中推行敏捷开发。不仅如此,还包括产品开发、新闻服务开发、广告计划和忠诚度计划等。不管他们要做什么,项目管理者都会面临点压力。
**Darrell Rigby**: 敏捷改变了他们的价值,因为他们正在逐步退出细节上的管理或干预。现在团队被赋予权力,对他们加以指导。
**00:13:00 - Saron Yitbarek**: 现在,敏捷并不能保证阻止中间轻微的干预。我承认,我第一次看到一个敏捷管理委员会时,我认为这是一个永无止境的待办事项清单,我有了点压迫感。但后来当我开始真正使用敏捷产品管理工具时,我完全变成了它们的粉丝。我是一个编码培训营的新人,我试图弄清楚如何确定功能的优先级并做出产品决策。
**00:13:30**: 那些看起来很可怕的工具让我有了所有这些想法,然后给它们命名、顺序和结构。从而可以帮助我更好地管理我的项目。所以,我确实同意 Rigby 的观点。有些人可能会看到这些工具产生的影响并认为,如果敏捷赋予开发人员权力,那么就会剥夺经理们的管理权。
但是,它的价值比任何一个职位都要大,敏捷开发的发展势如破竹。更重要的是,它正在证明自己。
**00:14:00 - Darrell Rigby**: 目前,成千上万的团队已经采用敏捷开发。因此,我们有很多关于此数据。答案是,无论何时你开始创新,相比你现在使用的方式,敏捷团队能更好实现目标。
**00:14:30**: 有许多更大的、知名的公司都在变革自身。亚马逊是敏捷方法的重要用户。奈飞、Facebook 和 Salesforce —— 他们都是敏捷的重度用户,实际上敏捷方法不仅重新定义了工作方式,更是重新定义了行业的运作方式。
**Saron Yitbarek**: 当 Rigby 第一次听说<ruby> 敏捷 <rt> agile </rt></ruby>时,他认为这是一种奇怪的语言。他当时正在与许多大型零售商的 IT 部门合作。无意间听到他们谈论 “time boxes”、“sprint” 和 “scrum master” 。起初,他并不懂他们在说什么。他告诉我他实际上是试图忽略任何有关敏捷的字眼,就像这是他不需要学习的另一种语言。毕竟,他本人不是开发人员。
**00:15:00**: 但是如今,他却成为了敏捷信徒,把敏捷带到他的家里,带入他的教堂。
**Darrell Rigby**: 我不一定每天早上都和家人坐在一起,和他们一起参加敏捷开发式的会议。但是,我已经非常擅长为我要做的事情排优先级。
**00:15:30 - Saron Yitbarek**: 十多年来,敏捷已经从边缘走向主流。但是,企业认同还是有代价的。在某些情况下,这种同化甚至会使敏捷宣言的最初意图变得模糊。Dave Thomas 让我想起了这一点。他说,当他和其他 16 位雪鸟会议上的伙伴第一次写下宣言时,根本没有既定的指示。
**00:16:00**: 因此,即使宣言中没有告诉你如何应用这些条例,我猜想你已经对大概会发生什么,还有人们会怎么做,有一些大概的思路了吧?
**Dave Thomas**: 老实说啊,我还真没有。
**Saron Yitbarek**: 听到这里,你可能会感到惊讶。因为敏捷现在看起来很有说服力。有书籍、认证、工具、课程和产品的整个市场,向你展示如何“实现敏捷”。
Dave Thomas 表示,尽管有成千上万的手册和专业人士想要向你展示“唯一真理”,他们却错过了重点。
**Dave Thomas**: 实际上它是一组价值观。
**00:16:30 - Saron Yitbarek**: 嗯嗯(肯定的语气)。
**Dave Thomas**: 我想这就像黄金法则。你知道,如果你要做一些邪恶恶毒的事情,你会想,“好吧,如果有人这样做,我又怎么会喜欢。”你知道吗,这种场合也适合用黄金法则。
好吧,敏捷宣言也是如此。它并没有告诉你该做什么,不该做什么,它只是告诉你,你做的一切是否符合这个价值观。
**00:17:00 - Saron Yitbarek**: 是的。我想只要回到敏捷软件开发宣言的名称、真正脱颖而出并且经久不衰的一个词,也是人们真正关注的就是“敏捷”。那么现在使用“敏捷”这个词又出了什么问题呢?
**00:17:30 - Dave Thomas**: “敏捷”这个词的问题在于,在我们刚开始提出的时候,它是描述软件开发的形容词。但接下来人们就产生了疑问:“我该怎么着手实施敏捷呢?”
**00:18:00**: 突然之间,涌出了一大批咨询顾问,他们看到了<ruby> 极限编程 <rt> Extreme Programming </rt></ruby>(XP)的成功,看到了宣言的成功,“嘿,那里有座金山。” 然后就开始告诉人们如何“做敏捷”。这是一个问题,因为你不能“做”敏捷。敏捷不是你要“做”的事情,而是你如何做事情的方式。
然而,有些公司会乐意卖给你敏捷相关的套装。我觉得这很讽刺。这里的咨询就好像是进入一家财富 1000 强企业,然后帮助他们设定“敏捷”。然后带走了 500 万美元。你懂吗?太棒了,钱真好赚。
**00:18:30**: 但是,现实情况是,这就像告诉要老虎如何变得敏捷一样,说:“先走七步,然后左脚迈出来,然后再走两步,然后迈出右脚。”嗯,实际上只有瞪羚做同样的事情,这才会是有用的。你猜怎么着?没有人告诉瞪羚这样做。瞪羚基本都会跑到地平线尽头上大笑起来,因为老虎在“邯郸学步”。
**00:19:00**: 当你告诉团队如何敏捷时,会发生同样的事情。如果你对他们说,“这是你必须遵循的规则,这是你必须遵循的流程”,然后他们唯一能做的就是跟随职责,因为他们已被设定好该执行的程序。管理层将根据他们服从原则或程序的程度,而不是开发软件的水平来判断表现如何。
**00:19:30 - Saron Yitbarek**: 所以,回顾一下,宣言发布之前和之后的开发者的角色,是如何因为你的宣言本身改变或扩展的呢?
**00:20:00 - Dave Thomas**:我认为大多数程序员都能理解到关键点,这值得肯定。我觉得敏捷宣言给了许多开发人员按照这种方法去做的授权,某种程度上是他们以前就知道该如何,但从来没有权利这样做。像测试收集反馈,缩短迭代周期之类的事情。因此,在许多方面,工作变得更有趣,更充实。
同时我认为,程序员也可能会感到有点害怕,因为现在他们有了责任。过去,他们只是遵循命令。这个程序不起作用?好吧,但我遵循了规范。而如今,程序员肩负着责任。
**00:20:30**: 所以,我觉得这个职业因敏捷宣言而有所成长。我认为人们开始意识到,他们对自己所开发东西负有点对点的责任。
**00:21:00 - Saron Yitbarek**:敏捷取得了如此广泛得成功,改变了工作流程和态度,远远超出了开发者世界的范畴 —— 当然也超越了雪鸟会议召开的小木屋。我们不禁要问,“相比于 2001 年撰写宣言时,今天成为敏捷开发人员意味着什么?”
最初的敏捷精神是否仍然存在?如果确实发生了变化,这是一件坏事吗?对于谷歌的多元化业务合作伙伴 Ruha Devanesan 来说,敏捷的思维方式,可能已经发展到影响公平性和在工作场所中的平等性了。
**00:21:30 - Ruha Devanesan**:让团队具有包容性的部分原因,是他们在进行非常基础的工作时,可以评价和反思自己。当大多数团队一起工作时,他们没有足够的时间这么做。没有足够的动力停下来思考他们团队宗旨,是否每个人都在能桌上发表意见,关于是否有人在推动其他人,或者是否有人在一直都保持沉默。如果他们保持沉默,为什么他们保持沉默?
**00:22:00**: 因此,在考虑包容性时,我认为敏捷团队使用的一些工具在为团队创建架构,或更具包容性的框架方面非常有用。所以多样性包括性别、种族,还有功能多样性。功能多样性为团队带来了复杂性。
**00:22:30 - Saron Yitbarek**: 但是,我们在这里要声明他们的不同。Ruha 并不是说敏捷就等于多样性。她的意思是,“敏捷加多样性等于更好的团队。”Ruha 的想法在她写的一篇名为《论通过敏捷方法解锁多样性》的文章中得到了体现。我们将在演示笔记中添加一个链接 —— 这可是值得一读的文章。
在这篇文章中,她会引导你去了解,多元化不仅仅是人力资源部门一直在谈论的模糊概念。这里提供了一个强有力的商业案例。利用敏捷工具,可以创建一个包容性的工作场所,和创新效率提升。多样性可以与敏捷相辅相成。
**00:23:00 - Ruha Devanesan**: 这篇介绍复杂性的文章,最终目的是让大家从不同的角度看待你的结果或产品。当我们说为团队增加多样性可以带来更好的结果,带来更多的创新和创造力时,我们持有的是基本同样的观点。因为当你从多个角度去看待并协作解决工作中的问题时,你更有可能得出一个更好的结果。
**00:23:30 - Saron Yitbarek**: 团队中的每个人,甚至可以对日常会议这样简单的事情提出反馈,这会让内向的人或其他不爱说话的人发表自己的见解。
**Ruha Devanesan**: 我真正喜欢敏捷的原因是,有一些内置的机制来帮助团队停下来进行思考。这可能是因为敏捷开发是如此之快,并且有为时两周的冲刺任务。如果你没有建立这些机制,你可能会偏离轨道,没法再回到正轨。
**00:24:00**: 但是,我觉得,“停止并反馈”这种价值观非常重要。这对于团队的包容性增加也非常重要,因为让大家都能提出工作反馈,并借此不断改善,这是团队能够包容的基本表现。
**Saron Yitbarek**: 既然我们谈论的是包容性,现在可能是指出那些敏捷宣言的 17 位创始人的好时机,是的……他们都是白人。
**00:24:30 - Dave Thomas**: 实际上那个房间没有多样性。这是对该组织的一种非常普遍的批评,而且我对此深表同情。
**Saron Yitbarek**: 如果敏捷宣言创始人采用了这些敏捷原则,并将其应用于他们自己的会议,那么他们可能在完成部分工作后,会问他们自己……“嘿,你注意到我们没有邀请任何女性参加这次会议吗?”我在想会不会有一个有色人种会持有不同意见。
**00:25:00 - Ruha Devanesan**: 物以类聚,人以群分。所以,如果考虑敏捷宣言的第一个人是白人,他邀请到桌上的人也是白人也就不足为奇了。但是,我们有机会在那方面做得更好,我们有机会停下来说:“让我们退后一步,让我们扩大我们的视野,寻找我们现在拥有的关系网络之外的人。谁可以带来不同的视角并帮助我们更好地改进这种开发方式。”
**00:25:30 - Saron Yitbarek**: 对我来说这很有道理,因为敏捷开发正是如此……好吧,敏捷,我们可以将它应用于不同的问题和行业。敏捷的应用方面,以及其在现实生活中出现时候的样子,是不断变化、不断扩展的。我想它正在将宣扬的内容付诸实践。没有最正确的答案,没有最后的终点。这是我们有时会忘记的事情:硬规则是敏捷的敌人。
**00:26:00**: 因此,如果一个敏捷团队告诉你敏捷的一部分意味着你必须每两周开发一个新的版本,或者你必须做什么事,那么,根据定义,这可不是敏捷。你老是说“总是”,你也不再是敏捷了。
**00:26:30**: 那些在犹他州雪鸟会议碰面的 17 名男子,最后宣称成立敏捷联盟。该联盟成为一个非营利组织,每年都举办一次会议。这个联盟的成长和发展,催生了更多全新的理论和方法。
这正是我感觉非常有趣的东西。在 2008 年的会议上,比利时开发人员 Patrick Debois 参加了并开始引领一条道路,他发明了一种全新的软件开发实践 DevOps。我从未想到与敏捷的一系列原则与 DevOps 和整个行业是都紧密相关。
**00:27:00**: 但是,现在我在想,“敏捷的兴起与 DevOps 的发明之间有多少关联?一个突破是否孕育了另一个突破?”我们会一起去探索,因为我们的下一集是正是 DevOps,对!一整集的内容。
**00:27:30**: 《代码英雄》是红帽的原创播客。有关我们的播客和其他更多信息,请访问 [Redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 。在那里,你也可以关注我们的消息订阅。想要免费听取最新内容,请订阅我们的节目。也可以在 Apple Podcast、Spotify、 Google Play、CastBox 中搜索 “Command Line Heroes”,然后点击“订阅”,你将在第一时间获得我们的内容更新。
我是 Saron Yitbarek,感谢收听,请坚持编程。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
>
> **关于重制版**
>
>
> 本系列第一季的前三篇我们已经发布过,这次根据新的 SIG 规范重新修订发布。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-1/agile-revolution>
作者:[RedHat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[redhat](file:///Users/xingyuwang/develop/LCRH-wxy/translated/www.redhat.com) 校对:[acyanbird](https://github.com/acyanbird)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's the turn of the 21st century. Open source software is changing the tech landscape. But new patterns of work have now become necessary. Developers search for a revolutionary approach that will allow open source development to flourish. A group of developers convene at a ski resort in Utah. What emerges is a manifesto that changes everything.
[ Dave Thomas](https://twitter.com/pragdave), one of the authors of the "Manifesto for Agile Software Development", brings us back to that now famous retreat where the agile revolution was first organized. Not everyone was as quick to sign on to this new approach, though, and in this episode, we hear why.
*Saron Yitbarek*
There are certain stories that end up defining an industry. Stories we tell ourselves about where we come from, who we are, what we do. Last episode, we tracked the rise of Linux® , an open source technology. This story though, this one’s about what happened next. After the OS wars, developers were front and center.
**00:30** - *Saron Yitbarek*
And that new prominence meant they were going to reinvent their jobs. This episode, we'll learn how a focus on the developer brought about an entirely new methodology for software development. And how that new approach to workflow is having an unexpected impact—far beyond the action on our screens.
I'm Saron Yitbarek and this Command Line Heroes, an original podcast from Red Hat. Episode three, The Agile Revolution. Today's story begins in February 2001, and it's set at a ski lodge in Utah.
**01:00** - *Dave Thomas*
We turned up at a lodge, you know, the pine beams and the fireplace, and the entry way. We got there the night before, and we basically just sat around and talked about what we're going to talk about. And the next day, we turned up, and we'd reserved a meeting room. We took the tables and moved them out to the edge. And we just put the chairs in a circle, or an oval so we could basically be facing each other and somewhat more open.
**01:30** - *Saron Yitbarek*
These guys were open source developers, so staying open was kind of their thing. That was Dave Thomas, Dave and 16 others got together at Snowbird Ski Resort that winter. Not to ski, but to talk about what was wrong with the developers world in the 1990's. I say talk, but argue might be more like it. They had originally met at a conference called OOPSLA, Object-Oriented Programming, Languages and Systems.
**02:00** - *Saron Yitbarek*
And it was actually at that conference that they realized they all agreed that creating software was messy. They just hadn't agreed on what they should do about it.
So, the meeting on the mountain at Snowbird, that was where they were going to try and nail down a solution to that problem. And what was that problem exactly? I asked Dave what was wrong with the way developers used to do things.
*Dave Thomas*
So, have you ever ... I don't know, decorated a room-
*Saron Yitbarek*
I've tried.
**02:30** - *Dave Thomas*
... Or had ... Okay. If I said to you, upfront, “I want you to sit down please, here's a piece of paper. And I want you to specify exactly what this room should look like when you're finished.” Right?
*Saron Yitbarek*
Mm-hmm (affirmative).
*Dave Thomas*
Could you do that?
*Saron Yitbarek*
Actually, I did this for my own office. I tried making up a little sketch, and a little rendering and putting all the shelves where I thought they would be. It didn't really work though. It didn't end up the way that I planned.
*Dave Thomas*
But, even if you do that, what do you do? You put the shelves up, and you go, "Oh ... that's not going to work because the door is going to get in the way." So, you move the shelves somewhere else, or you say, "You know what, I can't really put carpet there because my chair is going to get stuck on it." Whatever it might be.
**03:00** - *Dave Thomas*
You always are going to iterate whenever it involves any unknowns at all. The human brain is just not up to modeling the real world accurately enough to be able to know what it wants upfront. So, software development is the same. People don't know upfront what they want. Right?
*Saron Yitbarek*
Mm-hmm (affirmative).
**03:00** - *Dave Thomas*
And the number of times where I have gone through that process, where I've got a spec from a customer and I have implemented it pretty much identical to that spec. It gets to the end, and they go, "But that's not what we wanted." And you go, "But that's what you asked for." And they said, "Yeah but that's not what I meant." You know?
*Saron Yitbarek*
Mm-hmm (affirmative).
*Dave Thomas*
So, this whole process that you can specify, and then move through some mechanical sort of steps, and then at the end you're done.
*Saron Yitbarek*
Yeah.
**04:00** - *Dave Thomas*
Doesn't work in software. It doesn't work in anything where there is ambiguity. It doesn't work in anything where there is some degree of judgment. Almost like any "artistic" endeavor, it's just not going to work. There always has to be feedback, and that was the missing step.
*Saron Yitbarek*
So, maybe you've heard of the software crisis that ran through the 1990's. Software development at the time was just a mess. Companies were spending more money fixing software than they were creating it in the first place. And meanwhile, developers like you and me, we were log jammed. In some cases, we could only put new software out every few years.
**04:30** - *Saron Yitbarek*
We were stuck with these sluggish, old, waterfall, workflows. A to B to C, totally predetermined. So, the search for new processes, for better ways to get software made, was sort of all consuming at the time. In fact, every month there seemed to be somebody new who had a grand vision for how they were going to fix the software development process.
**04:30** - *Saron Yitbarek*
We were stuck with these sluggish, old, waterfall, workflows. A to B to C, totally predetermined. So, the search for new processes, for better ways to get software made, was sort of all consuming at the time. In fact, every month there seemed to be somebody new who had a grand vision for how they were going to fix the software development process.
**05:00** - *Saron Yitbarek*
There was extreme programming, there was Kanban, there was rational unified process, the list goes on. The methodology wars saw a slew of competing new visions, new fixes. And that was the scuffle Dave Thomas, and his buddies up at Snowbird, were stepping into.
Their own salvo was something called the manifesto for agile software development. The speed of production was ramping up like never before—open source had made developers more powerful. And, in turn, developers needed a new, more agile mode of production.
**05:30** - *Saron Yitbarek*
The guys who met at Snowbird argued a long time before landing on that word, by the way. Agile. In the end, it was the descriptor that made sense. It's how you describe big cats in National Geographic. A word that describes the exact opposite of a waterfall’s preordained path. As new information came up, it's a word for people willing to change course on a dime. And notice that it's not a noun, it's an adjective.
**06:00** - *Saron Yitbarek*
Agile would be a mode of being, not a concrete saying. So, what did those agile guys have to offer? What was their big solution? The agile that many of us know today is a complex set or roles and systems. You've got a scrum master, a scrum team, a product owner. And they're all going through one or two week sprints of work.
**06:30** - *Saron Yitbarek*
Meanwhile, work is piling up in ice boxes, and sand boxes, and well, let's say it can feel like a lot of process. But none of that was there at the beginning. The guys who wrote that manifesto aimed for simplicity, and clarity. The vision was so simple, in fact, that it had the power to define the path of almost every developer's destiny from then on.
*Dave Thomas*
We came up with the, we prefer A over B, way of expressing the values. And we actually wrote down pretty much the full values that are now part of the manifesto over lunch.
*Saron Yitbarek*
Four big ideas that could govern development. In case you don't know those agile commandments by heart, they go like this:
**07:00** - *Saron Yitbarek*
Individuals and interactions over processes and tools. Working software over comprehensive documentation. Customer collaboration over contract negotiation. Responding to change over following a plan.
**07:30** - *Saron Yitbarek*
remember the first time I encountered the manifesto. I was newish to coding, and to be honest, I didn't get what the big deal was. Until I understood the tools and platforms that make agile work, to me, it was just some fuzzy concepts. But, for developers who had been struggling with these issues for a long time, it was a call to action.
The manifesto was designed to be a spark that could inspire something bigger. These four values and some supporting material were posted on a website, Agilemanifesto.org, and they just straight up asked other developers to sign their names to show support.
**08:00** - *Dave Thomas*
I think we were all stunned, when we got to 1,000 signatures, and then 10,000, and then it just keep growing and growing. It basically, it became a movement.
*Saron Yitbarek*
It was never their plan to walk out of that ski lodge with a manifesto, per se. They were just a group of people passionate about software development who felt a kind of evangelical zeal about helping others do development better. It became clear though, that agile had legs. Red Hat's ® chief developer advocate, Burr Sutter, talks about what a relief agile was for developers trapped under a waterfall.
**08:30** - *Burr Sutter*
So, the concept of agile fundamentally resonated with people because it basically said, "Look, we focus on people over processes. We focus on interactions and collaboration over tools and documentation. We value working software above all else, and we'd rather people work in small batches and be highly interactive and highly iterative."
**09:00** - *Saron Yitbarek*
For some, this developer's revolution went too far. Agile could even be seen as legitimizing an irresponsible hacker mindset. One of the most important voices that spoke out against agile early on was Steve Rakitin. He's a software engineer with over 40 years experience in the industry.
**09:30** - *Saron Yitbarek*
When he finished college, Rakitin went to work building the first digital control system for nuclear power plants. And for decades, he's kept on working on power plant software and software for medical devices. Safety-critical software. So, yeah. You can imagine that this is a guy not so interested in a fly-by-the-seat-of-your-pants approach.
So, when agile came out at the tail end of the methodology wars, Rakitin sort of rolled his eyes.
*Steve Rakitin*
It was like, “Well, here we go again, another bunch of people sat around drinking beer and coming up with other ideas for developing software.” Many of which, by the way, had already been developed and used in some of these earlier methods.
**10:00** - *Saron Yitbarek*
He wasn't wrong about giving them side eyes either. You can track back agile-ish philosophies decades before the Snowbird summit. For example, lean work full methodologies like Kanban go all the way back to the 1940's when Toyota got inspired by shelf-stocking techniques at supermarkets..
Their philosophy for lean manufacturing ended up being repurposed for software development. Rakitin had a whole other concern too.
**10:30** - *Steve Rakitin*
I was very skeptical when this manifesto was published because it basically came across as a way to allow software engineers to spend more time writing code, less time figuring out what needs to be done, and a lot less time documenting anything.
*Saron Yitbarek*
For Rakitin, this was about more than coming up with new workflow ideas. It was about the integrity of his profession.
**11:00** - *Steve Rakitin*
For a long time, software engineering was not viewed as a legitimate engineering discipline like electrical engineering, and all the other engineering disciplines. And in my opinion, part of the reason was because there was a general lack of accepted practices that software engineers used.
**11:30** - *Steve Rakitin*
As we got through the decade of the 90's, and we started identifying some of these processes, it seemed like some of them were actually starting to take hold, and many of them made a lot of sense.
Then comes along the manifesto. If software engineering is ever going to become a legitimate engineering discipline, you need to process. Every other engineering discipline has processes, why not software?
**12:00** - *Saron Yitbarek*
I'm Saron Yitbarek, and you're listening to Command Line Heroes, original podcast from Red Hat. So, if we leave aside people working at nuclear power plants, and focus instead on the larger corporate world, we find that agile has bit by bit taken over. But, not without a little corporate resistance, naturally.
*Darrell Rigby*
I think the greatest resistance that we tend to see in agile adoption comes from senior and middle management.
**12:30** - *Saron Yitbarek*
This is Darrell Rigby, a partner at Bain & Company. They've been experimenting with using agile at software development companies. But, also with product development, news service development, advertising programs, and loyalty programs. And everywhere they go, there's the potential for the managers to get a little nervous.
*Darrell Rigby*
It changes the very notion of how they believe they add value because they're moving away from micromanaging, or micro-meddling, with these teams to empowering them, and coaching them.
**13:00** - *Saron Yitbarek*
Now, agile is no guarantee against micro-meddlers. I admit, the first time I saw an agile management board, I thought it was a never- ending to-do list. A bit overwhelming. But then I started actually using an agile product management tool. And I was blown away. I was new out of a coding bootcamp, and I was trying to figure out how to prioritize features and make product decisions.
**13:30** - *Saron Yitbarek*
That scary-looking tool forced me to organize all these ideas, and give them names, order, and structure. It helped me manage my project. So, I do take Rigby's point. Some people might look at the effect of tools like that and think, if agile empowers developers, then it must disempower their managers.
But, this was larger than any one job title. Agile's forward momentum was growing. And more importantly, agile was proving itself.
**14:00** - *Darrell Rigby*
Agile has been used by tens of thousands of teams at this point. So, we've got a lot of great data on where agile can be used. The answer is, any time you're thinking about doing innovation, an agile team can probably do it better than the way you're doing it today.
**14:30** - *Darrell Rigby*
There are a lot of bigger, well-known companies that have transformed themselves. Amazon is a big user of agile approaches. Netflix, Facebook, and Salesforce—all of them heavy users of agile, and it has really not just redefined the way they work, but the way the industry works.
*Saron Yitbarek*
When Rigby first heard about agile, he thought it was just a weird language. He was working with the IT departments at a lot of big retailers. And he kept hearing them talk about time boxes, and sprints, and scrum masters. At first, he didn't have a clue what they were talking about. He told me he actually tried to ignore any mention of agile, like it was another language he didn't have to learn. After all, he wasn't a developer himself.
**15:00** - *Saron Yitbarek*
Today, he's such a believer that he's literally brought agile to his home, and into his church.
*Darrell Rigby*
I do not necessarily sit down with my family every morning and have a scrum meeting with them. But, I have become very good at prioritizing the things that I'm going to do.
**15:30** - *Saron Yitbarek*
Agile has gone from fringe to mainstream in just over a decade. But, the corporate assimilation came at a cost. And in some cases, that assimilation even met bastardizing the manifesto’s original intentions. Dave Thomas reminded me of that. He says that when he and those 16 other Snowbird guys first wrote it, there was no real prescription at all.
**16:00** - *Saron Yitbarek*
So even though the manifesto doesn't tell you how to apply the values, I'm assuming you had some idea of what you thought would happen or what people would do with it.
*Dave Thomas*
Honestly, I did not.
*Saron Yitbarek*
This might surprise you. Agile can seem so prescriptive today. There's a whole marketplace of books, certifications, tools, courses, and products that show you how to "do agile."
But despite the thousands of manuals and professionals who want to show you the one true way, Dave Thomas says, they're really missing the whole point.
*Dave Thomas*
It's a set of values.
**16:30** - *Saron Yitbarek*
Mm-hmm (affirmative).
*Dave Thomas*
It's like the golden rule, I guess. It's like, you know, if you're about to do something evil and vicious you think, “Okay, how would I like it if someone did that to me.” You know? The golden rule applies.
Well, it's the same with the Agile Manifesto. It's not telling you what to do, and what not to do, it's just telling you how to assess whether or not what you do is in line with that kind of way of doing things.
**17:00** - *Saron Yitbarek*
Yep. I think that just going back to that name of manifesto for agile software development, the one word that really stands out and that has been very persistent, and people really latched onto is the word agile. What is wrong with the use of the word agile today?
**17:30** - *Dave Thomas*
The problem with the word agile is that, in the title that we came up with, it is an adjective that describes software development. But what happens then is that people say, "How do I do this agile thing?"
**18:00** - *Dave Thomas*
Suddenly, out of the wood work springs a whole army of consultants, and consultancies, who look at the success of XP, look at the success of the manifesto, and say, "Hey, there's gold in them there hills." So, they start telling people how to "do agile." And that is a problem because you can't do agile. Agile is not what you do, it's how you do it.
And yet, there are companies out there who will happily sell you agile in a box. That, I think, is a travesty. The consult here is to go into a Fortune 1,000 company and help them set up "agile". They're walking away with five million dollars. You know? Great, good for them.
**18:30** - *Dave Thomas*
But, the reality is, that that's like telling a tiger to be agile by saying, “Take seven steps and then spring off your left foot, and then take two more steps, and spring off your right foot.” Well, that only works if the gazelle is doing the same thing. And guess what? No one has told the gazelle to be agile that way. It's basically running off to the horizon laughing its horns off because the tiger has gone the wrong way.
**19:00** - *Dave Thomas*
Same thing happens when you tell a team how to be agile. If you say to them, “Here are the rules you have to follow, here is the processes you have to follow,” then the last thing they have is a duty because they have been boxed into a particular path. Management is going to be judging them based on how well they follow those principles, or those procedures. Not on how well they're developing software.
**19:30** - *Saron Yitbarek*
So, looking back, when you think about the role of the developer before the manifesto, and then now after the manifesto, how has the role of the developer changed, or expanded, because of what you wrote?
*Dave Thomas*
To their credit, I think that the majority of programmers out there get it. I think that the manifesto has empowered a lot of developers to start following practices that, to some extent, they knew they should have been doing, but they never really had the authority to do.
**20:00** - *Dave Thomas*
Things like testing, for example, things like gathering feedback, things like short iterations. So, in many ways, the job is more interesting and more fulfilling.
I think, also, programmers are feeling a little bit more scared because now they have responsibility. In the old days, I was just following orders. Why doesn't this program work? Well, I followed the spec. Whereas nowadays, it's on your shoulders.
**20:30** - *Dave Thomas*
So, I think the job has grown up a bit because of the manifesto. I think people are beginning to realize that they have an end-to-end responsibility for what they deliver.
**21:00** - *Saron Yitbarek*
The success of agile has been so pervasive, that it's altering workflow and attitudes far beyond the development world—certainly beyond the Snowbird Lodge. We have to ask, “What does it even mean to be an agile developer today versus 2001 when the manifesto was written?”
Does the original spirit of agile persist? And if it did change, is that such a bad thing? For Ruha Devanesan, a diversity business partner at Google, the agile mindset might have evolved to the point where it's now influencing basic levels of fairness and workplace equality.
**21:30** - *Ruha Devanesan*
Part of what makes teams inclusive is their ability to evaluate and reflect on how they work together on a very fundamental level. And most teams, when they work together, don't get the space to do that. They don't get the space to stop and think about their team dynamics, about whether everyone is having a voice at the table, about whether someone is steamrolling someone else. Or whether someone is silent the entire time. And if they are silent, why are they silent?
**22:00** - *Ruha Devanesan*
So, when thinking about inclusion, I thought that some of the tools that agile teams use could be very useful in giving teams a structure, or a framework to be more inclusive. So diversity not just in terms of gender, and race, and ethnicity, but also functional diversity. And functional diversity introduces complexity into a team.
**22:30** - *Saron Yitbarek*
But, let’s make a distinction here. Ruha is not saying that agile equals diversity. She's saying, “Agile plus diversity equals better teams.” Ruha's ideas were crystallized in an article she wrote called, *Can Agile Methodology Unlock Diversity* . We'll throw a link in our show notes—it's worth the read.
In it, she walks you through this idea that diversity isn't just a fuzzy concept your HR department keeps talking about. It's actually a strong business case here. Intentionally creating an inclusive workplace by leveraging the tools agile gives us can improve rates of innovation. Diversity can dovetail with agile.
**23:00** - *Ruha Devanesan*
So, that introduction of complexity for the end goal of having an outcome or a product that has been looked at from many angels. That's the same fundamental point of view that we take when we say adding diversity to a team leads to a good outcome, leads to more innovation, and more creativity, because when you have multiple perspectives looking at a problem, helping to do problem-solving work, you're more likely to come out with an outcome that is more robust.
**23:30** - *Saron Yitbarek*
Even something as simple as a daily stand-up, where everybody on your team gets to report is going to give voice to introverts, or other people who have a hard time being heard.
*Ruha Devanesan*
The thing I really like about agile is it has some built-in mechanisms to help teams stop and reflect. And that may be because agile is so quick, and with two-week sprints, if you don't build in those mechanisms you're likely to go way off track and not have the consciousness to come back on track.
**24:00** - *Ruha Devanesan*
But, that “stop and reflect” value, I think, is really important. And it's really important to inclusion because just reflection on how we're working together, how can we course correct, is one of the fundamental ways in which teams can be inclusive.
*Saron Yitbarek*
Since we're talking about inclusivity, now might be a good time to point out that those 17 founders of the agile manifesto, yeah ... They were all white men.
**24:30** - *Dave Thomas*
There was zero diversity in that room. And that is a very common criticism of the group. And one that I have a lot of sympathy with.
*Saron Yitbarek*
If the manifesto founders used those agile principles, and applied it to their own meeting, they may have gotten part-way done and asked themselves ... “Hey, did you notice we didn't invite any women to this meeting?” I wonder if a person of color would have a different opinion.
**25:00** - *Ruha Devanesan*
People’s friends tend to be and look like they do. So, if the first person that thought about the agile manifesto was a white guy, it's not surprising that the people he invited to the table were also white guys. But, we have an opportunity to do better there, and we have an opportunity to stop and say, "Let’s take a step back, let’s expand our lens and look for people outside of the network that I currently have, who can bring a different perspective and help me elevate this methodology to something even better."
**25:30** - *Saron Yitbarek*
It makes sense to me that because agile is so ... well, agile, we can apply it to different problems and industries. The application of agile, and what it looks like in real life, is constantly shifting, expanding. I guess it's practicing what it preaches. There is no subtler answer, no subtler end point. That's something we sometimes forget: Hard rules are the enemy of agility.
**26:00** - *Saron Yitbarek*
So, if an agile team ever tells you that part of being agile means you have to produce a new release every two weeks, or you have to do that, then, by definition, that's not agile. The second you say “always,” you aren't being agile anymore.
**26:30** - *Saron Yitbarek*
Those 17 men who met in Snowbird, Utah, eventually dubbed themselves the Agile Alliance. That alliance became a nonprofit, and that nonprofit started hosting a conference every year. It's grown, and grown, spawning whole new theories and methodologies.
And here's something I think is super interesting. At the 2008 conference, Belgium developer Patrick Debois attends and sets off down a path that leads him to inventing a whole new practice of software development, DevOps. I'd never thought that agile, a set of principles, and DevOps, a whole industry, were related.
**27:00** - *Saron Yitbarek*
But, now I'm thinking, “How strong really is that line between the rise of agile and the invention of DevOps? Did the one breakthrough lead to the other organically?” We're going to find out together, because our next episode is all DevOps, all episode long.
**27:30** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. For more information about this and past episodes, go to Redhat.com/commandlineheroes. Once you're there, you can also sign up for our newsletter. And to get new episodes delivered automatically, for free, make sure to subscribe to the show. Just search for “Command Line Heroes” in Apple podcasts, Spotify, Google Play or however you get your podcasts.
Then, hit “subscribe” so you'll be the first to know when new episodes are available. I'm Saron Yitbarek, thanks for listening, and keep on coding.
### Featured in this episode
#### Dave Thomas
Programmer, one of the authors of the "Manifesto for Agile Software Development"
#### Ruha Devanesan
Diversity business partner at Google, author of "Can Agile Methodology Unlock Diversity?"
#### Darrell K. Rigby
Partner in the Boston office of Bain & Company, specializing in innovation and retail growth strategies |
12,515 | 如何在 Ubuntu 上安装最新版本的 Handbrake | https://itsfoss.com/install-handbrake-ubuntu/ | 2020-08-13T22:39:45 | [
"HandBrake"
] | https://linux.cn/article-12515-1.html |
>
> 此快速教程介绍了如何使用在基于 Ubuntu 的发行版上使用官方 PPA 安装最新版本的 HandBrake。
>
>
>

[HandBrake](https://handbrake.fr/) 是可用于 Linux、Windows 和 macOS 的最受欢迎的开源视频转换器之一。
此 GUI 应用让你只需单击几下即可将视频从一种格式转换为另一种格式。你还可以根据需要自定义输出视频。
[HandBrake](https://itsfoss.com/handbrake/) 存在于 [Ubuntu 的通用存储库](https://itsfoss.com/ubuntu-repositories/)中,但它可能并不总是最新版本。让我向你展示如何在 Ubuntu 和其他基于 Ubuntu 的发行版(如 Linux Mint、Linux Lite、elementray OS 等)上获得最新的 HandBrake。
### 在基于 Ubuntu 的 Linux 发行版上安装最新的 HandBrake
HandBrake 的开发人员维护着一个[官方的 PPA](https://launchpad.net/~stebbins/+archive/ubuntu/handbrake-releases)。[使用此 PPA](https://itsfoss.com/ppa-guide/),你可以轻松地在基于 Ubuntu 的发行版中安装最新版本的 HandBrake。
打开终端,然后使用以下命令添加 PPA 仓库。需要时按下回车键:
```
sudo add-apt-repository ppa:stebbins/handbrake-releases
```
你可能需要更新本地软件包缓存(在 Ubuntu 18.04 和更高版本中不是必需的):
```
sudo apt update
```
现在,使用以下命令安装最新版本的 HandBrake:
```
sudo apt-get install handbrake-gtk
```
这个方法最好的地方是会删除旧的 handbrake 软件包,从而避免安装两个不同版本的 handbrake。

在你的 Linux 系统上享受最新最好的 HandBrake 并转换视频。
### 从系统中卸载 HandBrake
由于某些原因,如果你不喜欢 HandBrake 并希望将它删除,那么需要执行以下操作。
打开终端并使用以下命令卸载 HandBrake:
```
sudo apt remove handbrake-gtk
```
现在,你已经删除了该应用,如果你不再需要它,那么[删除它的 PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/) 是一个好主意。
```
sudo add-apt-repository -r ppa:stebbins/handbrake-releases
```
在询问时确认。
在这篇快速 Ubuntu 教程中,你学习了使用 PPA 安装最新的 HandBrake 的步骤。你还了解了正确删除它的步骤。
我希望你觉得这篇快速教程有用。如果你有任何问题或建议,请在下面发表评论。
---
via: <https://itsfoss.com/install-handbrake-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

HandBrake is one of the most popular [open-source video converters for Linux](https://itsfoss.com/open-source-video-converters/), Windows, and macOS.
This GUI application enables you to convert videos from one format to another in just a few clicks. You can also customize the output video as per your requirements.
**Starting with version 20.04, **
**HandBrake**is available in the
**universe repository of Ubuntu**. This means you can install it using the command below:
`sudo apt install handbrake`
Or look for it in the Software Center.
**But you might not get the latest version of HandBrake this way.**
Let me show you how you can get the **latest HandBrake on Ubuntu** and other Ubuntu-based distributions like Linux Mint, Linux Lite, elementary OS etc.
## Installing the latest HandBrake on Ubuntu
The developers of [HandBrake](https://handbrake.fr/?ref=itsfoss.com) maintain an [official PPA](https://launchpad.net/~stebbins/+archive/ubuntu/handbrake-releases?ref=itsfoss.com) for **Ubuntu 20.04 LTS and older**. [Using this PPA](https://itsfoss.com/ppa-guide/), you can easily install the latest version of HandBrake on your Ubuntu-based distribution.
Open a terminal and use the following command to add the PPA repository. Press enter when asked for it:
`sudo add-apt-repository ppa:stebbins/handbrake-releases`
You may have to update the local package cache after adding the PPA (not required in Ubuntu 18.04 and higher versions):
`sudo apt update`
Now install the latest version of the HandBrake using this command:
`sudo apt install handbrake-gtk`
## Remove HandBrake
For some reason, if you don’t like HandBrake and want to remove it, here’s what you need to do.
Open a terminal and use the following command to uninstall HandBrake:
`sudo apt remove handbrake-gtk`
If that does not work, you can try:
`sudo apt remove handbrake`
Now that you have removed the application, it will be a good idea to [remove the PPA](https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/) (if you added it), as you don’t need it anymore.
`sudo add-apt-repository -r ppa:stebbins/handbrake-releases`
Confirm when asked for it.
## Bonus tip: Using the Flatpak package
You can also utilize the Flatpak package available on [Flathub](https://flathub.org/apps/details/fr.handbrake.ghb?ref=itsfoss.com). Follow our [Flatpak guide](https://itsfoss.com/flatpak-guide/) if you cannot install the Flatpak package on your system.
With the setup done, you can find it using the software center (or your package manager). In either case, you can use the following command to install it via the terminal:
`flatpak install flathub fr.handbrake.ghb`
## More on video converters
HandBrake is one of the several encoders available for Linux.
[Open Source Video Converters for Linux [GUI and CLI]Video downloads are fun until they become unplayable. So, here’s the list of top open-source video converters to help your downloads stay relevant everywhere. Video conversion is not the best thing you want to do with a video, but it becomes unavoidable sometimes. For instance, you can onl…](https://itsfoss.com/open-source-video-converters/)

FFmpeg is the most popular and popular of them all. It's a command-line tool and many [GUI converters](https://itsfoss.com/format-factory-alternative-linux/), including HandBrake, use it underneath.
[Install and Use ffmpeg in Linux [Complete Guide]This detailed guide shows how to install ffmpeg in Ubuntu and other Linux distributions. It also demonstrates some useful ffmpeg commands for practical usage.](https://itsfoss.com/ffmpeg/)

In this quick tutorial, you learned how to install the latest HandBrake on Ubuntu using the official PPA. You also learned the steps for removing it properly.
I hope you find this quick tip useful. If you have questions or suggestions, please leave a comment below. |
12,517 | 汇总你在 Linux 上的命令使用情况 | https://www.networkworld.com/article/3567050/summarizing-your-command-usage-on-linux.html | 2020-08-14T22:16:06 | [
"历史"
] | https://linux.cn/article-12517-1.html |
>
> 使用合适的命令,你可以快速了解 Linux 系统上使用的命令以及执行的频率。
>
>
>

汇总 Linux 系统上使用的命令只需一串相对简单的命令以及几条管道将它们绑定在一起。当你的历史记录缓冲区保留了最近的 1,000 或 2,000 条命令时,总结你的命令活动可能会变得很乏味。这篇文章提供了一种方便的方法来汇总命令的使用情况,并高亮显示最常用的命令。
首先,请记住,典型的命令历史记录可能看起来像这样。请注意,命令是显示在命令序列号之后,并紧跟其参数。
```
91 sudo apt-get install ccrypt
^
+-- command
```
请注意,`history` 命令遵循 `HISTSIZE` 的设置,这会决定保留多少条命令。可能是 500、1,000 或更多。如果你不喜欢它的设置,那么可以在 `.bashrc` 或其他启动文件中添加或更改 `HISTSIZE` 设置。
```
$ echo $HISTSIZE
1000
$ history | wc -l
1000
$ grep HISTSIZE ~/.bashrc
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
HISTSIZE=1000
```
记下大量命令的主要好处之一是,它可以让你轻松地重新运行过去使用的命令,而不必重新输入或记住它们。它还能让你轻松地查看你在一个任务中已经做了多少工作。单独使用 `history` 命令时,你会看到类似下面这样,最早的在最前面:
```
$ history
7 vi tasks
8 alias
9 echo $HISTTIMEFORMAT
10 history
11 date
…
```
查看最新使用命令需要查看记录的命令的尾部:
```
$ history | tail -4
1007 echo $HISTSIZE
1008 history | wc -l
1009 history
1010 history | tail -4
```
另外,你可以使用 `tail` 命令查看 `.bash_history` 文件的尾部,但是 `history` 命令显示的数字可以让你输入如 `!1010` 这样的数字重新运行命令,这点通常更有用。
要提供已使用命令的汇总(例如 `vi` 和 `echo`),你可以首先使用 `awk` 将命令与 `history` 中保存的其他信息分隔开来:
```
$ history | awk '{print $2}'
vi
alias
echo
history
date
…
```
如果你将历史记录中的命令列表传递给 `sort` 命令以按字母顺序对命令进行分组,那么会得到以下内容:
```
$ history | awk '{print $2}' | sort
7z
7z
alias
apropos
cd
cd
…
```
接下来,将 `sort` 命令的输出传递给 `uniq -c` ,这将计算每个命令使用了多少次:
```
$ history | awk '{print $2}' | sort | uniq -c
2 7z
1 alias
2 apropos
38 cd
21 chmod
…
```
最后,添加第二个 `sort` 命令按倒序对命令组计数进行排序,这将先列出最常用的命令:
```
$ history | awk '{print $2}' | sort | uniq -c | sort -nr
178 ls
95 vi
63 cd
53 sudo
41 more
…
```
这样可以让你了解使用最多的命令,但不会包括任何你可能故意从历史记录文件中删除的命令,例如:
```
HISTIGNORE="pwd:clear:man:history"
```
### 当修改了历史记录格式时
对于默认的历史记录格式,`history` 命令输出中的第一个字段将是每个命令的序号,第二个字段是使用的命令。因此,上面所有 `awk` 命令都设置成显示 `$2`。
```
$ alias cmds='history | awk '\''{print $2}'\'' | sort | uniq -c | sort -nr'
```
如果你像下面那样将日期和时间添加了到 `history` 命令中,那么你还必须修改所设置的别名:
```
$ echo $HISTTIMEFORMAT
%d/%m/%y %T
```
这个日期/时间信息有时会很有帮助,但是这意味着你必须在选择 `history` 命令的第 4 个字段而不是第 2 个字段来汇总命令,因为你的历史记录条目将如下所示:
```
91 05/07/20 16:37:39 sudo apt-get install ccrypt
^
+-- command
```
因此,在将 `$2` 变为 `$4` 之后,用于检查 `history` 命令的别名将改为这样:
```
$ alias cmds='history | awk '\''{print $4}'\'' | sort | uniq -c | sort -nr'
```
可将别名保存在 `.bashrc` 或其他启动文件中,请确保在 `$` 符号前面插入反斜杠,以便 bash 不会尝试解释 `$4`。
```
alias cmds='history | awk '\''{print \$2}'\'' | uniq -c | sort -nr'
alias cmds='history | awk '\''{print \$4}'\'' | uniq -c | sort -nr'
```
请注意,日期和时间信息与命令本身保存在历史记录文件的不同行中。因此,添加此信息后,bash 历史记录文件的行数将增加一倍,尽管在 `history` 命令输出时不会:
```
$ wc -l .bash_history
2000 .bash_history
$ history | wc -l
1000
```
### 总结
你可以随时决定要保留多少命令历史记录,哪些命令不值得记录,以使你的命令摘要最有用。
---
via: <https://www.networkworld.com/article/3567050/summarizing-your-command-usage-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,518 | 使用 RT-Thread 实时操作系统驱动你的硬件 | https://opensource.com/article/20/6/open-source-rtos | 2020-08-15T06:57:54 | [
"RT-Thread",
"RTOS"
] | /article-12518-1.html |
>
> 编程驱动一个微处理器芯片是相当有难度的,但在嵌入式系统开发上,实时操作系统可以为你解决很多此类的困难。
>
>
>

从通用计算的角度,操作系统是提供计算机基本功能的一组软件。操作系统保证了计算机硬件可以探测并响应外围器件(如键盘、屏幕、移动设备、打印机等),并管理内存空间和外部存储空间。
虽然一个 CPU 核心同一时间只能运行单个线程,但现代操作系统可以使多个程序表现的像是在同时运行。每一个任务执行的如此之短,一系列任务切换的如此之快,以至于看起来多个任务像是在并行进行。这一切都是由一个叫做 *调度器* 的子进程来控制的。
操作系统通常是为计算机准备的,安装在硬盘上,管理计算机所要执行的任务。
### 为什么实时操作系统对嵌入式系统而言不可或缺
我曾经在 2008 年接触过嵌入式软件,那时候我还是一名学生,正在学习 [MCS-51](https://en.wikipedia.org/wiki/Intel_MCS-51) 微处理器编程。因为我的主修专业是计算机科学,我在其它课程中的所有程序都是在 PC 上执行的。为微处理器芯片编程是完全不同的体验。人生中第一次,我看到我的程序在裸板上运行,即使到现在我仍然记得,在我看到自己人生中第一个走马灯程序成功运行时的那种兴奋和激动。
但那种兴奋转瞬即逝。随着为裸板写出越来越多的程序,我遇到了越来越多的问题。这种沮丧并不是我独有的。直接为芯片写程序很困难,这也是 PC 要运行操作系统的很重要的原因。不幸的是,微处理器芯片(或嵌入式系统)通常是没有操作系统的,它们只能采用“硬编码”的方式编程,没有操作系统帮助你管理代码的运行。
在以“硬编码”的方式为处理芯片编写代码的时候,可能会遇到下列问题:
#### 并发
在裸板上是没有管理程序运行的现成守护进程的。嵌入式系统软件中,无可避免的要把所有的逻辑功能放在一个巨大的 `while (1)` 循环中。每个功能可能包含一个或多个延时函数。CPU 在运行延时函数的时候是顺序执行的,没有任何办法跨越一个不必要的延时。正因如此,运行事务的复位操作只能是等待。最终结果就是很多的 CPU 处理时间浪费在空循环上,这对任务的并发非常不利。
#### 模块化
从软件工程的角度,高內聚低耦合原则在软件开发过程中被不厌其烦的频频强调,但是嵌入式软件的不同模块之间常常是重度耦合的,很多功能都集中在一个巨大的 `while (1)` 循环中,很难切分为模块。设计低耦合软件在编程上只是繁琐一些,但在嵌入式系统上,要低耦合就难以编写比较大型的软件。
与此同时,如果使用了看门狗定时器,程序员还得在调用延时函数时倍加小心。如果延时时间太长,主程序没有得到及时“喂狗”的时机,那么看门狗将在程序运行过程中被触发。嵌入式系统软件开发过程中,需要考虑的东西太多了,即便是个简单的延时函数,都不能掉以轻心。软件越复杂,就越需要细心。想象一下,试图将这一系列具有精细时间关系的交互功能拆分为模块会怎么样。
#### 软件生态
很多高级的软件组件依赖于其所基于的底层操作系统的实现。举个自身的例子,我曾开发过一个基于 [FreeModbus](https://www.embedded-solutions.at/files/freemodbus-v1.6-apidoc/) 的开源项目,原计划将它移植到多种平台上,包括裸板。但与适应不同操作系统的便利性相比,有些功能过于复杂,无法在所有裸机板上实现。更糟糕的是,很多硬件平台因为缺乏一致性,只能各自从头做起。
直至现在,我的 Modbus 栈仍然不支持在裸板上运行。
很多像 Realtek、TI 和 MediaTek 的大厂,所提供的 WiFi 软件开发工具只能在操作系统上运行,且他们不公开固件源码,所以在裸板上根本没法使用这些工具。
#### 实时性
有些应用领域对实时性有要求,比如有些场景中,必须在特定的时间触发特定的软件操作。在工业控制场景,机器实体控制过程中,机械部件必须以确定的时间和确定的顺序执行动作。如果不能保证控制系统的实时性,整个机器可能出现功能异常,甚至危及工人生命。在裸板平台,所有的功能都塞在一个巨大的 `while (1)` 循环中,实时性无从保证。
#### 重用性
重用性依赖于模块化。没谁愿意翻来覆去做一成不变的事,对程序员而言更是如此。这不单单是浪费时间,更要命的是这使得代码的维护异常复杂。尤其是,因为功能的实现依赖于底层的硬件,使用了不同芯片的不同硬件平台上,同样的功能必须适配不同的硬件平台。这种情况下,重新发明轮子是无法避免的。
### 实时操作系统的优势
幸运的是,现在有针对各种微处理器芯片的操作系统,它们被称为实时操作系统(RTOS),和大多数操作系统一样,它们拥有调度器,保证代码以可预见的顺序运行。
我是在 2010 年初次在裸板上使用实时操作系统。那时候,[STM32](https://en.wikipedia.org/wiki/STM32) 系列微处理器(MCU)开始流行,因为这种微处理器性能强大、功能丰富,很多人在上面跑操作系统。我使用的是 [RT-Thread](https://github.com/RT-Thread/rt-thread) 操作系统,有很多基于它的现成组件可用。它使用的是 Apache 2.0 许可,和其它操作系统相比,我觉得这个很舒心。我已经基于它作为平台从事开发工作 10 年了。
使用实时操作系统为裸板编程,操作系统为我们解决了需要处理的大部分问题。
#### 模块化
在操作系统支持下,整个软件可以分割为多个任务(即线程)。每个线程拥有自己独立的运行空间。线程之间互相独立,这促进了软件的模块化。
#### 并发
如果一个线程有延时函数,它将自动让出 CPU 资源给需要 CPU 的线程,这提高了 CPU 的整体利用率,也提升了系统的并发性能。
#### 实时性
实时操作系统从设计上就具备实时性。每个线程都被指定了特定的优先级,比较重要的线程设置为更高的优先级,不重要的线程优先级也低。正是以这种方式,软件整体的实时性得到了保证。
#### 开发效率
操作系统提供了统一的抽象接口,这使得可重用组件得以不断积累,同时提升了开发效率。
操作系统是软件极客集体智慧的结晶。很多通用的软件功能,如信号量、事件提醒、邮箱、环形缓冲、单向链表、双向链表等,被抽象出来并实现了封装,可随时调用。
Linux、RT-Thread 等操作系统为五花八门的硬件实现了一致的硬件接口,也就是常说的设备驱动框架。正因如此,软件工程师可以专注于软件开发,而不用关心底层的硬件,也不用重复造轮子。
#### 软件生态
RT-Thread 丰富的软件生态为大量的从业者带来了巨大的改变。操作系统带来的模块化和重用性,使得程序员可以基于 RT-Thread 封装出方便嵌入式系统开发使用的可重用组件。这些组件可以在其它项目中重用,也可以分享给其他的嵌入式应用开发者,以最大化软件的价值。
比如,LkdGui 是个开源的单色显示图形库,你可能在工业控制面板上简单而美观的设置界面上见过它。LkdGui 提供了像描点、画线、绘矩形及显示文本、按钮组件、进度条等绘图功能。

使用像 LkdGui 这样兼具扩展性和健壮性的功能库,程序员们可以在同行已有工作成果的基础上充分施展自己的才能。而这一切,没有实时操作系统这样一个统一的基础,是根本不可能的。
### 试用 RT-Thread
作为开源极客,我已经在 GitHub 上开源了一些嵌入式软件。在发布开源软件之前,我很少对他人谈及自己曾经的项目,因为不同的人在使用各种不同的微处理器芯片和硬件平台,我的代码极可能无法在他人的板子上运行。类似于 RT-Thread 这样的实时操作系统极大的提升了软件的可重用性,所以全世界的不同领域的专家得以就同一个项目展开探讨。这鼓励着越来越多的人分享和交流各自的项目。如果你在做裸板的软件开发,下次可以试试 TR-Thread。
---
via: <https://opensource.com/article/20/6/open-source-rtos>
作者:[Zhu Tianlong](https://opensource.com/users/zhu-tianlong) 选题:[lujun9972](https://github.com/lujun9972) 译者:[silentdawn-zz](https://github.com/silentdawn-zz) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,520 | 在树莓派 3 上安装 Fedora | https://fedoramagazine.org/install-fedora-on-a-raspberry-pi/ | 2020-08-15T23:21:49 | [
"Fedora",
"树莓派"
] | https://linux.cn/article-12520-1.html | 
>
> 在树莓派上运行 Fedora。
>
>
>
[树莓派基金会](https://www.raspberrypi.org/about/)这几年来生产了很多型号。本文的安装过程已经在第三代树莓派上进行了测试:[3B v1.2](https://www.raspberrypi.org/products/raspberry-pi-3-model-b/) 和 [B+](https://www.raspberrypi.org/products/raspberry-pi-3-model-b-plus/)(较旧的 [树莓派 2](https://www.raspberrypi.org/products/raspberry-pi-2-model-b/) 和新的 [树莓派 4](https://www.raspberrypi.org/products/raspberry-pi-4-model-b/) 都还没有测试)。这些是已经发布了几年的信用卡大小的树莓派。
### 获取硬件
你需要一些硬件组件,包括树莓派。你不需要任何 [HaT(安装在顶部的硬件)](https://www.raspberrypi.org/blog/introducing-raspberry-pi-hats/) 板或 USB 天线。如果你使用过树莓派,那么可能会有这些。
* **当前网络**。也许是你的家庭实验室。
* **网线**。连接当前网络到树莓派
* **树莓派 3**,型号 B 或 B+。
* **电源**。
* **8 GB 或更大容量的 micro-SD 卡**。
* **键盘**和**显示器**。
键盘和显示器共同组成本地控制台。即使没有控制台,也能进行操作(尽管很复杂),例如设置自动安装然后通过网络连接。在 Fedora 首次启动时,本地控制台可轻松回应配置问题。同样,在 AP 配置期间出错可能会破坏网络配置,从而阻止远程用户连入。
### 下载 Fedora Minimal
* 查找 Fedora 的[其他可选架构镜像](https://alt.fedoraproject.org/alt/)。
* 下载 [ARM® aarch64 架构镜像](https://download.fedoraproject.org/pub/fedora-secondary/releases/32/Spins/aarch64/images/Fedora-Minimal-32-1.6.aarch64.raw.xz)。
Fedora Minimal 镜像是 [Fedora 的其他可选下载之一](https://alt.fedoraproject.org/),它有所有必需的核心软件包和网络软件包(嗯,是几乎,注意下面的 dnsmasq)。该镜像包含一个现成的文件系统,它已经安装了 400 多个软件包。此最小镜像不包括流行的软件包,像开发环境、互联网服务或桌面。这些类型的软件不是这里所必需的,如果安装它们,可能会占用过多的内存。
Fedora Minimal 原始镜像可安装在小型 SD 卡上,并在少于 1GB 的内存中运行(这些旧的树莓派有 1GB 的内存)。
下载文件的名称类似于 `Fedora-Minimal-32-1.6.aarch64.raw.xz`。该文件已压缩,大小约为 700MB。文件解压缩后为 5GB。这是一个 ext4 文件系统,它大部分是空的:已使用约 1GB,空余 4GB。这些空的空间是压缩文件比未压缩的原始文件小得多的原因。
### 复制到 micro-SD 卡
* 将镜像复制到 micro-SD 卡。
这可能比听起来更复杂,而且会带来痛苦的体验。找到一个[良好的 micro-SD 卡](https://www.jeffgeerling.com/blog/2019/raspberry-pi-microsd-card-performance-comparison-2019)需要花费精力。然后是将卡插到计算机的挑战。也许你的笔记本电脑有全尺寸的 SD 卡插槽,你还需要卡适配器,或者你需要一个 USB 适配器。然后,在进行复制时,操作系统可能会帮助你,也可能会妨碍你。你可能很幸运有 [Fedora Media Writer](https://fedoramagazine.org/make-fedora-usb-stick/),或使用这些 Linux 命令:
```
unxz ./Fedora-Minimal-32-1.6.aarch64.raw.xz
dd if=./Fedora-Minimal-32-1.6.aarch64.raw of=/dev/mmcblk0 bs=8M status=progress oflag=direct
```
### 安装 Fedora
* 连接树莓派、电源线、网线和 micro-SD 卡。
* 打开电源。
* 当图形芯片通电时,看见彩色框。
* 等待 [anaconda 安装程序](https://fedoraproject.org/wiki/Anaconda)启动。
* 回答 anaconda 的设置问题。
操作系统的初始配置需要几分钟的时间。等待启动需要花费几分钟,还需要花费一些时间填写 anaconda 的文本安装程序的问题。在下面的例子中,用户名为 `nick`,并且还是管理员(`wheel` 组的成员)。
恭喜你!你的树莓派已启动并可运行。
### 更新软件
* 用 `dnf update` 更新软件包。
* 通过 `systemctl reboot` 重启。
多年来,很多人为使树莓派正常工作付出了很多工作。使用最新的软件,以确保你从他们的辛勤工作中受益。如果你跳过此步骤,你可能会发现有些东西无法正常工作。
此次更新下载并安装了约一百个软件包。由于存储设备是 micro-SD 卡,因此写入新软件的过程很慢。这就是 90 年代使用存储器的感觉。
### 可以摆弄的东西
如果你想摆弄的话,此时可以设置其他一些内容。这都是可选的。试试这些。
* `sudo hostnamectl set-hostname raspi` 替换 `localhost` 主机名。
* 用 `ip addr` 查找 IP 地址。
* 尝试 SSH 登录,甚至使用 `ssh-copy-id` 设置基于密钥的登录。
* 使用 `systemctl poweroff` 关机。
---
via: <https://fedoramagazine.org/install-fedora-on-a-raspberry-pi/>
作者:[Nick Hardiman](https://fedoramagazine.org/author/nickhardiman/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fire up a Raspberry Pi with Fedora.
The [Raspberry Pi Foundation](https://www.raspberrypi.org/about/) has produced quite a few models over the years. This procedure was tested on third generation Pis – a [Model B v1.2](https://www.raspberrypi.org/products/raspberry-pi-3-model-b/), and a [Model B+ ](https://www.raspberrypi.org/products/raspberry-pi-3-model-b-plus/)(the older [2](https://www.raspberrypi.org/products/raspberry-pi-2-model-b/) and the new [4](https://www.raspberrypi.org/products/raspberry-pi-4-model-b/) weren’t tested). These are the credit-card size Pis that have been around a few years.
### get hardware
You do need a few hardware items, including the Pi. You don’t need any [HaT (Hardware Attached on Top)](https://www.raspberrypi.org/blog/introducing-raspberry-pi-hats/) boards or USB antennas. If you have used your Pi in the past, you probably have all these items.
**current network**. Perhaps this is your home lab.**ethernet cable**. This connects the current network to the Raspberry Pi**Raspberry Pi 3**, model B or B+.**power supply****micro-SD card**, 8GB or larger.**keyboard**and**video monitor**.
The keyboard and video monitor together make up the local console. It’s possible – though complicated – to get by without a console, such as setting up an automated install then connecting over the network. A local console makes it easy to answer the configuration questions during Fedora’s first boot. Also, a mistake during AP configuration may break the network, locking out remote users.
### download Fedora Minimal
- Find Fedora’s
[alternate architecture images](https://alt.fedoraproject.org/alt/). - Download the
[ARM® aarch64 Architecture image](https://download.fedoraproject.org/pub/fedora-secondary/releases/32/Spins/aarch64/images/Fedora-Minimal-32-1.6.aarch64.raw.xz).
The *Fedora Minimal* image, one of [Fedora’s alt downloads](https://alt.fedoraproject.org/), has all the core packages and network packages required (well, nearly – check out *dnsmasq* below). The image contains a ready-made file system, with over 400 packages already installed. This minimal image does not include popular packages like a development environment, Internet service or desktop. These types of software aren’t required for this work, and may well use too much memory if you install them.
The *Fedora Minimal* raw image fits on a small SD card and runs in less than 1 GB of memory (these old Pis have 1GB RAM).
The name of the downloaded file is something like *Fedora-Minimal-32-1.6.aarch64.raw.xz*. The file is compressed and is about 700MB in size. When the file is uncompressed, it’s 5GB. It’s an ext4 file system that’s mostly empty – about 1GB is used and 4GB is empty. All that empty space is the reason the compressed download is so much smaller than the uncompressed raw image.
### copy to the micro-SD card
- Copy the image to a micro-SD card.
This can be a more complex than it sounds, and a painful experience. Finding a [good micro-SD card](https://www.jeffgeerling.com/blog/2019/raspberry-pi-microsd-card-performance-comparison-2019) takes work. Then there’s the challenge of physically attaching the card to your computer.Perhaps your laptop has a full SD card slot and you need a card adapter, or perhaps you need a USB adapter. Then, when it comes to copying, the OS may either help or get in your way. You may have luck with [Fedora Media Writer](https://fedoramagazine.org/make-fedora-usb-stick/), or with these Linux commands.
unxz ./Fedora-Minimal-32-1.6.aarch64.raw.xz dd if=./Fedora-Minimal-32-1.6.aarch64.raw of=/dev/mmcblk0 bs=8M status=progress oflag=direct
### set up Fedora
- Connect the Pi, power cable, network cable and micro-SD card.
- Hit the power.
- See the colored box as the graphics chip powers up.
- Wait for the
[anaconda installer](https://fedoraproject.org/wiki/Anaconda)to start. - Answer anaconda’s setup questions.
Initial configuration of the OS takes a few minutes – a couple minutes waiting for boot-up, and a couple to fill out the spokes of anaconda’s text-based installer. In the examples below, the user is named **nick** and is an administrator (a member of the *wheel* group).
Congratulations! Your Fedora Pi is up and operational.
### update software
- Update packages with `dnf update`.
- Reboot the machine with `systemctl reboot`.
Over the years, a lot of people have put a lot of work into making the Raspberry Pi devices work. Use the latest software to make sure you get the benefit of their hard work. If you skip this step, you may find some things just don’t work.
The update downloads and installs about a hundred packages. Since the storage is a micro-SD card, writing new software is a slow process. This is what using computing storage felt like in the 1990s.
### things to play with
There are a few other things that can be set up at this point, if you want to play around. It’s all optional. Try things like this.
- Replace the
*localhost*hostname with the command `sudo hostnamectl set-hostname raspi`. - Find the IP address with `ip addr`.
- Try an SSH login, or even set up key-based login with `ssh-copy-id`.
- Power down with `systemctl poweroff`.
## Shy
Hi world.
Does anyone have any hands-on experience with running Fedora on R181-T90, R181-T92, R281-T91 or R281-T94 or other Marvell ThunderX2 servers and would like to share their impressions, incites etc. please?
Thank you,
## L'rence Aldridge
Yes, but as a newbie (and of course finding this article via Google News) what are the advantages of fedora on a raspberry pi over raspian?
## Stephen
The advantage is you would have Fedora the best Distro on your RPi
## L'rence Aldridge
Thanks for your reply, Stephen. it’s an understandable position, given the blog is titled Fedora Magazine.
I guess the question now, is “Why do people consider fedora the best distro?” (Background: I don’t have much exposure to different distros – I have entered via the world of raspberry pi.)
## Stephen Snow
Well, in truth if you read other comments around here on the topic of RPi and Fedora, you can tell Fedora isn’t the first choice by many for an installation on a Raspberry Pi. Fedora is however the best Linux distribution IMO, and alot of my reason is coming from their stance on FOSS and their dogged support of it, also I like their near bleeding edge focus on the linux ecosystem, and release cadence. The four foundational core values of Fedora are “Freedom, Friends, Features, First”, this is at the core of the community and the distribution.
## fedora_usr
because it is the best 🙂
## Versace
It’s true, I love Fedore 🙂 but Fedora on Raspberry PI is a failure … SD card slot is too slow. You can run Fedore on an external SSD via USB 3.0 to make it run much faster, but you still don’t have the options you expect from a Raspberry Pi.
## Doug
Yeah, Fedora 32 Server uses the XFS filesystem on an SD Card which is just a performance disaster and needs to be fixed
## Edwin Buck
I find the consistency of RPM packaging to be the best real advantage.
At work, we already have the infrastructure set up for RPM builds and deployments, adding ARM to it is easy due to the tooling we can borrow from Fedora.
As there is no need to describe a hybrid packaging and release system, it cuts down on training, documentation, and effort of debugging when things go wrong.
## Phoenix
When it comes to the Raspberry Pi, I am mostly interested if the GPIO would work. The last time I checked, the binary was only readily available within its Debian derivative OS. Is the command “gpio” available now? Or was it already available longer and I simply did not find the right package/repo?
## emlen
not work, as is the vcgencmd
## bookwar
Standard libraries used on Raspbian most likely won’t work because they hardcode Raspbian configuration in their system-level functions.
New library
will work as it uses standard API of the vanilla kernel. It is packaged for Fedora and can be used as cli tool or via Python bindings. See
I also wrote a simple python library (https://github.com/bookwar/python-gpiodev/) to operate GPIO pins via kernel API. Haven’t packaged it for Fedora yet, but I will, someday.
## Edwin Buck
I had success getting the GPIO pins to work with a Raspberry Pi 2B running Fedora. It wasn’t as simple as it could have been, but if you can open up the source for the library you’ll have to install manually, as well as the source for the kernel drivers; at least for that hardware and set of code, I managed to individually light 16 leds.
Of course, it involved a bit of programming, and wasn’t quite as simple as I believed it should have been.
## Stephen
I thought, and this is going back a bit, that there was a python library for that, which is usable in Fedora too.
PHP lib https://github.com/PiPHP/GPIO
Python Lib https://maker.pro/raspberry-pi/tutorial/how-to-get-started-with-the-raspberry-pi-gpio-python-library
or howto with C https://www.digikey.com/en/maker/blogs/2019/how-to-use-gpio-on-the-raspberry-pi-with-c
## emlen
not work on 64 bit
## Pat
When it boots up it asks if you can’t to continue quit or refresh. So I press c to continue and then it asks for a localhost user name and password. Anyone know what it is?
## Jerald
Is YouTube and other HD video play fine in this fedora version.
I flashed android in raspberry Pi 3b, when i play video cpu usage raises high because of software rendering.
and video struck in middle.
## emlen
GPIO is supported with the use of libgpiod and associated bindings and utilities.
RPI.GPIO is not currently supported.
## Stephen Snow
Wouldn’t you just use pip install RPI.GPIO or some such? I’m not a python programmer so I am just asking, but that was my impression on how you went about doing it.
## emlen
I am a Fedora’s fan. So I tried off course.. )I’ll repeat again- it not work on 64 bit, 100%
## bookwar
Unfortunately libraries like RPI.GPIO internally have some checks which are basically saying “If system is not Raspbian – stop”. To be usable on other systems they need to be refactored to use standard API.
## emlen
vcgencmd not compile or install too..
## Sophia
Hello,
I use the Samsung EVO 256GB microSDXC UHS-I U3 100MB/s Full HD & 4K UHD, it has never had any issues with speed. I have tried a lot of Distro’s for my RPi. I did not like the speed that the SanDisk was giving me and I had a few that had issues. I am happy Fedora has a Pi version, as it is the only distro that I use daily at work and at home. I am also the only Support Tech where I work that uses Linux. It is by choice also!!
Just my 2 cents,
Miss. McKnight
## Calvato
Hi everybody, has anybody ever got Fedora running on a Raspbi 4?
## van
Not ready yet. CentOS7.8/Debian10/Ubuntu20.04/ArchLinux/RaspiOS now works on Raspbi 4.
## Calvato
Okay, thank you van.
## Emblaze
Actually, while it’s not officially supported, Fedora 32 runs perfectly well on my 4GB Raspberry Pi 4 with Mate (Gnome also worked but it’s a bit resource consuming). Start with the minimal aarch64 image, then customise it up as you see fit.
## Arjan Hulsebos
I’ve had a number of micro-sd cards go bad in a relative quick time, so I looked at getting th Pi to run from a usb stick. You cannot completely do away with the micro-sd as it really is needed in the first boot stage, but you can run your file systems, including /dev, /etc, and /sbin from the usb stick. I noticed one odd thing, some Pi do need /boot on the micro-sd, others are happy with /boot on the usb, don’t know why (and I haven’t looked into it, I must say).
It’s fairly easy to do, it requires editing a few files, and assigning new UUIDs to a few partitions. All can be found on Google 🙂
## tsyang
Boot from USB without SD card is possible
https://www.raspberrypi.org/forums/viewtopic.php?t=75784 |
12,521 | 为什么犯错让我成为一个更好的系统管理员 | https://opensource.com/article/20/8/sysadmin-mistakes | 2020-08-16T00:12:41 | [
"错误"
] | https://linux.cn/article-12521-1.html |
>
> 诀窍就是同一个错误不要犯两次。
>
>
>

到目前为止,我已做了十多年 [Fedora](http://getfedora.org) 贡献者。 Fedora 有一个由开发者和用户组成的大型社区,其中每一个人,不管是极富洞察力的用户还是出色的程序员,都有一些独有的技能。我喜欢这样的社区,因为它能激励我培养自己的新技能。
对我来说,培养技能最好的方法就是犯错,比如把事情搞得一团糟。犯什么样的错误不重要,因为相比错误本身,我在脱离困境的过程里学习到了什么更重要。
### 为什么犯错误是好事
我依然记得我犯的第一个计算机错误。我家的第一台电脑是我叔叔升职后送个我们的爱普生笔记本电脑,它有一个特别快的 10 MHz 处理器,因为太重了,所以还有一个手提把手。我很喜欢它。
它运行 DOS,但有一个基于文本的菜单应用,所以对新手用户比较友好。硬盘菜单有十个“页面”,每个“页面”可以配置十个命令。我们有一个游戏页面,还有一个页面放些“无聊的东西”,比如文字处理程序和电子表格等等。
硬盘菜单还有一些其他功能,当我玩腻了游戏,就会去探索它们。有一天,我决定使用菜单的账户功能。账户不会改变出现的应用程序,但在某种程度上,可以防止对应用程序未经授权的访问。你可以直接跳到 DOS 中取代它,但使用账户仍然是一个不错的尝试。
我为自己、父母和妹妹创建了账户。虽然我父母有点不开心,但他们最终迁就了我。万事顺遂了一段时间后,妹妹忘记了她的账户密码。于是,我父母让我删掉她的密码,但是没有妹妹的密码去登录账户,我就无法删除她的密码(那是在 90 年代初,一个比现在简单得多的时代)。要怎么办?要怎么办?
那以后一段时间,我们一直试着猜测密码,直到有一天,我决定尝试做一些我还没有做过的事情。当我第一次创建帐户时,我设置了一个主密码。如果我输入主密码来代替我妹妹的密码,会发生什么呢?
如果你在想,“这当然不会有用的”,那么显然你不熟悉 90 年代安全策略的天真幼稚。有了主密码(顺便说一下,主密码是 “worf” ,指的是企业号星舰的克林贡人安全主管,如果你不是《星际迷航:下一代》粉丝的话),我可以删除所有密码。于是,家里的每个人又都可以毫无障碍地使用电脑了。
### 试运行的重要性
在那之后,我又犯了更大更有益的错误。比如,在我第一次做系统管理员时,当时我正整理一些数据以重新配置存储阵列。有一次,我意外地颠倒了源路径和目标路径,而且那是一个带有 `——delete` 标志的 `rsync` 命令。真的是太糟糕了!
幸运的是,我自己的账户也崩溃了,这让我的道歉更容易被其他受影响的用户接受。对我们所有人来说更幸运的是,我们有备份。所以那天结束的时候,每个人的文件都找回来了,我还学到了一个宝贵的教训,那就是在进行破坏性同步之前,先使用 `--dry-run` 标志试运行。
### 以正确的方式处理错误
我不介意犯错误。这些年来,我积累了很多实践经验,学到的诀窍就是不要犯同样的错误。从错误中学习能让我在技能和事业上取得进步,并发现新的会犯的错误。作为 Linux 系统管理员,我总是试图在一个安全的环境(测试平台就很好)中犯错误,确保我可以从错误中恢复(备份真的非常非常重要!),并给以后的我留个笔记,这样他就不会重复犯错(文档是你的朋友)。当然,还要勇于承认自己的错误,并在出现问题时清楚地与用户沟通。如果我一直这样做,也许有一天我就会觉得我很清楚我在做什么!
---
via: <https://opensource.com/article/20/8/sysadmin-mistakes>
作者:[Ben Cotton](https://opensource.com/users/bcotton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Starryi](https://github.com/Starryi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've been a [Fedora](http://getfedora.org) Linux contributor for a little over a decade now. Fedora has a large community of developers and users, each with a unique set of skills ranging from being a particularly discerning user to being an amazing programmer. I like this because it inspires and motivates me to develop new skills of my own.
For me, the best way to develop skills has always been to make mistakes. Like, really mess things up. It doesn't really matter what kind of mistake it is because it's less about the mistake itself and more about what I learn in the process of having to dig myself out of whatever hole I managed to get myself into.
## Why mistakes are good
I remember my first computer mistake. My family's first computer was an Epson laptop that my uncle gave us when he upgraded. It had a blazing fast 10 MHz processor and a carrying handle because it was so heavy. I loved that machine.
It ran DOS, but it had a text-based menu application to make it a little friendlier for the novice user. Hard Disk Menu had ten "pages," each of which could have ten commands configured. We had a page for games, another for "boring stuff" like word processors and spreadsheets, etc.
Hard Disk Menu had some other features that, when I got bored of playing the games, I would explore. At some point, I decided that I should make use of the account feature. It didn't change what applications appeared, but it would prevent unauthorized access, sort of. You could just drop to the DOS shell instead, but still, it was a nice try.
I created accounts for myself, my parents, and my sisters. My parents were a little annoyed, but they humored me. Everything was fine for a while. Then my sister forgot her password. My parents told me to remove the passwords. But without my sister's password, I couldn't remove the password on her account (it was the early 90s, a much simpler time). What to do? What to do?
For a little while, we kept going with the attempted passwords until one day when I decided I'd try something I hadn't done yet. When I was first creating the accounts, I set a master password. What would happen if I typed the master password in place of my sister's password?
If you're thinking, "of course that didn't work," then you're clearly not familiar with the naivete of security policies back in the 90s. With the master password (it was "worf," by the way, a reference to the USS Enterprise-D's Klingon security chief, for those of you who may not be Star Trek: TNG fans) in hand, I was able to remove all of the passwords. Everyone in the family could use the computer without hassle again.
## The importance of a dry-run
Since then, I've gone on to make bigger and better mistakes. Like the time in my first sysadmin job when I was shuffling some data around to reconfigure a storage array. At one point, I accidentally got the source and destination paths backward. Of course, it was an rsync with the `--delete`
flag. Whoops!
Thankfully, my own account was among those that went "poof." That helped the apology go down a little easier with the rest of the affected users. Even better for us all, we had backups, so by the end of the day, everyone had their files back. And I learned a valuable lesson about using the `--dry-run`
flag before running a destructive sync.
## Dealing with mistakes the right way
I don't mind making mistakes. I've amassed a LOT of practice over the years. The trick, I've learned, is never to make the same mistake twice. Learning from my mistakes is what has allowed me to advance in my skills and career, and find new mistakes to make. As a Linux sysadmin, I've always tried to make my mistakes in a safe environment (test platforms are great), make sure that I recover from my mistakes (backups FTW!), and to leave a note for Future Ben, so he didn't repeat my mistakes (documentation is your friend). And of course, admitting my mistakes and clearly communicating to my users when things go wrong. If I keep this up, maybe one day I'll feel like I know what I'm doing!
## 2 Comments |
12,523 | 使用 PDF Mix Tool 执行常见的 PDF 编辑任务 | https://itsfoss.com/pdf-mix-tool/ | 2020-08-16T20:43:00 | [
"PDF"
] | https://linux.cn/article-12523-1.html |
>
> PDF Mix Tool 是一个简单、轻巧的开源 PDF 编辑应用,可让你从 PDF 中提取页面、合并两个 PDF、从 PDF 中删除页面等。
>
>
>

### PDF Mix Tool:一个简单的开源 PDF 编辑工具

有[几个可以在 Linux 中使用的 PDF 编辑器](https://itsfoss.com/pdf-editors-linux/),我通常将它们分为两类:
* 可让你编辑内容(注释、高亮、更改文本、添加/删除图像等)的 PDF 编辑器,
* 可让你通过合并、分割、提取页面等来修改文件的 PDF 编辑器。
[PDF Mix Tool](https://scarpetta.eu/pdfmixtool/) 属于第二类。它是用 C++ 和 Qt5 编写的开源软件。它可让你合并两个或更多 PDF 文件,并为每个文件指定页面,还有旋转页面、添加空白页、删除页面以及从 PDF 文件提取页面。
在本周的开源软件亮点中,让我们看一下使用 PDF Mix Tool。
### 使用 PDF Mix Tool 在 Linux 中编辑 PDF

PDF Mix Tool 并没有很多功能,但是有一些非常重要的功能。
#### 合并 PDF 文件

你可以轻松合并多个 PDF 文件,同时指定确切的页面。它让你能够调整页面数、旋转,还能使用 “<ruby> 交替混合 <rt> Alternate mix </rt></ruby>” 反转页面顺序合并。

你只需要单击 “<ruby> 添加 PDF 文件 <rt> Add PDF File </rt></ruby>” 添加文件,然后使用可用的选项对其进行编辑(如上图所示),最后生成编辑的 PDF。
#### 旋转页面
你可以在合并多个文件或仅对单个 PDF 文件进行操作时旋转 PDF 文件的页面。
对于合并文件,你可以参考上面的截图。但是当你选择一个文件时,它看上去像这样:

你有多种选择,但是要旋转页面,需要选择 “<ruby> 编辑页面布局 <rt> Edit page layout </rt></ruby>” 选项,如上截图所示。
#### 添加或删除页面
要从其他 PDF 文件添加新页面,最好利用此选项。
但是,如果要添加空白页,你可以选择一个文件进行添加。不只是添加空白页面,还可以删除特定页面。下面的截图圈出了高亮选项:

#### 从 PDF 文件提取页面

除了所有其他选项之外,你还可以从给定的 PDF 文件中提取特定页面(或全部)。你还可以为所有提取的页面生成一个新的 PDF 文件,或者为提取的每个页面制作单独的 PDF 文件。在许多场景中,它应该派上用场。
#### 其他功能
利用上面所有功能,你可以生成自己选择的全新 PDF,颠倒顺序、提取页面、制作单独的 PDF 文件等等。
它不会减小 PDF 文件的大小。你必须使用其他工具[在 Linux 中压缩 PDF 文件](https://itsfoss.com/compress-pdf-linux/)。
因此,当你组合使用可用选项时,它是功能丰富的工具。
### 在 Linux 上安装 PDF Mix Tool

PDF Mix Tool 存在于 Snap 和 [Flatpak 软件包](https://flathub.org/apps/details/eu.scarpetta.PDFMixTool)中。这意味着如果发行版支持这任意一种,你都可以在软件管理器中找到它。
或者,如果你[启用了 Snap 软件包支持](https://itsfoss.com/install-snap-linux/),那么可以使用以下命令进行安装:
```
sudo snap install pdfmixtool
```
如果你想[使用 Flatpak](https://itsfoss.com/flatpak-guide/),那么使用:
```
flatpak install flathub eu.scarpetta.PDFMixTool
```
如果你使用的是 Arch Linux,那么可以从[社区仓库](https://www.archlinux.org/packages/community/x86_64/pdfmixtool/)中获取。
```
sudo pacman -S pdfmixtool
```
你也可以选择查看它的 [GitLab 页面](https://gitlab.com/scarpetta/pdfmixtool)获取源码。
* [下载 PDF Mix Tool 源码](https://www.scarpetta.eu/pdfmixtool/)
### 总结
它可能不是功能最丰富的 PDF 编辑工具,但考虑到它是轻量级的开源工具,因此它是已安装的应用中非常有用的。过去我们也介绍过类似的工具 [PDF Arranger](https://itsfoss.com/pdfarranger-app/)。你可能会想了解一下。
你如何看待它?你有尝试过么?在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/pdf-mix-tool/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: PDF Mix Tool is a simple, lightweight open-source PDF editing application that lets you extract pages from PDF, merge two PDFs, delete pages from PDF files among a few other things.*
## PDF Mix Tool: A Simple Open Source PDF Editing Tool
There are [several PDF editors available for Linux](https://itsfoss.com/pdf-editors-linux/). I usually categorize them in two categories:
- PDF editors that let you edit the content (annotate, highlight, change text, add/remove images etc)
- PDF editors that let you modify the files by merging files, splitting files, extracting pages from files etc.
[PDF Mix Tool](https://scarpetta.eu/pdfmixtool/) falls in the second category. It is an open source software written in C++ and uses Qt5. It lets you [merge two or more PDF files](https://itsfoss.com/merge-pdf-linux/) specifying a page set for each of them, rotate pages, add white pages, delete pages and extract pages from PDF files.
In this week’s open source software highlight, let’s take a look at using PDF Mix Tool.
## Using PDF Mix Tool for editing PDFs in Linux
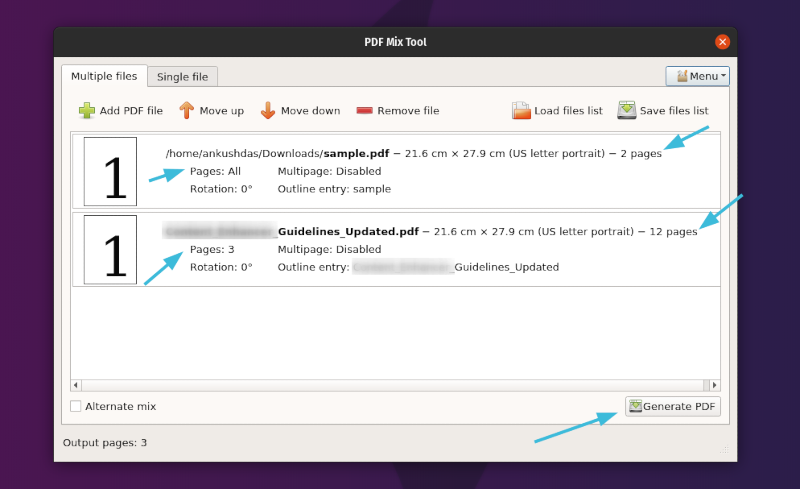
PDF Mix Tool does not boast a bunch of features but a handful of things that are incredibly important.
### Merge PDF files
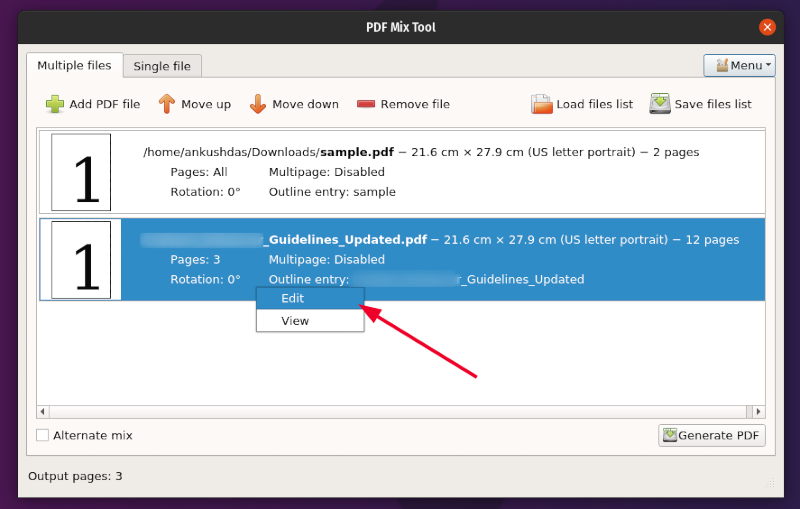
You can easily merge multiple PDF files while specifying the exact pages as well. It gives you the ability to tweak the number of pages, rotation, and also the option to reverse the order of pages to merge with “**Alternate mix**“.
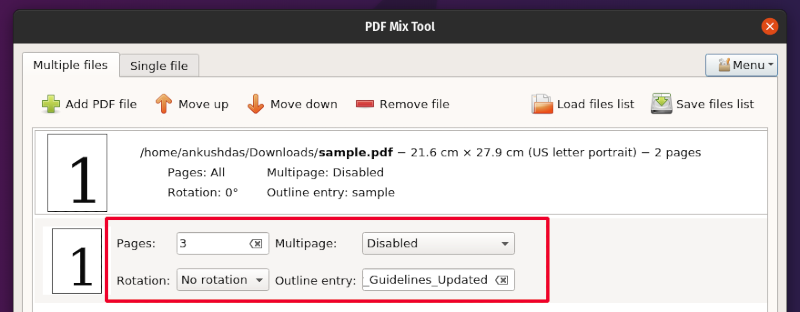
You just need to click on “**Add PDF Fil**e” to add the files and then edit it with the options available (as shown in the image above) and finally generate the edited PDF.
### Rotate pages
You can rotate pages of a PDF file while merging multiple files or when simply operating on a single PDF file.
For merging files, you can refer to the screenshots above — but when you select a single file, this is how it looks:
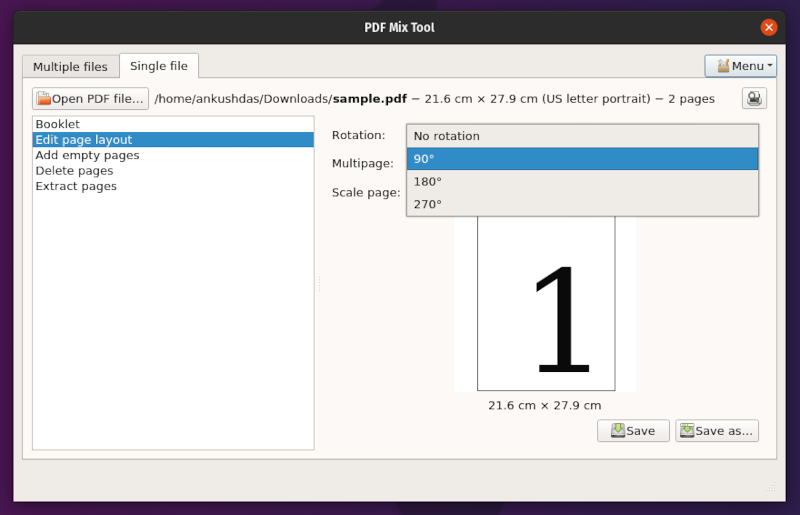
You get a variety of options, but to rotate the pages, you need to select the “**Edit page layout**” option as shown in the screenshot above.
### Add or delete pages
To add new pages from a different PDF file, it’s best to utilize the option.
But, if you want to add an empty page, you can do that when selecting a single file to process. Not just limited to the addition of empty pages — but you can delete specific pages as well. Here’s a screenshot that highlights the delete option:
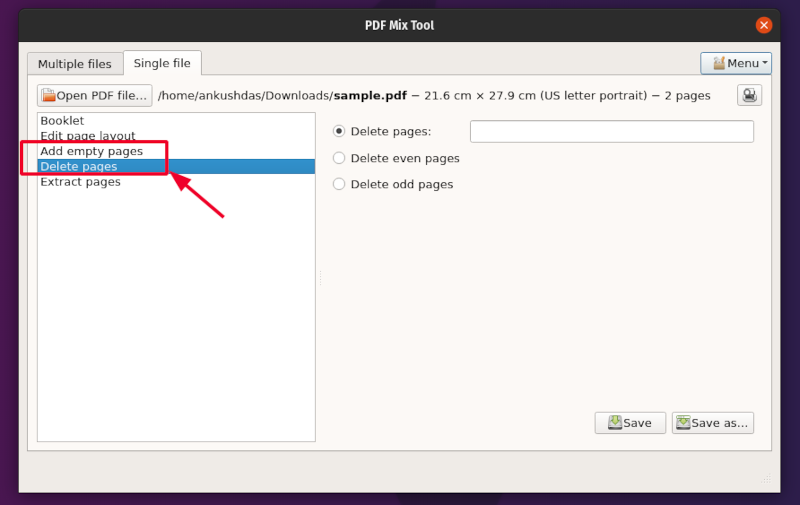
### Extract pages from a PDF file
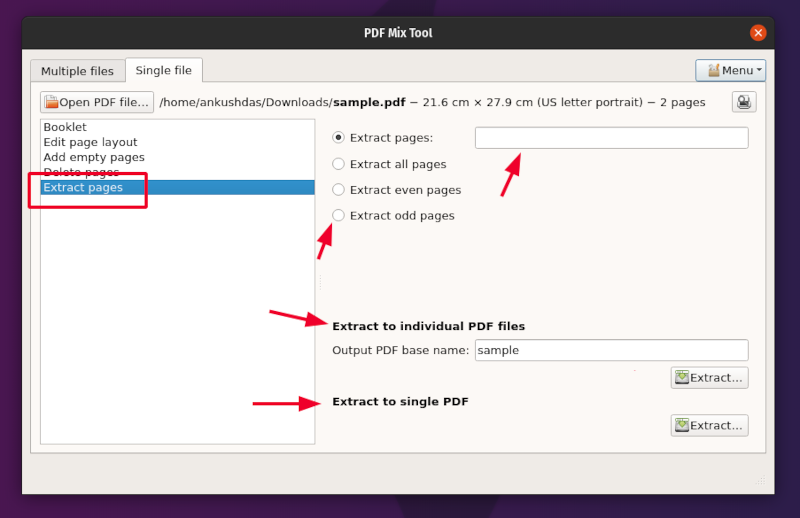
In addition to all the other options, you can also extract a certain page (or all) from a given PDF file. You can then generate a new PDF file for all the extracted pages or make separate PDF files for every page you extract. It should come in handy in a lot of use-cases.
### Other functionalities
With all the features mentioned above, you can generate an entirely new PDF of your choice, reverse the order, extract the pages, make separate PDF files, and so on.
It does not reduce size of the PDF file. You’ll have to use other tools for [compressing PDF files on Linux](https://itsfoss.com/compress-pdf-linux/).
So, it’s a mixed bag of things when you combine and use the options available.
## Installing PDF Mix Tool on Linux
PDF Mix Tool is available as Snap and [Flatpak packages](https://flathub.org/apps/details/eu.scarpetta.PDFMixTool). This means ** you may find it in your distribution’s software manager** if it supports either of these packages.
Alternatively, if you have [Snap package support enabled](https://itsfoss.com/install-snap-linux/), you can use the following command to install it:
`sudo snap install pdfmixtool`
If you want to [use Flatpak](https://itsfoss.com/flatpak-guide/), you can use:
`flatpak install flathub eu.scarpetta.PDFMixTool`
In case you’re using Arch Linux, you can get it from the [community repository](https://www.archlinux.org/packages/community/x86_64/pdfmixtool/).
`sudo pacman -S pdfmixtool`
You can also choose to take a look at their [GitLab page](https://gitlab.com/scarpetta/pdfmixtool) for its source code.
**Wrapping Up**
It may not be the most feature-rich PDF editing tool — but considering it as a lightweight open-source tool, it is a very useful application to have installed. We have also covered a similar tool [PDF Arranger](https://itsfoss.com/pdfarranger-app/) in the past. You may want to take a look at that as well.
What do you think about it? Have you tried it yet? Let me know your thoughts in the comments below. |
12,524 | 不要忽视 .gitignore | https://opensource.com/article/20/8/dont-ignore-gitignore | 2020-08-16T21:17:19 | [
"git"
] | /article-12524-1.html |
>
> 使用 .gitignore 文件是提高代码和 Git 仓库质量的最佳实践之一。
>
>
>

我注意到很多开发者没有使用 `.gitignore` 文件,尽管使用 `.gitignore` 文件来指定你不希望 Git 在版本控制中跟踪的文件是[最佳实践](https://opensource.com/article/20/7/git-repos-best-practices)之一。`.gitignore` 可以提高代码质量,所以你不应该忽略版本库中的 [.gitignore](https://git-scm.com/docs/gitignore)。
### 什么是 .gitignore?
Git 仓库中的文件可以是:
1. **未跟踪的**:未被暂存或提交的变更。
2. **跟踪的**:已暂存或提交的变更。
3. **忽略的**:你让 Git 忽略的文件。
有些文件你希望 Git 忽略,不要在你的版本库中跟踪它,这些文件包括许多自动生成的或特定于平台的文件,以及其他本地配置文件,如:
1. 含有敏感信息的文件
2. 编译出的代码,如 `.dll` 或 `.class`。
3. 系统文件,如 `.DS_Store` 或 `Thumbs.db`。
4. 含有临时信息的文件,如日志、缓存等。
5. 生成的文件,如 `dist` 文件夹。
如果你不想让 Git 跟踪版本库中的某些文件,不过这不能通过 [Git 命令](https://acompiler.com/git-commands/)做到。(虽然你可以用 `git rm` 命令停止跟踪一个文件,比如 `git rm --cached`。)相反,你需要使用 `.gitignore` 文件,这是一个告诉 Git 不要跟踪哪些文件的文本文件。
创建 `.gitignore` 文件很简单,只需创建一个文本文件并命名为 `.gitignore`。记得在文件名的开头有一个点(`.`)。就这样就完成了。
### 编写 .gitignore 文件的规则
根据[文档](https://git-scm.com/docs/gitignore),“`.gitignore` 文件中的每一行都指定了一个模式。”
在此上下文中,“模式”可以指一个特定的文件名,或者指文件名的某些部分结合上通配符。换句话说,`example.txt` 是匹配名为 `example.txt` 的文件的有效模式,而 `ex*txt` 是匹配名为 `example.txt` 以及 `export.txt` 的文件的有效模式。
以下是一些帮助你正确设置 `.gitignore` 文件的基本规则:
1. 任何以哈希(`#`)开头的行都是注释。
2. `\` 字符可以转义特殊字符。
3. `/` 字符表示该规则只适用于位于同一文件夹中的文件和文件夹。
4. 星号(`*`)表示任意数量的字符(零个或更多)。
5. 两个星号(`**`)表示任意数量的子目录。
6. 一个问号(`?`)代替零个或一个字符。
7. 一个感叹号(`!`)会反转特定的规则(即包括了任何被前一个模式排除的文件)。
8. 空行会被忽略,所以你可以用它们来增加空间,使你的文件更容易阅读。
9. 在末尾添加 `/` 会忽略整个目录路径。
### 本地与全局 .gitignore 文件的比较
有两种类型的 `.gitignore` 文件:
* **本地**:放在 Git 仓库的根目录下,只在该仓库中工作,并且必须提交到该仓库中。
* **全局**:放在你的主目录根目录下,影响你在你的机器上使用的每个仓库,不需要提交。
很多开发者在项目仓库中使用本地的 `.gitignore` 文件,但很少有人使用全局的 `.gitignore` 文件。使用全局文件最显著的优势是,你不需要提交就可以使用它,而且做一个改动会影响你所有的版本库。
### Git 忽略的优势
除了确保特定的文件不被 Git 追踪之外,使用 `.gitignore` 文件还有其他好处。
1. 通过忽略不需要的文件,它可以帮助你保持代码库的干净。
2. 它可以控制代码库的大小,这在你正在做一个大项目的时候特别有用。
3. 你的每一次提交、推送和拉取请求都将是干净的。
### 结束语
Git 很强大,但归根结底,它只是一个计算机程序而已。使用最佳实践并保持你的代码仓库稳定是一个团队的努力,其中要做到一件事就是使用 `.gitignore` 文件。
---
via: <https://opensource.com/article/20/8/dont-ignore-gitignore>
作者:[Rajeev Bera](https://opensource.com/users/acompiler) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,526 | 如何在 Ubuntu 和其它的 Linux 发现版上安装 Itch | https://itsfoss.com/install-itch-linux/ | 2020-08-18T10:02:37 | [
"游戏"
] | https://linux.cn/article-12526-1.html | 
[Itch](https://itch.io/?ac=ywUpyBMGXvG) 是独立数字创造者的平台,主要专注于独立游戏。它最初是一个托管、销售和下载独立视频游戏的网站。但是现在,Itch 也提供书籍、漫画、工具、棋类游戏、原声带等来自独立创造者的数字内容。
作为一名用户,你或者能够免费下载这些数字内容,或者按照创造者设定的价格下载。你所有下载和购买的东西都同步到你的账户,以便你可以在任何你想的时间内下载它们。
它有点像 Steam,但是更专注于独立开发者和创作者。
你可以从它的网站浏览 Itch ,但是 Itch 也提供了一个 [开源的桌面客户端](https://github.com/itchio/itch),有一些额外的优势。使用桌面客户端:
* 你可以浏览游戏和其它的内容,并下载它们到你的系统上。
* 桌面客户端会自动更新所有新功能。
* 你下载的游戏也自动更新。
* 如果你在 Itch 玩基于浏览器的游戏, 那么你可以使用 Itch 桌面客户端离线玩。
在这篇教程中,我将向你展示在 Ubuntu 或其它任何 Linux 发行版上安装 Itch 的步骤。
### 在 Linux 桌面上安装 Itch
Itch 提供一个名称为 itch-setup 的安装器。你可以从它的下载网页下载这个文件。
* [下载 Linux 版 Itch](https://itch.io/app)
这个 itch-setup 文件可以工作在任何的 Linux 发行版上,只要它已经安装有 GTK 3 (libgtk-3-0)。大多数当前的 Linux 发行版应该已经有它了。
在你下载安装文件后,在其上面右击并给予它可执行权限。

现在在这个安装文件上通过双击来运行。它将下载 Itch 的最新版本。

实际花费的时间取决于你的网速。几分钟后,你应该会看到这个屏幕,要求你登录你的 Itch 账号。

在你登录后,你可以浏览游戏和其它的内容,并下载/购买它们。
整个安装过程类似于 [在 Ubuntu 上安装 Steam](https://itsfoss.com/install-steam-ubuntu-linux/)。
你可以在 `~/.itch` 文件夹中找到 Itch 的文件。你从 Itch 下载的内容通常位于 `~/.config/itch` 。补充一句,`~` 意味着你的家目录。
### 从你的系统中移除 Itch 桌面应用程序
出于某些原因,如果你不想再使用 Itch ,你可以从你的系统中移除它。为此,麻烦的是,你需要使用终端。
打开一个终端,并使用下面的命令:
```
~/.itch/itch-setup --uninstall
```
它不会移除你的内容库。如果你想移除下载的游戏和材料,你可以手动删除 `~/.config/itch` 文件夹。
```
rm -r ~/.config/itch
```
### 你用 Itch 吗?
Itch 是一个独立创作者的道德平台,也是这种模式的支持者。Itch 使用 “你想付多少钱就付多少钱”,买家可以支付大于或相等内容创作者设置的任何金额。
Itch 也有开放收益分享模式。创作者可以与 Itch 分享部分他们产生的收入,也可以不分享。
就我个人而言,我更喜欢像 Itch 和 Humble Bundle 这些有道德的商店。像 Humble Bundle 一样,Itch 也时不时地进行销售和捆绑销售。这有助于你节省资金,并支持独立开发者和创作者。
你使用 Itch ,还是 Humble Bundle ?你还使用哪种类似的平台?
---
via: <https://itsfoss.com/install-itch-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Itch](https://itch.io/?ac=ywUpyBMGXvG) is a platform for independent digital creators with main focus on indie games. It was actually started as website to host, sell and download indie video games but these days, Itch also provides books, comics, tools, board games, soundtracks and more digital content from indie creators.
As a user, you can download these digital content either for free or for a price set by the creator. All your downloads and purchases are synced to your account so that you can download them whenever you want.
Consider it like Steam but more focused on indie developers and creators.
You can browse Itch from its website but Itch also provides and [open source desktop client](https://github.com/itchio/itch) that gives you some additional advantages. With the desktop client:
- You can browse games and other content and download them on your system.
- The desktop client is automatically updated with all the new features.
- Your downloaded games are also automatically updated.
- If you play browser-based game on Itch, you can play it offline using the Itch desktop client.
In this tutorial, I’ll show you the steps to install Itch on Ubuntu or any other Linux distribution.
## Installing Itch on Linux desktop
Itch provides an installer file named itch-setup. You can download this file from its download page.
This itch-setup file should work on any Linux distribution as long as it has GTK 3 (libgtk-3-0) installed. Most recent Linux distributions should have it.
Once you download the setup file, right click on it and give it execute permission.
Now run this setup file by double-clicking on it. It will start downloading the latest version of Itch.

It will take some time depending upon your internet speed. In a few minutes, you should see the this screen asking you to log in to your Itch account.
Once you are logged in, you can browse games and other contents and download/purchase them.
The entire installation process is similar to [Steam installation on Ubuntu](https://itsfoss.com/install-steam-ubuntu-linux/).
You can find the Itch files in ~/.itch folder. The content you download from Itch usually resides in ~/.config/itch. If you didn’t know, ~ means your home directory.
## Remove Itch desktop application from your system
For some reasons, if you do not want to use Itch anymore, you can remove it from your system. For that, unfortunately, you’ll have to use the terminal.
Open a terminal and use the following command:
`~/.itch/itch-setup --uninstall`
It won’t remove your content library. If you want to remove the downloaded games and stuff, you can delete the ~/.config/itch folder manually.
`rm -r ~/.config/itch`
**Do you use Itch?**
Itch is an ethical platform for indie creators and supporters of such models. Itch uses “pay what you want to pay” where the buyer can pay any amount equal or greater than the price set by the content creator.
Itch also has open revenue sharing model. The creators can share some or no part of their generated revenue with Itch.
Personally, I prefer such ethical businesses like Itch and Humble Bundle. Like Humble Bundle, Itch also runs sales and bundles from time to time. This helps you save money and support indie developers and creators.
Do you use Itch or Humble Bundle? Which other similar platform do you use?
*It’s FOSS is an affiliate partner with Itch. Please read our affiliate policy for more information.* |
12,527 | Manjaro 和 Arch Linux 有何不同,哪个更好? | https://itsfoss.com/manjaro-vs-arch-linux/ | 2020-08-18T11:08:00 | [
"Manjaro",
"Arch"
] | https://linux.cn/article-12527-1.html |
>
> Manjaro 还是 Arch Linux?如果说 Manjaro 是基于 Arch 的,那么它和 Arch 又有什么不同呢?请在这篇比较文章中阅读 Arch 和 Manjaro 的不同之处吧。
>
>
>
大多数[适合初学者的 Linux 发行版](https://itsfoss.com/best-linux-beginners/)都是基于 Ubuntu 的。随着 Linux 用户经验的增加,一些人开始尝试使用更高级的发行版,主要是在“Arch 领域”。
这个所谓的 “Arch 领域”以两个发行版为主。[Arch Linux](https://www.archlinux.org/) 本身和 [Manjaro](https://manjaro.org/)。还有其他[基于 Arch 的 Linux 发行版](https://itsfoss.com/arch-based-linux-distros/),但都没有这两个发行版受欢迎。
如果你在 Arch 和 Manjaro 之间感到困惑,那么这个比较应该能帮助你。
### Manjaro 和 Arch Linux:它们有什么不同或相似之处?

我试图在各个方面比较这两种发行版。请记住,我并没有只关注差异,我还指出了它们的相似之处。
#### 两者都是滚动发布的版本,但不是同一种类型
在 Arch 和 Manjaro 中,没有像 Ubuntu 或 Fedora 那样每隔几个月或几年就会有一次“发布”。只要[保持你的 Arch 或 Manjaro 系统的更新](https://itsfoss.com/update-arch-linux/),你将永远拥有最新版本的操作系统和软件包。你不需要像以往一样担心升级你的安装版本。
如果你打算在某个时候进行全新安装,请记住,Manjaro 和 Arch 都会定期更新它的安装 ISO。这被称为 ISO 刷新,它确保新安装的系统不必安装过去几个月中所有可用的新系统更新。
但 Arch 和 Manjaro 的滚动发布模式是有区别的。
除了社区维护的 <ruby> Arch 用户软件库 <rt> Arch User Repository </rt></ruby>(AUR)之外,Manjaro 也维护着自己的独立软件库,这些软件库也包含了非 Arch 提供的软件包。那些原本由 Arch 官方软件库提供的流行软件包将首先进行彻底的测试(必要时打上补丁),然后 Manjaro 再次发布,这通常比 Arch 晚两周左右,发布到 Manjaro 自己的稳定软件库供公众使用。

适应这个测试过程的一个后果是,Manjaro 永远不会像 Arch 一样那么激进尝鲜。但这样一来,就使得 Manjaro 比 Arch 稍微稳定一些,也不容易破坏你的系统。
#### 包管理 - Pacman 和 Pamac
Arch 和 Manjaro 都提供了基于命令行的软件包管理工具 Pacman,它是用 C 语言编写的,使用 `tar` 来打包应用程序。换句话说,你可以[使用相同的 pacman 命令](https://itsfoss.com/pacman-command/)来管理两个发行版的软件包。
除了 Pacman,Manjaro 还开发了一个名为 Pamac 的 GUI 应用程序,用于在 Manjaro 上轻松安装软件。这使得使用 Manjaro 比使用 Arch 更容易。

请注意,你也可以在 Arch Linux 中从 AUR 安装 Pamac,但该工具是 Manjaro 的组成部分。
#### Manjaro 硬件检测工具(MHWD)
Pamac 并不是 Manjaro 团队开发的唯一帮助用户的 GUI 工具。Manjaro 还有一个专门的工具,用于检测硬件并为其推荐驱动程序。

这个硬件检测工具非常有用,可以说是 [Manjaro 受到社区喜爱的主要原因](https://itsfoss.com/why-use-manjaro-linux/)之一。它使得检测、安装、使用或从一个驱动切换到另一个驱动都非常简单,让硬件兼容性成为了过去。
#### 驱动程序支持
Manjaro 为 GPU 驱动提供了极大的支持。我们都知道多年来 Linux 在安装驱动程序(特别是 Nvidia)方面存在问题。
当[安装 Manjaro](https://itsfoss.com/install-manjaro-linux/) 时,它给出了从开源(自由)或非开源(非自由)图形驱动安装开始的选项。当你选择“非自由”时,它会自动检测你的显卡,并为其安装最合适的驱动程序,因此 GPU 可以开箱即用。
由于有了上一节中看到的硬件检测工具,甚至在安装 Manjaro 时,安装显卡驱动会更加容易。
如果你有一个带有 Nvidia Optimus 卡(混合 GPU)的系统,它与 Manjaro 配合良好。你会有很多方式来让它工作。
在 Arch Linux 中,你必须为你的机器安装(如果你能找到)合适的驱动程序。
#### 访问 Arch 用户软件库(AUR)
[Arch 用户软件库](/article-12107-1.html)(AUR)是一个面向基于 Arch 的 Linux 发行版用户的社区驱动的软件库。AUR 的创建是为了组织和分享来自社区的新软件包,并帮助加快流行软件包被纳入[社区软件库](https://wiki.archlinux.org/index.php/Community_repository)。
大量进入官方软件库的新软件包都是从 AUR 开始的。在 AUR 中,用户能够贡献自己的软件包构建(`PKGBUILD` 和相关文件)。
你可以在 Arch 和 Manjaro 中使用 AUR。
#### 桌面环境
好吧!你可以在任何 Linux 发行版上使用几乎所有的桌面环境。Arch 和 Manjaro 也不例外。
然而,一个专门的桌面风格或版本可以让用户更容易地在桌面环境里获得顺畅的体验。
默认的 Arch ISO 并不包含任何桌面环境。例如,你想[在 Arch Linux 上安装 KDE](/article-12258-1.html),你必须在[安装 Arch Linux](https://itsfoss.com/install-arch-linux/) 时或在之后下载安装它。
而 Manjaro 则为 Xfce、KDE 和 GNOME 等桌面环境提供了不同的 ISO。Manjaro 社区还维护着 MATE、Cinnamon、LXDE、LXQt、OpenBox 等桌面环境的 ISO。
#### 安装程序

Manjaro 是基于 Arch Linux 的,它是兼容 Arch 的,但**它不是 Arch**。它甚至不是只有一个图形安装程序的预配置版本的 Arch。Arch 并不具备通常的舒适的开箱即用,这也是为什么大多数人喜欢更简单的东西。Manjaro 为你提供了简单的入口,但支持你成为经验丰富的用户或资深用户。
#### 文档和支持
Arch 和 Manjaro 都有自己的维基页面和支持论坛来帮助各自的用户。
虽然 Manjaro 有一个不错的[维基](https://wiki.manjaro.org/index.php?title=Main_Page)文档,但 [Arch 维基](https://wiki.archlinux.org/)则不可同日而语。你可以在 Arch 维基中找到关于 Arch Linux 各方面的详细信息。
#### 目标受众
关键的区别在于 [Arch 针对的是抱着自己动手的态度的用户](/article-12445-1.html),他们愿意阅读文档,自己解决问题。
而 Manjaro 则是针对那些没有那么多经验或者不想花时间组装操作系统的 Linux 用户。
### 结论
有些人经常说 Manjaro 是给那些不会安装 Arch 的人用的。但我认为这是不对的。不是每个人都想从头配置 Arch,或者没有太多时间。
Manjaro 绝对是一只野兽,但与 Arch 截然不同。**快速、强大,并总是保持更新**,Manjaro 提供了 Arch 操作系统的所有优点,但特别强调**稳定性、用户友好性和可访问性**,既适合新手,也适合有经验的用户。
Manjaro 并不像 Arch Linux 那样极简主义。在 Arch 中,你从一个空白的画布开始,手动调整每个设置。当默认的 Arch 安装完成后,你在命令行就有了一个正在运行的 Linux 实例。想要一个[图形化桌面环境](https://itsfoss.com/best-linux-desktop-environments/)?那就自己来吧 —— 有很多选择。选择一个,安装,然后配置它。你可以从中学到很多东西,特别是如果你是 Linux 新手的话。你会对系统是如何组合在一起的,以及为什么要以这样的方式安装东西有很好的理解。
我希望你现在对 Arch 和 Manjaro 有了更好的理解。现在,你明白了它们是相似而不同的了吧。
我已经发表了我的看法。不要犹豫,请在评论区分享你的观点。在 Arch 和 Manjaro 之间,你更喜欢哪一个,为什么。
Abhishek Prakash 也对此文补充了内容。
---
via: <https://itsfoss.com/manjaro-vs-arch-linux/>
作者:[Dimitrios Savvopoulos](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

*Manjaro or Arch Linux? If Manjaro is based on Arch, how come is it different from Arch? Read how Arch and Manjaro are different in this comparison article.*
Most of the [beginner-friendly Linux distributions](https://itsfoss.com/best-linux-beginners/) are based on Ubuntu. As Linux users gain more experience, some try their hands on the more ‘advanced distributions’, mostly in the ‘Arch domain’.
This Arch domain is dominated by two distributions: [Arch Linux](https://www.archlinux.org/) itself and [Manjaro](https://manjaro.org/). There are other [Arch-based Linux distributions](https://itsfoss.com/arch-based-linux-distros/) but none are as popular as these two.
If you are confused between Arch and Manjaro, this comparison should help you out.
## Manjaro and Arch Linux: How different or similar are they?

I have tried to compare these two distributions on various points. Please keep in mind that I have not exclusively focused on the differences. I have also pointed out where they are similar.
### Both are rolling release distributions but not of the same kind
There are no “releases” every few months or years in Arch and Manjaro like Ubuntu or Fedora. Just [keep your Arch or Manjaro system updated](https://itsfoss.com/update-arch-linux/) and you’ll always have the latest version of the operating system and the software packages. You don’t need to worry about upgrading your installed version like ever.
If you are planning to do a fresh install at some point, keep in mind that both Manjaro and Arch update the installation ISO regularly. It is called ISO refresh and it ensures that newly installed systems don’t have to install all the new system updates made available in last few months.
But there is a difference between the rolling release model of Arch and Manjaro.
Manjaro maintains its own independent repositories except for the community-maintained Arch User Repository (AUR). These repositories also contain software packages not provided by Arch. Popular software packages initially provided by the official Arch repositories will first be thoroughly tested (and if necessary, patched), prior to being released, usually about two weeks behind Arch, to Manjaro’s own Stable Repositories for public use.
A consequence of accommodating this testing process is that Manjaro will never be quite as bleeding-edge as Arch. But then, it makes Manjaro slightly more stable than Arch and less susceptible to breaking your system.
### Package Management – Pacman and Pamac
Both Arch and Manjaro ship with command-line based package management tool called Pacman which was coded in C and uses tar to package applications. In other words, you can [use the same pacman commands](https://itsfoss.com/pacman-command/) for managing packages in both distributions.
In addition to the Pacman, Manjaro has also developed a GUI application called Pamac for easily installing software on Manjaro. This makes using Manjaro easier than Arch.
Do note that you may also install Pamac from AUR in Arch Linux but the tool is integral part of Manjaro.
### Manjaro Hardware Detection Tool (MHWD)
Pamac is not the only GUI tool developed by Manjaro team to help its users. Manjaro also has a dedicated tool for detecting hardware and suggest drivers for them.
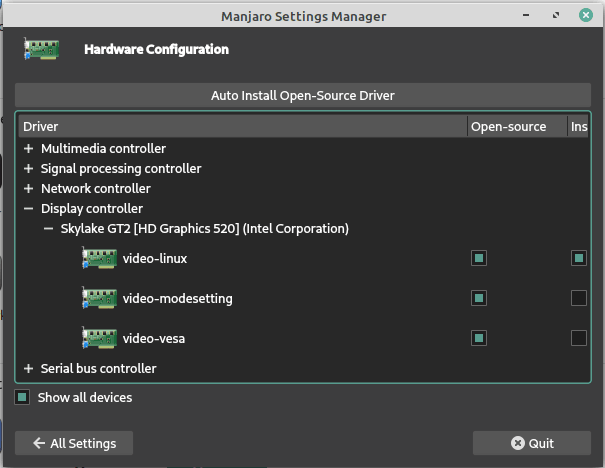
This hardware detection tool is so useful that it can be one of the [main reasons why Manjaro is loved by the community](https://itsfoss.com/why-use-manjaro-linux/). It is insanely easy to detect/install/use or switch from one driver to another and makes the hardware compatibility an issue from the past.
### Drivers support
Manjaro offers great support for GPU drivers. As we all know for many years Linux has issues installing drivers (Specially Nvidia).
While [installing Manjaro](https://itsfoss.com/install-manjaro-linux/) it gives options to start with open source (free) or non-open source (non-free) graphics driver installation. When you choose “non-free” it automatically detects your graphics card and install the most appropriate driver for it and hence GPU works out of the box.
Installing graphics driver is easier even after installing Manjaro thanks to the hardware detection tool you saw in the previous section.
And if you have a system with Nvidia Optimus card (Hybrid GPU) it works fine with Manjaro. You will get plenty of options of get it working.
In Arch Linux, you have to install (if you could find) the appropriate drivers for your machine.
### Access to the Arch User Repository (AUR)
[Arch User Repository](https://itsfoss.com/aur-arch-linux/) (AUR) is a community-driven repository for Arch-based Linux distributions users. The AUR was created to organize and share new packages from the community and to help accelerate popular packages’ inclusion into the [community repository](https://wiki.archlinux.org/index.php/Community_repository).
A good number of new packages that enter the official repositories start in the AUR. In the AUR, users are able to contribute their own package builds (PKGBUILD and related files).
You can use AUR in both Arch and Manjaro.
### Desktop environments
Alright! You can use virtually any desktop environments on any Linux distribution. Arch and Manjaro are no exceptions.
However, a dedicated desktop flavor or version makes it easier for users to have a seamless experience of the said desktop environments.
The default Arch ISO doesn’t include any desktop environment. For example, you want to [install KDE on Arch Linux](https://itsfoss.com/install-kde-arch-linux/), you will have to either download and install it while [installing Arch Linux](https://itsfoss.com/install-arch-linux/) or after that.
Manjaro, on the other hand, provides different ISO for desktop environments like Xfce, KDE and GNOME. Manjaro community also maintains ISO for MATE, Cinnamon, LXDE, LXQt, OpenBox and more.
### Installation procedure
Manjaro is based on Arch Linux and it is Arch compatible, but **it is not Arch**. It’s not even a pre-configured version of Arch with just a graphical installer. Arch doesn’t come with the usual comfort out of the box, which is why most people prefer something easier. Manjaro offers you the easy entry, but supports you on your way to becoming an experienced user or power user.
### Documentation and support
Both Arch and Manjaro have their own wiki pages and support forums to help their respective users.
While Manjaro has a decent [wiki](https://wiki.manjaro.org/index.php?title=Main_Page) for documentation, the [Arch wiki](https://wiki.archlinux.org/) is in a different league altogether. You can find detailed information on every aspect of Arch Linux in the Arch wiki.
### Targeted audience
The key difference is that [Arch is aimed to users with a do-it-yourself attitude](https://itsfoss.com/why-arch-linux/) who are willing to read the documentation, and solve their own problems.
On the other hand Manjaro is targeted at Linux users who are not that experienced or who don’t want to spend time assembling the operating system.
## Conclusion
Some people often say that Manjaro is for those who can’t install Arch. But I think that’s not true. Not everyone wants to configure Arch from scratch or doesn’t have much time.
Manjaro is definitely a beast, but a very different kind of beast than Arch. **Fast, powerful, and always up to date**, Manjaro provides all the benefits of an Arch operating system, but with an especial emphasis on **stability, user-friendliness and accessibility** for newcomers and experienced users.
Manjaro doesn’t take its minimalism as far as Arch Linux does. With Arch, you start with a blank canvas and adjust each setting manually. When the default Arch installation completes, you have a running Linux instance at the command line. Want a [graphical desktop environment](https://itsfoss.com/best-linux-desktop-environments/)? Go right ahead—there’s plenty to choose from. Pick one, install, and configure it. You learn so much doing that especially if you are new to Linux. You get a superb understanding of how the system goes together and why things are installed they way are.
I hope you have a better understanding of Arch and Manjaro now. You understand how they are similar and yet different.
*I have voiced my opinion. Don’t hesitate to share yours in the comment section. Between Arch and Manjaro, which one do you prefer and why.* |
12,529 | 《代码英雄》第一季(4):DevOps,拆掉那堵墙 | https://www.redhat.com/en/command-line-heroes/season-1/devops-tear-down-that-wall | 2020-08-18T18:23:13 | [
"DevOps",
"代码英雄"
] | https://linux.cn/article-12529-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(4):DevOps,拆掉那堵墙](https://www.redhat.com/en/command-line-heroes/season-1/devops-tear-down-that-wall)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/20f736e5-7a08-4701-ae2d-e523f6754e17/beffda00.mp3)脚本。
当应用开发的争斗暂告一段落,横亘在开发者与运维之间的那堵墙开始崩塌。在墙彻底倒塌的时候,墙两边的人都应该学会如何合作,彼此变得亲密无间。
不过到底什么是 DevOps?开发者一方的嘉宾,包括来自微软的 Scott Hanselman 和 Cindy Sridharan(即 @copyconstruct),他们从开发者的角度认为 DevOps 是一种惯实践。而来自运维一方的成员则他们一直在努力捍卫的东西。双方依然存在差异,不过因为 DevOps 的诞生,大家的合作效率会比之前更上一层楼。这集节目讲述了这种方法的诞生对于大家有多重要。
**Saron Yitbarek**: 请你想象这样一堵墙:这堵墙从你目之所及的最右侧延伸到最左侧。墙比你高,你无法看见墙背后。你知道墙的另一侧有很多很多人,但你不清楚他们是否和你一样,不清楚他们是敌是友。
**00:00:30 - Gordon Haff**: 开发者创造代码,然后把代码扔过墙丢给运维,之后发生的问题都是运维的责任了。
**Richard Henshall**: 他们随心所欲,并不真正关心服务质量。
**Sandra Henry-Stocker**: 墙这两面的人几乎做着相反的工作 —— 一方做出改变,另一方尽可能抵制那些改变。
**Richard Henshall**: 但对于他们到底想共同达成什么,却没有在同一幅蓝图中规划过。
**00:01:00 - Saron Yitbarek**: 我是 Saron Yitbarek,这里是《代码英雄》,由红帽公司推出的原创播客栏目。第四期,我们的标题是《DevOps,拆掉那堵墙》。
是的,数十年来,IT 界划分为各种角色。一边是开发者,他们要尽可能快地去创造更多变化。然后另一边是运维团队,他们要去阻止太多改变发生。与此同时,代码在没有充分共鸣和沟通的条件下,被盲目扔过两方之间的墙。怎样才能拆掉这堵墙呢?这需要一个重大的转变。
**00:01:30 - Saron Yitbarek**: 开源运动震撼了整个战场。[上一期](/article-12508-1.html),我们看到了新的敏捷方法论,它重视不间断的迭代改进,而这种对速度的要求将迫使我们改变彼此的工作方式。一群彼此孤立的人工作的速度是有极限的,而这个极限是一个问题,因为……
**00:02:00 - Richard Henshall**: 因为都是为了更快的将产品推向市场、提高敏捷性、更多的迭代,而不是长期而大量的工作。
**Saron Yitbarek**: Richard Henshall 是 Ansible 的一位产品经理。
**Richard Henshall**: 是的。还记得你以前下单购买服务器,四个月后到货。所有东西都整合在一起,所以整个堆栈是一个整体,要花几年时间来设计和建造那些东西。现在这种情况已经不存在了,对于很多组织来说,这种方法已经……已经寿终正寝,偶尔拿过来试试,然后放弃它。
**00:02:30 - Saron Yitbarek**: 如今,像亚马逊这样的公司每分钟都会部署几次新的代码。想象一下,用按部就班的瀑布式工作流,简直不可能完成这些工作。所以为了继续快速完成工作,那些关于稳定性、安全性、可靠性的顾虑都会被运维丢到一边不管。
**00:03:00 - Saron Yitbarek**: 同时,开发者也没有意识到他们的责任是创造真实环境可用的代码。开发者对稳定性和安全性毫无兴趣,但这些恰恰是我们需要解决的问题。所以,我们最终会有很多无谓的修改,在双方之间来来回回。
想象一下过度分工会如何拖慢公司效率,但开发法者很少被鼓励思考除代码之外的其他事务。
**Sandra Henry-Stocker**: 他们的目录规模只会越来越臃肿,但他们从不清理。除非已经无法工作才不得不清理。
**00:03:30 - Saron Yitbarek**: Sandra Henry-Stocker 是位退休的系统管理员,为 IDG 杂志撰稿。
**Sandra Henry-Stocker**: 我过去经常劝说别人,说,“嘿,你看,你用了这么多的磁盘空间。是不是有什么东西你可以整理一下,这样我们就有更多的存储空间来运行了 —— 因为服务器上的存储空间快用完了。”是的,我们经常经历这些事。
**Saron Yitbarek**: 归根结底,这是一个心态问题。这种开发者和运维之间的态度分裂,一方不必去理解另一方的担忧。好吧,在过去这还没太大问题,但随着开发速度成为一种重要的优势,这种分裂的文化急需改进。孤立在自己的工作圈子里,效率太低了。
Jonah Horowitz 在 Stripe 的可靠性工程团队工作。他描述了即使开发人员和运维人员想一起工作,他们也无法做到。因为从某种意义上说,他们被安排在对立的团队中。
**00:04:30 - Jonah Horowitz**: 运维团队经常以正常运行时间和可靠性来衡量,而提高正常运行时间的最大方法之一,就是减少系统的变化量。当然,发布新功能就是在改变系统,而做产品工作的软件工程师有动力去尽快发布尽可能多的功能。所以,当开发和运维的职责不同时,他们自然有了冲突。
**00:05:00 - Saron Yitbarek**: 开发者致力于新建功能,运营致力于维持运行,两者目标相互矛盾。但就像我说的,由于对速度的需求越来越大,对快速迭代发布的需求越来越大,开发和运维之间的脱节已经到了一个临界点,必须要有所改变。
**00:05:30 - Saron Yitbarek**: 在 2009 年左右,将开发和运维分开的那堵墙看起来像是监狱的墙。我们需要的是一种新的方法论,它能使开发和运维之间的隔阂顺畅过度,让双方以更快、更整体化的方式工作。
视频平台 Small Town Heroes 的首席技术官 Patrick Debois 为想要拆掉这堵墙的人发起了一场会议。他把这个的脑洞叫做 DevOps Days(开发运维日)。为了便利,他将其缩短为 DevOps,于是这场改革就有了名字。
**00:06:00 - Saron Yitbarek**: 不过名字并不代表改革的一步,我们知道为什么我们需要 DevOps,但究竟该如何做?我们应该如何将开发和运维结合起来而不引发战争?幸运的是,我有 Scott Hanselman 来指导我。Scott 是微软 .NET 和 [ASP.NET](http://ASP.NET) 的首席项目经理。
所以,Scott,我认识你确实有几年了,但感觉还是相见恨晚啊。
**00:06:30 - Scott Hanselman**: 我也是,相见恨晚哈。
**Saron Yitbarek**: 我想和你聊聊你如何成为一个开发者,和 DevOps 这些年的变化。觉得如何?
**Scott Hanselman**: 嗯,听上去挺有意思。
**00:07:00 - Saron Yitbarek**: 好的。我认为究竟什么是 DevOps 是一个好的开场问题。你会怎么定义它呢?
**Scott Hanselman**: 在 2008 年,维基百科有个关于 DevOps 的定义确实很棒。它说,这是一套“惯例”,目的是在保证质量的前提下,缩短提交变更和变更投入生产之间的时间。所以,如果你想想,假如今天是周二,我检查了一些代码,而这些代码将在 6 月的版本中上线。这就很糟糕了,因为这不是持续集成,而是一年几次的集成。
**00:07:30 - Scott Hanselman**: 如果你有一个健康的 DevOps 体系,如果你已经有“<ruby> 设置 - 上线 <rt> set - up </rt></ruby>”的惯例,那么你就可以不断地将代码集成到生产中去。那么,你能做什么?你可以定义、创造怎样是最佳“惯例”,这将决定你能否成功。所以,我在周二检查的一些代码,周四就上线了。那么现在,为了保证高质量,最重要的事情就会是 —— 谨慎上线。
**00:08:00 - Saron Yitbarek**: 这个定义真的很有趣呢,是个“惯例”。但我觉得当我听人们谈论 DevOps 时,它具体一点。他们谈论它就像它是一个角色、一个工作、一个职位或一个头衔。你觉得这与它是一套“惯例”的观点是否有冲突?
**Scott Hanselman**: 我认为,当一套新的方法或一个新的流行语出现时,人们喜欢把它加在名片上。我不是不尊重那些正在收听这个播客,并且感到被我冒犯、正骂骂咧咧把名片掏出来看的人们。虽然,他们现在可能正要怒盖笔电、退出这个播客。
**00:08:30 - Scott Hanselman**: 有一个帖子写得非常好,作者是 Brian Guthrie,他是一个脑力劳动者,在 SoundCloud 工作。他是一个超级聪明的人,几天前他在 Twitter 上的帖子中说到 DevOps。他说 DevOps 就是一套惯例,不是一个工作头衔、不是一个软件工具、不是一个你安装的东西、也不是一个团队的名字。
**00:09:00 - Scott Hanselman**: 他的原话是:“DevOps 不是神奇的‘企业万能药’”。如果你没有好的惯例,如果你没有良好的习惯,你就没有 DevOps。所以,这更多的是一种心态,而不是摆出一个工作头衔,然后“我们要雇佣一个 DevOps 工程师,然后我们要把这些神奇的 DevOps 工程师撒到组织中。虽然整个组织没有意志力,也没有信奉 DevOps 的想法。” 所以,如果你认为 DevOps 是一个工具或者是用来安装的东西,那么你就完全理解错了。
**00:09:30 - Saron Yitbarek**: 好吧,让我们回到过去,在 DevOps 这个名词出现之前,在我们往名片上写 DevOps 或者把它作为一套“惯例”来讨论之前。在 10 年前,你会如何描述开发者和那些运维人员之间的关系?
**Scott Hanselman**: 那是相当的水火不容。举个例子,运维控制着生产,但开发人员从来没有接近过生产。我们站在一堵不透明的墙的两侧。我们在开发部的时候,尽可能地去做一些看起来像生产环境能用的东西,但实际上从来没有……从来没有像样的产品。
**00:10:00 - Scott Hanselman**: 我们有相当多问题。我们的开发环境从各个方面来说都不像生产环境,所以你不可避免地会遇到那些 “嘿,它在生产环境中的工作方式和在开发环境中的不同” 的问题。然后,从开发到投入生产之间的间距是几周几周的长久间隔,所以你的大脑甚至不在正确的频道上。比如说,我在一月份的时候就在研究这个功能,现在四月份才刚刚上线,那么当 bug 不可避免地出现的时候,要等到六月份才能修复,我甚至不记得我们之前在干嘛。
所以运维团队的人,他们的工作是……他们的工作几乎就是有意识地让我们慢下来。好像他们的存在是为了让开发人员更慢,然后他们还觉得我们随时会让生产环境崩坏。
**00:11:00 - Saron Yitbarek**: 那么为什么会这样呢?是对开发者想要做什么和他们做了什么不了解?还是信任问题?为什么会有这么大的冲突?
**Scott Hanselman**: 我觉得你已经回答了,而且回答得很到位。你说的很对,确实是信任的问题。我觉得开发人员认为他们是特殊的,或者某些方面比 IT 人员更优越,而 IT 人员认为开发人员不尊重生产。
**00:11:30 - Scott Hanselman**: 我认为这种文化的产生,一部分来源于高层。他们认为我们是不同的组织,并且我们的目标也不同。我认为软件业正在走向成熟,因为我们都意识到,无论业务是什么,我们写软件都是为了推动业务发展。
所以现在有种 “我们都在往正确的方向推进” 的感觉,就像他们说的,“专注一件产品并做到极致”。但这是需要绝对的信任,可 DevOps 工程师不信任产品工程师来部署代码,对吧?
**00:12:00 - Scott Hanselman**: 但 DevOps 工程师传统上并不写代码,所以他们并不了解什么被修改了。所以他们对于在各个层面的人都缺乏信任。没有人理解部署过程,人们只信任自己,他们的心态……举个例子,就像“我只信任自己的工作。我不能相信 Saron 的工作,她甚至不知道她在干些什么。我会做完所有的事情。”
**00:12:30 - Scott Hanselman**: 所以如果没有人真正理解这个系统,那么<ruby> 全栈工程师 <rt> full stack engineer </rt></ruby>的概念就是一个神话。但是现在,我们开始将一整个组织称之为全栈。我们已经有了<ruby> 全产品所有权 <rt> full product ownership </rt></ruby>这样的名词,敏捷方法论也出现了,也就是说每个人都应该拥有产品。社区对于软件所有权和对于代码的想法都慢慢发生了变化,这种改变带来了一个充满信任的环境。
**00:13:00 - Saron Yitbarek**: 我是 Saron Yitbarek,你现在收听的是《代码英雄》,来自红帽公司的一档原创播客栏目。所以,要想让 DevOps 发挥出它的潜力,我们就需要双方都有更多的信任,这就意味着要有更多的沟通。回到 Richard Henshall 身上,他认为双方的共情是 DevOps 的基石 。
**00:13:30 - Richard Henshall**: 一些 DevOps 的从业者,一群真正优秀的从业者,都参与过这两种角色。我认为这才是真正的力量所在 —— 当人们真正做过了两种角色,而不是只看到其中一种。所以,你不该保持孤立,你实际上……你应该去和双方都一起工作一段时间。我想这才是让人恢复同理心的方法。
**Saron Yitbarek**: 现在,这不仅仅是为了温情的沟通。Richard Henshall 所描述的是行业重点的转向 —— Scott 刚刚提到过。
**00:14:00 - Saron Yitbarek**: 一个关于<ruby> 持续集成 <rt> continuous integration </rt></ruby>(CI)的观点。软件不仅要以小批量快速编写和发布,还要以小批量进行快速测试。这意味着,开发人员需要即时反馈他们正在编写的代码在现实世界中的表现。
随着上市时间从几个月缩短到几天,再到几个小时,我们四处寻找一套新的工具,可以将任何可以自动化的元素自动化。
**00:14:30 - Gordon Haff**: 你需要一个全新的生态系统和工具,来最有效地进行 DevOps。
**Saron Yitbarek**: Gordon Haff 是一位红帽公司高级工程师。
**Gordon Haff**: 我们看到有很多巨大的、DevOps 可以利用的新种集合工具和平台,它们都诞生于开源。
**Saron Yitbarek**: Gordon 是对的。新的集合工具是很庞大,关于开源这点他说的也对。在一个严格的专有系统中,自动化工具是不可能发展的。
**00:15:00 - Gordon Haff**: 其中有很多监控工具,Prometheus 是其中一个常见的工具。它开始引起很多人兴趣,用于编排服务的 STO 也出自这里。
**Saron Yitbarek**: GitHub 让你跟踪变化,PagerDuty 管理数字业务,NFS 可以跨网络挂载文件系统,Jenkins 让你自动测试你的构建。
**00:15:30 - Saron Yitbarek**: 这么多工具,这么多自动化流程。最终的结果是,开发人员可以将他们的变更直接推送到生产现场,自动创建构造,实行经过严格管理的编译与针对性的自动测试。Sandra Henry-Stocker 描述了这是怎样的变化。
**Sandra Henry-Stocker**: 所以,我可以把我正在工作编写的东西快速部署。我可以只在一个系统上,通过命令行控制许多系统,而不是必须在在很多不同的系统上工作,也不用学习就可以利用网络,将代码部署到其他机器上。
**00:16:00 - Sandra Henry-Stocker**: 现在,在计算机系统中进行改动更容易了。坐在一个地方,就能实行一切操作。
**Saron Yitbarek**: 自动化工具已经解决了速度问题。但我不希望我们只赞美工具,而忽略了实际的方法论,文化的转变。Scott Hanselman 和我谈到了这个微妙的界限。
**00:16:30 - Saron Yitbarek**: 你在这次谈话开始时说,DevOps 是一套惯例,是一种心态,是一种思维方式。听起来,我们创造的工具是我们应该思考和操作方式的具体代码实现。
**Scott Hanselman**: 我喜欢这句话,你真是个天才。没错,我们以前让产品开发在 Word 文档中写下这些代码是如何工作的。他们写的是规范,对吧?这些文档过期了吗?
**00:17:00 - Saron Yitbarek**: 没错。(答非所问)
**Scott Hanselman**: 哈?
**Saron Yitbarek**: 好吧,我只是很高兴 Scott 刚才说我是天才。但我也确实认为,这些工具几乎是我们文化转变的象征。它们鼓励我们拓宽我们的角色定义。我们开发者已经被迫,至少偶尔关注代码的运行。这样一来,开发和运维的主要职责就部分统一了。事实上,DevOps 的兴起告诉我们的是,在一个速度不断提升的世界里,没有人能够保持孤岛状态。
**00:17:30 - Saron Yitbarek**: Jonah Horowitz 曾在湾区多家公司工作,包括 Quantcast 和 Netflix。他说即使是世界上一些最大的公司,也从这个角度重新塑造了他们的文化。
**Jonah Horowitz**: 我们在文化上得到了整个公司的认同,就像,“这就是我们要部署软件的方式,我们将以小批量的方式进行部署,我们将使用这些程序帮助部署。” 如果 DevOps 只是被运营团队所驱动,我不认为它可以……我不认为它可以成功。
**00:18:00 - Jonah Horowitz**: 这必须成为公司的管理层和领导层所认同的东西才能发挥作用,而这件事很大程度上,意味着一种文化转变。
**Saron Yitbarek**: 当 MacKenzie 对 800 名 CIO 和 IT 高管进行调查时,80% 的人表示,他们正在规划让自己的一部分下属组织实施 DevOps,超过一半的人计划到 2020 年,在全公司范围内实施。高管们意识到,自动化工具可以提升交付速度。
**00:18:30 - Saron Yitbarek**: 这些人过去也是这样的人,他们习惯于让一个货板先到达数据中心,然后在新机器上线之前让它在那里放上整整一个月。不过在今天,如果你等待的时间超过 10 分钟,就说明你做错了什么。随着竞争对手的速度增加,没有人能够承受得起落后。
**00:19:00 - Saron Yitbarek**: 我可以想象,运维团队一定很紧张,因为他们把所有的工具都交给开发人员。运维团队习惯了做成年人,而现在叫他们把车钥匙交给一贯的孩子 —— 开发人员?呀,我想我们开发人员正在学习,如何在不破坏东西的前提下快速移动。但随着 DevOps 革命的尘埃落定,变化最大的可能是运维团队。
**00:19:30 - Saron Yitbarek**: DevOps 是否真的威胁到了运维的存在?开发是否在用它闪亮的新工具来吃掉运维?Cindy Sridharan 是一位开发者,她写了一篇长篇调查文章来讨论这些问题。在你的文章和博客中,你提到运维人员对事情这样的发展并不一定满意。到底发生了什么?你会说什么?
**Cindy Sridharan**: 这么说吧,DevOps 的理想是责任共享。开发者和运维将有,就像你知道的,更多的是五五分成,以真正确保软件的整体交付。
**00:20:00 - Cindy Sridharan**: 我认为很多运维工程师的不快乐源于这样一个事实,那就是这些改变都没有实际功效。他们仍然是总被鸡蛋挑骨头的人,他们仍然是总做苦力工作的那些人,他们还是那些主要肩负着实际运行应用的责任的人,而开发者不一定要做得足够好。
**Saron Yitbarek**: 这个问题在未来几年将至关重要。DevOps 的作用到底有多大?随着我们的自动化进程,运维的作用是会被削弱,还是会发生转变?
**00:20:30 - Saron Yitbarek**: 但是我们要记住,DevOps 不仅仅是工具和新技术的应用。这种方法论实际上是在塑造技术,反过来技术也在塑造方法论,这样就有了一个神奇的反馈循环。文化造就了工具,而工具又强化了文化。
**00:22:00 - Saron Yitbarek**: 最后,我们在节目开头描述的那堵墙,也就是把开发和运维划分开来的那堵墙,我甚至不知道五年后“把你的代码扔过墙”的比喻对一个开发者来说是否有意义,如果五年后大家都听不懂这个比喻,那真是一件大好事。不过目前为止的访谈很有价值,我听到了很多新的故事。
现在说话的是云架构师 Richard Henshall。
**Richard Henshall**: 我觉得 DevOps 开始让人们意识到对方关心的是什么,我看到了更多对彼此的理解。
**00:23:00 - Saron Yitbarek**: 现在是系统管理员 Jonah Horowitz。
**00:23:00 - Jonah Horowitz**: 我认为你需要很棒的技巧来写出真正好的软件,我在与我合作过最棒的开发者身上看到了一件事,那就是他们真的,他们贡献了关于的软件工程新技巧,或者说他们推动了软件开发这个行业的发展。
**Saron Yitbarek**: 最后一个是系统管理员 Sandra Henry-Stocker。
**Sandra Henry-Stocker**: 我认为,开发者会变得更加精明、更加谨慎。他们始终要提升自己的技能,我知道这需要很多辛苦的学习。
**00:23:30 - Saron Yitbarek**: DevOps 是个爱的结晶。原来,在那堵墙的另一边还有一些朋友,很高兴认识你们。所以,坦白一下,我以前总觉得 DevOps 很无聊,就是一堆硬核的自动化脚本和扩展问题。我的抵触情绪有一部分是出于它的实践难度。作为开发者,我每周都要面对一些新出来的工具,一些新的框架。DevOps 一直是那些可怕的、快速变化的一部分。但现在,尤其是听了这些故事之后,我明白了。
**00:24:00 - Saron Yitbarek**: DevOps 不仅仅是其工具。它是教导我们如何合作,更快地构建更好的产品的方法。
好消息是,随着为你我这样的开发者准备的新平台出现,我们的工作变得更好、更快、更能适应不同的环境,我的业务圈也可以不断扩大。你会看到人们将 DevOps 扩大到安全部分,所以我们能得到 Sec DevOps。或者他们开始包含商务,那我们就得到了 Business DevOps。我们现在要辩论的话题是:对于一个开发者来说,不仅要了解如何使用这些工具,还有了解所有 DevOps 的东西是如何工作的必要吗?以及我们需要所有开发者都去了解这个新世界吗?
**00:24:30 - Saron Yitbarek**: 这场辩论的结果将决定未来一期《代码英雄》的内容。
你可能已经注意到,在所有关于工具和自动化的谈话中,我漏掉了一些工具。好吧,我把这些留到下一期,当所有这些 DevOps 自动化达到光速时,我们将追踪容器的崛起。
**00:25:00 - Saron Yitbarek**: 是的,这些都会留到第五期。
《代码英雄》是红帽公司推出的原创播客栏目。想要了解更多关于本期节目和以往节目的信息,请访问 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 。在那里,你还可以注册我们的新闻资讯。想免费获得新剧集的自动推送,请务必订阅该节目。
**00:25:30 - Saron Yitbarek**: 只要在苹果播客、Spotify、Google Play、CastBox 中搜索《代码英雄》,或者通过其他方式收听,并点击订阅,这样你就能在第一时间知道最新剧集。我是 Saron Yitbarek。感谢您的收听,编程不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-1/devops-tear-down-that-wall>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[LikChung](https://github.com/LikChung) 校对:[acyanbird](https://github.com/acyanbird)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As the race to deliver applications ramps up, the wall between development and operations comes crashing down. When it does, those on both sides learn to work together like never before.
But what is DevOps, really? Developer guests, including Microsoft's [ Scott Hanselman](https://twitter.com/shanselman) and
[(better known as @copyconstruct) think about DevOps as a practice from their side of the wall, while members from various operations teams explain what they've been working to defend. Differences remain but with DevOps, teams are working better than ever. And this episode explores why that matters for the command line heroes of tomorrow.](https://twitter.com/copyconstruct)
__Cindy Sridharan__*Saron Yitbarek*
I want you to imagine a wall. The wall stretches as far as you can see to the right and all the way off to the left. It's taller than you, you can't see over it, and you know there are people on the other side, lots of people. But you just don't know if they're anything like you. Are they enemies or friends?
**00:30** - *Gordon Haff*
Developers created their code and threw it over the wall to operations, and then it was operations' problem.
*Richard Henshall*
Just doing whatever they feel like, not really caring about the quality of the service.
*Sandra Henry-Stocker*
These two sides have almost opposing jobs—one to make changes and one to resist those changes as much as possible.
*Richard Henshall*
But there's no talking on the same page about what it actually is they're trying to achieve.
**01:00** - *Saron Yitbarek*
I'm Saron Yitbarek and this is Command Line Heroes, an original podcast from Red Hat. Episode 4, DevOps, tear down that wall.
So yeah, for decades the IT world was defined by that division of roles. You had developers on one side. They were incentivized to create as much change as quickly as possible. And then you had the operations team on the other side. They were incentivized to prevent too much change from happening. In the meantime, code was getting tossed blindly over that wall with no real empathy o r communication between these two worlds. What would it take to tear down a wall like that? It would take a seismic shift.
**01:30** - *Saron Yitbarek*
The open source movement shook the battlefield. Last episode, we saw how new a gile methodologies put a premium on constant iterative improvements, and that need for speed would force us to change the way we work with each other. There's a limit to how fast a bunch of siloed people can work, and that limit became a problem because…
**02:00** - *Richard Henshall*
It's all about faster time to market, increased agility, doing more iterative, rather than longer - term big pieces of work.
*Saron Yitbarek*
Richard Henshall is an Ansible product manager.
*Richard Henshall*
You know, I remember the days when you put in an order for a server and it turned up four months later. Everything was converged together, so that the entire stack was one thing and it took years for those to be designed and built. That doesn't fly anymore and it's just disappeared, to the point that it is just… it’s up, try it, bring it back down again, for a lot of organizations.
**02:30** - *Saron Yitbarek*
These days, a company like Amazon will deploy new code several times every minute. Imagine trying to get that done using some step-by-step waterfall workflow. It's just impossible. Soon enough, those ops concerns about stability, security, reliability, will get pushed to the side in favor of moving fast.
**03:00** - *Saron Yitbarek*
Developers meanwhile didn't see it as their responsibility to produce code that worked in the real world. Developers had little interest in stability and security issues, but those are very real issues that we need to address. So, we end up with a lot of needless revisions down the pipe, back and forth across the divide.
Think how much that division can slow a company down. Think how inefficient that could get. But developers were rarely encouraged to look beyond their own command line.
*Sandra Henry-Stocker*
The size of their directories would just grow and grow, and they would never clean up, unless they wouldn't be able to get any work done without cleaning up.
**03:30** - *Saron Yitbarek*
Sandra Henry-Stocker is a retire d sysadmin who write s for the IDG magazines.
*Sandra Henry-Stocker*
I was kind of often having a debate, saying, "Hey look, you're using this much disk space . Isn't there something you can get rid of so that we have more space to work, because we're running out of space on this server." And yeah, we'd go through that a lot.
*Saron Yitbarek*
Ultimately, this is a mindset problem. This divisive attitude between developers and operations, where one didn't have to understand the concerns of the other. Well, in the past that had been just fine, but as speed became a premium that culture became more and more unstable. Being siloed in your work bubble was just way too inefficient.
Jonah Horowitz works for the Reliability Engineering team at Stripe. He describes how, even if developers and operations had wanted to work together, they couldn't have because in a sense they'd been placed on opposite teams.
**04:30** - *Jonah Horowitz*
The operations team is often measured by uptime and reliability, and one of the biggest ways to increase uptime is to decrease the amount of change in the system. But of course, releasing new features is changing the system, and the software engineers who are doing product work are incentivized to ship as many features as quickly as possible. So you set up this conflict between dev and ops when you've got these separate roles.
**05:00** - *Saron Yitbarek*
Developers committed to building features. Operations committed to keeping the site working. Two goals at odds with each other. But like I said, because of the increasing need for speed, for iterative rapid-fire releases, this disconnect between dev and ops was reaching a crisis point and something had to give.
**05:30** - *Saron Yitbarek*
Around 2009, the wall dividing dev and ops was looking a lot more like a prison wall than anything else. What we needed was a new methodology that would smooth the transition from development to operations, allowing both sides to work in a faster, more holistic way.
Patrick Debois, CTO of the video platform Small Town Heroes, launched a conference for people who wanted to tear down that wall. He called his brain child DevOps Days. He shortened it to DevOps for the hashtag, and thus the movement was given a name.
**06:00** - *Saron Yitbarek*
But a name is not a process, it was clear why DevOps was needed, but how would it work? How are we supposed to bring dev and ops together without starting a war? Thankfully, I have Scott Hanselman to walk me through this. Scott's the principal program manager for .NET and ASP.NET at Microsoft.
So Scott, I've known you for, I feel like I've known for forever, definitely a few years.
**06:30** - *Scott Hanselman*
Forever.
*Saron Yitbarek*
Forever. I want to talk to you about the relationship between being a developer and what DevOps has looked like over the years. How does that sound?
*Scott Hanselman*
Yeah, that sounds like a plan.
**07:00** - *Saron Yitbarek*
Okay. So I think a good place to start is just defining what DevOps is. How would you describe it?
*Scott Hanselman*
The Wikipedia entry from 2008 that defines DevOps is actually very good. So, it's a set of practices that is intended to reduce the time between committing a change and that change going into production while ensuring quality. So if you think about, hey, I checked in some code. It's Tuesday and that will be going out in the June release. That sucks. That would be not continuous integration. That would be a couple-of-times-a-year integration.
**07:30** - *Scott Hanselman*
If you have a good healthy DevOps system, if you've done the set - up practices, then you are going to be continuously integrating into production. So it's, what can you do? What best practices can you define, can you create, that will allow you to get it? So, I checked in some code on Tuesday and it's in production on Thursday. Now here's the important part—pause for effect—while ensuring high quality.
**08:00** - *Saron Yitbarek*
So what's really interesting about that definition is it's a set of practices, but I feel like when I hear people talk about DevOps , it's a little bit more crystallized, I guess. They talk about it like it's a role, a job, a position, a title. Does that conflict with the idea that it's a set of practices?
*Scott Hanselman*
I think that when a new set of practices or a new buzzword comes out, people like to put it on a business card. No disrespect to people who are listening to this podcast and now are offended and looking at their business card and going, "This sucks." And now they're going to like, I don't know, slam their laptop shut, rage, quit this podcast.
**08:30** - *Scott Hanselman*
There was a really great thread by Brian Guthrie, who is a thought worker, and he worked at SoundCloud. He's just a super smart individual. He talked about DevOps and he said in this thread a couple of days ago on Twitter that DevOps is a set of practices, period. It's not a job title. It's not a software tool. It's not a thing you install. It's not a team name.
**09:00** - *Scott Hanselman*
The way he phrased it was, "It's not magic enterprise fairy dust." If you don't have best practices, if you don't have good practices, you have no DevOps . So it's more a mindset than it is putting out a job title and like, "We're going to a hire DevOps engineers and then we're going to sprinkle these magical DevOps engineers into the organization, without the organization having organizational willpower and buying into the mindset that is DevOps ." So, if you think it's a toolkit or a thing you install, then you've missed the point.
**09:30** - *Saron Yitbarek*
Okay, so let's go back in time, before DevOps was a term, before we had DevOps on our business cards or talked about it as a set of practices. 10 years ago, how would you describe the relationship between developers and those people who are on the ops side of things?
*Scott Hanselman*
It was rather combative. Like, the people in ops controlled production, and developers never got near production. We were on different sides of a wall that was an opaque wall. We, over in development, tried as much as we could to make something that looked like production, but you never actually ... it never looks like production.
**10:00** - *Scott Hanselman*
We had a couple of issues. We had development environments that didn't look or feel or smell like production, so inevitably you'd have those, "Hey, it works different in production than it does in development," kind of environments. And then, the distance between the check-in and when it got into production was weeks and weeks and weeks, so your brain wasn't even in the right headspace . Because I worked on that feature in January and it's just now rolling out in April, so then when the bug inevitably comes down, it's not going to be fixed until June and I don't even remember what we were talking about.
So people in ops, their jobs was to... It was almost like their job was to consciously slow us down. Like, they existed to make developers slower, and then of course they felt that we wanted to break production at all times.
**11:00** - *Saron Yitbarek*
So why was it like that? Was it just a fundamental misunderstanding of what developers wanted and were trying to do? Was it a trust issue? Why was it so combative?
*Scott Hanselman*
I think that you answered, you nailed that. You answered it all correctly. There was a trust issue. There was a sense I think that developers thought they were special, or somehow better than IT people, and IT people thought that developers had no respect for production.
**11:30** - *Scott Hanselman*
I think that that culture came kind of from the top, the idea that we were different orgs and that somehow our goals were different. I think that there's some maturity that's happened in software, where we all realized that we write software in order to move the business forward, whatever that business is.
So that sense of, "We're all pushing in the right direction," as they say, "all the wood behind the same arrow." But it was definitely trust, because DevOps engineers don't trust product engineers to deploy, right?
**12:00** - *Scott Hanselman*
And DevOps engineers didn't traditionally write code, so they didn't understand what got changed. So there was a lack of trust at all the levels. And no one understood the deployment process, and people trusted only themselves, and they also ... Like, "I only trust myself to go into production. I can't trust Saron to go into production, she doesn't know what she's talking about. I'll do it."
**12:30** - *Scott Hanselman*
So if no one truly understood the system, like the idea of a full stack engineer was a mythic thing. But now, we are starting to think about the whole stack as an organization. We've had terms like full product ownership, and the agile methodology has come along saying that everyone should own the product, and that sense of community ownership and community around the code all slowly changed, changes things to bring an environment of trust.
**13:00** - *Saron Yitbarek*
I'm Saron Yitbarek and you're listening to Command Line Heroes, an original podcast from Red Hat. So, for DevOps to hit its potential we were going to need a lot of trust on both sides, and that means a lot more communication. Back to Richard Henshall. He sees empathy for both sides as the cornerstone of DevOps .
**13:30** - *Richard Henshall*
Some of the DevOps practitioners, some of the really good ones, have done both roles. I think that is where the real power comes, is when people actually get to do both roles, rather than just seeing the other side. So you don't keep the separation, you're actually... You go and live in their shoes for a period of time. I think that's what brings the empathy back.
*Saron Yitbarek*
Now this isn't just communication for the sake of warm fuzzies. What Richard Henshall is describing is the industry swerving toward that focus Scott mentioned.
**14:00** - *Saron Yitbarek*
A focus on continuous integration. Software was going to be, not just written and released in small rapid-fire batches, but also tested in small rapid-fire batches. And that meant, developers needed instant feedback on the code they were writing, and how it would perform in the real world.
As time to market shrank from months to days, to hours, we cast around for a new set of tools that could automate any element that could be automated.
**14:30** - *Gordon Haff*
You really need a whole new ecosystem of tooling to do DevOps most effectively.
*Saron Yitbarek*
Gordon Haff is a senior manager at Red Hat.
*Gordon Haff*
What we see is this huge collection of new types of tooling and platforms that DevOps can make use of. They're really all coming out of open source.
*Saron Yitbarek*
Gordon's right. The collection of new tools is huge, and he's right about the open source angle too. The growth of automation tools never would have been possible in a strictly proprietary system.
**15:00** - *Gordon Haff*
Lot of monitoring tools out there. Prometheus is a common one. STO for service orchestration is starting to interest a lot of people, so that's out there.
*Saron Yitbarek*
GitHub let's you track changes. PagerDuty manages digital operations. NFS mounts file systems across a network. Jenkins lets you automate testing on your build.
**15:30** - *Saron Yitbarek*
So many tools, so much automation. The end result, developers can push their changes live, the build is automatically created, compilation is managed, and automated tests are run against it. Sandra Henry-Stocker describes what a change this made.
*Sandra Henry-Stocker*
So I could take something that I was working on and rapidly deploy it, and I could control many systems just from the command line on one, rather than having to work at a lot of different places or wonder how I was going to get something that I was working on sent across a network and deployed on a lot of different machines.
**16:00** - *Sandra Henry-Stocker*
It became easier to basically sit in one spot, and yet make my changes across a wide range of computer systems.
*Saron Yitbarek*
Automation tools had solved the speed problem. But I don't want us to just praise tools at the expense of the actual methodology, the cultural shift. Scott Hanselman and I talked about that fine line.
**16:30** - *Saron Yitbarek*
You started this conversation by saying DevOps is a set of practices, it's a mindset, it's a way of thinking. It sounds like the tools that we created are the manifestation, the code version of the way we should be thinking and we should be operating.
*Scott Hanselman*
I love that, you're a genius. Exactly. We used to have the product owners write in these Word documents about how the code should work. They write the spec, right? When was the last time a Word document broke the build?
**17:00** - *Saron Yitbarek*
Right.
*Scott Hanselman*
Right?
*Saron Yitbarek*
Okay, partly I just wanted you to hear Scott calling me a genius. But I do think those tools are almost like symbols of our cultural shift. They encourage us to broaden our roles. We developers have been forced to look, at least occasionally, from the command line. That way the priorities of dev and ops partly come into alignment. In fact, what the rise of DevOps has made clear is that in a world of ever-increasing speed, nobody can afford to remain siloed.
**17:30** - *Saron Yitbarek*
Jonah Horowitz has worked for a number of Bay-area companies, including Quantcast and Netflix. He explains how even some of the largest companies in the world have re-imagined their culture in this light.
*Jonah Horowitz*
We had sort of this cultural buy-in from the entire company, that was like, "This is how we're going to deploy software. We're going to do it in these small batches. We're going to do it using these deployment procedures." I don't think DevOps can be... I don't think it can be successful if it's just being driven by the ops team.
**18:00** - *Jonah Horowitz*
It has to be something that the management and leadership at the company buy into. It's very much a cultural shift.
*Saron Yitbarek*
When MacKenzie surveyed 800 CIOs and IT executives, 80% said they were implementing DevOps in some part of their organization, and more than half planned to implement it company-wide by 2020. Executives are realizing that automation tools ramp up the speed of delivery.
**18:30** - *Saron Yitbarek*
These are the same people who used to be okay with having a pallet arrive in a datacenter, and then have it sit there for a whole month before a new machine was brought online. Today, if you're waiting longer than 10 minutes to have something provisioned, you're doing something wrong. With competitors hitting speeds like that, nobody can afford to be left behind.
**19:00** - *Saron Yitbarek*
I can imagine that ops teams must have been nervous, handing all those tools over to developers. Ops was used to being the grownup, and now they were supposed to hand over the keys to the car? Yikes. I think we developers are learning to move fast without breaking things. But as the dust settles on the DevOps revolution, the biggest changes may be for the ops team.
**19:30** - *Saron Yitbarek*
Does DevOps actually threaten the role of operations? Is dev using its shiny new tools to eat ops? Cindy Sridharan is a developer who wrote a long investigative piece about all this. In your article and your blog post, you mentioned that operations people were not necessarily happy with the way things were going. What was going on? What would you say?
*Cindy Sridharan*
Let's put it this way, the DevOps ideal was that responsibilities will be shared. That developers and operations would have, like you know, more of a 50-50 split, for really ensuring the holistic delivery of software.
**20:00** - *Cindy Sridharan*
I think a lot of the unhappiness from engineers, from operations engineers, stems from the fact that that is not really the reality on the ground, and that they're still the ones who are always picking the short straw. They're still the ones who are sort like always doing the grunt work. They're still the ones who are primarily shouldering responsibility for actually running the applications, and the developers aren't necessarily doing enough.
*Saron Yitbarek*
The question will be a crucial one over the next few years. How opsy is DevOps going to be? As we automate, does the role of ops get diminished, or does it transform?
**20:30** - *Saron Yitbarek*
But we have to remember, DevOps isn't just about the tools and the application of new technologies. This methodology is actually shaping the tech, and in turn the tech is shaping the methodology. There's this amazing feedback loop. Culture makes the tools, and the tools reinforce the culture.
**22:00** - *Saron Yitbarek*
In the end, that wall we described at the top of the episode, the one dividing dev from ops, I don't even know if the whole throw - your - code - over - the - wall analogy is going to make sense to a developer in five years, and that's sort of a great thing. Already, when I talk to folks today, I'm hearing a new story.
Cloud architect Richard Henshall.
*Richard Henshall*
I think it is starting to make people realize what the other side of the equation was concerned about more. I've seen a lot more understanding.
**23:00** - *Saron Yitbarek*
Sysadmin Jonah Horowitz.
**23:00** - *Jonah Horowitz*
I think there's a craft to writing really good software, and one thing that I see in the best developers that I work with, is that they really, they push the craft of software engineering, or software development, forward.
*Saron Yitbarek*
Sysadmin, Sandra Henry-Stocker.
*Sandra Henry-Stocker*
I think that developers are becoming much more astute and much more careful. They're consistently having to up their skills, and I know that takes a lot of work.
**23:30** - *Saron Yitbarek*
It's a love-in. Turns out, there were some friends on the other side of that wall. Nice to meet you. So, a confession, I always used to think DevOps was boring, just a bunch of hardcore automation scripts and scaling issues. My resistance was partly just practical. As developers, every week there's some new tool coming out, some new framework. DevOps has been part of those scary, fast changes. But now, especially after hearing these stories, I get it.
**24:00** - *Saron Yitbarek*
DevOps is more than its tools. It's how we can work together to build better products faster.
Here's the good news, as we develop new platforms for developers like you and me, my work is becoming better, faster, and more adaptive to different environments. The circle of interest can keep expanding too. You see people widening DevOps to include security, so we get Sec DevOps , or they include business, so we get B iz DevOps . The debate we're going to have now is, how important is it for a developer to understand not just how to use these tools but how all that DevOps stuff even works, and how realistic is it to expect developers to understand that new world?
**24:30** - *Saron Yitbarek*
The way we settle that debate is going to define the work of tomorrow's Command Line Heroes.
You might have noticed that in all that talk about tools and automation I left out some big ones. Well, I'm saving those for next time, when all this DevOps automation hits lightspeed and we track the rise of containers.
**25:00** - *Saron Yitbarek*
It's all in episode 5.
Command Line Heroes is an original podcast from Red Hat. For more information about this and past episodes, go to redhat.com/commandlineheroes. Once you're there, you can also sign up for our newsletter, and to get new episodes delivered automatically for free, make sure to subscribe to the show.
**25:30** - *Saron Yitbarek*
Just search for Command Line Heroes in Apple Podcasts, Spotify, Google Play, CastBox, or however you get your podcasts. Then hit subscribe, so you'll be the first to know when new episodes are available. I'm Saron Yitbarek. Thanks for listening, and keep on coding.
### Keep going
### From manual to automated DevOps: One man’s journey
Matt St. Onge, senior partner solutions architect at Red Hat, shares his journey in search of the Holy Grail or the great unicorn called DevOps.
### My journey from BASIC to Linux
Gordon Haff looks back as his career in tech, describing his evolution from BASIC programer to Red Hat technology evangelist.
### Featured in this episode
#### Scott Hanselman
Web developer working in open source on ASP.NET and the Azure Cloud for Microsoft
#### Cindy Sridharan
Engineer at imgix, working on API development, infrastructure, and other miscellaneous backend engineering tasks
#### Richard Henshall
Red Hat Ansible Automation Lead for EMEA |
12,530 | 将 Vim 设置为 Rust IDE | https://opensource.com/article/20/7/vim-rust-ide | 2020-08-19T08:00:16 | [
"Rust",
"Vim"
] | https://linux.cn/article-12530-1.html |
>
> Vim 编辑器是很好的 Rust 应用开发环境。
>
>
>

[Rust](https://www.rust-lang.org/) 语言旨在以 C++ 开发人员熟悉的方式实现具有安全并发性和高内存性能的系统编程。它也是 [Stack Overflow 的 2019 年开发人员调查](https://insights.stackoverflow.com/survey/2019#technology-_-most-loved-dreaded-and-wanted-languages)中最受欢迎的编程语言之一。
文本编辑器和[集成开发环境(IDE)工具](https://en.wikipedia.org/wiki/Integrated_development_environment)使编写 Rust 代码更加轻松快捷。有很多编辑器可供选择,但是我相信 [Vim 编辑器](https://opensource.com/resources/what-vim)非常适合作为 Rust IDE。在本文中,我将说明如何为 Rust 应用开发设置 Vim。
### 安装 Vim
Vim 是 Linux 和 Unix 中最常用的命令行文本编辑器之一。最新版本(在编写本文时)是 [8.2](https://github.com/vim/vim),它在使用方式上提供了前所未有的灵活性。
[Vim 的下载页面](https://www.vim.org/download.php)提供了多种二进制或软件包形式安装。例如,如果使用 macOS,那么可以安装 [MacVim](https://github.com/macvim-dev/macvim) 项目,然后通过[安装 Vim 插件](https://opensource.com/article/20/2/how-install-vim-plugins) 扩展 Vim 的功能。
要设置 Rust 进行开发,请下载 [Rustup](https://rustup.rs/),这是一个方便的 Rust 安装器工具,并在你的终端上运行以下命令(如果你使用 macOS、Linux 或任何其他类 Unix 系统):
```
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
```
在提示中选择安装选项。然后,你将看到如下输出:
```
stable installed - rustc 1.43.1 (8d69840ab 2020-05-04)
Rust is installed now. Great!
To get started you need Cargo's bin directory ($HOME/.cargo/bin) in your PATH
environment variable. Next time you log in this will be done
automatically.
To configure your current shell run source $HOME/.cargo/env
```
### 语法高亮
Vim 能让你通过 `.vimrc` 文件配置你的运行时环境。要启用语法高亮,请打开 `.vimrc` 文件(如果不存在就创建一个):
```
$ vim ~/.vimrc
```
在 `.vimrc` 中添加以下内容并保存:
```
filetype plugin indent on
syntax on
```
第一行同时打开检测、插件和缩进配置。第二行启用语法高亮。这些功能将帮助你在 Rust 中管理开发流程。在 Vim 的[帮助文件](http://vimdoc.sourceforge.net/htmldoc/filetype.html#:filetype-overview)中了解更多信息。
### 在 Vim 中创建一个 Rust 应用
要使用 Vim 创建一个新的 Rust HelloWorld 应用(`hello.rs`),请输入:
```
$ vim hello.rs
```
输入以下 Rust 代码在控制台中打印 `Hello World!`:
```
fn main() {
println!("Hello World");
}
```
它看起来应该像这样:

没有语法高亮的样子如下:

你是否注意到 Vim 自动缩进和组织代码?那是因为你在 `.vimrc` 文件中输入了第一行。
很好!接下来,你将使用 Rust 的包管理器 [Cargo](https://opensource.com/article/20/3/rust-cargo) 构建此应用。
### Cargo 集成
Cargo 使创建应用更加容易。要查看操作方法,请创建一个基于 Cargo 的 HelloWorld 应用。如果你尚未在 Linux 或 macOS 系统上安装 Cargo,请输入:
```
$ curl https://sh.rustup.rs -sSf | sh
```
然后使用 Cargo 创建包:
```
$ cargo new my_hello_world
```
如果查看目录结构,你会看到 Cargo 自动生成一些源码和目录。如果你安装了 `tree`,请运行它查看目录结构:
```
$ tree my_hello_world
my_hello_world
├── Cargo.toml
└── src
└── main.rs
1 directory, 2 files
```
在 Vim 中打开 `main.rs` 源码文件:
```
$ vim my_hello_world/src/main.rs
```
它与你在上面手动创建的 HelloWorld 示例中的代码相同。用 `Rust with Vim` 代替 `World`:
```
fn main() {
println!("Hello, Rust with Vim");
}
```
使用 `:wq` 保存更改并退出 Vim。
### 编译你的应用
现在你可以使用 `cargo build` 编译你的第一个 Rust 应用:
```
$ cd my_hello_world
$ cargo build
```
你的终端输出将类似于以下内容:
```
Compiling my_hello_world v0.1.0 (/Users/danieloh/cloud-native-app-dev/rust/my_hello_world)
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
```
你可能会看到一条警告消息,因为你重用了示例包名 `my_hello_world`,但现在可以忽略它。
运行应用:
```
$ target/debug/my_hello_world
Hello, Rust with Vim!
```
你也可以使用 `cargo run` 一次构建和运行应用:
```
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/my_hello_world`
Hello, Rust with Vim!!
```
恭喜!你在本地的 Vim 编辑器中设置了 Rust IDE,开发了第一个 Rust 应用,并使用 Cargo 包管理器工具构建、测试和运行了它。如果你想学习其他 Cargo 命令,请运行 `cargo help`。
---
via: <https://opensource.com/article/20/7/vim-rust-ide>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Rust](https://www.rust-lang.org/) programming language is designed to implement systems programming with safe concurrency and high memory performance in a way that feels familiar to C++ developers. It's also one of the most loved programming languages in [Stack Overflow's 2019 Developer Survey](https://insights.stackoverflow.com/survey/2019#technology-_-most-loved-dreaded-and-wanted-languages).
Text editors and [integrated development environment (IDE) tools](https://en.wikipedia.org/wiki/Integrated_development_environment) make writing Rust code easier and quicker. There are many editors to choose from, but I believe the [Vim editor](https://opensource.com/resources/what-vim) is a great fit for a Rust IDE. In this article, I'll explain how to set up Vim for Rust application development.
## Install Vim
Vim is one of the most commonly used command-line text editors in Linux and Unix. The latest version (as of this writing) is [8.2](https://github.com/vim/vim), and it offers more flexibility than ever in how you can use it.
[Vim's download page](https://www.vim.org/download.php) provides multiple options to install it with binary or packages. For example, if you use macOS, you can install the [MacVim](https://github.com/macvim-dev/macvim) project, then expand Vim's capabilities by [installing Vim plugins](https://opensource.com/article/20/2/how-install-vim-plugins).
To set up Rust for development, download [Rustup](https://rustup.rs/), a handy Rust installer utility, and run the following in your terminal (if you use macOS, Linux, or any other Unix-like operating system):
`$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh`
Choose an installation option from the interactive prompt. Then you will see output like:
```
stable installed - rustc 1.43.1 (8d69840ab 2020-05-04)
Rust is installed now. Great!
To get started you need Cargo's bin directory ($HOME/.cargo/bin) in your PATH
environment variable. Next time you log in this will be done
automatically.
To configure your current shell run source $HOME/.cargo/env
```
## Syntax highlighting
Vim allows you to configure your runtime by defining it in the `.vimrc`
file. To enable syntax highlighting, open your `.vimrc`
file (or create one if it doesn't exist):
`$ vim ~/.vimrc`
Add the following in the `.vimrc`
file and save it:
```
filetype plugin indent on
syntax on
```
The first line turns on the detection, plugin, and indent configurations all at once. The second line enables syntax highlighting. These features will help you manage your developer workflow in Rust. Learn more in Vim's [help file](http://vimdoc.sourceforge.net/htmldoc/filetype.html#:filetype-overview).
## Create a Rust application in Vim
To create a new Rust HelloWorld application (`hello.rs`
) using Vim, enter:
`$ vim hello.rs`
Enter the following Rust code to print **Hello World!** in the console:
```
fn main() {
println!("Hello World");
}
```
It should look something like this:
(Daniel Oh, CC BY-SA 4.0)
Here's what it would look like without syntax highlighting:
(Daniel Oh, CC BY-SA 4.0)
Did you notice how Vim automatically indented and organized the code? That is because of the first line you entered in the `.vimrc`
file.
Great job! Next, you will build this application using Rust's package manager, [Cargo](https://opensource.com/article/20/3/rust-cargo).
## Cargo integrations
Cargo makes creating applications easier. To see how, create a Cargo-based HelloWorld application. If you don't already have Cargo installed on your Linux or macOS system, enter:
`$ curl https://sh.rustup.rs -sSf | sh`
Then create a package with Cargo:
`$ cargo new my_hello_world`
If you look at the directory structure, you'll see Cargo automatically generated some source code and directories. If you have `tree`
installed, run it to see the directory structure:
```
$ tree my_hello_world
my_hello_world
├── Cargo.toml
└── src
└── main.rs
1 directory, 2 files
```
Open the `main.rs`
source code file in Vim:
`$ vim my_hello_world/src/main.rs`
The code is the same as in the HelloWorld example you created manually above. Replace `World`
with `Rust with Vim`
:
```
fn main() {
println!("Hello, Rust with Vim");
}
```
Use `:wq`
to save your changes and quit Vim.
## Compile your application
Now you can compile your first Rust application using `cargo build`
:
```
$ cd my_hello_world
$ cargo build
```
Your terminal output will look similar to this:
```
Compiling my_hello_world v0.1.0 (/Users/danieloh/cloud-native-app-dev/rust/my_hello_world)
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
```
You may see a warning message because you reused the sample package name, `my_hello_world`
, but you can ignore it for now.
Run the application:
```
$ target/debug/my_hello_world
Hello, Rust with Vim!
```
You can also use `cargo run`
to build and run the application all at once:
```
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/my_hello_world`
Hello, Rust with Vim!!
```
Congratulations! You set up Vim editor for Rust IDE on your local machine, developed your first Rust application, and built, tested, and ran it using the Cargo package manager tool. Run `cargo help`
If you want to learn other Cargo commands.
## 2 Comments |
12,533 | 使用微软的 ProcDump 调试 Linux | https://opensource.com/article/20/7/procdump-linux | 2020-08-20T09:57:30 | [
"调试"
] | /article-12533-1.html |
>
> 用这个微软的开源工具,获取进程信息。
>
>
>

微软越来越心仪 Linux 和开源,这并不是什么秘密。在过去几年中,该公司稳步地增加了对开源的贡献,包括将其部分软件和工具移植到 Linux。2018 年底,微软[宣布](https://www.zdnet.com/article/microsoft-working-on-porting-sysinternals-to-linux/)将其 [Sysinternals](https://docs.microsoft.com/en-us/sysinternals/) 的部分工具以开源的方式移植到 Linux,[Linux 版的 ProcDump](https://github.com/Microsoft/ProcDump-for-Linux)是其中的第一个。
如果你在 Windows 上从事过调试或故障排除工作,你可能听说过 Sysinternals,它是一个“瑞士军刀”工具集,可以帮助系统管理员、开发人员和 IT 安全专家监控和排除 Windows 环境的故障。
Sysinternals 最受欢迎的工具之一是 [ProcDump](https://docs.microsoft.com/en-us/sysinternals/downloads/procdump)。顾名思义,它用于将正在运行的进程的内存转储到磁盘上的一个核心文件中。然后可以用调试器对这个核心文件进行分析,了解转储时进程的状态。因为之前用过 Sysinternals,所以我很想试试 ProcDump 的 Linux 移植版。
### 开始使用 Linux 上的 ProcDump
要试用 Linux 上的 ProcDump,你需要下载该工具并编译它。(我使用的是 Red Hat Enterprise Linux,尽管这些步骤在其他 Linux 发行版上应该是一样的):
```
$ cat /etc/redhat-release
Red Hat Enterprise Linux release 8.2 (Ootpa)
$
$ uname -r
4.18.0-193.el8.x86_64
$
```
首先,克隆 Linux 版 ProcDump 的版本库。
```
$ git clone https://github.com/microsoft/ProcDump-for-Linux.git
Cloning into 'ProcDump-for-Linux'...
remote: Enumerating objects: 40, done.
remote: Counting objects: 100% (40/40), done.
remote: Compressing objects: 100% (33/33), done.
remote: Total 414 (delta 14), reused 14 (delta 6), pack-reused 374
Receiving objects: 100% (414/414), 335.28 KiB | 265.00 KiB/s, done.
Resolving deltas: 100% (232/232), done.
$
$ cd ProcDump-for-Linux/
$
$ ls
azure-pipelines.yml CONTRIBUTING.md docs INSTALL.md Makefile procdump.gif src
CODE_OF_CONDUCT.md dist include LICENSE procdump.1 README.md tests
$
```
接下来,使用 `make` 构建程序。它能准确地输出编译源文件所需的 [GCC](https://gcc.gnu.org/) 命令行参数。
```
$ make
rm -rf obj
rm -rf bin
rm -rf /root/ProcDump-for-Linux/pkgbuild
gcc -c -g -o obj/Logging.o src/Logging.c -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/Events.o src/Events.c -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/ProcDumpConfiguration.o src/ProcDumpConfiguration.c -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/Handle.o src/Handle.c -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/Process.o src/Process.c -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/Procdump.o src/Procdump.c -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/TriggerThreadProcs.o src/TriggerThreadProcs.c -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/CoreDumpWriter.o src/CoreDumpWriter.c -Wall -I ./include -pthread -std=gnu99
gcc -o bin/procdump obj/Logging.o obj/Events.o obj/ProcDumpConfiguration.o obj/Handle.o obj/Process.o obj/Procdump.o obj/TriggerThreadProcs.o obj/CoreDumpWriter.o -Wall -I ./include -pthread -std=gnu99
gcc -c -g -o obj/ProcDumpTestApplication.o tests/integration/ProcDumpTestApplication.c -Wall -I ./include -pthread -std=gnu99
gcc -o bin/ProcDumpTestApplication obj/ProcDumpTestApplication.o -Wall -I ./include -pthread -std=gnu99
$
```
编译过程中会创建两个新的目录。第一个是 `obj/` 目录,存放编译期间创建的对象文件。第二个(也是更重要的)目录是 `bin/`,它是存储编译出的 `procdump` 程序的地方。它还会编译另一个名为 `ProcDumpTestApplication` 的测试二进制文件:
```
$ ls obj/
CoreDumpWriter.o Handle.o ProcDumpConfiguration.o ProcDumpTestApplication.o TriggerThreadProcs.o
Events.o Logging.o Procdump.o Process.o
$
$
$ ls bin/
procdump ProcDumpTestApplication
$
$ file bin/procdump
bin/procdump: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=6e8827db64835ea0d1f0941ac3ecff9ee8c06e6b, with debug_info, not stripped
$
$ file bin/ProcDumpTestApplication
bin/ProcDumpTestApplication: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=c8fd86f53c07df142e52518815b2573d1c690e4e, with debug_info, not stripped
$
```
在此情况下,每次运行 `procdump` 实用程序时,你都必须移动到 `bin/` 文件夹中。要使它在系统中的任何地方都可以使用,运行 `make install`。这将这个二进制文件复制到通常的 `bin/` 目录中,它是你的 shell `$PATH` 的一部分:
```
$ which procdump
/usr/bin/which: no procdump in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin)
$
$ make install
mkdir -p //usr/bin
cp bin/procdump //usr/bin
mkdir -p //usr/share/man/man1
cp procdump.1 //usr/share/man/man1
$
$ which procdump
/usr/bin/procdump
$
```
安装时,ProcDump 提供了一个手册页,你可以用 `man procdump` 访问:
```
$ man procdump
$
```
### 运行 ProcDump
要转储一个进程的内存,你需要向 ProcDump 提供它的进程 ID(PID)。你可以使用机器上任何正在运行的程序或守护进程。在这个例子中,我将使用一个永远循环的小 C 程序。编译程序并运行它(要退出程序,按 `Ctrl+C`,如果程序在后台运行,则使用 `kill` 命令并输入 PID):
```
$ cat progxyz.c
#include <stdio.h>
int main() {
for (;;)
{
printf(".");
sleep(1);
}
return 0;
}
$
$ gcc progxyz.c -o progxyz
$
$ ./progxyz &
[1] 350498
$
```
运行该程序,你可以使用 `pgrep` 或 `ps` 找到它的 PID。记下 PID:
```
$ pgrep progxyz
350498
$
$ ps -ef | grep progxyz
root 350498 345445 0 03:29 pts/1 00:00:00 ./progxyz
root 350508 347350 0 03:29 pts/0 00:00:00 grep --color=auto progxyz
$
```
当测试进程正在运行时,调用 `procdump` 并提供 PID。下面的输出表明了该进程的名称和 PID,并报告它生成了一个核心转储文件,并显示其文件名:
```
$ procdump -p 350498
ProcDump v1.1.1 - Sysinternals process dump utility
Copyright (C) 2020 Microsoft Corporation. All rights reserved. Licensed under the MIT license.
Mark Russinovich, Mario Hewardt, John Salem, Javid Habibi
Monitors a process and writes a dump file when the process exceeds the
specified criteria.
Process: progxyz (350498)
CPU Threshold: n/a
Commit Threshold: n/a
Polling interval (ms): 1000
Threshold (s): 10
Number of Dumps: 1
Press Ctrl-C to end monitoring without terminating the process.
[03:30:00 - INFO]: Timed:
[03:30:01 - INFO]: Core dump 0 generated: progxyz_time_2020-06-24_03:30:00.350498
$
```
列出当前目录的内容,你应该可以看到新的核心文件。文件名与 `procdump` 命令显示的文件名一致,日期、时间、PID 都会附加在文件名上:
```
$ ls -l progxyz_time_2020-06-24_03\:30\:00.350498
-rw-r--r--. 1 root root 356848 Jun 24 03:30 progxyz_time_2020-06-24_03:30:00.350498
$
$ file progxyz_time_2020-06-24_03\:30\:00.350498
progxyz_time_2020-06-24_03:30:00.350498: ELF 64-bit LSB core file, x86-64, version 1 (SYSV), SVR4-style, from './progxyz', real uid: 0, effective uid: 0, real gid: 0, effective gid: 0, execfn: './progxyz', platform: 'x86_64'
$
```
### 用 GNU 项目调试器分析核心文件。
要查看是否可以读取该转储文件,调用 [GNU 项目调试器](https://www.gnu.org/software/gdb/)(`gdb`)。记得提供测试二进制文件的路径,这样你就可以看到堆栈上所有的函数名。在这里,`bt`(回溯)表明,当转储被采集时,`sleep()` 函数正在执行:
```
$ gdb -q ./progxyz ./progxyz_time_2020-06-24_03\:30\:00.350498
Reading symbols from ./progxyz...(no debugging symbols found)...done.
[New LWP 350498]
Core was generated by `./progxyz'.
#0 0x00007fb6947e9208 in nanosleep () from /lib64/libc.so.6
Missing separate debuginfos, use: yum debuginfo-install glibc-2.28-101.el8.x86_64
(gdb) bt
#0 0x00007fb6947e9208 in nanosleep () from /lib64/libc.so.6
#1 0x00007fb6947e913e in sleep () from /lib64/libc.so.6
#2 0x00000000004005f3 in main ()
(gdb)
```
### gcore 怎么样?
Linux 用户会很快指出,Linux 已经有一个叫 `gcore` 的命令,大多数 Linux 发行版都有这个命令,它的作用和 ProcDump 完全一样。你说的对。如果你从来没有使用过它,可以尝试用 `gcore` 来转储一个进程的核心。再次运行测试程序,然后运行 `gcore`,并提供 PID 作为参数:
```
$ ./progxyz &
[1] 350664
$
$
$ pgrep progxyz
350664
$
$
$ gcore 350664
0x00007fefd3be2208 in nanosleep () from /lib64/libc.so.6
Saved corefile core.350664
[Inferior 1 (process 350664) detached]
$
```
`gcore` 打印一条消息,说它已将核心文件保存到一个特定的文件中。检查当前目录,找到这个核心文件,然后再次使用 `gdb` 加载它:
```
$
$ ls -l core.350664
-rw-r--r--. 1 root root 356848 Jun 24 03:34 core.350664
$
$
$ file core.350664
core.350664: ELF 64-bit LSB core file, x86-64, version 1 (SYSV), SVR4-style, from './progxyz', real uid: 0, effective uid: 0, real gid: 0, effective gid: 0, execfn: './progxyz', platform: 'x86_64'
$
$ gdb -q ./progxyz ./core.350664
Reading symbols from ./progxyz...(no debugging symbols found)...done.
[New LWP 350664]
Core was generated by `./progxyz'.
#0 0x00007fefd3be2208 in nanosleep () from /lib64/libc.so.6
Missing separate debuginfos, use: yum debuginfo-install glibc-2.28-101.el8.x86_64
(gdb) bt
#0 0x00007fefd3be2208 in nanosleep () from /lib64/libc.so.6
#1 0x00007fefd3be213e in sleep () from /lib64/libc.so.6
#2 0x00000000004005f3 in main ()
(gdb) q
$
```
为了使 `gcore` 可以工作,你需要确保以下设置到位。首先,确保为核心文件设置了 `ulimit`,如果设置为 `0`,核心文件将不会被生成。第二,确保 `/proc/sys/kernel/core_pattern` 有正确的设置来指定核心模式:
```
$ ulimit -c
unlimited
$
```
### 你应该使用 ProcDump 还是 gcore?
有几种情况下,你可能更喜欢使用 ProcDump 而不是 gcore,ProcDump 有一些内置的功能,在一些情况下可能很有用。
#### 等待测试二进制文件的执行
无论是使用 ProcDump 还是 gcore,测试进程必须被执行并处于运行状态,这样才能提供一个 PID 来生成核心文件。但 ProcDump 有一个功能,就是等待特定的二进制文件运行,一旦发现运行的测试二进制文件与给定的名称相匹配,它就会为该测试二进制文件生成一个核心文件。它可以使用 `-w` 参数和程序名称而不是 PID 来启用。这个功能在测试程序快速退出的情况下很有用。
下面是它的工作原理。在这个例子中,没有名为 `progxyz` 的进程在运行:
```
$ pgrep progxyz
$
```
用 `-w` 参数调用 `procdump`,让它保持等待。在另一个终端,调用测试二进制 `progxyz`:
```
$ procdump -w progxyz
ProcDump v1.1.1 - Sysinternals process dump utility
Copyright (C) 2020 Microsoft Corporation. All rights reserved. Licensed under the MIT license.
Mark Russinovich, Mario Hewardt, John Salem, Javid Habibi
Monitors a process and writes a dump file when the process exceeds the
specified criteria.
Process: progxyz (pending)
CPU Threshold: n/a
Commit Threshold: n/a
Polling interval (ms): 1000
Threshold (s): 10
Number of Dumps: 1
Press Ctrl-C to end monitoring without terminating the process.
[03:39:23 - INFO]: Waiting for process 'progxyz' to launch...
```
然后,从另一个终端调用测试二进制 `progxyz`:
```
$ ./progxyz &
[1] 350951
$
```
ProcDump 立即检测到该二进制正在运行,并转储这个二进制的核心文件:
```
[03:39:23 - INFO]: Waiting for process 'progxyz' to launch...
[03:43:22 - INFO]: Found process with PID 350951
[03:43:22 - INFO]: Timed:
[03:43:23 - INFO]: Core dump 0 generated: progxyz_time_2020-06-24_03:43:22.350951
$
$ ls -l progxyz_time_2020-06-24_03\:43\:22.350951
-rw-r--r--. 1 root root 356848 Jun 24 03:43 progxyz_time_2020-06-24_03:43:22.350951
$
$ file progxyz_time_2020-06-24_03\:43\:22.350951
progxyz_time_2020-06-24_03:43:22.350951: ELF 64-bit LSB core file, x86-64, version 1 (SYSV), SVR4-style, from './progxyz', real uid: 0, effective uid: 0, real gid: 0, effective gid: 0, execfn: './progxyz', platform: 'x86_64'
$
```
#### 多个核心转储
另一个重要的 ProcDump 功能是,你可以通过使用命令行参数 `-n <count>` 指定要生成多少个核心文件。核心转储之间的默认时间间隔是 `10` 秒,但你可以使用 `-s <sec>` 参数修改。这个例子使用 ProcDump 对测试二进制文件进行了三次核心转储:
```
$ ./progxyz &
[1] 351014
$
$ procdump -n 3 -p 351014
ProcDump v1.1.1 - Sysinternals process dump utility
Copyright (C) 2020 Microsoft Corporation. All rights reserved. Licensed under the MIT license.
Mark Russinovich, Mario Hewardt, John Salem, Javid Habibi
Monitors a process and writes a dump file when the process exceeds the
specified criteria.
Process: progxyz (351014)
CPU Threshold: n/a
Commit Threshold: n/a
Polling interval (ms): 1000
Threshold (s): 10
Number of Dumps: 3
Press Ctrl-C to end monitoring without terminating the process.
[03:45:20 - INFO]: Timed:
[03:45:21 - INFO]: Core dump 0 generated: progxyz_time_2020-06-24_03:45:20.351014
[03:45:31 - INFO]: Timed:
[03:45:32 - INFO]: Core dump 1 generated: progxyz_time_2020-06-24_03:45:31.351014
[03:45:42 - INFO]: Timed:
[03:45:44 - INFO]: Core dump 2 generated: progxyz_time_2020-06-24_03:45:42.351014
$
$ ls -l progxyz_time_2020-06-24_03\:45\:*
-rw-r--r--. 1 root root 356848 Jun 24 03:45 progxyz_time_2020-06-24_03:45:20.351014
-rw-r--r--. 1 root root 356848 Jun 24 03:45 progxyz_time_2020-06-24_03:45:31.351014
-rw-r--r--. 1 root root 356848 Jun 24 03:45 progxyz_time_2020-06-24_03:45:42.351014
$
```
#### 基于 CPU 和内存使用情况的核心转储
ProcDump 还可以让你在测试二进制或进程达到一定的 CPU 或内存阈值时触发核心转储。ProcDump 的手册页显示了调用 ProcDump 时使用的命令行参数:
* `-C`:当 CPU 超过或等于指定值时,触发核心转储生成(0 到 100 \* nCPU)。
* `-c`:当 CPU 小于指定值时,触发核心转储生成(0 到 100 \* nCPU)。
* `-M`:当内存提交超过或等于指定值(MB)时,触发核心转储生成。
* `-m`:当内存提交小于指定值(MB)时,触发核心转储生成。
* `-T`:当线程数超过或等于指定值时触发。
* `-F`:当文件描述符数量超过或等于指定值时触发。
* `-I`:轮询频率,单位为毫秒(默认为 1000)。
例如,当给定 PID 的 CPU 使用率超过 70% 时,可以要求 ProcDump 转储核心:
```
procdump -C 70 -n 3 -p 351014
```
### 结论
ProcDump 是一长串被移植到 Linux 的 Windows 程序中的一个有趣的补充。它不仅为 Linux 用户提供了额外的工具选择,而且可以让 Windows 用户在 Linux 上工作时更有熟悉的感觉。
---
via: <https://opensource.com/article/20/7/procdump-linux>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,535 | 《代码英雄》第一季(5):容器竞赛 | https://www.redhat.com/en/command-line-heroes/season-1/the-containers-derby | 2020-08-21T00:02:00 | [
"容器",
"代码英雄"
] | https://linux.cn/article-12535-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(5):容器竞赛](https://www.redhat.com/en/command-line-heroes/season-1/the-containers-derby)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/3aed4d5c.mp3)脚本。
容器的兴起为开发者们打开了一道新的大门,它简化了在机器与机器之间传递项目的成本。随着它变得广受欢迎,一场大战也悄悄拉开帷幕。这场战斗的奖品是容器编排的控制权,参赛者包括这个行业最快最强的玩家。
容器是开源运动中最重要的一项突破之一。在这一集里,特邀嘉宾 Kelsey Hightower、Laura Frank 和 Clayton Coleman 将告诉我们容器如何为未来添砖加瓦,以及编排技术为何如此重要。
**Saron Yitbarek**:
你有看过赛马吗?赛马们排成一行,蹄子刨着脚下的土壤。你可以想象出这么一副画面。比赛即将开始,在这些竞争者中脱颖而出的将是优胜者。
**00:00:30**:
不同的是,比赛的不是马。而是科技世界的诸侯。那么是什么让比赛如此重要?是怎样的珍贵的奖励,才会让这些参赛者们排着队,迫不及待地想要得到它? 这是一场赢家将掌握容器编排技术规则的竞赛,而且胜利者只有一个。重要的是,不同于其他的比赛,赢得这场比赛,你不仅仅会成为今天的冠军,更有可能在来持续领先。
**00:01:30**:
我是 Saron Yitbarek,这里是代码英雄,一款红帽公司原创的博客。
第五集,容器竞赛。[上一集](/article-12529-1.html)我们见证了 DevOps 的崛起,以及一组新工具如何影响了其他人对开发者这一概念的看法。在这一集栏目中,我们会追溯容器技术崛起的历史,讲述容器技术如何通过拥有支持全新工作的可能性,来进一步扩展开发者这一角色的概念。然后我们会一起见证容器标准化是如何为容器编排奠定比赛基础的。
**00:01:30**:
这是一场严肃的比赛,也是一场全球性的比赛,吸引了行业里最快,最强大的选手。他们都准备好了为冲刺终点线而奋力一搏。准备好了吗? 比赛开始了!
现在,随着这些“赛马”离开起点,也许我们应该弄清楚为什么这场比赛如此重要。谁会关心容器呢?好吧,算我一个。但是实际上,一开始我也并不知道容器是什么。以下我将讲述一个小故事 —— 我是如何醒悟容器之美的。
**00:02:00**:
不久之前,我还在为我网站写代码,然后有天我让我的朋友 Nadia 过来实现一些新的功能。我在保持代码干爽和可读性方面做得很好,当然,代码也经过了很好的测试。所以再加入一个新的网站开发者也不是一件难事。对吗?如果你也这样以为,那就错了。这是一个非常繁琐的过程,特别是当我们跑规范化测试时,这个问题尤为明显。
**00:02:30**:
代码运行正常,但我们不能在两台电脑上同时通过所有测试。我们有很奇怪的电脑时区设置问题,而且她的 Ruby on Rails 版本跟我的不同。就是一个很经典的问题:“我的电脑上可以代码运行”,“可是在我的电脑上就是不行”。我只好对代码做一些修改,直到它在我这里正常运行,但当我把它发送给 Nadia 时,程序又会崩溃。
**00:03:00**:
我很清楚,我和 Nadia 所碰到的这些问题,对于所有的开发者来说都或多或少经历过,甚至他们把这种经历当作玩笑来讲。有时候,我只能把这个当做是在我工作时必须要忍受的一部分。我没有意识到的是,这个问题有个最终解决办法。想象有一种方式可以降低人与人之间的隔阂;想象有一种方法可以让我们在开发中使用任意喜欢的工具,并且在传递工作成果时毫无阻碍;想象一下有一种办法,无论有多少人同时进行一个项目的开发,不管这些人散布在世界何地,都可以让项目从开发到测试,再到生产环境,保持连贯性。如果在我浪费好几周,用最笨的方式传递工作成果前就想到了容器该多好。
**00:03:30 - Liz Rice**:
一个容器实际上就是一个进程。
**Saron Yitbarek**:
Liz Rice 是 Aqua Security 的一名技术布道师。她描述了为何容器会如此实用。事实上容器把一切打包到了一个整洁、并且可以迁移的包中。
**00:04:00 - Liz Rice**:
这就像任何其他的进程一样,不同的是容器的世界非常小。比如,如果你启动一个容器,进程会被授予它自己的根目录。然后它认为自己在查看的是整台计算机的根目录,但实际上它只是在查看这个文件系统很小的一个子集。
**00:04:30 - Saron Yitbarek**:
通过打包一个可执行文件及其所有的依赖,容器可以在任何笔记本或者云中的虚拟机上运行。带着它自己的执行文件、库和依赖。所有的一切都包含在了容器中。所以,这就是容器神奇之处,容器在每个环境中的运行都会完全一样。这也就意味着开发者可以轻松地分享并协作应用开发,而不用担心计算机之间相互不兼容这个老问题。
**00:05:00**:
举一个类比的例子希望能够帮助你理解。你有听说过<ruby> 蓝围裙 <rt> Blue Apron </rt></ruby>这个服务吗?该服务提供你做饭所需的一切,包括精心按照菜谱卡片搭配好的,所有做饭需要的原料。好的,想象一下如果蓝围裙所能带给你的不仅仅只是还没有处理过的食材,而是一整个厨房,有煤气灶,还有你所需要的全部餐具,一切你需要的都会装到小盒子里,放在门阶上。这就是一个容器。在我提到的那种情况下,容器技术就可以很好地解决 Nadia 加入进来时所碰到的问题,简单到像使用蓝围裙服务做一顿晚餐一样。虚拟机同样也可以提供一个预装好的环境。但要解释这个,我们就不得不抛弃蓝围裙这个比喻,让我们来看一看具体的细节。
**00:05:30 - Liz Rice**:
许多人都认为容器是某种轻量级的虚拟化技术、轻量级的虚拟机,事实上并不是。容器与虚拟机有很大不同。虚拟机有独属于自己的一整个操作系统,相比起来容器是共享操作系统的。一个计算机上的所有容器共享同一个操作系统的。
**00:06:00 - Saron Yitbarek**:
最后一点,容器和虚拟机可以并肩工作。容器不能替代虚拟机。虚拟化技术仍然可以提高过时系统的效率,并且对于服务器整合非常关键。但容器技术的兴起也为我们打开了新的大门。不妨这样想,如果我们全部依靠虚拟机的话,运行所有仿真服务器将产生大量的额外负担。
**00:06:30**:
一台虚拟机的大小至少是以 G 为单位的,然而一个容器可能也就只有 20 M 左右。一台虚拟机可能会需要若干分钟来启动,如果我尝试用它部署一个网页应用的话,这可不是一个好消息。很长时间以来,人们都期盼一个轻量级的、更快速的完整机器虚拟化替代方案出现。
**00:00:07**:
回顾一下历史,1979 年就出现了容器的原型。Unix V7 的开发者们设计了一种根系统调用,使环境中只包括特定的程序。该突破为我们现在看到的容器技术指明了道路。另一个巨大的进展来源于 2008 年的 Linux 容器技术。现在,我们有了操作系统级的虚拟化技术。
**00:07:30**:
我们终于可以在一个单独的 Linux 内核上运行多个容器,而无需使用完整的虚拟机。这也就意味着程序对于基础架构的需求逐渐减少,但不是每一个人都能立马看到容器技术的潜力。
**Laura Frank**:
容器化真的是前所未有的、崭新的一个天才般的想法。
**Saron Yitbarek**:
Laura Frank 是 CloudBees 的技术总监。
**00:08:00 - Laura Frank**:
只有少部分人了解容器技术的来龙去脉,并可以运用它。不过相信随着时间的推移越来越多的人会接触到容器化的概念,随着越来越多的人开始使用这项技术,并且这些知识通过工程团队和工程组织,通过社区进行传播,就会变得更容易获得。
**Saron Yitbarek**:
因为和我们之前提到的与虚拟机的相似性,Laura 认为,因为我们之前提到的容器技术与虚拟机的相似性,容器的潜力被低估了。
**00:08:30 - Laura Frank**:
我在回想我的职业生涯,那是我还只是个普通的日常技术人员。如果你不是一个系统管理员或者 Linux 资深用户的话,容器还是一个你刚刚了解到的全新概念。我把它理解为使用一台虚拟机模式类似的东西,我可以去建立一个可以用完即弃的环境,而且这个环境完全独立,清理之后不留痕迹。
**Saron Yitbarek**:
容器除了能保持系统整洁之外,其实还大有可为。容器将会革新整个行业,并且随着开源项目和社区的兴起,在不久之后,容器标准化的充分实施将变为可能。
**00:09:00 - Scott McCarty**:
整个界面已经变得非常简单。
**Saron Yitbarek**:
Scott McCarty 是红帽的一名资深的容器策略顾问。他称得上是这个行业的资深人士,他在容器出现前,甚至是虚拟机出现前,就在做这方面的工作了。
**00:09:30 - Scott McCarty**:
在互联网 1.0 时代,我在一家线上零售商工作,我们有上千台实体机,我们用不同的方式,在所有这些不同的服务器上一遍又一遍地安装相同的软件。我们尝试了所有的方法。当你从原始的操作系统迁移到虚拟机,然后再到 Linux 容器、Solaris 容器,同样的问题一再出现,你仍然不得不在不同的虚拟机,或者类似操作系统实例的结构体之间管理配置。
**Saron Yitbarek**:
一旦容器变的规范化,一切都将改变。
**00:10:00 - Scott McCarty**:
比如,有了很多非常标准化的方式可以去处理现在这些打包好的应用,我认为容器技术的出现,从根本上改变了一切。它使得那些应用非常容易使用,而且容器还不会对系统本身造成损害,同时相比虚拟机更加小巧快捷。
**00:10:30 - Saron Yitbarek**:
借助 Linux 容器带来的进步,这些新的开源项目和社区使得开发者们可以更好地携手合作。很多我们对于后端的焦虑都被一扫而光。突然间,容器和由它促进的微服务变得十分有吸引力。一旦一种共同的容器语言出现了,障碍就消失了,与此同时容器技术改变了我们的工作方式,也改变了我们学习新技术的步伐。
**00:11:00**:
还记得之前我和同事 Nadia 遇到的反复出现的问题吗?“在我这代码能跑”的场景?在容器的世界,这个问题将不复存在。相比于我们之前使用的标准的操作系统,开发者社区见证了容器是如何变得更加快速,成本低廉,并且容易使用的 —— 比传统操作系统更加容易。容器技术被采纳的速度十分惊人。但是要记得:容器标准的出现仅仅是容器编排这场竞赛的热身。
赛马们已经整齐排列好,随着信号枪一声令下,它们为了这场比赛的冠军而拼尽全力。竞争的不是容器本身,而是我们部署和管理容器所使用的工具。
**00:11:30**:
我是 Saron Yitbarek,这里是代码英雄。在这场标准容器编排竞赛中,哪位会胜出成为管理所有容器的平台呢?起初有两位竞争者处于领先地位。
**00:12:00**:
由 Apache 驾驭的 Swarm,和 Docker 驾驭的 Mesos。但是等等,怎么?现在出现了一匹黑马改变了这个格局,那就是谷歌。Linux 设立了云原生计算基金会(CNCF),随后 CNCF 推动了谷歌开源的编排引擎 Kubernetes。
**00:12:30**:
现在,相比 Kubernetes,Mesos 和 Swarm 已经抢占了先机,对吗?它们得到了 Apache 和 Docker 的支持,已经入场了一段时间了。但是 Kubernetes 有其他的“赛马”所不具备的优势。Clayton Coleman 会告诉我们这个秘密是什么。Clayton 是红帽负责 Kubernetes 和 OpenShift 的一名架构师。
**00:13:00 - Clayton Coleman**:
在 Kubernetes 诞生之初,谷歌就在项目的开放上做的很好,它降低了项目的贡献和参与的难度。谷歌极其关注让开发者和运维人员能更加容易地开展工作。有这样一个强烈的关注点,就是要做一个能让大多数开发者和运维的生活更轻松的东西。我觉得 Kubernetes 和围绕着Kubernetes 的社区找到了一个足够好的方式,让大部分人参与进来,他们让 Kubernetes 具有足够的可扩展性,还可以解决一些极端的用例。
**Saron Yitbarek**:
在早期,来自于红帽、CoreOS 和谷歌的工程师们都参与到了 Kubernetes 的开发中。随着 Kubernetes 开发到 1.0,不管是初创公司还是大公司都参与其中,一起构建和完善它。关键的是,所有这些增长从来都不是只归功于谷歌或者任何一方。
**00:13:30 - Clayton Coleman**:
在这个例子中,我喜欢以 Linux 打比方。Linux 并不是始于 Linus 开始编写内核,然后告诉所有人,在用户空间如何写 GCC,如何去建立 NGINX 或者 Apache。相反,内核团队专注于建立一个高效的操作系统内核,并与其他诸如 GNU 项目的开源社区合作,并且将可以在其他 Unix 系统上工作的工具引入 Linux。
**00:14:00**:
因此,我们如今所使用的许多工具,都不是 Linux 核心团队交付的。
但是 Linux 作为一个整体,相比于其内核涵盖的范围要宽泛得多,而且我认为这种模式的优势是 Kubernetes 取得现在成就所不可或缺的。当我们建立社区并且专注于 Kubernetes 范围时,我们可以试图从“Kubernetes 内核”的角度来考虑它,这是分布式集群操作系统的内核。
**00:14:30 - Saron Yitbarek**:
Kubernetes 证明了自己在开源世界中建立社区的能力,令人难以置信。正如我们在操作系统之战中谈到的 Linux 崛起一样,现如今这场关于容器的战争中,获胜者往往懂得如何借助社区力量。事实上,尽管谷歌可能开创了 Kubernetes,但目前它属于每一位开发者,并由云原生计算基金会(CNCF)管理。
**00:15:00**:
在 GitHub 上,Kubernetes 有大约 3 万的星标数,而 Swarm 和 Mesos 只有数千,这已经很能说明问题了。这就是由社区所生,为社区所用的技术。
我想了解谷歌的态度,一个如此庞大并且以效益为导向的大公司,是怎么做到如此擅长跟其他开发者合作的呢?我找到了很适合回答这个问题的人 —— Kelsey Hightower,他是谷歌负责容器技术支持的技术专家。
**00:15:30**:
想想谷歌的地位:它在分布式系统领域具备丰富的经验,还运行着分布在世界各地的许许多多的服务器,因此它开发的 Kubernetes 似乎有着很大的优势,并且有信心一定能在这场容器竞赛中胜出。那么,当你想到 Kubernetes 和开源时,你是如何看待这种关系的?
**00:16:00 - Kelsey Hightower**:
我想当谈到基础架构工具,甚至编程语言时,大家没有什么选择 —— 你不可能用个专有工具,即使它很棒。如果它不是开源的,大多数人可能甚至都不会想去了解。而且我认为这也是大多数人会采用像 Kubernetes 这样的基础架构工具的原因,你可能会对自己说:“好吧,我们就要坚持使用这个版本四、五年,也可能我们需要根据自己的一些独特需求来对其进行修改。”
**00:16:30**:
一旦走到这一步,就很难说服企业接受,“嘿,每台服务器使用程序的价格是 200 美元,而且你看不到源代码,所以有需要的话也必须等我们来修改”。
那样的日子一去不复返了,所以我不确定是否真的可以在没有开源的情况下建立基础架构。开源的另一个意味是拥有一个与项目紧密联合的社区,所以我认为 Kubernetes 一开始就锁定了胜利。
**Saron Yitbarek**:
让我们回到这场容器竞赛。在这里不仅仅有你提到的 Kubernetes,还有 Docker 的 Swarm Apache 的 Mesos……
**00:17:00 - Kelsey Hightower**:
所以,我想当人们谈论容器竞赛时,我不确定竞争是否发生在我们和 Mesos、Docker 使用者之间。我认为,真正的竞争发生在争取目前没有使用容器的潜在用户身上。是的,你还在使用原生 Bash 脚本,你迷茫着,不知道自己该归属何方。这些尚未选择编排工具和平台之人的市场,比起已选择了 Mesos 或 Swarm 的一方,要多得多。
**00:17:30**:
这就是容器战争存在并将继续的原因,真正的关键点在于如何帮助最终用户。Mesos、Kubernetes 或 Docker Swarm 是否会成为寻求更好解决方案的人们的首选?这一切都还悬而未决(SIG 译注:现在已经尘埃落定,Kubernetes 取得了全胜),但我会告诉你,像我一样,在这个领域工作的工程师来说,如果你不考虑市场营销和供应商,我会使用这个短语“不同的公司,相同的团队。”
**00:18:00**:
我们为彼此开发了许多工具,最终以某种方式出现在其他产品中。没错吧?好主意就是好主意。没有理由说,“哦,这是 Mesos 的人正在做的事情,那就忽略吧”,这有点愚蠢。所以从技术和社区的角度来看,我们的想法需要交流。同时也需要竞争来迫使我们来进行独立思考,然后最棒的点子就会浮出水面,接着我们再选择采用哪种方式来正确满足用户的需要。
**00:18:30**:
因此,就这场竞赛而言,仍处于初期阶段,而且这个事情本身不会带来利润。明白我的意思吗?我们不是直接向任何人销售这个产品,这更像是一个平台之间的游戏,对所有人开放,然后用户会选择满足他们需求的那个,这就是我认为 Kubernetes 在社区方面做得很好的地方,真正开放,真正能解决实际问题。
**Saron Yitbarek**:
听起来很棒啊。我喜欢这个想法:在同一个球队踢球,而不要管球队是在什么地方。你对于容器和编排工具,还有 Kbubernetes 的未来有什么展望吗?
**00:19:00 - Kelsey Hightower**:
是的,我在 KubeCon 上做了一次主题演讲。所有这些工具都很棒,它们就像是乐高积木,我们有 Kubernetes,你可以选择一种产品用于安全,选择另一种产品用于网络,但最终,作为开发人员而言,你所想要的只是检查你的代码,并希望你的代码可以某种方式以呈现在客户面前。而我认为 Kubernetes 还有容器都会作为底层技术或者成为类似 Serverless 这种技术的基础平台。
**00:19:30**:
这是我的代码片段,已经打包完毕了。所有的平台都会把你的代码片段,用容器包装起来,然后帮你运行,但是不需要向你公开所有这些过程。因此,在未来,我认为随着 Kubernetes 变得普及,容器的应用场景将从大大小小的供应商或个人,提升到云供应商,因为这些事情往往需要专业知识和软件投资。容器将会遍布各个角落,但同时也就此隐藏起来。它会随着应用场景的扩展而渐渐隐形。
**00:20:00 - Saron Yitbarek**:
Kelsey Hightower 是 Google 的员工开发人员。在 2017 年秋天,Docker 宣布支持 Kubernetes。他们并不是说就放弃 Swarm 了,只是决定与容器编排竞赛的明显赢家和解。
**00:20:30**:
并不只有它一方,Azure 和 AWS 都宣布了对 Kubernetes 的支持。与此同时,像 OpenShift 这样的 Kubernetes 发行版仍在不断发展。我们得到的是一个可以扩展,支持新的用例的 Kubernetes 内核,这些用例包括微服务或持续集成项目。
**00:21:00 - Clayton Coleman**:
这个生态系统在类似 Linux 的模式下能得到最好的发展,而且我认为我们正朝着这条道路迈进。因此,就像所有优秀的开源项目一样,相对于单打独斗,让每个人都能够参与进来构建更好的东西,那就算是成功了。
**00:21:30 - Saron Yitbarek**:
所有这一切都在快速发生着,毕竟,这是一场竞赛,而这正是我们期望能从开源中获得的东西。在我们才刚刚理解什么是容器时,第一轮几乎就结束了,
这是来自 Red Hat 的 Scott McCarty。
**Scott McCarty**:
回想一下两年前,容器镜像格式还是一个巨大的战场,然后回到六个月至一年前,容器编排就成为了下一个巨大的战场。紧接着,如果你看看 2017 年的 KubeCon 及前几周,几乎每个主要供应商都宣布支持 Kubernetes。因此,很明显 Kubernetes 在这一方面上获胜了。
**00:22:00 - Saron Yitbarek**:
这章关于容器战争的故事即将结束。就像容器技术的开始一样迅速。
**Scott McCarty**:
因此,Kubernetes 已经成为标准,其美妙之处是,现在的应用定义已经变得标准化了。因此,任何人都可以在这些 YAML 文件中使用 Kubernetes 对象并定义应用,这就是我们共同所追求的事情。事实上,对于容器技术足够处理处理大型扩展系统这件事,我已经期待了 20 年。
**00:22:30 - Saron Yitbarek**:
Kubernetes 的成功看起来板上钉钉,但即使竞赛尘埃落定,我们仍然面临更大的一些问题。容器是否会成为未来几年的默认选择?是否会促使更多的云原生开发?这些转变将促生哪些工具和服务上?以下是我们目前所知道的。
**00:23:00**:
社区将通过 CNCF 继续改进 Kubernetes,并作为它最重要的使命之一,我们将建立一套全新的容器技术。
容器已经催生了大量新的基础设施,伴随而来的是全新的服务的需求。举个例子让你感受下容器的整合程度和发展速度,仅 Netflix 每周就运行超过一百万个容器。毫不夸张得说,容器是未来的构件。
**00:23:30**:
这一整季的栏目中,我们一直在追踪开源运动的演变。首先看到 Linux 如何主导战场,以及开源理念是如何改变商业、工作流程和每日使用的工具。容器真的是开源运动中最重要的里程碑之一。它们具有很好的迁移性、轻量、易于扩展。
**00:24:00**:
容器技术很好地体现了开源的优势,开源项目自然而然也推动了容器技术的发展。这是一个全新的世界,我们不用再担心从不同计算机或者云间的迁移产生的隔阂。
**00:24:30**:
容器的标准化比任何人预测的都要快。接下来的一集,我们将转向另一场悬而未决的战争。这场云间战争史无前例地催生者行业重量级人物。微软、阿里巴巴、谷歌和亚马逊四家云供应商的摩擦正在升温,随之而来的将是一场暴风骤雨。我们将会追随它们激发的闪电,和广受欢迎的几位代码英雄一起探讨云间战争。
**00:25:00**:
《代码英雄》是红帽公司推出的原创播客栏目。想要了解更多关于本期节目和以往节目的信息,请访问 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 。在那里,你还可以注册我们的新闻资讯。想免费获得新剧集的自动推送,请务必订阅该节目。
只要在苹果播客、Spotify、Google Play、CastBox 中搜索 “Command Line Heroes”,或者通过其他方式收听,并点击订阅,这样你就能在第一时间知道最新剧集。我是 Saron Yitbarek。感谢您的收听,编程不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-1/the-containers-derby>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[lujun9972](https://github.com/lujun9972) 校对:[acyanbird](https://github.com/acyanbird)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The rise of containers opens a new frontier for developers, simplifying the movement of work from machine to machine. As they become more popular, though, a new battle emerges. The race is on for the control of container orchestration and it involves the industry’s fastest, strongest players.
Containers are one of the most important evolutions in the open source movement. In this episode, featured guests—including [ Kelsey Hightower](https://twitter.com/kelseyhightower),
[, and](https://twitter.com/rhein_wein)
__Laura Frank__[—explain how this new technology is the building block of the future and why orchestration is so crucial.](https://twitter.com/smarterclayton)
__Clayton Coleman__*Saron Yitbarek*
So. Have you ever been to a horse race, seen the stallions lined up and pawing the dirt? That's what you need to picture. A race is about to begin, and the outcome is going to turn one of these contenders into a champion.
**00:30** - *Saron Yitbarek*
Only, they're not horses. They're powerhouses of the tech world. What's so important about their race? What prize could be so valuable that they're all lining up and chomping at the bit? This is an all out race to control the orchestration of container technology. And, oh yeah, this isn't like other races. Win this race and you're not just today's champion, you're securing your place as a champion of the future.
**01:00** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat. Episode Five: The Containers Derby. Last time we looked at the rise of DevOps and how a new set of tools is tied to new attitudes about the role of developers. In this episode, we track the rise of containers and how they expand the role of developers even further by supporting new kinds of unbounded work. And we'll see how the standardization of containers laid the track for that race toward container orchestration.
**01:30** - *Saron Yitbarek*
This is a serious race, and a global one, attracting some of the industry's fastest, strongest players. They're all ready to bolt for the finish line. Ready? And they're off.
Now, as those horses leave the gate, maybe we should clarify why this race really matters. Who cares about containers anyway? Well, I do for one, but I didn't know that at first. Here's the quick story on how I woke up to the beauty of container technology.
**02:00** - *Saron Yitbarek*
So, a little while back, I was working on the code base for my website and I brought in my friend Nadia to work on some features. I had been doing a pretty good job on my own keeping my code dry and readable and, of course, well tested. Onboarding a new developer would be easy. Right? Nope, wrong. It was pretty bumpy, especially when we were running specs.
**02:30** - *Saron Yitbarek*
The code worked, but we couldn't get all the tests to pass on both of our machines. We had weird time zone issues. Her version of Ruby on Rails was different from mine. It was the classic case of, "It works on my machine." "Well, it doesn't work on mine." I'd make changes until it worked for me, then it would all break when I sent it to Nadia.
**03:00** - *Saron Yitbarek*
I knew the struggle Nadia and I were going through was something all developers went through, even joked about. I just assumed it was part of the job, something you just gotta put up with. What I didn't realize is that there was finally a solution. Imagine there was a way to lower the barrier between people, a new approach where we can use whatever set of tools we prefer and still pass that work around with ease. Imagine there was a way to keep the work consistent as it moves from development to testing and into production, no matter how many people are working on it, or where those people are. Imagine that I had thought about containers before I wasted weeks doing it the hard way.
**03:30** - *Liz Rice*
A container is really, it's a process.
*Saron Yitbarek*
Liz Rice is a technology evangelist with Aqua Security. She's describing the thing that makes containers so useful, the fact that they wrap everything up in a neat transportable bundle.
**04:00** - *Liz Rice*
It's just like any other process, except it has a very restricted view of the world. So for example, you start a container. The process is given its own root directory, and it thinks that it's looking at the whole root directory of the whole computer, but it's actually only looking at a tiny subset of the file system.
**04:30** - *Saron Yitbarek*
By wrapping up an executable with all its dependencies, containers can run on any laptop or in any virtual machine in the cloud. It comes with its own executables, its own libraries and dependencies. Everything's contained in a container. So, and this is the magic part, a container is going to run exactly the same in every environment. That means developers can share applications without worrying about the old, "Works on my machine," issue.
**05:00** - *Saron Yitbarek*
Here's an analogy that might be helpful. You know Blue Apron? That service that delivers everything you need to make a meal? All nicely divided and portioned, recipe card and everything? Well, imagine if Blue Apron also brought you not just the pre-chopped ingredients, but a kitchen stove, and all your cutlery too. Everything you needed in a nice little box on your doorstep. That's a container. In my case, container technology would have made onboarding my friend Nadia a dream, easy as a Blue Apron dinner. VMs also give you a prepackaged deal, but that's where we have to leave the Blue Apron analogy behind and get to specifics.
**05:30** - *Liz Rice*
A lot of people are under the impression that containers are some sort of lightweight virtualization, lightweight virtual machines, and they're really not. It's very different from virtual machines. So a virtual machine has an entire operating system all to itself, whereas a container is sharing the operating system, you know, all the containers on one machine are sharing the same operating system.
**06:00** - *Saron Yitbarek*
Ultimately, containers and virtual machines are going to work side by side. Containers don't replace VMs. Virtualization is still going to increase efficiency in a date system and it's still crucial for server consolidation. But the rise of containers is opening a new door that was closed to us before. Think of it this way, if we relied on VMs entirely, running all those emulated servers, we'd be creating enormous overhead.
**06:30** - *Saron Yitbarek*
A VM might be gigabytes in size, whereas a container could be 20 megabytes. A VM could take several minutes to boot up. That's not a great pace if I'm trying to deploy web-based APPs. A lightweight, faster alternative to full machine virtualization has been a long time coming.
**07:00** -*Saron Yitbarek*
So a little history. There was a move toward a type of proto-container back in 1979. Developers working on the U nix V7 designed the root system call, which allowed for environments that contained only certain programs. That breakthrough pointed the way to the containers we have today. Another big step forward came with Linux containers in 2008. Now, we had Operation System-level virtualization.
**07:30** - *Saron Yitbarek*
We could finally run several containers using a single Linux kernel and that bypassed the need for full-fledged VMs. That means infrastructure costs start to drop. Not everybody saw the potential for containers right away.
*Laura Frank*
Containerization was really a genesis idea. It was something that was brand new.
*Saron Yitbarek*
Laura Frank is the director of engineering at CloudBees.
**08:00** - *Laura Frank*
Only a very small set of people understood the ins and outs and could operate the technology. And slowly over time, as more people are introduced to the idea and as more people begin to work on it and that knowledge is disseminated through engineering teams and engineering organizations and through communities, it becomes more available.
*Saron Yitbarek*
Because of that similarity to VMs we described earlier, Laura thinks the potential of containers got a bit lost.
**08:30** - *Laura Frank*
I think for where I was in my career and the general everyday technologist, containerization, if you weren't a Sys Admin or someone who had been deep in the guts of Linux, it was still kind of a new concept that I've had just passing familiarity with. So I kind of came to understand it as like, "Oh, this is kind of like how the pattern that I would use a virtual machine for, I can make a disposable environment that's totally isolated and then clean up really well after myself."
*Saron Yitbarek*
Containers were gonna do a lot more than keep things clean, though. They were going to revolutionize an industry. And with the rise of open-sourced projects and communities, soon enough container standardization became possible.
**09:00** - *Scott McCarty*
The interface became very simple.
*Saron Yitbarek*
Scott McCarty works at Red Hat as a senior strategist for containers. He's enough of a veteran that he remembers working at a time not just before containers, but pre-Virtual Machines too.
**09:30** - *Scott McCarty*
I worked at an online retailer in Dot-com 1.0 and we had thousands of physical machines, and we would deploy the same software stack over and over on all these different servers and we tried all different kinds of methodologies. It was really the same problem when you went from raw operating systems to virtual machines and then on to Linux containers, Solaris containers, you still had to manage the configuration across all these different virtual machines, essentially, or constructs that looked like operating system instances.
*Saron Yitbarek*
Once containers became standardized though, all that began to change.
**10:00** -*Scott McCarty*
Like, there were all these very standard ways to deal with this now packed application, and I think that's fundamentally what really changed it all. It just made it really easy to use and then it didn't hurt that they were smaller and faster than virtual machines as well.
**10:30** - *Saron Yitbarek*
Building on the advances made by Linux containers, these new open-source projects and communities took developers by the hand. Some of our anxieties about the back end were swept away. Suddenly containers, and the microservices they facilitated were looking very attractive. Once a common container language emerged barriers fell away and container technology changed the way we worked. It also changed the speed that we could learn about new tech.
**11:00** - *Saron Yitbarek*
Remember all that back and forth with my coworker Nadia? With the whole, "It works on my machine," shtick? That problem doesn't exist in a container world. The developer community saw how fast and cheap and easy containers had become, so much easier than the standard operating systems we'd used before. The rate of adoption has been pretty stunning. But remember: the emergence of a container standard was really just a warm up lap for the real race—orchestration.
The horses line up, the starting pistol fires and they're sprinting at last for the championship. Not for containers themselves, but for the tools that would deploy and manage them.
**11:30** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes. In the race to become the standard container orchestration engine, who would deliver the platform that manages all those containers? At first, there were two contestants who pulled into the lead.
**12:00** - *Saron Yitbarek*
Mesos, driven by Apache, and Swarm, driven by Docker. But then, what's this? A newcomer came tearing down the track. It was Google. Linux had set up the Cloud Native Computing Foundation and CNCF was pushing Google's new open-sourced orchestration engine, Kubernetes.
**12:30** - *Saron Yitbarek*
Now, Mesos and Swarm had headstarts on Kubernetes, right? They were backed by Apache and Docker, which had both been in this race for a while. But Kubernetes had something that the other horses were missing. And Clayton Coleman can tell us what that secret ingredient was. Clayton's an architect for Kubernetes and OpenShift, over at Red Hat.
**13:00** - *Clayton Coleman*
From the very beginning in Kubernetes, Google was very good at opening the project up and making it easy to contribute and participate. There was such a strong focus on making something that would make the majority of developers and operators lives easier. I think Kubernetes and the community around Kubernetes was able to find a sweet spot good enough for the majority of people and extensible enough to solve some of the more extreme use cases.
*Saron Yitbarek*
In the early days, Kubernetes involved engineers from Red Hat and CoreOS and Google. Then, as Kubernetes reached 1.0, people in startups and big companies began adopting it, building off it. And here's the thing. That growth was never dictated by Google, or anybody else.
**13:30** - *Clayton Coleman*
So, the analogy I love to use in this case is Linux. Linux didn't start by Linus writing the kernel and telling everybody in user space how to write GCC or how to go build NGINX or Apache. Instead, the kernel team focused on building a very effective core operating system and working with other open-sourced communities like the GNU project to bring the tools that worked on other Unix's into Linux.
**14:00** - *Clayton Coleman*
And so, many of the tools we run today, no one from the core Linux team has ever contributed to.
But Linux as a whole is much broader than just the kernel, and I think that that pattern is something that we believe Kubernetes is well positioned to take advantage of. And so as we've built community and focused on scoping Kubernetes, we've tried to think of it in terms of a core Kubernetes, which is about the kernel of a distributed cluster operating system.
**14:30** - *Saron Yitbarek*
Kubernetes proved itself incredibly good at building community in an open-sourced world. Just like we saw in Episode Two with the rise of Linux, the winner in today's races is often the one who knows how to rally the community. In fact, while Google may have started Kubernetes, now it really belongs to every developer, and it's managed by the Cloud Native Computing Foundation.
**15:00** - *Saron Yitbarek*
On GitHub, Kubernetes has about 30,000 stars, while Swarm and Mesos have just a few thousand each. That's pretty telling right there. This is technology made by our community, and for our community.
I wanted to understand their attitude. How does a massive for-profit company end up playing so well with others? And I found exactly the right person to answer that question. Kelsey Hightower is a technologist working at Google supporting all things container.
**15:30** - *Saron Yitbarek*
When you think about Google's position, they have a lot of experience doing distributive systems and running things on many, many servers all over the world, so they seem like they were in a really good position to do Kubernetes and to win, and to do this very well. So, when you think about the relationship between Kubernetes and open source, how do you see that relationship?
**16:00** - *Kelsey Hightower*
I think when it comes to infrastructure tools, and even programming languages, right, there's no choice. You can't really have a proprietary tool, even if it's great. Most people probably won't even look at it if it's not open source. And I think the reason there is that most people will adopt technologies like infrastructure tools like Kubernetes, and you may checkpoint yourself and say, "Well, we're gonna stick with this version for four or five years, or we need to modify it for maybe some of our own unique needs."
**16:30** - *Kelsey Hightower*
Once you get to that point, it's gonna be really hard to convince an enterprise to go down the road of, "Hey, it's gonna be $200 per server, and you can't see the source code, so wait for us to modify it."
That road is gone. So I don't know if you can actually do infrastructuring anymore without it being open source. And then the second part of open source would be the community that can be attached to it, which I think Kubernetes nailed out of the gate.
*Saron Yitbarek*
So I wanna go back to the competition. Because it wasn't just Kubernetes as you mentioned yourself, there was Swarm by Docker, there was Mesos by Apache ...
**17:00** - *Kelsey Hightower*
So, I think when people talk about the battle, I don't know if the battle was really between Mesos and Docker, I think the battle was between people that have nothing. Right, you're coming from homegrown Bash scripts, you're still floundering around trying to get to where you need to be, and the market of people not using orchestration tools is much bigger than the people that have already chosen, let's say, Mesos or Swarm.
**17:30** - *Kelsey Hightower*
So that's what the battle is and will remain. So it's really about helping the end users now. Does Mesos or Kubernetes or Docker Swarm become the preferred choice for people looking to get into a better solution? That's all up for debate, but I'll tell you, people like me, the engineers working on this thing, if you put some of the marketing aside, some of the vendors aside, the people that work on this, I use this phrase “different companies, same teams.”
**18:00** - *Kelsey Hightower*
A lot of the tools that we build for each other, they end up in the other products some way or other. Right? A good idea is a good idea. So there's no reason to say, "Oh, that's what the Mesos people are doing, let's ignore it. That's kind of silly. So from an engineering standpoint, and a community standpoint, we cross-pollinate these ideas. You almost need that kind of competition so we can all think independently, the best ideas surface to the top and we pick and choose which ones to adopt that target the users in the right way.
**18:30** - *Kelsey Hightower*
So it's still early in terms of this whole competition thing, and again, this thing is zero dollars. You know what I mean? We're not selling this to anyone directly, so it's really more of a platform play, open for everyone, and then users will choose the ones that meet their needs and that's where I think Kubernetes has done a great job in terms of community, being open, and actually solving problems.
*Saron Yitbarek*
That was very beautiful. I really like this idea of playing on the same team regardless where that team exists. I like it. What do you see is the future of containers and orchestration and maybe even Kubernetes?
**19:00** - *Kelsey Hightower*
Yeah, so I gave a keynote at KubeCon about, like, all of these tools are great. They're all Lego bricks, you know, we got Kubernetes, you may pick another product for security, pick another product for networking, but at the end of the day, as a developer, you really just want to kinda check your coding and expect that code to land in front of your customer somehow, some way. And I think what Kubernetes will become, and containers will become, they will just become the substrate or just the platform pieces for higher level things like serverless.
**19:30** - *Kelsey Hightower*
Right? Here's my code snippet, under the covers, all the platforms will take your code snippet, wrap it up in a container and run it for you, but they don't need to expose all that to you. So in the future, I think as Kubernetes becomes common, and it's going to level the playing field from big or small providers or people that want to do it themselves, to actually be able to offer these things that only cloud providers could have done, because of the expertise required or the investment in software that was required.
This thing will probably end up everywhere, but it'll also be hidden. So it will disappear as it expands.
**20:00** - *Saron Yitbarek*
Kelsey Hightower is staff developer advocate at Google. In the fall of 2017, Docker announced they'd be supporting Kubernetes. They hadn't given up on Swarm, but they have decided to make peace with the obvious winner of the orchestration race.
**20:30** - *Saron Yitbarek*
They weren't alone, either, Azure and AWS both announced native support for Kubernetes. Meanwhile, Kubernetes distros, like OpenShift, are still evolving. What we're getting is a core Kubernetes that can extend and support new use cases, like microservices or continuous integration projects. Clayton Coleman. .
**21:00** - *Clayton Coleman*
That ecosystem will work best with a model that resembles Linux and I think we're well on our way towards that outcome. So this, like all good open source projects, succeeds when everybody is able to participate together to build something that's better than what we could all build individually.
**21:30** - *Saron Yitbarek*
All this is happening fast. It is a race, after all, and that's something we've come to expect from open source. The first lap is almost over before we even had a grip on what containers are. Scott McCarty, from Red Hat.
*Scott McCarty*
So if you think back two years, you know, the container image format was a huge battleground and then I'd say if you go back six months to a year ago, orchestration was a huge battleground. And then if you look at KubeCon 2017 and the weeks leading up to it, pretty much every major vendor has now announced support for Kubernetes. And so, it's pretty obvious Kubernetes has won at this point.
**22:00** - *Saron Yitbarek*
One chapter in the story of containers is coming to a close. Almost as quickly as it began.
*Scott McCarty*
And so Kubernetes has become the standard, and the beauty there is that now application definitions have standardized. So, anybody can use Kubernetes objects in these YAML files and define applications, it's what we wanted for, literally, I've wanted this for like 20 years in dealing with large scale systems.
**22:30** - *Saron Yitbarek*
Kubernetes' success seems pretty concrete, but even after that big race is finished, we're still left with some bigger questions. Are containers going to become the default choice in the next couple years? Are they going to encourage more cloud native development? And what are all the tools and services that these shifts are going to inspire? Here's what we do know.
**23:00** - *Saron Yitbarek*
Through the CNCF, the community will continue to improve Kubernetes and as per the foundation's mission, we're also going to be building a whole new set of container technologies.
Containers are already producing massive new levels of infrastructure and demanding whole new kinds of service. Just to give you a sense of how integral they've become, and how quickly, Netflix alone is launching more than a million containers every week. It's not a stretch to say that containers are the building blocks of the future.
**23:30** - *Saron Yitbarek*
This whole season, we've been tracking the evolution of the open source movement. We've seen how Linux rose to dominance in the first place and how open source attitudes have changed business, workflow, and the tools we use everyday. But containers really are one of the most important evolutions in that open source d movement. They're mobile, they're lightweight, they're easily scalable.
**24:00** - *Saron Yitbarek*
Containers embody the best of open source and it's no wonder open source projects have driven the development of container technology. It's a new world. And we're not gonna be worried anymore about moving from machine to machine, or, in and out of clouds.
**24:30** - *Saron Yitbarek*
The standardization of containers is happening faster than anybody would have predicted. The next episode, we turn to a battle still very much up in the air. The cloud wars are bringing out industry heavyweights like nothing else. Microsoft, Alibaba, Google and Amazon are facing off and the friction from those four cloud vendors is heating up into one serious storm. We're chasing that lightning along with some of our favorite Command Line Heroes, next time in Episode Six.
**25:00** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. For more information about this and past episodes, go to RedHat.com/CommandLineHeroes. Once you're there, you can also sign up for our newsletter. And to get new episodes delivered automatically for free, make sure to subscribe to the show. Just search for Command Line Heroes in Apple Podcast, Spotify, Google Play, CastBox, or however you get your podcasts. Then, hit subscribe, so you'll be the first to know when new episodes are available.
I'm Saron Yitbarek, thanks for listening and keep on coding.
### Keep going
### Power, control structures, and open source
Scott McCarty (aka Father Linux) tells the story of how he became a command line hero—going from punk rocker to open source rebel.
### UNIX/Linux and me
William Henry, Red Hat engineer and technology evangelist, details his operating system adventure, from UNIX to Linux and everything in between.
### Featured in this episode
#### Kelsey Hightower
Google developer advocate
#### Laura Frank
Director of engineering at CloudBees
#### Clayton Coleman
Core contributor to Kubernetes and cloud architect at Red Hat |
12,536 | 凯蒂阿姨的自定义 Mac 终端 | https://opensource.com/article/20/7/mac-terminal | 2020-08-21T00:23:42 | [
"终端",
"Mac"
] | https://linux.cn/article-12536-1.html |
>
> 开源意味着我可以在任何终端上找到熟悉的 Linux。
>
>
>

十年前,我开始了我的第一份工作,它要求我使用 Linux 作为我的笔记本电脑的操作系统。如果我愿意的话,我可以使用各种 Linux 发行版,包括 Gentoo,但由于我过去曾短暂地使用过Ubuntu,所以我选择了 Ubuntu Lucid Lynx 10.04。
我的 [Konsole](https://konsole.kde.org/) 终端使用的是 [Zenburn](https://github.com/brson/zenburn-konsole) 主题,有一个类似于这样的 Bash 提示符:
```
machinename ~/path/to/folder $
```
现在,我使用 Mac,具体来说是 macOS Catalina,我使用 [iTerm2](https://www.iterm2.com/) 与 [Zenburn 主题](https://gist.github.com/fooforge/3373215),zsh 提示符是这样的:
```
machinename ~/path/to/folder
$
```
我想,十年来几乎相同的提示符,我已经赢得了*老古板*的称号,不过这只是标志着,我的喜好和习惯与现在耍酷的孩子们不一样而已。
仿佛是为了证明我的古板观点,我想改变我的终端和我的旧终端一样。在 Mac 上获得一个看起来和感觉像 Lucid Lynx 的设置并不简单,而且我很花了一些时间。
我最近最大的改变是从 Bash 转移到 zsh,并迁移了我的 [Bash 魔改](https://opensource.com/article/20/1/bash-scripts-aliases)。但这只是其中一个重大的转变。我学到了许多新式的经验,现在我把这些经验赠送给你,亲爱的读者。
### Coreutils 对选项的顺序更宽容
从 Ubuntu 转移到 macOS 并没有太大的转变,直到我开始觉得我失去了 Unix 范。我试着运行一些基本的操作,比如删除文件夹,但却被告知我错误地调用了 `rm`。
事实证明,GNU 风格的实用程序可能看起来 BSD 风格的差不多,但最大的可用性差异之一是*参数顺序*。未命名参数的排列顺序并不一致。例如:`rm`。
下面是我们熟悉的 GNU 风格的删除目录的命令:
```
$ rm path/to/folder -rf
```
这与同一命令的 BSD 风格版本形成鲜明对比:
```
$ rm path/to/folder -rf
rm: path/to/folder: is a directory
rm: -rf: No such file or directory
```
我通过 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 安装 [Coreutils](https://formulae.brew.sh/formula/coreutils) 解决了这个问题。这将 GNU 实用程序引入到了 macOS,并使我不必为那些已经深深扎根于我的肌肉记忆中的命令记住选项顺序,从而对选项顺序更加宽容。
### 强大的 iTerm2
我不知道有哪个操作系统的资深用户会对默认终端满意。在 macOS 这块土地上,我选择了 [iTerm2](https://www.iterm2.com/),它允许我比基本的操作系统终端应用更灵活。我最喜欢的 iTerm 强大功能之一是能够使用 `Command+D` 和 `Command+Shift+D` 来垂直和水平分割窗格。还有很多技巧需要学习,但仅是简单的分割窗格就值得用 iTerm2 换掉默认终端。
### 上下文感知的插件
即使是一个古板的用户也会自定义终端提示,其中一个原因是为了获得一些情境感知。我喜欢终端给我提供上下文,并回答所有想到的问题。不仅仅是我在哪个文件夹里,而是:我在什么机器上?这是个 Git 仓库吗?如果是,我在哪个分支?我是在 Python 虚拟环境中吗?
这些问题的答案最终都归结为一类称之为“上下文感知插件”的终端扩展。
对于当前的 Git 分支,我使用了这个 [parse\_git\_branch()](https://gist.github.com/kevinchappell/09ca3805a9531b818579) 方法(如果你使用的是 [Oh My Zsh](https://github.com/ohmyzsh/ohmyzsh/tree/master/plugins/git),也有类似的插件)。对于 Python 来说,virtualenv 会自动给提示符加前缀。Oh My Zsh 有如此多的[插件](https://github.com/ohmyzsh/ohmyzsh/wiki/Plugins),你一定能找到改善你生活的东西。
至于我的本地机?我就直接用 `PS1` 格式,因为我喜欢这样的基本信息,而且 macOS 并没有*真正*让你给机器起个名字。
### 多行提示符也不错
观察力强的读者可能会注意到,十年来我的提示符有一个变化,就是现在它是两行。这是最近的一个变化,我慢慢学会了喜欢,因为我前面提到的所有这些插件都让我的提示符变得很长很长。你在文件系统中导航不能太深,要不你试图做任何基本的事情都会输入换行。随之而来的是偶尔的重绘问题和可读性问题。
我收到的关于解决这个问题的建议大多围绕着“哦,你在用 zsh?用 [Powerlevel10k](https://github.com/romkatv/powerlevel10k) 吧!”这对于像我这样不固步自封的人来说是不错的,但我能够从这些主题中学习到一些,并从中获取一点技巧。
我所做的是在我的提示符中的最后一个 `$` 前加一个 `$'\n'`,这样我的上下文信息 —— 当前机器、当前文件夹、当前 GitHub 分支、当前 virtualenv 等等 —— 都可以在一行中出现,然后我的命令就可以顺利输入了。
我发现唯一的问题是学会在哪里*看*。我习惯于让我的眼睛从行的中心开始,因为以前我的提示符就是从那里开始的。我正在慢慢学会向左看提示符,但这是一个缓慢的过程。我有十几年的眼睛习惯要撤销。
### 使用适合你的方法
如果你喜欢某种风格或工具,那么你的这种偏好是绝对有效的。你可以尝试其他的东西,但千万不要认为你必须使用最新和最伟大的,只是为了像很酷的孩子一样。你的风格和喜好可以随着时间的推移而改变,但千万不要被迫做出对你来说不舒服的改变。
*等下一次,凯蒂阿姨再给你吐槽一下 IDE。*
---
via: <https://opensource.com/article/20/7/mac-terminal>
作者:[Katie McLaughlin](https://opensource.com/users/glasnt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A decade ago, I started my first job that required me to use Linux as my laptop's operating system. I was offered a range of variants, including Gentoo, if I was so inclined, but since I had used Ubuntu briefly in the past, I opted for Ubuntu Lucid Lynx 10.04.
My terminal, [Konsole](https://konsole.kde.org/), was themed in [Zenburn](https://github.com/brson/zenburn-konsole) and had a Bash prompt that looked like this:
`machinename ~/path/to/folder $`
Nowadays, I'm running on a Mac, specifically macOS Catalina using [iTerm2](https://www.iterm2.com/) with the [Zenburn theme](https://gist.github.com/fooforge/3373215) and a zsh prompt that looks like this:
```
machinename ~/path/to/folder
$
```
I think after a decade with a near-identical prompt, I have earned the title of *curmudgeon*, if only as a sign that I have preferences and habits that go against what the cool kids are doing nowadays.
As if to prove my curmudgeonly point, I wanted to change my terminal to match my old one. Getting a setup that looks and feels like Lucid Lynx on Mac isn't simple and took some time.
My biggest recent change was moving from Bash to zsh and migrating my [Bash hacks](https://opensource.com/article/20/1/bash-scripts-aliases). But that was only one of the major shifts. I learned many new-fangled lessons that I now bestow onto you, dear reader.
## Coreutils forgives flag order
Moving from Ubuntu to macOS wasn't too much of a shift until I started thinking I was losing my Unix-foo. I'd try running basic operations like removing folders and be told that I was invoking `rm`
incorrectly.
It turns out that the GNU-style utilities may look like BSD-style utilities, but one of the biggest usability differences is *flag order*. The order in which unnamed parameters are listed does not line up. For instance: `rm`
.
Here's the familiar GNU-style command to remove a directory:
`$ rm path/to/folder -rf`
This contrasts with the BSD-style version of the same command:
```
$ rm path/to/folder -rf
rm: path/to/folder: is a directory
rm: -rf: No such file or directory
```
I got around this by installing [Coreutils](https://formulae.brew.sh/formula/coreutils) through [Homebrew](https://opensource.com/article/20/6/homebrew-mac). This brings GNU utilities to macOS and makes flag order more forgiving by allowing me to not have to remember flag order for commands that are deeply ingrained into my muscle memory.
## iTerm2 is powerful
I'm not sure of any operating system where power users are happy with the default terminal. In macOS land, I settled on [iTerm2](https://www.iterm2.com/), which allows me more flexibility than the base OS's terminal application. One of my favorite iTerm power features is being able to use **Command**+**D** and **Command**+**Shift**+**D** to split panes vertically and horizontally. There are many more tricks to be learned, but easy split panes alone can make iTerm2 worth the switch from the default option.
## Context-aware plugins
One reason even a curmudgeon of a user customizes a terminal prompt is to gain some situational awareness. I enjoy it when a terminal gives me context and answers all the questions that come to mind. Not just what folder I'm in, but: What machine am I on? Is this a Git repository? If so, what branch am I in? Am I in a Python virtual environment?
Answers to these questions go into a category of terminal extensions that can be called "context-aware plugins."
For the current Git branch, I used this [parse_git_branch()](https://gist.github.com/kevinchappell/09ca3805a9531b818579) method (there is a similar plugin for [Oh My Zsh](https://github.com/ohmyzsh/ohmyzsh/tree/master/plugins/git), if you're using that). For Python, virtualenv prefixes to the prompt automatically. Oh My Zsh has so many [plugins](https://github.com/ohmyzsh/ohmyzsh/wiki/Plugins), you're sure to find something to improve your life.
As for my local machine? I just place it directly in the PS1 format because I'm basic like that, and macOS doesn't *really* let you name your machines.
## Multi-line prompts are fine
The observant reader may notice the one change in my prompt over a decade is that it's now two lines. This is a recent change that I'm slowly learning to love because all those plugins I mentioned earlier make my prompt looonnngggg. You can navigate only so deep in a filesystem before you start having line-wrapped command inputs trying to do anything basic. And with that comes occasional redraw issues and readability concerns.
The suggestions I received about resolving this revolved mostly around, "Oh, you're using zsh? Use [Powerlevel10k](https://github.com/romkatv/powerlevel10k)!" Which is fine for those who aren't stuck in their ways, like me. But I was able to learn from these themes and take a small bit of suggestion from them.
What I've done is to add a `$'\n'`
before the final `$`
in my prompt, which allows my context-aware information—current machine, current folder, current GitHub branch, current virtualenv, and the like—to all live on one line, and then my commands can be entered without issues.
The only problem I've found is learning where to *look*. I'm used to having my eyes start at the center of the line because that's where the prompt used to start. I'm slowly learning to look left to the prompt, but it's a slow process. I have a decade of eye training to undo.
## Use what works for you
If you prefer a certain style or tool, then you are absolutely valid in that preference. You can try other things, but never think you have to use the latest and greatest just to be like the cool kids. Your style and preferences can change over time, but never be forced into changes that aren't comfortable for you.
*Join us next time, when Aunty Katie complains about IDEs.*
## 3 Comments |
12,538 | Photoflare:满足简单编辑需求的开源图像编辑器 | https://itsfoss.com/photoflare/ | 2020-08-21T23:37:00 | [
"图像编辑器"
] | https://linux.cn/article-12538-1.html |
>
> Photoflare 是一款可用于 Linux 和 Windows 上的图像编辑器。它有一个免费而开源的社区版本。
>
>
>
在 Linux 上编辑图像时,GIMP 显然是首选。但是,如果你不需要高级编辑功能,GIMP 可能会让人不知所措。这是像 Photoflare 这样的应用立足的地方。
### PhotoFlare:一个简单的图像编辑器

Photoflare 是一个在简单易用的界面里提供了基本的图像编辑功能的编辑器。
它受流行的 Windows 应用 [PhotoFiltre](http://photofiltre.free.fr/frames_en.htm) 的启发。这个程序不是一个克隆品,它是用 C++ 从头开始编写的,并使用 Qt 框架作为界面。
它的功能包括裁剪、翻转/旋转、调整图像大小。你还可以使用诸如油漆刷、油漆桶、喷雾罐、模糊工具和橡皮擦之类的工具。魔术棒工具可让你选择图像的特定区域。
你还可以在图像上添加线条和文本。你还可以更改图像的色调。
你也可以像其他[画图应用](https://itsfoss.com/open-source-paint-apps/)一样从头开始创建图像。
批处理编辑选项可让你同时为多张图片调整大小、转换文件格式和添加滤镜。

### Photoflare 的功能
为了方便参考,我将列出 Photoflare 的主要功能:
* 创建/绘制图像
* 裁剪图像
* 旋转图像
* 调整图像大小
* 使用画笔、油漆桶、喷涂、模糊工具和图像等工具编辑图像
* 在图像上添加线条和文字
* 更改图像的色调
* 添加老照片滤镜
* 批量调整大小、滤镜等
### 在 Linux 上安装 Photflare

在 Photoflare 的网站上,你可以找到定价以及每月订阅的选项。但是,该应用是开源的,它的[源码可在 GitHub 上找到](https://github.com/PhotoFlare/photoflare)。
应用也是“免费”使用的。[定价/订购部分](https://photoflare.io/pricing/)用于该项目的财务支持。你可以免费下载它,如果你喜欢该应用并且会继续使用,请考虑给它捐赠。
Photoflare 有[官方 PPA](https://launchpad.net/~photoflare/+archive/ubuntu/photoflare-stable),适用于 Ubuntu 和基于 Ubuntu 的发行版。此 PPA 可用于 Ubuntu 18.04 和 20.04 版本。
打开终端,逐一输入下面的命令安装 Photoflare:
```
sudo add-apt-repository ppa:photoflare/photoflare-stable
sudo apt update
sudo apt install photoflare
```
要从基于 Ubuntu 的发行版中删除 Photoflare,请使用以下命令:
```
sudo apt remove photoflare
```
最好也删除 PPA:
```
sudo add-apt-repository -r ppa:photoflare/photoflare-stable
```
Arch Linux 和 Manjaro 用户可以[从 AUR 获取](https://aur.archlinux.org/packages/photoflare-git/)。
Fedora 没有现成的软件包,因此你需要获取源码:
* [Photoflare 源代码](https://github.com/PhotoFlare/photoflare)
### Photoflare 的经验
我发现它与 [Pinta](https://itsfoss.com/pinta-new-release/) 有点相似,但功能更多。它是用于基本图像编辑的简单工具。批处理功能是加分项。
我注意到图像在打开编辑时看起来不够清晰。我打开一张截图进行编辑,字体看起来很模糊。但是,保存图像并在[图像查看器](https://itsfoss.com/image-viewers-linux/)中打开后,没有显示此问题。
总之,如果你不需要专业级的图像编辑,它是一个不错的工具。
如果你曾经使用过或会去尝试它,请分享你的 Photoflare 使用经验。
---
via: <https://itsfoss.com/photoflare/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: Photoflare is an image editor available for Linux and Windows. The editor has a free and open source community edition. *
When it comes to image editing on Linux, GIMP is the first and obvious choice. But GIMP could be overwhelming if you don’t need advanced editing feature. This is where applications like Photoflare step in.
## PhotoFlare: A simple image editor

Photoflare is an editor that provides basic image editing features with a simple-to-use interface.
It is inspired by the popular Windows application [PhotoFiltre](http://photofiltre.free.fr/frames_en.htm). The application is not a clone though and it has been written in C++ from scratch and uses Qt framework for the interface.
The features include cropping, flipping/rotating, resizing image. You can also tools like paint brush, paint bucket, spray can, blur tool and eraser. The magic wand tool lets you select a specific area of the image.
You can also add lines and text on an image. You cal also change the hue variation to change the color tone of the image.
You can also create an image from scratch like any other [paint application](https://itsfoss.com/open-source-paint-apps/).
The batch editing option allows you to resize, convert file format and add filter to multiple photos simultaneously.
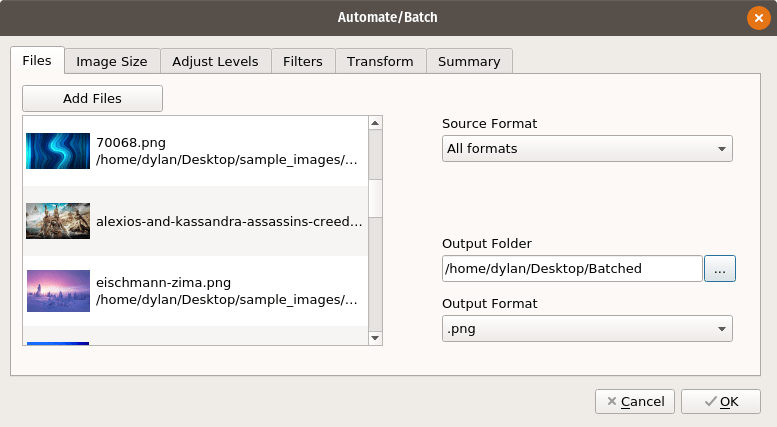
## Features of Photoflare
I’ll list the main features of Photoflare for easier reference:
- Create/draw an image
- Crop an image
- Rotate an image
- Resize image
- Edit images with tools like paint brush, paint bucket, spray, blur tool and image
- Add lines and text on images
- Change the color tone of images
- Add vintage filter
- Batch resize, filter etc
## Installing Photflare on Linux
On the website of Photoflare, you’ll find the pricing and the option for monthly subscription. However, the application is open source and its [source code is available on GitHub](https://github.com/PhotoFlare/photoflare).
The application is also **free** to use. The [pricing/subscription part](https://photoflare.io/pricing/) is for financial support of the project. You can download it for free and if you like the application and would continue to use it, consider donating to the project.
**Install on Ubuntu-based distributions**
Photoflare has an [official PPA](https://launchpad.net/~photoflare/+archive/ubuntu/photoflare-stable) for Ubuntu and Ubuntu based distributions. This PPA is available for Ubuntu 18.04 and 20.04 versions.
Open a terminal and use the following commands one by one to install Photoflare:
```
sudo add-apt-repository ppa:photoflare/photoflare-stable
sudo apt update
sudo apt install photoflare
```
To remove Photoflare from Ubuntu-based distributions, use this command:
`sudo apt remove photoflare`
It would be a good idea to remove the PPA as well:
`sudo add-apt-repository -r ppa:photoflare/photoflare-stable`
**Installing on Arch and Manjaro**
Photoflare is available in the community repository of Arch Linux. So Arch and Manjaro users can install it [using pacman command](https://itsfoss.com/pacman-command/).
**Installing on Fedora and other distribution using Flatpak**
The [Flatpak version of Photoflare](https://flathub.org/apps/details/io.photoflare.photoflare) is also available and you can install it on your distribution if it supports Flatpak.
You can also get the source code and compile it yourself (yes, it’s for you Gentoo users):
## Experience with Photoflare
I find it somewhat similar to [Pinta](https://itsfoss.com/pinta-new-release/) with a bit more features. It is a simple tool for some basic image editing. The batch feature is a plus.
I did notice image doesn’t look sharp when it is opened for editing. I opened a screenshot for editing and the fonts looked blurry. However, after saving the image and opening it in an [image viewer](https://itsfoss.com/image-viewers-linux/) showed no such issue.
Altogether, it is a decent tool if you are not looking for a professional grade image editing.
If you have used it in the past or if you give it a try, do share your experience with Photoflare. |
12,539 | 合并和排序 Linux 上的文件 | https://www.networkworld.com/article/3570508/merging-and-sorting-files-on-linux.html | 2020-08-22T10:23:31 | [
"文件"
] | https://linux.cn/article-12539-1.html | 
在 Linux 上合并和排序文本的方法有很多种,但如何去处理它取决于你试图做什么:你是只想将多个文件的内容放入一个文件中,还是以某种方式组织它,让它更易于使用。在本文中,我们将查看一些用于排序和合并文件内容的命令,并重点介绍结果有何不同。
### 使用 cat
如果你只想将一组文件放到单个文件中,那么 `cat` 命令是一个容易的选择。你所要做的就是输入 `cat`,然后按你希望它们在合并文件中的顺序在命令行中列出这些文件。将命令的输出重定向到要创建的文件。如果指定名称的文件已经存在,那么文件将被覆盖。例如:
```
$ cat firstfile secondfile thirdfile > newfile
```
如果要将一系列文件的内容添加到现有文件中,而不是覆盖它,只需将 `>` 变成 `>>`。
```
$ cat firstfile secondfile thirdfile >> updated_file
```
如果你要合并的文件遵循一些方便的命名约定,那么任务可能更简单。如果可以使用正则表达式指定所有文件名,那就不必列出所有文件。例如,如果文件全部以 `file` 结束,如上所示,你可以进行如下操作:
```
$ cat *file > allfiles
```
请注意,上面的命令将按字母数字顺序添加文件内容。在 Linux 上,一个名为 `filea` 的文件将排在名为 `fileA` 的文件的前面,但会在 `file7` 的后面。毕竟,当我们处理字母数字序列时,我们不仅需要考虑 `ABCDE`,还需要考虑 `0123456789aAbBcCdDeE`。你可以使用 `ls *file` 这样的命令来查看合并文件之前文件的顺序。
注意:首先确保你的命令包含合并文件中所需的所有文件,而不是其他文件,尤其是你使用 `*` 等通配符时。不要忘记,用于合并的文件仍将单独存在,在确认合并后,你可能想要删除这些文件。
### 按时间期限合并文件
如果要基于每个文件的时间期限而不是文件名来合并文件,请使用以下命令:
```
$ for file in `ls -tr myfile.*`; do cat $file >> BigFile.$$; done
```
使用 `-tr` 选项(`t` = 时间,`r` = 反向)将产生按照最早的在最前排列的文件列表。例如,如果你要保留某些活动的日志,并且希望按活动执行的顺序添加内容,则这非常有用。
上面命令中的 `$$` 表示运行命令时的进程 ID。不是很必要使用此功能,但它几乎不可能会无意添加到现有的文件,而不是创建新文件。如果使用 `$$`,那么生成的文件可能如下所示:
```
$ ls -l BigFile.*
-rw-rw-r-- 1 justme justme 931725 Aug 6 12:36 BigFile.582914
```
### 合并和排序文件
Linux 提供了一些有趣的方式来对合并之前或之后的文件内容进行排序。
#### 按字母对内容进行排序
如果要对合并的文件内容进行排序,那么可以使用以下命令对整体内容进行排序:
```
$ cat myfile.1 myfile.2 myfile.3 | sort > newfile
```
如果要按文件对内容进行分组,请使用以下命令对每个文件进行排序,然后再将它添加到新文件中:
```
$ for file in `ls myfile.?`; do sort $file >> newfile; done
```
#### 对文件进行数字排序
要对文件内容进行数字排序,请在 `sort` 中使用 `-n` 选项。仅当文件中的行以数字开头时,此选项才有用。请记住,按照默认顺序,`02` 将小于 `1`。当你要确保行以数字排序时,请使用 `-n` 选项。
```
$ cat myfile.1 myfile.2 myfile.3 | sort -n > xyz
```
如果文件中的行以 `2020-11-03` 或 `2020/11/03`(年月日格式)这样的日期格式开头,`-n` 选项还能让你按日期对内容进行排序。其他格式的日期排序将非常棘手,并且将需要更复杂的命令。
### 使用 paste
`paste` 命令允许你逐行连接文件内容。使用此命令时,合并文件的第一行将包含要合并的每个文件的第一行。以下是示例,其中我使用了大写字母以便于查看行的来源:
```
$ cat file.a
A one
A two
A three
$ paste file.a file.b file.c
A one B one C one
A two B two C two
A three B three C thee
B four C four
C five
```
将输出重定向到另一个文件来保存它:
```
$ paste file.a file.b file.c > merged_content
```
或者,你可以将每个文件的内容在同一行中合并,然后将文件粘贴在一起。这需要使用 `-s`(序列)选项。注意这次的输出如何显示每个文件的内容:
```
$ paste -s file.a file.b file.c
A one A two A three
B one B two B three B four
C one C two C thee C four C five
```
### 使用 join
合并文件的另一个命令是 `join`。`join` 命令让你能基于一个共同字段合并多个文件的内容。例如,你可能有一个包含一组同事的电话的文件,其中,而另一个包含了同事的电子邮件地址,并且两者均按个人姓名列出。你可以使用 `join` 创建一个包含电话和电子邮件地址的文件。
一个重要的限制是文件的行必须是相同的顺序,并在每个文件中包括用于连接的字段。
这是一个示例命令:
```
$ join phone_numbers email_addresses
Sandra 555-456-1234 [email protected]
Pedro 555-540-5405
John 555-333-1234 [email protected]
Nemo 555-123-4567 [email protected]
```
在本例中,即使缺少附加信息,第一个字段(名字)也必须存在于每个文件中,否则命令会因错误而失败。对内容进行排序有帮助,而且可能更容易管理,但只要顺序一致,就不需要这么做。
### 总结
在 Linux 上,你有很多可以合并和排序存储在单独文件中的数据的方式。这些方法可以使原本繁琐的任务变得异常简单。
---
via: <https://www.networkworld.com/article/3570508/merging-and-sorting-files-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,540 | 快来测试 Python 开发工具 pipenv 的新版本 | https://fedoramagazine.org/come-test-a-new-release-of-pipenv-the-python-development-tool/ | 2020-08-22T10:46:00 | [
"Python",
"pipenv"
] | https://linux.cn/article-12540-1.html | 
[pipenv](https://github.com/pypa/pipenv) 是一个可帮助 Python 开发人员维护具有特定一组依赖关系的隔离虚拟环境,以实现可重新复制的开发和部署环境的工具。它类似于其他编程语言中的工具如 bundler、composer、npm、cargo、yarn 等。
最近发布了新版本的 pipenv 2020.6.2。现在可以在 Fedora 33 和 Rawhide 中使用它。对于较旧的 Fedora,维护人员决定打包到 [COPR](https://copr.fedorainfracloud.org/coprs/g/python/pipenv/) 中来先进行测试。所以在他们把它推送到稳定的Fedora版本之前,来试试吧。新版本没有带来任何新颖的功能,但是经过两年的开发,它解决了许多问题,并且在底层做了很多不同的事情。之前可以正常工作的应该可以继续工作,但是可能会略有不同。
### 如何获取
如果你已经在运行 Fedora 33 或 Rawhide,请运行 `$ sudo dnf upgrade pipenv` 或者 `$ sudo dnf install pipenv`,你将获得新版本。
在 Fedora 31 或 Fedora 32 上,你需要使用 [copr 仓库](https://copr.fedorainfracloud.org/coprs/g/python/pipenv/),直到经过测试的包出现在官方仓库中为止。要启用仓库,请运行:
```
$ sudo dnf copr enable @python/pipenv
```
然后将 `pipenv` 升级到新版本,运行:
```
$ sudo dnf upgrade pipenv
```
或者,如果尚未安装,请通过以下方式安装:
```
$ sudo dnf install pipenv
```
如果你需要回滚到官方维护的版本,可以运行:
```
$ sudo dnf copr disable @python/pipenv
$ sudo dnf distro-sync pipenv
```
*COPR 不受 Fedora 基础架构的官方支持。使用软件包需要你自担风险。*
### 如何使用
如果你有用旧版本 `pipenv` 管理的项目,你应该可以毫无问题地使用新版本。如果有问题请让我们知道。
如果你还不熟悉 `pipenv` 或想开始一个新项目,请参考以下快速指南:
创建一个工作目录:
```
$ mkdir new-project && cd new-project
```
使用 Python 3 初始化 `pipenv`:
```
$ pipenv --three
```
安装所需的软件包,例如:
```
$ pipenv install six
```
生成 `Pipfile.lock` 文件:
```
$ pipenv lock
```
现在,你可以将创建的 `Pipfile` 和 `Pipfile.lock` 文件提交到版本控制系统(例如 git)中,其他人可以在克隆的仓库中使用此命令来获得相同的环境:
```
$ pipenv install
```
有关更多示例,请参见 [pipenv 的文档](https://pipenv.pypa.io/en/latest/install/)。
### 如何报告问题
如果你使用新版本的 `pipenv` 遇到任何问题,请[在 Fedora 的 Bugzilla中 报告问题](https://bugzilla.redhat.com/enter_bug.cgi?product=Fedora&component=pipenv)。Fedora 官方仓库和 copr 仓库中 `pipenv` 软件包的维护者是相同的人。请在报告中指出是新版本。
---
via: <https://fedoramagazine.org/come-test-a-new-release-of-pipenv-the-python-development-tool/>
作者:[torsava](https://fedoramagazine.org/author/torsava/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ** Pipenv** is a tool that helps Python developers maintain isolated virtual environments with specifacally defined set of dependencies to achieve reproducible development and deployment environments. It is similar to tools for different programming languages, such as bundler, composer, npm, cargo, yarn, etc.
A new version of pipenv, 2020.6.2, has been recently released. It is now available in Fedora 33 and rawhide. For older Fedoras, the maintainers decided to package it in [COPR](https://copr.fedorainfracloud.org/coprs/g/python/pipenv/) to be tested first. So come try it out, before they push it into stable Fedora versions. The new version doesn’t bring any fancy new features, but after two years of development it fixes a lot of problems and does many things differently under the hood. What worked for you previously should continue to work, but might behave slightly differently.
## How to get it
If you are already running Fedora 33 or rawhide, run *$ sudo dnf upgrade pipenv* or *$ sudo dnf install pipenv* and you’ll get the new version.
On Fedora 31 or Fedora 32, you’ll need to use a [copr repository](https://copr.fedorainfracloud.org/coprs/g/python/pipenv/) until such time comes that the tested package will be updated in the official place. To enable the repository, run:
$ sudo dnf copr enable @python/pipenv
Then to upgrade pipenv to the new version, run:
$ sudo dnf upgrade pipenv
Or, if you haven’t installed it yet, install it via:
$ sudo dnf install pipenv
In case you ever need to roll back to the officially maintained version, you can run:
$ sudo dnf copr disable @python/pipenv
$ sudo dnf distro-sync pipenv
*COPR is not officially supported by Fedora infrastructure. Use packages at your own risk.*
## How to use it
If you already have projects managed by the older version of pipenv, you should be able to use the new version in its place without issues. Let us know if something breaks.
If you are not yet familiar with pipenv or want to start a new project, here is a quick guide:
Create a working directory:
$ mkdir new-project && cd new-project
Initialize pipenv with Python 3:
$ pipenv --three
Install the packages you want, e.g.:
$ pipenv install six
Generate a Pipfile.lock file:
$ pipenv lock
Now you can commit the created Pipfile and Pipfile.lock files into your version control system (e.g. git) and others can use this command in the cloned repository to get the same environment:
$ pipenv install
See [pipenv’s documentation](https://pipenv.pypa.io/en/latest/install/) for more examples.
## How to report problems
If you encounter any problems with the new pipenv version, please [report any issues in Fedora’s Bugzilla](https://bugzilla.redhat.com/enter_bug.cgi?product=Fedora&component=pipenv). The maintainers of the pipenv package in official Fedora repositories and in the copr repository are the same. Please indicate in the text that the report is regarding this new version.
## Artur
The eternal war: pipenv vs virtualenv
## PatM
Hello! FWIW I enjoy using pyenv in conjunction with the pyenv-virtualenv plugin… since I can granularly control both python version and virtualenv from a single interface… https://fijiaaron.wordpress.com/2015/06/18/using-pyenv-with-virtualenv-and-pip-cheat-sheet/
## batisteo
For me it’s virtualenv vs Poetry.
pipenv is totally out of the equation, it’s very bad, buggy and miss a lot a convenient features.
## BigD
And also:
with a pip requirements file.
## DMH
Isn’t it risky to have people install Python packages with dnf instead of using
or
? Life is easier when you use pip for all things Python except the interpreter itself, in my experience. (Using pipenv when you want dependency-managed virtual environments, of course.)
## sloshy
It’s only risky if you do system-wide installs using pip. The problem with using pip exclusively for system wide python modules is that it isn’t really feasible, because an unrelated package might pull a python module as a dependency, so you can’t really avoid installing python modules from dnf, unless you completely avoid anything written in python. That’s why IMO you should install system wide utilities (like jupyter) with dnf even though you can use pip, and use pip install –user or a virtual environment for anything else. I don’t think you’ll run into conflicts using pip install –user, because it lives in your home directory.
## FeRD (Frank Dana)
nodWhat Sloshy said. Usingpipin the system directory is actually themorerisky proposition, because it risks trampling on what DNF is already doing in there.Basically, as long as you
neverrunpipwithsudo(so, IOW, you never let it mess around in/usr/{lib,lib64}/python3.x/site-packages/), then you’ll be OK. DNF will manage all of the system site-packages contents, and you can usepipto manage either/both of your$HOME/.local/lib/python3.x/site-packages/and whatever’s installed into any virtualenvs you create.## Miro Hrončok
Note that 2020.8.13 got out recently and we plan to update the packages in Fedora 33+ as well as in the copr repo to that version soon.
## Weverton
I’ve using poetry for a while and I don’t miss pipenv…
## Svetlozar Argirov
Yeah, pipenv is really terrible. Easily one of the worst package managers I’ve used.
## Géraud
That’s a very harsh judgment. Why would you recommend against pipenv?
## Sergey
https://github.com/pipxproject/pipx
## Sergey
It’s my personal opinion that after containerization all these things have lost their meaning. In Fedora, they even went from collections to modules.
## FeRD (Frank Dana)
Well… I mean, virtualenvs aren’t just for production, they’re also useful when setting up development environments. Or do you suggest even doing development work (or at least development testing/debugging) from within shells running inside container images as well?
(I’m honestly asking, I’d never even really considered that, so I have no immediate position on it one way or the other.)
## Bart
Containerization does not solve dependency resolution for Python.
## FeRD (Frank Dana)
@Bart
From what people are saying, neither does pipenv, really.
But I think Sergey was holding up containerization as a substitute for Python virtualenvs, which is definitely at least somewhat plausible. You’d still need to do dependency management within the container, of course, but you wouldn’t need that tool to do any of the venv-management tasks that have been rolled into so many tools like pipenv.
(Heck, there’s currently an open thread on the Python Discourse where someone is proposing that pip itself DEFAULT to installing packages into a virtualenv, and complain about attempts to use it outside of one.)
## Prediksi skor
I just now wanted to thank you one more time for this amazing web site you have produced here.
It’s full of useful tips for those who are seriously interested in this
kind of subject, primarily this very post. You’re really
all actually sweet plus thoughtful of others in addition to the fact that reading your website posts is an excellent delight if you ask me.
And that of a generous treat! Dan and I will certainly
have enjoyment making use of your suggestions in what we need to
do in the near future. Our listing is a kilometer long and simply put tips is going to be put
to beneficial use.
## Oshan Wisumperuma
https://github.com/python-poetry/poetry
## Bart
Pipenv is so slow and buggy that it is unusable.
Poetry is has a few bugs too but it’s fast and works most of the time. |
12,542 | 5 个开源的 Java IDE 工具 | https://opensource.com/article/20/7/ide-java | 2020-08-22T23:55:12 | [
"Java",
"IDE"
] | https://linux.cn/article-12542-1.html |
>
> Java IDE 工具提供了大量的方法来根据你的独特需求和偏好创建一个编程环境。
>
>
>

通过简化程序员的工作,[Java](https://opensource.com/resources/java) 框架可以使他们的生活更加轻松。这些框架是为了在各种服务器环境上运行各种应用程序而设计开发的;这包括解析注解、扫描描述符、加载配置以及在 Java 虚拟机(JVM)上启动实际的服务等方面的动态行为。控制这么多的任务需要更多的代码,这就很难降低内存占用、加快新应用的启动时间。无论如何,据 [TIOBE 指数](https://www.tiobe.com/tiobe-index/),在当今使用的编程语言中 Java 一直排名前三,拥有着 700 万到 1000 万开发者的社区。
有这么多用 Java 编写的代码,这意味着有一些很好的集成开发环境(IDE)可供选择,可以为开发人员提供有效地编写、整理、测试和运行 Java 应用程序所需的所有工具。
下面,我将按字母顺序介绍五个我最喜欢的用于编写 Java 的开源 IDE 工具,以及如何配置它们的基本功能。
### BlueJ
[BlueJ](https://www.bluej.org/about.html) 为 Java 初学者提供了一个集成的教育性 Java 开发环境。它也可以使用 Java 开发工具包(JDK)开发小型软件。各种版本和操作系统的安装方式都可以在[这里](https://www.bluej.org/versions.html)找到。
在笔记本电脑上安装 BlueJ IDE 后,启动一个新项目,点击<ruby> 项目 <rt> Project </rt></ruby>菜单中的<ruby> 新项目 <rt> New Project </rt></ruby>,然后从创建一个<ruby> 新类 <rt> New Class </rt></ruby>开始编写 Java 代码。生成的示例方法和骨架代码如下所示:

BlueJ 不仅为学校的 Java 编程课的教学提供了一个交互式的图形用户界面(GUI),而且可以让开发人员在不编译源代码的情况下调用函数(即对象、方法、参数)。
### Eclipse
[Eclipse](https://www.eclipse.org/ide/) 是桌面计算机上最著名的 Java IDE 之一,它支持 C/C++、JavaScript 和 PHP 等多种编程语言。它还允许开发者从 Eclipse 市场中的添加无穷无尽的扩展,以获得更多的开发便利。[Eclipse 基金会](https://www.eclipse.org/)提供了一个名为 [Eclipse Che](https://opensource.com/article/19/10/cloud-ide-che) 的 Web IDE,供 DevOps 团队在多个云平台上用托管的工作空间创建出一个敏捷软件开发环境。
[可以在这里下载](https://www.eclipse.org/downloads/);然后你可以创建一个新的项目或从本地目录导入一个现有的项目。在[本文](https://opensource.com/article/19/10/java-basics)中找到更多 Java 开发技巧。

### IntelliJ IDEA
[IntelliJ IDEA CE(社区版)](https://www.jetbrains.com/idea/)是 IntelliJ IDEA 的开源版本,为 Java、Groovy、Kotlin、Rust、Scala 等多种编程语言提供了 IDE。IntelliJ IDEA CE 在有经验的开发人员中也非常受欢迎,可以用它来对现有源码进行重构、代码检查、使用 JUnit 或 TestNG 构建测试用例,以及使用 Maven 或 Ant 构建代码。可在[这里](https://www.jetbrains.org/display/IJOS/Download)下载它。
IntelliJ IDEA CE 带有一些独特的功能;我特别喜欢它的 API 测试器。例如,如果你用 Java 框架实现了一个 REST API,IntelliJ IDEA CE 允许你通过 Swing GUI 设计器来测试 API 的功能。

IntelliJ IDEA CE 是开源的,但其背后的公司也提供了一个商业的终极版。可以在[这里](https://www.jetbrains.com/idea/features/editions_comparison_matrix.html)找到社区版和终极版之间的更多差异。
### Netbeans IDE
[NetBeans IDE](https://netbeans.org/) 是一个 Java 的集成开发环境,它允许开发人员利用 HTML5、JavaScript 和 CSS 等支持的 Web 技术为独立、移动和网络架构制作模块化应用程序。NetBeans IDE 允许开发人员就如何高效管理项目、工具和数据设置多个视图,并帮助他们在新开发人员加入项目时使用 Git 集成进行软件协作开发。
[这里](https://netbeans.org/downloads/8.2/rc/)下载的二进制文件支持 Windows、macOS、Linux 等多个平台。在本地环境中安装了 IDE 工具后,新建项目向导可以帮助你创建一个新项目。例如,向导会生成骨架代码(有部分需要填写,如 `// TODO 代码应用逻辑在此`),然后你可以添加自己的应用代码。
### VSCodium
[VSCodium](https://vscodium.com/) 是一个轻量级、自由的源代码编辑器,允许开发者在 Windows、macOS、Linux 等各种操作系统平台上安装,是基于 [Visual Studio Code](https://opensource.com/article/20/6/open-source-alternatives-vs-code) 的开源替代品。其也是为支持包括 Java、C++、C#、PHP、Go、Python、.NET 在内的多种编程语言的丰富生态系统而设计开发的。Visual Studio Code 默认提供了调试、智能代码完成、语法高亮和代码重构功能,以提高开发的代码质量。
在其[资源库](https://github.com/VSCodium/vscodium#downloadinstall)中有很多下载项。当你运行 Visual Studio Code 时,你可以通过点击左侧活动栏中的“扩展”图标或按下 `Ctrl+Shift+X` 键来添加新的功能和主题。例如,当你在搜索框中输入 “quarkus” 时,就会出现 Visual Studio Code 的 Quarkus 工具,该扩展允许你[在 VS Code 中使用 Quarkus 编写 Java](https://opensource.com/article/20/4/java-quarkus-vs-code):

### 总结
Java 作为最广泛使用的编程语言和环境之一,这五种只是 Java 开发者可以使用的各种开源 IDE 工具的一小部分。可能很难知道哪一个是正确的选择。和以往一样,这取决于你的具体需求和目标 —— 你想实现什么样的工作负载(Web、移动应用、消息传递、数据交易),以及你将使用 IDE 扩展功能部署什么样的运行时(本地、云、Kubernetes、无服务器)。虽然丰富的选择可能会让人不知所措,但这也意味着你可能可以找到一个适合你的特殊情况和偏好的选择。
你有喜欢的开源 Java IDE 吗?请在评论中分享吧。
---
via: <https://opensource.com/article/20/7/ide-java>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Java](https://opensource.com/resources/java) frameworks make life easier for programmers by streamlining their work. These frameworks were designed and developed to run any application on any server environment; that includes dynamic behaviors in terms of parsing annotations, scanning descriptors, loading configurations, and launching the actual services on a Java virtual machine (JVM). Controlling this much scope requires more code, making it difficult to minimize memory footprint or speed up startup times for new applications. Regardless, Java consistently ranks in the top three of programming languages in use today with a community of seven to ten million developers in the [TIOBE Index](https://www.tiobe.com/tiobe-index/).
With all that code written in Java, that means there are some great options for integrated development environments (IDE) to give developers all the tools needed to effectively write, lint, test, and run Java applications.
Below, I introduce—in alphabetical order—my five favorite open source IDE tools to write Java and how to configure their basics.
## BlueJ
[BlueJ](https://opensource.com/article/20/2/learn-java-bluej) provides an integrated educational Java development environment for Java beginners. It also aids in developing small-scale software using the Java Development Kit (JDK). The installation options for a variety of versions and operating systems are available [here](https://www.bluej.org/versions.html).
Once you install the BlueJ IDE on your laptop, start a new project. Click on New Project in the Project menu then begin writing Java codes from New Class. Sample methods and skeleton codes will be generated as below:
BlueJ not only provides an interactive graphical user interface (GUI) for teaching Java programming courses in schools but also allows developers to invoke functions (i.e., objects, methods, parameters) without source code compilation.
## Eclipse
[Eclipse](https://www.eclipse.org/ide/) is one of the most famous Java IDEs based on the desktop, and it supports a variety of programming languages such as C/C++, JavaScript, and PHP. It also allows developers to add unlimited extensions from the Eclipse Marketplace for more development conveniences. [Eclipse Foundation](https://www.eclipse.org/) provides a Web IDE called [Eclipse Che](https://opensource.com/article/19/10/cloud-ide-che) for DevOps teams to spin up an agile software development environment with hosted workspaces on multiple cloud platforms.
[The download](https://www.eclipse.org/downloads/) is available here; then you can create a new project or import an existing project from the local directory. Find more Java development tips in [this article](https://opensource.com/article/19/10/java-basics).
## IntelliJ IDEA
[IntelliJ IDEA CE (Community Edition)](https://www.jetbrains.com/idea/) is the open source version of IntelliJ IDEA, providing an IDE for multiple programming languages (i.e., Java, Groovy, Kotlin, Rust, Scala). IntelliJ IDEA CE is also very popular for experienced developers to use for existing source refactoring, code inspections, building testing cases with JUnit or TestNG, and building codes using Maven or Ant. Downloadable binaries are available [here](https://www.jetbrains.org/display/IJOS/Download).
IntelliJ IDEA CE comes with some unique features; I particularly like the API tester. For example, if you implement a REST API with a Java framework, IntelliJ IDEA CE allows you to test the API's functionality via Swing GUI designer:
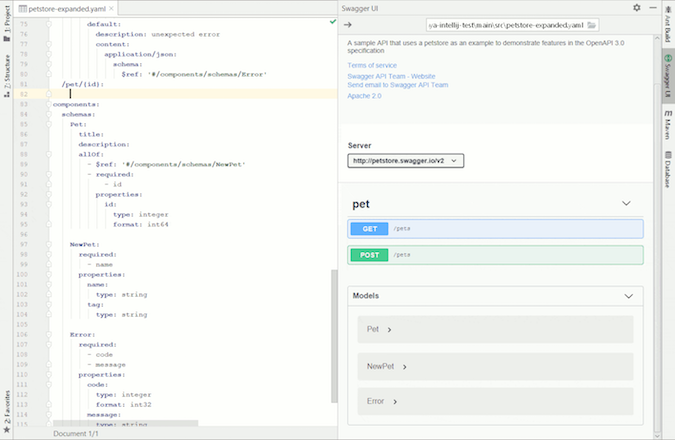
IntelliJ IDEA CE is open source, but the company behind it has a commercial option. Find more differences between the Community Edition and the Ultimate [here](https://www.jetbrains.com/idea/features/editions_comparison_matrix.html).
## Netbeans IDE
[NetBeans IDE](https://netbeans.org/) is an integrated Java development environment that allows developers to craft modular applications for standalone, mobile, and web architecture with supported web technologies (i.e., HTML5, JavaScript, and CSS). NetBeans IDE allows developers to set up multiple views on how to manage projects, tools, and data efficiently and helps them collaborate on software development—using Git integration—when a new developer joins the project.
Download binaries are available [here](https://netbeans.apache.org/download/index.html) for multiple platforms (i.e., Windows, macOS, Linux). Once you install the IDE tool in your local environment, the New Project wizard helps you create a new project. For example, the wizard generates the skeleton codes (with sections to fill in like `// TODO code application logic here`
) then you can add your own application codes.
## VSCodium
[VSCodium](https://vscodium.com/) is a lightweight, free source code editor that allows developers to install a variety of OS platforms (i.e., Windows, macOS, Linux) and is an open source alternative based on [Visual Studio Code](https://opensource.com/article/20/6/open-source-alternatives-vs-code). It was also designed and developed to support a rich ecosystem for multiple programming languages (i.e., Java, C++, C#, PHP, Go, Python, .NET). For high code quality, Visual Studio Code provides debugging, intelligent code completion, syntax highlighting, and code refactoring by default.
There are many download options available in the [repository](https://github.com/VSCodium/vscodium#downloadinstall). When you run the Visual Studio Code, you can add new features and themes by clicking on the Extensions icon in the activity bar on the left side or by pressing Ctrl+Shift+X in the keyboard. For example, the Quarkus Tools for Visual Studio Code comes up when you type "quarkus" in the search box. The extension allows you to use helpful tools for [writing Java with Quarkus in VS Code](https://opensource.com/article/20/4/java-quarkus-vs-code):
## Wrapping up
Java being one of the most widely used programming languages and environments, these five are just a fraction of the different open source IDE tools available for Java developers. It can be hard to know which is the right one to choose. As always, it depends on your specific needs and goals—what kinds of workloads (web, mobile, messaging, data transaction) you want to implement and what runtimes (local, cloud, Kubernetes, serverless) you will deploy using IDE extended features. While the wealth of options out there can be overwhelming, it does also mean that you can probably find one that suits your particular circumstances and preferences.
Do you have a favorite open source Java IDE? Share it in the comments!
## 5 Comments |
12,543 | FreeFileSync:开源的文件同步工具 | https://itsfoss.com/freefilesync/ | 2020-08-23T06:05:39 | [
"同步"
] | https://linux.cn/article-12543-1.html |
>
> FreeFileSync 是一个开源的文件夹比较和同步工具,你可以使用它将数据备份到外部磁盘、云服务(如 Google Drive)或任何其他存储路径。
>
>
>
### FreeFileSync:一个免费且开源的同步工具

[FreeFileSync](https://freefilesync.org/) 是一个令人印象深刻的开源工具,可以帮助你将数据备份到其他位置。
它们可以是外部 USB 磁盘、Google Drive 或使用 **SFTP 或 FTP** 连接到任何云存储。
你可能之前读过我们的[如何在 Linux 上使用 Google Drive](https://itsfoss.com/use-google-drive-linux/) 的教程。不幸的是,没有合适的在 Linux 上原生使用 Google Drive 的 FOSS 方案。有个 [Insync](https://itsfoss.com/recommends/insync/),但它是收费软件而非开源软件。
FreeFileSync 可使用 Google Drive 帐户同步文件。事实上,我用它把我的文件同步到 Google Drive 和一个单独的硬盘上。
### FreeFileSync 的功能

尽管 FreeFileSync 的 UI 看起来可能很老,但它为普通用户和高级用户提供了许多有用的功能。
我将在此处把所有能重点介绍的功能都介绍出来:
* 跨平台支持(Windows、macOS 和 Linux)
* 同步前比较文件夹
* 支持 Google Drive、[SFTP](https://en.wikipedia.org/wiki/SSH_File_Transfer_Protocol) 和 FTP 连接
* 提供在不同的存储路径(或外部存储设备)上同步文件的能力
* 多个可用的同步选项(从源更新文件到目标或镜像目标和源之间的文件)
* 支持双向同步(如果目标文件夹或源文件夹有任何修改,将同步更改)
* 适用于高级用户的版本控制
* 可进行实时同步
* 能安排批处理作业
* 同步完成时通过电子邮件收到通知(付费)
* 便携式版(付费)
* 并行文件复制(付费)
如果你看一下它提供的功能,它不仅是普通的同步工具,而且还免费提供了更多功能。
此外,为了让你了解,你还可以在同步文件之前先比较它们。例如,你可以比较文件内容/文件时间,或者简单地比较源文件夹和目标文件夹的文件大小。

你还有许多同步选项来镜像或更新数据。如下所示:

但是,它也为你提供了捐赠密钥的可选选项,它可解锁一些特殊功能,如在同步完成时通过电子邮件通知你等。
以下是免费版本和付费版本的不同:

因此,大多数基本功能是免费的。高级功能主要是针对高级用户,当然,如果你想支持他们也可以。(如果你觉得它有用,请这么做)。
此外,请注意,捐赠版单用户最多可在 3 台设备上使用。所以,这绝对不差!
### 在 Linux 上安装 FreeFileSync
你可以前往它的[官方下载页面](https://freefilesync.org/download.php),并下载 Linux 的 tar.gz 文件。如果你喜欢,你还可以下载源码。

接下来,你只需解压并运行可执行文件就可以了(如上图所示)
* [下载 FreeFileSync](https://freefilesync.org/)
### 如何开始使用 FreeFileSync?
虽然我还没有成功地尝试过创建自动同步作业,但它很容易使用。
[官方文档](https://freefilesync.org/manual.php)应该足以让你获得想要的。
但是,为了让你初步了解,这里有一些事情,你应该记住。

如上面的截图所示,你只需选择源文件夹和要同步的目标文件夹。你可以选择本地文件夹或云存储位置。
完成后,你需要选择在同步中文件夹比较的类型(通常是文件时间和大小),在右侧,你可以调整要执行的同步类型。
#### FreeFileSync 的同步类型
当你选择 “更新” 的方式进行同步时,它只需将新数据从源文件夹复制到目标文件夹。因此,即使你从源文件夹中删除了某些东西,它也不会在目标文件夹中被删除。
如果你希望目标文件夹有相同的文件副本,可以选择 “镜像”同步方式。这样,如果你从源文件夹中删除内容,它就会从目标文件夹中删除。
还有一个 “双向” 同步方式,它检测源文件夹和目标文件夹的更改(而不是只监视源文件夹)。因此,如果对源/目标文件夹进行了任何更改,都将同步修改。
有关更高级的用法,我建议你参考[文档](https://freefilesync.org/manual.php)。
### 总结
还有一个[开源文件同步工具是 Syncthing](https://itsfoss.com/syncthing/),你可能想要看看。
FreeFileSync 是一个相当被低估的文件夹比较和同步工具,适用于使用 Google Drive、SFTP 或 FTP 连接以及单独的存储位置进行备份的 Linux 用户。
而且,所有这些功能都免费提供对 Windows、macOS 和 Linux 的跨平台支持。
这难道不令人兴奋吗?请在下面的评论,让我知道你对 Freefilesync 的看法。
---
via: <https://itsfoss.com/freefilesync/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

FreeFileSync is **a free and open-source folder comparison and sync tool** with which you can back up your data to an external disk, a cloud service like Google Drive or any other storage path.
So, let's dive in and see what it is all about.
[FreeFileSync](https://freefilesync.org/?ref=itsfoss.com) is an impressive open-source tool that can help you back up your data to a different location.
This different location can be an external USB disk, Google Drive or any of your cloud storage locations using **SFTP or FTP** connections.
You might have read our tutorial on [how to use Google Drive on Linux](https://itsfoss.com/use-google-drive-linux/) before. Unfortunately, there’s no proper, free FOSS solution to use Google Drive natively on Linux, tools like FreeFileSync are as close as one can get.
FreeFileSync can be used to sync files with your Google Drive account. In fact, I have been using it to sync my files to Google Drive and to a separate hard drive.
## Features of FreeFileSync

Even though the UI of FreeFileSync might look old school — it offers a ton of useful features for both average and advanced users as well.
I’ll highlight some **key features** here:
- Cross-Platform Support (Linux, Windows, and macOS)
- Compare Folders before Synchronizing
- Supports Google Drive,
[SFTP](https://en.wikipedia.org/wiki/SSH_File_Transfer_Protocol?ref=itsfoss.com), and[FTP](https://en.wikipedia.org/wiki/File_Transfer_Protocol)connections - Two-way Synchronization Support
- Version control for Advanced Users
- Real-Time Sync Options
- Ability to Schedule Batch Jobs
So, if you take a look at the features it offers, it’s not just like any ordinary sync tool. But, also offers a lot free of charge.
Furthermore, to give you an idea how FreeFileSync works. You can compare the file content/file time or simply compare the file size of both source and target folder as shown below.
You also get **numerous synchronization options** to mirror or update your data. Here’s how it looks like:
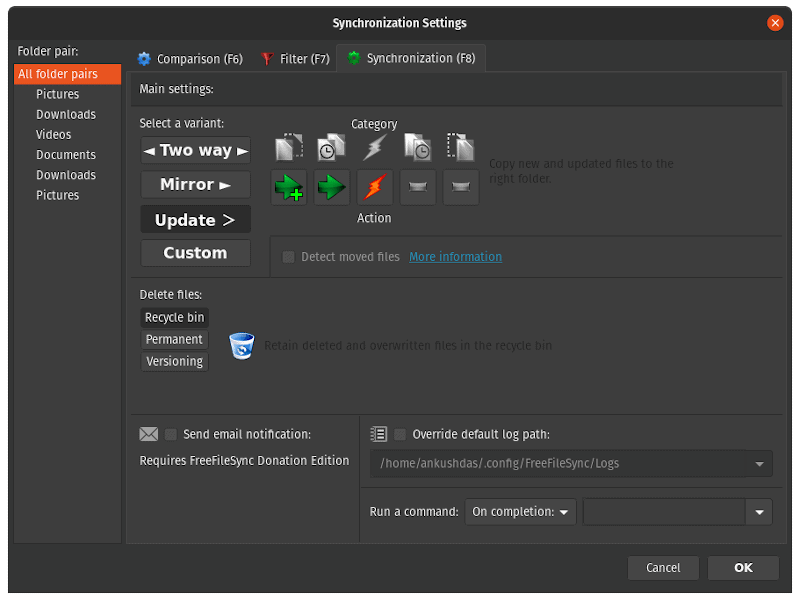
Seeing that the **essential features are available for free**. Should you choose to, you can donate something so that the project is kept alive with regular updates. You will find this page in the downloads section of the project website.
## Installing FreeFileSync on Linux
You can simply head on to its [official download page](https://freefilesync.org/download.php?ref=itsfoss.com) and grab the *tar.gz*** **file for Linux. If you like, you can download the source code as well.
After downloading, you just need to extract the archive and run the executable file to get started (as shown above).
## Getting Started With FreeFileSync
While I haven’t tried to successfully create an automatic sync job, it is pretty easy to use.
The [official documentation](https://freefilesync.org/manual.php?ref=itsfoss.com) should be more than enough to get what you want using the software. But, just to give you a head start, **here are a few things that you should keep in mind**.
As illustrated by the screenshot above, you have to select a source folder and the target folder to sync. You can choose a local folder or a cloud storage location in either case.
Once you do that, you need to tweak the type of folder comparison you want to do (usually the file time & size) for the synchronization process. And on the right-side, you get to tweak the type of sync that you would like to perform.
**Suggested Read 📖**
[Insync: The Hassleless Way of Using Google Drive on LinuxInsync can be your all-in-one solution to sync files to the cloud for Google Drive, OneDrive, and Dropbox.](https://itsfoss.com/insync-linux-review/)

### Types of synchronization in FreeFileSync
When you select the “**Update**” method for sync, it simply copies newer data from the source folder to the target folder. So, even if you delete something from your source folder, it won’t get deleted from your target folder.
In case you want the target folder to have the same file copies as your source folder, you can select the “**Mirror**” synchronization method. So, here, if you delete something from your source folder, it gets deleted from your target folder as well.
There’s also a “**Two way**” sync method, which detects changes on both source and target folders (instead of monitoring just the source folder). So, if you make any changes to the source/target folder, the modification will be synchronized on both folders.
For more advanced usage instructions, I suggest you refer to the [official documentation](https://freefilesync.org/manual.php?ref=itsfoss.com).
## Wrapping Up
Another open-source file synchronization tool that comes to mind is the popular [Syncthing](https://itsfoss.com/syncthing/), you might want to look at if you are looking for something different.
FreeFileSync is** a pretty underrated folder comparison and sync tool** available for Linux. Users who utilize Google Drive, SFTP, or FTP connections along with separate storage locations for backup should find it very useful.
All of this comes with cross-platform support for Linux, Windows, and macOS for free!
*💬 Isn’t that exciting? Let me know your thoughts on FreeFileSync in the comments below!* |
12,545 | 一次让字体看起来更像手写体的尝试 | https://jvns.ca/blog/2020/08/08/handwritten-font/ | 2020-08-24T11:11:16 | [
"字体",
"OpenType"
] | https://linux.cn/article-12545-1.html | 
其实我对这个实验的结果并不是特别满意,但我还是想分享一下,因为摆弄字体是件非常简单和有趣的事情。而且有人问我怎么做,我告诉她我会写一篇博文来介绍一下 :smiley:
### 背景:原本的手写体
先交代一些背景信息:我有一个我自己的手写字体,我已经在我的电子杂志中使用了好几年了。我用一个叫 [iFontMaker](https://2ttf.com/) 的令人愉快的应用程序制作了它。他们在网站上自诩为“你可以在 5 分钟内只用手指就能制作出你的手工字体”。根据我的经验,“5 分钟”的部分比较准确 —— 我可能花了更多的时间,比如 15 分钟。我对“只用手指”的说法持怀疑态度 —— 我用的是 Apple Pencil,它的精确度要好得多。但是,使用该应用程序制作你的笔迹的 TTF 字体是非常容易的,如果你碰巧已经有了 Apple Pencil 和 iPad,我认为这是一个有趣的方式,我只花了 7.99 美元。
下面是我的字体的样子。左边的“CONNECT”文字是我的实际笔迹,右边的段落是字体。其实有 2 种字体 —— 有一种是普通字体,一种是手写的“等宽”字体。(其实实际并不是等宽,我还没有想好如何在 iFontMaker 中制作一个实际的等宽字体)

### 目标:在字体上做更多的字符变化
在上面的截图中,很明显可以看出这是一种字体,而不是实际的笔迹。当你有两个相同的字母相邻时,就最容易看出来,比如“HTTP”。
所以我想,使用一些 OpenType 的功能,以某种方式为这个字体引入更多的变化,比如也许两个 “T” 可以是不同的。不过我不知道该怎么做!
### 来自 Tristan Hume 的主意:使用 OpenType!
然后我在 5 月份的 !!Con 2020 上(所有的[演讲录音都在这里!](http://bangbangcon.com/recordings.html))看到了 Tristan Hume 的这个演讲:关于使用 OpenType 通过特殊的字体将逗号插入到大的数字中。他的演讲和博文都很棒,所以这里有一堆链接 —— 下面现场演示也许是最快看到他的成果的方式。
* 一个现场演示: [Numderline 测试](https://thume.ca/numderline/)
* 博客文章:[将逗号插入到大的数字的各个位置:OpenType 冒险](https://blog.janestreet.com/commas-in-big-numbers-everywhere/)
* 谈话:[!!Con 2020 - 使用字体塑型,把逗号插入到大的数字的各个位置!](https://www.youtube.com/watch?v=Biqm9ndNyC8)
* GitHub 存储库: <https://github.com/trishume/numderline/blob/master/patcher.py>
### 基本思路:OpenType 允许你根据上下文替换字符
我一开始对 OpenType 到底是什么非常困惑。目前我仍然不甚了然,但我知道到你可以编写极其简单的 OpenType 规则来改变字体的外观,而且你甚至不需要真正了解字体。
下面是一个规则示例:
```
sub a' b by other_a;
```
这里 `sub a' b by other_a;` 的意思是:如果一个 `a` 字形是在一个 `b` 之前,那么替换 `a` 为字形 `other_a`。
所以这意味着我可以让 `ab` 和 `ac` 在字体中出现不同的字形。这并不像手写体那样随机,但它确实引入了一点变化。
### OpenType 参考文档:真棒
我找到的最好的 OpenType 文档是这个 [OpenType™ 特性文件规范](https://adobe-type-tools.github.io/afdko/OpenTypeFeatureFileSpecification.html) 资料。里面有很多你可以做的很酷的事情的例子,比如用一个连字替换 “ffi”。
### 如何应用这些规则:fonttools
为字体添加新的 OpenType 规则是超容易的。有一个 Python 库叫 `fonttools`,这 5 行代码会把放在 `rules.fea` 中的 OpenType 规则列表应用到字体文件 `input.ttf` 中。
```
from fontTools.ttLib import TTFont
from fontTools.feaLib.builder import addOpenTypeFeatures
ft_font = TTFont('input.ttf')
addOpenTypeFeatures(ft_font, 'rules.fea', tables=['GSUB'])
ft_font.save('output.ttf')
```
`fontTools` 还提供了几个名为 `ttx` 和 `fonttools` 的命令行工具。`ttx` 可以将 TTF 字体转换为 XML 文件,这对我很有用,因为我想重新命名我的字体中的一些字形,但我对字体一无所知。所以我只是将我的字体转换为 XML 文件,使用 `sed` 重命名字形,然后再次使用 `ttx` 将 XML 文件转换回 `ttf`。
`fonttools merge` 可以让我把我的 3 个手写字体合并成 1 个,这样我就在 1 个文件中得到了我需要的所有字形。
### 代码
我把我的极潦草的代码放在一个叫 [font-mixer](https://github.com/jvns/font-mixer/) 的存储库里。它大概有 33 行代码,我认为它不言自明。(都在 `run.sh` 和 `combine.py` 中)
### 结果
下面是旧字体和新字体的小样。我不认为新字体的“感觉”更像手写体 —— 有更多的变化,但还是比不上实际的手写体文字(在下面)。
我觉得稍微有点不可思议,它明明还是一种字体,但它却要假装成不是字体:

而这是实际手写的同样的文字的样本:

如果我在制作另外 2 种手写字体的时候,把原来的字体混合在一起,再仔细一点,可能效果会更好。
### 添加 OpenType 规则这么容易,真酷!
这里最让我欣喜的是,添加 OpenType 规则来改变字体的工作方式是如此的容易,比如你可以很容易地做出一个“the”单词总是被“teh”代替的字体(让错别字一直留着!)。
不过我还是不知道如何做出更逼真的手写字体:)。我现在还在用旧的那个字体(没有额外的变化),我对它很满意。
---
via: <https://jvns.ca/blog/2020/08/08/handwritten-font/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
12,546 | IBM 披露了下一代 POWER10 处理器细节 | https://www.networkworld.com/article/3571415/ibm-details-next-gen-power10-processor.html | 2020-08-24T11:49:04 | [
"IBM",
"CPU"
] | https://linux.cn/article-12546-1.html | 
>
> 新的 CPU 针对企业混合云和 AI 推断进行了优化,它采用了为 PB 级内存集群开发的新技术。
>
>
>
IBM 上周一公布了最新的 POWER RISC CPU 系列,该系列针对企业混合云计算和人工智能 (AI)推理进行了优化,同时还进行了其他一些改进。
Power 是上世纪 90 年代最后一款 Unix 处理器,当时 Sun Microsystems、HP、SGI 和 IBM 都有竞争性的 Unix 系统,以及与之配合的 RISC 处理器。后来,Unix 让位给了 Linux,RISC 让位给了 x86,但 IBM 坚持了下来。
这是 IBM 的第一款 7 纳米处理器,IBM 宣称它将在与前代 POWER9 相同的功率范围内,将容量和处理器能效提升多达三倍。该处理器采用 15 核设计(实际上是 16 核,但其中一个没有使用),并允许采用单芯片或双芯片型号,因此 IBM 可以在同一外形尺寸中放入两个处理器。每个核心最多可以有 8 个线程,每块 CPU 最多支持 4TB 的内存。
更有趣的是一种名为 Memory Inception 的新内存集群技术。这种形式的集群允许系统将另一台物理服务器中的内存当作自己的内存来看待。因此,服务器不需要在每个机箱中放很多内存,而是可以在内存需求激增的时候,从邻居那里借到内存。或者,管理员可以在集群的中间设置一台拥有大量内存的服务器,并在其周围设置一些低内存服务器,这些服务器可以根据需要从大内存服务器上借用内存。
所有这些都是在 50 到 100 纳秒的延迟下完成的。IBM 的杰出工程师 William Starke 在宣布前的视频会议上说:“这已经成为行业的圣杯了。与其在每个机器里放很多内存,不如当我们对内存的需求激增时,我可以向邻居借。”
POWER10 使用的是一种叫做开放内存接口(OMI)的东西,因此服务器现在可以使用 DDR4,上市后可以升级到 DDR5,它还可以使用 GPU 中使用的 GDDR6 内存。理论上,POWER10 将具备 1TB/秒的内存带宽和 1TB/秒的 SMP 带宽。
与 POWER9 相比,POWER10 处理器每个核心的 AES 加密引擎数量增加了四倍。这实现了多项安全增强功能。首先,这意味着在不降低性能的情况下进行全内存加密,因此入侵者无法扫描内存内容。
其次,它可以为容器提供隔离的硬件和软件安全。这是为了解决更高密度的容器相关的行安全考虑。如果一个容器被入侵,POWER10 处理器的设计能够防止同一虚拟机中的其他容器受到同样的入侵影响。
最后,POWER10 提供了核心内的 AI 业务推断。它通过片上支持用于训练的 bfloat16 以及 AI 推断中常用的 INT8 和 INT4 实现。这将允许事务性负载在应用中添加 AI 推断。IBM 表示,POWER10 中的 AI 推断是 POWER9 的 20 倍。
公告中没有提到的是对操作系统的支持。POWER 运行 IBM 的 Unix 分支 AIX,以及 Linux。这并不太令人惊讶,因为这个消息是在 Hot Chips 上发布的,Hot Chips 是每年在斯坦福大学举行的年度半导体会议。Hot Chips 关注的是最新的芯片进展,所以软件通常被排除在外。
IBM 一般会在发布前一年左右公布新的 POWER 处理器,所以有足够的时间进行 AIX 的更新。
---
via: <https://www.networkworld.com/article/3571415/ibm-details-next-gen-power10-processor.html>
作者:[Andy Patrizio](https://www.networkworld.com/author/Andy-Patrizio/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,549 | 使用 MinGW 在 Windows 上使用 GNU | https://opensource.com/article/20/8/gnu-windows-mingw | 2020-08-25T08:57:00 | [
"Windows",
"GNU",
"MinGW"
] | https://linux.cn/article-12549-1.html |
>
> 在 Windows 上安装 GNU 编译器集合(gcc)和其他 GNU 组件来启用 GNU Autotools。
>
>
>

如果你是一名使用 Windows 的黑客,你不需要专有应用来编译代码。借助 [Minimalist GNU for Windows](http://mingw.org)(MinGW)项目,你可以下载并安装 [GNU 编译器集合(GCC)](https://gcc.gnu.org/)以及其它几个基本的 GNU 组件,以在 Windows 计算机上启用 [GNU Autotools](https://opensource.com/article/19/7/introduction-gnu-autotools)。
### 安装 MinGW
安装 MinGW 的最简单方法是通过 mingw-get,它是一个图形用户界面 (GUI) 应用,可帮助你选择要安装哪些组件,并让它们保持最新。要运行它,请从项目主页[下载 mingw-get-setup.exe](https://osdn.net/projects/mingw/releases/)。像你安装其他 EXE 一样,在向导中单击完成安装。

### 在 Windows 上安装 GCC
目前为止,你只安装了一个程序,或者更准确地说,一个称为 mingw-get 的专用的*包管理器*。启动 mingw-get 选择要在计算机上安装的 MinGW 项目应用。
首先,从应用菜单中选择 mingw-get 启动它。

要安装 GCC,请单击 GCC 和 G++ 包来标记要安装 GNU C、C++ 编译器。要完成此过程,请从 mingw-get 窗口左上角的**安装**菜单中选择**应用更改**。
安装 GCC 后,你可以使用完整路径在 [PowerShell](https://opensource.com/article/19/8/variables-powershell) 中运行它:
```
PS> C:\MinGW\bin\gcc.exe --version
gcc.exe (MinGW.org GCC Build-x) x.y.z
Copyright (C) 2019 Free Software Foundation, Inc.
```
### 在 Windows 上运行 Bash
虽然它自称 “minimalist”(最小化),但 MinGW 还提供一个可选的 [Bourne shell](https://en.wikipedia.org/wiki/Bourne_shell) 命令行解释器,称为 MSYS(它代表<ruby> 最小系统 <rt> Minimal System </rt></ruby>)。它是微软的 `cmd.exe` 和 PowerShell 的替代方案,它默认是 Bash。除了是(自然而然的)最流行的 shell 之一外,Bash 在将开源应用移植到 Windows 平台时很有用,因为许多开源项目都假定了 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 环境。
你可以在 mingw-get GUI 或 PowerShell 内安装 MSYS:
```
PS> mingw-get install msys
```
要尝试 Bash,请使用完整路径启动它:
```
PS> C:\MinGW\msys/1.0/bin/bash.exe
bash.exe-$ echo $0
"C:\MinGW\msys/1.0/bin/bash.exe"
```
### 在 Windows 上设置路径
你可能不希望为要使用的每个命令输入完整路径。将包含新 GNU 可执行文件的目录添加到 Windows 中的路径中。需要添加两个可执行文件的根目录:一个用于 MinGW(包括 GCC 及其相关工具链),另一个用于 MSYS(包括 Bash、GNU 和 [BSD](https://opensource.com/article/19/3/netbsd-raspberry-pi) 项目中的许多常用工具)。
若要在 Windows 中修改环境,请单击应用菜单并输入 `env`。

这将打开“首选项”窗口。点击窗口底部附近的“环境变量”按钮。
在“环境变量”窗口中,双击底部面板中的“路径”选区。
在“编辑环境变量”窗口中,单击右侧的“新增”按钮。创建一个新条目 `C:\MinCW\msys\1.0\bin`,然后单击 “确定”。以相同的方式创建第二条 `C:\MinGW\bin`,然后单击 “确定”。

在每个首选项窗口中接受这些更改。你可以重启计算机以确保所有应用都检测到新变量,或者只需重启 PowerShell 窗口。
从现在开始,你可以调用任何 MinGW 命令而不指定完整路径,因为完整路径位于 PowerShell 继承的 Windows 系统的 `%PATH%` 环境变量中。
### Hello world
你已经完成设置,因此可以对新的 MinGW 系统进行小测试。如果你是 [Vim](https://opensource.com/resources/what-vim) 用户,请启动它,然后输入下面的 “hello world” 代码:
```
#include <stdio.h>
#include <iostream>
using namespace std;
int main() {
cout << "Hello open source." << endl;
return 0;
}
```
将文件保存为 `hello.cpp`,然后使用 GCC 的 C++ 组件编译文件:
```
PS> gcc hello.cpp --output hello
```
最后,运行它:
```
PS> .\a.exe
Hello open source.
PS>
```
MinGW 的内容远不止我在这里所能介绍的。毕竟,MinGW 打开了一个完整的开源世界和定制代码的潜力,因此请充分利用它。对于更广阔的开源世界,你还可以[试试 Linux](https://opensource.com/article/19/7/ways-get-started-linux)。当所有的限制都被消除后,你会惊讶于可能的事情。但与此同时,请试试 MinGW,并享受 GNU 的自由。
---
via: <https://opensource.com/article/20/8/gnu-windows-mingw>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're a hacker running Windows, you don't need a proprietary application to compile code. With the [Minimalist GNU for Windows](http://mingw.org) (MinGW) project, you can download and install the [GNU Compiler Collection](https://gcc.gnu.org/) (GCC) along with several other essential GNU components to enable [GNU Autotools](https://opensource.com/article/19/7/introduction-gnu-autotools) on your Windows computer.
## Install MinGW
The easiest way to install MinGW is through mingw-get, a graphical user interface (GUI) application that helps you select which components to install and keep them up to date. To run it, [download mingw-get-setup.exe](https://osdn.net/projects/mingw/releases/) from the project's host. Install it as you would any other EXE file by clicking through the installation wizard to completion.
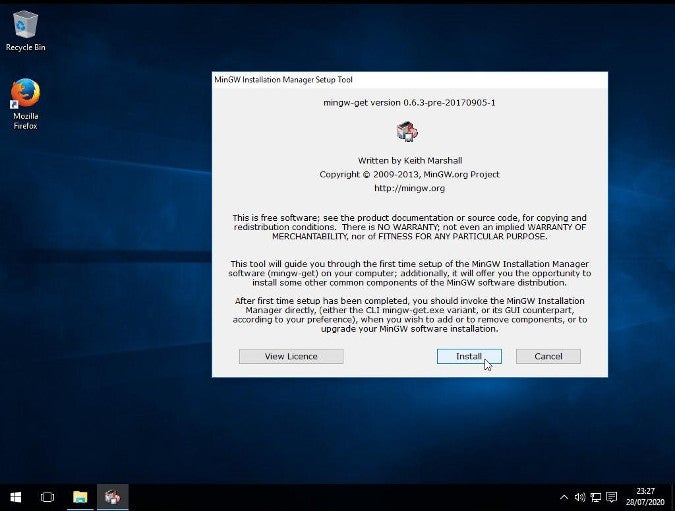
(Seth Kenlon, CC BY-SA 4.0)
## Install GCC on Windows
So far, you've only installed an installer—or more accurately, a dedicated *package manager* called mingw-get. Launch mingw-get to select which MinGW project applications you want to install on your computer.
First, select **mingw-get** from your application menu to launch it.
(Seth Kenlon, CC BY-SA 4.0)
To install GCC, click the GCC and G++ package to mark GNU C and C++ compiler for installation. To complete the process, select **Apply Changes** from the **Installation** menu in the top-left corner of the mingw-get window.
Once GCC is installed, you can run it from [PowerShell](https://opensource.com/article/19/8/variables-powershell) using its full path:
```
PS> C:\MinGW\bin\gcc.exe --version
gcc.exe (MinGW.org GCC Build-x) x.y.z
Copyright (C) 2019 Free Software Foundation, Inc.
```
## Run Bash on Windows
While it calls itself "minimalist," MinGW also provides an optional [Bourne shell](https://en.wikipedia.org/wiki/Bourne_shell) command-line interpreter called MSYS (which stands for Minimal System). It's an alternative to Microsoft's `cmd.exe`
and PowerShell, and it defaults to Bash. Aside from being one of the (justifiably) most popular shells, Bash is useful when porting open source applications to the Windows platform because many open source projects assume a [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) environment.
You can install MSYS from the mingw-get GUI or from within PowerShell:
`PS> mingw-get install msys`
To try out Bash, launch it using its full path:
```
PS> C:\MinGW\msys/1.0/bin/bash.exe
bash.exe-$ echo $0
"C:\MinGW\msys/1.0/bin/bash.exe"
```
## Set the path on Windows
You probably don't want to have to type the full path for every command you want to use. Add the directory containing your new GNU executables to your path in Windows. There are two root directories of executables to add: one for MinGW (including GCC and its related toolchain) and another for MSYS (including Bash and many common tools from the GNU and [BSD](https://opensource.com/article/19/3/netbsd-raspberry-pi) projects).
To modify your environment in Windows, click on the application menu and type `env`
.

(Seth Kenlon, CC BY-SA 4.0)
A Preferences window will open; click the **Environment variables** button located near the bottom of the window.
In the **Environment variables** window, double-click the **Path** selection from the bottom panel.
In the **Edit Environment variables** window that appears, click the **New** button on the right. Create a new entry reading **C:\MinCW\msys\1.0\bin** and click **OK**. Create a second new entry the same way, this one reading **C:\MinGW\bin**, and click **OK**.
(Seth Kenlon, CC BY-SA 4.0)
Accept these changes in each Preferences window. You can reboot your computer to ensure the new variables are detected by all applications, or just relaunch your PowerShell window.
From now on, you can call any MinGW command without specifying the full path, because the full path is in the `%PATH%`
environment variable of your Windows system, which PowerShell inherits.
## Hello world
You're all set up now, so put your new MinGW system to a small test. If you're a [Vim](https://opensource.com/resources/what-vim) user, launch it, and enter this obligatory "hello world" code:
```
#include <stdio.h>
#include <iostream>
using namespace std;
int main() {
cout << "Hello open source." << endl;
return 0;
}
```
Save the file as `hello.cpp`
, then compile it with the C++ component of GCC:
`PS> gcc hello.cpp --output hello`
And, finally, run it:
```
PS> .\a.exe
Hello open source.
PS>
```
There's much more to MinGW than what I can cover here. After all, MinGW opens a whole world of open source and potential for custom code, so take advantage of it. For a wider world of open source, you can also [give Linux a try](https://opensource.com/article/19/7/ways-get-started-linux). You'll be amazed at what's possible when all limits are removed. But in the meantime, give MinGW a try and enjoy the freedom of the GNU.
## 1 Comment |
12,551 | 《代码英雄》第一季(6):揭秘云计算 | https://www.redhat.com/en/command-line-heroes/season-1/crack-the-cloud-open | 2020-08-25T22:25:03 | [
"代码英雄",
"云计算"
] | https://linux.cn/article-12551-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(6):揭秘云计算](https://www.redhat.com/en/command-line-heroes/season-1/crack-the-cloud-open)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/83bb194b.mp3)脚本。
“没有什么云。这只是别人的电脑。”确切地说,还是服务器。大型云提供商提供了一种相对简单的方式来扩展工作负载。但真正的成本是什么?
在本期节目中,我们将讨论云中的战斗,说谁是赢家还很早。Major Hayden、微软的 Bridget Kromhout 等人会帮我们了解这场正在酝酿的风暴,以及它给开源开发者带来的影响。
**Saron Yitbarek**:
Ingrid Burrington 想要走进云的世界。不是真实的“一朵云”哟,而是“云计算”的世界。
**Ingrid Burrington**:
我不知道互联网真正的样子,我也不认为互联网是我想象中的那样,所以我想尝试找出它真实的模样。
**00:00:30 - Saron Yitbarek**:
Ingrid 是一名记者。在她为《<ruby> 大西洋 <rt> Atlantic </rt></ruby>》撰写的系列报道中,她讲述了自己参观一个数据中心的经历,一个我们网络生活越来越依赖的地方。她在那里并不是走马观花逛一圈,而是浸入式的复杂体验。首先,她要拍照登记,申请访客身份卡。然后,要通过安检站,签署一份保密协议。最后,她才能去看机房。机房基本上就像个仓库,就像超市的那样,但比它大得多。
**00:01:00**:
整个机房看起来有种别样的美,所有的东西都整齐陈列着。一堆光鲜靓丽的服务器上,连接着通往世界各地的光缆,光缆沿着天花板上的轨道整齐布线。正在通讯的光电信号闪烁着点点神秘的蓝光,仿佛粒子加速器一样。但本质上,它是一排排如猛兽般动力强劲的服务器。
**00:01:30**:
数据中心每年消耗的能源比整个英国还要多。这就意味着它会释放惊人的巨大热量,这就是为什么当 Ingrid 环顾四周时……
**Ingrid Burrington**:
对的,我发现这座建筑主要的设计理念,是建造最理想最完美的暖通系统(HAVC)。
**00:02:00 - Saron Yitbarek**:
Ingrid 发现围绕数据中心的一切都强调经济实用,简单说就是一堆主机、一摞风扇、一大块租金便宜的地皮、用很多便宜的用来冷却的工业用水。完全没有“云”这个词本身散发的浪漫,但另一方面,我们的生活、我们的工作以及我们的话语,都在这个服务器的仓库里搏动着。
**00:02:30 - Ingrid Burrington**:
是的,这有点超现实主义。并不是说我就知道那台机器里存有某人的电子邮件,这台机器又存有别的东西,而是我意识到周围有很多看不见的事情正在发生,我能听到服务器的呼呼声和大量运算产生的微小噪声。说来奇怪,我开始对工业充满敬畏……
**00:03:00 - Saron Yitbarek**:
时刻要记住,在我们使用服务的时候,它们的基础,这些建筑都在某个隐蔽的角落嗡嗡运作着。以前,当我们谈论在云上存储东西,或创建应用程序时,我们有时会自欺欺人地认为它就像天上的云,是没有人能触碰的存在。但现实恰恰相反,一旦我们认识到云数据中心真实存在于某地,我们就会开始思考谁拥有着云了。那么是谁在控制这些服务器、线缆和风扇呢?
**00:03:30 - Saron Yitbarek**:
它们是如何改变开发者构建未来的方式的呢?云让我们紧密地连接在一起。
我是 Saron Yitbarek,这里是《代码英雄》,一档由红帽公司推出的原创播客栏目,第六集,揭秘云计算。
**Chris Watterston**:
没有所谓的“云”。那只是别人的电脑。
**00:04:00 - Saron Yitbarek**:
Chris Watterston 是一名设计师,他对围绕云产生的误解很是恼火。这个词模糊了数据中心的形象,就像 Ingrid 参观过的那个一样。当 Chris 把这句口号做成贴纸时,他因此成为了网红。“**没有所谓的‘云’,那只是别人的电脑。**”这句话现在出现在 T 恤、帽衫、咖啡杯、海报、杯垫和许多主题演讲上。
**00:04:30 - Chris Watterston**:
人们完全不理解云是什么,还用的很欢乐又心安。他们可能完全误解了云,不明白他们的数据实际上是穿过铜轴电缆、或者光纤,来到某一个实际上由他人管理和拥有的存储设备。显然,对于一些有需要隐藏的私人内容的人来说,这是相当可怕的隐患。
**00:05:00**:
所以,下次你想把东西扔到云上的时候,想想 Chris 的贴纸吧。想想你到底要扔到哪里去。在 App 上工作也是同样道理,声称 App 跟服务器无关的说法都是骗人的,根本没有无服务器的 App。云就是别人的服务器、别人的电脑。不过云这件事情从某种意义上说,是一种成长。说到成长,在整一季节目里,我们会一直追溯开源的成长与变革。
**00:05:30**:
从最初的自由软件运动到 Linux 的诞生,直至今天,开源工具和方法把我们带到了远离家园的云端。可以打个比方,一个人找房东租房,他需要签合同、搬进去、把房子整理成自己的居所。当开发者寻找云供应商时,他们也在做着同样的事情。这就是我们现在所处的情况,全世界的开发者都在转向各种云上线产品,然后开始明白租赁的真实含义。
**00:06:00**:
严肃地发问一句,为什么我们一开始就急着跳上云端呢?
**Brandon Butler**:
因为开发者不想维护 App 运行所需的设备。
**Saron Yitbarek**:
这位是 Brandon Butler,《<ruby> 网络世界 <rt> Network World </rt></ruby>》的高级编辑,多年来致力于研究云计算。
**00:06:30 - Brandon Butler**:
开发者想要开发 App,部署 App,并只在乎 App 能不能正常运行。我们已经看到云孕育的,越来越多的服务,例如无服务器计算、功能即服务、容器和容器管理平台,如 Kubernetes。
**Saron Yitbarek**:
顺便打个广告,想了解容器和 Kubernetes,请看我们的[上期节目](/article-12535-1.html)。
**Brandon Butler**:
所有的这些成果都有助于抽象化 App 运行时所需要的底层基础设施。这将是一个可以在未来可预见的持续发展的趋势。
**00:07:00 - Saron Yitbarek**:
云拥有巨大吸引力的部分原因,可以用“超大规模”这个词来解释。通过云为你提供的所有基础设施,你可以根据自己的需求,快速创建和定制自己的服务器。你不再需要购买自己的设备,你只需要租赁你想要的规模的云。Brandon 解释了“超大规模”对初创公司的具体帮助。
**00:07:30 - Brandon Butler**:
使用公有云进行 App 开发的整套模型,对开发者来说是一个巨大的进步。它曾经成就了一系列全新的初创公司,这些初创公司也已经成长为大众都喜欢投资的公司。想想 Netflix 这样的公司,它的大部分后端都运行在亚马逊的以及其他的云上。
**00:08:00 - Brandon Butler**:
这些公司现在如此壮大的原因,正是因为他们在使用云。因此,云对开发者的影响是不可轻视的。云已经成为过去十年,App 开发领域的主要转变。
**Saron Yitbarek**:
Nick Bash 是 Meadowbrook 保险公司的一位系统管理员,他还记得在云计算诞生之前,调整基础设施是多么痛苦的事。
**00:08:30 - Nick Bush**:
以前,有些人想出新项目的点子,我们会说,“这需要硬件支持,而我们没有。”他们会问,“那么我们该怎么办?”我们以前总是受到内存的限制,尤其是运行虚拟机软件,通常是最困难的部分。我们经常需要在任意时间启动虚拟机,但能随时启动的虚拟机数量总是不多。所以我们不得不花很多钱买新处理器、新内存、新硬件,或者花 5000 美元加新的东西。一旦我们从几个不同的供应商得到报价,就得报给管理层,他们要花时间审核。这样,仅仅是购买硬件都需要漫长的过程。
**00:09:00**:
更不要说构建虚拟机,再反复考虑和测试等等。所以其实我的意思是,有了云,我们可以在几个小时内完成以往需要几个月完成的前期工作。让虚拟机运行起来,第二天就交付给其他人。所以这是一个很大的转变。
**00:09:30 - Saron Yitbarek**:
在拓展性、速度和价格这些方面,云计算相当吸引人。还是拿租房作比喻,云就像可以让你免费得到一个管家和司机的服务,你很难对云计算说不。如今市场上有主要的四家壮志雄心的云供应商在开疆拓土。他们都想成为你在云上的“新房东”。但是且慢,每个租过房子的人都知道,租房和买房不一样。你不能自己拆掉一堵墙,或者安装一个新的按摩浴缸,你得通过房东来干这些事。
**00:10:00**:
那么 Brandon Butler 先生,我们使用私有云,在某种程度上会受制于一家独资公司。这会不会对我们不利?
**00:10:30 - Brandon Butler**:
当你使用云供应商的私有云时,你有不同的使用方法:你可以拥抱开源标准和开源平台,并且在云上运行开源软件,即便这是个私有云;你也可以使用不是开源的原生工具,这些工具可能在公有云上有更好的集成。因此,这是终端用户必须考虑的一个重大问题:我是想使用云供应商的原生工具,这些工具可能与这个云供应商提供的服务,以及其他服务更好的集成;还是拥抱开源标准,使用一个开源平台,享受更大的自由度,在自己和其他提供商的平台上也能运行?
**00:11:00 - Saron Yitbarek**:
随着我们所依赖的云技术不断发展,四大云供应商相互竞争,我们作为开发者有了新选择。我们是放弃一些独立性,依靠单一的云供应商来保护我们的工作,还是选择另一条路,在保持独立性的同时最大化云的拓展性?
**00:11:30**:
换句话说,我们能否在租房合同上写明,“房客有权任意处置该房 ,例如拆墙或其他装修”?
**00:12:00**:
那么,放弃一点点独立性又有什么问题呢?如果你是一名开发者,可能没受到什么影响。因为大多数时候都有运维团队在背后监督开发者们小心行事,他们格外留心于具体细节。这位是 Major Hayden,他是 Rackspace 的首席架构师。
**00:12:30 - Major Hayden**:
有些时候,开发者经常发现他们有各种不同的需要,比如某些专门化的存储,或者可能想要一定大小的虚拟机,或者想要一种云供应商未能提供的东西。还有一些东西可能开发者没有第一时间想要,但你认为他们需要的,对这些东西你还要进行成本效益分析。好吧,虽然使用公有云我们有很大的灵活性,但我们到底付出了什么代价?
**Saron Yitbarek**:
Major 指出了另一个问题,这个问题超越了实用性,并且触及了像我这样的开发人员所信奉的核心,那就是开源实践。即使云供应商允许你使用自己的开源工具,但云本身并不是开源的
**00:13:00 - Major Hayden**:
因此,开源对于云来说是一个需要处理的有趣议题,因为有大量的开源技术支持用户去高效地利用公有云,但并不是所有公有云都把它们的基础设施开源了。举个例子,如果你使用亚马逊,你无法知道他们使用的什么技术来构建虚拟机和其他服务。所以,你不可能对这些东西做点调整,或者很难了解幕后的机理和运作方法。
**00:13:30 - Saron Yitbarek**:
如果你听过我们之前[关于 DevOps 的节目](/article-12529-1.html),你会知道打破开发者和运维之间的壁垒会让我们获益良多。架构师 Major 刚给了我们一些真知灼见,接下来的这位是系统管理员 Nick Bush,他所在的团队正准备向云端迁移。开发者们已经厌倦了每五年一次硬件换代,每个人都喜欢尽可能快地扩展,而 Nick 想指出一些开发者可能没有考虑到的东西。
**00:14:00 - Nick Bush**:
是的。我想说的是,云是存在延迟的。举个例子,就像远在蒙大拿的数据库服务器,对比我在街上用着 10-gig 的网络,本地数据库调用还是会花费更长的时间。要达到低延迟的云内数据库调用还有很长的路要走,还有其他的安全问题,因此我们暂时不需要担心物理上的前提。在本地,我们尚可以控制我们的硬件和其他类似的东西。一旦你进入了云端,你就得考虑连接问题。
**00:14:30**:
我认为,你也得稍微担心一下安全问题,虽然这更多也是一个成本问题。你想要按月租一个云端虚拟机,要求网速快并且带有充足的存储空间。每千兆的传输和存储都是要花钱的,以前我们都是一次性买断一个机器,我们只要买好了一个云端虚拟机,就可以存储和使用。只要余额和储存空间都还足够,我们就不用付更多钱。
**00:15:00 - Saron Yitbarek**:
声明一下,Nick 确实认为此事利大于弊。他只是不想让我们认为这是个完美的系统。如果你的云供应商宕机,而你想在其他云中重新部署应用程序,会发生什么情况?或者,如果在不同事务上使用不同的云能带来价格优势呢?运维人员提出的这些问题都可以被总结于一个词汇下,也就是<ruby> 供应商依赖 <rt> vender lock-in </rt></ruby>。你可能很熟悉这个词。
**00:15:30**:
供应商锁定的意思是,在别人的服务器上构建业务会让你越来越依赖于他们的平台。你被绑定在这个平台了。可能突然之间,你被迫升级系统、付出更多成本、接受新限制,你变得身不由己。你懂的。
**00:16:00**:
当我们都戴上 DevOps 的帽子时,我们开发者和运维就可以一起工作,面对供应商锁定,对症下药,但当我们沉浸在自己的代码中时,我们有时会忘记观览全局。为什么不找个折中方法,同时在公共和私有云上工作呢?终极解决方案可能是混合云,对于两方而言这都是最佳选择。我给 Bridget Kromhout 打了电话,询问她的看法。她是微软员工中的头号云开发提倡者,对这方面非常了解。
**00:16:30**:
如果我们考虑一种混合的解决方案,既包含一些公有云,也包含一些私有云,这是两者之间的完美平衡吗?对于开发者,这是理想的解决方案吗?如果云是混合的,那么我就能想做什么就做什么,想用什么工具就用什么,同时仍然可以从大型公有云提供商那里获得一些好处。
**00:17:00 - Bridget Kromhout**:
当然是的。举个例子,我有朋友在制造业中从事高性能计算研究工作,他们有各种各样的绝密资料,像 NDA 这样的东西,不适合放在公有云上。于是,他们可能会在自己的数据中心跟这些资料打交道,处理客户数据,或者研究数据,等等,也可能有其他的……
**00:17:30**:
他们也有适合放在公有云上的其他工作资料,不过我想这个问题就……有时也会有这样的问题,公有云是否适合某些工作资料,比如,如果你计划使用 InfiniBand 同步你的不同笔记,你能在公有云中做到什么程度呢?
**Saron Yitbarek**:
但这并不一定是完美的解决方案。Bridget 认为混合云也有自身的弊端。
**00:18:00 - Bridget Kromhout**:
混合云的问题在于,有时,人们欺骗自己,认为他们可以接受一些实际上不工作的东西,所以如果他们之前等待两周来获得一个虚拟机,如果有人经历过一个完整的这样的情况,并且这个虚拟机还不能正常工作的话,就会有一堆的人由于失望而开始和他们的公有云提供商谈论信用卡问题了,然后他们会试着把这些东西粘合在一起,但是还是有数据来源和延迟的问题,我不是很确定,脱同步的数据集有很多出错的方式。我认为,如果你和云服务提供商合作,你可以有一些可用的直接沟通这样你就可以更好地同步数据,这样是很有帮助的。
**00:18:30 - Saron Yitbarek**:
是的。当我们在开源的语境下谈到云的时候,我觉得,作为开发者,可能大多数人,都喜欢开源;如果你还在听我们的播客节目,就更是这样。对吧?你希望一切都是开放的,透明的,还向大众共享代码;但我觉得,当我们谈到云计算,因为它不会给人感觉是代码库,不会让人觉得云本身是个项目,它是环境,是可以用来帮助我们运行代码的东西,开发人员们还会坚持要让它像是传统的项目和代码库一样开源、透明吗?
**Bridget Kromhout**:
我觉得这是一个非常合理的问题,我觉得这可能也会归结到你到底要注目于技术栈的哪一部分。想一想,你对芯片的了解有多少?你又能在何种程度上操控它们?
**Saron Yitbarek**:
是的,这是真的。你说得不错。
**Bridget Kromhout**:
他们坐在那里,他们有硅,他们也有秘密。他们不一定会将后者给你。
**00:19:30 - Saron Yitbarek**
是啊,硅和秘密。顺便说一句,这是个好播客的名字。
**Bridget Kromhout**:
对吧?也许问题不在于是否一切都是开放的,而在于你需要开放的一切是否都是开放的,以及,当服务没有完全按照正确的方式运行时,你的服务提供者是否会对你保持信息透明,因为不该出的错误就是不该出。
**00:20:00 - Saron Yitbarek**:
所以,我得到了 Bridget 作为一个公有云提供商的观点,她提出了一个有趣的观点。开发者在云上的控制需要多细?至于我,我的看法不一样。我不想为了一点公有云的优势而牺牲的是什么呢?比如说,一个应用在公有云上运行,然后,等一下,现在我已经扩大了规模,或者有新的合规要求,我的应用在私有云上更合适。
**00:20:30**:
把应用从一个地方迁移到另一个地方之前,我需要知道它在迁移之后仍能工作。我需要知道它是以原先同样的方式打包,以同样的方式配置。换句话说,我需要知道从一个云跳到另一个云总是可能的。
除此之外,我们还有什么选择?仅仅锁定在一家云提供商?一个甚至可能完全垄断整个行业的供应商?不能选择迁移到另一个环境的话,这就像把一只手绑在背后写代码一样。
**00:21:00**:
所以,我们不想欠下任何一朵云的人情,并且被它困住。我们希望在合适的时候能够在云间跳转。用摇滚传奇<ruby> 皇后乐队 <rt> Queen </rt></ruby>的名言来说,“我想要挣脱束缚”。我们希望能够获得公有云的绝佳拓展性,但又不放弃使用开源工具和方法所带来的自由。
**00:21:30**:
有个好消息。混合云的建设正在顺利进行中。Mike Ferris,红帽公司的的业务架构副总裁,他给出了一个很好的解释,说明了混合云是如何帮助我们保持开源精神的。
**00:22:00 - Mike Ferris**:
开源是世界上几乎每一个云服务的基础,现在即便不是大多数,也有许多世界上应用程序的基础设施和工具是从这里发展出来的,管理能力,以及人们用于构建、部署应用程序(无论是任务关键型,还是非任务关键型应用程序)的工具都是基于开源的。
**00:22:30**:
混合云的概念和这一点非常兼容,这代表着,我们可以在混合云中处处使用开源工具,也可以最大程度地发挥出基础设施的优势。这是基于以下的一点事实:开源通过其在当今的强大影响力,能够在一定程度上定义下一代的开发模式。
**Saron Yitbarek**:
我认为云计算本身具有开放的意愿。在本季节目中,我们花了很多时间讨论开源的起源。你甚至可以证明,某些版本的混合云是这些相同理想的延伸。
**00:23:00 - Mike Ferris**:
在过去几十年里,开源开发活动的变化是越来越多的人参与进来了,包括像微软、IBM 这样的行业巨头。你知道,举个大公司的例子,他们要么使用开源软件来提供产品,要么构建开源软件并将其回馈给社区,或者两项都参与。
**00:23:30**:
这些来自客户的重要需求通过那些大公司涌入,确实帮助了开源世界的发展,使之从最初设想中 Solaris 和 UNIX 的替代方案,发展为不仅是社区和业余爱好者使用,而且肯定也是部分任务关键型企业使用的基础。
**00:24:00 - Saron Yitbarek**:
开源正在快速成长。现在,我们有机会确保我们记住我们从哪里来。当我们跃上云时,我们可以为自己声明开源的部分,以此来保持云的开放。幸运的是,由于有了 OpenStack® 平台这样的工具,在云之间构建开源桥梁变得更加容易了。Rackspace 的首席架构师 Major Hayden 描述了它的起源。
**00:24:30 - Major Hayden**:
OpenStack® 来自于 Rackspace 和 NASA 的合作:“你看,这是一种构建基础设施的新方式,我们应该公开进行。我们应该得到更多的投入,应该和更多的人交流。我们应该得到更多的用例。” OpenStack® 是一组应用,它能很好地协同创建基础设施,并全面管理基础设施。无论你需要复杂的虚拟机、复杂的网络,还是有奇怪的存储要求,OpenStack® 通常可以满足大部分的要求。
**Saron Yitbarek**:
Major 指的是,加入一些开源知道如何提供的东西:也就是适应性。
**00:25:00 - Major Hayden**:
在我看来,OpenStack® 是一组相互连接的开放源码应用程序,它允许你构建你想要的基础设施。如果它不能建立你想要的,那么你可以进入社区,对它做出改变。我喜欢我去和顾客交谈时他们的反应,他们说,“我们想改变这个。我们想要改变这一切。”我们会说,“嗯,你可以。”
**Saron Yitbarek**:
我们如何确保这样的的适应性被包含在明天的云中呢?就像我们在之前的节目中谈到的许多问题一样,这需要强大的社区。有请 Brandon Butler,《网络世界》的高级编辑。
**00:25:30 - Brandon Butler**:
例如,我们已经看到了云原生计算基金会的成立,这个基金会制定标准,推广应用容器的使用,并创造了 Kubernetes。我们也看到了 OpenStack 基金会的成立,好将 OpenStack® 用户聚集在一起,讨论创建开源基础设施服务云时的最佳实践。
**00:26:00**:
支撑这些开源社区的社群对于开发下一波开源工具,学习如何最好地使用这些开源平台的,以及鼓励公有云厂商接受这些开源标准都非常重要。
**Saron Yitbarek**:
一旦我们开始构建混合云,并使其尽可能地开放,潜力似乎真的无穷无尽。Major,请说。
**00:26:30 - Major Hayden**:
最让我兴奋的是看到更多的东西可以聚集在不同的云之上。例如,OpenStack® 提供了一个很好的基础设施基础层,但是你可以在它之上做很多事情。我想有时候不同的公司会采用 OpenStack®,然后说:“伙计,我现在该怎么办?我的自由程度太高了。我不知道该怎么办。”这就像你有一个装满食物的冰箱,你会想,“啊,我不知道该做什么菜。”
**00:27:00 - Saron Yitbarek**:
我喜欢这个问题。Chris Watterson 告诉我们的可能是对的。
**Chris Watterston**:
没有所谓的“云”,那只是别人的电脑。
**00:27:30 - Saron Yitbarek**:
但故事并未在此结束。我们要与混合云一起跨入下一章。创建混合云应用的关键可能还没有被破解。跨多云管理任务,对于今天的代码英雄们来说将是一项艰巨的任务。会有很多尝试和错误,但这是值得的,因为我们知道的唯一的一件事是,保持开源意味着开发人员总是可以构建他们想要工作的世界。这种灵活性正是紧紧抓住开源最擅长的叛逆精神的诀窍。
**00:28:00**:
下一集是我们本季的最后一集,我们将以一种让你惊讶的方式,从宏观角度来看开源作为一种全球现象是什么样的。我们也将展望开源的未来,我们的开发人员如何保持像 Linus Torvalds 这样的英雄的精神,即使当他们正在重塑他们的行业时。
**00:28:30**:
《代码英雄》是一档红帽公司推出的原创播客。想了解更多关于本期和往期节目的信息,请访问 [RedHat.com/CommandLineHeroes](http://RedHat.com/CommandLineHeroes) 。在那里你也可以注册我们的新闻通讯。想免费获得新一期节目推送,请务必订阅我们。只要在苹果播客、Spotify、Google Play、CastBox 和其他播客平台中搜索《代码英雄》,然后点击订阅,你就可以第一时间收听新一期。我是 Saron Yitbarek。感谢你的聆听,编程不止。
>
> OpenStack® 和 OpenStack 标志是 OpenStack 基金会在美国和其他国家的注册商标/服务标志或商标/服务标志,并经 OpenStack 基金会许可使用。我们不是 OpenStack 基金会或 OpenStack 社区的附属机构,也没有得到 OpenStack 基金会或 OpenStack 社区的认可或赞助。
>
>
>
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-1/crack-the-cloud-open>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[LikChung](https://github.com/likchung) 校对:[acyanbird](https://github.com/acyanbird)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | "There is no cloud. It's just someone else's computer." Or server, to be exact. Big cloud providers offer a relatively easy way to scale out workloads. But what's the real cost?
In this episode, we talk about the battle in the clouds, where any winner is still very much up in the air. [ Major Hayden](https://twitter.com/majorhayden), Microsoft's
[, and others help us understand the storm that's brewing and where that leaves open source developers.](https://twitter.com/bridgetkromhout)
__Bridget Kromhout__*Saron Yitbarek*
Ingrid Burrington wanted to walk inside a cloud. Not just “a cloud.” though. *The* cloud.
*Ingrid Burrington*
I don't know what the internet looks like, I don't think it looks like this. I wanted to just kind of find out.
**00:30** - *Saron Yitbarek*
Ingrid's a journalist. For a series she wrote for the Atlantic, she talked her way into one of the datacenters, where more and more of our online lives play out. What she found there wasn't all fluffy and white, it was downright physical. First up, getting her photo taken for an ID tag. Next, going through security checkpoints and signing a nondisclosure agreement. Finally, she gets to see the machines. The server rooms are basically warehouses, think Costco, but bigger.
**01:00** - *Saron Yitbarek*
And there's something beautiful about that warehouse look, because everything's just there on display. Racks of naked servers, and above them all the cables connecting to the world, running along tracks on the ceiling. There's a sort of fancy blue light going on, kind of a tron thing. But mostly, it's rows and rows of very hungry servers.
**01:30** - *Saron Yitbarek*
Datacenters use up more energy each year than the whole of the United Kingdom. And that means they're throwing off crazy amounts of heat, which is why when Ingrid looks around ...
*Ingrid Burrington*
This is a building that's mostly designed around having the most perfect HVAC system imaginable.
**02:00** - *Saron Yitbarek*
Ingrid discovered that everything about a datacenter is pragmatic, so yeah just a bunch of machines, a bunch of fans, on lots of cheap land, using lots of cheap water to keep it cool. Not quite what the word "cloud" represents, but on the other hand, it's our lives, our work, our voices bounces around in that warehouse of machines.
**02:30** - *Ingrid Burrington*
Yeah, it can be a little surreal because it's not as though it's like I know that machine has someone's email, and that machine has something else. But realizing kind of just how much is kind of happening around me implicitly that I can't see, but I can kind of hear in the sense of the w hirring of the machines and the larger kind of operation of the space. There is something a little bit eerie about it, and I mean there's sort of like an industrial awe ...
**03:00** - *Saron Yitbarek*
It's so important to remember that these buildings really are there, somewhere, humming behind the fence. Because here's the thing, when we talk about storing stuff on the cloud, or building an app on the cloud, we sometimes fool ourselves into thinking it's like a cloud in the sky, something nobody can touch. But the reality is exactly the opposite, and once we remember where the cloud lives, we can start talking about who owns the cloud. Who controls all those servers, and cables, and fans?
**03:30** - *Saron Yitbarek*
And how does that change the way developers build the future? Because in cloud city, we're all living there together.
I'm Saron Yitbarek, and this is Command Line Heroes. An original podcast from Red Hat, episode six, Crack the Cloud Open.
*Chris Watterston*
There is no cloud, it's just someone else's computer.
**04:00** - *Saron Yitbarek*
Chris Watterston is a designer who grew annoyed at the confusion around the cloud. That word had softened the edges of datacenters, like the one Ingrid visited. When he put that slogan on a sticker, he became internet famous. That line "There is no cloud, it's just someone else's computer," is now on t-shirts, hoodies, coffee mugs, posters, coasters, and more than a few keynote presentations.
**04:30** - *Chris Watterston*
People sort of still use the cloud as if it's going up there, people that don't understand fully what it is, they can still take it sort of the wrong way and not understand that their data is actually going across copper cables, or fibers, whatever it might be into a storage device that is actually managed and owned by someone else. Which obviously, for some people, if they've got private content they want to hide, could be quite scary.
**05:00** - *Saron Yitbarek*
So think of Chris's sticker next time you're tossing something onto the cloud. Where are you really tossing it? Same goes for working on an app, for all the talk of going serverless, there's really no such thing. It's somebody else's server, somebody else's computer. In a sense, this is a story about growing up. All season long, we've been tracking the evolution of open source.
**05:30** - *Saron Yitbarek*
From its rebellious origins with the free software movement, and the emergence of Linux, all the way to today when open source tools and methods have taken us far from home into the cloud. Think of it this way, when a person finds an apartment to rent, she's going to sign a contract, move in, and make it her own. When developers go looking for a cloud provider, they have to do the same thing. That's the moment we're in right now, the moment when a whole world of developers is making their move onto a series of clouds, and starting to figure out what the rental lease actually says.
**06:00** -*Saron Yitbarek*
Just for the record, why are we in such a rush to hop onto a cloud in the first place?
*Brandon Butler*
Developers don't want to have to manage the infrastructure that is running their applications.
*Saron Yitbarek*
This is Brandon Butler, he's the senior editor at Network World. And he's been covering cloud computing for years.
**06:30** -*Brandon Butler*
They want to develop apps, and they want to deploy those apps, and they want those apps to just run. And more and more, we've seen things like serverless computing, and functions-as-a-service, and containers, and container management platforms, like Kubernetes.
*Saron Yitbarek*
Check out episode five, by the way, for a run-down on containers and Kubernetes.
*Brandon Butler*
All these things are helping to abstract away the underlying infrastructure that applications need to run on. And that's going to be a trend that we're only going to see continue to develop into the future.
**07:00** - *Saron Yitbarek*
A big part of that attraction is summed up by the word hyperscale. With the cloud providing all your infrastructure, you can take a startup and scale it up, or down, as fast as you want. You're not building your own infrastructure anymore, you're just renting out however much of the cloud you need. Brandon explains what hyperscale means for a startup.
**07:30** - *Brandon Butler*
This whole model of using the public cloud for application development has been a huge advance for application developers. It's created a whole new range of startups, and companies that have grown past startups and become major publicly funded companies. You think about a company like Netflix that runs much of its backend infrastructure on Amazon's cloud, and other cloud providers as well.
**08:00** - *Brandon Butler*
They were able to turn into what they are, because they are using the cloud. So the impact that the cloud has had on developers cannot be understated. It's been the major shift in application development over the last decade.
*Saron Yitbarek*
Nick Bush, a sys admin at Meadowbrook Insurance remembers what a pain infrastructure changes were before the cloud.
**08:30** - *Nick Bush*
Before, it was somebody would come up with an idea to do a certain project, and we would say, "That would need hardware to do that." And they would ask, "Well, how do we do that?" So we were always constrained by memory, and VM-ware usually was the hard part. And we would be constrained by how many virtual machines we could spin up at any one given time. So we would have to go get a quote for new processors, new memory, new hardware, $5,000 added space, and stuff like that. And once we get those quotes from a couple of different vendors, it would go to management, and they would take time. It was a long, drawn-out process just to get the hardware in.
**09:00** - *Nick Bush*
Let alone, then build the VMs and turn them over and test and stuff like that. So I mean there were several months of front-end work versus now we can definitely get that okay within a couple hours usually. And go spin it up, and go turn it over to them the next day. So it is a big turnaround difference.
**09:30** -*Saron Yitbarek*
Between scalability, speed, and price, the cloud can look very tempting. To go back to the apartment rental analogy, cloud options can feel like you're getting a butler and a driver at no additional cost. It's hard to say no, and today we've got four very ambitious cloud providers doing the tempting. They all want to be your new landlord in cloud city. But hold up, everyone who's rented a home knows it's not the same as buying. You can't just knock down a wall, or install a new jacuzzi. You got to go through the landlord.
**10:00** - *Saron Yitbarek*
In some ways, could we be stuck if we find ourselves beholden to a single proprietary company? Brandon Butler.
**10:30** - *Brandon Butler*
When you use a proprietary cloud vendor, there are different ways you can use it. You can use it in a way that embraces open source standards and open source platforms and run those open source platforms on top of a cloud that even may be proprietary, or you can use native tools to those cloud providers that may not be open source, but they may have stronger integrations to the public cloud platform. So, it's a big trade-off that end users have to consider. Do I want to use tools that are native to the cloud provider that may be more heavily integrated with the services this cloud providers offers and other services that I might want to use also on that cloud, or do I want to prioritize using an open source platform that will give me more freedom to run that maybe on my own infrastructure or another cloud provider's infrastructure?
**11:00** - *Saron Yitbarek*
As the clouds we rely on keep growing and the big four cloud providers elbow past each other for dominance, we developers have a choice. Do we give up some of our independence, relying on a single cloud provider to protect our work, or could we take another road, maximize the scalability of the cloud while keeping our independence?
**11:30** - *Saron Yitbarek*
In other words, can we sign a lease that says, "Sure. Do what you want with the place. Knock a wall down. Make it your own?"
**12:00** - *Saron Yitbarek*
So, what's the problem with giving up a little independence? If you're a developer, it might not be so obvious. That's because it's mostly been the ops teams who've been encouraging us to tread lightly. They noticed the nuts-and-bolts issues. Here's Major Hayden. He's the principal architect at Rackspace.
**12:30** - *Major Hayden*
Developers will often find that over time they may have requirements for different things like a certain specialized kind of storage, or they may want to have a certain sized VM, or maybe they want a type of offering that the cloud provider doesn't offer, and there's also some of those things that you do have to look at that developers aren't always the first ones to look at, where you have to do that cost benefit analysis to understand, okay, I have a lot of flexibility in public cloud, but how much does that really cost me?
*Saron Yitbarek*
Major points out another issue, one that goes beyond practicalities and speaks to the heart of what developers like me believe in. I'm talking about open source practices. Even if cloud providers allow you to use your open source tools, they're not themselves open.
**13:00** - *Major Hayden*
So, open source in the cloud is an interesting subject to tackle because there's plenty of open source technologies that allow you to take advantage of a public cloud, but not all public clouds have their infrastructure offered as open source. So for example, if you take Amazon, you're not able to actually see what they're using to build VMs or build other services, so if you wanted to make an adjustment for that, you really wouldn't be able to, or if you wanted to look behind the scenes and understand more of how it fits together, that would be difficult.
**13:30** - *Saron Yitbarek*
If you listened to our episode on DevOps, you know there's a lot we can gain by tearing down the wall between developers and operations. Architects like Major give us some crucial insights, and then there's sys admin, Nick Bush. He's on a team where people are ready to jump on the cloud. Developers are tired of being stuck with physical hardware that ages every five years, and everyone likes the idea of expanding as fast as they want, but Nick wants to flag things that developers might not be considering.
**14:00** - *Nick Bush*
Yeah. I mean, there is inherent latency. I mean, that is a database server in Montana versus my 10-gig connection down the street, so just doing local database calls is gonna take longer. It is a longer path to get there, and there's other security stuff that's out there that we didn't have to worry about physical premise. Here, we were in control of our hardware and stuff like that. Once you're in the cloud, you gotta think about the other connections coming into that.
**14:30** - *Nick Bush*
You gotta worry about security, I think, a little bit more, and it is a price thing. Every month you want a sped-up VM, take up storage space. It is a cost per gigabyte transferred as well as stored, where before we had a one-time purchase and we just had it there, and we could store it, use it. We didn't have to pay anymore money as long as we had space for it.
**15:00** - *Saron Yitbarek*
For the record, Nick does think the pluses outweigh the minuses. He just doesn't want us to pretend it's a perfect system. What happens if your provider has an outage and you want to re-deploy an application in another cloud? Or what if there's a price advantage to using different clouds for different things? A lot of the issues that the ops folks bring up can fit under a single label, vendor lock-in. You're probably familiar with this term.
**15:30** - *Saron Yitbarek*
It's the concept that building on someone else's server gets you more and more tied to their platform. You get locked in. Suddenly, you're being force fed upgrades, cost changes, new limits you wouldn't have chosen for yourself. You get the idea.
**16:00** - *Saron Yitbarek*
When we put our DevOps hats on, we can work together to see lock-in coming and plan around it, but when we're buried in our own code, we sometimes forget to look at the whole picture. What about finding the right mix, working on both public and private clouds? The ultimate solution might be in a hybrid cloud, the best of both worlds. I called up Bridget Kromhout to get her perspective. She's a principal cloud developer advocate over at Microsoft, and knows this stuff backwards and forwards.
**16:30** - *Saron Yitbarek*
So, if we think about the hybrid solution having a little bit of that public cloud, but then also some of that private cloud, is that the perfect balance between the two? Is that the ideal solution for developers? If it's hybrid, then I can kind of do whatever I want and use whatever tools that I want on my end, but then still get some of the benefits of the big public cloud providers.
**17:00** - *Bridget Kromhout*
Yeah, absolutely. So, for example, I have friends who work in high-performance computing research at manufacturing companies, and they have all sorts of top secret, NDA, whatever stuff that they don't feel comfortable putting on public cloud, and so maybe they're going to work in their datacenters on these workloads, crunching these customer numbers or whatever, these research numbers, and then they may have other...
**17:30** - *Bridget Kromhout*
They do have other workloads that they feel comfortable having out in public cloud, but I think this is kind of a question of... And sometimes there's questions, too, of whether public cloud has suitability for some of the workloads, like if you're planning on using InfiniBand interconnects between your notes, how much of that are you gonna be able to provision in public cloud?
*Saron Yitbarek*
But this isn't necessarily the perfect solution. Bridget does think that hybrid clouds come with their own headaches.
**18:00** - *Bridget Kromhout*
The problem with hybrid is sometimes people fool themselves and think that they can take something that really wasn't working, so if they had their old processes with a two-week wait time to even get a single VM, if they have a whole scenario like that and it wasn't working well, and then they have a bunch of people who have started taking their credit cards to the public cloud providers because they're frustrated, and then they try to somehow glue those together, but then there's problems with data provenance and latency and, I don't know, de-synced data sets, there's a lot of ways it can go wrong. I think if you work with your cloud provider so you can add some of the direct connection things that are available so that you can sync things better, that can help.
**18:30** - *Saron Yitbarek*
Yeah. So, when we talk about the cloud in the context of open source, I feel like as developers we, I think most of us, really like open source, especially if you're listening to this podcast. Right? You want everything to be open and transparent and share the code and all that, but I feel like when we talk about the cloud, because it doesn't feel like its own code base, doesn't feel like its own project, it's the environment, it's the thing that we can use to help us run our code, are developers as insistent on that part of the story being open source and transparent the way that we sometimes feel very strongly about when it comes to our projects and our code base?
*Bridget Kromhout*
I think that's a really reasonable question, and I think that might also come down to exactly where in the stack are you going to pick to care about, because if you think about it, how much access to and info do you have about the chips?
*Saron Yitbarek*
Yeah, that's true. That's fair.
*Bridget Kromhout*
They're sitting over there with some silicon and some secrets. They're not necessarily giving that to you.
**19:30** - *Saron Yitbarek*
Yeah, silicon and secrets. That's a good podcast name, by the way.
*Bridget Kromhout*
Right? Maybe the question is not is everything open, but is everything open that you need to be open, and of course, is your provider gonna have transparency with you when things don't operate exactly as they should, because hopefully they will.
**20:00** - *Saron Yitbarek*
So, I get Bridget's perspective as a public cloud provider, and she makes an interesting point. How granular does a developer's control need to be on the cloud? As for me, I look at it differently. What don't I want to sacrifice in order to get some of that public cloud goodness? Say an app is running on a public cloud and then, wait a minute, now I've scaled up or there's new compliance requirements and it makes more sense for my app to be in a private cloud.
**20:30** - *Saron Yitbarek*
Moving that app point to point, I need to know it's going to work. I need to know things are packaged the same way, configured the same way. In other words, I need to know that jumping from cloud to cloud is always possible.
What's the alternative? Getting locked into just one cloud provider? A provider that might even gain a total monopoly over all the others? Not having the option to move to a different environment, that's like trying to code with one hand tied behind your back.
**21:00** - *Saron Yitbarek*
So, we don't want to be trapped and beholden to any one cloud. We want to be able to cloud hop when it suits us. In the immortal words of rock legend Queen, I want to break free. We want access to that fantastic scalability you find in public clouds, but without giving up the freedoms that we've come to expect from using open-sourced tools and methods.
**21:30** - *Saron Yitbarek*
Here's the good news. The work on those hybrid clouds is well underway. Mike Ferris, VP of Business Architecture at Red Hat gives a great explanation of how hybrid clouds help us maintain that open source ethos.
**22:00** - *Mike Ferris*
Open source is really the base for almost every cloud in the world and now many, if not most, of the application infrastructures in the world and the tooling evolves from that, the management capabilities, everything that people are using to build and employ mission-critical applications as well as non-mission-critical applications if it's all based on open source.
**22:30** - *Mike Ferris*
This concept of hybrid really flows alone with it meaning that they have the ability to use these things wherever they are to take advantage of the best feature sets on what infrastructure is there, all based upon this concept that open source is really helping define the standards that are driving this next generation of development while they continue to leverage all the investments that they've made in the past.
*Saron Yitbarek*
I think the cloud wants to be open. We've spent a lot of time this season talking about the origins of open source. You can even make the case that some version of hybrid would be an extension of those same ideals.
**23:00** - *Mike Ferris*
What has changed in the open source development activities over the past several decades has been that many more people have gotten involved, including people like Microsoft, IBM. You know, name a big corporation, they're either using open source for their offerings or they're building open source and contributing that back to the community or some combination of both.
**23:30** - *Mike Ferris*
This influx of really important needs from customers through those large corporations has really helped evolve open source from being what was originally intended to displace the Solaris and UNIX environments, to something that's the basis for not just community and hobbyist use but also certainly mission-critical enterprise use.
**24:00** - *Saron Yitbarek*
Open source is growing up, fast. Now, we have the chance to make sure we remember where we come from. As we hop on the cloud, we can claim part of it for ourselves and keep the cloud open. Luckily, building open source bridges between clouds is getting a lot easier thanks to work like the OpenStack® platform. Major Hayden, principal architect at Rackspace, describes its origins.
**24:30** - *Major Hayden*
It really came from Rackspace and NASA getting together and saying, "Hey look, this is a new way to build infrastructure and we should do it out in the open. We should get more of this input. We should talk to more people. We should get more use cases." What OpenStack is, it's a group of applications that work really well together to create infrastructure, to manage infrastructure all across the board. Whether you need complex virtual machines, complex networking, you have strange storage requirements, OpenStack can usually fit most of those.
*Saron Yitbarek*
Major is talking about adding something that open source knows how to deliver. Adaptability.
**25:00** - *Major Hayden*
When I look at OpenStack, I look at it as an interconnected set of open source applications that allow you to build the infrastructure that you want. If it can't build what you want then you can go in the community and make changes to it. I love the reaction when I go and talk to customers and they say, "Well we want to change this. We want to change this." We say, "Well, you can."
*Saron Yitbarek*
How do we make sure that level of adaptability is enshrined in the cloud of tomorrow? Like many issues we've talked about in past episodes, it's all about strong communities. Brandon Butler, senior editor at Network World.
**25:30** - *Brandon Butler*
For example, we've seen the Cloud Native Computing Foundation be created to create standards and the use of application containers and Kubernetes. We've seen the OpenStack foundation be created to bring OpenStack users together to talk about best practices when creating open source infrastructure service clouds.
**26:00** - *Brandon Butler*
The communities that underpin these open source communities are hugely important for developing the next wave of open source tools, for learning best practices about how to use these open source platforms, and for encouraging these public cloud vendors to embrace these open source standards.
*Saron Yitbarek*
Once we start building that hybrid cloud, making it as open as possible, the potential really seems endless. Here's Major.
**26:30** - *Major Hayden*
What I'm most excited about is just to see more things that can come together on top of different clouds. For example, OpenStack provides a great base layer of infrastructure, but then you can do so much on top of it. I think sometimes different companies will adopt OpenStack and then say, "Man, what do I do now? I have all this freedom. I don't know what to do." It's kind of like when you have a refrigerator full of food and you're like, "Ah, I don't know what to make."
**27:00** - *Saron Yitbarek*
I love having that problem. Chris Watterson might have been right when he told us.
*Chris Watterston*
There is no cloud. It's just someone else's' computer.
**27:30** - *Saron Yitbarek*
But that's not the end of the story. With hybrid clouds, we get to write ourselves back into the next chapter. The key to creating a hybrid cloud app probably hasn't been cracked yet. Managing work across multiple clouds, that's going to be a huge job for today's command line heroes. There'll be a lot of trial and error but it is so worth it, because the one thing we do know is that staying open source means developers can always build the world they want to work in. That kind of flexibility is how we're going to hold on to the rebel spirit that open source does best.
**28:00** - *Saron Yitbarek*
Next episode—our season finale—we are zooming out for a big picture view of what open source looks like as a global phenomenon, in ways that are going to surprise you. We'll also look to the future of open source, how our developers preserving the spirit of heroes like Linus Torvalds, even as they reinvent their industry.
**28:30** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. For more information about this and past episodes go to RedHat.com/CommandLineHeroes. Once you're there you can also sign up for our newsletter. To get new episodes delivered automatically for free, make sure to subscribe to the show. Just search for Command Line Heroes in Apple Podcasts, Spotify, Google Play, CastBox, and other podcast players. Then hit subscribe so you'll be the first to know when new episodes are available. I'm Saron Yitbarek. Thanks for listening and keep on coding.
The OpenStack® Word Mark and OpenStack Logo are either registered trademarks / service marks or trademarks / service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation or the OpenStack community.### Featured in this episode
#### Major Hayden
Principal architect formerly at Rackspace, focused on deploying secure OpenStack private clouds
#### Bridget Kromhout
Principal cloud developer advocate at Microsoft, and leader of __devopsdays__
#### Brandon Butler
Senior research analyst with IDC’s Network Infrastructure group covering enterprise networks |
12,552 | 微软利用 AI 提升服务器部件的重复使用和回收率 | https://www.networkworld.com/article/3570451/microsoft-uses-ai-to-boost-its-reuse-recycling-of-server-parts.html | 2020-08-25T23:41:24 | [
"AI",
"回收"
] | https://linux.cn/article-12552-1.html |
>
> 准备好在提到数据中心设备时,听到更多的“循环”一词。
>
>
>

微软正在将人工智能引入到对数百万台服务器进行分类的任务中,以确定哪些部件可以回收,在哪里回收。
新计划要求在微软全球各地的数据中心建立所谓的“<ruby> 循环中心 <rt> Circular Center </rt></ruby>”,在那里,人工智能算法将用于从退役的服务器或其他硬件中分拣零件,并找出哪些零件可以在园区内重新使用。
微软表示,它的数据中心有超过 300 万台服务器和相关硬件,一台服务器的平均寿命约为 5 年。另外,微软正在全球范围内扩张,所以其服务器数量应该会增加。
循环中心就是要快速整理库存,而不是让过度劳累的员工疲于奔命。微软计划到 2025 年将服务器部件的重复使用率提高 90%。微软总裁 Brad Smith 在宣布这一举措的一篇[博客](https://blogs.microsoft.com/blog/2020/08/04/microsoft-direct-operations-products-and-packaging-to-be-zero-waste-by-2030/)中写道:“利用机器学习,我们将对退役的服务器和硬件进行现场处理。我们会将那些可以被我们以及客户重复使用和再利用的部件进行分类,或者出售。”
Smith 指出,如今,关于废物的数量、质量和类型,以及废物的产生地和去向,都没有一致的数据。例如,关于建造和拆除废物的数据并不一致,我们要一个标准化的方法,有更好的透明度和更高的质量。
他写道:“如果没有更准确的数据,几乎不可能了解运营决策的影响,设定什么目标,如何评估进展,以及废物去向方法的行业标准。”
根据微软的说法,阿姆斯特丹数据中心的一个循环中心试点减少了停机时间,并增加了服务器和网络部件的可用性,供其自身再利用和供应商回购。它还降低了将服务器和硬件运输到处理设施的成本,从而降低了碳排放。
“<ruby> 循环经济 <rt> circular economy </rt></ruby>”一词正在科技界流行。它是基于服务器硬件的循环利用,将那些已经使用了几年但仍可用的设备重新投入到其他地方服务。ITRenew 是[我在几个月前介绍过](https://www.networkworld.com/article/3543810/for-sale-used-low-mileage-hyperscaler-servers.html)的一家二手超大规模服务器的转售商,它对这个词很感兴趣。
该公司表示,首批微软循环中心将建在新的主要数据中心园区或地区。它计划最终将这些中心添加到已经存在的园区中。
微软曾明确表示要在 2030 年之前实现“碳负排放”,而这只是其中几个项目之一。近日,微软宣布在其位于盐湖城的系统开发者实验室进行了一项测试,用一套 250kW 的氢燃料电池系统为一排服务器机架连续供电 48 小时,微软表示这是以前从未做过的事情。
微软首席基础设施工程师 Mark Monroe 在一篇[博客](https://news.microsoft.com/innovation-stories/hydrogen-datacenters/)中写道:“这是我们所知道的最大的以氢气运行的计算机备用电源系统,而且它的连续测试时间最长。”他说,近年来氢燃料电池的价格大幅下降,现在已经成为柴油发电机的可行替代品,但燃烧更清洁。
---
via: <https://www.networkworld.com/article/3570451/microsoft-uses-ai-to-boost-its-reuse-recycling-of-server-parts.html>
作者:[Andy Patrizio](https://www.networkworld.com/author/Andy-Patrizio/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,554 | 在 Linux 上创建并调试转储文件 | https://opensource.com/article/20/8/linux-dump | 2020-08-26T23:46:08 | [
"转储",
"调试"
] | https://linux.cn/article-12554-1.html |
>
> 了解如何处理转储文件将帮你找到应用中难以重现的 bug。
>
>
>

崩溃转储、内存转储、核心转储、系统转储……这些全都会产生同样的产物:一个包含了当应用崩溃时,在那个特定时刻应用的内存状态的文件。
这是一篇指导文章,你可以通过克隆示例的应用仓库来跟随学习:
```
git clone https://github.com/hANSIc99/core_dump_example.git
```
### 信号如何关联到转储
信号是操作系统和用户应用之间的进程间通讯。Linux 使用 [POSIX 标准](https://en.wikipedia.org/wiki/POSIX)中定义的信号。在你的系统上,你可以在 `/usr/include/bits/signum-generic.h` 找到标准信号的定义。如果你想知道更多关于在你的应用程序中使用信号的信息,这有一个信息丰富的 [signal 手册页](https://man7.org/linux/man-pages/man7/signal.7.html)。简单地说,Linux 基于预期的或意外的信号来触发进一步的活动。
当你退出一个正在运行的应用程序时,应用程序通常会收到 `SIGTERM` 信号。因为这种类型的退出信号是预期的,所以这个操作不会创建一个内存转储。
以下信号将导致创建一个转储文件(来源:[GNU C库](https://www.gnu.org/software/libc/manual/html_node/Program-Error-Signals.html#Program-Error-Signals)):
* `SIGFPE`:错误的算术操作
* `SIGILL`:非法指令
* `SIGSEGV`:对存储的无效访问
* `SIGBUS`:总线错误
* `SIGABRT`:程序检测到的错误,并通过调用 `abort()` 来报告
* `SIGIOT`:这个信号在 Fedora 上已经过时,过去在 [PDP-11](https://en.wikipedia.org/wiki/PDP-11) 上用 `abort()` 时触发,现在映射到 SIGABRT
### 创建转储文件
导航到 `core_dump_example` 目录,运行 `make`,并使用 `-c1` 开关执行该示例二进制:
```
./coredump -c1
```
该应用将以状态 4 退出,带有如下错误:

“Abgebrochen (Speicherabzug geschrieben) ”(LCTT 译注:这是德语,应该是因为本文作者系统是德语环境)大致翻译为“分段故障(核心转储)”。
是否创建核心转储是由运行该进程的用户的资源限制决定的。你可以用 `ulimit` 命令修改资源限制。
检查当前创建核心转储的设置:
```
ulimit -c
```
如果它输出 `unlimited`,那么它使用的是(建议的)默认值。否则,用以下方法纠正限制:
```
ulimit -c unlimited
```
要禁用创建核心转储,可以设置其大小为 0:
```
ulimit -c 0
```
这个数字指定了核心转储文件的大小,单位是块。
### 什么是核心转储?
内核处理核心转储的方式定义在:
```
/proc/sys/kernel/core_pattern
```
我运行的是 Fedora 31,在我的系统上,该文件包含的内容是:
```
/usr/lib/systemd/systemd-coredump %P %u %g %s %t %c %h
```
这表明核心转储被转发到 `systemd-coredump` 工具。在不同的 Linux 发行版中,`core_pattern` 的内容会有很大的不同。当使用 `systemd-coredump` 时,转储文件被压缩保存在 `/var/lib/systemd/coredump` 下。你不需要直接接触这些文件,你可以使用 `coredumpctl`。比如说:
```
coredumpctl list
```
会显示系统中保存的所有可用的转储文件。
使用 `coredumpctl dump`,你可以从最后保存的转储文件中检索信息:
```
[stephan@localhost core_dump_example]$ ./coredump
Application started…
(…….)
Message: Process 4598 (coredump) of user 1000 dumped core.
Stack trace of thread 4598:
#0 0x00007f4bbaf22625 __GI_raise (libc.so.6)
#1 0x00007f4bbaf0b8d9 __GI_abort (libc.so.6)
#2 0x00007f4bbaf664af __libc_message (libc.so.6)
#3 0x00007f4bbaf6da9c malloc_printerr (libc.so.6)
#4 0x00007f4bbaf6f49c _int_free (libc.so.6)
#5 0x000000000040120e n/a (/home/stephan/Dokumente/core_dump_example/coredump)
#6 0x00000000004013b1 n/a (/home/stephan/Dokumente/core_dump_example/coredump)
#7 0x00007f4bbaf0d1a3 __libc_start_main (libc.so.6)
#8 0x000000000040113e n/a (/home/stephan/Dokumente/core_dump_example/coredump)
Refusing to dump core to tty (use shell redirection or specify — output).
```
这表明该进程被 `SIGABRT` 停止。这个视图中的堆栈跟踪不是很详细,因为它不包括函数名。然而,使用 `coredumpctl debug`,你可以简单地用调试器(默认为 [GDB](https://www.gnu.org/software/gdb/))打开转储文件。输入 `bt`(<ruby> 回溯 <rt> backtrace </rt></ruby>的缩写)可以得到更详细的视图:
```
Core was generated by `./coredump -c1'.
Program terminated with signal SIGABRT, Aborted.
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50
50 return ret;
(gdb) bt
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50
#1 0x00007fc37a9aa8d9 in __GI_abort () at abort.c:79
#2 0x00007fc37aa054af in __libc_message (action=action@entry=do_abort, fmt=fmt@entry=0x7fc37ab14f4b "%s\n") at ../sysdeps/posix/libc_fatal.c:181
#3 0x00007fc37aa0ca9c in malloc_printerr (str=str@entry=0x7fc37ab130e0 "free(): invalid pointer") at malloc.c:5339
#4 0x00007fc37aa0e49c in _int_free (av=<optimized out>, p=<optimized out>, have_lock=0) at malloc.c:4173
#5 0x000000000040120e in freeSomething(void*) ()
#6 0x0000000000401401 in main ()
```
与后续帧相比,`main()` 和 `freeSomething()` 的内存地址相当低。由于共享对象被映射到虚拟地址空间末尾的区域,可以认为 `SIGABRT` 是由共享库中的调用引起的。共享对象的内存地址在多次调用之间并不是恒定不变的,所以当你看到多次调用之间的地址不同时,完全可以认为是共享对象。
堆栈跟踪显示,后续的调用源于 `malloc.c`,这说明内存的(取消)分配可能出了问题。
在源代码中,(即使没有任何 C++ 知识)你也可以看到,它试图释放一个指针,而这个指针并没有被内存管理函数返回。这导致了未定义的行为,并导致了 `SIGABRT`。
```
void freeSomething(void *ptr){
free(ptr);
}
int nTmp = 5;
int *ptrNull = &nTmp;
freeSomething(ptrNull);
```
systemd 的这个 `coredump` 工具可以在 `/etc/systemd/coredump.conf` 中配置。可以在 `/etc/systemd/systemd-tmpfiles-clean.timer` 中配置轮换清理转储文件。
你可以在其[手册页](https://man7.org/linux/man-pages/man1/coredumpctl.1.html)中找到更多关于 `coredumpctl` 的信息。
### 用调试符号编译
打开 `Makefile` 并注释掉第 9 行的最后一部分。现在应该是这样的:
```
CFLAGS =-Wall -Werror -std=c++11 -g
```
`-g` 开关使编译器能够创建调试信息。启动应用程序,这次使用 `-c2` 开关。
```
./coredump -c2
```
你会得到一个浮点异常。在 GDB 中打开该转储文件:
```
coredumpctl debug
```
这一次,你会直接被指向源代码中导致错误的那一行:
```
Reading symbols from /home/stephan/Dokumente/core_dump_example/coredump…
[New LWP 6218]
Core was generated by `./coredump -c2'.
Program terminated with signal SIGFPE, Arithmetic exception.
#0 0x0000000000401233 in zeroDivide () at main.cpp:29
29 nRes = 5 / nDivider;
(gdb)
```
键入 `list` 以获得更好的源代码概览:
```
(gdb) list
24 int zeroDivide(){
25 int nDivider = 5;
26 int nRes = 0;
27 while(nDivider > 0){
28 nDivider--;
29 nRes = 5 / nDivider;
30 }
31 return nRes;
32 }
```
使用命令 `info locals` 从应用程序失败的时间点检索局部变量的值:
```
(gdb) info locals
nDivider = 0
nRes = 5
```
结合源码,可以看出,你遇到的是零除错误:
```
nRes = 5 / 0
```
### 结论
了解如何处理转储文件将帮助你找到并修复应用程序中难以重现的随机错误。而如果不是你的应用程序,将核心转储转发给开发人员将帮助她或他找到并修复问题。
---
via: <https://opensource.com/article/20/8/linux-dump>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Crash dump, memory dump, core dump, system dump … all produce the same outcome: a file containing the state of an application's memory at a specific time—usually when the application crashes.
Knowing how to deal with these files can help you find the root cause(s) of a failure. Even if you are not a developer, dump files created on your system can be very helpful (as well as approachable) in understanding software.
This is a hands-on article, and can you follow along with the example by cloning the sample application repository with:
`git clone https://github.com/hANSIc99/core_dump_example.git`
## How signals relate to dumps
Signals are a kind of interprocess communication between the operating system and the user applications. Linux uses the signals defined in the [POSIX standard](https://en.wikipedia.org/wiki/POSIX). On your system, you can find the standard signals defined in `/usr/include/bits/signum-generic.h`
. There is also an informative [man signal](https://man7.org/linux/man-pages/man7/signal.7.html) page if you want more on using signals in your application. Put simply, Linux uses signals to trigger further activities based on whether they were expected or unexpected.
When you quit a running application, the application will usually receive the `SIGTERM`
signal. Because this type of exit signal is expected, this action will not create a memory dump.
The following signals will cause a dump file to be created (source: [GNU C Library](https://www.gnu.org/software/libc/manual/html_node/Program-Error-Signals.html#Program-Error-Signals)):
- SIGFPE: Erroneous arithmetic operation
- SIGILL: Illegal instruction
- SIGSEGV: Invalid access to storage
- SIGBUS: Bus error
- SIGABRT: An error detected by the program and reported by calling abort
- SIGIOT: Labeled archaic on Fedora, this signal used to trigger on
`abort()`
on a[PDP-11](https://en.wikipedia.org/wiki/PDP-11)and now maps to SIGABRT
## Creating dump files
Navigate to the `core_dump_example`
directory, run `make`
, and execute the sample with the `-c1`
switch:
`./coredump -c1`
The application should exit in state 4 with an error:

(Stephan Avenwedde, CC BY-SA 4.0)
"Abgebrochen (Speicherabzug geschrieben)" roughly translates to "Segmentation fault (core dumped)."
Whether it creates a core dump or not is determined by the resource limit of the user running the process. You can modify the resource limits with the `ulimit`
command.
Check the current setting for core dump creation:
`ulimit -c`
If it outputs `unlimited`
, then it is using the (recommended) default. Otherwise, correct the limit with:
`ulimit -c unlimited`
To disable creating core dumps' type:
`ulimit -c 0`
The number specifies the resource in kilobytes.
## What are core dumps?
The way the kernel handles core dumps is defined in:
`/proc/sys/kernel/core_pattern`
I'm running Fedora 31, and on my system, the file contains:
`/usr/lib/systemd/systemd-coredump %P %u %g %s %t %c %h`
This shows core dumps are forwarded to the `systemd-coredump`
utility. The contents of `core_pattern`
can vary widely between the different flavors of Linux distributions. When `systemd-coredump`
is in use, the dump files are saved compressed under `/var/lib/systemd/coredump`
. You don't need to touch the files directly; instead, you can use `coredumpctl`
. For example:
`coredumpctl list`
shows all available dump files saved on your system.
With `coredumpctl dump`
, you can retrieve information from the last dump file saved:
```
[stephan@localhost core_dump_example]$ ./coredump
Application started…
(…….)
Message: Process 4598 (coredump) of user 1000 dumped core.
Stack trace of thread 4598:
#0 0x00007f4bbaf22625 __GI_raise (libc.so.6)
#1 0x00007f4bbaf0b8d9 __GI_abort (libc.so.6)
#2 0x00007f4bbaf664af __libc_message (libc.so.6)
#3 0x00007f4bbaf6da9c malloc_printerr (libc.so.6)
#4 0x00007f4bbaf6f49c _int_free (libc.so.6)
#5 0x000000000040120e n/a (/home/stephan/Dokumente/core_dump_example/coredump)
#6 0x00000000004013b1 n/a (/home/stephan/Dokumente/core_dump_example/coredump)
#7 0x00007f4bbaf0d1a3 __libc_start_main (libc.so.6)
#8 0x000000000040113e n/a (/home/stephan/Dokumente/core_dump_example/coredump)
Refusing to dump core to tty (use shell redirection or specify — output).
```
This shows that the process was stopped by `SIGABRT`
. The stack trace in this view is not very detailed because it does not include function names. However, with `coredumpctl debug`
, you can simply open the dump file with a debugger ([GDB](https://www.gnu.org/software/gdb/) by default). Type `bt`
(short for backtrace) to get a more detailed view:
```
Core was generated by `./coredump -c1'.
Program terminated with signal SIGABRT, Aborted.
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50
50 return ret;
(gdb) bt
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50
#1 0x00007fc37a9aa8d9 in __GI_abort () at abort.c:79
#2 0x00007fc37aa054af in __libc_message (action=action@entry=do_abort, fmt=fmt@entry=0x7fc37ab14f4b "%s\n") at ../sysdeps/posix/libc_fatal.c:181
#3 0x00007fc37aa0ca9c in malloc_printerr (str=str@entry=0x7fc37ab130e0 "free(): invalid pointer") at malloc.c:5339
#4 0x00007fc37aa0e49c in _int_free (av=<optimized out>, p=<optimized out>, have_lock=0) at malloc.c:4173
#5 0x000000000040120e in freeSomething(void*) ()
#6 0x0000000000401401 in main ()
```
The memory addresses: `main()`
and `freeSomething()`
are quite low compared to subsequent frames. Due to the fact that shared objects are mapped to an area at the end of the virtual address space, you can assume that the `SIGABRT`
was caused by a call in a shared library. Memory addresses of shared objects are not constant between invocations, so it is totally fine when you see varying addresses between calls.
The stack trace shows that subsequent calls originate from `malloc.c`
, which indicates that something with memory (de-)allocation could have gone wrong.
In the source code, you can see (even without any knowledge of C++) that it tried to free a pointer, which was not returned by a memory management function. This results in undefined behavior and causes the `SIGABRT`
:
```
void freeSomething(void *ptr){
free(ptr);
}
int nTmp = 5;
int *ptrNull = &nTmp;
freeSomething(ptrNull);
```
The systemd coredump utility can be configured under `/etc/systemd/coredump.conf`
. Rotation of dump file cleaning can be configured in `/etc/systemd/system/systemd-tmpfiles-clean.timer`
.
You can find more information about `coredumpctl`
on its [man page](https://man7.org/linux/man-pages/man1/coredumpctl.1.html).
## Compiling with debug symbols
Open the `Makefile`
and comment out the last part of line 9. It should now look like:
`CFLAGS =-Wall -Werror -std=c++11 -g`
The `-g`
switch enables the compiler to create debug information. Start the application, this time with the `-c2`
switch:
`./coredump -c2`
You will get a floating-point exception. Open the dump in GDB with:
`coredumpctl debug`
This time, you are pointed directly to the line in the source code that caused the error:
```
Reading symbols from /home/stephan/Dokumente/core_dump_example/coredump…
[New LWP 6218]
Core was generated by `./coredump -c2'.
Program terminated with signal SIGFPE, Arithmetic exception.
#0 0x0000000000401233 in zeroDivide () at main.cpp:29
29 nRes = 5 / nDivider;
(gdb)
```
Type `list`
to get a better overview of the source code:
```
(gdb) list
24 int zeroDivide(){
25 int nDivider = 5;
26 int nRes = 0;
27 while(nDivider > 0){
28 nDivider--;
29 nRes = 5 / nDivider;
30 }
31 return nRes;
32 }
```
Use the command `info locals`
to retrieve the values of the local variables from the point in time when the application failed:
```
(gdb) info locals
nDivider = 0
nRes = 5
```
In combination with the source code, you can see that you ran into a division by zero:
`nRes = 5 / 0`
## Conclusion
Knowing how to deal with dump files will help you find and fix hard-to-reproduce random bugs in an application. And if it is not your application, forwarding a core dump to the developer will help her or him find and fix the problem.
## Comments are closed. |
12,555 | 一个用 Java 实现的超轻量级 RESTful Web 服务示例 | https://opensource.com/article/20/7/restful-services-java | 2020-08-27T07:19:00 | [
"RESTful"
] | https://linux.cn/article-12555-1.html |
>
> 通过管理一套图书的完整代码示例,来探索轻量级的 RESTful 服务。
>
>
>

Web 服务,以这样或那样的形式,已经存在了近二十年。比如,[XML-RPC 服务](http://xmlrpc.com/)出现在 90 年代后期,紧接着是用 SOAP 分支编写的服务。在 XML-RPC 和 SOAP 这两个开拓者之后出现后不久,REST 架构风格的服务在大约 20 年前也出现了。[REST](https://www.redhat.com/en/topics/integration/whats-the-difference-between-soap-rest) 风格(以下简称 Restful)服务现在主导了流行的网站,比如 eBay、Facebook 和 Twitter。尽管分布式计算的 Web 服务有很多替代品(如 Web 套接字、微服务和远程过程调用的新框架),但基于 Restful 的 Web 服务依然具有吸引力,原因如下:
* Restful 服务建立在现有的基础设施和协议上,特别是 Web 服务器和 HTTP/HTTPS 协议。一个拥有基于 HTML 的网站的组织可以很容易地为客户添加 Web 服务,这些客户对数据和底层功能更感兴趣,而不是对 HTML 的表现形式感兴趣。比如,亚马逊就率先通过网站和 Web 服务(基于 SOAP 或 Restful)提供相同的信息和功能。
* Restful 服务将 HTTP 当作 API,因此避免了复杂的软件分层,这种分层是基于 SOAP 的 Web 服务的明显特征。比如,Restful API 支持通过 HTTP 命令(POST-GET-PUT-DELETE)进行标准的 CRUD(增加-读取-更新-删除)操作;通过 HTTP 状态码可以知道请求是否成功或者为什么失败。
* Restful Web 服务可以根据需要变得简单或复杂。Restful 是一种风格,实际上是一种非常灵活的风格,而不是一套关于如何设计和构造服务的规定。(伴随而来的缺点是,可能很难确定哪些服务不能算作 Restful 服务。)
* 作为使用者或者客户端,Restful Web 服务与语言和平台无关。客户端发送 HTTP(S) 请求,并以适合现代数据交换的格式(如 JSON)接收文本响应。
* 几乎每一种通用编程语言都至少对 HTTP/HTTPS 有足够的(通常是强大的)支持,这意味着 Web 服务的客户端可以用这些语言来编写。
这篇文章将通过一段完整的 Java 代码示例来探讨轻量级的 Restful 服务。
### 基于 Restful 的“小说” Web 服务
基于 Restful 的“小说” web 服务包含三个程序员定义的类:
* `Novel` 类代表一个小说,只有三个属性:机器生成的 ID、作者和标题。属性可以根据实际情况进行扩展,但我还是想让这个例子看上去更简单一些。
* `Novels` 类包含了用于各种任务的工具类:将一个 `Novel` 或者它们的列表的纯文本编码转换成 XML 或者 JSON;支持在小说集合上进行 CRUD 操作;以及从存储在文件中的数据初始化集合。`Novels` 类在 `Novel` 实例和 servlet 之间起中介作用。
* `NovelsServlet` 类是从 `HttpServlet` 中继承的,`HttpServlet` 是一段健壮且灵活的代码,自 90 年代末的早期企业级 Java 就已经存在了。对于客户端的 CRUD 请求,servlet 可以当作 HTTP 的端点。 servlet 代码主要用于处理客户端的请求和生成相应的响应,而将复杂的细节留给 `Novels` 类中的工具类进行处理。
一些 Java 框架,比如 Jersey(JAX-RS)和 Restlet,就是为 Restful 服务设计的。尽管如此,`HttpServlet` 本身为完成这些服务提供了轻量、灵活、强大且充分测试过的 API。我会通过下面的“小说”例子来说明。
### 部署“小说” Web 服务
当然,部署“小说” Web 服务需要一个 Web 服务器。我的选择是 [Tomcat](http://tomcat.apache.org/),但是如果该服务托管在 Jetty 或者甚至是 Java 应用服务器上,那么这个服务应该至少可以工作(著名的最后一句话!)。[在我的网站上](https://condor.depaul.edu/mkalin)有总结了如何安装 Tomcat 的 README 文件和代码。还有一个附带文档的 Apache Ant 脚本,可以用来构建“小说”服务(或者任何其他服务或网站),并且将它部署在 Tomcat 或相同的服务。
Tomcat 可以从它的[官网](https://tomcat.apache.org/download-90.cgi)上下载。当你在本地安装后,将 `TOMCAT_HOME` 设置为安装目录。有两个子目录值得关注:
* `TOMCAT_HOME/bin` 目录包含了类 Unix 系统(`startup.sh` 和 `shutdown.sh`)和 Windows(`startup.bat` 和 `shutdown.bat`) 的启动和停止脚本。Tomcat 作为 Java 应用程序运行。Web 服务器的 servlet 容器叫做 Catalina。(在 Jetty 中,Web 服务器和容器的名字一样。)当 Tomcat 启动后,在浏览器中输入 `http://localhost:8080/`可以查看详细文档,包括示例。
* `TOMCAT_HOME/webapps` 目录是已部署的 Web 网站和服务的默认目录。部署网站或 Web 服务的直接方法是复制以 `.war` 结尾的 JAR 文件(也就是 WAR 文件)到 `TOMCAT_HOME/webapps` 或它的子目录下。然后 Tomcat 会将 WAR 文件解压到它自己的目录下。比如,Tomcat 会将 `novels.war` 文件解压到一个叫做 `novels` 的子目录下,并且保留 `novels.war` 文件。一个网站或 Web 服务可以通过删除 WAR 文件进行移除,也可以用一个新版 WAR 文件来覆盖已有文件进行更新。顺便说一下,调试网站或服务的第一步就是检查 Tomcat 已经正确解压 WAR 文件;如果没有的话,网站或服务就无法发布,因为代码或配置中有致命错误。
* 因为 Tomcat 默认会监听 8080 端口上的 HTTP 请求,所以本机上的 URL 请求以 `http://localhost:8080/` 开始。
通过添加不带 `.war` 后缀的 WAR 文件名来访问由程序员部署的 WAR 文件:
```
http://locahost:8080/novels/
```
如果服务部署在 `TOMCAT_HOME` 下的一个子目录中(比如,`myapps`),这会在 URL 中反映出来:
```
http://locahost:8080/myapps/novels/
```
我会在靠近文章结尾处的测试部分提供这部分的更多细节。
如前所述,我的主页上有一个包含 Ant 脚本的 ZIP 文件,这个文件可以编译并且部署网站或者服务。(这个 ZIP 文件中也包含一个 `novels.war` 的副本。)对于“小说”这个例子,命令的示例(`%` 是命令行提示符)如下:
```
% ant -Dwar.name=novels deploy
```
这个命令首先会编译 Java 源代码,并且创建一个可部署的 `novels.war` 文件,然后将这个文件保存在当前目录中,再复制到 `TOMCAT_HOME/webapps` 目录中。如果一切顺利,`GET` 请求(使用浏览器或者命令行工具,比如 `curl`)可以用来做一个测试:
```
% curl http://localhost:8080/novels/
```
默认情况下,Tomcat 设置为 <ruby> 热部署 <rt> hot deploys </rt></ruby>:Web 服务器不需要关闭就可以进行部署、更新或者移除一个 web 应用。
### “小说”服务的代码
让我们回到“小说”这个例子,不过是在代码层面。考虑下面的 `Novel` 类:
#### 例 1:Novel 类
```
package novels;
import java.io.Serializable;
public class Novel implements Serializable, Comparable<Novel> {
static final long serialVersionUID = 1L;
private String author;
private String title;
private int id;
public Novel() { }
public void setAuthor(final String author) { this.author = author; }
public String getAuthor() { return this.author; }
public void setTitle(final String title) { this.title = title; }
public String getTitle() { return this.title; }
public void setId(final int id) { this.id = id; }
public int getId() { return this.id; }
public int compareTo(final Novel other) { return this.id - other.id; }
}
```
这个类实现了 `Comparable` 接口中的 `compareTo` 方法,因为 `Novel` 实例是存储在一个线程安全的无序 `ConcurrentHashMap` 中。在响应查看集合的请求时,“小说”服务会对从映射中提取的集合(一个 `ArrayList`)进行排序;`compareTo` 的实现通过 `Novel` 的 ID 将它按升序排序。
`Novels` 类中包含多个实用工具函数:
#### 例 2:Novels 实用工具类
```
package novels;
import java.io.IOException;
import java.io.File;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.BufferedReader;
import java.nio.file.Files;
import java.util.stream.Stream;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.Collections;
import java.beans.XMLEncoder;
import javax.servlet.ServletContext; // not in JavaSE
import org.json.JSONObject;
import org.json.XML;
public class Novels {
private final String fileName = "/WEB-INF/data/novels.db";
private ConcurrentMap<Integer, Novel> novels;
private ServletContext sctx;
private AtomicInteger mapKey;
public Novels() {
novels = new ConcurrentHashMap<Integer, Novel>();
mapKey = new AtomicInteger();
}
public void setServletContext(ServletContext sctx) { this.sctx = sctx; }
public ServletContext getServletContext() { return this.sctx; }
public ConcurrentMap<Integer, Novel> getConcurrentMap() {
if (getServletContext() == null) return null; // not initialized
if (novels.size() < 1) populate();
return this.novels;
}
public String toXml(Object obj) { // default encoding
String xml = null;
try {
ByteArrayOutputStream out = new ByteArrayOutputStream();
XMLEncoder encoder = new XMLEncoder(out);
encoder.writeObject(obj);
encoder.close();
xml = out.toString();
}
catch(Exception e) { }
return xml;
}
public String toJson(String xml) { // option for requester
try {
JSONObject jobt = XML.toJSONObject(xml);
return jobt.toString(3); // 3 is indentation level
}
catch(Exception e) { }
return null;
}
public int addNovel(Novel novel) {
int id = mapKey.incrementAndGet();
novel.setId(id);
novels.put(id, novel);
return id;
}
private void populate() {
InputStream in = sctx.getResourceAsStream(this.fileName);
// Convert novel.db string data into novels.
if (in != null) {
try {
InputStreamReader isr = new InputStreamReader(in);
BufferedReader reader = new BufferedReader(isr);
String record = null;
while ((record = reader.readLine()) != null) {
String[] parts = record.split("!");
if (parts.length == 2) {
Novel novel = new Novel();
novel.setAuthor(parts[0]);
novel.setTitle(parts[1]);
addNovel(novel); // sets the Id, adds to map
}
}
in.close();
}
catch (IOException e) { }
}
}
}
```
最复杂的方法是 `populate`,这个方法从一个包含在 WAR 文件中的文本文件读取。这个文本文件包括了“小说”的初始集合。要打开此文件,`populate` 方法需要 `ServletContext`,这是一个 Java 映射类型,包含了关于嵌入在 servlet 容器中的 servlet 的所有关键信息。这个文本文件有包含了像下面这样的记录:
```
Jane Austen!Persuasion
```
这一行被解析为两部分(作者和标题),由感叹号(`!`)分隔。然后这个方法创建一个 `Novel` 实例,设置作者和标题属性,并且将“小说”加到容器中,保存在内存中。
`Novels` 类也有一些实用工具函数,可以将“小说”容器编码为 XML 或 JSON,取决于发出请求的人所要求的格式。默认是 XML 格式,但是也可以请求 JSON 格式。一个轻量级的 XML 转 JSON 包提供了 JSON。下面是关于编码的更多细节。
#### 例 3:NovelsServlet 类
```
package novels;
import java.util.concurrent.ConcurrentMap;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Arrays;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.OutputStream;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.beans.XMLEncoder;
import org.json.JSONObject;
import org.json.XML;
public class NovelsServlet extends HttpServlet {
static final long serialVersionUID = 1L;
private Novels novels; // back-end bean
// Executed when servlet is first loaded into container.
@Override
public void init() {
this.novels = new Novels();
novels.setServletContext(this.getServletContext());
}
// GET /novels
// GET /novels?id=1
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) {
String param = request.getParameter("id");
Integer key = (param == null) ? null : Integer.valueOf((param.trim()));
// Check user preference for XML or JSON by inspecting
// the HTTP headers for the Accept key.
boolean json = false;
String accept = request.getHeader("accept");
if (accept != null && accept.contains("json")) json = true;
// If no query string, assume client wants the full list.
if (key == null) {
ConcurrentMap<Integer, Novel> map = novels.getConcurrentMap();
Object list = map.values().toArray();
Arrays.sort(list);
String payload = novels.toXml(list); // defaults to Xml
if (json) payload = novels.toJson(payload); // Json preferred?
sendResponse(response, payload);
}
// Otherwise, return the specified Novel.
else {
Novel novel = novels.getConcurrentMap().get(key);
if (novel == null) { // no such Novel
String msg = key + " does not map to a novel.\n";
sendResponse(response, novels.toXml(msg));
}
else { // requested Novel found
if (json) sendResponse(response, novels.toJson(novels.toXml(novel)));
else sendResponse(response, novels.toXml(novel));
}
}
}
// POST /novels
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) {
String author = request.getParameter("author");
String title = request.getParameter("title");
// Are the data to create a new novel present?
if (author == null || title == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
// Create a novel.
Novel n = new Novel();
n.setAuthor(author);
n.setTitle(title);
// Save the ID of the newly created Novel.
int id = novels.addNovel(n);
// Generate the confirmation message.
String msg = "Novel " + id + " created.\n";
sendResponse(response, novels.toXml(msg));
}
// PUT /novels
@Override
public void doPut(HttpServletRequest request, HttpServletResponse response) {
/\* A workaround is necessary for a PUT request because Tomcat does not
generate a workable parameter map for the PUT verb. \*/
String key = null;
String rest = null;
boolean author = false;
/\* Let the hack begin. \*/
try {
BufferedReader br =
new BufferedReader(new InputStreamReader(request.getInputStream()));
String data = br.readLine();
/\* To simplify the hack, assume that the PUT request has exactly
two parameters: the id and either author or title. Assume, further,
that the id comes first. From the client side, a hash character
# separates the id and the author/title, e.g.,
id=33#title=War and Peace
\*/
String[] args = data.split("#"); // id in args[0], rest in args[1]
String[] parts1 = args[0].split("="); // id = parts1[1]
key = parts1[1];
String[] parts2 = args[1].split("="); // parts2[0] is key
if (parts2[0].contains("author")) author = true;
rest = parts2[1];
}
catch(Exception e) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_INTERNAL_SERVER_ERROR));
}
// If no key, then the request is ill formed.
if (key == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
// Look up the specified novel.
Novel p = novels.getConcurrentMap().get(Integer.valueOf((key.trim())));
if (p == null) { // not found
String msg = key + " does not map to a novel.\n";
sendResponse(response, novels.toXml(msg));
}
else { // found
if (rest == null) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
}
// Do the editing.
else {
if (author) p.setAuthor(rest);
else p.setTitle(rest);
String msg = "Novel " + key + " has been edited.\n";
sendResponse(response, novels.toXml(msg));
}
}
}
// DELETE /novels?id=1
@Override
public void doDelete(HttpServletRequest request, HttpServletResponse response) {
String param = request.getParameter("id");
Integer key = (param == null) ? null : Integer.valueOf((param.trim()));
// Only one Novel can be deleted at a time.
if (key == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
try {
novels.getConcurrentMap().remove(key);
String msg = "Novel " + key + " removed.\n";
sendResponse(response, novels.toXml(msg));
}
catch(Exception e) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_INTERNAL_SERVER_ERROR));
}
}
// Methods Not Allowed
@Override
public void doTrace(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
@Override
public void doHead(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
@Override
public void doOptions(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
// Send the response payload (Xml or Json) to the client.
private void sendResponse(HttpServletResponse response, String payload) {
try {
OutputStream out = response.getOutputStream();
out.write(payload.getBytes());
out.flush();
}
catch(Exception e) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_INTERNAL_SERVER_ERROR));
}
}
}
```
上面的 `NovelsServlet` 类继承了 `HttpServlet` 类,`HttpServlet` 类继承了 `GenericServlet` 类,后者实现了 `Servlet` 接口:
```
NovelsServlet extends HttpServlet extends GenericServlet implements Servlet
```
从名字可以很清楚的看出来,`HttpServlet` 是为实现 HTTP(S) 上的 servlet 设计的。这个类提供了以标准 HTTP 请求动词(官方说法,<ruby> 方法 <rt> methods </rt></ruby>)命名的空方法:
* `doPost` (Post = 创建)
* `doGet` (Get = 读取)
* `doPut` (Put = 更新)
* `doDelete` (Delete = 删除)
其他一些 HTTP 动词也会涉及到。`HttpServlet` 的子类,比如 `NovelsServlet`,会重载相关的 `do` 方法,并且保留其他方法为<ruby> 空 <rt> no-ops </rt></ruby>。`NovelsServlet` 重载了七个 `do` 方法。
每个 `HttpServlet` 的 CRUD 方法都有两个相同的参数。下面以 `doPost` 为例:
```
public void doPost(HttpServletRequest request, HttpServletResponse response) {
```
`request` 参数是一个 HTTP 请求信息的映射,而 `response` 提供了一个返回给请求者的输出流。像 `doPost` 的方法,结构如下:
* 读取 `request` 信息,采取任何适当的措施生成一个响应。如果该信息丢失或者损坏了,就会生成一个错误。
* 使用提取的请求信息来执行适当的 CRUD 操作(在本例中,创建一个 `Novel`),然后使用 `response` 输出流为请求者编码一个适当的响应。在 `doPost` 例子中,响应就是已经成功生成一个新“小说”并且添加到容器中的一个确认。当响应被发送后,输出流就关闭了,同时也将连接关闭了。
### 关于方法重载的更多内容
HTTP 请求的格式相对比较简单。下面是一个非常熟悉的 HTTP 1.1 的格式,注释由双井号分隔:
```
GET /novels ## start line
Host: localhost:8080 ## header element
Accept-type: text/plain ## ditto
...
[body] ## POST and PUT only
```
第一行由 HTTP 动词(在本例中是 `GET`)和以名词(在本例中是 `novels`)命名目标资源的 URI 开始。报头中包含键-值对,用冒号分隔左面的键和右面的值。报头中的键 `Host`(大小写敏感)是必须的;主机名 `localhost` 是当前机器上的本地符号地址,`8080` 端口是 Tomcat web 服务器上等待 HTTP 请求的默认端口。(默认情况下,Tomcat 在 8443 端口上监听 HTTP 请求。)报头元素可以以任意顺序出现。在这个例子中,`Accept-type` 报头的值是 MIME 类型 `text/plain`。
一些请求(特别是 `POST` 和 `PUT`)会有报文,而其他请求(特别是 `GET` 和 `DELETE`)没有。如果有报文(可能为空),以两个换行符将报头和报文分隔开;HTTP 报文包含一系列键-值对。对于无报文的请求,比如说查询字符串,报头元素就可以用来发送信息。下面是一个用 ID 2 对 `/novels` 资源的 `GET` 请求:
```
GET /novels?id=2
```
通常来说,查询字符串以问号开始,并且包含一个键-值对,尽管这个键-值可能值为空。
带有 `getParameter` 和 `getParameterMap` 等方法的 `HttpServlet` 很好地回避了有报文和没有报文的 HTTP 请求之前的差异。在“小说”例子中,`getParameter` 方法用来从 `GET`、`POST` 和 `DELETE` 方法中提取所需的信息。(处理 `PUT`请求需要更底层的代码,因为 Tomcat 没有提供可以解析 `PUT` 请求的参数映射。)下面展示了一段在 `NovelsServlet`中被重载的 `doPost` 方法:
```
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) {
String author = request.getParameter("author");
String title = request.getParameter("title");
...
```
对于没有报文的 `DELETE` 请求,过程基本是一样的:
```
@Override
public void doDelete(HttpServletRequest request, HttpServletResponse response) {
String param = request.getParameter("id"); // id of novel to be removed
...
```
`doGet` 方法需要区分 `GET` 请求的两种方式:一种是“获得所有”,而另一种是“获得某一个”。如果 `GET` 请求 URL 中包含一个键是一个 ID 的查询字符串,那么这个请求就被解析为“获得某一个”:
```
http://localhost:8080/novels?id=2 ## GET specified
```
如果没有查询字符串,`GET` 请求就会被解析为“获得所有”:
```
http://localhost:8080/novels ## GET all
```
### 一些值得注意的细节
“小说”服务的设计反映了像 Tomcat 这样基于 Java 的 web 服务器是如何工作的。在启动时,Tomcat 构建一个线程池,从中提取请求处理程序,这种方法称为 “<ruby> 每个请求一个线程 <rt> one thread per request </rt></ruby>” 模型。现在版本的 Tomcat 使用非阻塞 I/O 来提高个性能。
“小说”服务是作为 `NovelsServlet` 类的单个实例来执行的,该实例也就维护了一个“小说”集合。相应的,也就会出现竞态条件,比如出现两个请求同时被处理:
* 一个请求向集合中添加一个新“小说”。
* 另一个请求获得集合中的所有“小说”。
这样的结果是不确定的,取决与 *读* 和 *写* 的操作是以怎样的顺序进行操作的。为了避免这个问题,“小说”服务使用了线程安全的 `ConcurrentMap`。这个映射的关键是生成了一个线程安全的 `AtomicInteger`。下面是相关的代码片段:
```
public class Novels {
private ConcurrentMap<Integer, Novel> novels;
private AtomicInteger mapKey;
...
```
默认情况下,对客户端请求的响应被编码为 XML。为了简单,“小说”程序使用了以前的 `XMLEncoder` 类;另一个包含更丰富功能的方式是使用 JAX-B 库。代码很简单:
```
public String toXml(Object obj) { // default encoding
String xml = null;
try {
ByteArrayOutputStream out = new ByteArrayOutputStream();
XMLEncoder encoder = new XMLEncoder(out);
encoder.writeObject(obj);
encoder.close();
xml = out.toString();
}
catch(Exception e) { }
return xml;
}
```
`Object` 参数要么是一个有序的“小说” `ArraList`(用以响应“<ruby> 获得所有 <rt> get all </rt></ruby>”请求),要么是一个 `Novel` 实例(用以响应“<ruby> 获得一个 <rt> get one </rt></ruby>”请求),又或者是一个 `String`(确认消息)。
如果 HTTP 请求报头指定 JSON 作为所需要的类型,那么 XML 就被转化成 JSON。下面是 `NovelsServlet` 中的 `doGet` 方法中的检查:
```
String accept = request.getHeader("accept"); // "accept" is case insensitive
if (accept != null && accept.contains("json")) json = true;
```
`Novels`类中包含了 `toJson` 方法,可以将 XML 转换成 JSON:
```
public String toJson(String xml) { // option for requester
try {
JSONObject jobt = XML.toJSONObject(xml);
return jobt.toString(3); // 3 is indentation level
}
catch(Exception e) { }
return null;
}
```
`NovelsServlet`会对各种类型进行错误检查。比如,`POST` 请求应该包含新“小说”的作者和标题。如果有一个丢了,`doPost` 方法会抛出一个异常:
```
if (author == null || title == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
```
`SC_BAD_REQUEST` 中的 `SC` 代表的是 <ruby> 状态码 <rt> status code </rt></ruby>,`BAD_REQUEST` 的标准 HTTP 数值是 400。如果请求中的 HTTP 动词是 `TRACE`,会返回一个不同的状态码:
```
public void doTrace(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
```
### 测试“小说”服务
用浏览器测试 web 服务会很不顺手。在 CRUD 动词中,现代浏览器只能生成 `POST`(创建)和 `GET`(读取)请求。甚至从浏览器发送一个 `POST` 请求都有点不好办,因为报文需要包含键-值对;这样的测试通常通过 HTML 表单完成。命令行工具,比如说 [curl](https://curl.haxx.se/),是一个更好的选择,这个部分展示的一些 `curl` 命令,已经包含在我网站的 ZIP 文件中了。
下面是一些测试样例,没有展示相应的输出结果:
```
% curl localhost:8080/novels/
% curl localhost:8080/novels?id=1
% curl --header "Accept: application/json" localhost:8080/novels/
```
第一条命令请求所有“小说”,默认是 XML 编码。第二条命令请求 ID 为 1 的“小说”,XML 编码。最后一条命令通过 `application/json` 添加了 `Accept` 报头元素,作为所需要的 MIME 类型。“<ruby> 获得一个 <rt> get one </rt></ruby>”命令也可以用这个报头。这些请求用了 JSON 而不是 XML 编码作为响应。
下面两条命令在集合中创建了一个新“小说”,并且确认添加了进去:
```
% curl --request POST --data "author=Tolstoy&title=War and Peace" localhost:8080/novels/
% curl localhost:8080/novels?id=4
```
`curl` 中的 `PUT` 命令与 `POST` 命令相似,不同的地方是 `PUT` 的报文没有使用标准的语法。在 `NovelsServlet` 中关于 `doPut` 方法的文档中有详细的介绍,但是简单来说,Tomcat 不会对 `PUT` 请求生成合适的映射。下面是一个 `PUT` 命令和确认命令的的例子:
```
% curl --request PUT --data "id=3#title=This is an UPDATE" localhost:8080/novels/
% curl localhost:8080/novels?id=3
```
第二个命令确认了集合已经更新。
最后,`DELETE` 命令会正常运行:
```
% curl --request DELETE localhost:8080/novels?id=2
% curl localhost:8080/novels/
```
这个请求是删除 ID 为 2 的“小说”。第二个命令会显示剩余的“小说”。
### web.xml 配置文件
尽管官方规定它是可选的,`web.xml` 配置文件是一个生产级别网站或服务的重要组成部分。这个配置文件可以配置独立于代码的路由、安全性,或者网站或服务的其他功能。“小说”服务的配置通过为该服务的请求分配一个 URL 模式来配置路由:
```
<xml version = "1.0" encoding = "UTF-8">
<web-app>
<servlet>
<servlet-name>novels</servlet-name>
<servlet-class>novels.NovelsServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>novels</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
</web-app>
```
`servlet-name` 元素为 servlet 全名(`novels.NovelsServlet`)提供了一个缩写(`novels`),然后这个名字在下面的 `servlet-mapping` 元素中使用。
回想一下,一个已部署服务的 URL 会在端口号后面有 WAR 文件的文件名:
```
http://localhost:8080/novels/
```
端口号后斜杠后的 URI,是所请求资源的“路径”,在这个例子中,就是“小说”服务。因此,`novels` 出现在了第一个单斜杠后。
在 `web.xml` 文件中,`url-patter` 被指定为 `/*`,代表 “以 `/novels` 为起始的任意路径”。假设 Tomcat 遇到了一个不存在的 URL,像这样:
```
http://localhost:8080/novels/foobar/
```
`web.xml` 配置也会指定这个请求被分配到“小说” servlet 中,因为 `/*` 模式也包含 `/foobar`。因此,这个不存在的 URL 也会得到像上面合法路径的相同结果。
生产级别的配置文件可能会包含安全相关的信息,包括<ruby> 连接级别 <rt> wire-level </rt></ruby>和<ruby> 用户角色 <rt> users-roles </rt></ruby>。即使在这种情况下,配置文件的大小也只会是这个例子中的两到三倍大。
### 总结
`HttpServlet` 是 Java web 技术的核心。像“小说”这样的网站或 web 服务继承了这个类,并且根据需求重载了相应的 `do` 动词方法。像 Jersay(JAX-RS)或 Restlet 这样的 Restful 框架通过提供定制的 servlet 完成了基本相同的功能,针对框架中的 web 应用程序的请求,这个 servlet 扮演着 HTTP(S) <ruby> 终端 <rt> endpoint </rt></ruby>的角色。
当然,基于 servlet 的应用程序可以访问 web 应用程序中所需要的任何 Java 库。如果应用程序遵循<ruby> 关注点分离 <rt> separation-of-concerns </rt></ruby>原则,那么 servlet 代码仍然相当简单:代码会检查请求,如果存在缺陷,就会发出适当的错误;否则,代码会调用所需要的功能(比如,查询数据库,以特定格式为响应编码),然后向请求这发送响应。`HttpServletRequest` 和 `HttpServletReponse` 类型使得读取请求和编写响应变得简单。
Java 的 API 可以从非常简单变得相当复杂。如果你需要用 Java 交付一些 Restful 服务的话,我的建议是在做其他事情之前先尝试一下简单的 `HttpServlet`。
---
via: <https://opensource.com/article/20/7/restful-services-java>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Yufei-Yan](https://github.com/Yufei-Yan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Web services, in one form or another, have been around for more than two decades. For example, [XML-RPC services](http://xmlrpc.com/) appeared in the late 1990s, followed shortly by ones written in the SOAP offshoot. Services in the [REST architectural style](https://en.wikipedia.org/wiki/Representational_state_transfer) also made the scene about two decades ago, soon after the XML-RPC and SOAP trailblazers. [REST](https://www.redhat.com/en/topics/integration/whats-the-difference-between-soap-rest)-style (hereafter, Restful) services now dominate in popular sites such as eBay, Facebook, and Twitter. Despite the alternatives to web services for distributed computing (e.g., web sockets, microservices, and new frameworks for remote-procedure calls), Restful web services remain attractive for several reasons:
-
Restful services build upon existing infrastructure and protocols, in particular, web servers and the HTTP/HTTPS protocols. An organization that has HTML-based websites can readily add web services for clients interested more in the data and underlying functionality than in the HTML presentation. Amazon, for example, has pioneered making the same information and functionality available through both websites and web services, either SOAP-based or Restful.
-
Restful services treat HTTP as an API, thereby avoiding the complicated software layering that has come to characterize the SOAP-based approach to web services. For example, the Restful API supports the standard CRUD (Create-Read-Update-Delete) operations through the HTTP verbs POST-GET-PUT-DELETE, respectively; HTTP status codes inform a requester whether a request succeeded or why it failed.
-
Restful web services can be as simple or complicated as needed. Restful is a style—indeed, a very flexible one—rather than a set of prescriptions about how services should be designed and structured. (The attendant downside is that it may be hard to determine what does
*not*count as a Restful service.) -
For a consumer or client, Restful web services are language- and platform-neutral. The client makes requests in HTTP(S) and receives text responses in a format suitable for modern data interchange (e.g., JSON).
-
Almost every general-purpose programming language has at least adequate (and often strong) support for HTTP/HTTPS, which means that web-service clients can be written in those languages.
This article explores lightweight Restful services in Java through a full code example.
## The Restful novels web service
The Restful novels web service consists of three programmer-defined classes:
- The
`Novel`
class represents a novel with just three properties: a machine-generated ID, an author, and a title. The properties could be expanded for more realism, but I want to keep this example simple.
- The
`Novels`
class consists of utilities for various tasks: converting a plain-text encoding of a`Novel`
or a list of them into XML or JSON; supporting the CRUD operations on the novels collection; and initializing the collection from data stored in a file. The`Novels`
class mediates between`Novel`
instances and the servlet.
- The
`NovelsServlet`
class derives from`HttpServlet`
, a sturdy and flexible piece of software that has been around since the very early enterprise Java of the late 1990s. The servlet acts as an HTTP endpoint for client CRUD requests. The servlet code focuses on processing client requests and generating the appropriate responses, leaving the devilish details to utilities in the`Novels`
class.
Some Java frameworks, such as Jersey (JAX-RS) and Restlet, are designed for Restful services. Nonetheless, the `HttpServlet`
on its own provides a lightweight, flexible, powerful, and well-tested API for delivering such services. I'll demonstrate this with the novels example.
## Deploy the novels web service
Deploying the novels web service requires a web server, of course. My choice is [Tomcat](http://tomcat.apache.org/), but the service should work (famous last words!) if it's hosted on, for example, Jetty or even a Java Application Server. The code and a README that summarizes how to install Tomcat are [available on my website](https://condor.depaul.edu/mkalin). There is also a documented Apache Ant script that builds the novels service (or any other service or website) and deploys it under Tomcat or the equivalent.
Tomcat is available for download from its [website](https://tomcat.apache.org/download-90.cgi). Once you install it locally, let `TOMCAT_HOME`
be the install directory. There are two subdirectories of immediate interest:
-
The
`TOMCAT_HOME/bin`
directory contains startup and stop scripts for Unix-like systems (`startup.sh`
and`shutdown.sh`
) and Windows (`startup.bat`
and`shutdown.bat`
). Tomcat runs as a Java application. The web server's servlet container is named Catalina. (In Jetty, the web server and container have the same name.) Once Tomcat starts, enter`http://localhost:8080/`
in a browser to see extensive documentation, including examples. -
The
`TOMCAT_HOME/webapps`
directory is the default for deployed websites and web services. The straightforward way to deploy a website or web service is to copy a JAR file with a`.war`
extension (hence, a WAR file) to`TOMCAT_HOME/webapps`
or a subdirectory thereof. Tomcat then unpacks the WAR file into its own directory. For example, Tomcat would unpack`novels.war`
into a subdirectory named`novels`
, leaving`novels.war`
as-is. A website or service can be removed by deleting the WAR file and updated by overwriting the WAR file with a new version. By the way, the first step in debugging a website or service is to check that Tomcat has unpacked the WAR file; if not, the site or service was not published because of a fatal error in the code or configuration. -
Because Tomcat listens by default on port 8080 for HTTP requests, a request URL for Tomcat on the local machine begins:
`http://localhost:8080/`
Access a programmer-deployed WAR file by adding the WAR file's name but without the
`.war`
extension:`http://locahost:8080/novels/`
If the service was deployed in a subdirectory (e.g.,
`myapps`
) of`TOMCAT_HOME`
, this would be reflected in the URL:`http://locahost:8080/myapps/novels/`
I'll offer more details about this in the testing section near the end of the article.
As noted, the ZIP file on my homepage contains an Ant script that compiles and deploys a website or service. (A copy of `novels.war`
is also included in the ZIP file.) For the novels example, a sample command (with `%`
as the command-line prompt) is:
`% ant -Dwar.name=novels deploy`
This command compiles Java source files and then builds a deployable file named `novels.war`
, leaves this file in the current directory, and copies it to `TOMCAT_HOME/webapps`
. If all goes well, a `GET`
request (using a browser or a command-line utility, such as `curl`
) serves as a first test:
`% curl http://localhost:8080/novels/`
Tomcat is configured, by default, for *hot deploys*: the web server does not need to be shut down to deploy, update, or remove a web application.
## The novels service at the code level
Let's get back to the novels example but at the code level. Consider the `Novel`
class below:
### Example 1. The Novel class
```
package novels;
import java.io.Serializable;
public class Novel implements Serializable, Comparable<Novel> {
static final long serialVersionUID = 1L;
private String author;
private String title;
private int id;
public Novel() { }
public void setAuthor(final String author) { this.author = author; }
public String getAuthor() { return this.author; }
public void setTitle(final String title) { this.title = title; }
public String getTitle() { return this.title; }
public void setId(final int id) { this.id = id; }
public int getId() { return this.id; }
public int compareTo(final Novel other) { return this.id - other.id; }
}
```
This class implements the `compareTo`
method from the `Comparable`
interface because `Novel`
instances are stored in a thread-safe `ConcurrentHashMap`
, which does not enforce a sorted order. In responding to requests to view the collection, the novels service sorts a collection (an `ArrayList`
) extracted from the map; the implementation of `compareTo`
enforces an ascending sorted order by `Novel`
ID.
The class `Novels`
contains various utility functions:
### Example 2. The Novels utility class
```
package novels;
import java.io.IOException;
import java.io.File;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.BufferedReader;
import java.nio.file.Files;
import java.util.stream.Stream;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.Collections;
import java.beans.XMLEncoder;
import javax.servlet.ServletContext; // not in JavaSE
import org.json.JSONObject;
import org.json.XML;
public class Novels {
private final String fileName = "/WEB-INF/data/novels.db";
private ConcurrentMap<Integer, Novel> novels;
private ServletContext sctx;
private AtomicInteger mapKey;
public Novels() {
novels = new ConcurrentHashMap<Integer, Novel>();
mapKey = new AtomicInteger();
}
public void setServletContext(ServletContext sctx) { this.sctx = sctx; }
public ServletContext getServletContext() { return this.sctx; }
public ConcurrentMap<Integer, Novel> getConcurrentMap() {
if (getServletContext() == null) return null; // not initialized
if (novels.size() < 1) populate();
return this.novels;
}
public String toXml(Object obj) { // default encoding
String xml = null;
try {
ByteArrayOutputStream out = new ByteArrayOutputStream();
XMLEncoder encoder = new XMLEncoder(out);
encoder.writeObject(obj);
encoder.close();
xml = out.toString();
}
catch(Exception e) { }
return xml;
}
public String toJson(String xml) { // option for requester
try {
JSONObject jobt = XML.toJSONObject(xml);
return jobt.toString(3); // 3 is indentation level
}
catch(Exception e) { }
return null;
}
public int addNovel(Novel novel) {
int id = mapKey.incrementAndGet();
novel.setId(id);
novels.put(id, novel);
return id;
}
private void populate() {
InputStream in = sctx.getResourceAsStream(this.fileName);
// Convert novel.db string data into novels.
if (in != null) {
try {
InputStreamReader isr = new InputStreamReader(in);
BufferedReader reader = new BufferedReader(isr);
String record = null;
while ((record = reader.readLine()) != null) {
String[] parts = record.split("!");
if (parts.length == 2) {
Novel novel = new Novel();
novel.setAuthor(parts[0]);
novel.setTitle(parts[1]);
addNovel(novel); // sets the Id, adds to map
}
}
in.close();
}
catch (IOException e) { }
}
}
}
```
The most complicated method is `populate`
, which reads from a text file contained in the deployed WAR file. The text file contains the initial collection of novels. To open the text file, the `populate`
method needs the `ServletContext`
, a Java map that contains all of the critical information about the servlet embedded in the servlet container. The text file, in turn, contains records such as this:
`Jane Austen!Persuasion`
The line is parsed into two parts (author and title) separated by the bang symbol (`!`
). The method then builds a `Novel`
instance, sets the author and title properties, and adds the novel to the collection, which acts as an in-memory data store.
The `Novels`
class also has utilities to encode the novels collection into XML or JSON, depending upon the format that the requester prefers. XML is the default, but JSON is available upon request. A lightweight XML-to-JSON package provides the JSON. Further details on encoding are below.
### Example 3. The NovelsServlet class
```
package novels;
import java.util.concurrent.ConcurrentMap;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Arrays;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.OutputStream;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.beans.XMLEncoder;
import org.json.JSONObject;
import org.json.XML;
public class NovelsServlet extends HttpServlet {
static final long serialVersionUID = 1L;
private Novels novels; // back-end bean
// Executed when servlet is first loaded into container.
@Override
public void init() {
this.novels = new Novels();
novels.setServletContext(this.getServletContext());
}
// GET /novels
// GET /novels?id=1
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) {
String param = request.getParameter("id");
Integer key = (param == null) ? null : Integer.valueOf((param.trim()));
// Check user preference for XML or JSON by inspecting
// the HTTP headers for the Accept key.
boolean json = false;
String accept = request.getHeader("accept");
if (accept != null && accept.contains("json")) json = true;
// If no query string, assume client wants the full list.
if (key == null) {
ConcurrentMap<Integer, Novel> map = novels.getConcurrentMap();
Object[] list = map.values().toArray();
Arrays.sort(list);
String payload = novels.toXml(list); // defaults to Xml
if (json) payload = novels.toJson(payload); // Json preferred?
sendResponse(response, payload);
}
// Otherwise, return the specified Novel.
else {
Novel novel = novels.getConcurrentMap().get(key);
if (novel == null) { // no such Novel
String msg = key + " does not map to a novel.\n";
sendResponse(response, novels.toXml(msg));
}
else { // requested Novel found
if (json) sendResponse(response, novels.toJson(novels.toXml(novel)));
else sendResponse(response, novels.toXml(novel));
}
}
}
// POST /novels
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) {
String author = request.getParameter("author");
String title = request.getParameter("title");
// Are the data to create a new novel present?
if (author == null || title == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
// Create a novel.
Novel n = new Novel();
n.setAuthor(author);
n.setTitle(title);
// Save the ID of the newly created Novel.
int id = novels.addNovel(n);
// Generate the confirmation message.
String msg = "Novel " + id + " created.\n";
sendResponse(response, novels.toXml(msg));
}
// PUT /novels
@Override
public void doPut(HttpServletRequest request, HttpServletResponse response) {
/* A workaround is necessary for a PUT request because Tomcat does not
generate a workable parameter map for the PUT verb. */
String key = null;
String rest = null;
boolean author = false;
/* Let the hack begin. */
try {
BufferedReader br =
new BufferedReader(new InputStreamReader(request.getInputStream()));
String data = br.readLine();
/* To simplify the hack, assume that the PUT request has exactly
two parameters: the id and either author or title. Assume, further,
that the id comes first. From the client side, a hash character
# separates the id and the author/title, e.g.,
id=33#title=War and Peace
*/
String[] args = data.split("#"); // id in args[0], rest in args[1]
String[] parts1 = args[0].split("="); // id = parts1[1]
key = parts1[1];
String[] parts2 = args[1].split("="); // parts2[0] is key
if (parts2[0].contains("author")) author = true;
rest = parts2[1];
}
catch(Exception e) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_INTERNAL_SERVER_ERROR));
}
// If no key, then the request is ill formed.
if (key == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
// Look up the specified novel.
Novel p = novels.getConcurrentMap().get(Integer.valueOf((key.trim())));
if (p == null) { // not found
String msg = key + " does not map to a novel.\n";
sendResponse(response, novels.toXml(msg));
}
else { // found
if (rest == null) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
}
// Do the editing.
else {
if (author) p.setAuthor(rest);
else p.setTitle(rest);
String msg = "Novel " + key + " has been edited.\n";
sendResponse(response, novels.toXml(msg));
}
}
}
// DELETE /novels?id=1
@Override
public void doDelete(HttpServletRequest request, HttpServletResponse response) {
String param = request.getParameter("id");
Integer key = (param == null) ? null : Integer.valueOf((param.trim()));
// Only one Novel can be deleted at a time.
if (key == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
try {
novels.getConcurrentMap().remove(key);
String msg = "Novel " + key + " removed.\n";
sendResponse(response, novels.toXml(msg));
}
catch(Exception e) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_INTERNAL_SERVER_ERROR));
}
}
// Methods Not Allowed
@Override
public void doTrace(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
@Override
public void doHead(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
@Override
public void doOptions(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
// Send the response payload (Xml or Json) to the client.
private void sendResponse(HttpServletResponse response, String payload) {
try {
OutputStream out = response.getOutputStream();
out.write(payload.getBytes());
out.flush();
}
catch(Exception e) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_INTERNAL_SERVER_ERROR));
}
}
}
```
Recall that the `NovelsServlet`
class above extends the `HttpServlet`
class, which in turn extends the `GenericServlet`
class, which implements the `Servlet`
interface:
`NovelsServlet extends HttpServlet extends GenericServlet implements Servlet`
As the name makes clear, the `HttpServlet`
is designed for servlets delivered over HTTP(S). The class provides empty methods named after the standard HTTP request verbs (officially, *methods*):
`doPost`
(Post = Create)`doGet`
(Get = Read)`doPut`
(Put = Update)`doDelete`
(Delete = Delete)
Some additional HTTP verbs are covered as well. An extension of the `HttpServlet`
, such as the `NovelsServlet`
, overrides any `do`
method of interest, leaving the others as no-ops. The `NovelsServlet`
overrides seven of the `do`
methods.
Each of the `HttpServlet`
CRUD methods takes the same two arguments. Here is `doPost`
as an example:
`public void doPost(HttpServletRequest request, HttpServletResponse response) {`
The `request`
argument is a map of the HTTP request information, and the `response`
provides an output stream back to the requester. A method such as `doPost`
is structured as follows:
- Read the
`request`
information, taking whatever action is appropriate to generate a response. If information is missing or otherwise deficient, generate an error.
- Use the extracted request information to perform the appropriate CRUD operation (in this case, create a
`Novel`
) and then encode an appropriate response to the requester using the`response`
output stream to do so. In the case of`doPost`
, the response is a confirmation that a new novel has been created and added to the collection. Once the response is sent, the output stream is closed, which closes the connection as well.
## More on the do method overrides
An HTTP request has a relatively simple structure. Here is a sketch in the familiar HTTP 1.1 format, with comments introduced by double sharp signs:
```
GET /novels ## start line
Host: localhost:8080 ## header element
Accept-type: text/plain ## ditto
...
[body] ## POST and PUT only
```
The start line begins with the HTTP verb (in this case, `GET`
) and the URI (Uniform Resource Identifier), which is the noun (in this case, `novels`
) that names the targeted resource. The headers consist of key-value pairs, with a colon separating the key on the left from the value(s) on the right. The header with key `Host`
(case insensitive) is required; the hostname `localhost`
is the symbolic address of the local machine on the local machine, and the port number `8080`
is the default for the Tomcat web server awaiting HTTP requests. (By default, Tomcat listens on port 8443 for HTTPS requests.) The header elements can occur in arbitrary order. In this example, the `Accept-type`
header's value is the MIME type `text/plain`
.
Some requests (in particular, `POST`
and `PUT`
) have bodies, whereas others (in particular, `GET`
and `DELETE`
) do not. If there is a body (perhaps empty), two newlines separate the headers from the body; the HTTP body consists of key-value pairs. For bodyless requests, header elements, such as the query string, can be used to send information. Here is a request to `GET`
the `/novels`
resource with the ID of 2:
`GET /novels?id=2`
The query string starts with the question mark and, in general, consists of key-value pairs, although a key without a value is possible.
The `HttpServlet`
, with methods such as `getParameter`
and `getParameterMap`
, nicely hides the distinction between HTTP requests with and without a body. In the novels example, the `getParameter`
method is used to extract the required information from the
, `GET``POST`
, and `DELETE`
requests. (Handling a `PUT`
request requires lower-level code because Tomcat does not provide a workable parameter map for `PUT`
requests.) Here, for illustration, is a slice of the `doPost`
method in the `NovelsServlet`
override:
```
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) {
String author = request.getParameter("author");
String title = request.getParameter("title");
...
```
For a bodyless `DELETE`
request, the approach is essentially the same:
```
@Override
public void doDelete(HttpServletRequest request, HttpServletResponse response) {
String param = request.getParameter("id"); // id of novel to be removed
...
```
The `doGet`
method needs to distinguish between two flavors of a `GET`
request: one flavor means "get all*"*, whereas the other means *get a specified one*. If the `GET`
request URL contains a query string whose key is an ID, then the request is interpreted as "get a specified one":
`http://localhost:8080/novels?id=2 ## GET specified`
If there is no query string, the `GET`
request is interpreted as "get all":
`http://localhost:8080/novels ## GET all`
## Some devilish details
The novels service design reflects how a Java-based web server such as Tomcat works. At startup, Tomcat builds a thread pool from which request handlers are drawn, an approach known as the *one thread per request model*. Modern versions of Tomcat also use non-blocking I/O to boost performance.
The novels service executes as a *single* instance of the `NovelsServlet`
class, which in turn maintains a *single* collection of novels. Accordingly, a race condition would arise, for example, if these two requests were processed concurrently:
- One request changes the collection by adding a new novel.
- The other request gets all the novels in the collection.
The outcome is indeterminate, depending on exactly how the *read* and *write* operations overlap. To avoid this problem, the novels service uses a thread-safe `ConcurrentMap`
. Keys for this map are generated with a thread-safe `AtomicInteger`
. Here is the relevant code segment:
```
public class Novels {
private ConcurrentMap<Integer, Novel> novels;
private AtomicInteger mapKey;
...
```
By default, a response to a client request is encoded as XML. The novels program uses the old-time `XMLEncoder`
class for simplicity; a far richer option is the JAX-B library. The code is straightforward:
```
public String toXml(Object obj) { // default encoding
String xml = null;
try {
ByteArrayOutputStream out = new ByteArrayOutputStream();
XMLEncoder encoder = new XMLEncoder(out);
encoder.writeObject(obj);
encoder.close();
xml = out.toString();
}
catch(Exception e) { }
return xml;
}
```
The `Object`
parameter is either a sorted `ArrayList`
of novels (in response to a "get all" request); or a single `Novel`
instance (in response to a *get one* request); or a `String`
(a confirmation message).
If an HTTP request header refers to JSON as a desired type, then the XML is converted to JSON. Here is the check in the `doGet`
method of the `NovelsServlet`
:
```
String accept = request.getHeader("accept"); // "accept" is case insensitive
if (accept != null && accept.contains("json")) json = true;
```
The `Novels`
class houses the `toJson`
method, which converts XML to JSON:
```
public String toJson(String xml) { // option for requester
try {
JSONObject jobt = XML.toJSONObject(xml);
return jobt.toString(3); // 3 is indentation level
}
catch(Exception e) { }
return null;
}
```
The `NovelsServlet`
checks for errors of various types. For example, a `POST`
request should include an author and a title for the new novel. If either is missing, the `doPost`
method throws an exception:
```
if (author == null || title == null)
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_BAD_REQUEST));
```
The `SC`
in `SC_BAD_REQUEST`
stands for *status code*, and the `BAD_REQUEST`
has the standard HTTP numeric value of 400. If the HTTP verb in a request is `TRACE`
, a different status code is returned:
```
public void doTrace(HttpServletRequest request, HttpServletResponse response) {
throw new RuntimeException(Integer.toString(HttpServletResponse.SC_METHOD_NOT_ALLOWED));
}
```
## Testing the novels service
Testing a web service with a browser is tricky. Among the CRUD verbs, modern browsers generate only `POST`
(Create) and `GET`
(Read) requests. Even a `POST`
request is challenging from a browser, as the key-values for the body need to be included; this is typically done through an HTML form. A command-line utility such as [curl](https://curl.haxx.se/) is a better way to go, as this section illustrates with some `curl`
commands, which are included in the ZIP on my website.
Here are some sample tests without the corresponding output:
```
% curl localhost:8080/novels/
% curl localhost:8080/novels?id=1
% curl --header "Accept: application/json" localhost:8080/novels/
```
The first command requests all the novels, which are encoded by default in XML. The second command requests the novel with an ID of 1, which is encoded in XML. The last command adds an `Accept`
header element with `application/json`
as the MIME type desired. The `get one`
command could also use this header element. Such requests have JSON rather than the XML responses.
The next two commands create a new novel in the collection and confirm the addition:
```
% curl --request POST --data "author=Tolstoy&title=War and Peace" localhost:8080/novels/
% curl localhost:8080/novels?id=4
```
A `PUT`
command in `curl`
resembles a `POST`
command except that the `PUT`
body does not use standard syntax. The documentation for the `doPut`
method in the `NovelsServlet`
goes into detail, but the short version is that Tomcat does not generate a proper map on `PUT`
requests. Here is the sample `PUT`
command and a confirmation command:
```
% curl --request PUT --data "id=3#title=This is an UPDATE" localhost:8080/novels/
% curl localhost:8080/novels?id=3
```
The second command confirms the update.
Finally, the `DELETE`
command works as expected:
```
% curl --request DELETE localhost:8080/novels?id=2
% curl localhost:8080/novels/
```
The request is for the novel with the ID of 2 to be deleted. The second command shows the remaining novels.
## The web.xml configuration file
Although it's officially optional, a `web.xml`
configuration file is a mainstay in a production-grade website or service. The configuration file allows routing, security, and other features of a site or service to be specified independently of the implementation code. The configuration for the novels service handles routing by providing a URL pattern for requests dispatched to this service:
```
<?xml version = "1.0" encoding = "UTF-8"?>
<web-app>
<servlet>
<servlet-name>novels</servlet-name>
<servlet-class>novels.NovelsServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>novels</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
</web-app>
```
The `servlet-name`
element provides an abbreviation (`novels`
) for the servlet's fully qualified class name (`novels.NovelsServlet`
), and this name is used in the `servlet-mapping`
element below.
Recall that a URL for a deployed service has the WAR file name right after the port number:
`http://localhost:8080/novels/`
The slash immediately after the port number begins the URI known as the *path* to the requested resource, in this case, the novels service; hence, the term `novels`
occurs after the first single slash.
In the `web.xml`
file, the `url-pattern`
is specified as `/*`
, which means *any path that starts with /novels*. Suppose Tomcat encounters a contrived request URL, such as this:
`http://localhost:8080/novels/foobar/`
The `web.xml`
configuration specifies that this request, too, should be dispatched to the novels servlet because the `/*`
pattern covers `/foobar`
. The contrived URL thus has the same result as the legitimate one shown above it.
A production-grade configuration file might include information on security, both wire-level and users-roles. Even in this case, the configuration file would be only two or three times the size of the sample one.
## Wrapping up
The `HttpServlet`
is at the center of Java's web technologies. A website or web service, such as the novels service, extends this class, overriding the `do`
verbs of interest. A Restful framework such as Jersey (JAX-RS) or Restlet does essentially the same by providing a customized servlet, which then acts as the HTTP(S) endpoint for requests against a web application written in the framework.
A servlet-based application has access, of course, to any Java library required in the web application. If the application follows the separation-of-concerns principle, then the servlet code remains attractively simple: the code checks a request, issuing the appropriate error if there are deficiencies; otherwise, the code calls out for whatever functionality may be required (e.g., querying a database, encoding a response in a specified format), and then sends the response to the requester. The `HttpServletRequest`
and `HttpServletResponse`
types make it easy to perform the servlet-specific work of reading the request and writing the response.
Java has APIs that range from the very simple to the highly complicated. If you need to deliver some Restful services using Java, my advice is to give the low-fuss `HttpServlet`
a try before anything else.
## Comments are closed. |
12,557 | 《代码英雄》第一季(7):开启未来 | https://www.redhat.com/en/command-line-heroes/season-1/days-of-future-open | 2020-08-27T23:12:00 | [
"开源",
"代码英雄"
] | https://linux.cn/article-12557-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(7):开启未来](https://www.redhat.com/en/command-line-heroes/season-1/days-of-future-open)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/8a8244c8.mp3)脚本。
想象一下,在这个世界上,开源从来没有流行过,没有人认为将源代码提供给别人是个好主意。在本期节目中,我们将想象这种奇异的可能性。而我们也会庆祝那些让我们走到今天的开源工具和方法论。
加入我们,我们将对第一季进行总结,高屋建瓴地来了解开源世界是如何形成的。下一季,我们将把镜头放大,聚焦于当今的代码英雄们的史诗般的奋斗。
**配音**:
在一个没有开源的世界里,来自未来的执法者穿越时空去摧毁 Linus Torvalds 的计算机。
**Saron Yitbarek**:
天啊。我又做了那个噩梦。在梦里,我有一些很棒的想法,但我不能上手开发,因为没有相应的开源技术可以使用。
**Tristram Oaten**:
我认为一个没有开源的世界几乎注定是邪恶的。
**00:00:30 - Saron Yitbarek**:
我想,如果软件(LCTT 译注:这里的软件指 MINIX)在 20 世纪 80 年代遭到闭源,而源代码再也没有被打开过,肯定会少很多创新。
**Steven Vaughan-Nichols**:
那将是一个落后的世界。
**Hannah Cushman**:
我认为智能冰箱肯定会变得更少。
**配音**:
在一个没有智能冰箱的世界中。
**00:01:00 - Saron Yitbarek**:
好吧,好吧。你懂的。我们正在想象一个没有开放源代码技术的世界,这并不特别美好。想象一下:你的在线生活由一些大型私有公司管理,为此你得向它们缴费。网络中的每一处都被它们看守着。对于我们开发人员来说,没有开源的世界意味着更少的自由和影响力。
**00:01:30**:
在整整一季中,我们一直在纪录开发人员在开源世界中的角色。随着开源技术与工具的不断涌现,我们的工作也不断演进和扩展。无论是敏捷宣言,DevOps 的兴起,还是容器编排,我们宣称的力量和自由都与开源哲学紧密相关。
在本季的最后一集,我们将会回顾前几集中的内容。随着世界走向开源,这个词的原始含义能剩下多少呢?而我们,接下来,则将何去何从?
**00:02:00**:
我是 Saron Yitbarek,这里是《代码英雄》,一款红帽公司原创的播客节目。第 7 集:开启未来。
**Steven Vaughan-Nichols**:
没有开源的世界不是我想要的世界,也不是绝大多数人想在其中生活的世界。
**00:02:30 - Saron Yitbarek**:
这位是 Steven Vaughan-Nichols。你可能在[第一集](/article-12494-1.html)和[第二集](/article-12508-1.html)里谈论操作系统战争的时候记住了他。他是<ruby> 哥伦比亚广播集团互动媒体公司 <rt> CBS Interactive </rt></ruby>的特约编辑,从快速调制解调器的速度还是 300 比特每秒时以来,他就一直关注着科技。
**Steven Vaughan-Nichols**:
除了 Linux 之外,你可能无法叫出任何一个开源程序的名字,但是你当前的生活是建立在开源之上的。
**00:03:00 - Saron Yitbarek**:
如果不使用开源技术,绝大多数人甚至无法上网。开源技术几乎存在于地球上的每台超级计算机中。它运行在<ruby> 物联网 <rt> Internet of Things </rt></ruby>(IoT)中。它存在于你的手机、你的 Web 服务器,你的社交媒体———以及,大型强子对撞机中。而且,并非只有我们开发人员了解开源的诸多益处。开源态度现在已经超越了技术的范畴,影响了其它行业,例如经济学、音乐、科学和新闻业。
**00:03:30**:
如果建筑师以我们分享代码的同样方式分享建筑的蓝图会发生什么?如果一个记者打开她的档案,让任何人不仅可以检查她发表的文章,还能检查她的研究和采访记录,会发生什么?我们不应为此而惊讶,因为开发人员培育这份哲学已有多年。每个人都可以看到代码、注释代码、复制代码、提供补丁,这实际上是一件非常基础的事情,对吧?这就是分享。
**00:04:00**:
自最早的人类分享膳食食谱以来,我们就知道公开分享指令集,或者说算法,对人类有净收益。在某些方面,开源技术现在能使我们重温这个基本事实。
**Hannah Cushman**:
我认为,使更多的事物开源会促进和鼓励人们查阅原始资源,这总是很好的。
**00:04:30 - Saron Yitbarek**:
这位是 Hannah Cushman,她是 DataMade 的一位开发人员,他们一直在努力使城市变得更加开放。将来自政府的大量公开数据进行整理并合理地处理,就可以让普通市民使用它来采取行动。他们使用的技术是开源的,同时他们对政治的态度也是如此。
**00:05:00 - Hannah Cushman**:
我们在芝加哥与一个叫做 City Bureau 的组织进行了一个项目,和他们一起为公立学校测试铅含量。我们测试了这些学校中几乎全部的供水设备。这些全部公布的测试结果有 500 份 PDF 文件之多。
**Saron Yitbarek**:
是的,这太好了。但这并不完全是一种使数据公开的有效方式。
**00:05:30 - Hannah Cushman**:
在整个系统中,很难看到例如哪里发现了铅,以及哪里的铅含量更高。我们使用了另一个叫做 Tablua 的开源工具,可以在终端上运行;它能从 500 多个 PDF 文件中提取数据并将其放在一起,帮助我们把巨量信息转储到一个对人们有用的上下文中。
我认为查询源数据是一种非常有效的方式,这使人们可以了解信息的来源并验证其正确性。
**00:06:00 - Saron Yitbarek**:
市民可以访问健康报告的详细信息,获取游说者的数据,还可以查看城市政治的整个组织结构,DataMade 为此提供了浏览门户。这使芝加哥人有更多机会对市政的方方面面作出改变。
<ruby> 加州州立理工大学 <rt> Cal Poly </rt></ruby>的研究软件工程师 Carol Willing 认为,这种不断扩展的开源态度将给世界带来更广泛的变化。
**00:06:30 - Carol Willing**:
就个人而言,我认为开源将从开源软件发展到开放硬件、开放政府、开放教育、开放协作、开放创新等等。开源会不断进化。
**Saron Yitbarek**:
现在,开源逐渐变得更像是自然法则,而不仅仅是科技界的产物。
**00:07:00 - Carol Willing**:
人们慷慨奉献自己时间的事迹古而有之。但令人耳目一新的是,开源深刻地改变了世界,因为它使不同的小群体联合起来,一起致力于他们中任何一组都无法单独处理的大型项目。
**00:07:30 - Saron Yitbarek**:
“用全新的技术来践行古老的理念”——这个主意我喜欢。但先别急着高兴。随着开源这个词被越来越广泛地使用,它的定义可能会变得模糊。在某些场合下,它开始意味着“免费”,或者“众包”,甚至仅仅是“可定制”。
例如,如果我只是允许你选择在冰淇淋上哪撒些糖粉,这不代表我的冰淇淋是开源甜点。但是,如果我告诉你如何制作糖粉,让你改进我的糖粉配方——然后,如果你也想与他人分享糖粉制作的秘密,那么,恭喜你,我们得到了一些美味的开源。
**00:08:00**:
那么,开源的原始定义又是什么?它很简单,但我们应当恪守。要实现真正的开源,你需要公开代码,或者蓝图,或者你的菜谱。换句话说,就是使任何人都可以随意研究、修改和重新分发原始数据。这种哲学将带来变革,不过对于命令行外的世界,一切才刚刚开始。
**00:08:30 - Thomas Cameron**:
这是一种非常惊人的技术开发方式。无论是它的成功,还是我已经参与其中的这一事实,都让我感到震惊。
**Saron Yitbarek**:
Thomas Cameron 在 1998 年“开源”这个词被发明之前就一直从事开源工作。今天,他是 Red Hat 的高级首席云推广人员。他完全有资格谈论开源在如今的进展,以及其发展的过程中发究竟生了多少斗争。
**00:09:00 - Thomas Cameron**:
你知道,经理们不想承担风险,这是巨大的阻力。因为它是免费的,所以他们会想,“我没办法打电话寻求技术支持”,“我不得不依靠特定的开源软件”之类。这一类斗争还算简单,在部门服务器、群组服务器、小型 Web 服务器、小型文件服务器和打印服务器上,我们也赢过不少。随着时间的推移,在赢得这些简单的战斗之后,更艰难的战斗出现了。在每次“作战”中,你会发现,系统管理员和系统工程师对开源越来越着迷。
**00:09:30 - Saron Yitbarek**:
尽管有这些斗争,你也无法否认一直以来的进展。
**00:10:00 - Thomas Cameron**:
我目睹了开源给 IT 行业带来的改变,它最开始时用在某些系统管理员办公桌下私搭乱建的服务器里,并最终传播到家喻户晓的大公司之中——英特尔、IBM、AMD,每个你能想到的组织都开始为开源项目做出贡献。这绝对是一场斗争,我在不同的企业职位上都参加过如此多的相关争论;我曾说过,“我们需要把 Linux,或其他开源技术,引入数据中心。”
**00:10:30 - Saron Yitbarek**:
Thomas 观察到,开源软件开发正逐步占据市场。但对于某些人来说,这很令人不安。
**Thomas Cameron**:
我们能够分享信息与分析结果,这让那些一直占有信息并从中牟利的人感到害怕。这种模式使他们无法轻易获取利润,也难以哪怕得到对一个组织的完全控制,这是巨大的变化,随之而来的是恐惧。
**00:11:00 - Saron Yitbarek**:
我们在本季开始时描述的支持开源的反叛者们现在领导着这个行业。但从更长远的角度来看,故事绝不会在这里结束。Christopher Tozzi 是 Fixate IO 的高级编辑。他将开源带来的颠覆视为某种根本性转变的开始,这种转变将使世界各地的人们都能协同合作——而不仅是在软件开发行业中。
**00:11:30 - Christopher Tozzi**:
我认为,在过去的二十年里,开源变得如此强大的原因之一就是人们对去中心化一直保有兴趣。我认为,这也解释了开源如何影响其它技术创新。比如,区块链也建立在这样的思想上:如果我们摆脱集中的生产方式,去中心化的数据库或交易方式可能会更高效、更安全。重申一次,我认为今天的开源,自从 Torvalds 出现以来,就与开发工作的去中心化息息相关。
**00:12:00 - Saron Yitbarek**:
全面的分权意味着整个世界都在走向开源。体现了这一理念的开发人员,他们是最能想象未来的人。
这是 Tristram Oaten,他是伦敦的一位开发者,他肯定在考虑这场漫长的比赛。
**00:12:30 - Tristram Oaten**:
就像是 3D 打印机将通过在家生产零件来使我们的生活更轻松——而且多半能更环保一样。无论什么时候有东西坏了,你都可以在家里新制造一个。这是<ruby> 星际迷航 <rt> Star Trek </rt></ruby>式的未来的复制器,就和理想中一模一样。希望这样的生产方式能真正投入使用,这样,说不定,整座房子都能变得开源了。
**Saron Yitbarek**:
Tristram 设想了一个世界,在这个世界上,开源是各个领域都遵守的规则。这意味着,开发者即使不是大师,至少也会成为人们的向导——这种向导是至关重要的。
**00:13:00 - Tristram Oaten**:
在未来,我们作为开发人员的角色将越加重要,我们会变得越来越像“魔法师”——如果我们现在还不够像的话。
**Saron Yitbarek**:
好吧,魔法师。我们会成为魔法师。
**00:13:30 - Tristram Oaten**:
我们能用奇怪的语言驱使机器做奇妙的事,于是,我们会被高薪雇来做宫廷魔法师,或者公司魔法师。当每个人的身体中都有设备,并且无处不在的设备都可以通过互联网访问,还能被远程控制时,我们则需要作为一个团体,一个行会,以最好的信念行事,就像医疗行业要有不伤害他人的宪章等等。这非常重要。
我认为,开发人员需要共同决定不要制造杀手机器人,也不要在每个人的路由器和每个人的助听器中安置间谍软件。我们需要彼此确认,并向所有人保证,我们将为更大的利益而努力,而非为了伤害人类。
**00:14:00 - Saron Yitbarek**:
让我们现在保证不会造机器人杀手,对吧?好。在此之上,我确实认为 Tristram 说得对。在某些方面,我们开发者已经看到了未来,这代表我们有机会在塑造未来上出一份力。
10 年后,开源开发的道德标准将会是什么样子的?
**00:14:30 - Tristram Oaten**:
我们现在有着极大的特权,因此,我们有责任做正确的事。
**Saron Yitbarek**:
那么,魔法师们,我们将去向何方?我们能为开源创造一个健康的未来吗?我想和一个对这一切进行了深入思考的人谈谈,于是,我找到了这一位。Safia Abdalla 是一名软件工程师,她一直在为<ruby> 交互计划 <rt> Interact Project </rt></ruby>做开源贡献。我们将会讨论,真正的“可持续的、广泛的开源”会是什么样子。听听看。
在你心里,未来的开源会是怎么样的,和现在有什么不同之处?
**00:15:00 - Safia Abdalla**:
嗯,我想,我所看到的最大的新兴趋势之一就是对开源可持续性的高度关注,也就是关于如何让开源项目一直得到良好维护和更新的讨论。有一些项目对整个技术界生态都至关重要,讨论也集中于它们。我认为,在该领域,已经有了许多有趣的进展。
**00:15:30 - Saron Yitbarek**:
Safia 让我思考,如果我们能够建立她所描述的可持续发展的方法,如果公司能够贡献时间、代码和资源,我们的工作能够得到多少改善?又会发生多少变化?所以我问她,这样可持续的方式会给我们所创造的产品,和我们建构的工具,带来怎么样的改变?
**00:16:00 - Safia Abdalla**:
可悲的现实是,当你没有精力,时间和金钱来为每个人打造好东西时,你就会倾向于只为自己做好它。
**Saron Yitbarek**:
嗯,确实。
**Safia Abdalla**:
在这种情况下,你构建的产品会将把很多人排除在用户之外。因此,我相信,如果我们发现开放源代码的更具可持续性的模型,那么我们实际上将开始构建可供盲人、听障者或以其它方式残障的个人使用的软件。
**00:16:30 - Saron Yitbarek**:
有趣,我喜欢。考虑到开放源代码的原则、流程、文化和社区,以及你提到的所有这些内容该如何适用于技术之外、软件开发之外的行业时,你认为真正可以从开源中受益的领域是哪些?你认为接下来开源可能会出现在哪里?
**00:17:00 - Safia Abdalla**:
喔,这是个有趣的角度。我第一个想到的是,开源思维可以被用于科学界,使科学变得更加开放。之所以我会想到这一点,是因为,当你以开放方式分享软件时,你所分享的并不是一行行的代码 —— 好吧,你确实在分享代码 —— 但,更重要的是,你在分享知识和细节,在与其他人交流该如何做事。因此,你真正分享的是知识。
**00:17:30**:
开源的方式可以相当直接地应用于科学界,因为研究人员也会花费大量的时间来探究特定课题,随后就此课题发表论文。而且,我认为,我们需要向科学界倡议更加开放的科研方式,以确保科研成果能够对所有人开放,使所有人都能理解、分享和参与,这将会提高社会对科学的理解,并在一定程度上促进科学研究本身。
**00:18:00 - Saron Yitbarek**:
当我上大学时,我从事生物化学研究;我非常习惯于带着热情进行实验、研究、尝试新事物。然而,同时,你也不能让人随意插手研究,因为你需要做通讯作者。你需要信誉。这是学术界进步的一个很重要、很重要的组成部分。
**00:18:30**:
因此,开源的原则——即分享原始数据、贡献劳动,以及将未完成的产品公之于众,依靠集体智慧将其完工的这些原则——和某些更具保护意识的行业必然发生冲突。你如何看待这种冲突?
**00:19:00 - Safia Abdalla**:
这是个好问题。我认为这涉及一个更大、更复杂的问题。为了成功地将开源引入其他行业,外在的动机和鼓励在很大程度上是必要的。你不能依赖于鼓励人们只专注于自己的目标的现有体系,因为那样会牺牲他人的利益和社会的更大利好。
**00:19:30**:
我认为,我们必须根本地改变我们看待很多事情的方式,并更改许多体系的运作方式,以使它们关注集体利益而非单一利益。很难撤销像终身教职这样对大学有很多负面影响的制度。很难消除其它可能损害生态、损害他人,或者阻碍社会进步的激励机制。不管是采用开源的思维方式,还是主动取消这些体系,我们都有极长的路要走。
**00:20:00 - Saron Yitbarek**:
确实。如果你可以从头重新创造开源,那么,属于你的开源版本又会是什么样的?
**00:20:30 - Safia Abdalla**:
哇噻。关于开源,我要改变的第一件事是它的公共关系和形象。我可能会尝试建立一种开源文化或社区,让人们认识到,你即使不是精英,或者精湛的开发人员,也能活跃并取得成功。现有开源文化中的精英倾向使我感到震慑。
**00:21:00**:
另外,我也要重点关注开源的可持续性,增加公司的责任感和开源体系的健康程度。我认为很多人没有意识到的事情之一是,许多受欢迎的技术公司和平台都包含了开源要素。例如,有很多 Rails Web 应用程序是极其成功的,盈利能力可观。而且,我认为,对我们来说,重要的是确保这些公司对开源社区有管理权,认识到其价值所在,并给予回馈。
**00:21:30 - Saron Yitbarek**:
好的,在 Safia 的开源中,企业将会负起责任,并对开源的可持续性做出贡献。项目的贡献者和维护者可能会因为自己所做的工作而获得报酬。这样的开源多半会是更加开放、更具有关怀之心的模式。
**Safia Abdalla**:
是的。
**Saron Yitbarek**:
听起来像是一个很棒的开源的版本,我喜欢它。
**Safia Abdalla**:
谢谢。
**00:22:00 - Saron Yitbarek**:
Safia Abdalla 是<ruby> 交互计划 <rt> Interact Project </rt></ruby>的软件工程师和贡献者。她是一位新一代开发人员。而她在平时也对开源抱有自己的期望。所以,我想向这支新的代码英雄军队大声呼喊:“你们都将会向我们展示未来,因为你们现在正生活在未来之中,而你们也将负责领导我们走向明天。”
**00:22:30**:
现在,尽管我对开源革命心怀热情,但我也不想成为一个盲目乐观的人。开源也将会受到挑战。开源的存在越广泛,我们就越需要确保它的可持续性。我们找到了一种可扩展的方式来维护开源项目吗?我的意思是,虽然 Linux 内核的贡献者中有一些是全职员工,但是大多数的开源项目仍然是由志愿者维护的。
**00:23:00**:
开源的工作并不会因为我们不再“反叛”而终结。市值数十亿美元的公司都在运行 Linux,而开源先锋们现在是技术领袖。我们需要跟随这条道路,并试着想象接下来会发生什么。
尤其是,可能会出现什么问题?Christopher Tozzi 告诉我们,曾经作为规则破坏者的开源并不对破坏本身免疫。
**00:23:30 - Christopher Tozzi**:
开源革命尚未结束,因为挑战并没有停止。即使今天基本上地球上每个使用计算机的人都在以这样或那样的方式使用开源软件,但这并不代表开源必然是绝对安全的。尤其是从致力于开源社区最初目标的人们的角度来看,诸如云计算之类的事物确实使情况变得复杂了。
**00:24:00 - Saron Yitbarek**:
开源能有多开源呢?Christopher 提到了云计算,而在[第六集](/article-12551-1.html)中,我们描述了依赖于别人的数据中心肯定会使开源最初的目标复杂化。
这是一个棘手的领域,我们仍在了解这个领域的情况。在前进的过程中,我们必须不忘初心。
**00:24:30**:
每个年轻的反叛者都需要<ruby> 欧比旺·克诺比 <rt> Obi Wan </rt></ruby>的原力全息仪。他们会从过去吸取经验教训吗?<ruby> 林纳斯·托瓦兹 <rt> Linus Torvalds </rt></ruby>曾经说过,“在真正的开源中,你有权掌握自己的命运。” 如果开发人员能够在更大的世界中宣扬这种精神,那么,干得漂亮。
**00:25:00**:
到此为止,这是第一季的最后一集,真不敢相信。这一季过得很快。在着手编写这一系列播客之前,我从没有想过,是谁创造了 DevOps、敏捷开发和云计算;我从没有想过它们从何而来。我从没想过它们会有自己的家,有团队贡献才能、照顾它们,帮助它们成长。它们只是我工具箱里的一堆工具。但我现在不是这样看待它们的。
**00:25:30**:
它们不仅仅是随机的工具,而是我生活环境的一部分。在我之前,开发者们已经花了几十年的时间来塑造这一局面。现在,我要致力于塑造未来。真是棒极了。
**00:26:00**:
第一季即将结束,但好消息是,我们已经在准备第二季了。在这七集中,我们专注于开源工具和方法论,这些工具和方法使我们有了今天。这有点像是从 3 万英尺的高度看开源世界的形成史。在第二季中,我们将着眼于细节,并关注当今代码英雄们史诗般的奋斗。我们将跟随每一集,看看开发者如何挑战常规。这些都是塑造我们行业未来的真实故事。
**00:26:30**:
当我们寻找这些故事的时候,我们很希望收到您的来信。告诉我们,你的代码故事是什么?你参与过哪些史诗般的开源战役?访问 [redhat.com/command-line-heroes](http://redhat.com/command-line-heroes) 留下你的故事。我们正在倾听。
**00:27:00**:
如果现在你还在听的话,你可能想要看看将于 5 月 8 日至 10 日在旧金山举行的 2018 红帽峰会的阵容。峰会包括为期三天的分组会议、动手实验和主题演讲,其中包括了有关开源的主题演讲,而你也可以参与其中。希望能在那里见到你。
**00:27:30**:
代码英雄是红帽的原创播客。请确保你订阅了该节目,以在您的设备上免费获取第一季中的所有剧集,并在第二季开始时收到通知。只要在苹果播客、Spotify、Google Play、CastBox 和其他播客平台中搜索《代码英雄》,然后点击订阅,你就可以第一时间收听新一期。我是 Saron Yitbarek。感谢你的聆听,编程不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-1/days-of-future-open>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[LaingKe](https://github.com/laingke) 校对:[Northurland](https://github.com/Northurland)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Imagine a world where open source never caught on, where no one thought it'd be a good idea to make source code available to anyone. In this episode, we imagine this bizarre possibility. And we celebrate the open source tools and methodologies that got us where we are today.
Join us as we wrap up Season 1, an almost 30,000-foot view of how the open source world came to be. Next season, we're zooming in and focusing on the epic struggles of today's command line heroes.
*Voice Actor*
In a world without open source, enforcers from the future travel back through time to destroy Linus Torvalds's computer.
*Saron Yitbarek*
Oh, man. I had that nightmare again. The one where I've got these amazing ideas, but I can't develop them because there's no open source tech to work with.
*Tristram Oaten*
I think a world without open source is almost bound to be evil.
**00:30** - *Saron Yitbarek*
If software had been closed in the 1980s and the source code had never been opened up again, I think that there'd be a lot less innovation for sure.
* Steven Vaughan-Nichols*
It would be a backward world.
*Hannah Cushman*
I think there'd certainly be less smart refrigerators.
*Voice Actor*
In a world without smart refrigerators.
**01:00** - *Saron Yitbarek*
Okay, okay. You get the point. We're imagining a world without open source technology, and it's not very appealing. So picture it. Your online life managed and taxed by a few megalithic proprietary companies. Gatekeepers at every part of the road. For us developers, a world without open source would mean far less freedom—and influence.
**01:30** - *Saron Yitbarek*
All season long, we've been tracking the role of developers in an open source world. Our work has been evolving and expanding with the growth of the open source tools and techniques that make our work possible. Whether it's the Agile Manifesto, the rise of DevOps, or container orchestration, the power and freedom we've claimed for ourselves is tied to that philosophy of open source.
In our season finale, we're taking a step back and looking at how far we've come. As the world goes open source, how true to the original meaning of that term can we remain? And where are we headed next?
**02:00** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes. An original podcast from Red Hat. Episode 7: Days of Future Open
* Steven Vaughan-Nichols*
A world without open source is not a world that I would want to live in, nor do I think that it is a world that the vast majority of people out there would want to live in.
**02:30** - *Saron Yitbarek*
This is Steven Vaughan-Nichols. You might remember him from Episodes 1 and 2 when we were talking about the OS wars. He's a contributing editor at CBS Interactive and he's been following tech since 300 bits per second was a fast modem.
* Steven Vaughan-Nichols*
You may not be able to name a single open source program other than Linux, but you're current life is a life built on open source.
**03:00** - *Saron Yitbarek*
Most of us can't really go online without using open source tech. It's in almost every supercomputer on the planet. It's running the Internet of Things. It's in your phone, your web server, your social media, and oh yeah, it's running the Large Hadron Collider, too. And we developers aren't the only ones who've figured out the benefits of this stuff. Open source attitudes are now spreading beyond technology to influence other industries like economics, music, science, journalism.
**03:30** - *Saron Yitbarek*
What if an architect shared the blueprint for a building in the same way we share code? What if a reporter opened up her files and let anyone scrutinize not just her published article, but her research and interview notes? It shouldn't surprise us, the philosophy that developers have been nurturing for years. The idea that everyone gets to see and comment on the code, copy it, offer fixes, it's actually a pretty fundamental thing, right? It's sharing.
**04:00** - *Saron Yitbarek*
Ever since the earliest humans were sharing recipes for meals, we've known that openly sharing sets of instructions, algorithms in other words, has a net benefit for humanity. In some ways, open source technologies are now allowing us to get back to that basic truth.
*Hannah Cushman*
I think that more things being open source kind of facilitates and encourages people to go back and consult primary sources, which is always good.
**04:30** - *Saron Yitbarek*
That's Hannah Cushman, she's a developer at DataMade, where they've been trying to make our cities more open. Reams of open data from governments get compiled and made sensible so ordinary citizens can actually use it and take action. The tech they use is open source, but so is their attitude about politics.
**05:00** - *Hannah Cushman*
We did a project here in Chicago with a organization called City Bureau where we were working with them to get at lead test results for the public schools. So, the Chicago public schools went through and tested, if not all, a significant portion of the water fixtures in all of their school and published the results of those tests as a series of more than 500 PDFs.
*Saron Yitbarek*
So, that's great. But it's not exactly an effective way of making data open.
**05:30** - *Hannah Cushman*
It was really difficult to see where lead was found across the system and, like, higher numbers. We used another open source tool called Tablua, which you can run from your terminal, to extract data from over 500 PDFs and put it all together and help put this huge dump of information into a context that was useful for people.
I think being able to consult that source data is a really powerful way for people to kind of understand where information is coming from and verify that it is, in fact, correct.
**06:00** - *Saron Yitbarek*
Citizens can access the details of health reports, data on lobbyists, they get to look at the whole engine of city politics, and DataMade opens the hood. That means the people of Chicago have a better chance of bringing about the changes they want to see.
Carol Willing, a research software engineer over at Cal Poly, thinks that this expanding open source attitude is the start of something much larger.
**06:30** - *Carol Willing*
Personally, I think that we're gonna evolve beyond open source software to open hardware, to open government, to open education, open collaboration, innovation, so I think it's gonna continue to evolve.
*Saron Yitbarek*
Open source is starting to look more like a law of nature than just some outgrowth of the tech world.
**07:00** - *Carol Willing*
People have been charitable and giving of their time freely for thousands of years, so that's nothing new. But what is new about open source and has changed the world profoundly is the ability for groups to work together to build something bigger than what they could build on their own.
**07:30** - *Saron Yitbarek*
I love this idea! Taking some very new tech and using it to get back to some very old ideals. But before we get too excited, definitions can get wobbly as more and more folks start calling themselves open source. It starts meaning something that's just free, or something that's crowdsourced, or even just something that's customizable.
For example, if I let you choose what kind of sprinkles go on your ice cream, that's not necessarily an open source dessert. But if I show you how to make your own sprinkles, let you improve on my sprinkle recipe, and then give you my blessing if you wanted to share that secret with others, now that's some tasty open source right there.
**08:00** - *Saron Yitbarek*
So, what was that original definition again? It's pretty simple, but we should keep repeating it. To be truly open source, you need code, or a blueprint, or a recipe. In other words, some kind of raw data that anyone can study, change, and redistribute at will. It's a philosophy that's just starting to revolutionize the world beyond our command lines.
**08:30** -*Thomas Cameron*
It's a really phenomenal way to do technology, and I'm thrilled to death that is has been as successful as it has been and that I've gotten to be a part of it.
*Saron Yitbarek*
Thomas Cameron has been involved in open source since before the term was coined in 1998. Today, he's senior principal cloud evangelist at Red Hat. He's perfectly positioned to talk about how far open source has come, but also how many battles were fought along the way.
**09:00** - *Thomas Cameron*
Man there is huge pushback, you know, managers didn't want to take on the risk because, well, it's free; there's no one that I can pick up the phone and call for support; I have to depend on you. But we won a lot of these sort-of-easy fights, the departmental servers or divisional servers or a small web server, a small file and print server, and over time after winning these easier fights, the tougher ones came along. And with every single one of those, you saw sysadmins and systems engineers become more enamored of open source.
**09:30** - *Saron Yitbarek*
Despite these battles, you couldn't deny the ongoing progress.
**10:00** - *Thomas Cameron*
I have been able to watch open source transform the IT industry, and it’s gone from that rogue server that some sysadmin had under his desk to huge companies with household names—Intel, IBM, AMD, you know, every organization you can imagine has started contributing to open source projects. And it was absolutely a fight, there were so many arguments I had at various enterprise positions that I held where I said, "You know, we need to introduce Linux® or other open source technologies into the datacenter."
**10:30** - *Saron Yitbarek*
Thomas sees that open source software development is taking over. But for some people, that's pretty unsettling.
*Thomas Cameron*
We're able to share information and analysis, and so that scares folks who historically have been the ones to hold information and derive value from it, whether it's charging money or just having control of an organization, it's a huge change and with that comes fear.
**11:00** - *Saron Yitbarek*
The open source rebels that we described at the start of the season have now become industry leaders. But that's not the end of the story, not by a long shot. Christopher Tozzi is the senior editor at Fixate IO. He sees open source disruption as the start of a fundamental shift in the way people everywhere, not just software, are going to work together.
**11:30** - *Christopher Tozzi*
I think that one of the things that has made open source so powerful over the last two decades is this continued interest in decentralization. I think this also speaks to how open source has influenced other technological innovations. Things like blockchain, which is also founded centrally on the ideas that databases, for example, or transactions could be more efficient or could be more secure if they're decentralized, if we get away from centralized modes of production. And again, open source I think today, ever since Torvalds came along, had been about decentralization of development in labor basically.
**12:00** - *Saron Yitbarek*
That decentralization across the board means the whole world's going open source. The developers who embody that philosophy, they're the ones who have the best shot at imagining that future.
Here's Tristram Oaten, he's a developer based in London, and he's definitely thinking about that long game.
**12:30** - *Tristram Oaten*
It looks like 3D printers are going to make our lives easier and hopefully more ecologically sound by producing parts at home. Whenever something breaks, you can just make it at home. It's the ideal Star Trek replicator future that we were promised so very long ago. Hopefully, that will come into play so that entire houses can perhaps be open source.
*Saron Yitbarek*
Tristram imagines a world where open source is the rule of the land and that means developers become, if not gurus, then at least guides. Really critical guides.
**13:00** - *Tristram Oaten*
In the future, our role as developers is going to become increasingly more and more important, and it's going to get increasingly more and more like wizards if it isn't already.
*Saron Yitbarek*
Okay, wizards. We'll be wizards.
**13:30** - *Tristram Oaten*
We speak strange languages that make these machines do wonderful things, and we're paid a lot of money to be the court wizard, or the company wizard. And when there are devices in everyone's bodies and when there are devices everywhere that are internet-accessible and can be remote-controlled, it's going to be very important that we as a group, as a guild, act in best faith, that the medical profession has a charter to do no harm and so forth.
I think that as developers, we need to collectively decide that we're not going to build the killer robots, we're not going to build spying software into everyone's router and everybody's hearing aides. We need to assure each other, and assure everyone, that we're going to work for the greater good, and not against humanity.
**14:00** - *Saron Yitbarek*
Let's all just promise right now that we won't build killer robots, okay? Okay. And beyond that, I do think Tristram's on to something. In some ways, we developers have seen the future and that means we've got a chance to help shape it.
What are the ethics of open source development going to look like in 10 years?
**14:30** - *Tristram Oaten*
We're in a supremely privileged position, and it's up to us to do the right thing.
*Saron Yitbarek*
So, wizards, where are we heading? Can we conjure up a healthy future for open source? I wanted to talk with someone who's done some deep thinking about all of this, and I found her. Safia Abdalla is a software engineer who's been making open source contributions to the Interact Project. We started imagining what a real, sustainable, broad-reaching open source could look like. Have a listen. When you think about the future of open source and what that looks like, what are some differences we might see?
**15:00** - *Safia Abdalla*
Yeah, so I think one of the biggest emerging trends that I'm seeing is a lot of focus on open source sustainability, which is the discussion around how do you keep open source projects that are crucial to the entire tech ecosystem well-maintained and well-updated throughout their lifetime. And I think there's been a lot of interesting progress in that space.
**15:30** - *Saron Yitbarek*
Safia got me thinking, how much better could our work become? How much would change? If we could build that sustainable approach she's describing, if corporations were contributing time, code, and resources. So I asked her, how do you see that impacting that actual products we create and the tools that we build?
**16:00** - *Safia Abdalla*
The sad reality is that when you don't have the focus and time and energy and money to build something well for everyone, what you tend to do is just build it well for yourself.
*Saron Yitbarek*
Mm-hmm (affirmative), absolutely.
*Safia Abdalla*
And so you build a product that ostracizes a lot of individuals. So I believe that if we discover more sustainable model for open source, we're actually gonna start building software that's accessible to individuals who might be blind, or hard of hearing, or disabled in other ways.
**16:30** - *Saron Yitbarek*
Interesting, yeah I really like that. So, when you think about how the principles and processes and culture and community and all those things you mentioned of open source might be applied to industries outside of technology, outside of software development, what are some fields that you think could really benefit from open source, and where do you think open source might show up next?
**17:00** - *Safia Abdalla*
Oh that's a really interesting observation. The immediate answer that comes to me is an open source mindset in the science community and open science. I think the realization is that when you share software in an open fashion, what you're sharing is not the literal lines of code, well that is what you're sharing, but the other thing that you're sharing on top of that is knowledge and details about how to do something. So what you're really sharing is knowledge.
**17:30** - *Safia Abdalla*
That translates really directly to the scientific world where researchers will spend a lot of time exploring a particular topic and then publish a research paper on it. And I think focusing on an open science initiative that makes sure that researchers are producing work that is accessible to all people, understandable by all people, and shareable and extendable by all people is gonna improve society's understanding of science and how far we can push research forward.
**18:00** - *Saron Yitbarek*
When I was in college, I did biochemistry research and I was very much used to this passion for experimenting, for researching, for trying new things, but at the same time still being very protective over your discoveries because you need to be a published author. You need credit, that is a huge, huge part of moving up in academia.
**18:30** - *Saron Yitbarek*
So, when we're talking about bringing these open source principles of sharing and contributing and putting out unfinished products out there and hoping other people will fill it in, how do you see those principles possibly colliding in other industries where people might be more protective?
**19:00** - *Safia Abdalla*
Yeah, that's a great question, and I think that touches on a way hairier, bigger problem. For open source to be successful, the motivations and the incentives have to be, for the most part, extrinsic. You can't rely on systems that encourage people to focus on their own goals and motivations at the expense of others, and at the expense of the greater good of society.
**19:30** - *Safia Abdalla*
I think at a fundamental level, we have to restructure the way we see a lot of things and the way a lot of systems work to have them focus on the collective good instead of the singular good. It's hard to do, it's hard to undo systems, like tenure, which have a lot of negative repercussions at universities. It's hard to undo other incentive systems that can harm the planet, can harm other people, can harm progress as a society. But starting to adopt an open source mindset and taking the initiative to begin to undo those systems will go a long way.
**20:00** - *Saron Yitbarek*
Absolutely, so if you could recreate open source in its entirety from scratch, you could build it all over again, what would your version of open source look like?
**20:30** - *Safia Abdalla*
Oh, boy. The first thing that I would change about open source is its public relations and its image. I would probably attempt to build an open source culture or community that didn't issue that perception that you had to be elite or a fantastic developer in order to thrive and succeed, and that was one of the biggest things that deterred me.
**21:00** - *Safia Abdalla*
The other big thing I would focus on is open source sustainability, increasing corporate accountability and the health of open source systems. I think one of the things that a lot of people don't realize is that a lot of really popular technology companies and platforms that people use are mostly comprised of open source. Like, how many Rails web applications are super profitable and successful now. And I think it's important for us to ensure that those corporations have a stewardship to the open source community and recognize where their value is, and contribute it back.
**21:30** - *Saron Yitbarek*
Okay, so in Safia's open source—we'll call it S.O.S.—we have corporate accountability, and corporations contributing to the sustainability of open source. We have contributors and maintainers possibly being paid themselves for the work that they do, and generally a more loving and open brand for what open source is.
*Safia Abdalla*
Yeah.
*Saron Yitbarek*
Sounds like a great version of open source, I like it.
*Safia Abdalla*
Thank you.
**22:00** - *Saron Yitbarek*
Safia Abdalla is a software engineer and a contributor to the Interact Project. She's part of a new generation of developers. But even she's coming at it with the expectation of open source by default, so I wanna give a shout out to that new army of command line heroes. You all are going to show us the future. You're living it right now. You're going to lead the charge.
**22:30** - *Saron Yitbarek*
Now as excited as I am for the open source revolution, I don't wanna be a Pollyanna either. There are going to be challenges. The bigger open source gets, the more we have to make sure that it's actually sustainable. Have we honestly figured out a scalable way of maintaining open source projects? I mean, the Linux kernels got some contributors who are full-time employees, but most of the open source projects out there are still maintained by volunteers.
**23:00** - *Saron Yitbarek*
The work of open source isn't over just because we've graduated from rebel status. Multi-billion dollar companies are running on Linux, open source pioneers are now tech leaders, we need to track this trajectory and try to imagine what comes next.
In particular, what could go wrong? Christopher Tozzi describes how open source, once the disruptor, is not vulnerable to disruption itself.
**23:30** - *Christopher Tozzi*
The open source revolution is not over, because it's not as if the challenges are going to stop coming. Even though today basically everybody on the planet who uses a computer is using open source in one way or another, that doesn't mean that open source is necessarily totally safe from disruption. Especially from the perspective of people who are committed to the original goals of the open source communities, which things like cloud computing really complicate in certain ways.
**24:00** - *Saron Yitbarek*
How open source will open source be? Christopher mentioned cloud computing and in Episode 6, we described how becoming reliant on somebody else's datacenter definitely complicates the original goals of open source.
It's tricky territory, and we're still learning the lay of the land. As we move forward, we're gonna have to remind ourselves about our roots.
**24:30** - *Saron Yitbarek*
Every young rebel needs that Obi Wan hologram moment. Will they get a reminder from the past? Here's what our Linus Torvalds once said, "In real open source, you have the right to control your own destiny." If developers helped to encourage that spirit in the bigger world, that's a pretty good job.
**25:00** - *Saron Yitbarek*
So, this is the final episode of Season 1. Can you believe it? This season just flew by. Before working on this podcast, things like DevOps, agile, and cloud, I didn't really think about where they came from, and who made them. I never thought they had homes with teams and talent who cared for them and helped them grow. They were just a bunch of tools in my toolbox. But that's not how I see them now.
**25:30** - *Saron Yitbarek*
They're not just random tools, they're a part of the landscape I live in. A landscape the developers who came before me have been shaping for decades. Now, I get to help shape what comes next. That's amazing.
**26:00** - *Saron Yitbarek*
Season 1 may be coming to a close, but good news, we're already working on Season 2. Over these past 7 episodes, we focused on the open source tools and methodologies that brought us to where we are today. Sort of like the 30,000-foot view of how the open source world came to be. In Season 2, we're going to zoom in and focus on the epic struggles of today's command line heroes. We get to tag along each episode and see how developers on the ground are challenging the norm. These are the real life stories that shape the future of our industry.
**26:30** - *Saron Yitbarek*
And while we hunt those stories down, we'd love to heard from you. Tell us, what's your command line story? What epic open source battles have you been waging? Go to redhat.com/command-line-heroes to drop your story. We're listening.
**27:00** - *Saron Yitbarek*
While you're there, you might want to check out the lineup for the 2018 Red Hat Summit happening in San Francisco May 8-10. Three days of breakout sessions, hands-on labs, and keynotes including one from yours truly all about open source. Hope to see you there.
**27:30** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. To get all of the episodes from Season 1 delivered to your device for free and to get notified for the start of Season 2, make sure to subscribe to the show. Just search for, "Command Line Heroes" in Apple Podcasts, Spotify, Google Play, Pocket Casts, Stitcher, CastBox, or however you get your podcasts. I'm Saron Yitbarek, thanks for listening, and keep on coding!
### Featured in this episode
#### Safia Abdalla
Developer, focused on open source software, community management, and data science
#### Steven Vaughan-Nichols
Business and technology journalist, focused on operating systems, networking, Linux®, and open source
#### Tristram Oaten
Developer and composer, tinkering with source code and synthesizers in equal measure
#### Christopher Tozzi
Historian, researcher, and writer, most recently of "For Fun and Profit: A History of the Free and Open Source Software Revolution" |
12,558 | 如何将文本文件在 Unix 和 DOS(Windows)格式之间转换 | https://www.2daygeek.com/how-to-convert-text-files-between-unix-and-dos-windows-formats/ | 2020-08-27T23:57:03 | [
"文件格式",
"dos2unix"
] | https://linux.cn/article-12558-1.html | 
作为一名 Linux 管理员,你可能已经注意到了一些开发者请求将文件从 DOS 格式转换为 Unix 格式,反之亦然。
这是因为这些文件是在 Windows 系统上创建的,并由于某种原因被复制到 Linux 系统上。
这本身没什么问题,但 Linux 系统上的一些应用可能不能理解这些新的换行符,所以在使用之前,你需要转换它们。
DOS 文本文件带有回车(`CR` 或 `\r`)和换行(`LF` 或 `\n`)一对字符作为它们的换行符,而 Unix 文本只有换行(`LF`)符。
有很多方法可以将 DOS 文本文件转换为 Unix 格式。
但我推荐使用一个名为 `dos2unix` / `unix2dos` 的特殊工具将文本在 DOS 和 Unix 格式之间转换。
* `dos2unix` :将文本文件从 DOS 格式转换为 Unix 格式。
* `unix2dos` :将文本文件从 Unix 格式转换为 DOS 格式。
* `tr`、`awk` 和 [sed 命令](https://www.2daygeek.com/linux-sed-to-find-and-replace-string-in-files/):这些可以用于相同的目的。
使用 `od`(<ruby> 八进制转储 <rt> octal dump </rt></ruby>)命令可以很容易地识别文件是 DOS 格式还是 Unix 格式,如下图所示:
```
# od -bc windows.txt
0000000 125 156 151 170 040 151 163 040 141 040 146 162 145 145 040 157
U n i x i s a f r e e o
0000020 160 145 156 163 157 165 162 143 145 040 157 160 145 162 141 164
p e n s o u r c e o p e r a t
0000040 151 156 147 040 163 171 163 164 145 155 015 012 123 165 160 145
i n g s y s t e m \r \n S u p e
0000060 162 040 143 157 155 160 165 164 145 162 163 040 141 162 145 040
r c o m p u t e r s a r e
0000100 162 165 156 156 151 156 147 040 157 156 040 125 116 111 130 015
r u n n i n g o n U N I X \r
0000120 012 071 065 045 040 157 146 040 167 145 142 163 151 164 145 163
\n 9 5 % o f w e b s i t e s
0000140 040 141 162 145 040 162 165 156 156 151 156 147 040 157 156 040
a r e r u n n i n g o n
0000160 114 151 156 165 170 040 117 123 015 012 101 156 171 164 150 151
L i n u x O S \r \n A n y t h i
0000200 156 147 040 143 141 156 040 142 145 040 144 157 156 145 040 157
n g c a n b e d o n e o
0000220 156 040 114 151 156 165 170 015 012
n L i n u x \r \n
0000231
```
上面的输出清楚地表明这是一个 DOS 格式的文件,因为它包含了转义序列 `\r\n`。
同时,当你在终端上打印文件输出时,你会得到下面的输出:
```
# cat windows.txt
Unix is a free opensource operating system
Super computers are running on UNIX
95% of websites are running on Linux OS
Anything can be done on Linux
```
### 如何在 Linux 上安装 dos2unix?
`dos2unix` 可以很容易地从发行版的官方仓库中安装。
对于 RHEL/CentOS 6/7 系统,使用 [yum 命令](https://www.2daygeek.com/linux-yum-command-examples-manage-packages-rhel-centos-systems/) 安装 `dos2unix`。
```
$ sudo yum install -y dos2unix
```
对于 RHEL/CentOS 8 和 Fedora 系统,使用 [dnf 命令](https://www.2daygeek.com/linux-dnf-command-examples-manage-packages-fedora-centos-rhel-systems/) 安装 `dos2unix`。
```
$ sudo yum install -y dos2unix
```
对于基于 Debian 的系统,使用 [apt 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 或 [apt-get 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `dos2unix`。
```
$ sudo apt-get update
$ sudo apt-get install dos2unix
```
对于 openSUSE 系统,使用 [zypper命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 安装 `dos2unix`。
```
$ sudo zypper install -y dos2unix
```
### 1)如何将 DOS 文件转换为 UNIX 格式?
以下命令将 `windows.txt` 文件从 DOS 转换为 Unix 格式。
对该文件的修改是删除文件每行的 `\r`。
```
# dos2unix windows.txt
dos2unix: converting file windows.txt to Unix format …
```
```
# cat windows.txt
0000000 125 156 151 170 040 151 163 040 141 040 146 162 145 145 040 157
U n i x i s a f r e e o
0000020 160 145 156 163 157 165 162 143 145 040 157 160 145 162 141 164
p e n s o u r c e o p e r a t
0000040 151 156 147 040 163 171 163 164 145 155 012 123 165 160 145 162
i n g s y s t e m \n S u p e r
0000060 040 143 157 155 160 165 164 145 162 163 040 141 162 145 040 162
c o m p u t e r s a r e r
0000100 165 156 156 151 156 147 040 157 156 040 125 116 111 130 012 071
u n n i n g o n U N I X \n 9
0000120 065 045 040 157 146 040 167 145 142 163 151 164 145 163 040 141
5 % o f w e b s i t e s a
0000140 162 145 040 162 165 156 156 151 156 147 040 157 156 040 114 151
r e r u n n i n g o n L i
0000160 156 165 170 040 117 123 012 101 156 171 164 150 151 156 147 040
n u x O S \n A n y t h i n g
0000200 143 141 156 040 142 145 040 144 157 156 145 040 157 156 040 114
c a n b e d o n e o n L
0000220 151 156 165 170 012
i n u x \n
0000225
```
上面的命令将覆盖原始文件。
如果你想保留原始文件,请使用以下命令。这将把转换后的输出保存为一个新文件。
```
# dos2unix -n windows.txt unix.txt
dos2unix: converting file windows.txt to file unix.txt in Unix format …
```
#### 1a)如何使用 tr 命令将 DOS 文件转换为 UNIX 格式。
正如文章开头所讨论的,你可以如下所示使用 `tr` 命令将 DOS 文件转换为 Unix 格式。
```
Syntax: tr -d '\r' < source_file > output_file
```
下面的 `tr` 命令将 DOS 格式的文件 `windows.txt` 转换为 Unix 格式文件 `unix.txt`。
```
# tr -d '\r' < windows.txt >unix.txt
```
注意:不能使用 `tr` 命令将文件从 Unix 格式转换为 Windows(DOS)。
#### 1b)如何使用 awk 命令将 DOS 文件转换为 UNIX 格式。
使用以下 `awk` 命令格式将 DOS 文件转换为 Unix 格式。
```
Syntax: awk '{ sub("\r$", ""); print }' source_file.txt > output_file.txt
```
以下 `awk` 命令将 DOS 文件 `windows.txt` 转换为 Unix 格式文件 `unix.txt`。
```
# awk '{ sub("\r$", ""); print }' windows.txt > unix.txt
```
### 2)如何将 UNIX 文件转换为 DOS 格式?
当你把一个文件从 UNIX 转换为 DOS 格式时,它会在每一行中添加一个回车(`CR` 或 `\r`)。
```
# unix2dos unix.txt
unix2dos: converting file unix.txt to DOS format …
```
该命令将保留原始文件。
```
# unix2dos -n unix.txt windows.txt
unix2dos: converting file unix.txt to file windows.txt in DOS format …
```
#### 2a)如何使用 awk 命令将 UNIX 文件转换为 DOS 格式?
使用以下 `awk` 命令格式将 UNIX 文件转换为 DOS 格式。
```
Syntax: awk 'sub("$", "\r")' source_file.txt > output_file.txt
```
下面的 `awk` 命令将 `unix.txt` 文件转换为 DOS 格式文件 `windows.txt`。
```
# awk 'sub("$", "\r")' unix.txt > windows.txt
```
---
via: <https://www.2daygeek.com/how-to-convert-text-files-between-unix-and-dos-windows-formats/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
12,560 | 把 Linux 上的文件列表和排序玩出花来 | https://www.networkworld.com/article/3572590/11-ways-to-list-and-sort-files-on-linux.html | 2020-08-28T21:38:37 | [
"ls"
] | https://linux.cn/article-12560-1.html | 
>
> Linux 命令可以提供文件的详细信息,也可以自定义显示的文件列表,甚至可以深入到文件系统的目录中,只要你愿意看。
>
>
>
在 Linux 系统上,有许多方法可以列出文件并显示它们的信息。这篇文章回顾了一些提供文件细节的命令,并提供了自定义文件列表的选项,以满足你的需求。
大多数命令都会列出单个目录中的文件,而其他命令则可以深入到文件系统的目录中,只要你愿意看。
当然,最主要的文件列表命令是 `ls`。然而,这个命令有大量的选项,可以只查找和列出你想看的文件。另外,还有 `find` 可以帮助你进行非常具体的文件搜索。
### 按名称列出文件
最简单的方法是使用 `ls` 命令按名称列出文件。毕竟,按名称(字母数字顺序)列出文件是默认的。你可以选择 `ls`(无细节)或 `ls -l`(大量细节)来决定你看到什么。
```
$ ls | head -6
8pgs.pdf
Aesthetics_Thank_You.pdf
alien.pdf
Annual_Meeting_Agenda-20190602.pdf
bigfile.bz2
bin
$ ls -l | head -6
-rw-rw-r-- 1 shs shs 10886 Mar 22 2019 8pgs.pdf
-rw-rw-r-- 1 shs shs 284003 May 11 2019 Aesthetics_Thank_You.pdf
-rw-rw-r-- 1 shs shs 38282 Jan 24 2019 alien.pdf
-rw-rw-r-- 1 shs shs 97358 May 19 2019 Annual_Meeting_20190602.pdf
-rw-rw-r-- 1 shs shs 18115234 Apr 16 17:36 bigfile.bz2
drwxrwxr-x 4 shs shs 8052736 Jul 10 13:17 bin
```
如果你想一次查看一屏的列表,可以将 `ls` 的输出用管道送到 `more` 命令中。
### 按相反的名字顺序排列文件
要按名称反转文件列表,请添加 `-r`(<ruby> 反转 <rt> Reverse </rt></ruby>)选项。这就像把正常的列表倒过来一样。
```
$ ls -r
$ ls -lr
```
### 按文件扩展名列出文件
`ls` 命令不会按内容分析文件类型,它只会处理文件名。不过,有一个命令选项可以按扩展名列出文件。如果你添加了 `-X` (<ruby> 扩展名 <rt> eXtension </rt></ruby>)选项,`ls` 将在每个扩展名类别中按名称对文件进行排序。例如,它将首先列出没有扩展名的文件(按字母数字顺序),然后是扩展名为 `.1`、`.bz2`、`.c` 等的文件。
### 只列出目录
默认情况下,`ls` 命令将同时显示文件和目录。如果你想只列出目录,你可以使用 `-d`(<ruby> 目录 <rt> Directory </rt></ruby>)选项。你会得到一个像这样的列表:
```
$ ls -d */
1/ backups/ modules/ projects/ templates/
2/ html/ patches/ public/ videos/
bin/ new/ private/ save/
```
### 按大小排列文件
如果你想按大小顺序列出文件,请添加 `-S`(<ruby> 大小 <rt> Size </rt></ruby>)选项。但请注意,这实际上不会显示文件的大小(以及其他文件的细节),除非你还添加 `-l`(<ruby> 长列表 <rt> Long listing </rt></ruby>)选项。当按大小列出文件时,一般来说,看到命令在按你的要求做事情是很有帮助的。注意,默认情况下是先显示最大的文件。添加 `-r` 选项可以反过来(即 `ls -lSr`)。
```
$ ls -lS
total 959492
-rw-rw-r-- 1 shs shs 357679381 Sep 19 2019 sav-linux-free-9.tgz
-rw-rw-r-- 1 shs shs 103270400 Apr 16 17:38 bigfile
-rw-rw-r-- 1 shs shs 79117862 Oct 5 2019 Nessus-8.7.1-ubuntu1110_amd64.deb
```
### 按属主列出文件
如果你想按属主列出文件(例如,在一个共享目录中),你可以把 `ls` 命令的输出传给 `sort`,并通过添加 `-k3` 来按第三个字段排序,从而挑出属主一栏。
```
$ ls -l | sort -k3 | more
total 56
-rw-rw-r-- 1 dory shs 0 Aug 23 12:27 tasklist
drwx------ 2 gdm gdm 4096 Aug 21 17:12 tracker-extract-files.121
srwxr-xr-x 1 root root 0 Aug 21 17:12 ntf_listenerc0c6b8b4567
drwxr-xr-x 2 root root 4096 Aug 21 17:12 hsperfdata_root
^
|
```
事实上,你可以用这种方式对任何字段进行排序(例如,年份)。只是要注意,如果你要对一个数字字段进行排序,则要加上一个 `n`,如 `-k5n`,否则你将按字母数字顺序进行排序。这种排序技术对于文件内容的排序也很有用,而不仅仅是用于列出文件。
### 按年份排列文件
使用 `-t`(<ruby> 修改时间 <rt> Time modified </rt></ruby>)选项按年份顺序列出文件 —— 它们的新旧程度。添加 `-r` 选项,让最近更新的文件在列表中最后显示。我使用这个别名来显示我最近更新的文件列表。
```
$ alias recent='ls -ltr | tail -8'
```
请注意,文件的更改时间和修改时间是不同的。`-c`(<ruby> 更改时间 <rt> time Changed </rt></ruby>)和 `-t`(修改时间)选项的结果并不总是相同。如果你改变了一个文件的权限,而没有改变其他内容,`-c` 会把这个文件放在 `ls` 输出的顶部,而 `-t` 则不会。如果你想知道其中的区别,可以看看 `stat` 命令的输出。
```
$ stat ckacct
File: ckacct
Size: 200 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 829041 Links: 1
Access: (0750/-rwxr-x---) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
Access: 2020-08-20 16:10:11.063015008 -0400
Modify: 2020-08-17 07:26:34.579922297 -0400 <== content changes
Change: 2020-08-24 09:36:51.699775940 -0400 <== content or permissions changes
Birth: -
```
### 按组别列出文件
要按关联的组别对文件进行排序,你可以将一个长列表的输出传给 `sort` 命令,并告诉它在第 4 列进行排序。
```
$ ls -l | sort -k4
```
### 按访问日期列出文件
要按访问日期(最近访问的日期在前)列出文件,使用 `-ltu` 选项。`u` 强制“按访问日期”排列顺序。
```
$ ls -ltu
total 959500
-rwxr-x--- 1 shs shs 200 Aug 24 09:42 ckacct <== most recently used
-rw-rw-r-- 1 shs shs 1335 Aug 23 17:45 lte
```
### 单行列出多个文件
有时,精简的文件列表更适合手头的任务。`ls` 命令甚至有这方面的选项。为了在尽可能少的行上列出文件,你可以使用 `--format=comma` 来用逗号分隔文件名,就像这个命令一样:
```
$ ls --format=comma
1, 10, 11, 12, 124, 13, 14, 15, 16pgs-landscape.pdf, 16pgs.pdf, 17, 18, 19,
192.168.0.4, 2, 20, 2018-12-23_OoS_2.pdf, 2018-12-23_OoS.pdf, 20190512_OoS.pdf,
'2019_HOHO_application working.pdf' …
```
喜欢用空格?使用 `--format=across` 代替。
```
$ ls --format=across z*
z zip zipfiles zipfiles1.bat zipfiles2.bat
zipfiles3.bat zipfiles4.bat zipfiles.bat zoom_amd64.deb zoomap.pdf
zoom-mtg
```
### 增加搜索的深度
虽然 `ls` 一般只列出单个目录中的文件,但你可以选择使用 `-R` 选项(<ruby> 递归 <rt> Recursively </rt></ruby>)地列出文件,深入到整个目录的深处。
```
$ ls -R zzzzz | grep -v "^$"
zzzzz:
zzzz
zzzzz/zzzz:
zzz
zzzzz/zzzz/zzz:
zz
zzzzz/zzzz/zzz/zz:
z
zzzzz/zzzz/zzz/zz/z:
sleeping
```
另外,你也可以使用 `find` 命令,对深度进行限制或不限制。在这个命令中,我们指示 `find` 命令只在三个层次的目录中查找:
```
$ find zzzzz -maxdepth 3
zzzzz
zzzzz/zzzz
zzzzz/zzzz/zzz
zzzzz/zzzz/zzz/zz
```
### 选择 ls 还是 find
当你需要列出符合具体要求的文件时,`find` 命令可能是比 `ls` 更好的工具。
与 `ls` 不同的是,`find` 命令会尽可能地深入查找,除非你限制它。它还有许多其他选项和一个 `-exec` 子命令,允许在找到你要找的文件后采取一些特定的行动。
### 总结
`ls` 命令有很多用于列出文件的选项。了解一下它们。你可能会发现一些你会喜欢的选项。
---
via: <https://www.networkworld.com/article/3572590/11-ways-to-list-and-sort-files-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,561 | 对开放的价值观持开放态度 | https://opensource.com/open-organization/20/8/being-open-to-open-values | 2020-08-28T23:44:00 | [
"开放式管理"
] | https://linux.cn/article-12561-1.html |
>
> 开放管理可能会让人感到恐惧。一位经理人解释了为什么值得冒这个风险。
>
>
>

在本期的“[用开放的价值观管理](https://opensource.com/open-organization/managing-with-open-values)”系列中,我和美国一家全国性保险公司的定价总监、人事经理 Braxton 聊了聊。
2018 年 6 月,Braxton 联系到了开放组织社区的红帽人员。他想了解更多关于他*和*他的团队如何使用开放的价值观,以不同的方式工作。我们很乐意提供帮助。于是我帮助 Braxton 和他的团队组织了一个关于[开放组织原则](https://github.com/open-organization/open-org-definition)的研讨会,并在之后还保持着联系,这样我就可以了解他在变得更加开放的过程中的风险。
最近我们采访了 Braxton,并和他一起坐下来听了事情的进展。[产业/组织心理学家和员工参与度专家](https://opensource.com/open-organization/20/5/commitment-engagement-org-psychology) Tracy Guiliani 和 [Bryan Behrenshausen](https://opensource.com/users/bbehrens) 一起加入了采访。我们的谈话范围很广,探讨了了解开源价值观后的感受,如何利用它们来改变组织,以及它们如何帮助 Braxton 和他的团队更好地工作和提高参与度。
与 Braxton 合作是一次异常有意义的经历。它让我们直接见证了一个人如何将开放组织社区驱动的研讨会材料融入动态变化,并使他、他的团队和他的组织受益。开放组织大使*一直*在寻求帮助人们获得关于开放价值的见解和知识,使他们能够理解文化变革和[自己组织内的转型](https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization)。
他和他的团队正在以对他们有效的方式执行他们独特的开放价值观,并且让团队实现的利益超过了提议变革在时间和精力上的投入。
Braxton 对开放组织原则的*解释*和使组织更加开放的策略,让我们深受启发。
Braxton 承认,他的更开放的目标并不包括“制造另一个红帽”。相反,他和他的团队是在以对他们有效的方式,以及让团队实现的利益超过提议的变革所带来的时间和精力投入,来执行他们独特的开放价值观。
在我们采访的第一部分,你还会听到 Braxton 描述:
1. 在了解了透明性、协作性、适应性、社区性和包容性这五种开放式组织价值观之后,“开放式管理”对他意味着什么?
2. 他的一些开放式管理做法。
3. 他如何在他的团队中倡导开放文化,如何在后来者中鼓励开源价值观,以及他所体验到的好处。
4. 当人们试图改造自己的组织时,对开源价值观最大的误解是什么?
[收听对 Braxton 的采访:](https://opensource.com/sites/default/files/images/open-org/braxton_1.ogg)
---
via: <https://opensource.com/open-organization/20/8/being-open-to-open-values>
作者:[Heidi Hess von Ludewig](https://opensource.com/users/heidi-hess-von-ludewig) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this installment of our "[Managing with Open Values](https://opensource.com/open-organization/managing-with-open-values)" series, I chat with Braxton, Director of Pricing for a nationwide U.S. insurance company and people manager.
In June 2018, Braxton reached out to Red Hatters in the Open Organization community. He wanted to learn more about how both he *and* his team could work differently, using open values. We were happy to help. So I helped organize a workshop on [open organization principles](https://github.com/open-organization/open-org-definition) for Braxton and his team—and kept in touch afterward, so I could learn about his adventure in becoming more open.
We recently caught up with Braxton and sat down with him to hear how things were going. Tracy Guiliani, [industrial/organizational psychologist and expert in associate engagement](https://opensource.com/open-organization/20/5/commitment-engagement-org-psychology), joined me, as did [Bryan Behrenshausen](https://opensource.com/users/bbehrens). Our conversation was wide-ranging, exploring what it was like to learn firsthand about open source values, how to use them to transform an organization, and how they helped Braxton and his team perform better and increase engagement.
Working with Braxton has been an exceptionally meaningful experience. It has allowed us to witness—directly—how someone transformed Open Organization community-driven workshop material into dynamic change with benefits for him, his team, and his organization. Open Organization Ambassadors are *always* seeking to help people gain insights and knowledge on open values that empower them to understand culture change and [transformation within their own organization](https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization).
Braxton's embrace—both of his *own interpretation* of open organization principles and his strategies for making an organization more open—inspires us.
Braxton acknowledges that his goals in being more open didn't include "making another Red Hat." Instead, he and his team were performing their unique version of the open values in ways that worked for them, and in ways that allowed the benefits the team realized to outweigh the time and energy commitment of proposed changes.
In the first part of our interview, you'll also hear Braxton describe:
- What "open management" means to him, after learning about the five open organization values of transparency, collaboration, adaptability, community and inclusivity
- Some of his open management practices
- How he champions open culture on his team and how he encourages open source values among late adopters, and the benefits he's experienced
- What people most misunderstand about open source values when they try to transform their own organizations
Listen to the interview with Braxton
## 1 Comment |
12,563 | 去中心化的消息应用 Riot 改名为 Element | https://itsfoss.com/riot-to-element/ | 2020-08-29T22:46:33 | [
"Riot",
"IM"
] | https://linux.cn/article-12563-1.html | Riot 曾经是,现在也是一款基于开源 Matrix 协议的去中心化即时通讯应用。
6 月底,Riot 即时通讯客户端宣布将改名。他们透露,他们的新名字是 [Element](https://element.io/)。让我们来看看 Riot 为什么要改名,还有哪些要改。
### 为什么从 Riot 改名为 Element?

在说到最新的公告之前,我们先来看看他们当初为什么要改名。
根据 6 月 23 日的一篇[博客文章](https://element.io/blog/the-world-is-changing/),该组织改名有三个原因。
首先,他们表示“某大型游戏公司”曾多次阻止他们注册 Riot 和 [Riot.im](http://Riot.im) 产品名称的商标。如果要我猜的话,他们可能指的就是这家[“游戏公司”](https://en.wikipedia.org/wiki/Riot_Games))。
其次,他们选择 Riot 这个名字的初衷是为了“唤起一些破坏性和活力的东西”。他们担心人们反而认为这个应用是“专注于暴力”。我想,当前的情形下,这个名字并不算好。
第三,他们希望澄清 Riot 涉及的众多品牌名称所造成的混乱。例如,Riot 是由一家名为 New Vector 的公司创建的,而 Riot 是托管在 Modular 上,Modular 也是 New Vector 的产品。他们希望简化他们的命名系统,以避免混淆潜在客户。当人们寻找消息解决方案时,他们希望他们只需要寻找一个名字:Element。
### 元素即一切

从 7 月 15 日开始,该应用的名称和公司的名称已经改为 Element(元素)。他们的 Matrix 托管服务现在将被称为 Element Matrix Services。他们的公告很好地总结了这一点。
>
> “对于那些第一次发现我们的人来说,Element 是 Matrix 通信网络中的旗舰级安全协作应用。Element 让你拥有自己的端到端加密聊天服务器,同时还能与更广泛的 Matrix 网络中的其他人连接。”
>
>
>
他们之所以选择 Element 这个名字,是因为它“反映了我们在设计 RiotX 时对简单和清晰的强调;这个名字突出了我们一心一意将 Element 打造成可以想象的最优雅和最实用的主流通讯应用的使命”。他们还说,他们想要一个“能唤起数据所有权和自我主权的概念”的名字。他们还认为这是一个很酷的名字。
### 除了改个名之外

最近的公告也表明,此举不仅仅是简单的改名。Element 还发布了“新一代安卓版 Matrix 客户端”。该客户端的前身是 RiotX,现在改名为 Element。(还有呢?)它对以前的客户端进行了彻底的重写,现在支持 VoIP 通话和小部件。Element 还将在 iOS 上推出,支持 iOS 13,并提供“全新的推送通知支持”。
Element Web 客户端也得到了一些关爱,更新了 UI 和新的更容易阅读的字体。他们还“重写了房间列表控件 —— 增加了房间预览(!!)、按字母顺序排列、可调整列表大小、改进的通知用户界面等”。他们还开始努力改进端到端加密。
### 最后思考
Element 公司的人迈出了一大步,做出了这样的重大改名。他们可能会在短期内失去一些客户。(这可能主要是由于出于某种原因没有意识到名称的改变,或者不喜欢改变)。然而从长远来看,品牌简化将帮助他们脱颖而出。
我唯一要提到的负面说明是,这是他们在该应用历史上的第三次改名。在 2016 年发布时,它最初被命名为 Vector。当年晚些时候改名为 Riot。希望 Element 能一直用下去。
---
via: <https://itsfoss.com/riot-to-element/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Riot is/was a decentralized instant messaging app based on the open source Matrix protocol.
In late June, Riot (the instant messaging client) announced that they would be changing their name. Yesterday, they revealed that their new name is [Element](https://element.io/). Let’s see more details on why Riot changed its name and what else is being changed.
## Why change the name from Riot to Element?

Before we get to the most recent announcement, let us take a look at why they changed their name in the first place.
According to a [blog post](https://element.io/blog/the-world-is-changing/) dated June 23rd, the group had three reasons for the name change.
First, they stated that “a certain large games company” had repeatedly blocked them from trademarking the Riot and Riot.im product names. (If I had to guess, they are probably referring to this [“games company”](https://en.wikipedia.org/wiki/Riot_Games).)
Second, they originally chose the name Riot to “evoke something disruptive and vibrant”. They are worried that people are instead thinking that the app is “focused on violence”. I imagine that current world events have not helped that situation.
Thirdly, they want to clear up any confusion created by the many brand names involved with Riot. For example, Riot is created by a company named New Vector, while the Riot is hosted on Modular which is also a product of New Vector. They want to simplify their naming system to avoid confusing potential customers. When people look for a messaging solution, they want them to only have to look for one name: Element.
## Element is everywhere
As of July 15th, the name of the app and the name of the company has been changed to Element. Their Matrix hosting service will now be called Element Matrix Services. Their announcement sums it up nicely:
“For those discovering us for the first time: Element is the flagship secure collaboration app for the decentralised Matrix communication network. Element lets you own your own end-to-end encrypted chat server, while still connecting to everyone else in the wider Matrix network.
They chose the name Element because it “reflects the emphasis on simplicity and clarity that we aimed for when designing RiotX; a name that highlights our single-minded mission to make Element the most elegant and usable mainstream comms app imaginable”. They also said they wanted a name “evokes the idea of data ownership and self-sovereignty”. They also thought it was a cool name.
## More than just a name change
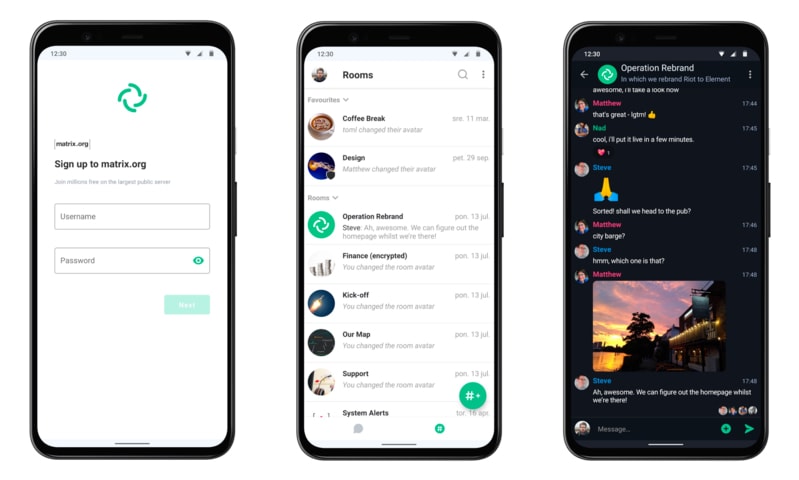
The recent announcement also makes it clear that this move is more than just a simple name change. Element has also released its “next generation Matrix client for Android”. The client was formerly known as RiotX and is now renamed Element. (What else?) It is a complete rewrite of the former client and now supports VoIP calls and widgets. Element will also be available on iOS with support for iOS 13 with “entirely new push notification support”.
The Element Web client has also received some love with a UI update and a new easier to read font. They have also “rewritten the Room List control – adding in room previews(!!), alphabetic ordering, resizable lists, improved notification UI and more”. They have also started working to improve end-to-end encryption.
## Final thought
The people over at Element are taking a big step by making a major name change like this. They may lose some customers in the short term. (This could mainly be due to not being aware of the name change for whatever reason or not liking change.) However in the long run the brand simplification will help them stand out from the crowd.
The only negative note I’ll mention is that this is the third name change they have made in the app’s history. It was originally named Vector when it was released in 2016. The name was changed to Riot later that year. Hopefully, Element is here to stay.
If you found this article interesting, please take a minute to share it on social media, Hacker News, or [Reddit](http://reddit.com/r/linuxusersgroup). |
12,564 | OnionShare:一个安全共享文件的开源工具 | https://itsfoss.com/onionshare/ | 2020-08-30T10:36:43 | [
"共享"
] | https://linux.cn/article-12564-1.html |
>
> OnionShare 是一个自由开源工具,它利用 Tor 网络安全和匿名地共享文件。
>
>
>

已经有很多在线服务可以安全地共享文件,但它可能不是完全匿名的。
此外,你必须依靠一个集中式服务来共享文件,如果服务决定像 [Firefox Send](https://itsfoss.com/firefox-send/) 那样关闭,那你不能真正依靠它来一直安全地共享文件。
考虑到这些,OnionShare 是一个让人惊叹的开源工具,它让你使用 [Tor Onion 服务](https://community.torproject.org/onion-services/)来共享文件。它应该是所有云端文件共享服务的一个很好的替代品。
让我们来看看它提供了什么以及它是如何工作的。

### OnionShare: 通过 Tor 匿名分享文件
[OnionShare](https://onionshare.org/) 是一款有趣的开源工具,可用于 Linux、Windows 和 macOS。
它可以让你安全地将文件直接从你的电脑分享给接收者,而不会在这个过程中暴露你的身份。你不必注册任何帐户,它也不依赖于任何集中式存储服务。
它基本上是在 Tor 网络上的点对点服务。接收者只需要有一个 [Tor 浏览器](https://itsfoss.com/install-tar-browser-linux/)就可以下载/上传文件到你的电脑上。如果你好奇的话,我也建议你去看看我们的 [Tor 指南](https://itsfoss.com/tor-guide/)来探索更多关于它的内容。
让我们来看看它的功能。
### OnionShare 的功能
对于一个只想要安全和匿名的普通用户来说,它不需要调整。不过,如果你有需要,它也有一些高级选项。
* 跨平台支持(Windows、macOS和 Linux)。
* 发送文件
* 接收文件
* 命令行选项
* 发布洋葱站点
* 能够使用桥接(如果你的 Tor 连接不起作用)
* 能够使用持久 URL 进行共享(高级用户)。
* 隐身模式(更安全)
你可以通过 GitHub 上的[官方用户指南](https://github.com/micahflee/onionshare/wiki)来了解更多关于它们的信息。
### 在 Linux 上安装 OnionShare
你应该可以在你的软件中心找到 OnionShare 并安装它。如果没有,你可以在 Ubuntu 发行版上使用下面的命令添加 PPA:
```
sudo add-apt-repository ppa:micahflee/ppa
sudo apt update
sudo apt install -y onionshare
```
如果你想把它安装在其他 Linux 发行版上,你可以访问[官方网站](https://onionshare.org/)获取 Fedora 上的安装说明以及构建说明。
* [下载 OnionShare](https://onionshare.org/)
### OnionShare 如何工作?
当你安装好后,一切都很明了且易于使用。但是,如果你想开始,让我告诉你它是如何工作的。
完成后,它加载并连接到 Tor 网络。
#### 共享文件

你只需要在电脑上添加你要分享的文件,然后点击 “**Start sharing**”。
完成后,右下角的状态应该是 “**Sharing**”,然后会生成一个 **OnionShare 地址**(自动复制到剪贴板),如下图所示。

现在接收方需要的是 OnionShare 的地址,它看上去是这样的。
```
http://onionshare:[email protected]
```
接着 Tor 浏览器开始下载文件。
值得注意的是,下载完成后(文件传输完成),文件共享就会停止。到时候也会通知你。
所以,如果你要再次分享或与他人分享,你必须重新分享,并将新的 OnionShare 地址发送给接收者。
#### 允许接收文件
如果你想生成一个 URL,让别人直接上传文件到你的电脑上(要注意你与谁分享),你可以在启动 OnionShare 后点击 **Receive Files** 标签即可。

你只需要点击 “**Start Receive Mode**” 按钮就可以开始了。接下来,你会得到一个 OnionShare 地址(就像共享文件时一样)。
接收者必须使用 Tor 浏览器访问它并开始上传文件。它应该像下面这样:

虽然当有人上传文件到你的电脑上时,你会收到文件传输的通知,但完成后,你需要手动停止接收模式。
#### 下载/上传文件
考虑到你已经安装了 Tor 浏览器,你只需要在 URL 地址中输入 OnionShare 的地址,确认登录(按 OK 键),它看上去像这样。

同样,当你得到一个上传文件的地址时,它看上去是这样的。

#### 发布洋葱站点
如果你想的话,你可以直接添加文件来托管一个静态的洋葱网站。当然,正因为是点对点的连接,所以在它从你的电脑上传输每个文件时,加载速度会非常慢。

我试着用[免费模板](https://www.styleshout.com/free-templates/kards/)测试了一下,效果很好(但很慢)。所以,这可能取决于你的网络连接。
### 总结
除了上面提到的功能,如果需要的话,你还可以使用命令行进行一些高级的调整。
OnionShare 的确是一款令人印象深刻的开源工具,它可以让你轻松地匿名分享文件,而不需要任何特殊的调整。
你尝试过 OnionShare 吗?你知道有类似的软件么?请在下面的评论中告诉我!
---
via: <https://itsfoss.com/onionshare/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: OnionShare is a free and open-source tool that utilizes the Tor network to share files securely and anonymously.*
You might have already come across a lot of online services to share files securely but it may not be completely anonymous.
Also, you do have to rely on a centralized service to share your files and if the service decides to shut down like [Firefox Send](https://itsfoss.com/firefox-send/) — you can’t really depend on it to safely share files all the time.
All things considered, OnionShare is an amazing open-source tool that lets you share files using the [Tor Onion service](https://community.torproject.org/onion-services/). It should be an amazing alternative to all the cloud file sharing services.
Let’s take a look at what it offers and how it works.
## OnionShare: Share files anonymously over Tor
[OnionShare](https://onionshare.org/) is an interesting open-source tool that’s available for Linux, Windows, and macOS.
It lets you securely share files directly from your computer to the receiver without revealing your identity in the process. You don’t have to sign up for any account — nor does it rely on any centralized storage service.
It is basically peer-to-peer over the Tor network. The receiver only needs to have a [Tor browser](https://itsfoss.com/install-tar-browser-linux/) to download/upload files to your computer. I’d also recommend you to go through our [Tor guide](https://itsfoss.com/tor-guide/) to explore more about it if you’re curious.
Let’s take a look at the features.
## Features of OnionShare
For an average user who just wants security and anonymity, there’s no tweak required. However, you do have some advanced options if you need.
- Cross-platform support (Windows, macOS, and Linux)
- Send files
- Receive files
- Command-line options
- Publish onion sites
- Ability to use bridges (if your tor connection isn’t working)
- Ability to use a persistent URL for sharing (advanced users)
- Stealth mode (more secure)
You can go through the [official user guide](https://github.com/micahflee/onionshare/wiki) on GitHub to learn more about them.
## Installing OnionShare on Linux
You should find OnionShare listed in your software center to get it installed. If it’s not there, you can add the PPA using the commands below on Ubuntu-based distros:
```
sudo add-apt-repository ppa:micahflee/ppa
sudo apt update
sudo apt install -y onionshare
```
If you’re looking to install it on other Linux distributions, you can visit the [official website](https://onionshare.org/) for installation instructions on Fedora and build instructions as well.
## How does OnionShare Work?
After you get it installed, everything is pretty self-explanatory and easy-to-use. But, if you want a heads up, let me show you how it works.
Once, it loads up and connects to the Tor network
### Sharing a File
You just have to add the file(s) that you want to share from your computer and then click on “**Start sharing**“.
Once you’re done, the status at the bottom-right should say “**Sharing**” and an **OnionShare address** will be generated (copied to clipboard automatically) as shown in the image below:
All the receiver needs now is the OnionShare address that should look like this:
`http://onionshare:`[[email protected]](/cdn-cgi/l/email-protection)
And, a Tor browser to start downloading the files.
It’s worth noting that once the download completes (file transfer is done), the file sharing stops. You will also be notified of the same when that happens.
So, if you have to share it again or with someone else, you will have to re-share it and send the new OnionShare address to the receiver.
### Allow Receiving Files
If you want to generate a URL that lets someone upload files directly to your computer (be careful with whom you share it), you can just click on the **Receive Files** tab after you launch OnionShare.
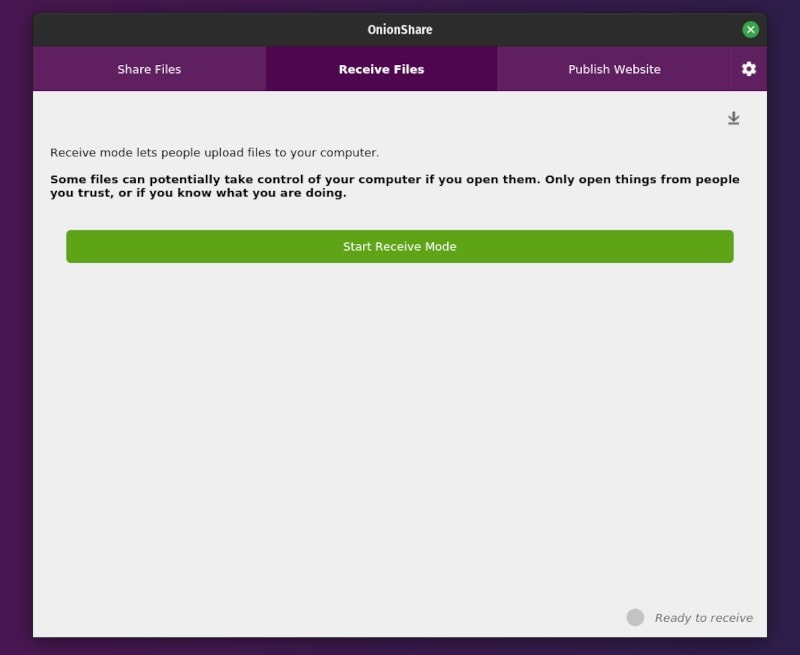
You just have to click on the “**Start Receive Mode**” button to get started. Next, you will get an OnionShare address (just like while sharing a file).
The receiver has to access it using the Tor browser and start uploading files. Here’s how it should look like:
Even though you will be notified of the file transfer when someone is uploading to your computer, you need to manually stop the receiving mode when you’re done.
### Downloading/Uploading Files
Considering that you have a Tor browser installed, you just need to hit the OnionShare address in the URL address, confirm log in (press OK) and here’s how it should look like:
Similarly, when you get an address to upload files, it should look like this:
### Publish Onion Sites
You can simply add the files to host a static onion website if you want. Of course, just because it’s peer-to-peer connection, it’ll be very slow to load up while it transfers every file from your computer.
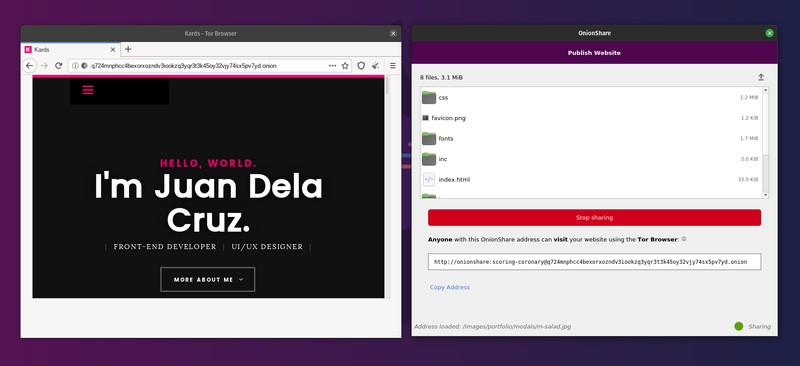
I tried using a [free template](https://www.styleshout.com/free-templates/kards/) to test it out and it works great (but very slow). So, it may depend on your network connection.
**Wrapping Up**
In addition to all the features mentioned above, you can also use the command line and opt for some advanced tweaks if needed.
OnionShare is indeed an impressive open-source tool that makes it easy to share files anonymously without needing any special tweaks.
Have you tried OnionShare yet? Is there something similar to this that you know of? Let me know in the comments below! |
12,566 | 九个用来构建容错系统的开源工具 | https://opensource.com/article/19/3/tools-fault-tolerant-system | 2020-08-30T20:51:00 | [
"容错"
] | https://linux.cn/article-12566-1.html |
>
> 这些开源工具可以最大化延长运行时间并且在最大程度上减少问题。
>
>
>

我一直对 Web 开发和软件体系结构很感兴趣,因为我喜欢看到一个工作系统的宏观视图。无论是构建一个移动应用程序还是一个 Web 应用程序,都必须连接到互联网,在不同的模块中交换数据,这意味着你需要 Web 服务。
如果选择云系统作为应用程序的后端,则可以利用更强大的计算能力,因为后端服务将会在水平和垂直方向上进行扩展并编排不同的服务。但无论你是否使用云后端,建造一个灵活、稳定、快速又安全的容错系统是必不可少的。
要了解容错系统,让我们以脸书、亚马逊、谷歌和奈飞为例。数以亿计的用户会同时接入这些平台并通过对等网络和用户-服务器网络传输大量数据,你可以肯定这其中还存在许多的带有不法目的的恶意用户,例如黑客攻击和拒绝服务(DoS)攻击。即使如此,这些平台无需停机也可以全年无休地运转。
虽然机器学习和智能算法是这些系统的基础,但它们实现持续的服务而不停机一分钟的事实值得称赞。它们昂贵的硬件设备和巨大的数据中心当然十分重要,但是支持服务的精密软件设计也同样重要。而且容错系统是一个构建如此精密系统的法则之一。
### 生产过程中导致错误的两种行为
这是考虑容错系统的另一种方法。当你在本地运行应用程序服务时,每件事似乎都很完美。棒极了!但当你提升服务到生产环境时,一切都会变得一团糟。在这种情况下,容错系统通过解决两个问题来提供帮助:故障停止行为和拜占庭行为。
#### 故障停止行为
故障停止行为是运行中系统突然停止运行或者系统中的某些部分发生了故障。服务器停机时间和数据库不可访问都属于此种类型。举个例子,在下图中,由于服务 2 无法访问,因此服务 1 无法与服务 2 进行通信。

但是,如果服务之间存在网络问题,也会出现此问题,如下图所示:

#### 拜占庭行为
拜占庭行为是指系统在持续运行,但并没有产生预期行为(例如:错误的数据或者无效的数据)。
如果服务 2 的数据(值)已损坏则可能会发生拜占庭故障,即使服务看起来运行得很好,比如下面的例子:

或者,可能存在恶意的中间人在服务之间进行拦截,并注入了不需要的数据:

无论是故障停止和拜占庭行为,都不是理想的情况,因此我们需要一些预防或修复它们的手段。这里容错系统就起作用了。以下是可以帮助你解决这些问题的 8 个开源工具。
### 构建容错系统的工具
尽管构建一个真正实用的容错系统涉及到深入的“分布式计算理论”和复杂的计算机科学原理,但有许多的软件工具(其中许多是开源软件)通过构建容错系统来减轻不良后果的影响。
#### 断路模式:Hystrix 和 Resilience4j
[断路模式](https://martinfowler.com/bliki/CircuitBreaker.html)是一种技术,它有助于在服务失败时返回准备好的虚拟回应或者简单回应。

奈飞开源的 [Hystrix](https://github.com/Netflix/Hystrix/wiki) 是断路模式中最流行的应用。
我之前工作过的很多家公司都在用这款出色的工具。令人意外的是,奈飞宣布将不再更新 Hystrix(是的,我知道了)。相反,奈飞建议使用另一种支持 Java 8 和函数式编程的 [Resilence4j](https://github.com/resilience4j/resilience4j) 之类的替代解决方案,或者类似于 [Adaptive Concurrency Limit](https://medium.com/@NetflixTechBlog/performance-under-load-3e6fa9a60581) 的替代解决方案。
#### 负载均衡:Nginx 和 HaProxy
负载均衡是分布式系统中最基本的概念之一,要想拥有一个生产质量的环境,必须有负载均衡的存在。要理解负载均衡器,首先我们需要明白冗余的概念。每个生产级的 Web 服务都有多个服务器在某个服务器宕机时提供冗余来接管和维持服务。

想想现代飞机:它们的双引擎提供冗余,使它们即使在一个引擎着火的情况下也能安全的着陆。(这也有助于大多数商用飞机拥有最先进的自动化系统)。但是,拥有多引擎(或者多服务器)也意味着必须存在一些调度机制在故障发生时有效地对系统进行路由。
负载均衡器是一种通过平衡多个服务节点来优化大流量事务的设备或者软件。举个例子,当数以千计的请求涌入时,负载均衡器可以作为中间层在不同的服务器间进行路由和平均分配流量。如果一台服务器宕机,负载均衡器会将请求转发给其它运行良好的服务器。
有许多可用的负载均衡器,但其中最出名的两个就是 Nginx 和 HaProxy。
[Nginx](https://www.nginx.com) 不仅仅是一个负载均衡器,它还是 HTTP 和反向代理服务器、邮件代理服务器和通用 TCP/UDP 代理服务器。Groupon、Capital One、Adobe 和 NASA 等公司都在使用它。
[HaProxy](https://www.haproxy.org) 也很受欢迎,因为它是一个免费的、非常快且可靠的解决方案,它为基于 TCP 和 HTTP 的应用程序提供高可用性、负载平衡和代理。许多大型网络公司,包括 Github、Reddit、Twitter 和 Stack Overflow 都使用 HaProxy。是的,Red Hat Enterprise Linux 同样支持 HaProxy 设置。
#### 参与者模型:Akka
[参与者模型](https://en.wikipedia.org/wiki/Actor_model)是一种并发设计模式,当作为基本计算单位的“参与者”接收到消息时,它会分派责任。一个参与者可以创建更多的参与者,并将消息委派给他们。
[Akka](https://akka.io) 是最著名的参与者模型实现之一。该框架同时支持基于 JVM 的 Java 和 Scala。
#### 使用消息队列的异步、非阻塞 I/O:Kafka 和 RabbitMQ
多线程开发在过去很流行,但是现在已经不鼓励这种做法了,取而代之的是异步的、非阻塞的 I/O 模式。对于 Java,这一点在 [EnterpriseJavaBean(EJB)规范](https://jcp.org/aboutJava/communityprocess/final/jsr220/index.html)中得到了明确的规定:
>
> “企业 bean 一定不能使用线程同步原语来同步多个实例的执行。”
>
>
> “企业 bean 不得试图去管理线程。企业 bean 不得试图启动、停止、挂起或恢复线程,或者去更改线程的优先级或者名称。企业 bean 不得试图管理线程组。”
>
>
>
如今,虽然还有其他做法,如流 API 和参与者模型,但像 [Kafka](https://kafka.apache.org) 和[RabbitMQ](https://www.rabbitmq.com) 之类的消息队列为异步和非阻塞 I/O 功能提供了开箱即用的支持,同时它们也是功能强大的开源工具,通过处理并发进程可以替代线程。
#### 其他的选择:Eureka 和 Chaos Monkey
用于容错系统其它有用的工具包括奈飞的 [Eureka](https://github.com/Netflix/eureka) 之类的监控工具,以及像 [Chaos Monkey](https://github.com/Netflix/chaosmonkey) 这样的压力测试工具。它们旨在通过在较低环境中的测试,如集成(INT)、质量保障(QA)和用户接受测试(UAT)来早早发现潜在问题以防止在转移到生产环境之前出现潜在问题。
你在使用什么开源工具来构建一个容错系统呢?请在评论中分享你的最爱。
---
via: <https://opensource.com/article/19/3/tools-fault-tolerant-system>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chenmu-kk](https://github.com/chenmu-kk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've always been interested in web development and software architecture because I like to see the broader picture of a working system. Whether you are building a mobile app or a web application, it has to be connected to the internet to exchange data among different modules, which means you need a web service.
If you use a cloud system as your application's backend, you can take advantage of greater computing power, as the backend service will scale horizontally and vertically and orchestrate different services. But whether or not you use a cloud backend, it's important to build a *fault-tolerant system*—one that is resilient, stable, fast, and safe.
To understand fault-tolerant systems, let's use Facebook, Amazon, Google, and Netflix as examples. Millions and billions of users access these platforms simultaneously while transmitting enormous amounts of data via peer-to-peer and user-to-server networks, and you can be sure there are also malicious users with bad intentions, like hacking or denial-of-service (DoS) attacks. Even so, these platforms can operate 24 hours a day and 365 days a year without downtime.
Although machine learning and smart algorithms are the backbones of these systems, the fact that they achieve consistent service without a single minute of downtime is praiseworthy. Their expensive hardware and gigantic datacenters certainly matter, but the elegant software designs supporting the services are equally important. And the fault-tolerant system is one of the principles to build such an elegant system.
## Two behaviors that cause problems in production
Here's another way to think of a fault-tolerant system. When you run your application service locally, everything seems to be fine. Great! But when you promote your service to the production environment, all hell breaks loose. In a situation like this, a fault-tolerant system helps by addressing two problems: Fail-stop behavior and Byzantine behavior.
### Fail-stop behavior
Fail-stop behavior is when a running system suddenly halts or a few parts of the system fail. Server downtime and database inaccessibility fall under this category. For example, in the diagram below, Service 1 can't communicate with Service 2 because Service 2 is inaccessible:
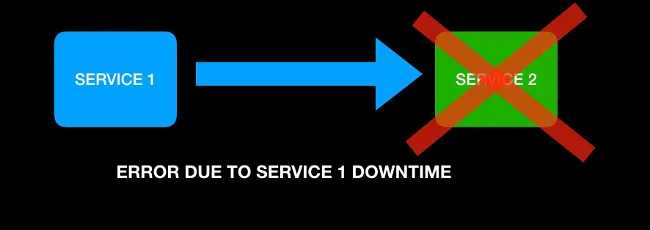
Fail-stop behavior due to Service 2 downtime
But the problem can also occur if there is a network problem between the services, like this:

Fail-stop behavior due to network failure
### Byzantine behavior
Byzantine behavior is when the system continuously runs but doesn't produce the expected behavior (e.g., wrong data or an invalid value).
Byzantine failure can happen if Service 2 has corrupted data or values, even though the service looks to be operating just fine, like in this example:

Byzantine failure due to corrupted service
Or, there can be a malicious middleman intercepting between the services and injecting unwanted data:

Byzantine failure due to malicious middleman
Neither fail-stop nor Byzantine behavior is a desired situation, so we need ways to prevent or fix them. That's where fault-tolerant systems come into play. Following are eight open source tools that can help you address these problems.
## Tools for building a fault-tolerant system
Although building a truly practical fault-tolerant system touches upon in-depth *distributed computing theory* and complex computer science principles, there are many software tools—many of them, like the following, open source—to alleviate undesirable results by building a fault-tolerant system.
### Circuit-breaker pattern: Hystrix and Resilience4j
The [circuit-breaker pattern](https://martinfowler.com/bliki/CircuitBreaker.html) is a technique that helps to return a prepared dummy response or a simple response when a service fails:
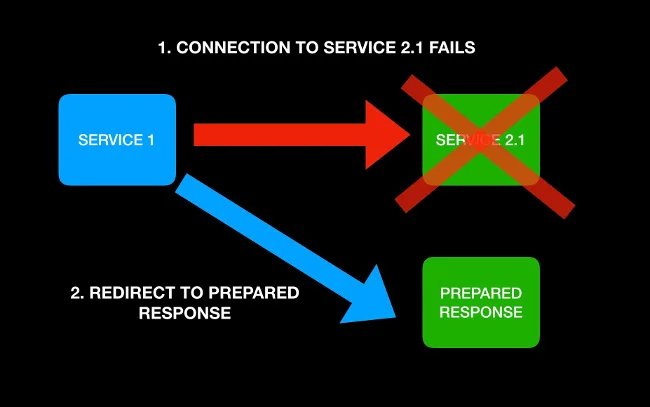
Circuit breaker pattern
Netflix's open source ** Hystrix** is the most popular implementation of the circuit-breaker pattern.
Many companies where I've worked previously are leveraging this wonderful tool. Surprisingly, Netflix announced that it will no longer update Hystrix. (Yeah, I know.) Instead, Netflix recommends using an alternative solution like [ Resilence4j](https://github.com/resilience4j/resilience4j), which supports Java 8 and functional programming, or an alternative practice like
[Adaptive Concurrency Limit](https://medium.com/@NetflixTechBlog/performance-under-load-3e6fa9a60581).
### Load balancing: Nginx and HaProxy
Load balancing is one of the most fundamental concepts in a distributed system and must be present to have a production-quality environment. To understand load balancers, we first need to understand the concept of *redundancy*. Every production-quality web service has multiple servers that provide redundancy to take over and maintain services when servers go down.
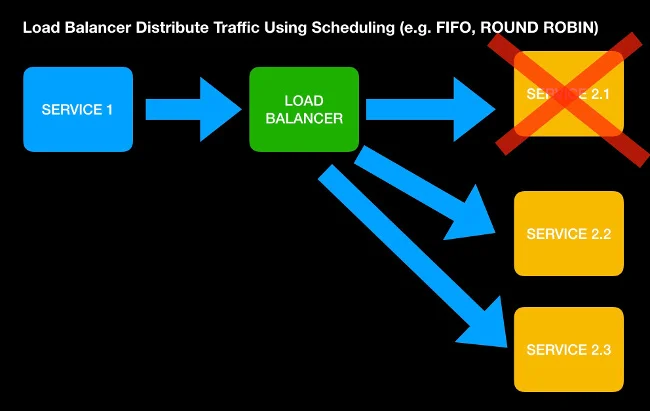
Think about modern airplanes: their dual engines provide redundancy that allows them to land safely even if an engine catches fire. (It also helps that most commercial airplanes have state-of-art, automated systems.) But, having multiple engines (or servers) means that there must be some kind of scheduling mechanism to effectively route the system when something fails.
A load balancer is a device or software that optimizes heavy traffic transactions by balancing multiple server nodes. For instance, when thousands of requests come in, the load balancer acts as the middle layer to route and evenly distribute traffic across different servers. If a server goes down, the load balancer forwards requests to the other servers that are running well.
There are many load balancers available, but the two best-known ones are Nginx and HaProxy.
[ Nginx](https://www.nginx.com) is more than a load balancer. It is an HTTP and reverse proxy server, a mail proxy server, and a generic TCP/UDP proxy server. Companies like Groupon, Capital One, Adobe, and NASA use it.
[ HaProxy](https://www.haproxy.org) is also popular, as it is a free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. Many large internet companies, including GitHub, Reddit, Twitter, and Stack Overflow, use HaProxy. Oh and yes, Red Hat Enterprise Linux also supports HaProxy configuration.
### Actor model: Akka
The [actor model](https://en.wikipedia.org/wiki/Actor_model) is a concurrency design pattern that delegates responsibility when an *actor*, which is a primitive unit of computation, receives a message. An actor can create even more actors and delegate the message to them.
[ Akka](https://akka.io) is one of the most well-known tools for the actor model implementation. The framework supports Java and Scala, which are both based on JVM.
### Asynchronous, non-blocking I/O using messaging queue: Kafka and RabbitMQ
Multi-threaded development has been popular in the past, but this practice has been discouraged and replaced with asynchronous, non-blocking I/O patterns. For Java, this is explicitly stated in its [Enterprise Java Bean (EJB) specifications](https://jcp.org/aboutJava/communityprocess/final/jsr220/index.html):
"An enterprise bean must not use thread synchronization primitives to synchronize execution of multiple instances.
"The enterprise bean must not attempt to manage threads. The enterprise bean must not attempt to start, stop, suspend, or resume a thread, or to change a thread's priority or name. The enterprise bean must not attempt to manage thread groups."
Now, there are other practices like stream APIs and actor models. But messaging queues like [ Kafka](https://kafka.apache.org) and
[offer the out-of-box support for asynchronous and non-blocking IO features, and they are powerful open source tools that can be replacements for threads by handling concurrent processes.](https://www.rabbitmq.com)
**RabbitMQ**### Other options: Eureka and Chaos Monkey
Other useful tools for fault-tolerant systems include monitoring tools, such as Netflix's ** Eureka**, and stress-testing tools, like
**. They aim to discover potential issues earlier by testing in lower environments, like integration (INT), quality assurance (QA), and user acceptance testing (UAT), to prevent potential problems before moving to the production environment.**
[Chaos Monkey](https://github.com/Netflix/chaosmonkey)What open source tools are you using for building a fault-tolerant system? Please share your favorites in the comments.
## 6 Comments |
12,567 | Glances:多功能 Linux 系统监控工具 | https://itsfoss.com/glances/ | 2020-08-30T21:28:00 | [
"Glances"
] | https://linux.cn/article-12567-1.html | 
Linux 上最常用的[命令行进程监控工具](https://itsfoss.com/linux-system-monitoring-tools/)是 `top` 和它那色彩斑斓、功能丰富的表弟 [htop](https://hisham.hm/htop/)。
要[监控 Linux 上的温度](https://itsfoss.com/monitor-cpu-gpu-temp-linux/),可以使用 [lm-sensors](https://github.com/lm-sensors/lm-sensors)。同样,还有很多实用工具可以监控其他实时指标,如磁盘 I/O、网络统计等。
[Glances](https://nicolargo.github.io/glances/) 是一个系统监控工具,它把这些都联系在一起,并提供了更多的功能。我最喜欢的是,你可以在远程 Linux 服务器上运行 Glances 来监控本地系统的系统资源,也可以通过 Web 浏览器监控。
下面是它的外观。下面截图中的终端已经[用 Pywal 工具美化过,可以根据壁纸自动改变颜色](https://itsfoss.com/pywal/)。

你也可以将它集成到像 [Grafana](https://grafana.com/) 这样的工具中,在一个直观的仪表盘中监控统计数据。
它是用 Python 编写的,这意味着它的绝大多数功能都可以在大多数平台上使用。
### Glances 的功能

让我们快速浏览一下 Glances 提供的主要功能:
* 可以监控系统上的 15 个之多的指标(包括 Docker 容器)。
* 灵活的使用模式:单机模式、客户端-服务器模式、通过 SSH 和 Web 模式。
* 可用于集成的各种 REST API 和 XML-RPC API。
* 支持将数据轻松导出到不同的服务和数据库。
* 高度的可配置性和适应不同的需求。
* 非常全面的文档。
### 在 Ubuntu 和其他 Linux 发行版上安装 Glances
Glances 在许多 Linux 发行版的官方软件库中都有。这意味着你可以使用你的发行版的软件包管理器来轻松安装它。
在基于 Debian/Ubuntu 的发行版上,你可以使用以下命令:
```
sudo apt install glances
```
你也可以使用 snap 包安装最新的 Glances:
```
sudo snap install glances
```
由于 Glances 是基于 Python 的,你也可以使用 PIP 在大多数 Linux 发行版上安装它。先[安装 PIP](https://itsfoss.com/install-pip-ubuntu/),然后用它来安装 Glances:
```
sudo pip3 install glances
```
如果没有别的办法,你还可以使用 Glances 开发者提供的自动安装脚本。虽然我们不建议直接在你的系统上随便运行脚本,但这完全取决于你自己:
```
curl -L https://bit.ly/glances | /bin/bash
```
你可以从他们的[文档](https://github.com/nicolargo/glances/blob/master/README.rst#installation)中查看其他安装 Glances 的方法,甚至你还可以把它作为一个 Docker 容器来安装。
### 使用 Glances 监控本地系统上的 Linux 系统资源(独立模式)
你可以通过在终端上运行这个命令,轻松启动 Glances 来监控你的本地机器:
```
glances
```
你可以立即观察到,它将很多不同的信息整合在一个屏幕上。我喜欢它在顶部显示电脑的公共和私人 IP:

Glances 也是交互式的,这意味着你可以在它运行时使用命令与它互动。你可以按 `s` 将传感器显示在屏幕上;按 `k` 将 TCP 连接列表显示在屏幕上;按 `1` 将 CPU 统计扩展到显示单个线程。
你也可以使用方向键在进程列表中移动,并按不同的指标对表格进行排序。
你可以通过各种命令行选项来启动 Glances。此外,它还有很多交互式命令。你可以在他们的[丰富的文档](https://glances.readthedocs.io/en/latest/cmds.html)中找到完整的列表。
按 `Ctrl+C` 键退出 Glances。
### 使用 Glances 监控远程 Linux 系统(客户端-服务器模式)
要监控远程计算机,你可以在客户端-服务器模式下使用 Glances。你需要在两个系统上都安装 Glances。
在远程 Linux 系统上,使用 `-s` 选项在服务器模式下启动 Glances:
```
glances -s
```
在客户端系统中,使用下面的命令在客户端模式下启动 Glances 并连接到服务器:
```
glances -c server_ip_address
```
你也可以通过 SSH 进入任何一台电脑,然后启动 Glances,它可以完美地工作。更多关于客户端-服务器模式的信息请看[这里](https://glances.readthedocs.io/en/latest/quickstart.html#central-client)。
### 使用 Glances 在 Web 浏览器中监控 Linux 系统资源(Web 模式)
Glances 也可以在 Web 模式下运行。这意味着你可以使用 Web 浏览器来访问 Glances。与之前的客户端-服务器模式不同,你不需要在客户端系统上安装 Glances。
要在 Web 模式下启动 Glances,请使用 `-w` 选项:
```
glances -w
```
请注意,即使在 Linux 服务器上,它也可能显示 “Glances Web User Interface started on <http://0.0.0.0:61208>”,而实际上它使用的是服务器的 IP 地址。
最主要的是它使用的是 61208 端口号,你可以用它来通过网络浏览器访问 Glances。只要在服务器的 IP 地址后面输入端口号,比如 <http://123.123.123.123:61208>。
你也可以在本地系统中使用 <http://0.0.0.0:61208/> 或 <https://localhost:61208/> 访问。

Web 模式也模仿终端的样子。网页版是根据响应式设计原则打造的,即使在手机上也很好看。
你可能想用密码来保护 Web 模式,这样只有授权的人才能使用它。默认的用户名是 `glances`。
```
root@localhost:~# glances -w --password
Define the Glances webserver password (glances username):
Password (confirm):
Do you want to save the password? [Yes/No]: n
Glances Web User Interface started on http://0.0.0.0:61208/
```
你可以在[快速入门指南](https://glances.readthedocs.io/en/stable/quickstart.html)中找到关于配置密码的更多信息。
### 导出 Glances 数据到不同的服务
使用 Glances 最大的优势之一就是开箱即用,它支持将数据导出到各种数据库、服务,并无缝集成到各种数据管道中。
你可以在监控的同时用这个命令导出到 CSV:
```
glances --export csv --export-csv-file /tmp/glances.csv
```
`/tmp/glances.csv` 是文件的位置。数据以时间序列的形式整齐地填入。

你也可以导出到其它大型应用程序,如 [Prometheus](https://prometheus.io/),以启用条件触发器和通知。
它可以直接插入到消息服务(如 RabbitMQ、MQTT)、流媒体平台(如 Kafka),并将时间序列数据导出到数据库(如 InfluxDB),并使用 Grafana 进行可视化。
你可以在[这里](https://glances.readthedocs.io/en/latest/gw/index.html)查看服务和导出选项的整个列表。
### 使用 REST API 将 Glances 与其他服务进行整合
这是整个栈中我最喜欢的功能。Glances 不仅可以将各种指标汇集在一起,还可以通过 API 将它们暴露出来。
这个简单而强大的功能使得为任何特定的用例构建自定义应用程序、服务和中间件应用程序变得非常容易。
当你在 Web 模式下启动 Glances 时,REST API 服务器会自动启动。要在 API 服务器模式下启动它,你可以使用以下命令:
```
glances -w --disable-webui
```
[REST API](https://github.com/nicolargo/glances/wiki/The-Glances-RESTFULL-JSON-API) 的文档很全面,其响应也很容易与 Web 应用集成。这使得使用类似 [Node-RED](https://nodered.org/) 这样的工具可以很容易地构建一个统一的仪表盘来监控多个服务器。

Glances 也提供了一个 XML-RPC 服务器,你可以在[这里](https://github.com/nicolargo/glances/wiki)查看文档。
### 关于 Glances 的结束语
Glances 使用 [psutil](https://pypi.org/project/psutil/) Python 库来访问不同的系统统计数据。早在 2017 年,我就曾使用相同的库构建了一个简单的 API 服务器来检索 CPU 的使用情况。我能够使用 Node-RED 构建的仪表盘监控一个集群中的所有树莓派。
Glances 可以为我节省一些时间,同时提供更多的功能,可惜我当时并不知道它。
在写这篇文章的时候,我确实尝试着在我的树莓派上安装 Glances,可惜所有的安装方法都出现了一些错误,失败了。当我成功后,我会更新文章,或者可能再写一篇文章,介绍在树莓派上安装的步骤。
我希望 Glances 能提供一种顶替 `top` 或 `htop` 等的方法。让我们希望在即将到来的版本中得到它。
我希望这能给你提供大量关于 Glances 的信息。你们使用什么系统监控工具呢,请在评论中告诉我。
---
via: <https://itsfoss.com/glances/>
作者:[Chinmay](https://itsfoss.com/author/chinmay/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The most commonly used command line [tools for process monitoring on Linux](https://itsfoss.com/linux-system-monitoring-tools/) are top and its colorful, feature rich cousin [htop](https://hisham.hm/htop/) .
To [monitor temperature on Linux](https://itsfoss.com/monitor-cpu-gpu-temp-linux/), you can use [lm-sensors](https://github.com/lm-sensors/lm-sensors). Similarly, there are many utilities to monitor other real-time metrics such as Disk I/O, Network Stats and others.
[Glances](https://nicolargo.github.io/glances/) is a system monitoring tool which ties them all together and offers a lot more features. What I like the most is that you can use run Glances on a remote Linux server and monitor the system resources on your local system or monitor it through your web browser.
Here’s what it looks like. The terminal in the below screenshot has been [beautified with Pywal tool that automatically changes the color based on wallpaper](https://itsfoss.com/pywal/).
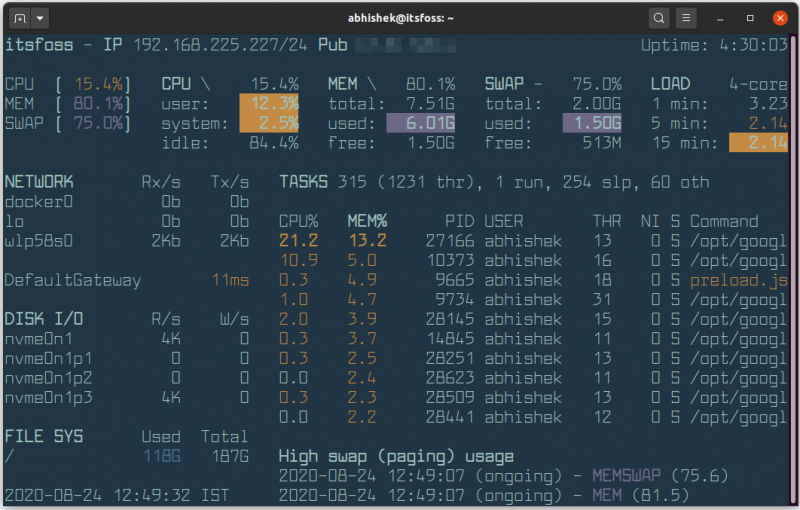
You can also integrate it to a tool like [Grafana](https://grafana.com/) to monitor the stats in an intuitive dashboard.
It is written in Python which means that it can be used on most platforms with almost all features.
## Features of Glances
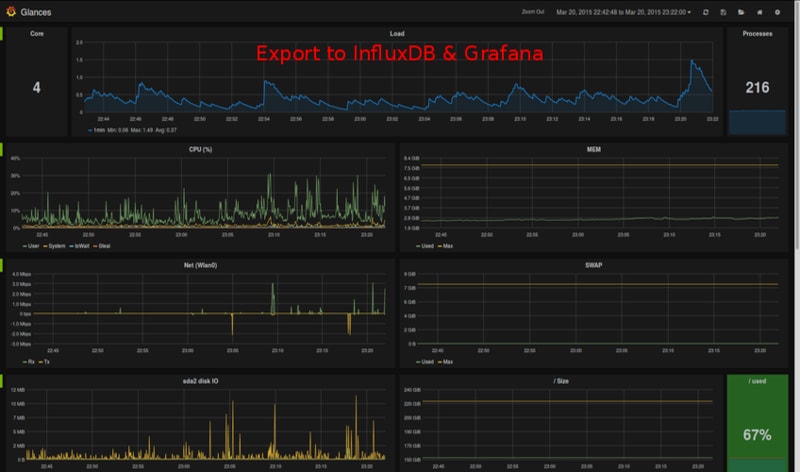
Let’s have a quick glance over the main feature Glances provides (pun intended).
- Can monitor 15+ metrics on a system (including docker containers).
- Flexible usage modes: standalone, client-server, over SSH and web mode.
- Versatile REST API and XML-RPC available for integrations.
- Readily supports exporting data to different services and databases.
- Highly configurable and adaptable to different needs.
- Very comprehensive Documentation.
## Installing Glances on Ubuntu and other Linux distributions
Glances is available in the official repositories of many Linux distributions. This means you can use your distribution’s package manager to install it easily.
On Debian/Ubuntu based distributions, you can use the following command:
`sudo apt install glances`
You can also install the latest Glances using snap package:
`sudo snap install glances `
Since Glances is based on Python, you can also use PIP to install it on most Linux distributions. [Install PIP](https://itsfoss.com/install-pip-ubuntu/) first and then use it to install Glances:
`sudo pip3 install glances`
If nothing else, you can always use the auto install script provided by Glances developer. Though we at It’s FOSS don’t recommend running random scripts directly on your system. It’s entirely your decision.
`curl -L https://bit.ly/glances | /bin/bash`
You can check out other ways to install Glances from their [documentation](https://github.com/nicolargo/glances/blob/master/README.rst#installation), you can also install it as a docker container.
## Using Glances to monitor Linux system resources on local system (standalone mode)
You can easily launch Glances to monitor your local machine by running this command n the terminal.
`glances`
You can instantly observe that it integrates a lot of different information in one single screen. I like that it shows the public and private IP’s of the computer right at the top.
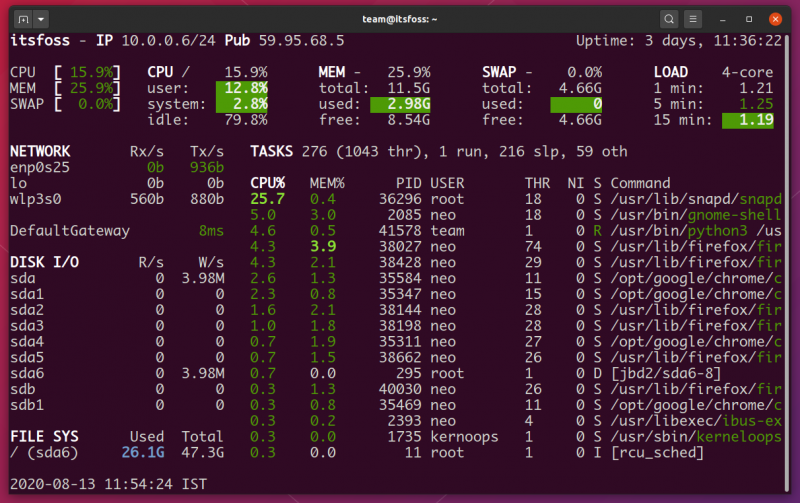
Glances is also interactive, meaning you can use commands to interact with it while it is running. You can press **“s”** to bring up the sensors onto the screen; **“k”** to bring up the TCP connections list; **“1”** to expand the CPU stats to show individual threads.
You can also use the arrow keys to move around the list of processes and sort the table by different metrics.
You can launch Glances with various command line options. There are plenty more interactive commands as well. You can find the complete list in their [comprehensive documentation](https://glances.readthedocs.io/en/latest/cmds.html).
Press Ctrl+C to exit Glances.
## Using Glances to monitor remote Linux systems (Client – Server mode)
To monitor a remote computer you can use Glances in client-server mode. You need to have Glances installed on both systems.
On the remote Linux system, you’ll have to launch glances in server mode using the -s option.
`glances -s`
On the client system, use this command to launch Glances in client mode and connect to the server.
`glances -c server_ip_address`
You can also SSH into any computer and launch Glances, which works flawlessly. More information about client-server mode [here](https://glances.readthedocs.io/en/latest/quickstart.html#central-client).
## Monitor Linux system resources in web browser using Glances (Web Mode)
Glances can also run in web mode. This means that you can use a web browser to access Glances. Unlike the previous client-server mode, you don’t need to install Glances on the client system.
To start Glances in web mode, use the -w option.
`glances -w`
Keep in mind that it may display “Glances Web User Interface started on http://0.0.0.0:61208” even on a Linux server when it is actually using the server’s IP address.
The main part is that it uses 61208 port number and you can use it to access Glances via web browser. Just type the server’s IP address followed by the port number like http://123.123.123.123:61208.
You can also use it on the local system using http://0.0.0.0:61208/ or [https://localhost:61208/](https://localhost:61208/).
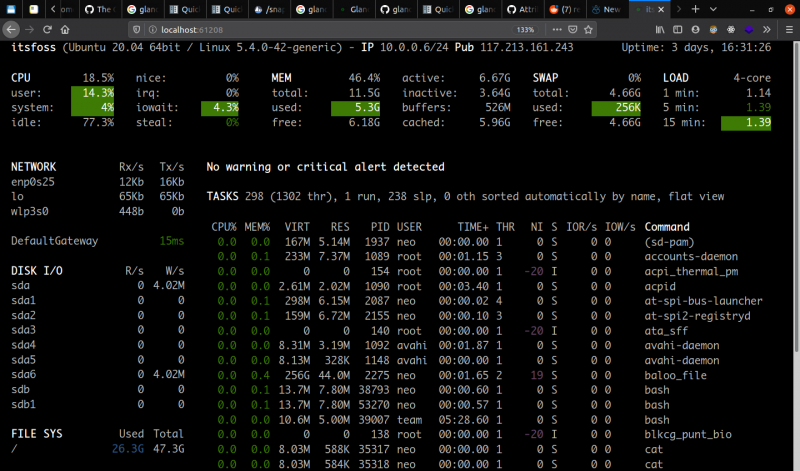
The web mode also emulates the terminal look. The web version is built with responsive design principles in mind and looks good even on phones.
You may want to protect the web mode with a password so that only authorized people could use it. The default username is glances.
```
root@localhost:~# glances -w --password
Define the Glances webserver password (glances username):
Password (confirm):
Do you want to save the password? [Yes/No]: n
Glances Web User Interface started on http://0.0.0.0:61208/
```
You can find more information on configuring password in the [quickstart guide](https://glances.readthedocs.io/en/stable/quickstart.html).
## Export Glances data to different services
One of the biggest advantage of using Glances is the out of the box support to export data to various databases, services and integration into various data pipelines seamlessly.
You can export to CSV while monitoring with this command.
`glances --export csv --export-csv-file /tmp/glances.csv`
‘/tmp/glances.csv’ is the location of the file. The data is filled in neatly as time series.
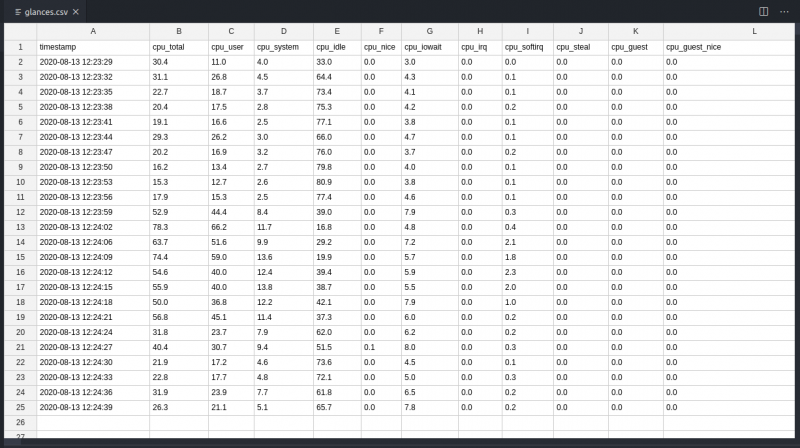
You can export to powerful applications like [Prometheus](https://prometheus.io/) to enable conditional triggers and notifications.
It can directly plug into messaging services like RabbitMQ, MQTT, streaming platforms like Kafka and export time series data to databases like InfluxDB and visualize using Grafana.
You can check out the whole list of services and export options [here](https://glances.readthedocs.io/en/latest/gw/index.html).
## Use REST API to integrate Glances with other services
This is my favorite feature in the whole stack. Glances not only brings together various metrics together, it also exposes them via APIs.
This simple yet powerful feature makes it very easy to build custom applications, services and middleware applications for any specific use cases.
REST API server stars automatically when you launch Glances in web mode. To launch it in API server only mode you can use the following command.
`glances -w --disable-webui`
The [REST API](https://github.com/nicolargo/glances/wiki/The-Glances-RESTFULL-JSON-API) documentation is comprehensive and the responses are easy to integrate with a web application. This makes it easy to build a unified dashboard to monitor multiple servers with a tool like [Node-RED](https://nodered.org/).
Glances also provides an XML-RPC server, you can check out the documentation [here](https://github.com/nicolargo/glances/wiki).
## Closing thoughts on Glances
Glances uses the [psutil](https://pypi.org/project/psutil/) python library to access different system stats. I had built a simple API server using the same library to retrieve CPU usage back in 2017. I was able to monitor all the Raspberry Pi’s in a cluster using a dashboard built with Node-RED.
Glances could have saved me some time while offering way more features, unfortunately I didn’t know about it back then.
I did try to install Glances on my Raspberry Pi’s while writing this article, unfortunately it failed with some errors with all the installation methods. I’ll update the article when I succeed or maybe write another article with steps to install on a Raspberry Pi.
I wish Glances offered a way to kill processes like top or htop. Let’s hope that we get it in upcoming releases.
I hope this gave you a good deal of information on Glances. What system monitoring tools do you guys use? let me know in the comments. |
12,569 | AI 系统向自动化编码迈进 | https://www.networkworld.com/article/3570389/ai-system-analyzes-code-similarities-makes-progress-toward-automated-coding.html | 2020-08-31T23:14:07 | [
"AI",
"编程"
] | https://linux.cn/article-12569-1.html |
>
> 来自 Intel、MIT 和佐治亚理工学院的研究人员正在研究一个 AI 引擎,它可以分析代码的相似性,以确定代码的实际作用,为自动化软件编写奠定了基础。
>
>
>

随着人工智能(AI)的快速发展,我们是否会进入计算机智能到足以编写自己的代码并和人类一起完成工作?新的研究表明,我们可能正在接近这个里程碑。
来自 MIT 和佐治亚理工学院的研究人员与 Intel 合作开发了一个人工智能引擎,被称为机器推断代码相似性(MISIM),它旨在分析软件代码并确定它与其他代码的相似性。最有趣的是,该系统有学习代码的潜力,然后利用这种智能来改变软件的编写方式。最终,人们可以解释希望程序做什么,然后机器编程(MP)系统可以拿出一个已经编写完的应用。
Intel 首席科学家兼机器编程研究总监/创始人 Justin Gottschlich 在该公司的[新闻稿](https://newsroom.intel.com/news/intel-mit-georgia-tech-machine-programming-code-similarity-system/#gs.d8qd40)中说:“当完全实现时,MP 能让每个人都能以任何最适合自己的方式 —— 无论是代码、自然语言还是其他东西 —— 来表达自己的意图以创建软件。这是一个大胆的目标,虽然还有很多工作要做,但 MISIM 是朝着这个目标迈出的坚实一步。”
### 它是如何工作的
Intel 解释说,神经网络“根据它们被设计执行的作业”给代码片段打出相似度分数。例如,两个代码样本可能看起来完全不同,但由于它们执行相同的功能,因此被评为相同。然后,该算法可以确定哪个代码片段更有效率。
例如,代码相似性系统的原始版本被用于抄袭检测。然而,有了 MISIM,该算法会查看代码块,并试图根据上下文确定这些代码段是否具有相似的特征,或者是否有相似的目标。然后,它可以提供性能方面的改进,例如说,总体效率的改进。
MISIM 的关键是创造者的意图,它标志着向基于意图的编程的进步,它可以使软件的设计基于非程序员创造者想要实现的目标。通过基于意图的编程,算法会借助于一个开源代码池,而不是依靠传统的、手工的方法,编译一系列类似于步骤的编程指令,逐行告诉计算机如何做某件事。
Intel 解释说:“MISIM 与现有代码相似性系统的核心区别在于其新颖的上下文感知语义结构 (CASS),其目的是将代码的实际作用提炼出来。与其他现有的方法不同,CASS 可以根据特定的上下文进行配置,使其能够捕捉到更高层次的代码描述信息。CASS 可以更具体地洞察代码的作用,而不是它是如何做的。”
这是在没有编译器(编程中的一个阶段,将人类可读代码转换为计算机程序)的情况下完成的。方便的是,可以执行部分片段,只是为了看看那段代码中会发生什么。另外,该系统摆脱了软件开发中一些比较繁琐的部分,比如逐行查找错误。更多细节可以在该小组的论文([PDF](https://arxiv.org/pdf/2006.05265.pdf))中找到。
Intel 表示,该团队的 MISIM 系统比之前的代码相似性系统识别相似代码的准确率高 40 倍。
一个 Redditor,Heres\_your\_sign [对 MISIM 报道](https://www.reddit.com/r/technology/comments/i2dxed/this_ai_could_bring_us_computers_that_can_write/)的评论中有趣地指出,幸好计算机不写需求。这位 Redditor 认为,那是自找麻烦。
---
via: <https://www.networkworld.com/article/3570389/ai-system-analyzes-code-similarities-makes-progress-toward-automated-coding.html>
作者:[Patrick Nelson](https://www.networkworld.com/author/Patrick-Nelson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
12,570 | 铜豌豆:给中文 Debian 社区的礼物 | https://gitee.com/atzlinux/www/blob/master/News/2020/introduction.md | 2020-09-01T10:24:00 | [
"铜豌豆",
"Debian"
] | https://linux.cn/article-12570-1.html | 
Debian Linux 作为颇受 Linux 爱好者青睐的老牌发行版,无论在服务器领域、嵌入式环境,还是个人作为桌面计算机操作系统使用,都有一大片铁杆粉丝。
不过就中文使用环境而言,普遍遇到的一个现状是针对中文、中国人使用习惯打造的软件比较少,也缺乏整理,很多人不知道在哪里可以找到。
前两天,老王在群内偶尔发现有朋友在分享一款名为“铜豌豆 Linux”的 Debian 定制版,颇感兴趣,下面将它分享给大家。
---
### 铜豌豆 Linux 是什么?
[铜豌豆 Linux](https://www.atzlinux.com/) 是一款基于 Debian 的 Linux 中文桌面操作系统。
Debian 是一款非常优秀的 Linux 操作系统,但由于版权限制等多方面的原因,其默认安装缺少中国人常用的软件。 将一个原生 Debian 安装好后,再修改配置为中国人可以使用的日常操作系统,就是对一个对 Debian 比较了解的技术人员来讲,也需要不少时间。
铜豌豆 Linux 操作系统在 Debian 基础上,优化安装步骤,收集整理制作中文常用软件、一键安装脚本,搭建软件源,一次性安装完成常用中文应用,节省大家定制 Debian 的时间,可以做到“开箱即用”。
### 你是否在爱着 Debian 的同时,也感受到了这些困扰?
* 由于 Debian 严格遵循源代码开放的自由协议,硬件厂家的闭源驱动固件默认是不会放在 Debian 官方 iso 里面。
* 目前笔记本电脑一般默认集成有无线网卡,但这类无线网卡的驱动,在原生 Debian 的安装过程中,需要自己先确认无线网卡芯片型号,手工用 U 盘拷贝对应固件文件,再进行加载。
* 由于受到 Debian iso 文件大小的限制,在安装的时候,即使安装界面选择中文,也没有安装中文字体,安装后第一次重启登录,中文显示是乱码,需要再手工用命令行安装中文字体才行。
* Debian 的在安装过程中的可定制化程度比较高,有较多安装选项在安装过程中需要选择,对用户的技术知识水平也有一定的要求。
### 响当当的铜豌豆 Linux
针对以上的这些问题,铜豌豆 Linux 定制化安装 iso 文件,对安装过程进行了大量优化:
* 采用 preseed 等技术,默认设置安装过程中的很多配置选项,无需用户输入
* 默认使用中文安装界面、中文字符集
* 默认集成常见无线网卡固件,让内核能够直接识别并驱动
* 默认采用 DHCP 方式自动获取网络参数
* 默认使用速度比较快的国内 Debian 官方镜像作为软件源和安全升级源
* 默认安装中文字体、搜狗输入法、WPS 等常用中文应用
* 默认设置 root 账号密码
* 默认设置新用户及密码
* 默认识别多个硬盘的多个操作系统,并自动将 GRUB 安装在 sda 硬盘引导区
在整个安装过程中,以尽量自动化和免交互输入为目标,只需要进行“WiFi 选择”、“WiFi 密码输入”、“硬盘分区”这三个步骤,就可以完成整个操作系统安装。而且这三个步骤,只需要在安装初期前面几分钟的时候需要用户输入。在硬盘分区完成后,后续大部分的安装耗时,都是系统自动完成,不需要人为再干预。安装完成后,会自动重启进入登录界面。
如果是使用的 SSD 硬盘,一般只需要半个小时,可以完成全部安装,而且后续 20 多分钟,是不需要人一直在旁边盯着看的。
### 铜豌豆 Linux 软件收录
除了安装方便之外,铜豌豆 Linux 中都有什么软件呢?
为方便大家安装各类中文软件,铜豌豆 Linux 软件源积极收集各类中文软件。收录的软件包中,既有开源项目软件,也有各类商业软件,丰富 Linux 桌面中文应用。
对收录的 deb 软件包,会用 Debian 官方软件包质量检查工具 lintian 进行质量检查,安装卸载测试等工作。 确保收录的软件包,维持在相当的质量水平。
铜豌豆 Linux 完全尊重软件包知识产权,所收录的软件包至少是可以个人免费使用才行,不收录破解版本。
* 全部软件包列表如下: <https://www.atzlinux.com/allpackages.htm>
* 软件包的收录规则: <https://www.atzlinux.com/allpackages.htm#pkgrules>
铜豌豆软件源同时支持 Debian 系发行版。
#### 收纳开源社区中文软件包
中国象棋、麻将 等中文开源软件,积极收集整理到“铜豌豆”软件源,并进行必要的调整、重新打包,共同打造 Linux 中文桌面生态。 目前[铜豌豆软件源](https://www.atzlinux.com/allpackages.htm)收录的中文应用软件包约 90 个。(不包括 Debian 官方软件包和底层依赖相关软件包)

铜豌豆软件源的软件源,都可以在“铜豌豆应用商店”里面轻松安装。
#### 自制中文字体等软件包
针对目前 Linux 桌面缺少中文字体的窘境, iso 文件默认安装自制字体包,让 WPS 打开不报缺少字体的错误。
“铜豌豆”项目组成员凡客做出了积极的贡献,收集整理了若干开源或者免费商用的中文字体,制作打包。目前已经制作好的字体软件包有:
* 微软 cascadia 英文字体
* 鸿雷板书简体
* 江西拙楷
* 演示春风楷(毛笔楷体)
* 演示秋鸿楷(毛笔楷体)
* 演示夏行楷(毛笔楷体)
* 演示悠然小楷(毛笔楷体)
* 优设标题黑
* 杨任东竹石体
* 小赖手写体
* 一点明体
* 江城斜宋体、江城斜黑体
* 萌神拼音体(自带拼音)
* 黄令东齐伋体、黄令东齐伋复刻体
* 演示佛系体
* 悠哉手写体
* 更纱黑体(自带常规体、斜体)
中文字体软件包还在持续制作增加中。
#### 商业软件互动
对中文商业软件在适配测试过程中发现的问题,也积极和商业公司沟通,进行良性互动。得到了百度网盘、WPS 、永中 office 等公司的反馈。而在向 linuxqq 反馈的意见,也在 linuxqq 新版本中得到了改进。

### 关于铜豌豆
* 官网: <https://www.atzlinux.com/>
* 开源仓库:<https://gitee.com/atzlinux/projects>
#### 历程
铜豌豆最早始于 2019 年 9 月在码云上创建的第一个仓库: <https://gitee.com/atzlinux/debian-cn>
* 前期是用的一键安装脚本的方式,在已经安装好 Debian 操作系统的上一次性安装常用中文应用: <https://www.atzlinux.com/yjaz.htm>
* 后来自己搭建了 apt 软件源,方便软件包下载: <https://www.atzlinux.com/allpackages.htm>
* 第一版定制化的 iso 文件发布于 2019 年 11 月初,目前已经经历了 9 次更新迭代到了 10.5.1 版本。
#### 项目团队成员
项目发布后,先后有多位 Linux 爱好者参与项目,目前总计有 5 位铜豌豆开发者贡献了软件包,项目核心成员约 10 人。
非常欢迎更多的 Linux 爱好者加入,具体请访问: <https://www.atzlinux.com/devel.htm>
### 来一起添砖加瓦吧
与其抱怨中文 Linux 社区匮乏,不如身体力行:
* 目前发现的中文软件,总体很少,大家有发现合适的软件,欢迎提交软件包新增需求: <https://gitee.com/atzlinux/debian-cn/issues/I13NQT>
* 欢迎大家反馈在使用铜豌豆过程中遇到的问题: <https://gitee.com/atzlinux/debian-cn/issues>
* 其它我们做的不够好的地方,比如 UE/UI 方面还不够漂亮,文档还不够完善,大家都可以参与贡献
* 甚至,你还可以捐赠:<https://www.atzlinux.com/juanzeng.htm>
### 结语
那么,你有没有试过铜豌豆呢,你对这个项目感兴趣吗?希望大家来反馈和参与,把这颗铜豌豆打造得圆坨坨、响当当。
| 200 | OK | 此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。 |
12,572 | 如何使用 Docsify 和 GitHub Pages 创建一个文档网站 | https://opensource.com/article/20/7/docsify-github-pages | 2020-09-01T21:17:00 | [
"GitHub",
"文档"
] | https://linux.cn/article-12572-1.html |
>
> 使用 Docsify 创建文档网页并发布到 GitHub Pages 上。
>
>
>

文档是帮助用户使用开源项目一个重要部分,但它并不总是开发人员的首要任务,因为他们可能更关注的是使他们的应用程序更好,而不是帮助人们使用它。对开发者来说,这就是为什么让发布文档变得更容易是如此有价值的原因。在本教程中,我将向你展示一个这样做的方式:将 [Docsify](https://docsify.js.org) 文档生成器与 [GitHub Pages](https://pages.github.com/) 结合起来。
默认情况下,GitHub Pages 会提示用户使用 [Jekyll](https://docs.github.com/en/github/working-with-github-pages/about-github-pages-and-jekyll),这是一个支持 HTML、CSS 和其它网页技术的静态网站生成器。Jekyll 可以从以 Markdown 格式编码的文档文件中生成一个静态网站,GitHub 会自动识别它们的 `.md` 或 `.markdown` 扩展名。虽然这种设置很好,但我想尝试一下其他的东西。
幸运的是,GitHub Pages 支持 HTML 文件,这意味着你可以使用其他网站生成工具(比如 Docsify)在这个平台上创建一个网站。Docsify 是一个采用 MIT 许可证的开源项目,其具有可以让你在 GitHub Pages 上轻松创建一个有吸引力的、先进的文档网站的[功能](https://docsify.js.org/#/?id=features)。

### 开始使用 Docsify
安装 Docsify 有两种方法:
1. 通过 NPM 安装 Docsify 的命令行界面(CLI)。
2. 手动编写自己的 `index.html`。
Docsify 推荐使用 NPM 方式,但我将使用第二种方案。如果你想使用 NPM,请按照[快速入门指南](https://docsify.js.org/#/quickstart?id=quick-start)中的说明进行操作。
### 从 GitHub 下载示例内容
我已经在[该项目的 GitHub 页面](https://github.com/bryantson/OpensourceDotComDemos/tree/master/DocsifyDemo)上发布了这个例子的源代码。你可以单独下载这些文件,也可以通过以下方式[克隆这个存储库](https://github.com/bryantson/OpensourceDotComDemos)。
```
git clone https://github.com/bryantson/OpensourceDotComDemos
```
然后 `cd` 进入 `DocsifyDemo` 目录。
我将在下面为你介绍这些代码,它们克隆自我的示例存储库中,这样你就可以理解如何修改 Docsify。如果你愿意,你也可以从头开始创建一个新的 `index.html` 文件,就像 Docsify 文档中的的[示例](https://docsify.js.org/#/quickstart?id=manual-initialization)一样:
```
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width,initial-scale=1">
<meta charset="UTF-8">
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify/themes/vue.css">
</head>
<body>
<div id="app"></div>
<script>
window.$docsify = {
//...
}
</script>
<script src="//cdn.jsdelivr.net/npm/docsify/lib/docsify.min.js"></script>
</body>
</html>
```
### 探索 Docsify 如何工作
如果你克隆了我的 [GitHub 存储库](https://github.com/bryantson/OpensourceDotComDemos),并切换到 `DocsifyDemo` 目录下,你应该看到这样的文件结构:

| 文件/文件夹名称 | 内容 |
| --- | --- |
| `index.html` | 主要的 Docsify 初始化文件,也是最重要的文件 |
| `_sidebar.md` | 生成导航 |
| `README.md` | 你的文档根目录下的默认 Markdown 文件 |
| `images` | 包含了 `README.md` 中的示例 .jpg 图片 |
| 其它目录和文件 | 包含可导航的 Markdown 文件 |
`index.html` 是 Docsify 可以工作的唯一要求。打开该文件,你可以查看其内容:
```
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width,initial-scale=1">
<meta charset="UTF-8">
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify/themes/vue.css">
<title>Docsify Demo</title>
</head>
<body>
<div id="app"></div>
<script>
window.$docsify = {
el: "#app",
repo: 'https://github.com/bryantson/OpensourceDotComDemos/tree/master/DocsifyDemo',
loadSidebar: true,
}
</script>
<script src="//cdn.jsdelivr.net/npm/docsify/lib/docsify.min.js"></script>
</body>
</html>
```
这本质上只是一个普通的 HTML 文件,但看看这两行:
```
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify/themes/vue.css">
... 一些其它内容 ...
<script src="//cdn.jsdelivr.net/npm/docsify/lib/docsify.min.js"></script>
```
这些行使用内容交付网络(CDN)的 URL 来提供 CSS 和 JavaScript 脚本,以将网站转化为 Docsify 网站。只要你包含这些行,你就可以把你的普通 GitHub 页面变成 Docsify 页面。
`<body>` 标签后的第一行指定了要渲染的内容:
```
<div id="app"></div>
```
Docsify 使用[单页应用](https://en.wikipedia.org/wiki/Single-page_application)(SPA)的方式来渲染请求的页面,而不是刷新一个全新的页面。
最后,看看 `<script>` 块里面的行:
```
<script>
window.$docsify = {
el: "#app",
repo: 'https://github.com/bryantson/OpensourceDotComDemos/tree/master/DocsifyDemo',
loadSidebar: true,
}
</script>
```
在这个块中:
* `el` 属性基本上是说:“嘿,这就是我要找的 `id`,所以找到它并在那里呈现。”
* 改变 `repo` 值,以确定当用户点击右上角的 GitHub 图标时,会被重定向到哪个页面。 
* 将 `loadSideBar` 设置为 `true` 将使 Docsify 查找包含导航链接的 `_sidebar.md` 文件。
你可以在 Docsify 文档的[配置](https://docsify.js.org/#/configuration?id=configuration)部分找到所有选项。
接下来,看看 `_sidebar.md` 文件。因为你在 `index.html` 中设置了 `loadSidebar` 属性值为 `true`,所以 Docsify 会查找 `_sidebar.md` 文件,并根据其内容生成导航文件。示例存储库中的 `_sidebar.md` 内容是:
```
<!-- docs/_sidebar.md -->
* [HOME](./)
* [Tutorials](./tutorials/index)
* [Tomcat](./tutorials/tomcat/index)
* [Cloud](./tutorials/cloud/index)
* [Java](./tutorials/java/index)
* [About](./about/index)
* [Contact](./contact/index)
```
这会使用 Markdown 的链接格式来创建导航。请注意 “Tomcat”、“Cloud” 和 “Java” 等链接是缩进的;这意味着它们被渲染为父链接下的子链接。
像 `README.md` 和 `images` 这样的文件与存储库的结构有关,但所有其它 Markdown 文件都与你的 Docsify 网页有关。
根据你的需求,随意修改你下载的文件。下一步,你将把这些文件添加到你的 GitHub 存储库中,启用 GitHub Pages,并完成项目。
### 启用 GitHub 页面
创建一个示例的 GitHub 存储库,然后使用以下 GitHub 命令检出、提交和推送你的代码:
```
$ git clone 你的 GitHub 存储库位置
$ cd 你的 GitHub 存储库位置
$ git add .
$ git commit -m "My first Docsify!"
$ git push
```
设置你的 GitHub Pages 页面。在你的新 GitHub 存储库中,点击 “Settings”:

向下滚动直到看到 “GitHub Pages”:

查找 “Source” 部分:

点击 “Source” 下的下拉菜单。通常,你会将其设置为 “master branch”,但如果你愿意,也可以使用其他分支:

就是这样!你现在应该有一个链接到你的 GitHub Pages 的页面了。点击该链接将带你到那里,然后用 Docsify 渲染:

它应该像这样:

### 结论
通过编辑一个 HTML 文件和一些 Markdown 文本,你可以用 Docsify 创建一个外观精美的文档网站。你觉得怎么样?请留言,也可以分享其他可以和 GitHub Pages 一起使用的开源工具。
---
via: <https://opensource.com/article/20/7/docsify-github-pages>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Documentation is an essential part of making any open source project useful to users. But it's not always developers' top priority, as they may be more focused on making their application better than on helping people use it. This is why making it easier to publish documentation is so valuable to developers. In this tutorial, I'll show you one option for doing so: combining the [Docsify](https://docsify.js.org) documentation generator with [GitHub Pages](https://pages.github.com/).
If you prefer to learn by video, you can access the YouTube version of this how-to:
By default, GitHub Pages prompts users to use [Jekyll](https://docs.github.com/en/github/working-with-github-pages/about-github-pages-and-jekyll), a static site generator that supports HTML, CSS, and other web technologies. Jekyll generates a static website from documentation files encoded in Markdown format, which GitHub automatically recognizes due to their .md or .markdown extension. While this setup is nice, I wanted to try something else.
Fortunately, GitHub Pages' HTML file support means you can use other site-generation tools, including Docsify, to create a website on the platform. Docsify is an MIT-Licensed open source project with [features](https://docsify.js.org/#/?id=features) that make it easy to create an attractive advanced documentation site on GitHub Pages.
(Bryant Son, CC BY-SA 4.0)
## Get started with Docsify
There are two ways to install Docsify:
- Docsify's command-line interface (CLI) through NPM
- Manually by writing your own
`index.html`
Docsify recommends the NPM approach, but I will use the second option. If you want to use NPM, follow the instructions in the [quick-start guide](https://docsify.js.org/#/quickstart?id=quick-start).
## Download the sample content from GitHub
I've published this example's source code on the [project's GitHub page](https://github.com/bryantson/OpensourceDotComDemos/tree/master/DocsifyDemo). You can download the files individually or [clone the repo](https://github.com/bryantson/OpensourceDotComDemos) with:
`git clone https://github.com/bryantson/OpensourceDotComDemos`
Then `cd`
into the DocsifyDemo directory.
I will walk you through the cloned code from my sample repo below, so you can understand how to modify Docsify. If you prefer, you can start from scratch by creating a new `index.html`
file, like in the [example](https://docsify.js.org/#/quickstart?id=manual-initialization) in Docsify's docs:
```
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width,initial-scale=1">
<meta charset="UTF-8">
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify/themes/vue.css">
</head>
<body>
<div id="app"></div>
<script>
window.$docsify = {
//...
}
</script>
<script src="//cdn.jsdelivr.net/npm/docsify/lib/docsify.min.js"></script>
</body>
</html>
```
## Explore how Docsify works
If you cloned my [GitHub repo](https://github.com/bryantson/OpensourceDotComDemos) and changed into the DocsifyDemo directory, you should see a file structure like this:
(Bryant Son, CC BY-SA 4.0)
File/Folder Name | What It Is |
---|---|
index.html | The main Docsify initiation file (and the most important file) |
_sidebar.md | Renders the navigation |
README.md | The default Markdown file at the root of your documentation |
images | Contains a sample .jpg image from the README.md |
Other directories and files | Contain navigatable Markdown files |
`Index.html`
is the only thing required for Docsify to work. Open the file, so you can explore the contents:
```
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width,initial-scale=1">
<meta charset="UTF-8">
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify/themes/vue.css">
<title>Docsify Demo</title>
</head>
<body>
<div id="app"></div>
<script>
window.$docsify = {
el: "#app",
repo: 'https://github.com/bryantson/OpensourceDotComDemos/tree/master/DocsifyDemo',
loadSidebar: true,
}
</script>
<script src="//cdn.jsdelivr.net/npm/docsify/lib/docsify.min.js"></script>
</body>
</html>
```
This is essentially just a plain HTML file, but take a look at these two lines:
```
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify/themes/vue.css">
... SOME OTHER STUFFS ...
<script src="//cdn.jsdelivr.net/npm/docsify/lib/docsify.min.js"></script>
```
These lines use content delivery network (CDN) URLs to serve the CSS and JavaScript scripts to transform the site into a Docsify site. As long as you include these lines, you can turn your regular GitHub page into a Docsify page.
The first line after the `body`
tag specifies what to render:
`<div id="app"></div>`
Docsify is using the [single page application](https://en.wikipedia.org/wiki/Single-page_application) (SPA) approach to render a requested page instead of refreshing an entirely new page.
Last, look at the lines inside the `script`
block:
```
<script>
window.$docsify = {
el: "#app",
repo: 'https://github.com/bryantson/OpensourceDotComDemos/tree/master/DocsifyDemo',
loadSidebar: true,
}
</script>
```
In this block:
- The
`el`
property basically says, "Hey, this is the`id`
I am looking for, so locate the`id`
and render it there." - Changing the
`repo`
value identifies which page users will be redirected to when they click the GitHub icon in the top-right corner.
(Bryant Son,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - Setting
`loadSideBar`
to`true`
will make Docsify look for the`_sidebar.md`
file that contains your navigation links.
You can find all the options in the [Configuration](https://docsify.js.org/#/configuration?id=configuration) section of Docsify's docs.
Next, look at the `_sidebar.md`
file. Because you set the `loadSidebar`
property value to `true`
in `index.html`
, Docsify will look for the `_sidebar.md`
file and generate the navigation file from its contents. The `_sidebar.md`
contents in the sample repo are:
```
<!-- docs/_sidebar.md -->
* [HOME](./)
* [Tutorials](./tutorials/index)
* [Tomcat](./tutorials/tomcat/index)
* [Cloud](./tutorials/cloud/index)
* [Java](./tutorials/java/index)
* [About](./about/index)
* [Contact](./contact/index)
```
This uses Markdown's link format to create the navigation. Note that the Tomcat, Cloud, and Java links are indented; this causes them to be rendered as sublinks under the parent link.
Files like `README.md`
and `images`
pertain to the repository's structure, but all the other Markdown files are related to your Docsify webpage.
Modify the files you downloaded however you want, based on your needs. In the next step, you will add these files to your GitHub repo, enable GitHub Pages, and finish the project.
## Enable GitHub Pages
Create a sample GitHub repo, then use the following GitHub commands to check, commit, and push your code:
```
$ git clone LOCATION_TO_YOUR_GITHUB_REPO
$ cd LOCATION_TO_YOUR_GITHUB_REPO
$ git add .
$ git commit -m "My first Docsify!"
$ git push
```
Set up your GitHub Pages page. From inside your new GitHub repo, click **Settings**:
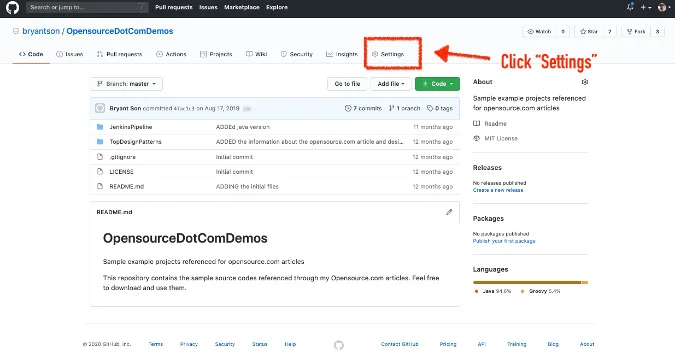
(Bryant Son, CC BY-SA 4.0)
Scroll down until you see **GitHub Pages**:
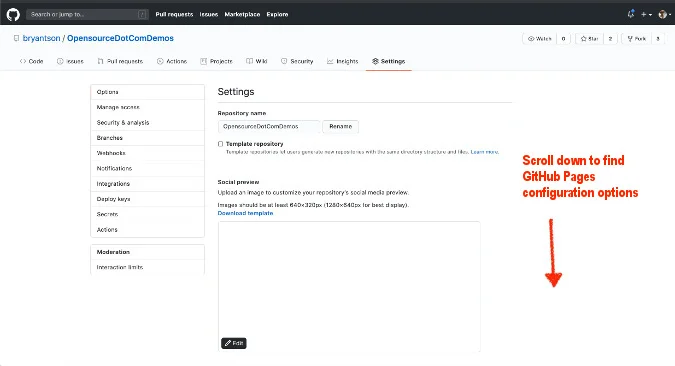
(Bryant Son, CC BY-SA 4.0)
Look for the **Source** section:
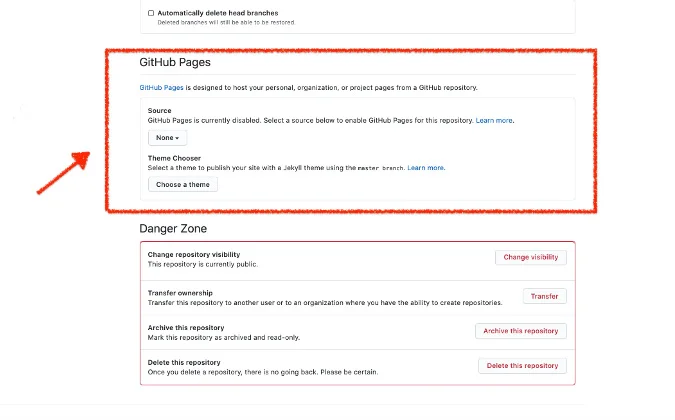
(Bryant Son, CC BY-SA 4.0)
Click the drop-down menu under **Source**. Usually, you will set this to the **master branch**, but you can use another branch, if you'd like:
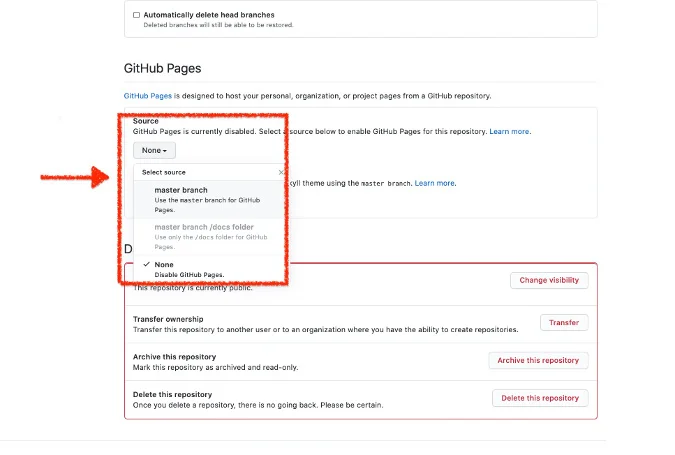
(Bryant Son, CC BY-SA 4.0)
That's it! You should now have a link to your GitHub Pages page. Clicking the link will take you there, and it should render with Docsify:
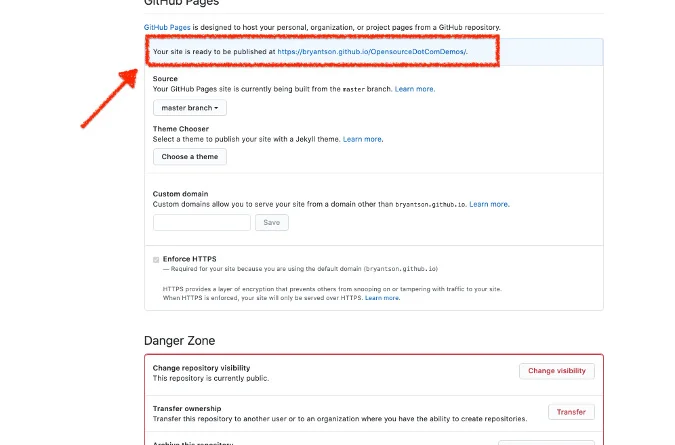
(Bryant Son, CC BY-SA 4.0)
And it should look something like this:
(Bryant Son, CC BY-SA 4.0)
## Conclusion
By editing a single HTML file and some Markdown text, you can create an awesome-looking documentation site with Docsify. What do you think? Please leave a comment and also share any other open source tools that can be used with GitHub Pages.
## 4 Comments |
12,573 | 如何使用 printf 来格式化输出 | https://opensource.com/article/20/8/printf | 2020-09-02T00:11:00 | [
"printf",
"输出"
] | /article-12573-1.html |
>
> 来了解一下 printf ,一个神秘的、灵活的和功能丰富的函数,可以替换 echo、print 和 cout。
>
>
>

当我开始学习 Unix 时,我很早就接触到了 `echo` 命令。同样,我最初的 [Python](https://opensource.com/resources/python) 课程也涉及到了 `print` 函数。再想起学习 C++ 和 [Java](https://opensource.com/resources/python) 时学到 `cout` 和 `systemout`。似乎每种语言都骄傲地宣称拥有一种方便的单行输出方法,并生怕这种方式要过时一样宣传它。
但是当我翻开中级教程的第一页后,我遇到了 `printf`,一个晦涩难懂的、神秘莫测的,又出奇灵活的函数。本文一反向初学者隐藏 `printf` 这个令人费解的传统,旨在介绍这个不起眼的 `printf` 函数,并解释如何在几乎所有语言中使用它。
### printf 简史
术语 `printf` 代表“<ruby> 格式化打印 <rt> print formatted </rt></ruby>”,它可能最早出现 [Algol 68](https://opensource.com/article/20/6/algol68) 编程语言中。自从它被纳入到 C 语言后,`printf` 已经在 C++、Java、Bash、PHP 中一次次重新实现,并且很可能在你最喜欢的 “后 C” 语言中再次出现。
显然,它很受欢迎,但很多人认为它的语法很复杂,尤其是与 `echo` 或 `print` 或 `cout` 等替代的函数相比尤为明显。例如,这是在 Bash 中的一个简单的 `echo` 语句:
```
$ echo hello
hello
$
```
这是在 Bash 中使用 `printf` 得到同样结果:
```
$ printf "%s\n" hello
hello
$
```
但是所增加的复杂性反而让你拥有很多功能,这是为什么 `printf` 值得学习的确切原因。
### printf 输出
在 `printf` 背后的基本思想是:它能够基于与内容*分离的*样式信息来格式化输出。例如,这里是 `printf` 认可的视作特殊字符的特定序列集合。你喜欢的语言可能会有或多或少的序列,但是通常包含:
* `\n`: 新行
* `\r`: 回车换行
* `\t`: 水平制表符
* `\NNN`: 一个包含一个到三个数字,使用八进制值表示的特殊字节
例如:
```
$ printf "\t\123\105\124\110\n"
SETH
$
```
在这个 Bash 示例中, `printf` 渲染一个制表符后,然后是分配给四个八进制值字符串的 ASCII 字符,并以一个生成一个新行(`\n`)的控制序列结束。
如果同样使用 `echo` 来输出会产生更多的字符:
```
$ echo "\t\123\105\124\110\n"
\t\123\105\124\110\n
$
```
使用 Python 的 `print` 函数来完成同样的任务,你会发现 Python 的 `print` 命令比你想象的要强大:
```
>>> print("\t\123\n")
S
>>>
```
显然,Python 的 `print` 包含传统的 `printf` 特性以及简单的 `echo` 或 `cout` 的特性。
不过,这些示例包括的只是文字字符,尽管在某些情况下它们也很有用,但它们可能是 `printf` 最不重要的部分。`printf` 的真正的威力在于格式化说明。
### 使用 printf 格式化输出
格式化说明符是以一个百分号(`%`)开头的字符。
常见的格式化说明符包括:
* `%s`: 字符串
* `%d`: 数字
* `%f`: 浮点数字
* `%o`: 一个八进制的数字
这些格式化说明符是 `printf` 语句的占位符,你可以使用一个在其它地方提供的值来替换你的 `printf` 语句中的占位符。这些值在哪里提供取决于你使用的语言和它的语法,这里有一个简单的 Java 例子:
```
string var="hello\n";
system.out.printf("%s", var);
```
把这个代码包裹在适当的样板文件中,在执行后,将呈现:
```
$ ./example
hello
$
```
但是,当一个变量的内容更改时,有意思的地方就来了。假设你想基于不断增加的数字来更新输出:
```
#include <stdio.h>
int main() {
int var=0;
while ( var < 100) {
var++;
printf("Processing is %d% finished.\n", var);
}
return 0;
}
```
编译并运行:
```
Processing is 1% finished.
[...]
Processing is 100% finished.
```
注意,在代码中的两个 `%` 将被解析为一个打印出来的 `%` 符号。
### 使用 printf 限制小数位数
数字也可以是很复杂,`printf` 提供很多格式化选项。你可以对浮点数使用 `%f` 限制打印出多少个小数位。通过把一个点(`.`)和一个限制的数放置在百分符号和 `f` 之间, 你可以告诉 `printf` 打印多少位小数。这是一个简单的用 Bash 写的简练示例:
```
$ printf "%.2f\n" 3.141519
3.14
$
```
类似的语法也适用于其它的语言。这里是一个 C 语言的示例:
```
#include <math.h>
#include <stdio.h>
int main() {
fprintf(stdout, "%.2f\n", 4 * atan(1.0));
return 0;
}
```
对于三位小数,使用 `.3f` ,依次类推。
### 使用 printf 来在数字上添加逗号
因为位数大的数字很难解读,所以通常使用一个逗号来断开大的数字。你可以在百分号和 `d` 之间放置一个撇号(`'`),让 `printf` 根据需要添加逗号:
```
$ printf "%'d\n" 1024
1,024
$ printf "%'d\n" 1024601
1,024,601
$
```
### 使用 printf 来添加前缀零
`printf` 的另一个常用的用法是对文件名称中的数字强制实行一种特定的格式。例如,如果你在一台计算机上有 10 个按顺序排列的文件,计算机可能会把 `10.jpg` 排在 `1.jpg` 之前,这可能不是你的本意。当你以编程的方式写一个到文件时,你可以使用 `printf` 来用前缀为 0 的字符形成文件名称。这是一个简单的用 Bash 写的简练示例:
```
$ printf "%03d.jpg\n" {1..10}
001.jpg
002.jpg
[...]
010.jpg
```
注意:每个数字最多使用 3 位数字。
### 使用 printf
正如这些 `printf` 示例所显示,包括控制字符,尤其是 `\n` ,可能会冗长,并且语法相对复杂。这就是为什么开发像 `echo` 和 `cout` 之类的快捷方式的原因。不过,如果你时不时地使用 `printf` ,你就会习惯于这种语法,并且它也会变成你的习惯。我不认为 `printf` 有任何理由成为你在日常活动中打印时的*首选*,但是它是一个很好的工具,当你需要它时,它不会拖累你。
花一些时间学习你所选择语言中的 `printf`,并且当你需要时就使用它。它是一个强有力的工具,你不会后悔随时可用的工具。
---
via: <https://opensource.com/article/20/8/printf>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
12,575 | scp 用户的 rsync 迁移指南 | https://fedoramagazine.org/scp-users-migration-guide-to-rsync/ | 2020-09-03T10:30:08 | [
"rsync",
"scp"
] | https://linux.cn/article-12575-1.html | 
在 [SSH 8.0 预发布公告](https://lists.mindrot.org/pipermail/openssh-unix-dev/2019-March/037672.html)中,OpenSSH 项目表示,他们认为 scp 协议已经过时,不灵活,而且不容易修复,然后他们继而推荐使用 `sftp` 或 `rsync` 来进行文件传输。
然而,很多用户都是从小用着 `scp` 命令长大的,所以对 `rsync` 并不熟悉。此外,`rsync` 可以做的事情也远不止复制文件,这可能会给菜鸟们留下复杂和难以掌握的印象。尤其是,`scp` 命令的标志大体上可以直接对应到 `cp` 命令的标志,而 `rsync` 命令的标志却和它大相径庭。
本文将为熟悉 `scp` 的人提供一个介绍和过渡的指南。让我们跳进最常见的场景:复制文件和复制目录。
### 复制文件
对于复制单个文件而言,`scp` 和 `rsync` 命令实际上是等价的。比方说,你需要把 `foo.txt` 传到你在名为 `server` 的服务器上的主目录下:
```
$ scp foo.txt me@server:/home/me/
```
相应的 `rsync` 命令只需要输入 `rsync` 取代 `scp`:
```
$ rsync foo.txt me@server:/home/me/
```
### 复制目录
对于复制目录,就有了很大的分歧,这也解释了为什么 `rsync` 会被认为比 `scp` 更复杂。如果你想把 `bar` 目录复制到 `server` 服务器上,除了指定 `ssh` 信息外,相应的 `scp` 命令和 `cp` 命令一模一样。
```
$ scp -r bar/ me@server:/home/me/
```
对于 `rsync`,考虑的因素比较多,因为它是一个比较强大的工具。首先,我们来看一下最简单的形式:
```
$ rsync -r bar/ me@server:/home/me/
```
看起来很简单吧?对于只包含目录和普通文件的简单情况,这就可以了。然而,`rsync` 更在意发送与主机系统中一模一样的文件。让我们来创建一个稍微复杂一些,但并不罕见的例子:
```
# 创建多级目录结构
$ mkdir -p bar/baz
# 在其根目录下创建文件
$ touch bar/foo.txt
# 现在创建一个符号链接指回到该文件
$ cd bar/baz
$ ln -s ../foo.txt link.txt
# 返回原位置
$ cd -
```
现在我们有了一个如下的目录树:
```
bar
├── baz
│ └── link.txt -> ../foo.txt
└── foo.txt
1 directory, 2 files
```
如果我们尝试上面的命令来复制 `bar`,我们会注意到非常不同的(并令人惊讶的)结果。首先,我们来试试 `scp`:
```
$ scp -r bar/ me@server:/home/me/
```
如果你 `ssh` 进入你的服务器,看看 `bar` 的目录树,你会发现它和你的主机系统有一个重要而微妙的区别:
```
bar
├── baz
│ └── link.txt
└── foo.txt
1 directory, 2 files
```
请注意,`link.txt` 不再是一个符号链接,它现在是一个 `foo.txt` 的完整副本。如果你习惯于使用 `cp`,这可能会是令人惊讶的行为。如果你尝试使用 `cp -r` 复制 `bar` 目录,你会得到一个新的目录,里面的符号链接和 `bar` 的一样。现在如果我们尝试使用之前的 `rsync` 命令,我们会得到一个警告:
```
$ rsync -r bar/ me@server:/home/me/
skipping non-regular file "bar/baz/link.txt"
```
`rsync` 警告我们它发现了一个非常规文件,并正在跳过它。因为你没有告诉它可以复制符号链接,所以它忽略了它们。`rsync` 在手册中有一节“符号链接”,解释了所有可能的行为选项。在我们的例子中,我们需要添加 `-links` 标志:
```
$ rsync -r --links bar/ me@server:/home/me/
```
在远程服务器上,我们看到这个符号链接是作为一个符号链接复制过来的。请注意,这与 `scp` 复制符号链接的方式不同。
```
bar/
├── baz
│ └── link.txt -> ../foo.txt
└── foo.txt
1 directory, 2 files
```
为了省去一些打字工作,并利用更多的文件保护选项,在复制目录时可以使用归档标志 `-archive`(简称 `-a`)。该归档标志将做大多数人所期望的事情,因为它可以实现递归复制、符号链接复制和许多其他选项。
```
$ rsync -a bar/ me@server:/home/me/
```
如果你感兴趣的话,`rsync` 手册页有关于存档标志的深入解释。
### 注意事项
不过,使用 `rsync` 有一个注意事项。使用 `scp` 比使用 `rsync` 更容易指定一个非标准的 ssh 端口。例如,如果 `server` 使用 8022 端口的 SSH 连接,那么这些命令就会像这样:
```
$ scp -P 8022 foo.txt me@server:/home/me/
```
而在使用 `rsync` 时,你必须指定要使用的“远程 shell”命令,默认是 `ssh`。你可以使用 `-e` 标志来指定。
```
$ rsync -e 'ssh -p 8022' foo.txt me@server:/home/me/
```
`rsync` 会使用你的 `ssh` 配置;但是,如果你经常连接到这个服务器,你可以在你的 `~/.ssh/config` 文件中添加以下代码。这样你就不需要再为 `rsync` 或 `ssh` 命令指定端口了!
```
Host server
Port 8022
```
另外,如果你连接的每一台服务器都在同一个非标准端口上运行,你还可以配置 `RSYNC_RSH` 环境变量。
### 为什么你还是应该切换到 rsync?
现在我们已经介绍了从 `scp` 切换到 `rsync` 的日常使用案例和注意事项,让我们花一些时间来探讨一下为什么你可能想要使用 `rsync` 的优点。很多人在很久以前就已经开始使用 `rsync` 了,就是因为这些优点。
#### 即时压缩
如果你和服务器之间的网络连接速度较慢或有限,`rsync` 可以花费更多的 CPU 处理能力来节省网络带宽。它通过在发送数据之前对数据进行即时压缩来实现。压缩可以用 `-z` 标志来启用。
#### 差量传输
`rsync` 也只在目标文件与源文件不同的情况下复制文件。这可以在目录中递归地工作。例如,如果你拿我们上面的最后一个 `bar` 的例子,并多次重新运行那个 `rsync` 命令,那么在最初的传输之后就不会有任何传输。如果你知道你会重复使用这些命令,例如备份到 U 盘,那么使用 `rsync` 即使是进行本地复制也是值得的,因为这个功能可以节省处理大型数据集的大量的时间。
#### 同步
顾名思义,`rsync` 可以做的不仅仅是复制数据。到目前为止,我们只演示了如何使用 `rsync` 复制文件。如果你想让 `rsync` 把目标目录变成源目录的样子,你可以在 `rsync` 中添加删除标志 `-delete`。这个删除标志使得 `rsync` 将从源目录中复制不存在于目标目录中的文件,然后它将删除目标目录中不存在于源目录中的文件。结果就是目标目录和源目录完全一样。相比之下,`scp` 只会在目标目录下添加文件。
### 结论
对于简单的使用情况,`rsync` 并不比老牌的 `scp` 工具复杂多少。唯一显著的区别是在递归复制目录时使用 `-a` 而不是 `-r`。然而,正如我们看到的,`rsync` 的 `-a` 标志比 `scp` 的 `-r` 标志更像 `cp` 的 `-r` 标志。
希望通过这些新命令,你可以加快你的文件传输工作流程。
---
via: <https://fedoramagazine.org/scp-users-migration-guide-to-rsync/>
作者:[chasinglogic](https://fedoramagazine.org/author/chasinglogic/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As part of the[ 8.0 pre-release announcement,](https://lists.mindrot.org/pipermail/openssh-unix-dev/2019-March/037672.html) the OpenSSH project stated that they consider the scp protocol outdated, inflexible, and not readily fixed. They then go on to recommend the use of sftp or rsync for file transfer instead.
Many users grew up on the *scp *command, however, and so are not familiar with rsync. Additionally, rsync can do much more than just copy files, which can give a beginner the impression that it’s complicated and opaque. Especially when broadly the scp flags map directly to the cp flags while the rsync flags do not.
This article will provide an introduction and transition guide for anyone familiar with scp. Let’s jump into the most common scenarios: Copying Files and Copying Directories.
## Copying files
For copying a single file, the scp and rsync commands are effectively equivalent. Let’s say you need to ship *foo.txt* to your home directory on a server named *server.*
$ scp foo.txt me@server:/home/me/
The equivalent rsync command requires only that you type rsync instead of scp:
$ rsync foo.txt me@server:/home/me/
## Copying directories
For copying directories, things do diverge quite a bit and probably explains why rsync is seen as more complex than scp. If you want to copy the directory *bar *to *server* the corresponding scp command looks exactly like the cp command except for specifying ssh information:
$ scp -r bar/ me@server:/home/me/
With rsync, there are more considerations, as it’s a more powerful tool. First, let’s look at the simplest form:
$ rsync -r bar/ me@server:/home/me/
Looks simple right? For the simple case of a directory that contains only directories and regular files, this will work. However, rsync cares a lot about sending files exactly as they are on the host system. Let’s create a slightly more complex, but not uncommon, example.
# Create a multi-level directory structure $ mkdir -p bar/baz # Create a file at the root directory $ touch bar/foo.txt # Now create a symlink which points back up to this file $ cd bar/baz $ ln -s ../foo.txt link.txt # Return to our original location $ cd -
We now have a directory tree that looks like the following:
bar ├── baz │ └── link.txt -> ../foo.txt └── foo.txt 1 directory, 2 files
If we try the commands from above to copy bar, we’ll notice very different (and surprising) results. First, let’s give scp a go:
$ scp -r bar/ me@server:/home/me/
If you ssh into your server and look at the directory tree of bar you’ll notice an important and subtle difference from your host system:
bar ├── baz │ └── link.txt └── foo.txt 1 directory, 2 files
Note that *link.txt* is no longer a symlink. It is now a full-blown copy of *foo.txt*. This might be surprising behavior if you’re used to *cp*. If you did try to copy the *bar* directory using *cp -r*, you would get a new directory with the exact symlinks that *bar* had. Now if we try the same rsync command from before we’ll get a warning:
$ rsync -r bar/ me@server:/home/me/ skipping non-regular file "bar/baz/link.txt"
Rsync has warned us that it found a non-regular file and is skipping it. Because you didn’t tell it to copy symlinks, it’s ignoring them. Rsync has an extensive manual section titled “SYMBOLIC LINKS” that explains all of the possible behavior options available to you. For our example, we need to add the –links flag.
$ rsync -r --links bar/ me@server:/home/me/
On the remote server we see that the symlink was copied over as a symlink. Note that this is different from how scp copied the symlink.
bar/ ├── baz │ └── link.txt -> ../foo.txt └── foo.txt 1 directory, 2 files
To save some typing and take advantage of more file-preserving options, use the –archive (-a for short) flag whenever copying a directory. The archive flag will do what most people expect as it enables recursive copy, symlink copy, and many other options.
$ rsync -a bar/ me@server:/home/me/
The rsync man page has in-depth explanations of what the archive flag enables if you’re curious.
## Caveats
There is one caveat, however, to using rsync. It’s much easier to specify a non-standard ssh port with scp than with rsync. If *server *was using port 8022 SSH connections, for instance, then those commands would look like this:
$ scp -P 8022 foo.txt me@server:/home/me/
With rsync, you have to specify the “remote shell” command to use. This defaults to *ssh*. You do so using the* *-e flag.
$ rsync -e 'ssh -p 8022' foo.txt me@server:/home/me/
Rsync does use your ssh config; however, so if you are connecting to this server frequently, you can add the following snippet to your *~/.ssh/config* file. Then you no longer need to specify the port for the rsync or ssh commands!
Host server Port 8022
Alternatively, if every server you connect to runs on the same non-standard port, you can configure the *RSYNC_RSH* environment variable.
## Why else should you switch to rsync?
Now that we’ve covered the everyday use cases and caveats for switching from scp to rsync, let’s take some time to explore why you probably want to use rsync on its own merits. Many people have made the switch to rsync long before now on these merits alone.
### In-flight compression
If you have a slow or otherwise limited network connection between you and your server, rsync can spend more CPU cycles to save network bandwidth. It does this by compressing data before sending it. Compression can be enabled with the -z flag.
### Delta transfers
Rsync also only copies a file if the target file is different than the source file. This works recursively through directories. For instance, if you took our final bar example above and re-ran that rsync command multiple times, it would do no work after the initial transfer. Using rsync even for local copies is worth it if you know you will repeat them, such as backing up to a USB drive, for this feature alone as it can save a lot of time with large data sets.
### Syncing
As the name implies, rsync can do more than just copy data. So far, we’ve only demonstrated how to copy files with rsync. If you instead want rsync to make the target directory look like your source directory, you can add the –delete flag to rsync. The delete flag makes it so rsync will copy files from the source directory which don’t exist on the target directory. Then it will remove files on the target directory which do not exist in the source directory. The result is the target directory is identical to the source directory. By contrast, scp will only ever add files to the target directory.
## Conclusion
For simple use cases, rsync is not significantly more complicated than the venerable scp tool. The only significant difference being the use of -a instead of -r for recursive copying of directories. However, as we saw rsync’s -a flag behaves more like cp’s -r flag than scp’s -r flag does.
Hopefully, with these new commands, you can speed up your file transfer workflow!
## Henrique
This post is missing the difference between dir/ and dir when copying directories, and the actual examples are wrong, as using dir/ will only copy the directory contents, but not the directory itself.
## Mohammed El-Afifi
Indeed.
## Daniel
The section on delta transfers misses that you need an extra flag to enable it on local transfers. I think but don’t remember for sure that it’s –no-whole-file.
## chasinglogic
Hey Daniel, rsync will not copy files that already exist even locally without the –no-whole-file option.
I use –archive in my backup scripts to personal drives but not the –no-whole-file option and observe this behavior.
–whole-file disables the delta transfer algorithim and –no-whole-file overwrites previous uses of –whole-file on the command line to turn it back on. –whole-file is not the default but can be implied by other options you may use that require you to pass –no-whole file.
## Sébastien Wilmet
I think it would be possible to implement the scp interface (or a subset of it) on top of rsync. So without using the scp protocol, but just having a wrapper around the rsync command.
## Sebastiaan Franken
You can do that with a shell alias as far as I know. Something like “alias scp=’rsync -a’ ” in your .bashrc (or .zshrc, or whatever). Once you source the file (source ~/.bashrc, or login again) scp will not call the actual scp binary but rsync with the -a option.
## X
Modifying sftp to act like scp would fix the issue, and be a welcome update. Currently, a batch file has to be written to get sftp to work without interaction. Rebasing scp on sftp is probably something that should have been done years ago.
## Carrete
I use this:
#!/usr/bin/env bash
rsync --archive --partial --progress --rsh=ssh "$@"
This works for local and remote transfers.
## Vernon Van Steenkist
Not sure why you were using scp if sftp is available. Simply put the URL
sftp://me@server:/home/me/
in your file manager directory window and you get a VFS where you can easily copy, paste, edit, play, etc remote files with your file manager.
For even more flexibility, use sshfs
mkdir home
sshfs me@server:/home/me home
and now you have a mounted remote file system at sub-directory me through sftp that any program can interact with directly.
From a terminal, mc (Midnight Commander) supports sftp virtual file systems as well.
I agree that using rsync is great for syncing photo directories etc. But for more simple copy and paste operations, I find sftp easier and more flexible – especially paired with a graphical file manager or sshfs.
Note that if you move files and directories around, you may want to add –delete to your rsync command. Otherwise, your destination can become filled with cruft.
## jtad
good advice. but sshfs is much slower than nfs due to encryption
## Charlie
Can I ask a stupid question?
Why can’t ssh formally do this:
C:\bin>pscp -h
PuTTY Secure Copy client
Release 0.72
..,
-sftp force use of SFTP protocol
-scp force use of SCP protocol
Why are we having this conversation again?
## Jim
This may well work, a lot of us just don’t have Windows.
## Shy
https://gist.github.com/xiaowl/3075638
Pure python implementation of
, using SFTP protocol. Depends on paramiko.
## X
It should be mentioned rsync needs to be installed on the source and destination systems. Some systems don’t install rsync by default, and it will throw an odd message when it fails to start a remote rsync process. This trips me up on occasion. 🙂
## Rob N
It is only required on the system from which the rsync command is run.
## Moritz
rsync doesn’t need to be installed on the opposite system, an ssh with a proper scpserver implementation suffices, and that is the case on most desktop and server openssh based installations (but often not on embedded devices, such as STBs, PVRs).
## Robin A. Meade
The rsync man page ( https://download.samba.org/pub/rsync/rsync.1 ) says
If I attempt to rsync to a server without rsync installed, I receive the following error message:
bash: rsync: command not found
## sitaram
I am pretty sure this command:
does NOT produce the output you showed subsequently; i.e., the “bar” directory itself being copied to the remote.
Makes me wonder, did you even try the examples you showed.
## Bruno Haible
rsync does not do encryption. Therefore anyone who uses rsync is vulnerable to man-in-the-middle attacks. Thus the only place where rsync, on its own, can be securely used is a small LAN.
Other than that, rsync can be combined with ssh or a VPN, to make it secure.
So, anyone who recommends plain rsync as a replacement of scp has not been thinking about security.
## Rob N
By default rsync uses ssh if you are using the scp syntax “user@host:”
## Bruno
By saying scp is “outdated, inflexible, and not readily fixed”, does that mean it is insecure in any way? Besides other advantages of rsync, should I stop using scp for security reasons?
In scripts I’ve been using rsync as it is indeed more flexible, but on interactive shell for simple operations I often use scp because it is analog to cp.
## Christopher Cox
Another ssh option, if you have reasonably contemporary machinery and reasonably new ssh is “-c [email protected]” as this will leverage the AES-NI instructions on the CPU. The results are quite staggering.
## Frank
how about [email protected]?
## Eduard Lucena
Also, I would comment how sensitive is rsync to directions. It’s no the same to do
rsync foo server:/bar
than
rsync foo/ server:/Bar
## Alberto Patino
Nice article! I did not know that scp is outdated. I have used rsync occasionally, indeed, it is a great tool. I know sometimes it is harder to get acquainted to rsync, but after read pre release notes I think I’ll be happy to use rsync instead of scp.
Honestly, I’ve used rsync for bulk data transfers and scp just to copy one or few files. It was a matter of convenience, so I’ll say goodbye to scp.
## Marcelo Mafra
Updated my system yesterday and rsync got update from 3.1.3 to 3.2.2.
It is receiving updates after 2 two years, maybe we can ask for the caveat of ssh to be addressed somehow.
Maybe an alias:
rsync -w 8022 foo.txt me@server:/home/me/
–ssh-custom-port, –ssh-port, –ssh, -w
This option is an alias for -e ‘ssh -p ‘.
rsync -w 2234 [SOURCE] [user@]host:[DEST]
There is a version 3.2.3 to be released.
https://download.samba.org/pub/rsync/NEWS
## Mark
On the mention of in flight compression. SCP has the option “-C” which does the same thing, so compression to minimise network traffic is not a valid reason to switch to rsync as scp provides the same facility.
As already mentioned rsync traffic is not encrypted so should never be used anywhere except on an internal physically cabled local network.
A benefit of SCP is that SCP uses ssh keys, so can be used for hands-off (no password prompt) secure copying of individual files.
rsync certainly has it’s uses if you need to keep entire directories in sync in a local environment between two machines, so thanks for this post.
## Nehemiah I. Dacres
How are we going to work with remote systems where local shell access is not available? Web Hosting providers don’t give shell access so we can’t rsync and sftp isn’t recursive.
## Theodore Cowan
I’m skeptical of this post. Calling SCP outmoded over a resolved CVE? scp has had lasting power for a reason.
## Daniel Martin
If the SCP
protocolis outdated, surely that simply means that the implementation of thecommandshould be changed to use the sftp protocol in its place.I don’t see why changing protocols should stop us from using a nice simple and intuitive interface,
## Cody
As a programmer I couldn’t disagree more.
You’re asking for trouble. Not only will that cause compatibility problems it will also cause major confusion. ‘I upgraded and now it’s doing something else!’ No. Bad, bad, bad idea. Very bad idea.
You don’t change the implementation of something like that. Also sftp is different from scp so why would you change the scp command to implement the sftp? As I recall they even use different ports so firewalls would have to be changed too.
There are other reasons that your suggestion is terrible. I don’t mean to be unkind about it but it really is a bad idea for so many reasons and some of the most important ones I just listed.
## Daniel Martin
So just throw it away entirely, and force people to use something less intuitive? Can’t you see that is even worse?
Breaking changes happen in software, changing the underlying protocol of the tool would be such a breaking change. You could do everything in your power to inform sysadmins of the change so that they can adapt to it. Possibly you would only upgrade to the new version in a new version of a distro such as Fedora.
## Ralph Grothe
One thing that I didn’t like so much about sftp, if my memory serves me correctly, was that in older versions (e.g. say on RHEL6 hosts) it lacked the -i option, where to use key based authentication you had to type something like
e.g.
scp -o identityfile=~/.ssh/my_rsa_id …
Also the usage of a batch file
(ok, using -b – you could pipe into sftp or read from a herestring some batch commands)
was a bit awkward in scripting.
As for rsync, I would like to know if rsync would honour any ssh_config option of the ssh client as documented in the ssh_config manpage that you would feed by
e.g. rsync -e ‘ssh -o opt1 -o opt2 … -o optN’ …
## SeeM
Thanks. I use -e for tunneling also:
rsync -[various_options] -e “ssh -p 1234” /dir/ user@localhost:/dir/
## Cody
There’s another caveat and one that you really should have covered. Let me rephrase that: you
reallyshould have covered it. Here – I’ll help by including what’s in the manpage:this directory" as opposed to "copy the directory by name", but in both cases the attributes of the containing directory are transferred to the containing directory on the destination. In other
words, each of the following commands copies the files in the same way, including their setting of the attributes of /dest/foo:
rsync -av /src/foo /dest
rsync -av /src/foo/ /dest/foo
Not knowing this can cause a lot of confusion and directories with files that you intended to be in a subdirectory rather than in the current working directory! You really ought to point this out. It will cause a lot of grief to people! You might also want to point out the dryrun option? If that was used some users might be able to pick up on the problem I described
beforeit’s too late!…Of course you could always use ssh itself to copy files over e.g. with the pipe tricks. But never mind that.
## Cody
…and of course the formatting got messed up in my previous post. Typical. |
12,576 | 使用命令行工具 Graudit 来查找你代码中的安全漏洞 | https://opensource.com/article/20/8/static-code-security-analysis | 2020-09-03T11:40:52 | [
"安全",
"静态审计"
] | https://linux.cn/article-12576-1.html |
>
> 凭借广泛的语言支持,Graudit 可以让你在开发过程中的审计你的代码安全。
>
>
>

测试是软件开发生命周期(SDLC)的重要组成部分,它有几个阶段。今天,我想谈谈如何在代码中发现安全问题。
在开发软件的时候,你不能忽视安全问题。这就是为什么有一个术语叫 DevSecOps,它的基本职责是识别和解决应用中的安全漏洞。有一些用于检查 [OWASP 漏洞](https://owasp.org/www-community/vulnerabilities/)的开源解决方案,它将通过创建源代码的威胁模型来得出结果。
处理安全问题有不同的方法,如静态应用安全测试(SAST)、动态应用安全测试(DAST)、交互式应用安全测试(IAST)、软件组成分析等。
静态应用安全测试在代码层面运行,通过发现编写好的代码中的错误来分析应用。这种方法不需要运行代码,所以叫静态分析。
我将重点介绍静态代码分析,并使用一个开源工具进行实际体验。
### 为什么要使用开源工具检查代码安全?
选择开源软件、工具和项目作为开发的一部分有很多理由。它不会花费任何金钱,因为你使用的是一个由志趣相投的开发者社区开发的工具,而他们希望帮助其他开发者。如果你有一个小团队或一个初创公司,找到开源软件来检查你的代码安全是很好的。这样可以让你不必单独雇佣一个 DevSecOps 团队,让你的成本降低。
好的开源工具总是考虑到灵活性,它们应该能够在任何环境中使用,覆盖尽可能多的情况。这让开发人员更容易将该软件与他们现有的系统连接起来。
但是有的时候,你可能需要一个功能,而这个功能在你选择的工具中是不可用的。那么你就可以选择复刻其代码,在其上开发自己的功能,并在你的系统中使用。
因为,大多数时候,开源软件是由社区驱动的,开发的速度往往是该工具的用户的加分项,因为他们会根据用户的反馈、问题或 bug 报告来迭代项目。
### 使用 Graudit 来确保你的代码安全
有各种开源的静态代码分析工具可供选择,但正如你所知道的,工具分析的是代码本身,这就是为什么没有通用的工具适用于所有的编程语言。但其中一些遵循 OWASP 指南,尽量覆盖更多的语言。
在这里,我们将使用 [Graudit](https://github.com/wireghoul/graudit),它是一个简单的命令行工具,可以让我们找到代码库中的安全缺陷。它支持不同的语言,但有一个固定的签名集。
Graudit 使用的 `grep` 是 GNU 许可证下的工具,类似的静态代码分析工具还有 Rough Auditing Tool for Security(RATS)、Securitycompass Web Application Analysis Tool(SWAAT)、flawfinder 等。但 Graudit 的技术要求是最低的,并且非常灵活。不过,你可能还是有 Graudit 无法满足的要求。如果是这样,你可以看看这个[列表](https://project-awesome.org/mre/awesome-static-analysis)的其他的选择。
我们可以将这个工具安装在特定的项目下,或者全局命名空间中,或者在特定的用户下,或者任何我们喜欢地方,它很灵活。我们先来克隆一下仓库。
```
$ git clone https://github.com/wireghoul/graudit
```
现在,我们需要创建一个 Graudit 的符号链接,以便我们可以将其作为一个命令使用。
```
$ cd ~/bin && mkdir graudit
$ ln --symbolic ~/graudit/graudit ~/bin/graudit
```
在 `.bashrc` (或者你使用的任何 shell 的配置文件)中添加一个别名。
```
#------ .bashrc ------
alias graudit="~/bin/graudit"
```
重新加载 shell:
```
$ source ~/.bashrc # 或
$ exex $SHELL
```
让我们通过运行这个来检查是否成功安装了这个工具。
```
$ graudit -h
```
如果你得到类似于这样的结果,那么就可以了。

*图 1 Graudit 帮助页面*
我正在使用我现有的一个项目来测试这个工具。要运行该工具,我们需要传递相应语言的数据库。你会在 signatures 文件夹下找到这些数据库。
```
$ graudit -d ~/gradit/signatures/js.db
```
我在现有项目中的两个 JavaScript 文件上运行了它,你可以看到它在控制台中抛出了易受攻击的代码。


你可以尝试在你的一个项目上运行这个,项目本身有一个长长的[数据库](https://github.com/wireghoul/graudit#databases)列表,用于支持不同的语言。
### Graudit 的优点和缺点
Graudit 支持很多语言,这使其成为许多不同系统上的用户的理想选择。由于它的使用简单和语言支持广泛,它可以与其他免费或付费工具相媲美。最重要的是,它们正在开发中,社区也支持其他用户。
虽然这是一个方便的工具,但你可能会发现很难将某个特定的代码识别为“易受攻击”。也许开发者会在未来版本的工具中加入这个功能。但是,通过使用这样的工具来关注代码中的安全问题总是好的。
### 总结
在本文中,我只介绍了众多安全测试类型中的一种:静态应用安全测试。从静态代码分析开始很容易,但这只是一个开始。你可以在你的应用开发流水线中添加其他类型的应用安全测试,以丰富你的整体安全意识。
---
via: <https://opensource.com/article/20/8/static-code-security-analysis>
作者:[Ari Noman](https://opensource.com/users/arinoman) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Testing is an important part of the software development lifecycle (SDLC), and there are several stages to it. Today, I want to talk about finding security issues in the code.
You can't ignore security when developing a piece of software. That's why there is a term called DevSecOps, which is fundamentally responsible for identifying and resolving security vulnerabilities in an application. There are open source solutions for checking [OWASP vulnerabilities](https://owasp.org/www-community/vulnerabilities/) and which will derive insights by creating a threat model of the source code.
There are different approaches to handling security issues, e.g., static application security testing (SAST), dynamic application security testing (DAST), interactive application security testing (IAST), software composition analysis, etc.
Static application security testing runs at the code level and analyzes applications by uncovering errors in the code that has already been written. This approach doesn't require the code to be running, which is why it's called static analysis.
I'll focus on static code analysis and use an open source tool to have a hands-on experience.
## Why use an open source tool to check code security
There are many reasons to choose open source software, tools, and projects as a part of your development. It won't cost any money, as you're using a tool developed by a like-minded community of developers who want to help other developers. If you have a small team or a startup, it's good to find open source software to check your code security. This keeps you from having to hire a separate DevSecOps team, keeping your costs lower.
Good open source tools are always made with flexibility in mind, and they should be able to be used in any environment, covering as many cases as possible. It makes life easier for developers to connect that piece of software with their existing system.
But there can be times where you need a feature that is not available within the tool that you chose. Then you have the option to fork the code and develop your own feature on top of it and use it in your system.
Since, most of the time, open source software is driven by a community, the pace of the development tends to be a plus for the users of that tool because they iterate the project based on user feedback, issues, or bug-posting.
## Using Graudit to ensure that your code is secure
There are various open source static code analysis tools available, but as you know, the tool analyzes the code itself, and that's why there is no generic tool for any and all programming languages. But some of them follow OWASP guidelines and try to cover as many languages as they can.
Here, we'll use [Graudit](https://github.com/wireghoul/graudit), which is a simple command-line tool that allows us to find security flaws in our codebase. It has support for different languages but a fixed signature set.
Graudit uses grep, which is a GNU-licensed utility tool, and there are similar types of static code analysis tools like Rough Auditing Tool for Security (RATS), Securitycompass Web Application Analysis Tool (SWAAT), flawfinder, etc. But the technical requirement it has is minimal and very flexible. Still, you might have requirements that are not served by Graudit. If so, you can look at this [list](https://project-awesome.org/mre/awesome-static-analysis) for other options.
We can install this tool under a specific project, or in the global namespace, or under a specific user—whatever we like, it's flexible. Let's clone the repo first:
`$ git clone https://github.com/wireghoul/graudit`
Now, we need to create a symbolic link of Graudit so that we can use it as a command:
```
$ cd ~/bin && mkdir graudit
$ ln --symbolic ~/graudit/graudit ~/bin/graudit
```
Add an alias to .bashrc (or the config file for whatever shell you're using):
```
#------ .bashrc ------
alias graudit="~/bin/graudit"
```
and reload the shell:
```
$ source ~/.bashrc # OR
$ exex $SHELL
```
Let's check whether or not we have successfully installed the tool by running this:
`$ graudit -h`
If you get something similar to this, then you're good to go.
Fig. 1 Graudit help page
I'm using one of my existing projects to test the tool. To run the tool, we need to pass the database of the respective language. You'll find the databases under the signatures folder:
`$ graudit -d ~/gradit/signatures/js.db`
I ran this on two JavaScript files from my existing projects, and you can see that it throws the vulnerable code in the console:
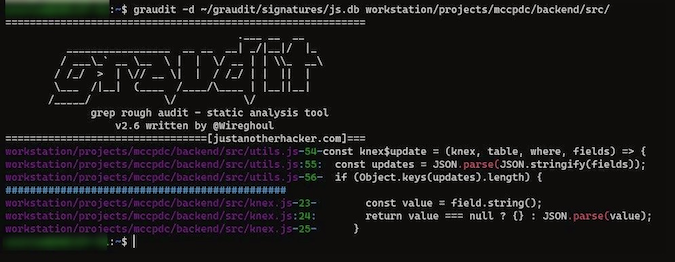
You can try running this on one of your projects, and they have a long list of [databases](https://github.com/wireghoul/graudit#databases) included in the project itself for supporting different languages.
## Graudit pros and cons
Graudit supports a lot of languages, which makes it a good bet for users on many different systems. It's comparable to other free or paid tools because of its simplicity of use and broad language support. Most importantly, they are under development, and the community supports other users too.
Though this is a handy tool, you may find it difficult to identify a specific code as "vulnerable." Maybe the developers will include this function in future versions of the tool. But, it is always good to keep an eye on security issues in the code by using tools like this.
## Conclusion
In this article, I've only covered one of the many types of security testing—static application security testing. It's easy to start with static code analysis, but that's just the beginning. You can add other types of application security testing in your application development pipeline to enrich your overall security awareness.
## 1 Comment |
12,578 | 《代码英雄》第二季(1):按下启动键 | https://www.redhat.com/en/command-line-heroes/season-2/press-start | 2020-09-03T22:28:00 | [
"游戏",
"代码英雄"
] | https://linux.cn/article-12578-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第二季(1):按下启动键](https://www.redhat.com/en/command-line-heroes/season-2/press-start)的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/196cf4bc.mp3)脚本。
>
> 导语:在“开源”和“互联网”这两个词被发明出来之前,就有了游戏玩家。他们创建了早期的开源社区,在彼此的工作基础上分享和创造。对于许多程序员来说,游戏引领他们走向了职业生涯。
>
>
>
>
> 在本期节目中,我们将探索在 ARPANET 平台上的,早期游戏开发天马行空的创意。游戏开发汇集了大量的创意并聚集了编程人才。虽然创建视频游戏在最开始是一个开放的过程,但如今很多事情已经发生了变化。听听你该如何参与打造我们自己的《命令行英雄》游戏,以及本着游戏的精神,找找本集的[复活节彩蛋](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/063401e1.mp3)。
>
>
>
**00:00:01 - Saron Yitbarek**:
一群朋友正在玩 《D&D》(<ruby> 龙与地下城 <rt> Dungeons and Dragons </rt></ruby> )游戏。 他们靠在一起,听他们的<ruby> 地下城城主 <rt> dungeon master </rt></ruby>(DM)说话。
>
> **00:00:09 - D20 菜鸟地下城城主**:
>
>
> 好的,你在念咒语,你拿起你的权杖,把自然的力量注入其中。你可以看到藤蔓从里面伸出来,和你结合在一起。它在你手中的重量明显不同了,你感觉到了更强大的力量。
>
>
> **00:00:26**:
>
>
> 所以我要施一个魔法……
>
>
> **00:00:27**:
>
>
> 好的,你做到了,你还有一次行动机会。你要做什么呢?
>
>
>
**00:00:34 - Saron Yitbarek**:
好吧,我得承认:我小的时候,从来没有坐在地下室里玩过《D&D》游戏,我也从没有渴望过成为一名 DM,不管它是什么。我不会在真人角色扮演游戏中的树林里找我的第一个男朋友,也不会在游览动漫展的过道上和我的死党黏在一起。那不是我。
**00:00:52**:
但我知道是,游戏把人们聚集到了一起并形成了社区。而且,对于众多的开发者而言,游戏是编程的入门良方。正是游戏让他们了解计算机,并第一次将他们带入一个,以极客为骄傲的空间。
**00:01:12**:
正是对游戏的热爱让他们想自己开发一款游戏,然后去打造游戏,不停超越自身。这是我非常喜欢的东西。
**00:01:23**:
在我们的[第一季](/article-12494-1.html)中,我们探讨了开源从何而来,以及它如何影响了开发者世界的每个部分。这一季我们就在代码里面讲述:在今天,成为一名开发人员意味着什么。
**00:01:39**:
这一切都是从找到你的伙伴开始的。所以,开始游戏吧。
**00:01:51**:
甚至在“<ruby> 开源 <rt> open source </rt></ruby>”和“<ruby> 互联网 <rt> Internet </rt></ruby>”这两个术语被创造之前,就已经有了游戏玩家。那些游戏玩家想要相互连接起来。因此,当世界开始联网时,他们走在了前列。他们要建立连接和共享所需的一切,并且 ——
>
> **00:02:09 - D20 菜鸟甲**:
>
>
> 哦,它上楼了。哦,天哪,要疯。
>
>
> **00:02:11 - D20 菜鸟乙**:
>
>
> 放心,这把武器可以打死它,伤害是 8 点呢。
>
>
> **00:02:16 - D20 菜鸟地下城城主**:
>
>
> 随便你,来吧!
>
>
> **00:02:17 - D20 菜鸟乙**:
>
>
> 所以,捅它!耶!
>
>
> **00:02:19 - D20 菜鸟丙**:
>
>
> 捅谁,德鲁伊吗?
>
>
> **00:02:19 - D20 菜鸟甲**:
>
>
> 我干掉它了!
>
>
>
**00:02:27 - Saron Yitbarek**:
好吧,接着玩吧。我是 Saron Yitbarek,这里是红帽原创播客 <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby> 第二季。今天的节目,《按下启动键,游戏和开源社区》。
**00:02:45 - 配音**:
你站在一条路的尽头,前面是一座砖砌的小型建筑。你周围是一片森林。一条小溪从建筑物里流出,顺着沟壑而下。
**00:02:56 - Saron Yitbarek**:
你对这些话有印象吗?如果你还记得,可以给你的历史知识打 10 分。但是,如果你和我一样,对它们没有印象,那么这些都是 <ruby> 《巨洞探险》 <rt> Colossal Cave Adventure </rt></ruby> 的开场白。
**00:03:09**:
什么是《巨洞探险》?我的朋友,一切的改变始于 1976 年。那条路,森林边的砖房,那条流入沟壑的小溪,当时没有人知道,但这款基于文本的游戏(是的,根本没有图形)将是一扇闪亮的红色大门,通向了新的社区和协作形式。
**00:03:38 - Jon-Paul Dyson**:
《巨洞探险》是一种被称为文本冒险的游戏。你可以通过输入命令与计算机交互:向西走、拿上剑、爬山等等。
**00:03:51 - Saron Yitbarek**:
这是 Jon-Paul Dyson。他是 <ruby> 斯特朗国家游乐博物馆 <rt> Strong National Museum of Play </rt></ruby> 的副馆长,也是其电子游戏历史中心的主任。是的,相当有趣的工作。
**00:04:04 - Jon-Paul Dyson**:
《巨洞探险》是一种非常不同类型的游戏。它更像是一款流程自由的探险游戏,就像在此时问世的《龙与地下城》一样。
**00:04:17**:
因此,它开启了想象力。这是一场真正革命性的游戏……
**00:04:22 - Saron Yitbarek**:
在 70 年代中期出现了一种新型游戏,这绝非偶然。正在其时,互联网的鼻祖 ——<ruby> 阿帕网 <rt> ARPANET </rt></ruby>出现了。
**00:04:32 - Jon-Paul Dyson**:
事情是这样的,一位在 ARPANET 上工作的人,他叫 Will Crowther,有了开发这个洞穴探险游戏的想法。他大致依据他曾探索过的,肯塔基州猛犸象洞穴的一部分为基础,创作了这款游戏。
**00:04:50**:
这真是革命性的突破,因为它给了玩家一个探索环境的机会。不过更有趣的是,他去度假了。而另一个人,叫 Don Woods 的伙计,因为当时 ARPANET 的存在而发现了这个游戏,然后做了些调整。
**00:05:09**:
因此,几乎从一开始,这个游戏的开发就是一个协作过程,因为它已在网络上被共享。这恰是一个很好的例子,说明了该游戏是如何被开发、修改、改进,然后广泛传播的,这一切都是因为这些计算机是连接在一起的。
**00:05:28 - Saron Yitbarek**:
因此,在计算机联网后,我们可以立即开始使用这些网络来分享游戏。而这些游戏本身也在不断演变。
**00:05:38**:
事情是这样的:不仅仅是网络改善了游戏,游戏也改善了网络。因为越多的人想要分享这些游戏,他们就越需要一个社区的论坛。
**00:05:53**:
因此,有了游戏技术,以及热爱它们的社区,它们彼此在相互促进。这是一个正反馈回路。同样,游戏开发人员彼此启发,相互借鉴。
**00:06:09**:
ARPANET 真是一片肥沃的土地。Jon-Paul Dyson 再次发言:
**00:06:16 - Jon-Paul Dyson**:
所以像《<ruby> 冒险 <rt> Adventure </rt></ruby>》这样的文本冒险游戏就在这个空间里运转,这个空间被技术先锋们占据,他们知道如何无厘头、搞笑,知道如何才好玩。
**00:06:28**:
早期的游戏确实为开发者社区该如何协同工作提供了一种模式。
**00:06:36 - Saron Yitbarek**:
记住,我们这里谈论的不是 <ruby> 《我的世界》 <rt> Minecraft </rt></ruby>,也不是 <ruby> 《英雄联盟》 <rt> League of Legends </rt></ruby>,我们谈论的是黑色屏幕上一行行绿色的文字,读完游戏内置的故事,并让你做出决定。这是一种相当简单的游戏文化,但它给了我们巨大的回报。
**00:06:56 - Jon-Paul Dyson**:
有一种共同体的信念,认为分享有好处,即与生产专有产品相比,更多的协作可以产生更好的结果。因此,结果就是你开发的游戏都是从社区中涌现出来的,这些游戏本身对改变持开放态度,并鼓励人们改变游戏,可能是小的方面,也可能是大的方面。但有一种感觉是,如果游戏变得更好,那么一切都是好的。
**00:07:31**
所以我认为历史上的这种早期的理念,尤其是计算机游戏方面,在推动计算机社区的发展方面确实很重要。
**00:07:45 - Saron Yitbarek**:
Dennis Jerz 教授特别研究了游戏的历史,尤其是《巨洞探险》。对他来说,这些原始开源社区对于所有创造力来说,都是一次自由的释放。
**00:07:58 - Dennis Jerz**:
当时的文化是,人们在自己工作的基础上建立和分享自己的想法。而且很常见的是找到源代码后,第一件事就是在现有的源代码上再增加一个属于自己的空间。
**00:08:22**:
这和同人小说的想法很像,就是人们创造自己的故事,这些故事穿插在《哈利·波特》的不同章节之间,或者是《<ruby> 饥饿游戏 <rt> the Hunger Games </rt></ruby>》中 Katniss 的世界里的小角色的故事。这种在主叙事的基础上进行补充、阐述和构建的文化。
>
> **00:08:44 - D20 菜鸟玩家甲**:
>
>
> 好吧,所以我现在急着要找 Van Tyler,看看她的伤口。哦,上面说武器的伤害变成了 d8。
>
>
>
**00:08:56 - Saron Yitbarek**:
在基于图像或视频的游戏出现之前,这些基于想象力的游戏风格为大规模的在线社区铺平了道路。游戏社区和在线社区之间的是共生的,拥有强韧的联系。
**00:09:11**:
但如果说有一件事是游戏玩家都知道,那就是强大的玩家可以将任务推动到一个新的方向。随着网络游戏的发展,它以社区为基础的根基开始被侵蚀。
>
> **00:09:24 - D20 菜鸟玩家甲**:
>
>
> 这次试着把它放在他的脖子后面。搞定!
>
>
>
**00:09:33 - Saron Yitbarek**:
好的,让我们快进到如今。互联网已经成熟。有了它,在线游戏社区已经有了很大进步。如今,游戏每年的收入超过 1000 亿美元。预计在未来十年,这一数字将翻一番以上。
**00:09:53 - Saron Yitbarek**:
但这些取得的成功也改变了游戏规则。这不是一群独立开发者在一个摇摇欲坠的论坛上分享他们的作品。今天尚存的游戏社区与《巨洞探险》早期的情况完全不同。
**00:10:11 - Saku Panditharatne**:
大家好,我叫 Saku,我是一家名为 Asteroid 的初创公司的创始人,我公司为游戏开发者制作增强现实(AR)工具。
**00:10:19 - Saron Yitbarek**:
Saku Panditharatne 觉得开放的互联网与游戏开发之间的关系最近已经扭曲。她说的很清楚,为什么游戏公司之间不共享部分代码,而有时候大型科技公司之间却能共享代码呢?
**00:10:37 - Saku Panditharatne**:
如果你是唯一一个与所有人共享你的代码的游戏公司,那么你的竞争对手只会复制你的代码,他们会拿走你的所有秘密,并且他们会制作出比你更好的 3A 游戏。
**00:10:47**:
这对大型科技公司来说也是个问题。但实际上,我认为是软件工程师的努力打破了这种平衡。因为如果没有人为一家闭源的公司工作,那么每个人都会被迫开源,然后所有的大科技公司都能尽可能地共享,这对软件整体来说是非常好的。
**00:11:11**:
但这在游戏行业中从未发生过。
**00:11:14 - Saron Yitbarek**:
Saku 的理论是,与其他领域相比,在游戏领域的传统上,开发者没有同样的决策控制权。那太糟糕了,因为这意味着我们都错过了开放。
**00:11:26 - Saku Panditharatne**:
我们基本上知道具体如何将渲染、着色以及物理操作做到很高的标准。那不应该是每个游戏工作室都在复制的东西。但是,奇怪的是,游戏工作室通常仍会在内部构建引擎。不幸的是,他们陷入了这种……
**00:11:46**:
我觉得游戏有点像电影,而不是像软件。你会使游戏开发陷入到地狱。你会遇到所有的问题,比如制作人的融资问题等等。
**00:11:59**:
我认为所有这些因素都不利于软件变得更好。
**00:12:05 - Saron Yitbarek**:
因此,游戏开发中的专有制度,导致了大量重复的工作,每个工作室都必须解决同样的问题。而且它们中的大多数都不是最佳解决方案。
**00:12:18**:
同时,对于可能会提供新东西的独立开发人员来说,事情很快变得难以承受。游戏开发人员通常必须购买某个主流游戏引擎的许可证。或者,他们必须得购买一个脚本。
**00:12:33**:
另一方面,Web 开发人员拥有更多可接受的选择。
**00:12:37 - Saku Panditharatne**:
我觉得真正有趣的一个事实是,拍一部电影比做一架飞机更复杂。这只是因为你拥有的所有这些各种人都具有不同的技能,他们的工作时间表不同,他们受到的激励也不同。
**00:12:51**:
所以,让他们一起工作就像一场组织挑战。而游戏引擎和其他游戏软件所做的事情之一:它是用来弥合这种鸿沟的,几乎成为最有效的工作软件。
**00:13:06 - Saron Yitbarek**:
游戏开发的问题很像电影制作问题。你有艺术家、编剧、角色设计师,都在与程序员和系统管理员角力。如果不采取开源的态度,或者没有建立共享和同步的方式,那一群不同角色的人就会变得混乱。
**00:13:27**:
这一切都归结为建设社区的挑战。那些最初的游戏,是由开发者利用自己的空闲,例如午休时间开发的。
**00:13:38**:
另一方面,像《<ruby> 魔兽世界 <rt> World of Warcraft </rt></ruby>》这样的游戏,他们有大量的创意人员和程序员。社区已经达到了极限。例如,我认为没有任何论坛可以让开发人员向角色设计师提出“PR”以供审查。
**00:13:54**:
但也许应该有 PR,Saku 知道我在说什么。
**00:13:57 - Saku Panditharatne**:
我认为游戏的一个大问题是,它是一个跨学科的东西。跨学科做任何事情都是困难的,因为这几乎就像 C.P.Snow Essay 的文章 《<ruby> 两种文化 <rt> The Two Cultures </rt></ruby>》,你必须把用右脑的、富有创造性思维的人和用左脑的、富有逻辑思维的人聚集在一起,让他们共同努力做一些事情。
**00:14:18 - Saron Yitbarek**:
我们能不能花点时间让全世界做点什么?如果 GitHub 上有人想找出一种开源游戏开发的方法,在开发者和艺术家之间进行转译,你就为世界做出了贡献。
**00:14:32 - Saku Panditharatne**:
我有点觉得,游戏的限制一直都是把两群不怎么说话的人聚集在一起,然后努力创造一些东西。
**00:14:42 - Saron Yitbarek**:
对我来说,简而言之就是开源的事。不过,特别值得一提的是,Saku 在想办法弥合两个社区之间的差距,从而形成一个更大的社区。
**00:14:53 - Saku Panditharatne**:
是的,我认为这实际上可以真正改善整个行业。我认为那些大型的新兴创业公司很多都出现在 2007 年左右,都是因为他们可以使用大量的开源软件。
**00:15:07**:
而且我认为,如果没有开发者把他们的东西免费放到网上,那股创业热潮就不会发生。
**00:15:13**:
如果类似的事情发生在游戏行业中,我想我们会有比现在更多的独立游戏开发者。
**00:15:21 - Saron Yitbarek**:
但有个好消息。游戏领域的开源革命,可能已经开始了。Jon-Paul Dyson 再次出现:
**00:15:30 - Jon-Paul Dyson**:
在视频游戏的历史上,确实存在两个流派:一个是人们创造专有产品的地方,即封闭系统。它们通常经过精心打磨,出于商业目的而发布。想想像<ruby> 任天堂 <rt> Nintendo </rt></ruby>这样的公司。任天堂创造了令人赞叹的游戏,但你无法真正进行修改。
**00:15:52**:
但在电子游戏和电脑游戏的历史上也出现了一种相反的趋势,这是一种更具协作性的方法。像《我的世界》这样的游戏就是一个现代的例子,人们正在参与对游戏的修改,那里有一个围绕游戏而生的社区。
**00:16:14**:
你可以从互联网上的某个地方下载 MOD,然后在游戏中引入。因此,你拥有的是一种非常不同的,几乎是有机的开发游戏的方式,而不是一种更结构化的,可能是商业化的、工程化的方式。
**00:16:35**:
在很多方面,《我的世界》都是诸如《太空大战》或《巨洞探险》等早期游戏的继承者,该游戏在社区中发展,对进行修改和改变的人们更开放。而且,其治理理念是,从某种意义上说,以长远角度来看,群体的工作将会比一个小团队或个人的工作更好。
**00:17:04 - Saron Yitbarek**:
我认为我们现在要说的是,游戏行业并没有完成社区的建设,你也永远不能消灭这种开源精神。
**00:17:14**:
这就是我们所知道的:游戏仍然激发了许多开发人员,这就是许多代码英雄最初进入该行业的原因。比如像 Josh Berkis 这样的代码英雄,
**00:17:28 - Josh Berkus**:
嗯,我是从 Atari 800 开始的,因为它可以设计自己的游戏。
**00:17:34 - Saron Yitbarek**:
以及 Ann Barcomb,
**00:17:36 - Ann Barcomb**:
我写的大多是冒险游戏,那是可怕的意大利面代码。
**00:17:42 - Saron Yitbarek**:
还有 Justin Flory。
**00:17:43 - Justin Flory**:
在我意识到我在做开源之前,我就已经开源了。我从一台运行着《我的世界》的游戏服务器开始的,那时我 15 岁。
**00:17:54 - Saron Yitbarek**:
当人们热爱某事时,那么对社区、对开源的态度就会蓬勃发展。Saku 对专有游戏元素的警告,实际上正是游戏在其旅程中必须克服的障碍。
**00:18:09**:
一些游戏行业的领先者正开始实现这一飞跃。
>
> **00:18:17 - 在玩堡垒之夜的孩子们**:
>
>
> 我们实际上做得很好。
>
>
> **00:18:18**:
>
>
> 我当时正在疯狂射击,我干掉了 3 个,他们干掉了 1 个。
>
>
> **00:18:21**:
>
>
> 哦,Campbell 在背着我。
>
>
>
**00:18:24 - Saron Yitbarek**:
如果你去年就快到 12 岁了,你很可能听说过一个叫《<ruby> 堡垒之夜 <rt> Fortnite </rt></ruby>》的小游戏。嗯,很小的游戏。在它发布的第一年,它就获得了超过 1.25 亿的玩家,所有玩家都在一场大逃杀中。
>
> **00:18:43 - 在玩堡垒之夜的孩子们**:
>
>
> 我得下线了,好吧,就一会,我得给我父母打个电话。
>
>
>
**00:18:47 - Saron Yitbarek**:
是的,游戏在建立社区方面还是很不错的。实际上,《堡垒之夜》 是有史以来最大的免费主机游戏。它背后的工作室 Epic 还创建了《堡垒之夜》所使用的<ruby> 虚幻游戏引擎 <rt> Unreal engine </rt></ruby>。
**00:19:02**:
很多其他的游戏也都使用虚幻引擎,因为 Epic 向世界免费发布了虚幻引擎。它不是直接开源的,但它的源代码是可访问的。这远超了大多数工作室。
**00:19:16**:
有了虚幻引擎,任何人都可以获取到源代码。他们不仅提供了代码,还致力于建立一个答案中心、论坛、开发者支持。Epic 正在加倍努力建设一个尽可能大而广泛的社区。
**00:19:32**:
而且他们并不孤单。你已经有了像 Godot 和 MonoGame 这样的完整的开源游戏引擎,它们正在催生自己的开发社区。红帽公司的软件工程师 Jared Sprague 是新一代的一员,他们可以使用所有这些工具和引擎来构建令人惊叹的游戏,如果没有这些社区,他们是永远不可能构建出来这种东西的。
**00:19:55 - Jared Sprague**:
独立游戏行业最近发展很快。因此,你应该发现几年前,大多数游戏都是由大型工作室制作的。这些都还在市场上,对吧,任天堂之类的。
**00:20:09**:
独立产业正在爆炸式增长。我认为这很大程度上是因为 Steam。
**00:20:17 - Saron Yitbarek**:
他说的就是 Steam 平台,它让开发者可以将游戏内聊天功能、社交网络服务等所有好的东西整合在一起。他们在这方面已经做了 15 年了。
**00:20:29 - Jared Sprague**:
Steam 使任何游戏开发者,都有可能发布一款游戏给数百万人。有很多大型游戏是从独立游戏开始的,也许只有一两个人在做,最后大放异彩。
**00:20:48**:
《我的世界》就是一个很好的例子。刚开始,只有一个人,是独立开发者。现在这是有史以来最大的游戏之一。但这只是一个例子,说明独立游戏是如何真正成为游戏行业的主要力量。
**00:21:06 - Saron Yitbarek**:
Jared 与他的红帽伙伴 Michael Clayton 合作制作了游戏 Jams,一群独立游戏开发人员聚集在一起,在很短的时间内开发出游戏。就像黑客马拉松一样,但用于游戏。
**00:21:17**:
GitHub 上有一个叫做 Game Off 的版本,Jared 的版本叫做 Open Jam。如果你问他,他会说这是基于社区的游戏开发未来的一部分,而且会变得越来越大。
**00:21:31 - Jared Sprague**:
例如,你可以使用 Linux,因为它是开源的,所有人都可以为它做贡献,添加工具、补丁等等,这就是它如此伟大的原因。比一个人独自完成的要好得多。
**00:21:47**:
而且我认为开源的游戏或某种游戏系统或虚拟世界仍有潜力,成千上万的人可以做出比一个人可以做的更大的东西。
**00:22:03 - Saron Yitbarek**:
游戏工作室已经开始转变了对开源态度。
**00:22:10 - Jordan Weisman**:
我认为游戏能够让你的社区开启创造,它的这种力量是毋庸置疑的。
**00:22:18 - Saron Yitbarek**:
Jordan Weisman 是 Harebrained Schemes 的联合创始人。 《<ruby> 血色苍穹 <rt> Crimson Skies </rt></ruby>》、 《<ruby> 战斗机甲 <rt> Battle Tech </rt></ruby>》、《<ruby> 机械战士 <rt> Mech Warrior </rt></ruby>》这些都是他的作品,他长期从事游戏开发。而他现在看到的是,随着工作室开始意识到好处,对开源的态度也在转变。
**00:22:35 - Jordan Weisman**:
甚至像《战斗机甲》之类的游戏也有很多…… 我们已经尝试向玩家开放尽可能多的游戏数据。而且我们已经看到玩家为游戏提供了惊人的 MOD。看到他们的创意和成果,令我们兴奋,这与我们的原创内容相比,它以不同的方式吸引着玩家。
**00:22:58**:
这只是关于你能做什么的一个小例子。随着游戏的发展,我们更加知晓了这一点,越来越开放,让玩家表达他们的创造力。
**00:23:10 - Saron Yitbarek**:
Jordan 认为,不断变化的文化有助于他的游戏成为最好的。但是,你知道,就像我们在本期节目的《D&D》开场白中所暗示的那样,对社区的推动始终存在。
**00:23:24 - Jordan Weisman**:
TRPG 来自于 GM 与玩家之间,互相用语言编织一场冒险的 RPG 游戏,人们围坐在一张桌子前合作讲故事并分享经验。在某段时间内,当我们开始分享某些电子游戏时,这两派非常分裂。
**00:23:41**:
我认为,随着 MOD 工具和大家都能接触的引擎的诞生,以及工具更高的可访问性,和开发商转向开源。这在某种程度上,让我们重新回到了游戏的创建之初,这种非常社交化的。具有娱乐形式的协作。
**00:23:58**:
所以我觉得这很令人兴奋。
**00:24:01 - Saron Yitbarek**:
我也这样认为。至于 Jared Sprague,他将再次与 Michael Clayton 合作,开发一款全新的社区驱动的开源游戏。它被称为…… <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>。
**00:24:21**:
是的,我们正式成为一个多平台 IP。当然,<ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby> 游戏将成为一个开源项目。所以我们邀请社区(也就是你)与我们一起打造这款游戏。我们所要做的就是一个目标。
**00:24:40**:
灵感来自 NASA,这将是一个火星之旅。它的细节?这取决于我们所有人的共同努力。这将是一个基于网络的游戏,我们将在整整这一季的播客节里致力于这项工作。GitHub 仓库将对任何想要贡献的人开放。
**00:24:59**:
而且,再说一次,如果你正在收听此内容,则邀请你参与,与我们一起开发该游戏。设计一个角色,提一个拉取请求。或者只是玩测试版,然后将你的反馈发送给我们。
**00:25:21**:
我们将利用我们在本期节目中谈到的所有开源魔法,共同构建一些东西。
**00:25:22**:
趣事:还记得《巨洞探险》吗? 好吧,虽然这个游戏的代码一直可以访问的,但《巨洞探险》在 40 年后终于完全开源了。2017 年,官方版本在 BSD 许可证下发布了。
**00:25:39**:
从最初的互动式文字游戏开始,游戏社区已经走过了很长一段路。
**00:25:45 - 配音**:
你站在一条路的尽头……
**00:25:50 - Saron Yitbarek**:
问题是,我们不是站在路的尽头。这条游戏之路绵延不绝。在此过程中,游戏正在帮助我们联合起来并建立整个宇宙。坦率地说,我们不知道我们的社区将如何安排自己沿着这条路走下去。
**00:26:07**:
但我们知道游戏将会推动这一进程,因为我们从来没有停止过 —— 按启动键。
**00:26:15**:
想了解更多关于早期开源社区和开源游戏起源的知识吗?在 <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby> 网站上有更多的内容等着你。你可以通过访问 [redhat.com/comandlineheros](http://redhat.com/comandlineheros) 更深入地挖掘。在我们告别之前,我想让你知道我们在导语中有一项特殊礼物在等着你。这是 [Warren Robinett 的故事](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/063401e1.mp3),他创造了 Atari 游戏《<ruby> 冒险 <rt> Adventure </rt></ruby>》,这款游戏的灵感来自于《巨洞探险》。
**00:26:48**:
他告诉我们,他与老板的争论是如何导致出现了第一个视频游戏的<ruby> 复活节彩蛋 <rt> Easter egg </rt></ruby>。这是一个很棒的故事,是我们发展史上很可爱的一部分,但我们想给它应有的空间。
**00:27:03**:
所以请到 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 网站上听一听。
**00:27:10**:
<ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby> 是 Red Hat 的原创播客。在 Apple Podcast、Google Podcast 或任何你收听播客的地方免费收听它。
**00:27:20 - Saron Yitbarek**:
我是 Saron Yitbarek,下次见,编程不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-2/press-start>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[gxlct008](https://github.com/gxlct008) 校对:[Bestony](https://github.com/bestony),[wxy](https://github.com/wxy),[acyanbird](https://github.com/acyanbird)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Before the terms 'open source' and 'internet' were even coined—there were gamers. They created proto-open source communities, sharing and building upon each other's work. For many programmers, gaming led them to their careers.
In this episode, we explore the creative free-for-all of early game development over ARPANET. Game development brings together a massive mix of creative and programming talent. But while creating video games started as an open process, a lot has changed. Hear how you can get involved in building our very own Command Line Heroes game—and in the spirit of games, hunt around for this episode's __Easter egg.__
**00:01** - *Saron Yitbarek*
A group of friends is partway through a game of D&D. They lean in together and listen to their dungeon master.
**00:09** - *D20 Babes dungeon master*
Okay, so you're casting the, so yeah, you grab your staff and you channel the forces of nature into it. And you can see vines coming out of it and it just bonds to you. And you, it feels differently weighted in your hands now and you feel much more powerful.
**00:26** -*D20 Babes dungeon master*
So that's what you do, you cast a spell that surrounds...
**00:27** - *D20 Babes dungeon master*
Alright, so you do that and you still have an action. What do you do?
**00:34** - *Saron Yitbarek*
Okay, a confession: when I was growing up I never sat in a basement playing D&D. I did not long to be a dungeon master, whatever that is. I did not find my first boyfriend while LARPing in the woods or bond with my BFF while cruising the aisles at Comic-Con. It just wasn't me.
**00:52** - *Saron Yitbarek*
But what I do get is that games brought people together into communities. And, for a huge number of developers out there, games were the gateway drug into programming. It was games that taught them about computers and got them in a room where they could geek out with pride for the first time.
**01:12** - *Saron Yitbarek*
It was the love of gameplay that made them want to build a game themselves. Then go beyond gameplay to just build. And that's something I'm very much into.
**01:23** - *Saron Yitbarek*
In our first season, we explored where open source came from, and how it's shaping every part of the developer's world. This season we're living right on the command line itself: what it means to be a developer today.
**01:39** - *Saron Yitbarek*
And all that starts with finding your people. So let the games begin.
**01:51** - *Saron Yitbarek*
Before the terms open source and internet were even coined, there were gamers. And those gamers wanted to connect with each other. When the world started going online, they were at the front of the pack. And they would build whatever it took to connect and share and—
**02:09** - *D20 Babes player 1*
Oh, and it goes up. Oh nice. And it goes crazy.
**02:11** - *D20 Babes player 2*
Yep, the weapon's damage die becomes 8.
**02:16** - *D20 Babes dungeon master*
There you go, you were right.
**02:17** - *D20 Babes player 2*
So stab it, yeah.
**02:19** - *D20 Babes player 3*
Which, the druid--
**02:19** - *D20 Babes player 1*
I did it!
**02:27** - *Saron Yitbarek*
Yeah, and play. I'm Saron Yitbarek and this is season two of Command Line Heroes, an original podcast from Red Hat. Today's episode, Press Start, gaming and open source communities.
**02:45** - *Voice actor*
You are standing at the end of a road before a small, brick building. Around you is a forest. A small stream flows out of the building and down a gully.
**02:56** - *Saron Yitbarek*
Do you recognize those words? If you do, ten points for knowing your history. But, if you're like me and they did not ring a bell, those are the opening lines of Colossal Cave Adventure.
**03:09** - *Saron Yitbarek*
What is Colossal Cave Adventure? That, my friend, is the 1976 that changed everything. That road, that brick building by the forest, that stream flowing down into a gully, nobody knew it at the time, but this text-based game—yep, no graphics at all—would be a shiny red door that led the way to new forms of community and collaboration.
**03:38** - *Jon-Paul Dyson*
Colossal Cave Adventure was a type of game that's known as a text-based adventure. You interact with the computer by typing in commands: go west, get sword, climb mountain.
**03:51** - *Saron Yitbarek*
That's Jon-Paul Dyson. He's a VP at the Strong National Museum of Play and the director of their Center for the History of Electronic Games. So, yeah, pretty fun job.
**04:04** - *Jon-Paul Dyson*
Colossal Cave Adventure was a very different type of game. It was more of a free flowing, exploratory game, like Dungeons and Dragons, which comes out at just this moment in time.
**04:17** - *Jon-Paul Dyson*
And so it opens the imagination. So it was a really revolutionary game..
**04:22** - *Saron Yitbarek*
It's no accident that a new kind of game appeared in the mid-'70s. Right at that time, the internet's granddaddy, the ARPANET, was coming to life.
**04:32** - *Jon-Paul Dyson*
What happened is, one of the guys working on ARPANET, a guy named Will Crowther, had this idea for developing this cave exploration game. Now he created this game based loosely on a section of Mammoth Cave in Kentucky that he had explored.
**04:50** - *Jon-Paul Dyson*
And it was really revolutionary in the way that it gave players a chance to explore this environment. But what's interesting was because ARPANET was now around, he went on vacation and someone else, this guy, Don Woods, was able to discover the game, and then make all these adjustments.
**05:09** - *Jon-Paul Dyson*
So almost from the very beginning, the game was a collaborative process because it had been shared on this network. And it was just a good example of how a game could be developed, and modified, improved and then distributed widely because these computers were connected.
**05:28** - *Saron Yitbarek*
So immediately after computers become networked, we're starting to use those networks to share games. And those games are evolving along the way.
**05:38** - *Saron Yitbarek*
Here's the thing, though: it wasn't just networks improving games, it was also games improving networks. Because the more people wanted to share those games, the more they needed usable forums for a community.
**05:53** - *Saron Yitbarek*
So you've got game technology and the communities that love them sort of egging each other on. A positive feedback loop. Likewise, the game developers are inspired by each other, growing off each other's ideas.
**06:09** - *Saron Yitbarek*
The ARPANET was hugely fertile ground. Here's Jon-Paul Dyson again:
**06:16** - *Jon-Paul Dyson*
So text-based adventures like Adventure operated at this space that was occupied by pioneering technologists who also knew how to be silly, laugh, and to have fun.
**06:28** - *Jon-Paul Dyson*
Early games really offer a pattern for how communities of developers can work together.
**06:36** - *Saron Yitbarek*
Remember, we're not talking about Minecraft here, we're not talking about League of Legends, we're talking about lines of green text on a black screen just reading out a story-based game and inviting you to make your decisions. It's a much simpler gaming culture. But it gave us huge rewards.
**06:56** - *Jon-Paul Dyson*
There's this communitarian belief in the benefits of sharing, that more collaboration produces better results than producing proprietary products. And so the result is that you have games developed that emerged out of communities and that are themselves open to being changed and encouraging people to make changes that might alter the game in minor ways or significant ways. But there's a feeling that if the game is made better, then that's all for the good.
**07:31** - *Jon-Paul Dyson*
And so I think there's this early spirit in the history, especially of computer games, that really is important in pushing forth computer communities.
**07:45** - *Saron Yitbarek*
Professor Dennis Jerz has studied the history of games and Colossal Cave Adventure in particular. For him, these proto-open-source communities were a free for all of creativity.
**07:58** - *Dennis Jerz*
The culture at the time involved people building upon and sharing their own ideas. And it was very common to find the source code, and then the first thing you would do is add another room to the existing source code.
**08:22** - *Dennis Jerz*
It was pretty much like the idea of fan fiction, the whole idea that you have people who are creating their own stories that fit in between various chapters of Harry Potter books or here's what happened to the minor characters in Katniss' world from the Hunger Games. This culture of adding to, and elaborating and building upon a main narrative.
**08:44** - *D20 Babes player 1*
Okay, so I am rushing over now to Van Tyler and looking at her wounds. Oh, the weapon's damage becomes a d8, it says.
**08:56** - *Saron Yitbarek*
Before image or video-based gaming, these imagination-based game styles paved the way for massive online communities down the road. The relationship between gaming and online communities was symbiotic and powerful.
**09:11** - *Saron Yitbarek*
But if there's one thing the gaming crowd knows, it's that powerful players can swerve the mission in a new direction. As online gaming grew up, its community-based roots have started to erode.
**09:24** - *D20 Babes player 1*
And this time try to bring it down on the back of his neck. Yeah!
**09:33** - *Saron Yitbarek*
Okay, let's fast forward to today. The internet's all grown up. And with it, the online gaming community has leveled up a lot. Gaming today generates more than 100 billion in revenue each year. And that's expected to more than double in the next decade.
**09:53** - *Saron Yitbarek*
But all that success has also changed the game. It's not a group of indie developers sharing their work on a rickety forum. Game communities that exist today are radically different from what was going on in the early days of Colossal Cave Adventure.
**10:11** - *Saku Panditharatne*
Hi, my name is Saku, I'm the founder of a startup called Asteroid, which makes augmented reality tools for game developers.
**10:19** - *Saron Yitbarek*
Saku Panditharatne wonders if that relationship between the open internet and game development has gotten a bit twisted lately. She's got a point, why aren't parts of code shared between game companies the same way code is sometimes shared between big tech companies?
**10:37** - *Saku Panditharatne*
If you’re the only game company that shares your code with everyone, your competitors will just copy you, and they'll take all your secrets and they'll make a better triple-A game than you.
**10:47** - *Saku Panditharatne*
And that was also a problem for big tech companies as well. But it was the efforts of software engineers that actually, I think, broke this equilibrium, I think. Because if no one worked for a company that kept its code source, then everyone was forced to go open source and then you get all the big tech companies sharing as much as they can, which is very good for software as a whole.
**11:11** - *Saku Panditharatne*
But that never happened with games.
**11:14** - *Saron Yitbarek*
Saku's theory that traditionally in gaming the developers haven't had the same control over decision making compared to other fields. And that's too bad, because it means we're all missing out.
**11:26** - *Saku Panditharatne*
We basically know exactly how to do rendering and shading and physics to a really high standard. And that shouldn't be something that every single game studio is replicating. But, weirdly enough, it is often the case that games studios still will build engines in-house. Unfortunately, they're stuck in this kind of ...
**11:46** - *Saku Panditharatne*
I kind of feel like games are a bit more like film than they are like software. You get games stuck in development hell. You get all these problems with producers financing them and stuff like that.
**11:59** - *Saku Panditharatne*
And I think all these factors work against adopting the best possible software.
**12:05** - *Saron Yitbarek*
So, that proprietary approach in game development leads to a lot of redundant work. Every studio is forced to solve the same problems. And most of them aren't optimal solutions, either.
**12:18** - *Saron Yitbarek*
Meantime, things quickly become unaffordable for indie developers that might have something new to offer. Game developers often have to buy licenses for one of the major game engines. Or, they'll have to buy, say, a lighting script.
**12:33** - *Saron Yitbarek*
Web developers, on the other hand, have way more affordable options.
**12:37** - *Saku Panditharatne*
One fact I find really interesting is that it's more complex to make a movie than it is to make an airplane. That's just because you have all these different people with very different skill sets, they work on a different schedule, they're incentivized by different things.
**12:51** - *Saku Panditharatne*
So, then, getting them to work together is like an organizational challenge. And one of the things that game engines and other game software does—it's about bridging that divide almost as much as it is about being the most efficient software for the job.
**13:06** - *Saron Yitbarek*
Game development's problem is a lot like that movie production problem. You've got artists, storytellers, character designers, all wrestling with programmers and sysadmins. Without adopting open source attitudes, without building in ways to share and sync up, that crowd of different people with different roles can get chaotic.
**13:27** - *Saron Yitbarek*
It all boils down to the challenge of building community. Those first games, they were being built by the developers themselves, like, during their lunch breaks.
**13:38** - *Saron Yitbarek*
Games like World of Warcraft, on the other hand, they've got this mammoth mix of creatives and programmers. The communities get stretched to their limit. For example, I don't think there's any forum where developers make pull requests for character designers to review.
**13:54** - *Saron Yitbarek*
But maybe there should be. Saku knows what I'm talking about.
**13:57** - *Saku Panditharatne*
I think one big issue for games is that it's a cross-disciplinary thing. And doing anything cross disciplinary is difficult, because it's almost like the C.P. Snow Essay, "The Two Cultures," you have to bring together people who are right-brained and creative-minded and people who are left-brained and logical and get them to work together on something.
**14:18** - *Saron Yitbarek*
Can we just take a second to ask the world to build something? If anybody on GitHub wants to figure out a way to do open source game development that translates for developers and artists at the same time, you'd be doing the world a solid.
**14:32** - *Saku Panditharatne*
I kinda think that the limit to games has always been bringing together two groups of people who don't really talk to each other and then trying to build something.
**14:42** - *Saron Yitbarek*
To me, that's the story of open source in a nutshell. In particular, though, Saku's imagining something to bridge the gap between two communities to make a larger community.
**14:53** - *Saku Panditharatne*
Yeah, I think it could actually really improve the industry as a whole. I think those big boom startups around 2007, and a lot of that was because there a ton of open-source stuff you could use. [inaudible 00:15:06]you could use.
**15:07** - *Saku Panditharatne*
And I don't think that startup boom could've happened without developers being able to put their stuff online for free.
**15:13** - *Saku Panditharatne*
If something like that happened in games, I think we'd have way more indie game developers than there are currently.
**15:21** - *Saron Yitbarek*
But there's good news. That open source revolution in gaming, it might already be happening. Here's Jon-Paul Dyson again:
**15:30** - *Jon-Paul Dyson*
So in the history of video games, there's really been two streams: one is where people create proprietary products, their closed-end systems. They're often highly polished, they release for commercial purposes. Think of a company like Nintendo. Nintendo creates amazing games and you can't really modify.
**15:52** - *Jon-Paul Dyson*
But there's also been a countervailing trend in the history of video games, computer games, and that's been a more collaborative approach. And something like Minecraft is an example of this, a modern example, where people are making modifications to the game, there's a community that revolves around the game.
**16:14** - *Jon-Paul Dyson*
You download from the internet, somewhere, and this set of mods that you're introducing into the game. And so what you have is a very different, almost more organic way of developing games, as opposed to a more structured, maybe commercial, engineered approach.
**16:35** - *Jon-Paul Dyson*
Minecraft is in many ways the heir to earlier games like Space War or Colossal Cave Adventure that develops in a community and is much more open to people making modifications and changes. And the governing philosophy is that somehow the work of the crowd is going to be better in the long term, than the work of one small selected team or individual.
**17:04** - *Saron Yitbarek*
I think what we're getting at here is that gaming isn't finished building communities, you're never going to stamp out that open source spirit.
**17:14** - *Saron Yitbarek*
Here's what we know: gaming still inspires legions of developers. It's what got a lot of Command Line Heroes into this industry in the first place. Command Line Heroes like Josh Berkis.
**17:28** - *Josh Berkus*
Well, I started out on the Atari 800, because you could design your own video games.
**17:34** - *Saron Yitbarek*
And Ann Barcomb.
**17:36** - *Ann Barcomb*
I wrote choose your own adventure games mostly. And it was horrible spaghetti code.
**17:42** - *Saron Yitbarek*
And Justin Flory.
**17:43** - *Justin Flory*
I started doing open source before I realized I was doing open source. I began with a game server, I was running a Minecraft server and at the time I was 15.
**17:54** - *Saron Yitbarek*
When there's this much love for something, this much community, open source attitudes are going to thrive. Saku's warnings about proprietary gaming elements are really just the hurdle that gaming has to overcome on its journey.
**18:09** - *Saron Yitbarek*
A few leaders in gaming are starting to make that leap.
**18:17** - *Kids playing Fortnite*
We actually did good.p>
**18:18** - *Kids playing Fortnite*
I was on freaking fire, I had 3 kills and they had one.
**18:21** - *Kids playing Fortnite*
Yeah, Campbell was carrying me.
**18:24** - *Saron Yitbarek*
If you've been anywhere near a 12-year-old this past year, you've likely heard of a little game called Fortnite. Well, little. In its first year, it gained more than 125 million players all interacting in a massive battle royale.
**18:43** - *Kid playing Fortnite*
I've got to, alright, one sec, I've just got to call my parents.
**18:47** - *Saron Yitbarek*
So, yeah, games are still pretty good at building community. In fact, Fortnite is the biggest free-to-play console game of all time. The studio behind it, Epic, also created the Unreal game engine, which Fortnite uses.
**19:02** - *Saron Yitbarek*
Lots of other games use Unreal, tool, because Epic released the Unreal engine to the world for free. It's not straight-up open source, but it is source-accessible. And that's well beyond what most studios do.
**19:16** - *Saron Yitbarek*
With Unreal engine, anybody can grab the source code. They didn't just make the code available though, they committed to building an answer hub, forums, developer support. Epic is doubling down on building as big and broad a community as possible.
**19:32** - *Saron Yitbarek*
And they're not alone. You've got full-on open source game engines like Godot and MonoGame, which are spawning their own development communities. Jared Sprague, a software engineer over at Red Hat, is part of a new generation that gets to use all these tools and engines to build amazing games they could never have built without those communities.
**19:55** - *Jared Sprague*
The indie game industry has grown a lot recently. So you've seen a while ago, like several years ago, most of the games were made by big studios. Those are still all out there, right, Nintendo and stuff.
**20:09** - *Jared Sprague*
The indie industry has exploded. And I think a lot of that is due to Steam, actually.
**20:17** - *Saron Yitbarek*
That'd be the Steam platform that lets developers incorporate things like in-game chat functionality, social-networking services, all that good stuff. They've been at this for about 15 years.
**20:29** - *Jared Sprague*
Steam made it possible for any game developer to get a game out in front of millions of people. There've been lots of big games that started as an indie, maybe just one or two people working on it that just exploded.
**20:48** - *Jared Sprague*
Minecraft is a perfect example. Started, just a guy, indie developer. And now it's one of the biggest games ever in history. But it's just an example of how indie has really become a major force in the game industry.
**21:06** - *Saron Yitbarek*
Jared's teamed up with his Red Hat pal, Michael Clayton, to produce game jams, where a bunch of indie game developers get together and build games in a short amount of time. Like a hackathon, but for games.
**21:17** - *Saron Yitbarek*
GitHub has one called Game Off. Jared's version is called Open Jam. If you ask him, it's part of a community-based game development future that could get much, much bigger.
**21:31** - *Jared Sprague*
You could use, like Linux, for example. Because it was open source and all these people could contribute to it and add tools and patches and stuff is what it made it so great. Way better than just one person could do on their own.
**21:47** - *Jared Sprague*
And I think there's still potential for a game or some sort of game system or virtual world that was open source, that thousands of people could contribute to build something bigger than one person could do.
**22:03** - *Saron Yitbarek*
It's already starting to happen, a shift towards open source attitudes in the gaming studios.
**22:10** - *Jordan Weisman*
I think the power of being able to enable your community to create is unquestioned.
**22:18** - *Saron Yitbarek*
Jordan Weisman's the co-founder of Harebrained Schemes. Crimson Skies, Battle Tech, Mech Warrior, those are all his. He's been deep in game development a long time. And what he's seeing now is a shift toward open source attitudes as studios start to realize the benefits.
**22:35** - *Jordan Weisman*
Even games like Battle Tech, which have a fair amount of ... We've tried to open up as much of the data of the game as possible to the audience. And we've seen the audience come up with amazing mods for the game. And it's super exciting for us to see where their creativity goes and what they've accomplished. And it engages players in different ways than our original content has.
**22:58** - *Jordan Weisman*
And that's a small example of what you can do. And as we go forward with our games, we're leaning on that even heavier, opening up more and more to allow players to express their creativity.
**23:10** - *Saron Yitbarek*
Jordan figures that a modifying culture helps his games become the best they can be. But, you know, like we hinted at with our D&D opener to this episode, that drive toward community was always there.
**23:24** - *Jordan Weisman*
They come from tabletop roots where it was a collaborative storytelling experience among the people at the table, between the game master and the players in an RPG. And as we moved into digital forms of those kinds of games, for a period of time, that was very separated.
**23:41** - *Jordan Weisman*
I think, as modding tools and democratization of the engines and tools that are accessible and moving to open sourcing, it kind of moves us back closer to that collaborative nature of creating this very social form of entertainment.
**23:58** - *Jordan Weisman*
So I think that's very exciting.
**24:01** - *Saron Yitbarek*
I think so too. As for Jared Sprague, he's teaming up with Michael Clayton, again, to build a brand new, community-driven, open source game. And it's called... Command Line Heroes.
**24:21** - *Saron Yitbarek*
Yep, we're officially a multi platform IP. And, naturally, the Command Line Heroes game is going to be an open source project. So we're inviting the community, that's you, yes you, to build this game with us. All we're starting with is a single objective.
**24:40** - *Saron Yitbarek*
Inspired by NASA, this is going to be a journey to Mars. The details? That's up to all of us, working together to hammer out. It'll be a web-based game, and we'll be working on it throughout this season of the podcast. The GitHub repos will be available to anybody who wants to contribute.
**24:59** - *Saron Yitbarek*
And, again, if you're listening to this, you are invited to get involved to build that game with us. Design a character, make a pull request. Or just play the beta and send us your feedback.
**25:21** - *Saron Yitbarek*
We're taking all the open source magic we talk about on this show and using it to build something together.
**25:22** - *Saron Yitbarek*
Fun fact: remember Colossal Cave Adventure? Well, while the code for that game was always accessible, Colossal finally went fully open source after 40 years. In 2017, the official version was released under a BSD Two Clause license.
**25:39** - *Saron Yitbarek*
Gaming communities have come a long way since those first interactive words.
**25:45** - *Voice actor*
You are standing at the end of a road...
**25:50** - *Saron Yitbarek*
And the thing is, we're not standing at the end of the road. This gaming road goes on and on. And along the way, games are helping us team up and build whole universes. Frankly, we don't know how our community will arrange themselves down this road.
**26:07** - *Saron Yitbarek*
But we do know games will be driving it. Because we never stop pressing start.
**26:15** - *Saron Yitbarek*
Want to learn more about early open source community and the origins of open source gaming? There's loads more content waiting for you over at the Command Line Heroes website. You can dig deeper by visiting redhat.com/comandlineheroes. Before we say goodbye, I want to let you know about a special treat we've got waiting for you over in the show notes. It's the story of Warren Robinett, who created the Atari game Adventure, a game inspired by Colossal Cave Adventure.
**26:48** - *Saron Yitbarek*
He tells us how a run-in with his bosses led to the creation of the very first video game Easter egg. It's a great story. A lovely part of our development history, but we wanted to give it the space it deserves.
**27:03** - *Saron Yitbarek*
So take a listen over at redhat.com/commandlineheroes.
**27:10** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Listen for free on Apple Podcasts, Google Podcasts, or wherever you do your thing.
**27:20** - *Saron Yitbarek*
I'm Saron Yitbarek, until next time, keep on coding.
### Keep going
### Go from gaming to Mars with season 2 of Red Hat's podcast series, Command Line Heroes
Check out what it means to live on the command line
### Command Line Heroes: The Game
All you need to know about the game and [Open Jam](https://opensource.com/article/18/9/open-jam-announcement). Or, jump [straight to github.](https://github.com/CommandLineHeroes/hero-engine)
### Colossal Cave Adventure: building and running 40-year-old code from the dawn of gaming
Find, build, and run the game that started it all.
Season 2, Episode 1 extra
### Easter Eggs

Warren Robinett wrote gaming's first Easter egg. Hear how he started this tradition.
[Listen to this episode later](#) |
12,579 | Linux 黑话解释:什么是桌面环境? | https://itsfoss.com/what-is-desktop-environment/ | 2020-09-03T23:00:00 | [
"桌面环境",
"DE"
] | https://linux.cn/article-12579-1.html | 
在桌面 Linux 世界中,最常用的术语之一就是<ruby> 桌面环境 <rt> Desktop Environment </rt></ruby>(DE)。如果你是 Linux 的新手,你应该了解一下这个经常使用的术语。
### 什么是 Linux 中的桌面环境?
桌面环境是一个组件的组合体,为你提供常见的<ruby> 图形用户界面 <rt> graphical user interface </rt></ruby>(GUI)元素组件,如图标、工具栏、壁纸和桌面小部件。借助桌面环境,你可以像在 Windows 中一样使用鼠标和键盘使用 Linux。
有几种不同的桌面环境,这些桌面环境决定了你的 Linux 系统的样子以及你与它的交互方式。
大多数桌面环境都有自己的一套集成的应用程序和实用程序,这样用户在使用操作系统时就能得到统一的感受。所以,你会得到一个文件资源管理器、桌面搜索、应用程序菜单、壁纸和屏保实用程序、文本编辑器等。
如果没有桌面环境,你的 Linux 系统就只有一个类似于终端的实用程序,你只能用命令与之交互。

### Linux 中各种桌面环境
桌面环境有时也被简称为 DE。
如前所述,Linux 有[各种桌面环境可供选择](https://itsfoss.com/best-linux-desktop-environments/)。为什么这么说呢?
可以把桌面环境看成是衣服。衣服决定了你的样子。如果你穿紧身牛仔裤和平底鞋,你会很好看,但穿着这些衣服跑步或登山就不舒服了。
[GNOME](https://www.gnome.org/) 这样桌面环境注重现代的外观和用户体验,而像 [Xfce](https://www.xfce.org/) 这样的桌面环境更注重使用更少的计算资源,而不是花哨的图形。

你的衣服取决于你的需要,决定了你的外观,桌面环境也是如此。你必须决定你是想要一些好看的东西,还是让你的系统运行得更快。
一些[流行的桌面环境](https://itsfoss.com/best-linux-desktop-environments/)有:
* GNOME - 使用大量的系统资源,但给你一个现代的、精致的系统
* Xfce - 外观复古但占用资源很少
* KDE - 可高度定制的桌面,适度占用系统资源
* LXDE - 唯一的重点是尽可能少地使用资源
* Budgie - 现代的外观和适度占用系统资源
### Linux 发行版及其桌面环境变体
同样的桌面环境可以在多个 Linux 发行版上使用,一个 Linux 发行版也可能提供多个桌面环境。
例如,Fedora 和 Ubuntu 都默认使用 GNOME 桌面,但 Fedora 和 Ubuntu 都提供了其他桌面环境。
Linux 的优点和灵活性在于,你可以自己在任何 Linux 发行版上安装桌面环境。但大多数 Linux 发行版都为你省去了这个麻烦,并为不同的桌面环境提供了随时安装的 ISO 镜像。
例如 [Manjaro Linux](https://manjaro.org/) 默认使用 Xfce,但如果你喜欢在 Manjaro 上使用 GNOME,也可以下载 GNOME 版本的 ISO。
### 最后...
桌面环境是 Linux 桌面计算机的重要组成部分,而 Linux 服务器通常依靠命令行界面。并不是说不能在 Linux 服务器上安装桌面环境,但这是画蛇添足,浪费了重要的系统资源,而这些资源可以被服务器上运行的应用程序所利用。
我希望你现在对 Linux 中的桌面环境有了一些了解。我强烈推荐你阅读我的[关于什么是 Linux 以及为什么有这么多 Linux 发行版](https://itsfoss.com/what-is-linux/)的解释文章。我很有预感,你会喜欢我用它做的比喻。
---
via: <https://itsfoss.com/what-is-desktop-environment/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

One of the most commonly used terms in the desktop Linux world is **Desktop Environment** (DE). If you are new to Linux, you should understand this frequently used term.
## What is Desktop Environment in Linux?
A desktop environment is the **bundle of components that provide you with common graphical user interface (GUI) elements **such as icons, toolbars, wallpapers, and desktop widget**s**. Thanks to the desktop environment, you can use Linux graphically using your mouse and keyboard like you do in other operating systems like Windows and macOS.
There are several desktop environments, and these determine what your Linux system looks like and how you interact with it.
Most of the desktop environments have their set of integrated applications and utilities so that users get a uniform feel while using the OS. So, you get a file explorer, desktop search, menu of applications, wallpaper and screensaver utilities, text editors and more.
Without a desktop environment, your Linux system will just have a terminal-like utility, and you will have to interact with it using commands only.
## Different desktop environments in Linux
As I mentioned earlier, there are [various desktop environments available for Linux](https://itsfoss.com/best-linux-desktop-environments/). Why so?
Think of the desktop environments as clothes. The clothes determine what you look like. If you wear skinny jeans and flat shoes, you would look good, but running or hiking in those clothes won’t be comfortable.
Some desktop environments such as [GNOME](https://www.gnome.org/?ref=itsfoss.com) focus on a modern look and user experience, while desktop environments like [Xfce](https://www.xfce.org/?ref=itsfoss.com) focus more on using fewer computing resources than on fancy graphics.
Your clothes depend on your need and determine your looks, the same is the case with the desktop environments. You have to decide whether you want something that looks good or something that lets your system run faster.
Some [popular desktop environments](https://itsfoss.com/best-linux-desktop-environments/) are:
- GNOME – Uses plenty of system resources but gives you a modern, polished system
- Xfce – Vintage look but light on resources
- KDE – Highly customizable desktop with moderate usage of system resources
- LXDE – The entire focus is on using as few resources as possible
- Budgie – Modern looks and moderate on system resources
[8 Best Desktop Environments For LinuxA list of the best Linux Desktop Environments with their pros and cons. Have a look and see which desktop environment you should use.](https://itsfoss.com/best-linux-desktop-environments/)

## Linux distributions and their DE variants

The same desktop environment can be available on several Linux distributions, and a Linux distribution may offer several desktop environments.
For example, Fedora and Ubuntu both use the GNOME desktop by default. But both Fedora and Ubuntu offer other desktop environments.
The beauty and flexibility of Linux is that you can install a desktop environment on any Linux distribution by yourself. But most Linux distributions save you this trouble and offer a ready-to-install ISO image for different desktop environments.
For example, [Manjaro Linux](https://manjaro.org/?ref=itsfoss.com) uses Xfce by default, but you can also download the ISO of the GNOME version if you prefer using GNOME with Manjaro.
## In the end…
Desktop environments are a crucial part of the Linux desktop. However, in the case of Linux servers, they usually rely on a command line interface.
It’s not that you cannot install a desktop environment on Linux servers, but it’s an overkill and waste of important system resources which can be utilized by the applications running on the server.
I hope you have a slightly better understanding of desktop environments in Linux now. I highly recommend reading my explainer article on [what is Linux](https://itsfoss.com/what-is-linux/) and why there are so many Linux distributions. I have a good feeling that you’ll love the analogy I have used:
[What is Linux? Why There are 100’s of Linux OS?Cannot figure out what is Linux and why there are so many of Linux? This analogy explains things in a simpler manner.](https://itsfoss.com/what-is-linux/)
 |
12,581 | 很快你就能在 Linux Mint 上将任何网站转化为桌面应用程序了 | https://itsfoss.com/web-app-manager-linux-mint/ | 2020-09-04T20:31:24 | [
"网页"
] | https://linux.cn/article-12581-1.html | 设想一下,你正忙于一项任务且需要在浏览器中打开超过 20 个页面,大多数页面都和工作有关。
还有一些是 YouTube 或其他音乐流媒体网站。
完成任务后需要关闭浏览器,但这会将包括工作相关和听音乐的网页等所有网页一起关掉。
然后你需要再次打开这些网页并登录账号以回到原来的进度。
这看起来令人沮丧,对吧?Linux Mint 理解你的烦恼,因此有了下面这个新项目帮助你应对这些问题。

在[最近的一篇文章](https://blog.linuxmint.com/?p=3960)中,Linux Mint 团队披露了正在开发一个名叫“<ruby> 网页应用管理器 <rt> Web App Manager </rt></ruby>”的新工具。
该工具让你能够像使用桌面程序那样以独立窗口运行你最喜爱的网页。
在将网页添加为网页应用程序的时候,你可以给这个程序取名字并添加图标。也可以将它添加到不同的分类,以便在菜单中搜索这个应用。还可以指定用什么浏览器打开应用。启用/禁用导航栏的选项也有。

例如,将 YouTube 添加为网页应用程序:

运行 YouTube 程序将通过你所使用的浏览器打开一个独立的页面。

网页应用程序拥有常规桌面应用程序有的大多数功能特点,如使用 `Alt+Tab` 切换。

甚至还能将应用固定到面板/任务栏方便打开。

该管理器目前处于 beta 开发阶段,但已经使用起来已经相对比较稳定了。不过目前还没有面向大众发放,因为翻译工作还未完成。
如果你在使用 Linux Mint 并想尝试这个工具,可在下方下载 beta 版本的 deb 文件:
* [下载 beta 版](http://www.linuxmint.com/tmp/blog/3960/webapp-manager_1.0.3_all.deb)
### 网页应用的好处
有读者问到这个网页应用管理器与 Chrome 和其他一些网页浏览器中已有的其他类似功能相比的好处。让我来展开一下这个话题。
* 你可以使用 URL 的特定部分([example.com/tool](http://example.com/tool) 而不是 [example.com](http://example.com))作为应用程序。
* 添加自定义图标的可能性对于没有清晰的 favicon 的网站来说非常方便。
* 你可以使用一个没有任何扩展的轻量级浏览器来打开网页应用,而不是像 Chrome/Chromium 这样的常规网页浏览器。它的速度应该更快。
* 你的网页应用可以被整合到应用菜单中。你可以像其他应用程序一样搜索它。
### 网页应用程序在桌面环境的 Linux 中不是什么新事物
网页应用程序不是由 Linux Mint 独创的,而是早在大约 10 年前就有了。
你可能还记得 Ubuntu 在 2013-2014 年向 Unity 桌面中加入了网页应用程序这项特性。
轻量级 Linux 发行版 PeppermintOS 自 2010 年起就将 ICE(网页应用程序工具)列为其主要特色之一。实际上,Linux Mint 的网页应用程序管理器也是基于 [ICE](https://github.com/peppermintos/ice) 的。
我个人喜欢网页应用程序,因为有用。
你怎么看 Linux Mint 中的网页应用程序呢,这是你期待使用的吗?欢迎在下方评论。
---
via: <https://itsfoss.com/web-app-manager-linux-mint/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[koolape](https://github.com/koolape) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Imagine this situation. You are working on a certain topic and you have more than twenty tabs open in your web browser, mostly related to the work.
Some of these tabs are for YouTube or some other music streaming website you are listening to.
You finished the work on the topic and close the browser. Your intent was to close all the work related tabs but it also closed the tabs that you were using for listening to music or some other activities.
Now you’ll have to log in to those websites again and find the track you were listening to or whatever you were doing.
Frustrating, isn’t it? Linux Mint understands your pain and they have an upcoming project to help you out in such scenario.
## Linux Mint’s Web App Manager

In a [recent post](https://blog.linuxmint.com/?p=3960), Linux Mint team revealed that it is working on a new tool called Web App Manager.
The Web App Manager tool will allow you to launch your favorite websites and have them run in their own window as if they were desktop applications.
While adding a website as a Web App, you can give it a custom name and icon. You can also give it a different category. This will help you search this app in the menu.
You may also specify which web browser you want the Web App to be opened in. Option for enabling/disabling navigation bar is also there.
Say, you add YouTube as a Web App:
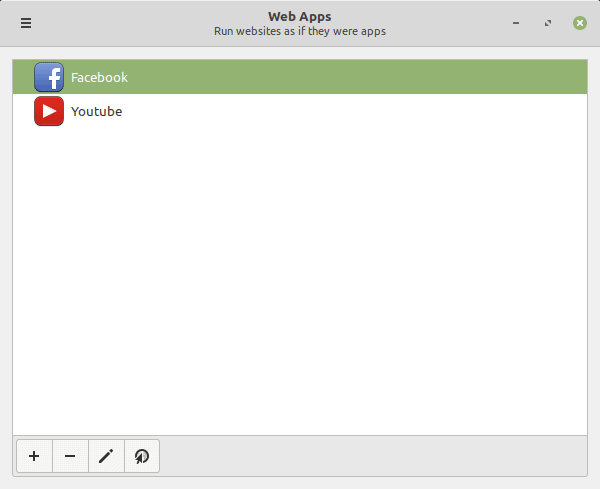
If you run this YouTube Web App, YouTube will now run in its own window and in a browser of your choice.
The Web App has most of the features you see in a regular desktop application. You can use it in Alt+Tab switcher:
You can even pin the Web App to the panel/taskbar for quick access.
The Web App Manager is in beta right now but it is fairly stable to use. It is not translation ready right now and this is why it is not released to the public.
If you are using Linux Mint and want to try the Web App Manager, you can download the DEB file for the beta version of this app from the link below:
## Benefits of the web apps
Some readers asked about the benefits of this Web App Manager over other similar feature already available in Chrome and some other web browsers. Let me expand on this topic.
- You can use a specific part of the URL (example.com/tool instead of example.com) as an app.
- The possibility of adding custom icons comes handy for websites without a clear fevicon.
- You can use a lightweight browser without any extension to open the web app instead of the regular web browser like Chrome/Chromium. It should be faster.
- Your web app is integrated into the application menu. You can search for it like any other application.
## Web apps are not new to desktop Linux
This is not something ground breaking from Linux Mint. Web apps have been on the scene for almost a decade now.
If you remember, Ubuntu had added the web app feature to its Unity desktop in 2013-14.
The lightweight Linux distribution PeppermintOS lists ICE (tool for web apps) as its main feature since 2010. In fact, Linux Mint’s Web App manager is based on Peppermint OS’s [ICE](https://github.com/peppermintos/ice).
Personally, I like web apps feature. It has its usefulness.
What do you think of Web Apps in Linux Mint? Is it something you look forward to use? Do share your views in the comment section.
[interaction id=”5f4f3bbf52874d57761b26bc”] |
12,582 | 在你的 Android 手机上创建和运行 Python 应用 | https://opensource.com/article/20/8/python-android-mobile | 2020-09-04T21:49:00 | [
"Python",
"手机",
"安卓"
] | https://linux.cn/article-12582-1.html |
>
> 使用 Termux 和 Flask 在你的移动设备上创建、开发和运行一个网页应用。
>
>
>

学习和使用 Python 是很有趣的。由于它越来越受欢迎,有越来越多的方式可以让计算世界比现在更好。
想象一下,只需一个 Android 移动设备和开源工具,就可以构建和运行一个 Python 应用,无论是开发一个命令行工具从互联网上获取你最喜欢的文章,还是启动一个直接在掌上设备运行的网页服务器,所有这些都可以实现。这将完全改变你对移动设备的看法,将它从一个仅仅让你消费内容的设备变成一个帮助你发挥创造力的设备。
在本文中,我将演示运行和测试一个简单的 Python 应用所需的所有的工具、软件包、步骤和各种零零散散的东西。我使用 [Flask 框架](https://opensource.com/article/18/4/flask)来创建一个简单的 “Hello, World!” 应用,并在一个简单而强大的网页服务器上运行。最棒的是,这一切都发生在手机上。不需要笔记本或台式机。
### 在 Android 上安装 Termux
首先,[安装 Termux 应用程序](https://opensource.com/article/20/8/termux)。Termux 是一个强大的终端仿真器,它提供了所有最流行的 Linux 命令,加上数百个额外的包,以便于安装。它不需要任何特殊的权限,你可以使用默认的 [Google Play](https://play.google.com/store/apps/details?id=com.termux) 商店或开源应用仓库 [F-Droid](https://f-droid.org/repository/browse/?fdid=com.termux) 来安装。

安装 Termux 后,启动它并使用 Termux 的 `pkg` 命令执行一些必要的软件安装。
订阅附加仓库 `root-repo`:
```
$ pkg install root-repo
```
执行更新,使所有安装的软件达到最新状态。
```
$ pkg update
```
最后,安装 Python:
```
$ pkg install python
```

安装和自动配置完成后,就可以构建你的应用了。
### 在 Android 上构建一个 Android 应用
现在你已经安装了一个终端,你可以在很大程度上像使用另一台 Linux 电脑一样使用你的 Android 手机。这很好地展示了终端到底有多强大。
首先创建一个项目目录:
```
$ mkdir Source
$ cd Source
```
接下来,创建一个 Python 虚拟环境。这是 Python 开发者的常见做法,它有助于让你的 Python 项目独立于你的开发系统(在本例中是你的手机)。在你的虚拟环境中,你将能够安装特定于你应用的 Python 模块。
```
$ python -m venv venv
```
激活你的新虚拟环境(注意,开头的两个点用空格隔开)
```
$ . ./venv/bin/activate
(env)$
```
请注意你的 shell 提示符现在以 `(env)` 开头,表示你在虚拟环境中。
现在使用 `pip` 安装 Flask Python 模块。
```
(env) $ pip install flask
```
### 在 Android 上写 Python 代码
你已经准备好了。现在你需要为你的应用编写代码。
要做到这一点,你需要有经典文本编辑器的经验。我使用的是 `vi`。如果你不熟悉 `vi`,请安装并试用 `vimtutor`,它(如其名称所暗示的)可以教你如何使用这个编辑器。如果你有其他你喜欢的编辑器,如 `jove`、`jed`、`joe` 或 `emacs`,你可以安装并使用其中一个。
现在,由于这个演示程序非常简单,你也可以直接使用 shell 的 heredoc 功能,它允许你直接在提示符中输入文本。
```
(env)$ cat << EOF >> hello_world.py
> from flask import Flask
> app = Flask(__name__)
>
> @app.route('/')
> def hello_world():
> return 'Hello, World!'
> EOF
(env)$
```
这只有六行代码,但有了它,你可以导入 Flask,创建一个应用,并将传入流量路由到名为 `hello_world` 的函数。

现在你已经准备好了网页服务器的代码。现在是时候设置一些[环境变量](https://opensource.com/article/19/8/what-are-environment-variables),并在你的手机上启动一个网页服务器了。
```
(env) $ export FLASK_APP=hello_world.py
(env) $ export FLASK_ENV=development
(evn) $ python hello_world.py
```

启动应用后,你会看到这条消息:
```
serving Flask app… running on http://127.0.0.1:5000/
```
这表明你现在在 localhost(也就是你的设备)上运行着一个微型网页服务器。该服务器正在监听来自 5000 端口的请求。
打开你的手机浏览器并进入到 `http://localhost:5000`,查看你的网页应用。

你并没有损害手机的安全性。你只运行了一个本地服务器,这意味着你的手机不接受来自外部世界的请求。只有你可以访问你的 Flask 服务器。
为了让别人看到你的服务器,你可以在 `run` 命令中加入 `--host=0.0.0.0` 来禁用 Flask 的调试模式。这会打开你的手机上的端口,所以要谨慎使用。
```
(env) $ export FLASK_ENV=””
(env) $ flask run –host=0.0.0.0
```
按 `Ctrl+C` 停止服务器(使用特殊的 `Termux` 键来作为 `Ctrl` 键)。
### 决定下一步怎么做
你的手机可能不是一个严肃的网页应用的理想服务器平台,但这个例子证明了可能性是无限的。你可能会在 Android 手机上编程,只是因为这是一种方便的实践方式,或者因为你有一个令人兴奋的本地化网页应用的新想法,或者你只是碰巧使用 Flask 应用来完成自己的日常任务。正如爱因斯坦曾经说过的“想象力比知识更重要”,对于任何一个新手编码者,或者一个经验丰富的 Linux 或 Android 爱好者来说,这是一个有趣的小项目。它可以扩展到无穷的层次,所以让你的好奇心接手,并做出一些令人兴奋的东西!
---
via: <https://opensource.com/article/20/8/python-android-mobile>
作者:[Phani Adabala](https://opensource.com/users/adabala) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Learning and using Python is fun. Thanks to its growing popularity, there are a plethora of ways it can be used to make the world of computing better than what it is today.
Imagine building and running python applications, whether it's a command-line tool developed to fetch your favorite curated articles from the Internet, or starting a web server that runs right in the palm of your hand, all with just an Android mobile device and open source tools. This would change how you view your mobile device entirely, changing it from a device that merely lets you consume content to a device that helps you be creative.
In this article, I'll demonstrate all of the tools, software packages, steps, and all the bells and whistles required to build, run, and test a simple Python application on any Android mobile device. I use the [Flask framework](https://opensource.com/article/18/4/flask) to create a simple “Hello, World!” app running on a simple but powerful web server. And best of all, it all happens on the phone. No laptop or desktop required.
## Install Termux on Android
First, [install the Termux application](https://opensource.com/article/20/8/termux). Termux is a powerful terminal emulator that offers all the most popular Linux commands, plus hundreds of additional packages for easy installation. It doesn't require any special permissions You can use either the default [Google Play](https://play.google.com/store/apps/details?id=com.termux) store or the open source app repository [F-Droid](https://f-droid.org/repository/browse/?fdid=com.termux) to install.
Once you have installed Termux, launch it and perform a few requisite software installations using Termux's **pkg** command:
Subscribe to the additional repository “root-repo”:
`$ pkg install root-repo`
Perform an update to bring all the installed software up to date:
`$ pkg update`
Finally, install Python:
`$ pkg install python`
Once the installation and auto set-up of configuration is complete, it’s time to build your application.
## Build an app for Android on Android
Now that you have a terminal installed, you can work on your Android phone largely as if it were just another Linux computer. This is a great demonstration of just how powerful a terminal really is.
Start by creating a project directory:
```
$ mkdir Source
$ cd Source
```
Next, create a Python virtual environment. This is a common practice among Python developers, and it helps keep your Python project independent of your development system (in this case, your phone). Within your virtual environment, you'll be able to install Python modules specific to your app.
`$ python -m venv venv`
Activate your new virtual environment (note that the two dots at the start are separated by a space):
```
$ . ./venv/bin/activate
(env)$
```
Notice that your shell prompt is now preceded by** (env) **to indicate that you're in a virtual environment.
Now install the Flask Python module using **pip**:
`(env) $ pip install flask`
## Write Python code on Android
You're all set up. All you need now is to write the code for your app.
To do this, you should have experience with a classic text editor. I use **vi**. If you’re unfamiliar with **vi**, install and try the **vimtutor** application, which (as its name suggests) can teach you how to use this editor. If you have a different editor you prefer, such as **jove**, **jed**, **joe**, or **emacs**, you can install and use one of those instead.
For now, because this demonstration app is so simple, you can also just use the shell's **heredoc** function, which allows you to enter text directly at your prompt:
```
(env)$ cat << EOF >> hello_world.py
> from flask import Flask
> app = Flask(__name__)
>
> @app.route('/')
> def hello_world():
> return 'Hello, World!'
> EOF
(env)$
```
That's just six lines of code, but with that you import Flask, create an app, and route incoming traffic to the function called **hello_world**.
Now you have the web-server code ready. It's time to set up some [environment variables](https://opensource.com/article/19/8/what-are-environment-variables) and start a web server on your phone.
```
(env) $ export FLASK_APP=hello_world.py
(env) $ export FLASK_ENV=development
(evn) $ python hello_world.py
```
After starting your app, you see this message:
`serving Flask app… running on http://127.0.0.1:5000/`
This indicates that you now have a tiny web server running on **localhost** (that is, your device). This server is listening for requests looking for port 5000.
Open your mobile browser and navigate to ** http://localhost:5000 **to see your web app.
You haven't compromised your phone's security. You're only running a local server, meaning that your phone isn't accepting requests from the outside world. Only you can access your Flask server.
To make your server visible to others, you can disable Flask's debugging mode by adding **--host=0.0.0.0** to the **run** command. This does open ports on your phone, so use this wisely.
```
(env) $ export FLASK_ENV=””
(env) $ flask run –host=0.0.0.0
```
Stop the server by pressing **Ctrl+C **(use the special Termux key for Control).
## Decide what comes next
Your phone is probably not the ideal server platform for a serious web app, but this demonstrates that the possibilities are endless. You might program on your Android phone just because it’s a convenient way to stay in practice, or because you have an exciting new idea for localized web apps, or maybe you just happen to use a Flask app for your own daily tasks. As Einstein once said “Imagination is more important than knowledge”, and this is a fun little project for any new coder, or a seasoned Linux or Android enthusiast. It can be expanded to endless levels, so let your curiosity take over, and make something exciting!
## 2 Comments |
12,585 | 关系造就成功——律师护航开源的三种方式 | https://opensource.com/article/20/8/open-source-legal-organization | 2020-09-06T10:02:36 | [
"开源",
"律师"
] | https://linux.cn/article-12585-1.html |
>
> 开源法规之所以独特,是因为它对成功的要求比较特殊。一起来了解开源组织的律师如何帮助其雇主达成目标。
>
>
>

我是<ruby> 红帽公司 <rp> ( </rp> <rt> Red Hat </rt> <rp> ) </rp></ruby>的一名开源律师,我工作中的一个重要部分是向其他公司(包括其内部法律顾问)提供有关红帽公司如何采用完全开源的开发模式来构建企业级产品的信息,并回答他们有关开源许可的一般问题。在听了红帽公司的成功经验之后,这些律师与我对话的话题常常转变为其所在组织如何发展成为更具开源意识和能力的组织,他们也经常询问我如何改善他们的做法,以便更熟练地为其组织的雇员提供开源法律咨询。
在本文和下一篇文章中,我想阐述一下针对这些话题我通常对企业内部法律顾问是怎么说的。如果你不是内部法律顾问,而是在软件领域为客户提供法律服务的律师事务所,你可能还会发现此信息也很有用。(如果你正在考虑上法学院并成为一名开源律师,则应在进入开源律师职业之前阅读 Luis Villa 的出色文章《[在入坑成为开源律师之前先要知道的那些事儿](https://opensource.com/article/16/12/open-source-lawyer)》)
我的观点基于我在各种工程实践、产品管理和律师职位上的个人经验,并且这种经验可能非常独特。我的非典型背景意味着我能通过与大多数律师不同的视角看世界。因此,下面介绍的想法可能不是传统做法,但是在我的实践中它们对我很有帮助,希望对你也有所帮助。
### 一、与开源组织保持联系
许多开源组织对开源律师来说特别有用,其中不少组织对开源许可协议的观点和解释具有可以衡量的影响。可以考虑加入一些著名组织,例如<ruby> <a href="https://opensource.org/"> 开源促进组织 </a> <rp> ( </rp> <rt> Open Source Initiative </rt> <rp> ) </rp></ruby>(OSI)、<ruby> <a href="https://sfconservancy.org/"> 软件自由保护组织 </a> <rp> ( </rp> <rt> Software Freedom Conservancy </rt> <rp> ) </rp></ruby>、<ruby> <a href="https://www.softwarefreedom.org/"> 软件自由法律中心 </a> <rp> ( </rp> <rt> Software Freedom Law Center </rt> <rp> ) </rp></ruby>、<ruby> <a href="https://www.fsf.org/"> 自由软件基金会 </a> <rp> ( </rp> <rt> Free Software Foundation </rt> <rp> ) </rp></ruby>(FSF)、<ruby> <a href="https://fsfe.org/index.en.html"> 欧洲自由软件基金会 </a> <rp> ( </rp> <rt> Free Software Foundation Europe </rt> <rp> ) </rp></ruby>和<ruby> <a href="https://www.linuxfoundation.org/"> Linux 基金会 </a> <rp> ( </rp> <rt> Linux Foundation </rt> <rp> ) </rp></ruby>。还有许多有用的邮件列表值得追踪甚至参与,例如 OSI 有关许可协议讨论和许可协议审查的邮件列表。
参加这些组织和列表将帮助你了解在落实开源法规时可能遇到的无数独特问题,比如社区如何解释开源许可协议文本里的各种术语。没有什么判例法可以指导你,但是有很多人乐于帮助你回答问题,这些资源是最好的指导来源。这也许是落实开源法规的非常独特而令人惊奇的一个方面——开发社区的开放性与法律社区提供观点和建议的开放性相匹配。你只要问就行啦!
### 二、采用业务经理的思维方式,并找到实现目标的途径
产品经理最终要对产品或服务的全周期负责,其中当然也包括让其产品或服务进入市场。由于我的职业生涯的大部分时间都花在服务产品管理型组织上,所以我的思路是无论如何要寻找一条途径,将可行的产品或服务推向市场。我鼓励所有律师都采用这种思维方式,因为产品和服务是所有企业的命脉。
因此,在发现问题并为面临风险的客户提供建议的法律实践中,我一直采用的方法是始终以寻找通向“YES”的途径为目标,尤其是当我的分析影响产品/服务开发和发布时。在为企业内部评估法律问题时,我的团队或我有时可能会认为风险过高。在这种情况下,请继续鼓励每个人都致力于去解决问题,因为以我的经验,解决方案最终会以一种意想不到的方式呈现出来。
确保利用你的所有资源,包括你的软件开发客户(参见下文),因为它们可以成为解决问题(通常使用技术来解决问题)的创造性方法的绝佳来源。我对这种方法感到非常高兴,我的客户似乎也对此感到满意。我鼓励所有律师考虑这种做法。
可悲的是,内部法律顾问出于自我保护总是很容易说“NO”,并消除可能对企业造成任何风险的因素。我总是发现这种回应是站不住脚的。所有商业交易都有风险。作为法律顾问,你必须了解这些风险并将其呈现给你的客户,以便他们做出有根据的业务决策。在存在任何风险时简单地说“NO”,而没有提供任何缓解风险的其他情境或途径,对组织的长期成功不利。企业需要提供产品和服务才能生存,你应该尽可能地帮助它找到通向“YES”的道路。当然,在某些情况下,你可以负有道德责任地说“NO”,但首先请穷尽所有合理的选择。
### 三、与开发人员建立积极关系
与你的软件开发客户建立积极关系绝对至关重要。融洽和信任是加强这些关系的两种重要方法。
#### 1、融洽
你作为开源律师的成功通常是与软件开发人员建立积极关系的直接结果。在许多情况下,你的软件开发人员是你的法律建议的直接或间接接受者,他们将寻求你的指导和咨询。不幸的是,许多软件开发人员对律师持怀疑态度,并经常将律师视为其开发和发布软件能力的障碍。克服这种弊端的最好方法是与客户建立融洽的关系。对于大多数人来说,操作方式有所不同,但是这里有一些建议。
对客户的工作表现出兴趣:对他们项目的细节、项目的工作方式、底层的编程语言、它如何与其他系统连接以及如何使公司受益感到好奇。在确定法律风险和减轻风险的方法时,其中一些答案将在你的法律分析中很有用,但是更重要的是,这为与客户保持积极的关系打下了坚实的基础。
让你的客户清楚,你正在努力寻找通向“YES”的途径:让你的客户知道你对他们项目的某些方面感到担忧,但随后提出减轻这些担忧的想法。向他们保证,与他们一起找到解决方案,而不是成为障碍。但是这里面不能夸大其词。
参与一个开源项目:如果你具有软件开发经验,则尤其应当如此。即使你没有这样的经验,也可以通过多种方式参与,例如帮助编制文档或进行社区拓展。或仅仅是为了更多地了解他们的工作,要求参加他们的进度会议。这也让你可以按需实时提供顾问服务,以便团队可以在此过程的早期进行纠正。
#### 2、信任
你的软件开发人员在其开源社区中非常活跃,并且是了解当前影响开源软件和开发问题的最佳资源。当你与当地的律师协会或国家层面的法律组织等保持联系,以了解最新法律进展时,你还应该与各种软件开发资源进行定期沟通,并就各种事项征求他们的意见(例如,对于此许可协议应用于某项目,社区的观点是什么?)。
### 四、关系造就成功
开源法规之所以独特,是因为其对成功的不寻常要求,其成功即是与其他开源律师、开源组织的联系以及与客户的深厚和互相尊重的关系。成功是这些关系的直接成果。
在本系列的第二部分中,我将探讨为什么给你的组织找到“开放”之路并开发可扩展的解决方案是如此重要,并告诉你如何去做。
---
作者简介:Jeffrey R. Kaufman 是全球领先的开源软件解决方案供应商<ruby> 红帽公司 <rp> ( </rp> <rt> Red Hat </rt> <rp> ) </rp></ruby>开源法务团队的资深商务法律顾问,还担任<ruby> 北卡罗来纳大学 <rp> ( </rp> <rt> University of North Carolina </rt> <rp> ) </rp></ruby>的兼职法律教授。在任职红帽公司之前,Jeffrey 曾担任<ruby> 高通公司 <rp> ( </rp> <rt> Qualcomm </rt> <rp> ) </rp></ruby>的专利和开源法律顾问。
译者简介:薛亮,集慧智佳知识产权咨询公司互联网事业部总监,擅长专利分析、专利布局、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | I am an open source lawyer for Red Hat. One important part of my job is to provide information to other companies, including their in-house counsel, about how Red Hat builds enterprise-class products with a completely open source development model and answering their questions about open source licensing in general. After hearing about Red Hat's success, these conversations often turn to discussions about how their organization can evolve to be more open source-aware and -capable, and lawyers at these meetings regularly ask how they can modify their practices to be more skilled in providing open source counsel to their employees.
In this article and the next, I'll convey what I normally tell in-house counsel about these topics. If you are not in-house counsel and instead work for a law firm supporting clients in the software space, you may also find this information useful. (If you are considering going to law school and becoming an open source lawyer, you should read Luis Villa's excellent article [ What to know before jumping into a career as an open source lawyer](https://opensource.com/article/16/12/open-source-lawyer).)
My perspective is based on my personal and possibly unique experience working in various engineering, product management, and lawyer roles. My atypical background means I see the world through a different lens from most lawyers. So, the ideas presented below may not be traditional, but they have served me well in my practice, and I hope they will benefit you.
## Connect with open source organizations
There are a multitude of open source organizations that are especially useful to open source lawyers. Many of these organizations have measurable influence over the views and interpretations of open source licenses. Consider getting involved with some of the more prominent organizations, such as the [Open Source Initiative](https://opensource.org/) (OSI), the [Software Freedom Conservancy](https://sfconservancy.org/), the [Software Freedom Law Center](https://www.softwarefreedom.org/), the [Free Software Foundation](https://www.fsf.org/), [Free Software Foundation Europe](https://fsfe.org/index.en.html), and the [Linux Foundation](https://www.linuxfoundation.org/). There are also a number of useful mailing lists, such as OSI's [license-discuss](https://lists.opensource.org/mailman/listinfo/license-discuss_lists.opensource.org) and [license-review](https://lists.opensource.org/mailman/listinfo/license-review_lists.opensource.org), that are worth monitoring and even participating in.
Participating in these groups and lists will help you understand the myriad and unique issues you may encounter when practicing open source law, including how various terms of the open source license texts are interpreted by the community. There is little case law to guide you, but there are plenty of people happy to help answer questions, and these resources are the best source of guidance. This is perhaps one of the very unique and amazing aspects of practicing open source law—the openness of the development community is equally matched by the openness of the legal community to provide perspective and advice. All you have to do is ask.
## Adopt the mindset of a business manager and find a path to yes
Product managers are ultimately held responsible for a product or service from cradle to grave, including enabling that product or service to get to market. Since the bulk of my career has been spent leading product-management organizations, my mind is programmed to find a path, no matter how, to get a viable product or service to market. I encourage any lawyer to adopt this mindset since products and services are the lifeblood of any business.
As such, the approach I have always taken in my legal practice involves issue spotting and advising clients of risk *but always having the objective of finding a path to "YES*," especially when my analysis impacts product/service development and release. When evaluating legal issues for internal clients, my executive management or I may, at times, view the risk to be too high. In such cases, continue encouraging everyone to work on the problem because, in my experience, solutions do eventually present themselves, often in unexpected ways.
Be sure to tap all your resources, including your software development clients (see below), as they can be an excellent source of creative approaches to solving problems, often using technology to resolve issues. I have found much joy in this method, and my clients seem pleased with this passion and sentiment. I encourage all lawyers to consider this approach.
Sadly, it is always easy to say "no" for self-preservation and to eliminate what may appear to be *any* risk to the company. I have always found this response untenable. All business transactions have risk. As a counselor, it is your job to understand these risks and present them to your clients so that they may make educated business decisions. Simply saying "no" when any risk is present, without providing any additional context or other paths forward to mitigate risks, does no good for the long-term success of the organization. Companies need to provide products and services to survive, and you should be helping find that path, whenever possible, to YES. You have an ethical responsibility to say "no" in certain situations, of course, but explore and exhaust all reasonable options first.
## Build relationships with developers
Building relationships with your software development clients is *absolutely critical*. Building rapport and trust with developers are two important ways to strengthen these relationships.
### Build rapport
Your success as an open source lawyer is most often a direct result of your positive relationships with your software developers. In many cases, your software developers are the direct or indirect recipients of your legal advice, and they will be looking to you for guidance and counsel. Unfortunately, many software developers are suspicious of lawyers and often view lawyers as obstacles to their ability to develop and release software. The best way to overcome this ill will is to build rapport with your clients. How you do that is different for most people, but here are some ideas.
**Show an interest in your clients' work:**Be inquisitive about the details of their project, how it works, the underlying programming language, how it connects to other systems, and how it will benefit the company. Some of these answers will be useful in your legal analysis when ascertaining legal risk and ways to mitigate such risk, but more importantly, this builds a solid foundation for an ongoing positive relationship with your client.**Be clear to your client that you are working to find a path to YES:**It is perfectly acceptable to let your client know you are concerned about certain aspects of their project, but follow that up with ideas for mitigating those concerns. Reassure them that it is your job to work with them to find a solution and not to be a roadblock. The effect of this cannot be overstated.**Participate in an open source project:**This is especially true if you have software development experience. Even if you do not have such experience, there are many ways to participate, such as helping with documentation or community outreach. Or request to join their status meetings just to learn more about their work. This will also allow you to provide counsel on-demand and in real time so that the team may course-correct early in the process.
### Have trust
Your software developers are very active in their open source communities and are some of the best resources for understanding current issues affecting open source software and development. Just as you connect with legal organizations, like your local bar or national legal organizations to keep current on the latest legal developments, you should also engage with your software development resources for periodic briefings and to gain their counsel on various matters (e.g., how would the community view the use of this license for a project?).
## Relationships breed success
Open source law is unique because of its unusual requirements for success, namely, connections to other open source attorneys, open source organizations, and a deep and respectful relationship with clients. Success is a direct function of these relationships.
In part two of this series, I will explore how and why it is important to find a path to "open" and to develop scalable solutions for your organization.
## Comments are closed. |
12,586 | 自定义你的 GNOME 桌面主题 | https://opensource.com/article/20/8/gnome-themes | 2020-09-06T11:01:46 | [
"GNOME"
] | https://linux.cn/article-12586-1.html |
>
> 使用“优化”和它的用户主题扩展来改变你的 Linux UI。
>
>
>

GNOME 是一个相当简单和精简的 Linux 图形用户界面(GUI),很多用户喜欢它的简约外观。虽然它基本上是开箱即用的,但你可以根据自己的喜好来定制 [GNOME](https://www.gnome.org/) 。有了 GNOME “优化” 和用户主题扩展,你可以改变顶部栏、窗口标题栏、图标、光标和许多其他 UI 选项的外观。
### 开始使用
在你改变你的 GNOME 主题之前,你必须安装 “<ruby> <a href="https://wiki.gnome.org/Apps/Tweaks"> 优化 </a> <rt> Tweaks </rt></ruby>” 并启用用户主题扩展。
#### 安装 GNOME “优化”
你可以在 GNOME “软件”中找到“优化”,只需点击一个按钮就可以快速安装。

如果你喜欢命令行,请使用你的软件包管理器。例如,在 Fedora 或 CentOS 上:
```
$ sudo dnf install gnome-tweaks
```
在 Debian 或类似的发行版:
```
$ sudo apt install gnome-tweaks
```
#### 启用用户主题
要启用用户主题扩展,启动“优化”并选择“<ruby> 扩展 <rt> Extensions </rt></ruby>”。找到 “用户主题User themes”,点击滑块启用。

### 获取主题
现在你已经完成了这些预先条件,你已经准备好寻找和下载一些主题了。一个寻找新主题的好网站是 [GNOME-Look.org](https://www.gnome-look.org)。
在页面的左侧有一个主题类别的列表。当你找到一个你想要的主题,你需要下载它。我直接把 `.tar` 文件下载到我的家目录下的 `.themes` 目录(你可能需要先创建这个目录)。
```
$ mkdir ~/.themes
```
如果你想让所有用户都能使用这个主题,请把它放在 `/usr/share/themes` 中。
```
$ tar xvf theme_archive.tar.xz
```
下载后,解压压缩包。你可以删除 `.tar.xz` 文件以节省一些磁盘空间。
### 应用主题
要应用你的新主题,在“优化”中进入“<ruby> 外观 <rt> Appearance </rt></ruby>”。在这里,你可以为你的桌面的每个方面选择不同的选项。

### 多样性是生活的调剂品
自从第一个图形界面面市以来,能够用不同的墙纸、颜色、字体等个性化电脑桌面一直是一个受欢迎的功能。GNOME “优化”和用户主题扩展可以在所有 GNU/Linux 操作系统上的 GNOME 桌面环境中实现这种自定义。而且开源社区还在持续提供广泛的主题、图标、字体和壁纸,任何人都可以下载、尝试和定制。
你最喜欢的 GNOME 主题是什么,你为什么喜欢它们?请在评论中分享。
---
via: <https://opensource.com/article/20/8/gnome-themes>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | GNOME is a fairly simple and streamlined Linux graphical user interface (GUI), and a lot of users appreciate its minimalist look. Although it's pretty basic out of the box, you can customize [GNOME](https://www.gnome.org/) to match your preferences. Thanks to GNOME Tweaks and the user themes extension, you can change the look and feel of the top bar, window title bars, icons, cursors, and many other UI options.
## Get started
Before you can change your GNOME theme, you have to install [Tweaks](https://wiki.gnome.org/Apps/Tweaks) and enable the user themes extension.
### Install GNOME Tweaks
You can find Tweaks in the GNOME Software Center, where you can install it quickly with just the click of a button.
(Alan Formy-Duval, CC BY-SA 4.0)
If you prefer the command line, use your package manager. For instance, on Fedora or CentOS:
`$ sudo dnf install gnome-tweaks`
On Debian or similar:
`$ sudo apt install gnome-tweaks`
### Enable user themes
To enable the user themes extension, launch Tweaks and select **Extensions**. Find **User themes** and click the slider to enable it.
(Alan Formy-Duval, CC BY-SA 4.0)
## Get a theme
Now that you've completed those prerequisites, you're ready to find and download some themes. A great site to find new themes is [GNOME-Look.org](https://www.gnome-look.org).
There's a list of theme categories on the left-hand side of the page. Once you find a theme you want, you need to download it. I downloaded the `.tar`
file directly to the `.themes`
directory under my home directory (you may need to create the directory first):
`$ mkdir ~/.themes`
If you want all the machine's users to be able to use the theme, place it in `/usr/share/themes`
.
`$ tar xvf theme_archive.tar.xz`
Once you have downloaded the file, extract the archive. You can delete the `.tar.xz`
file to save some disk space.
## Apply a theme
To apply your new theme, go to the **Appearance** section in Tweaks. Here, you can select different options for each aspect of your desktop.
(Alan Formy-Duval, CC BY-SA 4.0)
## Variety is the spice of life
Being able to personalize a computer desktop with different wallpaper, colors, fonts, and more has been a popular feature since the first graphical interfaces hit the market. GNOME Tweaks and the user themes extension enable this customization on the GNOME desktop environment on all the GNU/Linux operating systems where it is available. And the open source community continues to provide a wide range of themes, icons, fonts, and wallpapers that anyone can download, play with, and customize.
What are your favorite GNOME themes, and why do you like them? Please share in the comments.
## 5 Comments |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.