
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
10,563 | 5 个好用的开发者 Vim 插件 | https://opensource.com/article/19/1/vim-plugins-developers | 2019-02-23T11:11:55 | [
"Vim",
"开发"
] | https://linux.cn/article-10563-1.html |
>
> 通过这 5 个插件扩展 Vim 功能来提升你的编码效率。
>
>
>

我用 Vim 已经超过 20 年了,两年前我决定把它作为我的首要文本编辑器。我用 Vim 来编写代码、配置文件、博客文章及其它任意可以用纯文本表达的东西。Vim 有很多超级棒的功能,一旦你适合了它,你的工作会变得非常高效。
在日常编辑工作中,我更倾向于使用 Vim 稳定的原生功能,但开源社区对 Vim 开发了大量的插件,可以扩展 Vim 的功能、改进你的工作流程和提升工作效率。
以下列举 5 个非常好用的可以用于编写任意编程语言的插件。
### 1、Auto Pairs
[Auto Pairs](https://www.vim.org/scripts/script.php?script_id=3599) 插件可以帮助你插入和删除成对的文字,如花括号、圆括号或引号。这在编写代码时非常有用,因为很多编程语言都有成对标记的语法,就像圆括号用于函数调用,或引号用于字符串定义。
Auto Pairs 最基本的功能是在你输入一个左括号时会自动补全对应的另一半括号。比如,你输入了一个 `[`,它会自动帮你补充另一半 `]`。相反,如果你用退格键删除开头的一半括号,Auto Pairs 会删除另一半。
如果你设置了自动缩进,当你按下回车键时 Auto Pairs 会在恰当的缩进位置补全另一半括号,这比你找到放置另一半的位置并选择一个正确的括号要省劲多了。
例如下面这段代码:
```
package main
import "fmt"
func main() {
x := true
items := []string{"tv", "pc", "tablet"}
if x {
for _, i := range items
}
}
```
在 `items` 后面输入一个左花括号按下回车会产生下面的结果:
```
package main
import "fmt"
func main() {
x := true
items := []string{"tv", "pc", "tablet"}
if x {
for _, i := range items {
| (cursor here)
}
}
}
```
Auto Pairs 提供了大量其它选项(你可以在 [GitHub](https://github.com/jiangmiao/auto-pairs) 上找到),但最基本的功能已经很让人省时间了。
### 2、NERD Commenter
[NERD Commenter](https://github.com/scrooloose/nerdcommenter) 插件给 Vim 增加了代码注释的功能,类似在 <ruby> IDE <rt> integrated development environment </rt></ruby> 中注释功能。有了这个插件,你可以一键注释单行或多行代码。
NERD Commenter 可以与标准的 Vim [filetype](http://vim.wikia.com/wiki/Filetype.vim) 插件配合,所以它能理解一些编程语言并使用合适的方式来注释代码。
最易上手的方法是按 `Leader+Space` 组合键来切换注释当前行。Vim 默认的 Leader 键是 `\`。
在<ruby> 可视化模式 <rt> Visual mode </rt></ruby>中,你可以选择多行一并注释。NERD Commenter 也可以按计数注释,所以你可以加个数量 n 来注释 n 行。
还有个有用的特性 “Sexy Comment” 可以用 `Leader+cs` 来触发,它的块注释风格更漂亮一些。例如下面这段代码:
```
package main
import "fmt"
func main() {
x := true
items := []string{"tv", "pc", "tablet"}
if x {
for _, i := range items {
fmt.Println(i)
}
}
}
```
选择 `main` 函数中的所有行然后按下 `Leader+cs` 会出来以下注释效果:
```
package main
import "fmt"
func main() {
/*
* x := true
* items := []string{"tv", "pc", "tablet"}
*
* if x {
* for _, i := range items {
* fmt.Println(i)
* }
* }
*/
}
```
因为这些行都是在一个块中注释的,你可以用 `Leader+Space` 组合键一次去掉这里所有的注释。
NERD Commenter 是任何使用 Vim 写代码的开发者都必装的插件。
### 3、VIM Surround
[Vim Surround](https://www.vim.org/scripts/script.php?script_id=1697) 插件可以帮你“环绕”现有文本插入成对的符号(如括号或双引号)或标签(如 HTML 或 XML 标签)。它和 Auto Pairs 有点儿类似,但是用于处理已有文本,在编辑文本时更有用。
比如你有以下一个句子:
```
"Vim plugins are awesome !"
```
当你的光标处于引起来的句中任何位置时,你可以用 `ds"` 组合键删除句子两端的双引号。
```
Vim plugins are awesome !
```
你也可以用 `cs"'` 把双端的双引号换成单引号:
```
'Vim plugins are awesome !'
```
或者再用 `cs'[` 替换成中括号:
```
[ Vim plugins are awesome ! ]
```
它对编辑 HTML 或 XML 文本中的<ruby> 标签 <rt> tag </rt></ruby>尤其在行。假如你有以下一行 HTML 代码:
```
<p>Vim plugins are awesome !</p>
```
当光标在 “awesome” 这个单词的任何位置时,你可以按 `ysiw<em>` 直接给它加上着重标签(`<em>`):
```
<p>Vim plugins are <em>awesome</em> !</p>
```
注意它聪明地加上了 `</em>` 闭合标签。
Vim Surround 也可以用 `ySS` 缩进文本并加上标签。比如你有以下文本:
```
<p>Vim plugins are <em>awesome</em> !</p>
```
你可以用 `ySS<div class="normal">` 加上 `div` 标签,注意生成的段落是自动缩进的。
```
<div class="normal">
<p>Vim plugins are <em>awesome</em> !</p>
</div>
```
Vim Surround 有很多其它选项,你可以参照 [GitHub](https://github.com/tpope/vim-surround) 上的说明尝试它们。
### 4、Vim Gitgutter
[Vim Gitgutter](https://github.com/airblade/vim-gitgutter) 插件对使用 Git 作为版本控制工具的人来说非常有用。它会在 Vim 的行号列旁显示 `git diff` 的差异标记。假设你有如下已提交过的代码:
```
1 package main
2
3 import "fmt"
4
5 func main() {
6 x := true
7 items := []string{"tv", "pc", "tablet"}
8
9 if x {
10 for _, i := range items {
11 fmt.Println(i)
12 }
13 }
14 }
```
当你做出一些修改后,Vim Gitgutter 会显示如下标记:
```
1 package main
2
3 import "fmt"
4
_ 5 func main() {
6 items := []string{"tv", "pc", "tablet"}
7
~ 8 if len(items) > 0 {
9 for _, i := range items {
10 fmt.Println(i)
+ 11 fmt.Println("------")
12 }
13 }
14 }
```
`_` 标记表示在第 5 行和第 6 行之间删除了一行。`~` 表示第 8 行有修改,`+` 表示新增了第 11 行。
另外,Vim Gitgutter 允许你用 `[c` 和 `]c` 在多个有修改的块之间跳转,甚至可以用 `Leader+hs` 来暂存某个变更集。
这个插件提供了对变更的即时视觉反馈,如果你用 Git 的话,有了它简直是如虎添翼。
### 5、VIM Fugitive
[Vim Fugitive](https://www.vim.org/scripts/script.php?script_id=2975) 是另一个将 Git 工作流集成到 Vim 中的超棒插件。它对 Git 做了一些封装,可以让你在 Vim 里直接执行 Git 命令并将结果集成在 Vim 界面里。这个插件有超多的特性,更多信息请访问它的 [GitHub](https://github.com/tpope/vim-fugitive) 项目页面。
这里有一个使用 Vim Fugitive 的基础 Git 工作流示例。设想我们已经对下面的 Go 代码做出修改,你可以用 `:Gblame` 调用 `git blame` 来查看每行最后的提交信息:
```
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
```
可以看到第 8 行和第 11 行显示还未提交。用 `:Gstatus` 命令检查仓库当前的状态:
```
1 # On branch master
2 # Your branch is up to date with 'origin/master'.
3 #
4 # Changes not staged for commit:
5 # (use "git add <file>..." to update what will be committed)
6 # (use "git checkout -- <file>..." to discard changes in working directory)
7 #
8 # modified: vim-5plugins/examples/test1.go
9 #
10 no changes added to commit (use "git add" and/or "git commit -a")
--------------------------------------------------------------------------------------------------------
1 package main
2
3 import "fmt"
4
_ 5 func main() {
6 items := []string{"tv", "pc", "tablet"}
7
~ 8 if len(items) > 0 {
9 for _, i := range items {
10 fmt.Println(i)
+ 11 fmt.Println("------")
12 }
13 }
14 }
```
Vim Fugitive 在分割的窗口里显示 `git status` 的输出结果。你可以在该行按下 `-` 键用该文件的名字暂存这个文件的提交,再按一次 `-` 可以取消暂存。这个信息会随着你的操作自动更新:
```
1 # On branch master
2 # Your branch is up to date with 'origin/master'.
3 #
4 # Changes to be committed:
5 # (use "git reset HEAD <file>..." to unstage)
6 #
7 # modified: vim-5plugins/examples/test1.go
8 #
--------------------------------------------------------------------------------------------------------
1 package main
2
3 import "fmt"
4
_ 5 func main() {
6 items := []string{"tv", "pc", "tablet"}
7
~ 8 if len(items) > 0 {
9 for _, i := range items {
10 fmt.Println(i)
+ 11 fmt.Println("------")
12 }
13 }
14 }
```
现在你可以用 `:Gcommit` 来提交修改了。Vim Fugitive 会打开另一个分割窗口让你输入提交信息:
```
1 vim-5plugins: Updated test1.go example file
2 # Please enter the commit message for your changes. Lines starting
3 # with '#' will be ignored, and an empty message aborts the commit.
4 #
5 # On branch master
6 # Your branch is up to date with 'origin/master'.
7 #
8 # Changes to be committed:
9 # modified: vim-5plugins/examples/test1.go
10 #
```
按 `:wq` 保存文件完成提交:
```
[master c3bf80f] vim-5plugins: Updated test1.go example file
1 file changed, 2 insertions(+), 2 deletions(-)
Press ENTER or type command to continue
```
然后你可以再用 `:Gstatus` 检查结果并用 `:Gpush` 把新的提交推送到远程。
```
1 # On branch master
2 # Your branch is ahead of 'origin/master' by 1 commit.
3 # (use "git push" to publish your local commits)
4 #
5 nothing to commit, working tree clean
```
Vim Fugitive 的 GitHub 项目主页有很多屏幕录像展示了它的更多功能和工作流,如果你喜欢它并想多学一些,快去看看吧。
### 接下来?
这些 Vim 插件都是程序开发者的神器!还有另外两类开发者常用的插件:自动完成插件和语法检查插件。它些大都是和具体的编程语言相关的,以后我会在一些文章中介绍它们。
你在写代码时是否用到一些其它 Vim 插件?请在评论区留言分享。
---
via: <https://opensource.com/article/19/1/vim-plugins-developers>
作者:[Ricardo Gerardi](https://opensource.com/users/rgerardi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pityonline](https://github.com/pityonline) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I have used [Vim](https://www.vim.org/) as a text editor for over 20 years, but about two years ago I decided to make it my primary text editor. I use Vim to write code, configuration files, blog articles, and pretty much everything I can do in plaintext. Vim has many great features and, once you get used to it, you become very productive.
I tend to use Vim's robust native capabilities for most of what I do, but there are a number of plugins developed by the open source community that extend Vim's capabilities, improve your workflow, and make you even more productive.
Following are five plugins that are useful when using Vim to write code in any programming language.
## 1. Auto Pairs
The [Auto Pairs](https://www.vim.org/scripts/script.php?script_id=3599) plugin helps insert and delete pairs of characters, such as brackets, parentheses, or quotation marks. This is very useful for writing code, since most programming languages use pairs of characters in their syntax—such as parentheses for function calls or quotation marks for string definitions.
In its most basic functionality, Auto Pairs inserts the corresponding closing character when you type an opening character. For example, if you enter a bracket **[**, Auto-Pairs automatically inserts the closing bracket **]**. Conversely, if you use the Backspace key to delete the opening bracket, Auto Pairs deletes the corresponding closing bracket.
If you have automatic indentation on, Auto Pairs inserts the paired character in the proper indented position when you press Return/Enter, saving you from finding the correct position and typing the required spaces or tabs.
Consider this Go code block for instance:
```
package main
import "fmt"
func main() {
x := true
items := []string{"tv", "pc", "tablet"}
if x {
for _, i := range items
}
}
```
Inserting an opening curly brace **{** after **items** and pressing Return/Enter produces this result:
```
package main
import "fmt"
func main() {
x := true
items := []string{"tv", "pc", "tablet"}
if x {
for _, i := range items {
| (cursor here)
}
}
}
```
Auto Pairs offers many other options (which you can read about on [GitHub](https://github.com/jiangmiao/auto-pairs)), but even these basic features will save time.
## 2. NERD Commenter
The [NERD Commenter](https://github.com/scrooloose/nerdcommenter) plugin adds code-commenting functions to Vim, similar to the ones found in an integrated development environment (IDE). With this plugin installed, you can select one or several lines of code and change them to comments with the press of a button.
NERD Commenter integrates with the standard Vim [filetype](http://vim.wikia.com/wiki/Filetype.vim) plugin, so it understands several programming languages and uses the appropriate commenting characters for single or multi-line comments.
The easiest way to get started is by pressing **Leader+Space** to toggle the current line between commented and uncommented. The standard Vim Leader key is the **\** character.
In Visual mode, you can select multiple lines and toggle their status at the same time. NERD Commenter also understands counts, so you can provide a count *n* followed by the command to change *n* lines together.
Other useful features are the "Sexy Comment," triggered by **Leader+cs**, which creates a fancy comment block using the multi-line comment character. For example, consider this block of code:
```
package main
import "fmt"
func main() {
x := true
items := []string{"tv", "pc", "tablet"}
if x {
for _, i := range items {
fmt.Println(i)
}
}
}
```
Selecting all the lines in **function main** and pressing **Leader+cs** results in the following comment block:
```
package main
import "fmt"
func main() {
/*
* x := true
* items := []string{"tv", "pc", "tablet"}
*
* if x {
* for _, i := range items {
* fmt.Println(i)
* }
* }
*/
}
```
Since all the lines are commented in one block, you can uncomment the entire block by toggling any of the lines of the block with **Leader+Space**.
NERD Commenter is a must-have for any developer using Vim to write code.
## 3. VIM Surround
The [Vim Surround](https://www.vim.org/scripts/script.php?script_id=1697) plugin helps you "surround" existing text with pairs of characters (such as parentheses or quotation marks) or tags (such as HTML or XML tags). It's similar to Auto Pairs but, instead of working while you're inserting text, it's more useful when you're editing text.
For example, if you have the following sentence:
`"Vim plugins are awesome !"`
You can remove the quotation marks around the sentence by pressing the combination **ds"** while your cursor is anywhere between the quotation marks:
`Vim plugins are awesome !`
You can also change the double quotation marks to single quotation marks with the command **cs"'**:
`'Vim plugins are awesome !'`
Or replace them with brackets by pressing **cs'[**
`[ Vim plugins are awesome ! ]`
While it's a great help for text objects, this plugin really shines when working with HTML or XML tags. Consider the following HTML line:
`<p>Vim plugins are awesome !</p>`
You can emphasize the word "awesome" by pressing the combination **ysiw<em>** while the cursor is anywhere on that word:
`<p>Vim plugins are <em>awesome</em> !</p>`
Notice that the plugin is smart enough to use the proper closing tag **</em>**.
Vim Surround can also indent text and add tags in their own lines using **ySS**. For example, if you have:
`<p>Vim plugins are <em>awesome</em> !</p>`
Add a **div** tag with this combination: **ySS<div class="normal">**, and notice that the paragraph line is indented automatically.
```
<div class="normal">
<p>Vim plugins are <em>awesome</em> !</p>
</div>
```
Vim Surround has many other options. Give it a try—and consult [GitHub](https://github.com/tpope/vim-surround) for additional information.
## 4. Vim Gitgutter
The [Vim Gitgutter](https://github.com/airblade/vim-gitgutter) plugin is useful for anyone using Git for version control. It shows the output of **Git diff** as symbols in the "gutter"—the sign column where Vim presents additional information, such as line numbers. For example, consider the following as the committed version in Git:
```
1 package main
2
3 import "fmt"
4
5 func main() {
6 x := true
7 items := []string{"tv", "pc", "tablet"}
8
9 if x {
10 for _, i := range items {
11 fmt.Println(i)
12 }
13 }
14 }
```
After making some changes, Vim Gitgutter displays the following symbols in the gutter:
```
1 package main
2
3 import "fmt"
4
_ 5 func main() {
6 items := []string{"tv", "pc", "tablet"}
7
~ 8 if len(items) > 0 {
9 for _, i := range items {
10 fmt.Println(i)
+ 11 fmt.Println("------")
12 }
13 }
14 }
```
The **-** symbol shows that a line was deleted between lines 5 and 6. The **~** symbol shows that line 8 was modified, and the symbol **+** shows that line 11 was added.
In addition, Vim Gitgutter allows you to navigate between "hunks"—individual changes made in the file—with **[c** and **]c**, or even stage individual hunks for commit by pressing **Leader+hs**.
This plugin gives you immediate visual feedback of changes, and it's a great addition to your toolbox if you use Git.
## 5. VIM Fugitive
[Vim Fugitive](https://www.vim.org/scripts/script.php?script_id=2975) is another great plugin for anyone incorporating Git into the Vim workflow. It's a Git wrapper that allows you to execute Git commands directly from Vim and integrates with Vim's interface. This plugin has many features—check its [GitHub](https://github.com/tpope/vim-fugitive) page for more information.
Here's a basic Git workflow example using Vim Fugitive. Considering the changes we've made to the Go code block on section 4, you can use **git blame** by typing the command **:Gblame**:
```
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
```
You can see that lines 8 and 11 have not been committed. Check the repository status by typing **:Gstatus**:
```
1 # On branch master
2 # Your branch is up to date with 'origin/master'.
3 #
4 # Changes not staged for commit:
5 # (use "git add <file>..." to update what will be committed)
6 # (use "git checkout -- <file>..." to discard changes in working directory)
7 #
8 # modified: vim-5plugins/examples/test1.go
9 #
10 no changes added to commit (use "git add" and/or "git commit -a")
--------------------------------------------------------------------------------------------------------
1 package main
2
3 import "fmt"
4
_ 5 func main() {
6 items := []string{"tv", "pc", "tablet"}
7
~ 8 if len(items) > 0 {
9 for _, i := range items {
10 fmt.Println(i)
+ 11 fmt.Println("------")
12 }
13 }
14 }
```
Vim Fugitive opens a split window with the result of **git status**. You can stage a file for commit by pressing the **-** key on the line with the name of the file. You can reset the status by pressing **-** again. The message updates to reflect the new status:
```
1 # On branch master
2 # Your branch is up to date with 'origin/master'.
3 #
4 # Changes to be committed:
5 # (use "git reset HEAD <file>..." to unstage)
6 #
7 # modified: vim-5plugins/examples/test1.go
8 #
--------------------------------------------------------------------------------------------------------
1 package main
2
3 import "fmt"
4
_ 5 func main() {
6 items := []string{"tv", "pc", "tablet"}
7
~ 8 if len(items) > 0 {
9 for _, i := range items {
10 fmt.Println(i)
+ 11 fmt.Println("------")
12 }
13 }
14 }
```
Now you can use the command **:Gcommit** to commit the changes. Vim Fugitive opens another split that allows you to enter a commit message:
```
1 vim-5plugins: Updated test1.go example file
2 # Please enter the commit message for your changes. Lines starting
3 # with '#' will be ignored, and an empty message aborts the commit.
4 #
5 # On branch master
6 # Your branch is up to date with 'origin/master'.
7 #
8 # Changes to be committed:
9 # modified: vim-5plugins/examples/test1.go
10 #
```
Save the file with **:wq** to complete the commit:
```
[master c3bf80f] vim-5plugins: Updated test1.go example file
1 file changed, 2 insertions(+), 2 deletions(-)
Press ENTER or type command to continue
```
You can use **:Gstatus** again to see the result and **:Gpush** to update the remote repository with the new commit.
```
1 # On branch master
2 # Your branch is ahead of 'origin/master' by 1 commit.
3 # (use "git push" to publish your local commits)
4 #
5 nothing to commit, working tree clean
```
If you like Vim Fugitive and want to learn more, the GitHub repository has links to screencasts showing additional functionality and workflows. Check it out!
## What's next?
These Vim plugins help developers write code in any programming language. There are two other categories of plugins to help developers: code-completion plugins and syntax-checker plugins. They are usually related to specific programming languages, so I will cover them in a follow-up article.
Do you have another Vim plugin you use when writing code? Please share it in the comments below.
## 3 Comments |
10,564 | 如何在 Emacs 中使用 Magit 管理 Git 项目 | https://opensource.com/article/19/1/how-use-magit | 2019-02-23T22:58:04 | [
"Git",
"Emacs",
"Magit"
] | https://linux.cn/article-10564-1.html |
>
> Emacs 的 Magit 扩展插件使得使用 Git 进行版本控制变得简单起来。
>
>
>

[Git](https://git-scm.com) 是一个很棒的用于项目管理的 [版本控制](https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control) 工具,就是新人学习起来太难。Git 的命令行工具很难用,你不仅需要熟悉它的标志和选项,还需要知道什么环境下使用它们。这使人望而生畏,因此不少人只会非常有限的几个用法。
好在,现今大多数的集成开发环境 (IDE) 都包含了 Git 扩展,大大地简化了使用使用的难度。Emacs 中就有这么一款 Git 扩展名叫 [Magit](https://magit.vc)。
Magit 项目成立有差不多 10 年了,它将自己定义为 “一件 Emacs 内的 Git 瓷器”。也就是说,它是一个操作界面,每个操作都能一键完成。本文会带你领略一下 Magit 的操作界面并告诉你如何使用它来管理 Git 项目。
若你还没有做,请在开始本教程之前先 [安装 Emacs](https://www.gnu.org/software/emacs/download.html),再 [安装 Magit](https://magit.vc/manual/magit/Installing-from-Melpa.html#Installing-from-Melpa)。
### Magit 的界面
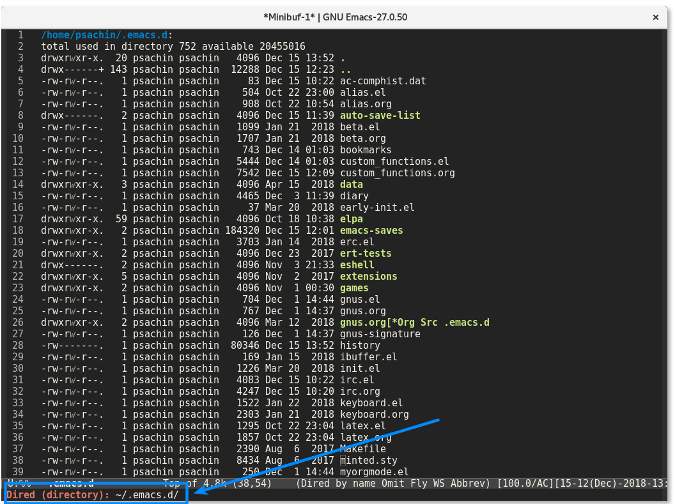
首先用 Emacs 的 [Dired 模式](https://www.gnu.org/software/emacs/manual/html_node/emacs/Dired-Enter.html#Dired-Enter) 访问一个项目的目录。比如我所有的 Emacs 配置存储在 `~/.emacs.d/` 目录中,就是用 Git 来进行管理的。

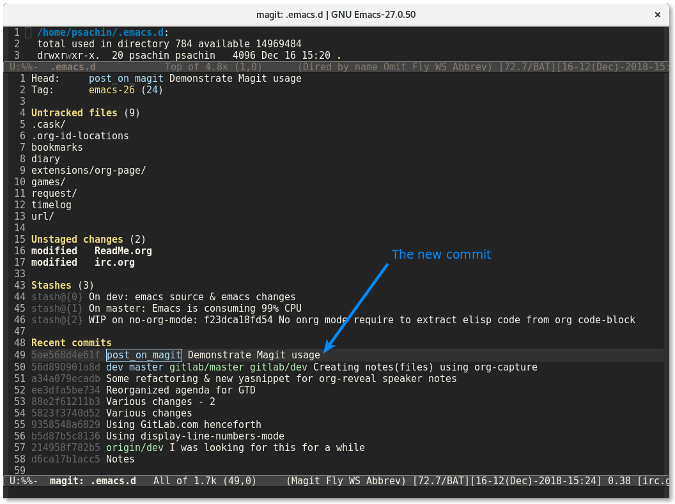
若你在命令行下工作,则你需要输入 `git status` 来查看项目的当前状态。Magit 也有类似的功能:`magit-status`。你可以通过 `M-x magit-status` (快捷方式是 `Alt+x magit-status` )来调用该功能。结果看起来像下面这样:

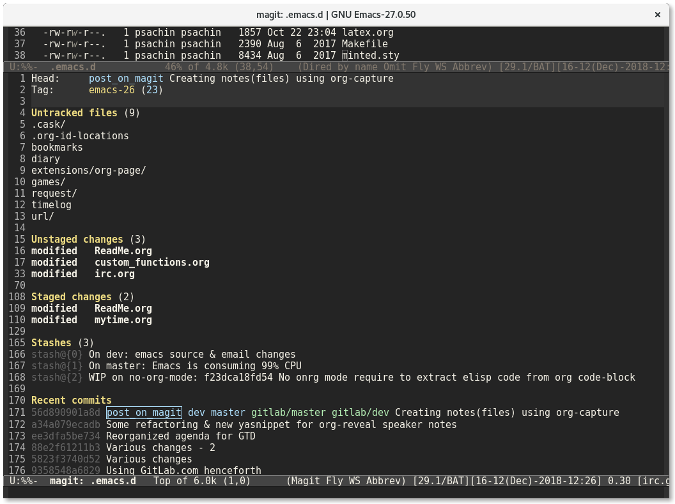
Magit 显示的信息比 `git status` 命令的要多得多。它分别列出了未追踪文件列表、未暂存文件列表以及已暂存文件列表。它还列出了<ruby> 储藏 <rt> stash </rt></ruby>列表以及最近几次的提交 —— 所有这些信息都在一个窗口中展示。
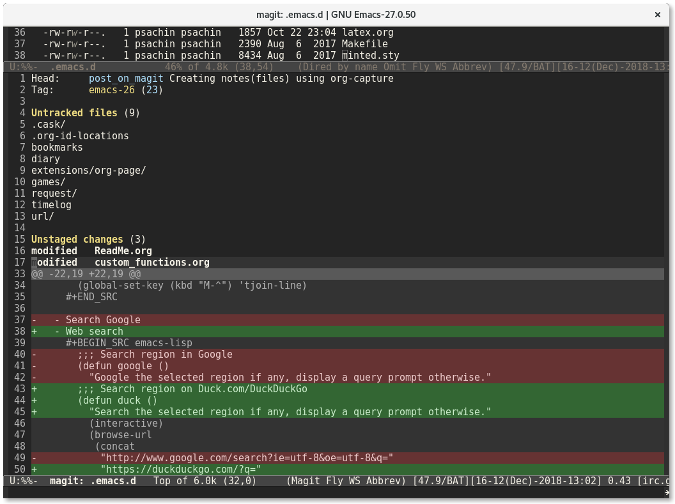
如果你想查看修改了哪些内容,按下 `Tab` 键。比如,我移动光标到未暂存的文件 `custom_functions.org` 上,然后按下 `Tab` 键,Magit 会显示修改了哪些内容:

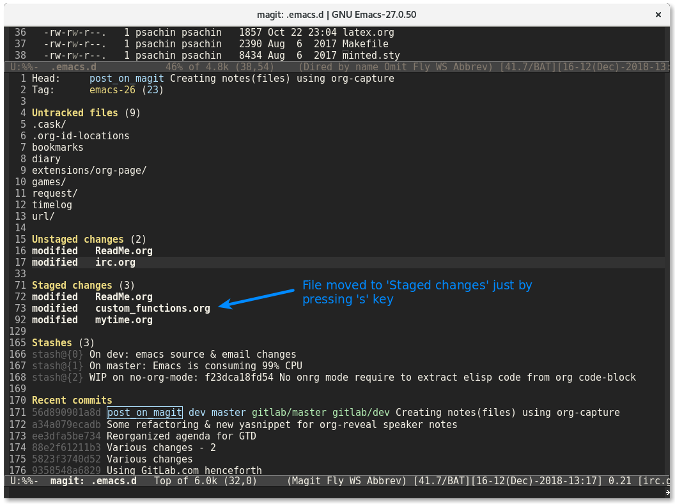
这跟运行命令 `git diff custom_functions.org` 类似。储藏文件更简单。只需要移动光标到文件上然后按下 `s` 键。该文件就会迅速移动到已储藏文件列表中:

要<ruby> 反储藏 <rt> unstage </rt></ruby>某个文件,使用 `u` 键。按下 `s` 和 `u` 键要比在命令行输入 `git add -u <file>` 和 `git reset HEAD <file>` 快的多也更有趣的多。
### 提交更改
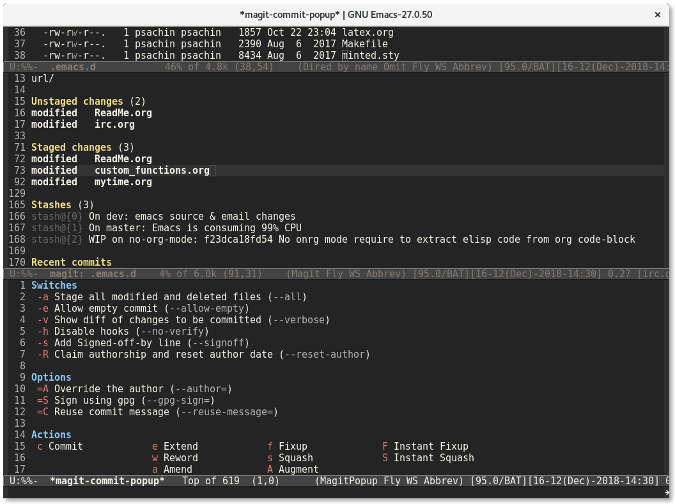
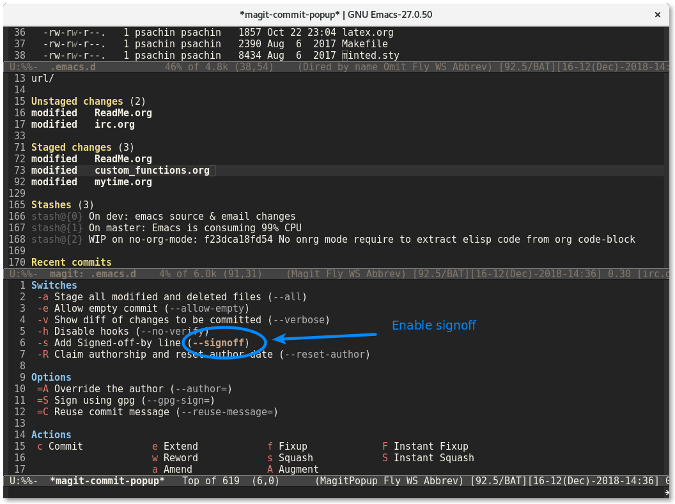
在同一个 Magit 窗口中,按下 `c` 键会显示一个提交窗口,其中提供了许多标志,比如 `--all` 用来暂存所有文件或者 `--signoff` 来往提交信息中添加签名行。

将光标移动到想要启用签名标志的行,然后按下回车。`--signoff` 文本会变成高亮,这说明该标志已经被启用。

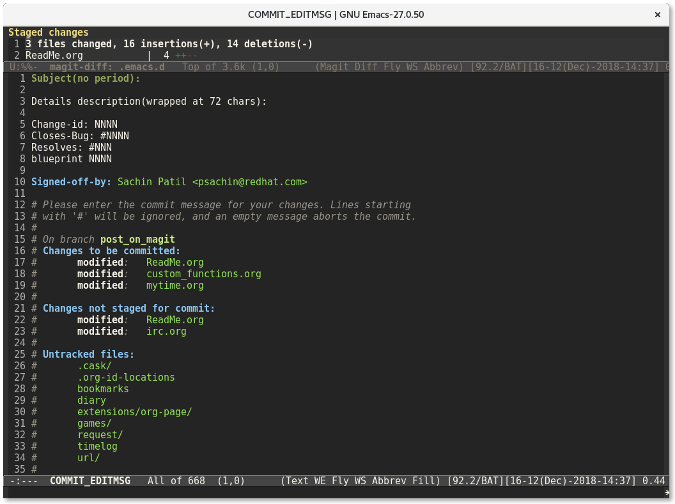
再次按下 `c` 键会显示一个窗口供你输入提交信息。

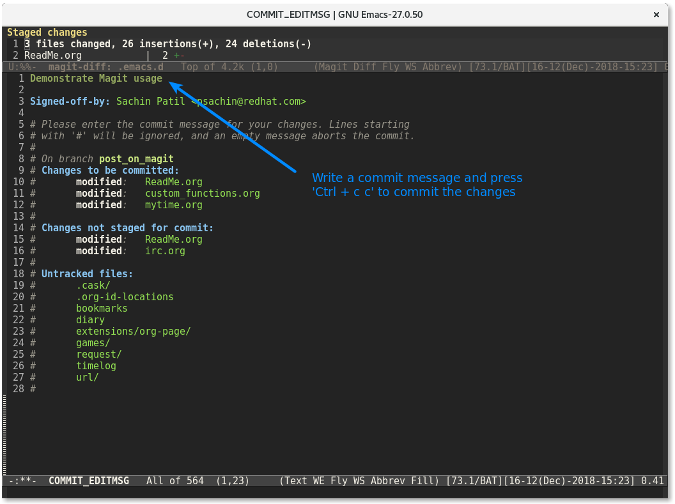
最后,使用 `C-c C-c`(按键 `Ctrl+cc` 的缩写形式) 来提交更改。

### 推送更改
更改提交后,提交行将会显示在 `Recent commits` 区域中显示。

将光标放到该提交处然后按下 `p` 来推送该变更。
若你想感受一下使用 Magit 的感觉,我已经在 YouTube 上传了一段 [演示](https://youtu.be/Vvw75Pqp7Mc)。本文只涉及到 Magit 的一点皮毛。它有许多超酷的功能可以帮你使用 Git 分支、变基等功能。你可以在 Magit 的主页上找到 [文档、支持,以及更多](https://magit.vc/) 的链接。
---
via: <https://opensource.com/article/19/1/how-use-magit>
作者:[Sachin Patil](https://opensource.com/users/psachin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Git](https://git-scm.com) is an excellent [version control](https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control) tool for managing projects, but it can be hard for novices to learn. It's difficult to work from the Git command line unless you're familiar with the flags and options and the appropriate situations to use them. This can be discouraging and cause people to be stuck with very limited usage.
Fortunately, most of today's integrated development environments (IDEs) include Git extensions that make using it a lot easier. One such Git extension available in Emacs is called [Magit](https://magit.vc).
The Magit project has been around for 10 years and defines itself as "a Git porcelain inside Emacs." In other words, it's an interface where every action can be managed by pressing a key. This article walks you through the Magit interface and explains how to use it to manage a Git project.
If you haven't already, [install Emacs](https://www.gnu.org/software/emacs/download.html), then [install Magit](https://magit.vc/manual/magit/Installing-from-Melpa.html#Installing-from-Melpa) before you continue with this tutorial.
## Magit's interface
Start by visiting a project directory in Emacs' [Dired mode](https://www.gnu.org/software/emacs/manual/html_node/emacs/Dired-Enter.html#Dired-Enter). For example, all my Emacs configurations are stored in the **~/.emacs.d/** directory, which is managed by Git.
If you were working from the command line, you would enter **git status** to find a project's current status. Magit has a similar function: **magit-status**. You can call this function using **M-x magit-status** (short for the keystroke **Alt+x magit-status**). Your result will look something like this:
Magit shows much more information than you would get from the **git status** command. It shows a list of untracked files, files that aren't staged, and staged files. It also shows the stash list and the most recent commits—all in a single window.
If you want to know what has changed, use the Tab key. For example, if I move my cursor over the unstaged file **custom_functions.org** and press the Tab key, Magit will display the changes:
This is similar to using the command **git diff custom_functions.org**. Staging a file is even easier. Simply move the cursor over a file and press the **s** key. The file will be quickly moved to the staged file list:
To unstage a file, use the **u** key. It is quicker and more fun to use **s** and **u** instead of entering **git add -u <file>** and **git reset HEAD <file>** on the command line.
## Commit changes
In the same Magit window, pressing the **c** key will display a commit window that provides flags like **--all** to stage all files or **--signoff** to add a signoff line to a commit message.
Move your cursor to the line where you want to enable a signoff flag and press Enter. This will highlight the **--signoff** text, which indicates that the flag is enabled.
Pressing **c** again will display the window to write the commit message.
Finally, use **C-c C-c **(short form of the keys Ctrl+cc) to commit the changes.
## Push changes
Once the changes are committed, the commit line will appear in the **Recent commits** section.
Place the cursor on that commit and press **p** to push the changes.
I've uploaded a [demonstration](https://youtu.be/Vvw75Pqp7Mc) on YouTube if you want to get a feel for using Magit. I have just scratched the surface in this article. It has many cool features to help you with Git branches, rebasing, and more. You can find [documentation, support, and more](https://magit.vc/) linked from Magit's homepage.
## 2 Comments |
10,565 | 书评:《Linux 基础》 | https://itsfoss.com/fundamentals-of-linux-book-review | 2019-02-23T23:54:18 | [
"书评"
] | https://linux.cn/article-10565-1.html | 介绍 Linux 的基础知识以及它的工作原理的书很多,今天,我们将会点评这样一本书。这次讨论的主题为 Oliver Pelz 所写的 《<ruby> <a href="https://www.packtpub.com/networking-and-servers/fundamentals-linux"> Linux 基础 </a> <rt> Fundamentals of Linux </rt></ruby>》,由 [PacktPub](https://www.packtpub.com/) 出版。
[Oliver Pelz](http://www.oliverpelz.de/index.html) 是一位拥有超过十年软件开发经验的开发者和系统管理员,拥有生物信息学学位证书。
### 《Linux 基础》

正如可以从书名中猜到那样,《Linux 基础》的目标是为读者打下一个从了解 Linux 到学习 Linux 命令行的坚实基础。这本书一共有两百多页,因此它专注于教给用户日常任务和解决经常遇到的问题。本书是为想要成为 Linux 管理员的读者而写的。
第一章首先概述了虚拟化。本书作者指导了读者如何在 [VirtualBox](https://www.virtualbox.org/) 中创建 [CentOS](https://centos.org/) 实例。如何克隆实例,如何使用快照。并且同时你也会学习到如何通过 SSH 命令连接到虚拟机。
第二章介绍了 Linux 命令行的基础知识,包括 shell 通配符,shell 展开,如何使用包含空格和特殊字符的文件名称。如何来获取命令手册的帮助页面。如何使用 `sed`、`awk` 这两个命令。如何浏览 Linux 的文件系统。
第三章更深入的介绍了 Linux 文件系统。你将了解如何在 Linux 中文件是如何链接的,以及如何搜索它们。你还将获得用户、组,以及文件权限的大概了解。由于本章的重点介绍了如何与文件进行交互。因此还将会介绍如何从命令行中读取文本文件,以及初步了解如何使用 vim 编辑器。
第四章重点介绍了如何使用命令行。以及涵盖的重要命令。如 `cat`、`sort`、`awk`、`tee`、`tar`、`rsync`、`nmap`、`htop` 等。你还将会了解到进程,以及它们如何彼此通讯。这一章还介绍了 Bash shell 脚本编程。
第五章同时也是本书的最后一章,将会介绍 Linux 和其他高级命令,以及网络的概念。本书的作者讨论了 Linux 是如何处理网络,并提供使用多个虚拟机的示例。同时还将会介绍如何安装新的程序,如何设置防火墙。
### 关于这本书的思考
Linux 的基础知识只有五章和少少的 200 来页可能看起来有些短,但是也涵盖了相当多的信息。同时也将会获得如何使用命令行所需要的知识的一切。
使用本书的时候,需要注意一件事情,即,本书专注于对命令行的关注,没有任何关于如何使用图形化的用户界面的任何教程。这是因为在 Linux 中有太多不同的桌面环境,以及很多的类似的系统应用,因此很难编写一本可以涵盖所有变种的书。此外,还有部分原因还因为本书的面向的用户群体为潜在的 Linux 管理员。
当我看到作者使用 Centos 教授 Linux 的时候有点惊讶。我原本以为他会使用更为常见的 Linux 的发行版本,例如 Ubuntu、Debian 或者 Fedora。原因在于 Centos 是为服务器设计的发行版本。随着时间的推移变化很小,能够为 Linux 的基础知识打下一个非常坚实的基础。
我自己使用 Linux 已经操作五年了。我大部分时间都在使用桌面版本的 Linux。我有些时候会使用命令行操作。但我并没有花太多的时间在那里。我使用鼠标完成了本书中涉及到的很多操作。现在呢。我同时也知道了如何通过终端做到同样的事情。这种方式不会改变我完成任务的方式,但是会有助于自己理解幕后发生的事情。
如果你刚刚使用 Linux,或者计划使用。我不会推荐你阅读这本书。这可能有点绝对化。但是如何你已经花了一些时间在 Linux 上。或者可以快速掌握某种技术语言。那么这本书很适合你。
如果你认为本书适合你的学习需求。你可以从以下链接获取到该书:
* [下载《Linux 基础》](https://www.packtpub.com/networking-and-servers/fundamentals-linux)
我们将在未来几个月内尝试点评更多 Linux 书籍,敬请关注我们。
你最喜欢的关于 Linux 的入门书籍是什么?请在下面的评论中告诉我们。
如果你发现这篇文章很有趣,请花一点时间在社交媒体、Hacker News或 [Reddit](http://reddit.com/r/linuxusersgroup) 上分享。
---
via: <https://itsfoss.com/fundamentals-of-linux-book-review>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[mySoul8012](https://github.com/mySoul8012) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,566 | 量子计算会打破现有的安全体系吗? | https://opensource.com/article/19/1/will-quantum-computing-break-security | 2019-02-24T11:21:06 | [
"量子计算"
] | https://linux.cn/article-10566-1.html |
>
> 你会希望<ruby> <a href="https://www.techopedia.com/definition/20225/j-random-hacker"> 某黑客 </a> <rt> J. Random Hacker </rt></ruby>假冒你的银行吗?
>
>
>

近年来,<ruby> 量子计算机 <rt> quantum computer </rt></ruby>已经出现在大众的视野当中。量子计算机被认为是第六类计算机,这六类计算机包括:
1. <ruby> 人力 <rt> Humans </rt></ruby>:在人造的计算工具出现之前,人类只能使用人力去进行计算。而承担计算工作的人,只能被称为“计算者”。
2. <ruby> 模拟计算工具 <rt> Mechanical analogue </rt></ruby>:由人类制造的一些模拟计算过程的小工具,例如<ruby> <a href="https://en.wikipedia.org/wiki/Antikythera_mechanism"> 安提凯希拉装置 </a> <rt> Antikythera mechanism </rt></ruby>、<ruby> 星盘 <rt> astrolabe </rt></ruby>、<ruby> 计算尺 <rt> slide rule </rt></ruby>等等。
3. <ruby> 机械工具 <rt> Mechanical digital </rt></ruby>:在这一个类别中包括了运用到离散数学但未使用电子技术进行计算的工具,例如<ruby> 算盘 <rt> abacus </rt></ruby>、Charles Babbage 的<ruby> 差分机 <rt> Difference Engine </rt></ruby>等等。
4. <ruby> 电子模拟计算工具 <rt> Electronic analogue </rt></ruby>:这一个类别的计算机多数用于军事方面的用途,例如炸弹瞄准器、枪炮瞄准装置等等。
5. <ruby> 电子计算机 <rt> Electronic digital </rt></ruby>:我在这里会稍微冒险一点,我觉得 Colossus 是第一台电子计算机,<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> :这一类几乎包含现代所有的电子设备,从移动电话到超级计算机,都在这个类别当中。
6. <ruby> 量子计算机 <rt> Quantum computer </rt></ruby>:即将进入我们的生活,而且与之前的几类完全不同。
### 什么是量子计算?
<ruby> 量子计算 <rt> Quantum computing </rt></ruby>的概念来源于<ruby> 量子力学 <rt> quantum mechanics </rt></ruby>,使用的计算方式和我们平常使用的普通计算非常不同。如果想要深入理解,建议从参考[维基百科上的定义](https://en.wikipedia.org/wiki/Quantum_computing)开始。对我们来说,最重要的是理解这一点:量子计算机使用<ruby> 量子位 <rt> qubit </rt></ruby>进行计算。在这样的前提下,对于很多数学算法和运算操作,量子计算机的计算速度会比普通计算机要快得多。
这里的“快得多”是按数量级来说的“快得多”。在某些情况下,一个计算任务如果由普通计算机来执行,可能要耗费几年或者几十年才能完成,但如果由量子计算机来执行,就只需要几秒钟。这样的速度甚至令人感到可怕。因为量子计算机会非常擅长信息的加密解密计算,即使在没有密钥的情况下,也能快速完成繁重的计算任务。
这意味着,如果拥有足够强大的量子计算机,那么你的所有信息都会被一览无遗,任何被加密的数据都可以被正确解密出来,甚至伪造数字签名也会成为可能。这确实是一个严重的问题。谁也不想被某个黑客冒充成自己在用的银行,更不希望自己在区块链上的交易被篡改得面目全非。
### 好消息
尽管上面的提到的问题非常可怕,但也不需要太担心。
首先,如果要实现上面提到的能力,一台可以操作大量量子位的量子计算机是必不可少的,而这个硬件上的要求就是一个很高的门槛。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup> 目前普遍认为,规模大得足以有效破解经典加密算法的量子计算机在最近几年还不可能出现。
其次,除了攻击现有的加密算法需要大量的量子位以外,还需要很多量子位来保证容错性。
还有,尽管确实有一些理论上的模型阐述了量子计算机如何对一些现有的算法作出攻击,但是要让这样的理论模型实际运作起来的难度会比我们<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 想象中大得多。事实上,有一些攻击手段也是未被完全确认是可行的,又或者这些攻击手段还需要继续耗费很多年的改进才能到达如斯恐怖的程度。
最后,还有很多专业人士正在研究能够防御量子计算的算法(这样的算法也被称为“<ruby> 后量子算法 <rt> post-quantum algorithms </rt></ruby>”)。如果这些防御算法经过测试以后投入使用,我们就可以使用这些算法进行加密,来对抗量子计算了。
总而言之,很多专家都认为,我们现有的加密方式在未来 5 年甚至未来 10 年内都是安全的,不需要过分担心。
### 也有坏消息
但我们也并不是高枕无忧了,以下两个问题就值得我们关注:
1. 人们在设计应用系统的时候仍然没有对量子计算作出太多的考量。如果设计的系统可能会使用 10 年以上,又或者数据加密和签名的时间跨度在 10 年以上,那么就必须考虑量子计算在未来会不会对系统造成不利的影响。
2. 新出现的防御量子计算的算法可能会是专有的。也就是说,如果基于这些防御量子计算的算法来设计系统,那么在系统落地的时候,可能会需要为此付费。尽管我是支持开源的,尤其是[开源密码学](https://opensource.com/article/17/10/many-eyes),但我最担心的就是无法开源这方面的内容。而且最糟糕的是,在建立新的协议标准时(不管是事实标准还是通过标准组织建立的标准),无论是故意的,还是无意忽略,或者是没有好的开源替代品,他们都很可能使用专有算法而排除使用开源算法。
### 我们要怎样做?
幸运的是,针对上述两个问题,我们还是有应对措施的。首先,在整个系统的设计阶段,就需要考虑到它是否会受到量子计算的影响,并作出相应的规划。当然了,不需要现在就立即采取行动,因为当前的技术水平也没法实现有效的方案,但至少也要[在加密方面保持敏捷性](https://aliceevebob.com/2017/04/04/disbelieving-the-many-eyes-hypothesis/),以便在任何需要的时候为你的协议和系统更换更有效的加密算法。<sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup>
其次是参与开源运动。尽可能鼓励密码学方面的有识之士团结起来,支持开放标准,并投入对非专有的防御量子计算的算法研究当中去。这一点也算是当务之急,因为号召更多的人重视起来并加入研究,比研究本身更为重要。
本文首发于《[Alice, Eve, and Bob](https://aliceevebob.com/2019/01/08/will-quantum-computing-break-security/)》,并在作者同意下重新发表。
---
1. 我认为把它称为第一台电子可编程计算机是公平的。我知道有早期的非可编程的,也有些人声称是 ENIAC,但我没有足够的空间或精力在这里争论这件事。 [↩](#fnref1)
2. 如果量子物理学家说很难,那么在我看来,就很难。 [↩](#fnref2)
3. 而且我假设我们都不是量子物理学家或数学家。 [↩](#fnref3)
4. 而且不仅仅是出于量子计算的原因:我们现有的一些经典算法很可能会陷入其他非量子攻击,例如新的数学方法。 [↩](#fnref4)
---
via: <https://opensource.com/article/19/1/will-quantum-computing-break-security>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Over the past few years, a new type of computer has arrived on the block: the quantum computer. It's arguably the sixth type of computer:
-
**Humans:**Before there were artificial computers, people used, well, people. And people with this job were called "computers." -
**Mechanical analogue:**These are devices such as the[Antikythera mechanism](https://en.wikipedia.org/wiki/Antikythera_mechanism), astrolabes, or slide rules. -
**Mechanical digital:**In this category, I'd count anything that allowed discrete mathematics but didn't use electronics for the actual calculation: the abacus, Babbage's Difference Engine, etc. -
**Electronic analogue:**Many of these were invented for military uses such as bomb sights, gun aiming, etc. -
**Electronic digital:**I'm going to go out on a limb here and characterise Colossus as the first electronic digital computer: these are basically what we use today for anything from mobile phones to supercomputers.1 -
**Quantum computers:**These are coming and are fundamentally different from all of the previous generations.
## What is quantum computing?
Quantum computing uses concepts from quantum mechanics to allow very different types of calculations from what we're used to in "classical computing." I'm not even going to try to explain, because I know I'd do a terrible job, so I suggest you try something like [Wikipedia's definition](https://en.wikipedia.org/wiki/Quantum_computing) as a starting point. What's important for our purposes is to understand that quantum computers use qubits to do calculations, and for quite a few types of mathematical algorithms—and therefore computing operations––they can solve problems much faster than classical computers.
What's "much faster"? Much, much faster: orders of magnitude faster. A calculation that might take years or decades with a classical computer could, in certain circumstances, take seconds. Impressive, yes? And scary. Because one of the types of problems that quantum computers should be good at solving is decrypting encrypted messages, even without the keys.
This means that someone with a sufficiently powerful quantum computer should be able to read all of your current and past messages, decrypt any stored data, and maybe fake digital signatures. Is this a big thing? Yes. Do you want J. Random Hacker to be able to pretend they're your bank? Do you want that transaction on the blockchain where you were sold a 10 bedroom mansion in Mayfair to be "corrected" to be a bedsit in Weston-super-Mare?
2
3## Some good news
This is all scary stuff, but there's good news of various types.
The first is that, in order to make any of this work at all, you need a quantum computer with a good number of qubits operating, and this is turning out to be hard.[ 4](#4) The general consensus is that we've got a few years before anybody has a "big" enough quantum computer to do serious damage to classical encryption algorithms.
The second is that, even with a sufficient number of qubits to attacks our existing algorithms, you still need even *more* to allow for error correction.
The third is that, although there are theoretical models to show how to attack some of our existing algorithms, actually making them work is significantly harder than you or I[ 5](#5) might expect. In fact, some of the attacks may turn out to be infeasible or just take more years to perfect than we worry about.
The fourth is that there are clever people out there who are designing quantum-computation-resistant algorithms (sometimes referred to as "post-quantum algorithms") that we can use, at least for new encryption, once they've been tested and become widely available.
All in all, in fact, there's a strong body of expert opinion that says we shouldn't be overly worried about quantum computing breaking our encryption in the next five or even 10 years.
## And some bad news
It's not all rosy, however. Two issues stick out to me as areas of concern.
-
People are still designing and rolling out systems that don't consider the issue. If you're coming up with a system that is likely to be in use for 10 or more years or will be encrypting or signing data that must remain confidential or attributable over those sorts of periods, then you should be considering the possible impact of quantum computing on your system.
-
Some of the new, quantum-computing-resistant algorithms are proprietary. This means that when you and I want to start implementing systems that are designed to be quantum-computing resistant, we'll have to pay to do so. I'm a big proponent of open source, and particularly of
[open source cryptography](https://opensource.com/article/17/10/many-eyes), and my big worry is that we just won't be able to open source these things, and worse, that when new protocol standards are created––either de-facto or through standards bodies––they will choose proprietary algorithms that*exclude*the use of open source, whether on purpose, through ignorance, or because few good alternatives are available.
## What to do?
Luckily, there are things you can do to address both of the issues above. The first is to think and plan when designing a system about what the impact of quantum computing might be on it. Often—very often—you won't need to implement anything explicit now (and it could be hard to, given the current state of the art), but you should at least embrace [the concept of crypto-agility](https://aliceevebob.com/2017/04/04/disbelieving-the-many-eyes-hypothesis/): designing protocols and systems so you can swap out algorithms if required.7
The second is a call to arms: Get involved in the open source movement and encourage everybody you know who has anything to do with cryptography to rally for open standards and for research into non-proprietary, quantum-computing-resistant algorithms. This is something that's very much on my to-do list, and an area where pressure and lobbying is just as important as the research itself.
[1. I think it's fair to call it the first electronic, programmable computer. I know there were earlier non-programmable ones, and that some claim ENIAC, but I don't have the space or the energy to argue the case here.]
[3. See ][ 2](#2). Don't get me wrong, by the way—I grew up near Weston-super-Mare, and it's got things going for it, but it's not Mayfair.
[4. And if a quantum physicist says something's hard, then to my mind, it's ]*hard*.
[5. And I'm assuming that neither of us is a quantum physicist or mathematician.]6
[7. And not just for quantum-computing reasons: There's a good chance that some of our existing classical algorithms may just fall to other, non-quantum attacks such as new mathematical approaches. ]
*This article was originally published on Alice, Eve, and Bob and is reprinted with the author's permission.*
## Comments are closed. |
10,567 | 开始使用 gPodder 吧,一个开源播客客户端 | https://opensource.com/article/19/1/productivity-tool-gpodder | 2019-02-24T22:42:37 | [
"播客"
] | https://linux.cn/article-10567-1.html |
>
> 使用 gPodder 将你的播客同步到你的设备上,gPodder 是我们开源工具系列中的第 17 个工具,它将在 2019 年提高你的工作效率。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 17 个工具来帮助你在 2019 年更有效率。
### gPodder
我喜欢播客。哎呀,我非常喜欢它们,因此我录制了其中的三个(你可以在[我的个人资料](https://opensource.com/users/ksonney)中找到它们的链接)。我从播客那里学到了很多东西,并在我工作时在后台播放它们。但是,如何在多台桌面和移动设备之间保持同步可能会有一些挑战。
[gPodder](https://gpodder.github.io/) 是一个简单的跨平台播客下载器、播放器和同步工具。它支持 RSS feed、[FeedBurner](https://feedburner.google.com/)、[YouTube](https://youtube.com) 和 [SoundCloud](https://soundcloud.com/),它还有一个开源的同步服务,你可以根据需要运行它。gPodder 不直接播放播客。相反,它会使用你选择的音频或视频播放器。

安装 gPodder 非常简单。安装程序适用于 Windows 和 MacOS,同时也有用于主要的 Linux 发行版的软件包。如果你的发行版中没有它,你可以直接从 Git 下载运行。通过 “Add Podcasts via URL” 菜单,你可以输入播客的 RSS 源 URL 或其他服务的 “特殊” URL。gPodder 将获取节目列表并显示一个对话框,你可以在其中选择要下载的节目或在列表上标记旧节目。

它一个更好的功能是,如果 URL 已经在你的剪贴板中,gPodder 会自动将它放入播放 URL 中,这样你就可以很容易地将新的播客添加到列表中。如果你已有播客 feed 的 OPML 文件,那么可以上传并导入它。还有一个发现选项,让你可搜索 [gPodder.net](http://gpodder.net) 上的播客,这是由编写和维护 gPodder 的人员提供的自由及开源的播客的列表网站。

[mygpo](https://github.com/gpodder/mygpo) 服务器在设备之间同步播客。gPodder 默认使用 [gPodder.net](http://gPodder.net) 的服务器,但是如果你想要运行自己的服务器,那么可以在配置文件中更改它(请注意,你需要直接修改配置文件)。同步能让你在桌面和移动设备之间保持列表一致。如果你在多个设备上收听播客(例如,我在我的工作电脑、家用电脑和手机上收听),这会非常有用,因为这意味着无论你身在何处,你都拥有最近的播客和节目列表而无需一次又一次地设置。

单击播客节目将显示与其关联的文本,单击“播放”将启动设备的默认音频或视频播放器。如果要使用默认之外的其他播放器,可以在 gPodder 的配置设置中更改此设置。
通过 gPodder,你可以轻松查找、下载和收听播客,在设备之间同步这些播客,在易于使用的界面中访问许多其他功能。
---
via: <https://opensource.com/article/19/1/productivity-tool-gpodder>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 17th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## gPodder
I like podcasts. Heck, I like them so much I record three of them (you can find links to them in [my profile](https://opensource.com/users/ksonney)). I learn a lot from podcasts and play them in the background when I'm working. But keeping them in sync between multiple desktops and mobile devices can be a bit of a challenge.
[gPodder](https://gpodder.github.io/) is a simple, cross-platform podcast downloader, player, and sync tool. It supports RSS feeds, [FeedBurner](https://feedburner.google.com/), [YouTube](https://youtube.com), and [SoundCloud](https://soundcloud.com/), and it also has an open source sync service that you can run if you want. gPodder doesn't do podcast playback; instead, it uses your audio or video player of choice.
Installing gPodder is very straightforward. Installers are available for Windows and MacOS, and packages are available for major Linux distributions. If it isn't available in your distribution, you can run it directly from a Git checkout. With the "Add Podcasts via URL" menu option, you can enter a podcast's RSS feed URL or one of the "special" URLs for the other services. gPodder will fetch a list of episodes and present a dialog where you can select which episodes to download or mark old episodes on the list.
One of its nicer features is that if a URL is already in your clipboard, gPodder will automatically place it in its URL field, which makes it really easy to add a new podcast to your list. If you already have an OPML file of podcast feeds, you can upload and import it. There is also a discovery option that allows you to search for podcasts on [gPodder.net](http://gpodder.net), the free and open source podcast listing site by the people who write and maintain gPodder.
A [mygpo](https://github.com/gpodder/mygpo) server synchronizes podcasts between devices. By default, gPodder uses [gPodder.net](http://gPodder.net)'s servers, but you can change this in the configuration files if want to run your own (be aware that you'll have to modify the configuration file directly). Syncing allows you to keep your lists consistent between desktops and mobile devices. This is very useful if you listen to podcasts on multiple devices (for example, I listen on my work computer, home computer, and mobile phone), as it means no matter where you are, you have the most recent lists of podcasts and episodes without having to set things up again and again.
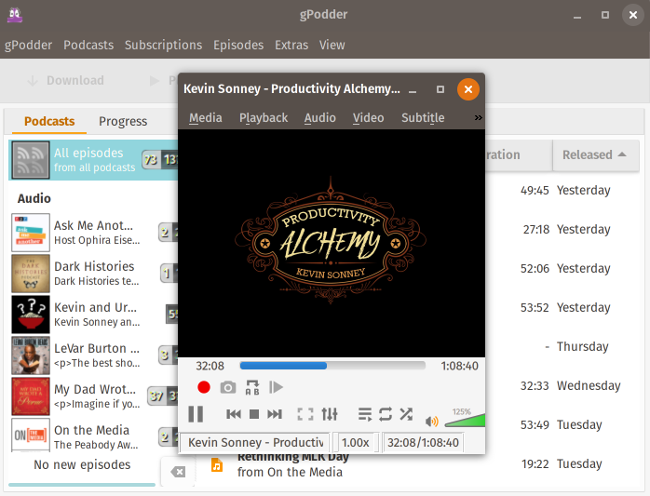
Clicking on a podcast episode will bring up the text post associated with it, and clicking "Play" will launch your device's default audio or video player. If you want to use something other than the default, you can change this in gPodder's configuration settings.
gPodder makes it simple to find, download, and listen to podcasts, synchronize them across devices, and access a lot of other features in an easy-to-use interface.
## Comments are closed. |
10,568 | Evil-Twin 框架:一个用于提升 WiFi 安全性的工具 | https://opensource.com/article/19/1/evil-twin-framework | 2019-02-25T00:08:52 | [
"WIFI",
"安全",
"渗透测试"
] | https://linux.cn/article-10568-1.html |
>
> 了解一款用于对 WiFi 接入点安全进行渗透测试的工具。
>
>
>

越来越多的设备通过无线传输的方式连接到互联网,以及,大范围可用的 WiFi 接入点为攻击者攻击用户提供了很多机会。通过欺骗用户连接到[虚假的 WiFi 接入点](https://en.wikipedia.org/wiki/Rogue_access_point),攻击者可以完全控制用户的网络连接,这将使得攻击者可以嗅探和篡改用户的数据包,将用户的连接重定向到一个恶意的网站,并通过网络发起其他的攻击。
为了保护用户并告诉他们如何避免线上的危险操作,安全审计人员和安全研究员必须评估用户的安全实践能力,用户常常在没有确认该 WiFi 接入点为安全的情况下就连接上了该网络,安全审计人员和研究员需要去了解这背后的原因。有很多工具都可以对 WiFi 的安全性进行审计,但是没有一款工具可以测试大量不同的攻击场景,也没有能和其他工具集成得很好的工具。
Evil-Twin Framework(ETF)用于解决 WiFi 审计过程中的这些问题。审计者能够使用 ETF 来集成多种工具并测试该 WiFi 在不同场景下的安全性。本文会介绍 ETF 的框架和功能,然后会提供一些案例来说明该如何使用这款工具。
### ETF 的架构
ETF 的框架是用 [Python](https://www.python.org/) 写的,因为这门开发语言的代码非常易读,也方便其他开发者向这个项目贡献代码。除此之外,很多 ETF 的库,比如 [Scapy](https://scapy.net),都是为 Python 开发的,很容易就能将它们用于 ETF。
ETF 的架构(图 1)分为不同的彼此交互的模块。该框架的设置都写在一个单独的配置文件里。用户可以通过 `ConfigurationManager` 类里的用户界面来验证并修改这些配置。其他模块只能读取这些设置并根据这些设置进行运行。

*图 1:Evil-Twin 的框架架构*
ETF 支持多种与框架交互的用户界面,当前的默认界面是一个交互式控制台界面,类似于 [Metasploit](https://www.metasploit.com) 那种。正在开发用于桌面/浏览器使用的图形用户界面(GUI)和命令行界面(CLI),移动端界面也是未来的一个备选项。用户可以使用交互式控制台界面来修改配置文件里的设置(最终会使用 GUI)。用户界面可以与存在于这个框架里的每个模块进行交互。
WiFi 模块(AirCommunicator)用于支持多种 WiFi 功能和攻击类型。该框架确定了 Wi-Fi 通信的三个基本支柱:数据包嗅探、自定义数据包注入和创建接入点。三个主要的 WiFi 通信模块 AirScanner、AirInjector,和 AirHost,分别用于数据包嗅探、数据包注入,和接入点创建。这三个类被封装在主 WiFi 模块 AirCommunicator 中,AirCommunicator 在启动这些服务之前会先读取这些服务的配置文件。使用这些核心功能的一个或多个就可以构造任意类型的 WiFi 攻击。
要使用中间人(MITM)攻击(这是一种攻击 WiFi 客户端的常见手法),ETF 有一个叫做 ETFITM(Evil-Twin Framework-in-the-Middle)的集成模块,这个模块用于创建一个 web 代理,来拦截和修改经过的 HTTP/HTTPS 数据包。
许多其他的工具也可以利用 ETF 创建的 MITM。通过它的可扩展性,ETF 能够支持它们,而不必单独地调用它们,你可以通过扩展 Spawner 类来将这些工具添加到框架里。这使得开发者和安全审计人员可以使用框架里预先配置好的参数字符来调用程序。
扩展 ETF 的另一种方法就是通过插件。有两类插件:WiFi 插件和 MITM 插件。MITM 插件是在 MITM 代理运行时可以执行的脚本。代理会将 HTTP(s) 请求和响应传递给可以记录和处理它们的插件。WiFi 插件遵循一个更加复杂的执行流程,但仍然会给想参与开发并且使用自己插件的贡献者提供一个相对简单的 API。WiFi 插件还可以进一步地划分为三类,其中每个对应一个核心 WiFi 通信模块。
每个核心模块都有一些特定事件能触发响应的插件的执行。举个例子,AirScanner 有三个已定义的事件,可以对其响应进行编程处理。事件通常对应于服务开始运行之前的设置阶段、服务正在运行时的中间执行阶段、服务完成后的卸载或清理阶段。因为 Python 允许多重继承,所以一个插件可以继承多个插件类。
上面的图 1 是框架架构的摘要。从 ConfigurationManager 指出的箭头意味着模块会从中读取信息,指向它的箭头意味着模块会写入/修改配置。
### 使用 ETF 的例子
ETF 可以通过多种方式对 WiFi 的网络安全或者终端用户的 WiFi 安全意识进行渗透测试。下面的例子描述了这个框架的一些渗透测试功能,例如接入点和客户端检测、对使用 WPA 和 WEP 类型协议的接入点进行攻击,和创建 evil twin 接入点。
这些例子是使用 ETF 和允许进行 WiFi 数据捕获的 WiFi 卡设计的。它们也在 ETF 设置命令中使用了下面这些缩写:
* **APS** Access Point SSID
* **APB** Access Point BSSID
* **APC** Access Point Channel
* **CM** Client MAC address
在实际的测试场景中,确保你使用了正确的信息来替换这些缩写。
#### 在解除认证攻击后捕获 WPA 四次握手的数据包。
这个场景(图 2)做了两个方面的考虑:<ruby> 解除认证攻击 <rt> de-authentication attack </rt></ruby>和捕获 WPA 四次握手数据包的可能性。这个场景从一个启用了 WPA/WPA2 的接入点开始,这个接入点有一个已经连上的客户端设备(在本例中是一台智能手机)。目的是通过常规的解除认证攻击(LCTT 译注:类似于 DoS 攻击)来让客户端断开和 WiFi 的网络,然后在客户端尝试重连的时候捕获 WPA 的握手包。重连会在断开连接后马上手动完成。

*图 2:在解除认证攻击后捕获 WPA 握手包的场景*
在这个例子中需要考虑的是 ETF 的可靠性。目的是确认工具是否一直都能捕获 WPA 的握手数据包。每个工具都会用来多次复现这个场景,以此来检查它们在捕获 WPA 握手数据包时的可靠性。
使用 ETF 来捕获 WPA 握手数据包的方法不止一种。一种方法是使用 AirScanner 和 AirInjector 两个模块的组合;另一种方法是只使用 AirInjector。下面这个场景是使用了两个模块的组合。
ETF 启用了 AirScanner 模块并分析 IEEE 802.11 数据帧来发现 WPA 握手包。然后 AirInjecto 就可以使用解除认证攻击来强制客户端断开连接,以进行重连。必须在 ETF 上执行下面这些步骤才能完成上面的目标:
1. 进入 AirScanner 配置模式:`config airscanner`
2. 设置 AirScanner 不跳信道:`config airscanner`
3. 设置信道以嗅探经过 WiFi 接入点信道的数据(APC):`set fixed_sniffing_channel = <APC>`
4. 使用 CredentialSniffer 插件来启动 AirScanner 模块:`start airscanner with credentialsniffer`
5. 从已嗅探的接入点列表中添加目标接入点的 BSSID(APS):`add aps where ssid = <APS>`
6. 启用 AirInjector 模块,在默认情况下,它会启用解除认证攻击:`start airinjector`
这些简单的命令设置能让 ETF 在每次测试时执行成功且有效的解除认证攻击。ETF 也能在每次测试的时候捕获 WPA 的握手数据包。下面的代码能让我们看到 ETF 成功的执行情况。
```
███████╗████████╗███████╗
██╔════╝╚══██╔══╝██╔════╝
█████╗ ██║ █████╗
██╔══╝ ██║ ██╔══╝
███████╗ ██║ ██║
╚══════╝ ╚═╝ ╚═╝
[+] Do you want to load an older session? [Y/n]: n
[+] Creating new temporary session on 02/08/2018
[+] Enter the desired session name:
ETF[etf/aircommunicator/]::> config airscanner
ETF[etf/aircommunicator/airscanner]::> listargs
sniffing_interface = wlan1; (var)
probes = True; (var)
beacons = True; (var)
hop_channels = false; (var)
fixed_sniffing_channel = 11; (var)
ETF[etf/aircommunicator/airscanner]::> start airscanner with
arpreplayer caffelatte credentialsniffer packetlogger selfishwifi
ETF[etf/aircommunicator/airscanner]::> start airscanner with credentialsniffer
[+] Successfully added credentialsniffer plugin.
[+] Starting packet sniffer on interface 'wlan1'
[+] Set fixed channel to 11
ETF[etf/aircommunicator/airscanner]::> add aps where ssid = CrackWPA
ETF[etf/aircommunicator/airscanner]::> start airinjector
ETF[etf/aircommunicator/airscanner]::> [+] Starting deauthentication attack
- 1000 bursts of 1 packets
- 1 different packets
[+] Injection attacks finished executing.
[+] Starting post injection methods
[+] Post injection methods finished
[+] WPA Handshake found for client '70:3e:ac:bb:78:64' and network 'CrackWPA'
```
#### 使用 ARP 重放攻击并破解 WEP 无线网络
下面这个场景(图 3)将关注[地址解析协议](https://en.wikipedia.org/wiki/Address_Resolution_Protocol)(ARP)重放攻击的效率和捕获包含初始化向量(IVs)的 WEP 数据包的速度。相同的网络可能需要破解不同数量的捕获的 IVs,所以这个场景的 IVs 上限是 50000。如果这个网络在首次测试期间,还未捕获到 50000 IVs 就崩溃了,那么实际捕获到的 IVs 数量会成为这个网络在接下来的测试里的新的上限。我们使用 `aircrack-ng` 对数据包进行破解。
测试场景从一个使用 WEP 协议进行加密的 WiFi 接入点和一台知道其密钥的离线客户端设备开始 —— 为了测试方便,密钥使用了 12345,但它可以是更长且更复杂的密钥。一旦客户端连接到了 WEP 接入点,它会发送一个不必要的 ARP 数据包;这是要捕获和重放的数据包。一旦被捕获的包含 IVs 的数据包数量达到了设置的上限,测试就结束了。

*图 3:在进行解除认证攻击后捕获 WPA 握手包的场景*
ETF 使用 Python 的 Scapy 库来进行包嗅探和包注入。为了最大限度地解决 Scapy 里的已知的性能问题,ETF 微调了一些低级库,来大大加快包注入的速度。对于这个特定的场景,ETF 为了更有效率地嗅探,使用了 `tcpdump` 作为后台进程而不是 Scapy,Scapy 用于识别加密的 ARP 数据包。
这个场景需要在 ETF 上执行下面这些命令和操作:
1. 进入 AirScanner 设置模式:`config airscanner`
2. 设置 AirScanner 不跳信道:`set hop_channels = false`
3. 设置信道以嗅探经过接入点信道的数据(APC):`set fixed_sniffing_channel = <APC>`
4. 进入 ARPReplayer 插件设置模式:`config arpreplayer`
5. 设置 WEP 网络目标接入点的 BSSID(APB):`set target_ap_bssid <APB>`
6. 使用 ARPReplayer 插件启动 AirScanner 模块:`start airscanner with arpreplayer`
在执行完这些命令后,ETF 会正确地识别加密的 ARP 数据包,然后成功执行 ARP 重放攻击,以此破坏这个网络。
#### 使用一款全能型蜜罐
图 4 中的场景使用相同的 SSID 创建了多个接入点,对于那些可以探测到但是无法接入的 WiFi 网络,这个技术可以发现网络的加密类型。通过启动具有所有安全设置的多个接入点,客户端会自动连接和本地缓存的接入点信息相匹配的接入点。

*图 4:在解除认证攻击后捕获 WPA 握手包数据。*
使用 ETF,可以去设置 `hostapd` 配置文件,然后在后台启动该程序。`hostapd` 支持在一张无线网卡上通过设置虚拟接口开启多个接入点,并且因为它支持所有类型的安全设置,因此可以设置完整的全能蜜罐。对于使用 WEP 和 WPA(2)-PSK 的网络,使用默认密码,和对于使用 WPA(2)-EAP 的网络,配置“全部接受”策略。
对于这个场景,必须在 ETF 上执行下面的命令和操作:
1. 进入 APLauncher 设置模式:`config aplauncher`
2. 设置目标接入点的 SSID(APS):`set ssid = <APS>`
3. 设置 APLauncher 为全部接收的蜜罐:`set catch_all_honeypot = true`
4. 启动 AirHost 模块:`start airhost`
使用这些命令,ETF 可以启动一个包含所有类型安全配置的完整全能蜜罐。ETF 同样能自动启动 DHCP 和 DNS 服务器,从而让客户端能与互联网保持连接。ETF 提供了一个更好、更快、更完整的解决方案来创建全能蜜罐。下面的代码能够看到 ETF 的成功执行。
```
███████╗████████╗███████╗
██╔════╝╚══██╔══╝██╔════╝
█████╗ ██║ █████╗
██╔══╝ ██║ ██╔══╝
███████╗ ██║ ██║
╚══════╝ ╚═╝ ╚═╝
[+] Do you want to load an older session? [Y/n]: n
[+] Creating ne´,cxzw temporary session on 03/08/2018
[+] Enter the desired session name:
ETF[etf/aircommunicator/]::> config aplauncher
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf ssid CatchMe
ssid = CatchMe
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf catch_all_honeypot true
catch_all_honeypot = true
ETF[etf/aircommunicator/airhost/aplauncher]::> start airhost
[+] Killing already started processes and restarting network services
[+] Stopping dnsmasq and hostapd services
[+] Access Point stopped...
[+] Running airhost plugins pre_start
[+] Starting hostapd background process
[+] Starting dnsmasq service
[+] Running airhost plugins post_start
[+] Access Point launched successfully
[+] Starting dnsmasq service
```
### 结论和以后的工作
这些场景使用常见和众所周知的攻击方式来帮助验证 ETF 测试 WIFI 网络和客户端的能力。这个结果同样证明了该框架的架构能在平台现有功能的优势上开发新的攻击向量和功能。这会加快新的 WiFi 渗透测试工具的开发,因为很多的代码已经写好了。除此之外,将 WiFi 技术相关的东西都集成到一个单独的工具里,会使 WiFi 渗透测试更加简单高效。
ETF 的目标不是取代现有的工具,而是为它们提供补充,并为安全审计人员在进行 WiFi 渗透测试和提升用户安全意识时,提供一个更好的选择。
ETF 是 [GitHub](https://github.com/Esser420/EvilTwinFramework) 上的一个开源项目,欢迎社区为它的开发做出贡献。下面是一些您可以提供帮助的方法。
当前 WiFi 渗透测试的一个限制是无法在测试期间记录重要的事件。这使得报告已经识别到的漏洞更加困难且准确性更低。这个框架可以实现一个记录器,每个类都可以来访问它并创建一个渗透测试会话报告。
ETF 工具的功能涵盖了 WiFi 渗透测试的方方面面。一方面,它让 WiFi 目标侦察、漏洞挖掘和攻击这些阶段变得更加容易。另一方面,它没有提供一个便于提交报告的功能。增加了会话的概念和会话报告的功能,比如在一个会话期间记录重要的事件,会极大地增加这个工具对于真实渗透测试场景的价值。
另一个有价值的贡献是扩展该框架来促进 WiFi 模糊测试。IEEE 802.11 协议非常的复杂,考虑到它在客户端和接入点两方面都会有多种实现方式。可以假设这些实现都包含 bug 甚至是安全漏洞。这些 bug 可以通过对 IEEE 802.11 协议的数据帧进行模糊测试来进行发现。因为 Scapy 允许自定义的数据包创建和数据包注入,可以通过它实现一个模糊测试器。
---
via: <https://opensource.com/article/19/1/evil-twin-framework>
作者:[André Esser](https://opensource.com/users/andreesser) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The increasing number of devices that connect over-the-air to the internet over-the-air and the wide availability of WiFi access points provide many opportunities for attackers to exploit users. By tricking users to connect to [rogue access points](https://en.wikipedia.org/wiki/Rogue_access_point), hackers gain full control over the users' network connection, which allows them to sniff and alter traffic, redirect users to malicious sites, and launch other attacks over the network..
To protect users and teach them to avoid risky online behaviors, security auditors and researchers must evaluate users' security practices and understand the reasons they connect to WiFi access points without being confident they are safe. There are a significant number of tools that can conduct WiFi audits, but no single tool can test the many different attack scenarios and none of the tools integrate well with one another.
The **Evil-Twin Framework** (ETF) aims to fix these problems in the WiFi auditing process by enabling auditors to examine multiple scenarios and integrate multiple tools. This article describes the framework and its functionalities, then provides some examples to show how it can be used.
## The ETF architecture
The ETF framework was written in [Python](https://www.python.org/) because the development language is very easy to read and make contributions to. In addition, many of the ETF's libraries, such as ** Scapy**, were already developed for Python, making it easy to use them for ETF.
The ETF architecture (Figure 1) is divided into different modules that interact with each other. The framework's settings are all written in a single configuration file. The user can verify and edit the settings through the user interface via the **ConfigurationManager** class. Other modules can only read these settings and run according to them.
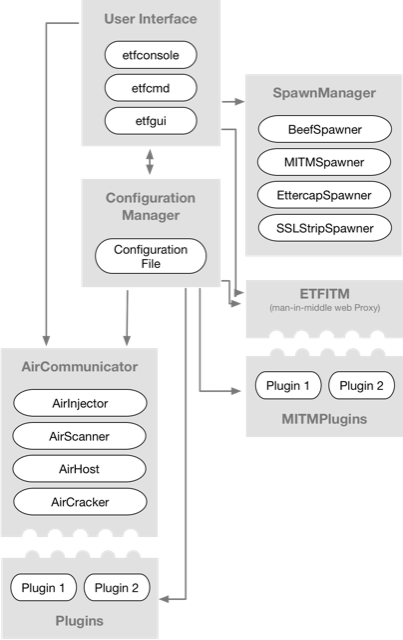
Figure 1: Evil-Twin Framework Architecture
The ETF supports multiple user interfaces that interact with the framework. The current default interface is an interactive console, similar to the one on [Metasploit](https://www.metasploit.com). A graphical user interface (GUI) and a command line interface (CLI) are under development for desktop/browser use, and mobile interfaces may be an option in the future. The user can edit the settings in the configuration file using the interactive console (and eventually with the GUI). The user interface can interact with every other module that exists in the framework.
The WiFi module (**AirCommunicator**) was built to support a wide range of WiFi capabilities and attacks. The framework identifies three basic pillars of Wi-Fi communication: **packet sniffing**, **custom packet injection**, and **access point creation**. The three main WiFi communication modules are **AirScanner**, **AirInjector**, and **AirHost**, which are responsible for packet sniffing, packet injection, and access point creation, respectively. The three classes are wrapped inside the main WiFi module, AirCommunicator, which reads the configuration file before starting the services. Any type of WiFi attack can be built using one or more of these core features.
To enable man-in-the-middle (MITM) attacks, which are a common way to attack WiFi clients, the framework has an integrated module called ETFITM (Evil-Twin Framework-in-the-Middle). This module is responsible for the creation of a web proxy used to intercept and manipulate HTTP/HTTPS traffic.
There are many other tools that can leverage the MITM position created by the ETF. Through its extensibility, ETF can support them—and, instead of having to call them separately, you can add the tools to the framework just by extending the Spawner class. This enables a developer or security auditor to call the program with a preconfigured argument string from within the framework.
The other way to extend the framework is through plugins. There are two categories of plugins: **WiFi plugins** and **MITM plugins**. MITM plugins are scripts that can run while the MITM proxy is active. The proxy passes the HTTP(S) requests and responses through to the plugins where they can be logged or manipulated. WiFi plugins follow a more complex flow of execution but still expose a fairly simple API to contributors who wish to develop and use their own plugins. WiFi plugins can be further divided into three categories, one for each of the core WiFi communication modules.
Each of the core modules has certain events that trigger the execution of a plugin. For instance, AirScanner has three defined events to which a response can be programmed. The events usually correspond to a setup phase before the service starts running, a mid-execution phase while the service is running, and a teardown or cleanup phase after a service finishes. Since Python allows multiple inheritance, one plugin can subclass more than one plugin class.
Figure 1 above is a summary of the framework's architecture. Lines pointing away from the ConfigurationManager mean that the module reads information from it and lines pointing towards it mean that the module can write/edit configurations.
## Examples of using the Evil-Twin Framework
There are a variety of ways ETF can conduct penetration testing on WiFi network security or work on end users' awareness of WiFi security. The following examples describe some of the framework's pen-testing functionalities, such as access point and client detection, WPA and WEP access point attacks, and evil twin access point creation.
These examples were devised using ETF with WiFi cards that allow WiFi traffic capture. They also utilize the following abbreviations for ETF setup commands:
**APS**access point SSID**APB**access point BSSID**APC**access point channel**CM**client MAC address
In a real testing scenario, make sure to replace these abbreviations with the correct information.
### Capturing a WPA 4-way handshake after a de-authentication attack
This scenario (Figure 2) takes two aspects into consideration: the de-authentication attack and the possibility of catching a 4-way WPA handshake. The scenario starts with a running WPA/WPA2-enabled access point with one connected client device (in this case, a smartphone). The goal is to de-authenticate the client with a general de-authentication attack then capture the WPA handshake once it tries to reconnect. The reconnection will be done manually immediately after being de-authenticated.
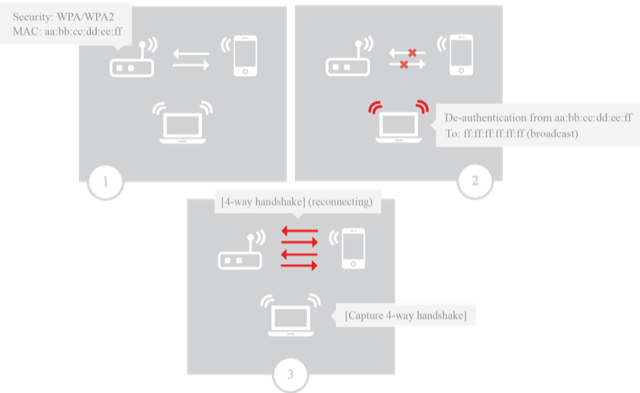
Figure 2: Scenario for capturing a WPA handshake after a de-authentication attack
The consideration in this example is the ETF's reliability. The goal is to find out if the tools can consistently capture the WPA handshake. The scenario will be performed multiple times with each tool to check its reliability when capturing the WPA handshake.
There is more than one way to capture a WPA handshake using the ETF. One way is to use a combination of the AirScanner and AirInjector modules; another way is to just use the AirInjector. The following scenario uses a combination of both modules.
The ETF launches the AirScanner module and analyzes the IEEE 802.11 frames to find a WPA handshake. Then the AirInjector can launch a de-authentication attack to force a reconnection. The following steps must be done to accomplish this on the ETF:
- Enter the AirScanner configuration mode:
**config airscanner** - Configure the AirScanner to not hop channels:
**config airscanner** - Set the channel to sniff the traffic on the access point channel (APC):
**set fixed_sniffing_channel = <APC>** - Start the AirScanner module with the CredentialSniffer plugin:
**start airscanner with credentialsniffer** - Add a target access point BSSID (APS) from the sniffed access points list:
**add aps where ssid = <APS>** - Start the AirInjector, which by default lauches the de-authentication attack:
**start airinjector**
This simple set of commands enables the ETF to perform an efficient and successful de-authentication attack on every test run. The ETF can also capture the WPA handshake on every test run. The following code makes it possible to observe the ETF's successful execution.
```
███████╗████████╗███████╗
██╔════╝╚══██╔══╝██╔════╝
█████╗ ██║ █████╗
██╔══╝ ██║ ██╔══╝
███████╗ ██║ ██║
╚══════╝ ╚═╝ ╚═╝
[+] Do you want to load an older session? [Y/n]: n
[+] Creating new temporary session on 02/08/2018
[+] Enter the desired session name:
ETF[etf/aircommunicator/]::> config airscanner
ETF[etf/aircommunicator/airscanner]::> listargs
sniffing_interface = wlan1; (var)
probes = True; (var)
beacons = True; (var)
hop_channels = false; (var)
fixed_sniffing_channel = 11; (var)
ETF[etf/aircommunicator/airscanner]::> start airscanner with
arpreplayer caffelatte credentialsniffer packetlogger selfishwifi
ETF[etf/aircommunicator/airscanner]::> start airscanner with credentialsniffer
[+] Successfully added credentialsniffer plugin.
[+] Starting packet sniffer on interface 'wlan1'
[+] Set fixed channel to 11
ETF[etf/aircommunicator/airscanner]::> add aps where ssid = CrackWPA
ETF[etf/aircommunicator/airscanner]::> start airinjector
ETF[etf/aircommunicator/airscanner]::> [+] Starting deauthentication attack
- 1000 bursts of 1 packets
- 1 different packets
[+] Injection attacks finished executing.
[+] Starting post injection methods
[+] Post injection methods finished
[+] WPA Handshake found for client '70:3e:ac:bb:78:64' and network 'CrackWPA'
```
### Launching an ARP replay attack and cracking a WEP network
The next scenario (Figure 3) will also focus on the [Address Resolution Protocol](https://en.wikipedia.org/wiki/Address_Resolution_Protocol) (ARP) replay attack's efficiency and the speed of capturing the WEP data packets containing the initialization vectors (IVs). The same network may require a different number of caught IVs to be cracked, so the limit for this scenario is 50,000 IVs. If the network is cracked during the first test with less than 50,000 IVs, that number will be the new limit for the following tests on the network. The cracking tool to be used will be **aircrack****-ng**.
The test scenario starts with an access point using WEP encryption and an offline client that knows the key—the key for testing purposes is 12345, but it can be a larger and more complex key. Once the client connects to the WEP access point, it will send out a gratuitous ARP packet; this is the packet that's meant to be captured and replayed. The test ends once the limit of packets containing IVs is captured.
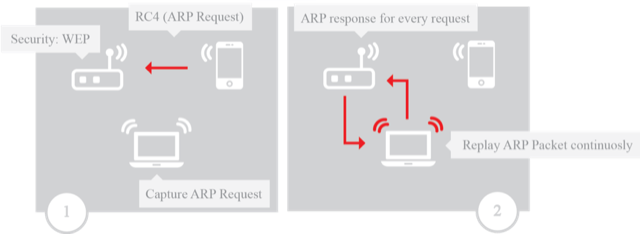
Figure 3: Scenario for capturing a WPA handshake after a de-authentication attack
ETF uses Python's Scapy library for packet sniffing and injection. To minimize known performance problems in Scapy, ETF tweaks some of its low-level libraries to significantly speed packet injection. For this specific scenario, the ETF uses **tcpdump** as a background process instead of Scapy for more efficient packet sniffing, while Scapy is used to identify the encrypted ARP packet.
This scenario requires the following commands and operations to be performed on the ETF:
- Enter the AirScanner configuration mode:
**config airscanner** - Configure the AirScanner to not hop channels:
**set hop_channels = false** - Set the channel to sniff the traffic on the access point channel (APC):
**set fixed_sniffing_channel = <APC>** - Enter the ARPReplayer plugin configuration mode:
**config arpreplayer** - Set the target access point BSSID (APB) of the WEP network:
**set target_ap_bssid <APB>** - Start the AirScanner module with the ARPReplayer plugin:
**start airscanner with arpreplayer**
After executing these commands, ETF correctly identifies the encrypted ARP packet, then successfully performs an ARP replay attack, which cracks the network.
### Launching a catch-all honeypot
The scenario in Figure 4 creates multiple access points with the same SSID. This technique discovers the encryption type of a network that was probed for but out of reach. By launching multiple access points with all security settings, the client will automatically connect to the one that matches the security settings of the locally cached access point information.
Figure 4: Scenario for capturing a WPA handshake after a de-authentication attack
Using the ETF, it is possible to configure the **hostapd** configuration file then launch the program in the background. Hostapd supports launching multiple access points on the same wireless card by configuring virtual interfaces, and since it supports all types of security configurations, a complete catch-all honeypot can be set up. For the WEP and WPA(2)-PSK networks, a default password is used, and for the WPA(2)-EAP, an "*accept all*" policy is configured.
For this scenario, the following commands and operations must be performed on the ETF:
- Enter the APLauncher configuration mode:
**config aplauncher** - Set the desired access point SSID (APS):
**set ssid = <APS>** - Configure the APLauncher as a catch-all honeypot:
**set catch_all_honeypot = true** - Start the AirHost module:
**start airhost**
With these commands, the ETF can launch a complete catch-all honeypot with all types of security configurations. ETF also automatically launches the DHCP and DNS servers that allow clients to stay connected to the internet. ETF offers a better, faster, and more complete solution to create catch-all honeypots. The following code enables the successful execution of the ETF to be observed.
```
███████╗████████╗███████╗
██╔════╝╚══██╔══╝██╔════╝
█████╗ ██║ █████╗
██╔══╝ ██║ ██╔══╝
███████╗ ██║ ██║
╚══════╝ ╚═╝ ╚═╝
[+] Do you want to load an older session? [Y/n]: n
[+] Creating ne´,cxzw temporary session on 03/08/2018
[+] Enter the desired session name:
ETF[etf/aircommunicator/]::> config aplauncher
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf ssid CatchMe
ssid = CatchMe
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf catch_all_honeypot true
catch_all_honeypot = true
ETF[etf/aircommunicator/airhost/aplauncher]::> start airhost
[+] Killing already started processes and restarting network services
[+] Stopping dnsmasq and hostapd services
[+] Access Point stopped...
[+] Running airhost plugins pre_start
[+] Starting hostapd background process
[+] Starting dnsmasq service
[+] Running airhost plugins post_start
[+] Access Point launched successfully
[+] Starting dnsmasq service
```
## Conclusions and future work
These scenarios use common and well-known attacks to help validate the ETF's capabilities for testing WiFi networks and clients. The results also validate that the framework's architecture enables new attack vectors and features to be developed on top of it while taking advantage of the platform's existing capabilities. This should accelerate development of new WiFi penetration-testing tools, since a lot of the code is already written. Furthermore, the fact that complementary WiFi technologies are all integrated in a single tool will make WiFi pen-testing simpler and more efficient.
The ETF's goal is not to replace existing tools but to complement them and offer a broader choice to security auditors when conducting WiFi pen-testing and improving user awareness.
The ETF is an open source project [available on GitHub](https://github.com/Esser420/EvilTwinFramework) and community contributions to its development are welcomed. Following are some of the ways you can help.
One of the limitations of current WiFi pen-testing is the inability to log important events during tests. This makes reporting identified vulnerabilities both more difficult and less accurate. The framework could implement a logger that can be accessed by every class to create a pen-testing session report.
The ETF tool's capabilities cover many aspects of WiFi pen-testing. On one hand, it facilitates the phases of WiFi reconnaissance, vulnerability discovery, and attack. On the other hand, it doesn't offer a feature that facilitates the reporting phase. Adding the concept of a session and a session reporting feature, such as the logging of important events during a session, would greatly increase the value of the tool for real pen-testing scenarios.
Another valuable contribution would be extending the framework to facilitate WiFi fuzzing. The IEEE 802.11 protocol is very complex, and considering there are multiple implementations of it, both on the client and access point side, it's safe to assume these implementations contain bugs and even security flaws. These bugs could be discovered by fuzzing IEEE 802.11 protocol frames. Since Scapy allows custom packet creation and injection, a fuzzer can be implemented through it.
## Comments are closed. |
10,569 | 如何在 Linux 上复制文件/文件夹到远程系统? | https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/ | 2019-02-25T12:30:00 | [
"复制"
] | https://linux.cn/article-10569-1.html | 
从一个服务器复制文件到另一个服务器,或者从本地到远程复制是 Linux 管理员的日常任务之一。
我觉得不会有人不同意,因为无论在哪里这都是你的日常操作之一。有很多办法都能处理这个任务,我们试着加以概括。你可以挑一个喜欢的方法。当然,看看其他命令也能在别的地方帮到你。
我已经在自己的环境下测试过所有的命令和脚本了,因此你可以直接用到日常工作当中。
通常大家都倾向 `scp`,因为它是文件复制的<ruby> 原生命令 <rt> native command </rt></ruby>之一。但本文所列出的其它命令也很好用,建议你尝试一下。
文件复制可以轻易地用以下四种方法。
* `scp`:在网络上的两个主机之间复制文件,它使用 `ssh` 做文件传输,并使用相同的认证方式,具有相同的安全性。
* `rsync`:是一个既快速又出众的多功能文件复制工具。它能本地复制、通过远程 shell 在其它主机之间复制,或者与远程的 `rsync` <ruby> 守护进程 <rt> daemon </rt></ruby> 之间复制。
* `pscp`:是一个并行复制文件到多个主机上的程序。它提供了诸多特性,例如为 `scp` 配置免密传输,保存输出到文件,以及超时控制。
* `prsync`:也是一个并行复制文件到多个主机上的程序。它也提供了诸多特性,例如为 `ssh` 配置免密传输,保存输出到 文件,以及超时控制。
### 方式 1:如何在 Linux 上使用 scp 命令从本地系统向远程系统复制文件/文件夹?
`scp` 命令可以让我们从本地系统复制文件/文件夹到远程系统上。
我会把 `output.txt` 文件从本地系统复制到 `2g.CentOS.com` 远程系统的 `/opt/backup` 文件夹下。
```
# scp output.txt [email protected]:/opt/backup
output.txt 100% 2468 2.4KB/s 00:00
```
从本地系统复制两个文件 `output.txt` 和 `passwd-up.sh` 到远程系统 `2g.CentOs.com` 的 `/opt/backup` 文件夹下。
```
# scp output.txt passwd-up.sh [email protected]:/opt/backup
output.txt 100% 2468 2.4KB/s 00:00
passwd-up.sh 100% 877 0.9KB/s 00:00
```
从本地系统复制 `shell-script` 文件夹到远程系统 `2g.CentOs.com` 的 `/opt/back` 文件夹下。
这会连同`shell-script` 文件夹下所有的文件一同复制到`/opt/back` 下。
```
# scp -r /home/daygeek/2g/shell-script/ root@:/opt/backup/
output.txt 100% 2468 2.4KB/s 00:00
ovh.sh 100% 76 0.1KB/s 00:00
passwd-up.sh 100% 877 0.9KB/s 00:00
passwd-up1.sh 100% 7 0.0KB/s 00:00
server-list.txt 100% 23 0.0KB/s 00:00
```
### 方式 2:如何在 Linux 上使用 scp 命令和 Shell 脚本复制文件/文件夹到多个远程系统上?
如果你想复制同一个文件到多个远程服务器上,那就需要创建一个如下面那样的小 shell 脚本。
并且,需要将服务器添加进 `server-list.txt` 文件。确保添加成功后,每个服务器应当单独一行。
最终,你想要的脚本就像下面这样:
```
# file-copy.sh
#!/bin/sh
for server in `more server-list.txt`
do
scp /home/daygeek/2g/shell-script/output.txt root@$server:/opt/backup
done
```
完成之后,给 `file-copy.sh` 文件设置可执行权限。
```
# chmod +x file-copy.sh
```
最后运行脚本完成复制。
```
# ./file-copy.sh
output.txt 100% 2468 2.4KB/s 00:00
output.txt 100% 2468 2.4KB/s 00:00
```
使用下面的脚本可以复制多个文件到多个远程服务器上。
```
# file-copy.sh
#!/bin/sh
for server in `more server-list.txt`
do
scp /home/daygeek/2g/shell-script/output.txt passwd-up.sh root@$server:/opt/backup
done
```
下面结果显示所有的两个文件都复制到两个服务器上。
```
# ./file-cp.sh
output.txt 100% 2468 2.4KB/s 00:00
passwd-up.sh 100% 877 0.9KB/s 00:00
output.txt 100% 2468 2.4KB/s 00:00
passwd-up.sh 100% 877 0.9KB/s 00:00
```
使用下面的脚本递归地复制文件夹到多个远程服务器上。
```
# file-copy.sh
#!/bin/sh
for server in `more server-list.txt`
do
scp -r /home/daygeek/2g/shell-script/ root@$server:/opt/backup
done
```
上述脚本的输出。
```
# ./file-cp.sh
output.txt 100% 2468 2.4KB/s 00:00
ovh.sh 100% 76 0.1KB/s 00:00
passwd-up.sh 100% 877 0.9KB/s 00:00
passwd-up1.sh 100% 7 0.0KB/s 00:00
server-list.txt 100% 23 0.0KB/s 00:00
output.txt 100% 2468 2.4KB/s 00:00
ovh.sh 100% 76 0.1KB/s 00:00
passwd-up.sh 100% 877 0.9KB/s 00:00
passwd-up1.sh 100% 7 0.0KB/s 00:00
server-list.txt 100% 23 0.0KB/s 00:00
```
### 方式 3:如何在 Linux 上使用 pscp 命令复制文件/文件夹到多个远程系统上?
`pscp` 命令可以直接让我们复制文件到多个远程服务器上。
使用下面的 `pscp` 命令复制单个文件到远程服务器。
```
# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt /opt/backup
[1] 18:46:11 [SUCCESS] 2g.CentOS.com
```
使用下面的 `pscp` 命令复制多个文件到远程服务器。
```
# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt ovh.sh /opt/backup
[1] 18:47:48 [SUCCESS] 2g.CentOS.com
```
使用下面的 `pscp` 命令递归地复制整个文件夹到远程服务器。
```
# pscp.pssh -H 2g.CentOS.com -r /home/daygeek/2g/shell-script/ /opt/backup
[1] 18:48:46 [SUCCESS] 2g.CentOS.com
```
使用下面的 `pscp` 命令使用下面的命令复制单个文件到多个远程服务器。
```
# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt /opt/backup
[1] 18:49:48 [SUCCESS] 2g.CentOS.com
[2] 18:49:48 [SUCCESS] 2g.Debian.com
```
使用下面的 `pscp` 命令复制多个文件到多个远程服务器。
```
# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt passwd-up.sh /opt/backup
[1] 18:50:30 [SUCCESS] 2g.Debian.com
[2] 18:50:30 [SUCCESS] 2g.CentOS.com
```
使用下面的命令递归地复制文件夹到多个远程服务器。
```
# pscp.pssh -h server-list.txt -r /home/daygeek/2g/shell-script/ /opt/backup
[1] 18:51:31 [SUCCESS] 2g.Debian.com
[2] 18:51:31 [SUCCESS] 2g.CentOS.com
```
### 方式 4:如何在 Linux 上使用 rsync 命令复制文件/文件夹到多个远程系统上?
`rsync` 是一个即快速又出众的多功能文件复制工具。它能本地复制、通过远程 shell 在其它主机之间复制,或者在远程 `rsync` <ruby> 守护进程 <rt> daemon </rt></ruby> 之间复制。
使用下面的 `rsync` 命令复制单个文件到远程服务器。
```
# rsync -avz /home/daygeek/2g/shell-script/output.txt [email protected]:/opt/backup
sending incremental file list
output.txt
sent 598 bytes received 31 bytes 1258.00 bytes/sec
total size is 2468 speedup is 3.92
```
使用下面的 `rsync` 命令复制多个文件到远程服务器。
```
# rsync -avz /home/daygeek/2g/shell-script/output.txt passwd-up.sh [email protected]:/opt/backup
sending incremental file list
output.txt
passwd-up.sh
sent 737 bytes received 50 bytes 1574.00 bytes/sec
total size is 2537 speedup is 3.22
```
使用下面的 `rsync` 命令通过 `ssh` 复制单个文件到远程服务器。
```
# rsync -avzhe ssh /home/daygeek/2g/shell-script/output.txt [email protected]:/opt/backup
sending incremental file list
output.txt
sent 598 bytes received 31 bytes 419.33 bytes/sec
total size is 2.47K speedup is 3.92
```
使用下面的 `rsync` 命令通过 `ssh` 递归地复制文件夹到远程服务器。这种方式只复制文件不包括文件夹。
```
# rsync -avzhe ssh /home/daygeek/2g/shell-script/ [email protected]:/opt/backup
sending incremental file list
./
output.txt
ovh.sh
passwd-up.sh
passwd-up1.sh
server-list.txt
sent 3.85K bytes received 281 bytes 8.26K bytes/sec
total size is 9.12K speedup is 2.21
```
### 方式 5:如何在 Linux 上使用 rsync 命令和 Shell 脚本复制文件/文件夹到多个远程系统上?
如果你想复制同一个文件到多个远程服务器上,那也需要创建一个如下面那样的小 shell 脚本。
```
# file-copy.sh
#!/bin/sh
for server in `more server-list.txt`
do
rsync -avzhe ssh /home/daygeek/2g/shell-script/ [email protected]$server:/opt/backup
done
```
上面脚本的输出。
```
# ./file-copy.sh
sending incremental file list
./
output.txt
ovh.sh
passwd-up.sh
passwd-up1.sh
server-list.txt
sent 3.86K bytes received 281 bytes 8.28K bytes/sec
total size is 9.13K speedup is 2.21
sending incremental file list
./
output.txt
ovh.sh
passwd-up.sh
passwd-up1.sh
server-list.txt
sent 3.86K bytes received 281 bytes 2.76K bytes/sec
total size is 9.13K speedup is 2.21
```
### 方式 6:如何在 Linux 上使用 scp 命令和 Shell 脚本从本地系统向多个远程系统复制文件/文件夹?
在上面两个 shell 脚本中,我们需要事先指定好文件和文件夹的路径,这儿我做了些小修改,让脚本可以接收文件或文件夹作为输入参数。当你每天需要多次执行复制时,这将会非常有用。
```
# file-copy.sh
#!/bin/sh
for server in `more server-list.txt`
do
scp -r $1 [email protected]$server:/opt/backup
done
```
输入文件名并运行脚本。
```
# ./file-copy.sh output1.txt
output1.txt 100% 3558 3.5KB/s 00:00
output1.txt 100% 3558 3.5KB/s 00:00
```
### 方式 7:如何在 Linux 系统上用非标准端口复制文件/文件夹到远程系统?
如果你想使用非标准端口,使用下面的 shell 脚本复制文件或文件夹。
如果你使用了<ruby> 非标准 <rt> Non-Standard </rt></ruby>端口,确保像下面 `scp` 命令那样指定好了端口号。
```
# file-copy-scp.sh
#!/bin/sh
for server in `more server-list.txt`
do
scp -P 2222 -r $1 [email protected]$server:/opt/backup
done
```
运行脚本,输入文件名。
```
# ./file-copy.sh ovh.sh
ovh.sh 100% 3558 3.5KB/s 00:00
ovh.sh 100% 3558 3.5KB/s 00:00
```
如果你使用了<ruby> 非标准 <rt> Non-Standard </rt></ruby>端口,确保像下面 `rsync` 命令那样指定好了端口号。
```
# file-copy-rsync.sh
#!/bin/sh
for server in `more server-list.txt`
do
rsync -avzhe 'ssh -p 2222' $1 [email protected]$server:/opt/backup
done
```
运行脚本,输入文件名。
```
# ./file-copy-rsync.sh passwd-up.sh
sending incremental file list
passwd-up.sh
sent 238 bytes received 35 bytes 26.00 bytes/sec
total size is 159 speedup is 0.58
sending incremental file list
passwd-up.sh
sent 238 bytes received 35 bytes 26.00 bytes/sec
total size is 159 speedup is 0.58
```
---
via: <https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LuuMing](https://github.com/LuuMing) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,570 | 8 个在 KDE Plasma 桌面环境下提高生产力的技巧和提示 | https://www.maketecheasier.com/kde-plasma-tips-tricks-improve-productivity/ | 2019-02-25T23:16:13 | [
"KDE"
] | https://linux.cn/article-10570-1.html | 
众所周知,KDE 的 Plasma 是 Linux 下最强大的桌面环境之一。它是高度可定制的,并且看起来也很棒。当你完成所有的配置工作后,你才能体会到它的所有特性。
你能够轻松地配置 Plasma 桌面并且使用它大量方便且节省时间的特性来加速你的工作,拥有一个能够帮助你而非阻碍你的桌面环境。
以下这些提示并没有特定顺序,因此你无需按次序阅读。你只需要挑出最适合你的工作流的那几个即可。
**相关阅读**:[10 个你应该尝试的最佳 KDE Plasma 应用](https://www.maketecheasier.com/10-best-kde-plasma-applications/ "10 of the Best KDE Plasma Applications You Should Try")
### 1、多媒体控制
这点不太算得上是一条提示,因为它是很容易被记在脑海里的。Plasma 可在各处进行多媒体控制。当你需要暂停、继续或跳过一首歌时,你不需要每次都打开你的媒体播放器。你能够通过将鼠标移至那个最小化窗口之上,甚至通过锁屏进行控制。当你需要切换歌曲或忘了暂停时,你也不必麻烦地登录再进行操作。
### 2、KRunner

KRunner 是 Plasma 桌面中一个经常受到赞誉的特性。大部分人习惯于穿过层层的应用启动菜单来找到想要启动的程序。当你使用 KRunner 时就不需要这么做。
为了使用 KRunner,确保你当前的活动焦点在桌面本身(点击桌面而不是窗口)。然后开始输入你想要启动的应用名称,KRunner 将会带着建议项从你的屏幕顶部自动下拉。在你寻找的匹配项上点击或敲击回车键。这比记住你每个应用所属的类别要更快。
### 3、跳转列表

跳转列表功能是最近才被添加进 Plasma 桌面的。它允许你在启动应用时直接跳转至特定的区域或特性部分。
因此如果你在菜单栏上有一个应用启动图标,你可以通过右键得到可跳转位置的列表。选择你想要跳转的位置,然后就可以“起飞”了。
### 4、KDE Connect

如果你有一个安卓手机,那么 [KDE Connect](https://www.maketecheasier.com/send-receive-sms-linux-kde-connect/) 会为你提供大量帮助。它可以将你的手机连接至你的桌面,由此你可以在两台设备间无缝地共享。
通过 KDE Connect,你能够在你的桌面上实时地查看 [Android 设备通知](https://www.maketecheasier.com/android-notifications-ubuntu-kde-connect/)。它同时也让你能够从 Plasma 中收发文字信息,甚至不需要拿起你的手机。
KDE Connect 也允许你在手机和电脑间发送文件或共享网页。你可以轻松地从一个设备转移至另一设备,而无需烦恼或打乱思绪。
### 5、Plasma Vaults

Plasma Vaults 是 Plasma 桌面的另一个新功能。它的 KDE 为加密文件和文件夹提供的简单解决方案。如果你不使用加密文件,此项功能不会为你节省时间。如果你使用,Vaults 是一个更简单的途径。
Plasma Vaults 允许你以无 root 权限的普通用户创建加密目录,并通过你的任务栏来管理它们。你能够快速地挂载或卸载目录,而无需外部程序或附加权限。
### 6、Pager 控件

配置你的桌面的 pager 控件。它允许你轻松地切换至另三个附加工作区,带来更大的屏幕空间。
将控件添加到你的菜单栏上,然后你就可以在多个工作区间滑动切换。每个工作区都与你原桌面的尺寸相同,因此你能够得到数倍于完整屏幕的空间。这就使你能够排布更多的窗口,而不必受到一堆混乱的最小化窗口的困扰。
### 7、创建一个 Dock

Plasma 以其灵活性和可配置性出名,同时也是它的优势。如果你有常用的程序,你可以考虑将常用程序设置为 OS X 风格的 dock。你能够通过单击启动,而不必深入菜单或输入它们的名字。
### 8、为 Dolphin 添加文件树

通过目录树来浏览文件夹会更加简单。Dolphin 作为 Plasma 的默认文件管理器,具有在文件夹窗口一侧,以树的形式展示目录列表的内置功能。
为了启用目录树,点击“控制”标签,然后“配置 Dolphin”、“显示模式”、“详细”,最后选择“可展开文件夹”。
记住这些仅仅是提示,不要强迫自己做阻碍自己的事情。你可能讨厌在 Dolphin 中使用文件树,你也可能从不使用 Pager,这都没关系。当然也可能会有你喜欢但是此处没列举出来的功能。选择对你有用处的,也就是说,这些技巧中总有一些能帮助你度过日常工作中的艰难时刻。
---
via: <https://www.maketecheasier.com/kde-plasma-tips-tricks-improve-productivity/>
作者:[Nick Congleton](https://www.maketecheasier.com/author/nickcongleton/) 译者:[cycoe](https://github.com/cycoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
KDE’s Plasma is easily one of the most powerful desktop environments available for Linux. It’s highly configurable, and it looks pretty good, too. That doesn’t amount to a whole lot unless you can actually get things done.
You can easily configure Plasma and make use of a lot of its convenient and time-saving features to boost your productivity and have a desktop that empowers you, rather than getting in your way.
These tips aren’t in any particular order, so you don’t need to prioritize. Pick the ones that best fit your workflow.
**Also read:** [10 of the Best KDE Plasma Applications You Should Try](https://www.maketecheasier.com/10-best-kde-plasma-applications/)
## 1. Multimedia Controls
This isn’t so much of a tip as it is something that’s good to keep in mind. Plasma keeps multimedia controls everywhere. You don’t need to open your media player every time you need to pause, resume, or skip a song; you can mouse over the minimized window or even control it via the lock screen. There’s no need to scramble to log in to change a song or because you forgot to pause one.
## 2. KRunner
KRunner is an often under-appreciated feature of the Plasma desktop. Most people are used to digging through the application launcher menu to find the program that they’re looking to launch. That’s not necessary with KRunner.
To use KRunner, make sure that your focus is on the desktop itself. (Click on it instead of a window.) Then, start typing the name of the program that you want. KRunner will automatically drop down from the top of your screen with suggestions. Click or press Enter on the one you’re looking for. It’s much faster than remembering which category your program is under.
## 3. Jump Lists
Jump lists are a fairly recent addition to the Plasma desktop. They allow you to launch an application directly to a specific section or feature.
So if you have a launcher on a menu bar, you can right-click and get a list of places to jump to. Select where you want to go, and you’re off.
## 4. KDE Connect
[KDE Connect](https://www.maketecheasier.com/send-receive-sms-linux-kde-connect/) is a massive help if you have an Android phone. It connects the phone to your desktop so you can share things seamlessly between the devices.
With KDE Connect, you can see your [Android device’s notification](https://www.maketecheasier.com/android-notifications-ubuntu-kde-connect/) on your desktop in real time. It also enables you to send and receive text messages from Plasma without ever picking up your phone.
KDE Connect also lets you send files and share web pages between your phone and your computer. You can easily move from one device to the other without a lot of hassle or losing your train of thought.
## 5. Plasma Vaults
Plasma Vaults are another new addition to the Plasma desktop. They are KDE’s simple solution to encrypted files and folders. If you don’t work with encrypted files, this one won’t really save you any time. If you do, though, vaults are a much simpler approach.
Plasma Vaults let you create encrypted directories as a regular user without root and manage them from your task bar. You can mount and unmount the directories on the fly without the need for external programs or additional privileges.
## 6. Pager Widget
Configure your desktop with the pager widget. It allows you to easily access three additional workspaces for even more screen room.
Add the widget to your menu bar, and you can slide between multiple workspaces. These are all the size of your screen, so you gain multiple times the total screen space. That lets you lay out more windows without getting confused by a minimized mess or disorganization.
## 7. Create a Dock
Plasma is known for its flexibility and the room it allows for configuration. Use that to your advantage. If you have programs that you’re always using, consider setting up an OS X style dock with your most used applications. You’ll be able to get them with a single click rather than going through a menu or typing in their name.
## 8. Add a File Tree to Dolphin
It’s much easier to navigate folders in a directory tree. Dolphin, Plasma’s default file manager, has built-in functionality to display a directory listing in the form of a tree on the side of the folder window.
To enable the directory tree, click on the “Control” tab, then “Configure Dolphin,” “View Modes,” and “Details.” Finally, select “Expandable Folders.”
Remember that these tips are just tips. Don’t try to force yourself to do something that’s getting in your way. You may hate using file trees in Dolphin. You may never use Pager. That’s alright. There may even be something that you personally like that’s not listed here. Do what works for you. That said, at least a few of these should shave some serious time out of your work day.
Our latest tutorials delivered straight to your inbox |
10,571 | 如何在 Linux 系统中判断安装、使用了多少内存 | https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html | 2019-02-26T00:02:19 | [
"内存"
] | https://linux.cn/article-10571-1.html |
>
> 有几个命令可以报告在 Linux 系统上安装和使用了多少内存。根据你使用的命令,你可能会被细节淹没,也可能获得快速简单的答案。
>
>
>

在 Linux 系统中有很多种方法获取有关安装了多少内存的信息及查看多少内存正在被使用。有些命令提供了大量的细节,而其他命令提供了简洁但不一定易于理解的答案。在这篇文章中,我们将介绍一些查看内存及其使用状态的有用的工具。
在我们开始之前,让我们先来回顾一些基础知识。物理内存和虚拟内存并不是一回事。后者包括配置为交换空间的磁盘空间。交换空间可能包括为此目的特意留出来的分区,以及在创建新的交换分区不可行时创建的用来增加可用交换空间的文件。有些 Linux 命令会提供关于两者的信息。
当物理内存占满时,交换空间通过提供可以用来存放内存中非活动页的磁盘空间来扩展内存。
`/proc/kcore` 是在内存管理中起作用的一个文件。这个文件看上去是个普通文件(虽然非常大),但它并不占用任何空间。它就像其他 `/proc` 下的文件一样是个虚拟文件。
```
$ ls -l /proc/kcore
-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
```
有趣的是,下面查询的两个系统并没有安装相同大小的内存,但 `/proc/kcore` 的大小却是相同的。第一个系统安装了 4 GB 的内存,而第二个系统安装了 6 GB。
```
system1$ ls -l /proc/kcore
-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
system2$ ls -l /proc/kcore
-r-------- 1 root root 140737477881856 Feb 5 13:00 /proc/kcore
```
一种不靠谱的解释说这个文件代表可用虚拟内存的大小(没准要加 4 KB),如果这样,这些系统的虚拟内存可就是 128TB 了!这个数字似乎代表了 64 位系统可以寻址多少内存,而不是当前系统有多少可用内存。在命令行中计算 128 TB 和这个文件大小加上 4 KB 很容易。
```
$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128
140737488355328
$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128 + 4096
140737488359424
```
另一个用来检查内存的更人性化的命令是 `free`。它会给出一个易于理解的内存报告。
```
$ free
total used free shared buff/cache available
Mem: 6102476 812244 4090752 13112 1199480 4984140
Swap: 2097148 0 2097148
```
使用 `-g` 选项,`free` 会以 GB 为单位返回结果。
```
$ free -g
total used free shared buff/cache available
Mem: 5 0 3 0 1 4
Swap: 1 0 1
```
使用 `-t` 选项,`free` 会显示与无附加选项时相同的值(不要把 `-t` 选项理解成 TB),并额外在输出的底部添加一行总计数据。
```
$ free -t
total used free shared buff/cache available
Mem: 6102476 812408 4090612 13112 1199456 4983984
Swap: 2097148 0 2097148
Total: 8199624 812408 6187760
```
当然,你也可以选择同时使用两个选项。
```
$ free -tg
total used free shared buff/cache available
Mem: 5 0 3 0 1 4
Swap: 1 0 1
Total: 7 0 5
```
如果你尝试用这个报告来解释“这个系统安装了多少内存?”,你可能会感到失望。上面的报告就是在前文说的装有 6 GB 内存的系统上运行的结果。这并不是说这个结果是错的,这就是系统对其可使用的内存的看法。
`free` 命令也提供了每隔 X 秒刷新显示的选项(下方示例中 X 为 10)。
```
$ free -s 10
total used free shared buff/cache available
Mem: 6102476 812280 4090704 13112 1199492 4984108
Swap: 2097148 0 2097148
total used free shared buff/cache available
Mem: 6102476 812260 4090712 13112 1199504 4984120
Swap: 2097148 0 2097148
```
使用 `-l` 选项,`free` 命令会提供高低内存使用信息。
```
$ free -l
total used free shared buff/cache available
Mem: 6102476 812376 4090588 13112 1199512 4984000
Low: 6102476 2011888 4090588
High: 0 0 0
Swap: 2097148 0 2097148
```
查看内存的另一个选择是 `/proc/meminfo` 文件。像 `/proc/kcore` 一样,这也是一个虚拟文件,它可以提供关于安装或使用了多少内存以及可用内存的报告。显然,空闲内存和可用内存并不是同一回事。`MemFree` 看起来代表未使用的 RAM。`MemAvailable` 则是对于启动新程序时可使用的内存的一个估计。
```
$ head -3 /proc/meminfo
MemTotal: 6102476 kB
MemFree: 4090596 kB
MemAvailable: 4984040 kB
```
如果只想查看内存总计,可以使用下面的命令之一:
```
$ awk '/MemTotal/ {print $2}' /proc/meminfo
6102476
$ grep MemTotal /proc/meminfo
MemTotal: 6102476 kB
```
`DirectMap` 将内存信息分为几类。
```
$ grep DirectMap /proc/meminfo
DirectMap4k: 213568 kB
DirectMap2M: 6076416 kB
```
`DirectMap4k` 代表被映射成标准 4 k 页的内存大小,`DirectMap2M` 则显示了被映射为 2 MB 的页的内存大小。
`getconf` 命令将会提供比我们大多数人想要看到的更多的信息。
```
$ getconf -a | more
LINK_MAX 65000
_POSIX_LINK_MAX 65000
MAX_CANON 255
_POSIX_MAX_CANON 255
MAX_INPUT 255
_POSIX_MAX_INPUT 255
NAME_MAX 255
_POSIX_NAME_MAX 255
PATH_MAX 4096
_POSIX_PATH_MAX 4096
PIPE_BUF 4096
_POSIX_PIPE_BUF 4096
SOCK_MAXBUF
_POSIX_ASYNC_IO
_POSIX_CHOWN_RESTRICTED 1
_POSIX_NO_TRUNC 1
_POSIX_PRIO_IO
_POSIX_SYNC_IO
_POSIX_VDISABLE 0
ARG_MAX 2097152
ATEXIT_MAX 2147483647
CHAR_BIT 8
CHAR_MAX 127
--More--
```
使用类似下面的命令来将其输出精简为指定的内容,你会得到跟前文提到的其他命令相同的结果。
```
$ getconf -a | grep PAGES | awk 'BEGIN {total = 1} {if (NR == 1 || NR == 3) total *=$NF} END {print total / 1024" kB"}'
6102476 kB
```
上面的命令通过将下方输出的第一行和最后一行的值相乘来计算内存。
```
PAGESIZE 4096 <==
_AVPHYS_PAGES 1022511
_PHYS_PAGES 1525619 <==
```
自己动手计算一下,我们就知道这个值是怎么来的了。
```
$ expr 4096 \* 1525619 / 1024
6102476
```
显然值得为以上的指令之一设置个 `alias`。
另一个具有非常易于理解的输出的命令是 `top` 。在 `top` 输出的前五行,你可以看到一些数字显示多少内存正被使用。
```
$ top
top - 15:36:38 up 8 days, 2:37, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 266 total, 1 running, 265 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.4 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3244.8 total, 377.9 free, 1826.2 used, 1040.7 buff/cache
MiB Swap: 3536.0 total, 3535.7 free, 0.3 used. 1126.1 avail Mem
```
最后一个命令将会以一个非常简洁的方式回答“系统安装了多少内存?”:
```
$ sudo dmidecode -t 17 | grep "Size.*MB" | awk '{s+=$2} END {print s / 1024 "GB"}'
6GB
```
取决于你想要获取多少细节,Linux 系统提供了许多用来查看系统安装内存以及使用/空闲内存的选择。
---
via: <https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[leommxj](https://github.com/leommxj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,572 | Qalculate! :全宇宙最好的计算器软件 | https://itsfoss.com/qalculate/ | 2019-02-26T14:22:21 | [
"计算器"
] | https://linux.cn/article-10572-1.html | 十多年来,我一直都是 GNU-Linux 以及 [Debian](https://www.debian.org/) 的用户。随着我越来越频繁的使用桌面环境,我发现对我来说除了少数基于 web 的服务以外我的大多数需求都可以通过 Debian 软件库里自带的[桌面应用](https://itsfoss.com/essential-linux-applications/)解决。
我的需求之一就是进行单位换算。尽管有很多很多在线服务可以做这件事,但是我还是需要一个可以在桌面环境使用的应用。这主要是因为隐私问题以及我不想一而再再而三的寻找在线服务做事。为此我搜寻良久,直到找到 Qalculate!。
### Qalculate! 最强多功能计算器应用

这是 aptitude 上关于 [Qalculate!](https://qalculate.github.io/) 的介绍,我没法总结的比他们更好了:
>
> 强大易用的桌面计算器 - GTK+ 版
>
>
> Qalculate! 是一款外表简单易用,内核强大且功能丰富的应用。其功能包含自定义函数、单位、高计算精度、作图以及可以输入一行表达式(有容错措施)的图形界面(也可以选择使用传统按钮)。
>
>
>
这款应用也发行过 KDE 的界面,但是至少在 Debian Testing 软件库里,只出现了 GTK+ 版的界面,你也可以在 GitHub 上的这个[仓库](https://github.com/Qalculate)里面看到。
不必多说,Qalculate! 在 Debian 的软件源内处于可用状态,因此可以使用 [apt](https://itsfoss.com/apt-command-guide/) 命令或者是基于 Debian 的发行版比如 Ubuntu 提供的软件中心轻松安装。在 Windows 或者 macOS 上也可以使用这款软件。
#### Qalculate! 特性一览
列出全部的功能清单会有点长,请允许我只列出一部分功能并使用截图来展示极少数 Qalculate! 提供的功能。这么做是为了让你熟悉 Qalculate! 的基本功能,并在之后可以自由探索 Qalculate! 到底还能干什么。
* 代数
* 微积分
* 组合数学
* 复数
* 数据集
* 日期与时间
* 经济学
* 对数和指数
* 几何
* 逻辑学
* 向量和矩阵
* 杂项
* 数论
* 统计学
* 三角学
#### 使用 Qalculate!
Qalculate! 的使用不是很难。你甚至可以在里面写简单的英文。但是我还是推荐先[阅读手册](https://qalculate.github.io/manual/index.html)以便充分发挥 Qalculate! 的潜能。


#### qalc 是 Qalculate! 的命令行版
你也可以使用 Qalculate! 的命令行版 `qalc`:
```
$ qalc 62499836 byte to gibibyte
62499836 * byte = approx. 0.058207508 gibibyte
$ qalc 40 degree celsius to fahrenheit
(40 * degree) * celsius = 104 deg*oF
```
Qalculate! 的命令行界面可以让不喜欢 GUI 而是喜欢命令行界面(CLI)或者是使用无头结点(没有 GUI)的人可以使用 Qalculate!。这些人大多是在服务器环境下工作。
如果你想要在脚本里使用这一软件的话,我想 libqalculate 是最好的解决方案。看一看 `qalc` 以及 qalculate-gtk 是如何依赖于它工作的就足以知晓如何使用了。
再提一嘴,你还可以了解下如何根据一系列数据绘图,其他应用方式就留给你自己发掘了。不要忘记查看 `/usr/share/doc/qalculate/index.html` 以获取 Qalculate! 的全部功能。
注释:注意 Debian 更喜欢 [gnuplot](http://www.gnuplot.info/),因为其输出的图片很精美。
#### 附加技巧:你可以通过在 Debian 下通过命令行感谢开发者
如果你使用 Debian 而且喜欢哪个包的话,你可以使用如下命令感谢 Debian 下这个软件包的开发者或者是维护者:
```
reportbug --kudos $PACKAGENAME
```
因为我喜欢 Qalculate!,我想要对 Debian 的开发者以及维护者 Vincent Legout 的卓越工作表示感谢:
```
reportbug --kudos qalculate
```
建议各位阅读我写的关于如何使用报错工具[在 Debian 中上报 BUG](https://itsfoss.com/bug-report-debian/)的详细指南。
#### 一位高分子化学家对 Qalculate! 的评价
经由作者 [Philip Prado](https://itsfoss.com/author/phillip/),我们联系上了 Timothy Meyers 先生,他目前是在高分子实验室工作的高分子化学家。
他对 Qaclulate! 的专业评价是:
>
> 看起来几乎任何科学家都可以使用这个软件,因为如果你知道指令以及如何使其生效的话,几乎任何数据计算都可以使用这个软件计算。
>
>
> 我觉得这个软件少了些物理常数,但我想不起来缺了哪些。我觉得它没有太多有关[流体动力学](https://en.wikipedia.org/wiki/Fluid_dynamics)的东西,再就是少了点部分化合物的[光吸收](https://en.wikipedia.org/wiki/Absorption_(electromagnetic_radiation))系数,但这些东西只对我这个化学家来说比较重要,我不知道这些是不是对别人来说也是特别必要的。[自由能](https://en.wikipedia.org/wiki/Gibbs_free_energy)可能也是。
>
>
>
最后,我分享的关于 Qalculate! 的介绍十分简陋,其实际功能与你的需要以及你的想象力有关系。希望你能喜欢 Qalculate!
---
via: <https://itsfoss.com/qalculate/>
作者:[Shirish](https://itsfoss.com/author/shirish/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[name1e5s](https://github.com/name1e5s) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I have been a GNU-Linux user and a [Debian](https://www.debian.org/) user for more than a decade. As I started using the desktop more and more, it seemed to me that apart from few web-based services most of my needs were being met with [desktop applications](https://itsfoss.com/essential-linux-applications/) within Debian itself.
One of such applications was the need for me to calculate between different measurements of units. While there are and were many web-services which can do the same, I wanted something which could do all this and more on my desktop for both privacy reasons as well as not having to hunt for a web service for doing one thing or the other. My search ended when I found Qalculate!.
## Qalculate! The most versatile calculator application

This is what aptitude says about [Qalculate!](https://qalculate.github.io/) and I cannot put it in better terms:
Powerful and easy to use desktop calculator – GTK+ version
Qalculate! is small and simple to use but with much power and versatility underneath. Features include customizable functions, units, arbitrary precision, plotting, and a graphical interface that uses a one-line fault-tolerant expression entry (although it supports optional traditional buttons).
It also did have a KDE interface as well as in its previous avatar, but at least in Debian testing, it just shows only the GTK+ version which can be seen from the github [repo](https://github.com/Qalculate) as well.
Needless to say that Qalculate! is available in Debian repository and hence can easily be installed [using apt command](https://itsfoss.com/apt-command-guide/) or through software center in Debian based distributions like Ubuntu. It is also availale for Windows and macOS.
### Features of Qalculate!
Now while it would be particularly long to go through the whole list of functionality it allows – allow me to list some of the functionality to be followed by a few screenshots of just a couple of functionalities that Qalculate! provides. The idea is basically to familiarize you with a couple of basic methods and then leave it up to you to enjoy exploring what all Qalculate! can do.
- Algebra
- Calculus
- Combinatorics
- Complex_Numbers
- Data_Sets
- Date_&_Time
- Economics
- Exponents_&_Logarithms
- Geometry
- Logical
- Matrices_&_Vectors
- Miscellaneous
- Number_Theory
- Statistics
- Trigonometry
### Using Qalculate!
Using Qalculate! is not complicated. You can even write in the simple natural language. However, I recommend [reading the manual](https://qalculate.github.io/manual/index.html) to utilize the full potential of Qalculate!
### qalc is the command line version of Qalculate!
You can achieve the same results as Qalculate! with its command-line brethren qalc
```
$ qalc 62499836 byte to gibibyte
62499836 * byte = approx. 0.058207508 gibibyte
```
```
$ qalc 40 degree celsius to fahrenheit
(40 * degree) * celsius = 104 deg*oF
```
I shared the command-line interface so that people who don’t like GUI interfaces and prefer command-line (CLI) or have headless nodes (no GUI) could also use qalculate, pretty common in server environments.
If you want to use it in scripts, I guess libqalculate would be the way to go and seeing how qalculate-gtk, qalc depend on it seems it should be good enough.
Just to share, you could also explore how to use plotting of series data but that and other uses will leave to you. Don’t forget to check the /usr/share/doc/qalculate/index.html to see all the different functionalities that Qalculate! has.
Note:- Do note that though Debian prefers [gnuplot](http://www.gnuplot.info/) to showcase the pretty graphs that can come out of it.
### Bonus Tip: You can thank the developer via command line in Debian
If you use Debian and like any package, you can quickly thank the Debian Developer or maintainer maintaining the said package using:
`reportbug --kudos $PACKAGENAME`
Since I liked QaIculate!, I would like to give a big shout-out to the Debian developer and maintainer Vincent Legout for the fantastic work he has done.
`reportbug --kudos qalculate`
I would also suggest reading my detailed article on using reportbug tool for [bug reporting in Debian](https://itsfoss.com/bug-report-debian/).
### The opinion of a Polymer Chemist on Qalculate!
Through my fellow author [Philip Prado](https://itsfoss.com/author/phillip/), we contacted a Mr. Timothy Meyers, currently a student working in a polymer lab as a Polymer Chemist.
His professional opinion on Qaclulate! is –
This looks like almost any scientist to use as any type of data calculations statistics could use this program issue would be do you know the commands and such to make it function
I feel like there’s some Physics constants that are missing but off the top of my head I can’t think of what they are but I feel like there’s not very many
[fluid dynamics]stuff in there and also some different like[light absorption]coefficients for different compounds but that’s just a chemist in me I don’t know if those are super necessary.[Free energy]might be one
In the end, I just want to share this is a mere introduction to what Qalculate! can do and is limited by what you want to get done and your imagination. I hope you like Qalculate! You may also check [Caligator](https://itsfoss.com/caligator/) which is a similar kind of application. |
10,573 | 在命令行查看文件的 3 个工具 | https://opensource.com/article/19/2/view-files-command-line | 2019-02-26T14:38:27 | [
"less",
"Word",
"ODT"
] | https://linux.cn/article-10573-1.html |
>
> 看一下 `less`、Antiword 和 `odt2xt` 这三个实用程序,它们都可以在终端中查看文件。
>
>
>

我常说,你不需要使用命令行也可以高效使用 Linux —— 我知道许多 Linux 用户从不打开终端窗口,并且也用的挺好。然而,即使我不认为自己是一名技术人员,我也会在命令行上花费大约 20% 的计算时间,包括操作文件、处理文本和使用实用程序。
我经常在终端窗口中做的一件事是查看文件,无论是文本还是需要用到文字处理器的文件。有时使用命令行实用程序比启动文本编辑器或文字处理器更容易。
下面是我在命令行中用来查看文件的三个实用程序。
### less
[less](https://www.gnu.org/software/less/) 的美妙之处在于它易于使用,它将你正在查看的文件分解为块(或页面),这使得它们更易于阅读。你可以使用它在命令行查看文本文件,例如 README、HTML 文件、LaTeX 文件或其他任何纯文本文件。我在[上一篇文章](https://opensource.com/article/18/4/using-less-view-text-files-command-line)中介绍了 `less`。
要使用 `less`,只需输入:
```
less file_name
```

通过按键盘上的空格键或 `PgDn` 键向下滚动文件,按 `PgUp` 键向上移动文件。要停止查看文件,按键盘上的 `Q` 键。
### Antiword
[Antiword](http://www.winfield.demon.nl/) 是一个很好地实用小程序,你可以使用它将 Word 文档转换为纯文本。只要你想,还可以将它们转换为 [PostScript](http://en.wikipedia.org/wiki/PostScript) 或 [PDF](http://en.wikipedia.org/wiki/Portable_Document_Format)。在本文中,让我们继续使用文本转换。
Antiword 可以读取和转换 Word 2.0 到 2003 版本创建的文件(LCTT 译注:此处疑为 Word 2000,因为 Word 2.0 for DOS 发布于 1984 年,而 WinWord 2.0 发布于 1991 年,都似乎太老了)。它不能读取 DOCX 文件 —— 如果你尝试这样做,Antiword 会显示一条错误消息,表明你尝试读取的是一个 ZIP 文件。这在技术上说是正确的,但仍然令人沮丧。
要使用 Antiword 查看 Word 文档,输入以下命令:
```
antiword file_name.doc
```
Antiword 将文档转换为文本并显示在终端窗口中。不幸的是,它不能在终端中将文档分解成页面。不过,你可以将 Antiword 的输出重定向到 `less` 或 [more](https://opensource.com/article/19/1/more-text-files-linux) 之类的实用程序,一遍对其进行分页。通过输入以下命令来执行此操作:
```
antiword file_name.doc | less
```
如果你是命令行的新手,那么我告诉你 `|` 称为管道。这就是重定向。

### odt2txt
作为一个优秀的开源公民,你会希望尽可能多地使用开放格式。对于你的文字处理需求,你可能需要处理 [ODT](http://en.wikipedia.org/wiki/OpenDocument) 文件(由诸如 LibreOffice Writer 和 AbiWord 等文字处理器使用)而不是 Word 文件。即使没有,也可能会遇到 ODT 文件。而且,即使你的计算机上没有安装 Writer 或 AbiWord,也很容易在命令行中查看它们。
怎样做呢?用一个名叫 [odt2txt](https://github.com/dstosberg/odt2txt) 的实用小程序。正如你猜到的那样,`odt2txt` 将 ODT 文件转换为纯文本。要使用它,运行以下命令:
```
odt2txt file_name.odt
```
与 Antiword 一样,`odt2txt` 将文档转换为文本并在终端窗口中显示。和 Antiword 一样,它不会对文档进行分页。但是,你也可以使用以下命令将 `odt2txt` 的输出管道传输到 `less` 或 `more` 这样的实用程序中:
```
odt2txt file_name.odt | more
```

你有一个最喜欢的在命令行中查看文件的实用程序吗?欢迎留下评论与社区分享。
---
via: <https://opensource.com/article/19/2/view-files-command-line>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I always say you don't need to use the command line to use Linux effectively—I know many Linux users who never crack open a terminal window and are quite happy. However, even though I don't consider myself a techie, I spend about 20% of my computing time at the command line, manipulating files, processing text, and using utilities.
One thing I often do in a terminal window is viewing files, whether text or word processor files. Sometimes it's just easier to use a command line utility than to fire up a text editor or a word processor.
Here are three of the utilities I use to view files at the command line.
## less
The beauty of [less](https://www.gnu.org/software/less/) is that it's easy to use and it breaks the files you're viewing down into discrete chunks (or *pages*), which makes them easier to read. You use it to view text files at the command line, such as a README, an HTML file, a LaTeX file, or anything else in plaintext. I took a look at less in a [previous article](https://opensource.com/article/18/4/using-less-view-text-files-command-line).
To use less, just type:
`less file_name`
Scroll down through the file by pressing the spacebar or PgDn key on your keyboard. You can move up through a file by pressing the PgUp key. To stop viewing the file, press the Q key on your keyboard.
## Antiword
[Antiword](http://www.winfield.demon.nl/) is great little utility that you can use to that can convert Word documents to plaintext. If you want, you can also convert them to [PostScript](http://en.wikipedia.org/wiki/PostScript) or [PDF](http://en.wikipedia.org/wiki/Portable_Document_Format). For this article, let's just stick with the conversion to text.
Antiword can read and convert files created with versions of Word from 2.0 to 2003. It doesn't read DOCX files—if you try, Antiword displays an error message that what you're trying to read is a ZIP file. That's technically correct, but it's still frustrating.
To view a Word document using Antiword, type the following command:
`antiword file_name.doc`
Antiword converts the document to text and displays it in the terminal window. Unfortunately, it doesn't break the document into pages in the terminal. You can, though, redirect Antiword's output to a utility like less or [more](https://opensource.com/article/19/1/more-text-files-linux) to paginate it. Do that by typing the following command:
`antiword file_name.doc | less`
If you're new to the command line, the | is called a *pipe*. That's what does the redirection.
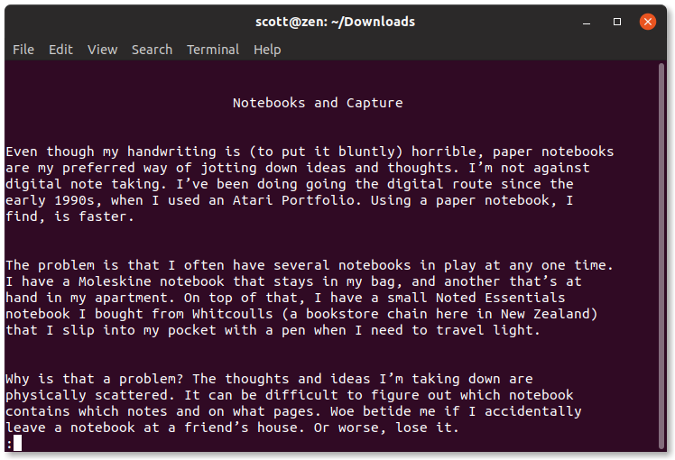
## odt2txt
Being a good open source citizen, you'll want to use as many open formats as possible. For your word processing needs, you might deal with [ODT](http://en.wikipedia.org/wiki/OpenDocument) files (used by such word processors as LibreOffice Writer and AbiWord) instead of Word files. Even if you don't, you might run into ODT files. And they're easy to view at the command line, even if you don't have Writer or AbiWord installed on your computer.
How? With a little utility called [odt2txt](https://github.com/dstosberg/odt2txt). As you've probably guessed, odt2txt converts an ODT file to plaintext. To use it, run the command:
`odt2txt file_name.odt`
Like Antiword, odt2txt converts the document to text and displays it in the terminal window. And, like Antiword, it doesn't page the document. Once again, though, you can pipe the output from odt2txt to a utility like less or more using the following command:
`odt2txt file_name.odt | more`
Do you have a favorite utility for viewing files at the command line? Feel free to share it with the community by leaving a comment.
## 2 Comments |
10,574 | 开始使用 Org 模式吧,在没有 Emacs 的情况下 | https://opensource.com/article/19/1/productivity-tool-org-mode | 2019-02-27T10:13:00 | [
"Org模式",
"Emacs"
] | https://linux.cn/article-10574-1.html |
>
> 不,你不需要 Emacs 也能用 Org,这是我开源工具系列的第 16 集,将会让你在 2019 年变得更加有生产率。
>
>
>

每到年初似乎总有这么一个疯狂的冲动来寻找提高生产率的方法。新年决心,正确地开始一年的冲动,以及“向前看”的态度都是这种冲动的表现。软件推荐通常都会选择闭源和专利软件。但这不是必须的。
这是我 2019 年改进生产率的 19 个新工具中的第 16 个。
### Org (非 Emacs)
[Org 模式](https://orgmode.org/) (或者就称为 Org) 并不是新鲜货,但依然有许多人没有用过。他们很乐意试用一下以体验 Org 是如何改善生产率的。但最大的障碍来自于 Org 是与 Emacs 相关联的,而且很多人都认为两者缺一不可。并不是这样的!一旦你理解了其基础,Org 就可以与各种其他工具和编辑器一起使用。

Org,本质上,是一个结构化的文本文件。它有标题、子标题,以及各种关键字,其他工具可以根据这些关键字将文件解析成日程表和代办列表。Org 文件可以被任何纯文本编辑器编辑(例如,[Vim](https://www.vim.org/)、[Atom](https://atom.io/) 或 [Visual Studio Code](https://code.visualstudio.com/)),而且很多编辑器都有插件可以帮你创建和管理 Org 文件。
一个基础的 Org 文件看起来是这样的:
```
* Task List
** TODO Write Article for Day 16 - Org w/out emacs
DEADLINE: <2019-01-25 12:00>
*** DONE Write sample org snippet for article
- Include at least one TODO and one DONE item
- Show notes
- Show SCHEDULED and DEADLINE
*** TODO Take Screenshots
** Dentist Appointment
SCHEDULED: <2019-01-31 13:30-14:30>
```
Org 是一种大纲格式,它使用 `*` 作为标识指明事项的级别。任何以 `TODO`(是的,全大些)开头的事项都是代办事项。标注为 `DONE` 的工作表示该工作已经完成。`SCHEDULED` 和 `DEADLINE` 标识与该事务相关的日期和时间。如何任何地方都没有时间,则该事务被视为全天活动。
使用正确的插件,你喜欢的文本编辑器可以成为一个充满生产率和组织能力的强大工具。例如,[vim-orgmode](https://github.com/jceb/vim-orgmode) 插件包括创建 Org 文件、语法高亮的功能,以及各种用来生成跨文件的日程和综合代办事项列表的关键命令。

Atom 的 [Organized](https://atom.io/packages/organized) 插件可以在屏幕右边添加一个侧边栏,用来显示 Org 文件中的日程和代办事项。默认情况下它从配置项中设置的路径中读取多个 Org 文件。Todo 侧边栏允许你通过点击未完事项来将其标记为已完成,它会自动更新源 Org 文件。

还有一大堆 Org 工具可以帮助你保持生产率。使用 Python、Perl、PHP、NodeJS 等库,你可以开发自己的脚本和工具。当然,少不了 [Emacs](https://www.gnu.org/software/emacs/),它的核心功能就包括支持 Org。

Org 模式是跟踪需要完成的工作和时间的最好工具之一。而且,与传闻相反,它无需 Emacs,任何一个文本编辑器都行。
---
via: <https://opensource.com/article/19/1/productivity-tool-org-mode>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 16th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Org (without Emacs)
[Org mode](https://orgmode.org/) (or just Org) is not in the least bit new, but there are still many people who have never used it. They would love to try it out to get a feel for how Org can help them be productive. But the biggest barrier is that Org is associated with Emacs, and many people think one requires the other. Not so! Org can be used with a variety of other tools and editors once you understand the basics.
Org, at its very heart, is a structured text file. It has headers, subheaders, and keywords that allow other tools to parse files into agendas and to-do lists. Org files can be edited with any flat-text editor (e.g., [Vim](https://www.vim.org/), [Atom](https://atom.io/), or [Visual Studio Code](https://code.visualstudio.com/)), and many have plugins that help create and manage Org files.
A basic Org file looks something like this:
```
* Task List
** TODO Write Article for Day 16 - Org w/out emacs
DEADLINE: <2019-01-25 12:00>
*** DONE Write sample org snippet for article
- Include at least one TODO and one DONE item
- Show notes
- Show SCHEDULED and DEADLINE
*** TODO Take Screenshots
** Dentist Appointment
SCHEDULED: <2019-01-31 13:30-14:30>
```
Org uses an outline format that uses ***** as bullets to indicate an item's level. Any item that begins with the word TODO (yes, in all caps) is just that—a to-do item. The work DONE indicates it is completed. SCHEDULED and DEADLINE indicate dates and times relevant to the item. If there's no time in either field, the item is considered an all-day event.
With the right plugins, your favorite text editor becomes a powerhouse of productivity and organization. For example, the [vim-orgmode](https://github.com/jceb/vim-orgmode) plugin's features include functions to create Org files, syntax highlighting, and key commands to generate agendas and comprehensive to-do lists across files.
The Atom [Organized](https://atom.io/packages/organized) plugin adds a sidebar on the right side of the screen that shows the agenda and to-do items in Org files. It can read from multiple files by default with a path set up in the configuration options. The Todo sidebar allows you to click on a to-do item to mark it done, then automatically updates the source Org file.
There are also a whole host of tools that "speak Org" to help keep you productive. With libraries in Python, Perl, PHP, NodeJS, and more, you can develop your own scripts and tools. And, of course, there is also [Emacs](https://www.gnu.org/software/emacs/), which has Org support within the core distribution.
Org mode is one of the best tools for keeping on track with what needs to be done and when. And, contrary to myth, it doesn't need Emacs, just a text editor.
## 6 Comments |
10,575 | 每个 Linux 游戏玩家都绝不想要的恼人体验 | https://itsfoss.com/linux-gaming-problems/ | 2019-02-27T23:24:00 | [
"Linux",
"游戏"
] | https://linux.cn/article-10575-1.html | 
(LCTT 译注:本文原文发表于 2016 年,可能有些信息已经过时。)
[在 Linux 平台上玩游戏](https://itsfoss.com/linux-gaming-guide/) 并不是什么新鲜事,现在甚至有专门的 [Linux 游戏发行版](https://itsfoss.com/linux-gaming-distributions/),但是这不意味着在 Linux 上打游戏的体验和在 Windows 上一样顺畅。
为了确保我们和 Windows 用户同样地享受游戏乐趣,哪些问题是我们应该考虑的呢?
[Wine](https://itsfoss.com/use-windows-applications-linux/)、[PlayOnLinux](https://www.playonlinux.com/en/) 和其它类似软件不总是能够让我们玩所有流行的 Windows 游戏。在这篇文章里,我想讨论一下为了拥有最好的 Linux 游戏体验所必须处理好的若干因素。
### #1 SteamOS 是开源平台,但 Steam for Linux 并不是
正如 [StemOS 主页](http://store.steampowered.com/steamos/)所说, 即便 SteamOS 是一个开源平台,但 Steam for Linux 仍然是专有的软件。如果 Steam for Linux 也开源,那么它从开源社区得到的支持将会是巨大的。既然它不是,那么 [Ascension 计划的诞生自然是不可避免的](http://www.ibtimes.co.uk/reddit-users-want-replace-steam-open-source-game-launcher-project-ascension-1498999):
Ascension 是一个开源的游戏启动器,旨在能够启动从任何平台购买、下载的游戏。这些游戏可以是 Steam 平台的、[Origin 游戏](https://www.origin.com/)平台的、Uplay 平台的,以及直接从游戏开发者主页下载的,或者来自 DVD、CD-ROM 的。
Ascension 计划的开端是这样:[某个观点的分享](https://www.reddit.com/r/pcmasterrace/comments/33xcvm/we_hate_valves_monopoly_over_pc_gaming_why/)激发了一场与游戏社区读者之间有趣的讨论,在这场讨论中读者们纷纷发表了自己的观点并给出建议。
### #2 与 Windows 平台的性能比较
在 Linux 平台上运行 Windows 游戏并不总是一件轻松的任务。但是得益于一个叫做 [CSMT](https://github.com/wine-compholio/wine-staging/wiki/CSMT)(多线程命令流)的特性,尽管离 Windows 级别的性能还有相当长的路要走,PlayOnLinux 现在依旧可以更好地解决这些性能方面的问题。
Linux 对游戏的原生支持在过去发行的游戏中从未尽如人意。
去年,有报道说 SteamOS 比 Windows 在游戏方面的表现要[差得多](http://arstechnica.com/gaming/2015/11/ars-benchmarks-show-significant-performance-hit-for-steamos-gaming/)。古墓丽影去年在 SteamOS 及 Steam for Linux 上发行,然而其基准测试的结果与 Windows 上的性能无法抗衡。
这明显是因为游戏是基于 [DirectX](https://en.wikipedia.org/wiki/DirectX) 而不是 [OpenGL](https://en.wikipedia.org/wiki/OpenGL) 开发的缘故。
古墓丽影是[第一个使用 TressFX 的游戏](https://www.gamingonlinux.com/articles/tomb-raider-released-for-linux-video-thoughts-port-report-included-the-first-linux-game-to-use-tresfx.7124)。下面这个视频包涵了 TressFX 的比较:
下面是另一个有趣的比较,它显示出使用 Wine + CSMT 带来的游戏性能比 Steam 上原生的 Linux 版游戏带来的游戏性能要好得多!这就是开源的力量!
以防 FPS 损失,TressFX 已经被关闭。
以下是另一个有关在 Linux 上最新发布的 “[Life is Strange](http://lifeisstrange.com/)” 在 Linux 与 Windows 上的比较:
[Steam for Linux](https://itsfoss.com/install-steam-ubuntu-linux/) 开始在这个新游戏上展示出比 Windows 更好的游戏性能,这是一件好事。
在发布任何 Linux 版的游戏前,开发者都应该考虑优化游戏,特别是基于 DirectX 并需要进行 OpenGL 转制的游戏。我们十分希望 Linux 上的<ruby> <a href="https://itsfoss.com/deus-ex-mankind-divided-linux/"> 杀出重围:人类分裂 </a> <rt> Deus Ex: Mankind Divided </rt></ruby> 在正式发行时能有一个好的基准测试结果。由于它是基于 DirectX 的游戏,我们希望它能良好地移植到 Linux 上。[该游戏执行总监说过这样的话](http://wccftech.com/deus-ex-mankind-divided-director-console-ports-on-pc-is-disrespectful/)。
### #3 专有的 NVIDIA 驱动
相比于 [NVIDIA](http://nvidia.com/),[AMD 对于开源的支持](http://developer.amd.com/tools-and-sdks/open-source/)绝对是值得称赞的。尽管 [AMD](http://amd.com/) 因其更好的开源驱动在 Linux 上的驱动支持挺不错,而 NVIDIA 显卡用户由于开源版本的 NVIDIA 显卡驱动 “Nouveau” 有限的能力,仍不得不用专有的 NVIDIA 驱动。
曾经,Linus Torvalds 大神也分享过他关于“来自 NVIDIA 的 Linux 支持完全不可接受”的想法。
你可以在这里观看完整的[谈话](https://youtu.be/MShbP3OpASA),尽管 NVIDIA 回应 [承诺更好的 Linux 平台支持](https://itsfoss.com/nvidia-optimus-support-linux/),但其开源显卡驱动仍如之前一样毫无起色。
### #4 需要 Linux 平台上的 Uplay 和 Origin 的 DRM 支持
以上的视频描述了如何在 Linux 上安装 [Uplay](http://uplay.com/) DRM。视频上传者还建议说并不推荐使用 Wine 作为 Linux 上的主要的应用和游戏支持软件。相反,更鼓励使用原生的应用。
以下视频是一个关于如何在 Linux 上安装 [Origin](http://origin.com/) DRM 的教程。
数字版权管理(DRM)软件给游戏运行又加了一层阻碍,使得在 Linux 上良好运行 Windows 游戏这一本就充满挑战性的任务更有难度。因此除了使游戏能够运行之外,W.I.N.E 不得不同时负责运行像 Uplay 或 Origin 之类的 DRM 软件。如果能像 Steam 一样,Linux 也能够有自己原生版本的 Uplay 和 Origin 那就好了。
### #5 DirectX 11 对于 Linux 的支持
尽管我们在 Linux 平台上有可以运行 Windows 应用的工具,每个游戏为了能在 Linux 上运行都带有自己的配套调整需求。尽管去年在 Code Weavers 有一篇关于 [DirectX 11 对于 Linux 的支持](http://www.pcworld.com/article/2940470/hey-gamers-directx-11-is-coming-to-linux-thanks-to-codeweavers-and-wine.html) 的公告,在 Linux 上畅玩新发大作仍是长路漫漫。
现在你可以[从 Codweavers 购买 Crossover](https://itsfoss.com/deal-run-windows-software-and-games-on-linux-with-crossover-15-66-off/) 以获得可得到的最佳 DirectX 11 支持。这个在 Arch Linux 论坛上的[频道](https://bbs.archlinux.org/viewtopic.php?id=214771)清楚展现了将这个梦想成真需要多少的努力。以下是一个 [Reddit 频道](https://www.reddit.com/r/linux_gaming/comments/3ap3uu/directx_11_support_coming_to_codeweavers/) 上的有趣 [发现](https://ghostbin.com/paste/sy3e2)。这个发现提到了[来自 Codeweavers 的 DirectX 11 补丁](https://www.codeweavers.com/about/blogs/caron/2015/12/10/directx-11-really-james-didnt-lie),现在看来这无疑是好消息。
### #6 不是全部的 Steam 游戏都可跑在 Linux 上
随着 Linux 游戏玩家一次次错过主要游戏的发行,这是需要考虑的一个重点,因为大部分主要游戏都在 Windows 上发行。这是[如何在 Linux 上安装 Windows 版的 Steam 的教程](https://itsfoss.com/linux-gaming-guide/)。
### #7 游戏发行商对 OpenGL 更好的支持
目前开发者和发行商主要着眼于用 DirectX 而不是 OpenGL 来开发游戏。现在随着 Steam 正式登录 Linux,开发者应该同样考虑在 OpenGL 下开发。
[Direct3D](https://en.wikipedia.org/wiki/Direct3D) 仅仅是为 Windows 平台而打造。而 OpenGL API 拥有开放性标准,并且它不仅能在 Windows 上同样也能在其它各种各样的平台上实现。
尽管是一篇很老的文章,但[这个很有价值的资源](http://blog.wolfire.com/2010/01/Why-you-should-use-OpenGL-and-not-DirectX)分享了许多有关 OpenGL 和 DirectX 现状的很有想法的信息。其所提出的观点确实十分明智,基于按时间排序的事件也能给予读者启迪。
在 Linux 平台上发布大作的发行商绝不应该忽视一个事实:在 OpenGL 下直接开发游戏要比从 DirectX 移植到 OpenGL 合算得多。如果必须进行平台转制,移植必须被仔细优化并谨慎研究。发布游戏可能会有延迟,但这绝对值得。
有更多的烦恼要分享?务必在评论区让我们知道。
---
via: <https://itsfoss.com/linux-gaming-problems/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Gaming on Linux](https://itsfoss.com/linux-gaming-guide/) has come a long way. There are dedicated [Linux gaming distributions](https://itsfoss.com/linux-gaming-distributions/) now. But this doesn’t mean that gaming experience on Linux is as smooth as on Windows.
What are the obstacles that should be thought about to ensure that we enjoy games as much as Windows users do?
[Wine](https://itsfoss.com/use-windows-applications-linux/), [PlayOnLinux](https://www.playonlinux.com/en/) and other similar tools are not always able to play every popular Windows game. In this article, I would like to discuss various factors that must be dealt with in order to have the best possible Linux gaming experience.
## #1 SteamOS is Open Source, Steam for Linux is NOT
As stated on the [SteamOS page](http://store.steampowered.com/steamos/), even though [SteamOS is open source](https://itsfoss.com/steamos/), Steam for Linux continues to be proprietary. Had it also been open source, the amount of support from the open source community would have been tremendous! Since it is not, [the birth of Project Ascension was inevitable](http://www.ibtimes.co.uk/reddit-users-want-replace-steam-open-source-game-launcher-project-ascension-1498999):
Project Ascension is an open source game launcher designed to launch games that have been bought and downloaded from anywhere – they can be Steam games, [Origin games](https://www.origin.com), Uplay games, games downloaded directly from game developer websites or from DVD/CD-ROMs.
Here is how it all began: [Sharing The Idea](https://www.reddit.com/r/pcmasterrace/comments/33xcvm/we_hate_valves_monopoly_over_pc_gaming_why/) resulted in a very interesting discussion with readers all over from the gaming community pitching in their own opinions and suggestions.
## #2 Performance compared to Windows
Getting Windows games to run on Linux is not always an easy task. But thanks to a feature called [CSMT](https://github.com/wine-compholio/wine-staging/wiki/CSMT) (command stream multi-threading), PlayOnLinux is now better equipped to deal with these performance issues, though it’s still a long way to achieve Windows level outcomes.
Native Linux support for games has not been so good for past releases.
Last year, it was reported that SteamOS performed [significantly worse](http://arstechnica.com/gaming/2015/11/ars-benchmarks-show-significant-performance-hit-for-steamos-gaming/) than Windows. Tomb Raider was released on SteamOS/Steam for Linux last year. However, benchmark results were [not at par](https://www.gamingonlinux.com/articles/tomb-raider-benchmark-video-comparison-linux-vs-windows-10.7138) with performance on Windows.
This was much obviously due to the fact that the game had been developed with [DirectX](https://en.wikipedia.org/wiki/DirectX) in mind and not [OpenGL](https://en.wikipedia.org/wiki/OpenGL).
Tomb Raider is the [first Linux game that uses TressFX](https://www.gamingonlinux.com/articles/tomb-raider-released-for-linux-video-thoughts-port-report-included-the-first-linux-game-to-use-tresfx.7124). This video includes TressFX comparisons:
Here is another interesting comparison which shows Wine+CSMT performing much better than the native Linux version itself on Steam! This is the power of Open Source!
TressFX has been turned off in this case to avoid FPS loss.
Here is another Linux vs Windows comparison for the recently released “[Life is Strange](http://lifeisstrange.com)” on Linux:
It’s good to know that [ Steam for Linux](https://itsfoss.com/install-steam-ubuntu-linux/) has begun to show better improvements in performance for this new Linux game.
Before launching any game for Linux, developers should consider optimizing them especially if it’s a DirectX game and requires OpenGL translation. We really do hope that [Deus Ex: Mankind Divided on Linux](https://itsfoss.com/deus-ex-mankind-divided-linux/) gets benchmarked well, upon release. As its a DirectX game, we hope it’s being ported well for Linux. Here’s [what the Executive Game Director had to say](http://wccftech.com/deus-ex-mankind-divided-director-console-ports-on-pc-is-disrespectful/).
## #3 Proprietary NVIDIA Drivers
[AMD’s support for Open Source](http://developer.amd.com/tools-and-sdks/open-source/) is definitely commendable when compared to [NVIDIA](http://nvidia.com). Though [AMD](http://amd.com) driver support is [pretty good on Linux](http://www.makeuseof.com/tag/open-source-amd-graphics-now-awesome-heres-get/) now due to its better open source driver, NVIDIA graphic card owners will still have to use the proprietary NVIDIA drivers because of the limited capabilities of the open-source version of NVIDIA’s graphics driver called Nouveau.
In the past, legendary Linus Torvalds has also shared his thoughts about Linux support from NVIDIA to be totally unacceptable:
You can watch the complete talk [here](https://youtu.be/MShbP3OpASA). Although NVIDIA responded with [a commitment for better linux support](https://itsfoss.com/nvidia-optimus-support-linux/), the open source graphics driver still continues to be weak as before.
## #4 Need for Uplay and Origin DRM support on Linux
The above video describes how to install the [Uplay](http://uplay.com) DRM on Linux. The uploader also suggests that the use of wine as the main tool of games and applications is not recommended on Linux. Rather, preference to native applications should be encouraged instead.
The following video is a guide about installing the [Origin](http://origin.com) DRM on Linux:
Digital Rights Management Software adds another layer for game execution and hence it adds up to the already challenging task to make a Windows game run well on Linux. So in addition to making the game execute, W.I.N.E has to take care of running the DRM software such as Uplay or Origin as well. It would have been great if, like Steam, Linux could have got its own native versions of Uplay and Origin.
## #5 DirectX 11 support for Linux
Even though we have tools on Linux to run Windows applications, every game comes with its own set of tweak requirements for it to be playable on Linux. Though there was an announcement about [DirectX 11 support for Linux](http://www.pcworld.com/article/2940470/hey-gamers-directx-11-is-coming-to-linux-thanks-to-codeweavers-and-wine.html) last year via Code Weavers, it’s still a long way to go to make playing newly launched titles on Linux a possibility. Currently, you can
Currently, you can [buy Crossover from Codeweavers](https://itsfoss.com/deal-run-windows-software-and-games-on-linux-with-crossover-15-66-off/) to get the best DirectX 11 support available. This [thread](https://bbs.archlinux.org/viewtopic.php?id=214771) on the Arch Linux forums clearly shows how much more effort is required to make this dream a possibility. Here is an interesting [find](https://ghostbin.com/paste/sy3e2) from a [Reddit thread](https://www.reddit.com/r/linux_gaming/comments/3ap3uu/directx_11_support_coming_to_codeweavers/), which mentions Wine getting [DirectX 11 patches from Codeweavers](https://www.codeweavers.com/about/blogs/caron/2015/12/10/directx-11-really-james-didnt-lie). Now that’s definitely some good news.
## #6 100% of Steam games are not available for Linux
This is an important point to ponder as Linux gamers continue to miss out on every major game release since most of them land up on Windows. Here is a guide to [install Steam for Windows on Linux](https://itsfoss.com/linux-gaming-guide/).
## #7 Better Support from video game publishers for OpenGL
Currently, developers and publishers focus primarily on DirectX for video game development rather than OpenGL. Now as Steam is officially here for Linux, developers should start considering development in OpenGL as well.
[Direct3D](https://en.wikipedia.org/wiki/Direct3D) is made solely for the Windows platform. The OpenGL API is an open standard, and implementations exist for not only Windows but a wide variety of other platforms.
Though quite an old article, [this valuable resource](http://blog.wolfire.com/2010/01/Why-you-should-use-OpenGL-and-not-DirectX) shares a lot of thoughtful information on the realities of OpenGL and DirectX. The points made are truly very sensible and enlightens the reader about the facts based on actual chronological events.
Publishers who are launching their titles on Linux should definitely not leave out the fact that developing the game on OpenGL would be a much better deal than translating it from DirectX to OpenGL. If conversion has to be done, the translations must be well optimized and carefully looked into. There might be a delay in releasing the games but still it would definitely be worth the wait.
Have more annoyances to share? Do let us know in the comments. |
10,576 | 如何在 Ubuntu 上为用户授予和移除 sudo 权限 | https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/ | 2019-02-28T00:12:00 | [
"sudo"
] | https://linux.cn/article-10576-1.html | 
如你所知,用户可以在 Ubuntu 系统上使用 sudo 权限执行任何管理任务。在 Linux 机器上创建新用户时,他们无法执行任何管理任务,直到你将其加入 `sudo` 组的成员。在这个简短的教程中,我们将介绍如何将普通用户添加到 `sudo` 组以及移除给定的权限,使其成为普通用户。
### 在 Linux 上向普通用户授予 sudo 权限
通常,我们使用 `adduser` 命令创建新用户,如下所示。
```
$ sudo adduser ostechnix
```
如果你希望新创建的用户使用 `sudo` 执行管理任务,只需使用以下命令将它添加到 `sudo` 组:
```
$ sudo usermod -a -G sudo hduser
```
上面的命令将使名为 `ostechnix` 的用户成为 `sudo` 组的成员。
你也可以使用此命令将用户添加到 `sudo` 组。
```
$ sudo adduser ostechnix sudo
```
现在,注销并以新用户身份登录,以使此更改生效。此时用户已成为管理用户。
要验证它,只需在任何命令中使用 `sudo` 作为前缀。
```
$ sudo mkdir /test
[sudo] password for ostechnix:
```
### 移除用户的 sudo 权限
有时,你可能希望移除特定用户的 `sudo` 权限,而不用在 Linux 中删除它。要将任何用户设为普通用户,只需将其从 `sudo` 组中删除即可。
比如说如果要从 `sudo` 组中删除名为 `ostechnix` 的用户,只需运行:
```
$ sudo deluser ostechnix sudo
```
示例输出:
```
Removing user `ostechnix' from group `sudo' ...
Done.
```
此命令仅从 `sudo` 组中删除用户 `ostechnix`,但不会永久地从系统中删除用户。现在,它成为了普通用户,无法像 `sudo` 用户那样执行任何管理任务。
此外,你可以使用以下命令撤消用户的 `sudo` 访问权限:
```
$ sudo gpasswd -d ostechnix sudo
```
从 `sudo` 组中删除用户时请小心。不要从 `sudo` 组中删除真正的管理员。
使用命令验证用户 `ostechnix` 是否已从 `sudo` 组中删除:
```
$ sudo -l -U ostechnix
User ostechnix is not allowed to run sudo on ubuntuserver.
```
是的,用户 `ostechnix` 已从 `sudo` 组中删除,他无法执行任何管理任务。
从 `sudo` 组中删除用户时请小心。如果你的系统上只有一个 `sudo` 用户,并且你将他从 `sudo` 组中删除了,那么就无法执行任何管理操作,例如在系统上安装、删除和更新程序。所以,请小心。在我们的下一篇教程中,我们将解释如何恢复用户的 `sudo` 权限。
就是这些了。希望这篇文章有用。还有更多好东西。敬请期待!
干杯!
---
via: <https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,577 | Olive:一款以 Final Cut Pro 为目标的开源视频编辑器 | https://itsfoss.com/olive-video-editor | 2019-02-28T21:46:00 | [
"视频编辑器"
] | https://linux.cn/article-10577-1.html | 
[Olive](https://www.olivevideoeditor.org/) 是一个正在开发的新的开源视频编辑器。这个非线性视频编辑器旨在提供高端专业视频编辑软件的免费替代品。目标高么?我认为是的。
如果你读过我们的 [Linux 中的最佳视频编辑器](https://itsfoss.com/best-video-editing-software-linux/)这篇文章,你可能已经注意到大多数“专业级”视频编辑器(如 [Lightworks](https://www.lwks.com/) 或 DaVinciResolve)既不免费也不开源。
[Kdenlive](https://kdenlive.org/en/) 和 Shotcut 也是此类,但它通常无法达到专业视频编辑的标准(这是许多 Linux 用户说的)。
爱好者级和专业级的视频编辑之间的这种差距促使 Olive 的开发人员启动了这个项目。

*Olive 视频编辑器界面*
Libre Graphics World 中有一篇详细的[关于 Olive 的点评](http://libregraphicsworld.org/blog/entry/introducing-olive-new-non-linear-video-editor)。实际上,这是我第一次知道 Olive 的地方。如果你有兴趣了解更多信息,请阅读该文章。
### 在 Linux 中安装 Olive 视频编辑器
>
> 提醒你一下。Olive 正处于发展的早期阶段。你会发现很多 bug 和缺失/不完整的功能。你不应该把它当作你的主要视频编辑器。
>
>
>
如果你想测试 Olive,有几种方法可以在 Linux 上安装它。
#### 通过 PPA 在基于 Ubuntu 的发行版中安装 Olive
你可以在 Ubuntu、Mint 和其他基于 Ubuntu 的发行版使用官方 PPA 安装 Olive。
```
sudo add-apt-repository ppa:olive-editor/olive-editor
sudo apt-get update
sudo apt-get install olive-editor
```
#### 通过 Snap 安装 Olive
如果你的 Linux 发行版支持 Snap,则可以使用以下命令进行安装。
```
sudo snap install --edge olive-editor
```
#### 通过 Flatpak 安装 Olive
如果你的 [Linux 发行版支持 Flatpak](https://itsfoss.com/flatpak-guide/),你可以通过 Flatpak 安装 Olive 视频编辑器。
* [Flatpak 地址](https://flathub.org/apps/details/org.olivevideoeditor.Olive)
#### 通过 AppImage 使用 Olive
不想安装吗?下载 [AppImage](https://itsfoss.com/use-appimage-linux/) 文件,将其设置为可执行文件并运行它。32 位和 64 位 AppImage 文件都有。你应该下载相应的文件。
* [下载 Olive 的 AppImage](https://github.com/olive-editor/olive/releases/tag/continuous)
Olive 也可用于 Windows 和 macOS。你可以从它的[下载页面](https://www.olivevideoeditor.org/download.php)获得它。
### 想要支持 Olive 视频编辑器的开发吗?
如果你喜欢 Olive 尝试实现的功能,并且想要支持它,那么你可以通过以下几种方式。
如果你在测试 Olive 时发现一些 bug,请到它们的 GitHub 仓库中报告。
* [提交 bug 报告以帮助 Olive](https://github.com/olive-editor/olive/issues)
如果你是程序员,请浏览 Olive 的源代码,看看你是否可以通过编码技巧帮助项目。
* [Olive 的 GitHub 仓库](https://github.com/olive-editor/olive)
在经济上为项目做贡献是另一种可以帮助开发开源软件的方法。你可以通过成为赞助人来支持 Olive。
* [赞助 Olive](https://www.patreon.com/olivevideoeditor)
如果你没有支持 Olive 的金钱或编码技能,你仍然可以帮助它。在社交媒体或你经常访问的 Linux/软件相关论坛和群组中分享这篇文章或 Olive 的网站。一点微小的口碑都能间接地帮助它。
### 你如何看待 Olive?
评判 Olive 还为时过早。我希望能够持续快速开发,并且在年底之前发布 Olive 的稳定版(如果我没有过于乐观的话)。
你如何看待 Olive?你是否认同开发人员针对专业用户的目标?你希望 Olive 拥有哪些功能?
---
via: <https://itsfoss.com/olive-video-editor>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,578 | 系统管理员的 7 个 CI/CD 工具 | https://opensource.com/article/18/12/cicd-tools-sysadmins | 2019-03-01T10:17:29 | [
"CD",
"CI",
"DevOps"
] | https://linux.cn/article-10578-1.html |
>
> 本文是一篇简单指南:介绍一些顶级的开源的持续集成、持续交付和持续部署(CI/CD)工具。
>
>
>

虽然持续集成、持续交付和持续部署(CI/CD)在开发者社区里已经存在很多年,一些机构在其运维部门也有实施经验,但大多数公司并没有做这样的尝试。对于很多机构来说,让运维团队能够像他们的开发同行一样熟练操作 CI/CD 工具,已经变得十分必要了。
无论是基础设施、第三方应用还是内部开发的应用,都可以开展 CI/CD 实践。尽管你会发现有很多不同的工具,但它们都有着相似的设计模型。而且可能最重要的一点是:通过带领你的公司进行这些实践,会让你在公司内部变得举足轻重,成为他人学习的榜样。
一些机构在自己的基础设施上已有多年的 CI/CD 实践经验,常用的工具包括 [Ansible](https://www.ansible.com/)、[Chef](https://www.chef.io/) 或者 [Puppet](https://puppet.com/)。另一些工具,比如 [Test Kitchen](https://github.com/test-kitchen/test-kitchen),允许在最终要部署应用的基础设施上运行测试。事实上,如果使用更高级的配置方法,你甚至可以将应用部署到有真实负载的仿真“生产环境”上,来运行应用级别的测试。然而,单单是能够测试基础设施就是一项了不起的成就了。配置管理工具 Terraform 可以通过 Test Kitchen 来快速创建更[短暂](https://www.merriam-webster.com/dictionary/ephemeral)和[冥等的](https://en.wikipedia.org/wiki/Idempotence)的基础设施配置,这比它的前辈要强不少。再加上 Linux 容器和 Kubernetes,在数小时内,你就可以创建一套类似于生产环境的配置参数和系统资源,来测试整个基础设施和其上部署的应用,这在以前可能需要花费几个月的时间。而且,删除和再次创建整个测试环境也非常容易。
当然,作为初学者,你也可以把网络配置和 DDL(<ruby> 数据定义语言 <rt> data definition language </rt></ruby>)文件加入版本控制,然后开始尝试一些简单的 CI/CD 流程。虽然只能帮你检查一下语义语法或某些最佳实践,但实际上大多数开发的管道都是这样起步的。只要你把脚手架搭起来,建造就容易得多了。而一旦起步,你就会发现各种管道的使用场景。
举个例子,我经常会在公司内部写新闻简报,我使用 [MJML](https://mjml.io/) 制作邮件模板,然后把它加入版本控制。我一般会维护一个 web 版本,但是一些同事喜欢 PDF 版,于是我创建了一个[管道](https://gitlab.com/devopskc/newsletter/blob/master/.gitlab-ci.yml)。每当我写好一篇新闻稿,就在 Gitlab 上提交一个合并请求。这样做会自动创建一个 index.html 文件,生成这篇新闻稿的 HTML 和 PDF 版链接。HTML 和 PDF 文件也会在该管道里同时生成。除非有人来检查确认,这些文件不会被直接发布出去。使用 GitLab Pages 发布这个网站后,我就可以下载一份 HTML 版,用来发送新闻简报。未来,我会修改这个流程,当合并请求成功或者在某个审核步骤后,自动发出对应的新闻稿。这些处理逻辑并不复杂,但的确为我节省了不少时间。实际上这些工具最核心的用途就是替你节省时间。
关键是要在抽象层创建出工具,这样稍加修改就可以处理不同的问题。值得留意的是,我创建的这套流程几乎不需要任何代码,除了一些[轻量级的 HTML 模板](https://gitlab.com/devopskc/newsletter/blob/master/index/index.html),一些[把 HTML 文件转换成 PDF 的 nodejs 代码](https://gitlab.com/devopskc/newsletter/blob/master/html-to-pdf.js),还有一些[生成索引页面的 nodejs 代码](https://gitlab.com/devopskc/newsletter/blob/master/populate-index.js)。
这其中一些东西可能看起来有点复杂,但其中大部分都源自我使用的不同工具的教学文档。而且很多开发人员也会乐意跟你合作,因为他们在完工时会发现这些东西也挺有用。上面我提供的那些代码链接是给 [DevOps KC](https://devopskc.com/)(LCTT 译注:一个地方性 DevOps 组织) 发送新闻简报用的,其中大部分用来创建网站的代码来自我在内部新闻简报项目上所作的工作。
下面列出的大多数工具都可以提供这种类型的交互,但是有些工具提供的模型略有不同。这一领域新兴的模型是用声明式的方法例如 YAML 来描述一个管道,其中的每个阶段都是短暂而幂等的。许多系统还会创建[有向无环图(DAG)](https://en.wikipedia.org/wiki/Directed_acyclic_graph),来确保管道上不同的阶段排序的正确性。
这些阶段一般运行在 Linux 容器里,和普通的容器并没有区别。有一些工具,比如 [Spinnaker](https://www.spinnaker.io/),只关注部署组件,而且提供一些其他工具没有的操作特性。[Jenkins](https://jenkins.io/) 则通常把管道配置存成 XML 格式,大部分交互都可以在图形界面里完成,但最新的方案是使用[领域专用语言(DSL)](https://martinfowler.com/books/dsl.html)(如 [Groovy](http://groovy-lang.org/))。并且,Jenkins 的任务(job)通常运行在各个节点里,这些节点上会装一个专门的 Java 代理,还有一堆混杂的插件和预装组件。
Jenkins 在自己的工具里引入了管道的概念,但使用起来却并不轻松,甚至包含一些禁区。最近,Jenkins 的创始人决定带领社区向新的方向前进,希望能为这个项目注入新的活力,把 CI/CD 真正推广开(LCTT 译注:详见后面的 Jenkins 章节)。我认为其中最有意思的想法是构建一个云原生 Jenkins,能把 Kubernetes 集群转变成 Jenkins CI/CD 平台。
当你更多地了解这些工具并把实践带入你的公司和运维部门,你很快就会有追随者,因为你有办法提升自己和别人的工作效率。我们都有多年积累下来的技术债要解决,如果你能给同事们提供足够的时间来处理这些积压的工作,他们该会有多感激呢?不止如此,你的客户也会开始看到应用变得越来越稳定,管理层会把你看作得力干将,你也会在下次谈薪资待遇或参加面试时更有底气。
让我们开始深入了解这些工具吧,我们将对每个工具做简短的介绍,并分享一些有用的链接。
### GitLab CI
* [项目主页](https://about.gitlab.com/product/continuous-integration/)
* [源代码](https://gitlab.com/gitlab-org/gitlab-ce/)
* 许可证:MIT
GitLab 可以说是 CI/CD 领域里新登场的玩家,但它却在权威调研机构 [Forrester 的 CI 集成工具的调查报告](https://about.gitlab.com/2017/09/27/gitlab-leader-continuous-integration-forrester-wave/)中位列第一。在一个高水平、竞争充分的领域里,这是个了不起的成就。是什么让 GitLab CI 这么成功呢?它使用 YAML 文件来描述整个管道。另有一个功能叫做 Auto DevOps,可以为较简单的项目用多种内置的测试单元自动生成管道。这套系统使用 [Herokuish buildpacks](https://github.com/gliderlabs/herokuish) 来判断语言的种类以及如何构建应用。有些语言也可以管理数据库,它真正改变了构建新应用程序和从开发的开始将它们部署到生产环境的过程。它原生集成于 Kubernetes,可以根据不同的方案将你的应用自动部署到 Kubernetes 集群,比如灰度发布、蓝绿部署等。
除了它的持续集成功能,GitLab 还提供了许多补充特性,比如:将 Prometheus 和你的应用一同部署,以提供操作监控功能;通过 GitLab 提供的 Issues、Epics 和 Milestones 功能来实现项目评估和管理;管道中集成了安全检测功能,多个项目的检测结果会聚合显示;你可以通过 GitLab 提供的网页版 IDE 在线编辑代码,还可以快速查看管道的预览或执行状态。
### GoCD
* [项目主页](https://www.gocd.org/)
* [源代码](https://github.com/gocd/gocd)
* 许可证:Apache 2.0
GoCD 是由老牌软件公司 Thoughtworks 出品,这已经足够证明它的能力和效率。对我而言,GoCD 最具亮点的特性是它的[价值流视图(VSM)](https://www.gocd.org/getting-started/part-3/#value_stream_map)。实际上,一个管道的输出可以变成下一个管道的输入,从而把管道串联起来。这样做有助于提高不同开发团队在整个开发流程中的独立性。比如在引入 CI/CD 系统时,有些成立较久的机构希望保持他们各个团队相互隔离,这时候 VSM 就很有用了:让每个人都使用相同的工具就很容易在 VSM 中发现工作流程上的瓶颈,然后可以按图索骥调整团队或者想办法提高工作效率。
为公司的每个产品配置 VSM 是非常有价值的;GoCD 可以使用 [JSON 或 YAML 格式存储配置](https://docs.gocd.org/current/advanced_usage/pipelines_as_code.html),还能以可视化的方式展示数据等待时间,这让一个机构能有效减少学习它的成本。刚开始使用 GoCD 创建你自己的流程时,建议使用人工审核的方式。让每个团队也采用人工审核,这样你就可以开始收集数据并且找到可能的瓶颈点。
### Travis CI
* [项目主页](https://docs.travis-ci.com/)
* [源代码](https://github.com/travis-ci/travis-ci)
* 许可证:MIT
我使用的第一个软件既服务(SaaS)类型的 CI 系统就是 Travis CI,体验很不错。管道配置以源码形式用 YAML 保存,它与 GitHub 等工具无缝整合。我印象中管道从来没有失效过,因为 Travis CI 的在线率很高。除了 SaaS 版之外,你也可以使用自行部署的版本。我还没有自行部署过,它的组件非常多,要全部安装的话,工作量就有点吓人了。我猜更简单的办法是把它部署到 Kubernetes 上,[Travis CI 提供了 Helm charts](https://github.com/travis-ci/kubernetes-config),这些 charts 目前不包含所有要部署的组件,但我相信以后会越来越丰富的。如果你不想处理这些细枝末节的问题,还有一个企业版可以试试。
假如你在开发一个开源项目,你就能免费使用 SaaS 版的 Travis CI,享受顶尖团队提供的优质服务!这样能省去很多麻烦,你可以在一个相对通用的平台上(如 GitHub)研发开源项目,而不用找服务器来运行任何东西。
### Jenkins
* [项目主页](https://jenkins.io/)
* [源代码](https://github.com/jenkinsci/jenkins)
* 许可证:MIT
Jenkins 在 CI/CD 界绝对是元老级的存在,也是事实上的标准。我强烈建议你读一读这篇文章:“[Jenkins: Shifting Gears](https://jenkins.io/blog/2018/08/31/shifting-gears/)”,作者 Kohsuke 是 Jenkins 的创始人兼 CloudBees 公司 CTO。这篇文章契合了我在过去十年里对 Jenkins 及其社区的感受。他在文中阐述了一些这几年呼声很高的需求,我很乐意看到 CloudBees 引领这场变革。长期以来,Jenkins 对于非开发人员来说有点难以接受,并且一直是其管理员的重担。还好,这些问题正是他们想要着手解决的。
[Jenkins 配置既代码](https://jenkins.io/projects/jcasc/)(JCasC)应该可以帮助管理员解决困扰了他们多年的配置复杂性问题。与其他 CI/CD 系统类似,只需要修改一个简单的 YAML 文件就可以完成 Jenkins 主节点的配置工作。[Jenkins Evergreen](https://github.com/jenkinsci/jep/blob/master/jep/300/README.adoc) 的出现让配置工作变得更加轻松,它提供了很多预设的使用场景,你只管套用就可以了。这些发行版会比官方的标准版本 Jenkins 更容易维护和升级。
Jenkins 2 引入了两种原生的管道功能,我在 LISA(LCTT 译注:一个系统架构和运维大会) 2017 年的研讨会上已经[讨论过了](https://danbarker.codes/talk/lisa17-becoming-plumber-building-deployment-pipelines/)。这两种功能都没有 YAML 简便,但在处理复杂任务时它们很好用。
[Jenkins X](https://jenkins-x.io/) 是 Jenkins 的一个全新变种,用来实现云端原生 Jenkins(至少在用户看来是这样)。它会使用 JCasC 及 Evergreen,并且和 Kubernetes 整合的更加紧密。对于 Jenkins 来说这是个令人激动的时刻,我很乐意看到它在这一领域的创新,并且继续发挥领袖作用。
### Concourse CI
* [项目主页](https://concourse-ci.org/)
* [源代码](https://github.com/concourse/concourse)
* 许可证:Apache 2.0
我第一次知道 Concourse 是通过 Pivotal Labs 的伙计们介绍的,当时它处于早期 beta 版本,而且那时候也很少有类似的工具。这套系统是基于微服务构建的,每个任务运行在一个容器里。它独有的一个优良特性是能够在你本地系统上运行任务,体现你本地的改动。这意味着你完全可以在本地开发(假设你已经连接到了 Concourse 的服务器),像在真实的管道构建流程一样从你本地构建项目。而且,你可以在修改过代码后从本地直接重新运行构建,来检验你的改动结果。
Concourse 还有一个简单的扩展系统,它依赖于“资源”这一基础概念。基本上,你想给管道添加的每个新功能都可以用一个 Docker 镜像实现,并作为一个新的资源类型包含在你的配置中。这样可以保证每个功能都被封装在一个不可变的独立工件中,方便对其单独修改和升级,改变其中一个时不会影响其他构建。
### Spinnaker
* [项目主页](https://www.spinnaker.io/)
* [源代码](https://github.com/spinnaker/spinnaker)
* 许可证:Apache 2.0
Spinnaker 出自 Netflix,它更关注持续部署而非持续集成。它可以与其他工具整合,比如 Travis 和 Jenkins,来启动测试和部署流程。它也能与 Prometheus、Datadog 这样的监控工具集成,参考它们提供的指标来决定如何部署。例如,在<ruby> 金丝雀发布 <rt> canary deployment </rt></ruby>里,我们可以根据收集到的相关监控指标来做出判断:最近的这次发布是否导致了服务降级,应该立刻回滚;还是说看起来一切 OK,应该继续执行部署。
谈到持续部署,一些另类但却至关重要的问题往往被忽略掉了,说出来可能有点让人困惑:Spinnaker 可以帮助持续部署不那么“持续”。在整个应用部署流程期间,如果发生了重大问题,它可以让流程停止执行,以阻止可能发生的部署错误。但它也可以在最关键的时刻让人工审核强制通过,发布新版本上线,使整体收益最大化。实际上,CI/CD 的主要目的就是在商业模式需要调整时,能够让待更新的代码立即得到部署。
### Screwdriver
* [项目主页](http://screwdriver.cd/)
* [源代码](https://github.com/screwdriver-cd/screwdriver)
* 许可证:BSD
Screwdriver 是个简单而又强大的软件。它采用微服务架构,依赖像 Nomad、Kubernetes 和 Docker 这样的工具作为执行引擎。官方有一篇很不错的[部署教学文档](https://docs.screwdriver.cd/cluster-management/kubernetes),介绍了如何将它部署到 AWS 和 Kubernetes 上,但如果正在开发中的 [Helm chart](https://github.com/screwdriver-cd/screwdriver-chart) 也完成的话,就更完美了。
Screwdriver 也使用 YAML 来描述它的管道,并且有很多合理的默认值,这样可以有效减少各个管道重复的配置项。用配置文件可以组织起高级的工作流,来描述各个任务间复杂的依赖关系。例如,一项任务可以在另一个任务开始前或结束后运行;各个任务可以并行也可以串行执行;更赞的是你可以预先定义一项任务,只在特定的拉取请求时被触发,而且与之有依赖关系的任务并不会被执行,这能让你的管道具有一定的隔离性:什么时候被构造的工件应该被部署到生产环境,什么时候应该被审核。
---
以上只是我对这些 CI/CD 工具的简单介绍,它们还有许多很酷的特性等待你深入探索。而且它们都是开源软件,可以自由使用,去部署一下看看吧,究竟哪个才是最适合你的那个。
---
via: <https://opensource.com/article/18/12/cicd-tools-sysadmins>
作者:[Dan Barker](https://opensource.com/users/barkerd427) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jdh8383](https://github.com/jdh8383) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Continuous integration, continuous delivery, and continuous deployment (CI/CD) have all existed in the developer community for many years. Some organizations have involved their operations counterparts, but many haven't. For most organizations, it's imperative for their operations teams to become just as familiar with CI/CD tools and practices as their development compatriots are.
CI/CD practices can equally apply to infrastructure and third-party applications and internally developed applications. Also, there are many different tools but all use similar models. And possibly most importantly, leading your company into this new practice will put you in a strong position within your company, and you'll be a beacon for others to follow.
Some organizations have been using CI/CD practices on infrastructure, with tools like [Ansible](https://www.ansible.com/), [Chef](https://www.chef.io/), or [Puppet](https://puppet.com/), for several years. Other tools, like [Test Kitchen](https://github.com/test-kitchen/test-kitchen), allow tests to be performed on infrastructure that will eventually host applications. In fact, those tests can even deploy the application into a production-like environment and execute application-level tests with production loads in more advanced configurations. However, just getting to the point of being able to test the infrastructure individually is a huge feat. Terraform can also use Test Kitchen for even more [ephemeral](https://www.merriam-webster.com/dictionary/ephemeral) and [idempotent](https://en.wikipedia.org/wiki/Idempotence) infrastructure configurations than some of the original configuration-management tools. Add in Linux containers and Kubernetes, and you can now test full infrastructure and application deployments with prod-like specs and resources that come and go in hours rather than months or years. Everything is wiped out before being deployed and tested again.
However, you can also focus on getting your network configurations or database data definition language (DDL) files into version control and start running small CI/CD pipelines on them. Maybe it just checks syntax or semantics or some best practices. Actually, this is how most development pipelines started. Once you get the scaffolding down, it will be easier to build on. You'll start to find all kinds of use cases for pipelines once you get started.
For example, I regularly write a newsletter within my company, and I maintain it in version control using [MJML](https://mjml.io/). I needed to be able to host a web version, and some folks liked being able to get a PDF, so I built a [pipeline](https://gitlab.com/devopskc/newsletter/blob/master/.gitlab-ci.yml). Now when I create a new newsletter, I submit it for a merge request in GitLab. This automatically creates an index.html with links to HTML and PDF versions of the newsletter. The HTML and PDF files are also created in the pipeline. None of this is published until someone comes and reviews these artifacts. Then, GitLab Pages publishes the website and I can pull down the HTML to send as a newsletter. In the future, I'll automatically send the newsletter when the merge request is merged or after a special approval step. This seems simple, but it has saved me a lot of time. This is really at the core of what these tools can do for you. They will save you time.
The key is creating tools to work in the abstract so that they can apply to multiple problems with little change. I should also note that what I created required almost no code except [some light HTML templating](https://gitlab.com/devopskc/newsletter/blob/master/index/index.html), some [node to loop through the HTML files](https://gitlab.com/devopskc/newsletter/blob/master/html-to-pdf.js), and some more [node to populate the index page with all the HTML pages and PDFs](https://gitlab.com/devopskc/newsletter/blob/master/populate-index.js).
Some of this might look a little complex, but most of it was taken from the tutorials of the different tools I'm using. And many developers are happy to work with you on these types of things, as they might also find them useful when they're done. The links I've provided are to a newsletter we plan to start for [DevOps KC](https://devopskc.com/), and all the code for creating the site comes from the work I did on our internal newsletter.
Many of the tools listed below can offer this type of interaction, but some offer a slightly different model. The emerging model in this space is that of a declarative description of a pipeline in something like YAML with each stage being ephemeral and idempotent. Many of these systems also ensure correct sequencing by creating a [directed acyclic graph](https://en.wikipedia.org/wiki/Directed_acyclic_graph) (DAG) over the different stages of the pipeline.
These stages are often run in Linux containers and can do anything you can do in a container. Some tools, like [Spinnaker](https://www.spinnaker.io/), focus only on the deployment component and offer some operational features that others don't normally include. [Jenkins](https://jenkins.io/) has generally kept pipelines in an XML format and most interactions occur within the GUI, but more recent implementations have used a [domain specific language](https://martinfowler.com/books/dsl.html) (DSL) using [Groovy](http://groovy-lang.org/). Further, Jenkins jobs normally execute on nodes with a special Java agent installed and consist of a mix of plugins and pre-installed components.
Jenkins introduced pipelines in its tool, but they were a bit challenging to use and contained several caveats. Recently, the creator of Jenkins decided to move the community toward a couple different initiatives that will hopefully breathe new life into the project—which is the one that really brought CI/CD to the masses. I think its most interesting initiative is creating a Cloud Native Jenkins that can turn a Kubernetes cluster into a Jenkins CI/CD platform.
As you learn more about these tools and start bringing these practices into your company or your operations division, you'll quickly gain followers. You will increase your own productivity as well as that of others. We all have years of backlog to get to—how much would your co-workers love if you could give them enough time to start tackling that backlog? Not only that, but your customers will start to see increased application reliability, and your management will see you as a force multiplier. That certainly can't hurt during your next salary negotiation or when interviewing with all your new skills.
Let's dig into the tools a bit more. We'll briefly cover each one and share links to more information.
## GitLab CI
GitLab is a fairly new entrant to the CI/CD space, but it's already achieved the top spot in the [Forrester Wave for Continuous Integration Tools](https://about.gitlab.com/2017/09/27/gitlab-leader-continuous-integration-forrester-wave/). That's a huge achievement in such a crowded and highly qualified field. What makes GitLab CI so great? It uses a YAML file to describe the entire pipeline. It also has a functionality called Auto DevOps that allows for simpler projects to have a pipeline built automatically with multiple tests built-in. This system uses [Herokuish buildpacks](https://github.com/gliderlabs/herokuish) to determine the language and how to build the application. Some languages can also manage databases, which is a real game-changer for building new applications and getting them deployed to production from the beginning of the development process. The system has native integrations into Kubernetes and will deploy your application automatically into a Kubernetes cluster using one of several different deployment methodologies, like percentage-based rollouts and blue-green deployments.
In addition to its CI functionality, GitLab offers many complementary features like operations and monitoring with Prometheus deployed automatically with your application; portfolio and project management using GitLab Issues, Epics, and Milestones; security checks built into the pipeline with the results provided as an aggregate across multiple projects; and the ability to edit code right in GitLab using the WebIDE, which can even provide a preview or execute part of a pipeline for faster feedback.
## GoCD
GoCD comes from the great minds at Thoughtworks, which is testimony enough for its capabilities and efficiency. To me, GoCD's main differentiator from the rest of the pack is its [Value Stream Map](https://www.gocd.org/getting-started/part-3/#value_stream_map) (VSM) feature. In fact, pipelines can be chained together with one pipeline providing the "material" for the next pipeline. This allows for increased independence for different teams with different responsibilities in the deployment process. This may be a useful feature when introducing this type of system in older organizations that intend to keep these teams separate—but having everyone using the same tool will make it easier later to find bottlenecks in the VSM and reorganize the teams or work to increase efficiencies.
It's incredibly valuable to have a VSM for each product in a company; that GoCD allows this to be [described in JSON or YAML](https://docs.gocd.org/current/advanced_usage/pipelines_as_code.html) in version control and presented visually with all the data around wait times makes this tool even more valuable to an organization trying to understand itself better. Start by installing GoCD and mapping out your process with only manual approval gates. Then have each team use the manual approvals so you can start collecting data on where bottlenecks might exist.
## Travis CI
Travis CI was my first experience with a Software as a Service (SaaS) CI system, and it's pretty awesome. The pipelines are stored as YAML with your source code, and it integrates seamlessly with tools like GitHub. I don't remember the last time a pipeline failed because of Travis CI or the integration—Travis CI has a very high uptime. Not only can it be used as SaaS, but it also has a version that can be hosted. I haven't run that version—there were a lot of components, and it looked a bit daunting to install all of it. I'm guessing it would be much easier to deploy it all to Kubernetes with [Helm charts provided by Travis CI](https://github.com/travis-ci/kubernetes-config). Those charts don't deploy everything yet, but I'm sure it will grow even more in the future. There is also an enterprise version if you don't want to deal with the hassle.
However, if you're developing open source code, you can use the SaaS version of Travis CI for free. That is an awesome service provided by an awesome team! This alleviates a lot of overhead and allows you to use a fairly common platform for developing open source code without having to run anything.
## Jenkins
Jenkins is the original, the venerable, de facto standard in CI/CD. If you haven't already, you need to read "[Jenkins: Shifting Gears](https://jenkins.io/blog/2018/08/31/shifting-gears/)" from Kohsuke, the creator of Jenkins and CTO of CloudBees. It sums up all of my feelings about Jenkins and the community from the last decade. What he describes is something that has been needed for several years, and I'm happy CloudBees is taking the lead on this transformation. Jenkins will be a bit overwhelming to most non-developers and has long been a burden on its administrators. However, these are items they're aiming to fix.
[Jenkins Configuration as Code](https://jenkins.io/projects/jcasc/) (JCasC) should help fix the complex configuration issues that have plagued admins for years. This will allow for a zero-touch configuration of Jenkins masters through a YAML file, similar to other CI/CD systems. [Jenkins Evergreen](https://github.com/jenkinsci/jep/blob/master/jep/300/README.adoc) aims to make this process even easier by providing predefined Jenkins configurations based on different use cases. These distributions should be easier to maintain and upgrade than the normal Jenkins distribution.
Jenkins 2 introduced native pipeline functionality with two types of pipelines, which [I discuss](https://danbarker.codes/talk/lisa17-becoming-plumber-building-deployment-pipelines/) in a LISA17 presentation. Neither is as easy to navigate as YAML when you're doing something simple, but they're quite nice for doing more complex tasks.
[Jenkins X](https://jenkins-x.io/) is the full transformation of Jenkins and will likely be the implementation of Cloud Native Jenkins (or at least the thing most users see when using Cloud Native Jenkins). It will take JCasC and Evergreen and use them at their best natively on Kubernetes. These are exciting times for Jenkins, and I look forward to its innovation and continued leadership in this space.
## Concourse CI
I was first introduced to Concourse through folks at Pivotal Labs when it was an early beta version—there weren't many tools like it at the time. The system is made of microservices, and each job runs within a container. One of its most useful features that other tools don't have is the ability to run a job from your local system with your local changes. This means you can develop locally (assuming you have a connection to the Concourse server) and run your builds just as they'll run in the real build pipeline. Also, you can rerun failed builds from your local system and inject specific changes to test your fixes.
Concourse also has a simple extension system that relies on the fundamental concept of resources. Basically, each new feature you want to provide to your pipeline can be implemented in a Docker image and included as a new resource type in your configuration. This keeps all functionality encapsulated in a single, immutable artifact that can be upgraded and modified independently, and breaking changes don't necessarily have to break all your builds at the same time.
## Spinnaker
Spinnaker comes from Netflix and is more focused on continuous deployment than continuous integration. It can integrate with other tools, including Travis and Jenkins, to kick off test and deployment pipelines. It also has integrations with monitoring tools like Prometheus and Datadog to make decisions about deployments based on metrics provided by these systems. For example, the canary deployment uses a judge concept and the metrics being collected to determine if the latest canary deployment has caused any degradation in pertinent metrics and should be rolled back or if deployment can continue.
A couple of additional, unique features related to deployments cover an area that is often overlooked when discussing continuous deployment, and might even seem antithetical, but is critical to success: Spinnaker helps make continuous deployment a little less continuous. It will prevent a stage from running during certain times to prevent a deployment from occurring during a critical time in the application lifecycle. It can also enforce manual approvals to ensure the release occurs when the business will benefit the most from the change. In fact, the whole point of continuous integration and continuous deployment is to be ready to deploy changes as quickly as the business needs to change.
## Screwdriver
Screwdriver is an impressively simple piece of engineering. It uses a microservices approach and relies on tools like Nomad, Kubernetes, and Docker to act as its execution engine. There is a pretty good [deployment tutorial](https://docs.screwdriver.cd/cluster-management/kubernetes) for deploying to AWS and Kubernetes, but it could be improved once the in-progress [Helm chart](https://github.com/screwdriver-cd/screwdriver-chart) is completed.
Screwdriver also uses YAML for its pipeline descriptions and includes a lot of sensible defaults, so there's less boilerplate configuration for each pipeline. The configuration describes an advanced workflow that can have complex dependencies among jobs. For example, a job can be guaranteed to run after or before another job. Jobs can run in parallel and be joined afterward. You can also use logical operators to run a job, for example, if *any* of its dependencies are successful or only if *all* are successful. Even better is that you can specify certain jobs to be triggered from a pull request. Also, dependent jobs won't run when this occurs, which allows easy segregation of your pipeline for when an artifact should go to production and when it still needs to be reviewed.
This is only a brief description of these CI/CD tools—each has even more cool features and differentiators you can investigate. They are all open source and free to use, so go deploy them and see which one fits your needs best.
## 3 Comments |
10,579 | 在 Fedora 中使用 FreeMind 介绍你自己 | https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/ | 2019-03-02T10:03:34 | [
"思维导图"
] | https://linux.cn/article-10579-1.html | 
介绍你自己的思维导图,一开始听起来有些牵强。它是关于神经通路么?还是心灵感应?完全不是。相反,自己的思维导图是一种在视觉上向他人描述自己的方式。它还展示了你拿来描述自己的特征之间的联系。这是一种以聪明又同时可控的与他人分享信息的有用方式。你可以使用任何思维导图应用来做到。本文向你展示如何使用 Fedora 中提供的 [FreeMind](http://freemind.sourceforge.net/wiki/index.php/Main_Page)。
### 获取应用
FreeMind 已经出现有一段时间了。虽然 UI 有点过时,应该做一些更新了,但它是一个功能强大的应用,提供了许多构建思维导图的选项。当然,它是 100% 开源的。还有其他思维导图应用可供 Fedora 和 Linux 用户使用。查看[此前一篇涵盖多个思维导图选择的文章](https://fedoramagazine.org/three-mind-mapping-tools-fedora/)。
如果你运行的是 Fedora Workstation,请使用“软件”应用从 Fedora 仓库安装 FreeMind。或者在终端中使用这个 [sudo](https://fedoramagazine.org/howto-use-sudo/) 命令:
```
$ sudo dnf install freemind
```
你可以从 Fedora Workstation 中的 GNOME Shell Overview 启动应用。或者使用桌面环境提供的应用启动服务。默认情况下,FreeMind 会显示一个新的空白脑图:

*FreeMind 初始(空白)思维导图*
脑图由链接的项目或描述(节点)组成。当你想到与节点相关的内容时,只需创建一个与其连接的新节点即可。
### 做你自己的脑图
单击初始节点。编辑文本并按回车将其替换为你的姓名。你就能开始你的思维导图。
如果你必须向某人充分描述自己,你会怎么想?可能会有很多东西。你平时做什么?你喜欢什么?你不喜欢什么?你有什么价值?你有家庭吗?所有这些都可以在节点中体现。
要添加节点连接,请选择现有节点,然后单击“Insert”,或使用“灯泡”图标作为新的子节点。要在与新子级相同的层级添加另一个节点,请使用回车。
如果你弄错了,别担心。你可以使用 `Delete` 键删除不需要的节点。内容上没有规则。但是最好是短节点。它们能让你在创建导图时思维更快。简洁的节点还能让其他浏览者更轻松地查看和理解。
该示例使用节点规划了每个主要类别:

*个人思维导图,第一级*
你可以为这些区域中的每个区域另外迭代一次。让你的思想自由地连接想法以生成导图。不要担心“做得正确“。最好将所有内容从头脑中移到显示屏上。这是下一级导图的样子。

*个人思维导图,第二级*
你可以以相同的方式扩展任何这些节点。请注意你在示例中可以了解多少有关 “John Q. Public” 的信息。
### 如何使用你的个人思维导图
这是让团队或项目成员互相介绍的好方法。你可以将各种格式和颜色应用于导图以赋予其个性。当然,这些在纸上做很有趣。但是在 Fedora 中安装一个就意味着你可以随时修复错误,甚至可以在你改变的时候做出修改。
祝你在探索个人思维导图上玩得开心!
---
via: <https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A mind map of yourself sounds a little far-fetched at first. Is this process about neural pathways? Or telepathic communication? Not at all. Instead, a mind map of yourself is a way to *describe yourself* to others visually. It also shows connections among the characteristics you use to describe yourself. It’s a useful way to share information with others in a clever but also controllable way. You can use any mind map application for this purpose. This article shows you how to get started using [FreeMind](http://freemind.sourceforge.net/wiki/index.php/Main_Page), available in Fedora.
## Get the application
The FreeMind application has been around a while. While the UI is a bit dated and could use a refresh, it’s a powerful app that offers many options for building mind maps. And of course it’s 100% open source. There are other mind mapping apps available for Fedora and Linux users, as well. Check out [this previous article that covers several mind map options](https://fedoramagazine.org/three-mind-mapping-tools-fedora/).
Install FreeMind from the Fedora repositories using the *Software* app if you’re running Fedora Workstation. Or use this [ sudo](https://fedoramagazine.org/howto-use-sudo/) command in a terminal:
$ sudo dnf install freemind
You can launch the app from the GNOME Shell Overview in Fedora Workstation. Or use the application start service your desktop environment provides. FreeMind shows you a new, blank map by default:
A map consists of linked items or descriptions — *nodes*. When you think of something related to a node you want to capture, simply create a new node connected to it.
## Mapping yourself
Click in the initial node. Replace it with your name by editing the text and hitting **Enter**. You’ve just started your mind map.
What would you think of if you had to fully describe yourself to someone? There are probably many things to cover. How do you spend your time? What do you enjoy? What do you dislike? What do you value? Do you have a family? All of this can be captured in nodes.
To add a node connection, select the existing node, and hit **Insert**, or use the “light bulb” icon for a new child node. To add another node at the same level as the new child, use **Enter**.
Don’t worry if you make a mistake. You can use the **Delete** key to remove an unwanted node. There’s no rules about content. Short nodes are best, though. They allow your mind to move quickly when creating the map. Concise nodes also let viewers scan and understand the map easily later.
This example uses nodes to explore each of these major categories:
You could do another round of iteration for each of these areas. Let your mind freely connect ideas to generate the map. Don’t worry about “getting it right.” It’s better to get everything out of your head and onto the display. Here’s what a next-level map might look like.
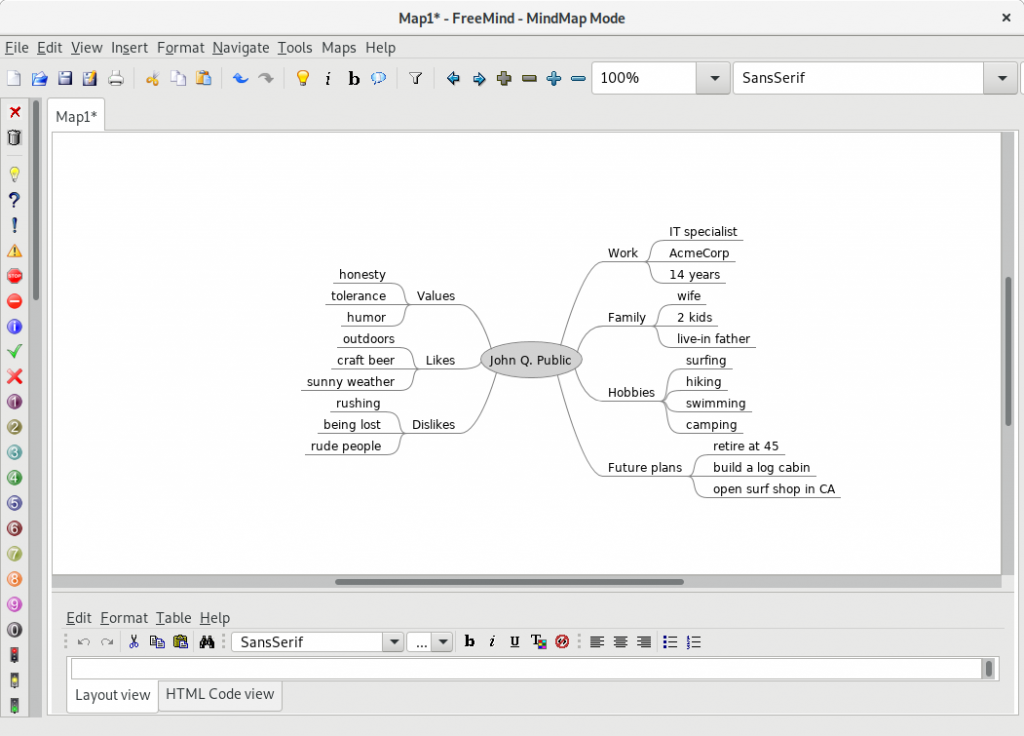
You could expand on any of these nodes in the same way. Notice how much information you can quickly understand about John Q. Public in the example.
## How to use your personal mind map
This is a great way to have team or project members introduce themselves to each other. You can apply all sorts of formatting and color to the map to give it personality. These are fun to do on paper, of course. But having one on your Fedora system means you can always fix mistakes, or even make changes as you change.
Have fun exploring your personal mind map!
*Photo by **Daniel Hjalmarsson** on *[ Unsplash](https://unsplash.com/search/photos/brain?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
## Andi
Great article thx! Personally, I’m not really a friend of using mind-maps. But I’m going to give it try again and test Free Mind:)
Cheers
Andi
## john
Wonderful! I didn’t know freemind could be installed with dnf. Thank you for the information.
## Kouassi Gérard
What about developping an internet cafe software (like cybercafépro) to help spreading fedora in poor country, where the main access to internet remains the internet cafe.
## Patrick
Tried it a while ago. I like VYM better (which is also available in the fedora repository)
## Brian
I’ve been meaning to learn how to use mindmapping.
I found that in Debian land, they’ve dropped freemind from the repositories, with a note about it being buggy and unsupported, and instead have freeplane, a fork of freemind. freeplane doesn’t seem to be in the Fedora repositories, though.
## Eric L.
Having been part of both projects and the original packager of both projects for Debian, I can confirm this, Freeplane is definitely more alive than FreeMind. Even though I’m still using Freeplane directly downloaded from freeplane.org, it belongs packaged in Fedora!
## Ross
Hopefully there will be a Flatpak soon! |
10,580 | 新手教程:Ubuntu 下如何修改用户密码 | https://itsfoss.com/change-password-ubuntu | 2019-03-02T10:33:57 | [
"密码",
"passwd"
] | https://linux.cn/article-10580-1.html |
>
> 想要在 Ubuntu 下修改 root 用户的密码?那我们来学习下如何在 Ubuntu Linux 下修改任意用户的密码。我们会讨论在终端下修改和在图形界面(GUI)修改两种做法。
>
>
>
那么,在 Ubuntu 下什么时候会需要修改密码呢?这里我给出如下两种场景。
* 当你刚安装 [Ubuntu](https://www.ubuntu.com/) 系统时,你会创建一个用户并且为之设置一个密码。这个初始密码可能安全性较弱或者太过于复杂,你会想要对它做出修改。
* 如果你是系统管理员,你可能需要去修改在你管理的系统内其他用户的密码。
当然,你可能会有其他的一些原因做这样的一件事。不过现在问题来了,我们到底如何在 Ubuntu 或其它 Linux 系统下修改单个用户的密码呢?
在这个快速教程中,我将会展示给你在 Ubuntu 中如何使用命令行和图形界面(GUI)两种方式修改密码。
### 在 Ubuntu 中修改用户密码 —— 通过命令行

在 Ubuntu 下修改用户密码其实非常简单。事实上,在任何 Linux 发行版上修改的方式都是一样的,因为你要使用的是叫做 `passwd` 的普通 Linux 命令来达到此目的。
如果你想要修改你的当前密码,只需要简单地在终端执行此命令:
```
passwd
```
系统会要求你输入当前密码和两次新的密码。
在键入密码时,你不会从屏幕上看到任何东西。这在 UNIX 和 Linux 系统中是非常正常的表现。
```
passwd
Changing password for abhishek.
(current) UNIX password:
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
```
由于这是你的管理员账户,你刚刚修改了 Ubuntu 下 sudo 密码,但你甚至没有意识到这个操作。(LCTT 译注:执行 sudo 操作时,输入的是的用户自身的密码,此处修改的就是自身的密码。而所说的“管理员账户”指的是该用户处于可以执行 `sudo` 命令的用户组中。本文此处描述易引起误会,特注明。)

如果你想要修改其他用户的密码,你也可以使用 `passwd` 命令来做。但是在这种情况下,你将不得不使用`sudo`。(LCTT 译注:此处执行 `sudo`,要先输入你的 sudo 密码 —— 如上提示已经修改,再输入给其它用户设置的新密码 —— 两次。)
```
sudo passwd <user_name>
```
如果你对密码已经做出了修改,不过之后忘记了,不要担心。你可以[很容易地在Ubuntu下重置密码](https://itsfoss.com/how-to-hack-ubuntu-password/).
### 修改 Ubuntu 下 root 用户密码
默认情况下,Ubuntu 中 root 用户是没有密码的。不必惊讶,你并不是在 Ubuntu 下一直使用 root 用户。不太懂?让我快速地给你解释下。
当[安装 Ubuntu](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/) 时,你会被强制创建一个用户。这个用户拥有管理员访问权限。这个管理员用户可以通过 `sudo` 命令获得 root 访问权限。但是,该用户使用的是自身的密码,而不是 root 账户的密码(因为就没有)。
你可以使用 `passwd` 命令来设置或修改 root 用户的密码。然而,在大多数情况下,你并不需要它,而且你不应该去做这样的事。
你将必须使用 `sudo` 命令(对于拥有管理员权限的账户)。~~如果 root 用户的密码之前没有被设置,它会要求你设置。另外,你可以使用已有的 root 密码对它进行修改。~~(LCTT 译注:此处描述有误,使用 `sudo` 或直接以 root 用户执行 `passwd` 命令时,不需要输入该被改变密码的用户的当前密码。)
```
sudo password root
```
### 在 Ubuntu 下使用图形界面(GUI)修改密码
我这里使用的是 GNOME 桌面环境,Ubuntu 版本为 18.04。这些步骤对于其他的桌面环境和 Ubuntu 版本应该差别不大。
打开菜单(按下 `Windows`/`Super` 键)并搜索 “Settings”(设置)。
在 “Settings” 中,向下滚动一段距离打开进入 “Details”。

在这里,点击 “Users” 获取系统下可见的所有用户。

你可以选择任一你想要的用户,包括你的主要管理员账户。你需要先解锁用户并点击 “Password” 区域。

你会被要求设置密码。如果你正在修改的是你自己的密码,你将必须也输入当前使用的密码。

做好这些后,点击上面的 “Change” 按钮,这样就完成了。你已经成功地在 Ubuntu 下修改了用户密码。
我希望这篇快速精简的小教程能够帮助你在 Ubuntu 下修改用户密码。如果你对此还有一些问题或建议,请在下方留下评论。
---
via: <https://itsfoss.com/change-password-ubuntu>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[An-DJ](https://github.com/An-DJ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,581 | ick:一个持续集成系统 | https://blog.liw.fi/posts/2018/01/22/ick_a_continuous_integration_system/ | 2019-03-02T11:06:15 | [
"CI"
] | https://linux.cn/article-10581-1.html |
>
> ick 是一个持续集成(CI)系统。访问 <http://ick.liw.fi/> 获取更多信息。
>
>
>

更加详细的内容如下:
### 首个公开版本发行
这个世界可能并不需要又一个持续集成系统(CI),但是我需要。我对我尝试过或者看过的持续集成系统感到不满意。更重要的是,有几样我感兴趣的东西比我所听说过的持续集成系统要强大得多。因此我开始编写我自己的 CI 系统。
我的新个人业余项目叫做 ick。它是一个 CI 系统,这意味着它可以运行自动化的步骤来构建、测试软件。它的主页是 <http://ick.liw.fi/>,[下载](http://ick.liw.fi/download/)页面有指向源代码、.deb 包和用来安装的 Ansible 脚本的链接。
我现已发布了首个公开版本,绰号 ALPHA-1,版本号 0.23。(LCTT 译注:截止至本译文发布,已经更新到 ALPHA-6)它现在是 alpha 品质,这意味着它并没拥有期望的全部特性,如果任何一个它已有的特性工作的话,那真是运气好。
### 诚邀贡献
ick 目前是我的个人项目。我希望能让它不仅限于此,同时我也诚邀更多贡献。访问[治理](http://ick.liw.fi/governance/)页面查看章程,[入门](http://ick.liw.fi/getting-started/)页面查看如何开始贡献的的小建议,[联系](http://ick.liw.fi/contact/)页面查看如何联络。
### 架构
ick 拥有一个由几个通过 HTTPS 协议通信使用 RESTful API 和 JSON 处理结构化数据的部分组成的架构。访问[架构](http://ick.liw.fi/architecture/)页面了解细节。
### 宣告
持续集成(CI)是用于软件开发的强大工具。它不应枯燥、易溃或恼人。它构建起来应简单快速,除非正在测试、构建的代码中有问题,不然它应在后台安静地工作。
一个持续集成系统应该简单、易用、清楚、干净、可扩展、快速、综合、透明、可靠,并推动你的生产力。构建它不应花大力气、不应需要专门为 CI 而造的硬件、不应需要频繁留意以使其保持工作、开发者永远不必思考为什么某样东西不工作。
一个持续集成系统应该足够灵活以适应你的构建、测试需求。只要 CPU 架构和操作系统版本没问题,它应该支持各种操作者。
同时像所有软件一样,CI 应该彻彻底底的免费,你的 CI 应由你做主。
(目前的 ick 仅稍具雏形,但是它会尝试着有朝一日变得完美 —— 在最理想的情况下。)
### 未来的梦想
长远来看,我希望 ick 拥有像下面所描述的特性。落实全部特性可能需要一些时间。
* 各种事件都可以触发构建。时间是一个明显的事件,因为项目的源代码仓库改变了。更强大的是任何依赖的改变,不管依赖是来自于 ick 构建的另一个项目,或者是包(比如说来自 Debian):ick 应当跟踪所有安装进一个项目构建环境中的包,如果任何一个包的版本改变,都应再次触发项目构建和测试。
* ick 应该支持构建于(或针对)任何合理的目标平台,包括任何 Linux 发行版,任何自由的操作系统,以及任何一息尚存的不自由的操作系统。
* ick 应该自己管理构建环境,并且能够执行与构建主机或网络隔离的构建。这部分工作:可以要求 ick 构建容器并在容器中运行构建。容器使用 systemd-nspawn 实现。 然而,这可以改进。(如果您认为 Docker 是唯一的出路,请为此提供支持。)
* ick 应当不需要安装任何专门的代理,就能支持各种它能够通过 ssh 或者串口或者其它这种中性的交流管道控制的<ruby> 操作者 <rt> worker </rt></ruby>。ick 不应默认它可以有比如说一个完整的 Java Runtime,如此一来,操作者就可以是一个微控制器了。
* ick 应当能轻松掌控一大批项目。我觉得不管一个新的 Debian 源包何时上传,ick 都应该要能够跟得上在 Debian 中构建所有东西的进度。(明显这可行与否取决于是否有足够的资源确实用在构建上,但是 ick 自己不应有瓶颈。)
* 如果有需要的话 ick 应当有选择性地补给操作者。如果所有特定种类的操作者处于忙碌中,且 ick 被设置成允许使用更多资源的话,它就应该这么做。这看起来用虚拟机、容器、云提供商等做可能会简单一些。
* ick 应当灵活提醒感兴趣的团体,特别是关于其失败的方面。它应允许感兴趣的团体通过 IRC、Matrix、Mastodon、Twitter、email、SMS 甚至电话和语音合成来接受通知。例如“您好,感兴趣的团体。现在是四点钟您想被通知 hello 包什么时候为 RISC-V 构建好。”
### 请提供反馈
如果你尝试过 ick 或者甚至你仅仅是读到这,请在上面分享你的想法。在[联系](http://ick.liw.fi/contact/)页面查看如何发送反馈。相比私下反馈我更偏爱公开反馈。但如果你偏爱私下反馈,那也行。
---
via: <https://blog.liw.fi/posts/2018/01/22/ick_a_continuous_integration_system/>
作者:[Lars Wirzenius](https://blog.liw.fi/) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [blog.liw.fi](../../../../../)→
[posts](../../../../)→
[2018](../../../../../)→
[01](../../../../../)→
[22](../../../../../)→ Ick: a continuous integration system
**TL;DR:** Ick is a continuous integration or CI system. See [http://ick.liw.fi/](http://ick.liw.fi/) for more information.
More verbose version follows.
## First public version released
The world may not need yet another continuous integration system (CI), but I do. I’ve been unsatisfied with the ones I’ve tried or looked at. More importantly, I am interested in a few things that are more powerful than what I’ve ever even heard of. So I’ve started writing my own.
My new personal hobby project is called ick. It is a CI system, which means it can run automated steps for building and testing software. The home page is at [http://ick.liw.fi/](http://ick.liw.fi/), and the [download](http://ick.liw.fi/download/) page has links to the source code and .deb packages and an Ansible playbook for installing it.
I have now made the first publicly advertised release, dubbed ALPHA-1, version number 0.23. It is of alpha quality, and that means it doesn’t have all the intended features and if any of the features it does have work, you should consider yourself lucky.
## Invitation to contribute
Ick has so far been my personal project. I am hoping to make it more than that, and invite contributions. See the [governance](http://ick.liw.fi/governance/) page for the constitution, the [getting started](http://ick.liw.fi/getting-started/) page for tips on how to start contributing, and the [contact](http://ick.liw.fi/contact/) page for how to get in touch.
## Architecture
Ick has an architecture consisting of several components that communicate over HTTPS using RESTful APIs and JSON for structured data. See the [architecture](http://ick.liw.fi/architecture/) page for details.
## Manifesto
Continuous integration (CI) is a powerful tool for software development. It should not be tedious, fragile, or annoying. It should be quick and simple to set up, and work quietly in the background unless there’s a problem in the code being built and tested.
A CI system should be simple, easy, clear, clean, scalable, fast, comprehensible, transparent, reliable, and boost your productivity to get things done. It should not be a lot of effort to set up, require a lot of hardware just for the CI, need frequent attention for it to keep working, and developers should never have to wonder why something isn’t working.
A CI system should be flexible to suit your build and test needs. It should support multiple types of workers, as far as CPU architecture and operating system version are concerned.
Also, like all software, CI should be fully and completely free software and your instance should be under your control.
(Ick is little of this yet, but it will try to become all of it. In the best possible taste.)
## Dreams of the future
In the long run, I would ick to have features like ones described below. It may take a while to get all of them implemented.
A build may be triggered by a variety of events. Time is an obvious event, as is source code repository for the project changing. More powerfully, any build dependency changing, regardless of whether the dependency comes from another project built by ick, or a package from, say, Debian: ick should keep track of all the packages that get installed into the build environment of a project, and if any of their versions change, it should trigger the project build and tests again.
Ick should support building in (or against) any reasonable target, including any Linux distribution, any free operating system, and any non-free operating system that isn’t brain-dead.
Ick should manage the build environment itself, and be able to do builds that are isolated from the build host or the network. This partially works: one can ask ick to build a container and run a build in the container. The container is implemented using systemd-nspawn. This can be improved upon, however. (If you think Docker is the only way to go, please contribute support for that.)
Ick should support any workers that it can control over ssh or a serial port or other such neutral communication channel, without having to install an agent of any kind on them. Ick won’t assume that it can have, say, a full Java run time, so that the worker can be, say, a micro controller.
Ick should be able to effortlessly handle very large numbers of projects. I’m thinking here that it should be able to keep up with building everything in Debian, whenever a new Debian source package is uploaded. (Obviously whether that is feasible depends on whether there are enough resources to actually build things, but ick itself should not be the bottleneck.)
Ick should optionally provision workers as needed. If all workers of a certain type are busy, and ick’s been configured to allow using more resources, it should do so. This seems like it would be easy to do with virtual machines, containers, cloud providers, etc.
Ick should be flexible in how it can notify interested parties, particularly about failures. It should allow an interested party to ask to be notified over IRC, Matrix, Mastodon, Twitter, email, SMS, or even by a phone call and speech syntethiser. “Hello, interested party. It is 04:00 and you wanted to be told when the hello package has been built for RISC-V.”
## Please give feedback
If you try ick, or even if you’ve just read this far, please share your thoughts on it. See the [contact](http://ick.liw.fi/contact/) page for where to send it. Public feedback is preferred over private, but if you prefer private, that’s OK too. |
10,582 | 使用 Emacs 创建 OAuth 2.0 的 UML 序列图 | https://www.onwebsecurity.com/configuration/use-emacs-to-create-oauth-2-0-uml-sequence-diagrams.html | 2019-03-02T21:25:59 | [
"Emacs",
"UML"
] | https://linux.cn/article-10582-1.html | 
看起来 [OAuth 2.0 框架](https://tools.ietf.org/html/rfc6749) 已经越来越广泛地应用于 web (和 移动) 应用。太棒了!
虽然协议本身并不复杂,但有很多的使用场景、流程和实现可供选择。正如生活中的大多数事物一样,魔鬼在于细节之中。
在审查 OAuth 2.0 实现或编写渗透测试报告时我习惯画出 UML 图。这方便让人理解发生了什么事情,并发现潜在的问题。毕竟,一图抵千言。
使用基于 GPL 开源协议 [Emacs](https://www.gnu.org/software/emacs/) 编辑器来实现,再加上基于 GPL 开源协议的工具 [PlantUML](https://plantuml.com) (也可以选择基于 Eclipse Public 协议的 [Graphviz](http://www.graphviz.org/)) 很容易做到这一点。
Emacs 是世界上最万能的编辑器。在这种场景中,我们用它来编辑文本,并自动将文本转换成图片。PlantUML 是一个允许你用人类可读的文本来写 UML 并完成该转换的工具。Graphviz 是一个可视化的软件,这里我们可以用它来显示图片。
下载 [预先编译好了的 PlantUML jar 文件](http://plantuml.com/download) ,[Emacs](https://www.gnu.org/software/emacs/download.html) 还可以选择下载并安装 [Graphviz](http://www.graphviz.org/Download.php)。
安装并启动 Emacs,然后将下面 Lisp 代码(实际上是配置)写入你的启动文件中(`~/.emacs.d/init.d`),这段代码将会:
* 配置 org 模式(一种用来组织并编辑文本文件的模式)来使用 PlantUML
* 将 `plantuml` 添加到可识别的 “org-babel” 语言中(这让你可以在文本文件中执行源代码)
* 将 PlantUML 代码标注为安全的,从而允许执行
* 自动显示生成的结果图片
```
;; tell org-mode where to find the plantuml JAR file (specify the JAR file)
(setq org-plantuml-jar-path (expand-file-name "~/plantuml.jar"))
;; use plantuml as org-babel language
(org-babel-do-load-languages 'org-babel-load-languages '((plantuml . t)))
;; helper function
(defun my-org-confirm-babel-evaluate (lang body)
"Do not ask for confirmation to evaluate code for specified languages."
(member lang '("plantuml")))
;; trust certain code as being safe
(setq org-confirm-babel-evaluate 'my-org-confirm-babel-evaluate)
;; automatically show the resulting image
(add-hook 'org-babel-after-execute-hook 'org-display-inline-images)
```
如果你还没有启动文件,那么将该代码加入到 `~/.emacs.d/init.el` 文件中然后重启 Emacs。
提示:`Control-c Control-f` 可以让你创建/打开(新)文件。`Control-x Control-s` 保存文件,而 `Control-x Control-c` 退出 Emacs。
这就结了!
要测试该配置,可以创建/打开(`Control-c Control-f`)后缀为 `.org` 的文件,例如 `test.org`。这会让 Emacs 切换到 org 模式并识别 “org-babel” 语法。
输入下面代码,然后在代码中输入 `Control-c Control-c` 来测试是否安装正常:
```
#+BEGIN_SRC plantuml :file test.png
@startuml
version
@enduml
#+END_SRC
```
一切顺利的话,你会在 Emacs 中看到文本下面显示了一张图片。
>
> **注意:**
>
>
> 要快速插入类似 `#+BEGIN_SRC` 和 `#+END_SRC` 这样的代码片段,你可以使用内置的 Easy Templates 系统:输入 `<s` 然后按下 `TAB`,它就会自动为你插入模板。
>
>
>
还有更复杂的例子,下面是生成上面图片的 UML 源代码:
```
#+BEGIN_SRC plantuml :file t:/oauth2-abstract-protocol-flow.png
@startuml
hide footbox
title Oauth 2.0 Abstract protocol flow
autonumber
actor user as "resource owner (user)"
box "token stays secure" #FAFAFA
participant client as "client (application)"
participant authorization as "authorization server"
database resource as "resource server"
end box
group user authorizes client
client -> user : request authorization
note left
**grant types**:
# authorization code
# implicit
# password
# client_credentials
end note
user --> client : authorization grant
end
group token is generated
client -> authorization : request token\npresent authorization grant
authorization --> client :var: access token
note left
**response types**:
# code
# token
end note
end group
group resource can be accessed
client -> resource : request resource\npresent token
resource --> client : resource
end group
@enduml
#+END_SRC
```
你难道会不喜欢 Emacs 和开源工具的多功能性吗?
---
via: <https://www.onwebsecurity.com/configuration/use-emacs-to-create-oauth-2-0-uml-sequence-diagrams.html>
作者:[Peter Mosmans](https://www.onwebsecurity.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It seems that the [OAuth 2.0 framework](https://tools.ietf.org/html/rfc6749)
is more and more being used by web (and mobile) applications. Great !
Although the protocol itself is not that complex, there are a number of different use-cases, flows and implementations to choose from. As with most things in life, the devil is in the detail.
When reviewing OAuth 2.0 implementations or writing penetration testing reports I like to draw UML diagrams. That makes it easier to understand what's going on, and to spot potential issues. After all, a picture is worth a thousand words.
This can be done extremely easy using the GPL-licensed open source [Emacs](https://www.gnu.org/software/emacs/) editor, in conjunction with the
GPL-licensed open source tool [PlantUML](https://plantuml.com) (and
optionally using Eclipse Public Licensed [Graphviz](http://www.graphviz.org/)).
Emacs is worlds' most versatile editor. In this case, it's being used to edit the text, and automatically convert the text to an image. PlantUML is a tool which allows you to write UML in human readable text and does the actual conversion. Graphviz is visualization software, and optionally - in this case, it's used to show certain images.
Download the [compiled PlantUML jar file](http://plantuml.com/download),
[Emacs](https://www.gnu.org/software/emacs/download.html) and optionally
download and install [Graphviz](http://www.graphviz.org/Download.php).
Once you have Emacs installed and running, the following Lisp code (actually
configuration) in your startup file (```
~/.emacs.d/init.d
```
) will
- configure
`org-mode`
(a mode to organize and edit text files) to use PlantUML - add
`plantuml`
to the recognized`org-babel`
languages (which allows you to execute source code from within text files) - allow the execution of PlantUML code as "safe"
- automatically show you the resulting image
```
;; tell org-mode where to find the plantuml JAR file (specify the JAR file)
(setq org-plantuml-jar-path (expand-file-name "~/plantuml.jar"))
;; use plantuml as org-babel language
(org-babel-do-load-languages 'org-babel-load-languages '((plantuml . t)))
;; helper function
(defun my-org-confirm-babel-evaluate (lang body)
"Do not ask for confirmation to evaluate code for specified languages."
(member lang '("plantuml")))
;; trust certain code as being safe
(setq org-confirm-babel-evaluate 'my-org-confirm-babel-evaluate)
;; automatically show the resulting image
(add-hook 'org-babel-after-execute-hook 'org-display-inline-images)
```
If you don't have a startup file yet, add this code to the file
```
~/.emacs.d/init.el
```
and restart Emacs.
Hint: `
Control-c Control-f`
allows you to create/open a (new) file.
`
Control-x Control-s`
saves a file, and `
Control-x Control-c`
exits
Emacs.
That's it!
To test the configuration, create/open a file (`
Control-c Control-f`
) with
the extension ```
.org
```
, e.g. ```
test.org
```
. This makes sure that Emacs switches
to "org-mode" and recognizes the "org-babel" syntax.
Insert the following code, and press `
Control-c Control-c`
within the code
to test the installation:
```
#+BEGIN_SRC plantuml :file test.png
@startuml
version
@enduml
#+END_SRC
```
If everything went well, you'll see an image appearing inside Emacs, below the text.
Note
To quickly insert code snippets like ```
#+BEGIN_SRC
```
and
```
#+END_SRC
```
, you can use the built-in *Easy Templates* system:
Type `
<s`
followed by a `
TAB`
, and it will automagically
insert a template for you.
For a more advanced example, this is the UML source code used to generate the image above:
```
#+BEGIN_SRC plantuml :file t:/oauth2-abstract-protocol-flow.png
@startuml
hide footbox
title Oauth 2.0 Abstract protocol flow
autonumber
actor user as "resource owner (user)"
box "token stays secure" #FAFAFA
participant client as "client (application)"
participant authorization as "authorization server"
database resource as "resource server"
end box
group user authorizes client
client -> user : request authorization
note left
**grant types**:
# authorization code
# implicit
# password
# client_credentials
end note
user --> client : authorization grant
end
group token is generated
client -> authorization : request token\npresent authorization grant
authorization --> client :var: access token
note left
**response types**:
# code
# token
end note
end group
group resource can be accessed
client -> resource : request resource\npresent token
resource --> client : resource
end group
@enduml
#+END_SRC
```
Don't you just love the versatility of Emacs, and open source tools ?
## Comments
comments powered by Disqus |
10,583 | 如何使用 Linux Cockpit 来管理系统性能 | https://www.networkworld.com/article/3340038/linux/sitting-in-the-linux-cockpit.html | 2019-03-02T21:37:58 | [
"系统管理"
] | https://linux.cn/article-10583-1.html |
>
> Linux Cockpit 是一个基于 Web 界面的应用,它提供了对系统的图形化管理。看下它能够控制哪些。
>
>
>

如果你还没有尝试过相对较新的 Linux Cockpit,你可能会对它所能做的一切感到惊讶。它是一个用户友好的基于 web 的控制台,提供了一些非常简单的方法来管理 Linux 系统 —— 通过 web。你可以通过一个非常简单的 web 来监控系统资源、添加或删除帐户、监控系统使用情况、关闭系统以及执行其他一些其他任务。它的设置和使用也非常简单。
虽然许多 Linux 系统管理员将大部分时间花在命令行上,但使用 PuTTY 等工具访问远程系统并不总能提供最有用的命令输出。Linux Cockpit 提供了图形和易于使用的表单,来查看性能情况并对系统进行更改。
Linux Cockpit 能让你查看系统性能的许多方面并进行配置更改,但任务列表可能取决于你使用的特定 Linux。任务分类包括以下内容:
* 监控系统活动(CPU、内存、磁盘 IO 和网络流量) —— **系统**
* 查看系统日志条目 —— **日志**
* 查看磁盘分区的容量 —— **存储**
* 查看网络活动(发送和接收) —— **网络**
* 查看用户帐户 —— **帐户**
* 检查系统服务的状态 —— **服务**
* 提取已安装应用的信息 —— **应用**
* 查看和安装可用更新(如果以 root 身份登录)并在需要时重新启动系统 —— **软件更新**
* 打开并使用终端窗口 —— **终端**
某些 Linux Cockpit 安装还允许你运行诊断报告、转储内核、检查 SELinux(安全)设置和列出订阅。
以下是 Linux Cockpit 显示的系统活动示例:

*Linux Cockpit 显示系统活动*
### 如何设置 Linux Cockpit
在某些 Linux 发行版(例如,最新的 RHEL)中,Linux Cockpit 可能已经安装并可以使用。在其他情况下,你可能需要采取一些简单的步骤来安装它并使其可使用。
例如,在 Ubuntu 上,这些命令应该可用:
```
$ sudo apt-get install cockpit
$ man cockpit <== just checking
$ sudo systemctl enable --now cockpit.socket
$ netstat -a | grep 9090
tcp6 0 0 [::]:9090 [::]:* LISTEN
$ sudo systemctl enable --now cockpit.socket
$ sudo ufw allow 9090
```
启用 Linux Cockpit 后,在浏览器中打开 `https://<system-name-or-IP>:9090`
可以在 [Cockpit 项目](https://cockpit-project.org/running.html) 中找到可以使用 Cockpit 的发行版列表以及安装说明。
没有额外的配置,Linux Cockpit 将无法识别 `sudo` 权限。如果你被禁止使用 Cockpit 进行更改,你将会在你点击的按钮上看到一个红色的通用禁止标志。
要使 `sudo` 权限有效,你需要确保用户位于 `/etc/group` 文件中的 `wheel`(RHEL)或 `adm` (Debian)组中,即服务器当以 root 用户身份登录 Cockpit 并且用户在登录 Cockpit 时选择“重用我的密码”时,已勾选了 “Server Administrator”。
在你管理的系统位在千里之外或者没有控制台时,能使用图形界面控制也不错。虽然我喜欢在控制台上工作,但我偶然也乐于见到图形或者按钮。Linux Cockpit 为日常管理任务提供了非常有用的界面。
---
via: <https://www.networkworld.com/article/3340038/linux/sitting-in-the-linux-cockpit.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,584 | 两款 Linux 桌面中的图形化操作 PDF 的工具 | https://opensource.com/article/19/2/manipulating-pdfs-linux | 2019-03-02T21:52:00 | [
"PDF"
] | /article-10584-1.html |
>
> PDF-Shuffler 和 PDF Chain 是在 Linux 中修改 PDF 的绝佳工具。
>
>
>

由于我谈论和写作了些 PDF 及使用它们的工具的文章,有些人认为我喜欢这种格式。其实我并不是,由于各种原因,我不会深入它。
我不会说 PDF 是我个人和职业生活中的一个躲不开的坏事 - 而实际上它们不是那么好。通常即使有更好的替代方案来交付文档,通常我也必须使用 PDF。
当我使用 PDF 时,通常是在白天工作时在其他的操作系统上使用,我使用 Adobe Acrobat 进行操作。但是当我必须在 Linux 桌面上使用 PDF 时呢?我们来看看我用来操作 PDF 的两个图形工具。
### PDF-Shuffler
顾名思义,你可以使用 [PDF-Shuffler](https://savannah.nongnu.org/projects/pdfshuffler/) 在 PDF 文件中移动页面。它可以做得更多,但该软件的功能是有限的。这并不意味着 PDF-Shuffler 没用。它有用,很有用。
你可以将 PDF-Shuffler 用来:
* 从 PDF 文件中提取页面
* 将页面添加到文件中
* 重新排列文件中的页面
请注意,PDF-Shuffler 有一些依赖项,如 pyPDF 和 python-gtk。通常,通过包管理器安装它是最快且最不令人沮丧的途径。
假设你想从 PDF 中提取页面,也许是作为你书中的样本章节。选择 “File > Add”打开 PDF 文件。

要提取第 7 页到第 9 页,请按住 `Ctrl` 并单击选择页面。然后,右键单击并选择 “Export selection”。

选择要保存文件的目录,为其命名,然后单击 “Save”。
要添加文件 —— 例如,要添加封面或重新插入已扫描的且已签名的合同或者应用 - 打开 PDF 文件,然后选择 “File > Add” 并找到要添加的 PDF 文件。单击 “Open”。
PDF-Shuffler 有个不好的地方就是添加页面到你正在处理的 PDF 文件末尾。单击并将添加的页面拖动到文件中的所需位置。你一次只能在文件中单击并拖动一个页面。

### PDF Chain
我是 [PDFtk](https://en.wikipedia.org/wiki/PDFtk) 的忠实粉丝,它是一个可以对 PDF 做一些有趣操作的命令行工具。由于我不经常使用它,我不记得所有 PDFtk 的命令和选项。
[PDF Chain](http://pdfchain.sourceforge.net/) 是 PDFtk 命令行的一个很好的替代品。它可以让你一键使用 PDFtk 最常用的命令。无需使用菜单,你可以:
* 合并 PDF(包括旋转一个或多个文件的页面)
* 从 PDF 中提取页面并将其保存到单个文件中
* 为 PDF 添加背景或水印
* 将附件添加到文件

你也可以做得更多。点击 “Tools” 菜单,你可以:
* 从 PDF 中提取附件
* 压缩或解压缩文件
* 从文件中提取元数据
* 用外部[数据](http://www.verypdf.com/pdfform/fdf.htm)填充 PDF 表格
* [扁平化](http://pdf-tips-tricks.blogspot.com/2009/03/flattening-pdf-layers.html) PDF
* 从 PDF 表单中删除 [XML 表格结构](http://en.wikipedia.org/wiki/XFA)(XFA)数据
老实说,我只使用 PDF Chain 或 PDFtk 提取附件、压缩或解压缩 PDF。其余的对我来说基本没听说。
### 总结
Linux 上用于处理 PDF 的工具数量一直让我感到吃惊。它们的特性和功能的广度和深度也是如此。无论是命令行还是图形,我总能找到一个能做我需要的。在大多数情况下,PDF Mod 和 PDF Chain 对我来说效果很好。
---
via: <https://opensource.com/article/19/2/manipulating-pdfs-linux>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,585 | 计算机实验室之树莓派:课程 8 屏幕03 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html | 2019-03-04T00:52:41 | [
"树莓派"
] | https://linux.cn/article-10585-1.html | 
屏幕03 课程基于屏幕02 课程来构建,它教你如何绘制文本,和一个操作系统命令行参数上的一个小特性。假设你已经有了[课程 7:屏幕02](/article-10551-1.html) 的操作系统代码,我们将以它为基础来构建。
### 1、字符串的理论知识
是的,我们的任务是为这个操作系统绘制文本。我们有几个问题需要去处理,最紧急的那个可能是如何去保存文本。令人难以置信的是,文本是迄今为止在计算机上最大的缺陷之一。原本应该是简单的数据类型却导致了操作系统的崩溃,从而削弱其他方面的加密效果,并给使用其它字母表的用户带来了许多问题。尽管如此,它仍然是极其重要的数据类型,因为它将计算机和用户很好地连接起来。文本是计算机能够理解的非常好的结构,同时人类使用它时也有足够的可读性。
那么,文本是如何保存的呢?非常简单,我们使用一种方法,给每个字母分配一个唯一的编号,然后我们保存一系列的这种编号。看起来很容易吧。问题是,那个编号的数量是不固定的。一些文本段可能比其它的长。保存普通数字,我们有一些固有的限制,即:32 位,我们不能超过这个限制,我们要添加方法去使用该长度的数字等等。“文本”这个术语,我们经常也叫它“字符串”,我们希望能够写一个可用于可变长度字符串的函数,否则就需要写很多函数!对于一般的数字来说,这不是个问题,因为只有几种通用的数字格式(字节、字、半字节、双字节)。
>
> 可变数据类型(比如文本)要求能够进行很复杂的处理。
>
>
>
因此,如何判断字符串长度?我想显而易见的答案是存储字符串的长度,然后去存储组成字符串的字符。这称为长度前缀,因为长度位于字符串的前面。不幸的是,计算机科学家的先驱们不同意这么做。他们认为使用一个称为空终止符(`NULL`)的特殊字符(用 `\0` 表示)来表示字符串结束更有意义。这样确定简化了许多字符串算法,因为你只需要持续操作直到遇到空终止符为止。不幸的是,这成为了许多安全问题的根源。如果一个恶意用户给你一个特别长的字符串会发生什么状况?如果没有足够的空间去保存这个特别长的字符串会发生什么状况?你可以使用一个字符串复制函数来做复制,直到遇到空终止符为止,但是因为字符串特别长,而覆写了你的程序,怎么办?这看上去似乎有些较真,但是,缓冲区溢出攻击还是经常发生。长度前缀可以很容易地缓解这种问题,因为它可以很容易地推算出保存这个字符串所需要的缓冲区的长度。作为一个操作系统开发者,我留下这个问题,由你去决定如何才能更好地存储文本。
>
> 缓冲区溢出攻击祸害计算机由来已久。最近,Wii、Xbox 和 Playstation 2、以及大型系统如 Microsoft 的 Web 和数据库服务器,都遭受到缓冲区溢出攻击。
>
>
>
接下来的事情是,我们需要确定的是如何最好地将字符映射到数字。幸运的是,这是高度标准化的,我们有两个主要的选择,Unicode 和 ASCII。Unicode 几乎将每个有用的符号都映射为数字,作为代价,我们需要有很多很多的数字,和一个更复杂的编码方法。ASCII 为每个字符使用一个字节,因此它仅保存拉丁字母、数字、少数符号和少数特殊字符。因此,ASCII 是非常易于实现的,与之相比,Unicode 的每个字符占用的空间并不相同,这使得字符串算法更棘手。通常,操作系统上字符使用 ASCII,并不是为了显示给最终用户的(开发者和专家用户除外),给终端用户显示信息使用 Unicode,因为 Unicode 能够支持像日语字符这样的东西,并且因此可以实现本地化。
幸运的是,在这里我们不需要去做选择,因为它们的前 128 个字符是完全相同的,并且编码也是完全一样的。
表 1.1 ASCII/Unicode 符号 0-127
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 00 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI | |
| 10 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US | |
| 20 | ! | “ | # | $ | % | & | . | ( | ) | \* | + | , | - | . | / | | |
| 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
| 40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
| 50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | \_ | |
| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
| 70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
这个表显示了前 128 个符号。一个符号的十六进制表示是行的值加上列的值,比如 A 是 41<sub> 16</sub>。你可以惊奇地发现前两行和最后的值。这 33 个特殊字符是不可打印字符。事实上,许多人都忽略了它们。它们之所以存在是因为 ASCII 最初设计是基于计算机网络来传输数据的一种方法。因此它要发送的信息不仅仅是符号。你应该学习的重要的特殊字符是 `NUL`,它就是我们前面提到的空终止符。`HT` 水平制表符就是我们经常说的 `tab`,而 `LF` 换行符用于生成一个新行。你可能想研究和使用其它特殊字符在你的操行系统中的意义。
### 2、字符
到目前为止,我们已经知道了一些关于字符串的知识,我们可以开始想想它们是如何显示的。为了显示一个字符串,我们需要做的最基础的事情是能够显示一个字符。我们的第一个任务是编写一个 `DrawCharacter` 函数,给它一个要绘制的字符和一个位置,然后它将这个字符绘制出来。
这就很自然地引出关于字体的讨论。我们已经知道有许多方式去按照选定的字体去显示任何给定的字母。那么字体又是如何工作的呢?在计算机科学的早期阶段,字体就是所有字母的一系列小图片而已,这种字体称为位图字体,而所有的字符绘制方法就是将图片复制到屏幕上。当人们想去调整字体大小时就出问题了。有时我们需要大的字母,而有时我们需要的是小的字母。尽管我们可以为每个字体、每种大小、每个字符都绘制新图片,但这种作法过于单调乏味。所以,发明了矢量字体。矢量字体不包含字体的图像,它包含的是如何去绘制字符的描述,即:一个 `o` 可能是最大字母高度的一半为半径绘制的圆。现代操作系统都几乎仅使用这种字体,因为这种字体在任何分辨率下都很完美。
>
> 在许多操作系统中使用的 TrueType 字体格式是很强大的,它内置有它自己的汇编语言,以确保在任何分辨率下字母看起来都是正确的。
>
>
>
不幸的是,虽然我很想包含一个矢量字体的格式的实现,但它的内容太多了,将占用这个网站的剩余部分。所以,我们将去实现一个位图字体,可是,如果你想去做一个像样的图形操作系统,那么矢量字体将是很有用的。
在下载页面上的字体节中,我们提供了几个 `.bin` 文件。这些只是字体的原始二进制数据文件。为完成本教程,从等宽、单色、8x16 节中挑选你喜欢的字体。然后下载它并保存到 `source` 目录中并命名为 `font.bin` 文件。这些文件只是每个字母的单色图片,它们每个字母刚好是 8 x 16 个像素。所以,每个字母占用 16 字节,第一个字节是第一行,第二个字节是第二行,依此类推。

这个示意图展示了等宽、单色、8x16 的字符 A 的 “Bitstream Vera Sans Mono” 字体。在这个文件中,我们可以找到,它从第 41<sub> 16</sub> × 10<sub> 16</sub> = 410<sub> 16</sub> 字节开始的十六进制序列:
```
00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
```
在这里我们将使用等宽字体,因为等宽字体的每个字符大小是相同的。不幸的是,大多数字体的复杂之处就是因为它的宽度不同,从而导致它的显示代码更复杂。在下载页面上还包含有几个其它的字体,并包含了这种字体的存储格式介绍。
我们回到正题。复制下列代码到 `drawing.s` 中的 `graphicsAddress` 的 `.int 0` 之后。
```
.align 4
font:
.incbin "font.bin"
```
>
> `.incbin "file"` 插入来自文件 “file” 中的二进制数据。
>
>
>
这段代码复制文件中的字体数据到标签为 `font` 的地址。我们在这里使用了一个 `.align 4` 去确保每个字符都是从 16 字节的倍数开始,这是一个以后经常用到的用于加快访问速度的技巧。
现在我们去写绘制字符的方法。我在下面给出了伪代码,你可以尝试自己去实现它。按惯例 `>>` 的意思是逻辑右移。
```
function drawCharacter(r0 is character, r1 is x, r2 is y)
if character > 127 then exit
set charAddress to font + character × 16
for row = 0 to 15
set bits to readByte(charAddress + row)
for bit = 0 to 7
if test(bits >> bit, 0x1)
then setPixel(x + bit, y + row)
next
next
return r0 = 8, r1 = 16
end function
```
如果直接去实现它,这显然不是个高效率的做法。像绘制字符这样的事情,效率是最重要的。因为我们要频繁使用它。我们来探索一些改善的方法,使其成为最优化的汇编代码。首先,因为我们有一个 `× 16`,你应该会马上想到它等价于逻辑左移 4 位。紧接着我们有一个变量 `row`,它只与 `charAddress` 和 `y` 相加。所以,我们可以通过增加替代变量来消除它。现在唯一的问题是如何判断我们何时完成。这时,一个很好用的 `.align 4` 上场了。我们知道,`charAddress` 将从包含 0 的低位半字节开始。这意味着我们可以通过检查低位半字节来看到进入字符数据的程度。
虽然我们可以消除对 `bit` 的需求,但我们必须要引入新的变量才能实现,因此最好还是保留它。剩下唯一的改进就是去除嵌套的 `bits >> bit`。
```
function drawCharacter(r0 is character, r1 is x, r2 is y)
if character > 127 then exit
set charAddress to font + character << 4
loop
set bits to readByte(charAddress)
set bit to 8
loop
set bits to bits << 1
set bit to bit - 1
if test(bits, 0x100)
then setPixel(x + bit, y)
until bit = 0
set y to y + 1
set chadAddress to chadAddress + 1
until charAddress AND 0b1111 = 0
return r0 = 8, r1 = 16
end function
```
现在,我们已经得到了非常接近汇编代码的代码了,并且代码也是经过优化的。下面就是上述代码用汇编写出来的代码。
```
.globl DrawCharacter
DrawCharacter:
cmp r0,#127
movhi r0,#0
movhi r1,#0
movhi pc,lr
push {r4,r5,r6,r7,r8,lr}
x .req r4
y .req r5
charAddr .req r6
mov x,r1
mov y,r2
ldr charAddr,=font
add charAddr, r0,lsl #4
lineLoop$:
bits .req r7
bit .req r8
ldrb bits,[charAddr]
mov bit,#8
charPixelLoop$:
subs bit,#1
blt charPixelLoopEnd$
lsl bits,#1
tst bits,#0x100
beq charPixelLoop$
add r0,x,bit
mov r1,y
bl DrawPixel
teq bit,#0
bne charPixelLoop$
charPixelLoopEnd$:
.unreq bit
.unreq bits
add y,#1
add charAddr,#1
tst charAddr,#0b1111
bne lineLoop$
.unreq x
.unreq y
.unreq charAddr
width .req r0
height .req r1
mov width,#8
mov height,#16
pop {r4,r5,r6,r7,r8,pc}
.unreq width
.unreq height
```
### 3、字符串
现在,我们可以绘制字符了,我们可以绘制文本了。我们需要去写一个方法,给它一个字符串为输入,它通过递增位置来绘制出每个字符。为了做的更好,我们应该去实现新的行和制表符。是时候决定关于空终止符的问题了,如果你想让你的操作系统使用它们,可以按需来修改下面的代码。为避免这个问题,我将给 `DrawString` 函数传递一个字符串长度,以及字符串的地址,和 `x` 和 `y` 的坐标作为参数。
```
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
set x0 to x
for pos = 0 to length - 1
set char to loadByte(string + pos)
set (cwidth, cheight) to DrawCharacter(char, x, y)
if char = '\n' then
set x to x0
set y to y + cheight
otherwise if char = '\t' then
set x1 to x
until x1 > x0
set x1 to x1 + 5 × cwidth
loop
set x to x1
otherwise
set x to x + cwidth
end if
next
end function
```
同样,这个函数与汇编代码还有很大的差距。你可以随意去尝试实现它,即可以直接实现它,也可以简化它。我在下面给出了简化后的函数和汇编代码。
很明显,写这个函数的人并不很有效率(感到奇怪吗?它就是我写的)。再说一次,我们有一个 `pos` 变量,它用于递增及与其它东西相加,这是完全没有必要的。我们可以去掉它,而同时进行长度递减,直到减到 0 为止,这样就少用了一个寄存器。除了那个烦人的乘以 5 以外,函数的其余部分还不错。在这里要做的一个重要事情是,将乘法移到循环外面;即便使用位移运算,乘法仍然是很慢的,由于我们总是加一个乘以 5 的相同的常数,因此没有必要重新计算它。实际上,在汇编代码中它可以在一个操作数中通过参数移位来实现,因此我将代码改变为下面这样。
```
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
set x0 to x
until length = 0
set length to length - 1
set char to loadByte(string)
set (cwidth, cheight) to DrawCharacter(char, x, y)
if char = '\n' then
set x to x0
set y to y + cheight
otherwise if char = '\t' then
set x1 to x
set cwidth to cwidth + cwidth << 2
until x1 > x0
set x1 to x1 + cwidth
loop
set x to x1
otherwise
set x to x + cwidth
end if
set string to string + 1
loop
end function
```
以下是它的汇编代码:
```
.globl DrawString
DrawString:
x .req r4
y .req r5
x0 .req r6
string .req r7
length .req r8
char .req r9
push {r4,r5,r6,r7,r8,r9,lr}
mov string,r0
mov x,r2
mov x0,x
mov y,r3
mov length,r1
stringLoop$:
subs length,#1
blt stringLoopEnd$
ldrb char,[string]
add string,#1
mov r0,char
mov r1,x
mov r2,y
bl DrawCharacter
cwidth .req r0
cheight .req r1
teq char,#'\n'
moveq x,x0
addeq y,cheight
beq stringLoop$
teq char,#'\t'
addne x,cwidth
bne stringLoop$
add cwidth, cwidth,lsl #2
x1 .req r1
mov x1,x0
stringLoopTab$:
add x1,cwidth
cmp x,x1
bge stringLoopTab$
mov x,x1
.unreq x1
b stringLoop$
stringLoopEnd$:
.unreq cwidth
.unreq cheight
pop {r4,r5,r6,r7,r8,r9,pc}
.unreq x
.unreq y
.unreq x0
.unreq string
.unreq length
```
这个代码中非常聪明地使用了一个新运算,`subs` 是从一个操作数中减去另一个数,保存结果,然后将结果与 0 进行比较。实现上,所有的比较都可以实现为减法后的结果与 0 进行比较,但是结果通常会丢弃。这意味着这个操作与 `cmp` 一样快。
>
> `subs reg,#val` 从寄存器 `reg` 中减去 `val`,然后将结果与 `0` 进行比较。
>
>
>
### 4、你的意愿是我的命令行
现在,我们可以输出字符串了,而挑战是找到一个有意思的字符串去绘制。一般在这样的教程中,人们都希望去绘制 “Hello World!”,但是到目前为止,虽然我们已经能做到了,我觉得这有点“君临天下”的感觉(如果喜欢这种感觉,请随意!)。因此,作为替代,我们去继续绘制我们的命令行。
有一个限制是我们所做的操作系统是用在 ARM 架构的计算机上。最关键的是,在它们引导时,给它一些信息告诉它有哪些可用资源。几乎所有的处理器都有某些方式来确定这些信息,而在 ARM 上,它是通过位于地址 100<sub> 16</sub> 处的数据来确定的,这个数据的格式如下:
```
1. 数据是可分解的一系列的标签。
2. 这里有九种类型的标签:`core`、`mem`、`videotext`、`ramdisk`、`initrd2`、`serial`、`revision`、`videolfb`、`cmdline`。
3. 每个标签只能出现一次,除了 `core` 标签是必不可少的之外,其它的都是可有可无的。
4. 所有标签都依次放置在地址 `0x100` 处。
5. 标签列表的结束处总是有两个<ruby>字<rt>word</rt></ruby>,它们全为 0。
6. 每个标签的字节数都是 4 的倍数。
7. 每个标签都是以标签中(以字为单位)的标签大小开始(标签包含这个数字)。
8. 紧接着是包含标签编号的一个半字。编号是按上面列出的顺序,从 1 开始(`core` 是 1,`cmdline` 是 9)。
9. 紧接着是一个包含 5441<sub>16</sub> 的半字。
10. 之后是标签的数据,它根据标签不同是可变的。数据大小(以字为单位)+ 2 的和总是与前面提到的长度相同。
11. 一个 `core` 标签的长度可以是 2 个字也可以是 5 个字。如果是 2 个字,表示没有数据,如果是 5 个字,表示它有 3 个字的数据。
12. 一个 `mem` 标签总是 4 个字的长度。数据是内存块的第一个地址,和内存块的长度。
13. 一个 `cmdline` 标签包含一个 `null` 终止符字符串,它是个内核参数。
```
在目前的树莓派版本中,只提供了 `core`、`mem` 和 `cmdline` 标签。你可以在后面找到它们的用法,更全面的参考资料在树莓派的参考页面上。现在,我们感兴趣的是 `cmdline` 标签,因为它包含一个字符串。我们继续写一些搜索这个命令行(`cmdline`)标签的代码,如果找到了,以每个条目一个新行的形式输出它。命令行只是图形处理器或用户认为操作系统应该知道的东西的一个列表。在树莓派上,这包含了 MAC 地址、序列号和屏幕分辨率。字符串本身也是一个由空格隔开的表达式(像 `key.subkey=value` 这样的)的列表。
>
> 几乎所有的操作系统都支持一个“命令行”的程序。它的想法是为选择一个程序所期望的行为而提供一个通用的机制。
>
>
>
我们从查找 `cmdline` 标签开始。将下列的代码复制到一个名为 `tags.s` 的新文件中。
```
.section .data
tag_core: .int 0
tag_mem: .int 0
tag_videotext: .int 0
tag_ramdisk: .int 0
tag_initrd2: .int 0
tag_serial: .int 0
tag_revision: .int 0
tag_videolfb: .int 0
tag_cmdline: .int 0
```
通过标签列表来查找是一个很慢的操作,因为这涉及到许多内存访问。因此,我们只想做一次。代码创建一些数据,用于保存每个类型的第一个标签的内存地址。接下来,用下面的伪代码就可以找到一个标签了。
```
function FindTag(r0 is tag)
if tag > 9 or tag = 0 then return 0
set tagAddr to loadWord(tag_core + (tag - 1) × 4)
if not tagAddr = 0 then return tagAddr
if readWord(tag_core) = 0 then return 0
set tagAddr to 0x100
loop forever
set tagIndex to readHalfWord(tagAddr + 4)
if tagIndex = 0 then return FindTag(tag)
if readWord(tag_core+(tagIndex-1)×4) = 0
then storeWord(tagAddr, tag_core+(tagIndex-1)×4)
set tagAddr to tagAddr + loadWord(tagAddr) × 4
end loop
end function
```
这段代码已经是优化过的,并且很接近汇编了。它尝试直接加载标签,第一次这样做是有些乐观的,但是除了第一次之外的其它所有情况都是可以这样做的。如果失败了,它将去检查 `core` 标签是否有地址。因为 `core` 标签是必不可少的,如果它没有地址,唯一可能的原因就是它不存在。如果它有地址,那就是我们没有找到我们要找的标签。如果没有找到,那我们就需要查找所有标签的地址。这是通过读取标签编号来做的。如果标签编号为 0,意味着已经到了标签列表的结束位置。这意味着我们已经查找了目录中所有的标签。所以,如果我们再次运行我们的函数,现在它应该能够给出一个答案。如果标签编号不为 0,我们检查这个标签类型是否已经有一个地址。如果没有,我们在目录中保存这个标签的地址。然后增加这个标签的长度(以字节为单位)到标签地址中,然后去查找下一个标签。
尝试去用汇编实现这段代码。你将需要简化它。如果被卡住了,下面是我的答案。不要忘了 `.section .text`!
```
.section .text
.globl FindTag
FindTag:
tag .req r0
tagList .req r1
tagAddr .req r2
sub tag,#1
cmp tag,#8
movhi tag,#0
movhi pc,lr
ldr tagList,=tag_core
tagReturn$:
add tagAddr,tagList, tag,lsl #2
ldr tagAddr,[tagAddr]
teq tagAddr,#0
movne r0,tagAddr
movne pc,lr
ldr tagAddr,[tagList]
teq tagAddr,#0
movne r0,#0
movne pc,lr
mov tagAddr,#0x100
push {r4}
tagIndex .req r3
oldAddr .req r4
tagLoop$:
ldrh tagIndex,[tagAddr,#4]
subs tagIndex,#1
poplt {r4}
blt tagReturn$
add tagIndex,tagList, tagIndex,lsl #2
ldr oldAddr,[tagIndex]
teq oldAddr,#0
.unreq oldAddr
streq tagAddr,[tagIndex]
ldr tagIndex,[tagAddr]
add tagAddr, tagIndex,lsl #2
b tagLoop$
.unreq tag
.unreq tagList
.unreq tagAddr
.unreq tagIndex
```
### 5、Hello World
现在,我们已经万事俱备了,我们可以去绘制我们的第一个字符串了。在 `main.s` 文件中删除 `bl SetGraphicsAddress` 之后的所有代码,然后将下面的代码放进去:
```
mov r0,#9
bl FindTag
ldr r1,[r0]
lsl r1,#2
sub r1,#8
add r0,#8
mov r2,#0
mov r3,#0
bl DrawString
loop$:
b loop$
```
这段代码简单地使用了我们的 `FindTag` 方法去查找第 9 个标签(`cmdline`),然后计算它的长度,然后传递命令和长度给 `DrawString` 方法,告诉它在 `0,0` 处绘制字符串。现在可以在树莓派上测试它了。你应该会在屏幕上看到一行文本。如果没有,请查看我们的排错页面。
如果一切正常,恭喜你已经能够绘制文本了。但它还有很大的改进空间。如果想去写了一个数字,或内存的一部分,或操作我们的命令行,该怎么做呢?在 [课程 9:屏幕04](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html) 中,我们将学习如何操作文本和显示有用的数字和信息。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html>
作者:[Alex Chadwick](https://www.cl.cam.ac.uk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 8 Screen03
The Screen03 lesson builds on Screen02, by teaching how to draw text, and also a
small feature on the command line arguments of the operating system. It is assumed
you have the code for the [Lesson 7: Screen02](screen02.html) operating
system as a basis.
## 1 String Theory
So, our task for this operating system is to draw text. We have several problems to address, the most pressing of which is probably about storing text. Unbelievably text has been one of the biggest flaws on computers to date. What should have been a straightforward type of data has brought down operating systems, crippled otherwise wonderful encryption, and caused many problems for users of different alphabets. Nevertheless, it is an incredibly important type of data, as it is an excellent link between the computer and the user. Text can be sufficiently structured that the operating system understands it, as well as sufficiently readable that humans can use it.
Variable data types such as text require much more complex handling.
So how exactly is text stored? Simply enough, we have some system by which we give each letter a unique number, and then store a sequence of such numbers. Sounds easy. The problem is that the number of numbers is not fixed. Some pieces of text are longer than others. With storing ordinary numbers, we have some fixed limit, e.g. 32 bits, and then we can't go beyond that, we write methods that use numbers of that length, etc. In terms of text, or strings as we often call it, we want to write functions that work on variable length strings, otherwise we would need a lot of functions! This is not a problem for numbers normally, as there are only a few common number formats (byte, word, half, double).
Buffer overrun attacks have plagued computers for years. Recently, the Wii, Xbox and Playstation 2 all suffered buffer overrun attacks, as well as large systems like Microsoft's Web and Database servers.
So, how do we determine how long the string is? I think the obvious answer is just to store how long the string is, and then to store the characters that make it up. This is called length prefixing, as the length comes before the string. Unfortunately, the pioneers of computer science did not agree. They felt it made more sense to have a special character called the null terminator (denoted \0) which represents when a string ends. This does indeed simplify many string algorithms, as you just keep working until the null terminator. Unfortunately this is the source of many security issues. What if a malicious user gives you a very long string? What if you didn't have enough space to store it. You might run a string copying function that copies until the null terminator, but because the string is so long, it overwrites your program. This may sound far fetched, but nevertheless, such buffer overrun attacks are incredibly common. Length prefixing mitigates this problem as it is easy to deduce the size of the buffer required to store the string. As an operating system developer, I leave it to you to decide how best to store text.
The next thing we need to establish is how best to map characters to numbers. Fortunately, this is reasonably well standardised, so you have two major choices, Unicode and ASCII. Unicode maps almost every single useful symbol that can be written to a number, in exchange for having a lot more numbers, and a more complicated encoding system. ASCII uses one byte per character, and so only stores the Latin alphabet, numbers, a few symbols and a few special characters. Thus, ASCII is very easy to implement, compared to Unicode, in which not every character takes the same space, making string algorithms tricky. Normally operating systems use ASCII for strings which will not be displayed to end users (but perhaps to developers or experts), and Unicode for displaying messages to users, as Unicode can support things like Japanese characters, and so could be localised.
Fortunately for us, this decision is irrelevant at the moment, as the first 128 characters of both are exactly the same, and are encoded exactly the same.
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
00 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
10 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
20 | ! | " | # | $ | % | & | . | ( | ) | * | + | , | - | . | / | |
30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
The table shows the first 128 symbols. The hexadecimal representation of the number
for a symbol is the row value added to the column value, for example A is 4116.
What you may find surprising is the first two rows, and the very last value. These
33 special characters are not printed at all. In fact, these days, many are ignored.
They exist because ASCII was originally intended as a system for transmitting data over
computer networks, and so a lot more information than just the symbols had
to be sent. The key special symbols that you should learn are NUL, the null terminator
character I mentioned before, HT, horizontal tab is what we normally refer to as
a tab and LF, the line feed character is used to make a new line. You may wish to
research and use the other characters for special meanings in your operating system.
## 2 Characters
So, now that we know a bit about strings, we can start to think about how they're displayed. The fundamental thing we need to do in order to be able to display a string is to be able to display a character. Our first task will be making a DrawCharacter function which takes in a character to draw and a location, and then draws the character.
The true type font format used in many Operating Systems is so powerful, it has its own assembly language built in to ensure letters look correct at any resolution.
Naturally, this leads to a discussion about fonts. We already know there are many ways to display any given letter in accordance with font choice. So how does a font work? In the very early days of computer science, a font was just a series of little pictures of all the letters, called a bitmap font, and all the draw character method would do is copy one of the pictures to the screen. The trouble with this is when people want to resize the text. Sometimes we need big letters, and sometimes small. Although we could keep drawing new pictures for every font at every size with every character, this would get tedious. Thus, vector fonts were invented. in vector fonts, rather than containing an image of the font, the font file contains a description of how to draw it, e.g. an 'o' could be circle with radius half that of the maximum letter height. Modern operating systems use such fonts almost exclusively, as they are perfect at any resolution.
Unfortunately, much though I would love to include an implementation of one of the vector font formats, it would take up the remainder of this website. Thus, we will implement a bitmap font, though if you wish to make a decent graphical operating system, a vector font would be useful.
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
On the downloads page, I have included several '.bin' files in the font section. These are just raw binary data files for a few fonts. For this tutorial, pick your favourite from the monospace, monochrome, 8x16 section. Download it and store it in the 'source' directory as 'font.bin'. These files are just monochrome images of each of the letters in turn, with each letter being exactly 8 by 16 pixels. Thus, each takes 16 bytes, the first byte being the top row, the second the next, etc.
The diagram shows the 'A' character in the monospace, monochrome, 8x16 font Bitstream
Vera Sans Mono. In the file, we would find this starting at the 4116
× 1016 = 41016th byte as the following sequence in hexadecimal:
00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
We're going to use a monospace font here, because in a monospace font every character is the same size. Unfortunately, yet another complication with most fonts is that the character's widths vary, leading to more complex display code. I've included a few other fonts on the downloads page, as well as an explanation of the format I've stored them all in.
So let's get down to business. Copy the following to 'drawing.s' after the .int 0 of graphicsAddress.
.align 4
font:
.incbin "font.bin"
.incbin "file" inserts the binary data from the file file.
This code copies the font data from the file to the address labelled font. We've used an .align 4 here to ensure each character starts on a multiple of 16 bytes, which can be used for a speed trick later.
Now we want to write the draw character method. I'll give the pseudo code for this, so you can try to implement it yourself if you want to. Conventionally >> means logical shift right.
function drawCharacter(r0 is
character, r1 is x, r2 is
y)
if character > 127 then exit
set charAddress to font
+ character × 16
for row = 0 to 15
set bits to readByte(charAddress
+ row)
for bit = 0 to 7
if test(bits >> bit, 0x1)
then setPixel(x + bit, y + row)
next
next
return r0 = 8, r1 = 16
end function
If implemented directly, this is deliberately not very efficient. With things like drawing characters, efficiency is a top priority, as we will do it a lot. Let's explore some improvements that bring this closer to optimal assembly code. Firstly, we have a × 16, which by now you should spot is the same as a logical shift left by 4 places. Next we have a variable row, which is only ever added to charAddress and to y. Thus, we can eliminate it by increasing these variables instead. The only issue now is how to tell when we've finished. This is where the .align 4 comes in handy. We know that charAddress will start with the low nibble containing 0. This means we can see how far into the character data we are by checking that low nibble.
Though we can eliminate the need for bits, we must introduce a new variable to do so, so it is best left in. The only other improvement that can be made is to remove the nested bits >> bit.
function drawCharacter(r0 is
character, r1 is x, r2 is
y)
if character > 127 then exit
set charAddress to font
+ character << 4
loop
set bits to readByte(charAddress)
set bit to 8
loop
set bits to bits <<
1
set bit to bit - 1
if test(bits, 0x100)
then setPixel(x + bit, y)
until bit = 0
set y to y + 1
set chadAddress to chadAddress
+ 1
until charAddress AND
0b1111 = 0
return r0 = 8, r1 = 16
end function
Now we've got code that is much closer to assembly code, and is near optimal. Below is the assembly code version of the above.
.globl DrawCharacter
DrawCharacter:
cmp r0,#127
movhi r0,#0
movhi r1,#0
movhi pc,lr
push {r4,r5,r6,r7,r8,lr}
x .req r4
y .req r5
charAddr .req r6
mov x,r1
mov y,r2
ldr charAddr,=font
add charAddr, r0,lsl #4
lineLoop$:
bits .req r7
bit .req r8
ldrb bits,[charAddr]
mov bit,#8
charPixelLoop$:
subs bit,#1
blt charPixelLoopEnd$
lsl bits,#1
tst bits,#0x100
beq charPixelLoop$
add r0,x,bit
mov r1,y
bl DrawPixel
teq bit,#0
bne charPixelLoop$
charPixelLoopEnd$:
.unreq bit
.unreq bits
add y,#1
add charAddr,#1
tst charAddr,#0b1111
bne lineLoop$
.unreq x
.unreq y
.unreq charAddr
width .req r0
height .req r1
mov width,#8
mov height,#16
pop {r4,r5,r6,r7,r8,pc}
.unreq width
.unreq height
## 3 Strings
Now that we can draw characters, we can draw text. We need to make a method that, for a given string, draws each character in turn, at incrementing positions. To be nice, we shall also implement new lines and tabs. It's decision time as far as null terminators are concerned, and if you want to make your operating system use them, feel free by changing the code below. To avoid the issue, I will have the length of the string passed as an argument to the DrawString function, along with the address of the string, and the x and y coordinates.
function drawString(r0 is
string, r1 is length, r2 is
x, r3 is y)
set x0 to x
for pos = 0 to length
- 1
set char to loadByte(string
+ pos)
set (cwidth, cheight) to
DrawCharacter(char, x, y)
if char = '\n' then /* \n is short hand for the character LF */
set x to x0
set y to y + cheight
otherwise if char = '\t' then
/* \t is short hand for the character HT */
set x1 to x
until x1 > x0
set x1 to x1 + 5 ×
cwidth
loop
set x to x1
otherwise
set x to x + cwidth
end if
next
end function
Once again, this function isn't that close to assembly code. Feel free to try to implement it either directly or by simplifying it. I will give the simplification and then the assembly code below.
Clearly the person who wrote this function wasn't being very efficient (me in case you were wondering). Once again we have a pos variable that just increments and is added to something else, which is completely unnecessary. We can remove it, and instead simultaneously decrement length until it is 0, saving the need for one register. The rest of the function is probably fine, except for that annoying multiplication by five. A key thing to do here would be to move the multiplication outside the loop; multiplication is slow even with bit shifts, and since we're always adding the same constant multiplied by 5, there is no need to recompute this. It can in fact be implemented in one operation using the argument shifting in assembly code, so I shall rephrase it like that.
function drawString(r0 is
string, r1 is length, r2 is
x, r3 is y)
set x0 to x
until length = 0
set length to length -
1
set char to loadByte(string)
set (cwidth, cheight) to
DrawCharacter(char, x, y)
if char = '\n' then
set x to x0
set y to y + cheight
otherwise if char = '\t' then
set x1 to x
set cwidth to cwidth +
cwidth << 2
until x1 > x0
set x1 to x1 + cwidth
loop
set x to x1
otherwise
set x to x + cwidth
end if
set string to string +
1
loop
end function
In assembly code:
.globl DrawString
DrawString:
x .req r4
y .req r5
x0 .req r6
string .req r7
length .req r8
char .req r9
push {r4,r5,r6,r7,r8,r9,lr}
mov string,r0
mov x,r2
mov x0,x
mov y,r3
mov length,r1
stringLoop$:
subs length,#1
blt stringLoopEnd$
ldrb char,[string]
add string,#1
mov r0,char
mov r1,x
mov r2,y
bl DrawCharacter
cwidth .req r0
cheight .req r1
teq char,#'\n'
moveq x,x0
addeq y,cheight
beq stringLoop$
teq char,#'\t'
addne x,cwidth
bne stringLoop$
add cwidth, cwidth,lsl #2
x1 .req r1
mov x1,x0
stringLoopTab$:
add x1,cwidth
cmp x,x1
bge stringLoopTab$
mov x,x1
.unreq x1
b stringLoop$
stringLoopEnd$:
.unreq cwidth
.unreq cheight
pop {r4,r5,r6,r7,r8,r9,pc}
.unreq x
.unreq y
.unreq x0
.unreq string
.unreq length
subs reg,#val subtracts val from the register reg and compares the result with 0.
This code makes clever use of a new operation, subs which subtracts one number from another, stores the result and then compares it with 0. In truth, all comparisons are implemented as a subtraction and then comparison with 0, but the result is normally discarded. This means that this operation is as fast as cmp.
## 4 Your Wish is My Command Line
Now that we can print strings, the challenge is to find an interesting one to draw. Normally in tutorials such as this, people just draw "Hello World!", but after all we've done so far, I feel that is a little patronising (feel free to do so if it helps). Instead we're going to draw our command line.
A convention has been made for computers running ARM. When they boot, it is important
they are given certain information about what they have available to them. Most
all processors have some way of ascertaining this information, and on ARM this is
by data left at the address 10016. The format of the data is as follows:
- The data is broken down into a series of 'tags'.
- There are nine types of tag: 'core', 'mem', 'videotext', 'ramdisk', 'initrd2', 'serial' 'revision', 'videolfb', 'cmdline'.
- Each can only appear once, but all but the 'core' tag don't have to appear.
- The tags are placed from 0x100 in order one after the other.
- The end of the list of tags always contains 2 words which are 0.
- Every tag's size in bytes is a multiple of 4.
- Each tag starts with the size of the tag in words in the tag, including this number.
- This is followed by a half word containing the tag's number. These are numbered from 1 in the order above ('core' is 1, 'cmdline' is 9).
- This is followed by a half word containing 5441
16. - After this comes the data of the tag, which varies depending on the tag. The size of the data in words + 2 is always the same as the length mentioned above.
- A 'core' tag is either 2 or 5 words in length. If it is 2, there is no data, if it is 5, it has 3 words.
- A 'mem' tag is always 4 words in length. The data is the first address in a block of memory, and the length of that block.
- A 'cmdline' tag contains a null terminated string which is the parameters of the kernel.
Almost all Operating Systems support the notion of programs having a 'command line'. The idea is to provide a common mechanism for choosing the desired behaviour of the program.
On the current version of the Raspberry Pi, only the 'core', 'mem' and 'cmdline' tags are present. You may find these useful later, and a more complete reference for these is on our Raspberry Pi reference page. The one we're interested in at the moment is the 'cmdline' tag, because it contains a string. We're going to write some code to search for the command line tag, and, if found, to print it out with each item on a new line. The command line is just a list of things that either the graphics processor or the user thought it might be nice for the Operating System to know. On the Raspberry Pi, this includes the MAC Address, serial number and screen resolution. The string itself is just a list of expressions such as 'key.subkey=value' separated by spaces.
Let's start by finding the 'cmdline' tag. In a new file called 'tags.s' copy the following code.
.section .data
tag_core: .int 0
tag_mem: .int 0
tag_videotext: .int 0
tag_ramdisk: .int 0
tag_initrd2: .int 0
tag_serial: .int 0
tag_revision: .int 0
tag_videolfb: .int 0
tag_cmdline: .int 0
Looking through the list of tags will be a slow operation, as it involves a lot of memory access. Therefore, we only want to have to do it once. This code creates some data which will store the memory address of the first tag of each of the types. Then, to find a tag the following pseudo code will suffice.
function FindTag(r0 is tag)
if tag > 9 or tag =
0 then return 0
set tagAddr to loadWord(tag_core
+ (tag - 1) × 4)
if not tagAddr = 0 then return
tagAddr
if readWord(tag_core) = 0 then return
0
set tagAddr to 0x100
loop forever
set tagIndex to readHalfWord(tagAddr
+ 4)
if tagIndex = 0 then return
FindTag(tag)
if readWord(tag_core+(tagIndex-1)×4) = 0
then storeWord(tagAddr, tag_core+(tagIndex-1)×4)
set tagAddr to tagAddr
+ loadWord(tagAddr) × 4
end loop
end function
This code is already quite well optimised and close to assembly. It is optimistic in that the first thing it tries is loading the tag directly, as all but the first time this should be the case. If that fails, it checks if the core tag has an address. Since there must always be a core tag, the only reason that it would not have an address is if it doesn't exist. If it does have an address, the tag we were looking for didn't. If it doesn't we need to find the addresses of all the tags. It does this by reading the number of the tag. If it is zero, that must mean we are at the end of the list. This means we've now filled in all the tags in our directory. Therefore if we run our function again, it will now be able to produce an answer. If the tag number is not zero, we check to see if this tag type already has an address. If not, we store the address of this tag in our directory. We then add the length of this tag in bytes to the tag address to find the next tag.
Have a go at implementing this code in assembly. You will need to simplify it. If you get stuck, my answer is below. Don't forget the .section .text!
.section .text
.globl FindTag
FindTag:
tag .req r0
tagList .req r1
tagAddr .req r2
sub tag,#1
cmp tag,#8
movhi tag,#0
movhi pc,lr
ldr tagList,=tag_core
tagReturn$:
add tagAddr,tagList, tag,lsl #2
ldr tagAddr,[tagAddr]
teq tagAddr,#0
movne r0,tagAddr
movne pc,lr
ldr tagAddr,[tagList]
teq tagAddr,#0
movne r0,#0
movne pc,lr
mov tagAddr,#0x100
push {r4}
tagIndex .req r3
oldAddr .req r4
tagLoop$:
ldrh tagIndex,[tagAddr,#4]
subs tagIndex,#1
poplt {r4}
blt tagReturn$
add tagIndex,tagList, tagIndex,lsl #2
ldr oldAddr,[tagIndex]
teq oldAddr,#0
.unreq oldAddr
streq tagAddr,[tagIndex]
ldr tagIndex,[tagAddr]
add tagAddr, tagIndex,lsl #2
b tagLoop$
.unreq tag
.unreq tagList
.unreq tagAddr
.unreq tagIndex
## 5 Hello World
Now that we have everything we need, we can draw our first string. In 'main.s' delete everything after bl SetGraphicsAddress, and replace it with the following:
mov r0,#9
bl FindTag
ldr r1,[r0]
lsl r1,#2
sub r1,#8
add r0,#8
mov r2,#0
mov r3,#0
bl DrawString
loop$:
b loop$
This code simply uses our FindTag method to find the 9th tag (cmdline) and then calculates its length and passes the command and the length to the DrawString method, and tells it to draw the string at 0,0. Now test this on the Raspberry Pi. You should see a line of text on the screen. If not please see our troubleshooting page.
Once it works, congratulations you've now got the ability to draw text. But there
is still room for improvement. What if we wanted to write out a number, or a section
of the memory or manipulate our command line? In [Lesson 9: Screen04](screen04.html),
we will look at manipulating text and displaying useful numbers and information. |
10,586 | 在 Firefox 上使用 Org 协议捕获 URL | http://www.mediaonfire.com/blog/2017_07_21_org_protocol_firefox.html | 2019-03-04T01:35:46 | [
"Emacs",
"Org模式"
] | https://linux.cn/article-10586-1.html | 
### 介绍
作为一名 Emacs 人,我尽可能让所有的工作流都在 <ruby> <a href="http://orgmode.org/"> Org 模式 </a> <rt> Org-mode </rt></ruby> 上进行 —— 我比较喜欢文本。
我倾向于将书签记录在 [Org 模式](http://orgmode.org/) 代办列表中,而 <ruby> <a href="http://orgmode.org/worg/org-contrib/org-protocol.html"> Org 协议 </a> <rt> Org-protocol </rt></ruby> 则允许外部进程利用 [Org 模式](http://orgmode.org/) 的某些功能。然而,要做到这一点配置起来很麻烦。([搜索引擎上](https://duckduckgo.com/?q=org-protocol+firefox&t=ffab&ia=qa))有很多教程,Firefox 也有这类 [扩展](https://addons.mozilla.org/en-US/firefox/search/?q=org-protocol&cat=1,0&appver=53.0&platform=linux),然而我对它们都不太满意。
因此我决定将我现在的配置记录在这篇博客中,方便其他有需要的人使用。
### 配置 Emacs Org 模式
启用 Org 协议:
```
(require 'org-protocol)
```
添加一个<ruby> 捕获模板 <rt> capture template </rt></ruby> —— 我的配置是这样的:
```
(setq org-capture-templates
(quote (...
("w" "org-protocol" entry (file "~/org/refile.org")
"* TODO Review %a\n%U\n%:initial\n" :immediate-finish)
...)))
```
你可以从 [Org 模式](http://orgmode.org/) 手册中 [捕获模板](http://orgmode.org/manual/Capture-templates.html) 章节中获取帮助。
设置默认使用的模板:
```
(setq org-protocol-default-template-key "w")
```
执行这些新增配置让它们在当前 Emacs 会话中生效。
### 快速测试
在下一步开始前,最好测试一下配置:
```
emacsclient -n "org-protocol:///capture?url=http%3a%2f%2fduckduckgo%2ecom&title=DuckDuckGo"
```
基于的配置的模板,可能会弹出一个捕获窗口。请确保正常工作,否则后面的操作没有任何意义。如果工作不正常,检查刚才的配置并且确保你执行了这些代码块。
如果你的 [Org 模式](http://orgmode.org/) 版本比较老(老于 7 版本),测试的格式会有点不同:这种 URL 编码后的格式需要改成用斜杠来分割 url 和标题。在网上搜一下很容易找出这两者的不同。
### Firefox 协议
现在开始设置 Firefox。浏览 `about:config`。右击配置项列表,选择 “New -> Boolean”,然后输入 `network.protocol-handler.expose.org-protocol` 作为名字并且将值设置为 `true`。
有些教程说这一步是可以省略的 —— 配不配因人而异。
### 添加 Desktop 文件
大多数的教程都有这一步:
增加一个文件 `~/.local/share/applications/org-protocol.desktop`:
```
[Desktop Entry]
Name=org-protocol
Exec=/path/to/emacsclient -n %u
Type=Application
Terminal=false
Categories=System;
MimeType=x-scheme-handler/org-protocol;
```
然后运行更新器。对于 i3 窗口管理器我使用下面命令(跟 gnome 一样):
```
update-desktop-database ~/.local/share/applications/
```
KDE 的方法不太一样……你可以查询其他相关教程。
### 在 FireFox 中设置捕获按钮
创建一个书签(我是在工具栏上创建这个书签的),地址栏输入下面内容:
```
javascript:location.href="org-protocol:///capture?url="+encodeURIComponent(location.href)+"&title="+encodeURIComponent(document.title||"[untitled page]")
```
保存该书签后,再次编辑该书签,你应该会看到其中的所有空格都被替换成了 `%20` —— 也就是空格的 URL 编码形式。
现在当你点击该书签,你就会在某个 Emacs 框架中,可能是一个任意的框架中,打开一个窗口,显示你预定的模板。
---
via: <http://www.mediaonfire.com/blog/2017_07_21_org_protocol_firefox.html>
作者:[Andreas Viklund](http://andreasviklund.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,587 | Linux 中的 & | https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux | 2019-03-04T01:49:50 | [
"命令行"
] | https://linux.cn/article-10587-1.html |
>
> 这篇文章将了解一下 & 符号及它在 Linux 命令行中的各种用法。
>
>
>

如果阅读过我之前的三篇文章([1](/article-10465-1.html)、[2](/article-10502-1.html)、[3](/article-10529-1.html)),你会觉得掌握连接各个命令之间的连接符号用法也是很重要的。实际上,命令的用法并不难,例如 `mkdir`、`touch` 和 `find` 也分别可以简单概括为“建立新目录”、“更新文件”和“在目录树中查找文件”而已。
但如果要理解
```
mkdir test_dir 2>/dev/null || touch images.txt && find . -iname "*jpg" > backup/dir/images.txt &
```
这一串命令的目的,以及为什么要这样写,就没有这么简单了。
关键之处就在于命令之间的连接符号。掌握了这些符号的用法,不仅可以让你更好理解整体的工作原理,还可以让你知道如何将不同的命令有效地结合起来,提高工作效率。
在这一篇文章和接下来的文章中,我会介绍如何使用 `&` 号和管道符号(`|`)在不同场景下的使用方法。
### 幕后工作
我来举一个简单的例子,看看如何使用 `&` 号将下面这个命令放到后台运行:
```
cp -R original/dir/ backup/dir/
```
这个命令的目的是将 `original/dir/` 的内容递归地复制到 `backup/dir/` 中。虽然看起来很简单,但是如果原目录里面的文件太大,在执行过程中终端就会一直被卡住。
所以,可以在命令的末尾加上一个 `&` 号,将这个任务放到后台去执行:
```
cp -R original/dir/ backup/dir/ &
```
任务被放到后台执行之后,就可以立即继续在同一个终端上工作了,甚至关闭终端也不影响这个任务的正常执行。需要注意的是,如果要求这个任务输出内容到标准输出中(例如 `echo` 或 `ls`),即使使用了 `&`,也会等待这些输出任务在前台运行完毕。
当使用 `&` 将一个进程放置到后台运行的时候,Bash 会提示这个进程的进程 ID。在 Linux 系统中运行的每一个进程都有一个唯一的进程 ID,你可以使用进程 ID 来暂停、恢复或者终止对应的进程,因此进程 ID 是非常重要的。
这个时候,只要你还停留在启动进程的终端当中,就可以使用以下几个命令来对管理后台进程:
* `jobs` 命令可以显示当前终端正在运行的进程,包括前台运行和后台运行的进程。它对每个正在执行中的进程任务分配了一个序号(这个序号不是进程 ID),可以使用这些序号来引用各个进程任务。
```
$ jobs
[1]- Running cp -i -R original/dir/* backup/dir/ &
[2]+ Running find . -iname "*jpg" > backup/dir/images.txt &
```
* `fg` 命令可以将后台运行的进程任务放到前台运行,这样可以比较方便地进行交互。根据 `jobs` 命令提供的进程任务序号,再在前面加上 `%` 符号,就可以把相应的进程任务放到前台运行。
```
$ fg %1 # 将上面序号为 1 的 cp 任务放到前台运行
cp -i -R original/dir/* backup/dir/
```
如果这个进程任务是暂停状态,`fg` 命令会将它启动起来。
* 使用 `ctrl+z` 组合键可以将前台运行的任务暂停,仅仅是暂停,而不是将任务终止。当使用 `fg` 或者 `bg` 命令将任务重新启动起来的时候,任务会从被暂停的位置开始执行。但 [sleep](https://ss64.com/bash/sleep.html) 命令是一个特例,`sleep` 任务被暂停的时间会计算在 `sleep` 时间之内。因为 `sleep` 命令依据的是系统时钟的时间,而不是实际运行的时间。也就是说,如果运行了 `sleep 30`,然后将任务暂停 30 秒以上,那么任务恢复执行的时候会立即终止并退出。
* `bg` 命令会将任务放置到后台执行,如果任务是暂停状态,也会被启动起来。
```
$ bg %1
[1]+ cp -i -R original/dir/* backup/dir/ &
```
如上所述,以上几个命令只能在同一个终端里才能使用。如果启动进程任务的终端被关闭了,或者切换到了另一个终端,以上几个命令就无法使用了。
如果要在另一个终端管理后台进程,就需要其它工具了。例如可以使用 [kill](https://bash.cyberciti.biz/guide/Sending_signal_to_Processes) 命令从另一个终端终止某个进程:
```
kill -s STOP <PID>
```
这里的 PID 就是使用 `&` 将进程放到后台时 Bash 显示的那个进程 ID。如果你当时没有把进程 ID 记录下来,也可以使用 `ps` 命令(代表 process)来获取所有正在运行的进程的进程 ID,就像这样:
```
ps | grep cp
```
执行以后会显示出包含 `cp` 字符串的所有进程,例如上面例子中的 `cp` 进程。同时还会显示出对应的进程 ID:
```
$ ps | grep cp
14444 pts/3 00:00:13 cp
```
在这个例子中,进程 ID 是 14444,因此可以使用以下命令来暂停这个后台进程:
```
kill -s STOP 14444
```
注意,这里的 `STOP` 等同于前面提到的 `ctrl+z` 组合键的效果,也就是仅仅把进程暂停掉。
如果想要把暂停了的进程启动起来,可以对进程发出 `CONT` 信号:
```
kill -s CONT 14444
```
这个给出一个[可以向进程发出的常用信号](https://www.computerhope.com/unix/signals.htm)列表。如果想要终止一个进程,可以发送 `TERM` 信号:
```
kill -s TERM 14444
```
如果进程不响应 `TERM` 信号并拒绝退出,还可以发送 `KILL` 信号强制终止进程:
```
kill -s KILL 14444
```
强制终止进程可能会有一定的风险,但如果遇到进程无节制消耗资源的情况,这样的信号还是能够派上用场的。
另外,如果你不确定进程 ID 是否正确,可以在 `ps` 命令中加上 `x` 参数:
```
$ ps x| grep cp
14444 pts/3 D 0:14 cp -i -R original/dir/Hols_2014.mp4
original/dir/Hols_2015.mp4 original/dir/Hols_2016.mp4
original/dir/Hols_2017.mp4 original/dir/Hols_2018.mp4 backup/dir/
```
这样就可以看到是不是你需要的进程 ID 了。
最后介绍一个将 `ps` 和 `grep` 结合到一起的命令:
```
$ pgrep cp
8
18
19
26
33
40
47
54
61
72
88
96
136
339
6680
13735
14444
```
`pgrep` 可以直接将带有字符串 `cp` 的进程的进程 ID 显示出来。
可以加上一些参数让它的输出更清晰:
```
$ pgrep -lx cp
14444 cp
```
在这里,`-l` 参数会让 `pgrep` 将进程的名称显示出来,`-x` 参数则是让 `pgrep` 完全匹配 `cp` 这个命令。如果还想了解这个命令的更多细节,可以尝试运行 `pgrep -ax`。
### 总结
在命令的末尾加上 `&` 可以让我们理解前台进程和后台进程的概念,以及如何管理这些进程。
在 UNIX/Linux 术语中,在后台运行的进程被称为<ruby> 守护进程 <rt> daemon </rt></ruby>。如果你曾经听说过这个词,那你现在应该知道它的意义了。
和其它符号一样,`&` 在命令行中还有很多别的用法。在下一篇文章中,我会更详细地介绍。
---
via: <https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,588 | FinalCrypt:一个开源文件加密应用 | https://itsfoss.com/finalcrypt/ | 2019-03-05T00:19:02 | [
"FinalCrypt",
"加密"
] | https://linux.cn/article-10588-1.html | 我通常不会加密文件,但如果我打算整理我的重要文件或凭证,加密程序就会派上用场。
你可能已经在使用像 [GnuPG](https://www.gnupg.org/) 这样的程序来帮助你加密/解密 Linux 上的文件。还有 [EncryptPad](https://itsfoss.com/encryptpad-encrypted-text-editor-linux/) 也可以加密你的笔记。
但是,我看到了一个名为 FinalCrypt 的新的免费开源加密工具。你可以在 [GitHub 页面](https://github.com/ron-from-nl/FinalCrypt)上查看其最新的版本和源码。
在本文中,我将分享使用此工具的经验。请注意,我不会将它与其他程序进行比较 —— 因此,如果你想要多个程序之间的详细比较,请在评论中告诉我们。

### 使用 FinalCrypt 加密文件
FinalCrypt 使用[一次性密码本](https://en.wikipedia.org/wiki/One-time_pad)密钥生成密码来加密文件。换句话说,它会生成一个 OTP 密钥,你将使用该密钥加密或解密你的文件。
根据你指定的密钥大小,密钥是完全随机的。因此,没有密钥文件就无法解密文件。
虽然 OTP 密钥用于加密/解密简单而有效,但管理或保护密钥文件对某些人来说可能是不方便的。
如果要使用 FinalCrypt,可以从它的网站下载 DEB/RPM 文件。FinalCrypt 也可用于 Windows 和 macOS。
* [下载 FinalCrypt](https://sites.google.com/site/ronuitholland/home/finalcrypt)
下载后,只需双击该 [deb](https://itsfoss.com/install-deb-files-ubuntu/) 或 rpm 文件就能安装。如果需要,你还可以从源码编译。
### 使用 FileCrypt
该视频演示了如何使用FinalCrypt:
安装 FinalCrypt 后,你将在已安装的应用列表中找到它。从这里启动它。
启动后,你将看到(分割的)两栏,一个进行加密/解密,另一个选择 OTP 文件。

首先,你必须生成 OTP 密钥。下面是做法:

请注意你的文件名可以是任何内容 —— 但你需要确保密钥文件的大小大于或等于要加密的文件。我觉得这很荒谬,但事实就是如此。

生成文件后,选择窗口右侧的密钥,然后选择要在窗口左侧加密的文件。
生成 OTP 后,你会看到高亮显示的校验和、密钥文件大小和有效状态:

选择之后,你只需要点击 “Encrypt” 来加密这些文件,如果已经加密,那么点击 “Decrypt” 来解密这些文件。

你还可以在命令行中使用 FinalCrypt 来自动执行加密作业。
#### 如何保护你的 OTP 密钥?
加密/解密你想要保护的文件很容易。但是,你应该在哪里保存你的 OTP 密钥?
如果你未能将 OTP 密钥保存在安全的地方,那么它几乎没用。
嗯,最好的方法之一是使用专门的 USB 盘保存你的密钥。只需要在解密文件时将它插入即可。
除此之外,如果你认为足够安全,你可以将密钥保存在[云服务](https://itsfoss.com/cloud-services-linux/)中。
有关 FinalCrypt 的更多信息,请访问它的网站:[FinalCrypt](https://sites.google.com/site/ronuitholland/home/finalcrypt)
### 总结
它开始时看上去有点复杂,但它实际上是 Linux 中一个简单且用户友好的加密程序。如果你想看看其他的,还有一些其他的[加密保护文件夹](https://itsfoss.com/password-protect-folder-linux/)的程序。
你如何看待 FinalCrypt?你还知道其他类似可能更好的程序么?请在评论区告诉我们,我们将会查看的!
---
via: <https://itsfoss.com/finalcrypt/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I usually don’t encrypt files – but if I am planning to organize my important documents or credentials, an encryption program would come in handy.
You may be already using a program like [GnuPG](https://www.gnupg.org/) that helps you encrypt/decrypt your files on your Linux machine. There is [EncryptPad](https://itsfoss.com/encryptpad-encrypted-text-editor-linux/) as well that encrypts your notes.
However, I have come across a new free encryption tool called FinalCrypt. The software is licensed with CC BY-NC-ND which is enote entirely compatible with the definition of open source.
You can check out their recent releases and the source on its [GitHub page](https://github.com/ron-from-nl/FinalCrypt).
In this article, I will be sharing my experience of using this tool. Do note that I won’t be comparing this with any other program available out there – so if you want a detailed comparison between multiple solutions, let us know in the comments.

## Using FinalCrypt to encrypt files
[FinalCrypt](http://www.finalcrypt.org/) uses the [One-Time pad](https://en.wikipedia.org/wiki/One-time_pad) key generation cipher to encrypt files. In other words, it generates an OTP key which you will use for encrypting or decrypting your files.
The key will be completely random as per the size of the key – which you can specify. So, it is impossible to decrypt the file without the key file.
While the OTP key method for encryption/decryption is simple and effective, but managing or securing the key file could be an inconvenience for some.
If you want to use FinalCrypt, you can install the DEB/RPM files from its website. FinalCrypt is also available for Windows and macOS.
Once downloaded, simply double click to [install it from deb](https://itsfoss.com/install-deb-files-ubuntu/) or rpm files. You can also build it from the source code if you want.
## FileCrypt in Action
This video shows how to use FinalCrypt:
If you like Linux related videos, please [subscribe to our YouTube channel](https://www.youtube.com/c/itsfoss?sub_confirmation=1).
Once you have installed FinalCrypt, you’ll find it in your list of installed applications. Launch it from there.
Upon launch, you will observe two sections (split) for the items to encrypt/decrypt and the other to select the OTP file.
First, you will have to generate an OTP key. Here’s how to do that:
Do note that your file name can be anything – but you need to make sure that the key file size is greater or equal to the file you want to encrypt. I found it weird but that’s how the [One-time pad encryption](https://en.wikipedia.org/wiki/One-time_pad) works.
After you generate the file, select the key on the right-side of the window and then select the files that you want to encrypt on the left-side of the window.
You will find the checksum value, key file size, and valid status highlighted after generating the OTP:
After making the selection, you just need to click on “**Encrypt**” to encrypt those files and if already encrypted, then “**Decrypt**” to decrypt those.
You can also use FinalCrypt in command line to automate your encryption job.
### How do you secure your OTP key?
It is easy to encrypt/decrypt the files you want to protect. But, where should you keep your OTP key?
It is literally useless if you fail to keep your OTP key in a safe storage location.
Well, one of the best ways would be to use a USB stick specifically for the keys you want to store. Just plug it in when you want to decrypt files and its all good.
In addition to that, you may save your key on a [cloud service](https://itsfoss.com/cloud-services-linux/), if you consider it secure enough.
More information about FinalCrypt can be found on its website.
**Wrapping Up**
It might seem a little overwhelming at the beginning but it is actually a simple and user-friendly encryption program available for Linux. There are other programs to [password protect folders](https://itsfoss.com/password-protect-folder-linux/) as well if you are interested in some additional reading.
What do you think about FinalCrypt? Do you happen to know about something similar which is potentially better? Let us know in the comments and we shall take a look at them! |
10,589 | Vim 可视化模式入门 | https://opensource.com/article/19/2/getting-started-vim-visual-mode | 2019-03-05T07:29:16 | [
"Vim"
] | https://linux.cn/article-10589-1.html |
>
> 可视化模式使得在 Vim 中高亮显示和操作文本变得更加容易。
>
>
>

Ansible 剧本文件是 YAML 格式的文本文件,经常与它们打交道的人通过他们偏爱的编辑器和扩展插件以使格式化更容易。
当我使用大多数 Linux 发行版中提供的默认编辑器来教学 Ansible 时,我经常使用 Vim 的可视化模式。它可以让我在屏幕上高亮显示我的操作 —— 我要编辑什么以及我正在做的文本处理任务,以便使我的学生更容易学习。
### Vim 的可视化模式
使用 Vim 编辑文本时,可视化模式对于识别要操作的文本块非常有用。
Vim 的可视模式有三个模式:字符、行和块。进入每种模式的按键是:
* 字符模式: `v` (小写)
* 行模式: `V` (大写)
* 块模式: `Ctrl+v`
下面是使用每种模式简化工作的一些方法。
### 字符模式
字符模式可以高亮显示段落中的一个句子或句子中的一个短语,然后,可以使用任何 Vim 编辑命令删除、复制、更改/修改可视化模式识别的文本。
#### 移动一个句子
要将句子从一个地方移动到另一个地方,首先打开文件并将光标移动到要移动的句子的第一个字符。

* 按下 `v` 键进入可视化字符模式。单词 `VISUAL` 将出现在屏幕底部。
* 使用箭头来高亮显示所需的文本。你可以使用其他导航命令,例如 `w` 高亮显示至下一个单词的开头,`$` 来包含该行的其余部分。
* 在文本高亮显示后,按下 `d` 删除文本。
* 如果你删除得太多或不够,按下 `u` 撤销并重新开始。
* 将光标移动到新位置,然后按 `p` 粘贴文本。
#### 改变一个短语
你还可以高亮显示要替换的一段文本。

* 将光标放在要更改的第一个字符处。
* 按下 `v` 进入可视化字符模式。
* 使用导航命令(如箭头键)高亮显示该部分。
* 按下 `c` 可更改高亮显示的文本。
* 高亮显示的文本将消失,你将处于插入模式,你可以在其中添加新文本。
* 输入新文本后,按下 `Esc` 返回命令模式并保存你的工作。

### 行模式
使用 Ansible 剧本时,任务的顺序很重要。使用可视化行模式将 Ansible 任务移动到该剧本文件中的其他位置。
#### 操纵多行文本

* 将光标放在要操作的文本的第一行或最后一行的任何位置。
* 按下 `Shift+V` 进入行模式。单词 `VISUAL LINE` 将出现在屏幕底部。
* 使用导航命令(如箭头键)高亮显示多行文本。
* 高亮显示所需文本后,使用命令来操作它。按下 `d` 删除,然后将光标移动到新位置,按下 `p` 粘贴文本。
* 如果要复制该 Ansible 任务,可以使用 `y`(yank)来代替 `d`(delete)。
#### 缩进一组行
使用 Ansible 剧本或 YAML 文件时,缩进很重要。高亮显示的块可以使用 `>` 和 `<` 键向右或向左移动。

* 按下 `>` 增加所有行的缩进。
* 按下 `<` 减少所有行的缩进。
尝试其他 Vim 命令将它们应用于高亮显示的文本。
### 块模式
可视化块模式对于操作特定的表格数据文件非常有用,但它作为验证 Ansible 剧本文件缩进的工具也很有帮助。
Ansible 任务是个项目列表,在 YAML 中,每个列表项都以一个破折号跟上一个空格开头。破折号必须在同一列中对齐,以达到相同的缩进级别。仅凭肉眼很难看出这一点。缩进 Ansible 任务中的其他行也很重要。
#### 验证任务列表缩进相同

* 将光标放在列表项的第一个字符上。
* 按下 `Ctrl+v` 进入可视化块模式。单词 `VISUAL BLOCK` 将出现在屏幕底部。
* 使用箭头键高亮显示单个字符列。你可以验证每个任务的缩进量是否相同。
* 使用箭头键向右或向左展开块,以检查其它缩进是否正确。

尽管我对其它 Vim 编辑快捷方式很熟悉,但我仍然喜欢使用可视化模式来整理我想要出来处理的文本。当我在讲演过程中演示其它概念时,我的学生将会在这个“对他们而言很新”的文本编辑器中看到一个可以高亮文本并可以点击删除的工具。
---
via: <https://opensource.com/article/19/2/getting-started-vim-visual-mode>
作者:[Susan Lauber](https://opensource.com/users/susanlauber) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ansible playbook files are text files in a YAML format. People who work regularly with them have their favorite editors and plugin extensions to make the formatting easier.
When I teach Ansible with the default editor available in most Linux distributions, I use Vim's visual mode a lot. It allows me to highlight my actions on the screen—what I am about to edit and the text manipulation task I'm doing—to make it easier for my students to learn.
## Vim's visual mode
When editing text with Vim, visual mode can be extremely useful for identifying chunks of text to be manipulated.
Vim's visual mode has three versions: character, line, and block. The keystrokes to enter each mode are:
- Character mode:
**v**(lower-case) - Line mode:
**V**(upper-case) - Block mode:
**Ctrl+v**
Here are some ways to use each mode to simplify your work.
## Character mode
Character mode can highlight a sentence in a paragraph or a phrase in a sentence. Then the visually identified text can be deleted, copied, changed, or modified with any other Vim editing command.
### Move a sentence
To move a sentence from one place to another, start by opening the file and moving the cursor to the first character in the sentence you want to move.
- Press the
**v**key to enter visual character mode. The word**VISUAL**will appear at the bottom of the screen. - Use the Arrow keys to highlight the desired text. You can use other navigation commands, such as
**w**to highlight to the beginning of the next word or**$**to include the rest of the line. - Once the text is highlighted, press the
**d**key to delete the text. - If you deleted too much or not enough, press
**u**to undo and start again. - Move your cursor to the new location and press
**p**to paste the text.
### Change a phrase
You can also highlight a chunk of text that you want to replace.
- Place the cursor at the first character you want to change.
- Press
**v**to enter visual character mode. - Use navigation commands, such as the Arrow keys, to highlight the phrase.
- Press
**c**to change the highlighted text. - The highlighted text will disappear, and you will be in Insert mode where you can add new text.
- After you finish typing the new text, press
**Esc**to return to command mode and save your work.
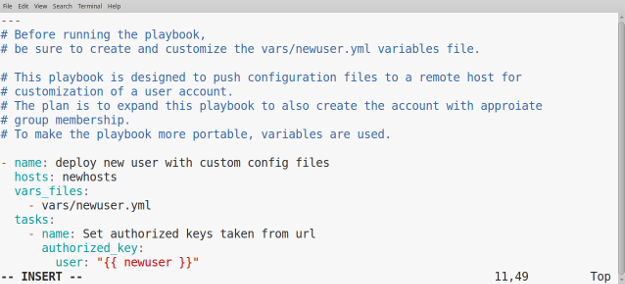
## Line mode
When working with Ansible playbooks, the order of tasks can matter. Use visual line mode to move a task to a different location in the playbook.
### Manipulate multiple lines of text
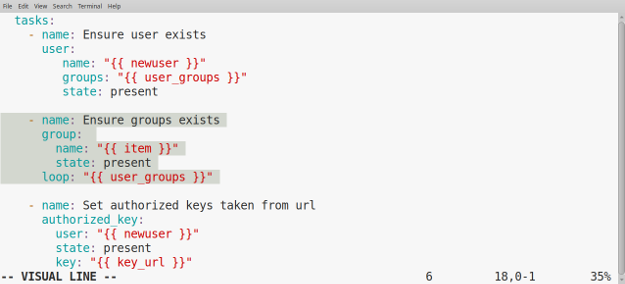
- Place your cursor anywhere on the first or last line of the text you want to manipulate.
- Press
**Shift+V**to enter line mode. The words**VISUAL LINE**will appear at the bottom of the screen. - Use navigation commands, such as the Arrow keys, to highlight multiple lines of text.
- Once the desired text is highlighted, use commands to manipulate it. Press
**d**to delete, then move the cursor to the new location, and press**p**to paste the text. **y**(yank) can be used instead of**d**(delete) if you want to copy the task.
### Indent a set of lines
When working with Ansible playbooks or YAML files, indentation matters. A highlighted block can be shifted right or left with the **>** and **<** keys.
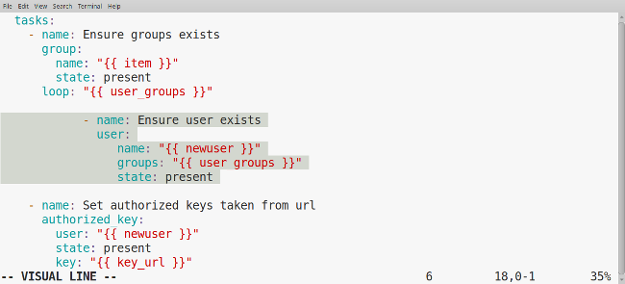
- Press
**>**to increase the indentation of all the lines. - Press
**<**to decrease the indentation of all the lines.
Try other Vim commands to apply them to the highlighted text.
## Block mode
The visual block mode is useful for manipulation of specific tabular data files, but it can also be extremely helpful as a tool to verify indentation of an Ansible playbook.
Tasks are a list of items and in YAML each list item starts with a dash followed by a space. The dashes must line up in the same column to be at the same indentation level. This can be difficult to see with just the human eye. Indentation of other lines within the task is also important.
### Verify tasks lists are indented the same
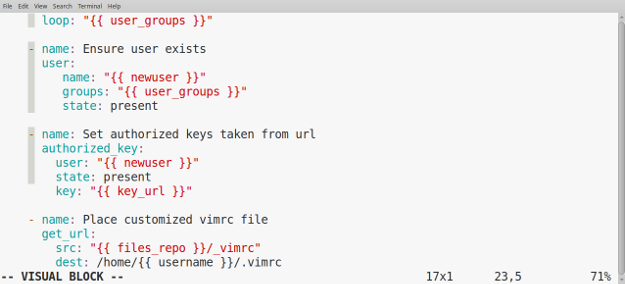
- Place your cursor on the first character of the list item.
- Press
**Ctrl+v**to enter visual block mode. The words**VISUAL BLOCK**will appear at the bottom of the screen. - Use the Arrow keys to highlight the single character column. You can verify that each task is indented the same amount.
- Use the Arrow keys to expand the block right or left to check whether the other indentation is correct.
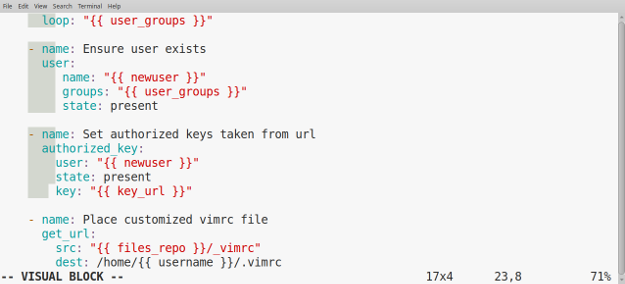
Even though I am comfortable with other Vim editing shortcuts, I still like to use visual mode to sort out what text I want to manipulate. When I demo other concepts during a presentation, my students see a tool to highlight text and hit delete in this "new to them" text only editor.
## 2 Comments |
10,590 | 3 款用于学术出版的开源工具 | https://opensource.com/article/18/3/scientific-publishing-software | 2019-03-05T10:52:45 | [
"出版"
] | /article-10590-1.html |
>
> 学术出版业每年的价值超过 260 亿美元。
>
>
>

有一个行业在采用数字化或开源工具方面已落后其它行业,那就是竞争与利润并存的学术出版业。根据 Stephen Buranyi 去年在 [卫报](https://www.theguardian.com/science/2017/jun/27/profitable-business-scientific-publishing-bad-for-science) 上发表的一份图表,这个估值超过 190 亿英镑(260 亿美元)的行业,即使是最重要的科学研究方面,至今其系统在选题、出版甚至分享方面仍受限于印刷媒介的诸多限制。全新的数字时代科技展现了一个巨大机遇,可以加速探索、推动科学协作而非竞争,以及将投入从基础建设导向有益于社会的研究。
非盈利性的 [eLife 倡议](https://elifesciences.org/about) 是由研究资金赞助方建立,旨在通过使用数字或者开源技术来走出上述僵局。除了为生命科学和生物医疗方面的重大成就出版开放式获取的期刊,eLife 已将自己变成了一个在研究交流方面的实验和展示创新的平台 —— 而大部分的实验都是基于开源精神的。
致力于开放出版基础设施项目给予我们加速接触、采用科学技术、提升用户体验的机会。我们认为这种机会对于推动学术出版行业是重要的。大而化之地说,开源产品的用户体验经常是有待开发的,而有时候这种情况会阻止其他人去使用它。作为我们在 OSS(开源软件)开发中投入的一部分,为了鼓励更多用户使用这些产品,我们十分注重用户体验。
我们所有的代码都是开源的,并且我们也积极鼓励社区参与进我们的项目中。这对我们来说意味着更快的迭代、更多的实验、更大的透明度,同时也拓宽了我们工作的外延。
我们现在参与的项目,例如 Libero (之前称作 [eLife Continuum](https://elifesciences.org/inside-elife/33e4127f/elife-introduces-continuum-a-new-open-source-tool-for-publishing))和 <ruby> <a href="https://elifesciences.org/for-the-press/e6038800/elife-supports-development-of-open-technology-stack-for-publishing-reproducible-manuscripts-online"> 可重现文档栈 </a> <rt> Reproducible Document Stack </rt></ruby> 的开发,以及我们最近和 [Hypothesis](https://elifesciences.org/for-the-press/81d42f7d/elife-enhances-open-annotation-with-hypothesis-to-promote-scientific-discussion-online) 的合作,展示了 OSS 是如何在评估、出版以及新发现的沟通方面带来正面影响的。
### Libero
Libero 是面向出版商的服务及应用套餐,它包括一个后期制作出版系统、整套前端用户界面样式套件、Libero 的镜头阅读器、一个 Open API 以及一个搜索及推荐引擎。
去年我们采取了用户驱动的方式重新设计了 Libero 的前端,可以使用户较少地分心于网站的“陈设”,而是更多地集中关注于研究文章上。我们和 eLife 社区成员测试并迭代了该站点所有的核心功能,以确保给所有人最好的阅读体验。该网站的新 API 也为机器阅读能力提供了更简单的访问途径,其中包括文本挖掘、机器学习以及在线应用开发。
我们网站上的内容以及引领新设计的样式都是开源的,以鼓励 eLife 和其它想要使用它的出版商后续的产品开发。
### 可重现文档栈
在与 [Substance](https://github.com/substance) 和 [Stencila](https://github.com/stencila/stencila) 的合作下,eLife 也参与了一个项目来创建可重现文档栈(RDS)—— 一个开放式的创作、编纂以及在线出版可重现的计算型手稿的工具栈。
今天越来越多的研究人员能够通过 [R Markdown](https://rmarkdown.rstudio.com/) 和 [Python](https://www.python.org/) 等语言记录他们的计算实验。这些可以作为实验记录的重要部分,但是尽管它们可以独立于最终的研究文章或与之一同分享,但传统出版流程经常将它们视为次级内容。为了发表论文,使用这些语言的研究人员除了将他们的计算结果用图片的形式“扁平化”提交外别无他法。但是这导致了许多实验价值和代码和计算数据可重复利用性的流失。诸如 [Jupyter](http://jupyter.org/) 这样的电子笔记本解决方案确实可以使研究员以一种可重复利用、可执行的简单形式发布,但是这种方案仍然是出版的手稿的补充,而不是不可或缺的一部分。
[可重现文档栈](https://elifesciences.org/labs/7dbeb390/reproducible-document-stack-supporting-the-next-generation-research-article) 项目旨在通过开发、发布一个可重现原稿的产品原型来解决这些挑战,该原型将代码和数据视为文档的组成部分,并展示了从创作到出版的完整端对端技术栈。它将最终允许用户以一种包含嵌入代码块和计算结果(统计结果、图表或图形)的形式提交他们的手稿,并在出版过程中保留这些可视、可执行的部分。那时出版商就可以将这些做为出版的在线文章的组成部分而保存。
### 用 Hypothesis 进行开放式注解
最近,我们与 [Hypothesis](https://github.com/hypothesis) 合作引进了开放式注解,使得我们网站的用户们可以写评语、高亮文章重要部分以及与在线阅读的群体互动。
通过这样的合作,开源的 Hypothesis 软件被定制得更具有现代化的特性,如单次登录验证、用户界面定制,给予了出版商在他们自己网站上实现更多的控制。这些提升正引导着关于出版学术内容的高质量讨论。
这个工具可以无缝集成到出版商的网站,学术出版平台 [PubFactory](http://www.pubfactory.com/) 和内容解决方案供应商 [Ingenta](http://www.ingenta.com/) 已经利用了它优化后的特性集。[HighWire](https://github.com/highwire) 和 [Silverchair](https://www.silverchair.com/community/silverchair-universe/hypothesis/) 也为他们的出版商提供了实施这套方案的机会。
### 其它产业和开源软件
随着时间的推移,我们希望看到更多的出版商采用 Hypothesis、Libero 以及其它开源项目去帮助他们促进重要科学研究的发现以及循环利用。但是 eLife 的创新机遇也能被其它行业所利用,因为这些软件和其它 OSS 技术在其他行业也很普遍。
数据科学的世界离不开高质量、良好支持的开源软件和围绕它们形成的社区;[TensorFlow](https://www.tensorflow.org/) 就是这样一个好例子。感谢 OSS 以及其社区,AI 和机器学习的所有领域相比于计算机的其它领域的提升和发展更加迅猛。与之类似的是以 Linux 作为云端 Web 主机的爆炸性增长、接着是 Docker 容器、以及现在 GitHub 上最流行的开源项目之一的 Kubernetes 的增长。
所有的这些技术使得机构们能够用更少的资源做更多的事情,并专注于创新而不是重新发明轮子上。最后,这就是 OSS 真正的好处:它使得我们从互相的失败中学习,在互相的成功中成长。
我们总是在寻找与研究和科技界面方面最好的人才和想法交流的机会。你可以在 [eLife Labs](https://elifesciences.org/labs) 上或者联系 [[email protected]](mailto:[email protected]) 找到更多这种交流的信息。
---
via: <https://opensource.com/article/18/3/scientific-publishing-software>
作者:[Paul Shanno](https://opensource.com/users/pshannon) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,591 | Bash 中的 & 符号和文件描述符 | https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash | 2019-03-05T20:34:00 | [
"连接符"
] | https://linux.cn/article-10591-1.html |
>
> 了解如何将 “&” 与尖括号结合使用,并从命令行中获得更多信息。
>
>
>

在我们探究大多数链式 Bash 命令中出现的所有的杂项符号(`&`、`|`、`;`、`>`、`<`、`{`、`[`、`(`、`)`、`]`、`}` 等等)的任务中,[我们一直在仔细研究 & 符号](/article-10587-1.html)。
[上次,我们看到了如何使用 & 把可能需要很长时间运行的进程放到后台运行](/article-10587-1.html)。但是,`&` 与尖括号 `<` 结合使用,也可用于将输出或输出通过管道导向其他地方。
在 [前面的](/article-10502-1.html) [尖括号教程中](/article-10529-1.html),你看到了如何使用 `>`,如下:
```
ls > list.txt
```
将 `ls` 输出传递给 `list.txt` 文件。
现在我们看到的是简写:
```
ls 1> list.txt
```
在这种情况下,`1` 是一个文件描述符,指向标准输出(`stdout`)。
以类似的方式,`2` 指向标准错误输出(`stderr`):
```
ls 2> error.log
```
所有错误消息都通过管道传递给 `error.log` 文件。
回顾一下:`1>` 是标准输出(`stdout`),`2>` 是标准错误输出(`stderr`)。
第三个标准文件描述符,`0<` 是标准输入(`stdin`)。你可以看到它是一个输入,因为箭头(`<`)指向`0`,而对于 `1` 和 `2`,箭头(`>`)是指向外部的。
### 标准文件描述符有什么用?
如果你在阅读本系列以后,你已经多次使用标准输出(`1>`)的简写形式:`>`。
例如,当(假如)你知道你的命令会抛出一个错误时,像 `stderr`(`2`)这样的东西也很方便,但是 Bash 告诉你的东西是没有用的,你不需要看到它。如果要在 `home/` 目录中创建目录,例如:
```
mkdir newdir
```
如果 `newdir/` 已经存在,`mkdir` 将显示错误。但你为什么要关心这些呢?(好吧,在某些情况下你可能会关心,但并非总是如此。)在一天结束时,`newdir` 会以某种方式让你填入一些东西。你可以通过将错误消息推入虚空(即 ``/dev/null`)来抑制错误消息:
```
mkdir newdir 2> /dev/null
```
这不仅仅是 “让我们不要看到丑陋和无关的错误消息,因为它们很烦人”,因为在某些情况下,错误消息可能会在其他地方引起一连串错误。比如说,你想找到 `/etc` 下所有的 `.service` 文件。你可以这样做:
```
find /etc -iname "*.service"
```
但事实证明,在大多数系统中,`find` 显示的错误会有许多行,因为普通用户对 `/etc` 下的某些文件夹没有读取访问权限。它使读取正确的输出变得很麻烦,如果 `find` 是更大的脚本的一部分,它可能会导致行中的下一个命令排队。
相反,你可以这样做:
```
find /etc -iname "*.service" 2> /dev/null
```
而且你只得到你想要的结果。
### 文件描述符入门
单独的文件描述符 `stdout` 和 `stderr` 还有一些注意事项。如果要将输出存储在文件中,请执行以下操作:
```
find /etc -iname "*.service" 1> services.txt
```
工作正常,因为 `1>` 意味着 “发送标准输出且自身标准输出(非标准错误)到某个地方”。
但这里存在一个问题:如果你想把命令抛出的错误信息记录到文件,而结果中没有错误信息你该怎么**做**?上面的命令并不会这样做,因为它只写入 `find` 正确的结果,而:
```
find /etc -iname "*.service" 2> services.txt
```
只会写入命令抛出的错误信息。
我们如何得到两者?请尝试以下命令:
```
find /etc -iname "*.service" &> services.txt
```
…… 再次和 `&` 打个招呼!
我们一直在说 `stdin`(`0`)、`stdout`(`1`)和 `stderr`(`2`)是“文件描述符”。文件描述符是一种特殊构造,是指向文件的通道,用于读取或写入,或两者兼而有之。这来自于将所有内容都视为文件的旧 UNIX 理念。想写一个设备?将其视为文件。想写入套接字并通过网络发送数据?将其视为文件。想要读取和写入文件?嗯,显然,将其视为文件。
因此,在管理命令的输出和错误的位置时,将目标视为文件。因此,当你打开它们来读取和写入它们时,它们都会获得文件描述符。
这是一个有趣的效果。例如,你可以将内容从一个文件描述符传递到另一个文件描述符:
```
find /etc -iname "*.service" 1> services.txt 2>&1
```
这会将 `stderr` 导向到 `stdout`,而 `stdout` 通过管道被导向到一个文件中 `services.txt` 中。
它再次出现:`&` 发信号通知 Bash `1` 是目标文件描述符。
标准文件描述符的另一个问题是,当你从一个管道传输到另一个时,你执行此操作的顺序有点违反直觉。例如,按照上面的命令。它看起来像是错误的方式。你应该像这样阅读它:“将输出导向到文件,然后将错误导向到标准输出。” 看起来错误输出会在后面,并且在输出到标准输出(`1`)已经完成时才发送。
但这不是文件描述符的工作方式。文件描述符不是文件的占位符,而是文件的输入和(或)输出通道。在这种情况下,当你做 `1> services.txt` 时,你的意思是 “打开一个写管道到 `services.txt` 并保持打开状态”。`1` 是你要使用的管道的名称,它将保持打开状态直到该行的结尾。
如果你仍然认为这是错误的方法,试试这个:
```
find /etc -iname "*.service" 2>&1 1>services.txt
```
并注意它是如何不工作的;注意错误是如何被导向到终端的,而只有非错误的输出(即 `stdout`)被推送到 `services.txt`。
这是因为 Bash 从左到右处理 `find` 的每个结果。这样想:当 Bash 到达 `2>&1` 时,`stdout` (`1`)仍然是指向终端的通道。如果 `find` 给 Bash 的结果包含一个错误,它将被弹出到 `2`,转移到 `1`,然后留在终端!
然后在命令结束时,Bash 看到你要打开 `stdout`(`1`) 作为到 `services.txt` 文件的通道。如果没有发生错误,结果将通过通道 `1` 进入文件。
相比之下,在:
```
find /etc -iname "*.service" 1>services.txt 2>&1
```
`1` 从一开始就指向 `services.txt`,因此任何弹出到 `2` 的内容都会导向到 `1` ,而 `1` 已经指向最终去的位置 `services.txt`,这就是它工作的原因。
在任何情况下,如上所述 `&>` 都是“标准输出和标准错误”的缩写,即 `2>&1`。
这可能有点多,但不用担心。重新导向文件描述符在 Bash 命令行和脚本中是司空见惯的事。随着本系列的深入,你将了解更多关于文件描述符的知识。下周见!
---
via: <https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zero-mk](https://github.com/zero-mk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,592 | ASLR 是如何保护 Linux 系统免受缓冲区溢出攻击的 | https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html | 2019-03-05T22:40:40 | [
"ASLR",
"缓冲区溢出",
"安全"
] | https://linux.cn/article-10592-1.html |
>
> 地址空间随机化(ASLR)是一种内存攻击缓解技术,可以用于 Linux 和 Windows 系统。了解一下如何运行它、启用/禁用它,以及它是如何工作的。
>
>
>

<ruby> 地址空间随机化 <rt> Address Space Layout Randomization </rt></ruby>(ASLR)是一种操作系统用来抵御缓冲区溢出攻击的内存保护机制。这种技术使得系统上运行的进程的内存地址无法被预测,使得与这些进程有关的漏洞变得更加难以利用。
ASLR 目前在 Linux、Windows 以及 MacOS 系统上都有使用。其最早出现在 2005 的 Linux 系统上。2007 年,这项技术被 Windows 和 MacOS 部署使用。尽管 ASLR 在各个系统上都提供相同的功能,却有着不同的实现。
ASLR 的有效性依赖于整个地址空间布局是否对于攻击者保持未知。此外,只有编译时作为<ruby> 位置无关可执行文件 <rt> Position Independent Executable </rt></ruby>(PIE)的可执行程序才能得到 ASLR 技术的最大保护,因为只有这样,可执行文件的所有代码节区才会被加载在随机地址。PIE 机器码不管绝对地址是多少都可以正确执行。
### ASLR 的局限性
尽管 ASLR 使得对系统漏洞的利用更加困难了,但其保护系统的能力是有限的。理解关于 ASLR 的以下几点是很重要的:
* 它不能*解决*漏洞,而是增加利用漏洞的难度
* 并不追踪或报告漏洞
* 不能对编译时没有开启 ASLR 支持的二进制文件提供保护
* 不能避免被绕过
### ASLR 是如何工作的
通过对攻击者在进行缓冲区溢出攻击时所要用到的内存布局中的偏移做了随机化,ASLR 加大了攻击成功的难度,从而增强了系统的控制流完整性。
通常认为 ASLR 在 64 位系统上效果更好,因为 64 位系统提供了更大的熵(可随机的地址范围)。
### ASLR 是否正在你的 Linux 系统上运行?
下面展示的两条命令都可以告诉你的系统是否启用了 ASLR 功能:
```
$ cat /proc/sys/kernel/randomize_va_space
2
$ sysctl -a --pattern randomize
kernel.randomize_va_space = 2
```
上方指令结果中的数值(`2`)表示 ASLR 工作在全随机化模式。其可能为下面的几个数值之一:
```
0 = Disabled
1 = Conservative Randomization
2 = Full Randomization
```
如果你关闭了 ASLR 并且执行下面的指令,你将会注意到前后两条 `ldd` 的输出是完全一样的。`ldd` 命令会加载共享对象并显示它们在内存中的地址。
```
$ sudo sysctl -w kernel.randomize_va_space=0 <== disable
[sudo] password for shs:
kernel.randomize_va_space = 0
$ ldd /bin/bash
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
$ ldd /bin/bash
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
```
如果将其重新设置为 `2` 来启用 ASLR,你将会看到每次运行 `ldd`,得到的内存地址都不相同。
```
$ sudo sysctl -w kernel.randomize_va_space=2 <== enable
[sudo] password for shs:
kernel.randomize_va_space = 2
$ ldd /bin/bash
linux-vdso.so.1 (0x00007fff47d0e000) <== first set of addresses
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007f1cb7ce0000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f1cb7cda000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1cb7af0000)
/lib64/ld-linux-x86-64.so.2 (0x00007f1cb8045000)
$ ldd /bin/bash
linux-vdso.so.1 (0x00007ffe1cbd7000) <== second set of addresses
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007fed59742000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fed5973c000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fed59552000)
/lib64/ld-linux-x86-64.so.2 (0x00007fed59aa7000)
```
### 尝试绕过 ASLR
尽管这项技术有很多优点,但绕过 ASLR 的攻击并不罕见,主要有以下几类:
* 利用地址泄露
* 访问与特定地址关联的数据
* 针对 ASLR 实现的缺陷来猜测地址,常见于系统熵过低或 ASLR 实现不完善。
* 利用侧信道攻击
### 总结
ASLR 有很大的价值,尤其是在 64 位系统上运行并被正确实现时。虽然不能避免被绕过,但这项技术的确使得利用系统漏洞变得更加困难了。这份参考资料可以提供 [在 64 位 Linux 系统上的完全 ASLR 的有效性](https://cybersecurity.upv.es/attacks/offset2lib/offset2lib-paper.pdf) 的更多有关细节,这篇论文介绍了一种利用分支预测 [绕过 ASLR](http://www.cs.ucr.edu/%7Enael/pubs/micro16.pdf) 的技术。
---
via: <https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[leommxj](https://github.com/leommxj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,593 | Bash-Insulter:一个在输入错误命令时嘲讽用户的脚本 | https://www.2daygeek.com/bash-insulter-insults-the-user-when-typing-wrong-command/ | 2019-03-06T19:12:00 | [
"命令行",
"嘲讽"
] | https://linux.cn/article-10593-1.html | 
这是一个非常有趣的脚本,每当用户在终端输入错误的命令时,它都会嘲讽用户。
它让你在解决一些问题时会感到快乐。有的人在受到终端嘲讽的时候感到不愉快。但是,当我受到终端的批评时,我真的很开心。
这是一个有趣的 CLI 工具,在你弄错的时候,会用随机短语嘲讽你。此外,它允许你添加自己的短语。
### 如何在 Linux 上安装 Bash-Insulter?
在安装 Bash-Insulter 之前,请确保你的系统上安装了 git。如果没有,请使用以下命令安装它。
对于 Fedora 系统, 请使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 安装 git。
```
$ sudo dnf install git
```
对于 Debian/Ubuntu 系统,请使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 安装 git。
```
$ sudo apt install git
```
对于基于 Arch Linux 的系统,请使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 安装 git。
```
$ sudo pacman -S git
```
对于 RHEL/CentOS 系统,请使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 安装 git。
```
$ sudo yum install git
```
对于 openSUSE Leap 系统,请使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 安装 git。
```
$ sudo zypper install git
```
我们可以通过<ruby> 克隆 <rt> clone </rt></ruby>开发人员的 GitHub 存储库轻松地安装它。
首先克隆 Bash-insulter 存储库。
```
$ git clone https://github.com/hkbakke/bash-insulter.git bash-insulter
```
将下载的文件移动到文件夹 `/etc` 下。
```
$ sudo cp bash-insulter/src/bash.command-not-found /etc/
```
将下面的代码添加到 `/etc/bash.bashrc` 文件中。
```
$ vi /etc/bash.bashrc
#Bash Insulter
if [ -f /etc/bash.command-not-found ]; then
. /etc/bash.command-not-found
fi
```
运行以下命令使更改生效。
```
$ sudo source /etc/bash.bashrc
```
你想测试一下安装是否生效吗?你可以试试在终端上输入一些错误的命令,看看它如何嘲讽你。
```
$ unam -a
$ pin 2daygeek.com
```

如果你想附加你自己的短语,则导航到以下文件并更新它。你可以在 `messages` 部分中添加短语。
```
# vi /etc/bash.command-not-found
print_message () {
local messages
local message
messages=(
"Boooo!"
"Don't you know anything?"
"RTFM!"
"Haha, n00b!"
"Wow! That was impressively wrong!"
"Pathetic"
"The worst one today!"
"n00b alert!"
"Your application for reduced salary has been sent!"
"lol"
"u suk"
"lol... plz"
"plz uninstall"
"And the Darwin Award goes to.... ${USER}!"
"ERROR_INCOMPETENT_USER"
"Incompetence is also a form of competence"
"Bad."
"Fake it till you make it!"
"What is this...? Amateur hour!?"
"Come on! You can do it!"
"Nice try."
"What if... you type an actual command the next time!"
"What if I told you... it is possible to type valid commands."
"Y u no speak computer???"
"This is not Windows"
"Perhaps you should leave the command line alone..."
"Please step away from the keyboard!"
"error code: 1D10T"
"ACHTUNG! ALLES TURISTEN UND NONTEKNISCHEN LOOKENPEEPERS! DAS KOMPUTERMASCHINE IST NICHT FÜR DER GEFINGERPOKEN UND MITTENGRABEN! ODERWISE IST EASY TO SCHNAPPEN DER SPRINGENWERK, BLOWENFUSEN UND POPPENCORKEN MIT SPITZENSPARKEN. IST NICHT FÜR GEWERKEN BEI DUMMKOPFEN. DER RUBBERNECKEN SIGHTSEEREN KEEPEN DAS COTTONPICKEN HÄNDER IN DAS POCKETS MUSS. ZO RELAXEN UND WATSCHEN DER BLINKENLICHTEN."
"Pro tip: type a valid command!"
"Go outside."
"This is not a search engine."
"(╯°□°)╯︵ ┻━┻"
"¯\_(ツ)_/¯"
"So, I'm just going to go ahead and run rm -rf / for you."
"Why are you so stupid?!"
"Perhaps computers is not for you..."
"Why are you doing this to me?!"
"Don't you have anything better to do?!"
"I am _seriously_ considering 'rm -rf /'-ing myself..."
"This is why you get to see your children only once a month."
"This is why nobody likes you."
"Are you even trying?!"
"Try using your brain the next time!"
"My keyboard is not a touch screen!"
"Commands, random gibberish, who cares!"
"Typing incorrect commands, eh?"
"Are you always this stupid or are you making a special effort today?!"
"Dropped on your head as a baby, eh?"
"Brains aren't everything. In your case they're nothing."
"I don't know what makes you so stupid, but it really works."
"You are not as bad as people say, you are much, much worse."
"Two wrongs don't make a right, take your parents as an example."
"You must have been born on a highway because that's where most accidents happen."
"If what you don't know can't hurt you, you're invulnerable."
"If ignorance is bliss, you must be the happiest person on earth."
"You're proof that god has a sense of humor."
"Keep trying, someday you'll do something intelligent!"
"If shit was music, you'd be an orchestra."
"How many times do I have to flush before you go away?"
)
```
---
via: <https://www.2daygeek.com/bash-insulter-insults-the-user-when-typing-wrong-command/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zero-mk](https://github.com/zero-mk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,594 | 正则表达式的分组和数字 | https://leancrew.com/all-this/2019/02/regex-groups-and-numerals/ | 2019-03-06T20:24:06 | [
"正则表达式"
] | https://linux.cn/article-10594-1.html | 
大约一周前,我在编辑一个程序时想要更改一些变量名。我之前认为这将是一个简单的正则表达式查找/替换。只是这没有我想象的那么简单。
变量名为 `a10`、`v10` 和 `x10`,我想分别将它们改为 `a30`、`v30` 和 `x30`。我想到使用 BBEdit 的查找窗口并输入:

我不能简单地 `30` 替换为 `10`,因为代码中有一些与变量无关的数字 `10`。我认为我很聪明,所以我不想写三个非正则表达式替换,`a10`、`v10` 和 `x10`,每个一个。但是我却没有注意到替换模式中的蓝色。如果我这样做了,我会看到 BBEdit 将我的替换模式解释为“匹配组 13,后面跟着 `0`,而不是”匹配组 1,后面跟着 `30`,后者是我想要的。由于匹配组 13 是空白的,因此所有变量名都会被替换为 `0`。
你看,BBEdit 可以在搜索模式中匹配多达 99 个分组,严格来说,我们应该在替换模式中引用它们时使用两位数字。但在大多数情况下,我们可以使用 `\1` 到 `\9` 而不是 `\01` 到 `\09`,因为这没有歧义。换句话说,如果我尝试将 `a10`、`v10` 和 `x10` 更改为 `az`、`vz` 和 `xz`,那么使用 `\1z`的替换模式就可以了。因为后面的 `z` 意味着不会误解释该模式中 `\1`。
因此,在撤消替换后,我将模式更改为这样:

它可以正常工作。
还有另一个选择:命名组。这是使用 `var` 作为模式名称:

我从来都没有使用过命名组,无论正则表达式是在文本编辑器还是在脚本中。我的总体感觉是,如果模式复杂到我必须使用变量来跟踪所有组,那么我应该停下来并将问题分解为更小的部分。
顺便说一下,你可能已经听说 BBEdit 正在庆祝它诞生[25周年](https://merch.barebones.com/)。当一个有良好文档的应用有如此长的历史时,手册的积累能让人愉快地回到过去的日子。当我在 BBEdit 手册中查找命名组的表示法时,我遇到了这个说明:

BBEdit 目前的版本是 12.5。第一次出现于 2001 年的 V6.5。但手册希望确保长期客户(我记得是在 V4 的时候第一次购买)不会因行为变化而感到困惑,即使这些变化几乎发生在二十年前。
---
via: <https://leancrew.com/all-this/2019/02/regex-groups-and-numerals/>
作者:[Dr.Drang](https://leancrew.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Regex groups and numerals](https://leancrew.com/all-this/2019/02/regex-groups-and-numerals/)
February 23, 2019 at 1:12 PM by Dr. Drang
A week or so ago, I was editing a program and decided I should change some variable names. I thought it would be a simple regex find/replace, and it was. Just not as simple as I thought.
The variables were named `a10`
, `v10`
, and `x10`
, and I wanted to change them to `a30`
, `v30`
, and `x30`
, respectively. I brought up BBEdit’s Find window and entered this:
I couldn’t just replace `10`
with `30`
because there were instances of `10`
in the code that weren’t related to the variables. And because I think I’m clever, I didn’t want to do three non-regex replacements, one each for `a10`
, `v10`
, and `x10`
. But I wasn’t clever enough to notice the blue coloring in the replacement pattern. Had I done so, I would have seen that BBEdit was interpreting my replacement pattern as “Captured group 13, followed by `0`
” instead of “Captured group 1, followed by `30`
,” which was what I intended. Since captured group 13 was blank, all my variable names were replaced with `0`
.
You see, BBEdit can capture up to 99 groups in the search pattern and, strictly speaking, we should use two-digit numbers when referring to them in the replacement pattern. But in most cases, we can use `\1`
through `\9`
instead of `\01`
through `\09`
because there’s no ambiguity. In other words, if I had been trying to change `a10`
, `v10`
, and `x10`
to `az`
, `vz`
, and `xz`
, a replacement pattern of `\1z`
would have been just fine, because the trailing `z`
means there’s no way to misinterpret the intent of the `\1`
in that pattern.
So after undoing the replacement, I changed the pattern to this,
and all was right with the world.
There was another option: a named group. Here’s how that would have looked, using `var`
as the pattern name:
I don’t think I’ve ever used a named group in any situation, whether the regex was in a text editor or a script. My general feeling is that if the pattern is so complicated I have to use variables to keep track of all the groups, I should stop and break the problem down into smaller parts.
By the way, you may have heard that BBEdit is celebrating its [25th anniversary](https://merch.barebones.com/) of not sucking. When a well-documented app has such a long history, the manual starts to accumulate delightful callbacks to the olden days. As I was looking up the notation for named groups in the BBEdit manual, I ran across this note:
BBEdit is currently on Version 12.5; Version 6.5 came out in 2001. But the manual wants to make sure that long-time customers (I believe it was on Version 4 when I first bought it) don’t get confused by changes in behavior, even when those changes occurred nearly two decades ago. |
10,595 | 如何查看 Linux 下 CPU、内存和交换分区的占用率? | https://www.2daygeek.com/linux-check-cpu-memory-swap-utilization-percentage/ | 2019-03-06T21:04:30 | [
"内存",
"CPU"
] | https://linux.cn/article-10595-1.html | 
在 Linux 下有很多可以用来查看内存占用情况的命令和选项,但是我并没有看见关于内存占用率的更多的信息。
在大多数情况下我们只想查看内存使用情况,并没有考虑占用的百分比究竟是多少。如果你想要了解这些信息,那你看这篇文章就对了。我们将会详细地在这里帮助你解决这个问题。
这篇教程将会帮助你在面对 Linux 服务器下频繁的内存高占用情况时,确定内存使用情况。
而在同时,如果你使用的是 `free -m` 或者 `free -g`,占用情况描述地也并不是十分清楚。
这些格式化命令属于 Linux 高级命令。它将会对 Linux 专家和中等水平 Linux 使用者非常有用。
### 方法-1:如何查看 Linux 下内存占用率?
我们可以使用下面命令的组合来达到此目的。在该方法中,我们使用的是 `free` 和 `awk` 命令的组合来获取内存占用率。
如果你正在寻找其他有关于内存的文章,你可以导航到如下链接。这些文章有 [free 命令](https://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/)、[smem 命令](https://www.2daygeek.com/smem-linux-memory-usage-statistics-reporting-tool/)、[ps\_mem 命令](https://www.2daygeek.com/ps_mem-report-core-memory-usage-accurately-in-linux/)、[vmstat 命令](https://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/) 及 [查看物理内存大小的多种方式](https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/)。
要获取不包含百分比符号的内存占用率:
```
$ free -t | awk 'NR == 2 {print "Current Memory Utilization is : " $3/$2*100}'
或
$ free -t | awk 'FNR == 2 {print "Current Memory Utilization is : " $3/$2*100}'
Current Memory Utilization is : 20.4194
```
要获取不包含百分比符号的交换分区占用率:
```
$ free -t | awk 'NR == 3 {print "Current Swap Utilization is : " $3/$2*100}'
或
$ free -t | awk 'FNR == 3 {print "Current Swap Utilization is : " $3/$2*100}'
Current Swap Utilization is : 0
```
要获取包含百分比符号及保留两位小数的内存占用率:
```
$ free -t | awk 'NR == 2 {printf("Current Memory Utilization is : %.2f%"), $3/$2*100}'
或
$ free -t | awk 'FNR == 2 {printf("Current Memory Utilization is : %.2f%"), $3/$2*100}'
Current Memory Utilization is : 20.42%
```
要获取包含百分比符号及保留两位小数的交换分区占用率:
```
$ free -t | awk 'NR == 3 {printf("Current Swap Utilization is : %.2f%"), $3/$2*100}'
或
$ free -t | awk 'FNR == 3 {printf("Current Swap Utilization is : %.2f%"), $3/$2*100}'
Current Swap Utilization is : 0.00%
```
如果你正在寻找有关于交换分区的其他文章,你可以导航至如下链接。这些链接有 [使用 LVM(逻辑盘卷管理)创建和扩展交换分区](https://www.2daygeek.com/how-to-create-extend-swap-partition-in-linux-using-lvm/),[创建或扩展交换分区的多种方式](https://www.2daygeek.com/add-extend-increase-swap-space-memory-file-partition-linux/) 和 [创建/删除和挂载交换分区文件的多种方式](https://www.2daygeek.com/shell-script-create-add-extend-swap-space-linux/)。
键入 `free` 命令会更好地作出阐释:
```
$ free
total used free shared buff/cache available
Mem: 15867 3730 9868 1189 2269 10640
Swap: 17454 0 17454
Total: 33322 3730 27322
```
细节如下:
* `free`:是一个标准命令,用于在 Linux 下查看内存使用情况。
* `awk`:是一个专门用来做文本数据处理的强大命令。
* `FNR == 2`:该命令给出了每一个输入文件的行数。其基本上用于挑选出给定的行(针对于这里,它选择的是行号为 2 的行)
* `NR == 2`:该命令给出了处理的行总数。其基本上用于过滤给出的行(针对于这里,它选择的是行号为 2 的行)
* `$3/$2*100`:该命令将列 3 除以列 2 并将结果乘以 100。
* `printf`:该命令用于格式化和打印数据。
* `%.2f%`:默认情况下,其打印小数点后保留 6 位的浮点数。使用后跟的格式来约束小数位。
### 方法-2:如何查看 Linux 下内存占用率?
我们可以使用下面命令的组合来达到此目的。在这种方法中,我们使用 `free`、`grep` 和 `awk` 命令的组合来获取内存占用率。
要获取不包含百分比符号的内存占用率:
```
$ free -t | grep Mem | awk '{print "Current Memory Utilization is : " $3/$2*100}'
Current Memory Utilization is : 20.4228
```
要获取不包含百分比符号的交换分区占用率:
```
$ free -t | grep Swap | awk '{print "Current Swap Utilization is : " $3/$2*100}'
Current Swap Utilization is : 0
```
要获取包含百分比符号及保留两位小数的内存占用率:
```
$ free -t | grep Mem | awk '{printf("Current Memory Utilization is : %.2f%"), $3/$2*100}'
Current Memory Utilization is : 20.43%
```
要获取包含百分比符号及保留两位小数的交换空间占用率:
```
$ free -t | grep Swap | awk '{printf("Current Swap Utilization is : %.2f%"), $3/$2*100}'
Current Swap Utilization is : 0.00%
```
### 方法-1:如何查看 Linux 下 CPU 的占用率?
我们可以使用如下命令的组合来达到此目的。在这种方法中,我们使用 `top`、`print` 和 `awk` 命令的组合来获取 CPU 的占用率。
如果你正在寻找其他有关于 CPU(LCTT 译注:原文误为 memory)的文章,你可以导航至如下链接。这些文章有 [top 命令](https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/)、[htop 命令](https://www.2daygeek.com/linux-htop-command-linux-system-performance-resource-monitoring-tool/)、[atop 命令](https://www.2daygeek.com/atop-system-process-performance-monitoring-tool/) 及 [Glances 命令](https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/)。
如果在输出中展示的是多个 CPU 的情况,那么你需要使用下面的方法。
```
$ top -b -n1 | grep ^%Cpu
%Cpu0 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 5.3 si, 0.0 st
%Cpu3 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 10.5 us, 15.8 sy, 0.0 ni, 73.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 0.0 us, 5.0 sy, 0.0 ni, 95.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu7 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
```
要获取不包含百分比符号的 CPU 占用率:
```
$ top -b -n1 | grep ^%Cpu | awk '{cpu+=$9}END{print "Current CPU Utilization is : " 100-cpu/NR}'
Current CPU Utilization is : 21.05
```
要获取包含百分比符号及保留两位小数的 CPU 占用率:
```
$ top -b -n1 | grep ^%Cpu | awk '{cpu+=$9}END{printf("Current CPU Utilization is : %.2f%"), 100-cpu/NR}'
Current CPU Utilization is : 14.81%
```
### 方法-2:如何查看 Linux 下 CPU 的占用率?
我们可以使用如下命令的组合来达到此目的。在这种方法中,我们使用的是 `top`、`print`/`printf` 和 `awk` 命令的组合来获取 CPU 的占用率。
如果在单个输出中一起展示了所有的 CPU 的情况,那么你需要使用下面的方法。
```
$ top -b -n1 | grep ^%Cpu
%Cpu(s): 15.3 us, 7.2 sy, 0.8 ni, 69.0 id, 6.7 wa, 0.0 hi, 1.0 si, 0.0 st
```
要获取不包含百分比符号的 CPU 占用率:
```
$ top -b -n1 | grep ^%Cpu | awk '{print "Current CPU Utilization is : " 100-$8}'
Current CPU Utilization is : 5.6
```
要获取包含百分比符号及保留两位小数的 CPU 占用率:
```
$ top -b -n1 | grep ^%Cpu | awk '{printf("Current CPU Utilization is : %.2f%"), 100-$8}'
Current CPU Utilization is : 5.40%
```
如下是一些细节:
* `top`:是一种用于查看当前 Linux 系统下正在运行的进程的非常好的命令。
* `-b`:选项允许 `top` 命令切换至批处理的模式。当你从本地系统运行 `top` 命令至远程系统时,它将会非常有用。
* `-n1`:迭代次数。
* `^%Cpu`:过滤以 `%CPU` 开头的行。
* `awk`:是一种专门用来做文本数据处理的强大命令。
* `cpu+=$9`:对于每一行,将第 9 列添加至变量 `cpu`。
* `printf`:该命令用于格式化和打印数据。
* `%.2f%`:默认情况下,它打印小数点后保留 6 位的浮点数。使用后跟的格式来限制小数位数。
* `100-cpu/NR`:最终打印出 CPU 平均占用率,即用 100 减去其并除以行数。
---
via: <https://www.2daygeek.com/linux-check-cpu-memory-swap-utilization-percentage/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[An-DJ](https://github.com/An-DJ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,596 | Bash 中的逻辑和(&) | https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash | 2019-03-07T21:40:15 | [] | https://linux.cn/article-10596-1.html |
>
> 在 Bash 中,你可以使用 & 作为 AND(逻辑和)操作符。
>
>
>

有人可能会认为两篇文章中的 `&` 意思差不多,但实际上并不是。虽然 [第一篇文章讨论了如何在命令末尾使用 & 来将命令转到后台运行](/article-10587-1.html),在之后剖析了流程管理,第二篇文章将 [& 看作引用文件描述符的方法](/article-10591-1.html),这些文章让我们知道了,与 `<` 和 `>` 结合使用后,你可以将输入或输出引导到别的地方。
但我们还没接触过作为 AND 操作符使用的 `&`。所以,让我们来看看。
### & 是一个按位运算符
如果你十分熟悉二进制数操作,你肯定听说过 AND 和 OR 。这些是按位操作,对二进制数的各个位进行操作。在 Bash 中,使用 `&` 作为 AND 运算符,使用 `|` 作为 OR 运算符:
**AND**:
```
0 & 0 = 0
0 & 1 = 0
1 & 0 = 0
1 & 1 = 1
```
**OR**:
```
0 | 0 = 0
0 | 1 = 1
1 | 0 = 1
1 | 1 = 1
```
你可以通过对任何两个数字进行 AND 运算并使用 `echo` 输出结果:
```
$ echo $(( 2 & 3 )) # 00000010 AND 00000011 = 00000010
2
$ echo $(( 120 & 97 )) # 01111000 AND 01100001 = 01100000
96
```
OR(`|`)也是如此:
```
$ echo $(( 2 | 3 )) # 00000010 OR 00000011 = 00000011
3
$ echo $(( 120 | 97 )) # 01111000 OR 01100001 = 01111001
121
```
说明:
1. 使用 `(( ... ))` 告诉 Bash 双括号之间的内容是某种算术或逻辑运算。`(( 2 + 2 ))`、 `(( 5 % 2 ))` (`%` 是[求模](https://en.wikipedia.org/wiki/Modulo_operation)运算符)和 `((( 5 % 2 ) + 1))`(等于 3)都可以工作。
2. [像变量一样](https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise),使用 `$` 提取值,以便你可以使用它。
3. 空格并没有影响:`((2+3))` 等价于 `(( 2+3 ))` 和 `(( 2 + 3 ))`。
4. Bash 只能对整数进行操作。试试这样做: `(( 5 / 2 ))` ,你会得到 `2`;或者这样 `(( 2.5 & 7 ))` ,但会得到一个错误。然后,在按位操作中使用除了整数之外的任何东西(这就是我们现在所讨论的)通常是你不应该做的事情。
**提示:** 如果你想看看十进制数字在二进制下会是什么样子,你可以使用 `bc` ,这是一个大多数 Linux 发行版都预装了的命令行计算器。比如:
```
bc <<< "obase=2; 97"
```
这个操作将会把 `97` 转换成十二进制(`obase` 中的 `o` 代表 “output” ,也即,“输出”)。
```
bc <<< "ibase=2; 11001011"
```
这个操作将会把 `11001011` 转换成十进制(`ibase` 中的 `i` 代表 “input”,也即,“输入”)。
### && 是一个逻辑运算符
虽然它使用与其按位表达相同的逻辑原理,但 Bash 的 `&&` 运算符只能呈现两个结果:`1`(“真值”)和`0`(“假值”)。对于 Bash 来说,任何不是 `0` 的数字都是 “真值”,任何等于 `0` 的数字都是 “假值”。什么也是 “假值”同时也不是数字呢:
```
$ echo $(( 4 && 5 )) # 两个非零数字,两个为 true = true
1
$ echo $(( 0 && 5 )) # 有一个为零,一个为 false = false
0
$ echo $(( b && 5 )) # 其中一个不是数字,一个为 false = false
0
```
与 `&&` 类似, OR 对应着 `||` ,用法正如你想的那样。
以上这些都很简单……直到它用在命令的退出状态时。
### && 是命令退出状态的逻辑运算符
[正如我们在之前的文章中看到的](/article-10591-1.html),当命令运行时,它会输出错误消息。更重要的是,对于今天的讨论,它在结束时也会输出一个数字。此数字称为“返回码”,如果为 0,则表示该命令在执行期间未遇到任何问题。如果是任何其他数字,即使命令完成,也意味着某些地方出错了。
所以 0 意味着是好的,任何其他数字都说明有问题发生,并且,在返回码的上下文中,0 意味着“真”,其他任何数字都意味着“假”。对!这 **与你所熟知的逻辑操作完全相反** ,但是你能用这个做什么? 不同的背景,不同的规则。这种用处很快就会显现出来。
让我们继续!
返回码 *临时* 储存在 [特殊变量](https://www.gnu.org/software/bash/manual/html_node/Special-Parameters.html) `?` 中 —— 是的,我知道:这又是一个令人迷惑的选择。但不管怎样,[别忘了我们在讨论变量的文章中说过](https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise),那时我们说你要用 `$` 符号来读取变量中的值,在这里也一样。所以,如果你想知道一个命令是否顺利运行,你需要在命令结束后,在运行别的命令之前马上用 `$?` 来读取 `?` 变量的值。
试试下面的命令:
```
$ find /etc -iname "*.service"
find: '/etc/audisp/plugins.d': Permission denied
/etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service
/etc/systemd/system/dbus-org.freedesktop.ModemManager1.service
[......]
```
[正如你在上一篇文章中看到的一样](/article-10591-1.html),普通用户权限在 `/etc` 下运行 `find` 通常将抛出错误,因为它试图读取你没有权限访问的子目录。
所以,如果你在执行 `find` 后立马执行……
```
echo $?
```
……,它将打印 `1`,表明存在错误。
(注意:当你在一行中运行两遍 `echo $?` ,你将得到一个 `0` 。这是因为 `$?` 将包含第一个 `echo $?` 的返回码,而这条命令按理说一定会执行成功。所以学习如何使用 `$?` 的第一课就是: **单独执行 `$?`** 或者将它保存在别的安全的地方 —— 比如保存在一个变量里,不然你会很快丢失它。)
一个直接使用 `?` 变量的用法是将它并入一串链式命令列表,这样 Bash 运行这串命令时若有任何操作失败,后面命令将终止。例如,你可能熟悉构建和编译应用程序源代码的过程。你可以像这样手动一个接一个地运行它们:
```
$ configure
.
.
.
$ make
.
.
.
$ make install
.
.
.
```
你也可以把这三行合并成一行……
```
$ configure; make; make install
```
…… 但你要希望上天保佑。
为什么这样说呢?因为你这样做是有缺点的,比方说 `configure` 执行失败了, Bash 将仍会尝试执行 `make` 和 `sudo make install`——就算没东西可 `make` ,实际上,是没东西会安装。
聪明一点的做法是:
```
$ configure && make && make install
```
这将从每个命令中获取退出码,并将其用作链式 `&&` 操作的操作数。
但是,没什么好抱怨的,Bash 知道如果 `configure` 返回非零结果,整个过程都会失败。如果发生这种情况,不必运行 `make` 来检查它的退出代码,因为无论如何都会失败的。因此,它放弃运行 `make`,只是将非零结果传递给下一步操作。并且,由于 `configure && make` 传递了错误,Bash 也不必运行`make install`。这意味着,在一长串命令中,你可以使用 `&&` 连接它们,并且一旦失败,你可以节省时间,因为其他命令会立即被取消运行。
你可以类似地使用 `||`,OR 逻辑操作符,这样就算只有一部分命令成功执行,Bash 也能运行接下来链接在一起的命令。
鉴于所有这些(以及我们之前介绍过的内容),你现在应该更清楚地了解我们在 [这篇文章开头](/article-10587-1.html) 出现的命令行:
```
mkdir test_dir 2>/dev/null || touch backup/dir/images.txt && find . -iname "*jpg" > backup/dir/images.txt &
```
因此,假设你从具有读写权限的目录运行上述内容,它做了什么以及如何做到这一点?它如何避免不合时宜且可能导致执行中断的错误?下周,除了给你这些答案的结果,我们将讨论圆括号,不要错过了哟!
---
via: <https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zero-MK](https://github.com/zero-mk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,597 | 《贡献者许可协议》是“人魔”般的怪物? | https://opensource.com/article/19/1/cla-proliferation | 2019-03-08T08:41:00 | [
"许可证",
"CLA",
"DCA"
] | /article-10597-1.html | 
>
> 非标准的开源贡献者许可协议正在创造类似电影《冲出人魔岛》中“人魔”般的怪物。
>
>
>
当我开启作为开源律师的职业生涯时,面临的一个重要问题是需要耗时费力去分析的新形式开源许可协议的激增,正如我的同事 Scott Peterson 在其文章中所述,“[开源许可协议是共享资源](https://opensource.com/law/16/11/licenses-are-shared-resources)”:
>
> 专注于少数许可协议更有好处。通过对少数许可协议达成更广泛共识所积累的经验和讨论更容易减少不确定性,而不是在成千上百的许可协议之间进行有关行动和辩论。
>
>
>
过去多年开源社区对许可协议扩散的反应持积极态度,我很高兴看到大多数开源项目都从一组被工程师和律师熟知的许可协议(例如 GPL、LGPL、AGPL、BSD、MIT、Apache 2)中进行选择。因此,不用将时间浪费在解释许可协议条款上,完全开启了一个低摩擦的生态系统。
一旦项目采用开源许可协议,它通常采用标准的“<ruby> 入站=出站 <rp> ( </rp> <rt> inbound=outbound </rt> <rp> ) </rp></ruby>”模式,创造该短语的 Richard Fontana 将其描述为贡献者不言自明地获得出站项目适用的许可协议的许可,使得贡献者可以轻松参与项目,[无需担心繁文缛节和受到威胁](https://opensource.com/law/11/7/trouble-harmony-part-1)。这是一个非常简单的模式,能够非常聪明地进行上面提到的许可协议选择。
不幸的是,许多项目不选择采用“入站=出站”模式,而是采用某种形式的《<ruby> 贡献者许可协议 <rp> ( </rp> <rt> Contributor License Agreement </rt> <rp> ) </rp></ruby>》(CLA)。CLA 的范围和目的各不相同。读者们可以在 Ben Cotton 的文章《[CLA 与 DCO 有什么不同?](https://opensource.com/article/18/3/cla-vs-dco-whats-difference)》中具体了解《贡献者许可协议》与《<ruby> 开发者原创证书 <rp> ( </rp> <rt> Developer Certificates of Origin </rt> <rp> ) </rp></ruby>》(DCO)的区别。
采用 CLA 的项目在接受贡献之前,要求贡献者提交作为个人或所在公司签署的 CLA 存档。除非是其条款能够被工程师和其代理律师很好理解的标准 CLA(例如下文提到的 Apache 软件基金会非实质性定制的 CLA),否则因为需要非常仔细阅读 CLA 以确保能够完全理解其条款,贡献者通常放弃去深究 CLA。理解非标准 CLA 的过程需要数天或上周才能完成,具体取决于工作负荷以及是否需要与许可协议提交人进行协商。根据我的经验,最终结果是回到标准的 CLA 条款!这个曲折的过程导致大量的时间和精力被浪费。此外,CLA 需要某种形式的签名,增添了许多在大型官僚组织可能更严重的延迟性和复杂性。这并不是一条令人开心的路径,对开源/协作开发模式具有高度侵蚀性。
*请注意,当我提到“标准 CLA”时,我所指的是基于众所周知 CLA(例如 Apache 软件基金会个人或企业 CLA)的 CLA。虽然 Apache 软件基金会的 CLA 由基金会本身以其原始形式使用,但它们通常被以非实质性方式进行修改以供其他组织使用。例如,大多数组织在开始时都小心翼翼地摆脱了许可协议的慈善使命,还定制了许可协议名称。Apache 软件基金会这类非实质性变体需要与本文中描述的类似“人魔”怪物的变体区分开。*
我对最近 CLA 数量的激增表示担忧,我们似乎正在经历十年前在开源许可协议扩散方面遇到的相同现象。事实上,在过去的一年里,在我的办公桌上至少看到 20 种不同的 CLA,它们与常见的 Apache 软件基金会个人或企业 CLA 存在细微但实质性的偏差。这些偏差通常小到无助于澄清条款语言或权利,但其中有些偏差会比较大,这种混合的可憎之物让我想起了 Moreau 博士通过他的活体解剖过程创造的新动物(参见维基百科上的《[冲出人魔岛](https://en.wikipedia.org/wiki/The_Island_of_Doctor_Moreau)》)。无论偏差是小还是大,它们造成的影响可能很大,经常导致混淆、更多的审查时间以及谈判。
例如,律师普遍接受的做法是对许可协议或合同中的术语使用初始定义。无意中使用同一术语的小写形式会导致是否应该使用该术语在标准/字典中定义或协议中更窄或更宽泛定义的模糊性。尽管这对于不经意的观察者来说似乎是一个微不足道的偏差,但这通常会导致许可协议接收/授予的权限显著减少或扩大,或者导致不可接受的歧义。其他偏差起草得如此之差,以至于它们的意义不明确,因此必须彻底拒绝。
在最近的例子中,有一种 CLA 的专利许可语言以令人困惑的方式将术语<ruby> “衍生作品” <rp> ( </rp> <rt> derivative works </rt> <rp> ) </rp></ruby>包括在内,偏离了 Apache 软件基金会 CLA 版本。此 CLA 授予专利许可的范围似乎过于宽泛且可能无限制,它是如此模糊,以至于我被迫拒绝使用它。我不确定这是否是这个特定 CLA 的起草人所预期的结果,但是这次审查花费了大量的时间和成本,最终限制了我们的工程师为该项目做出贡献。这是一个令人伤心的结果,没有人从中受益。
作为一个社区,让我们从之前关于开源许可协议扩散的错误中吸取教训,采用“入站=出站”模式,最好使用 [DCO](http://developercertificate.org/) 而不是 CLA。如果您选择使用 CLA,那么强烈建议使用 Apache 软件基金会个人或企业 CLA 等标准 CLA,而不是创建新的、幻想的或荒谬的类似“人魔”怪物的许可协议。
作者简介:Jeffrey R. Kaufman 是全球领先的开源软件解决方案供应商 Red Hat 公司的开源知识产权律师,还担任<ruby> 托马斯杰斐逊法学院 <rp> ( </rp> <rt> Thomas Jefferson School of Law </rt> <rp> ) </rp></ruby>的兼职教授。在任职 Red Hat 之前,Jeffrey 曾担任<ruby> 高通公司 <rp> ( </rp> <rt> Qualcomm Incorporated </rt> <rp> ) </rp></ruby>的专利顾问,为<ruby> 首席科学家办公室 <rp> ( </rp> <rt> Office of the Chief Scientist </rt> <rp> ) </rp></ruby>提供开源事务咨询。
译者简介:薛亮,集慧智佳知识产权咨询公司总监,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,598 | Ansible 入门秘诀 | https://opensource.com/article/18/2/tips-success-when-getting-started-ansible | 2019-03-08T09:24:53 | [
"Ansible"
] | https://linux.cn/article-10598-1.html |
>
> 用 Ansible 自动化你的数据中心的关键点。
>
>
>

Ansible 是一个开源自动化工具,可以从中央控制节点统一配置服务器、安装软件或执行各种 IT 任务。它采用一对多、<ruby> 无客户端 <rt> agentless </rt></ruby>的机制,从控制节点上通过 SSH 发送指令给远端的客户机来完成任务(当然除了 SSH 外也可以用别的协议)。
Ansible 的主要使用群体是系统管理员,他们经常会周期性地执行一些安装、配置应用的工作。尽管如此,一些非特权用户也可以使用 Ansible,例如数据库管理员就可以通过 Ansible 用 `mysql` 这个用户来创建数据库、添加数据库用户、定义访问权限等。
让我们来看一个简单的使用场景,一位系统管理员每天要配置 100 台服务器,并且必须在每台机器上执行一系列 Bash 命令,然后交付给用户。

这是个简单的例子,但应该能够证明:在 yaml 文件里写好命令然后在远程服务器上运行,是一件非常轻松的事。而且如果运行环境不同,就可以加入判断条件,指明某些命令只能在特定的服务器上运行(如:只在那些不是 Ubuntu 或 Debian 的系统上运行 `yum` 命令)。
Ansible 的一个重要特性是用<ruby> 剧本 <rt> playbook </rt></ruby>来描述一个计算机系统的最终状态,所以一个剧本可以在服务器上反复执行而不影响其最终状态(LCTT 译注:即是幂等的)。如果某个任务已经被实施过了(如,“用户 `sysman` 已经存在”),那么 Ansible 就会忽略它继续执行后续的任务。
### 定义
* <ruby> 任务 <rt> task </rt></ruby>:是工作的最小单位,它可以是个动作,比如“安装一个数据库服务”、“安装一个 web 服务器”、“创建一条防火墙规则”或者“把这个配置文件拷贝到那个服务器上去”。
* <ruby> 动作 <rt> play </rt></ruby>: 由任务组成,例如,一个动作的内容是要“设置一个数据库,给 web 服务用”,这就包含了如下任务:1)安装数据库包;2)设置数据库管理员密码;3)创建数据库实例;4)为该实例分配权限。
* <ruby> 剧本 <rt> playbook </rt></ruby>:(LCTT 译注:playbook 原指美式橄榄球队的[战术手册](https://usafootball.com/football-playbook/),也常指“剧本”,此处惯例采用“剧本”译名) 由动作组成,一个剧本可能像这样:“设置我的网站,包含后端数据库”,其中的动作包括:1)设置数据库服务器;2)设置 web 服务器。
* <ruby> 角色 <rt> role </rt></ruby>:用来保存和组织剧本,以便分享和再次使用它们。还拿上个例子来说,如果你需要一个全新的 web 服务器,就可以用别人已经写好并分享出来的角色来设置。因为角色是高度可配置的(如果编写正确的话),可以根据部署需求轻松地复用它们。
* <ruby> <a href="https://galaxy.ansible.com/"> Ansible 星系 </a> <rt> Ansible Galaxy </rt></ruby>:是一个在线仓库,里面保存的是由社区成员上传的角色,方便彼此分享。它与 GitHub 紧密集成,因此这些角色可以先在 Git 仓库里组织好,然后通过 Ansible 星系分享出来。
这些定义以及它们之间的关系可以用下图来描述:

请注意上面的例子只是组织任务的方式之一,我们当然也可以把安装数据库和安装 web 服务器的剧本拆开,放到不同的角色里。Ansible 星系上最常见的角色是独立安装、配置每个应用服务,你可以参考这些安装 [mysql](https://galaxy.ansible.com/bennojoy/mysql/) 和 [httpd](https://galaxy.ansible.com/xcezx/httpd/) 的例子。
### 编写剧本的小技巧
学习 Ansible 最好的资源是其[官方文档](http://docs.ansible.com/)。另外,像学习其他东西一样,搜索引擎是你的好朋友。我推荐你从一些简单的任务开始,比如安装应用或创建用户。下面是一些有用的指南:
* 在测试的时候少选几台服务器,这样你的动作可以执行的更快一些。如果它们在一台机器上执行成功,在其他机器上也没问题。
* 总是在真正运行前做一次<ruby> 测试 <rt> dry run </rt></ruby>,以确保所有的命令都能正确执行(要运行测试,加上 `--check-mode` 参数 )。
* 尽可能多做测试,别担心搞砸。任务里描述的是所需的状态,如果系统已经达到预期状态,任务会被简单地忽略掉。
* 确保在 `/etc/ansible/hosts` 里定义的主机名都可以被正确解析。
* 因为是用 SSH 与远程主机通信,主控节点必须要能接受密钥,所以你面临如下选择:1)要么在正式使用之前就做好与远程主机的密钥交换工作;2)要么在开始管理某台新的远程主机时做好准备输入 “Yes”,因为你要接受对方的 SSH 密钥交换请求(LCTT 译注:还有另一个不那么安全的选择,修改主控节点的 ssh 配置文件,将 `StrictHostKeyChecking` 设置成 “no”)。
* 尽管你可以在同一个剧本内把不同 Linux 发行版的任务整合到一起,但为每个发行版单独编写剧本会更明晰一些。
### 总结一下
Ansible 是你在数据中心里实施运维自动化的好选择,因为它:
* 无需客户端,所以比其他自动化工具更易安装。
* 将指令保存在 YAML 文件中(虽然也支持 JSON),比写 shell 脚本更简单。
* 开源,因此你也可以做出自己的贡献,让它更加强大!
你是怎样使用 Ansible 让数据中心更加自动化的呢?请在评论中分享您的经验。
---
via: <https://opensource.com/article/18/2/tips-success-when-getting-started-ansible>
作者:[Jose Delarosa](https://opensource.com/users/jdelaros1) 译者:[jdh8383](https://github.com/jdh8383) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ansible is an open source automation tool used to configure servers, install software, and perform a wide variety of IT tasks from one central location. It is a one-to-many agentless mechanism where all instructions are run from a control machine that communicates with remote clients over SSH, although other protocols are also supported.
While targeted for system administrators with privileged access who routinely perform tasks such as installing and configuring applications, Ansible can also be used by non-privileged users. For example, a database administrator using the `mysql`
login ID could use Ansible to create databases, add users, and define access-level controls.
Let's go over a very simple example where a system administrator provisions 100 servers each day and must run a series of Bash commands on each one before handing it off to users.
opensource.com
This is a simple example, but should illustrate how easily commands can be specified in yaml files and executed on remote servers. In a heterogeneous environment, conditional statements can be added so that certain commands are only executed in certain servers (e.g., "only execute `yum`
commands in systems that are not Ubuntu or Debian").
One important feature in Ansible is that a playbook describes a *desired* state in a computer system, so a playbook can be run multiple times against a server without impacting its state. If a certain task has already been implemented (e.g., "user `sysman`
already exists"), then Ansible simply ignores it and moves on.
## Definitions
**Tasks:****Plays:****Playbook:****Roles:****Ansible Galaxy:**[Galaxy](https://galaxy.ansible.com/)is an online repository where roles are uploaded so they can be shared with others. It is integrated with GitHub, so roles can be organized into Git repositories and then shared via Ansible Galaxy.
These definitions and their relationships are depicted here:
opensource.com
Please note this is just one way to organize the tasks that need to be executed. We could have split up the installation of the database and the web server into separate playbooks and into different roles. Most roles in Ansible Galaxy install and configure individual applications. You can see examples for installing [mysql](https://galaxy.ansible.com/bennojoy/mysql/) and installing [httpd](https://galaxy.ansible.com/xcezx/httpd/).
## Tips for writing playbooks
The best source for learning Ansible is the official [documentation](http://docs.ansible.com/) site. And, as usual, online search is your friend. I recommend starting with simple tasks, like installing applications or creating users. Once you are ready, follow these guidelines:
- When testing, use a small subset of servers so that your plays execute faster. If they are successful in one server, they will be successful in others.
- Always do a dry run to make sure all commands are working (run with
`--check-mode`
flag). - Test as often as you need to without fear of breaking things. Tasks describe a desired state, so if a desired state is already achieved, it will simply be ignored.
- Be sure all host names defined in
`/etc/ansible/hosts`
are resolvable. - Because communication to remote hosts is done using SSH, keys have to be accepted by the control machine, so either 1) exchange keys with remote hosts prior to starting; or 2) be ready to type in "Yes" to accept SSH key exchange requests for each remote host you want to manage.
- Although you can combine tasks for different Linux distributions in one playbook, it's cleaner to write a separate playbook for each distro.
## In the final analysis
Ansible is a great choice for implementing automation in your data center:
- It's agentless, so it is simpler to install than other automation tools.
- Instructions are in YAML (though JSON is also supported) so it's easier than writing shell scripts.
- It's open source software, so contribute back to it and make it even better!
How have you used Ansible to automate your data center? Share your experience in the comments.
## 4 Comments |
10,600 | 在 Ubuntu 上自动化安装基本应用的方法 | https://www.ostechnix.com/an-automated-way-to-install-essential-applications-on-ubuntu/ | 2019-03-08T23:28:39 | [
"Ubuntu"
] | https://linux.cn/article-10600-1.html | 
默认安装的 Ubuntu 并未预先安装所有必需的应用。你可能需要在网上花几个小时或者向其他 Linux 用户寻求帮助才能找到并安装 Ubuntu 所需的应用。如果你是新手,那么你肯定需要花更多的时间来学习如何从命令行(使用 `apt-get` 或 `dpkg`)或从 Ubuntu 软件中心搜索和安装应用。一些用户,特别是新手,可能希望轻松快速地安装他们喜欢的每个应用。如果你是其中之一,不用担心。在本指南中,我们将了解如何使用名为 “Alfred” 的简单命令行程序在 Ubuntu 上安装基本应用。
Alfred 是用 Python 语言编写的自由、开源脚本。它使用 Zenity 创建了一个简单的图形界面,用户只需点击几下鼠标即可轻松选择和安装他们选择的应用。你不必花费数小时来搜索所有必要的应用程序、PPA、deb、AppImage、snap 或 flatpak。Alfred 将所有常见的应用、工具和小程序集中在一起,并自动安装所选的应用。如果你是最近从 Windows 迁移到 Ubuntu Linux 的新手,Alfred 会帮助你在新安装的 Ubuntu 系统上进行无人值守的软件安装,而无需太多用户干预。请注意,还有一个名称相似的 Mac OS 应用,但两者有不同的用途。
### 在 Ubuntu 上安装 Alfred
Alfred 安装很简单!只需下载脚本并启动它。就这么简单。
```
$ wget https://raw.githubusercontent.com/derkomai/alfred/master/alfred.py
$ python3 alfred.py
```
或者,使用 `wget` 下载脚本,如上所示,只需将 `alfred.py` 移动到 `$PATH` 中:
```
$ sudo cp alfred.py /usr/local/bin/alfred
```
使其可执行:
```
$ sudo chmod +x /usr/local/bin/alfred
```
并使用命令启动它:
```
$ alfred
```
### 使用 Alfred 脚本轻松快速地在 Ubuntu 上安装基本应用程序
按照上面所说启动 Alfred 脚本。这就是 Alfred 默认界面的样子。

如你所见,Alfred 列出了许多最常用的应用类型,例如:
* 网络浏览器,
* 邮件客户端,
* 消息,
* 云存储客户端,
* 硬件驱动程序,
* 编解码器,
* 开发者工具,
* Android,
* 文本编辑器,
* Git,
* 内核更新工具,
* 音频/视频播放器,
* 截图工具,
* 录屏工具,
* 视频编码器,
* 流媒体应用,
* 3D 建模和动画工具,
* 图像查看器和编辑器,
* CAD 软件,
* PDF 工具,
* 游戏模拟器,
* 磁盘管理工具,
* 加密工具,
* 密码管理器,
* 存档工具,
* FTP 软件,
* 系统资源监视器,
* 应用启动器等。
你可以选择任何一个或多个应用并立即安装它们。在这里,我将安装 “Developer bundle”,因此我选择它并单击 OK 按钮。

现在,Alfred 脚本将自动你的 Ubuntu 系统上添加必要仓库、PPA 并开始安装所选的应用。

安装完成后,你将看到以下消息。

恭喜你!已安装选定的软件包。
你可以使用以下命令[在 Ubuntu 上查看最近安装的应用](https://www.ostechnix.com/list-installed-packages-sorted-installation-date-linux/):
```
$ grep " install " /var/log/dpkg.log
```
你可能需要重启系统才能使用某些已安装的应用。类似地,你可以方便地安装列表中的任何程序。
提示一下,还有一个由不同的开发人员编写的类似脚本,名为 `post_install.sh`。它与 Alfred 完全相同,但提供了一些不同的应用。请查看以下链接获取更多详细信息。
* [Ubuntu Post Installation Script](https://www.ostechnix.com/ubuntu-post-installation-script/)
这两个脚本能让懒惰的用户,特别是新手,只需点击几下鼠标就能够轻松快速地安装他们想要在 Ubuntu Linux 中使用的大多数常见应用、工具、更新、小程序,而无需依赖官方或者非官方文档的帮助。
就是这些了。希望这篇文章有用。还有更多好东西。敬请期待!
干杯!
---
via: <https://www.ostechnix.com/an-automated-way-to-install-essential-applications-on-ubuntu/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,601 | 预约 Emacs 心理医生 | https://opensource.com/article/18/12/linux-toy-eliza | 2019-03-09T08:53:41 | [
"Emacs",
"医生"
] | https://linux.cn/article-10601-1.html |
>
> Eliza 是一个隐藏于某个 Linux 最流行文本编辑器中的自然语言处理聊天机器人。
>
>
>

欢迎你,今天时期 24 天的 Linux 命令行玩具的又一天。如果你是第一次访问本系列,你可能会问什么是命令行玩具呢。我们将会逐步确定这个概念,但一般来说,它可能是一个游戏,或任何能让你在终端玩的开心的其他东西。
可能你们已经见过了很多我们之前挑选的那些玩具,但我们依然希望对所有人来说都至少有一件新鲜事物。
今天的选择是 Emacs 中的一个彩蛋:Eliza,Rogerian 心理医生,一个准备好倾听你述说一切的终端玩具。
旁白:虽然这个玩具很好玩,但你的健康不是用来开玩笑的。请在假期期间照顾好你自己,无论时身体上还是精神上,若假期中的压力和焦虑对你的健康产生负面影响,请考虑找专业人士进行指导。真的有用。
要启动 [Eliza](https://www.emacswiki.org/emacs/EmacsDoctor),首先,你需要启动 Emacs。很有可能 Emacs 已经安装在你的系统中了,但若没有,它基本上也肯定在你默认的软件仓库中。
由于我要求本系列的工具一定要时运行在终端内,因此使用 `-nw` 标志来启动 Emacs 让它在你的终端模拟器中运行。
```
$ emacs -nw
```
在 Emacs 中,输入 `M-x doctor` 来启动 Eliza。对于像我这样有 Vim 背景的人可能不知道这是什么意思,只需要按下 `escape`,输入 `x` 然后输入 `doctor`。然后,向它倾述所有假日的烦恼吧。
Eliza 历史悠久,最早可以追溯到 1960 年代中期的 MIT 人工智能实验室。[维基百科](https://en.wikipedia.org/wiki/ELIZA) 上有它历史的详细说明。
Eliza 并不是 Emacs 中唯一的娱乐工具。查看 [手册](https://www.gnu.org/software/emacs/manual/html_node/emacs/Amusements.html) 可以看到一整列好玩的玩具。

你有什么喜欢的命令行玩具值得推荐吗?我们时间不多了,但我还是想听听你的建议。请在下面评论中告诉我,我会查看的。另外也欢迎告诉我你们对本次玩具的想法。
请一定要看看昨天的玩具,[带着这个复刻版吃豆人来到 Linux 终端游乐中心](https://opensource.com/article/18/12/linux-toy-myman),然后明天再来看另一个玩具!
---
via: <https://opensource.com/article/18/12/linux-toy-eliza>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome to another day of the 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
Today's selection is a hidden gem inside of Emacs: Eliza, the Rogerian psychotherapist, a terminal toy ready to listen to everything you have to say.
*A brief aside: While this toy is amusing, your health is no laughing matter. Please take care of yourself this holiday season, physically and mentally, and if stress and anxiety from the holidays are having a negative impact on your wellbeing, please consider seeing a professional for guidance. It really can help.*
To launch [Eliza](https://www.emacswiki.org/emacs/EmacsDoctor), first, you'll need to launch Emacs. There's a good chance Emacs is already installed on your system, but if it's not, it's almost certainly in your default repositories.
Since I've been pretty fastidious about keeping this series in the terminal, launch Emacs with the **-****nw** flag to keep in within your terminal emulator.
`$ emacs -nw`
Inside of Emacs, type M-x doctor to launch Eliza. For those of you like me from a Vim background who have no idea what this means, just hit escape, type x and then type doctor. Then, share all of your holiday frustrations.
Eliza goes way back, all the way to the mid-1960s a the MIT Artificial Intelligence Lab. [Wikipedia](https://en.wikipedia.org/wiki/ELIZA) has a rather fascinating look at her history.
Eliza isn't the only amusement inside of Emacs. Check out the [manual](https://www.gnu.org/software/emacs/manual/html_node/emacs/Amusements.html) for a whole list of fun toys.
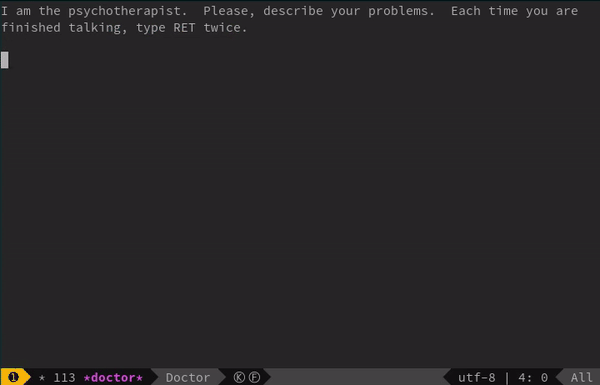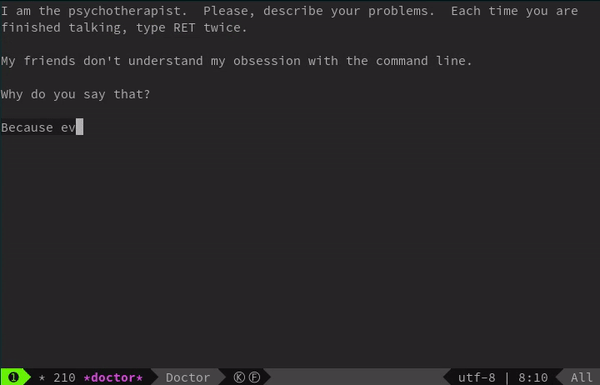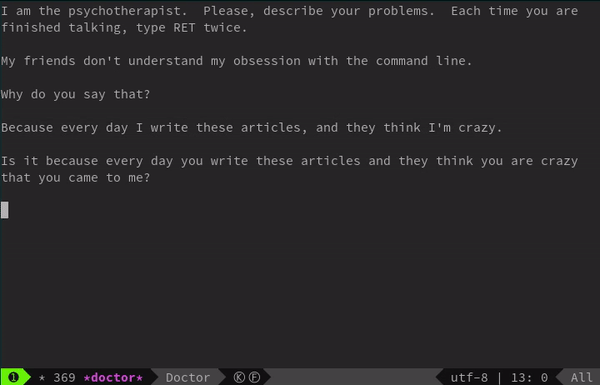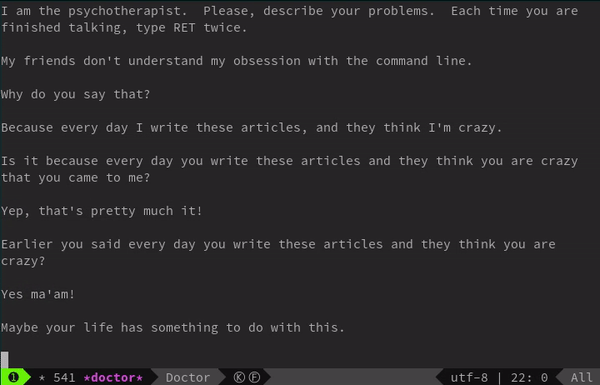
Do you have a favorite command-line toy that you think I ought to profile? We're running out of time, but I'd still love to hear your suggestions. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
Be sure to check out yesterday's toy, [Head to the arcade in your Linux terminal with this Pac-man clone](https://opensource.com/article/18/12/linux-toy-myman), and come back tomorrow for another!
## Comments are closed. |
10,602 | Midori:轻量级开源 Web 浏览器 | https://itsfoss.com/midori-browser | 2019-03-09T09:12:56 | [
"浏览器",
"Midori"
] | https://linux.cn/article-10602-1.html |
>
> 这是一个对再次回归的轻量级、快速、开源的 Web 浏览器 Midori 的快速回顾。
>
>
>
如果你正在寻找一款轻量级[网络浏览器替代品](https://itsfoss.com/open-source-browsers-linux/),请试试 Midori。
[Midori](https://www.midori-browser.org/)是一款开源的网络浏览器,它更注重轻量级而不是提供大量功能。
如果你从未听说过 Midori,你可能会认为它是一个新的应用程序,但实际上 Midori 首次发布于 2007 年。
因为它专注于速度,所以 Midori 很快就聚集了一群爱好者,并成为了 Bodhi Linux、SilTaz 等轻量级 Linux 发行版的默认浏览器。
其他发行版如 [elementary OS](https://itsfoss.com/elementary-os-juno-features/) 也使用了 Midori 作为其默认浏览器。但 Midori 的开发在 2016 年左右停滞了,它的粉丝开始怀疑 Midori 已经死了。由于这个原因,elementary OS 从最新版本中删除了它。
好消息是 Midori 还没有死。经过近两年的不活跃,开发工作在 2018 年的最后一个季度恢复了。在后来的版本中添加了一些包括广告拦截器的扩展。
### Midori 网络浏览器的功能

以下是 Midori 浏览器的一些主要功能
* 使用 Vala 编写,使用 GTK+3 和 WebKit 渲染引擎。 \* 标签、窗口和会话管理。 \* 快速拨号。 \* 默认保存下一个会话的选项卡。 \* 使用 DuckDuckGo 作为默认搜索引擎。可以更改为 Google 或 Yahoo。 \* 书签管理。 \* 可定制和可扩展的界面。 \* 扩展模块可以用 C 和 Vala 编写。 \* 支持 HTML5。 \* 少量的扩展程序包括广告拦截器、彩色标签等。没有第三方扩展程序。 \* 表单历史。 \* 隐私浏览。 \* 可用于 Linux 和 Windows。
小知识:Midori 是日语单词,意思是绿色。如果你因此而猜想的话,但 Midori 的开发者实际不是日本人。
### 体验 Midori

这几天我一直在使用 Midori。体验基本很好。它支持 HTML5 并能快速渲染网站。广告拦截器也没问题。正如你对任何标准 Web 浏览器所期望的那样,浏览体验挺顺滑。
缺少扩展一直是 Midori 的弱点,所以我不打算谈论这个。
我注意到的是它不支持国际语言。我找不到添加新语言支持的方法。它根本无法渲染印地语字体,我猜对其他非[罗曼语言](https://en.wikipedia.org/wiki/Romance_languages)也是一样。
我也在 YouTube 中也遇到了麻烦。有些视频会抛出播放错误而其他视频没问题。
Midori 没有像 Chrome 那样吃我的内存,所以这是一个很大的优势。
如果你想尝试 Midori,让我们看下你该如何安装。
### 在 Linux 上安装 Midori
在 Ubuntu 18.04 仓库中不再提供 Midori。但是,可以使用 [Snap 包](https://itsfoss.com/use-snap-packages-ubuntu-16-04/)轻松安装较新版本的 Midori。
如果你使用的是 Ubuntu,你可以在软件中心找到 Midori(Snap 版)并从那里安装。

对于其他 Linux 发行版,请确保你[已启用 Snap 支持](https://itsfoss.com/install-snap-linux/),然后你可以使用以下命令安装 Midori:
```
sudo snap install midori
```
你可以选择从源代码编译。你可以从 Midori 的网站下载它的代码。
* [下载 Midori](https://www.midori-browser.org/download/)
如果你喜欢 Midori 并希望帮助这个开源项目,请向他们捐赠或[从他们的商店购买 Midori 商品](https://www.midori-browser.org/shop)。
你在使用 Midori 还是曾经用过么?你的体验如何?你更喜欢使用哪种其他网络浏览器?请在下面的评论栏分享你的观点。
---
via: <https://itsfoss.com/midori-browser>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,603 | Python 七步捉虫法 | https://opensource.com/article/19/2/steps-hunting-code-python-bugs | 2019-03-10T11:21:00 | [
"Python",
"调试",
"debug"
] | https://linux.cn/article-10603-1.html |
>
> 了解一些技巧助你减少代码查错时间。
>
>
>

在周五的下午三点钟(为什么是这个时间?因为事情总会在周五下午三点钟发生),你收到一条通知,客户发现你的软件出现一个错误。在有了初步的怀疑后,你联系运维,查看你的软件日志以了解发生了什么,因为你记得收到过日志已经搬家了的通知。
结果这些日志被转移到了你获取不到的地方,但它们正在导入到一个网页应用中——所以到时候你可以用这个漂亮的应用来检索日志,但是,这个应用现在还没完成。这个应用预计会在几天内完成。我知道,你觉得这完全不切实际。然而并不是,日志或者日志消息似乎经常在错误的时间消失不见。在我们开始查错前,一个忠告:经常检查你的日志以确保它们还在你认为它们应该在的地方,并记录你认为它们应该记的东西。当你不注意的时候,这些东西往往会发生令人惊讶的变化。
好的,你找到了日志或者尝试了呼叫运维人员,而客户确实发现了一个错误。甚至你可能认为你已经知道错误在哪儿。
你立即打开你认为可能有问题的文件并开始查错。
### 1、先不要碰你的代码
阅读代码,你甚至可能会想到该阅读哪些部分。但是在开始搞乱你的代码前,请重现导致错误的调用并把它变成一个测试。这将是一个集成测试,因为你可能还有其他疑问,目前你还不能准确地知道问题在哪儿。
确保这个测试结果是失败的。这很重要,因为有时你的测试不能重现失败的调用,尤其是你使用了可以混淆测试的 web 或者其他框架。很多东西可能被存储在变量中,但遗憾的是,只通过观察测试,你在测试里调用的东西并不总是明显可见的。当我尝试着重现这个失败的调用时,我并不是说我要创建一个可以通过的测试,但是,好吧,我确实是创建了一个测试,但我不认为这特别不寻常。
>
> 从自己的错误中吸取教训。
>
>
>
### 2、编写错误的测试
现在,你有了一个失败的测试,或者可能是一个带有错误的测试,那么是时候解决问题了。但是在你开干之前,让我们先检查下调用栈,因为这样可以更轻松地解决问题。
调用栈包括你已经启动但尚未完成地所有任务。因此,比如你正在烤蛋糕并准备往面糊里加面粉,那你的调用栈将是:
* 做蛋糕
* 打面糊
* 加面粉
你已经开始做蛋糕,开始打面糊,而你现在正在加面粉。往锅底抹油不在这个列表中,因为你已经完成了,而做糖霜不在这个列表上因为你还没开始做。
如果你对调用栈不清楚,我强烈建议你使用 [Python Tutor](http://www.pythontutor.com/),它能帮你在执行代码时观察调用栈。
现在,如果你的 Python 程序出现了错误, Python 解释器会帮你打印出当前调用栈。这意味着无论那一时刻程序在做什么,很明显错误发生在调用栈的底部。
### 3、始终先检查调用栈底部
在栈底你不仅能看到发生了哪个错误,而且通常可以在调用栈的最后一行发现问题。如果栈底对你没有帮助,而你的代码还没有经过代码分析,那么使用代码分析是非常有用的。我推荐 pylint 或者 flake8。通常情况下,它会指出我一直忽略的错误的地方。
如果错误看起来很迷惑,你下一步行动可能是用 Google 搜索它。如果你搜索的内容不包含你的代码的相关信息,如变量名、文件等,那你将获得更好的搜索结果。如果你使用的是 Python 3(你应该使用它),那么搜索内容包含 Python 3 是有帮助的,否则 Python 2 的解决方案往往会占据大多数。
很久以前,开发者需要在没有搜索引擎的帮助下解决问题。那是一段黑暗时光。充分利用你可以使用的所有工具。
不幸的是,有时候问题发生在更早阶段,但只有在调用栈底部执行的地方才显现出来。就像当蛋糕没有膨胀时,忘记加发酵粉的事才被发现。
那就该检查整个调用栈。问题更可能在你的代码而不是 Python 标准库或者第三方包,所以先检查调用栈内你的代码。另外,在你的代码中放置断点通常会更容易检查代码。在调用栈的代码中放置断点,然后看看周围是否如你预期。
“但是,玛丽,”我听到你说,“如果我有一个调用栈,那这些都是有帮助的,但我只有一个失败的测试。我该从哪里开始?”
pdb,一个 Python 调试器。
找到你代码里会被这个调用命中的地方。你应该能够找到至少一个这样的地方。在那里打上一个 pdb 的断点。
#### 一句题外话
为什么不使用 `print` 语句呢?我曾经依赖于 `print` 语句。有时候,它们仍然很方便。但当我开始处理复杂的代码库,尤其是有网络调用的代码库,`print` 语句就变得太慢了。我最终在各种地方都加上了 `print` 语句,但我没法追踪它们的位置和原因,而且变得更复杂了。但是主要使用 pdb 还有一个更重要的原因。假设你添加一条 `print` 语句去发现错误问题,而且 `print` 语句必须早于错误出现的地方。但是,看看你放 `print` 语句的函数,你不知道你的代码是怎么执行到那个位置的。查看代码是寻找调用路径的好方法,但看你以前写的代码是恐怖的。是的,我会用 `grep` 处理我的代码库以寻找调用函数的地方,但这会变得乏味,而且搜索一个通用函数时并不能缩小搜索范围。pdb 就变得非常有用。
你遵循我的建议,打上 pdb 断点并运行你的测试。然而测试再次失败,但是没有任何一个断点被命中。留着你的断点,并运行测试套件中一个同这个失败的测试非常相似的测试。如果你有个不错的测试套件,你应该能够找到一个这样的测试。它会命中了你认为你的失败测试应该命中的代码。运行这个测试,然后当它运行到你的断点,按下 `w` 并检查调用栈。如果你不知道如何查看因为其他调用而变得混乱的调用栈,那么在调用栈的中间找到属于你的代码,并在堆栈中该代码的上一行放置一个断点。再试一次新的测试。如果仍然没命中断点,那么继续,向上追踪调用栈并找出你的调用在哪里脱轨了。如果你一直没有命中断点,最后到了追踪的顶部,那么恭喜你,你发现了问题:你的应用程序名称拼写错了。
>
> 没有经验,小白,一点都没有经验。
>
>
>
### 4、修改代码
如果你仍觉得迷惑,在你稍微改变了一些的地方尝试新的测试。你能让新的测试跑起来么?有什么是不同的呢?有什么是相同的呢?尝试改变一下别的东西。当你有了你的测试,以及可能也还有其它的测试,那就可以开始安全地修改代码了,确定是否可以缩小问题范围。记得从一个新提交开始解决问题,以便于可以轻松地撤销无效地更改。(这就是版本控制,如果你没有使用过版本控制,这将会改变你的生活。好吧,可能它只是让编码更容易。查阅“[版本控制可视指南](https://betterexplained.com/articles/a-visual-guide-to-version-control/)”,以了解更多。)
### 5、休息一下
尽管如此,当它不再感觉起来像一个有趣的挑战或者游戏而开始变得令人沮丧时,你最好的举措是脱离这个问题。休息一下。我强烈建议你去散步并尝试考虑别的事情。
### 6、把一切写下来
当你回来了,如果你没有突然受到启发,那就把你关于这个问题所知的每一个点信息写下来。这应该包括:
* 真正造成问题的调用
* 真正发生了什么,包括任何错误信息或者相关的日志信息
* 你真正期望发生什么
* 到目前为止,为了找出问题,你做了什么工作;以及解决问题中你发现的任何线索。
有时这里有很多信息,但相信我,从零碎中挖掘信息是很烦人。所以尽量简洁,但是要完整。
### 7、寻求帮助
我经常发现写下所有信息能够启迪我想到还没尝试过的东西。当然,有时候我在点击求助邮件(或表单)的提交按钮后立刻意识到问题是是什么。无论如何,当你在写下所有东西仍一无所获时,那就试试向他人发邮件求助。首先是你的同事或者其他参与你的项目的人,然后是该项目的邮件列表。不要害怕向人求助。大多数人都是友善和乐于助人的,我发现在 Python 社区里尤其如此。
Maria McKinley 已在 [PyCascades 2019](https://2019.pycascades.com/) 演讲 [代码查错](https://2019.pycascades.com/talks/hunting-the-bugs),2 月 23-24,于西雅图。
---
via: <https://opensource.com/article/19/2/steps-hunting-code-python-bugs>
作者:[Maria Mckinley](https://opensource.com/users/parody) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LazyWolfLin](https://github.com/LazyWolfLin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It is 3 pm on a Friday afternoon. Why? Because it is always 3 pm on a Friday when things go down. You get a notification that a customer has found a bug in your software. After you get over your initial disbelief, you contact DevOps to find out what is happening with the logs for your app, because you remember receiving a notification that they were being moved.
Turns out they are somewhere you can't get to, but they are in the process of being moved to a web application—so you will have this nifty application for searching and reading them, but of course, it is not finished yet. It should be up in a couple of days. I know, totally unrealistic situation, right? Unfortunately not; it seems logs or log messages often come up missing at just the wrong time. Before we track down the bug, a public service announcement: Check your logs to make sure they are where you think they are and logging what you think they should log, regularly. Amazing how these things just change when you aren't looking.
OK, so you found the logs or tried the call, and indeed, the customer has found a bug. Maybe you even think you know where the bug is.
You immediately open the file you think might be the problem and start poking around.
## 1. Don't touch your code yet
Go ahead and look at it, maybe even come up with a hypothesis. But before you start mucking about in the code, take that call that creates the bug and turn it into a test. This will be an integration test because although you may have suspicions, you do not yet know exactly where the problem is.
Make sure this test fails. This is important because sometimes the test you make doesn't mimic the broken call; this is especially true if you are using a web or other framework that can obfuscate the tests. Many things may be stored in variables, and it is unfortunately not always obvious, just by looking at the test, what call you are making in the test. I'm not going to say that I have created a test that passed when I was trying to imitate a broken call, but, well, I have, and I don't think that is particularly unusual. Learn from my mistakes.
## 2. Write a failing test
Now that you have a failing test or maybe a test with an error, it is time to troubleshoot. But before you do that, let's do a review of the stack, as this makes troubleshooting easier.
The stack consists of all of the tasks you have started but not finished. So, if you are baking a cake and adding the flour to the batter, then your stack would be:
- Make cake
- Make batter
- Add flour
You have started making your cake, you have started making the batter, and you are adding the flour. Greasing the pan is not on the list since you already finished that, and making the frosting is not on the list because you have not started that.
If you are fuzzy on the stack, I highly recommend playing around on [Python Tutor](http://www.pythontutor.com/), where you can watch the stack as you execute lines of code.
Now, if something goes wrong with your Python program, the interpreter helpfully prints out the stack for you. This means that whatever the program was doing at the moment it became apparent that something went wrong is on the bottom.
## 3. Always check the bottom of the stack first
Not only is the bottom of the stack where you can see which error occurred, but often the last line of the stack is where you can find the issue. If the bottom doesn't help, and your code has not been linted in a while, it is amazing how helpful it can be to run. I recommend pylint or flake8. More often than not, it points right to where there is an error that I have been overlooking.
If the error is something that seems obscure, your next move might just be to Google it. You will have better luck if you don't include information that is relevant only to your code, like the name of variables, files, etc. If you are using Python 3 (which you should be), it's helpful to include the 3 in the search; otherwise, Python 2 solutions tend to dominate the top.
Once upon a time, developers had to troubleshoot without the benefit of a search engine. This was a dark time. Take advantage of all the tools available to you.
Unfortunately, sometimes the problem occurred earlier and only became apparent during the line executed on the bottom of the stack. Think about how forgetting to add the baking powder becomes obvious when the cake doesn't rise.
It is time to look up the stack. Chances are quite good that the problem is in your code, and not Python core or even third-party packages, so scan the stack looking for lines in your code first. Plus it is usually much easier to put a breakpoint in your own code. Stick the breakpoint in your code a little further up the stack and look around to see if things look like they should.
"But Maria," I hear you say, "this is all helpful if I have a stack trace, but I just have a failing test. Where do I start?"
Pdb, the Python Debugger.
Find a place in your code where you know this call should hit. You should be able to find at least one place. Stick a pdb break in there.
### A digression
Why not a print statement? I used to depend on print statements. They still come in handy sometimes. But once I started working with complicated code bases, and especially ones making network calls, print just became too slow. I ended up with print statements all over the place, I lost track of where they were and why, and it just got complicated. But there is a more important reason to mostly use pdb. Let's say you put a print statement in and discover that something is wrong—and must have gone wrong earlier. But looking at the function where you put the print statement, you have no idea how you got there. Looking at code is a great way to see where you are going, but it is terrible for learning where you've been. And yes, I have done a grep of my code base looking for where a function is called, but this can get tedious and doesn't narrow it down much with a popular function. Pdb can be very helpful.
You follow my advice, and put in a pdb break and run your test. And it whooshes on by and fails again, with no break at all. Leave your breakpoint in, and run a test already in your test suite that does something very similar to the broken test. If you have a decent test suite, you should be able to find a test that is hitting the same code you think your failed test should hit. Run that test, and when it gets to your breakpoint, do a `w`
and look at the stack. If you have no idea by looking at the stack how/where the other call may have gone haywire, then go about halfway up the stack, find some code that belongs to you, and put a breakpoint in that file, one line above the one in the stack trace. Try again with the new test. Keep going back and forth, moving up the stack to figure out where your call went off the rails. If you get all the way up to the top of the trace without hitting a breakpoint, then congratulations, you have found the issue: Your app was spelled wrong. No experience here, nope, none at all.
## 4. Change things
If you still feel lost, try making a new test where you vary something slightly. Can you get the new test to work? What is different? What is the same? Try changing something else. Once you have your test, and maybe additional tests in place, it is safe to start changing things in the code to see if you can narrow down the problem. Remember to start troubleshooting with a fresh commit so you can easily back out changes that do not help. (This is a reference to version control, if you aren't using version control, it will change your life. Well, maybe it will just make coding easier. See "[A Visual Guide to Version Control](https://betterexplained.com/articles/a-visual-guide-to-version-control/)" for a nice introduction.)
## 5. Take a break
In all seriousness, when it stops feeling like a fun challenge or game and starts becoming really frustrating, your best course of action is to walk away from the problem. Take a break. I highly recommend going for a walk and trying to think about something else.
## 6. Write everything down
When you come back, if you aren't suddenly inspired to try something, write down any information you have about the problem. This should include:
- Exactly the call that is causing the problem
- Exactly what happened, including any error messages or related log messages
- Exactly what you were expecting to happen
- What you have done so far to find the problem and any clues that you have discovered while troubleshooting
Sometimes this is a lot of information, but trust me, it is really annoying trying to pry information out of someone piecemeal. Try to be concise, but complete.
## 7. Ask for help
I often find that just writing down all the information triggers a thought about something I have not tried yet. Sometimes, of course, I realize what the problem is immediately after hitting the *submit* button. At any rate, if you still have not thought of anything after writing everything down, try sending an email to someone. First, try colleagues or other people involved in your project, then move on to project email lists. Don't be afraid to ask for help. Most people are kind and helpful, and I have found that to be especially true in the Python community.
*Maria McKinley will present Hunting the Bugs at PyCascades 2019, February 23-24 in Seattle.*
## Comments are closed. |
10,604 | 在 Emacs 上配置 Anaconda | https://idevji.com/configure-anaconda-on-emacs/ | 2019-03-10T11:43:55 | [
"Anaconda",
"Emacs"
] | https://linux.cn/article-10604-1.html | 
也许我所追求的究极 IDE 就是 [Emacs](https://www.gnu.org/software/emacs/) 了。我的目标是使 Emacs 成为一款全能的 Python IDE。本文描述了如何在 Emacs 上配置 Anaconda。(LCTT 译注:Anaconda 自称“世界上最流行的 Python/R 的数据分析平台”)
我的配置信息:
* OS:Trisquel 8.0
* Emacs:GNU Emacs 25.3.2
快捷键说明([参见完全指南](https://www.math.uh.edu/%7Ebgb/emacs_keys.html)):
```
C-x = Ctrl + x
M-x = Alt + x
RET = ENTER
```
### 1、下载并安装 Anaconda
#### 1.1 下载
[从这儿](https://www.anaconda.com/download/#linux) 下载 Anaconda。你应该下载 Python 3.x 的版本,因为 Python 2 在 2020 年就不再支持了。你无需预先安装 Python 3.x。这个安装脚本会自动安装它。
#### 1.2 安装
```
cd ~/Downloads
bash Anaconda3-2018.12-Linux-x86.sh
```
### 2、将 Anaconda 添加到 Emacs
#### 2.1 将 MELPA 添加到 Emacs
我们需要用到 `anaconda-mode` 这个 Emacs 包。该包位于 MELPA 仓库中。Emacs25 需要手工添加该仓库。
* [注意:点击本文查看如何将 MELPA 添加到 Emacs](https://melpa.org/#/getting-started)
#### 2.2 为 Emacs 安装 anaconda-mode 包
```
M-x package-install RET
anaconda-mode RET
```
#### 2.3 为 Emacs 配置 anaconda-mode
```
echo "(add-hook 'python-mode-hook 'anaconda-mode)" > ~/.emacs.d/init.el
```
### 3、在 Emacs 上通过 Anaconda 运行你第一个脚本
#### 3.1 创建新 .py 文件
```
C-x C-f
HelloWorld.py RET
```
#### 3.2 输入下面代码
```
print ("Hello World from Emacs")
```
#### 3.3 运行之
```
C-c C-p
C-c C-c
```
输出为:
```
Python 3.7.1 (default, Dec 14 2018, 19:46:24)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> python.el: native completion setup loaded
>>> Hello World from Emacs
>>>
```
我是受到 [Codingquark](https://codingquark.com) 的影响才开始使用 Emacs 的。
有任何错误和遗漏请在评论中写下。干杯!
---
via: <https://idevji.com/configure-anaconda-on-emacs/>
作者:[Devji Chhanga](https://idevji.com/author/admin/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,605 | 计算机实验室之树莓派:课程 9 屏幕04 | https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html | 2019-03-10T20:59:01 | [
"树莓派"
] | https://linux.cn/article-10605-1.html | 
屏幕04 课程基于屏幕03 课程来构建,它教你如何操作文本。假设你已经有了[课程 8:屏幕03](/article-10585-1.html) 的操作系统代码,我们将以它为基础。
### 1、操作字符串
能够绘制文本是极好的,但不幸的是,现在你只能绘制预先准备好的字符串。如果能够像命令行那样显示任何东西才是完美的,而理想情况下应该是,我们能够显示任何我们期望的东西。一如既往地,如果我们付出努力而写出一个非常好的函数,它能够操作我们所希望的所有字符串,而作为回报,这将使我们以后写代码更容易。曾经如此复杂的函数,在 C 语言编程中只不过是一个 `sprintf` 而已。这个函数基于给定的另一个字符串和作为描述的额外的一个参数而生成一个字符串。我们对这个函数感兴趣的地方是,这个函数是个变长函数。这意味着它可以带可变数量的参数。参数的数量取决于具体的格式字符串,因此它的参数的数量不能预先确定。
>
> 变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
>
>
>
这个完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
函数通过读取格式化字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数的返回值是写入的字符数。如果方法失败,将返回一个负数。
表 1.1 sprintf 格式化规则
| 选项 | 含义 |
| --- | --- |
| 除了 `%` 之外的任何支付 | 复制字符到输出。 |
| `%%` | 写一个 % 字符到输出。 |
| `%c` | 将下一个参数写成字符格式。 |
| `%d` 或 `%i` | 将下一个参数写成十进制的有符号整数。 |
| `%e` | 将下一个参数写成科学记数法,使用 eN,意思是 ×10<sup> N</sup>。 |
| `%E` | 将下一个参数写成科学记数法,使用 EN,意思是 ×10<sup> N</sup>。 |
| `%f` | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
| `%g` | 与 `%e` 和 `%f` 的指数表示形式相同。 |
| `%G` | 与 `%E` 和 `%f` 的指数表示形式相同。 |
| `%o` | 将下一个参数写成八进制的无符号整数。 |
| `%s` | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
| `%u` | 将下一个参数写成十进制无符号整数。 |
| `%x` | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
| `%X` | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
| `%p` | 将下一个参数写成指针地址。 |
| `%n` | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
除此之外,对序列还有许多额外的处理,比如指定最小长度,符号等等。更多信息可以在 [sprintf - C++ 参考](http://www.cplusplus.com/reference/clibrary/cstdio/sprintf/) 上找到。
下面是调用方法和返回的结果的示例。
表 1.2 sprintf 调用示例
| 格式化字符串 | 参数 | 结果 |
| --- | --- | --- |
| `"%d"` | 13 | 13 |
| `"+%d degrees"` | 12 | +12 degrees |
| `"+%x degrees"` | 24 | +1c degrees |
| `"'%c' = 0%o"` | 65, 65 | ‘A’ = 0101 |
| `"%d * %d%% = %d"` | 200, 40, 80 | 200 \* 40% = 80 |
| `"+%d degrees"` | -5 | +-5 degrees |
| `"+%u degrees"` | -5 | +4294967291 degrees |
希望你已经看到了这个函数是多么有用。实现它需要大量的编程工作,但给我们的回报却是一个非常有用的函数,可以用于各种用途。
### 2、除法
虽然这个函数看起来很强大、也很复杂。但是,处理它的许多情况的最容易的方式可能是,编写一个函数去处理一些非常常见的任务。它是个非常有用的函数,可以为任何底的一个有符号或无符号的数字生成一个字符串。那么,我们如何去实现呢?在继续阅读之前,尝试快速地设计一个算法。
>
> 除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
>
>
>
最简单的方法或许就是我在 [课程 1:OK01](/article-10458-1.html) 中提到的“除法余数法”。它的思路如下:
1. 用当前值除以你使用的底。
2. 保存余数。
3. 如果得到的新值不为 0,转到第 1 步。
4. 将余数反序连起来就是答案。
例如:
表 2.1 以 2 为底的例子
转换
| 值 | 新值 | 余数 |
| --- | --- | --- |
| 137 | 68 | 1 |
| 68 | 34 | 0 |
| 34 | 17 | 0 |
| 17 | 8 | 1 |
| 8 | 4 | 0 |
| 4 | 2 | 0 |
| 2 | 1 | 0 |
| 1 | 0 | 1 |
因此答案是 10001001<sub> 2</sub>
这个过程的不幸之外在于使用了除法。所以,我们必须首先要考虑二进制中的除法。
我们复习一下长除法
>
> 假如我们想把 4135 除以 17。
>
>
>
> ```
> 0243 r 4
> 17)4135
> 0 0 × 17 = 0000
> 4135 4135 - 0 = 4135
> 34 200 × 17 = 3400
> 735 4135 - 3400 = 735
> 68 40 × 17 = 680
> 55 735 - 680 = 55
> 51 3 × 17 = 51
> 4 55 - 51 = 4
> ```
>
> 答案:243 余 4
>
>
> 首先我们来看被除数的最高位。我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
>
>
> 接下来我们看被除数倒数第二位和所有的高位。我们看到小于或等于那个数的除数的最小倍数是 34。我们在结果中写一个 2,和减去 3400。
>
>
> 接下来我们看被除数的第三位和所有高位。我们看到小于或等于那个数的除数的最小倍数是 68。我们在结果中写一个 4,和减去 680。
>
>
> 最后,我们看一下所有的余位。我们看到小于余数的除数的最小倍数是 51。我们在结果中写一个 3,减去 51。减法的结果就是我们的余数。
>
>
>
在汇编代码中做除法,我们将实现二进制的长除法。我们之所以实现它是因为,数字都是以二进制方式保存的,这让我们很容易地访问所有重要位的移位操作,并且因为在二进制中做除法比在其它高进制中做除法都要简单,因为它的数更少。
```
1011 r 1
1010)1101111
1010
11111
1010
1011
1010
1
```
这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 1101111<sub> 2</sub> ÷ 1010<sub> 2</sub> = 1011<sub> 2</sub> 余数为 1<sub> 2</sub>。用十进制表示就是,111 ÷ 10 = 11 余 1。
你自己尝试去实现这个长除法。你应该去写一个函数 `DivideU32` ,其中 `r0` 是被除数,而 `r1` 是除数,在 `r0` 中返回结果,在 `r1` 中返回余数。下面,我们将完成一个有效的实现。
```
function DivideU32(r0 is dividend, r1 is divisor)
set shift to 31
set result to 0
while shift ≥ 0
if dividend ≥ (divisor << shift) then
set dividend to dividend - (divisor << shift)
set result to result + 1
end if
set result to result << 1
set shift to shift - 1
loop
return (result, dividend)
end function
```
这段代码实现了我们的目标,但却不能用于汇编代码。我们出现的问题是,我们的寄存器只能保存 32 位,而 `divisor << shift` 的结果可能在一个寄存器中装不下(我们称之为溢出)。这确实是个问题。你的解决方案是否有溢出的问题呢?
幸运的是,有一个称为 `clz`(<ruby> 计数前导零 <rt> count leading zeros </rt></ruby>)的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 `divisor << shift` 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
我们来看一下进一步优化之后的汇编代码。
```
.globl DivideU32
DivideU32:
result .req r0
remainder .req r1
shift .req r2
current .req r3
clz shift,r1
lsl current,r1,shift
mov remainder,r0
mov result,#0
divideU32Loop$:
cmp shift,#0
blt divideU32Return$
cmp remainder,current
addge result,result,#1
subge remainder,current
sub shift,#1
lsr current,#1
lsl result,#1
b divideU32Loop$
divideU32Return$:
.unreq current
mov pc,lr
.unreq result
.unreq remainder
.unreq shift
```
你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 `clz` 命令并从中减去它来改进。在 `1 ÷ 1` 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
>
> `clz dest,src` 将第一个寄存器 `dest` 中二进制表示的值的前导零的数量,保存到第二个寄存器 `src` 中。
>
>
>
```
.globl DivideU32
DivideU32:
result .req r0
remainder .req r1
shift .req r2
current .req r3
clz shift,r1
clz r3,r0
subs shift,r3
lsl current,r1,shift
mov remainder,r0
mov result,#0
blt divideU32Return$
divideU32Loop$:
cmp remainder,current
blt divideU32LoopContinue$
add result,result,#1
subs remainder,current
lsleq result,shift
beq divideU32Return$
divideU32LoopContinue$:
subs shift,#1
lsrge current,#1
lslge result,#1
bge divideU32Loop$
divideU32Return$:
.unreq current
mov pc,lr
.unreq result
.unreq remainder
.unreq shift
```
复制上面的代码到一个名为 `maths.s` 的文件中。
### 3、数字字符串
现在,我们已经可以做除法了,我们来看一下另外的一个将数字转换为字符串的实现。下列的伪代码将寄存器中的一个数字转换成以 36 为底的字符串。根据惯例,a % b 表示 a 被 b 相除之后的余数。
```
function SignedString(r0 is value, r1 is dest, r2 is base)
if value ≥ 0
then return UnsignedString(value, dest, base)
otherwise
if dest > 0 then
setByte(dest, '-')
set dest to dest + 1
end if
return UnsignedString(-value, dest, base) + 1
end if
end function
function UnsignedString(r0 is value, r1 is dest, r2 is base)
set length to 0
do
set (value, rem) to DivideU32(value, base)
if rem > 10
then set rem to rem + '0'
otherwise set rem to rem - 10 + 'a'
if dest > 0
then setByte(dest + length, rem)
set length to length + 1
while value > 0
if dest > 0
then ReverseString(dest, length)
return length
end function
function ReverseString(r0 is string, r1 is length)
set end to string + length - 1
while end > start
set temp1 to readByte(start)
set temp2 to readByte(end)
setByte(start, temp2)
setByte(end, temp1)
set start to start + 1
set end to end - 1
end while
end function
```
上述代码实现在一个名为 `text.s` 的汇编文件中。记住,如果你遇到了困难,可以在下载页面找到完整的解决方案。
### 4、格式化字符串
我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 `a % b` 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 `%s` 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
实现这个函数的一个主要的障碍是它的参数个数是可变的。根据 ABI 规定,额外的参数在调用方法之前以相反的顺序先推送到栈上。比如,我们使用 8 个参数 1、2、3、4、5、6、7 和 8 来调用我们的方法,我们将按下面的顺序来处理:
1. 设置 r0 = 5、r1 = 6、r2 = 7、r3 = 8
2. 推入 {r0,r1,r2,r3}
3. 设置 r0 = 1、r1 = 2、r2 = 3、r3 = 4
4. 调用函数
5. 将 sp 和 #4\*4 加起来
现在,我们必须确定我们的函数确切需要的参数。在我的案例中,我将寄存器 `r0` 用来保存格式化字符串地址,格式化字符串长度则放在寄存器 `r1` 中,目标字符串地址放在寄存器 `r2` 中,紧接着是要求的参数列表,从寄存器 `r3` 开始和像上面描述的那样在栈上继续。如果你想去使用一个空终止符格式化字符串,在寄存器 r1 中的参数将被移除。如果你想有一个最大缓冲区长度,你可以将它保存在寄存器 `r3` 中。由于有额外的修改,我认为这样修改函数是很有用的,如果目标字符串地址为 0,意味着没有字符串被输出,但如果仍然返回一个精确的长度,意味着能够精确的判断格式化字符串的长度。
如果你希望尝试实现你自己的函数,现在就可以去做了。如果不去实现你自己的,下面我将首先构建方法的伪代码,然后给出实现的汇编代码。
```
function StringFormat(r0 is format, r1 is formatLength, r2 is dest, ...)
set index to 0
set length to 0
while index < formatLength
if readByte(format + index) = '%' then
set index to index + 1
if readByte(format + index) = '%' then
if dest > 0
then setByte(dest + length, '%')
set length to length + 1
otherwise if readByte(format + index) = 'c' then
if dest > 0
then setByte(dest + length, nextArg)
set length to length + 1
otherwise if readByte(format + index) = 'd' or 'i' then
set length to length + SignedString(nextArg, dest, 10)
otherwise if readByte(format + index) = 'o' then
set length to length + UnsignedString(nextArg, dest, 8)
otherwise if readByte(format + index) = 'u' then
set length to length + UnsignedString(nextArg, dest, 10)
otherwise if readByte(format + index) = 'b' then
set length to length + UnsignedString(nextArg, dest, 2)
otherwise if readByte(format + index) = 'x' then
set length to length + UnsignedString(nextArg, dest, 16)
otherwise if readByte(format + index) = 's' then
set str to nextArg
while getByte(str) != '\0'
if dest > 0
then setByte(dest + length, getByte(str))
set length to length + 1
set str to str + 1
loop
otherwise if readByte(format + index) = 'n' then
setWord(nextArg, length)
end if
otherwise
if dest > 0
then setByte(dest + length, readByte(format + index))
set length to length + 1
end if
set index to index + 1
loop
return length
end function
```
虽然这个函数很大,但它还是很简单的。大多数的代码都是在检查所有各种条件,每个代码都是很简单的。此外,所有的无符号整数的大小写都是相同的(除了底以外)。因此在汇编中可以将它们汇总。下面是它的汇编代码。
```
.globl FormatString
FormatString:
format .req r4
formatLength .req r5
dest .req r6
nextArg .req r7
argList .req r8
length .req r9
push {r4,r5,r6,r7,r8,r9,lr}
mov format,r0
mov formatLength,r1
mov dest,r2
mov nextArg,r3
add argList,sp,#7*4
mov length,#0
formatLoop$:
subs formatLength,#1
movlt r0,length
poplt {r4,r5,r6,r7,r8,r9,pc}
ldrb r0,[format]
add format,#1
teq r0,#'%'
beq formatArg$
formatChar$:
teq dest,#0
strneb r0,[dest]
addne dest,#1
add length,#1
b formatLoop$
formatArg$:
subs formatLength,#1
movlt r0,length
poplt {r4,r5,r6,r7,r8,r9,pc}
ldrb r0,[format]
add format,#1
teq r0,#'%'
beq formatChar$
teq r0,#'c'
moveq r0,nextArg
ldreq nextArg,[argList]
addeq argList,#4
beq formatChar$
teq r0,#'s'
beq formatString$
teq r0,#'d'
beq formatSigned$
teq r0,#'u'
teqne r0,#'x'
teqne r0,#'b'
teqne r0,#'o'
beq formatUnsigned$
b formatLoop$
formatString$:
ldrb r0,[nextArg]
teq r0,#0x0
ldreq nextArg,[argList]
addeq argList,#4
beq formatLoop$
add length,#1
teq dest,#0
strneb r0,[dest]
addne dest,#1
add nextArg,#1
b formatString$
formatSigned$:
mov r0,nextArg
ldr nextArg,[argList]
add argList,#4
mov r1,dest
mov r2,#10
bl SignedString
teq dest,#0
addne dest,r0
add length,r0
b formatLoop$
formatUnsigned$:
teq r0,#'u'
moveq r2,#10
teq r0,#'x'
moveq r2,#16
teq r0,#'b'
moveq r2,#2
teq r0,#'o'
moveq r2,#8
mov r0,nextArg
ldr nextArg,[argList]
add argList,#4
mov r1,dest
bl UnsignedString
teq dest,#0
addne dest,r0
add length,r0
b formatLoop$
```
### 5、一个转换操作系统
你可以使用这个方法随意转换你希望的任何东西。比如,下面的代码将生成一个换算表,可以做从十进制到二进制到十六进制到八进制以及到 ASCII 的换算操作。
删除 `main.s` 文件中 `bl SetGraphicsAddress` 之后的所有代码,然后粘贴以下的代码进去。
```
mov r4,#0
loop$:
ldr r0,=format
mov r1,#formatEnd-format
ldr r2,=formatEnd
lsr r3,r4,#4
push {r3}
push {r3}
push {r3}
push {r3}
bl FormatString
add sp,#16
mov r1,r0
ldr r0,=formatEnd
mov r2,#0
mov r3,r4
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
bl DrawString
add r4,#16
b loop$
.section .data
format:
.ascii "%d=0b%b=0x%x=0%o='%c'"
formatEnd:
```
你能在测试之前推算出将发生什么吗?特别是对于 `r3 ≥ 128` 会发生什么?尝试在树莓派上运行它,看看你是否猜对了。如果不能正常运行,请查看我们的排错页面。
如果一切顺利,恭喜你!你已经完成了屏幕04 教程,屏幕系列的课程结束了!我们学习了像素和帧缓冲的知识,以及如何将它们应用到树莓派上。我们学习了如何绘制简单的线条,也学习如何绘制字符,以及将数字格式化为文本的宝贵技能。我们现在已经拥有了在一个操作系统上进行图形输出的全部知识。你可以写出更多的绘制方法吗?三维绘图是什么?你能实现一个 24 位帧缓冲吗?能够从命令行上读取帧缓冲的大小吗?
接下来的课程是[输入](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html)系列课程,它将教我们如何使用键盘和鼠标去实现一个传统的计算机控制台。
---
via: <https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html>
作者:[Alex Chadwick](https://www.cl.cam.ac.uk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Raspberry Pi
# Lesson 9 Screen04
The Screen04 lesson builds on Screen03, by teaching how to manipulate text. It is
assumed you have the code for the [Lesson 8: Screen03](screen03.html)
operating system as a basis.
## 1 String Manipulation
Variadic functions look much less intuitive in assembly code. Nevertheless, they are useful and powerful concepts.
Being able to draw text is lovely, but unfortunately at the moment you can only draw strings which are already prepared. This is fine for displaying something like the command line, but ideally we would like to be able to display and text we so desire. As per usual, if we put the effort in and make an excellent function that does all the string manipulation we could ever want, we get much easier code later on in return. Once such complicated function in C programming is sprintf. This function generates a string based on a description given as another string and additional arguments. What is interesting about this function is that it is variadic. This means that it takes a variable number of parameters. The number of parameters depends on the exact format string, and so cannot be determined in advance.
The full function has many options, and I list a few here. I've highlighted the ones which we will implement in this tutorial, though you can try to implement more.
The function works by reading the format string, and then interpreting it using the table below. Once an argument is used, it is not considered again. The return value of the function is the number of characters written. If the method fails, a negative number is returned.
Sequence | Meaning |
---|---|
Any character except %
|
Copies the character to the output. |
%% | Writes a % character to the output. |
%c | Writes the next argument as a character. |
%d or %i
|
Writes the next argument as a base 10 signed integer. |
%e |
Writes the next argument in scientific notation using eN to mean
×10.
N |
%E |
Writes the next argument in scientific notation using EN to mean
×10.
N |
%f | Writes the next argument as a decimal IEEE 754 floating point number. |
%g | Same as the shorter of %e and %f. |
%G | Same as the shorter of %E and %f. |
%o | Writes the next argument as a base 8 unsigned integer. |
%s | Writes the next argument as if it were a pointer to a null terminated string. |
%u | Writes the next argument as a base 10 unsigned integer. |
%x | Writes the next argument as a base 16 unsigned integer, with lowercase a,b,c,d,e and f. |
%X | Writes the next argument as a base 16 unsigned integer, with uppercase A,B,C,D,E and F. |
%p | Writes the next argument as a pointer address. |
%n | Writes nothing. Copies instead the number of characters written so far to the location addressed by the next argument. |
Further to the above, many additional tweaks exist to the sequences, such as specifying
minimum length, signs, etc. More information can be found at [
sprintf - C++ Reference](http://www.cplusplus.com/reference/clibrary/cstdio/sprintf/).
Here are a few examples of calls to the method and their results to illustrate its use.
Format String | Arguments | Result |
---|---|---|
"%d" | 13 | "13" |
"+%d degrees" | 12 | "+12 degrees" |
"+%x degrees" | 24 | "+1c degrees" |
"'%c' = 0%o" | 65, 65 | "'A' = 0101" |
"%d * %d%% = %d" | 200, 40, 80 | "200 * 40% = 80" |
"+%d degrees" | -5 | "+-5 degrees" |
"+%u degrees" | -5 | "+4294967291 degrees" |
Hopefully you can already begin to see the usefulness of the function. It does take a fair amount of work to program, but our reward is a very general function we can use for all sorts of purposes.
## 2 Division
Division is the slowest and most complicated of the basic mathematical operators. It is not implemented directly in ARM assembly code because it takes so long to deduce the answer, and so isn't a 'simple' operation.
While this function does look very powerful, it also looks very complicated. The easiest way to deal with its many cases is probably to write functions to deal with some common tasks it has. What would be useful would be a function to generate the string for a signed and an unsigned number in any base. So, how can we go about doing that? Try to devise an algorithm quickly before reading on.
The easiest way is probably the exact way I mentioned in [Lesson 1:
OK01](ok01.html), which is the division remainder method. The idea is the following:
- Divide the current value by the base you're working in.
- Store the remainder.
- If the new value is not 0, go to 1.
- Reverse the order of the remainders. This is the answer.
For example:
Value | New Value | Remainder |
---|---|---|
137 | 68 | 1 |
68 | 34 | 0 |
34 | 17 | 0 |
17 | 8 | 1 |
8 | 4 | 0 |
4 | 2 | 0 |
2 | 1 | 0 |
1 | 0 | 1 |
So the answer is 100010012
The unfortunate part about this procedure is that it unavoidably uses division. Therefore, we must first contemplate division in binary.
For a refresher on long division expand the box below.
To implement division in assembly code, we will implement binary long division. We do this because the numbers are stored in binary, which gives us easy access to the all important bit shift operations, and because division in binary is simpler than in any higher base due to the much lower number of cases.
```
1011 r 1
1010)1101111
1010
11111
1010
1011
1010
1
```
This example shows how binary long division works. You simply shift the divisor
as far right as possible without exceeding the dividend, output a 1 according to
the poisition and subtract the number. Whatever remains is the remainder. In this
case we show 11011112 ÷ 10102 = 10112 remainder
12. In decimal, 111 ÷ 10 = 11 remainder 1.
Try to implement long division yourself now. You should write a function, DivideU32 which divides r0 by r1, returning the result in r0, and the remainder in r1. Below, we will go through a very efficient implementation.
function DivideU32(r0 is
dividend, r1 is divisor)
set shift to 31
set result to 0
while shift ≥ 0
if dividend ≥ (divisor << shift)
then
set dividend to dividend
- (divisor << shift)
set result to result +
1
end if
set result to result <<
1
set shift to shift - 1
loop
return (result, dividend)
end function
This code does achieve what we need, but would not work as assembly code. Our problem comes from the fact that our registers only hold 32 bits, and so the result of divisor << shift may not fit in a register (we call this overflow). This is a real problem. Did your solution have overflow?
Fortunately, an instruction exists called clz or count leading zeros, which counts the number of zeros in the binary representation of a number starting at the top bit. Conveniently, this is exactly the number of times we can shift the register left before overflow occurs. Another optimisation you may spot is that we compute divisor << shift twice each loop. We could improve upon this by shifting the divisor at the beginning, then shifting it down at the end of each loop to avoid any need to shift it elsewhere.
Let's have a look at the assembly code to make further improvements.
.globl DivideU32
DivideU32:
result .req r0
remainder .req r1
shift .req r2
current .req r3
clz shift,r1
lsl current,r1,shift
mov remainder,r0
mov result,#0
divideU32Loop$:
cmp shift,#0
blt divideU32Return$
cmp remainder,current
addge result,result,#1
subge remainder,current
sub shift,#1
lsr current,#1
lsl result,#1
b divideU32Loop$
divideU32Return$:
.unreq current
mov pc,lr
.unreq result
.unreq remainder
.unreq shift
clz dest,src stores the number of zeros from the top to the first one of register dest to register src
You may, quite rightly, think that this looks quite efficient. It is pretty good, but division is a very expensive operation, and one we may wish to do quite often, so it would be good if we could improve the speed in any way. When looking to optimise code with a loop in it, it is always important to consider how many times the loop must run. In this case, the loop will run a maximum of 31 times for an input of 1. Without making special cases, this could often be improved easily. For example when dividing 1 by 1, no shift is required, yet we shift the divisor to each of the positions above it. This could be improved by simply using the new clz command on the dividend and subtracting this from the shift. In the case of 1 ÷ 1, this means shift would be set to 0, rightly indicating no shift is required. If this causes the shift to be negative, the divisor is bigger than the dividend and so we know the result is 0 remainder the dividend. Another quick check we could make is if the current value is ever 0, then we have a perfect division and can stop looping.
.globl DivideU32
DivideU32:
result .req r0
remainder .req r1
shift .req r2
current .req r3
clz shift,r1
clz r3,r0
subs shift,r3
lsl current,r1,shift
mov remainder,r0
mov result,#0
blt divideU32Return$
divideU32Loop$:
cmp remainder,current
blt divideU32LoopContinue$
add result,result,#1
subs remainder,current
lsleq result,shift
beq divideU32Return$
divideU32LoopContinue$:
subs shift,#1
lsrge current,#1
lslge result,#1
bge divideU32Loop$
divideU32Return$:
.unreq current
mov pc,lr
.unreq result
.unreq remainder
.unreq shift
Copy the code above to a file called 'maths.s'.
## 3 Number Strings
Now that we can do division, let's have another look at implementing number to string conversion. The following is pseudo code to convert numbers from registers into strings in up to base 36. By convention, a % b means the remainder of dividing a by b.
function SignedString(r0 is
value, r1 is dest, r2 is
base)
if value ≥ 0
then return UnsignedString(value, dest, base)
otherwise
if dest > 0 then
setByte(dest, '-')
set dest to dest + 1
end if
return UnsignedString(-value, dest, base) + 1
end if
end function
function UnsignedString(r0 is
value, r1 is dest, r2 is
base)
set length to 0
do
set (value, rem) to DivideU32(value,
base)
if rem > 10
then set rem to rem +
'0'
otherwise set rem to rem
- 10 + 'a'
if dest > 0
then setByte(dest + length, rem)
set length to length +
1
while value > 0
if dest > 0
then ReverseString(dest, length)
return length
end function
function ReverseString(r0 is
string, r1 is length)
set end to string + length
- 1
while end > start
set temp1 to readByte(start)
set temp2 to readByte(end)
setByte(start, temp2)
setByte(end, temp1)
set start to start + 1
set end to end - 1
end while
end function
In a file called 'text.s' implement the above. Remember that if you get stuck, a full solution can be found on the downloads page.
## 4 Format Strings
Let's get back to our string formatting method. Since we're programming our own operating system, we can add or change formatting rules as we please. We may find it useful to add a %b operation that outputs a number in binary, and if you're not using null terminated strings, you may wish to alter the behaviour of %s to take the length of the string from another argument, or from a length prefix if you wish. I will use a null terminator in the example below.
One of the main obstacles to implementing this function is that the number of arguments varies. According to the ABI, additional arguments are pushed onto the stack before calling the method in reverse order. So, for example, if we wish to call our method with 8 parameters; 1,2,3,4,5,6,7 and 8, we would do the following:
- Set r0 = 5, r1 = 6, r2 = 7, r3 = 8
- Push {r0,r1,r2,r3}
- Set r0 = 1, r1 = 2, r2 = 3, r3 = 4
- Call the function
- Add sp,#4*4
Now we must decide what arguments our function actually needs. In my case, I used the format string address in r0, the length of the format string in r1, the destination string address in r2, followed by the list of arguments required, starting in r3 and continuing on the stack as above. If you wish to use a null terminated format string, the parameter in r1 can be removed. If you wish to have a maximum buffer length, you could store this in r3. As an additional modification, I think it is useful to alter the function so that if the destination string address is 0, no string is outputted, but an accurate length is still returned, so that the length of a formatted string can be accurately determined.
If you wish to attempt the implementation on your own, try it now. If not, I will first construct the pseudo code for the method, then give the assembly code implementation.
function StringFormat(r0 is
format, r1 is formatLength, r2 is
dest, ...)
set index to 0
set length to 0
while index < formatLength
if readByte(format + index) = '%'
then
set index to index + 1
if readByte(format + index) = '%'
then
if dest > 0
then setByte(dest + length, '%')
set length to length +
1
otherwise if readByte(format + index) = 'c'
then
if dest > 0
then setByte(dest + length, nextArg)
set length to length +
1
otherwise if readByte(format + index) = 'd'
or 'i' then
set length to length +
SignedString(nextArg, dest, 10)
otherwise if readByte(format + index) = 'o'
then
set length to length +
UnsignedString(nextArg, dest, 8)
otherwise if readByte(format + index) = 'u'
then
set length to length +
UnsignedString(nextArg, dest, 10)
otherwise if readByte(format + index) = 'b'
then
set length to length +
UnsignedString(nextArg, dest, 2)
otherwise if readByte(format + index) = 'x'
then
set length to length +
UnsignedString(nextArg, dest, 16)
otherwise if readByte(format + index) = 's'
then
set str to nextArg
while getByte(str) != '\0'
if dest > 0
then setByte(dest + length, getByte(str))
set length to length +
1
set str to str + 1
loop
otherwise if readByte(format + index) = 'n'
then
setWord(nextArg, length)
end if
otherwise
if dest > 0
then setByte(dest + length, readByte(format + index))
set length to length +
1
end if
set index to index + 1
loop
return length
end function
Although this function is massive, it is quite straightforward. Most of the code goes into checking all the various conditions, the code for each one is simple. Further, all the various unsigned integer cases are the same but for the base, and so can be summarised in assembly. This is given below.
.globl FormatString
FormatString:
format .req r4
formatLength .req r5
dest .req r6
nextArg .req r7
argList .req r8
length .req r9
push {r4,r5,r6,r7,r8,r9,lr}
mov format,r0
mov formatLength,r1
mov dest,r2
mov nextArg,r3
add argList,sp,#7*4
mov length,#0
formatLoop$:
subs formatLength,#1
movlt r0,length
poplt {r4,r5,r6,r7,r8,r9,pc}
ldrb r0,[format]
add format,#1
teq r0,#'%'
beq formatArg$
formatChar$:
teq dest,#0
strneb r0,[dest]
addne dest,#1
add length,#1
b formatLoop$
formatArg$:
subs formatLength,#1
movlt r0,length
poplt {r4,r5,r6,r7,r8,r9,pc}
ldrb r0,[format]
add format,#1
teq r0,#'%'
beq formatChar$
teq r0,#'c'
moveq r0,nextArg
ldreq nextArg,[argList]
addeq argList,#4
beq formatChar$
teq r0,#'s'
beq formatString$
teq r0,#'d'
beq formatSigned$
teq r0,#'u'
teqne r0,#'x'
teqne r0,#'b'
teqne r0,#'o'
beq formatUnsigned$
b formatLoop$
formatString$:
ldrb r0,[nextArg]
teq r0,#0x0
ldreq nextArg,[argList]
addeq argList,#4
beq formatLoop$
add length,#1
teq dest,#0
strneb r0,[dest]
addne dest,#1
add nextArg,#1
b formatString$
formatSigned$:
mov r0,nextArg
ldr nextArg,[argList]
add argList,#4
mov r1,dest
mov r2,#10
bl SignedString
teq dest,#0
addne dest,r0
add length,r0
b formatLoop$
formatUnsigned$:
teq r0,#'u'
moveq r2,#10
teq r0,#'x'
moveq r2,#16
teq r0,#'b'
moveq r2,#2
teq r0,#'o'
moveq r2,#8
mov r0,nextArg
ldr nextArg,[argList]
add argList,#4
mov r1,dest
bl UnsignedString
teq dest,#0
addne dest,r0
add length,r0
b formatLoop$
## 5 Convert OS
Feel free to try using this method however you wish. As an example, here is the code to generate a conversion chart from base 10 to binary to hexadecimal to octal and to ASCII.
Delete all code after bl SetGraphicsAddress in 'main.s' and replace it with the following:
mov r4,#0
loop$:
ldr r0,=format
mov r1,#formatEnd-format
ldr r2,=formatEnd
lsr r3,r4,#4
push {r3}
push {r3}
push {r3}
push {r3}
bl FormatString
add sp,#16
mov r1,r0
ldr r0,=formatEnd
mov r2,#0
mov r3,r4
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
bl DrawString
add r4,#16
b loop$
.section .data
format:
.ascii "%d=0b%b=0x%x=0%o='%c'"
formatEnd:
Can you work out what will happen before testing? Particularly what happens for r3 ≥ 128? Try it on the Raspberry Pi to see if you're right. If it doesn't work, please see our troubleshooting page.
When it does work, congratulations, you've completed the Screen04 tutorial, and reached the end of the screen series! We've learned about pixels and frame buffers, and how these apply to the Raspberry Pi. We've learned how to draw simple lines, and also how to draw characters, as well as the invaluable skill of formatting numbers into text. We now have all that you would need to make graphical output on an Operating System. Can you make some more drawing methods? What about 3D graphics? Can you implement a 24bit frame buffer? What about reading the size of the framebuffer in from the command line?
The next series is the [Input](input01.html) series, which teaches how
to use the keyboard and mouse to really get towards a traditional console computer. |
10,607 | 让 Linux 启动更快 | https://opensource.com/article/19/1/booting-linux-faster | 2019-03-11T15:01:09 | [
"启动",
"引导"
] | /article-10607-1.html |
>
> 进行 Linux 内核与固件开发的时候,往往需要多次的重启,会浪费大把的时间。
>
>
>

在所有我拥有或使用过的电脑中,启动最快的那台是 20 世纪 80 年代的电脑。在你把手从电源键移到键盘上的时候,BASIC 解释器已经在等待你输入命令了。对于现代的电脑,启动时间从笔记本电脑的 15 秒到小型家庭服务器的数分钟不等。为什么它们的启动时间有差别?
那台直接启动到 BASIC 命令行提示符的 20 世纪 80 年代微电脑,有着一颗非常简单的 CPU,它在通电的时候就立即开始从一个内存地址中获取和执行指令。因为这些系统的 BASIC 在 ROM 里面,基本不需要载入的时间——你很快就进到 BASIC 命令提示符中了。同时代更加复杂的系统,比如 IBM PC 或 Macintosh,需要一段可观的时间来启动(大约 30 秒),尽管这主要是因为需要从软盘上读取操作系统的缘故。在可以加载操作系统之前,只有很小一部分时间是花费在固件上的。
现代服务器往往在从磁盘上读取操作系统之前,在固件上花费了数分钟而不是数秒。这主要是因为现代系统日益增加的复杂性。CPU 不再能够只是运行起来就开始全速执行指令,我们已经习惯于 CPU 频率变化、节省能源的待机状态以及 CPU 多核。实际上,在现代 CPU 内部有数量惊人的更简单的处理器,它们协助主 CPU 核心启动并提供运行时服务,比如在过热的时候压制频率。在绝大多数 CPU 架构中,在你的 CPU 内的这些核心上运行的代码都以不透明的二进制 blob 形式提供。
在 OpenPOWER 系统上,所有运行在 CPU 内部每个核心的指令都是开源的。在有 [OpenBMC](https://en.wikipedia.org/wiki/OpenBMC)(比如 IBM 的 AC922 系统和 Raptor 的 TALOS II 以及 Blackbird 系统)的机器上,这还延伸到了运行在<ruby> 基板管理控制器 <rt> Baseboard Management Controller </rt></ruby>上的代码。这就意味着我们可以一探究竟,到底为什么从接入电源线到显示出熟悉的登录界面花了这么长时间。
如果你是内核相关团队的一员,你可能启动过许多内核。如果你是固件相关团队的一员,你可能要启动许多不同的固件映像,接着是一个操作系统,来确保你的固件仍能工作。如果我们可以减少硬件的启动时间,这些团队可以更有生产力,并且终端用户在搭建系统或重启安装固件或系统更新的时候会对此表示感激。
过去的几年,Linux 发行版的启动时间已经做了很多改善。现代的初始化系统在处理并行和按需任务上做得很好。在一个现代系统上,一旦内核开始执行,它可以在短短数秒内进入登录提示符界面。这里短短的数秒不是优化启动时间的下手之处,我们要到更早的地方:在我们到达操作系统之前。
在 OpenPOWER 系统上,固件通过启动一个存储在固件闪存芯片上的 Linux 内核来加载操作系统,它运行一个叫做 [Petitboot](https://github.com/open-power/petitboot) 的用户态程序去寻找用户想要启动的系统所在磁盘,并通过 [kexec](https://en.wikipedia.org/wiki/Kexec) 启动它。有了这些优化,启动 Petitboot 环境只占了启动时间的百分之几,所以我们还得从其他地方寻找优化项。
在 Petitboot 环境启动前,有一个先导固件,叫做 [Skiboot](https://github.com/open-power/skiboot),在它之前有个 [Hostboot](https://github.com/open-power/hostboot)。在 Hostboot 之前是 [Self-Boot Engine](https://github.com/open-power/sbe),一个晶圆切片(die)上的单独核心,它启动单个 CPU 核心并执行来自 Level 3 缓存的指令。这些组件是我们可以在减少启动时间上取得进展的主要部分,因为它们花费了启动的绝大部分时间。或许这些组件中的一部分没有进行足够的优化或尽可能做到并行?
另一个研究路径是重启时间而不是启动时间。在重启的时候,我们真的需要对所有硬件重新初始化吗?
正如任何现代系统那样,改善启动(或重启)时间的方案已经变成了更多的并行执行、解决遗留问题、(可以认为)作弊的结合体。
---
via: <https://opensource.com/article/19/1/booting-linux-faster>
作者:[Stewart Smith](https://opensource.com/users/stewart-ibm) 选题:[lujun9972](https://github.com/lujun9972) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,608 | Akira 是我们一直想要的 Linux 设计工具吗? | https://itsfoss.com/akira-design-tool | 2019-03-11T15:19:13 | [
"设计",
"软件",
"Inkscape",
"GIMP"
] | https://linux.cn/article-10608-1.html | 先说一下,我不是一个专业的设计师,但我在 Windows 上使用过某些工具(如 Photoshop、Illustrator 等)和 [Figma](https://www.figma.com/)(这是一个基于浏览器的界面设计工具)。我相信 Mac 和 Windows 上还有更多的设计工具。
即使在 Linux 上,也有数量有限的专用[图形设计工具](https://itsfoss.com/best-linux-graphic-design-software/)。其中一些工具如 [GIMP](https://itsfoss.com/gimp-2-10-release/) 和 [Inkscape](https://inkscape.org/) 也被专业人士使用。但不幸的是,它们中的大多数都不被视为专业级。
即使有更多解决方案,我也从未遇到过可以取代 [Sketch](https://www.sketchapp.com/)、Figma 或 Adobe XD 的原生 Linux 应用。任何专业设计师都同意这点,不是吗?
### Akira 是否会在 Linux 上取代 Sketch、Figma 和 Adobe XD?
所以,为了开发一些能够取代那些专有工具的应用,[Alessandro Castellani](https://github.com/Alecaddd) 发起了一个 [Kickstarter 活动](https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description),并与几位经验丰富的开发人员 [Alberto Fanjul](https://github.com/albfan)、[Bilal Elmoussaoui](https://github.com/bilelmoussaoui) 和 [Felipe Escoto](https://github.com/Philip-Scott) 组队合作。
是的,Akira 仍然只是一个想法,只有一个界面原型(正如我最近在 Kickstarter 的[直播流](https://live.kickstarter.com/alessandro-castellani/live-stream/the-current-state-of-akira)中看到的那样)。
### 如果它还不存在,为什么会发起 Kickstarter 活动?

Kickstarter 活动的目的是收集资金,以便雇用开发人员,并花几个月的时间开发,以使 Akira 成为可能。
尽管如此,如果你想支持这个项目,你应该知道一些细节,对吧?
不用担心,我们在他们的直播中问了几个问题 - 让我们看下:
### Akira:更多细节

*图片来源:Kickstarter*
如 Kickstarter 活动描述的那样:
>
> Akira 的主要目的是提供一个快速而直观的工具来**创建 Web 和移动端界面**,更像是 **Sketch**、**Figma** 或 **Adobe XD**,并且是 Linux 原生体验。
>
>
>
他们还详细描述了该工具与 Inkscape、Glade 或 QML Editor 的不同之处。当然,如果你想要了解所有的技术细节,请查看 [Kickstarter](https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description)。但是,在此之前,让我们看一看当我询问有关 Akira 的一些问题时他们说了些什么。
**问:**如果你认为你的项目类似于 Figma,人们为什么要考虑安装 Akira 而不是使用基于网络的工具?它是否只是这些工具的克隆 —— 提供原生 Linux 体验,还是有一些非常有趣的东西可以鼓励用户切换(除了是开源解决方案之外)?
**Akira:** 与基于网络的 electron 应用相比,Linux 原生体验总是更好、更快。此外,如果你选择使用 Figma,硬件配置也很重要,但 Akira 将会占用很少的系统资源,并且你可以在不需要上网的情况下完成类似工作。
**问:**假设它成为了 Linux 用户一直在等待的开源方案(拥有专有工具的类似功能)。你有什么维护计划?你是否计划引入定价方案,或依赖捐赠?
**Akira:**该项目主要依靠捐赠(类似于 [Krita 基金会](https://krita.org/en/about/krita-foundation/) 这样的想法)。但是,不会有“专业版”计划,它将免费提供,它将是一个开源项目。
根据我得到的回答,它看起来似乎很有希望,我们应该支持。
* [查看该 Kickstarter 活动](https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description)
### 总结
你怎么看 Akira?它只是一个概念吗?或者你希望看到进展?
请在下面的评论中告诉我们你的想法。
---
via: <https://itsfoss.com/akira-design-tool>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,610 | Windows 下 Emacs 中的 zsh shell | https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html | 2019-03-12T10:42:00 | [
"zsh",
"shell"
] | https://linux.cn/article-10610-1.html | 
运行跨平台 shell(例如 Bash 或 zsh)的最大优势在于你能在多平台上使用同样的语法和脚本。在 Windows 上设置(替换)shell 挺麻烦的,但所获得的回报远远超出这小小的付出。

MSYS2 子系统允许你在 Windows 上运行 Bash 或 zsh 之类的 shell。使用 MSYS2 很重要的一点在于确保搜索路径都指向 MSYS2 子系统本身:存在太多依赖关系了。
MSYS2 安装后默认的 shell 就是 Bash;zsh 则可以通过包管理器进行安装:
```
pacman -Sy zsh
```
通过修改 `/etc/passwd` 文件可以设置 zsh 作为默认 shell,例如:
```
mkpasswd -c | sed -e 's/bash/zsh/' | tee -a /etc/passwd
```
这会将默认 shell 从 bash 改成 zsh。
要在 Windows 上的 Emacs 中运行 zsh ,需要修改 `shell-file-name` 变量,将它指向 MSYS2 子系统中的 zsh 二进制文件。该二进制 shell 文件在 Emacs `exec-path` 变量中的某个地方。
```
(setq shell-file-name (executable-find "zsh.exe"))
```
不要忘了修改 Emacs 的 `PATH` 环境变量,因为 MSYS2 路径应该先于 Windows 路径。接上一个例子,假设 MSYS2 安装在 `c:\programs\msys2` 中,那么执行:
```
(setenv "PATH" "C:\\programs\\msys2\\mingw64\\bin;C:\\programs\\msys2\\usr\\local\\bin;C:\\programs\\msys2\\usr\\bin;C:\\Windows\\System32;C:\\Windows")
```
在 Emacs 配置文件中设置好这两个变量后,在 Emacs 中运行:
```
M-x shell
```
应该就能看到熟悉的 zsh 提示符了。
Emacs 的终端设置(eterm)与 MSYS2 的标准终端设置(xterm-256color)不一样。这意味着某些插件和主题(提示符)可能不能正常工作 - 尤其在使用 oh-my-zsh 时。
检测 zsh 否则在 Emacs 中运行很简单,使用变量 `$INSIDE_EMACS`。
下面这段代码片段取自 `.zshrc`(当以交互式 shell 模式启动时会被加载),它会在 zsh 在 Emacs 中运行时启动 git 插件并更改主题:
```
# Disable some plugins while running in Emacs
if [[ -n "$INSIDE_EMACS" ]]; then
plugins=(git)
ZSH_THEME="simple"
else
ZSH_THEME="compact-grey"
fi
```
通过在本地 `~/.ssh/config` 文件中将 `INSIDE_EMACS` 变量设置为 `SendEnv` 变量……
```
Host myhost
SendEnv INSIDE_EMACS
```
……同时在 ssh 服务器的 `/etc/ssh/sshd_config` 中设置为 `AcceptEnv` 变量……
```
AcceptEnv LANG LC_* INSIDE_EMACS
```
……这使得在 Emacs shell 会话中通过 ssh 登录另一个运行着 zsh 的 ssh 服务器也能工作的很好。当在 Windows 下的 Emacs 中的 zsh 上通过 ssh 远程登录时,记得使用参数 `-t`,`-t` 参数会强制分配伪终端(之所以需要这样,时因为 Windows 下的 Emacs 并没有真正的 tty)。
跨平台,开源真是个好东西……
---
via: <https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html>
作者:[Peter Mosmans](https://www.onwebsecurity.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
The most obvious advantage of running a cross-platform shell (for example Bash or zsh) is that you can use the same syntax and scripts on multiple platforms. Setting up (alternative) shells on Windows can be pretty tricky, but the small investment is well worth the reward.
The MSYS2 subsystem allows you to run shells like Bash or zsh on Windows. An important part of MSYS2 is making sure that the search paths are all pointing to the MSYS2 subsystem: There are a lot of dependencies.
Bash is the default shell once MSYS2 is installed; zsh can be installed using the package manager:
```
pacman -Sy zsh
```
Setting zsh as default shell can be done by modifying the ```
/etc/passwd
```
file, for instance:
```
mkpasswd -c | sed -e 's/bash/zsh/' | tee -a /etc/passwd
```
This will change the default shell from bash to zsh.
Running zsh under Emacs on Windows can be done by modifying the
```
shell-file-name
```
variable, and pointing it to the zsh binary from the MSYS2
subsystem. The shell binary has to be somewhere in the Emacs ```
exec-path
```
variable.
```
(setq shell-file-name (executable-find "zsh.exe"))
```
Don't forget to modify the PATH environment variable for Emacs, as the MSYS2 paths should be resolved before Windows paths. Using the same example, where MSYS2 is installed under
c:\programs\msys2:
```
(setenv "PATH" "C:\\programs\\msys2\\mingw64\\bin;C:\\programs\\msys2\\usr\\local\\bin;C:\\programs\\msys2\\usr\\bin;C:\\Windows\\System32;C:\\Windows")
```
After setting these two variables in the Emacs configuration file, running
M-x shellin Emacs should bring up the familiar zsh prompt.
Emacs' terminal settings (eterm) are different than MSYS2' standard terminal settings (xterm-256color). This means that some plugins or themes (prompts) might not work - especially when using oh-my-zsh.
Detecting whether zsh is started under Emacs is easy, using the variable
$INSIDE_EMACS. This codesnippet in
.zshrc(which will be sourced for interactive shells) only enables the git plugin when being run in Emacs, and changes the theme
```
# Disable some plugins while running in Emacs
if [[ -n "$INSIDE_EMACS" ]]; then
plugins=(git)
ZSH_THEME="simple"
else
ZSH_THEME="compact-grey"
fi
```
By adding the ```
INSIDE_EMACS
```
variable to the local ```
~/.ssh/config
```
as ```
SendEnv
```
variable...
```
Host myhost
SendEnv INSIDE_EMACS
```
... and to a ssh server as ```
AcceptEnv
```
variable in ```
/etc/ssh/sshd_config
```
...
```
AcceptEnv LANG LC_* INSIDE_EMACS
```
... this even works when ssh'ing inside an Emacs shell session to another ssh
server, running zsh. When ssh'ing in the zsh shell inside Emacs on Windows,
using the parameters ```
-t -t
```
forces pseudo-tty allocation (which is
necessary, as Emacs on Windows don't have a true tty).
Cross-platform, open-source goodyness...
## Comments
comments powered by Disqus |
10,611 | 树莓派使用入门:你应该选择哪种树莓派? | https://opensource.com/article/19/3/which-raspberry-pi-choose | 2019-03-12T10:57:58 | [
"树莓派"
] | https://linux.cn/article-10611-1.html |
>
> 在我们的《树莓派使用入门》系列的第一篇文章中,我们将学习选择符合你要求的树莓派型号的三个标准。
>
>
>

本文是《14 天学会[树莓派](https://www.raspberrypi.org/)使用》系列文章的第一篇。虽然本系列文章主要面向没有使用过树莓派或 Linux 或没有编程经验的人群,但是肯定有些东西还是需要有经验的读者的,我希望这些读者能够留下他们有益的评论、提示和补充。如果每个人都能贡献,这将会让本系列文章对初学者、其它有经验的读者、甚至是我更受益!
言归正传,如果你想拥有一个树莓派,但不知道应该买哪个型号。或许你希望为你的教学活动或你的孩子买一个,但面对这么多的选择,却不知道应该买哪个才是正确的决定。

关于选择一个新的树莓派,我有三个主要的标准:
* **成本:** 不能只考虑树莓派板的成本,还需要考虑到你使用它时外围附件的成本。在美国,树莓派的成本区间是从 5 美元(树莓派 Zero)到 35 美元(树莓派 3 B 和 3 B+)。但是,如果你选择 Zero,那么你或许还需要一个 USB hub 去连接你的鼠标、键盘、无线网卡、以及某种显示适配器。不论你想使用树莓派做什么,除非你已经有了(假如不是全部)大部分的外设,那么你一定要把这些外设考虑到预算之中。此外,在一些国家,对于许多学生和老师,树莓派(即便没有任何外设)的购置成本也或许是一个不少的成本负担。
* **可获得性:** 根据你所在地去查找你想要的树莓派,因为在一些国家得到某些版本的树莓派可能很容易(或很困难)。在新型号刚发布后,可获得性可能是个很大的问题,在你的市场上获得最新版本的树莓派可能需要几天或几周的时间。
* **用途:** 所在地和成本可能并不会影响每个人,但每个购买者必须要考虑的是买树莓派做什么。因内存、CPU 核心、CPU 速度、物理尺寸、网络连接、外设扩展等不同衍生出八个不同的型号。比如,如果你需要一个拥有更大的“马力”时健壮性更好的解决方案,那么你或许应该选择树莓派 3 B+,它有更大的内存、最快的 CPU、以及更多的核心数。如果你的解决方案并不需要网络连接,并不用于 CPU 密集型的工作,并且需要将它隐藏在一个非常小的空间中,那么一个树莓派 Zero 将是你的最佳选择。
[维基百科的树莓派规格表](https://en.wikipedia.org/wiki/Raspberry_Pi#Specifications) 是比较八种树莓派型号的好办法。
现在,你已经知道了如何找到适合你的树莓派了,下一篇文章中,我将介绍如何购买它。
---
via: <https://opensource.com/article/19/3/which-raspberry-pi-choose>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the first article in a 14-day series on getting started with the [Raspberry Pi](https://www.raspberrypi.org/). Although the series is geared towards people who have never used a Raspberry Pi or Linux or programming, there will definitely be things for more experienced readers—and I encourage those readers to leave comments and tips that build on what I write. If everyone contributes, we can make this series even more useful for beginners, other experienced readers, and even me!
So, you want to give the Raspberry Pi a shot, but you don't know which model to buy. Maybe you want one for your classroom or your kid, but there are so many options, and you aren't sure which one is right for you.
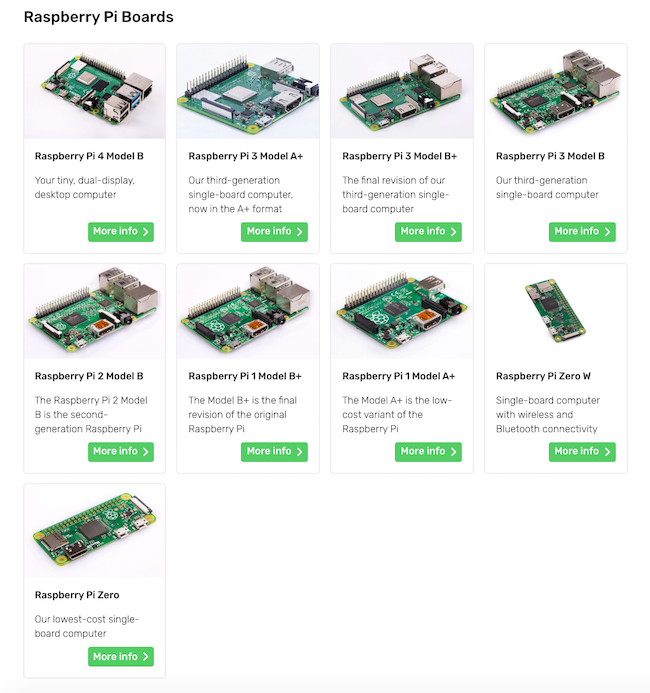
My three main criteria for choosing a new Raspberry Pi are:
-
**Cost:**Don't just consider the cost of the Raspberry Pi board, but also factor the peripherals you will need in order to use it. In the US, the Raspberry Pi's cost varies from $5 (for the Raspberry Pi Zero) to $35 (for the Raspberry Pi 3 B and 3 B+). However, if you pick the Zero you will probably also need a USB hub for your mouse and keyboard, possibly a wireless adapter, and some sort of display adapter. Unless you have most (if not all) of the peripherals needed for whatever you want to do with your Raspberry Pi, make sure to add those to your Pi budget. Also, in some countries, a Raspberry Pi on its own (even without any peripherals) may be a cost burden for many students and teachers. -
**Availability:**Finding the Raspberry Pi you want can vary depending on your location, as it may be easier (or harder) to get certain versions in some countries. Availability is an even bigger issue after new models are released, and it can take a few days or even weeks for new versions to become available in your market. -
**Purpose:**Location and cost may not affect everyone, but every buyer must consider*why*they want a Raspberry Pi. The eight different models vary in RAM, CPU core, CPU speed, physical size, network connectivity, peripheral expansion, etc. For example, if you want the most robust solution with more "horsepower," you probably will want the Raspberry Pi 3 B+, which has the most RAM, fastest CPU, and largest number of cores. If you want something that won't require network connectivity, won't be used for CPU-intensive work, and can be hidden in a small space, you could go with a Raspberry Pi Zero.
[Wikipedia's Raspberry Pi specs chart](https://en.wikipedia.org/wiki/Raspberry_Pi#Specifications) is an easy way to compare the eight Raspberry Pis models.
Now that you know what to look for in a Raspberry Pi, in the next article, I will explain how to buy one.
## 9 Comments |
10,614 | Linux 上最好的十六进制编辑器 | https://itsfoss.com/hex-editors-linux | 2019-03-13T11:07:00 | [
"十六进制"
] | https://linux.cn/article-10614-1.html | 十六进制编辑器可以让你以十六进制的形式查看/编辑文件的二进制数据,因此其被命名为“十六进制”编辑器。说实话,并不是每个人都需要它。只有必须处理二进制数据的特定用户组才会使用到它。
如果你不知道它是什么,让我来举个例子。假设你拥有一个游戏的配置文件,你可以使用十六进制编辑器打开它们并更改某些值以获得更多的弹药/分数等等。想要了解有关十六进制编辑器的更多信息,你可以参阅 [Wikipedia 页面](https://en.wikipedia.org/wiki/Hex_editor)。
如果你已经知道它用来干什么了 —— 让我们来看看 Linux 上最好的十六进制编辑器。
### 5 个最好的十六进制编辑器

**注意:**这里提到的十六进制编辑器没有特定的排名顺序。
#### 1、Bless Hex Editor

**主要特点:**
* 编辑裸设备(Raw disk)
* 多级撤消/重做操作
* 多个标签页
* 转换表
* 支持插件扩展功能
Bless 是 Linux 上最流行的十六进制编辑器之一。你可以在应用中心或软件中心中找到它。否则,你可以查看它们的 [GitHub 页面](https://github.com/bwrsandman/Bless) 获取构建和相关的说明。
它可以轻松处理编辑大文件而不会降低速度 —— 因此它是一个快速的十六进制编辑器。
* [GitHub 项目](https://github.com/bwrsandman/Bless)
#### 2、GNOME Hex Editor

**主要特点:**
* 以十六进制/ASCII 格式查看/编辑
* 编辑大文件
另一个神奇的十六进制编辑器 —— 专门为 GNOME 量身定做的。我个人用的是 Elementary OS, 所以我可以在应用中心找到它。你也可以在软件中心找到它。否则请参考 [GitHub 页面](https://github.com/GNOME/ghex) 获取源代码。
你可以使用此编辑器以十六进制或 ASCII 格式查看/编辑文件。用户界面非常简单 —— 正如你在上面的图像中看到的那样。
* [官方网站](https://wiki.gnome.org/Apps/Ghex)
#### 3、Okteta

**主要特点:**
* 可自定义的数据视图
* 多个标签页
* 字符编码:支持 Qt、EBCDIC 的所有 8 位编码
* 解码表列出常见的简单数据类型
Okteta 是一个简单的十六进制编辑器,没有那么奇特的功能。虽然它可以处理大部分任务。它有一个单独的模块,你可以使用它嵌入其他程序来查看/编辑文件。
与上述所有编辑器类似,你也可以在应用中心和软件中心上找到列出的编辑器。
* [官方网站](https://www.kde.org/applications/utilities/okteta/)
#### 4、wxHexEditor

**主要特点:**
* 轻松处理大文件
* 支持 x86 反汇编
* 对磁盘设备可以显示扇区指示
* 支持自定义十六进制面板格式和颜色
这很有趣。它主要是一个十六进制编辑器,但你也可以将其用作低级磁盘编辑器。例如,如果你的硬盘有问题,可以使用此编辑器以 RAW 格式编辑原始数据以修复它。
你可以在你的应用中心和软件中心找到它。否则,可以去看看 [Sourceforge](https://sourceforge.net/projects/wxhexeditor/)。
* [官方网站](http://www.wxhexeditor.org/home.php)
#### 5、Hexedit (命令行工具)

**主要特点:**
* 运行在命令行终端上
* 它又快又简单
如果你想在终端上工作,可以继续通过控制台安装 hexedit。它是我最喜欢的 Linux 命令行的十六进制编辑器。
当你启动它时,你必须指定要打开的文件的位置,然后它会为你打开它。
要安装它,只需输入:
```
sudo apt install hexedit
```
### 结束
十六进制编辑器可以方便地进行实验和学习。如果你是一个有经验的人,你应该选择一个有更多功能的——GUI。 尽管这一切都取决于个人喜好。
你认为十六进制编辑器的有用性如何?你用哪一个?我们没有列出你最喜欢的吗?请在评论中告诉我们!
### 额外福利
译者注:要我说,以上这些十六进制编辑器都太丑了。如果你只是想美美的查看一下十六进制输出,那么下面的这个查看器十分值得看看。虽然在功能上还有些不够成熟,但至少在美颜方面可以将上面在座的各位都视作垃圾。
它就是 hexyl,是一个面向终端的简单的十六进制查看器。它使用颜色来区分不同的字节类型(NULL、可打印的 ASCII 字符、ASCII 空白字符、其它 ASCII 字符和非 ASCII 字符)。
上图:


它不仅支持各种 Linux 发行版,还支持 MacOS、FreeBSD、Windows,请自行去其[项目页](https://github.com/sharkdp/hexyl)选用,
---
via: <https://itsfoss.com/hex-editors-linux>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zero-mk](https://github.com/zero-mk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,615 | 树莓派使用入门:如何购买一个树莓派 | https://opensource.com/article/19/3/how-buy-raspberry-pi | 2019-03-13T11:27:58 | [
"树莓派"
] | https://linux.cn/article-10615-1.html |
>
> 在我们的《树莓派使用入门》系列文章的第二篇中,我们将介绍获取树莓派的最佳途径。
>
>
>

在本系列指南的第一篇文章中,我们提供了一个关于 [你应该购买哪个版本的树莓派](/article-10611-1.html) 的一些建议。哪个版本才是你想要的,你应该有了主意了,现在,我们来看一下如何获得它。
最显而易见的方式 —— 并且也或许是最安全最简单的方式 —— 非 [树莓派的官方网站](https://www.raspberrypi.org/) 莫属了。如果你从官网主页上点击 “Buy a Raspberry Pi”,它将跳转到官方的 [在线商店](https://www.raspberrypi.org/products/),在那里,它可以给你提供你的国家所在地的授权销售商。如果你的国家没有在清单中,还有一个“其它”选项,它可以提供国际订购。
第二,查看亚马逊或在你的国家里允许销售新的或二手商品的其它主流技术类零售商。鉴于树莓派比较便宜并且尺寸很小,一些小商家基于转售目的的进出口它,应该是非常容易的。在你下订单时,一定要关注对卖家的评价。
第三,打听你的极客朋友!你可能从没想过一些人的树莓派正在“吃灰”。我已经给家人送了至少三个树莓派,当然它们并不是计划要送的礼物,只是因为他们对这个“迷你计算机”感到很好奇而已。我身边有好多个,因此我让他们拿走一个!
### 不要忘了外设
最后一个建设是:不要忘了外设,你将需要一些外设去配置和操作你的树莓派。至少你会用到键盘、一个 HDMI 线缆去连接显示器、一个 Micro SD 卡去安装操作系统,一个电源线、以及一个好用的鼠标。

如果你没有准备好这些东西,试着从朋友那儿借用,或与树莓派一起购买。你可以从授权的树莓派销售商那儿考虑订购一个起步套装 —— 它可以让你避免查找的麻烦而一次性搞定。

现在,你有了树莓派,在本系列的下一篇文章中,我们将安装树莓派的操作系统并开始使用它。
---
via: <https://opensource.com/article/19/3/how-buy-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The first article in this series on getting started with Raspberry Pi offered some advice on [which model you should buy](https://opensource.com/article/19/2/which-raspberry-pi-should-you-get). Now that you have an idea of which version you want, let's find out how to get one.
The most obvious—and probably the safest and simplest—way is through the [official Raspberry Pi website](https://www.raspberrypi.org/). If you click on "Buy a Raspberry Pi" from the homepage, you'll be taken to the organization's [online store](https://www.raspberrypi.org/products/), where you can find authorized Raspberry Pi sellers in your country where you can place an order. If your country isn't listed, there is a "Rest of the World" option, which should let you put in an international order.
Second, check Amazon.com or another major online technology retailer in your country that allows smaller shops to sell new and used items. Given the relatively low cost and size of the Raspberry Pi, it should be fairly easy for smaller shop owners to import and export the boards for reselling purposes. Before you place an order, keep an eye on the sellers' reviews though.
Third, ask your geek friends! You never know if someone has an unused Raspberry Pi gathering dust. I have given at least three Raspberry Pis away to family, not as planned gifts, but because they were just so curious about this mini-computer. I had so many lying around that I just told them to keep one!
## Don't forget the extras
One final thought: don't forget that you'll need some peripherals to set up and operate your Raspberry Pi. At a minimum, you'll need a keyboard, an HDMI cable to connect to a display (and a display), a Micro SD card to install the operating system, a power cord, and a mouse will be handy, too.

Raspberry Pi Zero W Starter Kit from CanaKit
If you don't already have these items, try borrowing them from friends or order them at the same time you buy your Raspberry Pi. You may want to consider one of the starter kits available from the authorized Raspberry Pi vendors—that will avoid the hassle of searching for parts one at a time.

V-Kits Raspberry Pi 3 B+ Starter Kit
Now that you have a Raspberry Pi, in the next article in this series, we'll install the operating system and start using it.
## 2 Comments |
10,616 | 如何在 WinSCP 中使用 sudo | https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/ | 2019-03-13T11:54:00 | [
"sudo",
"WinSCP"
] | https://linux.cn/article-10616-1.html |
>
> 用截图了解如何在 WinSCP 中使用 sudo。
>
>
>

首先你需要检查你尝试使用 WinSCP 连接的 sftp 服务器的二进制文件的位置。
你可以使用以下命令检查 SFTP 服务器二进制文件位置:
```
[root@kerneltalks ~]# cat /etc/ssh/sshd_config |grep -i sftp-server
Subsystem sftp /usr/libexec/openssh/sftp-server
```
你可以看到 sftp 服务器的二进制文件位于 `/usr/libexec/openssh/sftp-server`。
打开 WinSCP 并单击“高级”按钮打开高级设置。

*WinSCP 高级设置*
它将打开如下高级设置窗口。在左侧面板上选择“Environment”下的 “SFTP”。你会在右侧看到选项。
现在,使用命令 `sudo su -c` 在这里添加 SFTP 服务器值,如下截图所示:

*WinSCP 中的 SFTP 服务器设置*
所以我们在设置中添加了 `sudo su -c /usr/libexec/openssh/sftp-server`。单击“Ok”并像平常一样连接到服务器。
连接之后,你将可以从你以前需要 sudo 权限的目录传输文件了。
完成了!你已经使用 WinSCP 使用 sudo 登录服务器了。
---
via: <https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/>
作者:[kerneltalks](https://kerneltalks.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn how to use sudo access in winSCP with screenshots.*

Before you move into configurations, make sure that the user is having **NOPASSWD **access to sudo to target user or root account. This means `/etc/sudoers`
file must have entry something like below –
```
user1 ALL=(root) NOPASSWD: ALL
```
Once you have proper [sudo configuration](https://kerneltalks.com/config/guide-sudo-configuration-unix-linux/) you can go ahead with WinSCP config. This is to ensure that once shell tries sudo it should be non-interactive.
First of all, you need to check where is your SFTP server binary located on the server you are trying to connect with WinSCP.
You can check SFTP server binary location with below command –
```
[root@kerneltalks ~]# cat /etc/ssh/sshd_config |grep -i sftp-server
Subsystem sftp /usr/libexec/openssh/sftp-server
```
Here you can see sftp server binary is located at `/usr/libexec/openssh/sftp-server`
Now open winSCP and click `Advanced`
button to open up advanced settings.
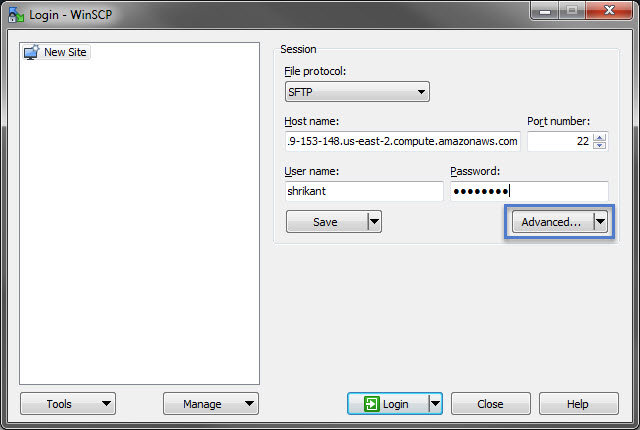
It will open up an advanced setting window like one below. Here select `SFTP `
under `Environment`
on the left-hand side panel. You will be presented with an option on the right hand side.
Now, add SFTP server value here with the command `sudo su -c`
here as displayed in the screenshot below –
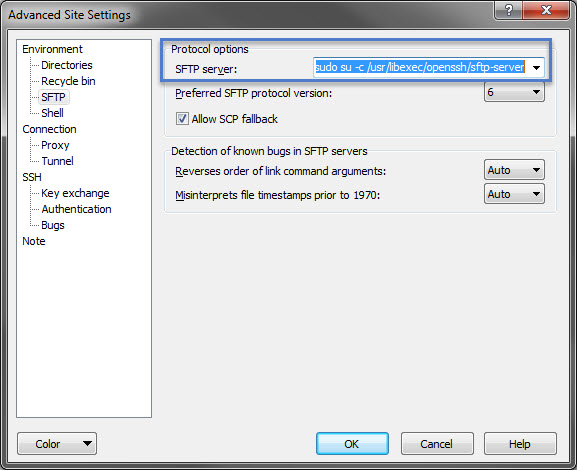
So we added `sudo su -c /usr/libexec/openssh/sftp-server`
in settings here. Now click Ok and connect to the server as you normally do.
After connection, you will be able to transfer files from the directory where you normally need sudo permission to access.
That’s it! You logged to server using WinSCP and sudo access.
Does the user profile retain NOPASSWD access to root from then on? If so, how would one protect against malicious executables?
NOPASSWD to target account or root account! If you are giving it to root account then you must be knowing user well and hence authorizing his sudo to root with NOPASSWD.
i am able to login but not able to copy file from local to server. It gives Network error: Software caused connection abort.
I get an error connecting. “Cannot initialize SFTP protocol. Is the host running an SFTP server?” |
10,617 | 关于圆周率日的趣事与庆祝方式 | https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate | 2019-03-14T10:56:00 | [
"树莓派",
"Pi",
"圆周率"
] | https://linux.cn/article-10617-1.html |
>
> 技术团队喜欢 3 月 14 日的圆周率日:你是否知道这也是阿尔伯特·爱因斯坦的生日和 Linux 内核1.0.0 发布周年纪念日?来看一些树莓派的趣事和 DIY 项目。
>
>
>

今天,全世界的技术团队都会为一个数字庆祝。3 月 14 日是<ruby> 圆周率日 <rt> Pi Day </rt></ruby>,人们会在这一天举行吃派比赛、披萨舞会,玩<ruby> 数学梗 <rt> math puns </rt></ruby>。如果这个数学领域中的重要常数不足以让 3 月 14 日成为一个节日的话,再加上爱因斯坦的生日、Linux 内核 1.0.0 发布的周年纪念日,莱伊·惠特尼在这一天申请了轧花机的专利这些原因,应该足够了吧。(LCTT译注:[轧花机](https://zh.wikipedia.org/wiki/%E8%BB%8B%E6%A3%89%E6%A9%9F)是一种快速而且简单地分开棉花纤维和种子的机器,生产力比人手分离高得多。)
很荣幸,我们能在这一个特殊的日子里一起了解有关它的趣事和与 π 相关的好玩的活动。来吧,和你的团队一起庆祝圆周率日:找一两个点子来进行团队建设,或用新兴技术做一个项目。如果你有为这个大家所喜爱的无限小数庆祝的独特方式,请在评论区与大家分享。
### 圆周率日的庆祝方法:
* 今天是圆周率日的第 31 次周年纪念(LCTT 译注:本文写于 2018 年的圆周率日,故在细节上存在出入。例如今天(2019 年 3 月 14 日)是圆周率日的第 31 次周年纪念)。第一次为它庆祝是在旧金山的<ruby> 探索博物馆 <rt> Exploratorium </rt></ruby>由物理学家 Larry Shaw 举行。“在[第 1 次周年纪念日](https://www.exploratorium.edu/pi/pi-day-history)当天,工作人员带来了水果派和茶壶来庆祝它。在 1 点 59 分(圆周率中紧接着 3.14 的数字),Shaw 在博物馆外领着队伍环馆一周。队伍中用扩音器播放着‘Pomp and Circumstance’。” 直到 21 年后,在 2009 年 3 月,圆周率正式成为了美国的法定假日。
* 虽然该纪念日起源于旧金山,可规模最大的庆祝活动却是在普林斯顿举行的,这个小镇举办了为期五天的[许多活动](https://princetontourcompany.com/activities/pi-day/),包括爱因斯坦模仿比赛、掷派比赛,圆周率背诵比赛等等。其中的某些活动甚至会给获胜者提供价值 314.5 美元的奖金。
* <ruby> 麻省理工的斯隆管理学院 <rt> MIT Sloan School of Management </rt></ruby>正在庆祝圆周率日。他们在 Twitter 上分享着关于 π 和派的圆周率日趣事,详情请关注<ruby> 推特话题 <rt> Twitter hashtag </rt></ruby> #PiVersusPie 。
### 与圆周率有关的项目与活动:
* 如果你想锻炼你的数学技能,<ruby> 美国国家航空航天局 <rt> National Aeronautics and Space Administration </rt></ruby>(NASA)的<ruby> 喷气推进实验室 <rt> Jet Propulsion Lab </rt></ruby>(JPL)发布了[一系列新的数学问题](https://www.jpl.nasa.gov/news/news.php?feature=7074),希望通过这些问题展现如何把圆周率用于空间探索。这也是美国国家航天局面向学生举办的第五届圆周率日挑战。
* 想要领略圆周率日的精神,最好的方法也许就是开展一个[树莓派](https://opensource.com/resources/raspberry-pi)项目了,无论是和你的孩子还是和你的团队一起完成,都是不错的。树莓派作为一项从 2012 年开启的项目,现在已经售出了数百万块的基本型的电脑主板。事实上,它已经在[通用计算机畅销榜上排名第三](https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64)了。这里列举一些可能会吸引你的树莓派项目或活动:
+ 来自谷歌的<ruby> 自己做 AI <rt> AI-Yourself </rt></ruby>(AIY)项目让你自己创造一个[语音控制的数字助手](http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/)或者[一个图像识别设备](http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/)。
+ 在树莓派上[使用 Kubernets](https://opensource.com/article/17/3/kubernetes-raspberry-pi)。
+ 组装一台[怀旧游戏系统](https://opensource.com/article/18/1/retro-gaming),目标:拯救桃子公主!
+ 和你的团队举办一场[树莓派 Jam](https://opensource.com/article/17/5/how-run-raspberry-pi-meetup)。树莓派基金会发布了一个帮助大家顺利举办活动的[指导手册](https://www.raspberrypi.org/blog/support-raspberry-jam-community/)。据该网站说明,树莓派 Jam 旨在“给数字创作中所有年龄段的人提供支持,让世界各地志同道合的人们汇聚起来讨论和分享他们的最新项目,举办讲习班,讨论和派相关的一切。”
### 其他有关圆周率的事情:
* 当前背诵圆周率的[世界纪录保持者](http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi)是 Suresh Kumar Sharma,他在 2015 年 10 月花了 17 小时零 14 分钟背出了 70,030 位数字。然而,[非官方记录](https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi)的保持者 Akira Haraguchi 声称他可以背出 111,700 位数字。
* 现在,已知的圆周率数字的长度比以往都要多。在 2016 年 11 月,R&D 科学家 Peter Trueb 计算出了 22,459,157,718,361 位圆周率数字,比 2013 年的世界记录多了 [9 万亿数字](https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071)。据《<ruby> 新科学家 <rt> New Scientist </rt></ruby>》所述,“最终文件包含了圆周率的 22 万亿位数字,大小接近 9 TB。如果将其打印出来,能用数百万本 1000 页的书装满一整个图书馆。”
祝你圆周率日快乐!

---
via: <https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate>
作者:[Carla Rudder](https://enterprisersproject.com/user/crudder) 译者:[wwhio](https://github.com/wwhio) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today, tech teams around the world will celebrate a number. March 14 (written 3/14 in the United States) is known as Pi Day, a holiday that people ring in with pie eating contests, pizza parties, and math puns. If the most important number in mathematics wasn’t enough of a reason to reach for a slice of pie, March 14 also happens to be Albert Einstein’s birthday, the release anniversary of Linux kernel 1.0.0, and the day Eli Whitney patented the cotton gin.
In honor of this special day, we’ve rounded up a dozen fun facts and interesting pi-related projects. Master you team’s Pi Day trivia, or borrow an idea or two for a team-building exercise. Do a project with a budding technologist. And let us know in the comments if you are doing anything unique to celebrate everyone’s favorite never-ending number.
## Pi Day celebrations:
- Today is the 30
thanniversary of Pi Day. The first was held in 1988 in San Francisco at the Exploratorium by physicist Larry Shaw. “On[the first Pi Day](https://www.exploratorium.edu/pi/pi-day-history), staff brought in fruit pies and a tea urn for the celebration. At 1:59 – the pi numbers that follow 3.14 – Shaw led a circular parade around the museum with his boombox blaring the digits of pi to the music of ‘Pomp and Circumstance.’” It wasn’t until 21 years later, March 2009, that Pi Day became an official national holiday in the U.S. - Although it started in San Francisco, one of the biggest Pi Day celebrations can be found in Princeton. The town holds a
[number of events](https://princetontourcompany.com/activities/pi-day/)over the course of five days, including an Einstein look-alike contest, a pie-throwing event, and a pi recitation competition. Some of the activities even offer a cash prize of $314.15 for the winner. - MIT Sloan School of Management (on Twitter as
[@MITSloan](https://twitter.com/MITSloan)) is celebrating Pi Day with fun facts about pi – and pie. Follow along with the Twitter hashtag #PiVersusPie
## Pi-related projects and activities:
- If you want to keep your math skills sharpened, NASA Jet Propulsion Lab has posted a
[new set of math problems](https://www.jpl.nasa.gov/news/news.php?feature=7074)that illustrate how pi can be used to unlock the mysteries of space. This marks the fifth year of NASA’s Pi Day Challenge, geared toward students. - There's no better way to get into the spirit of Pi Day than to take on a
[Raspberry Pi](https://opensource.com/resources/raspberry-pi)project. Whether you are looking for a project to do with your kids or with your team, there’s no shortage of ideas out there. Since its launch in 2012, millions of the basic computer boards have been sold. In fact, it’s the[third best-selling general purpose computer](https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64)of all time. Here are a few Raspberry Pi projects and activities that caught our eye:- Grab an AIY (AI-Yourself) kit from Google. You can create a
[voice-controlled digital assistant](http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/)or an[image-recognition device](http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/). [Run Kubernetes](https://opensource.com/article/17/3/kubernetes-raspberry-pi)on a Raspberry Pi.- Save Princess Peach by building a
[retro gaming system](https://opensource.com/article/18/1/retro-gaming). - Host a
[Raspberry Jam](https://opensource.com/article/17/5/how-run-raspberry-pi-meetup)with your team. The Raspberry Pi Foundation has released a[Guidebook](https://www.raspberrypi.org/blog/support-raspberry-jam-community/)to make hosting easy. According to the website, Raspberry Jams provide, “a support network for people of all ages in digital making. All around the world, like-minded people meet up to discuss and share their latest projects, give workshops, and chat about all things Pi.”
- Grab an AIY (AI-Yourself) kit from Google. You can create a
## Other fun Pi facts:
- The current
[world record holder](http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi)for reciting pi is Suresh Kumar Sharma, who in October 2015 recited 70,030 digits. It took him 17 hours and 14 minutes to do so. However, the[unofficial record](https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi)goes to Akira Haraguchi, who claims he can recite up to 111,700 digits. - And, there’s more to remember than ever before. In November 2016, R&D scientist Peter Trueb calculated 22,459,157,718,361 digits of pi –
[9 trillion more digits](https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071)than the previous world record set in 2013. According to New Scientist, “The final file containing the 22 trillion digits of pi is nearly 9 terabytes in size. If printed out, it would fill a library of several million books containing a thousand pages each."
Happy Pi Day!
**Want more wisdom like this, IT leaders? Sign up for our weekly email newsletter.** |
10,618 | 如何 SSH 登录到 Linux 上的特定目录 | https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/ | 2019-03-14T11:18:02 | [
"ssh"
] | https://linux.cn/article-10618-1.html | 
你是否遇到过需要 SSH 登录到远程服务器并立即 `cd` 到一个目录来继续交互式作业?你找对地方了!这个简短的教程描述了如何直接 SSH 登录到远程 Linux 系统的特定目录。而且不仅是 SSH 登录到特定目录,你还可以在连接到 SSH 服务器后立即运行任何命令。这些没有你想的那么难。请继续阅读。
### SSH 登录到远程系统的特定目录
在我知道这个方法之前,我通常首先使用以下命令 SSH 登录到远程系统:
```
$ ssh user@remote-system
```
然后如下 `cd` 进入某个目录:
```
$ cd <some-directory>
```
然而,你不需要使用两个单独的命令。你可以用一条命令组合并简化这个任务。
看看下面的例子。
```
$ ssh -t [email protected] 'cd /home/sk/ostechnix ; bash'
```
上面的命令将通过 SSH 连接到远程系统 (192.168.225.22) 并立即进入名为 `/home/sk/ostechnix/` 的目录,并停留在提示符中。
这里,`-t` 标志用于强制分配伪终端,这是一个必要的交互式 shell。
以下是上面命令的输出:

你也可以使用此命令:
```
$ ssh -t [email protected] 'cd /home/sk/ostechnix ; exec bash'
```
或者,
```
$ ssh -t [email protected] 'cd /home/sk/ostechnix && exec bash -l'
```
这里,`-l` 标志将 bash 设置为登录 shell。
在上面的例子中,我在最后一个参数中使用了 `bash`。它是我的远程系统中的默认 shell。如果你不知道远程系统上的 shell 类型,请使用以下命令:
```
$ ssh -t [email protected] 'cd /home/sk/ostechnix && exec $SHELL'
```
就像我已经说过的,它不仅仅是连接到远程系统后 `cd` 进入目录。你也可以使用此技巧运行其他命令。例如,以下命令将进入 `/home/sk/ostechnix/`,然后执行命令 `uname -a` 。
```
$ ssh -t [email protected] 'cd /home/sk/ostechnix && uname -a && exec $SHELL'
```
或者,你可以在远程系统上的 `.bash_profile` 文件中添加你想在 SSH 登录后执行的命令。
编辑 `.bash_profile` 文件:
```
$ nano ~/.bash_profile
```
每个命令一行。在我的例子中,我添加了下面这行:
```
cd /home/sk/ostechnix >& /dev/null
```
保存并关闭文件。最后,运行以下命令更新修改。
```
$ source ~/.bash_profile
```
请注意,你应该在远程系统的 `.bash_profile` 或 `.bashrc` 文件中添加此行,而不是在本地系统中。从现在开始,无论何时登录(无论是通过 SSH 还是直接登录),`cd` 命令都将执行,你将自动进入 `/home/sk/ostechnix/` 目录。
就是这些了。希望这篇文章有用。还有更多好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,619 | 如何使得支持 OpenGL 的 Flatpak 应用和游戏在专有 Nvidia 图形驱动下工作 | https://www.linuxuprising.com/2018/06/how-to-get-flatpak-apps-and-games-built.html | 2019-03-14T11:45:00 | [
"Flatpak",
"Nvidia"
] | https://linux.cn/article-10619-1.html |
>
> 一些支持 OpenGL 并打包为 Flatpak 的应用和游戏无法使用专有 Nvidia 驱动启动。本文将介绍如何在不安装开源驱动(Nouveau)的情况下启动这些 Flatpak 应用或游戏。
>
>
>

这有个例子。我在我的 Ubuntu 18.04 桌面上使用专有的 Nvidia 驱动程序 (`nvidia-driver-390`),当我尝试启动以 Flatpak 形式安装的最新版本 [Krita 4.1](https://www.linuxuprising.com/2018/06/free-painting-software-krita-410.html) (构建了 OpenGL 支持)时,显示了如下错误:
```
$ /usr/bin/flatpak run --branch=stable --arch=x86_64 --command=krita --file-forwarding org.kde.krita
Gtk-Message: Failed to load module "canberra-gtk-module"
Gtk-Message: Failed to load module "canberra-gtk-module"
libGL error: No matching fbConfigs or visuals found
libGL error: failed to load driver: swrast
Could not initialize GLX
```
[Winepak](https://www.linuxuprising.com/2018/06/winepak-is-flatpak-repository-for.html) 游戏(以 Flatpak 方式打包的绑定了 Wine 的 Windows 游戏)似乎也受到了这个问题的影响,这个问题从 2016 年出现至今。
要修复使用 OpenGL 和专有 Nvidia 图形驱动时无法启动的 Flatpak 游戏和应用的问题,你需要为已安装的专有驱动安装一个运行时环境。以下是步骤。
1、如果尚未添加 FlatHub 仓库,请添加它。你可以在[此处](https://flatpak.org/setup/)找到针对 Linux 发行版的说明。
2、现在,你需要确定系统上安装的专有 Nvidia 驱动的确切版本。
这一步取决于你使用的 Linux 发行版,我无法涵盖所有情况。下面的说明是面向 Ubuntu(以及 Ubuntu 风格的版本),但希望你可以自己弄清楚系统上安装的 Nvidia 驱动版本。
要在 Ubuntu 中执行此操作,请打开 “软件与更新”,切换到 “附加驱动” 选项卡并记下 Nvidia 驱动包的名称。
比如,你可以看到我的是 “nvidia-driver-390”:

这里还没完成。我们只是找到了 Nvidia 驱动的主要版本,但我们还需要知道次要版本。要获得我们下一步所需的确切 Nvidia 驱动版本,请运行此命令(应该适用于任何基于 Debian 的 Linux 发行版,如 Ubuntu、Linux Mint 等):
```
apt-cache policy NVIDIA-PACKAGE-NAME
```
这里的 “NVIDIA-PACKAGE-NAME” 是 “软件与更新” 中列出的 Nvidia 驱动包名称。例如,要查看 “nvidia-driver-390” 包的确切安装版本,请运行以下命令:
```
$ apt-cache policy nvidia-driver-390
nvidia-driver-390:
Installed: 390.48-0ubuntu3
Candidate: 390.48-0ubuntu3
Version table:
*** 390.48-0ubuntu3 500
500 http://ro.archive.ubuntu.com/ubuntu bionic/restricted amd64 Packages
100 /var/lib/dpkg/status
```
在这个命令的输出中,查找 “Installed” 部分并记下版本号(不包括 “-0ubuntu3” 之类)。现在我们知道了已安装的 Nvidia 驱动的确切版本(我例子中的是 “390.48”)。记住它,因为下一步我们需要。
3、最后,你可以从 FlatHub 为你已安装的专有 Nvidia 图形驱动安装运行时环境。
要列出 FlatHub 上所有可用的 Nvidia 运行时包,你可以使用以下命令:
```
flatpak remote-ls flathub | grep nvidia
```
幸运地是 FlatHub 上提供这个 Nvidia 驱动的运行时环境。你现在可以使用以下命令继续安装运行时:
针对 64 位系统:
```
flatpak install flathub org.freedesktop.Platform.GL.nvidia-MAJORVERSION-MINORVERSION
```
将 “MAJORVERSION” 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 “MINORVERSION” 替换为次要版本(步骤2,我例子中的为 48)。
例如,要为 Nvidia 图形驱动版本 390.48 安装运行时,你必须使用以下命令:
```
flatpak install flathub org.freedesktop.Platform.GL.nvidia-390-48
```
对于 32 位系统(或能够在 64 位上运行 32 位的应用或游戏),使用以下命令安装 32 位运行时:
```
flatpak install flathub org.freedesktop.Platform.GL32.nvidia-MAJORVERSION-MINORVERSION
```
再说一次,将 “MAJORVERSION” 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 “MINORVERSION” 替换为次要版本(步骤2,我例子中的为 48)。
比如,要为 Nvidia 图形驱动版本 390.48 安装 32 位运行时,你需要使用以下命令:
```
flatpak install flathub org.freedesktop.Platform.GL32.nvidia-390-48
```
以上就是你要运行支持 OpenGL 的 Flatpak 的应用或游戏的方法。
---
via: <https://www.linuxuprising.com/2018/06/how-to-get-flatpak-apps-and-games-built.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers
**Some applications and games built with OpenGL support and packaged as Flatpak fail to start with proprietary Nvidia drivers. This article explains how to get such Flatpak applications or games them to start, without installing the open source drivers (Nouveau).**
Here's an example. I'm using the proprietary Nvidia drivers on my Ubuntu 18.04 desktop (
`nvidia-driver-390`
) and when I try to launch the latest [Krita 4.1](https://www.linuxuprising.com/2018/06/free-painting-software-krita-410.html)installed as Flatpak (which is built with OpenGL support), the following errors are displayed:
```
$ /usr/bin/flatpak run --branch=stable --arch=x86_64 --command=krita --file-forwarding org.kde.krita
Gtk-Message: Failed to load module "canberra-gtk-module"
Gtk-Message: Failed to load module "canberra-gtk-module"
```**libGL error: No matching fbConfigs or visuals found
libGL error: failed to load driver: swrast
Could not initialize GLX**
[Winepak](https://www.linuxuprising.com/2018/06/winepak-is-flatpak-repository-for.html)games (Windows games bundled with Wine as Flatpak packages) also seem
[affected](https://github.com/winepak/applications/issues/23)by this Flatpak
[issue](https://github.com/flatpak/flatpak/issues/138), which is still open since 2016.
To fix Flatpak games and applications not starting when using OpenGL with proprietary Nvidia graphics drivers, you'll need to install a runtime for your currently installed proprietary Nvidia drivers. Here's how to do this.
**1. Add the FlatHub repository if you haven't already. You can find exact instructions for your Linux distribution**
[here](https://flatpak.org/setup/).**2. Now you'll need to figure out the exact version of the proprietary Nvidia drivers installed on your system.**
*This step is dependant of the Linux distribution you're using and I can't cover all cases. The instructions below are Ubuntu-oriented (and Ubuntu flavors) but hopefully you can figure out for yourself the Nvidia drivers version installed on your system.*
To do this in Ubuntu, open
`Software & Updates`
, switch to the `Additional Drivers`
tab and note the name of the Nvidia driver package.As an example, this is
`nvidia-driver-390`
in my case, as you can see here:That's not all. We've only found out the Nvidia drivers major version but we'll also need to know the minor version. To get the exact Nvidia driver version, which we'll need for the next step, run this command (should work in any Debian-based Linux distribution, like Ubuntu, Linux Mint and so on):
`apt-cache policy NVIDIA-PACKAGE-NAME`
Where NVIDIA-PACKAGE-NAME is the Nvidia drivers package name listed in
`Software & Updates`
. For example, to see the exact installed version of the `nvidia-driver-390`
package, run this command:```
$ apt-cache policy nvidia-driver-390
nvidia-driver-390:
```**Installed: 390.48**-0ubuntu3
Candidate: 390.48-0ubuntu3
Version table:
*** 390.48-0ubuntu3 500
500 http://ro.archive.ubuntu.com/ubuntu bionic/restricted amd64 Packages
100 /var/lib/dpkg/status
In this command's output, look for the
`Installed`
section and note the version numbers (excluding `-0ubuntu3`
and anything similar). Now we know the exact version of the installed Nvidia drivers (`390.48`
in my example). Remember this because we'll need it for the next step.**3. And finally, you can install the Nvidia runtime for your installed proprietary Nvidia graphics drivers, from FlatHub**
To list all the available Nvidia runtime packages available on FlatHub, you can use this command:
`flatpak remote-ls flathub | grep nvidia`
Hopefully the runtime for your installed Nvidia drivers is available on FlatHub. You can now proceed to install the runtime by using this command:
- For 64bit systems:
`flatpak install flathub org.freedesktop.Platform.GL.nvidia-`**MAJORVERSION**-**MINORVERSION**
Replace MAJORVERSION with the Nvidia driver major version installed on your computer (390 in my example above) and
MINORVERSION with the minor version (48 in my example from step 2).
For example, to install the runtime for Nvidia graphics driver version 390.48, you'd have to use this command:
`flatpak install flathub org.freedesktop.Platform.GL.nvidia-390-48`
- For 32bit systems (or to be able to run 32bit applications or games on 64bit), install the 32bit runtime using:
`flatpak install flathub org.freedesktop.Platform.`**GL32**.nvidia-**MAJORVERSION**-**MINORVERSION**
Once again, replace MAJORVERSION with the Nvidia driver major version installed on your computer (390 in my example above) and MINORVERSION with the minor version (48 in my example from step 2).
For example, to install the 32bit runtime for Nvidia graphics driver version 390.48, you'd have to use this command:
`flatpak install flathub org.freedesktop.Platform.`**GL32**.nvidia-390-48
That is all you need to do to get applications or games packaged as Flatpak that are built with OpenGL to run. |
10,620 | 将 VoIP 电话直接连接到 Asterisk 服务器 | https://feeding.cloud.geek.nz/posts/connecting-voip-phone-directly-to-asterisk-server/ | 2019-03-15T10:31:53 | [
"VoIP"
] | https://linux.cn/article-10620-1.html | 
在我的 [Asterisk](https://www.asterisk.org/) 服务器上正好有张以太网卡。由于我只用了其中一个,因此我决定将我的 VoIP 电话从本地网络交换机换成连接到 Asterisk 服务器。
主要的好处是这台运行着未知质量的专有软件的电话,在我的一般家庭网络中不能用了。最重要的是,它不再能访问互联网,因此无需手动配置防火墙。
以下是我配置的方式。
### 私有网络配置
在服务器上,我在 `/etc/network/interfaces` 中给第二块网卡分配了一个静态 IP:
```
auto eth1
iface eth1 inet static
address 192.168.2.2
netmask 255.255.255.0
```
在 VoIP 电话上,我将静态 IP 设置成 `192.168.2.3`,DNS 服务器设置成 `192.168.2.2`。我接着将 SIP 注册 IP 地址设置成 `192.168.2.2`。
DNS 服务器实际上是一个在 Asterisk 服务器上运行的 [unbound 守护进程](https://feeding.cloud.geek.nz/posts/setting-up-your-own-dnssec-aware/)。我唯一需要更改的配置是监听第二张网卡,并允许 VoIP 电话进入:
```
server:
interface: 127.0.0.1
interface: 192.168.2.2
access-control: 0.0.0.0/0 refuse
access-control: 127.0.0.1/32 allow
access-control: 192.168.2.3/32 allow
```
最后,我在 `/etc/network/iptables.up.rules` 中打开了服务器防火墙上的正确端口:
```
-A INPUT -s 192.168.2.3/32 -p udp --dport 5060 -j ACCEPT
-A INPUT -s 192.168.2.3/32 -p udp --dport 10000:20000 -j ACCEPT
```
### 访问管理页面
现在 VoIP 电话不能在本地网络上用了,因此无法访问其管理页面。从安全的角度来看,这是一件好事,但它有点不方便。
因此,在通过 ssh 连接到 Asterisk 服务器之后,我将以下内容放在我的 `~/.ssh/config` 中以便通过 `http://localhost:8081` 访问管理页面:
```
Host asterisk
LocalForward 8081 192.168.2.3:80
```
---
via: <https://feeding.cloud.geek.nz/posts/connecting-voip-phone-directly-to-asterisk-server/>
作者:[François Marier](https://fmarier.org/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Feeding the Cloud](../../)/
[posts](../)/ Connecting a VoIP phone directly to an Asterisk server
On my [Asterisk](https://www.asterisk.org/) server, I happen to have two
on-board ethernet boards. Since I only used one of these, I decided to move
my VoIP phone from the local network switch to being connected directly to
the Asterisk server.
The main advantage is that this phone, running proprietary software of unknown quality, is no longer available on my general home network. Most importantly though, it no longer has access to the Internet, without my having to firewall it manually.
Here's how I configured everything.
# Private network configuration
On the server, I started by giving the second network interface a static IP
address in `/etc/network/interfaces`
:
```
auto eth1
iface eth1 inet static
address 192.168.2.2
netmask 255.255.255.0
```
On the VoIP phone itself, I set the static IP address to `192.168.2.3`
and
the DNS server to `192.168.2.2`
. I then updated the SIP registrar IP address
to `192.168.2.2`
.
The DNS server actually refers to an [unbound
daemon](/posts/setting-up-your-own-dnssec-aware/)
running on the Asterisk server. The only configuration change I had to make
was to listen on the second interface and allow the VoIP phone in:
```
server:
interface: 127.0.0.1
interface: 192.168.2.2
access-control: 0.0.0.0/0 refuse
access-control: 127.0.0.1/32 allow
access-control: 192.168.2.3/32 allow
```
Finally, I opened the right ports on the server's firewall in
`/etc/network/iptables.up.rules`
:
```
-A INPUT -s 192.168.2.3/32 -p udp --dport 5060 -j ACCEPT
-A INPUT -s 192.168.2.3/32 -p tcp --dport 5060 -j ACCEPT
-A INPUT -s 192.168.2.3/32 -p udp --dport 10000:20000 -j ACCEPT
```
# Network time synchronization
In order for the phone to update its clock automatically using [NTP](https://en.wikipedia.org/wiki/Network_Time_Protocol), I installed [chrony](https://chrony.tuxfamily.org/) on the Asterisk server:
```
apt install chrony
```
then I configured it to listen on the private network interface and allow access from the VoIP phone by adding the following to `/etc/chrony/conf.d/asterisk-local.conf`
:
```
bindaddress 192.168.2.2
allow 192.168.2.3
```
Finally, I opened the right firewall port by adding a new rule to `/etc/network/iptables.up.rules`
:
```
-A INPUT -s 192.168.2.3 -p udp --dport 123 -j ACCEPT
```
# Accessing the admin page
Now that the VoIP phone is no longer available on the local network, it's not possible to access its admin page. That's a good thing from a security point of view, but it's somewhat inconvenient.
Therefore I put the following in my `~/.ssh/config`
to make the admin page
available on `http://localhost:8081`
after I connect to the Asterisk server
via ssh:
```
Host asterisk
LocalForward localhost:8081 192.168.2.3:80
```
# Allowing calls between local SIP devices
Because this local device is not connected to the local network
(`192.168.1.0/24`
), it's unable to negotiate a direct media connection to
any other local (i.e. one connected to the same Asterisk server) SIP device.
What this means is that while calls might get connected successfully, by
default, there will not be any audio in a call.
In order for the two local SIP devices to be able to hear one another, we
must enforce that all media be routed via Asterisk instead of going directly
from one device to the other. This can be done using the `directmedia`
directive (formerly
[ canreinvite](https://www.voip-info.org/asterisk-sip-canreinvite/)) in
`sip.conf`
:```
[1234]
directmedia=no
```
where `1234`
is the extension of the phone. |
10,621 | HTTP 简史 | https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol | 2019-03-15T11:31:00 | [
"HTTP"
] | https://linux.cn/article-10621-1.html | 
>
> 译注:本文来源于 2013 年出版的《[High Performance Browser Networking](https://hpbn.co)》的第九章,因此有些信息略有过时。事实上,现在 HTTP/2 已经有相当的不是,而新的 HTTP/3 也在设计和标准制定当中。
>
>
>
### 介绍
<ruby> 超文本传输协议 <rt> Hypertext Transfer Protocol </rt></ruby>(HTTP)是互联网上最普遍和广泛采用的应用程序协议之一。它是客户端和服务器之间的通用语言,支持现代 Web。从最初作为单个的关键字和文档路径开始,它已成为不仅仅是浏览器的首选协议,而且几乎是所有连接互联网硬件和软件应用程序的首选协议。
在本文中,我们将简要回顾 HTTP 协议的发展历史。对 HTTP 不同语义的完整讨论超出了本文的范围,但理解 HTTP 的关键设计变更以及每个变更背后的动机将为我们讨论 HTTP 性能提供必要的背景,特别是在 HTTP/2 中即将进行的许多改进。
### HTTP 0.9: 单行协议
<ruby> 蒂姆·伯纳斯·李 <rt> Tim Berners-Lee </rt></ruby> 最初的 HTTP 提案在设计时考虑到了简单性,以帮助他采用他的另一个新想法:<ruby> 万维网 <rt> World Wide Web </rt></ruby>。这个策略看起来奏效了:注意,他是一个有抱负的协议设计者。
1991 年,伯纳斯·李概述了这个新协议的动机,并列出了几个高级设计目标:文件传输功能、请求超文档存档索引搜索的能力,格式协商以及将客户端引用到另一个服务器的能力。为了证明该理论的实际应用,构建了一个简单原型,它实现了所提议功能的一小部分。
* 客户端请求是一个 ASCII 字符串。
* 客户端请求以回车符(CRLF)终止。
* 服务器响应是 ASCII 字符流。
* 服务器响应是一种超文本标记语言(HTML)。
* 文档传输完成后连接终止。
然而,即使这听起来也比实际复杂得多。这些规则支持的是一种非常简单的,对 Telnet 友好的协议,一些 Web 服务器至今仍然支持这种协议:
```
$> telnet google.com 80
Connected to 74.125.xxx.xxx
GET /about/
(hypertext response)
(connection closed)
```
请求包含这样一行:`GET` 方法和请求文档的路径。响应是一个超文本文档,没有标题或任何其他元数据,只有 HTML。真的是再简单不过了。此外,由于之前的交互是预期协议的子集,因此它获得了一个非官方的 HTTP 0.9 标签。其余的,就像他们所说的,都是历史。
从 1991 年这些不起眼的开始,HTTP 就有了自己的生命,并在接下来几年里迅速发展。让我们快速回顾一下 HTTP 0.9 的特性:
* 采用客户端-服务器架构,是一种请求-响应协议。
* 采用 ASCII 协议,运行在 TCP/IP 链路上。
* 旨在传输超文本文档(HTML)。
* 每次请求后,服务器和客户端之间的连接都将关闭。
>
> 流行的 Web 服务器,如 Apache 和 Nginx,仍然支持 HTTP 0.9 协议,部分原因是因为它没有太多功能!如果你感兴趣,打开 Telnet 会话并尝试通过 HTTP 0.9 访问 google.com 或你最喜欢的网站,并检查早期协议的行为和限制。
>
>
>
### HTTP/1.0: 快速增长和 Informational RFC
1991 年至 1995 年期间,HTML 规范和一种称为 “web 浏览器”的新型软件快速发展,面向消费者的公共互联网基础设施也开始出现并快速增长。
>
> **完美风暴:1990 年代初的互联网热潮**
>
>
> 基于蒂姆·伯纳斯·李最初的浏览器原型,美国国家超级计算机应用中心(NCSA)的一个团队决定实现他们自己的版本。就这样,第一个流行的浏览器诞生了:NCSA Mosaic。1994 年 10 月,NCSA 团队的一名程序员 Marc Andreessen 与 Jim Clark 合作创建了 Mosaic Communications,该公司后来改名为 Netscape(网景),并于 1994 年 12 月发布了 Netscape Navigator 1.0。从这一点来说,已经很清楚了,万维网已经不仅仅是学术上的好奇心了。
>
>
> 实际上,同年在瑞士日内瓦组织了第一次万维网会议,这导致<ruby> 万维网联盟 <rt> World Wide Web Consortium </rt></ruby>(W3C)的成立,以帮助指导 HTML 的发展。同样,在 IETF 内部建立了一个并行的<ruby> HTTP 工作组 <rt> HTTP Working Group </rt></ruby>(HTTP-WG),专注于改进 HTTP 协议。后来这两个团体一直对 Web 的发展起着重要作用。
>
>
> 最后,完美风暴来临,CompuServe,AOL 和 Prodigy 在 1994-1995 年的同一时间开始向公众提供拨号上网服务。凭借这股迅速的浪潮,Netscape 在 1995 年 8 月 9 日凭借其成功的 IPO 创造了历史。这预示着互联网热潮已经到来,人人都想分一杯羹!
>
>
>
不断增长的新 Web 所需功能及其在公共网站上的应用场景很快暴露了 HTTP 0.9 的许多基础限制:我们需要一种能够提供超文本文档、提供关于请求和响应的更丰富的元数据,支持内容协商等等的协议。相应地,新兴的 Web 开发人员社区通过一个特殊的过程生成了大量实验性的 HTTP 服务器和客户端实现来回应:实现,部署,并查看其他人是否采用它。
从这些急速增长的实验开始,一系列最佳实践和常见模式开始出现。1996 年 5 月,<ruby> HTTP 工作组 <rt> HTTP Working Group </rt></ruby>(HTTP-WG)发布了 RFC 1945,它记录了许多被广泛使用的 HTTP/1.0 实现的“常见用法”。请注意,这只是一个信息性 RFC:HTTP/1.0,如你所知的,它不是一个正式规范或 Internet 标准!
话虽如此,HTTP/1.0 请求看起来应该是:
```
$> telnet website.org 80
Connected to xxx.xxx.xxx.xxx
GET /rfc/rfc1945.txt HTTP/1.0 ❶
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Accept: */*
HTTP/1.0 200 OK ❷
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 01 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
Server: Apache 0.84
(plain-text response)
(connection closed)
```
* ❶ 请求行有 HTTP 版本号,后面跟请求头
* ❷ 响应状态,后跟响应头
前面的交互并不是 HTTP/1.0 功能的详尽列表,但它确实说明了一些关键的协议更改:
* 请求可能多个由换行符分隔的请求头字段组成。
* 响应对象的前缀是响应状态行。
* 响应对象有自己的一组由换行符分隔的响应头字段。
* 响应对象不限于超文本。
* 每次请求后,服务器和客户端之间的连接都将关闭。
请求头和响应头都保留为 ASCII 编码,但响应对象本身可以是任何类型:HTML 文件、纯文本文件、图像或任何其他内容类型。因此,HTTP 的“超文本传输”部分在引入后不久就变成了用词不当。实际上,HTTP 已经迅速发展成为一种超媒体传输,但最初的名称没有改变。
除了媒体类型协商之外,RFC 还记录了许多其他常用功能:内容编码、字符集支持、多部分类型、授权、缓存、代理行为、日期格式等。
>
> 今天,几乎所有 Web 上的服务器都可以并且仍将使用 HTTP/1.0。不过,现在你应该更加清楚了!每个请求都需要一个新的 TCP 连接,这会对 HTTP/1.0 造成严重的性能损失。参见[三次握手](https://hpbn.co/building-blocks-of-tcp/#three-way-handshake),接着会[慢启动](https://hpbn.co/building-blocks-of-tcp/#slow-start)。
>
>
>
### HTTP/1.1: Internet 标准
将 HTTP 转变为官方 IETF 互联网标准的工作与围绕 HTTP/1.0 的文档工作并行进行,并计划从 1995 年至 1999 年完成。事实上,第一个正式的 HTTP/1.1 标准定义于 RFC 2068,它在 HTTP/1.0 发布大约六个月后,即 1997 年 1 月正式发布。两年半后,即 1999 年 6 月,一些新的改进和更新被纳入标准,并作为 RFC 2616 发布。
HTTP/1.1 标准解决了早期版本中发现的许多协议歧义,并引入了一些关键的性能优化:保持连接,分块编码传输,字节范围请求,附加缓存机制,传输编码和请求管道。
有了这些功能,我们现在可以审视一下由任何现代 HTTP 浏览器和客户端执行的典型 HTTP/1.1 会话:
```
$> telnet website.org 80
Connected to xxx.xxx.xxx.xxx
GET /index.html HTTP/1.1 ❶
Host: website.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
Cookie: __qca=P0-800083390... (snip)
HTTP/1.1 200 OK ❷
Server: nginx/1.0.11
Connection: keep-alive
Content-Type: text/html; charset=utf-8
Via: HTTP/1.1 GWA
Date: Wed, 25 Jul 2012 20:23:35 GMT
Expires: Wed, 25 Jul 2012 20:23:35 GMT
Cache-Control: max-age=0, no-cache
Transfer-Encoding: chunked
100 ❸
<!doctype html>
(snip)
100
(snip)
0 ❹
GET /favicon.ico HTTP/1.1 ❺
Host: www.website.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
Accept: */*
Referer: http://website.org/
Connection: close ❻
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
Cookie: __qca=P0-800083390... (snip)
HTTP/1.1 200 OK ❼
Server: nginx/1.0.11
Content-Type: image/x-icon
Content-Length: 3638
Connection: close
Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
Cache-Control: max-age=315360000
Accept-Ranges: bytes
Via: HTTP/1.1 GWA
Date: Sat, 21 Jul 2012 21:35:22 GMT
Expires: Thu, 31 Dec 2037 23:55:55 GMT
Etag: W/PSA-GAu26oXbDi
(icon data)
(connection closed)
```
* ❶ 请求的 HTML 文件,包括编、字符集和 cookie 元数据
* ❷ 原始 HTML 请求的分块响应
* ❸ 以 ASCII 十六进制数字(256 字节)表示块中的八位元的数量
* ❹ 分块流响应结束
* ❺ 在相同的 TCP 连接上请求一个图标文件
* ❻ 通知服务器不再重用连接
* ❼ 图标响应后,然后关闭连接
哇,这里发生了很多事情!第一个也是最明显的区别是我们有两个对象请求,一个用于 HTML 页面,另一个用于图像,它们都通过一个连接完成。这就是保持连接的实际应用,它允许我们重用现有的 TCP 连接到同一个主机的多个请求,提供一个更快的最终用户体验。参见[TCP 优化](https://hpbn.co/building-blocks-of-tcp/#optimizing-for-tcp)。
要终止持久连接,注意第二个客户端请求通过 `Connection` 请求头向服务器发送显示的 `close`。类似地,一旦传输响应,服务器就可以通知客户端关闭当前 TCP 连接。从技术上讲,任何一方都可以在没有此类信号的情况下终止 TCP 连接,但客户端和服务器应尽可能提供此类信号,以便双方都启用更好的连接重用策略。
>
> HTTP/1.1 改变了 HTTP 协议的语义,默认情况下使用保持连接。这意味着,除非另有说明(通过 `Connection:close` 头),否则服务器应默认保持连接打开。
>
>
> 但是,同样的功能也被反向移植到 HTTP/1.0 上,通过 `Connection:keep-Alive` 头启用。因此,如果你使用 HTTP/1.1,从技术上讲,你不需要 `Connection:keep-Alive` 头,但许多客户端仍然选择提供它。
>
>
>
此外,HTTP/1.1 协议还添加了内容、编码、字符集,甚至语言协商、传输编码、缓存指令、客户端 cookie,以及可以针对每个请求协商的十几个其他功能。
我们不打算详细讨论每个 HTTP/1.1 特性的语义。这个主题可以写一本专门的书了,已经有了很多很棒的书。相反,前面的示例很好地说明了 HTTP 的快速进展和演变,以及每个客户端-服务器交换的错综复杂的过程,里面发生了很多事情!
>
> 要了解 HTTP 协议所有内部工作原理,参考 David Gourley 和 Brian Totty 共同撰写的权威指南: The Definitive Guide。
>
>
>
### HTTP/2: 提高传输性能
RFC 2616 自发布以来,已经成为互联网空前增长的基础:数十亿各种形状和大小的设备,从台式电脑到我们口袋里的小型网络设备,每天都在使用 HTTP 来传送新闻,视频,在我们生活中的数百万的其他网络应用程序都在依靠它。
一开始是一个简单的,用于检索超文本的简单协议,很快演变成了一种通用的超媒体传输,现在十年过去了,它几乎可以为你所能想象到的任何用例提供支持。可以使用协议的服务器无处不在,客户端也可以使用协议,这意味着现在许多应用程序都是专门在 HTTP 之上设计和部署的。
需要一个协议来控制你的咖啡壶?RFC 2324 已经涵盖了超文本咖啡壶控制协议(HTCPCP/1.0)- 它原本是 IETF 在愚人节开的一个玩笑,但在我们这个超链接的新世界中,它不仅仅意味着一个玩笑。
>
> 超文本传输协议(HTTP)是一个应用程序级的协议,用于分布式、协作、超媒体信息系统。它是一种通用的、无状态的协议,可以通过扩展请求方法、错误码和头,用于超出超文本之外的许多任务,比如名称服务器和分布式对象管理系统。HTTP 的一个特性是数据表示的类型和协商,允许独立于传输的数据构建系统。
>
>
> RFC 2616: HTTP/1.1, June 1999
>
>
>
HTTP 协议的简单性是它最初被采用和快速增长的原因。事实上,现在使用 HTTP 作为主要控制和数据协议的嵌入式设备(传感器,执行器和咖啡壶)并不罕见。但在其自身成功的重压下,随着我们越来越多地继续将日常互动转移到网络 —— 社交、电子邮件、新闻和视频,以及越来越多的个人和工作空间,它也开始显示出压力的迹象。用户和 Web 开发人员现在都要求 HTTP/1.1 提供近乎实时的响应能力和协议 性能,如果不进行一些修改,就无法满足这些要求。
为了应对这些新挑战,HTTP 必须继续发展,因此 HTTPbis 工作组在 2012 年初宣布了一项针对 HTTP/2 的新计划:
>
> 已经有一个协议中出现了新的实现经验和兴趣,该协议保留了 HTTP 的语义,但是没有保留 HTTP/1.x 的消息框架和语法,这些问题已经被确定为妨碍性能和鼓励滥用底层传输。
>
>
> 工作组将使用有序的双向流中生成 HTTP 当前语义的新表达式的规范。与 HTTP/1.x 一样,主要传输目标是 TCP,但是应该可以使用其他方式传输。
>
>
> HTTP/2 charter, January 2012
>
>
>
HTTP/2 的主要重点是提高传输性能并支持更低的延迟和更高的吞吐量。主要的版本增量听起来像是一个很大的步骤,但就性能而言,它将是一个重大的步骤,但重要的是要注意,没有任何高级协议语义收到影响:所有的 HTTP 头,值和用例是相同的。
任何现有的网站或应用程序都可以并且将通过 HTTP/2 传送而无需修改。你无需修改应用程序标记来利用 HTTP/2。HTTP 服务器将来一定会使用 HTTP/2,但这对大多数用户来说应该是透明的升级。如果工作组实现目标,唯一的区别应该是我们的应用程序以更低的延迟和更好的网络连接利用率来传送数据。
话虽如此,但我们不要走的太远了。在讨论新的 HTTP/2 协议功能之前,有必要回顾一下我们现有的 HTTP/1.1 部署和性能最佳实践。HTTP/2 工作组正在新规范上取得快速的进展,但即使最终标准已经完成并准备就绪,在可预见的未来,我们仍然必须支持旧的 HTTP/1.1 客户端,实际上,这得十年或更长时间。
---
via: <https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol>
作者:[Ilya Grigorik](https://www.igvita.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## Introduction
The Hypertext Transfer Protocol (HTTP) is one of the most ubiquitous and widely adopted application protocols on the Internet: it is the common language between clients and servers, enabling the modern web. From its simple beginnings as a single keyword and document path, it has become the protocol of choice not just for browsers, but for virtually every Internet-connected software and hardware application.
In this chapter, we will take a brief historical tour of the evolution of the HTTP protocol. A full discussion of the varying HTTP semantics is outside the scope of this book, but an understanding of the key design changes of HTTP, and the motivations behind each, will give us the necessary background for our discussions on HTTP performance, especially in the context of the many upcoming improvements in HTTP/2.
[§](#http-09-the-one-line-protocol)HTTP 0.9: The
One-Line Protocol
The original HTTP proposal by Tim Berners-Lee was designed with
*simplicity in mind* as to help with the adoption of his other
nascent idea: the World Wide Web. The strategy appears to have worked:
aspiring protocol designers, take note.
In 1991, Berners-Lee outlined the motivation for the new protocol and listed several high-level design goals: file transfer functionality, ability to request an index search of a hypertext archive, format negotiation, and an ability to refer the client to another server. To prove the theory in action, a simple prototype was built, which implemented a small subset of the proposed functionality:
-
Client request is a single ASCII character string.
-
Client request is terminated by a carriage return (CRLF).
-
Server response is an ASCII character stream.
-
Server response is a hypertext markup language (HTML).
-
Connection is terminated after the document transfer is complete.
However, even that sounds a lot more complicated than it really is. What these rules enable is an extremely simple, Telnet-friendly protocol, which some web servers support to this very day:
$> telnet google.com 80Connected to 74.125.xxx.xxx GET /about/ (hypertext response) (connection closed)
The request consists of a single line: `GET`
method and the
path of the requested document. The response is a single hypertext
document—no headers or any other metadata, just the HTML. It really
couldn’t get any simpler. Further, since the previous interaction is a
subset of the intended protocol, it unofficially acquired the HTTP 0.9
label. The rest, as they say, is history.
From these humble beginnings in 1991, HTTP took on a life of its own and evolved rapidly over the coming years. Let us quickly recap the features of HTTP 0.9:
-
Client-server, request-response protocol.
-
ASCII protocol, running over a TCP/IP link.
-
Designed to transfer hypertext documents (HTML).
-
The connection between server and client is closed after every request.
Popular web servers, such as Apache and Nginx, still support the HTTP 0.9 protocol—in part, because there is not much to it! If you are curious, open up a Telnet session and try accessing google.com, or your own favorite site, via HTTP 0.9 and inspect the behavior and the limitations of this early protocol.
[§](#http10-rapid-growth-and-informational-rfc)HTTP/1.0: Rapid Growth and Informational RFC
The period from 1991 to 1995 is one of rapid coevolution of the HTML specification, a new breed of software known as a "web browser," and the emergence and quick growth of the consumer-oriented public Internet infrastructure.
The growing list of desired capabilities of the nascent Web and their use cases on the public Web quickly exposed many of the fundamental limitations of HTTP 0.9: we needed a protocol that could serve more than just hypertext documents, provide richer metadata about the request and the response, enable content negotiation, and more. In turn, the nascent community of web developers responded by producing a large number of experimental HTTP server and client implementations through an ad hoc process: implement, deploy, and see if other people adopt it.
From this period of rapid experimentation, a set of best practices and common patterns began to emerge, and in May 1996 the HTTP Working Group (HTTP-WG) published RFC 1945, which documented the "common usage" of the many HTTP/1.0 implementations found in the wild. Note that this was only an informational RFC: HTTP/1.0 as we know it is not a formal specification or an Internet standard!
Having said that, an example HTTP/1.0 request should look very familiar:
$> telnet website.org 80Connected to xxx.xxx.xxx.xxx GET /rfc/rfc1945.txt HTTP/1.0[User-Agent: CERN-LineMode/2.15 libwww/2.17b3 Accept: */* HTTP/1.0 200 OK][Content-Type: text/plain Content-Length: 137582 Expires: Thu, 01 Dec 1997 16:00:00 GMT Last-Modified: Wed, 1 May 1996 12:45:26 GMT Server: Apache 0.84 (plain-text response) (connection closed)]
The preceding exchange is not an exhaustive list of HTTP/1.0 capabilities, but it does illustrate some of the key protocol changes:
-
Request may consist of multiple newline separated header fields.
-
Response object is prefixed with a response status line.
-
Response object has its own set of newline separated header fields.
-
Response object is not limited to hypertext.
-
The connection between server and client is closed after every request.
Both the request and response headers were kept as ASCII encoded, but
the response object itself could be of any type: an HTML file, a plain
text file, an image, or any other content type. Hence, the "hypertext
transfer" part of HTTP became a misnomer not long after its introduction.
In reality, HTTP has quickly evolved to become a *hypermedia
transport*, but the original name stuck.
In addition to media type negotiation, the RFC also documented a number of other commonly implemented capabilities: content encoding, character set support, multi-part types, authorization, caching, proxy behaviors, date formats, and more.
Almost every server on the Web today can and will still speak
HTTP/1.0. Except that, by now, you should know better! Requiring a new
TCP connection per request imposes a significant performance penalty on
HTTP/1.0; see [Three-Way Handshake](/building-blocks-of-tcp/#three-way-handshake),
followed by [Slow-Start](/building-blocks-of-tcp/#slow-start).
[§](#http11-internet-standard)HTTP/1.1: Internet Standard
The work on turning HTTP into an official IETF Internet standard proceeded in parallel with the documentation effort around HTTP/1.0 and happened over a period of roughly four years: between 1995 and 1999. In fact, the first official HTTP/1.1 standard is defined in RFC 2068, which was officially released in January 1997, roughly six months after the publication of HTTP/1.0. Then, two and a half years later, in June of 1999, a number of improvements and updates were incorporated into the standard and were released as RFC 2616.
The HTTP/1.1 standard resolved a lot of the protocol ambiguities found in earlier versions and introduced a number of critical performance optimizations: keepalive connections, chunked encoding transfers, byte-range requests, additional caching mechanisms, transfer encodings, and request pipelining.
With these capabilities in place, we can now inspect a typical HTTP/1.1 session as performed by any modern HTTP browser and client:
$> telnet website.org 80Connected to xxx.xxx.xxx.xxx GET /index.html HTTP/1.1[Host: website.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip) Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3 Cookie: __qca=P0-800083390... (snip) HTTP/1.1 200 OK][Server: nginx/1.0.11 Connection: keep-alive Content-Type: text/html; charset=utf-8 Via: HTTP/1.1 GWA Date: Wed, 25 Jul 2012 20:23:35 GMT Expires: Wed, 25 Jul 2012 20:23:35 GMT Cache-Control: max-age=0, no-cache Transfer-Encoding: chunked 100][<!doctype html> (snip) 100 (snip) 0][GET /favicon.ico HTTP/1.1][Host: www.website.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip) Accept: */* Referer: http://website.org/ Connection: close][Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3 Cookie: __qca=P0-800083390... (snip) HTTP/1.1 200 OK][Server: nginx/1.0.11 Content-Type: image/x-icon Content-Length: 3638 Connection: close Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT Cache-Control: max-age=315360000 Accept-Ranges: bytes Via: HTTP/1.1 GWA Date: Sat, 21 Jul 2012 21:35:22 GMT Expires: Thu, 31 Dec 2037 23:55:55 GMT Etag: W/PSA-GAu26oXbDi (icon data) (connection closed)]
-
Request for HTML file, with encoding, charset, and cookie metadata
-
Chunked response for original HTML request
-
Number of octets in the chunk expressed as an ASCII hexadecimal number (256 bytes)
-
End of chunked stream response
-
Request for an icon file made on same TCP connection
-
Inform server that the connection will not be reused
-
Icon response, followed by connection close
Phew, there is a lot going on in there! The first and most obvious
difference is that we have two object requests, one for an HTML page and
one for an image, both delivered over a single connection. This is
connection keepalive in action, which allows us to reuse the existing TCP
connection for multiple requests to the same host and deliver a much
faster end-user experience; see [Optimizing for TCP](/building-blocks-of-tcp/#optimizing-for-tcp).
To terminate the persistent connection, notice that the second client
request sends an explicit `close`
token to the server via the
`Connection`
header. Similarly, the server can notify the
client of the intent to close the current TCP connection once the
response is transferred. Technically, either side can terminate the TCP
connection without such signal at any point, but clients and servers
should provide it whenever possible to enable better connection reuse
strategies on both sides.
HTTP/1.1 changed the semantics of the HTTP protocol to use
connection keepalive by default. Meaning, unless told otherwise (via
`Connection: close`
header), the server should keep the
connection open by default.
However, this same functionality was also backported to HTTP/1.0 and
enabled via the `Connection: Keep-Alive`
header. Hence, if
you are using HTTP/1.1, technically you don’t need the
`Connection: Keep-Alive`
header, but many clients choose to
provide it nonetheless.
Additionally, the HTTP/1.1 protocol added content, encoding, character set, and even language negotiation, transfer encoding, caching directives, client cookies, plus a dozen other capabilities that can be negotiated on each request.
We are not going to dwell on the semantics of every HTTP/1.1 feature. This is a subject for a dedicated book, and many great ones have been written already. Instead, the previous example serves as a good illustration of both the quick progress and evolution of HTTP, as well as the intricate and complicated dance of every client-server exchange. There is a lot going on in there!
For a good reference on all the inner workings of the HTTP protocol,
check out O’Reilly’s *HTTP: The Definitive Guide* by David
Gourley and Brian Totty.
[§](#http2-improving-transport-performance)HTTP/2:
Improving Transport Performance
Since its publication, RFC 2616 has served as a foundation for the unprecedented growth of the Internet: billions of devices of all shapes and sizes, from desktop computers to the tiny web devices in our pockets, speak HTTP every day to deliver news, video, and millions of other web applications we have all come to depend on in our lives.
What began as a simple, one-line protocol for retrieving hypertext quickly evolved into a generic hypermedia transport, and now a decade later can be used to power just about any use case you can imagine. Both the ubiquity of servers that can speak the protocol and the wide availability of clients to consume it means that many applications are now designed and deployed exclusively on top of HTTP.
Need a protocol to control your coffee pot? RFC 2324 has you covered with the Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0)—originally an April Fools’ Day joke by IETF, and increasingly anything but a joke in our new hyper-connected world.
The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. It is a generic, stateless, protocol that can be used for many tasks beyond its use for hypertext, such as name servers and distributed object management systems, through extension of its request methods, error codes and headers. A feature of HTTP is the typing and negotiation of data representation, allowing systems to be built independently of the data being transferred.
RFC 2616: HTTP/1.1, June 1999
The simplicity of the HTTP protocol is what enabled its original adoption and rapid growth. In fact, it is now not unusual to find embedded devices—sensors, actuators, and coffee pots alike—using HTTP as their primary control and data protocols. But under the weight of its own success and as we increasingly continue to migrate our everyday interactions to the Web—social, email, news, and video, and increasingly our entire personal and job workspaces—it has also begun to show signs of stress. Users and web developers alike are now demanding near real-time responsiveness and protocol performance from HTTP/1.1, which it simply cannot meet without some modifications.
To meet these new challenges, HTTP must continue to evolve, and hence the HTTPbis working group announced a new initiative for HTTP/2 in early 2012:
There is emerging implementation experience and interest in a protocol that retains the semantics of HTTP without the legacy of HTTP/1.x message framing and syntax, which have been identified as hampering performance and encouraging misuse of the underlying transport.
The working group will produce a specification of a new expression of HTTP’s current semantics in ordered, bi-directional streams. As with HTTP/1.x, the primary target transport is TCP, but it should be possible to use other transports.
HTTP/2 charter, January 2012
The primary focus of HTTP/2 is on improving transport performance and enabling both lower latency and higher throughput. The major version increment sounds like a big step, which it is and will be as far as performance is concerned, but it is important to note that none of the high-level protocol semantics are affected: all HTTP headers, values, and use cases are the same.
Any existing website or application can and will be delivered over HTTP/2 without modification: you do not need to modify your application markup to take advantage of HTTP/2. The HTTP servers will have to speak HTTP/2, but that should be a transparent upgrade for the majority of users. The only difference if the working group meets its goal, should be that our applications are delivered with lower latency and better utilization of the network link!
Having said that, let’s not get ahead of ourselves. Before we get to the new HTTP/2 protocol features, it is worth taking a step back and examining our existing deployment and performance best practices for HTTP/1.1. The HTTP/2 working group is making fast progress on the new specification, but even if the final standard was already done and ready, we would still have to support older HTTP/1.1 clients for the foreseeable future—realistically, a decade or more. |
10,622 | 如何在 Linux 中安装、配置和使用 Fish Shell? | https://www.2daygeek.com/linux-fish-shell-friendly-interactive-shell/ | 2019-03-16T11:27:00 | [
"fish",
"shell"
] | https://linux.cn/article-10622-1.html | 
每个 Linux 管理员都可能听到过 shell 这个词。你知道什么是 shell 吗? 你知道 shell 在 Linux 中的作用是什么吗? Linux 中有多少个 shell 可用?
shell 是一个程序,它是提供用户和内核之间交互的接口。
内核是 Linux 操作系统的核心,它管理用户和操作系统之间的所有内容。Shell 可供所有用户在启动终端时使用。终端启动后,用户可以运行任何可用的命令。当 shell 完成命令的执行时,你将在终端窗口上获取输出。
Bash(全称是 Bourne Again Shell)是运行在今天的大多数 Linux 发行版上的默认的 shell,它非常受欢迎,并具有很多功能。但今天我们将讨论 Fish Shell 。
### 什么是 Fish Shell?
[Fish](https://fishshell.com/) 是友好的交互式 shell ,是一个功能齐全,智能且对用户友好的 Linux 命令行 shell ,它带有一些在大多数 shell 中都不具备的方便功能。
这些功能包括自动补全建议、Sane Scripting、手册页补全、基于 Web 的配置器和 Glorious VGA Color 。你对它感到好奇并想测试它吗?如果是这样,请按照以下安装步骤继续安装。
### 如何在 Linux 中安装 Fish Shell ?
它的安装非常简单,除了少数几个发行版外,它在大多数发行版中都没有。但是,可以使用以下 [fish 仓库](https://download.opensuse.org/repositories/shells:/fish:/release:/) 轻松安装。
对于基于 Arch Linux 的系统, 使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 fish shell。
```
$ sudo pacman -S fish
```
对于 Ubuntu 16.04/18.04 系统来说,请使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 安装 fish shell。
```
$ sudo apt-add-repository ppa:fish-shell/release-3
$ sudo apt-get update
$ sudo apt-get install fish
```
对于 Fedora 系统来说,请使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 安装 fish shell。
对于 Fedora 29 系统来说:
```
$ sudo dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:/fish:/release:/3/Fedora_29/shells:fish:release:3.repo
$ sudo dnf install fish
```
对于 Fedora 28 系统来说:
```
$ sudo dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:/fish:/release:/3/Fedora_28/shells:fish:release:3.repo
$ sudo dnf install fish
```
对于 Debian 系统来说,请使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或者 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 安装 fish shell。
对于 Debian 9 系统来说:
```
$ sudo wget -nv https://download.opensuse.org/repositories/shells:fish:release:3/Debian_9.0/Release.key -O Release.key
$ sudo apt-key add - < Release.key
$ sudo echo 'deb http://download.opensuse.org/repositories/shells:/fish:/release:/3/Debian_9.0/ /' > /etc/apt/sources.list.d/shells:fish:release:3.list
$ sudo apt-get update
$ sudo apt-get install fish
```
对于 Debian 8 系统来说:
```
$ sudo wget -nv https://download.opensuse.org/repositories/shells:fish:release:3/Debian_8.0/Release.key -O Release.key
$ sudo apt-key add - < Release.key
$ sudo echo 'deb http://download.opensuse.org/repositories/shells:/fish:/release:/3/Debian_8.0/ /' > /etc/apt/sources.list.d/shells:fish:release:3.list
$ sudo apt-get update
$ sudo apt-get install fish
```
对于 RHEL/CentOS 系统来说,请使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 安装 fish shell。
对于 RHEL 7 系统来说:
```
$ sudo yum-config-manager --add-repo https://download.opensuse.org/repositories/shells:/fish:/release:/3/RHEL_7/shells:fish:release:3.repo
$ sudo yum install fish
```
对于 RHEL 6 系统来说:
```
$ sudo yum-config-manager --add-repo https://download.opensuse.org/repositories/shells:/fish:/release:/3/RedHat_RHEL-6/shells:fish:release:3.repo
$ sudo yum install fish
```
对于 CentOS 7 系统来说:
```
$ sudo yum-config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
$ sudo yum install fish
```
对于 CentOS 6 系统来说:
```
$ sudo yum-config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/CentOS_6/shells:fish:release:2.repo
$ sudo yum install fish
```
对于 openSUSE Leap 系统来说,请使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 安装 fish shell。
```
$ sudo zypper addrepo https://download.opensuse.org/repositories/shells:/fish:/release:/3/openSUSE_Leap_42.3/shells:fish:release:3.repo
$ suod zypper refresh
$ sudo zypper install fish
```
### 如何使用 Fish Shell ?
一旦你成功安装了 fish shell 。只需在你的终端上输入 `fish` ,它将自动从默认的 bash shell 切换到 fish shell 。
```
$ fish
```

### 自动补全建议
当你在 fish shell 中键入任何命令时,它会在输入几个字母后以浅灰色自动建议一个命令。

一旦你得到一个建议然后按下向右光标键(LCTT 译注:原文是左,错的)就能完成它而不是输入完整的命令。

你可以在键入几个字母后立即按下向上光标键检索该命令以前的历史记录。它类似于 bash shell 的 `CTRL+r` 选项。
### Tab 补全
如果你想查看给定命令是否还有其他可能性,那么在键入几个字母后,只需按一下 `Tab` 键即可。

再次按 `Tab` 键可查看完整列表。

### 语法高亮
fish 会进行语法高亮显示,你可以在终端中键入任何命令时看到。无效的命令被着色为 `RED color` 。

同样的,有效的命令以不同的颜色显示。此外,当你键入有效的文件路径时,fish 会在其下面加下划线,如果路径无效,则不会显示下划线。

### 基于 Web 的配置器
fish shell 中有一个很酷的功能,它允许我们通过网络浏览器设置颜色、提示符、功能、变量、历史和键绑定。
在终端上运行以下命令以启动 Web 配置界面。只需按下 `Ctrl+c` 即可退出。
```
$ fish_config
Web config started at 'file:///home/daygeek/.cache/fish/web_config-86ZF5P.html'. Hit enter to stop.
qt5ct: using qt5ct plugin
^C
Shutting down.
```

### 手册页补全
其他 shell 支持可编程的补全,但只有 fish 可以通过解析已安装的手册页自动生成它们。
要使用该功能,请运行以下命令:
```
$ fish_update_completions
Parsing man pages and writing completions to /home/daygeek/.local/share/fish/generated_completions/
3466 / 3466 : zramctl.8.gz
```
### 如何将 Fish 设置为默认 shell
如果你想测试 fish shell 一段时间,你可以将 fish shell 设置为默认 shell,而不用每次都切换它。
要这样做,首先使用以下命令获取 Fish Shell 的位置。
```
$ whereis fish
fish: /usr/bin/fish /etc/fish /usr/share/fish /usr/share/man/man1/fish.1.gz
```
通过运行以下命令将默认 shell 更改为 fish shell 。
```
$ chsh -s /usr/bin/fish
```

提示:只需验证 Fish Shell 是否已添加到 `/etc/shells` 目录中。如果不是,则运行以下命令以附加它。
```
$ echo /usr/bin/fish | sudo tee -a /etc/shells
```
完成测试后,如果要返回 bash shell ,请使用以下命令。
暂时返回:
```
$ bash
```
永久返回:
```
$ chsh -s /bin/bash
```
---
via: <https://www.2daygeek.com/linux-fish-shell-friendly-interactive-shell/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zero-MK](https://github.com/zero-MK) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,623 | 如何在 Linux 中检查密码的复杂性/强度和评分? | https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/ | 2019-03-16T12:01:40 | [
"密码"
] | https://linux.cn/article-10623-1.html | 
我们都知道密码的重要性。最好的密码就是使用难以猜测密码。另外,我建议你为每个服务使用不同的密码,如电子邮件、ftp、ssh 等。最重要的是,我建议你们经常更改密码,以避免不必要的黑客攻击。
默认情况下,RHEL 和它的衍生版使用 cracklib 模块来检查密码强度。我们将教你如何使用 cracklib 模块检查密码强度。
如果你想检查你创建的密码评分,请使用 pwscore 包。
如果你想创建一个好密码,最起码它应该至少有 12-15 个字符长度。它应该按以下组合创建,如字母(小写和大写)、数字和特殊字符。Linux 中有许多程序可用于检查密码复杂性,我们今天将讨论有关 cracklib 模块和 pwscore 评分。
### 如何在 Linux 中安装 cracklib 模块?
cracklib 模块在大多数发行版仓库中都有,因此,请使用发行版官方软件包管理器来安装它。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)来安装 cracklib。
```
$ sudo dnf install cracklib
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/)来安装 libcrack2。
```
$ sudo apt install libcrack2
```
对于基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/)来安装 cracklib。
```
$ sudo pacman -S cracklib
```
对于 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)来安装 cracklib。
```
$ sudo yum install cracklib
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)来安装 cracklib。
```
$ sudo zypper install cracklib
```
### 如何在 Linux 中使用 cracklib 模块检查密码复杂性?
我在本文中添加了一些示例来助你更好地了解此模块。
如果你提供了任何如人名或地名或常用字,那么你将看到一条消息“它存在于字典的单词中”。
```
$ echo "password" | cracklib-check
password: it is based on a dictionary word
```
Linux 中的默认密码长度为 7 个字符。如果你提供的密码少于 7 个字符,那么你将看到一条消息“它太短了”。
```
$ echo "123" | cracklib-check
123: it is WAY too short
```
当你提供像我们这样的好密码时,你会看到 “OK”。
```
$ echo "ME$2w!@fgty6723" | cracklib-check
ME!@fgty6723: OK
```
### 如何在 Linux 中安装 pwscore?
pwscore 包在大多数发行版仓库中都有,因此,请使用发行版官方软件包管理器来安装它。
对于 Fedora 系统,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/)来安装 libpwquality。
```
$ sudo dnf install libpwquality
```
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/)来安装 libpwquality。
```
$ sudo apt install libpwquality
```
对于基于 Arch Linux 的系统,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/)来安装 libpwquality。
```
$ sudo pacman -S libpwquality
```
对于 RHEL/CentOS 系统,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/)来安装 libpwquality。
```
$ sudo yum install libpwquality
```
对于 openSUSE Leap 系统,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/)来安装 libpwquality。
```
$ sudo zypper install libpwquality
```
如果你提供了任何如人名或地名或常用字,那么你将看到一条消息“它存在于字典的单词中”。
```
$ echo "password" | pwscore
Password quality check failed:
The password fails the dictionary check - it is based on a dictionary word
```
Linux 中的默认密码长度为 7 个字符。如果你提供的密码少于 7 个字符,那么你将看到一条消息“密码短于 8 个字符”。
```
$ echo "123" | pwscore
Password quality check failed:
The password is shorter than 8 characters
```
当你像我们这样提供了一个好的密码时,你将会看到“密码评分”。
```
$ echo "ME!@fgty6723" | pwscore
90
```
---
via: <https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,624 | 浅析 Bash 中的 {花括号} | https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash | 2019-03-17T09:26:42 | [
"花括号"
] | https://linux.cn/article-10624-1.html |
>
> 让我们继续我们的 Bash 基础之旅,来近距离观察一下花括号,了解一下如何和何时使用它们。
>
>
>

在前面的 Bash 基础系列文章中,我们或多或少地使用了一些还没有讲到的符号。在之前文章的很多例子中,我们都使用到了括号,但并没有重点讲解关于括号的内容。
这个系列接下来的文章中,我们会研究括号们的用法:如何使用这些括号?将它们放在不同的位置会有什么不同的效果?除了圆括号、方括号、花括号以外,我们还会接触另外的将一些内容“包裹”起来的符号,例如单引号、双引号和反引号。
在这周,我们先来看看花括号 `{}`。
### 构造序列
花括号在之前的《[点的含义](/article-10465-1.html)》这篇文章中已经出现过了,当时我们只对点号 `.` 的用法作了介绍。但在构建一个序列的过程中,同样不可以缺少花括号。
我们使用
```
echo {0..10}
```
来顺序输出 0 到 10 这 11 个数。使用
```
echo {10..0}
```
可以将这 11 个数倒序输出。更进一步,可以使用
```
echo {10..0..2}
```
来跳过其中的奇数。
而
```
echo {z..a..2}
```
则从倒序输出字母表,并跳过其中的第奇数个字母。
以此类推。
还可以将两个序列进行组合:
```
echo {a..z}{a..z}
```
这个命令会将从 aa 到 zz 的所有双字母组合依次输出。
这是很有用的。在 Bash 中,定义一个数组的方法是在圆括号 `()` 中放置各个元素并使用空格隔开,就像这样:
```
month=("Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec")
```
如果需要获取数组中的元素,就要使用方括号 `[]` 并在其中填入元素的索引:
```
$ echo ${month[3]} # 数组索引从 0 开始,因此 [3] 对应第 4 个元素
Apr
```
先不要过分关注这里用到的三种括号,我们等下会讲到。
注意,像上面这样,我们可以定义这样一个数组:
```
letter_combos=({a..z}{a..z})
```
其中 `letter_combos` 变量指向的数组依次包含了从 aa 到 zz 的所有双字母组合。
因此,还可以这样定义一个数组:
```
dec2bin=({0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1})
```
在这里,`dec2bin` 变量指向的数组按照升序依次包含了所有 8 位的二进制数,也就是 00000000、00000001、00000010,……,11111111。这个数组可以作为一个十进制数到 8 位二进制数的转换器。例如将十进制数 25 转换为二进制数,可以这样执行:
```
$ echo ${dec2bin[25]}
00011001
```
对于进制转换,确实还有更好的方法,但这不失为一个有趣的方法。
### 参数展开
再看回前面的
```
echo ${month[3]}
```
在这里,花括号的作用就不是构造序列了,而是用于<ruby> 参数展开 <rt> parameter expansion </rt></ruby>。顾名思义,参数展开就是将花括号中的变量展开为这个变量实际的内容。
我们继续使用上面的 `month` 数组来举例:
```
month=("Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec")
```
注意,Bash 中的数组索引从 0 开始,因此 3 代表第 4 个元素 `"Apr"`。因此 `echo ${month[3]}` 在经过参数展开之后,相当于 `echo "Apr"`。
像上面这样将一个数组展开成它所有的元素,只是参数展开的其中一种用法。另外,还可以通过参数展开的方式读取一个字符串变量,并对其进行处理。
例如对于以下这个变量:
```
a="Too longgg"
```
如果执行:
```
echo ${a%gg}
```
可以输出 “too long”,也就是去掉了最后的两个 g。
在这里,
* `${...}` 告诉 shell 展开花括号里的内容
* `a` 就是需要操作的变量
* `%` 告诉 shell 需要在展开字符串之后从字符串的末尾去掉某些内容
* `gg` 是被去掉的内容
这个特性在转换文件格式的时候会比较有用,我来举个例子:
[ImageMagick](http://www.imagemagick.org/) 是一套可以用于操作图像文件的命令行工具,它有一个 `convert` 命令。这个 `convert` 命令的作用是可以为某个格式的图像文件制作一个另一格式的副本。
下面这个命令就是使用 `convert` 为 JPEG 格式图像 `image.jpg` 制作一个 PNG 格式的图像副本 `image.png`:
```
convert image.jpg image.png
```
在很多 Linux 发行版中都预装了 ImageMagick,如果没有预装,一般可以在发行版对应的软件管理器中找到。
继续来看,在对变量进行展开之后,就可以批量执行相类似的操作了:
```
i=image.jpg
convert $i ${i%jpg}png
```
这实际上是将变量 `i` 末尾的 `"jpg"` 去掉,然后加上 `"png"`,最终将整个命令拼接成 `convert image.jpg image.png`。
如果你觉得并不怎么样,可以想象一下有成百上千个图像文件需要进行这个操作,而仅仅运行:
```
for i in *.jpg; do convert $i ${i%jpg}png; done
```
就瞬间完成任务了。
如果需要去掉字符串开头的部分,就要将上面的 `%` 改成 `#` 了:
```
$ a="Hello World!"
$ echo Goodbye${a#Hello}
Goodbye World!
```
参数展开还有很多用法,但一般在写脚本的时候才会需要用到。在这个系列以后的文章中就继续提到。
### 合并输出
最后介绍一个花括号的用法,这个用法很简单,就是可以将多个命令的输出合并在一起。首先看下面这个命令:
```
echo "I found all these PNGs:"; find . -iname "*.png"; echo "Within this bunch of files:"; ls > PNGs.txt
```
以分号分隔开的几条命令都会执行,但只有最后的 `ls` 命令的结果输出会被重定向到 `PNGs.txt` 文件中。如果将这几条命令用花括号包裹起来,就像这样:
```
{ echo "I found all these PNGs:"; find . -iname "*.png"; echo "Within this bunch of files:"; ls; } > PNGs.txt
```
执行完毕后,可以看到 `PNGs.txt` 文件中会包含两次 `echo` 的内容、`find` 命令查找到的 PNG 文件以及最后的 `ls` 命令结果。
需要注意的是,花括号与命令之间需要有空格隔开。因为这里的花括号 `{` 和 `}` 是作为 shell 中的保留字,shell 会将这两个符号之间的输出内容组合到一起。
另外,各个命令之间要用分号 `;` 分隔,否则命令无法正常运行。
### 下期预告
在后续的文章中,我会介绍其它“包裹”类符号的用法,敬请关注。
---
via: <https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash>
作者:[Paul Brown](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,625 | 降低 Emacs 启动时间的高级技术 | https://blog.d46.us/advanced-emacs-startup/ | 2019-03-17T10:30:56 | [
"Emacs",
"优化"
] | https://linux.cn/article-10625-1.html | 
>
> 《[Emacs Start Up Profiler](https://github.com/jschaf/esup)》 的作者教你六项减少 Emacs 启动时间的技术。
>
>
>
简而言之:做下面几个步骤:
1. 使用 Esup 进行性能检测。
2. 调整垃圾回收的阀值。
3. 使用 use-package 来自动(延迟)加载所有东西。
4. 不要使用会引起立即加载的辅助函数。
5. 参考我的 [配置](https://github.com/jschaf/dotfiles/blob/master/emacs/start.el)。
### 从 .emacs.d 的失败到现在
我最近宣布了 .emacs.d 的第三次失败,并完成了第四次 Emacs 配置的迭代。演化过程为:
1. 拷贝并粘贴 elisp 片段到 `~/.emacs` 中,希望它能工作。
2. 借助 `el-get` 来以更结构化的方式来管理依赖关系。
3. 放弃自己从零配置,以 Spacemacs 为基础。
4. 厌倦了 Spacemacs 的复杂性,基于 `use-package` 重写配置。
本文汇聚了三次重写和创建 《[Emacs Start Up Profiler](https://github.com/jschaf/esup)》过程中的技巧。非常感谢 Spacemacs、use-package 等背后的团队。没有这些无私的志愿者,这项任务将会困难得多。
### 不过守护进程模式又如何呢
在我们开始之前,让我反驳一下优化 Emacs 时的常见观念:“Emacs 旨在作为守护进程来运行的,因此你只需要运行一次而已。”
这个观点很好,只不过:
* 速度总是越快越好。
* 配置 Emacs 时,可能会有不得不通过重启 Emacs 的情况。例如,你可能为 `post-command-hook` 添加了一个运行缓慢的 `lambda` 函数,很难删掉它。
* 重启 Emacs 能帮你验证不同会话之间是否还能保留配置。
### 1、估算当前以及最佳的启动时间
第一步是测量当前的启动时间。最简单的方法就是在启动时显示后续步骤进度的信息。
```
;; Use a hook so the message doesn't get clobbered by other messages.
(add-hook 'emacs-startup-hook
(lambda ()
(message "Emacs ready in %s with %d garbage collections."
(format "%.2f seconds"
(float-time
(time-subtract after-init-time before-init-time)))
gcs-done)))
```
第二步、测量最佳的启动速度,以便了解可能的情况。我的是 0.3 秒。
```
# -q ignores personal Emacs files but loads the site files.
emacs -q --eval='(message "%s" (emacs-init-time))'
;; For macOS users:
open -n /Applications/Emacs.app --args -q --eval='(message "%s" (emacs-init-time))'
```
### 2、检测 Emacs 启动指标对你大有帮助
《[Emacs StartUp Profiler](https://github.com/jschaf/esup)》(ESUP)将会给你顶层语句执行的详细指标。

*图 1: Emacs Start Up Profiler 截图*
>
> 警告:Spacemacs 用户需要注意,ESUP 目前与 Spacemacs 的 init.el 文件有冲突。遵照 <https://github.com/jschaf/esup/issues/48> 上说的进行升级。
>
>
>
### 3、调高启动时垃圾回收的阀值
这为我节省了 **0.3 秒**。
Emacs 默认值是 760kB,这在现代机器看来极其保守。真正的诀窍在于初始化完成后再把它降到合理的水平。这为我节省了 0.3 秒。
```
;; Make startup faster by reducing the frequency of garbage
;; collection. The default is 800 kilobytes. Measured in bytes.
(setq gc-cons-threshold (* 50 1000 1000))
;; The rest of the init file.
;; Make gc pauses faster by decreasing the threshold.
(setq gc-cons-threshold (* 2 1000 1000))
```
*~/.emacs.d/init.el*
### 4、不要 require 任何东西,而是使用 use-package 来自动加载
让 Emacs 变坏的最好方法就是减少要做的事情。`require` 会立即加载源文件,但是很少会出现需要在启动阶段就立即需要这些功能的。
在 [use-package](https://github.com/jwiegley/use-package) 中你只需要声明好需要哪个包中的哪个功能,`use-package` 就会帮你完成正确的事情。它看起来是这样的:
```
(use-package evil-lisp-state ; the Melpa package name
:defer t ; autoload this package
:init ; Code to run immediately.
(setq evil-lisp-state-global nil)
:config ; Code to run after the package is loaded.
(abn/define-leader-keys "k" evil-lisp-state-map))
```
可以通过查看 `features` 变量来查看 Emacs 现在加载了那些包。想要更好看的输出可以使用 [lpkg explorer](https://gist.github.com/RockyRoad29/bd4ca6fdb41196a71662986f809e2b1c) 或者我在 [abn-funcs-benchmark.el](https://github.com/jschaf/dotfiles/blob/master/emacs/funcs/abn-funcs-benchmark.el) 中的变体。输出看起来类似这样的:
```
479 features currently loaded
- abn-funcs-benchmark: /Users/jschaf/.dotfiles/emacs/funcs/abn-funcs-benchmark.el
- evil-surround: /Users/jschaf/.emacs.d/elpa/evil-surround-20170910.1952/evil-surround.elc
- misearch: /Applications/Emacs.app/Contents/Resources/lisp/misearch.elc
- multi-isearch: nil
- <many more>
```
### 5、不要使用辅助函数来设置模式
通常,Emacs 包会建议通过运行一个辅助函数来设置键绑定。下面是一些例子:
* `(evil-escape-mode)`
* `(windmove-default-keybindings) ; 设置快捷键。`
* `(yas-global-mode 1) ; 复杂的片段配置。`
可以通过 `use-package` 来对此进行重构以提高启动速度。这些辅助函数只会让你立即加载那些尚用不到的包。
下面这个例子告诉你如何自动加载 `evil-escape-mode`。
```
;; The definition of evil-escape-mode.
(define-minor-mode evil-escape-mode
(if evil-escape-mode
(add-hook 'pre-command-hook 'evil-escape-pre-command-hook)
(remove-hook 'pre-command-hook 'evil-escape-pre-command-hook)))
;; Before:
(evil-escape-mode)
;; After:
(use-package evil-escape
:defer t
;; Only needed for functions without an autoload comment (;;;###autoload).
:commands (evil-escape-pre-command-hook)
;; Adding to a hook won't load the function until we invoke it.
;; With pre-command-hook, that means the first command we run will
;; load evil-escape.
:init (add-hook 'pre-command-hook 'evil-escape-pre-command-hook))
```
下面来看一个关于 `org-babel` 的例子,这个例子更为复杂。我们通常的配置时这样的:
```
(org-babel-do-load-languages
'org-babel-load-languages
'((shell . t)
(emacs-lisp . nil)))
```
这不是个好的配置,因为 `org-babel-do-load-languages` 定义在 `org.el` 中,而该文件有超过 2 万 4 千行的代码,需要花 0.2 秒来加载。通过查看源代码可以看到 `org-babel-do-load-languages` 仅仅只是加载 `ob-<lang>` 包而已,像这样:
```
;; From org.el in the org-babel-do-load-languages function.
(require (intern (concat "ob-" lang)))
```
而在 `ob-<lang>.el` 文件中,我们只关心其中的两个方法 `org-babel-execute:<lang>` 和 `org-babel-expand-body:<lang>`。我们可以延时加载 org-babel 相关功能而无需调用 `org-babel-do-load-languages`,像这样:
```
;; Avoid `org-babel-do-load-languages' since it does an eager require.
(use-package ob-python
:defer t
:ensure org-plus-contrib
:commands (org-babel-execute:python))
(use-package ob-shell
:defer t
:ensure org-plus-contrib
:commands
(org-babel-execute:sh
org-babel-expand-body:sh
org-babel-execute:bash
org-babel-expand-body:bash))
```
### 6、使用惰性定时器来推迟加载非立即需要的包
我推迟加载了 9 个包,这帮我节省了 **0.4 秒**。
有些包特别有用,你希望可以很快就能使用它们,但是它们本身在 Emacs 启动过程中又不是必须的。这些软件包包括:
* `recentf`:保存最近的编辑过的那些文件。
* `saveplace`:保存访问过文件的光标位置。
* `server`:开启 Emacs 守护进程。
* `autorevert`:自动重载被修改过的文件。
* `paren`:高亮匹配的括号。
* `projectile`:项目管理工具。
* `whitespace`:高亮行尾的空格。
不要 `require` 这些软件包,**而是等到空闲 N 秒后再加载它们**。我在 1 秒后加载那些比较重要的包,在 2 秒后加载其他所有的包。
```
(use-package recentf
;; Loads after 1 second of idle time.
:defer 1)
(use-package uniquify
;; Less important than recentf.
:defer 2)
```
### 不值得的优化
不要费力把你的 Emacs 配置文件编译成字节码了。这只节省了大约 0.05 秒。把配置文件编译成字节码还可能导致源文件与编译后的文件不一致从而难以重现错误进行调试。
---
via: <https://blog.d46.us/advanced-emacs-startup/>
作者:[Joe Schafer](https://blog.d46.us/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Advanced Techniques for Reducing Emacs Startup Time
tl;dr: Do these steps:
- Profile with Esup.
- Adjust the garbage collection threshold.
- Autoload
**everything**with use-package. - Avoid helper functions which cause eager loads.
- See my Emacs
[config](https://github.com/jschaf/dotfiles/blob/master/emacs/start.el)for an example.
## From .emacs.d Bankruptcy to Now
I recently declared my third .emacs.d bankruptcy and finished the fourth iteration of my Emacs configuration. The evolution was:
- Copy and paste elisp snippets into
`~/.emacs`
and hope it works. - Adopt a more structured approach with
`el-get`
to manage dependencies. - Give up and outsource to Spacemacs.
- Get tired of Spacemacs intricacies and rewrite with
`use-package`
.
This article is a collection of tips collected during the 3 rewrites and from creating the Emacs Start Up Profiler. Many thanks to the teams behind Spacemacs, use-package and general. Without these dedicated voluteers, this task would be vastly more difficult.
## But What About Daemon Mode
Before we get started, let me acknowledge the common retort when optimizing Emacs: “Emacs is meant to run as a daemon so you’ll only start it once.” That’s all well and good except:
- Fast things feel nicer.
- When customizing Emacs, you sometimes get into weird states that can
be hard to recover from without restarting. For example, if you add
a slow
`lambda`
function to your`post-command-hook`
, it’s tough to remove it. - Restarting Emacs helps verify that customization will persist between sessions.
## 1. Establish the Current and Best Possible Start Up Time
The first step is to measure the current start up time. The easy way is to display the information at startup which will show progress through the next steps.
;; Use a hook so the message doesn't get clobbered by other messages. (add-hook 'emacs-startup-hook (lambda () (message "Emacs ready in %s with %d garbage collections." (format "%.2f seconds" (float-time (time-subtract after-init-time before-init-time))) gcs-done)))
Second, measure the best possible startup speed so you know what’s possible. Mine is 0.3 seconds.
# -q ignores personal Emacs files but loads the site files. emacs -q --eval='(message "%s" (emacs-init-time))' ;; For macOS users: open -n /Applications/Emacs.app --args -q --eval='(message "%s" (emacs-init-time))'
## 2. Profile Emacs Startup for Easy Wins
The [Emacs StartUp Profiler](https://github.com/jschaf/esup) (ESUP) will give you detailed metrics for
top-level expressions.

WARNING: Spacemacs users, ESUP currently chokes on the Spacemacs
init.el file. Follow [https://github.com/jschaf/esup/issues/48](https://github.com/jschaf/esup/issues/48) for
updates.
## 3. Set the Garbage Collection Threshold Higher during Startup
This saves about ** 0.3 seconds** on my configuration.
The default value for Emacs is 760kB which is extremely conservative on a modern machine. The real trick is to lower it back to something reasonable after initialization. This saves about 0.3 seconds on my init files.
;; Make startup faster by reducing the frequency of garbage ;; collection. The default is 800 kilobytes. Measured in bytes. (setq gc-cons-threshold (* 50 1000 1000)) ;; The rest of the init file. ;; Make gc pauses faster by decreasing the threshold. (setq gc-cons-threshold (* 2 1000 1000))
## 4. Never require anything; autoload with use-package instead
The best way to make Emacs faster is to do less. Running `require`
eagerly loads the underlying source file. It’s rare the you’ll need
functionality immediately at startup time.
With [ use-package](https://github.com/jwiegley/use-package), you declare which features you need from a package
and
`use-package`
does the right thing. Here’s what it looks like:
(use-package evil-lisp-state ; the Melpa package name :defer t ; autoload this package :init ; Code to run immediately. (setq evil-lisp-state-global nil) :config ; Code to run after the package is loaded. (abn/define-leader-keys "k" evil-lisp-state-map))
To see what packages Emacs currently has loaded, examine the
`features`
variable. For nice output see [lpkg explorer](https://gist.github.com/RockyRoad29/bd4ca6fdb41196a71662986f809e2b1c) or my variant
in [abn-funcs-benchmark.el](https://github.com/jschaf/dotfiles/blob/master/emacs/funcs/abn-funcs-benchmark.el). The output looks like:
479 features currently loaded - abn-funcs-benchmark: /Users/jschaf/.dotfiles/emacs/funcs/abn-funcs-benchmark.el - evil-surround: /Users/jschaf/.emacs.d/elpa/evil-surround-20170910.1952/evil-surround.elc - misearch: /Applications/Emacs.app/Contents/Resources/lisp/misearch.elc - multi-isearch: nil - <many more>
## 5. Avoid Helper Functions to Set Up Modes
Often, Emacs packages will suggest running a helper function to set up keybindings. Here’s a few examples:
`(evil-escape-mode)`
`(windmove-default-keybindings) ; Sets up keybindings.`
`(yas-global-mode 1) ; Complex snippet setup.`
Rewrite these with use-package to improve startup speed. These helper functions are really just sneaky ways to trick you into eagerly loading packages before you need them.
As an example, here’s how to autoload `evil-escape-mode`
.
;; The definition of evil-escape-mode. (define-minor-mode evil-escape-mode (if evil-escape-mode (add-hook 'pre-command-hook 'evil-escape-pre-command-hook) (remove-hook 'pre-command-hook 'evil-escape-pre-command-hook))) ;; Before: (evil-escape-mode) ;; After: (use-package evil-escape :defer t ;; Only needed for functions without an autoload comment (;;;###autoload). :commands (evil-escape-pre-command-hook) ;; Adding to a hook won't load the function until we invoke it. ;; With pre-command-hook, that means the first command we run will ;; load evil-escape. :init (add-hook 'pre-command-hook 'evil-escape-pre-command-hook))
For a much trickier example, consider `org-babel`
. The common recipe is:
(org-babel-do-load-languages 'org-babel-load-languages '((shell . t) (emacs-lisp . nil)))
This is bad because `org-babel-do-load-languages`
is defined in
`org.el`
, which is over 24k lines of code and takes about 0.2 seconds
to load. After examining the source code,
`org-babel-do-load-languages`
is simply requiring the `ob-<lang>`
package like so:
;; From org.el in the org-babel-do-load-languages function. (require (intern (concat "ob-" lang)))
In the `ob-<lang>.el`
, there’s only two methods we care about,
`org-babel-execute:<lang>`
and `org-babel-expand-body:<lang>`
. We can
autoload the org-babel functionality instead of
`org-babel-do-load-languages`
like so:
;; Avoid `org-babel-do-load-languages' since it does an eager require. (use-package ob-python :defer t :ensure org-plus-contrib :commands (org-babel-execute:python)) (use-package ob-shell :defer t :ensure org-plus-contrib :commands (org-babel-execute:sh org-babel-expand-body:sh org-babel-execute:bash org-babel-expand-body:bash))
## 6. Defer Packages you don’t need Immediately with Idle Timers
This saves about ** 0.4 seconds** for the 9 packages I defer.
Some packages are useful and you want them available soon, but are not essential for immediate editing. These modes include:
`recentf`
: Saves recent files.`saveplace`
: Saves point of visited files.`server`
: Starts Emacs daemon.`autorevert`
: Automatically reloads files that changed on disk.`paren`
: Highlight matching parenthesis.`projectile`
: Project management tools.`whitespace`
: Highlight trailing whitespace.
Instead of requiring these modes, ** load them after N seconds of idle
time**. I use 1 second for the more important packages and 2 seconds
for everything else.
(use-package recentf ;; Loads after 1 second of idle time. :defer 1) (use-package uniquify ;; Less important than recentf. :defer 2)
## Optimizations that aren’t Worth It
Don’t bother byte-compiling your personal Emacs files. It saved about 0.05 seconds. Byte compiling causes difficult to debug errors when the source file gets out of sync with compiled file. |
10,626 | 在 Linux 中如何删除文件中的空行 | https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/ | 2019-03-17T13:36:00 | [
"删除",
"空行"
] | https://linux.cn/article-10626-1.html | 
有时你可能需要在 Linux 中删除某个文件中的空行。如果是的,你可以使用下面方法中的其中一个。有很多方法可以做到,但我在这里只是列举一些简单的方法。
你可能已经知道 `grep`、`awk` 和 `sed` 命令是专门用来处理文本数据的工具。
如果你想了解更多关于这些命令的文章,请访问这几个 URL:[在 Linux 中创建指定大小的文件的几种方法](https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/),[在 Linux 中创建一个文件的几种方法](https://www.2daygeek.com/linux-command-to-create-a-file/) 以及 [在 Linux 中删除一个文件中的匹配的字符串](https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/)。
这些属于高级命令,它们可用在大多数 shell 脚本中执行所需的操作。
下列 5 种方法可以做到。
* `sed`:过滤和替换文本的流编辑器。
* `grep`:输出匹配到的行。
* `cat`:合并文件并打印内容到标准输出。
* `tr`:替换或删除字符。
* `awk`:awk 工具用于执行 awk 语言编写的程序,专门用于文本处理。
* `perl`:Perl 是一种用于处理文本的编程语言。
我创建了一个 `2daygeek.txt` 文件来测试这些命令。下面是文件的内容。
```
$ cat 2daygeek.txt
2daygeek.com is a best Linux blog to learn Linux.
It's FIVE years old blog.
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
He got two GIRL babys.
Her names are Tanisha & Renusha.
```
现在一切就绪,我们准备开始用多种方法来验证。
### 使用 sed 命令
`sed` 是一个<ruby> 流编辑器 <rt> stream editor </rt></ruby>。流编辑器是用来编辑输入流(文件或管道)中的文本的。
```
$ sed '/^$/d' 2daygeek.txt
2daygeek.com is a best Linux blog to learn Linux.
It's FIVE years old blog.
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
He got two GIRL babes.
Her names are Tanisha & Renusha.
```
以下是命令展开的细节:
* `sed`: 该命令本身。
* `//`: 标记匹配范围。
* `^`: 匹配字符串开头。
* `$`: 匹配字符串结尾。
* `d`: 删除匹配的字符串。
* `2daygeek.txt`: 源文件名。
### 使用 grep 命令
`grep` 可以通过正则表达式在文件中搜索。该表达式可以是一行或多行空行分割的字符,`grep` 会打印所有匹配的内容。
```
$ grep . 2daygeek.txt
or
$ grep -Ev "^$" 2daygeek.txt
or
$ grep -v -e '^$' 2daygeek.txt
2daygeek.com is a best Linux blog to learn Linux.
It's FIVE years old blog.
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
He got two GIRL babes.
Her names are Tanisha & Renusha.
```
以下是命令展开的细节:
* `grep`: 该命令本身。
* `.`: 替换任意字符。
* `^`: 匹配字符串开头。
* `$`: 匹配字符串结尾。
* `E`: 使用扩展正则匹配模式。
* `e`: 使用常规正则匹配模式。
* `v`: 反向匹配。
* `2daygeek.txt`: 源文件名。
### 使用 awk 命令
`awk` 可以执行使用 awk 语言写的脚本,大多是专用于处理文本的。awk 脚本是一系列 `awk` 命令和正则的组合。
```
$ awk NF 2daygeek.txt
or
$ awk '!/^$/' 2daygeek.txt
or
$ awk '/./' 2daygeek.txt
2daygeek.com is a best Linux blog to learn Linux.
It's FIVE years old blog.
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
He got two GIRL babes.
Her names are Tanisha & Renusha.
```
以下是命令展开的细节:
* `awk`: 该命令本身。
* `//`: 标记匹配范围。
* `^`: 匹配字符串开头。
* `$`: 匹配字符串结尾。
* `.`: 匹配任意字符。
* `!`: 删除匹配的字符串。
* `2daygeek.txt`: 源文件名。
### 使用 cat 和 tr 命令 组合
`cat` 是<ruby> 串联(拼接) <rt> concatenate </rt></ruby>的简写。经常用于在 Linux 中读取一个文件的内容。
`cat` 是在类 Unix 系统中使用频率最高的命令之一。它提供了常用的三个处理文本文件的功能:显示文件内容、将多个文件拼接成一个,以及创建一个新文件。
`tr` 可以将标准输入中的字符转换,压缩或删除,然后重定向到标准输出。
```
$ cat 2daygeek.txt | tr -s '\n'
2daygeek.com is a best Linux blog to learn Linux.
It's FIVE years old blog.
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
He got two GIRL babes.
Her names are Tanisha & Renusha.
```
以下是命令展开的细节:
* `cat`: cat 命令本身。
* `tr`: tr 命令本身。
* `|`: 管道符号。它可以将前面的命令的标准输出作为下一个命令的标准输入。
* `s`: 替换标数据集中任意多个重复字符为一个。
* `\n`: 添加一个新的换行。
* `2daygeek.txt`: 源文件名。
### 使用 perl 命令
Perl 表示<ruby> 实用的提取和报告语言 <rt> Practical Extraction and Reporting Language </rt></ruby>。Perl 在初期被设计为一个专用于文本处理的编程语言,现在已扩展应用到 Linux 系统管理,网络编程和网站开发等多个领域。
```
$ perl -ne 'print if /\S/' 2daygeek.txt
2daygeek.com is a best Linux blog to learn Linux.
It's FIVE years old blog.
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
He got two GIRL babes.
Her names are Tanisha & Renusha.
```
以下是命令展开的细节:
* `perl`: perl 命令。
* `n`: 逐行读入数据。
* `e`: 执行某个命令。
* `print`: 打印信息。
* `if`: if 条件分支。
* `//`: 标记匹配范围。
* `\S`: 匹配任意非空白字符。
* `2daygeek.txt`: 源文件名。
---
via: <https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pityonline](https://github.com/pityonline) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,627 | Emoji-Log:编写 Git 提交信息的新方法 | https://opensource.com/article/19/2/emoji-log-git-commit-messages | 2019-03-17T23:33:00 | [
"表情符",
"git"
] | https://linux.cn/article-10627-1.html |
>
> 使用 Emoji-Log 为你的提交添加上下文。
>
>
>

我是一名全职的开源开发人员,我喜欢称自己为“开源者”。我从事开源软件工作已经超过十年,并[构建了数以百计的](https://github.com/ahmadawais)开源软件应用程序。
同时我也是“<ruby> 避免重复工作 <rt> Don’t Repeat Yourself </rt></ruby>”(DRY)哲学的忠实粉丝,并且我相信编写更好的 Git 提交消息是 DRY 的一个重要组成部分。它们具有足够的上下文关联,可以作为你开源软件的变更日志。我编写的众多工作流之一是 [Emoji-Log](https://github.com/ahmadawais/Emoji-Log/),它是一个简单易用的开源 Git 提交日志标准。它通过使用表情符号来创建更好的 Git 提交消息,从而改善了开发人员的体验(DX)。
我使用 Emoji-Log 构建了 [VSCode Tips & Tricks 仓库](https://github.com/ahmadawais/VSCode-Tips-Tricks) 和我的 ? [紫色 VSCode 主题仓库](https://github.com/ahmadawais/shades-of-purple-vscode/commits/master),以及一个看起来很漂亮的[自动变更日志](https://github.com/ahmadawais/shades-of-purple-vscode/blob/master/CHANGELOG.md)。
### Emoji-Log 的哲学
我喜欢(很多)表情符号,我很喜欢它们。编程、代码、极客/书呆子、开源……所有这一切本质上都很枯燥,有时甚至很无聊。表情符号帮助我添加颜色和情感。想要将感受添加到这个 2D 的、平板的、基于文本的代码世界并没有错。
相比于[数百个表情符号](https://gitmoji.carloscuesta.me/),我学会的更好办法是让类别较小和普遍性。以下是指导使用 Emoji-Log 编写提交信息的原则:
* **必要的**
+ Git 提交信息是必要的。
+ 像下订单一样编写提交信息。
- 例如,使用 ✅ **Add** 而不是 ❌ **Added**
- 例如,使用 ✅ **Create** 而不是 ❌ **Creating**
* **规则**
+ 少数类别易于记忆。
+ 不多也不少
- 例如 **? NEW** 、 **? IMPROVE** 、 **? FIX** 、 **? DOC** 、 **? RELEASE** 、 **✅ TEST**
* **行为**
+ 让 Git 的提交基于你所采取的操作
+ 使用像 [VSCode](https://VSCode.pro) 这样的编辑器来提交带有提交信息的正确文件。
### 编写提交信息
仅使用以下 Git 提交信息。简单而小巧的占地面积是 Emoji-Log 的核心。
* **? NEW: 必要的信息**
+ 当你添加一些全新的东西时使用。
- 例如 **? NEW: 添加 Git 忽略的文件**
* **? IMPROVE: 必要的信息**
+ 用于改进/增强代码段,如重构等。
- 例如 **? IMPROVE: 远程 IP API 函数**
* **? FIX: 必要的信息**
+ 修复 bug 时使用,不用解释了吧?
- 例如 **? FIX: Case converter**
* **? DOC: 必要的信息**
+ 添加文档时使用,比如 README.md 甚至是内联文档。
- 例如 **? DOC: API 接口教程**
* **? RELEASE: 必要的信息**
+ 发布新版本时使用。例如, **? RELEASE: Version 2.0.0**
* **✅ TEST: 必要的信息**
+ 发布新版本时使用。
- 例如 **✅ TEST: 模拟用户登录/注销**
就这些了,不多不少。
### Emoji-Log 函数
为了快速构建原型,我写了以下函数,你可以将它们添加到 `.bashrc` 或者 `.zshrc` 文件中以快速使用 Emoji-Log。
```
#.# Better Git Logs.
### Using EMOJI-LOG (https://github.com/ahmadawais/Emoji-Log).
# Git Commit, Add all and Push — in one step.
function gcap() {
git add . && git commit -m "$*" && git push
}
# NEW.
function gnew() {
gcap "? NEW: $@"
}
# IMPROVE.
function gimp() {
gcap "? IMPROVE: $@"
}
# FIX.
function gfix() {
gcap "? FIX: $@"
}
# RELEASE.
function grlz() {
gcap "? RELEASE: $@"
}
# DOC.
function gdoc() {
gcap "? DOC: $@"
}
# TEST.
function gtst() {
gcap "✅ TEST: $@"
}
```
要为 [fish shell](https://en.wikipedia.org/wiki/Friendly_interactive_shell) 安装这些函数,运行以下命令:
```
function gcap; git add .; and git commit -m "$argv"; and git push; end;
function gnew; gcap "? NEW: $argv"; end
function gimp; gcap "? IMPROVE: $argv"; end;
function gfix; gcap "? FIX: $argv"; end;
function grlz; gcap "? RELEASE: $argv"; end;
function gdoc; gcap "? DOC: $argv"; end;
function gtst; gcap "✅ TEST: $argv"; end;
funcsave gcap
funcsave gnew
funcsave gimp
funcsave gfix
funcsave grlz
funcsave gdoc
funcsave gtst
```
如果你愿意,可以将这些别名直接粘贴到 `~/.gitconfig` 文件:
```
# Git Commit, Add all and Push — in one step.
cap = "!f() { git add .; git commit -m \"$@\"; git push; }; f"
# NEW.
new = "!f() { git cap \"? NEW: $@\"; }; f"
# IMPROVE.
imp = "!f() { git cap \"? IMPROVE: $@\"; }; f"
# FIX.
fix = "!f() { git cap \"? FIX: $@\"; }; f"
# RELEASE.
rlz = "!f() { git cap \"? RELEASE: $@\"; }; f"
# DOC.
doc = "!f() { git cap \"? DOC: $@\"; }; f"
# TEST.
tst = "!f() { git cap \"✅ TEST: $@\"; }; f"
```
### Emoji-Log 例子
这里列出了一些使用 Emoji-Log 的仓库:
* [Create-guten-block toolkit](https://github.com/ahmadawais/create-guten-block/commits/)
* [VSCode Shades of Purple theme](https://github.com/ahmadawais/shades-of-purple-vscode/commits/)
* [Ahmad Awais' GitHub repos](https://github.com/ahmadawais) (我的最新的仓库)
* [CaptainCore CLI](https://github.com/CaptainCore/captaincore-cli/commits/) (WordPress 管理工具)
* [CaptainCore GUI](https://github.com/CaptainCore/captaincore-gui/commits/) (WordPress 插件)
你呢?如果你的仓库使用 Emoji-Log,请将这个 [Emoji-Log 徽章](https://on.ahmda.ws/rOMZ/c)放到你的 README 中,并给我发送一个[拉取请求](https://github.com/ahmadawais/Emoji-Log/pulls),以让我可以将你的仓库列在这里。
---
via: <https://opensource.com/article/19/2/emoji-log-git-commit-messages>
作者:[Ahmad Awais](https://opensource.com/users/mrahmadawais) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I'm a full-time open source developer—or, as I like to call it, an ? open sourcerer. I've been working with open source software for over a decade and [built hundreds](https://github.com/ahmadawais) of open source software applications.
I also am a big fan of the Don't Repeat Yourself (DRY) philosophy and believe writing better Git commit messages—ones that are contextual enough to serve as a changelog for your open source software—is an important component of DRY. One of the many workflows I've written is [Emoji-Log](https://github.com/ahmadawais/Emoji-Log/), a straightforward, open source Git commit log standard. It improves the developer experience (DX) by using emoji to create better Git commit messages.
I've used Emoji-Log while building the [VSCode Tips & Tricks repo](https://github.com/ahmadawais/VSCode-Tips-Tricks), my ? [Shades of Purple VSCode theme repo](https://github.com/ahmadawais/shades-of-purple-vscode/commits/master), and even an [automatic changelog](https://github.com/ahmadawais/shades-of-purple-vscode/blob/master/CHANGELOG.md) that looks beautiful.
## Emoji-Log's philosophy
I like emoji (which is, in fact, the plural of emoji). I like 'em a lot. Programming, code, geeks/nerds, open source… all of that is inherently dull and sometimes boring. Emoji help me add colors and emotions to the mix. There's nothing wrong with wanting to attach feelings to the 2D, flat, text-based world of code.
Instead of memorizing [hundreds of emoji](https://gitmoji.carloscuesta.me/), I've learned it's better to keep the categories small and general. Here's the philosophy that guides writing commit messages with Emoji-Log:
**Imperative**- Make your Git commit messages imperative.
- Write commit message like you're giving an order.
- e.g., Use ✅
**Add**instead of ❌**Added** - e.g., Use ✅
**Create**instead of ❌**Creating**
- e.g., Use ✅
**Rules**- A small number of categories are easy to memorize.
- Nothing more, nothing less
- e.g.
**? NEW**,**? IMPROVE**,**? FIX**,**? DOC**,**? RELEASE**, and**✅ TEST**
- e.g.
**Actions**- Make Git commits based on actions you take.
- Use a good editor like
[VSCode](https://VSCode.pro)to commit the right files with commit messages.
## Writing commit messages
Use only the following Git commit messages. The simple and small footprint is the key to Emoji-Logo.
**? NEW: IMPERATIVE_MESSAGE**- Use when you add something entirely new.
- e.g.,
**? NEW: Add Git ignore file**
- e.g.,
- Use when you add something entirely new.
**? IMPROVE: IMPERATIVE_MESSAGE**- Use when you improve/enhance piece of code like refactoring etc.
- e.g.,
**? IMPROVE: Remote IP API Function**
- e.g.,
- Use when you improve/enhance piece of code like refactoring etc.
**? FIX: IMPERATIVE_MESSAGE**- Use when you fix a bug. Need I say more?
- e.g.,
**? FIX: Case converter**
- e.g.,
- Use when you fix a bug. Need I say more?
**? DOC: IMPERATIVE_MESSAGE**- Use when you add documentation, like README.md or even inline docs.
- e.g.,
**? DOC: API Interface Tutorial**
- e.g.,
- Use when you add documentation, like README.md or even inline docs.
**? RELEASE: IMPERATIVE_MESSAGE**- Use when you release a new version. e.g.,
**? RELEASE: Version 2.0.0**
- Use when you release a new version. e.g.,
**✅ TEST: IMPERATIVE_MESSAGE**- Use when you release a new version.
- e.g.,
**✅ TEST: Mock User Login/Logout**
- e.g.,
- Use when you release a new version.
That's it for now. Nothing more, nothing less.
## Emoji-Log functions
For quick prototyping, I have made the following functions that you can add to your **.bashrc**/**.zshrc** files to use Emoji-Log quickly.
```
#.# Better Git Logs.
### Using EMOJI-LOG (https://github.com/ahmadawais/Emoji-Log).
# Git Commit, Add all and Push — in one step.
function gcap() {
git add . && git commit -m "$*" && git push
}
# NEW.
function gnew() {
gcap "? NEW: $@"
}
# IMPROVE.
function gimp() {
gcap "? IMPROVE: $@"
}
# FIX.
function gfix() {
gcap "? FIX: $@"
}
# RELEASE.
function grlz() {
gcap "? RELEASE: $@"
}
# DOC.
function gdoc() {
gcap "? DOC: $@"
}
# TEST.
function gtst() {
gcap "✅ TEST: $@"
}
```
To install these functions for the [fish shell](https://en.wikipedia.org/wiki/Friendly_interactive_shell), run the following commands:
```
function gcap; git add .; and git commit -m "$argv"; and git push; end;
function gnew; gcap "? NEW: $argv"; end
function gimp; gcap "? IMPROVE: $argv"; end;
function gfix; gcap "? FIX: $argv"; end;
function grlz; gcap "? RELEASE: $argv"; end;
function gdoc; gcap "? DOC: $argv"; end;
function gtst; gcap "✅ TEST: $argv"; end;
funcsave gcap
funcsave gnew
funcsave gimp
funcsave gfix
funcsave grlz
funcsave gdoc
funcsave gtst
```
If you prefer, you can paste these aliases directly in your **~/.gitconfig** file:
```
# Git Commit, Add all and Push — in one step.
cap = "!f() { git add .; git commit -m \"$@\"; git push; }; f"
# NEW.
new = "!f() { git cap \"? NEW: $@\"; }; f"
# IMPROVE.
imp = "!f() { git cap \"? IMPROVE: $@\"; }; f"
# FIX.
fix = "!f() { git cap \"? FIX: $@\"; }; f"
# RELEASE.
rlz = "!f() { git cap \"? RELEASE: $@\"; }; f"
# DOC.
doc = "!f() { git cap \"? DOC: $@\"; }; f"
# TEST.
tst = "!f() { git cap \"✅ TEST: $@\"; }; f"
```
## Emoji-Log examples
Here's a list of repos that use Emoji-Log.
[Create-guten-block toolkit](https://github.com/ahmadawais/create-guten-block/commits/)[VSCode Shades of Purple theme](https://github.com/ahmadawais/shades-of-purple-vscode/commits/)[Ahmad Awais' GitHub repos](https://github.com/ahmadawais)(my latest repos)[CaptainCore CLI](https://github.com/CaptainCore/captaincore-cli/commits/)(WordPress management toolkit)[CaptainCore GUI](https://github.com/CaptainCore/captaincore-gui/commits/)(WordPress plugin)**You?**If your repo uses Emoji-Log, add the[Emoji-Log badge](https://on.ahmda.ws/rOMZ/c)to your README and send me a[pull request](https://github.com/ahmadawais/Emoji-Log/pulls)so I can list your repo in the repo.
## 12 Comments |
10,628 | 给大家安利一下 PowerShell | https://opensource.com/article/18/2/powershell-people | 2019-03-18T10:32:29 | [
"PowerShell"
] | /article-10628-1.html |
>
> 代码更简洁、脚本更清晰、跨平台一致性等好处是让 Linux 和 OS X 用户喜爱 PowerShell 的原因。
>
>
>

今年(2018)早些时候,[Powershell Core](https://github.com/PowerShell/PowerShell/blob/master/README.md) 以 [MIT](https://spdx.org/licenses/MIT) 开源协议发布了[正式可用版(GA)](https://blogs.msdn.microsoft.com/powershell/2018/01/10/powershell-core-6-0-generally-available-ga-and-supported/)。PowerShell 算不上是新技术。自 2006 年为 Windows 发布了第一版 PowerShell 以来,PowerShell 的创建者在[结合了](http://www.jsnover.com/Docs/MonadManifesto.pdf) Unⅸ shell 的强大和灵活的同时也在弥补他们所意识到的缺点,特别是从组合命令中获取值时所要进行的文本操作。
在发布了 5 个主要版本之后,PowerShell 已经可以在所有主流操作系统上(包括 OS X 和 Linux)本地运行同样创新的 shell 和命令行环境。一些人(应该说是大多数人)可能依旧在嘲弄这位诞生于 Windows 的闯入者的大胆和冒失:为那些远古以来(从千禧年开始算不算?)便存在着强大的 shell 环境的平台引荐自己。在本帖中,我希望可以将 PowerShell 的优势介绍给大家,甚至是那些经验老道的用户。
### 跨平台一致性
如果你计划将脚本从一个执行环境迁移到另一个平台时,你需要确保只使用了那些在两个平台下都起作用的命令和语法。比如在 GNU 系统中,你可以通过以下方式获取昨天的日期:
```
date --date="1 day ago"
```
在 BSD 系统中(比如 OS X),上述语法将没办法工作,因为 BSD 的 date 工具需要以下语法:
```
date -v -1d
```
因为 PowerShell 具有宽松的许可证,并且在所有的平台都有构建,所以你可以把 PowerShell 和你的应用一起打包。因此,当你的脚本运行在目标系统中时,它们会运行在一样的 shell 环境中,使用与你的测试环境中同样的命令实现。
### 对象和结构化数据
\*nix 命令和工具依赖于你使用和操控非结构化数据的能力。对于那些长期活在 `sed`、 `grep` 和 `awk` 环境下的人们来说,这可能是小菜一碟,但现在有更好的选择。
让我们使用 PowerShell 重写那个获取昨天日期的实例。为了获取当前日期,使用 `Get-Date` cmdlet(读作 “commandlet”):
```
> Get-Date
Sunday, January 21, 2018 8:12:41 PM
```
你所看到的输出实际上并不是一个文本字符串。不如说,这是 .Net Core 对象的一个字符串表现形式。就像任何 OOP 环境中的对象一样,它具有类型以及你可以调用的方法。
让我们来证明这一点:
```
> $(Get-Date).GetType().FullName
System.DateTime
```
`$(...)` 语法就像你所期望的 POSIX shell 中那样,计算括弧中的命令然后替换整个表达式。但是在 PowerShell 中,这种表达式中的 `$` 是可选的。并且,最重要的是,结果是一个 .Net 对象,而不是文本。因此我们可以调用该对象中的 `GetType()` 方法来获取该对象类型(类似于 Java 中的 `Class` 对象),`FullName` [属性](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/properties) 则用来获取该类型的全称。
那么,这种对象导向的 shell 是如何让你的工作变得更加简单呢?
首先,你可将任何对象排进 `Get-Member` cmdlet 来查看它提供的所有方法和属性。
```
> (Get-Date) | Get-Member
PS /home/yevster/Documents/ArticlesInProgress> $(Get-Date) | Get-Member
TypeName: System.DateTime
Name MemberType Definition
---- ---------- ----------
Add Method datetime Add(timespan value)
AddDays Method datetime AddDays(double value)
AddHours Method datetime AddHours(double value)
AddMilliseconds Method datetime AddMilliseconds(double value)
AddMinutes Method datetime AddMinutes(double value)
AddMonths Method datetime AddMonths(int months)
AddSeconds Method datetime AddSeconds(double value)
AddTicks Method datetime AddTicks(long value)
AddYears Method datetime AddYears(int value)
CompareTo Method int CompareTo(System.Object value), int ...
```
你可以很快的看到 DateTime 对象具有一个 `AddDays` 方法,从而可以使用它来快速的获取昨天的日期:
```
> (Get-Date).AddDays(-1)
Saturday, January 20, 2018 8:24:42 PM
```
为了做一些更刺激的事,让我们调用 Yahoo 的天气服务(因为它不需要 API 令牌)然后获取你的本地天气。
```
$city="Boston"
$state="MA"
$url="https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20weather.forecast%20where%20woeid%20in%20(select%20woeid%20from%20geo.places(1)%20where%20text%3D%22${city}%2C%20${state}%22)&format=json&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys"
```
现在,我们可以使用老派的方法然后直接运行 `curl $url` 来获取 JSON 二进制对象,或者……
```
$weather=(Invoke-RestMethod $url)
```
如果你查看了 `$weather` 类型(运行 `echo $weather.GetType().FullName`),你将会发现它是一个 `PSCustomObject`。这是一个用来反射 JSON 结构的动态对象。
然后 PowerShell 可以通过 tab 补齐来帮助你完成命令输入。只需要输入 `$weather.`(确报包含了 `.`)然后按下 `Tab` 键。你将看到所有根级别的 JSON 键。输入其中的一个,然后跟上 `.` ,再一次按下 `Tab` 键,你将看到它所有的子键(如果有的话)。
因此,你可以轻易的导航到你所想要的数据:
```
> echo $weather.query.results.channel.atmosphere.pressure
1019.0
> echo $weather.query.results.channel.wind.chill 41
```
并且如果你有非结构化的 JSON 或 CSV 数据(通过外部命令返回的),只需要将它相应的排进 `ConverFrom-Json` 或 `ConvertFrom-CSV` cmdlet,然后你可以得到一个漂亮干净的对象。
### 计算 vs. 自动化
我们使用 shell 用于两种目的。一个是用于计算,运行独立的命令然后手动响应它们的输出。另一个是自动化,通过写脚本执行多个命令,然后以编程的方式相应它们的输出。
我们大多数人都能发现这两种目的在 shell 上的不同且互相冲突的要求。计算任务要求 shell 简洁明了。用户输入的越少越好。但如果用户输入对其他用户来说几乎难以理解,那这一点就不重要了。脚本,从另一个角度来讲是代码。可读性和可维护性是关键。这一方面,POSIX 工具通常是失败的。虽然一些命令通常会为它们的参数提供简洁明了的语法(如:`-f` 和 `--force`),但是命令名字本身就不简洁明了。
PowerShell 提供了几个机制来消除这种浮士德式的平衡。
首先,tab 补齐可以消除键入参数名的需要。比如:键入 `Get-Random -Mi`,按下 `Tab` 然后 PowerShell 将会为你完成参数:`Get-Random -Minimum`。但是如果你想更简洁一些,你甚至不需要按下 `Tab`。如下所示,PowerShell 可以理解:
```
Get-Random -Mi 1 -Ma 10
```
因为 `Mi` 和 `Ma` 每一个都具有独立不同的补齐。
你可能已经留意到所有的 PowerShell cmdlet 名称具有动名词结构。这有助于脚本的可读性,但是你可能不想一而再、再而三的键入 `Get-`。所以并不需要!如果你之间键入了一个名词而没有动词的话,PowerShell 将查找带有该名词的 `Get-` 命令。
>
> 小心:尽管 PowerShell 不区分大小写,但在使用 PowerShell 命令是时,名词首字母大写是一个好习惯。比如,键入 `date` 将会调用系统中的 `date` 工具。键入 `Date` 将会调用 PowerShell 的 `Get-Date` cmdlet。
>
>
>
如果这还不够,PowerShell 还提供了别名,用来创建简单的名字。比如,如果键入 `alias -name cd`,你将会发现 `cd` 在 PowerShell 实际上时 `Set-Location` 命令的别名。
所以回顾以下 —— 你可以使用强大的 tab 补全、别名,和名词补全来保持命令名词简洁、自动化和一致性参数名截断,与此同时还可以享受丰富、可读的语法格式。
### 那么……你看呢?
这些只是 PowerShell 的一部分优势。还有更多特性和 cmdlet,我还没讨论(如果你想弄哭 `grep` 的话,可以查看 [Where-Object](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.core/where-object?view=powershell-6) 或其别称 `?`)。如果你有点怀旧的话,PowerShell 可以为你加载原来的本地工具。但是给自己足够的时间来适应 PowerShell 面向对象 cmdlet 的世界,然后你将发现自己会选择忘记回去的路。
---
via: <https://opensource.com/article/18/2/powershell-people>
作者:[Yev Bronshteyn](https://opensource.com/users/yevster) 译者:[sanfusu](https://github.com/sanfusu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,629 | 如何修复 Mozilla Firefox 中出现的 “Network Protocol Error” | https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/ | 2019-03-18T10:40:04 | [
"Firefox",
"缓存"
] | https://linux.cn/article-10629-1.html | 
Mozilla Firefox 多年来一直是我的默认 Web 浏览器,我每天用它来进行日常网络活动,例如访问邮件,浏览喜欢的网站等。今天,我在使用 Firefox 时遇到了一个奇怪的错误。我试图在 Reddit 平台上分享我们的一个指南时,在 Firefox 上出现了以下错误消息:
>
> Network Protocol Error
>
>
> Firefox has experienced a network protocol violation that cannot be repaired.
>
>
> The page you are trying to view cannot be shown because an error in the network protocol was detected.
>
>
> Please contact the website owners to inform them of this problem.
>
>
>

老实说,我有点慌,我以为可能是我的系统受到了某种恶意软件的影响。哈哈!但是我发现我错了。我在 Arch Linux 桌面上使用的是最新的 Firefox 版本,我在 Chromium 浏览器中打开了相同的链接,它正确显示了,我猜这是 Firefox 相关的错误。在谷歌上搜索后,我解决了这个问题,如下所述。
出现这种问题主要是因为“浏览器缓存”,如果你遇到此类错误,例如 “Network Protocol Error” 或 “Corrupted Content Error”,遵循以下任何一种方法。
**方法 1:**
要修复 “Network Protocol Error” 或 “Corrupted Content Error”,你需要在重新加载网页时绕过缓存。为此,按下 `Ctrl + F5` 或 `Ctrl + Shift + R` 快捷键,它将从服务器重新加载页面,而不是从 Firefox 缓存加载。这样网页就应该可以正常工作了。
**方法 2:**
如果方法 1 不起作用,尝试以下方法。
打开 “Edit - > Preferences”,在 “Preferences” 窗口中,打开左窗格中的 “Privacy & Security” 选项卡,单击 “Clear Data” 选项清除 Firefox 缓存。

确保你选中了 “Cookies and Site Data” 和 “Cached Web Content” 选项,然后单击 “Clear”。

完成!现在 Cookie 和离线内容将被删除。注意,Firefox 可能会将你从登录的网站中注销,稍后你可以重新登录这些网站。最后,关闭 Firefox 浏览器并重新启动系统。现在网页加载没有任何问题。
希望这对你有帮助。更多好东西要来了,敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,631 | Linux 安全:Cmd 提供可视化控制用户活动 | https://www.networkworld.com/article/3342454/linux-security-cmd-provides-visibility-control-over-user-activity.html | 2019-03-18T23:05:40 | [
"安全",
"Cmd"
] | https://linux.cn/article-10631-1.html |
>
> Cmd 可以帮助机构监控、验证和阻止那些超出系统预期使用范围的活动。
>
>
>

有一个新的 Linux 安全工具你值得了解一下:Cmd(读作 “see em dee”),它极大地改变了可以对 Linux 用户进行控制的类型。它远远超出了传统的用户权限配置,并在监视和控制用户能够在 Linux 系统上运行的命令方面发挥了积极作用。
Cmd 由同名公司开发,专注于云应用。鉴于越来越多的应用迁移到依赖于 Linux 的云环境中,而可用工具的缺口使得难以充分实施所需的安全性。除此以外,Cmd 还可用于管理和保护本地系统。
### Cmd 与传统 Linux 安全控件的区别
Cmd 公司的领导 Milun Tesovic 和 Jake King 表示,除非了解了用户日常如何工作以及什么被视是“正常”,机构无法自信地预测或控制用户行为。他们寻求提供一种能够精细控制、监控和验证用户活动的工具。
Cmd 通过形成用户活动配置文件(描绘这些用户通常进行的活动)来监视用户活动,注意其在线行为的异常(登录时间、使用的命令、用户位置等),以及预防和报告某些意味着系统攻击的活动(例如,下载或修改文件和运行特权命令)。产品的行为是可配置的,可以快速进行更改。
如今大多数人用来检测威胁、识别漏洞和控制用户权限的工具,我们已经使用了很久了,但我们仍在努力抗争保持系统和数据的安全。Cmd 让我们更能够确定恶意用户的意图,无论这些用户是设法侵入帐户还是代表内部威胁。

*查看实时 Linux 会话*
### Cmd 如何工作?
在监视和管理用户活动时,Cmd 可以:
* 收集描述用户活动的信息
* 使用基线来确定什么是正常的
* 使用特定指标检测并主动防止威胁
* 向负责人发送警报

*在 Cmd 中构建自定义策略*
Cmd 扩展了系统管理员通过传统方法可以控制的内容,例如配置 `sudo` 权限,提供更精细和特定情境的控制。
管理员可以选择可以与 Linux 系统管理员所管理的用户权限控制分开管理的升级策略。
Cmd 客户端提供实时可视化(而不是事后日志分析),并且可以阻止操作、要求额外的身份验证或根据需要进行协商授权。
此外,如果有用户位置信息,Cmd 支持基于地理定位的自定义规则。并且可以在几分钟内将新策略推送到部署在主机上的客户端。

*在 Cmd 中构建触发器查询*
### Cmd 的融资新闻
[Cmd](https://cmd.com) 最近完成了由 [GV](https://www.gv.com/) (前身为 Google Ventures)领投,Expa、Amplify Partners 和其他战略投资者跟投的 [1500 万美元的融资](https://www.linkedin.com/pulse/changing-cybersecurity-announcing-cmds-15-million-funding-jake-king/)。这使该公司的融资金额达到了 2160 万美元,这将帮助其继续为该产品增加新的防御能力并发展其工程师团队。
此外,该公司还任命 GV 的普通合伙人 Karim Faris 为董事会成员。
---
via: <https://www.networkworld.com/article/3342454/linux-security-cmd-provides-visibility-control-over-user-activity.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,632 | toplip:一款十分强大的文件加密解密 CLI 工具 | https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/ | 2019-03-19T00:26:03 | [
"toplip",
"加密"
] | https://linux.cn/article-10632-1.html | 
在市场上能找到许多用来保护文件的文档加密工具。我们已经介绍过其中一些例如 [Cryptomater](https://www.ostechnix.com/cryptomator-open-source-client-side-encryption-tool-cloud/)、[Cryptkeeper](https://www.ostechnix.com/how-to-encrypt-your-personal-foldersdirectories-in-linux-mint-ubuntu-distros/)、[CryptGo](https://www.ostechnix.com/cryptogo-easy-way-encrypt-password-protect-files/)、[Cryptr](https://www.ostechnix.com/cryptr-simple-cli-utility-encrypt-decrypt-files/)、[Tomb](https://www.ostechnix.com/tomb-file-encryption-tool-protect-secret-files-linux/),以及 [GnuPG](https://www.ostechnix.com/an-easy-way-to-encrypt-and-decrypt-files-from-commandline-in-linux/) 等加密工具。今天我们将讨论另一款叫做 “toplip” 的命令行文件加密解密工具。它是一款使用一种叫做 [AES256](http://en.wikipedia.org/wiki/Advanced_Encryption_Standard) 的强大加密方法的自由开源的加密工具。它同时也使用了 XTS-AES 设计以保护你的隐私数据。它还使用了 [Scrypt](http://en.wikipedia.org/wiki/Scrypt),一种基于密码的密钥生成函数来保护你的密码免于暴力破解。
### 优秀的特性
相比于其它文件加密工具,toplip 自带以下独特且杰出的特性。
* 非常强大的基于 XTS-AES256 的加密方法。
* <ruby> 合理的推诿 <rt> Plausible deniability </rt></ruby>。
* 加密并嵌入文件到图片(PNG/JPG)中。
* 多重密码保护。
* 可防护直接暴力破解。
* 无可辨识的输出标记。
* 开源(GPLv3)。
### 安装 toplip
没有什么需要安装的。`toplip` 是独立的可执行二进制文件。你所要做的仅是从 [产品官方页面](https://2ton.com.au/Products/) 下载最新版的 `toplip` 并赋予它可执行权限。为此你只要运行:
```
chmod +x toplip
```
### 使用
如果你不带任何参数运行 `toplip`,你将看到帮助页面。
```
./toplip
```

请允许我给你展示一些例子。
为了达到指导目的,我建了两个文件 `file1` 和 `file2`。我同时也有 `toplip` 可执行二进制文件。我把它们全都保存进一个叫做 `test` 的目录。

#### 加密/解密单个文件
现在让我们加密 `file1`。为此,运行:
```
./toplip file1 > file1.encrypted
```
这行命令将让你输入密码。一旦你输入完密码,它就会加密 `file1` 的内容并将它们保存进你当前工作目录下一个叫做 `file1.encrypted` 的文件。
上述命令行的示例输出将会是这样:
```
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip file1 Passphrase #1: generating keys...Done
Encrypting...Done
```
为了验证文件是否的确经过加密,试着打开它你会发现一些随机的字符。
为了解密加密过的文件,像以下这样使用 `-d` 参数:
```
./toplip -d file1.encrypted
```
这行命令会解密提供的文档并在终端窗口显示内容。
为了保存文档而不是写入到标准输出,运行:
```
./toplip -d file1.encrypted > file1.decrypted
```
输入正确的密码解密文档。`file1.encrypted` 的所有内容将会存入一个叫做 `file1.decrypted` 的文档。
请不要用这种命名方法,我这样用仅仅是为了便于理解。使用其它难以预测的名字。
#### 加密/解密多个文件
现在我们将使用两个分别的密码加密每个文件。
```
./toplip -alt file1 file2 > file3.encrypted
```
你会被要求为每个文件输入一个密码,使用不同的密码。
上述命令行的示例输出将会是这样:
```
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
file2 Passphrase #1 : generating keys...Done
file1 Passphrase #1 : generating keys...Done
Encrypting...Done
```
上述命令所做的是加密两个文件的内容并将它们保存进一个单独的叫做 `file3.encrypted` 的文件。在保存中分别给予各自的密码。比如说如果你提供 `file1` 的密码,`toplip` 将复原 `file1`。如果你提供 `file2` 的密码,`toplip` 将复原 `file2`。
每个 `toplip` 加密输出都可能包含最多四个单独的文件,并且每个文件都建有各自独特的密码。由于加密输出放在一起的方式,一下判断出是否存在多个文档不是一件容易的事。默认情况下,甚至就算确实只有一个文件是由 `toplip` 加密,随机数据都会自动加上。如果指定了多于一个文件,每个都有自己的密码,那么你可以有选择性地独立解码每个文件,以此来否认其它文件存在的可能性。这能有效地使一个用户在可控的暴露风险下打开一个加密的捆绑文件包。并且对于敌人来说,在计算上没有一种低廉的办法来确认额外的秘密数据存在。这叫做“<ruby> 合理的推诿 <rt> Plausible deniability </rt></ruby>”,是 toplip 著名的特性之一。
为了从 `file3.encrypted` 解码 `file1`,仅需输入:
```
./toplip -d file3.encrypted > file1.encrypted
```
你将会被要求输入 `file1` 的正确密码。
为了从 `file3.encrypted` 解码 `file2`,输入:
```
./toplip -d file3.encrypted > file2.encrypted
```
别忘了输入 `file2` 的正确密码。
#### 使用多重密码保护
这是我中意的另一个炫酷特性。在加密过程中我们可以为单个文件提供多重密码。这样可以保护密码免于暴力尝试。
```
./toplip -c 2 file1 > file1.encrypted
```
这里,`-c 2` 代表两个不同的密码。上述命令行的示例输出将会是这样:
```
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
file1 Passphrase #1: generating keys...Done
file1 Passphrase #2: generating keys...Done
Encrypting...Done
```
正如你在上述示例中所看到的,`toplip` 要求我输入两个密码。请注意你必须提供两个不同的密码,而不是提供两遍同一个密码。
为了解码这个文件,这样做:
```
$ ./toplip -c 2 -d file1.encrypted > file1.decrypted
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
file1.encrypted Passphrase #1: generating keys...Done
file1.encrypted Passphrase #2: generating keys...Done
Decrypting...Done
```
#### 将文件藏在图片中
将一个文件、消息、图片或视频藏在另一个文件里的方法叫做隐写术。幸运的是 `toplip` 默认包含这个特性。
为了将文件藏入图片中,像如下所示的样子使用 `-m` 参数。
```
$ ./toplip -m image.png file1 > image1.png
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
file1 Passphrase #1: generating keys...Done
Encrypting...Done
```
这行命令将 `file1` 的内容藏入一张叫做 `image1.png` 的图片中。
要解码,运行:
```
$ ./toplip -d image1.png > file1.decrypted This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
image1.png Passphrase #1: generating keys...Done
Decrypting...Done
```
#### 增加密码复杂度
为了进一步使文件变得难以破译,我们可以像以下这样增加密码复杂度:
```
./toplip -c 5 -i 0x8000 -alt file1 -c 10 -i 10 file2 > file3.encrypted
```
上述命令将会要求你为 `file1` 输入十条密码,为 `file2` 输入五条密码,并将它们存入单个叫做 `file3.encrypted` 的文件。如你所注意到的,我们在这个例子中又用了另一个 `-i` 参数。这是用来指定密钥生成循环次数。这个选项覆盖了 `scrypt` 函数初始和最终 PBKDF2 阶段的默认循环次数 1。十六进制和十进制数值都是允许的。比如说 `0x8000`、`10` 等。请注意这会大大增加计算次数。
为了解码 `file1`,使用:
```
./toplip -c 5 -i 0x8000 -d file3.encrypted > file1.decrypted
```
为了解码 `file2`,使用:
```
./toplip -c 10 -i 10 -d file3.encrypted > file2.decrypted
```
参考 `toplip` [官网](https://2ton.com.au/toplip/)以了解更多关于其背后的技术信息和使用的加密方式。
我个人对所有想要保护自己数据的人的建议是,别依赖单一的方法。总是使用多种工具/方法来加密文件。不要在纸上写下密码也不要将密码存入本地或云。记住密码,阅后即焚。如果你记不住,考虑使用任何了信赖的密码管理器。
* [KeeWeb – An Open Source, Cross Platform Password Manager](https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/)
* [Buttercup – A Free, Secure And Cross-platform Password Manager](https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/)
* [Titan – A Command line Password Manager For Linux](https://www.ostechnix.com/titan-command-line-password-manager-linux/)
今天就到此为止了,更多好东西后续推出,请保持关注。
顺祝时祺!
---
via: <https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,634 | 高效使用 Org 模式 | https://www.badykov.com/emacs/2018/08/26/be-productive-with-org-mode/ | 2019-03-19T18:10:00 | [
"Org模式"
] | https://linux.cn/article-10634-1.html | 
### 简介
在我 [前一篇关于 Emacs 的文章中](http://www.badykov.com/emacs/2018/07/31/why-emacs-is-a-great-editor/) 我提到了 <ruby> <a href="https://orgmode.org/"> Org 模式 </a> <rt> Org-mode </rt></ruby>,这是一个笔记管理工具和组织工具。本文中,我将会描述一下我日常的 Org 模式使用案例。
### 笔记和代办列表
首先而且最重要的是,Org 模式是一个管理笔记和待办列表的工具,Org 模式的所有工具都聚焦于使用纯文本文件记录笔记。我使用 Org 模式管理多种笔记。
#### 一般性笔记
Org 模式最基本的应用场景就是以笔记的形式记录下你想记住的事情。比如,下面是我正在学习的笔记内容:
```
* Learn
** Emacs LISP
*** Plan
- [ ] Read best practices
- [ ] Finish reading Emacs Manual
- [ ] Finish Exercism Exercises
- [ ] Write a couple of simple plugins
- Notification plugin
*** Resources
https://www.gnu.org/software/emacs/manual/html_node/elisp/index.html
http://exercism.io/languages/elisp/about
[[http://batsov.com/articles/2011/11/30/the-ultimate-collection-of-emacs-resources/][The Ultimate Collection of Emacs Resources]]
** Rust gamedev
*** Study [[https://github.com/SergiusIW/gate][gate]] 2d game engine with web assembly support
*** [[ggez][https://github.com/ggez/ggez]]
*** [[https://www.amethyst.rs/blog/release-0-8/][Amethyst 0.8 Relesed]]
** Upgrade Elixir/Erlang Skills
*** Read Erlang in Anger
```
借助 [org-bullets](https://github.com/sabof/org-bullets) 它看起来是这样的:

在这个简单的例子中,你能看到 Org 模式的一些功能:
* 笔记允许嵌套
* 链接
* 带复选框的列表
#### 项目待办
我在工作时时常会发现一些能够改进或修复的事情。我并不会在代码文件中留下 TODO 注释 (坏味道),相反我使用 [org-projectile](https://github.com/IvanMalison/org-projectile) 来在另一个文件中记录一个 TODO 事项,并留下一个快捷方式。下面是一个该文件的例子:
```
* [[elisp:(org-projectile-open-project%20"mana")][mana]] [3/9]
:PROPERTIES:
:CATEGORY: mana
:END:
** DONE [[file:~/Development/mana/apps/blockchain/lib/blockchain/contract/create_contract.ex::insufficient_gas_before_homestead%20=][fix this check using evm.configuration]]
CLOSED: [2018-08-08 Ср 09:14]
[[https://github.com/ethereum/EIPs/blob/master/EIPS/eip-2.md][eip2]]:
If contract creation does not have enough gas to pay for the final gas fee for
adding the contract code to the state, the contract creation fails (i.e. goes out-of-gas)
rather than leaving an empty contract.
** DONE Upgrade Elixir to 1.7.
CLOSED: [2018-08-08 Ср 09:14]
** TODO [#A] Difficulty tests
** TODO [#C] Upgrage to OTP 21
** DONE [#A] EIP150
CLOSED: [2018-08-14 Вт 21:25]
*** DONE operation cost changes
CLOSED: [2018-08-08 Ср 20:31]
*** DONE 1/64th for a call and create
CLOSED: [2018-08-14 Вт 21:25]
** TODO [#C] Refactor interfaces
** TODO [#B] Caching for storage during execution
** TODO [#B] Removing old merkle trees
** TODO do not calculate cost twice
* [[elisp:(org-projectile-open-project%20".emacs.d")][.emacs.d]] [1/3]
:PROPERTIES:
:CATEGORY: .emacs.d
:END:
** TODO fix flycheck issues (emacs config)
** TODO use-package for fetching dependencies
** DONE clean configuration
CLOSED: [2018-08-26 Вс 11:48]
```
它看起来是这样的:

本例中你能看到更多的 Org 模式的功能:
* 代办列表具有 `TODO`、`DONE` 两个状态。你还可以定义自己的状态 (`WAITING` 等)
* 关闭的事项有 `CLOSED` 时间戳
* 有些事项有优先级 - A、B、C
* 链接可以指向文件内部 (`[[file:~/。..]`)
#### 捕获模板
正如 Org 模式的文档中所描述的,捕获可以在不怎么干扰你工作流的情况下让你快速存储笔记。
我配置了许多捕获模板,可以帮我快速记录想要记住的事情。
```
(setq org-capture-templates
'(("t" "Todo" entry (file+headline "~/Dropbox/org/todo.org" "Todo soon")
"* TODO %? \n %^t")
("i" "Idea" entry (file+headline "~/Dropbox/org/ideas.org" "Ideas")
"* %? \n %U")
("e" "Tweak" entry (file+headline "~/Dropbox/org/tweaks.org" "Tweaks")
"* %? \n %U")
("l" "Learn" entry (file+headline "~/Dropbox/org/learn.org" "Learn")
"* %? \n")
("w" "Work note" entry (file+headline "~/Dropbox/org/work.org" "Work")
"* %? \n")
("m" "Check movie" entry (file+headline "~/Dropbox/org/check.org" "Movies")
"* %? %^g")
("n" "Check book" entry (file+headline "~/Dropbox/org/check.org" "Books")
"* %^{book name} by %^{author} %^g")))
```
做书本记录时我需要记下它的名字和作者,做电影记录时我需要记下标签,等等。
### 规划
Org 模式的另一个超棒的功能是你可以用它来作日常规划。让我们来看一个例子:

我没有挖空心思虚构一个例子,这就是我现在真实文件的样子。它看起来内容并不多,但它有助于你花时间在在重要的事情上并且帮你对抗拖延症。
#### 习惯
根据 Org 模式的文档,Org 能够跟踪一种特殊的代办事情,称为 “习惯”。当我想养成新的习惯时,我会将该功能与日常规划功能一起连用:

你可以看到,目前我在尝试每天早期并且每两天锻炼一次。另外,它也有助于让我每天阅读书籍。
#### 议事日程视图
最后,我还使用议事日程视图功能。待办事项可能分散在不同文件中(比如我就是日常规划和习惯分散在不同文件中),议事日程视图可以提供所有待办事项的总览:

### 更多 Org 模式的功能
* 手机应用([Android](https://play.google.com/store/apps/details%EF%BC%9Fid=com.orgzly&hl=en)、[ios](https://itunes.apple.com/app/id1238649962%5D))
* [将 Org 模式文档导出为其他格式](https://orgmode.org/manual/Exporting.html)(html、markdown、pdf、latex 等)
* 使用 [ledger](https://github.com/ledger/ledger-mode) [追踪财务状况](https://orgmode.org/worg/org-tutorials/weaving-a-budget.html)
### 总结
本文我描述了 Org 模式广泛功能中的一小部分,我每天都用它来提高工作效率,把时间花在重要的事情上。
---
via: <https://www.badykov.com/emacs/2018/08/26/be-productive-with-org-mode/>
作者:[Ayrat Badykov](https://www.badykov.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Redirecting…
Click here if you are not redirected. |
10,635 | 如何在 Linux 中查看可用的网络接口 | https://www.ostechnix.com/how-to-find-available-network-interfaces-on-linux/ | 2019-03-19T18:50:15 | [
"网络接口",
"网卡",
"IP"
] | https://linux.cn/article-10635-1.html | 
在我们安装完一个 Linux 系统后最为常见的任务便是网络配置了。当然,你可以在安装系统时进行网络接口的配置。但是,对于某些人来说,他们更偏爱在安装完系统后再进行网络的配置或者更改现存的设置。众所周知,为了在命令行中进行网络设定的配置,我们首先必须知道系统中有多少个可用的网络接口。本次这个简单的指南将列出所有可能的方式来在 Linux 和 Unix 操作系统中找到可用的网络接口。
### 在 Linux 中找到可用的网络接口
我们可以使用下面的这些方法来找到可用的网络接口。
#### 方法 1 使用 ifconfig 命令
使用 `ifconfig` 命令来查看网络接口仍然是最常使用的方法。我相信还有很多 Linux 用户仍然使用这个方法。
```
$ ifconfig -a
```
示例输出:
```
enp5s0: flags=4098<BROADCAST,MULTICAST> mtu 1500
ether 24:b6:fd:37:8b:29 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 171420 bytes 303980988 (289.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 171420 bytes 303980988 (289.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
wlp9s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.225.37 netmask 255.255.255.0 broadcast 192.168.225.255
inet6 2409:4072:6183:c604:c218:85ff:fe50:474f prefixlen 64 scopeid 0x0<global>
inet6 fe80::c218:85ff:fe50:474f prefixlen 64 scopeid 0x20<link>
ether c0:18:85:50:47:4f txqueuelen 1000 (Ethernet)
RX packets 564574 bytes 628671925 (599.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 299706 bytes 60535732 (57.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
```
如上面的输出所示,在我的 Linux 机器上有两个网络接口,它们分别叫做 `enp5s0`(主板上的有线网卡)和 `wlp9s0`(无线网卡)。其中的 `lo` 是环回网卡,被用来访问本地的网络的服务,通常它的 IP 地址为 `127.0.0.1`。
我们也可以在许多 UNIX 变种例如 FreeBSD 中使用相同的 `ifconfig` 来列出可用的网卡。
#### 方法 2 使用 ip 命令
在最新的 Linux 版本中, `ifconfig` 命令已经被弃用了。你可以使用 `ip` 命令来罗列出网络接口,正如下面这样:
```
$ ip link show
```
示例输出:
```
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp5s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 24:b6:fd:37:8b:29 brd ff:ff:ff:ff:ff:ff
3: wlp9s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DORMANT group default qlen 1000
link/ether c0:18:85:50:47:4f brd ff:ff:ff:ff:ff:ff
```

你也可以使用下面的命令来查看。
```
$ ip addr
```
```
$ ip -s link
```
你注意到了吗?这些命令同时还显示出了已经连接的网络接口的状态。假如你仔细查看上面的输出,你将注意到我的有线网卡并没有跟网络线缆连接(从上面输出中的 `DOWN` 可以看出)。另外,我的无线网卡已经连接了(从上面输出中的 `UP` 可以看出)。想知晓更多的细节,可以查看我们先前的指南 [在 Linux 中查看网络接口的已连接状态](https://www.ostechnix.com/how-to-find-out-the-connected-state-of-a-network-cable-in-linux/)。
这两个命令(`ifconfig` 和 `ip`)已经足够在你的 LInux 系统中查看可用的网卡了。
然而,仍然有其他方法来列出 Linux 中的网络接口,下面我们接着看。
#### 方法 3 使用 /sys/class/net 目录
Linux 内核将网络接口的详细信息保存在 `/sys/class/net` 目录中,你可以通过查看这个目录的内容来检验可用接口的列表是否和前面的结果相符。
```
$ ls /sys/class/net
```
示例输出:
```
enp5s0 lo wlp9s0
```
#### 方法 4 使用 /proc/net/dev 目录
在 Linux 操作系统中,文件 `/proc/net/dev` 中包含有关网络接口的信息。
要查看可用的网卡,只需使用下面的命令来查看上面文件的内容:
```
$ cat /proc/net/dev
```
示例输出:
```
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
wlp9s0: 629189631 566078 0 0 0 0 0 0 60822472 300922 0 0 0 0 0 0
enp5s0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
lo: 303980988 171420 0 0 0 0 0 0 303980988 171420 0 0 0 0 0 0
```
#### 方法 5 使用 netstat 命令
`netstat` 命令可以列出各种不同的信息,例如网络连接、路由表、接口统计信息、伪装连接和多播成员等。
```
$ netstat -i
```
示例输出:
```
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
lo 65536 171420 0 0 0 171420 0 0 0 LRU
wlp9s0 1500 565625 0 0 0 300543 0 0 0 BMRU
```
请注意 `netstat` 被弃用了, `netstat -i` 的替代命令是 `ip -s link`。另外需要注意的是这个方法将只列出激活的接口,而不是所有可用的接口。
#### 方法 6 使用 nmcli 命令
`nmcli` 是一个用来控制 NetworkManager 和报告网络状态的命令行工具。它可以被用来创建、展示、编辑、删除、激活、停用网络连接和展示网络状态。
假如你的 Linux 系统中安装了 NetworkManager,你便可以使用下面的命令来使用 `nmcli` 列出可以的网络接口:
```
$ nmcli device status
```
或者
```
$ nmcli connection show
```
现在你知道了如何在 Linux 中找到可用网络接口的方法,接下来,请查看下面的指南来知晓如何在 Linux 中配置 IP 地址吧。
* [如何在 Linux 和 Unix 中配置静态 IP 地址](https://www.ostechnix.com/configure-static-ip-address-linux-unix/)
* [如何在 Ubuntu 18.04 LTS 中配置 IP 地址](https://www.ostechnix.com/how-to-configure-ip-address-in-ubuntu-18-04-lts/)
* [如何在 Arch Linux 中配置静态和动态 IP 地址](https://www.ostechnix.com/configure-static-dynamic-ip-address-arch-linux/)
* [如何在 Linux 中为单个网卡分配多个 IP 地址](https://www.ostechnix.com/how-to-assign-multiple-ip-addresses-to-single-network-card-in-linux/)
假如你知道其他快捷的方法来在 Linux 中找到可用的网络接口,请在下面的评论部分中分享出来,我将检查你们的评论并更新这篇指南。
这就是全部的内容了,更多精彩内容即将呈现,请保持关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-find-available-network-interfaces-on-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,636 | 开始使用 CryptPad 吧,一个开源的协作文档编辑器 | https://opensource.com/article/19/1/productivity-tool-cryptpad | 2019-03-20T22:15:26 | [
"笔记"
] | https://linux.cn/article-10636-1.html |
>
> 使用 CryptPad 安全地共享你的笔记、文档、看板等,这是我们在开源工具系列中的第 5 个工具,它将使你在 2019 年更高效。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 5 个工具来帮助你在 2019 年更有效率。
### CryptPad
我们已经介绍过 [Joplin](https://opensource.com/article/19/1/productivity-tool-joplin),它能很好地保存自己的笔记,但是,你可能已经注意到,它没有任何共享或协作功能。
[CryptPad](https://cryptpad.fr/index.html) 是一个安全、可共享的笔记应用和文档编辑器,它能够安全地协作编辑。与 Joplin 不同,它是一个 NodeJS 应用,这意味着你可以在桌面或其他服务器上运行它,并使用任何现代 Web 浏览器访问。它开箱即用,它支持富文本、Markdown、投票、白板,看板和 PPT。

它支持不同的文档类型且功能齐全。它的富文本编辑器涵盖了你所期望的所有基础功能,并允许你将文件导出为 HTML。它的 Markdown 的编辑能与 Joplin 相提并论,它的看板虽然不像 [Wekan](https://opensource.com/article/19/1/productivity-tool-wekan) 那样功能齐全,但也做得不错。其他支持的文档类型和编辑器也很不错,并且有你希望在类似应用中看到的功能,尽管投票功能显得有些粗糙。

然而,CryptPad 的真正强大之处在于它的共享和协作功能。共享文档只需在“共享”选项中获取可共享 URL,CryptPad 支持使用 `<iframe>` 标签嵌入其他网站的文档。可以在“编辑”或“查看”模式下使用密码和会过期的链接共享文档。内置聊天能够让编辑者相互交谈(请注意,具有浏览权限的人也可以看到聊天但无法发表评论)。

所有文件都使用用户密码加密存储。服务器管理员无法读取文档,这也意味着如果你忘记或丢失了密码,文件将无法恢复。因此,请确保将密码保存在安全的地方,例如放在[密码保险箱](https://opensource.com/article/18/4/3-password-managers-linux-command-line)中。

当它在本地运行时,CryptPad 是一个用于创建和编辑文档的强大应用。当在服务器上运行时,它成为了用于多用户文档创建和编辑的出色协作平台。在我的笔记本电脑上安装它不到五分钟,并且开箱即用。开发者还加入了在 Docker 中运行 CryptPad 的说明,并且还有一个社区维护用于方便部署的 Ansible 角色。CryptPad 不支持任何第三方身份验证,因此用户必须创建自己的帐户。如果你不想运行自己的服务器,CryptPad 还有一个社区支持的托管版本。
---
via: <https://opensource.com/article/19/1/productivity-tool-cryptpad>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the fifth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## CryptPad
We already talked about [Joplin](https://opensource.com/article/19/1/productivity-tool-joplin), which is good for keeping your own notes but—as you may have noticed—doesn't have any sharing or collaboration features.
[CryptPad](https://cryptpad.fr/index.html) is a secure, shareable note-taking app and document editor that allows for secure, collaborative editing. Unlike Joplin, it is a NodeJS app, which means you can run it on your desktop or a server elsewhere and access it with any modern web browser. Out of the box, it supports rich text, Markdown, polls, whiteboards, kanban, and presentations.
The different document types are robust and fully featured. The rich text editor covers all the bases you'd expect from a good editor and allows you to export files to HTML. The Markdown editor is on par with Joplin, and the kanban board, though not as full-featured as [Wekan](https://opensource.com/article/19/1/productivity-tool-wekan), is really well done. The rest of the supported document types and editors are also very polished and have the features you'd expect from similar apps, although polls feel a little clunky.
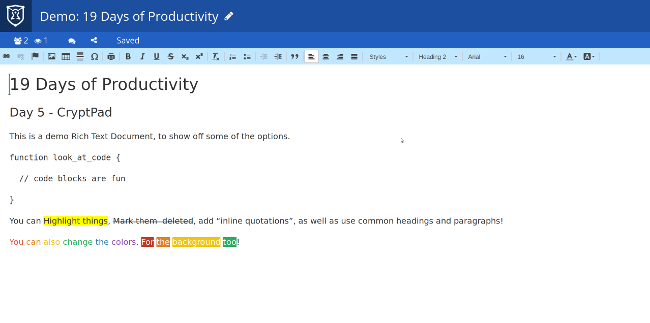
CryptPad's real power, though, comes in its sharing and collaboration features. Sharing a document is as simple as getting the sharable URL from the "share" option, and CryptPad supports embedding documents in iFrame tags on other websites. Documents can be shared in Edit or View mode with a password and with links that expire. The built-in chat allows editors to talk to each other (note that people with View access can also see the chat but can't comment).
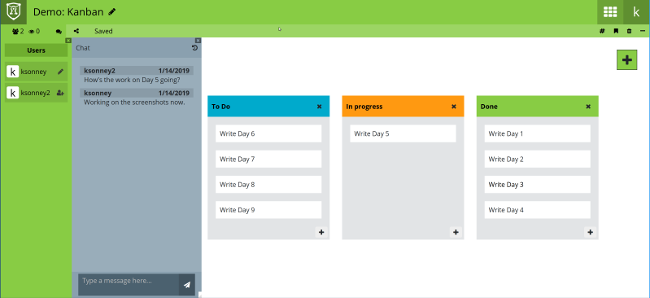
All files are stored encrypted with the user's password. Server administrators can't read the documents, which also means if you forget or lose your password, the files are unrecoverable. So make sure you keep the password in a secure place, like a [password vault](https://opensource.com/article/18/4/3-password-managers-linux-command-line).
When it's run locally, CryptPad is a robust app for creating and editing documents. When run on a server, it becomes an excellent collaboration platform for multi-user document creation and editing. Installation took less than five minutes on my laptop, and it just worked out of the box. The developers also include instructions for running CryptPad in Docker, and there is a community-maintained Ansible role for ease of deployment. CryptPad does not support any third-party authentication methods, so users must create their own accounts. CryptPad also has a community-supported hosted version if you don't want to run your own server.
## Comments are closed. |
10,637 | ODrive:Linux 中的 Google 云端硬盘图形客户端 | https://www.2daygeek.com/odrive-open-drive-google-drive-gui-client-for-linux/ | 2019-03-20T22:46:00 | [
"Google",
"云端硬盘"
] | https://linux.cn/article-10637-1.html | 
这个我们已经多次讨论过。但是,我还要简要介绍一下它。截至目前,还没有官方的 Google 云端硬盘的 Linux 客户端,我们需要使用非官方客户端。Linux 中有许多集成 Google 云端硬盘的应用。每个应用都提供了一组功能。
我们过去在网站上写过一些此类文章。
这些文章是 [DriveSync](https://www.2daygeek.com/drivesync-google-drive-sync-client-for-linux/) 、[Google Drive Ocamlfuse 客户端](/article-10517-1.html) 和 [在 Linux 中使用 Nautilus 文件管理器挂载 Google 云端硬盘](https://www.2daygeek.com/mount-access-setup-google-drive-in-linux/)。
今天我们也将讨论相同的主题,程序名字是 ODrive。
### ODrive 是什么?
ODrive 意即 Open Drive。它是 Google 云端硬盘的图形客户端,它用 electron 框架编写。
它简单的图形界面能让用户几步就能集成 Google 云端硬盘。
### 如何在 Linux 上安装和设置 ODrive?
由于开发者提供了 AppImage 包,因此在 Linux 上安装 ODrive 没有任何困难。
只需使用 `wget` 命令从开发者的 GitHub 页面下载最新的 ODrive AppImage 包。
```
$ wget https://github.com/liberodark/ODrive/releases/download/0.1.3/odrive-0.1.3-x86_64.AppImage
```
你必须为 ODrive AppImage 文件设置可执行文件权限。
```
$ chmod +x odrive-0.1.3-x86_64.AppImage
```
只需运行 ODrive AppImage 文件以启动 ODrive GUI 以进行进一步设置。
```
$ ./odrive-0.1.3-x86_64.AppImage
```
运行上述命令时,可能会看到下面的窗口。只需按下“下一步”按钮即可进行进一步设置。

点击“连接”链接添加 Google 云端硬盘帐户。

输入你要设置 Google 云端硬盘帐户的电子邮箱。

输入邮箱密码。

允许 ODrive 访问你的 Google 帐户。

默认情况下,它将选择文件夹位置。如果你要选择特定文件夹,则可以更改。

最后点击“同步”按钮开始将文件从 Google 下载到本地系统。

同步正在进行中。

同步完成后。它会显示所有已下载的文件。

我看到所有文件都下载到上述目录中。

如果要将本地系统中的任何新文件同步到 Google 。只需从应用菜单启动 “ODrive”,但它不会实际启动应用。它将在后台运行,我们可以使用 `ps` 命令查看。
```
$ ps -df | grep odrive
```

将新文件添加到 Google文件夹后,它会自动开始同步。从通知菜单中也可以看到。是的,我看到一个文件已同步到 Google 中。

同步完成后图形界面没有加载,我不确定这个功能。我会向开发者反馈之后,根据他的反馈更新。
---
via: <https://www.2daygeek.com/odrive-open-drive-google-drive-gui-client-for-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,639 | 在 Emacs 的 dired 和 tramp 中异步运行 rsync | https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp/ | 2019-03-21T20:47:00 | [
"emacs"
] | https://linux.cn/article-10639-1.html | 
[Trần Xuân Trường](https://truongtx.me/about.html) 写的 [tmtxt-dired-async](https://truongtx.me/tmtxt-dired-async.html) 是一个不为人知的 Emacs 包,它可以扩展 dired(Emacs 内置的文件管理器),使之可以异步地运行 `rsync` 和其他命令 (例如压缩、解压缩和下载)。
这意味着你可以拷贝上 GB 的目录而不影响 Emacs 的其他任务。
它的一个功能时让你可以通过 `C-c C-a` 从不同位置添加任意多的文件到一个等待列表中,然后按下 `C-c C-v` 异步地使用 `rsync` 将整个等待列表中的文件同步到目标目录中。光这个功能就值得一试了。
例如这里将 arduino 1.9 的 beta 存档同步到另一个目录中:

整个进度完成后,底部的窗口会在 5 秒后自动退出。下面是异步解压上面的 arduino 存档后出现的另一个会话:

这个包进一步增加了我 dired 配置的实用性。
我刚刚贡献了 [一个拉取请求来允许 tmtxt-dired-async 同步到远程 tramp 目录中](https://github.com/tmtxt/tmtxt-dired-async/pull/6),而且我立即使用该功能来将上 GB 的新照片传输到 Linux 服务器上。
若你想配置 tmtxt-dired-async,下载 [tmtxt-async-tasks.el](https://github.com/tmtxt/tmtxt-async-tasks)(被依赖的库)以及 [tmtxt-dired-async.el](https://github.com/tmtxt/tmtxt-dired-async)(若你想让它支持 tramp,请确保合并使用了我的拉取请求)到 `~/.emacs.d/` 目录中,然后添加下面配置:
```
;; no MELPA packages of this, so we have to do a simple check here
(setq dired-async-el (expand-file-name "~/.emacs.d/tmtxt-dired-async.el"))
(when (file-exists-p dired-async-el)
(load (expand-file-name "~/.emacs.d/tmtxt-async-tasks.el"))
(load dired-async-el)
(define-key dired-mode-map (kbd "C-c C-r") 'tda/rsync)
(define-key dired-mode-map (kbd "C-c C-z") 'tda/zip)
(define-key dired-mode-map (kbd "C-c C-u") 'tda/unzip)
(define-key dired-mode-map (kbd "C-c C-a") 'tda/rsync-multiple-mark-file)
(define-key dired-mode-map (kbd "C-c C-e") 'tda/rsync-multiple-empty-list)
(define-key dired-mode-map (kbd "C-c C-d") 'tda/rsync-multiple-remove-item)
(define-key dired-mode-map (kbd "C-c C-v") 'tda/rsync-multiple)
(define-key dired-mode-map (kbd "C-c C-s") 'tda/get-files-size)
(define-key dired-mode-map (kbd "C-c C-q") 'tda/download-to-current-dir))
```
祝你开心!
---
via: <https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp/>
作者:[cpbotha](https://vxlabs.com/author/cpbotha/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Asynchronous rsync with Emacs, dired and tramp.
## Contents
[tmtxt-dired-async](https://truongtx.me/tmtxt-dired-async.html) by [Trần Xuân Trường](https://truongtx.me/about.html) is an unfortunately lesser known Emacs package which extends dired, the Emacs file manager, to be able to run rsync and other commands (zip, unzip, downloading) asynchronously.
This means you can copy gigabytes of directories around whilst still happily continuing with all of your other tasks in the Emacs operating system.
It has a feature where you can add any number of files from different locations into a wait list with `C-c C-a`
, and then asynchronously rsync the whole wait list into a final destination directory with `C-c C-v`
. This alone is worth the price of admission.
For example here it is pointlessly rsyncing the arduino 1.9 beta archive to another directory:
When the process is complete, the window at the bottom will automatically be killed after 5 seconds. Here is a separate session right after the asynchronous unzipping of the above-mentioned arduino archive:
This package has further increased the utility of my dired configuration.
I just contributed [a pull request that enables tmtxt-dired-async to rsync to remote tramp-based directories](https://github.com/tmtxt/tmtxt-dired-async/pull/6), and I immediately used this new functionality to sort a few gigabytes of new photos onto the Linux server.
To add tmtxt-dired-async to your config, download [tmtxt-async-tasks.el](https://github.com/tmtxt/tmtxt-async-tasks) (a required library) and [tmtxt-dired-async.el](https://github.com/tmtxt/tmtxt-dired-async) (check that my PR is in there if you plan to use this with tramp) into your `~/.emacs.d/`
and add the following to your config:
;; no MELPA packages of this, so we have to do a simple check here (setq dired-async-el (expand-file-name "~/.emacs.d/tmtxt-dired-async.el")) (when (file-exists-p dired-async-el) (load (expand-file-name "~/.emacs.d/tmtxt-async-tasks.el")) (load dired-async-el) (define-key dired-mode-map (kbd "C-c C-r") 'tda/rsync) (define-key dired-mode-map (kbd "C-c C-z") 'tda/zip) (define-key dired-mode-map (kbd "C-c C-u") 'tda/unzip) (define-key dired-mode-map (kbd "C-c C-a") 'tda/rsync-multiple-mark-file) (define-key dired-mode-map (kbd "C-c C-e") 'tda/rsync-multiple-empty-list) (define-key dired-mode-map (kbd "C-c C-d") 'tda/rsync-multiple-remove-item) (define-key dired-mode-map (kbd "C-c C-v") 'tda/rsync-multiple) (define-key dired-mode-map (kbd "C-c C-s") 'tda/get-files-size) (define-key dired-mode-map (kbd "C-c C-q") 'tda/download-to-current-dir))
Enjoy! |
10,640 | x86 和 ARM 的 Python 爬虫速度对比 | https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/ | 2019-03-21T21:29:00 | [
"Python",
"ARM",
"CPU",
"爬虫"
] | /article-10640-1.html | 
假如说,如果你的老板给你的任务是一次又一次地访问竞争对手的网站,把对方商品的价格记录下来,而且要纯手工操作,恐怕你会想要把整个办公室都烧掉。
之所以现在网络爬虫的影响力如此巨大,就是因为网络爬虫可以被用于追踪客户的情绪和趋向、搜寻空缺的职位、监控房地产的交易,甚至是获取 UFC 的比赛结果。除此以外,还有很多意想不到的用途。
对于有这方面爱好的人来说,爬虫无疑是一个很好的工具。因此,我使用了 [Scrapy](https://scrapy.org/) 这个基于 Python 编写的开源网络爬虫框架。
鉴于我不太了解这个工具是否会对我的计算机造成伤害,我并没有将它搭建在我的主力机器上,而是搭建在了一台树莓派上面。
令人感到意外的是,Scrapy 在树莓派上面的性能并不差,或许这是 ARM 架构服务器的又一个成功例子?
我尝试 Google 了一下,但并没有得到令我满意的结果,仅仅找到了一篇相关的《[Drupal 建站对比](https://www.info2007.net/blog/2018/review-scaleway-arm-based-cloud-server.html)》。这篇文章的结论是,ARM 架构服务器性能比昂贵的 x86 架构服务器要更好。
从另一个角度来看,这种 web 服务可以看作是一个“被爬虫”服务,但和 Scrapy 对比起来,前者是基于 LAMP 技术栈,而后者则依赖于 Python,这就导致两者之间没有太多的可比性。
那我们该怎样做呢?只能在一些 VPS 上搭建服务来对比一下了。
### 什么是 ARM 架构处理器?
ARM 是目前世界上最流行的 CPU 架构。
但 ARM 架构处理器在很多人眼中的地位只是作为一个省钱又省电的选择,而不是跑在生产环境中的处理器的首选。
然而,诞生于英国剑桥的 ARM CPU,最初是用于极其昂贵的 [Acorn Archimedes](https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/) 计算机上的,这是当时世界上最强大的桌面计算机,甚至在很长一段时间内,它的运算速度甚至比最快的 386 还要快好几倍。
Acorn 公司和 Commodore、Atari 的理念类似,他们认为一家伟大的计算机公司就应该制造出伟大的计算机,让人感觉有点目光短浅。而比尔盖茨的想法则有所不同,他力图在更多不同种类和价格的 x86 机器上使用他的 DOS 系统。
拥有大量用户基数的平台会成为第三方开发者开发软件的平台,而软件资源丰富又会让你的计算机更受用户欢迎。
即使是苹果公司也几乎被打败。在 x86 芯片上投入大量的财力,最终,这些芯片被用于生产环境计算任务。
但 ARM 架构也并没有消失。基于 ARM 架构的芯片不仅运算速度快,同时也非常节能。因此诸如机顶盒、PDA、数码相机、MP3 播放器这些电子产品多数都会采用 ARM 架构的芯片,甚至在很多需要用电池或不配备大散热风扇的电子产品上,都可以见到 ARM 芯片的身影。
而 ARM 则脱离 Acorn 成为了一种特殊的商业模式,他们不生产实物芯片,仅仅是向芯片生产厂商出售相关的知识产权。
因此,这或多或少是 ARM 芯片被应用于如此之多的手机和平板电脑上的原因。当 Linux 被移植到这种架构的芯片上时,开源技术的大门就已经向它打开了,这才让我们今天得以在这些芯片上运行 web 爬虫程序。
#### 服务器端的 ARM
诸如[微软](https://www.computerworld.com/article/3178544/microsoft-windows/microsoft-and-arm-look-to-topple-intel-in-servers.html)和 [Cloudflare](https://www.datacenterknowledge.com/design/cloudflare-bets-arm-servers-it-expands-its-data-center-network) 这些大厂都在基础设施建设上花了重金,所以对于我们这些预算不高的用户来说,可以选择的余地并不多。
实际上,如果你的信用卡只够付每月数美元的 VPS 费用,一直以来只能考虑 [Scaleway](https://www.scaleway.com/) 这个高性价比的厂商。
但自从数个月前公有云巨头 [AWS](https://aws.amazon.com/) 推出了他们自研的 ARM 处理器 [AWS Graviton](https://www.theregister.co.uk/2018/11/27/amazon_aws_graviton_specs/) 之后,选择似乎就丰富了一些。
我决定在其中选择一款 VPS 厂商,将它提供的 ARM 处理器和 x86 处理器作出对比。
### 深入了解
所以我们要对比的是什么指标呢?
#### Scaleway
Scaleway 自身的定位是“专为开发者设计”。我觉得这个定位很准确,对于开发和原型设计来说,Scaleway 提供的产品确实可以作为一个很好的沙盒环境。
Scaleway 提供了一个简洁的仪表盘页面,让用户可以快速地从主页进入 bash shell 界面。对于很多小企业、自由职业者或者技术顾问,如果想要运行 web 爬虫,这个产品毫无疑问是一个物美价廉的选择。
ARM 方面我们选择 [ARM64-2GB](https://www.scaleway.com/virtual-cloud-servers/#anchor_arm) 这一款服务器,每月只需要 3 欧元。它带有 4 个 Cavium ThunderX 核心,这是在 2014 年推出的第一款服务器级的 ARMv8 处理器。但现在看来它已经显得有点落后了,并逐渐被更新的 ThunderX2 取代。
x86 方面我们选择 [1-S](https://www.scaleway.com/virtual-cloud-servers/#anchor_starter),每月的费用是 4 欧元。它拥有 2 个英特尔 Atom C3995 核心。英特尔的 Atom 系列处理器的特点是低功耗、单线程,最初是用在笔记本电脑上的,后来也被服务器所采用。
两者在处理器以外的条件都大致相同,都使用 2 GB 的内存、50 GB 的 SSD 存储以及 200 Mbit/s 的带宽。磁盘驱动器可能会有所不同,但由于我们运行的是 web 爬虫,基本都是在内存中完成操作,因此这方面的差异可以忽略不计。
为了避免我不能熟练使用包管理器的尴尬局面,两方的操作系统我都会选择使用 Debian 9。
#### Amazon Web Services(AWS)
当你还在注册 AWS 账号的时候,使用 Scaleway 的用户可能已经把提交信用卡信息、启动 VPS 实例、添加 sudo 用户、安装依赖包这一系列流程都完成了。AWS 的操作相对来说比较繁琐,甚至需要详细阅读手册才能知道你正在做什么。
当然这也是合理的,对于一些需求复杂或者特殊的企业用户,确实需要通过详细的配置来定制合适的使用方案。
我们所采用的 AWS Graviton 处理器是 AWS EC2(<ruby> 弹性计算云 <rt> Elastic Compute Cloud </rt></ruby>)的一部分,我会以按需实例的方式来运行,这也是最贵但最简捷的方式。AWS 同时也提供[竞价实例](https://aws.amazon.com/ec2/spot/pricing/),这样可以用较低的价格运行实例,但实例的运行时间并不固定。如果实例需要长时间持续运行,还可以选择[预留实例](https://aws.amazon.com/ec2/pricing/reserved-instances/)。
看,AWS 就是这么复杂……
我们分别选择 [a1.medium](https://aws.amazon.com/ec2/instance-types/a1/) 和 [t2.small](https://aws.amazon.com/ec2/instance-types/t2/) 两种型号的实例进行对比,两者都带有 2GB 内存。这个时候问题来了,这里提到的 vCPU 又是什么?两种型号的不同之处就在于此。
对于 a1.medium 型号的实例,vCPU 是 AWS Graviton 芯片提供的单个计算核心。这个芯片由被亚马逊在 2015 收购的以色列厂商 Annapurna Labs 研发,是 AWS 独有的单线程 64 位 ARMv8 内核。它的按需价格为每小时 0.0255 美元。
而 t2.small 型号实例使用英特尔至强系列芯片,但我不确定具体是其中的哪一款。它每个核心有两个线程,但我们并不能用到整个核心,甚至整个线程。
我们能用到的只是“20% 的基准性能,可以使用 CPU 积分突破这个基准”。这可能有一定的原因,但我没有弄懂。它的按需价格是每小时 0.023 美元。
在镜像库中没有 Debian 发行版的镜像,因此我选择了 Ubuntu 18.04。
### 瘪四与大头蛋爬取 Moz 排行榜前 500 的网站
要测试这些 VPS 的 CPU 性能,就该使用爬虫了。一个方法是对几个网站在尽可能短的时间里发出尽可能多的请求,但这种操作不太礼貌,我的做法是只向大量网站发出少数几个请求。
为此,我编写了 `beavis.py`(瘪四)这个爬虫程序(致敬我最喜欢的物理学家和制片人 Mike Judge)。这个程序会将 Moz 上排行前 500 的网站都爬取 3 层的深度,并计算 “wood” 和 “ass” 这两个单词在 HTML 文件中出现的次数。(LCTT 译注:beavis(瘪四)和 butt-head(大头蛋) 都是 Mike Judge 的动画片《瘪四与大头蛋》中的角色)
但我实际爬取的网站可能不足 500 个,因为我需要遵循网站的 `robot.txt` 协定,另外还有些网站需要提交 javascript 请求,也不一定会计算在内。但这已经是一个足以让 CPU 保持繁忙的爬虫任务了。
Python 的[全局解释器锁](https://wiki.python.org/moin/GlobalInterpreterLock)机制会让我的程序只能用到一个 CPU 线程。为了测试多线程的性能,我需要启动多个独立的爬虫程序进程。
因此我还编写了 `butthead.py`,尽管大头蛋很粗鲁,它也总是比瘪四要略胜一筹。
我将整个爬虫任务拆分为多个部分,这可能会对爬取到的链接数量有一点轻微的影响。但无论如何,每次爬取都会有所不同,我们要关注的是爬取了多少个页面,以及耗时多长。
### 在 ARM 服务器上安装 Scrapy
安装 Scrapy 的过程与芯片的不同架构没有太大的关系,都是安装 `pip` 和相关的依赖包之后,再使用 `pip` 来安装 Scrapy。
据我观察,在使用 ARM 的机器上使用 `pip` 安装 Scrapy 确实耗时要长一点,我估计是由于需要从源码编译为二进制文件。
在 Scrapy 安装结束后,就可以通过 shell 来查看它的工作状态了。
在 Scaleway 的 ARM 机器上,Scrapy 安装完成后会无法正常运行,这似乎和 `service_identity` 模块有关。这个现象也会在树莓派上出现,但在 AWS Graviton 上不会出现。
对于这个问题,可以用这个命令来解决:
```
sudo pip3 install service_identity --force --upgrade
```
接下来就可以开始对比了。
### 单线程爬虫
Scrapy 的官方文档建议[将爬虫程序的 CPU 使用率控制在 80% 到 90% 之间](https://docs.scrapy.org/en/latest/topics/broad-crawls.html),在真实操作中并不容易,尤其是对于我自己写的代码。根据我的观察,实际的 CPU 使用率变动情况是一开始非常繁忙,随后稍微下降,接着又再次升高。
在爬取任务的最后,也就是大部分目标网站都已经被爬取了的这个阶段,会持续数分钟的时间。这让人有点失望,因为在这个阶段当中,任务的运行时长只和网站的大小有比较直接的关系,并不能以之衡量 CPU 的性能。
所以这并不是一次严谨的基准测试,只是我通过自己写的爬虫程序来观察实际的现象。
下面我们来看看最终的结果。首先是 Scaleway 的机器:
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每百万页面费用(欧元) |
| --- | --- | --- | --- | --- |
| Scaleway ARM64-2GB | 108m 59.27s | 38,205 | 21,032.623 | 0.28527 |
| Scaleway 1-S | 97m 44.067s | 39,476 | 24,324.648 | 0.33011 |
我使用了 [top](https://linux.die.net/man/1/top) 工具来查看爬虫程序运行期间的 CPU 使用率。在任务刚开始的时候,两者的 CPU 使用率都达到了 100%,但 ThunderX 大部分时间都达到了 CPU 的极限,无法看出来 Atom 的性能会比 ThunderX 超出多少。
通过 `top` 工具,我还观察了它们的内存使用情况。随着爬取任务的进行,ARM 机器的内存使用率最终达到了 14.7%,而 x86 则最终是 15%。
从运行日志还可以看出来,当 CPU 使用率到达极限时,会有大量的超时页面产生,最终导致页面丢失。这也是合理出现的现象,因为 CPU 过于繁忙会无法完整地记录所有爬取到的页面。
如果仅仅是为了对比爬虫的速度,页面丢失并不是什么大问题。但在实际中,业务成果和爬虫数据的质量是息息相关的,因此必须为 CPU 留出一些用量,以防出现这种现象。
再来看看 AWS 这边:
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每百万页面费用(美元) |
| --- | --- | --- | --- | --- |
| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
为了方便比较,对于在 AWS 上跑的爬虫,我记录的指标和 Scaleway 上一致,但似乎没有达到预期的效果。这里我没有使用 `top`,而是使用了 AWS 提供的控制台来监控 CPU 的使用情况,从监控结果来看,我的爬虫程序并没有完全用到这两款服务器所提供的所有性能。
a1.medium 型号的机器尤为如此,在任务开始阶段,它的 CPU 使用率达到了峰值 45%,但随后一直在 20% 到 30% 之间。
让我有点感到意外的是,这个程序在 ARM 处理器上的运行速度相当慢,但却远未达到 Graviton CPU 能力的极限,而在 Intel Atom 处理器上则可以在某些时候达到 CPU 能力的极限。它们运行的代码是完全相同的,处理器的不同架构可能导致了对代码的不同处理方式。
个中原因无论是由于处理器本身的特性,还是二进制文件的编译,又或者是两者皆有,对我来说都是一个黑盒般的存在。我认为,既然在 AWS 机器上没有达到 CPU 处理能力的极限,那么只有在 Scaleway 机器上跑出来的性能数据是可以作为参考的。
t2.small 型号的机器性能让人费解。CPU 利用率大概 20%,最高才达到 35%,是因为手册中说的“20% 的基准性能,可以使用 CPU 积分突破这个基准”吗?但在控制台中可以看到 CPU 积分并没有被消耗。
为了确认这一点,我安装了 [stress](https://linux.die.net/man/1/stress) 这个软件,然后运行了一段时间,这个时候发现居然可以把 CPU 使用率提高到 100% 了。
显然,我需要调整一下它们的配置文件。我将 `CONCURRENT_REQUESTS` 参数设置为 5000,将 `REACTOR_THREADPOOL_MAXSIZE` 参数设置为 120,将爬虫任务的负载调得更大。
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每万页面费用(美元) |
| --- | --- | --- | --- | --- |
| a1.medium | 46m 13.619s | 40,283 | 52,285.047 | 0.48771 |
| t2.small | 41m7.619s | 36,241 | 52,871.857 | 0.43501 |
| t2.small(无 CPU 积分) | 73m 8.133s | 34,298 | 28,137.8891 | 0.81740 |
a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升到了 100%,随后下降到 80% 并持续了 20 分钟,然后再次攀升到 96%,直到任务接近结束时再次下降。这大概就是我想要的效果了。
而 t2.small 型号机器在爬虫任务的前期就达到了 50%,并一直保持在这个水平直到任务接近结束。如果每个核心都有两个线程,那么 50% 的 CPU 使用率确实是单个线程可以达到的极限了。
现在我们看到它们的性能都差不多了。但至强处理器的线程持续跑满了 CPU,Graviton 处理器则只是有一段时间如此。可以认为 Graviton 略胜一筹。
然而,如果 CPU 积分耗尽了呢?这种情况下的对比可能更为公平。为了测试这种情况,我使用 `stress` 把所有的 CPU 积分用完,然后再次启动了爬虫任务。
在没有 CPU 积分的情况下,CPU 使用率在 27% 就到达极限不再上升了,同时又出现了丢失页面的现象。这么看来,它的性能比负载较低的时候更差。
### 多线程爬虫
将爬虫任务分散到不同的进程中,可以有效利用机器所提供的多个核心。
一开始,我将爬虫任务分布在 10 个不同的进程中并同时启动,结果发现比每个核心仅使用 1 个进程的时候还要慢。
经过尝试,我得到了一个比较好的方案。把爬虫任务分布在 10 个进程中,但每个核心只启动 1 个进程,在每个进程接近结束的时候,再从剩余的进程中选出 1 个进程启动起来。
如果还需要优化,还可以让运行时间越长的爬虫进程在启动顺序中排得越靠前,我也在尝试实现这个方法。
想要预估某个域名的页面量,一定程度上可以参考这个域名主页的链接数量。我用另一个程序来对这个数量进行了统计,然后按照降序排序。经过这样的预处理之后,只会额外增加 1 分钟左右的时间。
结果,爬虫运行的总耗时超过了两个小时!毕竟把链接最多的域名都堆在同一个进程中也存在一定的弊端。
针对这个问题,也可以通过调整各个进程爬取的域名数量来进行优化,又或者在排序之后再作一定的修改。不过这种优化可能有点复杂了。
因此,我还是用回了最初的方法,它的效果还是相当不错的:
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每万页面费用(欧元) |
| --- | --- | --- | --- | --- |
| Scaleway ARM64-2GB | 62m 10.078s | 36,158 | 34,897.0719 | 0.17193 |
| Scaleway 1-S | 60m 56.902s | 36,725 | 36,153.5529 | 0.22128 |
毕竟,使用多个核心能够大大加快爬虫的速度。
我认为,如果让一个经验丰富的程序员来优化的话,一定能够更好地利用所有的计算核心。但对于开箱即用的 Scrapy 来说,想要提高性能,使用更快的线程似乎比使用更多核心要简单得多。
从数量来看,Atom 处理器在更短的时间内爬取到了更多的页面。但如果从性价比角度来看,ThunderX 又是稍稍领先的。不过总的来说差距不大。
### 爬取结果分析
在爬取了 38205 个页面之后,我们可以统计到在这些页面中 “ass” 出现了 24170435 次,而 “wood” 出现了 54368 次。

“wood” 的出现次数不少,但和 “ass” 比起来简直微不足道。
### 结论
从上面的数据来看,对于性能而言,CPU 的架构并没有它们的问世时间重要,2018 年生产的 AWS Graviton 是单线程情况下性能最佳的。
你当然可以说按核心来比,Xeon 仍然赢了。但是,你不但需要计算美元的变化,甚至还要计算线程数。
另外在性能方面 2017 年生产的 Atom 轻松击败了 2014 年生产的 ThunderX,而 ThunderX 则在性价比方面占优。当然,如果你使用 AWS 的机器的话,还是使用 Graviton 吧。
总之,ARM 架构的硬件是可以用来运行爬虫程序的,而且在性能和费用方面也相当有竞争力。
而这种差异是否足以让你将整个技术架构迁移到 ARM 上?这就是另一回事了。当然,如果你已经是 AWS 用户,并且你的代码有很强的可移植性,那么不妨尝试一下 a1 型号的实例。
希望 ARM 设备在不久的将来能够在公有云上大放异彩。
### 源代码
这是我第一次使用 Python 和 Scrapy 来做一个项目,所以我的代码写得可能不是很好,例如代码中使用全局变量就有点力不从心。
不过我仍然会在下面开源我的代码。
要运行这些代码,需要预先安装 Scrapy,并且需要 [Moz 上排名前 500 的网站](https://moz.com/top500)的 csv 文件。如果要运行 `butthead.py`,还需要安装 [psutil](https://pypi.org/project/psutil/) 这个库。
```
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from scrapy.crawler import CrawlerProcess
ass = 0
wood = 0
totalpages = 0
def getdomains():
moz500file = open('top500.domains.05.18.csv')
domains = []
moz500csv = moz500file.readlines()
del moz500csv[0]
for csvline in moz500csv:
leftquote = csvline.find('"')
rightquote = leftquote + csvline[leftquote + 1:].find('"')
domains.append(csvline[leftquote + 1:rightquote])
return domains
def getstartpages(domains):
startpages = []
for domain in domains:
startpages.append('http://' + domain)
return startpages
class AssWoodItem(scrapy.Item):
ass = scrapy.Field()
wood = scrapy.Field()
url = scrapy.Field()
class AssWoodPipeline(object):
def __init__(self):
self.asswoodstats = []
def process_item(self, item, spider):
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
def close_spider(self, spider):
asstally, woodtally = 0, 0
for asswoodcount in self.asswoodstats:
asstally += asswoodcount[1]
woodtally += asswoodcount[2]
global ass, wood, totalpages
ass = asstally
wood = woodtally
totalpages = len(self.asswoodstats)
class BeavisSpider(CrawlSpider):
name = "Beavis"
allowed_domains = getdomains()
start_urls = getstartpages(allowed_domains)
#start_urls = [ 'http://medium.com' ]
custom_settings = {
'DEPTH_LIMIT': 3,
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 1500,
'REACTOR_THREADPOOL_MAXSIZE': 60,
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
'LOG_LEVEL': 'INFO',
'RETRY_ENABLED': False,
'DOWNLOAD_TIMEOUT': 30,
'COOKIES_ENABLED': False,
'AJAXCRAWL_ENABLED': True
}
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
def parse_asswood(self, response):
if isinstance(response, scrapy.http.TextResponse):
item = AssWoodItem()
item['ass'] = response.text.casefold().count('ass')
item['wood'] = response.text.casefold().count('wood')
item['url'] = response.url
yield item
if __name__ == '__main__':
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
process.crawl(BeavisSpider)
process.start()
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
```
*beavis.py*
```
import scrapy, time, psutil
from scrapy.spiders import CrawlSpider, Rule, Spider
from scrapy.linkextractors import LinkExtractor
from scrapy.crawler import CrawlerProcess
from multiprocessing import Process, Queue, cpu_count
ass = 0
wood = 0
totalpages = 0
linkcounttuples =[]
def getdomains():
moz500file = open('top500.domains.05.18.csv')
domains = []
moz500csv = moz500file.readlines()
del moz500csv[0]
for csvline in moz500csv:
leftquote = csvline.find('"')
rightquote = leftquote + csvline[leftquote + 1:].find('"')
domains.append(csvline[leftquote + 1:rightquote])
return domains
def getstartpages(domains):
startpages = []
for domain in domains:
startpages.append('http://' + domain)
return startpages
class AssWoodItem(scrapy.Item):
ass = scrapy.Field()
wood = scrapy.Field()
url = scrapy.Field()
class AssWoodPipeline(object):
def __init__(self):
self.asswoodstats = []
def process_item(self, item, spider):
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
def close_spider(self, spider):
asstally, woodtally = 0, 0
for asswoodcount in self.asswoodstats:
asstally += asswoodcount[1]
woodtally += asswoodcount[2]
global ass, wood, totalpages
ass = asstally
wood = woodtally
totalpages = len(self.asswoodstats)
class ButtheadSpider(CrawlSpider):
name = "Butthead"
custom_settings = {
'DEPTH_LIMIT': 3,
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 250,
'REACTOR_THREADPOOL_MAXSIZE': 30,
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
'LOG_LEVEL': 'INFO',
'RETRY_ENABLED': False,
'DOWNLOAD_TIMEOUT': 30,
'COOKIES_ENABLED': False,
'AJAXCRAWL_ENABLED': True
}
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
def parse_asswood(self, response):
if isinstance(response, scrapy.http.TextResponse):
item = AssWoodItem()
item['ass'] = response.text.casefold().count('ass')
item['wood'] = response.text.casefold().count('wood')
item['url'] = response.url
yield item
def startButthead(domainslist, urlslist, asswoodqueue):
crawlprocess = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
crawlprocess.start()
asswoodqueue.put( (ass, wood, totalpages) )
if __name__ == '__main__':
asswoodqueue = Queue()
domains=getdomains()
startpages=getstartpages(domains)
processlist =[]
cores = cpu_count()
for i in range(10):
domainsublist = domains[i * 50:(i + 1) * 50]
pagesublist = startpages[i * 50:(i + 1) * 50]
p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
processlist.append(p)
for i in range(cores):
processlist[i].start()
time.sleep(180)
i = cores
while i != 10:
time.sleep(60)
if psutil.cpu_percent() < 66.7:
processlist[i].start()
i += 1
for i in range(10):
processlist[i].join()
for i in range(10):
asswoodtuple = asswoodqueue.get()
ass += asswoodtuple[0]
wood += asswoodtuple[1]
totalpages += asswoodtuple[2]
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
```
*butthead.py*
---
via: <https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/>
作者:[James Mawson](https://blog.dxmtechsupport.com.au/author/james-mawson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='blog.dxmtechsupport.com.au', port=443): Max retries exceeded with url: /speed-test-x86-vs-arm-for-web-crawling-in-python/ (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b83409d3100>: Failed to resolve 'blog.dxmtechsupport.com.au' ([Errno -2] Name or service not known)")) | null |
10,641 | 在 Linux 中运行特定命令而无需 sudo 密码 | https://www.ostechnix.com/run-particular-commands-without-sudo-password-linux/ | 2019-03-21T22:07:00 | [
"sudo"
] | https://linux.cn/article-10641-1.html | 
我有一台部署在 AWS 上的 Ubuntu 系统,在它的里面有一个脚本,这个脚本的原有目的是以一定间隔(准确来说是每隔 1 分钟)去检查某个特定服务是否正在运行,如果这个服务因为某些原因停止了,就自动重启这个服务。但问题是我需要 sudo 权限来开启这个服务。正如你所知道的那样,当我们以 sudo 用户运行命令时,我们应该提供密码,但我并不想这么做,实际上我想做的是以 sudo 用户的身份运行这个服务但无需提供密码。假如你曾经经历过这样的情形,那么我知道一个简单的方法来做到这点。今天,在这个简短的指南中,我将教你如何在类 Unix 的操作系统中运行特定命令而无需 sudo 密码。
就让我们看看下面的例子吧。
```
$ sudo mkdir /ostechnix
[sudo] password for sk:
```

正如上面的截图中看到的那样,当我在根目录(`/`)中创建一个名为 `ostechnix` 的目录时,我需要提供 sudo 密码。每当我们尝试以 sudo 特权执行一个命令时,我们必须输入密码。而在我的预想中,我不想提供 sudo 密码。下面的内容便是我如何在我的 Linux 机子上运行一个 `sudo` 命令而无需输入密码的过程。
### 在 Linux 中运行特定命令而无需 sudo 密码
基于某些原因,假如你想允许一个用户运行特定命令而无需提供 sudo 密码,则你需要在 `sudoers` 文件中添加上这个命令。
假如我想让名为 `sk` 的用户去执行 `mkdir` 而无需提供 sudo 密码,下面就让我们看看该如何做到这点。
使用下面的命令来编辑 `sudoers` 文件:
```
$ sudo visudo
```
将下面的命令添加到这个文件的最后。
```
sk ALL=NOPASSWD:/bin/mkdir
```

其中 `sk` 是用户名。根据上面一行的内容,用户 `sk` 可以从任意终端执行 `mkdir` 命令而不必输入 sudo 密码。
你可以用逗号分隔的值来添加额外的命令(例如 `chmod`),正如下面展示的那样。
```
sk ALL=NOPASSWD:/bin/mkdir,/bin/chmod
```
保存并关闭这个文件,然后注销(或重启)你的系统。现在以普通用户 `sk` 登录,然后试试使用 `sudo` 来运行这些命令,看会发生什么。
```
$ sudo mkdir /dir1
```

看到了吗?即便我以 sudo 特权运行 `mkdir` 命令,也不会弹出提示让我输入密码。从现在开始,当用户 `sk` 运行 `mkdir` 时,就不必输入 sudo 密码了。
当运行除了添加到 `sudoers` 文件之外的命令时,你将被提示输入 sudo 密码。
让我们用 `sudo` 来运行另一个命令。
```
$ sudo apt update
```

看到了吗?这个命令将提示我输入 sudo 密码。
假如你不想让这个命令提示你输入 sudo 密码,请编辑 `sudoers` 文件:
```
$ sudo visudo
```
像下面这样将 `apt` 命令添加到 `sudoers` 文件中:
```
sk ALL=NOPASSWD:/bin/mkdir,/usr/bin/apt
```
你注意到了上面命令中 `apt` 二进制执行文件的路径与 `mkdir` 的有所不同吗?是的,你必须提供一个正确的可执行文件路径。要找到任意命令的可执行文件路径,例如这里的 `apt`,可以像下面这样使用 `whichis` 命令来查看:
```
$ whereis apt
apt: /usr/bin/apt /usr/lib/apt /etc/apt /usr/share/man/man8/apt.8.gz
```
如你所见,`apt` 命令的可执行文件路径为 `/usr/bin/apt`,所以我将这个路径添加到了 `sudoers` 文件中。
正如我前面提及的那样,你可以添加任意多个以逗号分隔的命令。一旦你做完添加的动作,保存并关闭你的 `sudoers` 文件,接着注销,然后重新登录进你的系统。
现在就检验你是否可以直接运行以 `sudo` 开头的命令而不必使用密码:
```
$ sudo apt update
```

看到了吗?`apt` 命令没有让我输入 sudo 密码,即便我用 `sudo` 来运行它。
下面展示另一个例子。假如你想运行一个特定服务,例如 `apache2`,那么就添加下面这条命令到 `sudoers` 文件中:
```
sk ALL=NOPASSWD:/bin/mkdir,/usr/bin/apt,/bin/systemctl restart apache2
```
现在用户 `sk` 就可以运行 `sudo systemctl restart apache` 命令而不必输入 sudo 密码了。
我可以再次让一个特别的命令提醒输入 sudo 密码吗?当然可以!只需要删除添加的命令,注销然后再次登录即可。
除了这种方法外,你还可以在命令的前面添加 `PASSWD:` 指令。让我们看看下面的例子:
在 `sudoers` 文件中添加或者修改下面的一行:
```
sk ALL=NOPASSWD:/bin/mkdir,/bin/chmod,PASSWD:/usr/bin/apt
```
在这种情况下,用户 `sk` 可以运行 `mkdir` 和 `chmod` 命令而不用输入 sudo 密码。然而,当他运行 `apt` 命令时,就必须提供 sudo 密码了。
免责声明:本篇指南仅具有教育意义。在使用这个方法的时候,你必须非常小心。这个命令既可能富有成效但也可能带来摧毁性效果。例如,假如你允许用户执行 `rm` 命令而不输入 sudo 密码,那么他们可能无意或有意地删除某些重要文件。我警告过你了!
那么这就是全部的内容了。希望这个能够给你带来帮助。更多精彩内容即将呈现,请保持关注!
干杯!
---
via: <https://www.ostechnix.com/run-particular-commands-without-sudo-password-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,642 | 开始使用 Cypht 吧,一个开源的电子邮件客户端 | https://opensource.com/article/19/1/productivity-tool-cypht-email | 2019-03-22T21:10:05 | [
"邮件",
"Email"
] | https://linux.cn/article-10642-1.html |
>
> 使用 Cypht 将你的电子邮件和新闻源集成到一个界面中,这是我们 19 个开源工具系列中的第 4 个,它将使你在 2019 年更高效。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 4 个工具来帮助你在 2019 年更有效率。
### Cypht
我们花了很多时间来处理电子邮件,有效地[管理你的电子邮件](https://opensource.com/article/17/7/email-alternatives-thunderbird)可以对你的工作效率产生巨大影响。像 Thunderbird、Kontact/KMail 和 Evolution 这样的程序似乎都有一个共同点:它们试图复制 Microsoft Outlook 的功能,这在过去 10 年左右并没有真正改变。在过去十年中,甚至像 Mutt 和 Cone 这样的[著名控制台程序](https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients)也没有太大变化。

[Cypht](https://cypht.org/) 是一个简单、轻量级和现代的 Webmail 客户端,它将多个帐户聚合到一个界面中。除了电子邮件帐户,它还包括 Atom/RSS 源。在 “Everything” 中,不仅可以显示收件箱中的邮件,还可以显示新闻源中的最新文章,从而使得阅读不同来源的内容变得简单。

它使用简化的 HTML 消息来显示邮件,或者你也可以将其设置为查看纯文本版本。由于 Cypht 不会加载远程图像(以帮助维护安全性),HTML 渲染可能有点粗糙,但它足以完成工作。你将看到包含大量富文本邮件的纯文本视图 —— 这意味着很多链接并且难以阅读。我不会说是 Cypht 的问题,因为这确实是发件人所做的,但它确实降低了阅读体验。阅读新闻源大致相同,但它们与你的电子邮件帐户集成,这意味着可以轻松获取最新的(我有时会遇到问题)。

用户可以使用预配置的邮件服务器并添加他们使用的任何其他服务器。Cypht 的自定义选项包括纯文本与 HTML 邮件显示,它支持多个配置文件以及更改主题(并自行创建)。你要记得单击左侧导航栏上的“保存”按钮,否则你的自定义设置将在该会话后消失。如果你在不保存的情况下注销并重新登录,那么所有更改都将丢失,你将获得开始时的设置。因此可以轻松地实验,如果你需要重置,只需在不保存的情况下注销,那么在再次登录时就会看到之前的配置。

本地[安装 Cypht](https://cypht.org/install.html) 非常容易。虽然它不使用容器或类似技术,但安装说明非常清晰且易于遵循,并且不需要我做任何更改。在我的笔记本上,从安装开始到首次登录大约需要 10 分钟。服务器上的共享安装使用相同的步骤,因此它应该大致相同。
最后,Cypht 是桌面和基于 Web 的电子邮件客户端的绝佳替代方案,它有简单的界面,可帮助你快速有效地处理电子邮件。
---
via: <https://opensource.com/article/19/1/productivity-tool-cypht-email>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the fourth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Cypht
We spend a lot of time dealing with email, and effectively [managing your email](https://opensource.com/article/17/7/email-alternatives-thunderbird) can make a huge impact on your productivity. Programs like Thunderbird, Kontact/KMail, and Evolution all seem to have one thing in common: they seek to duplicate the functionality of Microsoft Outlook, which hasn't really changed in the last 10 years or so. Even the [console standard-bearers](https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients) like Mutt and Cone haven't changed much in the last decade.
[Cypht](https://cypht.org/) is a simple, lightweight, and modern webmail client that aggregates several accounts into a single view. Along with email accounts, it includes Atom/RSS feeds. It makes reading items from these different sources very simple by using an "Everything" screen that shows not just the mail from your inbox, but also the newest articles from your news feeds.
It uses a simplified version of HTML messages to display mail or you can set it to view a plain-text version. Since Cypht doesn't load images from remote sources (to help maintain security), HTML rendering can be a little rough, but it does enough to get the job done. You'll get plain-text views with most rich-text mail—meaning lots of links and hard to read. I don't fault Cypht, since this is really the email senders' doing, but it does detract a little from the reading experience. Reading news feeds is about the same, but having them integrated with your email accounts makes it much easier to keep up with them (something I sometimes have issues with).
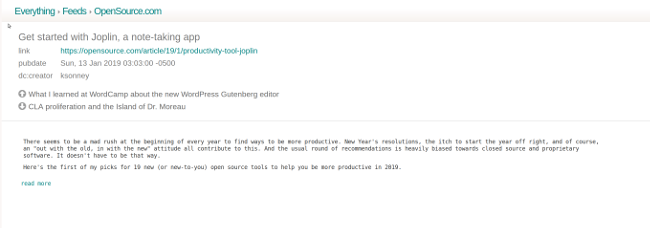
Users can use a preconfigured mail server and add any additional servers they use. Cypht's customization options include plain-text vs. HTML mail display, support for multiple profiles, and the ability to change the theme (and make your own). You have to remember to click the "Save" button on the left navigation bar, though, or your custom settings will disappear after that session. If you log out and back in without saving, all your changes will be lost and you'll end up with the settings you started with. This does make it easy to experiment, and if you need to reset things, simply logging out without saving will bring back the previous setup when you log back in.
[Installing Cypht](https://cypht.org/install.html) locally is very easy. While it is not in a container or similar technology, the setup instructions were very clear and easy to follow and didn't require any changes on my part. On my laptop, it took about 10 minutes from starting the installation to logging in for the first time. A shared installation on a server uses the same steps, so it should be about the same.
In the end, Cypht is a fantastic alternative to desktop and web-based email clients with a simple interface to help you handle your email quickly and efficiently.
## 2 Comments |
10,644 | 树莓派使用入门:如何启动一个新的树莓派 | https://opensource.com/article/19/3/how-boot-new-raspberry-pi | 2019-03-22T22:30:00 | [
"树莓派"
] | https://linux.cn/article-10644-1.html |
>
> 在本系列文章的第三篇中,我们将教你开始使用树莓派,学习如何安装一个 Linux 操作系统。
>
>
>

如果你按顺序看我们本系列的文章,那么你已经 [选择](/article-10611-1.html) 和 [购买](/article-10615-1.html) 了你的树莓派和外围设备,现在,你将要去使用它。在第三篇文章中,我们来看一下你需要做些什么才能让它启动起来。
与你的笔记本、台式机、智能手机、或平板电脑不一样的是,树莓派上并没有内置存储。而是需要使用一个 Micro SD 卡去存储操作系统和文件。这么做的最大好处就是携带你的文件比较方便(甚至都不用带着树莓派)。不利之处是存储卡丢失和损坏的风险可能很高,这将导致你的文件丢失。因此,只要保护好你的 Micro SD 卡就没什么问题了。
你应该也知道,SD 卡的读写速度比起机械硬件或固态硬盘要慢很多,因此,你的树莓派的启动、读取、和写入的速度将不如其它设备。
### 如何安装 Raspbian
你拿到新树莓派的第一件事情就是将它的操作系统安装到一个 Micro SD 卡上。尽管树莓派上可用的操作系统很多(基于 Linux 的或非基于 Linux 的都有),但本系列课程将专注于 [Raspbian](https://www.raspbian.org/RaspbianFAQ),它是树莓派的官方 Linux 版本。

安装 Raspbian 的最简单的方式是使用 [NOOBS](https://www.raspberrypi.org/downloads/noobs/),它是 “New Out Of Box Software” 的缩写。树莓派官方提供了非常详细的 [NOOBS 文档](https://www.raspberrypi.org/documentation/installation/noobs.md),因此,我就不在这里重复这些安装指令了。
NOOBS 可以让你选择安装以下的这些操作系统:
* [Raspbian](https://www.raspbian.org/RaspbianFAQ)
* [LibreELEC](https://libreelec.tv/)
* [OSMC](https://osmc.tv/)
* [Recalbox](https://www.recalbox.com/)
* [Lakka](http://www.lakka.tv/)
* [RISC OS](https://www.riscosopen.org/wiki/documentation/show/Welcome%20to%20RISC%20OS%20Pi)
* [Screenly OSE](https://www.screenly.io/ose/)
* [Windows 10 IoT Core](https://developer.microsoft.com/en-us/windows/iot)
* [TLXOS](https://thinlinx.com/)
再强调一次,我们在本系列的课程中使用的是 Raspbian,因此,拿起你的 Micro SD 卡,然后按照 NOOBS 文档去安装 Raspbian 吧。在本系列的第四篇文章中,我们将带你去看看,如何使用 Linux,包括你需要掌握的一些主要的命令。
---
via: <https://opensource.com/article/19/3/how-boot-new-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you've been following along in this series, you've [chosen](https://opensource.com/article/19/3/which-raspberry-pi-choose) and [bought](https://opensource.com/article/19/2/how-buy-raspberry-pi) your Raspberry Pi board and peripherals and now you're ready to start using it. Here, in the third article, let's look at what you need to do to boot it up.
Unlike your laptop, desktop, smartphone, or tablet, the Raspberry Pi doesn't come with built-in storage. Instead, it uses a Micro SD card to store the operating system and your files. The great thing about this is it gives you the flexibility to carry your files (even if you don't have your Raspberry Pi with you). The downside is it may also increase the risk of losing or damaging the card—and thus losing your files. Just protect your Micro SD card, and you should be fine.
You should also know that SD cards aren't as fast as mechanical or solid state drives, so booting, reading, and writing from your Pi will not be as speedy as you would expect from other devices.
## How to install Raspbian
The first thing you need to do when you get a new Raspberry Pi is to install its operating system on a Micro SD card. Even though there are other operating systems (both Linux- and non-Linux-based) available for the Raspberry Pi, this series focuses on [Raspbian](https://www.raspbian.org/RaspbianFAQ), Raspberry Pi's official Linux version.

The easiest way to install Raspbian is with [NOOBS](https://www.raspberrypi.org/downloads/noobs/), which stands for "New Out Of Box Software." Raspberry Pi offers great [documentation for NOOBS](https://www.raspberrypi.org/documentation/installation/noobs.md), so I won't repeat the installation instructions here.
NOOBS gives you the choice of installing the following operating systems:
Again, Raspbian is the operating system we'll use in this series, so go ahead, grab your Micro SD and follow the NOOBS documentation to install it. I'll meet you in the fourth article in this series, where we'll look at how to use Linux, including some of the main commands you'll need to know.
## 2 Comments |
10,645 | 树莓派使用入门:用树莓派学 Linux | https://opensource.com/article/19/3/learn-linux-raspberry-pi | 2019-03-24T07:56:16 | [
"树莓派"
] | https://linux.cn/article-10645-1.html |
>
> 我们的《树莓派使用入门》的第四篇文章将进入到 Linux 命令行。
>
>
>

在本系列的 [第三篇文章](/article-10644-1.html) 中开始了我们的树莓派探索之旅,我分享了如何安装 Raspbian,它是树莓派的官方 Linux 版本。现在,你已经安装好了 Raspbian 并用它引导你的新树莓派,你已经具备学习 Linux 相关知识的条件了。
在这样简短的文章中去解决像“如何使用 Linux” 这样的宏大主题显然是不切实际的,因此,我只是给你提供一些如何使用树莓派来学习更多的 Linux 知识的一些创意而已。
我们花一些时间从命令行(又称“终端”)开始。自上世纪九十年代中期以来,Linux 的 [窗口管理器](https://opensource.com/article/18/8/window-manager) 和图形界面已经得到长足的发展。如今,你可以在 Linux 上通过鼠标点击来做一些事情了,就如同其它的操作系统一样容易。在我看来,只是“使用 Linux”和成为“一个 Linux 用户”是有区别的,后者至少能够在终端中“遨游“。

如果你想成为一个 Linux 用户,从终端中尝试以下的命令行开始:
* 使用像 `ls`、`cd` 和 `pwd` 这样的命令导航到你的 Home 目录。
* 使用 `mkdir`、`rm`、`mv` 和 `cp` 命令创建、删除、和重命名目录。
* 使用命令行编辑器(如 Vi、Vim、Emacs 或 Nano)去创建一个文本文件。
* 尝试一些其它命令,比如 `chmod`、`chown`、`w`、`cat`、`more`、`less`、`tail`、`free`、`df`、`ps`、`uname` 和 `kill`。
* 尝试一下 `/bin` 和 `/usr/bin` 目录中的其它命令。
学习命令行的最佳方式还是阅读它的 “man 手册”(简称手册);在命令行中输入 `man <command>` 就可以像上面那样打开它。并且在互联网上搜索 Linux 命令速查表可以让你更清楚地了解命令的用法 —— 你应该会找到一大堆能帮你学习的资料。
Raspbian 就像主流的 Linux 发行版一样有非常多的命令,假以时日,你最终将比其他人会用更多的命令。我使用 Linux 命令行已经超过二十年了,即便这样仍然有一些命令我从来没有使用过,即便是那些我使用的过程中就一直存在的命令。
最后,你可以使用图形环境去更快地工作,但是只有深入到 Linux 命令行,你才能够获得操作系统真正的强大功能和知识。
---
via: <https://opensource.com/article/19/3/learn-linux-raspberry-pi>
作者:[Andersn Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the [third article](https://opensource.com/article/19/2/how-boot-new-raspberry-pi) in this series on getting started with Raspberry Pi, I shared info on installing Raspbian, the official version of Linux for Raspberry Pi. Now that you've installed Raspbian and booted up your new Pi, you're ready to start learning about Linux.
It's impossible to tackle a topic as big as "how to use Linux" in a short article like this, so instead I'll give you some ideas about how you can use the Raspberry Pi to learn more about Linux in general.
Start by spending time on the command line (aka the "terminal"). Linux [window managers](https://opensource.com/article/18/8/window-manager) and graphical interfaces have come a long way since the mid-'90s. Nowadays you can use Linux by pointing-and-clicking on things, just as easily as you can in *other* operating systems. In my opinion, there is a difference between just "using Linux" and being "a Linux user," and the latter means at a minimum being able to navigate in the terminal.
If you want to become a Linux *user*, start by trying out the following on the command line:
- Navigate your home directory with commands like
**ls**,**cd**, and**pwd**. - Create, delete, and rename directories using the
**mkdir**,**rm**,**mv**, and**cp**commands. - Create a text file with a command line editor such as Vi, Vim, Emacs, or Nano.
- Try out some other useful commands, such as
**chmod**,**chown**,**w**,**cat**,**more**,**less**,**tail**,**free**,**df**,**ps**,**uname**, and**kill** - Look around
**/bin**and**/usr/bin**for other commands.
The best way to get help with a command is by reading its "man page" (short for manual); type **man <command>** on the command line to pull it up. And make sure to search the internet for Linux command cheat sheets—you should find a lot of options that will help you learn.
Raspbian, like most Linux distributions, has many commands and over time you will end up using some commands a lot more than others. I've been using Linux on the command line for over two decades, and there are still some commands that I've never used, even ones that have been around as long as I've been using Linux.
At the end of the day, you can use your graphical interface environment to get work done faster, but make sure to dive into the Linux command line, for that's where you will get the true power and knowledge of the operating system.
## 6 Comments |
10,646 | 在 Fedora 上为 SSH 设置双因子验证 | https://fedoramagazine.org/two-factor-authentication-ssh-fedora/ | 2019-03-24T09:10:55 | [
"双因子",
"SSH",
"OTP"
] | https://linux.cn/article-10646-1.html | 
每天似乎都有一个安全漏洞的新闻报道,说我们的数据会因此而存在风险。尽管 SSH 是一种远程连接系统的安全方式,但你仍然可以使它更安全。本文将向你展示如何做到这一点。
此时<ruby> 双因子验证 <rt> two-factor authentication </rt></ruby>(2FA)就有用武之地了。即使你禁用密码并只允许使用公钥和私钥进行 SSH 连接,但如果未经授权的用户偷窃了你的密钥,他仍然可以借此访问系统。
使用双因子验证,你不能仅仅使用 SSH 密钥连接到服务器,你还需要提供手机上的验证器应用程序随机生成的数字。
本文展示的方法是<ruby> 基于时间的一次性密码 <rt> Time-based One-time Password </rt></ruby>(TOTP)算法。[Google Authenticator](https://en.wikipedia.org/wiki/Google_Authenticator) 用作服务器应用程序。默认情况下,Google Authenticator 在 Fedora 中是可用的。
至于手机,你可以使用与 TOTP 兼容的任何可以双路验证的应用程序。Andorid 或 iOS 有许多可以与 TOTP 和 Google Authenticator 配合使用的免费应用程序。本文与 [FreeOTP](https://freeotp.github.io/) 为例。
### 安装并设置 Google Authenticator
首先,在你的服务器上安装 Google Authenticator。 `$ sudo dnf install -y google-authenticator`
运行应用程序:
```
$ google-authenticator
```
该应用程序提供了一系列问题。下面的片段展示了如何进行合理的安全设置:
```
Do you want authentication tokens to be time-based (y/n) y
Do you want me to update your "/home/user/.google_authenticator" file (y/n)? y
```
这个应用程序为你提供一个密钥、验证码和恢复码。把它们放在安全的地方。如果你丢失了手机,恢复码是访问服务器的**唯一**方式。
### 设置手机验证
在你的手机上安装验证器应用程序(FreeOTP)。如果你有一台安卓手机,那么你可以在 Google Play 中找到它,也可以在苹果 iPhone 的 iTunes 商店中找到它。
Google Authenticator 会在屏幕上显示一个二维码。打开手机上的 FreeOTP 应用程序,选择添加新账户,在应用程序顶部选择二维码形状工具,然后扫描二维码即可。设置完成后,在每次远程连接服务器时,你必须提供验证器应用程序生成的随机数。
### 完成配置
应用程序会向你询问更多的问题。下面示例展示了如何设置合理的安全配置。
```
Do you want to disallow multiple uses of the same authentication token? This restricts you to one login about every 30s, but it increases your chances to notice or even prevent man-in-the-middle attacks (y/n) y
By default, tokens are good for 30 seconds. In order to compensate for possible time-skew between the client and the server, we allow an extra token before and after the current time. If you experience problems with poor time synchronization, you can increase the window from its default size of +-1min (window size of 3) to about +-4min (window size of 17 acceptable tokens).
Do you want to do so? (y/n) n
If the computer that you are logging into isn't hardened against brute-force login attempts, you can enable rate-limiting for the authentication module. By default, this limits attackers to no more than 3 login attempts every 30s.
Do you want to enable rate-limiting (y/n) y
```
现在,你必须设置 SSH 来利用新的双路验证。
### 配置 SSH
在完成此步骤之前,**确保你已使用公钥建立了一个可用的 SSH 连接**,因为我们将禁用密码连接。如果出现问题或错误,一个已经建立的连接将允许你修复问题。
在你的服务器上,使用 [sudo](https://fedoramagazine.org/howto-use-sudo/) 编辑 `/etc/pam.d/sshd` 文件。
```
$ sudo vi /etc/pam.d/ssh
```
注释掉 `auth substack password-auth` 这一行:
```
#auth substack password-auth
```
将以下行添加到文件底部:
```
auth sufficient pam_google_authenticator.so
```
保存并关闭文件。然后编辑 `/etc/ssh/sshd_config` 文件:
```
$ sudo vi /etc/ssh/sshd_config
```
找到 `ChallengeResponseAuthentication` 这一行并将其更改为 `yes`:
```
ChallengeResponseAuthentication yes
```
找到 `PasswordAuthentication` 这一行并将其更改为 `no`:
```
PasswordAuthentication no
```
将以下行添加到文件底部:
```
AuthenticationMethods publickey,password publickey,keyboard-interactive
```
保存并关闭文件,然后重新启动 SSH:
```
$ sudo systemctl restart sshd
```
### 测试双因子验证
当你尝试连接到服务器时,系统会提示你输入验证码:
```
[user@client ~]$ ssh [email protected]
Verification code:
```
验证码由你手机上的验证器应用程序随机生成。由于这个数字每隔几秒就会发生变化,因此你需要在它变化之前输入它。

如果你不输入验证码,你将无法访问系统,你会收到一个权限被拒绝的错误:
```
[user@client ~]$ ssh [email protected]
Verification code:
Verification code:
Verification code:
Permission denied (keyboard-interactive).
[user@client ~]$
```
### 结论
通过添加这种简单的双路验证,现在未经授权的用户访问你的服务器将变得更加困难。
---
via: <https://fedoramagazine.org/two-factor-authentication-ssh-fedora/>
作者:[Curt Warfield](https://fedoramagazine.org/author/rcurtiswarfield/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Every day there seems to be a security breach reported in the news where our data is at risk. Despite the fact that SSH is a secure way to connect remotely to a system, you can still make it even more secure. This article will show you how.
That’s where two-factor authentication (2FA) comes in. Even if you disable passwords and only allow SSH connections using public and private keys, an unauthorized user could still gain access to your system if they steal your keys.
With two-factor authentication, you can’t connect to a server with just your SSH keys. You also need to provide the randomly generated number displayed by an authenticator application on a mobile phone.
The Time-based One-time Password algorithm (TOTP) is the method shown in this article. [Google Authenticator](https://en.wikipedia.org/wiki/Google_Authenticator) is used as the server application. Google Authenticator is available by default in Fedora.
For your mobile phone, you can use any two-way authentication application that is compatible with TOTP. There are numerous free applications for Android or IOS that work with TOTP and Google Authenticator. This article uses [FreeOTP](https://freeotp.github.io/) as an example.
## Install and set up Google Authenticator
First, install the Google Authenticator package on your server.
$ sudo dnf install -y google-authenticator
Run the application.
$ google-authenticator
The application presents you with a series of questions. The snippets below show you how to answer for a reasonably secure setup.
Do you want authentication tokens to be time-based (y/n)y
Do you want me to update your "/home/user/.google_authenticator" file (y/n)?y
The app provides you with a secret key, verification code, and recovery codes. Keep these in a secure, safe location. The recovery codes are the **only** way to access your server if you lose your mobile phone.
## Set up mobile phone authentication
Install the authenticator application (FreeOTP) on your mobile phone. You can find it in Google Play if you have an Android phone, or in the iTunes store for an Apple iPhone.
A QR code is displayed on the screen. Open up the FreeOTP app on your mobile phone. To add a new account, select the QR code shaped tool at the top on the app, and then scan the QR code. After the setup is complete, you’ll have to provide the random number generated by the authenticator application every time you connect to your server remotely.
## Finish configuration
The application asks further questions. The example below shows you how to answer to set up a reasonably secure configuration.
Do you want to disallow multiple uses of the same authentication token? This restricts you to one login about every 30s, but it increases your chances to notice or even prevent man-in-the-middle attacks (y/n)y
By default, tokens are good for 30 seconds. In order to compensate for possible time-skew between the client and the server, we allow an extra token before and after the current time. If you experience problems with poor time synchronization, you can increase the window from its default size of +-1min (window size of 3) to about +-4min (window size of 17 acceptable tokens).
Do you want to do so? (y/n)n
If the computer that you are logging into isn't hardened against brute-force login attempts, you can enable rate-limiting for the authentication module. By default, this limits attackers to no more than 3 login attempts every 30s.
Do you want to enable rate-limiting (y/n)y
Now you have to set up SSH to take advantage of the new two-way authentication.
## Configure SSH
Before completing this step, **make sure you’ve already established a working SSH connection** using public SSH keys, since we’ll be disabling password connections. If there is a problem or mistake, having a connection will allow you to fix the problem.
On your server, use * sudo* to edit the
*/etc/pam.d/sshd*file.
$ sudo vi /etc/pam.d/sshd
Comment out the *auth substack password-auth* line:
#auth substack password-auth
Add the following line to the bottom of the file.
auth sufficient pam_google_authenticator.so
Save and close the file. Next, edit the /etc/ssh/sshd_config file.
$ sudo vi /etc/ssh/sshd_config
Look for the *ChallengeResponseAuthentication* line and change it to *yes*.
ChallengeResponseAuthentication yes
Look for the *PasswordAuthentication* line and change it to *no*.
PasswordAuthentication no
Add the following line to the bottom of the file.
AuthenticationMethods publickey,password publickey,keyboard-interactive
Save and close the file, and then restart SSH.
$ sudo systemctl restart sshd
## Testing your two-factor authentication
When you attempt to connect to your server you’re now prompted for a verification code.
[user@client ~]$ ssh [email protected]
Verification code:
The verification code is randomly generated by your authenticator application on your mobile phone. Since this number changes every few seconds, you need to enter it before it changes.
If you do not enter the verification code, you won’t be able to access the system, and you’ll get a permission denied error:
[user@client ~]$ ssh [email protected]
Verification code:
Verification code:
Verification code:
Permission denied (keyboard-interactive).
[user@client ~]$
## Conclusion
By adding this simple two-way authentication, you’ve now made it much more difficult for an unauthorized user to gain access to your server.
## zlopez
Isn’t there a non Google alternative for server?
I’m trying to get my life Google free.
## mike
duo
## Jake
A good alternative as long as you have less than ten users, yes! This Duo method Works excellent on my end. Past ten users would require a subscription with Duo.
https://duo.com/docs/duounix?utm_medium=paid_search&utm_source=google&utm_campaign=Brand
## czocher
It’s just called google-authenticator but in reality it’s completely free and open-source, not really requiring any google-related service to operate. The name is a bit unfortunate though.
## Turbovix
Congratulations, I really liked this solution!
## João Rodrigues
You’ve also made it much more difficult for you to access your own server.
Forgot your phone? Lost it? It was stolen? Well, you’re SOL.
## Paul W. Frields
@João: No, that’s not correct. Reread the article — even assuming you have no physical access to the server, the recovery codes provided give you several “get out of jail free” cards in case you lose or forget your phone.
## Curt Warfield
Hi João,
During the initial setup as noted in the article, recovery codes will be generated. If you lost access to your phone, you can use one of the recovery codes to regain access.
## Chris Hiner
When you initially set it up, after scanning the QR code with your phone, print the QR code and stick it in the safe.
You can then use that to set up a new device if you lose your phone.
Or there are some TOTP apps that let you back up the secret values.
## ricardotiellet
Hello everyone. I liked the article and I would like to make use of it if the sending of the password occurs through the Short Message Service (SMS).
## Saeed
I don’t think you should ever send password in clear text, in SMS!
## ricardotiellet
Hello @Saeed, I expressed myself incorrectly. Where I wrote “password”, I should have typed “random number verification”. SMS is a consolidated and compatible service for ANY mobile device by your long existence, different and restrictive to receive through mobile device that are currently using Android or IOS systems. In other words, or you acquire, purchase a modern mobile device (companies providing information and communication technology infrastructure (ICT) and smart devices will continue to thank consumers for preference and who doesn’t buy a current mobile device continues in the same, without security.
## D.a
Men if you and guy who wrote this topic doesn’t know: Google Authenticator uses TOTP protocol. Look at Wikipedia. One time passwords not random, like all in PC actually )). Them based on text from QR code what you scanned + hashed with time range of 30 sec. So that 6/8 digits ARE NOT A PASSWORD and because of that you see every 30 sec new code.
## Basri Azemi
Thank you very much for posting this article which is so useful in the wake of the bulnerabilities found even with the TLSv1.3.
I am going to implement these changes on my system ASAP
## Brett Stauner
This looks really interesting, and I’m looking forward to giving this a try, but I’m curious… Is there a way to make this work for automated processes as well? I could easily see putting this in place for human logins, but when you’ve got automated systems accessing your server to update code, config, etc. Can that account also use this method somehow?
## Kurt B
It would seem to me that having password in the AuthenticationMethods option would be useless since you have PasswordAuthentication set to no. Why not just set AuthenticationMethods to publickey,keyboard-interactive?
## Ondrej Kolin
By the way for the desktop is in Flatpak the Gnome Authenticator: https://flathub.org/apps/details/com.github.bilelmoussaoui.Authenticator
## Dmitriy Alekseev
What a point? Better use Authy app it crossplatform and ☁️ based
## svsv sarma
Beware that even phones are not secure! You get an interrupting call from an unknown number just at the time of the OTP and you will be in a dilemma.
You are secure as long as you are lucky or you are not that important.
I feel that there is some flaw in the keyboard itself.
May the 2FA help us all.
## James Susanka
Will one time password otop work on fedora? It works on Ubuntu and no google involvement and you keep track of everything.
## Jake
Make sure the time is set and synchronised properly to a time source (ntp or whatever) on both sides!
## Einer Petersen
Hey Folks,
SSH already has a 2FA setup that needs no 3rd party authenticator and it is easy to setup and use.
1) When you generate your ssh key-pair, passphrase protect the private key
2) copy the private key to a USB stick
3) copy your public key to the ~.ssh/authorized_keys of the accounts you want to log into via ssh (can use ssh-copy-id {user}@{host} to do this)
4) in /etc/ssh/sshd_config, set PermitRootLogin without-password
5) in /etc/ssh/sshd_config, set PasswordAuthentication no
6) restart sshd
when you want to ssh to that machine:
ssh -i {path_to_ssh-Private key} {user}@{host}
You will be prompted for your passphrase of your private key
2 Factor Authentication == something you have {your private key} + something you know {your private key passphrase}
As long as you keep your ssh private key on that usb stick with you, you are pretty much set 🙂
Einer
## Jakub Jelen
Do not use USB sticks for private keys, but try smart cards or yubikey, giving you much better assurance with a simple PIN. I wrote about that here last year:
https://fedoramag.wpengine.com/fedora-28-better-smart-card-support-openssh/
## Einer
Hi Jakub,
I would agree with you, don’t use USB keys for private keys, except … 🙂
1) IF the private key is passphrase protected (which also means it is encrypted AES 256) — then even if you loose the USB stick, the private key is useless to an unauthorized user
2) Not everyone has a SmartCard reader on their machine
3) SmartCards are not as readily available as USB sticks 🙂
4) a 20+ character passphrase used to encrypt an SSH private key is a whole lot stronger than a 4 digit PIN simply due to the fact that a 4 digit PIN only has a maximum of 9,999 possible combinations vs a 20 character passphrase which is approximately 10^74 combinations …. with an encryption algorithm (AES 256) which has not been broken to date 🙂
Einer
## Yaroslav Fedevych
You do realize that they restrict your PIN entry attempts to three for a reason, don’t you? Three incorrect attempts and your card is toast.
## Kurt Bechstein
It seems like that since you are disabling password authentication that you would only need AuthenticationMethods publickey,keyboard-interactive.
## Hoja
FreeOTP is also available on F-Droid
## Earl Ramirez
FreeOTP stopped working after F27 and was accepting any random code
## 0xSheepdog
In your Configure SSH section, you explain that we should edit /etc/pam.d/sshd but then your code example is editing /etc/pam.d/ssh
This will cause problems for copy-pasta people.
## Curt Warfield
Thanks so much for spotting that typo. It’s been fixed !
## Curt Warfield
Thanks so much for spotting that typo! It’s been fixed.
## UrsaTech
Thanks for posting this, very easy to follow. One comment I found while following the steps:
The first line of code under Configuring SSH is missing the final character ‘d’.
$ sudo vi /etc/pam.d/ssh
should be
$ sudo vi /etc/pam.d/sshd
## Curt Warfield
Thanks so much for spotting that typo! It’s been fixed.
## Rudra Banerjee
Can I do the sshd thing in my userspace, eg at ~/. ssh?
This article is good, but for me, I don’t want to repeat each step with each new install.
## Maikel Grep
Good to read about this, have this setup myself since 2014 on OpenSuse and Debian.
During that time I lost my phone a couple of times and needed the emergency codes.
After that it’s easy to restore the situation with a new phone.
## Earl
I have also enabled 2FA on the GDM in /etc/pam.d/gdm-password, for SSH you don’t need to disable password auth
## Einer
If you don’t disable password auth in SSHD, you are basically defeating the purpose of 2FA. The object in 2FA is to eliminate the use of typical password authentication in an effort to reduce password brute force attacks or the use of a valid password by an unauthorized person (someone stole your password and is now using it and your system privileges to compromise the system).
Einer
## Robert
Would love to the same for HTOP, like a Yubikey. I used to use TOTP a lot, but since I tried a Yubikey, I find it much more pleasant. You enter it into your laptop as long as you use it and experience basically no slowdown in your workflow. But you can worry less about your system getting compromised.
## Mark Tinberg
A place I like storing the TOTP tokens instead of the Authenticator app (Google, Microsoft, FreeOTP, Duo, whatever..) on a phone is to store them on a Yubikey that has NFC, then the tokens can’t be easily lost or stolen even if some app roots your phone, or your phone dies, additionally you can read the tokens using any NFC or USB device, so they are still copy/pastable on a phone but also on a computer. The Yubikey lasts for years attached to a regular keychain with your housekeys in my experience, and if it does start to wear out, it’s not too much trouble to load a new Yubikey with tokens.
## Dirk
Nice Article.
I personally prefer using my openPGP-Card for SSH authentication because I don’t want to rely on any third party service.
But, this article is very useful for people which are not able to use a smartcard or a Yubikey, anyway.
## rder
How do it without google? I need normal paper.
nothing more, only otp paper
## Johan Heikkila
From the comments we see that more education is needed for 2FA and especially TOTP/HOTP.
One funny thing. The Raspberry Pi doesn’t have an internal clock. For some reason the ntp on it had died, and being an internet connected device, I had enabled TOTP on ssh. When the clock now was drifting, it didn’t accept the TOTP code. I had to wait longer than 30s to enter the code. I guess rescue codes would have worked.
## Jeff
You say “scan the QR code” but how does the QR code appear? I would like to get this working on headless servers (no graphical display, only text.)
## Aarem
Would this break ssh-keygen passwordless entry?
Btw, I wonder if it is possible to aiutomate the code retrieval process fo the Google Authenticator and submit it. Is this possible? |
10,647 | Python 的 ChatOps 库:Opsdroid 和 Errbot | https://opensource.com/article/18/3/python-chatops-libraries-opsdroid-and-errbot | 2019-03-24T10:07:00 | [
"机器人",
"运维",
"chatbot"
] | https://linux.cn/article-10647-1.html |
>
> 学习一下 Python 世界里最广泛使用的 ChatOps 库:每个都能做什么,如何使用。
>
>
>

ChatOps 是基于会话导向而进行的开发。其思路是你可以编写能够对聊天窗口中的某些输入进行回复的可执行代码。作为一个开发者,你能够用 ChatOps 从 Slack 合并拉取请求,自动从收到的 Facebook 消息中给某人分配支持工单,或者通过 IRC 检查开发状态。
在 Python 世界,最为广泛使用的 ChatOps 库是 Opsdroid 和 Errbot。在这个月的 Python 专栏,让我们一起聊聊使用它们是怎样的体验,它们各自适用于什么方面以及如何着手使用它们。
### Opsdroid
[Opsdroid](https://opsdroid.github.io/) 是一个相对年轻的(始于 2016)Python 开源聊天机器人库。它有着良好的开发文档,不错的教程,并且包含能够帮助你对接流行的聊天服务的插件。
#### 它内置了什么
库本身并没有自带所有你需要上手的东西,但这是故意的。轻量级的框架鼓励你去运用它现有的连接器(Opsdroid 所谓的帮你接入聊天服务的插件)或者去编写你自己的,但是它并不会因自带你所不需要的连接器而自贬身价。你可以轻松使用现有的 Opsdroid 连接器来接入:
* 命令行
* Cisco Spark
* Facebook
* GitHub
* Matrix
* Slack
* Telegram
* Twitter
* Websocket
Opsdroid 会调用使聊天机器人能够展现它们的“技能”的函数。这些技能其实是异步 Python 函数,并使用 Opsdroid 叫做“匹配器”的匹配装饰器。你可以设置你的 Opsdroid 项目,来使用同样从你设置文件所在的代码中的“技能”。你也可以从外面的公共或私人仓库调用这些“技能”。
你同样可以启用一些现存的 Opsdroid “技能”,包括 [seen](https://github.com/opsdroid/skill-seen) —— 它会告诉你聊天机器人上次是什么时候看到某个用户的,以及 [weather](https://github.com/opsdroid/skill-weather) —— 会将天气报告给用户。
最后,Opdroid 允许你使用现存的数据库模块设置数据库。现在 Opdroid 支持的数据库包括:
* Mongo
* Redis
* SQLite
你可以在你的 Opdroid 项目中的 `configuration.yaml` 文件设置数据库、技能和连接器。
#### Opsdroid 的优势
**Docker 支持:**从一开始 Opsdroid 就打算在 Docker 中良好运行。在 Docker 中的指导是它 [安装文档](https://opsdroid.readthedocs.io/en/stable/#docker) 中的一部分。使用 Opsdroid 和 Docker Compose 也很简单:将 Opsdroid 设置成一种服务,当你运行 `docker-compose up` 时,你的 Opsdroid 服务将会开启你的聊天机器人也将就绪。
```
version: "3"
services:
opsdroid:
container_name: opsdroid
build:
context: .
dockerfile: Dockerfile
```
**丰富的连接器:** Opsdroid 支持九种像 Slack 和 Github 等从外部接入的服务连接器。你所要做的一切就是在你的设置文件中启用那些连接器,然后把必须的口令或者 API 密匙传过去。比如为了启用 Opsdroid 以在一个叫做 `#updates` 的 Slack 频道发帖,你需要将以下代码加入你设置文件的 `connectors` 部分:
```
- name: slack
api-token: "this-is-my-token"
default-room: "#updates"
```
在设置 Opsdroid 以接入 Slack 之前你需要[添加一个机器人用户](https://api.slack.com/bot-users)。
如果你需要接入一个 Opsdroid 不支持的服务,在[文档](https://opsdroid.readthedocs.io/en/stable/extending/connectors/)里有有添加你自己的连接器的教程。
**相当不错的文档:** 特别是对于一个在积极开发中的新兴库来说,Opsdroid 的文档十分有帮助。这些文档包括一篇带你创建几个不同的基本技能的[教程](https://opsdroid.readthedocs.io/en/stable/tutorials/introduction/)。Opsdroid 在[技能](https://opsdroid.readthedocs.io/en/stable/extending/skills/)、[连接器](https://opsdroid.readthedocs.io/en/stable/extending/connectors/)、[数据库](https://opsdroid.readthedocs.io/en/stable/extending/databases/),以及[匹配器](https://opsdroid.readthedocs.io/en/stable/matchers/overview/)方面的文档也十分清晰。
它所支持的技能和连接器的仓库为它的技能提供了富有帮助的示范代码。
**自然语言处理:** Opsdroid 的技能里面能使用正则表达式,但也同样提供了几个包括 [Dialogflow](https://opsdroid.readthedocs.io/en/stable/matchers/dialogflow/),[luis.ai](https://opsdroid.readthedocs.io/en/stable/matchers/luis.ai/),[Recast.AI](https://opsdroid.readthedocs.io/en/stable/matchers/recast.ai/) 以及 [wit.ai](https://opsdroid.readthedocs.io/en/stable/matchers/wit.ai/) 的 NLP API。
#### Opsdroid 可能的不足
Opsdroid 对它的一部分连接器还没有启用全部的特性。比如说,Slack API 允许你向你的消息添加颜色柱、图片以及其他的“附件”。Opsdroid Slack 连接器并没有启用“附件”特性,所以如果那些特性对你来说很重要的话,你需要编写一个自定义的 Slack 连接器。如果连接器缺少一个你需要的特性,Opsdroid 将欢迎你的[贡献](https://opsdroid.readthedocs.io/en/stable/contributing/)。文档中可以使用更多的例子,特别是对于预料到的使用场景。
#### 示例用法
```
from opsdroid.matchers import match_regex
import random
@match_regex(r'hi|hello|hey|hallo')
async def hello(opsdroid, config, message):
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
await message.respond(text)
```
*hello/\_\_init\_\_.py*
```
connectors:
- name: websocket
skills:
- name: hello
repo: "https://github.com/<user_id>/hello-skill"
```
*configuration.yaml*
### Errbot
[Errbot](http://errbot.io/en/latest/) 是一个功能齐全的开源聊天机器人。Errbot 发行于 2012 年,并且拥有人们从一个成熟的项目能期待的一切,包括良好的文档、优秀的教程以及许多帮你连入现有的流行聊天服务的插件。
#### 它内置了什么
不像采用了较轻量级方式的 Opsdroid,Errbot 自带了你需要可靠地创建一个自定义机器人的一切东西。
Errbot 包括了对于本地 XMPP、IRC、Slack、Hipchat 以及 Telegram 服务的支持。它通过社区支持的后端列出了另外十种服务。
#### Errbot 的优势
**良好的文档:** Errbot 的文档成熟易读。
**动态插件架构:** Errbot 允许你通过和聊天机器人交谈安全地安装、卸载、更新、启用以及禁用插件。这使得开发和添加特性十分简便。感谢 Errbot 的颗粒性授权系统,出于安全意识这所有的一切都可以被锁闭。
当某个人输入 `!help`,Errbot 使用你的插件的文档字符串来为可获取的命令生成文档,这使得了解每行命令的作用更加简便。
**内置的管理和安全特性:** Errbot 允许你限制拥有管理员权限的用户列表,甚至细粒度访问控制。比如说你可以限制特定用户或聊天房间访问特定命令。
**额外的插件框架:** Errbot 支持钩子、回调、子命令、webhook、轮询以及其它[更多特性](http://errbot.io/en/latest/features.html#extensive-plugin-framework)。如果那些还不够,你甚至可以编写[动态插件](http://errbot.io/en/latest/user_guide/plugin_development/dynaplugs.html)。当你需要基于在远程服务器上的可用命令来启用对应的聊天命令时,这个特性十分有用。
**自带测试框架:** Errbot 支持 [pytest](http://pytest.org/),同时也自带一些能使你简便测试插件的有用功能。它的“[测试你的插件](http://errbot.io/en/latest/user_guide/plugin_development/testing.html)”的文档出于深思熟虑,并提供了足够的资料让你上手。
#### Errbot 可能的不足
**以 “!” 开头:** 默认情况下,Errbot 命令发出时以一个惊叹号打头(`!help` 以及 `!hello`)。一些人可能会喜欢这样,但是另一些人可能认为这让人烦恼。谢天谢地,这很容易关掉。
**插件元数据** 首先,Errbot 的 [Hello World](http://errbot.io/en/latest/index.html#simple-to-build-upon) 插件示例看上去易于使用。然而我无法加载我的插件,直到我进一步阅读了教程并发现我还需要一个 `.plug` 文档,这是一个 Errbot 用来加载插件的文档。这可能比较吹毛求疵了,但是在我深挖文档之前,这对我来说都不是显而易见的。
### 示例用法
```
import random
from errbot import BotPlugin, botcmd
class Hello(BotPlugin):
@botcmd
def hello(self, msg, args):
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
return text
```
*hello.py*
```
[Core]
Name = Hello
Module = hello
[Python]
Version = 2+
[Documentation]
Description = Example "Hello" plugin
```
*hello.plug*
你用过 Errbot 或 Opsdroid 吗?如果用过请留下关于你对于这些工具印象的留言。
---
via: <https://opensource.com/article/18/3/python-chatops-libraries-opsdroid-and-errbot>
作者:[Jeff Triplett](https://opensource.com/users/laceynwilliams), [Lacey Williams Henschel](https://opensource.com/users/laceynwilliams) 译者:[tomjlw](https://github.com/tomjlw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ChatOps is conversation-driven development. The idea is you can write code that is executed in response to something typed in a chat window. As a developer, you could use ChatOps to merge pull requests from Slack, automatically assign a support ticket to someone from a received Facebook message, or check the status of a deployment through IRC.
In the Python world, the most widely used ChatOps libraries are Opsdroid and Errbot. In this month's Python column, let's chat about what it's like to use them, what each does well, and how to get started with them.
## Opsdroid
[Opsdroid](https://opsdroid.github.io/) is a relatively young (since 2016) open source chatbot library written in Python. It has good documentation, a great tutorial, and includes plugins to help you connect to popular chat services.
### What's built in
The library itself doesn't ship with everything you need to get started, but this is by design. The lightweight framework encourages you to enable its existing connectors (what Opsdroid calls the plugins that help you connect to chat services) or write your own, but it doesn't weigh itself down by shipping with connectors you may not need. You can easily enable existing Opsdroid connectors for:
Opsdroid calls the functions the chatbot performs "skills." Skills are `async`
Python functions and use Opsdroid's matching decorators, called "matchers." You can configure your Opsdroid project to use skills from the same codebase your configuration file is in or import skills from outside public or private repositories.
You can enable some existing Opsdroid skills as well, including [seen](https://github.com/opsdroid/skill-seen), which tells you when a specific user was last seen by the bot, and [weather](https://github.com/opsdroid/skill-weather), which will report the weather to the user.
Finally, Opdroid allows you to configure databases using its existing database modules. Current databases with Opsdroid support include:
You configure databases, skills, and connectors in the `configuration.yaml`
file in your Opsdroid project.
### Opsdroid pros
**Docker support:** Opsdroid is meant to work well in Docker from the get-go. Docker instructions are part of its [installation documentation](https://opsdroid.readthedocs.io/en/stable/#docker). Using Opsdroid with Docker Compose is also simple: Set up Opsdroid as a service and when you run `docker-compose up`
, your Opsdroid service will start and your chatbot will be ready to chat.
```
version: "3"
services:
opsdroid:
container_name: opsdroid
build:
context: .
dockerfile: Dockerfile
```
**Lots of connectors:** Opsdroid supports nine connectors to services like Slack and GitHub out of the box; all you need to do is enable those connectors in your configuration file and pass necessary tokens or API keys. For example, to enable Opsdroid to post in a Slack channel named `#updates`
, add this to the `connectors`
section of your configuration file:
```
- name: slack
api-token: "this-is-my-token"
default-room: "#updates"
```
You will have to [add a bot user](https://api.slack.com/bot-users) to your Slack workspace before configuring Opsdroid to connect to Slack.
If you need to connect to a service that Opsdroid does not support, there are instructions for adding your own connectors in the [docs](https://opsdroid.readthedocs.io/en/stable/extending/connectors/).
**Pretty good docs.** Especially for a young-ish library in active development, Opsdroid's docs are very helpful. The docs include a [tutorial](https://opsdroid.readthedocs.io/en/stable/tutorials/introduction/) that leads you through creating a couple of different basic skills. The Opsdroid documentation on [skills](https://opsdroid.readthedocs.io/en/stable/extending/skills/), [connectors](https://opsdroid.readthedocs.io/en/stable/extending/connectors/), [databases](https://opsdroid.readthedocs.io/en/stable/extending/databases/), and [matchers](https://opsdroid.readthedocs.io/en/stable/matchers/overview/) is also clear.
The repositories for its supported skills and connectors provide helpful example code for when you start writing your own custom skills and connectors.
**Natural language processing:** Opsdroid supports regular expressions for its skills, but also several NLP APIs, including [Dialogflow](https://opsdroid.readthedocs.io/en/stable/matchers/dialogflow/), [luis.ai](https://opsdroid.readthedocs.io/en/stable/matchers/luis.ai/), [Recast.AI](https://opsdroid.readthedocs.io/en/stable/matchers/recast.ai/), and [wit.ai](https://opsdroid.readthedocs.io/en/stable/matchers/wit.ai/).
### Possible Opsdroid concern
Opsdroid doesn't yet enable the full features of some of its connectors. For example, the Slack API allows you to add color bars, images, and other "attachments" to your message. The Opsdroid Slack connector doesn't enable the "attachments" feature, so you would need to write a custom Slack connector if those features were important to you. If a connector is missing a feature you need, though, Opsdroid would welcome your [contribution](https://opsdroid.readthedocs.io/en/stable/contributing/). The docs could use some more examples, especially of expected use cases.
### Example usage
`hello/__init__.py`
```
from opsdroid.matchers import match_regex
import random
@match_regex(r'hi|hello|hey|hallo')
async def hello(opsdroid, config, message):
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
await message.respond(text)
```
`configuration.yaml`
```
connectors:
- name: websocket
skills:
- name: hello
repo: "https://github.com/<user_id>/hello-skill"
```
## Errbot
[Errbot](http://errbot.io/en/latest/) is a batteries-included open source chatbot. Errbot was released in 2012 and has everything anyone would expect from a mature project, including good documentation, a great tutorial, and plenty of plugins to help you connect to existing popular chat services.
### What's built in
Unlike Opsdroid, which takes a more lightweight approach, Errbot ships with everything you need to build a customized bot safely.
Errbot includes support for XMPP, IRC, Slack, Hipchat, and Telegram services natively. It lists support for 10 other services through community-supplied backends.
### Errbot pros
**Good docs:** Errbot's docs are mature and easy to use.
**Dynamic plugin architecture:** Errbot allow you to securely install, uninstall, update, enable, and disable plugins by chatting with the bot. This makes development and adding features easy. For the security conscious, this can all be locked down thanks to Errbot's granular permission system.
Errbot uses your plugin docstrings to generate documentation for available commands when someone types `!help`
, which makes it easier to know what each command does.
**Built-in administration and security:** Errbot allows you to restrict lists of users who have administrative rights and even has fine-grained access controls. For example, you can restrict which commands may be called by specific users and/or specific rooms.
**Extensive plugin framework:** Errbot supports hooks, callbacks, subcommands, webhooks, polling, and many [more features](http://errbot.io/en/latest/features.html#extensive-plugin-framework). If those aren't enough, you can even write [Dynamic plugins](http://errbot.io/en/latest/user_guide/plugin_development/dynaplugs.html). This feature is useful if you want to enable chat commands based on what commands are available on a remote server.
**Ships with a testing framework:** Errbot supports [pytest](http://pytest.org/) and ships with some useful utilities that make testing your plugins easy and possible. Its "[testing your plugins](http://errbot.io/en/latest/user_guide/plugin_development/testing.html)" docs are well thought out and provide enough to get started.
### Possible Errbot concerns
**Initial !:** By default, Errbot commands are issued starting with an exclamation mark (`!help`
and `!hello`
). Some people may like this, but others may find it annoying. Thankfully, this is easy to turn off.
**Plugin metadata:** At first, Errbot's [Hello World](http://errbot.io/en/latest/index.html#simple-to-build-upon) plugin example seems easy to use. However, I couldn't get my plugin to load until I read further into the tutorial and discovered that I also needed a `.plug`
file, a file Errbot uses to load plugins. This is a pretty minor nitpick, but it wasn't obvious to me until I dug further into the docs.
### Example usage
`hello.py`
```
import random
from errbot import BotPlugin, botcmd
class Hello(BotPlugin):
@botcmd
def hello(self, msg, args):
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
return text
```
`hello.plug`
```
[Core]
Name = Hello
Module = hello
[Python]
Version = 2+
[Documentation]
Description = Example "Hello" plugin
```
Have you used Errbot or Opsdroid? If so, please leave a comment with your impressions on these tools.
## 1 Comment |
10,648 | 开始使用 Freeplane 吧,一款开源思维导图 | https://opensource.com/article/19/1/productivity-tool-freeplane | 2019-03-24T21:34:08 | [
"思维导图"
] | https://linux.cn/article-10648-1.html |
>
> 使用 Freeplane 进行头脑风暴,这是我们开源工具系列中的第 13 个,它将使你在 2019 年更高效。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 13 个工具来帮助你在 2019 年更有效率。
### Freeplane
[思维导图](https://en.wikipedia.org/wiki/Mind_map)是我用于快速头脑风暴和捕捉数据的最有价值的工具之一。思维导图是一个灵活的过程,有助于显示事物的相关性,并可用于快速组织相互关联的信息。从规划角度来看,思维导图让你快速将大脑中的单个概念、想法或技术表达出来。

[Freeplane](https://www.freeplane.org/wiki/index.php/Home) 是一款桌面应用,可以轻松创建、查看、编辑和共享思维导图。它是 [FreeMind](https://sourceforge.net/projects/freemind/) 这款很长时间内都是思维导图首选应用的重新打造。
安装 Freeplane 非常简单。它是一个 [Java](https://java.com) 应用,并使用 ZIP 文件分发,可使用脚本在 Linux、Windows 和 MacOS 上启动。在第一次启动它时,主窗口会包含一个示例思维导图,其中包含指向你可以使用 Freeplane 执行的所有不同操作的文档的链接。

创建新思维导图时,你可以选择模板。标准模板(可能位于列表底部)适用于大多数情况。你只需开始输入开头的想法或短语,你的文本就会替换中心的文本。按“Insert”键将从中心添加一个分支(或节点),其中包含一个空白字段,你可以在其中填写与该想法相关的内容。再次按“Insert”将添加另一个节点到第一个上。在节点上按回车键将添加与该节点平行的节点。

在添加节点时,你可能会想到与主题相关的另一个想法。使用鼠标或箭头键,返回到导图的中心,然后按“Insert”键。这将在主题之外创建一个新节点。
如果你想使用 Freeplane 其他功能,请右键单击任何节点以显示该节点的“属性”菜单。工具窗口(在视图 ->控制菜单下激活)包含丰富的自定义选项,包括线条形状和粗细、边框形状、颜色等等。“日历”选项允许你在节点中插入日期,并为节点设置到期提醒。 (请注意,提醒仅在 Freeplane 运行时有效。)思维导图可以导出为多种格式,包括常见的图像、XML、Microsoft Project、Markdown 和 OPML。

Freeplane 为你提供了创建生动和实用的思维导图所需的所有工具,让你表达头脑中的想法,并可采取行动。
---
via: <https://opensource.com/article/19/1/productivity-tool-freeplane>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Here's the 13th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
## Freeplane
[Mind maps](https://en.wikipedia.org/wiki/Mind_map) are one of the more valuable tools I've used for quickly brainstorming ideas and capturing data. Mind mapping is a versatile process that helps show how things are related and can be used to quickly organize interrelated information. From a planning perspective, mind mapping allows you to quickly perform a brain dump around a single concept, idea, or technology.
[Freeplane](https://www.freeplane.org/wiki/index.php/Home) is a desktop application that makes it easy to create, view, edit, and share mind maps. It is a redesign of [FreeMind](https://sourceforge.net/projects/freemind/), which was the go-to mind-mapping application for quite some time.
Installing Freeplane is pretty easy. It is a [Java](https://java.com) application and distributed as a ZIP file with scripts to start the application on Linux, Windows, and MacOS. At its first startup, its main window includes an example mind map with links to documentation about all the different things you can do with Freeplane.
You have a choice of templates when you create a new mind map. The standard template (likely at the bottom of the list) works for most cases. Just start typing the idea or phrase you want to start with, and your text will replace the center text. Pressing the Insert key will add a branch (or node) off the center with a blank field where you can fill in something associated with the idea. Pressing Insert again will add another node connected to the first one. Pressing Enter on a node will add a node parallel to that one.
As you add nodes, you may come up with another thought or idea related to the main topic. Using either the mouse or the Arrow keys, go back to the center of the map and press Insert. A new node will be created off the main topic.
If you want to go beyond Freeplane's base functionality, right-click on any of the nodes to bring up a Properties menu for that node. The Tool pane (activated under the View–>Controls menu) contains customization options galore, including line shape and thickness, border shapes, colors, and much, much more. The Calendar tab allows you to insert dates into the nodes and set reminders for when nodes are due. (Note that reminders work only when Freeplane is running.) Mind maps can be exported to several formats, including common images, XML, Microsoft Project, Markdown, and OPML.
Freeplane gives you all the tools you'll need to create vibrant and useful mind maps, getting your ideas out of your head and into a place where you can take action on them.
## Comments are closed. |
10,650 | 区块链 2.0:介绍(一) | https://www.ostechnix.com/blockchain-2-0-an-introduction/ | 2019-03-25T10:17:27 | [
"区块链",
"比特币"
] | https://linux.cn/article-10650-1.html | 
### 区块链 2.0:下一个计算范式
**区块链**现在显然被认为是一种转型技术,它将为人们使用互联网的方式带来革新。本系列文章将探讨即将到来的基于区块链 2.0 的技术和应用浪潮。不同的涉众对它表现出的极大兴趣证明了区块链的存在。
对于任何打算使用互联网做任何事情的人来说,了解它是什么以及它是如何工作的都是至关重要的。即使你所做的只是盯着 Instagram 上朋友们的早餐照片,或者寻找下一个最好的视频片段,你也需要知道这项技术能对这些提供什么样的帮助。
尽管区块链的基本概念早在上世纪 90 年代就被学术界提及,但它之所以成为网民热词,要归功于诸如**比特币**和**以太币**等支付平台的崛起。
比特币最初是一种去中心化的数字货币。它的出现意味着你基本上可以通过互联网进行完全匿名、安全可靠的支付。不过,在比特币这个简单的金融令牌系统背后,是区块链。您可以将比特币技术或任何加密货币看作是 3 层结构。区块链基础技术可以验证、记录和确认交易,在这个基础之上是协议,本质上来讲是一个规则或在线礼仪,用来兑现、记录和确认交易,当然,最重要的是通常被称作比特币的加密货币令牌。一旦记录了协议相关的事务,则由区块链生成令牌。
虽然大多数人只看到了最顶层,即代表比特币真正含义的硬币或代币,但很少有人知道,在区块链基础技术的帮助下,金融交易只是众多此类可能性中的一种。目前正在探讨这些可能性,以产生和开发所有去中心化交易方式的新标准。
在最基本的层面上,区块链可以被认为是一个包含所有记录和交易的账簿。这实际上意味着区块链理论上可以处理所有类型的记录。未来这方面的发展可能会导致各种硬资产(如房地产契约、实物钥匙等)和软无形资产(如身份记录、专利、商标、预约等)被编码为数字资产,通过区块链进行保护和转让。
对于不熟悉区块链的人来说,区块链上的事务本质上被认为是无偏见的永久记录。这是可能的,因为协议中内置了**共识系统**。所有交易均由系统参与者确认、审核和记录,在比特币加密货币平台中,该角色由**矿工**和交易所负责。这可能因不同的平台或区块链而异。构建该平台的协议栈是由开源代码所定义的,并且对任何具有技术能力的人都是免费的。与目前互联网上运行的许多其他平台不同,公开透明被内置进了该系统。
一旦事务被记录并编码到区块链中,它们就会被看到。参与者有义务按照它们最初的执行方式履行其交易和合约。除非原来的规则禁止了它,否则执行本身将由平台自动处理,因为它是硬编码的。区块链平台对于试图篡改记录、记录的持久性等方面的恢复能力,在因特网上是闻所未闻的。当这项技术的支持者们宣称其日益重要的意义时,这种能力是经常被提及的附加信任层。
这些特性并不是最近才被发现的隐藏的平台潜力,而是从一开始就被设想出来的。传说中的比特币创造者<ruby> 中本聪 <rt> Satoshi Nakamoto </rt></ruby>在一份公报中说**“我花了数年的时间来构造一个用来支撑巨大的各种可能事务类型的设计……如果比特币能够流行起来,这些就是我们未来要探索的……但是它们在最初就设计,以确保它们将来能够实现。”**。这些特性被设计并融入到已经存在的协议中的事实印证了这些话。关键的想法是,去中心化的事务分类账就像区块链的功能一样,可以用于传输、部署和执行各种形式的合约。
领先的机构目前正在探索重新发明股票、养老金和衍生品等金融工具的可能性,而世界各国政府更关注区块链的防篡改和永久性保存记录的潜力。该平台的支持者声称,一旦开发达到一个关键的门槛,从你的酒店钥匙卡到版权和专利,那时起,一切都将通过区块链记录和实现。
**Ledra Capital**在[这个](http://ledracapital.com/blog/2014/3/11/bitcoin-series-24-the-mega-master-blockchain-list)页面上汇编并维护了几乎完整的项目和细节列表,这些项目和细节理论上可以通过区块链模型实现。想要真正意识到区块链对我们生活的影响有多大是一项艰巨的任务,但看看这个清单就会再次证明这么做的重要性。
现在,上面提到的所有官僚和商业用途可能会让你相信,这样的技术只会出现在政府和大型私营企业领域。然而,事实远非如此。鉴于该系统的巨大潜力使其对此类用途具有吸引力,而区块链还具有其它可能性和特性。还有一些与该技术相关的更复杂的概念,如 DApp、DAO、DAC、DAS 等,本系列文章将深入讨论这些概念。
基本上,开发正在如火如荼地进行,任何人对基于区块链的系统的定义、标准和功能进行指点以便进行更广泛的推广还为时尚早,但是这种可能性及其即将产生的影响无疑是存在的。甚至有人谈到基于区块链的智能手机和选举期间的民意调查。
这只是一个简短的对这个平台能力的鸟瞰。我们将通过一系列这样详细的帖子和文章来研究这些不同的可能性。关注[本系列的下一篇文章](https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/),它将探索区块链是如何革新交易和契约的。
---
via: <https://www.ostechnix.com/blockchain-2-0-an-introduction/>
作者:[ostechnix](https://www.ostechnix.com/author/editor/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[sanfusu](https://github.com/sanfusu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
10,651 | Linux 中改变主机名的 4 种方法 | https://www.2daygeek.com/four-methods-to-change-the-hostname-in-linux/ | 2019-03-25T11:18:00 | [
"主机名",
"hostname"
] | https://linux.cn/article-10651-1.html | 
昨天我们已经在我们的网站中写过[如何在 Linux 中修改主机名的文章](https://www.2daygeek.com/linux-change-set-hostname/)。今天,我们将向你展示使用不同的方法来修改主机名。你可以从中选取最适合你的方法。
使用 `systemd` 的系统自带一个名为 `hostnamectl` 的好用工具,它可以使我们能够轻易地管理系统的主机名。
当你使用这个原生命令时,它可以立刻改变主机名而无需重启来生效。
但假如你通过手动修改某个配置文件来更改主机名,那么就可能需要经过重启来生效。
在这篇文章中,我们将展示在使用 `systemd` 的系统中改变主机名的 4 种方法。
`hostnamectl` 命令允许在 Linux 中设置三类主机名,它们的细节如下:
* **静态:** 这是静态主机名,由系统管理员添加。
* **瞬时/动态:** 这个由 DHCP 或者 DNS 服务器在运行时赋予。
* **易读形式:** 它可以由系统管理员赋予。这个是自由形式的主机名,以一种易读形式来表示服务器,例如 “JBOSS UAT Server” 这样的名字。
这些都可以使用下面 4 种方法来设置。
* `hostnamectl` 命令:控制系统主机名。
* `nmcli` 命令:是一个控制 NetworkManager 的命令行工具。
* `nmtui` 命令:是一个控制 NetworkManager 的文本用户界面。
* `/etc/hostname` 文件:这个文件中包含系统的静态主机名。
### 方法 1:在 Linux 中使用 hostnamectl 来改变主机名
`hostnamectl` 可被用来查询和改变系统的主机名,以及相关设定。只需运行 `hostnamectl` 便可以查看系统的主机名了。
```
$ hostnamectl
```
或者使用下面的命令:
```
$ hostnamectl status
Static hostname: daygeek-Y700
Icon name: computer-laptop
Chassis: laptop
Machine ID: 31bdeb7b83230a2025d43547368d75bc
Boot ID: 267f264c448f000ea5aed47263c6de7f
Operating System: Manjaro Linux
Kernel: Linux 4.19.20-1-MANJARO
Architecture: x86-64
```
假如你想改变主机名,可以使用下面的命令格式:
语法格式:
```
$ hostnamectl set-hostname [YOUR NEW HOSTNAME]
```
使用下面的命令来使用 `hostnamectl` 更改主机名。在这个例子中,我将把主机名从 `daygeek-Y700` 改为 `magi-laptop`。
```
$ hostnamectl set-hostname magi-laptop
```
你可以使用下面的命令来查看更新后的主机名。
```
$ hostnamectl
Static hostname: magi-laptop
Icon name: computer-laptop
Chassis: laptop
Machine ID: 31bdeb7b83230a2025d43547368d75bc
Boot ID: 267f264c448f000ea5aed47263c6de7f
Operating System: Manjaro Linux
Kernel: Linux 4.19.20-1-MANJARO
Architecture: x86-64
```
### 方法 2:在 Linux 中使用 nmcli 命令来更改主机名
`nmcli` 是一个命令行工具,旨在控制 NetworkManager 并报告网络状态。
`nmcli` 被用来创建、展示、编辑、删除、激活和注销网络连接,同时还可以用来控制和展示网络设备的状态。另外,它也允许我们更改主机名。
使用下面的命令来利用 `nmcli` 查看当前的主机名。
```
$ nmcli general hostname
daygeek-Y700
```
语法格式:
```
$ nmcli general hostname [YOUR NEW HOSTNAME]
```
使用下面的命令来借助 `nmcli` 命令可以更改主机名。在这个例子中,我将把主机名从 `daygeek-Y700` 变成 `magi-laptop`。
```
$ nmcli general hostname magi-laptop
```
它可以在不重启下设备的情况下生效,但为了安全目的,只需要重启 `systemd-hostnamed` 服务来使得更改生效。
```
$ sudo systemctl restart systemd-hostnamed
```
再次运行相同的 `nmcli` 命令来检查更改后的主机名。
```
$ nmcli general hostname
magi-laptop
```
### 方法 3:在 Linux 中使用 nmtui 来更改主机名
`nmtui` 是一个基于 `curses` 库的 TUI 应用,被用来和 NetworkManager 交互。当启动 `nmtui` 后,如果没有指定 `nmtui` 的第一个命令行参数,它将提醒用户选择执行某项活动。
在终端中运行下面的命令来开启文本用户界面。
```
$ nmtui
```
使用向下箭头按键来选择 “Set system hostname” 这个选项,然后敲击回车键。

下面的截图展示的是原来的主机名。

我们需要做的就是删除原来的主机名,再输入新的主机名,然后选中 “OK” 敲击回车确认就可以了。

然后它将在屏幕中向你展示更新后的主机名,再次选中 “OK” 敲击回车确认就完成更改了。

最后,选中 “Quit” 按钮来从 `nmtui` 终端界面离开。

它可以在不重启设备的情况下生效,但为了安全目的,需要重启 `systemd-hostnamed` 服务来使得更改生效。
```
$ sudo systemctl restart systemd-hostnamed
```
你可以运行下面的命令来查看更新后的主机名。
```
$ hostnamectl
Static hostname: daygeek-Y700
Icon name: computer-laptop
Chassis: laptop
Machine ID: 31bdeb7b83230a2025d43547368d75bc
Boot ID: 267f264c448f000ea5aed47263c6de7f
Operating System: Manjaro Linux
Kernel: Linux 4.19.20-1-MANJARO
Architecture: x86-64
```
### 方法 4:在 Linux 中使用 /etc/hostname 来更改主机名
除了上面的方法外,我们还可以通过修改 `/etc/hostname` 文件来达到修改主机名的目的。但这个方法需要服务器重启才能生效。
使用下面的命令来检查 `/etc/hostname` 文件以查看当前的主机名:
```
$ cat /etc/hostname
daygeek-Y700
```
要改变主机名,只需覆写这个文件就行了,因为这个文件只包含主机名这一项内容。
```
$ sudo echo "magi-daygeek" > /etc/hostname
$ cat /etc/hostname
magi-daygeek
```
然后使用下面的命令重启系统:
```
$ sudo init 6
```
最后查看 `/etc/hostname` 文件的内容来验证主机名是否被更改了。
```
$ cat /etc/hostname
magi-daygeek
```
---
via: <https://www.2daygeek.com/four-methods-to-change-the-hostname-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,652 | 正经的我,做了个不正经的项目 —— Pornhub 风格 Logo 生成器 | https://github.com/bestony/logoly | 2019-03-25T16:04:00 | [
"PornHub"
] | https://linux.cn/article-10652-1.html |
>
> [Logoly.Pro](https://logoly.pro/) 是一个在线的 PornHub 风格 Logo 生成工具,可以帮助你快速生成类似 PornHub 风格的 Logo。
>
>
>

目前项目已经上线:<https://logoly.pro/> 代码也已开源:<https://github.com/bestony/logoly>
**欢迎各位前来试用 && 求 Star !**
---
昨晚,我花了 5 个小时,在肝一个项目,如今,让它成功上线,我便向大家介绍一下它。
### 突发的灵感
我自己平时经常要做一些业余项目,在做业余项目的时候,就涉及到了要做 Logo ,但是作为一个没有设计感的程序员,在做 Logo 时总是会做出一些很丑的 Logo ,于是痛定思痛,想想有没有什么有用的工具可以帮助我生成好看的 Logo。对于我来说,也不需要太过复杂,能够满足我自己的要求就行。
那么这就要求这个 Logo 有一些特点
1. **设计简单**:很多带吉祥物的 Logo 就不适合我了,因为要去准备吉祥物的图片。
2. **辨识度高**:单纯的简单并没有太多的用处, Logo 需要让用户能够记住
经过一番筛选,PornHub 的 Logo 进入到我的视线。

### 设计产品
在开发之前,我先进行了产品方面的考虑,看看我需要做哪些功能,哪些不做,最终得到了这样一个清单:
**要做的项目**
1. **项目使用 Vue 开发**,因为可以快速上线
2. **项目使用 Netlify 部署**,这样就可以使用自己的域名,并使用 SSL,速度还要比 Github Pages 快一些。
3. **项目应当支持自定义文字**,这个是最基础的功能需求,必须要做的。
4. **项目应当支持自定义颜色**,毕竟可能有其他的方面,需要类似风格,但是不同的颜色的 Logo
5. **项目应当支持自定义文字大小**,毕竟我导出的是 PNG,如果不能自定义大小,大家可能会很困扰。
6. **项目应当加入 Google Analytics**,加入统计,就知道有多少人用过我的项目了,也是一种成就感。
7. **项目应当加入我的个人信息,用来给我自己推广**,顺便刷一波脸。
8. **社会化分享**,应当有个方便的分享方法,这样才能够更好的帮助项目在前期成长。
**不做的项目**
1. **自定义字体**:原汁原味的 PH 风格,怎能瞎改字体呢?
2. **导出 JPG**: 有了透明背景的 PNG,不透明的 JPG 的需求就没那么大了。
**后续迭代实现的**
1. **其他简单的 Logo**:比如 Youtube.
### 设计布局
在完成了产品的功能,我又进行了布局的设计,这次我用的是 Adobe XD,最近很喜欢用这个工具来设计产品的界面,非常的方便。最终设计完成的版本如下:

设计完成后,就要开始准备开始编码了。
### 找库
一开始,我考虑使用一些 UI 框架,不过,由于一开始没有引入 UI 框架,快写完了才发现基本不需要组件库,干脆将错就错,这样用了。
在完成了基本的界面后,就是涉及到的一些库的使用了,这里要感谢前端生态圈的繁荣,我从 [Picas](https://picas.now.sh/) 和 [Carbon](https://carbon.now.sh/) 的源码里找到了我想要用的库。
* **dom-to-image**:将 Dom 元素转换成为图片,以备下载。
* **file-save**:在 Vue 组件里调用系统的下载接口,下载图片
其他我用到的库还有
* **v-tooltips**:用户提醒,之前用的 Vue-Tour,但是跳跃感太强了,所以弃用了。
* **vue-analytics**:Vue 下的 Google Analytics 工具,可以很方便的调用 GA 进行统计。
### 上线
在完成了开发后,将代码上传到 Github,准备部署。
在前面提到,我考虑用 Netlify 进行部署,这里非常方便,在 Netlify 上直接创建项目,选择你的项目,然后填入命令即可。

并配置一下域名,将自己的域名设置为主域名:

稍等一会,就会自动为你的域名签注 Let’s Encrypt 的证书。

### 最后
关于这个项目的故事,我已经说完了所有我能想到的了,接下来,就是你的提问时间了,欢迎你针对项目对我提问,无论是产品、设计、编码,都可以~
**希望大家能够给这个项目一个 Star: <https://github.com/bestony/logoly>**
| 200 | OK | **A Simple Online Logo Generator for People Who Want to Design Logos Easily.**
- generate logo like
**PornHub**or**OnlyFans** - download your own logo in PNG/SVG format
- customize logo color
- customize logo font size
- open the Logoly website:
[https://logoly.pro/](https://logoly.pro/) - edit the text in the box
- change color & font size as you like
- click the
**Export**button to download the image
- share it on Facebook
- customize fonts
See [Changelog](/bestony/logoly/blob/master/Changelog.md)
For those who want to request new features or submit bug reports, click [this link](https://github.com/bestony/logoly/issues/new/choose) to open a new issue.
For those who want to play around with this project, read the `Get Started`
section.
At the end of this section, I suggest you read the [Contributing Guide](/bestony/logoly/blob/master/Contributing.md).
- Node.js
- clone this project
- install dependencies with
`npm install`
at the project root directory - start the development server with
`npm run dev`
- make changes
- build with
`npm run build` |
10,653 | 树莓派使用入门:教孩子们用树莓派学编程的 5 种方法 | https://opensource.com/article/19/3/teach-kids-program-raspberry-pi | 2019-03-25T22:58:44 | [
"树莓派",
"儿童"
] | https://linux.cn/article-10653-1.html |
>
> 这是我们的《树莓派入门指南》系列的第五篇文章,它探索了帮助孩子们学习编程的一些资源。
>
>
>

无数的学校、图书馆和家庭已经证明,树莓派是让孩子们接触编程的最好方式。在本系列的前四篇文章中,你已经学习了如何去[购买](/article-10615-1.html)、[安装](/article-10644-1.html)、和[配置](/article-10645-1.html)一个树莓派。在第五篇文章中,我们将分享一些帮助孩子们使用树莓派编程的入门级资源。
### Scratch
[Scratch](https://scratch.mit.edu/) 是让孩子们了解编程基本概念(比如变量、布尔逻辑、循环等等)的一个很好的方式。你在 Raspbian 中就可以找到它,并且在互联网上你可以找到非常多的有关 Scratch 的文章和教程,包括在 Opensource.com 上的 [今天的 Scratch 是不是像“上世纪八十年代教孩子学 LOGO 编程”?](https://opensource.com/article/17/3/logo-scratch-teach-programming-kids)。

### Code.org
[Code.org](https://code.org/) 是另一个非常好的教孩子学编程的在线资源。这个组织的使命是让更多的人通过课程、教程和流行的一小时学编程来接触编程。许多学校(包括我五年级的儿子就读的学校)都使用它,让更多的孩子学习编程和计算机科学的概念。
### 阅读
读书是学习编程的另一个很好的方式。学习如何编程并不需要你会说英语,当然,如果你会英语的话,学习起来将更容易,因为大多数的编程语言都是使用英文关键字去描述命令的。如果你的英语很好,能够轻松地阅读接下来的这个树莓派系列文章,那么你就完全有能力去阅读有关编程的书籍、论坛和其它的出版物。我推荐一本由 Jason Biggs 写的书: [儿童学 Python:非常有趣的 Python 编程入门](https://www.amazon.com/Python-Kids-Playful-Introduction-Programming/dp/1593274076)。
### Raspberry Jam
另一个让你的孩子进入编程世界的好方法是在聚会中让他与其他人互动。树莓派基金会赞助了一个称为 [Raspberry Jams](https://www.raspberrypi.org/jam/#map-section) 的活动,让世界各地的孩子和成人共同参与在树莓派上学习。如果你所在的地区没有 Raspberry Jam,基金会有一个[指南](https://static.raspberrypi.org/files/jam/Raspberry-Jam-Guidebook-2017-04-26.pdf)和其它资源帮你启动一个 Raspberry Jam。
### 游戏
最后一个(是本文的最后一个,当然还有其它的方式),[Minecraft](https://minecraft.net/en-us/edition/pi/) 有一个树莓派版本。<ruby> 我的世界 <rt> Minecraft </rt></ruby>已经从一个多玩家的、类似于”数字乐高“这样的游戏,成长为一个任何人都能使用 Python 和其它编程语言去构建我自己的虚拟世界。更多内容查看 [Minecraft Pi 入门](https://projects.raspberrypi.org/en/projects/getting-started-with-minecraft-pi) 和 [Minecraft 一小时入门教程](https://code.org/minecraft)。
你还有教孩子用树莓派学编程的珍藏资源吗?请在下面的评论区共享出来吧。
---
via: <https://opensource.com/article/19/3/teach-kids-program-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As countless schools, libraries, and families have proven, the Raspberry Pi is a great way to expose kids to programming. In the first four articles in this series, you've learned about [purchasing](https://opensource.com/article/19/2/how-buy-raspberry-pi), [installing](https://opensource.com/article/19/2/how-boot-new-raspberry-pi), and [configuring](https://opensource.com/article/19/3/learn-linux-raspberry-pi) a Raspberry Pi. In this fifth article, I'll share some helpful resources to get kids started programming with the Raspberry Pi.
## Scratch
[Scratch](https://scratch.mit.edu/) is a great way to introduce kids to basic programming concepts like variables, boolean logic, loops, and more. It's included in Raspbian, and you can find numerous articles and tutorials about Scratch on the internet, including [Is Scratch today like the Logo of the '80s for teaching kids to code?](https://opensource.com/article/17/3/logo-scratch-teach-programming-kids) on Opensource.com.
## Code.org
[Code.org](https://code.org/) is another great online resource for kids learning to program. The organization's mission is to expose more people to coding through courses, tutorials, and the popular Hour of Code event. Many schools—including my fifth-grade son's—use it to expose more kids to programming and computer science concepts.
## Reading
Reading books is another great way to learn how to program. You don't necessarily need to speak English to learn how to program, but the more you know, the easier it will be, as most programming languages use English keywords to describe the commands. If your English is good enough to follow this Raspberry Pi series, you are most likely well-equipped to read books, forums, and other publications about programming. One book I recommend is [ Python for Kids: A Playful Introduction to Programming](https://www.amazon.com/Python-Kids-Playful-Introduction-Programming/dp/1593274076) by Jason Biggs.
## Raspberry Jam
Another way to get your kids into programming is by helping them interact with others at meetups. The Raspberry Pi Foundation sponsors events called [Raspberry Jams](https://www.raspberrypi.org/jam/#map-section) around the world where kids and adults can join forces and learn together on the Raspberry Pi. If there isn't a Raspberry Jam in your area, the foundation has a [guidebook](https://static.raspberrypi.org/files/jam/Raspberry-Jam-Guidebook-2017-04-26.pdf) and other resources to help you start one.
## Gaming
Last, but not least, there's a version of [Minecraft](https://minecraft.net/en-us/edition/pi/) for the Raspberry Pi. Minecraft has grown from a multi-player "digital Lego"-like game into a programming platform where anyone can use Python and other languages to build on Minecraft's virtual world. Check out [Getting Started with Minecraft Pi](https://projects.raspberrypi.org/en/projects/getting-started-with-minecraft-pi) and [Minecraft Hour of Code Tutorials](https://code.org/minecraft).
What are your favorite resources for teaching kids to program with Raspberry Pi? Please share them in the comments.
## 6 Comments |
10,654 | 2019 年的 19 个高效日:失败了 | https://opensource.com/article/19/1/productivity-tool-wish-list | 2019-03-25T23:32:00 | [
"日历",
"高效"
] | https://linux.cn/article-10654-1.html |
>
> 以下是开源世界没有做到的一些工具。
>
>
>

每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
保持高效一部分是接受失败。我是 [Howard Tayler](https://www.schlockmercenary.com/) 的第 70 条座右铭的支持者:“失败不是一种选择,它是一定的。可以选择的是是否让失败成为你做的最后一件事。”在这个系列中我想谈的很多事情都没有找到好的答案。
关于我的 19 个新的(或对你而言新的)帮助你在 2019 年更高效的工具的最终版,我想到了一些我想要,但是有没有找到的。我希望读者你能够帮我找到下面这些项目的好的方案。如果你发现了,请在下面的留言中分享。
### 日历

如果开源世界有一件事缺乏,那就是日历。我尝试过的日历程序和电子邮件程序的数量一样多。共享日历基本上有三个很好的选择:[Evolution](https://wiki.gnome.org/Apps/Evolution)、[Thunderbird 中的 Lightning 附加组件](https://www.thunderbird.net/en-US/calendar/) 或 [KOrganizer](https://userbase.kde.org/KOrganizer)。我尝试过的所有其他应用 (包括 [Orage](https://github.com/xfce-mirror/orage)、[Osmo](http://clayo.org/osmo/) 以及几乎所有 [Org 模式](https://orgmode.org/)附加组件) 似乎只能可靠地支持对远程日历的只读访问。如果共享日历使用 [Google 日历](https://calendar.google.com) 或 [Microsoft Exchange](https://products.office.com/) 作为服务器,那么前三个是唯一易于配置的选择(即便如此,通常还需要其他附加组件)。
### Linux 内核的系统

我喜欢 [Chrome OS](https://en.wikipedia.org/wiki/Chrome_OS) 的简单性和轻量需求。我有几款 Chromebook,包括谷歌的最新型号。我发现它不会分散注意力、重量轻、易于使用。通过添加 Android 应用和 Linux 容器,几乎可以在任何地方轻松高效工作。
我想把它安装到我一些闲置的笔记本上,但除非我对 Chromium OS 进行全面编译,否则很难有相同的体验。像 [Bliss OS](https://blissroms.com/)、[Phoenix OS](http://www.phoenixos.com/) 和 [Android-x86](http://www.android-x86.org/) 这样的桌面 [Android](https://www.android.com/) 项目快要完成了,我正在关注它们的未来。
### 客户服务

对于大大小小的公司来说,客户服务是一件大事。现在,随着近来对 DevOps 的关注,有必要使用工具来弥补差距。我工作的几乎每家公司都使用 [Jira](https://www.atlassian.com/software/jira)、[GitHub](https://github.com) 或 [GitLab](https://about.gitlab.com/) 来报告代码问题,但这些工具都不是很擅长于客户支持工单(除非付出大量的工作)。虽然围绕客户支持工单和问题设计了许多应用,但大多数(如果不是全部)应用都是与其他系统不兼容的孤岛(同样除非付出了大量的工作)。
我的愿望是有一个开源解决方案,它能让客户、支持人员和开发人员一起工作,而无需笨重的代码将多个系统粘合在一起。
### 轮到你了

我相信这个系列中我错过了很多选择。我经常尝试新的应用,希望它们能帮助我提高工作效率。我鼓励每个人都这样做,因为当谈到使用开源工具提高工作效率时,总会有新的选择。如果你有喜欢的开源生产力应用没有进入本系列,请务必在评论中分享它们。
---
via: <https://opensource.com/article/19/1/productivity-tool-wish-list>
作者:[Kevin Sonney](https://opensource.com/users/ksonney "Kevin Sonney") 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
Part of being productive is accepting that failure happens. I am a big proponent of [Howard Tayler's](https://www.schlockmercenary.com/) Maxim 70: "Failure is not an option—it is mandatory. The option is whether or not to let failure be the last thing you do." And there were many things I wanted to talk about in this series that I failed to find good answers for.
So, for the final edition of my 19 new (or new-to-you) open source tools to help you be more productive in 2019, I present the tools I wanted but didn't find. I am hopeful that you, the reader, will be able to help me find some good solutions to the items below. If you do, please share them in the comments.
## Calendaring
If there is one thing the open source world is weak on, it is calendaring. I've tried about as many calendar programs as I've tried email programs. There are basically three good options for shared calendaring: [Evolution](https://wiki.gnome.org/Apps/Evolution), the [Lightning add-on to Thunderbird](https://www.thunderbird.net/en-US/calendar/), or [KOrganizer](https://userbase.kde.org/KOrganizer). All the other applications I've tried (including [Orage](https://github.com/xfce-mirror/orage), [Osmo](http://clayo.org/osmo/), and almost all of the [Org mode](https://orgmode.org/) add-ons) seem to reliably support only read-only access to remote calendars. If the shared calendar uses either [Google Calendar](https://calendar.google.com) or [Microsoft Exchange](https://products.office.com/) as the server, the first three are the only easily configured options (and even then, additional add-ons are often required).
## Linux on the inside
I love [Chrome OS](https://en.wikipedia.org/wiki/Chrome_OS), with its simplicity and lightweight requirements. I have owned several Chromebooks, including the latest models from Google. I find it to be reasonably distraction-free, lightweight, and easy to use. With the addition of Android apps and a Linux container, it's easy to be productive almost anywhere.
I'd like to carry that over to some of the older laptops I have hanging around, but unless I do a full compile of Chromium OS, it is hard to find that same experience. The desktop [Android](https://www.android.com/) projects like [Bliss OS](https://blissroms.com/), [Phoenix OS](http://www.phoenixos.com/), and [Android-x86](http://www.android-x86.org/) are getting close, and I'm keeping an eye on them for the future.
## Help desks
Customer service is a big deal for companies big and small. And with the added focus on DevOps these days, it is important to have tools to help bridge the gap. Almost every company I've worked with uses either [Jira](https://www.atlassian.com/software/jira), [GitHub](https://github.com), or [GitLab](https://about.gitlab.com/) for code issues, but none of these tools are very good at customer support tickets (without a lot of work). While there are many applications designed around customer support tickets and issues, most (if not all) of them are silos that don't play nice with other systems, again without a lot of work.
On my wishlist is an open source solution that allows customers, support, and developers to work together without an unwieldy pile of code to glue multiple systems together.
## Your turn
I'm sure there are a lot of options I missed during this series. I try new applications regularly, in the hopes that they will help me be more productive. I encourage everyone to do the same, because when it comes to being productive with open source tools, there is always something new to try. And, if you have favorite open source productivity apps that didn't make it into this series, please make sure to share them in the comments.
## 4 Comments |
10,655 | 13 个开源备份解决方案 | https://opensource.com/article/19/3/backup-solutions | 2019-03-26T09:27:46 | [
"备份",
"数据"
] | https://linux.cn/article-10655-1.html |
>
> 读者们推荐了超过一打的他们喜欢的数据保护解决方案。
>
>
>

最近,我发起了一个 [投票](https://opensource.com/article/19/2/linux-backup-solutions),让读者投票选出他们最喜欢的开源备份解决方案。在我们的 [版主社区](https://opensource.com/opensourcecom-team) 上,我们提供了六个推荐的解决方案 —— Cronopete、Deja Dup、Rclone、Rdiff-backup、Restic、和 Rsync,而参与的读者也在评论区分享了一些其它的选择。并且读者提供的这 13 个其它的解决方案,(到目前为止)我们要么是没有想到,要么是没有听说过。
到目前为止,最受欢迎的推荐是 [BorgBackup](https://www.borgbackup.org/)。它是一个带有压缩和加密特性以用具有数据去重功能的备份解决方案。它基于 BSD 许可证,支持 Linux、MacOS 和 BSD。
第二个是 [UrBackup](https://www.urbackup.org/),它可以做镜像和文件的完整和增量备份;你可以保存整个分区或单个目录。它有 Windows、Linux、和 MacOS 客户端,并且采用 GNU Affero 公共许可证。
第三个是 [LuckyBackup](http://luckybackup.sourceforge.net/);根据其网站介绍,“它是一个易于使用、快速(只传输变化部分,而不是全部数据)、安全(在做任何数据操作之前,先检查所有需要备份的目录,以确保数据安全)、可靠和完全可定制的备份解决方案。它在 GPL 许可证下发行。
[Casync](http://0pointer.net/blog/casync-a-tool-for-distributing-file-system-images.html) 是一个可寻址内容的同步解决方案 —— 它设计用于备份、同步、存储和检索大文件系统的多个相关版本。它使用 GNU Lesser 公共许可证。
[Syncthing](https://syncthing.net/) 是用于在两台计算机之间同步文件。它基于 Mozilla 公共许可证使用,根据其网站介绍,它是安全和私密的。它可以工作于 MacOS、Windows、Linux、FreeBSD、Solaris 和 OpenBSD。
[Duplicati](https://www.duplicati.com/) 是一个可工作于 Windows、MacOS 和 Linux 上的、并且支持多种标准协议(比如 FTP、SSH、WebDAV 和云服务)、免费的备份解决方案。它的特性是强大的加密功能,并且它使用 GPL 许可证。
[Dirvish](http://dirvish.org/) 是一个基于磁盘的虚拟镜像备份系统,它使用 OSL-3.0 许可证。它要求必须安装有 Rsync、Perl5、SSH。
[Bacula](https://www.bacula.org/) 的网站上介绍说:”它是允许系统管理员去管理备份、恢复、和跨网络的不同种类计算机上的多种数据的一套计算机程序“,它支持在 Linux、FreeBSD、Windows、MacOS、OpenBSD 和 Solaris 上运行,并且它的大部分源代码都是基于 AGPLv3 许可证的。
[BackupPC](https://backuppc.github.io/backuppc/) 的网站上介绍说:”它是一个高性能的、企业级的、可以备份 Linux、Windows 和 MacOS 系统的 PC 和笔记本电脑上的数据到服务器磁盘上的备份解决方案“。它是基于 GPLv3 许可证的。
[Amanda](http://www.amanda.org/) 是一个使用 C 和 Perl 写的备份系统,它允许系统管理员去备份整个网络中的客户端到一台服务器上的磁带、磁盘或基于云的系统。它是由马里兰大学于 1991 年开发并拥有版权,并且它有一个 BSD 式的许可证。
[Back in Time](https://github.com/bit-team/backintime) 是一个为 Linux 设计的简单的备份实用程序。它提供了命令行和图形用户界面,它们都是用 Python 写的。去执行一个备份,只需要指定存储快照的位置、需要备份的文件夹,和备份频率即可。它使用的是 GPLv2 许可证。
[Timeshift](https://github.com/teejee2008/timeshift) 是一个 Linux 上的备份实用程序,它类似于 Windows 上的系统恢复和 MacOS 上的时间胶囊。它的 GitHub 仓库上介绍说:“Timeshift 通过定期递增的文件系统快照来保护你的系统。这些快照可以在日后用于数据恢复,以撤销某些对文件系统的修改。”
[Kup](https://github.com/spersson/Kup) 是一个能够帮助用户备份它们的文件到 USB 驱动器上的备份解决方案,但它也可以用于执行网络备份。它的 GitHub 仓库上介绍说:”当插入你的外部硬盘时,Kup 将自动启动并复制你的最新的修改。“
感谢大家在我们的投票中分享你们喜爱的开源备份解决方案!如果还有其它的、没有提到的开源备份解决方案,请在下面的评论区分享它们。
---
via: <https://opensource.com/article/19/3/backup-solutions>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, we published a [poll](https://opensource.com/article/19/2/linux-backup-solutions) that asked readers to vote on their favorite open source backup solution. We offered six solutions recommended by our [moderator community](https://opensource.com/opensourcecom-team)—Cronopete, Deja Dup, Rclone, Rdiff-backup, Restic, and Rsync—and invited readers to share other options in the comments. And you came through, offering 13 other solutions (so far) that we either hadn't considered or hadn't even heard of.
By far the most popular suggestion was [BorgBackup](https://www.borgbackup.org/). It is a deduplicating backup solution that features compression and encryption. It is supported on Linux, MacOS, and BSD and has a BSD License.
Second was [UrBackup](https://www.urbackup.org/), which does full and incremental image and file backups; you can save whole partitions or single directories. It has clients for Windows, Linux, and MacOS and has a GNU Affero Public License.
Third was LuckyBackup. As of 2019, however, this project is no longer being mainained, so I recommend [rdiff-backup](https://opensource.com/article/20/9/rdiff-backup-linux). For the past two decades, rdiff-backup has helped Linux users maintain full backups of their data locally or remotely. This open source solution does reverse incremental backups—backing up only the files that changed since the previous backup. Restoring files is easy, too, featuring an intuitive and simple command-line interface.
[Casync](http://0pointer.net/blog/casync-a-tool-for-distributing-file-system-images.html) is content-addressable synchronization—it's designed for backup and synchronizing and stores and retrieves multiple related versions of large file systems. It is licensed with the GNU Lesser Public License.
[Syncthing](https://syncthing.net/) synchronizes files between two computers. It is licensed with the Mozilla Public License and, according to its website, is secure and private. It works on MacOS, Windows, Linux, FreeBSD, Solaris, and OpenBSD.
[Duplicati](https://www.duplicati.com/) is a free backup solution that works on Windows, MacOS, and Linux and a variety of standard protocols, such as FTP, SSH, and WebDAV, and cloud services. It features strong encryption and is licensed with the GPL.
[Dirvish](http://dirvish.org/) is a disk-based virtual image backup system licensed under OSL-3.0. It also requires Rsync, Perl5, and SSH to be installed.
[Bacula](https://www.bacula.org/)'s website says it "is a set of computer programs that permits the system administrator to manage backup, recovery, and verification of computer data across a network of computers of different kinds." It is supported on Linux, FreeBSD, Windows, MacOS, OpenBSD, and Solaris and the bulk of its source code is licensed under AGPLv3.
[BackupPC](https://backuppc.github.io/backuppc/) "is a high-performance, enterprise-grade system for backing up Linux, Windows, and MacOS PCs and laptops to a server's disk," according to its website. It is licensed under the GPLv3.
[Amanda](http://www.amanda.org/) is a backup system written in C and Perl that allows a system administrator to back up an entire network of client machines to a single server using tape, disk, or cloud-based systems. It was developed and copyrighted in 1991 at the University of Maryland and has a BSD-style license.
[Back in Time](https://github.com/bit-team/backintime) is a simple backup utility designed for Linux. It provides a command line client and a GUI, both written in Python. To do a backup, just specify where to store snapshots, what folders to back up, and the frequency of the backups. BackInTime is licensed with GPLv2.
[Timeshift](https://github.com/teejee2008/timeshift) is a backup utility for Linux that is similar to System Restore for Windows and Time Capsule for MacOS. According to its GitHub repository, "Timeshift protects your system by taking incremental snapshots of the file system at regular intervals. These snapshots can be restored at a later date to undo all changes to the system."
[Kup](https://github.com/spersson/Kup) is a backup solution that was created to help users back up their files to a USB drive, but it can also be used to perform network backups. According to its GitHub repository, "When you plug in your external hard drive, Kup will automatically start copying your latest changes."
Thanks for sharing your favorite open source backup solutions in our poll! If there are still others that haven't been mentioned yet, please share them in the comments.
## 6 Comments |
10,656 | 托管你自己的在线字体 | https://opensource.com/article/19/3/webfonts | 2019-03-27T09:35:56 | [
"字体"
] | https://linux.cn/article-10656-1.html |
>
> 使用自托管的开源字体来定制你的网页。
>
>
>

字体对许多计算机用户来说可能都是很神秘的东西。举个例子,你在制作好一张很酷的传单之后,你需要将它送到某个地方去打印,结果发现,你设计的所有字体都变成了 Arial,这多半是因为打印店没用安装你设计用到的那些字体。不过,我们仍有很多方法来避免这种情况:你可以将这些使用特定字体的单词转换为路径,你也可以将它封装为 PDF,或是把开源字体封装到你的设计文件中,或者至少列出所需字体。不过,我们总会忘记一些事情,所以这仍是一个问题。
Web 上也有类似的问题。如果你对 CSS 有所了解,你可能会见过这种声明:
```
h1 { font-family: "Times New Roman", Times, serif; }
```
这是设计师正在尝试定义网站使用要用到的特定字体,如果用户没有安装 Times New Roman 这个字体,便会回落到另一个字体;如果用户也没有安装 Times 这个字体,便再次回落。它比使用图片而不是文本更好一些,但是在没有字体托管的情况下,这仍是一种棘手且不雅观的方法。不过,在早期的互联网时代,我们不得不这样做。
### 在线字体
在线字体的登场,把字体管理从客户端搬上了服务端。如今网页上的字体通常由服务器为客户端渲染,而不是要求浏览器从用户的系统中查找字体。谷歌和其它供应商托管了许多开源字体,网站设计师们可以很轻松的用 CSS 来引用它们。
不过,问题是,引用这些字体并不是不花费任何代价的。虽然引用它们免费,但是像谷歌这样的巨头喜欢跟踪那些引用它们资源的网站,其中就包括了字体资源。如果你不想你的网站帮谷歌记录每个人的活动,你可以自己托管在线字体。别觉得这很难,它其实是很简单的,大概流程就是上传字体到你的主机,再使用一个简单的 CSS 便可完成。这样做还有个好处,你的网站能更快地加载,因为它会在加载每个页面的时候进行更少的外部调用。
### 自托管在线字体
首先,你需要一个开源字体。如果你没有了解过那些令人费解的软件协议,你可能会感到很疑惑,特别是很多字体看起来都是免费的。我们中应该很少有人有字体付费意识,但是他们却在电脑上安装了一些高价的字体。不过,由于授权协议,它使得你的电脑也许带着一些 [法律上不允许复制和再分发](https://docs.microsoft.com/en-us/typography/fonts/font-faq) 的字体。像 Arial、Verdana、Calibri、Georgia、Impact、Lucida 和 Lucida Grande、Times 和 Times New Roman、Trebuchet、Geneva 以及其它的很多字体都是被微软、苹果和 Adobe 这种大公司所拥有的。如果你购买了一台预装了 Windows 或 macOS 的电脑,你就获得了使用这些字体的权利,但是你并没有拥有那些字体,也没有被许可上传它们至服务器(除非额外说明)。
幸运的事,开源热潮在很久以前就席卷了字体界。然后就有了许多优秀的开源字体的合集和项目,比如 [The League of Moveable Type](https://www.theleagueofmoveabletype.com/)、[Font Library](https://fontlibrary.org/) 以及 [Omnibus Type](https://www.omnibus-type.com),甚至还有一些来自 [Google](https://github.com/googlefonts) 和 [Adobe](https://github.com/adobe-fonts) 的字体。
常见的字体格式有 TTF、OTF、WOFF、EOT 等。因为 Sorts Mill Goudy 发行过 <ruby> WOFF <rt> Web Open Font Format </rt></ruby>(互联网开放字体格式,Mozilla 参与了部分开发)版本,所以下文中我会用它来做例子。当然,其它字体的方法也是一样的。
假设你想在你的网站上使用 [Sorts Mill Goudy](https://www.theleagueofmoveabletype.com/sorts-mill-goudy) 这个字体:
1、将字体文件 `GoudyStM-webfont.woff` 上传至你的服务器:
```
scp GoudyStM-webfont.woff [email protected]:~/www/fonts/
```
你的主机可能带有像 cPanel 这样的图形化工具,通过它们上传也是一样的。
2、在你网站的 CSS 文件中,添加 `@font-face` 语句,添加后应该和这个差不多:
```
@font-face {
font-family: "titlefont";
src: url("../fonts/GoudyStM-webfont.woff");
}
```
`font-family` 的值是你来决定的。这是一个易于理解的名字,它用于放在使用字体名的地方。我在这里使用 “titlefont” 作为例子,是因为我希望它被用来显示标题字体。你也可以使用 “officialfont” 和 “myfont” 这样的名字。
`src` 值是你字体文件的路径。这是你服务器上字体的路径。在这里,我用 `fonts` 目录来作为示例,它和 `css` 在一个文件夹里。你服务器的文件结构可能和我的不一样,所以你需要调整一下这个路径。记住一点,一个点意味着*工作目录*,两个点则代表*父目录*。
3、现在,你已经定义了字体的名字和目录,你可以在任何指定的 CSS 类或 ID 来调用它了。举个例子,如果你希望以 Sorts Mill Goudy 字体来渲染 `<h1>`,只需要在 CSS 规则中加入你自己的字体名称:
```
h1 { font-family: "titlefont", serif; }
```
现在,你已经成功地托管并使用你自己的字体了。

---
via: <https://opensource.com/article/19/3/webfonts>
作者:[Seth Kenlon (Red Hat, Community Moderator)](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zhs852](https://github.com/zhs852) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fonts are often a mystery to many computer users. For example, have you designed a cool flyer and, when you take the file somewhere for printing, find all the titles rendered in Arial because the printer doesn't have the fancy font you used in your design? There are ways to prevent this, of course: you can convert words in special fonts into paths, bundle fonts into a PDF, bundle open source fonts with your design files, or—at least—list the fonts required. And yet it's still a problem because we're human and we're forgetful.
The web has the same sort of problem. If you have even a basic understanding of CSS, you've probably seen this kind of declaration:
`h1 { font-family: "Times New Roman", Times, serif; }`
This is a designer's attempt to define a specific font, provide a fallback if a user doesn't have Times New Roman installed, and offer yet another fallback if the user doesn't have Times either. It's better than using a graphic instead of text, but it's still an awkward, inelegant method of font non-management, However, in the early-ish days of the web, it's all we had to work with.
## Webfonts
Then webfonts happened, moving font management from the client to the server. Fonts on websites were rendered for the client by the server, rather than requiring the web browser to find a font on the user's system. Google and other providers even host openly licensed fonts, which designers can include on their sites with a simple CSS rule.
The problem with this free convenience, of course, is that it doesn't come without cost. It's $0 to use, but major sites like Google love to keep track of who references their data, fonts included. If you don't see a need to assist Google in building a record of everyone's activity on the web, the good news is you can host your own webfonts, and it's as simple as uploading fonts to your host and using one easy CSS rule. As a side benefit, your site may load faster, as you'll be making one fewer external call upon loading each page.
## Self-hosted webfonts
The first thing you need is an openly licensed font. This can be confusing if you're not used to thinking or caring about obscure software licenses, especially since it seems like all fonts are free. Very few of us have consciously paid for a font, and yet most people have high-priced fonts on their computers. Thanks to licensing deals, your computer may have shipped with fonts that [you aren't legally allowed to copy and redistribute](https://docs.microsoft.com/en-us/typography/fonts/font-faq). Fonts like Arial, Verdana, Calibri, Georgia, Impact, Lucida and Lucida Grande, Times and Times New Roman, Trebuchet, Geneva, and many others are owned by Microsoft, Apple, and Adobe. If you purchased a computer preloaded with Windows or MacOS, you paid for the right to use the bundled fonts, but you don't own those fonts and are not permitted to upload them to a web server (unless otherwise stated).
Fortunately, the open source craze hit the font world long ago, and there are excellent collections of openly licensed fonts from collectives and projects like [The League of Moveable Type](https://www.theleagueofmoveabletype.com/), [Font Library](https://fontlibrary.org/), [Omnibus Type](https://www.omnibus-type.com), and even [Google](https://github.com/googlefonts) and [Adobe](https://github.com/adobe-fonts).
You can use most common font file formats, including TTF, OTF, WOFF, EOT, and so on. Since Sorts Mill Goudy includes a WOFF (Web Open Font Format, developed in part by Mozilla) version, I'll use it in this example. However, other formats work the same way.
Assuming you want to use [Sorts Mill Goudy](https://www.theleagueofmoveabletype.com/sorts-mill-goudy) on your web page:
- Upload the
**GoudyStM-webfont.woff**file to your web server:
`scp GoudyStM-webfont.woff [email protected]:~/www/fonts/`
Your host may also provide a graphical upload tool through cPanel or a similar web control panel.
- In your site's CSS file, add an
**@font-face**rule, similar to this:
`@font-face { font-family: "titlefont"; src: url("../fonts/GoudyStM-webfont.woff"); }`
The
**font-family**value is something you make up. It's a human-friendly name for whatever the font face represents. I am using "titlefont" in this example because I imagine this font will be used for the main titles on an imaginary site. You could just as easily use "officialfont" or "myfont."
The**src**value is the path to the font file. The path to the font must be appropriate for your server's file structure; in this example, I have the**fonts**directory alongside a**css**directory. You may not have your site structured that way, so adjust the paths as needed, remembering that a single dot means*this folder*and two dots mean*a folder back*.
- Now that you've defined the font face name and the location, you can call it for any given CSS class or ID you desire. For example, if you want
**<h1>**to render in the Sorts Mill Goudy font, then make its CSS rule use your custom font name:
`h1 { font-family: "titlefont", serif; }`
You're now hosting and using your own fonts.
*Thanks to Alexandra Kanik for teaching me about @font-face and most everything else I know about good web design.*
## Comments are closed. |
10,657 | 在 Linux 终端下生成随机/强密码的五种方法 | https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-linux-terminal/ | 2019-03-27T10:05:00 | [
"密码"
] | https://linux.cn/article-10657-1.html | 
最近我们在网站上发表过一篇关于 [检查密码复杂性/强度和评分](/article-10623-1.html) 的文章。它可以帮助你检查你的密码的强度和评分。
我们可以手工创建我们需要的密码。但如果你想要为多个用户或服务器生成密码,解决方案是什么呢?
是的,Linux 中有许多可用的工具能满足这个需求。本文中我将会介绍五种最好的密码生成器。
这些工具可以为你生成高强度随机密码。如果你想要为多个用户和服务器更新密码,请继续读下去。
这些工具易于使用,这也是我喜欢用它们的原因。默认情况下它们会生成一个足够健壮的密码,你也可以通过使用其他可用的选项来生成一个超强的密码。
它会帮助你生成符合下列要求的超强密码。密码长度至少有 12-15 个字符,包括字母(大写及小写),数字及特殊符号。
工具如下:
* `pwgen`:生成易于人类记忆并且尽可能安全的密码。
* `openssl`:是一个用来从 shell 中调用 OpenSSL 加密库提供的多种密码学函数的命令行工具。
* `gpg`:OpenPGP 加密/签名工具。
* `mkpasswd`:生成新密码,可以选择直接设置给一名用户。
* `makepasswd`:使用 `/dev/urandom` 生成真随机密码,比起好记它更重视安全性。
* `/dev/urandom` 文件:两个特殊的字符文件 `/dev/random` 和 `/dev/urandom` (自 Linux 1.3.30 起出现)提供了内核随机数生成器的接口。
* `md5sum`:是一个用来计算及校验 128 位 MD5 哈希的程序。
* `sha256sum`:被设计用来使用 SHA-256 算法(SHA-2 系列,摘要长度为 256 位)校验数据完整性。
* `sha1pass`:生成一个 SHA1 密码哈希。在命令缺少盐值的情况下,将会生成一个随机的盐值向量。
### 怎么用 pwgen 命令在 linux 下生成一个随机的强壮密码?
`pwgen` 程序生成易于人类记忆并且尽可能安全的密码。
易于人类记忆的密码永远都不会像完全随机的密码一样安全。
使用 `-s` 选项来生成完全随机,难于记忆的密码。由于我们记不住,这些密码应该只用于机器。
在 Fedora 系统中,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `pwgen`。
```
$ sudo dnf install pwgen
```
在 Debian/Ubuntu 系统中,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `pwgen`。
```
$ sudo apt install pwgen
```
在 Arch Linux 系统中,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 `pwgen`。
```
$ sudo pacman -S pwgen
```
在 RHEL/CentOS 系统中,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 `pwgen`。
```
$ sudo yum install pwgen
```
在 openSUSE Leap 系统中,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 `pwgen`。
```
$ sudo zypper install pwgen
```
### 在 Linux 下如何使用 pwgen 命令?
使用方法非常简单直接。使用下列示例中更适合你的那种。默认情况下,它会生成一个方便记忆的密码。
想要这样做,只要在你的终端中运行 `pwgen` 命令。将会一下生成160个密码以8列20行打印出来。
```
$ pwgen
ameiK2oo aibi3Cha EPium0Ie aisoh1Ee Nidee9ae uNga0Bee uPh9ieM1 ahn1ooNg
oc5ooTea tai7eKid tae2yieS hiecaiR8 wohY2Ohk Uab2maed heC4aXoh Ob6Nieso
Shaeriu3 uy9Juk5u hoht7Doo Fah6yah3 faz9Jeew eKiek4ju as0Xuosh Eiwo4epo
oot8teeZ Ui1yoohi Aechae7A Ohdi2ael cae5Thoh Au1aeTei ais0aiC2 Cai2quin
Oox9ohz4 neev0Che ahza8AQu Ahz7eica meiBeeW0 Av3bo7ah quoiTu3f taeNg3ae
Aiko7Aiz SheiGh8E aesaeSh7 haet6Loo AeTel3oN Ath7zeer IeYah4ie UG3ootha
Ohch9Och Phuap6su iel5Xu7s diqui7Bu ieF2dier eeluHa1u Thagei0i Ceeth3oh
OCei1ahj zei2aiYo Jahgh1ia ooqu1Cej eez2aiPo Wahd5soo noo7Mei9 Hie5ashe
Uith4Or2 Xie3uh2b fuF9Eilu eiN2sha9 zae2YaSh oGh5ephi ohvao4Ae aixu6aeM
fo4Ierah iephei6A hae9eeGa eiBeiY3g Aic8Kee9 he8AheCh ohM4bid9 eemae3Zu
eesh2EiM cheiGa4j PooV2vii ahpeeg5E aezauX2c Xe7aethu Ahvaph7a Joh2heec
Ii5EeShi aij7Uo8e ooy2Ahth mieKe2ni eiQuu8fe giedaQu0 eiPhob3E oox1uo2U
eehia4Hu ga9Ahw0a ohxuZei7 eV4OoXio Kid2wu1n ku4Ahf5s uigh8uQu AhWoh0po
vo1Eeb2u Ahth7ve5 ieje4eiL ieci1Ach Meephie9 iephieY8 Eesoom7u eakai2Bo
uo8Ieche Zai3aev5 aGhahf0E Wowoo5th Oraeb0ah Gah3nah0 ieGhah0p aeCh0OhJ
ahQu2feZ ahQu0gah foik7Ush cei1Wai1 Aivi3ooY eephei5U MooZae3O quooRoh7
aequae5U pae6Ceiv eizahF1k ohmi7ETa ahyaeK1N Mohw2no8 ooc8Oone coo7Ieve
eePhei9h Weequ8eV Vie4iezu neeMiim4 ie6aiZoh Queegh2E shahwi3N Inichie8
Sid1aeji mohj4Ko7 lieDi0pe Zeemah6a thuevu2E phi4Ohsh paiKeix1 ooz1Ceph
ahV4yore ue2laePh fu1eThui qui7aePh Fahth1nu ohk9puLo aiBeez0b Neengai5
```
生成安全的随机密码,使用 `pwgen` 命令的 `-s` 选项。
```
$ pwgen -s
CU75lgZd 7HzzKgtA 2ktBJDpR F6XJVhBs UjAm3bNL zO7Dw7JJ pxn8fUvp Ka3lLilG
ywJX7iJl D9ajxb6N 78c1HOg2 g8vtWCra Jp6pBGBw oYuev9Vl gbA6gHV8 G6XQoVO5
uQN98IU4 50GgQfrX FrTsou2t YQorO4x6 UGer8Yi2 O7DB5nw1 1ax370UR 1xVRPkA1
RVaGDr2i Nt11ekUd 9Vm3D244 ck8Lnpd0 SjDt8uWn 5ERT4tf8 4EONFzyY Jc6T83jg
WZa6bKPW H4HMo1YU bsDDRik3 gBwV7LOW 9H1QRQ4x 3Ak7RcSe IJu2RBF9 e508xrLC
SzTrW191 AslxDa6E IkWWov2b iOb6EmTy qHt82OwG 5ZFO7B53 97zmjOPu A4KZuhYV
uQpoJR4D 0eKyOiUr Rz96smeO 3HTABu3N 6W0VmEls uPsp5zpw 8UD3VkMG YTct6Rd4
VKo0cVmq E07ZX7j9 kQSlvA69 Nm3fpv3i xWvF2xMu yEfcw8uA oQGVX3l9 grTzx7Xj
s4GVEYtM uJl5sYMe n3icRPiY ED3Mup4B k3M9KHI7 IkxqoSM0 dt2cxmMU yb2tUkut
2Q9wGZQx 8Rpo11s9 I13siOHu 7GV64Fjv 3VONzD8i SCDfVD3F oiPTx239 6BQakoiJ
XUEokiC4 ybL7VGmL el2RfvWk zKc7CLcE 3FqNBSyA NjDWrvZ5 KI3NSX4h VFyo6VPr
h4q3XeqZ FDYMoX6f uTU5ZzU3 6u4ob4Ep wiYPt05n CZga66qh upzH6Z9y RuVcqbe8
taQv11hq 1xsY67a8 EVo9GLXA FCaDLGb1 bZyh0YN8 0nTKo0Qy RRVUwn9t DuU8mwwv
x96LWpCb tFLz3fBG dNb4gCKf n6VYcOiH 1ep6QYFZ x8kaJtrY 56PDWuW6 1R0If4kV
2XK0NLQK 4XQqhycl Ip08cn6c Bnx9z2Bz 7gjGlON7 CJxLR1U4 mqMwir3j ovGXWu0z
MfDjk5m8 4KwM9SAN oz0fZ5eo 5m8iRtco oP5BpLh0 Z5kvwr1W f34O2O43 hXao1Sp8
tKoG5VNI f13fuYvm BQQn8MD3 bmFSf6Mf Z4Y0o17U jT4wO1DG cz2clBES Lr4B3qIY
ArKQRND6 8xnh4oIs nayiK2zG yWvQCV3v AFPlHSB8 zfx5bnaL t5lFbenk F2dIeBr4
C6RqDQMy gKt28c9O ZCi0tQKE 0Ekdjh3P ox2vWOMI 14XF4gwc nYA0L6tV rRN3lekn
lmwZNjz1 4ovmJAr7 shPl9o5f FFsuNwj0 F2eVkqGi 7gw277RZ nYE7gCLl JDn05S5N
```
假设你想要生成 5 个 14 字符长的密码,方法如下:
```
$ pwgen -s 14 5
7YxUwDyfxGVTYD em2NT6FceXjPfT u8jlrljbrclcTi IruIX3Xu0TFXRr X8M9cB6wKNot1e
```
如果你真的想要生成 20 个超强随机密码,方法如下:
```
$ pwgen -cnys 14 20
mQ3E=vfGfZ,5[B #zmj{i5|ZS){jg Ht_8i7OqJ%N`~2 443fa5iJ\W-L?] ?Qs$o=vz2vgQBR
^'Ry0Az|J9p2+0 t2oA/n7U_'|QRx EsX*%_(4./QCRJ ACr-,8yF9&eM[* !Xz1C'bw?tv50o
8hfv-fK(VxwQGS q!qj?sD7Xmkb7^ N#Zp\_Y2kr%!)~ 4*pwYs{bq]Hh&Y |4u=-Q1!jS~8=;
]{$N#FPX1L2B{h I|01fcK.z?QTz" l~]JD_,W%5bp.E +i2=D3;BQ}p+$I n.a3,.D3VQ3~&i
```
### 如何在 Linux 下使用 openssl 命令生成随机强密码?
`openssl` 是一个用来从 shell 中调用 OpenSSL 加密库提供的多种密码学函数的命令行工具。
像下面这样运行 `openssl` 命令可以生成一个 14 字符长的随机强密码。
```
$ openssl rand -base64 14
WjzyDqdkWf3e53tJw/c=
```
如果你想要生成 10 个 14 字符长的随机强密码,将 `openssl` 命令与 `for` 循环结合起来使用。
```
$ for pw in {1..10}; do openssl rand -base64 14; done
6i0hgHDBi3ohZ9Mil8I=
gtn+y1bVFJFanpJqWaA=
rYu+wy+0nwLf5lk7TBA=
xrdNGykIzxaKDiLF2Bw=
cltejRkDPdFPC/zI0Pg=
G6aroK6d4xVVYFTrZGs=
jJEnFoOk1+UTSx/wJrY=
TFxVjBmLx9aivXB3yxE=
oQtOLPwTuO8df7dIv9I=
ktpBpCSQFOD+5kIIe7Y=
```
### 如何在 Linux 下使用 gpg 命令生成随机强密码?
`gpg` 是 Gnu Privacy Guard (GnuPG) 中的 OpenPGP 实现部分。它是一个提供 OpenPGP 标准的数字加密与签名服务的工具。`gpg` 具有完整的密钥管理功能和其他完整 OpenPGP 实现应该具备的全部功能。
下面这样执行 `gpg` 命令来生成一个 14 字符长的随机强密码。
```
$ gpg --gen-random --armor 1 14
or
$ gpg2 --gen-random --armor 1 14
jq1mtY4gBa6gIuJrggM=
```
如果想要使用 `gpg` 生成 10 个 14 字符长的随机强密码,像下面这样使用 `for` 循环。
```
$ for pw in {1..10}; do gpg --gen-random --armor 1 14; done
or
$ for pw in {1..10}; do gpg2 --gen-random --armor 1 14; done
F5ZzLSUMet2kefG6Ssc=
8hh7BFNs8Qu0cnrvHrY=
B+PEt28CosR5xO05/sQ=
m21bfx6UG1cBDzVGKcE=
wALosRXnBgmOC6+++xU=
TGpjT5xRxo/zFq/lNeg=
ggsKxVgpB/3aSOY15W4=
iUlezWxL626CPc9omTI=
pYb7xQwI1NTlM2rxaCg=
eJjhtA6oHhBrUpLY4fM=
```
### 如何在 Linux 下使用 mkpasswd 命令生成随机强密码?
`mkpasswd` 生成密码并可以自动将其为用户设置。不加任何参数的情况下,`mkpasswd` 返回一个新的密码。它是 expect 软件包的一部分,所以想要使用 `mkpasswd` 命令,你需要安装 expect 软件包。
在 Fedora 系统中,使用 [DNF 命令](https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/) 来安装 `mkpasswd`。
```
$ sudo dnf install expect
```
在 Debian/Ubuntu 系统中,使用 [APT-GET 命令](https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/) 或 [APT 命令](https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/) 来安装 `mkpasswd`。
```
$ sudo apt install expect
```
在 Arch Linux 系统中,使用 [Pacman 命令](https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/) 来安装 `mkpasswd`。
```
$ sudo pacman -S expect
```
在 RHEL/CentOS 系统中,使用 [YUM 命令](https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/) 来安装 `mkpasswd`。
```
$ sudo yum install expect
```
在 openSUSE Leap 系统中,使用 [Zypper 命令](https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/) 来安装 `mkpasswd`。
```
$ sudo zypper install expect
```
在终端中执行 `mkpasswd` 命令来生成一个随机密码。
```
$ mkpasswd
37_slQepD
```
像下面这样执行 `mkpasswd` 命令可以生成一个 14 字符长的随机强密码。
```
$ mkpasswd -l 14
W1qP1uv=lhghgh
```
像下面这样执行 `mkpasswd` 命令 来生成一个 14 字符长,包含大小写字母、数字和特殊字符的随机强密码。
```
$ mkpasswd -l 14 -d 3 -C 3 -s 3
3aad!bMWG49"t,
```
如果你想要生成 10 个 14 字符长的随机强密码(包括大小写字母、数字和特殊字符),使用 `for` 循环和 `mkpasswd` 命令。
```
$ for pw in {1..10}; do mkpasswd -l 14 -d 3 -C 3 -s 3; done
zmSwP[q9;P1r6[
E42zcvzM"i3%B\
8}1#[email protected]
0X:zB(mmU22?nj
0sqqL44M}ko(O^
43tQ(.6jG;ceRq
-jB6cp3x1GZ$e=
$of?Rj9kb2N(1J
9HCf,nn#gjO79^
Tu9m56+Ev_Yso(
```
### 如何在 Linux 下使用 makepasswd 命令生成随机强密码?
`makepasswd` 使用 `/dev/urandom` 生成真随机密码,与易于记忆相比它更注重安全性。它也可以加密命令行中给出的明文密码。
在终端中执行 `makepasswd` 命令来生成一个随机密码。
```
$ makepasswd
HdCJafVaN
```
在终端中像下面这样执行 `makepasswd` 命令来生成 14 字符长的随机强密码。
```
$ makepasswd --chars 14
HxJDv5quavrqmU
```
像下面这样执行 `makepasswd` 来生成 10 个 14 字符长的随机强密码。
```
$ makepasswd --chars 14 --count 10
TqmKVWnRGeoVNr
mPV2P98hLRUsai
MhMXPwyzYi2RLo
dxMGgLmoFpYivi
8p0G7JvJjd6qUP
7SmX95MiJcQauV
KWzrh5npAjvNmL
oHPKdq1uA9tU85
V1su9GjU2oIGiQ
M2TMCEoahzLNYC
```
### 如何在 Linux 系统中使用多个命令生成随机强密码?
如果你还在寻找其他的方案,下面的工具也可以用来在 Linux 中生成随机密码。
使用 `md5sum`:它是一个用来计算及校验 128 位 MD5 哈希的程序。
```
$ date | md5sum
9baf96fb6e8cbd99601d97a5c3acc2c4 -
```
使用 `/dev/urandom`: 两个特殊的字符文件 `/dev/random` 和 `/dev/urandom` (自 Linux 1.3.30 起出现)提供了内核随机数生成器的接口。`/dev/random` 的主设备号为 1,次设备号为 8。`/dev/urandom` 主设备号为 1,次设备号为 9。
```
$ cat /dev/urandom | tr -dc 'a-zA-Z0-9' | head -c 14
15LQB9J84Btnzz
```
使用 `sha256sum`:它被设计用来使用 SHA-256 算法(SHA-2 系列,摘要长度为 256 位)校验数据完整性。
```
$ date | sha256sum
a114ae5c458ae0d366e1b673d558d921bb937e568d9329b525cf32290478826a -
```
使用 `sha1pass`:它生成一个 SHA1 密码哈希。在命令缺少盐值的情况下,将会生成一个随机的盐值向量。
```
$ sha1pass
$4$9+JvykOv$e7U0jMJL2yBOL+RVa2Eke8SETEo$
```
---
via: <https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-linux-terminal/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[leommx](https://github.com/leommxj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,658 | 如何在 Linux 中添加新磁盘 | https://kerneltalks.com/hardware-config/how-to-add-new-disk-in-linux/ | 2019-03-27T13:24:53 | [
"磁盘",
"LVM"
] | https://linux.cn/article-10658-1.html |
>
> 在 Linux 机器中添加磁盘的逐步过程。
>
>
>

本文将向你介绍在 Linux 机器中添加新磁盘的步骤。将原始磁盘添加到 Linux 机器可能非常依赖于你所拥有的服务器类型,但是一旦将磁盘提供给机器,将其添加到挂载点的过程几乎相同。
**目标**:向服务器添加新的 10GB 磁盘,并使用 lvm 和新创建的卷组创建 5GB 装载点。
### 向 Linux 机器添加原始磁盘
如果你使用的是 AWS EC2 Linux 服务器,可以 [按照以下步骤](https://kerneltalks.com/cloud-services/how-to-add-ebs-disk-on-aws-linux-server/) 添加原始磁盘。如果使用的是 VMware Linux VM,那么需要按照不同的步骤来添加磁盘。如果你正在运行物理机架设备/刀片服务器,那么添加磁盘将是一项物理任务。
一旦磁盘物理/虚拟地连接到 Linux 机器上,它将被内核识别,就可以开始了。
### 识别 Linux 最新添加的磁盘
原始磁盘连接后,需要让内核去 [扫描新磁盘](https://kerneltalks.com/disk-management/howto-scan-new-lun-disk-linux-hpux/)。在新版中,它主要是由内核自动完成。
第一件事是在内核中识别新添加的磁盘及其名称。实现这一点的方法有很多,以下作少量列举:
* 可以在添加/扫描磁盘前后观察 `lsblk` 输出,以获取新的磁盘名。
* 检查 `/dev` 文件系统中新创建的磁盘文件。匹配文件和磁盘添加时间的时间戳。
* 观察 `fdisk-l` 添加/扫描磁盘前后的输出,以获取新的磁盘名。
在本示例中,我使用的是 AWS EC2 服务器,向服务器添加了 5GB 磁盘。我的 lsblk 输出如下:
```
[root@kerneltalks ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 10G 0 disk
├─xvda1 202:1 0 1M 0 part
└─xvda2 202:2 0 10G 0 part /
xvdf 202:80 0 10G 0 disk
```
可以看到 `xvdf` 是新添加的磁盘。完整路径是 `/dev/xvdf`。
### 在 LVM 中添加新磁盘
我们这里使用 LVM,因为它是 Linux 平台上广泛使用的非常灵活的卷管理器。确认 lvm 或 lvm2 软件包[已经安装在系统上](https://kerneltalks.com/tools/check-package-installed-linux/)。如未安装,请 [安装 lvm/lvm2 程序包](https://kerneltalks.com/tools/package-installation-linux-yum-apt/)。
现在,我们将在逻辑卷管理器中添加这个原始磁盘,并从中创建 10GB 的挂接点。所用到的命令如下:
* [pvcreate](https://kerneltalks.com/disk-management/lvm-command-tutorials-pvcreate-pvdisplay/)
* [vgcreate](https://kerneltalks.com/disk-management/lvm-commands-tutorial-vgcreate-vgdisplay-vgscan/)
* [lvcreate](https://kerneltalks.com/disk-management/lvm-commands-tutorial-lvcreate-lvdisplay-lvremove/)
如果要将磁盘添加到现有挂接点,并使用其空间来[扩展挂接点](https://kerneltalks.com/disk-management/extend-file-system-online-lvm/) ,则 `vgcreate` 应替换为 `vgextend`。
会话示例输出如下:
```
[root@kerneltalks ~]# pvcreate /dev/xvdf
Physical volume "/dev/xvdf" successfully created.
[root@kerneltalks ~]# vgcreate vgdata /dev/xvdf
Volume group "vgdata" successfully created
[root@kerneltalks ~]# lvcreate -L 5G -n lvdata vgdata
Logical volume "lvdata" created.
```
现在,已完成逻辑卷创建。你需要使用所选的文件系统格式化它,并将其挂载。在这里选择 ext4 文件系统,并使用 `mkfs.ext4` 进行格式化。
```
[root@kerneltalks ~]# mkfs.ext4 /dev/vgdata/lvdata
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
327680 inodes, 1310720 blocks
65536 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1342177280
40 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
```
### 在挂载点上从新磁盘挂载卷
使用 `mount` 命令,在 `/data` 安装点上安装已创建并格式化的 5GB 逻辑卷。
```
[root@kerneltalks ~]# mount /dev/vgdata/lvdata /data
[root@kerneltalks ~]# df -Ph /data
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vgdata-lvdata 4.8G 20M 4.6G 1% /data
```
使用 `df` 命令验证挂载点。如上所述,你都完成了!你可以在 [/etc/fstab](https://kerneltalks.com/config/understanding-etcfstab-file/) 中添加一个条目,以便在重新启动时保持此装载。
你已将 10GB 磁盘连接到 Linux 计算机,并创建了 5GB 挂载点!
---
via: <https://kerneltalks.com/hardware-config/how-to-add-new-disk-in-linux/>
作者:[kerneltalks](https://kerneltalks.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[luckyele](https://github.com/luckyele) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Step by step procedure to add disk in Linux machine*

In this article, we will walk you through steps to add a new disk in the Linux machine. Adding a raw disk to the Linux machine may vary depending upon the type of server you have but once the disk is presented to the machine, the procedure of getting it to mount points is almost the same.
**Objective**: Add a new 10GB disk to the server and create a 5GB mount point out of it using LVM and newly created volume group.
#### Adding raw disk to Linux machine
If you are using the AWS EC2 Linux server, you may [follow these steps](https://kerneltalks.com/cloud-services/how-to-add-ebs-disk-on-aws-linux-server/) to add raw disk. If you are on VMware Linux VM you will have a different set of steps to follow to add disk. If you are running a physical rack-mount/blade server then adding disk will be a physical task.
Now once the disk is attached to the Linux machine physically/virtually, it will be identified by the kernel and then our rally starts.
#### Identifying newly added disk in Linux
After the attachment of the raw disk, you need to ask the kernel to [scan a new disk](https://kerneltalks.com/disk-management/howto-scan-new-lun-disk-linux-hpux/). Mostly it’s done now automatically by the kernel in new versions.
First thing is to identify the newly added disk and its name in the kernel. There are numerous ways to achieve this. I will list a few –
- You can observer
`lsblk`
output before and after adding/scanning disk to get a new disk name. - Check newly created disk files in
`/dev`
filesystem. Match timestamp of file and disk addition time. - Observer
`fdisk -l`
output before and after adding/scanning disk to get a new disk name.
For our example, I am using the AWS EC2 server and I added 5GB disk to my server. here is my `lsblk`
output –
```
[root@kerneltalks ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 10G 0 disk
├─xvda1 202:1 0 1M 0 part
└─xvda2 202:2 0 10G 0 part /
xvdf 202:80 0 10G 0 disk
```
You can see xvdf is our newly added disk. Full path for disk is `/dev/xvdf`
.
#### Add new disk in LVM
We are using LVM here since its widely used and flexible volume manager on the Linux platform. Make sure you have `lvm`
or `lvm2`
[package installed on your system](https://kerneltalks.com/tools/check-package-installed-linux/). If not, [install lvm/lvm2 package](https://kerneltalks.com/tools/package-installation-linux-yum-apt/).
Now, we are going to add this RAW disk in Logical Volume Manager and create 10GB of mount point out of it. List of commands you need to follow are –
If you are willing to add a disk to the existing mount point and use its space to [extend mount point](https://kerneltalks.com/disk-management/extend-file-system-online-lvm/) then `vgcreate `
should be replaced by `vgextend`
.
Sample outputs from my session –
```
[root@kerneltalks ~]# pvcreate /dev/xvdf
Physical volume "/dev/xvdf" successfully created.
[root@kerneltalks ~]# vgcreate vgdata /dev/xvdf
Volume group "vgdata" successfully created
[root@kerneltalks ~]# lvcreate -L 5G -n lvdata vgdata
Logical volume "lvdata" created.
```
Now, you have a logical volume created. You need to format it with the filesystem on your choice and mount it. We are choosing ext4 filesystem here and formatting using `mkfs.ext4`
.
```
[root@kerneltalks ~]# mkfs.ext4 /dev/vgdata/lvdata
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
327680 inodes, 1310720 blocks
65536 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1342177280
40 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
```
#### Mounting volume from new disk on mount point
Lets mount the logical volume of 5GB which we created and formatted on `/data`
mount point using `mount`
command.
```
[root@kerneltalks ~]# mount /dev/vgdata/lvdata /data
[root@kerneltalks ~]# df -Ph /data
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vgdata-lvdata 4.8G 20M 4.6G 1% /data
```
Verify your mount point with df command as above and you are all done! You can always add an entry in [/etc/fstab](https://kerneltalks.com/config/understanding-etcfstab-file/) to make this mount persistent over reboots.
You have attached a 10GB disk to the Linux machine and created a 5GB mount point out of it!
Good stuff.Please look at below it have more options how to do same in veritas as well.
How to create File system in Linux under LVM & VxVM
Cheers !!! |
10,659 | 如何打造更小巧的容器镜像 | https://opensource.com/article/18/7/building-container-images | 2019-03-27T23:07:29 | [
"容器",
"镜像"
] | https://linux.cn/article-10659-1.html |
>
> 五种优化 Linux 容器大小和构建更小的镜像的方法。
>
>
>

[Docker](https://www.docker.com/) 近几年的爆炸性发展让大家逐渐了解到容器和容器镜像的概念。尽管 Linux 容器技术在很早之前就已经出现,但这项技术近来的蓬勃发展却还是要归功于 Docker 对用户友好的命令行界面以及使用 Dockerfile 格式轻松构建镜像的方式。纵然 Docker 大大降低了入门容器技术的难度,但构建一个兼具功能强大、体积小巧的容器镜像的过程中,有很多技巧需要了解。
### 第一步:清理不必要的文件
这一步和在普通服务器上清理文件没有太大的区别,而且要清理得更加仔细。一个小体积的容器镜像在传输方面有很大的优势,同时,在磁盘上存储不必要的数据的多个副本也是对资源的一种浪费。因此,这些技术对于容器来说应该比有大量专用内存的服务器更加需要。
清理容器镜像中的缓存文件可以有效缩小镜像体积。下面的对比是使用 `dnf` 安装 [Nginx](https://www.nginx.com/) 构建的镜像,分别是清理和没有清理 yum 缓存文件的结果:
```
# Dockerfile with cache
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y nginx
-----
# Dockerfile w/o cache
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y nginx \
&& dnf clean all \
&& rm -rf /var/cache/yum
-----
[chris@krang] $ docker build -t cache -f Dockerfile .
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}"
| head -n 1
cache: 464 MB
[chris@krang] $ docker build -t no-cache -f Dockerfile-wo-cache .
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
no-cache: 271 MB
```
从上面的结果来看,清理缓存文件的效果相当显著。和清除了元数据和缓存文件的容器镜像相比,不清除的镜像体积接近前者的两倍。除此以外,包管理器缓存文件、Ruby gem 的临时文件、nodejs 缓存文件,甚至是下载的源码 tarball 最好都全部清理掉。
### 层:一个潜在的隐患
很不幸(当你往下读,你会发现这是不幸中的万幸),根据容器中的层的概念,不能简单地向 Dockerfile 中写一句 `RUN rm -rf /var/cache/yum` 就完事儿了。因为 Dockerfile 的每一条命令都以一个层的形式存储,并一层层地叠加。所以,如果你是这样写的:
```
RUN dnf install -y nginx
RUN dnf clean all
RUN rm -rf /var/cache/yum
```
你的容器镜像就会包含三层,而 `RUN dnf install -y nginx` 这一层仍然会保留着那些缓存文件,然后在另外两层中被移除。但缓存实际上仍然是存在的,当你把一个文件系统挂载在另外一个文件系统之上时,文件仍然在那里,只不过你见不到也访问不到它们而已。
在上一节的示例中,你会看到正确的做法是将几条命令链接起来,在产生缓存文件的同一条 Dockerfile 指令里把缓存文件清理掉:
```
RUN dnf install -y nginx \
&& dnf clean all \
&& rm -rf /var/cache/yum
```
这样就把几条命令连成了一条命令,在最终的镜像中只占用一个层。这样只会浪费一点缓存的好处,稍微多耗费一点点构建容器镜像的时间,但被清理掉的缓存文件就不会留存在最终的镜像中了。作为一个折衷方法,只需要把一些相关的命令(例如 `yum install` 和 `yum clean all`、下载文件、解压文件、移除 tarball 等等)连接成一个命令,就可以在最终的容器镜像中节省出大量体积,你也能够利用 Docker 的缓存加快开发速度。
层还有一个更隐蔽的特性。每一层都记录了文件的更改,这里的更改并不仅仅已有的文件累加起来,而是包括文件属性在内的所有更改。因此即使是对文件使用了 `chmod` 操作也会被在新的层创建文件的副本。
下面是一次 `docker images` 命令的输出内容。其中容器镜像 `layer_test_1` 是在 CentOS 基础镜像中增加了一个 1GB 大小的文件后构建出来的镜像,而容器镜像 `layer_test_2` 是使用了 `FROM layer_test_1` 语句创建出来的,除了执行一条 `chmod u+x` 命令没有做任何改变。
```
layer_test_2 latest e11b5e58e2fc 7 seconds ago 2.35 GB
layer_test_1 latest 6eca792a4ebe 2 minutes ago 1.27 GB
```
如你所见,`layer_test_2` 镜像比 `layer_test_1` 镜像大了 1GB 以上。尽管事实上 `layer_test_1` 只是 `layer_test_2` 的前一层,但隐藏在这第二层中有一个额外的 1GB 的文件。在构建容器镜像的过程中,如果在单独一层中进行移动、更改、删除文件,都会出现类似的结果。
### 专用镜像和公用镜像
有这么一个亲身经历:我们部门重度依赖于 [Ruby on Rails](https://rubyonrails.org/),于是我们开始使用容器。一开始我们就建立了一个正式的 Ruby 的基础镜像供所有的团队使用,为了简单起见(以及在“这就是我们自己在服务器上瞎鼓捣的”想法的指导下),我们使用 [rbenv](https://github.com/rbenv/rbenv) 将 Ruby 最新的 4 个版本都安装到了这个镜像当中,目的是让开发人员只用这个单一的镜像就可以将使用不同版本 Ruby 的应用程序迁移到容器中。我们当时还认为这是一个虽然非常大但兼容性相当好的镜像,因为这个镜像可以同时满足各个团队的使用。
实际上这是费力不讨好的。如果维护独立的、版本略微不同的镜像中,可以很轻松地实现镜像的自动化维护。同时,选择特定版本的特定镜像,还有助于在引入破坏性改变,在应用程序接近生命周期结束前提前做好预防措施,以免产生不可控的后果。庞大的公用镜像也会对资源造成浪费,当我们后来将这个庞大的镜像按照 Ruby 版本进行拆分之后,我们最终得到了共享一个基础镜像的多个镜像,如果它们都放在一个服务器上,会额外多占用一点空间,但是要比安装了多个版本的巨型镜像要小得多。
这个例子也不是说构建一个灵活的镜像是没用的,但仅对于这个例子来说,从一个公共镜像创建根据用途而构建的镜像最终将节省存储资源和维护成本,而在受益于公共基础镜像的好处的同时,每个团队也能够根据需要来做定制化的配置。
### 从零开始:将你需要的内容添加到空白镜像中
有一些和 Dockerfile 一样易用的工具可以轻松创建非常小的兼容 Docker 的容器镜像,这些镜像甚至不需要包含一个完整的操作系统,就可以像标准的 Docker 基础镜像一样小。
我曾经写过一篇[关于 Buildah 的文章](https://opensource.com/article/18/6/getting-started-buildah),我想在这里再一次推荐一下这个工具。因为它足够的灵活,可以使用宿主机上的工具来操作一个空白镜像并安装打包好的应用程序,而且这些工具不会被包含到镜像当中。
Buildah 取代了 `docker build` 命令。可以使用 Buildah 将容器的文件系统挂载到宿主机上并进行交互。
下面来使用 Buildah 实现上文中 Nginx 的例子(现在忽略了缓存的处理):
```
#!/usr/bin/env bash
set -o errexit
# Create a container
container=$(buildah from scratch)
# Mount the container filesystem
mountpoint=$(buildah mount $container)
# Install a basic filesystem and minimal set of packages, and nginx
dnf install --installroot $mountpoint --releasever 28 glibc-minimal-langpack nginx --setopt install_weak_deps=false -y
# Save the container to an image
buildah commit --format docker $container nginx
# Cleanup
buildah unmount $container
# Push the image to the Docker daemon’s storage
buildah push nginx:latest docker-daemon:nginx:latest
```
你会发现这里使用的已经不再是 Dockerfile 了,而是普通的 Bash 脚本,而且是从框架(或空白)镜像开始构建的。上面这段 Bash 脚本将容器的根文件系统挂载到了宿主机上,然后使用宿主机的命令来安装应用程序,这样的话就不需要把软件包管理器放置到容器镜像中了。
这样所有无关的内容(基础镜像之外的部分,例如 `dnf`)就不再会包含在镜像中了。在这个例子当中,构建出来的镜像大小只有 304 MB,比使用 Dockerfile 构建的镜像减少了 100 MB 以上。
```
[chris@krang] $ docker images |grep nginx
docker.io/nginx buildah 2505d3597457 4 minutes ago 304 MB
```
注:这个镜像是使用上面的构建脚本构建的,镜像名称中前缀的 `docker.io` 只是在推送到镜像仓库时加上的。
对于一个 300MB 级别的容器基础镜像来说,能缩小 100MB 已经是很显著的节省了。使用软件包管理器来安装 Nginx 会带来大量的依赖项,如果能够使用宿主机直接从源代码对应用程序进行编译然后构建到容器镜像中,节省出来的空间还可以更多,因为这个时候可以精细的选用必要的依赖项,非必要的依赖项一概不构建到镜像中。
[Tom Sweeney](https://twitter.com/TSweeneyRedHat) 有一篇文章《[用 Buildah 构建更小的容器](https://opensource.com/article/18/5/containers-buildah)》,如果你想在这方面做深入的优化,不妨参考一下。
通过 Buildah 可以构建一个不包含完整操作系统和代码编译工具的容器镜像,大幅缩减了容器镜像的体积。对于某些类型的镜像,我们可以进一步采用这种方式,创建一个只包含应用程序本身的镜像。
### 使用静态链接的二进制文件来构建镜像
按照这个思路,我们甚至可以更进一步舍弃容器内部的管理和构建工具。例如,如果我们足够专业,不需要在容器中进行排错调试,是不是可以不要 Bash 了?是不是可以不要 [GNU 核心套件](https://www.gnu.org/software/coreutils/coreutils.html)了?是不是可以不要 Linux 基础文件系统了?如果你使用的编译型语言支持[静态链接库](https://en.wikipedia.org/wiki/Static_library),将应用程序所需要的所有库和函数都编译成二进制文件,那么程序所需要的函数和库都可以复制和存储在二进制文件本身里面。
这种做法在 [Golang](https://golang.org/) 社区中已经十分常见,下面我们使用由 Go 语言编写的应用程序进行展示:
以下这个 Dockerfile 基于 golang:1.8 镜像构建一个小的 Hello World 应用程序镜像:
```
FROM golang:1.8
ENV GOOS=linux
ENV appdir=/go/src/gohelloworld
COPY ./ /go/src/goHelloWorld
WORKDIR /go/src/goHelloWorld
RUN go get
RUN go build -o /goHelloWorld -a
CMD ["/goHelloWorld"]
```
构建出来的镜像中包含了二进制文件、源代码以及基础镜像层,一共 716MB。但对于应用程序运行唯一必要的只有编译后的二进制文件,其余内容在镜像中都是多余的。
如果在编译的时候通过指定参数 `CGO_ENABLED=0` 来禁用 `cgo`,就可以在编译二进制文件的时候忽略某些函数的 C 语言库:
```
GOOS=linux CGO_ENABLED=0 go build -a goHelloWorld.go
```
编译出来的二进制文件可以加到一个空白(或框架)镜像:
```
FROM scratch
COPY goHelloWorld /
CMD ["/goHelloWorld"]
```
来看一下两次构建的镜像对比:
```
[ chris@krang ] $ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
goHello scratch a5881650d6e9 13 seconds ago 1.55 MB
goHello builder 980290a100db 14 seconds ago 716 MB
```
从镜像体积来说简直是天差地别了。基于 golang:1.8 镜像构建出来带有 goHelloWorld 二进制的镜像(带有 `builder` 标签)体积是基于空白镜像构建的只包含该二进制文件的镜像的 460 倍!后者的整个镜像大小只有 1.55MB,也就是说,有 713MB 的数据都是非必要的。
正如上面提到的,这种缩减镜像体积的方式在 Golang 社区非常流行,因此不乏这方面的文章。[Kelsey Hightower](https://twitter.com/kelseyhightower) 有一篇[文章](https://medium.com/@kelseyhightower/optimizing-docker-images-for-static-binaries-b5696e26eb07)专门介绍了如何处理这些库的依赖关系。
### 压缩镜像层
除了前面几节中讲到的将多个命令链接成一个命令的技巧,还可以对镜像进行压缩。镜像压缩的实质是导出它,删除掉镜像构建过程中的所有中间层,然后保存镜像的当前状态为单个镜像层。这样可以进一步将镜像缩小到更小的体积。
在 Docker 1.13 之前,压缩镜像层的的过程可能比较麻烦,需要用到 `docker-squash` 之类的工具来导出容器的内容并重新导入成一个单层的镜像。但 Docker 在 Docker 1.13 中引入了 `--squash` 参数,可以在构建过程中实现同样的功能:
```
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y nginx
RUN dnf clean all
RUN rm -rf /var/cache/yum
[chris@krang] $ docker build -t squash -f Dockerfile-squash --squash .
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
squash: 271 MB
```
通过这种方式使用 Dockerfile 构建出来的镜像有 271MB 大小,和上面连接多条命令的方案构建出来的镜像体积一样,因此这个方案也是有效的,但也有一个潜在的问题,而且是另一种问题。
“什么?还有另外的问题?”
好吧,有点像以前一样的问题,以另一种方式引发了问题。
### 过头了:过度压缩、太小太专用了
容器镜像之间可以共享镜像层。基础镜像或许大小上有几 Mb,但它只需要拉取/存储一次,并且每个镜像都能复用它。所有共享基础镜像的实际镜像大小是基础镜像层加上每个特定改变的层的差异内容,因此,如果有数千个基于同一个基础镜像的容器镜像,其体积之和也有可能只比一个基础镜像大不了多少。
因此,这就是过度使用压缩或专用镜像层的缺点。将不同镜像压缩成单个镜像层,各个容器镜像之间就没有可以共享的镜像层了,每个容器镜像都会占有单独的体积。如果你只需要维护少数几个容器镜像来运行很多容器,这个问题可以忽略不计;但如果你要维护的容器镜像很多,从长远来看,就会耗费大量的存储空间。
回顾上面 Nginx 压缩的例子,我们能看出来这种情况并不是什么大的问题。在这个镜像中,有 Fedora 操作系统和 Nginx 应用程序,没有缓存,并且已经被压缩。但我们一般不会使用一个原始的 Nginx,而是会修改配置文件,以及引入其它代码或应用程序来配合 Nginx 使用,而要做到这些,Dockerfile 就变得更加复杂了。
如果使用普通的镜像构建方式,构建出来的容器镜像就会带有 Fedora 操作系统的镜像层、一个安装了 Nginx 的镜像层(带或不带缓存)、为 Nginx 作自定义配置的其它多个镜像层,而如果有其它容器镜像需要用到 Fedora 或者 Nginx,就可以复用这个容器镜像的前两层。
```
[ App 1 Layer ( 5 MB) ] [ App 2 Layer (6 MB) ]
[ Nginx Layer ( 21 MB) ] ------------------^
[ Fedora Layer (249 MB) ]
```
如果使用压缩镜像层的构建方式,Fedora 操作系统会和 Nginx 以及其它配置内容都被压缩到同一层里面,如果有其它容器镜像需要使用到 Fedora,就必须重新引入 Fedora 基础镜像,这样每个容器镜像都会额外增加 249MB 的大小。
```
[ Fedora + Nginx + App 1 (275 MB)] [ Fedora + Nginx + App 2 (276 MB) ]
```
当你构建了大量在功能上趋于分化的的小型容器镜像时,这个问题就会暴露出来了。
就像生活中的每一件事一样,关键是要做到适度。根据镜像层的实现原理,如果一个容器镜像变得越小、越专用化,就越难和其它容器镜像共享基础的镜像层,这样反而带来不好的效果。
对于仅在基础镜像上做微小变动构建出来的多个容器镜像,可以考虑共享基础镜像层。如上所述,一个镜像层本身会带有一定的体积,但只要存在于镜像仓库中,就可以被其它容器镜像复用。这种情况下,数千个镜像也许要比单个镜像占用更少的空间。
```
[ specific app ] [ specific app 2 ]
[ customizations ]--------------^
[ base layer ]
```
一个容器镜像变得越小、越专用化,就越难和其它容器镜像共享基础的镜像层,最终会不必要地占用越来越多的存储空间。
```
[ specific app 1 ] [ specific app 2 ] [ specific app 3 ]
```
### 总结
减少处理容器镜像时所需的存储空间和带宽的方法有很多,其中最直接的方法就是减小容器镜像本身的大小。在使用容器的过程中,要经常留意容器镜像是否体积过大,根据不同的情况采用上述提到的清理缓存、压缩到一层、将二进制文件加入在空白镜像中等不同的方法,将容器镜像的体积缩减到一个有效的大小。
---
via: <https://opensource.com/article/18/7/building-container-images>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When [Docker](https://www.docker.com/) exploded onto the scene a few years ago, it brought containers and container images to the masses. Although Linux containers existed before then, Docker made it easy to get started with a user-friendly command-line interface and an easy-to-understand way to build images using the Dockerfile format. But while it may be easy to jump in, there are still some nuances and tricks to building container images that are usable, even powerful, but still small in size.
## First pass: Clean up after yourself
Some of these examples involve the same kind of cleanup you would use with a traditional server, but more rigorously followed. Smaller image sizes are critical for quickly moving images around, and storing multiple copies of unnecessary data on disk is a waste of resources. Consequently, these techniques should be used more regularly than on a server with lots of dedicated storage.
An example of this kind of cleanup is removing cached files from an image to recover space. Consider the difference in size between a base image with [Nginx](https://www.nginx.com/) installed by `dnf`
with and without the metadata and yum cache cleaned up:
```
``````
# Dockerfile with cache
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y nginx
-----
# Dockerfile w/o cache
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y nginx \
&& dnf clean all \
&& rm -rf /var/cache/yum
-----
[chris@krang] $ docker build -t cache -f Dockerfile .
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}"
| head -n 1
cache: 464 MB
[chris@krang] $ docker build -t no-cache -f Dockerfile-wo-cache .
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
no-cache: 271 MB
```
That is a significant difference in size. The version with the `dnf`
cache is almost twice the size of the image without the metadata and cache. Package manager cache, Ruby gem temp files, `nodejs`
cache, even downloaded source tarballs are all perfect candidates for cleaning up.
## Layers—a potential gotcha
Unfortunately (or fortunately, as you’ll see later), based on the way layers work with containers, you cannot simply add a `RUN rm -rf /var/cache/yum`
line to your Dockerfile and call it a day. Each instruction of a Dockerfile is stored in a layer, with changes between layers applied on top. So even if you were to do this:
```
``````
RUN dnf install -y nginx
RUN dnf clean all
RUN rm -rf /var/cache/yum
```
...you’d still end up with three layers, one of which contains all the cache, and two intermediate layers that "remove" the cache from the image. But the cache is actually still there, just as when you mount a filesystem over the top of another one, the files are there—you just can’t see or access them.
You’ll notice that the example in the previous section chains the cache cleanup in the same Dockerfile instruction where the cache is generated:
```
``````
RUN dnf install -y nginx \
&& dnf clean all \
&& rm -rf /var/cache/yum
```
This is a single instruction and ends up being a single layer within the image. You’ll lose a bit of the Docker (*ahem*) cache this way, making a rebuild of the image slightly longer, but the cached data will not end up in your final image. As a nice compromise, just chaining related commands (e.g., `yum install`
and `yum clean all`
, or downloading, extracting and removing a source tarball, etc.) can save a lot on your final image size while still allowing you to take advantage of the Docker cache for quicker development.
This layer "gotcha" is more subtle than it first appears, though. Because the image layers document the *changes* to each layer, one upon another, it’s not just the existence of files that add up, but any change to the file. For example, *even changing the mode* of the file creates a copy of that file in the new layer.
For example, the output of `docker images`
below shows information about two images. The first, `layer_test_1`
, was created by adding a single 1GB file to a base CentOS image. The second image, `layer_test_2`
, was created `FROM layer_test_1`
and did nothing but change the mode of the 1GB file with `chmod u+x`
.
```
``````
layer_test_2 latest e11b5e58e2fc 7 seconds ago 2.35 GB
layer_test_1 latest 6eca792a4ebe 2 minutes ago 1.27 GB
```
As you can see, the new image is more than 1GB larger than the first. Despite the fact that `layer_test_1`
is only the first two layers of `layer_test_2`
, there’s still an extra 1GB file floating around hidden inside the second image. This is true anytime you remove, move, or change any file during the image build process.
## Purpose-built images vs. flexible images
An anecdote: As my office heavily invested in [Ruby on Rails](https://rubyonrails.org/) applications, we began to embrace the use of containers. One of the first things we did was to create an official Ruby base image for all of our teams to use. For simplicity’s sake (and suffering under “this is the way we did it on our servers”), we used [rbenv](https://github.com/rbenv/rbenv) to install the latest four versions of Ruby into the image, allowing our developers to migrate all of their applications into containers using a single image. This resulted in a very large but flexible (we thought) image that covered all the bases of the various teams we were working with.
This turned out to be wasted work. The effort required to maintain separate, slightly modified versions of a particular image was easy to automate, and selecting a specific image with a specific version actually helped to identify applications approaching end-of-life before a breaking change was introduced, wreaking havoc downstream. It also wasted resources: When we started to split out the different versions of Ruby, we ended up with multiple images that shared a single base and took up very little extra space if they coexisted on a server, but were considerably smaller to ship around than a giant image with multiple versions installed.
That is not to say building flexible images is not helpful, but in this case, creating purpose-build images from a common base ended up saving both storage space and maintenance time, and each team could modify their setup however they needed while maintaining the benefit of the common base image.
## Start without the cruft: Add what you need to a blank image
As friendly and easy-to-use as the *Dockerfile* is, there are tools available that offer the flexibility to create very small Docker-compatible container images without the cruft of a full operating system—even those as small as the standard Docker base images.
[I’ve written about Buildah before](https://opensource.com/article/18/6/getting-started-buildah), and I’ll mention it again because it is flexible enough to create an image from scratch using tools from your host to install packaged software and manipulate the image. Those tools then never need to be included in the image itself.
Buildah replaces the `docker build`
command. With it, you can mount the filesystem of your container image to your host machine and interact with it using tools from the host.
Let’s try Buildah with the Nginx example from above (ignoring caches for now):
```
``````
#!/usr/bin/env bash
set -o errexit
# Create a container
container=$(buildah from scratch)
# Mount the container filesystem
mountpoint=$(buildah mount $container)
# Install a basic filesystem and minimal set of packages, and nginx
dnf install --installroot $mountpoint --releasever 28 glibc-minimal-langpack nginx --setopt install_weak_deps=false -y
# Save the container to an image
buildah commit --format docker $container nginx
# Cleanup
buildah unmount $container
# Push the image to the Docker daemon’s storage
buildah push nginx:latest docker-daemon:nginx:latest
```
You’ll notice we’re no longer using a Dockerfile to build the image, but a simple Bash script, and we’re building it from a scratch (or blank) image. The Bash script mounts the container’s root filesystem to a mount point on the host, and then uses the hosts’ command to install the packages. This way the package manager doesn’t even have to exist inside the container.
Without extra cruft—all the extra stuff in the base image, like `dnf`
, for example—the image weighs in at only 304 MB, more than 100 MB smaller than the Nginx image built with a Dockerfile above.
```
``````
[chris@krang] $ docker images |grep nginx
docker.io/nginx buildah 2505d3597457 4 minutes ago 304 MB
```
*Note: The image name has docker.io appended to it due to the way the image is pushed into the Docker daemon’s namespace, but it is still the image built locally with the build script above.*
That 100 MB is already a huge savings when you consider a base image is already around 300 MB on its own. Installing Nginx with a package manager brings in a ton of dependencies, too. For something compiled from source using tools from the host, the savings can be even greater because you can choose the exact dependencies and not pull in any extra files you don’t need.
If you’d like to try this route, [Tom Sweeney](https://twitter.com/TSweeneyRedHat) wrote a much more in-depth article, [Creating small containers with Buildah](https://opensource.com/article/18/5/containers-buildah), which you should check out.
Using Buildah to build images without a full operating system and included build tools can enable much smaller images than you would otherwise be able to create. For some types of images, we can take this approach even further and create images with *only* the application itself included.
## Create images with only statically linked binaries
Following the same philosophy that leads us to ditch administrative and build tools inside images, we can go a step further. If we specialize enough and abandon the idea of troubleshooting inside of production containers, do we need Bash? Do we need the [GNU core utilities](https://www.gnu.org/software/coreutils/coreutils.html)? Do we *really* need the basic Linux filesystem? You can do this with any compiled language that allows you to create binaries with [statically linked libraries](https://en.wikipedia.org/wiki/Static_library)—where all the libraries and functions needed by the program are copied into and stored within the binary itself.
This is a relatively popular way of doing things within the [Golang](https://golang.org/) community, so we’ll use a Go application to demonstrate.
The Dockerfile below takes a small Go Hello-World application and compiles it in an image `FROM golang:1.8`
:
```
``````
FROM golang:1.8
ENV GOOS=linux
ENV appdir=/go/src/gohelloworld
COPY ./ /go/src/goHelloWorld
WORKDIR /go/src/goHelloWorld
RUN go get
RUN go build -o /goHelloWorld -a
CMD ["/goHelloWorld"]
```
The resulting image, containing the binary, the source code, and the base image layer comes in at 716 MB. The only thing we actually need for our application is the compiled binary, however. Everything else is unused cruft that gets shipped around with our image.
If we disable `cgo`
with `CGO_ENABLED=0`
when we compile, we can create a binary that doesn’t wrap C libraries for some of its functions:
```
````GOOS=linux CGO_ENABLED=0 go build -a goHelloWorld.go`
The resulting binary can be added to an empty, or "scratch" image:
```
``````
FROM scratch
COPY goHelloWorld /
CMD ["/goHelloWorld"]
```
Let’s compare the difference in image size between the two:
```
``````
[ chris@krang ] $ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
goHello scratch a5881650d6e9 13 seconds ago 1.55 MB
goHello builder 980290a100db 14 seconds ago 716 MB
```
That’s a huge difference. The image built from `golang:1.8`
with the `goHelloWorld`
binary in it (tagged "builder" above) is *460* times larger than the scratch image with just the binary. The entirety of the scratch image with the binary is only 1.55 MB. That means we’d be shipping around 713 MB of unnecessary data if we used the builder image.
As mentioned above, this method of creating small images is used often in the Golang community, and there is no shortage of blog posts on the subject. [Kelsey Hightower](https://twitter.com/kelseyhightower) wrote [an article on the subject](https://medium.com/@kelseyhightower/optimizing-docker-images-for-static-binaries-b5696e26eb07) that goes into more detail, including dealing with dependencies other than just C libraries.
## Consider squashing, if it works for you
There’s an alternative to chaining all the commands into layers in an attempt to save space: Squashing your image. When you squash an image, you’re really exporting it, removing all the intermediate layers, and saving a single layer with the current state of the image. This has the advantage of reducing that image to a much smaller size.
Squashing layers used to require some creative workarounds to flatten an image—exporting the contents of a container and re-importing it as a single layer image, or using tools like `docker-squash`
. Starting in version 1.13, Docker introduced a handy flag, `--squash`
, to accomplish the same thing during the build process:
```
``````
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y nginx
RUN dnf clean all
RUN rm -rf /var/cache/yum
[chris@krang] $ docker build -t squash -f Dockerfile-squash --squash .
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
squash: 271 MB
```
Using `docker squash`
with this multi-layer Dockerfile, we end up with another 271MB image, as we did with the chained instruction example. This works great for this use case, but there’s a potential gotcha.
“What? ANOTHER gotcha?”
Well, sort of—it’s the same issue as before, causing problems in another way.
## Going too far: Too squashed, too small, too specialized
Images can share layers. The base may be *x* megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images sharing layers is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
This is a drawback with squashing or specializing too much. When you squash an image into a single layer, you lose any opportunity to share layers with other images. Each image ends up being as large as the total size of its single layer. This might work well for you if you use only a few images and run many containers from them, but if you have many diverse images, it could end up costing you space in the long run.
Revisiting the Nginx squash example, we can see it’s not a big deal for this case. We end up with Fedora, Nginx installed, no cache, and squashing that is fine. Nginx by itself is not incredibly useful, though. You generally need customizations to do anything interesting—e.g., configuration files, other software packages, maybe some application code. Each of these would end up being more instructions in the Dockerfile.
With a traditional image build, you would have a single base image layer with Fedora, a second layer with Nginx installed (with or without cache), and then each customization would be another layer. Other images with Fedora and Nginx could share these layers.
Need an image:
```
``````
[ App 1 Layer ( 5 MB) ] [ App 2 Layer (6 MB) ]
[ Nginx Layer ( 21 MB) ] ------------------^
[ Fedora Layer (249 MB) ]
```
But if you squash the image, then even the Fedora base layer is squashed. Any squashed image based on Fedora has to ship around its own Fedora content, adding another 249 MB for *each image!*
```
````[ Fedora + Nginx + App 1 (275 MB)] [ Fedora + Nginx + App 2 (276 MB) ] `
This also becomes a problem if you build lots of highly specialized, super-tiny images.
As with everything in life, moderation is key. Again, thanks to how layers work, you will find diminishing returns as your container images become smaller and more specialized and can no longer share base layers with other related images.
Images with small customizations can share base layers. As explained above, the base may be *x* megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
```
``````
[ specific app ] [ specific app 2 ]
[ customizations ]--------------^
[ base layer ]
```
If you go too far with your image shrinking and you have too many variations or specializations, you can end up with many images, none of which share base layers and all of which take up their own space on disk.
```
```` [ specific app 1 ] [ specific app 2 ] [ specific app 3 ]`
## Conclusion
There are a variety of different ways to reduce the amount of storage space and bandwidth you spend working with container images, but the most effective way is to reduce the size of the images themselves. Whether you simply clean up your caches (avoiding leaving them orphaned in intermediate layers), squash all your layers into one, or add only static binaries in an empty image, it’s worth spending some time looking at where bloat might exist in your container images and slimming them down to an efficient size.
## 3 Comments |
10,661 | 树莓派使用入门:可以使用树莓派学习的 3 种流行编程语言 | https://opensource.com/article/19/3/programming-languages-raspberry-pi | 2019-03-28T09:28:19 | [
"树莓派",
"编程"
] | https://linux.cn/article-10661-1.html |
>
> 通过树莓派学习编程,让你在就业市场上更值钱。
>
>
>

在本系列的上一篇文章中,我分享了 [教孩子们使用树莓派编程](/article-10653-1.html) 的一些方式。理论上,这些资源并不局限于只适用于孩子们,成人也是可以使用的。但是学习就业市场上急需的编程语言,可以让你得到更好的机会。
这里是你可以使用树莓派学习的三种编程语言。
### Python
[Python](https://opensource.com/resources/python) 已经成为开源世界里 [最流行的编程语言](https://www.economist.com/graphic-detail/2018/07/26/python-is-becoming-the-worlds-most-popular-coding-language)。它的解释器已经打包进每个流行的 Linux 发行版中。如果你在树莓派中安装的是 Raspbian,你就会看到一个名为 [Thonny](https://thonny.org/) 的应用,它是为新手准备的 Python 集成开发环境。简单来说,一个集成开发环境就是能够提供让你的代码运行起来所需要的任何东西的一个应用程序,一般来说,包括调试器、文档、自动编译,和仿真程序。[这是一个在树莓派上使用 Thonny 和 Python 入门的非常好的小教程](https://raspberrypihq.com/getting-started-with-python-programming-and-the-raspberry-pi/)。

### Java
虽然 [Java](https://opensource.com/resources/java) 已经不像以前那样引人注目了,但它仍然在世界各地的大学和企业中占据着重要的地位。因此,即便是一些人对我建议新手学习 Java 持反对意见,但我仍然强烈推荐大家去学习 Java;之所以这么做,原因之一是,它仍然很流行,原因之二是,它有大量的便于你学习的图书、课程和其它的可用信息。在树莓派上学习它,你可以从使用 Java 集成开发环境 [BlueJ](https://www.bluej.org/raspberrypi/) 开始。

### JavaScript
“我的黄金时代…" [JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript) 的本质是一个允许用户去组织和自动化浏览器中的用户事件以及修改 HTML 元素的客户端语言。目前,JavaScript 已经不仅限于浏览器中,它在其它类型的客户端(移动应用)中也是可以使用的,甚至也用在服务器端编程。[Node.js](https://nodejs.org/en/) 是一个流行的运行时环境,它允许开发者在客户端-浏览器范式之外写程序。想学习在树莓派上运行 Node.js 的更多知识,请查看 [W3Schools 教程](https://www.w3schools.com/nodejs/nodejs_raspberrypi.asp)。
### 其它编程语言
如果这里没有列出你想学习的编程语言,别失望。你可以使用你的树莓派去编译或解释任何你选择的语言,包括 C、C++、PHP 和 Ruby,这种可能性还是很大的。
微软的 [Visual Studio Code](https://code.visualstudio.com/) 也可以运行在 [树莓派](https://pimylifeup.com/raspberry-pi-visual-studio-code/) 上。它是来自微软的开源代码编辑器,它支持多种标记和编程语言。
---
via: <https://opensource.com/article/19/3/programming-languages-raspberry-pi>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the last article in this series, I shared some ways to [teach kids to program with Raspberry Pi](https://opensource.com/article/19/2/teach-kids-program-raspberry-pi). In theory, there is absolutely nothing stopping an adult from using resources designed for kids, but you might be better served by learning the programming languages that are in demand in the job market.
Here are three programming languages you can learn with the Raspberry Pi.
## Python
[Python](https://opensource.com/resources/python) has become one of the [most popular programming languages](https://www.economist.com/graphic-detail/2018/07/26/python-is-becoming-the-worlds-most-popular-coding-language) in the open source world. Its interpreter has been packaged and made available in every popular Linux distribution. If you install Raspbian on your Raspberry Pi, you will see an app called [Thonny](https://thonny.org/), which is a Python integrated development environment (IDE) for beginners. In a nutshell, an IDE is an application that provides all you need to get your code executed, often including things like debuggers, documentation, auto-completion, and emulators. Here is a [great little tutorial](https://raspberrypihq.com/getting-started-with-python-programming-and-the-raspberry-pi/) to get you started using Thonny and Python on the Raspberry Pi.
## Java
Although arguably not as attractive as it once was, [Java](https://opensource.com/resources/java) remains heavily used in universities around the world and deeply embedded in the enterprise. So, even though some will disagree that I'm recommending it as a beginner's language, I am compelled to do so; for one thing, it still very popular, and for another, there are a lot of books, classes, and other information available for you to learn Java. Get started on the Raspberry Pi by using the [BlueJ](https://www.bluej.org/raspberrypi/) Java IDE.
## JavaScript
"Back in my day…" [JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript) was a client-side language that basically allowed people to streamline and automate user events in a browser and modify HTML elements. Today, JavaScript has escaped the browser and is available for other types of clients like mobile apps and even server-side programming. [Node.js](https://nodejs.org/en/) is a popular runtime environment that allows developers to code beyond the client-browser paradigm. To learn more about running Node.js on the Raspberry Pi, check out [W3Schools tutorial](https://www.w3schools.com/nodejs/nodejs_raspberrypi.asp).
## Other languages
If there's another language you want to learn, don't despair. There's a high likelihood that you can use your Raspberry Pi to compile or interpret any language of choice, including C, C++, PHP, and Ruby.
Microsoft's [Visual Studio Code](https://code.visualstudio.com/) also [runs on the Raspberry Pi](https://pimylifeup.com/raspberry-pi-visual-studio-code/). It's an open source code editor from Microsoft that supports several markup and programming languages.
## 10 Comments |
10,663 | 在 Fedora 上使用 GNOME Recipes 烹饪 | https://fedoramagazine.org/get-cooking-with-gnome-recipes-on-fedora/ | 2019-03-28T23:10:00 | [
"食谱",
"烹饪"
] | https://linux.cn/article-10663-1.html | 
你喜欢烹饪吗?在 Fedora 中寻找管理食谱的更好方法么? GNOME Recipes 是一个非常棒的应用,可以在 Fedora 中安装,用于保存和组织你的食谱。

GNOME Recipes 是 GNOME 项目中的食谱管理工具。它有现代 GNOME 应用的视觉风格,类似于 GNOME “软件”,但它是针对食物的。
### 安装 GNOME Recipes
Recipes 可从第三方 Flathub 仓库安装。如果你之前从未安装过 Flathub 的应用,请使用以下指南进行设置:
* [在 Fedora 上安装 Flathub 应用](https://fedoramagazine.org/install-flathub-apps-fedora/)
正确设置 Flathub 作为软件源后,你将能够通过 GNOME “软件”搜索和安装 Recipes。
### 食谱管理
Recipes 能让你手动添加自己的食谱集合,包括照片、配料、说明,以及更多的元数据,如准备时间、烹饪风格和辛辣程度。

当输入新的食谱时,GNOME Recipes 可为该食谱选择一系列不同的测量单位,如温度等,让你可以轻松地切换单位。
### 社区食谱
除了手动输入你喜欢的菜肴供你自己使用外,它还能让你查找、使用和贡献食谱给社区。此外,你可以标记你的喜爱的食谱,并通过大量的食谱元数据搜索菜谱。

### 分步指导
GNOME Recipes 中一个非常棒的小功能是分步全屏模式。当你准备做饭时,只需激活此模式,将笔记本电脑拿到厨房,你就可以全屏显示烹饪方法中的当前步骤。此外,当食物在烤箱中时,你可以在这个模式下设置定时器。

---
via: <https://fedoramagazine.org/get-cooking-with-gnome-recipes-on-fedora/>
作者:[Ryan Lerch](https://fedoramagazine.org/introducing-flatpak/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you love to cook? Looking for a better way to manage your recipes using Fedora? GNOME Recipes is an awesome application available to install in Fedora to store and organize your recipe collection.
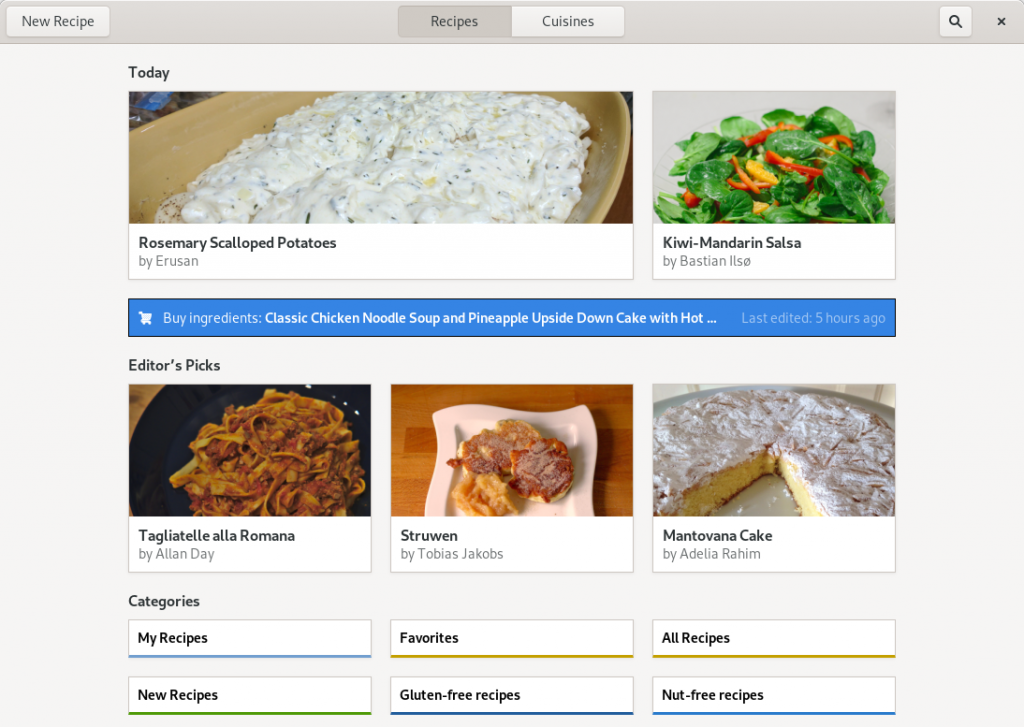
GNOME Recipes is an recipe management tool from the GNOME project. It has the visual style of a modern GNOME style application, and feels similar to GNOME Software, but for food.
### Installing GNOME Recipes
Recipes is available to install from the 3rd party Flathub repositories. If you have never installed an application from Flathub before, set it up using the following guide:
[Install Flathub apps on Fedora]
After correctly setting up Flathub as a software source, you will be able to search for and install Recipes via GNOME Software.
### Recipe management
Recipes allows you to manually add your own collection of recipes, including photos, ingredients, directions, as well as extra metadata like preparation time, cuisine style, and spiciness.
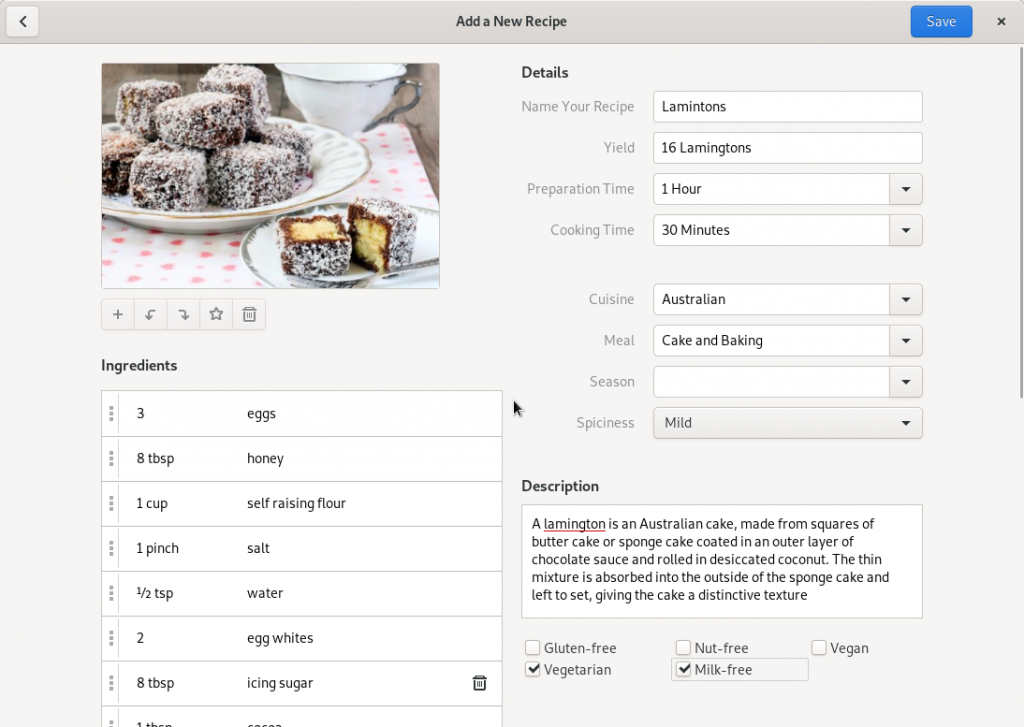
When entering in a new item, GNOME Recipes there are a range of different measurement units to choose from, as well as special tags for items like temperature, allowing you to easily switch units.
### Community recipes
In addition to manually entering in your favourite dishes for your own use, it also allows you to find, use, and contribute recipes to the community. Additionally, you can mark your favourites, and search the collection by the myriad of metadata available for each recipe.

## Step by step guidance
One of the awesome little features in GNOME Recipes is the step by step fullscreen mode. When you are ready to cook, simply activate this mode, move you laptop to the kitchen, and you will have a full screen display of the current step in the cooking method. Futhermore, you can set up the recipes to have timers displayed on this mode when something is in the oven.
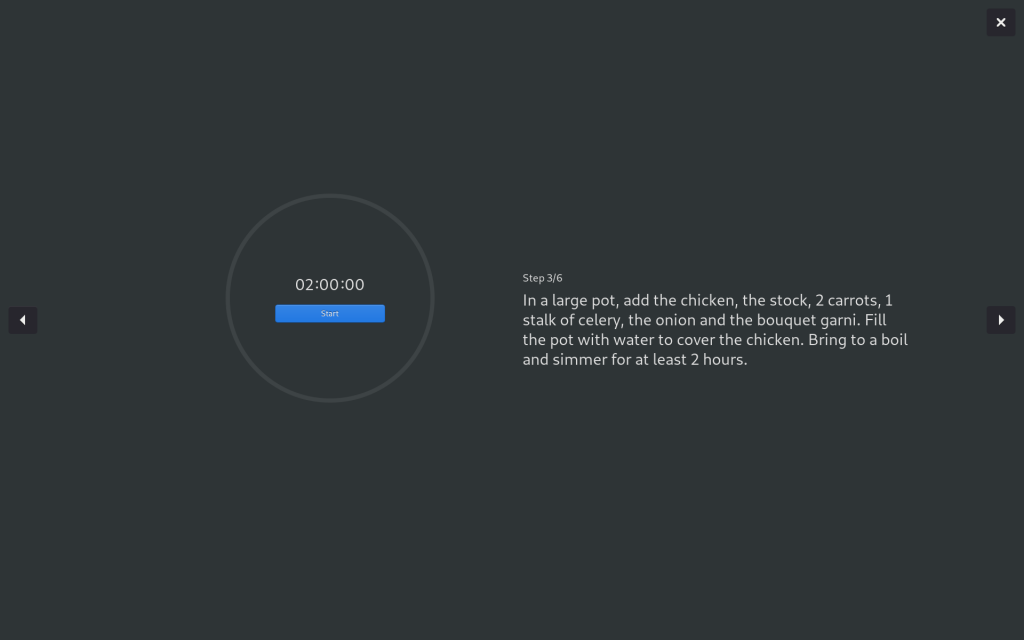
## Mustafa Yaman
I actually love it! Everyone likes food lol
## svsv sarma
At last a family friendly app also. Yes, who is not interested in food? I will try if any variety vegetarian (Indian) recipes can be learnt. Thank you.
## Daniel
How are the community recipes licensed? Creative Commons?
## Silvia
Any chances to have this in repos?
## Jason
Cool, can I search with it? I have 3 eggs, flour and sugar, what can I make?
## vancha
Not yet, but it would make for a great feature request 😉
## john duchek
This partially working on my Fedora 29. It installed and I can download programs, but when I do I get all sorts of SELinux security notifications, mostly about umount. After they announce themselves the software finally installs.
## Yazan Al Monshed
that cool, but it’s repo only available in flathubl?
## carl
I have used this for a while, and found it useful. My biggest complaint is about units of measure. Some measures that I enter in cups get changed to tablespoons, or similar changes. The conversions are accurate, but inconvenient to measure.
The change probably is caused by portion conversions, you can enter a recipe for a number of servings, like 4, and rescale the recipe for a different number, and the program will adjust ingredient amounts.
## anon
It would be nice if they added a few more common units like “dash” or “clove”.
Similar to Daniel’s question, I wonder who would be responsible if a user shared a large number of recipes from a cook book or blog. With or without attribution that seems like it might present a legal problem if the publisher or blogger complained.
## Michael
Recipes cannot be copyrighted. However, parts might be. For example, the text “My grandmother Mary used to make this every Sunday….” should not be carried over from a cookbook. The straight up ingredients and instructions are fine. Otherwise, we’d have a lot of authors in trouble for white sauce or boiled eggs.
## Luca
An android version would be nice! In kitchen often there’s no space for a notebook/PC…
## Receitas
Awesome post!
## Selva Ragavan
Super Wab |
10,664 | JSON、XML、TOML、CSON、YAML 大比拼 | https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/ | 2019-03-29T01:15:04 | [
"XML",
"JSON",
"YAML"
] | https://linux.cn/article-10664-1.html | 
### 一段超级严肃的关于样本序列化的集合、子集和超集的文字
我是一名开发者,我读代码,我写代码,我写会写代码的代码,我写会写出供其它代码读的代码的代码。这些都非常火星语,但是有其美妙之处。然而,最后一点,写会写出供其它代码读的代码的代码,可以很快变得比这段文字更费解。有很多方法可以做到这一点。一种不那么复杂而且开发者社区最爱的方式是数据序列化。对于那些不了解我刚刚抛给你的时髦词的人,数据序列化是从一个系统获取一些信息,将其转换为其它系统可以读取的格式,然后将其传递给其它系统的过程。
虽然[数据序列化格式](https://en.wikipedia.org/wiki/Comparison_of_data_serialization_formats)多到可以埋葬哈利法塔,但它们大多分为两类:
* 易于人类读写,
* 易于机器读写。
很难两全其美,因为人类喜欢让我们更具表现力的松散类型和灵活格式标准,而机器倾向于被确切告知一切事情而没有二义性和细节缺失,并且认为“严格规范”才是它们最爱的口味。
由于我是一名 web 开发者,而且我们是一个创建网站的机构,我们将坚持使用 web 系统可以理解或不需要太多努力就能理解的特殊格式,而且对人类可读性特别有用的格式:XML、JSON、TOML、CSON 以及 YAML。每个都有各自的优缺点和适当的用例场景。
### 事实最先
回到互联网的早期,[一些非常聪明的家伙](https://en.wikipedia.org/wiki/Standard_Generalized_Markup_Language#History)决定整合一种让每个系统都能理解的标准语言,并创造性地将其命名为<ruby> 标准通用标记语言 <rt> Standard Generalized Markup Language </rt></ruby>(简称 SGML)。SGML 非常灵活,发布者也很好地定义了它。它成为了 XML、SVG 和 HTML 等语言之父。所有这三个都符合 SGML 规范,可是它们都是规则更严格、灵活性更少的子集。
最终,人们开始看到非常小、简洁、易读且易于生成的数据的好处,这些数据可以在系统之间以编程的方式共享,而开销很小。大约在那个时候,JSON 诞生了并且能够满足所有的需求。而另一方面,其它语言也开始出现以处理更多的专业用例,如 CSON,TOML 和 YAML。
### XML:不行了
原本,XML 语言非常灵活且易于编写,但它的缺点是冗长,人类难以阅读、计算机非常难以读取,并且有很多语法对于传达信息并不是完全必要的。
今天,它在 web 上的数据序列化的用途已经消失了。除非你在编写 HTML 或者 SVG,否则你不太能在许多其它地方看到 XML。一些过时的系统今天仍在使用它,但是用它传递数据往往太重了。
我已经可以听到 XML 老爷爷开始在它们的石碑上乱写为什么 XML 是了不起的,所以我将提供一个小小的补充:XML 可以很容易地由系统和人读写。然而,真的,我的意思是荒谬的,很难创建一个可以规范的读取它的系统。这是一个简单美观的 XML 示例:
```
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
```
太棒了。易于阅读、理解、写入,也容易编码一个可以读写它的系统。但请考虑这个例子:
```
<!DOCTYPE r [ <!ENTITY y "a]>b"> ]>
<r>
<a b="&y;>" />
<![CDATA[[a>b <a>b <a]]>
<?x <a> <!-- <b> ?> c --> d
</r>
```
这上面是 100% 有效的 XML。几乎不可能阅读、理解或推理。编写可以使用和理解这个的代码将花费至少 36 根头发和 248 磅咖啡渣。我们没有那么多时间或咖啡,而且我们大多数老程序员们现在都是秃头。所以,让它活在我们的记忆里,就像 [css hacks](https://www.quirksmode.org/css/csshacks.html)、[IE 6 浏览器](http://www.ie6death.com/) 和[真空管](https://en.wikipedia.org/wiki/Vacuum_tube)一样好了。
### JSON:并列聚会
好吧,我们都同意,XML = 差劲。那么,好的替代品是什么?<ruby> JavaScript 对象表示法 <rt> JavaScript Object Notation </rt></ruby>,简称 JSON。JSON(读起来像 Jason 这个名字) 是 Brendan Eich 发明的,并且得到了伟大而强力的 [JavaScript 意见领袖](https://twitter.com/BrendanEich/status/773403975865470976) Douglas Crockford 的推广。它现在几乎用在任何地方。这种格式很容易由人和机器编写,按规范中的严格规则[解析](https://en.wikipedia.org/wiki/Parsing#Parser)也相当容易,并且灵活 —— 允许深层嵌套数据,支持所有的原始数据类型,及将集合解释为数组或对象。JSON 成为了将数据从一个系统传输到另一个系统的事实标准。几乎所有语言都有内置读写它的功能。
JSON语法很简单。方括号表示数组,花括号表示记录,由冒号分隔的两个值分别表示属性或“键”(在左边)、值(在右边)。所有键必须用双引号括起来:
```
{
"books": [
{
"id": "bk102",
"author": "Crockford, Douglas",
"title": "JavaScript: The Good Parts",
"genre": "Computer",
"price": 29.99,
"publish_date": "2008-05-01",
"description": "Unearthing the Excellence in JavaScript"
}
]
}
```
这对你来说应该是完全有意义的。它简洁明了,并且从 XML 中删除了大量额外废话,并传达相同数量的信息。JSON 现在是王道,本文剩下的部分会介绍其它语言格式,这些格式只不过是 JSON 的简化版,尝试让其更简洁或对人类更易读,可结构还是非常相似的。
### TOML: 缩短到彻底的利他主义
TOML(<ruby> Tom 的显而易见的最小化语言 <rt> Tom’s Obvious, Minimal Language </rt></ruby>)允许以相当快捷、简洁的方式定义深层嵌套的数据结构。名字中的 Tom 是指发明者 [Tom Preston Werner](https://en.wikipedia.org/wiki/Tom_Preston-Werner),他是一位活跃于我们行业的创造者和软件开发人员。与 JSON 相比,语法有点尴尬,更类似 [ini 文件](https://en.wikipedia.org/wiki/INI_file)。这不是一个糟糕的语法,但是需要一些时间适应。
```
[[books]]
id = 'bk101'
author = 'Crockford, Douglas'
title = 'JavaScript: The Good Parts'
genre = 'Computer'
price = 29.99
publish_date = 2008-05-01T00:00:00+00:00
description = 'Unearthing the Excellence in JavaScript'
```
TOML 中集成了一些很棒的功能,例如多行字符串、保留字符的自动转义、日期、时间、整数、浮点数、科学记数法和“表扩展”等数据类型。最后一点是特别的,是 TOML 如此简洁的原因:
```
[a.b.c]
d = 'Hello'
e = 'World'
```
以上扩展到以下内容:
```
{
"a": {
"b": {
"c": {
"d": "Hello"
"e": "World"
}
}
}
}
```
使用 TOML,你可以肯定在时间和文件长度上会节省不少。很少有系统使用它或非常类似的东西作为配置,这是它最大的缺点。根本没有很多语言或库可以用来解释 TOML。
### CSON: 特定系统所包含的简单样本
首先,有两个 CSON 规范。 一个代表 CoffeeScript Object Notation,另一个代表 Cursive Script Object Notation。后者不经常使用,所以我们不会关注它。我们只关注 CoffeeScript。
[CSON](https://github.com/bevry/cson#what-is-cson) 需要一点介绍。首先,我们来谈谈 CoffeeScript。[CoffeeScript](http://coffeescript.org/) 是一种通过运行编译器生成 JavaScript 的语言。它允许你以更加简洁的语法编写 JavaScript 并[转译](https://en.wikipedia.org/wiki/Source-to-source_compiler)成实际的 JavaScript,然后你可以在你的 web 应用程序中使用它。CoffeeScript 通过删除 JavaScript 中必需的许多额外语法,使编写 JavaScript 变得更容易。CoffeeScript 摆脱的一个大问题是花括号 —— 不需要它们。同样,CSON 是没有大括号的 JSON。它依赖于缩进来确定数据的层次结构。CSON 非常易于读写,并且通常比 JSON 需要更少的代码行,因为没有括号。
CSON 还提供一些 JSON 不提供的额外细节。多行字符串非常容易编写,你可以通过使用 `#` 符号开始一行来输入[注释](https://en.wikipedia.org/wiki/Comment_(computer_programming)),并且不需要用逗号分隔键值对。
```
books: [
id: 'bk102'
author: 'Crockford, Douglas'
title: 'JavaScript: The Good Parts'
genre: 'Computer'
price: 29.99
publish_date: '2008-05-01'
description: 'Unearthing the Excellence in JavaScript'
]
```
这是 CSON 的大问题。它是 <ruby> CoffeScript 对象表示法 <rt> CoffeeScript Object Notation </rt></ruby>。也就是说你要用 CoffeeScript 解析/标记化/lex/转译或其它方式来使用 CSON。CoffeeScript 是读取数据的系统。如果数据序列化的目的是允许数据从一个系统传递到另一个系统,这里我们有一个只能由单个系统读取的数据序列化格式,这使得它与防火火柴、防水海绵或者叉匙恼人的脆弱叉子部分一样有用。
如果这种格式被其它系统也采用,那它在开发者世界中可能非常有用。但到目前为止这基本上没有发生,所以在 PHP 或 JAVA 等替代语言中使用它是不行的。
### YAML:年轻人的呼喊
开发人员感到高兴,因为 YAML 来自[一个 Python 的贡献者](http://clarkevans.com/)。YAML 具有与 CSON 相同的功能集和类似的语法,有一系列新功能,以及几乎所有 web 编程语言都可用的解析器。它还有一些额外的功能,如循环引用、软包装、多行键、类型转换标签、二进制数据、对象合并和[集合映射](http://exploringjs.com/es6/ch_maps-sets.html)。它具有非常好的可读性和可写性,并且是 JSON 的超集,因此你可以在 YAML 中使用完全合格的 JSON 语法并且一切正常工作。你几乎不需要引号,它可以解释大多数基本数据类型(字符串、整数、浮点数、布尔值等)。
```
books:
- id: bk102
author: Crockford, Douglas
title: 'JavaScript: The Good Parts'
genre: Computer
price: 29.99
publish_date: !!str 2008-05-01
description: Unearthing the Excellence in JavaScript
```
业界的年轻人正在迅速采用 YAML 作为他们首选的数据序列化和系统配置格式。他们这样做很机智。YAML 具有像 CSON 一样简洁的所有好处,以及与 JSON 一样的数据类型解释的所有功能。YAML 像加拿大人容易相处一样容易阅读。
YAML 有两个问题,对我而言,第一个是大问题。在撰写本文时,YAML 解析器尚未内置于多种语言,因此你需要使用第三方库或扩展来为你选择的语言解析 .yaml 文件。这不是什么大问题,可似乎大多数为 YAML 创建解析器的开发人员都选择随机将“附加功能”放入解析器中。有些允许[标记化](https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm),有些允许[链引用](https://en.wikipedia.org/wiki/Fluent_interface),有些甚至允许内联计算。这一切都很好(某种意义上),只是这些功能都不是规范的一部分,因此很难在其他语言的其他解析器中找到。这导致系统限定,你最终遇到了与 CSON 相同的问题。如果你使用仅在一个解析器中找到的功能,则其他解析器将无法解释输入。大多数这些功能都是无意义的,不属于数据集,而是属于你的应用程序逻辑,因此最好简单地忽略它们和编写符合规范的 YAML。
第二个问题是很少有解析器完全实现规范。所有的基本要素都有,但是很难找到一些更复杂和更新的东西,比如软包装、文档标记和首选语言的循环引用。我还没有看到对这些东西的刚需,所以希望它们不让你很失望。考虑到上述情况,我倾向于保持 [1.1 规范](http://yaml.org/spec/1.1/current.html) 中呈现的更成熟的功能集,而避免在 [1.2 规范](http://www.yaml.org/spec/1.2/spec.html) 中找到的新东西。然而,编程是一个不断发展的怪兽,所以当你读完这篇文章时,你或许就可以使用 1.2 规范了。
### 最终哲学
这是最后一段话。每个序列化语言都应该以个案标准的方式评价。当涉及机器的可读性时,有些<ruby> 无出其右 <rt> the bee’s knees </rt></ruby>。对于人类可读性,有些<ruby> 名至实归 <rt> the cat’s meow </rt></ruby>,有些只是<ruby> 金玉其外 <rt> gilded turds </rt></ruby>。以下是最终细分:如果你要编写供其他代码阅读的代码,请使用 YAML。如果你正在编写能写出供其他代码读取的代码的代码,请使用 JSON。最后,如果你正在编写将代码转译为供其他代码读取的代码的代码,请重新考虑你的人生选择。
---
via: <https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/>
作者:[Tim Anderson](https://www.zionandzion.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[GraveAccent](https://github.com/GraveAccent) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## A Super Serious Segment About Sets, Subsets, and Supersets of Sample Serialization
I’m a developer. I read code. I write code. I write code that writes code. I write code that writes code for other code to read. It’s all very mumbo-jumbo, but beautiful in its own way. However, that last bit, writing code that writes code for other code to read, can get more convoluted than this paragraph—quickly. There are a lot of ways to do it. One not-so-convoluted way and a favorite among the developer community is through data serialization. For those who aren’t savvy on the super buzzword I just threw at you, data serialization is the process of taking some information from one system, churning it into a format that other systems can read, and then passing it along to those other systems.
While there are enough [data serialization formats](https://en.wikipedia.org/wiki/Comparison_of_data_serialization_formats) out there to bury the Burj Khalifa, they all mostly fall into two categories:
- simplicity for humans to read and write,
- and simplicity for machines to read and write.
It’s difficult to have both as we humans enjoy loosely typed, flexible formatting standards that allow us to be more expressive, whereas machines tend to enjoy being told exactly what everything is without doubt or lack of detail, and consider “strict specifications” to be their favorite flavor of Ben & Jerry’s.
Since I’m a web developer and we’re an agency who creates websites, we’ll stick to those special formats that web systems can understand, or be made to understand without much effort, and that are particularly useful for human readability: XML, JSON, TOML, CSON, and YAML. Each has benefits, cons, and appropriate use cases.
## Facts First
Back in the early days of the interwebs, [some really smart fellows](https://en.wikipedia.org/wiki/Standard_Generalized_Markup_Language#History) decided to put together a standard language which every system could read and creatively named it Standard Generalized Markup Language, or SGML for short. SGML was incredibly flexible and well defined by its publishers. It became the father of languages such as XML, SVG, and HTML. All three fall under the SGML specification, but are subsets with stricter rules and shorter flexibility.
Eventually, people started seeing a great deal of benefit in having very small, concise, easy to read, and easy to generate data that could be shared programmatically between systems with very little overhead. Around that time, JSON was born and was able to fulfil all requirements. In turn, other languages began popping up to deal with more specialized cases such as CSON, TOML, and YAML.
## XML: Ixnayed
Originally, the XML language was amazingly flexible and easy to write, but its drawback was that it was verbose, difficult for humans to read, really difficult for computers to read, and had a lot of syntax that wasn’t entirely necessary to communicate information.
Today, it’s all but dead for data serialization purposes on the web. Unless you’re writing HTML or SVG, both siblings to XML, you probably aren’t going to see XML in too many other places. Some outdated systems still use it today, but using it to pass data around tends to be overkill for the web.
I can already hear the XML greybeards beginning to scribble upon their stone tablets as to why XML is ah-may-zing, so I’ll provide a small addendum: XML *can* be easy to read and write by systems and people. However, it is really, and I mean ridiculously, hard to create a system that can read it to specification. Here’s a simple, beautiful example of XML:
```
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
```
Wonderful. Easy to read, reason about, write, and code a system that can read and write. But consider this example:
```
<!DOCTYPE r [ <!ENTITY y "a]>b"> ]>
<r>
<a b="&y;>" />
<![CDATA[[a>b <a>b <a]]>
<?x <a> <!-- <b> ?> c --> d
</r>
```
The above is 100% valid XML. Impossible to read, understand, or reason about. Writing code that can consume and understand this would cost at least 36 heads of hair and 248 pounds of coffee grounds. We don’t have that kind of time nor coffee, and most of us greybeards are balding nowadays. So let’s let it live only in our memory alongside [css hacks](https://www.quirksmode.org/css/csshacks.html), [internet explorer 6](http://www.ie6death.com/), and [vacuum tubes](https://en.wikipedia.org/wiki/Vacuum_tube).
## JSON: Juxtaposition Jamboree
Okay, we’re all in agreement. XML = bad. So, what’s a good alternative? JavaScript Object Notation, or JSON for short. JSON (read like the name Jason) was invented by Brendan Eich, and made popular by the great and powerful Douglas Crockford, the [Dutch Uncle of JavaScript](https://twitter.com/BrendanEich/status/773403975865470976). It’s used just about everywhere nowadays. The format is easy to write by both human and machine, fairly easy to [parse](https://en.wikipedia.org/wiki/Parsing#Parser) with strict rules in the specification, and flexible—allowing deep nesting of data, all of the primitive data types, and interpretation of collections as either arrays or objects. JSON became the de facto standard for transferring data from one system to another. Nearly every language out there has built-in functionality for reading and writing it.
JSON syntax is straightforward. Square brackets denote arrays, curly braces denote records, and two values separated by semicolons denote properties (or ‘keys’) on the left, and values on the right. All keys must be wrapped in double quotes:
```
{
"books": [
{
"id": "bk102",
"author": "Crockford, Douglas",
"title": "JavaScript: The Good Parts",
"genre": "Computer",
"price": 29.99,
"publish_date": "2008-05-01",
"description": "Unearthing the Excellence in JavaScript"
}
]
}
```
This should make complete sense to you. It’s nice and concise, and has stripped much of the extra nonsense from XML to convey the same amount of information. JSON is king right now, and the rest of this article will go into other language formats that are nothing more than JSON boiled down in an attempt to be either more concise or more readable by humans, but follow very similar structure.
## TOML: Truncated to Total Altruism
TOML (Tom’s Obvious, Minimal Language) allows for defining deeply-nested data structures rather quickly and succinctly. The name-in-the-name refers to the inventor, [Tom Preston-Werner](https://en.wikipedia.org/wiki/Tom_Preston-Werner), an inventor and software developer who’s active in our industry. The syntax is a bit awkward when compared to JSON, and is more akin to an [ini file](https://en.wikipedia.org/wiki/INI_file). It’s not a bad syntax, but could take some getting used to:
```
[[books]]
id = 'bk101'
author = 'Crockford, Douglas'
title = 'JavaScript: The Good Parts'
genre = 'Computer'
price = 29.99
publish_date = 2008-05-01T00:00:00+00:00
description = 'Unearthing the Excellence in JavaScript'
```
A couple great features have been integrated into TOML, such as multiline strings, auto-escaping of reserved characters, datatypes such as dates, time, integers, floats, scientific notation, and “table expansion”. That last bit is special, and is what makes TOML so concise:
```
[a.b.c]
d = 'Hello'
e = 'World'
```
The above expands to the following:
```
{
"a": {
"b": {
"c": {
"d": "Hello"
"e": "World"
}
}
}
}
```
You can definitely see how much you can save in both time and file length using TOML. There are few systems which use it or something very similar for configuration, and that is its biggest con. There simply aren’t very many languages or libraries out there written to interpret TOML.
## CSON: Simple Samples Enslaved by Specific Systems
First off, there are two CSON specifications. One stands for CoffeeScript Object Notation, the other stands for Cursive Script Object Notation. The latter isn’t used too often, so we won’t be getting into it. Let’s just focus on the CoffeeScript one.
[CSON](https://github.com/bevry/cson#what-is-cson) will take a bit of intro. First, let’s talk about CoffeeScript. [CoffeeScript](http://coffeescript.org/) is a language that runs through a compiler to generate JavaScript. It allows you to write JavaScript in a more syntactically concise way, and have it [transcompiled](https://en.wikipedia.org/wiki/Source-to-source_compiler) into actual JavaScript, which you would then use in your web application. CoffeeScript makes writing JavaScript easier by removing a lot of the extra syntax necessary in JavaScript. A big one that CoffeeScript gets rid of is curly braces—no need for them. In that same token, CSON is JSON without the curly braces. It instead relies on indentation to determine hierarchy of your data. CSON is very easy to read and write and usually requires fewer lines of code than JSON because there are no brackets.
CSON also offers up some extra niceties that JSON doesn’t have to offer. Multiline strings are incredibly easy to write, you can enter [comments](https://en.wikipedia.org/wiki/Comment_(computer_programming)) by starting a line with a hash, and there’s no need for separating key-value pairs with commas.
```
books: [
id: 'bk102'
author: 'Crockford, Douglas'
title: 'JavaScript: The Good Parts'
genre: 'Computer'
price: 29.99
publish_date: '2008-05-01'
description: 'Unearthing the Excellence in JavaScript'
]
```
Here’s the big issue with CSON. It’s ** CoffeeScript **Object Notation. Meaning CoffeeScript is what you use to parse/tokenize/lex/transcompile or otherwise use CSON. CoffeeScript is the system that reads the data. If the intent of data serialization is to allow data to be passed from one system to another, and here we have a data serialization format that’s only read by a single system, well that makes it about as useful as a fireproof match, or a waterproof sponge, or that annoyingly flimsy fork part of a spork.
If this format is adopted by other systems, it could be pretty useful in the developer world. Thus far that hasn’t happened in a comprehensive manner, so using it in alternative languages such as PHP or JAVA are a no-go.
## YAML: Yielding Yips from Youngsters
Developers rejoice, as YAML comes into the scene from [one of the contributors to Python](http://clarkevans.com/). YAML has the same feature set and similar syntax as CSON, a boatload of new features, and parsers available in just about every web programming language there is. It also has some extra features, like circular referencing, soft-wraps, multi-line keys, typecasting tags, binary data, object merging, and [set maps](http://exploringjs.com/es6/ch_maps-sets.html). It has incredibly good human readability and writability, and is a superset of JSON, so you can use fully qualified JSON syntax inside YAML and all will work well. You almost never need quotes, and it can interpret most of your base data types (strings, integers, floats, booleans, etc.).
```
books:
- id: bk102
author: Crockford, Douglas
title: 'JavaScript: The Good Parts'
genre: Computer
price: 29.99
publish_date: !!str 2008-05-01
description: Unearthing the Excellence in JavaScript
```
The younglings of the industry are rapidly adopting YAML as their preferred data serialization and system configuration format. They are smart to do so. YAML has all the benefits of being as terse as CSON, and all the features of datatype interpretation as JSON. YAML is as easy to read as Canadians are to hang out with.
There are two issues with YAML that stick out to me, and the first is a big one. At the time of this writing, YAML parsers haven’t yet been built into very many languages, so you’ll need to use a third-party library or extension for your chosen language to parse .yaml files. This wouldn’t be a big deal, however it seems most developers who’ve created parsers for YAML have chosen to throw “additional features” into their parsers at random. Some allow [tokenization](https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm), some allow [chain referencing](https://en.wikipedia.org/wiki/Fluent_interface), some even allow inline calculations. This is all well and good (sort of), except that none of these features are part of the specification, and so are difficult to find amongst other parsers in other languages. This results in system-locking; you end up with the same issue that CSON is subject to. If you use a feature found in only one parser, other parsers won’t be able to interpret the input. Most of these features are nonsense that don’t belong in a dataset, but rather in your application logic, so it’s best to simply ignore them and write your YAML to specification.
The second issue is there are few parsers that yet completely implement the specification. All the basics are there, but it can be difficult to find some of the more complex and newer things like soft-wraps, document markers, and circular references in your preferred language. I have yet to see an absolute need for these things, so hopefully they shouldn’t slow you down too much. With the above considered, I tend to keep to the more matured feature set presented in the [1.1 specification](http://yaml.org/spec/1.1/current.html), and avoid the newer stuff found in the [1.2 specification](http://www.yaml.org/spec/1.2/spec.html). However, programming is an ever-evolving monster, so by the time you finish reading this article, you’re likely to be able to use the 1.2 spec.
## Final Philosophy
The final word here is that each serialization language should be treated with a case-by-case reverence. Some are the bee’s knees when it comes to machine readability, some are the cat’s meow for human readability, and some are simply gilded turds. Here’s the ultimate breakdown: If you are writing code for other code to read, use YAML. If you are writing code that writes code for other code to read, use JSON. Finally, if you are writing code that transcompiles code into code that other code will read, rethink your life choices. |
10,665 | 树莓派使用入门:如何更新树莓派 | https://opensource.com/article/19/3/how-raspberry-pi-update | 2019-03-30T09:26:15 | [
"树莓派"
] | /article-10665-1.html |
>
> 在我们的树莓派入门指南的第七篇学习如何给树莓派打补丁。
>
>
>

像平板电脑、手机和笔记本电脑一样,你需要更新树莓派。最新的增强功能不仅可以使你的派运行顺畅,还可以让它更安全,特别是在如果你连接到网络的情况下。我们的树莓派入门指南中的第七篇会分享两条关于让派良好运行的建议。
### 更新 Raspbian
更新 Raspbian 有[两步](https://www.raspberrypi.org/documentation/raspbian/updating.md):
1. 在终端中输入:`sudo apt-get update`。
该命令的 `sudo` 让你以管理员(也就是 root)运行 `apt-get update`。请注意,`apt-get update` 不会在系统上安装任何新东西,而是将更新需要更新的包和依赖项列表。
2. 接着输入:`sudo apt-get dist-upgrade`。
摘自文档:“一般来说,定期执行此操作将使你的安装保持最新,因为它将等同于 [raspberrypi.org/downloads](https://www.raspberrypi.org/downloads/) 中发布的最新镜像。”

### 小心 rpi-update
Raspbian 带有另一个名为 [rpi-update](https://github.com/Hexxeh/rpi-update) 的更新工具。此程序可用于将派升级到最新固件,不管该固件是不是有损坏或问题。你可能会发现一些如何使用它的信息,但是建议你永远不要使用这个程序,除非你有充分的理由这样做。
一句话:保持系统更新!
---
via: <https://opensource.com/article/19/3/how-raspberry-pi-update>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,666 | 10 款你可以通过 Wine 在 Linux 上玩的游戏 | https://www.maketecheasier.com/games-play-on-linux-with-wine/ | 2019-03-30T11:18:57 | [
"游戏",
"Wine"
] | https://linux.cn/article-10666-1.html | 
Linux *确实* 能玩游戏,而且还能玩不少游戏。独立游戏在 Linux 平台上蓬勃发展,顶级的独立游戏也常常会在发售首日便发布 Linux 版本。然而,3A 游戏大作的开发者们却常常忽略 Linux,所以你不会很快就能玩上身边朋友们谈论正火的那些游戏。
但情况还没有糟透。Wine —— 一个能使 Windows 应用在类似 Linux、BSD 和 OS X 上运行的兼容层,在支持的游戏数量和性能表现上都取得了巨大进步。很多游戏大作都可以在 Wine 的支持下运行。你不能完全释放本机性能,但还是可以跑起来游戏,运行也还算流畅,当然这也要取决与你的系统配置。下面我们来盘点一下这些可能会令你大吃一惊的可以通过 Wine 在 Linux 上玩的游戏。(LCTT 译注:本文原文发表于 2017 年,有些信息可能有所过时。)
### 10、魔兽世界

这款经典的 MMORPG 之王仍旧坚挺并保持活力。虽然这不是一款以画面见长的游戏,但想要开到全画质也需要费一些功夫。魔兽世界已经在 Wine 的支持下运行了很多年。到了最新资料片发布时,魔兽世界为它的 Mac 版本提供了 OpenGL 支持,使得游戏也可以很轻松地在 Linux 下运行。这已经不再是个问题了。
你需要通过 DX9 来运行游戏并从 [Gallium Nine](https://www.maketecheasier.com/install-wine-gallium-nine-linux) 补丁来获得一些性能提升,不过你也可以放心大胆地在 Linux 中下副本了。
### 9、上古卷轴 5:天际

上古卷轴 5 已经不是款新游戏了,但它的 mod 社区依旧活跃。如果你的 Linux 系统有足够资源的话,你可以很轻松地加上很多很多 mod。需要记住的是 Wine 运行时要比游戏占用更多的系统资源,所以使用 mod 时也要考虑这一点。
### 8、星际争霸 II

星际争霸 II 是成为市场上最受欢迎的 RTS 游戏之一,并且在 Wine 下运作良好。它实际上也是 Wine 下表现最好的游戏之一。
考虑到这款游戏本身的竞技性,你当然希望游戏能够流畅地运行。不过不用担心,只要你的硬件够用就绝对没问题。
这是一个你可以从 “staging” 补丁获益的例子,所以在你设置游戏时请继续使用它们。
### 7、辐射 3 / 辐射:新维加斯

在你提问之前,辐射 4 已经很快就准备就绪,也许就在你正读这篇文章的时候就可以玩了。就目前而言,辐射 3 和 辐射:新维加斯都能在有没有 mod 的情况下良好运行。这些游戏在 Wine 下运行地非常好,甚至还能加载大量 mod 来保持游戏的新鲜性和趣味性。在辐射 4 获得全面支持前玩这些旧作也不算是个很大的妥协。
### 6、Doom (2016)

Doom(毁灭战士)是过去几年中最刺激的射击游戏之一。在 Wine 支持下并加载 “staging” 补丁可以流畅地运行最新版本。单人模式和多人模式都有很棒的游戏体验,而且也不需要花费大量时间来配置 Wine 和调整设置。所以你想在 Linux 上体验 3A 级射击游戏的话,不妨尝试一下 Doom 。
### 5、激战 2

激战 2 是一款无月卡(买断制)的融合了多人和迷宫探险元素的游戏。它在市场上很受欢迎,并自称在游戏中有着很多创新。你同样可以通过 Wine 在 Linux 上玩到这款游戏。
激战 2 也不算一款很老的 MMO 游戏。它试图以图像表现来保持现代风格,并具有着相当高分辨率的纹理和视觉效果。所有这些特点都能在 Wine 下顺利运行。
### 4、英雄联盟

在 MOBA 游戏的世界中有两个强者:DoTA2 和英雄联盟。Valve 已经将 DoTA2 移植到 Linux 上很久了,但玩家们却从没在 Linux 上玩过英雄联盟。如果你是 Linux 的使用者并热衷英雄联盟,你还是可以通过 Wine 来玩这款你最爱的 MOBA 游戏。
英雄联盟是个很有趣的例子。它的游戏本身运行良好,但安装程序却会因为需要 Adobe Air 而中断。一些安装程序脚本例如 Lutris 和 PlayOnLinux 能帮你通过这一步骤。一旦安装完毕,你就可以毫无困难地运行游戏,甚至在激烈的战况中依旧畅快玩耍。
### 3、炉石传说

炉石传说是一款流行且令人上瘾的免费卡牌游戏,你可在各种平台上来一局……除了 Linux。不过别担心,在 Wine 中你可以轻松玩到这款游戏。炉石并不大,所以即使在最低配置的系统里也都能玩,这是个好消息。不过由于它的竞技性所以还是要对游戏性能有一定要求。
玩炉石不需要任何特殊配置和补丁,直接开玩!
### 2、巫师 3

你不是唯一一个对在这份榜单中看到了巫师 3 而感到吃惊的人。在最新版 “stage” 补丁的支持下,你终于可以在 Linux 中体验这款游戏了。尽管最初承诺会有原生版本,但 Linux 玩家还是等了很久才迎来了巫师系列的第三部。
不过最好不要指望一切都能完美运行。巫师 3 *刚刚* 得到支持,有些内容可能还不会达到预期。也就是说,如果你只能用 Liux 来玩游戏,并且愿意处理一些问题。那么你也可以享受到这款完美游戏带来的初体验了。
### 1、守望先锋

最后,让我们来谈谈 Linux 玩家心中的另一个“白鲸”。很多人认为守望先锋会像大多数暴雪游戏一样,在发售当日就能在 Wine 上获得支持。不过情况非常不同,因为守望先锋只支持 DX11,这也正是 Wine 面临的一个痛点。
守望先锋目前还不能拥有最佳性能表现,但是你还是可以通过装有特殊补丁的 Wine 和包括“staging”在内的一系列定制补丁包来运行游戏。这也说明了 Linux 玩家们真的很渴望游玩这款游戏,以至于自己开发了一套补丁来为它提供支持。
这份榜单当然会遗漏一些其他游戏。大多数是由于受欢迎程度或只能从 Wine 中得到有限的支持。其他暴雪游戏,如“风暴英雄”和“暗黑破坏神 3”也能很好地运行,但这样来写就会使暴雪游戏霸占这份榜单,这不是我们想突出的重点。
如果你正打算玩以上任一款游戏,请使用 Wine 的 [Gallium Nine](https://www.maketecheasier.com/install-wine-gallium-nine-linux) 版本并装载“staging”补丁,否则游戏可能无法正常运行。“staging”中装载的最新补丁和提升要比正式的 Wine 发行版提供的内容要早很多,使用它会令你在性能上处于领先地位。
说到进步,Wine 目前在对 DirectX11 的支持有了很大进步。对于 Windows 玩家这可能不算什么,但对于 Linux 玩家来说绝对算是一件大事。大多数游戏新作支持 DX11 和 DX12,而最新版本的 Wine 仍只是支持 DX9。有了 DX11 的支持,Wine 将会让很多过去无法在 Linux 上玩的游戏运行起来。所以,定期查看你最喜欢的 Windows 游戏是否也可以开始在 Wine 上运行,你可能会非常惊喜。
---
via: <https://www.maketecheasier.com/games-play-on-linux-with-wine/>
作者:[Nick Congleton](https://www.maketecheasier.com/author/nickcongleton/) 译者:[Modrisco](https://github.com/Modrisco) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Linux *does* have games. It has a lot of them, actually. Linux is a thriving platform for indie gaming, and it’s not too uncommon for Linux to be supported on day one by top indie titles. In stark contrast, however, Linux is still largely ignored by the big-budget AAA developers, meaning that the games your friends are buzzing about probably won’t be getting a Linux port anytime soon.
It’s not all bad, though. Wine, the Windows compatibility layer for Linux, Mac, and BSD systems, is making huge strides in both the number of titles supported and performance. In fact, a lot of big name games now work under Wine. No, you won’t get native performance, but they are playable and can actually run very well, depending on your system. Here are some games that it might surprise you can run with Wine on Linux.
## 10. World of Warcraft
The venerable king of MMORPGs is still alive and going strong. Even though it might not be the most graphically advanced game, it still takes some power to crank all the settings up to max. World of Warcraft has actually worked under Wine for years. Until this latest expansion, WoW supported OpenGL for its Mac version, making it very easy to get working under Linux. That’s not quite the case anymore.
You’ll need to run WoW with DX9 and will definitely see some benefit from the [Gallium Nine](https://www.maketecheasier.com/install-wine-gallium-nine-linux/) patches, but you can confidently make the switch over to Linux without missing raid night.
## 9. Skyrim
Skyrim’s not exactly new, but it’s still fueled by a thriving modding community. You can now easily enjoy Skyrim and its many, many mods if you have a Linux system with enough resources to handle it all. Remember that Wine uses more system power than running the game natively, so account for that in your mod usage.
## 8. StarCraft II
StarCraft II is easily one of the most popular RTS games on the market and works very well under Wine. It is actually one of the best performing games under Wine. That means that you can play your favorite RTS on Linux with minimal hassle and near-native performance.
Given the competitive nature of this game, you obviously need the game to run well. Have no fear there. You should have no problem playing competitively with adequate hardware.
This is an instance where you’ll benefit from the “staging” patches, so continue using them when you’re getting the game set up.
## 7. Fallout 3/New Vegas
Before you ask, Fallout 4 is on the verge of working. At the time you’re reading this, it might. For now, though, Fallout 3 and New Vegas both work great, both with and without mods. These games run very well under Wine and can even handle loads of mods to keep them fresh and interesting. It doesn’t seem like a bad compromise to hold you over until Fallout 4 support matures.
## 6. Doom (2016)
Doom is one of the most exciting shooters of the past few years, and it run very well under Wine with the latest versions and the “staging” patches. Both single player and multiplayer work great, and you don’t need to spend loads of time configuring Wine and tweaking settings. Doom just works. So, if you’re looking for a brutal AAA shooter on Linux, consider giving Doom a try.
## 5. Guild Wars 2
Guild War 2 is a sort-of hybrid MMO/dungeon crawler without a monthly fee. It’s very popular and boasts some really innovative features for the genre. It also runs smoothly on Linux with Wine.
Guild Wars 2 isn’t some ancient MMO either. It’s tried to keep itself modern graphically and has fairly high resolution textures and visual effects for the genre. All of it looks and works very well under Wine.
## 4. League Of Legends
There are two top players in the MOBA world: DoTA2 and League of Legends. Valve ported DoTA2 to Linux some time ago, but League of Legends has never been made available to Linux gamers. If you’re a Linux user and a fan of League, you can still play your favorite MOBA through Wine.
League of Legends is an interesting case. The game itself runs fine, but the installer breaks because it requires Adobe Air. There are some installer scripts available from Lutris and PlayOnLinux that get you through the process. Once it’s installed, you should have no problem running League and even playing it smoothly in competitive situations.
## 3. Hearthstone
Hearthstone is a popular and addictive free-to-play digital card game that’s available on a variety of platforms … except Linux. Don’t worry, it works very well in Wine. Hearthstone is such a lightweight game that it’s actually playable through Wine on even the lowest powered systems. That’s good news, too, but because Hearthstone is another competitive game where performance matters.
Hearthstone doesn’t require any special configuration or even patches. It just works.
## 2. Witcher 3
If you’re surprised to see this one here, you’re not alone. With the latest “staging” patches, The Witcher 3 finally works. Despite originally being promised a native release, Linux gamers have had to wait a good long while to get the third installment in the Witcher franchise.
Don’t expect everything to be perfect just yet. Support for Witcher 3 is *very* new, and some things might not work as expected. That said, if you only have Linux to game on, and you’re willing to deal with a couple of rough edges, you can enjoy this awesome game for the first time with few, if any, troubles.
## 1. Overwatch
Finally, there’s yet another “white whale” for Linux gamers. Overwatch has been an elusive target that many feel should have been working on Wine since day one. Most Blizzard games have. Overwatch was a very different case. It only ever supported DX11, and that was a serious pain point for Wine.
Overwatch doesn’t have the best performance yet, but you can definitely still play Blizzard’s wildly popular shooter using a specially-patched version of Wine with the “staging” patches and additional ones just for Overwatch. That means Linux gamers wanted Overwatch so bad that they developed a special set of patches for it.
## Additional Thoughts
There were certainly games left off of this list. Most were just due to popularity or only conditional support under Wine. Other Blizzard games, like Heroes of the Storm and Diablo III also work, but this list would have been even more dominated by Blizzard, and that’s not the point.
If you’re going to try playing any of these games, consider using the “staging” or [Gallium Nine versions](https://www.maketecheasier.com/install-wine-gallium-nine-linux/) of Wine. Many of the games here won’t work without them. Even still, the latest patches and improvements land in “staging” long before they make it into the mainstream Wine release. Using it will keep you on the leading edge of progress.
Speaking of progress, right now Wine is making massive strides in DirectX11 support. While that doesn’t mean much to Windows gamers, it’s a huge deal for Linux. Most new games support DX11 and DX12, and until recently Wine only supported DX9. With DX11 support, Wine is gaining support for loads of games that were previously unplayable. So keep checking regularly to see if your favorite games from Windows started working in Wine. You might be very pleasantly surprised.
Our latest tutorials delivered straight to your inbox |
10,667 | 使用 Arch Linux 镜像列表管理器来管理你的镜像 | https://itsfoss.com/archlinux-mirrorlist-manager | 2019-03-30T11:46:06 | [
"Arch"
] | https://linux.cn/article-10667-1.html | 
>
> Arch Linux 镜像列表管理器是一个简单的图形化程序,它让你可以方便地管理 Arch Linux 中的镜像。
>
>
>
对于 Linux 用户来说,保持镜像列表规整非常重要。今天我们来介绍一个用来管理 Arch 镜像列表的应用程序。

*Arch Linux Mirrorlist Manager*
### 什么是镜像?
给新手的话,Linux 操作系统有赖于分布全球的的一系列服务器。这些服务器包含了特定发行版的所有可用的软件包的一样的副本。这就是为什么它们被称为“镜像”。
这些服务器的最终目标时让每个国家都有多个镜像。这样就能让当地的用户可以快速升级系统。然而,这并不绝对。有时别国的镜像反而更快。
### ArchLinux 镜像列表管理器让在 Arch Linux 中管理镜像更简单

*主界面*
在 Arch 中[管理并对有效镜像进行排序](https://wiki.archlinux.org/index.php/Mirrors) 不是个简单的事情。它需要用到很长的命令。还好,有人想出了一个解决方案。
去年,[RizwanHasan](https://github.com/Rizwan-Hasan) 用 Python 编写了一个名为 [Arch Linux 镜像列表管理器](https://github.com/Rizwan-Hasan/ArchLinux-Mirrorlist-Manager) 的 Qt 应用程序。你可能对 Rizwan 这个名字感到眼熟,因为这不是第一次我们在本站介绍他做的玩意了。一年多前,我介绍过一个名为 [MagpieOS](https://itsfoss.com/magpieos/) 的基于 Arch 的新 Linux 发行版就是 Rizwan 创造的。我想 Rizwan 创造 MagpieOS 的经历激励了他创建了这个程序。
Arch Linux 镜像列表管理器的功能并不多。它让你根据回应速度对镜像进行排序,并可以根据数量和国家进行过滤。
也就是说,若你在德国,你可以限制只保留在位于德国的最快的 3 个镜像。
### 安装 Arch Linux 镜像列表管理器
>
> **它仅适用于 Arch Linux 用户**
>
>
> 注意! Arch Linux 镜像列表管理器只能应用于 Arch linux 发行版. 不要在其他基于 Arch 的发行版中使用它,除非你能确定该发行版使用的是 Arch 镜像。否则,你将会遇到我在 Manjaro 中遇到的问题(在下面章节解释).
>
>
>
---
>
> **Manjaro 中的镜像管理器替代品**
>
>
> 当使用类 Arch 的系统时, 我选择了 Manjaro。在开始本文之前,我在 Manjaro 及其上安装了 Arch Linux 镜像列表管理器。它很快就对有效镜像进行了排序并保存到我的镜像列表中。
>
>
> 然后我尝试进行系统更新却立即遇到了问题。当 ArchLinux 镜像列表管理器对我系统使用的镜像进行排序时,它使用普通的 Arch 镜像替换了我的 Manjaro 镜像。(Manjaro 基于 Arch,但却有着自己的镜像,这是因为开发团队会在推送软件包之前对所有这些软件包进行测试以保证不会出现系统崩溃的 BUG。)还好,Manjaro 论坛帮我修复了这个错误。
>
>
> 若你是 Manjaro 用户,请不要重蹈我的覆辙。Arch Linux 镜像列表管理器 仅适用于 Arch 以及使用 Arch 镜像的衍生版本。
>
>
> 幸运的是,manjaro 有一个简单易用的终端程序来管理镜像列表。那就是 [Pacman-mirrors](https://wiki.manjaro.org/index.php?title=Pacman-mirrors)。跟 ArchLinux 镜像列表管理器一样,你可以根据回应速度进行排序。只需要运行 `sudo pacman-mirrors --fasttrack` 即可。若你像将结果局限在最快的 5 个镜像,可以运行 `sudo pacman-mirrors --fasttrack 5`。要像将结果局限在某个或某几个国家,运行 `sudo pacman-mirrors --country Germany,Spain,Austria`。你可以通过运行 `sudo pacman-mirrors --geoip` 来将结果局限在自己国家。更多关于 Pacman-mirrors 的信息请参见 [Manjaro wiki](https://wiki.manjaro.org/index.php?title=Pacman-mirrors)。
>
>
> 运行 Pacman-mirrors 后,你还需要运行 `sudo pacman -Syyu` 来同步软件包数据库并升级系统。
>
>
> 注意:Pacman-mirrors 仅仅适用于 **Manjaro**。
>
>
>
Arch Linux 镜像列表管理器包含在 [ArchUserRepository](https://aur.archlinux.org/packages/mirrorlist-manager) 中。高级 Arch 用户可以直接从 [theGitHubpage](https://github.com/Rizwan-Hasan/MagpieOS-Packages/tree/master/ArchLinux-Mirrorlist-Manager) 下载 PKGBUILD。
### 对 Arch Linux Mirrorlist Manager 的最后思考
虽然 [Arch Linux 镜像列表管理器](https://github.com/Rizwan-Hasan/ArchLinux-Mirrorlist-Manager) 对我不太有用,我很高兴有它的存在。这说明 Linux 用户正在努力让 Linux 更加易于使用。正如我之前说过的,在 Arch 中管理镜像并不容易。Rizwan 的小工具可以让 Arch 对新手更加友好。
你有用过 Arch Linux 镜像列表管理器吗?你是怎么管理 Arch 镜像的?请在下面的评论告诉我。
如果你觉的本文有趣的话,请花点时间将它分享到社交媒体中去。
---
via: <https://itsfoss.com/archlinux-mirrorlist-manager>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
10,668 | 区块链 2.0:金融体系改革(二) | https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/ | 2019-03-31T10:40:45 | [
"区块链",
"金融"
] | https://linux.cn/article-10668-1.html | 
这是我们区块链 2.0 系列的第二部分。区块链可以改变个人和机构处理他们财务状况的方式。本文着眼于现有货币体系如何演变,以及新的区块链系统如何为货币演变的下一个关键步骤带来改变。
两个关键思想将为本文奠定基础。**PayPal** 在推出之时,其运营操作上具有革命性。该公司收集、处理和确认大量的消费者数据,以促进各种在线交易,从而切实允许 eBay 等平台成长为可信赖的商业来源,并为全球数字支付系统奠定基准。其二,虽然要强调的是更为重要的关键思想,但却是一个存在性问题。我们都使用金钱或货币来满足我们的日常需求。一张 10 美元的账单可以让你从最喜欢的咖啡店买到一两杯咖啡,从而开始美好的一天。事实上,我们各方面都依赖于各自的国家货币。
当然,自从**易货系统**开始决定你的早餐是什么起,人类已经度过了漫长的时间。但是,货币到底是什么?谁或什么赋予它的价值?正如流行的谣言所说,去银行并给他们一美元钞票就可以获得货币“符号”所代表的真正价值吗?
大多数问题的答案都不存在。即便是给出了答案,最多也是不可思议的模糊和主观。早在文明开始建立小城镇的那一天,被统治者认为是合法的本地货币,几乎总是由那个社会中宝贵的东西组成。人们认为印第安人使用干胡椒进行交易,而古希腊人和罗马人则使用[盐](https://www.seasalt.com/history-of-salt)交易。渐渐地,这些史前启蒙文明中的大部分都采用贵重金属和石头作为代币进行交易。金币、银饰和红宝石开始与“价值”同名。随着工业革命,人们开始印刷这些交易凭证,我们终于似乎看到了对纸币需求的呼吁。纸币可靠且廉价,只要国家为其用户所持纸币提供担保,纸币所代表的“价值”可以在需要时,由同等价值的黄金或硬通货作支撑,人们便乐于使用它们。但是,如果你仍然认为你现在持有的纸币具有相同的保证,那么你就错了。我们目前生活在一个几乎所有主要货币都在全球流通的时代,经济学家称之为[法定货币](https://www.investopedia.com/terms/f/fiatmoney.asp)。缺少价值的纸片只能得到你所居住的国家的保证支持。法定货币的确切性质以及为什么它们可能是一个有缺陷的系统属于经济领域,我们目前不会涉及。
事实上,所有这一历史中与本篇文章相关的唯一的一点是,文明开始使用暗示或代表商品和服务的贸易价值的代币,而不是非实际的易货系统。代币,当然,这也是加密货币背后的关键概念。它们没有任何固有的价值。它们的价值取决于采用该特定平台的人数、采用者对系统的信任,当然还有监管实体本身的背景(如果有监管实体的话)。**比特币(BTC)**的高价格和市值并非巧合,它们是业内第一个加密货币并且有很多早期采用者。加密货币背后的最终真理使其如此重要而又具有如此难以理解的复杂性。这是“金钱”自然演变的下一步。有些人理解这一点,有些人仍然认为坚实的货币概念中“真正的”货币总是由某种[内在价值支持](https://bitcoin.org/en/faq#who-created-bitcoin)。虽然已经有无数关于这种困境的辩论和研究,但仍没有着眼于区块链的未来。
例如,**厄瓜多尔**在 2015 年成为头条新闻,因为它声称计划开发和发布[自己的国家加密货币](https://99bitcoins.com/official-ecuador-cryptocurrency/)。虽然官方尝试是为了援助和支持他们现有的货币体系。从那时起,其他国家及其监管机构已经或正在起草文件来控制加密货币的“流行病”,其中一些已经发布了框架,以创建区块链和加密货币开发的路线图。[德国](https://cointelegraph.com/news/german-government-to-introduce-blockchain-strategy-in-mid-2019)被认为正在长期投资区块链项目,以简化其税收和金融系统。发展中国家的银行正在加入一个名为银行链的体系中,用以合作创建**私有区块链**以提高他们的效率并优化其运营。
现在,当我们将故事的两端结合在一起时,还记得在休闲历史课之前首次提到 PayPal 吗?专家们将比特币(BTC)的采用率与 PayPal 的采用率进行了比较。消费者最初有所犹豫,只有少数早期采用者准备好使用上述产品,但随后更广泛的采用逐渐成为类似平台的标杆态势。比特币(BTC)已经成为类似加密货币平台的基准,而主要硬币包括[以太坊(ETH)和瑞波(XRP)](https://coinmarketcap.com/currencies/bitcoin/)。采用正在稳步增加,法律和监管框架也正在制定以支持它,积极的研究和开发也在进行中。与 PayPal 不同,专家认为,利用区块链技术为其数字基础设施提供加密货币和平台将很快成为标准规范而非个例。
尽管 2018 年加密货币价格的上涨可以被称为经济泡沫,但公司和政府仍在继续投资开发自己的区块链平台和金融代币。为了抵制和预防未来发生这样的事件,并同时同时继续在该领域投资,替代传统加密货币的**稳定币**已经开发成功。
金融巨头**摩根大通**推出了他们自己的用于企业的区块链解决方案,名为**Quorum**,用来处理被称为 [JPM 硬币](https://www.jpmorgan.com/global/news/digital-coin-payments)的稳定币。每个这样的 JPM 硬币都与 1 美元挂钩,其价值由母公司在支持法律框架下保证。像这样的平台使大型金融交易更容易通过互联网瞬间传输数百万或数十亿美元,而不必依赖 SWIFT 这样的传统银行系统,这些系统有着冗长的过程,而且本身已有数十年历史。
为了让区块链的精微之处可供所有人使用,以太坊平台允许第三方利用他们的区块链,或从中派生代币以创建和管理他们自己对**区块链-协议-令牌**三元组的主张,从而推动更广泛的标准采纳,并付出更少的基础工作量。
区块链允许通过网络快速创建、记录和交易现有金融工具的数字版本,而无需第三方监控。该系统固有的安全性和安保特性使整个过程完全安全,并且不受欺诈和篡改的影响,这基本上是现有金融工具需要第三方监控的唯一原因。政府和监管机构在金融服务和工具方面涉及的另一个领域是透明度和审计。通过区块链,银行和其他金融机构将能够维护完全透明、分层,几乎永久保存和防篡改的所有交易记录,使审计任务几乎无用。通过利用区块链,可以使当前金融系统和服务行业急需的发展和变化成为可能。分布式、防篡改、接近永久性存储和快速执行的平台对于银行家和政府监管机构来说都是非常有价值的,他们在这方面的投资似乎[很有用](https://www.pwc.com/jg/en/media-release/global-fintech-survey-2017.html)。
在本系列的下一篇文章中,我们将了解公司如何使用区块链来提供下一代金融服务。纵观在行业中创造涟漪的个别公司后,我们将探讨区块链下的经济未来会如何发展。
---
via: <https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/>
作者: [Ostechnix](https://www.ostechnix.com/author/editor/) 选题: [lujun9972](https://github.com/lujun9972) 译者: [sanfusu](https://github.com/sanfusu) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/)荣誉推出
| 403 | Forbidden | null |
10,669 | 树莓派使用入门:如何用树莓派来娱乐 | https://opensource.com/article/19/3/raspberry-pi-entertainment | 2019-03-31T10:54:22 | [
"树莓派",
"娱乐"
] | https://linux.cn/article-10669-1.html |
>
> 在我们的树莓派使用入门的第八篇文章中,我们将学习如何使用树莓派观看 Netflix 上的影片和用它来听音乐。
>
>
>

到目前为止,本系列文章已经学习了很多话题 — 如何 [挑选](/article-10611-1.html)、[购买](/article-10615-1.html)、[设置](/article-10644-1.html)、和 [更新](/article-10665-1.html) 你的树莓派,以及 [儿童](/article-10653-1.html) 和 [成人](/article-10661-1.html) 如何使用它来做的不同的事情(包括学习 [Linux](/article-10645-1.html))。今天我们换一个话题,将学习一些娱乐方面的内容!我们将学习如何使用树莓派来做一些娱乐方面的事情,明天我们继续这个话题,将用它来玩游戏。
### 观看电视和电影
你可以使用你的树莓派和 [开源媒体中心](https://osmc.tv/) (OSMC) 去 [观看 Netflix](https://www.dailydot.com/upstream/netflix-raspberry-pi/)!OSMC 是一个基于 [Kodi](http://kodi.tv/) 项目的系统,你可以使用它来播放来自本地网络、附加存储以及互联网上的多媒体。它因为良好的功能特性而在媒体播放应用界中拥有非常好的口碑。
NOOBS(我们在本系列的 [第三篇文章](/article-10644-1.html) 中介绍过它)可以让你在你的树莓派中很容易地 [安装 OSMC](https://www.raspberrypi.org/documentation/usage/kodi/)。在 NOOBS 中也提供了另外一个基于 Kodi 项目的媒体播放系统,它的名字叫 [LibreELEC](https://libreelec.tv/)。
### 听音乐

你还可以让你的树莓派借助 [Pi Music Box](https://github.com/pimusicbox/pimusicbox/tree/master) 项目通过网络来播放来自附加存储或像 Spotify 服务上的流媒体音乐。以前我 [写过关于这个主题的文章](https://opensource.com/life/15/3/pi-musicbox-guide),但是你可以在 [Pi Music Box 网站](https://www.pimusicbox.com/) 上找到最新的指导,包括如何使用和 DIY 项目。
---
via: <https://opensource.com/article/19/3/raspberry-pi-entertainment>
作者:[Anderson Silva](https://opensource.com/users/ansilva) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So far, this series has focused on more serious topics—how to [choose](https://opensource.com/article/19/3/which-raspberry-pi-choose), [buy](https://opensource.com/article/19/2/how-buy-raspberry-pi), [set up](https://opensource.com/article/19/2/how-boot-new-raspberry-pi), and [update](https://opensource.com/article/19/2/how-keep-your-raspberry-pi-updated-and-patched) your Raspberry Pi, and different things [kids](https://opensource.com/article/19/3/teach-kids-program-raspberry-pi) and [adults](https://opensource.com/article/19/2/3-popular-programming-languages-you-can-learn-raspberry-pi) can learn with it (including [Linux](https://opensource.com/article/19/2/learn-linux-raspberry-pi)). But now it's time to change up the subject and have some fun! Today we'll look at ways to use your Raspberry Pi for entertainment, and tomorrow we'll continue the fun with gaming.
## Watch TV and movies
You can use your Raspberry Pi and the [Open Source Media Center](https://osmc.tv/) (OSMC) to [watch Netflix](https://www.dailydot.com/upstream/netflix-raspberry-pi/)! The OSMC is a system based on the [Kodi](http://kodi.tv/) project that allows you to play back media from your local network, attached storage, and the internet. It's also known for having the best feature set and community among media center applications.
NOOBS (which we talked about in the [third article](https://opensource.com/article/19/3/how-boot-new-raspberry-pi) in this series) allows you to [install OSMC](https://www.raspberrypi.org/documentation/usage/kodi/) on your Raspberry Pi as easily as possible. NOOBS also offers another media center system based on Kodi called [LibreELEC](https://libreelec.tv/).
## Listen to music
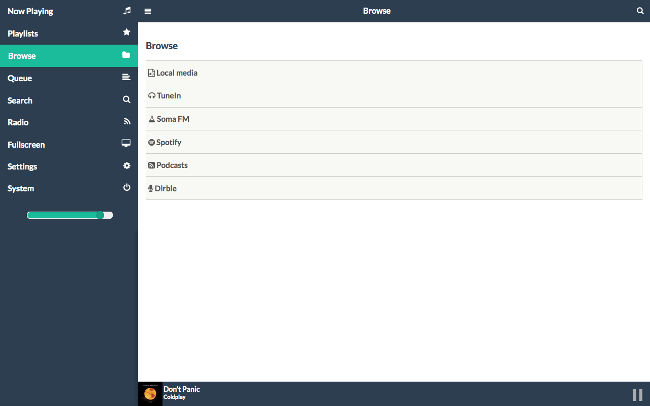
opensource.com
You can also stream music on your network via attached storage or services like Spotify on your Raspberry Pi with the [Pi Music Box](https://github.com/pimusicbox/pimusicbox/tree/master) project. I [wrote about it](https://opensource.com/life/15/3/pi-musicbox-guide) a while ago, but you can find newer instructions, including how to's and DIY projects, on the [Pi Music Box website](https://www.pimusicbox.com/).
## Comments are closed. |
10,670 | IRC vs IRL:如何召开一个良好的 IRC 会议 | https://opensource.com/article/19/2/irc-vs-irl-meetings | 2019-03-31T12:13:30 | [
"IRC",
"会议"
] | /article-10670-1.html |
>
> 若你遵守这些最佳实践,Internet Relay Chat(IRC)会议可以很好滴推进项目进展。
>
>
>

开展任何形式的会议都是门艺术。很多人已经学会了开展面对面会议和电话会议,但是 [Internet Relay Chat](https://en.wikipedia.org/wiki/Internet_Relay_Chat)(IRC)会议因其特殊的性质有别于“<ruby> 现实 <rt> in real life </rt></ruby>”(IRL) 会议。本文将会分享 IRC 这种会议形式的优势和劣势,以及帮你更有效地领导 IRC 会议的小技巧。
为什么用 IRC? 虽说现在有大量的实时聊天工具可供选择,[IRC 依然是开源项目的基石](https://opensource.com/article/16/6/getting-started-irc)。若你的项目使用其他沟通工具,也不要紧。这里大多数的建议都适用于同步的文本聊天机制,只需要进行一些微调。
### IRC 会议的挑战
与面对面会议相比,IRC 会议会遇到一些挑战。你应该知道一个人结束谈话到下一个人开始谈话之间会有间隙吧?在 IRC 中这更糟糕,因为人们需要输入他们的所想。这比说话要更慢,而且不像谈话,你不知道别人什么时候在组织消息。主持人在要求回复或转到下一主题前必须等待很长一段时间。而想要发言的人需要先插入一个简短的信息(例如,一个句号)来让主持人知道(他需要发言)。
IRC 会议还缺少其他方法中能够获得的那些元数据。你无法通过文本了解面部表情和语调。这意味着你必须小心你的措辞。
而且 IRC 会议很容易让人分心。至少在面对面会议中,当某人正在看搞笑的猫咪图片时,你可以看到他面带笑容而且在不合时宜的时候发出笑声。在 IRC 中,除非他们不小心粘贴了错误的短信,否则甚至都没有同伴的压力来让他们假装专注。你甚至可以同时参加多个 IRC 会议。我就这么做过,但如果你需要积极参与这些会议,那就很危险了。
### IRC 会议的优势
IRC 会议也有某些独一无二的优势。IRC 是一个非常轻资源的媒介。它并不怎么消耗带宽和 CPU。这降低了参与的门槛,这对贫困这和发展中的人都是有利的。对于志愿者来说,这意味着他们可以在工作日参加会议。同时它也意味着参与者无需寻找一个安静的地方来让他们沟通而不打扰到周围的人。
借助会议机器人,IRC 可以立即生成会议记录。在 Fedora 中,我们使用 Zodbot(Debian 的 [Meetbot](https://wiki.debian.org/MeetBot) 的一个实例)来记录会议并提供交互。会议结束后,会议记录和完整的日志立即可供社区使用。这减少了开展会议的管理开销。
### 这跟普通会议类似,但有所不同
通过 IRC 或其他基于文本的媒介进行会议意味着以稍微不同寻常的方式来看待会议。虽然它缺少一些更高带宽沟通模式的优点,但它也有自己的优点。开展 IRC 会议可以让你有机会开发出各种规则,而这些规则有助于你开展各种类型的会议。
与任何会议一样,IRC 会议最好有明确的日程和目的。一个好的会议主持者知道什么时候让谈话继续下去以及什么时候将话题拉回来。并没有什么硬性规定,这是一门艺术。但 IRC 在这方面有一个优势。通过设置频道主题为会议的当前主题,人们可以看到他们应该谈论的内容。
如果你的项目尚未实施过同步会议,你应该考虑一下。对于项目成员分布在不同时区的项目,找到一个大家都认可的时间来组织会议很难。你不能把会议作为你唯一的协调方式。但他们可以是项目工作的重要组成部分。
---
via: <https://opensource.com/article/19/2/irc-vs-irl-meetings>
作者:[Ben Cotton](https://opensource.com/users/bcotton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
10,671 | DevOps 对你意味着什么? | https://opensource.com/article/19/1/what-does-devops-mean-you | 2019-03-31T18:41:24 | [
"DevOps"
] | https://linux.cn/article-10671-1.html |
>
> 6 位专家为你解析 DevOps 及其实现、实践和哲学的关键。
>
>
>

如果你问 10 个人关于 DevOps 的问题,你会得到 12 个答案。这是对于 DevOps 的意见和期望的多样性的结果,更不用说它在实践中的差异。
为了解读 DevOps 的悖论,我们找到了最了解它的人 —— 这个行业的顶尖从业者。这些人熟悉 DevOps,了解技术的来龙去脉,并且已经有了多年 DevOps 实践。他们的观点应该能鼓励、刺激和激发你对 DevOps 的想法。
### DevOps 对你意味着什么?
让我们从基本原理开始。我们不能只在教科书上寻找答案,而应该需要知道专家们怎么说。
简而言之,专家们说的是关于 DevOps 的原则、实践和工具。
IBM 数字企业集团 DevOps 商业平台领导者 [Ann Marie Fred](https://twitter.com/DukeAMO),说,“对于我来说,DevOps 是一套实践和原则,旨在使团队在设计、开发、交付和操作软件方面有更好的效率。”
据红帽资深 DevOps 布道者 [Daniel Oh](https://twitter.com/danieloh30?lang=en),“通常来说,DevOps 促使企业基于当前的 IT 发展与应用开发、IT 运维和安全协议的流程和工具。”
Tactec 战略解决方案的创始人 [Brent Reed](https://twitter.com/brentareed),谈及了利益相关者的持续改进,“DevOps 对我来说意味着包括了一种思维方式的工作方式,它允许持续改进运维绩效,进而提升组织绩效,从而让利益相关者受益。”
许多专家也强调 DevOps 文化。Ann Marie 说,“这也是持续改进和学习的问题。它涉及的是人和文化,以及工具和技术。”
美国保监会 (NAIC) 首席架构师兼 DevOps 领导者 [Dan Barker](https://twitter.com/barkerd427),“DevOps 主要是关于文化…它将几个独立的领域聚集在一起,如精益生产、[公正文化](https://psnet.ahrq.gov/resources/resource/1582) 和持续的学习。我认为文化是最关键和最难执行的。”
Atos 的 DevOps 负责人 [Chris Baynham-Hughes](https://twitter.com/onlychrisbh?lang=en),说,“[DevOps] 实践是通过组织内的文化、流程和工具的发展而被采用的。重点是文化变革,DevOps 文化借鉴的关键是协作、试验、快速反馈和持续改进。”
云架构师 [Geoff Purdy](https://twitter.com/geoff_purdy),谈及敏捷和反馈,“缩短和放大反馈回路。我们希望团队在几分钟内而不是几周内获得反馈。”
但在最后,Daniel 通过解释开源和开源文化是如何让他以简单快捷的方式实现目标来强调这点,“在推动 DevOps 中,最重要的事情应该是开源文化而不是具体的工具或复杂的解决方案。”
### 你认为哪些 DevOps 实践有效?
专家列举的那些最佳实践是普遍存在的,但又各不相同。
Ann Marie 表示:“一些十分强大灵活的项目管理[实践],能在职能、独立的小组之间打破壁垒;全自动化持续部署,蓝/绿部署实现零时间停机状态;开发人员设置自己的监控和警告,无缝自我修复,自动化的安全性与合规性。”
Chris 说,“特别的突破是倾情合作、持续改进、开放领导、缩短业务距离、从垂直孤岛转向横向/跨功能的产品团队、工作透明化、相互影响、Mobius 循环、缩短反馈回路、自动化(从环境到 CI/CD)。”
Brent 支持“发展学习文化,包括 TTD [测试驱动开发] 和 BDD [行为驱动开发]捕获事件,并通过持续集成和持续交付从设计、构建和测试到实施在生产环境上一系列事件的自动化。测试采用故障优先的方法,能够自动化集成和交付流程,并在整个生命周期中包含快速反馈。”
Geoff 强调自动化配置。“选择一个自动化配置,对我的团队来说非常有效。更具体地说从版本控制代码库中自动配置。”
Dan 则玩的开心,“ 我们做了很多不同的事情来建立 DevOps 文化。我们举办 ‘午餐 & 学习’ 活动,提供免费的食物来鼓励大家一起学习。我们买书,分组学习。”
### 你如何激励你的团队实现 DevOps 这个目标?
Daniel 强调“自动化的问题就是为了减少 DevOps 计划中来自多个团队的异议,你应该鼓励你的团队提高开发、测试与 IT 运营的自动化能力,以及新的流程和程序。例如,Linux 容器是实现 DevOps 自动化功能的关键工具。”
Geoff 很是赞同,“机械化的劳作,你有讨厌现在做的任务吗?很棒。如果可能的话,让它们消失。不行,那就让它们自动化。它能使工作不会变得太枯燥,因为工作总是在变化。”
Dan、Ann Marie 和 Brent 强调团队的执行力。
Dan 说,“在 NAIC,我们有个很好的奖励系统来鼓励特定的行为。我们有多个级别的奖项,其中两个奖项可以由任何人颁布给某人。我们也会颁奖给完成重要任务的团队,但我们通常只奖励给个人贡献者。”
Ann Marie 表示,“我所在地区的团队最大的动力是看见其他人成功。我们每周都会彼此回放一次,其中一部分是分享我们从尝试新工具或实践中学到的东西。团队热衷于他们现在做的事情,并愿意帮助其他人开始,相信更多的团队很快也会加入进来。”
Brent 表示赞同。“让每个人学习,并掌握同样的基础知识至关重要……我喜欢从评估什么能帮助团队实现目标[以及]产品负责人和用户需要提供的内容入手。”
Chris 推荐采用双管齐下的方法。“运行可以每周可以实现的小目标,并且[在这]可以看到他们正在运做的功能工作之外的进展,庆祝你所取得的进步。”
### DevOps 和敏捷开发如何协同工作?
这是一个重要的问题,因为 DevOps 和敏捷开发都是现代软件开发的基石。
DevOps 是一个软件开发的过程,专注与沟通与协作,以促进快速部署应用程序和产品。而敏捷开发是一种开发方法,涉及持续开发、连续迭代和连续测试,以实现可预测和可交付的成果质量。
那么,它们又有怎样的联系?让我们去问问专家吧。
在 Brent 来看,“DevOps != 敏捷。其次 敏捷 != Scrum 流程……敏捷工具和工作方式支撑着 DevOps 策略和目标,它们是如此融合在一起的。”
Chris 说,“对我而言敏捷是 DevOps 的一个基本组件。当然,我们可以讨论如何在非敏捷开发环境中采用 DevOps 文化,但最终表明,提高软件设计方式的灵活性是采用 DevOps 成熟读的一个关键指标。”
Dan 将 DevOps 与更伟大的 [敏捷宣言](https://agilemanifesto.org/) 联系起来。“我在谈到敏捷时总会引用敏捷宣言来设置基准,而有许多实现中并不关注该宣言。当你阅读这份宣言时,你会发现它确实从开发的角度描述了 DevOps。因此,将敏捷融入 DevOps 文化非常容易,因为敏捷关注于沟通、协作、变化的灵活性以及快速地投入生产。”
Geoff 认为 “DevOps 是敏捷实施的众多实现之一。敏捷本质上是一套原则,而 DevOps 则是体现这些原则的文化、流程和工具链。”
Ann Marie 简洁说明,“敏捷是 DevOps 的先决条件。DevOps 使敏捷变得更加有效。”
### DevOps 是否受益于开源?
这个问题得到了所有参与者的热烈肯定,然后解释了他们看到的好处。
Ann Marie 说,“我们站在巨人的肩膀上,在已有的基础之上发展。拉取请求和代码评审的开源模式,对 DevOps 团队维护软件很有效果。”
Chris 赞同 DevOps “毫无疑问”受益于开源。“从设计和工具方面(例如,Ansible),到流程和人员方面,通分享行业内的故事和开源社区的领导。”
Geoff 提到一个好处是“基层的采纳”。免费的软件不需要签署购买申请。团队发现了满足他们需求的工具,可以自行进行修改。[然后]在它之上构建,并为更大的社区提供更好的功能。如此往复。
开源已经向 DevOps 展示着“就像开源软件开发者正在做的那样,采用更好的方式来克服新的变化”,Daniel 说。
Brent 同意道 “DevOps 从开源中获益良多。一种方法是使用这些工具来理解它们是如何加速 DevOps 的目标和策略;在自动化、自动伸缩、虚拟化和容器化等关键方面对开发人员和操作人员进行培训,如果不引入使 DevOps 更加容易的技术支持,就很难实现这些特性。”
Dan 指出了 DevOps 和开源之间的双向共生关系,“做好开源需要 DevOps 文化。大多数开源项目都具有非常开放的沟通结构,很少有不透明的地方。对于 Devops 实践者来说,这实际上是一个很好的学习机会,可以让他们了解到可能需要将什么引入自己的组织中。此外能够使用来自社区与组织类似的工具来鼓励自己的文化成长。我喜欢用 GitLab 作为这种共生关系的一个例子。当我把 GitLab 带入一家公司时,我们得到了一个很棒的工具,但我们真正购买的是他们独特的文化,通过我们与他们的互动以及我们的贡献带来了巨大价值。他们的工具也可以为 DevOps 组织提供更多东西,而他们的文化已经在我引入它的公司中引起了他们的敬畏。”
现在我们的 DevOps 专家已经参与进来了,请在评论中分享你对 DevOps 的理解,以及向我们提出其他问题。
---
via: <https://opensource.com/article/19/1/what-does-devops-mean-you>
作者:[Girish Managoli](https://opensource.com/users/gammay) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MZqk](https://github.com/MZqk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's said if you ask 10 people about DevOps, you will get 12 answers. This is a result of the diversity in opinions and expectations around DevOps—not to mention the disparity in its practices.
To decipher the paradoxes around DevOps, we went to the people who know it the best—its top practitioners around the industry. These are people who have been around the horn, who know the ins and outs of technology, and who have practiced DevOps for years. Their viewpoints should encourage, stimulate, and provoke your thoughts around DevOps.
## What does DevOps mean to you?
Let's start with the fundamentals. We're not looking for textbook answers, rather we want to know what the experts say.
In short, the experts say DevOps is about principles, practices, and tools.
[Ann Marie Fred](https://twitter.com/DukeAMO), DevOps lead for IBM Digital Business Group's Commerce Platform, says, "to me, DevOps is a set of principles and practices designed to make teams more effective in designing, developing, delivering, and operating software."
According to [Daniel Oh](https://twitter.com/danieloh30?lang=en), senior DevOps evangelist at Red Hat, "in general, DevOps is compelling for enterprises to evolve current IT-based processes and tools related to app development, IT operations, and security protocol."
[Brent Reed](https://twitter.com/brentareed), founder of Tactec Strategic Solutions, talks about continuous improvement for the stakeholders. "DevOps means to me a way of working that includes a mindset that allows for continuous improvement for operational performance, maturing to organizational performance, resulting in delighted stakeholders."
Many of the experts also emphasize culture. Ann Marie says, "it's also about continuous improvement and learning. It's about people and culture as much as it is about tools and technology."
To [Dan Barker](https://twitter.com/barkerd427), chief architect and DevOps leader at the National Association of Insurance Commissioners (NAIC), "DevOps is primarily about culture. … It has brought several independent areas together like lean, [just culture](https://psnet.ahrq.gov/resources/resource/1582), and continuous learning. And I see culture as being the most critical and the hardest to execute on."
[Chris Baynham-Hughes](https://twitter.com/onlychrisbh?lang=en), head of DevOps at Atos, says, "[DevOps] practice is adopted through the evolution of culture, process, and tooling within an organization. The key focus is culture change, and the key tenants of DevOps culture are collaboration, experimentation, fast-feedback, and continuous improvement."
[Geoff Purdy](https://twitter.com/geoff_purdy), cloud architect, talks about agility and feedback "shortening and amplifying feedback loops. We want teams to get feedback in minutes rather than weeks."
But in the end, Daniel nails it by explaining how open source and open culture allow him to achieve his goals "in easy and quick ways. In DevOps initiatives, the most important thing for me should be open culture rather than useful tools, multiple solutions."
## What DevOps practices have you found effective?
The most effective practices cited by the experts are pervasive yet disparate.
According to Ann Marie, "some of the most powerful [practices] are agile project management; breaking down silos between cross-functional, autonomous squads; fully automated continuous delivery; green/blue deploys for zero downtime; developers setting up their own monitoring and alerting; blameless post-mortems; automating security and compliance."
Chris says, "particular breakthroughs have been empathetic collaboration; continuous improvement; open leadership; reducing distance to the business; shifting from vertical silos to horizontal, cross-functional product teams; work visualization; impact mapping; Mobius loop; shortening of feedback loops; automation (from environments to CI/CD)."
Brent supports "evolving a learning culture that includes TDD [test-driven development] and BDD [behavior-driven development] capturing of a story and automating the sequences of events that move from design, build, and test through implementation and production with continuous integration and delivery pipelines. A fail-first approach to testing, the ability to automate integration and delivery processes and include fast feedback throughout the lifecycle."
Geoff highlights automated provisioning. "Picking one, automated provisioning has been hugely effective for my team. More specifically, automated provisioning from a versioned Infrastructure-as-Code codebase."
Dan uses fun. "We do a lot of different things to create a DevOps culture. We hold 'lunch and learns' with free food to encourage everyone to come and learn together; we buy books and study in groups."
## How do you motivate your team to achieve DevOps goals?
Daniel emphasizes "automation that matters. In order to minimize objection from multiple teams in a DevOps initiative, you should encourage your team to increase the automation capability of development, testing, and IT operations along with new processes and procedures. For example, a Linux container is the key tool to achieve the automation capability of DevOps."
Geoff agrees, saying, "automate the toil. Are there tasks you hate doing? Great. Engineer them out of existence if possible. Otherwise, automate them. It keeps the job from becoming boring and routine because the job constantly evolves."
Dan, Ann Marie, and Brent stress team motivation.
Dan says, "at the NAIC, we have a great awards system for encouraging specific behaviors. We have multiple tiers of awards, and two of them can be given to anyone by anyone. We also give awards to teams after they complete something significant, but we often award individual contributors."
According to Ann Marie, "the biggest motivator for teams in my area is seeing the success of others. We have a weekly playback for each other, and part of that is sharing what we've learned from trying out new tools or practices. When teams are enthusiastic about something they're doing and willing to help others get started, more teams will quickly get on board."
Brent agrees. "Getting everyone educated and on the same baseline of knowledge is essential ... assessing what helps the team achieve [and] what it needs to deliver with the product owner and users is the first place I like to start."
Chris recommends a two-pronged approach. "Run small, weekly goals that are achievable and agreed by the team as being important and [where] they can see progress outside of the feature work they are doing. Celebrate wins and visualize the progress made."
## How do DevOps and agile work together?
This is an important question because both DevOps and agile are cornerstones of modern software development.
DevOps is a process of software development focusing on communication and collaboration to facilitate rapid application and product deployment, whereas agile is a development methodology involving continuous development, continuous iteration, and continuous testing to achieve predictable and quality deliverables.
So, how do they relate? Let's ask the experts.
In Brent's view, "DevOps != Agile, second Agile != Scrum. … Agile tools and ways of working—that support DevOps strategies and goals—are how they mesh together."
Chris says, "agile is a fundamental component of DevOps for me. Sure, we could talk about how we adopt DevOps culture in a non-agile environment, but ultimately, improving agility in the way software is engineered is a key indicator as to the maturity of DevOps adoption within the organization."
Dan relates DevOps to the larger [Agile Manifesto](https://agilemanifesto.org/). "I never talk about agile without referencing the Agile Manifesto in order to set the baseline. There are many implementations that don't focus on the Manifesto. When you read the Manifesto, they've really described DevOps from a development perspective. Therefore, it is very easy to fit agile into a DevOps culture, as agile is focused on communication, collaboration, flexibility to change, and getting to production quickly."
Geoff sees "DevOps as one of many implementations of agile. Agile is essentially a set of principles, while DevOps is a culture, process, and toolchain that embodies those principles."
Ann Marie keeps it succinct, saying "agile is a prerequisite for DevOps. DevOps makes agile more effective."
## Has DevOps benefited from open source?
This question receives a fervent "yes" from all participants followed by an explanation of the benefits they've seen.
Ann Marie says, "we get to stand on the shoulders of giants and build upon what's already available. The open source model of maintaining software, with pull requests and code reviews, also works very well for DevOps teams."
Chris agrees that DevOps has "undoubtedly" benefited from open source. "From the engineering and tooling side (e.g., Ansible), to the process and people side, through the sharing of stories within the industry and the open leadership community."
A benefit Geoff cites is "grassroots adoption. Nobody had to sign purchase requisitions for free (as in beer) software. Teams found tooling that met their needs, were free (as in freedom) to modify, [then] built on top of it, and contributed enhancements back to the larger community. Rinse, repeat."
Open source has shown DevOps "better ways you can adopt new changes and overcome challenges, just like open source software developers are doing it," says Daniel.
Brent concurs. "DevOps has benefited in many ways from open source. One way is the ability to use the tools to understand how they can help accelerate DevOps goals and strategies. Educating the development and operations folks on crucial things like automation, virtualization and containerization, auto-scaling, and many of the qualities that are difficult to achieve without introducing technology enablers that make DevOps easier."
Dan notes the two-way, symbiotic relationship between DevOps and open source. "Open source done well requires a DevOps culture. Most open source projects have very open communication structures with very little obscurity. This has actually been a great learning opportunity for DevOps practitioners around what they might bring into their own organizations. Also, being able to use tools from a community that is similar to that of your own organization only encourages your own culture growth. I like to use GitLab as an example of this symbiotic relationship. When I bring [GitLab] into a company, we get a great tool, but what I'm really buying is their unique culture. That brings substantial value through our interactions with them and our ability to contribute back. Their tool also has a lot to offer for a DevOps organization, but their culture has inspired awe in the companies where I've introduced it."
Now that our DevOps experts have weighed in, please share your thoughts on what DevOps means—as well as the other questions we posed—in the comments.
## 2 Comments |
10,673 | 如何在 Linux 中不使用 CD 命令进入目录/文件夹? | https://www.2daygeek.com/navigate-switch-directory-without-using-cd-command-in-linux/ | 2019-03-31T21:59:00 | [
"目录",
"shopt"
] | https://linux.cn/article-10673-1.html | 
众所周知,如果没有 `cd` 命令,我们无法 Linux 中切换目录。这个没错,但我们有一个名为 `shopt` 的 Linux 内置命令能帮助我们解决这个问题。
[shopt](https://www.gnu.org/software/bash/manual/html_node/The-Shopt-Builtin.html) 是一个 shell 内置命令,用于设置和取消设置各种 bash shell 选项,由于它已安装,因此我们不需要再次安装它。
是的,我们可以在启用此选项后,可以不使用 `cd` 命令切换目录。
我们将在本文中向你展示如何操作。这是一个小的调整,但对于那些从 Windows 迁移到 Linux 的新手来说非常有用。
这对 Linux 管理员没用,因为我们不会在没有 `cd` 命令的情况下切换到该目录,因为我们对此有经验。
如果你尝试在没有 `cd` 命令的情况下切换 Linux 的目录/文件夹,你将看到以下错误消息。这在 Linux 中很常见。
```
$ Documents/
bash: Documents/: Is a directory
```
为此,我们需要在用户 `.bashrc` 中追加以下值。
### 什么是 .bashrc ?
`.bashrc` 是一个 shell 脚本,每次用户以交互模式打开新 shell 时都会运行该脚本。
你可以在该文件中添加要在命令提示符下输入的任何命令。
`.bashrc` 文件本身包含终端会话的一系列配置。包括设置和启用:着色、补全,shell 历史,命令别名等。
```
$ vi ~/.bashrc
```
加入这一行:
```
shopt -s autocd
```
运行以下命令使更改生效。
```
$ source ~/.bashrc
```
我们已完成所有配置。简单地对此进行测试以确认这是否有效。
```
$ Documents/
cd -- Documents/
$ daygeek/
cd -- daygeek/
$ /home/daygeek/Documents/daygeek
cd -- /home/daygeek/Documents/daygeek
$ pwd
/home/daygeek/Documents/daygeek
```

是的,它正如预期的那样正常工作。
而且,它在 fish shell 中工作正常,而无需对 `.bashrc` 进行任何更改。

如果要暂时执行此操作,请使用以下命令(设置或取消设置)。重启系统时,它将消失。
```
# shopt -s autocd
# shopt | grep autocd
autocd on
# shopt -u autocd
# shopt | grep autocd
autocd off
```
`shopt` 命令提供了许多其他选项,如果要验证这些选项,请运行以下命令。
```
$ shopt
autocd on
assoc_expand_once off
cdable_vars off
cdspell on
checkhash off
checkjobs off
checkwinsize on
cmdhist on
compat31 off
compat32 off
compat40 off
compat41 off
compat42 off
compat43 off
compat44 off
complete_fullquote on
direxpand off
dirspell off
dotglob off
execfail off
expand_aliases on
extdebug off
extglob off
extquote on
failglob off
force_fignore on
globasciiranges on
globstar off
gnu_errfmt off
histappend on
histreedit off
histverify off
hostcomplete on
huponexit off
inherit_errexit off
interactive_comments on
lastpipe off
lithist off
localvar_inherit off
localvar_unset off
login_shell off
mailwarn off
no_empty_cmd_completion off
nocaseglob off
nocasematch off
nullglob off
progcomp on
progcomp_alias off
promptvars on
restricted_shell off
shift_verbose off
sourcepath on
xpg_echo off
```
此外,我找到了一些其他程序,它们可以帮助我们在 Linux 中比 `cd` 命令更快地切换目录。
它们是 `pushd`、`popd`、`up` shell 脚本和 `bd` 工具。我们将在接下来的文章中介绍这些主题。
---
via: <https://www.2daygeek.com/navigate-switch-directory-without-using-cd-command-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
10,674 | Chaosnet 简史 | https://twobithistory.org/2018/09/30/chaosnet.html | 2019-03-31T23:34:00 | [
"DNS",
"TCP",
"Chaosnet"
] | https://linux.cn/article-10674-1.html | 
如果你输入 `dig` 命令对 `google.com` 进行 DNS 查询,你会得到如下答复:
```
$ dig google.com
; <<>> DiG 9.10.6 <<>> google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27120
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 194 IN A 216.58.192.206
;; Query time: 23 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Sep 21 16:14:48 CDT 2018
;; MSG SIZE rcvd: 55
```
这个输出一部分描述了你的问题(`google.com` 的 IP 地址是什么?),另一部分则详细描述了你收到的回答。在<ruby> 答案区段 <rp> ( </rp> <rt> ANSWER SECTION </rt> <rp> ) </rp></ruby>里,`dig` 为我们找到了一个包含五个字段的记录。从左数第四个字段 `A` 定义了这个记录的类型 —— 这是一个地址记录。在 `A` 的右边,第五个字段告知我们 `google.com` 的 IP 地址是 `216.58.192.206`。第二个字段,`194` 则代表这个记录的缓存时间是 194 秒。
那么,`IN` 字段告诉了我们什么呢?令人尴尬的是,在很长的一段时间里,我都认为这是一个介词。那时候我认为 DNS 记录大概是表达了“在 `A` 记录里,`google.com` 的 IP 地址是 `216.58.192.206`。”后来我才知道 `IN` 是 “internet” 的简写。`IN` 这一个部分告诉了我们这个记录分属的<ruby> 类别 <rt> class </rt></ruby>。
那么,除了 “internet” 之外,DNS 记录还会有什么别的类别吗?这究竟意味着什么?你怎么去搜寻一个*不位于* internet 上的地址?看起来 `IN` 是唯一一个可能有意义的值。而且的确,如果你尝试去获得除了 `IN` 之外的,关于 `google.com` 的记录的话,DNS 服务器通常不能给出恰当的回应。以下就是我们尝试向 `8.8.8.8`(谷歌公共 DNS 服务器)询问在 `HS` 类别里 `google.com` 的 IP 地址。我们得到了状态为 `SERVFAIL` 的回复。
```
$ dig -c HS google.com
; <<>> DiG 9.10.6 <<>> -c HS google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31517
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;google.com. HS A
;; Query time: 34 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Tue Sep 25 14:48:10 CDT 2018
;; MSG SIZE rcvd: 39
```
所以说,除了 `IN` 以外的类别没有得到广泛支持,但它们的确是存在的。除了 `IN` 之外,DNS 记录还有 `HS`(我们刚刚看到的)和 `CH` 这两个类别。`HS` 类是为一个叫做 [Hesiod](https://en.wikipedia.org/wiki/Hesiod_(name_service)) 的系统预留的,它可以利用 DNS 来存储并让用户访问一些文本资料。它通常在本地环境中作为 [LDAP](https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol) 的替代品使用。而 `CH` 这个类别,则是为 Chaosnet 预留的。
如今,大家都在使用 TCP/IP 协议族。这两种协议(TCP 及 UDP)是绝大部分电脑远程连接采用的协议。不过我觉得,从互联网的垃圾堆里翻出了一个布满灰尘,绝迹已久,被人们遗忘的系统,也是一件令人愉悦的事情。那么,Chaosnet 是什么?为什么它像恐龙一样,走上了毁灭的道路呢?
### 在 MIT 的机房里
Chaosnet 是在 1970 年代,由 MIT 人工智能实验室的研究员们研发的。它是一个宏伟目标的一部分 —— 设计并制造一个能比其他通用电脑更高效率运行 Lisp 代码的机器。
Lisp 是 MIT 教授 John McCarthy 的造物,他亦是人工智能领域的先驱者。在 1960 年发布的[一篇论文](http://www-formal.stanford.edu/jmc/recursive.pdf)中,他首次描述了 Lisp 这个语言。在 1962 年,Lisp 的编译器和解释器诞生了。Lisp 引入了非常多的新特性,这些特性在现在看来是每一门编程语言不可或缺的一部分。它是第一门拥有垃圾回收器的语言,是第一个有 REPL(Read-eval-print-loop:交互式解析器)的语言,也是第一个支持动态类型的语言。在人工智能领域工作的程序员们都十分喜爱这门语言,比如说,大名鼎鼎的 [SHRDLU](https://en.wikipedia.org/wiki/SHRDLU) 就是用它写的。这个程序允许人们使用自然语言,向机器下达挪动玩具方块这样的命令。
Lisp 的缺点是它太慢了。跟其它语言相比,Lisp 需要使用两倍的时间来执行相同的操作。因为 Lisp 在运行中仍会检查变量类型,而不仅是编译过程中。在 MIT 的 IBM 7090 上,它的垃圾回收器也需要长达一秒钟的时间来执行。<sup id="fnref1"> <a href="#fn1" rel="footnote"> 1 </a></sup> 这个性能问题急需解决,因为 AI 研究者们试图搭建类似 SHRDLU 的应用。他们需要程序与使用者进行实时互动。因此,在 1970 年代的晚期,MIT 人工智能实验室的研究员们决定去建造一个能更高效运行 Lisp 的机器来解决这个问题。这些“Lisp 机器”们拥有更大的存储和更精简的指令集,更加适合 Lisp。类型检查由专门的电路完成,因此在 Lisp 运行速度的提升上达成了质的飞跃。跟那时流行的计算机系统不同,这些机器并不支持分时,整台电脑的资源都用来运行一个单独的 Lisp 程序。每一个用户都会得到他自己单独的 CPU。MIT 的 <ruby> Lisp 机器小组 <rt> Lisp Machine Group </rt></ruby>在一个备忘录里提到,这些功能是如何让 Lisp 运行变得更简单的:
>
> Lisp 机器是个人电脑。这意味着处理器和主内存并不是分时复用的,每个人都能得到单独属于自己的处理器和内存。这个个人运算系统由许多处理器组成,每个处理器都有它们自己的内存和虚拟内存。当一个用户登录时,他就会被分配一个处理器,在他的登录期间这个处理器是独属于他的。当他登出,这个处理器就会重新可用,等待被分配给下一个用户。通过采取这种方法,当前用户就不用和其他用户竞争内存的使用,他经常使用的内存页也能保存在处理器核心里,因此页面换出的情况被显著降低了。这个 Lisp 机器解决了分时 Lisp 机器的一个基本问题。<sup id="fnref2"> <a href="#fn2" rel="footnote"> 2 </a></sup>
>
>
>
这个 Lisp 机器跟我们认知的现代个人电脑有很大的不同。该小组原本希望今后用户不用直接面对 Lisp 机器,而是面对终端。那些终端会与位于别处的 Lisp 机器进行连接。虽然每个用户都有自己专属的处理器,但那些处理器在工作时会发出很大的噪音,因此它们最好是位于机房,而不是放在本应安静的办公室里。<sup id="fnref3"> <a href="#fn3" rel="footnote"> 3 </a></sup> 这些处理器会通过一个“完全分布式控制”的高速本地网络共享访问一个文件系统和设备,例如打印机。<sup id="fnref4"> <a href="#fn4" rel="footnote"> 4 </a></sup> 这个网络的名字就是 Chaosnet。
Chaosnet 既是硬件标准也是软件协议。它的硬件标准与以太网类似,事实上 Chaosnet 软件协议是运行在以太网之上的。这个软件协议在网络层和传输层之间交互,它并不像 TCP/IP,而总是控制着本地网络。Lisp 机器小组的一个成员 David Moon 写的另一个备忘录中提到,Chaosnet “目前并不打算为低速链接、高信噪链接、多路径、长距离链接做特别的优化。” <sup id="fnref5"> <a href="#fn5" rel="footnote"> 5 </a></sup> 他们专注于打造一个在小型网络里表现极佳的协议。
因为 Chaosnet 连接在 Lisp 处理器和文件系统之间,所以速度十分重要。网络延迟会严重拖慢一些像打开文本文档这种简单操作的速度,为了提高速度,Chaosnet 结合了在<ruby> Network Control Program网络控制程序</ruby>中使用的一些改进方法,随后的 Arpanet 项目中也使用了这些方法。据 Moon 所说,“为了突破诸如在 Arpanet 中发现的速率瓶颈,很有必要采纳新的设计。目前来看,瓶颈在于由多个链接分享控制链接,而且在下一个信息发送之前,我们需要知道本次信息已经送达。” <sup id="fnref6"> <a href="#fn6" rel="footnote"> 6 </a></sup> Chaosnet 协议族的批量 ACK 包跟当今 TCP 的差不多,它减少了 1/3 到一半的需要传输的包的数量。
因为绝大多数 Lisp 机器使用较短的单线进行连接,所以 Chaosnet 可以使用较为简单的路由算法。Moon 在 Chaosnet 路由方案中写道“预计要适配的网络架构十分简单,很少有多个路径,而且每个节点之间的距离很短。所以我认为没有必要进行复杂的方案设计。” <sup id="fnref7"> <a href="#fn7" rel="footnote"> 7 </a></sup> 因为 Chaosnet 采用的算法十分简单,所以实现它也很容易。与之对比明显,其实现程序据说只有 Arpanet 网络控制程序的一半。<sup id="fnref8"> <a href="#fn8" rel="footnote"> 8 </a></sup>
Chaosnet 的另一个特性是,它的地址只有 16 位,是 IPv4 地址的一半。所以这也意味着 Chaosnet 只能在局域网里工作。Chaosnet 也不会去使用端口号;当一个进程试图连接另一个机器上的另外一个进程时,需要首先初始化连接,获取一个特定的目标“<ruby> 联系名称 <rt> contact name </rt></ruby>”。这个联系名称一般是某个特定服务的名字。比方说,一个主机试图使用 `TELNET` 作为联系名称,连接另一个主机。我认为它的工作方式在实践中有点类似于 TCP,因为有些非常著名的服务也会拥有联系名称,比如运行在 80 端口上的 `HTTP` 服务。
在 1986 年,[RFC 973](https://tools.ietf.org/html/rfc973) 通过了将 Chaosnet DNS 类别加入域名解析系统的决议。它替代了一个早先出现的类别 `CSNET`。`CSNET` 是为了支持一个名叫<ruby> 计算机科学网络 <rt> Computer Science Network </rt></ruby>而被制造出来的协议。我并不知道为什么 Chaosnet 能被域名解析系统另眼相待。很多别的协议族也有资格加入 DNS,但是却被忽略了。比如 DNS 的主要架构师之一 Paul Mockapetris 提到说在他原本的构想里,<ruby> 施乐 <rt> Xerox </rt></ruby>的网络协议应该被包括在 DNS 里。<sup id="fnref9"> <a href="#fn9" rel="footnote"> 9 </a></sup> 但是它并没有被加入。Chaosnet 被加入的原因大概是因为 Arpanet 项目和互联网的早期工作,有很多都在麻省剑桥的博尔特·贝拉尼克—纽曼公司,他们的雇员和 MIT 大多有紧密的联系。在这一小撮致力于发展计算机网络人中,Chaosnet 这个协议应该较为有名。
Chaosnet 随着 Lisp 机器的衰落渐渐变得不那么流行。尽管在一小段时间内 Lisp 机器有实际的商业产品 —— Symbolics 和 Lisp Machines Inc 在 80 年代售卖了这些机器。但它们很快被更便宜的微型计算机替代。这些计算机没有特殊制造的回路,但也可以快速运行 Lisp。Chaosnet 被制造出来的目的之一是解决一些 Apernet 协议的原始设计缺陷,但现在 TCP/IP 协议族同样能够解决这些问题了。
### 壳中幽灵
非常不幸的是,在互联网中留存的关于 Chaosnet 的资料不多。RFC 675 —— TCP/IP 的初稿于 1974 年发布,而 Chasnet 于 1975 年开始开发。<sup id="fnref10"> <a href="#fn10" rel="footnote"> 10 </a></sup> 但 TCP/IP 最终征服了整个互联网世界,Chaosnet 则被宣布技术性死亡。尽管 Chaosnet 有可能影响了接下来 TCP/IP 的发展,可我并没有找到能够支持这个猜测的证据。
唯一一个可见的 Chaosnet 残留就是 DNS 的 `CH` 类。这个事实让我着迷。`CH` 类别是那被遗忘的幽魂 —— 在 TCP/IP 广泛部署中存在的一个替代协议 Chaosnet 的最后栖身之地。至少对于我来说,这件事情是十分让人激动。它告诉我关于 Chaosnet 的最后一丝痕迹,仍然藏在我们日常使用的网络基础架构之中。DNS 的 `CH` 类别是有趣的数码考古学遗迹。但它同时也是活生生的标识,提醒着我们互联网并非天生完整成型的,TCP/IP 不是唯一一个能够让计算机们交流的协议。“万维网”也远远不是我们这全球交流系统所能有的,最酷的名字。
---
1. LISP 1.5 Programmer’s Manual, The Computation Center and Research Laboratory of Electronics, 90, accessed September 30, 2018, <http://www.softwarepreservation.org/projects/LISP/book/LISP%201.5%20Programmers%20Manual.pdf> [↩](#fnref1)
2. Lisp Machine Progress Report (Artificial Intelligence Memo 444), MIT Artificial Intelligence Laboratory, August, 1977, 3, accessed September 30, 2018, <https://dspace.mit.edu/bitstream/handle/1721.1/5751/AIM-444.pdf>. [↩](#fnref2)
3. Lisp Machine Progress Report (Artificial Intelligence Memo 444), 4. [↩](#fnref3)
4. 同上 [↩](#fnref4)
5. Chaosnet (Artificial Intelligence Memo 628), MIT Artificial Intelligence Laboratory, June, 1981, 1, accessed September 30, 2018, <https://dspace.mit.edu/bitstream/handle/1721.1/6353/AIM-628.pdf>. [↩](#fnref5)
6. 同上 [↩](#fnref6)
7. Chaosnet (Artificial Intelligence Memo 628), 16. [↩](#fnref7)
8. Chaosnet (Artificial Intelligence Memo 628), 9. [↩](#fnref8)
9. Paul Mockapetris and Kevin Dunlap, “The Design of the Domain Name System,” Computer Communication Review 18, no. 4 (August 1988): 3, accessed September 30, 2018, <http://www.cs.cornell.edu/people/egs/615/mockapetris.pdf>. [↩](#fnref9)
10. Chaosnet (Artificial Intelligence Memo 628), 1. [↩](#fnref10)
---
via: <https://twobithistory.org/2018/09/30/chaosnet.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[acyanbird](https://github.com/acyanbird) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you fire up `dig`
and run a DNS query for `google.com`
, you will get
a response somewhat like the following:
```
$ dig google.com
; <<>> DiG 9.10.6 <<>> google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27120
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 194 IN A 216.58.192.206
;; Query time: 23 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Sep 21 16:14:48 CDT 2018
;; MSG SIZE rcvd: 55
```
The output contains both a section describing the “question” you asked (“What
is the IP address of `google.com`
?”) and a section describing the answer you
received. In the answer section, we see that `dig`
found a single record with
what looks to be five fields. The record’s type is indicated by the `A`
in the
fourth field from the left—this is an “address” record. To the right of the
`A`
, in the fifth field, we can see that the IP address for `google.com`
is
`216.58.192.206`
. The `194`
value in the second field specifies how long in
seconds this particular record can be cached.
What does the `IN`
field tell us? For an embarrassingly long time, I thought
`IN`
functioned as a preposition, so that every DNS record was saying something
like “`google.com`
is *in* `A`
and has IP address `216.58.192.206`
.” It turns
out that `IN`
actually stands for “internet.” The `IN`
part of a DNS record
tells us the record’s *class*.
Why might a DNS record have a class other than “internet”? What would that even
mean? How do you search for a host that *isn’t* on the internet? It would seem
that `IN`
is the only value that could possibly make sense here. Indeed, when
you try to ask for the address of `google.com`
while specifying that you expect
a record with a class other than `IN`
, the DNS server you are asking will
probably complain. In the below, when we try to ask for the IP address of
`google.com`
using the `HS`
class, the name server at `8.8.8.8`
(Google Public
DNS) returns a status of `SERVFAIL`
:
```
$ dig -c HS google.com
; <<>> DiG 9.10.6 <<>> -c HS google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31517
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;google.com. HS A
;; Query time: 34 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Tue Sep 25 14:48:10 CDT 2018
;; MSG SIZE rcvd: 39
```
So classes other than `IN`
aren’t widely supported. But they do exist. In
addition to `IN`
, DNS records can have the `HS`
class (as we’ve
just seen) or the `CH`
class. The `HS`
class is reserved for use by a system
called [Hesiod](https://en.wikipedia.org/wiki/Hesiod_(name_service)) that
stores and distributes simple textual data using the Domain Name System. It is
typically used in local environments as a stand-in for
[LDAP](https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol).
The `CH`
class is reserved for something called Chaosnet.
Today, the world belongs to TCP/IP. Those two protocols (together with UDP) govern most of the remote communication that happens between computers. But I think it’s wonderful that you can still find, hidden in the plumbing of the internet, traces of this other, long-extinct, evocatively named system. What was Chaosnet? And why did it go the way of the dinosaurs?
## A Machine Room at MIT
Chaosnet was developed in the 1970s by researchers at the MIT Artificial Intelligence Lab. It was created as a part of a larger effort to design and build a machine that could run the Lisp programming language more efficiently than a general-purpose computer.
Lisp was the brainchild of MIT professor John McCarthy, who pioneered the field
of artificial intelligence. He first described Lisp to the world in [a
paper](http://www-formal.stanford.edu/jmc/recursive.pdf) published in 1960. By
1962, an interpreter and a compiler had been written. Lisp introduced an
astounding number of features that today we consider standard for many
programming languages. It was the first language to have a garbage collector.
It was the first to have a REPL. And it was the first to support dynamic
typing. It found favor among programmers working in artificial intelligence
and—to name just one example—was used to develop the famous
[SHRDLU](https://en.wikipedia.org/wiki/SHRDLU) demonstration, which allowed
a human to dictate simple actions involving toy blocks to a computer in natural
language.
The problem with Lisp was that it could be slow. Simple operations could take
twice as long to execute as was typical with other languages because Lisp
variables were type-checked at runtime and not just during compilation. Lisp’s
garbage collector was known to take up to an entire second to run on the IBM
7090 at MIT. 1 These performance issues were especially unwelcome because the
AI researchers using Lisp were trying to build applications like SHRDLU that
interacted with users in real time. In the late 1970s, a group of MIT
Artificial Intelligence Lab researchers decided to address these problems by
building machines specifically designed to run Lisp programs. These “Lisp
machines” had more memory and a compact instruction set better-suited to Lisp.
Type-checking would be done by dedicated circuitry, speeding it up by orders of
magnitude. And unlike most computer systems at the time, Lisp machines would
not be time-shared, since ambitious Lisp programs needed all the resources a
computer had available. Each user would be assigned his or her own CPU. In a
memo, the Lisp Machine Group at MIT described how this would make Lisp
programming significantly easier:
The Lisp Machine is a personal computer. Personal computing means that the processor and main memory are not time-division multiplexed, instead each person gets his own. The personal computation system consists of a pool of processors, each with its own main memory, and its own disk for swapping. When a user logs in, he is assigned a processor, and he has exclusive use of it for the duration of the session. When he logs out, the processor is returned to the pool, for the next person to use. This way, there is no competition from other users for memory; the pages the user is frequently referring to remain in core, and so swapping overhead is considerably reduced. Thus the Lisp Machine solves a basic problem of the time-sharing Lisp system.
[2]
The Lisp machine would be a personal computer in a different sense than the one
we think of today. As the Lisp Machine Group originally envisioned it, users
would sit down in their offices not in front of their own Lisp machines but in
front of terminals. The terminals would be connected to the actual Lisp
machine, which would be elsewhere. Even though each user would be assigned his
or her own processor, the processors would still be “kept off in a machine
room,” since they would make noise and take up space and thus be “unwelcome
office companions.” 3 The processors would share access to a file system and
to devices like printers via a high-speed local network “with completely
distributed control.”
That network was Chaosnet.
[4](#fn:4)Chaosnet is both a hardware standard and a software protocol. The hardware
standard resembles Ethernet, and in fact the Chaosnet software protocol was
eventually run over Ethernet. The software protocol, which specifies both
network-layer and transport-layer interactions, was, unlike TCP/IP, always
meant to govern a *local* network. In another memo released by the MIT
Artificial Intelligence Lab, David Moon, a member of the Lisp Machine Group,
explained that Chaosnet “contains no special provisions for things such as
low-speed links, noisy links, multiple paths, and long-distance links with
significant transit time.” 5 The focus was instead on designing a protocol
that could outperform other protocols on a small network.
Speed was important because Chaosnet sat between each Lisp processor and
the file system. Network delays would significantly slow rudimentary operations
like viewing the contents of a text document. To be fast enough, Chaosnet
incorporated several improvements over the Network Control Program then in use
on Arpanet. According to Moon, “it was important to design out bottlenecks such
as are found in Arpanet, for instance the control-link which is shared between
multiple connections and the need to acknowledge each message before the next
message is sent.” 6 The Chaosnet protocol batches packet acknowledgments in
much the same way that TCP does today and so reduced the number of packets that
needed to be transmitted by a half to a third.
Chaosnet could also get away with a relatively simple routing algorithm, since
most hosts on the Lisp machine network were probably connected by a single,
short wire. Moon wrote that the Chaosnet routing scheme “is predicated on the
assumption that the network geometry is simple, there are few multiple paths,
and the length of any path is quite short. This makes more sophisticated
schemes unnecessary.” 7 The simplicity of the algorithm meant that
implementing the Chaosnet protocol was easy. The implementation program was
supposedly half the size of the Arpanet Network Control Program.
[8](#fn:8)The Chaosnet protocol has other idiosyncrasies. A Chaosnet address is only 16
bits, half the size of an IPv4 address, which makes sense given that Chaosnet
was only ever meant to work on a local network. Chaosnet also doesn’t use port
numbers; instead, a process that wants to connect to another process on a
different machine first makes a connection request that specifies a target
“contact name.” That contact name is often just the name of a particular
service. For example, one host may try to connect to another host using the
contact name `TELNET`
. In practice, I assume this works more or less just like
TCP, since something well-known like port 80 might as well have the contact
name `HTTP`
.
The Chaosnet DNS class was added to the Domain Name System by [RFC
973](https://tools.ietf.org/html/rfc973) in 1986. It replaced another class
that had been available early on, the `CSNET`
class, which was there to support
a network called the Computer Science Network. I haven’t been able to figure
out why Chaosnet was picked out for special treatment by the Domain Name
System. There were other protocol families that could have been added but never
were. For example, Paul Mockapetris, one of the principal architects of the
Domain Name System, has written that he originally imagined that DNS would
include a class for Xerox’s network protocol. 9 That never happened.
Chaosnet may have been added just because so much of the early work on Arpanet
and the internet happened at Bolt, Beranek and Newman in Cambridge,
Massachusetts, whose employees were often connected in some way with MIT.
Chaosnet was probably well-known among the then relatively small group of
people working on computer networks.
Usage of Chaosnet presumably waned as Lisp machines became less and less popular. Though Lisp machines were for a short time commercially viable products—sold by companies such as Symbolics and Lisp Machines Inc. during the 1980s—they were soon displaced by cheaper microcomputers that could run Lisp just as quickly without special-purpose circuitry. TCP/IP also fixed many of the issues with the original Arpanet protocols that Chaosnet had been created to circumvent.
## Ghost in the Shell
There unfortunately isn’t a huge amount of information still around about
Chaosnet. RFC 675, which was essentially the first draft of TCP/IP, was
published in 1974. Chaosnet was first developed in 1975. 10 TCP/IP eventually
conquered the world, but Chaosnet seems to have been a technological dead end.
Though it’s possible that Chaosnet influenced subsequent work on TCP/IP, I
haven’t found any specific examples of that happening.
The only really visible remnant of Chaosnet is the `CH`
DNS class. There’s
something about that fact that I find strangely fascinating. The `CH`
class is
a vestigial ghost of an alternative network protocol in a world that has long
since settled on TCP/IP. It’s exciting, at least to me, to know that the last
traces of Chaosnet still lurk out there in the infrastructure of our networked
society. The `CH`
DNS class is a fun artifact of digital archaeology. But it’s
also a living reminder that the internet was not born fully formed, that TCP/IP
is not the only way to connect computers to each other, and that “the internet”
is far from the coolest name we could have had for our global communication
system.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
Where did RSS come from? Why are there so many competing formats? Why don't people seem to use it that much anymore?
— TwoBitHistory (@TwoBitHistory)
Answers to these questions and many more in this week's post about RSS:[https://t.co/BsCN5GQidR][September 17, 2018]
-
LISP 1.5 Programmer’s Manual, The Computation Center and Research Laboratory of Electronics, 90, accessed September 30, 2018,
[http://www.softwarepreservation.org/projects/LISP/book/LISP%201.5%20Programmers%20Manual.pdf](http://www.softwarepreservation.org/projects/LISP/book/LISP%201.5%20Programmers%20Manual.pdf)[↩](#fnref:1) -
Lisp Machine Progress Report (Artificial Intelligence Memo 444), MIT Artificial Intelligence Laboratory, August, 1977, 3, accessed September 30, 2018,
[https://dspace.mit.edu/bitstream/handle/1721.1/5751/AIM-444.pdf](https://dspace.mit.edu/bitstream/handle/1721.1/5751/AIM-444.pdf).[↩](#fnref:2) -
Lisp Machine Progress Report (Artificial Intelligence Memo 444), 4.
[↩](#fnref:3) -
ibid.
[↩](#fnref:4) -
Chaosnet (Artificial Intelligence Memo 628), MIT Artificial Intelligence Laboratory, June, 1981, 1, accessed September 30, 2018,
[https://dspace.mit.edu/bitstream/handle/1721.1/6353/AIM-628.pdf](https://dspace.mit.edu/bitstream/handle/1721.1/6353/AIM-628.pdf).[↩](#fnref:5) -
ibid.
[↩](#fnref:6) -
Chaosnet (Artificial Intelligence Memo 628), 16.
[↩](#fnref:7) -
Chaosnet (Artificial Intelligence Memo 628), 9.
[↩](#fnref:8) -
Paul Mockapetris and Kevin Dunlap, “The Design of the Domain Name System,” Computer Communication Review 18, no. 4 (August 1988): 3, accessed September 30, 2018,
[http://www.cs.cornell.edu/people/egs/615/mockapetris.pdf](http://www.cs.cornell.edu/people/egs/615/mockapetris.pdf).[↩](#fnref:9) -
Chaosnet (Artificial Intelligence Memo 628), 1.
[↩](#fnref:10) |
10,675 | 查看远程 Linux 系统中某个端口是否开启的 3 种方法 | https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/ | 2019-04-01T23:42:22 | [
"端口"
] | https://linux.cn/article-10675-1.html | 
这是一个很重要的话题,不仅对 Linux 管理员而言,对于我们大家而言也非常有帮助。我的意思是说对于工作在 IT 基础设施行业的用户来说,了解这个话题也是非常有用的。他们需要在执行下一步操作前,检查 Linux 服务器上某个端口是否开启。
假如这个端口没有被开启,则他们会直接找 Linux 管理员去开启它。如果这个端口已经开启了,则我们需要和应用团队来商量下一步要做的事。
在本篇文章中,我们将向你展示如何检查某个端口是否开启的 3 种方法。
这个目标可以使用下面的 Linux 命令来达成:
* `nc`:netcat 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
* `nmap`:(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络。
* `telnet`:被用来交互地通过 TELNET 协议与另一台主机通信。
### 如何使用 nc(netcat)命令来查看远程 Linux 系统中某个端口是否开启?
`nc` 即 `netcat`。`netcat` 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
它被设计成为一个可信赖的后端工具,可被直接使用或者简单地被其他程序或脚本调用。
与此同时,它也是一个富含功能的网络调试和探索工具,因为它可以创建你所需的几乎所有类型的连接,并且还拥有几个内置的有趣功能。
`netcat` 有三类功能模式,它们分别为连接模式、监听模式和隧道模式。
`nc`(`netcat`)命令的一般语法:
```
$ nc [-options] [HostName or IP] [PortNumber]
```
在下面的例子中,我们将检查远程 Linux 系统中的 22 端口是否开启。
假如端口是开启的,你将获得类似下面的输出。
```
# nc -zvw3 192.168.1.8 22
Connection to 192.168.1.8 22 port [tcp/ssh] succeeded!
```
命令详解:
* `nc`:即执行的命令主体;
* `z`:零 I/O 模式(被用来扫描);
* `v`:显式地输出;
* `w3`:设置超时时间为 3 秒;
* `192.168.1.8`:目标系统的 IP 地址;
* `22`:需要验证的端口。
当检测到端口没有开启,你将获得如下输出:
```
# nc -zvw3 192.168.1.95 22
nc: connect to 192.168.1.95 port 22 (tcp) failed: Connection refused
```
### 如何使用 nmap 命令来查看远程 Linux 系统中某个端口是否开启?
`nmap`(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络,尽管对于单个主机它也同样能够正常工作。
`nmap` 以一种新颖的方式,使用裸 IP 包来决定网络中的主机是否可达,这些主机正提供什么服务(应用名和版本号),它们运行的操作系统(系统的版本),它们正在使用的是什么包过滤软件或者防火墙,以及其他额外的特性。
尽管 `nmap` 通常被用于安全审计,许多系统和网络管理员发现在一些日常任务(例如罗列网络资产、管理服务升级的计划、监视主机或者服务是否正常运行)中,它也同样十分有用。
`nmap` 的一般语法:
```
$ nmap [-options] [HostName or IP] [-p] [PortNumber]
```
假如端口是开启的,你将获得如下的输出:
```
# nmap 192.168.1.8 -p 22
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 03:37 IST Nmap scan report for 192.168.1.8 Host is up (0.00031s latency).
PORT STATE SERVICE
22/tcp open ssh
Nmap done: 1 IP address (1 host up) scanned in 13.06 seconds
```
假如端口没有开启,你将得到类似下面的结果:
```
# nmap 192.168.1.8 -p 80
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 04:30 IST
Nmap scan report for 192.168.1.8
Host is up (0.00036s latency).
PORT STATE SERVICE
80/tcp closed http
Nmap done: 1 IP address (1 host up) scanned in 13.07 seconds
```
### 如何使用 telnet 命令来查看远程 Linux 系统中某个端口是否开启?
`telnet` 命令被用来交互地通过 TELNET 协议与另一台主机通信。
`telnet` 命令的一般语法:
```
$ telnet [HostName or IP] [PortNumber]
```
假如探测成功,你将看到类似下面的输出:
```
$ telnet 192.168.1.9 22
Trying 192.168.1.9...
Connected to 192.168.1.9.
Escape character is '^]'.
SSH-2.0-OpenSSH_5.3
^]
Connection closed by foreign host.
```
假如探测失败,你将看到类似下面的输出:
```
$ telnet 192.168.1.9 80
Trying 192.168.1.9...
telnet: Unable to connect to remote host: Connection refused
```
当前,我们只找到上面 3 种方法来查看远程 Linux 系统中某个端口是否开启,假如你发现了其他方法可以达到相同的目的,请在下面的评论框中告知我们。
---
via: <https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.